
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 11,017 | closed | Cannot run the gpt neo 2.7B example | ## Environment info
- `transformers` version: 4.4.2
- Platform: Windows and Linux (using wsl)
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.1+cpu (False)
- Tensorflow version (GPU?): 2.4.1 (False)
Library:
- text generation: @patrickvonplaten
- pipelines: @LysandreJik
## Information
When running the example for gpt-neo i.e.
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='EleutherAI/gpt-neo-2.7B')
>>> generator("EleutherAI has", do_sample=True, min_length=50)
```
I get this:
```
Downloading: 100%|█████████████████████████████████████████████████████████████████| 1.46k/1.46k [00:00<00:00, 2.27MB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/donno2048/.local/lib/python3.8/site-packages/transformers/pipelines/__init__.py", line 344, in pipeline
framework = framework or get_framework(model)
File "/home/donno2048/.local/lib/python3.8/site-packages/transformers/pipelines/base.py", line 71, in get_framework
model = AutoModel.from_pretrained(model, revision=revision)
File "/home/donno2048/.local/lib/python3.8/site-packages/transformers/models/auto/modeling_auto.py", line 809, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/home/donno2048/.local/lib/python3.8/site-packages/transformers/models/auto/configuration_auto.py", line 389, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
KeyError: 'gpt_neo'
``` | 04-01-2021 14:34:18 | 04-01-2021 14:34:18 | Hi @donno2048. the GPT Neo is available on the master branch, and is not yet in a release. I invite you to install transformers from source, with the following:
```
pip install git+https://github.com/huggingface/transformers
```<|||||>Thanks<|||||>Does the min_length param work for you? I do the same as above and it doesn't seem to change anything |
transformers | 11,016 | closed | Add new CANINE model | # 🌟 New model addition
## Model description
Google recently proposed a new **C**haracter **A**rchitecture with **N**o tokenization **I**n **N**eural **E**ncoders architecture (CANINE). Not only the title is exciting:
> Pipelined NLP systems have largely been superseded by end-to-end neural modeling, yet nearly all commonly-used models still require an explicit tokenization step. While recent tokenization approaches based on data-derived subword lexicons are less brittle than manually engineered tokenizers, these techniques are not equally suited to all languages, and the use of any fixed vocabulary may limit a model's ability to adapt. In this paper, we present CANINE, a neural encoder that operates directly on character sequences, without explicit tokenization or vocabulary, and a pre-training strategy that operates either directly on characters or optionally uses subwords as a soft inductive bias. To use its finer-grained input effectively and efficiently, CANINE combines downsampling, which reduces the input sequence length, with a deep transformer stack, which encodes context. CANINE outperforms a comparable mBERT model by 2.8 F1 on TyDi QA, a challenging multilingual benchmark, despite having 28% fewer model parameters.
Overview of the architecture:
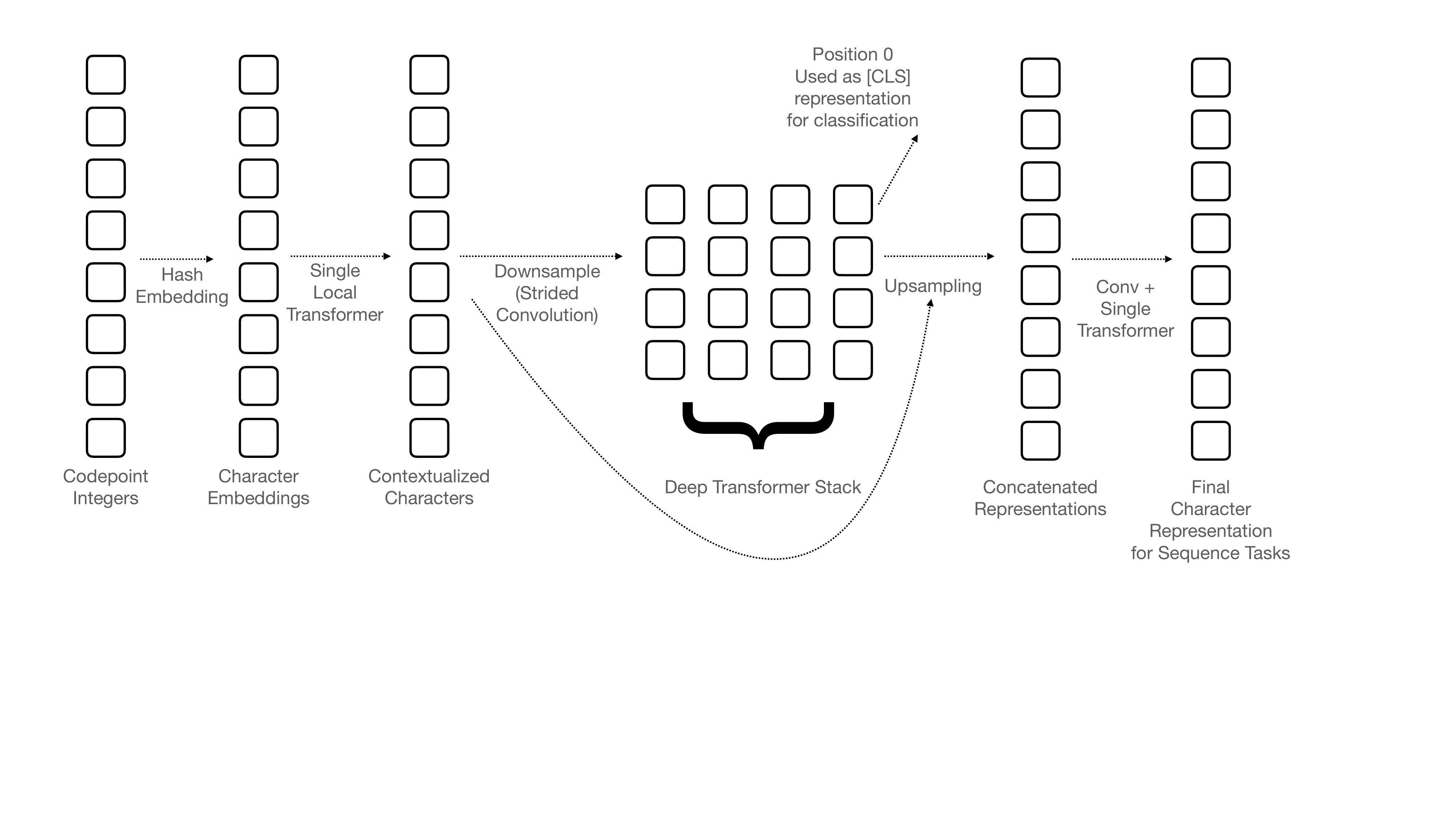
Paper is available [here](https://arxiv.org/abs/2103.06874).
We heavily need this architecture in Transformers (RIP subword tokenization)!
The first author (Jonathan Clark) said on [Twitter](https://twitter.com/JonClarkSeattle/status/1377505048029134856) that the model and code will be released in April :partying_face:
## Open source status
* [x] the model implementation is available: [here](https://caninemodel.page.link/code)
* [x] the model weights are available: [here](https://caninemodel.page.link/code)
* [x] who are the authors: @jhclark-google, @dhgarrette, @jwieting (not sure)
| 04-01-2021 13:53:21 | 04-01-2021 13:53:21 | Update on that: model and checkpoints are released:
https://github.com/google-research/language/tree/master/language/canine
:hugs: <|||||>Hi @stefan-it, thanks for the update.
Do you know how we can use those pre-trained tensorflow checkpoints to get the pooled text representations from CANINE model?
Thanks<|||||>any updates on this ? <|||||>Hi,
I've started working on this. Forward pass in PyTorch is working, and giving me the same output tensors as the TF implementation on the same input data.
Will open a PR soon<|||||>Hi @dhgarrette,
I don't want to spam the CANINE PR with this question/discussion, so I'm asking it here in this issue 😅
So I would like to use CANINE for token classification (I'm currently implementing it into Flair framwork...), and for that reason tokenized input is passed to the model. For token classification using e.g. BERT one would use the first subword as "pooling strategy". But when using CANINE and following the subword "analogy", using the embedding of the first - let's say - character is a good strategy (instead of e.g. `mean`) 🤔 |
transformers | 11,015 | closed | added new notebook and merge of trainer | # What does this PR do?
* Adds a new Notebook for SageMaker
* Adjusts documentation for the latest merge of `SageMakerTrainer` and `Trainer` | 04-01-2021 11:46:29 | 04-01-2021 11:46:29 | |
transformers | 11,014 | closed | OSError: Can't load config for '/content/wav2vec2-large-xlsr-asr-demo'. Make sure that: | I'm using
pip install transformers==4.4.2
After completing the training process of ASR I can not read the trained file from my local storage. Although the path is right. But can read from hugging face
model = Wav2Vec2ForCTC.from_pretrained("/content/wav2vec2-large-xlsr-asr-demo").to("cuda")
The error:
OSError: Can't load config for '/content/wav2vec2-large-xlsr-asr-demo'. Make sure that:
- '/content/wav2vec2-large-xlsr-asr-demo' is a correct model identifier listed on 'https://huggingface.co/models'
- or '/content/wav2vec2-large-xlsr-asr-demo' is the correct path to a directory containing a config.json file | 04-01-2021 11:19:17 | 04-01-2021 11:19:17 | Can you `ls` what's in `/content/wav2vec2-large-xlsr-asr-demo`?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 11,013 | open | use `BaseModelOutput` as common interface for all different `BaseModelOutputWith*`? | Hello team,
I have been taking a look at the `different` output models from your models, and I wonder if it would make sense to inherit all the `BaseModelOutputWithPool` and all the other flavours of modeling output, instead of using `ModelOutput`.
https://github.com/huggingface/transformers/blob/c301c26370dfa48f6a6d0408b5bb9eb70ca831b3/src/transformers/modeling_outputs.py#L24
We are trying to build a wrapper around many of the public models hosted on hugging face, and it would be useful to know if we can assume that all the potential `outputs` of the models will contain `hidden_states`. Since now they all only inherit from `ModelOutput` it seems a little confusing.
Am I missing something? Is it not something that can be assumed? | 04-01-2021 10:41:02 | 04-01-2021 10:41:02 | |
transformers | 11,012 | closed | Add multi-class, multi-label and regression to transformers | This PR adds support for single/multi column regression and single/multi label classification tasks to `SequenceClassification` models. The `problem_type` can be specified in the config: `regression`, `single_label_classification`, `multi_label_classification`. | 04-01-2021 09:06:59 | 04-01-2021 09:06:59 | |
transformers | 11,011 | closed | a memory leak in evaluation | ## Environment info
- `transformers` version: 4.4.0.dev0
- Platform: Linux-3.10.0-957.el7.x86_64-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyTorch version (GPU?): 1.7.1+cu101 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: False
### Who can help
@sgugger
## Information
Model I am using (Bert, XLNet ...):
albert-base-v2 but use a hidden_size of 2048 and a num_attention_heads of 16, distilled from albert-xlarge-v2.
The problem arises when using:
* [x] the official example scripts: (give details below)
examples/text-classification/run_glue.py
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
GLUE QQP task
## To reproduce
Steps to reproduce the behavior:
I want to evaluate my model on the GLUE QQP task. If I don't use eval_accumulation_step, my GPUs are OOM. But if I use eval_accumulation_step and my memory usage will grow up to the memory limit (>250GB) until the first process is killed due to this issue. So I assumed that maybe there is a memory leak.
My running script is as below.
```
CUDA_VISIBLE_DEVICES=0 ~/.conda/envs/thesis-lyh/bin/python run_glue.py \
--model_name_or_path $MODEL_PATH \
--task_name $TASK_NAME \
--eval_accumulation_step 1 \
--do_eval \
--max_seq_length 128 \
--per_device_eval_batch_size 1 \
--output_dir output/glue/$TASK_NAME/$MODEL_NAME/
```
No matter what batch_size and accumulation_step are set to, the above problem still occurs.
But I am doing fine in models hosted in the model hub and a smaller model I distilled in the same way.
## Expected behavior
I have 250GB RAM so it should be enough to save the result.
| 04-01-2021 06:52:18 | 04-01-2021 06:52:18 | Which model are you using? There is no reason the predictions for QQP should OOM even your GPU, unless the model is outputting more than the logits.<|||||>Thank you very much for your reply! My model config is as below:
```JSON
{
"architectures": [
"AlbertForMaskedLM"
],
"attention_probs_dropout_prob": 0,
"bos_token_id": 2,
"classifier_dropout_prob": 0.1,
"down_scale_factor": 1,
"embedding_size": 128,
"eos_token_id": 3,
"gap_size": 0,
"hidden_act": "gelu_new",
"hidden_dropout_prob": 0,
"hidden_size": 2048,
"initializer_range": 0.02,
"inner_group_num": 1,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "albert",
"net_structure_type": 0,
"num_attention_heads": 16,
"num_hidden_groups": 1,
"num_hidden_layers": 12,
"num_memory_blocks": 0,
"pad_token_id": 0,
"type_vocab_size": 2,
"vocab_size": 30000
}
```
And I'm loading my model like this:
```Python
state_dict = torch.load(os.path.join(model_args.model_name_or_path, "checkpoint.pth"))
model = AutoModelForSequenceClassification.from_pretrained(
pretrained_model_name_or_path=None,
config=config,
state_dict=state_dict,
use_auth_token=True if model_args.use_auth_token else None
)
```
And these are all the named parameters:
```
albert.embeddings.position_ids torch.Size([1, 512])
albert.embeddings.word_embeddings.weight torch.Size([30000, 128])
albert.embeddings.position_embeddings.weight torch.Size([512, 128])
albert.embeddings.token_type_embeddings.weight torch.Size([2, 128])
albert.embeddings.LayerNorm.weight torch.Size([128])
albert.embeddings.LayerNorm.bias torch.Size([128])
albert.encoder.embedding_hidden_mapping_in.weight torch.Size([2048, 128])
albert.encoder.embedding_hidden_mapping_in.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.full_layer_layer_norm.weight torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.full_layer_layer_norm.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.query.weight torch.Size([2048, 2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.query.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.key.weight torch.Size([2048, 2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.key.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.value.weight torch.Size([2048, 2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.value.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.dense.weight torch.Size([2048, 2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.dense.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.LayerNorm.weight torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.LayerNorm.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.ffn.weight torch.Size([3072, 2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.ffn.bias torch.Size([3072])
albert.encoder.albert_layer_groups.0.albert_layers.0.ffn_output.weight torch.Size([2048, 3072])
albert.embeddings.LayerNorm.weight torch.Size([128])
albert.embeddings.LayerNorm.bias torch.Size([128])
albert.encoder.embedding_hidden_mapping_in.weight torch.Size([2048, 128])
albert.encoder.embedding_hidden_mapping_in.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.full_layer_layer_norm.weight torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.full_layer_layer_norm.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.query.weight torch.Size([2048, 2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.query.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.key.weight torch.Size([2048, 2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.key.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.value.weight torch.Size([2048, 2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.value.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.dense.weight torch.Size([2048, 2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.dense.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.LayerNorm.weight torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.LayerNorm.bias torch.Size([2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.ffn.weight torch.Size([3072, 2048])
albert.encoder.albert_layer_groups.0.albert_layers.0.ffn.bias torch.Size([3072])
albert.encoder.albert_layer_groups.0.albert_layers.0.ffn_output.weight torch.Size([2048, 3072])
albert.encoder.albert_layer_groups.0.albert_layers.0.ffn_output.bias torch.Size([2048])
albert.pooler.weight torch.Size([2048, 2048])
albert.pooler.bias torch.Size([2048])
classifier.weight torch.Size([2, 2048])
classifier.bias torch.Size([2])
```
The training and evaluation code is run_glue.py.<|||||>By the way, my model is pretrained(distilled) in a distributed manner(distributedDataParallel). I'm wondering if it is ok to run GLUE tasks this way? I will be grateful for any help you can provide. @sgugger <|||||>I find these logs and I guess this is why my training and evaluation failed.
```
[INFO|trainer.py:472] 2021-04-04 23:14:56,386 >> The following columns in the training set don't have a corresponding argument in `AlbertForSequenceClassification.forward` and have been ignored: question1, question2, idx.
[INFO|trainer.py:472] 2021-04-04 23:14:56,389 >> The following columns in the evaluation set don't have a corresponding argument in `AlbertForSequenceClassification.forward` and have been ignored: question1, question2, idx.
```
But I am confused about what happened inside the trainer.<|||||>The fact the model has been trained in a distributed manner is not relevant and shouldn't impact this. The warning you get is also not related and normal if you're running the `run_glue` script: it's just informing you that the `Trainer` is dropping those columns after the preprocessing, since they is no model argument matching.
I'm trying to reproduce but everything is working fine on my side. If you just use a randomly initialized ALBERT with this config do you have the same problem? (I can run evaluation without problem on my side for that)<|||||>Thank you for your reply. I double-check my config today and find that I am reusing the config from distillation and the output_hidden_states is set to true......I am very sorry for my carelessness and thank you so much for your time and attention.<|||||>Ah I understand better now :-) |
transformers | 11,010 | closed | run_seq2seq.py meet bug in using huggingface datasets billsum | run code below
```shell
python examples/seq2seq/run_seq2seq_tune.py --model_name_or_path /home2/zhenggo1/checkpoint/pegasus_billsum --do_eval --task summarization_billsum --dataset_name billsum --output_dir /home2/zhenggo1/checkpoint/pegasus_billsum --per_device_train_batch_size=8 --per_device_eval_batch_size=8 --predict_with_generate --tune --tuned_checkpoint="/home2/zhenggo1/checkpoint/pegasus_billsum" --max_source_length 1024 --max_target_length=256 --val_max_target_length=256 --do_calibration
```
bug below,in my opinion,is that the newest dataset process module don't match the billsum?
```python
Traceback (most recent call last):
File "examples/seq2seq/run_seq2seq_tune.py", line 694, in <module>
main()
File "examples/seq2seq/run_seq2seq_tune.py", line 374, in main
column_names = datasets["validation"].column_names
KeyError: 'validation'
```
using `dataset_name` and print() it show as below
```
DatasetDict({
train: Dataset({
features: ['text', 'summary', 'title'],
num_rows: 18949
})
test: Dataset({
features: ['text', 'summary', 'title'],
num_rows: 3269
})
ca_test: Dataset({
features: ['text', 'summary', 'title'],
num_rows: 1237
})
})
```
I want to try another way to load the local dataset,but the dataset's oldest version is below
```
train.source
train.target
val.source
val.target
test.source
test.target
```
which can be process by the oldest code:
```python
train_dataset = (
dataset_class(
tokenizer,
type_path="train",
data_dir=data_args.data_dir,
n_obs=data_args.n_train,
max_target_length=data_args.max_target_length,
max_source_length=data_args.max_source_length,
prefix=model.config.prefix or "",
)
if training_args.do_train
else None
)
```
but not the newest code:
```python
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if data_args.test_file is not None:
data_files["test"] = data_args.test_file
extension = data_args.test_file.split(".")[-1]
datasets = load_dataset(extension, data_files=data_files)
``` | 04-01-2021 06:20:47 | 04-01-2021 06:20:47 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 11,009 | closed | How to load weights from a private server? | Hi, thank you for the great library!
I am trying instantiate a model with weights uploaded on my private server. By looking at [`is_remote_url`](https://github.com/huggingface/transformers/blob/8780caa388c7b2aa937454ed96bcdd3f097f851d/src/transformers/modeling_utils.py#L1011) function, it seems that transformers supports loading from a private server, but it seems a bit tricky.
```python
BertModel.from_pretrained('http://my-server/my-bert-cased/pytorch_model.bin') # cannot not find config
BertModel.from_pretrained('http://my-server/my-bert-cased/config.json') # finds config, but cannot find model weights
BertModel.from_pretrained('http://my-server/my-bert-cased', config='http://my-server/my-bert-cased/config.json') # works!
```
Although the third one works, it is cumbersome as I need to download config from private server to my local machine beforehand.
I would appreciate it if someone could share or point to a better way!
| 04-01-2021 05:35:52 | 04-01-2021 05:35:52 | My workaround was to manually download checkpoints using `cached_file` function to local, and instantiate a model from the download file using `from_pretrained`.<|||||>Yes that's indeed the preferred workaround. Thanks! |
transformers | 11,008 | closed | error: fine-tunes language model with added_tokens | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: version: 4.3.3
- Platform: Linux-4.15.0-29-generic-x86_64-with-debian-stretch-sid
- Python version: 3.6.9
- PyTorch version (GPU?): 1.4.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: False
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@LysandreJik, @LysandreJik
## Information
I fine-tune BERT on my own social media data, I do this follow the instruction in the `examples/language-modeling/README.md`. **I follow the official run_mlm.py file, and the only change is that I add some new tokens after the tokenizer inits, and then I got the Cuda runtime error. ** If I don't add some new tokens, it works well.
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Only add one line in `examples/language-modeling/run_mlm.py`
start from run_mlm.py L291:
https://github.com/huggingface/transformers/blob/838f83d84ccf57f968e0ace7f400e43b92643552/examples/language-modeling/run_mlm.py#L291
```Python
...
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
# only add this line!
tokenizer.add_tokens(['[awsl]', '[happy]', '[doge]', ... , '[cry]'])
...
```
running log
```
[INFO|configuration_utils.py:485] 2021-04-01 10:49:28,166 >> Model config BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"directionality": "bidi",
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"output_past": true,
"pad_token_id": 1,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"position_embedding_type": "absolute",
"transformers_version": "4.3.3",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 21128
}
[INFO|modeling_utils.py:1025] 2021-04-01 10:49:28,167 >> loading weights file /data/huyong/code/socialbert/pretrained_models/roberta/pytorch_model.bin
[WARNING|modeling_utils.py:1135] 2021-04-01 10:49:31,389 >> Some weights of the model checkpoint at /data/huyong/code/socialbert/pretrained_models/roberta were not used when initializing BertForMaskedLM: ['cls.seq_relationship.weight', 'cls.seq_relationship.bias']
- This IS expected if you are initializing BertForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
[INFO|modeling_utils.py:1152] 2021-04-01 10:49:31,389 >> All the weights of BertForMaskedLM were initialized from the model checkpoint at /data/huyong/code/socialbert/pretrained_models/roberta.
If your task is similar to the task the model of the checkpoint was trained on, you can already use BertForMaskedLM for predictions without further training.
[INFO|trainer.py:837] 2021-04-01 10:49:31,469 >> ***** Running training *****
[INFO|trainer.py:838] 2021-04-01 10:49:31,469 >> Num examples = 100000
[INFO|trainer.py:839] 2021-04-01 10:49:31,469 >> Num Epochs = 3
[INFO|trainer.py:840] 2021-04-01 10:49:31,469 >> Instantaneous batch size per device = 8
[INFO|trainer.py:841] 2021-04-01 10:49:31,469 >> Total train batch size (w. parallel, distributed & accumulation) = 8
[INFO|trainer.py:842] 2021-04-01 10:49:31,469 >> Gradient Accumulation steps = 1
[INFO|trainer.py:843] 2021-04-01 10:49:31,469 >> Total optimization steps = 37500
0%| | 0/37500 [00:00<?, ?it/s]
0%| | 1/37500 [00:00<1:48:39, 5.75it/s]/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [0,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [1,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [2,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [3,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [4,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [5,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [6,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [7,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [8,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [9,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [10,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [11,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [12,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [13,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [14,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [15,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [16,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [17,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [18,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [19,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [20,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [21,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [22,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [23,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [24,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [25,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [26,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [27,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [28,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [29,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [30,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [31,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [32,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [33,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [34,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [35,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [36,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [37,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [38,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [39,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [40,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [41,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [42,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [43,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [44,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [45,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [46,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [47,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [48,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [49,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [50,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [51,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [52,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [53,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [54,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [55,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [56,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [57,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [58,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [59,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [60,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [61,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [485,0,0], thread: [62,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
...
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [488,0,0], thread: [57,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [488,0,0], thread: [58,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [488,0,0], thread: [59,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [488,0,0], thread: [60,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [488,0,0], thread: [61,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [488,0,0], thread: [62,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [488,0,0], thread: [63,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
Traceback (most recent call last):
File "mlm.py", line 537, in <module>
main()
File "mlm.py", line 503, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/transformers/trainer.py", line 940, in train
tr_loss += self.training_step(model, inputs)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/transformers/trainer.py", line 1304, in training_step
loss = self.compute_loss(model, inputs)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/transformers/trainer.py", line 1334, in compute_loss
outputs = model(**inputs)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 1315, in forward
return_dict=return_dict,
File "/home/huyong/miniconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 976, in forward
return_dict=return_dict,
File "/home/huyong/miniconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 574, in forward
output_attentions,
File "/home/huyong/miniconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 496, in forward
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
File "/home/huyong/miniconda3/lib/python3.6/site-packages/transformers/modeling_utils.py", line 1787, in apply_chunking_to_forward
return forward_fn(*input_tensors)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 507, in feed_forward_chunk
intermediate_output = self.intermediate(attention_output)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 410, in forward
hidden_states = self.dense(hidden_states)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/torch/nn/modules/linear.py", line 87, in forward
return F.linear(input, self.weight, self.bias)
File "/home/huyong/miniconda3/lib/python3.6/site-packages/torch/nn/functional.py", line 1372, in linear
output = input.matmul(weight.t())
RuntimeError: CUDA error: CUBLAS_STATUS_INTERNAL_ERROR when calling `cublasSgemm( handle, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)`
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
I found in the `run_mlm.py` , it has `model.resize_token_embeddings(len(tokenizer))`, Why still get the error ? Thanks
<!-- A clear and concise description of what you would expect to happen. -->
| 04-01-2021 02:53:17 | 04-01-2021 02:53:17 | Could you share the command you are using to launch the script? I'm trying to reproduce but it works fine for me.
Also your error seems like a CUDA setup error, so is the script running properly without the change?<|||||>@sgugger
```
export BASE_PATH=/data/huyong/code/socialbert
export CUDA_VISIBLE_DEVICES=1
python run_mlm.py \
--config_name $BASE_PATH/pretrained_models/bert\
--model_type bert \
--max_seq_length 128 \
--preprocessing_num_workers 20 \
--model_name_or_path $BASE_PATH/pretrained_models/bert \
--train_file $BASE_PATH/data/mini.txt \
--line_by_line \
--do_train \
--save_total_limit 3 \
--per_device_train_batch_size 8 \
--max_train_samples 100000 \
--output_dir $BASE_PATH/checkpoint/bert
```<|||||>Thanks, but no one will be able to help you if you're using a personal model you don't share, as we can't debug something we can't reproduce. Also, you did not tell us if the script was running fine before the change.<|||||>@sgugger
Thanks.
Actually, I don't use my personal model, and the model I use to continue pre-train is the [hfl/chinese-roberta-wwm-ext](https://huggingface.co/hfl/chinese-roberta-wwm-ext). And I manually download three files: `vocab.txt`,`config.json` and `pytorch_model.bin`, and run the script by specifying the model dir and get wrong. But when I directly use the model name like the following, and it works!
```bash
export BASE_PATH=/data/huyong/code/socialbert
export CUDA_VISIBLE_DEVICES=1
python run_mlm.py \
--config_name hfl/chinese-roberta-wwm-ext \
--model_name_or_path hfl/chinese-roberta-wwm-ext \
--model_type bert \
--max_seq_length 128 \
--preprocessing_num_workers 20 \
--train_file $BASE_PATH/data/mini.txt \
--line_by_line \
--do_train \
--save_total_limit 3 \
--per_device_train_batch_size 8 \
--max_train_samples 100000 \
--output_dir $BASE_PATH/checkpoint/bert
```
Thanks a lot ! |
transformers | 11,007 | closed | about .py file | i can't download the file" convert_tf_checkpoint_to_pytorch.py" and three other .py file that you set a hyperlink on it. if i click on the link it notice me: 404. Where can i get them? thank you! | 04-01-2021 02:47:40 | 04-01-2021 02:47:40 | Hi, could you provide the location of the wrong links? Without additional information we cannot help you.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 11,006 | closed | "Converting Tensorflow Checkpoints" meets ('Pointer shape torch.Size([312]) and array shape (128,) mismatched', torch.Size([312]), (128,)) | when "Converting Tensorflow Checkpoints", I see this "Pointer shape {pointer.shape} and array shape {array.shape} mismatched"
AssertionError: ('Pointer shape torch.Size([312]) and array shape (128,) mismatched', torch.Size([312]), (128,)), and the pretrainmodel comes from https://github.com/ZhuiyiTechnology/pretrained-models
| 04-01-2021 02:35:58 | 04-01-2021 02:35:58 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 11,005 | open | ReduceLROnPlateau-like functionality? | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
**Description:** Dynamic learning rate reduction upon metric saturation, as in `torch.optim.lr_scheduler.ReduceLROnPlateau`, integrated into the `Trainer` API.
Alternately, if there's any way (if hacky) to get dynamic learning rate reduction using the `Trainer` API as it is, that would be extremely helpful as well.
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
LR schedules are a commonly used trick for ML optimization, and the `transformers` library already provides a significant number of baseline schedules (i.e. linear, cosine schedulers, warmup/no-warmup, restarts). However, these schedules are all static: updates to them occur at fixed steps in the optimization -- one can always tell what the learning rate at, say, step 1000 will be given these fixed schedules.
Reducing learning rate dynamically is also a common practical technique, usually applied when loss saturates (fails to improve after N iterations).
The difficulty is that dynamic learning rate reduction follows a non-fixed update schedule, meaning that working within the `LambdaLR` framework used by the other scheduler is less straightforward.
## Your contribution
I don't have a working implementation yet. At a high level, I tried to implement this myself as a `TrainerCallback` modeled on both the `EarlyStoppingCallback` in the `transformers` library as well as the `ReduceLROnPlateau` implementation in PyTorch. I was able to modify the optimizer object; however, learning rate updates to the optimizer would get overwritten by the scheduler. In any case, I also don't know if it's good style/even possible to modify the optimizer and scheduler in this way using a Callback -- seems like the `control` object is the only thing that changes within a `TrainerCallback`.
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| 03-31-2021 21:50:33 | 03-31-2021 21:50:33 | |
transformers | 11,004 | closed | Getting `raise NotImplementedError` for base_model.get_input_embeddings() when upgrading from pytorch-transformers | # 📚 Migration
## Information
<!-- Important information -->
Getting `raise NotImplementedError` at
the lines - https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_utils.py#L474-L477 when I am trying to upgrade my code from pytorch-transformers to transformers
Model I am using (Bert, XLNet ...): Bert
Language I am using the model on (English, Chinese ...): English
The problem arises when using:
* [ ] the official example scripts: (give details below): Not sure
* [ ] my own modified scripts: (give details below): Yes
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name) No
* [ ] my own task or dataset: (give details below): No
## Details
<!-- A clear and concise description of the migration issue.
If you have code snippets, please provide it here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
-->
I am using Oscar repo (https://github.com/microsoft/Oscar), which uses an older version of Huggingface pytorch-transformers (https://github.com/huggingface/transformers/tree/067923d3267325f525f4e46f357360c191ba562e). I am trying to upgrade the repo to use latest version of transformers (https://github.com/huggingface/transformers). However, I am getting below error :
```
Traceback (most recent call last):
File "oscar/run_captioning_airsplay.py", line 1019, in <module>
main()
File "oscar/run_captioning_airsplay.py", line 966, in main
from_tf=bool('.ckpt' in args.model_name_or_path), config=config)
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_edited/transformers/src/transformers/modeling_utils.py", line 1188, in from_pretrained
model.tie_weights()
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_edited/transformers/src/transformers/modeling_utils.py", line 504, in tie_weights
self._tie_or_clone_weights(output_embeddings, self.get_input_embeddings())
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_edited/transformers/src/transformers/modeling_utils.py", line 469, in get_input_embeddings
return base_model.get_input_embeddings()
File "/home/default/ephemeral_drive/work/image_captioning/Oscar_edited/transformers/src/transformers/modeling_utils.py", line 471, in get_input_embeddings
raise NotImplementedError
NotImplementedError
```
The error occurs at this block in the transformers code - https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_utils.py#L474-L477. My code runs fine when I use an older version of hugging face transformers - https://github.com/huggingface/transformers/tree/067923d3267325f525f4e46f357360c191ba562e, possibly, because pytorch-transformers did not have a requirement that `set_input_embeddings()` should be defined for base_model. The base model that I am using is a custom defined model `BertForImageCaptioning` (https://github.com/microsoft/Oscar/blob/df79152b708c3c46f2dc93324776a27406ccc634/oscar/modeling/modeling_bert.py#L604), which has a custom defined parent class ` CaptionPreTrainedModel` (https://github.com/microsoft/Oscar/blob/df79152b708c3c46f2dc93324776a27406ccc634/oscar/modeling/modeling_utils.py#L21), which has a parent class `BertPreTrainedModel`.
I have not seen any mention of how to deal with this issue in the migration documents from Pytorch-transformers or from transformers 3.x. (https://huggingface.co/transformers/migration.html#migrating-from-transformers-v3-x-to-v4-x).
I have looked into examples to check how to define the function, but this did not give enough details to define the function at my side - https://github.com/huggingface/transformers/blob/master/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py#L487-L488.
How should I define the function `get_input_embeddings()` for my use case and what are the guidelines for doing the same. Are there any examples explaining the process of defining the function.
## Environment info
<!-- You can run the command `python transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: https://github.com/huggingface/transformers
- Platform: x86_64 GNU/Linux
- Python version: 3.6.8
- PyTorch version (GPU?): 1.7.0+cu101 (GPU)
- Tensorflow version (GPU?): 2.3.0 (GPU)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: No
<!-- IMPORTANT: which version of the former library do you use? -->
* `pytorch-transformers` or `pytorch-pretrained-bert` version (or branch): https://github.com/huggingface/transformers/tree/067923d3267325f525f4e46f357360c191ba562e
## Checklist
- [ Yes] I have read the migration guide in the readme.
