
title
stringlengths 1
100
| titleSlug
stringlengths 3
77
| Java
int64 0
1
| Python3
int64 1
1
| content
stringlengths 28
44.4k
| voteCount
int64 0
3.67k
| question_content
stringlengths 65
5k
| question_hints
stringclasses 970
values |
|---|---|---|---|---|---|---|---|
🔥 [Python3] Optimized Heap solution || beats 99.7% 🥷🏼 | kth-largest-element-in-a-stream | 0 | 1 | ### Time and space complexity:\nConsider:\n**N** \u2014 number of elements in the heap,\n**M** \u2014 number elements in initial nums\n**P** \u2014 number of cals method add() :\n**Time complexity is:`O(N + (M-N)log(N) + Plog(N) )` or `O(N + (M+P-N)log(N))`\nSpace complexity is: `O(N)`**\n**M+P** constant can be reduced depends of input data, because of additional checking current value and heap top value. Also have a look that [heappushpop](https://docs.python.org/3/library/heapq.html#heapq.heappushpop) and [heapreplace](https://docs.python.org/3/library/heapq.html#heapq.heapreplace) are more efficient thant calling heappush() and heappop() separetly.\n - heapify takes O(N) where N is the number of elements in the heap\n - heappush takes O(log N)\n - heappushpop takes O(log N)\n - heapreplace takes O(log N)\n \n```python3 []\nclass KthLargest:\n def __init__(self, k: int, nums: List[int]):\n self.nums = nums[:k]\n self.k = k\n heapify(self.nums)\n for i in range(k, len(nums)):\n if nums[i] > self.nums[0]:\n heappushpop(self.nums, nums[i])\n \n def add(self, val: int) -> int:\n if len(self.nums) < self.k:\n heappush(self.nums, val)\n elif val > self.nums[0]:\n heapreplace(self.nums, val)\n \n return self.nums[0]\n```\n\n\n | 9 | Design a class to find the `kth` largest element in a stream. Note that it is the `kth` largest element in the sorted order, not the `kth` distinct element.
Implement `KthLargest` class:
* `KthLargest(int k, int[] nums)` Initializes the object with the integer `k` and the stream of integers `nums`.
* `int add(int val)` Appends the integer `val` to the stream and returns the element representing the `kth` largest element in the stream.
**Example 1:**
**Input**
\[ "KthLargest ", "add ", "add ", "add ", "add ", "add "\]
\[\[3, \[4, 5, 8, 2\]\], \[3\], \[5\], \[10\], \[9\], \[4\]\]
**Output**
\[null, 4, 5, 5, 8, 8\]
**Explanation**
KthLargest kthLargest = new KthLargest(3, \[4, 5, 8, 2\]);
kthLargest.add(3); // return 4
kthLargest.add(5); // return 5
kthLargest.add(10); // return 5
kthLargest.add(9); // return 8
kthLargest.add(4); // return 8
**Constraints:**
* `1 <= k <= 104`
* `0 <= nums.length <= 104`
* `-104 <= nums[i] <= 104`
* `-104 <= val <= 104`
* At most `104` calls will be made to `add`.
* It is guaranteed that there will be at least `k` elements in the array when you search for the `kth` element. | null |
🔥 [Python3] Optimized Heap solution || beats 99.7% 🥷🏼 | kth-largest-element-in-a-stream | 0 | 1 | ### Time and space complexity:\nConsider:\n**N** \u2014 number of elements in the heap,\n**M** \u2014 number elements in initial nums\n**P** \u2014 number of cals method add() :\n**Time complexity is:`O(N + (M-N)log(N) + Plog(N) )` or `O(N + (M+P-N)log(N))`\nSpace complexity is: `O(N)`**\n**M+P** constant can be reduced depends of input data, because of additional checking current value and heap top value. Also have a look that [heappushpop](https://docs.python.org/3/library/heapq.html#heapq.heappushpop) and [heapreplace](https://docs.python.org/3/library/heapq.html#heapq.heapreplace) are more efficient thant calling heappush() and heappop() separetly.\n - heapify takes O(N) where N is the number of elements in the heap\n - heappush takes O(log N)\n - heappushpop takes O(log N)\n - heapreplace takes O(log N)\n \n```python3 []\nclass KthLargest:\n def __init__(self, k: int, nums: List[int]):\n self.nums = nums[:k]\n self.k = k\n heapify(self.nums)\n for i in range(k, len(nums)):\n if nums[i] > self.nums[0]:\n heappushpop(self.nums, nums[i])\n \n def add(self, val: int) -> int:\n if len(self.nums) < self.k:\n heappush(self.nums, val)\n elif val > self.nums[0]:\n heapreplace(self.nums, val)\n \n return self.nums[0]\n```\n\n\n | 9 | You are playing a simplified PAC-MAN game on an infinite 2-D grid. You start at the point `[0, 0]`, and you are given a destination point `target = [xtarget, ytarget]` that you are trying to get to. There are several ghosts on the map with their starting positions given as a 2D array `ghosts`, where `ghosts[i] = [xi, yi]` represents the starting position of the `ith` ghost. All inputs are **integral coordinates**.
Each turn, you and all the ghosts may independently choose to either **move 1 unit** in any of the four cardinal directions: north, east, south, or west, or **stay still**. All actions happen **simultaneously**.
You escape if and only if you can reach the target **before** any ghost reaches you. If you reach any square (including the target) at the **same time** as a ghost, it **does not** count as an escape.
Return `true` _if it is possible to escape regardless of how the ghosts move, otherwise return_ `false`_._
**Example 1:**
**Input:** ghosts = \[\[1,0\],\[0,3\]\], target = \[0,1\]
**Output:** true
**Explanation:** You can reach the destination (0, 1) after 1 turn, while the ghosts located at (1, 0) and (0, 3) cannot catch up with you.
**Example 2:**
**Input:** ghosts = \[\[1,0\]\], target = \[2,0\]
**Output:** false
**Explanation:** You need to reach the destination (2, 0), but the ghost at (1, 0) lies between you and the destination.
**Example 3:**
**Input:** ghosts = \[\[2,0\]\], target = \[1,0\]
**Output:** false
**Explanation:** The ghost can reach the target at the same time as you.
**Constraints:**
* `1 <= ghosts.length <= 100`
* `ghosts[i].length == 2`
* `-104 <= xi, yi <= 104`
* There can be **multiple ghosts** in the same location.
* `target.length == 2`
* `-104 <= xtarget, ytarget <= 104` | null |
Awesome O(Log N) time complexity | binary-search | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def search(self, nums: List[int], target: int) -> int:\n //time complexity----->O(Log N)\n left,right=0,len(nums)-1\n while left<=right:\n mid=left+(right-left)//2\n if nums[mid]>target:\n right=mid-1\n elif nums[mid]<target:\n left=mid+1\n else:\n return mid\n return -1\n```\n```\nclass Solution:\n def search(self, nums: List[int], target: int) -> int:\n #time complexity---->O(N)\n return nums.index(target) if target in nums else -1\n``` | 4 | Given an array of integers `nums` which is sorted in ascending order, and an integer `target`, write a function to search `target` in `nums`. If `target` exists, then return its index. Otherwise, return `-1`.
You must write an algorithm with `O(log n)` runtime complexity.
**Example 1:**
**Input:** nums = \[-1,0,3,5,9,12\], target = 9
**Output:** 4
**Explanation:** 9 exists in nums and its index is 4
**Example 2:**
**Input:** nums = \[-1,0,3,5,9,12\], target = 2
**Output:** -1
**Explanation:** 2 does not exist in nums so return -1
**Constraints:**
* `1 <= nums.length <= 104`
* `-104 < nums[i], target < 104`
* All the integers in `nums` are **unique**.
* `nums` is sorted in ascending order. | null |
Awesome O(Log N) time complexity | binary-search | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def search(self, nums: List[int], target: int) -> int:\n //time complexity----->O(Log N)\n left,right=0,len(nums)-1\n while left<=right:\n mid=left+(right-left)//2\n if nums[mid]>target:\n right=mid-1\n elif nums[mid]<target:\n left=mid+1\n else:\n return mid\n return -1\n```\n```\nclass Solution:\n def search(self, nums: List[int], target: int) -> int:\n #time complexity---->O(N)\n return nums.index(target) if target in nums else -1\n``` | 4 | Given a string `s` and an array of strings `words`, return _the number of_ `words[i]` _that is a subsequence of_ `s`.
A **subsequence** of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
* For example, `"ace "` is a subsequence of `"abcde "`.
**Example 1:**
**Input:** s = "abcde ", words = \[ "a ", "bb ", "acd ", "ace "\]
**Output:** 3
**Explanation:** There are three strings in words that are a subsequence of s: "a ", "acd ", "ace ".
**Example 2:**
**Input:** s = "dsahjpjauf ", words = \[ "ahjpjau ", "ja ", "ahbwzgqnuk ", "tnmlanowax "\]
**Output:** 2
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `1 <= words.length <= 5000`
* `1 <= words[i].length <= 50`
* `s` and `words[i]` consist of only lowercase English letters. | null |
✔Beats 99.49% TC || Python Solution | binary-search | 0 | 1 | 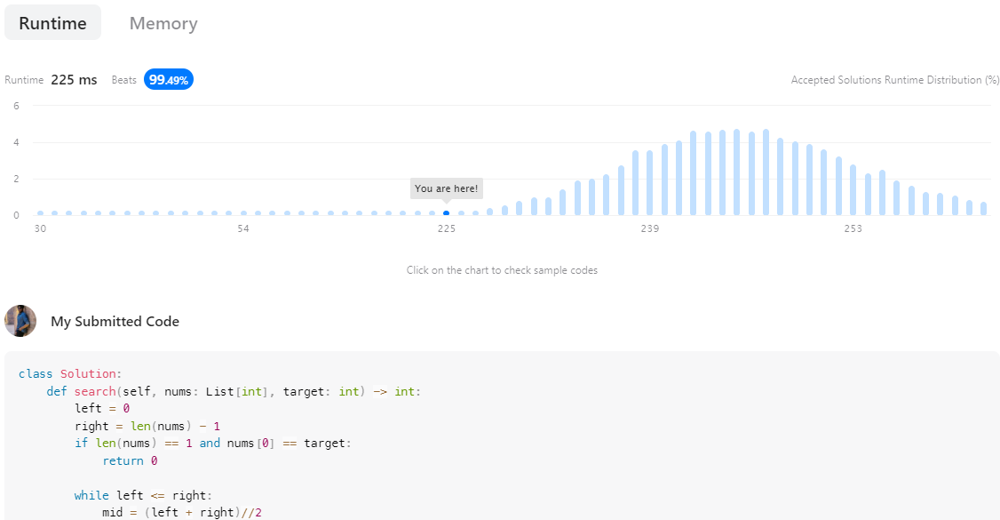\n\n\n\n# Code\n```\nclass Solution:\n def search(self, nums: List[int], target: int) -> int:\n left = 0\n right = len(nums) - 1\n if len(nums) == 1 and nums[0] == target:\n return 0\n \n while left <= right:\n mid = (left + right)//2\n \n if nums[mid] == target:\n return mid\n \n elif nums[mid] > target:\n right = mid - 1\n \n else:\n left = mid + 1\n \n return -1\n``` | 2 | Given an array of integers `nums` which is sorted in ascending order, and an integer `target`, write a function to search `target` in `nums`. If `target` exists, then return its index. Otherwise, return `-1`.
You must write an algorithm with `O(log n)` runtime complexity.
**Example 1:**
**Input:** nums = \[-1,0,3,5,9,12\], target = 9
**Output:** 4
**Explanation:** 9 exists in nums and its index is 4
**Example 2:**
**Input:** nums = \[-1,0,3,5,9,12\], target = 2
**Output:** -1
**Explanation:** 2 does not exist in nums so return -1
**Constraints:**
* `1 <= nums.length <= 104`
* `-104 < nums[i], target < 104`
* All the integers in `nums` are **unique**.
* `nums` is sorted in ascending order. | null |
✔Beats 99.49% TC || Python Solution | binary-search | 0 | 1 | \n\n\n\n# Code\n```\nclass Solution:\n def search(self, nums: List[int], target: int) -> int:\n left = 0\n right = len(nums) - 1\n if len(nums) == 1 and nums[0] == target:\n return 0\n \n while left <= right:\n mid = (left + right)//2\n \n if nums[mid] == target:\n return mid\n \n elif nums[mid] > target:\n right = mid - 1\n \n else:\n left = mid + 1\n \n return -1\n``` | 2 | Given a string `s` and an array of strings `words`, return _the number of_ `words[i]` _that is a subsequence of_ `s`.
A **subsequence** of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
* For example, `"ace "` is a subsequence of `"abcde "`.
**Example 1:**
**Input:** s = "abcde ", words = \[ "a ", "bb ", "acd ", "ace "\]
**Output:** 3
**Explanation:** There are three strings in words that are a subsequence of s: "a ", "acd ", "ace ".
**Example 2:**
**Input:** s = "dsahjpjauf ", words = \[ "ahjpjau ", "ja ", "ahbwzgqnuk ", "tnmlanowax "\]
**Output:** 2
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `1 <= words.length <= 5000`
* `1 <= words[i].length <= 50`
* `s` and `words[i]` consist of only lowercase English letters. | null |
simple one liners for each def | design-hashset | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass MyHashSet:\n\n def __init__(self):\n self.mp=defaultdict(int)\n \n\n def add(self, key: int) -> None:\n self.mp[key]=True\n \n\n def remove(self, key: int) -> None:\n self.mp[key]=False\n\n def contains(self, key: int) -> bool:\n return self.mp[key]\n \n\n# Your MyHashSet object will be instantiated and called as such:\n# obj = MyHashSet()\n# obj.add(key)\n# obj.remove(key)\n# param_3 = obj.contains(key)\n``` | 1 | Design a HashSet without using any built-in hash table libraries.
Implement `MyHashSet` class:
* `void add(key)` Inserts the value `key` into the HashSet.
* `bool contains(key)` Returns whether the value `key` exists in the HashSet or not.
* `void remove(key)` Removes the value `key` in the HashSet. If `key` does not exist in the HashSet, do nothing.
**Example 1:**
**Input**
\[ "MyHashSet ", "add ", "add ", "contains ", "contains ", "add ", "contains ", "remove ", "contains "\]
\[\[\], \[1\], \[2\], \[1\], \[3\], \[2\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, true, false, null, true, null, false\]
**Explanation**
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = \[1\]
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(1); // return True
myHashSet.contains(3); // return False, (not found)
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(2); // return True
myHashSet.remove(2); // set = \[1\]
myHashSet.contains(2); // return False, (already removed)
**Constraints:**
* `0 <= key <= 106`
* At most `104` calls will be made to `add`, `remove`, and `contains`. | null |
simple one liners for each def | design-hashset | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass MyHashSet:\n\n def __init__(self):\n self.mp=defaultdict(int)\n \n\n def add(self, key: int) -> None:\n self.mp[key]=True\n \n\n def remove(self, key: int) -> None:\n self.mp[key]=False\n\n def contains(self, key: int) -> bool:\n return self.mp[key]\n \n\n# Your MyHashSet object will be instantiated and called as such:\n# obj = MyHashSet()\n# obj.add(key)\n# obj.remove(key)\n# param_3 = obj.contains(key)\n``` | 1 | We had some 2-dimensional coordinates, like `"(1, 3) "` or `"(2, 0.5) "`. Then, we removed all commas, decimal points, and spaces and ended up with the string s.
* For example, `"(1, 3) "` becomes `s = "(13) "` and `"(2, 0.5) "` becomes `s = "(205) "`.
Return _a list of strings representing all possibilities for what our original coordinates could have been_.
Our original representation never had extraneous zeroes, so we never started with numbers like `"00 "`, `"0.0 "`, `"0.00 "`, `"1.0 "`, `"001 "`, `"00.01 "`, or any other number that can be represented with fewer digits. Also, a decimal point within a number never occurs without at least one digit occurring before it, so we never started with numbers like `".1 "`.
The final answer list can be returned in any order. All coordinates in the final answer have exactly one space between them (occurring after the comma.)
**Example 1:**
**Input:** s = "(123) "
**Output:** \[ "(1, 2.3) ", "(1, 23) ", "(1.2, 3) ", "(12, 3) "\]
**Example 2:**
**Input:** s = "(0123) "
**Output:** \[ "(0, 1.23) ", "(0, 12.3) ", "(0, 123) ", "(0.1, 2.3) ", "(0.1, 23) ", "(0.12, 3) "\]
**Explanation:** 0.0, 00, 0001 or 00.01 are not allowed.
**Example 3:**
**Input:** s = "(00011) "
**Output:** \[ "(0, 0.011) ", "(0.001, 1) "\]
**Constraints:**
* `4 <= s.length <= 12`
* `s[0] == '('` and `s[s.length - 1] == ')'`.
* The rest of `s` are digits. | null |
✅Python3 || C++|| Java✅ [Beats 97%] | design-hashset | 1 | 1 | # Please Upvote \uD83D\uDE07\n# Before\n# Python3\n```\nclass MyHashSet:\n\n def __init__(self):\n self.mp=defaultdict(int)\n \n\n def add(self, key: int) -> None:\n self.mp[key]=True\n \n\n def remove(self, key: int) -> None:\n self.mp[key]=False\n\n def contains(self, key: int) -> bool:\n return self.mp[key]\n \n```\n# After\n# C++\n```\nclass MyHashSet {\nprivate:\n std::vector<bool> mp;\n\npublic:\n MyHashSet() {\n mp.resize(1000001, false);\n }\n\n void add(int key) {\n mp[key] = true;\n }\n\n void remove(int key) {\n mp[key] = false;\n }\n\n bool contains(int key) {\n return mp[key];\n }\n};\n\n```\n# Python3\n```\nclass MyHashSet:\n\n def __init__(self):\n self.mp=[False]*1000001\n \n\n def add(self, key: int) -> None:\n self.mp[key]=True\n \n\n def remove(self, key: int) -> None:\n self.mp[key]=False\n\n def contains(self, key: int) -> bool:\n return self.mp[key]\n\n```\n# Java\n```\nclass MyHashSet {\n private boolean[] mp;\n\n public MyHashSet() {\n mp = new boolean[1000001];\n Arrays.fill(mp, false);\n }\n\n public void add(int key) {\n mp[key] = true;\n }\n\n public void remove(int key) {\n mp[key] = false;\n }\n\n public boolean contains(int key) {\n return mp[key];\n }\n}\n```\n | 53 | Design a HashSet without using any built-in hash table libraries.
Implement `MyHashSet` class:
* `void add(key)` Inserts the value `key` into the HashSet.
* `bool contains(key)` Returns whether the value `key` exists in the HashSet or not.
* `void remove(key)` Removes the value `key` in the HashSet. If `key` does not exist in the HashSet, do nothing.
**Example 1:**
**Input**
\[ "MyHashSet ", "add ", "add ", "contains ", "contains ", "add ", "contains ", "remove ", "contains "\]
\[\[\], \[1\], \[2\], \[1\], \[3\], \[2\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, true, false, null, true, null, false\]
**Explanation**
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = \[1\]
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(1); // return True
myHashSet.contains(3); // return False, (not found)
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(2); // return True
myHashSet.remove(2); // set = \[1\]
myHashSet.contains(2); // return False, (already removed)
**Constraints:**
* `0 <= key <= 106`
* At most `104` calls will be made to `add`, `remove`, and `contains`. | null |
✅Python3 || C++|| Java✅ [Beats 97%] | design-hashset | 1 | 1 | # Please Upvote \uD83D\uDE07\n# Before\n# Python3\n```\nclass MyHashSet:\n\n def __init__(self):\n self.mp=defaultdict(int)\n \n\n def add(self, key: int) -> None:\n self.mp[key]=True\n \n\n def remove(self, key: int) -> None:\n self.mp[key]=False\n\n def contains(self, key: int) -> bool:\n return self.mp[key]\n \n```\n# After\n# C++\n```\nclass MyHashSet {\nprivate:\n std::vector<bool> mp;\n\npublic:\n MyHashSet() {\n mp.resize(1000001, false);\n }\n\n void add(int key) {\n mp[key] = true;\n }\n\n void remove(int key) {\n mp[key] = false;\n }\n\n bool contains(int key) {\n return mp[key];\n }\n};\n\n```\n# Python3\n```\nclass MyHashSet:\n\n def __init__(self):\n self.mp=[False]*1000001\n \n\n def add(self, key: int) -> None:\n self.mp[key]=True\n \n\n def remove(self, key: int) -> None:\n self.mp[key]=False\n\n def contains(self, key: int) -> bool:\n return self.mp[key]\n\n```\n# Java\n```\nclass MyHashSet {\n private boolean[] mp;\n\n public MyHashSet() {\n mp = new boolean[1000001];\n Arrays.fill(mp, false);\n }\n\n public void add(int key) {\n mp[key] = true;\n }\n\n public void remove(int key) {\n mp[key] = false;\n }\n\n public boolean contains(int key) {\n return mp[key];\n }\n}\n```\n | 53 | We had some 2-dimensional coordinates, like `"(1, 3) "` or `"(2, 0.5) "`. Then, we removed all commas, decimal points, and spaces and ended up with the string s.
* For example, `"(1, 3) "` becomes `s = "(13) "` and `"(2, 0.5) "` becomes `s = "(205) "`.
Return _a list of strings representing all possibilities for what our original coordinates could have been_.
Our original representation never had extraneous zeroes, so we never started with numbers like `"00 "`, `"0.0 "`, `"0.00 "`, `"1.0 "`, `"001 "`, `"00.01 "`, or any other number that can be represented with fewer digits. Also, a decimal point within a number never occurs without at least one digit occurring before it, so we never started with numbers like `".1 "`.
The final answer list can be returned in any order. All coordinates in the final answer have exactly one space between them (occurring after the comma.)
**Example 1:**
**Input:** s = "(123) "
**Output:** \[ "(1, 2.3) ", "(1, 23) ", "(1.2, 3) ", "(12, 3) "\]
**Example 2:**
**Input:** s = "(0123) "
**Output:** \[ "(0, 1.23) ", "(0, 12.3) ", "(0, 123) ", "(0.1, 2.3) ", "(0.1, 23) ", "(0.12, 3) "\]
**Explanation:** 0.0, 00, 0001 or 00.01 are not allowed.
**Example 3:**
**Input:** s = "(00011) "
**Output:** \[ "(0, 0.011) ", "(0.001, 1) "\]
**Constraints:**
* `4 <= s.length <= 12`
* `s[0] == '('` and `s[s.length - 1] == ')'`.
* The rest of `s` are digits. | null |
PYTHON3 SOLUTION | design-hashset | 0 | 1 | # Code\n```\nclass MyHashSet:\n\n def __init__(self):\n self.arr = set()\n \n def add(self, key: int) -> None:\n self.arr.update({key})\n\n def remove(self, key: int) -> None:\n if key in self.arr:\n self.arr.remove(key)\n return True\n\n def contains(self, key: int) -> bool:\n return key in self.arr\n\n# Your MyHashSet object will be instantiated and called as such:\n# obj = MyHashSet()\n# obj.add(key)\n# obj.remove(key)\n# param_3 = obj.contains(key)\n``` | 2 | Design a HashSet without using any built-in hash table libraries.
Implement `MyHashSet` class:
* `void add(key)` Inserts the value `key` into the HashSet.
* `bool contains(key)` Returns whether the value `key` exists in the HashSet or not.
* `void remove(key)` Removes the value `key` in the HashSet. If `key` does not exist in the HashSet, do nothing.
**Example 1:**
**Input**
\[ "MyHashSet ", "add ", "add ", "contains ", "contains ", "add ", "contains ", "remove ", "contains "\]
\[\[\], \[1\], \[2\], \[1\], \[3\], \[2\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, true, false, null, true, null, false\]
**Explanation**
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = \[1\]
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(1); // return True
myHashSet.contains(3); // return False, (not found)
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(2); // return True
myHashSet.remove(2); // set = \[1\]
myHashSet.contains(2); // return False, (already removed)
**Constraints:**
* `0 <= key <= 106`
* At most `104` calls will be made to `add`, `remove`, and `contains`. | null |
PYTHON3 SOLUTION | design-hashset | 0 | 1 | # Code\n```\nclass MyHashSet:\n\n def __init__(self):\n self.arr = set()\n \n def add(self, key: int) -> None:\n self.arr.update({key})\n\n def remove(self, key: int) -> None:\n if key in self.arr:\n self.arr.remove(key)\n return True\n\n def contains(self, key: int) -> bool:\n return key in self.arr\n\n# Your MyHashSet object will be instantiated and called as such:\n# obj = MyHashSet()\n# obj.add(key)\n# obj.remove(key)\n# param_3 = obj.contains(key)\n``` | 2 | We had some 2-dimensional coordinates, like `"(1, 3) "` or `"(2, 0.5) "`. Then, we removed all commas, decimal points, and spaces and ended up with the string s.
* For example, `"(1, 3) "` becomes `s = "(13) "` and `"(2, 0.5) "` becomes `s = "(205) "`.
Return _a list of strings representing all possibilities for what our original coordinates could have been_.
Our original representation never had extraneous zeroes, so we never started with numbers like `"00 "`, `"0.0 "`, `"0.00 "`, `"1.0 "`, `"001 "`, `"00.01 "`, or any other number that can be represented with fewer digits. Also, a decimal point within a number never occurs without at least one digit occurring before it, so we never started with numbers like `".1 "`.
The final answer list can be returned in any order. All coordinates in the final answer have exactly one space between them (occurring after the comma.)
**Example 1:**
**Input:** s = "(123) "
**Output:** \[ "(1, 2.3) ", "(1, 23) ", "(1.2, 3) ", "(12, 3) "\]
**Example 2:**
**Input:** s = "(0123) "
**Output:** \[ "(0, 1.23) ", "(0, 12.3) ", "(0, 123) ", "(0.1, 2.3) ", "(0.1, 23) ", "(0.12, 3) "\]
**Explanation:** 0.0, 00, 0001 or 00.01 are not allowed.
**Example 3:**
**Input:** s = "(00011) "
**Output:** \[ "(0, 0.011) ", "(0.001, 1) "\]
**Constraints:**
* `4 <= s.length <= 12`
* `s[0] == '('` and `s[s.length - 1] == ')'`.
* The rest of `s` are digits. | null |
Python🔥Java🔥C++🔥Simple Solution🔥Easy to Understand | design-hashset | 1 | 1 | **!! BIG ANNOUNCEMENT !!**\nI am currently Giving away my premium content well-structured assignments and study materials to clear interviews at top companies related to computer science and data science to my current Subscribers. This is only for first 10,000 Subscribers. **DON\'T FORGET** to Subscribe\n\n# Search \uD83D\uDC49 `Tech Wired Leetcode` to Subscribe\n\n\n# or\n\n# Click the Link in my Profile\n\n# Approach:\n\n- Initialize a fixed-size array (bucket) to store the elements of the HashSet.\n- Implement a hashing function to map the keys to specific indices in the bucket.\n- Handle collisions (i.e., multiple keys mapping to the same index) by using separate chaining. Each index of the bucket will contain a linked list or a similar data structure to store the elements with the same hash value.\n- For adding an element, calculate the hash value of the key and insert it into the corresponding bucket if it doesn\'t already exist.\n- For removing an element, calculate the hash value of the key, find the corresponding bucket, and remove the element from it if it exists.\n- For checking if an element exists, calculate the hash value of the key, find the corresponding bucket, and check if the element is present in it.\n\n# Intuition:\nThe idea behind the HashSet implementation is to leverage the concept of hashing for efficient insertion, removal, and retrieval operations. By using a hashing function, we can map each key to a specific index in the array, which allows for constant-time operations on average.\n\n- During the addition process, the key\'s hash value is calculated, and if it doesn\'t already exist in the bucket, it is inserted. This ensures uniqueness of elements within the HashSet.\n- When removing an element, we calculate the hash value to determine the corresponding bucket and then remove the element if it exists. By using a linked list or similar data structure at each index, we can handle collisions and remove the element efficiently.\n- For checking if an element exists, the hash value of the key is computed, and the corresponding bucket is searched for the element. - \n- If it is found, we can conclude that the HashSet contains the element.\n\n```Python []\nclass MyHashSet:\n def __init__(self):\n self.size = 1000\n self.buckets = [[] for _ in range(self.size)]\n\n def add(self, key: int) -> None:\n index = self._hash(key)\n if key not in self.buckets[index]:\n self.buckets[index].append(key)\n\n def remove(self, key: int) -> None:\n index = self._hash(key)\n if key in self.buckets[index]:\n self.buckets[index].remove(key)\n\n def contains(self, key: int) -> bool:\n index = self._hash(key)\n return key in self.buckets[index]\n\n def _hash(self, key: int) -> int:\n return key % self.size\n```\n```Java []\n\nclass MyHashSet {\n private int size;\n private List<List<Integer>> buckets;\n\n public MyHashSet() {\n size = 1000;\n buckets = new ArrayList<>(size);\n for (int i = 0; i < size; i++) {\n buckets.add(new LinkedList<>());\n }\n }\n\n public void add(int key) {\n int index = hash(key);\n List<Integer> bucket = buckets.get(index);\n if (!bucket.contains(key)) {\n bucket.add(key);\n }\n }\n\n public void remove(int key) {\n int index = hash(key);\n List<Integer> bucket = buckets.get(index);\n bucket.remove(Integer.valueOf(key));\n }\n\n public boolean contains(int key) {\n int index = hash(key);\n List<Integer> bucket = buckets.get(index);\n return bucket.contains(key);\n }\n\n private int hash(int key) {\n return key % size;\n }\n}\n\n```\n```C++ []\n\nclass MyHashSet {\nprivate:\n int size;\n std::vector<std::list<int>> buckets;\n\npublic:\n MyHashSet() {\n size = 1000;\n buckets = std::vector<std::list<int>>(size);\n }\n\n void add(int key) {\n int index = hash(key);\n std::list<int>& bucket = buckets[index];\n if (!contains(key, bucket)) {\n bucket.push_back(key);\n }\n }\n\n void remove(int key) {\n int index = hash(key);\n std::list<int>& bucket = buckets[index];\n bucket.remove(key);\n }\n\n bool contains(int key) {\n int index = hash(key);\n std::list<int>& bucket = buckets[index];\n return contains(key, bucket);\n }\n\nprivate:\n int hash(int key) {\n return key % size;\n }\n\n bool contains(int key, std::list<int>& bucket) {\n for (int num : bucket) {\n if (num == key) {\n return true;\n }\n }\n return false;\n }\n};\n\n```\n# An Upvote will be encouraging \uD83D\uDC4D\n\n | 26 | Design a HashSet without using any built-in hash table libraries.
Implement `MyHashSet` class:
* `void add(key)` Inserts the value `key` into the HashSet.
* `bool contains(key)` Returns whether the value `key` exists in the HashSet or not.
* `void remove(key)` Removes the value `key` in the HashSet. If `key` does not exist in the HashSet, do nothing.
**Example 1:**
**Input**
\[ "MyHashSet ", "add ", "add ", "contains ", "contains ", "add ", "contains ", "remove ", "contains "\]
\[\[\], \[1\], \[2\], \[1\], \[3\], \[2\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, true, false, null, true, null, false\]
**Explanation**
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = \[1\]
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(1); // return True
myHashSet.contains(3); // return False, (not found)
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(2); // return True
myHashSet.remove(2); // set = \[1\]
myHashSet.contains(2); // return False, (already removed)
**Constraints:**
* `0 <= key <= 106`
* At most `104` calls will be made to `add`, `remove`, and `contains`. | null |
Python🔥Java🔥C++🔥Simple Solution🔥Easy to Understand | design-hashset | 1 | 1 | **!! BIG ANNOUNCEMENT !!**\nI am currently Giving away my premium content well-structured assignments and study materials to clear interviews at top companies related to computer science and data science to my current Subscribers. This is only for first 10,000 Subscribers. **DON\'T FORGET** to Subscribe\n\n# Search \uD83D\uDC49 `Tech Wired Leetcode` to Subscribe\n\n\n# or\n\n# Click the Link in my Profile\n\n# Approach:\n\n- Initialize a fixed-size array (bucket) to store the elements of the HashSet.\n- Implement a hashing function to map the keys to specific indices in the bucket.\n- Handle collisions (i.e., multiple keys mapping to the same index) by using separate chaining. Each index of the bucket will contain a linked list or a similar data structure to store the elements with the same hash value.\n- For adding an element, calculate the hash value of the key and insert it into the corresponding bucket if it doesn\'t already exist.\n- For removing an element, calculate the hash value of the key, find the corresponding bucket, and remove the element from it if it exists.\n- For checking if an element exists, calculate the hash value of the key, find the corresponding bucket, and check if the element is present in it.\n\n# Intuition:\nThe idea behind the HashSet implementation is to leverage the concept of hashing for efficient insertion, removal, and retrieval operations. By using a hashing function, we can map each key to a specific index in the array, which allows for constant-time operations on average.\n\n- During the addition process, the key\'s hash value is calculated, and if it doesn\'t already exist in the bucket, it is inserted. This ensures uniqueness of elements within the HashSet.\n- When removing an element, we calculate the hash value to determine the corresponding bucket and then remove the element if it exists. By using a linked list or similar data structure at each index, we can handle collisions and remove the element efficiently.\n- For checking if an element exists, the hash value of the key is computed, and the corresponding bucket is searched for the element. - \n- If it is found, we can conclude that the HashSet contains the element.\n\n```Python []\nclass MyHashSet:\n def __init__(self):\n self.size = 1000\n self.buckets = [[] for _ in range(self.size)]\n\n def add(self, key: int) -> None:\n index = self._hash(key)\n if key not in self.buckets[index]:\n self.buckets[index].append(key)\n\n def remove(self, key: int) -> None:\n index = self._hash(key)\n if key in self.buckets[index]:\n self.buckets[index].remove(key)\n\n def contains(self, key: int) -> bool:\n index = self._hash(key)\n return key in self.buckets[index]\n\n def _hash(self, key: int) -> int:\n return key % self.size\n```\n```Java []\n\nclass MyHashSet {\n private int size;\n private List<List<Integer>> buckets;\n\n public MyHashSet() {\n size = 1000;\n buckets = new ArrayList<>(size);\n for (int i = 0; i < size; i++) {\n buckets.add(new LinkedList<>());\n }\n }\n\n public void add(int key) {\n int index = hash(key);\n List<Integer> bucket = buckets.get(index);\n if (!bucket.contains(key)) {\n bucket.add(key);\n }\n }\n\n public void remove(int key) {\n int index = hash(key);\n List<Integer> bucket = buckets.get(index);\n bucket.remove(Integer.valueOf(key));\n }\n\n public boolean contains(int key) {\n int index = hash(key);\n List<Integer> bucket = buckets.get(index);\n return bucket.contains(key);\n }\n\n private int hash(int key) {\n return key % size;\n }\n}\n\n```\n```C++ []\n\nclass MyHashSet {\nprivate:\n int size;\n std::vector<std::list<int>> buckets;\n\npublic:\n MyHashSet() {\n size = 1000;\n buckets = std::vector<std::list<int>>(size);\n }\n\n void add(int key) {\n int index = hash(key);\n std::list<int>& bucket = buckets[index];\n if (!contains(key, bucket)) {\n bucket.push_back(key);\n }\n }\n\n void remove(int key) {\n int index = hash(key);\n std::list<int>& bucket = buckets[index];\n bucket.remove(key);\n }\n\n bool contains(int key) {\n int index = hash(key);\n std::list<int>& bucket = buckets[index];\n return contains(key, bucket);\n }\n\nprivate:\n int hash(int key) {\n return key % size;\n }\n\n bool contains(int key, std::list<int>& bucket) {\n for (int num : bucket) {\n if (num == key) {\n return true;\n }\n }\n return false;\n }\n};\n\n```\n# An Upvote will be encouraging \uD83D\uDC4D\n\n | 26 | We had some 2-dimensional coordinates, like `"(1, 3) "` or `"(2, 0.5) "`. Then, we removed all commas, decimal points, and spaces and ended up with the string s.
* For example, `"(1, 3) "` becomes `s = "(13) "` and `"(2, 0.5) "` becomes `s = "(205) "`.
Return _a list of strings representing all possibilities for what our original coordinates could have been_.
Our original representation never had extraneous zeroes, so we never started with numbers like `"00 "`, `"0.0 "`, `"0.00 "`, `"1.0 "`, `"001 "`, `"00.01 "`, or any other number that can be represented with fewer digits. Also, a decimal point within a number never occurs without at least one digit occurring before it, so we never started with numbers like `".1 "`.
The final answer list can be returned in any order. All coordinates in the final answer have exactly one space between them (occurring after the comma.)
**Example 1:**
**Input:** s = "(123) "
**Output:** \[ "(1, 2.3) ", "(1, 23) ", "(1.2, 3) ", "(12, 3) "\]
**Example 2:**
**Input:** s = "(0123) "
**Output:** \[ "(0, 1.23) ", "(0, 12.3) ", "(0, 123) ", "(0.1, 2.3) ", "(0.1, 23) ", "(0.12, 3) "\]
**Explanation:** 0.0, 00, 0001 or 00.01 are not allowed.
**Example 3:**
**Input:** s = "(00011) "
**Output:** \[ "(0, 0.011) ", "(0.001, 1) "\]
**Constraints:**
* `4 <= s.length <= 12`
* `s[0] == '('` and `s[s.length - 1] == ')'`.
