
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
spatie/laravel-medialibrary | 322532418 | Title: return default file, if there is none
Question:
username_0: Hi,
Is it possible to return a default file (an image for example), if the media collection is empty?
I have a model with following config:
```php
public function registerMediaCollections()
{
$this->addMediaCollection('image')
->singleFile()
->registerMediaConversions(function (Media $media) {
$this->addMediaConversion('resized')
->fit(Manipulations::FIT_FILL, 256, 256)
->background('white')
->nonQueued();
});
}
```
and I access the image with following code:
```php
$model->getFirstMediaUrl('image', 'resized');
```
Works great.
I was thinking about a way to return a default image when there is no image in the collection.
It's quite useful, for example when you use a seeder and don't mind to seed the images, or when you have a model where the image is required for your html template but you don't want to force the user to upload its own.
I know I can manually check and use a default one with:
```php
$model->getFirstMediaUrl('image', 'resized') ?? asset('path/to/img');
```
But I was thinking about a better way, like defining a default file in `registerMediaCollections` method.
Answers:
username_1: Sounds like a solid request! Feel free to send a PR that implements this.
The fallback should be some sort of `Media` null object, could be tricky to pull through but we'll see what it looks like when implemented.
username_0: I've got an idea about how this could be implemented:
We set the default file for each collection (or maybe for each conversion as well) like this:
```PHP
public function registerMediaCollections()
{
$this->addMediaCollection('image')
->singleFile()
->defaultFile('path/to/file/which/will/be/returned/as/it/is')
// This library won't touch the default file, it just get a file name
// as string and return it exactly as it is
// It doesn't care about file type, or if it exists or not
// ->defaultFile('images/user/default.png')
->registerMediaConversions(function (Media $media) {
$this->addMediaConversion('resized')
->fit(Manipulations::FIT_FILL, 256, 256)
->background('white')
->nonQueued();
});
}
```
Then there will be a new set of methods to retrieve file:
`->getMediaOrDefault()`
`->getFirstOrDefaultMedia()`
`->getFirstOrDefaultMediaUrl()`
So, we can use this methods in our frontend code to get the media (or the default one if there is none), and we can continue to use current methods (`getMedia`, `getFirstMedia`, `getFirstMediaUrl`) in our admin panel because we don't need the default file in there.
I know it's not complete and can get better, just wanted to start.
username_1: Maybe we should stick with URL's and paths instead of actual default media.
```php
$this
->addMediaCollection('image')
->defaultUrl('/url/to/image.jpg')
->defaultPath('/path/to/image.jpg');
```
I don't know, we could return a dummy `Media` object but that sounds complicated. Pinging @username_2
I'd rather not add to the public API for this, if you're setting a default, it should be used in the existing methods.
username_2: I'd also steer away from dummy media, that could become complicated real fast.
What @username_1 suggests I his code example seem pretty good. I'd slightly rename the methods
```php
$this
->addMediaCollection('image')
->withFallbackUrl('/url/to/image.jpg')
->withFallbackPath('/path/to/image.jpg');
```
username_0: Sounds cool.
There is only one more thing that should be considered.
There should be a way to tell whenever you want the fallback to be returned if there is no media. It shouldn't be the default behavior and even if it is, there should be a way to change it, something like:
```
$model->getMediaWithFallback()
$model->getFirstMediaWithFallback()
$model->getFirstMediaUrlWithFallback()
```
username_2: I don't want to add new methods on the model for now. Users can easily do that in their own app.
Let's start with adding `withFallbackUrl` and `withFallbackPath`.
username_0: OK, looking forward to it.
username_0: For anyone looking here for a [temporary] solution, add this method to your model (or use it as a trait):
```PHP
public function getFirstOrDefaultMediaUrl(string $collectionName = 'default', string $conversionName = ''): string
{
$url = $this->getFirstMediaUrl($collectionName, $conversionName);
return $url ? $url : $this::$defaultImage ?? '';
}
```
And define a static property inside your model (You can skip this if you don't mind have a default image):
```PHP
protected static $defaultImage = '/images/default/event.png';
```
And access the first media url, or the default one as simple as:
```PHP
$model->getFirstOrDefaultMediaUrl('collection');
```
username_2: Closing this issue for now, we'll continue the conversation in the PR you'll potentially submit.
Status: Issue closed
|
bokeh/bokeh | 109697090 | Title: Feature request: Constrain zoom out to fixed range/domain
Question:
username_0: On Twitter @username_2 asked about being able to constrain the zoom tool to within a fixed range/domain on a plot. It sounds like a reasonable feature to me.
Answers:
username_1: I was just looking at #1450 which asks for some similar improvements.
username_1: Are these constraints a feature on a the WheelZoomTool or on the axis?
username_0: I'd imagine it'd be on the zoom tool where the python spelling would be like:
```python
from bokeh.models import WheelZoomTool
wheelzoom = WheelZoomTool(x_range=(0,100), y_range(0,100))
### or
wheelzoom = WheelZoomTool(x_min=0, x_max=100, y_min=0, y_max=100)
```
Then on the BokehJS side, you just kill the zoom event if you're at the limit of the zoom range.
username_2: Folks! really glad to see this being discussed. Wonder if in the absence of constraints on the zoom the a fraction of the bounding box extent could be used to infer max/min zoom.
username_3: +1 this would be pretty useful. Too easy to zoom/scroll away from the plot entirely, or zoom in crazy far. Thanks for thinking about it.
username_0: A PR was recently merged to the BoxZoomTool where the zoom was killed if the zoom box was smaller than 5 pixels in height/width - assuming the user didn't intend the zoom and tried to "close" the box. I think it is a fairly opinionated feature, but feels very natural in terms of UX.
I'm becoming convinced that @username_2 's recommendation of adding zoom constraints based on the data ranges (perhaps a 1x data range buffer around the default range) would be a beneficial feature.
I can't immediately think of a use case where zooming way beyond the plot data is valuable to the user.
To make this optional, we could add a zoom/pan_limit bool flag to the plotObject to make this optional.
It is kind of a big change. @username_5 @username_4 Do either you of have feedback on adding a scroll constraint in terms of UX and cases where it'd be a problem?
also ref issue #2427, #2565,
username_1: Would this proposal have any effect on the limits of the PanZoomTool? If this does turn out to be a big change, is this the place to introduce aspect ratio on the zooming too?
username_4: I'm glad there is discussion on this we should implement some solution soon. Just so that it is on the radar: the complicating case is when there are multiple ranges.
>
username_2: @username_4 Also really glad to see this being discussed! What about just using a factor of the maximum range in both x and y?
username_5: For me, if you're data is updating based on your ranges e.g. in a map or
in any kind of remote data source, then you definitely want to zoom
outside the current plot data.
Having said that having optional/configurable constraints would be super
helpful.
To my mind its particularly helpful when you are zooming out beyond plot
data that you can't see yet (because it needs to load from a server) as
it constrains that action appropriately when the user has no other
option for feedback.
username_6: +1 on the ability to limit zoom. Accidentally zooming way out can be disorienting to the user.
username_5: I'm currently working on this.
username_3: Thanks Sarah! :) That's great to hear. :)
Status: Issue closed
username_2: This is excellent! |
facebook/infer | 267314800 | Title: infer-capture doesn't like compile_commands.json that uses "arguments" key
Question:
username_0: Some tools, notably https://github.com/rizsotto/scan-build (a Python reimplementation of Clang's `scan-build` command) produces JSON files like the example below that includes `arguments`.
`infer capture` fails on such input files because `parse_json` doesn't know about `arguments`: https://github.com/facebook/infer/blob/3df1e52928b966582445f9a51e32bf22543111d1/infer/src/integration/CompilationDatabase.ml#L57-L82
Sample run:
```
$ infer capture --debug --compilation-database ~/work/mono/compile_commands.json
Capturing using compilation database...
Uncaught exception:
(Failure "Json file doesn't have the expected format")
Raised at file "pervasives.ml", line 32, characters 17-33
Called from file "integration/CompilationDatabase.ml" (inlined), line 49, characters 4-59
Called from file "integration/CompilationDatabase.ml", line 76, characters 20-40
Called from file "list.ml", line 77, characters 12-15
Called from file "list.ml", line 77, characters 12-15
Called from file "src/core_list0.ml" (inlined), line 405, characters 16-30
Called from file "integration/CompilationDatabase.ml", line 87, characters 2-50
Called from file "backend/infer.ml", line 234, characters 29-73
Called from file "backend/infer.ml", line 510, characters 2-21
Called from file "backend/infer.ml", line 566, characters 32-45
```
This is using a version of `infer` from Homebrew:
```
$ infer --version
Infer version v0.12.1
Copyright 2009 - present Facebook. All Rights Reserved.
```
Example `compile_commands.json`:
```json
[
{
"arguments": [
"cc",
"-c",
"-DHAVE_CONFIG_H",
"-I.",
"-I../..",
"-I../..",
"-I../../mono",
"-I../../libgc/include",
"-I../../mono/eglib",
"-I../../mono/eglib",
"-fvisibility=hidden",
"-D_THREAD_SAFE",
"-DGC_MACOSX_THREADS",
"-DUSE_MMAP",
"-DUSE_MUNMAP",
"-g",
"-Wall",
"-Wunused",
"-Wmissing-prototypes",
"-Wmissing-declarations",
"-Wstrict-prototypes",
[Truncated]
"-Wno-attributes",
"-Wno-format-zero-length",
"-Qunused-arguments",
"-Wno-unused-function",
"-Wno-tautological-compare",
"-Wno-parentheses-equality",
"-Wno-self-assign",
"-Wno-return-stack-address",
"-Wno-constant-logical-operand",
"-Wno-zero-length-array",
"-Werror-implicit-function-declaration",
"-o",
"libmonoruntimesgen_la-opcodes.o",
"opcodes.c"
],
"directory": "/Users/user/mono/mono/metadata",
"file": "opcodes.c"
}
]
```
Answers:
username_1: Thanks for the report. It would make sense to support `"arguments"` too. |
AtomLinter/linter-php | 119082021 | Title: [Feature Request] Support Laravel Blade
Question:
username_0: Is it feasible to include Laravel Blade support in the php linter or would that be better off in a own project?
Answers:
username_1: Are Laravel Blade templates valid for _plain_ PHP? This linter simply runs `php -l` on the files...
username_0: Nope but you can use vanilla php inside .blade files
Status: Issue closed
username_1: That would be better off for its own project then as you would have to implement (or use) some parser to split out the PHP code from the rest of the file before passing it on to `php -l`.
Feel free to clone this and plug in whatever you need to get a working version for what you are intending, and if you have any problems as in #linter on Atom's Slack instance and we will do what we can to help. |
noiseconformist/noisethoughts | 350243951 | Title: wires might be an issue!
Question:
username_0: Right - this looks like a rat's nest!

Clean that up PLS!
Status: Issue closed
Answers:
username_1: ok, we leave that for now!
username_0: will this be re-opened then?
username_1: Right - this looks like a rat's nest!
xxx
Clean that up PLS!
username_1: yes - now you can test!
username_0: testing tests!
username_0: ok, check this out! Weird, huh?
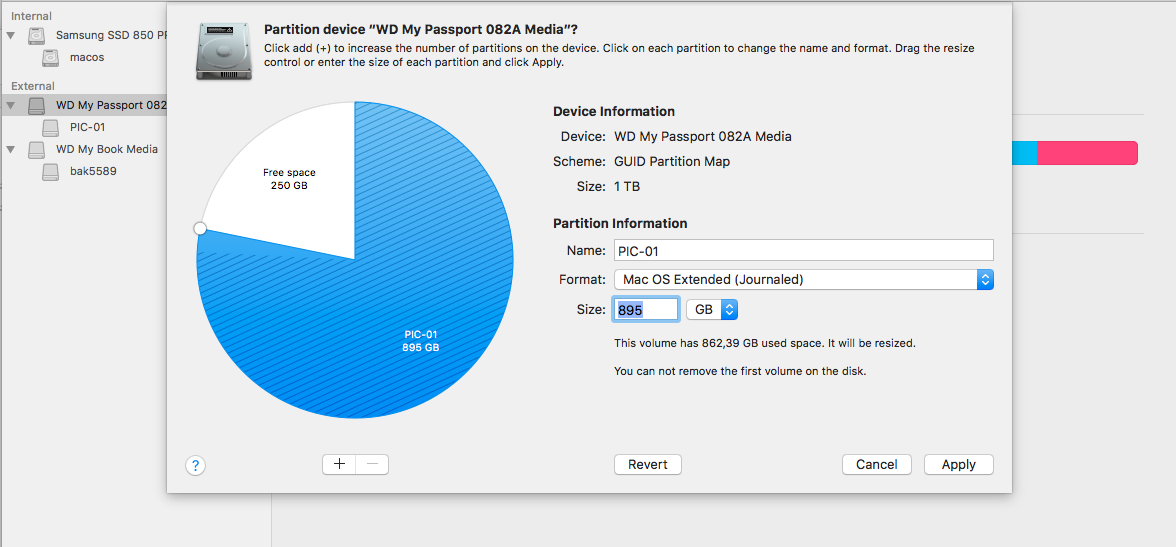
username_1: so, 895M + 250M = 1T ?? really?
username_0: looks like that ... |
jdillard/sphinx-sitemap | 333397039 | Title: Only references pages that are new or have changed since the last build
Question:
username_0: **Issue**
The builder currently doesn't access to the [saved environment](http://www.sphinx-doc.org/en/master/glossary.html#term-environment), so it can only see pages that are new or have changed since the last build, possibly leading to an incomplete sitemap.
**Work around**
To get around this you can manually clean the build directory or use the [-E flag](http://www.sphinx-doc.org/en/master/man/sphinx-build.html) to not use the saved environment and rebuild completely as part of your deployment process.
**Possible fix**
The saved environment is pickled after the parsing stage, so accessing it may make it possible to always produce a full sitemap. |
ubports/ubuntu-touch | 454594158 | Title: Blank OSK on the lock screen
Question:
username_0: - Device: BQ E4.5 (krillin)
- Channel: edge
- Build: Ubuntu 16.04 (2019-06-11)
### Steps to reproduce
Boot the device, go to the lock screen
### Expected behavior
OSK shows and you can enter the PIN / Password to unlock the device
### Actual behavior
OSK is blank, so you can't type anything
### Logfiles and additional information
- maliit-server.log https://paste.ubuntu.com/p/zksFnHF34k/
- unity8.log https://paste.ubuntu.com/p/PhCbJJCFG4/
- syslog is full of this kind of messages https://paste.ubuntu.com/p/J5H2jbtngv/ (I don't know if that's relevant but just in case)
- I can unlock the screen plugging an external keyboard
Answers:
username_1: I can confirm having the same issue with today's update on Meizu MX4 (arale).
Status: Issue closed
username_2: I've updated the changelog of keyboard-component in `xenial_-_edge` and the images are rebuilding now. This should be fixed by upgrading after that is finished. https://ci.ubports.com/job/xenial-hybris-edge-rootfs-armhf/316/ |
facebook/fresco | 310711120 | Title: I want to play GIF once and manually in my RN application
Question:
username_0: ### Description
I add a GIF to my RN application as described here(https://facebook.github.io/react-native/docs/image.html#gif-and-webp-support-on-android)
I want to click on the GIF cover - the 1st image of the GIF - and than it should play only once.
once it complete the image should be the last image of the GIF.
Actual Behavior
- on Android & iOS once the screen is rendered the GIF plays, I can't control it.
- play once - on iOS the gif is played in a loop without stopping
### Reproduction
Add gif as describe in here(https://facebook.github.io/react-native/docs/image.html#gif-and-webp-support-on-android)
### Solution
### Additional Information
* Fresco version: com.facebook.fresco:animated-base-support:1.3.0
* Fresco version: com.facebook.fresco:animated-gif:1.3.0
* OS 1: Windows 8.1
* OS 2: iOS - macOS High Sierra 10.13.3
* Node: 8.9.3
* npm: 5.6.0
* react: 16.2.0
* react-native: 0.52.0
Answers:
username_1: This is something that needs to be fixed / implemented on the React Native side -- please report this issue there.
Status: Issue closed
|
everypolitician/everypolitician | 145412562 | Title: Investigate why Czechia only has 19 Groups mapped to Wikidata
Question:
username_0: `bin/wikidata_info.rb` is reporting 19 Groups matched:

But we have 57 rows in the mapping file:
```wc -l sources/manual/group_wikidata.csv
58 sources/manual/group_wikidata.csv
```
Answers:
username_0: Closed by https://github.com/everypolitician/everypolitician-data/pull/11835
Status: Issue closed
|
Drakma/VacantSky | 197501895 | Title: Unable to get Chorus Fruit
Question:
username_0: I killed the Ender Dragon a couple of times now and went through the portals to the Outer Islands where normally you can find Chorus Fruit plants, but so far I haven't found any. Is Chorus fruit supposed to spawn on the tiny island you end up on after going through the portal with the ender pearl?
I also visited a bunch of End Cities and Ships and didn't find any.
Maybe I'm missing something where to find them? Or are they nowhere to be found? |
stfc/PSyclone | 813227014 | Title: Add field access details for gokernel based on stencil/access mode declaration
Question:
username_0: ATM if a field is accessed in a gocean kernel, the variable usage analysis adds the variable with index ``[1]`` (which was done to mark that this is an array access).
When implementing better testing for loop fusion, we need additional details about the access of fields in a kernel, which we can achieve only based on the meta-data (consistency of meta-data and code is a different issue). The suggestion is to add access as follows:
- if a field ``A`` is written in a kernel, add a write-access to ``A(i,j)``. This is the basic assumption for a gokernel that there are no 'stencil writes' to a field.
- if a field ``B`` is read in a kernel, add several read access, based on the stencil information. E.g. assume the stencil is ``010,112,003``, we would then add (assuming that the first line - 010 - represents ``j-1``, if it should be ``j+1``, swap all plusses and minuses :grin:):
- ``B(i,j-1)``
- ``B(i-1,j)``
- ``B(i,j)``
- ``B(i+1,j)`` and ``B(i+2,j)``
- ``B(i+1,j+1)``, ``B(i+2,j+2)`` and ``B(i+3,j+3)``
These array accesses would represent the stencil information.
Once we have the individual accesses, we can use the same code for dependency analysis in NEMO and gocean.
@username_2, @username_1, @sergisiso - feedback please :) (anyone else as well, but I think you three are the people involved in gocean).
Answers:
username_1: Hi @username_0. Yes that logic looks right to me. I think the top row is j+1 and the bottom j-1 as we treat it as a graph with the centre being 0,0. At least, that is how I read the documentation. So please swap the j +'s and -'s as you suspected, unless @username_2 and @sergisiso say I wrong. :-)
username_2: I think @username_1 is right about the indexing and I think @username_0's suggestion as to how to interpret the meta-data to get read/write information is good.
username_0: Thanks, changing from question to improvement 👍
username_2: #1133 is merged. Can this be closed now @username_0?
username_0: Thanks a lot, @username_2
Status: Issue closed
|
MicrosoftDocs/visualstudio-docs | 849769026 | Title: Additional Step To Enable Custom Nesting
Question:
username_0: To make custom nesting work in non web projects I had to add the following to the csproj:
```
<ItemGroup>
<ProjectCapability Include="DynamicFileNesting" />
</ItemGroup>
```
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 2d25dd44-f173-dd83-3afc-d6608613d450
* Version Independent ID: e121cedc-5cbe-a399-e2a8-5d192aaea770
* Content: [File nesting rules for Solution Explorer - Visual Studio](https://docs.microsoft.com/en-us/visualstudio/ide/file-nesting-solution-explorer?view=vs-2019)
* Content Source: [docs/ide/file-nesting-solution-explorer.md](https://github.com/MicrosoftDocs/visualstudio-docs/blob/master/docs/ide/file-nesting-solution-explorer.md)
* Product: **visual-studio-windows**
* Technology: **vs-ide-general**
* GitHub Login: @username_1
* Microsoft Alias: **angelpe**
Answers:
username_1: How can I help?
username_2: I think what he asks is that should be mentioned in the Docs. Appropriate section that this could be added in the .NET SDK (w.r.t. `Microsoft.NET.Sdk`) pages |
domasmas/esf | 211992792 | Title: Improve esf.Website gulp build
Question:
username_0: - fix release file references in Index.cshtml
- move non-system.js js files to system.js configuration and reference them from the main module
- remove unnecesary dependency jquery
- make sure release build is independent from dev build
- exclude building thrird party libaries from dev build
- clean wwwroot folder on invoking MsBuild clean on Esf.Website<issue_closed>
Status: Issue closed |
bevyengine/bevy | 796957575 | Title: Use `bevy-glsl-to-spirv` only on the supported targets, default to `shaderc` otherwise.
Question:
username_0: The current configuration uses `bevy-glsl-to-spirv` by default, while selectively enabling `shaderc` for specific targets.
I think this is the wrong way around.
`bevy-glsl-to-spirv` provides precompiled binaries to help with builds on the officially supported targets. By design, it can only work for specifically-supported build targets.
`shaderc` has additional build-time requirements and complexity, but it supports a much wider range of compilation targets.
It doesn't make sense to me that `bevy-glsl-to-spirv` is the blanket default, and `shaderc` is on a special whitelist.
This results in compilation failures whenever anyone tries building bevy on a new target (`aarch64-unknown-linux-gnu`? `x86_64-unknown-linux-musl`? etc.), leading to issues like #898. I've seen many instances of similar reports; someone tries to compile bevy on their raspberry pi or whatever, only to hit the `bevy-glsl-to-spirv` error.
With `shaderc`, such platforms should be able to work (and would have likely worked out of the box for users attempting them for the first time).
Can we flip the configuration around? Make `bevy-glsl-to-spirv` conditionally-enabled on the platforms it supports, and default to `shaderc` otherwise?
This would keep builds exactly the same for any existing users of bevy, but it will help make bevy work on new targets more seamlessly.
Answers:
username_1: Ooh i think that is a very good call. Thats the best (short term) solution to the problem I've heard to-date. I'm sold.
username_0: @username_1 where can I find a list of the exact targets that are supported with `bevy-glsl-to-spirv`?
I will go do this and make a PR, just want to make sure I don't miss anything.
username_1: You can see them outlined here: https://github.com/username_1/glsl-to-spirv/blob/master/Cargo.toml
There is also some nuance after this pr: https://github.com/username_1/glsl-to-spirv/pull/7, which adds the option to build non-precompiled windows platforms from source (we will publish a new glsl-to-spirv version before the next release).
I _think_ for the given "from source" windows platforms in glsl-to-spirv we will want to continue using glsl-to-spirv. The dependencies are already included in the VS C++ Build Tools, which is much more natural than the Ninja + Python requirement for shaderc+windows.