([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers);
[pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
- [ yes] I checked if a related official extension example runs on my machine.
| 03-31-2021 21:46:00 | 03-31-2021 21:46:00 | Hello! Do you have a reproducible code example so that we can try to understand what's happening here? Thank you!<|||||>I have generated a simplified version of the original Oscar (https://github.com/microsoft/Oscar) codebase here - https://github.com/gsrivas4/Oscar_latest. The branch `old_transformers` -https://github.com/gsrivas4/Oscar_latest/tree/old_transformers uses an old version of hugging face without an issue. However, the branch `latest_transformers` - https://github.com/gsrivas4/Oscar_latest/tree/latest_transformer gets below error when I run the command `oscar/run_captioning.py --model_name_or_path pretrained_models/base-vg-labels/ep_67_588997 --do_train --do_lower_case --evaluate_during_training --add_od_labels --learning_rate 0.00003 --per_gpu_train_batch_size 64 --num_train_epochs 30 --save_steps 5000 --output_dir output/`:
```
Traceback (most recent call last):
File "oscar/run_captioning.py", line 1010, in <module>
main()
File "oscar/run_captioning.py", line 966, in main
from_tf=bool('.ckpt' in args.model_name_or_path), config=config)
File "/usr/local/lib/python3.6/site-packages/transformers/modeling_utils.py", line 1185, in from_pretrained
model.tie_weights()
File "/usr/local/lib/python3.6/site-packages/transformers/modeling_utils.py", line 497, in tie_weights
self._tie_or_clone_weights(output_embeddings, self.get_input_embeddings())
File "/usr/local/lib/python3.6/site-packages/transformers/modeling_utils.py", line 462, in get_input_embeddings
return base_model.get_input_embeddings()
File "/usr/local/lib/python3.6/site-packages/transformers/modeling_utils.py", line 464, in get_input_embeddings
raise NotImplementedError
NotImplementedError
```
To replicate the experiment, follow the [README.md](https://github.com/gsrivas4/Oscar_latest/blob/old_transformers/README.md) file to use old version of transformers - https://github.com/huggingface/transformers/tree/067923d3267325f525f4e46f357360c191ba562e. Follow the [README.md](https://github.com/gsrivas4/Oscar_latest/blob/latest_transformer/README.md) to run the code with latest transformers.
The platform information is below:
Platform: x86_64 GNU/Linux
Python version: 3.6.8
PyTorch version (GPU?): 1.7.0+cu101 (GPU)
Tensorflow version (GPU?): 2.3.0 (GPU)
Using GPU in script?: yes
Using distributed or parallel set-up in script?: No
Let me know if you have any issues generating the setup.
<|||||>It seems your `BertForImageCaptioning` doesn't have a `get_input_embeddings()` method, and neither does your `CaptionPreTrainedModel`.
You should implement that method on either of those in order to be able to resize them, like it is done in the `BertModel` for example:
https://github.com/huggingface/transformers/blob/6c25f5228e7fb48a520f63ee82dd9ce25b27d6df/src/transformers/models/bert/modeling_bert.py#L853-L854
Sorry for the inconvenience!
<|||||>@LysandreJik I understand that I have to define the function `get_input_embeddings()` and I have also looked at the sample example where this function is defined - https://github.com/huggingface/transformers/blob/master/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py#L487-L488. It would be great if some description is given about the inputs and outputs of this function in a bit more detailed way. It would be also beneficial if the details about this function are documented in the migration document.
<|||||>@LysandreJik I could resolve the issue by adding definition for the function at following lines in my code - https://github.com/gsrivas4/Oscar_latest/blob/latest_transformer/oscar/modeling/modeling_bert.py#L190-L191. Thanks for the help.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 11,003 | closed | conda install transformers (not working) behaving differently from pip install transformers (working) for CentOS 7.9 | A fresh environment where I `conda install pytorch torchvision torchaudio -c pytorch` then `conda install transformers` produces a glibc2.18 error on CentOS 7.9 upon import with `python -c "from transformers import AutoTokenizer"`. I suspect this is a similar error to #2980, i.e., CentOS 7.9 might just be incompatible. However, a different fresh environment where I `pip install torch torchvision torchaudio` then `pip install transformers` does not produce any error upon import with `python -c "from transformers import AutoTokenizer"`.
## Environment info (pip-installed)
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: Linux-4.19.182-1.el7.retpoline.x86_64-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyTorch version (GPU?): 1.8.1+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: N/A
- Using distributed or parallel set-up in script?: <fill in>
## Environment info (conda-installed)
In fact, this command doesn't even work. See attached `cli_error_trace.txt`.
### Who can help
I'm not sure if I did this right since this seems to be more of a lower-level issue than implementation issue.
-huggingface/transformers/blob/master/src/transformers/models/auto/tokenization_auto.py @LysandreJik
## Information
Model I am using (Bert, XLNet ...):
N/A
## To reproduce
This is all done on CentOS 7.9.
##### Steps to reproduce the good, pip-installed behavior:
1. conda create --name test python=3.8
2. conda activate test
3. pip install torch torchvision torchaudio
4. pip install transformers
5. python -c "from transformers import AutoTokenizer"
##### Steps to reproduce the bad, conda-installed behavior:
1. conda create --name test2 python=3.8
2. conda activate test2
3. conda install pytorch torchvision torchaudio -c pytorch
4. conda install -c huggingface transformers
5. python -c "from transformers import AutoTokenizer"
Additionally, I have attached the `environment.yml` files for both environments and also the trace for the `transformers-cli env` command and the trace for the import error (both for the `conda install`-ed environment). The traces look pretty similar, and it seems the issue is with the dependencies of tokenizers. The .yml files have an appended .txt extension since apparently GitHub doesn't support the .yml extension for uploaded files.
[environment_pip.yml.txt](https://github.com/huggingface/transformers/files/6239328/environment_pip.yml.txt)
[environment_conda.yml.txt](https://github.com/huggingface/transformers/files/6239327/environment_conda.yml.txt)
[cli_error_trace.txt](https://github.com/huggingface/transformers/files/6239326/cli_error_trace.txt)
[import_error_trace.txt](https://github.com/huggingface/transformers/files/6239329/import_error_trace.txt)
## Expected behavior
I would expect `conda install`-ing and `pip install`-ing to both work as intended. | 03-31-2021 20:37:07 | 03-31-2021 20:37:07 | Hello! From what I'm seeing, the error comes from the `tokenizers` library instead:
```
[...]
File "/homes/gws/hcybay/miniconda3/envs/test2/lib/python3.8/site-packages/transformers-4.4.2-py3.8.egg/transformers/tokenization_utils_fast.py", line 25, in <module>
File "/homes/gws/hcybay/miniconda3/envs/test2/lib/python3.8/site-packages/tokenizers/__init__.py", line 79, in <module>
from .tokenizers import (
ImportError: /lib64/libc.so.6: version `GLIBC_2.18' not found (required by /homes/gws/hcybay/miniconda3/envs/test2/lib/python3.8/site-packages/tokenizers/tokenizers.cpython-38-x86_64-linux-gnu.so)
```
Do you mind opening an issue there? They'll probably be able to help out better.<|||||>Sure--sorry, didn't know which to open it in<|||||>Looks like I definitely should've searched the issues there first... https://github.com/huggingface/tokenizers/issues/585 |
transformers | 11,002 | closed | KeyError: 'gpt_neo' with EleutherAI/gpt-neo-1.3B | I am trying to try new GPT-3 checkpoint however I am getting an error on local and Google Colab platform as well.
Google Colab:
```
!pip install transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
```
The error I get is:
```
KeyError Traceback (most recent call last)
<ipython-input-5-333740565b3a> in <module>()
3 from transformers import AutoTokenizer, AutoModelForCausalLM
4
----> 5 tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
6 model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
1 frames
/usr/local/lib/python3.7/dist-packages/transformers/models/auto/configuration_auto.py in from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
387 config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
388 if "model_type" in config_dict:
--> 389 config_class = CONFIG_MAPPING[config_dict["model_type"]]
390 return config_class.from_dict(config_dict, **kwargs)
391 else:
KeyError: 'gpt_neo'
``` | 03-31-2021 19:54:34 | 03-31-2021 19:54:34 | Hello! GPT Neo is available on the master branch, while you're installing the version v4.2.2.
You should change `pip install transformers` to `pip install git+https://github.com/huggingface/transformers` and reload your kernel<|||||>Doing so results in this error:
```
>>> generator = pipeline('text-generation', model='EleutherAI/gpt-neo-2.7B')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\jerkm\AppData\Local\Programs\Python\Python38\lib\site-packages\transformers\pipelines\__init__.py", line 540, in pipeline
framework, model = infer_framework_load_model(
File "C:\Users\jerkm\AppData\Local\Programs\Python\Python38\lib\site-packages\transformers\pipelines\base.py", line 235, in infer_framework_load_model
raise ValueError(f"Could not load model {model} with any of the following classes: {class_tuple}.")
ValueError: Could not load model EleutherAI/gpt-neo-2.7B with any of the following classes: (<class 'transformers.models.auto.modeling_tf_auto.TFAutoModelForCausalLM'>,).
```<|||||>I think this was resolved when I installed pytorch |
transformers | 11,001 | closed | Add `examples/language_modeling/run_mlm_no_trainer.py` | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR adds an example of finetuning a Masked Language Model (without using `Trainer`) to show the functionalities of the new accelerate library.
## Who can review?
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-31-2021 18:27:20 | 03-31-2021 18:27:20 | Thanks again!<|||||>How to distributed training?~~~ In no trainer mlm<|||||>The same way as any other scripts: `python -m torch.distributed.launch --nproc_per_node xxx run_mlm_no_trainer.py --script_args`.<|||||>hello@sgugger , when I used multi-gpu, I got this error message:
(basic_dl) root@PM00011093:/data/zhaoyichen/workplace/transformers-master/examples# python -m torch.distributed.launch \
> --nproc_per_node 2 pytorch/language-modeling/run_mlm_no_trainer.py \
> --dataset_name wikitext \
> --dataset_config_name wikitext-2-raw-v1 \
> --model_name_or_path roberta-base \
> --output_dir /tmp/test-mlm
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
usage: run_mlm_no_trainer.py [-h] [--dataset_name DATASET_NAME]
[--dataset_config_name DATASET_CONFIG_NAME]
[--train_file TRAIN_FILE]
[--validation_file VALIDATION_FILE]
[--validation_split_percentage VALIDATION_SPLIT_PERCENTAGE]
[--pad_to_max_length] --model_name_or_path
MODEL_NAME_OR_PATH [--config_name CONFIG_NAME]
[--tokenizer_name TOKENIZER_NAME]
[--use_slow_tokenizer]
[--per_device_train_batch_size PER_DEVICE_TRAIN_BATCH_SIZE]
[--per_device_eval_batch_size PER_DEVICE_EVAL_BATCH_SIZE]
[--learning_rate LEARNING_RATE]
[--weight_decay WEIGHT_DECAY]
[--num_train_epochs NUM_TRAIN_EPOCHS]
[--max_train_steps MAX_TRAIN_STEPS]
[--gradient_accumulation_steps GRADIENT_ACCUMULATION_STEPS]
[--lr_scheduler_type {linear,cosine,cosine_with_restarts,polynomial,constant,constant_with_warmup}]
[--num_warmup_steps NUM_WARMUP_STEPS]
[--output_dir OUTPUT_DIR] [--seed SEED]
[--model_type {clip,bigbird_pegasus,deit,luke,gpt_neo,big_bird,speech_to_text,vit,wav2vec2,m2m_100,convbert,led,blenderbot-small,retribert,mt5,t5,pegasus,marian,mbart,blenderbot,distilbert,albert,camembert,xlm-roberta,bart,longformer,roberta,layoutlm,squeezebert,bert,openai-gpt,gpt2,megatron-bert,mobilebert,transfo-xl,xlnet,flaubert,fsmt,xlm,ctrl,electra,reformer,funnel,lxmert,bert-generation,deberta,deberta-v2,dpr,xlm-prophetnet,prophetnet,mpnet,tapas,ibert}]
[--max_seq_length MAX_SEQ_LENGTH]
[--line_by_line LINE_BY_LINE]
[--preprocessing_num_workers PREPROCESSING_NUM_WORKERS]
[--overwrite_cache OVERWRITE_CACHE]
[--mlm_probability MLM_PROBABILITY]
run_mlm_no_trainer.py: error: unrecognized arguments: --local_rank=0
usage: run_mlm_no_trainer.py [-h] [--dataset_name DATASET_NAME]
[--dataset_config_name DATASET_CONFIG_NAME]
[--train_file TRAIN_FILE]
[--validation_file VALIDATION_FILE]
[--validation_split_percentage VALIDATION_SPLIT_PERCENTAGE]
[--pad_to_max_length] --model_name_or_path
MODEL_NAME_OR_PATH [--config_name CONFIG_NAME]
[--tokenizer_name TOKENIZER_NAME]
[--use_slow_tokenizer]
[--per_device_train_batch_size PER_DEVICE_TRAIN_BATCH_SIZE]
[--per_device_eval_batch_size PER_DEVICE_EVAL_BATCH_SIZE]
[--learning_rate LEARNING_RATE]
[--weight_decay WEIGHT_DECAY]
[--num_train_epochs NUM_TRAIN_EPOCHS]
[--max_train_steps MAX_TRAIN_STEPS]
[--gradient_accumulation_steps GRADIENT_ACCUMULATION_STEPS]
[--lr_scheduler_type {linear,cosine,cosine_with_restarts,polynomial,constant,constant_with_warmup}]
[--num_warmup_steps NUM_WARMUP_STEPS]
[--output_dir OUTPUT_DIR] [--seed SEED]
[--model_type {clip,bigbird_pegasus,deit,luke,gpt_neo,big_bird,speech_to_text,vit,wav2vec2,m2m_100,convbert,led,blenderbot-small,retribert,mt5,t5,pegasus,marian,mbart,blenderbot,distilbert,albert,camembert,xlm-roberta,bart,longformer,roberta,layoutlm,squeezebert,bert,openai-gpt,gpt2,megatron-bert,mobilebert,transfo-xl,xlnet,flaubert,fsmt,xlm,ctrl,electra,reformer,funnel,lxmert,bert-generation,deberta,deberta-v2,dpr,xlm-prophetnet,prophetnet,mpnet,tapas,ibert}]
[--max_seq_length MAX_SEQ_LENGTH]
[--line_by_line LINE_BY_LINE]
[--preprocessing_num_workers PREPROCESSING_NUM_WORKERS]
[--overwrite_cache OVERWRITE_CACHE]
[--mlm_probability MLM_PROBABILITY]
run_mlm_no_trainer.py: error: unrecognized arguments: --local_rank=1
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/root/anaconda3/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/data/zhaoyichen/pyvenv/basic_dl/lib/python3.6/site-packages/torch/distributed/launch.py", line 261, in <module>
main()
File "/data/zhaoyichen/pyvenv/basic_dl/lib/python3.6/site-packages/torch/distributed/launch.py", line 257, in main
cmd=cmd)
subprocess.CalledProcessError: Command '['/data/zhaoyichen/pyvenv/basic_dl/bin/python', '-u', 'pytorch/language-modeling/run_mlm_no_trainer.py', '--local_rank=1', '--dataset_name', 'wikitext', '--dataset_config_name', 'wikitext-2-raw-v1', '--model_name_or_path', 'roberta-base', '--output_dir', '/tmp/test-mlm']' returned non-zero exit status 2.
<|||||>You need to launch it with `--use_env` when using the PyTorch launcher (or use `accelerate launch`). |
transformers | 11,000 | closed | In the group by length documentation length is misspelled as legnth | In the group by length documentation length is misspelled as legnth
## Before submitting
- [X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
| 03-31-2021 16:35:46 | 03-31-2021 16:35:46 | |
transformers | 10,999 | closed | ROUGE Multiple References | It appears the current ROUGE metric computes the score with 1 reference per candidate. I was wondering if there is way to compute ROUGE with multiple references per candidate? Thanks | 03-31-2021 16:27:19 | 03-31-2021 16:27:19 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,998 | closed | Get following error with EncoderDecoder model: TypeError: forward() got an unexpected keyword argument 'use_cache' | Hi
I am trying to create an EncoderDecoder model where i want to use a pre-trained encoder model and initialise decoder from scratch. Following the code snippet.
----------------------------------------------------------
encoder = AutoModel.from_pretrained('bert-base-uncased')
decoder_config = BertConfig(vocab_size = vocabsize,
max_position_embeddings = max_length,
num_attention_heads = num_attention_heads,
num_hidden_layers = num_hidden_layers,
hidden_size = hidden_size,
type_vocab_size = 1,
is_decoder=True)
decoder = BertForMaskedLM(config=decoder_config)
model = EncoderDecoderModel(encoder=encoder, decoder=decoder)
----------------------------------------------------------
Model gets built without any errors but when i try to make a forward pass, i get the error:
TypeError: forward() got an unexpected keyword argument 'use_cache'.
Following is the dummy forward pass function
outputs = model(input_ids=input_ids, decoder_input_ids=input_ids, labels=input_ids)
| 03-31-2021 15:42:11 | 03-31-2021 15:42:11 | Hi @mandareln
You should use `BertLMHeadModel` class if you want to use bert as decoder, here you are using `BertForMaskedLM` which is the reason for this error as it does not have the `use_cache` argument.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,997 | closed | [Docs] Add blog to BigBird docs | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-31-2021 15:24:58 | 03-31-2021 15:24:58 | cc @sgugger |
transformers | 10,996 | closed | GPT Neo, Print Most Probable Next Word: String Indices Must Be Integers |
This code is supposed to generate the next most probable word. However, the following problem arises.
```
!pip install git+https://github.com/huggingface/transformers.git
import torch
from transformers import GPTNeoForCausalLM, AutoTokenizer
model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
prompt = """In the"""
prompt = prompt.strip()
text = tokenizer.encode(prompt)
myinput, past = torch.tensor([text]), None
logits, past = model(myinput, past_key_values = past)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(10)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
for i in range(10):
m = (best_words[i])
print(m)
```
`TypeError: string indices must be integers` | 03-31-2021 14:25:29 | 03-31-2021 14:25:29 | You're doing something wrong here:
```py
logits, past = model(myinput, past_key_values = past)
```
The model returns a dict. Your `logits` and `past` are the keys of the dicts.
If you want the values, then either do:
```py
output = model(myinput, past_key_values = past)
logits = output.logits
past = output.past_key_values
```
or
```py
logits, past = model(myinput, past_key_values = past, return_dict=False)
```
This code must have worked with versions <=3. Please read the migration guide relative to switching to version 4 [here](https://huggingface.co/transformers/migration.html#switching-the-return-dict-argument-to-true-by-default)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,995 | closed | [Notebook] add BigBird trivia qa notebook | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-31-2021 13:57:58 | 03-31-2021 13:57:58 | |
transformers | 10,994 | closed | Fix the checkpoint for I-BERT | The I-BERT checkpoint was not configured correctly in the `_CHECKPOINT_FOR_DOC`
Fixes https://github.com/huggingface/transformers/issues/10990 | 03-31-2021 12:02:12 | 03-31-2021 12:02:12 | |
transformers | 10,993 | closed | [GPT Neo] fix example in config | # What does this PR do?
Fix example in doc
Thanks a lot for spotting this @NielsRogge
cc @LysandreJik | 03-31-2021 11:57:13 | 03-31-2021 11:57:13 | |
transformers | 10,992 | closed | GPT Neo configuration needs to be set to use GPT2 tokenizer | The tokenizer wasn't correctly set and ended up making ~200 slow tests fail. The run in question is here: https://github.com/huggingface/transformers/runs/2232656252?check_suite_focus=true
This PR fixes that! | 03-31-2021 11:55:02 | 03-31-2021 11:55:02 | |
transformers | 10,991 | closed | Add BigBirdPegasus | # What does this PR do?
This PR will add Google's BigBird-Pegasus. Extending #10183
Following checkpoints will be added:
- [x] [bigbird-pegasus-large-pubmed](https://huggingface.co/google/bigbird-pegasus-large-pubmed)
- [x] [bigbird-pegasus-large-arxiv](https://huggingface.co/google/bigbird-pegasus-large-arxiv)
- [x] [bigbird-pegasus-large-bigpatent](https://huggingface.co/google/bigbird-pegasus-large-bigpatent)
It is verified that uploaded models work correctly, see:
- BigBird Pegasus Arxiv: https://colab.research.google.com/drive/1ntBBkiDgccbKwKmOECB8VWEFeFmZebLN?usp=sharing
- BigBird Pegasus BigPatent: https://colab.research.google.com/drive/1RKI0BG3JUy4Hn8VdIzNLE5QduwtaiXYZ?usp=sharing
- BigBird Pegasus Pubmed: https://colab.research.google.com/drive/1LebnFVp4unqZWRx5gez1hVyqR9cibIoH?usp=sharing
Here a notebook showing how well BigBirdPegasus works on long-document summarization: https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the [documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@patrickvonplaten | 03-31-2021 11:49:26 | 03-31-2021 11:49:26 | For running conversion script for `BigBirdPegasus`:
```shell
python3 src/transformers/models/bigbird_pegasus/convert_bigbird_pegasus_tf_to_pytorch.py --tf_ckpt_path src/tf_ckpt/bigbird-pegasus-large-arxiv/model.ckpt-300000 --save_dir src/google/bigbird-pegasus-large-arxiv
```
For running conversion script for bigbird-roberta `EncoderDecoderModel`:
```shell
python3 src/transformers/models/bigbird_pegasus/convert_bigbird_roberta_tf_to_pytorch.py --tf_ckpt_path src/tf_ckpt/bigbird-roberta-arxiv/model.ckpt-300000 --save_dir src/google/bigbird-roberta-arxiv
```<|||||>@LysandreJik, yes we are planning to add this [notebook](https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) with a few modifications.<|||||>@patrickvonplaten, Test failing on CircleCi: `tests/test_modeling_bigbird_pegasus.py::BigBirdPegasusStandaloneDecoderModelTest::test_decoder_model_attn_mask_past` is passing for me locally.
Everything else is fixed!! |
transformers | 10,990 | closed | Can't find ibert-roberta-base model | ## Environment info
- `transformers` version: 4.4.2
- Platform: Linux-4.15.0-1109-azure-x86_64-with-Ubuntu-16.04-xenial
- Python version: 3.6.13
- PyTorch version (GPU?): 1.4.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
Models:
- ibert: @kssteven418
Documentation:
- @sgugger
## Information
Model I am using I-BERT:
The problem arises when using:
* [X] the official example scripts: (give details below)
## To reproduce
From [documentation](https://huggingface.co/transformers/model_doc/ibert.html):
```python
from transformers import RobertaTokenizer, IBertModel
import torch
tokenizer = RobertaTokenizer.from_pretrained('ibert-roberta-base')
model = IBertModel.from_pretrained('ibert-roberta-base')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
Steps to reproduce the behavior:
1. install pytorch and transformers
2. run the code example from docs
```python
Traceback (most recent call last):
File "/home/sotmazgi/PycharmProjects/s2e-coref/ibert_test.py", line 3, in <module>
tokenizer = RobertaTokenizer.from_pretrained('ibert-roberta-base')
File "/home/sotmazgi/PycharmProjects/s2e-coref/venv/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1693, in from_pretrained
raise EnvironmentError(msg)
OSError: Can't load tokenizer for 'ibert-roberta-base'. Make sure that:
- 'ibert-roberta-base' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'ibert-roberta-base' is the correct path to a directory containing relevant tokenizer files
```
## Expected behavior
get the embedding for the example sentence
| 03-31-2021 11:49:25 | 03-31-2021 11:49:25 | Hi @shon-otmazgin, here's the model: https://huggingface.co/kssteven/ibert-roberta-base
The documentation is unfortunately wrong. I'm updating it.<|||||>Fixing it in https://github.com/huggingface/transformers/pull/10994<|||||>Hello @LysandreJik,
We should specify `kssteven/ibert-roberta-base` in `from_pretrained` function?<|||||>Yes, that's right! That's the checkpoint you're looking for.
The docs are now updated on `master`, and the next release (next few days) will have them. <|||||>Thanks @LysandreJik
After reinstalling from source:
python
```
Traceback (most recent call last):
File "/home/sotmazgi/PycharmProjects/s2e-coref/ibert_test.py", line 3, in <module>
tokenizer = RobertaTokenizer.from_pretrained('kssteven/ibert-roberta-base')
File "/home/sotmazgi/PycharmProjects/s2e-coref/venv/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1705, in from_pretrained
resolved_vocab_files, pretrained_model_name_or_path, init_configuration, *init_inputs, **kwargs
File "/home/sotmazgi/PycharmProjects/s2e-coref/venv/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1776, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/home/sotmazgi/PycharmProjects/s2e-coref/venv/lib/python3.6/site-packages/transformers/models/roberta/tokenization_roberta.py", line 171, in __init__
**kwargs,
File "/home/sotmazgi/PycharmProjects/s2e-coref/venv/lib/python3.6/site-packages/transformers/models/gpt2/tokenization_gpt2.py", line 179, in __init__
with open(vocab_file, encoding="utf-8") as vocab_handle:
TypeError: expected str, bytes or os.PathLike object, not NoneType
```<|||||>Ah, it seems that the I-BERT authors have not uploaded some slow tokenizer files. Can you try it with a `RobertaTokenizerFast` instead of a `RobertaTokenizer` and let me know if it works for you?<|||||>Yes thank you |
transformers | 10,989 | closed | Fixed some typos and removed legacy url | # What does this PR do?
Removed legacy url to colab notebook in examples/multiple-choice/README.md
Fixed some typos.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger
@patil-suraj
| 03-31-2021 10:21:42 | 03-31-2021 10:21:42 | Thanks a lot for doing this! |
transformers | 10,988 | closed | unable to use multiple GPUs with HF integration of DeepSpeed on Jupyter notebooks | Hi ,
I'm using HF integration of DeepSpeed in my Jupyter Notebook by setting following env variables as suggested [here](https://huggingface.co/transformers/main_classes/trainer.html#deployment-in-notebooks)
```
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '9889'
os.environ['RANK'] = "0"
os.environ['LOCAL_RANK'] = "0"
os.environ['WORLD_SIZE'] = "1"
os.environ['NCCL_SOCKET_IFNAME'] = 'lo' ##because of my kubeflow setup
```
with this setup I'm unable to utilize both GPU's that I have and here's the log info before it starts training-
```
[2021-03-31 09:49:02,510] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed info: version=0.3.13+7fcc891, git-hash=7fcc891, git-branch=master
[2021-03-31 09:49:02,540] [INFO] [engine.py:80:_initialize_parameter_parallel_groups] data_parallel_size: 1, parameter_parallel_size: 1
[2021-03-31 09:49:05,758] [INFO] [engine.py:608:_configure_optimizer] Using DeepSpeed Optimizer param name adamw as basic optimizer
[2021-03-31 09:49:05,760] [INFO] [engine.py:612:_configure_optimizer] DeepSpeed Basic Optimizer = DeepSpeedCPUAdam
Checking ZeRO support for optimizer=DeepSpeedCPUAdam type=<class 'deepspeed.ops.adam.cpu_adam.DeepSpeedCPUAdam'>
[2021-03-31 09:49:05,761] [INFO] [logging.py:60:log_dist] [Rank 0] Creating fp16 ZeRO stage 2 optimizer
[2021-03-31 09:49:05,764] [INFO] [stage2.py:130:__init__] Reduce bucket size 150000000.0
[2021-03-31 09:49:05,765] [INFO] [stage2.py:131:__init__] Allgather bucket size 150000000.0
[2021-03-31 09:49:05,766] [INFO] [stage2.py:132:__init__] CPU Offload: True
[2021-03-31 09:49:12,585] [INFO] [stage2.py:399:__init__] optimizer state initialized
[2021-03-31 09:49:12,588] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed Final Optimizer = adamw
[2021-03-31 09:49:12,589] [INFO] [engine.py:445:_configure_lr_scheduler] DeepSpeed using configured LR scheduler = WarmupLR
[2021-03-31 09:49:12,590] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed LR Scheduler = <deepspeed.runtime.lr_schedules.WarmupLR object at 0x7fef53ed1d68>
[2021-03-31 09:49:12,591] [INFO] [logging.py:60:log_dist] [Rank 0] step=0, skipped=0, lr=[3e-05], mom=[[0.8, 0.999]]
[2021-03-31 09:49:12,593] [INFO] [config.py:737:print] DeepSpeedEngine configuration:
[2021-03-31 09:49:12,594] [INFO] [config.py:741:print] activation_checkpointing_config {
"contiguous_memory_optimization": false,
"cpu_checkpointing": false,
"number_checkpoints": null,
"partition_activations": false,
"profile": false,
"synchronize_checkpoint_boundary": false
}
[2021-03-31 09:49:12,594] [INFO] [config.py:741:print] allreduce_always_fp32 ........ False
[2021-03-31 09:49:12,595] [INFO] [config.py:741:print] amp_enabled .................. False
[2021-03-31 09:49:12,596] [INFO] [config.py:741:print] amp_params ................... False
[2021-03-31 09:49:12,596] [INFO] [config.py:741:print] checkpoint_tag_validation_enabled True
[2021-03-31 09:49:12,597] [INFO] [config.py:741:print] checkpoint_tag_validation_fail False
[2021-03-31 09:49:12,600] [INFO] [config.py:741:print] disable_allgather ............ False
[2021-03-31 09:49:12,601] [INFO] [config.py:741:print] dump_state ................... False
[2021-03-31 09:49:12,602] [INFO] [config.py:741:print] dynamic_loss_scale_args ...... {'init_scale': 4294967296, 'scale_window': 1000, 'delayed_shift': 2, 'min_scale': 1}
[2021-03-31 09:49:12,603] [INFO] [config.py:741:print] elasticity_enabled ........... False
[2021-03-31 09:49:12,603] [INFO] [config.py:741:print] flops_profiler_config ........ {
"detailed": true,
"enabled": false,
"module_depth": -1,
"profile_step": 1,
"top_modules": 3
}
[2021-03-31 09:49:12,604] [INFO] [config.py:741:print] fp16_enabled ................. True
[2021-03-31 09:49:12,605] [INFO] [config.py:741:print] global_rank .................. 0
[2021-03-31 09:49:12,605] [INFO] [config.py:741:print] gradient_accumulation_steps .. 1
[2021-03-31 09:49:12,606] [INFO] [config.py:741:print] gradient_clipping ............ 1.0
[2021-03-31 09:49:12,607] [INFO] [config.py:741:print] gradient_predivide_factor .... 1.0
[2021-03-31 09:49:12,607] [INFO] [config.py:741:print] initial_dynamic_scale ........ 4294967296
[2021-03-31 09:49:12,608] [INFO] [config.py:741:print] loss_scale ................... 0
[2021-03-31 09:49:12,609] [INFO] [config.py:741:print] memory_breakdown ............. False
[2021-03-31 09:49:12,610] [INFO] [config.py:741:print] optimizer_legacy_fusion ...... False
[2021-03-31 09:49:12,610] [INFO] [config.py:741:print] optimizer_name ............... adamw
[2021-03-31 09:49:12,611] [INFO] [config.py:741:print] optimizer_params ............. {'lr': 3e-05, 'betas': [0.8, 0.999], 'eps': 1e-08, 'weight_decay': 3e-07}
[2021-03-31 09:49:12,612] [INFO] [config.py:741:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}
[2021-03-31 09:49:12,612] [INFO] [config.py:741:print] pld_enabled .................. False
[2021-03-31 09:49:12,613] [INFO] [config.py:741:print] pld_params ................... False
[2021-03-31 09:49:12,614] [INFO] [config.py:741:print] prescale_gradients ........... False
[2021-03-31 09:49:12,616] [INFO] [config.py:741:print] scheduler_name ............... WarmupLR
[2021-03-31 09:49:12,616] [INFO] [config.py:741:print] scheduler_params ............. {'warmup_min_lr': 0, 'warmup_max_lr': 3e-05, 'warmup_num_steps': 500}
[2021-03-31 09:49:12,617] [INFO] [config.py:741:print] sparse_attention ............. None
[2021-03-31 09:49:12,618] [INFO] [config.py:741:print] sparse_gradients_enabled ..... False
[2021-03-31 09:49:12,618] [INFO] [config.py:741:print] steps_per_print .............. 2000
[2021-03-31 09:49:12,619] [INFO] [config.py:741:print] tensorboard_enabled .......... False
[2021-03-31 09:49:12,620] [INFO] [config.py:741:print] tensorboard_job_name ......... DeepSpeedJobName
[2021-03-31 09:49:12,620] [INFO] [config.py:741:print] tensorboard_output_path ......
