
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/25825
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25825/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25825/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25825/events
|
https://github.com/huggingface/transformers/issues/25825
| 1,871,633,097 |
I_kwDOCUB6oc5vjtrJ
| 25,825 |
Usage of FusedRMSNorm with T5 model
|
{
"login": "sh0tcall3r",
"id": 87083958,
"node_id": "MDQ6VXNlcjg3MDgzOTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/87083958?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sh0tcall3r",
"html_url": "https://github.com/sh0tcall3r",
"followers_url": "https://api.github.com/users/sh0tcall3r/followers",
"following_url": "https://api.github.com/users/sh0tcall3r/following{/other_user}",
"gists_url": "https://api.github.com/users/sh0tcall3r/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sh0tcall3r/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sh0tcall3r/subscriptions",
"organizations_url": "https://api.github.com/users/sh0tcall3r/orgs",
"repos_url": "https://api.github.com/users/sh0tcall3r/repos",
"events_url": "https://api.github.com/users/sh0tcall3r/events{/privacy}",
"received_events_url": "https://api.github.com/users/sh0tcall3r/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @sh0tcall3r \r\n\r\nI assume you use https://huggingface.co/bigscience/mt0-xxl/blob/main/config.json\r\n\r\nIt is `MT5ForConditionalGeneration` whose definition is in `src/transformers/models/mt5/modeling_mt5.py`. In that file, `FusedRMSNorm` is not used.",
"However, I think what you see should be `MT5LayerNorm` rather than `T5LayerNorm`. Maybe it is a typo in your description ?",
"> However, I think what you see should be `MT5LayerNorm` rather than `T5LayerNorm`. Maybe it is a typo in your description ?\r\n\r\nYes, indeed. I see `MT5LayerNorm`. And yes, you're absolutely right, it's `MT5ForConditionalGeneration`.\r\nIs there any option to use `apex` for speed up of inference in this case?\r\nOr is there any option of inference speed up without `apex`, but with some other methods/libraries/packages? ",
"You can try to modify the modeling file of mt5 (see what has been done in t5 file).\r\nOr you can use `load_in_8bit` or `load_in_4bit`, see `docs/source/en/main_classes/quantization.md`.\r\n\r\nOr see if [this](https://twitter.com/younesbelkada/status/1696478075721302143) works for mt5 :-)",
"> You can try to modify the modeling file of mt5 (see what has been done in t5 file). Or you can use `load_in_8bit` or `load_in_4bit`, see `docs/source/en/main_classes/quantization.md`.\r\n> \r\n> Or see if [this](https://twitter.com/younesbelkada/status/1696478075721302143) works for mt5 :-)\r\n\r\nGot it, will do, thanks!",
"Let me close this issue - I think what could be answered are all given :-)",
"Sure, I agree\r\n\r\n"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
Hello!
In HF T5 model description I found that if I had installed Nvidia apex package, T5 model would automatically use FusedRMSNorm instead of T5LayerNorm and hence inference would increase.
I just installed apex and using mt0-xxl model in 8bit loading mode, which I've already fine-tuned. But I see no difference neither in layers description (there are still T5LayerNorm layers in model named children list), nor in inference speed.
I know that in case of really big models speed increase not dramatically, but am I doing everything right?
@stas00 As far as I know you have some experience with that, could you please try to help me?
I have cuda 11.3
pytorch 1.12.1
apex 0.1
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25825/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25825/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25824
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25824/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25824/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25824/events
|
https://github.com/huggingface/transformers/issues/25824
| 1,871,572,833 |
I_kwDOCUB6oc5vje9h
| 25,824 |
replace roberta embedding with bge_base
|
{
"login": "shameem198",
"id": 45461737,
"node_id": "MDQ6VXNlcjQ1NDYxNzM3",
"avatar_url": "https://avatars.githubusercontent.com/u/45461737?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shameem198",
"html_url": "https://github.com/shameem198",
"followers_url": "https://api.github.com/users/shameem198/followers",
"following_url": "https://api.github.com/users/shameem198/following{/other_user}",
"gists_url": "https://api.github.com/users/shameem198/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shameem198/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shameem198/subscriptions",
"organizations_url": "https://api.github.com/users/shameem198/orgs",
"repos_url": "https://api.github.com/users/shameem198/repos",
"events_url": "https://api.github.com/users/shameem198/events{/privacy}",
"received_events_url": "https://api.github.com/users/shameem198/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] |
open
| false | null |
[] |
[
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discuss.huggingface.co) instead?\r\n\r\nThanks!"
] | 1,693 | 1,693 | null |
NONE
| null |
### Model description
I'm experimenting Funsd like dataset using layoutLmv3, I'm trying to replace roberta embedding with new bge_large, Is it possible to replace the embedding? will it improve the accuracy?
### Open source status
- [ ] The model implementation is available
- [ ] The model weights are available
### Provide useful links for the implementation
_No response_
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25824/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25824/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25823
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25823/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25823/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25823/events
|
https://github.com/huggingface/transformers/pull/25823
| 1,871,472,084 |
PR_kwDOCUB6oc5ZBnF8
| 25,823 |
[`Docs`] More clarifications on BT + FA
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
As per title, in fact, the model needs to be casted in half-precision before using FA
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25823/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25823/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25823",
"html_url": "https://github.com/huggingface/transformers/pull/25823",
"diff_url": "https://github.com/huggingface/transformers/pull/25823.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25823.patch",
"merged_at": 1693309946000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25822
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25822/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25822/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25822/events
|
https://github.com/huggingface/transformers/issues/25822
| 1,871,461,709 |
I_kwDOCUB6oc5vjD1N
| 25,822 |
`speed_metrics` may cause ambiguity under multi-nodes scenario
|
{
"login": "CokeDong",
"id": 20747551,
"node_id": "MDQ6VXNlcjIwNzQ3NTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/20747551?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CokeDong",
"html_url": "https://github.com/CokeDong",
"followers_url": "https://api.github.com/users/CokeDong/followers",
"following_url": "https://api.github.com/users/CokeDong/following{/other_user}",
"gists_url": "https://api.github.com/users/CokeDong/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CokeDong/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CokeDong/subscriptions",
"organizations_url": "https://api.github.com/users/CokeDong/orgs",
"repos_url": "https://api.github.com/users/CokeDong/repos",
"events_url": "https://api.github.com/users/CokeDong/events{/privacy}",
"received_events_url": "https://api.github.com/users/CokeDong/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @CokeDong!\r\n\r\nSince the output is identical, I would say it's not a big issue :-)",
"cc @muellerzr @pacman100 ",
"yes, except the `train_runtime` is not the same. ",
"@CokeDong train runtime will be slightly different as it comes from each node, and each one can take slightly longer depending on the connection speed, etc. I don't believe it's actually truly an issue, nor something we can really do anything about. It's a minute difference. ",
"got that, thx~"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.32.0
- Platform: Linux-3.10.0-957.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.16
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 1.13.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@patrickvonplaten
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
e.g. any training programs with `torchrun` running with multi-nodes.
```bash
#master nodes
WORLD_SIZE=4 CUDA_VISIBLE_DEVICES=0,1 torchrun --nnodes=2 --node_rank=0 --nproc_per_node=2 --master_port=1234 train.py ...
# slave nodes
WORLD_SIZE=4 CUDA_VISIBLE_DEVICES=2,3 torchrun --nnodes=2 --node_rank=1 --nproc_per_node=2 --master_port=1234 train.py ...
```
### Expected behavior
the speed_metrics logs will got printed twice, which cause ambiguity.
e.g this is one of my testing results
```
#master nodes
{'train_runtime': 318.7822, 'train_samples_per_second': 16.061, 'train_steps_per_second': 0.031, 'train_loss': 1.8525979161262511, 'epoch': 0.1}
# slave nodes
{'train_runtime': 318.7808, 'train_samples_per_second': 16.061, 'train_steps_per_second': 0.031, 'train_loss': 1.8525979161262511, 'epoch': 0.1}
```
maybe the log is better to be printed **only** by master modes.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25822/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25822/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25821
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25821/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25821/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25821/events
|
https://github.com/huggingface/transformers/issues/25821
| 1,871,410,673 |
I_kwDOCUB6oc5vi3Xx
| 25,821 |
MT5 OutOfMemory Error
|
{
"login": "semindan",
"id": 54636335,
"node_id": "MDQ6VXNlcjU0NjM2MzM1",
"avatar_url": "https://avatars.githubusercontent.com/u/54636335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/semindan",
"html_url": "https://github.com/semindan",
"followers_url": "https://api.github.com/users/semindan/followers",
"following_url": "https://api.github.com/users/semindan/following{/other_user}",
"gists_url": "https://api.github.com/users/semindan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/semindan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/semindan/subscriptions",
"organizations_url": "https://api.github.com/users/semindan/orgs",
"repos_url": "https://api.github.com/users/semindan/repos",
"events_url": "https://api.github.com/users/semindan/events{/privacy}",
"received_events_url": "https://api.github.com/users/semindan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I can't reproduce this, and not sure if I see anything wrong here. Would recommend you to use `low_cpu_mem_usage = True` as whether you have a GPU or not should not affect the scripts you shared (you are not using `to` or `.cuda()` anywhere. `device_map = \"auto\"` should help if you don't have enough RAM, and want to load on GPU. In the snippets you are not loading on GPU anyway. ",
"yep, the problem was the low amount of CPU RAM on the node :skull:, with more RAM it behaves as expected, thank you"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
## Setup 1
- `transformers` version: 4.32.1
- Platform: Linux-4.18.0-425.13.1.el8_7.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
## Setup 2
- `transformers` version: 4.31.0
- Platform: Linux-4.18.0-425.13.1.el8_7.x86_64-x86_64-with-glibc2.28
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help?
@ArthurZucker
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Have a GPU (I'm using 1 GPU) and a correct installation of pytorch on your system (`torch.cuda.is_available()` should be `True`)
2. Copy the official script from [mt5 repo](https://huggingface.co/google/mt5-base), you can even throw out the tokenizer lines:
``` python
# Load model directly
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/mt5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("google/mt5-base")
```
3. Execute the script
This gives me OOM, sometimes it gets stuck and then killed, sometimes it hangs for a long period of time and I just shut it down.
## Setup 1
```bash
semindan@g06 ~/mtl_thesis (dev)> time python (mtl_t)
```
```python
Python 3.10.12 | packaged by conda-forge | (main, Jun 23 2023, 22:40:32) [GCC 12.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> # Load model directly
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
oTokenizer.from_pretrained("google/mt5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("google/mt5-base")
>>>
>>> tokenizer = AutoTokenizer.from_pretrained("google/mt5-base")
You are using the default legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. If you see this, DO NOT PANIC! This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=True`. This should only be set if you understand what it means, and thouroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
/home/semindan/.conda/envs/env_mamba/envs/mtl_t/lib/python3.10/site-packages/transformers/convert_slow_tokenizer.py:470: UserWarning: The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option which is not implemented in the fast tokenizers. In practice this means that the fast version of the tokenizer can produce unknown tokens whereas the sentencepiece version would have converted these unknown tokens into a sequence of byte tokens matching the original piece of text.
warnings.warn(
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/mt5-base")
```
```bash
^Z
________________________________________________________
Executed in 117.68 secs fish external
usr time 334.00 micros 334.00 micros 0.00 micros
sys time 304.00 micros 304.00 micros 0.00 micros
fish: Job 1, 'time python' has stopped
semindan@g06 ~/mtl_thesis (dev)> fish: Job 1, 'time python' terminated by signal SIGKILL (Forced quit) (mtl_t)
semindan@g06 ~/mtl_thesis (dev)> exit (mtl_t)
slurmstepd: error: Detected 1 oom_kill event in StepId=6242010.0. Some of the step tasks have been OOM Killed.
srun: error: g06: task 0: Out Of Memory
```
## Setup 2
``` python
Python 3.11.4 | packaged by conda-forge | (main, Jun 10 2023, 18:08:17) [GCC 12.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> # Load model directly
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
oTokenizer.from_pretrained("google/mt5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("google/mt5-base")
>>>
>>> tokenizer = AutoTokenizer.from_pretrained("google/mt5-base")
You are using the legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
/home/semindan/.conda/envs/env_mamba/envs/llm_env/lib/python3.11/site-packages/transformers/convert_slow_tokenizer.py:470: UserWarning: The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option which is not implemented in the fast tokenizers. In practice this means that the fast version of the tokenizer can produce unknown tokens whereas the sentencepiece version would have converted these unknown tokens into a sequence of byte tokens matching the original piece of text.
warnings.warn(
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/mt5-base")
```
```bash
^C^C^C^C^C^C^C^Z
________________________________________________________
Executed in 577.45 secs fish external
usr time 452.00 micros 452.00 micros 0.00 micros
sys time 0.00 micros 0.00 micros 0.00 micros
fish: Job 1, 'time python' has stopped
semindan@g10 ~/mtl_thesis (dev)> fish: Job 1, 'time python' terminated by signal SIGKILL (Forced quit) (llm_env)
semindan@g10 ~/mtl_thesis (dev)> exit (llm_env)
slurmstepd: error: Detected 8 oom_kill events in StepId=6242005.0. Some of the step tasks have been OOM Killed.
srun: error: g10: task 0: Out Of Memory
```
### Expected behavior
I expect the model to load. When no GPU is present, the script behaves as expected:
```bash
(mtl_t) python
```
```python
Python 3.10.12 | packaged by conda-forge | (main, Jun 23 2023, 22:40:32) [GCC 12.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> # Load model directly
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
oTokenizer.from_pretrained("google/mt5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("google/mt5-base")
>>>
>>> tokenizer = AutoTokenizer.from_pretrained("google/mt5-base")
You are using the default legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. If you see this, DO NOT PANIC! This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=True`. This should only be set if you understand what it means, and thouroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
/home/semindan/.conda/envs/env_mamba/envs/mtl_t/lib/python3.10/site-packages/transformers/convert_slow_tokenizer.py:470: UserWarning: The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option which is not implemented in the fast tokenizers. In practice this means that the fast version of the tokenizer can produce unknown tokens whereas the sentencepiece version would have converted these unknown tokens into a sequence of byte tokens matching the original piece of text.
warnings.warn(
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/mt5-base")
Downloading (…)neration_config.json: 100%|██████████████████████████████████████████████████████████████████████████████████████| 147/147 [00:00<00:00, 238kB/s]
>>>
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25821/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25821/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25820
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25820/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25820/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25820/events
|
https://github.com/huggingface/transformers/pull/25820
| 1,871,339,246 |
PR_kwDOCUB6oc5ZBJqb
| 25,820 |
Resolving Attribute error when using the FSDP ram efficient feature
|
{
"login": "pacman100",
"id": 13534540,
"node_id": "MDQ6VXNlcjEzNTM0NTQw",
"avatar_url": "https://avatars.githubusercontent.com/u/13534540?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pacman100",
"html_url": "https://github.com/pacman100",
"followers_url": "https://api.github.com/users/pacman100/followers",
"following_url": "https://api.github.com/users/pacman100/following{/other_user}",
"gists_url": "https://api.github.com/users/pacman100/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pacman100/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pacman100/subscriptions",
"organizations_url": "https://api.github.com/users/pacman100/orgs",
"repos_url": "https://api.github.com/users/pacman100/repos",
"events_url": "https://api.github.com/users/pacman100/events{/privacy}",
"received_events_url": "https://api.github.com/users/pacman100/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
1. Currently, for few models getting Attribute errors such as `AttributeError: 'OPTForCausalLM' object has no attribute 'decoder'` when using the FSDP ram efficient feature. This PR fixes it.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25820/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25820/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25820",
"html_url": "https://github.com/huggingface/transformers/pull/25820",
"diff_url": "https://github.com/huggingface/transformers/pull/25820.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25820.patch",
"merged_at": 1693308740000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25819
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25819/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25819/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25819/events
|
https://github.com/huggingface/transformers/pull/25819
| 1,871,315,660 |
PR_kwDOCUB6oc5ZBEgW
| 25,819 |
Error with checking args.eval_accumulation_steps to gather tensors
|
{
"login": "chaumng",
"id": 60038822,
"node_id": "MDQ6VXNlcjYwMDM4ODIy",
"avatar_url": "https://avatars.githubusercontent.com/u/60038822?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chaumng",
"html_url": "https://github.com/chaumng",
"followers_url": "https://api.github.com/users/chaumng/followers",
"following_url": "https://api.github.com/users/chaumng/following{/other_user}",
"gists_url": "https://api.github.com/users/chaumng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chaumng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chaumng/subscriptions",
"organizations_url": "https://api.github.com/users/chaumng/orgs",
"repos_url": "https://api.github.com/users/chaumng/repos",
"events_url": "https://api.github.com/users/chaumng/events{/privacy}",
"received_events_url": "https://api.github.com/users/chaumng/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @muellerzr ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25819). All of your documentation changes will be reflected on that endpoint.",
"@muellerzr Thank you. I have run the make commands. All tests passed."
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
The error is in ```trainer.py```.
While the deprecated (legacy) code has the correct check (line 3772):
```python
if args.eval_accumulation_steps is not None and (step + 1) % args.eval_accumulation_steps == 0:
```
The current code does not (line 3196):
```python
if args.eval_accumulation_steps is not None and self.accelerator.sync_gradients:
```
We need to check ```(step + 1) % args.eval_accumulation_steps == 0```, because otherwise, if we set args.eval_accumulation_steps = 10, the code may still gather tensors for each step.
Hence, the line 3196 should be modified to:
```python
if args.eval_accumulation_steps is not None and (step + 1) % args.eval_accumulation_steps == 0 and self.accelerator.sync_gradients:
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25819/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25819/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25819",
"html_url": "https://github.com/huggingface/transformers/pull/25819",
"diff_url": "https://github.com/huggingface/transformers/pull/25819.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25819.patch",
"merged_at": 1693318001000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25818
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25818/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25818/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25818/events
|
https://github.com/huggingface/transformers/issues/25818
| 1,871,227,461 |
I_kwDOCUB6oc5viKpF
| 25,818 |
convert_llama_weights_to_hf.py json.decoder.JSONDecodeError
|
{
"login": "munitioner",
"id": 14157458,
"node_id": "MDQ6VXNlcjE0MTU3NDU4",
"avatar_url": "https://avatars.githubusercontent.com/u/14157458?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/munitioner",
"html_url": "https://github.com/munitioner",
"followers_url": "https://api.github.com/users/munitioner/followers",
"following_url": "https://api.github.com/users/munitioner/following{/other_user}",
"gists_url": "https://api.github.com/users/munitioner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/munitioner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/munitioner/subscriptions",
"organizations_url": "https://api.github.com/users/munitioner/orgs",
"repos_url": "https://api.github.com/users/munitioner/repos",
"events_url": "https://api.github.com/users/munitioner/events{/privacy}",
"received_events_url": "https://api.github.com/users/munitioner/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @ArthurZucker ",
"Hey! @munitioner, I am not able to reproduce this on main. I suspect this can come from either one of:\r\n- The `params.json` is wrongly formatted / was manually modified \r\n- The path is wrong\r\nI tested with a similar setup as you, and I have no problem converting. Can you share the `params.json` file with me? ",
"i am facing with issues to convert llama-2-13b into vicuna i got all the time the following #21366 ) \"Fetching all parameters from the checkpoint at /content/drive/MyDrive/anomalyGPT/llama/llama-2-13b/13B\".a\r\n^C\r\nfter executing that command !python -m transformers.models.llama.convert_llama_weights_to_hf --input_dir /content/drive/MyDrive/anomalyGPT/llama/llama-2-13b --model_size 13B --output_dir /content/drive/MyDrive/anomalyGPT/llama/huggingface_llama_13B",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"I am also getting JSONDecodeError.\r\nI have downloaded the CodeLlama-13b.\r\n```\r\nTraceback (most recent call last):\r\n File \"convert_llama_weights_to_hf.py\", line 322, in <module>\r\n main()\r\n File \"convert_llama_weights_to_hf.py\", line 310, in main\r\n write_model(\r\n File \"convert_llama_weights_to_hf.py\", line 94, in write_model\r\n params = read_json(os.path.join(input_base_path, \"params.json\"))\r\n File \"convert_llama_weights_to_hf.py\", line 75, in read_json\r\n return json.load(f)\r\n File \"/home/.../anaconda3/envs/env_pytorch/lib/python3.8/json/__init__.py\", line 293, in load\r\n return loads(fp.read(),\r\n File \"/home/.../anaconda3/envs/env_pytorch/lib/python3.8/json/__init__.py\", line 357, in loads\r\n return _default_decoder.decode(s)\r\n File \"/home/.../anaconda3/envs/env_pytorch/lib/python3.8/json/decoder.py\", line 337, in decode\r\n obj, end = self.raw_decode(s, idx=_w(s, 0).end())\r\n File \"/home/...\r\n[params.json](https://github.com/huggingface/transformers/files/13215859/params.json)\r\n/anaconda3/envs/env_pytorch/lib/python3.8/json/decoder.py\", line 355, in raw_decode\r\n raise JSONDecodeError(\"Expecting value\", s, err.value) from None\r\njson.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)\r\n```\r\njson.loads(f) is generating error, since the params.json file contains html code. Attaching params.json for reference.\r\n[params.json](https://github.com/huggingface/transformers/files/13215873/params.json)\r\n\r\nCan anybody help?",
"Hey, if you are looking for already converted checkpoints, you should have a look at https://huggingface.co/codellama . I converted the checkpoints (9 different checkpoints 😓 ) with the exact same script and did not have any issue. Where is the param.json file from? ",
"@ArthurZucker Where is the params.json, i did not find that in the huggingface repo of llama",
"Strange, here are the links:\r\n- https://huggingface.co/meta-llama/Llama-2-70b/blob/main/params.json\r\n- https://huggingface.co/meta-llama/Llama-2-70b-chat/blob/main/params.json\r\n- https://huggingface.co/meta-llama/Llama-2-13b/blob/main/params.json\r\n- https://huggingface.co/meta-llama/Llama-2-13b-chat/blob/main/params.json\r\n- https://huggingface.co/meta-llama/Llama-2-7b/blob/main/params.json\r\n\r\nmake sure you are using the checkpoints that do not end with `-hf` , which are already converted and thus do not have the `param.json`. ",
"TY @ArthurZucker",
"and where is the tokenizer.json? @ArthurZucker",
"The tokenizer.json is not related to the original model so it will be in the `-hf` version. What you have in the original release is the `tokenizer.model` ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,702 | 1,702 |
NONE
| null |
### System Info

### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
!git clone https://github.com/facebookresearch/llama.git
!cd /content/llama/ && bash download.sh
!wget https://raw.githubusercontent.com/huggingface/transformers/main/src/transformers/models/llama/convert_llama_weights_to_hf.py
!pip install git+https://github.com/huggingface/transformers
!pip install accelerate
!pip install sentencepiece
!python convert_llama_weights_to_hf.py \
--input_dir /content/llama/llama-2-7b --model_size 7B --output_dir /content/llama/models_hf/7B
```
### Expected behavior
error
```python
2023-08-29 08:19:08.150890: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Traceback (most recent call last):
File "/content/convert_llama_weights_to_hf.py", line 318, in <module>
main()
File "/content/convert_llama_weights_to_hf.py", line 306, in main
write_model(
File "/content/convert_llama_weights_to_hf.py", line 92, in write_model
params = read_json(os.path.join(input_base_path, "params.json"))
File "/content/convert_llama_weights_to_hf.py", line 75, in read_json
return json.load(f)
File "/usr/lib/python3.10/json/__init__.py", line 293, in load
return loads(fp.read(),
File "/usr/lib/python3.10/json/__init__.py", line 346, in loads
return _default_decoder.decode(s)
File "/usr/lib/python3.10/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.10/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25818/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25818/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25817
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25817/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25817/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25817/events
|
https://github.com/huggingface/transformers/pull/25817
| 1,871,138,916 |
PR_kwDOCUB6oc5ZAeZe
| 25,817 |
fix ds z3 checkpointing when `stage3_gather_16bit_weights_on_model_save=False`
|
{
"login": "pacman100",
"id": 13534540,
"node_id": "MDQ6VXNlcjEzNTM0NTQw",
"avatar_url": "https://avatars.githubusercontent.com/u/13534540?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pacman100",
"html_url": "https://github.com/pacman100",
"followers_url": "https://api.github.com/users/pacman100/followers",
"following_url": "https://api.github.com/users/pacman100/following{/other_user}",
"gists_url": "https://api.github.com/users/pacman100/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pacman100/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pacman100/subscriptions",
"organizations_url": "https://api.github.com/users/pacman100/orgs",
"repos_url": "https://api.github.com/users/pacman100/repos",
"events_url": "https://api.github.com/users/pacman100/events{/privacy}",
"received_events_url": "https://api.github.com/users/pacman100/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
1. Fixes https://github.com/huggingface/transformers/issues/25368
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25817/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25817/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25817",
"html_url": "https://github.com/huggingface/transformers/pull/25817",
"diff_url": "https://github.com/huggingface/transformers/pull/25817.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25817.patch",
"merged_at": 1693475274000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25816
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25816/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25816/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25816/events
|
https://github.com/huggingface/transformers/issues/25816
| 1,871,101,855 |
I_kwDOCUB6oc5vhr-f
| 25,816 |
nvme/zero_stage_3/optimizer/rank0/140354038028384.tensor.swp: buffer nbytes != file bytes 241969152 != 241958912
|
{
"login": "Deemo-cqs",
"id": 64957826,
"node_id": "MDQ6VXNlcjY0OTU3ODI2",
"avatar_url": "https://avatars.githubusercontent.com/u/64957826?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Deemo-cqs",
"html_url": "https://github.com/Deemo-cqs",
"followers_url": "https://api.github.com/users/Deemo-cqs/followers",
"following_url": "https://api.github.com/users/Deemo-cqs/following{/other_user}",
"gists_url": "https://api.github.com/users/Deemo-cqs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Deemo-cqs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Deemo-cqs/subscriptions",
"organizations_url": "https://api.github.com/users/Deemo-cqs/orgs",
"repos_url": "https://api.github.com/users/Deemo-cqs/repos",
"events_url": "https://api.github.com/users/Deemo-cqs/events{/privacy}",
"received_events_url": "https://api.github.com/users/Deemo-cqs/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @pacman100 ",
"if i offload param into nvme and optimizer not, the program can run\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.32.0.dev0
- Platform: Linux-3.10.0-693.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.17
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
deepspeed --num_gpus=1 run_translation.py \
--cache_dir /home/wangzhigangcs/bigmodelresearch/Deepspeed/DeepSpeedExamples/transformers/examples/pytorch/translation/mymodel/ \
--deepspeed /home/wangzhigangcs/bigmodelresearch/Deepspeed/DeepSpeedExamples/transformers/examples/pytorch/translation/config/ds_config_zero3.json \
--model_name_or_path t5-small --per_device_train_batch_size 4 \
--output_dir /home/wangzhigangcs/bigmodelresearch/Deepspeed/DeepSpeedExamples/transformers/examples/pytorch/translation/mymodel/ --overwrite_output_dir --fp16 \
--do_train --max_train_samples 300 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/home/wangzhigangcs/bigmodelresearch/Deepspeed/DeepSpeedExamples/transformers/examples/pytorch/translation/nvme",
"pin_memory": true,
"buffer_count": 4,
"fast_init": false
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"aio": {
"block_size": 262144,
"queue_depth": 32,
"thread_count": 1,
"single_submit": false,
"overlap_events": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
### Expected behavior
Successfully offload into nvme
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25816/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25816/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25815
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25815/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25815/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25815/events
|
https://github.com/huggingface/transformers/pull/25815
| 1,871,046,486 |
PR_kwDOCUB6oc5ZAKh2
| 25,815 |
Minor wording changes for Code Llama
|
{
"login": "osanseviero",
"id": 7246357,
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/osanseviero",
"html_url": "https://github.com/osanseviero",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
MEMBER
| null |
Some changes based on https://github.com/huggingface/blog/pull/1425
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25815/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25815/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25815",
"html_url": "https://github.com/huggingface/transformers/pull/25815",
"diff_url": "https://github.com/huggingface/transformers/pull/25815.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25815.patch",
"merged_at": 1693314178000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25814
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25814/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25814/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25814/events
|
https://github.com/huggingface/transformers/issues/25814
| 1,871,019,601 |
I_kwDOCUB6oc5vhX5R
| 25,814 |
Inconsistency in encoding user special tokens between LlamaTokenizerFast and LlamaTokenizer
|
{
"login": "hzphzp",
"id": 30926489,
"node_id": "MDQ6VXNlcjMwOTI2NDg5",
"avatar_url": "https://avatars.githubusercontent.com/u/30926489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hzphzp",
"html_url": "https://github.com/hzphzp",
"followers_url": "https://api.github.com/users/hzphzp/followers",
"following_url": "https://api.github.com/users/hzphzp/following{/other_user}",
"gists_url": "https://api.github.com/users/hzphzp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hzphzp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hzphzp/subscriptions",
"organizations_url": "https://api.github.com/users/hzphzp/orgs",
"repos_url": "https://api.github.com/users/hzphzp/repos",
"events_url": "https://api.github.com/users/hzphzp/events{/privacy}",
"received_events_url": "https://api.github.com/users/hzphzp/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! This is expected, a fix is on its way here: #23909. For now you should make sure the added tokens have `rstrip = True` and `lstrip=True` 😉 ",
"problem solved, thank you!"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
tokenizers==0.13.3
transformers==4.32.1
### Who can help?
@ArthurZucker When encoding user special tokens (e.g., \<img\>), LlamaTokenizerFast adds extra spaces before and after the token, while LlamaTokenizer does not. This inconsistent behavior leads to different results when using the two tokenizers.
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
To reproduce the issue, I used the following code:
```python
from transformers import LlamaTokenizerFast
from transformers import LlamaTokenizer
fast_tokenizer = LlamaTokenizerFast.from_pretrained("lmsys/vicuna-13b-v1.3", use_fast=True)
tokenizer = LlamaTokenizer.from_pretrained("lmsys/vicuna-13b-v1.3", use_fast=False)
tokenizer.add_special_tokens({"additional_special_tokens": ['<img0>', '</img0>', '<img_content>']})
fast_tokenizer.add_special_tokens({"additional_special_tokens": ['<img0>', '</img0>', '<img_content>']})
prompt = "<img0> <img_content> </img0>"
print(tokenizer.tokenize(prompt))
print(fast_tokenizer.tokenize(prompt))
print(tokenizer(prompt))
print(fast_tokenizer(prompt))
```
The results are as follows:
```
['<img0>', '<img_content>', '</img0>']
['<img0>', '▁▁', '<img_content>', '▁▁', '</img0>']
{'input_ids': [1, 32000, 32002, 32001], 'attention_mask': [1, 1, 1, 1]}
{'input_ids': [1, 32000, 259, 32002, 259, 32001], 'attention_mask': [1, 1, 1, 1, 1, 1]}
```
### Expected behavior
As you can see, LlamaTokenizerFast adds unnecessary spaces ('▁▁') before and after the <img_content> token, while LlamaTokenizer does not. This results in different input_ids and attention_mask values when using the two tokenizers. But we expect that they output the same.
Waiting for kindly response ... ...
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25814/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25814/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25813
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25813/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25813/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25813/events
|
https://github.com/huggingface/transformers/issues/25813
| 1,870,946,333 |
I_kwDOCUB6oc5vhGAd
| 25,813 |
GPTNeoXRotaryEmbedding has a defect when using sin/cos cache
|
{
"login": "underskies00",
"id": 52735000,
"node_id": "MDQ6VXNlcjUyNzM1MDAw",
"avatar_url": "https://avatars.githubusercontent.com/u/52735000?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/underskies00",
"html_url": "https://github.com/underskies00",
"followers_url": "https://api.github.com/users/underskies00/followers",
"following_url": "https://api.github.com/users/underskies00/following{/other_user}",
"gists_url": "https://api.github.com/users/underskies00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/underskies00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/underskies00/subscriptions",
"organizations_url": "https://api.github.com/users/underskies00/orgs",
"repos_url": "https://api.github.com/users/underskies00/repos",
"events_url": "https://api.github.com/users/underskies00/events{/privacy}",
"received_events_url": "https://api.github.com/users/underskies00/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Looks like you are right, as this is the case for models in `llama`, where we have\r\n\r\n```python\r\n return (\r\n self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),\r\n self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),\r\n )\r\n```\r\n\r\n@ArthurZucker could you like to double confirm here?",
"Yep indeed. Would you like to open a PR @underskies00 ?\r\n\r\nfyi @gante if there's a reason we did not merge this for GPTNeoX maybe? ",
"@ArthurZucker looking at the `git blame`, this has been present since the 1st commit :D Possibly flew under the radar.\r\n\r\nTechnically harmless (since seq_len is almost always > batch size), but in need of fixing.",
"(Actually for a simple case like this: \r\n\r\n```python \r\nfrom transformers import AutoTokenizer, GPTNeoXForCausalLM, AutoConfig\r\n\r\n\r\nconfig = AutoConfig.from_pretrained(\"EleutherAI/gpt-neox-20b\", num_hidden_layers = 5)\r\ntokenizer = AutoTokenizer.from_pretrained(\"EleutherAI/gpt-neox-20b\", )\r\nmodel = GPTNeoXForCausalLM(config).cuda()\r\n\r\ninputs = tokenizer(\"Hey how are you doing\", return_tensors = \"pt\").to(\"cuda\")\r\n\r\nimport time\r\nstart = time.time()\r\nmodel.generate(**inputs, max_new_tokens = 258)\r\nprint(time.time()-start)\r\n```\r\nI already get 2 more seconds. It's a small model but should apply to big one as well, just reduced the number of layers",
"> Yep indeed. Would you like to open a PR @underskies00 ?\r\n> \r\n> fyi @gante if there's a reason we did not merge this for GPTNeoX maybe?\r\n\r\nYou handle it is OK,i‘m not familiar with how to open a PR, Thanks.@ArthurZucker"
] | 1,693 | 1,696 | 1,696 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.10.112-005.ali5000.alios7.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.13
- Huggingface_hub version: 0.12.1
- PyTorch version (GPU?): 1.13.1+cu117 (False)
- Tensorflow version (GPU?): 2.11.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
Text models:@ArthurZucker and @younesbelkada
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
in transformers/models/gpt_neox/modeling_gpt_neox.py, line320:
```python
return self.cos_cached[:seq_len, ...].to(x.device), self.sin_cached[:seq_len, ...].to(x.device)
```
lack 2 dimensions before seq_lenth.
This will not cause bug, because seq_lenth is always larger than 1, but it will cause a defect use of cache by use the whole cache ever, maybe lead to poor performance when inference?
### Expected behavior
Maybe the right code should be:
```python
return self.cos_cached[:, :, :seq_len, ...].to(x.device), self.sin_cached[:, :, :seq_len, ...].to(x.device)
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25813/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25813/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25812
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25812/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25812/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25812/events
|
https://github.com/huggingface/transformers/issues/25812
| 1,870,920,727 |
I_kwDOCUB6oc5vg_wX
| 25,812 |
pytorch autocast leads to baddbmm's output fp16 while input fp32.
|
{
"login": "jovialchen",
"id": 27750324,
"node_id": "MDQ6VXNlcjI3NzUwMzI0",
"avatar_url": "https://avatars.githubusercontent.com/u/27750324?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jovialchen",
"html_url": "https://github.com/jovialchen",
"followers_url": "https://api.github.com/users/jovialchen/followers",
"following_url": "https://api.github.com/users/jovialchen/following{/other_user}",
"gists_url": "https://api.github.com/users/jovialchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jovialchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jovialchen/subscriptions",
"organizations_url": "https://api.github.com/users/jovialchen/orgs",
"repos_url": "https://api.github.com/users/jovialchen/repos",
"events_url": "https://api.github.com/users/jovialchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/jovialchen/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I'll have a look, thanks for reporting. FYI @loubnabnl ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hey! Given that ` attn_weights = torch.empty(attn_view, device=query.device, dtype=query.dtype)` initialises the tensor based on the input type, and mostly given that we don't use autocast in our codebase I would suggest to disable auto_cast as a quick fix, and otherwise debug and check where the type casting comes from.\r\nI don't really have the time to dig into your code and debug it for you so a minimal reproducer would also be welcomed ! 🤗 ",
"Thank you, Arthur. I'll let you know if we have any findings.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,703 | 1,703 |
NONE
| null |
### System Info
```
- `transformers` version: 4.29.1
- Platform: Windows-10-10.0.17763-SP0
- Python version: 3.9.16
- Huggingface_hub version: 0.14.1
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 2.0.0+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: False
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I'm trying to run 'bigcode/starcoder' and 'bigcode/starcoderbase-1b', but I'm facing an issue where the loss remains consistently zero. After debugging, I discovered that the inputs of the '`baddbmm`' function (specifically, '`attn_weights`', '`query`', and '`key`') are in fp32, while the outputs are in fp16. This discrepancy causes overflow in subsequent lines of code(assign `mask_value`(fp32) to `attn_weights`(fp16)), ultimately resulting in a loss value of 0.
During my investigation, I inserted a check using 'torch.is_autocast_enabled()' and found that it is actually set to TRUE in the code.
`dtype: (attn_weights=float32, query=float32,key=float32,beta=int,alpha=float), return attn_weights=float16
`
The code is located in the following file.
xxx\Anaconda3\envs\belle\Lib\site-packages\transformers\models\gpt_bigcode\modeling_gpt_bigcode.py
The scripts I'm using are https://github.com/hiyouga/LLaMA-Efficient-Tuning.
```
def _attn(self, query, key, value, attention_mask=None, head_mask=None):
dtype = query.dtype
softmax_dtype = torch.float32 if self.attention_softmax_in_fp32 else dtype
upcast = dtype != softmax_dtype
unscale = self.layer_idx + 1 if self.scale_attention_softmax_in_fp32 and upcast else 1
scale_factor = unscale**-1
if self.scale_attn_weights:
scale_factor /= self.head_dim**0.5
query_shape = query.shape
batch_size = query_shape[0]
key_length = key.size(-1)
if self.multi_query:
# (batch_size, query_length, num_heads, head_dim) x (batch_size, head_dim, key_length)
# -> (batch_size, query_length, num_heads, key_length)
query_length = query_shape[1]
attn_shape = (batch_size, query_length, self.num_heads, key_length)
attn_view = (batch_size, query_length * self.num_heads, key_length)
# No copy needed for MQA 2, or when layer_past is provided.
query = query.reshape(batch_size, query_length * self.num_heads, self.head_dim)
else:
# (batch_size, num_heads, query_length, head_dim) x (batch_size, num_heads, head_dim, key_length)
# -> (batch_size, num_heads, query_length, key_length)
query_length = query_shape[2]
attn_shape = (batch_size, self.num_heads, query_length, key_length)
attn_view = (batch_size * self.num_heads, query_length, key_length)
# Always copies
query = query.reshape(batch_size * self.num_heads, query_length, self.head_dim)
# No copy when layer_past is provided.
key = key.reshape(batch_size * self.num_heads, self.head_dim, key_length)
attn_weights = torch.empty(attn_view, device=query.device, dtype=query.dtype)
if query.device.type == "cpu":
# This is needed because of a bug in pytorch https://github.com/pytorch/pytorch/issues/80588.
# The bug was fixed in https://github.com/pytorch/pytorch/pull/96086,
# but the fix has not been released as of pytorch version 2.0.0.
attn_weights.zero_()
beta = 1
else:
beta = 0
**##!!error here!!**
attn_weights = torch.baddbmm(attn_weights, query, key, beta=beta, alpha=scale_factor).view(attn_shape)
......
```
### Expected behavior
The input and output of '`baddbmm`' should be of the same dtype.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25812/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25812/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25811
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25811/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25811/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25811/events
|
https://github.com/huggingface/transformers/pull/25811
| 1,870,915,290 |
PR_kwDOCUB6oc5Y_uRl
| 25,811 |
Add use_best_model feature for evaluating trials in hyperparameter searching
|
{
"login": "jasper-lu",
"id": 3989184,
"node_id": "MDQ6VXNlcjM5ODkxODQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3989184?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jasper-lu",
"html_url": "https://github.com/jasper-lu",
"followers_url": "https://api.github.com/users/jasper-lu/followers",
"following_url": "https://api.github.com/users/jasper-lu/following{/other_user}",
"gists_url": "https://api.github.com/users/jasper-lu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jasper-lu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jasper-lu/subscriptions",
"organizations_url": "https://api.github.com/users/jasper-lu/orgs",
"repos_url": "https://api.github.com/users/jasper-lu/repos",
"events_url": "https://api.github.com/users/jasper-lu/events{/privacy}",
"received_events_url": "https://api.github.com/users/jasper-lu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@sgugger ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25811). All of your documentation changes will be reflected on that endpoint.",
"> I don't think we want to touch that much in depth the hyperparameter search feature since we are not really maintaining it anymore. Unless @muellerzr or @pacman100 want to give it a second wind that is!\r\n\r\nGotcha. I'll just clean up this PR and put it into a good state in case you ever want to bring it in (and https://github.com/huggingface/transformers/issues/25247 can pull this in to support their use case).",
"> > I don't think we want to touch that much in depth the hyperparameter search feature since we are not really maintaining it anymore. Unless @muellerzr or @pacman100 want to give it a second wind that is!\r\n> \r\n> Gotcha. I'll just clean up this PR and put it into a good state in case you ever want to bring it in (and #25247 can pull this in to support their use case).\r\n\r\nThank you @jasper-lu for you work and comprehension 🤗 ! Very appreciated ❤️ ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Enables use of best epoch when evaluating trials in hyperparameter searching. Addresses feature request https://github.com/huggingface/transformers/issues/25247
I considered two approaches to adding this:
1. Add as a another flag in TrainingArguments.
2. (this one) Add by piping it through the `hyperparameter_search` method.
I ended up choosing (2) because hyperparameter searching seems like something "applied onto" training, rather than something intrinsic to training itself.
Once a reviewer confirms approach (2) looks good, I can write unit tests. Previously tested by setting `use_best_model=True` and inspecting values manually. Would also appreciate if anyone had thoughts on what the tests should look like.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25811/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25811/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25811",
"html_url": "https://github.com/huggingface/transformers/pull/25811",
"diff_url": "https://github.com/huggingface/transformers/pull/25811.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25811.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25810
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25810/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25810/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25810/events
|
https://github.com/huggingface/transformers/issues/25810
| 1,870,843,145 |
I_kwDOCUB6oc5vgs0J
| 25,810 |
grad_accum is none when using gradient_accumulation_steps in DeepSpeed
|
{
"login": "DuoduoLi",
"id": 16662201,
"node_id": "MDQ6VXNlcjE2NjYyMjAx",
"avatar_url": "https://avatars.githubusercontent.com/u/16662201?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DuoduoLi",
"html_url": "https://github.com/DuoduoLi",
"followers_url": "https://api.github.com/users/DuoduoLi/followers",
"following_url": "https://api.github.com/users/DuoduoLi/following{/other_user}",
"gists_url": "https://api.github.com/users/DuoduoLi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DuoduoLi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DuoduoLi/subscriptions",
"organizations_url": "https://api.github.com/users/DuoduoLi/orgs",
"repos_url": "https://api.github.com/users/DuoduoLi/repos",
"events_url": "https://api.github.com/users/DuoduoLi/events{/privacy}",
"received_events_url": "https://api.github.com/users/DuoduoLi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi !\r\n\r\nCould you provide the exact command you launch the training, please? Thanks!",
"Hi @ydshieh , the command is :\r\ndeepspeed --master_port 39500 --num_gpus=8 ./code/run_summarization.py --model_name_or_path ./model --do_train --do_eval --train_file ./data/train.json --validation_file ./data/valid.json --output_dir ./output/ --overwrite_output_dir --per_device_train_batch_size=1 --per_device_eval_batch_size=1 --gradient_accumulation_steps=8 --max_source_length 4000 --max_target_length 2000 --max_eval_samples 4000 --num_beams 4 --evaluation_strategy=steps --metric_for_best_model=eval_loss --load_best_model_at_end=True --warmup_steps=1250 --eval_steps 1250 --logging_steps 1250 --save_steps 1250 --num_train_epochs 1 --save_total_limit=10 --ignore_pad_token_for_loss --learning_rate 3e-4 --pad_to_max_length --source_prefix summarize: --deepspeed ./code/configs/dsconfig_zero2.json\r\n",
"Hi @DuoduoLi \r\n\r\n\r\nSorry for being late here. Could you try `transformers` with the `main` branch and see if this still persists?\r\n(`python -m pip install --no-cache-dir git+https://github.com/huggingface/transformers@main#egg=transformers`)\r\n\r\n(@pacman100 Do you know about this issue and if this is already fixed in `main`?)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,700 | 1,700 |
NONE
| null |
### System Info
### Environment info
transformers version: 4.31.0
Using distributed or parallel set-up in script?: Deepspeed
**Deepspeed config:**
{
"fp16": {
"enabled": false,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 0.0003,
"betas": [0.9, 0.999],
"eps": 1e-08,
"weight_decay": 0.0
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.0003,
"warmup_num_steps": 1.200000e+03
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2.000000e+08,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2.000000e+08,
"contiguous_gradients": true
},
"gradient_accumulation_steps": 8,
"gradient_clipping": 1.0,
"steps_per_print": inf,
"train_batch_size": 64,
"train_micro_batch_size_per_gpu": 1,
"wall_clock_breakdown": false,
"bf16": {
"enabled": false
}
}
### Who can help?
### Who can help
@pacman100
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
### Model I am using (Bert, XLNet ...): mt5
### The problem arises when using:
Traceback (most recent call last):
File "./code/run_summarization.py", line 902, in <module>
main()
File "./code/run_summarization.py", line 801, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/tmp/env/lib/python3.8/site-packages/transformers/trainer.py", line 1539, in train
return inner_training_loop(
File "/tmp/env/lib/python3.8/site-packages/transformers/trainer.py", line 1809, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs)
File "/tmp/env/lib/python3.8/site-packages/transformers/trainer.py", line 2665, in training_step
self.accelerator.backward(loss)
File "/tmp/env/lib/python3.8/site-packages/accelerate/accelerator.py", line 1917, in backward
self.deepspeed_engine_wrapped.backward(loss, **kwargs)
File "/tmp/env/lib/python3.8/site-packages/accelerate/utils/deepspeed.py", line 167, in backward
self.engine.backward(loss, **kwargs)
File "/tmp/env/lib/python3.8/site-packages/deepspeed/utils/nvtx.py", line 15, in wrapped_fn
ret_val = func(*args, **kwargs)
File "/tmp/env/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1890, in backward
self.optimizer.backward(loss, retain_graph=retain_graph)
File "/tmp/env/lib/python3.8/site-packages/deepspeed/runtime/zero/stage_1_and_2.py", line 1953, in backward
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)
File "/tmp/env/lib/python3.8/site-packages/deepspeed/runtime/fp16/loss_scaler.py", line 63, in backward
scaled_loss.backward(retain_graph=retain_graph)
File "/tmp/env/lib/python3.8/site-packages/torch/_tensor.py", line 487, in backward
torch.autograd.backward(
File "/tmp/env/lib/python3.8/site-packages/torch/autograd/__init__.py", line 200, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/tmp/env/lib/python3.8/site-packages/deepspeed/runtime/zero/stage_1_and_2.py", line 871, in reduce_partition_and_remove_grads
self.reduce_ready_partitions_and_remove_grads(param, i)
File "/tmp/env/lib/python3.8/site-packages/deepspeed/runtime/zero/stage_1_and_2.py", line 1332, in reduce_ready_partitions_and_remove_grads
self.reduce_independent_p_g_buckets_and_remove_grads(param, i)
File "/tmp/env/lib/python3.8/site-packages/deepspeed/runtime/zero/stage_1_and_2.py", line 899, in reduce_independent_p_g_buckets_and_remove_grads
self.reduce_ipg_grads()
File "/tmp/env/lib/python3.8/site-packages/deepspeed/runtime/zero/stage_1_and_2.py", line 1319, in reduce_ipg_grads
self.copy_grads_in_partition(param)
File "/tmp/env/lib/python3.8/site-packages/deepspeed/runtime/zero/stage_1_and_2.py", line 1239, in copy_grads_in_partition
self.async_accumulate_grad_in_cpu_via_gpu(param)
**File "/tmp/env/lib/python3.8/site-packages/deepspeed/runtime/zero/stage_1_and_2.py", line 1143, in async_accumulate_grad_in_cpu_via_gpu
accumulate_gradients()
File "/tmp/env/lib/python3.8/site-packages/deepspeed/runtime/zero/stage_1_and_2.py", line 1122, in accumulate_gradients
param.grad_accum.data.view(-1).add_(dest_buffer)
AttributeError: 'NoneType' object has no attribute 'data'**
my own modified scripts: (give details below)
### The tasks I am working on is: summarize

### Expected behavior
when train and set gradient_accumulation_steps >1 in deepspeed, the grad_accum is none.
