
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
mazi-project/portal | 237551058 | Title: adminstrator portal title confusing
Question:
username_0: The adminstrator portal's title is "Mazizone portal". It would be less confusing if it was called "Mazizone Admin Panel" (or Page) but not portal to make sure it is a different "layer" than the user portal
Answers:
username_1: Fixed in v1.8.5
Status: Issue closed
|
Pauan/rust-dominator | 607673570 | Title: Evaluate and Implement HTML Macros
Question:
username_0: I want to evaluate these HTML macro systems and any others. @username_1 and others, let me know if you have thoughts on a good html macro system for rust to enable JSX style in Dominator, thanks.
- https://crates.io/crates/typed-html-macros
- https://crates.io/crates/html-macro
-https://crates.io/crates/unhtml_derive
- https://crates.io/crates/render_macros
```
typed-html is a wonderful library. Unfortunately, it focused its power in strictness of the HTML spec itself, and doesn't allow arbitrary compositions of custom elements.
render takes a different approach. For now, HTML is not typed at all. It can get any key and get any string value. The main focus is custom components, so you can create a composable and declarative template with no runtime errors.
```
Answers:
username_0: http://hop.inria.fr/home/index.html
username_1: ```
Can all these problems be fixed? Maybe, but it would require a *lot* of changes to JSX which would make it very different from HTML, which defeats the point of JSX (which is to be similar to HTML).
Fundamentally, HTML was never designed for making apps, it was always designed for *static text*. If you have a lot of text and only a few tags then HTML works great. But web apps use lots of tags and very little text, so HTML just doesn't work well.
And JSX in particular was always designed specifically for vdom, I don't think it will ever work good for FRP systems (like dominator).
Rather than trying to shoehorn HTML into web apps, I think it would be better to create a new macro syntax from scratch which fixes the above issues.
Though personally I quite like dominator's existing syntax, I spent a lot of time making it readable and maintainable (at the cost of some verbosity). I designed dominator's syntax for large real apps, not toy code examples or code golfing. In real apps you end up using a lot of signals (and computed values), so the extra verbosity of typing out `.attribute` or `.property` or `.style` is actually beneficial.
username_1: P.S. The idea of having special syntax to distinguish between the client and server is cool, however there isn't any need for that in Rust, because Rust has [conditional compilation](https://doc.rust-lang.org/reference/conditional-compilation.html) (with `cfg`):
```rust
#[cfg(feature = "client")]
html!("div", { ... })
#[cfg(feature = "server")]
html!("div", { ... })
```
I could easily add a new method which would make it even easier:
```rust
html!("div", {
.with_cfg!(feature = "client", {
.event(|e: events::Click| {
...
})
})
.with_cfg!(feature = "server", {
...
})
})
```
username_2: Generally speaking - I think you're moving the inevitable complexity of _large real apps_ into the right place, where it's typechecked and clear. This is the main reason I'm interested in Dominator tbh... performance is icing on the cake (within a reasonable threshhold).
So why am I commenting on this particular issue?
The other thing that happens with _large real apps_ is, often enough, the need to work with a team. That team, on the web frontend, right now, will likely be very allergic to Rust. In a non-toy non-personal project setting, telling other frontend devs to learn Rust, or even enough Rust to get by, might not be realistic for all sorts of reasons (not always technical).
So, I don't know what the solution for this is. Lets assume for the sake of convenience that "them" here is someone who is focused solely on html/js/css, and the "me" here is much happier working in Rust. Some ideas:
1. Have them write web components in their JS framework of choice, and then I target those web components from Dominator (changing their properties via signals, passing callbacks down, etc.). I've been experimenting with this in a few different ways... it works quite well in small proofs of concept, but my spidey sense is going off like crazy that it's not going to scale - for exactly the reasons you mentioned! At first it's beautiful to have "presentational" logic and state totally separate from "app/business" logic and state - but it gets muddy due to the particular overlap here, and I don't think it's _actually_ going to scale well. I'd anticipate a lot of friction about what should be done where. In _theory_ it would be clear - but in reality, I don't think it will be.
2. The inverse: don't use Dominator - rather, do the frontend DOM work in, whatever, and then call into Rust libraries for logic/state management. I've been experimenting with this - but again, it is setting off my spidey sense that while it works great for small toy examples, it's not going to scale well and will require a lot of careful communication to keep things in sync. Already I'm hitting issues of needing to call things like `get_user()` from different places on the JS side, and serializing through JsValue means the typescript doesn't come through. There's a lot of manual bookkeeping.
3. Have them write clean, non-stateful components in plain html/css - perhaps in a visual reference library like storybook, and then re-create that from scratch in Dominator (sortof the way they will base their code on a design). This requires keeping them in sync, and is creating some double-work. I'm starting to lean toward this frankly because I've exhausted the above two options and this is the only one that's left. However, this route has its own problems, like if its possible to at least re-use the .css files (and respecting the encapsulation).
4. Some HTML macro thing that lets them edit HTML and CSS in my Rust source without having to know Rust. There can be a few simple "syntax" rules they can learn - like the need to quote strings... but, it can't be too different. They should basically be able to copy/paste from codepen.
I'm not sure there's a perfect answer here... but I figured it's worth commenting since it's very much on my mind. I'm currently leaning toward option 3 though. I'm skeptical that 4 will really be able to address everything, but very happy if it can!
username_2: The more I think about it, the more option 3 makes sense.
It's not unlike how a design will often progress from static wireframes to rough mockups to complete but static references to interactive, perhaps even responsive references.
This is just adding another step to the _design phase_ where the programmer or, let's say "technical layout artist", is bringing it to its next incarnation. These could even be user tested and vetted independently before going into full-on production. With a bit of JS sprinkled in they could probably even be done very close to the final thing (from a user's perspective).
Yes there's a bit of double-work, but we accept that when going between other design phases because the tradeoff is worth it, and I think the same idea applies here.
That then leaves the app code itself to be 100% Rust, with a pure focus, and the html/css is also done in its focused sandbox.
With that in mind, I don't think I personally have a need for html macros - though I'm happy to re-evaluate if/when you add them :)
username_1: Rather than having a macro, I think a better idea is to have some sort of CLI tool that can take in HTML and spit out some Rust code. Then you would just need to add interactivity (with signals/events) to the generated Rust code.
Now they can create their design entirely in Codepen (or wherever) using regular HTML + CSS, then just run the tool which will generate dominator code from it.
username_2: That is a really interesting idea! Could be like the way [diesel](http://diesel.rs/) does its thing... (write sql, run a cli tool, it generates rust macros, which then generate rust structs)
username_1: @username_2 Yes, and that means they can use whatever tools they are familiar with (HTML and CSS obviously, but also Codepen, etc.) They don't need to learn anything new, their existing workflow can stay the same.
And since the HTML is static, there aren't any computed or dynamic attributes, and there aren't any events, so all of the downsides I mentioned above don't apply.
But you still get the benefits of having everything done in dominator (which gives you the benefits of signals, events, futures, streams, static typing, etc.)
username_2: I'm having a bit of trouble envisioning _exactly_ how this would work - since I'd still need to take the result of the cli tool and add in all the functionality (like changing properties on signals, nesting dynamic children, etc.)
Excited to see where this goes though! :)
username_1: Well of course, the designer isn't adding in any of that, so you will have to. The point isn't to automate everything (ultimately you still have to do the porting by hand), the point is to avoid the tedious work of manually converting HTML tags, classes, and attributes into dominator. The actual tricky parts will still have to be done by hand. So it doesn't *replace* option 3, it instead just makes option 3 a bit easier and faster.
username_2: ok cool, and for unsupported things it will just ignore them? For example, given this:
```html
<div class="menu">
<ul class="left big">
<li onclick="do_something(1)">child 1</li>
<li onclick="do_something(2)">child 2</li>
</ul>
</div>
```
would it ignore the `onclick` and generate something like this?
```rust
html!("div", {
.class("menu")
.children(&mut [
html!("ul", {
.class("left")
.class("big")
.children(&mut [
html!("li", {
.text("child 1")
}),
html!("li", {
.text("child 2")
})
])
})
])
})
```
Or, alternatively - since it's not meant to be a perfect drop-in replacement, maybe it could add in the `.event()` stubs?
username_2: Another idea - is to create this as a npm/js package (whether it's developed in Rust or not).
That way it could be added as a plugin to Storybook...
So, designer/html person creates things in storybook, and then anyone can hit a button to "generate DomBuilder code"
username_2: Ok, check it out: https://github.com/username_2/storybook-for-dominator-boilerplate
This could be a really nice workflow :)
For the HTML->Dominator string conversion, I created a new [npm package](https://github.com/username_2/html-to-dominator-string)... since it's running in the DOM anyway it takes advantage of that and just walks through an ad-hoc element.
The code for that is not very elegant, but it's a start - and upgrades to the package won't break Storybook just work since it's just `String -> String`
username_1: I don't think you are understanding the problem. We are writing Rust, not JS. Rust is statically typed, which means there is a fundamental type difference between a `u32` and a `Signal<Item = u32>`, and so they cannot be handled with the same API (at least not without a *lot* of trait magic). That's why it has to be distinguished in the syntax (or in the case of dominator, with a different method call).
Also, I really like having a clear distinction between computed and dynamic values, because it means that you can tell at a glance what is changing and what is *not* changing. This helps a *lot* with maintainability. JSX (and JS frameworks in general) don't have that benefit. |
google-research/text-to-text-transfer-transformer | 612223858 | Title: GLUE task finetune params
Question:
username_0: Hi, In the T5 paper page 29, you mentioned the batch size(8) used for GLUE task finetune. Can you share what learning rate you used for this? Thanks.
"We therefore use a smaller batch size of 8 length-512 sequences during fine-tuning for each GLUE and SuperGLUE task."
Status: Issue closed
Answers:
username_1: Hello, We used a learning rate of 0.001 for finetuning the GLUE and SuperGLUE tasks, similar to all the other finetuning experiments in the paper. |
home-assistant/frontend | 647666696 | Title: Unable to authenticate to AdGuard Home in iFrame on Mobile Safari or HA Companion iOS app
Question:
username_0: ## Checklist
- [x] I have updated to the latest available Home Assistant version.
- [x] I have cleared the cache of my browser.
- [x] I have tried a different browser to see if it is related to my browser.
## The problem
I use AdGuard Home and have an iFrame component enabled to have the interface inline with Home Assistant. This appears to work fine with most Windows browsers, however on iOS in either Safari or HA Companion, when selecting the iFrame tab, the login screen is presented, but rather than authenticate and login to AdGuard Home, you are continuously returned to the login screen. Going directly to the AdGuard Home page in Safari works as expected, things only fail when in the HA iFrame. It appears that HA frontend is doing something unique on iOS with Safari/Webkit.
## Expected behavior
I would expect logging in to AdGuard Home to either display a login error message if something failed, or successfully log in to the management interface when in an iFrame run in any browser, or in the mobile apps, not just desktop browsers.
## Steps to reproduce
1. Install AdGuard Home (I used docker)
2. Add iFrame configuration in HA to AdGuard Home configuration page
3. Open HA in Safari on iOS (or in HA Companion App)
4. Navigate to AdGuard Home iFrame
5. Attempt to log in to AdGuard Home
6. Screen should flicker, then refresh back to login screen
## Environment
- Home Assistant release with the issue: 0.111.4
- Last working Home Assistant release (if known):
- Browser and browser version: Mobile Safari
- Operating system: iOS 13.5.1
- AdGuard Home: 0.102.0
- HA Companion App: 2020.3 (4) Testflight
## Problem-relevant configuration
```yaml
panel_iframe:
adguard_home:
title: AdGuard
icon: mdi:security-network
url: !secret adguard_home_url
require_admin: true
```
Answers:
username_1: I don't think this is something we do, but maybe something Adguard does in the login screen?
username_0: I've got an issue logged with them as well, but they were leaning towards it being something with the HA frontend since their stuff works fine outside of HA iFrame, and works from a desktop browser inside the HA iFrame. So it seems like something different that is happening with the way things are working in an HA iFrame on mobile Apple devices. I'm not a web developer at all, so don't even know how you'd troubleshoot something like this, but I'm happy to help on my setup if anyone had guidance. |
dnnsoftware/Dnn.Platform | 683864984 | Title: Page Output Caching conflicts with Anti-Forgery Token
Question:
username_0: ## Description of bug
I just ran across an issue I hadn't experienced before, and wanted to see if y'all thought there was a solution worth investing in. A client had turned on page output caching on a number of pages that had public-facing forms (you don't need to be logged in to submit the form). The form is using a Web API endpoint that's protected with the `[ValidateAntiForgeryToken]` attribute, and the form itself calls `DotNetNuke.Framework.ServicesFramework.Instance.RequestAjaxAntiForgerySupport()`. However, when the page was served from the cache, the `__RequestVerificationToken` cookie wasn't being sent with the request. This led to all of the requests returning a 401 response and the browser showing its built-in auth dialog.
## Current behavior
Requests from cached page fail.
## Expected behavior
Requests from cached page do not fail.
### Option 1
The caching mechanism has some way to know that an anti-forgery token was requested and saves that information with the cached page.
### Option 2
The caching mechanism always requests an anti-forgery token b/c why not.
### Option 3
Since we only serve cached pages to folks who aren't logged in (need to verify this), and a cross-site request forgery isn't possible with someone who's not logged in (need to verify this), we could decide that all unauthenticated requests pass the anti-forgery token check.
### Option 4
This is too hard to get right, it's just an unsupported configuration.
Answers:
username_1: Option 4 was the initial intention of the functionality, and what I have always educated people on.
Option 2 could be possible, but the performance hit could negate some of the gains, as you would have to parse & replace the anti-forgery token on every request. |
FAForever/downlords-faf-client | 816529963 | Title: Cant start application after update
Question:
username_0: **Describe the bug**
Application fails to start with exeption
**To Reproduce**
jdk-15.0.2
I tried v1.3 and v1.4 and both dont work for me
**Log or error message**
16:07:25.374 [main] DEBUG com.faforever.client.preferences.PreferencesService - Logger initialized
16:07:26.007 [JavaFX-Launcher] DEBUG org.springframework.boot.context.logging.ClasspathLoggingApplicationListener - Application failed to start with classpath: unknown
16:07:26.021 [JavaFX-Launcher] ERROR org.springframework.boot.SpringApplication - Application run failed
java.lang.IllegalStateException: ConfigFileApplicationListener [org.springframework.boot.context.config.ConfigFileApplicationListener] is deprecated and can only be used as an EnvironmentPostProcessor
at org.springframework.boot.context.config.ConfigFileApplicationListener.onApplicationEvent(ConfigFileApplicationListener.java:198)
at org.springframework.context.event.SimpleApplicationEventMulticaster.doInvokeListener(SimpleApplicationEventMulticaster.java:203)
at org.springframework.context.event.SimpleApplicationEventMulticaster.invokeListener(SimpleApplicationEventMulticaster.java:196)
at org.springframework.context.event.SimpleApplicationEventMulticaster.multicastEvent(SimpleApplicationEventMulticaster.java:170)
at org.springframework.context.event.SimpleApplicationEventMulticaster.multicastEvent(SimpleApplicationEventMulticaster.java:148)
at org.springframework.boot.context.event.EventPublishingRunListener.environmentPrepared(EventPublishingRunListener.java:82)
at org.springframework.boot.SpringApplicationRunListeners.lambda$environmentPrepared$2(SpringApplicationRunListeners.java:63)
at java.base/java.util.ArrayList.forEach(ArrayList.java:1511)
at org.springframework.boot.SpringApplicationRunListeners.doWithListeners(SpringApplicationRunListeners.java:117)
at org.springframework.boot.SpringApplicationRunListeners.doWithListeners(SpringApplicationRunListeners.java:111)
at org.springframework.boot.SpringApplicationRunListeners.environmentPrepared(SpringApplicationRunListeners.java:62)
at org.springframework.boot.SpringApplication.prepareEnvironment(SpringApplication.java:362)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:320)
at org.springframework.boot.builder.SpringApplicationBuilder.run(SpringApplicationBuilder.java:144)
at com.faforever.client.FafClientApplication.init(FafClientApplication.java:110)
at com.sun.javafx.application.LauncherImpl.launchApplication1(LauncherImpl.java:824)
at com.sun.javafx.application.LauncherImpl.lambda$launchApplication$2(LauncherImpl.java:195)
at java.base/java.lang.Thread.run(Thread.java:832)
**OS**
Ubuntu 18.04.5
Answers:
username_1: The client comes with its own JDK so 15.0.2 should be irrelevant. If for some reason however this interferes, which I can't tell from the log, that could (but is unlikely, from the logs) be an issue.
A more likely possibility is that there are files from previous versions (maybe an RC?) that didn't get uninstalled properly so you could try uninstalling the client, make sure that its installation directory is actually empty (delete files manually if it's not) and try installing it again.
username_2: Installed the 1.4.2 update today and the launcher is completely borked for me no matter what I try :(
`java.lang.RuntimeException: Exception in Application init method
at com.sun.javafx.application.LauncherImpl.launchApplication1(LauncherImpl.java:895)
at com.sun.javafx.application.LauncherImpl.lambda$launchApplication$2(LauncherImpl.java:195)
at java.base/java.lang.Thread.run(Thread.java:832)
Caused by: org.springframework.context.ApplicationContextException: Failed to start bean 'webServerStartStop'; nested exception is org.springframework.boot.web.server.PortInUseException: Port 8080 is already in use
at org.springframework.context.support.DefaultLifecycleProcessor.doStart(DefaultLifecycleProcessor.java:181)
at org.springframework.context.support.DefaultLifecycleProcessor.access$200(DefaultLifecycleProcessor.java:54)
at org.springframework.context.support.DefaultLifecycleProcessor$LifecycleGroup.start(DefaultLifecycleProcessor.java:356)
at java.base/java.lang.Iterable.forEach(Iterable.java:75)
at org.springframework.context.support.DefaultLifecycleProcessor.startBeans(DefaultLifecycleProcessor.java:155)
at org.springframework.context.support.DefaultLifecycleProcessor.onRefresh(DefaultLifecycleProcessor.java:123)
at org.springframework.context.support.AbstractApplicationContext.finishRefresh(AbstractApplicationContext.java:942)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:591)
at org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext.refresh(ServletWebServerApplicationContext.java:144)
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:767)
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:759)
at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:426)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:326)
at org.springframework.boot.builder.SpringApplicationBuilder.run(SpringApplicationBuilder.java:144)
at com.faforever.client.FafClientApplication.init(FafClientApplication.java:110)
at com.sun.javafx.application.LauncherImpl.launchApplication1(LauncherImpl.java:824)
... 2 more
Caused by: org.springframework.boot.web.server.PortInUseException: Port 8080 is already in use
at org.springframework.boot.web.server.PortInUseException.lambda$throwIfPortBindingException$0(PortInUseException.java:70)
at org.springframework.boot.web.server.PortInUseException.lambda$ifPortBindingException$1(PortInUseException.java:85)
at org.springframework.boot.web.server.PortInUseException.ifCausedBy(PortInUseException.java:103)
at org.springframework.boot.web.server.PortInUseException.ifPortBindingException(PortInUseException.java:82)
at org.springframework.boot.web.server.PortInUseException.throwIfPortBindingException(PortInUseException.java:69)
at org.springframework.boot.web.embedded.tomcat.TomcatWebServer.start(TomcatWebServer.java:228)
at org.springframework.boot.web.servlet.context.WebServerStartStopLifecycle.start(WebServerStartStopLifecycle.java:43)
at org.springframework.context.support.DefaultLifecycleProcessor.doStart(DefaultLifecycleProcessor.java:178)
... 17 more
Caused by: java.lang.IllegalArgumentException: standardService.connector.startFailed
at org.apache.catalina.core.StandardService.addConnector(StandardService.java:231)
at org.springframework.boot.web.embedded.tomcat.TomcatWebServer.addPreviouslyRemovedConnectors(TomcatWebServer.java:282)
at org.springframework.boot.web.embedded.tomcat.TomcatWebServer.start(TomcatWebServer.java:213)
... 19 more
Caused by: org.apache.catalina.LifecycleException: Protocol handler start failed
at org.apache.catalina.connector.Connector.startInternal(Connector.java:1067)
at org.apache.catalina.util.LifecycleBase.start(LifecycleBase.java:183)
at org.apache.catalina.core.StandardService.addConnector(StandardService.java:227)
... 21 more
Caused by: java.net.BindException: Address already in use: bind
at java.base/sun.nio.ch.Net.bind0(Native Method)
at java.base/sun.nio.ch.Net.bind(Net.java:550)
at java.base/sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:249)
at java.base/sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:88)
at org.apache.tomcat.util.net.NioEndpoint.initServerSocket(NioEndpoint.java:228)
at org.apache.tomcat.util.net.NioEndpoint.bind(NioEndpoint.java:211)
at org.apache.tomcat.util.net.AbstractEndpoint.bindWithCleanup(AbstractEndpoint.java:1141)
at org.apache.tomcat.util.net.AbstractEndpoint.start(AbstractEndpoint.java:1227)
at org.apache.coyote.AbstractProtocol.start(AbstractProtocol.java:592)
at org.apache.catalina.connector.Connector.startInternal(Connector.java:1064)
... 23 more
`
This is on 8.1 build 9600
username_2: After some testing, it seems like everything after 1.4.0 is broken in the same way for me. I tried all the 1.4.1 RCs and no dice.
username_3: #2170 fixes this. Workaround in the meantime: Make sure no other application runs on port 8080.
Status: Issue closed
username_4: How to make sure no other application is running on port 8080:

username_2: In my case, it was a service part of the National Instruments shared components for labview. Now theres nothing running on :8080 it just dies this death instead:
```
java.lang.RuntimeException: Exception in Application start method
at com.sun.javafx.application.LauncherImpl.launchApplication1(LauncherImpl.java:900)
at com.sun.javafx.application.LauncherImpl.lambda$launchApplication$2(LauncherImpl.java:195)
at java.base/java.lang.Thread.run(Thread.java:832)
Caused by: com.github.nocatch.NoCatchException: javafx.fxml.LoadException:
file:/C:/Program%20Files/Downlord's%20FAF%20Client/lib/downlords-faf-client-1.4.2.jar!/theme/statusbar/status_bar.fxml:13
file:/C:/Program%20Files/Downlord's%20FAF%20Client/lib/downlords-faf-client-1.4.2.jar!/theme/main.fxml:106
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:64)
at java.base/jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.base/java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:500)
at java.base/java.lang.reflect.Constructor.newInstance(Constructor.java:481)
at com.github.nocatch.NoCatch.wrapException(NoCatch.java:61)
at com.github.nocatch.NoCatch.noCatch(NoCatch.java:53)
at com.github.nocatch.NoCatch.noCatch(NoCatch.java:34)
at com.faforever.client.theme.UiService.loadFxml(UiService.java:420)
at com.faforever.client.theme.UiService$$FastClassBySpringCGLIB$$2b0b2208.invoke(<generated>)
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:687)
at com.faforever.client.theme.UiService$$EnhancerBySpringCGLIB$$d29e5a31.loadFxml(<generated>)
at com.faforever.client.FafClientApplication.showMainWindow(FafClientApplication.java:138)
at com.faforever.client.FafClientApplication.start(FafClientApplication.java:122)
at com.sun.javafx.application.LauncherImpl.lambda$launchApplication1$9(LauncherImpl.java:846)
at com.sun.javafx.application.PlatformImpl.lambda$runAndWait$12(PlatformImpl.java:455)
at com.sun.javafx.application.PlatformImpl.lambda$runLater$10(PlatformImpl.java:428)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:391)
at com.sun.javafx.application.PlatformImpl.lambda$runLater$11(PlatformImpl.java:427)
at com.sun.glass.ui.InvokeLaterDispatcher$Future.run(InvokeLaterDispatcher.java:96)
at com.sun.glass.ui.win.WinApplication._runLoop(Native Method)
at com.sun.glass.ui.win.WinApplication.lambda$runLoop$3(WinApplication.java:174)
... 1 more
Caused by: javafx.fxml.LoadException:
file:/C:/Program%20Files/Downlord's%20FAF%20Client/lib/downlords-faf-client-1.4.2.jar!/theme/statusbar/status_bar.fxml:13
file:/C:/Program%20Files/Downlord's%20FAF%20Client/lib/downlords-faf-client-1.4.2.jar!/theme/main.fxml:106
at javafx.fxml.FXMLLoader.constructLoadException(FXMLLoader.java:2707)
at javafx.fxml.FXMLLoader.loadImpl(FXMLLoader.java:2685)
at javafx.fxml.FXMLLoader.loadImpl(FXMLLoader.java:2548)
at javafx.fxml.FXMLLoader$IncludeElement.constructValue(FXMLLoader.java:1156)
at javafx.fxml.FXMLLoader$ValueElement.processStartElement(FXMLLoader.java:756)
at javafx.fxml.FXMLLoader.processStartElement(FXMLLoader.java:2808)
at javafx.fxml.FXMLLoader.loadImpl(FXMLLoader.java:2634)
at javafx.fxml.FXMLLoader.loadImpl(FXMLLoader.java:2548)
at javafx.fxml.FXMLLoader.load(FXMLLoader.java:2517)
at com.github.nocatch.NoCatch.noCatch(NoCatch.java:49)
... 17 more
Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'statusBarController' defined in URL [jar:file:/C:/Program%20Files/Downlord's%20FAF%20Client/lib/downlords-faf-client-1.4.2.jar!/com/faforever/client/ui/statusbar/StatusBarController.class]: Unsatisfied dependency expressed through constructor parameter 2; nested exception is org.springframework.beans.factory.NoUniqueBeanDefinitionException: No qualifying bean of type 'com.faforever.client.chat.ChatService' available: expected single matching bean but found 2: kittehChatService,pircBotXChatService
at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:798)
at org.springframework.beans.factory.support.ConstructorResolver.autowireConstructor(ConstructorResolver.java:228)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.autowireConstructor(AbstractAutowireCapableBeanFactory.java:1356)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBeanInstance(AbstractAutowireCapableBeanFactory.java:1206)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:571)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:531)
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:353)
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:233)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveNamedBean(DefaultListableBeanFactory.java:1235)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveBean(DefaultListableBeanFactory.java:494)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBean(DefaultListableBeanFactory.java:349)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBean(DefaultListableBeanFactory.java:342)
at org.springframework.context.support.AbstractApplicationContext.getBean(AbstractApplicationContext.java:1179)
at javafx.fxml.FXMLLoader$ValueElement.processAttribute(FXMLLoader.java:940)
at javafx.fxml.FXMLLoader$InstanceDeclarationElement.processAttribute(FXMLLoader.java:982)
at javafx.fxml.FXMLLoader$Element.processStartElement(FXMLLoader.java:229)
at javafx.fxml.FXMLLoader$ValueElement.processStartElement(FXMLLoader.java:754)
at javafx.fxml.FXMLLoader.processStartElement(FXMLLoader.java:2808)
at javafx.fxml.FXMLLoader.loadImpl(FXMLLoader.java:2634)
... 25 more
Caused by: org.springframework.beans.factory.NoUniqueBeanDefinitionException: No qualifying bean of type 'com.faforever.client.chat.ChatService' available: expected single matching bean but found 2: kittehChatService,pircBotXChatService
at org.springframework.beans.factory.config.DependencyDescriptor.resolveNotUnique(DependencyDescriptor.java:220)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1345)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1287)
at org.springframework.beans.factory.support.ConstructorResolver.resolveAutowiredArgument(ConstructorResolver.java:885)
at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:789)
... 43 more
```
username_3: Classic case of the installer didn't wipe the old version properly. Please uninstall, manually delete remaining files and reinstall.
