
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 10,211 | closed | Making TF XLM-like models XLA and AMP compliant | # What does this PR do?
This PR makes the TF XLM-like models compliant with XLA and AMP. All the slow tests are passing as well for these models. | 02-16-2021 13:52:19 | 02-16-2021 13:52:19 | |
transformers | 10,210 | closed | QA Documentation: I got error just copy and pasting documentation | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.1
- Platform:Manjaro Linux
- Python version: 1.5.1
- PyTorch version (GPU?): Yes
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@sgugger
## Information
I am trying the to train a QA model following the huggingface documentation, I just copied and pasted the code in my machine (and in Colab) but I was not able to proceed in the training phase because I got None value.
## To reproduce
Steps to reproduce the behavior:
1. Go to the documentation: https://huggingface.co/transformers/custom_datasets.html at Squad training section
2. Copy and paste the code as you can see from my pastebin: https://pastebin.com/hZvq7Zs7
3. And you got the following error
`File "/home/andrea/PycharmProjects/qa-srl/test.py", line 78, in __getitem__
return {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
RuntimeError: Could not infer dtype of NoneType
`
4. My naive solution was modifying the __getitem__ method from the SquadDataset class in order to avoid to serve the val[idx] == None
| 02-16-2021 13:13:29 | 02-16-2021 13:13:29 | Pinging @joeddav on this one, since he wrote this tutorial :-)<|||||>Thank you @sgugger for the reply.
Ok I can wait for the answer from @joeddav.
Have a nice day. <|||||>Figured it out. `answer_end` is the character position immediately _after_ the answer, so end_position should be derived from `answer_end - 1`. I'm not sure why I was able to run it without this error previously (perhaps a resolved tokenizer bug?), but this should be correct.
```python
def add_token_positions(encodings, answers):
start_positions = []
end_positions = []
for i in range(len(answers)):
start_positions.append(encodings.char_to_token(i, answers[i]['answer_start']))
end_positions.append(encodings.char_to_token(i, answers[i]['answer_end'] - 1))
# if start position is None, the answer passage has been truncated
if start_positions[-1] is None:
start_positions[-1] = tokenizer.model_max_length
end_positions[-1] = tokenizer.model_max_length
encodings.update({'start_positions': start_positions, 'end_positions': end_positions})
```<|||||>Closed by #10217 <|||||>Thank you @joeddav the posted code works perfectly.
<|||||>Sorry for bothering you @joeddav again, I have a question related to the code posted by you here.
I am still getting None with the dataset built by myself using this code. My dataset works perfectly with the run_squad original script.
In this snipped posted by you I encounter None in the vector of end_positions and I don't know how fix it. I saw the condition in which there's a None the start_positions but what I have to do in the case the None is only in the end_positions vector?
Kind regards,
Andrea |
transformers | 10,209 | closed | Make TF CTRL compliant with XLA and AMP | # What does this PR do?
This PR makes the TF CTRL model compliant with XLA and AMP. All the slow tests are passing as well.
| 02-16-2021 11:55:33 | 02-16-2021 11:55:33 | |
transformers | 10,208 | closed | different behavior for get_input_embeddings() between 4.2.x and 4.3.x in Tensorflow | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.2.x vs 4.3.x
- Platform: Colab
- Python version: 3.6
- Tensorflow version (GPU?): 2.4.1
@jplu
## Information
Model I am using (Bert, XLNet ...): Bert
## To reproduce
Steps to reproduce the behavior:
In version 4.3.x the following code
```
model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
input = tokenizer.batch_encode_plus(['this is a test'])
embeddings = model.get_input_embeddings()
embeddings(input_ids=np.array(input['input_ids']), token_type_ids=np.array(input['token_type_ids']))
```
Throws an error:
> TypeError: call() got an unexpected keyword argument 'token_type_ids'
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
In version 4.2.x the code returned a tensor:
> <tf.Tensor: shape=(1, 6, 768), dtype=float32, [...]
Test also as [colab](https://colab.research.google.com/drive/1z5rboqdz8y8IM90FX8fDzixez9K_Efdy?usp=sharing)
| 02-16-2021 11:38:23 | 02-16-2021 11:38:23 | Hello!
This is because in the 4.3 version the implementation of the embedding have changed and `get_input_embeddings()` returns only the word embeddings layer, hence only `input_ids` can be passed.
This was an unexpected behavior and will be fixed for the next release (the fix is already in master if you want). Sorry for the inconvenience.<|||||>thank you for the quick reply!
Ok, i was unaware it was already fixed in master
Thank you! |
transformers | 10,207 | closed | Unlock XLA test for TF ConvBert | # What does this PR do?
This PR allows the XLA test for TF ConvBert.
| 02-16-2021 11:05:59 | 02-16-2021 11:05:59 | |
transformers | 10,206 | closed | Tokenizer is working different from expected functionality. | Hi,
I updated the vocabulary for pre-trained tokenizer. Pretrained tokenizer was taken from this model - https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract
When I am using the updated tokenizer , it is creating the sub tokens of the word which are present in vocabulary dictionary. And those sub-tokens are also not starting with '##' , which is creating confusion.
`input_ids = TOKENIZER.encode('vancomycin')`
`TOKENIZER.decode(input_ids)`
`TOKENIZER.decode([16100]) #checked through manual rules that same word is present in vocabulary.`
**Sanpshot of the Code**

## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.3.1
- Platform: Windows
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.1 , Yes, Cuda 10.1
- Tensorflow version (GPU?):
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?:
| 02-16-2021 06:30:02 | 02-16-2021 06:30:02 | Hi! Could you provide a reproducible example? I don't understand what's your `TOKENIZER` here. Thanks<|||||>Hi @LysandreJik ,
Thanks for your response , I have done deep-dive and modified code a bit to reproduce the same issue. I am extending the vocabulary of tokenizer and using some automated logic to add the new words. I don't not have complete control on the words which are adding (but, I am making sure those are not the noise.)
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_checkpoint_tok = "microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint_tok)
enc_ids = tokenizer.encode('vancomycin')
tokenizer.decode(enc_ids)
```
```out
[CLS] vancomycin [SEP]
```
Adding the new vocabulary through some automated logic, I added thousands of words, To reproduce the same issue, I am manually adding one of the word in next line
```python
tokenizer.add_tokens(['vanco'])
enc_ids = tokenizer.encode('vancomycin')
tokenizer.decode(enc_ids)
```
```out
`Output : '[CLS] vanco mycin [SEP]'
```
The word 'vancomycin' is present in vocabulary, The word 'vanco' got added in vocabulary (by some automated logic), Now when I am again tokenizing "vancomycin" , It is splitting it into token id's of 'vanco' and 'mycin' (Mycin is not exactly present, So it got splitted into subwords).
My question is -
- Is it the expected functionality of tokenizer ( I know that its a Subword tokenization technique) , I am not sure but what I guess is there should be some word boundary detection technique and if the exact word in word boundary is not present, then only sub word tokenization should happen?
Please suggest how I can handle these scenarios ?
Please Find Below Screenshot for the same -

<|||||>Hi @LysandreJik , Are there any updates on this ? <|||||>Hi! That isn't a bug of itself, but expected behavior (which could be better documented). The tokens added to the tokenizers don't get added to the "vocabulary" that resulted from the tokenizer training.
Instead, they get added to the "added tokens", and these tokens take priority over the vocabulary tokens. It is, unfortunately, complex or near impossible to add tokens to the vocabulary itself in a way that all tokenizers could benefit. This is particularly complex in the case of subwords tokenizers, which is the case of the BERT tokenizer here.<|||||>You can check this thread https://github.com/huggingface/tokenizers/issues/370 for a similar issue.<|||||>Hi @LysandreJik , So, if we add the tokens and then continually pretrain the Bert Model (By Fine Tuning on Masked Language Modeling) on specific corpus , Then , Does the model learn embeddings for these added tokens ?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,205 | closed | set tgt_lang of MBart Tokenizer for summarization | # What does this PR do?
To set tgt_lang of MBart Tokenizer for summarization.
Otherwise, the error `AttributeError: 'MBartTokenizerFast' object has no attribute 'tgt_lang'` occurred.
I have read your discussion and know that you will modify the part of MBart later. So this PR will be meaningless at that time.
But at least it will be useful now :)
Sorry that I didn't take any tests, but it works well on my machine for summarization using MBart.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@stas00 @patil-suraj @patrickvonplaten @ @sgugger
| 02-16-2021 06:13:18 | 02-16-2021 06:13:18 | Thanks a lot for fixing this!<|||||>Other models/tasks have this issue as well https://github.com/huggingface/transformers/issues/10292
These features require tests. Without tests this is an endless work-work-work - otherwise we keep on breaking what was working before.
|
transformers | 10,204 | closed | 1.3GB dataset creates over 107GB of cache file! | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.0 dev0
- Platform: Google Colab
- Python version: 3.6
- PyTorch version (GPU?): 1.7
- Tensorflow version (GPU?): None
- Using GPU in script?: None. Colab TPU is used
- Using distributed or parallel set-up in script?: Using default ```run_mlm.py``` script
### Who can help
@sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): DistilBert
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```
!python /content/transformers/examples/xla_spawn.py --num_cores 8 /content/transformers/examples/language-modeling/run_mlm.py
--model_type distilbert --config_name /content/TokenizerFiles \
--tokenizer_name /content/drive/TokenizerFiles \
--train_file Corpus.txt \
--mlm_probability 0.15 \
--output_dir "/content/TrainingCheckpoints" \
--do_train \
--per_device_train_batch_size 32 \
--save_steps 500 --disable_tqdm False \
--line_by_line True \
--max_seq_length 128 \
--pad_to_max_length True \
--cache_dir /content/cache_dir --save_total_limit 2
```
The script ends up creating more than 107GB of cache files only with 54% processing done which crashes the Colab environment
This means that 200+ GB of space is required to cache and preprocess a mere 1GB file. Am I doing something wrong here? I ran the same script a few days ago and it didn't give me any such "Out of disk space" error. Because I wanted to use the TPU, I changed pad_to_max_length=True [(10192)](https://github.com/huggingface/transformers/issues/10192) . That's all I changed and it does this. Let me know if anyone requires any more data to help me out with this
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
The dataset should cache in a minimum amount of disk space. It currently occupies over 150-200x the space of the actual dataset | 02-16-2021 05:51:54 | 02-16-2021 05:51:54 | cc @lhoestq <|||||>Related to https://github.com/huggingface/datasets/issues/861
Maybe on-the-fly tokenization can help.
Or if we stick to having the tokenization in the preprocessing, at least reduce the precision of the integers stored on disk and maybe do the padding on the fly.<|||||>@lhoestq Are there any minor changes that could fix this temporarily? Will changing the map function to set transform as mentioned [here](https://github.com/huggingface/datasets/issues/1825) help?<|||||>Currently the Trainer doesn't handle `set_transform` but this will be supported soon.
Another think you could try is specify `features=` in the parameters of the map function to specify the precision of the integers that are written on disk. For example
```python
from datasets import Features, Sequence, Value
features = Features({
"input_ids": Sequence(Value("int32")),
"token_type_ids": Sequence(Value("bool")),
"attention_mask": Sequence(Value("bool")),
"special_tokens_mask": Sequence(Value("bool")),
})
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[text_column_name],
load_from_cache_file=not data_args.overwrite_cache,
features=features,
)
```
The tokenization will still be done during the preprocessing and store the tokenized texts on disk, but this time it will take much less space since you'll store int32 and booleans instead of int64 by default.<|||||>@lhoestq Nope. I get a casting error as attached below
```
Exception in device=TPU:4: Could not convert 1 with type int: tried to convert to boolean
Traceback (most recent call last):
File "/opt/conda/lib/python3.7/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 330, in _mp_start_fn
_start_fn(index, pf_cfg, fn, args)
File "/opt/conda/lib/python3.7/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 324, in _start_fn
fn(gindex, *args)
File "/kaggle/working/run_mlm_custom.py", line 461, in _mp_fn
main()
File "/kaggle/working/run_mlm_custom.py", line 355, in main
features=features
File "/opt/conda/lib/python3.7/site-packages/datasets/dataset_dict.py", line 386, in map
for k, dataset in self.items()
File "/opt/conda/lib/python3.7/site-packages/datasets/dataset_dict.py", line 386, in <dictcomp>
for k, dataset in self.items()
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1140, in map
update_data=update_data,
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 167, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/fingerprint.py", line 312, in wrapper
out = func(self, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1411, in _map_single
writer.write_batch(batch)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_writer.py", line 279, in write_batch
pa_table = pa.Table.from_pydict(typed_sequence_examples)
File "pyarrow/table.pxi", line 1474, in pyarrow.lib.Table.from_pydict
File "pyarrow/array.pxi", line 322, in pyarrow.lib.asarray
File "pyarrow/array.pxi", line 222, in pyarrow.lib.array
File "pyarrow/array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_writer.py", line 100, in __arrow_array__
out = pa.array(self.data, type=type)
pyarrow.lib.ArrowInvalid: Could not convert 1 with type int: tried to convert to boolean
Traceback (most recent call last):
File "transformers/examples/xla_spawn.py", line 85, in <module>
main()
File "transformers/examples/xla_spawn.py", line 81, in main
xmp.spawn(mod._mp_fn, args=(), nprocs=args.num_cores)
File "/opt/conda/lib/python3.7/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 395, in spawn
start_method=start_method)
File "/opt/conda/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 157, in start_processes
while not context.join():
File "/opt/conda/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 112, in join
(error_index, exitcode)
Exception: process 5 terminated with exit code 17
```
Fixed this using
features = Features({
"input_ids": Sequence(Value("int32")),
"attention_mask": Sequence(Value("int32")),
"special_tokens_mask": Sequence(Value("int32")),
})
but it still ends up taking a lot of space. Runs out of space again on kaggle notebook with 19GB free<|||||>Looks like PyArrow doesn't know how to convert 1 to True ^^'
I created an issue on Apache Arrow's JIRA [here](https://issues.apache.org/jira/browse/ARROW-11646) to track the issue.
Also I think we can add support for uint16 in the pytorch integration of `datasets` to reduce the size even more. Feel free to open an issue on the `datasets` repo about this if you want.
In the end I think the best solution is probably to not do padding during preprocessing and do it on the fly in the Trainer. This can use `dataset.set_transform` or a data collator. As long as padding is done before sending the data to the TPU it should be good.<|||||>@lhoestq
You said in the comment before that ```set-transform``` support hasn't been added to the trainer yet. How exactly do I do it on the fly then?<|||||>Yes you're right, we first need to make the Trainer support `set_transform`, sorry if it was confusing.<|||||>`Trainer` in master completely supports `set_transform`. If there are some columns removed that should not be, you just have to set the training arguments `remove_unused_columns` to `False` for the time being.<|||||>Nice ! so one could try to replace the .map with .set_transform(tokenize_function)<|||||>> `Trainer` in master completely supports `set_transform`. If there are some columns removed that should not be, you just have to set the training arguments `remove_unused_columns` to `False` for the time being.
I tried changing remove_unused_columns to False but it gives me an error during the Trainer call. The set_transform function returns a NoneType object and so the Trainer complains of getting a None instead of training data. The run_mlm_custom.py file below is the same run_mlm file, just with set_transform instead of map (you can have a look at it [here](https://drive.google.com/file/d/1--ijV3UK-Rq9TnzkcWFAjkk2A-0j_XWK/view?usp=sharing))
```
Traceback (most recent call last):
File "run_mlm_custom.py", line 452, in <module>
main()
File "run_mlm_custom.py", line 397, in main
train_dataset=tokenized_datasets["train"] if training_args.do_train else None, # print(tokenized_datasets) gives None
TypeError: 'NoneType' object is not subscriptable
```
Do you have any template code for passing the data to the trainer?<|||||>Indeed `set_transform` is in-place. For example you can do
```python
dataset.set_transform(tokenize) # return None, but sets the transform of the current dataset
```
If you want to use a non in-place function like what was doing map, you can do
```python
dataset = dataset.with_transform(tokenize) # return a new dataset object with the specified transform
```
Also I'm not a big fan of having two functions that does the same thing (except one is in-place) so we might deprecate one or the other in the future. I guess the second one is more convenient and is more aligned with the other Dataset functions. Let me know what you think<|||||>Returning the dataset is more intuitive I feel. Anyway, this is some really good news. I will try to modify the script and make it work. If it does then maybe, if you want, I can clean the code and create a pull request for the same.<|||||>@DarshanDeshpande did it work for you after you made the changes?
I have the same issue, trying to train a roberta mlm on 1.3G of text data on cloud TPU and got the no space on device error (the code works with 300M of data though). I changed the run_mlm.py code based on your PR to do tokenization on the fly, but now I get this error:
```
[INFO|trainer.py:946] 2021-03-16 17:51:34,455 >> ***** Running training *****
[INFO|trainer.py:947] 2021-03-16 17:51:34,456 >> Num examples = 14602056
[INFO|trainer.py:948] 2021-03-16 17:51:34,456 >> Num Epochs = 2
[INFO|trainer.py:949] 2021-03-16 17:51:34,456 >> Instantaneous batch size per device = 8
[INFO|trainer.py:950] 2021-03-16 17:51:34,456 >> Total train batch size (w. parallel, distributed & accumulation) = 256
[INFO|trainer.py:951] 2021-03-16 17:51:34,456 >> Gradient Accumulation steps = 4
[INFO|trainer.py:952] 2021-03-16 17:51:34,456 >> Total optimization steps = 114078
0%| | 0/114078 [00:00<?, ?it/s]Exception in thread Thread-2:
Traceback (most recent call last):
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/torch_xla/distributed/parallel_loader.py", line 141, in _loader_worker
_, data = next(data_iter)
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 435, in __next__
data = self._next_data()
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 475, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/datasets/arrow_dataset.py", line 1130, in __getitem__
format_kwargs=self._format_kwargs,
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/datasets/arrow_dataset.py", line 1117, in _getitem
pa_subtable, key, formatter=formatter, format_columns=format_columns, output_all_columns=output_all_columns
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/datasets/formatting/formatting.py", line 375, in format_table
return formatter(pa_table, query_type=query_type)
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/datasets/formatting/formatting.py", line 173, in __call__
return self.format_row(pa_table)
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/datasets/formatting/formatting.py", line 239, in format_row
formatted_batch = self.format_batch(pa_table)
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/datasets/formatting/formatting.py", line 268, in format_batch
return self.transform(batch)
File "/home/aida_delfan/pretrain/run_mlm.py", line 363, in tokenize_function
return_special_tokens_mask=True,
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 2266, in __call__
**kwargs,
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 2451, in batch_encode_plus
**kwargs,
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/transformers/models/gpt2/tokenization_gpt2_fast.py", line 163, in _batch_encode_plus
return super()._batch_encode_plus(*args, **kwargs)
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/transformers/tokenization_utils_fast.py", line 411, in _batch_encode_plus
for key in tokens_and_encodings[0][0].keys():
IndexError: list index out of range
```
wondering if you saw a similar error and if there is a fix for it.
