
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
LemADEC/WarpDrive | 646769559 | Title: Space has Lack of Distance
Question:
username_0: I know you have mentioned this in the config, I just think it _needs_ to be fixed (I'm working on a modpack, but it has a lot of planets using AR, and I want this mod to be able to get to them too. But, to take distance into account, I have to use more than the "recomended" distance. So, here's a question. Why does that distance cause issues? (The 220 km)
It's nowhere near the overworld's world border limitation, so why is it limited there? What I think you should do is create another dimension, make it like the overworld, but maybe have, instead of void, a special block that causes suffocation, but can be walked through (Warp Drive Space Air?), then planetoids could, in some cases, actualy generate a breatable atmosphere by not having this block (Breaking a block replaces it, unless it is surrounded by naturaly (Non preasurized), breathable air, in which case that's what it's replaced by.
That should give me enough distance, as should it with anyone!
But, that's just a suggestion!
Ultimatly, it's your mod!
Answers:
username_1: The configuration comment tells you where and why the limitation is there, watch the video before pretending it can be changed.
Status: Issue closed
username_0: Okay, look here. I didin't know about a video, the config, as far as I could tell, said "Charecter will start shaking, then death" (Slight summary, so I didin't find it there.
and, I'm not "pretending" it can change, I'm putting out possible workarounds. Would they work? Maybe. Maybe Not. But, just because someone comes up with an idea that you think is impossible is no reason to be rude! (Yes, that is how you came across. Rude and ungrateful)
username_1: Like I said, the video is linked in the configuration comments: https://github.com/username_1/WarpDrive/blob/MC1.12/src/main/resources/config/celestialObjects-default.xml#L31
You are asking for support without reading those comments, that is rude.
Answering without checking those actual comments, that is rude too.
username_0: I didin't mean to sound like I was asking for support, and I thought I read those comments (Obviously I missed it, eh)?
So, sorry. |
rs/zerolog | 572076479 | Title: Prepend a particular key:val when using the console writer
Question:
username_0: I have added context to the global logger using
```go
log.Logger = log.With().Str("component", "Global").Logger()
```
Right now the log will read something like:
```go
... some message component=Global
```
When using the console writer. Is there some way I can do:
```go
[Global] some message otherkey=val
```
When a key with the name `component` is present?
Answers:
username_1: Adding a custom key to PartsOrder is a partial workaround for this currently; at least for keys which will appear in all messages. You could then use the FormatFieldName formatter to exclude the specific key name as in your example. However, I don't see an eloquent way to prevent the chosen key from showing up twice on a line if this is done. The "special case" fields (Level, Timestamp, Message and Caller) are excluded in writeFields, which keeps them from being printed twice. Unfortunately these are hard-coded currently.
username_1: Actually - #204 seems to be referencing the same issue?
username_2: Oh yeah, "eloquent way", yes, I try find it but haven't found a good way so I wrote my own one
May I recommend below `ConsoleWriter` way?
```go
// Default output format:
// {Time} {Level} {Goid} {Caller} > {Message} {Key}={Value} {Key}={Value}
type ConsoleWriter struct {
// ColorOutput determines if used colorized output.
ColorOutput bool
// QuoteString determines if quoting string values.
QuoteString bool
// EndWithMessage determines if output message in the end of line.
EndWithMessage bool
// Writer is the output destination. using os.Stderr if empty.
Writer io.Writer
// Formatter specifies an optional text formatter for creating a customized output,
// If it is set, ColorOutput, QuoteString and EndWithMessage will be ignored.
Formatter func(w io.Writer, args *FormatterArgs) (n int, err error)
}
```
As you see, If you have some special requirement, you could use `fmt.Fprintf` to override the `Formatter` callback. A example, https://play.golang.org/p/UmJmLxYXwRO |
gomods/athens | 359217509 | Title: Spans should also have response status
Question:
username_0: Currently when we trace a span, there are spans that return an http response. It will be nice to store the HTTP status code in the span as well.
Proxy
Opencensus
observ package
Answers:
username_1: @username_0 can you explain more or point to documentation as to what this issue really is? Thanks!
username_0: @username_1 Yes sure!
If you open the spans, you can find that the spans have a status field which is basically the trace status.
It would be nice to record the http status in the status field so that we can know what exactly happened in that span.
https://opencensus.io/quickstart/go/tracing/
username_1: Got it, we need to wrap the http.ResponseWriter in this case which Buffalo doesn't make it very trivial because you have to wrap the entire Context.
username_0: Yep!
I think we should ask folks at opencensus on how they would do it. Ochttp does the same but it is not trivial to make it work with Buffalo again
Cheers
Manu
Status: Issue closed
|
paritytech/ink | 730876630 | Title: First class multi asset support
Question:
username_0: It is unfortunate that Solidity does not have first class multi asset support so we have ERC20 and wrapped Ether and contracts either needs to code different path for Ether and ERC20 or only support Ether via WETH.
Approve / transferFrom is another cumbersome thing for Ethereum users and it is also caused a lot security issues (user almost always approved too much and resulting been fund stolen).
We should avoid the same mistake on ink by provide a first class multi asset support. A payable message should be able to receive any kind of assets. So we don't need another WrappedNativeToken contract in ink and no need to have approve / transferFrom.
Answers:
username_1: I think having some example (maybe in the form of some abstract contract or group of contracts) could help us understand more clearly what you need or what new set of feature this would imply for ink!.
username_2: I assume it will require some interaction with the assets pallet https://substrate.dev/rustdocs/v2.0.0/pallet_assets/index.html
username_0: By asset I mean something like ERC20 or ERC721
It have nothing to do with pallet assets (for now).
User should be able to define their own ERC20 like tokens and send it to contracts.
username_2: In that case we would need to provide a standard trait for assets in `ink!`.
username_1: It might also be resolvable by the introduction of chain extensions.
username_0: The main point is, ink have first class support of the native token interaction, but not for custom tokens. This will likely requiring developers to code two paths to handle asset transfer, one for native and for ERC20 and that’s one drawback of Solidity and I think ink should try to avoid. The more code developers needs to write, the more bugs they are going to introduce.
username_1: I think what would really help this discussion is if you could come up with some example ink! contracts and how you imagine their inner workings before and after adding a feature like this.
username_0: Something like this so contract can issue their own token and require people paying that token for service
```
#[ink(payable)]
pub fn buy(&self) {
let token_id: address = self.env().transferred_token_id();
let balance = self.env().transferred_balance();
require!(token_id == self.address());
require!(balance == 100);
self.mint_item();
}
````
username_1: I guess something like that is possible with chain extensions.
username_0: In that case should allow people to write proc-macro so we can implement something like that ourself. Maybe it is already possible?
----
But I still insist a new smart contract framework should provide build-in support of multi assets. It is the mostly common use case of smart contracts. |
jasonkarns/brew-publish | 379437278 | Title: defaults for package name and version
Question:
username_0: default them to npm_package_version and npm_package_name, if set.
If not, default them to grabbing the values from ./package.json
Only if not passed, and not set, and no package.json should it error out.<issue_closed>
Status: Issue closed |
protolambda/zrnt | 596455102 | Title: Compilation issue due to bls dependency
Question:
username_0: Hi,
I tried to compile zrnt with go-fuzz but when i got this issue:
``` sh
$ go-fuzz-build -tags "preset_mainnet" .
failed to execute go build: exit status 2
# github.com/herumi/bls-eth-go-binary/bls
/tmp/go-fuzz-build338426294/gopath/src/github.com/herumi/bls-eth-go-binary/bls/bls.go:16:10: fatal error: mcl/bn_c384_256.h: No such file or directory
#include <mcl/bn_c384_256.h>
^~~~~~~~~~~~~~~~~~~
compilation terminated.
```
Is it possible to provide a way to switch bls library from herumi to another one?
Or do you know which command line can fix this issue?
thx,
Answers:
username_1: Hmm, looks like a file in herumi is missing. How are you including dependencies? Herumi has a Go repo that provides prebuilt binaries that get linked in. Something may be going wrong there. Can you build zrnt on your system with the regular got clone and go get? Let's confirm if it's build setup, or a broken dependency.
username_0: I just create a fuzz.go file:
``` golang
package fuzz
import (
"bytes"
)
import (
"github.com/username_1/zrnt/eth2/phase0"
"github.com/username_1/zssz"
)
func Fuzz(data []byte) int {
var state phase0.BeaconState
reader := bytes.NewReader(data)
if err := zssz.Decode(reader, uint64(len(data)), &state, phase0.BeaconStateSSZ); err != nil {
return 0
}
ffstate := phase0.NewFullFeaturedState(&state)
ffstate.LoadPrecomputedData()
ffstate.CurrentProposer()
return 1
}
```
Nothing fancy here.
Regarding command line:
``` sh
git clone --recursive https://github.com/username_1/zrnt
cd zrnt
go get -tags preset_mainnet ./...
cp ../../fuzz.go .
go-fuzz-build -tags "preset_mainnet" .
```
username_2: I've run into similar while upgrading `beacon-fuzz` to `v0.11.1`.
From what I understand, `go mod vendor` won't copy the herumi `lib` and `include` directories because they contain no go files.
Apparently cgo is only officially supported (at least for `go build` to detect that a binary needs rebuilding) when the all the c files are in the same directory as the go ones.
I have yet to confirm whether `go-fuzz` uses `go mod vendor` when using "go modules" mode (`GO111MODULE=on`), but the error is the same.
username_1: Yes, with `-work` you can see the temporary build files, and there's no CGO file at all in there anywhere, so logically this fails. CGO doesn't seem supported by go-fuzz currently: https://github.com/dvyukov/go-fuzz/issues/101
username_2: A dodgy workaround can apparently involve adding empty `.go` files to the relevant directories.
Ah here's the issue I was trying to find:
https://github.com/golang/go/issues/26366
And relevant comment:
https://github.com/golang/go/issues/26366#issuecomment-405683150
https://groups.google.com/forum/#!topic/golang-nuts/_GWRF1KIvFw
And perhaps an alternative tooling solution:
https://github.com/go-modules-by-example/index/blob/master/012_modvendor/README.md
https://github.com/golang/go/issues/26366#issuecomment-431917710
username_1: By all means, go ahead. Herumi was pretty welcoming to my earlier PRs to herumi-BLS to improve the build system. If adding dummy go files helps vendoring, then you can make it work.
username_1: Is this still a problem, I am not sure if I missed some information in other channels?
username_2: +1 to close
It can build fine with the go1.14 `go build` instrumentation.
Some modifications could make it usable for `go-fuzz-build -libfuzzer` but, in any case, would be asssociated with the herumi dependency, not ZRNT.
username_0: All good for me ;)
as mention by @username_2, we found a workaround to be able to make the fuzzing working using go1.14.
Thanks @username_1
Status: Issue closed
|
zawy12/difficulty-algorithms | 471084374 | Title: VDF + Reverse Nakamoto Consensus
Question:
username_0: All my work on difficulty was just fun and games compared to the importance of this. It will enable small coins to avoid 51% attacks and enable BTC to survive on fees-only. All coins have to eventually die, become centralized, or use this.
https://zawy1.blogspot.com/2019/03/reverse-nakamoto-consensus.html |
pombase/fypo | 743895004 | Title: PMID:33153481
Question:
username_0: FYPO:new
1. decreased DNA volume
in which DNA occupies a smaller portion of the total nuclear volume than normal. The nuclear volume itself may be normal.
2. increased chromatin mobility
in which chromatin moves within the nucleus to a greater extent than normal
3. increased transcription-induced DNA damage
syn increased DNA damage by transcription
4. normal DNA volume
PECO:new thiolutin CHEBI:156450
Answers:
username_0: decreased DNA volume FYPO:0007516
increased chromatin mobility FYPO:0007517
increased transcription-induced DNA damage FYPO:0007518
normal DNA volume FYPO:0007519
and PECO:0000373
Status: Issue closed
|
graphql-python/graphene | 110717983 | Title: Resolver Tagging
Question:
username_0: `graphql-core` supports "tagging" a resolver (via `core.execution.middlewares.utils`) as a way to signal special handling of the resolver in an `ExecutionMiddleware`.
The main example is that we have `GeventExecutionMiddleware`. By default, this middleware does nothing when processing resolvers. But when it is given a resolver that is tagged with (`@run_in_greenlet`) it will spawn a greenlet to execute the resolver, and allow the executor to continue to resolve other fields concurrently.
From the tests, here's a good example (not using Graphene):
```python
@run_in_greenlet
def resolve_a(context, *_):
gevent.sleep(3)
return 'resolved a'
@run_in_greenlet
def resolve_b(context, *_):
gevent.sleep(3)
return 'resolved b'
Type = GraphQLObjectType('Type', {
'a': GraphQLField(GraphQLString, resolver=resolver),
'b': GraphQLField(GraphQLString, resolver=resolver_2)
})
executor = Executor(GraphQLSchema(Type), [GeventExecutionMiddleware()])
doc = 'query Example { a, b }'
result = executor.execute(doc)
assert result.data == {'a': 'resolved a', 'b': 'resolved b'}
```
In this example, if each function was not tagged with `@run_in_greenlet`, then the execution time would be 6 seconds, as they have to run serially. However, since they are tagged, the middleware will run them concurrently, executing the query in only 3 seconds.
Answers:
username_0: `graphql-core` also supports py3.5 asyncio, graphene's resolve functions should also support `async/await` in py35.
```python
class Human(Character):
pet = Field(Pet)
async def resolve_pet(self, *args):
pet = await queryPetFromSomewhereWithOwner(self.instance.id)
return Pet(pet)
```
username_0: I have more testing to do with 40b88bc. I'll have an answer for you tomorrow. Was just super busy today.
Status: Issue closed
|
mezz/JustEnoughItems | 1077943001 | Title: Some Modded Items Textures are missing in The recipe window (1.18.1)
Question:
username_0: 