Is it possible that you updated, while the FAF client was still running?
username_5: @username_3 I know this is the case with people who updated who helped test tmm as there was a jar that had to be manually placed in the install folder and if it isnt removed there is namespace collision |
ueberdosis/tiptap | 907519958 | Title: Can not server side render html of tip tap using laravel SSR
Question:
username_0: In the following ticket:
https://github.com/ueberdosis/tiptap/issues/821
this is mentioned:
The current implementation still needs a document, but I’m going to add JSDOM support
and this is the error I get:
```
The command "/usr/bin/node /application/storage/app/ssr/69118be818c6f4103ba9177ae5b7d114.js" failed. Exit Code: 1(General error) Working directory: /application/public Output: ================ Error Output: ================ /application/storage/app/ssr/69118be818c6f4103ba9177ae5b7d114.js:27739 const res = document.querySelector(container); ^ ReferenceError: document is not defined at normalizeContainer (/application/storage/app/ssr/69118be818c6f4103ba9177ae5b7d114.js:27739:21) at Object.app.mount (/application/storage/app/ssr/69118be818c6f4103ba9177ae5b7d114.js:27697:27) at Module../resources/assets/js/app-client.js (/application/storage/app/ssr/69118be818c6f4103ba9177ae5b7d114.js:28413:5) at __webpack_require__ (/application/storage/app/ssr/69118be818c6f4103ba9177ae5b7d114.js:45628:42) at /application/storage/app/ssr/69118be818c6f4103ba9177ae5b7d114.js:45701:69 at /application/storage/app/ssr/69118be818c6f4103ba9177ae5b7d114.js:45714:3 at Object.<anonymous> (/application/storage/app/ssr/69118be818c6f4103ba9177ae5b7d114.js:45716:12) at Module._compile (internal/modules/cjs/loader.js:778:30) at Object.Module._extensions..js (internal/modules/cjs/loader.js:789:10) at Module.load (internal/modules/cjs/loader.js:653:32) (View: /application/resources/views/test.blade.php)
```
Is the JSDOM support already available?
the vue component:
```
<template>
<div>
{{ output}}
</div>
</template>
<script>
import {generateHTML} from "@tiptap/html";
export default {
computed: {
output() {
const doc = {
'type': 'document',
'content': [{
'type': 'paragraph',
'attrs': {
'align': 'left'
},
'content': [{
'type': 'text',
'text': 'My sample text'
}]
}]
}
return generateHTML(this.template.body, [
Document,
Text,
])
},
},
};
</script>
```
the blade view (using spatie package for ssr):
```<html>
<head>
<title>My server side rendered app</title>
<script defer src="{{ asset('assets/js/app-client.js') }}"></script>
</head>
<body>
<div id="app">
{!! ssr('assets/js/app-server.js')->render() !!}
</div>
</body>
</html>
```
tiptap versions:
```
"@tiptap/core": "^2.0.0-beta.73",
"@tiptap/extension-document": "^2.0.0-beta.1",
"@tiptap/extension-paragraph": "^2.0.0-beta.1",
"@tiptap/html": "^2.0.0-beta.9",
"@tiptap/starter-kit": "^2.0.0-beta.70",
"@tiptap/vue-3": "^2.0.0-beta.40",
```
Hope this is enough information, if something is missing please let me know
Answers:
username_1: Thanks for reporting! You pass only two extensions too `generateHTML`, that doesn’t look right. Your example JSON requires at least three extensions: `Document`, `Paragraph` and `Text`. Would you mind trying it with those three?
BTW, I’m working on a tiptap v2 compatible PHP package to render HTML.
username_0: even without generateHTML the build does not succeed. Then I must have messed up something in the setup of server side rendering. I have must have suffered from tunnel vision yesterday.
Thank you for your time and help, you have been really helpful.
is there anywhere I can follow the progress on your tiptap v2 compatible PHP package?
username_0: not a problem with tip-tap, closing issue.
Status: Issue closed
username_0: @username_1 , sorry to revive this issue, but I am still struggling. Would you mind helping me?
I got the SSR working with this package: https://github.com/cretueusebiu/laravel-nuxt
but this results in an error:
```
ERROR Document is not defined 16:00:11
at a.output (client/pages/tiptap.vue:30:0)
at a.output (node_modules/vue/dist/vue.runtime.common.prod.js:6:29698)
at a.render (client/pages/tiptap.vue)
at a.t._render (node_modules/vue/dist/vue.runtime.common.prod.js:6:35273)
at node_modules/vue-server-renderer/build.prod.js:1:70637
at Yi (node_modules/vue-server-renderer/build.prod.js:1:67201)
at io (node_modules/vue-server-renderer/build.prod.js:1:70613)
at ro (node_modules/vue-server-renderer/build.prod.js:1:70244)
at eo (node_modules/vue-server-renderer/build.prod.js:1:67491)
at node_modules/vue-server-renderer/build.prod.js:1:70711
```
I need to generate a PDF based on the result of tip-tap, but sending the HTML from the front-end doesn't feel safe. What I a missing?
username_1: What’s you’re code? The error message looks like you used tiptap, but you need to use the utility package.
https://github.com/ueberdosis/tiptap/issues/1397#issue-907519958
https://www.tiptap.dev/api/utilities/html
username_0: The utility package uses the same import:
```
<template>
<pre><code>{{ output }}</code></pre>
</template>
<script>
// Option 1: Browser + server-side
import { generateHTML } from '@tiptap/html'
// Option 2: Browser-only (lightweight)
// import { generateHTML } from '@tiptap/core'
import Document from '@tiptap/extension-document'
import Paragraph from '@tiptap/extension-paragraph'
import Text from '@tiptap/extension-text'
import Bold from '@tiptap/extension-bold'
const json = {
type: 'doc',
content: [
{
type: 'paragraph',
content: [
{
type: 'text',
text: 'Example ',
},
{
type: 'text',
marks: [
{
type: 'bold',
},
],
text: 'Text',
},
],
},
],
}
export default {
computed: {
output() {
return generateHTML(json, [
Document,
Paragraph,
Text,
Bold,
// other extensions …
])
},
},
}
</script>
```
as the code I use:
```
<template>
<div>
{{ output }}
[Truncated]
'type': 'text',
'text': 'My sample text'
}]
}]
}
return generateHTML(doc, [
Document,
Text,
])
},
},
}
</script>
<style scoped>
</style>
```
So I am using the utility package? I don't see it
username_1: You pass `Document` but don’t import it. That’s why ut’s undefined.
Also, for the JSON included in your example you’ll need `Document`, `Paragraph` and `Text`, as shown in the first code block in your comment.
ProseMirror/tiptap is very strict with the so called schema. It only has support for the exact set of passed extensions and nothing more. So make sure to add `Bold` and everything else you might need too.
username_0: That is just really stupid from my side. But now I am still not there, get a different error from prosemirror:
```
ERROR Unknown node type: document 07:33:59
at Schema.nodeType (node_modules/prosemirror-model/dist/index.js:2409:23)
at Function.fromJSON (node_modules/prosemirror-model/dist/index.js:1379:17)
at generateHTML (node_modules/@tiptap/html/dist/tiptap-html.cjs.js:21:47)
at a.output (client/pages/tiptap.vue:32:0)
at a.output (node_modules/vue/dist/vue.runtime.common.prod.js:6:29698)
at a.render (client/pages/tiptap.vue)
at a.t._render (node_modules/vue/dist/vue.runtime.common.prod.js:6:35273)
at node_modules/vue-server-renderer/build.prod.js:1:70637
at Yi (node_modules/vue-server-renderer/build.prod.js:1:67201)
at io (node_modules/vue-server-renderer/build.prod.js:1:70613)
```
code:
```
<template>
<div>
{{ output }}
</div>
</template>
<script>
import {generateHTML} from "@tiptap/html";
import Document from '@tiptap/extension-document'
import Paragraph from '@tiptap/extension-paragraph'
import Text from '@tiptap/extension-text'
import Bold from '@tiptap/extension-bold'
export default {
name: 'tiptap.vue',
computed: {
output() {
const doc = {
'type': 'document',
'content': [{
'type': 'paragraph',
'attrs': {
'align': 'left'
},
'content': [{
'type': 'text',
'text': 'My sample text'
}]
}]
}
return generateHTML(doc, [
Document,
Text,
Paragraph,
Bold,
])
},
},
}
</script>
<style scoped>
</style>
```
username_1: I know it’s a little bit confusing, but the internal type of `Document` is actually `doc`. Try changing that name in the passed JSON.
We wanted to go with `document` but changed it back to the ProseMirror default `doc` to avoid trouble with 3rd party packages.
Anyway, that shouldn’t happen if you use the real output of the editor.
username_0: That works, thank you so much. I feel so stupid now, bit overwhelmed by all the information I suppose.
username_1: No worries, it’s a lot to learn. Happy to help! |
mitchweaver/subs | 667791847 | Title: Add subs to `subs`!
Question:
username_0: Hi, I noticed that mpv automatically loads the embedded subtitles from youtube videos which have them, but does not select them automatically.
I would add it to the README that you can add `--sid=1` to the command line options, or `sid=1` to `~/.config/mpv/mpv.conf` in order to select the first available subtitles. Of course, if there are multiple languages, one can always switch between those using `j` and `J`, or turn them off with `v`.
I think that would be an helpful tip to mention!
Answers:
username_0: ok i realised this is not actually that useful nor related to the program, closing.
Status: Issue closed
|
hankinsoft/SQLPro | 206394544 | Title: Better JSON result support
Question:
username_0: Currently, it is very difficult to handle query results that return JSON. The results are packed into a single column in the datagrid, making it difficult to assess the result. In addition, exporting/copying it out into an external editor is problematic (\"\ get escaped, the entire result is wrapped in \"\).
SQLPro is my favorite sql editor, but I do a lot of JSON queries so any improvements here would be 👍
Answers:
username_1: Hmmm, first which database type is this? Is there a specific column that maps to json, or is it text with json in it? What I'm able to to may depend on those a bit.
Also, any suggestions for an alternative way to display them? :)
username_0: I'm using Postgres, and do a lot of `json_agg` queries, which basically takes the results of the query itself and converts it into a JSON array. In this case the entire result set is just a JSON string.
Option 1 - have a text based output window that pretty-prints the JSON so i can easily see the result of the query. But i totally get that this would take some work.
Option 2 - Make it so that when i copy the JSON out of the 1 row/1 column result set it's not being escaped that way i can easily copy it to a text editor and view it
I've attached a few screenshots to help illustrate
Thanks!
<img width="893" alt="screen shot 2017-02-09 at 9 03 21 am" src="https://cloud.githubusercontent.com/assets/532590/22786493/c5090086-eea6-11e6-90fe-21e353291a83.png">
<img width="766" alt="screen shot 2017-02-09 at 8 58 54 am" src="https://cloud.githubusercontent.com/assets/532590/22786494/c5095a36-eea6-11e6-9b28-4c24f8acfcd0.png">
username_1: Would allowing you to expand json rows help? Something like this:
<img width="1073" alt="screen shot 2017-02-09 at 10 27 44 am" src="https://cloud.githubusercontent.com/assets/3160528/22787384/82d8940e-eeb2-11e6-882f-dbd244a92cae.png">
username_0: ya, this would be *much* better!
username_1: Hi,
Can you give https://d3fwkemdw8spx3.cloudfront.net/studio/SQLProStudio.1.0.113.app.zip a try? That should allow for the popover (in both cases) and also fix the copy from results grid issue.
username_0: Uh oh.. looks the same
<img width="1225" alt="screen shot 2017-02-10 at 2 46 50 pm" src="https://cloud.githubusercontent.com/assets/532590/22841543/03e1b164-efa0-11e6-9c2c-93e98a5d1011.png">
username_1: If you mouse over the cell with data in it does a down arrow appear? Or nothing? Also if you copy the cell does it paste properly now?
username_0: ahh.. ya, my bad. yes, the drop down appears and the data looks right... copy/paste works!
awesome!
Status: Issue closed
username_1: Great! FYI, I'll add a future task to add some better json support (syntax highlighting, plus a maybe an option to view a clean version of the json), but no ETA on that at the moment. |
angular/material | 147108082 | Title: a11y: dialog is always restoring focus.
Question:
username_0: The dialog is currently always restoring the focus when it's closing.
```js
function detachAndClean() {
angular.element($document[0].body).removeClass('md-dialog-is-showing');
element.remove();
if (!options.$destroy) options.origin.focus();
}
```
This is a weird behavior, when clicking for example on a list-item which opens a dialog as an action.
So if the dialog is closing, then the focus will be restored back to the button inside the list-item, which triggered the `ngClick` action.
This causes the button, to have a focus effect, which shouldn't be. We're only showing the focus effect if there was no mouse click the last `100ms`.
In my opinion, we should have different accessibility actions, when the last interaction was from a keyboard / mouse or touch.
We currently have a PR pending, which adds the required functionality. (#5589)
It was an old PR, and I reworked it again.
This PR would allow fixes for:
- The dialog focus restore with a list-item (#7960)
- Focus Effect for Switches (#7837)
cc. @marcysutton @username_1 @EladBezalel
Answers:
username_1: Fixed by #7965
username_0: Status Update: Pull Request is in and solved the Sidenav issues (as intended) but now I can move on and use the new method for the Button and switches as well.
Status: Issue closed
|
sonicmax/ChromeLL-2.0 | 164713895 | Title: options menu changes aren't persisting
Question:
username_0: After restoring config from file, it loads correctly, but the changes do not persist. I'm guessing that options.js is overwriting the config object somehow (causing default config to be applied after closing the menu)
Answers:
username_0: Enabling Chrome Sync seems to fix the bug - the problem has to be something to do with localStorage or the way that default config settings are loaded
username_0: Trying to console.log the config object just outputs "[object Object]", I think the problem is definitely in localStorage
username_0: Closed, see https://github.com/username_0/ChromeLL-2.0/issues/56
Status: Issue closed
|
HodorNV/ALOps | 1082134583 | Title: ALOps Extension API: Exception in BCConnector.GetAPIData: The server committed a protocol violation. Section=ResponseStatusLine
Question:
username_0: **Describe the bug**
It seems when the environment is updated to Business Central version 19.1, the ALOps Extension API throws an error on publishing. The extension is successful published, so it seems the error is in the 'Show Deployment Status' ?
P.S. Not 100% sure about the BC version, but it seems that this error only recently occurred when the environment went from 19.0 to 19.1.
```
##[command]Invoke-RestMethod -Method Get -Uri 'https://api.businesscentral.dynamics.com/v2.0/***/sandbox/api/microsoft/automation/v1.0/companies(ac8a1700-641d-ea11-bb2f-000d3a2c3bc6)/extensionDeploymentStatus'
##[error]Exception in BCConnector.GetAPIData: The server committed a protocol violation. Section=ResponseStatusLine
```
**the used yaml**
```yaml
steps:
- task: Hodor.hodor-alops.ALOpsExtensionAPI.ALOpsExtensionAPI@1
displayName: 'ALOps Extension API'
inputs:
interaction: publish
api_endpoint: 'https://api.businesscentral.dynamics.com/v2.0/$(bc-azure-tenant-id)/Sandbox/api'
azure_tenant_id: '$(bc-azure-tenant-id)'
azure_app_client_id: '$(bc-azure-app-client-id)'
azure_app_client_secret: '$(bc-azure-app-client-secret)'
```
**the output**
Also the complete output is necessary for us to see what is going on. Also use backtics:
```
2021-12-16T10:29:20.7503875Z ##[section]Starting: ALOps Extension API
2021-12-16T10:29:20.7610547Z ==============================================================================
2021-12-16T10:29:20.7610755Z Task : ALOps Extension API
2021-12-16T10:29:20.7610939Z Description : Get/Publish extensions with the Business Central API
2021-12-16T10:29:20.7611095Z Version : 1.446.2728
2021-12-16T10:29:20.7611213Z Author : Hodor
2021-12-16T10:29:20.7611822Z Help : Get/Publish extensions with the Business Central API.
2021-12-16T10:29:20.7612022Z ==============================================================================
2021-12-16T10:29:21.8040507Z *** Validate configuration
2021-12-16T10:29:22.0760012Z *** Task Inputs:
2021-12-16T10:29:22.0789638Z
2021-12-16T10:29:22.0854371Z name value
2021-12-16T10:29:22.0855188Z ---- -----
2021-12-16T10:29:22.0856483Z usedocker False
2021-12-16T10:29:22.0857117Z fixed_tag
2021-12-16T10:29:22.0857665Z interaction publish
2021-12-16T10:29:22.0859753Z api_endpoint https://api.businesscentral.dynamics.com/v2.0/***/Sandbox/api
2021-12-16T10:29:22.0860573Z apiversion v1.0
2021-12-16T10:29:22.0862313Z authentication oauth
2021-12-16T10:29:22.0863952Z azure_tenant_id ***
2021-12-16T10:29:22.0865915Z azure_app_client_id ***
2021-12-16T10:29:22.0866270Z azure_app_client_secret ***
2021-12-16T10:29:22.0867186Z username
2021-12-16T10:29:22.0868782Z password
2021-12-16T10:29:22.0869151Z bccompany
2021-12-16T10:29:22.0870229Z artifact_path C:\azure-vsts-agent-deploy\_work\r33\a
2021-12-16T10:29:22.0871261Z artifact_filter *.app
2021-12-16T10:29:22.0872742Z showdeploymentstatus True
2021-12-16T10:29:22.0872943Z
2021-12-16T10:29:22.0885266Z
2021-12-16T10:29:22.0889623Z
2021-12-16T10:29:22.0988150Z *** For documentation, please visit : https://www.alops.be/documentation
2021-12-16T10:29:22.0990129Z
2021-12-16T10:29:22.4724985Z *** ALOps License:
[Truncated]
2021-12-16T10:29:32.6371227Z EDS Archive VanRoey.be Install Comp...
2021-12-16T10:29:32.6374770Z Customer - D365BC Extension VanRoey.be 1.0.24755.0 Upload Immediate InPr...
2021-12-16T10:29:32.6377366Z Customer - D365BC Extension VanRoey.be 1.0.24450.0 Upload Immediate Comp...
2021-12-16T10:29:32.6380107Z Customer - D365BC Extension VanRoey.be 1.0.24749.0 Upload Immediate InPr...
2021-12-16T10:29:32.6382241Z Customer - ForNAV Reports VanRoey.be 1.0.12528.0 Upload Direct Failed
2021-12-16T10:29:32.6384783Z Customer - ForNAV Reports VanRoey.be 1.0.24457.0 Upload Immediate Comp...
2021-12-16T10:29:32.6387429Z Extensie installeren 31e6154c-7bb5-4d51-a415-ccf39e06043f Install Comp...
2021-12-16T10:29:32.6390409Z Finance Extension (BE) VanRoey.be Install Comp...
2021-12-16T10:29:32.6390642Z
2021-12-16T10:29:32.6390760Z
2021-12-16T10:29:32.6601597Z *** Cleanup VSTS Environment: True
2021-12-16T10:29:34.9465022Z ##[section]Finishing: ALOps Extension API
```
**Expected behavior**
Not to throw an error :-)
**Screenshots**


Answers:
username_1: We never seen this error - but there is something going wrong, so we need to report it, right?
The only thing I can think of, is to set the "showdeploymentstatus" to false.. . But then you obviously don't get that feedback either 🤔.
I really don't know how we can circumvent this..
Status: Issue closed
username_0: After more researching from our side it seems to be that the issue is caused by our firewall from Fortinet.
Updating the policy for this domain and fine-tuning the TTL has resolved this issue. |
derUli/ulicms | 283803232 | Title: Funktion get_title() mit headline Parameter funktioniert nicht.
Question:
username_0: da get_title() bereits im <head> ohne headline = true aufgerufen wird, wird der Titel in Vars gecacht.
Bei einem weiteren Aufruf wird der gecachte Titel zurückgegeben, so dass die Alternative Überschrift niemals angezeigt wird, auch wenn diese gefüllt ist.
Lösung:
getrenntes Caching vom Titel in zwei verschiedenen Variablen:
```php
Vars::set("title", $title);
Vars::set("headline", $title);
```
Status: Issue closed
Answers:
username_0: behoben in 2018.2 |
mobeets/NBAclr | 125781640 | Title: create commentary types
Question:
username_0: __Stat__
* lead change
* points
* points per game
* rebounds
* assists
* ...
__Subject__
* team
* player
* matchup
__Timescale__
* current quarter
* current game
* current season
* last _ minutes
* last _ games
* since _
* all time
Answers:
username_0: Given the most recent play, a relevant or significant comment should be generated. The relevance of a comment is, for example, one that became true given the most recent play but wasn't true prior to that. The significance of a comment refers to how rare the event is; for example, if it's never happened before, or is in the top 5th percentile of some distribution, etc.
__Examples__
_Current play_: "<NAME> makes a corner 3, putting the Mavericks up 76-75 over the Bucks with 2 minutes left in the 3rd quarter."
_Simple comment_: "This is the 5th lead change this quarter." [Stat: # of lead changes. Subject: Matchup. Timescale: Current quarter. Relevance: The 5th lead change just happened. Significance: 5 lead changes in a quarter is rare.]
_Compound comment_: "The Mavericks are shooting 8 for 10 on threes this game. The Bucks are only 1 for 3."
username_0: __Finding significant comments__
At each point in time we assume significant comments in the past have already been made. For that reason, after each play we need only to update/check a few stats. For example, if the most recent play was a made two-point attempt, there is no need to check for significant comments regarding rebounds, or steals, but we do need to check for stats involving 2s, assists, point differential, lead changes, etc.
username_0: So for a prototype, let us assume our only dataset is an ordered list of 4-tuples: (Quarter, HomeTeam, HomeTeamScore, AwayTeam, AwayTeamScore).
Then our only stat streams are: point differential, lead changes.
Which means our only subject is: matchup.
And our only timescales are: current quarter, 1st quarter, 2nd quarter, 3rd quarter, 4th quarter
username_0: __Assessing relevance__
The baseline defines a set of comments of the same kind as the main comment. The comment's relevance then has to do with its position within the population defined by the baseline (e.g., which percentile of the baseline is the current comment).
A threshold defines a simple value-crossing to test on the current comment (e.g., is the stat above some fixed value).
For a compound comment, the comparator defines how we transform the comment--e.g., into a single dimension. (The identity comparator would keep it in 2d, for example.) So if the comment is about the Mavericks' and Bucks' 3-pt percentage, it might be that we want the difference of these numbers to be above a certain threshold. The comparator is then the _difference_, and the baseline is the set of all other differences. |
decalage2/oletools | 532624739 | Title: mraptor evasion via Workbook_BeforeClose
Question:
username_0: We received the attached Excel file (password 123), which contains a malicios macro that triggers on "Private Sub Workbook_BeforeClose". Unfortunately mraptor does not detect this file as suspicious, because it only looks for "Document_BeforeClose" or "Workbook_Close", but not "Workbook_BeforeClose". The same is true for olevba, which does not recognize an autoexec function
The fix is trivial, probably not worth a PR
[Balance payment.zip](https://github.com/username_1/oletools/files/3921556/Balance.payment.zip)
Answers:
username_0: After adding Workbook_BeforeClose to https://github.com/username_1/oletools/blob/master/oletools/olevba.py#L632 and _BeforeClose to https://github.com/username_1/oletools/blob/master/oletools/mraptor.py#L118 the AutoExec function is correctly recognized.
username_0: The milestone says 0.56, 0.55, but this bug is still open
Status: Issue closed
|
2amigos/yii2-usuario | 280485713 | Title: Validation problem
Question:
username_0: I think need add validation [here](https://github.com/2amigos/yii2-usuario/blob/f0915a284a5dc8a538235b601609b08e2a66b1a3/src/User/Controller/RecoveryController.php#L97) like a [RegistrationController::register()](https://github.com/2amigos/yii2-usuario/blob/f0915a284a5dc8a538235b601609b08e2a66b1a3/src/User/Controller/RegistrationController.php#L101), and check other places without non-ajax validation.
` if ($form->load(Yii::$app->request->post()) && $form->validate()) {`
Answers:
username_1: You are correct @username_0
username_0: #128
username_1: Fixed! Thanks @username_0
Status: Issue closed
|
opencv/opencv | 489588806 | Title: Error compiling opencv for android
Question:
username_0: Windows 10
opencv_master
I have got this error:
```
[ 30%] Building CXX object modules/core/CMakeFiles/opencv_core.dir/src/utils/datafile.cpp.o
[ 30%] Building CXX object modules/core/CMakeFiles/opencv_core.dir/src/utils/filesystem.cpp.o
[ 30%] Building CXX object modules/core/CMakeFiles/opencv_core.dir/src/utils/logtagconfigparser.cpp.o
G:\Lib\opencv\modules\core\src\utils\logtagconfigparser.cpp: In static member function 'static std::string cv::utils::logging::LogTagConfigParser::toString(cv::utils::logging::LogLevel)':
G:\Lib\opencv\modules\core\src\utils\logtagconfigparser.cpp:301:16: error: 'to_string' is not a member of 'std'
return std::to_string((int)level);
^
G:\Lib\opencv\modules\core\src\utils\logtagconfigparser.cpp:303:1: error: control reaches end of non-void function [-Werror=return-type]
}
^
cc1plus.exe: some warnings being treated as errors
make.exe[2]: *** [modules/core/CMakeFiles/opencv_core.dir/src/utils/logtagconfigparser.cpp.o] Error 1
make.exe[1]: *** [modules/core/CMakeFiles/opencv_core.dir/all] Error 2
make.exe: *** [all] Error 2
[ 0%] Built target libcpufeatures
[ 3%] Built target libjpeg-turbo
[ 5%] Built target libtiff
[ 11%] Built target libwebp
[ 12%] Built target libjasper
[ 13%] Built target libpng
[ 18%] Built target IlmImf
[ 22%] Built target libprotobuf
[ 22%] Built target quirc
[ 24%] Built target carotene_objs
[ 25%] Built target tegra_hal
[ 26%] Built target ittnotify
[ 26%] Built target opencv_videoio_plugins
[ 26%] Building CXX object modules/core/CMakeFiles/opencv_core.dir/src/utils/logtagconfigparser.cpp.o
G:\Lib\opencv\modules\core\src\utils\logtagconfigparser.cpp: In static member function 'static std::string cv::utils::logging::LogTagConfigParser::toString(cv::utils::logging::LogLevel)':
G:\Lib\opencv\modules\core\src\utils\logtagconfigparser.cpp:301:16: error: 'to_string' is not a member of 'std'
return std::to_string((int)level);
^
G:\Lib\opencv\modules\core\src\utils\logtagconfigparser.cpp:303:1: error: control reaches end of non-void function [-Werror=return-type]
}
^
cc1plus.exe: some warnings being treated as errors
make.exe[2]: *** [modules/core/CMakeFiles/opencv_core.dir/src/utils/logtagconfigparser.cpp.o] Error 1
make.exe[1]: *** [modules/core/CMakeFiles/opencv_core.dir/all] Error 2
make.exe: *** [all] Error 2
```
My cmake configuration is :
```
-- The CXX compiler identification is GNU 4.9.0
-- The C compiler identification is GNU 4.9.0
-- Check for working CXX compiler: F:/Android_ndk/android-ndk-r16b/toolchains/arm-linux-androideabi-4.9/prebuilt/windows-x86_64/bin/arm-linux-androideabi-g++.exe
-- Check for working CXX compiler: F:/Android_ndk/android-ndk-r16b/toolchains/arm-linux-androideabi-4.9/prebuilt/windows-x86_64/bin/arm-linux-androideabi-g++.exe -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Check for working C compiler: F:/Android_ndk/android-ndk-r16b/toolchains/arm-linux-androideabi-4.9/prebuilt/windows-x86_64/bin/arm-linux-androideabi-gcc.exe
-- Check for working C compiler: F:/Android_ndk/android-ndk-r16b/toolchains/arm-linux-androideabi-4.9/prebuilt/windows-x86_64/bin/arm-linux-androideabi-gcc.exe -- works
[Truncated]
-- Other third-party libraries:
-- Custom HAL: YES (carotene (ver 0.0.1))
-- Protobuf: build (3.5.1)
--
-- Python (for build): F:/msys64/mingw64/bin/python3.exe
--
-- Java: export all functions
-- ant: f:/apache-ant-1.10.5/bin/ant.bat (ver )
-- Java wrappers: YES
-- Java tests: NO
--
-- Install to: G:/lib/install/opencvandroid
-- -----------------------------------------------------------------
--
-- Configuring done
-- Generating done
-- Build files have been written to: G:/Lib/build/opencvandroid
```
Answers:
username_1: Android team has been deprecated and removed GCC toolchain from modern NDK builds (18+)
1. Try to switch to clang toolchain + switch `gnustl_static` => `c++shared`/`c++_static`
2. Install modern NDK
username_0: Ok same problem with 17b
problem with 18b in cmake
```
CMake Warning at platforms/android/android.toolchain.cmake:335 (message):
Could not determine machine name for compiler from
F:/Android_ndk/android-ndk-r18b/toolchains/aarch64-linux-android-4.9/prebuilt/windows-x86_64
Call Stack (most recent call first):
platforms/android/android.toolchain.cmake:562 (__DETECT_TOOLCHAIN_MACHINE_NAME)
platforms/android/android.toolchain.cmake:619 (__GLOB_NDK_TOOLCHAINS)
C:/Program Files/CMake/share/cmake-3.15/Modules/CMakeDetermineSystem.cmake:93 (include)
CMakeLists.txt:99 (enable_language)
CMake Warning at platforms/android/android.toolchain.cmake:335 (message):
Could not determine machine name for compiler from
F:/Android_ndk/android-ndk-r18b/toolchains/arm-linux-androideabi-4.9/prebuilt/windows-x86_64
Call Stack (most recent call first):
platforms/android/android.toolchain.cmake:562 (__DETECT_TOOLCHAIN_MACHINE_NAME)
platforms/android/android.toolchain.cmake:619 (__GLOB_NDK_TOOLCHAINS)
C:/Program Files/CMake/share/cmake-3.15/Modules/CMakeDetermineSystem.cmake:93 (include)
CMakeLists.txt:99 (enable_language)
CMake Warning at platforms/android/android.toolchain.cmake:335 (message):
Could not determine machine name for compiler from
F:/Android_ndk/android-ndk-r18b/toolchains/x86-4.9/prebuilt/windows-x86_64
Call Stack (most recent call first):
platforms/android/android.toolchain.cmake:562 (__DETECT_TOOLCHAIN_MACHINE_NAME)
platforms/android/android.toolchain.cmake:619 (__GLOB_NDK_TOOLCHAINS)
C:/Program Files/CMake/share/cmake-3.15/Modules/CMakeDetermineSystem.cmake:93 (include)
CMakeLists.txt:99 (enable_language)
CMake Warning at platforms/android/android.toolchain.cmake:335 (message):
Could not determine machine name for compiler from
F:/Android_ndk/android-ndk-r18b/toolchains/x86_64-4.9/prebuilt/windows-x86_64
Call Stack (most recent call first):
platforms/android/android.toolchain.cmake:562 (__DETECT_TOOLCHAIN_MACHINE_NAME)
platforms/android/android.toolchain.cmake:619 (__GLOB_NDK_TOOLCHAINS)
C:/Program Files/CMake/share/cmake-3.15/Modules/CMakeDetermineSystem.cmake:93 (include)
CMakeLists.txt:99 (enable_language)
CMake Error at platforms/android/android.toolchain.cmake:628 (message):
Could not find any working toolchain in the NDK. Probably your Android NDK
is broken.