@GrygrFlzr what are your thoughts?
username_0: Yes, if building `bevy-glsl-to-spirv` is supported, and it is simpler (less dependencies) than building `shaderc`, seems logical that it should be preferred on that platform.
username_0: BTW, while we are at it, should I make a feature flag to opt into `shaderc` even on platforms where `bevy-glsl-to-spirv` is supported (and normally used)? I don't see why we should limit users' options. Maybe they have reasons to prefer `shaderc`.
username_0: Also, what prevents the "building from source" functionality of `bevy-glsl-to-spirv` from being enabled for even more targets?
username_1: hmm yeah bevy-glsl-to-spirv only requires cmake and cc, which is preferable to Cmake + Git + Python + (on windows: Ninja). the only reason i can think of to use shaderc over bevy-glsl-to-spirv is the fact that it is well tested and proven to work on the platforms we currently use it on.
We just need to go through the process of validating bevy-glsl-to-spirv on iOS and Apple Silicon MacOS.
username_1: I vaguely remember some aspect of Cargo disallowing this functionality last time I looked in to it. Feel free to give it a whack though.
username_0: So, officially-supported platforms aside, if I understand you correctly, the only thing blocking support for unofficial platforms (like `aarch64-unknown-linux-gnu` or `x86_64-unknown-linux-musl`) for `bevy-glsl-to-spirv` with the new source-building configuration, is that it is not explicitly whitelisted / validated? I.e it is an artificially-imposed limitation?
If that is the case, then I'd want to reconsider this proposal of switching the default to `shaderc` in order to increase platform support (for not officially-supported targets). Should we not just lift the limitation from `bevy-glsl-to-spirv`, and let users use that?
username_1: Yup. Its a matter of validation / whitelisting. If we can prove bevy-glsl-to-spirv works on the relevant platforms then i think it makes sense to use that everywhere.
username_0: Well, my goal was to provide a "sane default" / fallback, so that people trying bevy on new platforms that haven't been tried, have a chance of it just working.
What's better for that? `shaderc` or `bevy-glsl-to-spirv`? That should be the default, and the more limited one should be on a whitelist.
username_1: We can't know which one to pick until we test the bevy-glsl-to-spirv changes on the relevant platforms.
If it works as expected, I think it's reasonable to assume it will work elsewhere. It would then be preferable to use glsl-to-spirv by default and opt in to shaderc, because then we can share the same code path across platforms.
However if it doesn't work then shaderc should probably be the default because we know it works well across many platforms
username_0: OK, now i understand you. :smile: I didn't understand you before, sorry.
I will try to compile `bevy-glsl-to-spirv` on some extra targets, whatever I have access to, to see if it works.
Those findings will inform the decision.
username_2: Temporary workaround is described here][https://discord.com/channels/691052431525675048/742884593551802431/812100952277516299](https://discord.com/channels/691052431525675048/742884593551802431/812100952277516299). |
EOL/tramea | 116116429 | Title: [8] Fix trusted image count file: the count needs to match the webpage.
Question:
username_0: Figure out where the count comes from on the web-page; re-write the script to use that same logic (probably re-written to handle counts in bulk/batches).
Answers:
username_1: read count from solr, branch -> https://github.com/EOL/eol/compare/trusted_images_count
Status: Issue closed
|
sile-typesetter/sile | 733794986 | Title: `luarocks install` on rockspec file does not work
Question:
username_0: When I try to install the required Lua packages as indicated in https://github.com/sile-typesetter/sile#from-source, it fails:
```
$ sudo luarocks install sile-dev-1.rockspec
Error: File not found: ...
```
Answers:
username_1: The file [does exist](https://github.com/sile-typesetter/sile/blob/master/sile-dev-1.rockspec) at the root of the repository. I suspect you tried running that command from somewhere else. You need to be `cd`'ed into the source directory (either your `git clone` or the extract of a source tarball) before running that command.
username_0: I am in the `.rockspec` file's directory. I suspect that the error message is rather related to this line of said file:
```
source = {
url = "..."
}
```
but having no knowledge of luarocks, I can't know for sure.
username_1: Sorry about that, the docs are what is at fault here. You're missing a key argument ;-)
```
$ sudo luarocks install --deps-only sile-dev-1.rockspec
```
username_0: It works! Thank you.
Status: Issue closed
|
zephyrproject-rtos/test_results | 1110159257 | Title:
tests-ci : filesystem: littlefs: custom test Timeout
Question:
username_0: **Describe the bug**
custom test is Timeout on v2.7.99-3293-g93b0ea978293 on mimxrt1060_evk
see logs for details
**To Reproduce**
1.
```
scripts/twister --device-testing --device-serial /dev/ttyACM0 -p mimxrt1060_evk --sub-test filesystem.littlefs
```
2. See error
**Expected behavior**
test pass
**Impact**
**Logs and console output**
```
*** Booting Zephyr OS build v2.7.99-3293-g93b0ea978293 ***
Running test suite littlefs_test
===================================================================
START - test_util_path_init_base
PASS - test_util_path_init_base in 0.1 seconds
===================================================================
START - test_util_path_init_overrun
PASS - test_util_path_init_overrun in 0.1 seconds
===================================================================
START - test_util_path_init_extended
PASS - test_util_path_init_extended in 0.1 seconds
===================================================================
START - test_util_path_extend
PASS - test_util_path_extend in 0.1 seconds
===================================================================
START - test_util_path_extend_up
PASS - test_util_path_extend_up in 0.0 seconds
===================================================================
START - test_util_path_extend_overrun
PASS - test_util_path_extend_overrun in 0.0 seconds
===================================================================
START - test_lfs_basic
clearing partition /sml
Erasing 65536 (0x10000) bytes
Wiped flash area 4 for /sml
mounting /sml
I: LittleFS version 2.4, disk version 2.0
I: FS at IS25WP064:0x630000 is 16 0x1000-byte blocks with 512 cycle
I: sizes: rd 16 ; pr 16 ; ca 64 ; la 32
E: WEST_TOPDIR/modules/fs/littlefs/lfs.c:1077: Corrupted dir pair at {0x0, 0x1}
W: can't mount (LFS -84); formatting
I: /sml mounted
checking clean statvfs of /sml
/sml: bsize 16 ; frsize 4096 ; blocks 16 ; bfree 14
creating and writing file
opening and verifying file
seek and tell in file
truncate in file
unlink hello
sync goodbye
[Truncated]
Erasing 983040 (0xf0000) bytes
Wiped flash area 5 for /med
I: LittleFS version 2.4, disk version 2.0
I: FS at IS25WP064:0x640000 is 240 0x1000-byte blocks with 512 cycle
I: sizes: rd 64 ; pr 64 ; ca 256 ; la 64
E: WEST_TOPDIR/modules/fs/littlefs/lfs.c:1077: Corrupted dir pair at {0x0, 0x1}
W: can't mount (LFS -84); formatting
I: /med mounted
/med: bsize 64 ; frsize 4096 ; blocks 240 ; bfree 238
I: /med unmounted
clearing partition /lrg
Erasing 3145728 (0x300000) bytes
```
**Environment (please complete the following information):**
- OS: (e.g. Linux )
- Toolchain (e.g Zephyr SDK)
- Commit SHA or Version used: v2.7.99-3293-g93b0ea978293
Answers:
username_0: Also fails on mimxrt1060_evk for v2.7.99-3293-g93b0ea978293
username_0: Also fails on mimxrt1170_evk_cm7 for v2.7.99-3293-g93b0ea978293
username_0: Also fails on lpcxpresso54114_m4 for v3.0.0-rc1
username_0: Also fails on lpcxpresso55s28 for v3.0.0-rc1
username_0: Also fails on mimxrt1015_evk for v3.0.0-rc1
username_0: Also fails on mimxrt1060_evk for v3.0.0-rc1
Status: Issue closed
|
Conchylicultor/DeepQA | 193467999 | Title: initialize_all_variables is deprecated.
Question:
username_0: # Description
Runing the current code against tensorflow 0.12.0-rc0.
```
initialize_all_variables (from tensorflow.python.ops.variables) is deprecated.
```
# Solution
```
I tensorflow/core/common_runtime/gpu/gpu_device.cc:916] 0: Y [26/579]
I tensorflow/core/common_runtime/gpu/gpu_device.cc:975] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GRID K520, pci bus id: 0000:00:03.0)
WARNING:tensorflow:From /home/ubuntu/git/chatbot_butterfly/chatbot/chatbot.py:173 in main.: initialize_all_variables (from tensorflow.python.ops.
variables) is deprecated and will be removed after 2017-03-02.
Instructions for updating:
Use `tf.global_variables_initializer` instead.
Training: 0%| | 3/4030 [00:00<22:14, 3.02it/s]I tensorflow/core/common_runtime/gpu/pool_allocator.cc:247] PoolAllocator: After 1768 get requests,
put_count=1460 evicted_count=1000 eviction_rate=0.684932 and unsatisfied allocation rate=0.79638
```
Answers:
username_1: Hello! See pull request here https://github.com/username_2/DeepQA/pull/26
Hope it helps.
username_0: Moment ago, I changed back to 0.11. As it turns out, **model.ckpt** is not generated with 0.12.
Check out #23. So, if we really want to use 0.12, we should better fix this problem first.
username_1: Looks like we need to migrate some stuff to tensorflow's 12 API.
But i don't have any warnings...
@username_0
username_2: initialize_all_variables is just a wrapper around global_variables_initializer: https://github.com/tensorflow/tensorflow/blob/20c3d37ecc9bef0e106002b9d01914efd548e66b/tensorflow/python/ops/variables.py#L1170
There have been change with `scalar_summary` > `summary.scalar` as well. As explain in #26, this change is too recent to change the program, but I'll certainly fix that in the future.
Status: Issue closed
username_2: It should be solved with #52
username_3: I had same problem before I've solved using:
try:
#code
except:
pass |
grxy/react-ad-block-detect | 489529322 | Title: no longer works
Question:
username_0: I am wondering if their is an update for this as I was not able to get it to work I tested in Google, Opera and IE
Answers:
username_1: @username_0 Do you mind providing specific versions of these browsers?
Also, it looks like the `adblockdetect` dependency doesn't have an update, so fixing this may require looking into an alternative detection lib or writing custom detection logic.
username_0: @username_1 does not trigger on Opera browsers (I am yet to test firefox)
username_2: Shit not working stop advertising it if you don't want to update the package
username_1: @username_0 @username_2 Unfortunately, this project is no longer at the top of my radar. You're welcome to send a PR to fix the issue if you'd like. |
OpenAPITools/openapi-generator | 603534514 | Title: [REQ] appDescription for Ruby?
Question:
username_0: ### Is your feature request related to a problem? Please describe.
I'd like the ability to have a customized section in my README, but still keep generated code on the README page.
## Describe the solution you'd like
I'd like to see `appDescription` get used, which AFAIK isn't used on the Ruby README files.
## Describe alternatives you've considered
Alternatives may be ignore the README and customizing it for my needs, but I'd lose out on the generated aspect by doing that.
## Additional context |
MicrosoftDocs/azure-docs | 681873482 | Title: Missing caveat that AAD cannot be enabled on an existing cluster
Question:
username_0: Hi all,
Documentation does not make it clear that you cannot add AAD integration to an existing cluster which was not created with AAD integration.
Is it possible to add this as a caveat/warning, as I am pretty sure that was present on the previous version we did call this out (to prevent any confusion)?
Thanks!
Adam
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: bc86c3af-f6c7-4c48-e157-54abbc5958ff
* Version Independent ID: 3611b478-6df6-f5cd-563d-2fff6cfec9ef
* Content: [Integrate Azure Active Directory with Azure Kubernetes Service (legacy) - Azure Kubernetes Service](https://docs.microsoft.com/en-us/azure/aks/azure-ad-integration-cli)
* Content Source: [articles/aks/azure-ad-integration-cli.md](https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/aks/azure-ad-integration-cli.md)
* Service: **container-service**
* GitHub Login: @username_1
* Microsoft Alias: **thomasge**
Answers:
username_1: thanks for your feedback. Yes, it should be called out in our limitation section. Just made a PR.
You may want to consider our new managed AAD integration experience. It allows you to enable AAD integration on existing RBAC enabled cluster. https://aka.ms/aks/managed-aad
username_1: going ahead closing this one. Feel free to keep commenting if you have further feedback. Doc change should go live latest in 24 hours.
#please-close
Status: Issue closed
username_3: Thanks @username_1 for the doc update. :)
username_0: Thank you @username_1 !
Should we add the same caveat here for managed AAD:
https://docs.microsoft.com/en-us/azure/aks/managed-aad
If so, shall I raise a new issue on that page instead?
username_1: @username_0
Enabling managed AAD Integration on existing cluster with RBAC enabled is supported. Do you have any issues doing it? |
Erriez/R421A08-rs485-8ch-relay-board | 1106789955 | Title: Is it possible to change the board baudrate?
Question:
username_0: Hi username_1 and thanks for you work
unfortunately this board is poorly documented, do you know if there is any way to change baudrate/parity for the board?
Answers:
username_1: Hi @username_0. Thanks for using my library. I could not change the baudrate. Maybe someone else knows this. |
robotframework/RIDE | 83843309 | Title: Navigation to variable definition
Question:
username_0: It should be possible to go to variable defintion from it's usage.
This is not trivial since variable may be defined from command line, in
variable file, in resource file, in same suite or as a user keyword argument
Answers:
username_0: Too abstract an issue. Waiting for a more concrete improvement idea.
Status: Issue closed
|
hotosm/tasking-manager | 584590908 | Title: Unfork iD
Question:
username_0: For the iD integration in Tasking Manager we've slightly [forked iD](https://github.com/hotosm/iD). Let's get things upstream, so we can ideally rely directly on the main iD version.
* [ ] Scope iD's CSS to its container (https://github.com/openstreetmap/iD/issues/7437) and respective changes in the Tasking Manager CSS.
Answers:
username_0: @username_1 is there anything else we would need to get upstream in order to rely on the standard iD directly?
username_1: @username_0 currently the https://github.com/openstreetmap/iD/ is not published as a package on npm, so we should suggest them to do it.
I'll do a PR with a small change to define the minimized file as the main file on the package.json.
username_2: I'm not sure why iD has never been published this way, but I don't see an immediate reason why it shouldn't be.
Let me know what else would improve the embedding experience!
Status: Issue closed
|
WormBase/wormbase-pipeline | 812241904 | Title: WS280 7: PolyA tail position warning
Question:
username_0: During the build, there is a warning about some polyA features. Are these issues which we need to do something about?
AF239999: low feature is past end of sequence
AF239999: polyA feature is past end of sequence
AF273835: polyA feature is past end of sequence
AF456360: polyA feature is past end of sequence
It is accurate that these should be flagged, and Stavros curated them, so there will hopefully not be any warnings next time run.<issue_closed>
Status: Issue closed |
parcel-bundler/parcel | 450103662 | Title: Remove svg's ref attribute at build
Question:
username_0: # 🐛 bug report
`parcel build`'s minifer erases `ref` attribute for vue.js of `<svg>`.
## 🎛 Configuration (.babelrc, package.json, cli command)
test.html:
```html
<!DOCTYPE html>
<html>
<body>
<p ref="p">p</p>
<svg ref="svg">svg</svg>
</body>
</html>
```
Run `parcel build test.html` with v1.12.3 and initial config.
## 🤔 Expected Behavior
dist/test.html:
```html
<!DOCTYPE html><html><body> <p ref="p">p</p> <svg ref="svg">svg</svg> </body></html>
```
## 😯 Current Behavior
dist/test.html:
```html
<!DOCTYPE html><html><body> <p ref="p">p</p> <svg>svg</svg> </body></html>
```
## 🌍 Your Environment
| Software | Version(s) |
| ---------------- | ---------- |
| Parcel | 1.12.3 |
| Node | v10.15.1 |
| npm | 6.7.0 |
| Operating System | macOS 10.14.4 |
Answers:
username_1: A `.htmlnanorc` file with
```
{
"minifySvg": false
}
```
should fix this.
Instead of completely disabling svg minification, you could also try figuring out which plugin is responsible for this: https://github.com/svg/svgo/blob/master/README.md#what-it-can-do
username_0: Thanks!
I got the desired result, after I put the `.htmlnanorc` file, remove the `.cache` directory and rebuild.
Status: Issue closed
|
usnistgov/mobile-threat-catalogue | 185375043 | Title: Modify CEL-3
Question:
username_0: General Comment
------------------------------------------
CEL-3
**Type of Comment**:
T
**Proposed Change**:
Add Ruxcon research to exploit examples for this threat:
http://www.theregister.co.uk/2016/10/23/every_lte_call_text_can_be_intercepted_blacked_out_hacker_finds/
**Justification**:
Adds further context to the relevance of this threat.<issue_closed>
Status: Issue closed |
keboola/gelf-server | 252712514 | Title: Warning: json_decode() expects parameter 1 to be string, array given in /src/vendor/keboola/gelf-server/src/AbstractServer.php on line 68
Question:
username_0: Using pygelf 0.2.6
```
# pygelf
logger.addHandler(GelfTcpHandler(host=os.getenv('KBC_LOGGER_ADDR'), port=os.getenv('KBC_LOGGER_PORT'), debug=False, **fields))
logging.info('A sample info message')
logging.warning('A sample warn message')
logging.critical('A sample emergency message')
```
this is the passed logging event
```json
{
"timestamp": 1503602965.1555362,
"host": "1ce587f5895d",
"_some": {
"structured": "data"
},
"short_message": "A sample emergency message",
"level": 2,
"full_message": null,
"version": "1.1",
"source": "1ce587f5895d"
}
```
looks like it's expecting the `_some` field to be stringified JSON
Status: Issue closed
Answers:
username_1: fixed in 83ff3fc272583fb0ef275dabc7e0480d21d9bb34 |
RhetTbull/osxphotos | 549573699 | Title: bug: get_last_library_path does not always return last library
Question:
username_0: In some cases, get_last_library_path will fail if Photos hasn't already been opened. I don't know if this is an issue with permissions or if /Library/Containers/com.apple.Photos/Data/Library/Preferences/com.apple.Photos.plist is missing.
Also, it will always fail on a "clean install" account where Photos has never been opened.
In these cases, should it return ~/Pictures/Photos Library.photoslibrary?
Answers:
username_1: I can't actually reproduce my initial error with this but my first thought was it expects the `~/Pictures/Photos Library.photoslibrary` to exist, which did exist already when the error first occurred. IMHO I actually think the use of the last opened library is somewhat inconsistent because the result of osxphotos depends on the use of the app. I would suggest to always default to the user standard library (as does OSX and access to iCloud is only possible in this lib) and non-standard locations need to be parsed with the --db argument on the CLI.
username_1: Another example where this going to fail if you trash the last opened lib btw. I just think this behaviour is more hassle than it is useful.
username_0: I agree the behavior of opening last library could be ambiguous and lead to unexpected behavior. I'll change the code to require the library be explicitly specified. Ideally, I'd use the system library as the default as you suggest but I've not been able to find a way to reliably do this. On Catalina, the system library seems to be specified in ~/Library/Containers/com.apple.photolibraryd/Data/Library/Preferences/com.apple.photolibraryd.plist (used by osxphotos.utils.get_system_library_path) but this doesn't work on older OS versions. I could default to ~/Pictures/Photos Library.photoslibrary but the user can change/rename the system library and I don't know if this naming convention holds across different languages.
username_0: Another option is to have the CLI print a list of all available libraries (e.g. as is done by `osxphotos list`) if the user does not specify one explicitly on the command line.
username_1: Sounds good to me. If `--db` not parsed, why not do:
1. try to determine system lib. If that fails, ...
2. try to list used libs (with a blocking prompt?). If that fails, ...
3. require `--db` to be parsed.
I am using Catalina too (and High Sierra on my old machine) and I thought the `~/Pictures/Photos Library.photoslibrary` was universal.
username_0: I've been playing with this. I've got the following behavior prototyped:
1. --db can be passed before or after the command e.g. `osxphotos --db ~/Pictures/Foo.photoslibrary info` or `osxphotos info --db ~Pictures/Foo.photoslibrary`
2. The path to the photos library can be specified as an argument after the command without using --db: `osxphotos info ~/Pictures/Foo.photoslibrary` This seems more natural than using an option, which by definition should be optional.
3. If neither 1 or 2 is specified, osxphotos will:
1. first try to get the last library opened in Photos
2. failing 1, will try to get system photos library
3. failing 2, will look for "~/Pictures/Photos Library.photoslibrary" (need to understand if this works under non-English installs)
4. failing 3, will list all available libraries and prompt user to select one
Rationale is that this will likely "just work" for the average user and "do what I mean". Downside is that it could lead to non-deterministic behavior.
username_0: Version 0.22.0 implements this new behavior with one exception to above -- if a database path isn't passed either as argument or --db option, osxphotos will list available databases but does not block with a prompt
Status: Issue closed
username_0: In some cases, get_last_library_path will fail if Photos hasn't already been opened. I don't know if this is an issue with permissions or if /Library/Containers/com.apple.Photos/Data/Library/Preferences/com.apple.Photos.plist is missing.
Also, it will always fail on a "clean install" account where Photos has never been opened.
In these cases, should it return ~/Pictures/Photos Library.photoslibrary?
username_1: Cool, works well. How come you ditched the search for a "default" library? The behaviour listed in 3) make sense except for 3.i to keep it deterministic.
username_0: @username_1 Mainly just to make it more clear which library is being operated on. I can't reliably find the system library and you found at least one case where default library didn't work. If you think it makes sense to keep search for default library I'm happy to put it back in. Another option might be to add a "--system-lib" and "--last-lib" options so you could explicitly say "look for the last library I opened". For 99% of users, they probably have only one library but I expect people using this module might be more likely to be in the 1% with more than one library. I'm open to suggestions on how to make this easier to use/more intuitive!
username_0: What about if --db or photo_library not specified, attempt to find default library then print a prompt saying something like: "Found Photos library at ~/Pictures/Photos Library.photoslibrary -- use this one (Y/n)?" If user says Y, use it, if N, then list the other libraries? What I'd like to avoid is user operating on the wrong library by accident.
username_1: Yes I agree that would be useful although I would think that if a system library can be found, it should still operate on it without prompt (with a warning to stderr maybe). That would make it easier for the 90% of (Catalina) users.
username_0: I just pushed a new update that implements # 3 above: looks for last library, then system library, then ~/Pictures/Photos Library.photosdb. As you suggested, it will print out a statement to stderr listing the library being used
username_0: osxphotos now works around this issue as described above.