[2021-03-31 09:49:12,621] [INFO] [config.py:741:print] train_batch_size ............. 4
[2021-03-31 09:49:12,622] [INFO] [config.py:741:print] train_micro_batch_size_per_gpu 4
[2021-03-31 09:49:12,622] [INFO] [config.py:741:print] wall_clock_breakdown ......... False
[2021-03-31 09:49:12,623] [INFO] [config.py:741:print] world_size ................... 1
[2021-03-31 09:49:12,624] [INFO] [config.py:741:print] zero_allow_untested_optimizer False
[2021-03-31 09:49:12,625] [INFO] [config.py:741:print] zero_config .................. {
"allgather_bucket_size": 150000000.0,
"allgather_partitions": true,
"contiguous_gradients": true,
"cpu_offload": true,
"cpu_offload_params": false,
"cpu_offload_use_pin_memory": false,
"elastic_checkpoint": true,
"gather_fp16_weights_on_model_save": false,
"load_from_fp32_weights": true,
"max_live_parameters": 1000000000,
"max_reuse_distance": 1000000000,
"overlap_comm": true,
"param_persistence_threshold": 100000,
"prefetch_bucket_size": 50000000,
"reduce_bucket_size": 150000000.0,
"reduce_scatter": true,
"stage": 2,
"sub_group_size": 1000000000000
}
[2021-03-31 09:49:12,625] [INFO] [config.py:741:print] zero_enabled ................. True
[2021-03-31 09:49:12,626] [INFO] [config.py:741:print] zero_optimization_stage ...... 2
[2021-03-31 09:49:12,628] [INFO] [config.py:748:print] json = {
"fp16":{
"enabled":true,
"hysteresis":2,
"loss_scale":0,
"loss_scale_window":1000,
"min_loss_scale":1
},
"gradient_accumulation_steps":1,
"gradient_clipping":1.0,
"optimizer":{
"params":{
"betas":[
0.8,
0.999
],
"eps":1e-08,
"lr":3e-05,
"weight_decay":3e-07
},
"type":"AdamW"
},
"scheduler":{
"params":{
"warmup_max_lr":3e-05,
"warmup_min_lr":0,
"warmup_num_steps":500
},
"type":"WarmupLR"
},
"steps_per_print":2000,
"train_micro_batch_size_per_gpu":4,
"wall_clock_breakdown":false,
"zero_optimization":{
"allgather_bucket_size":150000000.0,
"allgather_partitions":true,
"contiguous_gradients":true,
"cpu_offload":true,
"overlap_comm":true,
"reduce_bucket_size":150000000.0,
"reduce_scatter":true,
"stage":2
}
}
```
But both GPUs were used if I convert my notebook to python script and run script with command - `!NCCL_SOCKET_IFNAME=lo deepspeed Deberta_V2_XXLarge.py --deepspeed ds_config.json` and here's the log -
```
[2021-03-31 09:26:36,687] [WARNING] [runner.py:117:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
[2021-03-31 09:26:36,714] [INFO] [runner.py:358:main] cmd = /usr/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMCwgMV19 --master_addr=127.0.0.1 --master_port=29500 Deberta_V2_XXLarge.py --deepspeed ds_config.json
[2021-03-31 09:26:38,357] [INFO] [launch.py:73:main] 0 NCCL_SOCKET_IFNAME lo
[2021-03-31 09:26:38,357] [INFO] [launch.py:80:main] WORLD INFO DICT: {'localhost': [0, 1]}
[2021-03-31 09:26:38,357] [INFO] [launch.py:89:main] nnodes=1, num_local_procs=2, node_rank=0
[2021-03-31 09:26:38,357] [INFO] [launch.py:101:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0, 1]})
[2021-03-31 09:26:38,358] [INFO] [launch.py:102:main] dist_world_size=2
[2021-03-31 09:26:38,358] [INFO] [launch.py:105:main] Setting CUDA_VISIBLE_DEVICES=0,1
2021-03-31 09:26:40.269001: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2021-03-31 09:26:40.269004: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
[2021-03-31 09:27:27,272] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl
[2021-03-31 09:27:31,495] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed info: version=0.3.13+7fcc891, git-hash=7fcc891, git-branch=master
[2021-03-31 09:27:32,428] [INFO] [engine.py:80:_initialize_parameter_parallel_groups] data_parallel_size: 2, parameter_parallel_size: 2
[2021-03-31 09:27:32,834] [INFO] [engine.py:80:_initialize_parameter_parallel_groups] data_parallel_size: 2, parameter_parallel_size: 2
Adam Optimizer #0 is created with AVX512 arithmetic capability.
Config: alpha=0.000030, betas=(0.800000, 0.999000), weight_decay=0.000000, adam_w=1
[2021-03-31 09:27:36,438] [INFO] [engine.py:608:_configure_optimizer] Using DeepSpeed Optimizer param name adamw as basic optimizer
[2021-03-31 09:27:36,438] [INFO] [engine.py:612:_configure_optimizer] DeepSpeed Basic Optimizer = DeepSpeedCPUAdam
Checking ZeRO support for optimizer=DeepSpeedCPUAdam type=<class 'deepspeed.ops.adam.cpu_adam.DeepSpeedCPUAdam'>
[2021-03-31 09:27:36,439] [INFO] [logging.py:60:log_dist] [Rank 0] Creating fp16 ZeRO stage 2 optimizer
Adam Optimizer #0 is created with AVX512 arithmetic capability.
Config: alpha=0.000030, betas=(0.800000, 0.999000), weight_decay=0.000000, adam_w=1
[2021-03-31 09:27:36,441] [INFO] [stage2.py:130:__init__] Reduce bucket size 150000000.0
[2021-03-31 09:27:36,441] [INFO] [stage2.py:131:__init__] Allgather bucket size 150000000.0
[2021-03-31 09:27:36,441] [INFO] [stage2.py:132:__init__] CPU Offload: True
[2021-03-31 09:27:40,524] [INFO] [stage2.py:399:__init__] optimizer state initialized
[2021-03-31 09:27:40,530] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed Final Optimizer = adamw
[2021-03-31 09:27:40,533] [INFO] [engine.py:445:_configure_lr_scheduler] DeepSpeed using configured LR scheduler = WarmupLR
[2021-03-31 09:27:40,534] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed LR Scheduler = <deepspeed.runtime.lr_schedules.WarmupLR object at 0x7f105c6a0b00>
[2021-03-31 09:27:40,535] [INFO] [logging.py:60:log_dist] [Rank 0] step=0, skipped=0, lr=[3e-05], mom=[[0.8, 0.999]]
[2021-03-31 09:27:40,536] [INFO] [config.py:737:print] DeepSpeedEngine configuration:
[2021-03-31 09:27:40,537] [INFO] [config.py:741:print] activation_checkpointing_config {
"contiguous_memory_optimization": false,
"cpu_checkpointing": false,
"number_checkpoints": null,
"partition_activations": false,
"profile": false,
"synchronize_checkpoint_boundary": false
}
[2021-03-31 09:27:40,537] [INFO] [config.py:741:print] allreduce_always_fp32 ........ False
[2021-03-31 09:27:40,538] [INFO] [config.py:741:print] amp_enabled .................. False
[2021-03-31 09:27:40,538] [INFO] [config.py:741:print] amp_params ................... False
[2021-03-31 09:27:40,538] [INFO] [config.py:741:print] checkpoint_tag_validation_enabled True
[2021-03-31 09:27:40,538] [INFO] [config.py:741:print] checkpoint_tag_validation_fail False
[2021-03-31 09:27:40,538] [INFO] [config.py:741:print] disable_allgather ............ False
[2021-03-31 09:27:40,538] [INFO] [config.py:741:print] dump_state ................... False
[2021-03-31 09:27:40,538] [INFO] [config.py:741:print] dynamic_loss_scale_args ...... {'init_scale': 4294967296, 'scale_window': 1000, 'delayed_shift': 2, 'min_scale': 1}
[2021-03-31 09:27:40,539] [INFO] [config.py:741:print] elasticity_enabled ........... False
[2021-03-31 09:27:40,539] [INFO] [config.py:741:print] flops_profiler_config ........ {
"detailed": true,
"enabled": false,
"module_depth": -1,
"profile_step": 1,
"top_modules": 3
}
[2021-03-31 09:27:40,540] [INFO] [config.py:741:print] fp16_enabled ................. True
[2021-03-31 09:27:40,540] [INFO] [config.py:741:print] global_rank .................. 0
[2021-03-31 09:27:40,540] [INFO] [config.py:741:print] gradient_accumulation_steps .. 1
[2021-03-31 09:27:40,540] [INFO] [config.py:741:print] gradient_clipping ............ 1.0
[2021-03-31 09:27:40,540] [INFO] [config.py:741:print] gradient_predivide_factor .... 1.0
[2021-03-31 09:27:40,540] [INFO] [config.py:741:print] initial_dynamic_scale ........ 4294967296
[2021-03-31 09:27:40,541] [INFO] [config.py:741:print] loss_scale ................... 0
[2021-03-31 09:27:40,541] [INFO] [config.py:741:print] memory_breakdown ............. False
[2021-03-31 09:27:40,541] [INFO] [config.py:741:print] optimizer_legacy_fusion ...... False
[2021-03-31 09:27:40,541] [INFO] [config.py:741:print] optimizer_name ............... adamw
[2021-03-31 09:27:40,541] [INFO] [config.py:741:print] optimizer_params ............. {'lr': 3e-05, 'betas': [0.8, 0.999], 'eps': 1e-08, 'weight_decay': 3e-07}
[2021-03-31 09:27:40,541] [INFO] [config.py:741:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}
[2021-03-31 09:27:40,541] [INFO] [config.py:741:print] pld_enabled .................. False
[2021-03-31 09:27:40,541] [INFO] [config.py:741:print] pld_params ................... False
[2021-03-31 09:27:40,542] [INFO] [config.py:741:print] prescale_gradients ........... False
[2021-03-31 09:27:40,542] [INFO] [config.py:741:print] scheduler_name ............... WarmupLR
[2021-03-31 09:27:40,542] [INFO] [config.py:741:print] scheduler_params ............. {'warmup_min_lr': 0, 'warmup_max_lr': 3e-05, 'warmup_num_steps': 500}
[2021-03-31 09:27:40,542] [INFO] [config.py:741:print] sparse_attention ............. None
[2021-03-31 09:27:40,542] [INFO] [config.py:741:print] sparse_gradients_enabled ..... False
[2021-03-31 09:27:40,542] [INFO] [config.py:741:print] steps_per_print .............. 2000
[2021-03-31 09:27:40,542] [INFO] [config.py:741:print] tensorboard_enabled .......... False
[2021-03-31 09:27:40,542] [INFO] [config.py:741:print] tensorboard_job_name ......... DeepSpeedJobName
[2021-03-31 09:27:40,543] [INFO] [config.py:741:print] tensorboard_output_path ......
[2021-03-31 09:27:40,543] [INFO] [config.py:741:print] train_batch_size ............. 8
[2021-03-31 09:27:40,543] [INFO] [config.py:741:print] train_micro_batch_size_per_gpu 4
[2021-03-31 09:27:40,543] [INFO] [config.py:741:print] wall_clock_breakdown ......... False
[2021-03-31 09:27:40,543] [INFO] [config.py:741:print] world_size ................... 2
[2021-03-31 09:27:40,543] [INFO] [config.py:741:print] zero_allow_untested_optimizer False
[2021-03-31 09:27:40,544] [INFO] [config.py:741:print] zero_config .................. {
"allgather_bucket_size": 150000000.0,
"allgather_partitions": true,
"contiguous_gradients": true,
"cpu_offload": true,
"cpu_offload_params": false,
"cpu_offload_use_pin_memory": false,
"elastic_checkpoint": true,
"gather_fp16_weights_on_model_save": false,
"load_from_fp32_weights": true,
"max_live_parameters": 1000000000,
"max_reuse_distance": 1000000000,
"overlap_comm": true,
"param_persistence_threshold": 100000,
"prefetch_bucket_size": 50000000,
"reduce_bucket_size": 150000000.0,
"reduce_scatter": true,
"stage": 2,
"sub_group_size": 1000000000000
}
[2021-03-31 09:27:40,544] [INFO] [config.py:741:print] zero_enabled ................. True
[2021-03-31 09:27:40,545] [INFO] [config.py:741:print] zero_optimization_stage ...... 2
[2021-03-31 09:27:40,546] [INFO] [config.py:748:print] json = {
"fp16":{
"enabled":true,
"hysteresis":2,
"loss_scale":0,
"loss_scale_window":1000,
"min_loss_scale":1
},
"gradient_accumulation_steps":1,
"gradient_clipping":1.0,
"optimizer":{
"params":{
"betas":[
0.8,
0.999
],
"eps":1e-08,
"lr":3e-05,
"weight_decay":3e-07
},
"type":"AdamW"
},
"scheduler":{
"params":{
"warmup_max_lr":3e-05,
"warmup_min_lr":0,
"warmup_num_steps":500
},
"type":"WarmupLR"
},
"steps_per_print":2000,
"train_micro_batch_size_per_gpu":4,
"wall_clock_breakdown":false,
"zero_optimization":{
"allgather_bucket_size":150000000.0,
"allgather_partitions":true,
"contiguous_gradients":true,
"cpu_offload":true,
"overlap_comm":true,
"reduce_bucket_size":150000000.0,
"reduce_scatter":true,
"stage":2
}
}
```
Plz suggest whether I need to make some changes..
Verions I'm using -
```
torch-1.7.1+cu101
transformers-4.4.2
deepspeed-0.3.13
```
**Who can help**
@LysandreJik
@stas00
| 03-31-2021 10:06:30 | 03-31-2021 10:06:30 | That's correct.
You need a separate process for each gpu under DeepSpeed for communications to work. I will update the docs to make this clear.
If you want to use multiple gpus you must use the launcher. So you can still use the notebook to set things up, but the training must happen in external process, e.g. see:
https://github.com/stas00/porting/blob/master/transformers/deepspeed/DeepSpeed_on_colab_CLI.ipynb
but edit the launcher line to use `deepspeed --num_gpus 2`
I will close this for now as it's a clear "this is not possible due to the DeepSpeed design", but if you have some further questions please don't hesitate to follow up. |
transformers | 10,987 | closed | Sagemaker test fix | # What does this PR do?
Fixed test documentation `makefile` command and PyTorch-ddp test when #10975 is merged. Different validation function for `sagemaker-data-parallel`. Can be merged already. | 03-31-2021 09:41:26 | 03-31-2021 09:41:26 | |
transformers | 10,986 | closed | BART : Cannot run trainer.evaluate() after trainer.train() | ## Environment info
- `transformers` version: 4.4.2
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.10
- PyTorch version (GPU?): 1.8.1+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: False
### Who can help
trainer : @sgugger
bart : @patrickvonplaten
## Information
Model I am using : bart, barthez, mbart
I am working on text summarization.
The problem arises when using my own modified script, inspired by the official Seq2Seq example. I am using the Seq2SeqTrainer class.
I am unable to run trainer.evaluate(...) after trainer.train(...) as well as evaluating the model during training after x epochs or steps.
## To reproduce
I you want to try it out, here is a link to [my notebook](https://colab.research.google.com/drive/1CqxxM0nOdJRpre_SwLOajl_s9hlKTT9e?usp=sharing)
Steps to reproduce the behavior:
1. Download model, tokenizer, and dataset from hub
2. Run trainer.evaluate(...) (works)
3. Run trainer.train(...) (runs fine)
4. Run trainer.evaluate(...) (returns the error below)
```
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/bart/modeling_bart.py in forward(self, input_ids, attention_mask, decoder_input_ids, decoder_attention_mask, head_mask, decoder_head_mask, encoder_outputs, past_key_values, inputs_embeds, decoder_inputs_embeds, use_cache, output_attentions, output_hidden_states, return_dict)
1160 elif return_dict and not isinstance(encoder_outputs, BaseModelOutput):
1161 encoder_outputs = BaseModelOutput(
-> 1162 last_hidden_state=encoder_outputs[0],
1163 hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
1164 attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
KeyError: 0
```
| 03-31-2021 08:15:00 | 03-31-2021 08:15:00 | This is not an issue with Transformers but with using Apex with the "O3" opt-level. This changes your model during the training and results in the error you're seeing. The best is to re-instantiate a clean `Trainer` for evaluation after you're done with training.<|||||>Thank you for your reply, I just tried it and it actually only works with Apex "01" opt-level ! |
transformers | 10,985 | closed | [WIP] GPT Neo cleanup | # What does this PR do?
This PR refactors the `GPTNeoLocalSelfAttention` layer and adds more tests for it.
This PR
- adds the `AttentionMixin` class which contains the shared utilities for both global and local attention. The class is meant to be used as a mixin and makes it easy to test it.
- the `look_around` method is now replaced by the `AttentionMixin._look_back` method, which is now vectorized and can give up to 300x speed-up compared to old `look_around`
- The `GPTNeoLocalSelfAttention._create_attention_mask` is now simplified and is also giving nice speed-up as it uses `_look_back`. I've added more detailed comments to explain the mask creation logic.
- I've added multiple shape checks in the `AttentionMixin` to make it as robust as possible.
I didn't do a thorough benchmarking but I'm observing around ~3.9x speed-up when generating sequences of length 1024.
Verified that all slow-tets are passing. | 03-31-2021 07:29:25 | 03-31-2021 07:29:25 | As explained in https://github.com/huggingface/transformers/issues/11076#issuecomment-814218202, the loss did decrease over time on this small sample so it looks like there are no regressions w.r.t training.
~Merge when ready @patil-suraj.~ :point_down: <|||||>It seems I'm not passing the slow tests locally, `test_gpt_neo_sample` fails with:
```
AssertionError: 'Today is a nice day and a wonderful time to be in Rome, though the sun won’' != 'Today is a nice day and if you don’t get the memo here is what you can'
- Today is a nice day and a wonderful time to be in Rome, though the sun won’
+ Today is a nice day and if you don’t get the memo here is what you can
```<|||||>As seen with @patil-suraj, this is due to a wrongly initialized seed; and the other tests ensure that we have a correct attention mask and generation. Merging! |
transformers | 10,984 | closed | AttributeError due to multi-processing using PyTorchBenchmark | Hi there,
likely my fault, but I can't find a proper solution yet. Tried to follow the structure as in `examples/benchmarking/run_benchmark.py`.
My Code:
```python
from transformers import AutoConfig, PyTorchBenchmark, PyTorchBenchmarkArguments
def main():
config = AutoConfig.from_pretrained('roberta-base')
# define args
args = PyTorchBenchmarkArguments(
models=['roberta-base'],
inference=False,
training=True,
speed=True,
memory=True,
save_to_csv=True,
train_memory_csv_file=f'models/filmo-large/train_memory_benchmark.csv',
train_time_csv_file=f'models/filmo-large/train_time_benchmark.csv',
env_info_csv_file=f'models/filmo-large/env.csv',
sequence_lengths=[64, 128, 256, 512],
batch_sizes=[8, 16],
fp16=True,
multi_process=True,
)
# create benchmark
benchmark = PyTorchBenchmark(
configs=[config],
args=args,
)
# run benchmark
benchmark.run()
if __name__ == '__main__':
main()
```
The error it yields:
```python
1 / 1
Traceback (most recent call last):
File "c:/Users/.../lm-train-benchmark.py", line 47, in <module>
main()
File "c:/Users/.../lm-train-benchmark.py", line 43, in main
benchmark.run()
File "C:\Users\...\.venv\lib\site-packages\transformers\benchmark\benchmark_utils.py", line 715, in run
memory, train_summary = self.train_memory(model_name, batch_size, sequence_length)
File "C:\Users\...\.venv\lib\site-packages\transformers\benchmark\benchmark_utils.py", line 679, in train_memory
return separate_process_wrapper_fn(self._train_memory, self.args.do_multi_processing)(*args, **kwargs)
File "C:\Users\...\.venv\lib\site-packages\transformers\benchmark\benchmark_utils.py", line 101, in multi_process_func
p.start()
File "C:\Python\lib\multiprocessing\process.py", line 121, in start
self._popen = self._Popen(self)
File "C:\Python\lib\multiprocessing\context.py", line 224, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "C:\Python\lib\multiprocessing\context.py", line 327, in _Popen
return Popen(process_obj)
reduction.dump(process_obj, to_child)
File "C:\Python\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
AttributeError: Can't pickle local object 'separate_process_wrapper_fn.<locals>.multi_process_func.<locals>.wrapper_func'
PS C:\Users\...> Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\Python\lib\multiprocessing\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "C:\Python\lib\multiprocessing\spawn.py", line 126, in _main
self = reduction.pickle.load(from_parent)
EOFError: Ran out of input
```
Already tried to rearrange the order and place individual components on the top level, without success. I am grateful for any advice 😄
Simon | 03-31-2021 07:21:59 | 03-31-2021 07:21:59 | Same issue for me.
When running
```python
python run_benchmark.py --no_speed --models a-ware/roberta-large-squad-classification --sequence_lengths 32 --batch_sizes 32
```
I get:
```
AttributeError: Can't pickle local object 'separate_process_wrapper_fn.<locals>.multi_process_func.<locals>.wrapper_func'
```<|||||>Anyone from the `transformers` team got a solution for this?<|||||>Can you try setting `multi_process=False`?<|||||>@patrickvonplaten If I remember correctly the error disappeared when setting `multi_process` to false. However, I figured I should set it to true in order to obtain performance estimates which are as close as possible to reality?<|||||>For PyTorch it's totally fine to set `multi_process=False` -> it's only in TF where the memory consumption is a bit off then<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>This issue is still present in the latest version (4.11.3). I ran the example benchmark shown [here](https://huggingface.co/transformers/benchmarks.html) in TensorFlow (2.6.0) and got the same error:
> AttributeError: Can't pickle local object 'separate_process_wrapper_fn.<locals>.multi_process_func.<locals>.wrapper_func
|
transformers | 10,983 | closed | FineTune XLSR-Wav2Vec2 on New Langauge WER still 1 | Hi, can i ask is there anyone facing issues fine tuning wav2vec2 for languages not in the common dataset.
I am trying to finetune for a language not within in the common datasets, but i get a WER of 1 not matter how many steps i tried to finetune, I have a similar issue here #10884
You can check my code in the repo here: (Note i did make some small changes that weren't in the original notebook by the huggingface team to fit the training notebook they provided)
https://github.com/edwin-19/wave2vec2-hf-sprint/blob/master/Train.ipynb | 03-31-2021 06:53:27 | 03-31-2021 06:53:27 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,982 | closed | Update setup.py | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-31-2021 05:41:00 | 03-31-2021 05:41:00 | for error fixation |
transformers | 10,981 | closed | support passing path to a `config` variable in AutoClass | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
It enables loading weights from a private server like the following.
```python
AutoModel.from_pretrained('https://myserver/model/pytorch_model.bin', config='path/to/local/config.json')
```
**For the moment, the function to load weights from a private server like this way is supported in `PretrainedModel` but not in `AutoModel`.**
```python
BertModel.from_pretrained('https://myserver/model/pytorch_model.bin', config='path/to/local/config.json') # supported
AutoModel.from_pretrained('https://myserver/model/pytorch_model.bin', config='path/to/local/config.json') # not supported
```
To fix this issue, I copy and pasted code about `config_path` from `PretrainedModel` to `AutoModel`.
This features was requested in #10961 .
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@LysandreJik | 03-31-2021 05:28:32 | 03-31-2021 05:28:32 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,980 | closed | Enforce string-formatting with f-strings | # What does this PR do?
This PR removes any strings formatted with `.format` or `%` to use f-strings exclusively (unless there is a very good reason to use the other syntax, or the file is in a research_project/legacy folder).
The mix of three syntaxes does not make any sense and we all agree in the team that f-strings are more readable. Now that Python 3.5 is officially dead, there is no reason not to switch fully to f-strings.
cc @stas00 as we had a conversation about that.
| 03-31-2021 02:28:58 | 03-31-2021 02:28:58 | |
transformers | 10,979 | closed | Tagged Model Version Not Working | I am trying to download a specific version of the `roberta-large` model using the `revision` parameter of `from_pretrained()` as shown below:
```
from transformers import RobertaForSequenceClassification
model_type = "roberta-large"
v1 = "v3.5.0"
model = RobertaForSequenceClassification.from_pretrained(model_type, num_labels=2, revision=v1)
```
This code gives me the following 404 error:
```
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/roberta-large/resolve/v3.5.0/config.json
```
Am I using the `revision` parameter incorrectly?
Extra notes:
- I am using transformers v4.1.1
- Running the same code above with `v1 = "main"` works just fine | 03-31-2021 00:37:45 | 03-31-2021 00:37:45 | I think you're using it wrong indeed. As said in the [docs](https://huggingface.co/transformers/model_sharing.html#model-versioning), you can either specify a tag name, branch name, or commit hash.<|||||>To reiterate over what @NielsRogge already said, this is the revision of the *model*, not the repository. You can check the model commits here: https://huggingface.co/roberta-large/commits/main
Revisions also include branches and tags, but this particular model only has a single branch and no tag.<|||||>Ah, that makes sense. Thanks for the prompt reply! |
transformers | 10,978 | open | Add GPT Neo models to Write With Transformer | # 🚀 Feature request
Would it be possible to get the newly-added GPT Neo models usable on Write With Transformer?
## Motivation
It would be helpful to use the new models in the Write With Transformer app since it supports newlines.
CC @LysandreJik | 03-31-2021 00:10:23 | 03-31-2021 00:10:23 | Very much needed! |
transformers | 10,977 | closed | [Flax] Add other BERT classes | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR adds the other BERT model classes for Flax.
Also the following checkpoints have been uploaded for Flax:
- https://huggingface.co/bert-base-cased
- https://huggingface.co/bert-large-cased
- https://huggingface.co/bert-base-uncased
- https://huggingface.co/bert-large-uncased
- https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-30-2021 22:22:38 | 03-30-2021 22:22:38 | > It is so similar to the PyTorch implementation it seems a script could take care of the implementation by copying the PyTorch one and replacing a few strings!
@marcvanzee and I were also wondering about this in general -- is there a 80/20 solution that requires user input in some cases? It would have to not introduce silent errors (e.g. a model that seems to run the same but differs in some hard-to-find way).
|
transformers | 10,976 | closed | Transformers QA Online Demo is not working |
Transformers QA Online Demo is not working: https://huggingface.co/qa/
I am trying to recreate ELI5 but unable to find enough information @yjernite Can you Please help.
Please let me know if I can help
Thanks | 03-30-2021 21:15:21 | 03-30-2021 21:15:21 | I re-launched the app.
The app itself doesn't have much information to help recreate the system though (and is not designed for heavy use :) )
I'd recommend reading through the blog post instead: https://yjernite.github.io/lfqa.html<|||||>Thank you so much @yjernite |
transformers | 10,975 | closed | Merge trainers | # What does this PR do?
This PR merges the specific `SageMakerTrainer` into the main `Trainer` to make all the scripts work directly with model parallelism. In passing, a few internal breaking changes:
- `is_sagemaker_distributed_available` is renamed to `is_sagemaker_dp_enabled` since it's about data parallelism and not specifically distributed training, and it's True when the user has activated it, not when it's merely "available"
- in the ParallelMode enum, the case `SAGEMAKER_DISTRIBUTED` is renamed as well (but it wasn't used anywhere).
Both only concern the internals of the library and no public API is breaking. | 03-30-2021 20:06:25 | 03-30-2021 20:06:25 | I tested run all our `sagemaker/tests` and a few additional `model_parallel` tests. ✅
I also tested everything with the upcoming `pytorch 1.7.1` image with the new `smp 1.3.0` (their model parallelism library)✅
What is still open for me is how does this behaves with `Seq2SeqTrainer`. Can users now use the `Seq2SeqTrainer` for model parallelism too? Data parallelism works already. Tested with `BART`
After we have merged the `SageMakerTrainer` with the `Trainer` I would update the docs for sagemaker/model parallelism and the tests in tests/sagemaker.
|
transformers | 10,974 | closed | Reproducing DistilRoBERTa | I've been trying to retrain DistilRoBERTa from the information given [here](https://huggingface.co/distilroberta-base) along with the example code/documentation [here](https://github.com/huggingface/transformers/tree/master/examples/research_projects/distillation).
I'm a bit unclear on the exact configuration used to train the DistilRoBERTa model. I have been assuming it uses the same configuration as the DistilBERT model with minor changes, though some things, such as the loss coefficients are still a bit ambiguous.
**Would it be possible to share the exact command/configuration to train DistilRoBERTa?**
I've been able to replicate DistilRoBERTa to similar evaluation MLM perplexity but there still seems to be a small but statistically significant difference, I can share the full config if it's helpful.
Thank you! | 03-30-2021 18:49:48 | 03-30-2021 18:49:48 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discusss.huggingface.co) instead?
You can ping @VictorSanh as he'll be the most helpful regarding distillation.
Thanks!<|||||>Apologies, I've posted to the forum [here](https://discuss.huggingface.co/t/reproducing-distilroberta/5217?u=davidharrison).
Thanks! |
transformers | 10,973 | closed | accelerate scripts for question answering and qa with beam search | # What does this PR do?
Adding example script for question answering and question answering beam search using accelerate library .
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR. @sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-30-2021 18:38:18 | 03-30-2021 18:38:18 | |
transformers | 10,972 | closed | Add more metadata to the user agent | # What does this PR do?
This PR adds a bit more metadata to the user agent to allow us to have more statistics on the usage, more precisely, it registers:
- the type of the file asked on the hub ("config", "tokenizer", "model" or "model_card")
- the framework used for the model ("pytorch", "tensorflow" or "flax"). Note that this is the framework actually used even in the case of a conversion (so if download the PyTorch checkpoint but use it to instantiate a Flax model, it will be "flax")
- for a tokenizer, whether it's fast or slow (like from the framework it checks the class used at the end, not the files downloaded)
- whether the Auto API was used or not
- if the instantiation came from a given pipeline or not
- if the instantiation came from the CI or not (by using a specific env variable)
There is no personal data collected but if a user wants to deactivate this behavior, the `DISABLE_TELEMETRY` env variable can be set to any truthy value and none of this will be shared.
| 03-30-2021 17:45:10 | 03-30-2021 17:45:10 | |
transformers | 10,971 | closed | added py7zr | # What does this PR do?
This PR adds `py7zr` to use `samsum` as a dataset.
```python
[1,14]<stdout>: use_auth_token=use_auth_token,
[1,14]<stdout>: File "/opt/conda/lib/python3.6/site-packages/datasets/load.py", line 448, in prepare_module
[1,14]<stdout>: f"To be able to use this {module_type}, you need to install the following dependencies"
[1,14]<stdout>:ImportError: To be able to use this dataset, you need to install the following dependencies['py7zr'] using 'pip install py7zr' for instance'
``` | 03-30-2021 17:32:31 | 03-30-2021 17:32:31 | Thanks a lot for adding this! |
transformers | 10,970 | closed | Fixed a bug where the `pipeline.framework` would actually contain a fully qualified model. | # What does this PR do?
We simply forgot to change the call for this one when this landed:
https://github.com/huggingface/transformers/pull/10888
It's odd that tests didn't catch that. Should we add some ?
(It's a pretty edgy test case, but it does run within the API).
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | 03-30-2021 17:17:47 | 03-30-2021 17:17:47 | |
transformers | 10,969 | closed | [GPT Neo] defaults for max length and sampling | # What does this PR do?
Update defaults , `max_length=50` and `do_sample=True` | 03-30-2021 16:47:56 | 03-30-2021 16:47:56 | |
transformers | 10,968 | closed | GPT Neo few fixes | # What does this PR do?
- update checkpoint names
- auto model
| 03-30-2021 14:59:21 | 03-30-2021 14:59:21 | |
transformers | 10,967 | closed | [BigBird] Fix big bird gpu test | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
`torch.randint(...)` does not seem to be reproducible across versions and devices
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-30-2021 13:51:47 | 03-30-2021 13:51:47 | |
transformers | 10,966 | closed | improved sagemaker documentation for git_config and examples | # What does this PR do?
This PR improves Amazon SageMaker documentation to make it more clear how `git_config` works with `examples/`. Related to #10957. | 03-30-2021 13:45:39 | 03-30-2021 13:45:39 | |
transformers | 10,965 | closed | Gradient checkpointing in Wav2Vec2 | Hi,
Has anyone managed to fine-tune a **Wav2Vec2** model on long audio recordings which cannot fit into a GPU even with `batch_size=1`? I tried out to set `gradient_checkpointing=true`, but it didn't help to solve the _CUDA Out of Memory Error_. Could it mean that gradient checkpointing does not work properly with **Wav2Vec2** models or are there other tricks needed to be added to the fine-tuning script in addition to the gradient checkpointing? | 03-30-2021 13:31:38 | 03-30-2021 13:31:38 | Hi! You can check out this related issue: https://github.com/huggingface/transformers/issues/10366<|||||>Thanks @LysandreJik! Yeah, one solution could be modify the `run_asr.py` script and add segmenting long speech samples by manually splitting each `batch["speech"]` into smaller chunks before passing to the _wav2vec2 processor_ and converting to input values, then passing one chunk at a time to the model and after that merging the outputs into a single transcription and calculating the loss. Just wondering if there could be any other ways / built-in features to split a batch of size 1 into smaller mini-batches.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi @Getmany1 I also meet this error,But my audio file is no longer than 15s. How to solve the error? and how to pass one chunk at a time to the model.
|
transformers | 10,964 | closed | pkg_resources' working_set caching breaks transformers import on google colab | ## Environment info
- `transformers` version: 4.4.2
- Platform: google colab
- Python version: 3.7.10
- PyTorch version (GPU?): n/a
- Tensorflow version (GPU?): n/a
- Using GPU in script?: n/a
- Using distributed or parallel set-up in script?: n/a
### Who can help
CC @stas00 as this was implemented in #8645
## To reproduce
You can find a complete example in [this google colab](https://colab.research.google.com/drive/1WT7GSd4uk9TLle9q9ftRNFy4BLZWCvZa?usp=sharing), also exported to [this gist](https://gist.github.com/konstin/e42d8f428fa11ba389e31be69cdc5646).
To reproduce, first [create a new google colab notebook](https://colab.research.google.com/#create=true). Let's install recent transformers and tqdm versions in it:
```
!pip install -U pip
!pip install -U "transformers<5.0.0,>=4.0.0" "tqdm<5.0.0,>=4.45.0"
```
This currently install transformers 4.4.2 and tqdm 4.59.0.
Surprisingly, now running `import transformers` fails. We get an error in pkg_resources, which is looking for the .dist-info of tqdm 4.41.1, when the installed version is 4.59.0:
```
[...]
/usr/local/lib/python3.7/dist-packages/pkg_resources/__init__.py in _get(self, path)
1609
1610 def _get(self, path):
-> 1611 with open(path, 'rb') as stream:
1612 return stream.read()
1613
FileNotFoundError: [Errno 2] No such file or directory: '/usr/local/lib/python3.7/dist-packages/tqdm-4.41.1.dist-info/METADATA'
```
The cause is that pkg_resources uses the cached [WorkingSet](https://setuptools.readthedocs.io/en/latest/pkg_resources.html#workingset-objects), which contains the state before the pip install. We can confirm this by recreating pkg_resources' cache manually:
```python
import pkg_resources
pkg_resources.working_set = pkg_resources.WorkingSet()
```
Afterwards, importing transformers works.