* The rest of `s` are digits. | null |
Solution | design-hashset | 1 | 1 | ```C++ []\nclass MyHashSet {\npublic:\n vector<bool> ans;\n MyHashSet() {\n ans.resize(1e6+1,false);\n }\n void add(int key) {\n ans[key]=true;\n }\n void remove(int key) {\n ans[key]=false;\n }\n bool contains(int key) {\n return ans[key];\n }\n};\n```\n\n```Python3 []\nclass MyHashSet:\n\n def __init__(self):\n self.l={}\n\n def add(self, key: int) -> None:\n self.l[key]=1\n\n def remove(self, key: int) -> None:\n if key in self.l:\n del self.l[key]\n\n def contains(self, key: int) -> bool:\n return key in self.l\n```\n\n```Java []\nclass MyHashSet {\n \n boolean buckets[][];\n int bucket = 10000;\n int bucketItem = 10000;\n \n public MyHashSet() {\n buckets = new boolean[bucket][];\n }\n public int getBucket(int key){\n return key / bucket;\n }\n public int getBucketItem(int key){\n return key % bucketItem;\n }\n public void add(int key) {\n int bucketKey = getBucket(key);\n int bucketItemkey = getBucketItem(key);\n \n if(buckets[bucketKey] == null)\n buckets[bucketKey] = new boolean[bucketItem];\n buckets[bucketKey][bucketItemkey] = true;\n }\n public void remove(int key) {\n \n int bucketKey = getBucket(key);\n int bucketItemkey = getBucketItem(key);\n \n if(buckets[bucketKey] != null)\n buckets[bucketKey][bucketItemkey] = false;\n }\n public boolean contains(int key) {\n int bucketKey = getBucket(key);\n int bucketItemkey = getBucketItem(key);\n \n if(buckets[bucketKey] != null)\n return buckets[bucketKey][bucketItemkey];\n return false;\n }\n}\n```\n | 3 | Design a HashSet without using any built-in hash table libraries.
Implement `MyHashSet` class:
* `void add(key)` Inserts the value `key` into the HashSet.
* `bool contains(key)` Returns whether the value `key` exists in the HashSet or not.
* `void remove(key)` Removes the value `key` in the HashSet. If `key` does not exist in the HashSet, do nothing.
**Example 1:**
**Input**
\[ "MyHashSet ", "add ", "add ", "contains ", "contains ", "add ", "contains ", "remove ", "contains "\]
\[\[\], \[1\], \[2\], \[1\], \[3\], \[2\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, true, false, null, true, null, false\]
**Explanation**
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = \[1\]
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(1); // return True
myHashSet.contains(3); // return False, (not found)
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(2); // return True
myHashSet.remove(2); // set = \[1\]
myHashSet.contains(2); // return False, (already removed)
**Constraints:**
* `0 <= key <= 106`
* At most `104` calls will be made to `add`, `remove`, and `contains`. | null |
Solution | design-hashset | 1 | 1 | ```C++ []\nclass MyHashSet {\npublic:\n vector<bool> ans;\n MyHashSet() {\n ans.resize(1e6+1,false);\n }\n void add(int key) {\n ans[key]=true;\n }\n void remove(int key) {\n ans[key]=false;\n }\n bool contains(int key) {\n return ans[key];\n }\n};\n```\n\n```Python3 []\nclass MyHashSet:\n\n def __init__(self):\n self.l={}\n\n def add(self, key: int) -> None:\n self.l[key]=1\n\n def remove(self, key: int) -> None:\n if key in self.l:\n del self.l[key]\n\n def contains(self, key: int) -> bool:\n return key in self.l\n```\n\n```Java []\nclass MyHashSet {\n \n boolean buckets[][];\n int bucket = 10000;\n int bucketItem = 10000;\n \n public MyHashSet() {\n buckets = new boolean[bucket][];\n }\n public int getBucket(int key){\n return key / bucket;\n }\n public int getBucketItem(int key){\n return key % bucketItem;\n }\n public void add(int key) {\n int bucketKey = getBucket(key);\n int bucketItemkey = getBucketItem(key);\n \n if(buckets[bucketKey] == null)\n buckets[bucketKey] = new boolean[bucketItem];\n buckets[bucketKey][bucketItemkey] = true;\n }\n public void remove(int key) {\n \n int bucketKey = getBucket(key);\n int bucketItemkey = getBucketItem(key);\n \n if(buckets[bucketKey] != null)\n buckets[bucketKey][bucketItemkey] = false;\n }\n public boolean contains(int key) {\n int bucketKey = getBucket(key);\n int bucketItemkey = getBucketItem(key);\n \n if(buckets[bucketKey] != null)\n return buckets[bucketKey][bucketItemkey];\n return false;\n }\n}\n```\n | 3 | We had some 2-dimensional coordinates, like `"(1, 3) "` or `"(2, 0.5) "`. Then, we removed all commas, decimal points, and spaces and ended up with the string s.
* For example, `"(1, 3) "` becomes `s = "(13) "` and `"(2, 0.5) "` becomes `s = "(205) "`.
Return _a list of strings representing all possibilities for what our original coordinates could have been_.
Our original representation never had extraneous zeroes, so we never started with numbers like `"00 "`, `"0.0 "`, `"0.00 "`, `"1.0 "`, `"001 "`, `"00.01 "`, or any other number that can be represented with fewer digits. Also, a decimal point within a number never occurs without at least one digit occurring before it, so we never started with numbers like `".1 "`.
The final answer list can be returned in any order. All coordinates in the final answer have exactly one space between them (occurring after the comma.)
**Example 1:**
**Input:** s = "(123) "
**Output:** \[ "(1, 2.3) ", "(1, 23) ", "(1.2, 3) ", "(12, 3) "\]
**Example 2:**
**Input:** s = "(0123) "
**Output:** \[ "(0, 1.23) ", "(0, 12.3) ", "(0, 123) ", "(0.1, 2.3) ", "(0.1, 23) ", "(0.12, 3) "\]
**Explanation:** 0.0, 00, 0001 or 00.01 are not allowed.
**Example 3:**
**Input:** s = "(00011) "
**Output:** \[ "(0, 0.011) ", "(0.001, 1) "\]
**Constraints:**
* `4 <= s.length <= 12`
* `s[0] == '('` and `s[s.length - 1] == ')'`.
* The rest of `s` are digits. | null |
✔️ [Python] Simple, Easy Solution with HashTable, Array and LinkedList | design-hashset | 0 | 1 | #### Approach-1: Using Dictionary\n\n```\nclass MyHashSet:\n\n def __init__(self):\n self.d = {}\n\n def add(self, key: int) -> None:\n self.d[key] = 1\n\n def remove(self, key: int) -> None:\n self.d[key] = 0\n\n def contains(self, key: int) -> bool:\n return self.d.get(key,0)!=0\n```\n\n\n#### Approach-2: Using Array+Linked-List\n```\nclass ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n \nclass MyHashSet: \n \n def __init__(self):\n self.size = 1000\n self.arr = [None]*self.size\n\n def find_index(self, key):\n return key % self.size\n \n def find_value(self, key):\n idx = self.find_index(key)\n head = self.arr[idx]\n while head:\n if head.val == key: return 1\n head = head.next\n return 0\n\n def add(self, key: int) -> None:\n if self.find_value(key): return\n idx = self.find_index(key)\n self.arr[idx] = ListNode(key, self.arr[idx])\n\n def remove(self, key: int) -> None:\n idx = self.find_index(key)\n node = self.arr[idx]\n if node is None: \n return \n if node.val==key:\n self.arr[idx] = node.next\n return \n first, second = node, node.next\n while second:\n if second.val == key:\n first.next = second.next\n return\n first, second = first.next, second.next\n\n def contains(self, key: int) -> bool:\n return self.find_value(key)\n```\n\nIf you think this post is **helpful** for you, hit a **thums up.** Any questions or discussions are welcome!\n\n | 20 | Design a HashSet without using any built-in hash table libraries.
Implement `MyHashSet` class:
* `void add(key)` Inserts the value `key` into the HashSet.
* `bool contains(key)` Returns whether the value `key` exists in the HashSet or not.
* `void remove(key)` Removes the value `key` in the HashSet. If `key` does not exist in the HashSet, do nothing.
**Example 1:**
**Input**
\[ "MyHashSet ", "add ", "add ", "contains ", "contains ", "add ", "contains ", "remove ", "contains "\]
\[\[\], \[1\], \[2\], \[1\], \[3\], \[2\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, true, false, null, true, null, false\]
**Explanation**
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = \[1\]
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(1); // return True
myHashSet.contains(3); // return False, (not found)
myHashSet.add(2); // set = \[1, 2\]
myHashSet.contains(2); // return True
myHashSet.remove(2); // set = \[1\]
myHashSet.contains(2); // return False, (already removed)
**Constraints:**
* `0 <= key <= 106`
* At most `104` calls will be made to `add`, `remove`, and `contains`. | null |
✔️ [Python] Simple, Easy Solution with HashTable, Array and LinkedList | design-hashset | 0 | 1 | #### Approach-1: Using Dictionary\n\n```\nclass MyHashSet:\n\n def __init__(self):\n self.d = {}\n\n def add(self, key: int) -> None:\n self.d[key] = 1\n\n def remove(self, key: int) -> None:\n self.d[key] = 0\n\n def contains(self, key: int) -> bool:\n return self.d.get(key,0)!=0\n```\n\n\n#### Approach-2: Using Array+Linked-List\n```\nclass ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n \nclass MyHashSet: \n \n def __init__(self):\n self.size = 1000\n self.arr = [None]*self.size\n\n def find_index(self, key):\n return key % self.size\n \n def find_value(self, key):\n idx = self.find_index(key)\n head = self.arr[idx]\n while head:\n if head.val == key: return 1\n head = head.next\n return 0\n\n def add(self, key: int) -> None:\n if self.find_value(key): return\n idx = self.find_index(key)\n self.arr[idx] = ListNode(key, self.arr[idx])\n\n def remove(self, key: int) -> None:\n idx = self.find_index(key)\n node = self.arr[idx]\n if node is None: \n return \n if node.val==key:\n self.arr[idx] = node.next\n return \n first, second = node, node.next\n while second:\n if second.val == key:\n first.next = second.next\n return\n first, second = first.next, second.next\n\n def contains(self, key: int) -> bool:\n return self.find_value(key)\n```\n\nIf you think this post is **helpful** for you, hit a **thums up.** Any questions or discussions are welcome!\n\n | 20 | We had some 2-dimensional coordinates, like `"(1, 3) "` or `"(2, 0.5) "`. Then, we removed all commas, decimal points, and spaces and ended up with the string s.
* For example, `"(1, 3) "` becomes `s = "(13) "` and `"(2, 0.5) "` becomes `s = "(205) "`.
Return _a list of strings representing all possibilities for what our original coordinates could have been_.
Our original representation never had extraneous zeroes, so we never started with numbers like `"00 "`, `"0.0 "`, `"0.00 "`, `"1.0 "`, `"001 "`, `"00.01 "`, or any other number that can be represented with fewer digits. Also, a decimal point within a number never occurs without at least one digit occurring before it, so we never started with numbers like `".1 "`.
The final answer list can be returned in any order. All coordinates in the final answer have exactly one space between them (occurring after the comma.)
**Example 1:**
**Input:** s = "(123) "
**Output:** \[ "(1, 2.3) ", "(1, 23) ", "(1.2, 3) ", "(12, 3) "\]
**Example 2:**
**Input:** s = "(0123) "
**Output:** \[ "(0, 1.23) ", "(0, 12.3) ", "(0, 123) ", "(0.1, 2.3) ", "(0.1, 23) ", "(0.12, 3) "\]
**Explanation:** 0.0, 00, 0001 or 00.01 are not allowed.
**Example 3:**
**Input:** s = "(00011) "
**Output:** \[ "(0, 0.011) ", "(0.001, 1) "\]
**Constraints:**
* `4 <= s.length <= 12`
* `s[0] == '('` and `s[s.length - 1] == ')'`.
* The rest of `s` are digits. | null |
✅ 85.31% Hash Map | design-hashmap | 0 | 1 | # Intuition\n\nWhen we think of a HashMap or a Dictionary, we imagine a structure where we store key-value pairs. We want quick access to values given a key. But how do we achieve that?\n\nWell, one simple idea is to convert the key to an integer (if it isn\'t already), then use that integer to index into an array, and save the value there. Sounds easy, right? But there\'s a catch: different keys might give the same index, known as a collision. To handle this, we can use separate chaining: each slot in the array contains a list (or chain) of all key-value pairs that hash to the same index.\n\n## Live Coding\nhttps://youtu.be/_A6lNXRlWZw?si=Evt8t_HdjF1plDS4\n\n# Approach\n\n1. **Initialization**: \n - Define a fixed size for the array. This size can be a prime number to help reduce collisions.\n - Initialize an array (`table`) of that size where each slot is `None`.\n\n2. **Hash Function**:\n - Use the modulo operator (`key % size`) as a simple hash function to get the index for a given key.\n\n3. **Put Operation**:\n - Compute the index for the key.\n - If the slot is empty, create a new node with the key-value pair and place it there.\n - If the slot isn\'t empty, traverse the linked list. If we find the key, we update its value. Otherwise, we add a new node at the end.\n\n4. **Get Operation**:\n - Compute the index for the key.\n - Traverse the linked list at that index. If we find the key, return its value. Otherwise, return -1 indicating the key doesn\'t exist.\n\n5. **Remove Operation**:\n - Compute the index for the key.\n - Traverse the linked list. If we find the key, we remove its node from the list.\n\n# Why It Works\n\nThe beauty of the hash table is that it transforms the key into an index, allowing us to access the associated value in constant time. By using separate chaining, we handle collisions in a systematic way, ensuring that every key-value pair is stored and can be retrieved.\n\n# Why It\'s Useful To Know\n\nUnderstanding how hash tables work under the hood is essential because:\n - They\'re a fundamental data structure used in many applications and software systems.\n - Knowing their inner workings allows us to choose the right data structure for the job and helps in optimizing our applications.\n - It also helps in interviews, as hash table problems are quite common.\n\n# Complexity\n\n- **Time complexity**:\n - For the average case, operations like put, get, and remove are $$O(1)$$. However, in the worst case, when all keys collide and end up in the same index, the operations become $$O(n)$$, where $$n$$ is the number of keys.\n\n- **Space complexity**:\n - $$O(n)$$, where $$n$$ is the number of keys. This is because, in the worst case, all keys might be stored in the hash table.\n# Code\n``` Python []\nclass ListNode:\n def __init__(self, key, value):\n self.key = key\n self.value = value\n self.next = None\n\nclass MyHashMap:\n\n def __init__(self):\n self.size = 1000\n self.table = [None] * self.size\n\n def _index(self, key: int) -> int:\n return key % self.size\n\n def put(self, key: int, value: int) -> None:\n idx = self._index(key)\n if not self.table[idx]:\n self.table[idx] = ListNode(key, value)\n return\n current = self.table[idx]\n while current:\n if current.key == key:\n current.value = value\n return\n if not current.next:\n current.next = ListNode(key, value)\n return\n current = current.next\n\n def get(self, key: int) -> int:\n idx = self._index(key)\n current = self.table[idx]\n while current:\n if current.key == key:\n return current.value\n current = current.next\n return -1\n\n def remove(self, key: int) -> None:\n idx = self._index(key)\n current = self.table[idx]\n if not current:\n return\n if current.key == key:\n self.table[idx] = current.next\n return\n while current.next:\n if current.next.key == key:\n current.next = current.next.next\n return\n current = current.next\n\n``` | 26 | Design a HashMap without using any built-in hash table libraries.
Implement the `MyHashMap` class:
* `MyHashMap()` initializes the object with an empty map.
* `void put(int key, int value)` inserts a `(key, value)` pair into the HashMap. If the `key` already exists in the map, update the corresponding `value`.
* `int get(int key)` returns the `value` to which the specified `key` is mapped, or `-1` if this map contains no mapping for the `key`.
* `void remove(key)` removes the `key` and its corresponding `value` if the map contains the mapping for the `key`.
**Example 1:**
**Input**
\[ "MyHashMap ", "put ", "put ", "get ", "get ", "put ", "get ", "remove ", "get "\]
\[\[\], \[1, 1\], \[2, 2\], \[1\], \[3\], \[2, 1\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, 1, -1, null, 1, null, -1\]
**Explanation**
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // The map is now \[\[1,1\]\]
myHashMap.put(2, 2); // The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(1); // return 1, The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(3); // return -1 (i.e., not found), The map is now \[\[1,1\], \[2,2\]\]
myHashMap.put(2, 1); // The map is now \[\[1,1\], \[2,1\]\] (i.e., update the existing value)
myHashMap.get(2); // return 1, The map is now \[\[1,1\], \[2,1\]\]
myHashMap.remove(2); // remove the mapping for 2, The map is now \[\[1,1\]\]
myHashMap.get(2); // return -1 (i.e., not found), The map is now \[\[1,1\]\]
**Constraints:**
* `0 <= key, value <= 106`
* At most `104` calls will be made to `put`, `get`, and `remove`. | null |
✅ 85.31% Hash Map | design-hashmap | 0 | 1 | # Intuition\n\nWhen we think of a HashMap or a Dictionary, we imagine a structure where we store key-value pairs. We want quick access to values given a key. But how do we achieve that?\n\nWell, one simple idea is to convert the key to an integer (if it isn\'t already), then use that integer to index into an array, and save the value there. Sounds easy, right? But there\'s a catch: different keys might give the same index, known as a collision. To handle this, we can use separate chaining: each slot in the array contains a list (or chain) of all key-value pairs that hash to the same index.\n\n## Live Coding\nhttps://youtu.be/_A6lNXRlWZw?si=Evt8t_HdjF1plDS4\n\n# Approach\n\n1. **Initialization**: \n - Define a fixed size for the array. This size can be a prime number to help reduce collisions.\n - Initialize an array (`table`) of that size where each slot is `None`.\n\n2. **Hash Function**:\n - Use the modulo operator (`key % size`) as a simple hash function to get the index for a given key.\n\n3. **Put Operation**:\n - Compute the index for the key.\n - If the slot is empty, create a new node with the key-value pair and place it there.\n - If the slot isn\'t empty, traverse the linked list. If we find the key, we update its value. Otherwise, we add a new node at the end.\n\n4. **Get Operation**:\n - Compute the index for the key.\n - Traverse the linked list at that index. If we find the key, return its value. Otherwise, return -1 indicating the key doesn\'t exist.\n\n5. **Remove Operation**:\n - Compute the index for the key.\n - Traverse the linked list. If we find the key, we remove its node from the list.\n\n# Why It Works\n\nThe beauty of the hash table is that it transforms the key into an index, allowing us to access the associated value in constant time. By using separate chaining, we handle collisions in a systematic way, ensuring that every key-value pair is stored and can be retrieved.\n\n# Why It\'s Useful To Know\n\nUnderstanding how hash tables work under the hood is essential because:\n - They\'re a fundamental data structure used in many applications and software systems.\n - Knowing their inner workings allows us to choose the right data structure for the job and helps in optimizing our applications.\n - It also helps in interviews, as hash table problems are quite common.\n\n# Complexity\n\n- **Time complexity**:\n - For the average case, operations like put, get, and remove are $$O(1)$$. However, in the worst case, when all keys collide and end up in the same index, the operations become $$O(n)$$, where $$n$$ is the number of keys.\n\n- **Space complexity**:\n - $$O(n)$$, where $$n$$ is the number of keys. This is because, in the worst case, all keys might be stored in the hash table.\n# Code\n``` Python []\nclass ListNode:\n def __init__(self, key, value):\n self.key = key\n self.value = value\n self.next = None\n\nclass MyHashMap:\n\n def __init__(self):\n self.size = 1000\n self.table = [None] * self.size\n\n def _index(self, key: int) -> int:\n return key % self.size\n\n def put(self, key: int, value: int) -> None:\n idx = self._index(key)\n if not self.table[idx]:\n self.table[idx] = ListNode(key, value)\n return\n current = self.table[idx]\n while current:\n if current.key == key:\n current.value = value\n return\n if not current.next:\n current.next = ListNode(key, value)\n return\n current = current.next\n\n def get(self, key: int) -> int:\n idx = self._index(key)\n current = self.table[idx]\n while current:\n if current.key == key:\n return current.value\n current = current.next\n return -1\n\n def remove(self, key: int) -> None:\n idx = self._index(key)\n current = self.table[idx]\n if not current:\n return\n if current.key == key:\n self.table[idx] = current.next\n return\n while current.next:\n if current.next.key == key:\n current.next = current.next.next\n return\n current = current.next\n\n``` | 26 | You are given the `head` of a linked list containing unique integer values and an integer array `nums` that is a subset of the linked list values.
Return _the number of connected components in_ `nums` _where two values are connected if they appear **consecutively** in the linked list_.
**Example 1:**
**Input:** head = \[0,1,2,3\], nums = \[0,1,3\]
**Output:** 2
**Explanation:** 0 and 1 are connected, so \[0, 1\] and \[3\] are the two connected components.
**Example 2:**
**Input:** head = \[0,1,2,3,4\], nums = \[0,3,1,4\]
**Output:** 2
**Explanation:** 0 and 1 are connected, 3 and 4 are connected, so \[0, 1\] and \[3, 4\] are the two connected components.
**Constraints:**
* The number of nodes in the linked list is `n`.
* `1 <= n <= 104`
* `0 <= Node.val < n`
* All the values `Node.val` are **unique**.
* `1 <= nums.length <= n`
* `0 <= nums[i] < n`
* All the values of `nums` are **unique**. | null |
Video Solution | Explanation With Drawings | In Depth | Java | C++ | Python 3 | design-hashmap | 1 | 1 | # Intuition adn approach discussed in detail in video solution\nhttps://youtu.be/IF0Yv0XWLdc\n# Code\nJava\n```\nclass MyHashMap {\n //this array as will be used our hash map\n // the keys will be your indicies of the array and values will \n // elements stored at those indicies \n int map[] = null;\n public MyHashMap() {\n map = new int[1000001];\n //to represent no mapping of key value pair\n Arrays.fill(map, -1);\n }\n \n public void put(int key, int value) {\n map[key] = value;\n }\n \n public int get(int key) {\n return map[key];\n }\n \n public void remove(int key) {\n map[key] = -1;\n }\n}\n```\nC++\n```\nclass MyHashMap {\n std::vector<int> map;\npublic:\n MyHashMap() {\n map.resize(1000001, -1);\n }\n \n void put(int key, int value) {\n map[key] = value;\n }\n \n int get(int key) {\n return map[key];\n }\n \n void remove(int key) {\n map[key] = -1;\n }\n};\n```\nPython 3\n```\nclass MyHashMap:\n def __init__(self):\n self.map = [-1] * 1000001\n \n def put(self, key, value):\n self.map[key] = value\n \n def get(self, key):\n return self.map[key]\n \n def remove(self, key):\n self.map[key] = -1\n```\n | 2 | Design a HashMap without using any built-in hash table libraries.
Implement the `MyHashMap` class:
* `MyHashMap()` initializes the object with an empty map.
* `void put(int key, int value)` inserts a `(key, value)` pair into the HashMap. If the `key` already exists in the map, update the corresponding `value`.
* `int get(int key)` returns the `value` to which the specified `key` is mapped, or `-1` if this map contains no mapping for the `key`.
* `void remove(key)` removes the `key` and its corresponding `value` if the map contains the mapping for the `key`.
**Example 1:**
**Input**
\[ "MyHashMap ", "put ", "put ", "get ", "get ", "put ", "get ", "remove ", "get "\]
\[\[\], \[1, 1\], \[2, 2\], \[1\], \[3\], \[2, 1\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, 1, -1, null, 1, null, -1\]
**Explanation**
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // The map is now \[\[1,1\]\]
myHashMap.put(2, 2); // The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(1); // return 1, The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(3); // return -1 (i.e., not found), The map is now \[\[1,1\], \[2,2\]\]
myHashMap.put(2, 1); // The map is now \[\[1,1\], \[2,1\]\] (i.e., update the existing value)
myHashMap.get(2); // return 1, The map is now \[\[1,1\], \[2,1\]\]
myHashMap.remove(2); // remove the mapping for 2, The map is now \[\[1,1\]\]
myHashMap.get(2); // return -1 (i.e., not found), The map is now \[\[1,1\]\]
**Constraints:**
* `0 <= key, value <= 106`
* At most `104` calls will be made to `put`, `get`, and `remove`. | null |
Video Solution | Explanation With Drawings | In Depth | Java | C++ | Python 3 | design-hashmap | 1 | 1 | # Intuition adn approach discussed in detail in video solution\nhttps://youtu.be/IF0Yv0XWLdc\n# Code\nJava\n```\nclass MyHashMap {\n //this array as will be used our hash map\n // the keys will be your indicies of the array and values will \n // elements stored at those indicies \n int map[] = null;\n public MyHashMap() {\n map = new int[1000001];\n //to represent no mapping of key value pair\n Arrays.fill(map, -1);\n }\n \n public void put(int key, int value) {\n map[key] = value;\n }\n \n public int get(int key) {\n return map[key];\n }\n \n public void remove(int key) {\n map[key] = -1;\n }\n}\n```\nC++\n```\nclass MyHashMap {\n std::vector<int> map;\npublic:\n MyHashMap() {\n map.resize(1000001, -1);\n }\n \n void put(int key, int value) {\n map[key] = value;\n }\n \n int get(int key) {\n return map[key];\n }\n \n void remove(int key) {\n map[key] = -1;\n }\n};\n```\nPython 3\n```\nclass MyHashMap:\n def __init__(self):\n self.map = [-1] * 1000001\n \n def put(self, key, value):\n self.map[key] = value\n \n def get(self, key):\n return self.map[key]\n \n def remove(self, key):\n self.map[key] = -1\n```\n | 2 | You are given the `head` of a linked list containing unique integer values and an integer array `nums` that is a subset of the linked list values.
Return _the number of connected components in_ `nums` _where two values are connected if they appear **consecutively** in the linked list_.
**Example 1:**
**Input:** head = \[0,1,2,3\], nums = \[0,1,3\]
**Output:** 2
**Explanation:** 0 and 1 are connected, so \[0, 1\] and \[3\] are the two connected components.
**Example 2:**
**Input:** head = \[0,1,2,3,4\], nums = \[0,3,1,4\]
**Output:** 2
**Explanation:** 0 and 1 are connected, 3 and 4 are connected, so \[0, 1\] and \[3, 4\] are the two connected components.
**Constraints:**
* The number of nodes in the linked list is `n`.
* `1 <= n <= 104`
* `0 <= Node.val < n`
* All the values `Node.val` are **unique**.
* `1 <= nums.length <= n`
* `0 <= nums[i] < n`
* All the values of `nums` are **unique**. | null |
TC O(1) SC O(10^6) beginner friendly solution using array easy to understand | design-hashmap | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nHere we will use O(10^6) Extra space using array\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThis is basically a simple solution and we take an Array of size 10^6+1, Initialize all the elements in the array from 0 to 10^6 to -1 (indicates element not present ), and keep storing the given value to given key.\n\nGet return the value of given key\'s index default value is -1 ---> indicates that element is not present;\nelse it return the value that had store on it\n\nPut assign the value of of given key\'s index with the given value\n\nRemove assign the value -1 to given key\'s index\n\nHowever We can use the linkedlist to achieve the solution\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(1)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(10^6)\n\n# Code\n```\nclass MyHashMap {\npublic:\n int data[1000001];\n MyHashMap() {\n fill(data, data + 1000000, -1);\n }\n void put(int key, int val) {\n data[key] = val;\n }\n int get(int key) {\n return data[key];\n }\n void remove(int key) {\n data[key] = -1;\n }\n};\n```\n\n | 2 | Design a HashMap without using any built-in hash table libraries.
Implement the `MyHashMap` class:
* `MyHashMap()` initializes the object with an empty map.
* `void put(int key, int value)` inserts a `(key, value)` pair into the HashMap. If the `key` already exists in the map, update the corresponding `value`.
* `int get(int key)` returns the `value` to which the specified `key` is mapped, or `-1` if this map contains no mapping for the `key`.
* `void remove(key)` removes the `key` and its corresponding `value` if the map contains the mapping for the `key`.
**Example 1:**
**Input**
\[ "MyHashMap ", "put ", "put ", "get ", "get ", "put ", "get ", "remove ", "get "\]
\[\[\], \[1, 1\], \[2, 2\], \[1\], \[3\], \[2, 1\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, 1, -1, null, 1, null, -1\]
**Explanation**
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // The map is now \[\[1,1\]\]
myHashMap.put(2, 2); // The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(1); // return 1, The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(3); // return -1 (i.e., not found), The map is now \[\[1,1\], \[2,2\]\]
myHashMap.put(2, 1); // The map is now \[\[1,1\], \[2,1\]\] (i.e., update the existing value)
myHashMap.get(2); // return 1, The map is now \[\[1,1\], \[2,1\]\]
myHashMap.remove(2); // remove the mapping for 2, The map is now \[\[1,1\]\]
myHashMap.get(2); // return -1 (i.e., not found), The map is now \[\[1,1\]\]
**Constraints:**
* `0 <= key, value <= 106`
* At most `104` calls will be made to `put`, `get`, and `remove`. | null |
TC O(1) SC O(10^6) beginner friendly solution using array easy to understand | design-hashmap | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nHere we will use O(10^6) Extra space using array\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThis is basically a simple solution and we take an Array of size 10^6+1, Initialize all the elements in the array from 0 to 10^6 to -1 (indicates element not present ), and keep storing the given value to given key.\n\nGet return the value of given key\'s index default value is -1 ---> indicates that element is not present;\nelse it return the value that had store on it\n\nPut assign the value of of given key\'s index with the given value\n\nRemove assign the value -1 to given key\'s index\n\nHowever We can use the linkedlist to achieve the solution\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(1)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(10^6)\n\n# Code\n```\nclass MyHashMap {\npublic:\n int data[1000001];\n MyHashMap() {\n fill(data, data + 1000000, -1);\n }\n void put(int key, int val) {\n data[key] = val;\n }\n int get(int key) {\n return data[key];\n }\n void remove(int key) {\n data[key] = -1;\n }\n};\n```\n\n | 2 | You are given the `head` of a linked list containing unique integer values and an integer array `nums` that is a subset of the linked list values.
Return _the number of connected components in_ `nums` _where two values are connected if they appear **consecutively** in the linked list_.
**Example 1:**
**Input:** head = \[0,1,2,3\], nums = \[0,1,3\]
**Output:** 2
**Explanation:** 0 and 1 are connected, so \[0, 1\] and \[3\] are the two connected components.
**Example 2:**
**Input:** head = \[0,1,2,3,4\], nums = \[0,3,1,4\]
**Output:** 2
**Explanation:** 0 and 1 are connected, 3 and 4 are connected, so \[0, 1\] and \[3, 4\] are the two connected components.
**Constraints:**
* The number of nodes in the linked list is `n`.
* `1 <= n <= 104`
* `0 <= Node.val < n`
* All the values `Node.val` are **unique**.
* `1 <= nums.length <= n`
* `0 <= nums[i] < n`
* All the values of `nums` are **unique**. | null |
Easiest way to Design HaspMap in Python | design-hashmap | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Initialization (Constructor):\n\n- - In the constructor __init__(), the MyHashMap class initializes its attributes.\n- - self.size represents the number of buckets in the hash map. In this case, it\'s set to 10.\n- - self.mp is the main data structure, a list of empty lists representing the buckets. Each bucket will store key-value pairs.\n2. Hashing Function:\n\n- - The hash() method calculates the index (bucket) where a given key should be stored. It uses the modulo operation with the size of the hash map to ensure that the index is within the valid range of buckets.\n3. Put Method:\n\n- - The put() method is used to insert a key-value pair into the hash map.\n- - It first calculates the index i where the key should be stored using the hash() method.\n- - It then checks if the key already exists in the bucket. If it does, it updates the existing value. Otherwise, it appends a new key-value pair to the bucket.\n4. Get Method:\n\n- - The get() method retrieves the value associated with a given key.\n- - It calculates the index i using the hash() method.\n- - It iterates through the bucket at index i and looks for a key match. If it finds a match, it returns the corresponding value. If no match is found, it returns -1 to indicate that the key doesn\'t exist in the hash map.\n5. Remove Method:\n\n- - The remove() method is used to delete a key-value pair from the hash map.\nIt calculates the index i using the hash() method.\n- - It iterates through the bucket at index i and looks for a key match. If it finds a match, it removes the key-value pair using del.\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass MyHashMap:\n def __init__(self):\n self.size = 10\n self.mp = [[] for _ in range(self.size)]\n\n def hash(self, key):\n return key % self.size\n\n def put(self, key, value):\n i = self.hash(key)\n bucket = self.mp[i]\n\n for idx, pair in enumerate(bucket):\n if pair[0] == key:\n bucket[idx] = (key, value)\n return\n\n bucket.append((key, value))\n\n def get(self, key):\n i = self.hash(key)\n bucket = self.mp[i]\n\n for pair in bucket:\n if pair[0] == key:\n return pair[1]\n\n return -1\n\n def remove(self, key):\n i = self.hash(key)\n bucket = self.mp[i]\n\n for idx, pair in enumerate(bucket):\n if pair[0] == key:\n del bucket[idx]\n return\n``` | 4 | Design a HashMap without using any built-in hash table libraries.
Implement the `MyHashMap` class:
* `MyHashMap()` initializes the object with an empty map.
* `void put(int key, int value)` inserts a `(key, value)` pair into the HashMap. If the `key` already exists in the map, update the corresponding `value`.
* `int get(int key)` returns the `value` to which the specified `key` is mapped, or `-1` if this map contains no mapping for the `key`.
* `void remove(key)` removes the `key` and its corresponding `value` if the map contains the mapping for the `key`.
**Example 1:**
**Input**
\[ "MyHashMap ", "put ", "put ", "get ", "get ", "put ", "get ", "remove ", "get "\]
\[\[\], \[1, 1\], \[2, 2\], \[1\], \[3\], \[2, 1\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, 1, -1, null, 1, null, -1\]
**Explanation**
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // The map is now \[\[1,1\]\]
myHashMap.put(2, 2); // The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(1); // return 1, The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(3); // return -1 (i.e., not found), The map is now \[\[1,1\], \[2,2\]\]
myHashMap.put(2, 1); // The map is now \[\[1,1\], \[2,1\]\] (i.e., update the existing value)
myHashMap.get(2); // return 1, The map is now \[\[1,1\], \[2,1\]\]
myHashMap.remove(2); // remove the mapping for 2, The map is now \[\[1,1\]\]
myHashMap.get(2); // return -1 (i.e., not found), The map is now \[\[1,1\]\]
**Constraints:**
* `0 <= key, value <= 106`
* At most `104` calls will be made to `put`, `get`, and `remove`. | null |
Easiest way to Design HaspMap in Python | design-hashmap | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Initialization (Constructor):\n\n- - In the constructor __init__(), the MyHashMap class initializes its attributes.\n- - self.size represents the number of buckets in the hash map. In this case, it\'s set to 10.\n- - self.mp is the main data structure, a list of empty lists representing the buckets. Each bucket will store key-value pairs.\n2. Hashing Function:\n\n- - The hash() method calculates the index (bucket) where a given key should be stored. It uses the modulo operation with the size of the hash map to ensure that the index is within the valid range of buckets.\n3. Put Method:\n\n- - The put() method is used to insert a key-value pair into the hash map.\n- - It first calculates the index i where the key should be stored using the hash() method.\n- - It then checks if the key already exists in the bucket. If it does, it updates the existing value. Otherwise, it appends a new key-value pair to the bucket.\n4. Get Method:\n\n- - The get() method retrieves the value associated with a given key.\n- - It calculates the index i using the hash() method.\n- - It iterates through the bucket at index i and looks for a key match. If it finds a match, it returns the corresponding value. If no match is found, it returns -1 to indicate that the key doesn\'t exist in the hash map.\n5. Remove Method:\n\n- - The remove() method is used to delete a key-value pair from the hash map.\nIt calculates the index i using the hash() method.\n- - It iterates through the bucket at index i and looks for a key match. If it finds a match, it removes the key-value pair using del.\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass MyHashMap:\n def __init__(self):\n self.size = 10\n self.mp = [[] for _ in range(self.size)]\n\n def hash(self, key):\n return key % self.size\n\n def put(self, key, value):\n i = self.hash(key)\n bucket = self.mp[i]\n\n for idx, pair in enumerate(bucket):\n if pair[0] == key:\n bucket[idx] = (key, value)\n return\n\n bucket.append((key, value))\n\n def get(self, key):\n i = self.hash(key)\n bucket = self.mp[i]\n\n for pair in bucket:\n if pair[0] == key:\n return pair[1]\n\n return -1\n\n def remove(self, key):\n i = self.hash(key)\n bucket = self.mp[i]\n\n for idx, pair in enumerate(bucket):\n if pair[0] == key:\n del bucket[idx]\n return\n``` | 4 | You are given the `head` of a linked list containing unique integer values and an integer array `nums` that is a subset of the linked list values.