Status: Issue closed
|
seung-lab/neuroglancer | 467400281 | Title: Test: <EMAIL> | gesw5y3wg
Question:
username_0: | Email | Name | Type |
|---|---|---|
| <EMAIL> | Test | Bug and Suggestion |
Description: yuke56j4wh66h

<details>
<summary>State URL</summary>
https://seun-report2githubissue-dot-neuromancer-seung-import.appspot.com/#!%7B%22layout%22:%224panel%22%7D
</details>
Status: Issue closed
Answers:
username_1: This was me testing the PR. Closing. |
paulsoiya/teamj | 65557666 | Title: Exception Handling on Invailid Inputs
Question:
username_0: Sign Up screen needs to let users know passwords don't match.
Game/Stats input needs handling on non ints in text fields. Should just need a warning label.
Status: Issue closed
Answers:
username_0: This should be complete with Elliott's commit for the Validation for StatsController commit : <PASSWORD> |
ontodev/robot | 250682421 | Title: --annotate-inferred-axioms flagging assertions as inferred
Question:
username_0: Using the following command (after converting our `eco-edit.owl` file to RDF/XML):
```
robot reason --input eco.owl --reasoner elk --create-new-ontology false \
--annotate-inferred-axioms true --output reasoner-test.owl
```
Flags both asserted and inferred subclass statements as inferred (so all of them end up being annotated with is_inferred true). Am I missing something?
Answers:
username_0: Nevermind, I just added the `--exclude-duplicate-axioms true` flag and it works fine. Thanks!
Status: Issue closed
|
shu223/watchOS-2-Sampler | 97391735 | Title: Fails to build on device.
Question:
username_0: Hey! So I changed all the teams in all targets to mine, changed identifiers from com.shh.xxx.xxx to com.dv.xxx.xxx, Added app group entitlements to parent app and extension, changed that in Audio controller code.
But I'm getting this mysterious error.
error: WatchKit App doesn't contain any WatchKit Extensions whose WKAppBundleIdentifier matches "com.dv.sampler.watchos2.watchkitapp". Verify that the value of WKAppBundleIdentifier in your WatchKit Extension's Info.plist matches the value of CFBundleIdentifier in your WatchKit App's Info.plist.
I tried doing just what it wants, also renaming and any combinations of those. Nothing helps.
This is on Xcode 7 beta 4. Regards
Answers:
username_1: username_0, I'm not sure if Xcode tried to fix it wrong, or if I did, but in the info.plist for the extension you need to expand the NSExtension value and then NSExtensionAttributes. There you should find WKAppBundleIdentifier that needs to be updated to reflect the Bundle Identifier of the watch app. I figured it out from this http://stackoverflow.com/questions/30203079/watchkit-extension-bundle-identifiers question. It's been a few months, but hopefully it helps someone.
username_2: @username_1 thanks for that piece of info. It helped me further! |
neinteractiveliterature/intercode | 302935876 | Title: Event Proposals Page, event mistakenly shows "ulimited" capacity
Question:
username_0: Proposal for "Bound in Blood" submitted 2018-03-06 13:46.
Buckets configured for
- 0 Male
- 3 Female
- 8 Flex
- Unlimited NPC
For this proposal on the Event Proposals Page, capacity is listed as "Unlimited". It should be 11.
So, can "NPC" bet set with an attribute that says "do not count this towards game capacity"? What if some other bucket with similar meaning is set with "unlimited"?
Status: Issue closed
Answers:
username_1: This is going to be fixed by #633, which is next up on the queue after product sales. Closing this ticket in favor of that. |
MicrosoftDocs/powerquery-docs | 811131703 | Title: Date Error? Salesforce connector
Question:
username_0: On the following site: https://docs.microsoft.com/en-us/power-query/connectors/salesforceobjects
In the enabling OAuth section (https://docs.microsoft.com/en-us/power-query/connectors/salesforceobjects#enabling-oauth-authentication-in-power-bi-desktop)
We use the date December 2021. Is this supposed to read December 2020?
Thanks
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 8c78a664-32c4-68c5-97ec-99d5fa4e5aab
* Version Independent ID: 75152c2f-8bed-c5df-5fa3-2470920f6dde
* Content: [Power Query Salesforce Objects connector](https://docs.microsoft.com/en-us/power-query/connectors/salesforceobjects)
* Content Source: [powerquery-docs/Connectors/SalesforceObjects.md](https://github.com/MicrosoftDocs/powerquery-docs/blob/master/powerquery-docs/Connectors/SalesforceObjects.md)
* Service: **powerquery**
* GitHub Login: @username_1
* Microsoft Alias: **bezhan**
Answers:
username_1: Hi @username_0 -
This date in the documentation has been corrected to 2020.
Status: Issue closed
|
dtag-dev-sec/dtag-dev-sec.github.io | 337534376 | Title: 2015-03-17-concept.markdown - stale link?
Question:
username_0: The background section of the page [2015-03-17-concept.markdown](
https://github.com/dtag-dev-sec/dtag-dev-sec.github.io/blob/master/_posts/2015-03-17-concept.markdown#background) provides two links: [Sicherheitstacho](http://sicherheitstacho.eu/) / [Securitydashboard](http://securitydashboard.eu/).
However, the link "Securitydashboard" results in ERR_NAME_NOT_RESOLVED. Accessed: 2018-07-02.
Answers:
username_1: mhmh..
Domain: securitydashboard.eu
Status: AVAILABLE
username_2: <NAME>, thx,
Markus?
Best regards
Markus
username_3: Now the domain is owned by another person, not by the Telekom anymore.
So I think its really time to remove the link...
I opened a pull request (#9) removing the link, maybe this brings the attention of @dtag-dev-sec / @t3chn0m4g3 or @vorband to this.
username_4: Hello all,
many thanks for the hint! :pray: Originally we wanted to use this domain too, but in the end we only used sicherheitstacho.eu. However, it's planned to offer an english domain in the future :+1:
Cheers
Simon
username_4: Hello all,
many thanks for the hint! :pray: Originally we wanted to use this domain too, but in the end we only used sicherheitstacho.eu. However, it's planned to offer an english domain in the future :+1:
Cheers
Simon
Status: Issue closed
|
kubesphere/kubekey | 627374132 | Title: Failed to install K8s in CentOs 7.6 on QingCloud
Question:
username_0: See the failed logs:
```
[ks-allinone] Downloading image: calico/pod2daemon-flexvol:v3.13.0
INFO[23:51:06 CST] Generating etcd certs
ERRO[23:51:06 CST] Failed to generate etcd certs: Failed to exec command: sudo -E /bin/sh -c "mkdir -p /etc/ssl/etcd/ssl && /bin/bash -x /tmp/kubekey/make-ssl-etcd.sh -f /tmp/kubekey/openssl.conf -d /etc/ssl/etcd/ssl": Process exited with status 127 node=192.168.0.2
WARN[23:51:06 CST] Task failed ...
WARN[23:51:06 CST] error: interrupted by error
Error: Failed to generate etcd certs: interrupted by error
Usage:
kk create cluster [flags]
Flags:
--all deploy kubernetes and kubesphere
--debug debug info (default true)
-f, --file string configuration file name
-h, --help help for cluster
```
Answers:
username_0: Is this issue resolved by this [PR](https://github.com/kubesphere/kubekey/pull/50)?
username_1: @username_0
No, you should execute `sudo -E /bin/sh -c "mkdir -p /etc/ssl/etcd/ssl && /bin/bash -x /tmp/kubekey/make-ssl-etcd.sh -f /tmp/kubekey/openssl.conf -d /etc/ssl/etcd/ssl"` in node 192.168.0.2 .
username_1: @username_0
I think this issues is caused by that this machine is missing `openssl`.
You can execute` yum install openssl` to install openssl.
I will add it to requirements.
Status: Issue closed
username_0: You are right, thanks |
macvim-dev/macvim | 1015031412 | Title: Not showing new window in OS X 10.9
Question:
username_0: I can run Macvim.app in the current (8.2.3455 (172)) version, but there is no new window with empty file (no matter what setup I use). I can select the recent file, but the new window with text doesn't appear. Drag'n'drop doesn't work either.
Last version I used without issues was a very ancient one. When I try to user a newer version, it breaks even the older one into the same non-working behaviour, so to get back to the working state is not easy.
When I try to run the native app (/Applications/MacVim.app/Contents/MacOS/MacVim) from the shell, it runs non-graphical vim. After I quit with :q it says:
2021-10-04 12:54:44.989 MacVim[34079:507] -[MMWindow setTitlebarAppearsTransparent:]: unrecognized selector sent to instance 0x7fb5dad3d8e0, but I don't return to shell before I quit the graphical interface.
If I try to select e. g. a file from Recents, it opens in terminal, but with very limited possibilities of work, no graphical window.
Answers:
username_1: Do you know what "ancient one" means? a few months / a year / a few years ago?
username_0: I am sorry, I added those extra pieces into the original post, it might have been missed. So once again:
1. I did try to manually remove all .vimrc and files found in ~/Library (everything found which had *macvim* in name/directory).
2. IMHO the last version working on OS X 10.9 is 163 released on 12 Apr 2020.
I tried to compile recent git version and it fails on XIB file for preferences compilation. The file is for X Code 8.0 and up, there is only XCode 6.2 on 10.9. I don't really understand UI Designer being mostly just a console guy. :-) Sorry.
username_1: Is there a reason why you need to build MacVim from scratch? Because we moved from NIB to XIB it could be hard for you to build locally on 10.9
username_0: No real reason. I just wanted to give it a try, with an opportunity to try a bit of debugging. But it's really of a very little use for me, I usually program in plain C. |
storybookjs/storybook | 1042399034 | Title: `@storybook/[email protected]` has lots of incorrect peer dependencies
Question:
username_0: **Describe the bug**
This package should support latest `react`, `react-dom` and other `@storybook` packages.
**To Reproduce**
Really isn't necessary, run `yarn install` locally on your `@storybook/[email protected]` package.
**System**
Please paste the results of `npx sb@next info` here.
```
System:
OS: macOS 11.6
CPU: (16) x64 Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
Binaries:
Node: 16.11.1 - /usr/local/bin/node
Yarn: 1.22.17 - /usr/local/bin/yarn
npm: 8.0.0 - /usr/local/bin/npm
Browsers:
Chrome: 95.0.4638.69
Firefox: 90.0.2
Safari: 15.0
npmPackages:
@storybook/addon-a11y: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/addon-actions: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/addon-controls: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/addon-essentials: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/addons: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/builder-webpack5: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/components: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/core-events: ^6.4.0-beta.25 => 6.4.0-beta.25
@storybook/manager-webpack5: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/react: ^6.4.0-beta.25 => 6.4.0-beta.25
@storybook/theming: ^6.4.0-beta.25 => 6.4.0-beta.25
```
**Additional context**
```
warning "@react-theming/storybook-addon > @storybook/[email protected]" has incorrect peer dependency "@storybook/addons@^5.0.0".
warning "@react-theming/storybook-addon > @storybook/[email protected]" has incorrect peer dependency "@storybook/react@^5.0.0".
warning "@react-theming/storybook-addon > @storybook/[email protected]" has incorrect peer dependency "react@^16.0.0".
warning "@react-theming/storybook-addon > @storybook/[email protected]" has incorrect peer dependency "react-dom@^16.0.0".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @reach/[email protected]" has incorrect peer dependency "react@^16.8.0".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @reach/[email protected]" has incorrect peer dependency "react-dom@^16.8.0".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @reach/rect > @reach/[email protected]" has incorrect peer dependency "react@^16.4.0".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @reach/rect > @reach/[email protected]" has incorrect peer dependency "react-dom@^16.4.0".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @storybook/addons > @storybook/api > @reach/[email protected]" has incorrect peer dependency "[email protected] || 16.x || 16.4.0-alpha.0911da3".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @storybook/addons > @storybook/api > @reach/[email protected]" has incorrect peer dependency "[email protected] || 16.x || 16.4.0-alpha.0911da3".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @storybook/addons > @storybook/api > @reach/router > [email protected]" has incorrect peer dependency "react@^0.14.0 || ^15.0.0 || ^16.0.0".
warning " > [email protected]" has incorrect peer dependency "@storybook/addon-actions@^4.0.0||^5.0.0||5.2.0-beta.13".
```
Answers:
username_1: Thanks for the issue @username_0. That's on the way out because many of the APIs are now apart of Storybook.
If you're looking to build a new addon, I'd start with our [official addon kit template](https://github.com/storybookjs/addon-kit).
username_0: Hey @username_1, sounds like I need to talk to the author of `@react-theming/storybook-addon` and have them update to use the new APIs then?
username_2: Thanks, guys! I am aware of this new API and I am happy that many of the useful abilities of storybook-addon finally come to Storybook itself. But at the same time the new API isn't just a replacemnt of the original package but rather a brand new API and in most cases much simplified. So this way while it's recomended to create new addons with the new API, it's not easy to migrate existing ones.
Also I beleive there're can't be strict restriction to use the original package when it's nessary. So probably it can still exist alongside with the new API.
Regarding to the question of @react-theming/storybook-addon I'd happy to discuss what could we do to improve it. Let's continue it in the projects issues.
username_2: **Describe the bug**
This package should support latest `react`, `react-dom` and other `@storybook` packages.
**To Reproduce**
Really isn't necessary, run `yarn install` locally on your `@storybook/[email protected]` package.
**System**
Please paste the results of `npx sb@next info` here.
```
System:
OS: macOS 11.6
CPU: (16) x64 Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
Binaries:
Node: 16.11.1 - /usr/local/bin/node
Yarn: 1.22.17 - /usr/local/bin/yarn
npm: 8.0.0 - /usr/local/bin/npm
Browsers:
Chrome: 95.0.4638.69
Firefox: 90.0.2
Safari: 15.0
npmPackages:
@storybook/addon-a11y: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/addon-actions: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/addon-controls: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/addon-essentials: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/addons: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/builder-webpack5: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/components: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/core-events: ^6.4.0-beta.25 => 6.4.0-beta.25
@storybook/manager-webpack5: 6.4.0-beta.25 => 6.4.0-beta.25
@storybook/react: ^6.4.0-beta.25 => 6.4.0-beta.25
@storybook/theming: ^6.4.0-beta.25 => 6.4.0-beta.25
```
**Additional context**
```
warning "@react-theming/storybook-addon > @storybook/[email protected]" has incorrect peer dependency "@storybook/addons@^5.0.0".
warning "@react-theming/storybook-addon > @storybook/[email protected]" has incorrect peer dependency "@storybook/react@^5.0.0".
warning "@react-theming/storybook-addon > @storybook/[email protected]" has incorrect peer dependency "react@^16.0.0".
warning "@react-theming/storybook-addon > @storybook/[email protected]" has incorrect peer dependency "react-dom@^16.0.0".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @reach/[email protected]" has incorrect peer dependency "react@^16.8.0".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @reach/[email protected]" has incorrect peer dependency "react-dom@^16.8.0".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @reach/rect > @reach/[email protected]" has incorrect peer dependency "react@^16.4.0".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @reach/rect > @reach/[email protected]" has incorrect peer dependency "react-dom@^16.4.0".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @storybook/addons > @storybook/api > @reach/[email protected]" has incorrect peer dependency "[email protected] || 16.x || 16.4.0-alpha.0911da3".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @storybook/addons > @storybook/api > @reach/[email protected]" has incorrect peer dependency "[email protected] || 16.x || 16.4.0-alpha.0911da3".
warning "@react-theming/storybook-addon > @storybook/addon-devkit > @storybook/addons > @storybook/api > @reach/router > [email protected]" has incorrect peer dependency "react@^0.14.0 || ^15.0.0 || ^16.0.0".
warning " > [email protected]" has incorrect peer dependency "@storybook/addon-actions@^4.0.0||^5.0.0||5.2.0-beta.13".
```
Status: Issue closed
username_1: Thanks Oleg! I totally get that migrating can be tricky so I appreciate you taking the time to respond. Maybe @username_0 would be interested in helping out?
username_0: Thanks @username_1 & @username_2 I'm happy to help where I can. |
stwe/DatatablesBundle | 182547352 | Title: refresh datatable
Question:
username_0: Hello, thanks to this bundle. I have a question. Is there any way to refresh a datatable without refresh de complete page. For example, I want to delete some fields via ajax and reload the table with ajax to.
Answers:
username_1: You can follow my example project. You can solve this using an ActionButton. The associated controller should not be a problem.
Status: Issue closed
|
scrapy/scrapy | 160209337 | Title: Some of the errors occurred in the Chinese web crawling
Question:
username_0: The html source is :
<dd>
<a href="5367496.html" =style="" style="">书友群</a>
</dd>
<dd>
<a href="5367497.html" =style="" style="">十月份打赏清单。</a>
</dd>
<dt>《修真聊天群》九洲一号群</dt>
<dd>
<a class="firefinder-match" href="5367498.html" =style="" style="">第一章 黄山真君和九洲一号群</a>
</dd>
<dd>
<a class="firefinder-match" href="5367499.html" =style="" style="">第二章 且待本尊算上一卦</a>
</dd>
my spider is :
def parse(self, response):
# a = '第'.encode('Unicode')\"h1title\"
arr = response.xpath("//dd//a[contains(.,\"第\")]").extract()
print arr[0]
I just want the a tag with the word "第" in the beginning.
but it not work , but in the fixfox firexpath i can find right.
some error is :
2016-06-14 20:14:11 [scrapy] ERROR: Spider error processing <GET http://www.23us.cc/html/101/101573/> (referer: None)
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/Twisted-16.2.0-py2.7-linux-x86_64.egg/twisted/internet/defer.py", line 588, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "/home/chenhao/Desktop/ssss/sinaweibo/sinaweibo/spiders/xiao.py", line 18, in parse
arr = response.xpath("//dd//a[contains(.,\"第\")]").extract()
File "/usr/local/lib/python2.7/dist-packages/scrapy/http/response/text.py", line 115, in xpath
return self.selector.xpath(query)
File "/usr/local/lib/python2.7/dist-packages/parsel/selector.py", line 179, in xpath
smart_strings=self._lxml_smart_strings)
File "lxml.etree.pyx", line 1507, in lxml.etree._Element.xpath (src/lxml/lxml.etree.c:52198)
File "xpath.pxi", line 295, in lxml.etree.XPathElementEvaluator.__call__ (src/lxml/lxml.etree.c:151999)
File "apihelpers.pxi", line 1393, in lxml.etree._utf8 (src/lxml/lxml.etree.c:27125)
ValueError: All strings must be XML compatible: Unicode or ASCII, no NULL bytes or control characters
Answers:
username_1: Can you try with a `u` prefix on the XPath selector? i.e.
```
response.xpath(u"//dd//a[contains(.,\"第\")]").extract()
```
Status: Issue closed
username_1: ```
username_0: Oh, my God, it's been a long time for me to find the mistake. Thank you so much. |
spring-projects/spring-security | 340470001 | Title: Return Type Of RectiveUserDetailService
Question:
username_0: https://github.com/spring-projects/spring-security/issues
package com.username_0.springsessionreactivetest;
import org.springframework.security.core.userdetails.ReactiveUserDetailsService;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.core.userdetails.UsernameNotFoundException;
import reactor.core.publisher.Mono;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
public class CustomReactiveUserDetailsService extends ReactiveUserDetailsService {
public static final String USERNAME_NOT_FOUND_MESSAGE = "Username %s not found.";
@Override
public Mono<? extends UserDetails> findByUsername(String username) {
return users.stream()
.filter(user -> Objects.equals(username, user.getEmail()) || Objects.equals(username, String.valueOf(user.getId())))
.findFirst()
.map(CustomUserDetails::new)
.map(Mono::just)
.orElseThrow(() -> new UsernameNotFoundException(String.format(USERNAME_NOT_FOUND_MESSAGE, username)));
}
public static final List<User> users = new ArrayList<>();
static {
users.add(User.getInstance().id("1").firstName("Ankur").lastName("Pathak").addRole(Role.ROLE_ADMIN).email("<EMAIL>").password("<PASSWORD>"));
users.add(User.getInstance().id("2").firstName("Amar").lastName("Mule").addRole(Role.ROLE_ADMIN).email("<EMAIL>").password("<PASSWORD>"));
}
}
Return type should be Mono<? extend UserDetail> to allow broader returns by inheritance. In absence of' this we will have to have ugly casting or hack of some type. This will also support the principal
of preferring Composition over Inheritance.
Answers:
username_0: In absence of above we have to do some hack of this type:
@Override
public Mono<UserDetails> findByUsername(String username) {
return users.stream()
.filter(user -> Objects.equals(username, user.getEmail()) || Objects.equals(username, String.valueOf(user.getId())))
.findFirst()
.map(CustomUserDetails::new)
.map(x-> (UserDetails)x)
.map(Mono::just)
.orElseThrow(() -> new UsernameNotFoundException(String.format(USERNAME_NOT_FOUND_MESSAGE, username)));
}
username_1: Even if we wanted to, we cannot change the code as this is a non passive change. Additionally, it is generally bad practice to return a value with a wildcard since it forces programmers using the code to deal with wildcards. This is the same reason that `Optional.orElseThrow` doesn't use a wildcard.
You can rewrite your code like this:
```java
public Mono<UserDetails> findByUsername(String username) {
return Flux.fromIterable(users)
.filter(user -> Objects.equals(username, user.getEmail()) || Objects.equals(username, String.valueOf(user.getId())))
.next()
.switchIfEmpty(Mono.defer(() -> Mono.error(new UsernameNotFoundException(String.format(USERNAME_NOT_FOUND_MESSAGE, username)))))
.map(CustomUserDetails::new);
}
```
You probably want to consider using a different data structure as well since this is O(n) vs a Map which would be O(1).
Status: Issue closed
|
pothosware/PothosCore | 760305981 | Title: Cannot convert Object of type long long to long
Question:
username_0: "long long" declaration: https://github.com/pothosware/PothosCore/blob/master/lib/Object/Builtin/ConvertIntegers.cpp#L9
Macro: https://github.com/pothosware/PothosCore/blob/master/lib/Object/Builtin/ConvertCommonImpl.hpp#L152
"long" typedef: https://github.com/pothosware/PothosCore/blob/master/lib/Object/Builtin/ConvertCommonImpl.hpp#L26
In theory, with this, conversion should be supported between "long long" and "long", but it errors out.
Answers:
username_1: like this fails for you?