I have transformers 4.4.0 and datasets 1.4.0.
Thanks!<|||||>@aidad This looks like a tokenizer issue. The script in the PR works for me. Try checking your tokenizer files or altering the script to use the Roberta tokenizer specifically instead of the included AutoTokenizer |
transformers | 10,203 | closed | [run_glue] Add MNLI compatible mode | In this PR:
- Upgrade `datasets` to `1.3.0`
- Rename `datasets` variable to `task_datasets` in `run_glue.py` to avoid confusion with the library `datasets`
- Add a `--mnli_compat_mode` option to use the old label assignment for MNLI | 02-16-2021 05:40:53 | 02-16-2021 05:40:53 | The CI failed but it seems irrelevant. Could you please give it a check? @LysandreJik <|||||>The CI issue is with `test_hf_api`, which is fixed on master now, rebasing should make the CI green!<|||||>@sgugger Sorry but I can't really agree with you here. It is a problem introduced by mistake and we shouldn't just try to ignore or downplay that. It just adds a few lines of if-else and I don't think it'll add too much burden for users. I can add some comments if it helps explain the code.
I am never a fan of trainer-style code since IMO in the context of ML, capsulation is not simplicity, instead, transparency is simplicity (I believe our user survey supports my claim here). Thus, I don't think our example here is meant for beginners at all. Besides, I do think back-compatibility matters especially when our success depends heavily on the prosperity of the model hub. This PR is meant to fix a bug though it's harsh. I want the users won't feel confused when they load a community model and wonder why it doesn't work. (Because I myself spent one whole day debugging this)
Happy to have more discussion here.<|||||>So we discussed it a bit more internally. This particular example script will stay as is with the backward-compatibility problem (which isn't one IMO since the problem is in the model config not having the right labels). As I said before it's an example aimed at data scientists that shouldn't necessarily have all the functionality.
There will be another script for GLUE (probably by the end of the month) very soon that doesn't use `Trainer` and has the training loop exposed, where we can integrate your fix.<|||||>Looking forward to the new script you mentioned! |
transformers | 10,202 | closed | Fast Tokenizers instantiated via vocab/merge files do not respect skip_special_tokens=True | ## Environment info
- `transformers` version: 4.3.2
- Platform: macOS-11.2.1-x86_64-i386-64bit
- Python version: 3.9.1
- PyTorch version (GPU?): 1.7.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
## Information
See title; this issue does not reproduce with slow tokenizers. Does not reproduce with serialized tokenizers.
Found while investigating https://github.com/minimaxir/aitextgen/issues/88
## To reproduce
Using [gpt2_merges.txt](https://github.com/minimaxir/aitextgen/blob/master/aitextgen/static/gpt2_merges.txt) and [gpt2_vocab.json](https://github.com/minimaxir/aitextgen/blob/master/aitextgen/static/gpt2_vocab.json) as linked:
```py
from transformers import AutoModelForCausalLM, GPT2Tokenizer, GPT2TokenizerFast
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
outputs = model.generate(max_length=40)
# tensor([[50256, 383, 471, 13, 50, 13, 2732, 286, 4796, 468,
# 587, 10240, 262, 1918, 286, 257, 1966, 5349, 5797, 508,
# 373, 2823, 290, 2923, 416, 257, 23128, 287, 262, 471,
# 13, 50, 13, 13241, 319, 3583, 13, 198, 198, 198]])
tokenizer_fast = GPT2TokenizerFast(vocab_file="gpt2_vocab.json", merges_file="gpt2_merges.txt")
tokenizer_fast.decode(outputs[0], skip_special_tokens=True)
# '<|endoftext|> The U.S. Department of Justice has been investigating the death of a former FBI agent who was shot and killed by a gunman in the U.S. Capitol on Wednesday.\n\n\n'
tokenizer_slow = GPT2Tokenizer(vocab_file="gpt2_vocab.json", merges_file="gpt2_merges.txt")
tokenizer_slow.decode(outputs[0], skip_special_tokens=True)
# ' The U.S. Department of Justice has been investigating the death of a former FBI agent who was shot and killed by a gunman in the U.S. Capitol on Wednesday.\n\n\n'
```
| 02-16-2021 05:36:08 | 02-16-2021 05:36:08 | Indeed, I can reproduce! Do you know what might be causing this @n1t0?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>I think this is happening because when you load it from the vocab and merge files, it doesn't know `<|endoftext|>` is a special token. For the `skip_special_tokens` to work, I believe it would be necessary to add them to the tokenizer:
```python
tokenizer_fast.add_special_tokens({
"additional_special_tokens": "<|endoftext|>"
})
```
The `tokenizer.json` file on the hub, available for `gpt2` does have this special token registered, that's why it works in this case.<|||||>That workaround is sufficient for my needs and appears to have done the trick. Thanks! |
transformers | 10,201 | open | Better Fine-Tuning by Reducing Representational Collapse | # 🚀 Feature request
Add r3f/r4f to some popular objective functions as suggested by [Armen et. al](https://arxiv.org/abs/2008.03156).
## Motivation
Finetuning is a primary use case of many users of the transformers library.
We can use r3f/r4f to reduce representation collapse by vocabulary inefficiencies.
This is also a relatively cheap feature to implement.
## Your contribution
Understand that this is a relatively new paper with not too much benchmarking done. Will do PR if requested. | 02-16-2021 03:51:53 | 02-16-2021 03:51:53 | Would be lovely to see it, seems promising!<|||||>Any progress? @LysandreJik |
transformers | 10,200 | closed | Bugfix: Removal of padding_idx in BartLearnedPositionalEmbedding | # What does this PR do?
This PR removes the unnecessary padding_idx argument from positional embedding and instead uses the pre-determined offset.
In the event that padding_idx > 2, positional embedding at some position can be fixed to 0 instead of being learnable.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Please help 😄 @patrickvonplaten @patil-suraj | 02-16-2021 03:32:32 | 02-16-2021 03:32:32 | Thanks for the PR @mingruimingrui !
But I'm not sure how filling the embeddings with 0 will avoid them being learnable, and `nn.Embedding` actually handles this itself, if pad index is specified then the output of the embedding layer at that index will be all zeros.
Plus BART's offest is very specific to the padding index, so I'm not sure if it's a good idea to change the padding index of BART.<|||||>@patil-suraj
Zeroing of weights at positions 0 and 1 is merely code sugar, they do not carry any implication to model behavior.
My point is that the current implementation causes some weights to be untrainable.
The issue this PR is attempting to solve is `padding_idx`.
Here's a demonstration of the effects of `padding_idx` on the training of `torch.nn.Embedding`.
```python
import torch
for padding_idx in [None, 0, 1]:
print(f'padding_idx: {padding_idx}')
module = torch.nn.Embedding(2, 1, padding_idx=padding_idx)
print(f'Starting weight: {module.weight.data.tolist()}')
x = torch.LongTensor([0, 1])
y = torch.FloatTensor([1, 1]).reshape(2, 1)
optimizer = torch.optim.Adam(module.parameters(), lr=1.0)
for _ in range(10):
optimizer.zero_grad()
pred = module(x)
loss = torch.sum((pred - y) ** 2)
loss.backward()
optimizer.step()
print(f'Ending weight: {module.weight.data.tolist()}', end='\n\n')
```
You can expect output similar to the following.
```txt
padding_idx: None
Starting weight: [[-0.696786642074585], [1.2698755264282227]]
Ending weight: [[0.39832496643066406], [0.7758995294570923]]
padding_idx: 0
Starting weight: [[0.0], [0.7031512260437012]]
Ending weight: [[0.0], [1.2048938274383545]]
padding_idx: 1
Starting weight: [[-0.8316971659660339], [0.0]]
Ending weight: [[0.48533281683921814], [0.0]]
```
Notice the weight stays 0 at the respective `padding_idx` position.
`padding_idx` can easily be 2 or greater as this is dependent on how the user train/config their tokenizer.<|||||>Hey @mingruimingrui,
The positional embedding for the padding token is not really relevant since padding tokens are only used in training for tokens that are discarded anyways during training/evaluation (all padding tokens by design cannot influence the attention mechanism). Could you give us an example/use case which would require your fix here?<|||||>@patrickvonplaten
I am aware that the masks used for attention and loss computation allow model output to not get affected by the positions containing the padding token.
But positional embedding is not gathered using token id but rather sequence position.
Given padding_idx = 2, the positional embedding of the first token of every sequence will be untrainable regardless of what it is.<|||||>@patrickvonplaten try this out. This is tested on transformers 4.3.2 (latest release as time of writing)
```python
import torch
import transformers
from transformers.models.bart.modeling_bart import \
BartLearnedPositionalEmbedding
print(f'Running script on transformers=={transformers.__version__}')
# Init positional embedding with padding_idx = 2
pe = BartLearnedPositionalEmbedding(128, 1, padding_idx=2)
# Fix input embedding to a tensor of seq_len = 5
input_ids = torch.randint(0, 32000, (4, 5))
# Print out pos_embs of input_ids
pos_embs = pe.forward(input_ids.shape)
print('Initial pos_embs:', pos_embs.tolist())
# Backprop to make positional embeddings = 1.0
optimizer = torch.optim.Adam(pe.parameters(), lr=1.0)
for _ in range(100):
optimizer.zero_grad()
pos_embs = pe.forward(input_ids.shape)
target = torch.ones_like(pos_embs)
loss = torch.sum((pos_embs - target) ** 2)
loss.backward()
optimizer.step()
# Print out pos_embs of input_ids after optimization
# Expectation: A tensor of arppox. 1.0
# Result: A tensor arppox. 1.0 but first embedding has a value of 0.0
pos_embs = pe.forward(input_ids.shape)
print('Initial pos_embs:', pos_embs.tolist())
```
stdout
```txt
Running script on transformers==4.3.2
Initial pos_embs: [[0.0], [-0.2676548659801483], [-0.31950631737709045], [-0.9886524081230164], [0.6115532517433167]]
Initial pos_embs: [[0.0], [1.0013480186462402], [0.9954316020011902], [1.0088629722595215], [0.9995125532150269]]
```<|||||>A major problem with the current behavior is when a user uploads a model with padding_idx >= 2, the position embedding at the padding_idx will be zeroed out.
Multi-head-attention-based encoder and decoders can be hugely affected (since the concept of the sequence is represented using this embedding).
Using an extreme but realistic example, an English to German translation model translates "hello world" to "halo welt" correctly.
However, when exported to huggingface BART, the model can produce "welt halo" instead (due to the mix-up of position).
When this happens, the root cause (this issue) can be extremely difficult to discover/debug.<|||||>Hey @mingruimingrui,
Thanks for clarifying! And yes, I agree with you now - sorry I missed your point the first time! This bug is then actually in multiple spots in the library...It would be awesome if you could fix the bug also for the following models:
- `modeling_mbart.py`: https://github.com/huggingface/transformers/blob/e94d63f6cbf5efe288e41d9840a96a5857090617/src/transformers/models/mbart/modeling_mbart.py#L117
- `modeling_blenderbot.py`: https://github.com/huggingface/transformers/blob/e94d63f6cbf5efe288e41d9840a96a5857090617/src/transformers/models/blenderbot/modeling_blenderbot.py#L115
- `modeling_blenderbot_small.py`:
https://github.com/huggingface/transformers/blob/e94d63f6cbf5efe288e41d9840a96a5857090617/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py#L115
- `modleing_led.py`:
https://github.com/huggingface/transformers/blob/e94d63f6cbf5efe288e41d9840a96a5857090617/src/transformers/models/led/modeling_led.py#L115
- The cookie-cutter:
https://github.com/huggingface/transformers/blob/e94d63f6cbf5efe288e41d9840a96a5857090617/templates/adding_a_new_model/cookiecutter-template-%7B%7Bcookiecutter.modelname%7D%7D/modeling_%7B%7Bcookiecutter.lowercase_modelname%7D%7D.py#L1619
Great catch :-)<|||||>Thanks @patrickvonplaten
But before I make the changes, I thought it might be good to do something about backward compatibility when users use `XXLearnedPositionalEmbedding` directly.
I suggest that we raise a warning when `padding_idx` is not `None` so that the function interface can be kept as is.
```python
def __init__(self, num_embeddings: int, embedding_dim: int, padding_idx: Optional[int] = None):
assert padding_idx is not None, "`padding_idx` should not be None, but of type int"
if padding_idx is not None:
warnings.warn(
f'padding_idx should not be provided for {self.__class__.__name__}. '
'An exception will be raised in future versions of transformers.'
)
...
```
Let me know if this is alright.<|||||>@patrickvonplaten Btw can I also ask how to quote code chunks from repos in github comments like above?
> It is very cool and useful<|||||>> Thanks @patrickvonplaten
>
> But before I make the changes, I thought it might be good to do something about backward compatibility when users use `XXLearnedPositionalEmbedding` directly.
> I suggest that we raise a warning when `padding_idx` is not `None` so that the function interface can be kept as is.
>
> ```python
> def __init__(self, num_embeddings: int, embedding_dim: int, padding_idx: Optional[int] = None):
> assert padding_idx is not None, "`padding_idx` should not be None, but of type int"
> if padding_idx is not None:
> warnings.warn(
> f'padding_idx should not be provided for {self.__class__.__name__}. '
> 'An exception will be raised in future versions of transformers.'
> )
>
> ...
> ```
>
> Let me know if this is alright.
`XXLearnedPositionalEmbedding` is not available in init, *e.g.* one cannot do:
```python
from transformers import BartLearnedPositionalEmbedding
```
doesn't work, so in this case we don't have to care about backwards compatibility. As you pointed out, it is simply wrong to pass a padding_idx to the position embeddings.
<|||||>@patrickvonplaten That should be all the changes that are required.<|||||>Hey @mingruimingrui,
Thanks a lot for applying the changes also to the other models - it looks very nice already :-) Could you also completely remove the `padding_idx` from the call to the `PositionalEmbeddings`, *e.g.* `BartLearnedPositionalEmbedding`<|||||>> Hey @mingruimingrui,
>
> Thanks a lot for applying the changes also to the other models - it looks very nice already :-) Could you also completely remove the `padding_idx` from the call to the `PositionalEmbeddings`, _e.g._ `BartLearnedPositionalEmbedding`
Noted, what do you say about leaving `TFLearnedPositionalEmbeddings` as is?
This way, padding_idx wouldn't sneak its way into `kwargs`.<|||||>Anything else I've missed out on?<|||||>Looks great to me! I'll run the slow tests of the respective models just to be sure and then I think we are good to go! <|||||>Slow tests are all passing.
Pinging @LysandreJik @sgugger @patil-suraj for review. To be concise, this PR removes the dependency of the `LearnedPositionalEmbedding` on the `pad_token_id`. After discussion with @mingruimingrui , I think positional encodings should **not** be dependent on the padding idx and the padding idx should not get a special positional embedding. The reason is the following:
- The padding idx can be at every position so it doesn't make sense to have one positional embedding be reserved for the padding idx
- For a padded input - let's say `<pad><pad> Hello <pad> <pad>` my name, the position ids should be `0 0 0 1 1 1 2` IMO and not `pad_pos pad_pos 0 pad_pos pad_pos 1 2`
- Forcing one token to be a padding token, let's say 3 means that the positional embedding for 3 doesn't exist anymore which can then be very awkward when fine-tuning a model or training it from scratch
=> This PR fixes this behavior without any breaking changes. |
transformers | 10,199 | closed | StopIteration error happened | I'm using cuda11.0 with RTX3090.(using ubuntu 18.04)
I don't know how can I solve this problem.
I saw some people solve this StopIteration error with downgrade torch.
But rtx3090 is only compatible with cuda 11.
Please help!
[pip list]
anytree 2.8.0
apex 0.1
boto3 1.16.63
botocore 1.19.63
certifi 2020.12.5
chardet 4.0.0
cycler 0.10.0
decorator 4.4.2
future 0.18.2
idna 2.10
imageio 2.9.0
jmespath 0.10.0
kiwisolver 1.3.1
matplotlib 3.3.4
mkl-fft 1.2.0
mkl-random 1.1.1
mkl-service 2.3.0
networkx 2.5
numpy 1.20.0
olefile 0.46
oscar 0.1.0 /home/u2/바탕화면/Kim_Project/Oscar
Pillow 8.1.0
pip 20.3.3
pyparsing 2.4.7
python-dateutil 2.8.1
PyWavelets 1.1.1
PyYAML 5.4.1
regex 2020.11.13
requests 2.25.1
s3transfer 0.3.4
scikit-image 0.18.1
scipy 1.6.0
setuptools 52.0.0.post20210125
six 1.15.0
tifffile 2021.1.14
torch 1.7.1+cu110
torchaudio 0.7.2
torchvision 0.8.2+cu110
tqdm 4.56.0
typing-extensions 3.7.4.3
urllib3 1.26.3
wheel 0.36.2
here is the full traceback.
