
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
waruqi/tboox.github.io | 496790979 | Title: Uses xmake to build c++20 modules
Question:
username_0: https://tboox.org/2019/09/22/xmake-c++20-modules/
c++ modules have been officially included in the c++20 draft, and msvc and clang have been basically implemented on modules-ts Support, as c++20’s footsteps ... |
linode/linodego | 686930424 | Title: Consider refactoring WaitForEventFinished "seen" filter optimization
Question:
username_0: ### General:
When using the [Linode Terraform Provider](https://github.com/linode/terraform-provider-linode), I would intermittently get boot and disk errors while specifying an explicit disk configuration for my instance.
On the Terraform side, this manifests in errors like:
`Error booting Linode instance xxxxxxxx: [002] Get "https://api.linode.com/v4/account/events?page=1": context deadline exceeded`
`Error waiting for Linode instance xxxxxxxx disk: [002] Get "https://api.linode.com/v4/account/events?page=1": context deadline exceeded`
Digging through this code a bit I came across the comment added in [Pull Request #76](https://github.com/linode/linodego/pull/76/files#diff-18dc188a67872bccb91f231d01326eecR174)
```go
// With potentially 1000+ events coming back, we should filter on something
// Warning: This optimization has the potential to break if users are clearing
// events before we see them.
"seen": false,
```
While Terraform was running, I was actively working in the Linode Manager and clicking on the notification bell icon to follow along with the progress. After finding that comment in the code, I finally realized that reading the notification events what was causing the errors. If I run the Terraform without clicking on the notification bell icon, the instance will then be successfully created.
I am not sure what possible options there might be for refactoring the "seen" filter optimization, but I wanted to at least open an issue incase others run in to the same errors I was seeing.
### Expected Behavior:
The Linode Terraform Provider (linodego) can be used while also using the Linode Manager and viewing notification events (the bell icon).
### Actual Behavior:
Viewing notification events in the Linode Manager (the bell icon) can cause the Linode Terraform Provider (linodego) to error while waiting for events.
### Steps to Reproduce the Problem:
1. Start an API call that utilizes `WaitForEventFinished`
1. View notification events in the Linode Manager (the bell icon)
1. API call will timeout
### Environment Specifications
macOS: 0.14.6
Terraform: 0.13.0
Linode Terraform Provider: 1.12.4
Status: Issue closed
Answers:
username_1: Closing because the `seen` optimization has been removed in https://github.com/linode/linodego/pull/215.
username_0: Thank you! 🎉 |
mozilla/network-pulse | 199561357 | Title: Pulse v2 launch meta
Question:
username_0: Hi team. We are on the final stretch to launch our new build. We will need this ready for the network launch. Let's aim for Jan 31 to production, so we have time to QA and squash bugs. The work seems manageable, but there's risk from conflicting priorities.
Meta tasks below. Tried to order them logically. I'm on mobile. Can someone link relevant issues?
1. Finish tests
1. Prep and import data
1. Connect frontend to backend. How many dev days do we expect?
1. Build Form - design spec done, but there is error handling to wrangle. Expect this to take non-trivial time.
1. Add quality analytics
1. Favs - persist for users with auth. This feature shouldn't block launch. We can bump.
Anything missing from this list?
Later:
1. Revisit back button
Answers:
username_0: CC @kristinashu @mmmavis @pomax @username_1 =:-)
username_1: Edited original comment with links
username_0: @pomax – we all chatted on Friday. Anything on your plate missing from this list?
username_2: @username_0 I don't think so, I'm working with Alan on the testing and thinking out loud with him about the favouriting mechanism, and don't see anything missing from the above list.
username_0: Let's all peek at this meta ticket as we prep for work next week before people travel and shift to other projects. @kristinashu @mmmavis @username_2 @username_1
Any big revisions, concerns, new items we've identified as mvp work?
username_1: @username_0 We reviewed the milestone today with @simonwex, so those are up to date
Status: Issue closed
username_0: Closing this. Final tasks are filed and tracking just fine without this overhead. |
phenology/hsr-phenological-modelling | 242314326 | Title: Ingest MODIS data
Question:
username_0: MCD12Q2. Let's try pyMODIS. Bounding box CONUS
Other RS data (AVHRR, etc) with longer time series are in the making...
Answers:
username_0: Before I forget, we should mask out water, and other less relevant classes (snow, urban) before doing our SVD analysis. We will create this mask based on [MCD12Q1](https://lpdaac.usgs.gov/dataset_discovery/modis/modis_products_table/mcd12q1)
username_1: The data was loaded with success and documentation was added in how to load it.
https://github.com/phenology/hsr-phenological-modelling/tree/master/modis
Status: Issue closed
|
firecracker-microvm/firecracker | 386944358 | Title: Create a Tool to Check Prod Host Setup
Question:
username_0: Create a tool that automatically checks a Linux host for all the recommended [prod configuration](https://github.com/firecracker-microvm/firecracker/blob/master/docs/prod-host-setup.md).
Answers:
username_1: I'd be happy to tackle this. I imagine it would be best implemented as a script, similar to `devtool`?
username_2: Yes, ideally this would go in a separate script `prodtool` or a more inspired name. But please use a common scripting language to keep life simple 😄
Right now this script could handle two commands:
- _can I run Firecracker on this system?_ - should check that all prerequisites for running Firecracker are satisfied.
- _Is my system production worthy?_ - should check and report all the necessary steps needed on the host system to provie safety and efficiency when running Firecracker.
These commands can be added independently and we can also iterate.
So @username_1, if you can tackle any of them, we're all for it! 🎉
username_1: @username_2 Sounds good. I will just use bash to maintain consistency with devtool.
username_0: @username_1 we're wondering if you're still looking at this.
username_1: @username_0 My apologies — I was a bit busy with the holidays, but yes, I am still interested in working on this.
Status: Issue closed
username_3: Addressed by #1054 |
SVGKit/SVGKit | 945287762 | Title: SVGKitSwift SPM build issue (when archiving only)
Question:
username_0: I'm using Xcode 12.5.1 and SwiftUI
I'm able to use SVGKit just fine. the issue is when archiving
I tried using a fresh test project and always got this issue:
<img width="379" alt="Screenshot 2021-07-15 at 12 32 54" src="https://user-images.githubusercontent.com/77971847/125781583-bf18d49a-86bd-4594-aa6b-c831407f9679.png">
Could you please help me? thank you.
Answers:
username_2: I think there's a fundamental issue here, whereby having the SVGKitSwift dependency in the package seems to indicate to the compiler that it must be built. The only way I was able to get this to archive was to change the package spec to `.v13` - I'm also on 12.5.1
This obviously bumps the minimum version a lot higher, when it may not be necessary except for that one product (SVGKitSwift).
Some thoughts:
- Maybe this is just an issue in latest Xcode? I haven't tested it on others.
- Change SVGKitSwift to SVGKitSwiftUI to avoid confusion (the name tripped me up on import, though made more sense after looking at Package.swift and the sources)
- Perhaps move SVGKitSwiftUI to it's own Package to avoid issues with backward compatibility if `.v9` is necessary.
I'll file a PR for convenience. Though it's quick fix, I'm not sure if it's the most optimal solution, depending on what route @username_1 wants to take with this...
username_0: Thank you! @username_2
Status: Issue closed
username_3: I don't get it how to fix it ? , I have same issue with archiving only.
@[username_0](https://github.com/username_0) how did you solve it ? |
ContainerSolutions/minimesos | 118555024 | Title: exception is handled wrongly
Question:
username_0: Please, handle exception in `MesosClusterTest` correctly. This should either brake the test (seems to be the case here) or ignored with explanation in comments.
```java
@Test
public void dockerExposeResourcesPorts() {
DockerClient docker = CONFIG.dockerClient;
List<MesosSlave> containers = Arrays.asList(CLUSTER.getSlaves());
ArrayList<Integer> ports = new ArrayList<>();
for (MesosSlave container : containers) {
try {
ports = MesosSlave.parsePortsFromResource(((MesosSlaveExtended)container).getResources());
} catch (Exception e) {
// TODO: no printing to System.err. Either handle or throw
e.printStackTrace();
}
InspectContainerResponse response = docker.inspectContainerCmd(container.getContainerId()).exec();
Map bindings = response.getNetworkSettings().getPorts().getBindings();
for (Integer port : ports) {
Assert.assertTrue(bindings.containsKey(new ExposedPort(port)));
}
}
}
```<issue_closed>
Status: Issue closed |
bitstadium/HockeySDK-Windows | 281835574 | Title: Error in package manager console
Question:
username_0: Every time i load my application in visual studio, i get the following error in the package manager console:
```
You cannot call a method on a null-valued expression.
At C:\Code\CoBRAGit2\ClientApplications\DroneLocApp\packages\HockeySDK.WPF.4.1.6\tools\init.ps1:3 char:1
+ $project.DTE.ItemOperations.Navigate('https://github.com/bitstadium/H ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : InvalidOperation: (:) [], RuntimeException
+ FullyQualifiedErrorId : InvokeMethodOnNull
```
there are no actual errors in my application error list, so i can't see what affect this has if any. Is there any way of clearing this issue?
Answers:
username_1: Hey @username_0,
thx for reporting this. We'll be looking at this.
Best,
Benjamin
username_2: Hi @username_0
Just FYI, the init.ps1 script runs the first time a package is installed in a solution and also it runs every time the solution is opened. The problem is there is no way to tell inside script if we are running during the installation process or simple opening. I think the best we can do it is just check for object existence, which #130 PR is doing. Thanks!
Best,
Murat |
kasper/phoenix | 230954737 | Title: Feature for make osx El Capitan mouse larger temporarily
Question:
username_0: https://support.apple.com/kb/PH21543?locale=en_US
Sometimes when I mv mouse to a position, make the mouse temporarily larger would be useful.
So, Mouse need a function like Mouse.showUp()
Answers:
username_0: I think I should mock mouse shake first
username_1: Yes, I’m not sure if there’s an API to achieve this directly. Of course you can just mock the shake feature by rapidly changing/shaking the position of the pointer and see if that causes the effect.
username_0: I mock the mouse to shake, but it doesn't work, may be I did not figure out the trigger condition。
Instead, I use modal to solve my problem.
username_2: It seems `Mouse.move` simply moves the mouse pointer, but does not seem to *trigger* a mouse move in macOS. For example, if I'm currently dragging an item and use Phoenix to move the pointer somewhere else, the dragged item will not move until I move the physical mouse around.
username_1: Yes, @username_2 is likely right on point.
username_1: Seems like there is a private API to change the cursor size: `CGSGetCursorScale` and `CGSSetCursorScale`. 🙈 |
MicrosoftDocs/office-docs-powershell | 390242175 | Title: Clarity for the -Alias parameter in New-Team cmdlet
Question:
username_0: By running the **Get-Help New-Team -Full** in PowerShell, and referring to the `-Alias` parameter, the output says different from the docs.
The output in PowerShell says "*Same as displayName without any spaces. Team Alias Characters Limit - 64*". But the docs say it only has to be a unique name (re O365 Group in the background).
I had a look at the #1796, however, it would mean that it only has to be unique, AND NOT be mandatory for it to be the DisplayName w/o spaces then?
Can we get some clarity?
Thanks
---
#### Document details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 549c7d86-87b3-5c82-d2b3-a0cc0b4faa11
* Version Independent ID: b3377099-854a-50d0-0fe1-bbdd7ddec332
* Content: [New-Team (teams)](https://docs.microsoft.com/en-gb/powershell/module/teams/New-Team?view=teams-ps)
* Content Source: [teams/teams-ps/teams/New-Team.md](https://github.com/MicrosoftDocs/office-docs-powershell/blob/master/teams/teams-ps/teams/New-Team.md)
* Service: **teams-powershell**
* GitHub Login: @kenwith
* Microsoft Alias: **kenwith**
Answers:
username_1: Hi @username_0 , thank you for your contribution.
I think someone update the description of this parameter:
"The Alias parameter specifies the alias for the associated Office 365 Group. This value will be used for the mail enabled object and will be used as PrimarySmtpAddress for this Office 365 Group. The value of the Alias parameter has to be unique across your tenant.
For more details about the naming conventions see here: New-UnifiedGroup, Parameter: -Alias."
Conclusion: Alias hast to be unique across tenant and it could be different to DisplayName.
username_2: @username_1 Thank you very much for the contribution and sharing this explanation. @veronicabeek
Hope this comment is helpful for you. Thanks for taking out some time to open the issue. Appreciate and encourage you to do the same in future also.
Status: Issue closed
|
weirdyang/sgsew-frontend | 963508645 | Title: Restrict product type selection to hardware and services
Question:
username_0: see username_0/sgsew-backend#2
Status: Issue closed
Answers:
username_0: f6e86f61314b486aa9abd4600053dc35893cb11e
2451ab8b4120e9cfa3a91568fb682201a9af451c
f29d6da0244eaef1854542e5ac433929b746990e
671ea0a9376d5fe2642c8b593e0677cdc6bb6ced
dcfc8727fc5232219919bea478f3b42a5a129ee5 |
Clever/wag | 834016797 | Title: None
Question:
username_0: I can't figure out what went wrong here. Does `dependabot-preview` not understand that the import path `github.com/Clever/wag/v6/clients/go` is a package named `goclient`? Or does it not understand the module suffix?
I'm going to close this ticket and see if dependabot reopens it?<issue_closed>
Status: Issue closed |
dotnet/core | 250404686 | Title: Publish .NET Core SDK to Homebrew
Answers:
username_1: I don't have a full understanding of what's involved; but as I understand Homebrew, couldn't anyone create a homebrew installer for .NET Core?
username_2: +1 for Homebrew; also FYI there's a very active discussion already at dotnet/cli#533.
I'm far from an expert on Homebrew, but I have made [a number of contributions](https://github.com/Homebrew/homebrew-core/pulls?utf8=%E2%9C%93&q=author%3Ausername_2) and would be glad to help write one for .NET Core 😄
I work at Microsoft, so feel free to ping me here or offline if there's anything I can do to help! 🙂
username_3: I"m going to close this in favor of the conversation continuing in the cli repo which is the correct place. https://github.com/dotnet/cli/issues/533
Status: Issue closed
|
TechEmpower/FrameworkBenchmarks | 431219169 | Title: Enable accelerated networking in Azure
Question:
username_0: See discussion in https://github.com/TechEmpower/FrameworkBenchmarks/issues/4281#issuecomment-481319521 for context.
Apparently, if you create new VMs in Azure with our instance type and recommended OS now, accelerated networking is enabled by default. Also, Microsoft wanted us to use accelerated networking in the past, but we couldn't because of the OS we used at the time. For both of those reasons, it makes sense to enable accelerated networking in TFB's Azure environment moving forward.
In the past few rounds we used an Azure environment that was provisioned "manually" through the Azure portal UI. When we created that environment, TFB still required Ubuntu 14.04, and accelerated networking was not supported there. We may have later upgraded the OS in place but not re-provisioned the instances, so we never enabled accelerated networking.
We retired that Azure environment and are creating a new one with Terraform. This is still a work in progress. Enabling accelerated networking there should be a one-line change.
The Terraform setting to enable:
https://www.terraform.io/docs/providers/azurerm/r/network_interface.html#enable_accelerated_networking
The area of our Terraform script to change:
https://github.com/jsongte/tfb-azure-terraform/blob/f88cec19a3a8c2f6a4f1858b67af5ccb3b0e5864/terraform/tfb-app.tf#L27-L40
We expect this change to noticeably affect performance so we should call this change out in a blog post.
Answers:
username_0: This is done. We applied this change in our [Terraform scripts](https://github.com/TechEmpower/tfb-azure-terraform/blob/9c25325de0f3518f81ae13ac8abdef2e19207619/terraform/tfb-app.tf#L32) before capturing Round 18, and then we called it out in the [Round 18 blog post](https://www.techempower.com/blog/2019/07/09/framework-benchmarks-round-18/).
Status: Issue closed
|
Metatavu/pakkasmarja-berries | 295071348 | Title: Contact transfer support
Question:
username_0: As an user i would like to be have feature for synchronizing contacts from SAP into Keycloak. As a part of this story a job queue is created
Answers:
username_1:  [Yhteystietojen synkronointi SAPista Keycloakiin (siirtotiedosto)](https://trello.com/c/KLLGDymW/1-yhteystietojen-synkronointi-sapista-keycloakiin-siirtotiedosto)
Status: Issue closed
|
microsoft/BotFramework-Composer | 752101416 | Title: Error: getaddrinfo ENOTFOUND bottested-rg-dev.scm.azurewebsites.net
Question:
username_0: I have manually created the resources needed for my Bot to run. And built publishing profile.
My resource group name is "bottested-rg", and my app service name is "bottested-webapp", so ideally my Kudu console or publishing endpoint will be bottested-webapp.scm.azurewebsites.net
Now, while publishing my Composer Bot to Azure it gives below error
**ISSUE:**

What it is doing is appending "environment" value to resource group name or name value like this "bottested-rg-dev" and looking for "scm" - bottested-rg-dev.scm.azurewebsites.net which obviously will not present.
How can I make it publish to "bottested-webapp.scm.azurewebsites.net"?
**Note:** Azure App service name is globally unique value so I did not get to use "bottested-rg". So I created an App Service under the name "bottested-webapp".
**Things I tried:**
Changed environment value to something like this "environment": "webapp", but it's still looking for "bottested-rg-webapp.scm.azurewebsites.net" which is not present and gives the same error as expected.
So the real question is how to bypass this environment value getting attached to RG or Bot name?
Or How can I make it to publish to an App Service that I created manually?
Answers:
username_1: @username_0 you can add another field in your publish profile:
{
"hostname": "bottested-webapp"
}
The logic is:
if hostname is null or empty, we use "name-environment, otherwise just use hostname.
btw, if you use luis services, use luisResourse to override "name-environment-luis"
username_0: @username_1 Thank you this could resolve the issue, I have not tested it yet. But your explanation helps and makes sense.
username_2: @username_0 I'll close this as a how-to question. Please create a new issue if you are seeing errors
Status: Issue closed
|
cmen/CMENGoogleChartsBundle | 835111630 | Title: Getting data from a Timeline row
Question:
username_0: Is there a way to access the data in a Timeline row with just the provided Twig functions?
On select I need to get the name of the bar, for example "M210001 -"

So far I haven't found a way to do this. |
akarnokd/rng-76 | 1011174890 | Title: Enclave Plasma with Flamer mod wrong ammo capacity
Question:
username_0: From reddit [u/Andamarokk](https://www.reddit.com/user/Andamarokk)
Hey, wasnt sure where to reach out to you and saw youre active on reddit. I've got a question regarding the fo76 damage calc, if youre still working on that. I was using it earlier today and noticed the (Enclave) Plasma flamer doesnt get its clip size updated to 300 when putting on the Flamer barrel. This leads to Quad being better than both AA/Bloodied (which obviously isnt true). Heres the profiles i used: click me!
Thanks for your time!
Status: Issue closed
Answers:
username_0: Fixed via https://github.com/username_0/rng-76/commit/4f518d6e33f59105ccf5d0cad25a0feb239751e6 . |
naser44/1 | 113201742 | Title: زرقاء اليمامة: امرأة كانت تبصر الشعرة البيضاء في اللبن وتنظر الراكب على مسيرة 3 أيام وتنذر قومها الجيوش...
Question:
username_0: <a href="http://ift.tt/1kDYEts">زرقاء اليمامة: امرأة كانت تبصر الشعرة البيضاء في اللبن، وتنظر الراكب على مسيرة 3 أيام، وتنذر قومها الجيوش...</a> |
kubernetes/website | 768103027 | Title: Generate feature gates list from data
Question:
username_0: **This is a Feature Request**
<!-- Please only use this template for submitting feature/enhancement requests -->
<!-- See https://kubernetes.io/docs/contribute/start/ for guidance on writing an actionable issue description. -->
**What would you like to be added**
Track a list of feature gates as, eg, YAML, and generate https://kubernetes.io/docs/reference/command-line-tools-reference/feature-gates/ from that data.
**Why is this needed**
- This improvement lets people update the feature state for a gate with a one line change, eg
```diff
--- feature_gates.yaml 2020-01-21 15:24:34.907668274 +0000
+++ feature_gates.yaml 2020-03-15 10:39:43.852042785 +0000
@@ -16,6 +16,8 @@
- name: AllowExtTrafficLocalEndpoints
betaFromVersion: v1.4
deprecatedFromVersion: v1.8
+ - name: AnyVolumeDataSource
+ alphaFromVersion: v1.18
- name: APIListChunking
alphaFromVersion: v1.8
betaFromVersion: v1.9
```
- This change enables future work to:
- autogenerate the input data
- improve the `feature-state` shortcode
- Combining this with other data could let the Kubernetes project have a single view of new features and deprecations for a release, generating that view automatically.
**Comments**
/kind feature
Answers:
username_0: To clarify something: we need to localize the descriptions for each feature gate, so those descriptions would still be part of the content. The good thing about having this list as data is that we can lint to make sure that each added feature gate has a matching description.
username_1: I love this idea! On compiling major themes for 1.20, I had to go back and forth between k/k PR and k/website PR to see if the changes are in sync. Is this a step towards generating [from the actual code itself](https://github.com/kubernetes/kubernetes/blob/master/pkg/features/kube_features.go)?
username_0: /remove-lifecycle rotten
username_2: we missed more than a few of these in the past, i'd like to make this happen.
/assign
i hope to be able to submit a PR soonish.
username_0: I've updated the PR I opened about this. I've left it as draft so that we can discuss the approach to take.
username_0: I also wrote up a [rationale](https://github.com/kubernetes/website/pull/28036#issuecomment-862284989).
username_0: (yes, it is)
username_0: https://github.com/kubernetes/website/pull/28036#issuecomment-883482828 mentions running this past SIG Architecture to check that folks are happy with the approach.