Only mods I had issues with were Gobber and Supplimentaries
Answers:
username_1: Thanks for the report!
Please report this to the individual mods involved and link back here. I am not sure why they do not display here. |
aungwinthant/apilogger | 500205296 | Title: Laravel 5.X / 6.X Auto Discover
Question:
username_0: Consider adding the ability for the package to be auto-discovered.
Answers:
username_1: Thanks I will add it.
username_0: Discovered Package: awt/apilogger
Discovered Package: barryvdh/laravel-debugbar
Discovered Package: barryvdh/laravel-ide-helper
Discovered Package: facade/ignition
Discovered Package: fideloper/proxy
Discovered Package: laravel/tinker
Discovered Package: laravel/ui
Discovered Package: nesbot/carbon
Discovered Package: nunomaduro/collision
Package manifest generated successfully.
```
I need to propose some changes to the README.md (my first step was to see if it actually registered properly).
username_1: Sure. Feel free to submit a PR. I will include it with other fixes.
Status: Issue closed
|
themefisher/navigator-hugo | 606905629 | Title: The git clone line in the instructions may need to be updated.
Question:
username_0: I tried the line in your installation instructions:
`git clone [email protected]:themefisher/navigator-hugo.git`
And got the following result:
```
Cloning into 'navigator-hugo'...
Warning: Permanently added the RSA host key for IP address '{redacted}' to the list of known hosts.
<EMAIL>: Permission denied (publickey).
fatal: Could not read from remote repository.
```
So, I used this instead which worked fine:
git clone https://github.com/themefisher/navigator-hugo.git
Answers:
username_1: Hey there, thanks for your concern. I will fix it.
Status: Issue closed
|
ginkgo-project/ginkgo | 522215400 | Title: hypre matrix format
Question:
username_0: With the intention to have a smoother interface to [hypre](https://computing.llnl.gov/projects/hypre-scalable-linear-solvers-multigrid-methods), it would be good to implement a matrix format composed of CSR + diag (this is how hypre stores matrices on a node). I see two options how to realize this:
1. creating the new matrix format completely independent of what already exists
+ we keep the flat hierarchy
+ we may design special kernels that avoid a two-kernel-call in the SpMV
- we run into the problem which Csr strategy to use
2. compose the new matrix format as combination of to existing formats (Csr + Dense)
+ we can leaverage the distinct strategies of Csr SpMV already implemented
+ we have less code duplication
- we loose the flat hierarchy and it may get complicated with the different Csr strategies
I welcome opinions!
Answers:
username_1: Is it just the diagonal, or kind of a band (for example 3 elements per row)?
Is it required that the diagonal is completely separated from the CSR matrix (I would assume so)?
Just a note for the Part 2.: We can't really use a plain Dense matrix here since storing the diagonal in dense would take as much storage as the whole matrix in dense. I assume you meant something like an Array, containing only the diagonal elements.
Since we will have a normal CSR matrix anyway, we can compose the new matrix format out of a CSR matrix and an Array containing the diagonal elements. That way, we don't have to reimplement the functionality of the CSR matrix, but we need to forward the corresponding calls. We should not use inheritance here, since it would not be [subtyping](https://en.wikipedia.org/wiki/Subtyping), which would likely confuse the user (since the new format is not just a CSR matrix).
That way, we can simply use the CSR strategies and kernels while adding one to handle the diagonal. However, we might want to hand-write a kernel for this specific format to get the best performance possible if we plan to use it in Ginkgo as well.
username_2: I looked through the code and it seems that they have a [serial CSR format](https://github.com/hypre-space/hypre/blob/master/src/seq_mv/csr_matrix.h#L43) where they store where it looks like they store row pointers, col idxs and values normally as we do. Then for a [distributed matrix storage](https://github.com/hypre-space/hypre/blob/master/src/parcsr_mv/_hypre_parcsr_mv.h#L282), it looks like they do store the diagonal and off-diagonal entries separately but both in CSR format. So, even the diagonal elements are stored in the normal CSR fashion.
For example, this function [hypre_CSRMatrixToParCSRMatrix](https://github.com/hypre-space/hypre/blob/master/src/parcsr_mv/par_csr_matrix.c#L1157) takes in a CSR matrix on one rank and distributes it to all ranks by first creating a normal `hypre_CSRMatrix` on each process after [sending it from root](https://github.com/hypre-space/hypre/blob/master/src/parcsr_mv/par_csr_matrix.c#L1329), and then generates the separation of the diagonal and the off-diagonal elements storing both of them in CSR on each of the ranks, which is in the [`par_matrix` object](https://github.com/hypre-space/hypre/blob/master/src/parcsr_mv/par_csr_matrix.c#L1183) which is of `hypre_ParCSRMatrix` type.
For the SpMV, atleast according to what I see, both the diagonal and the off-diagonal CSR matrices seem to be calling the same function, [hypre_CSRMatvecOutOfPlace](https://github.com/hypre-space/hypre/blob/master/src/seq_mv/csr_matvec.c#L24), [for diagonal](https://github.com/hypre-space/hypre/blob/master/src/parcsr_mv/par_csr_matvec.c#L275) and [off-diagonal](https://github.com/hypre-space/hypre/blob/master/src/parcsr_mv/par_csr_matvec.c#L305).
So, I am not sure it will be efficient to have to store the diagonal elements as a CSR matrix as well ?
username_0: I discussed with the hypre team: Diag is not a diagonal matrix, but a CSR matrix that contains only local to the process connections whereas Offd contains the coefficients that connect to off processor rows. Think of a 1D matrix partitioning. So I guess it is just a combination of two CSR matrices, then.
username_3: According to what you say then we do not have to do anything for hypre as in the end the local data is stored in a plain CSR format, and we do not do anything MPI related?
username_4: When looking at the hypre format, have a look at petsc too, as they share the same data model as I understand it where each process gets two data sets in CSR format. A continuous block of rows is assigned to each process in from of TWO data sets in CSR format. One data set containing the elements of the diagonal block (n x n), the other data set containing the off-diagonal elements of the assigned block of rows to exploit MPI functionality for higher performance.
I think http://www.gaspils.de/ also uses a data model leveraging a continuous block of rows which is exploited in a different way - for inspiration.
username_5: @username_0 I guess this is being addressed with the current distributed setup, so can we close it?
username_0: yes, I agree to close this issue.
Status: Issue closed
|
spring-cloud/spring-cloud-stream | 198812895 | Title: Schema registry support: bypass dynamic registration if `contentType` header set
Question:
username_0: The use case is producing `GenericRecord` outputs with schema already attached. The current process will try to infer the `contentType` header by comparing with known schemas - this process could be bypassed if the user populates the `contentType` header appropriately.
Answers:
username_1: @username_0 I believe that by implementing #832 we will no longer need this feature. Unless performance tests prove otherwise, I see no overhead on looking up parsedSchemas from a cache.
username_1: This is going back to the icebox, #832 should fix any performance related issues, and if this level of control is required by the user, they could use the AvroMessageConverter that does not rely on the SchemaRegistry. If any use case shows a need for this, we can revisit in the future
Status: Issue closed
|
cashshuffle/cashshuffle | 426747771 | Title: put any singleton/long-term structures on the tracker
Question:
username_0: It might be only the ban cleanup ticker. Behaviorally it does not matter now because the tracker has the same lifespan. For the same reason though, it seems reasonable to explicitly connect them.
@username_1
Answers:
username_1: Yeah if anything so that maintainers down the road have a slightly easier time when reading the code. "Hidden side-effect" objects can take a little while to discover the existence of when you first start working with a piece of code.
That being said I inserted a bunch of these into EC already for performance reasons but.. EC already is a beast for readability due to the large codebase that was ad-hoc added as needs arose. It's a drop in the ocean there. but.. here we can do things good from the get-go!
Status: Issue closed
|
TriggerAu/KerbalAlarmClock | 509513257 | Title: Quick Add does not respect default rules
Question:
username_0: Quick adding an alarm does not use the default actions configured in the Specifics tab. Also, alarms added via Remote Tech's nav computer do not use the default actions, though that might be a problem with Remote Tech. |
QuentinHsu/Document-Page | 807879487 | Title: ADGuardHome的使用方法
Question:
username_0: ### 本文根据前文安装的树莓派固件提供使用方法,不对docker版openwrt提供解决方案
**本文会说明基本使用ADGuardHome如遇错误请大佬解答,本文点击按钮均会加粗标识**

不管怎样先点击更新**核心版本**,可能对于ADGuardHome的执行文件路径寻找出错,目前的执行文件路径为`/usr/bin/AdGuardHome/AdGuardHome` 如果你的固件可以正常使用请勿更改路径

我个人推荐将下面红框全部打钩,然后点击**启用**

什么都不管,点击红框,开启AdGuardHome
点击**开启配置**


点击**下一步**

点击**下一步**

直接**下一步**
然后**打开仪表盘**
输入设置的用户名和密码

恭喜初始化设置完毕
Answers:
username_0: 在**设置** - **常规设置**

根据自己喜好进行配置
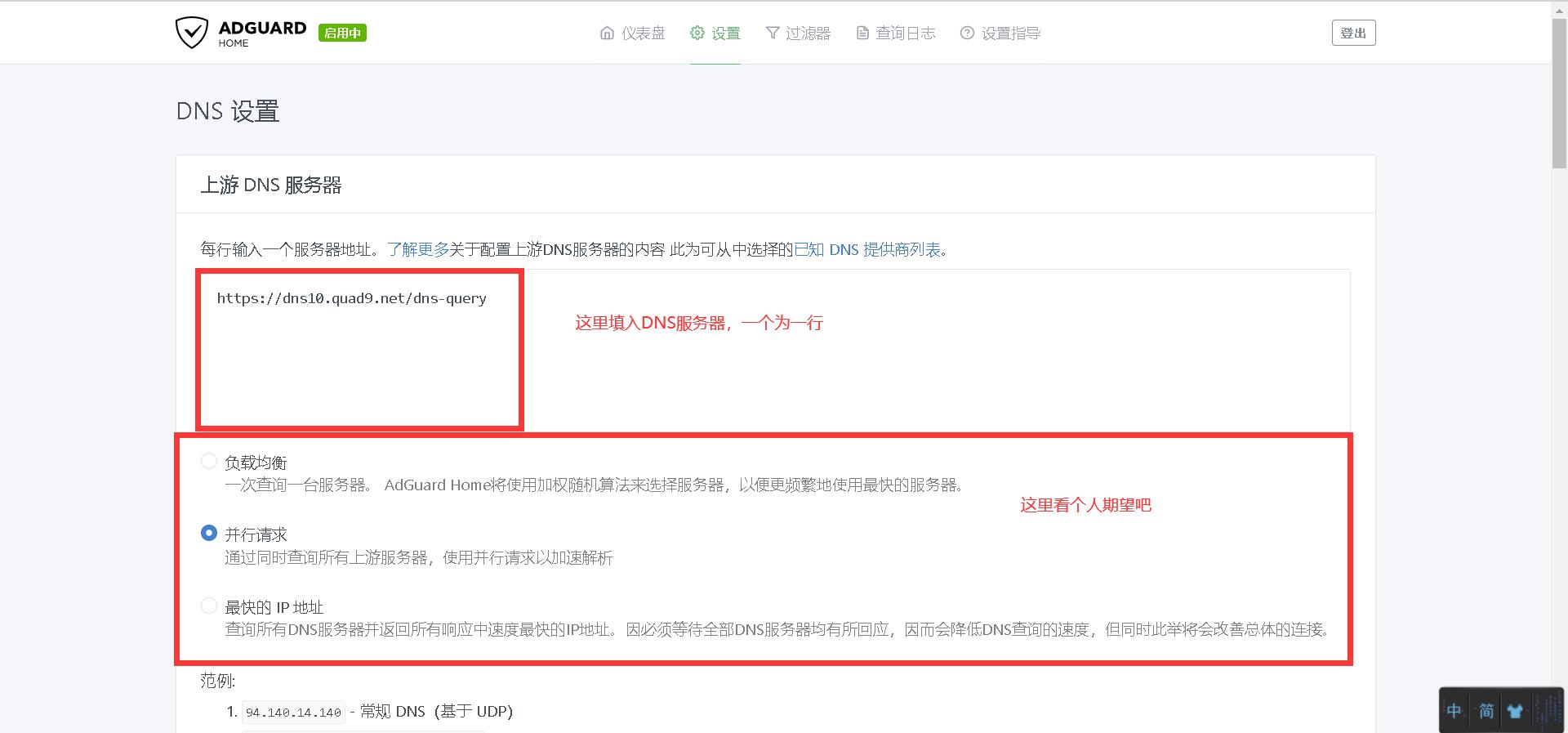
在**设置** - **DNS设置** - **关键**
提供DNS,请合理使用,会更新,也欢迎大佬补充
```
国内DNS
114 DNS
172.16.58.3
172.16.31.10
Ali DNS
172.16.31.10
172.16.58.3
https://dns.alidns.com/dns-query
https://192.168.3.11/dns-query
https://233.6.6.6/dns-query
Baidu DNS
192.168.127.12
火绒
172.16.58.3
172.16.17.32
https://dns.flymc.cc/dns-query
https://dns.tw.flymc.cc/dns-query)
Tencent DNS
192.168.3.11
192.168.127.12
172.16.31.10
172.16.58.3
https://doh.pub/dns-query
https://dns.pub/dns-query
DNS派
192.168.127.12
172.16.58.3
https://doh.360.cn/dns-query
CNNIC DNS
192.168.127.12
192.168.127.12
https://dns.cfiec.net/dns-query
TUNA DNS
172.16.58.3
oneDNS
192.168.3.11
172.16.17.32
红鱼rubyfish DNS
https://rubyfish.cn/dns-query
https://dns.rubyfish.cn/dns-query
国外
Google DNS
[Truncated]
https://doh.cleanbrowsing.org/doh/family-filter/ (家庭保护)
PowerDNS
https://doh.powerdns.org
Worldlink DNS
172.16.17.32
172.16.58.3
日本IIJ DNS
https://public.dns.iij.jp/dns-query
Blahdns 日本节点
https://doh-jp.blahdns.com/dns-query
```
单一国内和国外DNS,请勿一起使用



username_0: ### 配置ssrplus或passwall或openclash请仅使用AdGuardHome的DNS功能,你去广告也没用,直连可以使用去广告,但是效果不怎么好,自己选择
**过滤器** - **DNS封锁清单**
```
HalfLife,规则合并自 EasylistChina、EasylistLite、CJX’sAnnoyance 合并规则(几乎每天更新)
https://gitee.com/halflife/list/raw/master/ad.txt
xinggsf,乘风广告过滤规则 + 视频过滤规则,乘风规则更新详情
https://gitee.com/xinggsf/Adblock-Rule/raw/master/rule.txt
https://gitee.com/xinggsf/Adblock-Rule/raw/master/mv.txt
cjx82630,cjxlist 国内备用地址
一、CJX’s Annoyance List (去自推列表)
https://gitee.com/cjx82630/cjxlist/raw/master/cjx-annoyance.txt
二、CJX’s uBlock list (uBlock 规则)
https://gitee.com/cjx82630/cjxlist/raw/master/cjx-ublock.txt
EasyList China : 国内网站广告过滤的主规则。
链接:https://easylist-downloads.adblockplus.org/easylistchina.txt
EasyPrivacy : EasyPrivacy 是隐私保护,不被跟踪。
链接:https://easylist-downloads.adblockplus.org/easyprivacy.txt
CJX’s Annoyance List : 过滤烦人的自我推广,并补充 EasyPrivacy 隐私规则。
链接:https://raw.githubusercontent.com/cjx82630/cjxlist/master/cjx-annoyance.txt
I don’t care about cookies : 我不关心 Cookie 的问题,屏蔽网站的 cookies 相关的警告。
链接:https://www.i-dont-care-about-cookies.eu/abp/
EasyList
可从国际网页上删除大部分广告,包括不需要的框架,图像和对象
https://easylist-downloads.adblockplus.org/easylist.txt
EasyList China
EasyList的中文补充过滤器
https://easylist-downloads.adblockplus.org/easylistchina.txt
EasyPrivacy
可选的补充过滤器列表,该列表从网络删除了所有形式的跟踪,包括Web错误,跟踪脚本和信息收集器,从而保护您的个人数据
https://easylist-downloads.adblockplus.org/easyprivacy.txt
EasyList Cookie List
阻止cookie横幅,GDPR覆盖窗口和其他与隐私相关的通知
https://easylist-downloads.adblockplus.org/easylist-cookie.txt
Anti-AD
使用anti-AD能够屏蔽广告域名,能屏蔽电视盒子广告,屏蔽app内置广告,同时屏蔽了一些日志收集,大数据统计等涉及个人隐私信息的站点,能够保护个人隐私不被偷偷上传
https://raw.githubusercontent.com/privacy-protection-tools/anti-AD/master/anti-ad-easylist.txt
```

添加就行
username_0: 本人不对DNS服务器和广告过滤提供支持,如不满意请勿使用本人提供规则,配置ssrplus或passwall或openclash请设置为下游DNS,你流量都加密了,用个锤子的去广告,设置为下游我不会,如有人发现内容不妥,直接私聊开项目的人,我不经常看issue
username_0: AdGuardHome填写DNS要么全国内DNS要么全国外,AdGuardHome全部国外DNS在ssrplus直接填入127.0.0.1:5000这里演示用5000,即可,如果想分开请docker安装AdGuardHome设置方法依旧,本文不涉及docker故不讲解docker使用
username_0: ## 具体设置
第一步 **<font color="red">打开仪表盘或输入路由器IP:3000</font>**
第二步 **<font color="red">输入设置的用户名和密码</font>**
第三步 **<font color="red">点击设置中的常规设置</font>**
*<font color="blue">这里推荐默认,如果勾选下面会导致DNS查询速度大于100ms</font>*

*<font color="blue">推荐24小时或7天,日志要占空间</font>*

*<font color="blue">同上</font>*

第四步 **<font color="red">点击设置中的DNS设置</font>**
*<font color="blue">上游DNS服务器中填几个国内或国外的DNS服务器,推荐单一性原则</font>*
*<font color="blue">下面推荐使用并行请求或最快的IP地址</font>*

*<font color="blue">推荐2到3个以IP为主的DNS服务器可以选供应商提供的DNS服务器</font>*

*<font color="blue">树莓派4B性能完全可以不限制</font>*
*<font color="blue">可以勾选下面两个框</font>*
*<font color="blue">IPV6发育不完全,推挤禁用IPV6</font>*

*<font color="blue">缓存可以设置大一点</font>*
*<font color="blue">下面两个是缓存失效时间,最大建议3600,最小建议300</font>*

第五步 **<font color="red">点击过滤器中的DNS封锁清单</font>**
*<font color="blue">添加就好了</font>*

username_0: ## 具体设置
第一步 **<font color="red">打开仪表盘或输入路由器IP:3000</font>**
第二步 **<font color="red">输入设置的用户名和密码</font>**
第三步 **<font color="red">点击设置中的常规设置</font>**
*<font color="blue">这里推荐默认,如果勾选下面会导致DNS查询速度大于100ms</font>*

*<font color="blue">推荐24小时或7天,日志要占空间</font>*

*<font color="blue">同上</font>*

第四步 **<font color="red">点击设置中的DNS设置</font>**
*<font color="blue">上游DNS服务器中填几个国内或国外的DNS服务器,推荐单一性原则</font>*
*<font color="blue">下面推荐使用并行请求或最快的IP地址</font>*

*<font color="blue">推荐2到3个以IP为主的DNS服务器可以选供应商提供的DNS服务器</font>*

*<font color="blue">树莓派4B性能完全可以不限制</font>*
*<font color="blue">可以勾选下面两个框</font>*
*<font color="blue">IPV6发育不完全,推挤禁用IPV6</font>*

*<font color="blue">缓存可以设置大一点</font>*
*<font color="blue">下面两个是缓存失效时间,最大建议3600,最小建议300</font>*

第五步 **<font color="red">点击过滤器中的DNS封锁清单</font>**
*<font color="blue">添加就好了</font>*

username_0: ## 使用设置
*如果你不使用任何出国插件,推荐使用**重定向53端口到AdGuardHome**或**使用53端口替换dnsmasq***
因为AdGuardHome不能分流DNS,所以如果使用出国插件,推荐配合docker版的AdGuardHome
插件重定向任意,docker版作为国外分流

使用5335端口时,SSR Plus+选择使用本机端口为5335的DNS服务

使用PassWall,可以使用自定义DNS

username_1: 在初始化ADGuardHome的时候提示80和53端口被占用,这种要怎么排查
Status: Issue closed
|
hpssjellis/dfu-util-windows-spark-core-photon | 84347373 | Title: Is this project still active
Question:
username_0: Hi
I'm looking for a DFU driver for the Particle aka Spark , Photon
Is this repo still active, or has it been superseded by another driver ?
Answers:
username_1: Not sure but the information in the readme should help get you started. I
wanted to simplify the process but found it just too confusing. I
eventually got mine working but not really sure the steps I did. Good luck.
I hope someone makes a simple youtube video of the process for windows.
username_0: OK.
Thanks.
I think I'll need to make my own driver installer if I want to use the photon.
Using https://github.com/pbatard/libwdi
I have tried all the other hacky workarounds and none of them are particularly successful, especially on Windows 7.
To be honest, I'm not sure now that my Photons have finally arrived, whether they are worth the hassle, as I have since moved to using ES8266 and as they have an Arduino IDE version, which makes things far simpler to use than the cloud dev process
username_1: Good to know about the ES8266 I will have to look into that. Really, the
DFU thing is the only down side to the spark core (other than spotty WiFi).
Once you get over that, the rest is very good. I have a link at
https://community.particle.io/t/teaching-high-school-robotics-with-the-spark-photon/11684
which covers most of what I have found out so far.
username_0: OK.
Its definitely worth looking at the ESP8266. e.g.
http://www.ebay.com/itm/ESP8266-Serial-Port-WIFI-Wireless-Transceiver-Module-Send-Receive-IO-Lead-Out-/371288595024?pt=LH_DefaultDomain_0&hash=item5672865a50
or
http://www.ebay.com/itm/1pcs-ESP8266-Esp-07-ESP07-Remote-Serial-Port-WIFI-Transceiver-Module-AP-STA-/181758230418?pt=LH_DefaultDomain_0&hash=item2a51a27f92
You also need USB to Serial to flash it.
But Arduino IDE support is now quite good
https://github.com/esp8266/Arduino
I think you can even add it via the boards manager (1.6.4), |
EasyNetQ/EasyNetQ.Management.Client | 268027370 | Title: Creating a VHOST doesn't check for the correct status codes (201=Created)
Question:
username_0: Status 201-Created should not throw an exception:
System.Reflection.TargetInvocationException: Exception has been thrown by the target of an invocation. ---> EasyNetQ.Management.Client.UnexpectedHttpStatusCodeException: Unexpected Status Code: 201 Created
at EasyNetQ.Management.Client.ManagementClient.Put(String path)
at EasyNetQ.Management.Client.ManagementClient.CreateVirtualHost(String virtualHostName)
at AerData.Bus.Host.Tasks.RabbitMqRecreateVHost.Run(RabbitMqConnectionSettings options, CancellationToken token)
Answers:
username_1: Please check if it stills happens and provide further details with links to the source code points where it fails. |
rakudo/rakudo | 1115373875 | Title: Lexical with name '$foo' has a different type in this frame
Question:
username_0: ````raku
use JSON::Fast:ver<0.16>;
sub foo(@a, :$sorted-keys) {
@a.map({to-json $_, :$sorted-keys});
}
dd foo(<a b c d e>);
````
Running this code on:
````
$ raku --version
Welcome to Rakudo™ v2021.12-161-g4365d9b6d.
Implementing the Raku® Programming Language v6.d.
Built on MoarVM version 2021.12-81-gf1101b95d.
````
produces the below very strange error and stacktrace.
Note that the use of `:$sorted-keys` named argument / parameter is essential producing this issue.
````
Lexical with name '$spacing' has a different type in this frame
at gen/moar/BOOTSTRAP/v6c.nqp:440 (/Users/liz/Github/rakudo.moar/install/share/perl6/lib/Perl6/BOOTSTRAP/v6c.moarvm:bind_one_param)
from gen/moar/BOOTSTRAP/v6c.nqp:923 (/Users/liz/Github/rakudo.moar/install/share/perl6/lib/Perl6/BOOTSTRAP/v6c.moarvm:bind)
from gen/moar/BOOTSTRAP/v6c.nqp:976 (/Users/liz/Github/rakudo.moar/install/share/perl6/lib/Perl6/BOOTSTRAP/v6c.moarvm:bind)
from gen/moar/BOOTSTRAP/v6c.nqp:4156 (/Users/liz/Github/rakudo.moar/install/share/perl6/lib/Perl6/BOOTSTRAP/v6c.moarvm:)
from site#sources/EA6CA341123ECF37C6657DBCBE16F4B077343BB6 (JSON::Fast):153 (/Users/liz/.raku/precomp/1F854AC164D9D4CFFA325BE6116B141DE5BAAB36/EA/EA6CA341123ECF37C6657DBCBE16F4B077343BB6:to-json)
from 1:4 (<ephemeral file>:)
from SETTING::src/core.c/Any-iterable-methods.pm6:368 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:push-all)
from SETTING::src/core.c/Iterator.pm6:66 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:push-until-lazy)
from SETTING::src/core.c/List.pm6:97 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:reify-until-lazy)
from SETTING::src/core.c/List.pm6:915 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:is-lazy)
from SETTING::src/core.c/List.pm6:812 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:)
from SETTING::src/core.c/Mu.pm6:847 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:)
from SETTING::src/core.c/Mu.pm6:841 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:)
from SETTING::src/core.c/Mu.pm6:838 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:rakuseen)
from SETTING::src/core.c/Mu.pm6:859 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:)
from SETTING::src/core.c/Mu.pm6:838 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:rakuseen)
from SETTING::src/core.c/List.pm6:810 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:raku)
from SETTING::src/core.c/Seq.pm6:75 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:raku)
from SETTING::src/core.c/Any.pm6:599 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:)
from SETTING::src/core.c/Any.pm6:592 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:)
from SETTING::src/core.c/Any.pm6:592 (/Users/liz/Github/rakudo.moar/install/share/perl6/runtime/CORE.c.setting.moarvm:dd)
from 1:7 (<ephemeral file>:<unit>)
from 1:1 (<ephemeral file>:<unit-outer>)
````
Answers:
username_1: Looks like a funny side-effect of `unit` work merge. The real error, and this is what is reported on 2021.12, is failing typecheck against `$sorted-keys`, which remains uninitialized but the corresponding named parameter is `Bool`. But the exception is thrown over the preceding `$spacing` parameter, which is a native `int`.
username_0: Indeed, changing the signature to `sub foo(@a, Bool :$sorted-keys) {` makes the problem go away.
Anyways, it seems to affect things that are pre-compiled: This code produces the correct error message:
````raku
sub a(Bool :$a) { }; sub b(:$a) { a :$a }; b
Type check failed in binding to parameter '$a'; expected Bool but got Any (Any)
````
username_2: Is this related to <https://github.com/rakudo/rakudo/issues/4647>?
username_0: No, I don't think so. In the end in this case, the error message is LTA. My code example *was* doing something wrong, and the error message sent me on a goose chase.
#4647 is about a case that *should* be ok, but isn't.
username_1: No, you haven't done the complete test and missed two important details: an `int`-typed named, and default values:
```raku
sub a(int :$s = 2, Bool :$a = False) { }; sub b(:$a) { a :$a }; b
# Lexical with name '$s' has a different type in this frame
```
But defaults are possibly masking the real cause:
```raku
sub a(int :$s, Bool :$a) { }; sub b(:$a) { a :$a }; b
# Cannot unbox a type object (int) to an int.
```
This looks more like the real one. |
tensorflow/tensorflow | 603228720 | Title: InternalError: Unsupported object type float
Question:
username_0: Getting this error even though there are no NaNs and X_train and y_train have relevant datatype.
```
InternalError Traceback (most recent call last)
C:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\client\session.py in _do_call(self, fn, *args)
1366 try:
-> 1367 return fn(*args)
1368 except errors.OpError as e:
C:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\client\session.py in _run_fn(feed_dict, fetch_list, target_list, options, run_metadata)
1351 return self._call_tf_sessionrun(options, feed_dict, fetch_list,
-> 1352 target_list, run_metadata)
1353
C:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\client\session.py in _call_tf_sessionrun(self, options, feed_dict, fetch_list, target_list, run_metadata)
1444 fetch_list, target_list,
-> 1445 run_metadata)
1446
InternalError: Unsupported object type float
During handling of the above exception, another exception occurred:
InternalError Traceback (most recent call last)
<ipython-input-69-24be0b0bc7db> in <module>
----> 1 lin_reg.train(train_input_fn, steps=1000)
C:\ProgramData\Anaconda3\lib\site-packages\tensorflow_estimator\python\estimator\estimator.py in train(self, input_fn, hooks, steps, max_steps, saving_listeners)
372
373 saving_listeners = _check_listeners_type(saving_listeners)
--> 374 loss = self._train_model(input_fn, hooks, saving_listeners)
375 logging.info('Loss for final step: %s.', loss)
376 return self
C:\ProgramData\Anaconda3\lib\site-packages\tensorflow_estimator\python\estimator\estimator.py in _train_model(self, input_fn, hooks, saving_listeners)
1162 return self._train_model_distributed(input_fn, hooks, saving_listeners)
1163 else:
-> 1164 return self._train_model_default(input_fn, hooks, saving_listeners)
1165
1166 def _train_model_default(self, input_fn, hooks, saving_listeners):
C:\ProgramData\Anaconda3\lib\site-packages\tensorflow_estimator\python\estimator\estimator.py in _train_model_default(self, input_fn, hooks, saving_listeners)
1196 return self._train_with_estimator_spec(estimator_spec, worker_hooks,
1197 hooks, global_step_tensor,
-> 1198 saving_listeners)
1199
1200 def _train_model_distributed(self, input_fn, hooks, saving_listeners):
C:\ProgramData\Anaconda3\lib\site-packages\tensorflow_estimator\python\estimator\estimator.py in _train_with_estimator_spec(self, estimator_spec, worker_hooks, hooks, global_step_tensor, saving_listeners)
1496 while not mon_sess.should_stop():
1497 _, loss = mon_sess.run([estimator_spec.train_op, estimator_spec.loss])
-> 1498 any_step_done = True
1499 if not any_step_done:
1500 logging.warning('Training with estimator made no steps. '
C:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\training\monitored_session.py in __exit__(self, exception_type, exception_value, traceback)
883 if exception_type in [errors.OutOfRangeError, StopIteration]:
884 exception_type = None
--> 885 self._close_internal(exception_type)
886 # __exit__ should return True to suppress an exception.
887 return exception_type is None
[Truncated]
1185 results = []
C:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\client\session.py in _do_run(self, handle, target_list, fetch_list, feed_dict, options, run_metadata)
1359 if handle is None:
1360 return self._do_call(_run_fn, feeds, fetches, targets, options,
-> 1361 run_metadata)
1362 else:
1363 return self._do_call(_prun_fn, handle, feeds, fetches)
C:\ProgramData\Anaconda3\lib\site-packages\tensorflow_core\python\client\session.py in _do_call(self, fn, *args)
1384 '\nsession_config.graph_options.rewrite_options.'
1385 'disable_meta_optimizer = True')
-> 1386 raise type(e)(node_def, op, message)
1387
1388 def _extend_graph(self):
InternalError: Unsupported object type float
```
Answers:
username_1: @username_0
please share the tensorflow version and simple stand alone code for us to replicate the issue
username_0: Tensorflow version is 2.1.0,
Here's the code:
`
import tensorflow.compat.v1 as tf
symbol = tf.feature_column.categorical_column_with_hash_bucket('Symbol', hash_bucket_size=500)
cols = X_train.columns
feat_cols = []
for col in cols:
feat_cols.append(tf.feature_column.numeric_column(col, dtype=tf.float32))
feat_cols[0]=symbol
train_input_fn = tf.estimator.inputs.pandas_input_fn(X_train, y_train, batch_size=32, num_epochs=1000, shuffle=True)
lin_reg = tf.estimator.LinearRegressor(feat_cols)
lin_reg.train(train_input_fn, steps=1000)
`
X_train is a pandas dataframe and y_train is a pandas Series.
username_1: @username_0
i ran the code shared by you, please find the [gist here](https://colab.sandbox.google.com/gist/username_1/a5a97b612af3ed7ec7da6d4633dd8ae8/untitled152.ipynb)
Status: Issue closed
|
i-net-software/jlessc | 747334023 | Title: :extend() syntax not working as expected for referenced Imports
Question:
username_0: Consider the following two files:
_root.css_
@import (reference) "import.less";
.c {
content: 'c';
}
_import.css_
.a {
content: 'a';
}
.b:extend( .a ) {
content: 'b';
};
The expected out put, due to the *reference* (as per the less compiler) is:
.c {
content: 'c';
}
But the *wrongly* output css ist:
.b {
content: 'a';
}
.c {
content: 'c';
}
Answers:
username_1: It look like that the behavior has changed in newer versions. This was correct in older versions.
Status: Issue closed
|
ant-design-blazor/ant-design-blazor | 783087202 | Title: DatePicker time selection window is not displayed completely
Question:
username_0: When the DatePicker is at the bottom or right of the page, the time selection window is not fully displayed.
I hope it can be modified to display on the DatePicker at the bottom of the page,
If the time selection window can be aligned to the right when it is on the far right of the page, the excess part is on the left, so that it will not affect the use.
Answers:
username_1: Hi @username_0 , we have fix this at #1109. Please try the latest 0.7 nightly NuGet package.
Status: Issue closed
|
geneontology/go-annotation | 746592217 | Title: PTN004500658
Question:
username_0: Can you block propagation to FBgn0037979 GCC185 from PTN004500658.
Perhaps this is not a great node to propagate from - proteins that are used for 'nucleoplasm' exp are all from HPA and they are a fairly unrelated bunch. Think it's just a sequence quirk.
FBgn0037979 GCC185 is a golgin and already has a lot of annotations from this node PTN004500662 that seems more consistent with golgin function.
There is definitely a sharp dropoff in ortholog calls.