```
2021-02-16 03:37:03,483 vlpretrain WARNING: Device: cuda, n_gpu: 2
2021-02-16 03:37:07,380 vlpretrain INFO: Training/evaluation parameters Namespace(adam_epsilon=1e-08, add_od_labels=True, config_name='', data_dir='', device=device(type='cuda'), do_eval=False, do_lower_case=True, do_test=False, do_train=True, drop_out=0.1, eval_model_dir='', evaluate_during_training=True, gradient_accumulation_steps=1, img_feature_dim=2054, img_feature_type='frcnn', learning_rate=3e-05, length_penalty=1, logging_steps=20, loss_type='sfmx', mask_prob=0.15, max_gen_length=20, max_grad_norm=1.0, max_img_seq_length=50, max_masked_tokens=3, max_seq_a_length=40, max_seq_length=70, max_steps=-1, min_constraints_to_satisfy=2, model_name_or_path='pre_trained/base-vg-labels/ep_67_588997', n_gpu=2, no_cuda=False, num_beams=5, num_keep_best=1, num_labels=2, num_return_sequences=1, num_train_epochs=30, num_workers=4, output_dir='output/', output_hidden_states=False, output_mode='classification', per_gpu_eval_batch_size=128, per_gpu_train_batch_size=64, repetition_penalty=1, save_steps=5000, scheduler='linear', scst=False, seed=88, temperature=1, test_yaml='oscar/coco_caption/test.yaml', tokenizer_name='', top_k=0, top_p=1, train_yaml='oscar/coco_caption/train.yaml', use_cbs=False, val_yaml='oscar/coco_caption/val.yaml', warmup_steps=0, weight_decay=0.05)
/home/u2/바탕화면/Kim_Project/Oscar/oscar/utils/misc.py:33: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.
return yaml.load(fp)
2021-02-16 03:37:09,671 vlpretrain INFO: ***** Running training *****
INFO:vlpretrain:***** Running training *****
2021-02-16 03:37:09,672 vlpretrain INFO: Num examples = 566747
INFO:vlpretrain: Num examples = 566747
2021-02-16 03:37:09,672 vlpretrain INFO: Num Epochs = 30
INFO:vlpretrain: Num Epochs = 30
2021-02-16 03:37:09,672 vlpretrain INFO: Batch size per GPU = 64
INFO:vlpretrain: Batch size per GPU = 64
2021-02-16 03:37:09,672 vlpretrain INFO: Total train batch size (w. parallel, & accumulation) = 128
INFO:vlpretrain: Total train batch size (w. parallel, & accumulation) = 128
2021-02-16 03:37:09,672 vlpretrain INFO: Gradient Accumulation steps = 1
INFO:vlpretrain: Gradient Accumulation steps = 1
2021-02-16 03:37:09,672 vlpretrain INFO: Total optimization steps = 132840
INFO:vlpretrain: Total optimization steps = 132840
oscar/run_captioning.py:110: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)
return torch.Tensor(features)
oscar/run_captioning.py:110: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)
return torch.Tensor(features)
oscar/run_captioning.py:110: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)
return torch.Tensor(features)
oscar/run_captioning.py:110: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)
return torch.Tensor(features)
Traceback (most recent call last):
File "oscar/run_captioning.py", line 884, in <module>
main()
File "oscar/run_captioning.py", line 863, in main
global_step, avg_loss = train(args, train_dataset, val_dataset, model, tokenizer)
File "oscar/run_captioning.py", line 434, in train
outputs = model(**inputs)
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 161, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 171, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py", line 86, in parallel_apply
output.reraise()
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/_utils.py", line 428, in reraise
raise self.exc_type(msg)
StopIteration: Caught StopIteration in replica 0 on device 0.
Original Traceback (most recent call last):
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker
output = module(*input, **kwargs)
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/u2/바탕화면/Kim_Project/Oscar/oscar/modeling/modeling_bert.py", line 440, in forward
return self.encode_forward(*args, **kwargs)
File "/home/u2/바탕화면/Kim_Project/Oscar/oscar/modeling/modeling_bert.py", line 448, in encode_forward
encoder_history_states=encoder_history_states)
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/u2/바탕화면/Kim_Project/Oscar/oscar/modeling/modeling_bert.py", line 223, in forward
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
StopIteration
``` | 02-15-2021 18:44:37 | 02-15-2021 18:44:37 | Hi! It seems that you're on a very old transformers library version. I would recommend you upgrade to a more recent versions, as this particular has been patched several months ago.<|||||>@LysandreJik Hi! thank you for answering. But I'm using version 4.3.2<|||||>Are you sure? The error happens on the following line:
```py
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
```
This does not exist in recent Transformers versions.<|||||>It was changed in may: https://github.com/huggingface/transformers/pull/4300<|||||>@LysandreJik Oh.. sorry. i was confused. I installed and uninstalled because it interupted run the code, saying it can't import pytorch_transformers.
The code can run with transformers from "https://github.com/huggingface/transformers/tree/067923d3267325f525f4e46f357360c191ba562e."
Is there any way that i can run?
this is the full traceback when i install transformers
```
Traceback (most recent call last):
File "oscar/run_captioning.py", line 20, in <module>
from oscar.utils.cbs import ConstraintFilter, ConstraintBoxesReader
File "/home/u2/바탕화면/Oscar/oscar/utils/cbs.py", line 13, in <module>
from oscar.modeling.modeling_utils import BeamHypotheses
File "/home/u2/바탕화면/Oscar/oscar/modeling/modeling_utils.py", line 8, in <module>
from transformers.pytorch_transformers.modeling_bert import (BertConfig,
ModuleNotFoundError: No module named 'transformers.pytorch_transformers'
```
<|||||>Oh that's a very old version indeed! Unfrotunately, without knowing what's in your `oscar` folder it's a bit complicated to help you.
For example, the following line is erroneous:
```
from transformers.pytorch_transformers.modeling_bert import (BertConfig,
```
It should simply be
```
from transformers import BertConfig
```<|||||>@LysandreJik It imports many .py files from pytorch_transformers/modeling_bert.
Do you think if i chage below code, I can fix it?
` extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility`


<|||||>This is the try/except we implemented to prevent that error from happening. You can add it to your file:
```py
try:
dtype = next(self.parameters()).dtype
except StopIteration:
# For nn.DataParallel compatibility in PyTorch 1.5
def find_tensor_attributes(module: nn.Module) -> List[Tuple[str, Tensor]]:
tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
return tuples
gen = self._named_members(get_members_fn=find_tensor_attributes)
first_tuple = next(gen)
dtype = first_tuple[1].dtype
extended_attention_mask = extended_attention_mask.to(dtype)
```<|||||>@LysandreJik I added it on my modeling_bert.py.
I got this traceback.
I guess it's hard to fix it just editing some code from original file.
I really appreciate your help!
if you have any idea to solve it, please share with me.
Thank you again.
```
Traceback (most recent call last):
File "oscar/run_captioning.py", line 886, in <module>
main()
File "oscar/run_captioning.py", line 865, in main
global_step, avg_loss = train(args, train_dataset, val_dataset, model, tokenizer)
File "oscar/run_captioning.py", line 436, in train
outputs = model(**inputs)
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 161, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 171, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py", line 86, in parallel_apply
output.reraise()
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/_utils.py", line 428, in reraise
raise self.exc_type(msg)
NameError: Caught NameError in replica 0 on device 0.
Original Traceback (most recent call last):
File "/home/u2/바탕화면/Oscar/oscar/modeling/modeling_bert.py", line 224, in forward
dtype = next(self.parameters()).dtype
StopIteration
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker
output = module(*input, **kwargs)
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/u2/바탕화면/Oscar/oscar/modeling/modeling_bert.py", line 453, in forward
return self.encode_forward(*args, **kwargs)
File "/home/u2/바탕화면/Oscar/oscar/modeling/modeling_bert.py", line 461, in encode_forward
encoder_history_states=encoder_history_states)
File "/home/u2/anaconda3/envs/oscar/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/u2/바탕화면/Oscar/oscar/modeling/modeling_bert.py", line 227, in forward
def find_tensor_attributes(module: nn.Module) -> List[Tuple[str, Tensor]]:
NameError: name 'List' is not defined
```
<|||||>These are the type hints. Just remove them if you don't need them or don't want to import them:
```py
try:
dtype = next(self.parameters()).dtype
except StopIteration:
# For nn.DataParallel compatibility in PyTorch 1.5
def find_tensor_attributes(module):
tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
return tuples
gen = self._named_members(get_members_fn=find_tensor_attributes)
first_tuple = next(gen)
dtype = first_tuple[1].dtype
extended_attention_mask = extended_attention_mask.to(dtype)
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,198 | closed | ONNX Export - cannot resolve operator 'Shape' with opsets: ai.onnx v11 | ## Environment info
- `transformers` version: 4.3.2
- Platform: Windows-10-10.0.18362-SP0
- Python version: 3.8.7
- PyTorch version (GPU?): 1.7.1+cu110 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@LysandreJik
## Information
Model I am using: DistilBertForTokenClassification
The problem arises when using:
Exporting the model to ONNX and trying to load it with onnxjs in NodeJS.
The tasks I am working on is:
Classifying tokens with DistilBertForTokenClassification
## To reproduce
Try to convert DistilBertForTokenClassification to ONNX and load it with onnxjs. I have prepared this minimal repo https://github.com/biro-mark/transformers-onnx-shape-operator-issue
1. python save_model.py
2. python -m transformers.convert_graph_to_onnx --model ./model --framework pt --tokenizer distilbert-base-uncased onnx/out.onnx
3. node index.js
This outputs ```RuntimeError: abort(TypeError: cannot resolve operator 'Shape' with opsets: ai.onnx v11). Build with -s ASSERTIONS=1 for more info.
at process.abort (C:\Users\marki\node_modules\onnxjs\dist\onnx-wasm.js:9:13921)
at process.emit (events.js:314:20)
at processPromiseRejections (internal/process/promises.js:209:33)
at processTicksAndRejections (internal/process/task_queues.js:98:32)```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Expected no error to be thrown. ONNX export should only use operators that are valid for the opset. `Shape` operator looks like it was added in opset v13 but I might also be misinterpreting this table https://github.com/onnx/onnx/blob/master/docs/Operators.md. Adding `--opset 13` flag to the `convert_graph_to_onnx` gives
```
====== Converting model to ONNX ======
ONNX opset version set to: 13
Loading pipeline (model: ./model, tokenizer: distilbert-base-uncased)
Creating folder C:\Users\marki\eg\onnx
Using framework PyTorch: 1.7.1+cu110
Found input input_ids with shape: {0: 'batch', 1: 'sequence'}
Found input attention_mask with shape: {0: 'batch', 1: 'sequence'}
Found output output_0 with shape: {0: 'batch', 1: 'sequence'}
Ensuring inputs are in correct order
head_mask is not present in the generated input list.
Generated inputs order: ['input_ids', 'attention_mask']
Error while converting the model: Unsupported ONNX opset version: 13
```
| 02-15-2021 18:38:22 | 02-15-2021 18:38:22 | Sorry I think I misinterpreted the operators table https://github.com/onnx/onnx/blob/master/docs/Operators.md and `Shape` should have been available since opset 1, getting an update in opset 13.
This seems to be an issue with `onnxjs` not implementing the full set of operators in opset 11. |
transformers | 10,197 | closed | Fine-tuning Seq2Seq models for Machine translation | Good morning,
@micheledaddetta1
We were experimenting with Seq2Seq models such as MarianMT or T5.
I was wondering if there is a common way to fine-tune those models with custom datasets for the machine translation task.
Specifically we did the following:
```python
embeddings = self.batch_encode_plus(sentences, padding=True, verbose=False)
embeddings = embeddings.to(self.model.device)
labels = self.batch_encode_plus(target_sentences, padding=True, verbose=False).input_ids.to(self.model.device) # expected output tokens
outputs = self.model(input_ids=embeddings.input_ids, labels=decoder_input_ids, return_dict=True)
output_sentences = self.model.generate(**embeddings)
output_sentences = self.decode(output_sentences)
# we also compute sentence embeddings for embedding alignment purposes.
return output_sentences, outputs.loss
```
Is it correct to directly use `outputs.loss` to optimize the model for the machine translation task? | 02-15-2021 18:07:41 | 02-15-2021 18:07:41 | Maybe @patrickvonplaten or @patil-suraj can chime in here!<|||||>Hey @MorenoLaQuatra
The `run_seq2seq.py` supports translation with custom dataset. And you can use T5, mT5, MarianMT, mBART, mBART-50 for fine-tuning.
https://github.com/huggingface/transformers/tree/master/examples/seq2seq
And the best place to ask this question is our forum https://discuss.huggingface.co/
Hope this helps :) <|||||>Hi @patil-suraj, thank you for the feedback.
Actually we are trying to train it in a python script (the overall architecture is more complex than the single network). We were asking about the translation loss. If we do as reported in the above snippet, do we optimize the translation loss?
The finetuning for MarianMT use the same head and loss of the training phase?
Thank you for your time.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,196 | closed | [CI] make the examples sub-group of tests run always | the examples tests weren't running if some previous job failed. this fixes it to always run.
@LysandreJik | 02-15-2021 18:00:36 | 02-15-2021 18:00:36 | |
transformers | 10,195 | closed | Specify dataset dtype | There was an issue in `datasets` <1.3.0 where the datasets type wouldn't be kept. Since this bug was patched, we have to specify the correct type for the dataset.
Co-authored-by: Quentin Lhoest <[email protected]>
| 02-15-2021 17:48:22 | 02-15-2021 17:48:22 | |
transformers | 10,194 | closed | Uploaded a new model but is not found on the hub. | # 🌟 New model addition
I recently added this model: https://huggingface.co/flexudy/t5-small-wav2vec2-grammar-fixer
However, I get this error whilst trying to download it.
```
Can't load tokenizer for 'flexudy/t5-small-wav2vec2-grammar-fixer'
```
How can I fix it please?
| 02-15-2021 16:55:03 | 02-15-2021 16:55:03 | Hi @zolekode ,
the folder structure is not quite correct:
https://huggingface.co/flexudy/t5-small-wav2vec2-grammar-fixer/tree/main
You just need to move everything from the `t5-small-wav2vec2-grammar-fixer` folder to the root folder. Then it should work :hugs: <|||||>Ah I see. awesome. Thanks alot @stefan-it |
transformers | 10,193 | closed | Make use of our copy-consistency script for task-specific models | This is an intermediate issue, which is why it gets both the good first issue and good second issue tags.
We have an automated script to check when copies of the same code are consistent inside the library, which allows us to avoid subclassing and keep all code for one model's forward pass inside one file (see our [philosophy]() for more details on this).
The XxxModelForYyy are very similar to one another and should be able to leverage that functionality, so we can easily change only one file when there is a bug/docstring to tweak and all the others are updated. More precisely, models that have a pooler layer could probably base themselves on BERT and models that don't could be based on ELECTRA. The Seq2Seq models that are a bit particular could be based on BART.
To enable this, the checkpoint use in the decorator `@add_code_sample_docstrings` needs to be defined in a constant (otherwise it will end up being copied which we don't want) so to tackle this issue, your mission, should you accept it, will have two steps:
1. Define in all modeling files a `_CHECKPOINT_FOR_DOC` at the beginning (with `_TOKENIZER_FOR_DOC` and `_CONFIG_FOR_DOC`) that should then be used in all the XxxModelForYyy.
2. Adds the relevant `# Copied from xxx with Xxx -> Yyy` whenever possible. | 02-15-2021 15:32:12 | 02-15-2021 15:32:12 | Hi @sgugger I'm up for the mission. After looking though the code I think I have a basic understanding of what you mean. However, would you be able to provide an example on one model just for clarification? I'm a bit confused on the second step
>modeling_bert.py
```
_CONFIG_FOR_DOC = "BertConfig"
_TOKENIZER_FOR_DOC = "BertTokenizer"
_CHECKPOINT_FOR_DOC = "bert-base-uncased"
```
...
```
class BertForSequenceClassification(BertPreTrainedModel):
...
...
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
```
Thank you<|||||>I've given an example of the first step in the issue above. Sadly the second step can't fully work with our utils just yet, I need to make some adjustments to our internal tooling. If you want to begin on step 1 though, don't hesitate! |
transformers | 10,192 | closed | run_mlm.py not utilizing TPU | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.2 and Latest version forked from github
- Platform: Linux (Colab env)
- Python version: 3.6
- PyTorch version (GPU?): XLA 1.7
- Tensorflow version (GPU?): None
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: Colab TPU with xla_spawn.py
### Who can help
@sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): DistilBert
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```
!python /content/transformers/examples/xla_spawn.py --num_cores 8 /content/transformers/examples/language-modeling/run_mlm.py \
--model_type distilbert \
--config_name /content/TokenizerFiles \
--tokenizer_name /content/TokenizerFiles \
--train_file Files/file_aa.txt \
--mlm_probability 0.15 \
--output_dir "/content/TrainingCheckpoints" \
--do_train --per_device_train_batch_size 32 \
--save_steps 500 --disable_tqdm False \
--line_by_line True --max_seq_length 150 \
--pad_to_max_length False \
--cache_dir /content/cache_dir \
--save_total_limit 2
```
My tokenizer and config files are both just {model_type: "distilbert"} and are present in TokenizerFiles folder along with my vocab.txt
The output I get is
```
WARNING:root:TPU has started up successfully with version pytorch-1.7
2021-02-15 14:40:37.816883: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
WARNING:root:TPU has started up successfully with version pytorch-1.7
2021-02-15 14:40:57.239070: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
2021-02-15 14:40:57.283838: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
2021-02-15 14:40:57.446951: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
2021-02-15 14:40:57.470266: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
2021-02-15 14:40:57.473336: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
2021-02-15 14:40:57.686903: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
2021-02-15 14:40:57.863940: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
2021-02-15 14:40:58.555214: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
WARNING:run_mlm:Process rank: -1, device: xla:1, n_gpu: 0distributed training: False, 16-bits training: False
INFO:run_mlm:Training/evaluation parameters TrainingArguments(output_dir=/content/TrainingCheckpoints, overwrite_output_dir=False, do_train=True, do_eval=None, do_predict=False, evaluation_strategy=EvaluationStrategy.NO, prediction_loss_only=False, per_device_train_batch_size=32, per_device_eval_batch_size=8, gradient_accumulation_steps=1, eval_accumulation_steps=None, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=-1, lr_scheduler_type=SchedulerType.LINEAR, warmup_steps=0, logging_dir=runs/Feb15_14-41-21_34a4105ebd5a, logging_first_step=False, logging_steps=500, save_steps=500, save_total_limit=2, no_cuda=False, seed=42, fp16=False, fp16_opt_level=O1, fp16_backend=auto, local_rank=-1, tpu_num_cores=8, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=500, dataloader_num_workers=0, past_index=-1, run_name=/content/TrainingCheckpoints, disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=False, deepspeed=None, label_smoothing_factor=0.0, adafactor=False, group_by_length=False, report_to=['tensorboard'], ddp_find_unused_parameters=None, dataloader_pin_memory=True, _n_gpu=0)
Using custom data configuration default
Downloading and preparing dataset text/default-e939092a7eff14a8 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab...