The above example is the minimized version of our real [notebooks examples](https://github.com/sacdallago/bio_embeddings/tree/develop/notebooks):
```python
!pip install -U pip
!pip install -U bio_embeddings[all]
from bio_embeddings.embed import SeqVecEmbedder # This line fails with the tqdm .dist-info not found error
```
## Expected behavior
transformers should use the actual installed versions for checking compatibility instead of pkg_resources cache. This could be achieved e.g. by using [importlib_metadata](https://github.com/python/importlib_metadata) instead of pkg_resources [here](https://github.com/huggingface/transformers/blob/1c06240e1b3477728129bb58e7b6c7734bb5074e/src/transformers/utils/versions.py#L80) or by recreating pkg_resources` cache with `pkg_resources.working_set = pkg_resources.WorkingSet()` before checking versions.
I've used the following snippet to check that importlib_metadata works, which prints `4.41.1` and `4.59.0`:
```python
import pkg_resources
import importlib_metadata
print(pkg_resources.get_distribution("tqdm").version)
print(importlib_metadata.version("tqdm"))
```
I can prepare a pull request for either solution. | 03-30-2021 11:34:47 | 03-30-2021 11:34:47 | Thank you for this awesome report, @konstin, and identifying the cause of the problem and the solution.
This looks like a bug in `pkg_resources`. It should update its cache after install.
The other workaround that seems to work is to just do:
```
!pip install -U "transformers<5.0.0,>=4.0.0" "tqdm<5.0.0,>=4.45.0"
!pip install -U "transformers<5.0.0,>=4.0.0" "tqdm<5.0.0,>=4.45.0"
```
So the 2nd one updates the cache.
You may want to report this bug to `pkg_resources`.
Since `transformers` has started using `importlib_metadata` extensively as of recent I think your proposed solution sounds great, so yes please - the proposed PR sounds perfect.
Thank you. |
transformers | 10,963 | closed | compute perplexity using a custom metric function | Hello,
I am trying to replicate the "On the Cross-lingual Transferability of Monolingual Representations" paper from Artetxe et al. and I am using the code you're providing, specifically [run_mlm.py]
(https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm.py)
I wanted to log the perplexity to tensorboard during the evaluation step. I found out that the best option is to add a custom compute_metrics function in the trainer that uses the evaluation results (predictions and target) to compute perplexity. However, I didn't manage to do that because I couldn't understand what the output of predictions represents.
I am really new to NLP and your help is very much appreciated. | 03-30-2021 11:14:18 | 03-30-2021 11:14:18 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discusss.huggingface.co) instead?
cc @sgugger
Thanks!<|||||>The predictions are the logits of your model, so in the case of a language model, it will be a big array `num_samples x seq_length x vocab_size`. Your labels will be a big array of `num_samples x seq_length` with the tokens corresponding to something not masked at -100 (index that is ignored).<|||||>First, I would like to apologize for writing to you here, I wasn't aware that there is a dedicated forum.
Thank you @sgugger, I appreciate your help, my function is working now. |
transformers | 10,962 | closed | fix md file to avoid evaluation crash | # What does this PR do?
Fix the crash due to the memory usage in the instructions for model evaluation in `FINE_TUNE_XLSR_WAV2VEC2.md`.
The original version `test_dataset["speech"][:2]` load the whole speech array into memory which is too large.
Change it to `test_dataset[:2]["speech"]` runs smoothly and much faster.
## Before submitting
- [ ] This PR improves the docs
## Who can review?
@patrickvonplaten
| 03-30-2021 10:28:12 | 03-30-2021 10:28:12 | @patrickvonplaten It seems the finetune notebook is on your own github repository, not on HuggingFace's transformers.<|||||>@ydshieh yes this is correct - if it's ok for you feel free to open a PR there :-) |
transformers | 10,961 | closed | Supporting `config_path` for `AutoModel` | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
Creating a model like this:
```python
AutoModel.from_pretrained('https://myserver/model/pytorch_model.bin', config='path/to/local/config.json')
```
## Motivation
For the moment, instantiating a model like above is possible with `PretrainedModel` but not with `AutoModel`. i.e.
```python
BertModel.from_pretrained('https://myserver/model/pytorch_model.bin', config='path/to/local/config.json') # possible
AutoModel.from_pretrained('https://myserver/model/pytorch_model.bin', config='path/to/local/config.json') # not possible
```
To elaborate, the optional `config` argument passed to **`AutoModel.from_pretrained`** method should be `PretrainedConfig`, while it could be either `PretrainedConfig` or 'a string or path valid as input to `PretrainedConfig.from_pretrained`' in the case of **`PretrainedModel.from_pretrained`**.
The difference comes from the lack of [this line](https://github.com/huggingface/transformers/blob/8780caa388c7b2aa937454ed96bcdd3f097f851d/src/transformers/modeling_utils.py#L974) in `AutoModel`.
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
## Your contribution
I would like to submit a PR.
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| 03-30-2021 09:42:33 | 03-30-2021 09:42:33 | Hey @hwijeen! Would the `AutoModel.from_config()` method work for you?<|||||>Thank you @LysandreJik for your quick reply! I checked out the `AutoModel.from_config()` method. It is a convenient method but does not fit my use case, as **it does NOT load weights**.<|||||>Hi @LysandreJik , I update this issue to clarify. I would appreciate if you could give it a pass! I am sorry to nudge you twice but I think this issue and related PR(#10981) could be useful for those who try to load pretrained weights from private server!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,960 | closed | What is the score of trainer.predict()? | I want to know the meaning of output of trainer.predict().
example:
`PredictionOutput(predictions=array([[-2.2704859, 2.442343 ]], dtype=float32), label_ids=array([1]), metrics={'eval_loss': 0.008939245715737343, 'eval_runtime': 0.0215, 'eval_samples_per_second': 46.56})`
What is this score? -> predictions=array([[-2.2704859, 2.442343 ]]
I use it for Sequence Classification.
| 03-30-2021 07:53:13 | 03-30-2021 07:53:13 | These are the logits from your model, check:- https://github.com/huggingface/transformers/blob/8780caa388c7b2aa937454ed96bcdd3f097f851d/src/transformers/trainer.py#L1852<|||||>I see! Thank you so much!! |
transformers | 10,959 | closed | Fix summarization notebook link | This PRs fixes the link to the new summarization notebook | 03-30-2021 06:33:39 | 03-30-2021 06:33:39 | |
transformers | 10,958 | open | Returning Confidence Score For Extractive QA Task When Using Non-Pipeline Approach | # 🚀 Feature request
HF's Extract QA pipeline provides an excellent interface for start. It returns 4 values including a **probability score / confidence score**. Unfortunately same is not the case when using the non-pipeline approach i.e using model and tokenizer for question answering.
[Both methods are mentioned here, The pipeline one and the other](https://huggingface.co/transformers/task_summary.html#extractive-question-answering)
## Motivation
The confidence score will help a lot in various tasks. For example when I am developing a complete pipeline for QA, consisting of recall, retriever and some other models for entity matching and etc. I need to calculate scores of each models and then rank the final list of documents based on the weighted sum of score from each model. I believe this is a very common practice among NLP practitioners and not just for QA task. The point is confidence scores are usually a pretty standard requirement for each model output because we have to take further actions based on its score.
## Your contribution
I want to. but unfortunately I am not at the level where I can understand the code. I have went through the code and I believe its the "decode" function in "QuestionAnsweringPipeline" class which has the code the which generates the probability scores. If you guys can just provide an interface for it or provide docs for how to calculate this score using the model and tokenizer approach then that would be great too. And if you do decide to do this then please also add this addition to docs in the link mentioned at the top.
Thanks. | 03-30-2021 05:54:35 | 03-30-2021 05:54:35 | Correct me if I am wrong but I think the reason why it's not included in the model output is because it's an utility function and not a direct output of the model.
If I am not wrong, calculating the confidence score in a non-pipeline method is straight forward, like how it's done below
https://github.com/huggingface/transformers/blob/8d171628fe84bdf92ee40b5375d7265278180f14/examples/pytorch/question-answering/utils_qa.py#L151
From the example you shared, adding couple of lines should give us the score.
````
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
import torch
tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
model = AutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
text = r"""
🤗 Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides general-purpose
architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural
Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between
TensorFlow 2.0 and PyTorch.
"""
questions = [
"How many pretrained models are available in 🤗 Transformers?",
"What does 🤗 Transformers provide?",
"🤗 Transformers provides interoperability between which frameworks?",
]
for question in questions:
inputs = tokenizer(question, text, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(
answer_start_scores
) # Get the most likely beginning of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1 # Get the most likely end of answer with the argmax of the score
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
# Compute the Score using start_logits and end_logits
score = outputs.start_logits[0][answer_start] + outputs.end_logits[0][answer_end-1]
print(f"Question: {question}")
print(f"Answer: {answer}")
print(f"Confidence Score: {score}")
````
This also gives us the flexibility to design the confidence score. For example it might also be interesting to boost the confidence score based on intent similarity and entity/NP intersection.
Hope this helps!<|||||>
Thanks for replying to this @lawliet19189 . This is good insight.
I do agree with @UmerTariq1 that there should be an option to return a basic confidence score without jumping through hoops. At the very least it would save us some time to document that it doesn't exist and a method (like this) that can be used. That way you don't spend a lot of time searching the documentation for a parameter or method to get them.
So I vote for this feature. |
transformers | 10,957 | closed | check_version not valid | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: AWS Sagemaker
- Python version: 3.6
- PyTorch version (GPU?): N/A
- Tensorflow version (GPU?): 2.4.1 (kernal: conda_tensorflow2_p36)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
@LysandreJik, @sgugger, @patil-suraj
Models: Bert
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): Bert
The problem arises when using:
* [X ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Run sample Sagemaker notebook: ./notebooks/sagemaker/02_getting_started_tensorflow/
2. Change the entry_point from "train.py" to "run_ner.py"
3. Copy run_ner.py from the examples for ner: .\transformers\examples\token-classification\run_ner.py
3. Execute notebook
4. Line 47 executes a check_min_version("4.5.0.dev0") but that version does not exist. Newest version I see is 4.4.2. This results in the following error message:
Lines 47-48:
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.5.0.dev0")

<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
I am trying to get a baseline Sagemaker notebook working that fine tunes Bert for token classification. (Using Colnn2003 or other.) This should use the new Sagemaker Deep Learning Containers. This is a first step for the project where we will next use custom data to fine tune the model. | 03-29-2021 23:13:06 | 03-29-2021 23:13:06 | Hi, what's the problem?<|||||>> Hi, what's the problem?
Sorry, I accidentally saved the ticket before I was done. Then I had to leave my desk for a while. I have updated the ticket with all the info now.
Thanks!<|||||>Ah, I see! This is because you're using a script which comes from the `master` branch. Version `v4.5.0dev0` is the development version of the v4.5.0 version, which is the current `master`.
The scripts you use from the GitHub repository are always synced with `master`, so please be sure to use the source installation of the `master` branch of `transformers` alongside it.
If you want to use a script compatible with version `v4.4.2`, I would suggest taking the script from the tag `v4.4.2`, as this one will work with that version:
https://github.com/huggingface/transformers/blob/9f43a425fe89cfc0e9b9aa7abd7dd44bcaccd79a/examples/token-classification/run_ner.py#L43-L55<|||||>Hello @gwc4github,
Happy to see that you are already using the new Hugging Face Deep Learning Container and the Sagemaker-sdk. Regarding your issue. If you want to use the `examples` script you have to configure the `git_config` like that.
```python
# configure git settings
git_config = {'repo': 'https://github.com/huggingface/transformers.git','branch': 'v4.4.2'}
```
While branch `v4.4.1` is referring to the `transformers_version` in the HuggingFace estimator.
For your example, the estimator would look like
```python
# git configuration to download our fine-tuning script
git_config = {'repo': 'https://github.com/huggingface/transformers.git','branch': 'v4.4.2'}
# hyperparameters, which are passed into the training job
hyperparameters={'epochs': 1,
'train_batch_size': 32,
'model_name':'distilbert-base-uncased'
}
huggingface_estimator = HuggingFace(entry_point='run_ner.py', # script
source_dir='./examples/token-classification', # relative path to example
base_job_name='huggingface-sdk-extension',
git_config=git_config,
instance_type='ml.p3.2xlarge',
instance_count=1,
transformers_version='4.4',
tensorflow_version='2.4',
py_version='py37',
role=role,
hyperparameters = hyperparameters)
```
You can find more information about using `git_config` [here](https://huggingface.co/transformers/sagemaker.html#git-repository)
<|||||>Thanks Lysandre and Phil.
I didn't follow what Lysandre was explaining enough to do anything with it yet, but I did the following with Phil's information.
I added the git_config line and then had to add a dataset_name as well. So no my code is as follows below. However, when I run it I get the error that I have also included *after* the code. I have also attached the full cell output.
```
from sagemaker.huggingface import HuggingFace
# hyperparameters, which are passed into the training job
hyperparameters={'epochs': 1,
'train_batch_size': 32,
'model_name':'bert-base-uncased',
'output_dir':'/opt/ml/model',
'dataset_name':'conll2003'
}
# git configuration to download our fine-tuning script
git_config = {'repo': 'https://github.com/huggingface/transformers.git','branch': 'v4.4.2'}
huggingface_estimator = HuggingFace(entry_point='run_ner.py', # script
source_dir='./examples/token-classification', # relative path to example
base_job_name='huggingface-sdk-extension',
git_config=git_config,
instance_type='ml.p3.2xlarge',
instance_count=1,
transformers_version='4.4',
tensorflow_version='2.4',
py_version='py37',
role=role,
hyperparameters = hyperparameters)
```
ERROR:
```
Invoking script with the following command:
/usr/local/bin/python3.7 run_ner.py --dataset_name conll2003 --epochs 1 --model_name bert-base-uncased --output_dir /opt/ml/model --train_batch_size 32
2021-03-30 21:48:35.696262: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
2021-03-30 21:48:35.696429: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
2021-03-30 21:48:35.740003: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
Traceback (most recent call last):
File "run_ner.py", line 501, in <module>
main()
File "run_ner.py", line 181, in main
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
File "/usr/local/lib/python3.7/site-packages/transformers/hf_argparser.py", line 196, in parse_args_into_dataclasses
raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
ValueError: Some specified arguments are not used by the HfArgumentParser: ['--epochs', '1', '--train_batch_size', '32']
2021-03-30 21:48:37,576 sagemaker-training-toolkit ERROR ExecuteUserScriptError:
Command "/usr/local/bin/python3.7 run_ner.py --dataset_name conll2003 --epochs 1 --model_name bert-base-uncased --output_dir /opt/ml/model --train_batch_size 32"
2021-03-30 21:48:35.696262: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
2021-03-30 21:48:35.696429: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
2021-03-30 21:48:35.740003: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
Traceback (most recent call last):
File "run_ner.py", line 501, in <module>
main()
File "run_ner.py", line 181, in main
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
File "/usr/local/lib/python3.7/site-packages/transformers/hf_argparser.py", line 196, in parse_args_into_dataclasses
raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
ValueError: Some specified arguments are not used by the HfArgumentParser: ['--epochs', '1', '--train_batch_size', '32']
2021-03-30 21:48:45 Uploading - Uploading generated training model
2021-03-30 21:49:27 Failed - Training job failed
```
[errLogs2021.03.30.txt](https://github.com/huggingface/transformers/files/6232459/errLogs2021.03.30.txt)
<|||||>Hey @gwc4github,
as the error is saying
```
ValueError: Some specified arguments are not used by the HfArgumentParser: ['--epochs', '1', '--train_batch_size', '32']
```
you pass in the wrong `hyperparameters`. If you take a look at the `run_ner.py` script and how it parses the arguments, you will notice it. The script parses the `parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))`. The `ModelArguments` and `DataTrainingArguments` are defined directly in the script and the `TrainingArguments` can you find [here](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments).
The hyperparameters you use `epochs`, `train_batch_size` and `model_name` have been only defined in the script for the [example](https://github.com/huggingface/notebooks/blob/4c909862282d551958629bec59c5712c010e4420/sagemaker/02_getting_started_tensorflow/scripts/train.py#L16)
When you use the existing examples you stay need to provide the arguments as they are defined in the script in your example it would be
```python
hyperparameters={'num_train_epochs': 1,
'per_device_train_batch_size': 32,
'model_name_or_path':'bert-base-uncased',
'output_dir':'/opt/ml/model',
'dataset_name':'conll2003'
}
```
**Additionally:** I noticed that you want to use the `Tensorflow` and the `Tensorflow` based DLC with `run_ner.py`. The `run_ner.py` only works with `Pytorch` so you have to replace `tensorflow_version` with `pytorch_version` and change the `py_version`. Please take a look at the [documentation here](https://huggingface.co/transformers/sagemaker.html). All your problems are addressed there.
<|||||>Thanks @philschmid and team. This did fix that problem and I understand completely what you are saying. I have gotten a lot further.
There are some new issues but they are unrelated to this original problem so I will open new tickets as needed. This ticket can be closed. THANKS again for your quick and detailed help!!!
Gregg |
transformers | 10,956 | open | [T5/MT5] resolve inf/nan under amp (mixed precision) | As reported in multiple issues t5/mt5 models produce loss of `nan` under mixed precision training, starting with t5-large and mt5-small and up. This PR is an attempt to fix this issue. This is crucial for DeepSpeed where it's always mixed precision training.
I spent some time with the debugger and the new `detect_overflow` helper util (added in this PR) and discovered that the best place to fix the whole problem is to not `T5LayerFF` in mixed precision. This slightly slows things down/consumes more gpu memory, but no longer requires clamping and running after ever overflowing `hidden_states`.
This PR:
* turns `autocast` off during `T5LayerFF` if run under amp
* removes the previous attempt to clamp the values as it now works without it
* introduces `debug_utils.py` with a helper function `detect_overflow` which is super-handy for tracking overflows automatically (as it's silent if all goes well). It also has some extra features, such as reporting a number of large elements - disabled by default.
Important:
* The fix is only for pytorch built-in amp. apex still has this problem since I haven't researched if the same could be done there, but it's probably a waste of time since apex is being phased out. And deepspeed doesn't use amp so it's till affected.
## Variations
Other possible variations to this solution:
1. to do the `autocast` disabling dynamically. That is trying with `autocast` and checking if any elements of output are `inf` (not sure of the overhead) and re-running this layer in full fp32 and setting a flag to continue in fp32 from then on. Here the main price will be paid by models that don't need this workaround, but they will gain but not having `autocast` turned off - so it might still be a beneficial solution to all
2. give users a switch to turn this feature on if they discover they need it - or have it on by default and allow users to turn it off if they "know what they are doing".
I am suggesting this since I don't know if all t5/mt5 models are impacted. Definitely t5-small doesn't need this.
## Penalizing large activation
See the details comment: https://github.com/huggingface/transformers/pull/10956#issuecomment-820712267
```
@@ -1578,6 +1618,15 @@ class T5ForConditionalGeneration(T5PreTrainedModel):
loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1))
# TODO(thom): Add z_loss https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/layers.py#L666
+ # z_loss
+ log_z = lm_logits.view(-1).logsumexp(-1)
+ z_loss = 7e-5
+ loss_extra = z_loss*log_z.square()
+ #z_loss = 1e-5
+ #loss_extra = z_loss*log_z.pow(3)
+ #print(f"loss={loss}, loss_extra={loss_extra}")
+ loss += loss_extra
```
## Questions:
* If this solution solves the problem at large and is accepted then we probably should document somewhere in t5/mt5 docs that it won't run AMP 100%?
* Test is needed: any suggestions to how we could write a test that is not too big and still gets nans prior to this PR? `t5-small` and `t5-base` don't have this problem (at least with a small sample), in my experiments the first model that gets `inf/nan` on the first batch is `mt5-small` (1.2GB), so my minimal test is:
```
rm -rf output_dir; CUDA_VISIBLE_DEVICES=0 USE_TF=0 PYTHONPATH=src python examples/seq2seq/run_translation.py \
--model_name_or_path google/mt5-small --do_train --source_lang en --target_lang ro --dataset_name wmt16 \
--dataset_config_name ro-en --output_dir output_dir --per_device_train_batch_size=4 --logging_step 2 --save_steps 0 \
--fp16 --max_train_samples 10 --save_total_limit 0 --save_strategy no
```
We can then run this as a test and check for `nan` in loss reports.
But the 1.2GB download is somewhat big even for `@slow` tests.
**edit**: @LysandreJik says it's not a problem since we are now caching the models on the test machine.
If it is ok I will just stick this with all the extended tests under `examples/tests/trainer/test_trainer_ext.py` where we have a setup for this type of full application-based tests.
* I also know some users mentioned that `inf` may happen much later in the game. I haven't run very long tests.
TODO:
* [ ] I left all the debug prints in place so that you could experiment with it easily - will remove when this is approved to be a good change
Related discussions:
- https://discuss.pytorch.org/t/bfloat16-transformers/96260 pegasus is affected too
Fixes: https://github.com/huggingface/transformers/issues/10830
Fixes: https://github.com/huggingface/transformers/issues/10819
@patrickvonplaten, @patil-suraj, @LysandreJik | 03-29-2021 22:43:37 | 03-29-2021 22:43:37 | > But the 1.2GB download is somewhat big even for @slow tests.
The downloads are cached on a shared disk across slow self-hosted runners, so that's not an issue!<|||||>Before I approached this problem, I did a bit of a study on the bfloat16 vs float16 properties. This is not fully complete, but you can see most of the useful data here: https://github.com/stas00/ml-ways/blob/master/numbers/bfloat16-vs-float16-study.ipynb
Comments/requests/suggestions are welcome though. It's a bit on a terse-side.<|||||>I spent some more time staring at the numbers, as I think @patrickvonplaten mentioned in one of the related threads, something trained in `bfloat16` isn't going to work with `float16`. You can see why by looking at this debug output:
```
min=-2.77e+05 max= 2.75e+05 var= 5.45e+07 mean= 5.16e+01 (T5Stack loop start)
min=-2.77e+05 max= 2.75e+05 var= 5.45e+07 mean= 5.16e+01 (T5Block)
min=-2.77e+05 max= 2.75e+05 var= 5.45e+07 mean= 5.16e+01 (T5LayerNorm)
min= 1.31e+06 max= 6.90e+08 var= 9.52e+15 mean= 5.45e+07 (T5LayerNorm variance)
min=-1.46e+01 max= 1.46e+01 var= 1.00e+00 mean=-2.69e-03 (T5LayerNorm hidden_states)
min=-1.46e+01 max= 1.46e+01 var= 1.00e+00 mean=-2.69e-03 (T5LayerNorm hidden_states before return)
min=-2.76e+05 max= 2.74e+05 var= 5.41e+07 mean= 4.83e+01 (T5Block after T5LayerSelfAttention)
min=-2.76e+05 max= 2.74e+05 var= 5.41e+07 mean= 4.83e+01 (T5LayerNorm)
min= 1.38e+06 max= 6.86e+08 var= 9.37e+15 mean= 5.41e+07 (T5LayerNorm variance)
min=-1.45e+01 max= 1.46e+01 var= 1.00e+00 mean=-2.98e-03 (T5LayerNorm hidden_states)
min=-1.45e+01 max= 1.46e+01 var= 1.00e+00 mean=-2.98e-03 (T5LayerNorm hidden_states before return)
min=-2.76e+05 max= 2.73e+05 var= 5.40e+07 mean= 3.93e+01 (T5Block before T5LayerFF)
min=-2.76e+05 max= 2.73e+05 var= 5.40e+07 mean= 3.93e+01 (T5LayerFF: 1)
min=-2.76e+05 max= 2.73e+05 var= 5.40e+07 mean= 3.93e+01 (T5LayerNorm)
min= 1.61e+06 max= 6.84e+08 var= 9.28e+15 mean= 5.40e+07 (T5LayerNorm variance)
min=-1.44e+01 max= 1.46e+01 var= 1.00e+00 mean=-5.14e-03 (T5LayerNorm hidden_states)
min=-1.44e+01 max= 1.46e+01 var= 1.00e+00 mean=-5.14e-03 (T5LayerNorm hidden_states before return)
min=-2.47e+00 max= 3.03e+00 var= 4.43e-02 mean=-8.23e-05 (T5LayerFF: 2)
min=-1.70e-01 max= 4.95e+01 var= 6.34e-01 mean= 3.00e-01 (gelu 1)
min=-3.70e+02 max= 3.93e+02 var= 3.79e+02 mean= 2.79e-01 (gelu 2)
min=-4.71e+03 max= 3.67e+03 var= 1.89e+03 mean=-3.80e-01 (gelu 3)
min=-5.23e+03 max= 4.08e+03 var= 2.21e+03 mean=-4.75e-01 (gelu 4)
min=-7.11e+04 max= 5.32e+04 var= 8.27e+06 mean=-1.36e+02 (gelu 5)
min=-7.11e+04 max= 5.32e+04 var= 8.27e+06 mean=-1.36e+02 (T5LayerFF: 3)
min=-2.61e+05 max= 2.68e+05 var= 4.41e+07 mean=-1.04e+02 (T5LayerFF: 5)
min=-2.61e+05 max= 2.68e+05 var= 4.41e+07 mean=-1.04e+02 (T5Block after T5LayerFF)
min=-2.61e+05 max= 2.68e+05 var= 4.41e+07 mean=-1.04e+02 (T5Stack loop end)
min=-2.61e+05 max= 2.68e+05 var= 4.41e+07 mean=-1.04e+02 (T5LayerNorm)
min= 2.99e+06 max= 6.12e+08 var= 5.65e+15 mean= 4.41e+07 (T5LayerNorm variance)
min=-1.45e+01 max= 1.62e+01 var= 1.00e+00 mean=-2.27e-02 (T5LayerNorm hidden_states)
min=-1.45e+01 max= 1.62e+01 var= 1.00e+00 mean=-2.27e-02 (T5LayerNorm hidden_states before return)
```
Because `bfloat16` lacks precision - it trained itself to compensate for this by switching to the range of large numbers. If you look at the numbers above you can see that many of them are a way beyond fp16 range, which can only do `+-64K`.
So if I understand the nature of this problem correctly expecting this to work is a bit of fantasy. But of course, let's try to do our best to come as close to the solution as possible.
I found that it's enough to cancel autocast just for `self.DenseReluDense` for the simple case to not produce NaN. <|||||>@yuvalkirstain, let's switch the discussion to the actual PR
wrt your newly discovered overflow.
Please try to add this penalizing for large logits:
```
@@ -1578,6 +1618,15 @@ class T5ForConditionalGeneration(T5PreTrainedModel):
loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1))
# TODO(thom): Add z_loss https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/layers.py#L666
+ # z_loss
+ log_z = lm_logits.view(-1).logsumexp(-1)
+ z_loss = 7e-5
+ loss_extra = z_loss*log_z.square()
+ #z_loss = 1e-5
+ #loss_extra = z_loss*log_z.pow(3)
+ #print(f"loss={loss}, loss_extra={loss_extra}")
+ loss += loss_extra
```
May need some tuning for `z_loss` factor for best convergence. The recommended one is 1e-4, so I've experimented with a few. Also tried the `pow(3)` instead of `pow(2)`.
It seem that the network gets the hint within just a 100 steps - `loss_extra` drops down very quickly.
Perhaps this was the missing piece?
<|||||>Here is the output of the proposed [overflow/underflow detector](https://github.com/huggingface/transformers/pull/11274) in progress tool for mt5. This is prior to any modifications proposed in this PR. So one can see the progression as the weights and activations change from forward to forward.
```
rm -rf output_dir; CUDA_VISIBLE_DEVICES=0 USE_TF=0 PYTHONPATH=src \
python examples/pytorch/translation/run_translation.py --model_name_or_path google/mt5-small --do_train \
--source_lang en --target_lang ro --dataset_name \
wmt16 --dataset_config_name ro-en --output_dir output_dir --per_device_train_batch_size=4 --logging_step 2 --save_steps 0 \
--fp16 --max_train_samples 10 --save_total_limit 0 --save_strategy no --debug underflow_overflow
```
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
encoder.block.1.layer.1.DenseReluDense.dropout Dropout
0.00e+00 2.57e+02 input[0]
0.00e+00 2.85e+02 output
encoder.block.1.layer.1.DenseReluDense.wo Linear
4.80e-06 8.62e+00 weight
0.00e+00 2.85e+02 input[0]
8.50e-05 1.53e+03 output
encoder.block.1.layer.1.DenseReluDense T5DenseGatedGeluDense
0.00e+00 2.04e+00 input[0]
8.50e-05 1.53e+03 output
encoder.block.1.layer.1.dropout Dropout
8.50e-05 1.53e+03 input[0]
0.00e+00 1.70e+03 output
encoder.block.1.layer.1 T5LayerFF
0.00e+00 1.50e+03 input[0]
6.78e-04 3.15e+03 output
encoder.block.1 T5Block
0.00e+00 1.40e+03 input[0]
6.78e-04 3.15e+03 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.0.layer_norm T5LayerNorm
6.54e-02 2.75e-01 weight
6.78e-04 3.15e+03 input[0]
5.75e-06 2.12e+00 output
encoder.block.2.layer.0.SelfAttention.q Linear
3.75e-08 3.40e-01 weight
5.75e-06 2.12e+00 input[0]
2.21e-06 1.20e+00 output
encoder.block.2.layer.0.SelfAttention.k Linear
4.84e-08 2.62e+00 weight
5.75e-06 2.12e+00 input[0]
5.47e-05 1.40e+01 output
encoder.block.2.layer.0.SelfAttention.v Linear
7.21e-06 2.59e+00 weight
5.75e-06 2.12e+00 input[0]
1.20e-04 7.56e+00 output
encoder.block.2.layer.0.SelfAttention.o Linear
6.65e-06 1.44e+01 weight
0.00e+00 5.30e+00 input[0]
5.20e-04 2.66e+02 output
encoder.block.2.layer.0.SelfAttention T5Attention
5.75e-06 2.12e+00 input[0]
5.20e-04 2.66e+02 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.0.dropout Dropout
5.20e-04 2.66e+02 input[0]
0.00e+00 2.96e+02 output
encoder.block.2.layer.0 T5LayerSelfAttention
6.78e-04 3.15e+03 input[0]
2.65e-04 3.42e+03 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.dropout Dropout
0.00e+00 8.76e+03 input[0]
0.00e+00 9.74e+03 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```<|||||>Hi there, I'm wondering what the current status of this is, as my team would benefit from a fix to fp16 issue with large T5 models. And is there anything we could do to help to move the PR along?
In the mean time, it should be sufficient to simply disable autocast for the DenseReluDense, correct?<|||||>> Hi there, I'm wondering what the current status of this is, as my team would benefit from a fix to fp16 issue with large T5 models. And is there anything we could do to help to move the PR along?
@yuvalkirstain, who is one of the original reporters mentioned elsewhere that he still had an issue during the long training, so I was waiting for him to provide more details.
> In the mean time, it should be sufficient to simply disable autocast for the DenseReluDense, correct?
If you're not using deepspeed, then yes, that is all that is needed. At least for the tests I have done. But they weren't long.
Perhaps you could test this PR and report back if it solves your problem?
I'm not sure if I should remove the clamping or not.
I cleaned up the PR to remove all the debug noise, so it's very simple now.<|||||>Hi, I ran some experiments and it appears to me that this branch does fix the inf/nan issue for both T5-large and T5-3b--I trained both models for 10,000 steps on a language modeling task and never had the NaN loss issue I was having before. However, as far as I can tell the fix comes at a large cost in time and memory usage.
Using t5-large on an A6000 card (48 GB), I found:
- no fp16: 25.00 GB, 3.06 iters/s
- fp16 without the fix from this branch: 15.01 GB, 4.10 iters/s [but loss was `NaN`]
- fp16 with the fix from this branch: 23.99 GB, 2.90 iters/s
(collected using the `torch.autograd.profiler` tool)
In other words, fp16 with this fix uses about 1.6x more memory than before.
Disclaimer: the experiments I ran were using an LM task that's internal to my team, so you won't be able to replicate it exactly. But I wanted to report back anyway since it's been a few days. However, in the next few days I'd like to repeat these experiments using one of the HF example scripts so that you can verify by running the exact same code.<|||||>That's a fantastic feedback, @dblakely - Thank you! Looking forward to seeing the stats on non-custom code.
It's interesting that you get even slower results than full fp32. But since you're no A6000 you're probably running on tf32 automatically if you're on the recent pytorch, that would explain it.
And I trust you're not using the overflow detector which would add to the slowdown a bit.
BTW, apparently there is a new `torch.profiler` tool - I haven't tried it yet.
Also earlier I wrote:
> I found that it's enough to cancel autocast just for `self.DenseReluDense` for the simple case to not produce NaN.
So you might want to try this slightly tighter version:
```
class T5LayerFF(nn.Module):
def __init__(self, config):
super().__init__()
if config.feed_forward_proj == "relu":
self.DenseReluDense = T5DenseReluDense(config)
elif config.feed_forward_proj == "gated-gelu":
self.DenseReluDense = T5DenseGatedGeluDense(config)
else:
raise ValueError(
f"{self.config.feed_forward_proj} is not supported. Choose between `relu` and `gated-gelu`"
)
self.layer_norm = T5LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
self.dropout = nn.Dropout(config.dropout_rate)
def forward(self, hidden_states):
forwarded_states = self.layer_norm(hidden_states)
if torch.is_autocast_enabled():
with torch.cuda.amp.autocast(enabled=False):
forwarded_states = self.DenseReluDense(forwarded_states)
else:
forwarded_states = self.DenseReluDense(forwarded_states)
hidden_states = hidden_states + self.dropout(forwarded_states)
return hidden_states
```
but given that the bulk of everything comes from `DenseReluDense` it probably won't make much of a difference speed and memory requirements-wise.
<|||||>Hi all,
If `bf16` is what's native to these models, how about we do `autocast` with `bf16` instead of `fp16` (and then don't scale)? There is a pull request [here](https://github.com/pytorch/pytorch/issues/55374) to add a `bf16` option to autocast.<|||||>That would be the best solution assuming you have high-end Ampere GPUs which support bf16 natively. (rtx-3090, a100, ...). So once this is finalized in pytorch we will support it in the HF trainer as well.