Answers:
username_1: Sorry @username_0 - what do you want us to remove ? All annotations ? or the CC ?
Thanks, Pascale
username_0: PANTHER:PTN004500658 only has a CC, but block all please.
username_1: What about FBgn0037979, GCC185, isn't that Golgi ?
username_1: Fixed.
Status: Issue closed
username_0: Yes, it is, the issue is nucleoplasm from PTN004500658
Annotations coming from PTN004500662 are golgi and fine
but the nucleoplasm one inherrited from PTN004500658 isn't.

username_1: OK good, that's gone. This family is weird, I opened a ticket for the Panther group to review it.
username_0: Thanks! |
Zrips/CMI | 442989190 | Title: jail and bossbar
Question:
username_0: **Description of issue or feature request:**
/cmi bossbarmsg all -sec:1 Healing incomming in [autoTimeLeft]! -t:2 -p:1
when a player is jailed they also get no damage when they are in there, any way to solve that?
it counts upwards, and not downwards. anyway to solve this?
---
**Cmi Version (using`/cmi version`):**
§f§eCMI§e §eplugin§e §eversion:§e §e§6172.16.31.10
[14:38:25] [Client thread/INFO]: [CHAT] Server version: Paper(624) 1.13.2-R0.1-SNAPSHOT
[14:38:25] [Client thread/INFO]: [CHAT] Vault version: 1.7.2-b107(CMIEInjector)
**Server Type (Spigot/Paperspigot/etc):**
paperspigot
**Server Version (using `/ver`):**
[14:40:05] [Client thread/INFO]: [CHAT] This server is running Paper version git-Paper-624 (MC: 1.13.2) (Implementing API version 1.13.2-R0.1-SNAPSHOT)
[14:40:05] [Client thread/INFO]: [CHAT] Previous version: git-Paper-1606 (MC: 1.12.2)
[14:40:05] [Client thread/INFO]: [CHAT] Checking version, please wait...
[14:40:06] [Client thread/INFO]: [CHAT] You are 1 version(s) behind |
Holzhaus/mixxx-gh-issue-migration | 873289363 | Title: Add naming pattern to recorded files
Question:
username_0: It would be nice if we offered a way to add a (customisable) naming pattern to the recorded files.
Like %Year-%Month-%Day %Hour%Minute%Second %Name %Extension
Also the recorded files could be automatically available in an "Recordings" sub-menue in the library pane. |
sql-machine-learning/sqlflow | 579289598 | Title: Support Tekton backend in workflow
Question:
username_0: Argo should mount host `/var/run/docker.sock` that assumes the Kubernetes cluster using the Docker runtime, but some customized Kubernetes cluster may may use Docker such as https://github.com/alibaba/pouch in Alibaba, another side is that `/var/run/docker.sock` need the privilege, but sometimes it is not secure in a common Kubernetes cluster. related issue: https://github.com/argoproj/argo/issues/1888
So we plan to support the Tekton as workflow backend, and Tekton is widely used in Ant Financial: https://github.com/tektoncd/friends/tree/master/antfinancial
TODOs:
- [ ] setup Tekton CI.
- [ ] Add `fluid_codegen.go` to translate SQL program into Tektoncd YAML.
- [ ] Implement Submit gRPC interface to submit the Tekton Task.
- [ ] Implement Fetch gRPC interface to retrieve step status. |
hpbuniat/jquery-popunder | 22898827 | Title: IE doesn't send `referer` header
Question:
username_0: IE (tested on ie10) doesn't send `referer` header. It makes jquery.popunder pretty usesless in case of ad popups. According to this - http://stackoverflow.com/questions/7580613/url-referer-not-working-on-pop-up-windows - I've changed
```
} else {
t.lastWin = (t._top.window.open(t.o, t.rand(o.name, !opts.name), t.getOptions(o.window)) || t.lastWin);
}
```
```
} else if (t.ua.ie) {
t.lastWin = (t._top.window.open('', t.rand(o.name, !opts.name), t.getOptions(o.window)) || t.lastWin);
if (t.lastWin && t.lastWin.location) t.lastWin.location.href = t.o;
} else {
t.lastWin = (t._top.window.open(t.o, t.rand(o.name, !opts.name), t.getOptions(o.window)) || t.lastWin);
}
```
Status: Issue closed
Answers:
username_1: For accurate ad-popup-tracking i'd recommend an affiliate redirecting approach, e.g. zanox. |
Avery3R/MMMJTAG | 665875227 | Title: Investigate dma on CNP and KBP chipsets
Question:
username_0: The OpenIPC dma service doesn't work by default on DCI_USB_DMA with a KBP chipset, maybe it will with a CNP chipset? Probably going to try messing around in the OpenIPC config/python stuff to copy the DMA config from CNP to KBP, and if that doesn't work I'll mobo swap.
Answers:
username_0: Can't get it working on KBP, CNP will have to wait until I swap mobos |
alexwforsythe/code-blocks | 298479478 | Title: Add more documentation
Question:
username_0: One common complaint from Chrome Web Store reviews is a general lack of documentation. Here are some possible improvements:
* Web store description
* [ ] Add link to GitHub repo
* [ ] Add basic usage section
* [ ] Add advanced usage section
* README
* [ ] Add basic usage section
* [ ] Add advanced usage section
* [ ] List OAuth scopes |
carbon-design-system/carbon | 867559108 | Title: [carbon-components]: component tokens.scss files import CSS reset and base styles
Question:
username_0: Related issue on : https://github.ibm.com/ibmcloud/pal/issues/4430
Answers:
username_1: A few other references:
i talked through the token import w/ @username_2 here: https://github.com/carbon-design-system/carbon/issues/8196
and the PR that originally tokenized: https://github.com/carbon-design-system/carbon/pull/7808
username_2: You can also set `$css--reset: false` above the imports if you do not wish to include the reset file
username_3: As @username_2 noted, I believe you will need to set `$css--reset` to `false` to exclude any reset styles for this kind of use case.
Unfortunately having these files _not_ bring in the reset would be considered a breaking change (since the emitted CSS would change) but we could totally look at having this behavior in v11 where component modules don't necessarily bring in the reset.
username_3: @username_0 thanks for the detailed response! It helps a ton when tracking this stuff down.
Could you speak more to the output that you would expect from including the tokens file? is it that no CSS should be emitted and that it's used for only variables?
username_0: Yes, the intent with the theme file is that it contains color related CSS variables only, so it can be served globally to all microservices. Any additional styles would conflict with various services: https://github.ibm.com/Bluemix/core-dev/issues/10513.
So to reiterate, our issue is that we were hoping to acquire the component specific tokens for tags and notifications through the `_tokens.scss` files, but received additional styles along with the CSS variables. Disabling those styles using `$css--reset` and `$css--default-type` seems to disable them also outside of theme file, which is not what we would want.
username_3: Awesome, thanks so much @username_0 that helps a ton 🙏
I think the reset is ultimately coming from the import to `scss/globals/scss/theme` in `component-tokens`. I think we can have the component token files for tag/notification import from theme-tokens directly instead of the `component-tokens` file / theme file directly and it should get around this reset issue.
Curious what you think @username_2 🤔
username_2: @username_3 Yeah I think that may do the trick |
ansible/galaxy | 564745598 | Title: 'Error when finding available api versions' message
Question:
username_0: <!---
Verify first that your issue/request is not already reported on GitHub.
-->
## Bug Report
##### SUMMARY
When trying to install new roles to my project, I'm now seeing this message:
```
[WARNING]: - username_0.drupal_settings_files was NOT installed successfully: Error when finding available api versions from
default (https://galaxy.ansible.com) (HTTP Code: 404, Message: Not Found)
```
I wondered if I was due to it being a new role, but it's also happening for established roles like `geerlingguy.certbot`.
##### STEPS TO REPRODUCE
Run `ansible-galaxy install username_0.drupal_settings_files`.
The same error happens if I try and run it from a `requirements.yml` file.
##### EXPECTED RESULTS
The role would be installed.
##### ACTUAL RESULTS
The error message is displayed and the role is not installed. I'm using Ansible version 2.9.4.
Answers:
username_0: The same command works though on a different laptop, though that is running Ansible 2.9.3.
username_1: Seems like an `ansible-galaxy` bug that should be filed in the [ansible](https://github.com/ansible/ansible) project.
username_0: @username_1 Do I need to create a new issue, or can you transfer it?
username_0: I've managed to fix it for now by downgrading to Ansible 2.8.7 using Homebrew as I'm running macOS:
```
brew tap homebrew/cask-versions
brew install [email protected]
brew unlink ansible && brew link [email protected] --force
```
After which, `ansible --version` is 2.8.7.
Running the original command, e.g. `ansible-galaxy install -r tools/ansible/requirements.yml` now works as expected.
username_1: @username_0
I believe the issue you're running into is specific to your environment. If `ansible-galaxy` can't reach or connect to `https://galaxy.ansible.com/api`, it catches the error and tries `https://galaxy.ansible.com/api/api`, which of course fails and returns the error you're seeing.
My environment was returning the same until I killed Kaspersky. For some reason that was interfering with `https` requests. Once I killed the `kav` process, `ansible-galaxy` started working fine.
Here's running the latest code from the `devel` branch of ansible:
```
ansible-galaxy install -vvvv username_0.drupal_settings_files
ansible-galaxy 2.10.0.dev0
config file = /Users/username_1/ansible.cfg
configured module search path = [u'/Users/username_1/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /Users/username_1/projects/ansible/lib/ansible
executable location = /Users/username_1/.pyenv/versions/venv27/bin/ansible-galaxy
python version = 2.7.14 (default, Nov 14 2017, 23:24:24) [GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.38)]
Using /Users/username_1/ansible.cfg as config file
Processing role username_0.drupal_settings_files
Initial connection to galaxy_server: https://galaxy.ansible.com
Opened /Users/username_1/.ansible/galaxy_token
Calling Galaxy at https://galaxy.ansible.com/api/
Found API version 'v1, v2' with Galaxy server default (https://galaxy.ansible.com/api/)
- downloading role 'drupal_settings_files', owned by username_0
Opened /Users/username_1/.ansible/galaxy_token
Calling Galaxy at https://galaxy.ansible.com/api/v1/roles/?owner__username=username_0&name=drupal_settings_files
Opened /Users/username_1/.ansible/galaxy_token
Calling Galaxy at https://galaxy.ansible.com/api/v1/roles/46512/versions/?page_size=50
- downloading role from https://github.com/username_0/ansible-role-drupal-settings/archive/master.tar.gz
- extracting username_0.drupal_settings_files to /Users/username_1/roles/username_0.drupal_settings_files
- username_0.drupal_settings_files (master) was installed successfully
```
username_1: @username_0
Here it is working with `2.9.4`:
ansible-galaxy install -vvvv username_0.drupal_settings_files
ansible-galaxy 2.9.4
config file = /Users/username_1/ansible.cfg
configured module search path = [u'/Users/username_1/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /Users/username_1/projects/ansible/lib/ansible
executable location = /Users/username_1/.pyenv/versions/venv27/bin/ansible-galaxy
python version = 2.7.14 (default, Nov 14 2017, 23:24:24) [GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.38)]
Using /Users/username_1/ansible.cfg as config file
Processing role username_0.drupal_settings_files
Initial connection to galaxy_server: https://galaxy.ansible.com
Opened /Users/username_1/.ansible/galaxy_token
Calling Galaxy at https://galaxy.ansible.com/api/
Found API version 'v1, v2' with Galaxy server default (https://galaxy.ansible.com/api/)
- downloading role 'drupal_settings_files', owned by username_0
Opened /Users/username_1/.ansible/galaxy_token
Calling Galaxy at https://galaxy.ansible.com/api/v1/roles/?owner__username=username_0&name=drupal_settings_files
Opened /Users/username_1/.ansible/galaxy_token
Calling Galaxy at https://galaxy.ansible.com/api/v1/roles/46512/versions/?page_size=50
- downloading role from https://github.com/username_0/ansible-role-drupal-settings/archive/master.tar.gz
- extracting username_0.drupal_settings_files to /Users/username_1/roles/username_0.drupal_settings_files
- username_0.drupal_settings_files (master) was installed successfully
Status: Issue closed
username_1: Closing. This issue is not a bug in ansible. It seems to be something related to the user's environment. Also, issues related to `ansible-galaxy` should be opened in the Ansible project. |
net-ssh/net-ssh | 119037448 | Title: already initialized constant DL::RUBY_FREE
Question:
username_0: when running net-ssh I got this message:
C:/Ruby21/lib/ruby/2.1.0/i386-mingw32/dl.so: warning: already initialized constant DL::RUBY_FREE
C:/Ruby21/lib/ruby/gems/2.1.0/gems/net-ssh-3.0.1/lib/net/ssh/authentication/pageant.rb:16: warning: previous definition of RUBY_FREE was here<issue_closed>
Status: Issue closed |
mezz/JustEnoughItems | 317805558 | Title: [1.12.2] Duplicate fuel entries for items with multipe oredict
Question:
username_0: Forge : 14-23.2.2654 1.12.2
JEI : 1.12.2-4.9.1.169
I have a simple item that can burn as furnace fuel and has multiple ore dictionary tags for usage in other mods. When the other mods aren't here (and so this item is the only one with those tags) it appears multiple times as furnace fuel in JEI. For context on screenshots: 2 oredicts are from Rustic and 1 from Pam's Harvestcraft.
None of the other mods or Pam's Harvestcraft :