* _This_ issue is about switching the page to be driven by local data (in `/data` within the repo)
* a future change could build on that to switch to using remote data. Hugo can fetch and deserialize JSON data, via https, then render it. |
ag-grid/ag-grid | 903305909 | Title: TypeError: Cannot read property 'EnterpriseCoreModule' of undefined
Question:
username_0: <!--
IF YOU DON'T FILL OUT THE FOLLOWING INFORMATION WE MIGHT CLOSE YOUR ISSUE WITHOUT INVESTIGATING
-->
**I'm submitting a ...** (check one with "x")
```
[] bug report => see 'Providing a Reproducible Scenario'
[] feature request => do not use Github for feature requests, see 'Customers of AG Grid'
[] support request => see 'Requesting Community Support'
```
**Customers of AG Grid**
If you are a customer you are entitled to use the AG Grid's customer support system (powered by Zendesk). Please use that channel for guaranteed response from the AG Grid team with regards bugs, feature requests and support.
**Requesting Community Support**
If you are not a customer of AG Grid, ag-grid staff will label your issue as managed-by-the-community. This means that AG Grid staff is not going to be actively looking into it and it will get closed if inactive for more than one month. The community is welcome to help with this question/support issue.
**Providing a Reproducible Scenario**
Accepted reproducible scenarios are
- A description of the detailed steps to reproduce your behaviour in one of our examples in the docs.
- A plunker
If you decide to send us a plunkr, from any example in our website use the plunkr button in there to fork your own code by following the steps below:
- Select the framework that is appropriate to you from the drop-down
- Open it in plunker. (Use the button plunker in our example)
- Add your changes so that the behaviour is reproduced
- Save and Freeze the plunker(On the top left corner)
- Send us the link to the plunker(You can copy the URL from the browser)
If reporting a bug make sure to state.
Current behaviour.
Expected behaviour. If possible back this up with our docs/examples if possible
**Current behavior**
<!-- Describe how the bug manifests. -->
**Expected behavior**
<!-- Describe what the behavior would be without the bug. If possible back this up with our docs/examples if possible-->
**Please tell us about your environment:**
<!-- Operating system, IDE, package manager, HTTP server, ... -->
* **AG Grid version:** X.X.X
<!-- Check whether this is still an issue in the most recent AG Grid version -->
* **Browser:**
<!-- Run `navigator.userAgent` in console of all of the browsers where this could be reproduced -->
* **Language:** [all | TypeScript X.X | ES6/7 | ES5]
Answers:
username_1: Hi,
This ticket has been flagged as managed-by-community/waiting-for-repro for a while now and there has not been any activity, to help us tidy up we are going to close it.
Thanks
Status: Issue closed
|
Dakova1994/Angular-Test | 298989630 | Title: Draw button should draw cards from current deck
Question:
username_0: When implemented, 'Draw' button always creates new deck. We want it to draw cards from the current deck.
Requirement 1.
Change logic to 'Draw' button., so that it draws cards from current deck.
Answers:
username_1: It is done?
username_0: If so, then close please.
Status: Issue closed
username_0: When implemented, 'Draw' button always creates new deck. We want it to draw cards from the current deck.
Requirement 1.
Change logic to 'Draw' button., so that it draws cards from current deck.
Status: Issue closed
|
5CS024-Team1/embedded_system_code | 575835948 | Title: NO INFORMATION DISPLAYED
Question:
username_0: When running the code, nothing is displayed in the serial monitor. This may be something to do with my print lines.
Answers:
username_0: Update - Stripped the code to the very basics, using no formatting on the data. I seem to be able to display data when I am not trying to use tinyGPS to format it (see basecamp for an image of this)...
This is still a problem as I have no clue what any of the data means without it being formatted, will continue to work on a fix over the next few weeks.
username_0: Update - This looks to be an issue with the hardware and not the code.
I have tried leaving it running overnight and have seen no difference in functionality.
For now we are going to just have to use dummy data, I will keep working on a fix until the deadline, if one cannot be found, I will just do my best with what I have. |
elixir-ecto/ecto | 468811683 | Title: Ecto 3.1 %DateTime{} error with `date()` fragment
Question:
username_0: ### Environment
* Elixir version (elixir -v): Elixir 1.9.0, Erlang/OTP 22
* Database and version (PostgreSQL 9.4, MongoDB 3.2, etc.): (PostgreSQL) 9.6.13
* Ecto version (mix deps): ~> 3.1
* Database adapter and version (mix deps): {:postgrex, "~> 0.14.3"},
* Operating system: Debian GNU/Linux 9.9 (stretch) (4.9.0-9-amd64)
### Current behavior
This code to work with Ecto 2.2, but now throws a `Postgrex expected %DateTime{}, got ~N[2018-11-07 11:26:56]` error (like #2796) in Ecto 3.1 (even after `@timestamps_opts [type: :naive_datetime_usec]` adjustment made per Platformatec post):
```
where([l],
fragment("date(?) between date(?) and date(?)", l.inserted_at, ^start_date, ^end_date)
)
```
However, this does work in Ecto 3.1:
```
where([l],
(l.inserted_at >= ^start_date) and (l.inserted_at <= ^end_date)
)
```
### Expected behavior
For `date(?)` fragments to behave as they did under Ecto 2.2.
Answers:
username_1: Because you are bypassing Ecto and using fragments, the database is the one dictating which input is necessary. That's why `@timestamp_opts` has no effect.
Also, can you please include the full stacktrace and error message? Thanks.
username_0: Will have to revert to a prior version to reproduce the stack trace, so give me a day or two.
Also upgraded postgrex from 0.13.5 to 0.14.3. Was there some change in that driver which would alter how NaiveDateTime parameters are bound to the query? With the old libs, the fragment query ran successfully.
BTW, postgres columns are type `timestamp without time zone` for the `date(?)` fragments.
username_1: We didn’t have naive and DateTime before, which is why the issue didn’t
appear.
--
*José Valimwww.plataformatec.com.br
<http://www.plataformatec.com.br/>Founder and Director of R&D*
username_0: Could you clarify "didn't have"? From this [post](http://blog.plataformatec.com.br/2018/10/a-sneak-peek-at-ecto-3-0-breaking-changes/), it has handled NaiveDateTime since 2.1.
username_1: Oh, sorry. I should have said they were not the defaults. It was most likely that you were using Ecto.DateTime before, no?
username_0: Prior to 3.1 upgrade, `@timestamp_opts` was left as default. The value passed into the fragment was an Elixir `NaiveDateTime`.
username_1: Ah, this does look like a regression then. Sometimes the Ecto versions are
all fuzzied in my head, I will take a look then, thanks!
--
*José Valimwww.plataformatec.com.br
<http://www.plataformatec.com.br/>Founder and Director of R&D*
username_1: Looking at the code for Postgrex v0.14.3, we can see it handles both Naive and Datetime:
https://github.com/elixir-ecto/postgrex/blob/v0.14.3/lib/postgrex/extensions/timestamp.ex#L9-L21
But not for timestamptz:
https://github.com/elixir-ecto/postgrex/blob/v0.14.3/lib/postgrex/extensions/timestamptz.ex#L14-L21
So I believe you are getting the former and that indeed won't work with naive datetimes.
You can give a hint to PG by writing:
```
where([l],
fragment("date(?) between date(?::timestamp) and date(?::timestamp)", l.inserted_at, ^start_date, ^end_date)
)
```
Status: Issue closed
username_1: In any case, it could indeed work on previous Ecto versions, but that's was when ecto implemented those callbacks and we have more lax rules on casting than Postgrex. :) |
Masuzu/ZooeyBot | 226841093 | Title: Salves Mode Problem
Question:
username_0: Hello
I want to use salves mode.
However, the bot keep refreshing my chrome window.
And the Co-op quest never start but only refreshing.
Thank you

Status: Issue closed
Answers:
username_1: This will happen if you have a very slow internet connection: Zooey waits for the "Ready" (must not be pressed for the first run) and "Start" button to be visible. |
auth0/express-openid-connect | 611713508 | Title: Make redirect optional
Question:
username_0: ### Describe the problem you'd like to have solved
I want to call the login endpoint via AJAX request and simply get the redirect URL in the response.
I've not found a way to change this behavior without modifying the library source code.
### Describe the ideal solution
So the possible solution is to have two methods: login, loginWithRedirec in the RequestContext class.
Answers:
username_1: Hi @username_0 - could you explain more about your use case? What would you do with the redirect URL when you got it back from an AJAX request?
username_0: Just redirect via JavaScript
`window.location.href = url`
username_1: So is there anything stopping you from doing: `window.location.href = '/login';`?
username_0: I plan to do redirect to auth0 login page, not to `/login` route
username_1: The `/login` route will redirect you to the auth0 login page https://github.com/auth0/express-openid-connect/blob/master/lib/context.js#L103 - so `window.location.href = '/login';` will have exactly the same effect as `window.location.href = authorizeUrl;` - with the added bonus that you don't need to make an additional AJAX request to get the `authorizeUrl`
username_0: I'm doing an ajax request to the /login with axios. Browser is not able to proceed redirect response properly from ajax request. That's why I want to get redirect url in from the /login response and do perform the redirect manually
username_0: @username_1 is it clear, or I need to provide more details?
Status: Issue closed
username_1: Hi, sorry - we don't offer an API where you can get the authorize url - I recommend you have another look at https://github.com/auth0/express-openid-connect/issues/96#issuecomment-626548563
If you really want to use the authorize url directly - it should be fairly trivial to create: https://github.com/auth0/node-auth0/issues/173#issuecomment-381767911
username_0: Thx |
UCDavisLibrary/ava | 221667944 | Title: creston_district
Question:
username_0: # AVA: Creston District (creston_district)
name | value
--- | ---
ava_id | creston_district
cfr_index | 9.239
revision | [T.D. TTB-125, 79 FR 60960, Oct. 9, 2014]
state | CA
county | San Luis Obispo
within | Central Coast\|Paso Robles
contains |
[src]: https://www.ecfr.gov/cgi-bin/retrieveECFR?gp=&SID=371db32ecca6629af6dccad2a39d7833&mc=true&n=sp27.1.9.c
## Approved Maps [src]
(1) Creston, Calif., 1948, photorevised 1980;
(2) <NAME>, Calif., 1961;
(3) <NAME>, CA, 1995;
(4) Camatta Ranch, CA, 1995; and
(5) <NAME>, Calif., 1965, revised 1993.
## Boundary [src]
(c) Boundary. The Creston District viticultural area is located in San Luis Obispo County, California. The boundary of the Creston District viticultural area is as described below:
(1) The beginning point is located on the Creston map along the common boundary line of the Huerhuero Land Grant and section 34, T27S/R13E, at the eastern-most intersection of State Route 41 and an unnamed light-duty road locally known as Cripple Creek Road. From the beginning point, proceed northerly on Cripple Creek Road approximately 1 mile to the road's intersection with an unnamed light duty road locally known as El Pomar Drive (at BM 1052), section 27, T27S/R13E; then
(2) Proceed northeasterly in a straight line approximately 0.75 mile to the unnamed 1,142-foot elevation point, T27S/R13E; then
(3) Proceed north in a straight line approximately 1.2 miles to the line's intersection with an unnamed light duty road locally known as Creston Road at the southwest corner of section 14, T27S/R13E; then
(4) Proceed east on Creston Road approximately 0.35 mile to the road's intersection with an unnamed light-duty road known locally as Geneseo Road (at BM 1014), T27S/R13E; then
(5) Proceed north-northwesterly on Geneseo Road approximately 0.7 mile to the road's intersection with a jeep trail (locally known as Rancho Verano Place) and the western boundary line of section 14, T27S/R13E; then
(6) Proceed due east in a straight line approximately 0.2 mile to the line's intersection with the Huerhuero Land Grant boundary line, section 14, T27S/R13E; then
(7) Proceed north-northeasterly along the Huerhuero Land Grant boundary line approximately 0.7 mile to the land grant's northern-most point, and then continue east-southeasterly along the land grant's boundary line approximately 0.4 mile to the line's intersection with the northern boundary line of section 14, T27S/R13E; then
(8) Proceed east approximately 1.3 miles along the northern boundary lines of sections 14 and 13, T27S/R13E, and continue east approximately 0.25 mile along the northern boundary line of section 18, T27S/R14E, to the T-intersection of two unnamed unimproved roads; then
(9) Proceed east-southeasterly on the generally east-west unnamed unimproved road approximately 0.85 mile, crossing onto the Shedd Canyon map, to the road's intersection with the eastern boundary line of section 18, T27S/R14E; then
(10) Proceed southeasterly in a straight line approximately 1.2 miles to the 1,641-foot elevation point located at the southeast corner of section 17, T27S/R14E; then
(11) Proceed southeasterly approximately 0.55 mile in a straight line to BM 1533 (located beside Creston Shandon Road (State Route 41)) and continue southeasterly in a straight line approximately 1.8 miles to the 1,607 elevation point near the western boundary line of section 27, T27S/R14E; then
(12) Proceed east-southeasterly in a straight line approximately 1.1 miles to the 1.579-foot elevation point at the southeast corner of section 27, T27S/R14E; then
(13) Proceed east approximately 1.9 miles along the northern boundary lines of sections 35 and 36, T27S/R14E, to the section 36 boundary line's intersection with Indian Creek; then
(14) Proceed southerly (upstream) along Indian Creek approximately 5.3 miles in straight-line distance, crossing onto the Wilson Corner map, to the creek's intersection with an unnamed light-duty road locally known as La Panza Road, section 20, T28S/R15E; then
(15) Proceed southeasterly on La Panza Road approximately 0.15 mile to the road's intersection with State Route 58 at Wilson Corner, section 29, T28S/R15E; then
(16) Proceed easterly on State Route 58 approximately 1.4 miles, crossing onto the Camatta Ranch map, to the road's intersection with the eastern boundary line of section 28, T28S/R15E; then
(17) Proceed south approximately 1.5 miles along the eastern boundary lines of sections 28 and 33, T28S/R15E, to the T28S/T29S common boundary line at the southeast corner of section 33, T28S/15E; then
(18) Proceed west along the T28S/T29S common boundary line approximately 9.1 miles, crossing over the Wilson Corner map and onto the Santa Margarita map, to the boundary line's intersection with the Middle Branch of Huerhuero Creek, section 31, T28S/R14E; then
(19) Proceed north-northwesterly (downstream) along the Middle Branch of Huerhuero Creek approximately 2.3 miles in straight-line distance to the creek's intersection with the southern boundary line of section 24, T28S/R13E; then
(20) Proceed west along the southern boundary line of section 24, T28S/R13E, approximately 0.45 mile to that section's southwestern corner; then
(21) Proceed north along the western boundary line of section 24, T28S/R13E, approximately 1.0 mile to the boundary line's intersection with an unnamed unimproved road at the section's northwestern corner; then
(22) Proceed northwesterly on the unnamed unimproved road approximately 0.7 mile to the road's intersection with State Route 229 near BM 1138, section 14, T28S/R13E; then
(23) Proceed northeasterly on State Route 229 approximately 0.2 mile to the road's intersection with the Huerhuero Land Grant boundary line, section 14, T28S/R13E; then
(24) Proceed north-northwesterly along the boundary of the Huerhuero Land Grant approximately 3 miles, crossing onto the Creston map and returning to the beginning point.
Status: Issue closed
Answers:
username_2: Reviewed.
- Add scale information of the used maps. |
americanexpress/jest-image-snapshot | 459276038 | Title: Can you make a new release for the customSnapshotIdentifier to be a function
Question:
username_0: I see the new changes for the customSnapshotIdentifier to be a function is merged into master but has not been packaged. Can you please cut a new release and publish to npm these changes?
Answers:
username_1: Hopefully tomorrow I will be able to!
username_1: 2.9.0 has now been published.
Status: Issue closed
|
kubernetes/kubernetes | 957405349 | Title: The test `TestVolumeUnmountAndDetachControllerDisabled` test if failing from `kubelet_volumes_test.go`
Question:
username_0: #### Which jobs are failing:
pull-kubernetes-unit
#### Which test(s) are failing:
TestVolumeUnmountAndDetachControllerDisabled
#### Since when has it been failing:
It failed on `07/24/2021` but after that the test is passing
#### Testgrid link:
https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/103631/pull-kubernetes-unit/1418992044973494272#1:build-log.txt%3A2386
#### Reason for failure:
DATA RACE
It seems that the data race is caused by below code
https://github.com/kubernetes/kubernetes/blob/5be21c50c269fc1d28e0bd31ab9dcb572ae7fac5/pkg/kubelet/kubelet_volumes_test.go#L317-L320
#### Anything else we need to know:
It failing of test is Flaky, it was not reproducible on my local machine too, I have used below command to run the test
```
sudo make test WHAT="./pkg/kubelet" GOFLAGS="-v -count=1" KUBE_TEST_ARGS='-run ^TestVolumeUnmountAndDetachControllerDisabled$'
```
output on my local machine
```
+++ [0801 06:08:49] Running tests without code coverage and with -race
=== RUN TestVolumeUnmountAndDetachControllerDisabled
W0801 06:08:55.941792 4176 mutation_detector.go:53] Mutation detector is enabled, this will result in memory leakage.
I0801 06:08:55.942831 4176 desired_state_of_world_populator.go:146] "Desired state populator starts to run"
I0801 06:08:55.943127 4176 volume_manager.go:291] "Starting Kubelet Volume Manager"
E0801 06:08:55.945783 4176 reflector.go:138] k8s.io/client-go/informers/factory.go:134: Failed to watch *v1.CSIDriver: unhandled watch: testing.WatchActionImpl{ActionImpl:testing.ActionImpl{Namespace:"", Verb:"watch", Resource:schema.GroupVersionResource{Group:"storage.k8s.io", Version:"v1", Resource:"csidrivers"}, Subresource:""}, WatchRestrictions:testing.WatchRestrictions{Labels:labels.internalSelector(nil), Fields:fields.andTerm{}, ResourceVersion:""}}
I0801 06:08:56.145474 4176 reconciler.go:244] "operationExecutor.AttachVolume started for volume \"vol1\" (UniqueName: \"fake/fake-device\") pod \"foo\" (UID: \"12345678\") "
I0801 06:08:56.145588 4176 reconciler.go:157] "Reconciler: start to sync state"
I0801 06:08:56.145710 4176 operation_generator.go:369] AttachVolume.Attach succeeded for volume "vol1" (UniqueName: "fake/fake-device") from node "127.0.0.1"
I0801 06:08:56.246900 4176 operation_generator.go:587] MountVolume.WaitForAttach entering for volume "vol1" (UniqueName: "fake/fake-device") pod "foo" (UID: "12345678") DevicePath "/dev/vdb-test"
I0801 06:08:56.247005 4176 operation_generator.go:597] MountVolume.WaitForAttach succeeded for volume "vol1" (UniqueName: "fake/fake-device") pod "foo" (UID: "12345678") DevicePath "/dev/sdb"
I0801 06:08:56.247084 4176 operation_generator.go:630] MountVolume.MountDevice succeeded for volume "vol1" (UniqueName: "fake/fake-device") pod "foo" (UID: "12345678") device mount path ""
I0801 06:08:56.548217 4176 reconciler.go:196] "operationExecutor.UnmountVolume started for volume \"vol1\" (UniqueName: \"fake/fake-device\") pod \"12345678\" (UID: \"12345678\") "
I0801 06:08:56.548267 4176 operation_generator.go:866] UnmountVolume.TearDown succeeded for volume "fake/fake-device" (OuterVolumeSpecName: "vol1") pod "12345678" (UID: "12345678"). InnerVolumeSpecName "vol1". PluginName "fake", VolumeGidValue ""
I0801 06:08:56.649605 4176 reconciler.go:312] "operationExecutor.UnmountDevice started for volume \"vol1\" (UniqueName: \"fake/fake-device\") on node \"127.0.0.1\" "
I0801 06:08:56.649609 4176 operation_generator.go:974] UnmountDevice succeeded for volume "vol1" %!(EXTRA string=UnmountDevice succeeded for volume "vol1" (UniqueName: "fake/fake-device") on node "127.0.0.1" )
I0801 06:08:56.750200 4176 reconciler.go:333] "operationExecutor.DetachVolume started for volume \"vol1\" (UniqueName: \"fake/fake-device\") on node \"127.0.0.1\" "
I0801 06:08:56.750269 4176 operation_generator.go:484] DetachVolume.Detach succeeded for volume "vol1" (UniqueName: "fake/fake-device") on node "127.0.0.1"
I0801 06:08:56.844405 4176 volume_manager.go:297] "Shutting down Kubelet Volume Manager"
--- PASS: TestVolumeUnmountAndDetachControllerDisabled (0.91s)
PASS
ok k8s.io/kubernetes/pkg/kubelet 1.052s
```
I would like to work on this issue, is it possible to reproduce this issue locally? |
BoboTiG/ebook-reader-dict | 748264222 | Title: [FR] Handle the 'régionalisme' template
Question:
username_0: - Wiktionary page: https://fr.wiktionary.org/wiki/mace
Wikicode:
```
{{régionalisme|Bretagne|fr}}
```
Output:
```
None
```
Expected:
```
<i>(Bretagne)</i>
```
---
Model link, if any: https://fr.wiktionary.org/wiki/Mod%C3%A8le:r%C3%A9gion<issue_closed>
Status: Issue closed |
tldr-pages/tldr | 182604776 | Title: Decide what branding to use
Question:
username_0: I noticed many names are used for this project, so I think it should be clarified. For example, you can find *TL;DR pages*, *tldr*, *tldr pages* and *TLDR pages* in various documents and website.
My suggestion is to use and *tldr* for the name of npm package and *TLDR pages* or *tldr pages* for everything else. How does that sound?
Answers:
username_1: I normally don't like when brands attempt to enforce specific capitalization styling of the brand name, so I'd preferif we avoided the capitalized version, and the pedantic version with the semicolon. I suppose I'd either go with **tldr pages** or **tldr-pages**, but I'm open to hear other arguments.
username_0: Agree @username_1, I like that version more. *TLDR pages* sounds a bit too administrative. *tldr-pages* sounds cool in dev matter of cool.
username_2: `tldr` has my vote.
username_3: I like **tldr pages**. Contrasts nicely with **man pages**.
username_1: If we are willing to deviate a little more from the current name, we could consider rebranding as tldr.sh (which is akin to how many projects nowadays now use .js to indicate their context), or even go as far as ditching the hard-to-pronounce (and somewhat jargon-y) "tldr" altogether and pick something like "miniman" or "lil' man" :P just some fresh/wild (crazy?) ideas to spice up the discussion, not something I'm advocating at the moment.