Return _the number of connected components in_ `nums` _where two values are connected if they appear **consecutively** in the linked list_.
**Example 1:**
**Input:** head = \[0,1,2,3\], nums = \[0,1,3\]
**Output:** 2
**Explanation:** 0 and 1 are connected, so \[0, 1\] and \[3\] are the two connected components.
**Example 2:**
**Input:** head = \[0,1,2,3,4\], nums = \[0,3,1,4\]
**Output:** 2
**Explanation:** 0 and 1 are connected, 3 and 4 are connected, so \[0, 1\] and \[3, 4\] are the two connected components.
**Constraints:**
* The number of nodes in the linked list is `n`.
* `1 <= n <= 104`
* `0 <= Node.val < n`
* All the values `Node.val` are **unique**.
* `1 <= nums.length <= n`
* `0 <= nums[i] < n`
* All the values of `nums` are **unique**. | null |
One-Liner Short and Concise TC: O(1) SC: O(N) | design-hashmap | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(1) for put and get operations.\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(N) where N is 10^6\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass MyHashMap:\n\n def __init__(self):\n MAX_ARR=10**6+1\n self.arr_map=[-1]*(MAX_ARR)\n\n def put(self, key: int, value: int) -> None:\n self.arr_map[key]=value\n\n def get(self, key: int) -> int:\n return self.arr_map[key]\n\n def remove(self, key: int) -> None:\n self.arr_map[key]=-1\n\n\n# Your MyHashMap object will be instantiated and called as such:\n# obj = MyHashMap()\n# obj.put(key,value)\n# param_2 = obj.get(key)\n# obj.remove(key)\n``` | 1 | Design a HashMap without using any built-in hash table libraries.
Implement the `MyHashMap` class:
* `MyHashMap()` initializes the object with an empty map.
* `void put(int key, int value)` inserts a `(key, value)` pair into the HashMap. If the `key` already exists in the map, update the corresponding `value`.
* `int get(int key)` returns the `value` to which the specified `key` is mapped, or `-1` if this map contains no mapping for the `key`.
* `void remove(key)` removes the `key` and its corresponding `value` if the map contains the mapping for the `key`.
**Example 1:**
**Input**
\[ "MyHashMap ", "put ", "put ", "get ", "get ", "put ", "get ", "remove ", "get "\]
\[\[\], \[1, 1\], \[2, 2\], \[1\], \[3\], \[2, 1\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, 1, -1, null, 1, null, -1\]
**Explanation**
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // The map is now \[\[1,1\]\]
myHashMap.put(2, 2); // The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(1); // return 1, The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(3); // return -1 (i.e., not found), The map is now \[\[1,1\], \[2,2\]\]
myHashMap.put(2, 1); // The map is now \[\[1,1\], \[2,1\]\] (i.e., update the existing value)
myHashMap.get(2); // return 1, The map is now \[\[1,1\], \[2,1\]\]
myHashMap.remove(2); // remove the mapping for 2, The map is now \[\[1,1\]\]
myHashMap.get(2); // return -1 (i.e., not found), The map is now \[\[1,1\]\]
**Constraints:**
* `0 <= key, value <= 106`
* At most `104` calls will be made to `put`, `get`, and `remove`. | null |
One-Liner Short and Concise TC: O(1) SC: O(N) | design-hashmap | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(1) for put and get operations.\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(N) where N is 10^6\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass MyHashMap:\n\n def __init__(self):\n MAX_ARR=10**6+1\n self.arr_map=[-1]*(MAX_ARR)\n\n def put(self, key: int, value: int) -> None:\n self.arr_map[key]=value\n\n def get(self, key: int) -> int:\n return self.arr_map[key]\n\n def remove(self, key: int) -> None:\n self.arr_map[key]=-1\n\n\n# Your MyHashMap object will be instantiated and called as such:\n# obj = MyHashMap()\n# obj.put(key,value)\n# param_2 = obj.get(key)\n# obj.remove(key)\n``` | 1 | You are given the `head` of a linked list containing unique integer values and an integer array `nums` that is a subset of the linked list values.
Return _the number of connected components in_ `nums` _where two values are connected if they appear **consecutively** in the linked list_.
**Example 1:**
**Input:** head = \[0,1,2,3\], nums = \[0,1,3\]
**Output:** 2
**Explanation:** 0 and 1 are connected, so \[0, 1\] and \[3\] are the two connected components.
**Example 2:**
**Input:** head = \[0,1,2,3,4\], nums = \[0,3,1,4\]
**Output:** 2
**Explanation:** 0 and 1 are connected, 3 and 4 are connected, so \[0, 1\] and \[3, 4\] are the two connected components.
**Constraints:**
* The number of nodes in the linked list is `n`.
* `1 <= n <= 104`
* `0 <= Node.val < n`
* All the values `Node.val` are **unique**.
* `1 <= nums.length <= n`
* `0 <= nums[i] < n`
* All the values of `nums` are **unique**. | null |
1 Line functions - Simple Approach - O(1) Get, Put, Remove | design-hashmap | 0 | 1 | # Intuition\nUsed constraints to assist with finding solution.\n\n# Approach\nDefine array with -1 as default value, if the value doesn\'t exist in a get we\'ll return a -1, otherwise just overwrite.\n\n# Complexity\n- Time complexity:\nGET: $$O(1)$$\nPUT: $$O(1)$$\nREMOVE: $$O(1)$$\n\nindex the array / key / index\n\n- Space complexity:\n$$O(10E6)$$\n# Code\n```\nclass MyHashMap:\n\n def __init__(self):\n self.map = [-1] * 10000000\n\n def put(self, key: int, value: int) -> None:\n self.map[key] = value\n\n def get(self, key: int) -> int:\n return self.map[key]\n\n def remove(self, key: int) -> None:\n self.map[key] = -1\n \n``` | 1 | Design a HashMap without using any built-in hash table libraries.
Implement the `MyHashMap` class:
* `MyHashMap()` initializes the object with an empty map.
* `void put(int key, int value)` inserts a `(key, value)` pair into the HashMap. If the `key` already exists in the map, update the corresponding `value`.
* `int get(int key)` returns the `value` to which the specified `key` is mapped, or `-1` if this map contains no mapping for the `key`.
* `void remove(key)` removes the `key` and its corresponding `value` if the map contains the mapping for the `key`.
**Example 1:**
**Input**
\[ "MyHashMap ", "put ", "put ", "get ", "get ", "put ", "get ", "remove ", "get "\]
\[\[\], \[1, 1\], \[2, 2\], \[1\], \[3\], \[2, 1\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, 1, -1, null, 1, null, -1\]
**Explanation**
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // The map is now \[\[1,1\]\]
myHashMap.put(2, 2); // The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(1); // return 1, The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(3); // return -1 (i.e., not found), The map is now \[\[1,1\], \[2,2\]\]
myHashMap.put(2, 1); // The map is now \[\[1,1\], \[2,1\]\] (i.e., update the existing value)
myHashMap.get(2); // return 1, The map is now \[\[1,1\], \[2,1\]\]
myHashMap.remove(2); // remove the mapping for 2, The map is now \[\[1,1\]\]
myHashMap.get(2); // return -1 (i.e., not found), The map is now \[\[1,1\]\]
**Constraints:**
* `0 <= key, value <= 106`
* At most `104` calls will be made to `put`, `get`, and `remove`. | null |
1 Line functions - Simple Approach - O(1) Get, Put, Remove | design-hashmap | 0 | 1 | # Intuition\nUsed constraints to assist with finding solution.\n\n# Approach\nDefine array with -1 as default value, if the value doesn\'t exist in a get we\'ll return a -1, otherwise just overwrite.\n\n# Complexity\n- Time complexity:\nGET: $$O(1)$$\nPUT: $$O(1)$$\nREMOVE: $$O(1)$$\n\nindex the array / key / index\n\n- Space complexity:\n$$O(10E6)$$\n# Code\n```\nclass MyHashMap:\n\n def __init__(self):\n self.map = [-1] * 10000000\n\n def put(self, key: int, value: int) -> None:\n self.map[key] = value\n\n def get(self, key: int) -> int:\n return self.map[key]\n\n def remove(self, key: int) -> None:\n self.map[key] = -1\n \n``` | 1 | You are given the `head` of a linked list containing unique integer values and an integer array `nums` that is a subset of the linked list values.
Return _the number of connected components in_ `nums` _where two values are connected if they appear **consecutively** in the linked list_.
**Example 1:**
**Input:** head = \[0,1,2,3\], nums = \[0,1,3\]
**Output:** 2
**Explanation:** 0 and 1 are connected, so \[0, 1\] and \[3\] are the two connected components.
**Example 2:**
**Input:** head = \[0,1,2,3,4\], nums = \[0,3,1,4\]
**Output:** 2
**Explanation:** 0 and 1 are connected, 3 and 4 are connected, so \[0, 1\] and \[3, 4\] are the two connected components.
**Constraints:**
* The number of nodes in the linked list is `n`.
* `1 <= n <= 104`
* `0 <= Node.val < n`
* All the values `Node.val` are **unique**.
* `1 <= nums.length <= n`
* `0 <= nums[i] < n`
* All the values of `nums` are **unique**. | null |
Python3 Solution | design-hashmap | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass MyHashMap:\n\n def __init__(self):\n MAX=10**6+5\n self.lookup=[None]*MAX\n \n\n def put(self, key: int, value: int) -> None:\n self.lookup[key]=value\n\n def get(self, key: int) -> int:\n if self.lookup[key]==None:\n return -1\n return self.lookup[key]\n\n\n def remove(self, key: int) -> None:\n self.lookup[key]=None\n \n\n\n# Your MyHashMap object will be instantiated and called as such:\n# obj = MyHashMap()\n# obj.put(key,value)\n# param_2 = obj.get(key)\n# obj.remove(key)\n``` | 2 | Design a HashMap without using any built-in hash table libraries.
Implement the `MyHashMap` class:
* `MyHashMap()` initializes the object with an empty map.
* `void put(int key, int value)` inserts a `(key, value)` pair into the HashMap. If the `key` already exists in the map, update the corresponding `value`.
* `int get(int key)` returns the `value` to which the specified `key` is mapped, or `-1` if this map contains no mapping for the `key`.
* `void remove(key)` removes the `key` and its corresponding `value` if the map contains the mapping for the `key`.
**Example 1:**
**Input**
\[ "MyHashMap ", "put ", "put ", "get ", "get ", "put ", "get ", "remove ", "get "\]
\[\[\], \[1, 1\], \[2, 2\], \[1\], \[3\], \[2, 1\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, 1, -1, null, 1, null, -1\]
**Explanation**
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // The map is now \[\[1,1\]\]
myHashMap.put(2, 2); // The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(1); // return 1, The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(3); // return -1 (i.e., not found), The map is now \[\[1,1\], \[2,2\]\]
myHashMap.put(2, 1); // The map is now \[\[1,1\], \[2,1\]\] (i.e., update the existing value)
myHashMap.get(2); // return 1, The map is now \[\[1,1\], \[2,1\]\]
myHashMap.remove(2); // remove the mapping for 2, The map is now \[\[1,1\]\]
myHashMap.get(2); // return -1 (i.e., not found), The map is now \[\[1,1\]\]
**Constraints:**
* `0 <= key, value <= 106`
* At most `104` calls will be made to `put`, `get`, and `remove`. | null |
Python3 Solution | design-hashmap | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass MyHashMap:\n\n def __init__(self):\n MAX=10**6+5\n self.lookup=[None]*MAX\n \n\n def put(self, key: int, value: int) -> None:\n self.lookup[key]=value\n\n def get(self, key: int) -> int:\n if self.lookup[key]==None:\n return -1\n return self.lookup[key]\n\n\n def remove(self, key: int) -> None:\n self.lookup[key]=None\n \n\n\n# Your MyHashMap object will be instantiated and called as such:\n# obj = MyHashMap()\n# obj.put(key,value)\n# param_2 = obj.get(key)\n# obj.remove(key)\n``` | 2 | You are given the `head` of a linked list containing unique integer values and an integer array `nums` that is a subset of the linked list values.
Return _the number of connected components in_ `nums` _where two values are connected if they appear **consecutively** in the linked list_.
**Example 1:**
**Input:** head = \[0,1,2,3\], nums = \[0,1,3\]
**Output:** 2
**Explanation:** 0 and 1 are connected, so \[0, 1\] and \[3\] are the two connected components.
**Example 2:**
**Input:** head = \[0,1,2,3,4\], nums = \[0,3,1,4\]
**Output:** 2
**Explanation:** 0 and 1 are connected, 3 and 4 are connected, so \[0, 1\] and \[3, 4\] are the two connected components.
**Constraints:**
* The number of nodes in the linked list is `n`.
* `1 <= n <= 104`
* `0 <= Node.val < n`
* All the values `Node.val` are **unique**.
* `1 <= nums.length <= n`
* `0 <= nums[i] < n`
* All the values of `nums` are **unique**. | null |
Beginner-friendly || Simple solution with HashMap in Python3/TypeScript | design-hashmap | 0 | 1 | # Intuition\nOur goal is to design the [HashMap DS](https://en.wikipedia.org/wiki/Hash_table).\n\n```\n# This data structure is one of common in using.\n\n# The approximated inner implementation is to map KEYS to VALUES.\n# {"1": "test", "2": "test1"}\n\n# At most cases a key has a string/integer type, while a value\n# can have a different type.\n\n# HashMap Time Complexity is O(1) to search/index/delete/put/create\n# items and O(n) to store them, respectively.\n```\n\n# Approach\n1. initialize an empty `map`\n2. implement `put` method to create/update `key` values\n3. implement `get` method to get value by key, if the `key` isn\'t in `map`, return `-1`\n4. implement `remove` method to delete the value by `key`\n\n# Complexity\n- Time complexity: **O(1)**, for all operations.\n\n- Space complexity: **O(n)**, to store keys in `map`.\n\n# Code in Python3\n```\nclass MyHashMap:\n\n def __init__(self):\n self.map = dict()\n\n def put(self, key: int, value: int) -> None:\n self.map[key] = value\n\n def get(self, key: int) -> int:\n return self.map[key] if key in self.map else -1\n\n def remove(self, key: int) -> None:\n if key in self.map: del self.map[key]\n```\n\n# Code in TypeScript\n```\nclass MyHashMap {\n map = {}\n\n put(key: number, value: number): void {\n this.map[key] = value\n }\n\n get(key: number): number {\n return key in this.map ? this.map[key] : -1\n }\n\n remove(key: number): void {\n delete this.map[key]\n }\n}\n\n/**\n * Your MyHashMap object will be instantiated and called as such:\n * var obj = new MyHashMap()\n * obj.put(key,value)\n * var param_2 = obj.get(key)\n * obj.remove(key)\n */\n``` | 1 | Design a HashMap without using any built-in hash table libraries.
Implement the `MyHashMap` class:
* `MyHashMap()` initializes the object with an empty map.
* `void put(int key, int value)` inserts a `(key, value)` pair into the HashMap. If the `key` already exists in the map, update the corresponding `value`.
* `int get(int key)` returns the `value` to which the specified `key` is mapped, or `-1` if this map contains no mapping for the `key`.
* `void remove(key)` removes the `key` and its corresponding `value` if the map contains the mapping for the `key`.
**Example 1:**
**Input**
\[ "MyHashMap ", "put ", "put ", "get ", "get ", "put ", "get ", "remove ", "get "\]
\[\[\], \[1, 1\], \[2, 2\], \[1\], \[3\], \[2, 1\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, 1, -1, null, 1, null, -1\]
**Explanation**
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // The map is now \[\[1,1\]\]
myHashMap.put(2, 2); // The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(1); // return 1, The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(3); // return -1 (i.e., not found), The map is now \[\[1,1\], \[2,2\]\]
myHashMap.put(2, 1); // The map is now \[\[1,1\], \[2,1\]\] (i.e., update the existing value)
myHashMap.get(2); // return 1, The map is now \[\[1,1\], \[2,1\]\]
myHashMap.remove(2); // remove the mapping for 2, The map is now \[\[1,1\]\]
myHashMap.get(2); // return -1 (i.e., not found), The map is now \[\[1,1\]\]
**Constraints:**
* `0 <= key, value <= 106`
* At most `104` calls will be made to `put`, `get`, and `remove`. | null |
Beginner-friendly || Simple solution with HashMap in Python3/TypeScript | design-hashmap | 0 | 1 | # Intuition\nOur goal is to design the [HashMap DS](https://en.wikipedia.org/wiki/Hash_table).\n\n```\n# This data structure is one of common in using.\n\n# The approximated inner implementation is to map KEYS to VALUES.\n# {"1": "test", "2": "test1"}\n\n# At most cases a key has a string/integer type, while a value\n# can have a different type.\n\n# HashMap Time Complexity is O(1) to search/index/delete/put/create\n# items and O(n) to store them, respectively.\n```\n\n# Approach\n1. initialize an empty `map`\n2. implement `put` method to create/update `key` values\n3. implement `get` method to get value by key, if the `key` isn\'t in `map`, return `-1`\n4. implement `remove` method to delete the value by `key`\n\n# Complexity\n- Time complexity: **O(1)**, for all operations.\n\n- Space complexity: **O(n)**, to store keys in `map`.\n\n# Code in Python3\n```\nclass MyHashMap:\n\n def __init__(self):\n self.map = dict()\n\n def put(self, key: int, value: int) -> None:\n self.map[key] = value\n\n def get(self, key: int) -> int:\n return self.map[key] if key in self.map else -1\n\n def remove(self, key: int) -> None:\n if key in self.map: del self.map[key]\n```\n\n# Code in TypeScript\n```\nclass MyHashMap {\n map = {}\n\n put(key: number, value: number): void {\n this.map[key] = value\n }\n\n get(key: number): number {\n return key in this.map ? this.map[key] : -1\n }\n\n remove(key: number): void {\n delete this.map[key]\n }\n}\n\n/**\n * Your MyHashMap object will be instantiated and called as such:\n * var obj = new MyHashMap()\n * obj.put(key,value)\n * var param_2 = obj.get(key)\n * obj.remove(key)\n */\n``` | 1 | You are given the `head` of a linked list containing unique integer values and an integer array `nums` that is a subset of the linked list values.
Return _the number of connected components in_ `nums` _where two values are connected if they appear **consecutively** in the linked list_.
**Example 1:**
**Input:** head = \[0,1,2,3\], nums = \[0,1,3\]
**Output:** 2
**Explanation:** 0 and 1 are connected, so \[0, 1\] and \[3\] are the two connected components.
**Example 2:**
**Input:** head = \[0,1,2,3,4\], nums = \[0,3,1,4\]
**Output:** 2
**Explanation:** 0 and 1 are connected, 3 and 4 are connected, so \[0, 1\] and \[3, 4\] are the two connected components.
**Constraints:**
* The number of nodes in the linked list is `n`.
* `1 <= n <= 104`
* `0 <= Node.val < n`
* All the values `Node.val` are **unique**.
* `1 <= nums.length <= n`
* `0 <= nums[i] < n`
* All the values of `nums` are **unique**. | null |
【Video】How we think about a solution - Python, JavaScript, Java, C++ | design-hashmap | 1 | 1 | Welcome to my post! This post starts with "How we think about a solution". In other words, that is my thought process to solve the question. This post explains how I get to my solution instead of just posting solution codes or out of blue algorithms. I hope it is helpful for someone.\n\n# Intuition\nUsing Linked List to store data\n\n---\n\n# Solution Video\n\nhttps://youtu.be/k7rm2jq5Ams\n\n\u25A0 Timeline of the video\n`0:00` Read the question of Number of Design HashMap\n`0:42` How we think about a solution\n`2:25` Coding\n`10:52` Time Complexity and Space Complexity\n\n### \u2B50\uFE0F\u2B50\uFE0F Don\'t forget to subscribe to my channel! \u2B50\uFE0F\u2B50\uFE0F\n\n**\u25A0 Subscribe URL**\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\nSubscribers: 2,606\nMy initial goal is 10,000\nThank you for your support!\n\n---\n\n# Approach\n### How we think about a solution\n\nWe have constraints saying "without using any built-in hash table libraries" and "At most `10^4` calls will be made to `put`, `get`, and `remove`". Given that we might have the same hash key, we can\'t use `Set`and hard to use `Tree`, so seems like simply we should use `Array` with `Linked List`.\n\n---\n\u2B50\uFE0F Points\n\n- Why do we use `Linked List`?\nThat\'s because basically `Array` can keep one data in a place(index). But there is possibility that we have the same hash key with different data. In that case, we need to put multiple data in the same place. That\'s why we need to connect each data with links.\n\nFor example,\n```\n[0] \u2192 node1 \u2192 node2 \u2192 node3\n[1] \u2192 node1 \u2192 node2\n[2] \u2192 node1 \u2192 node2 \u2192 node3 \u2192 node4\n```\n`[0]`,`[1]`,`[2]` are `Array` and `node` part is `Linked List` \n\n---\n\nLet\'s see one by one. First of all, `constructor`.\n\n- constructor\n\nIn `constructor`, we create `Array` with length of `1000 (10^4)`. I think it\'s good idea to create default node `1000` times and put them at each index of the `Array`, so that we can connect data immediately.\n\nInitializing with Length of `1000` is very important because we want to use the length when we calcualte `hash key`. Let\'s see `hash`\n\n- hash function\n\nThere are many ways to calculate hash key but the simplest way to calculate it is `modulo`. the formula is\n\n```\nkey % length of Array(1000)\n```\n\nThat\'s why we should initialize `Array` with length of `1000` in `constructor`. If `Array` is empty, we have to divide by `0`.\n\n- put function\n\nFirst of all, try to get `default node` with a `key`.\n\n`default node` doesn\'t have any data, so check `node.next.key` until we find `target key`. If we find the same key, update the value with new value. If not, put new data to `node.next`. That `node` should be `default node`.\n\n- get function\n\nWe do the almost same thing. First of all, try to get `default node` with a `key`. Check `node.next.key` until we find `target key`.\n\nIf we find the same key, just return `value`. If not, return `-1`\n\n- remove function\n\nFirst of all, try to get `default node` with a `key`. Check `node.next.key` until we find `target key`.\n\nIf we find the target key, connect `node.next` and `node.next.next`, so that we can remove `node.next`.\n\nIt works like this. Let\'s say node2.key is a target key.\n```\n[0] \u2192 node1 \u2192 node2 \u2192 node3\n\nFrom node1, node1.next.next should be node3, \nso update node1.next with node1.next.next which is node 3.\nIn the end, Linked List should be\n\n[0] \u2192 node1 \u2192 node3\n```\n\nAlgorithm Overview:\n1. Initialize a hash map using chaining for collision resolution.\n2. Implement methods to insert a key-value pair, retrieve the value for a given key, and remove a key-value pair.\n\nDetailed Explanation:\n1. **Node Class**:\n - Create a class `Node` to represent key-value pairs.\n - Initialize the `Node` with a key (default to -1), value (default to -1), and a reference to the next node (default to None).\n\n2. **MyHashMap Class Initialization**:\n - Create a class `MyHashMap` to represent the hash map.\n - Initialize an array `map` to store nodes, with a length of 1000.\n - For each index in the `map` array, create a new `Node` and append it to the array.\n\n3. **Put Method**:\n - Accepts a `key` (integer) and a `value` (integer).\n - Calculate the hash using the `hash` method based on the key.\n - Access the node at the calculated hash index.\n - Traverse the linked list starting from this node.\n - If a node with the given key is found, update its value and return.\n - If the end of the linked list is reached, add a new node with the given key and value.\n\n4. **Get Method**:\n - Accepts a `key` (integer).\n - Calculate the hash using the `hash` method based on the key.\n - Access the node at the calculated hash index.\n - Traverse the linked list starting from this node.\n - If a node with the given key is found, return its value.\n - If the end of the linked list is reached, return -1.\n\n5. **Remove Method**:\n - Accepts a `key` (integer).\n - Calculate the hash using the `hash` method based on the key.\n - Access the node at the calculated hash index.\n - Traverse the linked list starting from this node.\n - If a node with the given key is found, remove it by adjusting the next reference.\n - If the end of the linked list is reached, do nothing.\n\n6. **Hash Method**:\n - Accepts a `key` (integer).\n - Calculate the hash by taking the remainder of the key divided by the length of the `map` array.\n\n# Complexity\n\nTime Complexity:\n- Insertion (put): O(1) on average, assuming a good hash function and uniform distribution of keys. However, in the worst case, it could be O(n) if all keys hash to the same index, and we have to traverse a long linked list.\n- Retrieval (get): O(1) on average for the same reasons as insertion. In the worst case (all keys hashing to the same index), it could be O(n) due to traversing the linked list.\n- Deletion (remove): O(1) on average, similar to insertion and retrieval. In the worst case (all keys hashing to the same index), it could be O(n) due to traversing the linked list.\n\nSpace Complexity:\n- The space complexity of the hash map is O(n + m), where n is the number of buckets in the hash map (in this case, 1000), and m is the number of unique keys inserted into the hash map.\n- Additionally, the space complexity of each node (i.e., key, value, next) is O(1), as it does not depend on the size of the input or the total number of elements in the hash map.\n\nOverall, the space complexity is dominated by the size of the array used to store buckets and the unique keys inserted into the hash map, resulting in O(n + m) space complexity.\n\n```python []\nclass Node:\n def __init__(self, key = -1, val = -1, next = None):\n self.key = key\n self.val = val\n self.next = next\n\nclass MyHashMap:\n\n def __init__(self):\n self.map = []\n\n for _ in range(1000):\n self.map.append(Node())\n\n def put(self, key: int, value: int) -> None:\n cur = self.map[self.hash(key)]\n\n while cur.next:\n if cur.next.key == key:\n cur.next.val = value\n return\n \n cur = cur.next\n\n cur.next = Node(key, value)\n\n def get(self, key: int) -> int:\n cur = self.map[self.hash(key)]\n\n while cur.next:\n if cur.next.key == key:\n return cur.next.val\n cur = cur.next\n\n return -1\n \n def remove(self, key: int) -> None:\n cur = self.map[self.hash(key)]\n\n while cur.next:\n if cur.next.key == key:\n cur.next = cur.next.next\n return\n\n cur = cur.next\n\n def hash(self, key):\n return key % len(self.map) \n\n\n# Your MyHashMap object will be instantiated and called as such:\n# obj = MyHashMap()\n# obj.put(key,value)\n# param_2 = obj.get(key)\n# obj.remove(key)\n```\n```javascript []\nclass Node {\n constructor(key = -1, val = -1, next = null) {\n this.key = key;\n this.val = val;\n this.next = next;\n }\n}\n\nclass MyHashMap {\n constructor() {\n this.map = new Array(1000).fill(null).map(() => new Node());\n }\n\n /** \n * @param {number} key \n * @param {number} value\n * @return {void}\n */\n put(key, value) {\n let cur = this.map[this.hash(key)];\n\n while (cur.next) {\n if (cur.next.key === key) {\n cur.next.val = value;\n return;\n }\n\n cur = cur.next;\n }\n\n cur.next = new Node(key, value);\n }\n\n /** \n * @param {number} key\n * @return {number}\n */\n get(key) {\n let cur = this.map[this.hash(key)];\n\n while (cur.next) {\n if (cur.next.key === key) {\n return cur.next.val;\n }\n\n cur = cur.next;\n }\n\n return -1;\n }\n\n /** \n * @param {number} key\n * @return {void}\n */\n remove(key) {\n let cur = this.map[this.hash(key)];\n\n while (cur.next) {\n if (cur.next.key === key) {\n cur.next = cur.next.next;\n return;\n }\n\n cur = cur.next;\n }\n }\n\n /** \n * @param {number} key\n * @return {number}\n */\n hash(key) {\n return key % this.map.length;\n }\n}\n```\n```java []\nclass Node {\n int key;\n int val;\n Node next;\n\n Node(int key, int val) {\n this.key = key;\n this.val = val;\n this.next = null;\n }\n}\n\nclass MyHashMap {\n\n private Node[] map;\n\n public MyHashMap() {\n map = new Node[1000];\n for (int i = 0; i < 1000; i++) {\n map[i] = new Node(-1, -1);\n }\n }\n\n public void put(int key, int value) {\n int hash = hash(key);\n Node cur = map[hash];\n\n while (cur.next != null) {\n if (cur.next.key == key) {\n cur.next.val = value;\n return;\n }\n cur = cur.next;\n }\n\n cur.next = new Node(key, value);\n }\n\n public int get(int key) {\n int hash = hash(key);\n Node cur = map[hash].next;\n\n while (cur != null) {\n if (cur.key == key)\n return cur.val;\n cur = cur.next;\n }\n\n return -1;\n }\n\n public void remove(int key) {\n int hash = hash(key);\n Node cur = map[hash];\n\n while (cur.next != null) {\n if (cur.next.key == key) {\n cur.next = cur.next.next;\n return;\n }\n cur = cur.next;\n }\n }\n\n private int hash(int key) {\n return key % 1000;\n }\n}\n\n/**\n * Your MyHashMap object will be instantiated and called as such:\n * MyHashMap obj = new MyHashMap();\n * obj.put(key,value);\n * int param_2 = obj.get(key);\n * obj.remove(key);\n */\n```\n```C++ []\nclass Node {\npublic:\n int key;\n int val;\n Node* next;\n\n Node(int k = -1, int v = -1, Node* n = nullptr) : key(k), val(v), next(n) {}\n};\n\nclass MyHashMap {\nprivate:\n vector<Node*> map;\n\npublic:\n MyHashMap() {\n map.resize(1000);\n for (int i = 0; i < 1000; ++i) {\n map[i] = new Node();\n }\n }\n\n int hash(int key) {\n return key % 1000;\n }\n\n void put(int key, int value) {\n int hash_key = hash(key);\n Node* cur = map[hash_key];\n\n while (cur->next) {\n if (cur->next->key == key) {\n cur->next->val = value;\n return;\n }\n cur = cur->next;\n }\n\n cur->next = new Node(key, value);\n }\n\n int get(int key) {\n int hash_key = hash(key);\n Node* cur = map[hash_key];\n\n while (cur->next) {\n if (cur->next->key == key) {\n return cur->next->val;\n }\n cur = cur->next;\n }\n\n return -1;\n }\n\n void remove(int key) {\n int hash_key = hash(key);\n Node* cur = map[hash_key];\n\n while (cur->next) {\n if (cur->next->key == key) {\n Node* temp = cur->next;\n cur->next = cur->next->next;\n delete temp;\n return;\n }\n cur = cur->next;\n }\n }\n};\n\n\n\n/**\n * Your MyHashMap object will be instantiated and called as such:\n * MyHashMap* obj = new MyHashMap();\n * obj->put(key,value);\n * int param_2 = obj->get(key);\n * obj->remove(key);\n */\n```\n\n---\n\nThank you for reading my post.\n\u2B50\uFE0F Please upvote it and don\'t forget to subscribe to my channel!\n\nMy next post for daily coding challenge on October 5th, 2023\nhttps://leetcode.com/problems/majority-element-ii/solutions/4131998/video-how-we-think-about-a-solution-boyer-moore-majority-vote-algorithm/ | 24 | Design a HashMap without using any built-in hash table libraries.
Implement the `MyHashMap` class:
* `MyHashMap()` initializes the object with an empty map.
* `void put(int key, int value)` inserts a `(key, value)` pair into the HashMap. If the `key` already exists in the map, update the corresponding `value`.
* `int get(int key)` returns the `value` to which the specified `key` is mapped, or `-1` if this map contains no mapping for the `key`.
* `void remove(key)` removes the `key` and its corresponding `value` if the map contains the mapping for the `key`.