Rustic (none of the 2 oredicted items corresponding to mine are furnace fuels) :

One of the 3 oredict tags removed (no other mods) :

[Item's class](https://github.com/username_0/MysticalWildlife/blob/master/src/main/java/lykrast/mysticalwildlife/common/item/ItemFuel.java) if that's of any help, but this same class worked perfectly fine with JEI for items that don't have multiple oredict, which leads me to think it's a JEI issue. |
w3c/csswg-drafts | 159103569 | Title: [css-round-display][mediaquery] Properly define 'viewport-fit'
Question:
username_0: I modified the draft about [viewport-fit](https://drafts.csswg.org/css-round-display/#viewport-fit-descriptor) to apply the resolution we made at the SF f2f. (Check the resolution in [here](https://lists.w3.org/Archives/Public/www-style/2016May/0233.html))
I have some unclear things related to it:
- When viewport-fit: auto, is it right that the initial viewport will not change?
- The result of the examples below have the same meanings?
- `@viewport (viewport-fit: cover) { ... }`
- `@viewport (width: auto) { ... }`
Answers:
username_1: 5. “Because of this, some part of the page is clipped.” –> “Because of this, depending on the size of the viewport, some part of the page may be clipped.”
username_1: Also, the syntax in your examples is incorrect.
`@viewport (viewport-fit: cover) { /* styles for the round screen */ }
`
should be
```
@viewport {
viewport-fit: cover;
}
@media (shape: round) {
/* styles for the round screen */
}
@media (shape: rect) {
/* styles for the rectangular screen */
}
```
username_1: `@viewport {width: auto; }` is the default value if there's nothing else in the UA stylesheet. It does not cancel viewport-fit. Here's how they work together:
Let's say with have a round screen with a diameter of 200px. The size of the inscribed rectangle is diameter / sqrt(2) = 141 px.
* Example 1: `@viewport { width: auto; viewport-fit: cover; }`
The width and height of the layout viewport and visual viewport are 200px, so the initial zoom level is 1.
* Example 2: `@viewport { width: auto; viewport-fit: contain; }`
The width and height of the layout viewport and visual viewport are 141px, so the initial zoom level is 1.
* Example 3: `@viewport { min-width: 400px; viewport-fit: cover; }`
The width and height of the layout viewport are 400px, and the width and height of the visual viewport are 200px, so the initial zoom level is 0.5.
* Example 4: `@viewport { min-width: 400px; viewport-fit: contain; }`
The width and height of the layout viewport are 400px, and the width and height of the visual viewport are 141px, so the initial zoom level is 0.3525.
You would use example 1 if you have content that takes into account rounded corners and has a layout that deals with very small sizes well.
You would use example 2 if you have content that **does not** take into account rounded corners but has a layout that deals with very small sizes well.
You would use example 3 if you have content that takes into account rounded corners but has a layout that **does not** deal well with small sizes of less than 400px.
You would use example 4 if you have content that **does not** take into account rounded corners and has a layout that **does not** deal well with small sizes of less than 400px.
The UA stylesheet of mobile browser typically contains `@viewport {min-width: 980px;}` (or behaves as if they did), so authors need to use `@viewport {width: auto; }` to override that when they have designed for small screens. UAs for watches should do the same, as specified at https://drafts.csswg.org/css-device-adapt/#small-screen-ua
username_2: That wording doesn't cut it, though I know what you mean. Current UAs don't do that. Content that is absolutely positioned far to the left or top, or with a huge negative indent or negative margin, or with a negative z-axis to put it under the canvas, or even with 'visibility: hidden' or 'display:none' can often not be viewed by the user (unless you count the inclusion of developer tools to change the CSS)..
username_1: @username_2 Good point: do you have a better wording? Something like "the UA must ensure that **the entire layout viewport and any content overflowing it on the block-end and inline-end sides** can be viewed [...]". That's not a terribly nice phrasing, but it is probably more correct. Do you have a better suggestion?
username_2: I wish I did. It's tricky. There is also the `body { overflow: hidden; }` situation that should not be disallowed.
username_1: Defining this in terms of "what would be reachable / visible on a rectangular display" is probably the right way to deal with it: this is actually the intent, so why not spell it out, and it is a verifiable non-fuzzy claim (regardless of whether an automated testing setup is easy to put together).
I am less sure about restricting it to “significant” content. While I agree that insignificant things, by definition, aren't important, agreeing on what's significant is trickier, and I think the fuzziness that this introduces in the definition will cause more problems than it solves.
username_2: It seems like we need to allow some latitude for the UA to determine significance, or else we should define it. We shouldn't consider a UA as no conforming if it had 2mm corner rounding covering up some white background, for instance. The line between how much it can obscure or not should be defined either fuzzily or clearly.
username_0: The width and height of the layout viewport and visual viewport are 200px, so the initial zoom level is 1.
Example 2: @viewport { width: auto; viewport-fit: contain; }
The width and height of the layout viewport and visual viewport are 141px, so the initial zoom level is 1.
Example 3: @viewport { min-width: 400px; viewport-fit: cover; }
The width and height of the layout viewport are 400px, and the width and height of the visual viewport are 200px, so the initial zoom level is 0.5.
Example 4: @viewport { min-width: 400px; viewport-fit: contain; }
The width and height of the layout viewport are 400px, and the width and height of the visual viewport are 141px, so the initial zoom level is 0.3525.
Those are really nice examples to understand how `width` and `viewport-fit` work.
In the example, more precisely, does 'layout viewport' mean 'actual layout viewport'?
Also, I think it's better to change the definition of 'viewport-fit' from "set the size of the initial viewport" to "set the size of the visual viewport" if 'visual viewport' is defined in Device Adaptation Spec.
(I suggested the definition of that terminology in #206.)
username_1: I don't think so. If you set the initial viewport, it will also indirectly set the visual viewport, but it will do more than that. Unless there is some other `@viewport` rule doing something to the width or height of the viewport, it will also set the layout viewport to that size.
I realize that this would be a lot clearer if all these terms were properly defined, and that it is on me to go do that. I hope to be able to have time to do that soon, but so far I have not been able to prioritize it. Really sorry about that. |
sameersbn/docker-gitlab | 251457946 | Title: Integrations on push don't work anymore
Question:
username_0: Hi,
I just noticed that webhooks simply don't work anymore.
Scenario:

If I click the "Test" button it should send a request to the given URL, but it doesn't - and I get the following error message

This happens with all my integrations. Does anyone else has this issue too?<issue_closed>
Status: Issue closed |
domoinc/domo-python-sdk | 265057434 | Title: Enable streaming to disk for "data_export_to_file()"
Question:
username_0: Currently, pydomo pulls csv http responses into memory, which can be arbitrarily large. Improve the data export functions to write csv data directly to disk, avoiding a memory error on large files.
Answers:
username_0: Resolved by version 0.2.1: https://github.com/domoinc/domo-python-sdk/commit/95f9c1c79e2d0c3e1f4b1d257a82985dfdef15c7
Status: Issue closed
|
Kisesy/gscan_quic | 243292128 | Title: IP去重,小白专用
Question:
username_0: 主任说不开项目也开了,怎么着也得捧场啊,是吧
---------------
**前戏:**
一、简单粗暴,删除所有的有些麻烦的“格式”,只保留x.x.x.x-y.y.y.y【意会即可,别抠】,172.16.31.10【往往中间加了|、"",、空格、或者单独一行,这个嘛,格式转换,看是否有需要,再说,这里就先省下了,免得搞复杂了】,222.222.222.**0/24**【记住,最后的那个模样,即以0/24结尾,其他的什么0/16什么的,麻烦,全咔嚓了】
**只留3种格式!只留3种格式!只留3种格式!**
x.x.x.x-y.y.y.y
172.16.31.10
222.222.222.**0/24**
二、安装excel 2007及以上版本,或者EmEditor Pro【新版好像已经集成了去重插件。老旧些的,就不怎么知道了,可能需要额外安装插件?可以搜“emeditor插件”,XP的只能用14.8.1及以下了。自己找啊】
EmEditor Pro,有钱的可以去捧个场,感觉还是一款不错的软件,就是比较贵……1000多,好像……
三、把之前的3种格式,只留**2**种格式:172.16.31.10以及剩下的二选一!
172.16.31.10用来快速筛选,x.x.x.x-y.y.y.y或者222.222.222.**0/24**用来寻花问柳
四、分别建立两种“格式”的文件,一种“格式”,一个文件,别混了
至于怎么筛选,再说,或者你也可以开动下脑筋,搜索下——其实,只要你安装了excel或者EmEditor,都不是事,排序一下,就能搞定?
**一分钟解决:**
一、复制粘贴到excel,然后点击“数据”→“删除重复项”
可以参照:https://jingyan.baidu.com/article/86f4a73e356f1c37d7526962.html
二、或者复制粘贴到EmEditor Pro,点击“删除重复行”,之前可以先排序下,好像有两个插件,一个老的,一个新的,是不是需要排序,有点迷糊了,反正俺用的这个,不用排序也行?
**后话,或者说前话?**
其他的怎么筛选,怎么怎么整,有人提起,再说,个人建议:多用搜索引擎多动手,从简单的开始,能用就行,**你可以的**
Answers:
username_1: 写的不错
username_1: 我现在的去重用了排除
1.9.22.0
1.9.22.0/24
1.9.22.0-255
1.9.22.0-1.9.22.255
1.9.0.0/16
比如以上5个,经过去重之后只会剩下 1.9.0.0/16 一个
username_0: @username_1
主任这样,可以让程序计算嘛,那是无所谓了
其实对于俺们这种小白,个人觉得1.9.22.0/24最好理解了 😀
可能效率也相对高些,因为毕竟0/16覆盖后面两位,“打击面”比较广
0/24则只覆盖末尾,扫描个数大大减少 😀
但谁让1.9.0.0/16省事呢
能用就行,太精细了,反而容易得病 😀
不干不净,吃了放心
username_2: 我是网络抄的hosts去重
IP去重也行的
awk '!x[$0]++' hosts > hosts1
username_3: 很好很好
我把我那个未经整理的拽上来吧,一方面可以让@username_1 当个实例再研究研究去重算法,一方面方便大家当个扫描的列表自己扫
[iprange.txt](https://github.com/username_1/gscan_quic/files/1151884/iprange.txt)
[iprange.zip](https://github.com/username_1/gscan_quic/files/1151886/iprange.zip)
俩文件一样的,一个得自己改扩展名,个头稍大,一个zip打包小一些,解压缩覆盖就能使,看大家方便吧
我自己北京联通线路,用这个,配置选项比较严格的前提下扫到接近两万的可用ip
username_3: 学习了一下正则,花了一点儿时间我把我那个未经整理的数据源整理好了
https://github.com/username_1/gscan_quic/files/1157961/iprange.zip
username_0: 恭喜,正则入手,这种整理都是小case了啦 😀
看了下,2700多,剩下的ip,对于你来说,也是寥寥无几了 😀
username_4: 感谢
username_5: @username_0 @username_1 多谢主任建仓!谢谢@username_0推荐的软件很好用!阿弥陀佛! |
Samgithub1997/TwitterAutomation | 302171720 | Title: Change '*' for specific node
Question:
username_0: https://github.com/username_1/TwitterAutomation/blob/2348ed86ef92c1d158ee13566f399cb1a80ccf24/tests/_support/Page/Login.php#L19
please avoid to use "*" . when we use "*" we must me find all nodes and it make process slower
Answers:
username_1: issue resolved
Status: Issue closed
|
HeligPfleigh/react-native-thermal-receipt-printer | 896925305 | Title: Predefined tag are not working on iOS
Question:
username_0: Hi,
I have tried to use the predefined tag <B> in an iOS app. It's not working, meaning that the font is staying in normal size.
I have then tried to use any other tags, none is working, the text is alway left align with a normal size,
Could you please solve this issue ?
Regards |
wsu-cpts489-fa20/bp-kliks | 758838817 | Title: Tests for receiving feedback after submitting a response - Student
Question:
username_0: **Overview**:
Write the tests for being view a message after submitting a response as a student.
**Acceptance Criteria**:
- [ ] Tests to view a message of success or failure after submitting a response.
**Connected Issue(s)**:
Tests for issue #5
Status: Issue closed
Answers:
username_0: Won't have time to complete. |
10258392511/ImageAnalysis | 1101018684 | Title: Apply ADMM to the program
Question:
username_0: Hello! I'd like to apply ADMM to my program so that the speed of the algorithm can be improved. How can I do that? Any suggestion will be OK. Thank you!
```python
from numpy import double, linalg
import pyvips
import gc
image = pyvips.Image.tiffload('E:\\testpicture_jupyter\\4colour_ceshitu\\unc9.ome.tif')
image /= 255
y = image.log()
stain_vectors_1 = [
[0.571, 0.095, 0.767],
[0.584, 0.258, 0.576],
[0.577, 0.961, 0.284]
]
stain_inverse_1 = linalg.inv(stain_vectors_1).tolist()
stain_space_1 = y.recomb(stain_inverse_1)
y1 = stain_space_1.recomb(stain_vectors_1)
stain_vectors_2 = [
[0.095, 0.105, 0.767],
[0.258, 0.758, 0.576],
[0.961, 0.644, 0.284]
]
stain_inverse_2 = linalg.inv(stain_vectors_2).tolist()
stain_space_2 = y.recomb(stain_inverse_2)
y2 = stain_space_2.recomb(stain_vectors_2)
stain_vectors_3 = [
[0.571, 0.767, -0.48],
[0.584, 0.576, 0.808],
[0.577, 0.284, -0.343]
]
stain_inverse_3 = linalg.inv(stain_vectors_3).tolist()
stain_space_3 = y.recomb(stain_inverse_3)
y3 = stain_space_3.recomb(stain_vectors_3)
stain_vectors_4 = [
[0.095, 0.767, -0.553],
[0.258, 0.576, 0.817],
[0.961, 0.284, -0.165]
]
stain_inverse_4 = linalg.inv(stain_vectors_4).tolist()
stain_space_4 = y.recomb(stain_inverse_4)
y4 = stain_space_4.recomb(stain_vectors_4)
stain_vectors_5 = [
[0.105, 0.767, -0.218],
[0.758, 0.576, 0.649],
[0.644, 0.284, -0.729]
]
stain_inverse_5 = linalg.inv(stain_vectors_5).tolist()
stain_space_5 = y.recomb(stain_inverse_5)
y5 = stain_space_5.recomb(stain_vectors_5)
stain_space_1_exp = stain_space_1.exp()
stain_space_2_exp = stain_space_2.exp()
[Truncated]
http://www.openmicroscopy.org/Schemas/OME/2016-06/ome.xsd">
<Image ID="Image:0">
<!-- Minimum required fields about image dimensions -->
<Pixels DimensionOrder="XYCZT"
ID="Pixels:0"
Interleaved="false"
SizeC="1"
SizeT="1"
SizeX="61659"
SizeY="65001"
SizeZ="1"
Type="uint16">
<Channel Color="-16718848" ID="Channel:0:0" Name="Channel 1" SamplesPerPixel="1"><LightPath/></Channel><TiffData FirstC="0" FirstT="0" FirstZ="0" IFD="0" PlaneCount="1">
</TiffData>
</Pixels>
</Image>
</OME>
""")
CD8.tiffsave('CD8.tif', tile=True, pyramid=True, subifd=True)
``` |
codecentric/spring-boot-admin | 440792948 | Title: Spring Boot Admin - Insights - Environment view should list profile(s) of each configuration source (YAML)
Question:
username_0: It would be helpful if the title of each section also has the effective profile that item is being included in.
For property files this may be obvious based on the name but for things such as YAML it might not be as clear.
For example:
If you have a YAML document with JPA (jpa) and MongoDB (mongo) sub-documents the title will say this:
- `applicationConfig: [classpath:/config/application.yaml] (document #0)`
- `applicationConfig: [classpath:/config/application.yaml] (document #1)`
But it would be more helpful if it listed:
- `applicationConfig: [classpath:/config/application.yaml] (document #0) (profiles: jpa)`
- `applicationConfig: [classpath:/config/application.yaml] (document #1) (profiles: mongo)`
Where the profiles would come from the spring.profiles property of the YAML document. This may not be easy to get in other property sources like application-jpa.properties and non-relevant in other such as systemProperties but very helpful in YAML property sources.
Note this value from the endpoint is returned is based on how it is defined in the document. So if only one profile is defined it will define a property spring.profiles or if multiple profiles are defined it will expose them as spring.profiles[0] ... spring.profiles[n].
Answers:
username_1: We take this string from the `/env` actuator endpoint as-is, so please open an issue for spring-boot, as I don't think this easy to implement with the current information given by the endpointn
Status: Issue closed
|
iyzico/iyzipay-php | 705067651 | Title: How the subscription will be processed & How user will be charged for subscription ?
Question:
username_0: Hi there
May you explain purpose of this file https://github.com/iyzico/iyzipay-php/blob/master/samples/subscription-samples/create_subscription_with_customer_reference_code.php ?
I think it should create a subscription for user with existing reference code, right?
But in create customer file (https://github.com/iyzico/iyzipay-php/blob/master/samples/subscription-samples/create_customer.php), we do not have card details of user, how the subscription will be processed & how user will be charged for subscription?
Thanks |
archolewa/Maude-PSL | 169749025 | Title: Malformed terms are not caught correctly
Question:
username_0: Suppose we have the following signature:
```
type Nonce .
op t : Nonce -> Nonce .
var x : Msg .
```
and then we have the following output line:
```
Out(R) = t(x) .
```
Clearly, `t(x)` is malformed (it expects a term of type `Nonce` but is receiving one of type `Msg`). However, if a specification containing these lines were run through the tool, the only error message would be:
```
Traceback (most recent call last):
File "psl.py", line 791, in <module>
maudify()
File "psl.py", line 322, in maudify
gen_NPA_code(intermediate, theoryFileName, parseTree)
File "psl.py", line 418, in gen_NPA_code
process_error(stdout[errorIndex:], parseTree)
File "psl.py", line 431, in process_error
errorTermStart = error.index("$$$")
ValueError: substring not found
```
Which is less than helpful. This problem comes from the fact that Maude is excessively flexible, so that a term `t(x)` is technically a valid term (it exists at the kind) in Maude even though it isn't in Maude-PSL. The longterm fix is to actually implement a proper term parser ourselves, and validate all of the types.
The short term solution is to take each statement in the specification, and type check them in Maude. Then, if any of them are typed to the kind, print an error message indicating that one of the terms in that line is malformed, and should be checked. This is less than ideal (it doesn't tell you which term, or how it is malformed), but it at least tells you there is a problem, and on which line the problem is. |
github-vet/rangeloop-pointer-findings | 771607571 | Title: jetstack/cert-manager: pkg/controller/ingress-shim/helper_test.go; 19 LoC
Question:
username_0: [Click here to see the code in its original context.](https://github.com/jetstack/cert-manager/blob/7cef4582ec8e33ff2f3b8dcf15b3f293f6ef82cc/pkg/controller/ingress-shim/helper_test.go#L88-L106)
<details>
<summary>Click here to show the 19 line(s) of Go which triggered the analyzer.</summary>
```go
for name, tc := range tests {
t.Run(name, func(t *testing.T) {
if tc.mutate != nil {
tc.mutate(&tc)
}
crt := tc.crt.DeepCopy()
err := translateIngressAnnotations(crt, tc.annotations)
if tc.expectedError != nil {
assertErrorIs(t, err, tc.expectedError)
} else {
assert.NoError(t, err)
}
if tc.check != nil {
tc.check(assert.New(t), crt)
}
})
}
```
</details>
Leave a reaction on this issue to contribute to the project by classifying this instance as a **Bug** :-1:, **Mitigated** :+1:, or **Desirable Behavior** :rocket:
See the descriptions of the classifications [here](https://github.com/github-vet/rangeclosure-findings#how-can-i-help) for more information.
commit ID: 7cef4582ec8e33ff2f3b8dcf15b3f293f6ef82cc<issue_closed>
Status: Issue closed |
King-of-Infinite-Space/thoughts | 350706923 | Title: Blue moon wanes, blue moon waxes
Question:
username_0: 尽管二十年前的那场逆转胜利只是卑微的通向第二级别联赛的升级附加赛,但是回头来看,曼城的重振旗鼓,为后来发生的事情提供了可能——
2002年英联邦运动会在曼彻斯特举行,城市体育场是为此修建的主场馆。赛事结束后,该体育场被改造为专业足球场,由市政府租给曼城俱乐部使用。2003年曼城离开了使用了80年的Maine Road,将主场从迁到了这里。2008年,俱乐部被阿联酋财团收购,开始了金元足球的时代。从2009年开始球队一直保持在英超前五,并在2012、 2014、 2018三次夺冠。