```
POTHOS_TEST_BLOCK("/object/tests", test_long_long_to_long)
{
Pothos::Object obj((long long)1234);
auto out = obj.convert<long>();
printf("out = %d\n", (int)out);
}
```
Status: Issue closed
username_0: Closing issue. Taking another look at the error message, it's from Object::extract(), where the type has to be exact. |
chromealex/ecs.example | 710216634 | Title: Error when hit "Play"
Question:
username_0: 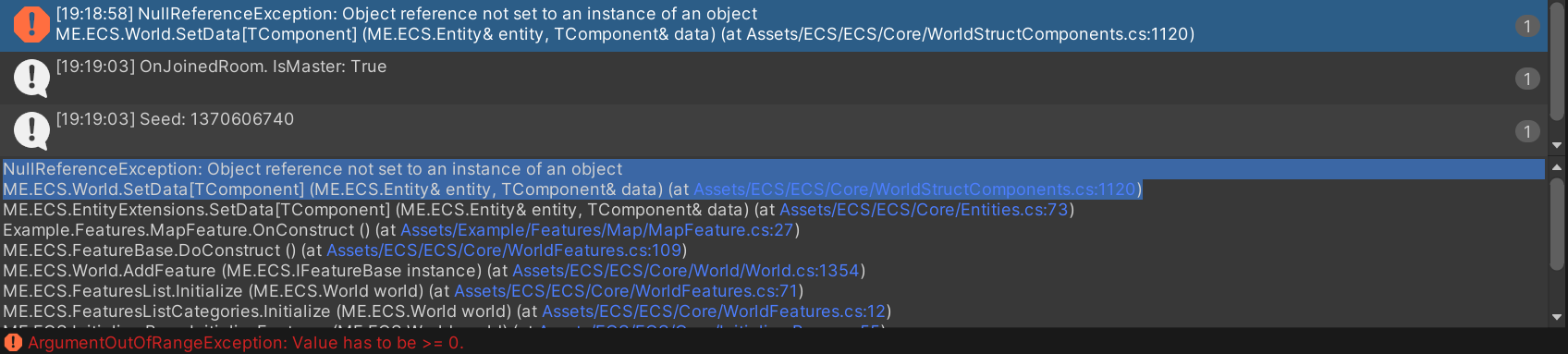
Is there a workaround?
Answers:
username_1: Yeah. You are using windows os, there is a bug in Generator.cs. You can
copy-paste it from the main repo.
Thanks;)
Status: Issue closed
|
sanity-io/sanity-plugin-mux-input | 987556252 | Title: put duration in better place in graphQL
Question:
username_0: When querying my video content with graphql (gatsby) with the following query:
```
allSanityVideos {
edges {
node {
video {
asset {
playbackId
thumbTime
assetId
status
}
_rawAsset(resolveReferences: {maxDepth: 2})
}
_id
}
}
}
```
I am getting the duration only via _rawAsset and not via video -> asset structure. See the result below
```
{
"data": {
"allSanityVideos": {
"edges": [
{
"node": {
"video": null,
"_id": "drafts.d970338c-1ebb-4f88-b9b4-cec9615c7e63"
}
},
{
"node": {
"video": {
"asset": {
"playbackId": "cxsHvFHCpnedi02nL8kNrmvzzHYuSx84LyoA4Nh00Lv6s",
"thumbTime": null,
"assetId": "BSt8QSrjyqUhrEGLnMKBNqGrq8wfBmhwwZH8LyRe74A",
"status": "ready"
},
"_rawAsset": {
"_id": "296f5350-2cf9-40ea-9264-733f3af3ba7d",
"_type": "mux.videoAsset",
"_rev": "cWhOHnBK4b0ef4hteFMZbG",
"_createdAt": "2021-09-03T01:09:50Z",
"_updatedAt": "2021-09-03T01:09:57Z",
"assetId": "BSt8QSrjyqUhrEGLnMKBNqGrq8wfBmhwwZH8LyRe74A",
"data": {
"aspect_ratio": "16:9",
"created_at": "1630631394",
"duration": 1.368033,
"id": "BSt8QSrjyqUhrEGLnMKBNqGrq8wfBmhwwZH8LyRe74A",
"master_access": "none",
"max_stored_frame_rate": 29.97,
"max_stored_resolution": "SD",
"mp4_support": "none",
"passthrough": "296f5350-2cf9-40ea-9264-733f3af3ba7d",
[Truncated]
"status": "ready",
"uploadId": "qOpRpZwWIaWniLFIolTiOL5kduC65GPjGLth8xdrPA00",
"id": "-51e61cef-8d54-5622-821d-20e7758f6d6a",
"children": [],
"internal": {
"type": "SanityMuxVideoAsset",
"contentDigest": "bd28bb324a2e85b9d376e57a4220a842",
"owner": "gatsby-source-sanity",
"counter": 651
},
"parent": null
}
},
"_id": "027b7daa-58b1-479c-840e-40baa23f771c"
}
},
]}}}
```
I simply cant find the codeblock who is responsible for putting the clip duration which is burried under _rawAsset.data into the perfect slot right beneath playbackId and thumbTime. |
val-ramon/Web-VM | 575432608 | Title: Problema con los templates y carpeta de archivos static
Question:
username_0: Al estar los templates y static en carpeta separada de los scripts, tiene conflictos Flask al buscarlas
Answers:
username_0: Se solucionó indicándole a Flask donde buscarlas al crear la app, pondiendo que vaya una carpeta hacia atras y luego busque ahí
Status: Issue closed
|
jj1bdx/emprng | 64924148 | Title: Please add PCG
Question:
username_0: http://www.pcg-random.org/
And if the table is true, should probably be the default.
Cheers.
Answers:
username_1: @username_0 the code seems to be simple enough, and I see the code looks quite similar to XorShift*'s. I'll give it a try, probably studying it first and making it as an independent repository (as all the algorithms included here are), and then as a part of emprng. Thx for suggestion.
username_0: Cool, keeps me posted, I am intrigued but nowhere knowledgeable enough to know whether the claims are correct.
username_1: One criticism from <NAME> against PCG. http://v8project.blogspot.jp/2015/12/theres-mathrandom-and-then-theres.html?showComment=1452592903162#c1549004517443909784
username_1: According to the later development of PCG .vs. Xorshift\*/+, I conclude, for the time being as of September 2016, that PCG will not be included in the "rand" module candidate, due to the following facts:
* Benchmarking of PCG by <NAME> does not indicate PCG's substantial advantage against Xorshift\*/+ (See <http://xoroshiro.di.unimi.it/#quality>)
* PCG's author has not publicly compare the results with exsplus (Xorshift116+) and exs1024 (Xorshift1024*) algorithms
* exs64 (Xorshift64*) has been phased out from Sebastiano Vigna's latest (as of September 2016) algorithm choice
Note: the exs64 code will remain in the rand module to use it as the initialization function of generating longer seed from the given three-element integers (See https://github.com/username_1/emprng/blob/0.5.0/src/rand.erl#L311L313 for the details)
username_1: Issue closed for the time being; any further development of PCG may result in reopening the issue.
Status: Issue closed
username_0: Good enough reasons, thanks! |
VoyagerScientific/react-jsonschema-form-ui | 799508368 | Title: ReactPhotoGalleryField needs to accept onAcceptedFiles as a prop.
Question:
username_0: In the responsevault app, I have a function for the ReactDropZoneWidget that uploads the files to S3 via network request. When I use the ReactPhotoGalleryField in the app, I need to be able to pass down a custom function for onAcceptedFiles through the defaultProps Option. I'm already using defaultProps.
in ReactPhotoGalleryField/index.js
```js
{!isDisabled && (
<UploadComponent
isReading={isReading}
accepted={["image/*"]}
onAcceptedFiles={onAcceptedFiles}
className={"d-print-none"}
/>
)}
```
in the responsevault app
```js
const fileUploadProps = {
options: {
"fileUploadUrl": `/forms/${props.form.hash_id}/update_attachments`,
"authenticity_token": props.authenticity_token
}
}
ReactDropZoneWidget.defaultProps = fileUploadProps;
```
Then in the app's ReactDropZoneWidget
```js
_onDrop(acceptedFiles){
const fileUploadUrl = this.state.options.fileUploadUrl || "/handleFileUpload";
this.setState({isSaving: true});
// console.log("Send these to the server: ", acceptedFiles);
var data = new FormData()
for (const file of acceptedFiles) {
data.append('attachments', file, file.name)
}
data.append('authenticity_token', this.state.options.authenticity_token);
fetch(fileUploadUrl, {
method: "POST",
headers: {
"Accept": 'application/json',
'X-CSRF-Token': this.state.options.authenticity_token
},
body: data
})
.then((response) => {
if(response.status === 200){
response.json().then(data => {
// console.log(data);
this.state.attachments.push(data);
this.setState({attachments: this.state.attachments, isSaving: false});
this.state.onChange(this.state.attachments);
});
}else{
this.setState({isSaving: false});
alert("The file failed to save. Try again.")
}
}).catch(
error => console.log(error) // Handle the error response object
);
}
```
It would be good to be able to add a setting to the drop zone widget where the widget defaults to saving as base64 like it does now, but also takes an option to save externally with a URL and headers(the authenticity token).<issue_closed>
Status: Issue closed |
woocommerce/woocommerce | 1165783639 | Title: [Enhancement]: Look Up Country and State
Question:
username_0: ### Describe the solution you'd like
### Quick summary
On checkout when folks enter their zip code to calculate shopping the state is not updated, for example, [https://d.pr/i/3lWPY4](https://d.pr/i/3lWPY4)
Example site: [https://shop.tumblr.com/cart/](https://shop.tumblr.com/cart/)
Is it possible to update the state when a zip code is entered, please?
If so, could this be expanded for folks in other countries, for example, if someone in the UK enters just their post code, their county is updated.
### Steps to reproduce
1. Visit [https://shop.tumblr.com/](https://shop.tumblr.com/) and go to 'Browse Shop'
2. Select an item and add to Cart.
3. Click 'View Cart'
4. Click 'Calculate Shipping'
5. Enter a non-Arizona zip code (90202 for example).
6. Press 'Update'
7. Note that Arizona is still the selected state despite the zip code that was entered is in California.
### What you expected to happen
We would like the state to be updated when a zip code is entered.
### What actually happened
The default state was retained.
### Describe alternatives you've considered
_No response_
### Additional context
Original issue: https://github.com/Automattic/wp-calypso/issues/61811
Answers:
username_1: Hi @username_0,
Thank you for taking the time to share this idea, we really appreciate your help.
Side note: for something like that to work we'll probably need to integrate with local APIs or carries in each country to be able to identify the correct list of postcodes for each region. While it may be very helpful it sounds out of the scope of the core plugin, this could be a nice addition for WooCommerce Services. For Brazil I wrote a 3rd party plugin to help fill addresses based in a Brazilian postcode, there's also some other plugins like that in the WordPress plugins repository.
I'm leaving for the core team to evaluate this enhancement.
Thanks! |
julien-gargot/kirby-devkit | 164554291 | Title: better out-of-the-box experience
Question:
username_0: Shouldn't we add the output code to the social network menu ?
Something link this, in the footer :
```
<ul>
<?php foreach($site->socialnetworks()->toStructure() as $social): ?>
<li>
<a href="<?php echo $social->link() ?>">
<i class="fa <?php echo $social->icon()?>" aria-hidden="true"></i>
</a>
</li>
<?php endforeach ?>
</ul>
```
Answers:
username_0: Also, maybe a bit of basic type to get started with just enough to not have to write everything from scratch all the time. A very simple css < 15 lines with barely enough, in the spirit of normalize, especially if we abandon bootstrap by default.
username_0: We should also probably set `c::set('debug',true);` in `config.{localhost}.php`
username_0: just did "debug:true" : 0b3d2313e834e7bc4766c3f60f25dd50a95fd6d7
Seemed appropriate considering the purpose of this file
username_1: Totally agree on the debug variable.
For the social networks, I feel like it’s better to remove them from the site settings. It’s not relevant to a lot of websites. Especially all the ones who don’t give a s*** of helping private companies to scrap users data. ;) ?
username_1: Removed social networks.
Status: Issue closed
|
moby/moby | 620645686 | Title: `docker build` hangs on FROM line
Question:
username_0: ```
The cursor just hangs on a newline, showing no output.
**Describe the results you expected:**
`docker build` to execute the lines in the Dockerfile.
**Additional information you deem important (e.g. issue happens only occasionally):**
`docker build` was working fine for me all day. I went to make dinner, came back, and now it hangs.
This also happened to me on another machine - `docker build` had been working fine for months, then one day it started hanging.
This happens both when swarm mode is active and not.
**Output of `docker version`:**
```
Client:
Version: 19.03.6
API version: 1.40
Go version: go1.12.17
Git commit: 369ce74a3c
Built: Fri Feb 28 23:45:43 2020
OS/Arch: linux/amd64
Experimental: false
Server:
Engine:
Version: 19.03.6
API version: 1.40 (minimum version 1.12)
Go version: go1.12.17
Git commit: 369ce74a3c
Built: Wed Feb 19 01:06:16 2020
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.3.3-0ubuntu1~18.04.2
GitCommit:
runc:
Version: spec: 1.0.1-dev
GitCommit:
docker-init:
Version: 0.18.0
GitCommit:
```
Also seen on:
```
Client: Docker Engine - Community
Version: 19.03.8
API version: 1.40
Go version: go1.12.17
Git commit: afacb8b7f0
Built: Wed Mar 11 01:25:46 2020
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
[Truncated]
Architecture: x86_64
CPUs: 4
Total Memory: 15.66GiB
Name: [redacted]
ID: WV76:MUZJ:KSJC:USSR:V5TI:EAPR:JRJT:5KNY:2ARO:347H:QF25:3NA7
Docker Root Dir: /var/lib/docker
Debug Mode: false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
WARNING: No swap limit support
```
**Additional environment details (AWS, VirtualBox, physical, etc.):**
These are both on-prem virtual machines.
Answers:
username_1: Are you able to reproduce this issue on the current patch release of 19.03? (19.03.9 at time of writing).
Docker 19.03.7 and up have a fix for a deadlock in the builder when using BuildKit (see the [release notes](https://docs.docker.com/engine/release-notes/#19037), and the related pull-request: https://github.com/moby/moby/pull/40557
username_1: oh, I just see your second `docker version` shows 19.03.8. 🤔
Just a random thought; have you tried running `docker builder prune`, to cleanup build cache?
username_0: ```docker builder prune
WARNING! This will remove all dangling build cache. Are you sure you want to continue? [y/N] y
Total reclaimed space: 0B```
Did not help.
username_0: @username_1 Any idea what might be going on?
username_1: No, can't tell from the information that's here.
- Are you seeing the same both with `DOCKER_BUILDKIT=1` and with `DOCKER_BUILDKIT=0` ?
- Is there anything in the daemon or system logs?
- Is build only failing with that specific image, or also with other images?
- You mention "These are both on-prem virtual machines."; are you connecting to all of those VM's from the same CLI, or using a CLI inside the VM?
username_0: Not sure what you mean by "connecting to all of those VMs from the same CLI". I'm SSHing into the VMs then running `docker` commands while SSH'd into them.
username_2: @username_1 @username_0 I have experienced this exact behavior on my local machine after updating to Ubuntu 20.04. One thing to add that I don't see mentioned anywhere else in this thread is that `sudo docker build` works fine for me, and the solution of `DOCKER_BUILDKIT=1` also works without `sudo`. I have included relevant information below, including a snippet from `strace docker build`.
<details>
<summary>docker info</summary>
```
Client:
Debug Mode: false
Server:
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 4
Server Version: 19.03.13
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 8fba4e9a7d01810a393d5d25a3621dc101981175
runc version: dc9208a3303feef5b3839f4323d9beb36df0a9dd
init version: fec3683
Security Options:
apparmor
seccomp
Profile: default
Kernel Version: 5.4.0-48-generic
Operating System: Ubuntu 20.04.1 LTS
OSType: linux
Architecture: x86_64
CPUs: 12
Total Memory: 15.29GiB
Docker Root Dir: /var/lib/docker
Debug Mode: false
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
```
</details>
<details>
<summary>strace docker build</summary>
After a bunch of `EPERM (Operation not permitted)` I just get the following forever:
```
futex(0x562d31cc5748, FUTEX_WAIT_PRIVATE, 0, NULL) = 0
futex(0x562d31cc5748, FUTEX_WAIT_PRIVATE, 0, NULL) = 0
futex(0x562d31cc5748, FUTEX_WAIT_PRIVATE, 0, NULL) = 0
futex(0x562d31cc5748, FUTEX_WAIT_PRIVATE, 0, NULL) = 0
futex(0x562d31cc5748, FUTEX_WAIT_PRIVATE, 0, NULL) = 0
futex(0x562d31cc5748, FUTEX_WAIT_PRIVATE, 0, NULL) = 0
```
</details>
username_1: Closing as this went stale, but if you are still running into this, and think there's a bug at hand (and have ways to reproduce), feel free to open a new ticket
Status: Issue closed
|
jeanropke/RDR2CollectorsMap | 506224677 | Title: Marker For Treasure Hunter Locations
Question:
username_0: Spot for treasure hunter locations
Answers:
username_1: Treasure Hunter Locations: always found on cliff edges near treasure map search areas.
Treasure Hunter, The Heartlands: On the cliff's edge around dusk Monday :
lat: -66.37510692265303
lng: 114.578125
https://youtu.be/9bhPMTCq_uk
Treasure Hunter, Cumberland Falls: on cliff edge near Cumberland Falls around afternoon Wednesday.
lat: -57.20290953465374
lng: 93.96875
https://youtu.be/B6-dUHzeq50
Treasure Hunter, Little Creek: On a cliff by little creek river near Wallace station
lat: -59.17067722335054
lng: 89.9765625
Treasure Hunter, Riggs Station: on a cliff looking toward Riggs Station
lat: -69.921875
lng: 94.5078125
Treasure Hunter, Dakota River: on a cliff looking toward Dakota river
lat: -61.28125
lng: 91.2734375
Treasure Hunter, Monto’s Nest: on a cliff looking toward Monto’s Nest 8pm in game time
lat: -65.2734375
lng: 85.734375
Treasure Map Locations, found at night, stuck to trees. Look for lantern light
Treasure Map, Del Lobo Rock:
lat: -119.39959906882154
lng: 53.5078125
Treasure Map, Cumberland Forrest:
lat: -47.6171875
lng: 112.2109375
Treasure Map, The Heartlands
lat: -63.328125
lng: 128.328125
Treasure Map, Hanging Rock
lat: -98.6328125
lng: 57.71875
Treasure Map: Dewberry Creek
lat: -63.1796875
lng: 128.1640625
Grave Digger Treasure Map Hunts:
Grave Digger, Saint Denis
lat: -80.265625
lng: 154.0546875
Grave Digger, Strawberry
lat: -67.21875
lng: 83.9765625
Grave Digger, Valentine
lat: -50.8984375
lng: 107.8046875
Status: Issue closed
|
riot/riot | 123080191 | Title: riot.mount(jQuery, tagName, [opts])
Question:
username_0: what about
```
riot.mount(jQuery, tagName, [opts])
```
?
Answers:
username_1: what about `riot.mount($('#my-fancy-id')[0], 'my-tag', opts)`? We don't need to reinvent the wheel jquery is just javascript and riot plays well with it like with any other js framework. I am closing this issue hoping my suggestion was enough
Status: Issue closed
|
noironetworks/neutron | 148209725 | Title: init/upstart file miising for mcast_daemon
Question:
username_0: I am opening it here because I could not open this in opflex. mcast_daemon does not start on boot and is needed in vxlan mode. This causes ARP not to propogate.
In RedHat/CentOS there is a systemd file that gets installed when we install the agent-ovs RPM and it is enabled to start at boot. I do not see any upstart or SysVinit file in .deb version, so I guess this is a packaging issue not a puppet issue.
Answers:
username_0: I created /etc/init/mcast-daemon.conf with below content and it is all good now:
#Content
description "Opflex multicast Agent"
start on (local-filesystems)
stop on runlevel [!2345]
kill signal SIGINT
respawn
respawn limit 10 5
pre-start script
test -x /usr/bin/mcast_daemon || { stop; exit 0; }
test -e /etc/opflex-agent-ovs/opflex-agent-ovs.conf || { stop; exit 0; }
end script
exec /usr/bin/mcast_daemon --syslog --daemon
username_0: actually the mcast-daemon is not enabled to start on boot on CentOS/RedHat. I guess agent-ovs is responsible for starting it.
systemctl is-enabled mcast-daemon
disabled
Status: Issue closed
|
iknow/iknow_view_models | 275673290 | Title: Make `changes` robust to typos and string/symbol confusion.
Question:
username_0: We often inspect `changes` in access control definitions as values, which means we can mix strings and symbols, and also have unchecked typos render policies ineffective.
Define an API for `changes` so that every comparison has the chance to be string/symbol coerced, and checked against the defined properties of that model. |
mrvux/dx11-vvvv | 33755236 | Title: RWTexture2D / RWTexture3D does not create pin in fx node
Question:
username_0: Trying to port some cool effects here, but seems RWTexture2D and RWTexture3D are not supported for compute shaders. Would be nice, though.
Simple example fx shader:
````
RWTexture2D<float4> output : register (u0);
Texture3D<float4> speed : register (t0);
RWTexture3D<float4> speedRW : register (u0);
[numthreads(16, 4, 4)]
void CS_Example( uint3 Gid : SV_GroupID, uint3 i : SV_DispatchThreadID, uint3 GTid : SV_GroupThreadID, uint GI : SV_GroupIndex )
{
return;
}
technique11 Example
{
pass P0
{
SetComputeShader( CompileShader( cs_5_0, CS_Example() ) );
}
}`
````<issue_closed>
Status: Issue closed |
appwrite/appwrite | 1149698702 | Title: 🚀 Feature: Make users searchable using email
Question:
username_0: ### 🔖 Feature description
**This feature is meant for the server SDKs.**
I think it's an important feature to make users searchable using their email addresses. Something like
```JS
const users = new sdk.Users(appwrite);
users.search('<EMAIL>');
```
would be really useful.
A related feature would be to make users searchable using their preferences or name, but I think those wouldn't be as useful as this.
### 🎤 Pitch
Let's say I'm making an invitation system for users. Currently, I have to create a collection containing all user ids + their email addresses. This collection has to always be kept up to date when let's say a user changes their email address.
If my idea would be implemented I could just query the user using their email address with information already in the database.
This would of course scale better since I won't need to save the same information twice, but also be more reliable (see example above).