02/15/2021 14:41:22 - WARNING - run_mlm - Process rank: -1, device: xla:0, n_gpu: 0distributed training: False, 16-bits training: False
Dataset text downloaded and prepared to /root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab. Subsequent calls will reuse this data.
[INFO|configuration_utils.py:447] 2021-02-15 14:41:22,465 >> loading configuration file /content/TokenizerFiles/config.json
[INFO|configuration_utils.py:485] 2021-02-15 14:41:22,466 >> Model config DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.3.2",
"vocab_size": 30522
}
[INFO|configuration_utils.py:447] 2021-02-15 14:41:22,467 >> loading configuration file /content/TokenizerFiles/config.json
[INFO|configuration_utils.py:485] 2021-02-15 14:41:22,476 >> Model config DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.3.2",
"vocab_size": 30522
}
[INFO|tokenization_utils_base.py:1688] 2021-02-15 14:41:22,476 >> Model name '/content/TokenizerFiles' not found in model shortcut name list (distilbert-base-uncased, distilbert-base-uncased-distilled-squad, distilbert-base-cased, distilbert-base-cased-distilled-squad, distilbert-base-german-cased, distilbert-base-multilingual-cased). Assuming '/content/TokenizerFiles' is a path, a model identifier, or url to a directory containing tokenizer files.
[INFO|tokenization_utils_base.py:1721] 2021-02-15 14:41:22,477 >> Didn't find file /content/TokenizerFiles/tokenizer.json. We won't load it.
[INFO|tokenization_utils_base.py:1721] 2021-02-15 14:41:22,478 >> Didn't find file /content/TokenizerFiles/added_tokens.json. We won't load it.
[INFO|tokenization_utils_base.py:1721] 2021-02-15 14:41:22,478 >> Didn't find file /content/special_tokens_map.json. We won't load it.
[INFO|tokenization_utils_base.py:1784] 2021-02-15 14:41:22,479 >> loading file /content/TokenizerFiles/vocab.txt
[INFO|tokenization_utils_base.py:1784] 2021-02-15 14:41:22,479 >> loading file None
[INFO|tokenization_utils_base.py:1784] 2021-02-15 14:41:22,480 >> loading file None
[INFO|tokenization_utils_base.py:1784] 2021-02-15 14:41:22,480 >> loading file None
[INFO|tokenization_utils_base.py:1784] 2021-02-15 14:41:22,480 >> loading file /content/TokenizerFiles/tokenizer_config.json
INFO:run_mlm:Training new model from scratch
Using custom data configuration default
Reusing dataset text (/root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab)
02/15/2021 14:41:22 - WARNING - run_mlm - Process rank: -1, device: xla:0, n_gpu: 0distributed training: False, 16-bits training: False
Using custom data configuration default
Reusing dataset text (/root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab)
02/15/2021 14:41:23 - WARNING - run_mlm - Process rank: -1, device: xla:0, n_gpu: 0distributed training: False, 16-bits training: False
Using custom data configuration default
Reusing dataset text (/root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab)
02/15/2021 14:41:23 - WARNING - run_mlm - Process rank: -1, device: xla:0, n_gpu: 0distributed training: False, 16-bits training: False
02/15/2021 14:41:23 - WARNING - run_mlm - Process rank: -1, device: xla:0, n_gpu: 0distributed training: False, 16-bits training: False
02/15/2021 14:41:23 - WARNING - run_mlm - Process rank: -1, device: xla:0, n_gpu: 0distributed training: False, 16-bits training: False
Using custom data configuration default
Reusing dataset text (/root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab)
Using custom data configuration default
Reusing dataset text (/root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab)
Using custom data configuration default
Reusing dataset text (/root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab)
02/15/2021 14:41:24 - WARNING - run_mlm - Process rank: -1, device: xla:0, n_gpu: 0distributed training: False, 16-bits training: False
Using custom data configuration default
Reusing dataset text (/root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab)
100% 2/2 [00:01<00:00, 1.72ba/s]
100% 2/2 [00:01<00:00, 1.65ba/s]
Loading cached processed dataset at /root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab/cache-0028d6bfc2eb6117.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab/cache-0028d6bfc2eb6117.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab/cache-0028d6bfc2eb6117.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab/cache-0028d6bfc2eb6117.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab/cache-0028d6bfc2eb6117.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/text/default-e939092a7eff14a8/0.0.0/daf90a707a433ac193b369c8cc1772139bb6cca21a9c7fe83bdd16aad9b9b6ab/cache-0028d6bfc2eb6117.arrow
[INFO|trainer.py:432] 2021-02-15 14:41:59,875 >> The following columns in the training set don't have a corresponding argument in `DistilBertForMaskedLM.forward` and have been ignored: special_tokens_mask.
[INFO|trainer.py:837] 2021-02-15 14:41:59,879 >> ***** Running training *****
[INFO|trainer.py:838] 2021-02-15 14:41:59,879 >> Num examples = 2000
[INFO|trainer.py:839] 2021-02-15 14:41:59,879 >> Num Epochs = 3
[INFO|trainer.py:840] 2021-02-15 14:41:59,879 >> Instantaneous batch size per device = 32
[INFO|trainer.py:841] 2021-02-15 14:41:59,879 >> Total train batch size (w. parallel, distributed & accumulation) = 256
[INFO|trainer.py:842] 2021-02-15 14:41:59,879 >> Gradient Accumulation steps = 1
[INFO|trainer.py:843] 2021-02-15 14:41:59,879 >> Total optimization steps = 24
17% 4/24 [03:56<17:13, 51.67s/it] # <------------------- HERE ------------------------>
Traceback (most recent call last):
Error in atexit._run_exitfuncs:
Traceback (most recent call last):
File "/usr/lib/python3.6/multiprocessing/popen_fork.py", line 28, in poll
pid, sts = os.waitpid(self.pid, flag)
KeyboardInterrupt
```
The file used here is only for testing and has a total of 2000 lines of text. It almost seems like the training is taking place on the CPU instead of the TPU.
The installation of xla was done using
```!pip install cloud-tpu-client==0.10 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.7-cp36-cp36m-linux_x86_64.whl```
I ran the same script a couple of days back and it worked fine so I don't know what is wrong now. At that time I had saved the tokenizer using ```.save()``` but due to some recent changes in the library, that doesn't work anymore. So I saved it using ```save_model()``` and it works fine now. Can this issue be because of that?
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
The training should be faster. The last time I ran run_mlm.py, I got almost 3 iterations per second | 02-15-2021 15:03:24 | 02-15-2021 15:03:24 | `--pad_to_max_length False` is the reason you have a very slow training: this creates batches of different sequence lengths but TPUs need fixed shapes to be efficient.
There was a bug in our argument parser before that ignored bool setting like this, so it may be the reason you are seeing that slow down now instead of before (but it was applying `pad_to_max_length=True` before because of that bug, even if you said the opposite). If you remove that option, you should see a faster training.<|||||>Perfect! Thank you so much! Closing this issue |
transformers | 10,191 | closed | Making TF BART-like models XLA and AMP compliant | # What does this PR do?
This PR makes the TF BART-like models compliant with AMP and XLA. The main issue for XLA was all the asserts, XLA is not compliant with them (see the [TF doc](https://www.tensorflow.org/xla/known_issues)), so I had to disable them if the model is run with another mode than eager.
TF Marian and Pegasus have still their XLA test locked because they are not working for XLA_GPU. I need to investigate more in order to better understand why. My first guess is because of the `TFXSinusoidalPositionalEmbedding` class. | 02-15-2021 14:44:15 | 02-15-2021 14:44:15 | I succeed to fix Marian and Pegasus, and my first guess was the good one. I basically reworked a bit how the embedding was created, and now it works in XLA_GPU. Of course, all the corresponding slow tests are passing, and the weights are properly loaded. |
transformers | 10,190 | closed | 0% GPU usage when using `hyperparameter_search` | _##_ Environment info
- `transformers` version: 4.4.0.dev0
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No (Single GPU) --> Colab
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
Models:
- ray/raytune: @richardliaw, @amogkam
- trainer: @sgugger
## Information
Model I am using (Bert, XLNet ...): RoBERTa
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
This is in continuation with #10055 where the underlying code is the same, and it is more or less the same as the official example. The problem is that when I start `hyperparameter_search` then it just keeps running with 0% GPU usage (memory is occupied) and the CPU also remains relatively idle:-
```
== Status ==
Memory usage on this node: 5.9/25.5 GiB
PopulationBasedTraining: 0 checkpoints, 0 perturbs
Resources requested: 1/4 CPUs, 1/1 GPUs, 0.0/14.99 GiB heap, 0.0/5.18 GiB objects (0/1.0 accelerator_type:P100)
Result logdir: /root/ray_results/_inner_2021-02-15_11-45-33
Number of trials: 1/100 (1 RUNNING)
+--------------------+----------+-------+-------------+--------------+--------------+----------------+-----------------+-----------------+--------------------+-------------------------------+---------+----------------+
| Trial name | status | loc | adafactor | adam_beta1 | adam_beta2 | adam_epsilon | learning_rate | max_grad_norm | num_train_epochs | per_device_train_batch_size | seed | weight_decay |
|--------------------+----------+-------+-------------+--------------+--------------+----------------+-----------------+-----------------+--------------------+-------------------------------+---------+----------------|
| _inner_4fd43_00000 | RUNNING | | True | 0.862131 | 0.813033 | 1e-09 | 2.34754e-05 | 0.0056821 | 2 | 16 | 21.1968 | 0.95152 |
+--------------------+----------+-------+-------------+--------------+--------------+----------------+-----------------+-----------------+--------------------+-------------------------------+---------+----------------+
```
Sometimes, there are also warnings that the single worker is pending due to lack of resources, however my CPU usage is minimum, plenty of RAM is free (~24 Gb) and GPU also some about a gig of free memory.
```
2021-02-15 13:56:53,761 WARNING worker.py:1107 -- The actor or task with ID ffffffffffffffff44ed5e1383be630817647ecd01000000 cannot be scheduled right now. It requires {CPU: 1.000000}, {GPU: 1.000000} for placement, but this node only has remaining {3.000000/4.000000 CPU, 14.990234 GiB/14.990234 GiB memory, 0.000000/1.000000 GPU, 1.000000/1.000000 node:172.28.0.2, 5.126953 GiB/5.126953 GiB object_store_memory, 1.000000/1.000000 accelerator_type:V100}
. In total there are 0 pending tasks and 1 pending actors on this node. This is likely due to all cluster resources being claimed by actors. To resolve the issue, consider creating fewer actors or increase the resources available to this Ray cluster. You can ignore this message if this Ray cluster is expected to auto-scale.
```
This is how the tuner looks like:-
```
from ray.tune.suggest.hyperopt import HyperOptSearch
from ray.tune.schedulers import PopulationBasedTraining
from ray import tune
import random
pbt = PopulationBasedTraining(
time_attr="training_iteration",
metric="accuracy",
mode="max",
perturbation_interval=10, # every 10 `time_attr` units
# (training_iterations in this case)
hyperparam_mutations={
"weight_decay": tune.uniform(1, 0.0001),
"seed": tune.uniform(1,20000),
"learning_rate": tune.choice([1e-5, 2e-5, 3e-5, 4e-5, 5e-5, 6e-5, 2e-7, 1e-7, 3e-7, 2e-8]),
"adafactor": tune.choice(['True','False']),
"adam_beta1": tune.uniform(1.0, 0.0),
"adam_beta2": tune.uniform(1.0, 0),
"adam_epsilon": tune.choice([1e-8, 2e-8, 3e-8, 1e-9, 2e-9, 3e-10]),
"max_grad_norm": tune.uniform(1.0, 0),
})
best_run = trainer.hyperparameter_search(n_trials=100, compute_objective='accuracy', direction="maximize", backend='ray',
scheduler=pbt)
```
Using `HyperOptScheduler` causes OOMs | 02-15-2021 13:48:23 | 02-15-2021 13:48:23 | I tried decorating a function that contains the tranier command like this:-
```
@ray.remote(num_cpus=3, num_gpus=1, accelerator_type=ray.accelerators.NVIDIA_TESLA_V100)
def search():
trainer.hyperparameter_search(n_trials=100, compute_objective='accuracy', direction="maximize", backend='ray',
scheduler=pbt)
search.remote()
```
but I am constantly getting:
`AttributeError: module 'ray' has no attribute 'accelerators'`
which I think is there because I may have written it the wrong way. can anyone shed any light on this?
<|||||>Hi @neel04 can you add this arg to `trainer.hyperparameter_search`:
```
resources_per_trial={"cpu": 1, "gpu": 1}
```
This will let Tune know to reserve 1 CPU and 1 GPU for each trial.
Also, after instantiating your training_args, but before passing it into the `Trainer` can you also add this: `training_args._n_gpu = 1`.
Here is a more up to date example if you want to try it out and see if it works for you: https://github.com/amogkam/ray/blob/hf-pbt/python/ray/tune/examples/pbt_transformers/pbt_transformers.py
<|||||>@amogkam Bless you sir! I am now getting mostly 100% GPU usage (but only around 6-7GB VRAM usage out of available 16Gb).
However, each of my trial is failing with this error:-
```
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/ray/tune/trial_runner.py", line 586, in _process_trial
results = self.trial_executor.fetch_result(trial)
File "/usr/local/lib/python3.6/dist-packages/ray/tune/ray_trial_executor.py", line 609, in fetch_result
result = ray.get(trial_future[0], timeout=DEFAULT_GET_TIMEOUT)
File "/usr/local/lib/python3.6/dist-packages/ray/_private/client_mode_hook.py", line 47, in wrapper
return func(*args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/ray/worker.py", line 1456, in get
raise value.as_instanceof_cause()
ray.exceptions.RayTaskError(TuneError): ray::ImplicitFunc.train_buffered() (pid=415, ip=172.28.0.2)
File "python/ray/_raylet.pyx", line 480, in ray._raylet.execute_task
File "python/ray/_raylet.pyx", line 432, in ray._raylet.execute_task.function_executor
File "/usr/local/lib/python3.6/dist-packages/ray/tune/trainable.py", line 167, in train_buffered
result = self.train()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/trainable.py", line 226, in train
result = self.step()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 366, in step
self._report_thread_runner_error(block=True)
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 513, in _report_thread_runner_error
("Trial raised an exception. Traceback:\n{}".format(err_tb_str)
ray.tune.error.TuneError: Trial raised an exception. Traceback:
ray::ImplicitFunc.train_buffered() (pid=415, ip=172.28.0.2)
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 248, in run
self._entrypoint()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 316, in entrypoint
self._status_reporter.get_checkpoint())
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 576, in _trainable_func
output = fn()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 651, in _inner
inner(config, checkpoint_dir=None)
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 645, in inner
fn(config, **fn_kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/integrations.py", line 160, in _objective
local_trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 983, in train
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1059, in _maybe_log_save_evaluate
self._report_to_hp_search(trial, epoch, metrics)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 640, in _report_to_hp_search
self.objective = self.compute_objective(metrics.copy())
TypeError: 'str' object is not callable
```
Is it something related to `ray/tune` or is this a wrong argument on my part?