如果曼城没能及时重回英超,那么他们或许没有足够的资金和筹码来获得城市球场的使用权。如果没有这座现代化的球场,曼城或许不会受到中东财团青睐,也就失去了发迹的机会,继续流连于中下游。
这场比赛的照片同后来曼城几次捧杯的照片一起,展示于城市球场的外墙上。
如今的曼城志在建立王朝、成为豪门。上赛季他们达到了新的高度。此时重温二十年前低谷之时的挣扎,颇有深意。
--- |
pyca/cryptography | 820972944 | Title: Missing Extended Keys Usages Microsoft Smartcard Logon & KDCAuth
Question:
username_0: I've come across [ExtendedKeyUsages](https://www.pki.dfn.de/fileadmin/PKI/anleitungen/DFN-PKI-Zertifikatprofile_Global.pdf) with are unknown to cryptography:
Microsoft Smartcard Logon 1.3.6.1.4.1.311.20.2.2
KDCAuth 1.3.6.1.5.2.3.5
(Rhode & Schwarz) TrustedDisk 1.3.6.1.4.1.30205.13.1.1
Is there any interest in getting Smartcard Logon & KDCAuth added?
Answers:
username_1: EKUs can contain arbitrary OIDs, so in general we've chosen to only list the ones specified directly in relevant RFCs. I am a bit reluctant to add more since then we need to come up with a measurement of notability. KDCAuth isn't part of the PEN arc so maybe that one is worth adding, but Microsoft is also an important company. @username_0 is this just a presentational issue for you or is cryptography failing to properly parse the OID value?
username_2: Just one datapoint, but Smartcard Logon & KDCAuth were already requested by another indirect cryptography user: username_2/django-ca#46.
username_1: For that use case it appears that there's just a desire for a pre-existing OID object so that users don't have to construct it themselves? I'm okay with adding prominent ones on a case-by-case basis as long as we can have docs that describe what their use is.
username_1: If anyone wants to send a PR for this I'm happy to review.
username_2: Would do, for attributes I would propose:
* `SMARTCARD_LOGON` (don't use company name?)
* `KERBEROS_KEY_DISTRIBUTION_CENTER` - what KDC actually stands for: https://docs.microsoft.com/en-us/windows-server/security/kerberos/kerberos-authentication-overview
* `TRUSTED_DISK` - again no company name?
Status: Issue closed
|
tree-sitter/tree-sitter-cpp | 360173816 | Title: Math Operators
Question:
username_0: The only Math operator that is properly highlighted is the *

Answers:
username_1: Thanks for the report!
This was fixed in https://github.com/atom/language-c/pull/300 that shipped in Atom 1.32.1. We are working on fixing more operators and scopes in https://github.com/atom/language-c/pull/303
Status: Issue closed
|
KhronosGroup/Vulkan-ValidationLayers | 958735544 | Title: Bug in "Validate creating pipeline with read-only depth/stencil"
Question:
username_0: A change (2eafdd8607e80b1c2477082a4d2212b74c9a7d27) to validate that pipelines don't write to depth if the layout is read-only is flakily asserting in ANGLE. For example, the following test produces a validation error once every few runs. The test itself is fine (i.e. there is no error in the Vulkan stream generated):
```bash
./angle_white_box_tests --gtest_filter=VulkanPerformanceCounterTest.ReadOnlyDepthStencilFeedbackLoopUsesSingleRenderPass/ES3_Vulkan
```
Running the test through `valgrind` didn't show anything interesting.
The above failing test does the following:
- Start render pass with `DEPTH_STENCIL_ATTACHMENT` layout + a draw call that writes to depth
- Start render pass with `READ_ONLY_DEPTH_STENCIL` layout + 6 draw calls that only do depth testing but no write
- Start render pass with `DEPTH_STENCIL_ATTACHMENT` layout + a draw call that writes to depth
The validation error happens when recording the second render pass. It almost seems like the value `pPipeline->graphicsPipelineCI.pDepthStencilState->depthWriteEnable` being tested is stale, though unclear why that is flaky.
Answers:
username_0: Could we revert this change until it's fixed? @ziga-lunarg
username_1: @username_0 this should be reverted with https://github.com/KhronosGroup/Vulkan-ValidationLayers/commit/592ea4ecb1c8c2838135dd46219ad50ea02ac719.
username_0: Thank you. Let me know if you need help reproducing the issue with ANGLE. |
tensorflow/tensorflow | 781728672 | Title: Normalisation layer save standard deviation instead of variance
Question:
username_0: **System information**
- TensorFlow version (you are using): 2.2.0
- Are you willing to contribute it (Yes/No): No
**Describe the feature and the current behavior/state.**
The Normalisation layer in tensorflow/python/keras/layers/preprocessing/normalization.py seems to save the variance instead of the standard deviation. And calculates the std on runtime std = sqrt(var).
This seems a bit wastfull to me as instead of saving the std once.
It would be a very small change with not much impact, but easy to implement.
**Will this change the current api? How?**
When using adapt() to initialize it doesn't matter which metric is saved -> no change in api
When directly initializing it, it could still take the variance (or std as an option) and save std in the background
**Any Other info.**
Could be changed at the next big change e.g: together with the behaviour I stated in [keras #14356](https://github.com/keras-team/keras/issues/14356#issue-781559372)
Answers:
username_1: We should not change the weight format (in particular for backwards compatibility and because we want the weights of multiple normalizable layers to be easily mergeable), but what we could do is compute the `sqrt` in the constructor of the layer (or upon weight loading) and store it on the layer. |
HaveAGitGat/Tdarr | 793458363 | Title: Revise v2 Instructions to install linux prerequisite packages
Question:
username_0: **Describe the bug**
Current instructions do not fully detail all required packages for Linux operating systems. For example: wget is required to pull Tdarr_Updater.zip, unzip is necessary to extract it, software-properties-common is needed to add repo’s, handbrake-cli ffmpeg and mkvtoolnix are needed for encoding. At minimum, it might help the less line savvy to understand the list of prerequisites.
I suggest advising the following line of code prior to downloading Tdarr_Updater.zip:
(optional) add repositories for [Handbrake](https://launchpad.net/~stebbins/+archive/ubuntu/handbrake-releases) and [mkvtoolnix](https://mkvtoolnix.download/downloads.html)
For Debian and Ubuntu: apt-get -q update && apt-get -y -q dist-upgrade && apt install -y wget unzip handbrake-cli ffmpeg mkvtoolnix software-properties-common && apt-get -q autoremove --purge && apt-get -q clean
**To Reproduce**
Download v2 on linux. Without unzip package, the user can’t extract the archive. Etc etc.
OS: Ubuntu 20.04.1 LTS as LXC container on Proxmox 5.4.78-2
Tdarr Version: 2.00.00
Status: Issue closed
Answers:
username_1: Thanks, I'll add this to the instructions
username_2: @username_1
These appear to still be missing? Or if they're in there it is not clear.
This, along with the systemd config mentioned in another issue, would be useful for those of us who do not wish to use the docker image. |
fabric8io/kubernetes-client | 532054168 | Title: Can Kubernetes Client get endpoints from another namespace using externalName?
Question:
username_0: See:
I have a kubernetes cluster with serviceA on namespaceA and serviceB on namespaceB.
I want, from serviceA, use kubernetes service discovery to programmatically list serviceB. I am planning to use spring cloud kubernetes ( @EnableDiscoveryClient ).
However, there is a company wide policy to block the use of the configuration below that should have solved the problem: spring.cloud.kubernetes.discovery.all-namespaces=true
If I set ExternalName = namespaceA.serviceb will it work?
https://stackoverflow.com/questions/37221483/service-located-in-another-namespace |
rfjakob/gocryptfs | 232790269 | Title: binaries for Debian 9 stretch
Question:
username_0: Hi,
since Debian 9 is scheduled for mid June, are there any plans for "official" binaries? Building from source seems to work out fine without issues. Central builds would be great!
Answers:
username_1: I'll release gocryptfs v1.4 this or next week, and I will switch to
providing a single static binary. This should run equally well on all Linux
distributions.
The static binary does not have openssl support, but you can always compile
from source if you need it. Hint: "openssl -speed" tells you if you do.
Status: Issue closed
username_1: I have released gocryptfs v1.4: https://github.com/username_1/gocryptfs/releases
Let me know if any problem on Debian 9.
PS: I meant `gocryptfs -speed` in the post above, not `openssl -speed` |
mirelon/membrane_computing | 147117300 | Title: Explain the usefulness of simulation for inhibitors
Question:
username_0: I do not really see the necessity of such a complicated proof of Theorem 4.1.2 when much simpler construction used in Theorem 4.1.3 is applicable to the generative case, too. The author claims that the proof technique itself may be of interest, but he does not provide any arguments. (Sosik)
Answers:
username_0: This is in the Conclusions:
The constructive proof for the generating case is valuable not only for the universality, but also can be seen as a method of conversion between P systems in sequential manner and maximally parallel manner, which may be essential for future works on P systems and other multiset rewriting systems.
Status: Issue closed
|
department-of-veterans-affairs/va.gov-team | 622140665 | Title: PDF the Submitted 686: Section 6
Question:
username_0: ## Story
As a Veteran submitting the 21-686c, I want a copy saved in my folder as a pdf for my records so that I can retain them as record, validate the submission, or any number of other pdf actions.
## Considerations
- This is a utility that is used throughout the platform and most likely leverages the submitted form schema through a process ending up as a pdf, that might then need to be sent or saved for the Veteran in their eFolder.
- Lighthouse has already built a VBMS uploading function that should help.
- The submission process and the creation of the pdf is most likely independent of each other, not interdependent.
- Can we test this pdf creation, eFolder saving in staging?
- If possible, it would be great to provide this to the user to download after submission
- <NAME> had some work done in this area
- URLs from Steve:
- https://github.com/department-of-veterans-affairs/vets-api/tree/master/spec/lib/pdf_fill/forms
- https://github.com/department-of-veterans-affairs/va.gov-team-sensitive/blob/master/VA-Systems/VBMS/VBMS%20Web%20Services%20Startup%20Guide.pdf
- Numbered questions: is that a 1:1 map to the paper form or does it need to be dynamic because we are using multiple workflows?
- Check with Form 527 and see how they are doing this
- The pdf: https://www.vba.va.gov/pubs/forms/VBA-21-686c-ARE.pdf
### Different Parts to the Form 686 [WIP]
- [x] [Section 1](https://zh-file.s3.amazonaws.com/133843125/57ea8fd5-db30-4e3e-8059-844e7a7d32e8?Expires=1589957316&AWSAccessKeyId=AKIAI5X57DET3FHKSALA&Signature=qKCplWA%2FfOXM4U8fCN5ubFtXnWY%3D)
- [ ] Section 2
- [ ] Section 3
- [ ] Section 4
- [ ] Section 5
- [ ] Section 6
- [ ] Section 7
- [ ] Section 8
- [ ] Section 9
- [ ] Section 10
- [ ] Section 11
## Tasks
- [ ] Test pdf creation
- [ ] Consider reaching out to Lihan on this
## Acceptance Criteria
- [ ] A PDF can be created from form submission
## Next step
- [ ] Test PDF upload
- [ ] Leverage Lighthouse VBMS upload functions
- [ ] A PDF is found in the users eFolder shortly after submission via VBMS
Answers:
username_1: 
Status: Issue closed
|
pulibrary/orangelight | 145776372 | Title: Some items may not be available
Question:
username_0: Currently when a mfhd has multiple items the availability is "All items available" until checked out items are found. Then the text updates to "Some items not available." However this status text also appears for recently returned books, which are actually available. In this case, the status text should update to "Some items may not be available"
The statuses that should activate the "may not be available" label are the following:
```
returned_statuses = ['In transit discharged', 'Discharged']
in_process_statuses = ['In process']
```
Also this [line](https://github.com/pulibrary/orangelight/blob/development/app/assets/javascripts/availability.js.coffee#L61) should be updated to `if item['status'] not in available_statuses` so that "On shelf" statuses are considered available.<issue_closed>
Status: Issue closed |
jaredLunde/masonic | 775998103 | Title: Expose interval tree module
Question:
username_0: Hey, firstly, thanks a lot for this great package!
Exposing most of the functionality as hooks has made it very modular and easy to customize. Right now, I'm attempting to implement a custom positioner, and would love to use masonic's interval tree. However, the interval tree and its types don't seem to be exposed. Is there any reason for that, or would that be a reasonable feature request?
Answers:
username_1: This is a completely reasonable request and an oversight on my part. You’re doing exactly what I want people to do when the positioning algorithm doesn’t satisfy a use case.
username_0: Thanks for the quick response! Let me know if you’d like a PR for this.
username_1: Go for it! I’m AFK right now but I’ll be back in an hour. Can merge/release your PR then.
Status: Issue closed
|
airspeed-velocity/asv | 1110661334 | Title: Replace Appveyor by GitHub Actions
Question:
username_0: What are others thoughts on using GitHub Actions for the CI? Probably not a huge difference, but seems slightly simpler not to run in cygwin, would allow for Windows+Linux builds, I guess it comes with a larger quota, and I think it's becoming more standard, so it may be easier to maintain for most people.
Answers:
username_1: I was playing with GitHub Actions on my asv fork https://github.com/username_1/asv. I have linux and macOS builds with python 3.7, 3.8 on GitHub Actions. They all have test failures related to environment creation. But the Appveyor build was always green.
username_0: Thanks @username_1 that's very useful to know. We'll be releasing what's in master early next week, and after that aim at having a larger matrix in the CI, so we can make sure asv works with different OSs and Python versions. |
whaleygeek/pyenergenie | 440487374 | Title: Clarify use of SPI in docs
Question:
username_0: Re: https://github.com/username_0/pyenergenie/issues/82
Update README to explain use of a software SPI driver, and please turn off hardware SPI
Answers:
username_1: Hi David, I'm still struggling to get the timings correct to hit the Rx window for the eTRV with your software spi driver, can you share some information why you decided to re-code this?
What is the difference between this, the bcm2835 driver and the spi that uses ioctl?
username_0: Hi, well, as always, there was a very good reason at the time, but things may be very different now.
The software SPI driver was written because in those days it meant 'download this zip file, run it, and it all works out of the box'. The BCM SPI driver required config changes at the time the Pi was new, and posed install complexities for users I didn't want.
GPIOzero even today has a soft SPI driver in it as a fall-back if the hardware one doesn't work for some reason of configuration etc (as it often failed on the very early Pi's). Also at the time, the BCM C library wasn't well controlled (it was just a random zip file that people used to share) and it was yet something else you had to download before it all worked. That's how the original Energenie code was delivered to me, it was quite a bag of bits to be fair!
Also, the simple sockets we were testing against had no strict requirements on timing, so a slower but more compatible SPI driver (zero install, zero extra downloads) was better at that time for what we were trying to achieve.
I aways had a view that given the maturing of hardware SPI support, I would one day look to see if there is now a pre-installed driver with the latest distro's and a pre-installed (or sufficiently licenced so the code could be copied verbatim here safely).
The drv/spi in this repo is written to easily allow this switch, spi.h provides a generic SPI interface, and spis.c is the software driver. spih.c could easily be the hardware driver that implements the identical interface, providing that the code fits the MIT licence and can be provided verbatim in this repo.
You could easily prove if a hardware SPI driver solves the issue by doing a quick hack and sitting the BCM SPI driver under the spi.h interface (call it spih.c) and see if your turnaround time improves.
I'd hazard a guess that polling isn't much better as the FIFO size read is only a couple of bytes, But getting the whole payload in would take longer as it is a few 10's of bytes (but interestingly, once it is in the FIFO you should be able to shift it out at your leisure, which suggests the poll cycle IS instrumental in any latecy you are seeing).
Myself I would do a quick experiment comparing both soft and hard approaches, toggle a GPIO around the poll window in each and measure it. If the performance significantly improves and improves the probability of hitting the receive window, it's worth properly integrating the BCM SPI driver under spi.h and feel free to send a PR if that works without breaking any of the other devices (doubtful, but we'd really have to re-test all devices again to make sure).
Thanks
Status: Issue closed
username_0: I have added a message in setup_tool.py and also a note in the README that say to turn off hardware SPI.
I have a separate issue open regarding introducing the SPI hardware driver: https://github.com/username_0/pyenergenie/issues/120
I also have a separate issue open regarding moving to a scheduled driver rather than a blocking driver, which would probably have more of an impact on the eTRV support than the hardware driver would: https://github.com/username_0/pyenergenie/issues/9
So, I'm closing this issue, as it is already described in other issues. |
indico/indico | 124366175 | Title: Event export iCal
Question:
username_0: I created an event of type lectures with description and some speakers, but when I try to export the event on iCalendar file (ics) on file downloaded not appears anywhere info about speakers of the event.
I try to find when your code make export of an event, I found in the ical.py file on row 45 on "serialize_event" you prepend the speakers info on the description variable, but i don't know why export is execute on file generated not appears speakers in description field.
I try to suggest you to append a new properties to file generated as non standard properties (https://tools.ietf.org/html/rfc5545#page-142) like X-SPEAKERS with all info about speakers of an event.
Sorry for my bad english. |
Ayatallah/Looprac | 66696505 | Title: Add new Model (userrating)
Question:
username_0: @ISpoonJelly Please add new model userrating,or whatever you wanna name it, to db
rails g model userrating rating:integer review:text
rails g migration add_rater_id_to_userratings rater_id:integer
rails g migration add_rated_id_to_userratings rated_id:integer<issue_closed>
Status: Issue closed |
backbrace/backbrace | 678019481 | Title: Edit link missing on guides
Question:
username_0: <!-- Please search existing issues to avoid creating duplicates. -->
- Backbrace Version: 0.2.4
- Browser:
Steps to Reproduce:
1. Browse to https://backbrace.io/guides
2. The edit button (usually top left) is missing |
CodersCommunity/front-next | 951686276 | Title: Obsłużyć klucze "closed" i "favorite" w podglądzie pytania
Question:
username_0: Zamknięte pytanie:

Ulubione pytanie:

W ulubionym pytaniu proponuję zmienić border-left na gwiazdkę przed tytułem (coś jak z kłódką przy zamkniętym pytaniu)<issue_closed>
Status: Issue closed |
doctrine/dbal | 312497130 | Title: Updating from dbal 2.6.3 to 2.7.1 breaks the gedmo timestampable
Question:
username_0: We've updated from dbal 2.6.3 to 2.7.1 and have the issue, that the gedmo timestampable stopped working, when the column is on the main table of a JOINED table.
SQLSTATE[42S22]: Column not found: 1054 Unknown column 'updated_at' in 'field list'<issue_closed>
Status: Issue closed |
vernemq/vernemq | 435954467 | Title: arduino pubsub doesn't work with the proker
Question:
username_0: I can't make connection with vernemq broker by pubsub client from my arduino client. Also I should mention that there's no any problem with my computer client and also I should say that my board can connect to the mosquitto broker without any problem.
### Environment
- VerneMQ Version: 1.7.1
- OS: ubuntu 18.04
- Erlang/OTP version (if building from source): Binary version
- VerneMQ configuration (vernemq.conf) or the changes from the default
anonymous is enabled
listening address changed to 0.0.0.0:1883
- Cluster size/standalone: standalone
Answers:
username_1: Hi, it could be a number of things. A network issue for example; is the arduino able to connect to the broker at all or is there a routing problem? If it is able to connect you could try to trace the client-id `vmq-admin trace client client-id=<insert-client-id-here>` and see what happens. If that doesn't help, perhaps you could try with wireshark or add debug logs in the arduino code which outputs the connection error to the console.
FYI I got an arduino board at home connecting to VerneMQ without any issues. I'm using this library: https://github.com/knolleary/pubsubclient/
Status: Issue closed
username_0: Ok let me describe it better.
1- I have a server which I started both the mosquitto and vernemq together. when I want to test with each one of them I start that service and stop another one. so the environment is the same (even the ports)
2- I'm using exactly the library you mentioned with esp8266 processor
3- I can connect to both of the brokers with my pc client without any problem which shows that the config of the broker is correct
4- I can connect to the mosquitto with the esp board but I can't connect with vernemq
5- I checked with the tcpdump tool and found that at the connection request moment there's some packets exchanging between the broker and the board but the connection does not successfully establish.
I checked the state of the client after connection failed and it returns MQTT_CONNECT_UNAUTHORIZED. But as I said, I turned the anonymous connection on this way:
allow_anonymous = on
Is there any thing that may be important for your broker which is not important for mosquitto or any other thing which I can check for more investigation? for example I don't know if the client_id has any specification in your broker or not?
username_2: @username_0 hmm, as far as i know that esp client can use only `tlsv1`;
so if you're using certificates, this might be the problem.
username_1: If `allow_anonymous=on` is configured then authentication is completely disabled in VerneMQ. So either the config hasn't been properly set somehow (was VerneMQ restarted after the change) or the client isn't actually connecting to the running VerneMQ instance. What was the output of the trace command mentioned above?
username_0: Thanks for your answers.
I found the problem.
As I was tweaking the settings, I accidentally had changed the acl config in this way:
plugins.vmq_acl = off
The problem solved by turning it back on. But I still don't know why the pc client could connect to the broker while the board couldn't in that situation ?!!!
But anyway sorry for my bad mistake
And thanks for your great efforts and this neat project, keep it up
username_1: Great you got it to work and thanks for the nice words! |
boyle/2018-measure-stress | 370327621 | Title: Clocks calibration
Question:
username_0: **Problem:**
Inevitably, the event timestamps will have some offset with respect to the physiological measurements. These two types of data (measurements and events) will need to be aligned.
I am assuming that there will be two devices:
1. The tablet
2. A desktop computer to which the sensors are connected
**Potential solutions:**
**Simplest** Have the person holding the tablet and the person at the computer press a button simultaneously at the beginning of the session. The timestamps can be used to compute offsets.
Answers:
username_0: Could likely be done via Bluetooth with a small Java program on the computer.
Status: Issue closed
|
flutter/flutter | 762074551 | Title: Cloud Firstore Plugin Should Support Logical Or Query
Question:
username_0: Currently, we can do logical And operations using the where clause something like this
## Logical AND
```
Firestore.instance.collection("messages")
.where("field1", isEqualTo: "value1")
.where("field2", isEqualTo: 'value2')
```
I would propose a similar functionality for logical OR
## Proposal
```
Firestore.instance.collection("messages")
.where("field1", isEqualTo: "value1")
.orWhere("field1", isEqualTo: 'value2')
```
The current approach which works for me is using the [CombineLatestStream](https://pub.dev/documentation/rxdart/latest/rx/CombineLatestStream-class.html) from the [rxdart ](https://pub.dev/packages/rxdart)package
## Current Approach
```
final stream1 = Firestore.instance.collection("messages")
.where("field1", isEqualTo: "value1");
final stream2 = Firestore.instance.collection("messages")
.where("field1", isEqualTo: "value2");
StreamBuilder(
stream: CombineLatestStream.list([
stream0,
stream1,
]),
builder: (context, snapshot) {
final data0 = snapshot.data[0];
final data1 = snapshot.data[1];
})
```
I am not sure how efficient the current approach is, or what are the technical challenges involved with adding support for Logical Or query to firestore plugin I would love to hear more about it. Feel free to close this issue if this is a duplicate or is not related.
Answers:
username_1: Hi @username_0
From what I can see, the issue is related to a FlutterFire plugin rather than to Flutter itself. Please open the issue in the dedicated [repository](https://github.com/FirebaseExtended/flutterfire/issues).
Closing, as this isn't an issue with Flutter itself.
If you disagree, please write in the comments,
providing your `flutter doctor -v`, your `flutter run -v`, your `pubspec.yaml`
a minimal reproducible code sample that does not use 3rd party plugins,
and I will reopen it.
Thank you
Status: Issue closed
|
orange-cloudfoundry/paas-templates | 735349110 | Title: syslog_forwarder / blackbox out of memory
Question:
username_0: ### Expected behavior
* As a paas-templates operator | paas-templates maintainer
* In order to reduce the number of alarm
* I need to do not have out of memory from the blackbox process
### Observed behavior
When the log files are very large (more than 2Gb), syslog_forwarder / blackbox get a out of memory every 10 minutes.
The process is automatically restart by bosh, but it is not a good behaviour.
The issue is visible on deployment :
* prometheus / minio-s3-thanos (haproxy/sdtout.log size = 30G !!!)
* intranet-interco-relay / ops-relay (haproxy/sdtout.log size = 2G !)
### Affected releases
* 47.0.3
* earlier versions
Answers:
username_0: An other question is why the haproxy log is too big (30G!!)
My feeling is that the log rotate process not working correctly and the file grow unlimited.
username_0: In addition, about the strange behaviour of le log file :
With different tools, I don't have the same result for the file size
```
minio-s3-thanos/b47d1c5c-d543-450b-b99d-e818f501bec4:/var/vcap/sys/log/haproxy$ du -h haproxy.stdout.log
2.1M haproxy.stdout.log
minio-s3-thanos/b47d1c5c-d543-450b-b99d-e818f501bec4:/var/vcap/sys/log/haproxy$ ls -lh haproxy.stdout.log
-rw------- 1 vcap vcap 1.1G Nov 5 08:58 haproxy.stdout.log
```
username_1: same on 48.0.2.
Thanos should be solved when removing built in minio s3 (leveraging corporate s3 for long term metrics)
Intranet interco relay might be solved by reducing verbosity level on haproxy bosh release.
username_2: - [x] Thanos has be done in v50
- [] `intranet-interco-relay/ops-relay`
Status: Issue closed
|
29th/personnel | 53351084 | Title: Suggestion: Game specific prefixes when posting in Public Discussion
Question:
username_0: PFC Toumainen wrote:
Similar feature to TWI forums where you can select a game specific prefix for your topic (within Public Discussion board only) would be nice. So you could select between ARMA - DH - RO2/RS
Answers:
username_1: @Tuomainen are there any other forums where this would be helpful? There's a [vanilla plugin](http://vanillaforums.org/addon/discussionmarker-plugin) for this, but not sure you can just apply it to one forum. May be easier to just use text if we only want to keep it to one forum.
username_1: Closing since we're moving to discourse
Status: Issue closed
|
pandas-dev/pandas | 495725284 | Title: DataFrameGroupBy.first() affects group without assignment
Question:
username_0: #### Code Sample, a copy-pastable example if possible
```python
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar'], 'B' : [1, 2, 3, 4]})
grouped = df.groupby('A')
print(grouped.apply(lambda x: x))
grouped.first()
print(grouped.apply(lambda x: x))
```
Output:
```
A B
0 foo 1
1 bar 2
2 foo 3
3 bar 4
B
0 1
1 2
2 3
3 4
```
#### Problem description
The invoking method, without re-assignment of result or specifying that it should work in place, should not affect the object upon which it is being called.
#### Expected Output
```
A B
0 foo 1
1 bar 2
2 foo 3
3 bar 4
A B
0 foo 1
1 bar 2
2 foo 3
3 bar 4
```
#### Output of ``pd.show_versions()``
<details>
INSTALLED VERSIONS
------------------
commit : None
python : 3.6.7.final.0
python-bits : 64
OS : Linux
OS-release : 4.15.0-62-generic
machine : x86_64
processor : x86_64
byteorder : little
LC_ALL : None
LANG : en_US.UTF-8
[Truncated]
fastparquet : None
gcsfs : None
lxml.etree : 4.2.6
matplotlib : 2.0.2
numexpr : None
odfpy : None
openpyxl : None
pandas_gbq : 0.11.0
pyarrow : 0.13.0
pytables : None
s3fs : None
scipy : 1.0.0
sqlalchemy : 1.3.7
tables : None
xarray : None
xlrd : None
xlwt : None
xlsxwriter : None
</details>
Answers:
username_1: Can you check where things go wrong? We do have a `mutated` property on BaseGrouper. That's where I would start looking.
username_2: This affects a few functions like sum, prod, min, max, first, last, nth, and maybe more.
I *think* the issue is a call to `self._set_group_selection()` without resetting that selection after the fact. There is a `_group_selection_context` context manager that should be used instead.
@username_0 interested in trying a PR to fix?
username_3: i created an issue for this already but may have to search for it
username_4: Duplicate of #34656 and closed by #35314
Status: Issue closed
|
MicrosoftDocs/azure-docs | 471214511 | Title: Public IP Prefix can also be used for VMSS and Application Gateway v2 SKU
Question:
username_0: Missing documentation.
I'm the PM, created this issue for tracking purposes only.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 6f5d33e9-bcb3-3358-f859-c2ff3e71b131
* Version Independent ID: 5498280e-dd3c-bd46-9877-3506ad926dbd
* Content: [Azure Public IP address prefix](https://docs.microsoft.com/en-us/azure/virtual-network/public-ip-address-prefix#feedback)
* Content Source: [articles/virtual-network/public-ip-address-prefix.md](https://github.com/Microsoft/azure-docs/blob/master/articles/virtual-network/public-ip-address-prefix.md)
* Service: **virtual-network**
* GitHub Login: @username_0
* Microsoft Alias: **anavin**
Answers:
username_1: @username_0 Hi! We're interested in starting a VMSS from a Public IP prefix, could you share an ARM template example for doing this? It would be really helpful!
username_0: @username_1 yes, @username_2 created this: https://github.com/Azure/azure-quickstart-templates/tree/master/101-vmms-with-public-ip-prefix
username_2: This has been resolved, so closing.
#please-close
Status: Issue closed
|
webkinder/wp-cli-csv-import | 574696342 | Title: Error: Package installation failed.
Question:
username_0: Warning: Package name mismatch...Updating from git name 'webkinder/wp-cli-csv-import' to composer.json name 'wp-cli/import-csv'.
Installing package wp-cli/import-csv (dev-master)
Updating /home/azja1/.wp-cli/packages/composer.json to require the package...
Registering https://github.com/webkinder/wp-cli-csv-import.git as a VCS repository...
Using Composer to install the package...
---
Loading composer repositories with package information
Warning: Failed to execute git clone --mirror '<EMAIL>:webkinder/wp-cli-csv-import.git' '/home/azja1/.cache/composer/vcs/git-github.com-webkinder-wp-cli-csv-import.git/'
---
Error: Package installation failed.
Reverted composer.json. |
NMGRL/pychron | 159494588 | Title: error when running blanks
Question:
username_0: error when running blanks
data was actually saved, experiment queue stopped with no message from pychron
```
ClientSwitchManager -- State checksums do not match. Local:1187265529 Remote:2098661531
ClientSwitchManager -- Valve word length is too short. All valve states will not be updated! Word:14, Num Valves: 25
AutomatedRun -- No value "sensitivity_multiplier" in metadata
ExperimentExecutor -- extraction did not complete successfully
AutomatedRun -- No value "sensitivity_multiplier" in metadata
AutomatedRun -- Skipping peak center. intensities to small. 1.07581747286<3
AutomatedRunPersister -- No database instance. Not saving post measurement to isotopedb database
```<issue_closed>
Status: Issue closed |
Sidoine/Ovale | 284117989 | Title: Demon Hunter T21 spell rotation wrong
Question:
username_0: 737 which is the latest version still isn't working for Demon Hunter Havoc with 4 x Tier 21 rotation. Demonic Spec for Tier 21.
It keeps suggesting glave and other things on single target bosses.
I have reverted to an earlier version 7.3.0.3 and for the most seems to be working.
I'm not sure why the latest is flashing other spells. I will keep testing the latest when ever release one and let you know when it is right.
YOUR ADDON ROCKS. Been using it a long time. Helps me learn new rotations like demonic spec and helps me learn what to do when.<issue_closed>
Status: Issue closed |
aarondcoleman/Fitbit.NET | 225709832 | Title: Token Expiring
Question:
username_0: I'm using Fitbit.NET in my application. Its working great except that the toke keeps expiring. I try refreshing the token and storing it after each request but this doesn't help.
### Controller
```
public async Task<HttpResponseMessage> Activity(FitbitRequestDTO request)
{
FitbitClient client = null;
try
{
var val = await ValidateUserAndPatientDataAccess(request.PatientId, Guid.Empty);
if (!val.IsValid)
return CustomErrorResponse(val.Error.Status, val.Error.Code);
var token = HealthDeviceUtils.FindHealthDevice(CurrentUser.Org, CurrentTarget, "Fitbit");
if (string.IsNullOrEmpty(token?.OauthToken))
{
return InvalidHealthDeviceAccountResponse();
}
Token = DeserializeOAuth2AccessToken(token.OauthToken);
client = GetFitbitClient();
IEnumerable<DateTime> days = DateHelper.DatesBetween(request.StartDate, request.EndDate);
var metrics = new List<object>();
foreach (var dateTime in days)
{
var activities = await client.GetDayActivityAsync(dateTime);
var miles = activities.Summary.Distances.FirstOrDefault(d => d.Activity == "total");
var distance = new Distance
{
date_observed = dateTime,
distance = miles?.Distance ?? 0,
unit = "miles"
};
var steps = new Steps
{
date_observed = dateTime,
steps = activities.Summary.Steps,
unit = ""
};
metrics.Add(new object[] {distance, steps});
}
await RefreshAndStoreToken(client);
return OkResponse(metrics);
}
catch (FitbitTokenException e)
{
AppUtils.LogException(nameof(Activity), e);
//if (_refreshAttempted)
return FitbitTokenExecptionResponseMessage();
//await RefreshAndStoreToken(client);
//_refreshAttempted = true;
//return await Activity(request);
}
catch (AggregateException e)
{
AppUtils.LogException(nameof(Activity), e);
//if (_refreshAttempted)
return FitbitTokenExecptionResponseMessage();
//await RefreshAndStoreToken(client);
//_refreshAttempted = true;
[Truncated]
protected static HealthDeviceToken UpdateHealthDeviceToken(HealthDeviceToken healthDeviceToken, object accessToken, string manufacturer, string userId)
{
try
{
healthDeviceToken.OauthToken = manufacturer == OAuthProviderType.Fitbit.Value ? JsonConvert.SerializeObject((OAuth2AccessToken)accessToken) : JsonConvert.SerializeObject((IToken)accessToken);
healthDeviceToken.OauthSecret = manufacturer == OAuthProviderType.Fitbit.Value ? string.Empty : ((IToken)accessToken).TokenSecret;
healthDeviceToken.OauthUserId = userId;
healthDeviceToken.InputDeviceId = manufacturer;
healthDeviceToken.LastUpdate = DateTime.UtcNow;
HealthDeviceUtils.Update(healthDeviceToken);
return healthDeviceToken;
}
catch (Exception e)
{
AppUtils.LogException(" UpdateHealthDeviceToken ", e);
return null;
}
}
```
Answers:
username_1: @username_0 the Fitbit OA2 tokens expire after 8 hours (see https://dev.fitbit.com/docs/oauth2/#refreshing-tokens ).
The strategy you describe isn't guaranteed to perform a refresh within that window. A better strategy is to implement code that refreshes your token at least once every 8 hours, and do your data access separately.
username_0: @jonathonwalz Even when trying to refresh the token, after that 8 hour window, I get an exception saying that the token is invalid.
username_0: @username_1 With you OOB automatic token refresh, does that automatically update the AccessToken on the client instance?
Status: Issue closed
|
rancher/rancher | 865561870 | Title: Update CIS chart to support k8s 1.22
Question:
username_0: **What kind of request is this:**
Task
**Other details that may be helpful:**
CustomResourceDefinition is deprecated in k8s v1.16+, unavailable in v1.22 - we need to update the CIS charts accordingly.
From the error logs on 2.5-head, it looks like CIS is returning:
```
CIS:
apiextensions.k8s.io/v1beta1 CustomResourceDefinition is deprecated in v1.16+, unavailable in v1.22+; use apiextensions.k8s.io/v1 CustomResourceDefinition
rbac.authorization.k8s.io/v1beta1 ClusterRole is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 ClusterRole
rbac.authorization.k8s.io/v1beta1 ClusterRoleBinding is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 ClusterRoleBinding
```
Answers:
username_1: On master-head commit id: `f33188d`
- Deploy CIS charts on a downstream cluster
- No errors seen as mentioned in original issue
- Logs:
```
helm upgrade --install=true --namespace=cis-operator-system --timeout=10m0s --values=/home/shell/helm/values-rancher-cis-benchmark-crd-2.0.0.yaml --version=2.0.0 --wait=true rancher-cis-benchmark-crd /home/shell/helm/rancher-cis-benchmark-crd-2.0.0.tgz
--
Sun, Jul 18 2021 8:25:58 am | Release "rancher-cis-benchmark-crd" does not exist. Installing it now.
Sun, Jul 18 2021 8:25:59 am | creating 4 resource(s)
Sun, Jul 18 2021 8:25:59 am | beginning wait for 4 resources with timeout of 10m0s
Sun, Jul 18 2021 8:26:01 am | NAME: rancher-cis-benchmark-crd
Sun, Jul 18 2021 8:26:01 am | LAST DEPLOYED: Sun Jul 18 15:25:59 2021
Sun, Jul 18 2021 8:26:01 am | NAMESPACE: cis-operator-system
Sun, Jul 18 2021 8:26:01 am | STATUS: deployed
Sun, Jul 18 2021 8:26:01 am | REVISION: 1
Sun, Jul 18 2021 8:26:01 am | TEST SUITE: None
Sun, Jul 18 2021 8:26:01 am |
Sun, Jul 18 2021 8:26:01 am | ---------------------------------------------------------------------
Sun, Jul 18 2021 8:26:01 am | SUCCESS: helm upgrade --install=true --namespace=cis-operator-system --timeout=10m0s --values=/home/shell/helm/values-rancher-cis-benchmark-crd-2.0.0.yaml --version=2.0.0 --wait=true rancher-cis-benchmark-crd /home/shell/helm/rancher-cis-benchmark-crd-2.0.0.tgz
Sun, Jul 18 2021 8:26:01 am | ---------------------------------------------------------------------
Sun, Jul 18 2021 8:26:01 am | helm upgrade --install=true --namespace=cis-operator-system --timeout=10m0s --values=/home/shell/helm/values-rancher-cis-benchmark-2.0.0.yaml --version=2.0.0 --wait=true rancher-cis-benchmark /home/shell/helm/rancher-cis-benchmark-2.0.0.tgz
Sun, Jul 18 2021 8:26:02 am | Release "rancher-cis-benchmark" does not exist. Installing it now.
Sun, Jul 18 2021 8:26:02 am | creating 38 resource(s)
Sun, Jul 18 2021 8:26:03 am | beginning wait for 38 resources with timeout of 10m0s
Sun, Jul 18 2021 8:26:03 am | Deployment is not ready: cis-operator-system/cis-operator. 0 out of 1 expected pods are ready
Sun, Jul 18 2021 8:26:05 am | Deployment is not ready: cis-operator-system/cis-operator. 0 out of 1 expected pods are ready
Sun, Jul 18 2021 8:26:07 am | Deployment is not ready: cis-operator-system/cis-operator. 0 out of 1 expected pods are ready
Sun, Jul 18 2021 8:26:09 am | Starting delete for "patch-sa" Job
Sun, Jul 18 2021 8:26:09 am | jobs.batch "patch-sa" not found
Sun, Jul 18 2021 8:26:09 am | creating 1 resource(s)
Sun, Jul 18 2021 8:26:09 am | Watching for changes to Job patch-sa with timeout of 10m0s
Sun, Jul 18 2021 8:26:09 am | Add/Modify event for patch-sa: ADDED
Sun, Jul 18 2021 8:26:09 am | patch-sa: Jobs active: 0, jobs failed: 0, jobs succeeded: 0
Sun, Jul 18 2021 8:26:09 am | Add/Modify event for patch-sa: MODIFIED
Sun, Jul 18 2021 8:26:09 am | patch-sa: Jobs active: 1, jobs failed: 0, jobs succeeded: 0
Sun, Jul 18 2021 8:26:12 am | Add/Modify event for patch-sa: MODIFIED
Sun, Jul 18 2021 8:26:12 am | Starting delete for "patch-sa" Job
Sun, Jul 18 2021 8:26:12 am | NAME: rancher-cis-benchmark
Sun, Jul 18 2021 8:26:12 am | LAST DEPLOYED: Sun Jul 18 15:26:02 2021
Sun, Jul 18 2021 8:26:12 am | NAMESPACE: cis-operator-system
Sun, Jul 18 2021 8:26:12 am | STATUS: deployed
Sun, Jul 18 2021 8:26:12 am | REVISION: 1
Sun, Jul 18 2021 8:26:12 am | TEST SUITE: None
Sun, Jul 18 2021 8:26:12 am |
Sun, Jul 18 2021 8:26:12 am | ---------------------------------------------------------------------
Sun, Jul 18 2021 8:26:12 am | SUCCESS: helm upgrade --install=true --namespace=cis-operator-system --timeout=10m0s --values=/home/shell/helm/values-rancher-cis-benchmark-2.0.0.yaml --version=2.0.0 --wait=true rancher-cis-benchmark /home/shell/helm/rancher-cis-benchmark-2.0.0.tgz
```
Status: Issue closed
|
rse/node-prince | 248140535 | Title: Prince 11.2 is out !
Question:
username_0: Could be nice to update the module so that it downloads 11.2 ! ;)
Thanks for this wrapper, it helps a lot :)
Status: Issue closed
Answers:
username_1: A new version 1.4.1 was released which now downloads PrinceXML 11.2. As a workround, you can always install PrinceXML locally and put it into your PATH, then node-prince will pick it up (instead of downloading it). |
jaddison/certbot_py | 276754569 | Title: isn't cerbot already in python?
Question:
username_0: just curious why we need to spawn an executable when certbot's source itself is written in python?
can't we use import the certbot library from python?
Answers:
username_1: You certainly can (the `acme` client)! If I recall, at the time of developing this module, `acme` was harder to use. That's why the label in the README here still states **Very Alpha, Proof of Concept**.
Integrate with `acme` if you can.
Status: Issue closed
|
etcaterva/deployment | 758378235 | Title: Fix Sentry integration
Question:
username_0: Where does the DSN, and more config lives? Is it the same for backend/frontend?
Nothing coming through, fix it!
Answers:
username_1: I think we need to change the current account to use the echaloasuerte email, as right now I configured it and only I see the alerts.
I tried adding more people, but that requires a business account.
username_1: Done, moved to echaloasuerte, see the password in our sheet.
Status: Issue closed
username_1: I;d expect for it to be in the vault and it injects it via env var. See https://github.com/etcaterva/eas-backend/blob/master/eas/settings/prod.py#L26
username_0: Yes, I found that one too, but we need to sort this for the frontend
username_0: Where does the DSN, and more config lives? Is it the same for backend/frontend?
Nothing coming through, fix it!
username_1: @dnaranjo89 moved frontend sentry
Status: Issue closed
|
NVIDIA/DALI | 465504585 | Title: How to release the allocated GPU memory of a Pipeline object?
Question:
username_0: Hi,
I am working with the VideoReader in DALI. Unfortunately, the it hasn't supported varied resolution yet (see this [issue](https://github.com/NVIDIA/DALI/issues/725)). One way to get around this is to create a series of Pipeline objects on the fly. However, after deleting a Pipeline object, the allocated GPU memory is not released. I wonder how I can free the allocated GPU memory.
Thanks in advance!
Answers:
username_1: Hi,
What kind of indicator do you use to determine that memory has not been freed? Can you provide some simple reproduction script that shows that problem?
username_0: Hi @username_1,
I really appreciate your quick response. The VideoReader is working correctly for me now. The GPU memory is released as I expected. I guess there might be some problem with my GPU.
I'm closing this issue. I'll reopen it if this happens and I can reproduce it.
Status: Issue closed
|
aws/aws-cli | 94106936 | Title: aws s3 sync --delete: delete files _after_ uploading
Question:
username_0: Hello,
With `awscli==1.7.37`, when using `s3 sync --delete`, is there a way to have the files be deleted after the rest is uploaded? It seems like they’re always deleted before uploading.
```
$ aws s3 sync --delete dist s3://bucket
delete: s3://bucket/scripts/bundle.65406bc3e1133110.js
upload: dist/index.html to s3://bucket/index.html
upload: dist/scripts/bundle.9ad9b21077147aa5.js to s3://bucket/scripts/bundle.9ad9b21077147aa5.js
upload: dist/styles/bundle.6de17660ab595a44.css to s3://bucket/styles/bundle.6de17660ab595a44.css
```
Answers:
username_1: What's the reasoning for waiting to delete until after all uploads are complete? If we did that, then we'd have to keep every delete request in memory, which could consume a large amount of memory for large buckets.
username_0: @username_1 all the reasoning that’s behind rsync’s `--delete-after`.
For example, if the transfer fails while syncing, let’s say right after the delete, I’ve deleted the old files, but haven’t added any of the new, which could be a problem.
username_1: Interesting. I suppose we could also evaluate adding other delete strategies similar to the delete options offered by rsync. I'll mark this as a feature request, and we'll add it to our backlog.
username_2: I second the need to a delete-after option.
I use s3 to deliver some media files to a live media player server, and the most beautiful scenario would be to always delete after, to garantee the server would always have ready media files to play, when old files are deleted, and have delete before behavior Only/If the disk is full.
username_0: A quick workaround is to run the `sync` command twice, once without `--delete`, then with the `--delete` flag.
username_3: Good Morning!
We're closing this issue here on GitHub, as part of our migration to [UserVoice](https://aws.uservoice.com/forums/598381-aws-command-line-interface) for feature requests involving the AWS CLI.
This will let us get the most important features to you, by making it easier to search for and show support for the features you care the most about, without diluting the conversation with bug reports.
As a quick UserVoice primer (if not already familiar): after an idea is posted, people can vote on the ideas, and the product team will be responding directly to the most popular suggestions.
We’ve imported existing feature requests from GitHub - Search for this issue there!
And don't worry, this issue will still exist on GitHub for posterity's sake. As it’s a text-only import of the original post into UserVoice, we’ll still be keeping in mind the comments and discussion that already exist here on the GitHub issue.
GitHub will remain the channel for reporting bugs.
Once again, this issue can now be found by searching for the title on: https://aws.uservoice.com/forums/598381-aws-command-line-interface
-The AWS SDKs & Tools Team
Status: Issue closed
username_4: Hello,
With `awscli==1.7.37`, when using `s3 sync --delete`, is there a way to have the files be deleted after the rest is uploaded? It seems like they’re always deleted before uploading.
```
$ aws s3 sync --delete dist s3://bucket
delete: s3://bucket/scripts/bundle.65406bc3e1133110.js
upload: dist/index.html to s3://bucket/index.html
upload: dist/scripts/bundle.9ad9b21077147aa5.js to s3://bucket/scripts/bundle.9ad9b21077147aa5.js
upload: dist/styles/bundle.6de17660ab595a44.css to s3://bucket/styles/bundle.6de17660ab595a44.css
```
username_4: Based on community feedback, we have decided to return feature requests to GitHub issues.
username_0: @mehditlili use [rclone](github.com/ncw/rclone) instead.
username_5: Run your command twice, second time with `--delete` will delete the files after and won't re-upload the files the second time you run it. |
casbin/casbin | 446147442 | Title: DeleteUser does not remove user related permissions
Question:
username_0: Hello,
I'm trying to delete everything related to a user when it is deleted from the database. I'm using a standard rbac model.
My version of casbin is v1.8.1
I saw the method **enforcer.DeleteUser** but it seems to delete only the roles and not the permissions attached to the user. Could you explain why ?
The workaround I found was to use **enforcer.RemoveFilteredPolicy**. It works great but it should be doable with the rbac api.
Thanks !
Answers:
username_1: @username_2 do you have any opinion on this?
username_2: @username_0
Maybe it help you to understand.
See [https://casbin.org/docs/en/rbac#how-to-distinguish-role-from-user](https://casbin.org/docs/en/rbac#how-to-distinguish-role-from-user) for more details.
username_0: @username_2 Thank you for your answer.
I understand that well and I understand the source code as well. I just found it weird:
**DeleteUser** does actually the exact same thing as **DeleteRolesForUser** but shouldn't it be an alias for **DeleteRole** instead ?
username_2: @username_0
`DeleteUser()` and `DeleteRolesForUser()` is exact same, deletes a specified user from `group policy`.
`DeleteRole()` is deletes a specified role from `policy` and deletes associated user.
username_0: How do I delete everything related to a user then ? I mean when a user is removed from the database, I want every permission and every role given to this user to be removed as well
username_2: Call `GetRolesForUser()` then call `DeleteRole()`.
Status: Issue closed
username_2: @username_0 Closed as resolved. |
aminroosta/sqlite_modern_cpp | 225683473 | Title: Cannot compile because of #include <codecvt>?
Question:
username_0: gcc --version
gcc (SUSE Linux) 4.8.5
Answers:
username_1: @username_0 I recommend updating gcc.
`libstdc++`, gcc's C++ standard library, wasn't C++11 feature-complete at version 4.8.5.
@username_3 But we may want to migrate away from `<codecvt>` anyway, since it will be deprecated with C++17. Any ideas for alternatives regarding UTF-16 to UTF-8 conversion?
username_2: Thanks for this awesome library. I can see this helping me greatly in my current project, a genealogy program. I have split off parts of this project into a small library for general use.. https://github.com/username_2/easyUtils.
Here you can see how I solved the codecvt issue. Feel free to use it in whole or in part.
username_3: @username_2 Thanks for sharing easyUtils, I hope we can find something in the standard library otherwise we can your implementation as a basis.
@username_1 According to [this stackoverflow question](https://stackoverflow.com/questions/42946335/deprecated-header-codecvt-replacement) `std::codecvt` template from `<locale>` itself isn't deprecated. For `UTF-8` to `UTF-16`, there is still `std::codecvt<char16_t, char, std::mbstate_t>` specialization.
We should try it first
username_2: Take what I say as nothing more than one more opinion: your code, your rules.
I think that you should use a library, or code your own, if you want code which will be guaranteed portable now and in the future. For now codecvt works in modern compilers. Personally, I have no issues with your library regardless of how you do the conversion. That is no more than an implementation detail. As long as it compiles wherever I need it and works well, I like it.
These are the reasons that I made the decision to write my own solution.
Unicode transformation doesn't belong in \<locale\> as nothing in converting UTF from one representation to another is/should be locale dependent. It makes me wonder "What are they thinking"? The only reason that I can think of to put it there is to put it near other text handling functions which are locale dependent. ie collate True, this is not just transforming 16 bits to 8 bits. There is some bit shuffling involved. That bit shuffling is the same the world over though, and putting this in locale is somewhat scary.
My reading of http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2017/p0618r0.html doesn't make it clear that any codecvt code isn't deprecated. This https://twitter.com/StephanTLavavej/status/837822661094846465 does nothing to reassure me.
The issues cited for deprecation are security, lack of clarity in the spec and non-use. My code throws an exception on bad input, which is what security experts recommend. I have no comment on the other reasons.
Unicode conversion is a straightforward problem involving a transformation of one clearly defined type to another clearly defined type. Templating it does not really make sense. There are several combinations of to/from, but each one is different as it involves a different encoding/decoding. You would be better served with a limited set of encoders and decoders and calling these as necessary. I have implemented the ones necessary for my own use. The only reason I did this was because I couldn't find a suitable library. Honestly, I would have used codecvt had it not been deprecated, despite its other blemishes. In general I trust the STL more than my own code. After all it has been reviewed by people much more experienced and knowledgeable than I am.
Again, just my opinon.
Mike
username_1: @username_3 I replaced the deprecated stuff with the non-deprecated `std::codecvt<>` in #143. Apart from migrating away from the deprecated library, it might also fix the original issue
about compatibility with ancient gcc versions.
@username_2 [P0618r0](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2017/p0618r0.html) deprecates all of the `<codecvt>` header, but this does not include `std::codecvt<char16_t, char, std::mbstate_t>` because this is part of `<locale>`, not of `<codecvt>`.
Actually `std::codecvt<...>` can't be deprecated because it is reponsible for writing Unicode strings to files with the `<iostreams>` system.
Personally I would love to see better conversion utilitys in the standard library, but until then I think we should rely on `codecvt`.
Status: Issue closed
username_3: @username_1 Awesome ... Thank you so much 👍 |
shawnmcmahon/overlook | 916714657 | Title: Create Hotel Properties and test them
Question:
username_0: this.rooms = rooms;
this.bookings = bookings;
this.customers = customers;
this.dateRequested = ' ';
this.availableRooms = [];
this.filteredRooms = [];
this.bookingData = [];
this.selectedRoom = [];<issue_closed>
Status: Issue closed |
netlify/build-image | 294158708 | Title: Upgrade to recent yarn by default
Question:
username_0: right now you can set YARN_VERSION as desired but then you will almost certainly clash with the `--ignore-optional` we have as default to cope with problems in our current version.
When updating, make sure we do something conditional to preserve the behavior of older builds pinned at yarn 0.18.1
Answers:
username_0: wow, this happened a couple days ago almost by accident. There's some additional work to do around here: https://www.netlify.com/docs/build-gotchas/#yarn - we need to not set --ignore-optional by default for yarn >1.3.2 (Support has seen dozens of cases of this breaking builds - some new, some upgraded from our old default). But that work needs to be in a different repo, so closing and moving there.
Status: Issue closed
username_1: I think there is still work to be done here: https://github.com/netlify/build-image/blob/master/Dockerfile#L163
Status: Issue closed
|
fossasia/susi_linux | 335210692 | Title: To move the user authentication code to a different file
Question:
username_0: **Actual Behaviour**
Right now the user is authenticated and the device is registered through the `config-generator.py` script. At that moment, no internet connection would be available since the speaker would be in wap mode.
**Expected Behaviour**
To move it to a script which will run when there is access to the internet
**Would you like to work on the issue?**
Yes<issue_closed>
Status: Issue closed |
dotnet/sdk | 977014274 | Title: Unable to reference Net5.0 C# project from Net5.0 C++ project
Question:
username_0: I have C# library which is targeting *net5.0*. This is referenced by a C++ project where the *TargetFrameworkVersion* property is set to "5.0*. Unfortunately this results in this error
`2>C:\Program Files\Microsoft Visual Studio\2022\Preview\MSBuild\Current\Bin\amd64\Microsoft.Common.CurrentVersion.targets(1806,5): error : Project '..\cslib\cslib.csproj' targets 'net5.0'. It cannot be referenced by a project that targets '.NETFramework,Version=v5.0'.`
This occurs regardless of whether *PlatformToolset* is at *v142* or *v143* (VS2020 preview)
Is there a workaround for this or do we just have to wait for the tools to catch up?
Answers:
username_1: I don't think 5.0* is a valid string. It would be either
<html>
<body>
<!--StartFragment-->
TFM | Compatible with
-- | --
net5.0 | net1..4 (with NU1701 warning)netcoreapp1..3.1 (warning when WinForms or WPF is referenced)netstandard1..2.1
net5.0-windows | netcoreapp1..3.1 (plus everything else inherited from net5.0)
<!--EndFragment-->
</body>
</html>
https://docs.microsoft.com/en-us/dotnet/standard/frameworks#net-5-os-specific-tfms
username_0: @username_1 *vcxproj* files use the *TargetFrameworkVersion* element (not *TargetFramework*) and don't recognise those identifiers. You get this kind of error for example....