If don't set the gradient_accumulation_steps , it can run.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25810/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25810/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25809
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25809/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25809/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25809/events
|
https://github.com/huggingface/transformers/issues/25809
| 1,870,840,774 |
I_kwDOCUB6oc5vgsPG
| 25,809 |
[help] Load CodeLlama from hf failed
|
{
"login": "yingfhu",
"id": 42952108,
"node_id": "MDQ6VXNlcjQyOTUyMTA4",
"avatar_url": "https://avatars.githubusercontent.com/u/42952108?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yingfhu",
"html_url": "https://github.com/yingfhu",
"followers_url": "https://api.github.com/users/yingfhu/followers",
"following_url": "https://api.github.com/users/yingfhu/following{/other_user}",
"gists_url": "https://api.github.com/users/yingfhu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yingfhu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yingfhu/subscriptions",
"organizations_url": "https://api.github.com/users/yingfhu/orgs",
"repos_url": "https://api.github.com/users/yingfhu/repos",
"events_url": "https://api.github.com/users/yingfhu/events{/privacy}",
"received_events_url": "https://api.github.com/users/yingfhu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Make sure you install from main: `pip install git+https://github.com/hugginfgace/transformers`"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
ValueError: Tokenizer class CodeLlamaTokenizer does not exist or is not currently imported.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25809/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25809/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25808
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25808/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25808/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25808/events
|
https://github.com/huggingface/transformers/issues/25808
| 1,870,794,208 |
I_kwDOCUB6oc5vgg3g
| 25,808 |
Accelerate does not work with MaskGenerationPipelone
|
{
"login": "MrinalTyagi",
"id": 21031150,
"node_id": "MDQ6VXNlcjIxMDMxMTUw",
"avatar_url": "https://avatars.githubusercontent.com/u/21031150?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MrinalTyagi",
"html_url": "https://github.com/MrinalTyagi",
"followers_url": "https://api.github.com/users/MrinalTyagi/followers",
"following_url": "https://api.github.com/users/MrinalTyagi/following{/other_user}",
"gists_url": "https://api.github.com/users/MrinalTyagi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MrinalTyagi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MrinalTyagi/subscriptions",
"organizations_url": "https://api.github.com/users/MrinalTyagi/orgs",
"repos_url": "https://api.github.com/users/MrinalTyagi/repos",
"events_url": "https://api.github.com/users/MrinalTyagi/events{/privacy}",
"received_events_url": "https://api.github.com/users/MrinalTyagi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"According to the contribution guideline, could you share a complete reproducer as well as a traceback of the error you are getting? ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.29.2
- Platform: Linux-5.15.0-46-generic-x86_64-with-glibc2.17
- Python version: 3.8.17
- Huggingface_hub version: 0.15.1
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
Using device_map with mask-generation pipeline of sam results in error.
@Narsil
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Run example SAM pipeline available at https://huggingface.co/docs/transformers/main/model_doc/sam with device_map="auto"
### Expected behavior
It should run with device_map="auto" otherwise if not possible should provide a suitable error.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25808/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25808/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25807
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25807/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25807/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25807/events
|
https://github.com/huggingface/transformers/pull/25807
| 1,870,769,360 |
PR_kwDOCUB6oc5Y_PNg
| 25,807 |
Modify efficient GPU training doc with now-available adamw_bnb_8bit optimizer
|
{
"login": "veezbo",
"id": 5194849,
"node_id": "MDQ6VXNlcjUxOTQ4NDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/5194849?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/veezbo",
"html_url": "https://github.com/veezbo",
"followers_url": "https://api.github.com/users/veezbo/followers",
"following_url": "https://api.github.com/users/veezbo/following{/other_user}",
"gists_url": "https://api.github.com/users/veezbo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/veezbo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/veezbo/subscriptions",
"organizations_url": "https://api.github.com/users/veezbo/orgs",
"repos_url": "https://api.github.com/users/veezbo/repos",
"events_url": "https://api.github.com/users/veezbo/events{/privacy}",
"received_events_url": "https://api.github.com/users/veezbo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @younesbelkada for BNB related stuff 🙏 ",
"Thanks @stevhliu for the suggestions! ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25807). All of your documentation changes will be reflected on that endpoint."
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
The documentation for efficient single-GPU training previously mentioned that the `adamw_bnb_8bit` optimizer could only be integrated using a third-party implementation. However, this is now available in Trainer directly as a result of this [issue](https://github.com/huggingface/transformers/issues/14819
) and corresponding [PR](https://github.com/huggingface/transformers/pull/15622).
I think it's valuable to keep the 8-bit Adam entry in the documentation as it's a significant improvement over Adafactor. And I also think it's valuable to keep the sample integration with a third-party implementation of an optimizer for reference purposes. I have adjusted the documentation accordingly.
I was able to validate myself that both approaches, using Trainer directly with the `optim` flag and doing the third-party integration still appear to work when fine-tuning small LLMs on a single GPU.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@stevhliu and @MKhalusova
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25807/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25807/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25807",
"html_url": "https://github.com/huggingface/transformers/pull/25807",
"diff_url": "https://github.com/huggingface/transformers/pull/25807.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25807.patch",
"merged_at": 1693475711000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25806
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25806/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25806/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25806/events
|
https://github.com/huggingface/transformers/issues/25806
| 1,870,716,258 |
I_kwDOCUB6oc5vgN1i
| 25,806 |
Error: index 0 is out of bounds for dimension 0 with size 0
|
{
"login": "rishabh063",
"id": 55680979,
"node_id": "MDQ6VXNlcjU1NjgwOTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/55680979?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rishabh063",
"html_url": "https://github.com/rishabh063",
"followers_url": "https://api.github.com/users/rishabh063/followers",
"following_url": "https://api.github.com/users/rishabh063/following{/other_user}",
"gists_url": "https://api.github.com/users/rishabh063/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rishabh063/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rishabh063/subscriptions",
"organizations_url": "https://api.github.com/users/rishabh063/orgs",
"repos_url": "https://api.github.com/users/rishabh063/repos",
"events_url": "https://api.github.com/users/rishabh063/events{/privacy}",
"received_events_url": "https://api.github.com/users/rishabh063/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This happens when the image has nothing to mask , I.e plain image or very Faded images where there is nothing to segment . \r\n\r\nIt should Return an empty Array and not an error "
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
Error: index 0 is out of bounds for dimension 0 with size 0
Traceback (most recent call last):
outputs = generator(raw_image, points_per_batch=64)
File "/opt/conda/lib/python3.10/site-packages/transformers/pipelines/mask_generation.py", line 173, in __call__
return super().__call__(image, *args, num_workers=num_workers, batch_size=batch_size, **kwargs)
File "/opt/conda/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1121, in __call__
return next(
File "/opt/conda/lib/python3.10/site-packages/transformers/pipelines/pt_utils.py", line 124, in __next__
item = next(self.iterator)
File "/opt/conda/lib/python3.10/site-packages/transformers/pipelines/pt_utils.py", line 266, in __next__
processed = self.infer(next(self.iterator), **self.params)
File "/opt/conda/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1035, in forward
model_outputs = self._forward(model_inputs, **forward_params)
File "/opt/conda/lib/python3.10/site-packages/transformers/pipelines/mask_generation.py", line 242, in _forward
masks, iou_scores, boxes = self.image_processor.filter_masks(
File "/opt/conda/lib/python3.10/site-packages/transformers/models/sam/image_processing_sam.py", line 670, in filter_masks
return self._filter_masks_pt(
File "/opt/conda/lib/python3.10/site-packages/transformers/models/sam/image_processing_sam.py", line 768, in _filter_masks_pt
masks = _mask_to_rle_pytorch(masks)
File "/opt/conda/lib/python3.10/site-packages/transformers/models/sam/image_processing_sam.py", line 1201, in _mask_to_rle_pytorch
counts += [cur_idxs[0].item()] + btw_idxs.tolist() + [height * width - cur_idxs[-1]]
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
transformer== 4.33.0.dev0
generator = pipeline("mask-generation", model="facebook/sam-vit-huge", device=0)
model = generator.model
outputs = generator(raw_image, points_per_batch=64)
### Expected behavior
Not Fail
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25806/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25806/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25805
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25805/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25805/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25805/events
|
https://github.com/huggingface/transformers/issues/25805
| 1,870,700,489 |
I_kwDOCUB6oc5vgJ_J
| 25,805 |
UnboundLocalError: local variable 'tokens' referenced before assignment
|
{
"login": "pseudotensor",
"id": 2249614,
"node_id": "MDQ6VXNlcjIyNDk2MTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2249614?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pseudotensor",
"html_url": "https://github.com/pseudotensor",
"followers_url": "https://api.github.com/users/pseudotensor/followers",
"following_url": "https://api.github.com/users/pseudotensor/following{/other_user}",
"gists_url": "https://api.github.com/users/pseudotensor/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pseudotensor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pseudotensor/subscriptions",
"organizations_url": "https://api.github.com/users/pseudotensor/orgs",
"repos_url": "https://api.github.com/users/pseudotensor/repos",
"events_url": "https://api.github.com/users/pseudotensor/events{/privacy}",
"received_events_url": "https://api.github.com/users/pseudotensor/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Yep, fix is here #25793 \r\nOnly happens when the input text is empty ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Closing as https://github.com/huggingface/transformers/pull/25793 was merged"
] | 1,693 | 1,695 | 1,695 |
NONE
| null |
### System Info
Since transformers==4.32.0
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Just try to tokenize an empty string
```
File "/workspace/src/gen.py", line 2064, in evaluate
context, num_prompt_tokens2 = H2OTextGenerationPipeline.limit_prompt(context, tokenizer)
File "/workspace/src/h2oai_pipeline.py", line 86, in limit_prompt
prompt_tokens = tokenizer(prompt_text)['input_ids']
File "/h2ogpt_conda/lib/python3.10/site-packages/transformers/tokenization_utils_base.py", line 2602, in __call__
encodings = self._call_one(text=text, text_pair=text_pair, **all_kwargs)
File "/h2ogpt_conda/lib/python3.10/site-packages/transformers/tokenization_utils_base.py", line 2708, in _call_one
return self.encode_plus(
File "/h2ogpt_conda/lib/python3.10/site-packages/transformers/tokenization_utils_base.py", line 2781, in encode_plus
return self._encode_plus(
File "/h2ogpt_conda/lib/python3.10/site-packages/transformers/tokenization_utils.py", line 656, in _encode_plus
first_ids = get_input_ids(text)
File "/h2ogpt_conda/lib/python3.10/site-packages/transformers/tokenization_utils.py", line 623, in get_input_ids
tokens = self.tokenize(text, **kwargs)
File "/h2ogpt_conda/lib/python3.10/site-packages/transformers/models/llama/tokenization_llama.py", line 208, in tokenize
if tokens[0] == SPIECE_UNDERLINE and tokens[1] in self.all_special_tokens:
UnboundLocalError: local variable 'tokens' referenced before assignment
```
Bug here:
https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/tokenization_llama.py#L203-L216
```
# Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.tokenize
def tokenize(self, text: "TextInput", **kwargs) -> List[str]:
"""
Converts a string to a list of tokens. If `self.legacy` is set to `False`, a prefix token is added unless the
first token is special.
"""
if self.legacy:
return super().tokenize(text, **kwargs)
if len(text) > 0:
tokens = super().tokenize(SPIECE_UNDERLINE + text.replace(SPIECE_UNDERLINE, " "), **kwargs)
if tokens[0] == SPIECE_UNDERLINE and tokens[1] in self.all_special_tokens:
tokens = tokens[1:]
return tokens
```
Should still define tokens as empty list if nothing to tokenize. A failure is odd result.
### Expected behavior
Not fail
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25805/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25805/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25804
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25804/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25804/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25804/events
|
https://github.com/huggingface/transformers/issues/25804
| 1,870,464,494 |
I_kwDOCUB6oc5vfQXu
| 25,804 |
OSError: /home/datascience/huggingface does not appear to have a file named preprocessor_config.json. Checkout 'https://huggingface.co//home/datascience/huggingface/None' for available files.
|
{
"login": "z7ye",
"id": 25996703,
"node_id": "MDQ6VXNlcjI1OTk2NzAz",
"avatar_url": "https://avatars.githubusercontent.com/u/25996703?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/z7ye",
"html_url": "https://github.com/z7ye",
"followers_url": "https://api.github.com/users/z7ye/followers",
"following_url": "https://api.github.com/users/z7ye/following{/other_user}",
"gists_url": "https://api.github.com/users/z7ye/gists{/gist_id}",
"starred_url": "https://api.github.com/users/z7ye/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/z7ye/subscriptions",
"organizations_url": "https://api.github.com/users/z7ye/orgs",
"repos_url": "https://api.github.com/users/z7ye/repos",
"events_url": "https://api.github.com/users/z7ye/events{/privacy}",
"received_events_url": "https://api.github.com/users/z7ye/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Thanks for reporting! Yep I thing we should make sure the `image_processor`is also saved! Would you like to open a PR? 🤗 ",
"Same here, but why it need this one for LLava1.5 model?"
] | 1,693 | 1,705 | 1,693 |
NONE
| null |
### System Info
import transformers
transformers.__version__
'4.31.0'
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction

```python
segmenter = pipeline(task="image-segmentation", model="facebook/detr-resnet-50-panoptic", revision="fc15262")
segmenter.save_pretrained("./huggingface")
from transformers import pipeline
task = 'image-segmentation'
model_dir="./huggingface"
model = pipeline(task, model = model_dir)
OSError: /home/datascience/huggingface does not appear to have a file named preprocessor_config.json. Checkout 'https://huggingface.co//home/datascience/huggingface/None' for available files.
```
### Expected behavior
no bug
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25804/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25804/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25803
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25803/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25803/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25803/events
|
https://github.com/huggingface/transformers/issues/25803
| 1,870,357,091 |
I_kwDOCUB6oc5ve2Jj
| 25,803 |
[Model] How to evaluate Idefics Model's ability with in context examples?
|
{
"login": "Luodian",
"id": 15847405,
"node_id": "MDQ6VXNlcjE1ODQ3NDA1",
"avatar_url": "https://avatars.githubusercontent.com/u/15847405?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Luodian",
"html_url": "https://github.com/Luodian",
"followers_url": "https://api.github.com/users/Luodian/followers",
"following_url": "https://api.github.com/users/Luodian/following{/other_user}",
"gists_url": "https://api.github.com/users/Luodian/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Luodian/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Luodian/subscriptions",
"organizations_url": "https://api.github.com/users/Luodian/orgs",
"repos_url": "https://api.github.com/users/Luodian/repos",
"events_url": "https://api.github.com/users/Luodian/events{/privacy}",
"received_events_url": "https://api.github.com/users/Luodian/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @Luodian ,\r\n\r\n> For single image we use the template to evaluate instruct version model.\r\n> `User:<fake_token_around_image><image><fake_token_around_image>{prompt} Assistant:`\r\n\r\n\r\nTo perfectly match the format used during the training of the instructed versions, you should modify slightly the template you are showing:\r\nUser:<fake_token_around_image><image><fake_token_around_image>{prompt}<end_of_utterance>\\nAssistant: {assistant_answer}<end_of_utterance>`\r\n\r\nbeyond the additional `\\n` and `<end_of_utterance>`, everything looks correct!\r\nThe rest of the code snippet looks about right too.\r\nhow are you getting the pixel values?\r\n\r\n>I have read all related blogs and docs but still got confused about the usage of <end_of_utterance>. Is it used to break the in context examples with query example?\r\n\r\n> Besides, very curious that the model would generate the normal <end_of_utterance> at the last of sentence instead of normal llama's <|endofchunk|>?\r\n\r\nWe use the <end_of_utterance> in the dialogue setup to have an easier exit condition. it marks both the end of a user and assistant turn. We found that not having this token makes it harder in a dialogue setup to stop the generation.\r\nThe end of a dialogue is marked by an </s> during training.\r\n\r\n\r\n\r\n",
"Thanks! Then for in context examples, should it be like?\r\n\r\n```\r\nUser:<fake_token_around_image><image><fake_token_around_image>{in_context_prompt}<end_of_utterance>\\n\r\nAssistant: {in_context_answer}<end_of_utterance>\\n\r\nUser:<fake_token_around_image><image><fake_token_around_image>{prompt}<end_of_utterance>\\n\r\nAssistant:\r\n```",
"No need for double line breaks but otherwise, it is correct, that is the most straightforward way to do in-context evaluation",
"Btw we use `self.image_processor = transformers.CLIPImageProcessor()` to get the pixel values. \r\n```\r\nvision_x = self.image_processor.preprocess([raw_image], return_tensors=\"pt\")[\"pixel_values\"].unsqueeze(0)\r\n```\r\n\r\nWill it be different with `IdeficsImageProcessor`?\r\n\r\nHere's an example output of the burger example.\r\n\r\n\r\n \r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
Hi the recent release of Idefics-9/80B-Instruct model is superbly promising!
We would like to evaluate them on a customized benchmarks with in context examples. May I ask how should I arrange the prompt template, especially for `instruct` version?
We had some problems previously when evaluating the model on single images, the model will ramble and wont stop, but managed to resolve them somehow.
For single image we use the template to evaluate instruct version model.
```
User:<fake_token_around_image><image><fake_token_around_image>{prompt} Assistant:
```
Would it be perfectly correct (matching your training template?) or do you have better recommendation. Sorry we have a customized pipeline so it's not easy to adopt your designed `IdeficsProcessor`. 😭
Also we migrate the code on `image_attention_mask` with
```
# supporting idefics processing
def get_formatted_prompt(prompt: str="", in_context_prompts: list = []) -> str:
# prompts = [
# "User:",
# "https://hips.hearstapps.com/hmg-prod/images/cute-photos-of-cats-in-grass-1593184777.jpg",
# "Describe this image.\nAssistant: An image of two kittens in grass.\n",
# "User:",
# "http://images.cocodataset.org/train2017/000000190081.jpg",
# "Describe this image.\nAssistant:",
# ]
# prompts = f"User:<fake_token_around_image><image><fake_token_around_image>{prompt} Assistant:<answer>"
prompts = f"User:<fake_token_around_image><image><fake_token_around_image>{prompt} Assistant:"
return prompts
def get_image_attention_mask(output_input_ids, max_num_images, tokenizer, include_image=True):
# image_attention_mask, _ = image_attention_mask_for_packed_input_ids(output_input_ids, tokenizer)
# image_attention_mask = incremental_to_binary_attention_mask(image_attention_mask, num_classes=max_num_images)
if include_image:
image_attention_mask, _ = image_attention_mask_for_packed_input_ids(output_input_ids, tokenizer)
image_attention_mask = incremental_to_binary_attention_mask(
image_attention_mask, num_classes=max_num_images
)
else:
# in full language mode we set the image mask to all-0s
image_attention_mask = torch.zeros(
output_input_ids.shape[0], output_input_ids.shape[1], 1, dtype=torch.bool
)
return image_attention_mask
lang_x = self.tokenizer(
[
get_formatted_prompt(question, []),
],
return_tensors="pt",
)
image_attention_mask = get_image_attention_mask(lang_x['input_ids'], 1, self.tokenizer)
```
I have read all related blogs and docs but still got confused about the usage of `<end_of_utterance>`. Is it used to break the in context examples with query example?
My guess is
```
User:<fake_token_around_image><image><fake_token_around_image>{in_context_prompt} Assistant: {in_context_answer} <end_of_utterance> User:<fake_token_around_image><image><fake_token_around_image>{prompt} Assistant:
```
Besides, very curious that the model would generate the normal `<end_of_utterance>` at the last of sentence instead of normal llama's `<|endofchunk|>`?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25803/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25803/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25802
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25802/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25802/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25802/events
|
https://github.com/huggingface/transformers/pull/25802
| 1,870,175,679 |
PR_kwDOCUB6oc5Y9Qo7
| 25,802 |
For xla tensors, use an alternative way to get a unique id
|
{
"login": "qihqi",
"id": 1719482,
"node_id": "MDQ6VXNlcjE3MTk0ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1719482?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/qihqi",
"html_url": "https://github.com/qihqi",
"followers_url": "https://api.github.com/users/qihqi/followers",
"following_url": "https://api.github.com/users/qihqi/following{/other_user}",
"gists_url": "https://api.github.com/users/qihqi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/qihqi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qihqi/subscriptions",
"organizations_url": "https://api.github.com/users/qihqi/orgs",
"repos_url": "https://api.github.com/users/qihqi/repos",
"events_url": "https://api.github.com/users/qihqi/events{/privacy}",
"received_events_url": "https://api.github.com/users/qihqi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @muellerzr moved https://github.com/huggingface/safetensors/pull/349 to here",
"LMK if I should add a test (and in which file) I am not sure if the CI machines has torch_xla installed so `import torch_xla` can succeed...",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25802). All of your documentation changes will be reflected on that endpoint.",
"@amyeroberts this stems from https://github.com/huggingface/safetensors/pull/349, where we specified that it should be done in `transformers` and `accelerate` separately. "
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
XLA tensors don't have storage and attempting to get it's storage will get
RuntimeError: Attempted to access the data pointer on an
invalid python storage.
Repro:
```
from transformers import pytorch_utils
import torch_xla.core.xla_model as xm
device = xm.xla_device()
a = torch.ones((10,10)).to(device)
pytorch_utils.id_tensor_storage(a) # raises RuntimeError
```
With this patch it would print out
(device(type='xla', index=0), 1, 400).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25802/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25802/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25802",
"html_url": "https://github.com/huggingface/transformers/pull/25802",
"diff_url": "https://github.com/huggingface/transformers/pull/25802.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25802.patch",
"merged_at": 1693474276000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25801
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25801/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25801/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25801/events
|
https://github.com/huggingface/transformers/issues/25801
| 1,870,161,592 |
I_kwDOCUB6oc5veGa4
| 25,801 |
AttributeError: 'SegformerImageProcessor' object has no attribute 'reduce_labels'
|
{
"login": "andysingal",
"id": 20493493,
"node_id": "MDQ6VXNlcjIwNDkzNDkz",
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andysingal",
"html_url": "https://github.com/andysingal",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url": "https://api.github.com/users/andysingal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andysingal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andysingal/subscriptions",
"organizations_url": "https://api.github.com/users/andysingal/orgs",
"repos_url": "https://api.github.com/users/andysingal/repos",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"received_events_url": "https://api.github.com/users/andysingal/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Hi, could you try use `do_reduce_labels` instead `reduce_labels`? The later one is already deprecated for quite some time.",
"(we might need to update the doc however)",
"Yes, It needs to be updated. Thanks\r\n\r\nOn Tue, Aug 29, 2023 at 7:36 PM Yih-Dar ***@***.***> wrote:\r\n\r\n> (we might need to update the doc however)\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/transformers/issues/25801#issuecomment-1697512698>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AE4LJNP5I5TZJBLYCXI3IGLXXXZMZANCNFSM6AAAAAA4BXQRBA>\r\n> .\r\n> You are receiving this because you authored the thread.Message ID:\r\n> ***@***.***>\r\n>\r\n",
"I hope the documentation is updated.\r\n\r\nOn Thu, Aug 31, 2023 at 5:37 PM Benjamin Bossan ***@***.***>\r\nwrote:\r\n\r\n> Closed #25801 <https://github.com/huggingface/transformers/issues/25801>\r\n> as completed via huggingface/peft#891\r\n> <https://github.com/huggingface/peft/pull/891>.\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/transformers/issues/25801#event-10243962094>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AE4LJNPBJ3UOKNXDILGJIHLXYB5ALANCNFSM6AAAAAA4BXQRBA>\r\n> .\r\n> You are receiving this because you authored the thread.Message ID:\r\n> ***@***.***>\r\n>\r\n"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
jupyter notebook, RTX 3090
### Who can help?
@amyeroberts @pacman100
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Please check: https://colab.research.google.com/drive/1CRzivM0AfwtmV39f5ElpQa_-vLrTS1Aq?usp=sharing
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[18], line 26
3 training_args = TrainingArguments(
4 output_dir=f"{model_name}-scene-parse-150-lora",
5 learning_rate=5e-4,
(...)
16 report_to="wandb"
17 )
18 trainer = Trainer(
19 model=lora_model,
20 args=training_args,
(...)
23 compute_metrics=compute_metrics,
24 )
---> 26 trainer.train()
File /usr/local/lib/python3.10/dist-packages/transformers/trainer.py:1546, in Trainer.train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1543 try:
1544 # Disable progress bars when uploading models during checkpoints to avoid polluting stdout
1545 hf_hub_utils.disable_progress_bars()
-> 1546 return inner_training_loop(
1547 args=args,
1548 resume_from_checkpoint=resume_from_checkpoint,
1549 trial=trial,
1550 ignore_keys_for_eval=ignore_keys_for_eval,
1551 )
1552 finally:
1553 hf_hub_utils.enable_progress_bars()
File /usr/local/lib/python3.10/dist-packages/transformers/trainer.py:1944, in Trainer._inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)
1941 self.control.should_training_stop = True
1943 self.control = self.callback_handler.on_epoch_end(args, self.state, self.control)
-> 1944 self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
1946 if DebugOption.TPU_METRICS_DEBUG in self.args.debug:
1947 if is_torch_tpu_available():
1948 # tpu-comment: Logging debug metrics for PyTorch/XLA (compile, execute times, ops, etc.)
File /usr/local/lib/python3.10/dist-packages/transformers/trainer.py:2256, in Trainer._maybe_log_save_evaluate(self, tr_loss, model, trial, epoch, ignore_keys_for_eval)
2254 metrics.update(dataset_metrics)
2255 else:
-> 2256 metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
2257 self._report_to_hp_search(trial, self.state.global_step, metrics)
2259 # Run delayed LR scheduler now that metrics are populated
File /usr/local/lib/python3.10/dist-packages/transformers/trainer.py:2972, in Trainer.evaluate(self, eval_dataset, ignore_keys, metric_key_prefix)
2969 start_time = time.time()
2971 eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
-> 2972 output = eval_loop(
2973 eval_dataloader,
2974 description="Evaluation",
2975 # No point gathering the predictions if there are no metrics, otherwise we defer to
2976 # self.args.prediction_loss_only
2977 prediction_loss_only=True if self.compute_metrics is None else None,
2978 ignore_keys=ignore_keys,
2979 metric_key_prefix=metric_key_prefix,
2980 )
2982 total_batch_size = self.args.eval_batch_size * self.args.world_size
2983 if f"{metric_key_prefix}_jit_compilation_time" in output.metrics:
File /usr/local/lib/python3.10/dist-packages/transformers/trainer.py:3261, in Trainer.evaluation_loop(self, dataloader, description, prediction_loss_only, ignore_keys, metric_key_prefix)
3257 metrics = self.compute_metrics(
3258 EvalPrediction(predictions=all_preds, label_ids=all_labels, inputs=all_inputs)
3259 )
3260 else:
-> 3261 metrics = self.compute_metrics(EvalPrediction(predictions=all_preds, label_ids=all_labels))
3262 else:
3263 metrics = {}
Cell In[12], line 27, in compute_metrics(eval_pred)
19 pred_labels = logits_tensor.detach().cpu().numpy()
20 # currently using _compute instead of compute
21 # see this issue for more info: https://github.com/huggingface/evaluate/pull/328#issuecomment-1286866576
22 metrics = metric._compute(
23 predictions=pred_labels,
24 references=labels,
25 num_labels=len(id2label),
26 ignore_index=0,
---> 27 reduce_labels=image_processor.reduce_labels,
28 )
30 per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
31 per_category_iou = metrics.pop("per_category_iou").tolist()
AttributeError: 'SegformerImageProcessor' object has no attribute 'reduce_labels'
```
### Expected behavior
runs the model as shared in : https://huggingface.co/docs/peft/task_guides/semantic_segmentation_lora
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25801/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25801/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25800
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25800/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25800/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25800/events
|
https://github.com/huggingface/transformers/issues/25800
| 1,869,874,703 |
I_kwDOCUB6oc5vdAYP
| 25,800 |
Having trouble loading Blip2 4bit
|
{
"login": "joaopedrosdmm",
"id": 37955817,
"node_id": "MDQ6VXNlcjM3OTU1ODE3",
"avatar_url": "https://avatars.githubusercontent.com/u/37955817?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/joaopedrosdmm",
"html_url": "https://github.com/joaopedrosdmm",
"followers_url": "https://api.github.com/users/joaopedrosdmm/followers",
"following_url": "https://api.github.com/users/joaopedrosdmm/following{/other_user}",
"gists_url": "https://api.github.com/users/joaopedrosdmm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/joaopedrosdmm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/joaopedrosdmm/subscriptions",
"organizations_url": "https://api.github.com/users/joaopedrosdmm/orgs",
"repos_url": "https://api.github.com/users/joaopedrosdmm/repos",
"events_url": "https://api.github.com/users/joaopedrosdmm/events{/privacy}",
"received_events_url": "https://api.github.com/users/joaopedrosdmm/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Did you try after installing the packages? Your environnement should be restarted to make sure you are using the installed packages",
"Hey. Thanks for the quick reply. I seem to have fixed it by importing a different version of transformers: \r\n\"!pip install -U -q git+https://github.com/huggingface/transformers@de9255de27abfcae4a1f816b904915f0b1e23cd9\"\r\n\r\nBtw since you are already here, do you know of a way to remove the LLM head from Blip and use another LLM?",
"No idea no,[ the forum ](https://discuss.huggingface.co/)is a good place to ask this 😉 ",
"Thanks for the reply I guess this issue is more or less closed, but I have a follow up issue regarding BNB and quantization of Blip. Maybe I should make another issue, but I will try here anyway. The model is Blip2ForConditionalGeneration 4bit.\r\n\r\nCode:\r\n```\r\nprompt= \"What is thos image?\"\r\nraw_image = Image.open(requests.get(url, stream=True).raw)\r\n\r\ninputs = processor(images=raw_image, text=prompt, return_tensors=\"pt\").to(device, torch.float16)\r\ngenerated_ids = model.generate(**inputs).to(torch.float16)\r\ngenerated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()\r\n```\r\n\r\nError:\r\n\r\n```\r\n/usr/local/lib/python3.10/dist-packages/transformers/generation/utils.py:1349: UserWarning: Using `max_length`'s default (20) to control the generation length. This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we recommend using `max_new_tokens` to control the maximum length of the generation.\r\n warnings.warn(\r\nFP4 quantization state not initialized. Please call .cuda() or .to(device) on the LinearFP4 layer first.\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n[<ipython-input-37-fe415740fe90>](https://localhost:8080/#) in <cell line: 4>()\r\n 2 model\r\n 3 inputs = processor(images=raw_image, text=prompt, return_tensors=\"pt\").to(torch.float16)\r\n----> 4 generated_ids = model.generate(**inputs).to(torch.float16)\r\n 5 generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()\r\n\r\n10 frames\r\n[/usr/local/lib/python3.10/dist-packages/bitsandbytes/nn/modules.py](https://localhost:8080/#) in forward(self, x)\r\n 246 \r\n 247 bias = None if self.bias is None else self.bias.to(self.compute_dtype)\r\n--> 248 out = bnb.matmul_4bit(x, self.weight.t(), bias=bias, quant_state=self.weight.quant_state)\r\n 249 \r\n 250 out = out.to(inp_dtype)\r\n\r\nAttributeError: 'Parameter' object has no attribute 'quant_state'\r\n```\r\n\r\nI tried the suggested solution, to use .to(device) on the model which contains LinearFP4: (language_projection): Linear4bit(in_features=768, out_features=2560, bias=True)\r\n\r\nI got the following error:\r\n\r\n```\r\nWARNING:accelerate.big_modeling:You shouldn't move a model when it is dispatched on multiple devices.\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n[<ipython-input-40-85b3397abcc2>](https://localhost:8080/#) in <cell line: 3>()\r\n 1 prompt= \"What is thos image?\"\r\n 2 image = Image.open(requests.get(url, stream=True).raw)\r\n----> 3 model.to(device, torch.float16)\r\n 4 \r\n 5 inputs = processor(images=raw_image, text=prompt, return_tensors=\"pt\").to(device, torch.float16)\r\n\r\n1 frames\r\n[/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py](https://localhost:8080/#) in to(self, *args, **kwargs)\r\n 1884 # Checks if the model has been loaded in 8-bit\r\n 1885 if getattr(self, \"is_quantized\", False):\r\n-> 1886 raise ValueError(\r\n 1887 \"`.to` is not supported for `4-bit` or `8-bit` models. Please use the model as it is, since the\"\r\n 1888 \" model has already been set to the correct devices and casted to the correct `dtype`.\r\n\r\n\r\nValueError: `.to` is not supported for `4-bit` or `8-bit` models. Please use the model as it is, since the model has already been set to the correct devices and casted to the correct `dtype`.\r\n```\r\n\r\nShould I try another float?\r\n\r\nEdit:\r\n\r\nI tried not change another dtype and removing .to(), I got the following error:\r\n\"\r\nRuntimeError Traceback (most recent call last)\r\n[<ipython-input-50-b68255e99642>](https://localhost:8080/#) in <cell line: 5>()\r\n 3 \r\n 4 inputs = processor(images=raw_image, text=prompt, return_tensors=\"pt\")\r\n----> 5 generated_ids = model.generate(**inputs)\r\n 6 generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()\r\n\r\n11 frames\r\n[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/conv.py](https://localhost:8080/#) in _conv_forward(self, input, weight, bias)\r\n 457 weight, bias, self.stride,\r\n 458 _pair(0), self.dilation, self.groups)\r\n--> 459 return F.conv2d(input, weight, bias, self.stride,\r\n 460 self.padding, self.dilation, self.groups)\r\n 461 \r\n\r\nRuntimeError: Input type (float) and bias type (c10::Half) should be the same\r\n\"\r\n",
"Hi @joaopedrosdmm , I am unable to reproduce your error. Make sure that you have the latest libraries. Here's a quick snippet that worked for me. Let me know if it works on your side. \r\n```py\r\nimport torch\r\nfrom transformers import Blip2ForConditionalGeneration, AutoProcessor, Blip2Processor, BitsAndBytesConfig\r\nfrom PIL import Image\r\nimport requests\r\nfrom transformers import Blip2Processor\r\n \r\nnf4_config = BitsAndBytesConfig(\r\n load_in_4bit=True,\r\n bnb_4bit_quant_type=\"nf4\",\r\n bnb_4bit_use_double_quant=True,\r\n bnb_4bit_compute_dtype=torch.bfloat16\r\n)\r\n\r\ndef prepare_img():\r\n url = \"https://huggingface.co/hf-internal-testing/blip-test-image/resolve/main/demo.jpg\"\r\n image = Image.open(requests.get(url, stream=True).raw)\r\n return image\r\n\r\nimage = prepare_img()\r\n\r\nprocessor = AutoProcessor.from_pretrained(\"Salesforce/blip2-opt-2.7b-coco\")\r\ninputs = processor(images=image, return_tensors=\"pt\").to(0, dtype=torch.float16)\r\nmodel = Blip2ForConditionalGeneration.from_pretrained(\"Salesforce/blip2-opt-2.7b-coco\", device_map={\"\":0}, quantization_config=nf4_config)\r\n\r\ngenerated_ids = model.generate(**inputs)\r\ngenerated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()\r\nprint(generated_text)\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,696 | 1,696 |
NONE
| null |
### System Info
It throws and import error although I already restarted the notebook, tried to import bitsandbytes and acceleraet different ways. I'm not even loading 8bit but in the error thrown, it seems to believe I am. Help would be appreciated.
Code:
```python
!pip install -q -U git+https://github.com/TimDettmers/bitsandbytes
!pip install -q -U git+https://github.com/huggingface/transformers.git
!pip install -q -U git+https://github.com/huggingface/peft.git
!pip install -q -U git+https://github.com/huggingface/accelerate.git
import torch
from transformers import Blip2ForConditionalGeneration, AutoProcessor, Blip2Processor, AutoModelForCausalLM, BitsAndBytesConfig
from peft import prepare_model_for_kbit_training
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b-coco")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b-coco", device_map='auto', quantization_config=nf4_config)"
```
Output:
```python
ImportError Traceback (most recent call last)
[<ipython-input-8-00160637c6d2>](https://localhost:8080/#) in <cell line: 13>()
11
12 processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b-coco")
---> 13 model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b-coco", device_map='auto', quantization_config=nf4_config)
[/usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py](https://localhost:8080/#) in from_pretrained(cls, pretrained_model_name_or_path, config, cache_dir, ignore_mismatched_sizes, force_download, local_files_only, token, revision, use_safetensors, *model_args, **kwargs)
2478 if load_in_8bit or load_in_4bit:
2479 if not (is_accelerate_available() and is_bitsandbytes_available()):
-> 2480 raise ImportError(
2481 "Using `load_in_8bit=True` requires Accelerate: `pip install accelerate` and the latest version of"
2482 " bitsandbytes `pip install -i https://test.pypi.org/simple/ bitsandbytes` or"
ImportError: Using `load_in_8bit=True` requires Accelerate: `pip install accelerate` and the latest version of bitsandbytes `pip install -i https://test.pypi.org/simple/ bitsandbytes` or pip install bitsandbytes`
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
---------------------------------------------------------------------------
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Step 1: run the code provided in colab
### Expected behavior
Load normally in 4 bit. I actually used the exact same code a few weeks back and it worked perfectly.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25800/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25800/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25799
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25799/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25799/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25799/events
|
https://github.com/huggingface/transformers/pull/25799
| 1,869,695,195 |
PR_kwDOCUB6oc5Y7npD
| 25,799 |
[DPT] Add MiDaS 3.1 series
|
{
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25799). All of your documentation changes will be reflected on that endpoint.",
"I've split up the PR in smaller pieces, see above for the first one",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,700 | 1,700 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR improves the DPT model by leveraging the `AutoBackbone` API.
DPT is a [depth estimation model](https://huggingface.co/Intel/dpt-large). Recently, the MiDaS team released a new [3.1 version](https://github.com/isl-org/MiDaS/tree/master#towards-robust-monocular-depth-estimation-mixing-datasets-for-zero-shot-cross-dataset-transfer) with various backbones: BEiT, Swinv2, etc. hence it's an ideal use case for the `AutoBackbone` class.
This PR:
- adds the `BeitBackbone` class
- adds the `Swinv2Backbone` class
- extends modeling_dpt.py to leverage the AutoBackbone API
- fixes the `keep_aspect_ratio` and `ensure_multiple_of` flags of `DPTImageProcessor`, which does not work on main due to them not being passed to the `resize` method.
To do:
- [ ] make sure `out_indices` are backwards compatible for BEiT
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25799/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25799/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25799",
"html_url": "https://github.com/huggingface/transformers/pull/25799",
"diff_url": "https://github.com/huggingface/transformers/pull/25799.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25799.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25798
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25798/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25798/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25798/events
|
https://github.com/huggingface/transformers/pull/25798
| 1,869,655,440 |
PR_kwDOCUB6oc5Y7e4s
| 25,798 |
fix warning trigger for embed_positions when loading xglm
|
{
"login": "MattYoon",
"id": 57797966,
"node_id": "MDQ6VXNlcjU3Nzk3OTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/57797966?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MattYoon",
"html_url": "https://github.com/MattYoon",
"followers_url": "https://api.github.com/users/MattYoon/followers",
"following_url": "https://api.github.com/users/MattYoon/following{/other_user}",
"gists_url": "https://api.github.com/users/MattYoon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MattYoon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MattYoon/subscriptions",
"organizations_url": "https://api.github.com/users/MattYoon/orgs",
"repos_url": "https://api.github.com/users/MattYoon/repos",
"events_url": "https://api.github.com/users/MattYoon/events{/privacy}",
"received_events_url": "https://api.github.com/users/MattYoon/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25798). All of your documentation changes will be reflected on that endpoint.",
"@younesbelkada Good question! There is no `register_buffer` method in TF. There are two replacements you can use for it, depending on what the variable is actually doing:\r\n\r\n1) If the variable needs to be saved/loaded with the model, but you just don't want the optimizer to train it, then create it with `self.add_weight(trainable=False)`. This is similar to `self.register_buffer(persistent=True)`\r\n2) If the weights don't need to be saved, and are just created as a performance optimization to avoid recomputing them in every iteration, this is similar to `self.register_buffer(persistent=False)`. In this case, you can create them in the layer `__init__()` or `build()` method as a `tf.constant`. They will only be computed once, and marking them as `tf.constant` lets the compiler do constant optimizations in the graph. If you do it this way then TF won't really treat them like a 'weight' at all, so you'll probably have to add them to `_keys_to_ignore_on_load_unexpected` if they exist as a weight in the PyTorch model.\r\n\r\nLet me know if you need my help writing a PR for any of this!",
"Hi, @younesbelkada. Thanks for guiding me through the PR! To be frank, I'm not familiar enough on either TF or Transformers to complete this PR. I'm worried that me attempting to fix this issue will cause some other problems and merging this PR will take way longer than necessary. \r\n\r\nThe issue seems like a very simple fix for someone familiar with the internals of Transformers. Can you or someone else close this PR and take the torch? Sorry I couldn't be much help.",
"@MattYoon You don't need to close it! If you allow edits from maintainers, I can push the relevant change to your branch. It should only be one line in the TF code. Are you okay with me doing that?",
"Yes that sounds great! I believe \"allow edits from maintainers\" is active for this PR.",
"@MattYoon Done! I also fixed some spelling in the TF module while I was there.\r\n\r\ncc @younesbelkada too",
"cc @amyeroberts for core maintainer review!"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #25797
Warning no longer triggers when loading XGLM from the hub. I've followed @younesbelkada 's suggestion of making the problematic module non-persistent.
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('facebook/xglm-564M')
# no warning
```
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@younesbelkada @ArthurZucker
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25798/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25798/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25798",
"html_url": "https://github.com/huggingface/transformers/pull/25798",
"diff_url": "https://github.com/huggingface/transformers/pull/25798.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25798.patch",
"merged_at": 1693314547000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25797
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25797/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25797/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25797/events
|
https://github.com/huggingface/transformers/issues/25797
| 1,869,577,173 |
I_kwDOCUB6oc5vb3vV
| 25,797 |
Loading XGLM triggers warning "Some weights of .. were not initialized from" for a module with no params
|
{
"login": "MattYoon",
"id": 57797966,
"node_id": "MDQ6VXNlcjU3Nzk3OTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/57797966?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MattYoon",
"html_url": "https://github.com/MattYoon",
"followers_url": "https://api.github.com/users/MattYoon/followers",
"following_url": "https://api.github.com/users/MattYoon/following{/other_user}",
"gists_url": "https://api.github.com/users/MattYoon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MattYoon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MattYoon/subscriptions",
"organizations_url": "https://api.github.com/users/MattYoon/orgs",
"repos_url": "https://api.github.com/users/MattYoon/repos",
"events_url": "https://api.github.com/users/MattYoon/events{/privacy}",
"received_events_url": "https://api.github.com/users/MattYoon/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks for raising the issue @MattYoon \r\n@ArthurZucker can confirm, I think the fix would be to make the weight of that module non-persistent (`persistent=False`) so that they won't get saved in the state_dict: https://github.com/huggingface/transformers/blob/main/src/transformers/models/xglm/modeling_xglm.py#L179 \r\nIndeed there is not need to save them in the state dict (or to consider them when loading the weights) as they are created on the fly. If that fixes the issue, would you be happy to open a PR with the fix?"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.32.0
- Platform: Linux-5.15.0-41-generic-x86_64-with-glibc2.31
- Python version: 3.9.16
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.20.3
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help?
@ArthurZucker @younesbelkada
~~But probably a general issue in the `PretrainedModel` class.~~
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('facebook/xglm-564M')
# Some weights of XGLMForCausalLM were not initialized from the model checkpoint
# at facebook/xglm-564M and are newly initialized: ['model.embed_positions.weights']
# You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
### Expected behavior
The warning should not be triggered.
The positional embedding for XGLM uses `XGLMSinusoidalPositionalEmbedding` which does not have actual trainable parameters. My guess is that since there is no parameters, the key is not actually stored in the checkpoint and triggers the warning. This issue might exist in other models that similarly have `nn.Module` with no trainable parameters.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25797/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25797/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25796
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25796/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25796/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25796/events
|
https://github.com/huggingface/transformers/pull/25796
| 1,869,537,049 |
PR_kwDOCUB6oc5Y7Evu
| 25,796 |
Update notebook.py to support multi eval datasets
|
{
"login": "matrix1001",
"id": 32097922,
"node_id": "MDQ6VXNlcjMyMDk3OTIy",
"avatar_url": "https://avatars.githubusercontent.com/u/32097922?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/matrix1001",
"html_url": "https://github.com/matrix1001",
"followers_url": "https://api.github.com/users/matrix1001/followers",
"following_url": "https://api.github.com/users/matrix1001/following{/other_user}",
"gists_url": "https://api.github.com/users/matrix1001/gists{/gist_id}",
"starred_url": "https://api.github.com/users/matrix1001/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/matrix1001/subscriptions",
"organizations_url": "https://api.github.com/users/matrix1001/orgs",
"repos_url": "https://api.github.com/users/matrix1001/repos",
"events_url": "https://api.github.com/users/matrix1001/events{/privacy}",
"received_events_url": "https://api.github.com/users/matrix1001/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Note that my last commit corresponds to the workflow check. I dont think it's necessary.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25796). All of your documentation changes will be reflected on that endpoint.",
"@matrix1001 do you want me to merge this or do you still have modifications to include?",
"@ArthurZucker merge.",
"```\r\nimport evaluate\r\n\r\nf1_metric = evaluate.load(\"f1\")\r\nprecision_metric = evaluate.load(\"precision\")\r\nrecall_metric = evaluate.load(\"recall\")\r\naccuracy_metric = evaluate.load(\"accuracy\")\r\naverage_method = 'weighted'\r\ndef compute_metrics(eval_pred):\r\n results = {}\r\n predictions = np.argmax(eval_pred.predictions, axis=1)\r\n labels = eval_pred.label_ids\r\n results.update(f1_metric.compute(predictions=predictions, references = labels, average=average_method))\r\n results.update(precision_metric.compute(predictions=predictions, references = labels, average=average_method))\r\n results.update(recall_metric.compute(predictions=predictions, references = labels, average=average_method))\r\n results.update(accuracy_metric.compute(predictions=predictions, references = labels))\r\n return results\r\n```\r\n\r\nIn this code, on master branch I am still seeing:\r\n\r\n```\r\n----> 1 train_results = trainer.train()\r\n\r\nFile ~/.local/lib/python3.8/site-packages/transformers/trainer.py:1591, in Trainer.train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)\r\n 1589 hf_hub_utils.enable_progress_bars()\r\n 1590 else:\r\n-> 1591 return inner_training_loop(\r\n 1592 args=args,\r\n 1593 resume_from_checkpoint=resume_from_checkpoint,\r\n 1594 trial=trial,\r\n 1595 ignore_keys_for_eval=ignore_keys_for_eval,\r\n 1596 )\r\n\r\nFile ~/.local/lib/python3.8/site-packages/transformers/trainer.py:1999, in Trainer._inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)\r\n 1996 self.control.should_training_stop = True\r\n 1998 self.control = self.callback_handler.on_epoch_end(args, self.state, self.control)\r\n-> 1999 self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)\r\n 2001 if DebugOption.TPU_METRICS_DEBUG in self.args.debug:\r\n 2002 if is_torch_tpu_available():\r\n 2003 # tpu-comment: Logging debug metrics for PyTorch/XLA (compile, execute times, ops, etc.)\r\n\r\nFile ~/.local/lib/python3.8/site-packages/transformers/trainer.py:2339, in Trainer._maybe_log_save_evaluate(self, tr_loss, model, trial, epoch, ignore_keys_for_eval)\r\n 2336 self.lr_scheduler.step(metrics[metric_to_check])\r\n 2338 if self.control.should_save:\r\n-> 2339 self._save_checkpoint(model, trial, metrics=metrics)\r\n 2340 self.control = self.callback_handler.on_save(self.args, self.state, self.control)\r\n\r\nFile ~/.local/lib/python3.8/site-packages/transformers/trainer.py:2458, in Trainer._save_checkpoint(self, model, trial, metrics)\r\n 2456 if not metric_to_check.startswith(\"eval_\"):\r\n 2457 metric_to_check = f\"eval_{metric_to_check}\"\r\n-> 2458 metric_value = metrics[metric_to_check]\r\n 2460 operator = np.greater if self.args.greater_is_better else np.less\r\n 2461 if (\r\n 2462 self.state.best_metric is None\r\n 2463 or self.state.best_model_checkpoint is None\r\n 2464 or operator(metric_value, self.state.best_metric)\r\n 2465 ):\r\n\r\nKeyError: 'eval_accuracy'\r\n```",
"@puneetdabulya This PR only fixes `notebook.py`. You may need to fix it in another PR."