**Example 1:**
**Input**
\[ "MyHashMap ", "put ", "put ", "get ", "get ", "put ", "get ", "remove ", "get "\]
\[\[\], \[1, 1\], \[2, 2\], \[1\], \[3\], \[2, 1\], \[2\], \[2\], \[2\]\]
**Output**
\[null, null, null, 1, -1, null, 1, null, -1\]
**Explanation**
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // The map is now \[\[1,1\]\]
myHashMap.put(2, 2); // The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(1); // return 1, The map is now \[\[1,1\], \[2,2\]\]
myHashMap.get(3); // return -1 (i.e., not found), The map is now \[\[1,1\], \[2,2\]\]
myHashMap.put(2, 1); // The map is now \[\[1,1\], \[2,1\]\] (i.e., update the existing value)
myHashMap.get(2); // return 1, The map is now \[\[1,1\], \[2,1\]\]
myHashMap.remove(2); // remove the mapping for 2, The map is now \[\[1,1\]\]
myHashMap.get(2); // return -1 (i.e., not found), The map is now \[\[1,1\]\]
**Constraints:**
* `0 <= key, value <= 106`
* At most `104` calls will be made to `put`, `get`, and `remove`. | null |
【Video】How we think about a solution - Python, JavaScript, Java, C++ | design-hashmap | 1 | 1 | Welcome to my post! This post starts with "How we think about a solution". In other words, that is my thought process to solve the question. This post explains how I get to my solution instead of just posting solution codes or out of blue algorithms. I hope it is helpful for someone.\n\n# Intuition\nUsing Linked List to store data\n\n---\n\n# Solution Video\n\nhttps://youtu.be/k7rm2jq5Ams\n\n\u25A0 Timeline of the video\n`0:00` Read the question of Number of Design HashMap\n`0:42` How we think about a solution\n`2:25` Coding\n`10:52` Time Complexity and Space Complexity\n\n### \u2B50\uFE0F\u2B50\uFE0F Don\'t forget to subscribe to my channel! \u2B50\uFE0F\u2B50\uFE0F\n\n**\u25A0 Subscribe URL**\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\nSubscribers: 2,606\nMy initial goal is 10,000\nThank you for your support!\n\n---\n\n# Approach\n### How we think about a solution\n\nWe have constraints saying "without using any built-in hash table libraries" and "At most `10^4` calls will be made to `put`, `get`, and `remove`". Given that we might have the same hash key, we can\'t use `Set`and hard to use `Tree`, so seems like simply we should use `Array` with `Linked List`.\n\n---\n\u2B50\uFE0F Points\n\n- Why do we use `Linked List`?\nThat\'s because basically `Array` can keep one data in a place(index). But there is possibility that we have the same hash key with different data. In that case, we need to put multiple data in the same place. That\'s why we need to connect each data with links.\n\nFor example,\n```\n[0] \u2192 node1 \u2192 node2 \u2192 node3\n[1] \u2192 node1 \u2192 node2\n[2] \u2192 node1 \u2192 node2 \u2192 node3 \u2192 node4\n```\n`[0]`,`[1]`,`[2]` are `Array` and `node` part is `Linked List` \n\n---\n\nLet\'s see one by one. First of all, `constructor`.\n\n- constructor\n\nIn `constructor`, we create `Array` with length of `1000 (10^4)`. I think it\'s good idea to create default node `1000` times and put them at each index of the `Array`, so that we can connect data immediately.\n\nInitializing with Length of `1000` is very important because we want to use the length when we calcualte `hash key`. Let\'s see `hash`\n\n- hash function\n\nThere are many ways to calculate hash key but the simplest way to calculate it is `modulo`. the formula is\n\n```\nkey % length of Array(1000)\n```\n\nThat\'s why we should initialize `Array` with length of `1000` in `constructor`. If `Array` is empty, we have to divide by `0`.\n\n- put function\n\nFirst of all, try to get `default node` with a `key`.\n\n`default node` doesn\'t have any data, so check `node.next.key` until we find `target key`. If we find the same key, update the value with new value. If not, put new data to `node.next`. That `node` should be `default node`.\n\n- get function\n\nWe do the almost same thing. First of all, try to get `default node` with a `key`. Check `node.next.key` until we find `target key`.\n\nIf we find the same key, just return `value`. If not, return `-1`\n\n- remove function\n\nFirst of all, try to get `default node` with a `key`. Check `node.next.key` until we find `target key`.\n\nIf we find the target key, connect `node.next` and `node.next.next`, so that we can remove `node.next`.\n\nIt works like this. Let\'s say node2.key is a target key.\n```\n[0] \u2192 node1 \u2192 node2 \u2192 node3\n\nFrom node1, node1.next.next should be node3, \nso update node1.next with node1.next.next which is node 3.\nIn the end, Linked List should be\n\n[0] \u2192 node1 \u2192 node3\n```\n\nAlgorithm Overview:\n1. Initialize a hash map using chaining for collision resolution.\n2. Implement methods to insert a key-value pair, retrieve the value for a given key, and remove a key-value pair.\n\nDetailed Explanation:\n1. **Node Class**:\n - Create a class `Node` to represent key-value pairs.\n - Initialize the `Node` with a key (default to -1), value (default to -1), and a reference to the next node (default to None).\n\n2. **MyHashMap Class Initialization**:\n - Create a class `MyHashMap` to represent the hash map.\n - Initialize an array `map` to store nodes, with a length of 1000.\n - For each index in the `map` array, create a new `Node` and append it to the array.\n\n3. **Put Method**:\n - Accepts a `key` (integer) and a `value` (integer).\n - Calculate the hash using the `hash` method based on the key.\n - Access the node at the calculated hash index.\n - Traverse the linked list starting from this node.\n - If a node with the given key is found, update its value and return.\n - If the end of the linked list is reached, add a new node with the given key and value.\n\n4. **Get Method**:\n - Accepts a `key` (integer).\n - Calculate the hash using the `hash` method based on the key.\n - Access the node at the calculated hash index.\n - Traverse the linked list starting from this node.\n - If a node with the given key is found, return its value.\n - If the end of the linked list is reached, return -1.\n\n5. **Remove Method**:\n - Accepts a `key` (integer).\n - Calculate the hash using the `hash` method based on the key.\n - Access the node at the calculated hash index.\n - Traverse the linked list starting from this node.\n - If a node with the given key is found, remove it by adjusting the next reference.\n - If the end of the linked list is reached, do nothing.\n\n6. **Hash Method**:\n - Accepts a `key` (integer).\n - Calculate the hash by taking the remainder of the key divided by the length of the `map` array.\n\n# Complexity\n\nTime Complexity:\n- Insertion (put): O(1) on average, assuming a good hash function and uniform distribution of keys. However, in the worst case, it could be O(n) if all keys hash to the same index, and we have to traverse a long linked list.\n- Retrieval (get): O(1) on average for the same reasons as insertion. In the worst case (all keys hashing to the same index), it could be O(n) due to traversing the linked list.\n- Deletion (remove): O(1) on average, similar to insertion and retrieval. In the worst case (all keys hashing to the same index), it could be O(n) due to traversing the linked list.\n\nSpace Complexity:\n- The space complexity of the hash map is O(n + m), where n is the number of buckets in the hash map (in this case, 1000), and m is the number of unique keys inserted into the hash map.\n- Additionally, the space complexity of each node (i.e., key, value, next) is O(1), as it does not depend on the size of the input or the total number of elements in the hash map.\n\nOverall, the space complexity is dominated by the size of the array used to store buckets and the unique keys inserted into the hash map, resulting in O(n + m) space complexity.\n\n```python []\nclass Node:\n def __init__(self, key = -1, val = -1, next = None):\n self.key = key\n self.val = val\n self.next = next\n\nclass MyHashMap:\n\n def __init__(self):\n self.map = []\n\n for _ in range(1000):\n self.map.append(Node())\n\n def put(self, key: int, value: int) -> None:\n cur = self.map[self.hash(key)]\n\n while cur.next:\n if cur.next.key == key:\n cur.next.val = value\n return\n \n cur = cur.next\n\n cur.next = Node(key, value)\n\n def get(self, key: int) -> int:\n cur = self.map[self.hash(key)]\n\n while cur.next:\n if cur.next.key == key:\n return cur.next.val\n cur = cur.next\n\n return -1\n \n def remove(self, key: int) -> None:\n cur = self.map[self.hash(key)]\n\n while cur.next:\n if cur.next.key == key:\n cur.next = cur.next.next\n return\n\n cur = cur.next\n\n def hash(self, key):\n return key % len(self.map) \n\n\n# Your MyHashMap object will be instantiated and called as such:\n# obj = MyHashMap()\n# obj.put(key,value)\n# param_2 = obj.get(key)\n# obj.remove(key)\n```\n```javascript []\nclass Node {\n constructor(key = -1, val = -1, next = null) {\n this.key = key;\n this.val = val;\n this.next = next;\n }\n}\n\nclass MyHashMap {\n constructor() {\n this.map = new Array(1000).fill(null).map(() => new Node());\n }\n\n /** \n * @param {number} key \n * @param {number} value\n * @return {void}\n */\n put(key, value) {\n let cur = this.map[this.hash(key)];\n\n while (cur.next) {\n if (cur.next.key === key) {\n cur.next.val = value;\n return;\n }\n\n cur = cur.next;\n }\n\n cur.next = new Node(key, value);\n }\n\n /** \n * @param {number} key\n * @return {number}\n */\n get(key) {\n let cur = this.map[this.hash(key)];\n\n while (cur.next) {\n if (cur.next.key === key) {\n return cur.next.val;\n }\n\n cur = cur.next;\n }\n\n return -1;\n }\n\n /** \n * @param {number} key\n * @return {void}\n */\n remove(key) {\n let cur = this.map[this.hash(key)];\n\n while (cur.next) {\n if (cur.next.key === key) {\n cur.next = cur.next.next;\n return;\n }\n\n cur = cur.next;\n }\n }\n\n /** \n * @param {number} key\n * @return {number}\n */\n hash(key) {\n return key % this.map.length;\n }\n}\n```\n```java []\nclass Node {\n int key;\n int val;\n Node next;\n\n Node(int key, int val) {\n this.key = key;\n this.val = val;\n this.next = null;\n }\n}\n\nclass MyHashMap {\n\n private Node[] map;\n\n public MyHashMap() {\n map = new Node[1000];\n for (int i = 0; i < 1000; i++) {\n map[i] = new Node(-1, -1);\n }\n }\n\n public void put(int key, int value) {\n int hash = hash(key);\n Node cur = map[hash];\n\n while (cur.next != null) {\n if (cur.next.key == key) {\n cur.next.val = value;\n return;\n }\n cur = cur.next;\n }\n\n cur.next = new Node(key, value);\n }\n\n public int get(int key) {\n int hash = hash(key);\n Node cur = map[hash].next;\n\n while (cur != null) {\n if (cur.key == key)\n return cur.val;\n cur = cur.next;\n }\n\n return -1;\n }\n\n public void remove(int key) {\n int hash = hash(key);\n Node cur = map[hash];\n\n while (cur.next != null) {\n if (cur.next.key == key) {\n cur.next = cur.next.next;\n return;\n }\n cur = cur.next;\n }\n }\n\n private int hash(int key) {\n return key % 1000;\n }\n}\n\n/**\n * Your MyHashMap object will be instantiated and called as such:\n * MyHashMap obj = new MyHashMap();\n * obj.put(key,value);\n * int param_2 = obj.get(key);\n * obj.remove(key);\n */\n```\n```C++ []\nclass Node {\npublic:\n int key;\n int val;\n Node* next;\n\n Node(int k = -1, int v = -1, Node* n = nullptr) : key(k), val(v), next(n) {}\n};\n\nclass MyHashMap {\nprivate:\n vector<Node*> map;\n\npublic:\n MyHashMap() {\n map.resize(1000);\n for (int i = 0; i < 1000; ++i) {\n map[i] = new Node();\n }\n }\n\n int hash(int key) {\n return key % 1000;\n }\n\n void put(int key, int value) {\n int hash_key = hash(key);\n Node* cur = map[hash_key];\n\n while (cur->next) {\n if (cur->next->key == key) {\n cur->next->val = value;\n return;\n }\n cur = cur->next;\n }\n\n cur->next = new Node(key, value);\n }\n\n int get(int key) {\n int hash_key = hash(key);\n Node* cur = map[hash_key];\n\n while (cur->next) {\n if (cur->next->key == key) {\n return cur->next->val;\n }\n cur = cur->next;\n }\n\n return -1;\n }\n\n void remove(int key) {\n int hash_key = hash(key);\n Node* cur = map[hash_key];\n\n while (cur->next) {\n if (cur->next->key == key) {\n Node* temp = cur->next;\n cur->next = cur->next->next;\n delete temp;\n return;\n }\n cur = cur->next;\n }\n }\n};\n\n\n\n/**\n * Your MyHashMap object will be instantiated and called as such:\n * MyHashMap* obj = new MyHashMap();\n * obj->put(key,value);\n * int param_2 = obj->get(key);\n * obj->remove(key);\n */\n```\n\n---\n\nThank you for reading my post.\n\u2B50\uFE0F Please upvote it and don\'t forget to subscribe to my channel!\n\nMy next post for daily coding challenge on October 5th, 2023\nhttps://leetcode.com/problems/majority-element-ii/solutions/4131998/video-how-we-think-about-a-solution-boyer-moore-majority-vote-algorithm/ | 24 | You are given the `head` of a linked list containing unique integer values and an integer array `nums` that is a subset of the linked list values.
Return _the number of connected components in_ `nums` _where two values are connected if they appear **consecutively** in the linked list_.
**Example 1:**
**Input:** head = \[0,1,2,3\], nums = \[0,1,3\]
**Output:** 2
**Explanation:** 0 and 1 are connected, so \[0, 1\] and \[3\] are the two connected components.
**Example 2:**
**Input:** head = \[0,1,2,3,4\], nums = \[0,3,1,4\]
**Output:** 2
**Explanation:** 0 and 1 are connected, 3 and 4 are connected, so \[0, 1\] and \[3, 4\] are the two connected components.
**Constraints:**
* The number of nodes in the linked list is `n`.
* `1 <= n <= 104`
* `0 <= Node.val < n`
* All the values `Node.val` are **unique**.
* `1 <= nums.length <= n`
* `0 <= nums[i] < n`
* All the values of `nums` are **unique**. | null |
One Liner/List 98%Beast | design-linked-list | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass MyLinkedList:\n def __init__(self):\n self.arr=[]\n def get(self, index: int) -> int:\n return -1 if index>=len(self.arr) else self.arr[index]\n def addAtHead(self, val: int) -> None:\n self.arr=[val]+self.arr\n def addAtTail(self, val: int) -> None:\n self.arr.append(val)\n def addAtIndex(self, index: int, val: int) -> None:\n if index<=len(self.arr):self.arr=self.arr[:index]+[val]+self.arr[index:]\n def deleteAtIndex(self, index: int) -> None:\n if index<len(self.arr):self.arr.pop(index)\n\n\n# Your MyLinkedList object will be instantiated and called as such:\n# obj = MyLinkedList()\n# param_1 = obj.get(index)\n# obj.addAtHead(val)\n# obj.addAtTail(val)\n# obj.addAtIndex(index,val)\n# obj.deleteAtIndex(index)\n``` | 3 | Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: `val` and `next`. `val` is the value of the current node, and `next` is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute `prev` to indicate the previous node in the linked list. Assume all nodes in the linked list are **0-indexed**.
Implement the `MyLinkedList` class:
* `MyLinkedList()` Initializes the `MyLinkedList` object.
* `int get(int index)` Get the value of the `indexth` node in the linked list. If the index is invalid, return `-1`.
* `void addAtHead(int val)` Add a node of value `val` before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
* `void addAtTail(int val)` Append a node of value `val` as the last element of the linked list.
* `void addAtIndex(int index, int val)` Add a node of value `val` before the `indexth` node in the linked list. If `index` equals the length of the linked list, the node will be appended to the end of the linked list. If `index` is greater than the length, the node **will not be inserted**.
* `void deleteAtIndex(int index)` Delete the `indexth` node in the linked list, if the index is valid.
**Example 1:**
**Input**
\[ "MyLinkedList ", "addAtHead ", "addAtTail ", "addAtIndex ", "get ", "deleteAtIndex ", "get "\]
\[\[\], \[1\], \[3\], \[1, 2\], \[1\], \[1\], \[1\]\]
**Output**
\[null, null, null, null, 2, null, 3\]
**Explanation**
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
**Constraints:**
* `0 <= index, val <= 1000`
* Please do not use the built-in LinkedList library.
* At most `2000` calls will be made to `get`, `addAtHead`, `addAtTail`, `addAtIndex` and `deleteAtIndex`. | null |
One Liner/List 98%Beast | design-linked-list | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass MyLinkedList:\n def __init__(self):\n self.arr=[]\n def get(self, index: int) -> int:\n return -1 if index>=len(self.arr) else self.arr[index]\n def addAtHead(self, val: int) -> None:\n self.arr=[val]+self.arr\n def addAtTail(self, val: int) -> None:\n self.arr.append(val)\n def addAtIndex(self, index: int, val: int) -> None:\n if index<=len(self.arr):self.arr=self.arr[:index]+[val]+self.arr[index:]\n def deleteAtIndex(self, index: int) -> None:\n if index<len(self.arr):self.arr.pop(index)\n\n\n# Your MyLinkedList object will be instantiated and called as such:\n# obj = MyLinkedList()\n# param_1 = obj.get(index)\n# obj.addAtHead(val)\n# obj.addAtTail(val)\n# obj.addAtIndex(index,val)\n# obj.deleteAtIndex(index)\n``` | 3 | There are `n` dominoes in a line, and we place each domino vertically upright. In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left. Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
You are given a string `dominoes` representing the initial state where:
* `dominoes[i] = 'L'`, if the `ith` domino has been pushed to the left,
* `dominoes[i] = 'R'`, if the `ith` domino has been pushed to the right, and
* `dominoes[i] = '.'`, if the `ith` domino has not been pushed.
Return _a string representing the final state_.
**Example 1:**
**Input:** dominoes = "RR.L "
**Output:** "RR.L "
**Explanation:** The first domino expends no additional force on the second domino.
**Example 2:**
**Input:** dominoes = ".L.R...LR..L.. "
**Output:** "LL.RR.LLRRLL.. "
**Constraints:**
* `n == dominoes.length`
* `1 <= n <= 105`
* `dominoes[i]` is either `'L'`, `'R'`, or `'.'`. | null |
Very Clean Python Solution | design-linked-list | 0 | 1 | Hope this helps someone.\n\n```\nclass ListNode:\n def __init__(self, val):\n self.val = val\n self.next = None\n\n\nclass MyLinkedList(object):\n def __init__(self):\n """\n Initialize your data structure here.\n """\n self.head = None\n self.size = 0\n\n def get(self, index: int) -> int:\n """\n Get the value of the index-th node in the linked list. If the index is invalid, return -1.\n """\n if index < 0 or index >= self.size:\n return -1\n\n current = self.head\n\n for _ in range(0, index):\n current = current.next\n\n return current.val\n\n def addAtHead(self, val: int) -> None:\n """\n Add a node of value val before the first element of the linked list. After the insertion, the new node will be\n the first node of the linked list.\n """\n self.addAtIndex(0, val)\n\n def addAtTail(self, val: int) -> None:\n """\n Append a node of value val to the last element of the linked list.\n """\n self.addAtIndex(self.size, val)\n\n def addAtIndex(self, index: int, val: int) -> None:\n """\n Add a node of value val before the index-th node in the linked list. If index equals to the length of linked\n list, the node will be appended to the end of linked list. If index is greater than the length, the node will not\n be inserted.\n """\n if index > self.size:\n return\n\n current = self.head\n new_node = ListNode(val)\n\n if index <= 0:\n new_node.next = current\n self.head = new_node\n else:\n for _ in range(index - 1):\n current = current.next\n new_node.next = current.next\n current.next = new_node\n\n self.size += 1\n\n def deleteAtIndex(self, index: int) -> None:\n """\n Delete the index-th node in the linked list, if the index is valid.\n """\n if index < 0 or index >= self.size:\n return\n\n current = self.head\n\n if index == 0:\n self.head = self.head.next\n else:\n for _ in range(0, index - 1):\n current = current.next\n current.next = current.next.next\n\n self.size -= 1\n``` | 128 | Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: `val` and `next`. `val` is the value of the current node, and `next` is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute `prev` to indicate the previous node in the linked list. Assume all nodes in the linked list are **0-indexed**.
Implement the `MyLinkedList` class:
* `MyLinkedList()` Initializes the `MyLinkedList` object.
* `int get(int index)` Get the value of the `indexth` node in the linked list. If the index is invalid, return `-1`.
* `void addAtHead(int val)` Add a node of value `val` before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
* `void addAtTail(int val)` Append a node of value `val` as the last element of the linked list.
* `void addAtIndex(int index, int val)` Add a node of value `val` before the `indexth` node in the linked list. If `index` equals the length of the linked list, the node will be appended to the end of the linked list. If `index` is greater than the length, the node **will not be inserted**.
* `void deleteAtIndex(int index)` Delete the `indexth` node in the linked list, if the index is valid.
**Example 1:**
**Input**
\[ "MyLinkedList ", "addAtHead ", "addAtTail ", "addAtIndex ", "get ", "deleteAtIndex ", "get "\]
\[\[\], \[1\], \[3\], \[1, 2\], \[1\], \[1\], \[1\]\]
**Output**
\[null, null, null, null, 2, null, 3\]
**Explanation**
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
**Constraints:**
* `0 <= index, val <= 1000`
* Please do not use the built-in LinkedList library.
* At most `2000` calls will be made to `get`, `addAtHead`, `addAtTail`, `addAtIndex` and `deleteAtIndex`. | null |
Very Clean Python Solution | design-linked-list | 0 | 1 | Hope this helps someone.\n\n```\nclass ListNode:\n def __init__(self, val):\n self.val = val\n self.next = None\n\n\nclass MyLinkedList(object):\n def __init__(self):\n """\n Initialize your data structure here.\n """\n self.head = None\n self.size = 0\n\n def get(self, index: int) -> int:\n """\n Get the value of the index-th node in the linked list. If the index is invalid, return -1.\n """\n if index < 0 or index >= self.size:\n return -1\n\n current = self.head\n\n for _ in range(0, index):\n current = current.next\n\n return current.val\n\n def addAtHead(self, val: int) -> None:\n """\n Add a node of value val before the first element of the linked list. After the insertion, the new node will be\n the first node of the linked list.\n """\n self.addAtIndex(0, val)\n\n def addAtTail(self, val: int) -> None:\n """\n Append a node of value val to the last element of the linked list.\n """\n self.addAtIndex(self.size, val)\n\n def addAtIndex(self, index: int, val: int) -> None:\n """\n Add a node of value val before the index-th node in the linked list. If index equals to the length of linked\n list, the node will be appended to the end of linked list. If index is greater than the length, the node will not\n be inserted.\n """\n if index > self.size:\n return\n\n current = self.head\n new_node = ListNode(val)\n\n if index <= 0:\n new_node.next = current\n self.head = new_node\n else:\n for _ in range(index - 1):\n current = current.next\n new_node.next = current.next\n current.next = new_node\n\n self.size += 1\n\n def deleteAtIndex(self, index: int) -> None:\n """\n Delete the index-th node in the linked list, if the index is valid.\n """\n if index < 0 or index >= self.size:\n return\n\n current = self.head\n\n if index == 0:\n self.head = self.head.next\n else:\n for _ in range(0, index - 1):\n current = current.next\n current.next = current.next.next\n\n self.size -= 1\n``` | 128 | There are `n` dominoes in a line, and we place each domino vertically upright. In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left. Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
You are given a string `dominoes` representing the initial state where:
* `dominoes[i] = 'L'`, if the `ith` domino has been pushed to the left,
* `dominoes[i] = 'R'`, if the `ith` domino has been pushed to the right, and
* `dominoes[i] = '.'`, if the `ith` domino has not been pushed.
Return _a string representing the final state_.
**Example 1:**
**Input:** dominoes = "RR.L "
**Output:** "RR.L "
**Explanation:** The first domino expends no additional force on the second domino.
**Example 2:**
**Input:** dominoes = ".L.R...LR..L.. "
**Output:** "LL.RR.LLRRLL.. "
**Constraints:**
* `n == dominoes.length`
* `1 <= n <= 105`
* `dominoes[i]` is either `'L'`, `'R'`, or `'.'`. | null |
Quite Ordinary Solution | design-linked-list | 0 | 1 | # Complexity\n- Time complexity: $$O(n)$$\n\n- Space complexity: $$O(1)$$\n\n# Code\n```\nclass Node:\n def __init__(self, val):\n self.val = val\n self.next = None\n\n\nclass MyLinkedList:\n def __init__(self):\n self.head = None\n self.tail = None\n self.lenn = 0\n \n\n def get(self, index: int) -> int:\n if index >= self.lenn:\n return -1\n \n cur = self.head\n while index:\n cur = cur.next\n index -= 1\n return cur.val\n \n\n def addAtHead(self, val: int) -> None:\n new = Node(val)\n self.head, new.next = new, self.head\n if not self.tail:\n self.tail = self.head\n\n self.lenn += 1\n \n\n def addAtTail(self, val: int) -> None:\n new = Node(val)\n if self.head:\n self.tail.next, self.tail = new, new\n else:\n self.head = self.tail = new\n\n self.lenn += 1\n \n\n def addAtIndex(self, index: int, val: int) -> None:\n if index > self.lenn:\n return\n elif index == self.lenn:\n self.addAtTail(val)\n elif index == 0:\n self.addAtHead(val)\n else:\n cur = self.head\n index -= 1\n while index:\n cur = cur.next\n index -= 1\n\n new = Node(val)\n cur.next, new.next = new, cur.next\n\n self.lenn += 1\n \n\n def deleteAtIndex(self, index: int) -> None:\n if index >= self.lenn:\n return\n elif index == 0:\n self.head = self.head.next\n else:\n cur = self.head\n i = index - 1\n while i:\n cur = cur.next\n i -= 1\n \n cur.next = cur.next.next\n if index == self.lenn - 1:\n self.tail = cur\n\n self.lenn -= 1\n if self.lenn == 0:\n self.head = self.tail = None\n\n\n# Your MyLinkedList object will be instantiated and called as such:\n# obj = MyLinkedList()\n# param_1 = obj.get(index)\n# obj.addAtHead(val)\n# obj.addAtTail(val)\n# obj.addAtIndex(index,val)\n# obj.deleteAtIndex(index)\n``` | 9 | Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: `val` and `next`. `val` is the value of the current node, and `next` is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute `prev` to indicate the previous node in the linked list. Assume all nodes in the linked list are **0-indexed**.
Implement the `MyLinkedList` class:
* `MyLinkedList()` Initializes the `MyLinkedList` object.
* `int get(int index)` Get the value of the `indexth` node in the linked list. If the index is invalid, return `-1`.
* `void addAtHead(int val)` Add a node of value `val` before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
* `void addAtTail(int val)` Append a node of value `val` as the last element of the linked list.
* `void addAtIndex(int index, int val)` Add a node of value `val` before the `indexth` node in the linked list. If `index` equals the length of the linked list, the node will be appended to the end of the linked list. If `index` is greater than the length, the node **will not be inserted**.
* `void deleteAtIndex(int index)` Delete the `indexth` node in the linked list, if the index is valid.
**Example 1:**
**Input**
\[ "MyLinkedList ", "addAtHead ", "addAtTail ", "addAtIndex ", "get ", "deleteAtIndex ", "get "\]
\[\[\], \[1\], \[3\], \[1, 2\], \[1\], \[1\], \[1\]\]
**Output**
\[null, null, null, null, 2, null, 3\]
**Explanation**
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
**Constraints:**
* `0 <= index, val <= 1000`
* Please do not use the built-in LinkedList library.
* At most `2000` calls will be made to `get`, `addAtHead`, `addAtTail`, `addAtIndex` and `deleteAtIndex`. | null |
Quite Ordinary Solution | design-linked-list | 0 | 1 | # Complexity\n- Time complexity: $$O(n)$$\n\n- Space complexity: $$O(1)$$\n\n# Code\n```\nclass Node:\n def __init__(self, val):\n self.val = val\n self.next = None\n\n\nclass MyLinkedList:\n def __init__(self):\n self.head = None\n self.tail = None\n self.lenn = 0\n \n\n def get(self, index: int) -> int:\n if index >= self.lenn:\n return -1\n \n cur = self.head\n while index:\n cur = cur.next\n index -= 1\n return cur.val\n \n\n def addAtHead(self, val: int) -> None:\n new = Node(val)\n self.head, new.next = new, self.head\n if not self.tail:\n self.tail = self.head\n\n self.lenn += 1\n \n\n def addAtTail(self, val: int) -> None:\n new = Node(val)\n if self.head:\n self.tail.next, self.tail = new, new\n else:\n self.head = self.tail = new\n\n self.lenn += 1\n \n\n def addAtIndex(self, index: int, val: int) -> None:\n if index > self.lenn:\n return\n elif index == self.lenn:\n self.addAtTail(val)\n elif index == 0:\n self.addAtHead(val)\n else:\n cur = self.head\n index -= 1\n while index:\n cur = cur.next\n index -= 1\n\n new = Node(val)\n cur.next, new.next = new, cur.next\n\n self.lenn += 1\n \n\n def deleteAtIndex(self, index: int) -> None:\n if index >= self.lenn:\n return\n elif index == 0:\n self.head = self.head.next\n else:\n cur = self.head\n i = index - 1\n while i:\n cur = cur.next\n i -= 1\n \n cur.next = cur.next.next\n if index == self.lenn - 1:\n self.tail = cur\n\n self.lenn -= 1\n if self.lenn == 0:\n self.head = self.tail = None\n\n\n# Your MyLinkedList object will be instantiated and called as such:\n# obj = MyLinkedList()\n# param_1 = obj.get(index)\n# obj.addAtHead(val)\n# obj.addAtTail(val)\n# obj.addAtIndex(index,val)\n# obj.deleteAtIndex(index)\n``` | 9 | There are `n` dominoes in a line, and we place each domino vertically upright. In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left. Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
You are given a string `dominoes` representing the initial state where:
* `dominoes[i] = 'L'`, if the `ith` domino has been pushed to the left,
* `dominoes[i] = 'R'`, if the `ith` domino has been pushed to the right, and
* `dominoes[i] = '.'`, if the `ith` domino has not been pushed.
Return _a string representing the final state_.
**Example 1:**
**Input:** dominoes = "RR.L "
**Output:** "RR.L "
**Explanation:** The first domino expends no additional force on the second domino.
**Example 2:**
**Input:** dominoes = ".L.R...LR..L.. "
**Output:** "LL.RR.LLRRLL.. "
**Constraints:**
* `n == dominoes.length`
* `1 <= n <= 105`
* `dominoes[i]` is either `'L'`, `'R'`, or `'.'`. | null |
[Python] | [Java] | Dummy Head Node | Very Clean | Easy to Understand | design-linked-list | 1 | 1 | # Approach\nEmploy dummy head node in initializing and traversing linked list.\n\n# Complexity\n- Time complexity: O(1) for addAtHead, O(n) for others\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```Python []\nclass ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass MyLinkedList:\n\n def __init__(self):\n self.dummy_head = ListNode() # dummy head node\n self.size = 0\n\n def get(self, index: int) -> int:\n if index >= self.size or index < 0:\n return -1\n \n cur = self.dummy_head.next # cur is real head node\n for i in range(index): # traversal\n cur = cur.next\n \n return cur.val\n\n def addAtHead(self, val: int) -> None:\n # real head node\n cur = ListNode(val, self.dummy_head.next)\n \n self.dummy_head.next = cur\n self.size += 1\n\n\n def addAtTail(self, val: int) -> None:\n cur = self.dummy_head\n \n # when cur.next == None, cur points to the last node\n while cur.next != None:\n cur = cur.next\n\n cur.next = ListNode(val)\n\n self.size += 1\n\n def addAtIndex(self, index: int, val: int) -> None:\n if index < 0 or index > self.size:\n return \n \n # if index = 0, add at head\n # if index = size, add at tail\n cur = self.dummy_head\n for i in range(index): \n cur = cur.next\n cur.next = ListNode(val, cur.next)\n \n self.size += 1\n\n def deleteAtIndex(self, index: int) -> None:\n if index < 0 or index >= self.size:\n return\n \n cur = self.dummy_head\n for i in range(index): \n cur = cur.next\n cur.next = cur.next.next\n\n self.size -= 1\n```\n```Java []\nclass ListNode {\n int val;\n ListNode next;\n\n public ListNode(int val, ListNode next) {\n this.val = val;\n this.next = next;\n }\n}\n\nclass MyLinkedList {\n ListNode dummyhead;\n int size;\n\n public MyLinkedList() {\n this.dummyhead = new ListNode(0, null);\n this.size = 0;\n }\n \n public int get(int index) {\n // invalid index\n if (index < 0 || index >= this.size) {\n return -1;\n }\n\n ListNode cur = this.dummyhead.next;\n for (int i = 0; i < index; i++) {\n cur = cur.next;\n }\n return cur.val;\n }\n \n public void addAtHead(int val) {\n this.dummyhead.next = new ListNode(val, this.dummyhead.next);\n this.size++;\n }\n \n public void addAtTail(int val) {\n ListNode cur = this.dummyhead;\n while (cur.next != null) {\n cur = cur.next;\n }\n cur.next = new ListNode(val, null);\n this.size++;\n }\n \n public void addAtIndex(int index, int val) {\n // index = this.size the same as addAtTail\n if (index < 0 || index > this.size) {\n return;\n }\n\n // find the node at index-1\n ListNode cur = this.dummyhead;\n for (int i = 0; i < index; i++) {\n cur = cur.next;\n }\n cur.next = new ListNode(val, cur.next);\n this.size++;\n }\n \n public void deleteAtIndex(int index) {\n // invalid index\n if (index < 0 || index >= size) {\n return;\n }\n\n // find the node at index-1\n ListNode cur = this.dummyhead;\n for (int i = 0; i < index; i++) {\n cur = cur.next;\n }\n cur.next = cur.next.next;\n this.size--;\n }\n}\n``` | 1 | Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: `val` and `next`. `val` is the value of the current node, and `next` is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute `prev` to indicate the previous node in the linked list. Assume all nodes in the linked list are **0-indexed**.
Implement the `MyLinkedList` class:
* `MyLinkedList()` Initializes the `MyLinkedList` object.
* `int get(int index)` Get the value of the `indexth` node in the linked list. If the index is invalid, return `-1`.
* `void addAtHead(int val)` Add a node of value `val` before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
* `void addAtTail(int val)` Append a node of value `val` as the last element of the linked list.
* `void addAtIndex(int index, int val)` Add a node of value `val` before the `indexth` node in the linked list. If `index` equals the length of the linked list, the node will be appended to the end of the linked list. If `index` is greater than the length, the node **will not be inserted**.
* `void deleteAtIndex(int index)` Delete the `indexth` node in the linked list, if the index is valid.
**Example 1:**
**Input**
\[ "MyLinkedList ", "addAtHead ", "addAtTail ", "addAtIndex ", "get ", "deleteAtIndex ", "get "\]
\[\[\], \[1\], \[3\], \[1, 2\], \[1\], \[1\], \[1\]\]
**Output**
\[null, null, null, null, 2, null, 3\]
**Explanation**
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
**Constraints:**
* `0 <= index, val <= 1000`
* Please do not use the built-in LinkedList library.
* At most `2000` calls will be made to `get`, `addAtHead`, `addAtTail`, `addAtIndex` and `deleteAtIndex`. | null |
[Python] | [Java] | Dummy Head Node | Very Clean | Easy to Understand | design-linked-list | 1 | 1 | # Approach\nEmploy dummy head node in initializing and traversing linked list.\n\n# Complexity\n- Time complexity: O(1) for addAtHead, O(n) for others\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```Python []\nclass ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass MyLinkedList:\n\n def __init__(self):\n self.dummy_head = ListNode() # dummy head node\n self.size = 0\n\n def get(self, index: int) -> int:\n if index >= self.size or index < 0:\n return -1\n \n cur = self.dummy_head.next # cur is real head node\n for i in range(index): # traversal\n cur = cur.next\n \n return cur.val\n\n def addAtHead(self, val: int) -> None:\n # real head node\n cur = ListNode(val, self.dummy_head.next)\n \n self.dummy_head.next = cur\n self.size += 1\n\n\n def addAtTail(self, val: int) -> None:\n cur = self.dummy_head\n \n # when cur.next == None, cur points to the last node\n while cur.next != None:\n cur = cur.next\n\n cur.next = ListNode(val)\n\n self.size += 1\n\n def addAtIndex(self, index: int, val: int) -> None:\n if index < 0 or index > self.size:\n return \n \n # if index = 0, add at head\n # if index = size, add at tail\n cur = self.dummy_head\n for i in range(index): \n cur = cur.next\n cur.next = ListNode(val, cur.next)\n \n self.size += 1\n\n def deleteAtIndex(self, index: int) -> None:\n if index < 0 or index >= self.size:\n return\n \n cur = self.dummy_head\n for i in range(index): \n cur = cur.next\n cur.next = cur.next.next\n\n self.size -= 1\n```\n```Java []\nclass ListNode {\n int val;\n ListNode next;\n\n public ListNode(int val, ListNode next) {\n this.val = val;\n this.next = next;\n }\n}\n\nclass MyLinkedList {\n ListNode dummyhead;\n int size;\n\n public MyLinkedList() {\n this.dummyhead = new ListNode(0, null);\n this.size = 0;\n }\n \n public int get(int index) {\n // invalid index\n if (index < 0 || index >= this.size) {\n return -1;\n }\n\n ListNode cur = this.dummyhead.next;\n for (int i = 0; i < index; i++) {\n cur = cur.next;\n }\n return cur.val;\n }\n \n public void addAtHead(int val) {\n this.dummyhead.next = new ListNode(val, this.dummyhead.next);\n this.size++;\n }\n \n public void addAtTail(int val) {\n ListNode cur = this.dummyhead;\n while (cur.next != null) {\n cur = cur.next;\n }\n cur.next = new ListNode(val, null);\n this.size++;\n }\n \n public void addAtIndex(int index, int val) {\n // index = this.size the same as addAtTail\n if (index < 0 || index > this.size) {\n return;\n }\n\n // find the node at index-1\n ListNode cur = this.dummyhead;\n for (int i = 0; i < index; i++) {\n cur = cur.next;\n }\n cur.next = new ListNode(val, cur.next);\n this.size++;\n }\n \n public void deleteAtIndex(int index) {\n // invalid index\n if (index < 0 || index >= size) {\n return;\n }\n\n // find the node at index-1\n ListNode cur = this.dummyhead;\n for (int i = 0; i < index; i++) {\n cur = cur.next;\n }\n cur.next = cur.next.next;\n this.size--;\n }\n}\n``` | 1 | There are `n` dominoes in a line, and we place each domino vertically upright. In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left. Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
You are given a string `dominoes` representing the initial state where:
* `dominoes[i] = 'L'`, if the `ith` domino has been pushed to the left,
* `dominoes[i] = 'R'`, if the `ith` domino has been pushed to the right, and
* `dominoes[i] = '.'`, if the `ith` domino has not been pushed.
Return _a string representing the final state_.
**Example 1:**
**Input:** dominoes = "RR.L "
**Output:** "RR.L "
**Explanation:** The first domino expends no additional force on the second domino.
**Example 2:**
**Input:** dominoes = ".L.R...LR..L.. "
**Output:** "LL.RR.LLRRLL.. "
**Constraints:**
* `n == dominoes.length`
* `1 <= n <= 105`
* `dominoes[i]` is either `'L'`, `'R'`, or `'.'`. | null |
Solution | design-linked-list | 1 | 1 | ```C++ []\nclass MyLinkedList {\npublic:\n vector<int>ans;\n MyLinkedList() {\n }\n int get(int index) {\n for(int i=0;i<ans.size();i++){\n if(i==index)\n return ans[i];\n } \n return -1;\n }\n void addAtHead(int val) {\n ans.insert(ans.begin(),val);\n }\n void addAtTail(int val) {\n ans.push_back(val); \n }\n void addAtIndex(int index, int val) {\n if(index < ans.size())\n ans.insert(ans.begin()+index,val);\n else if(index==ans.size())\n ans.push_back(val);\n }\n void deleteAtIndex(int index) {\n if(index < ans.size())\n ans.erase(ans.begin()+index); \n }\n};\n```\n\n```Python3 []\nclass MyLinkedList:\n\n def __init__(self):\n self._storage = []\n \n def get(self, index: int) -> int:\n if index > len(self._storage) - 1:\n return -1\n \n return self._storage[index]\n \n def addAtHead(self, val: int) -> None:\n self._storage.insert(0, val)\n \n def addAtTail(self, val: int) -> None:\n self._storage.append(val)\n \n def addAtIndex(self, index: int, val: int) -> None:\n if index < len(self._storage):\n self._storage.insert(index, val)\n elif index == len(self._storage):\n self._storage.append(val)\n \n def deleteAtIndex(self, index: int) -> None:\n if index > len(self._storage) - 1:\n return\n \n self._storage.pop(index)\n```\n\n```Java []\nclass MyLinkedList {\n List<Integer> list;\n public MyLinkedList() {\n list = new ArrayList<Integer>();\n }\n public int get(int index) {\n if(index >= list.size()){\n return -1;\n }\n return list.get(index);\n }\n public void addAtHead(int val) {\n list.add(0,val);\n }\n public void addAtTail(int val) {\n list.add(val);\n }\n public void addAtIndex(int index, int val) {\n if(index <= list.size()){\n list.add(index,val);\n }\n }\n public void deleteAtIndex(int index) {\n if(index < list.size()){\n list.remove(index);\n }\n }\n}\n```\n | 2 | Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: `val` and `next`. `val` is the value of the current node, and `next` is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute `prev` to indicate the previous node in the linked list. Assume all nodes in the linked list are **0-indexed**.
Implement the `MyLinkedList` class:
* `MyLinkedList()` Initializes the `MyLinkedList` object.
* `int get(int index)` Get the value of the `indexth` node in the linked list. If the index is invalid, return `-1`.
* `void addAtHead(int val)` Add a node of value `val` before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
* `void addAtTail(int val)` Append a node of value `val` as the last element of the linked list.