I suppose it's possible that C++ projects don't yet support .net5 and that the "5.0" identifier is actually resolving to 4.7.2.
username_2: If you want to target .NET 5 and set `<TargetFrameworkVersion>5.0</TargetFrameworkVersion>`, I think you need to set `<TargetFrameworkIdentifier>.NETCoreApp</TargetFrameworkIdentifier>` as well. This is what [Microsoft.NET.TargetFrameworkInference.targets](https://github.com/dotnet/sdk/blob/b87df7565f0fa4b4eb7f3da747358b88a8dbc0da/src/Tasks/Microsoft.NET.Build.Tasks/targets/Microsoft.NET.TargetFrameworkInference.targets#L49-L56) would infer from `<TargetFramework>net5.0</TargetFramework>`. I don't know whether the C++/CLI or C++/CX build system supports that, though.
username_0: Thanks @username_2 - that's a great suggestion. Alas, that results in this build error:
`Microsoft.Common.CurrentVersion.targets(1217,5): error MSB3644: The reference assemblies for .NETCoreApp,Version=v5.0 were not found.`
(Note, I can build *other* .net5 projects on this machine so confident the appropriate SDKS are present)
username_2: The next step could be to collect more detailed MSBuild logs from C++ and C# projects and compare the input parameters of the GetReferenceAssemblyPaths task. |
Pushwoosh/pushwoosh-appcelerator-titanium | 239754785 | Title: [iOS] Rich Notifications
Question:
username_0: Hello,
how to configure app for receive Rich Notifications?
by default my app doesn't show image in push notification.
Answers:
username_1: Hi,
Am I correct that you talk about iOS 10 Rich notifications?
If so, this functionality is not yet available out of the box. Since Titanium does not save a native project after building, however still creates it during the process, it is theoretically possible to modify your native code to make media attachments work.
The detailed guide on the integration process (a native one) can be found here:
http://docs.pushwoosh.com/docs/ios-10-rich-notifications-integration
You can access an XCode project as described [in this StackOverflow thread](https://stackoverflow.com/a/35261140/5408632).
Status: Issue closed
username_0: Thanks! |
kousen/Advanced_Java | 898253322 | Title: 🚨 Potential Improper Access Control
Question:
username_0: 👋 Hello, @kousen - a potential high severity Improper Access Control vulnerability in your repository has been disclosed to us.
#### Next Steps
1️⃣ Visit **https://huntr.dev/bounties/1-other-kousen/Advanced_Java** for more advisory information.
2️⃣ **[Sign-up](https://huntr.dev/)** to validate or speak to the researcher for more assistance.
3️⃣ Propose a patch or outsource it to our community - whoever fixes it gets paid.
---
#### Confused or need more help?
- Join us on our **[Discord](https://huntr.dev/discord)** and a member of our team will be happy to help! 🤗
- Speak to a member of our team: @JamieSlome
---
*This issue was automatically generated by [huntr.dev](https://huntr.dev) - a bug bounty board for securing open source code.* |
esphome/issues | 428783543 | Title: Error while toggle switch on remote device Teckin Sp22
Question:
username_0: Operating environment/Installation (Hass.io/Docker/pip/etc.):
HassIO running on Docker, ESPHome addon running in HassIO
ESP (ESP32/ESP8266, Board/Sonoff):
Teckin SP22 switch, ESP8266, running ESPHome v 1.11.2
Affected component:
https://esphome.io/guides/getting_started_hassio.html
Description of problem:
i have two teckin sp22 power plug (named p1 and p2). if i push the button on plug p1 i want that on plug p2 the power switch shuld toggle on/off.
this doesent work:
on_press:
then:
switch.toggle: p2_Relay
Couldn't find ID 'p2_Relay'
if i try this with the local device button it works.
Problem-relevant YAML-configuration entries:
substitutions:
plug_name: p1
Higher value gives lower watt readout
current_res: "0.00182"
Lower value gives lower voltage readout
voltage_div: "788"
esphome:
name: ${plug_name}
platform: ESP8266
board: esp8285
wifi:
ssid: 'myssid'
password: '********'
Enable logging
logger:
Enable Web server
web_server:
port: 80
Enable Home Assistant API
api:
password: '*********'
ota:
password: '********'
time:
platform: homeassistant
id: homeassistant_time
binary_sensor:
platform: gpio
[Truncated]
id: "${plug_name}_Wattage"
change_mode_every: 8
update_interval: 10s
platform: total_daily_energy
name: "${plug_name}_Total Daily Energy"
power_id: "${plug_name}_Wattage"
filters:
# Multiplication factor from W to kW is 0.001
- multiply: 0.001
unit_of_measurement: kWh
Extra sensor to keep track of plug uptime
platform: uptime
name: ${plug_name}_Uptime Sensor
Traceback (if applicable):
Additional information and things you've tried: |
mattlewis92/angular-calendar | 238659566 | Title: Day view event alignment
Question:
username_0: <!---
FAQ:
Problems with build tooling? Please check the examples folder first: https://github.com/username_1/angular-calendar/tree/master/build-tool-examples
Styling not appearing? Make sure you're including node_modules/angular-calendar/dist/css/angular-calendar.css
Need an example of how to do something? Check the demo page, it probably has you covered: https://username_1.github.io/angular-calendar/demos/
Need a full list of all API options? Check the docs for each component:
https://username_1.github.io/angular-calendar/docs/components/CalendarMonthViewComponent.html
https://username_1.github.io/angular-calendar/docs/components/CalendarWeekViewComponent.html
https://username_1.github.io/angular-calendar/docs/components/CalendarDayViewComponent.html
Please note that issues that ignore this template will be closed without notice!
-->
### Bug description / Feature request:
The events are misaligned with the time in the day view (See below)