If you have been actively watching that development please kindly ping us when it's completed in pytorch. Thank you.<|||||>We use rtx a6000s, so I believe we are ok on that front. I'll monitor the aforementioned PR and keep you updated
UPDATE: the fix has migrated to [this pr](https://github.com/pytorch/pytorch/pull/61002)<|||||>The [torch pr](https://github.com/pytorch/pytorch/pull/61002) is almost through, so I'm coming back to this. Would the ensuing pr here be as simple as changing autocast in t5 to the bf16 option?<|||||>Thank you for keeping on top of torch's side, @JamesDeAntonis
No, we will have to rework the HF Trainer to support bf16. The model doesn't need to be changed.
My recommendation is to wait till that PR lands in pt-nightly so we have something to test with. And then we can work on having bf16 support in the trainer.
If you're not using the HF Trainer, then you can do it independently by wrapping the training step in the new autocast.<|||||>Sounds good, thanks for the quick response! I'll continue to watch the pr.
We do indeed use the HF Trainer, so I'll probably be active on the HF pr as well.<|||||>It looks like the PR was just merged in torch! I think the ball is now in our court once the nightly build hits (so I think starting tomorrow)<|||||>Awesome! Thank you for keeping us abreast of this development, @JamesDeAntonis.
This is a month of August and most team members are on vacation at the moment, so this might take longer than normal.
My plate is very full at the moment, so unless someone beats me to it, I probably won't have any time in the next few weeks to work on this.
But, first, please create a new Issue and tag me there, so that we have an easy way to track this feature request.
Second, if one of you would like to work on the PR to integrate bf16 that would be great. I think the change itself should be relatively simple, add a new CLI arg `--bf16` and set amp to bf16 instead of fp16 in trainer.py. We may have to deprecate `fp16_backend` and rename it to something more generic, but just doing the above is a good start. The devil is in the detail though, so it may take longer to figure out.<|||||>Hi, after reading all the replies and related issues in torch and transformers, I still don't know how to fix the nan problem. I get `loss=nan` on every simple example using mt5-base.
```
from transformers import AutoConfig, AutoTokenizer, AutoModelForSeq2SeqLM, AutoModel
import torch
device = 'cuda'
tokenizer = AutoTokenizer.from_pretrained('google/mt5-base')
model = AutoModelForSeq2SeqLM.from_pretrained('google/mt5-base')
model.to(device)
scaler = torch.cuda.amp.GradScaler()
toks = tokenizer(['Je vous invite à vous lever pour cette minute de silence.',"Please rise, then, for this minute' s silence."], return_tensors='pt', padding='max_length',max_length=512, truncation=True).to(device)
inputs = {'input_ids': toks['input_ids'][0:1], 'attention_mask': toks['attention_mask'][0:1], 'labels': toks['input_ids'][1:], 'output_hidden_states':True}
with torch.cuda.amp.autocast():
outputs = model(**inputs)
loss = outputs.loss
scaler.scale(loss).backward()
loss.item()
> nan
```
torch=1.8.1+cu101
transformers=4.9.2
any help would be much appreciated!<|||||>>Hi, after reading all the replies and related issues in torch and transformers, I still don't know how to fix the nan problem. I get `loss=nan` on every simple example using mt5-base.
If you want to use `bf16`, you need to include the `fast_dtype` as seen [here](https://github.com/pytorch/pytorch/blob/master/torch/autocast_mode.py#L128) (I think)<|||||>> > Hi, after reading all the replies and related issues in torch and transformers, I still don't know how to fix the nan problem. I get `loss=nan` on every simple example using mt5-base.
>
> If you want to use `bf16`, you need to include the `fast_dtype` as seen [here](https://github.com/pytorch/pytorch/blob/master/torch/autocast_mode.py#L128) (I think)
Thank you very much. I switch to pt nightly build 1.10.0+cu111 and test the `fast_dtype =torch.bfloat16` in `amp`. It seems that cuda device does not support bfloat16.
```
RuntimeError: Current CUDA Device does not support bfloat16. Switching fast_dtype to float16.
```
I tried Tesla M40, GTX TITAN X and Quadro RTX 8000, same error.
<|||||>> I tried Tesla M40, GTX TITAN X and Quadro RTX 8000, same error.
For bf16 you want the high end Ampere cards https://en.wikipedia.org/wiki/Ampere_(microarchitecture)#Products_using_Ampere - so 3090 and below on that list.<|||||>this PR isn't merged yet? :( is the issue resolved?<|||||>Well, it introduces a small slowdown as it forces one FF in fp32 under mixed precision, so I wasn't sure whether this solves the problem for everybody. Or whether this should be configurable. Some users reported that it solved their problem, other that it didn't.
Additionally I proposed in this PR
- ~to remove the clamping, but got no feedback whether it's safe to do. https://github.com/huggingface/transformers/pull/10956/files/1ddec2c860617230a5171f3a95be74d27f4c8e9d#r603663224~ (Patrick suggested to keep it, so I restored that part)
- to add an additional penalty to lm loss as described in the original codebase (it's not in PR, but the code is in the OP), which would stir the finetuning into the direction of fp16 weights. Perhaps it should be only added for when autocast is detected? But then bf16 is imminent, so probably need to find a way to check the autocast dtype is fp16? (and the dtype was introduced in pt-1.10 only)
Here is a possible plan of action:
1. leave everything as is and just have this PR add the FF override in fp32
2. ~discuss clamping and keep or remove it~ (Patrick suggested to keep it, so I restored that part)
3. discuss large weight lm loss penalty factor and add the code in
<|||||>This PR forces T5 FF Layer in fp32. With this change, there is almost no benefit to training in fp16.
The memory usage and training speed improvements are very limited. <|||||>@Liangtaiwan, also you may to try the loss penalty factor. The patch to apply (instead of this PR) is in the OP.<|||||>Hi everyone, I am testing a method of adjusting the T5 weights for FP16 training and so far it's promising. However, I would like to see if there is a way to "validate" how much of the model performance is still retained for both pre-trained and fine-tuned tasks.
The TLDR is: we scale the weights down, for as few parameters and as little as possible, until the model can be trained without NaN. Basically, to perform the minimum amount of "surgery" on the weights.
Currently, I am reducing about 2-3% of parameters in the model by a factor of 2 only and seeing some good initial results. These parameters are in the feed-forward layers in the encoder only. The resulting model still seems to work on existing tasks and I can fine-tune T5-large just fine in FP16 on my own task, where previously it would NaN. So far, nothing seems to be wrong with the outputs, and I have not encountered NaN.
For example of a converted model: https://github.com/tlkh/t5-fp16-surgery/blob/main/t5-large.ipynb
I have uploaded the converted models for people to play with:
* [`tlkh/t5_large_fp16_untuned`](https://huggingface.co/tlkh/t5_large_fp16_untuned)
* [`tlkh/t5_3B_fp16_untuned`](https://huggingface.co/tlkh/t5_3B_fp16_untuned)
Note: for the 3B model, after the conversion, the pre-trained translation task seems to be more unstable, but given it can still generate coherent text, my hunch is that after fine-tuning on another task, it should have negligible difference. However, it would be great to know for sure, so wonder if there is some kind of benchmark suite we can try.
I do not have the resources to convert the 11B one, but I do not see why that wouldn't work similarly. It is also very quick to convert models.
GitHub repo to demo/show code for the conversion, and also included inference testing to show the model seems to be working fine: https://github.com/tlkh/t5-fp16-surgery
My hopeful outcome from this is that we can fine-tune T5 in FP16 without any real penalty. <|||||>I'm trying to use this for T5-3B with A100. Is bf16 available experimentally?
BTW, I'm heading towards this direction because the `fairscale sharded_ddp` option for some reason hangs when it should run evaluation. Any pointers to solve this issue as well?<|||||>> I'm trying to use this for T5-3B with A100. Is bf16 available experimentally?
There is a WIP PR: https://github.com/huggingface/transformers/pull/13207
> BTW, I'm heading towards this direction because the `fairscale sharded_ddp` option for some reason hangs when it should run evaluation. Any pointers to solve this issue as well?
Use deepspeed: https://huggingface.co/transformers/master/main_classes/deepspeed.html#deepspeed-trainer-integration
<|||||>> @Liangtaiwan, also you may to try the loss penalty factor. The patch to apply (instead of this PR) is in the OP.
@stas00 Could you point out where is the patch or the PR?
<|||||>https://github.com/huggingface/transformers/pull/10956 Scroll down to "Penalizing large activation"<|||||>FYI, there is another solution posted by @ibeltagy here: https://github.com/huggingface/transformers/issues/14189#issuecomment-961571628
it too is based on custom scaling. Please have a look.
cc: @tlkh
<|||||>So heads up to all those watching this PR - if you have Ampere GPUs start using `--bf16` which was just added (i.e. use `master`) and the overflow problem will be no more: https://huggingface.co/docs/transformers/master/performance#bf16
p.s. I haven't actually tested that it's so with this particular issue, so if you do and find that it is not so, please kindly flag this to me.<|||||>So I got a chance to test the new `--bf16` flag on this issue with RTX-3090 (Ampere) and now mt5 doesn't overflow:
```
rm -rf output_dir; CUDA_VISIBLE_DEVICES=0 USE_TF=0 PYTHONPATH=src python \
examples/pytorch/translation/run_translation.py --model_name_or_path google/mt5-small --do_train \
--source_lang en --target_lang ro --dataset_name wmt16 --dataset_config_name ro-en --output_dir \
output_dir --per_device_train_batch_size=4 --logging_step 2 --save_steps 0 --max_train_samples 10 \
--save_total_limit 0 --save_strategy no --bf16
***** train metrics *****
epoch = 3.0
train_loss = 28.7758
train_runtime = 0:00:01.94
train_samples = 10
train_samples_per_second = 15.458
train_steps_per_second = 4.637
```
we get the same outcome with fp32 (i.e. w/o `--bf16`).
With `--fp16` we still overflow (no surprise here, I have just re-checked that):
```
rm -rf output_dir; CUDA_VISIBLE_DEVICES=0 USE_TF=0 PYTHONPATH=src python \
examples/pytorch/translation/run_translation.py --model_name_or_path google/mt5-small --do_train \
--source_lang en --target_lang ro --dataset_name wmt16 --dataset_config_name ro-en --output_dir \
output_dir --per_device_train_batch_size=4 --logging_step 2 --save_steps 0 --max_train_samples 10 \
--save_total_limit 0 --save_strategy no --fp16
***** train metrics *****
epoch = 3.0
train_loss = 0.0
train_runtime = 0:00:01.74
train_samples = 10
train_samples_per_second = 17.24
train_steps_per_second = 5.172
```<|||||>> This PR forces T5 FF Layer in fp32. With this change, there is almost no benefit to training in fp16. The memory usage and training speed improvements are very limited.
Hi, same issue here. Did you find a way to fix it?<|||||>@GaryYufei
I don't think it's almost impossible to fix this issue.
The best way is to use GPUs that support bf16 training.
You may also try to use @tlkh proposed method but not sure there would be any side-effect.
In my case, I choose to use fp32 to finetune the model.
<|||||>The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_10956). All of your documentation changes will be reflected on that endpoint.<|||||>Is this problem solved in the latest release of transformers?<|||||>It's not really a problem in `transformers` per se, but a limitation of the model.
This PR didn't get merged as it helped only in some cases and it would introduce a slowdown.
This thread contains various possible workarounds, but the best solution at the moment is to use bf16-able hardware to finetune t5 and any other bf16-pretrained models (Ampere GPUs or TPUs)<|||||>I see, thank you for your answer<|||||>Can someone approve this ? I'm getting nan values .. on main branch<|||||>It hasn't been merged because it's not the ideal solution as it introduces a degradation in performance (scales to fp32 = more memory used) and it doesn't work always resolve the problem.
This is a curse of many bf16-pre-trained models used in fp16 mode and not just of T5 and its derivatives.
Do you by chance have access to Ampere gpus and are able to use bf16 instead of fp16 - this would solve the problem w/o changing the code. https://github.com/huggingface/transformers/pull/10956#issuecomment-997230177
|
transformers | 10,955 | closed | Input gets lost when converting mBART decoder to onnx | I'm trying to convert the mBART decoder to onnx and have the problem, that one of the inputs gets lost during the conversion, which leads to errors when trying to use the onnx model. (See code example below.)
I'm trying to understand why this is the case and how to circumvent this.
Thanks alot for any help!
## Environment info
- `transformers` version: 4.4.2
- Platform: Linux-5.4.0-65-generic-x86_64-with-glibc2.29
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
## Who can help
@mfuntowicz @patil-suraj @patrickvonplaten
## Information
Model I am using (Bert, XLNet ...): mBART
The problem arises when using:
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] my own task or dataset: (give details below)
## To reproduce
If you run the code below, you should see the following print output:
```
['input_ids', 'encoder_attention_mask', 'encoder_hidden_states']
```
Now, if we uncomment the commented line in `DecoderWithLMhead.forward` and pass the `past_key_values` to the decoder and run the code again, the additional inputs will be added, but `encoder_hidden_states` is not present as an input any longer.
If we run `torch.onnx.export` with `verbose=True`, `encoder_hidden_states` seems not to be part of the graph. Is there a condition in the mBART decoder implementation that excludes `encoder_hidden_states` from the graph, when `past_key_values` is given to the decoder?
Code to reproduce the issue (adapted from [FastT5](https://github.com/Ki6an/fastT5/blob/master/fastT5/onnx_exporter.py)):
```python
import functools
import operator
import os
import tempfile
from transformers import AutoTokenizer, MBartForConditionalGeneration, AutoConfig
from onnxruntime import InferenceSession
import torch
model_or_model_path = 'facebook/mbart-large-cc25'
model = MBartForConditionalGeneration.from_pretrained(model_or_model_path)
model_config = AutoConfig.from_pretrained(model_or_model_path)
class DecoderWithLMhead(torch.nn.Module):
def __init__(self, decoder, lm_head, config):
super().__init__()
self.decoder = decoder
self.lm_head = lm_head
self.config = config
def forward(self, *inputs):
input_ids, attention_mask, encoder_hidden_states = inputs[:3]
list_pkv = inputs[3:]
past_key_values = tuple(list_pkv[i : i + 4] for i in range(0, len(list_pkv), 4))
decoder_output = self.decoder(
input_ids=input_ids,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=attention_mask,
# past_key_values=past_key_values,
)
lm_head_out = self.lm_head(decoder_output[0] * (self.config.d_model ** -0.5))
return lm_head_out, decoder_output[1]
decoder_with_lm_head = DecoderWithLMhead(
decoder=model.get_decoder(),
lm_head=model.get_output_embeddings(),
config=model_config
)
batch_size = 5
sequence_length = 10
input_ids_dec = torch.ones((batch_size, 1), dtype=torch.int64)
attention_mask_dec = torch.ones((batch_size, sequence_length), dtype=torch.int64)
enc_out = torch.ones(
(batch_size, sequence_length, model_config.d_model), dtype=torch.float32
)
head_dim = model_config.d_model // model_config.encoder_attention_heads
a = torch.ones((batch_size, model_config.decoder_attention_heads, sequence_length, head_dim), dtype=torch.float32)
attention_block = (a, a, a, a)
past_key_values = (attention_block,) * model_config.decoder_layers
flat_past_key_values = functools.reduce(operator.iconcat, past_key_values, [])
decoder_all_inputs = tuple(
[input_ids_dec, attention_mask_dec, enc_out] + flat_past_key_values
)
num_of_inputs = 4 * model_config.decoder_layers
with torch.no_grad():
decoder_inputs = [
"input_ids",
"encoder_attention_mask",
"encoder_hidden_states",
]
pkv_input_names = ["input_{}".format(i) for i in range(0, num_of_inputs)]
decoder_input_names = decoder_inputs + pkv_input_names
decoder_output_names = ["logits", "output_past_key_values"]
dyn_axis = {
"input_ids": {0: "batch", 1: "sequence"},
"encoder_attention_mask": {0: "batch", 1: "sequence"},
"encoder_hidden_states": {0: "batch", 1: "sequence"},
"logits": {0: "batch", 1: "sequence"},
"output_past_key_values": {0: "batch", 1: "sequence"},
}
dyn_pkv = {
"input_{}".format(i): {0: "batch", 1: "n_head", 2: "seq_length", 3: "d_kv"}
for i in range(0, num_of_inputs)
}
dyn_axis_params = {**dyn_axis, **dyn_pkv}
temp_dir = tempfile.TemporaryDirectory()
onnx_output_path = os.path.join(temp_dir.name, "decoder.onnx")
torch.onnx.export(
decoder_with_lm_head,
decoder_all_inputs,
onnx_output_path,
export_params=True,
do_constant_folding=True,
opset_version=12,
input_names=decoder_input_names,
output_names=decoder_output_names,
dynamic_axes=dyn_axis_params,
use_external_data_format=True,
)
session = InferenceSession(onnx_output_path)
print(list(map(lambda x: x.name, session.get_inputs()))) # encoder_hidden_states should be in here
temp_dir.cleanup()
```
## Expected behavior
All inputs passed to the onnx export function are present in the created onnx model.
| 03-29-2021 21:21:16 | 03-29-2021 21:21:16 | It seems that the `encoder_hidden_states` are passed as `key_value_states` into the `MBartAttention` down the line and are not used in case `past_key_value` is given.
https://github.com/huggingface/transformers/blob/90ecc29656ce37fdbe7279cf586511ed678c0cb7/src/transformers/models/mbart/modeling_mbart.py#L183
In that case I guess it's expected that they are not in the graph of the decoder, so I'll see how I can work around that when converting to ONNX. |
transformers | 10,954 | closed | [vulnerability] dep fix | Fixes https://github.com/huggingface/transformers/security/dependabot/examples/research_projects/lxmert/requirements.txt/Pygments/open
@LysandreJik
| 03-29-2021 21:09:19 | 03-29-2021 21:09:19 | Oh, is this process somehow automated and I didn't know about it? All I see is the file which it complains about and no suggestion to automate the fix.<|||||>Yeah, but usually it's not as good as your suggestion as it offers `==` while you offer `>=`.
I think I mentioned it here: https://github.com/huggingface/transformers/pull/10817
But thank you nonetheless, these are helpful!<|||||>Hmm, I have been copying exactly what the vulnerability bot suggested - which is always `>=` - so it's probably the dependabot that could use a bit of an update to match the vulnerability report.
But it's good to know that this is already automated, I will know not to make a PR next time. |
transformers | 10,953 | closed | Use pre-computed lengths, if available, when grouping by length | # What does this PR do?
A new argument `length_column_name` has been added to
`TrainingArguments`, with default value `"length"`. If this column
exists and `group_by_length` is `True`, the train sampler will use
it for grouping rather than computing all lengths before training starts.
This is an optimization that allows the user to prepare data for fast
processing, preventing sequential access to the dataset as described in
issue #10909.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? [Discussion](https://discuss.huggingface.co/t/spanish-asr-fine-tuning-wav2vec2/4586/6), related issue #10909.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@sgugger, this is what we discussed during the fine-tuning week. | 03-29-2021 19:17:21 | 03-29-2021 19:17:21 | |
transformers | 10,952 | closed | [Trainer] possible DDP memory regression | I think we may have created a memory regression somewhere recently.
I tried with pt-1.7 and pt-1.8 with the same results.
memory limit on this setup is 8gb
on `transformers` master:
This takes about 5.5GB/gpu:
```
PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0,1 python examples/seq2seq/run_translation.py --model_name_or_path google/mt5-small --do_train --do_eval --source_lang en --target_lang ro --dataset_name wmt16 --dataset_config_name ro-en --output_dir /tmp/test --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_generate --logging_step 10
```
(no need to run more than a few secs, we are just trying to see that the job can start training)
switching to DDP immediately OOMs:
```
PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 examples/seq2seq/run_translation.py --model_name_or_path google/mt5-small --do_train --do_eval --source_lang en --target_lang ro --dataset_name wmt16 --dataset_config_name ro-en --output_dir /tmp/test --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_generate --logging_step 10
```
even if I reduce the bs from 4 to 1 it still goes over 8GB.
@sgugger, could you please confirm if you're seeing the same?
| 03-29-2021 17:25:25 | 03-29-2021 17:25:25 | I don't have a setup with 8Gb so I have to rely on nvidia-smi numbers. First command is 13.2Gb on GPU0, 6.5Gb on GPU1, second command is 11.2GB on GPU0 and 10.1GB on GPU1.<|||||>Thank you for the sanity check, @sgugger
This is very odd that we get such a discrepancy in memory allocation between the 2 gpus on DP! 2x gpu ram on card0.
But this explains why it works for me since I have precisely 24gb + 8gb, so this discrepancy fits just right. So it's unclear if it's a problem in DP or DDP.
I will investigate.<|||||>With DP the gradients and optimizer states are only on one GPU, I think that is why we have the big difference. With DDP they are copied over the two.<|||||>Oh wow, that's a huge difference. Clearly DP wins here for those with lopsided setups like mine!
OK, then it's by design then. Closing this.<|||||>This is a bit of a problem with our memory metrics reporting as we only report gpu0, but I guess since most users will have symmetrical setups (cards of the same size) and gpu0 consumes the biggest amount of memory in DP/DDP then it's OK.
Will have to think how to extend the metrics for setups where it's critical to know each gpu's allocations - e.g. pipeline or model parallel. |
transformers | 10,951 | closed | Fixes in the templates | # What does this PR do?
Fixes a few things I noticed from new models PR in the templates directly. | 03-29-2021 16:45:09 | 03-29-2021 16:45:09 | |
transformers | 10,950 | closed | Add Vision Transformer and ViTFeatureExtractor | # What does this PR do?
Opening up a new PR based on #10513 which uses @sgugger's new `image_utils.py` instead of `torchvision` for the image transformations, and is up-to-date with master.
Things to do:
- [x] fix one integration test (currently `ViTFeatureExtractor` converts the numpy arrays into DoubleTensors, but the model expects FloatTensors)
- [x] fix styling (`make style` is not working as expected on my machine, see remaining comments in previous PR)
- [x] perhaps change pooler logic? Design (and updated conversion script) currently at branch "add_pooler_to_vit"
cc @LysandreJik | 03-29-2021 12:45:10 | 03-29-2021 12:45:10 | I've addressed all comments. The pooler now more closely matches the one of `BertModel`.
Only `make fix-copies` is giving an error on CircleCI for now. Other than that the PR is ready.
<|||||>Thanks for all your work on this @NielsRogge ! |
transformers | 10,949 | closed | How to freeze Camembert model for Classification tasks? | # 📚 Migration
## Information
<!-- Important information -->
Model I am using (Bert, XLNet ...):
Language I am using the model on (English, Chinese ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## Details
<!-- A clear and concise description of the migration issue.
If you have code snippets, please provide it here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
-->
## Environment info
<!-- You can run the command `python transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
<!-- IMPORTANT: which version of the former library do you use? -->
* `pytorch-transformers` or `pytorch-pretrained-bert` version (or branch):
## Checklist
- [ ] I have read the migration guide in the readme.
([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers);
[pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
- [ ] I checked if a related official extension example runs on my machine.
| 03-29-2021 12:11:04 | 03-29-2021 12:11:04 | See #400<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,948 | closed | [MarianMTModel] 'list' object has no attribute 'size' | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.1.1
- Platform: Google Colab
- Python version: 3.7
- PyTorch version (GPU?): 1.8.1
- Tensorflow version (GPU?):
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
```
!pip install transformers==4.1.1 sentencepiece==0.1.94
!pip install mosestokenizer==1.1.0
from transformers import MarianMTModel, MarianTokenizer
target_model_name = 'Helsinki-NLP/opus-mt-en-ROMANCE'
target_tokenizer = MarianTokenizer.from_pretrained(target_model_name)
target_model = MarianMTModel.from_pretrained(target_model_name)
en_model_name = 'Helsinki-NLP/opus-mt-ROMANCE-en'
en_tokenizer = MarianTokenizer.from_pretrained(en_model_name)
en_model = MarianMTModel.from_pretrained(en_model_name)
def translate(texts, model, tokenizer, language="fr"):
# Prepare the text data into appropriate format for the model
template = lambda text: f"{text}" if language == "en" else f">>{language}<< {text}"
src_texts = [template(text) for text in texts]
# Tokenize the texts
encoded = tokenizer.prepare_seq2seq_batch(src_texts)
# Generate translation using model
translated = model.generate(**encoded)
# Convert the generated tokens indices back into text
translated_texts = tokenizer.batch_decode(translated, skip_special_tokens=True)
return translated_texts
def back_translate(texts, source_lang="en", target_lang="vi"):
# Translate from source to target language
fr_texts = translate(texts, target_model, target_tokenizer,
language=target_lang)
# Translate from target language back to source language
back_translated_texts = translate(fr_texts, en_model, en_tokenizer,
language=source_lang)
return back_translated_texts
en_texts = ['This is so cool', 'I hated the food', 'They were very helpful']
aug_texts = back_translate(en_texts, source_lang="en", target_lang="es")
print(aug_texts)
```
The problem arises when using:
* [x] my own modified scripts:
```
<ipython-input-1-83d3425f13db> in back_translate(texts, source_lang, target_lang)
36 # Translate from source to target language
37 fr_texts = translate(texts, target_model, target_tokenizer,
---> 38 language=target_lang)
39
40 # Translate from target language back to source language
<ipython-input-1-83d3425f13db> in translate(texts, model, tokenizer, language)
26
27 # Generate translation using model
---> 28 translated = model.generate(**encoded)
29
30 # Convert the generated tokens indices back into text
/usr/local/lib/python3.7/dist-packages/torch/autograd/grad_mode.py in decorate_context(*args, **kwargs)
25 def decorate_context(*args, **kwargs):
26 with self.__class__():
---> 27 return func(*args, **kwargs)
28 return cast(F, decorate_context)
29
/usr/local/lib/python3.7/dist-packages/transformers/generation_utils.py in generate(self, input_ids, max_length, min_length, do_sample, early_stopping, num_beams, temperature, top_k, top_p, repetition_penalty, bad_words_ids, bos_token_id, pad_token_id, eos_token_id, length_penalty, no_repeat_ngram_size, encoder_no_repeat_ngram_size, num_return_sequences, max_time, decoder_start_token_id, use_cache, num_beam_groups, diversity_penalty, prefix_allowed_tokens_fn, output_attentions, output_hidden_states, output_scores, return_dict_in_generate, forced_bos_token_id, forced_eos_token_id, **model_kwargs)
914 if self.config.is_encoder_decoder:
915 # add encoder_outputs to model_kwargs
--> 916 model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(input_ids, model_kwargs)
917
918 # set input_ids as decoder_input_ids
/usr/local/lib/python3.7/dist-packages/transformers/generation_utils.py in _prepare_encoder_decoder_kwargs_for_generation(self, input_ids, model_kwargs)
409 argument: value for argument, value in model_kwargs.items() if not argument.startswith("decoder_")
410 }
--> 411 model_kwargs["encoder_outputs"]: ModelOutput = encoder(input_ids, return_dict=True, **encoder_kwargs)
412 return model_kwargs
413
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/marian/modeling_marian.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
712 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
713 elif input_ids is not None:
--> 714 input_shape = input_ids.size()
715 input_ids = input_ids.view(-1, input_shape[-1])
716 elif inputs_embeds is not None:
AttributeError: 'list' object has no attribute 'size'
```
Thanks for your support
| 03-29-2021 10:46:22 | 03-29-2021 10:46:22 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>I confirm the error:
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model_path="Helsinki-NLP/opus-mt-en-de"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSeq2SeqLM.from_pretrained(model_path)
batch = tokenizer.prepare_seq2seq_batch(src_texts=["Alice has a cat."])
gen = model.generate(**batch)
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,947 | closed | Save model error: list index out of range after pass input_processing call | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.0
- Platform: Linux-4.19.0-14-cloud-amd64-x86_64-with-debian-10.8
- Python version: 3.7.10
- PyTorch version (GPU?): 1.7.0 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
### Who can help
Maybe @LysandreJik or @jplu
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using albert:
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## Code for Tensorflow
* albert_zh: https://github.com/brightmart/albert_zh
```python
strategy = tf.distribute.MirroredStrategy()
max_seq_len = 128
cache_folder = '/tmp'
pretrain_model = 'voidful/albert_chinese_tiny'
albert_config = AlbertConfig.from_json_file(albert_zh / 'albert_config' / 'albert_config_tiny.json')
def sms_classifier_model(pretrain_model, config, max_seq_len, cache_folder):
input_ids = tf.keras.layers.Input(shape=(max_seq_len, ), name='input_ids', dtype=tf.int32)
input_token_type_ids = tf.keras.layers.Input(shape=(max_seq_len, ), name='token_type_ids', dtype=tf.int32)
input_attention_mask = tf.keras.layers.Input(shape=(max_seq_len, ), name='attention_mask', dtype=tf.int32)
albert_model = TFAlbertForSequenceClassification.from_pretrained(
pretrain_model,
config=config,
from_pt=True,
cache_dir=cache_folder)
x = albert_model([input_ids, input_token_type_ids, input_attention_mask])
output = tf.keras.activations.softmax(x[0])
model = tf.keras.models.Model(
inputs=[input_ids, input_token_type_ids, input_attention_mask],
outputs={'target': output}, name='sms_classifier')
return model
K.clear_session()
albert_config.hidden_act = 'gelu_new'
albert_config.num_labels = 4
with strategy.scope():
albert_model = sms_classifier_model(pretrain_model, albert_config, 128, cached_pretarin_model_folder)
with strategy.scope():
albert_model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=tf.keras.metrics.CategoricalAccuracy())
albert_model.fit(
x=training_dataset,
validation_data=validation_dataset,
steps_per_epoch=200,
validation_steps=100,
epochs=2,
verbose=1,
use_multiprocessing=True)
albert_model.save('/tmp/albert_model')
```
## Error Message
```python
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-33-9fbc26d706ab> in <module>
1 albert_model.save(
----> 2 str(saved_tf_model_folder / f'{run_id}')
3 )
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py in save(self, filepath, overwrite, include_optimizer, save_format, signatures, options, save_traces)
2000 # pylint: enable=line-too-long
2001 save.save_model(self, filepath, overwrite, include_optimizer, save_format,
-> 2002 signatures, options, save_traces)
2003
2004 def save_weights(self,
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/save.py in save_model(model, filepath, overwrite, include_optimizer, save_format, signatures, options, save_traces)
155 else:
156 saved_model_save.save(model, filepath, overwrite, include_optimizer,
--> 157 signatures, options, save_traces)
158
159
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save.py in save(model, filepath, overwrite, include_optimizer, signatures, options, save_traces)
87 with distribution_strategy_context._get_default_replica_context(): # pylint: disable=protected-access
88 with utils.keras_option_scope(save_traces):
---> 89 save_lib.save(model, filepath, signatures, options)
90
91 if not include_optimizer:
/opt/conda/lib/python3.7/site-packages/tensorflow/python/saved_model/save.py in save(obj, export_dir, signatures, options)
1031
1032 _, exported_graph, object_saver, asset_info = _build_meta_graph(
-> 1033 obj, signatures, options, meta_graph_def)
1034 saved_model.saved_model_schema_version = constants.SAVED_MODEL_SCHEMA_VERSION
1035
/opt/conda/lib/python3.7/site-packages/tensorflow/python/saved_model/save.py in _build_meta_graph(obj, signatures, options, meta_graph_def)
1196
1197 with save_context.save_context(options):
-> 1198 return _build_meta_graph_impl(obj, signatures, options, meta_graph_def)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/saved_model/save.py in _build_meta_graph_impl(obj, signatures, options, meta_graph_def)
1131 if signatures is None:
1132 signatures = signature_serialization.find_function_to_export(
-> 1133 checkpoint_graph_view)
1134
1135 signatures, wrapped_functions = (
/opt/conda/lib/python3.7/site-packages/tensorflow/python/saved_model/signature_serialization.py in find_function_to_export(saveable_view)
73 # If the user did not specify signatures, check the root object for a function
74 # that can be made into a signature.
---> 75 functions = saveable_view.list_functions(saveable_view.root)
76 signature = functions.get(DEFAULT_SIGNATURE_ATTR, None)
77 if signature is not None:
/opt/conda/lib/python3.7/site-packages/tensorflow/python/saved_model/save.py in list_functions(self, obj, extra_functions)
149 if obj_functions is None:
150 obj_functions = obj._list_functions_for_serialization( # pylint: disable=protected-access
--> 151 self._serialization_cache)
152 self._functions[obj] = obj_functions
153 if extra_functions:
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py in _list_functions_for_serialization(self, serialization_cache)
2611 self.predict_function = None
2612 functions = super(
-> 2613 Model, self)._list_functions_for_serialization(serialization_cache)
2614 self.train_function = train_function
2615 self.test_function = test_function
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py in _list_functions_for_serialization(self, serialization_cache)
3085 def _list_functions_for_serialization(self, serialization_cache):
3086 return (self._trackable_saved_model_saver
-> 3087 .list_functions_for_serialization(serialization_cache))
3088
3089 def __getstate__(self):
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/base_serialization.py in list_functions_for_serialization(self, serialization_cache)
92 return {}
93
---> 94 fns = self.functions_to_serialize(serialization_cache)
95
96 # The parent AutoTrackable class saves all user-defined tf.functions, and
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/layer_serialization.py in functions_to_serialize(self, serialization_cache)
77 def functions_to_serialize(self, serialization_cache):
78 return (self._get_serialized_attributes(
---> 79 serialization_cache).functions_to_serialize)
80
81 def _get_serialized_attributes(self, serialization_cache):
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/layer_serialization.py in _get_serialized_attributes(self, serialization_cache)
93
94 object_dict, function_dict = self._get_serialized_attributes_internal(
---> 95 serialization_cache)
96
97 serialized_attr.set_and_validate_objects(object_dict)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/model_serialization.py in _get_serialized_attributes_internal(self, serialization_cache)
55 objects, functions = (
56 super(ModelSavedModelSaver, self)._get_serialized_attributes_internal(
---> 57 serialization_cache))
58 functions['_default_save_signature'] = default_signature
59 return objects, functions
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/layer_serialization.py in _get_serialized_attributes_internal(self, serialization_cache)
102 """Returns dictionary of serialized attributes."""