Call Stack (most recent call first):
C:/Program Files/CMake/share/cmake-3.15/Modules/CMakeDetermineSystem.cmake:93 (include)
CMakeLists.txt:99 (enable_language)
CMake Error: CMAKE_CXX_COMPILER not set, after EnableLanguage
CMake Error: CMAKE_C_COMPILER not set, after EnableLanguage
-- Configuring incomplete, errors occurred!
************************* -->devenv debug
Error: could not find CMAKE_PROJECT_NAME in Cache
Error: could not find CMAKE_PROJECT_NAME in Cache
```
username_1: Looks like you are using toolchain from OpenCV. It is still here for legacy toolchains only (up to NDK 16).
Use toolchain from NDK directly: `<ndk_dir>/build/cmake/android.toolchain.cmake` (available since NDK 15+, but with some bugs)
Take a look on build_sdk.py script: https://github.com/opencv/opencv/blob/4.1.1/platforms/android
username_0: ok I use ndk <ndk_dir>/build/cmake/android.toolchain.cmake with android-ndk-r18b. My cmake is now :
```
CMAKE_CONFIG_GENERATOR="MinGW Makefiles"
ANDROID_NDK=/F/Android_ndk/android-ndk-r18b
cd Build/opencvandroid18
CMAKE_OPTIONS='-DBUILD_opencv_world:BOOL=OFF -DBUILD_PERF_TESTS:BOOL=OFF -DBUILD_TESTS:BOOL=OFF -DBUILD_DOCS:BOOL=OFF -DWITH_CUDA:BOOL=OFF -DBUILD_EXAMPLES:BOOL=ON -DENABLE_PRECOMPILED_HEADERS=OFF -DWITH_IPP=OFF -DWITH_MSMF=OFF -DCPU_DISPATCH='
cmake -DCMAKE_MAKE_PROGRAM=${ANDROID_NDK}/prebuilt/windows-x86_64/bin/make.exe \
-DANDROID_TOOLCHAIN_NAME=arm-linux-androideabi \
-DJAVA_AWT_INCLUDE_PATH:PATH="C:/Program Files/Java/jdk1.8.0_152/include" \
-DJAVA_AWT_INCLUDE_PATH:PATH="C:/Program Files/Java/jdk1.8.0_152/include" \
-DJAVA_AWT_LIBRARY:FILEPATH="C:/Program Files/Java/jdk1.8.0_152/lib/jawt.lib" \
-DJAVA_INCLUDE_PATH:PATH="C:/Program Files/Java/jdk1.8.0_152/include" \
-DJAVA_INCLUDE_PATH2:PATH="C:/Program Files/Java/jdk1.8.0_152/include/win32" \
-DJAVA_JVM_LIBRARY:FILEPATH="C:/Program Files/Java/jdk1.8.0_152/lib/jvm.lib" \
-DCMAKE_TOOLCHAIN_FILE=${ANDROID_NDK}/build/cmake/android.toolchain.cmake \
-DANDROID_SDK_ROOT:PATH=/F/Data_SDK_Android \
-DANDROID_NATIVE_API_LEVEL=21 \
-DANDROID_ARM_NEON=ON \
-DBUILD_ANDROID_PROJECTS:BOOL=ON \
-DANT_EXECUTABLE:FILEPATH=f:/apache-ant-1.10.5/bin/ant.bat \
-G"$CMAKE_CONFIG_GENERATOR" \
$CMAKE_OPTIONS -DOPENCV_EXTRA_MODULES_PATH=../../opencv_contrib/modules -DOPENCV_ENABLE_NONFREE:BOOL=ON \
-DINSTALL_CREATE_DISTRIB=ON -DCMAKE_INSTALL_PREFIX=/g/lib/install/opencvandroid18 ../../"$RepoSource"
cd ..
echo "************************* $Source_DIR -->devenv debug"
cmake --build opencvandroid18 --config release
cmake --build opencvandroid18 --target install --config release
cd ..
```
I compare [cmakecache ](https://pullrequest.opencv.org/buildbot/builders/precommit_android/builds/20526/steps/cmake/logs/cache)and my cmakecache and I cannot find difference
but I have got some errors :
```
[ 75%] Built target gen_opencv_java_source
[ 75%] Built target opencv_java_android_source_copy
[ 76%] Building OpenCV Android library project
[subant] No sub-builds to iterate on
[javac] G:\Lib\build\opencvandroid18\android_sdk\src\org\opencv\android\CameraActivity.java:52: error: cannot find symbol
[javac] @TargetApi(Build.VERSION_CODES.M)
[javac] ^
[javac] symbol: variable M
[javac] location: class VERSION_CODES
[javac] G:\Lib\build\opencvandroid18\android_sdk\src\org\opencv\android\CameraActivity.java:40: error: cannot find symbol
[javac] if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.M) {
[javac] ^
[javac] symbol: variable M
[javac] location: class VERSION_CODES
[javac] G:\Lib\build\opencvandroid18\android_sdk\src\org\opencv\android\CameraActivity.java:41: error: cannot find symbol
[javac] if (checkSelfPermission(CAMERA) != PackageManager.PERMISSION_GRANTED) {
[javac] ^
[javac] symbol: method checkSelfPermission(String)
[javac] location: class CameraActivity
[javac] G:\Lib\build\opencvandroid18\android_sdk\src\org\opencv\android\CameraActivity.java:42: error: cannot find symbol
[javac] requestPermissions(new String[]{CAMERA}, CAMERA_PERMISSION_REQUEST_CODE);
[javac] ^
[javac] symbol: method requestPermissions(String[],int)
[javac] location: class CameraActivity
[javac] G:\Lib\build\opencvandroid18\android_sdk\src\org\opencv\android\CameraActivity.java:51: error: method does not overrid e or implement a method from a supertype
[Truncated]
[javac] Note: Some input files use or override a deprecated API.
[javac] Note: Recompile with -Xlint:deprecation for details.
[javac] 6 errors
Target '-compile' failed with message 'The following error occurred while executing this line:
F:\Data_SDK_Android\tools\ant\build.xml:730: Compile failed; see the compiler error output for details.'.
Cannot execute '-dex' - '-compile' failed or was not executed.
Cannot execute '-package' - '-dex' failed or was not executed.
Cannot execute '-do-debug' - '-package' failed or was not executed.
Cannot execute 'debug' - '-do-debug' failed or was not executed.
BUILD FAILED
F:\Data_SDK_Android\tools\ant\build.xml:716: The following error occurred while executing this line:
F:\Data_SDK_Android\tools\ant\build.xml:730: Compile failed; see the compiler error output for details.
Total time: 2 seconds
make.exe[2]: *** [bin/classes.jar] Error 1
make.exe[1]: *** [modules/java/android_sdk/CMakeFiles/opencv_java_android.dir/all] Error 2
make.exe: *** [all] Error 2
```
username_1: After that message Java-based projects should be skipped completely.
Try to upgrade your Android SDK "BuildTools".
username_0: Download it with SDK manager.
* Try:
Run with --stacktrace option to get the stack trace. Run with --debug option to get more log output. Run with --scan to get full insights.
* Get more help at https://help.gradle.org
BUILD FAILED in 1s
make.exe[2]: *** [opencv_android/opencv/build/outputs/aar/opencv-release.aar] Error 1
make.exe[1]: *** [modules/java/android_sdk/CMakeFiles/opencv_java_android.dir/all] Error 2
make.exe: *** [all] Error 2
[
```
I tried Ninja :
```
-- Check for working CXX compiler: F:/Android_ndk/android-ndk-r18b/toolchains/llvm/prebuilt/windows-x86_64/bin/clang++.exe
CMake Error:
The detected version of Ninja (GNU Make 3.81
Copyright (C) 2006 Free Software Foundation, Inc.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE.
This program built for i686-w64-mingw32) is less than the version of Ninja
required by CMake (1.3).
```
username_1: Environment variables in bash scripts should be added via "export" command.
If not help, try to additionally add ANDROID_NDK_HOME / NDKROOT environment variables (with "export").
username_1: If you need bash shell, then try bash from "git" Windows package (it is based on lightweight mingw).
username_0: my environement variables :

I installed inside android studio :

and

I unzipped https://dl.google.com/android/repository/android-ndk-r18b-windows-x86_64.zip?hl=fr in F:\Android_ndk
my git-bash script buildocvandroid.sh (to build ocv using cmake) is
```
myRepo=$(pwd)
RepoSource=opencv
CMAKE_CONFIG_GENERATOR="Ninja"
CMAKE_CONFIG_GENERATOR="MinGW Makefiles"
ANDROID_NDK=/F/Android_ndk/android-ndk-r18b
ANDROID_HOME=/F/Data_SDK_Android
cd Build/opencvandroid18
CMAKE_OPTIONS='-DBUILD_opencv_world:BOOL=OFF -DBUILD_PERF_TESTS:BOOL=OFF -DBUILD_TESTS:BOOL=OFF -DBUILD_DOCS:BOOL=OFF -DWITH_CUDA:BOOL=OFF -DBUILD_EXAMPLES:BOOL=ON -DENABLE_PRECOMPILED_HEADERS=OFF -DWITH_IPP=OFF -DWITH_MSMF=OFF -DCPU_DISPATCH='
cmake -DCMAKE_MAKE_PROGRAM=${ANDROID_NDK}/prebuilt/windows-x86_64/bin/make.exe \
-DANDROID_ABI=armeabi-v7a \
-DANDROID_TOOLCHAIN_NAME=arm-linux-androideabi \
-DJAVA_AWT_INCLUDE_PATH:PATH="C:/Program Files/Java/jdk1.8.0_152/include" \
-DJAVA_AWT_INCLUDE_PATH:PATH="C:/Program Files/Java/jdk1.8.0_152/include" \
-DJAVA_AWT_LIBRARY:FILEPATH="C:/Program Files/Java/jdk1.8.0_152/lib/jawt.lib" \
-DJAVA_INCLUDE_PATH:PATH="C:/Program Files/Java/jdk1.8.0_152/include" \
-DJAVA_INCLUDE_PATH2:PATH="C:/Program Files/Java/jdk1.8.0_152/include/win32" \
-DJAVA_JVM_LIBRARY:FILEPATH="C:/Program Files/Java/jdk1.8.0_152/lib/jvm.lib" \
-DCMAKE_TOOLCHAIN_FILE=${ANDROID_NDK}/build/cmake/android.toolchain.cmake \
-DANDROID_SDK_ROOT:PATH=/F/Data_SDK_Android \
-DANDROID_NATIVE_API_LEVEL=21 \
-DANDROID_ARM_NEON=ON \
-DBUILD_ANDROID_PROJECTS:BOOL=ON \
-DANT_EXECUTABLE:FILEPATH=f:/apache-ant-1.10.5/bin/ant.bat \
-G"$CMAKE_CONFIG_GENERATOR" \
$CMAKE_OPTIONS -DOPENCV_EXTRA_MODULES_PATH=../../opencv_contrib/modules -DOPENCV_ENABLE_NONFREE:BOOL=ON \
-DINSTALL_CREATE_DISTRIB=ON -DCMAKE_INSTALL_PREFIX=/g/lib/install/opencvandroid18 ../../"$RepoSource"
cd ..
cmake --build opencvandroid18 --config release
cmake --build opencvandroid18 --target install --config release
cd ..
```
in in git bash I run my script ( to build ocv using cmake ) ./buildocvandroid.sh
and results is OK no error and I have got all apk
[full_ouput.txt](https://github.com/opencv/opencv/files/3582655/full_ouput.txt)
@username_1 Thanks
Status: Issue closed
username_2: Why don't you deprecate opencv toolchain...
username_2: thx, solved my same problem
username_3: I have tested with toolchain file in the OpenCV resource folder. It's not working. However,
I successfully build the Android SDK in Windows with the NDK r21 with NDK toolchain + unchecked all of the tests + increase Java heap size. |
spring-cloud/spring-cloud-dataflow | 130057866 | Title: Remove ModuleLauncher dependency from `local` deployer
Question:
username_0: As a developer, I'd like to remove the dependency of `ModuleLauncher` from the `local` out of process `admin` deployer. Instead, I'd want to move the scope of 1) downloading the jars and 2) launching either a single or multiple applications to the `admin` itself.
**Acceptance:**
- `ModuleLauncher` contract from SCS repo is not a dependency for `local` deployer
- Deploying a stream (ex: `time | log`) using `local-admin` includes the functionality of downloading and launching all with in itself, as a self-contained thing
Status: Issue closed
Answers:
username_0: Duplicate of spring-cloud/spring-cloud-dataflow#449 |
komoot/photon | 374707918 | Title: Typo tolerance not working
Question:
username_0: It's a great tool but I'm having this issue.
#
I'm using version 3.0 and have imported data from Nominatim correctly, the server is running fine but in my instance, typo tolerance is not working, I'm trying to find this: "colon 3000, cordoba" (it should be "Avenida Colón 3000, Córdoba") and I dont get results, but if I try the same query on komoot server it works fine and I get that street on the first result. I didn't find any configuration about typos, I guess I'm missing something here? |
WebDevJL/XeroxMissionTasks | 134894747 | Title: Valider la vente du produit 10/6
Question:
username_0: J'ai lancé le usecase 411:
```
<usecase name="UseCase411_SetBankingInformation">
<param name="accountNumber" value="00000001500"/>
<param name="bankCode" value="12548"/>
<param name="bankName" value="AXXA"/>
<param name="branchCode" value="02998"/>
<param name="checkDigits" value="86"/>
<param name="internationalBankAccountNumber" value="FR7612548029980000000150086"/>
<param name="bankInternationalCode" value="AXABFRPP"/>
<param name="userCode" value="TWP41511201347550262"/>
</usecase>
```
Résultat : Les informations bancaires ne doivent pas être fournies pour ce parmaètrage (Error code -20479)
Answers:
username_0: J'ai lancé le usecase 411:
```
<usecase name="UseCase411_SetBankingInformation">
<param name="accountNumber" value="00000001500"/>
<param name="bankCode" value="12548"/>
<param name="bankName" value="AXXA"/>
<param name="branchCode" value="02998"/>
<param name="checkDigits" value="86"/>
<param name="internationalBankAccountNumber" value="FR7612548029980000000150086"/>
<param name="bankInternationalCode" value="AXABFRPP"/>
<param name="userCode" value="TWP41511201347550262"/>
</usecase>
```
Résultat : Les informations bancaires ne doivent pas être fournies pour ce parmaètrage (Error code -20479)
username_0: Il faut un gestionnaire bancaire (fichier paramètre GPA)
username_0: Abandonné car on ne peut faire du multi ban sur PVSBO.
Status: Issue closed
|
square/retrofit | 277447598 | Title: Kotlin support using kotlinx.serialization
Question:
username_0: This was previously closed in #2530 since `kotlinx.serialization` was not stable.
But as of today, IT IS! 🎉
https://blog.jetbrains.com/kotlin/2017/11/kotlin-1-2-released/
Status: Issue closed
Answers:
username_1: It's still unstable a v0.2: https://github.com/Kotlin/kotlinx.serialization/releases |
onmyway133/blog | 269967239 | Title: Diff algorithm
Question:
username_0: - Myers [An O(ND) Difference Algorithm and Its Variations](http://www.xmailserver.org/diff2.pdf)
- Wu [An O(NP) Sequence Comparison Algorithm](https://publications.mpi-cbg.de/Wu_1990_6334.pdf)
- [Wagner–Fischer algorithm](https://en.wikipedia.org/wiki/Wagner%E2%80%93Fischer_algorithm) |
wwt-ambassadors/star-life-cycle | 679491625 | Title: Add a pop-up of life cycle schematic to the interactive
Question:
username_0: @heywooddogwood, I can work on this when I'm back if you don't have time, but just want to put a placeholder here so I don't forget. Reviewers suggested we put a link to the cycle schematic directly on the interactive (which we were planning to do anyway.) I think [this](https://imagine.gsfc.nasa.gov/Images/objects/stars_lifecycle_full.jpg) is the image we planned on, and I believe WGBH is reaching out regarding permissions, but please correct me if you remember this differently. Thanks!
Answers:
username_0: Fixed via [https://github.com/wwt-ambassadors/star-life-cycle/pull/24](#24)
Status: Issue closed
|
frontendbr/vagas | 372093904 | Title: [Salvador e região] Front-End developer com foco Mobile (Vuejs ou Angular)
Question:
username_0: <!--
==================================================
POR FAVOR, SÓ POSTE SE A VAGA FOR PARA FRONT-END!
Não faça distinção de gênero no título da vaga.
## Descrição da vaga
Desenvolver aplicativo Mobile da empresa e auxiliar no sistema já existente.
## Local
Remoto - Preferência por quem mora em Salvador ou Região -BA
## Requisitos
**Obrigatórios:**
- 2 anos de experiência com JavaScript
- 2 anos de experiência com Front-End em geral (CSS, HTML5, Bootstrap)
- 2 anos de experiência com VueJs + Quasar Framework ou Angular 4+ e Ionic.
**Desejáveis:**
- Laravel
- PHP
**Diferenciais:**
- projetos opensource
## Contratação
PJ
## Nossa empresa
Oportunidade em startup com sede em Genebra na Suiça, com abertura de filial em Salvador. Previsto lançamento Janeiro 2019. Oportunidade de crescimento profissional.
## Como se candidatar
Por favor envie um email para <EMAIL> com seu CV anexado - enviar no assunto: Vaga Front-End
## Labels
- PJ
- Júnior
- Pleno
- Remoto<issue_closed>
Status: Issue closed |
MidnightJabber/twitterGame | 102955246 | Title: Repeating Same User Tweet in GameObject
Question:
username_0: 
As you can see in the image, in a `gameObject` sometimes a random Twitter User's Tweet is assigned to 2 Twitter Users. In this case <NAME>.<issue_closed>
Status: Issue closed |
multicaret/laravel-acquaintances | 1104778622 | Title: anonymous block user/model (regardless of friendship status)
Question:
username_0: Hi, is there a way to implement this so that a user can block another user regardless of friendship status?
as I understand the docs, to block someon, they must first be a friend. Blocks are also something you may wish impose of another user to prevent seing thier posts.
*I'm sure that in this case i can create a friendship first, then block them so it's not a biggie but i's really like it to work like an anti-follow<issue_closed>
Status: Issue closed |
dano/aioprocessing | 345620668 | Title: Way to terminate a hanging process?
Question:
username_0: Is it possible to detect whether a process is taking too long to execute the code, and then terminate it, maybe through a timeout?
Answers:
username_1: You would do this the same when you'd do it if you were using `multiprocessing` directly. If you're using an `AioProcess`, you can call `terminate()` on it to kill the process. There's nothing built into `multiprocessing` to set a timeout, so you'd have to set that up yourself.
If you're using `AioPool`, you can't kill a individual worker in the pool, nor is there a way to set a timeout on how long a particular item you give the pool can take. You'd have to do your own co-operative implementation, where you have a hook in the method you're passing to the pool that allows you to interrupt it, and then flip whatever bit you decide to use to activate the hook after your timeout expires.
Status: Issue closed
|
palantir/plottable | 229064236 | Title: Plot interactions don't work inside Polymer elements when using shadow DOM mode
Question:
username_0: I have a plottable v3 chart inside of a Polymer 1.x component and have interactions set up on the chart (click and pointer interactions). Polymer by default uses shady DOM, and in this mode the click interactions work as intended (see https://www.polymer-project.org/1.0/docs/devguide/settings for details and how to set the DOM rendering mode).
But, if I set Polymer to use the shadow DOM mode then the click interactions no longer work. I am running into this because I am embedding this Polymer element in a jupyter notebook through the declarativewidgets plugin (https://github.com/jupyter-widgets/declarativewidgets) which hard-codes shadow DOM mode.
Stepping through the plottable code, the interactions fail because of the Translator.prototype.isInside method. It checks if the event.target element is contained in the click-enabled component's root element (which seems to be the element that plottable is rendering the chart to).
With shady DOM, when clicking on an interactive chart element, the event.target is the correct svg element in the chart, so isInside returns true. With shady DOM, the event.target is the Polymer component's top-level HTML element, so isInside returns false. This happens because of shadow DOM event retargeting (https://www.polymer-project.org/2.0/docs/devguide/shadow-dom#event-retargeting).
If I change the plottable Translator.prototype.isInside method to use event.path[0] or event.composedPath()[0] (which is the actual clicked svg element in the chart) instead of event.target, then the interactions work correctly in both case, but I'm not sure of the support of path and composedPath() across all browsers. I am working in the latest Chrome for reference.
Answers:
username_1: Thanks for the detailed report @username_0 , cool to hear about Plottable being used inside Polymer! I couldn't find any docs on `event.path` - is it polymer specific? I'm wary of adding shadow DOM specific features since I don't know of a good way to unit test it/make it part of the build (admittedly I know little about Polymer/shadow DOM). Perhaps there's another property or different strategy to solve the problem?
username_0: event.path may be a chrome-specific implementation detail. I think event.composedPath() is the actual spec'd method. I see event.composedPath() mentioned both in the polymer link above about event retargeting and also in the dom event spec (https://dom.spec.whatwg.org/#dom-event-composedpath)
username_2: For people interested in a monkey patch for 3.4.1:
```Plottable.Utils.Translator.isEventInside = (component, e) =>
Plottable.Utils.DOM.contains(component.root().rootElement().node(), e.composedPath()[0]);
username_2: For 3.5.4 you also require the following:
```
Plottable.Utils.DOM.getHtmlElementAncestors = elem => {
const elems = [];
while (elem && elem instanceof HTMLElement) {
elems.push(elem);
elem = elem.offsetParent || elem.parentElement || elem.parentNode;
}
return elems;
};
```
username_3: Sorry for rebooting this old thread.
This issue seems to be a general webcomponent issue[1]. As you have remarked, an event listener attached at document cannot access shadowDom via `event.target` which I think is by design.
Instead of the monkey patches, would it be possible to allow modification to _eventTarget? https://github.com/palantir/plottable/blob/88158e2883f7e03bbf2ca5499e0a8ec9fd65cc94/src/dispatchers/dispatcher.ts#L24
Because the constructor is private, I can't even subclass the Mouse/Touch/Key dispatchers :(
https://github.com/palantir/plottable/blob/88158e2883f7e03bbf2ca5499e0a8ec9fd65cc94/src/dispatchers/mouseDispatcher.ts#L50
[1]:
```js
(function() {
class Hello extends HTMLElement {
constructor() {
super();
const shadow = this.attachShadow({mode: 'open'});
const button = document.createElement('button');
button.innerText = "click me";
shadow.appendChild(button);
}
}
window.customElements.define('hello-world', Hello);
const el = document.createElement("hello-world");
document.body.appendChild(el);
document.addEventListener('click', (e) => {
console.log('click!', e.target);
});
})();
``` |
anthraxx/intellij-awesome-console | 971054215 | Title: "AbstractMethodError" from AwesomeLinkFilter
Question:
username_0: Hi, in the IDE I only see an "unknown plugin" error, so I am not 100% sure if the problem comes from this plugin?