I made a repo since I couldn't reproduce the problem on plunkr
### Versions
Angular: 4.0.0
Calendar library: 0.18.1
Browser name and version: Chrome 58.0.3029.110 (64-bit) / Windows 10
Status: Issue closed
Answers:
username_1: Ah it seems like the issue is because you're not using bootstrap, somewhere its document normalising ensures that each segment is 30px in height which is what the algorithm assumes is each segments height when positioning events. I've just released 0.18.2 with a hacky fix which should solve it for you. Hope that helps! 😄
username_0: Ah, thats why I didn't noticed earlier.
I just migrated from Bootstrap to Material. The new version worked like a charm !
Thanks for the blazing fast responde ! 😄
username_1: Np, happy to help! 😀 |
Azure/azure-sdk-for-java | 939568581 | Title: How to query data from graph cosmos DB using gremlin query in case insensitive manner?
Question:
username_0: How to query data from graph cosmos DB using gremlin query in case insensitive manner?
How can we implement the toUppercase or toLowercase operation to fetch data from the graph db?
Answers:
username_1: @username_2 @yiliuTo could you please follow up on @username_0's question?
username_0: Could you share the work around, if there is any? |
Azure/Azure-Sentinel | 1002109524 | Title: Azure AD Sign-in logs' Sign-ins by Location not working for large amounts of data
Question:
username_0: **Describe the bug**
The Sign-ins by Location query looks fine to me, it works when I run it separately in a LAW, but for some reason it's not working correctly in the workbook. All other queries are working correctly.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'Azure AD Sign-in logs'
2. Have almost 1M sign-ins
3. Scroll down to 'Sign-ins by Location'
4. See error
**Expected behavior**
Correct values as shown in LAW
**Screenshots**

Answers:
username_1: @nazang - Is it possible to please look into this? Thanks.
username_0: Seeing this same problem across multiple (10+) workspaces
 |
foerstner-lab/gffpandas | 481029846 | Title: error in documentation
Question:
username_0: * pandasgff version:
* Python version:
* Operating System:
### Description
In https://gffpandas.readthedocs.io/en/latest/background.html there is a link to a local file
'How to use gffpandas'. It links to file:///home/vivian/gffPandas/gffpandas/docs/build/html/tutorial.html
Status: Issue closed
Answers:
username_1: Many thanks and sorry for the late response. It is solved now. |
eclipsesource/papyrus-seqd | 318617532 | Title: [Model Explorer Edition:012]: Delete Combined Fragments
Question:
username_0: It SHALL be possible to delete a combined fragment from the project explorer. Its content and any related fragments and elements SHALL be deleted also.
The fragment order may need to be recalculated and the diagram will need to be reconciled. |
osoc16/mijn-viaa | 166310998 | Title: logout button
Answers:
username_1: go to url `/logout`
username_1: Backend needs to redirect to idp's logout link
Status: Issue closed
username_1: - [ ] frontend
- [ ] first AJAX call to `https://idp-qas.viaa.be/module.php/core/authenticate.php?as=viaa-ldap&logout`
- [ ] after successful ajax call: get `/logout`
- [ ] spinner while waiting to logout?
- [x] backend
username_2: 
username_2: @brechtvdv
username_1: Backend can do the whole logout process aparently:
http://stackoverflow.com/questions/25271072/logging-out-using-passport-saml-req-logout-or-strategy-logout-or-both
So only a `/logout` redirect is needed.
username_2: redirecting to /logout now but it's just a href, not a link |
Alluxio/alluxio | 725850665 | Title: Alluxio master failed to start sometimes after stopping and restart
Question:
username_0: io.netty.handler.codec.http2.Http2Exception$StreamException: Received DATA frame for an unknown stream 377
at io.netty.handler.codec.http2.Http2Exception.streamError(Http2Exception.java:147)
at io.netty.handler.codec.http2.DefaultHttp2ConnectionDecoder$FrameReadListener.shouldIgnoreHeadersOrDataFrame(DefaultHttp2ConnectionDecoder.java:596)
at io.netty.handler.codec.http2.DefaultHttp2ConnectionDecoder$FrameReadListener.onDataRead(DefaultHttp2ConnectionDecoder.java:239)
at io.netty.handler.codec.http2.Http2InboundFrameLogger$1.onDataRead(Http2InboundFrameLogger.java:48)
at io.netty.handler.codec.http2.DefaultHttp2FrameReader.readDataFrame(DefaultHttp2FrameReader.java:422)
at io.netty.handler.codec.http2.DefaultHttp2FrameReader.processPayloadState(DefaultHttp2FrameReader.java:251)
at io.netty.handler.codec.http2.DefaultHttp2FrameReader.readFrame(DefaultHttp2FrameReader.java:160)
at io.netty.handler.codec.http2.Http2InboundFrameLogger.readFrame(Http2InboundFrameLogger.java:41)
at io.netty.handler.codec.http2.DefaultHttp2ConnectionDecoder.decodeFrame(DefaultHttp2ConnectionDecoder.java:174)
at io.netty.handler.codec.http2.Http2ConnectionHandler$FrameDecoder.decode(Http2ConnectionHandler.java:378)
at io.netty.handler.codec.http2.Http2ConnectionHandler.decode(Http2ConnectionHandler.java:438)
at io.netty.handler.codec.ByteToMessageDecoder.decodeRemovalReentryProtection(ByteToMessageDecoder.java:501)
at io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:440)
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:276)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:379)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:365)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:357)
at io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1410)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:379)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:365)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:919)
at io.netty.channel.epoll.AbstractEpollStreamChannel$EpollStreamUnsafe.epollInReady(AbstractEpollStreamChannel.java:792)
at io.netty.channel.epoll.EpollEventLoop.processReady(EpollEventLoop.java:475)
at io.netty.channel.epoll.EpollEventLoop.run(EpollEventLoop.java:378)
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:989)
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.base/java.lang.Thread.run(Thread.java:834)
<<< EOF
**To Reproduce**
1. Stop the master
2. Try to restart
**Expected behavior**
1. The Master should be able to start with the last checkpoint. If it failed due to some issues at least it should start from
backup.
2. It should give a proper error so that will be able to understand why it's failing to start.
**Urgency**
All alluxio data is getting loose whenever we restart the master.
[logs_start.tar.gz](https://github.com/Alluxio/alluxio/files/5410832/logs_start.tar.gz)
**Additional context**
Attaching the master log when I try to restart.
[logs_start.tar.gz](https://github.com/Alluxio/alluxio/files/5410839/logs_start.tar.gz)
[start with backup master.log](https://github.com/Alluxio/alluxio/files/5410843/master.log)
[start with backup master.out](https://github.com/Alluxio/alluxio/files/5410854/master_out.log)
Answers:
username_1: @username_2 do you have any idea about this issue?
username_2: @username_3 FYI
username_0: any thought around this as I am not able to use backup and every time my master down I have to format it.
username_3: @username_0 The logs indicate there are some journal flushing issues. Do you mind sharing your Alluxio cluster site property file?
username_0: This is my alluxio-site.properties
alluxio.master.mount.table.root.ufs=s3://bounce-alluxio/
alluxio.user.file.metadata.sync.interval=30m
alluxio.worker.network.async.cache.manager.threads.max=10
alluxio.worker.tieredstore.levels=2
alluxio.worker.tieredstore.level0.alias=MEM
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
alluxio.worker.tieredstore.level0.dirs.mediumtype=MEM
alluxio.worker.tieredstore.level0.dirs.quota=32GB
alluxio.worker.tieredstore.level1.alias=SSD
alluxio.worker.tieredstore.level1.dirs.path=/alluxio_data
alluxio.worker.tieredstore.level0.dirs.mediumtype=SSD
alluxio.worker.tieredstore.level1.dirs.quota=400GB
alluxio.worker.network.max.inbound.message.size=320MB
alluxio.user.metrics.collection.enabled=true
alluxio.underfs.s3.directory.suffix=_$folder$
alluxio.master.journal.type=EMBEDDED
alluxio.master.daily.backup.enabled=true
alluxio.master.daily.backup.time=18:05
alluxio.user.streaming.data.timeout=90sec
username_2: @username_0 Thanks for reporting the issue. There are two issues reported in your ticket,
1. Failed to start after stopping
2. Failed to start with backup.
I took a look at the first issue, there is no obvious error exist in the master.log, but master do takes longer than expected to start
```
2020-10-20 17:15:57,450 INFO RaftJournalSystem - Initializing Raft Journal System
2020-10-20 17:15:57 to 17:16:13 Reading local copycat segment files
2020-10-20 17:16:13,680 INFO AbstractPrimarySelector - Primary selector transitioning to SECONDARY
2020-10-20 17:16:14,567 INFO JournalUtils - Reading journal entries
2020-10-20 17:16:15,314 INFO Database - Adding new table ...
2020-10-20 17:16:14 to 16:59 Adding and Updating database tables
2020-10-20 17:17:03,100 INFO AbstractPrimarySelector - Primary selector transitioning to PRIMARY
2020-10-20 17:17:03,108 INFO AlluxioMasterProcess - All masters started
2020-10-20 17:17:08 to 2020-10-20 17:19:31 Database - Updating table ...
2020-10-20 17:19:31,082 INFO RaftJournalSystem - Performing catchup. Last applied SN: 9920755. Catchup ID: -3286135040307079950
2020-10-20 17:19:32,090 Caught up RaftJournalSystem - Caught up in 1008ms. Last sequence number from
2020-10-20 17:19:32,094 INFO RaftJournalSystem - Shutting down raft journal
2020-10-20 17:19:32,127 INFO RaftJournalSystem - Journal shutdown complete
```
The master takes 3.5mins to start which is longer than what `alluxio-start.sh master` tracks, that's why you saw the error log that master is not serving. After master starts, it immediately being killed maybe by `alluxio-stop.sh master`.
@username_0 I noticed that the master takes a lot of time to updating database tables, are you using Alluxio catalog service and have many tables and/or partitions?
Will continue looking into the second issue.
username_2: For the failed to start from backup, I guess it takes way too long to restore from backup as well, from the logs, i saw
```
.....
2020-10-20 17:37:27,609 INFO BackupManager - 1854417 entries from backup applied so far...
2020-10-20 17:37:44,696 INFO AbstractMaster - TableMaster: Stopped secondary master.
2020-10-20 17:37:44,697 INFO AbstractMaster - MetaMaster: Stopped secondary master.
2020-10-20 17:37:44,697 INFO AbstractMaster - FileSystemMaster: Stopped secondary master.
start with backup master.log
2020-10-20 17:37:44,700 INFO RaftJournalSystem - Shutting down raft journal
2020-10-20 17:37:44,703 INFO RaftJournalWriter - Closing journal writer. Last sequence numbers written/submitted/committed: 1854416/1854416/1854130
2020-10-20 17:37:45,128 ERROR ProcessUtils - Uncaught exception while running Alluxio master @172.20.6.164:19998, stopping it and exiting. Exception "java.lang.RuntimeException: alluxio.exception.status.UnavailableException: Failed to complete request: Cannot flush. Journal writer has been closed", Root Cause "alluxio.exception.JournalClosedException: Cannot flush. Journal writer has been closed"
```
Could be restoring from backup takes unexpected long and then users think the master failed to start and killed it (so that rat journal gets shutting down).
username_2: The unexpected long time to start a master with journal/backup may come from the heavy usage of catalog service.
FYI @username_1 @gpang
username_2: The current version is Alluxio-2.4.0-SNAPSHOT, is the version before merging Ratis back to master branch. so the cluster is running with original Copycat embedded journal.
username_0: Thanks, @username_2 for looking at the issue.
1. are you using Alluxio catalog service and have many tables and/or partitions?
yes, I am using an alluxio catalog and I have around 300 tables with each table contains many partitions.
2. So is this expected behavior if the master is taking a long time to start it will throw an error and get killed ?
3. What is the solution to make this work. Is there any timeout that I can increase?
username_2: For the second question: If the master is taking a long time to start, the master process will not be killed (as I know), but the `alluxio-start.sh` command will error out since it's not able to check master serving in the given timeout.
I would say try to wait for the master to come up, let the master process running for like 5-10 minutes and see if the master is able to serve requests after that time.
username_0: @username_2 I do not see master process is running so it means it getting killed or not even started
username_2: For the `logs_start.tar.gz`, looks like master process should be able to come up after an unexpected long time (like 5-10mins), but user kill the process.
For the given `start with backup master.log`, the master does error out with
```
2020-10-20 17:37:44,700 INFO RaftJournalSystem - Shutting down raft journal
2020-10-20 17:37:44,703 INFO RaftJournalWriter - Closing journal writer. Last sequence numbers written/submitted/committed: 1854416/1854416/1854130
2020-10-20 17:37:45,128 ERROR ProcessUtils - Uncaught exception while running Alluxio master @172.20.6.164:19998, stopping it and exiting. Exception "java.lang.RuntimeException: alluxio.exception.status.UnavailableException: Failed to complete request: Cannot flush. Journal writer has been closed", Root Cause "alluxio.exception.JournalClosedException: Cannot flush. Journal writer has been closed"
java.lang.RuntimeException: alluxio.exception.status.UnavailableException: Failed to complete request: Cannot flush. Journal writer has been closed
at alluxio.master.AlluxioMasterProcess.startMasters(AlluxioMasterProcess.java:219)
at alluxio.master.FaultTolerantAlluxioMasterProcess.gainPrimacy(FaultTolerantAlluxioMasterProcess.java:127)
at alluxio.master.FaultTolerantAlluxioMasterProcess.start(FaultTolerantAlluxioMasterProcess.java:90)
at alluxio.ProcessUtils.run(ProcessUtils.java:36)
at alluxio.master.AlluxioMaster.main(AlluxioMaster.java:55)
Caused by: alluxio.exception.status.UnavailableException: Failed to complete request: Cannot flush. Journal writer has been closed
at alluxio.master.journal.MasterJournalContext.waitForJournalFlush(MasterJournalContext.java:80)
at alluxio.master.journal.MasterJournalContext.close(MasterJournalContext.java:91)
at alluxio.master.journal.StateChangeJournalContext.close(StateChangeJournalContext.java:53)
at alluxio.master.BackupManager.lambda$initFromBackup$8(BackupManager.java:293)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
Caused by: alluxio.exception.JournalClosedException: Cannot flush. Journal writer has been closed
at alluxio.master.journal.raft.RaftJournalWriter.flush(RaftJournalWriter.java:84)
at alluxio.master.journal.AsyncJournalWriter.doFlush(AsyncJournalWriter.java:295)
... 1 more
2020-10-20 17:37:54,731 INFO RaftJournalSystem - Journal shutdown complete
2020-10-20 17:37:54,731 ERROR ProcessUtils - Uncaught exception while stopping Alluxio master @172.20.6.164:19998, simply exiting. Exception "java.lang.IllegalStateException: Journal is not running", Root Cause "java.lang.IllegalStateException: Journal is not running"
java.lang.IllegalStateException: Journal is not running
at com.google.common.base.Preconditions.checkState(Preconditions.java:508)
at alluxio.master.journal.AbstractJournalSystem.stop(AbstractJournalSystem.java:56)
at alluxio.master.AlluxioMasterProcess.stop(AlluxioMasterProcess.java:170)
at alluxio.master.FaultTolerantAlluxioMasterProcess.stop(FaultTolerantAlluxioMasterProcess.java:175)
at alluxio.ProcessUtils.run(ProcessUtils.java:43)
at alluxio.master.AlluxioMaster.main(AlluxioMaster.java:55)
2020-10-20 17:37:54,731 DEBUG NettyClientHandler - [id: 0xd1a31255
```
username_2: @username_0 Contacted you via Alluxio community slack, please take a look! Thanks
username_4: @username_2 is issue here related to embedded journal? If yes, we will aim to fix it in the next release
username_2: @username_4 It's a joint effort from catalog service + restoring from backup (may related to journaling). I think we should get it fix or at least understand what's happening
username_2: PR #12649 helps Alluxio log the correct Ratis error that helps to debug the related journal issues.
PR #12650 expose Ratis journal size related configuration to Alluxio configuration and enlarge those values to support journaling entries larger than 3MB. Note that this is mainly helping the Ratis journal write path. Ratis journal read path has a hard limit of 30MB per entry.
PR #12658 change from logging a table with all its partitions to logging a table entry and multiple partitions entries based on alluxio.table.journal.partitions.chunk.size (=500 by default, a single entry only contains up to 500 partitions). In the future, Journal restore or restart will not be crashed by large table entries anymore.
PR #12695 helps resolve or prevents unexpected large journal entries coming from other places of Alluxio by flushing journal entries bigger than `MASTER_EMBEDDED_JOURNAL_ENTRY_SIZE_MAX / 3` and log error when journal entries bigger than the `MASTER_EMBEDDED_JOURNAL_ENTRY_SIZE_MAX`.
@username_0 Could you help validate if the above fixes solve the issue? We have done some testing on our side but may not be similar to your actual environment. Thanks! |
Wei-1/Scala-Machine-Learning | 263627114 | Title: Neural Turing Machine
Question:
username_0: - [ ] Neural Turing Machine
Answers:
username_0: Will test the algorithm independently here: https://github.com/username_0/Scala-NTM
Before merging into this repository.
username_0: NTM code in a separate repo: https://github.com/username_0/Scala-NTM
Doc status in bb40740
Status: Issue closed
|
microsoftgraph/microsoft-graph-explorer | 554824935 | Title: Hitting enter on the preview explorer doesn't execute the request
Question:
username_0: ### Expected behavior
Request to be executed and result to be displayed.
### Actual behavior
Nothing happens.
### Steps to reproduce the behavior
1. Navigate to the Graph Explorer preview (toggle the button)
1. Sign-in
1. Click on the address-bar (next to the version selector)
1. Hit the [enter] key
Answers:
username_1: @username_0 Thanks for reporting this, we worked on it should be available in our next release but you can test it in our test environment.
Status: Issue closed
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.