Getting back down to earth, I suspect that "tldr-pages" may be better than "tldr pages" as it clearly identifies as a single word, in the absence of capitalization or formatting. But it's not a super-strong preference.
username_0: I agree with @username_1. `tldr-pages` seems the best at this moment.
username_0: Any news on this? Branding is an important part of the project.
username_1: I'd like to hear @username_3 and @username_2's responses to my previous comment.
username_2: I reeeeally need to setup tldr.sh
username_3: My preference is still "tldr pages", but I am okay with "tldr.sh" too.
username_1: If tldr.sh is ok with you guys, I'd vote for it too.
@username_3 any thoughts about my arguments for using a hyphen? Besides those, we must also consider that using a space makes it awkward to refer to a single page. Is it a "tldr page" (which would mean the project identifies as "tldr" alone)? Using "tldr-pages page" would be consistent but admittedly kinda silly, so we could instead recommend something like "tldr-pages entry" for that case (that's one of the ways a branding guideline can be useful).
username_3: Referring to a single page is indeed an issue. My vote is for tldr.sh then.
username_1: @username_0, @username_5, @username_4, @fluxw42 what do you guys think? Any change since your last reactions?
username_4: My vote is for "tldr pages". The dash is overly verbose and doesn't fit well with how the english language is constructed.
username_1: @username_4 what about the issues I mentioned [here](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-255104786) and [here](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-262176332)?
username_0: `tldr.sh` seems perfectly fine to me.
username_4: `tldr.sh` suggest that it's a program, library or is otherwise related to the linux shell, which is not the case?
Do we want that?
username_5: I have split thoughts here. On one hand I agree with @username_1 that since we want to think about rebranding, we could consider something different than "tldr" (I always have to think about "too long didn't read" when typing, because I cannot think of a pronounceable form of "tldr"). On the other hand I like the name and the idea behind it, and then I would go with "tldr pages" (no hyphen)...
username_2: For the record I meant the domain `www.tldr.sh`, which we have registered but haven't setup yet.
username_1: So... shall we make a decision? The options raised here have been: (1) **tldr-pages**, (2) **tldr pages**, (3) **tldr.sh**, (4) **tldr**, and also (5) **miniman** and (6) **shortman**.
I would be OK with (1), (3) and (5).
(3) depends on @username_2's feedback -- what kind of setup are you planning for the domain? Would you like help keeping the domain registration? (Not sure how expensive it is.) I was thinking maybe we could start by simply making it a custom domain for http://tldr-pages.github.io, which is easy enough to setup, and later we could work on something more involved, to avoid delaying this much further.
IMO (2) would make it hard to distinguish when we're talking about the project and when we're talking about individual pages, and (4) would be too ambiguous with other uses of the term (and would make googling this a nightmare).
Thoughts?
username_2: Hey! The domain is up :) should I configure the DNS to point to the github pages?
username_3: Cool, I am good with tldr.sh. I have a concern though - the org name is "tldr-pages". Are we going to change the org name too ?
username_1: It would make sense, I suppose, and I'd personally be fine with that. We'd keep the primary identifier in our name, the "tldr" part, so that doesn't bother me too much.
username_2: @username_1 domain's A record pointing to Github -- http://tldr.sh -- you can take it from here 👍
username_1: Annnd, it's working already :D that was easy :)
So now, **tldr.sh** is a viable option for the project name. Is everyone on board with that? Pinging @username_6, @username_7, @igorshubovych.
username_3: If I try https://tldr.sh, I get a `NET::ERR_CERT_COMMON_NAME_INVALID`. Something we can do about it ?
username_1: There might be alternatives, see [here](https://gist.github.com/cvan/8630f847f579f90e0c014dc5199c337b) and [here](https://hackernoon.com/set-up-ssl-on-github-pages-with-custom-domains-for-free-a576bdf51bc).
username_3: Ah .. going the cloudflare way. @username_2 - is this something that you can do ? The nameserver change has to be done from your side.
username_2: @username_3 @username_1 Cloudflare setup done 👍 it'll take a few hours to work according to their website.
username_3: Works now. Can you enable HSTS also ?
username_6: I'm a little late to the party but I like "tldr pages", akin to "man pages". A single page is then a "tldr page" (man page). I think the name is still compatible with [tldr.sh](https://tldr.sh) which is a cool domain name!
If we choose to go with that, I've heard people pronounce it as `tilder` so we could do as many open-source projects do and mention it in the README `tldr pages (pronounced "tilder pages")`.
That being said I'm also happy with `tldr.sh` as the main branding or coming up with a newer fancy name like `miniman` too :)
username_7: `miniman` just cracks me up
username_1: I haven't pushed for `miniman` much, as I was the one to suggest it, but gotta say I really like it, too: it's self-descriptive, memorable, and very easy to pronounce (it kinda sounds like "minivan", an already existing word). Plus it doesn't include a jargon term, which better aligns with the project's ethos.
It really seems to tick all the boxes -- the only reason I haven't advocate adopting that name (but I'm tempted), is because "tldr" has definitely become sort of the main element of the project's "brand". But name changes have occurred for projects before, and large ones at that (e.g. IPython --> Jupyter comes to mind), without serious issues other than nostalgia of the old-timers, so it might well be a valid choice.
username_8: Interesting thread!
Would you want the various clients to start using the "tldr.sh" name?
username_1: @username_8 I think we already have enough problems form all the clients calling themselves simply "tldr", so I wouldn't recommend going down that road. Of course, once we pick a definitive name for the project, the clients ought to refer to it (the project, not themselves) by that name, yeah.
@username_7 I couldn't figure out whether your reaction to "miniman" is neutral, positive or negative. Would it be something you'd consider? (Just trying to tie up loose ends here.)
username_7: Let's say I'm neutral about it.
username_1: @username_6, @username_3, @username_2, @username_9, @username_0, @username_4, @username_5: I'd like to hear your thoughts on renaming the project `miniman` so we can make a decision here. I've already [listed a bunch of reasons](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-302388562) that compel me to favor it above `tldr` / `tldr.sh`; @username_7 is neutral about it per the comment immediately above, and @username_6 [said](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-302383621) he is open to the idea.
Let's seize the 10,000th star event (#1464) to make a final call on this :)
username_0: I really support miniman. Never thought about it before, but it's pretty descriptive. :1st_place_medal: :+1:
username_5: Besides the "brand change" factor that @username_1 mentioned [before](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-302388562), I like `miniman`. Easier to remember than `tldr`...
Although the creative use of the TL;DR jargon gave the project something we can instantly attach to, maybe they way it's not easily pronounceable or beginner-friendly also lead to all the discussion above... Sad, but necessary, to see the name go...
username_3: Sorry to be "that" guy here 😛 , but I don't like miniman. Strong negative on that. I would really like to keep some part of "tldr" in the name. Losing that feels like losing the core identity of this project.
username_6: What about `howto`? Then on the CLI you'd type `howto tar`, `howto du` etc.
username_4: I like howto! It's descriptive and short.
username_1: `howto` is descriptive and potentially even more self-explanatory than `miniman` (both are better than `tldr` IMO), because it subtly conveys what to expect (usage examples).
My only fear is that it's too generic and thus basically ungoogleable. Here's a table based on [the nominology post](http://messymatters.com/nominology/) I linked above:
Property | Description | tldr.sh | miniman | howto
-------- | ----------- | ------- | ------- | -----
Evocativity | Conveys at least a hint of what it’s naming | ★☆☆ | ★★☆ | ★★★
Brevity | Shorter = better | ★★★ | ★★☆ | ★★★
Greppability | Not a substring of common words | ★★★ | ★★☆ | ★★☆
Googlability | Reasonably unique (and domain name available) | ★★☆ | ★★☆ | ☆☆☆
Pronounceability | You can read it out loud when you see it | ☆☆☆ | ★★★ | ★★★
Spellability | You know how it’s spelled when you hear it | ☆☆☆ | ★★☆ | ★★☆
Playfulness | Catchy and memorable (e.g. a play on words) | ★★☆ | ★★★ | ☆☆☆
(I've excluded the "verbability" property, which all 3 score zero, to reduce visual noise, and added a "playfulness" property, which IMO is important for a good name to stick.)
It looks to me that objectively (to the extent that my scores are agreeable -- happy to adjust them to reflect consensus), "miniman" is the most balanced option, as it basically ticks all the "good project name" boxes.
username_1: @username_3 can you clarify whether you dislike "miniman" in particular, or dislike anything that doesn't include "tldr" in general?
username_3: The latter.
username_9: Nice table! I'm inclined to say no to "howto", since it not only is difficult to google, but is additionally awkward to say - since it sounds like the beginning of a sentence.
username_1: Good point @username_9: the natural sentence would indeed be "how to use gcc?", not "how to gcc?". That said, most command names are pretty short and I could kind of see them used as a verb, e.g. "how to gcc <a file>" as a stand-in for "how to compile a file with gcc". This doesn't work in all cases, though.
username_6: That's true @username_1, I think it probably be the case with every name we have: it's hard to form a valid sentence on the command line :smile:.
The only thing I dislike about `miniman` is that it doesn't sound very serious. Will that put off part of the target audience? (although it might be hard to please both novice *nix users, and people who are command-line fans but need the occasional reminder).
username_1: While "miniman" certainly has a playfulness to it, I also find it to be quite a good objective description of what we provide: compact manuals for the commands.
Yes, "mini-" is often used in a humorous/child-like context, but it is also used without any diminutive conotation (besides its literal meaning) in many common words, such as "minibar", "miniskirt", "minidisc", "miniseries", "Mini SUV", and [many more](https://en.wiktionary.org/wiki/Category:English_words_prefixed_with_mini-).
Even if that weren't the case, I think a user-base that readily adopted a project called "tldr-pages" would have no problem embracing a similarly playful (IMO) name :smile:
username_6: Never realised that Markdown was wordplay on Markup 😲 D'oh!
username_2: `tldr(.sh) > miniman > anything else > tldr[-]pages > howto`
That’d be my short answer. So if we ain’t sticking to tldr for legacy reasons, I’d friggin love miniman to be the name.
username_1: Great comment, @username_2. For a moment I was tempted to convert the other comments into a similar ranking for each participant in the discussion, tally up the votes and provide a table with numbers and total scores according to [various ranked-ballot counting methods](http://www.cs.wustl.edu/~legrand/rbvote/calc.html) (Borda, Schulze, etc.) — however, in my experience making these decisions based on cold numbers ends up feeling empty and unconvincing to most participants.
I believe at this point it is possible to identify a consensus (even if not unanimous) in the community, so I'll leave it to @username_6 to make the final decision.
(Note that the effects of the decision will likely not be effective _immediately_ — we'll need to then start discussing a transition plan, to avoid doing things too hastily.)
username_2: So keep in mind that this is a _branding_ discussion.
username_0: Seems like this has been solved.
Status: Issue closed
username_1: @username_0 I guess you're referring to the discussion at #2986. That one is about visual identity more than naming, as this one was. I will update the title of both issues to make that distinction clearer.
That said, re-reading this discussion, I feel that, while there were valid and even compelling arguments for a rebranding towards "miniman", the overall sentiment in the thread is one of strong attachment to the "tldr" name, so it makes sense to keep that in the core of our branding.
Still, I do bump into the issue of awkwardly having to refer to "tldr-pages pages" all the time, and people in the thread were not too keen on the usage of a hyphen to make the project name stand out as a single word, so I would suggest fully embracing the tldr.sh name. I'll reopen this issue to allow us to make a decision on that regard.
So, question for all those who were involved in this discussion (@username_0, @username_2, @username_6, @username_3, @username_4, @username_5, @username_7, @username_8, @username_9) as well as more recent members of the org (@username_10, @username_11) and everyone in the community:
_In light of the discussed above, what do you guys think about consolidating **tldr.sh** as the project name?_
Please use the reactions so we can gauge the overall sentiment more easily. 👍 👎
username_1: I noticed many names are used for this project, so I think it should be clarified. For example, you can find _TL;DR pages_, _tldr_, _tldr pages_ and _TLDR pages_ in various documents and website.
My suggestion is to use and _tldr_ for the name of npm package and _TLDR pages_ or _tldr pages_ for everything else. How does that sound?
username_10: I've seen this project almost always being called "TLDR pages" (with a variation of the case e.g. "tldr pages", "TLDR Pages" etc). I don't recall seeing any client referring to it differently. This project has been around for quite a while and this name is spread among countless repos, clients and documentation pages. I would therefore vote for "**TLDR Pages**" (or variation of the case) if I had to. Furthermore, "tldr.sh" just feels like a domain name to me.
username_3: There was no neutral reaction button, so I put "eyes" on it. As a single short name, "tldr.sh" is okay .. I guess. But as you can see .. there are concerns being raised with it looking like a domain name.
username_1: Good point, @username_3, I added that option above :)
As for looking like a domain name, I don't see why that's a bad thing; quite the contrary, it helps solidify the branding and is one less thing to memorize. Besides, it's shorter, more distinctive, and works as a single word (Incidentally, I find it interesting that a domain, rather than a shell script, is what the `.sh` extension evoked!)
I do want to hear about your experience with referring to the project's pages, due to the inherent duplication of "tldr pages page". Does that not bother you at all? If we decide to stick with "tldr pages" as the project name, maybe we could call the pages something else (files? documents? entries?), which would resolve the situation in a different way.
username_10: @username_1 if the name is "TLDR pages" then a single page would be called either "TLDR pages page" or "TLDR page" (or maybe even "page of TLDR pages". It of course depends on the context though. There surely is no need to prefix it with "TLDR pages", most of the times it can be clearly understood what the term "page" refers to.
username_10: Also, adding to my previous comment: the project's organization GitHub name is "tldr-pages", which would make naming it differently rather confusing to me, so there's that.
username_3: We would have to rename the org of course. Github will redirect old links pointing to the old org - https://help.github.com/en/github/setting-up-and-managing-organizations-and-teams/renaming-an-organization.
username_11: The only issue is that anyone can then take the old org name. 🤔
username_2: At the risk of stating the obvious, remember the org name has *tons* of searchability value attached to it already.
Can you ask GitHub for a org level redirect?
username_3: They indeed can. But links to old repos will automatically redirect. Only a link to the exact org - "github.com/tldr-pages" will now point to the newly acquired org.
See the link above.
username_10: This. Renaming the org will inevitably break this and also any script/code/auth token/**client** and whatever else uses that name to do anything.
username_3: Yep, so only the exact link and the API requests will return an error. Github will redirect everything else.
username_1: Evidently we wouldn't simply swap things around all of a sudden, unannounced. This change would have to be synced with client maintainers.
Also, we could re-register the org name if we wanted to set up renaming notices or prevent others from taking over the name, etc. Look, none of this is meant to be painless or easy. But we are a capable and technically competent community -- I don't think we should be stopped from taking this sort of decision based on possible technical challenges of a project rename. If we do think the current name is better, even assuming a transition to another name would be completely seamless, then it's fair to stick with it on its merits -- but let's not do so based merely on the technical difficulty of adopting an alternative.
username_10: @username_1 valid point. I genuinely think the current name is better though.
username_9: Personally I've always used `tldr-pages` myself. I agree with @username_10 and @username_2 here personally.
username_0: @username_1 I'm not completely for `.sh` extension since it's generally used for projects developed in Shell only. However it nicely indicates the project's use, and that's a big plus. :+1:
username_1: @username_9 the problem is that previous suggestions (in the older comments of this thread) to use a hyphenized form were met with a lukewarm reception, so unless we can swap that sentiment, we'd be stuck with the awkward two-word, unclearly separated "tldr pages". Any thoughts about that? 😕
username_10: What's the hyphen thing? Whether to use "tldr-pages" or "TLDR pages" would of course depend on the context. If we talk about the GH repo/url user we say "tldr-pages", otherwise "TLDR pages". I don't see a problem.
@username_9 are you suggesting to use "tldr-pages" *as the project name* instead of "TLDR pages"? That wouldn't make sense IMHO.
@username_0 how does `.sh` indicate the project's use? `.sh` makes me think of a shell script, not a collection of manual pages. Could you elaborate on that?
username_0: @username_10 for me it's more indicative of being used in shell. I have to say tldr-pages sounds more like it's a print publication and not a computer program.
username_1: @username_10 please note that at the start of this thread there was some discussion aboout using the capitalized version, and the consensus seemed to be that the lowercase version was preferable.
username_10: @username_1 I was just differentiating between the two alternatives with or without hyphen, I already said that case wasn't important for me.
username_0: Reviewing most of the project's repositories, it seems this and #1192 are the omnipresent issues. Website, docs and clients all have own version of brand name and description.
I suggest we focus on these two (quite correlated) issues over any other, in order to finally move on. The issues hurt the project's branding, promotion, portability (clients) and on top of that, confuses everyone involved. However, I am sure we'll be able to solve this as soon as possible. :hugs:
username_0: ping @username_1 @username_10 @username_3 @username_11
(it seems @username_9 agreed with the point)
username_10: @username_0 I don't think capitalization is a problem, but I nonetheless agree that "tldr pages" should be the name.
username_3: I have already given my opinion above. I am neutral.
username_0: So we agreed on this? Maybe it's the time to close the issue?
username_10: @username_0 doesn't seem like we all agree to me, I *think* the majority prefers "tldr pages" but I'm not sure, cannot read all the history now.
username_0: I meant the majority of course, it's quite impossible everybody completely agrees on something.
username_9: See [this comment](https://github.com/tldr-pages/tldr/issues/2339#issuecomment-423808210) and [this comment](https://github.com/tldr-pages/tldr/issues/3041#issuecomment-495004004) @username_0 :-)
username_1: I'll give a shot at summarizing the main points of the discussion above (I'm interpreting consensus as no strong objections):
- **Semicolon**: there is consensus to _not_ use it (so `tldr` instead of `tl;dr`)
- **Capitalization**: there is consensus to use lowercase (so `tldr` instead of `TLDR`)
- **Rebranding**: no consensus to change. The closest alternative that garnered some support was "miniman", but there was opposition due to the "tldr" name being too ingrained now. Even [the proposal](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-556620205) to make a softer change towards "tldr.sh" had a lukewarm reception, with no clear preference.
- **Hyphenization**: no consensus. Using a hyphenized form was proposed [here](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-255104786) and [here](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-262176332), but was argued against [here](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-262217401); additional signals (comments, reaction) did not accumulate significantly in favor either approach.
Gathering a more global view of what has been discussed, I'd say there are only three alternatives with any chance of being adopted:
1. The progressive option: Biting the bullet and making the change to **miniman**, with the understanding that there are potential downsides but they are manageable, and balanced out by the [upsides](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-326894332) (including [enthusiasm](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-302388562) by [various](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-326822759) [community](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-326827966) [members](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-327083318), [even the project creator](https://github.com/tldr-pages/tldr/issues/1109#issuecomment-302383621)!);
2. The moderate option: Consolidating in **tldr.sh** as a simpler, shorter and more distinctively "brand-y" name;
3. The conservative option: Sticking with **tldr pages** (this exact spelling: no capitals, no semicolon, no hyphen) as the evil we know, to avoid the inconveniences of changing the name and benefit from the historical weight of the name.
I must admit 😢 that option 3 seems to be the only one that nobody objects to, so if you guys agree this assessment is correct, we can close the issue with that decision.
I would only ask for a compromise in order to reduce the "tldr pages page" issue: can we start referring to each individual file as an "entry" rather than a "page"? That's not part of the branding itself, but would greatly facilitate it, and would remove the ambiguity of the project name being "tldr pages" vs. "tldr".
username_9: Great summary @username_1! This is indeed a thorny issue. Personally I've always called it a "tldr page", but a "tldr-pages entry" would be fine too. If this is the case we should update any documentation where this is referenced.
I've always used `tldr-pages` myself, but that's only because that's the name of the org.
username_0: It doesn't seem wrong to use the term *page(s)* for the actual pages. tldr pages as a project is basically a collection of those pages. The more terms we add, the more complicated documentation becomes. I'm against defining more terms such as *entries*.
username_1: @username_0 please note that the suggestion of using "entries" is not frivolous: it's only to overcome the _existing_ issue of referring to an individual file as a "tldr page" (which is ambiguous by making it seem like the project's name is "tldr" alone, which is precisely the type of confusion this issue was created to address) or as "tdlr pages page" (which is very awkward and essentially unusable).
That's one of the reasons I was hoping for alternative project names that didn't include "pages" in the name (i.e. _tldr.sh_ or _miniman_), because those would automatically avoid the issue. But if we can't agree to make such a change, then the issue needs to be addressed elsewhere, hence the proposal to use "entries".
username_10: I think you summarized that pretty well @username_1. I don't think I've ever referred to a page as "tldr page". Why not just use the word "page" alone? It probably depends on the context, but I don't really see this as an issue.
username_1: It's very context-sensitive and would make it hard to talk about tldr pages among other page-like entities (e.g. man pages, actual pagination of content, etc.)
Of course, we can _live_ with the ambiguity (we have done just that so far); I was just suggesting a way that we could get rid of it without much effort (IMO).
username_0: @username_1 It's the same way for man pages and I don't see them having any issues. The command is called `tldr` (just like `man`) and its pages are called `tldr pages` (just like `man pages`), which is what the project mostly is.
username_1: That's a good point. I don't agree that there are no issues, as I described in several comments above, but I can accept that they're not super-problematic. Do you all prefer keeping "page" as the name of each entry, then?
username_10: @username_1 I do, I don't think other options would help that much.
username_12: @username_1
I see your point but I think we could keep _page_
username_0: To be fair, this seems to have already been decided. `tldr pages` is the standard name for the whole project, and `tldr` for this repository and the command-line clients. I'm in for closing this and moving on with more important issues.
Status: Issue closed
username_3: Sounds reasonable to me. I just did a quick scan of the last couple of comments, and it seems like the discussion was about what to call a single item in our repo - and that seems to have converged on "page".
To conclude:
- Project name remains as - "tldr pages". Exact spelling, no semicolon, no hypen, and not just "tldr" too.
- A single item in the project will be termed as a "page". Similar to man pages, a page here implies a page from the "tldr pages" project. Short and simple.