```
java.lang.AbstractMethodError: Receiver class awesome.console.AwesomeLinkFilter$$Lambda$6694/0x0000000802bfa440 does not define or inherit an implementation of the resolved method 'abstract void onLinkFollowed(com.intellij.openapi.project.Project, com.intellij.openapi.vfs.VirtualFile, com.intellij.openapi.editor.Editor, com.intellij.openapi.editor.Editor)' of interface com.intellij.execution.filters.HyperlinkInfoFactory$HyperlinkHandler.
at com.intellij.execution.filters.impl.MultipleFilesHyperlinkInfo.open(MultipleFilesHyperlinkInfo.java:133)
at com.intellij.execution.filters.impl.MultipleFilesHyperlinkInfo.navigate(MultipleFilesHyperlinkInfo.java:101)
at com.intellij.execution.filters.HyperlinkInfoBase.navigate(HyperlinkInfoBase.java:28)
at com.intellij.terminal.JBTerminalWidget.lambda$convertInfo$3(JBTerminalWidget.java:123)
at com.jediterm.terminal.model.hyperlinks.LinkInfo.navigate(LinkInfo.java:33)
at com.jediterm.terminal.ui.TerminalPanel$3.mouseClicked(TerminalPanel.java:243)
at java.desktop/java.awt.AWTEventMulticaster.mouseClicked(AWTEventMulticaster.java:278)
at java.desktop/java.awt.Component.processMouseEvent(Component.java:6655)
at java.desktop/javax.swing.JComponent.processMouseEvent(JComponent.java:3345)
at java.desktop/java.awt.Component.processEvent(Component.java:6417)
at java.desktop/java.awt.Container.processEvent(Container.java:2263)
at java.desktop/java.awt.Component.dispatchEventImpl(Component.java:5027)
at java.desktop/java.awt.Container.dispatchEventImpl(Container.java:2321)
at java.desktop/java.awt.Component.dispatchEvent(Component.java:4859)
at java.desktop/java.awt.LightweightDispatcher.retargetMouseEvent(Container.java:4918)
at java.desktop/java.awt.LightweightDispatcher.processMouseEvent(Container.java:4556)
at java.desktop/java.awt.LightweightDispatcher.dispatchEvent(Container.java:4488)
at java.desktop/java.awt.Container.dispatchEventImpl(Container.java:2307)
at java.desktop/java.awt.Window.dispatchEventImpl(Window.java:2784)
at java.desktop/java.awt.Component.dispatchEvent(Component.java:4859)
at java.desktop/java.awt.EventQueue.dispatchEventImpl(EventQueue.java:778)
at java.desktop/java.awt.EventQueue$4.run(EventQueue.java:727)
at java.desktop/java.awt.EventQueue$4.run(EventQueue.java:721)
at java.base/java.security.AccessController.doPrivileged(Native Method)
at java.base/java.security.ProtectionDomain$JavaSecurityAccessImpl.doIntersectionPrivilege(ProtectionDomain.java:85)
at java.base/java.security.ProtectionDomain$JavaSecurityAccessImpl.doIntersectionPrivilege(ProtectionDomain.java:95)
at java.desktop/java.awt.EventQueue$5.run(EventQueue.java:751)
at java.desktop/java.awt.EventQueue$5.run(EventQueue.java:749)
at java.base/java.security.AccessController.doPrivileged(Native Method)
at java.base/java.security.ProtectionDomain$JavaSecurityAccessImpl.doIntersectionPrivilege(ProtectionDomain.java:85)
at java.desktop/java.awt.EventQueue.dispatchEvent(EventQueue.java:748)
at com.intellij.ide.IdeEventQueue.defaultDispatchEvent(IdeEventQueue.java:886)
at com.intellij.ide.IdeEventQueue.dispatchMouseEvent(IdeEventQueue.java:815)
at com.intellij.ide.IdeEventQueue._dispatchEvent(IdeEventQueue.java:752)
at com.intellij.ide.IdeEventQueue.lambda$dispatchEvent$7(IdeEventQueue.java:442)
at com.intellij.openapi.progress.impl.CoreProgressManager.computePrioritized(CoreProgressManager.java:825)
at com.intellij.ide.IdeEventQueue.lambda$dispatchEvent$8(IdeEventQueue.java:441)
at com.intellij.openapi.application.impl.ApplicationImpl.runIntendedWriteActionOnCurrentThread(ApplicationImpl.java:794)
at com.intellij.ide.IdeEventQueue.dispatchEvent(IdeEventQueue.java:493)
at java.desktop/java.awt.EventDispatchThread.pumpOneEventForFilters(EventDispatchThread.java:203)
at java.desktop/java.awt.EventDispatchThread.pumpEventsForFilter(EventDispatchThread.java:124)
at java.desktop/java.awt.EventDispatchThread.pumpEventsForHierarchy(EventDispatchThread.java:113)
at java.desktop/java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:109)
at java.desktop/java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:101)
at java.desktop/java.awt.EventDispatchThread.run(EventDispatchThread.java:90)
```
---
PhpStorm 2021.2
Build #PS-212.4746.100, built on July 28, 2021
Licensed to Portable UTF-8 / Lars Moelleken
Subscription is active until March 25, 2022.
For non-commercial open source development only.
Runtime version: 11.0.11+9-b1504.13 amd64
VM: OpenJDK 64-Bit Server VM by JetBrains s.r.o.
Linux 4.15.0-153-generic
GC: G1 Young Generation, G1 Old Generation
Memory: 5120M
Cores: 4
Registry: run.processes.with.pty=TRUE, ide.tooltip.initialDelay=885, ide.balloon.shadow.size=0
Non-Bundled Plugins: awesome.console (0.1337.11), com.intellij.ideolog (172.16.17.32), net.seesharpsoft.intellij.plugins.csv (2.17.1), mobi.hsz.idea.gitignore (4.2.0), name.kropp.intellij.makefile (212.4746.52), pronskiy.elephpant (0.1.1), com.github.inxilpro.intellijalpine (v0.4.2), NEON support (0.5.1), com.kalessil.phpStorm.phpInspectionsEA (4.0.6.4), me.artspb.idea.eval.plugin (0.4), lv.midiana.misc.phpstorm-plugins.deep-keys (2021.07.18.002), ru.adelf.idea.dotenv (2021.3.0.212)
Current Desktop: ubuntu:GNOME
Answers:
username_1: Also seeing this error.
username_2: Same here, happens every now and then.
username_3: This error happens regularly when running commands in Pycharm terminal that output many links. Such as test command resulting in failures with links to code.
```
java.lang.AbstractMethodError: Receiver class awesome.console.AwesomeLinkFilter$$Lambda$8328/0x000000080326e040 does not define or inherit an implementation of the resolved method 'abstract void onLinkFollowed(com.intellij.openapi.project.Project, com.intellij.openapi.vfs.VirtualFile, com.intellij.openapi.editor.Editor, com.intellij.openapi.editor.Editor)' of interface com.intellij.execution.filters.HyperlinkInfoFactory$HyperlinkHandler.
at com.intellij.execution.filters.impl.MultipleFilesHyperlinkInfo.open(MultipleFilesHyperlinkInfo.java:133)
at com.intellij.execution.filters.impl.MultipleFilesHyperlinkInfo.navigate(MultipleFilesHyperlinkInfo.java:101)
at com.intellij.execution.filters.HyperlinkInfoBase.navigate(HyperlinkInfoBase.java:28)
at com.intellij.terminal.JBTerminalWidget.lambda$convertInfo$3(JBTerminalWidget.java:124)
at com.jediterm.terminal.model.hyperlinks.LinkInfo.navigate(LinkInfo.java:33)
```
```
PyCharm 2021.2.2 (Professional Edition)
Build #PY-212.5284.44, built on September 14, 2021
Runtime version: 11.0.12+7-b1504.28 x86_64
VM: OpenJDK 64-Bit Server VM by JetBrains s.r.o.
macOS 11.5
GC: G1 Young Generation, G1 Old Generation
Memory: 2048M
Cores: 8
```
username_4: Same here, happens a lot since recent updates of IntelliJ IDEA Ultimate (simple use case: I displayed git status and clicked a file link and the error happened)
```
java.lang.AbstractMethodError: Receiver class awesome.console.AwesomeLinkFilter$$Lambda$8518/0x00000008033da040 does not define or inherit an implementation of the resolved method 'abstract void onLinkFollowed(com.intellij.openapi.project.Project, com.intellij.openapi.vfs.VirtualFile, com.intellij.openapi.editor.Editor, com.intellij.openapi.editor.Editor)' of interface com.intellij.execution.filters.HyperlinkInfoFactory$HyperlinkHandler.
at com.intellij.execution.filters.impl.MultipleFilesHyperlinkInfo.open(MultipleFilesHyperlinkInfo.java:133)
at com.intellij.execution.filters.impl.MultipleFilesHyperlinkInfo.navigate(MultipleFilesHyperlinkInfo.java:101)
at com.intellij.execution.filters.HyperlinkInfoBase.navigate(HyperlinkInfoBase.java:28)
at com.intellij.terminal.JBTerminalWidget.lambda$convertInfo$3(JBTerminalWidget.java:124)
at com.jediterm.terminal.model.hyperlinks.LinkInfo.navigate(LinkInfo.java:33)
at com.jediterm.terminal.ui.TerminalPanel$3.mouseClicked(TerminalPanel.java:243)
at java.desktop/java.awt.AWTEventMulticaster.mouseClicked(AWTEventMulticaster.java:278)
at java.desktop/java.awt.Component.processMouseEvent(Component.java:6655)
at java.desktop/javax.swing.JComponent.processMouseEvent(JComponent.java:3345)
at java.desktop/java.awt.Component.processEvent(Component.java:6417)
at java.desktop/java.awt.Container.processEvent(Container.java:2263)
at java.desktop/java.awt.Component.dispatchEventImpl(Component.java:5027)
at java.desktop/java.awt.Container.dispatchEventImpl(Container.java:2321)
at java.desktop/java.awt.Component.dispatchEvent(Component.java:4859)
at java.desktop/java.awt.LightweightDispatcher.retargetMouseEvent(Container.java:4918)
at java.desktop/java.awt.LightweightDispatcher.processMouseEvent(Container.java:4556)
at java.desktop/java.awt.LightweightDispatcher.dispatchEvent(Container.java:4488)
at java.desktop/java.awt.Container.dispatchEventImpl(Container.java:2307)
at java.desktop/java.awt.Window.dispatchEventImpl(Window.java:2784)
at java.desktop/java.awt.Component.dispatchEvent(Component.java:4859)
at java.desktop/java.awt.EventQueue.dispatchEventImpl(EventQueue.java:778)
at java.desktop/java.awt.EventQueue$4.run(EventQueue.java:727)
at java.desktop/java.awt.EventQueue$4.run(EventQueue.java:721)
at java.base/java.security.AccessController.doPrivileged(Native Method)
at java.base/java.security.ProtectionDomain$JavaSecurityAccessImpl.doIntersectionPrivilege(ProtectionDomain.java:85)
at java.base/java.security.ProtectionDomain$JavaSecurityAccessImpl.doIntersectionPrivilege(ProtectionDomain.java:95)
at java.desktop/java.awt.EventQueue$5.run(EventQueue.java:751)
at java.desktop/java.awt.EventQueue$5.run(EventQueue.java:749)
at java.base/java.security.AccessController.doPrivileged(Native Method)
at java.base/java.security.ProtectionDomain$JavaSecurityAccessImpl.doIntersectionPrivilege(ProtectionDomain.java:85)
at java.desktop/java.awt.EventQueue.dispatchEvent(EventQueue.java:748)
at com.intellij.ide.IdeEventQueue.defaultDispatchEvent(IdeEventQueue.java:885)
at com.intellij.ide.IdeEventQueue.dispatchMouseEvent(IdeEventQueue.java:814)
at com.intellij.ide.IdeEventQueue._dispatchEvent(IdeEventQueue.java:751)
at com.intellij.ide.IdeEventQueue.lambda$dispatchEvent$6(IdeEventQueue.java:441)
at com.intellij.openapi.progress.impl.CoreProgressManager.computePrioritized(CoreProgressManager.java:825)
at com.intellij.ide.IdeEventQueue.lambda$dispatchEvent$7(IdeEventQueue.java:440)
at com.intellij.openapi.application.impl.ApplicationImpl.runIntendedWriteActionOnCurrentThread(ApplicationImpl.java:794)
at com.intellij.ide.IdeEventQueue.dispatchEvent(IdeEventQueue.java:492)
at java.desktop/java.awt.EventDispatchThread.pumpOneEventForFilters(EventDispatchThread.java:203)
at java.desktop/java.awt.EventDispatchThread.pumpEventsForFilter(EventDispatchThread.java:124)
at java.desktop/java.awt.EventDispatchThread.pumpEventsForHierarchy(EventDispatchThread.java:113)
at java.desktop/java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:109)
at java.desktop/java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:101)
at java.desktop/java.awt.EventDispatchThread.run(EventDispatchThread.java:90)
``` |
llvm/circt | 1049841541 | Title: IMConstantProp It must be field sensitive
Question:
username_0: I thought about the extension to represent aggregate types in lattice. I think (only?) one option would be to use inheritance and virtual functions like this:
```cpp
class LatticeValue {
....
virtual void markOverdefined() = 0;
virtual void markInvalidValue(InvalidValueAttr value = 0;
virtual void markConstant(IntegerAttr) = 0;
virtual bool isUnknown() const = 0;
virtual bool isInvalidValue() const = 0;
virtual bool isConstant() const = 0;
virtual bool isOverdefined() const = 0;
}
class GroundTypeLatticeValue : public LatticeValue {
...
llvm::PointerIntPair<Attribute, 2, LatticeValue::Kind> valueAndTag;
}
// Use for bundle and vector types
class AggregateTypeLatticeValue : public LatticeValue {
....
// index to lattice value
SmallVector<std::unique_ptr<LatticeValue>> values;
};
```
This change might cause performance regressions so do you have any thoughts about this?
Answers:
username_0: I thought about the extension to represent aggregate types in lattice. I think (only?) one option would be to use inheritance and virtual functions like this:
```cpp
class LatticeValue {
....
virtual void markOverdefined() = 0;
virtual void markInvalidValue(InvalidValueAttr value = 0;
virtual void markConstant(IntegerAttr) = 0;
virtual bool isUnknown() const = 0;
virtual bool isInvalidValue() const = 0;
virtual bool isConstant() const = 0;
virtual bool isOverdefined() const = 0;
}
class GroundTypeLatticeValue : public LatticeValue {
...
llvm::PointerIntPair<Attribute, 2, LatticeValue::Kind> valueAndTag;
}
// Use for bundle and vector types
class AggregateTypeLatticeValue : public LatticeValue {
....
// index to lattice value
SmallVector<std::unique_ptr<LatticeValue>> values;
};
```
This change might cause performance regressions so do you have any thoughts about this?
username_1: I'm not entirely convinced of the best approach here. One thing to consider is that aggregate lattice values are really (as you show) just storage for the underlying ground type lattice values. It may be possible to keep the lattice values as ground types and then do more complicated updating of these when a connect/partial connect involves a ground type. E.g., when examining an aggregate connect, you need to figure out which lattice values on the LHS (and RHS if dealing with bundles with flips on the LHS) need to get updated.
One alternative would be to do an "expand connects" pass like the Scala FIRRTL Compiler does. This converts all aggregate connections to connections between ground types. After this, the existing IMCP pass may be a lot simpler to update because it shouldn't see any aggregate types on the operations its sensitive to, i.e., connects and partial connects. Doing it this way would, however, mean connects are blown out and we may not want to lower out of aggregate connections.
username_0: I see, it sounds exactly what `LowerTypes` is currently doing for vector types 😅
username_2: It is possible to expand out the lattice value so that you maintain the "one lattice value to one SSA value" invariant we have now, and then model each field as part of that huge aggregate lattice value. The problem with this is that the "height" of the lattice will be very high, and propagation through the graph will cause many many many lattice transitions as each field gets resolved. This will lead to inefficient compilation.
The alternative approach is to change LatticeValues from `DenseMap<Value, LatticeValue> latticeValues;` to `DenseMap<pair<Value, unsigned>, LatticeValue> latticeValues;`, where the unsigned value is the field # in question (the depth first enumeration of the field position). This allows each of the lattice values to be tracked independently, and allows updates to only flow through to the users that are affected.
This only works in cases where we have static knowledge of which field is being accessed: this is true for struct fields but not for arrays that have subaccesses with dynamic index. There are a couple different ways to handle that, but it will take some exploration.
username_0: Oh, I have misunderstood "expand connects". It makes a lot sense. Considering that we have to modify ExpandWhen too, I feel it is much better representation. |
portis-project/ethdenver2019-hackathon | 406878964 | Title: Integrate Portis into ETHDenver DApp
Question:
username_0: If you created a functional DApp as part of the ETHDenver 2019 Hackathon, which runs on a live environment ([deploying for free is super easy nowadays](https://zeit.co/now)) and you integrated Portis into it as its default or fallback web3 provider, please claim one of the bounties we opened on [GitCoin](https://gitcoin.co/explorer?bounty_type=feature&network=mainnet&idx_status=open&order_by=-web3_created&org=Portis) by submitting a PR to this issue that contains a link to your live DApp powered by Portis. If all the above conditions are met, then you will be rewarded the ETH in the bounty!
For more information check out our [docs](https://docs.portis.io)
Answers:
username_1: Good
Status: Issue closed
|
Shippable/shipit | 294351958 | Title: add reqProc_tag_push_w16 job to tag and push windows reqproc
Question:
username_0: https://github.com/Shippable/pm/issues/10038
Status: Issue closed
Answers:
username_0: this is verified by pinning to older tag -https://hub.docker.com/r/drydock/w16reqproc/tags/
https://app.shippable.com/github/Shippable/jobs/reqProc_tag_push_w16/builds/5a7849daa6e8350700def631/console
closing |
iamturns/eslint-config-airbnb-typescript | 828958172 | Title: Dot Notation vs. Bracket Notation
Question:
username_0: Hi!
I use `angular 9` and `typescript 4.1.5`, how can I change rules of `'airbnb-typescript/base'` relative to dot\bracket notation?
For example:
`control['inputType']` => `control.inputType`
and I get error what inputType doesnt exist on control. What if I dont want that refactor? How can I save bracket notation? Why this rule applied only dot notation? |
brittyazel/Neuron | 327159205 | Title: Bar list on left side of the editor doesn't scroll
Question:
username_0: it shows the arrows, but no scroll bar until i click an arrow or use my mouse wheel, but nothing will scroll no matter which method i try and no matter how many bars past 15 i make... mouse scrolling.. clicking arrows.. dragging the scroll bar once it shows up... it just stays where it is on the list.
I can get the list to move sort of tho. if i were to be seeing say the top of the list "action bar 1" and needed to see whatever name is the 16th bar that doesn't show up on the screen, i can click the arrow at the bottom of that side area and then click the bar name name and it will scroll down basically all the way down.. so if i had like 40 bars.. i would only be able to see the bottom 15 bars now.. but nothing in between unless i manually move the scroll bar to like the bottom middle.. and then click a bar also on the bottom middle it would move down in more of an increment.. so technically there's still a way to view everything on the bars list.. its just.. really annoying trying to if you have an excessive amount of bars.. which i don't but i tested it because i figure you never know.. someone might!
Answers:
username_1: This is a solid point. The reason this isn't working is because Blizzard removed the FauxScrollFrame functions that this part of the GUI was built on. I don't want to spend time rewriting it right now, becasue i'm just going to end up deleting all that code anyway. None of the GUI code is going to be used in my new AceGUI port |
urecio/axelilla | 67329871 | Title: Grunt bump
Question:
username_0: Commit everything. Not only the package.json
Status: Issue closed
Answers:
username_0: done. Now it's possible to run `npm run publish` from the main folder and it will build, commit everything to the dist branch and bump the version on package.json |
Blood-Asp/IndustryGigant | 183669142 | Title: items disappear in shelving unit
Question:
username_0: hi,
I had been suspecting this for a while, but it seems like shelving units don't probably store their content and sometimes when the chunk unloads itemstack stored in it disappear.
I can't reproduce it on demand, but I just noticed the absent of stack of slag that I definitely placed in it.
Answers:
username_1: It's a known bug. [https://github.com/cout970/Magneticraft-API-and-Issues/issues/84](url)
I use https://github.com/Belgabor/MagneticraftPatcher and it looks fine so far.
username_2: oh, nice to know that there is a patcher, will take a look at that. are there ready builds, or do i have to make them myself?
username_3: There is ready release. I use 0.2. |
argoproj/argo-cd | 876120640 | Title: Be more transparent when adding new clusters via CLI
Question:
username_0: # Summary
`argocd cluster add` should give the user an indication that it will create a service account with full cluster admin privileges on the remote cluster, and possibly ask for confirmation.
# Motivation
Since this behavior could be unexpected by some, and might break some organisational rules, we should provide users with the required transparency and a possibility to abort.
# Proposal
`argocd cluster add` should print out something like the following and ask the user for confirmation:
```shell
$ argocd cluster add some-context
WARNING: This will create a service account `argocd-manager` on the cluster referenced by context `some-context` with full cluster level admin privileges. Do you want to continue [y/N]? _
```
For automation purposes, the query can be skipped if
* command line flag `--yes` is given to `cluster add` command
* the execution context doesn't have a TTY (to not break existing automation scripts)<issue_closed>
Status: Issue closed |
json-schema-org/json-schema-spec | 95953248 | Title: Define the abstract instance validation function
Question:
username_0: It may be useful to define, in somewhat mathematical terms, what it means to validate an instance, and which inputs are used.
I imagine the validation function being defined as such:
Validate[_collection_, _schema_, _version_, _iriBase_, _instance_] → Boolean ∪ Indeterminate
Where:
* _collection_ ∈ set of all Map[ IRI → valid JSON Schema instance ]
* _schema_ ∈ set of all IRIs
* _version_ ∈ set of all IRIs
* _iriBase_ ∈ set of all IRIs
* _instance_ ∈ set of all JSON documents (i.e. with a media type application/json)
This may also help to resolve issue #4. If the validation function is defined to have no side-effects, then we can just reiterate that point within the "default" keyword. We can also say the keyword is "not used for validation, but may be used for other purposes not defined here."
This is not to say that JSON Schema libraries can't implement other functions, they might desire to implement a "coerce" function that turns an arbitrary JSON instance into a validating one (casting strings to numbers, filling in missing required values using the default, etc).
Aside: Defining a "coerce" might be something useful for v6 (or, the next version with feature additions).
Answers:
username_1: I agree that validation should not have side effects. I would keep "coerce" out of the standard.
username_2: Agreed. -1 for side effects, -1 for _"coerce"_ in v5.
username_3: Perhaps more something like:
Validate[_collection_, _schema_, _version_, _iriBase_, _instance_] → Boolean
Where:
* _collection_ ∈ set of all Map[ IRI → valid JSON Schema instance ]
* _schema_ ∈ set of all IRIs found in _collection_
* _version_ ∈ set of all IRIs identifying meta-schemas
* _iriBase_ ∈ set of all IRIs
* _instance_ ∈ set of all JSON documents (i.e. with a media type application/json)
By this definition, invalid schemas, and schemas linking to non-existent schemas, are outside of the domain, and the function can always return valid/invalid.
username_3: There's two questions we have to figure out here:
0. Is it possible to change schema versions, intra-document, with a $schema keyword? How can we indicate where a schema version change may take place?
0. Should the function include an indeterminate return value; or should invalid schemas be considered outside the domain of the function? (I.e. the value of this function is only defined for valid schemas). This may have a few ramifications, for example, it's possible to construct a schema that can produce all three invalid, valid, and error conditions depending on the instance that you feed it.
username_4: An invalid schema should be out of scope. In a similar way, if you try to parse invalid json, you get an error from your json parser... you don't get up to the point of the error in parsed json.
username_4: @username_2 You have given two -1's but without reason. A -1 without reason is invalid.
username_5: One thing I think we can say for sure is that invalid schemas should not return `validation: false`, either the shouldn't be part of the domain of the function at all or they should get their own result (like the `indeterminate` suggested by @username_3). If they did return false then then invalid schemas would be indistinguishable from `{"not":{}}` valid schemas. No one has actually suggested we do this, I'm just writing the argument against it out for completeness.
Also, I think the questions brought up by @username_3 are super important and I'd like to hear more people's thoughts on this.
username_5: This should absolutely be a blocker for new drafts of the spec until it's resolved.
How can we be releasing specifications for something that we can't even formally describe?
username_6: @username_5 from a practical perspective, it's obviously been working out OK. We are very close to Draft 06 and I am reluctant to postpone it for an issue that will no doubt involve a lot of debate.
What about this would prevent someone from successfully implementing Draft 06?
username_5: This has been an issue since the Foundations of JSON Schema paper. Has it been resolved in the current draft?
Here I should say my apologies if it's in the current draft and I missed it -- the question above is a genuine question because I haven't read the draft as closely as I'm sure you have.
My full opinion on this is actually stronger than just resolving this issue -- I think that the specification should be based on a formal model such at the one in _Foundations of JSON Schema_, and that English specs for things like this are fundamentally inadequate.
username_6: @username_5 coould you see if PR #248 sufficiently addresses your "$schema" concerns at least enough to get draft 06 out?
username_5: @username_6: I shouldn't have underestimated you guys, glad to see others were concerned about it as well.
To answer your question: it looks like I have a different impression of what a "draft" is than you all (which is good!). While language like "implementation behavior is subject to be revised or liberalized in future drafts" the draft is obviously pretty casual and nothing needs to be a blocker.
I just think that it makes more sense to do a formal spec first -- it's likely to save time and confusion.
Also: thanks for being so nice even when I'm clearly a little annoyed. You're awesome 😃
Also also: note that I still have two more concerns: the domain of the validation function and the idea that the spec should be based on a formal language instead of English.
username_6: @username_5 credit to @username_1 on this one- I confess I was totally fine with being able to switch schemas :-)
These sorts of drafts are just checkpoints for gathering feedback. It's unusual (even pathological) that draft 04 became a de-facto "standard" for years.
As for the "more formal language instead of English", is there some way you think this should be treated differently than other RFCs? ABNF isn't really useful here, I don't think, and generally RFCs do not use formal language (beyond the MUST/SHOULD/MAY/etc. from RFC 2119.
(also, you clearly haven't seen the issues where I got annoyed- trust me, you're fine, and I'm in no position to throw stones anyway :-)
username_5: This is a great question. The [Foundations of JSON Schema](http://www2016.net/proceedings/proceedings/p263.pdf) paper uses mathematical notation. I'm not convinced that would be a huge gain for us though, but I don't know much about the subject.
One thing that would could consider would be to have a canonical reference implementation of JSON Schema that we try to keep exactly correct. Then if parts of the spec are unclear we'll be forced to think about them immediately instead of later on when someone brings them up in the test suite.
username_6: @username_3 @username_4 @username_5 how do we resolve this issue?
Is this really something that needs to go in the specification, or is it better handled as a paper or something hosted on the json-schema.org web site?
username_5: The quasi-mathematical language isn't the important part, the important part is that the specification is extremely precise about what implementations should do when they hit edge cases. (E.g. if they're 90% through validating a schema and it references an invalid schema, is the result "MUST be invalid, MAY be invalid, MUST be indeterminate, etc.)
Another example would be if the implementation is partway through validating and a schema is referenced for a really old draft of JSON Schema -- what is the implementation allowed to do?
As long as those kind of things are exhaustively addressed the notation doesn't matter too much.
That said, I'm bowing out of JSON Schema stuff in general, so I'll leave the rest of this to you and @username_3. But those are my thoughts in case they're helpful.
username_6: @username_5 thanks, that is helpful. I think the useful thing to do here would be to file some specific issues around particular gaps in the spec. Those are things that I think will get nailed down as we get into the working group phase- we're still trying to just get the feature scope right. Anyway, since you are not active with the project anymore, I'll look into filing these.
I want to give @username_3 a chance to weigh in as this is his issue, and he's been busy in recent weeks, but my inclination is to move the general "let's define the abstract function" part of this over to the web site repo as supplemental information.
BTW if there's anything to your moving on from JSON Schema other than just not needing it for your current work, I'd be grateful for any parting feedback on any aspect of the project, technical or otherwise. My email address is on the last version of the spec if you'd rather send feedback that way.
username_5: Sounds good @username_6. I actually can answer you here instead of emailing because some of my reasons are on-topic: my personal preference is extremely small, well-defined specs that start with a theoretical foundation and build based off of that. So from this perspective a well-defined validation function would be reassuring to me.
(There's also an off-topic reason: for my projects I realized that human-readability doesn't matter much compared to the simplicity of the spec. Obviously JSON Schema can't toss human-readability out just for one person though!)
I do still like the JSON Schema community and think it's a cool project, so I look forward to seeing what you all come up with.
username_4: I have no opinion on this. Goes beyond my maths theory understanding =/
username_6: @username_3 @username_5 are there any examples of how such a function is defined in existing RFCs? I'm really just looking for the right sort of language, syntax, notation, etc. to use for such a thing.
username_5: Great question. Unfortunately I don't know of a good example, but I'll keep an eye out.
username_4: @username_6 How does this link to `output`?
username_4: @username_6 How does this link to `output`?
username_6: I admit I really don't know what to do about this issue. I've tried a few times to get it into something that feels actionable to me, or to close it, but I've not been able to accomplish either thing.
username_4: eep...
username_4: Can you give an example where this could be true? (I'll be honest, I have very little understanding of this issue. I do not understand your initial post.)
username_3: That's a good question. I may have forgotten some of my line of thinking since then.
Maybe I should try to identify a problem this is actually supposed to be solving, first.