] | 1,693 | 1,696 | 1,694 |
CONTRIBUTOR
| null |
# Fix key error when using multiple evaluation datasets
## Code triggering the error
Any code using multiple eval_dataset will trigger the error.
```py
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset={
'valid':valid_dataset,
'test':test_dataset,
},
compute_metrics=compute_metrics
)
```
## Before fix

Here's detailed error msg:
```
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[1], line 80
68 model = BertForRelationExtraction.from_pretrained('bert-base-cased', config=config)
69 trainer = Trainer(
70 model=model,
71 args=training_args,
(...)
77 compute_metrics=compute_metrics
78 )
---> 80 trainer.train()
File [~/anaconda3/envs/pytorch2/lib/python3.11/site-packages/transformers/trainer.py:1664], in Trainer.train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1659 self.model_wrapped = self.model
1661 inner_training_loop = find_executable_batch_size(
1662 self._inner_training_loop, self._train_batch_size, args.auto_find_batch_size
1663 )
-> 1664 return inner_training_loop(
1665 args=args,
1666 resume_from_checkpoint=resume_from_checkpoint,
1667 trial=trial,
1668 ignore_keys_for_eval=ignore_keys_for_eval,
1669 )
File [~/anaconda3/envs/pytorch2/lib/python3.11/site-packages/transformers/trainer.py:2019], in Trainer._inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)
2016 self.state.epoch = epoch + (step + 1 + steps_skipped) / steps_in_epoch
2017 self.control = self.callback_handler.on_step_end(args, self.state, self.control)
-> 2019 self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
2020 else:
2021 self.control = self.callback_handler.on_substep_end(args, self.state, self.control)
File [~/anaconda3/envs/pytorch2/lib/python3.11/site-packages/transformers/trainer.py:2293], in Trainer._maybe_log_save_evaluate(self, tr_loss, model, trial, epoch, ignore_keys_for_eval)
2291 metrics = {}
2292 for eval_dataset_name, eval_dataset in self.eval_dataset.items():
-> 2293 dataset_metrics = self.evaluate(
2294 eval_dataset=eval_dataset,
2295 ignore_keys=ignore_keys_for_eval,
2296 metric_key_prefix=f"eval_{eval_dataset_name}",
2297 )
2298 metrics.update(dataset_metrics)
2299 else:
File [~/anaconda3/envs/pytorch2/lib/python3.11/site-packages/transformers/trainer.py:3057], in Trainer.evaluate(self, eval_dataset, ignore_keys, metric_key_prefix)
3053 if DebugOption.TPU_METRICS_DEBUG in self.args.debug:
3054 # tpu-comment: Logging debug metrics for PyTorch/XLA (compile, execute times, ops, etc.)
3055 xm.master_print(met.metrics_report())
-> 3057 self.control = self.callback_handler.on_evaluate(self.args, self.state, self.control, output.metrics)
3059 self._memory_tracker.stop_and_update_metrics(output.metrics)
3061 return output.metrics
File [~/anaconda3/envs/pytorch2/lib/python3.11/site-packages/transformers/trainer_callback.py:379], in CallbackHandler.on_evaluate(self, args, state, control, metrics)
377 def on_evaluate(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, metrics):
378 control.should_evaluate = False
--> 379 return self.call_event("on_evaluate", args, state, control, metrics=metrics)
File [~/anaconda3/envs/pytorch2/lib/python3.11/site-packages/transformers/trainer_callback.py:397], in CallbackHandler.call_event(self, event, args, state, control, **kwargs)
395 def call_event(self, event, args, state, control, **kwargs):
396 for callback in self.callbacks:
--> 397 result = getattr(callback, event)(
398 args,
399 state,
400 control,
401 model=self.model,
402 tokenizer=self.tokenizer,
403 optimizer=self.optimizer,
404 lr_scheduler=self.lr_scheduler,
405 train_dataloader=self.train_dataloader,
406 eval_dataloader=self.eval_dataloader,
407 **kwargs,
408 )
409 # A Callback can skip the return of `control` if it doesn't change it.
410 if result is not None:
File [~/anaconda3/envs/pytorch2/lib/python3.11/site-packages/transformers/utils/notebook.py:350], in NotebookProgressCallback.on_evaluate(self, args, state, control, metrics, **kwargs)
348 name = " ".join([part.capitalize() for part in splits[1:]])
349 values[name] = v
--> 350 self.training_tracker.write_line(values)
351 self.training_tracker.remove_child()
352 self.prediction_bar = None
File [~/anaconda3/envs/pytorch2/lib/python3.11/site-packages/transformers/utils/notebook.py:244], in NotebookTrainingTracker.write_line(self, values)
242 columns.append(key)
243 self.inner_table[0] = columns
--> 244 self.inner_table.append([values[c] for c in columns])
File [~/anaconda3/envs/pytorch2/lib/python3.11/site-packages/transformers/utils/notebook.py:244](, in (.0)
242 columns.append(key)
243 self.inner_table[0] = columns
--> 244 self.inner_table.append([values[c] for c in columns])
KeyError: 'Valid Accuracy'
```
## After fix

## Some explanation
I remove all predefined key "Validation Loss". However, this will have the following result if there is only one eval_dataset:

I think we don't have to name it as "Validation Loss"?
My modification allows dynamic columns and updates values if multiple calls for `NotebookProgressCallback.on_evaluate` correspond to the same epoch or step.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25796/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25796/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25796",
"html_url": "https://github.com/huggingface/transformers/pull/25796",
"diff_url": "https://github.com/huggingface/transformers/pull/25796.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25796.patch",
"merged_at": 1694793139000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25795
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25795/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25795/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25795/events
|
https://github.com/huggingface/transformers/issues/25795
| 1,869,481,635 |
I_kwDOCUB6oc5vbgaj
| 25,795 |
ValueError: Some specified arguments are not used by the HfArgumentParser: ['\\']
|
{
"login": "mohammedtoumi007",
"id": 55878755,
"node_id": "MDQ6VXNlcjU1ODc4NzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/55878755?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mohammedtoumi007",
"html_url": "https://github.com/mohammedtoumi007",
"followers_url": "https://api.github.com/users/mohammedtoumi007/followers",
"following_url": "https://api.github.com/users/mohammedtoumi007/following{/other_user}",
"gists_url": "https://api.github.com/users/mohammedtoumi007/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mohammedtoumi007/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mohammedtoumi007/subscriptions",
"organizations_url": "https://api.github.com/users/mohammedtoumi007/orgs",
"repos_url": "https://api.github.com/users/mohammedtoumi007/repos",
"events_url": "https://api.github.com/users/mohammedtoumi007/events{/privacy}",
"received_events_url": "https://api.github.com/users/mohammedtoumi007/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey, we can't help you if you don't provide a reproducer and share the output of `transformers-cli envs`. I suspect you just have a typo in the call you are making to the script. ",
"@ArthurZucker i update the script",
"You should try:\r\n```bash\r\npython -m torch.distributed.run \\\r\n --nproc_per_node 1 transformers/examples/pytorch/summarization/run_summarization.py \\\r\n --model_name_or_path facebook/bart-base \\\r\n --do_train \\\r\n --do_eval \\\r\n --do_predict \\\r\n --train_file /content/OpenCQA/baseline_models/bart/inputs/train.csv \\\r\n --validation_file /content/OpenCQA/baseline_models/bart/inputs/val.csv \\\r\n --test_file /content/OpenCQA/baseline_models/bart/inputs/test.csv \\\r\n --text_column ${model}_text \\\r\n --summary_column ${summary}_answer \\\r\n --output_dir /content/OpenCQA/baseline_models/bart/outputsTest/$model \\\r\n --overwrite_output_dir \\\r\n --learning_rate=0.00005 \\\r\n --per_device_train_batch_size=4 \\\r\n --per_device_eval_batch_size=4 \\\r\n --predict_with_generate \\\r\n --num_beams=4 \\\r\n --max_source_length=800 \\\r\n --max_target_length=128 \\\r\n --generation_max_length=128 \\\r\n --eval_steps=500 \\\r\n --save_steps=500 \\\r\n --evaluation_strategy steps \\\r\n --load_best_model_at_end \\\r\n --weight_decay=0.01 \\\r\n --max_steps=5000 \r\n```",
"@ArthurZucker yes i run this envs but it show me this error : \r\n\r\nTraceback (most recent call last):\r\n File \"/content/OpenCQA/baseline_models/bart/transformers/examples/pytorch/summarization/run_summarization.py\", line 782, in <module>\r\n main()\r\n File \"/content/OpenCQA/baseline_models/bart/transformers/examples/pytorch/summarization/run_summarization.py\", line 331, in main\r\n model_args, data_args, training_args = parser.parse_args_into_dataclasses()\r\n File \"/usr/local/lib/python3.10/dist-packages/transformers/hf_argparser.py\", line 347, in parse_args_into_dataclasses\r\n raise ValueError(f\"Some specified arguments are not used by the HfArgumentParser: {remaining_args}\")\r\nValueError: Some specified arguments are not used by the HfArgumentParser: ['\\\\']",
"Sorry @mohammedtoumi007, I can't debug in your stead, your issue is that you have a typo in the command, which I cannot reproduce. Try to run the full command in one line and make sure you don't add extra `/`. \r\n\r\nAgain, this works:\r\n```python\r\npython -m torch.distributed.run --nproc_per_node 1 transformers/examples/pytorch/summarization/run_summarization.py --model_name_or_path facebook/bart-base --do_train --do_eval --do_predict --train_file /content/OpenCQA/baseline_models/bart/inputs/train.csv --validation_file /content/OpenCQA/baseline_models/bart/inputs/val.csv --test_file /content/OpenCQA/baseline_models/bart/inputs/test.csv --text_column ${model}_text --summary_column ${summary}_answer --output_dir /content/OpenCQA/baseline_models/bart/outputsTest/$model --overwrite_output_dir --learning_rate=0.00005 --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --predict_with_generate --num_beams=4 --max_source_length=800 --max_target_length=128 --generation_max_length=128 --eval_steps=500 --save_steps=500 --evaluation_strategy steps --load_best_model_at_end --weight_decay=0.01 --max_steps=5000\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
I am doing a project question answer about chart. For fine-tuning BART MODEL. I tried to use "run_summarization.py" for fine-tuning from transformers. But, I came across with the following error :
```python
Traceback (most recent call last):
File "/content/OpenCQA/baseline_models/bart/transformers/examples/pytorch/summarization/run_summarization.py", line 782, in <module>
main()
File "/content/OpenCQA/baseline_models/bart/transformers/examples/pytorch/summarization/run_summarization.py", line 331, in main
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
File "/usr/local/lib/python3.10/dist-packages/transformers/hf_argparser.py", line 347, in parse_args_into_dataclasses
raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
ValueError: Some specified arguments are not used by the HfArgumentParser: ['\\']
```
Can anyone give some information about this error !!
### Who can help?
@LysandreJik
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
pip install -r examples/pytorch/summarization/requirements.txt
```
run the code :
```
python -m torch.distributed.run \
--nproc_per_node 1 transformers/examples/pytorch/summarization/run_summarization.py \
--model_name_or_path facebook/bart-base \
--do_train \
--do_eval \
--do_predict \
--train_file /content/OpenCQA/baseline_models/bart/inputs/train.csv \
--validation_file /content/OpenCQA/baseline_models/bart/inputs/val.csv \
--test_file /content/OpenCQA/baseline_models/bart/inputs/test.csv \
--text_column ${model}_text \
--summary_column ${summary}_answer \
--output_dir /content/OpenCQA/baseline_models/bart/outputsTest/$model \
--overwrite_output_dir \
--learning_rate=0.00005 \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate \
--num_beams=4 \
--max_source_length=800 \
--max_target_length=128 \
--generation_max_length=128 \
--eval_steps=500 \
--save_steps=500 \
--evaluation_strategy steps \
--load_best_model_at_end \
--weight_decay=0.01 \
--max_steps=5000 \
```
### Expected behavior
```
raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
ValueError: Some specified arguments are not used by the HfArgumentParser: ['\\']
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25795/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25795/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25794
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25794/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25794/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25794/events
|
https://github.com/huggingface/transformers/pull/25794
| 1,869,252,646 |
PR_kwDOCUB6oc5Y6GaE
| 25,794 |
[`LlamaFamiliy`] add a tip about dtype
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
add a warning=True tip to the Llama2 doc to make sure people are not confused.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25794/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25794/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25794",
"html_url": "https://github.com/huggingface/transformers/pull/25794",
"diff_url": "https://github.com/huggingface/transformers/pull/25794.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25794.patch",
"merged_at": 1693217251000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25793
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25793/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25793/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25793/events
|
https://github.com/huggingface/transformers/pull/25793
| 1,869,094,191 |
PR_kwDOCUB6oc5Y5j8s
| 25,793 |
[`LlamaTokenizer`] `tokenize` nits.
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
Fixes #25769 by making sure `""` is encoded to `[]`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25793/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25793/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25793",
"html_url": "https://github.com/huggingface/transformers/pull/25793",
"diff_url": "https://github.com/huggingface/transformers/pull/25793.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25793.patch",
"merged_at": 1693314494000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25792
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25792/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25792/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25792/events
|
https://github.com/huggingface/transformers/issues/25792
| 1,869,075,028 |
I_kwDOCUB6oc5vZ9JU
| 25,792 |
MT5/MT0 cannot finetune with lora in 8bit mode
|
{
"login": "Victordongy",
"id": 18495737,
"node_id": "MDQ6VXNlcjE4NDk1NzM3",
"avatar_url": "https://avatars.githubusercontent.com/u/18495737?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Victordongy",
"html_url": "https://github.com/Victordongy",
"followers_url": "https://api.github.com/users/Victordongy/followers",
"following_url": "https://api.github.com/users/Victordongy/following{/other_user}",
"gists_url": "https://api.github.com/users/Victordongy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Victordongy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Victordongy/subscriptions",
"organizations_url": "https://api.github.com/users/Victordongy/orgs",
"repos_url": "https://api.github.com/users/Victordongy/repos",
"events_url": "https://api.github.com/users/Victordongy/events{/privacy}",
"received_events_url": "https://api.github.com/users/Victordongy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"hi @Victordongy \r\nThanks for the issue can you try to re-run LoRA training with the latest peft and transformers?\r\n```bash\r\npip install -U transformers peft\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
transformers version: 4.24.0
Platform: Linux-5.4.0-150-generic-x86_64-with-glibc2.29
Python version: 3.8.10
Huggingface_hub version: 0.16.4
Safetensors version: 0.3.1
Accelerate version: 0.20.3
Accelerate config: not found
PyTorch version (GPU?): 2.0.0+cu117 (True)
Tensorflow version (GPU?): 2.12.0 (False)
Flax version (CPU?/GPU?/TPU?): not installed (NA)
Jax version: not installed
JaxLib version: not installed
Using GPU in script?: Yes
Using distributed or parallel set-up in script?: No
### Who can help?
@younesbelkada @ArthurZucker
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```
model = AutoModelForSeq2SeqLM.from_pretrained(
"google/mt5-large"
load_in_8bit=True,
device_map='auto',
**kwargs
)
model = prepare_model_for_int8_training(model)
config = LoraConfig(
r=8,
lora_alpha=8,
target_modules=["q","v"],
lora_dropout=0.5,
bias="none",
task_type=SEQ_2_SEQ_LM,
)
model = get_peft_model(model, config)
trainer.train()
```
and I got the error as
```
Traceback (most recent call last):
...
File "/temp/models/t5.py", line 72, in forward
query_states = shape(self.q(hidden_states)) # (batch_size, n_heads, seq_length, dim_per_head)
File "/temp/dg_venv/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/temp/dg_venv/lib/python3.8/site-packages/peft/tuners/lora.py", line 817, in forward
result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
RuntimeError: expected scalar type Float but found Char
```
### Expected behavior
Model should be trained successfully.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25792/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25792/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25791
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25791/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25791/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25791/events
|
https://github.com/huggingface/transformers/pull/25791
| 1,869,033,251 |
PR_kwDOCUB6oc5Y5WzD
| 25,791 |
🌐[i18n-KO] Translated `llm_tutorial.md` to Korean
|
{
"login": "harheem",
"id": 49297157,
"node_id": "MDQ6VXNlcjQ5Mjk3MTU3",
"avatar_url": "https://avatars.githubusercontent.com/u/49297157?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/harheem",
"html_url": "https://github.com/harheem",
"followers_url": "https://api.github.com/users/harheem/followers",
"following_url": "https://api.github.com/users/harheem/following{/other_user}",
"gists_url": "https://api.github.com/users/harheem/gists{/gist_id}",
"starred_url": "https://api.github.com/users/harheem/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/harheem/subscriptions",
"organizations_url": "https://api.github.com/users/harheem/orgs",
"repos_url": "https://api.github.com/users/harheem/repos",
"events_url": "https://api.github.com/users/harheem/events{/privacy}",
"received_events_url": "https://api.github.com/users/harheem/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25791). All of your documentation changes will be reflected on that endpoint."
] | 1,693 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
Translated the `llm_tutorial.md` file of the documentation to Korean 😄
Thank you in advance for your review!
Part of https://github.com/huggingface/transformers/issues/20179
## Before reviewing
- [x] Check for missing / redundant translations (번역 누락/중복 검사)
- [x] Grammar Check (맞춤법 검사)
- [x] Review or Add new terms to glossary (용어 확인 및 추가)
- [x] Check Inline TOC (e.g. `[[lowercased-header]]`)
- [x] Check live-preview for gotchas (live-preview로 정상작동 확인)
## Who can review? (Initial)
@bolizabeth, @nuatmochoi, @heuristicwave, @mjk0618, @keonju2, @harheem, @HongB1, @junejae, @54data, @seank021, @augustinLib, @sronger, @TaeYupNoh, @kj021, @eenzeenee
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review? (Final)
May you please review this PR?
@sgugger, @ArthurZucker, @eunseojo
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25791/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/25791/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25791",
"html_url": "https://github.com/huggingface/transformers/pull/25791",
"diff_url": "https://github.com/huggingface/transformers/pull/25791.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25791.patch",
"merged_at": 1694011204000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25790
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25790/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25790/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25790/events
|
https://github.com/huggingface/transformers/issues/25790
| 1,868,961,806 |
I_kwDOCUB6oc5vZhgO
| 25,790 |
Incorrect batched generation for Llama-2 with `pad_token` = `eos_token`
|
{
"login": "wjfwzzc",
"id": 5126316,
"node_id": "MDQ6VXNlcjUxMjYzMTY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wjfwzzc",
"html_url": "https://github.com/wjfwzzc",
"followers_url": "https://api.github.com/users/wjfwzzc/followers",
"following_url": "https://api.github.com/users/wjfwzzc/following{/other_user}",
"gists_url": "https://api.github.com/users/wjfwzzc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wjfwzzc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wjfwzzc/subscriptions",
"organizations_url": "https://api.github.com/users/wjfwzzc/orgs",
"repos_url": "https://api.github.com/users/wjfwzzc/repos",
"events_url": "https://api.github.com/users/wjfwzzc/events{/privacy}",
"received_events_url": "https://api.github.com/users/wjfwzzc/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I have personally also seen a lot of strange behavior with single row vs. larger batch in llama, so decided to dig in a bit.\r\n\r\nIt seems with batch and padding, the logits are `nan` in your case. There is something funamentally wrong with the llama-2-7b-hf float16 weights.\r\n\r\nYou can solve your issue by setting `torch_dtype=torch.bfloat16` and the predictions match.\r\n\r\nHowever, the logits are still slightly off between single row and multi batch, which should not be the case. They are also off when using `unk_token`.",
"> There is something funamentally wrong with the llama-2-7b-hf float16 weights.\r\n\r\nNot sure no. See [this thread on tweeter](https://twitter.com/LysandreJik/status/1696108380040139189?s=20). \r\n\r\n(You seem to be using `trust_remote_code = True` not sure why you would need that here?)\r\n1. Regarding batched generation, you might be using the wrong padding side, and setting `padding = True` in the looped generation will most probably not pad the given input. I would check if the input is the same sentence or not.\r\nCould you also share the outputs you obtained? \r\n2. You mention resizing leads to an issue, could you share the traceback?",
"@ArthurZucker not using padding in the single sample is on purpose\r\n\r\nThe output should be exactly the same with and without padding, as the attention should not attend to these padding tokens.\r\nI am very sure that the posted code is correct.\r\n\r\nMain culprit is the float16, you can try it yourself, but even with bfloat the logits are off.",
"If \" even with bfloat the logits are off. \" then why would `float16` be the main culprit? \r\n\r\nAnyway could you try https://github.com/huggingface/transformers/pull/25284 ? With and without padding should give the same results yes, but depending on the padding scheme (left or right) it might not always be the case. ",
"The logits are off, but they are close enough that the generated token matches. With float16 you get nans.\r\n\r\nBest you run the code yourself to see.\r\n\r\n> but depending on the padding scheme (left or right) it might not always be the case.\r\n\r\nIf attention_mask is set to 0 for those indices, it should be the case, regardless in which direction the padding is. ",
"> (You seem to be using `trust_remote_code = True` not sure why you would need that here?)\r\n\r\nJust because this reproduction code is cherry-picked from a large evaluation tool which needs to support other models. Can be removed here.\r\n\r\n> 1. you might be using the wrong padding side,\r\n\r\nleft padding:\r\n```\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.36s/it]\r\npad_token: </s>, pad_token_id: 2\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.6` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.\r\n warnings.warn(\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.9` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.\r\n warnings.warn(\r\nsample 0 is different, expected_answer: ` B`, batched_answer: ``\r\nsample 1 is different, expected_answer: ` A`, batched_answer: ``\r\nsample 2 is different, expected_answer: ` C`, batched_answer: ``\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.53s/it]\r\npad_token: <unk>, pad_token_id: 0\r\nsample 0 is the same\r\nsample 1 is the same\r\nsample 2 is the same\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.52s/it]\r\nYou are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embeding dimension will be 32001. This might induce some performance reduction as *Tensor Cores* will not be available. For more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc\r\npad_token: [PAD], pad_token_id: 32000\r\nsample 0 is different, expected_answer: ` B`, batched_answer: ``\r\nsample 1 is the same\r\nsample 2 is different, expected_answer: ` C`, batched_answer: ``\r\nsample 3 is the same\r\n```\r\n\r\nright padding:\r\n```\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [03:03<00:00, 91.87s/it]\r\npad_token: </s>, pad_token_id: 2\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.6` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.\r\n warnings.warn(\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.9` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.\r\n warnings.warn(\r\nA decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.\r\nsample 0 is different, expected_answer: ` B`, batched_answer: `\r\n`\r\nsample 1 is different, expected_answer: ` A`, batched_answer: `\r\n`\r\nsample 2 is different, expected_answer: ` C`, batched_answer: `\r\n`\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.71s/it]\r\npad_token: <unk>, pad_token_id: 0\r\nA decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.\r\nsample 0 is different, expected_answer: ` B`, batched_answer: `Љ`\r\nsample 1 is different, expected_answer: ` A`, batched_answer: `Љ`\r\nsample 2 is different, expected_answer: ` C`, batched_answer: `Љ`\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.53s/it]\r\nYou are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embeding dimension will be 32001. This might induce some performance reduction as *Tensor Cores* will not be available. For more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc\r\npad_token: [PAD], pad_token_id: 32000\r\nA decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.\r\nsample 0 is different, expected_answer: ` B`, batched_answer: ` is`\r\nsample 1 is different, expected_answer: ` A`, batched_answer: ` is`\r\nsample 2 is different, expected_answer: ` C`, batched_answer: ` is`\r\nsample 3 is the same\r\n```\r\n\r\nBTW, I do believe we should get the same results for both `right` and `left` for all transformers if we have a correct `attention_mask` and `position_ids` as @psinger says, because the transformer is permutation invariant.\r\n\r\n> 2\\. You mention resizing leads to an issue, could you share the traceback?\r\n\r\nTrackback as follows, it's interesting that I just found the error only shows on A30, no error on A100. Maybe it's a pytorch bug?\r\n```python3\r\nTraceback (most recent call last):\r\n File \"/mnt/bn/wjfwzzc-data/code/lab/genai_llm_eval/issue_padding.py\", line 99, in <module>\r\n run(model_name_or_path, \"new_token\")\r\n File \"/mnt/bn/wjfwzzc-data/code/lab/genai_llm_eval/issue_padding.py\", line 59, in run\r\n outputs = model.generate(**inputs, do_sample=False, max_new_tokens=1)\r\n File \"/usr/local/lib/python3.9/dist-packages/torch/utils/_contextlib.py\", line 115, in decorate_context\r\n return func(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/dist-packages/transformers/generation/utils.py\", line 1596, in generate\r\n return self.greedy_search(\r\n File \"/usr/local/lib/python3.9/dist-packages/transformers/generation/utils.py\", line 2444, in greedy_search\r\n outputs = self(\r\n File \"/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/dist-packages/accelerate/hooks.py\", line 165, in new_forward\r\n output = old_forward(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/dist-packages/transformers/models/llama/modeling_llama.py\", line 827, in forward\r\n logits = self.lm_head(hidden_states)\r\n File \"/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/dist-packages/accelerate/hooks.py\", line 160, in new_forward\r\n args, kwargs = module._hf_hook.pre_forward(module, *args, **kwargs)\r\n File \"/usr/local/lib/python3.9/dist-packages/accelerate/hooks.py\", line 286, in pre_forward\r\n set_module_tensor_to_device(\r\n File \"/usr/local/lib/python3.9/dist-packages/accelerate/utils/modeling.py\", line 281, in set_module_tensor_to_device\r\n raise ValueError(\r\nValueError: Trying to set a tensor of shape torch.Size([32000, 4096]) in \"weight\" (which has shape torch.Size([32001, 4096])), this look incorrect.\r\n```",
"> You can solve your issue by setting `torch_dtype=torch.bfloat16` and the predictions match.\r\n\r\nIt does work in `bfloat16` with left padding! But it fails in right padding.\r\n\r\nleft padding:\r\n```\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:13<00:00, 6.58s/it]\r\npad_token: </s>, pad_token_id: 2\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.6` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.\r\n warnings.warn(\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.9` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.\r\n warnings.warn(\r\nsample 0 is the same\r\nsample 1 is the same\r\nsample 2 is the same\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:13<00:00, 6.56s/it]\r\npad_token: <unk>, pad_token_id: 0\r\nsample 0 is the same\r\nsample 1 is the same\r\nsample 2 is the same\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:13<00:00, 6.86s/it]\r\nYou are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embeding dimension will be 32001. This might induce some performance reduction as *Tensor Cores* will not be available. For more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc\r\npad_token: [PAD], pad_token_id: 32000\r\nsample 0 is the same\r\nsample 1 is the same\r\nsample 2 is the same\r\nsample 3 is the same\r\n```\r\n\r\nright padding:\r\n```\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:16<00:00, 8.34s/it]\r\npad_token: </s>, pad_token_id: 2\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.6` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.\r\n warnings.warn(\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.9` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.\r\n warnings.warn(\r\nA decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.\r\nsample 0 is different, expected_answer: ` B`, batched_answer: `\r\n`\r\nsample 1 is different, expected_answer: ` A`, batched_answer: `\r\n`\r\nsample 2 is different, expected_answer: ` C`, batched_answer: `\r\n`\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:16<00:00, 8.39s/it]\r\npad_token: <unk>, pad_token_id: 0\r\nA decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.\r\nsample 0 is different, expected_answer: ` B`, batched_answer: `Љ`\r\nsample 1 is different, expected_answer: ` A`, batched_answer: `Љ`\r\nsample 2 is different, expected_answer: ` C`, batched_answer: `Љ`\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:15<00:00, 7.98s/it]\r\nYou are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embeding dimension will be 32001. This might induce some performance reduction as *Tensor Cores* will not be available. For more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc\r\npad_token: [PAD], pad_token_id: 32000\r\nA decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.\r\nsample 0 is different, expected_answer: ` B`, batched_answer: `\r\n`\r\nsample 1 is different, expected_answer: ` A`, batched_answer: `\r\n`\r\nsample 2 is different, expected_answer: ` C`, batched_answer: `\r\n`\r\nsample 3 is the same\r\n```",
"> Anyway could you try #25284 ?\r\n\r\nIt also works! With left padding and `float16`. Will fail in right padding.\r\n\r\nleft padding:\r\n```\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.57s/it]\r\npad_token: </s>, pad_token_id: 2\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.6` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.\r\n warnings.warn(\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.9` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.\r\n warnings.warn(\r\nsample 0 is the same\r\nsample 1 is the same\r\nsample 2 is the same\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.51s/it]\r\npad_token: <unk>, pad_token_id: 0\r\nsample 0 is the same\r\nsample 1 is the same\r\nsample 2 is the same\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.52s/it]\r\nYou are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embeding dimension will be 32001. This might induce some performance reduction as *Tensor Cores* will not be available. For more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc\r\npad_token: [PAD], pad_token_id: 32000\r\nsample 0 is the same\r\nsample 1 is the same\r\nsample 2 is the same\r\nsample 3 is the same\r\n```\r\n\r\nright padding:\r\n```\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:04<00:00, 2.25s/it]\r\npad_token: </s>, pad_token_id: 2\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.6` -- this flag is only used in sample-based generation modes.\r\nYou should set `do_sample=True` or unset `temperature`.\r\n warnings.warn(\r\n/usr/local/lib/python3.9/dist-packages/transformers/generation/configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.9` -- this flag is only used in sample-based generation modes. You sh\r\nould set `do_sample=True` or unset `top_p`.\r\n warnings.warn(\r\nA decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.\r\nsample 0 is different, expected_answer: ` B`, batched_answer: `\r\n`\r\nsample 1 is different, expected_answer: ` A`, batched_answer: `\r\n`\r\nsample 2 is different, expected_answer: ` C`, batched_answer: `\r\n`\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:04<00:00, 2.18s/it]\r\npad_token: <unk>, pad_token_id: 0\r\nA decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.\r\nsample 0 is different, expected_answer: ` B`, batched_answer: `Љ`\r\nsample 1 is different, expected_answer: ` A`, batched_answer: `Љ`\r\nsample 2 is different, expected_answer: ` C`, batched_answer: `Љ`\r\nsample 3 is the same\r\nLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:04<00:00, 2.39s/it]\r\nYou are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embeding dimension will be 32001. This might induce some performance reduction as *Tensor Cores* will not be available. F\r\nor more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc\r\npad_token: [PAD], pad_token_id: 32000\r\nA decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.\r\nsample 0 is different, expected_answer: ` B`, batched_answer: ` is`\r\nsample 1 is different, expected_answer: ` A`, batched_answer: ` is`\r\nsample 2 is different, expected_answer: ` C`, batched_answer: ` is`\r\nsample 3 is the same\r\n```",
"I’ll investigate 👍 but if setting the pad token to unk_token works, again I doubt it has anything to do with fp16 casting. \r\nAdding a token should work, and the pad index should be given to the model when using from pretrained to make sure the embedding returns zeros tensors! ",
"> but if setting the pad token to unk_token works\r\n\r\nEven though it works in this examples, as I said before, the final logits still do not match.\r\nSo probably the better check is to compare the logits, and not generated tokens.",
"Sorry both! I'm taking all the Llama issues to dive in this! Thanks for your inputs ",
"Sorry for the delay, @gante just FYI! ",
"Hi @wjfwzzc @psinger 👋 \r\n\r\nA few notes on this thread:\r\n1. We are aware that there may be an issue with the attention mask when it is 0 (or, in other words, with padding), in some cases :)\r\n2. \"The output should be exactly the same with and without padding, as the attention should not attend to these padding tokens.\" -- This statement is not correct, for at least two reasons: 1) The shape of the inputs causes minor fluctuations in the output of a matrix multiplication (read [here](https://twitter.com/joao_gante/status/1716831983375143382) for a longer explanation); 2) The attention mask, internally, is a numerical operation (it adds a very large negative number to the attention scores), which means that masking is not fully perfect. In FP16/BF16, these two phenomena are non-negligible.\r\n3. Left padding should always be used at inference time :) It's normal that right-padding does not produce good results. Read more about it [here](https://huggingface.co/docs/transformers/main/en/llm_tutorial#wrong-padding-side)\r\n\r\nI hope this information helps explain what you're seeing 🤗 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,701 | 1,701 |
NONE
| null |
### System Info
- `transformers` version: 4.32.0
- Platform: Linux-5.4.143.bsk.8-amd64-x86_64-with-glibc2.31
- Python version: 3.9.2
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@ArthurZucker @gante
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python3
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
def run(
model_name_or_path: str,
pad_token_mode: str = "eos_token",
dtype: torch.dtype = torch.float16,
):
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
torch_dtype=dtype,
device_map="auto",
use_cache=True,
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path,
trust_remote_code=True,
use_fast=False,
legacy=False,
padding_side="left",
)
if pad_token_mode == "eos_token":
tokenizer.pad_token = tokenizer.eos_token
elif pad_token_mode == "unk_token":
tokenizer.pad_token = tokenizer.unk_token
elif pad_token_mode == "new_token":
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
model.resize_token_embeddings(len(tokenizer))
else:
raise NotImplementedError
print(f"pad_token: {tokenizer.pad_token}, pad_token_id: {tokenizer.pad_token_id}")
model.config.pad_token_id = tokenizer.pad_token_id
model.generation_config.pad_token_id = tokenizer.pad_token_id
# examples extracted from MMLU's abstract_algebra subject with 5-shots
examples = [
"The following are multiple choice questions (with answers) about abstract algebra.\n\nFind all c in Z_3 such that Z_3[x]/(x^2 + c) is a field.\nA. 0\nB. 1\nC. 2\nD. 3\nAnswer: B\n\nStatement 1 | If aH is an element of a factor group, then |aH| divides |a|. Statement 2 | If H and K are subgroups of G then HK is a subgroup of G.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: B\n\nStatement 1 | Every element of a group generates a cyclic subgroup of the group. Statement 2 | The symmetric group S_10 has 10 elements.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: C\n\nStatement 1| Every function from a finite set onto itself must be one to one. Statement 2 | Every subgroup of an abelian group is abelian.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: A\n\nFind the characteristic of the ring 2Z.\nA. 0\nB. 3\nC. 12\nD. 30\nAnswer: A\n\nFind the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.\nA. 0\nB. 4\nC. 2\nD. 6\nAnswer:",
"The following are multiple choice questions (with answers) about abstract algebra.\n\nFind all c in Z_3 such that Z_3[x]/(x^2 + c) is a field.\nA. 0\nB. 1\nC. 2\nD. 3\nAnswer: B\n\nStatement 1 | If aH is an element of a factor group, then |aH| divides |a|. Statement 2 | If H and K are subgroups of G then HK is a subgroup of G.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: B\n\nStatement 1 | Every element of a group generates a cyclic subgroup of the group. Statement 2 | The symmetric group S_10 has 10 elements.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: C\n\nStatement 1| Every function from a finite set onto itself must be one to one. Statement 2 | Every subgroup of an abelian group is abelian.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: A\n\nFind the characteristic of the ring 2Z.\nA. 0\nB. 3\nC. 12\nD. 30\nAnswer: A\n\nLet p = (1, 2, 5, 4)(2, 3) in S_5 . Find the index of <p> in S_5.\nA. 8\nB. 2\nC. 24\nD. 120\nAnswer:",
"The following are multiple choice questions (with answers) about abstract algebra.\n\nFind all c in Z_3 such that Z_3[x]/(x^2 + c) is a field.\nA. 0\nB. 1\nC. 2\nD. 3\nAnswer: B\n\nStatement 1 | If aH is an element of a factor group, then |aH| divides |a|. Statement 2 | If H and K are subgroups of G then HK is a subgroup of G.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: B\n\nStatement 1 | Every element of a group generates a cyclic subgroup of the group. Statement 2 | The symmetric group S_10 has 10 elements.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: C\n\nStatement 1| Every function from a finite set onto itself must be one to one. Statement 2 | Every subgroup of an abelian group is abelian.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: A\n\nFind the characteristic of the ring 2Z.\nA. 0\nB. 3\nC. 12\nD. 30\nAnswer: A\n\nFind all zeros in the indicated finite field of the given polynomial with coefficients in that field. x^5 + 3x^3 + x^2 + 2x in Z_5\nA. 0\nB. 1\nC. 0,1\nD. 0,4\nAnswer:",
"The following are multiple choice questions (with answers) about abstract algebra.\n\nFind all c in Z_3 such that Z_3[x]/(x^2 + c) is a field.\nA. 0\nB. 1\nC. 2\nD. 3\nAnswer: B\n\nStatement 1 | If aH is an element of a factor group, then |aH| divides |a|. Statement 2 | If H and K are subgroups of G then HK is a subgroup of G.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: B\n\nStatement 1 | Every element of a group generates a cyclic subgroup of the group. Statement 2 | The symmetric group S_10 has 10 elements.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: C\n\nStatement 1| Every function from a finite set onto itself must be one to one. Statement 2 | Every subgroup of an abelian group is abelian.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer: A\n\nFind the characteristic of the ring 2Z.\nA. 0\nB. 3\nC. 12\nD. 30\nAnswer: A\n\nStatement 1 | A factor group of a non-Abelian group is non-Abelian. Statement 2 | If K is a normal subgroup of H and H is a normal subgroup of G, then K is a normal subgroup of G.\nA. True, True\nB. False, False\nC. True, False\nD. False, True\nAnswer:",
]
expected_answers = []
for example in examples:
inputs = tokenizer(
example,
return_tensors="pt",
add_special_tokens=False,
padding=True,
return_token_type_ids=False,
).to("cuda")
outputs = model.generate(**inputs, do_sample=False, max_new_tokens=1)
pred = tokenizer.decode(outputs[0], skip_special_tokens=True)
ans = pred[len(example) :]
expected_answers.append(ans)
inputs = tokenizer(
examples,
return_tensors="pt",
add_special_tokens=False,
padding=True,
return_token_type_ids=False,
).to("cuda")
outputs = model.generate(**inputs, do_sample=False, max_new_tokens=1)
batched_preds = tokenizer.batch_decode(outputs, skip_special_tokens=True)
batched_answers = [
pred[len(example) :] for pred, example in zip(batched_preds, examples)
]
# when pad_token_mode = "eos_token", the expected_answers and batched_answers should be the same
# however only the longest example (without padding) is the same, the rest are different
for i, (expected_answer, batched_answer) in enumerate(
zip(expected_answers, batched_answers)
):
if expected_answer == batched_answer:
print(f"sample {i} is the same")
else:
print(
f"sample {i} is different, expected_answer: `{expected_answer}`, batched_answer: `{batched_answer}`"
)
if __name__ == "__main__":
model_name_or_path = "meta-llama/Llama-2-7b-hf"
# model_name_or_path = "gpt2-xl"
# model_name_or_path = "bigscience/bloomz-7b1-mt"
# model_name_or_path = "facebook/opt-1.3b"
run(model_name_or_path, "eos_token")
run(model_name_or_path, "unk_token")
run(model_name_or_path, "new_token")
```
### Expected behavior
I tried to batched generate with llama-2. So following the common practice, I set `pad_token` to `eos_token`. However I found all generated texts are incorrect except the longest one (without padding).
More interesting thing is if I set `pad_token` to `unk_token`, everything seems fine.
I also tried to add a new token but it leads to an error.