### 👀 Have you spent some time to check if this issue has been raised before?
- [X] I checked and didn't find similar issue
### 🏢 Have you read the Code of Conduct?
- [X] I have read the [Code of Conduct](https://github.com/appwrite/appwrite/blob/HEAD/CODE_OF_CONDUCT.md)
Answers:
username_1: There is a search parameter in the list users api call: https://appwrite.io/docs/server/users#usersList
would that work for you?
username_0: I think? How exactly would I write a search query to check for email or name?
username_1: Considering [this](https://github.com/appwrite/sdk-for-node/blob/master/lib/services/users.js#L21) is the function signature, possibly:
```javascript
const users = new sdk.Users(appwrite);
users.list('<EMAIL>');
```
username_1: Were you able to try the search?
username_0: Yeah, it kind of works. The syntax is this:
```TS
const users = new sdk.Users(appwrite);
console.log(await users.list(Query.equal('email', '<EMAIL>')));
```
But the problem is that the search is not really "exact" enough if you can call it that. Lets say I have two users: "<EMAIL>" and "<EMAIL>". If I search for "<EMAIL>" I get only that user, but if I search for "<EMAIL>" I get both users.
username_1: You should definitely only be passing the search term rather than `Query.equal('email', '<EMAIL>')`. However, I do see that pass `"<EMAIL>"` causes a 500 error. This sounds related to https://github.com/appwrite/appwrite/issues/2394 since the search mode has been changed back to boolean mode.
For now, the workaround is to wrap in double quotes, like `'""<EMAIL>""'`, however, it would be nice if Appwrite handled this automatically.
username_1: Related PR: https://github.com/utopia-php/database/pull/113.
After this PR is merged, I would assume this would work:
```javascript
const users = new sdk.Users(appwrite);
console.log(await users.list('<EMAIL>');
```
FYI, searching for `<EMAIL>` might be returning both because words less than 3 characters are ignored so it's actually only searching for `appwrite`.
username_2: 0.13.3 got released and this should be fixed now 👏🏻
One downside of the current approach is that you would need to wrap the email in quotes. Reference => https://github.com/appwrite/appwrite/issues/2394#issuecomment-1067882013
username_2: ### 🔖 Feature description
**This feature is meant for the server SDKs.**
I think it's an important feature to make users searchable using their email addresses. Something like
```JS
const users = new sdk.Users(appwrite);
users.search('<EMAIL>');
```
would be really useful.
A related feature would be to make users searchable using their preferences or name, but I think those wouldn't be as useful as this.
### 🎤 Pitch
Let's say I'm making an invitation system for users. Currently, I have to create a collection containing all user ids + their email addresses. This collection has to always be kept up to date when let's say a user changes their email address.
If my idea would be implemented I could just query the user using their email address with information already in the database.
This would of course scale better since I won't need to save the same information twice, but also be more reliable (see example above).
### 👀 Have you spent some time to check if this issue has been raised before?
- [X] I checked and didn't find similar issue
### 🏢 Have you read the Code of Conduct?
- [X] I have read the [Code of Conduct](https://github.com/appwrite/appwrite/blob/HEAD/CODE_OF_CONDUCT.md)
username_2: Actually I am gonna re-open this issue again - until we allow proper filtering by an email 👍🏻 |
python/psf-salt | 54081981 | Title: gzip off?
Question:
username_0: Is there a reason I'm not thinking of that gzip is turned off?
https://github.com/python/psf-salt/blob/master/salt/pydotorg/config/pydotorg.nginx.jinja#L264
This hurts site performance quite a bit, was wondering if it was there by mistake.
psf-salt frank]$ curl -I -H 'Accept-Encoding: gzip,deflate' https://www.python.org/
HTTP/1.1 200 OK
Date: Mon, 12 Jan 2015 17:27:34 GMT
Server: nginx
Content-Type: text/html; charset=utf-8
X-Frame-Options: SAMEORIGIN
Content-Length: 46032
Accept-Ranges: bytes
Via: 1.1 varnish
Age: 2865
X-Served-By: cache-dfw1834-DFW
X-Cache: HIT
X-Cache-Hits: 33
Vary: Cookie
Public-Key-Pins: max-age=600; includeSubDomains; pin-sha256="WoiWRyIOVNa9ihaBciRSC7XHjliYS9VwUGOIud4PB18="; pin-sha256="5C8kvU039KouVrl52D0eZSGf4Onjo4Khs8tmyTlV3nU="; pin-sha256="5C8kvU039KouVrl52D0eZSGf4Onjo4Khs8tmyTlV3nU="; pin-sha256="lCppFqbkrlJ3EcVFAkeip0+44VaoJUymbnOaEUk7tEU="; pin-sha256="TUDnr0MEoJ3of7+YliBMBVFB4/gJsv5zO7IxD9+YoWI="; pin-sha256="x4QzPSC810K5/cMjb05Qm4k3Bw5zBn4lTdO/nEW/Td4=";
Strict-Transport-Security: max-age=63072000; includeSubDomains
gzip should take say the front page content down from 45K to 9K which is a big win on mobile, results will be even better/greater for things like the site CSS and JS.
Answers:
username_1: Maybe due to BREACH mitigation. @username_2, you know? If so, maybe we should only turn off gzip when there's a 3-rd party referrer per https://community.qualys.com/blogs/securitylabs/2013/08/07/defending-against-the-breach-attack.
username_2: BREACH mitigation is the only thing I can think of. It's super easy to turn it on for things like static files and the like since they will never have secret data in them. For the actual pages themselves I'm not sure of the state of the art in BREACH mitigation if there's a good way of actually handling that or not.
username_0: Yeah gzip even for just the static assets would be a big win on performance.
username_2: It might be worth handling gzip on the Fastly side of things fwiw. I believe Fastly will only cache one object then and dynamically do the gziping for us instead of needing to cache 2 objects, one with compression and one without.
username_0: Yep that's what I was thinking too. I'm not super familiar with Fastly's interface, but I could take a stab at changing the config this weekend when traffic is lower.
username_1: I enabled Fastly gzip on static mime types.
username_0: Hmmm I'm still seeing uncompressed css and in fact, it seems Fastly isn't caching these at all as it is always a miss. Check out:
curl -I https://www.python.org/
curl -I https://www.python.org/static/stylesheets/style.css
curl -I https://www.python.org/static/stylesheets/mq.css
curl -I https://www.python.org/static/js/libs/masonry.pkgd.min.js
username_1: Curl doesn't send the `Accept-Encoding` header by default.
```
% curl -I -H 'Accept-Encoding: gzip,deflate' https://www.python.org/static/stylesheets/style.css
HTTP/1.1 200 OK
Server: nginx
Content-Type: text/css
Last-Modified: Thu, 16 Apr 2015 20:31:00 GMT
ETag: "55301c04-46683"
Cache-Control: max-age=604800, public
X-Clacks-Overhead: GNU Terry Pratchett
Content-Encoding: gzip
Content-Length: 110709
Accept-Ranges: bytes
Date: Sat, 02 May 2015 16:25:26 GMT
Via: 1.1 varnish
Age: 53490
Connection: keep-alive
X-Served-By: cache-atl6226-ATL
X-Cache: HIT
X-Cache-Hits: 14
Vary: Accept-Encoding
Public-Key-Pins: max-age=600; includeSubDomains; pin-sha256="WoiWRyIOVNa9ihaBciRSC7XHjliYS9VwUGOIud4PB18="; pin-sha256="5C8kvU039KouVrl52D0eZSGf4Onjo4Khs8tmyTlV3nU="; pin-sha256="5C8kvU039KouVrl52D0eZSGf4Onjo4Khs8tmyTlV3nU="; pin-sha256="lCppFqbkrlJ3EcVFAkeip0+44VaoJUymbnOaEUk7tEU="; pin-sha256="TUDnr0MEoJ3of7+YliBMBVFB4/gJsv5zO7IxD9+YoWI="; pin-sha256="x4QzPSC810K5/cMjb05Qm4k3Bw5zBn4lTdO/nEW/Td4=";
Strict-Transport-Security: max-age=63072000; includeSubDomains
```
username_1: Better yet, just look in browser devtools.
Status: Issue closed
username_0: Yep you're right, for some reason I always forget curl doesn't send that header. YSlow was showing them as not gzipped as well, but it does seem it's working fine. Thanks! |
spring-projects/spring-boot | 594883492 | Title: Reactive Repositories are not supported after upgrade to spring boot 2.3.0.M4
Question:
username_0: Spring data jpa, this code work fine in spring boot 2.2.
` @Async
fun findByIdIn(ids: List<Long>): CompletableFuture<List<Role>>`
After upgrade to 2.3.0.M4 I got exception
` by: org.springframework.dao.InvalidDataAccessApiUsageException: Reactive Repositories are not supported by JPA. Offending repository is org.appsugar.archetypes.repository.RoleRepository!
at org.springframework.data.repository.config.RepositoryConfigurationExtensionSupport.useRepositoryConfiguration(RepositoryConfigurationExtensionSupport.java:367)
at org.springframework.data.repository.config.RepositoryConfigurationExtensionSupport.getRepositoryConfigurations(RepositoryConfigurationExtensionSupport.java:107)
at org.springframework.data.repository.config.RepositoryConfigurationDelegate.registerRepositoriesIn(RepositoryConfigurationDelegate.java:148)
at org.springframework.data.repository.config.RepositoryBeanDefinitionRegistrarSupport.registerBeanDefinitions(RepositoryBeanDefinitionRegistrarSupport.java:107)
at org.springframework.context.annotation.ConfigurationClassBeanDefinitionReader.lambda$loadBeanDefinitionsFromRegistrars$1(ConfigurationClassBeanDefinitionReader.java:385)
at java.util.LinkedHashMap.forEach(LinkedHashMap.java:684)
at org.springframework.context.annotation.ConfigurationClassBeanDefinitionReader.loadBeanDefinitionsFromRegistrars(ConfigurationClassBeanDefinitionReader.java:384)
at org.springframework.context.annotation.ConfigurationClassBeanDefinitionReader.loadBeanDefinitionsForConfigurationClass(ConfigurationClassBeanDefinitionReader.java:148)
at org.springframework.context.annotation.ConfigurationClassBeanDefinitionReader.loadBeanDefinitions(ConfigurationClassBeanDefinitionReader.java:120)
at org.springframework.context.annotation.ConfigurationClassPostProcessor.processConfigBeanDefinitions(ConfigurationClassPostProcessor.java:331)
at org.springframework.context.annotation.ConfigurationClassPostProcessor.postProcessBeanDefinitionRegistry(ConfigurationClassPostProcessor.java:236)
at org.springframework.context.support.PostProcessorRegistrationDelegate.invokeBeanDefinitionRegistryPostProcessors(PostProcessorRegistrationDelegate.java:275)
at org.springframework.context.support.PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(PostProcessorRegistrationDelegate.java:95)
at org.springframework.context.support.AbstractApplicationContext.invokeBeanFactoryPostProcessors(AbstractApplicationContext.java:706)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:532)
at org.springframework.boot.web.reactive.context.ReactiveWebServerApplicationContext.refresh(ReactiveWebServerApplicationContext.java:67)
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:758)
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:750)
at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:397)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:315)
at org.springframework.boot.test.context.SpringBootContextLoader.loadContext(SpringBootContextLoader.java:122)`
Answers:
username_1: Thanks for the report. The error message is accurate in that reactive repositories are not supported by Spring Data JPA. Perhaps you're saying that your `RoleRepository` isn't a reactive repository and it's now being incorrectly identified as one? If that's the case you may have found a bug in Spring Data JPA. They use [JIRA](https://jira.spring.io/browse/DATAJPA) for issue tracking so please raise an issue there if that's the case.
Status: Issue closed
|
projectsyn/commodore | 725504698 | Title: Define a Kapitan target per component
Question:
username_0: ## Context
We've found some instances (e.g. #156) where it would be beneficial to have a Kapitan target per component. For #156, having specific targets per component would allow us to reduce the amount of information that must be provided for the postprocessing filter definition (e.g. the component defining the filter would be clear based on the target).
There are some challenges in the implementation, if we want to make this change in a backwards-compatible manner. The current architecture relies on the single target Kapitan inventory for a number of features, the big ones being the dynamic hierarchy and component discovery. Additionally, some approaches for implementing this change would require refactoring all component classes.
Below we outline an approach which should be backwards compatible for the dynamic hierarchy and component discovery implementation, while not requiring any refactoring in the existing components.
## Proposal
The best approach which doesn't require component refactoring and allows us to reuse the current implementation for the dynamic hierarchy and component discovery is to reorganize the Kapitan inventory slightly.
The new inventory structure will be constructed with empty files in `classes/components/` for each component. This way, the existing class includes of form `components.<component-name>` do not pull in the component class which has the `parameters.kapitan` key anymore. The actual component classes will be made available in `classes/_components` (exact naming TBD).
With this inventory structure, each target can have the dynamic hierarchy class include of `global.commodore` without defining compilation instructions for each component. Each target still needs to include all component default classes, to ensure all inventory references can be resolved. Additionally each target will need to include class `_components.<component-name>` to pull in the Kapitan compile instructions for the targeted component.
A target will have the following form:
```
classes:
- [ ... all component defaults for the cluster ... ]
- global.commodore
- _components.<comonent-name>
parameters:
kapitan:
vars:
target: <component-name>
```
## Alternatives
An alternative approach which requires refactoring of all components would be to change components to define their Kapitan configuration in `parameters.<component-name>.kapitan` instead of `parameters.kapitan`. This allows us to continue using the component classes in the hierarchy exactly the same way as previously.
Commodore could then generate individual targets per component where `parameters.kapitan` is extended as follows
```
parameters:
kapitan: ${<component_name>:kapitan}
```
Each component is then responsible that their `parameters.<component-name>.kapitan` entry has `vars.target` set to `<component-name>`.
Answers:
username_1: Reclass also has the concept of [aplications](https://reclass.pantsfullofunix.net/concepts.html) (basically a list of strings?). Maybe we can use this to specify the components to include in the hierarchy? (To prevent creating these empty class files).
This would require a refactoring of the whole inventory and moving the `components.$component_name` includes to the `applications:` array.
This could also allow the removal of components further "down" the hierarchy by using the `~` prefix in the `applications` array (xref #71 ).
username_0: Thanks for the hint about applications, I'll have a look at those as well. Looks like that approach might work for component includes in the hierarchy.
username_1: I'm not sure if there's anything special about the `applications` array. We could also call it `components` for example:
```
classes:
- cloud.cloudscale
components:
- csi-cloudscale
parameters:
csi_cloudscale:
some: value
```
username_1: Basically the idea boils down to having a separate data structure to define components which should be included (instead of using classes directly) and having Commodore generate the appropriate class includes for each component.
username_0: Turns out it needs to be called `applications` for the reclass magic to work, cf. https://github.com/kapicorp/reclass/blob/1869c478624b37d3479d6c4ea4769dc9ec41fadd/reclass/core.py#L253-L284
username_1: I also did a quick test with `components` but this (obviously in hindsight) doesn't work since only things in `classes`, `applications` and `parameters` are merged together (the rest is dropped).
username_0: There's also some interesting (buggy?) behavior with regard to reclass's documented feature of prefixing entries in applications with a `~`: due to the way the recursive processing of the applications field is managed, dropping entries doesn't always work.
For example, with the following snippets, the final value of `applications` for `targets/test.yml` is `["argocd", "resource-locker", "steward", "storageclass"]`.
```
# targets/test.yml
classes:
- global.kubernetes
- tenant.cluster
```
```
# global/kubernetes.yml
applications:
- argocd
- resource-locker
- steward
- storageclass
```
```
# tenant/cluster.yml
applications:
- ~storageclass
```
I've spent a good amount of time investigating this issue in reclass, and have found the cause in https://github.com/projectsyn/reclass/blob/2585bfc620ddd8c2cd7d159c4eb6d117a526a819/reclass/core.py#L148-L159, where the calls to `_recurse_entity` while processing the entries in `classes` are passed `merge_base=None`, which has the effect that the `applications` field is processed in isolation for each class included in the same file (class or target). Since entries prefixed with `~` in applications are not preserved across calls, but immediately resolved during the calls to `merge_base.merge()`, we get the behavior outlined above.
The fix appears to be to change the linked snippet to the version present in https://github.com/projectsyn/reclass/tree/fix/application-removal. Note that this change needs https://github.com/kapicorp/reclass/pull/4 to be merged to work correctly.
username_0: Implemented in #227.
Status: Issue closed
|
moloch--/RootTheBox | 380632155 | Title: Design problem - display the description of the box
Question:
username_0: There is a problem in the display the description of the box when enabling "Autoformat Description" it breaks the statements!!!
I sent an email for the issue with some pics to <EMAIL>
Thanks
Answers:
username_1: @username_0 I pushed a change to the autoformat. Can you verify it resolves your issue?
username_0: /admin/view/game_objects - 404
/admin/view/game_levels - 404
/admin/upgrades/source_code_market - 404
http://x.x.x.x/user - 404
http://x.x.x.x/user/missions - 404
http://x.x.x.x/teams - 404
username_0: [E 181115 21:43:07 web:1670] Uncaught exception GET /admin/view/game_objects (x.x.x.x)
HTTPServerRequest(protocol='http', host='x.x.x.x', method='GET', uri='/admin/view/game_objects', version='HTTP/1.1', remote_ip='x.x.x.x')
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/tornado/web.py", line 1590, in _execute
result = method(*self.path_args, **self.path_kwargs)
File "/home/ubuntu/RootTheBox/libs/SecurityDecorators.py", line 63, in wrapper
return method(self, *args, **kwargs)
File "/home/ubuntu/RootTheBox/libs/SecurityDecorators.py", line 38, in wrapper
return method(self, *args, **kwargs)
File "/home/ubuntu/RootTheBox/libs/SecurityDecorators.py", line 93, in wrapper
return method(self, *args, **kwargs)
File "/home/ubuntu/RootTheBox/handlers/AdminHandlers/AdminGameObjectHandlers.py", line 362, in get
self.render(uri[args[0]], errors=None)
File "/usr/local/lib/python2.7/dist-packages/tornado/web.py", line 766, in render
html = self.render_string(template_name, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/tornado/web.py", line 907, in render_string
return t.generate(**namespace)
File "/usr/local/lib/python2.7/dist-packages/tornado/template.py", line 346, in generate
return execute()
File "admin/view/game_objects_html.generated.py", line 160, in _tt_execute
for box in Box.all(): # admin/view/game_objects.html:263 (via main.html:27)
File "/home/ubuntu/RootTheBox/models/Box.py", line 109, in all
return dbsession.query(cls).all()
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/orm/query.py", line 2843, in all
return list(self)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/orm/query.py", line 2995, in __iter__
return self._execute_and_instances(context)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/orm/query.py", line 3018, in _execute_and_instances
result = conn.execute(querycontext.statement, self._params)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/base.py", line 948, in execute
return meth(self, multiparams, params)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/sql/elements.py", line 269, in _execute_on_connection
return connection._execute_clauseelement(self, multiparams, params)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/base.py", line 1060, in _execute_clauseelement
compiled_sql, distilled_params
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/base.py", line 1200, in _execute_context
context)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/base.py", line 1413, in _handle_dbapi_exception
exc_info
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/util/compat.py", line 265, in raise_from_cause
reraise(type(exception), exception, tb=exc_tb, cause=cause)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/base.py", line 1193, in _execute_context
context)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/default.py", line 509, in do_execute
cursor.execute(statement, parameters)
File "/usr/local/lib/python2.7/dist-packages/MySQLdb/cursors.py", line 205, in execute
self.errorhandler(self, exc, value)
File "/usr/local/lib/python2.7/dist-packages/MySQLdb/connections.py", line 36, in defaulterrorhandler
raise errorclass, errorvalue
OperationalError: (_mysql_exceptions.OperationalError) (1054, "Unknown column 'box.flag_submission_type' in 'field list'") [SQL: u'SELECT box.id AS box_id, box.created AS box_created, box.uuid AS box_uuid, box.corporation_id AS box_corporation_id, box.category_id AS box_category_id, box._name AS box__name, box._operating_system AS box__operating_system, box._description AS box__description, box._difficulty AS box__difficulty, box.game_level_id AS box_game_level_id, box._avatar AS box__avatar, box.autoformat AS box_autoformat, box.garbage AS box_garbage, box.flag_submission_type AS box_flag_submission_type \nFROM box'] (Background on this error at: http://sqlalche.me/e/e3q8)
[E 181115 21:43:07 BaseHandlers:192] Request from x.x.x.x resulted in an error code 500:
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/tornado/web.py", line 1590, in _execute
result = method(*self.path_args, **self.path_kwargs)
File "/home/ubuntu/RootTheBox/libs/SecurityDecorators.py", line 63, in wrapper
return method(self, *args, **kwargs)
File "/home/ubuntu/RootTheBox/libs/SecurityDecorators.py", line 38, in wrapper
return method(self, *args, **kwargs)
File "/home/ubuntu/RootTheBox/libs/SecurityDecorators.py", line 93, in wrapper
return method(self, *args, **kwargs)
[Truncated]
return connection._execute_clauseelement(self, multiparams, params)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/base.py", line 1060, in _execute_clauseelement
compiled_sql, distilled_params
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/base.py", line 1200, in _execute_context
context)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/base.py", line 1413, in _handle_dbapi_exception
exc_info
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/util/compat.py", line 265, in raise_from_cause
reraise(type(exception), exception, tb=exc_tb, cause=cause)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/base.py", line 1193, in _execute_context
context)
File "/usr/local/lib/python2.7/dist-packages/sqlalchemy/engine/default.py", line 509, in do_execute
cursor.execute(statement, parameters)
File "/usr/local/lib/python2.7/dist-packages/MySQLdb/cursors.py", line 205, in execute
self.errorhandler(self, exc, value)
File "/usr/local/lib/python2.7/dist-packages/MySQLdb/connections.py", line 36, in defaulterrorhandler
raise errorclass, errorvalue
OperationalError: (_mysql_exceptions.OperationalError) (1054, "Unknown column 'box.flag_submission_type' in 'field list'") [SQL: u'SELECT box.id AS box_id, box.created AS box_created, box.uuid AS box_uuid, box.corporation_id AS box_corporation_id, box.category_id AS box_category_id, box._name AS box__name, box._operating_system AS box__operating_system, box._description AS box__description, box._difficulty AS box__difficulty, box.game_level_id AS box_game_level_id, box._avatar AS box__avatar, box.autoformat AS box_autoformat, box.garbage AS box_garbage, box.flag_submission_type AS box_flag_submission_type \nFROM box'] (Background on this error at: http://sqlalche.me/e/e3q8)
[E 181115 21:43:07 web:2162] 500 GET /admin/view/game_objects (x.x.x.x) 50.62ms
username_1: Sorry, there was a version change since your last git update. Run this SQL on your DB.