Status: Issue closed
username_3: Since I can't really come up with a solid example of what there is to improve, I'll close this out. If I can come up with something, and a better way to phrase the issue, I'll open a new issue. |
karlcow/ymir | 671276464 | Title: createmonthlyindex.
Question:
username_0: Not called from the right place. Error happening once a month and it's why I lazily let it slip.
```
(env) ~/code/ymir % python -m ymir.ymir ~/Sites/la-grange.net/2020/08/01/ocean.html
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/Users/karl/code/ymir/ymir/ymir.py", line 284, in <module>
main()
File "/Users/karl/code/ymir/ymir/ymir.py", line 247, in main
createmonthlyindex(indexmarkup, monthindexpath)
NameError: name 'createmonthlyindex' is not defined
```<issue_closed>
Status: Issue closed |
matthieugrieger/mumbledj | 133459597 | Title: Youtube API keys not working?
Question:
username_0: "MumbleDJ does not have a valid YouTube API key."
The bot is being set up on a VPS, it worked before, We've tried server API keys and bowser API keys. The bot can connect to the mumble server without a issue,
The youtube -dl works, but the bot doesn't work. Can anyone help us out here?
Answers:
username_1: Hi there!
Can you show me what you get as a response when you put this in your web browser?
```
https://www.googleapis.com/youtube/v3/videos?part=snippet,contentDetails&id=[ANY_YOUTUBE_ID_HERE]&key=[YOUR_API_KEY_HERE]
```
Make sure that you replace the strings within the brackets with the appropriate data, and also be sure to hide your API key if it shows up anywhere in the request response.
username_2: the problem seems to be, that in https://github.com/username_1/mumbledj/blob/master/youtube_dl.go#L59 the program tries to download always a m4a sound file.
but many youtube videos don't have a m4a file.
username_1: Ah, I see. Try out the newest release. It should be fixed. :)
username_2: newest release of youtube-dl?
i already have the newest one (2016-02-13)
what i have done, is changed the line to
`cmd := exec.Command("youtube-dl", "--verbose", "--no-mtime", "--output", fmt.Sprintf("%s/.mumbledj/songs/%s", dj.homeDir, dl.Filename()), "--format", "bestaudio", "--prefer-ffmpeg", dl.url)`
so it downloads the best audio file and i just save it as a .m4a, doesn't matter for ffmpeg playback
username_1: Sorry, I meant the newest version of MumbleDJ. Do a `git pull` and recompile.
username_3: Hello, I'm username_0's partner in crime :). Following the advise above: Use v2.8.14, I can not seem to compile and get an executable that is v2.8.14.
What I have done:
1. Take existing local git repo and git pull -> "Already up-to-date"
2. Check git logs -> same
3. make clean -> make -> make install -> ./mumbledj -> !version -> v2.8.13
4. rm -r *
5. git clone https://github.com/username_1/mumbledj.git
6. git pull -> "Already up-to-date"
7. Check git logs -> same
8. make -> make install -> ./mumbledj -> !version -> v2.8.13
9. rm -r *
10. wget https://github.com/username_1/mumbledj/archive/2.8.14.tar.gz
11. tar -zxvf 2.18.14.tar.gz -> cd mumbledj-2.8.14
12. make -> make install -> ./mumbledj -> !version -> v2.8.13
And I am still having the same problems as the OP has stated.
username_1: Sorry, I believe I simply forgot to update the version number in the code. Although I did not make any changes in the last update related to this issue, can you please try updating and verify that you are still having the issue?
username_3: I updated to v2.8.15. I am still having the issue of "MumbleDJ does not have a valid YouTube API key.". I tried using two different keys one of them was a fresh key.
username_1: @username_3, can you tell me what response you get if you put the API request from my first comment in your browser?
username_3: ```
{
"kind": "youtube#videoListResponse",
"etag": "\"DsOZ7qVJA4mxdTxZeNzis6uE6ck/ZDiIGfaGdlaLOyRRhHv2ioolO-4\"",
"pageInfo": {
"totalResults": 0,
"resultsPerPage": 0
},
"items": []
}
```
Used a project id and a server key.
username_1: Can you tell me what YouTube ID you used?
Also, do you have any IP addresses listed in your API configuration on Google's website?
username_3: id: digitalocean-1219
Not for the key I used above.
username_1: The ID for the API request should be an ID to a YouTube video, not a DigitalOcean ID. Sorry if I was unclear. Let me know what response you get.
username_3: ```
{
"kind": "youtube#videoListResponse",
"etag": "\"DsOZ7qVJA4mxdTxZeNzis6uE6ck/ajlzOcCEd9G87ocnM7zkeJHZVro\"",
"pageInfo": {
"totalResults": 1,
"resultsPerPage": 1
},
"items": [
{
"kind": "youtube#video",
"etag": "\"DsOZ7qVJA4mxdTxZeNzis6uE6ck/PLlAVfhuxutKl2TGf6YQu3TK5Xg\"",
"id": "GQQMLE4FuIQ",
"snippet": {
"publishedAt": "2016-02-15T13:59:52.000Z",
"channelId": "UCZGYJFUizSax-yElQaFDp5Q",
"title": "Star Wars: Episode VIII Production Announcement",
"description": "Cameras roll for the next chapter of the Star Wars saga, written and directed by <NAME>. \n\nVisit Star Wars at http://www.starwars.com\nSubscribe to Star Wars on YouTube at http://www.youtube.com/starwars\nLike Star Wars on Facebook at http://www.facebook.com/starwars\nFollow Star Wars on Twitter at http://www.twitter.com/starwars\nFollow Star Wars on Instagram at http://www.instagram.com/starwars\nFollow Star Wars on Tumblr at http://starwars.tumblr.com/",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/GQQMLE4FuIQ/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/GQQMLE4FuIQ/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/GQQMLE4FuIQ/hqdefault.jpg",
"width": 480,
"height": 360
},
"standard": {
"url": "https://i.ytimg.com/vi/GQQMLE4FuIQ/sddefault.jpg",
"width": 640,
"height": 480
},
"maxres": {
"url": "https://i.ytimg.com/vi/GQQMLE4FuIQ/maxresdefault.jpg",
"width": 1280,
"height": 720
}
},
"channelTitle": "Star Wars",
"tags": [
"Star Wars",
"Episode VIII"
],
"categoryId": "24",
"liveBroadcastContent": "none",
"localized": {
"title": "Star Wars: Episode VIII Production Announcement",
"description": "Cameras roll for the next chapter of the Star Wars saga, written and directed by <NAME>. \n\nVisit Star Wars at http://www.starwars.com\nSubscribe to Star Wars on YouTube at http://www.youtube.com/starwars\nLike Star Wars on Facebook at http://www.facebook.com/starwars\nFollow Star Wars on Twitter at http://www.twitter.com/starwars\nFollow Star Wars on Instagram at http://www.instagram.com/starwars\nFollow Star Wars on Tumblr at http://starwars.tumblr.com/"
}
},
"contentDetails": {
"duration": "PT35S",
"dimension": "2d",
"definition": "hd",
"caption": "false",
"licensedContent": true
}
}
]
}
```
ID: GQQMLE4FuIQ
key: Same one I used last time.
username_1: Hmmm.. I'm a bit stumped as to what the problem is then. If you get this kind of response when using the bot you should not be receiving the invalid API key error.
Are you sure that your API key was correctly copied into the configuration file?
username_3: Solved it. I was running into two simple problems (can't believe it took me this long to figure them out).
Problem 1:
I run the bot in a user account (userB) without sudo, su, or root privileges, and I use another account (userA) with privileges to make/make install/make clean/etc. Anyway, the /home/userB/.mumbledj/* files were either not being updated to reflect */mumbledj/config.gcfg changes, environment variable changes, or permission changes (files being created with root ownership for instance).
Problem 2:
I had the youtube and soundcloud Api keys both listed in the /etc/environment file as well as the */mumbldj/config.gcfg file. So when I would run make install, the make command would copy the keys twice (youtube = "KeyKey", soundcloud = "KeyKey") into the /home/userB/.mumbledj/config/mumbledj.gcfg file.
Status: Issue closed
username_1: Awesome, glad you figured it out! |
appium/appium | 411160134 | Title: Unable to call chrome browser in latest version of appium 1.10
Question:
username_0: ## The problem
Hi I am not able to call application in the real devices
## Environment
* Appium version (or git revision) that exhibits the issue:1.10
* Last Appium version that did not exhibit the issue (if applicable):1.5
* Desktop OS/version used to run Appium:Window 10
* Node.js version (unless using Appium.app|exe):10.14.2
* Npm or Yarn package manager:
* Mobile platform/version under test: 8.1.0
* Real device or emulator/simulator:Real device
* Appium CLI or Appium.app|exe: CLI
## Details
I want launch a application is mobile browser below are my code
public static void main(String args[]){
DesiredCapabilities caps = new DesiredCapabilities();
//caps.setCapability("deviceName", "BandAndOlfusen");
caps.setCapability("deviceName", "Chandra");
caps.setCapability("udid", "7c9a8ac"); //Give Device ID of your mobile phone
caps.setCapability("platformName", "Android");
caps.setCapability("platformVersion", "8.1.0");
caps.setCapability("browserName", "Chrome");
caps.setCapability("noReset", true);
caps.setCapability("automationName","uiautomator2");
//Set ChromeDriver location
//System.setProperty("webdriver.chrome.driver","C:\\Users\\abc\\Desktop\\AppiumAll\\chrome72\\chromedriver_win32\\chromedriver.exe");
//Instantiate Appium Driver
AppiumDriver<MobileElement> driver = null;
try {
driver = new AndroidDriver<MobileElement>(new URL("http://0.0.0.0:4723/wd/hub"), caps);
} catch (MalformedURLException e) {
System.out.println(e.getMessage());
}
//Open URL in Chrome Browser
driver.get("https://gmail.com");
}
## Link to Appium logs
Create a [GIST](https://gist.github.com) which is a paste of your _full_ Appium logs, and link them here.
Do _NOT_ paste your full Appium logs he
[AppiumLogs.txt](https://github.com/appium/appium/files/2872335/AppiumLogs.txt)
re, as it will make this issue very long and hard to read!
If you are reporting a bug, _always_ include Appium logs!
## Code To Reproduce Issue [ Good To Have ]
Please remember that with sample code it's easier to reproduce the bug and it's much faster to fix it.
Please git clone https://github.com/appium/appium and from the `sample-code` directory, use one of your favourite languages and sample apps to reproduce the issue.
In case a similar scenario is missing in sample-code, please submit a PR with one of the sample apps provided.
Answers:
username_0: so what action i have to take now ?
username_1: fix local permissions?
username_0: can you tell me where this permission exist while i have given enableusb debug --
username_1: sorry, I don't understand the question
username_0: My mean where I can find it my phone bcoz I have given all the permission
on my phone
Is there any command by using we can give to appium
username_1: I was talking about local file system permissions
username_0: If this is the issue then it shold not call browser in other mobile
username_1: Feel free to push a PR if you consider the current behaviour wrong.
Closed as not an issue
Status: Issue closed
|
octokit/octokit.net | 28534090 | Title: Add classes corresponding to webhook payloads
Question:
username_0: Currently, deserialization of webhook payloads into classes is not included in octokit.net. If these were included, it'd make webhooks easier to create because devs wouldn't have to one-off their own classes for handling webhook payloads.
Answers:
username_1: Would you take implementations for the Create and Delete Payloads ?
If so, what else needs to be done for this?
- [ ] implementing the classes in the ActivityPayloads folder.
- [ ] Add serialization tests to https://github.com/octokit/octokit.net/blob/master/Octokit.Tests/Clients/EventsClientTests.cs
username_2: Webhook payloads are now supported in the [Octokit .NET webhooks package](https://github.com/octokit/webhooks.net) |
kubernetes-sigs/metrics-server | 530349147 | Title: Allowed client names are not loaded dynamically
Question:
username_0: We noted errors like this in the metrics-server: ` Unable to authenticate the request due to an error: [x509: subject with cn=apiserver-aggregator is not in the allowed list`.
After fixing the apiserver aggregator config to allow that name, we still needed to restart the metrics server to make it pick up the change.
This seems to be caused by:
* https://github.com/kubernetes-sigs/metrics-server/blob/019bda9fb8562dbc7996f0c38e31c709628df316/cmd/metrics-server/app/start.go#L135
* https://github.com/kubernetes/kubernetes/blob/cf16e4988f58a5b816385898271e70c3346b9651/staging/src/k8s.io/apiserver/pkg/server/options/authentication.go#L313
And now that I am here and looking at the latest HEAD of k/k I see its fixed over there, so this will be fixed with a dependency update. |
khaytsus/gqrx-scan | 218701743 | Title: Ubuntu 16.04 issues
Question:
username_0: Under Ubuntu 16.04, gqrx-scan doesn't seem to connect to gqrx 2.61. It complains when the remote control is disabled but when it's enabled, it doesn't seem to connect. I see lots of the following errors:
Can't write to /home/username_0gqrxscan.log, logging to /tmp/gqrxscan.log
Use of uninitialized value $tmpfreq in scalar chomp at ./gqrx-scan line 279.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 11.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 12.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 13.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 14.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 15.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 16.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 17.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 18.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 19.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 20.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 21.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 22.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 23.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 24.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 25.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 26.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 27.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 28.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 29.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 30.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 31.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 32.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 33.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 34.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 35.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 36.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 37.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 38.
Use of uninitialized value $freq in string eq at ./gqrx-scan line 864, <$csvfile> line 39.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $level in string ne at ./gqrx-scan line 542.
118.700 000 - TMP Tower - [ AM] [ -150 / -150] [Line 6]
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $level in string ne at ./gqrx-scan line 542.
119.700 000 - TMP TowerApproach - [ AM] [ -150 / -150] [Line 7]
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $level in string ne at ./gqrx-scan line 542.
120.250 000 - TMP Approach - [ AM] [ -150 / -150] [Line 8]
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $level in string ne at ./gqrx-scan line 542.
126.200 000 - TMP Approach - [ AM] [ -150 / -150] [Line 9]
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $level in string ne at ./gqrx-scan line 542.
133.550 000 - TMP ATIS - [ AM] [ -150 / -150] [Line 10]
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
Use of uninitialized value $tmpfreq in string eq at ./gqrx-scan line 403.
and so on...
Answers:
username_0: Wireshark shows that there's an initial connection handshake but nothing after that.
username_0: Bug is in gqrx IP settings.
*** Remote connection attempt from fd00:c2b6:b24b:be67:2827:688d:e6a1:6a3b:127.0.0.1 (not in allowed list)
*** Remote connection attempt from fd00:c2b6:b24b:be67:2827:688d:e6a1:6a3b:192.168.10.1 (not in allowed list)
username_1: Ah, yes, I've seen this on fresh installs too. I'll make a note in the gqrx scan readme, do you think that's sufficient for that issue? As for the others, it should fail immediately.. I'm a bit confused about that. It should say something like..
Unable to open connection to GQRX at line 262
Make sure TCP Remote is enabled and listening on 127.0.0.1 and port 7356
Also, make sure you're up to date, I fixed a few issues with CSV loading, it wasn't sanitizing or sanity checking input very well.
username_0: Yeah, I was planning to report a bug for gqrx on that. Just didn't get to that yet. It seems, the allowed IP settings in gqrx are messed up. If you just enter an IPv4 address, it doesn't work. You have to enter fd00:c2b6:b24b:be67:2827:688d:e6a1:6a3b:<IPv4 address> to make it work properly which is a bit nasty.
Status: Issue closed
|
cloudcreativity/laravel-json-api | 232110353 | Title: with not being called in single record request
Question:
username_0: Hey guys, I have been using the package for a while and love all the updates. One thing I am having problems with is the with function in the Adapter class. I believe this is supposed to be called on index and read, however I am only able to load the include relationships on an index call. This is causing a lot of N+1 queries in my application.
Here is my Adapter
```
<?php namespace App\JsonApi\Auctions;
use App\Models\Auction;
use Carbon\Carbon;
use CloudCreativity\LaravelJsonApi\Pagination\StandardStrategy;
use CloudCreativity\LaravelJsonApi\Store\EloquentAdapter;
use Illuminate\Database\Eloquent\Builder;
use Illuminate\Support\Collection;
class Adapter extends EloquentAdapter
{
/**
* Adapter constructor.
* @param StandardStrategy $paging
*/
public function __construct(StandardStrategy $paging)
{
parent::__construct(new Auction(), $paging);
}
/**
* Apply the supplied filters to the builder instance.
*
* @param Builder $query
* @param Collection $filters
* @return void
*/
protected function filter(Builder $query, Collection $filters)
{
if (!$filters->has('ended')) {
$query->where('ends_at', '>', Carbon::now('UTC'));
}
$query->orderBy('ends_at', 'asc');
}
protected function with(Builder $query, Collection $includePaths)
{
if($includePaths->contains('location')) {
$query->with('location');
}
}
/**
* Is this a search for a singleton resource?
*
* @param Collection $filters
* @return bool
*/
protected function isSearchOne(Collection $filters)
{
return false;
}
[Truncated]
$return = [];
if (isset($includeRelationships['items'])) {
$return['items'] = [
self::SHOW_SELF => true,
self::SHOW_RELATED => true,
self::DATA => $resource->items,
];
}
$return['location'] = [
self::SHOW_SELF => true,
self::SHOW_RELATED => true,
self::DATA => isset($includeRelationships['location']) ? $resource->location : $this->createBelongsToIdentity($resource, 'location'),
];
return $return;
}
}
```
Answers:
username_1: Hi. The `with` is only called on index calls at the moment. I can change this but wasn't sure what the point of calling it on a read call is? Because N+1 would only occur if you are loading multiple Auction objects, which you wouldn't on a read request (because it is for a single record).
Unless I'm missing something?! Happy to discuss as if there's a good reason it's needed for the `with` request this can be added.
username_0: @username_1 In my case, I am including the nested relationships "items,items.bids,items.bids.bidder"
I need to eager load the Bidder object which is N+1ed on a read. Unless I am looking at this wrong?
username_1: ah, ok that makes sense - couldn't see that in your adapter's `with` method.
it makes sense for the change to be implemented. I'll take a look at what it involves - I suspect I'd need to include it in the next release because it'll be breaking (I'll have to modify the `AdapterInterface` so that the find method receives the encoding parameters from the client).
username_1: Hi @username_0
I've looked into this and it's going to involve some interface changes. As I'm probably going to have to make interface changes when I sort out all the relationships stuff (see #60) I'll include it in that change.
I'm going to do a release of the 1.0 changes I've already made on #60, then will probably move on to the relationship stuff next.
Status: Issue closed
username_1: This change is now included on the `develop` (1.0) branch.
The Eloquent adapter now converts JSON API include paths into Eloquent relationship paths for eager loading e.g. `comments.created-by` is converted to `comments.createdBy` for eager loading. If you need to map these paths differently, you can specify this using the `$includePaths` property of your adapter. See https://github.com/cloudcreativity/laravel-json-api/blob/develop/src/Eloquent/Concerns/IncludesModels.php#L18-L47
It also continues to support default paths for eager loading on the `$defaultWith` property.
In addition, eager loading is now also supported when reading and updating specific resources. |
MaxDZ8/M8M | 48889063 | Title: Web monitor broken if pool unreachable
Question:
username_0: Trying to connect will cause M8M to hang with connection reset. This is clearly not the correct thing to do (as it will prevent the user from understanding the problem).
Perhaps more interestingly, sometimes connection browser->web monitor will suceed, work unbelievably slow and hang more or less at random (likely connection to remote server times out?).
This has been first observed on 0.0.520 but very likely affects all previous versions as well.
Answers:
username_0: As of 5c999bede5fe0c9bf52dcb8740f822b241a31036, some refactoring has been initiated. Quite ugly in its current form but a first step.
Status: Issue closed
|
simupy/simupy | 525392696 | Title: LTISystem(A,B,C,D)
Question:
username_0: How to represent a linear time invariant system with A,B,C,D matrices ?
```
sys=LTISystem(A,B,C,D)
Traceback (most recent call last):
File "<ipython-input-99-af8b714e7c2f>", line 1, in <module>
sys=LTISystem(A,B,C,D)
File "D:\Anaconda3\lib\site-packages\simupy-1.0.0-py3.7.egg\simupy\systems\__init__.py", line 378, in __init__
raise ValueError("LTI system expects 1, 2, or 3 args")
ValueError: LTI system expects 1, 2, or 3 args
```
Answers:
username_1: The consequence of this modeling choice is that for LTI systems, you can have a system with state and three matrices (state matrix A, input matrix B, output matrix C) or a system with no state and single (gain or output) matrix. If your model with state requires a direct feedthrough from input to output, you can augment the system by incorporating the input as an additional state variable and replace the input with its derivative.
Status: Issue closed
|
dials/dials | 296767051 | Title: Restarting scan-varying refinement from a varying model
Question:
username_0: At the moment, scan-varying refinement always starts from the static model, even if the input contains varying models. Allowing refinement to restart from an existing scan-varying model may have some advantages:
1. If the real variation during an experiment is severe then outlier rejection can be poor. This could be helped by doing scan-varying prediction with a model determined in a previous macrocycle.
2. A scan-varying model may be re-expressed with different smoother parameters. In future, this might be useful in combination with restraints. For example, a highly-smoothed model could be determined first, which may capture, for example, overall increase in cell parameters for a radiation-damaged case. A second macrocycle could add higher-frequency variation to the overall trend, with restraints to the trend line stopping the model wandering off unreasonably in regions where the data are poor (or missing).
3. Scan-varying refinement of multiple models, such as the crystal and the beam simultaneously, can be unstable. If scan-varying restart is made possible, then the variation in these models can be determined in separate macrocycles, iteratively alternated to convergence.
4. ...? |
cmeng-git/atalk-android | 460839995 | Title: Joint effort to modernize the look?
Question:
username_0: I would like to update the graphical look of aTalk taking interface graphics from other open source messaging apps. Probably Movim and/or the Telegramm client.
Is there any hints what the requirements are? Any other guidance?
I am planning some time for this probably in 4-6 weeks. Maybe it can be a joint sprint with multiple contributors?
Answers:
username_1: No sure how extend of the UI changes you have in mind:
a. Only replacement of icon and product logo
Currently there are around 400~500 icons used by aTalk. If changes are required, any graphic designer needs to fully understand each icon usage and android specifications on icons/screen resolutions, in order to generate a harmonize and family look icons for use in aTalk.
b. Changing theme and background colors
At start of aTalk development, resource is to concentrate in getting a working aTalk and add features. No much attention is paid to the app themes. The base theme used by aTalk is android Theme.Holo, but there are some adaptation. It will requires some effort to clean up current aTalk Theme implementation before one can proceed to change.
c. Change the UI layout and application flow.
There will be a major effort required in this areas, as this affects the source coding, layout and system testings.
Changes in any of the above, the effort is not small. The changes not only affect aTalk app itself; but also all the online documentation in atalk.sytes.net. This means all the video clips, screenshots etc must be recreated.
If UI changes are to be in the main aTalk project development, this will disrupt aTalk normal project development. I would prefer that UI changes are to be carried out as a branch project, until such point that it is ready for merging into the main aTalk project.
However before this project can kick off, we need to have some insight of the proposed changes, ui design directions, and even with some simple scratches of the new UI's.
Currently all my times are already consumed by aTalk project activities; afraid that I will no have much spare time for aTalk UI improvement. No sure if you have persons in mind whom would like to contribute to aTalk project. Pending on the changes, for a and b changes alone, we are likely to need a 2~3 people project team, and a minimum of 3 months full time effort to get a beta version for testing.
username_0: Ok maybe I am underestimating the amount of work required... I was thinking of mostly a) with a bit of b) mixed in. Mainly because every time I tell people about aTalk they immediately complain about the dated look of it, which really just seems like cosmetics that should not be that hard to change.
Of course if you are thinking of custom making all the graphics for aTalk then yes I agree that is a lot of work... but there are some really nice open messenger projects which can be the source of a consistent set of icons in a modern style.
I agree that it is best done in a separate branch and later merged back in. I also was not expecting you to contribute much other than some guidance in cases where it is not immediately obvious what to change. Better focus your limited time on improving actual functionality like you are already doing :)
username_1: Do you have any xmpp client that has the attributes for modern look that you are referring to? Would like to take a look at what are the effort required and impact to the aTalk progress.
username_0: Well, obviously there is the Conversations client, but I don't think it would do much good to make atalk look too much like it.
I was rather thinking about looking at non-xmpp messenger projects such as https://delta.chat/ (actually a fork of the open source telegram client) or Movim to reuse graphics and stickers etc. if the license of the art assets allows it.
username_1: Sorry for my ignorant, I really cannot see what are the major differences between conversations, delta.chat and aTalk.
I see the major differences are the color scheme and avatar shape.
Can it because of avatar is perfect square or round, instead of square with rounded corner as in aTalk?
Or the color scheme used in aTalk is too dark?
Or the chat background colors used are too bright? aTalk uses different backgrounds to denote plain, OTR and OMEMO chat sessions.
username_0: Heh, yeah I think you need some support with graphics design if you don't even see the huge difference in design consistency :)
aTalk right now is a clear case of "programmer's art".
Totally understandable that you are prioritizing other things, so I hope you don't take this as critizism :)
username_1: Yes agreed, at least from my point, I really need some graphics design expert advice on this area.
username_2: @username_0 DeltaChat was based on the Telegram UI, but now it's based on Signal.
Status: Issue closed
username_1: Closed with no activity to follow up.
username_3: Holo theme is like 10 years outdated. It's like using Windows XP still. Even if atalk has all XMPP features, its UI alone dissuades wider adoption.
Google has made Design Guidelines called Material Design. It has Open Source UI libs, fonts, icons etc
Start from here:
https://github.com/material-components/material-components-android
https://material.io/develop/android/
https://material.io/resources
username_1: Would you like to be contribute to the ID design?
I am an engineer by nature and does not have any ID background. So it is not my field to improve in this area.
By the way, I am still using WIndows XP, and I dislike windows 10 UI. Each and individual has his/her preference.
username_3: I'm not an android dev, sorry, but if you want you can try posting a (gratis, free) job to https://github.com/opensourcedesign/jobs https://opensourcedesign.net job board
username_2: @username_3 Read issue title, then re-read your request. :)
username_3: @username_2 are you hinting that I should submit it? :)
username_3: I already had typed a job half. I'll fill it up then
username_1: I feel that aTalk is not a social application that is used by general public. aTalk users are likely to have professional background or companies that would like to host their own server for privacy and security. If a company wants to have its own UI, it can always put in their own resources to make changes to aTalk. Also there are many social chat clients available that have modernize interfaces that users can choose from.
Modernizing an app UI is not a simple task; it needs major effort and time. aTalk goal is to develop an app so it has good ergonomic and simple to use. Sometimes it is simple to say than actually doing it. aTalk app is a 5 man-year effort. Modernization aTalk UI and make it stable can easy demand another 1 man-year effort. Unless there are public community willing to contribute and help, changing UI is of lowest priority to aTalk development.
As I have mentioned, an UI may appear attractive to one but not everyone. Although windows 10 has good UI, I would distance myself from using it. Likewise I only use Ubuntu classic gnome GUI, rather the default fancy UI that comes with it.
username_4: Functionality is orders of magnitude more important than cosmetics
username_5: That's true and even re-using the GUI of a different app is effort, but it is substantially less work than writing a new one from scratch. In hopes that someone wants to help it I made a list:
GPLv3+ licensed (+ means "or any later version"):
Signal https://github.com/signalapp/Signal-Android/blob/master/LICENSE (not sure if this also allow "any later version")
Kontalk https://github.com/kontalk/androidclient/blob/master/COPYING
GNU Jami https://git.jami.net/savoirfairelinux/ring-client-android/blob/master/COPYING
Conversations: https://github.com/iNPUTmice/Conversations/blob/master/LICENSE
permissive licenses (wouldn't require using GPLv3 for the combined work (it's MIT right now)):
RiotX (Apache v2) https://github.com/vector-im/riotX-android/blob/develop/LICENSE
Rocket.Chat (MIT) https://github.com/RocketChat/Rocket.Chat.ReactNative/blob/develop/LICENSE -- Uses React Native so can be used for other platforms as well.