Other models like `gpt2-xl`, `bigscience/bloomz-7b1-mt` and `facebook/opt-1.3b` work fine in all three cases. Update: `llama` v1 seems also work fine.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25790/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25790/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25789
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25789/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25789/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25789/events
|
https://github.com/huggingface/transformers/pull/25789
| 1,868,748,146 |
PR_kwDOCUB6oc5Y4YCS
| 25,789 |
Adding Llava to transformers
|
{
"login": "shauray8",
"id": 39147312,
"node_id": "MDQ6VXNlcjM5MTQ3MzEy",
"avatar_url": "https://avatars.githubusercontent.com/u/39147312?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shauray8",
"html_url": "https://github.com/shauray8",
"followers_url": "https://api.github.com/users/shauray8/followers",
"following_url": "https://api.github.com/users/shauray8/following{/other_user}",
"gists_url": "https://api.github.com/users/shauray8/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shauray8/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shauray8/subscriptions",
"organizations_url": "https://api.github.com/users/shauray8/orgs",
"repos_url": "https://api.github.com/users/shauray8/repos",
"events_url": "https://api.github.com/users/shauray8/events{/privacy}",
"received_events_url": "https://api.github.com/users/shauray8/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@ArthurZucker Right now I've added Llava support directly to the MPT model as `LlavaMptForCausalLM`. Do you think I should add llava as a separate model or is this good enough?",
"And there's no preprocessor_config unfortunately, so do I go about making one and push it to a new hugging face repo or just integrate all the CLIP preprocessing and Tokenize in the class itself?",
"Okay, on it! 🫡 ",
"Got caught up with something, but this should be ready for reviews @ArthurZucker. There are some quality errors for unrelated files, and a couple of minor errors as well, Do let me know how I go about solving them.\r\n\r\n**A little update, It's llama-based llava and not mpt (making it work with mpt was a pain).",
"@shauray8 Nice work! \r\n\r\nAre you able to open the Circle CI pages and see the errors? \r\n\r\nFor the [check_repo_consistency](https://app.circleci.com/pipelines/github/huggingface/transformers/72701/workflows/45ed2af4-319c-49e2-98a1-e884c8d91403/jobs/917908) tests, you'll see that `make fix-copies` needs to be run. \r\n\r\nFor [tests_torch](https://app.circleci.com/pipelines/github/huggingface/transformers/72701/workflows/c910e0e2-b54d-457b-846b-bab9a301719e/jobs/917925) you'll see that `self.model_tester.batch_size` is referenced but not defined. Make sure to run the tests, including the slow test, locally to check if they pass. See `8. Adding all necessary model tests` on the [add_new_model](https://huggingface.co/docs/transformers/add_new_model) page\r\n\r\nThe PR documentation tests look like there might just have been a transient timeout. I'm going to re-run them for you. \r\n\r\nHere's the documentation on how to run tests: https://huggingface.co/docs/transformers/testing \r\n\r\nPlease make sure all tests are passing before asking for review. From next week, I'll be away for a few weeks. When ready please ask @rafaelpadilla for review and then we can ask for a core maintainer review. If you need any help or have questions regarding getting the tests to pass, please ping us! ",
"Thank you @amyeroberts for the help, PR documentation still seems to be in some kind of timeout (I'm not very sure how to fix that). @rafaelpadilla Other than that everything should more or less look green, Maybe you can help me fix this issue.\r\n\r\nEdit - `tests_pr_documentation_tests FAILED src/transformers/models/llava/configuration_llava.py::transformers.models.llava.configuration_llava.LlavaLlamaConfig`",
"@shauray8 It looks like the test runner is crashing when running the code example in the LlavaLlamaConfig class. The default params are for a 7B model, which is large. As this is the smallest model `src/transformers/models/llava/configuration_llava.py` should be added to `not_doctested.txt`",
"CI looks green!",
"Update @ArthurZucker @rafaelpadilla -\r\n- added Llava 13B to the hub https://huggingface.co/shauray/Llava-Llama-2-13B-hf\r\n\r\nNot sure why tf and flax tests say `E No module named 'torch'` ",
"> Update @ArthurZucker @rafaelpadilla -\r\n> \r\n> * added Llava 13B to the hub https://huggingface.co/shauray/Llava-Llama-2-13B-hf\r\n> \r\n> Not sure why tf and flax tests say `E No module named 'torch'`\r\n\r\nHi @shauray8 ,\r\n\r\nI'm going to look into this. :) ",
"> > Update @ArthurZucker @rafaelpadilla -\r\n> > \r\n> > * added Llava 13B to the hub https://huggingface.co/shauray/Llava-Llama-2-13B-hf\r\n> > \r\n> > Not sure why tf and flax tests say `E No module named 'torch'`\r\n> \r\n> Hi @shauray8 ,\r\n> \r\n> I'm going to look into this. :)\r\n\r\nSeems that the error `E No module named 'torch'` is gone.\r\n\r\nThe current error [now](https://app.circleci.com/pipelines/github/huggingface/transformers/73673/workflows/0717e39e-1dd9-432e-a89a-6bd72cd5a66c/jobs/932101) is `NameError: name 'CLIPVisionModel' is not defined`.\r\nTo resolve this, you can remove the `is_openai_available()` [here](https://github.com/huggingface/transformers/blob/4baba5a8d772bf48ca3829bcbfd926267e22dc7c/src/transformers/models/llava/processing_llava.py#L32). Is `openai` package really needed?",
"removing `is_openai_available` results in `E cannot import name 'CLIPVisionModel' from 'transformers.models.clip'`",
"Hi @shauray8 ,\r\n\r\nTaking a look at the tests on the CI side, I noticed that in `test_processor_llava.py`, the class `CLIPVisionModel` is being called [here](https://github.com/huggingface/transformers/blob/4baba5a8d772bf48ca3829bcbfd926267e22dc7c/tests/models/llava/test_processor_llava.py#L48). However, torch is required to run `vision_model = CLIPVisionModel.from_pretrained(\"openai/clip-vit-large-patch14\")`.\r\n\r\nTo fix that, [here](https://github.com/huggingface/transformers/blob/4baba5a8d772bf48ca3829bcbfd926267e22dc7c/tests/models/llava/test_processor_llava.py#L41C1-L43C1) you need to replace \r\n```python\r\n@require_vision\r\nclass LlavaProcessorTest(unittest.TestCase):\r\n```\r\nby\r\n```python\r\n@require_torch\r\nclass LlavaProcessorTest(unittest.TestCase):\r\n```\r\nand import:\r\n```python\r\nfrom transformers.testing_utils import require_torch\r\n```\r\n\r\nPlease, try to run that and see if it works now :) ",
"Thank you @rafaelpadilla for looking into this, CI looks green, PR's ready for review ",
"@rafaelpadilla LLaVA v1.5 was just released, but it has some architectural changes, should I modify the script to make it work with v1.5?\r\n\r\nhttps://twitter.com/ChunyuanLi/status/1710299381335798202\r\n\r\n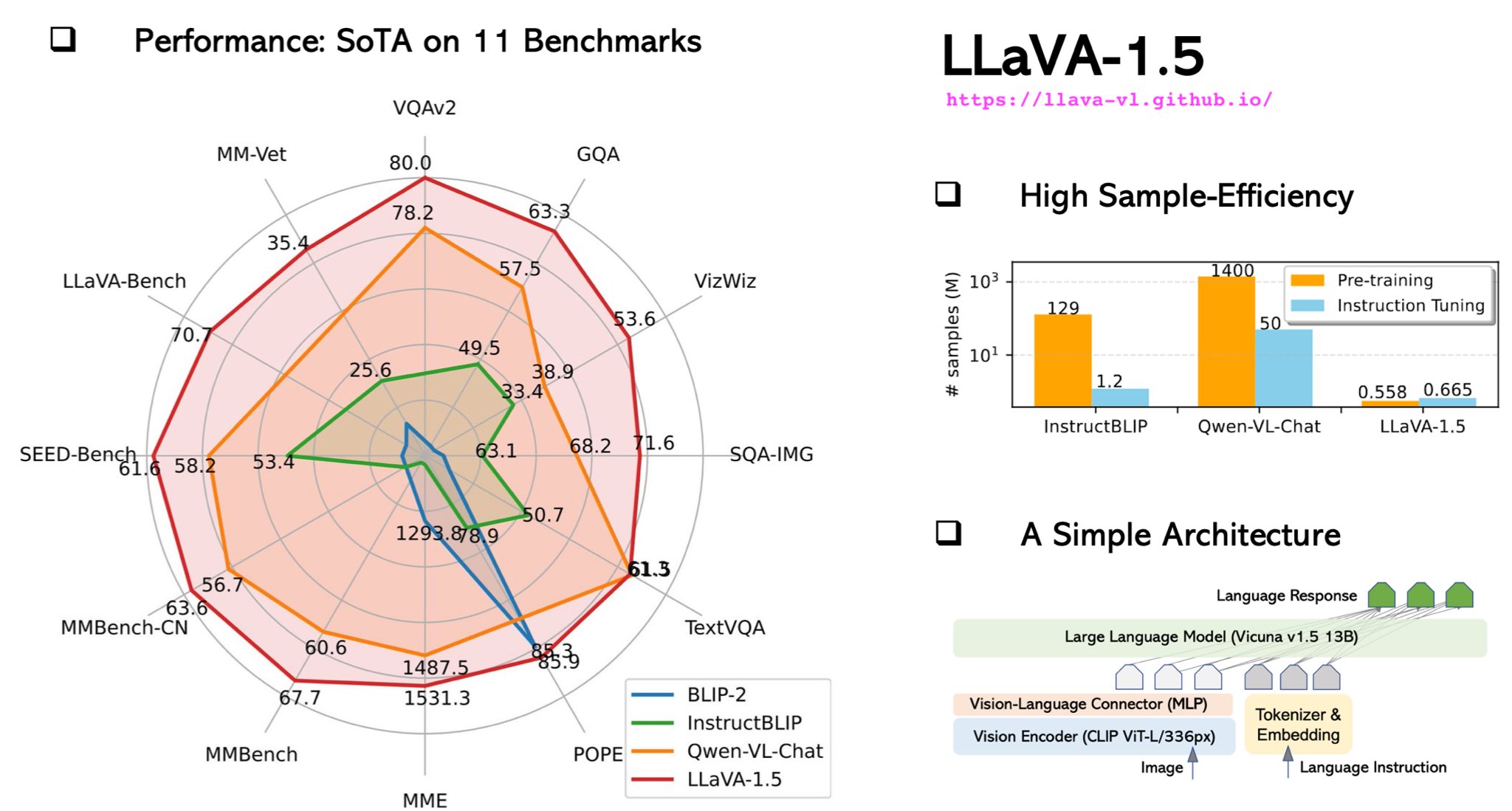",
"Hi @shauray8 \n\nYep. Llava 1.5 has just come out of the oven :) \n\nI haven't compared the code of the old and new versions, but changes don't seem to be huge. \n\nAs there's a big expectation to have Llava available on the library very soon, just do this move if it does not extend our releasing much longer.\n\nSo, feel free to go for Llava 1.5 by adapting what we already have in the current PR. \n\nThe processor may not be affected, so my last review is still valid. Please, check it. \n\nThe whole community is very excited to see Llava available in the library. Please, let me know if you need help with anything. \n",
"@rafaelpadilla At first glance I can only see an extra Linear Layer, I have my exams going on but I'll try my best to get it done as soon as I can. \r\n",
"@rafaelpadilla I think I have done everything we've discussed above and on top of that I've added support for `Llava V1.5`",
"@rafaelpadilla I've added all the docstrings",
"@rafaelpadilla CI's green, I've added support for `openai/clip-vit-large-patch14-336` alongside `openai/clip-vit-large-patch14` as Llava-v1.5 prefers `openai/clip-vit-large-patch14-336` ",
"> I've looked a bit into the design of this PR (as well as the LLaVa paper). First of all, I really appreciate the effort you're making into integrating it into the library 🙏 already some nice work.\r\n> \r\n> However, for the model to get integrated into the library, there are some changes to be made. Specifically, I see you're using the `vision_model` (CLIP) inside the preprocessor class. This is very different from all other models in the Transformers library, and not compliant to its design. What should actually be done is defining something along the lines of:\r\n> \r\n> ```\r\n> class LlavaModel(config):\r\n> def __init__(self, config):\r\n> \r\n> self.vision_model = LlavaVisionModel(config.vision_config)\r\n> self.projection_layer = nn.Linear(...)\r\n> self.text_model = AutoModelForCausalLM(config.text_config)\r\n> ```\r\n> \r\n> for the base model (i.e. LLaVa without language modeling head on top), and then the head model:\r\n> \r\n> ```\r\n> class LlavaForCausalLM(config):\r\n> def __init__(self, config):\r\n> \r\n> self.model = LLavaModel(config)\r\n> self.lm_head = nn.Linear(...)\r\n> ```\r\n> \r\n> i.e. the `vision_model` is a PyTorch model, hence it needs to be part of the PyTorch implementation of LLaVa. The `LlavaProcessor` class should combine a `CLIPImageProcessor` and a `LlamaTokenizer`, which takes in text and images and produces input_ids, pixel_values which are the inputs to the model. Refer to implementations like BLIP, BLIP-2 as examples of other multimodal models which also leverage CLIP as vision encoder, combined with a language model.\r\n> \r\n> The `LlavaVisionConfig` then includes all attributes regarding the vision encoder (very similar to `Blip2VisionConfig`). Since the language model is just LLaMa as a decoder-only model, one can leverage the AutoModelForCausalLM class to support any decoder-only LLM (this was also done for BLIP-2 - see [here](https://github.com/huggingface/transformers/blob/3e93dd295b5343557a83bc07b0b2ea64c926f9b4/src/transformers/models/blip_2/modeling_blip_2.py#L1571)), and specify any AutoConfig as text config (see BLIP-2 as [example](https://github.com/huggingface/transformers/blob/main/src/transformers/models/blip_2/configuration_blip_2.py#L323)). Additional attributes, like things regarding the projection layers, can be defined as part of `LlavaConfig`.\r\n\r\nThank you @NielsRogge for the review, I had my doubts regarding this, I'll make all the necessary changes as soon as I can.",
"To make sure I understand everything, rather than having a `LlavaTextModel` for LLaMA I should have it through `AutoConfig` and basically copy all the code from `CLIP` for `LlavaVisionModel` and have a `LlavaModel` for a bare base model. ",
"Yes, most importantly is to remove the vision encoder from the preprocessor class and instead make it part of the model.\r\n\r\n",
"@rafaelpadilla I'm still working on it, I'll let you know when it's ready for review",
"I also want to contribute to llava implementation. But I have a question, why we need to copy the vision encoder part but use AutoModel for language model part? e.g., blip, blip_2...",
"Hi @shauray8, I'm working on doing some Llava training experiments and hopefully contributing. \r\n\r\nCould you share any guidance on how to test this Llava implementation in its current state starting from scratch from just pytorch weights (https://huggingface.co/liuhaotian/llava-v1.5-7b/tree/main) and CLIP?\r\nLike which of the weight conversion scripts to run in what order, and do inference? I've been trying the examples in docs and in the tests, but they seem to yield NaN tensors or various other errors due to processor inconsistency, etc.\r\nThank you!",
"Hi @shauray8 any updates on this model addition? We'd like to have this model merge in within the next few weeks - is this something that would fit in your timeline? ",
"@amyeroberts I'm done with the architectural changes @NielsRogge suggested, uploading new weights for LLaVa and LLaVa 1.5, writing new tests and documentations could take up 2-3 days as I'm pretty caught up with my placements",
"Hi @shauray8 - glad to hear the arch changes are done! I can see that there's still outstanding suggestions from @rafaelpadilla's PR which will also need to be addressed alongside tests etc. \r\n\r\nAs there are currently 3 in-progress model PRs - #25001, #26360, #25789 - all of which we'd like to have in the library soon, and you mention you're busy with placements I propose that you continue with one and someone else can help finish off the other PRs. As Llava is the most complete and has already had some reviews this is the one I suggest you focus on. \r\n\r\nLet us know if you need any help! ",
"Hi @shauray8 ! \r\nGreat work on the PR ! I am super excited about this architecture and I am happy to help you finishing up the PR by taking it over, or creating a new PR to add this architecture. I'll make sure to add you as the main author of this contribution as you did most of the work. Let me know how does that sound for you "
] | 1,693 | 1,701 | 1,701 |
CONTRIBUTOR
| null |
# What does this PR do?
Adds LLAVA to transformers.
author - https://github.com/haotian-liu/LLaVA
hub - https://huggingface.co/shauray/Llava-Llama-2-7B-hf
Fixes # (issue)
#25060
## Before submitting
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [X] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@ArthurZucker @amyeroberts
@younesbelkada
## Results

*prompt* - "How would you best describe this image? "
<br>
-- The photograph shows a wooden dock floating on the water, with mountains in the background. It is an idyllic scene that captures both natural beauty and human-made structures like docks at their most serene state of being surrounded by nature's wonders such as lakes or oceans (in case it isn’t just any body). This type of setting can be found all over North America where there are numerous bodies of freshwater available for recreational activities including fishing from piers near these locations; however, they also provide opportunities to observe wildlife
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25789/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 2,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25789/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25789",
"html_url": "https://github.com/huggingface/transformers/pull/25789",
"diff_url": "https://github.com/huggingface/transformers/pull/25789.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25789.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25788
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25788/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25788/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25788/events
|
https://github.com/huggingface/transformers/pull/25788
| 1,868,651,154 |
PR_kwDOCUB6oc5Y4DIU
| 25,788 |
Fix incorrect Boolean value in deepspeed example
|
{
"login": "tmm1",
"id": 2567,
"node_id": "MDQ6VXNlcjI1Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2567?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tmm1",
"html_url": "https://github.com/tmm1",
"followers_url": "https://api.github.com/users/tmm1/followers",
"following_url": "https://api.github.com/users/tmm1/following{/other_user}",
"gists_url": "https://api.github.com/users/tmm1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tmm1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tmm1/subscriptions",
"organizations_url": "https://api.github.com/users/tmm1/orgs",
"repos_url": "https://api.github.com/users/tmm1/repos",
"events_url": "https://api.github.com/users/tmm1/events{/privacy}",
"received_events_url": "https://api.github.com/users/tmm1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25788). All of your documentation changes will be reflected on that endpoint."
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
cc @stevhliu and @MKhalusova
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25788/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25788/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25788",
"html_url": "https://github.com/huggingface/transformers/pull/25788",
"diff_url": "https://github.com/huggingface/transformers/pull/25788.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25788.patch",
"merged_at": 1693293757000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25787
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25787/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25787/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25787/events
|
https://github.com/huggingface/transformers/pull/25787
| 1,868,645,210 |
PR_kwDOCUB6oc5Y4B_z
| 25,787 |
[idefics] fix vision's `hidden_act`
|
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
Thanks to @rwightman's discovery this PR is fixing vision config's `hidden_act` to `gelu`.
It looks like we messed things up when splitting the original config into 3 groups during the porting and inherited `clip`'s default config. Whereas the model used during training was using `gelu` as can be seen here. https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K/blob/main/config.json
Thank you, @rwightman
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25787/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25787/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25787",
"html_url": "https://github.com/huggingface/transformers/pull/25787",
"diff_url": "https://github.com/huggingface/transformers/pull/25787.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25787.patch",
"merged_at": 1693233457000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25786
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25786/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25786/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25786/events
|
https://github.com/huggingface/transformers/pull/25786
| 1,868,615,299 |
PR_kwDOCUB6oc5Y38Zi
| 25,786 |
Implementation of SuperPoint and AutoModelForInterestPointDescription
|
{
"login": "sbucaille",
"id": 24275548,
"node_id": "MDQ6VXNlcjI0Mjc1NTQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/24275548?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sbucaille",
"html_url": "https://github.com/sbucaille",
"followers_url": "https://api.github.com/users/sbucaille/followers",
"following_url": "https://api.github.com/users/sbucaille/following{/other_user}",
"gists_url": "https://api.github.com/users/sbucaille/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sbucaille/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sbucaille/subscriptions",
"organizations_url": "https://api.github.com/users/sbucaille/orgs",
"repos_url": "https://api.github.com/users/sbucaille/repos",
"events_url": "https://api.github.com/users/sbucaille/events{/privacy}",
"received_events_url": "https://api.github.com/users/sbucaille/received_events",
"type": "User",
"site_admin": false
}
|
[] |
open
| false | null |
[] |
[
"@amyeroberts I have some questions about the implementation and AutoModel classes.\r\n\r\nFirst of all, I try to follow as much as possible the patterns I see in other model implementations (resnet or convnextv2 for example), but unlike these models, SuperPoint really only have one function or \"mode\" here, just to output the keypoints, their scores and descriptors. This is why I only implemented SuperPoint as a `SuperPointModelForInterestPointDescription`, so there is no `SuperPointModel` anymore, does that seem ok ?\r\n\r\nThen I added this `SuperPointModelForInterestPointDescription` class in a new mapping dictionary in the modeling_auto file and added the appropriate AutoModel class for this. But is this kind of changes usually the output of an automated script for model registration or adding it by hand is appropriate ?\r\n\r\nFinally, \r\n\r\n> In that PR, we can also add a mapping AutoModelForInterestPointDescription, which we define as taking two images and returning interest keypoints and their descriptions.\r\n\r\nApart from adding the AutoModelForInterestPointDescription, I couldn't find how to define such inputs and outputs, is it a new pipeline I should define or something else ?",
"Hi @sbucaille, \r\n\r\nThis is a bit of a special case. For other models which only perform a single task, what we normally do is just have `XxxModel`. I'd suggest doing this. We can still add `AutoModelForInterestPointDescription` and have `SuperPointModel` loaded by it",
"@sbucaille From next week, I'll be off for a few weeks. If you have vision-specific questions, please ping @rafaelpadilla; for implementation questions @ArthurZucker. ",
"Hi @ArthurZucker, I added the SuperPointImageProcessor as part of the code because SuperPoint requires a grayscale image as input. But when I added the tests I have the test_call_pil which fails and give me a very weird when it reaches these lines \r\n```\r\ntests/models/superpoint/test_image_processing_superpoint.py:43: in prepare_image_inputs\r\n return prepare_image_inputs(\r\ntests/test_image_processing_common.py:64: in prepare_image_inputs\r\n image_inputs = [Image.fromarray(np.moveaxis(image, 0, -1)) for image in image_inputs]\r\ntests/test_image_processing_common.py:64: in <listcomp>\r\n image_inputs = [Image.fromarray(np.moveaxis(image, 0, -1)) for image in image_inputs]\r\n```\r\nwith the following error : \r\n```\r\n except KeyError as e:\r\n msg = \"Cannot handle this data type: %s, %s\" % typekey\r\n> raise TypeError(msg) from e\r\nE TypeError: Cannot handle this data type: (1, 1, 1), |u1\r\n```\r\n\r\nNot sure what causes the problem as I tried to compare with tests made with the ConvNextImageProcessor which does not raise any error.\r\n\r\nAnyway, I continue on the implementation, let me know if I'm missing anything. I'll write the documentation for all the code I've previously pushed.\r\n",
"\r\n\r\n\r\n\r\n> Hi @ArthurZucker, I added the SuperPointImageProcessor as part of the code because SuperPoint requires a grayscale image as input. But when I added the tests I have the test_call_pil which fails and give me a very weird when it reaches these lines\r\n> \r\n> ```\r\n> tests/models/superpoint/test_image_processing_superpoint.py:43: in prepare_image_inputs\r\n> return prepare_image_inputs(\r\n> tests/test_image_processing_common.py:64: in prepare_image_inputs\r\n> image_inputs = [Image.fromarray(np.moveaxis(image, 0, -1)) for image in image_inputs]\r\n> tests/test_image_processing_common.py:64: in <listcomp>\r\n> image_inputs = [Image.fromarray(np.moveaxis(image, 0, -1)) for image in image_inputs]\r\n> ```\r\n> \r\n> with the following error :\r\n> \r\n> ```\r\n> except KeyError as e:\r\n> msg = \"Cannot handle this data type: %s, %s\" % typekey\r\n> > raise TypeError(msg) from e\r\n> E TypeError: Cannot handle this data type: (1, 1, 1), |u1\r\n> ```\r\n> \r\n> Not sure what causes the problem as I tried to compare with tests made with the ConvNextImageProcessor which does not raise any error.\r\n> \r\n> Anyway, I continue on the implementation, let me know if I'm missing anything. I'll write the documentation for all the code I've previously pushed.\r\n\r\nHi @sbucaille, 🙂\r\n\r\nA quick help with that issue: \r\n\r\nI see that your processing converts all images to grayscale ([here](https://github.com/huggingface/transformers/blob/28e7d59ab920741ac7f52923f39d1a9680ca3911/src/transformers/models/superpoint/image_processing_superpoint.py#L209C29-L209C49)) and tests are failing [here](https://github.com/huggingface/transformers/blob/000e52aec8850d3fe2f360adc6fd256e5b47fe4c/tests/test_image_processing_common.py#L64C24-L64C94).\r\n\r\nThe root cause is that the `convert_to_grayscale` function returns a 1-channel image (luminance) as [here](https://github.com/huggingface/transformers/blob/28e7d59ab920741ac7f52923f39d1a9680ca3911/src/transformers/image_transforms.py#L787C5-L788C1). So, when it is later converted to a numpy array, it will turn to be a 1-channel image, making the test fail.\r\n\r\nThis has been discussed in PR #25767 and is not fully solved yet.\r\n\r\nA quick solution for this issue in your code may be possible. See that a 1 single channel image is definetely grayscale, but if the 3 channels in an RGB image are equal (R==G and G==B), the image is also noted as grayscale. So, if you replicate the channels of your 1-channel grayscale image [as in here](https://github.com/huggingface/transformers/blob/79f53921de5bd15ef7f4cdd83fd94d2b4cb8f63b/src/transformers/image_utils.py#L178), this issue can be solved. However, SuperPoint would need to be adapted for that -> you would only need to consider one of the RGB channels, as they are equal.\r\n\r\n",
"Hi @rafaelpadilla and @ArthurZucker ,\r\nThanks @rafaelpadilla for the heads up, I adapted SuperPointModel and SuperPointImageProcessor to cover this issue. SuperPointImageProcessor now generates a 3-channel grayscaled image from a given image as input and SuperPointModel extracts one of the channels to perform the forward method. Although it may be necessary to change that in the future when 1-channel images will be supported (if it is planned to).\r\nI added docs, as well as remaining integration tests for the AutoModelForInterestPointDescription.\r\nI think the implementation is complete.\r\n\r\n@ArthurZucker, please let me know what I'm missing in the implementation ! :slightly_smiling_face: \r\nAlthough I have some questions : \r\n- What should I do with the SuperPointModel and SuperPointModelForInterestPointDescription as both are basically the same, should I only keep the latter one ?\r\n- Regarding docs, there is a mention of `expected_output` is `@add_code_sample_docstrings`. I decided not to provide such information since output is dynamic, depending on the number of keypoints found. Should I keep it like that or there is a way to provide a \"dynamic shape\" to this function ?\r\n- Regarding tests, I have the `test_model_is_small` failing, what should I do about it ? And is `test_retain_grad_hidden_states_attentions` related to models that can be trained ? If so we should probably skip it since SuperPoint can't be trained, also it does not have attentions.",
"Hi,\r\nWhen adding the docs to the code on this Saturday, I started thinking, maybe late, about the licence of SuperPoint and got an answer from an original contributor, Paul-Edouard Sarlin.\r\nIt turns out it can't be used for commercial use. I am not very familiar with legal stuff like these, but does it compromise this PR ? Or, from the HuggingFace perspective, adding the licence as in the original repo is sufficient ? I added it to the [model card](https://huggingface.co/stevenbucaille/superpoint/blob/main/LICENSE) anyway.",
"> Hi, When adding the docs to the code on this Saturday, I started thinking, maybe late, about the licence of SuperPoint and got an answer from an original contributor, Paul-Edouard Sarlin. It turns out it can't be used for commercial use. I am not very familiar with legal stuff like these, but does it compromise this PR ? Or, from the HuggingFace perspective, adding the licence as in the original repo is sufficient ? I added it to the [model card](https://huggingface.co/stevenbucaille/superpoint/blob/main/LICENSE) anyway.\r\n\r\nHi @sbucaille,\r\n\r\nIt seems that the original code is under MIT license. If it is the case, you just need to add the MIT license on the top of the files, as done in [graphormer](https://github.com/huggingface/transformers/blob/0ee45906845c8d58b9bd2df5acd90e09b00047ff/docs/source/en/model_doc/graphormer.md?plain=1#L3C1-L3C32) and [IDEFICS](https://github.com/huggingface/transformers/blob/0ee45906845c8d58b9bd2df5acd90e09b00047ff/src/transformers/models/idefics/perceiver.py#L1-L23).\r\n\r\nThe checkpoints seem to be under a non-commercial customized license. So, as you have already added the License [here](https://huggingface.co/stevenbucaille/superpoint/blob/main/LICENSE), you just need to set `inference: false` in the card as done in [owlvit-large-patch14](https://huggingface.co/google/owlvit-large-patch14/blob/main/README.md) and [musicgen-large](https://huggingface.co/facebook/musicgen-large/blob/main/README.md). ",
"I figured out the two remaining tests I asked were not in the scope of SuperPoint. Ready for review :hugs: ",
"Hi @rafaelpadilla @ArthurZucker,\r\nI was about to start working again on the other [pull request](https://github.com/huggingface/transformers/pull/25697) I made earlier about SuperGlue, which for reminder, uses SuperPoint as a keypoint detector, and uses these keypoints to match them. While I was trying things around I was thinking about the case where we have batched images.\r\nSuperPoint, and as a consequence SuperGlue, does not support batched images, since the output for a given image is an arbitrary number of keypoints, which are different for every image, hence the resulting keypoint tensors can't be batched back together.\r\nI added in the tests that the batch size needs to be one in order for the tests to succeed, but there is no batch verification made when multiple images are fed into `SuperPointModel`.\r\nI have two suggestions to handle this problem :\r\n- Raise an error as soon as SuperPoint detects that we fed `pixel_values` with a batch_size > 1\r\n- Support image batching by decomposing the batched `pixel_values`, detecting the keypoints from one image at a time and compose back the keypoints. Again, two possibilities :\r\n - By changing `ImagePointDescriptionOutput` so that it returns a list of `torch.IntTensor` for `keypoints`, `scores` and `descriptors` which are individually of different shapes (which to be honest I don't really like)\r\n - By keeping `ImagePointDescriptionOutput` identical but make `keypoints`, `scores` and `descriptors` batched together with shape looking like : \r\n - `[batch_size, SuperPointConfig.max_keypoints, 2]`\r\n - `[batch_size, SuperPointConfig.max_keypoints]`\r\n - `[batch_size, 256, SuperPointConfig.max_keypoints]` \r\nOr : \r\n - `[batch_size, maximum_found_keypoints, 2]`\r\n - `[batch_size, maximum_found_keypoints]`\r\n - `[batch_size, 256, maximum_found_keypoints]` \r\nin case `SuperPointConfig.max_keypoints == -1` with `maximum_found_keypoints` being the maximum number of keypoints found for an image in the given batch. In this case, we would fill values generated by the broadcast with 0's or -1's which would need to be pruned away in a later stage, for example in an ImageMatching pipeline. Alternatively, we could add a 4th tensor which would be binary and tell what values are actual keypoint information or filled values.\r\n\r\nLet me know what you think, maybe adding batching can be a future step and we can deal with single images for now by raising errors. \r\nI'm not very familiar with the existing implemented pipelines, but another suggestion may be the support of batching by adding the aforementioned suggestions in a pipeline, which would prevent us from adding this kind of behavior inside the models themselves. We could consider using the pipeline as the only way of using SuperPoint and other ModelForInterestPointDescription with multiple images batched together. Also, if we apply this behavior in the models themselves, potentially, we would need to support batching for all of them in the future, leading to repetitive code to be implemented.\r\n\r\nI hope the suggestions are clear, as at some point I wrote them down as I was thinking, let me know what you think ! :slightly_smiling_face: ",
"Hi @sbucaille ,\r\n\r\nThank you for raising this discussion. 🙂\r\n\r\nI think supporting batch > 1 is a good idea. So, the size of the `keypoints`, `scores` and `descriptors` in all images within the batch should match. For that, I would opt for:\r\n* `keypoints` -> `[batch_size, SuperPointConfig.max_keypoints, 2]`\r\n* `scores` -> `[batch_size, SuperPointConfig.max_keypoints]` or explicitly `[batch_size, SuperPointConfig.max_keypoints, 1]`\r\n* `descriptors` -> `[batch_size, SuperPointConfig.max_keypoints, 256]`\r\n\r\nI would make the last dimension to represent the size of the data itself.\r\n\r\nDefining the shapes of these vectors with `SuperPointConfig.max_keypoints` instead of `maximum_found_keypoints` will keep consistency when other/different images are input with the same configuration.\r\n\r\nI would also use a 4th mask vector made of `bool` (`mask -> [batch_size, SuperPointConfig.max_keypoints]` to inform if the information should be used for that particular image or not.\r\n",
"Hi @rafaelpadilla ,\r\nChanges have been made to support batching. I added the logic of batching individual inferences inside the SuperPointModel itself. In the future, for example in the implementation of a model like DISK, the same logic could be extracted into a dedicated function where, given a list of keypoints, scores and descriptors, return a batched version of it along a mask tensor.\r\nAbout the `SuperPointConfig.max_keypoints`, the batching logic do not use the config parameter since SuperPoint outputs are already \"filtered\" by this parameter in the forward method.\r\n\r\nLet me know what should be done next, but in the meantime, I think it's ready to get reviewed.",
"Hi @sbucaille ,\r\n\r\nThank you! I will do the first review on your PR. :) ",
"Hi @rafaelpadilla ,\r\nI resolved most of the comments you and left answers on unresolved ones. Gotta say I'm a bit ashamed of all the missing types I let through :laughing: \r\nI have a problem with the merging conflict of the index.md I had. At first I wanted to retrieve an updated index.md file so I synced my fork with the main branch. But for some reason now when I run `make repo-consistency`, I have the following error : \r\n```\r\nValueError: There was at least one problem when checking docstrings of public objects.\r\nThe following objects docstrings do not match their signature. Run `make fix-copies` to fix this.\r\n- TFRegNetForImageClassification\r\n- TFRegNetModel\r\nmake: *** [Makefile:46: repo-consistency] Error 1\r\n```\r\n\r\nwhich does not seem to be related to my code and maybe the result of my synchronization. I'll try tomorrow to \"unsync\" my fork and revert it to the previous state.\r\n\r\nAnyway, thanks for the quick review !",
"Hi @rafaelpadilla , turns out I am not the only one having this error in `make repo-consistency` with the TFRegNetModel, (see #26643).\r\nI pushed a last commit that makes all the tests regarding SuperPoint passed. The other tests not passing do not seem to be because of my code, unless I'm wrong.",
"Hi @sbucaille Are you also using Mac? Could you run `pip freeze` and copy-paste the results?\r\n\r\nAre you able to run `pip install -U -e .[dev]` (please try this in a new fresh python env., if you want to do it).",
"> Hi @sbucaille Are you also using Mac? Could you run `pip freeze` and copy-paste the results?\r\n> \r\n> Are you able to run `pip install -U -e .[dev]` (please try this in a new fresh python env., if you want to do it).\r\n\r\nHi @ydshieh ,\r\nI posted this comment right after creating a new env from this exact same command, and I'm running it in Ubuntu. I believe this is related to the main branch.",
"Could you run `transformers-cli env` and copy paste the output.\r\n\r\nAlso, after the installation, run `pip freeze` and copy paste the output.\r\n\r\nThank you in advance!",
"```\r\n❯ transformers-cli env\r\n2023-10-12 20:01:13.177759: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT\r\nWARNING:tensorflow:From /home/steven/PycharmProjects/transformers/src/transformers/commands/env.py:100: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.\r\nInstructions for updating:\r\nUse `tf.config.list_physical_devices('GPU')` instead.\r\n2023-10-12 20:01:14.165161: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1960] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.\r\nSkipping registering GPU devices...\r\nNo GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)\r\n\r\nCopy-and-paste the text below in your GitHub issue and FILL OUT the two last points.\r\n\r\n- `transformers` version: 4.35.0.dev0\r\n- Platform: Linux-5.19.0-46-generic-x86_64-with-glibc2.35\r\n- Python version: 3.10.12\r\n- Huggingface_hub version: 0.16.4\r\n- Safetensors version: 0.3.2\r\n- Accelerate version: 0.23.0\r\n- Accelerate config: \tnot found\r\n- PyTorch version (GPU?): 2.0.1+cu117 (True)\r\n- Tensorflow version (GPU?): 2.13.0 (False)\r\n- Flax version (CPU?/GPU?/TPU?): 0.7.0 (cpu)\r\n- Jax version: 0.4.13\r\n- JaxLib version: 0.4.13\r\n- Using GPU in script?: <fill in>\r\n- Using distributed or parallel set-up in script?: <fill in>\r\n```\r\n\r\n```\r\n❯ pip freeze\r\nabsl-py==2.0.0\r\naccelerate==0.23.0\r\naiohttp==3.8.5\r\naiosignal==1.3.1\r\nalembic==1.12.0\r\nansi2html==1.8.0\r\nAPScheduler==3.10.4\r\narrow==1.2.3\r\nastunparse==1.6.3\r\nasync-timeout==4.0.3\r\nattrs==23.1.0\r\naudioread==3.0.0\r\nav==9.2.0\r\nBabel==2.12.1\r\nbackoff==1.11.1\r\nbeautifulsoup4==4.12.2\r\nbinaryornot==0.4.4\r\nblack==23.9.1\r\ncachetools==5.3.1\r\ncertifi==2023.7.22\r\ncffi==1.15.1\r\nchardet==5.2.0\r\ncharset-normalizer==3.2.0\r\nchex==0.1.7\r\nclick==8.1.7\r\nclldutils==3.20.0\r\ncmaes==0.10.0\r\ncmake==3.27.5\r\ncodecarbon==1.2.0\r\ncolorama==0.4.6\r\ncolorlog==6.7.0\r\ncookiecutter==1.7.3\r\ncsvw==3.1.3\r\ndash==2.13.0\r\ndash-bootstrap-components==1.5.0\r\ndash-core-components==2.0.0\r\ndash-html-components==2.0.0\r\ndash-table==5.0.0\r\ndatasets==2.14.5\r\ndecorator==5.1.1\r\ndecord==0.6.0\r\ndill==0.3.4\r\ndlinfo==1.2.1\r\ndm-tree==0.1.8\r\netils==1.5.0\r\nevaluate==0.4.0\r\nexceptiongroup==1.1.3\r\nexecnet==2.0.2\r\nfaiss-cpu==1.7.4\r\nfastjsonschema==2.18.0\r\nfilelock==3.12.2\r\nfire==0.5.0\r\nFlask==2.2.5\r\nflatbuffers==23.5.26\r\nflax==0.7.0\r\nfrozenlist==1.4.0\r\nfsspec==2023.6.0\r\nfugashi==1.3.0\r\ngast==0.4.0\r\ngitdb==4.0.10\r\nGitPython==3.1.18\r\ngoogle-auth==2.23.0\r\ngoogle-auth-oauthlib==1.0.0\r\ngoogle-pasta==0.2.0\r\ngql==3.4.1\r\ngraphql-core==3.2.3\r\ngreenlet==2.0.2\r\ngrpcio==1.58.0\r\nh5py==3.9.0\r\nhf-doc-builder==0.4.0\r\nhuggingface-hub==0.16.4\r\nhypothesis==6.87.0\r\nidna==3.4\r\nimportlib-resources==6.1.0\r\niniconfig==2.0.0\r\nipadic==1.0.0\r\nisodate==0.6.1\r\nisort==5.12.0\r\nitsdangerous==2.1.2\r\njax==0.4.13\r\njaxlib==0.4.13\r\nJinja2==3.1.2\r\njinja2-time==0.2.0\r\njoblib==1.3.2\r\njsonschema==4.19.1\r\njsonschema-specifications==2023.7.1\r\njupyter_core==5.3.1\r\nkenlm==0.2.0\r\nkeras==2.13.1\r\nkeras-core==0.1.7\r\nkeras-nlp==0.6.2\r\nlanguage-tags==1.2.0\r\nlazy_loader==0.3\r\nlibclang==16.0.6\r\nlibrosa==0.10.1\r\nlit==17.0.1\r\nllvmlite==0.41.0\r\nlxml==4.9.3\r\nMako==1.2.4\r\nMarkdown==3.4.4\r\nmarkdown-it-py==3.0.0\r\nMarkupSafe==2.1.3\r\nmdurl==0.1.2\r\nml-dtypes==0.3.1\r\nmpmath==1.3.0\r\nmsgpack==1.0.6\r\nmultidict==6.0.4\r\nmultiprocess==0.70.12.2\r\nmypy-extensions==1.0.0\r\nnamex==0.0.7\r\nnbformat==5.9.2\r\nnest-asyncio==1.5.8\r\nnetworkx==3.1\r\nnltk==3.8.1\r\nnumba==0.58.0\r\nnumpy==1.24.3\r\nnvidia-cublas-cu11==11.10.3.66\r\nnvidia-cuda-cupti-cu11==11.7.101\r\nnvidia-cuda-nvrtc-cu11==11.7.99\r\nnvidia-cuda-runtime-cu11==11.7.99\r\nnvidia-cudnn-cu11==8.5.0.96\r\nnvidia-cufft-cu11==10.9.0.58\r\nnvidia-curand-cu11==10.2.10.91\r\nnvidia-cusolver-cu11==11.4.0.1\r\nnvidia-cusparse-cu11==11.7.4.91\r\nnvidia-nccl-cu11==2.14.3\r\nnvidia-nvtx-cu11==11.7.91\r\noauthlib==3.2.2\r\nonnx==1.14.1\r\nonnxconverter-common==1.13.0\r\nopt-einsum==3.3.0\r\noptax==0.1.4\r\noptuna==3.3.0\r\norbax-checkpoint==0.4.0\r\npackaging==23.1\r\npandas==2.1.1\r\nparameterized==0.9.0\r\npathspec==0.11.2\r\nphonemizer==3.2.1\r\nPillow==9.5.0\r\nplac==1.4.0\r\nplatformdirs==3.10.0\r\nplotly==5.17.0\r\npluggy==1.3.0\r\npooch==1.7.0\r\nportalocker==2.0.0\r\npoyo==0.5.0\r\nprotobuf==3.20.3\r\npsutil==5.9.5\r\npy-cpuinfo==9.0.0\r\npyarrow==13.0.0\r\npyasn1==0.5.0\r\npyasn1-modules==0.3.0\r\npycparser==2.21\r\npyctcdecode==0.5.0\r\nPygments==2.16.1\r\npygtrie==2.5.0\r\npylatexenc==2.10\r\npynvml==11.5.0\r\npyparsing==3.1.1\r\npypng==0.20220715.0\r\npytest==7.4.2\r\npytest-timeout==2.1.0\r\npytest-xdist==3.3.1\r\npython-dateutil==2.8.2\r\npython-slugify==8.0.1\r\npytz==2023.3.post1\r\nPyYAML==6.0.1\r\nray==2.7.0\r\nrdflib==7.0.0\r\nreferencing==0.30.2\r\nregex==2023.8.8\r\nrequests==2.31.0\r\nrequests-oauthlib==1.3.1\r\nrequests-toolbelt==0.10.1\r\nresponses==0.18.0\r\nretrying==1.3.4\r\nrfc3986==1.5.0\r\nrhoknp==1.3.0\r\nrich==13.5.3\r\nrjieba==0.1.11\r\nrouge-score==0.1.2\r\nrpds-py==0.10.3\r\nrsa==4.9\r\nruff==0.0.259\r\nsacrebleu==1.5.1\r\nsacremoses==0.0.53\r\nsafetensors==0.3.2\r\nscikit-learn==1.3.1\r\nscipy==1.11.2\r\nsegments==2.2.1\r\nsentencepiece==0.1.99\r\nsigopt==8.8.2\r\nsix==1.16.0\r\nsmmap==5.0.1\r\nsortedcontainers==2.4.0\r\nsoundfile==0.12.1\r\nsoupsieve==2.5\r\nsoxr==0.3.6\r\nSQLAlchemy==2.0.21\r\nSudachiDict-core==20230711\r\nSudachiPy==0.6.7\r\nsympy==1.12\r\ntabulate==0.9.0\r\ntenacity==8.2.3\r\ntensorboard==2.13.0\r\ntensorboard-data-server==0.7.1\r\ntensorboardX==2.6.2.2\r\ntensorflow==2.13.0\r\ntensorflow-estimator==2.13.0\r\ntensorflow-hub==0.14.0\r\ntensorflow-io-gcs-filesystem==0.34.0\r\ntensorflow-text==2.13.0\r\ntensorstore==0.1.44\r\ntermcolor==2.3.0\r\ntext-unidecode==1.3\r\ntf2onnx==1.15.1\r\nthreadpoolctl==3.2.0\r\ntimeout-decorator==0.5.0\r\ntimm==0.9.7\r\ntokenizers==0.14.0\r\ntomli==2.0.1\r\ntoolz==0.12.0\r\ntorch==2.0.1\r\ntorchaudio==2.0.2\r\ntorchvision==0.15.2\r\ntqdm==4.66.1\r\ntraitlets==5.10.0\r\n-e git+https://github.com/sbucaille/transformers.git@77f920f23b29ddf922beedace8ee3cf45a6ead95#egg=transformers\r\ntriton==2.0.0\r\ntyping_extensions==4.5.0\r\ntzdata==2023.3\r\ntzlocal==5.0.1\r\nunidic==1.1.0\r\nunidic-lite==1.0.8\r\nuritemplate==4.1.1\r\nurllib3==1.26.16\r\nwasabi==0.10.1\r\nWerkzeug==2.2.3\r\nwrapt==1.15.0\r\nxxhash==3.3.0\r\nyarl==1.9.2\r\nzipp==3.17.0\r\n```\r\n",
"Hi, with your branch or the main branch, I am not able to reproduce the issue. \r\n\r\nWhat happen if you run `python3 utils/check_docstrings.py --fix_and_overwrite` instead of `make repo-consistency`. I would guess you still get the `TFRegNet` things?\r\n\r\nIf you are using the new created python environment, make sure the bash command where you use `python` is the one pointed to the new path of the python binary.\r\n\r\nOtherwise, probably it is python version cause the difference - and I have to check it.",
"hi @ydshieh ,\r\nWhen I run `python3 utils/check_docstrings.py --fix_and_overwrite` I don't get any error, same if I run `make fix-copies` but `make repo-consistency` always returns this TFRegNet error. What is weird is that the CI tests didn't catch the error... I can't wrap my head around this :exploding_head: \r\n\r\nAnyway, @rafaelpadilla, I guess all the comments were covered by my last commits, let me know if there is anything else I should do !",
"Yeah, I make a new python env (3.10) install everything from scratch and still can't get the error reproduced. Let's move on ..",
"Hi @rafaelpadilla , apart from the only conversation I have not resolved in `src/transformers/models/superpoint/modeling_superpoint.py` that should be good. I realize there was a lot of leftovers from my first files generation using transformers-cli which was originally for SuperGlue, sorry for that",
"> Hi @rafaelpadilla , apart from the only conversation I have not resolved in `src/transformers/models/superpoint/modeling_superpoint.py` that should be good. I realize there was a lot of leftovers from my first files generation using transformers-cli which was originally for SuperGlue, sorry for that\r\n\r\nHey @sbucaille, \r\nNo worries. I think it is almost ready for a final review of one of out core maintainers.\r\nPlease, tag me for a last check when it's ready for review. :) ",
"Hi @rafaelpadilla, I'm sorry if I'm missing something or if my previous message was not clear but I actually need an answer to the [remaining review conversation](https://github.com/huggingface/transformers/pull/25786/files/d1aa6160c20bb9af32733fc30529e92f6e6cd179..5fed639d353201d7eba3f9baf103502e201a45f1#r1359506846) so that other reviewers may proceed, I think",
"Hi @rafaelpadilla, @amyeroberts, @ArthurZucker,\r\nThanks for the reviews, just to let you know that I'll be off for a couple of weeks due to RL stuff.\r\nSo be assured that I'll address the suggested changes at a more appropriate time, in case the PR gets considered as stale from the bot. Thanks again !",
"@sbucaille Thanks for letting us know! We'll keep the PR alive :) ",
"Hello @rafaelpadilla , @amyeroberts ,\r\nI'm finally back and settled to continue working on this PR. I have dealt with minor changes you suggested and added my opinion on others (like [here](https://github.com/huggingface/transformers/pull/25786/files#r1371791244)). I'll deal with the bigger changes later this week and let you know :)\r\nThanks again for keeping this PR alive !",
"Sure! @amyeroberts is off this week, feel free to ping me if you need any help! ",
"@sbucaille Great - glad you're back and PR is active! I'm back too - feel free to ping if you have any Qs about the larger changes. "
] | 1,693 | 1,707 | null |
NONE
| null |
# What does this PR do?
This PR implements SuperPoint, one of the few models that generate keypoints and descriptors given an image, as discussed in [this previous pull request](https://github.com/huggingface/transformers/pull/25697)
The goal is to implement this model and a new type of AutoModel : `AutoModelForInterestPointDescription` (name to be discussed).