* `void addAtIndex(int index, int val)` Add a node of value `val` before the `indexth` node in the linked list. If `index` equals the length of the linked list, the node will be appended to the end of the linked list. If `index` is greater than the length, the node **will not be inserted**.
* `void deleteAtIndex(int index)` Delete the `indexth` node in the linked list, if the index is valid.
**Example 1:**
**Input**
\[ "MyLinkedList ", "addAtHead ", "addAtTail ", "addAtIndex ", "get ", "deleteAtIndex ", "get "\]
\[\[\], \[1\], \[3\], \[1, 2\], \[1\], \[1\], \[1\]\]
**Output**
\[null, null, null, null, 2, null, 3\]
**Explanation**
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
**Constraints:**
* `0 <= index, val <= 1000`
* Please do not use the built-in LinkedList library.
* At most `2000` calls will be made to `get`, `addAtHead`, `addAtTail`, `addAtIndex` and `deleteAtIndex`. | null |
Solution | design-linked-list | 1 | 1 | ```C++ []\nclass MyLinkedList {\npublic:\n vector<int>ans;\n MyLinkedList() {\n }\n int get(int index) {\n for(int i=0;i<ans.size();i++){\n if(i==index)\n return ans[i];\n } \n return -1;\n }\n void addAtHead(int val) {\n ans.insert(ans.begin(),val);\n }\n void addAtTail(int val) {\n ans.push_back(val); \n }\n void addAtIndex(int index, int val) {\n if(index < ans.size())\n ans.insert(ans.begin()+index,val);\n else if(index==ans.size())\n ans.push_back(val);\n }\n void deleteAtIndex(int index) {\n if(index < ans.size())\n ans.erase(ans.begin()+index); \n }\n};\n```\n\n```Python3 []\nclass MyLinkedList:\n\n def __init__(self):\n self._storage = []\n \n def get(self, index: int) -> int:\n if index > len(self._storage) - 1:\n return -1\n \n return self._storage[index]\n \n def addAtHead(self, val: int) -> None:\n self._storage.insert(0, val)\n \n def addAtTail(self, val: int) -> None:\n self._storage.append(val)\n \n def addAtIndex(self, index: int, val: int) -> None:\n if index < len(self._storage):\n self._storage.insert(index, val)\n elif index == len(self._storage):\n self._storage.append(val)\n \n def deleteAtIndex(self, index: int) -> None:\n if index > len(self._storage) - 1:\n return\n \n self._storage.pop(index)\n```\n\n```Java []\nclass MyLinkedList {\n List<Integer> list;\n public MyLinkedList() {\n list = new ArrayList<Integer>();\n }\n public int get(int index) {\n if(index >= list.size()){\n return -1;\n }\n return list.get(index);\n }\n public void addAtHead(int val) {\n list.add(0,val);\n }\n public void addAtTail(int val) {\n list.add(val);\n }\n public void addAtIndex(int index, int val) {\n if(index <= list.size()){\n list.add(index,val);\n }\n }\n public void deleteAtIndex(int index) {\n if(index < list.size()){\n list.remove(index);\n }\n }\n}\n```\n | 2 | There are `n` dominoes in a line, and we place each domino vertically upright. In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left. Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
You are given a string `dominoes` representing the initial state where:
* `dominoes[i] = 'L'`, if the `ith` domino has been pushed to the left,
* `dominoes[i] = 'R'`, if the `ith` domino has been pushed to the right, and
* `dominoes[i] = '.'`, if the `ith` domino has not been pushed.
Return _a string representing the final state_.
**Example 1:**
**Input:** dominoes = "RR.L "
**Output:** "RR.L "
**Explanation:** The first domino expends no additional force on the second domino.
**Example 2:**
**Input:** dominoes = ".L.R...LR..L.. "
**Output:** "LL.RR.LLRRLL.. "
**Constraints:**
* `n == dominoes.length`
* `1 <= n <= 105`
* `dominoes[i]` is either `'L'`, `'R'`, or `'.'`. | null |
[Python] Singly Linked List & Double Linked List - Clean & Concise | design-linked-list | 0 | 1 | ## 1. Singly Linked List\n<iframe src="https://leetcode.com/playground/FMRev7Ba/shared" frameBorder="0" width="100%" height="920"></iframe>\n\nComplexity:\n- Time: where `N` is length of `nums` array.\n - `get`: O(N)\n - `addAtHead`: O(1)\n - `addAtTail`: O(N), can optimize to (1) if we store `tail` pointer\n - `addAtIndex`: O(N)\n - `deleteAtIndex`: O(N)\n- Space: `O(1)` each operation\n\n---\n## 2. Doubly Linked List\n<iframe src="https://leetcode.com/playground/j55jxEkk/shared" frameBorder="0" width="100%" height="1000"></iframe>\n\nComplexity:\n- Time: where `N` is length of `nums` array.\n - `get`: O(N)\n - `addAtHead`: O(1)\n - `addAtTail`: O(1)\n - `addAtIndex`: O(N)\n - `deleteAtIndex`: O(N)\n- Space: `O(1)` each operation\n | 18 | Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: `val` and `next`. `val` is the value of the current node, and `next` is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute `prev` to indicate the previous node in the linked list. Assume all nodes in the linked list are **0-indexed**.
Implement the `MyLinkedList` class:
* `MyLinkedList()` Initializes the `MyLinkedList` object.
* `int get(int index)` Get the value of the `indexth` node in the linked list. If the index is invalid, return `-1`.
* `void addAtHead(int val)` Add a node of value `val` before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
* `void addAtTail(int val)` Append a node of value `val` as the last element of the linked list.
* `void addAtIndex(int index, int val)` Add a node of value `val` before the `indexth` node in the linked list. If `index` equals the length of the linked list, the node will be appended to the end of the linked list. If `index` is greater than the length, the node **will not be inserted**.
* `void deleteAtIndex(int index)` Delete the `indexth` node in the linked list, if the index is valid.
**Example 1:**
**Input**
\[ "MyLinkedList ", "addAtHead ", "addAtTail ", "addAtIndex ", "get ", "deleteAtIndex ", "get "\]
\[\[\], \[1\], \[3\], \[1, 2\], \[1\], \[1\], \[1\]\]
**Output**
\[null, null, null, null, 2, null, 3\]
**Explanation**
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
**Constraints:**
* `0 <= index, val <= 1000`
* Please do not use the built-in LinkedList library.
* At most `2000` calls will be made to `get`, `addAtHead`, `addAtTail`, `addAtIndex` and `deleteAtIndex`. | null |
[Python] Singly Linked List & Double Linked List - Clean & Concise | design-linked-list | 0 | 1 | ## 1. Singly Linked List\n<iframe src="https://leetcode.com/playground/FMRev7Ba/shared" frameBorder="0" width="100%" height="920"></iframe>\n\nComplexity:\n- Time: where `N` is length of `nums` array.\n - `get`: O(N)\n - `addAtHead`: O(1)\n - `addAtTail`: O(N), can optimize to (1) if we store `tail` pointer\n - `addAtIndex`: O(N)\n - `deleteAtIndex`: O(N)\n- Space: `O(1)` each operation\n\n---\n## 2. Doubly Linked List\n<iframe src="https://leetcode.com/playground/j55jxEkk/shared" frameBorder="0" width="100%" height="1000"></iframe>\n\nComplexity:\n- Time: where `N` is length of `nums` array.\n - `get`: O(N)\n - `addAtHead`: O(1)\n - `addAtTail`: O(1)\n - `addAtIndex`: O(N)\n - `deleteAtIndex`: O(N)\n- Space: `O(1)` each operation\n | 18 | There are `n` dominoes in a line, and we place each domino vertically upright. In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left. Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
You are given a string `dominoes` representing the initial state where:
* `dominoes[i] = 'L'`, if the `ith` domino has been pushed to the left,
* `dominoes[i] = 'R'`, if the `ith` domino has been pushed to the right, and
* `dominoes[i] = '.'`, if the `ith` domino has not been pushed.
Return _a string representing the final state_.
**Example 1:**
**Input:** dominoes = "RR.L "
**Output:** "RR.L "
**Explanation:** The first domino expends no additional force on the second domino.
**Example 2:**
**Input:** dominoes = ".L.R...LR..L.. "
**Output:** "LL.RR.LLRRLL.. "
**Constraints:**
* `n == dominoes.length`
* `1 <= n <= 105`
* `dominoes[i]` is either `'L'`, `'R'`, or `'.'`. | null |
Explained Implementation (Python3) | design-linked-list | 0 | 1 | Hope it is helpful to you\n\n```\n"""\n Singly LinkedList Implementation\n"""\n\nclass ListNode:\n """\n Init ListNode Object\n """\n def __init__(self, val):\n self.val = val \n self.next = None\n \nclass MyLinkedList(object):\n """\n Init your data structure \n """\n #Takes nothing at first, to initialize Head(Sentinel) Node\n def __init__(self):\n # Starts at 0\n self.size = 0\n # Head of a linkedlist is always 0 or NULL\n # self.head = None \n self.head = ListNode(0)\n """\n Find the predecessor of the node to insert. \n If a node is to be inserted at head, its predecessor is a sentinel head.\n If a node is to be inserted at tail, its predecessor is the last node.\n """\n def addAtHead(self, val:int) -> None: # O(1) time and space complexity\n """\n Add a node of value \'val\' before the first element of the LinkedList.\n After the insertion, the node will become the first node of the LinkedList\n ================\n O(1) time and space complexity | You are iterating the same regardless of the size of LinkedList\n """\n # use index 0 to get the head node in order to use as predecessor\n self.addAtIndex(0,val)\n \n def addAtTail(self, val:int) -> None:\n """\n Append a node of value \'val\' to the last element of the LinkedList.\n ================\n O(N) time and O(1) space complexity\n """\n # use size of LinkedList in order to get last node and use as predecessor\n self.addAtIndex(self.size, val)\n \n def addAtIndex(self, index:int, val:int) -> None:\n """\n Add a node of value \'val\' beofre the index-th node in the LinkedList.\n If index equals the length of the LinkedList, the node will be appended to the end of the LinkedList\n If index is greater than the length \'self.size\', the node will not be inserted.\n ================\n O(index) time and O(1) space complexity\n """\n if index > self.size:\n return \n # needs to iterate size to add new node\n self.size += 1\n \n pred = self.head # First predecessor is head (singly linked list)\n \n #iterate through LinkedList through index-th amount of times\n for _ in range(index):\n pred = pred.next\n # Node to be added to list \n to_add = ListNode(val)\n # Pointing to original predecessor\n to_add.next = pred.next\n # Add new node to next index\n pred.next = to_add\n \n def deleteAtIndex(self, index:int) -> None:\n """\n Delete the index-th node in the LinkedList.\n If index is not valid, will return -1\n ================\n O(index) time and O(1) space complexity\n """\n #check to see if getting valid index\n if index < 0 or index >= self.size:\n return \n \n #reduce the size, due to removing list node \n self.size -= 1 \n \n pred = self.head\n #iterate through LinkedList through index-th amount of times\n for _ in range(index):\n pred = pred.next\n # Skip a connection because we are getting rid of the node \n pred.next = pred.next.next\n \n def get(self, index:int) -> int:\n """\n Get the value of the index-th node in the LinkedList. \n If the index is invalid, return -1\n ================\n O(index) time and O(1) space complexity\n """\n #check to see if getting valid index\n if index < 0 or index >= self.size:\n return -1\n \n #start at head\n current = self.head\n \n #iterate through LinkedList through index-th amount of times\n for _ in range(index + 1):\n current = current.next\n \n return current.val \n``` | 13 | Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: `val` and `next`. `val` is the value of the current node, and `next` is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute `prev` to indicate the previous node in the linked list. Assume all nodes in the linked list are **0-indexed**.
Implement the `MyLinkedList` class:
* `MyLinkedList()` Initializes the `MyLinkedList` object.
* `int get(int index)` Get the value of the `indexth` node in the linked list. If the index is invalid, return `-1`.
* `void addAtHead(int val)` Add a node of value `val` before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
* `void addAtTail(int val)` Append a node of value `val` as the last element of the linked list.
* `void addAtIndex(int index, int val)` Add a node of value `val` before the `indexth` node in the linked list. If `index` equals the length of the linked list, the node will be appended to the end of the linked list. If `index` is greater than the length, the node **will not be inserted**.
* `void deleteAtIndex(int index)` Delete the `indexth` node in the linked list, if the index is valid.
**Example 1:**
**Input**
\[ "MyLinkedList ", "addAtHead ", "addAtTail ", "addAtIndex ", "get ", "deleteAtIndex ", "get "\]
\[\[\], \[1\], \[3\], \[1, 2\], \[1\], \[1\], \[1\]\]
**Output**
\[null, null, null, null, 2, null, 3\]
**Explanation**
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
**Constraints:**
* `0 <= index, val <= 1000`
* Please do not use the built-in LinkedList library.
* At most `2000` calls will be made to `get`, `addAtHead`, `addAtTail`, `addAtIndex` and `deleteAtIndex`. | null |
Explained Implementation (Python3) | design-linked-list | 0 | 1 | Hope it is helpful to you\n\n```\n"""\n Singly LinkedList Implementation\n"""\n\nclass ListNode:\n """\n Init ListNode Object\n """\n def __init__(self, val):\n self.val = val \n self.next = None\n \nclass MyLinkedList(object):\n """\n Init your data structure \n """\n #Takes nothing at first, to initialize Head(Sentinel) Node\n def __init__(self):\n # Starts at 0\n self.size = 0\n # Head of a linkedlist is always 0 or NULL\n # self.head = None \n self.head = ListNode(0)\n """\n Find the predecessor of the node to insert. \n If a node is to be inserted at head, its predecessor is a sentinel head.\n If a node is to be inserted at tail, its predecessor is the last node.\n """\n def addAtHead(self, val:int) -> None: # O(1) time and space complexity\n """\n Add a node of value \'val\' before the first element of the LinkedList.\n After the insertion, the node will become the first node of the LinkedList\n ================\n O(1) time and space complexity | You are iterating the same regardless of the size of LinkedList\n """\n # use index 0 to get the head node in order to use as predecessor\n self.addAtIndex(0,val)\n \n def addAtTail(self, val:int) -> None:\n """\n Append a node of value \'val\' to the last element of the LinkedList.\n ================\n O(N) time and O(1) space complexity\n """\n # use size of LinkedList in order to get last node and use as predecessor\n self.addAtIndex(self.size, val)\n \n def addAtIndex(self, index:int, val:int) -> None:\n """\n Add a node of value \'val\' beofre the index-th node in the LinkedList.\n If index equals the length of the LinkedList, the node will be appended to the end of the LinkedList\n If index is greater than the length \'self.size\', the node will not be inserted.\n ================\n O(index) time and O(1) space complexity\n """\n if index > self.size:\n return \n # needs to iterate size to add new node\n self.size += 1\n \n pred = self.head # First predecessor is head (singly linked list)\n \n #iterate through LinkedList through index-th amount of times\n for _ in range(index):\n pred = pred.next\n # Node to be added to list \n to_add = ListNode(val)\n # Pointing to original predecessor\n to_add.next = pred.next\n # Add new node to next index\n pred.next = to_add\n \n def deleteAtIndex(self, index:int) -> None:\n """\n Delete the index-th node in the LinkedList.\n If index is not valid, will return -1\n ================\n O(index) time and O(1) space complexity\n """\n #check to see if getting valid index\n if index < 0 or index >= self.size:\n return \n \n #reduce the size, due to removing list node \n self.size -= 1 \n \n pred = self.head\n #iterate through LinkedList through index-th amount of times\n for _ in range(index):\n pred = pred.next\n # Skip a connection because we are getting rid of the node \n pred.next = pred.next.next\n \n def get(self, index:int) -> int:\n """\n Get the value of the index-th node in the LinkedList. \n If the index is invalid, return -1\n ================\n O(index) time and O(1) space complexity\n """\n #check to see if getting valid index\n if index < 0 or index >= self.size:\n return -1\n \n #start at head\n current = self.head\n \n #iterate through LinkedList through index-th amount of times\n for _ in range(index + 1):\n current = current.next\n \n return current.val \n``` | 13 | There are `n` dominoes in a line, and we place each domino vertically upright. In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left. Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
You are given a string `dominoes` representing the initial state where:
* `dominoes[i] = 'L'`, if the `ith` domino has been pushed to the left,
* `dominoes[i] = 'R'`, if the `ith` domino has been pushed to the right, and
* `dominoes[i] = '.'`, if the `ith` domino has not been pushed.
Return _a string representing the final state_.
**Example 1:**
**Input:** dominoes = "RR.L "
**Output:** "RR.L "
**Explanation:** The first domino expends no additional force on the second domino.
**Example 2:**
**Input:** dominoes = ".L.R...LR..L.. "
**Output:** "LL.RR.LLRRLL.. "
**Constraints:**
* `n == dominoes.length`
* `1 <= n <= 105`
* `dominoes[i]` is either `'L'`, `'R'`, or `'.'`. | null |
All time easiest solution | design-linked-list | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Node:\n def __init__(self, data):\n self.data = data\n self.next = None\n\nclass MyLinkedList:\n def __init__(self):\n self.head = None\n\n def get(self, index: int) -> int:\n count = 0\n temp = self.head\n while temp:\n if count==index:\n return temp.data\n temp = temp.next\n count+=1\n return -1\n \n def addAtHead(self, val: int) -> None:\n new_node = Node(val)\n new_node.next = self.head\n self.head = new_node\n \n\n def addAtTail(self, val: int) -> None:\n new_node = Node(val)\n if not self.head:\n self.head = new_node\n return\n temp = self.head\n while temp.next:\n temp = temp.next\n temp.next = new_node\n\n def addAtIndex(self, index: int, val: int) -> None:\n if index <= 0:\n self.addAtHead(val)\n return\n new_node = Node(val)\n count=0\n temp = self.head\n while temp:\n if count==index-1:\n new_node.next = temp.next\n temp.next = new_node\n temp=temp.next\n count+=1\n\n def deleteAtIndex(self, index: int) -> None:\n if index==0:\n if self.head:\n self.head = self.head.next\n temp = self.head\n count=0\n while temp:\n if count==index-1 and temp.next:\n temp.next = temp.next.next\n temp=temp.next\n count+=1\n\n\n \n\n\n# Your MyLinkedList object will be instantiated and called as such:\n# obj = MyLinkedList()\n# param_1 = obj.get(index)\n# obj.addAtHead(val)\n# obj.addAtTail(val)\n# obj.addAtIndex(index,val)\n# obj.deleteAtIndex(index)\n``` | 2 | Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: `val` and `next`. `val` is the value of the current node, and `next` is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute `prev` to indicate the previous node in the linked list. Assume all nodes in the linked list are **0-indexed**.
Implement the `MyLinkedList` class:
* `MyLinkedList()` Initializes the `MyLinkedList` object.
* `int get(int index)` Get the value of the `indexth` node in the linked list. If the index is invalid, return `-1`.
* `void addAtHead(int val)` Add a node of value `val` before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
* `void addAtTail(int val)` Append a node of value `val` as the last element of the linked list.
* `void addAtIndex(int index, int val)` Add a node of value `val` before the `indexth` node in the linked list. If `index` equals the length of the linked list, the node will be appended to the end of the linked list. If `index` is greater than the length, the node **will not be inserted**.
* `void deleteAtIndex(int index)` Delete the `indexth` node in the linked list, if the index is valid.
**Example 1:**
**Input**
\[ "MyLinkedList ", "addAtHead ", "addAtTail ", "addAtIndex ", "get ", "deleteAtIndex ", "get "\]
\[\[\], \[1\], \[3\], \[1, 2\], \[1\], \[1\], \[1\]\]
**Output**
\[null, null, null, null, 2, null, 3\]
**Explanation**
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
**Constraints:**
* `0 <= index, val <= 1000`
* Please do not use the built-in LinkedList library.
* At most `2000` calls will be made to `get`, `addAtHead`, `addAtTail`, `addAtIndex` and `deleteAtIndex`. | null |
All time easiest solution | design-linked-list | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Node:\n def __init__(self, data):\n self.data = data\n self.next = None\n\nclass MyLinkedList:\n def __init__(self):\n self.head = None\n\n def get(self, index: int) -> int:\n count = 0\n temp = self.head\n while temp:\n if count==index:\n return temp.data\n temp = temp.next\n count+=1\n return -1\n \n def addAtHead(self, val: int) -> None:\n new_node = Node(val)\n new_node.next = self.head\n self.head = new_node\n \n\n def addAtTail(self, val: int) -> None:\n new_node = Node(val)\n if not self.head:\n self.head = new_node\n return\n temp = self.head\n while temp.next:\n temp = temp.next\n temp.next = new_node\n\n def addAtIndex(self, index: int, val: int) -> None:\n if index <= 0:\n self.addAtHead(val)\n return\n new_node = Node(val)\n count=0\n temp = self.head\n while temp:\n if count==index-1:\n new_node.next = temp.next\n temp.next = new_node\n temp=temp.next\n count+=1\n\n def deleteAtIndex(self, index: int) -> None:\n if index==0:\n if self.head:\n self.head = self.head.next\n temp = self.head\n count=0\n while temp:\n if count==index-1 and temp.next:\n temp.next = temp.next.next\n temp=temp.next\n count+=1\n\n\n \n\n\n# Your MyLinkedList object will be instantiated and called as such:\n# obj = MyLinkedList()\n# param_1 = obj.get(index)\n# obj.addAtHead(val)\n# obj.addAtTail(val)\n# obj.addAtIndex(index,val)\n# obj.deleteAtIndex(index)\n``` | 2 | There are `n` dominoes in a line, and we place each domino vertically upright. In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left. Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
You are given a string `dominoes` representing the initial state where:
* `dominoes[i] = 'L'`, if the `ith` domino has been pushed to the left,
* `dominoes[i] = 'R'`, if the `ith` domino has been pushed to the right, and
* `dominoes[i] = '.'`, if the `ith` domino has not been pushed.
Return _a string representing the final state_.
**Example 1:**
**Input:** dominoes = "RR.L "
**Output:** "RR.L "
**Explanation:** The first domino expends no additional force on the second domino.
**Example 2:**
**Input:** dominoes = ".L.R...LR..L.. "
**Output:** "LL.RR.LLRRLL.. "
**Constraints:**
* `n == dominoes.length`
* `1 <= n <= 105`
* `dominoes[i]` is either `'L'`, `'R'`, or `'.'`. | null |
87% TC and 85% Sc easy python solution using singly linked list | design-linked-list | 0 | 1 | ```\nclass Node:\n def __init__(self, val, n=None):\n self.val = val\n self.next = n\nclass MyLinkedList: \n def __init__(self):\n self.head = None\n self.tail = None\n self.l = 0\n\n def get(self, index: int) -> int:\n if(index >= self.l):\n return -1\n temp = self.head\n while(index > 0):\n temp = temp.next\n index -= 1\n return temp.val\n\n def addAtHead(self, val: int) -> None:\n if(self.head == None):\n self.head = self.tail = Node(val)\n else:\n self.head = Node(val, self.head)\n self.l += 1\n\n def addAtTail(self, val: int) -> None:\n if(self.head == None):\n self.head = self.tail = Node(val)\n else:\n self.tail.next = Node(val)\n self.tail = self.tail.next\n self.l += 1\n\n def addAtIndex(self, index: int, val: int) -> None:\n if(index > self.l): return -1\n if(index == 0):\n self.head = Node(val, self.head)\n elif(index == self.l):\n self.tail.next = Node(val)\n self.tail = self.tail.next\n else:\n curr = self.head\n while(index > 0):\n index -= 1\n prev = curr\n curr = curr.next\n prev.next = Node(val, curr)\n self.l += 1\n\n def deleteAtIndex(self, index: int) -> None:\n i = index\n if(index >= self.l): return -1\n if(index == 0):\n self.head = self.head.next\n else:\n curr = self.head\n while(index > 0):\n index -= 1\n prev = curr\n curr = curr.next\n prev.next = curr.next\n curr = self.head\n while(curr):\n curr = curr.next\n if(i == self.l-1):\n curr = self.head\n while(curr != None):\n self.tail = curr\n curr = curr.next\n self.l -= 1\n``` | 1 | Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: `val` and `next`. `val` is the value of the current node, and `next` is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute `prev` to indicate the previous node in the linked list. Assume all nodes in the linked list are **0-indexed**.
Implement the `MyLinkedList` class:
* `MyLinkedList()` Initializes the `MyLinkedList` object.
* `int get(int index)` Get the value of the `indexth` node in the linked list. If the index is invalid, return `-1`.
* `void addAtHead(int val)` Add a node of value `val` before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
* `void addAtTail(int val)` Append a node of value `val` as the last element of the linked list.
* `void addAtIndex(int index, int val)` Add a node of value `val` before the `indexth` node in the linked list. If `index` equals the length of the linked list, the node will be appended to the end of the linked list. If `index` is greater than the length, the node **will not be inserted**.
* `void deleteAtIndex(int index)` Delete the `indexth` node in the linked list, if the index is valid.
**Example 1:**
**Input**
\[ "MyLinkedList ", "addAtHead ", "addAtTail ", "addAtIndex ", "get ", "deleteAtIndex ", "get "\]
\[\[\], \[1\], \[3\], \[1, 2\], \[1\], \[1\], \[1\]\]
**Output**
\[null, null, null, null, 2, null, 3\]
**Explanation**
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
**Constraints:**
* `0 <= index, val <= 1000`
* Please do not use the built-in LinkedList library.
* At most `2000` calls will be made to `get`, `addAtHead`, `addAtTail`, `addAtIndex` and `deleteAtIndex`. | null |
87% TC and 85% Sc easy python solution using singly linked list | design-linked-list | 0 | 1 | ```\nclass Node:\n def __init__(self, val, n=None):\n self.val = val\n self.next = n\nclass MyLinkedList: \n def __init__(self):\n self.head = None\n self.tail = None\n self.l = 0\n\n def get(self, index: int) -> int:\n if(index >= self.l):\n return -1\n temp = self.head\n while(index > 0):\n temp = temp.next\n index -= 1\n return temp.val\n\n def addAtHead(self, val: int) -> None:\n if(self.head == None):\n self.head = self.tail = Node(val)\n else:\n self.head = Node(val, self.head)\n self.l += 1\n\n def addAtTail(self, val: int) -> None:\n if(self.head == None):\n self.head = self.tail = Node(val)\n else:\n self.tail.next = Node(val)\n self.tail = self.tail.next\n self.l += 1\n\n def addAtIndex(self, index: int, val: int) -> None:\n if(index > self.l): return -1\n if(index == 0):\n self.head = Node(val, self.head)\n elif(index == self.l):\n self.tail.next = Node(val)\n self.tail = self.tail.next\n else:\n curr = self.head\n while(index > 0):\n index -= 1\n prev = curr\n curr = curr.next\n prev.next = Node(val, curr)\n self.l += 1\n\n def deleteAtIndex(self, index: int) -> None:\n i = index\n if(index >= self.l): return -1\n if(index == 0):\n self.head = self.head.next\n else:\n curr = self.head\n while(index > 0):\n index -= 1\n prev = curr\n curr = curr.next\n prev.next = curr.next\n curr = self.head\n while(curr):\n curr = curr.next\n if(i == self.l-1):\n curr = self.head\n while(curr != None):\n self.tail = curr\n curr = curr.next\n self.l -= 1\n``` | 1 | There are `n` dominoes in a line, and we place each domino vertically upright. In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left. Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
You are given a string `dominoes` representing the initial state where:
* `dominoes[i] = 'L'`, if the `ith` domino has been pushed to the left,
* `dominoes[i] = 'R'`, if the `ith` domino has been pushed to the right, and
* `dominoes[i] = '.'`, if the `ith` domino has not been pushed.
Return _a string representing the final state_.
**Example 1:**
**Input:** dominoes = "RR.L "
**Output:** "RR.L "
**Explanation:** The first domino expends no additional force on the second domino.
**Example 2:**
**Input:** dominoes = ".L.R...LR..L.. "
**Output:** "LL.RR.LLRRLL.. "
**Constraints:**
* `n == dominoes.length`
* `1 <= n <= 105`
* `dominoes[i]` is either `'L'`, `'R'`, or `'.'`. | null |
EAZY PYTHON SOLUTION | design-linked-list | 0 | 1 | ```\nclass ListNode: \n def __init__(self,val, next = None):\n self.val = val\n self.next = next\n\nclass MyLinkedList:\n def __init__(self):\n self.head = None\n self.size = 0 \n \n def get(self, index: int) -> int:\n if index >= self.size:\n return -1\n node = self.head\n for _ in range(index):\n node = node.next\n return node.val\n \n def addAtHead(self, val: int) -> None:\n self.addAtIndex(0,val)\n \n def addAtTail(self, val: int) -> None:\n self.addAtIndex(self.size,val)\n \n def addAtIndex(self, index: int, val: int) -> None:\n if index > self.size: \n return\n node = self.head\n new_node = ListNode(val)\n \n if index == 0:\n new_node.next = node\n self.head = new_node\n else: \n for _ in range(index - 1): \n node = node.next\n new_node.next = node.next\n node.next = new_node\n self.size += 1\n \n\n\n def deleteAtIndex(self, index: int) -> None:\n if index >= self.size:\n return \n if index == 0: \n self.head = self.head.next\n else:\n node = self.head\n for _ in range(index-1):\n node = node.next\n node.next = node.next.next\n self.size -= 1\n```\n | 2 | Design your implementation of the linked list. You can choose to use a singly or doubly linked list.
A node in a singly linked list should have two attributes: `val` and `next`. `val` is the value of the current node, and `next` is a pointer/reference to the next node.
If you want to use the doubly linked list, you will need one more attribute `prev` to indicate the previous node in the linked list. Assume all nodes in the linked list are **0-indexed**.
Implement the `MyLinkedList` class:
* `MyLinkedList()` Initializes the `MyLinkedList` object.
* `int get(int index)` Get the value of the `indexth` node in the linked list. If the index is invalid, return `-1`.
* `void addAtHead(int val)` Add a node of value `val` before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
* `void addAtTail(int val)` Append a node of value `val` as the last element of the linked list.
* `void addAtIndex(int index, int val)` Add a node of value `val` before the `indexth` node in the linked list. If `index` equals the length of the linked list, the node will be appended to the end of the linked list. If `index` is greater than the length, the node **will not be inserted**.
* `void deleteAtIndex(int index)` Delete the `indexth` node in the linked list, if the index is valid.
**Example 1:**
**Input**
\[ "MyLinkedList ", "addAtHead ", "addAtTail ", "addAtIndex ", "get ", "deleteAtIndex ", "get "\]
\[\[\], \[1\], \[3\], \[1, 2\], \[1\], \[1\], \[1\]\]
**Output**
\[null, null, null, null, 2, null, 3\]
**Explanation**
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // linked list becomes 1->2->3
myLinkedList.get(1); // return 2
myLinkedList.deleteAtIndex(1); // now the linked list is 1->3
myLinkedList.get(1); // return 3
**Constraints:**
* `0 <= index, val <= 1000`
* Please do not use the built-in LinkedList library.
* At most `2000` calls will be made to `get`, `addAtHead`, `addAtTail`, `addAtIndex` and `deleteAtIndex`. | null |
EAZY PYTHON SOLUTION | design-linked-list | 0 | 1 | ```\nclass ListNode: \n def __init__(self,val, next = None):\n self.val = val\n self.next = next\n\nclass MyLinkedList:\n def __init__(self):\n self.head = None\n self.size = 0 \n \n def get(self, index: int) -> int:\n if index >= self.size:\n return -1\n node = self.head\n for _ in range(index):\n node = node.next\n return node.val\n \n def addAtHead(self, val: int) -> None:\n self.addAtIndex(0,val)\n \n def addAtTail(self, val: int) -> None:\n self.addAtIndex(self.size,val)\n \n def addAtIndex(self, index: int, val: int) -> None:\n if index > self.size: \n return\n node = self.head\n new_node = ListNode(val)\n \n if index == 0:\n new_node.next = node\n self.head = new_node\n else: \n for _ in range(index - 1): \n node = node.next\n new_node.next = node.next\n node.next = new_node\n self.size += 1\n \n\n\n def deleteAtIndex(self, index: int) -> None:\n if index >= self.size:\n return \n if index == 0: \n self.head = self.head.next\n else:\n node = self.head\n for _ in range(index-1):\n node = node.next\n node.next = node.next.next\n self.size -= 1\n```\n | 2 | There are `n` dominoes in a line, and we place each domino vertically upright. In the beginning, we simultaneously push some of the dominoes either to the left or to the right.
After each second, each domino that is falling to the left pushes the adjacent domino on the left. Similarly, the dominoes falling to the right push their adjacent dominoes standing on the right.
When a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.
For the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.
You are given a string `dominoes` representing the initial state where:
* `dominoes[i] = 'L'`, if the `ith` domino has been pushed to the left,
* `dominoes[i] = 'R'`, if the `ith` domino has been pushed to the right, and
* `dominoes[i] = '.'`, if the `ith` domino has not been pushed.
Return _a string representing the final state_.
**Example 1:**
**Input:** dominoes = "RR.L "
**Output:** "RR.L "
**Explanation:** The first domino expends no additional force on the second domino.
**Example 2:**
**Input:** dominoes = ".L.R...LR..L.. "
**Output:** "LL.RR.LLRRLL.. "
**Constraints:**
* `n == dominoes.length`
* `1 <= n <= 105`
* `dominoes[i]` is either `'L'`, `'R'`, or `'.'`. | null |
toLowerCase | to-lower-case | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n answerString = ""\n for i in s:\n if \'A\' <= i <= \'Z\':\n answerString = answerString + chr(ord(i)+32)\n else:\n answerString = answerString + i\n\n return answerString\n \n``` | 1 | Given a string `s`, return _the string after replacing every uppercase letter with the same lowercase letter_.
**Example 1:**
**Input:** s = "Hello "
**Output:** "hello "
**Example 2:**
**Input:** s = "here "
**Output:** "here "
**Example 3:**
**Input:** s = "LOVELY "
**Output:** "lovely "
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of printable ASCII characters. | null |
toLowerCase | to-lower-case | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n answerString = ""\n for i in s:\n if \'A\' <= i <= \'Z\':\n answerString = answerString + chr(ord(i)+32)\n else:\n answerString = answerString + i\n\n return answerString\n \n``` | 1 | Given the `root` of a binary tree where every node has **a unique value** and a target integer `k`, return _the value of the **nearest leaf node** to the target_ `k` _in the tree_.
**Nearest to a leaf** means the least number of edges traveled on the binary tree to reach any leaf of the tree. Also, a node is called a leaf if it has no children.
**Example 1:**
**Input:** root = \[1,3,2\], k = 1
**Output:** 2
**Explanation:** Either 2 or 3 is the nearest leaf node to the target of 1.
**Example 2:**
**Input:** root = \[1\], k = 1
**Output:** 1
**Explanation:** The nearest leaf node is the root node itself.
**Example 3:**
**Input:** root = \[1,2,3,4,null,null,null,5,null,6\], k = 2
**Output:** 3
**Explanation:** The leaf node with value 3 (and not the leaf node with value 6) is nearest to the node with value 2.
**Constraints:**
* The number of nodes in the tree is in the range `[1, 1000]`.
* `1 <= Node.val <= 1000`
* All the values of the tree are **unique**.
* There exist some node in the tree where `Node.val == k`. | Most languages support lowercase conversion for a string data type. However, that is certainly not the purpose of the problem. Think about how the implementation of the lowercase function call can be done easily. Think ASCII! Think about the different capital letters and their ASCII codes and how that relates to their lowercase counterparts. Does there seem to be any pattern there? Any mathematical relationship that we can use? |
Python one liner | to-lower-case | 0 | 1 | # Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n return s.lower()\n \n``` | 1 | Given a string `s`, return _the string after replacing every uppercase letter with the same lowercase letter_.
**Example 1:**
**Input:** s = "Hello "
**Output:** "hello "
**Example 2:**
**Input:** s = "here "
**Output:** "here "
**Example 3:**
**Input:** s = "LOVELY "
**Output:** "lovely "
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of printable ASCII characters. | null |
Python one liner | to-lower-case | 0 | 1 | # Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n return s.lower()\n \n``` | 1 | Given the `root` of a binary tree where every node has **a unique value** and a target integer `k`, return _the value of the **nearest leaf node** to the target_ `k` _in the tree_.
**Nearest to a leaf** means the least number of edges traveled on the binary tree to reach any leaf of the tree. Also, a node is called a leaf if it has no children.
**Example 1:**
**Input:** root = \[1,3,2\], k = 1
**Output:** 2
**Explanation:** Either 2 or 3 is the nearest leaf node to the target of 1.
**Example 2:**
**Input:** root = \[1\], k = 1
**Output:** 1
**Explanation:** The nearest leaf node is the root node itself.
**Example 3:**
**Input:** root = \[1,2,3,4,null,null,null,5,null,6\], k = 2
**Output:** 3
**Explanation:** The leaf node with value 3 (and not the leaf node with value 6) is nearest to the node with value 2.
**Constraints:**
* The number of nodes in the tree is in the range `[1, 1000]`.