Thanks everyone who participated in this, and special thanks to @username_1 who took a lot of pain in steering the discussion in a coherent way ! Really glad to see how this turned out.
username_1: Thanks guys for wrapping this up. I think we need to remove the remnants of the semicolon, right? I know it's present in the [banner](https://github.com/tldr-pages/tldr/blob/master/images/banner.svg); do you know if any additional instances remain?
username_3: Thanks @username_1. That sounds great. Let's open a new one ? This issue is already overloaded with discussion on the brand name. I think a new issue to track the changes to be made might be more clear.
username_0: @username_1 I suggest you open a PR with that change. You don't have to work on it extensively, as the other contributors can finish the job. :)
Also, the descriptions of other repos in this org should be updated.
username_1: Makes sense @username_3. I'll work on this tomorrow night, time permitting.
username_9: I noticed many names are used for this project, so I think it should be clarified. For example, you can find _TL;DR pages_, _tldr_, _tldr pages_ and _TLDR pages_ in various documents and website.
My suggestion is to use and _tldr_ for the name of npm package and _TLDR pages_ or _tldr pages_ for everything else. How does that sound?
Status: Issue closed
|
MikeMcl/decimal.js | 325703365 | Title: Add sum function
Question:
username_0: How about adding a sum helper?
```js
const numbers = [Decimal(1), Decimal(2), Decimal(3)]
Decimal.sum(numbers) // => 6
```
This would be sugar for:
```js
numbers.reduce((acc, current) => acc.add(current), Decimal(0))
```
Answers:
username_1: Is it possible we could get this soon? bignumber.js has it and this is supposed to be the most comprehensive version of the library.
username_2: I am using that kind of idea like so:
```
export const summation = (accumulator, currentValue) => accumulator + currentValue;
export const exactSummation = (accumulator, currentValue) => {
return (new Decimal(accumulator).plus(new Decimal(currentValue)));
};
```
and then one can apply / use it with array.reduce:
```
array.reduce(tools.exactSummation, 0)
```
username_3: Added `Decimal.sum` method in *v10.3.0*.
Status: Issue closed
|
bencoveney/ts-function-docs | 305071161 | Title: Should be consistent with decorator naming
Question:
username_0: Current @ignore decorator for params is too generic:
- In a large codebase it could conflict with an existing decorator
- It doesn't really tell us anything about what the decorator actually does (what ignores it?)
I suggest all of the documentation decorators should be prefixed with a common name e.g. `@doc...`:
```
/**
* Class documentation
*/
export class documentedClass {
/**
* This one generates documentation
*/
@docGenerate()
public static documentedFunction(@docIgnore sample: string, sample2: number) {
console.log("Hello World");
}
}
```
Any suggestions for a better prefix (or better way of denoting the documentation decorators) are welcome
Answers:
username_1: Sounds good to me 👍
A couple of alternatives:
- Could use an existing JSDoc tag e.g. ([ignore?](http://usejsdoc.org/tags-ignore.html) - not sure we could combine these with the @param tag though.
- Could use a custom JSDoc tag AKA [plugin](http://usejsdoc.org/about-plugins.html).
- Could allow the user to define a function to test which parameters to ignore - so ignoring certain decorators (or parameters for other reasons) is up to them.
Status: Issue closed
|
holoviz/holoviews | 1009940498 | Title: Error adding hover tool to HLine
Question:
username_0: #### ALL software version info
Python 3.8.7
bokeh==2.4.0
holoviews==1.14.6
#### Description of expected behavior and the observed behavior
I would expect to see this plot, with the hover tool displaying the y value

however, I am receiving this error
`ValueError: failed to validate HoverTool(id='1420', ...).renderers: expected an element of either Auto or List(Instance(DataRenderer)), got [None]`.
Using bokeh==2.3.3 and holoviews==1.14.4 results in the expected plot, but with the hover information not displaying.
#### Complete, minimal, self-contained example code that reproduces the issue
```
import holoviews as hv
hv.extension("bokeh")
plot = hv.HLine(0.5).opts(tools=["hover"])
plot
```
#### Stack traceback and/or browser JavaScript console output
```
ValueError: failed to validate HoverTool(id='1006', ...).renderers: expected an element of either Auto or List(Instance(DataRenderer)), got [None]
---------------------------------------------------------------------------
ValueError
Traceback (most recent call last)
~/XXX/venv/lib/python3.8/site-packages/IPython/core/formatters.py in __call__(self, obj, include, exclude)
968
969 if method is not None:
--> 970 return method(include=include, exclude=exclude)
971 return None
972 else:
~/XXX/venv/lib/python3.8/site-packages/holoviews/core/dimension.py in _repr_mimebundle_(self, include, exclude)
1314 combined and returned.
1315 """
-> 1316 return Store.render(self)
1317
1318
~/XXX/venv/lib/python3.8/site-packages/holoviews/core/options.py in render(cls, obj)
1403 data, metadata = {}, {}
1404 for hook in hooks:
-> 1405 ret = hook(obj)
1406 if ret is None:
1407 continue
~/XXX/venv/lib/python3.8/site-packages/holoviews/ipython/display_hooks.py in pprint_display(obj)
280 if not ip.display_formatter.formatters['text/plain'].pprint:
281 return None
--> 282 return display(obj, raw_output=True)
283
284
~/XXX/venv/lib/python3.8/site-packages/holoviews/ipython/display_hooks.py in display(obj, raw_output, **kwargs)
250 elif isinstance(obj, (CompositeOverlay, ViewableElement)):
251 with option_state(obj):
[Truncated]
--> 169 descriptor._notify_mutated(owner, old, hint=hint)
170
171 def _saved_copy(self):
~/XXX/venv/lib/python3.8/site-packages/bokeh/core/property/descriptors.py in _notify_mutated(self, obj, old, hint)
592 # re-validate because the contents of 'old' have changed,
593 # in some cases this could give us a new object for the value
--> 594 value = self.property.prepare_value(obj, self.name, value, hint=hint)
595
596 self._set(obj, old, value, hint=hint)
~/XXX/venv/lib/python3.8/site-packages/bokeh/core/property/bases.py in prepare_value(self, owner, name, value, hint)
363 else:
364 obj_repr = owner if isinstance(owner, HasProps) else owner.__name__
--> 365 raise ValueError(f"failed to validate {obj_repr}.{name}: {error}")
366
367 if isinstance(owner, HasProps):
ValueError: failed to validate HoverTool(id='1006', ...).renderers: expected an element of either Auto or List(Instance(DataRenderer)), got [None]
```
Answers:
username_1: I believe that is because HLine is a Bokeh Annotation, and Bokeh Annotations currently support only a limited subset of what you can do with Bokeh glyphs like Line. See https://github.com/bokeh/bokeh/issues/10644, and in the meantime maybe you can use a finite hv.Line object instead?
username_2: I agree it is unfortunate that you can't hover on HLines and VLines so as Jim suggested, you have to use a `Curve` or `Path` instead. I'll file this as a feature request related to the bokeh backends.
username_3: There is no action we can take here, except request this be supported upstream in Bokeh. Once that's done this will just work in HoloViews so I'm going to close.
Status: Issue closed
|
Shopify/js-buy-sdk | 163825783 | Title: "_global2.default.require is not a function" error on Node - Introduced in version 0.1.7
Question:
username_0: Hey guys,
I have upgraded to 0.1.7 yesterday and started experiencing the following error when the node application runs (I use Shopify Buy SDK both on the server and on the client):
```
d:\Development\Experiments\tmp_node_test\node_modules\shopify-buy\lib\isomorphic-fetch.js:16
_global2.default.fetch = _global2.default.require('node-fetch');
^
TypeError: _global2.default.require is not a function
at Object.<anonymous> (d:\Development\Experiments\tmp_node_test\node_modules\shopify-buy\lib\isomorphic-fetch.js:16:45)
at Module._compile (module.js:413:34)
at Object.Module._extensions..js (module.js:422:10)
at Module.load (module.js:357:32)
at Function.Module._load (module.js:314:12)
at Module.require (module.js:367:17)
at require (internal/module.js:16:19)
at Object.<anonymous> (d:\Development\Experiments\tmp_node_test\node_modules\shopify-buy\lib\shopify.js:19:1)
at Module._compile (module.js:413:34)
at Object.Module._extensions..js (module.js:422:10)
```
I have created a minimal possible scenario to make sure it is not something specific to my code:
1. empty folder - `npm init`
2. `npm install shopify-buy -- save`
3. created index.js with the following contents:
`var s = require("shopify-buy");`
4. Running `node index` produces the above error
Node version used: v5.6.0
Npm version used: 3.10.2
From my investigation, the `global.require` access used instead of globally using `require` (pre 0.1.7) is the culprit. For some reason, when running node as a REPL - `global.require` is defined. But when running it with a script - `global.require` is not defined.
So far, digging into node's repl and c++ code I could not find any reason for this difference. Also I am currently not able to test on node V4.2.2 which is the highest version your CI tests on.
@username_1 Is there a reason you chose to not use the globally available "require" (after you confirmed it's a "node like environment") ?
Answers:
username_1: Hey!
Thanks for investigating this so thoroughly. The problem with using `require` on its own is only that babel chokes on it. It's module compilers get confused when they see require conditionally nested. I'll look into this right away and see if there's a better workaround. I'm also open to recommendations if you think you have some insight into what the root of the problem may be.
Thanks Again!
username_0: I am sorry, but I'm still unable to build on windows even after you converted the scripts to node.
The environment is Windows 10, using Git Bash.
(I can see the source of the problem, if you think it's worth it I can open another issue with a repro and description..)
username_0: Another update, on my machine this issue occurs on node 4.4.2 as well.
I'm unclear as to how this passes CI.
username_2: If you refer to how the require issue passes, our CI tests currently run within a browser (PhantomJS). So that bit is never really experienced during the test. #131 will make that possible when completed.
re: build on windows, are you referring to the same issue described here @username_0?
username_0: @username_2 Thanks, good to know how the CI works - I Only briefly looked at the setup yaml.
Regarding the build on windows, you have not referred to any issue number, but anyway it's an aside I don't want to pollute this thread with it.
username_0: @username_1 Hey, I eventually created a working build env under docker running linux (But really, I wish it was windows compatible so I could help more).
Having done that, I have observed the babel problem you described. Without investigating that I did try some naaive work around which worked for me:
`isomorphic-fetch.js`:
```
import global from './metal/global';
import isNodeLikeEnvironment from './metal/is-node-like-environment';
const fetch = global.fetch;
var _require = require;
if (!fetch && isNodeLikeEnvironment()) {
global.fetch = _require('node-fetch');
global.Response = global.fetch.Response;
}
```
Which transpiles to:
```
'use strict';
var _global = require('./metal/global');
var _global2 = _interopRequireDefault(_global);
var _isNodeLikeEnvironment = require('./metal/is-node-like-environment');
var _isNodeLikeEnvironment2 = _interopRequireDefault(_isNodeLikeEnvironment);
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }
var fetch = _global2.default.fetch;
var _require = require;
if (!fetch && (0, _isNodeLikeEnvironment2.default)()) {
_global2.default.fetch = _require('node-fetch');
_global2.default.Response = _global2.default.fetch.Response;
```
Since you already check if it's "node like" env, even if `_require` is undefined things would work fine in the browser. (I assume?)
username_2: That, definitely looks interesting. Could be the way to go. We'd see.
Good one @username_0.
username_0: @username_1 @username_2 Sure - This got me curious as to why the transpilation fails this way (when require used as is).
When running your build pipeline I get the same error you got:
```
File: isomorphic-fetch.js
TypeError: isomorphic-fetch.js: Property right of AssignmentExpression expected node to be of a type ["Expression"] but instead got null
...
```
But when trying to install babel (`[email protected]`) and use that directly on the command line:
`babel --presets es2015 --plugins babel-plugin-transform-es2015-modules-commonjs,babel-plugin-transform-es2015-block-scoping,babel-plugin-transform-strict-mode ./src/isomorphic-fetch.js`
(Hopefully the right configuration as you use it in your pipeline)
It passes with no problem producing:
```
use strict';
var _global = require('./metal/global');
var _global2 = _interopRequireDefault(_global);
var _isNodeLikeEnvironment = require('./metal/is-node-like-environment');
var _isNodeLikeEnvironment2 = _interopRequireDefault(_isNodeLikeEnvironment);
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }
var fetch = _global2.default.fetch;
if (!fetch && (0, _isNodeLikeEnvironment2.default)()) {
_global2.default.fetch = require('node-fetch');
_global2.default.Response = _global2.default.fetch.Response;
```
as expected.
So I can only think the difference is in how the broccoli-babel (internally using babel 6.10 I believe) transpiler activates the transpilation or a version mismatch.
HTH
username_1: It's specifically the AMD transpiler that chokes up. The commonjs one seems to pass.
As for working on windows: We've tested under powershell, and native bash on linux and mac. I'm not sure how git bash works on windows though. I'd certainly appreciate it if you could open an issue in regard to what's going on there.
I haven't had a ton of time to investigate a better way to grab the require var, but I'm glad your way seems to work. I should hopefully have something more concrete for you soon getting this to work.
username_1: Relates to #164
username_2: fixed in v0.2.2
Status: Issue closed
|
TablePlus/uuid-generator | 783186642 | Title: UUID generator not working on windows
Question:
username_0: I am unable to find the Generate UUID option in the menu on TablePlus Windows. I have already tried to reinstall plugin and even uninstall and install again. It works on mac.


 |
mkristian/jar-dependencies | 56031824 | Title: bundler bad file descriptor
Question:
username_0: Gemfile:
```
gem 'example', :path => '../example'
gemspec
```
where both gemspecs are missing the license which would produce a warning and which fails with:
```
Errno::EBADF: Bad file descriptor - Bad file descriptor
```
Answers:
username_0: fixed via 3155ff3dcd73c91aad14e70f34ff897da541aa43
Status: Issue closed
|
IATI/IATI-Codelists-NonEmbedded | 234451547 | Title: “Last updated” on recently updated codelists is incorrect
Question:
username_0: If it’s not going to be fixed (with the current website architecture), then I am definitely in favour of removing it.
Answers:
username_1: This is something to do with the magic involved in the website generation process, with dates being brought in from a range of different locations, combined, smushed and something being output at the end of the process.
The upcoming work on the website will make the page generation process more streamlined and prevent situations like this from occurring. It will also allow for this sort of information to be displayed on a wider range of pages. As such, this won't be fixed with the current website architecture (though could be removed so as to prevent incorrect information from being displayed?).
username_0: If it’s not going to be fixed (with the current website architecture), then I am definitely in favour of removing it.
username_0: It looks like this is the bit that does it:
https://github.com/IATI/IATI-Standard-SSOT/blob/695c8456045f80eefd2bc4d8ac02f7972e3dc068/combined_gen.sh#L23-L25
I.e. it’s relatively straightforward. But perhaps the git repository in /docs on the build server is broken in some way?
username_1: There are several parts of the generation process that *just work* and modifying them is a somewhat risky business (there are limited tests, and reverting even the simplest of changes can be... not entirely straightforward).
Status: Issue closed
|
videojs/video.js | 206635835 | Title: Add support for "bubbling" unused keypresses up through control bar components to the player
Question:
username_0: We've been working hard on keyboard accessibility for the video.js control bar, using Tab/Shift-Tab, Enter, Space, and the arrow keys. Each component knows what key presses it supports, and which ones it ignores. There's a basic structure in place to pass keypresses up through the component hierarchy to the base `Component`, but it would make sense to then pass them to the `parent` Component, and onwards up to the player itself.
That way, we could either implement hotkeys ourselves later on, or provide a single point to attach a plug-in to handle keypresses which aren't used by the controls themselves.
Thoughts?
Answers:
username_1: Has anyone followed up on this issue? I think hotkey support would be a very valuable feature.
I might try to work on this myself and make a pull request if nothing is in the works yet.
username_0: @username_1 I've got a project on the back burner to implement this; I'll do a little more work on it and create a PR, so you can at least take a look at it. Give me a day or two.
Status: Issue closed
|
Merubokkusu/Discord-S.C.U.M | 948826447 | Title: Error: AttributeError: 'GatewayServer' object has no attribute 'subscribeToGuildEvents'
Question:
username_0: I am trying the following as per the example but it is giving the above error:
```
if resp.event.ready_supplemental: # ready_supplemental is sent after ready
bot.gateway.subscribeToGuildEvents(wait=1)
user = bot.gateway.session.user
```
The error is:
```
File "/Users/AdnanAhmad/Data/anaconda3/lib/python3.7/site-packages/discum/gateway/gateway.py", line 233, in _response_loop
func(resp)
File "/discum_indigo_plateau.py", line 20, in fetch
bot.gateway.subscribeToGuildEvents(wait=1)
AttributeError: 'GatewayServer' object has no attribute 'subscribeToGuildEvents'
``` |
opentok/opentok-react-native-samples | 392229148 | Title: OTRN JS: There was an error: logging
Question:
username_0: Getting this error on running the BasicVideo application on device with Android 7.0. Running just fine in android emulator.
Status: Issue closed
Answers:
username_1: @username_0 I've just updated the samples to use the latest version of the library and React Native. You should not be seeing this issue anymore. |
topcoder-platform/submissions-api | 451311475 | Title: Fix issues found during submission api wrapper contest
Question:
username_0: Two issues reported during submission api wrapper contest:
- Missing definitions:
```
# request headers
- $ref: '#/parameters/IfNoneMatchParamHeader'
- $ref: '#/parameters/IfModifiedSinceParamHeader'
```
- For review type creation, id field is marked as a required input in swagger, when in fact, it is auto generated.
Answers:
username_0: Issues reported during wrapper contest (Reviews)
- POST /reviews returns 200 as status code. Swagger says 201. Swagger needs correction.
- For reviews resource, swagger specification says that `scorecardId` can be an integer or string. Code also says so, but since we did not specify the schema when interfacing with ES, ES has taken the schema to be that of an integer. Update the code and the swagger specification to indicate that `scorecardId` needs to be an integer
username_0: Review Summations:
- `isFinal` field exists in code but not in swagger
username_0: Submission:
- PUT `/submissions/{submissionId}` says `type` field is required. Code does not
username_0: Contest Launched for remaining fixes: http://www.topcoder.com/challenge-details/30098900/?type=develop
username_0: PR ready: https://github.com/topcoder-platform/submissions-api/pull/127
Status: Issue closed
username_0: PR merged. Closing ticket. |
mthadley/outlander-ui | 173507525 | Title: Color of modified tabs.
Question:
username_0: First of all, thanks so much for the theme. It is by far the best looking theme for Atom I have tried and itlooks amazing with Numix or Flatabulous. I was wondering if you would perhaps considering adding a small option to make it even better.
Specifically, it would be great if the user could specify the highlight color of modified tabs - the bright teal one is not bad but something more pastel and warm would look better with the GTK theme.
Or perhaps it can already be done through configuration files?
Many thanks!
Answers:
username_1: Thanks for the suggestion! It seems reasonable to add a configuration option for that. I think I'll add something like "Theme Color" (and maybe a few others) so that teal can be replaced with whatever the user find more appealing.
username_0: Fantastic, thanks for the prompt reply and for the enhancement. Looking forward to the new version.
username_1: Sorry this has still not been implemented. For my own reference:
I was waiting to use a newer feature of `less`, which will only be available when `[email protected]` makes it into atom. See [this](https://github.com/atom/atom/pull/12176) pull request. |
flutter/flutter | 881413110 | Title: DragStartBehavior makes no effect on when `onStart` is called
Question:
username_0: ## Steps to Reproduce
1. Run the code sample below
2. Click the blue box
3. (Optionally) drag horizontally to see that the `onStart` fires only when gesture wins the arena
**Expected results:**
Per [this documentation](https://github.com/flutter/flutter/blob/e74c15cac49af6fa4cad8670cff033219f5a4982/packages/flutter/lib/src/gestures/monodrag.dart#L87-L105
), `DragStartBehavior.down` should make `onStart` fire as soon as pointer goes down
**Actual results:**
No difference, `onStart` in both cases fires after recognizer has won the arena
<details>
<summary>Code sample</summary>
```dart
import 'package:flutter/gestures.dart';
import 'package:flutter/material.dart';
void main() => runApp(const MyApp());
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
body: Home(),
),
);
}
}
class Home extends StatelessWidget {
const Home({Key? key}) : super(key: key);
void _handleStart(DragStartDetails details) {
print(details.sourceTimeStamp);
}
@override
Widget build(BuildContext context) {
return Center(
child: GestureDetector(
// dragStartBehavior: DragStartBehavior.start,
dragStartBehavior: DragStartBehavior.down,
onHorizontalDragStart: _handleStart,
onVerticalDragStart: (_) {},
child: Container(
width: 100.0,
height: 100.0,
color: Colors.blue,
),
),
);
}
}
```
[Truncated]
• IntelliJ at C:\Program Files\JetBrains\IntelliJ IDEA Community Edition 2020.3.3
• Flutter plugin can be installed from:
https://plugins.jetbrains.com/plugin/9212-flutter
• Dart plugin can be installed from:
https://plugins.jetbrains.com/plugin/6351-dart
[√] VS Code (version 1.56.0)
• VS Code at C:\Users\danya\AppData\Local\Programs\Microsoft VS Code
• Flutter extension version 3.22.0
[√] Connected device (4 available)
• sdk gphone x86 (mobile) • emulator-5554 • android-x86 • Android 11 (API 30) (emulator)
• Windows (desktop) • windows • windows-x64 • Microsoft Windows [Version 10.0.19041.928]
• Chrome (web) • chrome • web-javascript • Google Chrome 90.0.4430.93
• Edge (web) • edge • web-javascript • Microsoft Edge 90.0.818.46
• No issues found!
```
</details>
Answers:
username_1: @username_0 Hi,
In my understanding, this is an issue described in the documentation. At any time, the call of the callbacks occurs when someone wins the arena.