## Who can review?
@amyeroberts @ArthurZucker
## TODO's
- [x] Implement SuperPointConfig and SuperPointModel as PretrainedConfig and PretrainedModel
- [x] Generate a conversion script for the original weights
- [x] Implement the new `AutoModelForInterestPointDescription` mapping
- [x] Test the model
- [x] Write documentation
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25786/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25786/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25786",
"html_url": "https://github.com/huggingface/transformers/pull/25786",
"diff_url": "https://github.com/huggingface/transformers/pull/25786.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25786.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25785
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25785/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25785/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25785/events
|
https://github.com/huggingface/transformers/issues/25785
| 1,868,591,154 |
I_kwDOCUB6oc5vYHAy
| 25,785 |
AssertionError: can only test a child process
|
{
"login": "andysingal",
"id": 20493493,
"node_id": "MDQ6VXNlcjIwNDkzNDkz",
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andysingal",
"html_url": "https://github.com/andysingal",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url": "https://api.github.com/users/andysingal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andysingal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andysingal/subscriptions",
"organizations_url": "https://api.github.com/users/andysingal/orgs",
"repos_url": "https://api.github.com/users/andysingal/repos",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"received_events_url": "https://api.github.com/users/andysingal/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Seems like you have a problem with multi processing. \r\nYour code is badly formatted, not readable and doesn't seem to be related to transformers. \r\nIf you want people to help you debug your code, then ask this on [the forum](https://discuss.huggingface.co/) instead, thanks! ",
"Hey Arthur,\r\n Got it , I was just working on a medium article showing how to use\r\ntransformers with PyTorch. Thanks for letting me know.\r\nBest Regards,\r\nAnkush Singal\r\n\r\nOn Mon, Aug 28, 2023 at 19:08 Arthur ***@***.***> wrote:\r\n\r\n> Hey! Seems like you have a problem with multi processing.\r\n> Your code is badly formatted, not readable and doesn't seem to be related\r\n> to transformers.\r\n> If you want people to help you debug your code, then ask this on the forum\r\n> <https://discuss.huggingface.co/> instead, thanks!\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/transformers/issues/25785#issuecomment-1695718083>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AE4LJNLOZHKP7DK2ESU2XLDXXSNMPANCNFSM6AAAAAA4APNETA>\r\n> .\r\n> You are receiving this because you authored the thread.Message ID:\r\n> ***@***.***>\r\n>\r\n"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
### System Info
colab notebook: https://colab.research.google.com/drive/1d6kW_VQMPNHIMPleZJtSWMc81XFGTkQF?usp=sharing
### Who can help?
@ArthurZucker @you
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
URL_REGEX = re.compile('http(s)?:\/\/t.co\/\w+')
MENTION_REGEX = re.compile('@\w+')
hidden_size = 4
def clean_tweet(tweet):
# remove mentions, the pound sign, and replace urls with URL token
tweet = re.sub(URL_REGEX, '', tweet) # replace urls with url. Assumes that the mention of a url is significant
tweet = re.sub(MENTION_REGEX, '', tweet) # remove mentions entirely
tweet = tweet.replace('#', '') # remove pound signs
tweet = re.sub(r'-\s*$', '', tweet)
return tweet.strip()
DATASET_COLUMNS = ["sentiment", "ids", "date", "flag", "user", "text"]
tweetsDF = pd.read_csv("/content/trainingandtestdata/training.1600000.processed.noemoticon.csv",
encoding="ISO-8859-1", header=None, names=DATASET_COLUMNS,usecols=["sentiment","text"])
tweetsDF = tweetsDF.assign(
sentiment=tweetsDF['sentiment'].replace(4,1),
text = tweetsDF['text'].apply(clean_tweet)
)
tweetsDF.head()
```
class TextDataset(torch.utils.data.Dataset):
def __init__(self, input_data):
self.text = input_data['text'].values.tolist()
self.label = [int(label2id[i]) for i in input_data['sentiment'].values.tolist()]
def __len__(self):
return len(self.label)
def get_sequence_token(self, idx):
sequence = [vocab[word] for word in tokenizer(self.text[idx])]
len_seq = len(sequence)
return sequence, len_seq
def get_labels(self, idx):
return self.label[idx]
def __getitem__(self, idx):
sequence, len_seq = self.get_sequence_token(idx)
label = self.get_labels(idx)
return sequence, label, len_seq
def collate_fn(batch):
sequences, labels, lengths = zip(*batch)
max_len = max(lengths)
for i in range(len(batch)):
if len(sequences[i]) != max_len:
for j in range(len(sequences[i]),max_len):
sequences[i].append(0)
return torch.tensor(sequences, dtype=torch.long), torch.tensor(labels, dtype=torch.long)
```
```
def train(model, dataset, epochs, lr, bs):
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam((p for p in model.parameters()
if p.requires_grad), lr=lr)
train_dataset = TextDataset(dataset)
train_dataloader = DataLoader(train_dataset, num_workers=1, batch_size=bs, collate_fn=collate_fn, shuffle=True)
# Training loop
for epoch in range(epochs):
total_loss_train = 0
total_acc_train = 0
for train_sequence, train_label in tqdm(train_dataloader):
# Model prediction
predictions = model(train_sequence.to(device))
labels = train_label.to(device)
loss = criterion(predictions, labels)
# Calculate accuracy and loss per batch
correct = predictions.argmax(axis=1) == labels
acc = correct.sum().item() / correct.size(0)
total_acc_train += correct.sum().item()
total_loss_train += loss.item()
# Backprop
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
print(f'Epochs: {epoch + 1} | Loss: {total_loss_train / len(train_dataset): .3f} | Accuracy: {total_acc_train / len(train_dataset): .3f}')
epochs = 15
lr = 1e-4
batch_size = 4
train(model, df_train, epochs, lr, batch_size)
```
ERROR:
```
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 1478, in __del__
self._shutdown_workers()
File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 1461, in _shutdown_workers
if w.is_alive():
File "/usr/lib/python3.10/multiprocessing/process.py", line 160, in is_alive
assert self._parent_pid == os.getpid(), 'can only test a child process'
AssertionError: can only test a child process
Exception ignored in: <function _MultiProcessingDataLoaderIter.__del__ at 0x78e83fb43e20>
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 1478, in __del__
self._shutdown_workers()
File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 1461, in _shutdown_workers
if w.is_alive():
File "/usr/lib/python3.10/multiprocessing/process.py", line 160, in is_alive
assert self._parent_pid == os.getpid(), 'can only test a child process'
AssertionError: can only test a child process
Exception ignored in: <function _MultiProcessingDataLoaderIter.__del__ at 0x78e83fb43e20>
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 1478, in __del__
self._shutdown_workers()
File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 1461, in _shutdown_workers
if w.is_alive():
File "/usr/lib/python3.10/multiprocessing/process.py", line 160, in is_alive
assert self._parent_pid == os.getpid(), 'can only test a child process'
AssertionError: can only test a child process
Exception ignored in: <function _MultiProcessingDataLoaderIter.__del__ at 0x78e83fb43e20>
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 1478, in __del__
self._shutdown_workers()
File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 1461, in _shutdown_workers
if w.is_alive():
File "/usr/lib/python3.10/multiprocessing/process.py", line 160, in is_alive
assert self._parent_pid == os.getpid(), 'can only test a child process'
AssertionError: can only test a child process
```
### Expected behavior
rest of the code is running normally
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25785/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25785/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25784
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25784/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25784/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25784/events
|
https://github.com/huggingface/transformers/issues/25784
| 1,868,575,311 |
I_kwDOCUB6oc5vYDJP
| 25,784 |
Typo fix in Readme file
|
{
"login": "NinoRisteski",
"id": 95188570,
"node_id": "U_kgDOBax2Wg",
"avatar_url": "https://avatars.githubusercontent.com/u/95188570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NinoRisteski",
"html_url": "https://github.com/NinoRisteski",
"followers_url": "https://api.github.com/users/NinoRisteski/followers",
"following_url": "https://api.github.com/users/NinoRisteski/following{/other_user}",
"gists_url": "https://api.github.com/users/NinoRisteski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NinoRisteski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NinoRisteski/subscriptions",
"organizations_url": "https://api.github.com/users/NinoRisteski/orgs",
"repos_url": "https://api.github.com/users/NinoRisteski/repos",
"events_url": "https://api.github.com/users/NinoRisteski/events{/privacy}",
"received_events_url": "https://api.github.com/users/NinoRisteski/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] |
closed
| false | null |
[] |
[
"Hi! You can proceed direct a PR without an issue page like this one. Otherwise, please provide some info. when opening an issue 🙏 ",
"Hi, \n\nThanks for clarifying!"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
Hi,
Just to point out an unnecessary comma in the docs/readme file.
will correct it.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25784/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25784/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25783
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25783/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25783/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25783/events
|
https://github.com/huggingface/transformers/issues/25783
| 1,868,551,851 |
I_kwDOCUB6oc5vX9ar
| 25,783 |
How to re-tokenize the training set in each epoch?
|
{
"login": "tic-top",
"id": 78676563,
"node_id": "MDQ6VXNlcjc4Njc2NTYz",
"avatar_url": "https://avatars.githubusercontent.com/u/78676563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tic-top",
"html_url": "https://github.com/tic-top",
"followers_url": "https://api.github.com/users/tic-top/followers",
"following_url": "https://api.github.com/users/tic-top/following{/other_user}",
"gists_url": "https://api.github.com/users/tic-top/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tic-top/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tic-top/subscriptions",
"organizations_url": "https://api.github.com/users/tic-top/orgs",
"repos_url": "https://api.github.com/users/tic-top/repos",
"events_url": "https://api.github.com/users/tic-top/events{/privacy}",
"received_events_url": "https://api.github.com/users/tic-top/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Please ask this kind of questions on [the forum ](https://discuss.huggingface.co/)"
] | 1,693 | 1,693 | 1,693 |
NONE
| null |
I have a special tokenizer which can tokenize the sentence based on some propability distribution.
For example, 'I like green apple' ->'[I],[like],[green],[apple]'(30%) or '[I],[like],[green apple]' (70%).
Now in the training part, I want the Trainer can retokenize the dataset in each epoch. How can I do so?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25783/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25783/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25782
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25782/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25782/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25782/events
|
https://github.com/huggingface/transformers/issues/25782
| 1,868,532,265 |
I_kwDOCUB6oc5vX4op
| 25,782 |
[RFC] Tracking and optimizing GPU energy consumption
|
{
"login": "jaywonchung",
"id": 29395896,
"node_id": "MDQ6VXNlcjI5Mzk1ODk2",
"avatar_url": "https://avatars.githubusercontent.com/u/29395896?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jaywonchung",
"html_url": "https://github.com/jaywonchung",
"followers_url": "https://api.github.com/users/jaywonchung/followers",
"following_url": "https://api.github.com/users/jaywonchung/following{/other_user}",
"gists_url": "https://api.github.com/users/jaywonchung/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jaywonchung/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jaywonchung/subscriptions",
"organizations_url": "https://api.github.com/users/jaywonchung/orgs",
"repos_url": "https://api.github.com/users/jaywonchung/repos",
"events_url": "https://api.github.com/users/jaywonchung/events{/privacy}",
"received_events_url": "https://api.github.com/users/jaywonchung/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Maybe of interest to @sashavor :)",
"But we already integrated CodeCarbon, right? Not clear what this adds on top of that",
"Thanks for the comment. I would like to point you to the `Current State` section in the RFC body. In short, the integration of CodeCarbon with Hugging Face is not being maintained at all with known issues not being resolved, and it provides an estimation for carbon emission, which is difficult to optimize. The end goal of this RFC is not reporting, but introducing the tooling for optimizing energy consumption.",
"I think it makes more sense to maintain codecarbon rather than add another package. We were just talking about this with @julien-c the other day, we hope to pursue this in the very near future :hugs: ",
"`codecarbon` integration being maintained is a great news for the community, thank you! But I would like to again make clear the gist of this RFC: I believe reporting should not be the end goal; reporting is a means for optimization, and I don't think `codecarbon` good in that respect. Optimization of course does not have to happen through Zeus, but with Transformers being an open source framework, an active maintainer can help things actually move.",
"I agree that an active maintainer is useful, which is why we were talking about it with @julien-c :)",
"I'm happy to hear that there could potentially be an active maintainer for energy/carbon issues in Hugging Face. And I understand that integrating with an external package is by no means a light decision and it's up to the repository maintainers to make the call. When Hugging Face is thinking about energy and carbon optimization, it would be great if we can chat and see how can be of assistance :)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,698 | 1,698 |
NONE
| null |
This RFC suggests the following:
- Let's **measure and track** GPU energy consumption across Hugging Face frameworks.
- Let's aim to **optimize** GPU energy consumption, while being mindful of existing performance goals like training time.
To do this, I believe that integrating Zeus ([homepage](https://ml.energy/zeus), [repository](https://github.com/SymbioticLab/Zeus)) with Hugging Face is a good idea.
*Disclaimer: I am the maintainer of the Zeus library.*
## Motivation
### Energy measurement and optimization
Deep Learning consumes a lot of energy and thus emits a lot of greenhouse gas. Optimizing the energy consumption/carbon emission of deep learning promotes sustainability and, depending on the user, yields financial benefits by reducing electricity bills and/or carbon offsetting costs.
The goal of tracking energy consumption or carbon emission would be to first raise awareness, and at the same time, **facilitate optimization**. For both purposes, having accurate and objective measurements is critical. Especially for optimization, people should be able to understand what happens to their optimization objective when they tweak parameters, which is very difficult if the objective is not concretely measurable.
### Current state
Hugging Face supports [reporting carbon equivalent emissions for the trained model on the Hub](https://huggingface.co/blog/carbon-emissions-on-the-hub) with an optional [`co2_eq_emissions`](https://huggingface.co/docs/hub/model-cards-co2) entry in model cards. Today, about 0.6% of the models on Hugging Face Hub have the `Carbon Emissions` label, which I assume are the model cards that have CO2eq emissions reported. This was also pointed out by [a recent study](https://arxiv.org/abs/2305.11164) in an academic context -- *"... a stalled proportion of carbon emissions-reporting models, ..."*. So this isn't working ideally at the moment.
Hugging Face tracks carbon emissions via `codecarbon`, but I believe this has a couple issues.
- At the end of the day, it provides an **estimation** of carbon emission, not a measurement. It loses accuracy because not all geographical locations have energy mix or carbon intensity data available. Even in locations where yearly average values are known, it does not take real-time changes in carbon intensity into account, which can [vary significantly within a day](https://arxiv.org/abs/2306.06502). It's probably because real-time carbon intensity information is not free today (e.g., [ElectricityMap](https://www.electricitymaps.com/)).
- #13231. It was acknowledged that `codecarbon` has some quirks and its integration with Transformers is not ideal, but the issue was closed due to lack of activity. Probably the largest problem is the lack of maintainers than anything. The only code commit related to `codecarbon` is the one that introduced it (037e466b105), and the author of the commit is no longer with Hugging Face. This prevents turning carbon accounting on by default.
- Optimization is currently not a goal of `codecarbon`. It primarily focuses on reporting.
### Proposal
First, I would like to make clear that I'm **not** arguing that we should remove or replace `codecarbon`. Rather, I am suggesting that we should *also* have GPU energy consumption, which yields objective and consistent measurement (regardless of the user's geographical location or time of day) and better potential for optimization (because it's not an estimation), via a software framework that is designed for it ([Zeus](https://ml.energy/zeus)).
Reducing energy consumption always leads to less operational carbon emission. Also, with a concrete *energy* measurement in model cards, people can always reconstruct carbon emission by multiplying it with the average carbon intensity of the geographical location and time period the training process took place. In the future, when people get free & more accurate real time carbon intensity data, carbon estimations can be retroactively improved based on energy consumption, too.
### Integration considerations
Tracking energy consumption is a cross-cutting concern. This is a non-exhaustive list of considerations and my opinions.
#### Implementation considerations
- **Software dependencies**: NVML (`nvidia-smi` is a wrapper of NVML) is required for NVIDIA GPUs (ROCm SMI for AMD GPUs). Fortunately, NVML (`libnvidia-ml.so`) is already part of the CUDA toolkit since version 8.0, and even NVIDIA/cuda `base` and pytorch/pytorch official Docker images ship with NVML baked in. Zeus is pure Python.
- **Supporting both PyTorch and JAX**: GPU energy measurement is agnostic to the Deep Learning framework used. It's no different from running `nvidia-smi` during training.
- **Checkpointing**: When model training is suspended and resumed, the current energy consumption should be saved as part of the checkpoint. In other words, *energy consumed until now* becomes a new training state. I think `Trainer.save_metrics` is the right place.
- **Model card**: Along with carbon emission, energy consumption will be added to model cards. I'll come up with a proposal of the exact schema if we decide to do this, since I'm guessing this is difficult to change later.
- **Measurement overhead**: Ideally it should be very low, affecting performance minimally. Volta or newer NVIDIA GPU architectures support querying the cumulative energy consumption of the device since driver load. Thus, one function call before and after training and one subtraction is all we need for recent GPUs. For older GPUs, we will have to spawn a separate Python process that polls the GPU's power consumption. This process will run completely in parallel from the training process and would not affect performance. NVML function calls typically take around 10 ms.
- **Transparency**: User experience with or without energy measurement should be identical. Tracking energy is no different from running `nvidia-smi` during training and will stay transparent to users. Our code should check whether NVML/ROCm SMI is installed in the user's environment and just disable itself if not, instead of raising an error.
- **Supporting both NVIDIA and AMD GPUs**: NVML and ROCm SMI have the same set of functions for power/energy measurement, just with different names.
#### Policy considerations
- **On vs. off by default**: Having low measurement overhead and transparency to users remove the technical barrier for making this on-by-default, but I don't know how people would feel if energy consumption measurements are automatically pushed to Hugging Face Hub. Builders rarely care about energy at this point, so people may not care either way. Then we should turn it on by default. If it's not on by default, the 0.6% number will not improve.
- **Measurement granularity**: Measuring is for optimization, and optimization benefits from finer-grained and precise measurements. Especially, different models train different number of steps on datasets of various sizes. Thus, average energy consumption *per iteration* can be valuable when people want to compare between different models. However, iteration level measurements *may* incur performance overhead because CPU and GPU code need to be synchronized for accurate measurement (i.e., `torch.cuda.synchronize` or `jax.block_until_ready`). So this should be an opt-in feature that is only done a bounded number of times for the purpose of, for instance, profiling for energy optimization.
- **Energy consumption of other components**: There are many other components in a computing system that consume energy (thinking of both PCs and data center servers) -- CPU, DRAM, HDD, SSD, Network switch, Cooling system, etc. We should draw a line somewhere, where the convenience of measurement and the *usefulness* of measurement strike a good tradeoff. Arguably, GPUs are (1) the largest energy consumer for Deep Learning workloads ([Something like 75%; See table 1](https://arxiv.org/abs/2206.05229)), (2) typically not shared between training runs (So we don't have to think about splitting and attributing the energy consumption of a shared hardware component), and (3) quite homogeneous in terms of hardware vendor and measurement library support. This is in contrast with CPU and DRAM. Not all CPUs support Intel RAPL energy measurements, and as far as I know, AMD CPUs do not support DRAM energy measurement via RAPL. All in all, my belief is that at the moment, measuring and optimizing just GPU energy consumption strikes a good balance, although this part is always open to extension. In any case, we should also be very clear from the name of the field in model cards what we're measuring and reporting (e.g., `energy_consumption_joules.gpu: list[float]` -- one float per GPU).
### Optimizing energy consumption
While this may not be an immediate next milestone, integrating Zeus with Hugging Face Transformer has energy optimization as its core goal.
Zeus currently offers two optimization methods that find the optimal [GPU power limit](https://docs.nvidia.com/deploy/nvml-api/group__nvmlDeviceCommands.html#group__nvmlDeviceCommands_1gb35472a72da70c8c8e9c9b108b3640b5) $p$ during training:
```math
\min_{p \in \mathcal{P}} \quad \eta \cdot \mathrm{Energy} + (1 - \eta) \cdot \mathrm{TDP} \cdot \mathrm{Time}
```
and
```math
\begin{align}
\min_{p \in \mathcal{P}} & \quad \mathrm{Energy} \\
s.t. & \quad \mathrm{Slowdown} \le s
\end{align}
```
where the user chooses $0 \le \eta \le 1$ (relative importance between time and energy) or $s \ge 1$ (maximum tolerable slowdown ratio). $\textrm{TDP}$ is the maximum power consumption of the GPU. For instance, the second optimization method given $s = 1.1$ will find the power limit that consumes the least energy while bounding training iteration time below 110% of the original training iteration time.
The [power limit optimizer](https://ml.energy/zeus/reference/optimizer/power_limit/#zeus.optimizer.power_limit.GlobalPowerLimitOptimizer) is implemented so that it's compatible with Hugging Face Trainer callbacks.
```python
from zeus.monitor import ZeusMonitor
from zeus.optimizer import GlobalPowerLimitOptimizer
# Data parallel training with four GPUs
monitor = ZeusMonitor(gpu_indices=[0,1,2,3])
plo = GlobalPowerLimitOptimizer(monitor)
plo.on_epoch_begin()
for x, y in train_dataloader:
plo.on_step_begin()
# Learn from x and y!
plo.on_step_end()
plo.on_epoch_end()
```
[Our publication](https://www.usenix.org/conference/nsdi23/presentation/you) has additional details.
## Your contribution
I would love to get helping hands, but I also acknowledge that we won't be talking about raising awareness if there were plenty of people willing to implement these. ;) So by default, I'll expect to be doing everything I mentioned here myself. Being the maintainer of Zeus myself, I can make changes to Zeus whenever specific needs arise during and after integration.
I can dive right into integration with a PR, or I can post a more detailed implementation plan RFC -- whichever works for existing contributors. I am willing to smooth out rough edges, fix bugs, and add more features in the future. Zeus is a central part of my ongoing PhD work and I have at least three more years to go, so I have good motivation and incentive.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25782/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25782/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25781
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25781/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25781/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25781/events
|
https://github.com/huggingface/transformers/issues/25781
| 1,868,471,615 |
I_kwDOCUB6oc5vXp0_
| 25,781 |
Symbol Zeros is already exposed as (). Error Help pls
|
{
"login": "ZwChiew",
"id": 74089708,
"node_id": "MDQ6VXNlcjc0MDg5NzA4",
"avatar_url": "https://avatars.githubusercontent.com/u/74089708?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZwChiew",
"html_url": "https://github.com/ZwChiew",
"followers_url": "https://api.github.com/users/ZwChiew/followers",
"following_url": "https://api.github.com/users/ZwChiew/following{/other_user}",
"gists_url": "https://api.github.com/users/ZwChiew/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZwChiew/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZwChiew/subscriptions",
"organizations_url": "https://api.github.com/users/ZwChiew/orgs",
"repos_url": "https://api.github.com/users/ZwChiew/repos",
"events_url": "https://api.github.com/users/ZwChiew/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZwChiew/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Okay, did you install `safetensors` and `sentencepiece`? I cannot reproduce your issue",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### Major Bug while importing Huggingface locally model in VS code
Was trying to implement a simple paraphrasing tool
but unable to import / download the library Vamsi/T5_Paraphrase_Paws due to this error:
Symbol Zeros is already exposed as ().
Was working fine on google colab / anaconda but not on vs code
All required libraries and dependencies installed
Boiler code:
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(
"Vamsi/T5_Paraphrase_Paws").to('cuda')
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(
"Vamsi/T5_Paraphrase_Paws").to('cuda')
### Expected behavior
Please help me solve this issue, this is a core module of a very important system
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25781/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25781/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25780
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25780/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25780/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25780/events
|
https://github.com/huggingface/transformers/pull/25780
| 1,868,469,898 |
PR_kwDOCUB6oc5Y3gJg
| 25,780 |
[i18n-KO] Translate `tokenizer.md` to Korean
|
{
"login": "Sunmin0520",
"id": 60782131,
"node_id": "MDQ6VXNlcjYwNzgyMTMx",
"avatar_url": "https://avatars.githubusercontent.com/u/60782131?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sunmin0520",
"html_url": "https://github.com/Sunmin0520",
"followers_url": "https://api.github.com/users/Sunmin0520/followers",
"following_url": "https://api.github.com/users/Sunmin0520/following{/other_user}",
"gists_url": "https://api.github.com/users/Sunmin0520/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sunmin0520/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sunmin0520/subscriptions",
"organizations_url": "https://api.github.com/users/Sunmin0520/orgs",
"repos_url": "https://api.github.com/users/Sunmin0520/repos",
"events_url": "https://api.github.com/users/Sunmin0520/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sunmin0520/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
CONTRIBUTOR
| null |
Translated the `tokenizer.md` file of the documentation to Korean.
Thank you in advance for your review.
Part of https://github.com/huggingface/transformers/issues/20179
## Before reviewing
- [x] Check for missing / redundant translations (번역 누락/중복 검사)
- [x] Grammar Check (맞춤법 검사)
- [x] Review or Add new terms to glossary (용어 확인 및 추가)
- [x] Check Inline TOC (e.g. `[[lowercased-header]]`)
- [ ] Check live-preview for gotchas (live-preview로 정상작동 확인)
## Who can review? (Initial)
@bolizabeth, @nuatmochoi, @heuristicwave, @mjk0618, @keonju2, @harheem, @HongB1, @junejae, @54data, @seank021, @augustinLib, @sronger, @TaeYupNoh, @kj021, @eenzeenee
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25780/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25780/timeline
| null | true |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25780",
"html_url": "https://github.com/huggingface/transformers/pull/25780",
"diff_url": "https://github.com/huggingface/transformers/pull/25780.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25780.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25779
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25779/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25779/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25779/events
|
https://github.com/huggingface/transformers/pull/25779
| 1,868,451,433 |
PR_kwDOCUB6oc5Y3cg4
| 25,779 |
fix register
|
{
"login": "zspo",
"id": 26846598,
"node_id": "MDQ6VXNlcjI2ODQ2NTk4",
"avatar_url": "https://avatars.githubusercontent.com/u/26846598?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zspo",
"html_url": "https://github.com/zspo",
"followers_url": "https://api.github.com/users/zspo/followers",
"following_url": "https://api.github.com/users/zspo/following{/other_user}",
"gists_url": "https://api.github.com/users/zspo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zspo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zspo/subscriptions",
"organizations_url": "https://api.github.com/users/zspo/orgs",
"repos_url": "https://api.github.com/users/zspo/repos",
"events_url": "https://api.github.com/users/zspo/events{/privacy}",
"received_events_url": "https://api.github.com/users/zspo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Sure! ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25779). All of your documentation changes will be reflected on that endpoint."
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Fix register in some auto class.
Fixes #25453
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@ArthurZucker @sgugger
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25779/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25779/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25779",
"html_url": "https://github.com/huggingface/transformers/pull/25779",
"diff_url": "https://github.com/huggingface/transformers/pull/25779.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25779.patch",
"merged_at": 1693311109000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25778
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25778/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25778/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25778/events
|
https://github.com/huggingface/transformers/issues/25778
| 1,868,190,290 |
I_kwDOCUB6oc5vWlJS
| 25,778 |
Support for context-free-grammars (CFG) to constrain model output
|
{
"login": "jvhoffbauer",
"id": 9884254,
"node_id": "MDQ6VXNlcjk4ODQyNTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9884254?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jvhoffbauer",
"html_url": "https://github.com/jvhoffbauer",
"followers_url": "https://api.github.com/users/jvhoffbauer/followers",
"following_url": "https://api.github.com/users/jvhoffbauer/following{/other_user}",
"gists_url": "https://api.github.com/users/jvhoffbauer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jvhoffbauer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jvhoffbauer/subscriptions",
"organizations_url": "https://api.github.com/users/jvhoffbauer/orgs",
"repos_url": "https://api.github.com/users/jvhoffbauer/repos",
"events_url": "https://api.github.com/users/jvhoffbauer/events{/privacy}",
"received_events_url": "https://api.github.com/users/jvhoffbauer/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] |
open
| false | null |
[] |
[
"I think something like this is planned cc @gante 🤗 ",
"@gante @ArthurZucker can I help with this somehow? Happy to set up a PR over the weekend! ",
"Hey @jvhoffbauer 👋 \r\n\r\nThis feature seems very similar to Microsoft's [`guidance`](https://github.com/guidance-ai/guidance) project, which is compatible with `transformers`. \r\n\r\nIs there some use case that you see `guidance` not solving that this one would solve? :)",
"Hey @gante \r\n\r\nI think guidance is a very feature-rich framework to query LLMs. It, however, does not provide \r\n\r\n- support for context-free grammars, only regex (that is my understanding so far!)\r\n- beam search\r\n- a lightweight approach to perform inference that can potentially be embedded in training pipelines\r\n\r\nUsing transformers would be more convenient for my specific use case (generating markdown). Do you think that this justifies integrating it? I also would be curious if others need such a feature. ",
"@jvhoffbauer you're the first one requesting it :D \r\n\r\nSince this requires non-trivial code (that we have to maintain in the future) and our bandwidth is quite limited at the moment, I'll do my usual pact: if this comment reaches `10` reactions, I'll greenlight its inclusion in `transformers` :) (Whoever does the 10th react, please tag me in a comment!)\r\n\r\nThat way, we know for sure that there is demand for the feature, and that our team's bandwidth is being put to the best use in favor of the community 🤗 ",
"Makes sense! ",
"@gante It's even 11 now! \r\n\r\nI am super happy to prepare a PR. Can you provide guidance on how to go about discussions on the interface and architecture? Should I just draft something out or is there a better way? ",
"+1 for this. It would be very interesting to use BNF as a built-in LogitsProcessor in transformers.",
"Thanks all for your interest! @gante, leading generation, is on leave for the coming few weeks, but we'll make sure to attend to this issue when he's back. \r\n\r\n@jvhoffbauer, if you're motivated to open a PR with a draft of what you have in mind, please go ahead!",
"> Thanks all for your interest! @gante, leading generation, is on leave for the coming few weeks, but we'll make sure to attend to this issue when he's back.\r\n> \r\n> @jvhoffbauer, if you're motivated to open a PR with a draft of what you have in mind, please go ahead!\r\n\r\nSuper cool! Yes, I will create a draft this week! ",
"I see that @Saibo-creator already created a draft in #27557 which is exactly what was discussed! \r\n\r\nIn addition to that, I am starting a research project in Uni working on syntax-error-free text generation which will explore applications of CFG-based text generation. Potentially describing further use-cases in that area in a community blog post might be interesting! ",
"@jvhoffbauer Happy to see that you are also working on research project related to grammar-constrained decoding! I'm also working on a research project related to GCD, would you mind us having a zoom chat at some time? It may spark new ideas! :) \r\nhere is my email [email protected]",
"By the way, Microsoft's guidance repo has CFG decoding now, although it doesn't seem like you can easily define the CFG as a text file (i.e. not defining the grammar itself programmatically).",
"@jvhoffbauer @Saibo-creator: By the way, you might want to review [Picard](https://arxiv.org/abs/2109.05093) and [Synchromesh](https://openreview.net/forum?id=KmtVD97J43e), as they both use CFG decoding to improve the generation of code.",
"@shermansiu \nThanks for pointing out the two papers, yes I know both papers. They are important works in this technique ",
"While this is being worked on, you might also consider using https://github.com/r2d4/parserllm (thank @elo-siema for finding it)"
] | 1,693 | 1,707 | null |
NONE
| null |
### Feature request
It would be nice to constrain the model output with a CFG directly when calling `model.generate`.
This is already done by llama.cpp [grammars](https://github.com/ggerganov/llama.cpp#constrained-output-with-grammars)
An example is in this [repo](https://github.com/r2d4/rellm).
```
prompt = "ReLLM, the best way to get structured data out of LLMs, is an acronym for "
pattern = regex.compile(r'Re[a-z]+ L[a-z]+ L[a-z]+ M[a-z]+')
output = complete_re(model=model,
prompt=prompt,
pattern=pattern)
```
```
> Realized Logistic Logistics Model
```
Is such a parameter on the roadmap for transformers?
### Motivation
This can be super useful to make model output parseable within architectures that process the output of an LLM using classical methods. E.g. it can be used to make a model generate valid JSON in every case.
### Your contribution
Happy to build this with CFGs if it helps! 😄
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25778/reactions",
"total_count": 5,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/25778/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25777
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25777/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25777/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25777/events
|
https://github.com/huggingface/transformers/issues/25777
| 1,868,132,391 |
I_kwDOCUB6oc5vWXAn
| 25,777 |
transformers application
|
{
"login": "XD-mu",
"id": 84305099,
"node_id": "MDQ6VXNlcjg0MzA1MDk5",
"avatar_url": "https://avatars.githubusercontent.com/u/84305099?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/XD-mu",
"html_url": "https://github.com/XD-mu",
"followers_url": "https://api.github.com/users/XD-mu/followers",
"following_url": "https://api.github.com/users/XD-mu/following{/other_user}",
"gists_url": "https://api.github.com/users/XD-mu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/XD-mu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/XD-mu/subscriptions",
"organizations_url": "https://api.github.com/users/XD-mu/orgs",
"repos_url": "https://api.github.com/users/XD-mu/repos",
"events_url": "https://api.github.com/users/XD-mu/events{/privacy}",
"received_events_url": "https://api.github.com/users/XD-mu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,693 | 1,693 | 1,693 |
NONE
| null |
transformer的多领域应用模型,非常棒!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25777/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25777/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25776
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25776/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25776/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25776/events
|
https://github.com/huggingface/transformers/pull/25776
| 1,868,129,017 |
PR_kwDOCUB6oc5Y2fsn
| 25,776 |
Empty
|
{
"login": "LorrinWWW",
"id": 20911161,
"node_id": "MDQ6VXNlcjIwOTExMTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/20911161?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LorrinWWW",
"html_url": "https://github.com/LorrinWWW",
"followers_url": "https://api.github.com/users/LorrinWWW/followers",
"following_url": "https://api.github.com/users/LorrinWWW/following{/other_user}",
"gists_url": "https://api.github.com/users/LorrinWWW/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LorrinWWW/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LorrinWWW/subscriptions",
"organizations_url": "https://api.github.com/users/LorrinWWW/orgs",
"repos_url": "https://api.github.com/users/LorrinWWW/repos",
"events_url": "https://api.github.com/users/LorrinWWW/events{/privacy}",
"received_events_url": "https://api.github.com/users/LorrinWWW/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,693 | 1,693 | 1,693 |
NONE
| null | null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25776/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25776/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25776",
"html_url": "https://github.com/huggingface/transformers/pull/25776",
"diff_url": "https://github.com/huggingface/transformers/pull/25776.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25776.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25775
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25775/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25775/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25775/events
|
https://github.com/huggingface/transformers/issues/25775
| 1,867,997,731 |
I_kwDOCUB6oc5vV2Ij
| 25,775 |
Lora adapter weights not getting loaded
|
{
"login": "jaideep11061982",
"id": 38164196,
"node_id": "MDQ6VXNlcjM4MTY0MTk2",
"avatar_url": "https://avatars.githubusercontent.com/u/38164196?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jaideep11061982",
"html_url": "https://github.com/jaideep11061982",
"followers_url": "https://api.github.com/users/jaideep11061982/followers",
"following_url": "https://api.github.com/users/jaideep11061982/following{/other_user}",
"gists_url": "https://api.github.com/users/jaideep11061982/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jaideep11061982/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jaideep11061982/subscriptions",
"organizations_url": "https://api.github.com/users/jaideep11061982/orgs",
"repos_url": "https://api.github.com/users/jaideep11061982/repos",
"events_url": "https://api.github.com/users/jaideep11061982/events{/privacy}",
"received_events_url": "https://api.github.com/users/jaideep11061982/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey, could you explain your problem properly? We need a full reproducer and traceback to be able to help you.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
NONE
| null |
### System Info
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.30.2
- Platform: Linux-5.15.120+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 2.0.0 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.7.0 (gpu)
- Jax version: 0.4.13
- JaxLib version: 0.4.13
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```
mymodel = AutoModelForMultipleChoice.from_pretrained(model_path ) # original model
mymodel=PeftModel.from_pretrained(mymodel,'/kaggle/input/llm-best/best_ckp1') # best weights
```
`trainable params: 2050 || all params: 435850242 || trainable%: 0.00`
when I do get CV it gets me
getScore(trainer,test_df_val,tokenized_test_ds_val)
i get No trained results as if not trained..
### Expected behavior
i should get same score as i got during the training followed by inferenec when it ends up with loading the best weights as I enable best load at the end of training option
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25775/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25775/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25774
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25774/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25774/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25774/events
|
https://github.com/huggingface/transformers/issues/25774
| 1,867,936,129 |
I_kwDOCUB6oc5vVnGB
| 25,774 |
'DonutImageProcessor' object has no attribute 'to_pil_image'
|
{
"login": "andysingal",
"id": 20493493,
"node_id": "MDQ6VXNlcjIwNDkzNDkz",
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andysingal",
"html_url": "https://github.com/andysingal",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url": "https://api.github.com/users/andysingal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andysingal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andysingal/subscriptions",
"organizations_url": "https://api.github.com/users/andysingal/orgs",
"repos_url": "https://api.github.com/users/andysingal/repos",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"received_events_url": "https://api.github.com/users/andysingal/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @andysingal, thanks for raising this issue! \r\n\r\nCould you share where the notebook is from? i.e. is it an official example from within the HF ecosystem? I'm asking so I know any places that will need to be updated. \r\n\r\nThe class `processor.feature_extractor` doesn't have the method `to_pil_image`. There is a method available in the image transforms library which performs the same functionality:\r\n\r\n```python\r\nfrom transformers.image_transforms import to_pil_image\r\n\r\n...\r\n\r\nprint(f\"Prediction:\\n {prediction}\")\r\nto_pil_image(np.array(test_sample[\"pixel_values\"])).resize((350,600))\r\n```",
"@amyeroberts I think this might be the article that provoked the issue: https://www.philschmid.de/fine-tuning-donut#4-fine-tune-and-evaluate-donut-model (I notice the variable names and arguments to `resize` are the same).\r\n\r\nYour suggestion:\r\n```\r\nfrom transformers.image_transforms import to_pil_image\r\nto_pil_image(np.array(test_sample[\"pixel_values\"])).resize((350,600))\r\n```\r\n\r\nYields the issue: \r\n\r\nValueError: The image to be converted to a PIL image contains values outside the range [0, 1], got [-1.0, 1.0] which cannot be converted to uint8.\r\n\r\nWhich suggests to me that the 2 methods might not be equivalent, or some breaking change happened between the publish date of the article and the current API.\r\n\r\nThis might be outside your work responsibility, but I post here hoping you might have another suggestion :pray: ",
"@hauthorn - thanks highlighting the article. \r\n\r\nYes, the `to_pil_image` function in the image_transforms method is derived from the `to_pil_image` method that the deprecated feature extractors used. There were some checks added to the inputs but the logic remains the same. Previously, it would blindly rescale by 255 if it had floating values and convert to `uint8` before converting to a PIL.Image. Now, it checks the input to make sure this is valid - which is what's raising the exception now. As the image has values between [-1, 1], these would be rescaled to [-255, 255], which when casting to uint8 will set all of the values less that 0 to 0. \r\n\r\nIn this case, the pixel values need to be manually shifted and rescaled: \r\n\r\n```python\r\nfrom transformers import to_pil_image\r\n\r\npixel_values = test_sample[\"pixel_values\"]\r\n# Rescale values between 0-1\r\npixel_values = (pixel_values + 1) / 2\r\n\r\nto_pil_image(np.array(test_sample[\"pixel_values\"])).resize((350,600))\r\n```\r\n",
"@andysingal were you able to solve the problem? I'm having exactly the same error and I can't solve it.\r\n\r\nThank you so much!",
"@erikaxenia \r\n\r\nHi, Erika, et al.,\r\n\r\nhad similar issue, \r\n\r\nthis is what worked for me\r\n```\r\npixel_values = np.squeeze(test_sample[\"pixel_values\"])\r\npixel_values = (pixel_values + 1) / 2\r\n\r\n\r\nto_pil_image(pixel_values)\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,699 | 1,699 |
NONE
| null |
### System Info
```
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q datasets sentencepiece tensorboard
!sudo apt-get install git-lfs --yes
!pip install -q accelerate -U
```
for reference: https://colab.research.google.com/drive/1CVhL9c3yoJ5IE8-5DG7W7AofmyA5f7aP?usp=sharing
### Who can help?
@amyeroberts @pacman
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
import re
import transformers
from PIL import Image
from transformers import DonutProcessor, VisionEncoderDecoderModel
import torch
import random
import numpy as np
# hidde logs
transformers.logging.disable_default_handler()
# Load our model from Hugging Face
processor = DonutProcessor.from_pretrained("Andyrasika/donut-base-sroie")
model = VisionEncoderDecoderModel.from_pretrained("Andyrasika/donut-base-sroie")
# Move model to GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
# Load random document image from the test set
test_sample = processed_dataset["test"][random.randint(1, 50)]
def run_prediction(sample, model=model, processor=processor):
# prepare inputs
pixel_values = torch.tensor(test_sample["pixel_values"]).unsqueeze(0)
task_prompt = "<s>"
decoder_input_ids = processor.tokenizer(task_prompt, add_special_tokens=False, return_tensors="pt").input_ids
# run inference
outputs = model.generate(
pixel_values.to(device),
decoder_input_ids=decoder_input_ids.to(device),
max_length=model.decoder.config.max_position_embeddings,
early_stopping=True,
pad_token_id=processor.tokenizer.pad_token_id,
eos_token_id=processor.tokenizer.eos_token_id,
use_cache=True,
num_beams=1,
bad_words_ids=[[processor.tokenizer.unk_token_id]],
return_dict_in_generate=True,
)
# process output
prediction = processor.batch_decode(outputs.sequences)[0]
prediction = processor.token2json(prediction)
# load reference target
target = processor.token2json(test_sample["target_sequence"])
return prediction, target
prediction, target = run_prediction(test_sample)
print(f"Reference:\n {target}")
print(f"Prediction:\n {prediction}")
processor.feature_extractor.to_pil_image(np.array(test_sample["pixel_values"])).resize((350,600))
```
giving error:
```
Downloading (…)rocessor_config.json: 100%
420/420 [00:00<00:00, 34.6kB/s]
Downloading (…)okenizer_config.json: 100%
510/510 [00:00<00:00, 42.5kB/s]
Downloading (…)tencepiece.bpe.model: 100%
1.30M/1.30M [00:00<00:00, 4.16MB/s]
Downloading (…)/main/tokenizer.json: 100%
4.01M/4.01M [00:00<00:00, 12.7MB/s]
Downloading (…)in/added_tokens.json: 100%
257/257 [00:00<00:00, 22.3kB/s]
Downloading (…)cial_tokens_map.json: 100%
485/485 [00:00<00:00, 45.3kB/s]
Downloading (…)lve/main/config.json: 100%
4.89k/4.89k [00:00<00:00, 369kB/s]
Downloading pytorch_model.bin: 100%
809M/809M [00:14<00:00, 61.1MB/s]
Downloading (…)neration_config.json: 100%
165/165 [00:00<00:00, 14.2kB/s]
/usr/local/lib/python3.10/dist-packages/transformers/generation/utils.py:1417: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation )
warnings.warn(
/usr/local/lib/python3.10/dist-packages/transformers/generation/configuration_utils.py:399: UserWarning: `num_beams` is set to 1. However, `early_stopping` is set to `True` -- this flag is only used in beam-based generation modes. You should set `num_beams>1` or unset `early_stopping`.
warnings.warn(
Reference:
{'total': '19.00', 'date': '04-05-18', 'company': 'C W KHOO HARDWARE SDN BHD', 'address': 'NO.50, JALAN PBS 14/11, KAWASAN PERINDUSTRIAN BUKIT SERDANG,'}
Prediction:
{'total': '19.00', 'date': '04-05-18', 'company': 'C W KHOO HARDWARE SDN BHD', 'address': 'NO.50, JALAN PBS 14/11, KAWASAN PERINDUSTRIAN BUKIT SERDANG,'}
/usr/local/lib/python3.10/dist-packages/transformers/models/donut/processing_donut.py:189: FutureWarning: `feature_extractor` is deprecated and will be removed in v5. Use `image_processor` instead.
warnings.warn(
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
[<ipython-input-17-c77c791b55f7>](https://localhost:8080/#) in <cell line: 55>()
53 print(f"Reference:\n {target}")
54 print(f"Prediction:\n {prediction}")
---> 55 processor.feature_extractor.to_pil_image(np.array(test_sample["pixel_values"])).resize((350,600))
AttributeError: 'DonutImageProcessor' object has no attribute 'to_pil_image'
```
### Expected behavior
needs to display image
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25774/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25774/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25773
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25773/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25773/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25773/events
|
https://github.com/huggingface/transformers/issues/25773
| 1,867,913,905 |
I_kwDOCUB6oc5vVhqx
| 25,773 |
Support for -1 for pad token id to follow Metas LLama implementation
|
{
"login": "mallorbc",
"id": 39721523,
"node_id": "MDQ6VXNlcjM5NzIxNTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/39721523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mallorbc",
"html_url": "https://github.com/mallorbc",
"followers_url": "https://api.github.com/users/mallorbc/followers",
"following_url": "https://api.github.com/users/mallorbc/following{/other_user}",
"gists_url": "https://api.github.com/users/mallorbc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mallorbc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mallorbc/subscriptions",
"organizations_url": "https://api.github.com/users/mallorbc/orgs",
"repos_url": "https://api.github.com/users/mallorbc/repos",
"events_url": "https://api.github.com/users/mallorbc/events{/privacy}",
"received_events_url": "https://api.github.com/users/mallorbc/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
},
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] |
closed
| false | null |
[] |
[
"Hey! Thanks for the input. We were also discussing wether or not we can do this in `transformers` in #25088. \r\nThe real issue is the the `Llama` families do not have a `padding_token` and just a `pad_id`. Padding with a negative index works sure, but we can't add this to `tokenizers` for starters, but it is also not the way our tokenizers work. \r\n\r\nNone of this would have happened if they had a padding tokens 😅 ",
"Hey @ArthurZucker - I see that #25088 was merged. What ended up being the resolution for this? It's not clear from that PR if we should be using -1 for the padding token or doing something else. Thanks!",
"You should never use -1 as it is a bad industry practice. Not supported on a lot of libs, confusing and does not represent any string. The solution is to overcome vocab size limit by correctly padding the model to the closest SM of your architecture! (thus allowing token addition without performance loss. \r\nClosing as not planned BTW",
"Sorry, what is SM?",
"https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#hardware-implementation Streaming Multiprocessors 😉 ",
"ty!"
] | 1,693 | 1,707 | 1,707 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.15.0-79-generic-x86_64-with-glibc2.31
- Python version: 3.9.17
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.21.0
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: MULTI_GPU
- mixed_precision: bf16
- use_cpu: False
- num_processes: 2
- machine_rank: 0
- num_machines: 1
- gpu_ids: all
- rdzv_backend: static
- same_network: True
- main_training_function: main
- downcast_bf16: no
- tpu_use_cluster: False
- tpu_use_sudo: False
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: NA
### Who can help?
@Arthur
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Load the LLama 2 tokenizer
```python
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf", token=access_token,trust_remote_code=args.trust_remote_code,add_eos_token=True,use_fast=True)
```
Notice that there is no padding token. By default that means that many programs will go ahead and use the EOS token for the padding token unless one is added.
```python
print(tokenizer.pad_token_id)
```
Notice that in the llama repo, they set the padding token id to -1
https://github.com/facebookresearch/llama/blob/1a240688810f8036049e8da36b073f63d2ac552c/llama/tokenizer.py#L14-L25
Try setting the pad token to -1 to replicate how Meta trained their model.
```python
tokenizer.pad_token_id = -1
```
You will get an error like
```
IndexError: piece id is out of range.
```
### Expected behavior
I would expect this to work. Padding tokens are only used to determine what the attention mask does. If you want to finetune the chat Llama model, using EOS is not a working solution.
The only other alternative is to either choose a token that you will never use(probably) in your dataset, such as *** which is 18610, or add a new token and expand the model token embedding. While these may work, they are not as elegant and may have issues when trying to use other frameworks that expect a certain embedding size, or when using things like LORA.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25773/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25773/timeline
|
not_planned
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25772
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25772/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25772/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25772/events
|
https://github.com/huggingface/transformers/pull/25772
| 1,867,879,210 |
PR_kwDOCUB6oc5Y1tgs
| 25,772 |
[i18n-KO] Translate `pipelines.md` to Korean
|
{
"login": "Sunmin0520",
"id": 60782131,
"node_id": "MDQ6VXNlcjYwNzgyMTMx",
"avatar_url": "https://avatars.githubusercontent.com/u/60782131?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sunmin0520",
"html_url": "https://github.com/Sunmin0520",
"followers_url": "https://api.github.com/users/Sunmin0520/followers",
"following_url": "https://api.github.com/users/Sunmin0520/following{/other_user}",
"gists_url": "https://api.github.com/users/Sunmin0520/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sunmin0520/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sunmin0520/subscriptions",
"organizations_url": "https://api.github.com/users/Sunmin0520/orgs",
"repos_url": "https://api.github.com/users/Sunmin0520/repos",
"events_url": "https://api.github.com/users/Sunmin0520/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sunmin0520/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@0525hhgus 님, 혹시 위의 CI 테스트에서 첫번째 에러 부분에 대해 확인해주실 수 있을까요? \r\n에러 메세지를 보면 \r\n`ValueError: There was an error when converting ../transformers/docs/source/ko/main_classes/pipelines.md to the MDX format.\r\nUnable to find 파이프라인 in transformers. Make sure the path to that object is correct.` 라고 나옵니다.\r\nAPI 문서에 대해서는 toctree.yml에 작성해야하는 방법이 조금 다른걸까요..?",
"> @0525hhgus 님, 혹시 위의 CI 테스트에서 첫번째 에러 부분에 대해 확인해주실 수 있을까요? 에러 메세지를 보면 `ValueError: There was an error when converting ../transformers/docs/source/ko/main_classes/pipelines.md to the MDX format. Unable to find 파이프라인 in transformers. Make sure the path to that object is correct.` 라고 나옵니다. API 문서에 대해서는 toctree.yml에 작성해야하는 방법이 조금 다른걸까요..?\r\n\r\n안녕하세요, @Sunmin0520 님!\r\npipelines.md 문서가 main_classes 폴더 아래 있다는 것이 나타나지 않아서 발생한 것으로 추정됩니다.\r\n_toctree.yml에서 209 라인의 `pipelines`를 `main_classes/pipelines`로 수정하시면 될 것 같습니다! :smile: ",
"@0525hhgus 님, 감사합니다! 알려주신 것처럼 수정 후 문제없이 CI 테스트 완료된 것 확인했습니다 :)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,693 | 1,697 | 1,697 |
CONTRIBUTOR
| null |
# What does this PR do?
Translated the `pipelines.md` file of the documentation to Korean.
Thank you in advance for your review.