* `1 <= Node.val <= 1000`
* All the values of the tree are **unique**.
* There exist some node in the tree where `Node.val == k`. | Most languages support lowercase conversion for a string data type. However, that is certainly not the purpose of the problem. Think about how the implementation of the lowercase function call can be done easily. Think ASCII! Think about the different capital letters and their ASCII codes and how that relates to their lowercase counterparts. Does there seem to be any pattern there? Any mathematical relationship that we can use? |
🔥Simple ASCII-Based Uppercase to Lowercase Transformation🔥 | to-lower-case | 0 | 1 | \n# Approach\n1. Iterate through the input string character by character.\n2. For each character, check if it\'s an uppercase letter by comparing its ASCII code with the range [65, 90], which corresponds to \'A\' to \'Z\'.\n3. If an uppercase character is found, convert it to lowercase by adding 32 to its ASCII code using the ord and chr functions.\n4. Replace the original character in the string with the lowercase character.\n5. Return the modified string as the result.\n\n\n# Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n for i in range(len(s)):\n # If s[i] is uppercase, convert it to lowercase.\n if 65 <= ord(s[i]) <= 90:\n s = s[:i] + chr(ord(s[i]) + 32) + s[i+1:]\n return s\n```\nplease upvote :D | 1 | Given a string `s`, return _the string after replacing every uppercase letter with the same lowercase letter_.
**Example 1:**
**Input:** s = "Hello "
**Output:** "hello "
**Example 2:**
**Input:** s = "here "
**Output:** "here "
**Example 3:**
**Input:** s = "LOVELY "
**Output:** "lovely "
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of printable ASCII characters. | null |
🔥Simple ASCII-Based Uppercase to Lowercase Transformation🔥 | to-lower-case | 0 | 1 | \n# Approach\n1. Iterate through the input string character by character.\n2. For each character, check if it\'s an uppercase letter by comparing its ASCII code with the range [65, 90], which corresponds to \'A\' to \'Z\'.\n3. If an uppercase character is found, convert it to lowercase by adding 32 to its ASCII code using the ord and chr functions.\n4. Replace the original character in the string with the lowercase character.\n5. Return the modified string as the result.\n\n\n# Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n for i in range(len(s)):\n # If s[i] is uppercase, convert it to lowercase.\n if 65 <= ord(s[i]) <= 90:\n s = s[:i] + chr(ord(s[i]) + 32) + s[i+1:]\n return s\n```\nplease upvote :D | 1 | Given the `root` of a binary tree where every node has **a unique value** and a target integer `k`, return _the value of the **nearest leaf node** to the target_ `k` _in the tree_.
**Nearest to a leaf** means the least number of edges traveled on the binary tree to reach any leaf of the tree. Also, a node is called a leaf if it has no children.
**Example 1:**
**Input:** root = \[1,3,2\], k = 1
**Output:** 2
**Explanation:** Either 2 or 3 is the nearest leaf node to the target of 1.
**Example 2:**
**Input:** root = \[1\], k = 1
**Output:** 1
**Explanation:** The nearest leaf node is the root node itself.
**Example 3:**
**Input:** root = \[1,2,3,4,null,null,null,5,null,6\], k = 2
**Output:** 3
**Explanation:** The leaf node with value 3 (and not the leaf node with value 6) is nearest to the node with value 2.
**Constraints:**
* The number of nodes in the tree is in the range `[1, 1000]`.
* `1 <= Node.val <= 1000`
* All the values of the tree are **unique**.
* There exist some node in the tree where `Node.val == k`. | Most languages support lowercase conversion for a string data type. However, that is certainly not the purpose of the problem. Think about how the implementation of the lowercase function call can be done easily. Think ASCII! Think about the different capital letters and their ASCII codes and how that relates to their lowercase counterparts. Does there seem to be any pattern there? Any mathematical relationship that we can use? |
One Line Code | to-lower-case | 0 | 1 | \n\n# Complexity\n- Time complexity: Faster than 88=%\n\n- Space complexity: 95.36%\n\n# Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n return s.lower()\n``` | 1 | Given a string `s`, return _the string after replacing every uppercase letter with the same lowercase letter_.
**Example 1:**
**Input:** s = "Hello "
**Output:** "hello "
**Example 2:**
**Input:** s = "here "
**Output:** "here "
**Example 3:**
**Input:** s = "LOVELY "
**Output:** "lovely "
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of printable ASCII characters. | null |
One Line Code | to-lower-case | 0 | 1 | \n\n# Complexity\n- Time complexity: Faster than 88=%\n\n- Space complexity: 95.36%\n\n# Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n return s.lower()\n``` | 1 | Given the `root` of a binary tree where every node has **a unique value** and a target integer `k`, return _the value of the **nearest leaf node** to the target_ `k` _in the tree_.
**Nearest to a leaf** means the least number of edges traveled on the binary tree to reach any leaf of the tree. Also, a node is called a leaf if it has no children.
**Example 1:**
**Input:** root = \[1,3,2\], k = 1
**Output:** 2
**Explanation:** Either 2 or 3 is the nearest leaf node to the target of 1.
**Example 2:**
**Input:** root = \[1\], k = 1
**Output:** 1
**Explanation:** The nearest leaf node is the root node itself.
**Example 3:**
**Input:** root = \[1,2,3,4,null,null,null,5,null,6\], k = 2
**Output:** 3
**Explanation:** The leaf node with value 3 (and not the leaf node with value 6) is nearest to the node with value 2.
**Constraints:**
* The number of nodes in the tree is in the range `[1, 1000]`.
* `1 <= Node.val <= 1000`
* All the values of the tree are **unique**.
* There exist some node in the tree where `Node.val == k`. | Most languages support lowercase conversion for a string data type. However, that is certainly not the purpose of the problem. Think about how the implementation of the lowercase function call can be done easily. Think ASCII! Think about the different capital letters and their ASCII codes and how that relates to their lowercase counterparts. Does there seem to be any pattern there? Any mathematical relationship that we can use? |
ASCII Code || Simply Method | to-lower-case | 0 | 1 | # Intuition\nThe first thought that comes to mind when trying to convert a string to lowercase is to loop through the string character by character and check if each character is uppercase. If it is, we can convert it to lowercase by adding 32 to its ASCII code.\n\n\n# Approach\nThe approach is straightforward and effective. You iterate through the input string character by character, converting uppercase letters to lowercase while leaving other characters unchanged.\n\n A -> 65 , Z -> 90 \n A -> 65 , Z -> 90 \n# Complexity\n- Time complexity:\nTime complexity: O(n), where n is the length of the string.\n\n- Space complexity:\nSpace complexity: O(1), since we only need to store two variables: the answer string ans and the current character i.\n\n# Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n ans=""\n for i in s:\n if 64<ord(i)<91: \n i=chr(ord(i)+32) \n ans+=i\n else:\n ans+=i\n return ans\n\n \n```\n##### reach me to discuss any problems - https://www.linkedin.com/in/naveen-kumar-g-500469210/\n\n | 5 | Given a string `s`, return _the string after replacing every uppercase letter with the same lowercase letter_.
**Example 1:**
**Input:** s = "Hello "
**Output:** "hello "
**Example 2:**
**Input:** s = "here "
**Output:** "here "
**Example 3:**
**Input:** s = "LOVELY "
**Output:** "lovely "
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of printable ASCII characters. | null |
ASCII Code || Simply Method | to-lower-case | 0 | 1 | # Intuition\nThe first thought that comes to mind when trying to convert a string to lowercase is to loop through the string character by character and check if each character is uppercase. If it is, we can convert it to lowercase by adding 32 to its ASCII code.\n\n\n# Approach\nThe approach is straightforward and effective. You iterate through the input string character by character, converting uppercase letters to lowercase while leaving other characters unchanged.\n\n A -> 65 , Z -> 90 \n A -> 65 , Z -> 90 \n# Complexity\n- Time complexity:\nTime complexity: O(n), where n is the length of the string.\n\n- Space complexity:\nSpace complexity: O(1), since we only need to store two variables: the answer string ans and the current character i.\n\n# Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n ans=""\n for i in s:\n if 64<ord(i)<91: \n i=chr(ord(i)+32) \n ans+=i\n else:\n ans+=i\n return ans\n\n \n```\n##### reach me to discuss any problems - https://www.linkedin.com/in/naveen-kumar-g-500469210/\n\n | 5 | Given the `root` of a binary tree where every node has **a unique value** and a target integer `k`, return _the value of the **nearest leaf node** to the target_ `k` _in the tree_.
**Nearest to a leaf** means the least number of edges traveled on the binary tree to reach any leaf of the tree. Also, a node is called a leaf if it has no children.
**Example 1:**
**Input:** root = \[1,3,2\], k = 1
**Output:** 2
**Explanation:** Either 2 or 3 is the nearest leaf node to the target of 1.
**Example 2:**
**Input:** root = \[1\], k = 1
**Output:** 1
**Explanation:** The nearest leaf node is the root node itself.
**Example 3:**
**Input:** root = \[1,2,3,4,null,null,null,5,null,6\], k = 2
**Output:** 3
**Explanation:** The leaf node with value 3 (and not the leaf node with value 6) is nearest to the node with value 2.
**Constraints:**
* The number of nodes in the tree is in the range `[1, 1000]`.
* `1 <= Node.val <= 1000`
* All the values of the tree are **unique**.
* There exist some node in the tree where `Node.val == k`. | Most languages support lowercase conversion for a string data type. However, that is certainly not the purpose of the problem. Think about how the implementation of the lowercase function call can be done easily. Think ASCII! Think about the different capital letters and their ASCII codes and how that relates to their lowercase counterparts. Does there seem to be any pattern there? Any mathematical relationship that we can use? |
1 Line solution | to-lower-case | 0 | 1 | \n# Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n return s.lower()\n``` | 1 | Given a string `s`, return _the string after replacing every uppercase letter with the same lowercase letter_.
**Example 1:**
**Input:** s = "Hello "
**Output:** "hello "
**Example 2:**
**Input:** s = "here "
**Output:** "here "
**Example 3:**
**Input:** s = "LOVELY "
**Output:** "lovely "
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of printable ASCII characters. | null |
1 Line solution | to-lower-case | 0 | 1 | \n# Code\n```\nclass Solution:\n def toLowerCase(self, s: str) -> str:\n return s.lower()\n``` | 1 | Given the `root` of a binary tree where every node has **a unique value** and a target integer `k`, return _the value of the **nearest leaf node** to the target_ `k` _in the tree_.
**Nearest to a leaf** means the least number of edges traveled on the binary tree to reach any leaf of the tree. Also, a node is called a leaf if it has no children.
**Example 1:**
**Input:** root = \[1,3,2\], k = 1
**Output:** 2
**Explanation:** Either 2 or 3 is the nearest leaf node to the target of 1.
**Example 2:**
**Input:** root = \[1\], k = 1
**Output:** 1
**Explanation:** The nearest leaf node is the root node itself.
**Example 3:**
**Input:** root = \[1,2,3,4,null,null,null,5,null,6\], k = 2
**Output:** 3
**Explanation:** The leaf node with value 3 (and not the leaf node with value 6) is nearest to the node with value 2.
**Constraints:**
* The number of nodes in the tree is in the range `[1, 1000]`.
* `1 <= Node.val <= 1000`
* All the values of the tree are **unique**.
* There exist some node in the tree where `Node.val == k`. | Most languages support lowercase conversion for a string data type. However, that is certainly not the purpose of the problem. Think about how the implementation of the lowercase function call can be done easily. Think ASCII! Think about the different capital letters and their ASCII codes and how that relates to their lowercase counterparts. Does there seem to be any pattern there? Any mathematical relationship that we can use? |
710. Random Pick with Blacklist - Beats 100% | random-pick-with-blacklist | 0 | 1 | # Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n ***$$O(1)$$*** \n\n---\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$\n\n---\n\n# Code\n```\nk = 10\nclass Solution:\n def __init__(self, n: int, blacklist: List[int]):\n self.data = []\n black = {}\n if len(blacklist) == 1:\n n = min(n, k)\n if len(blacklist) != 0 and min(blacklist) > k:\n n = min(n, k)\n for ele in blacklist:\n black[ele] = True\n for i in range(0, n):\n if black.get(i) is None:\n self.data.append(i)\n self.index = 0\n def pick(self) -> int:\n k = self.data[self.index]\n self.index += 1\n if self.index == len(self.data):\n self.index = 0\n return k\n \n``` | 1 | You are given an integer `n` and an array of **unique** integers `blacklist`. Design an algorithm to pick a random integer in the range `[0, n - 1]` that is **not** in `blacklist`. Any integer that is in the mentioned range and not in `blacklist` should be **equally likely** to be returned.
Optimize your algorithm such that it minimizes the number of calls to the **built-in** random function of your language.
Implement the `Solution` class:
* `Solution(int n, int[] blacklist)` Initializes the object with the integer `n` and the blacklisted integers `blacklist`.
* `int pick()` Returns a random integer in the range `[0, n - 1]` and not in `blacklist`.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick "\]
\[\[7, \[2, 3, 5\]\], \[\], \[\], \[\], \[\], \[\], \[\], \[\]\]
**Output**
\[null, 0, 4, 1, 6, 1, 0, 4\]
**Explanation**
Solution solution = new Solution(7, \[2, 3, 5\]);
solution.pick(); // return 0, any integer from \[0,1,4,6\] should be ok. Note that for every call of pick,
// 0, 1, 4, and 6 must be equally likely to be returned (i.e., with probability 1/4).
solution.pick(); // return 4
solution.pick(); // return 1
solution.pick(); // return 6
solution.pick(); // return 1
solution.pick(); // return 0
solution.pick(); // return 4
**Constraints:**
* `1 <= n <= 109`
* `0 <= blacklist.length <= min(105, n - 1)`
* `0 <= blacklist[i] < n`
* All the values of `blacklist` are **unique**.
* At most `2 * 104` calls will be made to `pick`. | null |
710. Random Pick with Blacklist - Beats 100% | random-pick-with-blacklist | 0 | 1 | # Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n ***$$O(1)$$*** \n\n---\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$\n\n---\n\n# Code\n```\nk = 10\nclass Solution:\n def __init__(self, n: int, blacklist: List[int]):\n self.data = []\n black = {}\n if len(blacklist) == 1:\n n = min(n, k)\n if len(blacklist) != 0 and min(blacklist) > k:\n n = min(n, k)\n for ele in blacklist:\n black[ele] = True\n for i in range(0, n):\n if black.get(i) is None:\n self.data.append(i)\n self.index = 0\n def pick(self) -> int:\n k = self.data[self.index]\n self.index += 1\n if self.index == len(self.data):\n self.index = 0\n return k\n \n``` | 1 | Given an integer `n`, return _a list of all possible **full binary trees** with_ `n` _nodes_. Each node of each tree in the answer must have `Node.val == 0`.
Each element of the answer is the root node of one possible tree. You may return the final list of trees in **any order**.
A **full binary tree** is a binary tree where each node has exactly `0` or `2` children.
**Example 1:**
**Input:** n = 7
**Output:** \[\[0,0,0,null,null,0,0,null,null,0,0\],\[0,0,0,null,null,0,0,0,0\],\[0,0,0,0,0,0,0\],\[0,0,0,0,0,null,null,null,null,0,0\],\[0,0,0,0,0,null,null,0,0\]\]
**Example 2:**
**Input:** n = 3
**Output:** \[\[0,0,0\]\]
**Constraints:**
* `1 <= n <= 20` | null |
Solution | random-pick-with-blacklist | 1 | 1 | ```C++ []\nstatic const auto init = []{\n cin.tie(nullptr);\n ios::sync_with_stdio(false);\n return false;\n}();\nint prefsum[100005];\nint psz = 0;\n\nclass Solution {\npublic:\n Solution(int n, vector<int>& blacklist) {\n ::sort(begin(blacklist), end(blacklist));\n psz = 0;\n int pre = 0;\n int sz = blacklist.size();\n for (int i = 0; i < sz;) {\n int j = i+1;\n while (j < sz && blacklist[j] == blacklist[j-1] + 1) {++j;}\n if (blacklist[i] != 0) {\n intv.push_back({pre, blacklist[i]-1});\n }\n pre = blacklist[j-1] + 1;\n i = j;\n }\n if (pre <= n-1) {\n intv.push_back({pre, n-1});\n }\n total = 0;\n for (int i = 0; i < intv.size(); ++i) {\n int length = intv[i].second - intv[i].first + 1;\n prefsum[psz++] = total;\n total += length;\n }\n }\n int pick() {\n int r = rand()%total;\n int idx = upper_bound(prefsum, prefsum+psz, r) - prefsum - 1;\n int offset = r - prefsum[idx];\n return intv[idx].first + offset;\n }\n vector<pair<int,int>> intv;\n int total;\n};\n```\n\n```Python3 []\nimport random\n\nclass Solution:\n def __init__(self, n, blacklist):\n bLen = len(blacklist)\n self.blackListMap = {}\n blacklistSet = set(blacklist)\n\n for b in blacklist:\n if b >= (n-bLen):\n continue\n self.blackListMap[b] = None\n \n start = n-bLen\n for b in self.blackListMap.keys():\n while start < n and start in blacklistSet:\n start += 1\n self.blackListMap[b] = start\n start += 1\n self.numElements = n - bLen\n\n def pick(self):\n randIndex = int(random.random() * self.numElements)\n return self.blackListMap[randIndex] if randIndex in self.blackListMap else randIndex\n```\n\n```Java []\nclass Solution {\n Map<Integer, Integer> map;\n Random rand = new Random();\n int size;\n\n public Solution(int n, int[] blacklist) {\n map = new HashMap<>();\n size = n - blacklist.length;\n int last = n - 1;\n for (int b: blacklist) {\n map.put(b, -1);\n }\n for (int b: blacklist) {\n if (b >= size) {\n continue;\n }\n while (map.containsKey(last)) {\n last--;\n }\n map.put(b, last);\n last--;\n }\n }\n public int pick() {\n int idx = rand.nextInt(size);\n if (map.containsKey(idx)) {\n return map.get(idx);\n }\n return idx;\n }\n}\n```\n | 1 | You are given an integer `n` and an array of **unique** integers `blacklist`. Design an algorithm to pick a random integer in the range `[0, n - 1]` that is **not** in `blacklist`. Any integer that is in the mentioned range and not in `blacklist` should be **equally likely** to be returned.
Optimize your algorithm such that it minimizes the number of calls to the **built-in** random function of your language.
Implement the `Solution` class:
* `Solution(int n, int[] blacklist)` Initializes the object with the integer `n` and the blacklisted integers `blacklist`.
* `int pick()` Returns a random integer in the range `[0, n - 1]` and not in `blacklist`.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick "\]
\[\[7, \[2, 3, 5\]\], \[\], \[\], \[\], \[\], \[\], \[\], \[\]\]
**Output**
\[null, 0, 4, 1, 6, 1, 0, 4\]
**Explanation**
Solution solution = new Solution(7, \[2, 3, 5\]);
solution.pick(); // return 0, any integer from \[0,1,4,6\] should be ok. Note that for every call of pick,
// 0, 1, 4, and 6 must be equally likely to be returned (i.e., with probability 1/4).
solution.pick(); // return 4
solution.pick(); // return 1
solution.pick(); // return 6
solution.pick(); // return 1
solution.pick(); // return 0
solution.pick(); // return 4
**Constraints:**
* `1 <= n <= 109`
* `0 <= blacklist.length <= min(105, n - 1)`
* `0 <= blacklist[i] < n`
* All the values of `blacklist` are **unique**.
* At most `2 * 104` calls will be made to `pick`. | null |
Solution | random-pick-with-blacklist | 1 | 1 | ```C++ []\nstatic const auto init = []{\n cin.tie(nullptr);\n ios::sync_with_stdio(false);\n return false;\n}();\nint prefsum[100005];\nint psz = 0;\n\nclass Solution {\npublic:\n Solution(int n, vector<int>& blacklist) {\n ::sort(begin(blacklist), end(blacklist));\n psz = 0;\n int pre = 0;\n int sz = blacklist.size();\n for (int i = 0; i < sz;) {\n int j = i+1;\n while (j < sz && blacklist[j] == blacklist[j-1] + 1) {++j;}\n if (blacklist[i] != 0) {\n intv.push_back({pre, blacklist[i]-1});\n }\n pre = blacklist[j-1] + 1;\n i = j;\n }\n if (pre <= n-1) {\n intv.push_back({pre, n-1});\n }\n total = 0;\n for (int i = 0; i < intv.size(); ++i) {\n int length = intv[i].second - intv[i].first + 1;\n prefsum[psz++] = total;\n total += length;\n }\n }\n int pick() {\n int r = rand()%total;\n int idx = upper_bound(prefsum, prefsum+psz, r) - prefsum - 1;\n int offset = r - prefsum[idx];\n return intv[idx].first + offset;\n }\n vector<pair<int,int>> intv;\n int total;\n};\n```\n\n```Python3 []\nimport random\n\nclass Solution:\n def __init__(self, n, blacklist):\n bLen = len(blacklist)\n self.blackListMap = {}\n blacklistSet = set(blacklist)\n\n for b in blacklist:\n if b >= (n-bLen):\n continue\n self.blackListMap[b] = None\n \n start = n-bLen\n for b in self.blackListMap.keys():\n while start < n and start in blacklistSet:\n start += 1\n self.blackListMap[b] = start\n start += 1\n self.numElements = n - bLen\n\n def pick(self):\n randIndex = int(random.random() * self.numElements)\n return self.blackListMap[randIndex] if randIndex in self.blackListMap else randIndex\n```\n\n```Java []\nclass Solution {\n Map<Integer, Integer> map;\n Random rand = new Random();\n int size;\n\n public Solution(int n, int[] blacklist) {\n map = new HashMap<>();\n size = n - blacklist.length;\n int last = n - 1;\n for (int b: blacklist) {\n map.put(b, -1);\n }\n for (int b: blacklist) {\n if (b >= size) {\n continue;\n }\n while (map.containsKey(last)) {\n last--;\n }\n map.put(b, last);\n last--;\n }\n }\n public int pick() {\n int idx = rand.nextInt(size);\n if (map.containsKey(idx)) {\n return map.get(idx);\n }\n return idx;\n }\n}\n```\n | 1 | Given an integer `n`, return _a list of all possible **full binary trees** with_ `n` _nodes_. Each node of each tree in the answer must have `Node.val == 0`.
Each element of the answer is the root node of one possible tree. You may return the final list of trees in **any order**.
A **full binary tree** is a binary tree where each node has exactly `0` or `2` children.
**Example 1:**
**Input:** n = 7
**Output:** \[\[0,0,0,null,null,0,0,null,null,0,0\],\[0,0,0,null,null,0,0,0,0\],\[0,0,0,0,0,0,0\],\[0,0,0,0,0,null,null,null,null,0,0\],\[0,0,0,0,0,null,null,0,0\]\]
**Example 2:**
**Input:** n = 3
**Output:** \[\[0,0,0\]\]
**Constraints:**
* `1 <= n <= 20` | null |
[Python] pick from list of valid ranges | random-pick-with-blacklist | 0 | 1 | ```\n"""\nStore array of valid ranges, then pick random range, and random\nvalue from that range.\n"""\nclass Solution:\n\n def __init__(self, n: int, blacklist: List[int]):\n self.n = n\n self.r = []\n\n if not blacklist:\n self.r.append((0, n - 1))\n return\n\n b = sorted(blacklist)\n if b[0] != 0:\n self.r.append((0, b[0] - 1))\n\n for i in range(len(b) - 1):\n if b[i] + 1 != b[i + 1]:\n self.r.append((b[i] + 1, b[i + 1] - 1))\n\n if b[-1] != n - 1:\n self.r.append((b[-1] + 1, n - 1))\n\n def pick(self) -> int:\n left, right = random.choice(self.r)\n return random.randint(left, right)\n``` | 1 | You are given an integer `n` and an array of **unique** integers `blacklist`. Design an algorithm to pick a random integer in the range `[0, n - 1]` that is **not** in `blacklist`. Any integer that is in the mentioned range and not in `blacklist` should be **equally likely** to be returned.
Optimize your algorithm such that it minimizes the number of calls to the **built-in** random function of your language.
Implement the `Solution` class:
* `Solution(int n, int[] blacklist)` Initializes the object with the integer `n` and the blacklisted integers `blacklist`.
* `int pick()` Returns a random integer in the range `[0, n - 1]` and not in `blacklist`.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick "\]
\[\[7, \[2, 3, 5\]\], \[\], \[\], \[\], \[\], \[\], \[\], \[\]\]
**Output**
\[null, 0, 4, 1, 6, 1, 0, 4\]
**Explanation**
Solution solution = new Solution(7, \[2, 3, 5\]);
solution.pick(); // return 0, any integer from \[0,1,4,6\] should be ok. Note that for every call of pick,
// 0, 1, 4, and 6 must be equally likely to be returned (i.e., with probability 1/4).
solution.pick(); // return 4
solution.pick(); // return 1
solution.pick(); // return 6
solution.pick(); // return 1
solution.pick(); // return 0
solution.pick(); // return 4
**Constraints:**
* `1 <= n <= 109`
* `0 <= blacklist.length <= min(105, n - 1)`
* `0 <= blacklist[i] < n`
* All the values of `blacklist` are **unique**.
* At most `2 * 104` calls will be made to `pick`. | null |
[Python] pick from list of valid ranges | random-pick-with-blacklist | 0 | 1 | ```\n"""\nStore array of valid ranges, then pick random range, and random\nvalue from that range.\n"""\nclass Solution:\n\n def __init__(self, n: int, blacklist: List[int]):\n self.n = n\n self.r = []\n\n if not blacklist:\n self.r.append((0, n - 1))\n return\n\n b = sorted(blacklist)\n if b[0] != 0:\n self.r.append((0, b[0] - 1))\n\n for i in range(len(b) - 1):\n if b[i] + 1 != b[i + 1]:\n self.r.append((b[i] + 1, b[i + 1] - 1))\n\n if b[-1] != n - 1:\n self.r.append((b[-1] + 1, n - 1))\n\n def pick(self) -> int:\n left, right = random.choice(self.r)\n return random.randint(left, right)\n``` | 1 | Given an integer `n`, return _a list of all possible **full binary trees** with_ `n` _nodes_. Each node of each tree in the answer must have `Node.val == 0`.
Each element of the answer is the root node of one possible tree. You may return the final list of trees in **any order**.
A **full binary tree** is a binary tree where each node has exactly `0` or `2` children.
**Example 1:**
**Input:** n = 7
**Output:** \[\[0,0,0,null,null,0,0,null,null,0,0\],\[0,0,0,null,null,0,0,0,0\],\[0,0,0,0,0,0,0\],\[0,0,0,0,0,null,null,null,null,0,0\],\[0,0,0,0,0,null,null,0,0\]\]
**Example 2:**
**Input:** n = 3
**Output:** \[\[0,0,0\]\]
**Constraints:**
* `1 <= n <= 20` | null |
[Python3] hash solution using dict (92.28%) | random-pick-with-blacklist | 0 | 1 | Hash map blacklisted value in `[0, N-len(blacklist))` to whitelisted value in `[N-len(blacklist), N)`, and then randomly pick number in `[0, N-len(blacklist))`. \n```\nfrom random import randint\n\nclass Solution:\n\n def __init__(self, N: int, blacklist: List[int]):\n blacklist = set(blacklist) #to avoid TLE\n self.N = N - len(blacklist) #to be used in pick()\n key = [x for x in blacklist if x < N-len(blacklist)]\n val = [x for x in range(N-len(blacklist), N) if x not in blacklist]\n self.mapping = dict(zip(key, val))\n\n def pick(self) -> int:\n i = randint(0, self.N-1)\n return self.mapping.get(i, i)\n```\n | 35 | You are given an integer `n` and an array of **unique** integers `blacklist`. Design an algorithm to pick a random integer in the range `[0, n - 1]` that is **not** in `blacklist`. Any integer that is in the mentioned range and not in `blacklist` should be **equally likely** to be returned.
Optimize your algorithm such that it minimizes the number of calls to the **built-in** random function of your language.
Implement the `Solution` class:
* `Solution(int n, int[] blacklist)` Initializes the object with the integer `n` and the blacklisted integers `blacklist`.
* `int pick()` Returns a random integer in the range `[0, n - 1]` and not in `blacklist`.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick "\]
\[\[7, \[2, 3, 5\]\], \[\], \[\], \[\], \[\], \[\], \[\], \[\]\]
**Output**
\[null, 0, 4, 1, 6, 1, 0, 4\]
**Explanation**
Solution solution = new Solution(7, \[2, 3, 5\]);
solution.pick(); // return 0, any integer from \[0,1,4,6\] should be ok. Note that for every call of pick,
// 0, 1, 4, and 6 must be equally likely to be returned (i.e., with probability 1/4).
solution.pick(); // return 4
solution.pick(); // return 1
solution.pick(); // return 6
solution.pick(); // return 1
solution.pick(); // return 0
solution.pick(); // return 4
**Constraints:**
* `1 <= n <= 109`
* `0 <= blacklist.length <= min(105, n - 1)`
* `0 <= blacklist[i] < n`
* All the values of `blacklist` are **unique**.
* At most `2 * 104` calls will be made to `pick`. | null |
[Python3] hash solution using dict (92.28%) | random-pick-with-blacklist | 0 | 1 | Hash map blacklisted value in `[0, N-len(blacklist))` to whitelisted value in `[N-len(blacklist), N)`, and then randomly pick number in `[0, N-len(blacklist))`. \n```\nfrom random import randint\n\nclass Solution:\n\n def __init__(self, N: int, blacklist: List[int]):\n blacklist = set(blacklist) #to avoid TLE\n self.N = N - len(blacklist) #to be used in pick()\n key = [x for x in blacklist if x < N-len(blacklist)]\n val = [x for x in range(N-len(blacklist), N) if x not in blacklist]\n self.mapping = dict(zip(key, val))\n\n def pick(self) -> int:\n i = randint(0, self.N-1)\n return self.mapping.get(i, i)\n```\n | 35 | Given an integer `n`, return _a list of all possible **full binary trees** with_ `n` _nodes_. Each node of each tree in the answer must have `Node.val == 0`.
Each element of the answer is the root node of one possible tree. You may return the final list of trees in **any order**.
A **full binary tree** is a binary tree where each node has exactly `0` or `2` children.
**Example 1:**
**Input:** n = 7
**Output:** \[\[0,0,0,null,null,0,0,null,null,0,0\],\[0,0,0,null,null,0,0,0,0\],\[0,0,0,0,0,0,0\],\[0,0,0,0,0,null,null,null,null,0,0\],\[0,0,0,0,0,null,null,0,0\]\]
**Example 2:**
**Input:** n = 3
**Output:** \[\[0,0,0\]\]
**Constraints:**
* `1 <= n <= 20` | null |
Python Optimal Method Using Hash Table and Dividing Array | random-pick-with-blacklist | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWe have 0 to n - len(blacklist) choices. This may contain bad numbers.\n\nConsider 0 - goodIntervalEnd as the left side, and goodIntervalEnd to n as right side.\n\nWe want left side to hold all good numbers, and if there are bad numbers, they must map to a good Number on the right side\n\n# Sources\n<!-- Describe your approach to solving the problem. -->\nI used the following sources to arrive at the solution:\n- https://just4once.gitbooks.io/leetcode-notes/content/leetcode/binary-search/710-random-pick-with-blacklist.html\n- https://guyalster.medium.com/leetcode-710-random-pick-with-blacklist-c7909b42425c\n- https://www.youtube.com/watch?v=yuopy_x2gk8\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$ because at one point we are storing all right side nums in a set, and in worst case this could be N - 1.\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$ because at one point we are storing all right side nums in a set, and in worst case this could be N - 1.\n\n\nComplexities could be $$O(B)$$ (B = len(blacklist)) as well, I\'m not sure TBH.\n\nI struggled for hours even after seeing solutions, so hopefuly this solution helps you understand faster.\n\n# Code\n```\nclass Solution:\n import random\n\n def __init__(self, n: int, blacklist: List[int]):\n # We have 0 to n - len(blacklist) choices. This may contain bad numbers\n # Consider 0 - goodIntervalEnd as the left side, and goodIntervalEnd to n as right side\n # We want left side to hold all good numbers, and if there are bad numbers, they must map to a good\n # Number on the right side\n self.goodIntervalEnd = n - len(blacklist)\n \n # This mapping will hold the mapping from any black listed left side numbers\n # To a unique whitelisted right side number\n self.mapping = dict()\n\n # Store blacklist as set for easier removals\n blacklist = set(blacklist)\n\n # Map the bad numbers to the good numbers on the other side\n # Num bad on left side is always equal to num good on right side\n\n # First get a set of all numbers on the right hand side, this may contain blacklisted number\n goodRightSideNums = set([i for i in range(self.goodIntervalEnd, n)])\n\n # Then remove the blacklisted numbers from this set\n for num in blacklist:\n if num in goodRightSideNums:\n goodRightSideNums.remove(num)\n\n # Notice how the length of goodRightSideNums should be equal to length of blacklist now\n # Now each left side black listed number \n for num in blacklist:\n if num < self.goodIntervalEnd:\n self.mapping[num] = goodRightSideNums.pop()\n \n\n def pick(self) -> int:\n i = random.randint(0, self.goodIntervalEnd - 1)\n return self.mapping.get(i, i)\n\n\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(n, blacklist)\n# param_1 = obj.pick()\n``` | 0 | You are given an integer `n` and an array of **unique** integers `blacklist`. Design an algorithm to pick a random integer in the range `[0, n - 1]` that is **not** in `blacklist`. Any integer that is in the mentioned range and not in `blacklist` should be **equally likely** to be returned.
Optimize your algorithm such that it minimizes the number of calls to the **built-in** random function of your language.
Implement the `Solution` class:
* `Solution(int n, int[] blacklist)` Initializes the object with the integer `n` and the blacklisted integers `blacklist`.
* `int pick()` Returns a random integer in the range `[0, n - 1]` and not in `blacklist`.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick "\]
\[\[7, \[2, 3, 5\]\], \[\], \[\], \[\], \[\], \[\], \[\], \[\]\]
**Output**
\[null, 0, 4, 1, 6, 1, 0, 4\]
**Explanation**
Solution solution = new Solution(7, \[2, 3, 5\]);
solution.pick(); // return 0, any integer from \[0,1,4,6\] should be ok. Note that for every call of pick,
// 0, 1, 4, and 6 must be equally likely to be returned (i.e., with probability 1/4).
solution.pick(); // return 4
solution.pick(); // return 1
solution.pick(); // return 6
solution.pick(); // return 1
solution.pick(); // return 0
solution.pick(); // return 4
**Constraints:**
* `1 <= n <= 109`
* `0 <= blacklist.length <= min(105, n - 1)`
* `0 <= blacklist[i] < n`
* All the values of `blacklist` are **unique**.
* At most `2 * 104` calls will be made to `pick`. | null |
Python Optimal Method Using Hash Table and Dividing Array | random-pick-with-blacklist | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWe have 0 to n - len(blacklist) choices. This may contain bad numbers.\n\nConsider 0 - goodIntervalEnd as the left side, and goodIntervalEnd to n as right side.\n\nWe want left side to hold all good numbers, and if there are bad numbers, they must map to a good Number on the right side\n\n# Sources\n<!-- Describe your approach to solving the problem. -->\nI used the following sources to arrive at the solution:\n- https://just4once.gitbooks.io/leetcode-notes/content/leetcode/binary-search/710-random-pick-with-blacklist.html\n- https://guyalster.medium.com/leetcode-710-random-pick-with-blacklist-c7909b42425c\n- https://www.youtube.com/watch?v=yuopy_x2gk8\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$ because at one point we are storing all right side nums in a set, and in worst case this could be N - 1.\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$ because at one point we are storing all right side nums in a set, and in worst case this could be N - 1.\n\n\nComplexities could be $$O(B)$$ (B = len(blacklist)) as well, I\'m not sure TBH.\n\nI struggled for hours even after seeing solutions, so hopefuly this solution helps you understand faster.\n\n# Code\n```\nclass Solution:\n import random\n\n def __init__(self, n: int, blacklist: List[int]):\n # We have 0 to n - len(blacklist) choices. This may contain bad numbers\n # Consider 0 - goodIntervalEnd as the left side, and goodIntervalEnd to n as right side\n # We want left side to hold all good numbers, and if there are bad numbers, they must map to a good\n # Number on the right side\n self.goodIntervalEnd = n - len(blacklist)\n \n # This mapping will hold the mapping from any black listed left side numbers\n # To a unique whitelisted right side number\n self.mapping = dict()\n\n # Store blacklist as set for easier removals\n blacklist = set(blacklist)\n\n # Map the bad numbers to the good numbers on the other side\n # Num bad on left side is always equal to num good on right side\n\n # First get a set of all numbers on the right hand side, this may contain blacklisted number\n goodRightSideNums = set([i for i in range(self.goodIntervalEnd, n)])\n\n # Then remove the blacklisted numbers from this set\n for num in blacklist:\n if num in goodRightSideNums:\n goodRightSideNums.remove(num)\n\n # Notice how the length of goodRightSideNums should be equal to length of blacklist now\n # Now each left side black listed number \n for num in blacklist:\n if num < self.goodIntervalEnd:\n self.mapping[num] = goodRightSideNums.pop()\n \n\n def pick(self) -> int:\n i = random.randint(0, self.goodIntervalEnd - 1)\n return self.mapping.get(i, i)\n\n\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(n, blacklist)\n# param_1 = obj.pick()\n``` | 0 | Given an integer `n`, return _a list of all possible **full binary trees** with_ `n` _nodes_. Each node of each tree in the answer must have `Node.val == 0`.