BTW would you also happen to know how to set a fixed batch size for all trials? for some reason, it is overriding the `batch_size` provided in the Trainer_arguments and trying out it's own random ones<|||||>Ah this is because you are passing in `'accuracy'` as the `compute_objective` to `hyperparameter_search`. The `compute_objective` should actually be a function that computes the objective to minimize or maximize from the metrics returned by `evaluate`. You can also not pass one in, and it will default to `trainer_utils.default_compute_objective`. <|||||>@amogkam MIssed that :( thanx a lot for taking the time out to help me!! :+1: :100: :1st_place_medal:
Thanx to amogkam's comment, the issuse described here has been resolved, so I am closing this. but it is still giving the error:-
```
2021-02-15 18:58:56,343 ERROR worker.py:1053 -- Possible unhandled error from worker: ray::ImplicitFunc.train_buffered() (pid=2319, ip=172.28.0.2)
File "python/ray/_raylet.pyx", line 480, in ray._raylet.execute_task
File "python/ray/_raylet.pyx", line 432, in ray._raylet.execute_task.function_executor
File "/usr/local/lib/python3.6/dist-packages/ray/tune/trainable.py", line 167, in train_buffered
result = self.train()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/trainable.py", line 226, in train
result = self.step()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 366, in step
self._report_thread_runner_error(block=True)
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 513, in _report_thread_runner_error
("Trial raised an exception. Traceback:\n{}".format(err_tb_str)
ray.tune.error.TuneError: Trial raised an exception. Traceback:
ray::ImplicitFunc.train_buffered() (pid=2319, ip=172.28.0.2)
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 248, in run
self._entrypoint()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 316, in entrypoint
self._status_reporter.get_checkpoint())
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 576, in _trainable_func
output = fn()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 651, in _inner
inner(config, checkpoint_dir=None)
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 645, in inner
fn(config, **fn_kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/integrations.py", line 160, in _objective
local_trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 983, in train
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1059, in _maybe_log_save_evaluate
self._report_to_hp_search(trial, epoch, metrics)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 640, in _report_to_hp_search
self.objective = self.compute_objective(metrics.copy())
File "<ipython-input-20-4880cfa49052>", line 5, in compute_metrics
AttributeError: 'dict' object has no attribute 'label_ids'
```
It's not clear to me why there is a whole string of errors on code copy/pasted from training models (which executes successfully). but there are 2 issues:-
1. Firstly, the `train_bs` is randomly selected and almost always causes OOM's - arguments do not override this behavior
2. The above "dict" error happens, if OOM does not get it.
can anyone also explain why the method in the official docs doesn't work even though it is the same task with the same libraries? Has the `ray` framework changed and the docs do not reflect it? Honestly, it is becoming difficult exactly where to post these errors - ray OR HuggingFace. They require a person intimately familiar with both.<|||||>@neel04 are you running this example- https://github.com/amogkam/ray/blob/hf-pbt/python/ray/tune/examples/pbt_transformers/pbt_transformers.py? This is the most up to date one and should work with transformers v4.<|||||>I think the example is a bit verbose and some of it goes over my head :) So I am having difficulty in identifying what steps I have configured wrong and what exactly needs to be corrected. Understanding things like passing the `tune_configs` are easy to get, but the errors are much more difficult to track<|||||>OK got it. The stack trace you just posted is coming from the `compute_metrics` that is passed into your `Trainer`. What does that look like?<|||||>`compute_metrics` is standard code from the official example:-
```
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted') #none gives score for each class
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
```
It worked perfectly when training the model without any tuning, so I doubt the true error originates from here.
Also, would you mind telling me how you tracked the problem to `compute_metrics` since I couldn't sniff any clues to there in the error?<|||||>The stack trace says `line 5, in compute_metrics` so I thought it was coming from there. Do you mind sharing your full code to reproduce this?<|||||>Sure. Sorry if the code is a bit verbose.
```
%%capture
!pip install ray[tune]
!pip install ray
!pip install -q transformers
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from transformers import RobertaForSequenceClassification, Trainer, TrainingArguments
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted') #none gives score for each class
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
training_args = TrainingArguments(
output_dir='./results', # output directory
overwrite_output_dir = True,
num_train_epochs=20, # total number of training epochs
per_device_train_batch_size=8, # batch size per device during training
per_device_eval_batch_size=8, # batch size for evaluation,
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
evaluation_strategy='steps',
learning_rate=2e-5,
fp16 = True,
load_best_model_at_end = True,
metric_for_best_model = 'accuracy',
greater_is_better = True,
seed = 101,
do_eval = True,
do_train = True,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-8,
max_grad_norm=1.0,
adafactor = False
)
training_args._n_gpu = 1
def model_init():
return RobertaForSequenceClassification.from_pretrained('/content/drive/MyDrive/checkpoint-2700', num_labels=20)
trainer = Trainer(
model_init=model_init,
args=training_args,
train_dataset=train_dataset, # Indexing
eval_dataset=val_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics)
from ray.tune.suggest.hyperopt import HyperOptSearch
from ray.tune.schedulers import PopulationBasedTraining
from ray.tune import CLIReporter
from ray import tune
import random
pbt = PopulationBasedTraining(
time_attr="training_iteration",
metric="accuracy",
mode="max",
perturbation_interval=10, # every 10 `time_attr` units
# (training_iterations in this case)
hyperparam_mutations={
"weight_decay": tune.uniform(1, 0.0001),
"seed": tune.uniform(1,20000),
"learning_rate": tune.choice([1e-5, 2e-5, 3e-5, 4e-5, 5e-5, 6e-5, 2e-7, 1e-7, 3e-7, 2e-8]),
"adafactor": tune.choice(['True','False']),
"adam_beta1": tune.uniform(1.0, 0.0),
"adam_beta2": tune.uniform(1.0, 0),
"adam_epsilon": tune.choice([1e-8, 2e-8, 3e-8, 1e-9, 2e-9, 3e-10]),
"max_grad_norm": tune.uniform(1.0, 0),
})
reporter = CLIReporter(
parameter_columns={
"weight_decay": "w_decay",
"learning_rate": "lr",
"per_device_train_batch_size": "train_bs/gpu",
"num_train_epochs": "num_epochs"},
metric_columns=["eval_acc", "eval_loss", "epoch", "training_iteration"])
tune_config = {
"per_device_train_batch_size": 8,
"per_device_eval_batch_size": 16,
"num_train_epochs": tune.choice([15,20,25])
}
best = trainer.hyperparameter_search(hp_space = lambda _: tune_config,
n_trials=100, compute_objective=compute_metrics, direction="maximize", backend='ray', #search_alg=HyperOptSearch(metric='accuracy', mode='max', use_early_stopped_trials=True)
scheduler=pbt, resources_per_trial={"cpu": 2, "gpu": 1}, keep_checkpoints_num=1,
name = "tune_transformer_pbt", progress_reporter=reporter)
```<|||||>Ah @neel04, the error message is happening because `compute_metrics` is being passed as the `compute_objective` arg in `trainer.hyperparameter_search`. If you remove this arg your code runs fine.
`compute_objective` should be a function that takes in the output of `evaluate` (which is the dictionary returned `compute_metrics`) as an input and returns a single float value (see the docstring). It is not the same as `compute_metrics`. So here you should just be returning the "accuracy" value from the input dictionary. Something like this should work I believe:
```
def compute_objective(metrics):
return metrics["accuracy"]
```<|||||>So I tried that above, but apparently `evaluate` does not return "accuracy", so as a workaround I switched to `eval_accuracy`.
But this creates a new problem; this error comes in the first trial **but** it doesn't go on to the next trial. Could be that it is training? GPU usage seems to be 0, so I doubt it is training but it is not terminating the process or moving on. Strange.
```
2021-02-17 10:57:12,244 ERROR worker.py:1053 -- Possible unhandled error from worker: ray::ImplicitFunc.train_buffered() (pid=1340, ip=172.28.0.2)
File "python/ray/_raylet.pyx", line 480, in ray._raylet.execute_task
File "python/ray/_raylet.pyx", line 432, in ray._raylet.execute_task.function_executor
File "/usr/local/lib/python3.6/dist-packages/ray/tune/trainable.py", line 167, in train_buffered
result = self.train()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/trainable.py", line 226, in train
result = self.step()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 366, in step
self._report_thread_runner_error(block=True)
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 513, in _report_thread_runner_error
("Trial raised an exception. Traceback:\n{}".format(err_tb_str)
ray.tune.error.TuneError: Trial raised an exception. Traceback:
ray::ImplicitFunc.train_buffered() (pid=1340, ip=172.28.0.2)
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 248, in run
self._entrypoint()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 316, in entrypoint
self._status_reporter.get_checkpoint())
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 576, in _trainable_func
output = fn()
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 651, in _inner
inner(config, checkpoint_dir=None)
File "/usr/local/lib/python3.6/dist-packages/ray/tune/function_runner.py", line 645, in inner
fn(config, **fn_kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/integrations.py", line 160, in _objective
local_trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 925, in train
for step, inputs in enumerate(epoch_iterator):
File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py", line 435, in __next__
data = self._next_data()
File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py", line 475, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "<ipython-input-12-cd510628f360>", line 10, in __getitem__
TypeError: new(): invalid data type 'str'
```
It looks like it Is pointing to 'objective', which is the same function you wrote above:-
```
def compute_objective(metrics):
return metrics["eval_accuracy"] #does not return accuracy
```
Interestingly, removing the args `compute_objective`and `direction` does not yield anything, so I figured the problem must be elsewhere.
Putting `eval_accuracy` in the PBT parameters and making the `compute_objective` solves the issue.
Thanks a lot @amogkam for your support!! we need more people like you :+1: :rocket: :partying_face:
|
transformers | 10,189 | closed | Fix TF template | # What does this PR do?
This PR fixes the TF template for the tests by adding the missing onnx boolean. | 02-15-2021 13:27:18 | 02-15-2021 13:27:18 | |
transformers | 10,188 | closed | Failing Multi-GPU trainer test | This test is currently [failing in a multi-GPU setup](https://github.com/huggingface/transformers/runs/1902689616?check_suite_focus=true):
```
FAILED tests/test_trainer_distributed.py::TestTrainerDistributed::test_trainer
```
The error is the following:
```
RuntimeError: NCCL error in: /pytorch/torch/lib/c10d/ProcessGroupNCCL.cpp:784, unhandled system error, NCCL version 2.7.8
```
cc @sgugger @stas00 | 02-15-2021 12:27:58 | 02-15-2021 12:27:58 | I have tried on my machine and the test passes, so the bug is linked to the setup of the machine executing the multi-GPU tests. I have never seen that error before but I would guess there is something wrong with nccl/cuda?<|||||>Retrieved the backtrace:
The error is: `RuntimeError: Address already in use`
Which means that more than one of these was running at the same time or one from a previous run is zombie and is holding this port. Probably need to try to catch that case and try a different port. I will have a look
Full trace:
```
tests/test_trainer_distributed.py:72:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
cmd = ['/home/github_actions/actions-runner/_work/transformers/transformers/.env/bin/python', '-m', 'torch.distributed.launc.../github_actions/actions-runner/_work/transformers/transformers/tests/test_trainer_distributed.py', '--output_dir', ...]
env = {'CI': 'true', 'GITHUB_ACTION': 'run7', 'GITHUB_ACTIONS': 'true', 'GITHUB_ACTION_REF': '', ...}
stdin = None, timeout = 180, quiet = False, echo = True
def execute_subprocess_async(cmd, env=None, stdin=None, timeout=180, quiet=False, echo=True) -> _RunOutput:
loop = asyncio.get_event_loop()
result = loop.run_until_complete(
_stream_subprocess(cmd, env=env, stdin=stdin, timeout=timeout, quiet=quiet, echo=echo)
)
cmd_str = " ".join(cmd)
if result.returncode > 0:
stderr = "\n".join(result.stderr)
raise RuntimeError(
> f"'{cmd_str}' failed with returncode {result.returncode}\n\n"
f"The combined stderr from workers follows:\n{stderr}"
)
E RuntimeError: '/home/github_actions/actions-runner/_work/transformers/transformers/.env/bin/python -m torch.distributed.launch --nproc_per_node=2 /home/github_actions/actions-runner/_work/transformers/transformers/tests/test_trainer_distributed.py --output_dir /tmp/tmpsdmi_ca2' failed with returncode 1
E
E The combined stderr from workers follows:
E Traceback (most recent call last):
E File "/home/github_actions/actions-runner/_work/transformers/transformers/tests/test_trainer_distributed.py", line 82, in <module>
E training_args = parser.parse_args_into_dataclasses()[0]
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/hf_argparser.py", line 180, in parse_args_into_dataclasses
E obj = dtype(**inputs)
E File "<string>", line 59, in __init__
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/training_args.py", line 479, in __post_init__
E if is_torch_available() and self.device.type != "cuda" and self.fp16:
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/file_utils.py", line 1346, in wrapper
E return func(*args, **kwargs)
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/training_args.py", line 601, in device
E return self._setup_devices
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/file_utils.py", line 1336, in __get__
E cached = self.fget(obj)
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/file_utils.py", line 1346, in wrapper
E return func(*args, **kwargs)
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/training_args.py", line 586, in _setup_devices
E torch.distributed.init_process_group(backend="nccl")
E File "/home/github_actions/actions-runner/_work/transformers/transformers/.env/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 436, in init_process_group
E store, rank, world_size = next(rendezvous_iterator)
E File "/home/github_actions/actions-runner/_work/transformers/transformers/.env/lib/python3.7/site-packages/torch/distributed/rendezvous.py", line 179, in _env_rendezvous_handler
E store = TCPStore(master_addr, master_port, world_size, start_daemon, timeout)
E RuntimeError: Address already in use
E Traceback (most recent call last):
E File "/usr/lib/python3.7/runpy.py", line 193, in _run_module_as_main
E "__main__", mod_spec)
E File "/usr/lib/python3.7/runpy.py", line 85, in _run_code
E exec(code, run_globals)
E File "/home/github_actions/actions-runner/_work/transformers/transformers/.env/lib/python3.7/site-packages/torch/distributed/launch.py", line 260, in <module>
E main()
E File "/home/github_actions/actions-runner/_work/transformers/transformers/.env/lib/python3.7/site-packages/torch/distributed/launch.py", line 256, in main
E cmd=cmd)
E subprocess.CalledProcessError: Command '['/home/github_actions/actions-runner/_work/transformers/transformers/.env/bin/python', '-u', '/home/github_actions/actions-runner/_work/transformers/transformers/tests/test_trainer_distributed.py', '--local_rank=1', '--output_dir', '/tmp/tmpsdmi_ca2']' returned non-zero exit status 1.
E Traceback (most recent call last):
E File "/home/github_actions/actions-runner/_work/transformers/transformers/tests/test_trainer_distributed.py", line 82, in <module>
E training_args = parser.parse_args_into_dataclasses()[0]
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/hf_argparser.py", line 180, in parse_args_into_dataclasses
E obj = dtype(**inputs)
E File "<string>", line 59, in __init__
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/training_args.py", line 479, in __post_init__
E if is_torch_available() and self.device.type != "cuda" and self.fp16:
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/file_utils.py", line 1346, in wrapper
E return func(*args, **kwargs)
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/training_args.py", line 601, in device
E return self._setup_devices
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/file_utils.py", line 1336, in __get__
E cached = self.fget(obj)
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/file_utils.py", line 1346, in wrapper
E return func(*args, **kwargs)
E File "/home/github_actions/actions-runner/_work/transformers/transformers/src/transformers/training_args.py", line 586, in _setup_devices
E torch.distributed.init_process_group(backend="nccl")
E File "/home/github_actions/actions-runner/_work/transformers/transformers/.env/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 455, in init_process_group
E barrier()
E File "/home/github_actions/actions-runner/_work/transformers/transformers/.env/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 1960, in barrier
E work = _default_pg.barrier()
E RuntimeError: NCCL error in: /pytorch/torch/lib/c10d/ProcessGroupNCCL.cpp:784, unhandled system error, NCCL version 2.7.8
src/transformers/testing_utils.py:1062: RuntimeError
```<|||||>We can close this one, right, @LysandreJik?
It was happening because some zombies from previous jobs, which will now kill before the job starts. i.e. this test wasn't at fault.<|||||>Yes, we can close! Thanks. |
transformers | 10,187 | closed | Add new model to labels that should not stale | The `New model` label gets added to the labels that should not become stale. | 02-15-2021 11:31:17 | 02-15-2021 11:31:17 | |
transformers | 10,186 | closed | Support for DeBERTa V2 models | Hi,
I downloaded [DeBERTa V2-XLarge](https://github.com/microsoft/DeBERTa) from [here](https://huggingface.co/microsoft/deberta-v2-xlarge) and trying to implement V2-XLarge model but I'm getting this error -
**RuntimeError: Error(s) in loading state_dict for DebertaForSequenceClassification:
size mismatch for deberta.encoder.rel_embeddings.weight: copying a param with shape torch.Size([512, 1536]) from checkpoint, the shape in current model is torch.Size([1024, 1536]).**
I saw that vocab got changed for V2 models. If that is the reason for above issue, is there any workaround to implement V2 models with HF ? | 02-15-2021 11:24:03 | 02-15-2021 11:24:03 | Hi, no workaround, we're working on the implementation now (https://github.com/huggingface/transformers/pull/10018). It should be available in a few days.<|||||>Thanks @LysandreJik <|||||>@saichandrapandraju the PR was merged, so I think this issue can be closed now?<|||||>ok @yaysummeriscoming ,
May I know when will be the stable release( I think 4.4.0) for these merges?<|||||>Yes, this issue can be closed! v4.4.0 should be released in the next two weeks.<|||||>Has this been fixed? I'm downloading the model direct from huggingface [here](https://huggingface.co/microsoft/deberta-v2-xlarge) and i still get this error thrown<|||||>Are you using the `DebertaV2Model` or the `DebertaModel` ?<|||||>@LysandreJik I am using the simpletransformers library, i'm not sure if you're familiar with it but i believe by default it uses the DebertaModel, not sure how and if i can change it to DebertaV2Model |
transformers | 10,185 | closed | Saving HF wrapped in Keras | Hi,
Trying to save a Keras model which has a HF model and a liner layer (Dense layer) on top of it.
To save a model, Keras requires that every layer would have a serialize_layer_fn implemented.
However it seems that HF models don't include this function.
Spending some time understanding and googling this issue I came across the @keras_serializable
which I assume is supposed to allow a HF layer to be serialized.
However when I wrap my class with this, I get this issue:
AttributeError: Must set `config_class` to use @keras_serializable
Although the attached code which describes this issue does have a config_class member.
To test this behaviour I generated a code which creates a model based on BERT or some Bionlp-BERT variant.
Then the code tries to train the model.
After the short training period, we try to save the model, which includes the BERT model, BERT tokenizer (using save_pretrained) and the liner layer.
For me, the best way to save this model would be using the to_json function, which converts the Keras model into a serialized model. However, I couldn't manage to get this working. Any idea how can this be done? Or any objection about saving HF model using the "to_json" method?