`DragStartBehavior` only affects the value of `DragStartDetails.globalPosition`
username_1: CC @dkwingsmt @username_2
username_2: There appear to be some inaccuracies in our documentation compared to the implementation. As implemented, `DragStartBehavior` only changes what offsets are reported to `onStart`, but not the timing of when it is called. We should update the documentation to reflect that. |
johnpelquingua/freightbit-logistics | 75833518 | Title: Customer Relations Report: Listing of customer has no grid lines
Question:
username_0: Steps to replicate:
1. On the Reports submenu, select Customer Relations.
2. On the Statistics tab, select "Total Number of Bookings".
3. Select dates for report period.
4. Click "View Statistics" button.
Actual result: A new window was displayed showing the report but there were no grid lines for the list of customers.
Expected result: The customer list should have grid lines.

Answers:
username_0: Issue no longer exists due to change of template design
Status: Issue closed
|
ZupIT/ritchie-cli | 778340725 | Title: Add command rit rename formula
Question:
username_0: <!-- Please only use this template for submitting new feature or enhancement requests -->
**What would you like to be added**:
Develop the command `rit rename formula` to change the name of a formula
**Why is this needed**:
Currently, if a developer needs to rename a formula, he renames the folder names. However, due to auto-rebuild, the new name is not detected and renaming a formula becomes cumbersome
- [X] Check this box if this issue needs a documentation update
Answers:
username_0: We were discussing a way to not need this command and let it happen inherently by allowing the user to simply rename the folders. However, it seems that the `tree.json` would need to be updated any way. We need a command that would rename the folders and adjust the tree.
username_0: Should only work for local formulas
username_1: I'm working on this issue.
Status: Issue closed
|
itayperl/mako-dl | 287919456 | Title: ValueError: Input strings must be a multiple of 16 in length
Question:
username_0: ```
File "/Users/user/Documents/Apps/mako-dl/mako-dl/libmako.py", line 69, in get_playlist
return urllib.unquote_plus(decrypt(requests.get(url).content, PLAYLIST_KEY))
File "/Users/user/Documents/Apps/mako-dl/mako-dl/libmako.py", line 62, in decrypt
decrypted = aes.decrypt(encrypted.decode('base64'))
File "/usr/local/lib/python2.7/site-packages/Crypto/Cipher/blockalgo.py", line 295, in decrypt
return self._cipher.decrypt(ciphertext)
ValueError: Input strings must be a multiple of 16 in length
```
tried:
```
./mako -s 9:6 /mako-vod-keshet/uvda
```
Status: Issue closed
Answers:
username_0: awesome. thanks man ! |
topcoder-platform/community-app | 252759038 | Title: Start and End Date filtering will give wrong results
Question:
username_0: Steps to Reproduce
-----------------------------------------------------------------
- Login as a valid user
- Go to http://community-app.topcoder.com/challenges?
- Click 'Filters'
- Set 'Date range' as Aug 01, 2017 - Aug 21, 2017
- Check the 'Predix - Integration with Alexa Voice Service' in Open for registration
- Start Aug 24, 2017 - Sept 7, 2017
Actual Result(s)
-----------------------------------------------------------------
- Start and End Date filtering will give wrong results
Expected Result(s)
-----------------------------------------------------------------
- Must display the challenges that falls within the date range
Environment
-----------------------------------------------------------------
- **Device(s):** Laptop
- **Operating System:** Windows 7 64bit
- **Browser(s):** Chrome 60.0.3112.101 (Official Build) (64-bit)
Image/Video/JS Log/Console Log (If not attached here, Please check the comments section)
-----------------------------------------------------------------
Answers:
username_0: 
username_1: Accepted, 3 points. I believe, the problem is that now the search looks at the date of specification creation (when the challenge was first drafted, and not when it was actually started). This Predix Alexa challenge was drafted like a week before we got the green light to launch. This should be fixed.
Othewise, it is fine that the end does not fit into the search range. I believe, we should find a challenge if at least some of its dates intersect with the search range.
Status: Issue closed
|
oeg-upm/gtfs-bench | 566154225 | Title: Add function to process exception_type in calendar_dates GTFS file
Question:
username_0: [L180](https://github.com/oeg-upm/gtfs-bench/blob/b98243582180f4b956e856c2d7a43f5cd3efae3a/mappings/gtfs-csv.yml#L180) `exception_type` is not of boolean type since it uses 1 and 2 as values in GTFS. This can cause mixed boolean/string values (1 is converted, 2 no). A function is required during lifting to match gtfs:dateAddition range as boolean or the input files should be changed accordingly.
Answers:
username_1: This issue shouldn't be part of the Knowledge Graph Generation process as it is currently out of the scope of the benchmark, it should be achieved in a pre-processing task of the date (only for original data, gtfs-1)
username_1: to be tested in the generation process by morph-csv + vig
username_1: @daniel-dona could you include this change in the new SQL dump for VIG?
username_1: solved for `exception_type` in the new generator software
Status: Issue closed
|
razorpay/razorpay-ruby | 206133365 | Title: NameError: uninitialized constant Razorpay::Customer
Question:
username_0: When I write on console..
customer = Razorpay::Customer.create email: '<EMAIL>', contact: '9876543210'
it shows me an error: NameError: uninitialized constant Razorpay::Customer
Answers:
username_1: Please put `require 'razorpay/customer` before where you want to use the customer class
username_0: Thanks @username_1 Ideally razorpay class should load all nested classes.
username_1: Agreed, we faced the same issue with #10 earlier. Will try to take care of this from future releases.
Will close this once I push out a new release for this
username_0: Even I can create a PR for that.. will add `require 'razorpay/customer'` and `require 'razorpay/invoice'` to razorpay.rb
username_1: Feel free to :100:
I can merge and push out a new release :+1:
Status: Issue closed
username_2: Fixed in #21 |
anoChick/kanipan | 314199219 | Title: ハサミ動かす
Question:
username_0: pivot rotator の rigidbody 対応する
https://github.com/username_0/neo-c-sky/blob/master/Assets/Scripts/VoxelModel/PivotRotator.cs
pivot は joint の anchor からいい感じに取得すれば、 joint と共存してオンオフ可能でいいかも?
それぞれの関節の角度を制御できれば、あとはマウスの vector 方向の角度に向かうように関節を動かしていく
Status: Issue closed
Answers:
username_0: pivot rotator の rigidbody 対応する
https://github.com/username_0/neo-c-sky/blob/master/Assets/Scripts/VoxelModel/PivotRotator.cs
pivot は joint の anchor からいい感じに取得すれば、 joint と共存してオンオフ可能でいいかも?
それぞれの関節の角度を制御できれば、あとはマウスの vector 方向の角度に向かうように関節を動かしていく
Status: Issue closed
|
gravitational/teleport | 754863237 | Title: Update audit log UI to support new database access events
Question:
username_0: ### Feature Request
Database access introduced new audit event types:
* `db.session.start`: user connected to a database
* `db.session.end`: user disconnected from a database
* `db.query`: user executed a query
The audit log UI needs to be updated to recognize these events and display appropriate messages/icons.
The actual events format and available fields can be seen in RFD 11.
### Motivation
Audit log UX.
### Who's it for?
OSS User, Pro, Enterprise<issue_closed>
Status: Issue closed |
harvard-lil/capstone | 591972754 | Title: Tracking: cite extraction / linking nitpicks
Question:
username_0: - [ ] cite urls should have normalized reporter names to avoid a redirect on click
- [ ] "123 U. S. 456" urls redirect to /u-s/123/456/, which isn't found
- [ ] "2 or 3" is extracted as "2 Or. 3"
Answers:
username_0: Closing this in favor of https://github.com/harvard-lil/capstone/projects/45
Status: Issue closed
|
NationalSecurityAgency/ghidra | 476694364 | Title: gradle integrationTestJar not working
Question:
username_0: **Describe the bug**
Attempt to run task `gradle integrationTestJar` produce compilation error.
```
Ghidra\Test\IntegrationTest\src\test.slow\java\ghidra\server\remote\ServerTestUtil.java:947: error: cannot find symbol
ServerAdmin serverAdmin = new ServerAdmin();
```
**To Reproduce**
Steps to reproduce the behavior:
1. Run `gradle integrationTestJar`
4. PROFIT<issue_closed>
Status: Issue closed |
horiajurcut/opencv-template-matching | 716983506 | Title: youtube_dl.utils.DownloadError: ERROR: giving up after 0 retries
Question:
username_0: hello I tried the code and i got this error do you have an idea to who to solve it . or i can download the video and directly use it without need for Youtube_dl .
I would like to use this code to another video in my local pc what should I modify to the code so I can use it with any type of videos if I have templates of them.
your help will be appreciated . Thank you . |
kubernetes/minikube | 405479737 | Title: VirtualBox & minikube: misleading error message "The host-only adapter we just created is not visible"
Question:
username_0: <!-- Thanks for filing an issue! Before hitting the button, please answer these questions.-->
**Is this a BUG REPORT or FEATURE REQUEST?**
Bug report for misleading error message / request for improved docs & error messages
<!--
If this is a BUG REPORT, please:
- Fill in as much of the template below as you can. If you leave out
information, we can't help you as well.
If this is a FEATURE REQUEST, please:
- Describe *in detail* the feature/behavior/change you'd like to see.
In both cases, be ready for followup questions, and please respond in a timely
manner. If we can't reproduce a bug or think a feature already exists, we
might close your issue. If we're wrong, PLEASE feel free to reopen it and
explain why.
-->
Please provide the following details:
**Environment**:
**Minikube version** : v0.33.1
- **OS** : macOS Mojave 10.14.2 (18C54)
- **VM Driver** : VirtualBox 6.0
- **ISO version** : minikube-v0.33.1.iso
**What happened**:
```
minikube start
Starting local Kubernetes v1.13.2 cluster...
Starting VM...
E0131 14:39:29.593152 91186 start.go:205] Error starting host: Error starting stopped host: Error setting up host only network on machine start: The host-only adapter we just created is not visible. This is a well known VirtualBox bug. You might want to uninstall it and reinstall at least version 5.0.12 that is is supposed to fix this issue.
Retrying.
E0131 14:39:29.595252 91186 start.go:211] Error starting host: Error starting stopped host: Error setting up host only network on machine start: The host-only adapter we just created is not visible. This is a well known VirtualBox bug. You might want to uninstall it and reinstall at least version 5.0.12 that is is supposed to fix this issue
minikube failed :( exiting with error code 1
```
**What you expected to happen**:
1. minikube to work correctly,
2. OR, a helpful error message
**How to reproduce it** (as minimally and precisely as possible):
1. Completely fresh install of VirtualBox & minikube
2. Try running `minikube start`
3. See the abovementioned error
**NOTE:** the relevant workaround / fix is to _reboot your machine after you have installed VirtualBox_. Yes, even on macOS. This is _not_ mentioned in either the docs or the error message - as a user, I had to dig up GitHub issues to find a reference to [this](https://github.com/kubernetes/minikube/issues/2439#issuecomment-427669372).
It would be super useful to have a) better documentation about this, e.g. in [readme quickstart](https://github.com/kubernetes/minikube#quickstart) b) better error messages
Answers:
username_0: Update: if like me, you have tried to run `minikube start` right after a VirtualBox install, without rebooting, the minikube cluster can be in an inconsistent, non-starting state, and not work _even after a reboot_. But you'll get a new, different error.
```
minikube start
Starting local Kubernetes v1.13.2 cluster...
Starting VM...
Getting VM IP address...
Moving files into cluster...
Setting up certs...
Connecting to cluster...
Setting up kubeconfig...
Stopping extra container runtimes...
Machine exists, restarting cluster components...
E0131 15:16:18.034551 2345 start.go:382] Error restarting cluster: restarting kube-proxy: waiting for kube-proxy to be up for configmap update: timed out waiting for the condition
minikube failed :( exiting with error code 1
```
This above error has been also reported here https://github.com/kubernetes/minikube/issues/3354
However, after running `minikube delete` and `minikube start`, I seemed to get into a working state:
```
minikube delete
minikube start
Deleting local Kubernetes cluster...
Machine deleted.
Starting local Kubernetes v1.13.2 cluster...
Starting VM...
Getting VM IP address...
Moving files into cluster...
Setting up certs...
Connecting to cluster...
Setting up kubeconfig...
Stopping extra container runtimes...
Starting cluster components...
Verifying kubelet health ...
Verifying apiserver health ...
Kubectl is now configured to use the cluster.
Loading cached images from config file.
Everything looks great. Please enjoy minikube!```
To wrap up:
1. Install VirtualBox and minikube, don't reboot
2. Run `minikube start`, observe error 1 of "the host-only adapter we just created is not visible"
3. Reboot the machine, run `minikube start`, observe error 2 of "timed out waiting for the condition"
4. Run `minikube delete`, `minikube start`, observe minikube working correctly.
So: running `minikube start` after VirtualBox installation but **before rebooting** can cause minikube to be in an error state.
username_1: Agreed. We should update the error message to cover this much more likely scenario.
username_2: So, from my point of view, the first message is pretty descriptive;)
Which messages do you expect to see?
I can take care of it by the way))
username_3: Just an addition to the @username_0 's comment for the people who are looking for solution to the problem and end up here... Your VirtualBox might have security issues on MacOS. To solve it you should go to Security&Privacy settings and allow VirtualBox. Allow option only visible after the fresh installation of VirtualBox. If you do not see allow button, try removing the VirtualBox via uninstaller then install it again. After that check the Security&Privacy settings, you should be able to see the allow option.
username_1: Perhaps the error message should be:
"Error starting host: The network adapter is not visible. If you just installed VirtualBox, you may need to reboot it before creating a VM."
username_4: @username_1 Is it still open? i would like to take it.
username_5: I'm getting the same error on my Debian Linux.
So, I started with `minikube start -v 9` and get this log:
```
Progress state: NS_ERROR_FAILURE
VBoxManage: error: Failed to create the host-only adapter
VBoxManage: error: VBoxNetAdpCtl: Error while adding new interface: failed to open /dev/vboxnetctl: No such file or directory
VBoxManage: error: Details: code NS_ERROR_FAILURE (0x80004005), component HostNetworkInterfaceWrap, interface IHostNetworkInterface
VBoxManage: error: Context: "RTEXITCODE handleCreate(HandlerArg*)" at line 94 of file VBoxManageHostonly.cpp
```
I fixed that loading the missing kernel modules (as root):
```
modprobe vboxdrv
modprobe vboxnetadp
modprobe vboxnetflt
```
No restart or delete required.
Installed Versions:
```
||/ Name Version Architecture
+++-===============-============-============
ii virtualbox 6.0.4-dfsg-5 amd64
ii virtualbox-dkms 6.0.4-dfsg-5 all
```
```
$ minikube version
minikube version: v0.34.1
```
username_6: I'm having the same problems with minikube, I'm on
- ***macos mojave 10.14.3 (18D109)***
- ***minikube version: v0.34.1***
- ***VirtualBox 6.0.4***
username_1: @username_6 - did a reboot fix it?
username_7: So, Is it not solved @username_1 ?
This is same like my sympton.
username_8: Same problem with:
* macOS Mojave Version 10.14.5
* VirtualBox Version 6.0.8 r130520 (Qt5.6.3)
* minikube version: v1.0.1
Despite restarts and ensuring [Security&Privacy](https://github.com/kubernetes/minikube/issues/3614#issuecomment-462194662) settings were clear, I still get the same error. I do not observe the above [timeout]
Here's my output from `minikube start -v 9`
```
$ minikube start -v 9
😄 minikube v1.0.1 on darwin (amd64)
🤹 Downloading Kubernetes v1.14.1 images in the background ...
💡 Tip: Use 'minikube start -p <name>' to create a new cluster, or 'minikube delete' to delete this one.
COMMAND: /usr/local/bin/VBoxManage showvminfo minikube --machinereadable
STDOUT:
{
name="minikube"
groups="/"
ostype="Linux 2.6 / 3.x / 4.x (64-bit)"
UUID="9f06ee79-d1ee-4e9b-b734-26b9c1aba221"
CfgFile="/Users/harrison/.minikube/machines/minikube/minikube/minikube.vbox"
SnapFldr="/Users/harrison/.minikube/machines/minikube/minikube/Snapshots"
LogFldr="/Users/harrison/.minikube/machines/minikube/minikube/Logs"
hardwareuuid="9f06ee79-d1ee-4e9b-b734-26b9c1aba221"
memory=2048
pagefusion="off"
vram=8
cpuexecutioncap=100
hpet="on"
cpu-profile="host"
chipset="piix3"
firmware="BIOS"
cpus=2
pae="on"
longmode="on"
triplefaultreset="off"
apic="on"
x2apic="off"
nested-hw-virt="off"
cpuid-portability-level=0
bootmenu="disabled"
boot1="dvd"
boot2="dvd"
boot3="disk"
boot4="none"
acpi="on"
ioapic="on"
biosapic="apic"
biossystemtimeoffset=0
rtcuseutc="on"
hwvirtex="on"
nestedpaging="on"
largepages="on"
vtxvpid="on"
vtxux="on"
paravirtprovider="default"
effparavirtprovider="kvm"
VMState="poweroff"
VMStateChangeTime="2019-05-16T17:11:28.000000000"
[Truncated]
COMMAND: /usr/local/bin/VBoxManage list hostonlyifs
STDOUT:
{
}
STDERR:
{
}
COMMAND: /usr/local/bin/VBoxManage list hostonlyifs
STDOUT:
{
}
STDERR:
{
}
💣 Unable to start VM: start: Error setting up host only network on machine start: The host-only adapter we just created is not visible. This is a well known VirtualBox bug. You might want to uninstall it and reinstall at least version 5.0.12 that is is supposed to fix this issue
😿 Sorry that minikube crashed. If this was unexpected, we would love to hear from you:
👉 https://github.com/kubernetes/minikube/issues/new
```
username_9: I got it work by:
1) Ensuring [Security&Privacy](https://github.com/kubernetes/minikube/issues/3614#issuecomment-462194662) settings were clear.
2) minikube delete
3) Restart machine
4) rm -rf .minikube
5) minikube start
username_1: Closing as a workaround was found. minikube will now suggest that the user reinstalls VirtualBox and reboots.
Status: Issue closed
username_10: I think still have same problem after reboot
username_11: This problem can also occur after upgrading to kernel 5.8.x, I switched back to 5.7.x and the problem has gone away.
username_12: I got it work by:
System Preferences -> Security & Privacy -> Allow -> Then allow the software corporation (in this case Oracle) |
Queueing-Systems-Assistance/qsa-calculator | 619793166 | Title: Recalculate M | M | 1 | K | K
Question:
username_0: **Description**
The `M | M | 1 | K | K` system `P0`, `QAvg`, `WAvg`, `EWW0` features are incorrect for sure. Also, the `US` feature is missing, and we should validate the `Lambda` value: 0 <= Lambda <= K - 1 and the Mu value as well: 1 <= Mu <= K
**Reproduction**
Use the following input values:
| Feature | Input value |
|--|--|
|Lambda|1 |
|Mu| 1 |
|K|2|
|n| 2 |
|t| 3 |
**Expected**
|Feature|Output |
|--|--|
|P0| 0.3333333333333333|
|QAvg| 0.33333333333333326|
|WAvg| 0.49999999999999983|
|EWW0| 0.7499999999999997|
**Actual**
|Feature|Output |
|--|--|
|P0| NaN|
|QAvg| NaN|
|WAvg| NaN |
|EWW0| NaN|<issue_closed>
Status: Issue closed |
raynor85/Blue-Economics-New | 98566050 | Title: Wire up html views for application flow
Question:
username_0: Several people have created views for different pages of the application. We need to create Angular controllers for each of those views and wire them up so that clicking buttons/links/etc takes the user from one page to the next.
Answers:
username_1: where are these views? |
jcberquist/commandbox-cfformat | 696836654 | Title: Mac < 10.15 issues with cftoken
Question:
username_0: ```
Error invoking external process
dyld: lazy symbol binding failed: Symbol not found: ____chkstk_darwinReferenced from: /Users/ortus/Sites/projects/commandbox/src/cfml/modules/commandbox-cfformat/bin/v0.16.0/cftokens_osx (which was built for Mac OS X 10.15)Expected in: /usr/lib/libSystem.B.dylibdyld: Symbol not found: ____chkstk_darwinReferenced from: /Users/ortus/Sites/projects/commandbox/src/cfml/modules/commandbox-cfformat/bin/v0.16.0/cftokens_osx (which was built for Mac OS X 10.15)Expected in: /usr/lib/libSystem.B.dylib
```
I have my test mac running with High Sierra (10.13.6) but it can't run cfformat as it seems the cftokens has been compiled for use on 10.15+. Is there a way we can get a build to support older macs?
Answers:
username_1: @username_0 I don't have access to 10.13 so I am not going to be able to test this right now, but I tried recompiling cftokens with 10.13 specified as the minimum version.
Could you try replacing the `cftokens_osx` binary you have on your system (location specified in the error message) with the binary I have attached here?
[cftokens_osx.zip](https://github.com/username_1/commandbox-cfformat/files/5196998/cftokens_osx.zip)
Status: Issue closed
username_0: I can verify that it works @username_1 !! Now my old mac can format ❤️ |
mcollina/autocannon | 481886851 | Title: Basic HTTP auth support?
Question:
username_0: Hi 👋
I have a staging server, which is protected with [basic HTTP authentication](https://en.wikipedia.org/wiki/Basic_access_authentication) to avoid accidental indexing by search engines. For manual testing, I simply enter login and password in the browser and for tools like [HTTPie](https://httpie.org/) or [Lighthouse](https://developers.google.com/web/tools/lighthouse/) I prepend my login and password to the URL like this:
```bash
http https://login:[email protected]/
lighthouse --view https://login:[email protected]/
```
All works – the response is 200.