Each element of the answer is the root node of one possible tree. You may return the final list of trees in **any order**.
A **full binary tree** is a binary tree where each node has exactly `0` or `2` children.
**Example 1:**
**Input:** n = 7
**Output:** \[\[0,0,0,null,null,0,0,null,null,0,0\],\[0,0,0,null,null,0,0,0,0\],\[0,0,0,0,0,0,0\],\[0,0,0,0,0,null,null,null,null,0,0\],\[0,0,0,0,0,null,null,0,0\]\]
**Example 2:**
**Input:** n = 3
**Output:** \[\[0,0,0\]\]
**Constraints:**
* `1 <= n <= 20` | null |
Python A Multi-modal Approach (Runtime 75%) | random-pick-with-blacklist | 0 | 1 | # Intuition\nBasically, when dealing with random generation over a large range and with blacklists, there are two general approaches:\n\n1. Create a uniform mapping between blacklisted numbers and valid numbers, so whenever we encounter a blacklisted result, we can immediately look up its mapped value.\n2. Use the strategy of rejection sampling: whenever we encounter a blacklisted value, we regenerate a random number. This process continues until we get a valid result.\n\nBoth strategies, however, face unique problems for this question:\n\n1. The mapping we create must not be a sequential mapping onto the valid numbers, since in that case the distribution would favor those valid numbers near the start of the enumeration point. At the same time, precalculate a large mapping between the blacklist and valid numbers could take up significant memory.\n2. If we rely on rejection sampling, we would potentially need to call the built-in random generation functions many times: the larger the proportion of blacklisted values to the entire range, the higher expected number of function calls. This goes against the question\'s requirement.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nMy solution involves a three modal approach to deal with different scenarios:\n1. When the n is small enough, there is no reason to not use a simple rejection sampling (you could, of course, use a list of valid numbers and directly choice, but here I want to showcase when rejection sampling is a reasonable choice)\n2. When the number of blacklisted values is very high, then there is a very high likelihood that using either a rejection sampling or a pseudo-random generation would involve multiple iterations before a "hit". At this point the more reasonable approach is to directly choose from a list of acceptable values, instead of generating over the entire range. An added advantage of this approach is that, the bigger the blacklist is, the smaller the space that would need to be taken up by the valid list.\n3. When the number of blacklisted values is not very high, we can ditch the idea of creating a one-to-one mapping between blacklisted values and valid values: instead, we can iterate over an internal pseudo-random generator sequence to get a valid value. Whenever we hit a blacklisted value, we proceed with this sequence to find the next valid result. This approach hit two goals at once: not only does it ensure the uniform distribution of mapped values, it also minimizes the number of calls to built-in random generator objects.\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: varies\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: varies\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# import random\n\n# class Solution:\n\n# def __init__(self, n: int, blacklist: List[int]):\n# self.N = n\n# self.valid_mapping = {}\n# self.valid_count = n - len(blacklist)\n# self.base = self.valid_count + 1\n \n# for b in blacklist:\n# if b < self.valid_count:\n# self.valid_mapping[b] = None\n \n# valid_value = n - 1\n# for b in blacklist:\n# if b < self.valid_count:\n# while valid_value in self.valid_mapping:\n# valid_value = (valid_value + self.base) % self.valid_count\n# self.valid_mapping[b] = valid_value\n# valid_value = (valid_value + self.base - 1) % self.valid_count\n\n# def pick(self) -> int:\n# rand = random.randint(0, self.valid_count - 1)\n# return self.valid_mapping.get(rand, rand)\n\n\nfrom random import randint, choice\n\n\n\ndef LCG(n):\n return ( (n*20501397 + 1) & (2**31 - 1) )\n\n\n\nclass Solution:\n n = 0\n blacklist = set()\n p0 = -1 # Pseudo-random seed initiated using the first encountered blacklisted value\n #pi = (A*p0+C) % m (m>n)\n #value = pi % n\n mode = None #"Rejection", "Valid", "Pseudo"\n validlist = None\n def __init__(self, n: int, blacklist: List[int]):\n # if n <= 50, simple rejection sampling\n # if n > 50 and len(blacklist) > n/2, keeping a list of valid numbers\n # if n > 50 and len(blacklist) <= n/2, using pseudo-random sequence when encountering a blacklisted number\n self.n = n\n self.blacklist = set(blacklist)\n if n<= 50:\n self.mode = "Rejection"\n elif len(blacklist)>= n/2:\n self.mode = "Valid"\n self.validlist = [i for i in range(n) if i not in self.blacklist]\n else:\n self.mode = "Pseudo"\n\n def pick(self) -> int:\n if self.mode == "Rejection":\n rand = randint(0,self.n-1)\n while rand in self.blacklist:\n rand = randint(0,self.n-1)\n return rand\n elif self.mode == "Valid":\n return choice(self.validlist)\n elif self.mode == "Pseudo":\n rand = randint(0,self.n-1)\n if rand not in self.blacklist:\n return rand\n if self.p0 == -1: #Initializing Pseudo-random Generator\n self.p0 = rand\n while self.p0 % self.n in self.blacklist:\n self.p0 = LCG(self.p0)\n return self.p0 % self.n\n else:\n self.p0 = LCG(self.p0)\n while self.p0 % self.n in self.blacklist:\n self.p0 = LCG(self.p0)\n return self.p0 % self.n\n``` | 0 | You are given an integer `n` and an array of **unique** integers `blacklist`. Design an algorithm to pick a random integer in the range `[0, n - 1]` that is **not** in `blacklist`. Any integer that is in the mentioned range and not in `blacklist` should be **equally likely** to be returned.
Optimize your algorithm such that it minimizes the number of calls to the **built-in** random function of your language.
Implement the `Solution` class:
* `Solution(int n, int[] blacklist)` Initializes the object with the integer `n` and the blacklisted integers `blacklist`.
* `int pick()` Returns a random integer in the range `[0, n - 1]` and not in `blacklist`.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick "\]
\[\[7, \[2, 3, 5\]\], \[\], \[\], \[\], \[\], \[\], \[\], \[\]\]
**Output**
\[null, 0, 4, 1, 6, 1, 0, 4\]
**Explanation**
Solution solution = new Solution(7, \[2, 3, 5\]);
solution.pick(); // return 0, any integer from \[0,1,4,6\] should be ok. Note that for every call of pick,
// 0, 1, 4, and 6 must be equally likely to be returned (i.e., with probability 1/4).
solution.pick(); // return 4
solution.pick(); // return 1
solution.pick(); // return 6
solution.pick(); // return 1
solution.pick(); // return 0
solution.pick(); // return 4
**Constraints:**
* `1 <= n <= 109`
* `0 <= blacklist.length <= min(105, n - 1)`
* `0 <= blacklist[i] < n`
* All the values of `blacklist` are **unique**.
* At most `2 * 104` calls will be made to `pick`. | null |
Python A Multi-modal Approach (Runtime 75%) | random-pick-with-blacklist | 0 | 1 | # Intuition\nBasically, when dealing with random generation over a large range and with blacklists, there are two general approaches:\n\n1. Create a uniform mapping between blacklisted numbers and valid numbers, so whenever we encounter a blacklisted result, we can immediately look up its mapped value.\n2. Use the strategy of rejection sampling: whenever we encounter a blacklisted value, we regenerate a random number. This process continues until we get a valid result.\n\nBoth strategies, however, face unique problems for this question:\n\n1. The mapping we create must not be a sequential mapping onto the valid numbers, since in that case the distribution would favor those valid numbers near the start of the enumeration point. At the same time, precalculate a large mapping between the blacklist and valid numbers could take up significant memory.\n2. If we rely on rejection sampling, we would potentially need to call the built-in random generation functions many times: the larger the proportion of blacklisted values to the entire range, the higher expected number of function calls. This goes against the question\'s requirement.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nMy solution involves a three modal approach to deal with different scenarios:\n1. When the n is small enough, there is no reason to not use a simple rejection sampling (you could, of course, use a list of valid numbers and directly choice, but here I want to showcase when rejection sampling is a reasonable choice)\n2. When the number of blacklisted values is very high, then there is a very high likelihood that using either a rejection sampling or a pseudo-random generation would involve multiple iterations before a "hit". At this point the more reasonable approach is to directly choose from a list of acceptable values, instead of generating over the entire range. An added advantage of this approach is that, the bigger the blacklist is, the smaller the space that would need to be taken up by the valid list.\n3. When the number of blacklisted values is not very high, we can ditch the idea of creating a one-to-one mapping between blacklisted values and valid values: instead, we can iterate over an internal pseudo-random generator sequence to get a valid value. Whenever we hit a blacklisted value, we proceed with this sequence to find the next valid result. This approach hit two goals at once: not only does it ensure the uniform distribution of mapped values, it also minimizes the number of calls to built-in random generator objects.\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: varies\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: varies\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# import random\n\n# class Solution:\n\n# def __init__(self, n: int, blacklist: List[int]):\n# self.N = n\n# self.valid_mapping = {}\n# self.valid_count = n - len(blacklist)\n# self.base = self.valid_count + 1\n \n# for b in blacklist:\n# if b < self.valid_count:\n# self.valid_mapping[b] = None\n \n# valid_value = n - 1\n# for b in blacklist:\n# if b < self.valid_count:\n# while valid_value in self.valid_mapping:\n# valid_value = (valid_value + self.base) % self.valid_count\n# self.valid_mapping[b] = valid_value\n# valid_value = (valid_value + self.base - 1) % self.valid_count\n\n# def pick(self) -> int:\n# rand = random.randint(0, self.valid_count - 1)\n# return self.valid_mapping.get(rand, rand)\n\n\nfrom random import randint, choice\n\n\n\ndef LCG(n):\n return ( (n*20501397 + 1) & (2**31 - 1) )\n\n\n\nclass Solution:\n n = 0\n blacklist = set()\n p0 = -1 # Pseudo-random seed initiated using the first encountered blacklisted value\n #pi = (A*p0+C) % m (m>n)\n #value = pi % n\n mode = None #"Rejection", "Valid", "Pseudo"\n validlist = None\n def __init__(self, n: int, blacklist: List[int]):\n # if n <= 50, simple rejection sampling\n # if n > 50 and len(blacklist) > n/2, keeping a list of valid numbers\n # if n > 50 and len(blacklist) <= n/2, using pseudo-random sequence when encountering a blacklisted number\n self.n = n\n self.blacklist = set(blacklist)\n if n<= 50:\n self.mode = "Rejection"\n elif len(blacklist)>= n/2:\n self.mode = "Valid"\n self.validlist = [i for i in range(n) if i not in self.blacklist]\n else:\n self.mode = "Pseudo"\n\n def pick(self) -> int:\n if self.mode == "Rejection":\n rand = randint(0,self.n-1)\n while rand in self.blacklist:\n rand = randint(0,self.n-1)\n return rand\n elif self.mode == "Valid":\n return choice(self.validlist)\n elif self.mode == "Pseudo":\n rand = randint(0,self.n-1)\n if rand not in self.blacklist:\n return rand\n if self.p0 == -1: #Initializing Pseudo-random Generator\n self.p0 = rand\n while self.p0 % self.n in self.blacklist:\n self.p0 = LCG(self.p0)\n return self.p0 % self.n\n else:\n self.p0 = LCG(self.p0)\n while self.p0 % self.n in self.blacklist:\n self.p0 = LCG(self.p0)\n return self.p0 % self.n\n``` | 0 | Given an integer `n`, return _a list of all possible **full binary trees** with_ `n` _nodes_. Each node of each tree in the answer must have `Node.val == 0`.
Each element of the answer is the root node of one possible tree. You may return the final list of trees in **any order**.
A **full binary tree** is a binary tree where each node has exactly `0` or `2` children.
**Example 1:**
**Input:** n = 7
**Output:** \[\[0,0,0,null,null,0,0,null,null,0,0\],\[0,0,0,null,null,0,0,0,0\],\[0,0,0,0,0,0,0\],\[0,0,0,0,0,null,null,null,null,0,0\],\[0,0,0,0,0,null,null,0,0\]\]
**Example 2:**
**Input:** n = 3
**Output:** \[\[0,0,0\]\]
**Constraints:**
* `1 <= n <= 20` | null |
random pick with blacklist | random-pick-with-blacklist | 0 | 1 | \nclass Solution:\n def __init__(self, N: int, blacklist: List[int]):\n # return range from 0 to n-len(blacklist)\n self.sz = N - len(blacklist)\n # give bigger val to elements in blacklist in order to avoid pick\n self.mapping = {}\n for b in blacklist:\n self.mapping[b] = 666\n \n # if elements in blacklist and store new index in mapping\n last = N - 1\n for b in blacklist:\n #ignore the last elements\n if b >= self.sz:\n continue\n # replace blacklist index with new one\n while last in self.mapping:\n last -= 1\n # change index to the last\n self.mapping[b] = last\n last -= 1\n print(self.mapping)\n\n\n def pick(self) -> int:\n # pick a random number\n index = random.randint(0, self.sz-1)\n # check index exist in blacklist or not\n if index in self.mapping:\n return self.mapping[index]\n # if not return index\n return index\n\n | 0 | You are given an integer `n` and an array of **unique** integers `blacklist`. Design an algorithm to pick a random integer in the range `[0, n - 1]` that is **not** in `blacklist`. Any integer that is in the mentioned range and not in `blacklist` should be **equally likely** to be returned.
Optimize your algorithm such that it minimizes the number of calls to the **built-in** random function of your language.
Implement the `Solution` class:
* `Solution(int n, int[] blacklist)` Initializes the object with the integer `n` and the blacklisted integers `blacklist`.
* `int pick()` Returns a random integer in the range `[0, n - 1]` and not in `blacklist`.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick "\]
\[\[7, \[2, 3, 5\]\], \[\], \[\], \[\], \[\], \[\], \[\], \[\]\]
**Output**
\[null, 0, 4, 1, 6, 1, 0, 4\]
**Explanation**
Solution solution = new Solution(7, \[2, 3, 5\]);
solution.pick(); // return 0, any integer from \[0,1,4,6\] should be ok. Note that for every call of pick,
// 0, 1, 4, and 6 must be equally likely to be returned (i.e., with probability 1/4).
solution.pick(); // return 4
solution.pick(); // return 1
solution.pick(); // return 6
solution.pick(); // return 1
solution.pick(); // return 0
solution.pick(); // return 4
**Constraints:**
* `1 <= n <= 109`
* `0 <= blacklist.length <= min(105, n - 1)`
* `0 <= blacklist[i] < n`
* All the values of `blacklist` are **unique**.
* At most `2 * 104` calls will be made to `pick`. | null |
random pick with blacklist | random-pick-with-blacklist | 0 | 1 | \nclass Solution:\n def __init__(self, N: int, blacklist: List[int]):\n # return range from 0 to n-len(blacklist)\n self.sz = N - len(blacklist)\n # give bigger val to elements in blacklist in order to avoid pick\n self.mapping = {}\n for b in blacklist:\n self.mapping[b] = 666\n \n # if elements in blacklist and store new index in mapping\n last = N - 1\n for b in blacklist:\n #ignore the last elements\n if b >= self.sz:\n continue\n # replace blacklist index with new one\n while last in self.mapping:\n last -= 1\n # change index to the last\n self.mapping[b] = last\n last -= 1\n print(self.mapping)\n\n\n def pick(self) -> int:\n # pick a random number\n index = random.randint(0, self.sz-1)\n # check index exist in blacklist or not\n if index in self.mapping:\n return self.mapping[index]\n # if not return index\n return index\n\n | 0 | Given an integer `n`, return _a list of all possible **full binary trees** with_ `n` _nodes_. Each node of each tree in the answer must have `Node.val == 0`.
Each element of the answer is the root node of one possible tree. You may return the final list of trees in **any order**.
A **full binary tree** is a binary tree where each node has exactly `0` or `2` children.
**Example 1:**
**Input:** n = 7
**Output:** \[\[0,0,0,null,null,0,0,null,null,0,0\],\[0,0,0,null,null,0,0,0,0\],\[0,0,0,0,0,0,0\],\[0,0,0,0,0,null,null,null,null,0,0\],\[0,0,0,0,0,null,null,0,0\]\]
**Example 2:**
**Input:** n = 3
**Output:** \[\[0,0,0\]\]
**Constraints:**
* `1 <= n <= 20` | null |
Python3 Solution | random-pick-with-blacklist | 0 | 1 | # Intuition\nInspired by labuladong\'s note, we could consider the range from 0 to $$n$$ as an array, and switch elements in the `blacklist` to the end of this array to minimize the time complexity.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n\n1. The `Solution` class is initialized with two parameters: $$n$$ (the maximum number) and `blacklist` (a list of numbers to be excluded).\n2. During initialization, a dictionary `map` is created to redirect any blacklisted number that\'s less than the size of the valid number range to a valid number.\n3. The `pick` method randomly selects a number from the valid range. If the number is blacklisted (i.e., it exists in the `map`), it will be replaced with a valid number.\n\n# Complexity\n\n- Time complexity:\n\n - Initialization: $$O(b)$$ where $$b$$ is the size of the blacklist.\n - `pick` method: $$O(1)$$\n\n- Space complexity: \n\n - $$O(b)$$ where $$b$$ is the size of the blacklist.\n\n# Code\n```\nclass Solution:\n\n def __init__(self, n: int, blacklist: List[int]):\n self.size = n - len(blacklist)\n self.map = {}\n\n for i in blacklist:\n self.map[i] = 0\n\n end = n - 1\n\n for i in blacklist:\n if i >= self.size:\n continue\n\n while end in self.map:\n end -= 1\n \n self.map[i] = end\n end -= 1\n \n\n def pick(self) -> int:\n idx = random.randint(0, self.size - 1)\n\n if idx in self.map:\n return self.map[idx]\n \n return idx\n \n\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(n, blacklist)\n# param_1 = obj.pick()\n``` | 0 | You are given an integer `n` and an array of **unique** integers `blacklist`. Design an algorithm to pick a random integer in the range `[0, n - 1]` that is **not** in `blacklist`. Any integer that is in the mentioned range and not in `blacklist` should be **equally likely** to be returned.
Optimize your algorithm such that it minimizes the number of calls to the **built-in** random function of your language.
Implement the `Solution` class:
* `Solution(int n, int[] blacklist)` Initializes the object with the integer `n` and the blacklisted integers `blacklist`.
* `int pick()` Returns a random integer in the range `[0, n - 1]` and not in `blacklist`.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick "\]
\[\[7, \[2, 3, 5\]\], \[\], \[\], \[\], \[\], \[\], \[\], \[\]\]
**Output**
\[null, 0, 4, 1, 6, 1, 0, 4\]
**Explanation**
Solution solution = new Solution(7, \[2, 3, 5\]);
solution.pick(); // return 0, any integer from \[0,1,4,6\] should be ok. Note that for every call of pick,
// 0, 1, 4, and 6 must be equally likely to be returned (i.e., with probability 1/4).
solution.pick(); // return 4
solution.pick(); // return 1
solution.pick(); // return 6
solution.pick(); // return 1
solution.pick(); // return 0
solution.pick(); // return 4
**Constraints:**
* `1 <= n <= 109`
* `0 <= blacklist.length <= min(105, n - 1)`
* `0 <= blacklist[i] < n`
* All the values of `blacklist` are **unique**.
* At most `2 * 104` calls will be made to `pick`. | null |
Python3 Solution | random-pick-with-blacklist | 0 | 1 | # Intuition\nInspired by labuladong\'s note, we could consider the range from 0 to $$n$$ as an array, and switch elements in the `blacklist` to the end of this array to minimize the time complexity.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n\n1. The `Solution` class is initialized with two parameters: $$n$$ (the maximum number) and `blacklist` (a list of numbers to be excluded).\n2. During initialization, a dictionary `map` is created to redirect any blacklisted number that\'s less than the size of the valid number range to a valid number.\n3. The `pick` method randomly selects a number from the valid range. If the number is blacklisted (i.e., it exists in the `map`), it will be replaced with a valid number.\n\n# Complexity\n\n- Time complexity:\n\n - Initialization: $$O(b)$$ where $$b$$ is the size of the blacklist.\n - `pick` method: $$O(1)$$\n\n- Space complexity: \n\n - $$O(b)$$ where $$b$$ is the size of the blacklist.\n\n# Code\n```\nclass Solution:\n\n def __init__(self, n: int, blacklist: List[int]):\n self.size = n - len(blacklist)\n self.map = {}\n\n for i in blacklist:\n self.map[i] = 0\n\n end = n - 1\n\n for i in blacklist:\n if i >= self.size:\n continue\n\n while end in self.map:\n end -= 1\n \n self.map[i] = end\n end -= 1\n \n\n def pick(self) -> int:\n idx = random.randint(0, self.size - 1)\n\n if idx in self.map:\n return self.map[idx]\n \n return idx\n \n\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(n, blacklist)\n# param_1 = obj.pick()\n``` | 0 | Given an integer `n`, return _a list of all possible **full binary trees** with_ `n` _nodes_. Each node of each tree in the answer must have `Node.val == 0`.
Each element of the answer is the root node of one possible tree. You may return the final list of trees in **any order**.
A **full binary tree** is a binary tree where each node has exactly `0` or `2` children.
**Example 1:**
**Input:** n = 7
**Output:** \[\[0,0,0,null,null,0,0,null,null,0,0\],\[0,0,0,null,null,0,0,0,0\],\[0,0,0,0,0,0,0\],\[0,0,0,0,0,null,null,null,null,0,0\],\[0,0,0,0,0,null,null,0,0\]\]
**Example 2:**
**Input:** n = 3
**Output:** \[\[0,0,0\]\]
**Constraints:**
* `1 <= n <= 20` | null |
Simple python solution | random-pick-with-blacklist | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(B) preprocessing; O(1) for pick\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(B)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n\n def __init__(self, n: int, blacklist: List[int]):\n self.n = n\n self.num_black = len(blacklist)\n self.mapper = {b: b for b in blacklist}\n end = n-1\n for b in blacklist:\n if b < self.n - self.num_black:\n while end in self.mapper:\n end = end - 1\n self.mapper[b] = end\n end = end - 1\n print(self.mapper)\n\n def pick(self) -> int:\n idx=random.randint(0, self.n-self.num_black-1)\n return idx if idx not in self.mapper else self.mapper[idx] \n\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(n, blacklist)\n# param_1 = obj.pick()\n``` | 0 | You are given an integer `n` and an array of **unique** integers `blacklist`. Design an algorithm to pick a random integer in the range `[0, n - 1]` that is **not** in `blacklist`. Any integer that is in the mentioned range and not in `blacklist` should be **equally likely** to be returned.
Optimize your algorithm such that it minimizes the number of calls to the **built-in** random function of your language.
Implement the `Solution` class:
* `Solution(int n, int[] blacklist)` Initializes the object with the integer `n` and the blacklisted integers `blacklist`.
* `int pick()` Returns a random integer in the range `[0, n - 1]` and not in `blacklist`.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick ", "pick "\]
\[\[7, \[2, 3, 5\]\], \[\], \[\], \[\], \[\], \[\], \[\], \[\]\]
**Output**
\[null, 0, 4, 1, 6, 1, 0, 4\]
**Explanation**
Solution solution = new Solution(7, \[2, 3, 5\]);
solution.pick(); // return 0, any integer from \[0,1,4,6\] should be ok. Note that for every call of pick,
// 0, 1, 4, and 6 must be equally likely to be returned (i.e., with probability 1/4).
solution.pick(); // return 4
solution.pick(); // return 1
solution.pick(); // return 6
solution.pick(); // return 1
solution.pick(); // return 0
solution.pick(); // return 4
**Constraints:**
* `1 <= n <= 109`
* `0 <= blacklist.length <= min(105, n - 1)`
* `0 <= blacklist[i] < n`
* All the values of `blacklist` are **unique**.
* At most `2 * 104` calls will be made to `pick`. | null |
Simple python solution | random-pick-with-blacklist | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(B) preprocessing; O(1) for pick\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(B)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n\n def __init__(self, n: int, blacklist: List[int]):\n self.n = n\n self.num_black = len(blacklist)\n self.mapper = {b: b for b in blacklist}\n end = n-1\n for b in blacklist:\n if b < self.n - self.num_black:\n while end in self.mapper:\n end = end - 1\n self.mapper[b] = end\n end = end - 1\n print(self.mapper)\n\n def pick(self) -> int:\n idx=random.randint(0, self.n-self.num_black-1)\n return idx if idx not in self.mapper else self.mapper[idx] \n\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(n, blacklist)\n# param_1 = obj.pick()\n``` | 0 | Given an integer `n`, return _a list of all possible **full binary trees** with_ `n` _nodes_. Each node of each tree in the answer must have `Node.val == 0`.
Each element of the answer is the root node of one possible tree. You may return the final list of trees in **any order**.
A **full binary tree** is a binary tree where each node has exactly `0` or `2` children.
**Example 1:**
**Input:** n = 7
**Output:** \[\[0,0,0,null,null,0,0,null,null,0,0\],\[0,0,0,null,null,0,0,0,0\],\[0,0,0,0,0,0,0\],\[0,0,0,0,0,null,null,null,null,0,0\],\[0,0,0,0,0,null,null,0,0\]\]
**Example 2:**
**Input:** n = 3
**Output:** \[\[0,0,0\]\]
**Constraints:**
* `1 <= n <= 20` | null |
Python3 Solution | minimum-ascii-delete-sum-for-two-strings | 0 | 1 | \n```\nclass Solution:\n def minimumDeleteSum(self, s1: str, s2: str) -> int:\n n=len(s1)\n m=len(s2)\n dp=[[0 for x in range(m+1)] for x in range(n+1)]\n for i in range(1,n+1):\n dp[i][0]=dp[i-1][0]+ord(s1[i-1])\n\n for i in range(1,m+1):\n dp[0][i]=dp[0][i-1]+ord(s2[i-1])\n for i in range(1,n+1):\n for j in range(1,m+1):\n if s1[i-1]==s2[j-1]:\n dp[i][j]=dp[i-1][j-1]\n else:\n dp[i][j]=min(dp[i-1][j]+ord(s1[i-1]),dp[i][j-1]+ord(s2[j-1]))\n\n return dp[n][m] \n``` | 6 | Given two strings `s1` and `s2`, return _the lowest **ASCII** sum of deleted characters to make two strings equal_.
**Example 1:**
**Input:** s1 = "sea ", s2 = "eat "
**Output:** 231
**Explanation:** Deleting "s " from "sea " adds the ASCII value of "s " (115) to the sum.
Deleting "t " from "eat " adds 116 to the sum.
At the end, both strings are equal, and 115 + 116 = 231 is the minimum sum possible to achieve this.
**Example 2:**
**Input:** s1 = "delete ", s2 = "leet "
**Output:** 403
**Explanation:** Deleting "dee " from "delete " to turn the string into "let ",
adds 100\[d\] + 101\[e\] + 101\[e\] to the sum.
Deleting "e " from "leet " adds 101\[e\] to the sum.
At the end, both strings are equal to "let ", and the answer is 100+101+101+101 = 403.
If instead we turned both strings into "lee " or "eet ", we would get answers of 433 or 417, which are higher.
**Constraints:**
* `1 <= s1.length, s2.length <= 1000`
* `s1` and `s2` consist of lowercase English letters. | Let dp(i, j) be the answer for inputs s1[i:] and s2[j:]. |
🔥 100% DP [VIDEO] Decoding Approach to Minimum ASCII Delete Sum 📝 | minimum-ascii-delete-sum-for-two-strings | 1 | 1 | # Intuition\nThe problem is asking us to make two strings equal by deleting characters, while also minimizing the sum of the ASCII values of the deleted characters. This immediately brings to mind dynamic programming, as we can leverage the overlapping subproblems inherent in this task - that is, making smaller substrings equal and expanding upon that. \n\nhttps://youtu.be/OT6zcEATv1c\n\n# Approach\n\nTo solve this problem, we use a dynamic programming approach. In dynamic programming, we break down a complex problem into simpler sub-problems and solve them, often iteratively. Our solutions to these sub-problems then feed into the solution for our overall problem. Here are the step by step details of our approach for this problem:\n\n1. **Initialization and Swap**: If the length of `s1` is greater than the length of `s2`, we swap `s1` and `s2`. This ensures we use less space in our solution. After ensuring `s1` is the shorter string, we initialize an array `prev_row` of length equal to the length of `s2` plus one. Each entry in this array, indexed by `j`, holds the cumulative ASCII sum of the first `j` characters of `s2`. This essentially means that if we were to make `s1` empty by deleting all its characters, the minimum ASCII sum of deleted characters to make `s1` and the first `j` characters of `s2` equal would be the ASCII sum of those `j` characters. We are effectively considering all possible substrings of `s2` paired with an empty string.\n\n2. **Iteration through `s1`**: We then iterate over each character of `s1`, indexed by `i`. For each `i`, we generate a new array `curr_row`. The first entry of `curr_row` is the cumulative ASCII sum of the first `i` characters of `s1` plus the last entry in `prev_row`. This effectively considers the case where we make `s2` empty by deleting all its characters. In that case, the minimum ASCII sum of deleted characters to make the first `i` characters of `s1` and `s2` equal would be the ASCII sum of those `i` characters.\n\n3. **Iteration within `s1` through `s2`**: Within this iteration through `s1`, we iterate through each character of `s2`, indexed by `j`. For each `j`, we compare the `i`-th character of `s1` and the `j`-th character of `s2`.\n\n - If they are equal, we append the value of `prev_row[j - 1]` to `curr_row`. This is because we don\'t need to delete any characters in this case, so the minimum ASCII sum of deleted characters to make the first `i` characters of `s1` and the first `j` characters of `s2` equal would be the same as that to make the first `i - 1` characters of `s1` and the first `j - 1` characters of `s2` equal.\n \n - If they are not equal, we calculate two quantities: `prev_row[j]` + the ASCII value of `s1[i - 1]`, and `curr_row[j - 1]` + the ASCII value of `s2[j - 1]`. The former represents the minimum ASCII sum if we delete the `i`-th character of `s1`, while the latter represents the minimum ASCII sum if we delete the `j`-th character of `s2`. We append the minimum of these two quantities to `curr_row`.\n\n4. **Completion of an iteration of `s1`**: After we have gone through all characters of `s2` for the current `i`, we set `prev_row` to `curr_row`, effectively storing our results for the current `i` and preparing to move to the next `i`.\n\n5. **Final Result**: After we have iterated through all characters of `s1`, `prev_row` will have been updated to hold the minimum ASCII sums for all possible substring pairings of `s1` and `s2`. The last entry in `prev_row` represents the minimum ASCII sum of deleted characters to make `s1` and `s2` equal, which is the final result we return.\n\nThe transitions of the dynamic programming table `prev_row` / `curr_row` essentially represent our evolving solutions to the sub-problems of making the first `i` characters of `s1` and the first `j` characters of `s2` equal. As we expand `i` and `j` to cover all possible substring pairings, we eventually obtain our solution for the overall problem.\n\n# Complexity\n- Time complexity: O(n*m), where `n` and `m` are the lengths of `s1` and `s2`, respectively. This is because we need to iterate through all possible pairs of substrings from `s1` and `s2`.\n\n- Space complexity: O(m), where `m` is the length of `s2`. This is because we only need to store the current and the previous rows of the dynamic programming table at any given time, not the entire table.\n\nThis solution iterates through each possible substring pairing, and calculates the minimum ASCII sum for each pair. By only storing the current and previous rows, it efficiently uses space while still providing the correct result.\n\n# Code\n``` Python []\n#\nclass Solution:\n def minimumDeleteSum(self, s1: str, s2: str) -> int:\n if len(s1) > len(s2):\n s1, s2 = s2, s1\n prev_row = [0] * (len(s2) + 1) \n for j in range(1, len(s2) + 1): \n prev_row[j] = prev_row[j - 1] + ord(s2[j - 1]) \n\n for i in range(1, len(s1) + 1): \n curr_row = [prev_row[0] + ord(s1[i - 1])] \n for j in range(1, len(s2) + 1): \n if s1[i - 1] == s2[j - 1]: \n curr_row.append(prev_row[j - 1]) \n else: \n curr_row.append(min(prev_row[j] + ord(s1[i - 1]), curr_row[j - 1] + ord(s2[j - 1]))) \n prev_row = curr_row \n\n return prev_row[-1] \n```\n``` C++ []\nclass Solution {\npublic:\n int minimumDeleteSum(string s1, string s2) {\n vector<vector<int>> dp(s1.size() + 1, vector<int>(s2.size() + 1, 0));\n\n for (int i = 1; i <= s1.size(); i++)\n dp[i][0] = dp[i - 1][0] + s1[i - 1];\n\n for (int j = 1; j <= s2.size(); j++)\n dp[0][j] = dp[0][j - 1] + s2[j - 1];\n\n for (int i = 1; i <= s1.size(); i++) {\n for (int j = 1; j <= s2.size(); j++) {\n if (s1[i - 1] == s2[j - 1]) {\n dp[i][j] = dp[i - 1][j - 1];\n } else {\n dp[i][j] = min(dp[i - 1][j] + s1[i - 1], dp[i][j - 1] + s2[j - 1]);\n }\n }\n }\n \n return dp[s1.size()][s2.size()];\n }\n};\n```\n``` JavaScript []\n/**\n * @param {string} s1\n * @param {string} s2\n * @return {number}\n */\nvar minimumDeleteSum = function(s1, s2) {\n let prev_row = new Array(s2.length + 1).fill(0);\n for (let j = 1; j <= s2.length; j++)\n prev_row[j] = prev_row[j - 1] + s2.charCodeAt(j - 1);\n \n for (let i = 1; i <= s1.length; i++) {\n let curr_row = [prev_row[0] + s1.charCodeAt(i - 1)];\n for (let j = 1; j <= s2.length; j++) {\n if (s1[i - 1] === s2[j - 1])\n curr_row.push(prev_row[j - 1]);\n else\n curr_row.push(Math.min(prev_row[j] + s1.charCodeAt(i - 1), curr_row[curr_row.length - 1] + s2.charCodeAt(j - 1)));\n }\n prev_row = curr_row;\n }\n \n return prev_row[prev_row.length - 1];\n};\n```\n``` Java []\nclass Solution {\n public int minimumDeleteSum(String s1, String s2) {\n int[][] dp = new int[s1.length() + 1][s2.length() + 1];\n\n for (int i = 1; i <= s1.length(); i++)\n dp[i][0] = dp[i - 1][0] + s1.charAt(i - 1);\n \n for (int j = 1; j <= s2.length(); j++)\n dp[0][j] = dp[0][j - 1] + s2.charAt(j - 1);\n \n for (int i = 1; i <= s1.length(); i++) {\n for (int j = 1; j <= s2.length(); j++) {\n if (s1.charAt(i - 1) == s2.charAt(j - 1)) {\n dp[i][j] = dp[i - 1][j - 1];\n } else {\n dp[i][j] = Math.min(dp[i - 1][j] + s1.charAt(i - 1), dp[i][j - 1] + s2.charAt(j - 1));\n }\n }\n }\n \n return dp[s1.length()][s2.length()];\n }\n}\n```\n``` C# []\npublic class Solution {\n public int MinimumDeleteSum(string s1, string s2) {\n int[,] dp = new int[s1.Length + 1, s2.Length + 1];\n\n for (int i = 1; i <= s1.Length; i++)\n dp[i, 0] = dp[i - 1, 0] + s1[i - 1];\n\n for (int j = 1; j <= s2.Length; j++)\n dp[0, j] = dp[0, j - 1] + s2[j - 1];\n \n for (int i = 1; i <= s1.Length; i++) {\n for (int j = 1; j <= s2.Length; j++) {\n if (s1[i - 1] == s2[j - 1]) {\n dp[i, j] = dp[i - 1, j - 1];\n } else {\n dp[i, j] = Math.Min(dp[i - 1, j] + s1[i - 1], dp[i, j - 1] + s2[j - 1]);\n }\n }\n }\n \n return dp[s1.Length, s2.Length];\n }\n}\n```\n``` Rust []\nimpl Solution {\n pub fn minimum_delete_sum(s1: String, s2: String) -> i32 {\n let mut prev_row = vec![0; s2.len() + 1];\n let s1 = s1.chars().collect::<Vec<_>>();\n let s2 = s2.chars().collect::<Vec<_>>();\n\n for j in 1..=s2.len() {\n prev_row[j] = prev_row[j - 1] + s2[j - 1] as i32;\n }\n\n for i in 1..=s1.len() {\n let mut curr_row = vec![prev_row[0] + s1[i - 1] as i32];\n for j in 1..=s2.len() {\n if s1[i - 1] == s2[j - 1] {\n curr_row.push(prev_row[j - 1]);\n } else {\n curr_row.push(std::cmp::min(prev_row[j] + s1[i - 1] as i32, curr_row[j - 1] + s2[j - 1] as i32));\n }\n }\n prev_row = curr_row;\n }\n\n *prev_row.last().unwrap()\n }\n}\n```\n\n# Performance\n\nHere\'s the table sorted by Runtime in ascending order:\n\n| Language | Runtime | Beats (Runtime) | Memory | Beats (Memory) |\n|-----------|---------|-----------------|--------|----------------|\n| Rust | 6 ms | 80% | 2.1 MB | 86.67% |\n| Java | 23 ms | 84.93% | 44.3 MB| 48.12% |\n| C++ | 38 ms | 79.40% | 15.3 MB| 41.16% |\n| C# | 71 ms | 90.63% | 39.9 MB| 62.50% |\n| JavaScript| 88 ms | 96.51% | 49.5 MB| 60.46% |\n| Python3 | 440 ms | 95.34% | 16.5 MB| 91.25% |\n\n\nThis table provides a summary of the performance metrics (runtime and memory usage) for each programming language for the given LeetCode problem, sorted by runtime in ascending order (from fastest to slowest). The "Beats" columns indicate the percentage of other LeetCode users\' submissions that the corresponding solution outperforms in terms of runtime or memory usage.\n\n# Video for JavaScript:\nhttps://youtu.be/BSFWVKT-UNI\n\nI hope this step-by-step guide aids you in understanding this problem and the thought process behind its solution. I am eager to hear any questions, suggestions, or comments you might have! | 24 | Given two strings `s1` and `s2`, return _the lowest **ASCII** sum of deleted characters to make two strings equal_.