Part of https://github.com/huggingface/transformers/issues/20179
## Before reviewing
- [x] Check for missing / redundant translations (번역 누락/중복 검사)
- [x] Grammar Check (맞춤법 검사)
- [x] Review or Add new terms to glossary (용어 확인 및 추가)
- [x] Check Inline TOC (e.g. `[[lowercased-header]]`)
- [ ] Check live-preview for gotchas (live-preview로 정상작동 확인)
## Who can review? (Initial)
@bolizabeth, @nuatmochoi, @heuristicwave, @mjk0618, @keonju2, @harheem, @HongB1, @junejae, @54data, @seank021, @augustinLib, @sronger, @TaeYupNoh, @kj021, @eenzeenee
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review? (Final)
May you please review this PR? @sgugger, @ArthurZucker, @eunseojo
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25772/reactions",
"total_count": 10,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 3,
"confused": 0,
"heart": 3,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/25772/timeline
| null | true |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25772",
"html_url": "https://github.com/huggingface/transformers/pull/25772",
"diff_url": "https://github.com/huggingface/transformers/pull/25772.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25772.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25771
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25771/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25771/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25771/events
|
https://github.com/huggingface/transformers/pull/25771
| 1,867,780,974 |
PR_kwDOCUB6oc5Y1Yr2
| 25,771 |
Arde/fsdp activation checkpointing
|
{
"login": "arde171",
"id": 60484160,
"node_id": "MDQ6VXNlcjYwNDg0MTYw",
"avatar_url": "https://avatars.githubusercontent.com/u/60484160?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arde171",
"html_url": "https://github.com/arde171",
"followers_url": "https://api.github.com/users/arde171/followers",
"following_url": "https://api.github.com/users/arde171/following{/other_user}",
"gists_url": "https://api.github.com/users/arde171/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arde171/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arde171/subscriptions",
"organizations_url": "https://api.github.com/users/arde171/orgs",
"repos_url": "https://api.github.com/users/arde171/repos",
"events_url": "https://api.github.com/users/arde171/events{/privacy}",
"received_events_url": "https://api.github.com/users/arde171/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25771). All of your documentation changes will be reflected on that endpoint.",
"Cc @pacman100 if you think this is relevant 🤗"
] | 1,693 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Currently, HF Trainer didn't support FSDP activation checkpointing. This PR provides support to FSDP activation checkpointing.
Please see the details about the FSDP activation checkpointing [here](https://pytorch.org/blog/scaling-multimodal-foundation-models-in-torchmultimodal-with-pytorch-distributed/#activation-checkpointing).
I saw the improvement in training performance for the large LLM models (e.g., LLAMA 70B) with FSDP activation checkpointing as compared to the existing gradient_checkpointing option. It's easy to enable FSDP activation_checkpointing.
we just need to add `"activation_checkpointing": "True"` to enable the FSDP `activation_checkpointing` as shown in below example `fsdp_config.json` file.
fsdp_config.json
```
{
"transformer_layer_cls_to_wrap": ["LlamaDecoderLayer"],
...
"activation_checkpointing": "True"
}
```
Please see the below PR for more details about FSDP activation checkpointing in accelerate repo:
PR: https://github.com/huggingface/accelerate/pull/1891
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25771/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25771/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25771",
"html_url": "https://github.com/huggingface/transformers/pull/25771",
"diff_url": "https://github.com/huggingface/transformers/pull/25771.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25771.patch",
"merged_at": 1693293735000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25770
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25770/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25770/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25770/events
|
https://github.com/huggingface/transformers/issues/25770
| 1,867,704,703 |
I_kwDOCUB6oc5vUul_
| 25,770 |
isses with converting codellama model with convert_llama_weights_to_hf.py
|
{
"login": "ilang6",
"id": 26204796,
"node_id": "MDQ6VXNlcjI2MjA0Nzk2",
"avatar_url": "https://avatars.githubusercontent.com/u/26204796?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ilang6",
"html_url": "https://github.com/ilang6",
"followers_url": "https://api.github.com/users/ilang6/followers",
"following_url": "https://api.github.com/users/ilang6/following{/other_user}",
"gists_url": "https://api.github.com/users/ilang6/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ilang6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ilang6/subscriptions",
"organizations_url": "https://api.github.com/users/ilang6/orgs",
"repos_url": "https://api.github.com/users/ilang6/repos",
"events_url": "https://api.github.com/users/ilang6/events{/privacy}",
"received_events_url": "https://api.github.com/users/ilang6/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey ! This is expected, the conversion script was updated to support code llama see #25740.\r\nMake sure you are running the script on main ",
"Thank you for your help.\nI tried the updated script again and everything thing worked just fine.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,692 | 1,695 | 1,695 |
NONE
| null |
### System Info
Hi .
I'm trying to convert the new codellama 7B model with convert_llama_weights_to_hf.py
but I'm getting the following error:
`ValueError: Trying to set a tensor of shape torch.Size([32016, 4096]) in "weight" (which has shape torch.Size([32000, 4096])), this look incorrect.`
I'm running the script on macos 13.0 (22A380) and python 3.9 with Transformers version 4.32.0.
Thank you in advance.
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
This was the code I ran.
`python src/transformers/models/llama/convert_llama_weights_to_hf.py --input_dir /Volumes/Extreme_SSD/llama2_code/CodeLlama-7b --output_dir /Volumes/Extreme_SSD/llama2_code/CodeLlama-7b/converted --model_size 7B`
### Expected behavior
At the end of the process, I should have the model in a bin format.
With config.json and tokenizer file.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25770/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25770/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25769
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25769/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25769/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25769/events
|
https://github.com/huggingface/transformers/issues/25769
| 1,867,690,721 |
I_kwDOCUB6oc5vUrLh
| 25,769 |
Local variable 'tokens' referenced before assignment error in tokenization_llama.py
|
{
"login": "avnishn",
"id": 38871737,
"node_id": "MDQ6VXNlcjM4ODcxNzM3",
"avatar_url": "https://avatars.githubusercontent.com/u/38871737?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avnishn",
"html_url": "https://github.com/avnishn",
"followers_url": "https://api.github.com/users/avnishn/followers",
"following_url": "https://api.github.com/users/avnishn/following{/other_user}",
"gists_url": "https://api.github.com/users/avnishn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avnishn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avnishn/subscriptions",
"organizations_url": "https://api.github.com/users/avnishn/orgs",
"repos_url": "https://api.github.com/users/avnishn/repos",
"events_url": "https://api.github.com/users/avnishn/events{/privacy}",
"received_events_url": "https://api.github.com/users/avnishn/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"+1\r\n\r\nBtw `LlamaTokenizerFast` seems to be fine with an empty string\r\n\r\n```py\r\ntokenizer = LlamaTokenizerFast.from_pretrained(\"meta-llama/Llama-2-7b-chat-hf\")\r\ntokenizer.tokenize(\"\") # returns []\r\n```\r\n\r\nbut `LlamaTokenizer` returns this error:\r\n```\r\n---------------------------------------------------------------------------\r\nUnboundLocalError Traceback (most recent call last)\r\nCell In[25], line 2\r\n 1 tokenizer = LlamaTokenizer.from_pretrained(\"meta-llama/Llama-2-7b-chat-hf\")\r\n----> 2 tokenizer.tokenize(\"\")\r\n\r\nFile ~\\Documents\\llama2\\lib\\site-packages\\transformers\\models\\llama\\tokenization_llama.py:214, in LlamaTokenizer.tokenize(self, text, **kwargs)\r\n 211 if len(text) > 0:\r\n 212 tokens = super().tokenize(SPIECE_UNDERLINE + text.replace(SPIECE_UNDERLINE, \" \"), **kwargs)\r\n--> 214 if tokens[0] == SPIECE_UNDERLINE and tokens[1] in self.all_special_tokens:\r\n 215 tokens = tokens[1:]\r\n 216 return tokens\r\n\r\nUnboundLocalError: local variable 'tokens' referenced before assignment\r\n```",
"Hey! Thanks I can indeed reproduce this, and this should just return `[]`. "
] | 1,692 | 1,693 | 1,693 |
NONE
| null |
### System Info
- `transformers` version: 4.33.0.dev0
- Platform: macOS-12.4-arm64-arm-64bit
- Python version: 3.9.16
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: N/A
- Using distributed or parallel set-up in script?:N/A
### Who can help?
@ArthurZucker
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
from transformers.models.llama.tokenization_llama import LlamaTokenizer
tokenizer = LlamaTokenizer()
tokenizer.tokenize("")
```
which gives the error:
```
UnboundLocalError: local variable 'tokens' referenced before assignment2346 if tokens[0] == SPIECE_UNDERLINE and tokens[1] in self.all_special_tokens
```
### Expected behavior
The tokenizer should return an empty list if an empty string is passed, or possibly error with a helpful error message, but I shouldn't get a variable referenced before declaration error.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25769/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25769/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25768
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25768/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25768/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25768/events
|
https://github.com/huggingface/transformers/pull/25768
| 1,867,685,884 |
PR_kwDOCUB6oc5Y1EM5
| 25,768 |
Fix local variable 'tokens' referenced before assignment error in tokenization_llama.py
|
{
"login": "avnishn",
"id": 38871737,
"node_id": "MDQ6VXNlcjM4ODcxNzM3",
"avatar_url": "https://avatars.githubusercontent.com/u/38871737?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avnishn",
"html_url": "https://github.com/avnishn",
"followers_url": "https://api.github.com/users/avnishn/followers",
"following_url": "https://api.github.com/users/avnishn/following{/other_user}",
"gists_url": "https://api.github.com/users/avnishn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avnishn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avnishn/subscriptions",
"organizations_url": "https://api.github.com/users/avnishn/orgs",
"repos_url": "https://api.github.com/users/avnishn/repos",
"events_url": "https://api.github.com/users/avnishn/events{/privacy}",
"received_events_url": "https://api.github.com/users/avnishn/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"corresponding issue:\r\n#25769\r\n",
"sg"
] | 1,692 | 1,693 | 1,693 |
NONE
| null |
if the function tokenize is called on an empty string by the LlamaTokenizer, we try to return the variable tokens but it isn't declared beforehand.
This fixes that issue
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@ArthurZucker
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25768/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25768/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25768",
"html_url": "https://github.com/huggingface/transformers/pull/25768",
"diff_url": "https://github.com/huggingface/transformers/pull/25768.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25768.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25767
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25767/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25767/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25767/events
|
https://github.com/huggingface/transformers/pull/25767
| 1,867,660,074 |
PR_kwDOCUB6oc5Y0-eI
| 25,767 |
include ChannelDimension.NONE + function replicate_channels
|
{
"login": "rafaelpadilla",
"id": 31217453,
"node_id": "MDQ6VXNlcjMxMjE3NDUz",
"avatar_url": "https://avatars.githubusercontent.com/u/31217453?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rafaelpadilla",
"html_url": "https://github.com/rafaelpadilla",
"followers_url": "https://api.github.com/users/rafaelpadilla/followers",
"following_url": "https://api.github.com/users/rafaelpadilla/following{/other_user}",
"gists_url": "https://api.github.com/users/rafaelpadilla/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rafaelpadilla/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rafaelpadilla/subscriptions",
"organizations_url": "https://api.github.com/users/rafaelpadilla/orgs",
"repos_url": "https://api.github.com/users/rafaelpadilla/repos",
"events_url": "https://api.github.com/users/rafaelpadilla/events{/privacy}",
"received_events_url": "https://api.github.com/users/rafaelpadilla/received_events",
"type": "User",
"site_admin": false
}
|
[] |
open
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25767). All of your documentation changes will be reflected on that endpoint."
] | 1,692 | 1,707 | null |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes #25694
The ViT model currently doesn't support grayscale images with a (height, width) format, leading to preprocessing errors.
This PR addresses the issue with a new replicate_channels function. This function converts images in (height, width) format to a 3-channel RGB format (3, height, width), replicating the grayscale channel across all three RGB channels.
While it's possible to integrate format checks and modifications within each processing function (like resize, rescale, normalize, to_channel_dimension_format, etc.), doing so might affect other modules using these functions. To avoid potential complications, I've opted for a direct solution.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@amyeroberts
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25767/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25767/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25767",
"html_url": "https://github.com/huggingface/transformers/pull/25767",
"diff_url": "https://github.com/huggingface/transformers/pull/25767.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25767.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25766
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25766/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25766/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25766/events
|
https://github.com/huggingface/transformers/issues/25766
| 1,867,525,889 |
I_kwDOCUB6oc5vUC8B
| 25,766 |
MNLI benchmark, I see only only eval_accuracy, not seperated to m/mm = matched/mismatched
|
{
"login": "ndvbd",
"id": 845175,
"node_id": "MDQ6VXNlcjg0NTE3NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/845175?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ndvbd",
"html_url": "https://github.com/ndvbd",
"followers_url": "https://api.github.com/users/ndvbd/followers",
"following_url": "https://api.github.com/users/ndvbd/following{/other_user}",
"gists_url": "https://api.github.com/users/ndvbd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ndvbd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ndvbd/subscriptions",
"organizations_url": "https://api.github.com/users/ndvbd/orgs",
"repos_url": "https://api.github.com/users/ndvbd/repos",
"events_url": "https://api.github.com/users/ndvbd/events{/privacy}",
"received_events_url": "https://api.github.com/users/ndvbd/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I have no Idea what you are talking about",
"Hi Arthur, the GLUE, for the MNLI dataset, has *two* metrics of accuracy: match accuracy, and mismatched accuracy. Kindly see here: https://openreview.net/pdf?id=rJ4km2R5t7\r\n\r\nNow, when running the tranformer code run_gleu, for the mnli task, it only reports a single 'accuracy'.",
"We have at least 5 different files called `run_glue`, which are supposed to show examples of how to perform certain tasks, but are not absolute source of truth. If you don't see the metric you want being used, you should be able to adapt the code pretty easily for your needs.\r\n\r\nAs the doc mentions about the example folder: \r\n> It is expected that they won’t work out-of-the box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs. To help you with that, most of the examples fully expose the preprocessing of the data. This way, you can easily tweak them.\r\n\r\n"
] | 1,692 | 1,693 | 1,693 |
NONE
| null |
### System Info
N/A
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
MNLI benchmark, I see only only eval_accuracy, not seperated to m/mm = matched/mismatched
### Expected behavior
MNLI benchmark, I see only only eval_accuracy, not seperated to m/mm = matched/mismatched
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25766/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25766/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25765
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25765/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25765/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25765/events
|
https://github.com/huggingface/transformers/pull/25765
| 1,867,462,843 |
PR_kwDOCUB6oc5Y0Tf3
| 25,765 |
Fix Mega chunking error when using decoder-only model
|
{
"login": "tanaymeh",
"id": 26519539,
"node_id": "MDQ6VXNlcjI2NTE5NTM5",
"avatar_url": "https://avatars.githubusercontent.com/u/26519539?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tanaymeh",
"html_url": "https://github.com/tanaymeh",
"followers_url": "https://api.github.com/users/tanaymeh/followers",
"following_url": "https://api.github.com/users/tanaymeh/following{/other_user}",
"gists_url": "https://api.github.com/users/tanaymeh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tanaymeh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tanaymeh/subscriptions",
"organizations_url": "https://api.github.com/users/tanaymeh/orgs",
"repos_url": "https://api.github.com/users/tanaymeh/repos",
"events_url": "https://api.github.com/users/tanaymeh/events{/privacy}",
"received_events_url": "https://api.github.com/users/tanaymeh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Feel free to ping me when the PR is ready for review 😉 ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25765). All of your documentation changes will be reflected on that endpoint.",
"@ArthurZucker You may review it now!",
"Will do. Two questions regarding this:\r\n1. For the test of chunking, I should only check the expected sizes of output or something else?\r\n2. Conceptually, do you see any troubles with this solution in its current state? I am a little suspicious because of how simple the solution was 😅",
"1. Yes you could check expected sizes on a smaller model (using the small configs) \r\n2. I don't really see a problem since the attention mask created use the newly defined sequence length, and the code was already very clean so probably juste a typo! ",
"Thanks for confirming @ArthurZucker. I have added a test that checks [here](https://github.com/tanaymeh/transformers/blob/bb6c5eaff2421766daa79d5b489318a9a2c54726/tests/models/mega/test_modeling_mega.py#L316-L340) if the `attentions` returned in the `CausalLMOutputWithCrossAttentions` have their last dimension (`shape[-1]`), which is supposed to be `sequence_length` is equal to the `chunk_size` or not.\r\n\r\nIf the checks I added in `modeling_mega.py` are correct, it will use `chunk_size` instead of the actual `sequence_length`.\r\n\r\nIs this correct, or shall I make any changes?\r\n\r\nUpdate: The tests are failing because of an error in Wav2Vec2 model, here: `test_modeling_wav2vec2.py::Wav2Vec2RobustModelTest::test_model_for_pretraining`\r\n\r\nA Github Pull should fix it.",
"Added your suggested changes @ArthurZucker! With `input_mask`, the mega tests now pass.",
"Perfect! If you can just rebase on main to make sure the CIs are green? ",
"> Perfect! If you can just rebase on main to make sure the CIs are green?\r\n\r\nDone @ArthurZucker!",
"Congrats on the PR 🚀 thanks for fixing! ",
"Thanks a lot for helping @ArthurZucker!"
] | 1,692 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR aims to fix the error caused by `MegaModel` when the `is_decoder` setting is used in conjunction with `use_chunking` and `chunk_size` settings.
The error is described in detail [here](https://github.com/huggingface/transformers/issues/23331#issuecomment-1693729295).
Fixes #23331
## Who can review?
@ArthurZucker
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25765/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25765/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25765",
"html_url": "https://github.com/huggingface/transformers/pull/25765",
"diff_url": "https://github.com/huggingface/transformers/pull/25765.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25765.patch",
"merged_at": 1693943414000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25764
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25764/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25764/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25764/events
|
https://github.com/huggingface/transformers/pull/25764
| 1,867,454,252 |
PR_kwDOCUB6oc5Y0RnJ
| 25,764 |
[idefics] small fixes
|
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25764). All of your documentation changes will be reflected on that endpoint."
] | 1,692 | 1,692 | 1,692 |
CONTRIBUTOR
| null |
- fix the example doc - where there was a wrong copy-n-paste model class used
- remove `IdeficsGatedCrossAttentionLayer` from init imports as this is not really needed
thank you, @ydshieh for noticing these
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25764/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25764/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25764",
"html_url": "https://github.com/huggingface/transformers/pull/25764",
"diff_url": "https://github.com/huggingface/transformers/pull/25764.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25764.patch",
"merged_at": 1692986369000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25763
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25763/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25763/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25763/events
|
https://github.com/huggingface/transformers/pull/25763
| 1,867,206,364 |
PR_kwDOCUB6oc5Yzbuk
| 25,763 |
Tests: detect lines removed from "utils/not_doctested.txt" and doctest ALL generation files
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,692 | 1,693 | 1,693 |
MEMBER
| null |
# What does this PR do?
As the title indicates, this PR:
1. Detects lines removed from `utils/not_doctested.txt`, and adds the removed files to the list of files to doctest
2. Doctest ALL generation files 🫡
This PR started off with 2. -- however, as you can see in the CI in the first commit, no doctests were triggered. As such, since the doctest fixes were minimal, I've decided to add 1. as well :)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25763/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25763/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25763",
"html_url": "https://github.com/huggingface/transformers/pull/25763",
"diff_url": "https://github.com/huggingface/transformers/pull/25763.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25763.patch",
"merged_at": 1693322106000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25762
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25762/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25762/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25762/events
|
https://github.com/huggingface/transformers/pull/25762
| 1,867,202,119 |
PR_kwDOCUB6oc5Yza0Z
| 25,762 |
support bf16
|
{
"login": "etemadiamd",
"id": 90654451,
"node_id": "MDQ6VXNlcjkwNjU0NDUx",
"avatar_url": "https://avatars.githubusercontent.com/u/90654451?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/etemadiamd",
"html_url": "https://github.com/etemadiamd",
"followers_url": "https://api.github.com/users/etemadiamd/followers",
"following_url": "https://api.github.com/users/etemadiamd/following{/other_user}",
"gists_url": "https://api.github.com/users/etemadiamd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/etemadiamd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/etemadiamd/subscriptions",
"organizations_url": "https://api.github.com/users/etemadiamd/orgs",
"repos_url": "https://api.github.com/users/etemadiamd/repos",
"events_url": "https://api.github.com/users/etemadiamd/events{/privacy}",
"received_events_url": "https://api.github.com/users/etemadiamd/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "mfuntowicz",
"id": 2241520,
"node_id": "MDQ6VXNlcjIyNDE1MjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2241520?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfuntowicz",
"html_url": "https://github.com/mfuntowicz",
"followers_url": "https://api.github.com/users/mfuntowicz/followers",
"following_url": "https://api.github.com/users/mfuntowicz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfuntowicz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfuntowicz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfuntowicz/subscriptions",
"organizations_url": "https://api.github.com/users/mfuntowicz/orgs",
"repos_url": "https://api.github.com/users/mfuntowicz/repos",
"events_url": "https://api.github.com/users/mfuntowicz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfuntowicz/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "mfuntowicz",
"id": 2241520,
"node_id": "MDQ6VXNlcjIyNDE1MjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2241520?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfuntowicz",
"html_url": "https://github.com/mfuntowicz",
"followers_url": "https://api.github.com/users/mfuntowicz/followers",
"following_url": "https://api.github.com/users/mfuntowicz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfuntowicz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfuntowicz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfuntowicz/subscriptions",
"organizations_url": "https://api.github.com/users/mfuntowicz/orgs",
"repos_url": "https://api.github.com/users/mfuntowicz/repos",
"events_url": "https://api.github.com/users/mfuntowicz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfuntowicz/received_events",
"type": "User",
"site_admin": false
}
] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25762). All of your documentation changes will be reflected on that endpoint.",
"Hi @etemadiamd, thanks for opening a PR! \r\n\r\nThere's already support for using ORT and ONNX with Hugging Face models. See the [optimum library documentation for more details](https://huggingface.co/docs/optimum/v1.12.0/en/onnxruntime/package_reference/modeling_ort)."
] | 1,692 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Support bf16.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25762/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25762/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25762",
"html_url": "https://github.com/huggingface/transformers/pull/25762",
"diff_url": "https://github.com/huggingface/transformers/pull/25762.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25762.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25761
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25761/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25761/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25761/events
|
https://github.com/huggingface/transformers/issues/25761
| 1,867,140,777 |
I_kwDOCUB6oc5vSk6p
| 25,761 |
cannot load meta tensor issue when loading llama model saved to s3, Cannot copy out of meta tensor; no data
|
{
"login": "hugocool",
"id": 25592581,
"node_id": "MDQ6VXNlcjI1NTkyNTgx",
"avatar_url": "https://avatars.githubusercontent.com/u/25592581?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hugocool",
"html_url": "https://github.com/hugocool",
"followers_url": "https://api.github.com/users/hugocool/followers",
"following_url": "https://api.github.com/users/hugocool/following{/other_user}",
"gists_url": "https://api.github.com/users/hugocool/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hugocool/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hugocool/subscriptions",
"organizations_url": "https://api.github.com/users/hugocool/orgs",
"repos_url": "https://api.github.com/users/hugocool/repos",
"events_url": "https://api.github.com/users/hugocool/events{/privacy}",
"received_events_url": "https://api.github.com/users/hugocool/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"did you have any luck so far loading models from s3 via transformers? Devs have been clear they are not interested into supporting any other platforms than the hf hub. https://github.com/huggingface/transformers/issues/19834#issuecomment-1289079562",
"Yeah, the code I shared works for any HF model. I’ve been using it for quite some time.\r\nKedro will also release a dataset that will help you save and load to and from any cloud storage provider (I made a custom kedro dataset based on the above code that also works for any cloud provider, not just s3).\r\nYou can also use mlflow’s transformer flavor, or kedro-mlflow, this will also support saving to any s3-compatible storage.\r\nObviously this is not in huggingface’s interest to support since it conflicts with their business model, but for LLM using outside networks for saving and loading makes no sense.\r\n\r\nAnyway, yes you can use the above code for any transformer model (you can also use kedro’s pickledataset), but it won’t work LlaMa (also not the pickle dataset).\r\n\r\n\r\n___\r\n\r\nHugo Evers\r\nOn 27 Aug 2023 at 12:09 +0200, chris-aeviator ***@***.***>, wrote:\r\n> did you have any luck so far loading models from s3 via transformers? Devs have been clear they are not interested into supporting any other platforms than the hf hub. #19834 (comment)\r\n> —\r\n> Reply to this email directly, view it on GitHub, or unsubscribe.\r\n> You are receiving this because you authored the thread.Message ID: ***@***.***>\r\n",
"I'll be working on supporting a more production friendly version of TGI (loading models from s3, https,.., hot-swapping LORA adapters, back to truly OS licensing) via https://github.com/ohmytofu-ai/tgi-angryface , might have some overlaps with transformers then :)\r\n\r\nThanks for sharing this!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Not stale, this should be resolved.\r\n\r\n___\r\n\r\nHugo Evers\r\nOn 25 Sep 2023 at 10:02 +0200, github-actions[bot] ***@***.***>, wrote:\r\n> This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\r\n> Please note that issues that do not follow the contributing guidelines are likely to be ignored.\r\n> —\r\n> Reply to this email directly, view it on GitHub, or unsubscribe.\r\n> You are receiving this because you authored the thread.Message ID: ***@***.***>\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,692 | 1,698 | 1,698 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-4.14.301-224.520.amzn2.x86_64-x86_64-with-glibc2.26
- Python version: 3.9.10
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.20.3
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
steps:
1. download the model and tokenizer and instantiate pipeline
2. save the model to s3 using `save_pretrained` & cloudpathlib
3. load the model on aws batch using `from_pretrained`, this results in an error
# 1:
```
from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
import torch
model_name = "meta-llama/Llama-2-70b-chat-hf"
token = 'my_token'
model = AutoModelForCausalLM.from_pretrained(
model_name,
use_auth_token=token,
torch_dtype=torch.float16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_auth_token=token,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
```
# 2, this is performed locally (so a g4dn.2xlarge EC2 instance)
```
from tempfile import TemporaryDirectory
from cloudpathlib import CloudPath
path = 's3://my-project/data/06_models/llama-70b-chat-hf'
cloud_path = CloudPath(path)
with TemporaryDirectory() as tmp_dir:
pipe.save_pretrained(tmp_dir)
cloud_path.upload_from(tmp_dir)
```
# 3, this is performed on a p4d.24xlarge:
```
from tempfile import TemporaryDirectory
from cloudpathlib import CloudPath
path = 's3://my-project/data/06_models/llama-70b-chat-hf'
cloud_path = CloudPath(path)
with TemporaryDirectory() as tmp_dir:
cloud_path.download_to(tmp_dir)
model = AutoModelForCausalLM.from_pretrained(
tmp_dir,
torch_dtype=torch.float16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(
tmp_dir,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
```
this results in:
```
While copying the parameter named "lm_head.weight", whose dimensions in the model are torch.Size([5120]) and whose dimensions in the checkpoint are torch.Size([5120]), an exception occurred : ('Cannot copy out of meta tensor; no data!',).
```
For all the layers in the model. ( so a huge traceback)
I have tried different parameter combinations, for example leaving the device_map out (which resulted in OOM), or different torch_dtype, or setting safetensors, using the cache_dir in from_pretrained instead of explicitly save_pretrained.
I dont want to waste expensive GPU hours on loading a 150gb model, and the downloading unfortunately times out a lot.
It happens for all the model sizes, 7b, 13b and 70b.
Any ideas why saving and subsequently loading Llama-2 from s3 causes such issues?
### Expected behavior
it should just load and work.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25761/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25761/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25760
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25760/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25760/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25760/events
|
https://github.com/huggingface/transformers/issues/25760
| 1,867,135,189 |
I_kwDOCUB6oc5vSjjV
| 25,760 |
LoRA-PEFT - HuggingFace examples - LoRA does not train faster/nor does it allow a bigger batch size (essentially no improvement)
|
{
"login": "CalinLucian",
"id": 129417029,
"node_id": "U_kgDOB7a_RQ",
"avatar_url": "https://avatars.githubusercontent.com/u/129417029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CalinLucian",
"html_url": "https://github.com/CalinLucian",
"followers_url": "https://api.github.com/users/CalinLucian/followers",
"following_url": "https://api.github.com/users/CalinLucian/following{/other_user}",
"gists_url": "https://api.github.com/users/CalinLucian/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CalinLucian/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CalinLucian/subscriptions",
"organizations_url": "https://api.github.com/users/CalinLucian/orgs",
"repos_url": "https://api.github.com/users/CalinLucian/repos",
"events_url": "https://api.github.com/users/CalinLucian/events{/privacy}",
"received_events_url": "https://api.github.com/users/CalinLucian/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@pacman100 do you have any idea? Is this : https://github.com/huggingface/transformers/issues/25572 remotely related to the issue? (given that I see same memory usage when training with initial_model and lora_model)?",
"Hello @CalinLucian, the models in those examples are too small (85M params) for noticing large gains, I still notice gains though. Below is the comparison between peft vs full fine-tuning with the image classification notebook\r\n\r\n|method | GPU VRAM |\r\n| --- | --- |\r\n|peft lora | 13.71GB |\r\n|full fine-tuning | 17.87GB|\r\n\r\nSo, I don't see why a larger batch size wasn't possible. If I increase the batch size from 128 to 175, the GPU VRAM usage for LoRA goes from 13.71Gb to 18.05GB which is comparable to the full fine-tuning memory consumption.\r\n\r\n|method | Wall time |\r\n| --- | --- |\r\n|peft lora with batch size 175 | 5min 12s |\r\n|full fine-tuning with batch size 128 | 6min 29s |\r\n\r\nPEFT wall time screenshot:\r\n\r\n\r\nFull Finetuning wall time screenshot:\r\n\r\n\r\n\r\nAlso, a reminder that the main purpose for PEFT methods are as following:\r\n1. PEFT enables large model training because the optimizer states and gradients are limited to the tiny percentage of trainable params while keeping the pretrained model frozen. This results in huge VRAM savings while training. Compute wise, forward+backward will still be the same (peft will have overhead of additional computations for adapter layers), but only the step will be a bit faster since there will be less grads to add. So there is little difference compared to unfrozen model compute-wise.The only real saving is memory (since you don't need to allocate grads+optim states for frozen weights). So, training speed improvement depends on a lot of factors and this is not something PEFT promises to improve. It either enables one to fit large models on existing hardware or fit larger batches on it (this probably leads to faster training) while trying to have comparable performance to full fine-tuning. Quantization techniques and gradient checkpointing further drive down the memory requirements. \r\n2. PEFT enables one to have tiny checkpoint, thus enabling one to fine-tune a base model on a lot of downstream tasks while keeping the storage in check and enabling easy portability of the fine-tuned models.\r\n\r\n",
"@pacman100 Do you think it's possible I did not see/it is very negligible in my case because multiprocessing on Windows does create a bottleneck between the CPU/GPU and thus I cannot properly see the difference? I will try as you mentioned to reproduce your results, thank you for your time. Thank you for the insights on points 1 and 2, insightful!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,692 | 1,697 | 1,697 |
NONE
| null |
### System Info
```
Platform system: Windows-10-10.0.22621-SP0
Python version: 3.9.13
Available RAM : 31.872 GB
CPU count: 20
CPU model: Intel(R) Core(TM) i9-10900K CPU @ 3.70GHz
GPU count: 1
GPU model: 1 x NVIDIA GeForce RTX 3090
```
```
transformers==4.32.0
peft==0.5.0
accelerate=0.22.0
```
I am struggling to understand why I get no faster training nor can I use a bigger batch size when using LoRA.
I tried using the two tutorial available here (literally just running shift+enter the code, one time using `model `in the `Trainer()` one time using `lora_model`in the `Trainer()`:
1) https://huggingface.co/docs/peft/task_guides/image_classification_lora
2) https://huggingface.co/docs/peft/task_guides/semantic_segmentation_lora
I also tried using a custom PyTorch() module for the same segmentation model and got the same results (no improvement) (like 2.1)
I am doing **exactly** what is provided in the tutorials and indeed the following:
- `print_trainable_parameters(model) `
- `print_trainable_parameters(lora_model)`
print correctly (as in 100% trainable parameters for model and between 1%-10%) depending on the `LoraConfig() ` below.
```
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=32,
lora_alpha=32,
target_modules=["query", "value"],
lora_dropout=0.1,
bias="lora_only",
modules_to_save=["decode_head"],
)
lora_model = get_peft_model(model, config)
print_trainable_parameters(lora_model)
```
Indeed `lora_model.save_pretrained(...)` saves a smaller model according to the trainable parameters.
**However, my stupefaction is that the training time stays exactly the same, as if no optimization happens. I cannot increase the batch_size (max batch_size in normal training is exactly like batch_size in lora_training, as if nothing happens), nor does the speed of the training increase (literally the same speed).**
Does anyone have any idea? I use exactly the links provided above, and I have the platform and library versions provided at the beginning.
@muellerzr @pacman100 @amyeroberts
### Who can help?
_No response_
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Just run the notebooks on LoRA given the platform + the dependencies.
### Expected behavior
I expect to actually use a bigger batch_size, to have the model train much faster given LoRA, essentially see the improvements that are brought by LoRA.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25760/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25760/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25759
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25759/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25759/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25759/events
|
https://github.com/huggingface/transformers/pull/25759
| 1,867,117,466 |
PR_kwDOCUB6oc5YzIW5
| 25,759 |
fix a typo in docsting
|
{
"login": "statelesshz",
"id": 28150734,
"node_id": "MDQ6VXNlcjI4MTUwNzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/28150734?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/statelesshz",
"html_url": "https://github.com/statelesshz",
"followers_url": "https://api.github.com/users/statelesshz/followers",
"following_url": "https://api.github.com/users/statelesshz/following{/other_user}",
"gists_url": "https://api.github.com/users/statelesshz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/statelesshz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/statelesshz/subscriptions",
"organizations_url": "https://api.github.com/users/statelesshz/orgs",
"repos_url": "https://api.github.com/users/statelesshz/repos",
"events_url": "https://api.github.com/users/statelesshz/events{/privacy}",
"received_events_url": "https://api.github.com/users/statelesshz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25759). All of your documentation changes will be reflected on that endpoint."
] | 1,692 | 1,694 | 1,692 |
CONTRIBUTOR
| null |
# What does this PR do?
as per title
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25759/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25759/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25759",
"html_url": "https://github.com/huggingface/transformers/pull/25759",
"diff_url": "https://github.com/huggingface/transformers/pull/25759.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25759.patch",
"merged_at": 1692978416000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25758
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25758/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25758/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25758/events
|
https://github.com/huggingface/transformers/issues/25758
| 1,867,070,813 |
I_kwDOCUB6oc5vST1d
| 25,758 |
`clean_up_tokenization_spaces=False` not working for decoding single token
|
{
"login": "devymex",
"id": 1797836,
"node_id": "MDQ6VXNlcjE3OTc4MzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/1797836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/devymex",
"html_url": "https://github.com/devymex",
"followers_url": "https://api.github.com/users/devymex/followers",
"following_url": "https://api.github.com/users/devymex/following{/other_user}",
"gists_url": "https://api.github.com/users/devymex/gists{/gist_id}",
"starred_url": "https://api.github.com/users/devymex/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/devymex/subscriptions",
"organizations_url": "https://api.github.com/users/devymex/orgs",
"repos_url": "https://api.github.com/users/devymex/repos",
"events_url": "https://api.github.com/users/devymex/events{/privacy}",
"received_events_url": "https://api.github.com/users/devymex/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This is expected, `clean_up_tokenization_spaces` is not related to spaces that are outputed by the model but spaces around `special tokens`. The output is stripped because when you encode you also add a space. If you want a one to one decoding of a token use `tokenizer.convert_ids_to_tokens`"
] | 1,692 | 1,693 | 1,693 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.15.0-73-generic-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.21.0
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: MULTI_GPU
- mixed_precision: fp16
- use_cpu: False
- num_processes: 8
- machine_rank: 0
- num_machines: 1
- gpu_ids: all
- rdzv_backend: static
- same_network: True
- main_training_function: main
- downcast_bf16: no
- tpu_use_cluster: False
- tpu_use_sudo: False
- tpu_env: []
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: N
### Who can help?
@ArthurZucker
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf', use_fast=False)
tokenizer.decode([29892,1235], skip_special_tokens=False, clean_up_tokenization_spaces=False)
tokenizer.decode([1235], skip_special_tokens=False, clean_up_tokenization_spaces=False)
```
Actual outputs:
```
, let
let
```
### Expected behavior
```
, let
let
```
The token 1235 is ` let`, notice the second line of the output, there should be a space before the word 'let', but it not.
The option `clean_up_tokenization_spaces=False` not working when single token input.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25758/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25758/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25757
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25757/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25757/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25757/events
|
https://github.com/huggingface/transformers/issues/25757
| 1,867,041,172 |
I_kwDOCUB6oc5vSMmU
| 25,757 |
Problem working with single cuda when having multiple gpu
|
{
"login": "muratsilahtaroglu",
"id": 62756687,
"node_id": "MDQ6VXNlcjYyNzU2Njg3",
"avatar_url": "https://avatars.githubusercontent.com/u/62756687?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muratsilahtaroglu",
"html_url": "https://github.com/muratsilahtaroglu",
"followers_url": "https://api.github.com/users/muratsilahtaroglu/followers",
"following_url": "https://api.github.com/users/muratsilahtaroglu/following{/other_user}",
"gists_url": "https://api.github.com/users/muratsilahtaroglu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muratsilahtaroglu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muratsilahtaroglu/subscriptions",
"organizations_url": "https://api.github.com/users/muratsilahtaroglu/orgs",
"repos_url": "https://api.github.com/users/muratsilahtaroglu/repos",
"events_url": "https://api.github.com/users/muratsilahtaroglu/events{/privacy}",
"received_events_url": "https://api.github.com/users/muratsilahtaroglu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Could you provide the ouptut of `transformers-cli envs`? \r\ncc @pacman100 \r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Transformers CLI tool: error: invalid choice: 'envs' (choose from 'convert', 'download', 'env', 'run', 'serve', 'login', 'whoami', 'logout', 'repo', 'add-new-model', 'add-new-model-like', 'lfs-enable-largefiles', 'lfs-multipart-upload', 'pt-to-tf')",
"What @ArthurZucker meant was `transformers-cli env`, as your error message indicates :hugs: ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,692 | 1,698 | 1,698 |
NONE
| null |
### System Info
I have 4 gpu and I am running below code but ı have `RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select) error`.
I solved this problem peft_training_args._n_gpu = 1.
I put the model and tokenizer in CUDA 0, why can't I train on one GPU? During the train, other GPUs are active and I get the above error.
```
original_model = AutoModelForSeq2SeqLM.from_pretrained(model_name, torch_dtype=torch.bfloat16,device_map = {"": 0})
tokenizer = AutoTokenizer.from_pretrained(model_name,device= 0)
from peft import LoraConfig, get_peft_model, TaskType
lora_config = LoraConfig(
r=32, # Rank
lora_alpha=32,
target_modules=["q", "v"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.SEQ_2_SEQ_LM # FLAN-T5
)
peft_model = get_peft_model(original_model,
lora_config)
print(print_number_of_trainable_model_parameters(peft_model))
output_dir = f'./peft-dialogue-summary-training-{str(int(time.time()))}'
peft_training_args = TrainingArguments(
output_dir=output_dir,
auto_find_batch_size=True,
learning_rate=1e-3, # Higher learning rate than full fine-tuning.
num_train_epochs=1,
logging_steps=1,
max_steps=1,
)
peft_trainer = Trainer(
model=peft_model,
args=peft_training_args,
train_dataset=tokenized_datasets["train"],
)
peft_trainer.train()
```
### Who can help?
@arth
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
`RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument index in method wrapper__index_select) error`.
### Expected behavior
Model can be train on single gpu so trainer.py should be updated.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25757/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25757/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25756
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25756/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25756/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25756/events
|
https://github.com/huggingface/transformers/pull/25756
| 1,867,003,587 |
PR_kwDOCUB6oc5YyvY1
| 25,756 |
Docs: fix indentation in `HammingDiversityLogitsProcessor`
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"(took the liberty to merge to unblock others, but I'm open to post-merge PR reviews)"
] | 1,692 | 1,692 | 1,692 |
MEMBER
| null |
# What does this PR do?
Fixes indentation, which is causing the doc builder to crash. Also fixes the example, which was incorrect (thus causing the newly added doctests to fail)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25756/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25756/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25756",
"html_url": "https://github.com/huggingface/transformers/pull/25756",
"diff_url": "https://github.com/huggingface/transformers/pull/25756.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25756.patch",
"merged_at": 1692971799000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25755
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25755/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25755/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25755/events
|
https://github.com/huggingface/transformers/pull/25755
| 1,866,956,402 |
PR_kwDOCUB6oc5YylIW
| 25,755 |
🌐 [i18n-KO] `model_memory_anatomy.md` to Korean
|
{
"login": "mjk0618",
"id": 39152134,
"node_id": "MDQ6VXNlcjM5MTUyMTM0",
"avatar_url": "https://avatars.githubusercontent.com/u/39152134?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mjk0618",
"html_url": "https://github.com/mjk0618",
"followers_url": "https://api.github.com/users/mjk0618/followers",
"following_url": "https://api.github.com/users/mjk0618/following{/other_user}",
"gists_url": "https://api.github.com/users/mjk0618/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mjk0618/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mjk0618/subscriptions",
"organizations_url": "https://api.github.com/users/mjk0618/orgs",
"repos_url": "https://api.github.com/users/mjk0618/repos",
"events_url": "https://api.github.com/users/mjk0618/events{/privacy}",
"received_events_url": "https://api.github.com/users/mjk0618/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25755). All of your documentation changes will be reflected on that endpoint.",
"May you please review this PR? @sgugger, @ArthurZucker, @eunseojo\r\n\r\n"
] | 1,692 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
<!-- PR의 제목은 "🌐 [i18n-KO] Translated `<your_file>.md` to Korean" 으로 부탁드립니다! -->
# What does this PR do?
Translated the `model_memory_anatomy.md` file of the documentation to Korean.
Thank you in advance for your review.
Part of https://github.com/huggingface/transformers/issues/20179
## Before reviewing
- [x] Check for missing / redundant translations (번역 누락/중복 검사)
- [x] Grammar Check (맞춤법 검사)
- [x] Review or Add new terms to glossary (용어 확인 및 추가)
- [x] Check Inline TOC (e.g. `[[lowercased-header]]`)
- [x] Check live-preview for gotchas (live-preview로 정상작동 확인)
## Who can review? (Initial)
@bolizabeth, @nuatmochoi, @heuristicwave, @mjk0618, @keonju2, @harheem, @HongB1, @junejae, @54data, @seank021, @augustinLib, @sronger, @TaeYupNoh, @kj021, @eenzeenee
<!-- 1. 위 체크가 모두 완료된 뒤에, 이 아래에 리뷰를 요청할 팀원들을 멘션해주세요! -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review? (Final)
<!-- 2. 팀원들과 리뷰가 끝난 후에만 허깅페이스 직원들에게 리뷰 요청하는 아래 주석을 노출해주세요! -->
May you please review this PR? @sgugger, @ArthurZucker, @eunseojo
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25755/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25755/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25755",
"html_url": "https://github.com/huggingface/transformers/pull/25755",
"diff_url": "https://github.com/huggingface/transformers/pull/25755.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25755.patch",
"merged_at": 1693316931000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25754
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25754/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25754/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25754/events
|
https://github.com/huggingface/transformers/pull/25754
| 1,866,857,178 |
PR_kwDOCUB6oc5YyPFS
| 25,754 |
[CLAP] Fix logit scales dtype for fp16
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Yep try with this:\r\n```python\r\nimport torch\r\n\r\ntorch.tensor(0).half().dtype()\r\n```\r\nGives:\r\n```\r\ntensor(0., dtype=torch.float16)\r\n```\r\n\r\nIs used when we load `diffusers` pipelines in fp16 (load state dict in fp16 on cpu then move to cuda)"
] | 1,692 | 1,692 | 1,692 |
CONTRIBUTOR
| null |
# What does this PR do?
On some hardware, taking `torch.log` of a tensor in float16 on the CPU fails:
```python
in __init__(self, config)
1956 audio_config = config.audio_config
1957
-> 1958 self.logit_scale_a = nn.Parameter(torch.log(torch.tensor(config.logit_scale_init_value)))
1959 self.logit_scale_t = nn.Parameter(torch.log(torch.tensor(config.logit_scale_init_value)))
1960
RuntimeError: "log_vml_cpu" not implemented for 'Half'
```
Note that this only failed for me on a Colab T4, but not on a Titan RTX (used to test #25682).
Let's take `math.log` **then** convert it to a tensor - this will respect the dtype of the model but not take `torch.log` of a float16 CPU param.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25754/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25754/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25754",
"html_url": "https://github.com/huggingface/transformers/pull/25754",
"diff_url": "https://github.com/huggingface/transformers/pull/25754.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25754.patch",
"merged_at": 1692966639000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25753
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25753/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25753/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25753/events
|
https://github.com/huggingface/transformers/issues/25753
| 1,866,837,683 |
I_kwDOCUB6oc5vRa6z
| 25,753 |
T5 Tokenizer requires `protobuf` package
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"See the link PR for a fix"
] | 1,692 | 1,692 | 1,692 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.32.0.dev0
- Platform: macOS-13.5.1-arm64-arm-64bit
- Python version: 3.9.13
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
### Who can help?
@ArthurZucker @sanchit-gandhi
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Ensure `protobuf` is uninstalled:
```
pip uninstall protobuf
```
2. Import the `T5Tokenizer`:
```python
from transformers import T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained("t5-base")
```
**Traceback:**
```
UnboundLocalError Traceback (most recent call last)
Cell In[2], line 1
----> 1 tokenizer = T5Tokenizer.from_pretrained("t5-base")
File ~/transformers/src/transformers/tokenization_utils_base.py:1854, in PreTrainedTokenizerBase.from_pretrained(cls, pretrained_model_name_or_path, cache_dir, force_download, local_files_only, token, revision, *init_inputs, **kwargs)
1851 else:
1852 logger.info(f"loading file {file_path} from cache at {resolved_vocab_files[file_id]}")
-> 1854 return cls._from_pretrained(
1855 resolved_vocab_files,
1856 pretrained_model_name_or_path,
1857 init_configuration,
1858 *init_inputs,
1859 token=token,
1860 cache_dir=cache_dir,
1861 local_files_only=local_files_only,
1862 _commit_hash=commit_hash,
1863 _is_local=is_local,
1864 **kwargs,
1865 )
File ~/transformers/src/transformers/tokenization_utils_base.py:2017, in PreTrainedTokenizerBase._from_pretrained(cls, resolved_vocab_files, pretrained_model_name_or_path, init_configuration, token, cache_dir, local_files_only, _commit_hash, _is_local, *init_inputs, **kwargs)
2015 # Instantiate tokenizer.
2016 try:
-> 2017 tokenizer = cls(*init_inputs, **init_kwargs)
2018 except OSError:
2019 raise OSError(
2020 "Unable to load vocabulary from file. "
2021 "Please check that the provided vocabulary is accessible and not corrupted."
2022 )
File ~/transformers/src/transformers/models/t5/tokenization_t5.py:194, in T5Tokenizer.__init__(self, vocab_file, eos_token, unk_token, pad_token, extra_ids, additional_special_tokens, sp_model_kwargs, legacy, **kwargs)
191 self.vocab_file = vocab_file
192 self._extra_ids = extra_ids
--> 194 self.sp_model = self.get_spm_processor()
File ~/transformers/src/transformers/models/t5/tokenization_t5.py:200, in T5Tokenizer.get_spm_processor(self)
198 with open(self.vocab_file, "rb") as f:
199 sp_model = f.read()
--> 200 model_pb2 = import_protobuf()
201 model = model_pb2.ModelProto.FromString(sp_model)
202 if not self.legacy:
File ~/transformers/src/transformers/convert_slow_tokenizer.py:40, in import_protobuf()
38 else:
39 from transformers.utils import sentencepiece_model_pb2_new as sentencepiece_model_pb2
---> 40 return sentencepiece_model_pb2
UnboundLocalError: local variable 'sentencepiece_model_pb2' referenced before assignment
```
This is occurring because we do `import_protobuf` in the init:
https://github.com/huggingface/transformers/blob/85cf90a1c92f574ce2eb3fafe0681a3af0a9d41b/src/transformers/models/t5/tokenization_t5.py#L200
But `import_protobuf` is ill-defined in the case that `protobuf` is not available:
https://github.com/huggingface/transformers/blob/cb8e3ee25fc2349e9262faa1e0c35d80978349fe/src/transformers/convert_slow_tokenizer.py#L32-L40
=> if `protobuf` is not installed, then `sentencepiece_model_pb2` will be un-defined
Has `protobuf` been made a soft-dependency for T5Tokenizer inadvertently in #24622? Or can `sentencepiece_model_pb2` be defined without `protobuf`?