See for example Google Play Store to see how each app's GUI looks.
I'm interested in more alternatives with interfaces you like if you know any. Cheers! |
viskvortsov/1C-developer | 233403136 | Title: Исаев
Question:
username_0: Индекс бизнеса:
Что это такое?
Явно нуждается в более понятном названии.
Продажа блюд:

Производство:
Производство должны быть все таки отдельным документом.
Во-первых, это явно указано в задании.
Во-вторых, теперь нельзя реализовать прямую схему производства.
За производство: 3/5
За все остальное: 5/5<issue_closed>
Status: Issue closed |
material-components/material-components-web | 487689125 | Title: [Button] Inconsistent Text/Background Colors When Using CSS Variables on Edge
Question:
username_0: <!--
Thanks for reporting the issue!
- Use these starter kits to host your demo:
Glitch: https://glitch.com/edit/#!/remix/new-web
Codepen: https://codepen.io/username_1/pen/gQWarJ
- For general questions:
Stack Overflow: https://stackoverflow.com/questions/tagged/material-components+web
Discord chat room: https://discord.gg/material-components
-->
## Bug report
<!-- A clear and concise description of what the bug is. -->
`edgeOptOut` is enabled for button container fill color but not icon or ink color, leading to buttons that have poor contrast due to the inconsistency in Edge
```scss
@mixin mdc-button-container-fill-color($color, $query: mdc-feature-all()) {
$feat-color: mdc-feature-create-target($query, color);
// :not(:disabled) is used to support link styled as button
// as link does not support :enabled style
&:not(:disabled) {
@include mdc-feature-targets($feat-color) {
@include mdc-theme-prop(background-color, $color, $edgeOptOut: true);
}
}
}
@mixin mdc-button-ink-color($color, $query: mdc-feature-all()) {
$feat-color: mdc-feature-create-target($query, color);
&:not(:disabled) {
@include mdc-feature-targets($feat-color) {
@include mdc-theme-prop(color, $color);
}
}
}
```
Note the `mdc-theme-prop` calls in the mdc code above.
### Steps to reproduce
1. Go to https://codepen.io/username_0/pen/dybzWBv
### Actual behavior
The "themed button" has a light red background with dark text in Chrome/Firefox, but a dark purple background with dark text in Edge (I use browserstack to compare)
### Expected behavior
The "themed" button should ideally have a light red background in Edge (css variables appear to be supported now)... or at least keep the white text from the sass configuration
### Screenshots
<!-- If applicable, add screenshots to help explain your issue. -->
### Your Environment:
<!-- please complete the following information -->
| Software | Version(s) |
| ---------------- | ---------- |
| MDC Web | 3.1.0 |
| Browser | Edge 18 |
| Operating System | Windows 10 |
### Additional context
<!-- Add any other context about the problem here. -->
None I can think of
### Possible solution
<!-- Add any other context about the problem here. -->
Preferably remove edgeOptOut functionality... if I'm wrong and there's some edge cases that still don't work then possibly make it global so people can opt in or not? If global isn't a good option, possibly every mixin needs to pass it down so people can override it on a case-by-case basis?
Answers:
username_1: Thanks for reporting this issue.
You suggestion to add global flag to edgeOptIn or edgeOptOut looks good to me. PR Welcome! :)
username_0: Compiling source files
pbjs --target=static-module --wrap=commonjs --keep-case --out=test/screenshot/infra/proto/cbt.pb.js test/screenshot/infra/proto/cbt.proto
ERROR: Error: pbjs process exited with code 1
at ProcessManager.spawnChildProcessSync (C:\projects\material-components-web\test\screenshot\infra\lib\process-manager.js:88:15)
at ProtoCommand.runAsync (C:\projects\material-components-web\test\screenshot\infra\commands\proto.js:49:22)
at buildRightNow (C:\projects\material-components-web\test\screenshot\infra\commands\build.js:94:58)
at BuildCommand.buildProtoFiles_ (C:\projects\material-components-web\test\screenshot\infra\commands\build.js:98:13)
at BuildCommand.runAsync (C:\projects\material-components-web\test\screenshot\infra\commands\build.js:68:16)
at <anonymous>
Run time: 454 milliseconds
```
I assume this is the issue.. I'm on Win10 using Git Bash. Tried setting breakpoints and looking into pbjs and I'm just circling now... anyone have any ideas?
Here's the failing code.. fails on first loop iteration with the `cbt` file
```js
for (const protoFilePath of protoFilePaths) {
const jsFilePath = protoFilePath.replace(/.proto$/, '.pb.js');
processManager.spawnChildProcessSync(
cmd, args.concat(`--out=${jsFilePath}`, protoFilePath), undefined, isWatching
);
}
```
username_1: What error are you getting when running `npm run start`? It'll just bring up the local development server at 8080 port.
username_0: ==========================================================
Local development server running on http://localhost:8080/
==========================================================
Compiling source files
npm run screenshot:webpack -- --watch --mode=development
test/screenshot/infra/proto/cbt.pb.js
pbjs --target=static-module --wrap=commonjs --keep-case --out=test/screenshot/infra/proto/cbt.pb.js test/screenshot/infra/proto/cbt.proto
pbjs process exited with code 1
test/screenshot/infra/proto/github.pb.js
pbjs --target=static-module --wrap=commonjs --keep-case --out=test/screenshot/infra/proto/github.pb.js test/screenshot/infra/proto/github.proto
pbjs process exited with code 1
test/screenshot/infra/proto/mdc.pb.js
pbjs --target=static-module --wrap=commonjs --keep-case --out=test/screenshot/infra/proto/mdc.pb.js test/screenshot/infra/proto/mdc.proto
pbjs process exited with code 1
test/screenshot/infra/proto/selenium.pb.js
pbjs --target=static-module --wrap=commonjs --keep-case --out=test/screenshot/infra/proto/selenium.pb.js test/screenshot/infra/proto/selenium.proto
pbjs process exited with code 1
```


 |
alacritty/alacritty | 842584559 | Title: Cursor thickness is increased incorrectly on wide cells
Question:
username_0: When a cursor like the underline is below a wide cell, its thickness is increased (I'd assume doubled).
Answers:
username_1: Hi @username_0 I'd like to work on this issue, but how can I set wide cell on my pc?
username_0: I noticed this by typing `echo "https://example.org/test汉字"`, just copy/pasting this and moving your cursor on top of one of the Chinese characters should be sufficient.
Status: Issue closed
|
aws/aws-sdk-java | 332553943 | Title: InputStreams are confusing EOF states with timeouts
Question:
username_0: I've also written up this bug and a possible work-around for Hadoop (https://issues.apache.org/jira/browse/HADOOP-15541), but I think there may be some flawed logic in the SDK regardless that we might want to fix. In a nutshell, when recovering from a read timeout, Hadoop tries to drain the stream (I'm trying to figure out what benefit we gain from doing that), but it gets an SdkClientException for an unexpected reason. Upon reading the stream, we check the lengths are what we expect. Having timed out, the stream reports -1, which is interpreted by the SDK to mean we've hit EOF. Since it think we've hit EOF, the SDK expects bytes read to match expected bytes. Since we haven't actually hit EOF, they don't match. The relevant code is here:
https://github.com/aws/aws-sdk-java/blob/master/aws-java-sdk-core/src/main/java/com/amazonaws/util/LengthCheckInputStream.java#L90-L93
https://github.com/aws/aws-sdk-java/blob/master/aws-java-sdk-core/src/main/java/com/amazonaws/util/LengthCheckInputStream.java#L148
I suspect our attempt at "draining the stream" when recovering from a failure would have to fail eventually anyway, so I don't know how big of a deal it is to simply abort after this particular failure. But regardless, the SDK seems to be assuming we've hit EOF when we haven't, and that feels wrong regardless.
Answers:
username_1: Its possible that aborting the stream will close the underlying connection instead of releasing it to the pool. We have similar logic where we try to drain the stream instead of aborting to release the underlying connection to pool.
username_0: When it times out, it does throw a SocketTimeoutException. The concern is just that later, retrieving the bytes read returns -1 at the lines I linked to above, and that is equated with EOF.
username_2: oh, so after the ex, any read() returns -1, not 'failed'?
username_2: ...we should force an abort() here to stop the connection going back to the pool. Socket timeouts don't suddenly heal themselves, do they?
username_3: Maybe I'm misunderstanding, but if an`IOException`s occurs when reading from the connection, it should not be getting released back into the pool. Are you observing something different?
username_2: It sounds a bit like that; we can just abort() in our client to make sure that this is guaranteed to happen.
username_4: Is there anything further pending from the SDK team on this issue?
username_2: @username_4 I don't think there is. We're treating any input stream IOE raised as a non-closing-stream failure; socket timeouts = break the input stream before retrying. And as I regression test the update to [1.11.374](https://issues.apache.org/jira/browse/HADOOP-15642); I'm not seeing any new problems here. That said, it's not something our fault-injection layer simulates failures with.
username_3: Cool, in that case I'm going to go ahead and close this. Feel free to reopen if any further questions come up.
Status: Issue closed
|
SoftUni-Internal/suls-issues-public | 244494608 | Title: How to apply button redirects to home page
Question:
username_0: Browser - Opera
Username - username_0Luci
Resolution - 1536 x 864
When I click on 'How to apply' button in the footer it simply redirects me to home page ( https://dev.platform.softuni.bg:8080 ) with no message and no nothing
Expected behavior - to redirect me to a page where I can see how to apply.
Actual behavior - redirects me to home page with no message or anything.
Answers:
username_1: Could not reproduce it. Please add more specifics or screenshots and check again please if the issue is still valid - when i follow the steps this page is loaded: https://dev.platform.softuni.bg:8080/how-to-apply
username_2: Expected Behavior
Redirects to page "How-to-apply"
Actual Behavior
On click reloads the current page
Steps to Reproduce
-> visit softuni.bg
-> scroll down to the footer
-> click on "Как да кандидатствам" / "How to apply"

Specifications
Platform: https://softuni.bg/
Browser used: Google Chrome
URL :https://softuni.bg/
Username: ivakis
username_3: @username_1 try to reproduce it in incognito window (or without logged in user) |
juijs/jui-chart | 145931742 | Title: 라인차트 관련 문의
Question:
username_0: http://chartplay.jui.io/?p=line 라인차트 툴팁 시
data : [
{ apple : 26.1, microsoft : 24.86, oracle : 0 },
{ apple : 43.83, microsoft : 25.14, oracle : 0 },
{ apple : 55.03, microsoft : 24, oracle : 0 },
{ apple : 72.95, microsoft : 25.39, oracle : 0 }
]
1.oracle 값을 0으로 설정 시 microsoft : 24.86 라인에 마우스 오버시 툴팁 24.86이 정상적으로 발생되고 oracle 라인에 마우스 오버시 0값이 아닌 microsoft 라인의 값인 24.86이 툴팁에 나옵니다. (설명이 잘되었나..)
2.filter : true 레전드에 필터시 색깔이 자기 마음되로 변경되고 모두 0인값(oracle) filter 제거하여도 보여지네요
----JS
var chart = jui.include("chart.builder");
chart("#result", {
axis : {
x : {
type : "fullblock",
domain : [ "2010", "2011", "2012", "2013" ],
line : true
},
y : {
type : "range",
domain : function(d) {
return Math.max(d.apple, d.microsoft, d.oracle);
},
step : 10
},
data : [
{ apple : 26.1, microsoft : 24.86, oracle : 0 },
{ apple : 43.83, microsoft : 25.14, oracle : 0 },
{ apple : 55.03, microsoft : 24, oracle : 0 },
{ apple : 72.95, microsoft : 25.39, oracle : 0 }
]
},
brush : [{
type : "line",
animate : true
}, {
type : "scatter",
hide : true
}],
widget : [
{ type : "title", text : "Line Sample" },
{ type : "legend" ,filter : true},
{ type : "tooltip", brush : 1 , }
]
});
Answers:
username_0: 
username_0: 


username_1: @username_0 친절하게 스샷까지!
금일 확인해서 알려드리겠습니다! ㅎㅎ
username_0: oracle 값이 0이여도 그래프에 표시가 되요ㅠ
username_1: @username_0 문제의 원인이 파악되었습니다.
수정되면 알려드릴게요. ㅋㅋ
username_1: @username_0 답변이 늦어서 죄송합니다. develop 브랜치 체크아웃 받으시면 됩니다!
Status: Issue closed
|
mbanting/meteor-reactive-ibeacons | 149426314 | Title: [email protected] does not exist
Question:
username_0: Quick fix: paste [email protected] into .meteor/cordova-plugins
Answers:
username_1: +1, I'm getting this error and haven't been able to figure it out. @username_0 can you please elaborate on how you did that? I don't understand what you mean by paste ? Thx
username_0: Hi @username_1In. In the directory .meteor u should find a file named cordova-plugins. Copy and paste [email protected] into that file.
username_2: Real sorry for the delay. Will try and get to this this weekend.
Does this have anything to do with a Meteor 1.3 upgrade or did this just stop working?
Status: Issue closed
|
sir-dunxalot/ember-tooltips | 328599334 | Title: Expand push access to others?
Question:
username_0: @username_2 is it possible to grant push access to others? I know you are probably very busy, but I'd hate to have to depend on a random fork for a small fix. Thank you! :)
Answers:
username_1: I'd love to see this expanded too -- I've been banking on my fork for quite some time that improves integration with the run-loop.
Status: Issue closed
username_2: Hi there, I appreciate the nudge. I just opened #261 and am actively looking for a co-maintainer in order to keep this addon up-to-date.
username_2: Hi gents, @maxfierke is up-and-running as a co-maintainer of this project so you should see better stewardship moving forwards. :) |
danger/danger-js | 288968500 | Title: Renamed files appear within modified_files, but fail when passed to danger.git.diffForFile
Question:
username_0: I've got a file within my repo which has had a parent folder renamed
(e.g. from `/tests/seach/index.spec.js` to `/tests/search/index.spec.js`)
I'm running some tests on the diff of modified files, and this renamed (but not modified) file is turning up within `danger.git.modified_files`.
It appears that when I run `danger.git.diffForFile` on the file's path, danger fires off 1 request for the branch file (which succeeds) and 1 request for the master file using the new path (which fails, 404).
I'd expect Danger to either:
- Know that the file has been renamed but not modified, not include it within `danger.git.modified_files`
- If that's not possible then include it within `danger.git.created_files`
- Handle renames, request the old version using the old name (if possible?)
- More graceful handling / error reporting of 404s during the requests for diffs
Answers:
username_1: I agree, that logic should be pretty feasible to look up using the existing calls we have (e.g. inside the diff we get) then to use that instead of simply looking for the same named file twice
username_2: I've also ran into the issues described above with renamed folders, and agree that it shouldn't be included in `modified_files` and including it in `created_files` would make more sense if it's not possible to recognise these files as having been moved rather than modified.
username_3: On a related note, when I have a new file added and try to run `danger local`, `diffForFile` fails as it tries to run ` 'git show master:"<my_new_file.ext>"'`. It says:
```
Path '<my_new_file.ext>' exists on disk, but not in 'master'.
```
But if I change it to `JSONPatchForFile`, it reports the diff with no errors. So I think it might extend to `created_files` as well as renamed ones.
username_3: I spoke too soon - it reports an empty diff if I use `JSONPatchForFile`, but at least it doesn't crash. ><
username_4: Experiencing this, although I'm not sure it's a major issue. How can we tell that a file has been renamed? |
Azure/azure-iot-sdk-python | 508242522 | Title: No module named 'iothub_client'
Question:
username_0: Hello,
I am developing now several python modules that are going on production inmediatly.
Now, in my last module I find this message when I run it in the edge device:
No module named 'iothub_client'
The rest of the modules go on working fine, they are alredy installed.
Is this messege generated because of the new SDK? I have asked Microsoft team and they told me that maybe i should upgrade to the new SDK, but i have a doubt if my old modules will go on working if I need to do any change.
Thanks in advance for any feedback you can give me
Status: Issue closed
Answers:
username_1: @username_0, thank you for your contribution to our open-sourced project! Please help us improve by filling out this 2-minute [customer satisfaction survey](https://forms.office.com/Pages/ResponsePage.aspx?id=v4j5cvGGr0GRqy180BHbRx8jpG79OudPqY-BojcKjkJUMFFBQjgxNkw5ODJIRjBWTzI0Nk85R0pUQiQlQCN0PWcu) |
UniversalDependencies/docs | 245528315 | Title: Partitive with preposition in French (and other languages)
Question:
username_0: French, and some other languages, use a preposition to make a partitive e.g. "je voudrais de l'eau" and not "je voudrais l'eau".
In the French treebank, this use of "de" seems to be annotated as a determiner(!!)
```
# sent_id = fr-ud-train_00600
# text = La chambre n'avait pas de chauffage, résultat -> impossible de dormir le premier soir.
1 La le DET _ Definite=Def|Gender=Fem|Number=Sing|PronType=Art 2 det _ _
2 chambre chambre NOUN _ Gender=Fem|Number=Sing 4 nsubj _ _
3 n' ne ADV _ Polarity=Neg 4 advmod _ SpaceAfter=No
4 avait avoir VERB _ Mood=Ind|Number=Sing|Person=3|Tense=Imp|VerbForm=Fin 0 root _ _
5 pas pas ADV _ Polarity=Neg 4 advmod _ _
6 de un DET _ Definite=Ind|Gender=Masc|Number=Sing|PronType=Art 7 det _ _
7 chauffage chauffage NOUN _ Gender=Masc|Number=Sing 4 obj _ SpaceAfter=No
```
I looked in the French docs and there doesn't seem to be a description of this (e.g. no mention of "de" as a determiner in `DET.md` or `det.md`.
Would it be possible to document the diagnostics for when it is a deteminer ? It seems to be when there is no other determiner.
Answers:
username_1: Isn't it just a confusion with the determiner _des_?
The _de_ seems like `ADP` to me but I don't speak French. @mcdm?
username_2: We are working on the guidelines for French, but we have now 6 UD treebanks for French (including the French-Spoken coming soon) developped by at least 4 different teams. The treebank called just French (developped by Google) is the worst one and should not be taken as a reference (I already asked that its name be changed).
username_2: The question of _de_ is very complex.
There exists a weak form of the determiner _des_ used only before an ADJ:
```
des pommes 'apples'
*de pommes
de belles pommes 'beautiful apples'
```
But _des_ itself is a portmanteau of _de + les_ 'of + the'. And _des_ cannot occur after the preposition _de_:
```
Je rêve de cette pomme 'I dream of this apple'
Je rêve de pommes 'I dream of apples'
```
This _de_ will be analyzed as an ADP but the determiner has disappeared and it could also be analyzed as a portmanteau 'de + des'.
The _de_ after a negation (_Je n'avais pas de chauffage._ 'I had no heating') is the most controversial one. It is often analyzed as a DET occuring only after a negation. But il could also be analyzed as an ADP, as in _J'avais trop de chauffage_ 'I had too much heating_. I really think that the latter is the best solution.
username_0: Which treebank is the best one to use for reference ?
Incidentally in Basque the negative is analysed as `Case=Par|Definite=Ind` _Derbietan ez dago faboritorik_, and in Finnish as `Case=Par`, _Sisällissodan uhka ei ole pelkkää retoriikkaa._
In Basque, certain grammars like de Rijks (2008) describe -rik as being a partitive determiner along the lines of _-a_ and _bat_
Coming back to French, in that case would you have a different analysis for _Je n'avais pas de chauffage_ and _J'avais trop de chauffage_ ?
Status: Issue closed
|
chatwoot/chatwoot | 697594771 | Title: Popup Chat Messages based on the web page of the user
Question:
username_0: When the user is on a particular page popup a personalized message to initiate the conversation with the user.
Eg: If the customer is on the pricing page -> popup a message from the chat widget and ask "Do you have any questions regarding pricing?
Answers:
username_1: Seems like this is a duplicate of #1209. Please feel free to reopen the issue if it is not the case.
Status: Issue closed
|
hallegu/Time-management-app | 802748301 | Title: Project update video prep
Question:
username_0: Details here: https://hallertau.cs.gsu.edu/~mweeks/update_video.html
A major portion of the video, along with basic information like team introductions, will be the "project mockup". This sounds like a low-tech visual representation of our app--the user interface, features, etc. to show off our concept.
In order to make this presentation work, we will need to have a solid understanding of our app as well as enough matlab knowledge to form a rough idea of how we can build it.
Once we are comfortable with the concept, we can start building our mockup.
Finally, we will be able to record our video(s), splice them together if needed, then submit the final product to iCollege, ending this first "sprint" of the project.<issue_closed>
Status: Issue closed |
videojs/video.js | 222435360 | Title: Volume Control not displaying on iphone iOS 10.2
Question:
username_0: The Volume Control is not displaying on my iPhone under iOS 10.2, and it always has the class "vjs-hidden". It seems it was disabled because iOS used to forbid to change volume programmatically, so, the decision was made to just hide the volume control.
I tried using the options for the volume, doing:
```
videojs($el, {
...
controls: true,
controlBar: {
volumeMenuBar: true,
muteToggle: true,
volumeControl: true
}
}
```
But it didn't change anything.
I'm using videojs with these plugins:
videojs-contrib-ads: 4.2.4
videojs-ima: 0.5.0
videojs-vast-vpaid: 1.0.0
videojs-contrib-hls: 5.4.1
videojs-contrib-quality-levels : 2.0.2
Answers:
username_1: It's hidden by apply a class that hides it. You can either force it to be displayed via CSS, or you can do something like:
```js
var player = videojs('vid');
player.controlBar.volumeMenuButton.show();
```
which should re-show it.
Hope that helps.
Status: Issue closed
username_0: Yes it kinda fixes it, but if I change the source I have to call it again to display the volume button. Actually, I'd like to be able to set this in the options.
The problem is that Html5.canControlVolume is always False for iOS. Indeed it is not possible to control the volume, but it's possible to mute/unmute it. But in volume-menu-button.js it hides it because Html5.featureVolumeControl is false.
`
// hide mute toggle if the current tech doesn't support volume control
function updateVisibility() {
if (player.tech_ && player.tech_.featuresVolumeControl === false) {
this.addClass('vjs-hidden');
} else {
this.removeClass('vjs-hidden');
}
}
` |
paul-tqh-nguyen/mutag_graph2vec_neural_classifier | 718955989 | Title: Add "Experiment Results" Documentation Content
Question:
username_0: This task is to add content to the "Experiment Results" section of the documentation.
Answers:
username_0: https://github.com/username_0/mutag_graph2vec_neural_classifier/commit/decc19671e7307f0bdea9bfca53d3c41af7b78ab completes this task.
Status: Issue closed
|
ant-design/ant-design-pro | 944303381 | Title: 🧐[问题] 在eslint的rules中设置了`"semi": [2, "never"]`,并且通过`yarn lint:fix`去除了分号,但在`git commit`的时候,报错:`error Extra semicolon semi`
Question:
username_0: ### 🧐 问题描述
举例:`git commit`的时候,报错显示在`abc.js`的第3行第2列的位置有多余的分号 `error Extra semicolon semi`,但事实上这个位置并没有分号。
<!--
详细地描述问题,让大家都能理解
-->
### 💻 示例代码
<!--
如果你有解决方案,在这里清晰地阐述
-->
### 🚑 其他信息
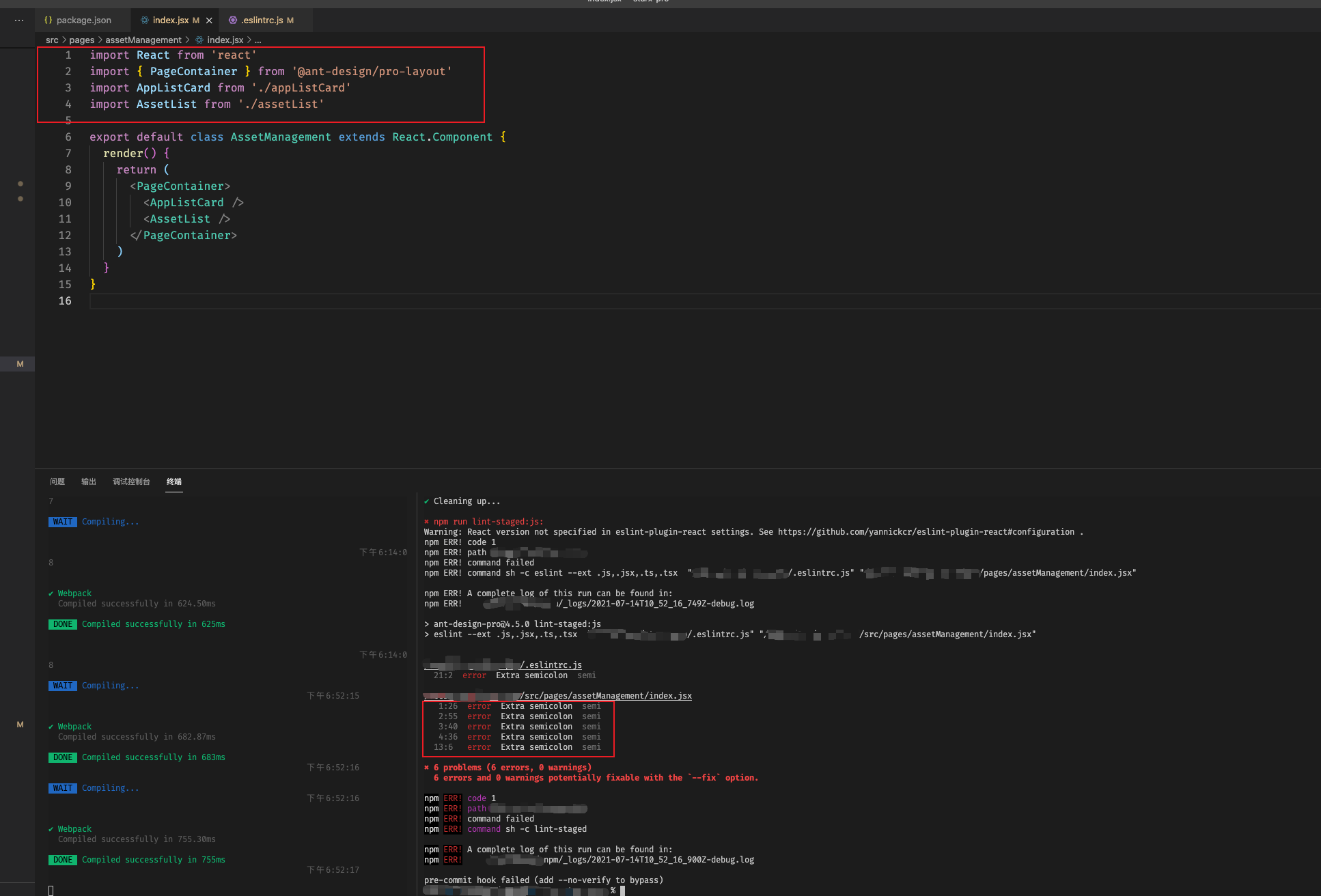

<!--
如截图等其他信息可以贴在这里
-->
Answers:
username_1: 是被prettier掉了,这里不推荐你自定义,代码风格没什么好坏和别人一样才重要。
如果你要改,还需要改动 prettier 的配置
Status: Issue closed
username_0: 非常谢谢,通过修改prettier配置解决了这个问题。因为我之前一直遵循 `JavaScript Standard Style` 规范,所以在开发这个项目的时候也希望可以继续编写无分号代码。 |
kubernetes/kops | 342275099 | Title: kops toolbox template: ignores config file for clusterName in templates
Question:
username_0: ------------- BUG REPORT TEMPLATE --------------------
1. What `kops` version are you running? The command `kops version`, will display
this information.