```
ALTER TABLE `rootthebox`.`box`
ADD COLUMN `flag_submission_type` enum('CLASSIC','SINGLE_SUBMISSION_BOX') DEFAULT 'CLASSIC' AFTER `garbage`;
```
username_0: if I put a URL in the box description, how to make it clickable?
username_1: Don't support that at the moment. We'd have to implement some markup syntax, but not sure if that would work in the pre tags of the description box.
username_1: I pushed a new branch that has [Markdown](https://guides.github.com/features/mastering-markdown/) support, which will allow you to add hyperlinks along with other formatting. https://github.com/moloch--/RootTheBox/tree/Description-Markdown
While working on it, I rewrote the formatting of the description to remove "pre" tags, but maintaining a fixed width font. This allowed some text justification, so that we don't have words cut off for new lines. I think I got it looking very close to the original. I also removed the autoformat option, since it's unnecessary with the justification pre-wrap.
@moloch-- you want to take a look at this one before I merge it in? See if this would cause any security or formatting issues that I'm unaware of.
Status: Issue closed
username_1: Markdown support added and description formatting reworked. https://github.com/moloch--/RootTheBox/commit/1715824b881db0c255a37b36b28366588bb393df |
platformio/platformio-core-installer | 793745768 | Title: Installation Manager
Question:
username_0: %23 Description of problem
Leave a comment...
BEFORE SUBMITTING, PLEASE SEARCH FOR DUPLICATES IN
- https://github.com/platformio/platformio-vscode-ide/issues%3Fq=is%3Aissue
%23 Configuration
VSCode: 1.52.1
PIO IDE: v2.2.0
System: Windows_NT, 10.0.18363, x64
%23 Exception
```
Error: Traceback (most recent call last):
File "C:\Users\gabri\.platformio\.cache\tmp\get-platformio-0.3.5.py", line 69, in <module>
main()
File "C:\Users\gabri\.platformio\.cache\tmp\get-platformio-0.3.5.py", line 61, in main
bootstrap()
File "C:\Users\gabri\.platformio\.cache\tmp\get-platformio-0.3.5.py", line 45, in bootstrap
import pioinstaller.__main__
File "C:\Users\gabri\.platformio\.cache\tmp\.piocore-installer-a1ovcvw8\tmpu7l0fgxd\pioinstaller.zip\pioinstaller\__main__.py", line 20, in <module>
File "C:\Users\gabri\.platformio\.cache\tmp\.piocore-installer-a1ovcvw8\tmpu7l0fgxd\pioinstaller.zip\click\__init__.py", line 7, in <module>
File "C:\Users\gabri\.platformio\.cache\tmp\.piocore-installer-a1ovcvw8\tmpu7l0fgxd\pioinstaller.zip\click\core.py", line 5, in <module>
ModuleNotFoundError: No module named 'contextlib'
at c:\Users\gabri\.vscode\extensions\platformio.platformio-ide-2.2.0\node_modules\platformio-node-helpers\dist\index.js:1:879275
at ChildProcess.c (c:\Users\gabri\.vscode\extensions\platformio.platformio-ide-2.2.0\node_modules\platformio-node-helpers\dist\index.js:1:879169)
at ChildProcess.emit (events.js:223:5)
at ChildProcess.cp.emit (c:\Users\gabri\.vscode\extensions\platformio.platformio-ide-2.2.0\node_modules\cross-spawn\lib\enoent.js:34:29)
at maybeClose (internal/child_process.js:1021:16)
at Process.ChildProcess._handle.onexit (internal/child_process.js:283:5)
``` |
kovisoft/slimv | 789777195 | Title: Add option to disable slimv indent plugins
Question:
username_0: Is there a way to disable the indent plugins provided by slimv (i.e. `slimv/indent/lisp.vim`, `slimv/indent/scheme.vim`, `slimv/indent/clojure.vim`)? I would like to keep the default vim indentation behavior provided by its bundled filetype plugins. If no such option exists, would it be possible to add an option to disable the indentation provided by slimv?
Answers:
username_1: Added option `g:slimv_indent_disable`. If you set it to 1 in your `.vimrc` then slimv won't override vim's built-in indenting. See commit https://github.com/username_1/slimv/commit/<PASSWORD>
Status: Issue closed
|
vnen/godot-tiled-importer | 509170827 | Title: YSort node not working properly
Question:
username_0: **Plugin version**
plugin 2.3 for godot 3.1, downloaded from asset library
**Issue description**
Sorting isn't working properly with imported tilemaps
**Steps to reproduce**
1. Create YSort node, enable sorting
2. Add a tilemap to this node (walls) at runtime (script is below)
3. Add a sprite (player) as a child to the tilemap
Setup:

Issues:

I have a code which does required reparenting at YSort node
```gdscript
extends Node
func _ready():
call_deferred("reparent", "/root/Level1/Map1")
func reparent(node_name):
var old = get_node(node_name)
if !old:
return
var children = old.get_children()
for n in children:
if n.name != "Walls":
continue
old.remove_child(n)
add_child(n)
var player = get_node("/root/Level1/YSort/Player")
player.get_parent().remove_child(player)
n.add_child(player)
```
Tilemaps created manually in godot editor works fine.
**Sample map or tileset**
[0x72_DungeonTilesetII_v1.1.zip](https://github.com/vnen/godot-tiled-importer/files/3744785/0x72_DungeonTilesetII_v1.1.zip) |
Njack-IITP/IITP-Connect | 266737421 | Title: Fix travis.yml
Question:
username_0: Currently all the builds are failing with the following error message :
```
Error: Target id is not valid. Use 'android list targets' to get the target ids.
The command "echo no | android create avd --force -n test -t android-22 --abi armeabi-v7a" failed and exited with 1 during .
Your build has been stopped.
```
Full report 
Answers:
username_0: @mayank8318 Can you look into it
username_1: @username_0 I am working on this.
Status: Issue closed
|
edwardstock/bip3x | 889508499 | Title: Generating ethereum addresses from HDKey ?
Question:
username_0: Hi Eduard, hope you're doing well.
It looks like your library used to implement functions to get addresses (see https://github.com/username_1/bip3x/blob/master/src/main.cpp#L71) but I can't find such things with the current version. Am I missing something ?
Anyway thank you very much for sharing your code, this is a very useful lib !
Answers:
username_1: Hi @username_0 ! Yes, you're right. Library does not support generating eth address as it requires full implementation of secp256k1.
Example how to create valid public key you can see here:
https://github.com/username_1/native-secp256k1-java/blob/7cd4aeddd4ccf96d6d69e9d46b8d2b6e0c33ad02/src/java/NativeSecp256k1.cpp#L187
And how to generate address here:
https://github.com/MinterTeam/cpp-minter/blob/3dc9bc864eb3f78711a2c4ad163e97c9a74e2cf1/src/data/address.cpp#L57
But this example not related directly to ethereum, as it used for another BC and of course, you need to get all related functions (such as sha256 keccak256) to do what you need
Status: Issue closed
|
TeamMetallurgy/Atum | 112300403 | Title: Smokescreen Traps should spawn in Pyramids and blind those who trigger them.
Question:
username_0: 
Answers:
username_0: 
username_0:  |
Automattic/mongoose | 368039457 | Title: How to abort transection in mongoose.
Question:
username_0: F.Y.I- I am using mongoose 5.3.2 with transection support and mongo relica set on version 4.0.2.
I just want to know how to abort transection in mongoose. I could not found a method in mongoose official guide.
I tried session.abortTransection(). but threw an error saying
`session.abortTransection is not a function`
What is valid mechanism to abort transection using mongoose?
Answers:
username_1: @username_0 try `session.abortTrans`**a**`ction()` instead. The [mongoose trans**a**ction guide](https://mongoosejs.com/docs/transactions.html) would be improved by including an example of aborting a trans**a**ction. We'll add one.
username_0: sorry my bad |
rust-lang/rust | 314407263 | Title: [tracking issue] warnings on long running constant evaluations
Question:
username_0: https://github.com/rust-lang/rust/pull/49947 introduces a warning (removing the previous hard error).
This warning is currently unsilenceable and should probably become a lint. For simplicity (https://github.com/rust-lang/rust/pull/49947 needs to be backported to beta) this has not been done.
"When" the warning appears is deterministic, but depends on MIR, so it might change between versions of rustc.
Answers:
username_1: Seems like this will also require a small amount of refactoring? I don't think the evaluator where the warning is currently emitted knows the `NodeId` that is needed when emitting the lint.
username_0: We should be reporting the lint on the constant that is being evaluated, not the place that we are currently at, because that place might change between rustc versions
username_0: Note that just turning this into a lint is probably not enough. We need to also check whether the lint is `deny` in the constant's scope. If it is, we need to abort the interpretation. Otherwise we'd just keep getting these lints as errors without ever stopping compilation.
username_2: Triage: I'm not aware of any changes here. I'm also not sure what to do to reproduce this issue, to be honest.
Status: Issue closed
username_0: `static FOO: () = loop {};` gives (on beta)
```
error[E0080]: could not evaluate static initializer
--> src/lib.rs:1:18
|
1 | static FOO: () = loop {};
| ^^^^^^^ exceeded interpreter step limit (see `#[const_eval_limit]`)
```
So I think we're good here |
angular/material | 256862491 | Title: Chromevox reads 'Status' as you type in a md-autocomplete when verbose description is enabled
Question:
username_0: Add more lines if needed.
Answers:
username_1: +1 to this issue- I'm not sure a user using ChromeVox will be able to use md-autocompletes as they won't know which option they've highlighted.
We've also had reports of this with JAWS.
username_2: This is not reproducible with VoiceOver for macOS.
username_2: I can reproduce this on ChromeOS Version 68.0.3440.87 (Official Build) beta (64-bit) with the latest AngularJS Material.
It appears that Chromevox does not support the following:
```html
<div class="md-visually-hidden" role="status" aria-atomic="true" aria-live="assertive">Florida</div>
```
It should read "Florida" but instead reads "Status".
username_2: It's not clear that Chromevox supports the `status` role.
[MDN's docs on status compatibility](https://developer.mozilla.org/en-US/docs/Web/Accessibility/ARIA/ARIA_Techniques/Using_the_status_role#Compatibility) are TODO.
The MDN site also has a link to [ARIA Best Practices – Implementing Live Regions](http://www.w3.org/TR/wai-aria-practices/#LiveRegions) which has been removed from the latest WAI-ARIA docs 😞
...
OK, I fixed MDN's link.
Docs for [role="status"](https://www.w3.org/TR/wai-aria-1.1/#status) and docs for [aria-live and aria-atomic can be found here](https://www.w3.org/TR/wai-aria-1.1/#attrs_liveregions). These point to the 1.1 Published Recommendation.
username_2: I submitted a request for documentation of what Live Region roles/attributes are supported in Chromevox here:
https://groups.google.com/forum/#!topic/chromevox-discuss/M2gb3CFsois
I also opened up a Chromium bug here:
https://bugs.chromium.org/p/chromium/issues/detail?id=873466
username_3: I did reproduce the issue with Chrome 69 and was able to verify that it seems fixed in Chrome 70 build. It will now read the message, followed by `Status` on Chrome 70 with ChromeVox on a Chromebook.
username_2: @username_3 thank you very much for testing this out! That's good news. We'll have some additional autocomplete fixes in 1.1.11 as well.
Status: Issue closed
|
godotengine/godot | 287890651 | Title: Label nodes should respect their content when using the shrink size flags.
Question:
username_0: When using a Label control node, none of the `shrink*` options for the size flag respect the text content of the node.
For comparison, here's what a label and a button look like with `Fill`:

now with `shrink_center`:
I would expect something maybe like that instead:

Answers:
username_1: You should be able to set a minimum width. If the content inside a control doesn't have a minimum width in this case because of line wrap there is no way to know when to stop shrinking.
It could maybe stop when it reaches the largest single letter on a line, but that's not any better than ignoring the width of the letters.
I'd recommend just setting some minimum width you like.
username_0: @username_1 that doesn't really work if I need to dynamically change the text.
Label, like Button has a `clip_text` property. Here's what Button looks like with `clip_text` on then off:

I understand that `autowrap` makes it more complicated, but Label should not clip it's content unless `clip_text` is set to true. |
doorkeeper-gem/doorkeeper | 622155190 | Title: Recent Change Token Revocation Endpoint Behavior Breaks Revocation of Tokens for Public Client
Question:
username_0: ### Steps to reproduce
I have a mobile app using a Rails server, which in turn depends on Doorkeeper to generate access tokens for API calls. I used to be able to logout successfully from the client using a call to `Doorkeeper::TokensController.revoke`. However, after upgrading to version Doorkeeper 5.4.0, I got HTTP response 401 during logout.
### Expected behavior
Token revocation using a valid access token from Resource Owner Password Credentials Flow should work.
### Actual behavior
Token revocation fails with a valid access token from Resource Owner Password Credentials Flow.
### System configuration
In version 5.3.3, before this change https://github.com/doorkeeper-gem/doorkeeper/pull/1370/commits/d194bc40e335464e67bc36dfd7e2e61247547545, a token granted to a public client (https://tools.ietf.org/html/rfc6749#section-2.1) via Resource Owner Password Credentials Flow works fine as the method `Doorkeeper::TokensController.authorized?` is used for authentication.
In version 5.4.0, the method `Doorkeeper::TokensController.revoke` is modified to require a `server.client`, which is a confidential client (https://tools.ietf.org/html/rfc6749#section-2.1).
**Ruby version**: `2.6.5`
Answers:
username_1: `server.client` stores client instance that performs a request. And if it's blank - no auth passed - request is blocked as stated in the the RFC.
You need to call /token/revoke with ?token value of access token you wanna to revoke and auth headers to inform the server that this request is authorized to perform an action.
username_2: I've got a similar problem. I'm trying to upgrade from Doorkeeper 5.1 to latest.
Token revocation stopped working for me. I'm getting 403 with `{"error"=>"unauthorized_client", "error_description"=>"You are not authorized to revoke this token"}` in my spec.
Previously `post oauth_revoke_path` spec was passing, returning 200 with an empty response. I tried changing to `post oauth_revoke_path, headers: { 'Authorization': "Bearer #{access_token.token}" }` but this does not pass either (this is basically what I was doing in the UI when "logging out").
Current upgrade PR: https://github.com/username_2/tournaments-api/pull/8
PS `allow_token_introspection false` doesn't seem to prevent the route from appearing in annotations but that's separate issue.
username_1: @username_2 does your token issued to public or private client? Do you use the same client for authorization that the token you wanna to revoke issued for?
This all covered by specs, would be great if you could provide a reproducable spec to fix the bug (if it's a bug)
username_2: @username_1, my project is public repository so I think it can be treated as reproducible? (you can see Travis running spec on the PR I linked) I'm using `password` grant flow, nothing more, there are no clients. It works fine on 5.2 and 5.3. The 5.4 version breaks token revocation for me.
username_1: Even password grant flow requires auth. And if token issued to a client (has application_id filled) - it could be revoked only by the same app.
If I have the time - I'll take a look at your repo, but it could take long time
username_2: `/token/info` has `"application":{"uid":null}` in my case when I authenticate.
No, I haven't tried `Basic client_id:client_secret`. I have no such thing like client. Unless I'm misunderstanding something. I'm using doorkeeper with simple email + password authentication for users, nothing more.
username_1: Please take a look at 2.1. Revocation Request of the RFC6749 and then Section 2.3. about client authentication.
Before the changes Doorkeeper had a **bug** and allowed to revoke token _without any authentication_. That was fixed according to OAuth RFC. You can find specs for changes here https://github.com/doorkeeper-gem/doorkeeper/pull/1370/files to find use cases for public/private clients and authentication.
username_1: @username_2 if you didn't use any client (Doorkeeper Application instances before) - you may need to create a new one (let it be non-confidential) and use it's credentials to authorize the request.
username_2: May. Doesn't have to. So shouldn't this have worked when testing:
```
post oauth_revoke_path,
params: { token: access_token.token }
```
It has `token` which is required. That token has no application (client). Before the changes in latest version, token was derived from `headers: { 'Authorization': "Bearer #{access_token.token}" }` implicitly somehow.
I feel like I'm still getting this wrong or missing some crucial part here.
username_1: Nope. Lack of authentication just open a security hole for brute-forcing (throtling) any tokens you have.
username_0: Do you mean to use the `client_id` and `client_secret` issued by the authorization server to my app server?
Thanks,
Edmond
username_1: Exactly. You need to add a new header `Authorization: Basic Base64(client_id:client_secret)` to your revocation request (or at least provide them in request body but this is not recommended by the RFC).
Here - https://github.com/doorkeeper-gem/doorkeeper/commit/d194bc40e335464e67bc36dfd7e2e61247547545 - you could find specs at the end of the PR which have all the test cases for authorizing the request
username_0: I found out that the token granted by the authorization server to the mobile app via the Resource Owner Password Credentials Flow does not have the application_id set in the database. Is that a bug? If not, how to work around the issue?
username_1: There are no issue with Password flow, it just allows to authenticate without passing client credentials. If the access token doesn't have `application_id` - it's OK, it means that any application could revoke it (because it wasn't issued by some specific app).
But to revoke the token you need to authorize. Authorization server requires authentication in order to protect your from bruteforcing your tokens. Without protection I could just revoke all the tokens you have on the server.
As I already answered above for username_2, you could just create a new Doorkeeper Application instance and use it's credentials in the revocation request from your mobile/web application. All you need is:
1) Some application registered on authorization server (where Doorkeeper installed) - it's ID and secret
2) New header for revocation request that will include this headers
username_1: Also it's a question for me how both of you could obtain an access token using password grant flow without requiring `client_id` (for public) or `client_id` + `client_secret` (for private) :thinking: I need to check if Doorkeeper has some bug here :thinking:
username_1: We have `confidential` column that indicates if application is public/private and **always** generate an ID (and secret in case of private client). So we must always **require** authorization for this grant flow
username_2: You're saying that all those years I was using doorkeeper with password grant flow and without creating an application... was a bug. That bug is probably the reason a lot of people love doorkeeper. Simplicity and literally zero setup to have email+password authentication in any project. :D
username_1: Yep, it's sad, but true :(
I don't sure why it's so hard to create one record and use it's credentials in requests... Anyway I need to conform the RFC. So I must fix this. I'll try to do it in a backward compatible way with first just a deprecation message and then with a totally removed credentials-free behavior.
More examples:
- https://auth0.com/docs/api-auth/tutorials/password-grant#ask-for-a-token
- https://docs.microsoft.com/en-us/azure/active-directory/develop/v2-oauth-ropc
username_2: It's not exactly about it being hard. It's pointless when it's for a front-end app that's all in a browser. Right now I can have two dockerized projects that require running `docker-compose up` and everything works out of the box. UI communicates with the API and everything's great. I don't have to go into oauth applications endpoint, then create an app, then update env var so the UI knows client_id (or I don't have to provide client_id at build time so compiled code has it) and so on.
username_1: You could just use seeds for this:
```ruby
Doorkeeper::Application.find_or_create!(name: "freontend", uid "set your long own value", secret: "the same", ...)
```
And use this credentials in the FE application. All you need is to also to run seeds after your database is up. Nothing special btw
username_2: I know that seeding kinda solves the problem but IMHO enforcing application makes little sense here. It provides no additional security in this particular use-case because front-end code is fully accessible in the browser so neither client_id nor client_secret would actually be secret.
username_1: Yep, and this is one of the reasons (except sharing user credentials) why this grant flow *isn't recommended for use** by the RFC (and even more - forbidden in latest _Security considerations_ document), and could be used only by **highly trusted applications**.
Btw whether we want it or not - we have a document that specifies the behavior and we need to follow it. Everybody who don't wanna to do it could path Doorkeeper internals and use any desired behavior :)
username_2: Personally, I'd rather have an option to disable this client/application requirement in the configuration so Doorkeeper still would be usable as is with such front-end apps. With it being required by default, of course, and documenting how bad disabling it is.
username_1: Yep, this is one of the options I think about. I just don't like to bloat the configuration with a lot of options, especially when there is no need in them.
So I think I'll add such option, but with deprecation and it will be removed in some major update.
username_1: @username_0 can we close this issue now? Do you need more help with it?
username_0: Since there is nothing much I can do except to downgrade to version 5.3.3, I guess you can make this a known issue on the release notes before closing this. That could save other's time to research on this. Thanks.
username_1: It's not an issue actually, and it's a known breaking change:
* It's pointed in upgrade guides - https://github.com/doorkeeper-gem/doorkeeper/wiki/Migration-from-old-versions#from-5x-to-54x
* It's pointed in the CHANGELOG - https://github.com/doorkeeper-gem/doorkeeper/blob/master/CHANGELOG.md#540rc1
Known (at least now) issue is that you guys could use ROPC grant **without** using a client which would be fixed soon, yep.
Status: Issue closed
username_3: So if I am interpreting the current status of things correctly. I can request tokens without client credentials. These tokens will have no Application client association.
But when I revoke a token it will fail without a client id. I can't image that a revoke request with a client id is able to revoke a token with no associated client. So how would anyone ever revoke a clientless token?
username_4: FYI for anyone interested in this - https://github.com/doorkeeper-gem/doorkeeper/pull/1458 |
uhulinux/ub-ubk3 | 1071268112 | Title: python3-automat hiba
Question:
username_0: Traceback (most recent call last):
File "/bin/automat-visualize", line 11, in <module>
load_entry_point('Automat==0.3.0', 'console_scripts', 'automat-visualize')()
File "/usr/lib/python3.7/site-packages/pkg_resources/__init__.py", line 479, in load_entry_point
return get_distribution(dist).load_entry_point(group, name)
File "/usr/lib/python3.7/site-packages/pkg_resources/__init__.py", line 2860, in load_entry_point
return ep.load()
File "/usr/lib/python3.7/site-packages/pkg_resources/__init__.py", line 2464, in load
return self.resolve()
File "/usr/lib/python3.7/site-packages/pkg_resources/__init__.py", line 2470, in resolve
module = __import__(self.module_name, fromlist=['__name__'], level=0)
File "/usr/lib/python3.7/site-packages/automat/_visualize.py", line 5, in <module>
import graphviz
ModuleNotFoundError: No module named 'graphviz'
attila@attila-pc:~$
A frissített is így pofázik vissza.
(python3-automat-20.2.0)
Answers:
username_0: Kellet neki egy új python3 csomag. https://github.com/uhulinux/ub-ubk3/commit/9389493d38b8a5b580c10ec7971bf19911d69150
Így már némiképp jobb, de nem sok értelmét látom ennek a python3-automat csomagnak, kétlem, hogy valakinikenk hiányozna, ha nem lenne.
Status: Issue closed
|
sardana-org/sardana | 447504005 | Title: Independent acquistion of timerable does not work if SimulationMode is set to 1
Question:
username_0: If SimulationMode in a timerable is set to 1 the independent acquisiton does not work:
-> command Start makes nothing
-> macro ct with the timerable set as argument stays for ever and has to be killed with ctrl-c
Tested with ct and 1D/2D with dummy controllers and real ones.