However, `autocannon` seems to ignore my auth credentials written the same way:
```bash
autocannon https://login:[email protected]/
```
```
Running 10s test @ https://login:[email protected]/
10 connections
┌─────────┬───────┬───────┬────────┬────────┬─────────┬──────────┬───────────┐
│ Stat │ 2.5% │ 50% │ 97.5% │ 99% │ Avg │ Stdev │ Max │
├─────────┼───────┼───────┼────────┼────────┼─────────┼──────────┼───────────┤
│ Latency │ 77 ms │ 89 ms │ 117 ms │ 144 ms │ 93.8 ms │ 30.49 ms │ 394.45 ms │
└─────────┴───────┴───────┴────────┴────────┴─────────┴──────────┴───────────┘
┌───────────┬─────────┬─────────┬─────────┬─────────┬───────┬─────────┬─────────┐
│ Stat │ 1% │ 2.5% │ 50% │ 97.5% │ Avg │ Stdev │ Min │
├───────────┼─────────┼─────────┼─────────┼─────────┼───────┼─────────┼─────────┤
│ Req/Sec │ 71 │ 71 │ 110 │ 117 │ 105.6 │ 12.54 │ 71 │
├───────────┼─────────┼─────────┼─────────┼─────────┼───────┼─────────┼─────────┤
│ Bytes/Sec │ 12.1 kB │ 12.1 kB │ 18.7 kB │ 19.9 kB │ 18 kB │ 2.13 kB │ 12.1 kB │
└───────────┴─────────┴─────────┴─────────┴─────────┴───────┴─────────┴─────────┘
Req/Bytes counts sampled once per second.
0 2xx responses, 1056 non 2xx responses
1k requests in 10.05s, 180 kB read
```
↑ `1056 non 2xx responses` suggests that HTTP auth was ignored and `401 Unauthorized` was returned in all cases. Could autocannon be improved so that it worked just like other tools with regards to basic auth?
Answers:
username_1: Yes, definitely! Would you like to send a PR?
Il giorno sab 17 ago 2019 alle 15:35 <NAME> <
username_0: Hi @username_1 👋
I'm not sure I'll have capacity to do this at least in the next few weeks. If you or anyone else is interested in making a PR, feel free to! 🙌
Status: Issue closed
|
vtex-apps/store-components | 630016146 | Title: Image link prop not working
Question:
username_0: **Describe the bug**
Trying to add la link to an image but the "href" attribute is not rendered in the frontend.
**To Reproduce**
Steps to reproduce the behavior:
1. Add an image using the image block
`"image#img-vegan": {
"props":{
"src": "assets/imagini/icon-vegan.svg",
"link":"/diete-speciale/vegan"
}
}
`
2. Link the app
**Expected behavior**
The image should redirect the user to the specified link, but the <a> tag wrapping the img has a blank href.
**Screenshots**

**Desktop (please complete the following information):**
- OS: macOS
- Browser: chrome
- Version 3.x
**Additional context**
You can see the live bug here: beta--sanovita.myvtex.com
Answers:
username_1: Hi @username_0, the prop `link` is not a string, you can check the values here https://github.com/vtex-apps/store-image/tree/master/docs
username_2: Just complementing
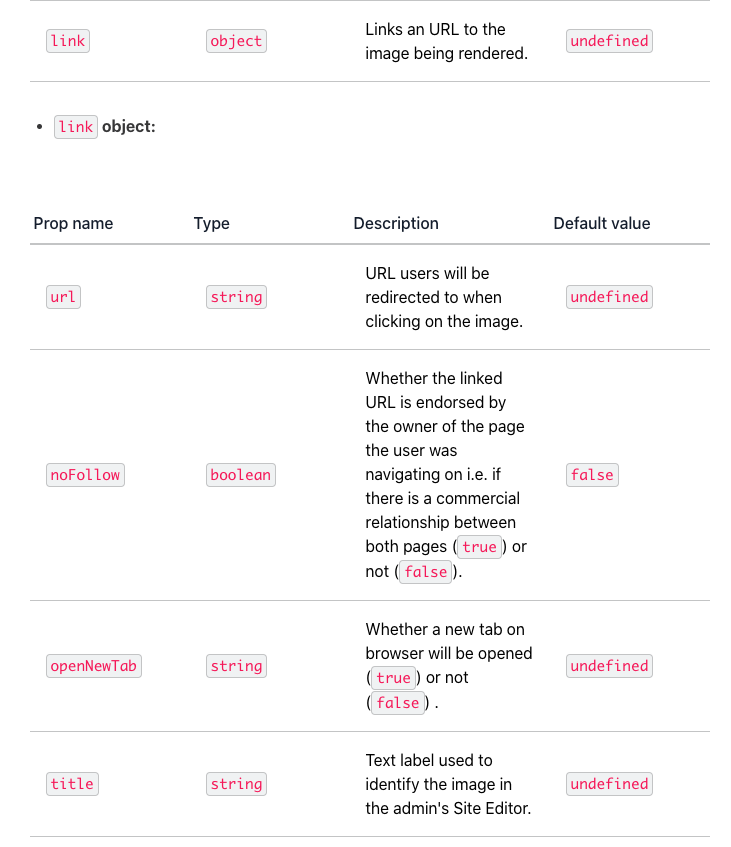
username_0: #omg, didn't see that in the documentation (https://vtex.io/docs/components/all/[email protected]/image/). Thanks x 23482974239!!
Status: Issue closed
|
duckpuppy/algolia-hugo | 299482189 | Title: "he" should be "he-u-rg-IL High"
Question:
username_0: ----
*opened via [imdone.io](https://imdone.io) from a code comment on [eb845f3](https://github.com/username_0/algolia-hugo/commit/eb845f3) by <NAME>*
----
https://github.com/username_0/algolia-hugo/blob/b0bb3033ab1ad912e97356b8c5f7e7b588f0974a/vendor/golang.org/x/text/language/examples_test.go#L341-L346<issue_closed>
Status: Issue closed |
Donkie/I3DShapesTool | 558612576 | Title: Change struct Shape.
Question:
username_0: Shape (Type 1) has the following structure (010 Editor Template):
```C
struct I3DTri{
ushort P1;
ushort P2;
ushort P3;
};
struct I3DVector{
float P1;
float P2;
float P3;
};
struct I3DUV{
float V;
float U;
};
struct UnkFloat3{
float unk1;
float unk2;
float unk3;
};
void Align(int mod){
local int pos = FTell();
local int newPos = ((pos+3)/4)*4;
if(newPos - pos != 0) {
byte Skip[newPos - pos] <bgcolor=0x808080,fgcolor=0x0000F0>;
}
//FSeek(newPos);
Printf("Seed: %d -> %d\n", pos, newPos);
}
uint nameLen;
char Name[nameLen] <fgcolor=0xF0F000>;
Align(4);
uint ShapeId <bgcolor=0x20F080,fgcolor=0x800000>;
float BoundingVolumeX <bgcolor=0x20F0F0>;
float BoundingVolumeY <bgcolor=0xF08080>;
float BoundingVolumeZ <bgcolor=0x20F080>;
float BoundingVolumeR <bgcolor=0x20F0F0>;
int VertexCount <bgcolor=0xF08080>;
int Unknown6 <bgcolor=0x20F080>;
int Vertices <bgcolor=0x20F0F0>;
int Unknown7 <bgcolor=0xF08080>;
int Unknown8 <bgcolor=0x20F080>;
int UvCount <bgcolor=0x20F0F0>;
int Unknown9 <bgcolor=0xF08080>;
int VertexCount2 <bgcolor=0x20F080>;
I3DTri Triangles[VertexCount / 3] <bgcolor=0x20F0F0>;
Align(4);
I3DVector Positions[Vertices] <bgcolor=0xF08080>;
I3DVector Normals[Vertices] <bgcolor=0x20F080>;
if(Unknown7 & 0x80) {
[Truncated]
Printf("Seed: %d -> %d\n", pos, newPos);
}
uint nameLen;
char Name[nameLen];
Align(4);
struct Point{
float x;
float y;
float z;
};
uint ShapeId;
byte unknowFlags[4];
uint PointCount;
Point Points[PointCount];
```
P.S. Is help needed or is the project abandoned? I need only a decryption key from the project. Just my pull request is ignored ...
Answers:
username_1: You're fully welcome to contribute. I forgot about your previous PR, I'll merge it soon.
username_0: Extract library in my project: https://github.com/username_0/I3dShapes
Status: Issue closed
|
kalexmills/github-vet-tests-dec2020 | 758866110 | Title: commshare/testRPC: rpccommon/time/tickers.go; 9 LoC
Question:
username_0: [Click here to see the code in its original context.](https://github.com/commshare/testRPC/blob/b1025a21acb532460bc9c72390fdcd9419cf46c4/rpccommon/time/tickers.go#L112-L120)
<details>
<summary>Click here to show the 9 line(s) of Go which triggered the analyzer.</summary>
```go
for k, t := range tickers {
go func(t *Ticker) {
ok := t.Stop()
if !ok {
g.Error(errors.Errorf("ticker[%s] stop faild.", k))
}
wg.Done()
}(t)
}
```
</details>
Leave a reaction on this issue to contribute to the project by classifying this instance as a **Bug** :-1:, **Mitigated** :+1:, or **Desirable Behavior** :rocket:
See the descriptions of the classifications [here](https://github.com/github-vet/rangeclosure-findings#how-can-i-help) for more information.
commit ID: b1025a21acb532460bc9c72390fdcd9419cf46c4 |
ToddSpainhour/WhatIsVotingLike | 752514588 | Title: Module Navigation Component
Question:
username_0: ## User Story
As a user, I should see `next` and `previous` buttons.
## AC
When the training module loads
Then `next` and `previous` buttons should be at the bottom of the screen
And the `next` button could be disabled until the user had completed that slide's tasks
## Dev Notes
- all the individual training components (intro, outro, ect) should be called from within this "frame"
- some slide will require some sort of user action, so the `next ` button could be greyed out until the "slide" is considered complete
- build the component to have the title at the top and `next and `previous` buttons at the bottom.<issue_closed>
Status: Issue closed |
mobxjs/mobx | 305495804 | Title: async/await simplification with flow and babel in strictMode
Question:
username_0: For example you have store code like this:
```js
class Test {
@action
async login() {
const result = await api.get('http://mycoolapi.ru/get/1');
runInAction(() => {
globalStore.user.data = result;
});
}
}
```
if you use `@babel/plugin-transform-async-to-generator`
with this configuration in your babelrc:
```
...
"plugins": [
["@babel/plugin-transform-async-to-generator", {
"module": "mobx",
"method": "flow"
}],
]
```
you can simpify your code to this:
```js
class Test {
async login() {
const result = await api.get('http://mycoolapi.ru/get/1');
globalStore.user.data = result;
}
}
```
And all will be working like a charm :)
Answers:
username_1: That's genious!
username_2: Wow, I didn't know of this babel feature!
Isn't this goong to mangle with any other async/await use though? :)
username_0: Yes, it would. This is the downside of this method. Do you see any problem with this approach?
username_0: Yes, i am currently using this approach, but because all my async code essentially modify mobx observables i would use `runInAction` anyway. Regarding perfomance, you mean penalties from action wrap or from transpailing to generators?
username_2: Yes, I mean penalties from action wrap!
I'm curious on what @mattiamanzati thinks about this :)
username_0: Here is my small proof of concept: https://gist.github.com/username_0/eb33731aac1c5b098e4c6937805b4734
this babel transform apply mobx flow only to functions with `// action` or `/* action */` comments.
username_3: Wow, didn't check this issue exists. Just released my plugin, which can handle typescript's emitted decorator too: https://github.com/username_3/babel-plugin-mobx-async-action
username_4: FYI, We did a TS transformer plugin for transforming async functions into generators wrapped into mobx flow https://github.com/AurorNZ/ts-transform-async-to-mobx-flow
username_5: Can this solution also be implemented by checking `@action`, it seems more reasonable
username_5: @username_1
I think about this issus, it seems ```action``` can jack into function who returns promise, and wrap returned promise to a thenable object
Then we can do nothing but just set `@action` to a async function
```javascript
function wrapPromise(thing) {
if (!isThenable(thing) || thing.isWrappedByMobx) {
return thing
}
return {
isWrappedByMobx: true,
then(...callbacks) {
return thing.then(...callbacks.map((callback => action(callback)))
},
// catch function, and other
}
}
```
username_5: Hi, @username_10. @username_0 has provided a [workable solution](https://github.com/mobxjs/mobx/issues/1410#issuecomment-375245646)
username_6: thanks
username_7: wouldn't this be a good candidate for the new flow api?
https://mobx.js.org/refguide/api.html#flow
username_0: @username_7 It is using new flow api under the hood. This plugin allows default async await, without generators, very usefull with typings.
username_8: @username_0 I was unable to make your code work, but the proposed solution in the first post worked well enough
username_9: I forked AurorNZ/ts-transform-async-to-mobx-flow, and made https://github.com/username_9/ts-transform-async-to-mobx-flow/tree/feature/action-decorators
It works on `@action` decorator instead, Thanks everyone here! This is really cleaning up my codebase.
**Input**
```ts
class Test {
value: string = '';
@action
async func(input: string) {
this.value = await Promise.resolve(input);
}
}
```
**Output**
```ts
class Test {
func(input) {
return flow_1(function* func() {
this.value = yield Promise.resolve(input);
}).call(this);
}
}
```
username_10: I'm super excited to try this out! 🥇
username_4: @username_9 the reason `@transformToMobxFlow` was chosen as the name to make it quite unique to avoid name clashes (action is quite a common function name), to make it very clear that it is not the standard behaviour of `action` and to avoid handling named imports, eg.
```ts
import {action as action2} from 'mobx';
action2(async function(){}) // that wouldn't be transformed because the code only checks for keyword `action`
```
username_11: This thread is awesome.
I agree with @username_4. `@action` is commonly used and wrapping it can create bugs that would be hard to realise.
Maybe rename to `@asyncAction` or @username_4 idea
username_12: Btw, there seem to be another issue with name conflicts:
```
import { someFunc } from './someFile';
class SomeClass {
@transformToMobxFlow
someFunc = async () => {
await someFunc();
}
}
```
This code will run fine without `@transformToMobxFlow`. When adding it, after it is transformed, the inner call `await someFunc()` will reference the transformed function, and not the imported one. Is there a way to resolve this? I know it's bad practice to have conflicting names, but these are different scopes and this can happen. |
OHDSI/PatientLevelPrediction | 874953620 | Title: Error with Default Temporal Covariate Settings + PLP Lasso Logistic Regression
Question:
username_0: When using settings = CreateDefaultTemporalCovariateSettings(), running the getPlpData + createStudyPopulation works fine, but when running the lasso logistic regression model I receive the error below. Error still occurs even when segment to different subsets of temporal covariates (i.e. just demographics and condition). However, when using settings = CreateDefaultCovariateSettings(), the lasso logistic regression model runs smoothly with no error.
<img width="773" alt="Screen Shot 2021-05-03 at 1 26 29 PM" src="https://user-images.githubusercontent.com/61995037/116940775-436d4700-ac23-11eb-9d89-d9d3a050668a.png">
Answers:
username_1: Hello. This error is expected, but we should have an input check to warn people and clearer documentation. The majority of the PLP classifiers only support 2d (patient x covariate) data, the CreateDefaultTemporalCovariateSettings() creates 3d (patient x covariate x time) data. The deep learning classifiers generally accept 3d data, but those are the only ones that will. I'll add in an input check and stop() to make sure the plpData are 2d for the non-deep learning classifiers. I'll also make sure this is clear in the PLP manual files. Thanks, Jenna. |
EdwardZZZ/articles | 780988872 | Title: factory bind
Question:
username_0: ```js
class A {
constructor(readonly name: string) {}
getName(n: number) {
console.log(this.name, n);
}
}
function Factory<T>(clazz: new (...props: any) => T, name: string) {
const clzProto = clazz.prototype;
Reflect.ownKeys(clzProto).forEach((method) => {
if (method === 'constructor') return;
const { value, configurable, enumerable } = Reflect.getOwnPropertyDescriptor(clzProto, method);
if (typeof value !== 'function') return;
Reflect.defineProperty(clzProto, method, {
configurable,
enumerable,
get() {
return value.bind(this);
}
});
});
// TODO
return Reflect.construct(clazz, [name]);
}
const a = Factory(A, 'aaa');
const { getName } = a;
a.getName(123);
getName(234);
``` |
gravitee-io/issues | 237452668 | Title: Error popup in management-ui for non EN/FR browsers
Question:
username_0: <!--- Provide a general summary of the issue in the Title above -->
When using an non EN/FR browser the resource text are correctly loaded now in 1.7.0
But there is still an error popup shown once the browser has loaded the management ui.
See screenshot: [screenshot.docx](https://github.com/gravitee-io/issues/files/1090807/screenshot.docx)
### Possible Solution
<!--- Not mandatory, but suggest a fix/reason for the bug, -->
<!--- or ideas how to implement the addition or change -->
The management-ui is trying to retrieve an nl.json file which is not found, In that case do no show a popup just continue
Status: Issue closed
Answers:
username_1: Closed by https://github.com/gravitee-io/gravitee-management-webui/commit/774042e487ceb4dc5700b0cb56277d6c0e9052d1 |
ModernFlyouts-Community/ModernFlyouts | 972072025 | Title: Bug:
Question:
username_0: <!-- 🟥🟥🟥 A few rules to keep in mind- 🟥🟥🟥
1. Please check if there is already an issue for the bug you are facing.
2. It would be best to create the issue in English language.
3. Properly follow the issue template and do not delete the template.
🟥🟥🟥 All good? Continue with your issue :) 🟥🟥🟥
-->
**Describe the bug:**
<!-- Sometimes i can not pin the Widget to the Monitor. -->
**To Reproduce:**
Steps to reproduce the behavior:
<!--
1. Go to 'Volume up'
2. Click on 'pin'
3. See error: Sometimes it disappeared
-->
**Screenshots / Video :**
<!-- https://i.imgur.com/OkapNdx.mp4. -->
**OS Version:**
- Windows 10 Version: Windows 10 20H2 190.42.1165
**ModernFlyouts Version:**
- Version: <!-- v0.9.3.0 -->
**Additional context:**
<!-- Add any other info about the problem below this line. -->
Status: Issue closed
Answers:
username_1: Thats not how that feature works :smile:
Clicking that button keeps the topbar expanded.
Closing as duplicate of #368 |
ai-se/ZheYu | 196212978 | Title: 12/20/2016
Question:
username_0: ## DOING:
1. Submit "how2readless"
2. Drafting "transfer learning in SLR"
## DONE:
1. Submitted "how2readless" to IST
2. Uploaded"how2readless" to arxiv
3. Update Zenodo, ver 1.0.2 MAR
## TODO:
1. literature review on updating SLR
2. Drafting "transfer learning in SLR"
## ADMIN
1. Create "transfer learning (Reuse knowledge) in SLR" on sharelatex and share with me.
Answers:
username_1: k |
TwanoO67/ngx-admin-lte | 273180356 | Title: Support for Angular 5
Question:
username_0: There is currently no support for Angular 5.
I dabbled a bit, have a somehow working solution.
BUT, I had to completely switch off the translation functionality.
See for inspiration https://github.com/username_0/ngx-admin-lte.
Answers:
username_1: So doesn't it support i18n?
username_2: Hello guys,
To achieve that i need help on issue #47
If you have any idea it would be much appreciated
username_2: seems fixed by 2.0.0.beta-7
Can you confirm ?
username_0: Not quite fixed yet.
With 2.0.0.beta-7 I get
ERROR in : Unexpected value 'undefined' declared by the module 'NgxAdminLteModule in node_modules/ngx-admin-lte/ngx-admin-lte.d.ts'
I did not see this error in 1.x before.
username_0: Hang on, seems to be an angular build problem.
This build statement causes the error: `ng build --environment prod --build-optimizer --aot`.
This build statement succeeds: `ng build --environment prod`.
Will open an issue against NG cli.
Status: Issue closed
username_0: This is now implemented with 2.0.0-beta.9. |
danawoodman/tint | 117662171 | Title: App is not signed
Question:
username_0: I know you probably know this, but this app isn't signed, so people see an unwelcoming message upon opening it.
<img width="420" alt="screen shot 2015-11-18 at 11 26 49 am" src="https://cloud.githubusercontent.com/assets/107480/11251747/83b48914-8de7-11e5-8329-2b609554c199.png">
Answers:
username_1: @username_0 thanks for the repot and you are correct! I will be adding it to the App Store/signing soon :smile: |
bmewburn/vscode-intelephense | 666158333 | Title: Wrong prioritization of property types
Question:
username_0: **Describe the bug**
When you extend from a class and that class assigns an object to a property in it's constructor or the `getPropertyName()` method, Intelephense will ignore assignments in the child class and think the type remains what the parent may set at some point.
**To Reproduce**
```
class Foo {}
class Bar {
function fooCantDoThis() {}
}
class Base {
protected $blub;
function getBlub() {
$this->blub = new Foo();
return $this->blub;
}
}
class Child extends Base {
function something() {
$this->blub = new Bar();
$this->blub->fooCantDoThis(); // linting will mark error here
}
}
```
**Expected behavior**
The assignment should have top priority. PHP doesn't magically change the type of a property in the same code block / function :D
**Screenshots**


**Platform and version**
Windows 10 x64, VSCode Intelephense 1.5.3
Answers:
username_1: A workaround is to add a property annotation.
```php
<?php
/**
* @property Bar $blub
*/
class Child extends Base {
function something() {
$this->blub = new Bar();
$this->blub->fooCantDoThis(); // linting will mark error here
}
}
```
username_0: Will try that out and report back if i remember, thanks for the response
username_2: I took wayy to long to test this - it works! Thanks a lot. Should this issue stay open? It technically still is one, even though there's a solid workaround. |
crystal-lang/crystal | 349272384 | Title: Crash with constants and begin, end
Question:
username_0: This:
```crystal
CONSTANT = begin
SOMETHING = "hello" # This can also be an Array, Tuple, Int, Float etc. the type doesn't matters.
end
CONSTANT
```
gives
```shell
Nil assertion failed (Exception)
from ???
from ???
from ???
from ???
from ???
from ???
from ???
from ???
from ???
from ???
from ???
from ???
from ???
from ???
from __crystal_main
from main
from __libc_start_main
from _start
from ???
Error: you've found a bug in the Crystal compiler. Please open an issue, including source code that will allow us to reproduce the bug: https://github.com/crystal-lang/crystal/issues
```
https://play.crystal-lang.org/#/r/4pbd
Answers:
username_1: Declaring a constant in a constant initializer should probably be a syntax error.
username_0: Oh I searched for "Nil assertion failed (Exception)" instead of just "Nil assertion failed" so I couldn't find this issue.