Version 1.10.0-alpha.1
2. What Kubernetes version are you running? `kubectl version` will print the
version if a cluster is running or provide the Kubernetes version specified as
a `kops` flag.
v1.10.5
3. What cloud provider are you using?
AWS
4. What commands did you run? What is the simplest way to reproduce this issue?
`kops toolbox template --values=test.yml --template=template.yml --format-yaml`
```
test.yml
-----------
clusterName: bob
```
```
template.yml
---------
kops.k8s.io/cluster: {{ .clusterName }}
```
5. What happened after the commands executed?
```
Using cluster from kubectl context: kube.huobidev.com
kops.k8s.io/cluster: kube.huobidev.com
```
with no ~/.kube/config
```
kops toolbox template --values=config/test.yml --template=instance_groups/sample.yml --format-yaml
W0718 18:37:54.026010 44048 root.go:248] no context set in kubecfg
kops.k8s.io/cluster: null
```
I did not have a kube config file with multple clusters in it so I can not test for that behavior
6. What did you expect to happen?
```
kops.k8s.io/cluster: bob
```
Template generation should use the config file, pulling things out of kube config can lead to nasty suprises
7. Please provide your cluster manifest. Execute
`kops get --name my.example.com -o yaml` to display your cluster manifest.
You may want to remove your cluster name and other sensitive information.
N/A
8. Please run the commands with most verbose logging by adding the `-v 10` flag.
Paste the logs into this report, or in a gist and provide the gist link here.
N/A
9. Anything else do we need to know?
Workaround is just uses a different string for key
Answers:
username_1: Possible duplicate of #5015
username_0: similar, If I remember correctly it died with no ~/.kube/conf file. Related issue: are there any other magic variables in the code base? when making templates I really do not want it reading ~/.kube/conf for anything.
username_0: I wonder if there are any other magic variables floating around.
username_0: /remove-lifecycle rotten
username_0: @rifelpet thanks for looking into it
I just might get a micro commit out of this
username_2: same issue with Version 1.11.0 (git-2c2042465)
username_3: Any update on this? It seems to render the template function unusable without a kubecfg. I was hoping to use this feature in a CI pipeline.
username_0: @username_3 I do not think you need a kubeconfig, you just need to have a config varable not called "clusterName" ( "myClusterName" works fine) that you call from the template to insert the cluster name in the yaml file. kops will still put out a message though, if I remember correctly.
username_3: Thanks for the tip. That was the first thing I tried due to the example.
That not working, and the log message certainly don’t make me trust it but
I will keep at it. |
DzoQiEuoi/pure-bind | 239409216 | Title: Usage Case Equality
Question:
username_0: I'm reviewing the functionality of this within my existing application. I believe the main goal of this library is memoization. To test this I have created the following sample.
I am expecting that x1A and x2A to have the same object (pointer reference). However, this is comparing as false. Am I miss understanding the nature of this library?
```
var bind = require("pure-bind")
var doSomething = (a,b) => {
return {
a, b, answer: a * b
}
}
var x1 = bind.default(doSomething,2,3)
var x2 = bind.default(doSomething,2,3)
x1A = x1()
x2A = x2()
x1A == x2A // Expected True, but get False
````
Answers:
username_1: This is the correct behavior since it caches only the function not the result.
```
var pureBind = require("pure-bind")
var doSomething = (a,b) => {
return {
a, b, answer: a * b
}
}
var x1 = pureBind.default(doSomething,2,3)
var x2 = pureBind.default(doSomething,2,3)
x1A = x1()
x2A = x2()
x1B = x1()
console.log(x1 === x2);//True since they are the same function
//Return false as the function returns new instance on every invocation
console.log(x1A == x2A) //Return false
console.log(x1A == x1B)//Return false
```
Status: Issue closed
username_2: username_1 is correct.
The purpose of the library is to maintain reference equality of the functions rather than their return values. This can be useful when you want to bind a value to a function as your pass it into a React component because it prevents unnecessary virtual DOM re-renders. |
lab11/OINK | 327138127 | Title: Payment return should explicitly check success true
Question:
username_0: https://github.com/lab11/OINK/blob/master/src/firebase_functions/functions/oink/core1.f.js#L180
There's a corner case to consider here where _something_ comes back, but it's not what we expect, and it doesn't have `success === true` in it. We should change this `else` to be a check for success === true, then add a final `else` case for something completely unexpected that raises an alarm or some such<issue_closed>
Status: Issue closed |
googleapis/python-tasks | 757153654 | Title: Task level retries documentation wrong.
Question:
username_0: Hello.
In the documentation for create_task, retry is documented as
`(Optional[google.api_core.retry.Retry]) – A retry object used to retry client library requests. If None is specified, requests will be retried using a default configuration.`
However currently according to this [feature request](https://issuetracker.google.com/issues/141314105), they are not supported by cloud tasks.
I tried it and it seems like the task does not work as of now, it seems like the retry option is ignored. Considering the issue I'm guessing that it was a problem with the documentation rather than the code.
If it is an issue with the code the steps to reproduce amount to making a task with a short deadline in a queue without one/a longer one and the task-level deadline will be ignored.
Answers:
username_1: Hi @username_0, the retry input is how the [client library retries the request](https://googleapis.dev/python/google-api-core/latest/retry.html#google.api_core.retry.Retry). Retries for tasks can be specified for the [queue](https://googleapis.dev/python/cloudtasks/latest/tasks_v2/types.html#google.cloud.tasks_v2.types.Queue) and you are correct you can't specify retries on per task.
Status: Issue closed
|
dKvale/aqi-watch | 205904578 | Title: 1-hr AQI at 122 for PM25
Question:
username_0: **AQI Watch** </br>2 monitors are reporting a 1-hr AQI above 90. A value of **122** for PM2.5 was reported at **LACROSSE DOT** (Wisconsin DNR). For more details visit the <a href=http://dkvale.github.io/aqi-watch> AQI Watch</a>. </br>_Feb 07, 2017 at 08:32 CDT_ </br> </br>Attention: @monikav21 @rrobers @Mr-Frank @Rstrass @krspalmer |
CDLUC3/mrt-dashboard | 616215623 | Title: Feature request: Provide file hashes in UI and/or RSS feed
Question:
username_0: Occasionally we find a batch of files sitting around that were supposed to have gone to Merritt, while on Merritt we find files with similar but not identical filenames. In order to determine whether the files are in fact the same, it would be handy to be able to get the hashes of the files in Merritt without having to download the files.
There are some tricks one can use to get it now, like following the presigned URL redirect chain till we get to the final S3 or MinIO link, sending a range request for zero bytes, and then getting a hash out of the ETag or the X-Amz-Meta-Sha256 header. But especially for large files, it would be handy just to be able to get the hash stored in the Merritt inventory database.
Answers:
username_1: Hi @username_0 – thanks for filing this. I'm going to "move" it over to mrt-doc for prioritization (will close this issue and create a new one there).
username_1: https://github.com/CDLUC3/mrt-doc/issues/318
Status: Issue closed
|
littleflute/ffmpeg | 862505640 | Title: ffmpeg mix audio at specific time
Question:
username_0: https://stackoverflow.com/questions/32949824/ffmpeg-mix-audio-at-specific-time
Answers:
username_0: ffmpeg -i a1.mp3 -i a2.mp3 -filter_complex "aevalsrc=0:d= 10 [s1];[s1][1:a]concat=n=2:v=0:a=1[aout]" -c:v copy -map 0:v? -map [aout] a3.mp3
username_0: ffmpeg -i <output from silent and short clip> -i <original long clip> -filter_complex "amix=inputs=2:duration=longest:dropout_transition=0, volume=2" <output audio file>
username_0: ffmpeg -i <output from silent and short clip> -i <original long clip> -filter_complex "amix=inputs=2:duration=longest:dropout_transition=0, volume=2" <output audio file>
Status: Issue closed
|
autodeployai/ai-serving | 680279475 | Title: AI-Serving not supporting ONNX models with dynamic axes
Question:
username_0: Hello, I got AI Serving Server up and running:
- pulled autodeployai/ai-serving:0.9.0-cuda image,
- started server: `docker run --rm -it -v $(pwd):/opt/ai-serving -p 9090:9090 -p 9091:9091 IMAGE_ID`
- tried out mnist example (AIServingMnistOnnxModel.ipynb notebook) and it works.
However, when I load my custom model with dynamic axes (batch axis, or some other) I get Response 500 (Internal Server Error). My models are pytorch models converted to .onnx with torch.onnx.export function.
I also got this error in terminal:

(here batch size axis is static, seconda axis is dynamic)
Does this mean that AI-Serving is not supporting dynamic axes, and when will this feature be available?
Thank you.
Answers:
username_0: I used PyTorch function [torch.onnx.export](https://pytorch.org/docs/stable/_modules/torch/onnx.html#export) for converting pytorch model into .onnx format. One of the parameters is `dynamic_axes` which enables .onnx model to have dynamic axes. I used `dynamic_axes={0:"batch"}` to set the batch size dynamic.
Locally (with onnruntime-gpu) I can run inference on the model with various batch sizes and it works. However when I deploy the model on AI-Serving server and send request messages I get this error in terminal:
(Using ai-serving:0.9.1-cuda docker image.)
<img width="965" alt="slika" src="https://user-images.githubusercontent.com/41293217/90765050-95667a80-e2e9-11ea-9f04-a57570b3ffba.png"> |
jamesdaniels/onSnapshot | 306951613 | Title: Broken link
Question:
username_0: I'm trying to access the link: https://onsnapshot.com/ but it shows **504 Gateway Time-out**. Any ideas of what is happening?

Status: Issue closed
Answers:
username_1: Seems like you found it, but just adding incase anyone else runs into this. Having a problem with the Cloud Functions deployment, I have it up on Flex here though http://onsnapshot-flex.appspot.com/ |
NIEM/NIEM-Releases | 592988219 | Title: Review metadata-related components
Question:
username_0: Review metadata-related components for consistency and good naming practices.
### nc:MetadataType
A data type for information that further qualifies primary data; data about data.
1. Use "Data" as the class term?
2. Sort elements alphabetically?
- nc:CaveatText
- nc:AdministrativeID
- nc:DistributionText
- nc:EffectiveDate
- nc:ExpirationDate
- nc:LastUpdatedDate
- nc:LastVerifiedDate
- nc:ProbabilityPercent
- nc:QualityComment
- nc:ConfidencePercent
- nc:ReportedDate
- nc:ReportingOrganizationText
- nc:ReportingPersonRoleText
- nc:ReportingPersonText
- nc:SensitivityText
- nc:CreatorName
- nc:DescriptionText
- nc:SourceIDText
- nc:SourceContactPersonText
- nc:PublisherName
- nc:ReleaseDate
- nc:RepositoryID
- nc:SourceText
- nc:LanguageAbstract
- nc:Comment
### cbrn:TotalDoseMetadataType
A data type for metadata about TotalDose data.
- cbrn:RadRawTotalDoseValue
- cbrn:RadDetectorInformation
### cbrn:TotalExposureMetadataType
A data type for metadata about TotalExposure data.
- cbrn:RadDetectorInformation
- cbrn:RadRawTotalExposureValue
### hs:MetadataType
A data type for metadata about a record.
- hs:CreationDate
- hs:LastUpdatedTrackingID
- hs:ProtectedHealthInformationIndicator
- hs:SubmissionDateTime
### j:JusticeMetadataType
A data type for information that further qualifies the kind of data represented.
- j:CriminalInformationIndicator
- j:IntelligenceInformationIndicator
*Remove "Justice" from the name?*
### scr:PersonMetadataType
A data type for metadata about the data associated with a person being screened.
- scr:ConfidenceLevel (scr:ConfidenceLevelType) - A classification of the reliability of the PERSON ALERT.
- scr:PersonConfidenceLevelPercent (niem-xs:decimal) - A Quantitative based on the number of encounters. Measured as an overall percentage.
Answers:
username_1: At ESDC, we had a couple pieces of Metadata that were not easy to implement using the MetadataType - sort:direction (used on requests payloads and response payloads) and a sort:order number to maintain order across model transformations. We implemented them using attributes on structures:SimpleObjectAttributeGroup by defining their namespace as "urn:us:gov:ic:ism". This allows schema validation of those attributes in a certain context (e.g. creating a unique constraint on that element within a specific element) which would not be possible using the MetadataType constructs. Simple attributes also allow XPath selection (filtering) and simple XSLT sorting.
In some cases (e.g. document management system) the MetadataType and structures:metadata approach works well (many pieces of unique metadata about one thing, e.g. document). In other cases, the processing required to use simple metadata about any element become onerous and inhibits simple implementation of filtering and sorting of the data.
Possible solution?
In niem/utility implement a new schema (metadata.xsd) for metadata attributes and allow simple attribute-only metadata to be added in the namespace say "http://release.niem.gov/niem/metadata/5.0/" with namespace prefix "metadata" and add that "metadata" namespace to namespace list in structures:SimpleObjectAttributeGroup. Note that cleanup of structures.xsd needed to use structures:SimpleObjectAttributeGroup in all type definitions - so that even Metadata can have Metadata.
Examples of some simple attributes could be a subset of the Metadata elements that can logically only occur once and would be useful for filtering and sorting:
- any data processing information describing how the data is presented (e.g. sortDirection, sortOrder)
- any dates related to currency of the information which could be used to filter the data (e.g. createdDate,lastUpdatedDate,...)
- any security or sensitivity information that could be used to redact (filter) the data - like the IC Trusted Data Format already enabled by the urn:us:gov:ic:ism and urn:us:gov:ic:ntk namespaces.
Schema developers could add their own extension(s) with the metadata namespace to add additional attributes between NIEM major versions.
username_2: The NTAC is reworking MetadataType as part of it's 5.0 metamodeling work. Anything beyond re-aligning names should probably be kicked over the wall to NTAC.
username_2: Don, could you provide NTAC with an example?
username_1: [metadata.zip](https://github.com/NIEM/NIEM-Releases/files/4445873/metadata.zip)
Here is an example of change to structures.xsd, new metadata.xsd and an nc:Document with four nc:DocumentContentListText that have metadata attributes (as allowed by metadata.xsd) that can be easily used to filter content. Same as currently an attribute from IC Trusted Data Format schemas (IC-ISM.xsd or IC-NTK.xsd) can be used to filter elements for example to redact elements where ism:classification="TS" (redact elements that are Top Secret).
username_1: Brian,
Attached is an example of change to structures.xsd, new metadata.xsd and an example nc:Document with four nc:DocumentContentListText that have metadata attributes (as allowed by metadata.xsd) that can be easily used to filter content. Same as currently an attribute from IC Trusted Data Format schemas (IC-ISM.xsd or IC-NTK.xsd) can be used to filter elements for example to redact elements where ism:classification="TS" (redact elements that are Top Secret).
Don
username_3: The example that was provided was a proposed revision to NIEM, rather than an example of what NIEM can't do. The NTAC discussed the topics in this issue.
- the NTAC does not embrace a method that involves overriding contents of a namespace, such as the “metadata” namespace that @username_1 proposed..
- This use case can be handled by either (1) adding desired attributes to the appropriate types as extensions, or (2) adding content as elements as augmentations, or (3) using the existing `structures:metadata` method for adding content
- The NTAC does not want to introduce more wildcards into the NIEM release without very concrete, specific requirements. The ISM requirements that introduced the `xs:anyAttribute` in structures was to achieve a very specific requirement.
username_0: The Harmonization Workgroup recommends using class term "Metadata".
Status: Issue closed
|
giantswarm/aws-operator | 217268860 | Title: aws-operator fails during processing the existing master node
Question:
username_0: When aws-operator processes the existing cluster, the following error occurs:
```
{"caller":"github.com/giantswarm/aws-operator/service/create/service.go:289","error":"master nodes had invalid instance IDs","time":"17-03-27 13:26:28.827"}
```
This started to happen after introducing the elastic IP functionality.<issue_closed>
Status: Issue closed |
marcellinodour/MIDO-SVG | 630710490 | Title: Récupération des formations
Question:
username_0: Bonjour,
L'équipe BDD est parvenue à récupérer les formations du département MIDO en utilisant leurs clés d'identification mais cette solution ne nous parait pas viable. Il serait préférable de récupérer automatiquement toutes les formations en fonction du département souhaité.
Cependant, l'utilisation de méthodes de recherche telles que "contain" ne permet pas de répondre à ce besoin car les formations d'un même département n'ont pas de clé commune.
Avez-vous un avis ou des conseils à nous donner sur ce sujet ?
l'équipe SMPO
Answers:
username_1: N’y a-t-il pas de lien d’une formation vers son département ? Indiquez SVP ici un lien vers votre documentation de la base ROF. |
pytorch/pytorch | 680136557 | Title: Error with division in a Categorical distribution
Question:
username_0: ## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Hi. You have added a ban on using division on LongTensor, but in this case normalization in the categorical distribution does not work
Steps to reproduce the behavior:
```
a = torch.randint(10,size=(5,6))
torch.distributions.categorical.Categorical(probs=torch.ones_like(a))
```
return error
```
Traceback (most recent call last):
File "<input>", line 1, in <module>
File "/home/username_0/PythonVenv/lib/python3.7/site-packages/torch/distributions/categorical.py", line 50, in __init__
self.probs = probs / probs.sum(-1, keepdim=True)
RuntimeError: Integer division of tensors using div or / is no longer supported, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead.
```
Answers:
username_1: Hmm, I think we should disallow `LongTensor` inputs to probs.
username_0: @username_1 Why? I used most of the distributions, and after the update, the only problem was with this distribution.
username_0: LongTensor makes it possible to use torch in genetic algorithms for discrete optimization problems. Please do not need to remove the support LongTensor. I also plan to offer a PR with the GentTorch module, which will implement the ability to use torch for discrete optimization tasks.
username_1: @username_0 don't worry, even if we were to disallow `LongTensor` probs, you cold easily cast manually
```diff
- Categorical(probs=my_long_tensor) # error
+ Categorical(probs=my_long_tensor.float()) # ok
```
My concern is that `Categorical` did not originally allow `LongTensor` because PyTorch did not allow implicit casting. Then I assume support for casting temporarily allowed `LongTensor` inputs to `Categorical`; this was not intended. Now that unsafe division again raises an error. I think that error is real and that we should raise it even earlier in distribution arg validation (namely in [constraints.real.check()](https://github.com/pytorch/pytorch/blob/d5bc2a8058c79d3a2d5fc9c9a186a78de3342d70/torch/distributions/constraints.py#L158)).
@username_4 @fehiepsi do you have an opinion on whether `constraints.real` should allow integer tensors? How do you do this in JAX? Conversely we do allow float storage for `constraints.nonnegative_integer` as in e.g. Poisson, which makes sense for computational reasons (see discussion in #31779).
username_2: cc @username_3. If indeed it makes sense to have Long probs tensor, the test for this behavior should be added.
username_3: And note that division behavior is about to change again to always perform true division, like Python3 does, so this would start "working" again but compute its results differently.
username_4: I think handling this in `constraints.real`, i.e. disallowing integer arguments sounds reasonable. Right now, we are not doing this though, but we raise an error in `jax.random.bernoulli` when we call `sample` and the `probs` attribute doesn't have a float dtype. I think failing earlier, as you suggest, would be better.
@username_0's: IIUC, your concerns were around the additional overhead that casting would take when it is avoidable. Have you done any benchmarking to see what the actual overhead of using `probs.float()` is (from @username_1's snippet above) for your GA application?
username_0: @username_4 I'm not sure if I'm taking the correct speed measurement
```
import torch
import time
population_size = 1000
max_score = 1000
device = torch.device("cuda:0")
start = time.time()
for _ in range(10000):
a = torch.randint(max_score, size=(100 * population_size,),
device=device) # selection,mutation create x100 instance.
cat = torch.distributions.categorical.Categorical(probs=a.float())
print(time.time() - start)
start = time.time()
for _ in range(10000):
a = torch.randint(max_score, size=(100 * population_size,),
device=device) # selection,mutation create x100 instance.
cat = torch.distributions.categorical.Categorical(probs=a)
print(time.time() - start)
```
output:
```
2.0080626010894775
0.4780709743499756
```
It is worth noting that in this case I use true_divide in the categorical distribution,since without this, the error started to come out, which is in the iisue header
username_1: can you add timings for
```
...
a = torch.randint(..., dtype=float)
...
```
username_2: Please use `Timer` form `torch.utils._benchmark` , you are not synchronizing cuda calls correctly.
username_4: @username_0 - Could you use @username_2's advice to correctly time on the GPU? A slightly modified version of your snippet (which is effectively what is happening in `Categorical.__init__` shows that the timings on the CPU are unaffected:
```python
import torch
import time
population_size = 1000
max_score = 1000
start = time.time()
for _ in range(10000):
a = torch.randint(max_score, size=(100 * population_size,)) # selection,mutation create x100 instance.
probs = a.float()
probs = probs / probs.sum(-1, keepdim=True)
print(time.time() - start)
start = time.time()
for _ in range(10000):
a = torch.randint(max_score, size=(100 * population_size,)) # selection,mutation create x100 instance.
probs = a.true_divide(a.sum(-1, keepdim=True))
print(time.time() - start)
----------------------
10.444790840148926
10.281699895858765
```
username_0: I'm sorry, I really didn't compare the speed correctly. The fact is that in my code in the version with the conversion to float, I made a mistake, which caused the speed to fall. after the correction, the speed of both algorithms was approximately the same (it felt like without measurements). The script measurement shows that the speed does not differ much.
```python
import torch
from torch.utils._benchmark import Timer
population_size = 10000
max_score = 10000
device = torch.device("cuda:0")
s1, s2 = [], []
def first():
for _ in range(1000):
a = torch.randint(max_score, size=(100 * population_size,)) # selection,mutation create x100 instance.
probs = a.float()
probs = probs / probs.sum(-1, keepdim=True)
s1.append(probs)
def second():
for _ in range(1000):
a = torch.randint(max_score, size=(100 * population_size,)) # selection,mutation create x100 instance.
probs = a.true_divide(a.sum(-1, keepdim=True))
s2.append(probs)
start = Timer('lambda: first()')
print(torch.__version__)
print(start.timeit())
start = Timer('lambda: second()')
print(start.timeit())
```
output
```
<torch.utils._benchmark.utils.common.Measurement object at 0x7faf5730aa10>
lambda: first()
47.77 ns
1 measurement, 1000000 runs , 1 thread
<torch.utils._benchmark.utils.common.Measurement object at 0x7faf645d1910>
lambda: second()
47.17 ns
1 measurement, 1000000 runs , 1 thread
```
once again, I apologize for what happened. I wonder why the conversion to float is so fast? This also requires memory allocation, and this should be noticeable on such large arrays.
username_2: Don't send `lambda`, it's measuring empty statement then, you slightly modified benchmark provides more reasonable results:
```
import torch
from torch.utils._benchmark import Timer
population_size = 10000
max_score = 10000
device = torch.device("cuda:0")
def first():
for _ in range(10):
s1=[]
a = torch.randint(max_score, size=(100 * population_size,)) # selection,mutation create x100 instance.
probs = a.float()
probs = probs / probs.sum(-1, keepdim=True)
s1.append(probs)
def second():
for _ in range(10):
s2=[]
a = torch.randint(max_score, size=(100 * population_size,)) # selection,mutation create x100 instance.
probs = a.true_divide(a.sum(-1, keepdim=True))
s2.append(probs)
start = Timer("first()", globals=globals())
print(start.timeit(10))
start = Timer("second()", globals=globals())
print(start.timeit(10))
```
```
<torch.utils._benchmark.utils.common.Measurement object at 0x7f9363bfded0>
first()
136.24 ms
1 measurement, 10 runs , 1 thread
<torch.utils._benchmark.utils.common.Measurement object at 0x7f9363691450>
second()
134.64 ms
1 measurement, 10 runs , 1 thread
```
username_0: @username_1 @username_4 @username_2 @username_3 thank you very much for helping solve this problem.
username_2: Before we close this issue, @username_1, @username_4 do you think we should disallow integer probs? https://github.com/pytorch/pytorch/pull/43139#issuecomment-675774946 or explicitly cast integer probs to float? I'd vote for disallowing. Can someone submit a PR then?
username_1: @username_2 I do agree we should disallow integer probs and more generally integer inputs to many real parameters. I'll try to submit a PR this week.
Status: Issue closed
|
rust-lang/cargo | 122789547 | Title: Pre-release version numbers
Question:
username_0: Should Cargo do something special when a dependency has versions published with pre-release version numbers? Maybe not select them unless requested explicitly with `cargo update --precise`?
CC https://github.com/username_1/rust-xdg/pull/9, @username_1, @username_3
Answers:
username_2: Yes, Cargo should follow SemVer here.
I think that this might be the fault of the `semver` crate itself...
username_0: Ok, sorting should be fixed, but that’s separate from the original issue.
username_1: Well, given that `*` is not a valid dependency spec now, what is left in this issue?
username_0: Let me rephrase. Let’s say a package has three versions published: 1.0.0, 1.0.1, and 1.1.0-beta. If I depend on it with version requirement `1.0.0`, Cargo will currently pick 1.1.0-beta since it’s the latest. But maybe "pre-release" should signal a version that is published for opt-in testing, but is not ready for general use? In that case, Cargo should default to ignore any pre-release version and pick 1.0.1 instead, unless explicitly requested.
Or, more generally, should we assign meaning (and tool behavior) other than the relative ordering to "pre-release"?
username_1: That is exactly what I am speaking about in https://github.com/rust-lang/cargo/issues/2222#issuecomment-165532916
username_0: Should Cargo consider 1.1.0-beta incompatible with 1.0.0 in the same way that 2.0.0 is incompatible with 1.0.0? (Whereas 1.1.0 *is* compatible with 1.0.0.)
username_1: As far as I'm aware, Cargo's notion of "compatible with x.y" is just `>=x.y <x.(y+1)`, "compatible with x.y.z" is `>=x.y.z <x.y.(z+1)`, and so on for any amount of parts, which is why precedence counts. The part of paragraph 9 you're talking about is illustrative and follows from the precedence rules.
username_1: I.e. since "compatible with 1.0" is `>=1.0 <1.1` and `1.1.0-beta < 1.0`, `1.1.0-beta` will not be considered "compatible with 1.0".
username_0: No. It’s `>=1.0 <2.0`
username_0: Or rather something like `>=1.0 <=1.9999.9999` with an infinity of nines, given how pre-releases sorts.
username_1: Er, sorry, yes, you are correct (4AM here...). But my point still stands.
username_3: I agree with @username_0 that it seems odd if I say "semver compatible with 1.0.0" that I'll start picking up `1.1.0-beta.1` or whatever new prelease becomes available. I think that Cargo may want to specially treat prerelease versions from that form of compatibility, but I think I've also seen some behavior like this in bundler in the past (@username_4 perhaps you could clarify?)
I agree that there also may be an issue with the semver crate which needs to be handled as well, especially if we consider `1.0.0-beta` to satisfy a requirement for `1.0.0`
username_4: Two things that I think are somewhat uncontroversial:
* `1.3.0-beta` does not supersede `1.2.0`
* `1.3.0-beta-2` supersedes `1.3.0-beta-1`
I'd like to suggest canonizing the concept of channels, so that:
* `1.3.0-beta-1` supersedes `1.2.0-beta-6`
* `1.4.0-alpha-1` does not supersede `1.3.0-beta-6`
The idea is to make the Rust-style release cycle more first class and give people a way, through their Cargo.toml, of subscribing to a particular "release channel".
We could also make subscription explicit through additional metadata:
```toml
[dependencies.nix]
version = "1.3.0"
channel = "beta"
```
This would always select the latest betathat also matches the semver versioning (`1.5.0-beta-X` would match, but `2.0.0-beta-X` would not).
username_0: Would there be a list of allowed keywords? semver.org allows arbitrary identifiers for pre-release versions.
username_4: Arbitrary identifiers for channels would be allowed, but you could only upgrade across versions on the same "channel".
In practice, it is probably good to stick to a few well-known names like "nightly", "alpha", "beta", "rc", but they would not be interpreted as having any relation to each other across versions.