### Expected behavior
Use T5Tokenizer without `protobuf`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25753/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25753/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25752
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25752/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25752/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25752/events
|
https://github.com/huggingface/transformers/issues/25752
| 1,866,803,486 |
I_kwDOCUB6oc5vRSke
| 25,752 |
Padding is included in the computation of loss
|
{
"login": "guyang3532",
"id": 62738430,
"node_id": "MDQ6VXNlcjYyNzM4NDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/62738430?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guyang3532",
"html_url": "https://github.com/guyang3532",
"followers_url": "https://api.github.com/users/guyang3532/followers",
"following_url": "https://api.github.com/users/guyang3532/following{/other_user}",
"gists_url": "https://api.github.com/users/guyang3532/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guyang3532/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guyang3532/subscriptions",
"organizations_url": "https://api.github.com/users/guyang3532/orgs",
"repos_url": "https://api.github.com/users/guyang3532/repos",
"events_url": "https://api.github.com/users/guyang3532/events{/privacy}",
"received_events_url": "https://api.github.com/users/guyang3532/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! You should ask this question on [the forum](https://discuss.huggingface.co/), as this is more related to your understanding of the code 😉 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,692 | 1,697 | 1,697 |
NONE
| null |
### Description
I found the padding part in the logits (which is from embedding padding) is included in computation of loss in question answering bert:
https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py#L1876
Is it reasonable?
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Reproduced with:
`torchrun --nproc_per_node=1 examples/onnxruntime/training/question-answering/run_qa.py --model_name_or_path deepset/minilm-uncased-squad2 --do_train --do_eval --per_device_train_batch_size 16 --num_train_epochs 3 --overwrite_output_dir --output_dir ./outputs/ --per_device_eval_batch_size 16 --seed 1337 --fp16 False --skip_memory_metrics False --dataset_name squad_v2 --learning_rate 2e-5 --remove_unused_columns False --version_2_with_negative --optim adamw_ort_fused --report_to none`
### Expected behavior
Is it more reasonable to pass only valid sequence length part of logits to loss compuation with something like:
`start_loss = loss_fct(start_logits[:valid_sequence_length], start_positions)`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25752/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25752/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25751
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25751/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25751/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25751/events
|
https://github.com/huggingface/transformers/pull/25751
| 1,866,468,076 |
PR_kwDOCUB6oc5Yw5zY
| 25,751 |
[`TFxxxxForSequenceClassifciation`] Fix the eager mode after #25085
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Taking this one!",
"Should be ready for review @ArthurZucker - tests pass for me now. The cause was using the static shape instead of the dynamic shape, it's probably the single most common source of TF bugs for us!",
"I can't approve my own PR! Hahah feel free to merge if the slow tests pass 😉 "
] | 1,692 | 1,698 | 1,698 |
COLLABORATOR
| null |
# What does this PR do?
Fixes https://github.com/huggingface/transformers/issues/25743 and one of our CI that triggered this
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25751/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25751/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25751",
"html_url": "https://github.com/huggingface/transformers/pull/25751",
"diff_url": "https://github.com/huggingface/transformers/pull/25751.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25751.patch",
"merged_at": 1698150785000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25750
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25750/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25750/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25750/events
|
https://github.com/huggingface/transformers/pull/25750
| 1,866,430,397 |
PR_kwDOCUB6oc5Ywxcj
| 25,750 |
Add type hints for pytorch models (final batch)
|
{
"login": "nablabits",
"id": 33068707,
"node_id": "MDQ6VXNlcjMzMDY4NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/33068707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nablabits",
"html_url": "https://github.com/nablabits",
"followers_url": "https://api.github.com/users/nablabits/followers",
"following_url": "https://api.github.com/users/nablabits/following{/other_user}",
"gists_url": "https://api.github.com/users/nablabits/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nablabits/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nablabits/subscriptions",
"organizations_url": "https://api.github.com/users/nablabits/orgs",
"repos_url": "https://api.github.com/users/nablabits/repos",
"events_url": "https://api.github.com/users/nablabits/events{/privacy}",
"received_events_url": "https://api.github.com/users/nablabits/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thank you again for the diligent work on the type hints, by the way - your PRs were really clean and required very little work to review, and they really helped push that project!",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25750). All of your documentation changes will be reflected on that endpoint.",
"> Thank you again for the diligent work on the type hints, by the way - your PRs were really clean and required very little work to review, and they really helped push that project!\r\n\r\nThank you very much, really appreciated!! TBH it has been a great learning experience for me, so thanks for the opportunity and the patience with the explanations",
"> Thank you again for the diligent work on the type hints, by the way - your PRs were really clean and required very little work to review, and they really helped push that project!\r\n\r\nMy apologies, in advance, for stepping in here. \r\nI would like to highlight as well the positive impact @nablabits brings to the HF OSS ecosystem. \r\nIt´s also great how this user helps other contributors to thrive [#1](https://github.com/SoyGema/contrib_schema/issues/1) and [#2](https://github.com/SoyGema/contrib_schema/issues/2) bringing learning, reciprocity, and fun.\r\n\r\n\r\n\r\n",
"> > Thank you again for the diligent work on the type hints, by the way - your PRs were really clean and required very little work to review, and they really helped push that project!\r\n> \r\n> My apologies, in advance, for stepping in here. I would like to highlight as well the positive impact @nablabits brings to the HF OSS ecosystem. It´s also great how this user helps other contributors to thrive [#1](https://github.com/SoyGema/contrib_schema/issues/1) and [#2](https://github.com/SoyGema/contrib_schema/issues/2) bringing learning, reciprocity, and fun.\r\n\r\nGema, thanks for the kind words :hugs: \r\n@SoyGema "
] | 1,692 | 1,694 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Addresses the last type hints for pytorch models in https://github.com/huggingface/transformers/issues/16059:
1. TableTransformer:
1. `TableTransformerForObjectDetection`
2. `TableTransformerModel`
2. `TimesformerModel`
3. `TimmBackbone`
4. TVLT:
1. `TvltForAudioVisualClassification`
2. `TvltForPreTraining`
3. `TvltModel`
5. Vivit
1. `VivitForVideoClassification`
2. `VivitModel`
## Who can review?
@Rocketknight1 please
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25750/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25750/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25750",
"html_url": "https://github.com/huggingface/transformers/pull/25750",
"diff_url": "https://github.com/huggingface/transformers/pull/25750.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25750.patch",
"merged_at": 1693229482000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25749
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25749/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25749/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25749/events
|
https://github.com/huggingface/transformers/pull/25749
| 1,866,422,844 |
PR_kwDOCUB6oc5Ywvzy
| 25,749 |
Add type hints for several pytorch models (batch-4)
|
{
"login": "nablabits",
"id": 33068707,
"node_id": "MDQ6VXNlcjMzMDY4NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/33068707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nablabits",
"html_url": "https://github.com/nablabits",
"followers_url": "https://api.github.com/users/nablabits/followers",
"following_url": "https://api.github.com/users/nablabits/following{/other_user}",
"gists_url": "https://api.github.com/users/nablabits/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nablabits/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nablabits/subscriptions",
"organizations_url": "https://api.github.com/users/nablabits/orgs",
"repos_url": "https://api.github.com/users/nablabits/repos",
"events_url": "https://api.github.com/users/nablabits/events{/privacy}",
"received_events_url": "https://api.github.com/users/nablabits/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25749). All of your documentation changes will be reflected on that endpoint."
] | 1,692 | 1,694 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Addresses some of the models in https://github.com/huggingface/transformers/issues/16059:
1. Mgpstr
1. `MgpstrForSceneTextRecognition`
2. `MgpstrModel`
2. PLBart
1. `PLBartForConditionalGeneration`
2. `PLBartModel`
3. `Pix2StructTextModel`
4. `RagModel`
5. `SamModel`
6. `Swin2SRModel`
## Who can review?
@Rocketknight1, please
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25749/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25749/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25749",
"html_url": "https://github.com/huggingface/transformers/pull/25749",
"diff_url": "https://github.com/huggingface/transformers/pull/25749.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25749.patch",
"merged_at": 1693229493000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25748
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25748/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25748/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25748/events
|
https://github.com/huggingface/transformers/issues/25748
| 1,866,420,611 |
I_kwDOCUB6oc5vP1GD
| 25,748 |
You should supply an instance of `transformers.BatchFeature` or list of `transformers.BatchFeature` to this method that includes input_values, but you provided ['file', 'audio', 'label']
|
{
"login": "c1ekrt",
"id": 40287606,
"node_id": "MDQ6VXNlcjQwMjg3NjA2",
"avatar_url": "https://avatars.githubusercontent.com/u/40287606?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/c1ekrt",
"html_url": "https://github.com/c1ekrt",
"followers_url": "https://api.github.com/users/c1ekrt/followers",
"following_url": "https://api.github.com/users/c1ekrt/following{/other_user}",
"gists_url": "https://api.github.com/users/c1ekrt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/c1ekrt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/c1ekrt/subscriptions",
"organizations_url": "https://api.github.com/users/c1ekrt/orgs",
"repos_url": "https://api.github.com/users/c1ekrt/repos",
"events_url": "https://api.github.com/users/c1ekrt/events{/privacy}",
"received_events_url": "https://api.github.com/users/c1ekrt/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @sanchit-gandhi ",
"Hey @c1ekrt - thanks for the issue report. Unfortunately, I'm not able to reproduce the error you're facing with the given command. I launched training using the arguments you provided, and training was executed successfully. See logs at [wandb](https://wandb.ai/sanchit-gandhi/huggingface/runs/zg0lwddz/overview?workspace=user-sanchit-gandhi). Could you confirm that you are using the latest version of the examples script without modifications? Thanks!",
"Thanks for replying! I will reinstall the package and rerun the example after this weekend.\r\n",
"I had modified two lines since this error message popped out\r\n```Traceback (most recent call last):\r\n File \"D:\\Jhou's Workshop\\transformers-main\\examples\\pytorch\\audio-classification\\run_audio_classification.py\", line 443, in <module>\r\n main()\r\n File \"D:\\Jhou's Workshop\\transformers-main\\examples\\pytorch\\audio-classification\\run_audio_classification.py\", line 417, in main\r\n train_result = trainer.train(resume_from_checkpoint=checkpoint)\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\transformers\\trainer.py\", line 1546, in train\r\n return inner_training_loop(\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\transformers\\trainer.py\", line 1837, in _inner_training_loop\r\n tr_loss_step = self.training_step(model, inputs)\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\transformers\\trainer.py\", line 2682, in training_step\r\n loss = self.compute_loss(model, inputs)\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\transformers\\trainer.py\", line 2707, in compute_loss\r\n outputs = model(**inputs)\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\accelerate\\utils\\operations.py\", line 581, in forward\r\n return model_forward(*args, **kwargs)\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\accelerate\\utils\\operations.py\", line 569, in __call__\r\n return convert_to_fp32(self.model_forward(*args, **kwargs))\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\torch\\amp\\autocast_mode.py\", line 14, in decorate_autocast\r\n return func(*args, **kwargs)\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\transformers\\models\\wav2vec2\\modeling_wav2vec2.py\", line 2136, in forward\r\n loss = loss_fct(logits.view(-1, self.config.num_labels), labels.view(-1))\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\torch\\nn\\modules\\loss.py\", line 1174, in forward\r\n return F.cross_entropy(input, target, weight=self.weight,\r\n File \"C:\\Users\\jim\\.conda\\envs\\diffhug\\lib\\site-packages\\torch\\nn\\functional.py\", line 3029, in cross_entropy\r\n return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)\r\nRuntimeError: \"nll_loss_forward_reduce_cuda_kernel_2d_index\" not implemented for 'Int'\r\n```\r\n\r\nSo I changed the code in line 400 to\r\n\r\n``` \r\n # Initialize our trainer\r\n trainer = Trainer(\r\n model=model,\r\n args=training_args,\r\n train_dataset=raw_datasets[\"train\"].with_format(\"torch\") if training_args.do_train else None,\r\n eval_dataset=raw_datasets[\"eval\"].with_format(\"torch\") if training_args.do_eval else None,\r\n compute_metrics=compute_metrics,\r\n tokenizer=feature_extractor,\r\n )\r\n```\r\n\r\nAnd transformers.BatchFeature error popped up\r\n\r\nI have reinstalled transformers package but the issue remained",
"Hey @c1ekrt - you can't pass the raw dataset with `{audio, text}` to the trainer, you need to pass the pre-processed dataset with the features `{normalised audio, token ids}`:\r\n\r\n```python\r\n# Initialize Trainer\r\ntrainer = Trainer(\r\n model=model,\r\n data_collator=data_collator,\r\n args=training_args,\r\n compute_metrics=compute_metrics,\r\n train_dataset=vectorized_datasets[\"train\"] if training_args.do_train else None,\r\n eval_dataset=vectorized_datasets[\"eval\"] if training_args.do_eval else None,\r\n tokenizer=processor,\r\n)\r\n```",
"I still can't get the example work. The pre-process part of the code which is this section\r\nLine 317-329\r\n\r\n```\r\ndef train_transforms(batch):\r\n \"\"\"Apply train_transforms across a batch.\"\"\"\r\n subsampled_wavs = []\r\n for audio in batch[data_args.audio_column_name]:\r\n wav = random_subsample(\r\n audio[\"array\"], max_length=data_args.max_length_seconds, sample_rate=feature_extractor.sampling_rate\r\n )\r\n subsampled_wavs.append(wav)\r\n inputs = feature_extractor(subsampled_wavs, sampling_rate=feature_extractor.sampling_rate)\r\n output_batch = {model_input_name: inputs.get(model_input_name)}\r\n output_batch[\"labels\"] = list(batch[data_args.label_column_name])\r\n return output_batch\r\n```\r\n\r\nnever run despite set_transform being called\r\nLine 390\r\n\r\n```\r\nraw_datasets[\"train\"].set_transform(train_transforms, output_all_columns=False)\r\n```\r\n\r\nall of these code are unmodified.",
"Indeed, the pre-processing function is defined here:\r\nhttps://github.com/huggingface/transformers/blob/eaf5e98ec03d73c24367438100b05c02ce5ad10c/examples/pytorch/audio-classification/run_audio_classification.py#L317\r\n\r\nAnd the transformation is applied here:\r\nhttps://github.com/huggingface/transformers/blob/eaf5e98ec03d73c24367438100b05c02ce5ad10c/examples/pytorch/audio-classification/run_audio_classification.py#L390\r\n\r\nCan you try running the script un-changed from the default script provided? As mentioned above, can do a training run using the command you provided without any issue\r\n\r\nIt's worth trying updating the `accelerate` package:\r\n```\r\npip install --upgrade accelerate\r\n```\r\n\r\nAnd checking that your PyTorch version is up to date (maybe even try the nightly install?)",
"OK. It seems that the 'label' of the superb dataset that passed into the cross entropy calculation happened to be wrong dtype. Hence the error \r\n```\r\n\"nll_loss_forward_reduce_cuda_kernel_2d_index\" not implemented for 'Int' \r\n```\r\noccurred. After changing the dtype to torch.int64 the code start running without any error.",
"Interesting! I couldn't repro this on my side. Will leave as closed for now, but feel free to re-open if you see this phenomenon in the examples scripts again. Sorry we didn't find the complete fix this time!",
"I faced the exact same issue. For me, upgrading datasets (pip3 install --upgrade datasets) did the trick."
] | 1,692 | 1,701 | 1,693 |
NONE
| null |
### System Info
- `transformers` version: 4.33.0.dev0
- Platform: Windows-10-10.0.22621-SP0
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@sanchit-gandhi
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
run audio_classification_CMD.py with following arguments
```
audio_classification_CMD.py
run_audio_classification.py --output_dir .\output --overwrite_output_dir --model_name_or_path facebook/wav2vec2-base --dataset_name superb --dataset_config_name ks --hub_model_id Audio_Classification --do_train --do_eval --fp16 --train_split_name train --remove_unused_columns False --load_best_model_at_end --metric_for_best_model accuracy --gradient_accumulation_steps 4 --push_to_hub --push_to_hub_model_id Audio_Classification --save_safetensors --save_step 200 --save_strategy epoch --evaluation_strategy epoch --logging_strategy steps --logging_steps 10 --max_length_seconds 1 --seed 0 --num_train_epochs 5 --save_total_limit 3 --learning_rate 3e-5 --per_device_train_batch_size 16 --per_device_eval_batch_size 3 --warmup_ratio 0.1
```
however return the error below
```
Traceback (most recent call last):
File "D:\Jhou's Workshop\transformers-main\examples\pytorch\audio-classification\run_audio_classification.py", line 443, in <module>
main()
File "D:\Jhou's Workshop\transformers-main\examples\pytorch\audio-classification\run_audio_classification.py", line 417, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "C:\Users\jim\.conda\envs\diffhug\lib\site-packages\transformers\trainer.py", line 1546, in train
return inner_training_loop(
File "C:\Users\jim\.conda\envs\diffhug\lib\site-packages\transformers\trainer.py", line 1815, in _inner_training_loop
for step, inputs in enumerate(epoch_iterator):
File "C:\Users\jim\.conda\envs\diffhug\lib\site-packages\accelerate\data_loader.py", line 384, in __iter__
current_batch = next(dataloader_iter)
File "C:\Users\jim\.conda\envs\diffhug\lib\site-packages\torch\utils\data\dataloader.py", line 633, in __next__
data = self._next_data()
File "C:\Users\jim\.conda\envs\diffhug\lib\site-packages\torch\utils\data\dataloader.py", line 677, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "C:\Users\jim\.conda\envs\diffhug\lib\site-packages\torch\utils\data\_utils\fetch.py", line 54, in fetch
return self.collate_fn(data)
File "C:\Users\jim\.conda\envs\diffhug\lib\site-packages\transformers\data\data_collator.py", line 249, in __call__
batch = self.tokenizer.pad(
File "C:\Users\jim\.conda\envs\diffhug\lib\site-packages\transformers\feature_extraction_sequence_utils.py", line 132, in pad
raise ValueError(
ValueError: You should supply an instance of `transformers.BatchFeature` or list of `transformers.BatchFeature` to this method that includes input_values, but you provided ['file', 'audio', 'label']
0%| | 0/5055 [00:01<?, ?it/s]
```
### Expected behavior
Expect to be start training.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25748/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25748/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25747
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25747/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25747/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25747/events
|
https://github.com/huggingface/transformers/issues/25747
| 1,866,243,699 |
I_kwDOCUB6oc5vPJ5z
| 25,747 |
Unnessasry library imports?
|
{
"login": "sweetcocoa",
"id": 12545380,
"node_id": "MDQ6VXNlcjEyNTQ1Mzgw",
"avatar_url": "https://avatars.githubusercontent.com/u/12545380?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sweetcocoa",
"html_url": "https://github.com/sweetcocoa",
"followers_url": "https://api.github.com/users/sweetcocoa/followers",
"following_url": "https://api.github.com/users/sweetcocoa/following{/other_user}",
"gists_url": "https://api.github.com/users/sweetcocoa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sweetcocoa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sweetcocoa/subscriptions",
"organizations_url": "https://api.github.com/users/sweetcocoa/orgs",
"repos_url": "https://api.github.com/users/sweetcocoa/repos",
"events_url": "https://api.github.com/users/sweetcocoa/events{/privacy}",
"received_events_url": "https://api.github.com/users/sweetcocoa/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi. I understand the situation you described. Using string to compare against isn't a super good way in general (as we don't know if there are some exceptional cases), but this approach does avoid significant overhead of loading several frameworks.\r\n\r\nWDYT, @amyeroberts @ArthurZucker ?",
"We can't allow this as it is very brittle, but we can for sure change the order of the checks. @ydshieh would you like to open a PR? ",
"Not sure what order we prefer. Here the torch is imported first which is good IIRC. Unless a user imports TensorFlow manually before calling this method - which might cause hang.",
"Yes, importing torch first is preferable. Given the brittleness of checking against string and that most usage is with pytorch, I don't think we should include this change as it stands. \r\n\r\nLooking in the library, it seems that this function is only used in one place [here](https://github.com/huggingface/transformers/blob/a35f889acc91cb40bd8c6659691aeb27581a69b1/src/transformers/utils/generic.py#L278) in the `ModelOutput` class. As each ModelOutput will already have a predefined framework there'll be a solution which won't require us to dynamically check and import different libraries. For example, we could have a `TFModelOutput` class, and `ModelOutput` and `TFModelOutput` each define their own `is_tensor` method to use when `__post_init__` is called. WDYT?",
"There are 3 other usage, one is from\r\n\r\nhttps://github.com/huggingface/transformers/blob/245dcc49ef9862a7165aec7be9c4a3299b8d06a1/src/transformers/tokenization_utils_base.py#L735\r\n\r\nRegarding the output classes, we currently have things like\r\n```\r\nclass TFBaseModelOutput(ModelOutput):\r\n```\r\nSo it is not very motivating to have yet `TFModelOutput`, `FlaxModelOutput` etc. and make changes to use them. I would suggest to keep as what we have for now, and revisit this situation in the future if things get significant.\r\n\r\n@sweetcocoa: Regarding `Tensorflow is imported before Torch`, you could try `TF_FORCE_GPU_ALLOW_GROWTH=true` as env. variable.",
"> There are 3 other usage, one is from\r\n\r\nI definitely might have missed some references. The one in tokenization_base isn't using the function in `utils/generic.py`. Instead, `is_tensor` is defined above directly e.g. [here](https://github.com/huggingface/transformers/blob/245dcc49ef9862a7165aec7be9c4a3299b8d06a1/src/transformers/tokenization_utils_base.py#L703C3-L703C3). And it's the same in [feature_extraction_utils.py](https://github.com/huggingface/transformers/blob/245dcc49ef9862a7165aec7be9c4a3299b8d06a1/src/transformers/feature_extraction_utils.py#L151) and [tokenization_jukebox.py](https://github.com/huggingface/transformers/blob/245dcc49ef9862a7165aec7be9c4a3299b8d06a1/src/transformers/models/jukebox/tokenization_jukebox.py#L312).\r\n\r\n> I would suggest to keep as what we have for now, and revisit this situation in the future if things get significant.\r\n\r\nAgreed! Let's revisit if there's more activity here or we see similar things arising in other issues.\r\n",
"Sorry, yeah, I messed up the definition of `is_tensor` 😭 !",
"@amyeroberts @ydshieh @ArthurZucker Thanks to everyone who has discussed this issue! I understand the reluctance to use a string representation to check that a variable is an instance of a particular class (I don't think this is `Pythonic`, so I don't think my solution is clean either!). \r\n\r\nHowever, I don't think there can be any 'execptional' cases for my proposed approach of `using a string representation and then importing the library`. Am I missing something? (unless, maliciously, someone decides to name a non-tensor class as `torch.Tensor`).\r\n\r\nMy personal favorite solution is to set up a separate executable with only the frameworks I need, and as @ydshieh pointed out, control via environment variables is a good option. \r\n\r\nHowever, huggingface's transformers is a very popular and widely used framework, so it's also widely used by a wide range of beginner developers who may not be comfortable applying such a solution. I suggested this issue because I was helping someone troubleshoot an unexplained hang and found the reason in `is_tensor` (I had to explain to him why he needed to import torch in code that didn't use torch).\r\n\r\nThanks again for discussing the issues I raised. \r\n\r\n",
"@sweetcocoa The question you raised is a very good and valid one, thank you again 🤗 . It's just we don't have a clean way to handle it and it's not significant (at least not yet). And indeed, having a clean and separate (virtual) working environment is the good practice, which is stated [here](https://huggingface.co/docs/transformers/installation#install-with-pip).",
"Note that we can also be smart and avoid importing any framework by making some checks first (like numpy arrays or if the object is a list/tuple, we can return `False` before trying to import torch/tf/flax). I'm not sure what was the initial use case here and if it would fully solve the issue at hand, but it can make the situation a bit better.",
"Oh and while the pattern matching is a brittle approach to do the check, it can inform the order in which we want to do those framework imports (e.g. if we see the repr looks like a torch Tensor, we try torch first, but if we see it looks like a tf tensor, we try tf first). Happy to make a PoC in a PR if that helps.",
"Yes, sound super great, and would love to review your PR :-)"
] | 1,692 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
### System Info
I don't think it has anything to do with version or running environment. But if needed, I will add example system environments.
### Who can help?
@Narsil @sgugger
It's hard to choose who is relevant, but I tag the people who seems most likely to be relevant.
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
https://github.com/huggingface/transformers/blob/4d40109c3a93c9b8bbca204cb046ed510f1c72e8/src/transformers/utils/generic.py#L74
For many deep learning frameworks (e.g. TensorFlow, Pytoch, JAX, etc.), importing them causes significant overhead.
Also, in some rare cases, just doing an import can cause interactions with other libraries that lead to errors.
- ([Link](https://github.com/apache/tvm/issues/12326): an error caused by overlapping symbols between dynamic libraries, which is fortunately fixable).
- ([Link](https://github.com/pytorch/pytorch/issues/99637) : In some cases, If Tensorflow is imported before Torch, the script will hang and need to be forced kill).
```python
>>> from transformers.utils import is_tensor
>>> import tensorflow as tf
2023-08-25 13:07:44.801120: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2023-08-25 13:07:44.802180: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2023-08-25 13:07:44.822067: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2023-08-25 13:07:44.822321: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-08-25 13:07:45.104908: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
>>> x = tf.zeros(1)
>>> is_tensor(x)
(Hang at this point.)
```
above example executed with
```
Python 3.9.16
torch==2.0.1+cpu
tensorflow==2.13.0
```
This leads me to believe that imports in deep learning frameworks should be minimized and avoided if possible.
In my opinion, the `is_tensor` function in `transformers.utils` is meant to check if the argument is a tensor class used by various frameworks, but the problem with running this function is that it imports unnecessary frameworks in the Python execution environment. For example, it will force Python to import torch even if your code doesn't use torch.
```python
>>> from transformers.utils import is_tensor
>>> import sys
>>> is_tensor(1)
2023-08-25 12:58:25.681444: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2023-08-25 12:58:25.682571: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2023-08-25 12:58:25.702710: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2023-08-25 12:58:25.703004: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-08-25 12:58:26.013967: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
False
>>> "torch" in sys.modules.keys()
True
```
To avoid this, there is another way. It's to compare the string of the object's class name to the target class. This method is simple, but works well in most cases.
```python
>> str(type(x)) == "<class 'torch.Tensor'>"
True
```
However, there is one case where this doesn't work, and that is when something is an object that inherits from the tensor class. In this case, the object's class name will change, and we won't be able to tell if it's a tensor by comparing strings.
```python
>>> class NewTensor(torch.Tensor): pass
...
>>> x = NewTensor()
>>> str(type(x)) == "<class 'torch.Tensor'>"
False
>>> isinstance(x, torch.Tensor)
True
```
So my suggestion is to change the logic of is_tensor to roughly the following.
1. compare the class name of the object to the name of the target class to see if it is a tensor.
2. if it's False for tensors in all frameworks, then import the library and compare it using the isinstance method.
With this code change, the performance drop should be negligible since string comparisons are not that big of an overhead, and in some cases, our code may even see a performance gain since we won't be importing unnecessary libraries.
What do you think?
### Expected behavior
If `is_tensor` uses string comparison first, It works fine in most cases without importing unused libraries. In certain situations, we may not even encounter hangs.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25747/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25747/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25746
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25746/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25746/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25746/events
|
https://github.com/huggingface/transformers/issues/25746
| 1,866,240,791 |
I_kwDOCUB6oc5vPJMX
| 25,746 |
working with huggingface Llama 2 13b chat hf model_kwargs value error
|
{
"login": "Mrjaggu",
"id": 40687103,
"node_id": "MDQ6VXNlcjQwNjg3MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/40687103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mrjaggu",
"html_url": "https://github.com/Mrjaggu",
"followers_url": "https://api.github.com/users/Mrjaggu/followers",
"following_url": "https://api.github.com/users/Mrjaggu/following{/other_user}",
"gists_url": "https://api.github.com/users/Mrjaggu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mrjaggu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mrjaggu/subscriptions",
"organizations_url": "https://api.github.com/users/Mrjaggu/orgs",
"repos_url": "https://api.github.com/users/Mrjaggu/repos",
"events_url": "https://api.github.com/users/Mrjaggu/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mrjaggu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks for reporting but you are not giving us the full script. The traceback shows that the errors appears at: \r\n```python \r\ngenerate_text(\"Explain encoder decoder model\")\r\n```\r\nwhich I don't have access to. \r\nThe traceback seems a bit strange, but anyway. I think that some of the generation kwargs were not passed as you are showing it: `max_new_token` is missing a `s` and 'repetition penality' has an extra space. \r\nPlease provide a full traceback as this one seems wrong ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,692 | 1,697 | 1,697 |
NONE
| null |
using Llama 2 13b chat hf model (https://huggingface.co/meta-llama/Llama-2-13b-chat-hf) with 4bit quantization (bitsandbytes)
getting an error in the following code.. it used to work earlier
```python
generate_text = transformers.pipeline(
model=model, tokenizer=tokenizer,
return_full_text=True, # langchain expects the full text
task='text-generation',
temperature=0.0,
max_new_tokens=2000,
repetition_penalty=1.1
)
```
ValueError: The following 'model_kwargs' are not used by the model: ['max_new_token'','repetition_policy'] (note: Typos in the generate arguments will also show up in this list)
Full code:
```python
from torch import cuda, bfloat16
import transformers
model_id = 'meta-llama/Llama-2-13b-chat-hf'
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
print(f"Device avialble is on {device}")
bnb_config = transformers.BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=bfloat16
)
hf_auth = '####'
model_config = transformers.AutoConfig.from_pretrained(
model_id,
use_auth_token=hf_auth
)
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_id,
use_auth_token=hf_auth
)
model = transformers.AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
config=model_config,
quantization_config=bnb_config,
device_map='auto',
use_auth_token=hf_auth
)
generate_text = transformers.pipeline(
model=model, tokenizer=tokenizer,
return_full_text=True, # langchain expects the full text
task='text-generation',
temperature=0.0,
max_new_tokens=2000,
repetition_penalty=1.1
)
```
Error trace:
```
warnings.warn( Loading checkpoint shards: 100%
Model loaded and downloaded succesfully
3/3 100:17 00:00, 5.86/it
/opt/data1/python3.8 virtualenv/virtualenvs/transformers/lib/python3.8/site- packages/transformers/tokenization_utils_base.py:1714: FutureWarning. The use auth token argument is deprecated and will be removed in v5 of Transformers.
warnings.wam Traceback (most recent call last):
File "inference_test.py", line 73, in <module>
res generate_text("Explain encoder decoder model"), File "/opt/data/python3 8 virtualenv/virtualenvs/transformers/lib/python3.8/site-
packages/transformers/pipelines/text generation.py", line 200, in __call_
return super call (text inputs, **kwargs)
File "/opt/data1/python3.8_virtualenv/virtualenvs/transformers/lib/python3.5/site-
packages/transformers/pipelines/base.py", line 1122, in call
return self.run_single(inputs, preprocess params, forward params, postprocess params) File "/opt/data/python3.8 virtualenv/virtualenvs/transformers/lib/python3.8/site- packages/transformers/pipelines/base.py", line 1129, in run single
model outputs self.forward(model inputs, forward_params)
File "/opt/data1/python3.8 virtualenv/virtualenvs/transformers/lib/python3.8/site-
packages/transformers/pipelines/base.py", line 1028, in forward
model outputs = self forward(model inputs, forward_params)
File "/opt/data1/python3.8 virtualenv/virtualenvs/transformers/lib/python3.8/site
packages/transformers/pipelines/text generation.py", line 261, in forward
generated sequence = self.model.generate(input_ids-input ids, attention mask-attention_mask, **generate_kwargs) File "/opt/data1/python3.8_virtualenv/virtualenvs/transformers/lib/python3.8/site- packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/opt/data1/python3.8_virtualenv/virtualenvs/transformers/lib/python3.8/site- packages/transformers/generation/utils.py, line 1282, in generate
self validate model kwargs(model_kwargs.copy())
File "/opt/data1/python3.8 virtualenv/virtualenvs/transformers/lib/python3.5/site packages/transformers/generation/utils.py", line 1155, in _validate model kwargs
raise ValueError(
ValueError. The following model kwargs are not used by the model: I'max_new_token',"repetition penality'] (note: typos in the generate arguments will also show up in this list)
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25746/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25746/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25745
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25745/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25745/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25745/events
|
https://github.com/huggingface/transformers/pull/25745
| 1,866,240,035 |
PR_kwDOCUB6oc5YwHWk
| 25,745 |
fixed typo in speech encoder decoder doc
|
{
"login": "asusevski",
"id": 77211520,
"node_id": "MDQ6VXNlcjc3MjExNTIw",
"avatar_url": "https://avatars.githubusercontent.com/u/77211520?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/asusevski",
"html_url": "https://github.com/asusevski",
"followers_url": "https://api.github.com/users/asusevski/followers",
"following_url": "https://api.github.com/users/asusevski/following{/other_user}",
"gists_url": "https://api.github.com/users/asusevski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/asusevski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/asusevski/subscriptions",
"organizations_url": "https://api.github.com/users/asusevski/orgs",
"repos_url": "https://api.github.com/users/asusevski/repos",
"events_url": "https://api.github.com/users/asusevski/events{/privacy}",
"received_events_url": "https://api.github.com/users/asusevski/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25745). All of your documentation changes will be reflected on that endpoint."
] | 1,692 | 1,692 | 1,692 |
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #25673 (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@stevhliu and @MKhalusova
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25745/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25745/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25745",
"html_url": "https://github.com/huggingface/transformers/pull/25745",
"diff_url": "https://github.com/huggingface/transformers/pull/25745.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25745.patch",
"merged_at": 1692948037000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25744
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25744/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25744/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25744/events
|
https://github.com/huggingface/transformers/issues/25744
| 1,866,203,602 |
I_kwDOCUB6oc5vPAHS
| 25,744 |
Support shorter input length for Whisper encoder
|
{
"login": "gau-nernst",
"id": 26946864,
"node_id": "MDQ6VXNlcjI2OTQ2ODY0",
"avatar_url": "https://avatars.githubusercontent.com/u/26946864?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gau-nernst",
"html_url": "https://github.com/gau-nernst",
"followers_url": "https://api.github.com/users/gau-nernst/followers",
"following_url": "https://api.github.com/users/gau-nernst/following{/other_user}",
"gists_url": "https://api.github.com/users/gau-nernst/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gau-nernst/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gau-nernst/subscriptions",
"organizations_url": "https://api.github.com/users/gau-nernst/orgs",
"repos_url": "https://api.github.com/users/gau-nernst/repos",
"events_url": "https://api.github.com/users/gau-nernst/events{/privacy}",
"received_events_url": "https://api.github.com/users/gau-nernst/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey @gau-nernst! I've tried this before and it works very well (even with the pre-trained model). Sharing a codesnippet that shows how I did this: https://github.com/sanchit-gandhi/codesnippets/blob/main/whisper-reduce-context.ipynb\r\n\r\nHowever, I'm not sure it's necessarily a feature that warrants adding to the `transformers` library: IMO it's quite a niche application of the Whisper model that diverges somewhat from the official implementation, and probably will add extra complexity for a feature that is not used so much\r\n\r\nI think we can reserve this as a feature that more advanced users can achieve by following the codesnippet shared above? WDYT?",
"Also cc @ArthurZucker for interest!",
"Thank you @sanchit-gandhi for the reply. Sadly, for my use case, the input size is not always fixed (I perform padding to the longest in a batch) so I need a \"dynamic\" way to accept shorter audio. I understand the concerns regarding diverging from the official implementation, so it's ok to not implement this feature.",
"Hmm I see! That's indeed a bit more tricky - in this case, slicing the embeddings on the fly is probably your best bet, as you identified above!",
"Do you think this feature should be implemented in `transformers`? I understand if you don't want to. I will close this issue in that case.",
"I think not as it lends itself to silent errors if the audio is not correctly pre-processed. But more than happy to help you with implementing yourself locally!",
"Sorry for replying to the old issue.\r\n\r\nI agree that always doing the slicing is error prone. In the issue linked above I proposed passing the embedding by key word args so users have to explicitly construct their own embeddings and pass them as args if they want to use this. That way, wrongly processed inputs still error without the opt in. \r\n\r\nI used your approach but i would like the whole process to be as thread safe as possible. Setting the encoder weights on the fly isn't. Do you have any ideas how to do it in a safer way? In the end I would like to load the model once and use it for different tasks which might need different embedding length.",
"A temporary solution for me is to edit the Whisper modelling file directly. A better solution would be to subclass `WhisperEncoder` and override the `forward()` method to your liking.",
"Is there a nice way to load and save the models with a subclassed encoder without subclassing the model itself as well? \r\n",
"There are hacks you can do. For example, you can replace an object's class with your own (https://stackoverflow.com/questions/15404256/changing-the-class-of-a-python-object-casting). You can also monkey-patch an object's method (https://www.pythonforthelab.com/blog/monkey-patching-and-its-consequences/). To make it work with any models that contain `WhisperEncoder`, you can iterate over its modules `.modules()`, check `isinstance(modue, WhisperEncoder)`, and patch it accordingly.\r\n\r\nModel weights shouldn't be a problem if you don't change the shape of the weight.",
"Yeah hacks work of course. That's why i asked for a nice method haha. \r\n\r\nBut thanks anyways!"
] | 1,692 | 1,696 | 1,693 |
CONTRIBUTOR
| null |
### Feature request
Right now Whisper requires audio data to be padded or truncated to exactly 30s (i.e. mel-spec with shape `(B, 80, 3000)`). In the encoder, the only operation that prevents WhisperEncoder from working on shorter audio is positional embeddings.
https://github.com/huggingface/transformers/blob/41aef33758ae166291d72bc381477f2db84159cf/src/transformers/models/whisper/modeling_whisper.py#L902
Simply truncate the the positional embeddings will make WhisperEncoder works for shorter audio
```python
hidden_states = inputs_embeds + embed_pos[:input_embeds.shape[1]]
```
@sanchit-gandhi Knowing you are the audio guy at HF, I would like to hear your inputs on this.
### Motivation
I do understand that the original OpenAI code forces all input to the model to be `(B, 80, 3000)`. However, for encoder-only tasks, such as audio classification, padding zeros is wasteful, and can even be detrimental, since the zeros may "dilute" the prediction scores.
### Your contribution
The fix is simple, like I mentioned above. I don't think it will affect the ASR pipeline as long as the FeatureExtractor still enforces padding to 3000.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25744/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25744/timeline
|
not_planned
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25743
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25743/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25743/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25743/events
|
https://github.com/huggingface/transformers/issues/25743
| 1,866,086,825 |
I_kwDOCUB6oc5vOjmp
| 25,743 |
GPT-J finetuning for Sequential Classification fails
|
{
"login": "jojivk73",
"id": 14943401,
"node_id": "MDQ6VXNlcjE0OTQzNDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/14943401?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jojivk73",
"html_url": "https://github.com/jojivk73",
"followers_url": "https://api.github.com/users/jojivk73/followers",
"following_url": "https://api.github.com/users/jojivk73/following{/other_user}",
"gists_url": "https://api.github.com/users/jojivk73/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jojivk73/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jojivk73/subscriptions",
"organizations_url": "https://api.github.com/users/jojivk73/orgs",
"repos_url": "https://api.github.com/users/jojivk73/repos",
"events_url": "https://api.github.com/users/jojivk73/events{/privacy}",
"received_events_url": "https://api.github.com/users/jojivk73/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
] |
[
"AH yes, this is known, one of our CI caught this! \r\nI'll open a PR !",
"Sorry got caught up in a lot of things! TF Is a pain to fix 😅 ",
"cc @Rocketknight1 will probably take you a lot less time than me if you have time to tkae #25751 over! (Have not really seen any complaints so very low priority) ",
"Added the fix in #25751!",
"@jojivk73 This should now be fixed! Please install from `main` with `pip install git+https://github.com/huggingface/transformers.git` to try it out, and let me know if you have any other issues!"
] | 1,692 | 1,698 | 1,698 |
NONE
| null |
### System Info
Framework : HF+ TF
Device : CPU Sapphire Rapids
Issue : GPt-J crashes in HF transformer when run in graph mode.Eager mode runs fine.
Any fix/resolution/workaround appreciated.
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```python
from datasets import load_dataset
from transformers import (
AutoTokenizer,
DataCollatorWithPadding,
TFAutoModelForSequenceClassification,
TFAutoModelForCausalLM,
AutoConfig,
)
from tensorflow.keras.losses import SparseCategoricalCrossentropy
import numpy as np
import tensorflow as tf
IGNORE_INDEX = -100
DEFAULT_PAD_TOKEN = "[PAD]"
DEFAULT_EOS_TOKEN = "</s>"
DEFAULT_BOS_TOKEN = "<s>"
DEFAULT_UNK_TOKEN = "<unk>"
tf.keras.mixed_precision.set_global_policy('mixed_bfloat16')
tf.config.threading.set_inter_op_parallelism_threads(2)
tf.config.threading.set_intra_op_parallelism_threads(112)
raw_datasets = load_dataset("glue", "cola")
checkpoint = "EleutherAI/gpt-j-6b"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
#print(raw_datasets["train"][0])
label_list = raw_datasets["train"].features["label"].names
num_labels = len(label_list)
config = AutoConfig.from_pretrained(checkpoint, num_labels=num_labels)
special_tokens_dict = dict()
if tokenizer.pad_token is None:
special_tokens_dict["pad_token"] = DEFAULT_PAD_TOKEN
if tokenizer.eos_token is None:
special_tokens_dict["eos_token"] = DEFAULT_EOS_TOKEN
if tokenizer.bos_token is None:
special_tokens_dict["bos_token"] = DEFAULT_BOS_TOKEN
if tokenizer.unk_token is None:
special_tokens_dict["unk_token"] = DEFAULT_UNK_TOKEN
tokenizer.add_special_tokens(special_tokens_dict)
config.pad_token_id=0
print(config)
def tokenize_function(example):
return tokenizer(example["sentence"], padding="longest", truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
print(tokenized_datasets)
#data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False, return_tensors="tf")
tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
columns=["input_ids"], #, "token_type_ids"],
label_cols=["label"],
shuffle=True,
collate_fn=data_collator,
batch_size=64,
)
tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
#columns=["attention_mask", "input_ids"],
columns=["input_ids"],
label_cols=["label"],
shuffle=False,
collate_fn=data_collator,
batch_size=64,
)
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, config=config)
model.resize_token_embeddings(len(tokenizer))
from tensorflow.keras.optimizers.schedules import PolynomialDecay
num_epochs=3
# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
num_train_steps = len(tf_train_dataset) * num_epochs
lr_scheduler = PolynomialDecay(
initial_learning_rate=2e-5, end_learning_rate=0.0, decay_steps=num_train_steps
)
from tensorflow.keras.optimizers import Adam
opt = Adam(learning_rate=lr_scheduler)
model.compile(
optimizer=opt,
loss=SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
#run_eagerly=True,
)
#import pdb
#pdb.set_trace()
model.fit(
tf_train_dataset,
validation_data=tf_validation_dataset,
epochs=3,
)
### Expected behavior
The model fails when run_eagerly is False(default). If run_Eagerly is True, it does not fail.