Status: Issue closed
username_2: I searched "constant inside constant" |
DEXDEVS/ic | 559946483 | Title: Test Examination System from Scratch
Question:
username_0: There were some errors while generating ABC School's Result. Those errors were not removed but the data was manually entered into the database of the school.
A thoroughly scan of this module is needed. Apply following test techniques:
Black Box Testing, White Box Testing, Grey Box Testing |
serenity-bdd/serenity-core | 373888957 | Title: Get NPE On ScenarioFilter class
Question:
username_0: I got error when tried to use parallel testing in my automation. the error shows that I got `NullPointerException` on `ScenarioFilter` class. Looks like method geMethodName() is returning null.
```
String methodName = description.getMethodName();
boolean shouldRun = scenarios.stream().anyMatch(methodName::equals) || displayName.startsWith("Examples") || displayName.contains("|");
```
Did I miss something? Here is the log:
```
17:51:51.818 [main] ERROR net.serenitybdd.cucumber.CucumberWithSerenity - Test failed to start
java.lang.NullPointerException: null
at net.serenitybdd.cucumber.suiteslicing.ScenarioFilter.shouldRun(ScenarioFilter.java:36)
at org.junit.runners.ParentRunner.shouldRun(ParentRunner.java:434)
at org.junit.runners.ParentRunner.filter(ParentRunner.java:382)
at net.serenitybdd.cucumber.CucumberWithSerenity.lambda$toPossibleFeatureRunner$3(CucumberWithSerenity.java:161)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1382)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at net.serenitybdd.cucumber.CucumberWithSerenity.getChildren(CucumberWithSerenity.java:136)
at org.junit.runners.ParentRunner.getFilteredChildren(ParentRunner.java:426)
at org.junit.runners.ParentRunner.getDescription(ParentRunner.java:351)
at org.apache.maven.surefire.junit4.JUnit4Provider.execute(JUnit4Provider.java:363)
at org.apache.maven.surefire.junit4.JUnit4Provider.executeWithRerun(JUnit4Provider.java:273)
at org.apache.maven.surefire.junit4.JUnit4Provider.executeTestSet(JUnit4Provider.java:238)
at org.apache.maven.surefire.junit4.JUnit4Provider.invoke(JUnit4Provider.java:159)
at org.apache.maven.surefire.booter.ForkedBooter.invokeProviderInSameClassLoader(ForkedBooter.java:384)
at org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:345)
at org.apache.maven.surefire.booter.ForkedBooter.execute(ForkedBooter.java:126)
at org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:418)
```
Answers:
username_1: Try not using forks.
username_0: still happening. already tried use:
`mvn clean verify -Dserenity.batch.count=3 -Dserenity.batch.number=2 -Dserenity.test.statistics.dir=/statistics`
username_0: Here is my maven failsafe plugin in pom.xml
` <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>${maven.failsafe.plugin}</version>
<executions>
<execution>
<id>integration-test</id>
<goals>
<goal>integration-test</goal>
<goal>verify</goal>
</goals>
</execution>
</executions>
<configuration>
<includes>
<include>**/CucumberRunner*.java</include>
</includes>
<systemPropertyVariables>
<cucumber.options>--junit,--step-notifications</cucumber.options>
<spring.config.location>classpath:/application-UATA.properties</spring.config.location>
<!--<serenity.fork.count>2</serenity.fork.count>-->
<!--<serenity.fork.number>1</serenity.fork.number>-->
</systemPropertyVariables>
</configuration>
</plugin>`
username_0: Note: I didn't add configuration for parallel testing on systemPropertiesVariables and in serenity.properties
username_1: Are you trying to do parallel testing or batch testing (they are very different things)?
username_0: Oh sorry, I tried this command. I want to run in parallel actually.
```
mvn clean verify -Dserenity.batch.count=3 -Dserenity.batch.number=2 -Dserenity.fork.number=1 -Dserenity.fork.count=2 -Dserenity.test.statisti
cs.dir=/statistics
```
username_1: Try https://johnfergusonsmart.com/running-parallel-tests-serenity-bdd-cucumber/
username_0: I tried this actually:
[](https://serenity-bdd.github.io/theserenitybook/latest/serenity-parallel.html)
username_0: I just following the steps and got error. already implemented the sample code here also
[https://github.com/serenity-bdd/serenity-cucumber](https://github.com/serenity-bdd/serenity-cucumber)
IDK why it is still getting NPE. Already using latest version of Serenity 2.0.10
username_0: Ok will try
username_0: Hi @username_1, I already found the problem. IDK when I add cucumber options `--junit,--step-notifications`, the methodname data is getting null. that's why it is getting error. but IDK how to solve this since it is in Junit library.
username_1: Maybe @username_2 could help (he wrote the sliding code)
username_2: Hi @username_0 - It looks like you've fixed it now by removing those cucumber options (which I have to admit I have no knowledge of). In all cases when I've developed and tested the batching, `description.getMethodName()` always returns the scenario name. For instance I just put a breakpoint inside that filter and ran a feature and you can see that is is populated with the scenario name (scenario preview in background):
Do you need those cucumber options or can you live without them?
username_0: Actually those cucumber options is used for displaying the detail step in my IDE (Intellij IDEA) whe I run using JUnit. if I am not use the options, it will show the output like this:
<img width="960" alt="withoutstepnotifications" src="https://user-images.githubusercontent.com/6661010/47597127-269e8b80-d9b6-11e8-9df8-5af41b3308ee.png">
If I use those cucumber Options, it will show more detailed steps and it will make us easier to debug and check the error.
<img width="960" alt="witstepnotifications" src="https://user-images.githubusercontent.com/6661010/47597142-459d1d80-d9b6-11e8-96e1-6a9f9f54a0f3.png">
username_1: If Cucumber is not populating those fields when certain options are used, it sounds like a Cucumber defect not a Serenity one.
username_2: To me, the need to run in parallel batches is a separate concern to the need to debug and see real-time output and in practice you'd be doing those things at separate points in your story development lifecycle. In my experience, It's only really worth trying to get test suites running in parallel when you've completed the development of the test and it's reliable. Hope this helps?
username_0: @username_2 yah I agree with you. So we can create different profile just like in the tutorial to run. One for parallel and one for not parallel.
@username_1 ok. should be cucucumber defect.
Status: Issue closed
|
denzill/mantis-custom-field-autocomplete | 718591839 | Title: plugin throws error when trying to install
Question:
username_0: Hello,
I've installed Mantis V2.24..1
When I try to install the plugin it throws the following error:
APPLICATION WARNING #2400
Event "EVENT_VIEW_BUG_AFTER_USERS" has not yet been declared. (in 'C:\xampp\htdocs\mantisbt\core\event_api.php' line 96)
Please use the "Back" button in your web browser to return to the previous page. There you can correct whatever problems were identified in this error or select another action. You can also click an option from the menu bar to go directly to a new section.
Kindly assist
Answers:
username_1: Hello
We no use EVENT_VIEW_BUG_AFTER_USERS hook.
And i install 2.24.4 and enable plugin:

May be you need to upgrade?
username_1: Version 2.24.1 also working fine |
RyanGlScott/eliminators | 302276005 | Title: eliminate term-level code
Question:
username_0: (I hope term-level is the right expression...).
I have a HList:
```Haskell
data HList (ts :: [Type]) where
HNil :: HList '[]
(:&:) :: t -> HList ts -> HList (t ': ts)
infixr 5 :&:
```
And I want to write the following method:
```Haskell
length :: HList ts -> Sing (Length ts)
```
by not explicitly storing the length, but recursing on the HList(just like `length` for the normal list) and "reflecting it back to the type-level". Can I prove that this is correct (using eliminators)?
Answers:
username_1: I think you might be over-complicating the problem a bit. Here are three ways you could write your `length` functions, none of which require the use of eliminators:
```haskell
{-# LANGUAGE FlexibleContexts #-}
{-# LANGUAGE GADTs #-}
{-# LANGUAGE ScopedTypeVariables #-}
{-# LANGUAGE TypeApplications #-}
{-# LANGUAGE TypeInType #-}
{-# LANGUAGE TypeOperators #-}
{-# OPTIONS_GHC -Wall #-}
{-# OPTIONS_GHC -Wno-unticked-promoted-constructors #-}
module Bug where
import Data.Kind
import Data.Singletons.Prelude
import Data.Singletons.Prelude.List
import Data.Singletons.TypeLits
data HList :: [Type] -> Type where
HNil :: HList '[]
(:&:) :: t -> HList ts -> HList (t:ts)
infixr 5 :&:
length1 :: SingI (Length ts) => HList ts -> Sing (Length ts)
length1 _ = sing
length2 :: forall (ts :: [Type]). SingI ts => HList ts -> Sing (Length ts)
length2 _ = sLength (sing @_ @ts)
length3 :: HList ts -> Sing (Length ts)
length3 HNil = SNat @0
length3 (_ :&: xs) = SNat @1 %:+ length3 xs
```
`length3` could, conceivably, be rewritten to use an eliminator over `HList`s, but that would first require writing `Sing`/`SingKind` instances for `HList` and, well, doing so [isn't pretty](https://gist.github.com/username_1/63480e23f49fc686950dbd46b776a759#file-gadtsingletons-hs-L414-L454). So I'd avoid that if possible.
username_0: ah ok, that's enlightening 🙂
Status: Issue closed
|
dersimn/simplehue2mqtt | 441582404 | Title: Error when sending too many commands at once (≈10)
Question:
username_0: ```
root@Nuc:~# docker logs --tail 0 -f hue
2019-05-07 22:50:28.156 <error> { RequestError: Error: connect ECONNRESET 10.1.1.52:80
at new RequestError (/node/node_modules/request-promise-core/lib/errors.js:14:15)
at Request.plumbing.callback (/node/node_modules/request-promise-core/lib/plumbing.js:87:29)
at Request.RP$callback [as _callback] (/node/node_modules/request-promise-core/lib/plumbing.js:46:31)
at self.callback (/node/node_modules/request/request.js:185:22)
at Request.emit (events.js:193:13)
at Request.onRequestError (/node/node_modules/request/request.js:881:8)
at ClientRequest.emit (events.js:193:13)
at Socket.socketErrorListener (_http_client.js:397:9)
at Socket.emit (events.js:193:13)
at emitErrorNT (internal/streams/destroy.js:91:8)
at emitErrorAndCloseNT (internal/streams/destroy.js:59:3)
at processTicksAndRejections (internal/process/task_queues.js:81:17)
name: 'RequestError',
message: 'Error: connect ECONNRESET 10.1.1.52:80',
cause:
{ Error: connect ECONNRESET 10.1.1.52:80
at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1087:14)
errno: 'ECONNRESET',
code: 'ECONNRESET',
syscall: 'connect',
address: '10.1.1.52',
port: 80 },
error:
{ Error: connect ECONNRESET 10.1.1.52:80
at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1087:14)
errno: 'ECONNRESET',
code: 'ECONNRESET',
syscall: 'connect',
address: '10.1.1.52',
port: 80 },
options:
{ uri:
'http://10.1.1.52/api/espOog21cLQWT6bim9eemEAK-iHRXo-LcjzfzJQ5/lights',
json: true,
callback: [Function: RP$callback],
transform: undefined,
simple: true,
resolveWithFullResponse: false,
transform2xxOnly: false },
response: undefined }
2019-05-07 22:50:28.156 <error> { RequestError: Error: connect ECONNRESET 10.1.1.52:80
at new RequestError (/node/node_modules/request-promise-core/lib/errors.js:14:15)
at Request.plumbing.callback (/node/node_modules/request-promise-core/lib/plumbing.js:87:29)
at Request.RP$callback [as _callback] (/node/node_modules/request-promise-core/lib/plumbing.js:46:31)
at self.callback (/node/node_modules/request/request.js:185:22)
at Request.emit (events.js:193:13)
at Request.onRequestError (/node/node_modules/request/request.js:881:8)
at ClientRequest.emit (events.js:193:13)
at Socket.socketErrorListener (_http_client.js:397:9)
at Socket.emit (events.js:193:13)
at emitErrorNT (internal/streams/destroy.js:91:8)
at emitErrorAndCloseNT (internal/streams/destroy.js:59:3)
at processTicksAndRejections (internal/process/task_queues.js:81:17)
name: 'RequestError',
message: 'Error: connect ECONNRESET 10.1.1.52:80',
cause:
{ Error: connect ECONNRESET 10.1.1.52:80
[Truncated]
2019-05-07 22:50:28.346 <error> [ { success: { '/lights/8/state/alert': 'none' } },
{ error:
{ type: 6,
address: '/lights/8/state/effect',
description: 'parameter, effect, not available' } },
{ success: { '/lights/8/state/on': false } } ]
2019-05-07 22:50:28.497 <error> [ { success: { '/lights/11/state/alert': 'none' } },
{ error:
{ type: 6,
address: '/lights/11/state/effect',
description: 'parameter, effect, not available' } },
{ success: { '/lights/11/state/on': false } } ]
2019-05-07 22:50:28.652 <error> [ { success: { '/lights/14/state/alert': 'none' } },
{ error:
{ type: 6,
address: '/lights/14/state/effect',
description: 'parameter, effect, not available' } },
{ success: { '/lights/14/state/on': false } } ]
``` |
danemacmillan/dotfiles | 338721660 | Title: A fresh install will not work
Question:
username_0: For some reason as of now, `dpm --install` will not work on a fresh install. It suddenly starts working if `brew` is installed, but of course, that should be part of the install, and not an initial step. This used to work. Look at pre-installation and includes to see if they are calling `brew` before it's available.
Also, check that `__git_ps1` is available before attempting to use it in `.bash_prompt`.<issue_closed>
Status: Issue closed |
divamgupta/image-segmentation-keras | 357191732 | Title: ValueError: You are trying to load a weight file containing 16 layers into a model with 19 layers.
Question:
username_0: This error happens when i call the function "m.load_weights(load_weights)" in train.py file, how i can fix it ?
Answers:
username_1: you can change the " m.load_weights( "/home/miranda/competition_OPPO/image-segmentation-keras/vgg16_weights_th_dim_ordering_th_kernels.h5") " to " m.load_weights( "/home/miranda/competition_OPPO/image-segmentation-keras/vgg16_weights_th_dim_ordering_th_kernels.h5" ,by_name=True ) "
username_2: @username_1 I don't believe that solves the issue of loading in weights after you have trained the network and saved out the weights.
username_3: vgg16_weights_th_dim_ordering_th_kernels.h5 is 19 layers,but vgg16_weights_th_dim_ordering_th_kernels_notop.h5 is 16 layers
username_4: Image segmentation keras has been updated. The new version should fix the issue.
Status: Issue closed
|
CIMDBORG/CIMMigrationProject | 733182731 | Title: Change Owners field to a Drop Down so that Managers/Supervisors can change the owner of an open item
Question:
username_0: Convert the Owners field to a Drop Down. This will allow Managers AND/OR Supervisor to change who the owner of an item open in the issues database is. This will be beneficial when an item is opened to an incorrect person or if someone leaves the group then we can easily change the owner without having to manually do this in the SQL server table. This function should only be allowed at the Managers level but we will discuss and see if Supervisors should be allowed to change the Owner field too.
Answers:
username_0: Tau and I sent code for this change this week. Waiting for coding to be completed.
Status: Issue closed
|
stellar/go | 308665931 | Title: Heartbeat in streaming
Question:
username_0: To protect against such proxy servers, authors can include a comment line
(one starting with a ':' character) every 15 seconds or so.
Are there any disadvantages other than sending a few more bytes every 15 seconds?
Status: Issue closed
Answers:
username_2: btw, we solved this issue by putting an nginx in front of horizon, which returns HTTP 200 after a certain amount of time. Thus, the client is forced to reconnect afterwards. It might not suit all needs, but it is an alternative solution to using heartbeats.
```nginx
server {
# ...
proxy_read_timeout 60;
location / {
proxy_pass http://localhost:8000; # horizon
# if the request is for sse, return 200 instead of 504
#
# we identify sse by looking for "text/event-stream" header
if ($http_accept = "text/event-stream"){
error_page 504 = @sse_response;
}
}
location @sse_response {
return 200;
}
# ...
``` |
picoe/Eto | 276731854 | Title: How to create a Splash screen?
Question:
username_0: I apologize for my very basic question, but how do I create a splash screen that updates while the main form is loading?
I first tried to launch a second form from a different thread but obviously didn't work since the UI thread has to be one.
Now I'm thinking to use a PixelLayout to show/update/hide the splash but doing so not only I have to wait for the main form to appear before showing the splash but I'm also limited to the size of the main window too.
So what is the best way to have a splash screen with Eto?
Thanks
Answers:
username_0: A second form from the same UI thread does the job! How silly of me :(
username_0: At the end I ended up with a code similar to the following:
using System;
using Eto;
using Eto.Forms;
using Eto.Drawing;
namespace VisualSEO.EtoFormGui
{
public class Program
{
[STAThread]
public static void Main(string[] args)
{
Application app = new Application(Platform.Detect);
Form form = new MySplash(app);
app.Run(form);
}
}
public class MySplash : Form
{
Label label;
UITimer timer;
int seconds;
Application app;
public MySplash(Application app)
{
this.app = app;
WindowStyle = WindowStyle.None;
Topmost = true;
// size the splash
Size = new Size(500, 300);
// position it at the center of the screen
Location = new Point((int)(Screen.WorkingArea.Width - Size.Width) / 2, (int)(Screen.WorkingArea.Height - Size.Height) / 2);
Content = new StackLayout
{
VerticalContentAlignment = VerticalAlignment.Center,
HorizontalContentAlignment = HorizontalAlignment.Center,
Items =
{
null,
new StackLayoutItem(label = new Label()),
null
}
};
}
protected override void OnShown(EventArgs e)
{
base.OnShown(e);
timer = new UITimer();
timer.Interval = 1;
timer.Elapsed += (sender, ev) =>
{
label.Text = seconds.ToString();
if (seconds == 5)
[Truncated]
seconds++;
};
timer.Start();
}
}
public class MyMainForm : Form
{
public MyMainForm()
{
WindowState = WindowState.Maximized;
}
}
}
Unfortunately on wpf the splash still keeps a little border and can be resized (I'm running it on Win7, I haven't tried on Win10). How can it be avoided?

Note that in order to close the splash I had to apply the patch in issue #816 (thanks TomQv)
username_0: I tried this other approch creating and showing both the splash and the main form in the Application.Initialized (Inspired by issue #416) and simulating a long processing afterward, but the risult is the same: the label in the splash is never refreshed apart from the very end and I do not really understand why.
using System;
using Eto;
using Eto.Forms;
using Eto.Drawing;
using System.Threading;
namespace VisualSEO.EtoFormGui
{
public class Program
{
[STAThread]
public static void Main(string[] args)
{
Application app = new Application(Platform.Detect);
app.Initialized += (sender, e) =>
{
MySplash splash = new MySplash();
MyMainForm mainform = new MyMainForm(splash);
splash.MainForm = mainform;
app.MainForm = mainform;
splash.Show();
mainform.Show();
};
app.Run();
}
}
public class MySplash : Form
{
Label label;
UITimer timer;
int counter;
public MySplash()
{
WindowStyle = WindowStyle.None;
Topmost = true;
// size the splash
Size = new Size(500, 300);
// position it at the center of the screen
Location = new Point((int)(Screen.WorkingArea.Width - Size.Width) / 2, (int)(Screen.WorkingArea.Height - Size.Height) / 2);
Content = new StackLayout
{
VerticalContentAlignment = VerticalAlignment.Center,
HorizontalContentAlignment = HorizontalAlignment.Center,
Items =
{
null,
new StackLayoutItem(label = new Label()),
null
}
};
}
protected override void OnShown(EventArgs e)
{
base.OnShown(e);
[Truncated]
public void SimulateWork()
{
System.Threading.Thread.Sleep(1000);
splash.IncrementCounter();
System.Threading.Thread.Sleep(1000);
splash.IncrementCounter();
System.Threading.Thread.Sleep(1000);
splash.IncrementCounter();
System.Threading.Thread.Sleep(1000);
splash.IncrementCounter();
System.Threading.Thread.Sleep(1000);
splash.IncrementCounter();
WorkCompleted = true;
}
public bool WorkCompleted { get; set; }
}
}
Basically I'm still stuck in managing to have a splash screen that updates on the progress of the initialization of the main form :(
username_1: Hey, this is all I needed for borders to dissapear:
```csharp
new Application().Run(new Form {
WindowStyle = WindowStyle.None,
Resizable = false
});
```
username_0: Hi @username_1,
Resizable = false makes the border disappear, thanks a lot! :)
Your suggestion for the label increment however has no effect :(
Temporarily I've found a very ugly trick that does the magic: if after updating the label I pop up a form (on Wpf) or a dialog (on Mac) the label gets updated, so I show and immediately close a small empty form/dialog behind the splash and I'm done. But as I said it's really an ugly trick that I hope I'll remove soon.
username_1: Well, label doesn't update most likely because UI thread gets locked, that's why I put those sleep actions in Task.Run... For you it might not work because I didn't put `counter++` to UI thread too.
username_0: Sorry, my mistake, I forgot to add the Task.Run() part. Your code works, thanks a lot! :)
I now need to apply it in my real code but that is my problem. Thanks again!
(I think that this issue can be closed now)
Status: Issue closed
username_0: I apologize for my very basic question, but what is the best way to have a splash screen that updates while the main form is loading?
Thanks
username_0: One more thing (sorry if I'm getting boring):
In my real application even if I moved lots of logic outside the constructor of main form the constructor itself still takes a lot of time to complete. Back to the given example if MyMainForm takes a lot of time and since both MySplash and MyMainForm are created and shown together in Application.Instanziated they are also shown at the same time but only after the constructor of MyMainForm has finished to create the form.
It becomes evident just adding a sleep in the constructor of MyMainForm like this:
public MyMainForm(MySplash splash)
{
this.splash = splash;
WindowState = WindowState.Maximized;
System.Threading.Thread.Sleep(5000);
}
My desiderata is to see the splash screen right after I launch the application and make it disappear when everything is fully created and initialized.