Answers:
username_0: @reszelaz, should we ignore the flag SimulationMode at the timerable level?. |
ArkEcosystem/core | 512432246 | Title: Misleading error message when updating bridgechain not registered by user
Question:
username_0: **Summary**
When a user tries to update an existing bridgechain / ID that has not been registered with the same account, the following error is returned:
```
[
{
"type": "ERR_APPLY",
"message": "Failed to apply transaction, because bridgechain is not registered error."
}
]
```
This message implies that the bridgechain is not registered at all (it returns the same message when that is the case), while the issue it actually that the user is not the owner of the bridgechain.
**Expected Behavior**
Return a more accurate error message, describing that the account is not the owner of the bridgechain.
**Your Environment**
Devnet 2.6
Answers:
username_1: Do you want to change error message to be more accurate?
username_0: Not sure if it's aimed at me, but I'll reply anyway :)
Let's imagine you're a business owner running one or more bridgechains. You want to update a bridgechain, but you made a small error by entering an incorrect ID.. when you send the update, you get an error message `bridgechain is not registered`.
I believe that this will be very confusing to the business owner, because in his experience his bridgechain _is_ registered. After seeing such message, he might think something is wrong with the system or that he broke something, even though the issue is nothing to worry about and he just entered the incorrect ID.
So yeah, I believe it would be beneficial to the user experience to change the error message to something more accurate 👍
username_2: @username_0 the questions was more if you would like to fix the issue by submitting a PR for it.
username_0: @username_2 Sure, will do 👍
username_2: Great, assigned you to the issue.
Status: Issue closed
|
donatj/CLI-Toolkit | 188370185 | Title: Wrap and noWrap required.
Question:
username_0: Don't wrap for the following text:
\033[?7l
Wrap for the following txt:
\033[?7h
Answers:
username_1: Interesting, I will look into adding these.
username_0: Any updates?
username_1: I need to make some decisions on how I want to implement them, and I've been super sick the last couple weeks. On top of that I'm going to Las Vegas on tuesday, lol. If I find the time tomorrow I'll review - it's not forgotten, just a lot going on at the moment ;)
username_0: Any updates?
username_1: I'm so sorry I forgot about this! Holy cow. I'm legitimately putting an event on my calendar for midday tomorrow to look at this! Thank you for your continued patience, and my sincere appoligies!
username_0: Thanks.
username_1: Cursor now has a method "wrap" that takes a bool, e.g. disable wrap via `Cursor::wrap(false);`
Status: Issue closed
username_1: It has been tagged in release v0.2.0 |
wangeditor-team/wangEditor | 833378516 | Title: firefox使用剪切功能后导致编辑器的空内容是的p标签无法出现
Question:
username_0: ## bug 描述
firefox使用剪切功能后导致编辑器的空内容是的p标签无法出现
## 你预期的样子是?
*请输入内容……*

## 浏览器及版本号
*请输入内容……*
## wangEditor 版本
官网复现
## 官网能否复现该 bug ?
能
## 最小成本的复现步骤
1.输入内容<issue_closed>
Status: Issue closed |
NiceneNerd/BCML | 1159412470 | Title: bcml not downloading itself
Question:
username_0: when I use python to get bcml it appears to work like I saw in the tutorial video but when I type bcml I get
'bcml' is not recognized as an internal or external command, operable program or batch file.
Answers:
username_0: nevermind im just dumb
Status: Issue closed
|
matthewkmayer/matthewkmayer.github.io | 527584390 | Title: Working on Rusoto on EC2
Question:
username_0: Compiling Rusoto on my old, low-spec Macbook is painful: 45-ish minutes to build integration tests, battery is worked hard, space is a concern, etc...
Let's compare options:
* using my desktop to build through VS Code
* cost of upgrading that desktop
* renting an EC2 server: cost for that?
* if we rent a server how do we keep costs from spiraling out of control? A lambda using Rusoto to ensure it's not running!
Answers:
username_0: `time make generate unit_test_no_doctests check_integration_test` on:
## Current desktop: Intel(R) Core(TM) i5-4690 CPU @ 3.50GHz
```
real 8m44.805s
user 30m43.625s
sys 1m3.539s
```
## Work laptop: Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz
```
real 9m14.061s
user 72m6.399s
sys 3m24.604s
```
username_0: Four hours a day, every day, on an m5a.2XL: $42 a month.
https://pcpartpicker.com/list/pQMhk6 is about $900, so breakeven would be ~22 months, not including power costs of running the home desktop.
username_0: How about Spot Instances with [durations](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-requests.html#fixed-duration-spot-instances) ?
username_0: Not gonna happen.
Status: Issue closed
|
Taritsyn/MsieJavaScriptEngine | 169596621 | Title: How to get data back from JS to C#?
Question:
username_0: I have executed the following script:
`
var obj = { n: 123, s: 'str' }
`
GetVariableValue("obj") has returned COM Object.
How can I get data from JS to C# as ExpandoObject or Dictionary<string, object>?
Answers:
username_1: Hello, Andrey!
In no way. Supports only primitive types.
But it is possible serialize the object to a string:
```js
JSON.stringify(obj);
```
And then deserialize the string result by using the [Json.NET](http://www.newtonsoft.com/json) library:
```csharp
var json = JObject.Parse(result);
…
```
As an example, I recommend you see the source code of the [BundleTransformer.Less](http://bundletransformer.codeplex.com/SourceControl/latest#BundleTransformer.Less/Internal/LessCompiler.cs). There used the [JavaScript Engine Switcher](https://github.com/username_1/JavaScriptEngineSwitcher), but it has a very similar API.
Status: Issue closed
|
sysrepo/sysrepo | 550239499 | Title: leaf with default value in input xml leads internal error
Question:
username_0: Hi
Two configurations which have some leafs unchanged and the value is similar to default value causes internal error in function `sr_diff_apply_r` at below code in case `EDIT_REPLACE`
```
/* update its value */
if ((ret = lyd_change_leaf((struct lyd_node_leaf_list *)match, sr_ly_leaf_value_str(diff_node))) < 0) {
sr_errinfo_new_ly(&err_info, ly_ctx);
return err_info;
}
/* a change must occur */
SR_CHECK_INT_RET(ret, err_info);
```
Thanks & Regards,
Sriram.K
Answers:
username_0: Hi,
Any update on this please, `sr_get_items` fails due to this.
Thanks & Regards,
Sriram.K
username_1: Hi,
please, be a bit more patient, I see all the issues. For the past several weeks I have not done almost anything else than fixing issues and I do need to work on other things, you can wait a few days.
As for the issue, I have tested this quite extensively so this will not be such a trivial use-case as you described, I have not managed to reproduce it based on the provided information. But it should be quite simple to provide exact steps, so please do so.
Regards,
Michal
username_0: Hi Michal,
Please follow below steps with attached configuration files.
**Steps**
```
sysrepoctl -i iana-if-type.yang
sysrepoctl -i ietf-interfaces.yang
sysrepoctl -i ietf-ip.yang
~/data/sriram/new/sysrepo/build/examples/application_changes_example ietf-interfaces &
sysrepocfg --import=./test_0.xml -m ietf-interfaces
sysrepocfg --edit=./test_1.xml -m ietf-interfaces
sysrepocfg --import=./test_2.xml -m ietf-interfaces
```
**Config xmls**
[config_xmls.tar.gz](https://github.com/sysrepo/sysrepo/files/4077272/config_xmls.tar.gz)
**OutPut**
Import test_0.xml
```
$ sysrepocfg --import=./test_0.xml -m ietf-interfaces
========== EVENT change CHANGES: ====================================
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1'] (list instance)
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/name = WAN1
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/description = WAN
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/type = iana-if-type:ethernetCsmacd
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/enabled = true
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4 (container)
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4/enabled = true
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4/mtu = 1500
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4/forwarding = false
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6 (container)
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/enabled = true
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/mtu = 1500
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/forwarding = false
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/dup-addr-detect-transmits = 1
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/autoconf (container)
CREATED: /ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/autoconf/create-global-addresses = true [default]
========== END OF CHANGES =======================================
========== CONFIG HAS CHANGED, CURRENT RUNNING CONFIG: ==========
/ietf-interfaces:interfaces (container)
/ietf-interfaces:interfaces/interface[name='WAN1'] (list instance)
/ietf-interfaces:interfaces/interface[name='WAN1']/name = WAN1
/ietf-interfaces:interfaces/interface[name='WAN1']/description = WAN
/ietf-interfaces:interfaces/interface[name='WAN1']/type = iana-if-type:ethernetCsmacd
/ietf-interfaces:interfaces/interface[name='WAN1']/enabled = true
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4 (container)
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4/enabled = true
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4/mtu = 1500
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4/forwarding = false
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6 (container)
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/enabled = true
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/mtu = 1500
[Truncated]
/ietf-interfaces:interfaces (container)
/ietf-interfaces:interfaces/interface[name='WAN1'] (list instance)
/ietf-interfaces:interfaces/interface[name='WAN1']/name = WAN1
/ietf-interfaces:interfaces/interface[name='WAN1']/description = WAN
/ietf-interfaces:interfaces/interface[name='WAN1']/type = iana-if-type:ethernetCsmacd
/ietf-interfaces:interfaces/interface[name='WAN1']/enabled = true
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4 (container)
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4/enabled = true
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4/mtu = 1400
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv4/forwarding = false [default]
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6 (container)
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/enabled = true
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/mtu = 1400
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/forwarding = false [default]
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/dup-addr-detect-transmits = 1 [default]
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/autoconf (container)
/ietf-interfaces:interfaces/interface[name='WAN1']/ietf-ip:ipv6/autoconf/create-global-addresses = true [default]
```
username_1: Hi Sriram,
the bug was actually similar to #1756 but an individual fix was required because `sysrepocfg` does not use `sr_apply_changes()` API but `sr_replace_config()`. Should work now.
Regards,
Michal
username_0: Hi Michal,
Working with given changes.
Thanks & Regards,
Sriram.K
Status: Issue closed
|
topcoder-platform/community-app | 444842334 | Title: Marathon Matches details not shown to the user
Question:
username_0: Details page for marathon challenges is not working for users. Its giving error "ailed to get member marathons".
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'https://www.topcoder.com/members/</InsertHandle/>/details/?track=DATA_SCIENCE&subTrack=MARATHON_MATCH&tab=statistics'
2. You ll be able to see the records along with the chart for rating.
3. Click on challenges will take you to the next page which can be accessed directly by link "https://www.topcoder.com/members/</InsertHandle/>/details/?track=DATA_SCIENCE&subTrack=MARATHON_MATCH&tab=challenges" as well
4. You ll be able to see below error
Console throws below error
**Expected behavior**
Challenge details pertaining to marathon matches should be shown to the user.
Answers:
username_1: @username_0 any handle with lot of MMs?
username_2: I have reported the issue for my handle: "username_2". However, I've participated only in two MMs.
username_1: @username_3 please have a look
username_3: @username_1 check https://api.topcoder.com/v4/members/ardavel/mms/?filter=status%3DPAST%26isRatedForMM%3Dtrue&orderBy=endDate%20desc&limit=36&offset=0, it returns
```
{"id":"-7151b0f2:16b1b2cdf7e:-2fe2","result":{"success":true,"status":500,"metadata":null,"content":"{\"root_cause\":[{\"type\":\"index_not_found_exception\",\"reason\":\"no such index\",\"resource.type\":\"index_or_alias\",\"resource.id\":\"mmatches3\",\"index\":\"mmatches3\"}],\"type\":\"index_not_found_exception\",\"reason\":\"no such index\",\"resource.type\":\"index_or_alias\",\"resource.id\":\"mmatches3\",\"index\":\"mmatches3\"}"},"version":"v3"}
```
long time ago, we used a separate indexes for marathon matches and srms matches, for now, I think we should members/ardavel/challenges instead of members/ardavel/mms/
what do you think?
username_1: @username_3 please go ahead, I'll link issues
username_3: @username_1 change in api side, or directly use member/<handle>/challenges, I think we should drop the usage of `members/ardavel/mms/`
username_1: this is not working
https://api.topcoder.com/v4/members/ardavel/challenges/?filter=status%3DPAST%26isRatedForMM%3Dtrue&orderBy=endDate%20desc&limit=36&offset=0
username_3: @username_1 try
https://api.topcoder.com/v4/members/ardavel/challenges/?filter=status%3DCOMPLETED%26subTrack%3DDEVELOP_MARATHON_MATCH&limit=36&offset=0
username_1: Thanks, this also works now
https://api.topcoder.com/v4/members/ardavel/challenges/?filter=status%3DCOMPLETED%26subTrack%3DMARATHON_MATCH&limit=36&offset=0
username_4: Contest https://www.topcoder.com/challenges/30092667 has been created for this ticket.<br/><br/>```This is an automated message for thomaskranitsas via Topcoder X```
username_4: Contest https://www.topcoder.com/challenges/30092667 has been updated - the new changes has been updated for this ticket.<br/><br/>```This is an automated message for thomaskranitsas via Topcoder X```
username_1: The current call is failing to pull past marathon matches because endpoint and filter params are outdated. This fix is to update endpoint and filter params to include PAST Marathon matches. Past marathon matches are of two types (on system level, users do not care)
```
1. MARATHON_MATCH
2. DEVELOP_MARATHON_MATCH
```
GET call :
https://api.topcoder.com/v4/members/ardavel/challenges/?filter=status%3DCOMPLETED%26subTrack%3DMARATHON_MATCH,DEVELOP_MARATHON_MATCH&limit=36&offset=0
@topcoder-platform/topcodercompetitors this is open for pickup.
PR on `hot-fixes-3` branch.
username_4: Contest https://www.topcoder.com/challenges/30092667 has been updated - it has been assigned to username_5.<br/><br/>```This is an automated message for thomaskranitsas via Topcoder X```
username_5: @username_1 is it just front end change?
username_1: @username_5 yes, it is P1 and urgent
username_5: @username_1 PR has been raised at both repos.
Primary change is at topcoder-react-lib to change param and url.
currently at develop branch PR has been raised
and here PR is raised on hot-fixes-3 for minor model change.
https://github.com/topcoder-platform/community-app/pull/2417
https://github.com/topcoder-platform/topcoder-react-lib/pull/70
username_1: @username_5 thanks. Deployment pipeline has been a little busy, so it's taking time.
username_6: Hey @username_1 has this been deployed? :)
username_5: @username_1 any updates on this? I do not wish to lose my efforts.
username_5: @username_1 waiting here
username_5: @username_6 @thomaskranitsas @nithyaasworld @username_1 can anyone atleast please respond?
username_5: @username_6 @username_4 @nithyaasworld @username_1 some reply would be really helpful from anybody. keeping aside other tasks this task was taken at priority and completed to best.but then it disappoints that no one is ready to reply anything whether this task is ignored? it will be merged later? PR is not proper?
efforts are wasted? I am in real need of money hence it is a discouragement to see efforts go wasted like this and no one responds being a P1 task.
username_1: Your efforts will not be wasted that I can guarranty you. This do not happen often I apologize for this one but there are/were some other internal priorities, so everybody is busy with that.
I can't attend this right away, but this is on my list.
username_5: @username_1 thanks for the response, Yes I see there are many Accesiblity issues open/reviewed and merged, till then waiting no problem. I just wanted to bring it your notice that this issue is pending, as you commented so I am assured now. thanks
username_7: [500]: Challenge for the updated issue 2359 is creating, rescheduling this event<br/><br/>```This is an automated message for lazybaer via Topcoder X```
username_7: [500]: Challenge for the updated issue 2359 is creating, rescheduling this event<br/><br/>```This is an automated message for lazybaer via Topcoder X```
username_7: [504]: Failed to create challenge.<br/><br/>```This is an automated message for lazybaer via Topcoder X```
username_7: [504]: Failed to create challenge.<br/><br/>```This is an automated message for lazybaer via Topcoder X```
username_7: Contest https://www.topcoder.com/challenges/30097469 has been created for this ticket.<br/><br/>```This is an automated message for lazybaer via Topcoder X```
username_7: Contest https://www.topcoder.com/challenges/30097469 has been updated - it has been assigned to username_5.<br/><br/>```This is an automated message for lazybaer via Topcoder X```
username_5: @username_1 any updates on this?
username_5: @username_1 can I get anything on this? thank you
username_8: @username_7 @username_9 @username_1 @username_5 it looks like this one fell through the cracks.
The [contest to fix this](https://www.topcoder.com/challenges/30097469?tab=details) has, theoretically, been live since July. But since @username_5 is here asking for more help, I suspect that the contest was not as "live" or set up as it needed to be.
username_7: @username_8 that's a placeholder for the task payment and it looks like this ticket has been languishing. @username_1 can we pick this one back up?
Status: Issue closed
username_9: This ticket was not processed for payment. If you would like to process it for payment, please reopen it, add the ```tcx_FixAccepted``` label, and then close it again<br/><br/>```This is an automated message for crazyk via Topcoder X``` |
snowplow/snowplow | 250886308 | Title: RDB Loader: jsonpath resolution caching not caching
Question:
username_0: When running some local tests with the RDB loader jar I was surprised at what seemed to be very slow execution for a small data set.
On stepping through the code it seems that the caching mechanism for jsonpath resolution isn't working as expected. I added some `println` statements to demonstrate what I see:
https://gist.github.com/username_0/4be9f38610d8d0a321bce4deb9a4a72e#file-shreddedtype-scala-L119-L131
The result is as follows:
https://gist.github.com/username_0/a7d3fe23cdb0729fc5590f2a00140986
I'm happy to write a fix if you guys can confirm this is indeed incorrect.
Answers:
username_1: @username_0 the 2nd gist 404s
username_1: Initially suspected tagged types but they seem to behave fine at as far as the cache is concerned.
username_2: Thanks for report @username_0! We will look into it.
Btw, we now have a dedicated repository for RDB Loader: https://github.com/snowplow/snowplow-rdb-loader, all code and issues will migrate there soon.
Moving ticket into new repository, closing this one.
Status: Issue closed
username_0: @username_1 I replaced the 2nd gist to censor our bucket names, perhaps you caught the old version
The correct link is https://gist.github.com/username_0/6d2d5a4ffdd0c77396e38799781708c4
username_1: @username_0 yup, got it :+1: |
victronenergy/venus | 980305956 | Title: Add feature accepting run script in self-installing archive
Question:
username_0: Discussed here: https://victrondevelopment.slack.com/archives/C7C1ZU6UD/p1629730820132300
Trigger is the html-app installs on the data partition, and the wish to be able to remove old files when installing a new version. To prevent dangling old unused files.
Answers:
username_0: As discussed: a hook that checks for- and runs a pre script, and one that checks for- and runs a post script
Status: Issue closed
username_0: included in v2.90 - closing. |
serverless/serverless | 160270898 | Title: Project Init Should Not Rewrite Existing JSON Files
Question:
username_0: I created a project using `sls project create`, and then modified the created JSON files to do the following:
1. make the indentation match our internal indentation standards (three spaces over the default two that SLS uses)
2. add a newline character to the end of all files that we commit to our repo (see #1321)
3. remove unnecessary parameters where the value in the config file was the same as the default or the parameter is otherwise unnecessary
Then I cloned that repo on another workstation and was going to initialize my `_meta` folder by using `sls project init`. The first step that `init` does is apparently rewriting all of my committed JSON files - function configs, templates files, even project.json. This seems entirely unnecessary. It reverts the changes that mentioned above.
For example, this is a snippet of output from `git diff --ignore-all-space` after running `sls project init` and then cancelling it at the first prompt.
```
index efa5912..34ca03e 100644
--- a/src/functions/categories/s-function.json
+++ b/src/functions/categories/s-function.json
@@ -2,9 +2,15 @@
"name": "v1-categories",
"runtime": "nodejs4.3",
"description": "Categories data endpoint",
+ "customName": false,
+ "customRole": false,
"handler": "categories/Categories.handler",
"timeout": 2,
"memorySize": 128,
+ "authorizer": {},
+ "custom": {
+ "excludePatterns": []
+ },
"endpoints": [
{
"path": "v1/categories/{LangCode}",
@@ -30,5 +36,9 @@
}
],
"events": [],
- "environment": "$${standardApiEnvironment}"
+ "environment": "$${standardApiEnvironment}",
+ "vpc": {
+ "securityGroupIds": [],
+ "subnetIds": []
+ }
}
\ No newline at end of file
```
And here's a list of all the files that it changed (note that I replaced actual function names for the sake of privacy, but this is representative of every function).
```
modified: package.json
modified: s-project.json
modified: s-resources-cf.json
modified: s-templates.json
modified: src/functions/one-of-my-functions/s-function.json
modified: src/functions/one-of-my-functions/s-function.json
modified: src/functions/one-of-my-functions/s-function.json
modified: src/functions/one-of-my-functions/s-templates.json
modified: src/functions/one-of-my-functions/s-function.json
modified: src/functions/one-of-my-functions/s-function.json
modified: src/functions/one-of-my-functions/s-function.json
modified: src/functions/one-of-my-functions/s-function.json
modified: src/functions/one-of-my-functions/s-function.json
modified: src/functions/one-of-my-functions/s-function.json
```
I don't see any reason that `init` should modify any file - it should be reading from those files, but not writing them.
Answers:
username_1: I encountered same issue, and it's annoyed to me. In my case, it became worse not just change indentation but also revise cloudfront cache behavior.
Status: Issue closed
username_2: Hi, thank you for reaching out to us! At this point we've stopped working on 0.5 of Serverless to fully focus on V1.0 that we're currently working on. Therefore we're not taking any changes for 0.5 and do not plan any future releases at this point. We only have a limited set of resources and just need to make sure we're putting everything we have into our next release (and can provide great long term support and backwards compatibility from then on). Hope you understand.
We would love to get your feedback on V1 of the framework and I'm happy to walk you through any questions to make sure its all working great for you. |
xws-bench/battles | 134019666 | Title: Human:199 Computer:1
Question:
username_0: Whisper*Veteran_Instincts*Fire-Control_System*Gunner*Advanced_Cloaking_Device.Soontir_Fel*Push_the_Limit*Autothrusters*Royal_Guard_TIE*Stealth_Device.Howlrunner*Stealth_Device.VSRed_Ace*R2-D2*Comm_Relay.Poe_Dameron*Veteran_Instincts*R5-P9*Autothrusters.Gold_Squadron_Pilot*Twin_Laser_Turret*R3-A2*BTL-A4_Y-Wing.<br>
http://bit.ly/1ol05yr<br> |
kulshekhar/ts-jest | 465552048 | Title: Import from index.ts export not working
Question:
username_0: <!-- First of all, check the troubleshooting wiki page for common issues at:
https://github.com/kulshekhar/ts-jest/wiki/Troubleshooting -->
## Issue <!-- describe the issue below -->:
Import from index.ts export not working, ex:
file structure:
app
|--shared
|--index.ts
|--utils.ts
utils.ts:
```
export function myFunction(){...