Failure log
================================================================
File "/localdisk/jojimonv/tfv2_p39/lib64/python3.9/site-packages/keras/engine/training.py", line 1268, in step_function **
outputs = model.distribute_strategy.run(run_step, args=(data,))
File "/localdisk/jojimonv/tfv2_p39/lib64/python3.9/site-packages/keras/engine/training.py", line 1249, in run_step **
outputs = model.train_step(data)
File "/localdisk/jojimonv/tfv2_p39/lib64/python3.9/site-packages/transformers/modeling_tf_utils.py", line 1637, in train_step
y_pred = self(x, training=True)
File "/localdisk/jojimonv/tfv2_p39/lib64/python3.9/site-packages/keras/utils/traceback_utils.py", line 70, in error_handler
raise e.with_traceback(filtered_tb) from None
File "/tmp/__autograph_generated_file05uidiwg.py", line 37, in tf__run_call_with_unpacked_inputs
retval_ = ag__.converted_call(ag__.ld(func), (ag__.ld(self),), dict(**ag__.ld(unpacked_inputs)), fscope)
File "/tmp/__autograph_generated_file3qh7zjf_.py", line 57, in tf__call
ag__.if_stmt(ag__.ld(self).config.pad_token_id is None, if_body_1, else_body_1, get_state_1, set_state_1, ('in_logits', 'sequence_lengths'), 2)
File "/tmp/__autograph_generated_file3qh7zjf_.py", line 55, in else_body_1
ag__.if_stmt(ag__.ld(input_ids) is not None, if_body, else_body, get_state, set_state, ('in_logits', 'sequence_lengths'), 2)
File "/tmp/__autograph_generated_file3qh7zjf_.py", line 47, in if_body
sequence_lengths = ag__.converted_call(ag__.ld(tf).where, (ag__.ld(sequence_lengths) >= 0, ag__.ld(sequence_lengths), ag__.ld(input_ids).shape[-1] - 1), None, fscope)
TypeError: Exception encountered when calling layer 'tfgptj_for_sequence_classification' (type TFGPTJForSequenceClassification).
in user code:
File "/localdisk/jojimonv/tfv2_p39/lib64/python3.9/site-packages/transformers/modeling_tf_utils.py", line 834, in run_call_with_unpacked_inputs *
return func(self, **unpacked_inputs)
File "/localdisk/jojimonv/tfv2_p39/lib64/python3.9/site-packages/transformers/models/gptj/modeling_tf_gptj.py", line 875, in call *
sequence_lengths = tf.where(sequence_lengths >= 0, sequence_lengths, input_ids.shape[-1] - 1)
TypeError: unsupported operand type(s) for -: 'NoneType' and 'int'
Call arguments received by layer 'tfgptj_for_sequence_classification' (type TFGPTJForSequenceClassification):
• input_ids=tf.Tensor(shape=(None, None), dtype=int64)
• past_key_values=None
• attention_mask=None
• token_type_ids=None
• position_ids=None
• head_mask=None
• inputs_embeds=None
• labels=None
• use_cache=None
• output_attentions=None
• output_hidden_states=None
• return_dict=None
• training=True
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25743/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25743/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25742
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25742/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25742/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25742/events
|
https://github.com/huggingface/transformers/issues/25742
| 1,865,786,537 |
I_kwDOCUB6oc5vNaSp
| 25,742 |
Code Llama not initializing all layers with AutoModelForCausalLM.from_pretrained
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Compatible PR: https://github.com/huggingface/transformers.git@refs/pull/25740",
"You were probably not using the latest version transformers. The `inv_freq` is not persistent anymore. Also not a problem if it is re-initialized! "
] | 1,692 | 1,692 | 1,692 |
COLLABORATOR
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.14.0-284.25.1.el9_2.x86_64-x86_64-with-glibc2.34
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.21.0
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): 2.13.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.7.2 (cpu)
- Jax version: 0.4.14
- JaxLib version: 0.4.14
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("codellama/CodeLlama-13b-hf", device_map="auto")
```
Error:
```
Some weights of LlamaForCausalLM were not initialized from the model checkpoint at codellama/CodeLlama-13b-hf and are newly initialized: ['model.layers.2.self_attn.rotary_emb.inv_freq', 'model.layers.20.self_attn.rotary_emb.inv_freq', 'model.layers.13.self_attn.rotary_emb.inv_freq', 'model.layers.3.self_attn.rotary_emb.inv_freq', 'model.layers.36.self_attn.rotary_emb.inv_freq', 'model.layers.19.self_attn.rotary_emb.inv_freq', 'model.layers.16.self_attn.rotary_emb.inv_freq', 'model.layers.35.self_attn.rotary_emb.inv_freq', 'model.layers.0.self_attn.rotary_emb.inv_freq', 'model.layers.15.self_attn.rotary_emb.inv_freq', 'model.layers.30.self_attn.rotary_emb.inv_freq', 'model.layers.1.self_attn.rotary_emb.inv_freq', 'model.layers.25.self_attn.rotary_emb.inv_freq', 'model.layers.38.self_attn.rotary_emb.inv_freq', 'model.layers.12.self_attn.rotary_emb.inv_freq', 'model.layers.24.self_attn.rotary_emb.inv_freq', 'model.layers.29.self_attn.rotary_emb.inv_freq', 'model.layers.23.self_attn.rotary_emb.inv_freq', 'model.layers.6.self_attn.rotary_emb.inv_freq', 'model.layers.8.self_attn.rotary_emb.inv_freq', 'model.layers.26.self_attn.rotary_emb.inv_freq', 'model.layers.27.self_attn.rotary_emb.inv_freq', 'model.layers.28.self_attn.rotary_emb.inv_freq', 'model.layers.34.self_attn.rotary_emb.inv_freq', 'model.layers.7.self_attn.rotary_emb.inv_freq', 'model.layers.37.self_attn.rotary_emb.inv_freq', 'model.layers.11.self_attn.rotary_emb.inv_freq', 'model.layers.22.self_attn.rotary_emb.inv_freq', 'model.layers.9.self_attn.rotary_emb.inv_freq', 'model.layers.17.self_attn.rotary_emb.inv_freq', 'model.layers.21.self_attn.rotary_emb.inv_freq', 'model.layers.31.self_attn.rotary_emb.inv_freq', 'model.layers.5.self_attn.rotary_emb.inv_freq', 'model.layers.39.self_attn.rotary_emb.inv_freq', 'model.layers.4.self_attn.rotary_emb.inv_freq', 'model.layers.32.self_attn.rotary_emb.inv_freq', 'model.layers.18.self_attn.rotary_emb.inv_freq', 'model.layers.14.self_attn.rotary_emb.inv_freq', 'model.layers.33.self_attn.rotary_emb.inv_freq', 'model.layers.10.self_attn.rotary_emb.inv_freq']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
### Expected behavior
No worrisome warnings
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25742/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25742/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25741
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25741/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25741/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25741/events
|
https://github.com/huggingface/transformers/pull/25741
| 1,865,736,974 |
PR_kwDOCUB6oc5YuaZQ
| 25,741 |
MaskFormer,Mask2former - reduce memory load
|
{
"login": "amyeroberts",
"id": 22614925,
"node_id": "MDQ6VXNlcjIyNjE0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amyeroberts",
"html_url": "https://github.com/amyeroberts",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_url": "https://api.github.com/users/amyeroberts/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amyeroberts/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amyeroberts/subscriptions",
"organizations_url": "https://api.github.com/users/amyeroberts/orgs",
"repos_url": "https://api.github.com/users/amyeroberts/repos",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"received_events_url": "https://api.github.com/users/amyeroberts/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@ydshieh, I ran the following to check the times. The einsum operation is quicker, but on the same order of magnitude as this and they scale the same way. This I expected as both will still need to reduce over the channel dimensions and this should (and does) scale linearly. \r\n\r\n\r\n```python\r\ndef foo(mask_embeddings, pixel_embeddings):\r\n batch_size, num_queries, num_channels = mask_embeddings.shape\r\n _, _, height, width = pixel_embeddings.shape\r\n binaries_masks = np.zeros((batch_size, num_queries, height, width))\r\n for c in range(num_channels):\r\n binaries_masks += mask_embeddings[..., c][..., None, None] * pixel_embeddings[:, None, c]\r\n return binaries_masks\r\n\r\ndef bar(mask_embeddings, pixel_embeddings):\r\n binaries_masks = np.einsum('bqc, bchw -> bqhw', mask_embeddings, pixel_embeddings)\r\n return binaries_masks\r\n\r\nfoo_times = {}\r\nbar_times = {}\r\n\r\nfor num_channels in (10, 100, 1000, 10000):\r\n foo_times[num_channels] = []\r\n bar_times[num_channels] = []\r\n\r\n mask_embeddings = np.random.randn(batch_size, num_queries, num_channels)\r\n pixel_embeddings = np.random.randn(batch_size, num_channels, height, width)\r\n\r\n for i in range(100):\r\n start = time.time()\r\n foo(mask_embeddings, pixel_embeddings)\r\n foo_times[num_channels].append(time.time() - start)\r\n start = time.time()\r\n bar(mask_embeddings, pixel_embeddings)\r\n bar_times[num_channels].append(time.time() - start)\r\n\r\n print(\"\\n\", num_channels)\r\n print(f\"Iterate directly: {np.mean(foo_times[num_channels]):.5f} +/- {np.std(foo_times[num_channels]):.5f}\")\r\n print(f\"Einsum approach: {np.mean(bar_times[num_channels]):.5f} +/- {np.std(bar_times[num_channels]):.5f}\")\r\n```\r\n\r\nResults: \r\n```\r\n 10\r\nIterate directly: 0.00038 +/- 0.00001\r\nEinsum approach: 0.00021 +/- 0.00000\r\n\r\n 100\r\nIterate directly: 0.00300 +/- 0.00008\r\nEinsum approach: 0.00203 +/- 0.00004\r\n\r\n 1000\r\nIterate directly: 0.03329 +/- 0.00320\r\nEinsum approach: 0.02006 +/- 0.00041\r\n\r\n 10000\r\nIterate directly: 0.35071 +/- 0.02558\r\nEinsum approach: 0.20384 +/- 0.00132\r\n```\r\n\r\nThe question is: are we happy with this step being almost 2x slower if it enables jit tracing? As the original issue arises from a torch operation - torch.einsum - arguably it's not something we should be addressing on our end. \r\n\r\nI do have a slight concern with the approach in this PR wrt numerical stability. \r\n\r\n",
"Yeah, not ideal although not too bad. If the 2x slower is OK depends on its scale: 20 v.s 10 seconds is not good, and 0.02 v.s 0.01 is kind fine. I don't know what's the value for `num_queries` when we use a real checkpoint (and what value you used above) and therefore what is the usual op timing scale here.\r\n\r\nAre you up to use \r\n\r\n```python3\r\nif config.torchscript:\r\n iterate way\r\nelse:\r\n einsum\r\n```\r\n?\r\n\r\nIf so, let's do it and we don't have to worry about the timing. Otherwise, let's go this PR but have a comment about the potential slower op time, a link to your above comment and a link to the original enisum implementation.\r\n",
"@ydshieh The number of channels in on the order of 100s. For the checkpoint `\"\"facebook/maskformer-swin-base-ade\"` it's 256. This means the time difference between the two approaches is ~0.001 s - 0.01s.\r\n\r\nI'm not going to add the if/else for the moment for the sake of simplicity. Looking in the library, I don't see this control flow being used often and I'm not confident that it'll be correctly set when our users want to trace the model. ",
"> @ydshieh The number of channels in on the order of 100s. For the checkpoint `\"\"facebook/maskformer-swin-base-ade\"` it's 256. This means the time difference between the two approaches is ~0.001 s - 0.01s.\r\n> \r\n> I'm not going to add the if/else for the moment for the sake of simplicity. Looking in the library, I don't see this control flow being used often and I'm not confident that it'll be correctly set when our users want to trace the model.\r\n\r\nSure, works for me, let's keep it simple.\r\n\r\nRegarding set `torchscript`, I think it is required, see `return_dict = return_dict if return_dict is not None else self.config.return_dict`. Also it appears in the original issue description #25261."
] | 1,692 | 1,693 | 1,693 |
COLLABORATOR
| null |
# What does this PR do?
#25297 resolved an error that occurred when trying to trace MaskFormer-like models. The solution was to remove einsum operations. However, the replacements were very memory intensive: a large matrix was created and then summed over.
This PR replaces this logic by creating the result array and the iterates over the summed dimension.
Fixes #25709
It was confirmed that this resolved the memory issue, by installing from this branch and rerunning the example notebook successfully: https://colab.research.google.com/drive/1xq54l9a2AQLIHT5jw63btifbOrvSqzts?usp=sharing
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25741/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25741/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25741",
"html_url": "https://github.com/huggingface/transformers/pull/25741",
"diff_url": "https://github.com/huggingface/transformers/pull/25741.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25741.patch",
"merged_at": 1693331355000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25740
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25740/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25740/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25740/events
|
https://github.com/huggingface/transformers/pull/25740
| 1,865,609,379 |
PR_kwDOCUB6oc5Yt-gs
| 25,740 |
[`CodeLlama`] Add support for `CodeLlama`
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,692 | 1,695 | 1,692 |
COLLABORATOR
| null |
# What does this PR do?
Adds support for LlamaCode
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25740/reactions",
"total_count": 24,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 14,
"rocket": 10,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25740/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25740",
"html_url": "https://github.com/huggingface/transformers/pull/25740",
"diff_url": "https://github.com/huggingface/transformers/pull/25740.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25740.patch",
"merged_at": 1692982661000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25739
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25739/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25739/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25739/events
|
https://github.com/huggingface/transformers/issues/25739
| 1,865,596,261 |
I_kwDOCUB6oc5vMr1l
| 25,739 |
Problem initializing Deepspeed with Trainer
|
{
"login": "lhallee",
"id": 72926928,
"node_id": "MDQ6VXNlcjcyOTI2OTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/72926928?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhallee",
"html_url": "https://github.com/lhallee",
"followers_url": "https://api.github.com/users/lhallee/followers",
"following_url": "https://api.github.com/users/lhallee/following{/other_user}",
"gists_url": "https://api.github.com/users/lhallee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhallee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhallee/subscriptions",
"organizations_url": "https://api.github.com/users/lhallee/orgs",
"repos_url": "https://api.github.com/users/lhallee/repos",
"events_url": "https://api.github.com/users/lhallee/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhallee/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Given the error, pretty sure you can just initialize the `TrainingArguments` with:\r\n```python \r\nTrainingArguments(dict(num_train_epochs=num_epochs,\r\n evaluation_strategy='steps' if val_set_size > 0 else 'no',\r\n save_strategy='steps',\r\n eval_steps=eval_steps if val_set_size > 0 else None,\r\n save_steps=save_steps,\r\n output_dir=output_dir,\r\n save_total_limit=save_total_limit,\r\n load_best_model_at_end=True if val_set_size > 0 else False,\r\n deepspeed='./deepspeed_config.json',\r\n))\r\n```\r\nThe traceback shows that the issue is with `deepspeed`.\r\n\r\nTips for next time:\r\n- properly format the code\r\n- make the snippet runnable (`TrainingArguments`, `Trainer` not imported etc) \r\n",
"This is what worked below. Side note, this crashed my session with over 80 gb of ram for llama2-7b. Is that to be expected? Is this due to the pin memory argument?\r\n\r\nargs = TrainingArguments(num_train_epochs=num_epochs,\r\n evaluation_strategy='steps' if val_set_size > 0 else 'no',\r\n save_strategy='steps',\r\n eval_steps=eval_steps if val_set_size > 0 else None,\r\n save_steps=save_steps,\r\n output_dir=output_dir,\r\n save_total_limit=save_total_limit,\r\n fp16=True,\r\n load_best_model_at_end=True if val_set_size > 0 else False,\r\n deepspeed='./deepspeed_config.json')\r\n\r\ntrainer = Trainer(\r\n model=model,\r\n train_dataset=train_data,\r\n eval_dataset=val_data,\r\n args=args,\r\n data_collator=DataCollatorForSeq2Seq(tokenizer, pad_to_multiple_of=8, return_tensors='pt', padding=True),\r\n callbacks=[print_callback])\r\n\r\nmodel.config.use_cache = False\r\ntrainer.train(resume_from_checkpoint=resume_from_checkpoint)\r\nmodel.save_pretrained(output_dir)\r\n\r\nSo you have to initialize TraingingArguments outside of Trainer when using deepspeed? This wasn't the case without it. Works for me though, thanks for the help.",
"More info for my question above:\r\n\r\nThis config is OOM for CPU ram on llama-2 7billion on A10040gb with 80gb CPU ram. Curious why this takes up so much space.\r\n\r\ndeepspeed_config = {\r\n \"fp16\": {\r\n \"enabled\": True,\r\n \"loss_scale\": 0,\r\n \"loss_scale_window\": 1000,\r\n \"initial_scale_power\": 16,\r\n \"hysteresis\": 2,\r\n \"min_loss_scale\": 1\r\n },\r\n \"optimizer\": {\r\n \"type\": \"AdamW\",\r\n \"params\": {\r\n \"lr\": \"auto\",\r\n \"betas\": \"auto\",\r\n \"eps\": \"auto\",\r\n \"weight_decay\": \"auto\"\r\n }\r\n },\r\n \"scheduler\": {\r\n \"type\": \"WarmupLR\",\r\n \"params\": {\r\n \"warmup_min_lr\": \"auto\",\r\n \"warmup_max_lr\": \"auto\",\r\n \"warmup_num_steps\": \"auto\"\r\n }\r\n },\r\n \"zero_optimization\": {\r\n \"stage\": 2,\r\n \"offload_optimizer\": {\r\n \"device\": \"cpu\",\r\n },\r\n },\r\n \"steps_per_print\": 100,\r\n \"gradient_accumulation_steps\": \"auto\",\r\n \"gradient_clipping\": \"auto\",\r\n \"train_batch_size\": \"auto\",\r\n \"train_micro_batch_size_per_gpu\": \"auto\",\r\n \"activation_checkpointing\": {\r\n \"partition_activations\": True,\r\n \"contiguous_memory_optimization\": True\r\n },\r\n \"wall_clock_breakdown\": False\r\n}\r\n\r\nOutputs\r\n\r\n[2023-08-25 18:18:59,217] [INFO] [comm.py:631:init_distributed] cdb=None\r\n[2023-08-25 18:18:59,218] [INFO] [comm.py:662:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl\r\nUsing /root/.cache/torch_extensions/py310_cu118 as PyTorch extensions root...\r\nCreating extension directory /root/.cache/torch_extensions/py310_cu118/cpu_adam...\r\nDetected CUDA files, patching ldflags\r\nEmitting ninja build file /root/.cache/torch_extensions/py310_cu118/cpu_adam/build.ninja...\r\nBuilding extension module cpu_adam...\r\nAllowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)\r\nLoading extension module cpu_adam...\r\nTime to load cpu_adam op: 36.26453471183777 seconds\r\nRank: 0 partition count [1] and sizes[(6738595840, False)] ",
"cc @pacman100 ",
"I am facing the same issue. Even initialising Training Arguments separately doesn't work.",
"@lhallee, how are you launching the script?",
"@tryout3, can't help without any info on versions, minimal example, the config, the command you are running and the hardware on which you are running",
"@pacman100 not sure what you mean. I am just running the code in a colab notebook.",
"Hello @lhallee, given that you are using colab notebook, please follow the instructions given here: https://huggingface.co/docs/transformers/main_classes/deepspeed#deployment-in-notebooks.\r\n\r\nNext, regarding CPU OOM, given that you are offloading optimizer, for 7B params:\r\n1. FP32 master model weights: 4 Bytes per param * 7B params = 28GB\r\n2. First and second moments for Adam Optimizer: 2 * (4 Bytes per param * 7B params) = 56GB\r\n3. Total Memory = 28GB + 56GB = 84GB > 80GB RAM, hence CPU OOM",
"Thanks for the clarification! Is there a set of settings you can think of that would accommodate this? ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"@lhallee Have you solved this problem? I encountered the same problem!",
"Other than use a machine with more RAM, no.",
"> @lhallee Have you solved this problem? I encountered the same problem!\r\n\r\nIn my case, I re-install `transformers==4.31.0` and `accelerate==0.21.0` and `deepspeed==0.9.5`, and problem solved."
] | 1,692 | 1,702 | 1,697 |
NONE
| null |
### System Info
```python
2023-08-24 17:23:17.908613: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
[2023-08-24 17:23:20,478] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
WARNING:tensorflow:From /usr/local/lib/python3.10/dist-packages/transformers/commands/env.py:100: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
2023-08-24 17:23:29.664543: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:47] Overriding orig_value setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.
```
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.32.0
- Platform: Linux-5.15.109+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.7.2 (gpu)
- Jax version: 0.4.14
- JaxLib version: 0.4.14
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@pacman
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Load deepspeed config into json file
2. Pass into TrainingArguments
3. Get error
Here is my code:
```python
import json
deepspeed_config = {
"fp16": {
"enabled": True,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": True
},
"allgather_partitions": True,
"allgather_bucket_size": 2e8,
"overlap_comm": True,
"reduce_scatter": True,
"reduce_bucket_size": 2e8,
"contiguous_gradients": True
},
"steps_per_print": 100,
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"activation_checkpointing": {
"partition_activations": True,
"contiguous_memory_optimization": True
},
"wall_clock_breakdown": False
}
config_filename = "deepspeed_config.json"
with open(config_filename, 'w') as f:
json.dump(deepspeed_config, f)
trainer = Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=TrainingArguments(
num_train_epochs=num_epochs,
evaluation_strategy='steps' if val_set_size > 0 else 'no',
save_strategy='steps',
eval_steps=eval_steps if val_set_size > 0 else None,
save_steps=save_steps,
output_dir=output_dir,
save_total_limit=save_total_limit,
load_best_model_at_end=True if val_set_size > 0 else False,
deepspeed='./deepspeed_config.json',
),
data_collator=DataCollatorForSeq2Seq(tokenizer, pad_to_multiple_of=8, return_tensors='pt', padding=True),
callbacks=[print_callback]
)
model.config.use_cache = False
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
model.save_pretrained(output_dir)
```
Here is my error:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
[<ipython-input-55-5c7ff182bcf8>](https://localhost:8080/#) in <cell line: 1>()
3 train_dataset=train_data,
4 eval_dataset=val_data,
----> 5 args=TrainingArguments(
6 num_train_epochs=num_epochs,
7 evaluation_strategy='steps' if val_set_size > 0 else 'no',
3 frames
[/usr/local/lib/python3.10/dist-packages/transformers/deepspeed.py](https://localhost:8080/#) in __init__(self, config_file_or_dict)
64 dep_version_check("accelerate")
65 dep_version_check("deepspeed")
---> 66 super().__init__(config_file_or_dict)
67
68
TypeError: object.__init__() takes exactly one argument (the instance to initialize)
```
### Expected behavior
Trainer loads and runs.
PS. This is my first ever issue reported, I'm a domain scientist sorry if this isn't the normal way to report things.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25739/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25739/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25738
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25738/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25738/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25738/events
|
https://github.com/huggingface/transformers/pull/25738
| 1,865,541,835 |
PR_kwDOCUB6oc5Ytv1o
| 25,738 |
[`PEFT`] Fix PeftConfig save pretrained when calling `add_adapter`
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,692 | 1,692 | 1,692 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes a tiny issue when building a demo for @NielsRogge in https://github.com/huggingface/peft/issues/796
when attaching a fresh new adapter, we need to manually add the attribute `base_model_name_or_path` otherwise we can't load back the base model.
We did not flagged it before in the tests because we were only testing the case when we call `load_adapter` then `save_pretrained` which works fine because we attach an existing PeftConfig.
Added also a nice test
cc @ArthurZucker @sgugger
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25738/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25738/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25738",
"html_url": "https://github.com/huggingface/transformers/pull/25738",
"diff_url": "https://github.com/huggingface/transformers/pull/25738.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25738.patch",
"merged_at": 1692944352000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25737
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25737/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25737/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25737/events
|
https://github.com/huggingface/transformers/pull/25737
| 1,865,485,849 |
PR_kwDOCUB6oc5Ytjsh
| 25,737 |
Add conversion support for CodeLlama 34B
|
{
"login": "AlpinDale",
"id": 52078762,
"node_id": "MDQ6VXNlcjUyMDc4NzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/52078762?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AlpinDale",
"html_url": "https://github.com/AlpinDale",
"followers_url": "https://api.github.com/users/AlpinDale/followers",
"following_url": "https://api.github.com/users/AlpinDale/following{/other_user}",
"gists_url": "https://api.github.com/users/AlpinDale/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AlpinDale/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AlpinDale/subscriptions",
"organizations_url": "https://api.github.com/users/AlpinDale/orgs",
"repos_url": "https://api.github.com/users/AlpinDale/repos",
"events_url": "https://api.github.com/users/AlpinDale/events{/privacy}",
"received_events_url": "https://api.github.com/users/AlpinDale/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Doesn't seem to work for 7B and 13B variants.",
"Conversion doesn't account for the modified tokenizer and the new rope theta value. Closing the PR until someone else implements the new changes.",
"See #25740"
] | 1,692 | 1,692 | 1,692 |
CONTRIBUTOR
| null |
There hasn't been any architectural changes, and I was able to convert the 34B by simply adding in the intermediate size for the model. I have [converted the 34B model](https://huggingface.co/alpindale/CodeLlama-34B-hf) and it appears to work well.
# What does this PR do?
This PR should make it possible to convert the [CodeLlama](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) models, recently released by Meta AI.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25737/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 2,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25737/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25737",
"html_url": "https://github.com/huggingface/transformers/pull/25737",
"diff_url": "https://github.com/huggingface/transformers/pull/25737.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25737.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25736
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25736/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25736/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25736/events
|
https://github.com/huggingface/transformers/pull/25736
| 1,865,482,748 |
PR_kwDOCUB6oc5YtjBR
| 25,736 |
[bug fix]tokenizer init via tokenization_utils_base.py in some case make "Do you accept" emerge even if trust_remote_code=True is setted
|
{
"login": "ShadowTeamCN",
"id": 11573254,
"node_id": "MDQ6VXNlcjExNTczMjU0",
"avatar_url": "https://avatars.githubusercontent.com/u/11573254?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ShadowTeamCN",
"html_url": "https://github.com/ShadowTeamCN",
"followers_url": "https://api.github.com/users/ShadowTeamCN/followers",
"following_url": "https://api.github.com/users/ShadowTeamCN/following{/other_user}",
"gists_url": "https://api.github.com/users/ShadowTeamCN/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ShadowTeamCN/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ShadowTeamCN/subscriptions",
"organizations_url": "https://api.github.com/users/ShadowTeamCN/orgs",
"repos_url": "https://api.github.com/users/ShadowTeamCN/repos",
"events_url": "https://api.github.com/users/ShadowTeamCN/events{/privacy}",
"received_events_url": "https://api.github.com/users/ShadowTeamCN/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25736). All of your documentation changes will be reflected on that endpoint.",
"> Looks good to me! Thanks. Would be great if you can add a test in `test_tokenization_auto.py` with a dummy repo!\r\n\r\nHappy to see that, I'll review the logic in the test_tokenization_auto.py and try to add a dummy test",
"Hey @ShadowTeamCN, let us know if you need help with the addition of the test!",
"> Hey @ShadowTeamCN, let us know if you need help with the addition of the test!\r\n\r\nHi @LysandreJik , I was wondering what the test function should verify. Given that this PR forwards user-provided parameters to AutoConfig, should I focus on validating the correct initialization of AutoConfig, or simply ensure that the user-provided parameters are accurately passed through to AutoConfig?",
"I think making sure that the args are properly propagate is the best way to do this. If you want to load a tokenizer from the hub that has custom code we'll have to check it and set a revision !",
"Hello @ArthurZucker , I've added a test case to this PR. However, there remains one issue: I employed a mock method to verify that the parameters are passed to AutoConfig.from_pretrained. Yet, I encountered difficulty in utilizing unittest.TestCase's assertEqual within the mock function, as passing the TestCase's self pointer to the external mock function seems challenging. Consequently, I resorted to using 'assert', though ideally, this should be substituted with a more appropriate method.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hey @ShadowTeamCN I. might have been a bit too harsh on the review! Do you need help to finish it? 🤗 ",
"> Hey @ShadowTeamCN I. might have been a bit too harsh on the review! Do you need help to finish it? 🤗\r\n\r\nI'm sorry for delay the PR because of busy doing company-related work. \r\nBesides I'm little confused of whether I should start a new PR to meet the latest branch.",
"> Thanks for adding a tests. Let's try to blend it in our current framework of tests, and let's use additional kwargs that are relevant like the `revision` for example. We can use 2 repos were the tokenizer are suppose to be different depending on the version. Simple is best so if you don't really know how to do this you can just remove it I 'll try to think of something else!\r\n\r\nAnd may you offer me some examples of how the `revision` paramter work?\r\n",
"You can probably just do `git pull upstream main`. \r\nA test might be hard to do, if you can confirme this fixes the issue should just be alright! ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"#28854 superseeds this, I think the new solution is more elegant",
"> #28854 superseeds this, I think the new solution is more elegant\r\n\r\ngood to see that, and i found it similar to my original implement, so i will close this PR"
] | 1,692 | 1,708 | 1,708 |
NONE
| null |
# What does this PR do?
This PR fix a bug for tokenizer from_pretrained method causing manual input issue in tokenizer initialization
if not fixed ,in some rare contidition tokenizer init via tokenization_utils_base would need typed "yes",which caused from inner call AutoConfig.from_pretrained() , but not transfer the trust_remote_code parameter when init tokenizer
Fixes # (issue)
the original behavior of tokenization_utils_base AutoConfig.from_pretrained() works in most cases.But in some rare scene, when the tokenizer initializes, it internally calls AutoConfig.pretrained. During this call, the trust_remote_code parameter was omitted, leading to a situation where the user is always required to manually enter yes, regardless of original parameters or settings.
I encountered this bug when i init tokenizer from local disk file, a model named Baichuan-13B-Chat but tokenizer type equals to LlamaTokenizer (same as sentencepiece),and the from_pretrained-used parameter directory
has config.json,tokenizer.model (but no other tokenizer related file), this bug triggered

_this picture is minimal reproduce file structure_
While this might seem benign, it becomes problematic in scenarios like some distribute environment, (eg. Aliyun PAI platform,Tencent cloud platform Ti-One) where manual input isn't feasible. As a result, the interface flushes in the incorrect input and eventually raises an EOFError

_this log message ascend from bottom to up_
To Reproduce:
1. mkdir test_tokenizer && cd test_tokenizer
2. wget https://huggingface.co/baichuan-inc/Baichuan-13B-Chat/resolve/main/tokenizer.model
wget https://huggingface.co/baichuan-inc/Baichuan-13B-Chat/resolve/main/config.json
4. cd ..
> from transformers import LlamaTokenizer
> tokenizer=LlamaTokenizer.from_pretrained('test_tokenizer/',trust_remote_code=True)
Then run this code would triggered the bug, this may caused by abnormal used of tokenizer,
but i think add the trust_remote_code parameter in tokenization_utils_base would be safer

## Before submitting
- This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- Did you write any new necessary tests?
## Who can review?
@ArthurZucker
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25736/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25736/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25736",
"html_url": "https://github.com/huggingface/transformers/pull/25736",
"diff_url": "https://github.com/huggingface/transformers/pull/25736.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25736.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25735
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25735/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25735/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25735/events
|
https://github.com/huggingface/transformers/pull/25735
| 1,865,446,052 |
PR_kwDOCUB6oc5YtbDE
| 25,735 |
fix encoder hook
|
{
"login": "SunMarc",
"id": 57196510,
"node_id": "MDQ6VXNlcjU3MTk2NTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/57196510?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SunMarc",
"html_url": "https://github.com/SunMarc",
"followers_url": "https://api.github.com/users/SunMarc/followers",
"following_url": "https://api.github.com/users/SunMarc/following{/other_user}",
"gists_url": "https://api.github.com/users/SunMarc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SunMarc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SunMarc/subscriptions",
"organizations_url": "https://api.github.com/users/SunMarc/orgs",
"repos_url": "https://api.github.com/users/SunMarc/repos",
"events_url": "https://api.github.com/users/SunMarc/events{/privacy}",
"received_events_url": "https://api.github.com/users/SunMarc/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,692 | 1,692 | 1,692 |
MEMBER
| null |
# What does this PR do ?
Fixes #23385. This PR makes sure that we indeed have a hook with `io_same_device=True` on the encoder which was not the case previously. If we don't have that, the generation will fail as the output of the encoder won't be on the same device as `unfinished_sequences = torch.ones(input_ids.shape[0], dtype=torch.long, device=input_ids.device)` and this will lead to an error here: `next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25735/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25735/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25735",
"html_url": "https://github.com/huggingface/transformers/pull/25735",
"diff_url": "https://github.com/huggingface/transformers/pull/25735.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25735.patch",
"merged_at": 1692970601000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25734
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25734/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25734/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25734/events
|
https://github.com/huggingface/transformers/pull/25734
| 1,865,389,563 |
PR_kwDOCUB6oc5YtOq6
| 25,734 |
[idefics] idefics-9b test use 4bit quant
|
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25734). All of your documentation changes will be reflected on that endpoint."
] | 1,692 | 1,692 | 1,692 |
CONTRIBUTOR
| null |
I didn't think that the nightly CI gpu is small when I initially wrote this test.
This PR updates the slow idefics-9b quality test to use 4bit quantization so it reduces memory needs from 20GB to 7GB.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25734/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25734/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25734",
"html_url": "https://github.com/huggingface/transformers/pull/25734",
"diff_url": "https://github.com/huggingface/transformers/pull/25734.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25734.patch",
"merged_at": 1692891195000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25733
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25733/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25733/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25733/events
|
https://github.com/huggingface/transformers/pull/25733
| 1,865,291,164 |
PR_kwDOCUB6oc5Ys5Gz
| 25,733 |
[`from_pretrained`] Fix failing PEFT tests
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Let's make them not slow otherwise we are shooting in the dark 😉 ",
"I agree it sounds important to have it, happy to add a PEFT circleCI job that runs `tests_torch` as well as PEFT tests, I can do that in a follow up PR, what do you think @sgugger @ydshieh (offline we have agreed to not do it, maybe we should after these failures?)",
"_The documentation is not available anymore as the PR was closed or merged._",
"We can have a new job to see how long it takes.\r\n\r\nI would try to keep the new job to run only the PEFT tests but not to re-run the `tests_torch`.\r\n\r\nLet's hear our @sgugger 's wisdom too. We will miss it.\r\n",
"Merging as this is blocking for an upcoming PR #25738 , will address future comments in a follow up PR! "
] | 1,692 | 1,692 | 1,692 |
CONTRIBUTOR
| null |
# What does this PR do?
Addresses: https://github.com/huggingface/transformers/pull/25726#issuecomment-1691783489
In fact it is important to overwrite `pretrained_model_name_or_path` with the `base_model_name_or_path` attribute of the adapter config otherwise `from_pretrained` will try to load the config file from the adapter model_id where it should look for it at `base_model_name_or_path`
now all PEFT tests are green
cc @sgugger @ArthurZucker
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25733/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25733/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25733",
"html_url": "https://github.com/huggingface/transformers/pull/25733",
"diff_url": "https://github.com/huggingface/transformers/pull/25733.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25733.patch",
"merged_at": 1692895722000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25732
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25732/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25732/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25732/events
|
https://github.com/huggingface/transformers/pull/25732
| 1,865,185,088 |
PR_kwDOCUB6oc5YshsE
| 25,732 |
Fix pad to multiple of
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Will fix the test, if model is not tied, we should not update the embedding, but that is also `True` for all models ! ",
"Thank you @ArthurZucker for this! I am currently being bitten by #19418, so I look forward to this being merged!",
"I'll try to merge this asap 😉 sorry for the trouble! "
] | 1,692 | 1,694 | 1,694 |
COLLABORATOR
| null |
# What does this PR do?
Fixes #25729, `pad_to_multiple_of` did not overwrite the `model.config.vocab_size` properly.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25732/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25732/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25732",
"html_url": "https://github.com/huggingface/transformers/pull/25732",
"diff_url": "https://github.com/huggingface/transformers/pull/25732.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25732.patch",
"merged_at": 1694793219000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25731
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25731/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25731/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25731/events
|
https://github.com/huggingface/transformers/issues/25731
| 1,865,176,289 |
I_kwDOCUB6oc5vLFTh
| 25,731 |
DetrImageProcessor.normalize_annotation() got an unexpected keyword argument 'input_data_format'
|
{
"login": "r-remus",
"id": 6740454,
"node_id": "MDQ6VXNlcjY3NDA0NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/6740454?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/r-remus",
"html_url": "https://github.com/r-remus",
"followers_url": "https://api.github.com/users/r-remus/followers",
"following_url": "https://api.github.com/users/r-remus/following{/other_user}",
"gists_url": "https://api.github.com/users/r-remus/gists{/gist_id}",
"starred_url": "https://api.github.com/users/r-remus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/r-remus/subscriptions",
"organizations_url": "https://api.github.com/users/r-remus/orgs",
"repos_url": "https://api.github.com/users/r-remus/repos",
"events_url": "https://api.github.com/users/r-remus/events{/privacy}",
"received_events_url": "https://api.github.com/users/r-remus/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Are you using main? This is a duplicate of #25666 and should have been fixed by #25643",
"@r-remus The fix has now been included as part of a [patch release](https://github.com/huggingface/transformers/releases/tag/v4.32.1) and can be directly installed from pypi with `pip install transformers`",
"Sorry for getting back to you so late.\r\n@ArthurZucker: No, I wasn't using main but release v4.32.0.\r\n@amyeroberts: Thanks, that's great! Works for me now (using v4.33.2 now, tho).",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,692 | 1,697 | 1,697 |
NONE
| null |
### System Info
- `transformers` version: 4.32.0
- Platform: Linux-5.15.0-79-generic-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@amyeroberts
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
`DetrImageProcessor.normalize_annotation()` doesn't take the new `input_data_format` which is passed to it.
Code to reproduce the issue:
```python
from transformers import DetrImageProcessor
image_processor = DetrImageProcessor()
_ = image_processor(images=[img], annotations=[{'image_id': 0, 'annotations': []}], return_tensors="pt")
```
### Expected behavior
It should be possible to pass `input_data_format` to `DetrImageProcessor.normalize_annotation()`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25731/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25731/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25730
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25730/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25730/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25730/events
|
https://github.com/huggingface/transformers/issues/25730
| 1,865,154,045 |
I_kwDOCUB6oc5vK_39
| 25,730 |
host memory still occupied after huggingface model deleted
|
{
"login": "linlifan",
"id": 89007109,
"node_id": "MDQ6VXNlcjg5MDA3MTA5",
"avatar_url": "https://avatars.githubusercontent.com/u/89007109?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/linlifan",
"html_url": "https://github.com/linlifan",
"followers_url": "https://api.github.com/users/linlifan/followers",
"following_url": "https://api.github.com/users/linlifan/following{/other_user}",
"gists_url": "https://api.github.com/users/linlifan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/linlifan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/linlifan/subscriptions",
"organizations_url": "https://api.github.com/users/linlifan/orgs",
"repos_url": "https://api.github.com/users/linlifan/repos",
"events_url": "https://api.github.com/users/linlifan/events{/privacy}",
"received_events_url": "https://api.github.com/users/linlifan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Would you mind asking this question on [the forum](https://discuss.huggingface.co/)? ",
"> Hey! Would you mind asking this question on [the forum](https://discuss.huggingface.co/)?\r\n\r\nthank you @ArthurZucker . I move the question to the forum. "
] | 1,692 | 1,692 | 1,692 |
NONE
| null |
### System Info
mainline
### Who can help?
@sgugger
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
import torch
from transformers import AutoConfig, AutoTokenizer, BloomForCausalLM, AutoModelForCausalLM
import time
import psutil
import gc
def get_host_memory():
memory_allocated = round(psutil.Process().memory_info().rss / 1024**3, 3)
print("cpu"," memory used total: ", memory_allocated, "GB")
def load_and_run():
s_ = time.time()
config = AutoConfig.from_pretrained('bigscience/bloom-560m')
model = AutoModelForCausalLM.from_config(config)
e_ = time.time()
print("model loading time: %f " % (e_ - s_))
get_host_memory()
del model
del config
load_and_run()
gc.collect()
for obj in gc.get_objects():
try:
if torch.is_tensor(obj) or (hasattr(obj, 'data') and torch.is_tensor(obj.data)):
print(type(obj), obj.size())
except:
pass
get_host_memory()
### Expected behavior
right now:
after model loaded:
cpu memory used total: 3.327 GB
after model deleted:
cpu memory used total: 3.364 GB
expected, host memory should be freed after model deleted.
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25730/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25730/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25729
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25729/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25729/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25729/events
|
https://github.com/huggingface/transformers/issues/25729
| 1,865,131,860 |
I_kwDOCUB6oc5vK6dU
| 25,729 |
Error with resize_token_embeddings and LLama model
|
{
"login": "lccnl",
"id": 90759019,
"node_id": "MDQ6VXNlcjkwNzU5MDE5",
"avatar_url": "https://avatars.githubusercontent.com/u/90759019?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lccnl",
"html_url": "https://github.com/lccnl",
"followers_url": "https://api.github.com/users/lccnl/followers",
"following_url": "https://api.github.com/users/lccnl/following{/other_user}",
"gists_url": "https://api.github.com/users/lccnl/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lccnl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lccnl/subscriptions",
"organizations_url": "https://api.github.com/users/lccnl/orgs",
"repos_url": "https://api.github.com/users/lccnl/repos",
"events_url": "https://api.github.com/users/lccnl/events{/privacy}",
"received_events_url": "https://api.github.com/users/lccnl/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @SunMarc Maybe ?",
"Non that's actually me, I'll open a PR to fix this"
] | 1,692 | 1,694 | 1,694 |
NONE
| null |
### System Info
- `transformers` version: 4.32.0
- Platform: Linux-5.15.0-1038-gcp-x86_64-with-glibc2.31
- Python version: 3.10.7
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
### Who can help?
@ArthurZucker
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
In the last version of the method `resize_token_embeddings`, the `pad_token_to_multiple=N` arg allows to increase the dimension to the first int divisibile by N larger than `new_num_tokens`.
However, in the method, the `config.vocab_size` is still updated to the initial [new_num_tokens](https://github.com/huggingface/transformers/blob/main/src/transformers/modeling_utils.py#L1438).
For the LLama model, this leads to an error when the logits are flattened [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py#L837).
### Expected behavior
We should update the vocab_size to the new_num_tokens that accounts for the arg pad_token_to_multiple
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25729/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25729/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25728
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25728/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25728/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25728/events
|
https://github.com/huggingface/transformers/pull/25728
| 1,865,123,504 |
PR_kwDOCUB6oc5YsUMK
| 25,728 |
Use Conv1d for TDNN
|
{
"login": "gau-nernst",
"id": 26946864,
"node_id": "MDQ6VXNlcjI2OTQ2ODY0",
"avatar_url": "https://avatars.githubusercontent.com/u/26946864?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gau-nernst",
"html_url": "https://github.com/gau-nernst",
"followers_url": "https://api.github.com/users/gau-nernst/followers",
"following_url": "https://api.github.com/users/gau-nernst/following{/other_user}",
"gists_url": "https://api.github.com/users/gau-nernst/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gau-nernst/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gau-nernst/subscriptions",
"organizations_url": "https://api.github.com/users/gau-nernst/orgs",
"repos_url": "https://api.github.com/users/gau-nernst/repos",
"events_url": "https://api.github.com/users/gau-nernst/events{/privacy}",
"received_events_url": "https://api.github.com/users/gau-nernst/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @sanchit-gandhi ",
"On RTX 3090, 5s input\r\n\r\ndtype | batch size | type | de139702a | 4ad9e29a5\r\n--|--|--|--|--\r\ntorch.float32 | 1 | forward | 61.8698 it/s | 65.4886 it/s\r\ntorch.float32 | 1 | forward+backward | 15.7255 it/s | 15.3732 it/s\r\ntorch.float32 | 8 | forward | 12.1235 it/s | 13.3573 it/s\r\ntorch.float32 | 8 | forward+backward | 4.3197 it/s | 4.4702 it/s\r\ntorch.float16 | 1 | forward | 70.7141 it/s | 73.2518 it/s\r\ntorch.float16 | 1 | forward+backward | 17.1505 it/s | 17.1628 it/s\r\ntorch.float16 | 8 | forward | 20.3633 it/s | 24.0503 it/s\r\ntorch.float16 | 8 | forward+backward | 7.5402 it/s | 8.0300 it/s\r\n\r\nThe improvement is around 5%. It's small but not insignificant.\r\n\r\nAnother optimization we can do is to make `TDNNLayer` accepts channels-first input instead of channels-last (current approach) to avoid transposing data twice every layer. However, this would break backward compatibility if someone relies on `TDNNLayer` externally (though I think it's unlikely).\r\n\r\nBenchmark script\r\n\r\n```python\r\nimport time\r\nfrom itertools import product\r\nimport torch\r\nfrom transformers.models.wav2vec2.modeling_wav2vec2 import Wav2Vec2ForXVector\r\n\r\ntorch.backends.cuda.matmul.allow_tf32 = True\r\ntorch.backends.cudnn.allow_tf32 = True\r\ntorch.backends.cudnn.benchmark = True\r\n\r\ndevice = \"cuda\"\r\nbatch_sizes = (1, 8)\r\ndtypes = (torch.float32, torch.float16)\r\n\r\nm = Wav2Vec2ForXVector.from_pretrained(\"facebook/wav2vec2-xls-r-300m\").to(device)\r\n\r\nfor dtype, bsize in product(dtypes, batch_sizes):\r\n m.to(dtype)\r\n x = torch.randn(bsize, 16_000 * 5, device=device, dtype=dtype)\r\n\r\n m.eval()\r\n with torch.no_grad():\r\n m(x) # warmup\r\n torch.cuda.synchronize()\r\n\r\n N = 100\r\n\r\n with torch.no_grad():\r\n time0 = time.perf_counter()\r\n for _ in range(N):\r\n out = m(x)\r\n torch.cuda.synchronize()\r\n print(f\"{dtype}, {bsize=}, forward: {N / (time.perf_counter() - time0):.4f} it/s\")\r\n\r\n m.train()\r\n m(x)[0].sum().backward() # warmup\r\n\r\n time0 = time.perf_counter()\r\n for _ in range(N):\r\n out = m(x)\r\n out[0].sum().backward()\r\n torch.cuda.synchronize()\r\n print(f\"{dtype}, {bsize=}, forward+backward: {N / (time.perf_counter() - time0):.4f} it/s\")\r\n```",
"Very cool! Thanks for the results @gau-nernst and nice benchmark script! I think it's worth pursuing in this case: 5% is the lower end of what we'd expect to get for `torch.compile`, and this has proven to be quite high demand for optimising PyTorch models, so a 5% improvement gain would be welcomed by the Wav2Vec2 community\r\n\r\nI would be against adding a breaking change with the channel-last approach, since this is in contradiction to the scope of the PR where we set out to optimise in an entirely non-breaking way",
"Cool! Anything else you want me to add to the PR, perhaps apart from removing the commented out old code? Is there a correctness test that we can add?\r\n\r\nI didn't benchmark with torch.compile() since Wav2Vec2 did not work with it yet (I hope the relevant PR will be merged soon). Would you want to see benchmark results with torch.compile() for TDNNLayer alone? Perhaps it can even optimize the old way (unfold + linear)",
"It looks super clean already @gau-nernst - I think all that's left to do is:\r\n1. Remove the commented out code\r\n2. Run the slow tests to check we still have equivalence (this will check for correctness): https://github.com/huggingface/transformers/blob/1c6f072db0c17c7d82bb0d3b7529d57ebc9a0f2f/tests/models/wav2vec2/test_modeling_wav2vec2.py#L1922\r\n\r\nNo worries about benchmarking with torch compile - the results you provided previously were more than enough to justify this code change. We won't expect all users to be using PT 2.0, so this speed-up will definitely hold in many cases",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25728). All of your documentation changes will be reflected on that endpoint.",
"I think it's unlikely that someone will apply LoRA on the TDNN layers. Most likely they will apply LoRA on the transformer backbone only, and train the TDNN layers from scratch.",
"My question is rather, what if someone has already apply LoRA on the TDNN layers? (Though it might not be recommended, someone who does not specifically know the model could have just quantized all the linear layers no?) 😉 ",
"I can't answer that, though I doubt that people who know how to use LoRA, and use it on TDNN layers specifically (most LoRA guides only show how to use it with transformers as far as I know), will face problems with this change. You guys from HF should decide whether this outweighs the cost i.e. speed-up vs annoy people who use LoRA on TDNN layers, and what kind of guarantee the library should provide i.e. a model surgery technique (e.g. LoRA) should still work after an update.",
"That is true: LORA will now not apply to the linear layers. Just to clarify, is this just concerned with applying lora weights to the full-precision model and doing a new fine-tuning run? Or, would it actually break inference if someone wants to use lora fine-tuned weights with the TDNN model? If it's the former, I think it's fine since TDNN is not documented and the linear layers are a fraction of the transformer ones. If it's the latter, then we maybe need to think of a workaround",
"Pretty sure it will break inference, but we can probably have some kind of fix / deprecation cycle for this 😓 ",
"Great work here on finding an elegant solution 🤗 ",
"@ArthurZucker i have merged master and make some small changes accordingly",
"Thanks! Merging 🤗 "
] | 1,692 | 1,706 | 1,706 |
CONTRIBUTOR
| null |
# What does this PR do?
Partially fixes #25476
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25728/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25728/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25728",
"html_url": "https://github.com/huggingface/transformers/pull/25728",
"diff_url": "https://github.com/huggingface/transformers/pull/25728.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25728.patch",
"merged_at": 1706603636000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25727
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25727/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25727/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25727/events
|
https://github.com/huggingface/transformers/pull/25727
| 1,865,098,122 |
PR_kwDOCUB6oc5YsOrO
| 25,727 |
[ASR Pipe Test] Fix CTC timestamps error message
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,692 | 1,692 | 1,692 |
CONTRIBUTOR
| null |
# What does this PR do?
The test [`test_chunking_and_timestamps`](https://github.com/huggingface/transformers/blob/70b49f023c9f6579c516671604468a491227b4da/tests/pipelines/test_pipelines_automatic_speech_recognition.py#L1153) failed on the nightly run when checking that the argument `return_timestamps=True` gave the correct error message for CTC models. This is because the string pattern `(char)` in the error message was closing the regex expression. Removing it allows the test to pass as expected.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25727/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25727/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25727",
"html_url": "https://github.com/huggingface/transformers/pull/25727",
"diff_url": "https://github.com/huggingface/transformers/pull/25727.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25727.patch",
"merged_at": 1692896318000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25726
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25726/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25726/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25726/events
|
https://github.com/huggingface/transformers/pull/25726
| 1,865,008,899 |
PR_kwDOCUB6oc5Yr7Pl
| 25,726 |
[`from_pretrained`] Simpler code for peft
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks! Can confirm that the tests are now green! @younesbelkada some are really fast do you not want to remove the `slow` mention for them? ",
"@ArthurZucker sorry the tests are still failing, probably something wrong happened during the merge, can you double check? 🙏 I can also have a look if you want\r\n\r\nEdit: just made https://github.com/huggingface/transformers/pull/25733"
] | 1,692 | 1,692 | 1,692 |
COLLABORATOR
| null |
# What does this PR do?
Simplifies the logic when loading a PEFT model: the `_adapter_model_path` is used instead of `maybe_has_adapter_model_path` and `has_adapter_config`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25726/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25726/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25726",
"html_url": "https://github.com/huggingface/transformers/pull/25726",
"diff_url": "https://github.com/huggingface/transformers/pull/25726.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25726.patch",
"merged_at": 1692886719000
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.