I therefore changed my example a little bit in order to create MyMainForm only after the Splash is shown
So I removed the creation of MyMainForm from Application.Instanziated and placed the following code in the MySplash.OnShown
protected override void OnShown(EventArgs e)
{
base.OnShown(e);
Thread thread = new Thread(new ThreadStart(CreateMyMainForm));
thread.SetApartmentState(ApartmentState.STA);
thread.Start();
where CreateMyMainForm() is:
void CreateMyMainForm()
{
MyMainForm mainform = new MyMainForm(this);
this.MainForm = mainform;
Application.Instance.AsyncInvoke(() =>
{
Application.Instance.MainForm = mainform; // this should ensure that closing MySplash is not closing the whole application
});
mainform.Show();
mainform.SimulateWork();
}
Now everything seems to work apart from the fact that when I close the splash screen the whole application closes (or crashes, it's not clear). To be precise on Mac the application exits, on Wpf all forms close and the application remains running in background (note that on Wpf I applied TomQv's patch #816).
What am I doing wrong?
Here is the full code:
using System;
using Eto;
using Eto.Forms;
using Eto.Drawing;
using System.Threading;
using System.Threading.Tasks;
namespace VisualSEO.EtoFormGui
{
public class Program
{
[STAThread]
public static void Main(string[] args)
{
[Truncated]
public void SimulateWork()
{
splash.SetText("SimulateWork()");
System.Threading.Thread.Sleep(1000);
splash.IncrementCounter();
System.Threading.Thread.Sleep(1000);
splash.IncrementCounter();
System.Threading.Thread.Sleep(1000);
splash.IncrementCounter();
System.Threading.Thread.Sleep(1000);
splash.IncrementCounter();
System.Threading.Thread.Sleep(1000);
splash.IncrementCounter();
WorkCompleted = true;
}
public bool WorkCompleted { get; set; }
}
}
username_1: There are quite a few problems here:
- In Form you should only create Controls that form uses and maybe some styling, nothing more nothing less. Right now you block UI thread with heavy jobs that's why they do not update :).
- All Jobs must be done in different classes, and update Form using Control binding (MVVM Design pattern) how to bind you can find [here](https://github.com/picoe/Eto/wiki/Data-Binding).
I solve this by creating services that do heavy lifting in a different thread and they communicate with ViewModel, through Messaging pattern or Event aggregator pattern.
username_0: Ok, thank you @username_1, I'll try to follow your advise :)
username_2: @username_3 This should be closed, not a bug or a feature request.
Status: Issue closed
|
oSoc15/biblo-server | 99240878 | Title: ignore build
Question:
username_0: You have a build directory in your public directory. This gets generated by elixer/gulp. This should never be commited. This is the reason why this repository is labeled as a javascript project.
Status: Issue closed
Answers:
username_0: You have a build directory in your public directory. This gets generated by elixer/gulp. This should never be commited. This is the reason why this repository is labeled as a javascript project.
Status: Issue closed
|
jlippold/tweakCompatible | 617392743 | Title: `Volume Amplifier` working on iOS 13.4.1
Question:
username_0: ```
{
"packageId": "org.hacx.volumeamplifier",
"action": "working",
"userInfo": {
"arch32": false,
"packageId": "org.hacx.volumeamplifier",
"deviceId": "iPhone10,5",
"url": "http://cydia.saurik.com/package/org.hacx.volumeamplifier/",
"iOSVersion": "13.4.1",
"packageVersionIndexed": false,
"packageName": "Volume Amplifier",
"category": "Tweaks",
"repository": "Packix",
"name": "Volume Amplifier",
"installed": "2.06",
"packageIndexed": true,
"packageStatusExplaination": "A matching version of this tweak for this iOS version could not be found. Please submit a review if you choose to install.",
"id": "org.hacx.volumeamplifier",
"commercial": false,
"packageInstalled": true,
"tweakCompatVersion": "0.1.5",
"shortDescription": "Speaker Volume Amplifier",
"latest": "2.06",
"author": "<NAME> (hacx)",
"packageStatus": "Unknown"
},
"base64": "<KEY>
"chosenStatus": "working",
"notes": ""
}
```<issue_closed>
Status: Issue closed |
solid/specification | 796196428 | Title: CORS proxy support
Question:
username_0: Clients need to use a CORS proxy (for age old reasons.., https://github.com/w3ctag/design-reviews/issues/76 , ..)
Server needs to offer a CORS proxy endpoint.
Doublecheck authn/z requirements..
Related: discover preferred/trusted proxies https://github.com/solid/vocab/issues/26
Answers:
username_1: Can CORS proxy be an independent component in the ecosystem which one can choose to deploy together or separate from storage servers? |
babel/babel-sublime | 855339140 | Title: Template literal operators lost syntax highlighting in v10
Question:
username_0: 
As you can see the backticks and the expression operator inside the template literal is not red like the assignment operator.
Might be something on my end, but that worked before updating to v10 today. So any pointers would be helpful.
Answers:
username_1: This is working as intended. The new release is derived from the core syntax and uses the same scopes, including the standard scopes for interpolations in strings.
If you prefer the way the old scopes looked, you can target `punctuation.section.interpolation` in your color scheme.
username_0: Thanks, that worked for the expression, but not for the backticks:

Can you point to the place where I can find all scopes available .. even though I have a custom theme I can't remember.
username_0: Found it, it's in the syntax obviously, and now I see that the template literal uses the same scope as string, which makes sense.
Not an issue for me, thanks for the help :+1:
Status: Issue closed
|
geerlingguy/ansible-for-devops | 344344158 | Title: Can't create symlink
Question:
username_0: I'm following an example about creating symlink and got this error.
[khoi@ansible-01 tmp]$ ansible multi -m file -a "dest=/src/test mode=644 state=directory"
[DEPRECATION WARNING]: DEFAULT_SUDO_EXE option, In favor of Ansible Become, which is a generic framework. See become_exe. , use become instead. This feature will be
removed in version 2.8. Deprecation warnings can be disabled by setting deprecation_warnings=False in ansible.cfg.
[DEPRECATION WARNING]: DEFAULT_ASK_SUDO_PASS option, In favor of Ansible Become, which is a generic framework. See become_ask_pass. , use become instead. This feature
will be removed in version 2.8. Deprecation warnings can be disabled by setting deprecation_warnings=False in ansible.cfg.
SUDO password:
ansible-02 | FAILED! => {
"changed": false,
"msg": "There was an issue creating /src as requested: [Errno 13] Permission denied: '/src'",
"path": "/src/test",
"state": "absent"
}
ansible-03 | FAILED! => {
"changed": false,
"msg": "There was an issue creating /src as requested: [Errno 13] Permission denied: '/src'",
"path": "/src/test",
"state": "absent"
}
localhost | FAILED! => {
"changed": false,
"msg": "There was an issue creating /src as requested: [Errno 13] Permission denied: '/src'",
"path": "/src/test",
"state": "absent"
}
Answers:
username_1: The error that Ansible is reporting:
There was an issue creating /src as requested: [Errno 13] Permission denied: '/src'
is a generic one regarding the permissions your user has on that system. In short, the Ansible playbook is attempting to make the `/src` directory, but your user lacks the permissions to create that in the root directory.
The version of the file I have shows this example:
ansible multi -m file -a "dest=/tmp/test mode=644 state=directory"
In most Unix systems the `/tmp` directory exists and lets all users create files and directories there. Assuming the `/tmp/test` directory doesn't already exist, this example should work for you.
username_0: Thank you.
Status: Issue closed
|
fatih/vim-go | 365449224 | Title: let g:go_doc_keywordprg_enabled = 0 hasn't any effects
Question:
username_0: ### What did you do? (required. The issue will be **closed** when not provided.)
At some point recently, maybe after the running PlugUpdate command, the default vim-go's K binding stating overriding vimrc configuration despite the fact that g:go_doc_keywordprg_enabled sets to 0: let g:go_doc_keywordprg_enabled = 0
### What did you expect to happen?
:nnoremap <s-k> some_mapping works
### What happened instead?
:nnoremap <s-k> some_mapping doesn't work, and the documentation buffer is opening
### Configuration (**MUST** fill this out):
* vim-go version:
3d8e82ecb4f66a151f3c1bff84728fa4e3db0ca9
* `vimrc` you used to reproduce (use a *minimal* vimrc with other plugins disabled; do not link to a 2,000 line vimrc):
nnoremap <s-j> :tabprev<cr>
nnoremap <s-k> :tabnext<cr>
function! s:GoFileSettings()
let g:go_doc_keywordprg_enabled = 0
endfunction
augroup filetype_go
autocmd!
autocmd BufRead,BufNewFile *.go call s:GoFileSettings()
augroup END
* Vim version (first three lines from `:version`):
VIM - Vi IMproved 8.1 (2018 May 18, compiled Sep 8 2018 13:02:13)
macOS version
Included patches: 1-350
Compiled by Homebrew
* Go version (`go version`):
go version go1.11 darwin/amd64
* Go environment (`go env`):
GOARCH="amd64"
GOBIN=""
GOCACHE="/Users/osend/Library/Caches/go-build"
GOEXE=""
GOFLAGS=""
GOHOSTARCH="amd64"
GOHOSTOS="darwin"
GOOS="darwin"
GOPATH="/Users/osend/Go"
GOPROXY=""
GORACE=""
GOROOT="/usr/local/go"
GOTMPDIR=""
GOTOOLDIR="/usr/local/go/pkg/tool/darwin_amd64"
GCCGO="gccgo"
CC="clang"
CXX="clang++"
CGO_ENABLED="1"
GOMOD=""
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=/<KEY>622902505=/tmp/go-build -gno-record-gcc-switches -fno-common"
Status: Issue closed
Answers:
username_0: The stupid thing happened: the line `let g:go_doc_keywordprg_enabled = 0` has evaluated right after the Plug initializes vim-go |
apify/proxy-chain | 807735927 | Title: Enforce authentication
Question:
username_0: Yeah, as proxy-authorization headers ain't requested from the client, they ain't being sent and therefore the username and password comes as null.
I'm currently requiring them manually on prepareRequestFunction,
`if (!request.headers['proxy-authorization']) {
request.socket.write([
'HTTP/1.1 407 Proxy Authentication Required',
'Proxy-Authenticate: Basic realm="proxy"',
'Proxy-Connection: close',
].join('\r\n'))
request.socket.end('\r\n\r\n') // empty body
return
}`
Would love to see this fixed.
Thanks!
Answers:
username_1: Isn't this a standard and expected behavior? The client needs to send `proxy-authorization` header, and if not, they get an error.
username_0: Most extensions, browsers, don't send by default. Even the most famous extension on chrome for proxies, SwitchyOmega requires a proxy-authenticate header.
username_1: But this is exactly what is done - see https://github.com/apify/proxy-chain/blob/master/src/server.js#L401
Please can you be more specific what is the problem? What is the current behavior?
username_0: I'm talking about clients connecting to ProxyChain server, not ProxyChain connecting to upstream...
Currently, proxy-chain server doesn't send a 407 Proxy Authentication Required status code when proxy-authorization header ain't present.
username_1: If you set `requestAuthentication: true` in your implementation of `prepareRequestFunction()`, then the server will send the `Proxy-Authenticate` header back to client. You're fully in control of this behavior.
username_0: But afaik upstream doesn't work with `requestAuthentication: true`
username_1: requestAuthentication is only use with respect to client connecting to
ProxyChain server, the upstream authentication is done automatically
depending on the upstreamProxyUrl that you provided in the prepare function.
(I’m writing from mobile)
username_1: Closing this for now, as it's not a bug
Status: Issue closed
|
Kneelawk/analog-synth-1 | 253463558 | Title: Transistors may be too tall to fit on the top side of the PCB
Question:
username_0: The transistors (especially the thermocoupled transistors) are likely too tall (taller than 10cm) to fit between the circuit board and the front panel. The transistors should be moved to the back side. |
brawer/proposal-intl-displaynames | 341557704 | Title: Script and variants info
Question:
username_0: The proposal as is includes regions, locales, and language display names. Would it include scripts and variants too?
https://github.com/unicode-cldr/cldr-localenames-modern/tree/master/main/en
Answers:
username_1: @username_0 I am taking over the champion of this proposal now. Somehow, as a novice of github I messed up the transfer process and use a different process that won't carry all the fired issues to https://github.com/tc39/proposal-intl-displaynames. Could you refile your issue in https://github.com/tc39/proposal-intl-displaynames/issues ? Check my two proposed changes on https://github.com/tc39/proposal-intl-displaynames/pulls first. I think that address the issue you have here. I would like to ask to abandon this old one but move all discussion to https://github.com/tc39/proposal-intl-displaynames/issues instead. |
cta-observatory/dl1-data-handler | 457886009 | Title: Mapped images turned into double
Question:
username_0: Images returned by image mapper (except the vector in case of axial addressing) are of `np.float64` while the original data are of `np.float32`.
Using `float` as dtype for numpy array is equivalent to `np.float64`.<issue_closed>
Status: Issue closed |
gwu-libraries/sfm-ui | 158333763 | Title: Graceful shut down of harvesters/exporterts
Question:
username_0: For the purposes of performing upgrades, there needs to be a way of gracefully shutting down harvesters/exporters (i.e., completing the current request and handling no more).
Answers:
username_0: And in general, need a procedure for performing upgrades to the SFM that minimize negative impacts.
username_0: http://stackoverflow.com/questions/37515686/stop-a-running-docker-container-by-sending-sigterm
https://docs.docker.com/engine/reference/commandline/stop/
https://medium.com/@gchudnov/trapping-signals-in-docker-containers-7a57fdda7d86#.9ragb8vc8
https://www.ctl.io/developers/blog/post/gracefully-stopping-docker-containers/
http://engineeringblog.yelp.com/2016/01/dumb-init-an-init-for-docker.html
username_0: Here's my thoughts on this ticket:
1. The general process for an upgrade should be `docker-compose stop` then `docker-compose pull` then `docker-compose up -d`. Note that `docker-compose stop` will send a SIGINT and then 10 seconds later a SIGKILL.
2. Each container should manage its own temp space. That temp space should be in /sfm-data. Containers should cleanup the temp space as necessary, e.g., after an unclean shutdown.
3. Optional retry functionality should be added to the BaseConsumer. This will persist a message to disk when it is received and delete it when processing is completed. If the message is found on startup it will be retried. What happens on retry depends on the BaseConsumer implementation.
4. The exporters, web harvester, and elk loader should cleanup any files and retry.
5. The other harvesters should resume. See below for changes to BaseHarvester.
Changes to BaseHarvester to support resuming:
1. Upon starting a harvest, the harvester should send a harvest status message with status PROCESSING.
2. A separate process/thread should monitor for completed WARC files. (For warcprox, files have a .open extension until completed.) Upon finding a completed WARC file, it should iterate over the WARC for the purposes of determining state (note that this is the state of the harvest that is actually committed to completed WARCs, not that is in an interdeterminate state as seen by the social media client), extracting URLs, and making counts. Upon completing, it should move the file, send a WARC created message, send web harvest requests, and send harvest status messages, persist state, and persist counts. (Note that the need to persist counts was previously noted, but left as a todo.)
3. To resume (i.e., when a message is found on disk on startup), any remaining completed WARC files are processed. Then the harvest is resumed based on the persisted state.
username_1: Also entails updates to Twitter, Flickr, Tumblr, and Weibo harvesters and exporters.
username_0: Here's how this works for all harvesters and exporters except Twitter Stream Harvester:
When a harvest/export request is received, the message is persisted to disk. When it is completed, the persisted message is deleted. When the harvester/exporter is started, it looks for persisted messages. If it finds one, is executed it before starting to consume from the queue.
When executing a persisted message on start, the exporter always starts over. Thus, if it was in the middle of an export when it was stopped, it starts from scratch.
During execution, a harvester checkpoints itself whenever it processes a WARC file. Checkpointing consists of copying the WARC file to its destination, updating state in the state store, and persisting the counts to disk. Thus, when executing a persisted message on start the harvester will continue for the last state in the state store and the counts from disk.
For the Twitter Stream Harvester, restart is automatically handled by supervisor. Upon reaching a stop signal, the harvester will attempt to stop harvesting tweets and close warcprox. Closing warcprox will also close the WARC file, allowing it to be processed now or on a later resume.
username_0: Here are the PRs for this ticket:
* https://github.com/gwu-libraries/sfm-utils/pull/17
* https://github.com/gwu-libraries/sfm-flickr-harvester/pull/9
* https://github.com/gwu-libraries/sfm-weibo-harvester/pull/19
* https://github.com/gwu-libraries/sfm-tumblr-harvester/pull/4
* https://github.com/gwu-libraries/sfm-web-harvester/pull/3
* https://github.com/gwu-libraries/sfm-twitter-harvester/pull/16
username_0: Suggestions for testing:
* You will need to build the containers.
* Attached is an example [docker-compose.yml](https://github.com/gwu-libraries/sfm-ui/files/474788/docker-compose.txt).
* Test every harvest and export type.
* Test killing a container during a harvest/export.
* Test killing Twitter Stream Harvester during a harvest.
* Test shutting down all containers with `docker-compose stop` during harvests/exports.
* Run all of the unit and integration tests.
Note that the travis tests will fail since they depend on changes to sfmutils and containers.
username_0: @username_1 This is ready to go for testing.
username_1: Fixed by #444
Status: Issue closed
|
guardian/frontend | 71892108 | Title: Hide "popular" component on fronts if query result has empty "most-viewed"
Question:
username_0: To help guard against issues such as https://github.com/guardian/frontend/issues/9034,
it is recommended that we hide the "popular" container in the case where CAPI is returning an empty "most-viewed" block, rather than displaying the "results" block instead.
The reasons for this are
1 - if we show the results block we are returning the most recently published articles, not the most popular
2 - if the container is hidden, it is really obvious to us that something has gone wrong, this is less obvious if we are showing the most recent.
Answers:
username_1: @janua Is this possible?
username_2: Given the current set up it's not trivial to do this, and I wouldn't like to add a bunch of spaghetti code to do so.
I think 1 is a valid concern, but 2 isn't. We ought to have an alarm set up in the correct place for when this happens, not rely on people seeing the container is missing on the front page.
Status: Issue closed
|
gyomuitaku/kawaqiita | 738829794 | Title: meta_tagsを作る
Question:
username_0: ## [what]
- gemのmeta_tagsを入れて、discriptionなどを入れる
## [why]
-
## [details]
-
## [example]
-
## [what was difficult]
-
## [how to solved]
Status: Issue closed
Answers:
username_0: ## [what]
- gemのmeta_tagsを入れて、discriptionなどを入れる
## [why]
-
## [details]
-
## [example]
-
## [what was difficult]
-
## [how to solved]
Status: Issue closed
|
uclibs/aaec | 605780990 | Title: Implement a phased restart
Question:
username_0: At the moment, capistrano will stop and then start puma when it does a deploy. While this is a good first step, it is not the best possible outcome. Puma has something called a phased restart, which will allow for a better restart that won't restart all sessions that are currently active. Implement this instead of the current setup.
https://github.com/puma/puma/blob/master/docs/restart.md
Potentially Useful Link:
https://www.digitalocean.com/community/tutorials/how-to-set-up-zero-downtime-rails-deploys-using-puma-and-foreman |
holdenk/spark-testing-base | 171863821 | Title: DataFrameSuiteBase: assertDataFrameEquals throws a scalactic NoSuchMethodError
Question:
username_0: Hi,
I am working on a spark project written in scala / maven. I use spark-testing-base framework to execute my tests but when I do an `assertDataFrameEquals`, I got the following error:
```
An exception or error caused a run to abort: org.scalactic.Bool$.binaryMacroBool(Ljava/lang/Object;Ljava/lang/String;Ljava/lang/Object;Z)Lorg/scalactic/Bool;
java.lang.NoSuchMethodError: org.scalactic.Bool$.binaryMacroBool(Ljava/lang/Object;Ljava/lang/String;Ljava/lang/Object;Z)Lorg/scalactic/Bool;
at com.username_3arau.spark.testing.TestSuite$class.assert(TestSuite.scala:13)
at fr.***.***.***.FooSpec.assert(FooSpec.scala:8)
at com.username_3arau.spark.testing.DataFrameSuiteBaseLike$class.assertDataFrameEquals(DataFrameSuiteBase.scala:83)
at fr.***.***.***.FooSpec.assertDataFrameEquals(FooSpec.scala:8)
at fr.***.***.***.FooSpec$$anonfun$1.apply(FooSpec.scala:14)
at fr.***.***.***.FooSpec$$anonfun$1.apply(FooSpec.scala:9)
at org.scalatest.OutcomeOf$class.outcomeOf(OutcomeOf.scala:85)
...
```
Here are my pom dependencies and the test itself:
pom.xml:
```
<properties>
<spark.version>1.6.1</spark.version>
<scala.version>2.10.6</scala.version>
<scala.version.binary>2.10</scala.version.binary>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version.binary}</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version.binary}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version.binary}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
[Truncated]
class FooSpec extends DataFrameSuiteBase {
test("awesomeTest") {
val sqlCtx = sqlContext
import sqlCtx.implicits._
val input1 = sc.parallelize(List(1, 2, 3)).toDF
assertDataFrameEquals(input1, input1) // equal
val input2 = sc.parallelize(List(4, 5, 6)).toDF
intercept[org.scalatest.exceptions.TestFailedException] {
assertDataFrameEquals(input1, input2) // not equal
}
}
}
```
Any idea?
Thanks
Answers:
username_1: This is probably because you are specifying Scalatest 3.0.0 but spark-testing-base is built with 2.2.1.
username_0: Oh thank you, I'll test it tomorrow
username_2: I get the same error - I can run the sample code in a standalone project with no issues. But when I try to use the framework within an existing project (using Scalatest 3.0.0) I get the same NoSuchMethodError - as it's an existing project already using 3.0.0 I'm entering jar hell when I try to use 2.2.1 :(
Can we get a version compiled against 3.0.0? I haven't tried yet (and it may or may not be doable without a lot of time and energy) but can I raise a PR for this?
Status: Issue closed
username_3: I'll look at updating this to scalatest 3.0.0 soon, but for now closing this as not an issue with spark-testing-base rather issue with missmatched scalatest versions. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.