**Example 1:**
**Input:** s1 = "sea ", s2 = "eat "
**Output:** 231
**Explanation:** Deleting "s " from "sea " adds the ASCII value of "s " (115) to the sum.
Deleting "t " from "eat " adds 116 to the sum.
At the end, both strings are equal, and 115 + 116 = 231 is the minimum sum possible to achieve this.
**Example 2:**
**Input:** s1 = "delete ", s2 = "leet "
**Output:** 403
**Explanation:** Deleting "dee " from "delete " to turn the string into "let ",
adds 100\[d\] + 101\[e\] + 101\[e\] to the sum.
Deleting "e " from "leet " adds 101\[e\] to the sum.
At the end, both strings are equal to "let ", and the answer is 100+101+101+101 = 403.
If instead we turned both strings into "lee " or "eet ", we would get answers of 433 or 417, which are higher.
**Constraints:**
* `1 <= s1.length, s2.length <= 1000`
* `s1` and `s2` consist of lowercase English letters. | Let dp(i, j) be the answer for inputs s1[i:] and s2[j:]. |
Variation of the [1143. Longest Common Subsequence] problem | minimum-ascii-delete-sum-for-two-strings | 1 | 1 | # Similar Problem:\nVery popular problem: [1143. Longest Common Subsequence](https://leetcode.com/problems/longest-common-subsequence/description/)\n\n# Intuition\nBasic recursion + memoization problem.\n\n- Start from `i=0, j=0`\n- Each time compare `s1.charAt(i)` with `s2.charAt(j)`.\n- If they are equal, move to `recurse(i+1, j+1)`\n- If they are not, we have two options:\n - delete `i` so, `ascii(s1.charAt(i)) + recurse(i+1, j)`\n - delete `j` so, `ascii(s2.charAt(j)) + recurse(i, j+1)`\n - return minimum of those two.\n- It will give TLE. So, make sure to memoize it. `Memo[i][j]` will be helpful.\n<!-- Describe your first thoughts on how to solve this problem. -->\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: $$O(n^2)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n^2)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n``` java []\nclass Solution {\n int[][] memo;\n int n, m;\n public int minimumDeleteSum(String s1, String s2) {\n n = s1.length();\n m = s2.length();\n memo = new int[n][m];\n for(int i=0; i<n; i++){\n Arrays.fill(memo[i], -1);\n }\n return recurse(s1,s2, 0, 0);\n }\n\n int recurse(String s1, String s2, int i, int j) {\n if(i==n && j==m) {\n return 0;\n }\n if(i == n){\n int sum = 0;\n for(int k=j; k<m; k++){\n sum+=(int)s2.charAt(k);\n }\n return sum;\n }\n if(j==m){\n int sum = 0;\n for(int k=i; k<n; k++){\n sum+=(int)s1.charAt(k);\n }\n return sum;\n }\n \n if(memo[i][j]!=-1) {\n return memo[i][j];\n }\n\n if(s1.charAt(i)==s2.charAt(j)){\n return memo[i][j] = recurse(s1, s2, i+1, j+1);\n }\n return memo[i][j] = Math.min((int)s1.charAt(i)+recurse(s1, s2, i+1, j), (int)s2.charAt(j)+recurse(s1,s2, i, j+1));\n\n }\n}\n``` | 3 | Given two strings `s1` and `s2`, return _the lowest **ASCII** sum of deleted characters to make two strings equal_.
**Example 1:**
**Input:** s1 = "sea ", s2 = "eat "
**Output:** 231
**Explanation:** Deleting "s " from "sea " adds the ASCII value of "s " (115) to the sum.
Deleting "t " from "eat " adds 116 to the sum.
At the end, both strings are equal, and 115 + 116 = 231 is the minimum sum possible to achieve this.
**Example 2:**
**Input:** s1 = "delete ", s2 = "leet "
**Output:** 403
**Explanation:** Deleting "dee " from "delete " to turn the string into "let ",
adds 100\[d\] + 101\[e\] + 101\[e\] to the sum.
Deleting "e " from "leet " adds 101\[e\] to the sum.
At the end, both strings are equal to "let ", and the answer is 100+101+101+101 = 403.
If instead we turned both strings into "lee " or "eet ", we would get answers of 433 or 417, which are higher.
**Constraints:**
* `1 <= s1.length, s2.length <= 1000`
* `s1` and `s2` consist of lowercase English letters. | Let dp(i, j) be the answer for inputs s1[i:] and s2[j:]. |
Solution | subarray-product-less-than-k | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int numSubarrayProductLessThanK(vector<int>& nums, int k) {\n ios_base::sync_with_stdio(false);\n cin.tie(0); cout.tie(0);\n int j=0;\n int n=nums.size();\n int s=1;\n int c=0;\n for(int i=0;i<n;i++)\n {\n s*=nums[i];\n if(s<k)\n {\n int x=(i-j+1);\n c+=x;\n }\n else\n {\n while(s>=k&&j<=i)\n {\n s/=nums[j];\n j++;\n }\n int x=(i-j+1);\n c+=x;\n }\n } \n return c;\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def numSubarrayProductLessThanK(self, nums: List[int], k: int) -> int:\n if k == 0 or k == 1: return 0\n pro = 1\n cnt = 0 \n j = 0 \n for i in range(len(nums)):\n pro *= nums[i]\n while pro >= k: \n pro //= nums[j]\n j += 1 \n cnt += i - j + 1 \n return cnt\n```\n\n```Java []\nclass Solution {\n public int numSubarrayProductLessThanK(int[] nums, int k) {\n \n int n=nums.length;\n int j=0; double pro=1; int ans=0;\n for(int i=0; i<n; i++) {\n pro*=nums[i];\n while(j<=i && pro>=k) {\n pro/=nums[j]; j++;\n }\n ans+=(i-j+1);\n }\n return ans;\n }\n}\n```\n | 2 | Given an array of integers `nums` and an integer `k`, return _the number of contiguous subarrays where the product of all the elements in the subarray is strictly less than_ `k`.
**Example 1:**
**Input:** nums = \[10,5,2,6\], k = 100
**Output:** 8
**Explanation:** The 8 subarrays that have product less than 100 are:
\[10\], \[5\], \[2\], \[6\], \[10, 5\], \[5, 2\], \[2, 6\], \[5, 2, 6\]
Note that \[10, 5, 2\] is not included as the product of 100 is not strictly less than k.
**Example 2:**
**Input:** nums = \[1,2,3\], k = 0
**Output:** 0
**Constraints:**
* `1 <= nums.length <= 3 * 104`
* `1 <= nums[i] <= 1000`
* `0 <= k <= 106` | For each j, let opt(j) be the smallest i so that nums[i] * nums[i+1] * ... * nums[j] is less than k. opt is an increasing function. |
Python Simple Solution Explained (video + code) (Fastest) | subarray-product-less-than-k | 0 | 1 | [](https://www.youtube.com/watch?v=4775IgUKfww)\nhttps://www.youtube.com/watch?v=4775IgUKfww\n```\nclass Solution:\n def numSubarrayProductLessThanK(self, nums: List[int], k: int) -> int: \n l = 0\n res = 0\n product = 1\n \n for r in range(len(nums)):\n product *= nums[r]\n \n if product >= k:\n while product >= k and l <= r:\n product /= nums[l]\n l += 1\n \n res += r - l + 1\n \n return res\n``` | 35 | Given an array of integers `nums` and an integer `k`, return _the number of contiguous subarrays where the product of all the elements in the subarray is strictly less than_ `k`.
**Example 1:**
**Input:** nums = \[10,5,2,6\], k = 100
**Output:** 8
**Explanation:** The 8 subarrays that have product less than 100 are:
\[10\], \[5\], \[2\], \[6\], \[10, 5\], \[5, 2\], \[2, 6\], \[5, 2, 6\]
Note that \[10, 5, 2\] is not included as the product of 100 is not strictly less than k.
**Example 2:**
**Input:** nums = \[1,2,3\], k = 0
**Output:** 0
**Constraints:**
* `1 <= nums.length <= 3 * 104`
* `1 <= nums[i] <= 1000`
* `0 <= k <= 106` | For each j, let opt(j) be the smallest i so that nums[i] * nums[i+1] * ... * nums[j] is less than k. opt is an increasing function. |
Python simple solution with sliding window pattern | subarray-product-less-than-k | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThis problem is a classic sliding window problem. We need to find a subarray where the product of all elements is less than a given value \'k\'. If we start from each index and try to find a subarray, the time complexity will be high. Therefore, we can use a sliding window approach to solve this problem. The window expands until it encounters a number which makes the product greater than \'k\' and then the window contracts until the product is less than \'k\' again.\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Initialize two pointers, left and right both at 0, and initialize a variable product at 1.\n2. Expand the window to the right by incrementing right and multiplying product by nums[right].\n3. If product is now greater than or equal to k, contract the window from the left by dividing product by nums[left] and incrementing left. Do this until product is less than k again.\n4. After each step, add the size of the current window right - left + 1 to the result. This is because the new element at right could form that many new subarrays.\n5. Repeat steps 2-4 until right has traversed through the entire array.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n), where n is the number of elements in the array. This is because each element is visited at most twice, once by the right pointer (when we move right) and (possibly) once more by the left pointer (when we move left).\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(1), since we are not using any additional space that scales with input size.\n# Code\n```\nclass Solution:\n def numSubarrayProductLessThanK(self, nums: List[int], k: int) -> int:\n if k <= 1:\n return 0\n product = 1\n result = 0\n left = 0\n for right in range(len(nums)):\n product *= nums[right]\n while product >= k:\n product /= nums[left]\n left += 1\n result += right - left + 1\n return result\n\n``` | 3 | Given an array of integers `nums` and an integer `k`, return _the number of contiguous subarrays where the product of all the elements in the subarray is strictly less than_ `k`.
**Example 1:**
**Input:** nums = \[10,5,2,6\], k = 100
**Output:** 8
**Explanation:** The 8 subarrays that have product less than 100 are:
\[10\], \[5\], \[2\], \[6\], \[10, 5\], \[5, 2\], \[2, 6\], \[5, 2, 6\]
Note that \[10, 5, 2\] is not included as the product of 100 is not strictly less than k.
**Example 2:**
**Input:** nums = \[1,2,3\], k = 0
**Output:** 0
**Constraints:**
* `1 <= nums.length <= 3 * 104`
* `1 <= nums[i] <= 1000`
* `0 <= k <= 106` | For each j, let opt(j) be the smallest i so that nums[i] * nums[i+1] * ... * nums[j] is less than k. opt is an increasing function. |
✅Beats 100% || C++ || JAVA || PYTHON || Beginner Friendly🔥🔥🔥 | best-time-to-buy-and-sell-stock-with-transaction-fee | 1 | 1 | **Explore Related Problems to Enhance Conceptual Understanding**\n1. [Best Time to Buy and Sell Stock](https://leetcode.com/problems/best-time-to-buy-and-sell-stock/description/)\n2. [Best Time to Buy and Sell Stock II](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-ii/description/)\n3. [Best Time to Buy and Sell Stock III](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/description/)\n4. [Best Time to Buy and Sell Stock III](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iv/description/)\n5. [Best Time to Buy and Sell Stock with Cooldown](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-cooldown/description/)\n\n# Intuition\nThe intuition behind the solution is to keep track of the minimum cost to buy a stock at each day and the maximum profit that can be achieved by selling the stock at each day.\n\n# Approach:\n1. Initialize two variables: `buy` and `sell`. Set `buy` to negative infinity and `sell` to zero. These variables will keep track of the maximum profit at each day.\n2. Iterate through the prices of the stocks starting from the first day.\n3. Update the `buy` variable by taking the maximum of its current value and the previous `sell` value minus the stock price. This represents the maximum profit after buying the stock.\n `buy = max(buy, sell - price)`\n\n4. Update the `sell` variable by taking the maximum of its current value and the previous `buy` value plus the stock price minus the transaction fee. This represents the maximum profit after selling the stock.\n `sell = max(sell, buy + price - fee)`\n\n5. After iterating through all the prices, the maximum profit will be stored in the `sell` variable.\n6. Return the value of `sell` as the maximum profit.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(1)$$\n\n# Code\n\n```C++ []\nclass Solution {\npublic:\n int maxProfit(vector<int>& prices, int fee) {\n int buy = INT_MIN;\n int sell = 0;\n\n for (int price : prices) {\n buy = max(buy, sell - price);\n sell = max(sell, buy + price - fee);\n }\n\n return sell;\n }\n};\n```\n```Java []\nclass Solution {\n public int maxProfit(int[] prices, int fee) {\n int buy = Integer.MIN_VALUE;\n int sell = 0;\n\n for (int price : prices) {\n buy = Math.max(buy, sell - price);\n sell = Math.max(sell, buy + price - fee);\n }\n\n return sell;\n }\n}\n```\n```Python3 []\nclass Solution:\n def maxProfit(self, prices: List[int], fee: int) -> int:\n buy = float(\'-inf\')\n sell = 0\n\n for price in prices:\n buy = max(buy, sell - price)\n sell = max(sell, buy + price - fee)\n\n return sell\n```\n\nRelated problems\n\n\n\n**If you found my solution helpful, I would greatly appreciate your upvote, as it would motivate me to continue sharing more solutions.**\n\n\n | 202 | You are given an array `prices` where `prices[i]` is the price of a given stock on the `ith` day, and an integer `fee` representing a transaction fee.
Find the maximum profit you can achieve. You may complete as many transactions as you like, but you need to pay the transaction fee for each transaction.
**Note:** You may not engage in multiple transactions simultaneously (i.e., you must sell the stock before you buy again).
**Example 1:**
**Input:** prices = \[1,3,2,8,4,9\], fee = 2
**Output:** 8
**Explanation:** The maximum profit can be achieved by:
- Buying at prices\[0\] = 1
- Selling at prices\[3\] = 8
- Buying at prices\[4\] = 4
- Selling at prices\[5\] = 9
The total profit is ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
**Example 2:**
**Input:** prices = \[1,3,7,5,10,3\], fee = 3
**Output:** 6
**Constraints:**
* `1 <= prices.length <= 5 * 104`
* `1 <= prices[i] < 5 * 104`
* `0 <= fee < 5 * 104` | Consider the first K stock prices. At the end, the only legal states are that you don't own a share of stock, or that you do. Calculate the most profit you could have under each of these two cases. |
Easiest Python Solution beating 81% | best-time-to-buy-and-sell-stock-with-transaction-fee | 0 | 1 | \n# Code\n```\nclass Solution(object):\n def maxProfit(self, prices, fee):\n """\n :type prices: List[int]\n :type fee: int\n :rtype: int\n """\n pos=-prices[0]\n profit=0\n n=len(prices)\n for i in range(1,n):\n pos=max(pos,profit-prices[i])\n profit=max(profit,pos+prices[i]-fee)\n return profit\n \n``` | 1 | You are given an array `prices` where `prices[i]` is the price of a given stock on the `ith` day, and an integer `fee` representing a transaction fee.
Find the maximum profit you can achieve. You may complete as many transactions as you like, but you need to pay the transaction fee for each transaction.
**Note:** You may not engage in multiple transactions simultaneously (i.e., you must sell the stock before you buy again).
**Example 1:**
**Input:** prices = \[1,3,2,8,4,9\], fee = 2
**Output:** 8
**Explanation:** The maximum profit can be achieved by:
- Buying at prices\[0\] = 1
- Selling at prices\[3\] = 8
- Buying at prices\[4\] = 4
- Selling at prices\[5\] = 9
The total profit is ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
**Example 2:**
**Input:** prices = \[1,3,7,5,10,3\], fee = 3
**Output:** 6
**Constraints:**
* `1 <= prices.length <= 5 * 104`
* `1 <= prices[i] < 5 * 104`
* `0 <= fee < 5 * 104` | Consider the first K stock prices. At the end, the only legal states are that you don't own a share of stock, or that you do. Calculate the most profit you could have under each of these two cases. |
Python | O(n) time, O(1) space | Iterate through array | Beats 96 %for time | best-time-to-buy-and-sell-stock-with-transaction-fee | 0 | 1 | # Intuition\nYou know what they say, hindsight is 20/20. Going through the array backwards would allow us to identify the starting point as the high price a sale happened at, and the ending point as the lowest point preceding that. If we keep a running tally that changes as we pass the end of the transaction, we will have the answer when we reach the end.\n\nIgnoring the fee for a moment, let\'s evaluate a case without a fee. As we iterate backwards looking for a high point, if the price keeps going up, we havent found the high point, as the price was falling over this period. Once the price started going down, we\'d remember the high point as the sale price. As long as the price keeps going down, we haven\'t found the low we bought it at. Once the price starts going up again, we found the low point. With no fee, it is always more profit to sell at every peak and buy at every valley.\n\nThe transaction fee complicates it a bit, but not by much. The fee is just a buffer zone above the valley. If the high values on either side are above that buffer zone, then it behaves exactly the same as above. \n\nIf the recorded high we saw before the valley is still in that fee buffer zone above the low when we go higher again, that is not a tranaction worth taking yet. If the new peak is higher than the old, we reset to that, the span from peak to peak had less variance than the fee and any transaction there would have been a loss. If the new peak is lower than the old, we just keep going, waiting for a lower low or a higher high. \n\nOnce the recorded high is above the fee buffer zone, there will definitely be a transaction, but not every time the price goes up like in the easier case. If the new peak is within the fee buffer zone, it would not have made sense to sell at that peak and buy at the valley. If the values go down again, great we have a new low to have bought at. If the values go up, once they cross the threshold of the fee buffer, it behaves exactly like the simpler no fee case, you make more by transacting more when profit is availible. \n\n# Approach\nFirst the skeleton we know we\'ll need. The while loop here should probably be a for loop, but I originally tried 2 pointers, found one wasn\'t needed and never refactored:\n\n```\n+class Solution:\n+ def maxProfit(self, prices: List[int], fee: int) -> int:\n+ total_profit_taken = 0\n+ i = len(prices) - 1\n+ high, low = prices[i], prices[i]\n+\n+ while i >= 0:\n+ value = prices[i]\n+ # Todo\n+ i -= 1\n+\n+ return total_profit_taken\n```\n\nThe first case we will tackle is when we see new higher prices (`value > high`), and there wasn\'t a transaction worth taking (`low + fee >= high`). In this case we want to reset high and low values to the new high without recording a sale.I\'ll be leaving in some commented print commands you can uncomment if you want to see the algorithm in action.\n\n```\n= while i >= 0:\n= value = prices[i]\n+ #print(f"high: {high}, low: {low}, min_to_profit = {low + fee}, next value: {value}")\n+ if low + fee >= high and value > high:\n+ #print(f"reset high and low to {value}")\n+ high, low = value, value\n= # Todo\n```\n\nNext we\'ll tackle the super simple case of finding a new low number. We just record this as we go as the low price we bought at. If we find lower, we\'ll do the same again.\n\n```\n= if low + fee >= high and value > high:\n= #print(f"reset high and low to {value}")\n= high, low = value, value\n+ elif value < low:\n+ low = value\n+ #print(f"new low to {low}")\n= # Todo\n```\n\nNext we look at the case of the value crossing the threshold of being a peak we would have sold at (`value > low + fee`). Note that this doesn\'t have to be higher than the high value, only higher than the low and high enough to make the transaction worthwhile. For this case, we record the transaction we just passed the end of, before resetting to this new peak.\n\n```\n= elif value < low:\n= low = value\n= #print(f"new low to {low}")\n+ elif value > low + fee:\n+ total_profit_taken += (high - low) - fee\n+ #print(f"added {(high - low) - fee} to profit, reset to to {value}")\n+ high, low = value, value\n- # Todo\n= i -= 1\n=\n= return total_profit_taken\n```\n\nFinally, and for completeness, the else condition is `value >= low and value <= low + fee`. In plain english, this is a peak higher than the low valley, but lower than the fee buffer zone. Selling at this peak and buying the valley would incur a loss. All we want to do in this case is continue iterating until one of the other cases occur, so the `else: pass` we will leave as implicit\n\nThis solution is incomplete, there is a corner case at the edge. If we recorded a peak and a valley, but then ran out of numbers, those last numbers could have been a profitable transaction. Instead of applying this conditionally with `low + fee < high`, this time I just chose to use max(0, ) in case the transaction spit out a negative number.\n\n```\n= i -= 1\n+ total_profit_taken += max(0, (high - low) - fee)\n=\n= return total_profit_taken\n```\n\nAnd that is job done in one iteration, taking what must be the high and low sale points using hindsight.\n\n\n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(1)\n\n# Code\n```\nclass Solution:\n def maxProfit(self, prices: List[int], fee: int) -> int:\n total_profit_taken = 0\n i = len(prices) - 1\n high, low = prices[i], prices[i]\n\n while i >= 0:\n value = prices[i]\n #print(f"high: {high}, low: {low}, min_to_profit = {low + fee}, next value: {value}")\n if low + fee >= high and value > high:\n #print(f"reset high and low to {value}")\n high, low = value, value\n elif value < low:\n low = value\n #print(f"new low to {low}")\n elif value > low + fee:\n total_profit_taken += (high - low) - fee\n #print(f"added {(high - low) - fee} to profit, reset to to {value}")\n high, low = value, value\n i -= 1\n total_profit_taken += max(0, (high - low) - fee)\n\n return total_profit_taken\n``` | 1 | You are given an array `prices` where `prices[i]` is the price of a given stock on the `ith` day, and an integer `fee` representing a transaction fee.
Find the maximum profit you can achieve. You may complete as many transactions as you like, but you need to pay the transaction fee for each transaction.
**Note:** You may not engage in multiple transactions simultaneously (i.e., you must sell the stock before you buy again).
**Example 1:**
**Input:** prices = \[1,3,2,8,4,9\], fee = 2
**Output:** 8
**Explanation:** The maximum profit can be achieved by:
- Buying at prices\[0\] = 1
- Selling at prices\[3\] = 8
- Buying at prices\[4\] = 4
- Selling at prices\[5\] = 9
The total profit is ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
**Example 2:**
**Input:** prices = \[1,3,7,5,10,3\], fee = 3
**Output:** 6
**Constraints:**
* `1 <= prices.length <= 5 * 104`
* `1 <= prices[i] < 5 * 104`
* `0 <= fee < 5 * 104` | Consider the first K stock prices. At the end, the only legal states are that you don't own a share of stock, or that you do. Calculate the most profit you could have under each of these two cases. |
Solution | best-time-to-buy-and-sell-stock-with-transaction-fee | 1 | 1 | ```C++ []\nconst static auto initialize = [] { std::ios::sync_with_stdio(false); std::cin.tie(nullptr); std::cout.tie(nullptr); return nullptr; }();\nclass Solution {\npublic:\n\tint maxProfit(std::vector<int>& prices, int fee)\n\t{\n\t\tauto buy_state = -1 * prices[0];\n\t\tauto sell_state = 0;\n\t\tfor (auto i = 1; i != static_cast<int>(std::size(prices)); ++i)\n\t\t{\n\t\t\tbuy_state = std::max(buy_state, sell_state - prices[i]);\n\t\t\tsell_state = std::max(sell_state, prices[i] + buy_state - fee);\n\t\t}\n\t\treturn sell_state;\n\t}\n};\n```\n\n```Python3 []\nclass Solution:\n def maxProfit(self, prices: List[int], fee: int) -> int:\n min_p = prices[0] + fee\n res = 0\n \n for p in prices:\n if min_p < p:\n res += p-min_p\n min_p = p\n elif p+fee < min_p:\n min_p = p + fee\n \n return res\n```\n\n```Java []\nclass Solution {\n public int maxProfit(int[] P, int F) {\n int len = P.length, buying = 0, selling = -P[0];\n for (int i = 1; i < len; i++) {\n buying = Math.max(buying, selling + P[i] - F);\n selling = Math.max(selling, buying - P[i]);\n }\n return buying;\n }\n}\n```\n | 4 | You are given an array `prices` where `prices[i]` is the price of a given stock on the `ith` day, and an integer `fee` representing a transaction fee.
Find the maximum profit you can achieve. You may complete as many transactions as you like, but you need to pay the transaction fee for each transaction.
**Note:** You may not engage in multiple transactions simultaneously (i.e., you must sell the stock before you buy again).
**Example 1:**
**Input:** prices = \[1,3,2,8,4,9\], fee = 2
**Output:** 8
**Explanation:** The maximum profit can be achieved by:
- Buying at prices\[0\] = 1
- Selling at prices\[3\] = 8
- Buying at prices\[4\] = 4
- Selling at prices\[5\] = 9
The total profit is ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
**Example 2:**
**Input:** prices = \[1,3,7,5,10,3\], fee = 3
**Output:** 6
**Constraints:**
* `1 <= prices.length <= 5 * 104`
* `1 <= prices[i] < 5 * 104`
* `0 <= fee < 5 * 104` | Consider the first K stock prices. At the end, the only legal states are that you don't own a share of stock, or that you do. Calculate the most profit you could have under each of these two cases. |
Python || DP || Recursion->Space Optimization | best-time-to-buy-and-sell-stock-with-transaction-fee | 0 | 1 | ```\n#Recursion \n#Time Complexity: O(2^n)\n#Space Complexity: O(n)\nclass Solution1:\n def maxProfit(self, prices: List[int], fee: int) -> int:\n def solve(ind,buy):\n if ind==n:\n return 0\n profit=0\n if buy==0: #buy a stock\n take=-prices[ind]+solve(ind+1,1) \n not_take=0+solve(ind+1,0)\n profit=max(take,not_take)\n else: # sell a stock\n take=prices[ind]-fee+solve(ind+1,0)\n not_take=0+solve(ind+1,1)\n profit=max(take,not_take)\n return profit\n n=len(prices)\n return solve(0,0)\n\n#Memoization (Top-Down)\n#Time Complexity: O(n*2)\n#Space Complexity: O(n*2) + O(n)\nclass Solution2:\n def maxProfit(self, prices: List[int], fee: int) -> int:\n def solve(ind,buy):\n if ind==n:\n return 0\n if dp[ind][buy]!=-1:\n return dp[ind][buy]\n profit=0\n if buy==0: #buy a stock\n take=-prices[ind]+solve(ind+1,1) \n not_take=0+solve(ind+1,0)\n profit=max(take,not_take)\n else:\n take=prices[ind]-fee+solve(ind+1,0) \n not_take=0+solve(ind+1,1)\n profit=max(take,not_take)\n dp[ind][buy]=profit\n return dp[ind][buy]\n n=len(prices)\n dp=[[-1,-1] for i in range(n)]\n return solve(0,0)\n \n#Tabulation (Bottom-Up)\n#Time Complexity: O(n*2)\n#Space Complexity: O(n*2)\nclass Solution3:\n def maxProfit(self, prices: List[int], fee: int) -> int:\n n=len(prices)\n dp=[[0,0] for i in range(n+1)]\n for ind in range(n-1,-1,-1):\n for buy in range(2):\n profit=0\n if buy==0: #buy a stock\n take=-prices[ind]+dp[ind+1][1] \n not_take=0+dp[ind+1][0]\n profit=max(take,not_take)\n else:\n take=prices[ind]-fee+dp[ind+1][0] \n not_take=0+dp[ind+1][1]\n profit=max(take,not_take)\n dp[ind][buy]=profit\n return dp[0][0]\n \n#Space Optimization\n#Time Complexity: O(n*2)\n#Space Complexity: O(1)\nclass Solution:\n def maxProfit(self, prices: List[int], fee: int) -> int:\n n=len(prices)\n ahead=[0]*2\n curr=[0]*2\n for ind in range(n-1,-1,-1):\n for buy in range(2):\n profit=0\n if buy==0: #buy a stock\n take=-prices[ind]+ahead[1] \n not_take=0+ahead[0]\n profit=max(take,not_take)\n else:\n take=prices[ind]-fee+ahead[0] # +2 for cooldown\n not_take=0+ahead[1]\n profit=max(take,not_take)\n curr[buy]=profit\n ahead=curr[:]\n return curr[0]\n```\n**An upvote will be encouraging** | 3 | You are given an array `prices` where `prices[i]` is the price of a given stock on the `ith` day, and an integer `fee` representing a transaction fee.
Find the maximum profit you can achieve. You may complete as many transactions as you like, but you need to pay the transaction fee for each transaction.
**Note:** You may not engage in multiple transactions simultaneously (i.e., you must sell the stock before you buy again).
**Example 1:**
**Input:** prices = \[1,3,2,8,4,9\], fee = 2
**Output:** 8
**Explanation:** The maximum profit can be achieved by:
- Buying at prices\[0\] = 1
- Selling at prices\[3\] = 8
- Buying at prices\[4\] = 4
- Selling at prices\[5\] = 9
The total profit is ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
**Example 2:**
**Input:** prices = \[1,3,7,5,10,3\], fee = 3
**Output:** 6
**Constraints:**
* `1 <= prices.length <= 5 * 104`
* `1 <= prices[i] < 5 * 104`
* `0 <= fee < 5 * 104` | Consider the first K stock prices. At the end, the only legal states are that you don't own a share of stock, or that you do. Calculate the most profit you could have under each of these two cases. |
Easy C++/Python/C solutions|| buy & sell | best-time-to-buy-and-sell-stock-with-transaction-fee | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nGreedy to solve several stock problems.\nUse buy and sell!!\n# Approach\n<!-- Describe your approach to solving the problem. -->\nSeveral stock profit problems are solved in the similar manner.\n[Please turn on English subtitles if neccessary]\n[https://youtu.be/zWS6E0ntTkM](https://youtu.be/zWS6E0ntTkM)\n\nGreedy greedy calculus solution LeetCode714, 121, 122 has the largest profit in the stock market with transaction fees (the main question is Best Time to Buy and Sell Stock with Transaction Fee, and the other two questions can be solved in the same way). These three problems seek local optimal solutions, and greed can solve the overall situation (the real stock market does not seem to be the case, this method is feasible because the stock price is known), greedy calculus is not a panacea, but it is easy to implement, and it is more than enough to solve such problems. Simple and fast O(n) time.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(1)$$\n# Code\n```C++ []\nclass Solution {\npublic:\n int maxProfit(vector<int>& prices, int fee) {\n int s=prices.size();\n if (s <= 1) return 0;\n int buy = -prices[0], sell=0;\n for (int i = 1; i < s; i++) {\n buy = max(buy, sell-prices[i]);\n sell = max(sell, prices[i] - fee + buy);\n // cout<<buy<<"|"<<sell<<endl; \n }\n return sell;\n }\n};\n```\n```python []\nclass Solution:\n def maxProfit(self, prices: List[int], fee: int) -> int:\n s=len(prices)\n if s<=1: return 0\n buy=-prices[0]\n sell=0\n for price in prices[1:]:\n buy=max(buy, sell-price)\n sell=max(sell, price-fee+buy)\n return sell\n```\n```C []\nint maxProfit(int* prices, int n, int fee){\n int buy=INT_MAX, sell=0;\n for (int i=0; i<n; i++){\n if (buy>prices[i]-sell) buy=prices[i]-sell;\n if (sell<prices[i]-fee-buy) sell=prices[i]-fee-buy;\n }\n return sell;\n}\n```\n | 5 | You are given an array `prices` where `prices[i]` is the price of a given stock on the `ith` day, and an integer `fee` representing a transaction fee.
Find the maximum profit you can achieve. You may complete as many transactions as you like, but you need to pay the transaction fee for each transaction.
**Note:** You may not engage in multiple transactions simultaneously (i.e., you must sell the stock before you buy again).
**Example 1:**
**Input:** prices = \[1,3,2,8,4,9\], fee = 2
**Output:** 8
**Explanation:** The maximum profit can be achieved by:
- Buying at prices\[0\] = 1
- Selling at prices\[3\] = 8
- Buying at prices\[4\] = 4
- Selling at prices\[5\] = 9
The total profit is ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
**Example 2:**
**Input:** prices = \[1,3,7,5,10,3\], fee = 3
**Output:** 6
**Constraints:**
* `1 <= prices.length <= 5 * 104`
* `1 <= prices[i] < 5 * 104`
* `0 <= fee < 5 * 104` | Consider the first K stock prices. At the end, the only legal states are that you don't own a share of stock, or that you do. Calculate the most profit you could have under each of these two cases. |
717. 1-bit and 2-bit Characters, Solution with step by step explanation | 1-bit-and-2-bit-characters | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nTo solve this problem, we can use a greedy approach. The main insight here is that whenever we encounter a 1, it will always consume the next bit because 1 represents the start of a two-bit character. Hence, when we see a 1, we can skip the next bit. If we encounter a 0, it stands for a one-bit character, so we just move one step forward.\n\nIn essence, we can start from the beginning of the array and keep decoding the characters until we reach the end. After this, if the last character is a one-bit character, it must be represented by a single 0.\n\n1. We initialize i to 0 to start from the first bit.\n2. Inside the while loop, if the current bit is 1, we increment i by 2 to move past the two-bit character.\n3. If the current bit is 0, we increment i by 1 to move past the one-bit character.\n4. After the loop, if i is pointing to the last position, it means the last character is a one-bit character and we return True, otherwise we return False.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isOneBitCharacter(self, bits: List[int]) -> bool:\n\n # Starting index\n i = 0\n # Iterate through the bits\n while i < len(bits) - 1: # We stop at one less than the length to make sure we can check the last character\n if bits[i] == 1:\n # If the current bit is 1, it\'s a start of a two-bit character\n i += 2 # Skip the next bit\n else:\n # If the current bit is 0, it\'s a one-bit character\n i += 1\n\n # If the loop ends with i exactly at the last position, it means the last character is a one-bit character.\n return i == len(bits) - 1\n``` | 2 | We have two special characters:
* The first character can be represented by one bit `0`.
* The second character can be represented by two bits (`10` or `11`).
Given a binary array `bits` that ends with `0`, return `true` if the last character must be a one-bit character.
**Example 1:**
**Input:** bits = \[1,0,0\]
**Output:** true
**Explanation:** The only way to decode it is two-bit character and one-bit character.
So the last character is one-bit character.
**Example 2:**
**Input:** bits = \[1,1,1,0\]
**Output:** false
**Explanation:** The only way to decode it is two-bit character and two-bit character.
So the last character is not one-bit character.
**Constraints:**
* `1 <= bits.length <= 1000`
* `bits[i]` is either `0` or `1`. | Keep track of where the next character starts. At the end, you want to know if you started on the last bit. |
Basic Python Solution - Iterative Method | 1-bit-and-2-bit-characters | 0 | 1 | # Code\n```\nclass Solution:\n def isOneBitCharacter(self, bits: List[int]) -> bool:\n i = 0\n while i < len(bits):\n if bits[i] == 0:\n if i == len(bits) - 1:\n return True\n i = i + 1\n else:\n i = i + 2\n return False \n \n``` | 1 | We have two special characters:
* The first character can be represented by one bit `0`.
* The second character can be represented by two bits (`10` or `11`).
Given a binary array `bits` that ends with `0`, return `true` if the last character must be a one-bit character.
**Example 1:**
**Input:** bits = \[1,0,0\]
**Output:** true
**Explanation:** The only way to decode it is two-bit character and one-bit character.
So the last character is one-bit character.
**Example 2:**
**Input:** bits = \[1,1,1,0\]
**Output:** false
**Explanation:** The only way to decode it is two-bit character and two-bit character.
So the last character is not one-bit character.
**Constraints:**
* `1 <= bits.length <= 1000`
* `bits[i]` is either `0` or `1`. | Keep track of where the next character starts. At the end, you want to know if you started on the last bit. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.