103 objects = save_impl.wrap_layer_objects(self.obj, serialization_cache)
--> 104 functions = save_impl.wrap_layer_functions(self.obj, serialization_cache)
105 # Attribute validator requires that the default save signature is added to
106 # function dict, even if the value is None.
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in wrap_layer_functions(layer, serialization_cache)
163 call_fn_with_losses = call_collection.add_function(
164 _wrap_call_and_conditional_losses(layer),
--> 165 '{}_layer_call_and_return_conditional_losses'.format(layer.name))
166 call_fn = call_collection.add_function(
167 _extract_outputs_from_fn(layer, call_fn_with_losses),
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in add_function(self, call_fn, name)
503 # Manually add traces for layers that have keyword arguments and have
504 # a fully defined input signature.
--> 505 self.add_trace(*self._input_signature)
506 return fn
507
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in add_trace(self, *args, **kwargs)
418 fn.get_concrete_function(*args, **kwargs)
419
--> 420 trace_with_training(True)
421 trace_with_training(False)
422 else:
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in trace_with_training(value, fn)
416 utils.set_training_arg(value, self._training_arg_index, args, kwargs)
417 with K.deprecated_internal_learning_phase_scope(value):
--> 418 fn.get_concrete_function(*args, **kwargs)
419
420 trace_with_training(True)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in get_concrete_function(self, *args, **kwargs)
548 if not self.call_collection.tracing:
549 self.call_collection.add_trace(*args, **kwargs)
--> 550 return super(LayerCall, self).get_concrete_function(*args, **kwargs)
551
552
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py in get_concrete_function(self, *args, **kwargs)
1297 ValueError: if this object has not yet been called on concrete values.
1298 """
-> 1299 concrete = self._get_concrete_function_garbage_collected(*args, **kwargs)
1300 concrete._garbage_collector.release() # pylint: disable=protected-access
1301 return concrete
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py in _get_concrete_function_garbage_collected(self, *args, **kwargs)
1203 if self._stateful_fn is None:
1204 initializers = []
-> 1205 self._initialize(args, kwargs, add_initializers_to=initializers)
1206 self._initialize_uninitialized_variables(initializers)
1207
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py in _initialize(self, args, kwds, add_initializers_to)
724 self._concrete_stateful_fn = (
725 self._stateful_fn._get_concrete_function_internal_garbage_collected( # pylint: disable=protected-access
--> 726 *args, **kwds))
727
728 def invalid_creator_scope(*unused_args, **unused_kwds):
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/function.py in _get_concrete_function_internal_garbage_collected(self, *args, **kwargs)
2967 args, kwargs = None, None
2968 with self._lock:
-> 2969 graph_function, _ = self._maybe_define_function(args, kwargs)
2970 return graph_function
2971
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/function.py in _maybe_define_function(self, args, kwargs)
3359
3360 self._function_cache.missed.add(call_context_key)
-> 3361 graph_function = self._create_graph_function(args, kwargs)
3362 self._function_cache.primary[cache_key] = graph_function
3363
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/function.py in _create_graph_function(self, args, kwargs, override_flat_arg_shapes)
3204 arg_names=arg_names,
3205 override_flat_arg_shapes=override_flat_arg_shapes,
-> 3206 capture_by_value=self._capture_by_value),
3207 self._function_attributes,
3208 function_spec=self.function_spec,
/opt/conda/lib/python3.7/site-packages/tensorflow/python/framework/func_graph.py in func_graph_from_py_func(name, python_func, args, kwargs, signature, func_graph, autograph, autograph_options, add_control_dependencies, arg_names, op_return_value, collections, capture_by_value, override_flat_arg_shapes)
988 _, original_func = tf_decorator.unwrap(python_func)
989
--> 990 func_outputs = python_func(*func_args, **func_kwargs)
991
992 # invariant: `func_outputs` contains only Tensors, CompositeTensors,
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py in wrapped_fn(*args, **kwds)
632 xla_context.Exit()
633 else:
--> 634 out = weak_wrapped_fn().__wrapped__(*args, **kwds)
635 return out
636
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in wrapper(*args, **kwargs)
525 with autocast_variable.enable_auto_cast_variables(
526 layer._compute_dtype_object): # pylint: disable=protected-access
--> 527 ret = method(*args, **kwargs)
528 _restore_layer_losses(original_losses)
529 return ret
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/utils.py in wrap_with_training_arg(*args, **kwargs)
169 return control_flow_util.smart_cond(
170 training, lambda: replace_training_and_call(True),
--> 171 lambda: replace_training_and_call(False))
172
173 # Create arg spec for decorated function. If 'training' is not defined in the
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/utils/control_flow_util.py in smart_cond(pred, true_fn, false_fn, name)
113 pred, true_fn=true_fn, false_fn=false_fn, name=name)
114 return smart_module.smart_cond(
--> 115 pred, true_fn=true_fn, false_fn=false_fn, name=name)
116
117
/opt/conda/lib/python3.7/site-packages/tensorflow/python/framework/smart_cond.py in smart_cond(pred, true_fn, false_fn, name)
52 if pred_value is not None:
53 if pred_value:
---> 54 return true_fn()
55 else:
56 return false_fn()
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/utils.py in <lambda>()
168
169 return control_flow_util.smart_cond(
--> 170 training, lambda: replace_training_and_call(True),
171 lambda: replace_training_and_call(False))
172
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/utils.py in replace_training_and_call(training)
165 def replace_training_and_call(training):
166 set_training_arg(training, training_arg_index, args, kwargs)
--> 167 return wrapped_call(*args, **kwargs)
168
169 return control_flow_util.smart_cond(
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in call_and_return_conditional_losses(inputs, *args, **kwargs)
568 def call_and_return_conditional_losses(inputs, *args, **kwargs):
569 """Returns layer (call_output, conditional losses) tuple."""
--> 570 call_output = layer_call(inputs, *args, **kwargs)
571 if version_utils.is_v1_layer_or_model(layer):
572 conditional_losses = layer.get_losses_for(inputs)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/functional.py in call(self, inputs, training, mask)
423 """
424 return self._run_internal_graph(
--> 425 inputs, training=training, mask=mask)
426
427 def compute_output_shape(self, input_shape):
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/functional.py in _run_internal_graph(self, inputs, training, mask)
558
559 args, kwargs = node.map_arguments(tensor_dict)
--> 560 outputs = node.layer(*args, **kwargs)
561
562 # Update tensor_dict.
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py in __call__(self, *args, **kwargs)
1010 with autocast_variable.enable_auto_cast_variables(
1011 self._compute_dtype_object):
-> 1012 outputs = call_fn(inputs, *args, **kwargs)
1013
1014 if self._activity_regularizer:
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/utils.py in return_outputs_and_add_losses(*args, **kwargs)
71 inputs = args[inputs_arg_index]
72 args = args[inputs_arg_index + 1:]
---> 73 outputs, losses = fn(inputs, *args, **kwargs)
74 layer.add_loss(losses, inputs=inputs)
75
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/utils.py in wrap_with_training_arg(*args, **kwargs)
169 return control_flow_util.smart_cond(
170 training, lambda: replace_training_and_call(True),
--> 171 lambda: replace_training_and_call(False))
172
173 # Create arg spec for decorated function. If 'training' is not defined in the
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/utils/control_flow_util.py in smart_cond(pred, true_fn, false_fn, name)
113 pred, true_fn=true_fn, false_fn=false_fn, name=name)
114 return smart_module.smart_cond(
--> 115 pred, true_fn=true_fn, false_fn=false_fn, name=name)
116
117
/opt/conda/lib/python3.7/site-packages/tensorflow/python/framework/smart_cond.py in smart_cond(pred, true_fn, false_fn, name)
52 if pred_value is not None:
53 if pred_value:
---> 54 return true_fn()
55 else:
56 return false_fn()
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/utils.py in <lambda>()
168
169 return control_flow_util.smart_cond(
--> 170 training, lambda: replace_training_and_call(True),
171 lambda: replace_training_and_call(False))
172
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/utils.py in replace_training_and_call(training)
165 def replace_training_and_call(training):
166 set_training_arg(training, training_arg_index, args, kwargs)
--> 167 return wrapped_call(*args, **kwargs)
168
169 return control_flow_util.smart_cond(
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in __call__(self, *args, **kwargs)
542 def __call__(self, *args, **kwargs):
543 if not self.call_collection.tracing:
--> 544 self.call_collection.add_trace(*args, **kwargs)
545 return super(LayerCall, self).__call__(*args, **kwargs)
546
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in add_trace(self, *args, **kwargs)
418 fn.get_concrete_function(*args, **kwargs)
419
--> 420 trace_with_training(True)
421 trace_with_training(False)
422 else:
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in trace_with_training(value, fn)
416 utils.set_training_arg(value, self._training_arg_index, args, kwargs)
417 with K.deprecated_internal_learning_phase_scope(value):
--> 418 fn.get_concrete_function(*args, **kwargs)
419
420 trace_with_training(True)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in get_concrete_function(self, *args, **kwargs)
548 if not self.call_collection.tracing:
549 self.call_collection.add_trace(*args, **kwargs)
--> 550 return super(LayerCall, self).get_concrete_function(*args, **kwargs)
551
552
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py in get_concrete_function(self, *args, **kwargs)
1297 ValueError: if this object has not yet been called on concrete values.
1298 """
-> 1299 concrete = self._get_concrete_function_garbage_collected(*args, **kwargs)
1300 concrete._garbage_collector.release() # pylint: disable=protected-access
1301 return concrete
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py in _get_concrete_function_garbage_collected(self, *args, **kwargs)
1215 # run the first trace but we should fail if variables are created.
1216 concrete = self._stateful_fn._get_concrete_function_garbage_collected( # pylint: disable=protected-access
-> 1217 *args, **kwargs)
1218 if self._created_variables:
1219 raise ValueError("Creating variables on a non-first call to a function"
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/function.py in _get_concrete_function_garbage_collected(self, *args, **kwargs)
3017 args, kwargs = None, None
3018 with self._lock:
-> 3019 graph_function, _ = self._maybe_define_function(args, kwargs)
3020 seen_names = set()
3021 captured = object_identity.ObjectIdentitySet(
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/function.py in _maybe_define_function(self, args, kwargs)
3359
3360 self._function_cache.missed.add(call_context_key)
-> 3361 graph_function = self._create_graph_function(args, kwargs)
3362 self._function_cache.primary[cache_key] = graph_function
3363
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/function.py in _create_graph_function(self, args, kwargs, override_flat_arg_shapes)
3204 arg_names=arg_names,
3205 override_flat_arg_shapes=override_flat_arg_shapes,
-> 3206 capture_by_value=self._capture_by_value),
3207 self._function_attributes,
3208 function_spec=self.function_spec,
/opt/conda/lib/python3.7/site-packages/tensorflow/python/framework/func_graph.py in func_graph_from_py_func(name, python_func, args, kwargs, signature, func_graph, autograph, autograph_options, add_control_dependencies, arg_names, op_return_value, collections, capture_by_value, override_flat_arg_shapes)
988 _, original_func = tf_decorator.unwrap(python_func)
989
--> 990 func_outputs = python_func(*func_args, **func_kwargs)
991
992 # invariant: `func_outputs` contains only Tensors, CompositeTensors,
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py in wrapped_fn(*args, **kwds)
632 xla_context.Exit()
633 else:
--> 634 out = weak_wrapped_fn().__wrapped__(*args, **kwds)
635 return out
636
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in wrapper(*args, **kwargs)
525 with autocast_variable.enable_auto_cast_variables(
526 layer._compute_dtype_object): # pylint: disable=protected-access
--> 527 ret = method(*args, **kwargs)
528 _restore_layer_losses(original_losses)
529 return ret
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/utils.py in wrap_with_training_arg(*args, **kwargs)
169 return control_flow_util.smart_cond(
170 training, lambda: replace_training_and_call(True),
--> 171 lambda: replace_training_and_call(False))
172
173 # Create arg spec for decorated function. If 'training' is not defined in the
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/utils/control_flow_util.py in smart_cond(pred, true_fn, false_fn, name)
113 pred, true_fn=true_fn, false_fn=false_fn, name=name)
114 return smart_module.smart_cond(
--> 115 pred, true_fn=true_fn, false_fn=false_fn, name=name)
116
117
/opt/conda/lib/python3.7/site-packages/tensorflow/python/framework/smart_cond.py in smart_cond(pred, true_fn, false_fn, name)
52 if pred_value is not None:
53 if pred_value:
---> 54 return true_fn()
55 else:
56 return false_fn()
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/utils.py in <lambda>()
168
169 return control_flow_util.smart_cond(
--> 170 training, lambda: replace_training_and_call(True),
171 lambda: replace_training_and_call(False))
172
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/utils.py in replace_training_and_call(training)
165 def replace_training_and_call(training):
166 set_training_arg(training, training_arg_index, args, kwargs)
--> 167 return wrapped_call(*args, **kwargs)
168
169 return control_flow_util.smart_cond(
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/saving/saved_model/save_impl.py in call_and_return_conditional_losses(inputs, *args, **kwargs)
568 def call_and_return_conditional_losses(inputs, *args, **kwargs):
569 """Returns layer (call_output, conditional losses) tuple."""
--> 570 call_output = layer_call(inputs, *args, **kwargs)
571 if version_utils.is_v1_layer_or_model(layer):
572 conditional_losses = layer.get_losses_for(inputs)
/opt/conda/lib/python3.7/site-packages/transformers/models/albert/modeling_tf_albert.py in call(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict, labels, training, **kwargs)
1144 labels=labels,
1145 training=training,
-> 1146 kwargs_call=kwargs,
1147 )
1148 outputs = self.albert(
/opt/conda/lib/python3.7/site-packages/transformers/modeling_tf_utils.py in input_processing(func, config, input_ids, **kwargs)
372 output[tensor_name] = input
373 else:
--> 374 output[parameter_names[i]] = input
375 elif isinstance(input, allowed_types) or input is None:
376 output[parameter_names[i]] = input
IndexError: list index out of range
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
In version <= 4.0.0 use save method was without the error, but after `input_processing` function comment that the error happened.
Does any advice to fix the problem?
| 03-29-2021 09:36:16 | 03-29-2021 09:36:16 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>I am having the same problem with BERT. My solution so far was to downgrade to `transformers==4.0.1` which seems to be the last version which does not use `input_processing` in `TFBertMainLayer`.
In my case, the values of the relevant variables are
```
input_ids = [<tf.Tensor 'input_ids:0' shape=(None, 384) dtype=int32>, <tf.Tensor 'input_ids_1:0' shape=(None, 384) dtype=int32>]
parameter_names = ['args']
```
The error arises because of the second item in `input_ids`. Like in the previous example I am using BERT as a part of a larger Keras model. Both the larger model and BERT have one input layer with name `input_ids`. I suspect that this is the reason why the list `input_ids` contains two elements. If I wrap `output[parameter_names[i]] = input` in a try-catch, it works as intended. |
transformers | 10,946 | closed | [Feature] Add a new tiny feature for self-attention analysis | # What does this PR do?
To implement the integral in [this paper](https://arxiv.org/abs/2004.11207), users need to take two items out: Output and Attention weights. However, the "Output" here is somewhat special; the attention weights of each layer should be multiplied by a scalar "alpha". I try to put this "alpha" in and set default to 1.0 (which is the same as the original BERT).
@LysandreJik
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 03-29-2021 08:55:12 | 03-29-2021 08:55:12 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,945 | closed | Are there memory leaks when using DeepSpeed on training T5? | We’ve been pretraining a T5-small model from scratch with using DeepSpeed v0.3.10.
We’ve found that cpu memory was increasing over time. (We’ve trained about 150 hours)
Are there memory leaks when using DeepSpeed on training T5?
| 03-29-2021 08:47:41 | 03-29-2021 08:47:41 | Hi, we'll need a bit more information to understand what's going on here. What command did you use? Did you use one of our scripts? What data are you using? What version of Transformers? The more information, the more we'll be able to understand and help you.
Pinging @stas00 <|||||>Thank you for reporting this, @avionkmh
I've been only doing short functionality tests so far, so can't really tell.
The only general RAM leak I found so far is when `deepspeed.initialize` is called more than once and the fix is here:
https://github.com/microsoft/DeepSpeed/issues/879
I suppose this is not your case.
As @LysandreJik recommended we need a lot more details to reproduce the problem and then we or the Deepspeed team if it's in their land can fix it.
<|||||>@LysandreJik @stas00
Thank you for your interests.
Here are the more detailed situations.
- Command
```
python -u -m deepspeed.launcher.launch \
--world_info=eyJsb2NhbGhvc3QiOiBbMywgNF19 --master_addr=127.0.0.1 --master_port=29503 \
examples/seq2seq/finetune_trainer.py \
--overwrite_output_dir \
--output_dir ./output \
--data_dir ./input \
--model_name_or_path ./t5-small-empty \
--per_device_train_batch_size 16 --gradient_accumulation_steps 2 \
--logging_steps 500 \
--save_steps 10000 \
--warmup_steps 10 \
--num_train_epochs 8 \
--deepspeed run_ds_config-cpu_offload=X.json \
--do_train
```
- the script we used
examples/seq2seq/finetune_trainer.py
<-- We modified the script(finetune_trainer.py) for T5 pretraining
- Version of Transformers
v4.3.2
- DeepSpeed version: v0.3.10
- "run_ds_config-cpu_offload=X.json" file
```
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true,
"cpu_offload": false
},
"zero_allow_untested_optimizer": true,
"optimizer": {
"type": "AdamW",
"params": {
"lr": 5e-5,
"betas": [
0.9,
0.999
],
"eps": 1e-8,
"weight_decay": 0.0
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 5e-5,
"warmup_num_steps": 10
}
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
```
- when using "torch.distributed.launch"
We've found there was no memory leak until the end of pretraining.
The followings are the script for using "torch.distributed.launch"
```
export NODE_RANK=0
export N_NODES=1
export N_GPU_NODE=2
export WORLD_SIZE=2
export MASTER_ADDR="129.254.164.234"
export MASTER_PORT=1233
python -m torch.distributed.launch \
--nproc_per_node=$N_GPU_NODE \
--nnodes=$N_NODES \
--node_rank $NODE_RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT \
examples/seq2seq/finetune_trainer.py \
--model_name_or_path t5-small-empty \
--output_dir ./output \
--data_dir ./input \
--do_train \
--save_steps 10000 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 2 \
--num_train_epochs 8 \
--overwrite_output_dir
```
<|||||>Unfortunately, there is nothing we can do w/o you providing us a way to reproduce the problem in a simple to setup and quick to run script.
> We modified this scripts for T5 pretraining
How could we possibly know what that means?
> We've found there was no memory leak until the end of pretraining.
I'd love to help, but I have no idea what to do with this information.
Please try to put yourself in the shoes of someone who isn't sitting in front of your computer seeing your software and what you're doing and what are the problems that you're seeing.
If we continue please first sync your code base to the latest training scripts and `transformers` since many issues have been fixed in deepspeed integration since the version you're using.
p.s. also when pasting code/config files please use code formatting as what you shared above is very difficult to read. Thank you.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,944 | open | Please implement DUMA: Reading Comprehension with Transposition Thinking | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
This one is on the race leaderborad top, will you guys consider implement this?
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| 03-29-2021 08:42:13 | 03-29-2021 08:42:13 | Are the source code and the model weights avaiable?
https://arxiv.org/abs/2001.09415<|||||>> Are the source code and the model weights avaiable?
>
> https://arxiv.org/abs/2001.09415
I do not have the source code and model weights. |
transformers | 10,943 | closed | Converting marian tatoeba models | ## Environment info
- `transformers` version: 4.4.2
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.10
- PyTorch version (GPU?): 1.8.0+cu101 (False)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: False
- Using distributed or parallel set-up in script?: False
### Who can help
- marian: @patrickvonplaten, @patil-suraj
## Information
Model I am using (Bert, XLNet...): marian
The problem arises when using:
* [x] the official example scripts: Tatoeba models converting script
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: machine translation
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
All steps are the same as in [official script](https://github.com/huggingface/transformers/blob/master/scripts/tatoeba/README.md) for converting marian tatoeba models to pytorch.
Error log:
```
Traceback (most recent call last):
File "src/transformers/models/marian/convert_marian_tatoeba_to_pytorch.py", line 1267, in <module>
resolver = TatoebaConverter(save_dir=args.save_dir)
File "src/transformers/models/marian/convert_marian_tatoeba_to_pytorch.py", line 80, in __init__
released.columns = released_cols
File "/usr/local/lib/python3.7/dist-packages/pandas/core/generic.py", line 5154, in __setattr__
return object.__setattr__(self, name, value)
File "pandas/_libs/properties.pyx", line 66, in pandas._libs.properties.AxisProperty.__set__
File "/usr/local/lib/python3.7/dist-packages/pandas/core/generic.py", line 564, in _set_axis
self._mgr.set_axis(axis, labels)
File "/usr/local/lib/python3.7/dist-packages/pandas/core/internals/managers.py", line 227, in set_axis
f"Length mismatch: Expected axis has {old_len} elements, new "
ValueError: Length mismatch: Expected axis has 7 elements, new values have 9 elements
```
## Expected behavior
IMO, main problem is in changes in fields of file [Tatoeba-Challenge/models/released-models.txt](https://github.com/Helsinki-NLP/Tatoeba-Challenge/blob/master/models/released-models.txt).
I'm expecting clean conversion of model for choosed language pair. | 03-29-2021 08:31:28 | 03-29-2021 08:31:28 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>@patil-suraj unstale?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Unstale<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Unstale<|||||>@patil-suraj - do you think you find time to take a look here? Otherwise I can probably free some time for it<|||||>I will take a look at it this week.<|||||>Gently pinging @patil-suraj here again - I think the conversion works now no? Could you maybe check? :-)<|||||>The conversion should work now, it has been fixed in #13757 |
transformers | 10,942 | closed | Wav2Vec2CTCTokenizer does not take the vocabulary into account when identifying tokens in a sentence | ## Environment info
- `transformers` version: 4.4.0
- Platform: Darwin-19.6.0-x86_64-i386-64bit
- Python version: 3.7.9
- PyTorch version (GPU?): 1.8.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
@patrickvonplaten @LysandreJik
## Information
Model I am using (Bert, XLNet ...): wav2vec2
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
We are trying to train an automatic phonemic transcription system for a low-resource language using the instructions [here](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2 )
I created a `Wav2Vec2CTCTokenizer` tokenizer as follows:
```python
from transformers import Wav2Vec2CTCTokenizer
# example of a phonemic transcription
sent = "ʈʰ æ æ̃ ˧ kʰ"
# phonemes are separated by spaces in the transcription
vocab = {phoneme for phoneme in sent.split()}
vocab_dict = {k: v for v, k in enumerate(vocab)}
# <space> will be our phoneme separator
vocab_dict[" "] = len(vocab_dict)
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)
tokenizer = Wav2Vec2CTCTokenizer("./vocab.json",
unk_token="[UNK]",
pad_token="[PAD]",
word_delimiter_token=" ")
```
The result of the sentence tokenization is:
```
>>> tokenizer(sent)
{'input_ids': [6, 6, 5, 2, 5, 2, 6, 5, 4, 5, 6, 6], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
Where 6 is the id of the <unk> token. The vocabulary is :
`{'æ̃': 0, 'kʰ': 1, 'æ': 2, 'ʈʰ': 3, '˧': 4, ' ': 5, '[UNK]': 6, '[PAD]': 7}`
It appears that phonemes made of several characters (e.g. ʈʰ) are not recognized as a whole but rather taken separately (ʈ and than ʰ) each token being mapped to a separate id (here `<unk>` as the separated characters are not in the vocabulary).
The tokenization output results from the `Wav2Vec2CTCTokenizer._tokenize` function being called before looking in the dictionary representing the vocabulary to map tokens into IDs. This function converts the string representing the sentence to tokenize into a list without taking into account the tokens defined in the vocabulary.
I do not know if this is the intended behaviour or if we are not using the tokenizer correctly (in which case the documentation might be improved)
| 03-29-2021 08:31:05 | 03-29-2021 08:31:05 | Hey @guillaume-wisniewski ,
Thanks a lot for the very clear error description.The PR attached should fix the problem :-) Let me know if you still encounter any problems. |
transformers | 10,941 | closed | Added documentation for data collator. | # What does this PR do?
This PR aims to improve coverage of the documentation for the Data Collators.
Fixes #9035
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| 03-28-2021 21:37:32 | 03-28-2021 21:37:32 | Thanks again for your contribution! |
transformers | 10,940 | closed | Addition of SequenceClassification config specific documentation to XModelForSequenceClassification. | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: Windows 10
- Python version: 3.6.12
- Tensorflow version (GPU?): 2.3.1
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help: @sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (DistilBert, Longformer):
The tasks I am working on is:
* [ ] my own task or dataset:
A document classification task with 2 or more custom classes.
## To reproduce
Steps to reproduce the behavior:
1. Navigate to the documentation of any [transformers.XForSequenceClassification](https://huggingface.co/transformers/model_doc/longformer.html#transformers.LongformerForSequenceClassification)
2. You will notice an absence of documentation for setting of any Sequence Classification related configs.
3. For example: `id2label, label2id, num_labels`
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Documentation for SequenceClassification specific settings like: `id2label, label2id, num_labels` in the documentation page for [transformers.XForSequenceClassification](https://huggingface.co/transformers/model_doc/longformer.html#transformers.LongformerForSequenceClassification)
Additionally in the documentation of the `from_pretrained` method, when loading models fine-tuned on non `SequenceClassification` tasks.
| 03-28-2021 20:39:50 | 03-28-2021 20:39:50 | Those are generic config parameters and as such, they can't be documented on a model (they are config parameters, not model parameters). The documentation is in the [config page](https://huggingface.co/transformers/main_classes/configuration.html).
The documentation of the `from_pretrained` [method](https://huggingface.co/transformers/main_classes/model.html#transformers.PreTrainedModel.from_pretrained) also tells the user any parameter of the config can be passed to this method as a kwarg.<|||||>Understood, the params in question are mentioned there in detail. Thanks 👍🏽 @sgugger |
transformers | 10,939 | closed | [Example] Fixed finename for Saving null_odds in the evaluation stage in QA Examples | # What does this PR do?
Earlier file `eval_null_odds_eval.json` because of a typo in code now it will save it like `eval_null_odds.json` for squadv2 dataset Saving null_odds in the evaluation stage
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? I mentioned it in #10482
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@stas00 @sgugger | 03-28-2021 13:32:20 | 03-28-2021 13:32:20 | |
transformers | 10,938 | closed | saving pretrained models that were obtained from another model | I am trying to save a pretrained model that I created from RobertaForQuestionAnswering by changing some layers.
However, when I load the model with from_pretrained, my new layers disappear.. It makes sense since binary seems to save only the model weights, but I wonder if there's a way to work around this? | 03-28-2021 11:02:26 | 03-28-2021 11:02:26 | @dar-tau even though the file stores only weights, but if you added more layers those weights should be saved right? And when you try to load that model into RobertaForQuestionAnswering without your extra layers it should fail. <|||||>Thanks for your reply.
I'm using AutoModelForQuestionAnswering.from_pretrained(...) and not RobertaForQuestionAnswering (and as a matter of fact I'm actually replacing layers rather than just adding some).
What I am aiming for is a way to make it "forget" it originated from Roberta, and save the entire model.
My desire is that it will be loadable with from_pretrained(..) and semantically equivalent to:
torch.save(model, "file.pt")
model=torch.load("file.pt")<|||||>@dar-tau I don't think this is something you can do with transformers, you need to probably do it using torch directly. You might want to check the config.json file which is saved.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,937 | closed | [trainer metrics] fix cpu mem metrics; reformat runtime metric | This PR improves and fixes trainer metrics:
* reworks the general ram memory tracking replacing `tracemalloc`, with "sampling" via `psutil` - in particular for peak tracking using a thread. `tracemalloc` proved to not track anything but python memory allocations, so we were missing most of the general RAM from reports. Now we are reporting much more. (other than swapped out memory).
* adds important details to memory metrics docs
* moves `psutil` dependency from just-for-tests to the core. I tried to find a built-in python equivalent, but the closest that I found is `resource.getrusage(resource.RUSAGE_SELF).ru_maxrss` which doesn't report what we need and it's not cross-platform.
* reformats secs to be in `hh:mm:ss.msec` format so it's much easier to read the runtime metric
Discovered the `tracemalloc` limitation while tracking a huge memory leak in DeepSpeed when re-using deepspeed in the same process. My tests were consuming hundreds of MBs of general RAM and the metrics were reporting nothing.
before:
```
BS=4; PYTHONPATH=src USE_TF=0 python examples/seq2seq/run_translation.py --model_name_or_path \
t5-small --output_dir /tmp/zero3 --overwrite_output_dir --max_train_samples 64 --max_val_samples 64 \
--max_source_length 128 --max_target_length 128 --val_max_target_length 128 --do_train \
--num_train_epochs 1 --per_device_train_batch_size $BS --per_device_eval_batch_size $BS \
--learning_rate 3e-3 --warmup_steps 500 --predict_with_generate --logging_steps 0 --save_steps 0 \
--eval_steps 0 --group_by_length --adafactor --dataset_name wmt16 --dataset_config ro-en \
--source_lang en --target_lang ro --source_prefix "translate English to Romanian: "
***** train metrics *****
epoch = 1.0
init_mem_cpu_alloc_delta = 3MB
init_mem_cpu_peaked_delta = 0MB
init_mem_gpu_alloc_delta = 230MB
init_mem_gpu_peaked_delta = 0MB
train_mem_cpu_alloc_delta = 60MB
train_mem_cpu_peaked_delta = 0MB
train_mem_gpu_alloc_delta = 232MB
train_mem_gpu_peaked_delta = 472MB
train_runtime = 5.5261
train_samples = 64
train_samples_per_second = 1.448
```
after this PR:
```
***** train metrics *****
epoch = 1.0
init_mem_cpu_alloc_delta = 1298MB
init_mem_cpu_peaked_delta = 154MB
init_mem_gpu_alloc_delta = 230MB
init_mem_gpu_peaked_delta = 0MB
train_mem_cpu_alloc_delta = 3446MB
train_mem_cpu_peaked_delta = 0MB
train_mem_gpu_alloc_delta = 232MB
train_mem_gpu_peaked_delta = 472MB
train_runtime = 0:00:05.66
train_samples = 64
train_samples_per_second = 1.412
```
@sgugger, @LysandreJik | 03-28-2021 05:48:46 | 03-28-2021 05:48:46 | Woops, didn't mean to approve<|||||>> Thanks for the fix! Like @LysandreJik I would avoid adding `psutils` as a main dependency. We can have it come with a `is_psutils_available` and only compute the mems metrics when it's there.
Oh, I was thinking to assert to say to install it. They can disable the mem metrics flags if they don't want to install it.
So we have:
A. `assert("pip install psutil to use memory metrics")`
B. `return if not is_psutils_available()`
Either way works for me.
<|||||>I would use option B personally. Having an error because something is not installed is not something we like (cf wandb).<|||||>looks like I did something wrong with the runtime metrics - checking.
```
Trainer is attempting to log a value of "0:00:02.18" of type <class 'str'> for key "train/train_runtime" as a scalar. This invocation of Tensorboard's writer.add_scalar() is incorrect so we dropped this attribute.
```
**edit**: fixed<|||||>@sgugger, so the only missing part is how can the user reach the extensive docs in `TrainerMemoryTracker` docstring? It's sort of an internal class.
Perhaps I should move the docs elsewhere so that the user can understand what the memory metrics are? Perhaps I can do the following:
1. move the bulk of the current `TrainerMemoryTracker` docstring explaning the metrics to `save_metrics` and then it'll automatically be documented in the right place
2. and add a note to `log_metrics` docstring to read the docstring of `save_metrics` for details
3. and add a note to `TrainerMemoryTracker` docstring to read the details in `save_metrics` for details<|||||>I think your approach for making the doc more visible is a good one, so I'm fine with it. Also add there that `pip install psutil` is necessary to get the memory metrics?<|||||>> I think your approach for making the doc more visible is a good one, so I'm fine with it.
Great!
> Also add there that `pip install psutil` is necessary to get the memory metrics?
It's already there ;)<|||||>Ah, missed it. Sorry about that!<|||||>OK, docs moved/reshaped/cross linked from 2 places. Decided to put the main doc in `log_metrics` since that's where they are most "visual".
If you could get one last look at the final version of the docs, that would be great. I expanded it a little bit more. I checked that they render well and cross-reference is a working link.<|||||>Hmm, I'm having second thoughts about skipping and not asserting if `psutil` is unavailable. Since there is a function flag to skip memory metrics, if the flag is `False` and we skip the metrics, that's not super intuitive. So if a user doesn't want the memory metrics they don't have to install `pustil` but can simply disable the metrics by setting the skip flag to `True`.
Perhaps it'd be agreeable with you to change the behavior to option A. in https://github.com/huggingface/transformers/pull/10937#issuecomment-809529412, i.e. to assert.<|||||>I'd personally really like to avoid the script failing even if you can set an argument to avoid that. |
transformers | 10,936 | closed | Fix initializing BertJapaneseTokenizer with AutoTokenizers | # What does this PR do?
This PR fixes a bug in loading some kinds of tokenizers using `AutoTokenizers.from_pretrained()`.
This issue is discussed in https://github.com/cl-tohoku/bert-japanese/issues/25.
When `sentencepiece` is not installed, the initialization of several tokenizers such as `BertJapaneseTokenizer`, `BarthezTokenizer`, and `MBart50Tokenizer` fails.
The exception is raised in `tokenizer_class_from_name()` when iterating over tokenizer classes which are `NoneType` objects.
Such tokenizer classes are set to `None` in `is_sentencepiece_available()` if `sentencepiece` is not available.
This error affects the initialization of `BertJapaneseTokenizer` even though it does not depend on `sentencepiece`.