```
index.ts:
```
export * from 'utils.ts';
```
import {myFunction} from 'app/shared' doesn't work in jest (works when running the app).
export {myFunction} from 'app/shared.index' works.
## Expected behavior <!-- describe the expected behavior below -->:
Answers:
username_1: I am experiencing this error too. Getting the `Jest encountered an unexpected token` error pointing to the first line of my index.ts file which is exporting modules like `export * from './moduleFile';`. I've tried all sorts of fixes with babel plugins and other configurations with no luck. Here's my jest config (in my package.json file):
```json
"jest": {
"preset": "jest-expo",
"globals": {
"NODE_ENV": "test"
},
"moduleFileExtensions": [
"ts",
"tsx",
"js",
"jsx",
"json"
],
"transform": {
"^.+\\.jsx?$": "<rootDir>/node_modules/babel-jest",
"^.+\\.tsx?$": "ts-jest"
},
"testRegex": "(/__tests__/.*|(\\.|/)(test|spec))\\.(jsx?|tsx?)$",
"transformIgnorePatterns": [
"node_modules/(?!((jest-)?react-native|react-clone-referenced-element|expo(nent)?|@expo(nent)?/.*|react-navigation|@react-navigation/.*|sentry-expo|native-base|react-dom|@unimodules))"
]
},
```
username_2: hi, would you please provide a minimum repo ?
username_1: I am no longer having this issue. I've gone through a considerable amount of refactoring and changes so I can't pinpoint what fixed it. For anyone running into this here's what my jest.config looks like now:
```js
const { defaults: tsjPreset } = require('ts-jest/presets');
module.exports = {
preset: 'jest-expo',
globals: {
'ts-jest': {
tsConfig: './tsconfig.jest.json',
},
},
transform: {
'^.+\\.(js|jsx)?$': '<rootDir>/node_modules/babel-jest',
...tsjPreset.transform,
},
moduleFileExtensions: ['ts', 'tsx', 'js', 'jsx', 'json'],
testRegex: '(/__tests__/.*|(\\.|/)(test|spec))\\.(jsx?|tsx?)$',
transformIgnorePatterns: [
'node_modules/(?!((jest-)?react-native|react-clone-referenced-element|expo(nent)?|@expo(nent)?/.*|react-navigation|@react-navigation/.*|sentry-expo|@sentry|native-base|native-base-shoutem-theme|react-dom|unimodules|@unimodules|expo-asset))',
'local_modules',
],
testPathIgnorePatterns: ['/node_modules', '/local_modules/'],
coveragePathIgnorePatterns: [
'/node_modules',
'/local_modules/',
'/src/theme/components/',
'/src/theme/variables/',
'/__test-data__/',
],
moduleNameMapper: {
'\\.(jpg|ico|jpeg|png|gif|eot|otf|webp|svg|ttf|woff|woff2|mp4|webm|wav|mp3|m4a|aac|oga)$':
'<rootDir>/__mocks__/fileMock.js',
},
};
```
username_3: I can confirm that explicitly adding `index` in the import statement works, `tsconfig.json` is the one automatically generated by `create-react-app`.
In my case, the erroneous import statement looks like this `import {...} from "./App/";` which works fine in the app but not in jest. It works after changing to `import {...} from "./App/index";`
username_2: @username_3 do you still encounter the same issue ? If yes, please us provide a repo :) thanks
username_4: I am having the same issue and using `import {...} from "./module/index"` doesn't work I need to specify the module when i import it. I create e minimal repo where I can reproduce it [repo](https://github.com/username_4/ts-jest-error-import-from-index-export-example) in `master` the problem exist but in this branch `remove-import-from-index-export` works well and the diff is
```diff
diff --git a/src/services/api/http.ts b/src/services/api/http.ts
index 80bd1a1..2f422c4 100644
--- a/src/services/api/http.ts
+++ b/src/services/api/http.ts
@@ -2,3 +2,3 @@ import axios, { AxiosRequestConfig, Method } from "axios"
-import { logger } from "../../loaders"
+import { logger } from "../../loaders/logger"
```
You can see the runs of github actions to see the errors @username_2
username_2: Thanks a lot for the reproduce repo. I will take a look when there are some free times 👍
username_2: | ^
6 | url: "http://localhost:8080",
7 | headers: {
8 | Accept: "application/json",
at Object.<anonymous> (src/routes/index.ts:5:17)
at Object.<anonymous> (src/loaders/index.ts:6:1)
```
Status: Issue closed
username_2: close as this is not `ts-jest` problem. I have debugged `ts-jest` codes and everything went well. This is the problem of upstream `jest`.
username_3: @username_2 Adding to the context, some recent projects of mine in React Native seems do tests correctly, didn't have chance for a greenfield web project yet.
Since React Native typescript template uses `jest` directly, at least we know some version of it can handle these imports, upgrading dependent version in `ts-jest` may very well fix this.
username_2: Oh it’s nice to hear that.
FYI the error comes from jest runtime, not typescript itself and ts-jest internal typescript compiler delivered the compiled js and jest runtime takes care of the rest.
Since it’s related to how jest runtime accepts the transpiled codes, ts-jest can’t do anything. |
plonegovbr/brasil.gov.temas | 428850878 | Title: Tema é alterado na visão padrão de um item multimídia
Question:
username_0: Usando IDG 2.1.1.
Estamos usando o tema azul:

Quando vamos para a visão individual de um item Multimídia, o cabeçalho passa a ser preto:
Isso é o previsto? Ou erro? Não consegui encontrar em http://www.portalpadrao.gov.br/manuais/guia-de-estilo/ a explicação para esse comportamento. @username_1
Answers:
username_1: @username_0 sim, isso é um recurso do tema, solicitado pela Secom.
Existem variações para a Central de conteúdo, NITF e para o Fale Conosco.
Os valores estão declarados aqui:
https://github.com/plonegovbr/brasil.gov.temas/blob/e615c1e053c878a96ae89859afa3932dbacbcc6e/webpack/app/padrao/brasilgovtemas.scss#L51 |
kiooeht/ModTheSpire | 341691903 | Title: ERROR: No method [instantObtain] found on class [com.megacrit.cardcrawl.relics.AbstractRelic]
Question:
username_0: **Before submitting, have you read the [Troubleshooting guide](https://github.com/username_1/ModTheSpire/wiki/Troubleshooting)?**
Yes/No.
**Crash Log**
```
Running with debug mode turned ON...
Version Info:
- Java version (1.8.0_144)
- Slay the Spire (07-12-2018)
- ModTheSpire (2.8.0)
Mod list:
- basemod (2.5.0)
- ReplayTheSpireMod (1.0.3)
Begin patching...
Finding core patches...
Finding patches...
ERROR: No method [instantObtain] found on class [com.megacrit.cardcrawl.relics.AbstractRelic]
javassist.NotFoundException: com.megacrit.cardcrawl.gashapon.NeowReward
at javassist.ClassPool.get(ClassPool.java:445)
at com.evacipated.cardcrawl.modthespire.Patcher.injectPatches(Patcher.java:206)
at com.evacipated.cardcrawl.modthespire.Patcher.injectPatches(Patcher.java:174)
at com.evacipated.cardcrawl.modthespire.Loader.runMods(Loader.java:229)
at com.evacipated.cardcrawl.modthespire.ui.ModSelectWindow.lambda$null$1(ModSelectWindow.java:199)
at java.lang.Thread.run(Thread.java:748)
```
This happens right after I run the MST script. basemod is always checked, replay is checked for one run, unchecked for another, same results.
Status: Issue closed
Answers:
username_1: You're using a really old version of BaseMod. You can get the newest version at https://github.com/daviscook477/BaseMod/releases/latest |
awaescher/RepoZ | 648162493 | Title: Open in VS Code
Question:
username_0: It would be cool if I could open a repo in VS Code...or make that menu configurable so I can add a custom "open in".
Answers:
username_1: Oh my gosh, of course ... VS Code. How could I NOT come up with this?
Thanks. Yes, I'll have to open up the context menu, I think ...
username_0: :)
One thing. Lots of people use code insiders. Which has al the same commands as code.exe but it is called code-insiders.exe
username_1: Good to know, thanks.
Btw, I actually just read this:
- https://techcrunch.com/2020/05/19/the-mystery-of-rgv2cw-microsofts-extremely-nerdy-secret-message-to-developers/
And the last sentence was like:

You were behind all this?
How cool's that? 😄
username_0: Yeah, very cool :)
Status: Issue closed
username_0: When you gonna release new version that includes this?
username_1: I hope I find some time this week.
username_1: [Version 5.4](https://github.com/username_1/RepoZ/releases/tag/v5.4) was just released 🥳 |
hpe-dev-incubator/hpe-dev-portal | 903807547 | Title: Two Pull Requests #500 and #501 with a single check :AWS amplify instead of 2 checks - Netlify and Amplify?
Question:
username_0: Hi @reddypramod85 , @username_2
<NAME> submitted two new blog posts through the CMS editor.
- https://github.com/hpe-dev-incubator/hpe-dev-portal/pull/501
- https://github.com/hpe-dev-incubator/hpe-dev-portal/pull/500
Would you know why there is only one check (AWS Amplify) instead of two checks (Netlify and AWS Amplify)?
Best regards
Denis
Answers:
username_1: In my opinion, this is due to the fact that these PR are not tagged with any netlifycms label like the other are. Seem like this doesn't trigger the Netlify CMS builds while working fine with Amplify.
username_0: Looks like something changed recently in the check process. One of the side effects is that the status flag “View Preview” and the “Check for Preview” are no longer available in CMS editor (Netlify). This breaking the guidelines we documented in the CMS v2 editor guide for external contributors.
Status: Issue closed
|
dotnet/roslyn | 382216797 | Title: Assembly reference is added when not needed
Question:
username_0: **Version Used**: Visual C# Compiler version 2.8.2.62916 (2ad4aabc)
**Steps to Reproduce**:
1. Compile following code
```c#
using ImportantForBug = System.Net.IPAddress;
class X
{
public static void Main ()
{
}
}
```
Disassembly the output
**Expected Behavior**:
No System assembly reference or make it consistent with /refonly option which does not have the unused assembly reference right now.
**Actual Behavior**:
it includes
```
.assembly extern System
{
.publickeytoken = (B7 7A 5C 56 19 34 E0 89 ) // .z\V.4..
.ver 4:0:0:0
}
```
Answers:
username_1: Duplicate of #31192
Status: Issue closed
|
storybookjs/storybook | 859512543 | Title: Using args with Typescript
Question:
username_0: **Describe the bug**
I followed the TS pattern outlined [here.](https://storybook.js.org/docs/react/writing-stories/args#story-args)
Is this documentation already outdated?
I have two errors reported by Typescript:
```
Property 'to' is missing in type . . . . but required in type . . . .
```
and
```
Property 'args' does not exist on type '(args: Story<{ to: string; }>) => Element'.
```
**Screenshots**
<img width="808" alt="Screen Shot 2021-04-16 at 4 42 33 pm" src="https://user-images.githubusercontent.com/26566353/114982430-c9268e00-9ed2-11eb-8a77-8da917aa7c98.png">
**System**
```
Environment Info:
System:
OS: macOS 11.2.3
CPU: (8) x64 Intel(R) Core(TM) i7-6920HQ CPU @ 2.90GHz
Binaries:
Node: 15.5.0 - /usr/local/bin/node
Yarn: 1.22.10 - /usr/local/bin/yarn
npm: 7.3.0 - /usr/local/bin/npm
Browsers:
Chrome: 89.0.4389.128
Firefox: 87.0
Safari: 14.0.3
npmPackages:
@storybook/addon-a11y: ^6.2.8 => 6.2.8
@storybook/addon-essentials: ^6.2.8 => 6.2.8
@storybook/addon-links: ^6.2.8 => 6.2.8
@storybook/addons: ^6.2.8 => 6.2.8
@storybook/node-logger: ^6.2.8 => 6.2.8
@storybook/preset-create-react-app: ^3.1.7 => 3.1.7
@storybook/react: ^6.2.8 => 6.2.8
```
Answers:
username_1: That's not what the documentation says. Story is the type of the template, not the type of the argument to the template
Status: Issue closed
username_0: Thanks username_1, I feel extremely smart 🤣 |
webgme/webgme | 150106354 | Title: New connections in meta-editor are dashed after using the mixin connection.
Question:
username_0: 
Answers:
username_0: 
Proposed new look. Get rid of dashed lines and make the with 2px instead of 1px
Status: Issue closed
|
serge-sans-paille/pythran | 639432201 | Title: Unsupported code leads to a long and nasty traceback
Question:
username_0: Trying to compile this unsupported code
```python
from numpy.random import uniform
# pythran export f()
def f():
return uniform(-0.5, 0.5)
```
gives this quite nice message
```
CRITICAL: I am in trouble. Your input file does not seem to match Pythran's constraints...
bug_from_numpy_random.py:7:0 error: identifier 'uniform' not found in module 'numpy.random'
----
from numpy.random import uniform
^~~~ (o_0)
----
```
However, with this one
```
from numpy import random
# pythran export f()
def f():
return random.uniform(-0.5, 0.5)
```
Pythran becomes very angry and crashes with a bad traceback
```
Traceback (most recent call last):
File "/home/pierre/.pyenv/versions/3.8.2/bin/pythran", line 11, in <module>
load_entry_point('pythran', 'console_scripts', 'pythran')()
File "/home/pierre/Dev/pythran/pythran/run.py", line 175, in run
pythran.compile_pythranfile(args.input_file,
File "/home/pierre/Dev/pythran/pythran/toolchain.py", line 471, in compile_pythranfile
output_file = compile_pythrancode(module_name, open(file_path).read(),
File "/home/pierre/Dev/pythran/pythran/toolchain.py", line 394, in compile_pythrancode
module, error_checker = generate_cxx(module_name, pythrancode, specs, opts,
File "/home/pierre/Dev/pythran/pythran/toolchain.py", line 138, in generate_cxx
pm, ir, docstrings = front_middle_end(module_name, code, optimizations,
File "/home/pierre/Dev/pythran/pythran/toolchain.py", line 105, in front_middle_end
refine(pm, ir, optimizations)
File "/home/pierre/Dev/pythran/pythran/middlend.py", line 43, in refine
pm.gather(ExtendedSyntaxCheck, node)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 217, in gather
return a.run(node)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 143, in run
return super(ModuleAnalysis, self).run(node)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 122, in run
super(Analysis, self).run(node)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 95, in run
self.prepare(node)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 90, in prepare
result = d.run(node)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 143, in run
return super(ModuleAnalysis, self).run(node)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 122, in run
super(Analysis, self).run(node)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 96, in run
return self.visit(node)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 78, in visit
return super(ContextManager, self).visit(node)
File "/home/pierre/.pyenv/versions/3.8.2/lib/python3.8/ast.py", line 360, in visit
[Truncated]
ret_aliases = self.visit(node.value)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 78, in visit
return super(ContextManager, self).visit(node)
File "/home/pierre/.pyenv/versions/3.8.2/lib/python3.8/ast.py", line 360, in visit
return visitor(node)
File "/home/pierre/Dev/pythran/pythran/analyses/aliases.py", line 350, in visit_Call
self.generic_visit(node)
File "/home/pierre/.pyenv/versions/3.8.2/lib/python3.8/ast.py", line 370, in generic_visit
self.visit(value)
File "/home/pierre/Dev/pythran/pythran/passmanager.py", line 78, in visit
return super(ContextManager, self).visit(node)
File "/home/pierre/.pyenv/versions/3.8.2/lib/python3.8/ast.py", line 360, in visit
return visitor(node)
File "/home/pierre/Dev/pythran/pythran/analyses/aliases.py", line 378, in visit_Attribute
return self.add(node, {Aliases.access_path(node)})
File "/home/pierre/Dev/pythran/pythran/analyses/aliases.py", line 102, in access_path
return Aliases.access_path(node.value)[demangle(node.attr)]
KeyError: 'uniform'
```
Ok, at least there is 'uniform' at the end...
Answers:
username_1: I can reproduce, I'll have a look tonight.
Status: Issue closed
|
istio/proxy | 213944695 | Title: Add TCP Filter
Question:
username_0: Add TCP filters to call Mixer check, report and Quota
Answers:
username_1: duplicate of #44. Is this really for alpha?
Status: Issue closed
username_0: That was my understanding based on the feature prioritization we did a few weeks ago. But I agree it's not needed for MVP, more of a nice-to-have for Alpha. |
glebm/i18n-tasks | 543383941 | Title: setup of ignore_missing only for non base_locale locales
Question:
username_0: I would like setup following:
- I have 3 user interfaces in my app: Admin, Teacher, Client
- Admin and Teacher is English only
- Client is multiple languages
I would like to run "i18n-tasks missing" so that:
- for "en" locale it tooks everything into the consideration (all interfaces have to be English)
- for other locales ("de", "es", etc...) it ignores missing with following setup:
```
ignore_missing:
- 'admin.*'
- 'admin_mailer.*'
- 'teacher.*'
- 'teacher_mailer.*'
```
I don't need translations of admin* and teacher* in other then English language.
Thank you very much for any hint how to automate this task.
Answers:
username_1: Or is it possible to exclude a complete translation file?
username_2: We need to ignore a specific language for pluralization.
i.e. Vietnamese doesn't have a concept of `one`
en:
errors:
record_count:
one: there is one record
other: there are %{count} records
In VI or ID we don't have `one`. `i18n-tasks missing` always complains about the one key missing from VI or ID.yml files. |
jlippold/tweakCompatible | 417896201 | Title: `ClearFolders` working on iOS 12.1.2
Question:
username_0: ```
{
"packageId": "com.daniel63194.clearfolders",
"action": "working",
"userInfo": {
"arch32": false,
"packageId": "com.daniel63194.clearfolders",
"deviceId": "iPhone9,3",
"url": "http://cydia.saurik.com/package/com.daniel63194.clearfolders/",
"iOSVersion": "12.1.2",
"packageVersionIndexed": true,
"packageName": "ClearFolders",
"category": "Tweaks",
"repository": "BigBoss",
"name": "ClearFolders",
"installed": "1.3-1",
"packageIndexed": true,
"packageStatusExplaination": "A matching version of this tweak for this iOS version could not be found. Please submit a review if you choose to install.",
"id": "com.daniel63194.clearfolders",
"commercial": false,
"packageInstalled": true,
"tweakCompatVersion": "0.1.3",
"shortDescription": "Make your folders cleaner with this tweak!",
"latest": "1.3-1",
"author": "daniel63194/Infinite",
"packageStatus": "Unknown"
},
"base64": "<KEY>
"chosenStatus": "working",
"notes": ""
}
```<issue_closed>
Status: Issue closed |
JSQLParser/JSqlParser | 322192854 | Title: DB2: Fetch first row only gives exception (also with UR problem)
Question:
username_0: ### Actual Behavior
This code gives ParseException:
String str =
"select distinct T1.A "
+" from T2 join T1 on (T2.B = T1.C) "
+ " fetch first row only with UR";
// + "fetch first 3 rows only with UR";
Statement stmt1 = CCJSqlParserUtil.parse(str);
Exception:
Exception in thread "main" net.sf.jsqlparser.JSQLParserException
at net.sf.jsqlparser.parser.CCJSqlParserUtil.parse(CCJSqlParserUtil.java:55)
at csn.mier.test.sqlparser.App.main(App.java:56)
Caused by: net.sf.jsqlparser.parser.ParseException: Encountered unexpected token: "row" "ROW"
at line 1, column 74.
Was expecting one of:
"?"
<S_LONG>
at net.sf.jsqlparser.parser.CCJSqlParser.generateParseException(CCJSqlParser.java:18047)
at net.sf.jsqlparser.parser.CCJSqlParser.jj_consume_token(CCJSqlParser.java:17900)
Note that "FETCH FIRST 1 ROW ONLY" works, but then adding "WITH UR" gives another exception.
net.sf.jsqlparser.parser.ParseException: Encountered unexpected token: "with" "WITH"
at line 1, column 85.
Was expecting one of:
";"
"EXCEPT"
"FOR"
"INTERSECT"
"MINUS"
"ORDER"
"UNION"
<EOF>
at net.sf.jsqlparser.parser.CCJSqlParser.generateParseException(CCJSqlParser.java:18047)
at net.sf.jsqlparser.parser.CCJSqlParser.jj_consume_token(CCJSqlParser.java:17900)
at net.sf.jsqlparser.parser.CCJSqlParser.Statement(CCJSqlParser.java:91)
at net.sf.jsqlparser.parser.CCJSqlParserUtil.parse(CCJSqlParserUtil.java:53)
### Expected Behavior
Not get an exception
### Steps to Reproduce the Problem
Run the code above
### Specifications
- Version: 1.2
- Platform: Windows
- Subsystem: NA<issue_closed>
Status: Issue closed |
PostgREST/postgrest | 390513887 | Title: Recursive embed yields same entity for secondary embed
Question:
username_0: ### Environment
* PostgreSQL version: docker, PG_VERSION=10.5-1.pgdg90+1
* PostgREST version: v5.1.0
* Operating system: Ubuntu/postgrest Docker
### Description of issue
In a recursive embed, embedding another resource will always yield the same entity.
Here you can find a minimal example including a schema definition: https://gist.github.com/username_0/2a6e9257fcf89dfd09016fdce8f2618f
Answers:
username_1: Thanks for the detailed report. Here's the underlying issue, this is the generated query:
```sql
WITH pg_source AS (
SELECT
"test"."post".*,
row_to_json("author_author".*) AS "author",
COALESCE(
(SELECT json_agg("post".*)
FROM (
SELECT
"post_1".*,
row_to_json("author_author".*) AS "author"
FROM "test"."post" AS "post_1"
LEFT JOIN LATERAL(
SELECT "test"."author".*
FROM "test"."author"
-- Here "test"."post"."author" should be "post_1"
WHERE "test"."author"."id" = "test"."post"."author") AS "author_author" ON TRUE
WHERE "post_1"."parent_post" = "post"."id" ) "post"), '[]') AS "comments"
FROM "test"."post"
LEFT JOIN LATERAL(
SELECT "test"."author".*
FROM "test"."author"
WHERE "test"."author"."id" = "test"."post"."author" ) AS "author_author" ON TRUE
WHERE "test"."post"."parent_post" IS null )
SELECT
coalesce(json_agg(_postgrest_t), '[]')::character varying AS body
FROM ( SELECT * FROM pg_source) _postgrest_t;
```
By running the query with "test"."post."author" replaced by "post_1" it gives the correct result.
Status: Issue closed
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.