A possible workaround would be to use the save_pretrained method for the BERT model and tokenizer but then how would I save also the linear layer?
This issue relates to this issue https://github.com/huggingface/transformers/issues/2733.
[compile_model.txt](https://github.com/huggingface/transformers/files/5981406/compile_model.txt)
| 02-15-2021 10:49:27 | 02-15-2021 10:49:27 | Hello @saboof!
First of all, which version of Transformers and TF are you using? And can you share with us a Colab from which we can reproduce the issue. Thanks!!<|||||>version of transformers: transformers==4.2.2
version of TF2: tensorflow==2.3.1
after editing, the code is attached to the main issue <|||||>Ok, Thanks for sharing! I now see better what you are trying to do. The results you get are different mostly because how the models are implemented don't support what you are trying to do and then some unexpected behavior might occur.
Usually, a model should not belong to another model, and using a tokenizer inside a model is currently not recommended because not stable. Sorry, for your use case you will have to use `TFBertModel` and tokenize/pad your documents outside the model.
It is in our plans to give the possibility to integrate the tokenization process directly inside the model, and then be also part of a SavedModel, but we don't have an ETA yet. Sorry :(<|||||>hi @jplu
Thanks for the quick reply :), I don't think your comment answers my question.
Even when I take the tokenizer outside the bert class model, we still get the same error:
AttributeError: Must set `config_class` to use @keras_serializable<|||||>Sorry I should have been much clearrer. More specifically, you cannot use `TFBertMainLayer` publicly. You have to directly use `TFBertModel`.
Also, in case you don't know, TF doesn't recommend to use a model inside another model because some unstable behaviour might occur.<|||||>Thanks,
But I don't use `TFBertMainLayer` at all, the opposite, I use `TFBertModel`.
Regarding your second point I'll try to take the BERT model outside the general model and only pass it as an argument.
Generally - how would you go about creating additional linear layer on top of BERT CLS embedding?
<|||||>> Regarding your second point I'll try to take the BERT model outside the general model and only pass it as an argument.
This might bring unexpected behaviour as well.
> Generally - how would you go about creating additional linear layer on top of BERT CLS embedding?
I suggest you to take a look at how the `TFBertForSequenceClassification` is built :)<|||||>Great, I'll take a look at this, thanks @jplu <|||||>Looking at the code of `TFBertForSequenceClassification` -
https://github.com/huggingface/transformers/blob/d1b14c9b548de34b6606946482946008622967db/src/transformers/models/bert/modeling_bert.py#L1496
It has a linear layer and the BERT model within the same model, (although written in Pytorch). This doesn't give me insights as to how to combine these two models/layers in the same Keras model so we would be able to save them both in the same command.
The only option that I see now is to completely adopt the `TFBertForSequenceClassification` as my full model. Unfortunately, This doesn't give the dynamic architecture generation which I would like to achieve. <|||||>What do you mean by dynamic architecture? Can you detail a bit more about what you would like to do?<|||||>For example, having two types of outputs based on the same CLS embedding.
The first type would be based on a single linear layer and the second type would have two layers with some activation function between the layers.
sketch of the model.
Input -> BERT CLS embedded vector -> output based on a single layer -> another output based on a second layer
More generally, we would like to get the CLS embedded vector and to add on top of that whatever other layers.
These layers should be part of the Keras model so they all will be saved as part of the model.
I hope this is somehow clearer now.
<|||||>Ok this is much clearer now, thanks!!
The best way to do that would be to build your model as we do for ours, it means something like:
```python
class MyModel(TFBertPreTrainedModel):
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.bert = TFBertMainLayer(config, name="bert")
self.my_first_layer = .....
self.my_second_layer = ....
def call(inputs, training=None):
bert_output = bert(inputs)
# below all the processes that you have to implement for your models
....
```
Once you have your model you can instantiate it like our models with ```model = MyModel.from_pretrained("model_path")```<|||||>Hi @jplu
Again, thanks for the help.
Sorry, I think we are back in square one.
My initial issue was how to save a Keras model which includes a HF model within it?
Attached is an example of a code that generates a Keras model which incorporates a BERT model.
[example.txt](https://github.com/huggingface/transformers/files/6015722/example.txt)
How would you go about saving this model in such a way that I'd be able to load the model with the additional layer on top of it? can I save the tokenizer in the same place?
<|||||>> Sorry, I think we are back in square one. My initial issue was how to save a Keras model which includes a HF model within it?
Once again, you should not integrate a model inside another model, What I proposed you to do is exactly what you would like to do because `TFBertMainLayer == TFBertModel`.
> How would you go about saving this model in such a way that I'd be able to load the model with the additional layer on top of it? can I save the tokenizer in the same place?
I would go to what I proposed :)<|||||>Thanks @jplu
For the best of my understanding, your proposed code doesn't instantiate a Keres model. right?
If I get your suggestions correctly what you say is that I can't wrap HF model inside a Keras model since integrating a model inside another model, is discouraged by Keras.
<|||||>Yes! I proposed you to use such a way to do that is 100% equivalent to what you would like.<|||||>Thanks! <|||||>Keras discouraging nested models is new information for me.
And this is weird as in their Keras official examples they do exactly that.
They have a nested HF model inside a Keras model.
https://keras.io/examples/nlp/text_extraction_with_bert/#preprocess-the-data
Please look under the function create_model().
Do you have any pointers in which Keras discouraging nested models is mentioned? <|||||>What you point out is a totally different way to what you are doing. In the link you proposed, the model is built in a functional manner which is totally different of building a model in a subclassing manner.
Please use the TFBertMainLayer, this is the exact same thing.<|||||>Sorry, I can't find the difference between the Keras example and my previous example under the create_model function.
Attached is the function I used in my example file.
```
def create_model(bert_variant, max_len):
## BERT encoder
encoder = TFBertModel.from_pretrained(bert_variant)
## findings classifer Model
input_word_ids = tf.keras.layers.Input(shape=(max_len,), dtype=tf.int32,
name="input_word_ids")
embedding = encoder([input_word_ids]).last_hidden_state
cls_layer = embedding[:,0,:]
logits = layers.Dense(4, name="prediction", use_bias=True)(cls_layer)
logits = layers.Reshape((1, 4))(logits)
pred_probs = layers.Activation(tf.keras.activations.softmax)(logits)
model = tf.keras.Model(
inputs=[input_word_ids],
outputs=[pred_probs],
)
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=False)
optimizer = tf.keras.optimizers.Adam(lr=5e-5)
model.compile(optimizer=optimizer, loss=loss)
return model
```
<|||||>Sorry, this way of creating a model is fine, I was referencing to your first example script called `compile_model.txt`.
Now to properly save the model you can do something like this:
```python
def create_model(bert_variant, max_len):
## BERT encoder
encoder = TFBertModel.from_pretrained(bert_variant).bert # ====> look at this change here :)
## findings classifer Model
input_word_ids = tf.keras.layers.Input(shape=(max_len,), dtype=tf.int32,
name="input_word_ids")
embedding = encoder([input_word_ids]).last_hidden_state
cls_layer = embedding[:,0,:]
logits = layers.Dense(4, name="prediction", use_bias=True)(cls_layer)
logits = layers.Reshape((1, 4))(logits)
pred_probs = layers.Activation(tf.keras.activations.softmax)(logits)
model = tf.keras.Model(
inputs=[input_word_ids],
outputs=[pred_probs],
)
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=False)
optimizer = tf.keras.optimizers.Adam(lr=5e-5)
model.compile(optimizer=optimizer, loss=loss)
return model
model = create_model("bert-base-cased", 128)
model.save("model_path")
loaded_model = tf.keras.models.load_model("model_path")
```<|||||>Or a much nicer version IMO:
```python
def create_model(bert_variant, max_len):
config = BertConfig.from_pretrained(bert_variant)
input_word_ids = tf.keras.layers.Input(shape=(max_len,), dtype=tf.int32,
name="input_word_ids")
embedding = TFBertMainLayer(config)(input_word_ids)
cls_layer = embedding.last_hidden_state[:,0,:]
logits = tf.keras.layers.Dense(4, name="prediction", use_bias=True)(cls_layer)
logits = tf.keras.layers.Reshape((1, 4))(logits)
pred_probs = tf.keras.layers.Activation(tf.keras.activations.softmax)(logits)
model = tf.keras.Model(inputs=[input_word_ids], outputs=[pred_probs])
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=False)
optimizer = tf.keras.optimizers.Adam(lr=5e-5)
model.compile(optimizer=optimizer, loss=loss)
return model
model = create_model("bert-base-cased", 128)
model.save("model_path")
```
Once saved you can load and use it like this:
```python
model = tf.keras.models.load_model("model_path")
l = [1]*128
inp = tf.constant([l])
model(inp)
```<|||||>Thanks, @jplu <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,184 | closed | Fixing NER pipeline for list inputs. | # What does this PR do?
- Changes TokenArgumentHandler(*args) into (inputs) signature to follow `__call__` signature.
- Fixes the bug.
- Backward compatible for single sentences
- Not backward compatible for multiple sentences, but it "worked" only for same length sentences in tokens (the result was bogus as it contained only the first sentence)
- This make NER *not* pass any batching to the model, which is not in line with other pipelines, however this is what was done beforehand. And not all pipelines support batching (and even batching is counterproductive in a lot of cases because the user cannot control number of tokens from raw strings).
- All slow tests now pass, argparser test was updated.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #10168
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@LysandreJik
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | 02-15-2021 10:24:21 | 02-15-2021 10:24:21 | |
transformers | 10,183 | closed | BigBird | # What does this PR do?
This PR will add Google's BigBird "Roberta".
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #6113.
This PR adds three checkpoints of BigBird:
- [bigbird-roberta-base](https://huggingface.co/google/bigbird-roberta-large)
- [bigbird-roberta-large](https://huggingface.co/google/bigbird-roberta-base)
- [bigbird-base-trivia-itc](https://huggingface.co/google/bigbird-base-trivia-itc)
Here a notebook showing how well BigBird works on long-document question answering: https://colab.research.google.com/drive/1DVOm1VHjW0eKCayFq1N2GpY6GR9M4tJP?usp=sharing
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the [documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed.
@patrickvonplaten
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-15-2021 09:22:26 | 02-15-2021 09:22:26 | Will BigBird-Pegasus be added, and then `BigBirdForConditionalGeneration` so that summarization will be possible?<|||||>Yes, we will be adding that soon.
> Will BigBird-Pegasus be added, and then `BigBirdForConditionalGeneration` so that summarization will be possible?
<|||||>Once pre-trained checkpoints are uploaded to `huggingface_hub`, model & tokenizer can be accessed this way:
```python
from transformers import BigBirdForMaskedLM, BigBirdForPreTraining, BigBirdTokenizer
tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
# model with LM head
model_with_lm = BigBirdForMaskedLM.from_pretrained("google/bigbird-roberta-base")
# model with pertaining heads
model_for_pretraining = BigBirdForPreTraining.from_pretrained("google/bigbird-roberta-base")
```<|||||>```python
from transformers import BigBirdConfig
# config for bigbird base
config = BigBirdConfig(hidden_size=768, num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072)
# or simply
config = BigBirdConfig()
# config for bigbird trivia ckpts (both ITC & ETC)
config = BigBirdConfig(type_vocab_size=16)
# config for bigbird large
config = BigBirdConfig(hidden_size=1024, num_hidden_layers=24, num_attention_heads=16, intermediate_size=4096)
```
Running this script will enable checkpoints conversion:
```shell
python src/transformers/models/big_bird/convert_bigbird_original_tf_checkpoint_to_pytorch.py --tf_checkpoint_path ./tf_checkpoint/ckpt/model.ckpt-0 --big_bird_config_file ./tf_checkpoint/config.json --pytorch_dump_path ./hf_ckpt
```<|||||>I will fix everything up & add tests for auto padding.<|||||>Failing tests are unrelated to this PR.<|||||>@sgugger, @LysandreJik I updated the code based on your suggestions. Please let me know if I have missed something.<|||||>Thank you for taking care of the comments @vasudevgupta7 and for this PR altogether!<|||||>@vasudevgupta7 great work, when are you planning to add the BigBirdForConditionalGeneration? And any plans on adding the pubmed pre-trained models?<|||||>@sayakmisra I am currently working on it. You can track PR #10991.<|||||>@vasudevgupta7 currently loading `vasudevgupta/bigbird-pegasus-large-bigpatent` into `BigBirdForConditionalGeneration` leads to some weights of the checkpoint not being used for initializing the model. Is there a workaround for this?
Can we have separate pretrained checkpoints for BigBird and Pegasus without the finetuning, so that we can use the Pegasus decoder along with the BigBird encoder in our code?<|||||>Hey @jigsaw2212,
we are still working on integrating `BigBirdPegasus` -> for now only the `google/bigbird-...` are fully supported. `BigBirdPegasus` will be merged in 1,2 weeks |
transformers | 10,182 | closed | `super()` does not have `prepare_seq2seq_batch()` in `transformers/models/rag/tokenization_rag.py` | ## Environment info
- `transformers` version: 4.3.2
- Platform: Linux-5.4.0-52-generic-x86_64-with-debian-bullseye-sid
- Python version: 3.6.12
- PyTorch version (GPU?): 1.7.1+cu110 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: N/A
- Using distributed or parallel set-up in script?: nope
### Who can help
Models:
- rag: @patrickvonplaten, @lhoestq
## Information
Model I am using (Bert, XLNet ...): RAG
The problem arises when using:
* [ x ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Run any of the scripts in the examples on https://huggingface.co/transformers/model_doc/rag.html#overview , ex.
```
from transformers import RagTokenizer, RagRetriever, RagModel
import torch
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base")
retriever = RagRetriever.from_pretrained("facebook/rag-token-base", index_name="exact", use_dummy_dataset=True)
# initialize with RagRetriever to do everything in one forward call
model = RagModel.from_pretrained("facebook/rag-token-base", retriever=retriever)
input_dict = tokenizer.prepare_seq2seq_batch("How many people live in Paris?", "In Paris, there are 10 million people.", return_tensors="pt")
input_ids = input_dict["input_ids"]
outputs = model(input_ids=input_ids)
```
2. Get an error on https://github.com/huggingface/transformers/blob/master/src/transformers/models/rag/tokenization_rag.py#L77 about how `super()` does not have `prepare_seq2seq_batch()`
* Indeed, looking at the relevant file, RagTokenizer does not inherit from any other class.
## Expected behavior
RAG works properly.
Note that if I copy/paste the code in the file prior to https://github.com/huggingface/transformers/pull/9524 , it works fine. CC: @sgugger of that change.
| 02-15-2021 06:45:59 | 02-15-2021 06:45:59 | Hi ! Thanks for reporting
#10167 should fix this issue<|||||>Convenient to see that the fix was already in the pipeline. Thanks! |
transformers | 10,181 | closed | Inconsistent loss computation? | `transformers` version: 4.3.2, Python version: 3.7, Tensorflow version (GPU?): 2.3.1, Using GPU in script?: No, Using distributed or parallel set-up in script?: No
## To reproduce
Steps to reproduce the behavior:
``` python
import tensorflow as tf
from transformers import TFGPT2LMHeadModel
from transformers.modeling_tf_utils import TFCausalLanguageModelingLoss
import copy
import numpy as np
model = TFGPT2LMHeadModel.from_pretrained('gpt2')
one_line_dset = (np.random.rand(1, 1024)>.5)*1
input_ids = one_line_dset
target_ids = one_line_dset
# explicit loss calculation
prediction = model.predict(input_ids).logits
prediction = tf.convert_to_tensor(prediction)
l = TFCausalLanguageModelingLoss().compute_loss(target_ids, prediction)
# internal loss calculation
outputs = model(input_ids, labels=target_ids)
print(tf.math.reduce_mean(l), tf.math.reduce_mean(outputs[0]))
print(l.shape, outputs[0].shape)
print('How many are the same? ', np.mean(outputs.loss==l[:-1]))
print('Are they equal? ', tf.math.reduce_mean(l) == tf.math.reduce_mean(outputs[0]))
```
I'm trying to understand how the loss is computed inside the model when the argument labels is provided, but what I am trying above doesn't seem to work. What am I doing wrong?
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
I would expect `tf.math.reduce_mean(l) == tf.math.reduce_mean(outputs[0])` to be True. | 02-15-2021 01:23:51 | 02-15-2021 01:23:51 | Hello! If you look inside the `TFGPT2LMHeadModel`, you'll see it automatically shifts the labels for you.
The model generates tokens given a past. It then compares the generated token to the "true" token contained in the labels you passed to it. If you shift the tokens as it is done in the model, you should get identical results:
```py
import tensorflow as tf
from transformers import TFGPT2LMHeadModel
from transformers.modeling_tf_utils import TFCausalLanguageModelingLoss
import numpy as np
model = TFGPT2LMHeadModel.from_pretrained('gpt2')
one_line_dset = (np.random.rand(1, 1024)>.5)*1
input_ids = one_line_dset
target_ids = one_line_dset
# explicit loss calculation
prediction = model.predict(input_ids).logits
prediction = tf.convert_to_tensor(prediction)
# internal loss calculation
outputs = model(input_ids, labels=target_ids, training=False)
target_ids = target_ids[:, 1:]
prediction = prediction[:, :-1]
l = TFCausalLanguageModelingLoss().compute_loss(target_ids, prediction)
print(tf.math.reduce_mean(l), tf.math.reduce_mean(outputs[0]))
```
You'll see that the two results are very close to being equal. Note the very close, as they are not exactly equal. @jplu can chime in here but I believe this has to do with the switch to graph mode happening with the call to `.predict`.<|||||>I entirely second what @LysandreJik said! Nice and clear explanation 👍 <|||||>@LysandreJik @jplu you are super fast guys! Thanks! a lot!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,180 | closed | ONNX Export for Fine-Tuned DistilBertForTokenClassification | # 🚀 Feature request
I'd like to export a fine-tuned DistilBertForTokenClassification model to ONNX. Right now the conversion script convert_graph_to_onnx.py looks like it takes a string like "--model bert-base-cased" but I'd like to pass in the model object that I've fine tuned on my data set.