```sh
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese")
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 479/479 [00:00<00:00, 143kB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/m-suzuki/.pyenv/versions/py3.7/lib/python3.7/site-packages/transformers/models/auto/tokenization_auto.py", line 370, in from_pretrained
tokenizer_class = tokenizer_class_from_name(tokenizer_class_candidate)
File "/Users/m-suzuki/.pyenv/versions/py3.7/lib/python3.7/site-packages/transformers/models/auto/tokenization_auto.py", line 273, in tokenizer_class_from_name
if c.__name__ == class_name:
AttributeError: 'NoneType' object has no attribute '__name__'
```
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@LysandreJik
| 03-28-2021 05:42:00 | 03-28-2021 05:42:00 | |
transformers | 10,935 | open | Add DALL-E: Zero-Shot Text-to-Image Generation | # 🚀 Feature request
Please add DALLE-E model to huggingface's Transformers library.
1. [Announcement](https://openai.com/blog/dall-e/)
2. [Abstract](https://arxiv.org/abs/2102.12092v2)
3. [Paper](https://arxiv.org/pdf/2102.12092v2.pdf)
4. Code:
- [openai/DALL-E](https://github.com/openai/DALL-E) (official)
- [lucidrains/DALLE-pytorch](https://github.com/lucidrains/DALLE-pytorch) ([Colab](https://colab.research.google.com/drive/1dWvA54k4fH8zAmiix3VXbg95uEIMfqQM?usp=sharing))
## Motivation
> DALL·E is a 12-billion parameter version of [GPT-3](https://huggingface.co/transformers/model_doc/gpt.html) trained to generate images from text descriptions, using a dataset of text–image pairs
>
> We (Open AI) decided to name our model using a portmanteau of the artist Salvador Dalí and Pixar’s WALL·E.
| 03-28-2021 04:13:41 | 03-28-2021 04:13:41 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>+1<|||||>Does dall-e mini currently added to transformers?
Currently, it doesn't `eBart` is not recognized in transformers library.<|||||>cc @patil-suraj who's currently working on making it easier to use from transformers |
transformers | 10,934 | closed | Add `examples/multiple-choice/run_swag_no_trainer.py` | This PR adds an example of a multiple-choice task on the SWAG dataset to show the functionalities of the new `accelerate` library.
<hr>
**Reviewers:** @sgugger | 03-27-2021 23:16:33 | 03-27-2021 23:16:33 | Tested on one GPU, two GPUs and TPUs, this runs fine everywhere. So just waiting for the small adjustments and it should be good to be merged :-) <|||||>Thanks a lot! |
transformers | 10,933 | closed | Can't download the facebook/bart-large-mnli tensorflow model | Hello! When I try to create a pipeline with the model specified as "facebook/bart-large-mnli" I get a 404 Client Error: Not Found for url: https://huggingface.co/facebook/bart-large-mnli/resolve/main/tf_model.h5
And when I try to go directly to that url I do also notice it throws a 404 error. Any ideas on how to fix this would be greatly appreciated! Thanks!
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Python version: 3.8.6
- Tensorflow version: 2.2.0
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
Models:
blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
The code I tried running is:
```python:
from transformers import pipeline
classifier = pipeline('zero-shot-classification', model='facebook/bart-large-mnli')
```
The full error message is:
```
404 Client Error: Not Found for url: https://huggingface.co/facebook/bart-large-mnli/resolve/main/tf_model.h5
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
~/Documents/github/econ2355/version2env/lib/python3.8/site-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
1219 # Load from URL or cache if already cached
-> 1220 resolved_archive_file = cached_path(
1221 archive_file,
~/Documents/github/econ2355/version2env/lib/python3.8/site-packages/transformers/file_utils.py in cached_path(url_or_filename, cache_dir, force_download, proxies, resume_download, user_agent, extract_compressed_file, force_extract, use_auth_token, local_files_only)
1133 # URL, so get it from the cache (downloading if necessary)
-> 1134 output_path = get_from_cache(
1135 url_or_filename,
~/Documents/github/econ2355/version2env/lib/python3.8/site-packages/transformers/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, use_auth_token, local_files_only)
1299 r = requests.head(url, headers=headers, allow_redirects=False, proxies=proxies, timeout=etag_timeout)
-> 1300 r.raise_for_status()
1301 etag = r.headers.get("X-Linked-Etag") or r.headers.get("ETag")
~/Documents/github/econ2355/version2env/lib/python3.8/site-packages/requests/models.py in raise_for_status(self)
942 if http_error_msg:
--> 943 raise HTTPError(http_error_msg, response=self)
944
HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/facebook/bart-large-mnli/resolve/main/tf_model.h5
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
<ipython-input-2-7aad78410119> in <module>
14
15 from transformers import pipeline
---> 16 classifier = pipeline('zero-shot-classification',
17 model='facebook/bart-large-mnli')
18
~/Documents/github/econ2355/version2env/lib/python3.8/site-packages/transformers/pipelines/__init__.py in pipeline(task, model, config, tokenizer, framework, revision, use_fast, model_kwargs, **kwargs)
342 model = get_default_model(targeted_task, framework, task_options)
343
--> 344 framework = framework or get_framework(model)
345
346 task_class, model_class = targeted_task["impl"], targeted_task[framework]
~/Documents/github/econ2355/version2env/lib/python3.8/site-packages/transformers/pipelines/base.py in get_framework(model, revision)
66 model = AutoModel.from_pretrained(model, revision=revision)
67 elif is_tf_available() and not is_torch_available():
---> 68 model = TFAutoModel.from_pretrained(model, revision=revision)
69 else:
70 try:
~/Documents/github/econ2355/version2env/lib/python3.8/site-packages/transformers/models/auto/modeling_tf_auto.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
616
617 if type(config) in TF_MODEL_MAPPING.keys():
--> 618 return TF_MODEL_MAPPING[type(config)].from_pretrained(
619 pretrained_model_name_or_path, *model_args, config=config, **kwargs
620 )
~/Documents/github/econ2355/version2env/lib/python3.8/site-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
1234 f"- or '{pretrained_model_name_or_path}' is the correct path to a directory containing a file named one of {TF2_WEIGHTS_NAME}, {WEIGHTS_NAME}.\n\n"
1235 )
-> 1236 raise EnvironmentError(msg)
1237 if resolved_archive_file == archive_file:
1238 logger.info("loading weights file {}".format(archive_file))
OSError: Can't load weights for 'facebook/bart-large-mnli'. Make sure that:
- 'facebook/bart-large-mnli' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'facebook/bart-large-mnli' is the correct path to a directory containing a file named one of tf_model.h5, pytorch_model.bin.
```
| 03-27-2021 20:30:21 | 03-27-2021 20:30:21 | @mayanb I don't think this model has a TF version till now, check:- https://huggingface.co/facebook/bart-large-mnli/tree/main<|||||>@frankhart2018 ah you're right! thanks! |
transformers | 10,932 | closed | Updated colab links in readme of examples | # What does this PR do?
Updated the Google Colab links for the The Big Table of Tasks in the examples folder readme.
Google Colab links were replace to the appropriate examples found [here](https://github.com/huggingface/notebooks/tree/master/examples)
text_generation.ipynb is not present in the [notebook repo](https://github.com/huggingface/notebooks/tree/master/examples). Will text_generation.ipynb be added in the future?
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger
| 03-27-2021 18:22:28 | 03-27-2021 18:22:28 | |
transformers | 10,931 | closed | Another way to express masked_index = torch.nonzero(input_ids == self.tokenizer.mask_token_id, as_tuple=False) | Dear,
We use PyTorch 1.1.0 to run a masked word completion with BERT. However, we found an error
`TypeError: nonzero() got an unexpected keyword argument 'as_tuple'`
The error refers to this:
`masked_index = torch.nonzero(input_ids == self.tokenizer.mask_token_id, as_tuple=False)`
Is there another way to express the syntax above with keep using PyTorch 1.1.0?
Best regards,
Mohammad YANI
| 03-27-2021 16:10:14 | 03-27-2021 16:10:14 | Hello! Unfortunately, recent transformers versions only work with torch 1.4.0+. The README is incorrect respective to that, and I'll update it in the coming days.<|||||>> Hello! Unfortunately, recent transformers versions only work with torch 1.4.0+. The README is incorrect respective to that, and I'll update it in the coming days.
Thank you for the response.
Okay. Does it mean that there is no another way for expressing `masked_index = torch.nonzero(input_ids == self.tokenizer.mask_token_id, as_tuple=False)` in pytorch 1.1.0? Is it still possible to use `torch.where(...)`? if yes, how to express it with `torch.where()`?
This is because the available machine we used is in an old driver version of CUDA.
Sincerely,
MY<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,930 | closed | Error while predicting on single sentence for token classification task | Hi
I have fine-tuned BERT for NER task. I am predicting on the fine-tuned model as:
`output = self.tokenizer(text)
trainer = Trainer(model=self.model, tokenizer=self.tokenizer)
trainer.predict(output)`
This code snippet is throwing the following error:
File "run_ner_test_3.py", line 486, in <module>
obj.predict(text="i require to send 9330793.33 by account")
File "run_ner_test_3.py", line 430, in predict
trainer.predict(output)
File "/home/dev01/python_3/lib/python3.6/site-packages/transformers/trainer.py", line 1596, in predict
test_dataloader, description="Prediction", ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix
File "/home/dev01/python_3/lib/python3.6/site-packages/transformers/trainer.py", line 1658, in prediction_loop
for step, inputs in enumerate(dataloader):
File "/home/dev01/python_3/lib64/python3.6/site-packages/torch/utils/data/dataloader.py", line 435, in __next__
data = self._next_data()
File "/home/dev01/python_3/lib64/python3.6/site-packages/torch/utils/data/dataloader.py", line 475, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/home/dev01/python_3/lib64/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/dev01/python_3/lib64/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/dev01/python_3/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 305, in __getitem__
return self._encodings[item]
IndexError: list index out of range
Can you please suggest how to predict on a single sentence? | 03-27-2021 15:57:23 | 03-27-2021 15:57:23 | @saurabhhssaurabh `trainer.predict()` expects an instance of `torch.utils.data.Dataset` to be passed and not a single sentence. I think it will be easier to use the trained model at self.model to predict rather than trying to use trainer object, as it does not have any single prediction method yet.<|||||>@frankhart2018
Thank you for replying. I will implement code using prediction from self.model. |
transformers | 10,929 | closed | Training with DeepSpeed takes more GPU memory than without DeepSpeed | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.5.0.dev0
- deepspeed version: 0.3.13
- Platform: Linux-4.15.0-66-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.8
- PyTorch version (GPU?): 1.8.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@stas00
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
I'm interested in training the large T5 models with deepspeed and huggingface. More specifically, I'm interested in fine-tuning a T5-11B model on one RTX-8000 48 GB GPU (similarly to https://huggingface.co/blog/zero-deepspeed-fairscale, https://github.com/huggingface/transformers/issues/9996).
However, when I try to use deepspeed the amount of memory on the GPU increases. For example, running the example seq2seq/run_summarization.py script with T5-Small and without deepspeed takes ~6GB, and running it with deepspeed takes ~8GB.
Model I am using: T5
The problem arises when using: The official examples/seq2seq/run_summarization.py script.
Without deepspeed:
python examples/seq2seq/run_summarization.py --model_name_or_path t5-small --do_train --do_eval --dataset_name cnn_dailymail --dataset_config "3.0.0" --source_prefix "summarize: " --output_dir /tmp/tst-summarization --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_genera
With deepspeed:
deepspeed examples/seq2seq/run_summarization.py --model_name_or_path t5-small --do_train --do_eval --dataset_name cnn_dailymail --dataset_config "3.0.0" --source_prefix "summarize: " --output_dir /tmp/tst-summarization --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_generate --deepspeed examples/tests/deepspeed/ds_config.json
The tasks I am working on is:
Sequence to sequence generation.
## To reproduce
Steps to reproduce the behavior:
1. Clone transformers repo
2. Install requirements (including deepspeed: pip install deepspeed)
3. Run summarization example without deeepspeed:
python examples/seq2seq/run_summarization.py --model_name_or_path t5-small --do_train --do_eval --dataset_name cnn_dailymail --dataset_config "3.0.0" --source_prefix "summarize: " --output_dir /tmp/tst-summarization --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_genera
4. Run summarization example with deepspeed:
deepspeed examples/seq2seq/run_summarization.py --model_name_or_path t5-small --do_train --do_eval --dataset_name cnn_dailymail --dataset_config "3.0.0" --source_prefix "summarize: " --output_dir /tmp/tst-summarization --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_generate --deepspeed examples/tests/deepspeed/ds_config.json
## Expected behavior
I would expect using deepspeed would reduce the amount of memory being used by the GPU. | 03-27-2021 14:06:38 | 03-27-2021 14:06:38 | Also adding the logs from the beginning of training with deepspeed:
deepspeed examples/seq2seq/run_summarization.py --model_name_or_path t5-small --do_train --do_eval --dataset_name cnn_dailymail --dataset_config "3.0.0" --source_prefix "summarize: " --output_dir /tmp/tst-summarization --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_generate --deepspeed examples/tests/deepspeed/ds_config.json
[2021-03-27 17:02:34,357] [WARNING] [runner.py:117:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
[2021-03-27 17:02:34,381] [INFO] [runner.py:358:main] cmd = /media/disk1/oriyor/hf_venv_3.6/bin/python -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMF19 --master_addr=127.0.0.1 --master_port=29500 examples/seq2seq/run_summarization.py --model_name_or_path t5-small --do_train --do_eval --dataset_name cnn_dailymail --dataset_config 3.0.0 --source_prefix summarize: --output_dir /tmp/tst-summarization --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_generate --deepspeed examples/tests/deepspeed/ds_config.json
[2021-03-27 17:02:34,981] [INFO] [launch.py:80:main] WORLD INFO DICT: {'localhost': [0]}
[2021-03-27 17:02:34,981] [INFO] [launch.py:89:main] nnodes=1, num_local_procs=1, node_rank=0
[2021-03-27 17:02:34,981] [INFO] [launch.py:101:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0]})
[2021-03-27 17:02:34,981] [INFO] [launch.py:102:main] dist_world_size=1
[2021-03-27 17:02:34,981] [INFO] [launch.py:105:main] Setting CUDA_VISIBLE_DEVICES=0
[2021-03-27 17:02:36,820] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl
WARNING:__main__:Process rank: 0, device: cuda:0, n_gpu: 1distributed training: True, 16-bits training: False
INFO:__main__:Training/evaluation parameters Seq2SeqTrainingArguments(output_dir='/tmp/tst-summarization', overwrite_output_dir=True, do_train=True, do_eval=True, do_predict=False, evaluation_strategy=<IntervalStrategy.NO: 'no'>, prediction_loss_only=False, per_device_train_batch_size=4, per_device_eval_batch_size=4, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, eval_accumulation_steps=None, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=-1, lr_scheduler_type=<SchedulerType.LINEAR: 'linear'>, warmup_ratio=0.0, warmup_steps=0, logging_dir='runs/Mar27_17-02-36_rack-jonathan-g04', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=False, logging_steps=500, save_strategy=<IntervalStrategy.STEPS: 'steps'>, save_steps=500, save_total_limit=None, no_cuda=False, seed=42, fp16=False, fp16_opt_level='O1', fp16_backend='auto', fp16_full_eval=False, local_rank=0, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=500, dataloader_num_workers=0, past_index=-1, run_name='/tmp/tst-summarization', disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=[], deepspeed='examples/tests/deepspeed/ds_config.json', label_smoothing_factor=0.0, adafactor=False, group_by_length=False, report_to=['tensorboard'], ddp_find_unused_parameters=None, dataloader_pin_memory=True, skip_memory_metrics=False, sortish_sampler=False, predict_with_generate=True)
WARNING:datasets.builder:Reusing dataset cnn_dailymail (/home/oriy/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0/0a01b1abede4f646130574f203de57a293ded8a7a11e3406a539453afdfeb2c0)
loading configuration file https://huggingface.co/t5-small/resolve/main/config.json from cache at /home/oriy/.cache/huggingface/transformers/fe501e8fd6425b8ec93df37767fcce78ce626e34cc5edc859c662350cf712e41.406701565c0afd9899544c1cb8b93185a76f00b31e5ce7f6e18bbaef02241985
Model config T5Config {
"architectures": [
"T5WithLMHeadModel"
],
"d_ff": 2048,
"d_kv": 64,
"d_model": 512,
"decoder_start_token_id": 0,
"dropout_rate": 0.1,
"eos_token_id": 1,
"feed_forward_proj": "relu",
"initializer_factor": 1.0,
"is_encoder_decoder": true,
"layer_norm_epsilon": 1e-06,
"model_type": "t5",
"n_positions": 512,
"num_decoder_layers": 6,
"num_heads": 8,
"num_layers": 6,
"output_past": true,
"pad_token_id": 0,
"relative_attention_num_buckets": 32,
"task_specific_params": {
"summarization": {
"early_stopping": true,
"length_penalty": 2.0,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
},
"transformers_version": "4.5.0.dev0",
"use_cache": true,
"vocab_size": 32128
}
loading configuration file https://huggingface.co/t5-small/resolve/main/config.json from cache at /home/oriy/.cache/huggingface/transformers/fe501e8fd6425b8ec93df37767fcce78ce626e34cc5edc859c662350cf712e41.406701565c0afd9899544c1cb8b93185a76f00b31e5ce7f6e18bbaef02241985
Model config T5Config {
"architectures": [
"T5WithLMHeadModel"
],
"d_ff": 2048,
"d_kv": 64,
"d_model": 512,
"decoder_start_token_id": 0,
"dropout_rate": 0.1,
"eos_token_id": 1,
"feed_forward_proj": "relu",
"initializer_factor": 1.0,
"is_encoder_decoder": true,
"layer_norm_epsilon": 1e-06,
"model_type": "t5",
"n_positions": 512,
"num_decoder_layers": 6,
"num_heads": 8,
"num_layers": 6,
"output_past": true,
"pad_token_id": 0,
"relative_attention_num_buckets": 32,
"task_specific_params": {
"summarization": {
"early_stopping": true,
"length_penalty": 2.0,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
},
"transformers_version": "4.5.0.dev0",
"use_cache": true,
"vocab_size": 32128
}
loading file https://huggingface.co/t5-small/resolve/main/spiece.model from cache at /home/oriy/.cache/huggingface/transformers/65fc04e21f45f61430aea0c4fedffac16a4d20d78b8e6601d8d996ebefefecd2.3b69006860e7b5d0a63ffdddc01ddcd6b7c318a6f4fd793596552c741734c62d
loading file https://huggingface.co/t5-small/resolve/main/tokenizer.json from cache at /home/oriy/.cache/huggingface/transformers/06779097c78e12f47ef67ecb728810c2ae757ee0a9efe9390c6419783d99382d.8627f1bd5d270a9fd2e5a51c8bec3223896587cc3cfe13edeabb0992ab43c529
loading file https://huggingface.co/t5-small/resolve/main/added_tokens.json from cache at None
loading file https://huggingface.co/t5-small/resolve/main/special_tokens_map.json from cache at None
loading file https://huggingface.co/t5-small/resolve/main/tokenizer_config.json from cache at None
loading weights file https://huggingface.co/t5-small/resolve/main/pytorch_model.bin from cache at /home/oriy/.cache/huggingface/transformers/fee5a3a0ae379232608b6eed45d2d7a0d2966b9683728838412caccc41b4b0ed.ddacdc89ec88482db20c676f0861a336f3d0409f94748c209847b49529d73885
All model checkpoint weights were used when initializing T5ForConditionalGeneration.
All the weights of T5ForConditionalGeneration were initialized from the model checkpoint at t5-small.
If your task is similar to the task the model of the checkpoint was trained on, you can already use T5ForConditionalGeneration for predictions without further training.
WARNING:datasets.arrow_dataset:Loading cached processed dataset at /home/oriy/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0/0a01b1abede4f646130574f203de57a293ded8a7a11e3406a539453afdfeb2c0/cache-3c2d8ad9af1d1a3e.arrow
WARNING:datasets.arrow_dataset:Loading cached processed dataset at /home/oriy/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0/0a01b1abede4f646130574f203de57a293ded8a7a11e3406a539453afdfeb2c0/cache-2e7e82c8de410d07.arrow
Updating the `scheduler` config from examples/tests/deepspeed/ds_config.json with other command line arguments
setting optimizer.params.lr to 5e-05
setting optimizer.params.betas to [0.9, 0.999]
setting optimizer.params.eps to 1e-08
setting optimizer.params.weight_decay to 0.0
Updating the `scheduler` config from examples/tests/deepspeed/ds_config.json with other command line arguments
setting scheduler.params.warmup_max_lr to 5e-05
setting scheduler.params.warmup_num_steps to 0
[2021-03-27 17:02:46,871] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed info: version=0.3.13, git-hash=unknown, git-branch=unknown
[2021-03-27 17:02:48,970] [INFO] [engine.py:77:_initialize_parameter_parallel_groups] data_parallel_size: 1, parameter_parallel_size: 1
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Using /home/oriy/.cache/torch_extensions as PyTorch extensions root...
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Detected CUDA files, patching ldflags
Emitting ninja build file /home/oriy/.cache/torch_extensions/cpu_adam/build.ninja...
Building extension module cpu_adam...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
ninja: no work to do.
Loading extension module cpu_adam...
Time to load cpu_adam op: 0.43370747566223145 seconds
Adam Optimizer #0 is created with AVX2 arithmetic capability.
Config: alpha=0.000050, betas=(0.900000, 0.999000), weight_decay=0.000000, adam_w=1
[2021-03-27 17:02:52,144] [INFO] [engine.py:602:_configure_optimizer] Using DeepSpeed Optimizer param name adam as basic optimizer
[2021-03-27 17:02:52,145] [INFO] [engine.py:606:_configure_optimizer] DeepSpeed Basic Optimizer = DeepSpeedCPUAdam
Checking ZeRO support for optimizer=DeepSpeedCPUAdam type=<class 'deepspeed.ops.adam.cpu_adam.DeepSpeedCPUAdam'>
[2021-03-27 17:02:52,145] [INFO] [logging.py:60:log_dist] [Rank 0] Creating fp16 ZeRO stage 2 optimizer
Using /home/oriy/.cache/torch_extensions as PyTorch extensions root...
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Emitting ninja build file /home/oriy/.cache/torch_extensions/utils/build.ninja...
Building extension module utils...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
ninja: no work to do.
Loading extension module utils...
Time to load utils op: 0.29197263717651367 seconds
[2021-03-27 17:02:52,437] [INFO] [stage2.py:130:__init__] Reduce bucket size 200000000.0
[2021-03-27 17:02:52,438] [INFO] [stage2.py:131:__init__] Allgather bucket size 200000000.0
[2021-03-27 17:02:52,438] [INFO] [stage2.py:132:__init__] CPU Offload: True
[2021-03-27 17:02:52,846] [INFO] [stage2.py:399:__init__] optimizer state initialized
[2021-03-27 17:02:52,846] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed Final Optimizer = adam
[2021-03-27 17:02:52,847] [INFO] [engine.py:439:_configure_lr_scheduler] DeepSpeed using configured LR scheduler = WarmupLR
[2021-03-27 17:02:52,847] [INFO] [logging.py:60:log_dist] [Rank 0] DeepSpeed LR Scheduler = <deepspeed.runtime.lr_schedules.WarmupLR object at 0x7fea742ef2b0>
[2021-03-27 17:02:52,847] [INFO] [logging.py:60:log_dist] [Rank 0] step=0, skipped=0, lr=[5e-05], mom=[[0.9, 0.999]]
[2021-03-27 17:02:52,847] [INFO] [config.py:737:print] DeepSpeedEngine configuration:
[2021-03-27 17:02:52,847] [INFO] [config.py:741:print] activation_checkpointing_config {
"contiguous_memory_optimization": false,
"cpu_checkpointing": false,
"number_checkpoints": null,
"partition_activations": false,
"profile": false,
"synchronize_checkpoint_boundary": false
}
[2021-03-27 17:02:52,847] [INFO] [config.py:741:print] allreduce_always_fp32 ........ False
[2021-03-27 17:02:52,847] [INFO] [config.py:741:print] amp_enabled .................. False
[2021-03-27 17:02:52,847] [INFO] [config.py:741:print] amp_params ................... False
[2021-03-27 17:02:52,847] [INFO] [config.py:741:print] checkpoint_tag_validation_enabled True
[2021-03-27 17:02:52,847] [INFO] [config.py:741:print] checkpoint_tag_validation_fail False
[2021-03-27 17:02:52,847] [INFO] [config.py:741:print] disable_allgather ............ False
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] dump_state ................... False
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] dynamic_loss_scale_args ...... {'init_scale': 4294967296, 'scale_window': 1000, 'delayed_shift': 2, 'min_scale': 1}
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] elasticity_enabled ........... False
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] flops_profiler_config ........ {
"detailed": true,
"enabled": false,
"module_depth": -1,
"profile_step": 1,
"top_modules": 3
}
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] fp16_enabled ................. True
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] global_rank .................. 0
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] gradient_accumulation_steps .. 1
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] gradient_clipping ............ 1.0
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] gradient_predivide_factor .... 1.0
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] initial_dynamic_scale ........ 4294967296
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] loss_scale ................... 0
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] memory_breakdown ............. False
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] optimizer_legacy_fusion ...... False
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] optimizer_name ............... adam
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] optimizer_params ............. {'lr': 5e-05, 'betas': [0.9, 0.999], 'eps': 1e-08, 'weight_decay': 0.0}
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] pld_enabled .................. False
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] pld_params ................... False
[2021-03-27 17:02:52,848] [INFO] [config.py:741:print] prescale_gradients ........... False
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] scheduler_name ............... WarmupLR
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] scheduler_params ............. {'warmup_min_lr': 0, 'warmup_max_lr': 5e-05, 'warmup_num_steps': 0}
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] sparse_attention ............. None
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] sparse_gradients_enabled ..... False
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] steps_per_print .............. 10
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] tensorboard_enabled .......... False
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] tensorboard_job_name ......... DeepSpeedJobName
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] tensorboard_output_path ......
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] train_batch_size ............. 4
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] train_micro_batch_size_per_gpu 4
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] wall_clock_breakdown ......... False
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] world_size ................... 1
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] zero_allow_untested_optimizer False
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] zero_config .................. {
"allgather_bucket_size": 200000000.0,
"allgather_partitions": true,
"contiguous_gradients": true,
"cpu_offload": true,
"cpu_offload_params": false,
"cpu_offload_use_pin_memory": false,
"elastic_checkpoint": true,
"load_from_fp32_weights": true,
"max_live_parameters": 1000000000,
"max_reuse_distance": 1000000000,
"overlap_comm": true,
"param_persistence_threshold": 100000,
"prefetch_bucket_size": 50000000,
"reduce_bucket_size": 200000000.0,
"reduce_scatter": true,
"stage": 2,
"sub_group_size": 1000000000000
}
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] zero_enabled ................. True
[2021-03-27 17:02:52,849] [INFO] [config.py:741:print] zero_optimization_stage ...... 2
[2021-03-27 17:02:52,850] [INFO] [config.py:748:print] json = {
"fp16":{
"enabled":true,
"hysteresis":2,
"loss_scale":0,
"loss_scale_window":1000,
"min_loss_scale":1
},
"gradient_accumulation_steps":1,
"gradient_clipping":1.0,
"optimizer":{
"params":{
"betas":[
0.9,
0.999
],
"eps":1e-08,
"lr":5e-05,
"weight_decay":0.0
},
"type":"Adam"
},
"scheduler":{
"params":{
"warmup_max_lr":5e-05,
"warmup_min_lr":0,
"warmup_num_steps":0
},
"type":"WarmupLR"
},
"train_micro_batch_size_per_gpu":4,
"zero_optimization":{
"allgather_bucket_size":200000000.0,
"allgather_partitions":true,
"contiguous_gradients":true,
"cpu_offload":true,
"overlap_comm":true,
"reduce_bucket_size":200000000.0,
"reduce_scatter":true,
"stage":2
}
}
Using /home/oriy/.cache/torch_extensions as PyTorch extensions root...
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
Time to load utils op: 0.0005881786346435547 seconds
***** Running training *****
Num examples = 287113
Num Epochs = 3
Instantaneous batch size per device = 4
Total train batch size (w. parallel, distributed & accumulation) = 4
Gradient Accumulation steps = 1
Total optimization steps = 215337
0%| | 0/215337 [00:00<?, ?it/s][2021-03-27 17:02:53,333] [INFO] [stage2.py:1391:step] [deepspeed] fp16 dynamic loss scale overflow! Rank 0 Skipping step. Attempted loss scale: 4294967296, reducing to 4294967296
0%| | 1/215337 [00:00<26:38:16, 2.25it/s][2021-03-27 17:02:53,687] [INFO] [stage2.py:1391:step] [deepspeed] fp16 dynamic loss scale overflow! Rank 0 Skipping step. Attempted loss scale: 4294967296, reducing to 2147483648.0
<|||||>Next week I hope https://github.com/huggingface/transformers/pull/10753 will be finished, but for now here are the results on rtx-3090 24GB card with the unfinished zero-3 PR.
As you can see Deepspeed zero3's cpu offload is a way way more memory-efficient:
```
# baseline
BS=4; CUDA_VISIBLE_DEVICES=0 PYTHONPATH=src USE_TF=0 python examples/seq2seq/run_translation.py --model_name_or_path t5-small --output_dir /tmp/zero3 --overwrite_output_dir --max_train_samples 64 --max_val_samples 64 --max_source_length 128 --max_target_length 128 --val_max_target_length 128 --do_train --num_train_epochs 1 --per_device_train_batch_size $BS --per_device_eval_batch_size $BS --learning_rate 3e-3 --warmup_steps 500 --predict_with_generate --logging_steps 0 --save_steps 0 --eval_steps 1 --group_by_length --adafactor --dataset_name wmt16 --dataset_config ro-en --source_lang en --target_lang ro --source_prefix "translate English to Romanian: "
***** train metrics *****
epoch = 1.0
init_mem_cpu_alloc_delta = 3MB
init_mem_cpu_peaked_delta = 0MB
init_mem_gpu_alloc_delta = 230MB
init_mem_gpu_peaked_delta = 0MB
train_mem_cpu_alloc_delta = 60MB
train_mem_cpu_peaked_delta = 0MB
train_mem_gpu_alloc_delta = 231MB
train_mem_gpu_peaked_delta = 226MB
train_runtime = 3.619
train_samples = 64
train_samples_per_second = 4.421
# zero2
BS=4; PYTHONPATH=src USE_TF=0 deepspeed --num_gpus 1 examples/seq2seq/run_translation.py --model_name_or_path t5-small --output_dir /tmp/zero3 --overwrite_output_dir --max_train_samples 64 --max_val_samples 64 --max_source_length 128 --max_target_length 128 --val_max_target_length 128 --do_train --num_train_epochs 1 --per_device_train_batch_size $BS --per_device_eval_batch_size $BS --learning_rate 3e-3 --warmup_steps 500 --predict_with_generate --logging_steps 0 --save_steps 0 --eval_steps 1 --group_by_length --adafactor --dataset_name wmt16 --dataset_config ro-en --source_lang en --target_lang ro --source_prefix "translate English to Romanian: " --deepspeed examples/tests/deepspeed/ds_config_zero2.json
***** train metrics *****
epoch = 1.0
init_mem_cpu_alloc_delta = 7MB
init_mem_cpu_peaked_delta = 0MB
init_mem_gpu_alloc_delta = 0MB
init_mem_gpu_peaked_delta = 0MB
train_mem_cpu_alloc_delta = 70MB
train_mem_cpu_peaked_delta = 0MB
train_mem_gpu_alloc_delta = 148MB
train_mem_gpu_peaked_delta = 3559MB
train_runtime = 5.0669
train_samples = 64
train_samples_per_second = 3.158
# zero3
BS=4; PYTHONPATH=src USE_TF=0 deepspeed --num_gpus 1 examples/seq2seq/run_translation.py --model_name_or_path t5-small --output_dir /tmp/zero3 --overwrite_output_dir --max_train_samples 64 --max_val_samples 64 --max_source_length 128 --max_target_length 128 --val_max_target_length 128 --do_train --num_train_epochs 1 --per_device_train_batch_size $BS --per_device_eval_batch_size $BS --learning_rate 3e-3 --warmup_steps 500 --predict_with_generate --logging_steps 0 --save_steps 0 --eval_steps 1 --group_by_length --adafactor --dataset_name wmt16 --dataset_config ro-en --source_lang en --target_lang ro --source_prefix "translate English to Romanian: " --deepspeed examples/tests/deepspeed/ds_config_zero3.json
***** train metrics *****
epoch = 1.0
init_mem_cpu_alloc_delta = 7MB
init_mem_cpu_peaked_delta = 0MB
init_mem_gpu_alloc_delta = 0MB
init_mem_gpu_peaked_delta = 0MB
train_mem_cpu_alloc_delta = 71MB
train_mem_cpu_peaked_delta = 0MB
train_mem_gpu_alloc_delta = -52MB
train_mem_gpu_peaked_delta = 244MB
train_runtime = 7.6324
train_samples = 64
train_samples_per_second = 2.096
```
The config files are from the PR I linked to in the first para.
So please give us a few more days - this is also depending on deepspeed merging several PRs and making a new release.
<|||||>I suspect my cpu memory profiling functions are missing some allocations, which is odd. Surely, there must be more cpu memory used with cpu_offload. I will investigate this.
Suspecting that `tracemalloc` doesn't tracks c++ allocations, which is what deepspeed does. might have to switch to sampling, but python threads's GIL is a big problem to get correct results.
**edit:** this should fix it: https://github.com/huggingface/transformers/pull/10937<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,928 | closed | Add example for registering callbacks with trainers | # What does this PR do?