Just like in Rust, if you subscribe to the "beta" channel, you stick to beta.
username_3: One thing we'd need to figure out is what to do when we see a request like:
```toml
foo = "1.0.2-beta2"
```
That's valid by today's rules, but should that *only* match the package `1.0.2-beta2`? Or perhaps `1.0.2-foo` would auto-subscribe you to the channel `foo`?
username_5: I'm not seeing the behavior that's being talked about in the beginning of the post. In particular, cargo seems to not select prerelease versions at all? I don't see any code changes linked here that suggest the behavior has changed though.
It seems people in here want cargo to not automatically update to *higher* prerelease versions, e.g. if the spec is "^0.3.19", it wouldn't update to "0.3.20-alpha". I understand that sentiment, but I think cargo should allow manually updating to that version in this case by using `--precise`.
username_2: In general, it shouldn't select prerelease versions unless you explicitly ask for prerelease versions.
username_6: Sorry to jump in out of the blue but I've got a quick question: If a package has no stable releases yet, what is the SemVer requirement I should use now to get the latest pre-release?
Currently if I use wildcard, `cargo` will tell me that there are no matching packages. This problem was originally found in kbknapp/cargo-outdated#75.
username_7: Another comment on the same topic is, is it expected that `cargo install crate` installs the pre-release version of `crate`? I would have expected opt-in testing for this too.
username_8: What's the status here? Can I safely release a `0.7-alpha` of my crate?
username_9: Just a note that anyone considering multiple pre-release versions should read the precedence rules closely (https://semver.org/), while this example is true it’s also the case that `1.3.0-beta-2` supersedes `1.3.0-beta-11`. If you want multiple beta releases you should use separate pre-release identifiers like `1.3.0-beta.2`. (Similarly if “channels” happen I would hope they’re based on something like literally matching the first pre-release identifier rather than require parsing a concatenated channel+release-in-channel-number from the identifier).
username_10: I have a dependency `rust-htslib = { version = "0.26" }`. I'd like to locally test the head of the `master` branch of this repository, version `0.26.2-alpha.0` whose SHA-1 is `0ba0f088e5b5adf032d8d206e23fec509df03a56`. This version is in GitHub, but it's not on crates.io. I've used a `[patch]` block:
```toml
[patch.crates-io]
rust-htslib = { git = "https://github.com/rust-bio/rust-htslib.git", rev = "0ba0f088e5b5adf032d8d206e23fec509df03a56"
```
I've tried the following three `cargo update` commands.
```console
$ cargo update -p rust-htslib
Updating crates.io index
warning: Patch `rust-htslib v0.26.2-alpha.0 (https://github.com/rust-bio/rust-htslib.git?rev=0ba0f088e5b5adf032d8d206e23fec509df03a56#0ba0f088)` was not used in the crate graph.
Check that the patched package version and available features are compatible
with the dependency requirements. If the patch has a different version from
what is locked in the Cargo.lock file, run `cargo update` to use the new
version. This may also occur with an optional dependency that is not enabled.
```
```console
$ cargo update -p rust-htslib --precise=0.26.2-alpha.0
Updating crates.io index
error: no matching package named `rust-htslib` found
location searched: registry `https://github.com/rust-lang/crates.io-index`
required by package `orbit v0.1.0 (/Users/shaun.jackman/work/orbit)
````
```console
$ cargo update -p rust-htslib --precise=0ba0f088e5b5adf032d8d206e23fec509df03a56
Updating crates.io index
error: no matching package named `rust-htslib` found
location searched: registry `https://github.com/rust-lang/crates.io-index`
required by package `orbit v0.1.0 (/Users/shaun.jackman/work/orbit)`
```
I'm working on a crate that depends on `rust-htslib = { version = "0.26" }` and `orbit`, and `orbit` itself also depends on `rust-htslib = { version = "0.26" }`.
How do I locally test a prerelease version of a dependency?
username_11: FWIW, a variant of this recently bit me as well: a deeply transitive dependency of a project of mine got bumped from an `rc` to the next semver-compatible stable version, causing build breakage.
Apart from whether or not this is correct from semver's perspective: it might make sense to have a check on `cargo build` and/or `cargo publish` that spits out warnings about unpinned `rc` (or other pre-tag) dependencies. That at least would nudge people in the right direction :slightly_smiling_face:
username_12: So cargo should not "update" from `v0.2.0-beta.1` to `v0.2.0`.
username_13: if 0.2.0-beta is less than 0.2.0, can't it update?
username_12: @username_13 It's less but not semver compatible.
username_14: I just ran into this: I had `rustbreak` in `2.0.0-rc3` in my Cargo.toml and updated it to `2.0.0`. A subsequent `cargo check` did not pick up this change, I had to run `cargo update` for it to pick up the change. I would expect otherwise, as this seems not to be semver compatible...
username_9: Updating crates.io index
rustbreak v2.0.0
└── foo v0.1.0 (/tmp/tmp.6sQUs3MEK6/foo)
```
username_14: Well, okay. Maybe messed up somehow in the heat of the moment. Never mind! :laughing:
username_15: I had a problem recently with a published binary (see #9999). I published cargo-temp v0.2.3 using clap `3.0.0-beta.2`, Today i was trying to install it via `cargo install` but it was not possible because i was trying to compile clap with `3.0.0-beta.5`, with some breaking change compared to the beta.2.
I use a fixed version `=3.0.0-beta.5` to avoid this, but this pitfall can be really silent |
MessageKit/MessageKit | 449010107 | Title: Feature Request: Thread
Question:
username_0: **### Summary**
- Post any feature requests below
**### Contributors**
- Feel free to tackle any of the items listed on this list
Answers:
username_1: This library won't support a UI design for threaded conversations
Status: Issue closed
|
pingcap/tidb-tools | 214603930 | Title: make syncer idempotent
Question:
username_0: In some cases, syncer don't keep Idempotency:
- problem 1: if the table don't have primary (even if have unique key), the replay can't keep idempotency.
- problem 2: if we have multiple unique keys, replay can meet key already exist error.
Answers:
username_0: problem 1: check whether the table contains primary keys before syncing. If not, we can give up sync
or give some directions
problem 2: in the premise of ensuring a primary key,we can try to treat unique keys as normal index, but it's just an idea, there is still no specific way now
username_0: Now syncer's sql execution model is completely wrong, 😢
Status: Issue closed
|
shogun-toolbox/shogun | 28467570 | Title: Multiclass Laplace approximation for GPs
Question:
username_0: This task is to implement the multiclass version of the Laplace approximation for GPs. This is based on the soft-max likelihood from #1898 and will be used from the GP multiclass machines from #1900
Code for this can be found in the GPstuff toolbox, algorithm again the the GP book or the original barber paper, see #1900
The task requires to implement a few non-trivial algorithms. It would be best if the existing CLaplacianInferenceMethod class could be extended for this case.
Answers:
username_1: this PR is partially solved at https://github.com/shogun-toolbox/shogun/pull/2484
TODO: implicit gradient wrt hyper-parameter
username_2: Hi @username_0 and @username_1 , I would like to work on this and #1902 issue. But I haven't too much knowledge about GPs, so could I learn GPs from now and try to fix them by reading codes in Shogun and read relative documents? I do know some basic ideas about ML, so I think the whole process(learn and commit some workable code ) will spend one or two months? Is that ok? Thank you :)
username_0: Yes contributions are welcome here. Let us know if you need help. Reading existing codes, examples, and the gp book by Rasmussen is probably the best start
username_3: Is this issue still open? |
oconnor663/blake2_c.rs | 273066956 | Title: no_std by default
Question:
username_0: Proof of concept working in https://github.com/username_0/blake2_c.rs/tree/no_std. We should probably make implementing `std::io::Write` conditional on a `std` feature.
Answers:
username_0: https://rust-lang-nursery.github.io/api-guidelines/naming.html#feature-names-are-free-of-placeholder-words-c-feature
username_0: 2962cf3b5f9cdf077d2510ea5753a9a43da1e6fe and c9c8921b00ad2834a7df9ea147c3be3c9d41756c
Status: Issue closed
|
berrberr/streamkeys | 233892301 | Title: Tag releases
Question:
username_0: Can you `git tag` the versions you publish with their version number so that they show up on [the releases page?](https://github.com/username_1/streamkeys/releases) I currently have v1.6.7, but it is unclear what code it does or doesn't include.
Thank you!
Answers:
username_0: I found the commits. I don't quite have a script that does the tagging, yet. 😉
```sh
git log --oneline --grep='Bump to ' |
sed 's/^\([0-9a-f]*\) .* \([0-9]*\.[0-9]*\.[0-9]*\).*/\1 v\2/'
```
username_1: Yes good idea! I will do this going forwards |
InventivetalentDev/HypixelAPI | 737929551 | Title: Calendar respond with 404
Question:
username_0: Same issue as #10
According to the logs, the issue was first seen on the 3rd of October

Answers:
username_0: Bump 😅
Status: Issue closed
username_0: It's working again now. Thank you 😄 |
kembolanh/kembo | 399270702 | Title: Bí quyết ứng phó với bệnh nhồi máu cơ tim hiệu quả
Question:
username_0: Bệnh nhồi máu cơ tim xảy ra khi một trong hai động mạch vành hoặc phân nhánh của nó bị tắc nghẽn một cách đột ngột khiến một phần của cơ tim không được cung cấp đầy đủ oxy. Cơn đau tim thường xảy ra trong vài tiếng, nhưng nếu tình trạng này kéo dài và không được điều trị kịp thời thì phần cơ tim bị thiếu oxy sẽ bị chết.
https://imedicare.vn/bi-quyet-ung-pho-voi-benh-nhoi-mau-co-tim-hieu-qua/
• Tai biến mạch máu não
• Người bệnh suy tim có tập thể dục hay không |
Computational-Content-Analysis-2020/Readings-Responses | 567343964 | Title: Deep Classification, Embedding & Text Generation - Radford et al 2019
Question:
username_0: Radford, Alec, <NAME>, <NAME>, <NAME>, <NAME>, and <NAME>. 2019. [“Language models are unsupervised multitask learners.”](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) OpenAI Blog 1(8).
Answers:
username_1: This week's reading is pretty technical. I tried my best to get an idea of what is going on. They developed a multi-tasking language model GPT-2 which could be performed on 7 out of 8 language modeling test datasets.
What surprises me is the low accuracy of the result. As they admitted in the paper, it is "still far from usable". I am wondering whether the low performance is caused by the sacrifice for multi-tasking, or the NLP algorithms themselves are still overall underdeveloped.
username_2: This paper also felt quite technical for me. I was fascinated with the GPT-2s ability to answer new questions based on a transcript of conversational questions and answers (COQA). Could you explain the mechanics (generally) for how the model is able to achieve this?
username_3: It is important to have a model that can generalize to various texts from a different domain. However, I believe it entails tradeoff because it can be harder to train the machine when there is a large variation in the data. I was curious about how multitask learning can overcome this issue or whether it is an issue at all. |
swagger-api/swagger-ui | 14270357 | Title: Swagger doesn't work on IE 9
Question:
username_0: I can't do the Swagger work on IE 9. FF and Chrome work fine. But when I enable the IE debugger and refresh my swagger html, it works fine too.
Have anyone ever had the same problem?
Answers:
username_1: I came across this today. Can you review the log function, make sure it's working. If I add the below in the index.html it doesn't load.
```
} else {
url = "http://petstore.swagger.io/v2/swagger.json";
}
+ log(url);
window.swaggerUi = new SwaggerUi({
url: url,
dom_id: "swagger-ui-container",
```
username_2: @username_1 please open a new issue |
junhg0211/SloOS | 374595337 | Title: 오랫동안 창 움직일 때 에러 발생함
Question:
username_0: ```python
Traceback (most recent call last):
File ".\Main.pyw", line 662, in <module>
obj.tick()
File ".\Main.pyw", line 448, in tick
self.dock_y += (self.dock_y_target - self.dock_y) / (root.display.display_fps / slo.slo['appearance']['motion_speed'])
ZeroDivisionError: float division by zero
```
오랫동안 창 움직이고 있다가 놓으면 FPS 0 돼서 `ZeroDivisionError` 뜸.
Answers:
username_0: tick-render 부분에 프레임 0일 때 작동 안 하는 if문 걸어서 해결했습니당
Status: Issue closed
|
sinnerschrader/schlump | 191444866 | Title: Scoped CSS: Support attribute selectors
Question:
username_0: Attribute selectors are the most complicated, therefore we moved them into its own issue.
- [ ] existence `[attr]`
- [ ] exact value `[attr=value]`
- [ ] whitespaced list exact value `[attr~=value]`
- [ ] start with and dash `[attr|=value]`
- [ ] prefix `[attr^=value]`
- [ ] suffix `[attr$=value]`
- [ ] contains `[attr*=value]`
- [ ] case insensitive extension `[attr operator value i]`<issue_closed>
Status: Issue closed |
pythonnet/pythonnet | 235206603 | Title: Invalid method binding with specified .NET parameters
Question:
username_0: ### Environment
- Pythonnet version: 2.3.0.0
- Python version: 3.5.3
- Operating System: Windows 10.
### Details
- Call to .NET method fails with passed arguments (Double.NegativeInfinity, Double.PositiveInfinity, Single.NegativeInfinity, Single.PositiveInfinity).
There is an example, how you can reproduce this bug.
C# code
```csharp
namespace Bugs
{
public class InvalidMethodBinding
{
public static void WriteDouble(System.Double value)
{
System.Console.WriteLine(value);
}
}
}
```
Python code:
```python
import clr
clr.AddReference('PathToDll')
from System import Double
from Bugs import *
InvalidMethodBinding.WriteDouble(0.01)
InvalidMethodBinding.WriteDouble(Double.NegativeInfinity)
```
- Traceback:
```python
Traceback (most recent call last):
0.01
File "X", line Y, in <module>
Program.WriteDouble(Double.NegativeInfinity)
TypeError: No method matches given arguments
```
Answers:
username_1: related: https://github.com/pythonnet/pythonnet/issues/100
Status: Issue closed
|
aem-design/aemdesign-aem-support | 806700361 | Title: Add command line param to limit test execution to specific viewport
Question:
username_0: ## Feature Request
Would be nice to have a parameter you can specify that would only run tests for specific viewport size.
`-TEST_VIEWPORTS` XLG,SM`
This option will run test for Mobile (SM) and Desktop (XLG) sizes. This should make tests run faster.
Answers:
username_0: done, you can run following to achieve this:
`.\test-spec -TEST_SPECS PageListPub* -AEM_PORT 4512 -TEST_VIEWPORTS "XLG"`
Status: Issue closed
|
OfficeDev/office-js-docs-pr | 1157440985 | Title: Outlook Add-in Compose - Dynamic Control Button Text Updating
Question:
username_0: <!---
Welcome to the Office Add-ins documentation repository.
To report an issue with the Office-Add-ins documentation, please provide the article URL and describe the issue below. Alternatively, if you want to submit a pull request with your recommended documentation changes, we will review your contributions and update our documentation accordingly.
If your issue is not related to the Office Add-ins documentation, please post it to one of the following channels instead.
- To ask a question about using the Office.js API, post your question to Stack Overflow and tag it with the "office-js" tag (http://stackoverflow.com/questions/tagged/office-js).
- To report an issue with the Office.js API or platform, create the issue in the OfficeDev/office-js repository (https://github.com/OfficeDev/office-js), which members of the product team monitor for customer-reported issues.
- To submit a feature request for the Office.js API or platform, post your idea to the Microsoft 365 Developer Platform Tech Community(https://techcommunity.microsoft.com/t5/microsoft-365-developer-platform/idb-p/Microsoft365DeveloperPlatform), or if the feature request already exists there, add your vote for it.
-->
<!--- Provide a general summary of the documentation issue in the Title above -->
## Article URL
<!-- Provide the URL of the article that this documentation issue relates to -->
N/A
## Issue
<!-- Provide a thorough description of the documentation issue -->
I developed an add-in built with yo generator (Node.js) that works as a configurator which enables the outlook compose to enable/disable sending a copy of the new email to a custom url on-send.
There's a control button added that says 'Toggle Send to cCRM' but I would prefer a toggle text dynamically from 'Enable send to cCRM' to 'Disable send to cCRM' and vice-versa when clicking the control button to improve UI experience. Is it possible to accomplish?
Answers:
username_0: Thanks you for your quick response @AlexJerabek
Status: Issue closed
username_1: @username_0 We use this repo to track problems with the documentation. Programming questions like this are best asked on [Stack Overflow](https://stackoverflow.com/). In your case, you want to toggle the button label whenever the button is pushed. This is a common web application scenario, so it has no particular connection with Office Add-ins. The standard way to do this is to have the handler for the button click event change the button label. The best way to do this would depend on whether you are using vanilla JavaScript or a framework like React or jQuery.
I will close this issue for now, but you can still add comments to it, and you can request that it be reopened. |
lethuyduong2000/Data_science-Project | 993792850 | Title: Review Project
Question:
username_0: 
Ở dòng trong hình nếu được nhóm bạn có thể show 2 dòng đó vì đôi khi các giá trị thiếu của các cột có thể nằm trên các dòng khác nhau
Theo mình đọc thì nhóm bạn drop 2 dòng có giá trị thiếu, 14 dòng lặp và 23 dòng có id trùng vậy dữ liệu sau khi xử lý phải là 20021-2-14-23 = 19982 thay vì 19993 không. Mình không chắc mình hiểu đúng không hay giữa 14 dòng lặp có 23 dòng trùng id có chung dòng với nhau. Nên nhóm bạn có thể viết markdown giải thích rõ hơn thì tốt quá.

Mình thấy sau khi chạy mô hình thì điểm của r2 khá thấp thì nên có thêm nhận xét sẽ giúp bài của bạn nhóm tốt hơn
Mình thấy cách các bạn lấy data từ tiki khá hay và đề tài rất thú vị.
Cảm ơn các bạn đã đọc ý kiến của mình. 😄
Answers:
username_1: Cảm ơn bạn đã góp ý cho nhóm.
Đúng là các dòng trùng ID và các dòng trùng nhau có bị trùng, mình sẽ bổ sung markdown giải thích.
R2 score thấp thật, mình có thử LinearRegression, RandomForestRegressor mà kết quả không tốt hơn MLPRegressor |
hodea/hodea-review-minder | 305063825 | Title: Change "author" to "reporter"
Question:
username_0: @R0cketMan82 can we please change **author** to **reporter**?
Rational:
With autor it is slightly unclear if it means the author of the review issue, or the author of the code under review.
With reporter it should be clear that it is the name or names of the guy(s) which is/are reporting a review finding.
Status: Issue closed
Answers:
username_0: @R0cketMan82: done |
trias-project/wrims-checklist | 463091665 | Title: Duplicate distribution
Question:
username_0: `taxonKey`: 157128772
Distributions: http://api.gbif.org/v1/species/157128772/distributions
The following distribution is present twice:
```
{
"taxonKey": 157128772,
"locationId": "http://marineregions.org/mrgid/5481",
"locality": "<NAME>",
"country": "BE",
"status": "PRESENT",
"temporal": "2005",
"establishmentMeans": "INTRODUCED"
}
```
Answers:
username_1: Thanks for reporting this.
This is a bug in the WRiMS export, which has been fixed now.
As soon as GBIF re-indexes, this should OK |
swoole/swoole-src | 677352660 | Title: WARNING swPipeUnsock_create(:83): socketpair() failed, Error: Too many open files[24]
Question:
username_0: Please answer these questions before submitting your issue. Thanks!
1. What did you do? If possible, provide a simple script for reproducing the error.
I'm downloading many small files from the Internet using file_get_contents, then writing using file_put_contents. I have these inside a swoole process function. At around the 500 file mark, I get this error:
`WARNING swPipeUnsock_create(:83): socketpair() failed, Error: Too many open files[24]`
Example script:
`
$data = array(<URLs of over 500 files>);
foreach($data as $abc) {
$processes[ $abc ] = new \Swoole\Process(function () use ($abc) {
$bca = file_get_contents($abc);
file_put_contents("dir/path/to/new/file.abc",$bca);
}
$processes[ $data ]->start();
}
`
Do
2. What did you expect to see?
No error
3. What did you see instead?
`WARNING swPipeUnsock_create(:83): socketpair() failed, Error: Too many open files[24]`
4. What version of Swoole are you using (show your `php --ri swoole`)?
Latest
5. What is your machine environment used (show your `uname -a` & `php -v` & `gcc -v`) ?
Debian 10 Buster
Answers:
username_1: @username_0
You need to adjust the maximum number of handles, (`ulimit -n 100000`) or set the third parameter to `0` to close the process pipe.
```php
new Swoole\Process($fn, false, 0);
```
Status: Issue closed
username_0: Thanks. Just curious, why would anyone want to leave the process pipe open?
username_2: @username_0
1. Pipes are used to communicate between processes. If processes need to communicate with each other, then you need to keep the pipes.
2. Closing the pipes won't kill the process, just like opening a file and then closing the file. In fact, you can also use files for interprocess communication.
3. A Channel can be accessed between two processes, for example:
```php
<?php
use Swoole\Coroutine;
use Swoole\Coroutine\Channel;
use Swoole\Process;
$chan = new Channel();
$process = new Process(function () use (&$chan) {
Coroutine::create(function () use (&$chan) {
var_dump('process: ' . getmypid());
$chan->push('data');
});
});
Coroutine::create(function () use (&$chan) {
var_dump('process: ' . getmypid());
$data = $chan->pop();
var_dump($data);
});
$process->start();
$process->wait();
```
You can see the following output on my machine:
```bash
string(14) "process: 94399"
string(14) "process: 94400"
string(4) "data"
```
However, this approach relies on the operating system's write-time replication feature, where memory can be shared between multiple processes. However, there is no guarantee that all operating system versions will support this. It is recommended that a channel be used within a process's coroutine.
username_0: I see, okay, thank you for your help! |
jedori0228/SKFlatAnalyzer | 359244357 | Title: EGamma Cutbased seleciton updated in V2
Question:
username_0: https://twiki.cern.ch/twiki/bin/view/CMS/CutBasedElectronIdentificationRun2#Offline_selection_criteria_for_V
We should update the values https://github.com/username_0/SKFlatAnalyzer/blob/023ba1f08a410a163a7ed22a79b9c0e2eca09881/include/Electron.h#L400-L526
Answers:
username_0: Fixed in https://github.com/username_0/SKFlatAnalyzer/commit/1ecc8261e33401ce13f6c6ea6c2adea9703d4a1e
Status: Issue closed
|
nextauthjs/next-auth | 1091318387 | Title: Adapter for Mongoose or GraphQL with v4
Question:
username_0: ### Question 💬
Hi,
I love next-auth and I used v3 in multiple projects.
Recently I started a new one which will either use mongoose as ORM for MongoDB or GraphQL.
Unfortunately, there isn't an Adapter for either one and the mongoose adapter example (e.g. https://github.com/nextauthjs/next-auth/issues/1175) from v3 are not working anymore. I'm struggling to set up the model ( basically because Adapters.TypeORM.Models.User.model is not available anymore).
Is there any chance to have a mongoose or GraphQL adapter or can you point me to a good resource how use next-auth with either of them?
Thank you in advance,
Martin
### How to reproduce ☕️
n/a
### Contributing 🙌🏽
Yes, I am willing to help answer this question in a PR
Answers:
username_1: Hi, please take a look at https://github.com/nextauthjs/adapters/pull/355 regarding the Mongoose adapter question.
The adapter in that PR takes in MongoDB URI and establishes a connection. However, there are some limitations. The adapter uses a separate connection instead of the one you would use in your application to avoid conflict between models. That means your app will establish two connections to the database: one for the adapter (and its models), one for your application (and its models).
So, I'm not sure if it's even worth it to have a separate Mongoose adapter. Why? Because you can use MongoDB adapter. Simply establish the connection in `[...nextauth].js` like this and pass the connection to the MongoDB adapter:
```js
import NextAuth from "next-auth"
import { MongoDBAdapter } from "@next-auth/mongodb-adapter"
import { MongoClient } from "mongodb"
client = new MongoClient(process.env.MONGODB_URI);
clientPromise = client.connect();
export default NextAuth({
adapter: MongoDBAdapter(clientPromise),
...
})
```
Status: Issue closed
username_2: In addition to the above, we have exhaustive documentation/examples on how to create your own adapter (which is objectively much easier than it was with v3)
See our docs on Adapters:
https://next-auth.js.org/adapters/overview
https://next-auth.js.org/tutorials/creating-a-database-adapter
Or see our official adapters for implementation details and how to test your adapter to be conformant: https://github.com/nextauthjs/adapters/tree/main/packages
username_0: Thank you for pointing me into the right direction. ❤️
username_3: the official adapters exmaple is about mogodb, but how to do with mongoose?
username_1: I explained it above. You can use MongoDB adapter, even though you are using Mongoose in your project.
username_4: Can you pls show us how to do that @username_1
username_0: https://github.com/nextauthjs/next-auth/issues/3542#issuecomment-1003202402
username_1: @username_0 How many connections does your application establish to the DB when running this code on `localhost`, or simply put `npm run dev`?
username_0: Hey @username_1
I was just copying the relevant code to answer your question. For an in-depth view please read the original issue about a Mongoose adapter and MongoDB at https://github.com/nextauthjs/adapters/pull/355
Cheers,
Martin
username_0: Hi @username_1,
thank you for your interest.
I was using it but ultimately decided to store the session only in a JWT Token and add the relevant user-data to a custom collection leveaging th `signIn` callback. Using the [collections generated by next-auth](https://next-auth.js.org/adapters/models) was not necessary for my usecase.
Cheers
username_4: I think one can use a custom adapter to connect mongoose + mongodb with next-auth v4.
Can you recommend your example for me to use @username_1
username_4: Tbh with you, I'm still learning. If you can make you explanation here https://www.npmjs.com/package/@username_1/mongoose-adapter. more simpler, I will like to try it out. I checked the mongoose-adapter on npm too but it's having few download
username_4: Why is there no example for mongoose?
username_1: Give me a few minutes. I will prepare an example for you.
username_4: Thanks so much @username_1
username_1: @username_4 Take a look at https://github.com/username_1/next-auth-mongoose
There's pretty much everything you need as an explanation.
username_4: Thanks so much @username_1, I'm checking it out now
username_4: Thanks for creating this example @username_1. But mongoose-adapter is still a new npm package, and for security reason( company/client I work for in future), I would like to learn something everyone is using for now.
username_1: Of course it's new, because it's mine and I use it for my personal projects. I'm not telling you to use it. I'm saying, you can create your own adapter, until the PR for the Mongoose adapter gets merged. Or you can fork the adapter, so it isn't dependent on my _npm_ package.
But as I have already said, **you don't have to use the Mongoose adapter**. **You can use the MongoDB adapter**, as I have already wrote in the comments of the `[...nextauth].js` file and as already presented in the repository.
username_4: Okay great, I will check that out now |
AndrewKeig/express-validation | 749976113 | Title: Default configs can result submitted field values being logged
Question:
username_0: Example:
```
[1] error "Validation Failed" {
[1] "name": "ValidationError",
[1] "statusCode": 400,
[1] "error": "Bad Request",
[1] "details": {
[1] "body": [
[1] {
[1] "message": "\"users[0].passwordOrSecureField\" length must be 12 characters long",
[1] "path": [
[1] "users",
[1] 0,
[1] "passwordOrSecureField"
[1] ],
[1] "type": "string.length",
[1] "context": {
[1] "limit": 12,
[1] "value": "super-secret-value-should-not-be-in-logs",
[1] "label": "users[0].passwordOrSecureField",
[1] "key": "passwordOrSecureField"
[1] }
[1] }
[1] ]
[1] },
```
This is due to the nature of `Joi` including the `value` as part of the context about the error details.
https://github.com/AndrewKeig/express-validation/blob/b5da57abb1d7eefa36fa6c31808147f602fa6cef/lib/index.js#L20
I'm wondering if folks have thoughts about adding a config to `express-validation` to scrub `context.value` from error detail responses? This would be API compliant with the Joi `Context` interface since all of it's fields are optional. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.