## Motivation
I've trained a custom token classifier that I want to run on the ONNX runtime.
| 02-14-2021 18:09:29 | 02-14-2021 18:09:29 | I figured out how to do it. Within python, you have to use `model.save_pretrained("path/to/output_dir")` where `model` is the fine-tuned `model = DistilBertForTokenClassification.from_pretrained('distilbert-base-uncased', num_labels=...)`
Then inside an empty directory, run
`python -m transformers.convert_graph_to_onnx --model path/to/output_dir --framework pt --tokenizer distilbert-base-uncased out.onnx`
|
transformers | 10,179 | closed | Why is the attention_mask added to the attn_weights instead of multiplying/masking? | https://github.com/huggingface/transformers/blob/8fae93ca1972c39d19c8cf3d3c6a3dd2530cc59a/src/transformers/models/bart/modeling_bart.py#L219-L227
As far as I understand, attention_mask is to prevent the model peek into the future or padded positions, shouldn't the weights in these positions be masked out? What does this addition do? | 02-14-2021 16:28:00 | 02-14-2021 16:28:00 | Hello, Maybe this comment can help you out https://github.com/huggingface/transformers/issues/1935#issuecomment-561305086!<|||||>@LysandreJik Oh, I got it now, thank you! |
transformers | 10,178 | closed | Fix datasets set_format | # What does this PR do?
This PR fixes a problem in `Trainer` when user provide a dataset using the new functionality in the upcoming v2 of `datasets` `set_transform` (see [here](https://github.com/huggingface/datasets/issues/1867) for more details). This is a hotfix that is not perfect and we will need to take some time to make this column ignoring more general (probably after batch creation) but I will look deeper into this at the end of next week. | 02-14-2021 15:34:18 | 02-14-2021 15:34:18 | |
transformers | 10,177 | closed | Loading a model from local files achieves way too lower accuracy in comparison to model downloading | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.2
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@LysandreJik, @sgugger, @patrickvonplaten
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
I am using a few models from the 'Models hub' ( https://huggingface.co/models ) and
I am working on token classification task. Since I have to repeat some of the experiments several times I have downloaded the models locally, to avoid downloading on each run.
Downloading:
```
model_name = "X"
model = AutoModelForTokenClassification.from_pretrained(model_name, num_labels=len(tag2idx))
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
Saving locally the model and tokenizer ( and renaming tokenizer_config.json to config.json)
```
model.save_pretrained("/content/drive/MyDrive/model/model_name/")
tokenizer.save_pretrained("/content/drive/MyDrive/tokenizer/model_name/")
```
Loading the model and tokenizer from local directories
```
config = AutoConfig.from_pretrained("/content/drive/MyDrive/model/model_name/")
config.num_labels = len(tag2idx)
model = AutoModelForTokenClassification.from_config(config)
tokenizer = AutoTokenizer.from_pretrained("/content/drive/MyDrive/tokenizer/model_name/")
```
The problem arises when using the model from local files. I have noticed that the accuracy of the local model for the exact same configuration (same data, number of epochs, lr, etc.) is around 20% lower than downloading the model for each experiment.
I would like to know why this happens.
## Expected behavior
The model should achieve similar results whether being loaded from local files or downloaded from the models hub.
| 02-14-2021 14:21:05 | 02-14-2021 14:21:05 | > The problem arises when using the model from local files. I have noticed that the accuracy of the local model for the exact same configuration (same data, number of epochs, lr, etc.) is around 20% lower than downloading the model for each experiment.
This is extremely vague and we can't help you solve your bug if you don't give us something more tangible than this. What code are you then running? What's the difference in accuracy?
<|||||>Thanks. It was my mistake.
The issue was that I was trying to dynamically change the model config file and reuse it for models with different number of output labels.
|
transformers | 10,176 | closed | Conditional generation with T5 | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.2
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- t5: @patrickvonplaten, @patil-suraj
Library:
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
-->
## Information
Model I am using (Bert, XLNet ...): T5
The problem arises when using:
* [ ] the official example scripts: (give details below)
* Generating conditional text from T5
```
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('t5-3b')
model = T5ForConditionalGeneration.from_pretrained('t5-3b')
input_ids = tokenizer('The <extra_id_0> walks in <extra_id_1> park', return_tensors='pt').input_ids
labels = tokenizer('<extra_id_0> cute dog <extra_id_1> the <extra_id_2> </s>', return_tensors='pt').input_ids
outputs = model(input_ids=input_ids, labels=labels)
loss = outputs.loss
logits = outputs.logits
input_ids = tokenizer("summarize: studies have shown that owning a dog is good for you ", return_tensors="pt").input_ids # Batch size 1
outputs = model.generate(input_ids)
```
## To reproduce
Steps to reproduce the behavior:
1. Run the code above
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
To see the generated text. Rather, the model outputs a torch Tensor like so
`tensor([[ 0, 363, 19, 8, 1784, 13, 1473, 58, 1]])`
How do I get words out of it rather than a tensor? | 02-14-2021 09:49:34 | 02-14-2021 09:49:34 | You can decode them back to a string using `T5Tokenizer`, like so:
`tokenizer.decode(outputs.squeeze().tolist(), skip_special_tokens=True)`
Btw, for a really good guide on the different generation strategies of models like T5, see this blog post: https://huggingface.co/blog/how-to-generate<|||||>This post was really helpful, thanks! |
transformers | 10,175 | closed | Speech2TextTransformer | # What does this PR do?
This PR adds the S2T model from [fairseq](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text) for end-to-end ASR and Speech-Translation (ST).
The model architecture is somewhat similar to the mBART model, except
- the encoder contains the convolutional subsampling module to downsample the speech features.
- no token embeddings in encoder.
This PR also adds the `Speech2TextFeatureExtractor`, and `Speech2TextProcessor` classes analogous to `Wav2Vec2` extractor and processor.
The `Speech2TextFeatureExtractor` here has an extra dependency on `torchaudio` which is required for extracting fbank features
The `generate` method works out-of-the-box for S2T! Usage example
```python
import torch
from transformers import Speech2TextForConditionalGeneration, Speech2TextProcessor
from datasets import load_dataset
import soundfile as sf
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
samples = ds.map(map_to_array)[5:8]
model = Speech2TextForConditionalGeneration.from_pretrained("valhalla/s2t_librispeech_small")
processor = Speech2TextProcessor.from_pretrained("valhalla/s2t_librispeech_small")
features = processor(samples["speech"], sampling_rate=16_000, padding=True, return_tensors="pt")
gen_tokens = model.generate(
input_ids=features["input_features"],
attention_mask=features["attention_mask"],
)
generated = processor.batch_decode(gen_tokens, skip_special_tokens=True)
```
TODOs:
- [x] add tests
- [x] implement `Speech2TextProcessor` after #10324 is merged
- [x] finish docs
- [ ] port and eval the CoVoST2 and MuSTc checkpoints
- [ ] add training/fine-tuning script in a follow-up PR
| 02-14-2021 08:33:04 | 02-14-2021 08:33:04 | @patrickvonplaten, @sgugger , @LysandreJik The PR is now finalized and ready for your review :) <|||||>I've added proper instructions to install the extra dependencies and addressed Patrick and Sylvain's comments regarding the docs and imports. All slow/non-slow tests are passing!
Merging!<|||||>Edit: please see this issue: #10631 <|||||>hi @xjdeng
Thanks for reporting this. This PR is now merged. So could you please open an issue with this error, we will discuss it there.
|
transformers | 10,174 | closed | How to train an MBart model from scratch for a new language pair? | I want to train an MBART model from scratch, for a new language pair, unsupervised translation. I have monolingual data from both languages. Specifically, how do I prepare the data for the same?
Currently I start with a code as follows
_tokenizer = MBartTokenizer.from_pretrained('./tokenizer_de_hsb.model') //My own tokenizer trained with google sentencepiece
batch = tokenizer.prepare_seq2seq_batch(src_texts=src_txts, src_lang="en_XX",
tgt_texts=tgt_txts, tgt_lang="ro_RO",
return_tensors="pt") //The src and tgt language codes are dummy here.
config = MBartConfig()
model = MBartModel(config)
model(input_ids=batch['input_ids'], decoder_input_ids=batch['labels']) # forward pass
model.save_pretrained('./trained_model')_
Following are the doubts I have.
- For pre-training mbart, what should input_ids and decoder_input_id in the forward pass be? Is there a function that generates the input with the masked tokens?
- Is the approach to combine src and tgt language data and train once on the combined data?
- Is there a sample code for this?
| 02-14-2021 03:54:31 | 02-14-2021 03:54:31 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discusss.huggingface.co) instead?
Thanks! |
transformers | 10,173 | closed | What does the "<s> token" mean in Longformer's global_attention_mask? | This might be a stupid question, but I couldn't find an answer. The documentation says "For example, for classification, the \<s\> token should be given global attention.". I've also checked the original [longformer paper](https://arxiv.org/pdf/2004.05150.pdf), but "\<s\> token" was only mentioned once. Can someone tell me what does it mean? Thanks for any help! | 02-13-2021 23:53:08 | 02-13-2021 23:53:08 | Ok, I got it. That means [CLS] token. |
transformers | 10,172 | closed | Saving PruneBERT notebook fails to run on torch > 1.5 | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.0.dev0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.1 (False)
- Tensorflow version (GPU?): 2.3.1 (False)
- Using GPU in script?: False
- Using distributed or parallel set-up in script?: False
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@VictorSanh
## Information
The Saving PruneBERT [notebook](https://github.com/huggingface/transformers/blob/b11386e158e86e62d4041eabd86d044cd1695737/examples/movement-pruning/Saving_PruneBERT.ipynb) from the _examples/movement-pruning/_ directory is not compatible with PyTorch > 1.5 because Torchbind is used for `_packed_params` in v1.6 and higher (see PR [here](https://github.com/pytorch/pytorch/pull/34140)).
In particular, cell 4 of the notebook
```python
# Elementary representation: we decompose the quantized tensors into (scale, zero_point, int_repr).
# See https://pytorch.org/docs/stable/quantization.html
# We further leverage the fact that int_repr is sparse matrix to optimize the storage: we decompose int_repr into
# its CSR representation (data, indptr, indices).
elementary_qtz_st = {}
for name, param in qtz_st.items():
if param.is_quantized:
print("Decompose quantization for", name)
# We need to extract the scale, the zero_point and the int_repr for the quantized tensor and modules
scale = param.q_scale() # torch.tensor(1,) - float32
zero_point = param.q_zero_point() # torch.tensor(1,) - int32
elementary_qtz_st[f"{name}.scale"] = scale
elementary_qtz_st[f"{name}.zero_point"] = zero_point
# We assume the int_repr is sparse and compute its CSR representation
# Only the FCs in the encoder are actually sparse
int_repr = param.int_repr() # torch.tensor(nb_rows, nb_columns) - int8
int_repr_cs = sparse.csr_matrix(int_repr) # scipy.sparse.csr.csr_matrix
elementary_qtz_st[f"{name}.int_repr.data"] = int_repr_cs.data # np.array int8
elementary_qtz_st[f"{name}.int_repr.indptr"] = int_repr_cs.indptr # np.array int32
assert max(int_repr_cs.indices) < 65535 # If not, we shall fall back to int32
elementary_qtz_st[f"{name}.int_repr.indices"] = np.uint16(int_repr_cs.indices) # np.array uint16
elementary_qtz_st[f"{name}.int_repr.shape"] = int_repr_cs.shape # tuple(int, int)
else:
elementary_qtz_st[name] = param
```
fails with the following error
```
AttributeError Traceback (most recent call last)
<ipython-input-14-1266eb0d5085> in <module>
9 # if isinstance(param, tuple):
10 # param = param[0]
---> 11 if "dtype" not in name and param.is_quantized:
12 print("Decompose quantization for", name)
13 # We need to extract the scale, the zero_point and the int_repr for the quantized tensor and modules
AttributeError: 'tuple' object has no attribute 'is_quantized'
```
This is because in torch >= 1.6, the `layer_name.weight` and `layer_name.bias` tensors have been bundled as a tuple of the form `(weight, bias)` in `param`.
A simple fix I tried was to pick out the weight tensor directly by checking for a tuple in the for loop:
```
elementary_qtz_st = {}
for name, param in qtz_st.items():
if isintstance(param, tuple):
param = param[0]
if param.is_quantized:
print("Decompose quantization for", name)
```
but this produces mismatch between the keys of `qtz_st` and `elementary_qtz_st` because we append the `.scale` and `.zero_point` attributes to `_packed_params` and lose the bias term.
I'm currently trying to find a proper fix, but thought I should report this in the meantime.
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Clone `transformers` and follow the steps to install the `movement-pruning` example
2. Upgrade torch to v1.6 with `pip install torch==1.6`
3. Try to run the `Saving_PruneBERT.ipynb` notebook
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
The `Saving_PruneBERT.ipynb` notebook runs end-to-end without errors.
<!-- A clear and concise description of what you would expect to happen. -->
| 02-13-2021 17:31:45 | 02-13-2021 17:31:45 | Thanks for reporting that @lewtun!
Feel free to open a PR when you have a working solution for higher versions of PyTorch!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,171 | closed | Revert propagation | The proposition offered in https://github.com/huggingface/transformers/pull/10092 unfortunately can't be applied as having a default handler and propagation across handlers results in several logged items.
Reverting that PR here as seen offline with @lhoestq and leaving the docs regarding the default handler introduced in #10092. | 02-13-2021 13:19:04 | 02-13-2021 13:19:04 | |
transformers | 10,170 | closed | T5 training with Keras: InvalidArgumentError: logits and labels must have the same first dimension | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.0.dev0
- Platform: Linux version 4.19.0-14-cloud-amd64 ([email protected]) (gcc version 8.3.0 (Debian 8.3.0-6)) #1 SMP Debian 4.19.171-2 (2021-01-30)
- Python version: 3.7
- PyTorch version (GPU?): 1.7.1, No
- Tensorflow version (GPU?): 2.3.1, No
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@patrickvonplaten, @patil-suraj
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): T5
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
See code below:
```
import numpy as np
import tensorflow as tf
from transformers import T5TokenizerFast, TFT5ForConditionalGeneration
MODEL_NAME = "t5-small"
INPUT_TEXTS = [
"When Liana Barrientos was 23 years old, she got married in Westchester County, New York.",
"Only 18 days after that marriage, she got hitched yet again.",
"Then, Barrientos declared 'I do' five more times, sometimes only within two weeks of each other.",
"In 2010, she married once more, this time in the Bronx.",
"In an application for a marriage license, she stated it was her 'first and only' marriage.",
"Prosecutors said the marriages were part of an immigration scam.",
"In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002.",
"All occurred either in Westchester County, Long Island, New Jersey or the Bronx.",
"Any divorces happened only after such filings were approved.",
"It was unclear whether any of the men will be prosecuted.",
]
LABEL_TEXTS = ["Yes", "No", "Yes", "Yes", "No", "Yes", "No", "No", "Well, you never know, right?", "Yes"]
tokenizer = T5TokenizerFast.from_pretrained(MODEL_NAME)
tokenized_inputs = tokenizer(INPUT_TEXTS, padding="max_length", truncation=True, return_tensors="tf")
tokenized_labels = tokenizer(LABEL_TEXTS, padding="max_length", truncation=True, return_tensors="tf")
decoder_input_texts = ["<pad> " + _txt for _txt in LABEL_TEXTS]
tokenized_decoder_inputs = tokenizer(decoder_input_texts, padding="max_length", truncation=True, return_tensors="tf")
def add_dec_inp_ids(_features, _labels, _dec_inp_ids):
_features["decoder_input_ids"] = _dec_inp_ids
return (_features, _labels)
ds = tf.data.Dataset.from_tensor_slices(
(tokenized_inputs.data, tokenized_decoder_inputs.input_ids, tokenized_labels.input_ids))\
.map(add_dec_inp_ids)
batch_size = 2
steps_per_epoch = np.ceil(len(INPUT_TEXTS) / batch_size)
train_ds = ds.repeat().prefetch(tf.data.experimental.AUTOTUNE).batch(batch_size)
model = TFT5ForConditionalGeneration.from_pretrained(MODEL_NAME)
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer=optimizer, loss=loss)
model.fit(train_ds, epochs=2, steps_per_epoch=steps_per_epoch)
```
And what I get:
```
tensorflow.python.framework.errors_impl.InvalidArgumentError: logits and labels must have the same first dimension, got logits shape [8192,64] and labels shape [1024]
[[node sparse_categorical_crossentropy_4/SparseSoftmaxCrossEntropyWithLogits/SparseSoftmaxCrossEntropyWithLogits (defined at <ipython-input-2-0152c3165ef3>:51) ]] [Op:__inference_train_function_27365]
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Training starts and then finishes without error.