Fixes the issue addressed in #9036 by adding an example for registering a custom callback with the Trainer.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
Fixes: https://github.com/huggingface/transformers/issues/9036
## Who can review?
Anyone in the community is free to review the PR. But @sgugger seems the most appropriate. | 03-27-2021 03:55:28 | 03-27-2021 03:55:28 | Thanks for updating, this looks great! |
transformers | 10,927 | closed | Add Pooler to DistilBERT | # 🚀 Feature request
Hi, I'd like to add a Pooler class to the DistilBERT model, whose interface is similar to BertPooler [here](https://github.com/huggingface/transformers/blob/7da995c00c025c4180c7fb0357256b7f83d342ef/src/transformers/models/bert/modeling_bert.py#L610)
## Motivation
I was using your DistilBERT model and discovered that I needed a pooler, so I wrote my own class. Thought I would add it to the repo in case others would like it.
## Your contribution
If this is something you're interested in, I can submit a PR
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| 03-26-2021 20:24:04 | 03-26-2021 20:24:04 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,926 | closed | Typo in examples/text-classification README | In the examples/text-classification README, the example scripts for "PyTorch version, no Trainer" are slightly incorrect. They should be adjusted as:
```diff
export TASK_NAME=mrpc
python run_glue_no_trainer.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
- --max_seq_length 128 \
+ --max_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/
```
Thanks for your great repo!
Luke | 03-26-2021 19:53:56 | 03-26-2021 19:53:56 | Indeed, do you want to open a PR with the fix since you found it?
PS: I didn't know that \`\`\`diff feature, it's soooo pretty 🤩 !<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,925 | closed | Sagemaker test | # What does this PR do?
This PR creates tests for `SageMaker`. This PR creates tests for the `Pytorch` and `tensorflow` DLC. I added a documentation `README.md` which explains when the Tests need to be run and how. Currently, not all tests are leveraging our `examples/` due to limitations like `SageMakerTrainer` not being integrated into `Trainer` and missing implementation for `keras` for SageMaker specific libraries for data/model parallel. In the near future all scripts in `tests/sagemaker/scripts` are going to be removed and copy the scripts from `examples/` before executing the tests.
## Current Tests
| ID | description | plattform | #GPUS | collected & evaluated metrics |
|-------------------------------------|-------------------------------------------------------------------|-----------------------------|-------|------------------------------------------|
| pytorch-transfromers-test-single | test bert finetuning using BERT fromtransformerlib+PT | SageMaker createTrainingJob | 1 | train_runtime, eval_accuracy & eval_loss |
| pytorch-transfromers-test-2-ddp | test bert finetuning using BERT from transformer lib+ PT DPP | SageMaker createTrainingJob | 16 | train_runtime, eval_accuracy & eval_loss |
| pytorch-transfromers-test-2-smd | test bert finetuning using BERT from transformer lib+ PT SM DDP | SageMaker createTrainingJob | 16 | train_runtime, eval_accuracy & eval_loss |
| pytorch-transfromers-test-1-smp | test roberta finetuning using BERT from transformer lib+ PT SM MP | SageMaker createTrainingJob | 8 | train_runtime, eval_accuracy & eval_loss |
| tensorflow-transfromers-test-single | Test bert finetuning using BERT from transformer lib+TF | SageMaker createTrainingJob | 1 | train_runtime, eval_accuracy & eval_loss |
| tensorflow-transfromers-test-2-smd | test bert finetuning using BERT from transformer lib+ TF SM DDP | SageMaker createTrainingJob | 16 | train_runtime, eval_accuracy & eval_loss | | 03-26-2021 17:51:28 | 03-26-2021 17:51:28 | > LGTM! Should the images be added before merge?
Are you referring to container images? they will be added after the release of `transformers`. If you are referring to the `TODO: Add a screenshot of PR + Text template to make it easy to open.` nope I would add them as soon as we went through the process. To make screenshots while doing it. |
transformers | 10,924 | closed | Models not able to run when packed with PyInstaller | ## Environment info
- `transformers` version: 4.1.1
- Platform: Linux-5.8.0-48-generic-x86_64-with-glibc2.27
- Python version: 3.8.8
- PyTorch version (GPU?): 1.7.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
-
## Information
I am trying to create an executable for a flask application that uses [haystack](https://github.com/deepset-ai/haystack/) to serve a QA System. Haystack uses transformers.
If I run my API normally with python with `python api.py` it works fine.
When I run `pyinstaller main.spec --distpath distAPI` the executable gets created fine (note that I will post main.spec down in the **To reproduce** section). However, when I run it with `./distAPI/main/main` I get the following error:
```
03/26/2021 16:45:35 - INFO - faiss - Loading faiss with AVX2 support.
03/26/2021 16:45:35 - INFO - faiss - Loading faiss.
Traceback (most recent call last):
File "torch/_utils_internal.py", line 49, in get_source_lines_and_file
File "inspect.py", line 979, in getsourcelines
File "inspect.py", line 798, in findsource
OSError: could not get source code
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "main.py", line 8, in <module>
from haystack.preprocessor.cleaning import clean_wiki_text
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "haystack/__init__.py", line 5, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "haystack/finder.py", line 9, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "haystack/retriever/base.py", line 9, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "haystack/document_store/base.py", line 6, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "haystack/preprocessor/utils.py", line 11, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "farm/data_handler/utils.py", line 18, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "farm/file_utils.py", line 26, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "transformers/__init__.py", line 91, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "transformers/modelcard.py", line 31, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "transformers/models/auto/__init__.py", line 20, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "transformers/models/auto/configuration_auto.py", line 28, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "transformers/models/deberta/__init__.py", line 25, in <module>
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "PyInstaller/loader/pyimod03_importers.py", line 531, in exec_module
File "transformers/models/deberta/modeling_deberta.py", line 462, in <module>
File "torch/jit/_script.py", line 936, in script
File "torch/jit/frontend.py", line 197, in get_jit_def
File "torch/_utils_internal.py", line 56, in get_source_lines_and_file
OSError: Can't get source for <function c2p_dynamic_expand at 0x7f45cc4d85e0>. TorchScript requires source access in order to carry out compilation, make sure original .py files are available.
[104072] Failed to execute script main
```
It seems that it cannot get the source code for the `function c2p_dynamic_expand` in `transformers/models/deberta/modeling_deberta.py`.
## Additional information
This is a problem that already happened in the past when using Pyinstaller and Torch.
See this issue [here](https://github.com/pyinstaller/pyinstaller/issues/4926) for example.
## To reproduce
Steps to reproduce the behavior:
1.Make a main.py :
```
from haystack.preprocessor.cleaning import clean_wiki_text
if __name__=='__main__':
print('Hello World')
```
2. Install haystack 'pip install haystack`
3. See if it runs with `python main.py' (it should)
4. Install pyinstaller with `pip install pyinstaller`
5. Create a hooks/ folder containing the following files:
**hook-justext.py hook-packaging.py hook-requests.py hook-tokenizers.py hook-tqdm.py hook-transformers.py hook-filelock.py hook-numpy.py hook-regex.py hook-sacremoses.py hook-torch.py**
Each of these files should provide a hook for pyinstaller to to download that module. So, for example the hook-numpy.py file should be:
```
from PyInstaller.utils.hooks import collect_all
datas, binaries, hiddenimports = collect_all('numpy')
```
And so the rest of them.
6. create a main.spec file:
```
# -*- mode: python ; coding: utf-8 -*-
block_cipher = None
a = Analysis(['main.py'],
pathex=['/Wexond/QandA/api'],
binaries=[],
datas=[],
hiddenimports=['justext'],
hookspath=['./hooks/'], ## <-------------- Specifying the hooks
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
pyz = PYZ(a.pure, a.zipped_data, source_files_toc,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
[],
exclude_binaries=True,
name='main',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
console=True )
coll = COLLECT(exe,
a.binaries,
a.zipfiles,
a.datas,
strip=False,
upx=True,
upx_exclude=[],
name='main')
```
7. Pack the app with `pyinstaller main.spec --distpath distAPI`
8. Try to run it with `./distAPI/main/main` .
You should now get the `OsError` metioned above..
| 03-26-2021 17:45:42 | 03-26-2021 17:45:42 | Hello! Do you get the same error when not installing PyInstaller, instead using `haystack` in a virtual environment?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Any update on this one? |
transformers | 10,923 | closed | /pytorch/xla/torch_xla/csrc/helpers.h:100 : Check failed: scalar_value.isIntegral() | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.10
- PyTorch version (GPU?): 1.8.0+cu101 (False)
- Tensorflow version (GPU?):
- Using GPU in script?: TPU
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@patrickvonplaten @sgugger
## Information
I am using LongformerForSequenceClassification and LongformerTokenizerFast for a simple text classification problem on Google Colab TPU:
The problem arises when using:
* [ ] my own modified scripts: (Script shared) If I replace the LongformerForSequenceClassification model with the DistilBertForSequenceClassification model, the same code works perfectly fine and the training starts without any issues. However, with LongformerForSequenceClassification, I start getting weird errors on TPU.
```
from pathlib import Path
def read_imdb_split(split_dir):
split_dir = Path(split_dir)
texts = []
labels = []
for label_dir in ["pos", "neg"]:
for text_file in (split_dir/label_dir).iterdir():
texts.append(text_file.read_text())
labels.append(0 if label_dir is "neg" else 1)
return texts, labels
train_texts, train_labels = read_imdb_split('aclImdb/train')
test_texts, test_labels = read_imdb_split('aclImdb/test')
from sklearn.model_selection import train_test_split
train_texts, val_texts, train_labels, val_labels = train_test_split(train_texts, train_labels, test_size=.2)
from transformers import DistilBertTokenizerFast, LongformerTokenizerFast
# tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased')
tokenizer = LongformerTokenizerFast.from_pretrained('allenai/longformer-base-4096', max_length = 8)
train_encodings = tokenizer(train_texts, truncation=True, padding=True)
val_encodings = tokenizer(val_texts, truncation=True, padding=True)
test_encodings = tokenizer(test_texts, truncation=True, padding=True)
import torch
class IMDbDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_dataset = IMDbDataset(train_encodings, train_labels)
val_dataset = IMDbDataset(val_encodings, val_labels)
test_dataset = IMDbDataset(test_encodings, test_labels)
from transformers import DistilBertForSequenceClassification, Trainer, TrainingArguments, LongformerForSequenceClassification
import torch_xla.distributed.xla_multiprocessing as xmp
import torch_xla.core.xla_model as xm
def _mp_fn(index):
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
)
# model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased')
model = LongformerForSequenceClassification.from_pretrained("allenai/longformer-base-4096", attention_window = 2)
trainer = Trainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset # evaluation dataset
)
trainer.train()
xmp.spawn(_mp_fn, args=(), nprocs=1, start_method='fork')
```
The tasks I am working on is:
* [ ] my own task or dataset: Using the IMDB Dataset for Text Classification
## To reproduce
Steps to reproduce the behavior:
1. Setup TPU-client on google Colab: !pip install cloud-tpu-client==0.10 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.8-cp37-cp37m-linux_x86_64.whl
2. Download the dataset:
a. !wget http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
b. !tar -xf aclImdb_v1.tar.gz
3. Execute the given script
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```
RuntimeError: /pytorch/xla/torch_xla/csrc/helpers.h:100 : Check failed: scalar_value.isIntegral()
*** Begin stack trace ***
tensorflow::CurrentStackTrace()
torch_xla::XlaHelpers::ScalarValue(c10::Scalar, xla::PrimitiveType, xla::XlaBuilder*)
torch_xla::ir::ops::InferOutputShape(absl::lts_2020_02_25::Span<xla::Shape const>, std::function<xla::XlaOp (absl::lts_2020_02_25::Span<xla::XlaOp const>)> const&)
torch_xla::ir::Node::GetOpShape(std::function<xla::Shape ()> const&) const
torch_xla::ir::Node::Node(torch_xla::ir::OpKind, absl::lts_2020_02_25::Span<torch_xla::ir::Value const>, std::function<xla::Shape ()> const&, unsigned long, absl::lts_2020_02_25::uint128)
torch_xla::ir::ops::ConstantPadNd::ConstantPadNd(torch_xla::ir::Value const&, std::vector<long, std::allocator<long> >, c10::Scalar)
void __gnu_cxx::new_allocator<torch_xla::ir::ops::ConstantPadNd>::construct<torch_xla::ir::ops::ConstantPadNd, torch_xla::ir::Value, std::vector<long, std::allocator<long> >&, c10::Scalar&>(torch_xla::ir::ops::ConstantPadNd*, torch_xla::ir::Value&&, std::vector<long, std::allocator<long> >&, c10::Scalar&)
torch_xla::XLATensor::constant_pad_nd(torch_xla::XLATensor const&, absl::lts_2020_02_25::Span<long const>, c10::Scalar)
torch_xla::AtenXlaType::constant_pad_nd(at::Tensor const&, c10::ArrayRef<long>, c10::Scalar)
c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoRuntimeFunctor_<at::Tensor (*)(at::Tensor const&, c10::ArrayRef<long>, c10::Scalar), at::Tensor, c10::guts::typelist::typelist<at::Tensor const&, c10::ArrayRef<long>, c10::Scalar> >, at::Tensor (at::Tensor const&, c10::ArrayRef<long>, c10::Scalar)>::call(c10::OperatorKernel*, at::Tensor const&, c10::ArrayRef<long>, c10::Scalar)
at::constant_pad_nd(at::Tensor const&, c10::ArrayRef<long>, c10::Scalar)
at::constant_pad_nd(at::Tensor const&, c10::ArrayRef<long>, c10::Scalar)
_PyMethodDef_RawFastCallKeywords
_PyCFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
_PyObject_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallDict
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
PyEval_EvalCode
_PyMethodDef_RawFastCallKeywords
_PyCFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallDict
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallDict
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallDict
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_FastCallDict
_PyObject_FastCallKeywords
_PyEval_EvalFrameDefault
_PyObject_Call_Prepend
_PyObject_FastCallKeywords
_PyMethodDef_RawFastCallDict
PyCFunction_Call
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
PyEval_EvalCode
*** End stack trace ***
Scalar type not supported
```
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Model training should have started but instead got the error
| 03-26-2021 17:27:52 | 03-26-2021 17:27:52 | I don't think Longformer is supported on TPU, @patrickvonplaten will confirm.<|||||>@sgugger Thanks!
Looking forward to @patrickvonplaten confirmation. <|||||>Hey @mabdullah1994, yeah `Longformer` is sadly not yet supported on TPU. We just merged Big Bird: https://huggingface.co/transformers/master/model_doc/bigbird.html though, which should work on TPU. It would be amazing if you could try it out :-)<|||||>@patrickvonplaten Thanks for the update Patrick!
Just a quick query: I have a dataset with large sequences and I don't want to truncate the text. What options do I have? Will XLNet be able to handle large sequences with pre-trained models? Could you point me towards an example of using stride for this use case? Thanks!<|||||>Well, tried `BigBird` and getting a similar error on Google Colab
```
RuntimeError: torch_xla/csrc/tensor_methods.cpp:880 : Check failed: xla::ShapeUtil::Compatible(shapes.back(), tensor_shape)
*** Begin stack trace ***
tensorflow::CurrentStackTrace()
torch_xla::XLATensor::cat(absl::lts_2020_02_25::Span<torch_xla::XLATensor const>, long)
torch_xla::AtenXlaType::cat(c10::ArrayRef<at::Tensor>, long)
c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoRuntimeFunctor_<at::Tensor (*)(c10::ArrayRef<at::Tensor>, long), at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<at::Tensor>, long> >, at::Tensor (c10::ArrayRef<at::Tensor>, long)>::call(c10::OperatorKernel*, c10::ArrayRef<at::Tensor>, long)
at::cat(c10::ArrayRef<at::Tensor>, long)
at::cat(c10::ArrayRef<at::Tensor>, long)
_PyMethodDef_RawFastCallKeywords
_PyCFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
_PyObject_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
_PyObject_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
_PyObject_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
_PyObject_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
_PyObject_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallDict
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
PyEval_EvalCode
_PyMethodDef_RawFastCallKeywords
_PyCFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallDict
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallDict
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyFunction_FastCallKeywords
_PyEval_EvalFrameDefault
_PyObject_Call_Prepend
PyObject_Call
_PyEval_EvalFrameDefault
_PyEval_EvalCodeWithName
_PyFunction_FastCallKeywords
*** End stack trace ***
s64[1,1,1]{2,1,0} vs. f32[1,1,1]{2,1,0}
```<|||||>Hey @mabdullah1994,
Could you maybe open a new issue showcasing that big bird doesn't work on PyTorch/XLA? :-)<|||||>Hey @patrickvonplaten
Just created a new issue #11363 with the details of the BigBird issue. Please advice. Thanks!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Any updates on this?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>hey @patrickvonplaten, with the release of the new trainer should this issue be resolved. I'm using the latest version of transformers and still getting this for models like [allenai/led-base-16384](https://huggingface.co/allenai/led-base-16384) running on TPU. |
transformers | 10,922 | closed | Use reformer in down stream task meet problem | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:4.2.2
- Platform:CentOS
- Python version:3.7
- PyTorch version (GPU?):1.5.1 cpu only
- Tensorflow version (GPU?):
- Using GPU in script?:no
- Using distributed or parallel set-up in script?:no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [x] the official example scripts:
### sequence classification task under glue
- bug
```
Traceback (most recent call last):
File "examples/text-classification/run_glue.py", line 584, in <module>
main()
File "examples/text-classification/run_glue.py", line 410, in main
datasets = datasets.map(preprocess_function, batched=True, load_from_cache_file=not data_args.overwrite_cache)
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/dataset_dict.py", line 386, in map
for k, dataset in self.items()
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/dataset_dict.py", line 386, in <dictcomp>
for k, dataset in self.items()
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1120, in map
update_data = does_function_return_dict(test_inputs, test_indices)
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1091, in does_function_return_dict
function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
File "examples/text-classification/run_glue.py", line 403, in preprocess_function
result = tokenizer(*args, padding=padding, max_length=data_args.max_seq_length, truncation=True)
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/tokenization_utils_base.py", line 2335, in __call__
**kwargs,
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/tokenization_utils_base.py", line 2500, in batch_encode_plus
**kwargs,
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/tokenization_utils_base.py", line 2217, in _get_padding_truncation_strategies
"Asking to pad but the tokenizer does not have a padding token. "
ValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`.
```
- shell code
```python
python examples/text-classification/run_glue.py --model_type reformer --model_name_or_path google/reformer-crime-and-punishment --task_name $TASK_NAME --do_train --do_eval --max_seq_length 512 --per_gpu_eval_batch_size=32 --per_gpu_train_batch_size=32 --learning_rate 2e-5 --num_train_epochs 3.0 --output_dir /home2/zhenggo1/checkpoint/reformer_mrpc
```
### translation task under wmt_en_ro
- bug
```
Traceback (most recent call last):
File "examples/seq2seq/finetune_trainer.py", line 451, in <module>
main()
File "examples/seq2seq/finetune_trainer.py", line 215, in main
cache_dir=model_args.cache_dir,
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/models/auto/modeling_auto.py", line 1226, in from_pretrained
", ".join(c.__name__ for c in MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING.keys()),
ValueError: Unrecognized configuration class <class 'transformers.models.reformer.configuration_reformer.ReformerConfig'> for this kind of AutoModel: AutoModelForSeq2SeqLM.
Model type should be one of LEDConfig, BlenderbotSmallConfig, MT5Config, T5Config, PegasusConfig, MarianConfig, MBartConfig, BlenderbotConfig, BartConfig, FSMTConfig, EncoderDecoderConfig, XLMProphetNetConfig, ProphetNetConfig.
```
- shell code
```python
python examples/seq2seq/finetune_trainer.py --model_name_or_path google/reformer-crime-and-punishment --do_train --do_eval --task translation_en_to_ro --data_dir examples/seq2seq/test_data/wmt_en_ro/ --output_dir /home2/zhenggo1/checkpoint/reformer_translation --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_generate
```
### clm task under wikitext
- bug
```
Traceback (most recent call last):
File "examples/language-modeling/run_clm.py", line 472, in <module>
main()
File "examples/language-modeling/run_clm.py", line 365, in main
train_result = trainer.train(model_path=model_path)
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/trainer.py", line 888, in train
tr_loss += self.training_step(model, inputs)
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/trainer.py", line 1250, in training_step
loss = self.compute_loss(model, inputs)
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/trainer.py", line 1277, in compute_loss
outputs = model(**inputs)
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/models/reformer/modeling_reformer.py", line 2244, in forward
return_dict=return_dict,
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/models/reformer/modeling_reformer.py", line 2090, in forward
start_idx_pos_encodings=start_idx_pos_encodings,
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/models/reformer/modeling_reformer.py", line 264, in forward
position_embeddings = self.position_embeddings(position_ids)
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home2/zhenggo1/LowPrecisionInferenceTool/examples/pytorch/huggingface_transformers/src/transformers/models/reformer/modeling_reformer.py", line 158, in forward
self.axial_pos_shape, self.axial_pos_shape, sequence_length, reduce(mul, self.axial_pos_shape)
AssertionError: If training, make sure that config.axial_pos_shape factors: (512, 1024) multiply to sequence length. Got prod((512, 1024)) != sequence_length: 1024. You might want to consider padding your sequence length to 524288 or changing config.axial_pos_shape.
```
- shell code
```python
python examples/language-modeling/run_clm.py --model_name_or_path google/reformer-crime-and-punishment --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train --do_eval --output_dir /home2/zhenggo1/checkpoint/reformer_clm
```
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. run shell code as shown as above(translation dataset may not use the local)
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
I just need a task to do evaluation and can compute a metrics.
Thks a lot if you can help me to give just a task that I can do evaluation!!!
<!-- A clear and concise description of what you would expect to happen. -->
| 03-26-2021 12:15:55 | 03-26-2021 12:15:55 | If I train the model on the crime-and-punishment
```shell
python examples/language-modeling/run_clm.py --model_name_or_path google/reformer-crime-and-punishment --dataset_name crime_and_punish --do_train --do_eval --output_dir /home2/zhenggo1/checkpoint/reformer_clm
```
the bug is below
```python
AssertionError: If training, make sure that config.axial_pos_shape factors: (512, 1024) multiply to sequence length. Got prod((512, 1024)) != sequence_length: 1024. You might want to consider padding your sequence length to 524288 or changing config.axial_pos_shape.
```<|||||>Hi,
I have been playing around with Reformer these few days so I hope I can give some insights. Axial positional encoding in Reformer requires that sequence length must be fixed to the product of `axial_pos_embds_dim`. See the documentation here
https://huggingface.co/transformers/model_doc/reformer.html#axial-positional-encodings
So you have to either pad the sequence length to that fixed size, or change the value for `axial_pos_embds_dim` to a smaller value. Due to this reason, I believe example scripts won't work with Reformer out of the box.
The Reformer examples from Google's Trax actually don't use axial positional encoding, just normal positional encoding (see [here](https://github.com/google/trax/blob/master/trax/examples/NER_using_Reformer.ipynb)). So I actually disable axial positional encoding (passing `axial_pos_embds=False` to Reformer config) and it works fine. By disabling this, I can also use dynamic padding (pad to max length within a batch) and saves even more memory.
I haven't tested the accuracy difference between with and without axial positional encoding. But axial positional encoding is so slow for a dataset with varying sequence lengths that I find it impractical.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,921 | closed | Tokenizer is adding ## to every word from the second. | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: Linux-5.8.0-44-generic-x86_64-with-Ubuntu-20.04-focal
- Python version: 3.6.13
- PyTorch version (GPU?): 1.8.1+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
tokenizers: @LysandreJik
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ O ] the official example scripts: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. The tokenizer is adding ## to every words from the second.
For example, the code is:
text = 'テレビでサッカーの試合を見る。'
tokenized_text = tokenizer.tokenize(text)
Output is expected to be:['テレビ', 'で', 'サッカー', 'の', '試合', 'を', '見る', '。']
But I get ['テレビ', '##で', '##サッカー', '##の', '##試', '##合', '##を', '##見', '##る', '。']
I dont know why it add ## at the start of the words...
```
import torch
from transformers import BertJapaneseTokenizer, BertForMaskedLM
# Model path
def sel_model(pre_model='32d'):
if pre_model == '32d':
sel = '/home/Xu_Zhenyu/cl-tohoku/BERT-base_mecab-ipadic-bpe-32k_do-whole-word-mask/'
elif pre_model == '4d':
sel = '/home/Xu_Zhenyu/cl-tohoku/BERT-base_mecab-ipadic-char-4k_do-whole-word-mask/'
elif pre_model == '32n':
sel = '/home/Xu_Zhenyu/cl-tohoku/BERT-base_mecab-ipadic-bpe-32k_no-whole-word-mask/'
elif pre_model == '4n':
sel = '/home/Xu_Zhenyu/cl-tohoku/BERT-base_mecab-ipadic-char-4k_no-whole-word-mask/'
else:
sel = '/home/Xu_Zhenyu/cl-tohoku/BERT-base_mecab-ipadic-bpe-32k_do-whole-word-mask/'
return sel
# Load pre-trained tokenizer
tokenizer = BertJapaneseTokenizer.from_pretrained(sel_model())
# Tokenize input
text = 'テレビでサッカーの試合を見る。'
tokenized_text = tokenizer.tokenize(text)
# ['テレビ', 'で', 'サッカー', 'の', '試合', 'を', '見る', '。']
# Mask a token that we will try to predict back with `BertForMaskedLM`
masked_index = 2
tokenized_text[masked_index] = '[MASK]'
print(tokenized_text)
# ['テレビ', 'で', '[MASK]', 'の', '試合', 'を', '見る', '。']
# Convert token to vocabulary indices
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
# [571, 12, 4, 5, 608, 11, 2867, 8]
# Convert inputs to PyTorch tensors
tokens_tensor = torch.tensor([indexed_tokens])
# tensor([[ 571, 12, 4, 5, 608, 11, 2867, 8]])
# Load pre-trained model
model = BertForMaskedLM.from_pretrained(sel_model())
model.eval()
# Predict
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0][0, masked_index].topk(5) # 予測結果の上位5件を抽出
# Show results
for i, index_t in enumerate(predictions.indices):
index = index_t.item()
token = tokenizer.convert_ids_to_tokens([index])[0]
print(i, token)
```
| 03-26-2021 06:42:46 | 03-26-2021 06:42:46 | Maybe @polm or @singletongue have an idea!<|||||>I didn't implement BertTokenizer so I'm a little out of my depth here, but the code below in a clean environment worked fine for me with no weird hashes.
```
from transformers import BertJapaneseTokenizer
name = "cl-tohoku/bert-base-japanese-whole-word-masking"
name = "cl-tohoku/bert-base-japanese"
tokenizer = BertJapaneseTokenizer.from_pretrained(name)
text = "テレビでサッカーの試合を見る。"
out = tokenizer.tokenize(text)
print(out)
```
I will note it is especially weird that the last word in your list (`。`) doesn't have the hashes.<|||||>Thank you for you reply.
Here is the result.
['テレビ', '##で', '##サッカー', '##の', '##試', '##合', '##を', '##見', '##る', '。']
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>@leoxu1007
Could it be possible that you set `word_tokenizer_type` to `basic` ?
I reproduced the same result by this configuration.
I mean I got ['テレビ', '##で', '##サッカー', '##の', '##試', '##合', '##を', '##見', '##る', '。'].
Now, `BertJapaneseTokenizer` pretrained tokenizer's default configuration is `word_tokenizer_type='mecab'`.
So we don't usually get this unexpected result.
I tried the example with `mecab` I got ['テレビ', 'で', 'サッカー', 'の', '試合', 'を', '見る', '。'].
|
transformers | 10,920 | closed | Rename NLP library to Datasets library | # What does this PR do?
Fixes #10897
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
| 03-26-2021 06:34:00 | 03-26-2021 06:34:00 | @sgugger Please review |
transformers | 10,919 | closed | GPT2 on TPU, training is so slow. | When training GPT2 on TPU from scratch, training loss is constant & evaluation loss is decreasing very small amount.
> [INFO|trainer.py:1776] 2021-03-26 04:06:22,551 >> Num examples = 100000
> [INFO|trainer.py:1777] 2021-03-26 04:06:22,551 >> Batch size = 2
> {'eval_loss': 4.687133312225342, 'eval_runtime': 736.3302, 'eval_samples_per_second': 135.809, 'epoch': 0.05}
> 1%|# | 22000/2080235 [22:38:08<2499:54:52, 4.37s/it] [INFO|trainer.py:1528] 2021-03-26 04:18:38,885 >> Saving model checkpoint to outputs/line_by_line/checkpoint-22000
> [INFO|configuration_utils.py:314] 2021-03-26 04:18:38,912 >> Configuration saved in outputs/line_by_line/checkpoint-22000/config.json
> [INFO|modeling_utils.py:837] 2021-03-26 04:18:56,125 >> Model weights saved in outputs/line_by_line/checkpoint-22000/pytorch_model.bin
> [INFO|tokenization_utils_base.py:1896] 2021-03-26 04:18:56,130 >> tokenizer config file saved in outputs/line_by_line/checkpoint-22000/tokenizer_config.json
> [INFO|tokenization_utils_base.py:1902] 2021-03-26 04:18:56,131 >> Special tokens file saved in outputs/line_by_line/checkpoint-22000/special_tokens_map.json
> {'loss': 2.56, 'learning_rate': 0.0004963706023598295, 'epoch': 0.05}
> {'loss': 2.56, 'learning_rate': 0.0004963465666138682, 'epoch': 0.05}
> {'loss': 2.56, 'learning_rate': 0.0004963225308679067, 'epoch': 0.05}
> {'loss': 2.56, 'learning_rate': 0.0004962984951219453, 'epoch': 0.05}
> {'loss': 2.56, 'learning_rate': 0.000496274459375984, 'epoch': 0.05}
> {'loss': 2.56, 'learning_rate': 0.0004962504236300226, 'epoch': 0.05}
> {'loss': 2.56, 'learning_rate': 0.0004962263878840611, 'epoch': 0.05}
> {'loss': 2.56, 'learning_rate': 0.0004962023521380998, 'epoch': 0.05}
> {'loss': 2.56, 'learning_rate': 0.0004961783163921384, 'epoch': 0.06}
> {'loss': 2.56, 'learning_rate': 0.000496154280646177, 'epoch': 0.06}
> 1%|#1 | 23000/2080235 [23:52:03<2524:57:42, 4.42s/it][INFO|trainer.py:1775] 2021-03-26 05:32:34,207 >> ***** Running Evaluation *****
> [INFO|trainer.py:1776] 2021-03-26 05:32:34,317 >> Num examples = 100000
> [INFO|trainer.py:1777] 2021-03-26 05:32:34,317 >> Batch size = 2
> {'eval_loss': 4.667241096496582, 'eval_runtime': 739.6907, 'eval_samples_per_second': 135.192, 'epoch': 0.06}`
| 03-26-2021 06:04:49 | 03-26-2021 06:04:49 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,918 | closed | OSError: file bert-base-uncased/config.json not found | ## Environment info
- `transformers` version: 4.4.2
- Python version: 3.6
- PyTorch version (GPU?): 1.8.0 (Tesla V100)
## Information
The problem arises when using:
```
from transformers import BertModel
model = BertModel.from_pretrained('bert-base-uncased')
```
Error Info (Some personal info has been replaced by ---)
```
file bert-base-uncased/config.json not found
Traceback (most recent call last):
File "---/anaconda3/envs/attn/lib/python3.6/site-packages/transformers-4.2.2-py3.8.egg/transformers/configuration_utils.py", line 420, in get_config_dict
File "---/anaconda3/envs/attn/lib/python3.6/site-packages/transformers-4.2.2-py3.8.egg/transformers/file_utils.py", line 1063, in cached_path
OSError: file bert-base-uncased/config.json not found
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "---.py", line 107, in <module>
from_pretrained_input()
File "---.py", line 96, in from_pretrained_input
model = BertModel.from_pretrained('bert-base-uncased')
File "---/anaconda3/envs/attn/lib/python3.6/site-packages/transformers-4.2.2-py3.8.egg/transformers/modeling_utils.py", line 962, in from_pretrained
File "---/anaconda3/envs/attn/lib/python3.6/site-packages/transformers-4.2.2-py3.8.egg/transformers/configuration_utils.py", line 372, in from_pretrained
File "---/anaconda3/envs/attn/lib/python3.6/site-packages/transformers-4.2.2-py3.8.egg/transformers/configuration_utils.py", line 432, in get_config_dict
OSError: Can't load config for 'bert-base-uncased'. Make sure that:
- 'bert-base-uncased' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'bert-base-uncased' is the correct path to a directory containing a config.json file
```
#### what I have read:
https://github.com/huggingface/transformers/issues/353
#### what I have tried:
1. loading from a downloaded model file works well
```
wget https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz
```
unzip the file and rename ```bert_config.json``` as ```config.json```, then
```
model = BertModel.from_pretrained(BERT_BASE_UNCASED_CACHE)
```
2. enough disk space, enough memory, free GPU
3. open internet connection, no proxy
4.
```
import pytorch_pretrained_bert as ppb
assert 'bert-large-cased' in ppb.modeling.PRETRAINED_MODEL_ARCHIVE_MAP
```
5. The following models work well
```
model = BertModel.from_pretrained('bert-base-cased')
model = RobertaModel.from_pretrained('roberta-base')
```
6. working well in server cmd but not in local pycharm (remote deployment to server)
Observation:
- Pycharm can found the ```transfromers``` installed with pip, but that will trigger this problem
- Pycharm cannot find the current ```transformers``` installed with conda
```conda install transformers=4.4 -n env -c huggingface```
| 03-26-2021 05:16:10 | 03-26-2021 05:16:10 | I'm also facing the same issue. Did you find any fix yet . ??<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>I'm also facing the same issue. Did you guys find any fix yet . ??<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Same problem here, please write if someone found a valid solution.<|||||>Facing same error<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi, I've had the same error but with `roberta-base`. It appeared that I had an empty folder named `roberta-base` in my working directory. Removing it solved the issue.<|||||>I found this issue is caused by setting cache directory using checkpoint name
TrainingArguments(checkpoint,evaluation_strategy='steps')
change checkpoint to something else resolve the issue
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>> #353
Got the same issue, thanks for reporting it here. Was able to fix it following after going through your comment. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.