<!-- A clear and concise description of what you would expect to happen. -->
| 02-13-2021 12:57:56 | 02-13-2021 12:57:56 | Would like to help you here, I've created a [Colab notebook](https://colab.research.google.com/drive/1PtRxbK4oNUsm4lrsOvWoNYzA-BhOWwf2?usp=sharing) that illustrates how to fine-tune `TFT5ForConditionalGeneration` using Keras. However, I'm having the same issue as posted in #6817, namely:
`ValueError: No gradients provided for any variable: ['shared/shared/weight:0', 'tf_t5for_conditional_generation_2/encoder/block_._0/layer_._0/SelfAttention/q/kernel:0', 'tf_t5for_conditional_generation_2/encoder/block_._0/layer_._0/SelfAttention/k/kernel:0', 'tf_t5for_conditional_generation_2/encoder/block_._0/layer_._0/SelfAttention/v/kernel:0', 'tf_t5for_conditional_generation_2/encoder/block_._0/layer_._0/SelfAttention/o/kernel:0', 'tf_t5for_conditional_generation_2/encoder/block_._0/layer_._0/SelfAttention/relative_attention_bias/embeddings:0', 'tf_t5for_conditional_generation_2/encoder/block_._0/layer_._0/layer_norm/weight:0', 'tf_t5for_conditional_generation_2/encoder/block_._0/layer_._1/DenseReluDense/wi/kernel:0', 'tf_t5for_conditional_generation_2/encoder/block_._0/layer_._1/DenseReluDense/wo/kernel:0', 'tf_t5for_conditional_generation_2/encoder/block_._0/layer_._1/layer_norm/weight:0', 'tf_t5for_conditional_generation_2/encoder/block_._1/layer_._0/SelfAttention/q/kernel:0', 'tf_t5for_conditional_generation_2/encoder/block_._1/layer_._0/SelfAttention/k/kernel:0', 'tf_t5for_conditional_generation_2/encoder/block_._1/layer_._0/SelfAttention/v/kernel:0', 'tf_t5for_conditional_generation_2/encoder/block_._1/layer_._0/SelfAttention/o/kernel:0', 'tf_t5for_conditional_generation_2/encoder/block_._1/layer_._0/layer_norm/weight:0', 'tf_t5for_conditional_generation_2/encoder/block_._1/layer_._1/DenseReluDense/wi/kernel:0', 'tf_t5for_conditional_generation_2/encoder/bloc...`
UPDATE: this issue was resolved by providing the data in the correct format, namely a tuple of `(inputs, outputs)`. A forward pass on a random batch is now working. However, having the following error when calling `model.fit()`:
```
ValueError: in user code:
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py:805 train_function *
return step_function(self, iterator)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py:795 step_function **
outputs = model.distribute_strategy.run(run_step, args=(data,))
/usr/local/lib/python3.6/dist-packages/tensorflow/python/distribute/distribute_lib.py:1259 run
return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/distribute/distribute_lib.py:2730 call_for_each_replica
return self._call_for_each_replica(fn, args, kwargs)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/distribute/distribute_lib.py:3417 _call_for_each_replica
return fn(*args, **kwargs)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py:788 run_step **
outputs = model.train_step(data)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py:758 train_step
self.compiled_metrics.update_state(y, y_pred, sample_weight)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/compile_utils.py:387 update_state
self.build(y_pred, y_true)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/compile_utils.py:318 build
self._metrics, y_true, y_pred)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/util/nest.py:1163 map_structure_up_to
**kwargs)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/util/nest.py:1245 map_structure_with_tuple_paths_up_to
expand_composites=expand_composites)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/util/nest.py:878 assert_shallow_structure
input_length=len(input_tree), shallow_length=len(shallow_tree)))
ValueError: The two structures don't have the same sequence length. Input structure has length 4, while shallow structure has length 3.
```<|||||>Hello!
For now T5 cannot be trained with usual `.compile()` and `.fit()` methods (such as multiple other models but we are currently working on this). You have to either use the TFTrainer or to update yourself the behavior of the internal training loop of Keras. An example of how to deal with T5 and properly training it, is showed in this nice [Colab](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb).<|||||>Ok, I saw that Colab but now understand why the author defined his own `train_step` (this was failing for me). Will update my notebook to add this.
Thank you!<|||||>@marton-avrios Here's an updated version of my Colab notebook, illustrating how to fine-tune `TFT5ForConditionalGeneration` on your data: https://colab.research.google.com/drive/1PtRxbK4oNUsm4lrsOvWoNYzA-BhOWwf2?usp=sharing<|||||>@NielsRogge Your colab looks much better but will be buggy for a few cases. Your train step must look something like this:
```python
def train_step(self, data):
x, y = data
with tf.GradientTape() as tape:
y_pred = self(x, training=True)
loss = self.compiled_loss(y, y_pred.logits, regularization_losses=self.losses)
gradients = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables))
self.compiled_metrics.update_state(y, y_pred.logits)
return {m.name: m.result() for m in self.metrics}
```
Nice adaptation in your Colab BTW :)<|||||>Thank you guys, very useful resource! Will it work on TPU or with other distribution strategies? Keras handles that when I stick to using ```compile()``` and ```fit()``` even if I redefine ```train_step()```, right? I mean dividing loss with global batch size, etc.<|||||>I doubt you will be able to train a T5 on TPU because T5 is not entirely XLA compliant so that you might encounter some unexpected issues. Sorry for that, it is also something on which we are currently working :)<|||||>So PyTorch version won't work either on TPU? Any hints as to which parts? I might be able to look into it. I get this error:
```
Invalid argument: {{function_node __inference_distributed_training_steps_51234}} Compilation failure: Detected unsupported operations when trying to compile graph cluster_distributed_training_steps_2864851955408122598[] on XLA_TPU_JIT: StringFormat (No registered 'StringFormat' OpKernel for XLA_TPU_JIT devices compatible with node {{node tf_t5for_conditional_generation/encoder/StringFormat}}){{node tf_t5for_conditional_generation/encoder/StringFormat}}
```<|||||>There are still a lot of work to make TFT5 XLA compliant, so I don't suggest you to use it for this case. The Pytorch version is fully TPU compliant yes.<|||||>@marton-avrios turns out that the Tensorflow implementation of T5 already creates the `decoder_input_ids` for you as seen [here](https://github.com/huggingface/transformers/blob/587197dcd2b50ad9e96aedbfa389bf4fcc294c3c/src/transformers/models/t5/modeling_tf_t5.py#L1376), you don't need to prepare them yourself (I thought this was only supported in the PyTorch version for now). So I've updated my notebook, it's simpler now
<|||||>Thank you @NielsRogge ! I think you need to provide either label input ids as ```labels``` or shifted label input ids as ```decoder_input_ids``` in input dictionary. At least it failed for me with only ```input_ids``` and ```attention_mask```.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,169 | closed | run_langauge_modeling for T5 | Hi
Based on readme on [1], run_langauge_modeling.py does not support T5 model so far, it would be really nice to include this model as well.
There is also this line "data_args.block_size = tokenizer.max_len", max_len does not exist anymore, I searched in pretrainedTokernizer class and did not find an equivalent variable to substitue, do you mind telling me how I can update this line to make this example work?
thank you.
[1] https://github.com/huggingface/transformers/blob/master/examples/legacy/run_language_modeling.py | 02-13-2021 11:57:31 | 02-13-2021 11:57:31 | Hi
Seems to me this script is the repetition of this other script: transformers/examples/language-modeling/run_mlm.py
Do you mind adding T5 also to this script? thanks <|||||>Actually, we can not simply add T5 to this script, because `run_mlm.py` is for encoder-only models (such as BERT, RoBERTa, DeBERTa, etc.). T5 is an encoder-decoder (seq2seq) model, so this would require a new script. The [seq2seq scripts](https://github.com/huggingface/transformers/tree/master/examples/seq2seq) currently only support fine-tuning, not pre-training.
cc @patil-suraj @sgugger <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,168 | closed | NER pipeline doesn't work for a list of sequences | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: transformers==4.3.2
- Platform: Linux Ubuntu 20.04
- Python version: 3.6
- PyTorch version (GPU?): torch==1.7.0+cu101
- Tensorflow version (GPU?): tensorflow==2.4.1
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
Library:
- pipelines: @LysandreJik
Documentation: @sgugger
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. i used the steps [here](https://huggingface.co/transformers/task_summary.html#named-entity-recognition) to use pipelines for NER task with a little change, so my script is as follow:
```
from transformers import pipeline
nlp = pipeline("ner")
sequence = [
"Hugging Face Inc. is a company based in New York City.",
"Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, therefore very close to the Manhattan Bridge which is visible from the window."
]
print(nlp(sequence))
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
i expected to get a list like this:
```
[
[
{'word': 'Hu', 'score': 0.999578595161438, 'entity': 'I-ORG', 'index': 1, 'start': 0, 'end': 2}
{'word': '##gging', 'score': 0.9909763932228088, 'entity': 'I-ORG', 'index': 2, 'start': 2, 'end': 7}
{'word': 'Face', 'score': 0.9982224702835083, 'entity': 'I-ORG', 'index': 3, 'start': 8, 'end': 12}
{'word': 'Inc', 'score': 0.9994880557060242, 'entity': 'I-ORG', 'index': 4, 'start': 13, 'end': 16}
{'word': 'New', 'score': 0.9994344711303711, 'entity': 'I-LOC', 'index': 11, 'start': 40, 'end': 43}
{'word': 'York', 'score': 0.9993196129798889, 'entity': 'I-LOC', 'index': 12, 'start': 44, 'end': 48}
{'word': 'City', 'score': 0.9993793964385986, 'entity': 'I-LOC', 'index': 13, 'start': 49, 'end': 53}
],
[
{'word': 'Hu', 'score': 0.9995632767677307, 'entity': 'I-ORG'},
{'word': '##gging', 'score': 0.9915938973426819, 'entity': 'I-ORG'},
{'word': 'Face', 'score': 0.9982671737670898, 'entity': 'I-ORG'},
{'word': 'Inc', 'score': 0.9994403719902039, 'entity': 'I-ORG'},
{'word': 'New', 'score': 0.9994346499443054, 'entity': 'I-LOC'},
{'word': 'York', 'score': 0.9993270635604858, 'entity': 'I-LOC'},
{'word': 'City', 'score': 0.9993864893913269, 'entity': 'I-LOC'},
{'word': 'D', 'score': 0.9825621843338013, 'entity': 'I-LOC'},
{'word': '##UM', 'score': 0.936983048915863, 'entity': 'I-LOC'},
{'word': '##BO', 'score': 0.8987102508544922, 'entity': 'I-LOC'},
{'word': 'Manhattan', 'score': 0.9758241176605225, 'entity': 'I-LOC'},
{'word': 'Bridge', 'score': 0.990249514579773, 'entity': 'I-LOC'}
]
]
```
but i got this error
```
ValueError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py in convert_to_tensors(self, tensor_type, prepend_batch_axis)
770 if not is_tensor(value):
--> 771 tensor = as_tensor(value)
772
ValueError: expected sequence of length 16 at dim 1 (got 38)
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
6 frames
/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py in convert_to_tensors(self, tensor_type, prepend_batch_axis)
786 )
787 raise ValueError(
--> 788 "Unable to create tensor, you should probably activate truncation and/or padding "
789 "with 'padding=True' 'truncation=True' to have batched tensors with the same length."
790 )
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length.
```
i know the problem is from tokenizer and i should use tokenizer with some arguments like this:
```
tokenizer(
sequence,
return_tensors="pt",
truncation=True,
padding=True,
max_length=512,
)
```
but it's not clear from the documentation how can we define these argument("truncation=True", "padding=True", "max_length=512") when using pipelines for NER task
<!-- A clear and concise description of what you would expect to happen. -->
| 02-13-2021 11:52:50 | 02-13-2021 11:52:50 | @Narsil, do you want to take a look at this?<|||||>Took a look, it seems the issue was not padding, but argument handling.
|
transformers | 10,167 | closed | [RAG] fix tokenizer | # What does this PR do?
- Introduce `as_target_tokenizer` context manager in `RagTokenizer` to later update the docs when `prepare_seq2seq_batch` is depricated.
- `RagTokenizer.prepare_seq2seq_batch` calls `super().prepare_seq2seq_batch`, but it does not inherit from `PreTrainedTokenizer`. Fix the method temporarily using the context manager. | 02-13-2021 07:02:43 | 02-13-2021 07:02:43 | |
transformers | 10,166 | closed | [tests] failing test only when run in a group | If someone wants to solve a puzzle, this test:
```
RUN_SLOW=1 pytest examples/seq2seq/test_finetune_trainer.py::TestFinetuneTrainer::test_finetune_trainer_slow
```
works on its own, but fails if it's run in the group with other tests:
```
RUN_SLOW=1 pytest examples/seq2seq/test_finetune_trainer.py
```
it doesn't learn anything - eval_blue remains 0.0
The only small issue is that the test is being renamed and moved to use `run_seq2seq.py`, so if you're reading this in a few days, most likely it will be the following case instead - which has the exact same problem:
```
RUN_SLOW=1 pytest examples/tests/trainer/test_trainer_ext.py::TestTrainerExt::test_run_seq2seq_slow
```
works on its own, but fails if it's run in the group with other tests:
```
RUN_SLOW=1 pytest examples/tests/trainer/test_trainer_ext.py
```
it doesn't learn anything - eval_blue remains 0.0
Thanks. | 02-13-2021 05:47:33 | 02-13-2021 05:47:33 | Hi @stas00,
I could not understand how to use `RUN_SLOW` in the windows command line, When I run it I was getting
```
'RUN_SLOW' is not recognized as an internal or external command,
operable program or batch file.
```
It was mentioned in the contribution guidelines but I don't know how to enable it<|||||>Sorry, I don't know much about windows.
Aren't you using some unixy shell on windows to run this? In which case it should support it?
Otherwise look up how to setup env vars in your windows shell.
And of course the simplest hack is for the duration of your test to simply comment out the `@slow` decorator inside the test file.
<|||||>oh, but I actually just fixed it here https://github.com/huggingface/transformers/pull/10584 - thank you for unearthing this one. I can close it now. |
transformers | 10,165 | closed | [example scripts] inconsistency around eval vs val | * `val` == validation set (split)
* `eval` == evaluation (mode)
those two are orthogonal to each other - one is a split, another is a model's run mode.
the trainer args and the scripts are inconsistent around when it's `val` and when it's `eval` in variable names and metrics.
examples:
* `eval_dataset` but `--validation_file`
* `eval_*` metrics key for validation dataset - why the prediction is then `test_*` metric keys?
* `data_args.max_val_samples` vs `eval_dataset` in the same line
the 3 parallels:
- `train` is easy - it's both the process and the split
- `prediction` is almost never used in the scripts it's all `test` - var names and metrics and cl args
- `eval` vs `val` vs `validation` is very inconsistent. when writing tests I'm never sure whether I'm looking up `eval_*` or `val_*` key. And one could run evaluation on the test dataset.
Perhaps asking a question would help and then a consistent answer is obvious:
Are metrics reporting stats on a split or a mode?
A. split - rename all metrics keys to be `train|val|test`
B. mode - rename all metrics keys to be `train|eval|predict`
Thank you.
@sgugger, @patil-suraj, @patrickvonplaten | 02-13-2021 04:03:13 | 02-13-2021 04:03:13 | While what you say make sense, I'm unsure it warrants a new change of argument names on all example scripts as it seems more cosmetic to me.
The `TrainingArguments` have the proper mode already (`--do_train`, `--do_eval`, `--do_predict`) so it's only the examples. We're less attached to no breaking changes there for now but we will soon need them to be production ready, so if we want to do this, it should be done by end of next week if possible.
Also cc @LysandreJik <|||||>> we will soon need them to be production ready
This examples-are-not-production and examples-are-production back and forth depending on the context is incredibly difficult to sustain.
I'm proposing to improve clarity and consistency so that the user can have an easier understanding, and if these are honest examples then the goal is to improve that - exemplification. If you make a slide presentation and people find typos in it, you don't say, but I already showed it to a group so the typos have to remain. Examples are that slide presentation that try to do the best exemplification of the core code. At least based on much feedback I received on my PRs.
And if we want to have programs that are production quality see my rfc https://github.com/huggingface/transformers/issues/10155. I really hope this project will make a clear cut decision wrt this back and forth and stand by it.
My fantasy is that there will be:
1. examples - change and improve those any time to make things easier - these are living and working tutorials. Nothing is fixed in stone here and which are a subject to evolve at any moment. No fixed API, but really easy to understand the code.
2. apps - production quality programs that are part of the core, with well thought out API, clean refactored code, thorough testing and tests relying on these apps to do testing.
<|||||>Not really my area of expertise here, but I do agree with @stas00 -> I think we should keep the liberty of quickly adapting the examples<|||||>> Are metrics reporting stats on a split or a mode?
> A. split - rename all metrics keys to be `train|val|test`
> B. mode - rename all metrics keys to be `train|eval|predict`
So what it should be? - either A or B - the current `train|eval|test` is a very odd amalgamation of A and B. Unless we just say that the `validation` set is really an `evaluation` set and let it be.
This impacts the results json files too in example scripts.
<|||||>This really is broken. I was just trying to write some code that was using the splits and again run into this some args are "*val*" others "*eval*" :( so can't even write automated attribute retrieval by split and have to write the code as:
```
def get_actual_samples(self, split):
if not split in ["train", "eval", "test"]:
raise ValueError(f"Unknown split {split}")
dataset = getattr(self, f"{split}_dataset")
split_fixed = split if split != "eval" else "val"
max_samples_arg = getattr(self.args, f"max_{split_fixed}_samples")
max_samples = max_samples_arg if max_samples_arg is not None else len(dataset)
return min(max, len(dataset))
```
as you can see this is so strange.
Please, please, please - make your vote and let's make the examples use either the splits or the modes and not the mix of both:
A. split - rename all metrics keys to be `train|val|test`
B. mode - rename all metrics keys to be `train|eval|predict`
To remind currently it's:
- `train|val-eval|test`
If option B is chosen we rename all cl arg keys + metrics: "val" => "eval" and "test" => "predict"
If option A is chosen we rename all cl arg keys + metrics: "eval" => "val"
My vote is B: `train|eval|predict` because we are reporting on and configuring a specific Trainer mode and not the split.
<|||||>I vote for B, for consistency with `do_train`, `do_eval`, `do_predict`.
For examples: switching an arg name can be done without taking precautions for BC as long as the README is updated at the same time, but for `TrainingArguments `(if any is concerned), a proper deprecation cycle has to be made.<|||||>@bhadreshpsavani, would this be something you'd like to work on by chance? If you haven't tired of examples yet.<|||||>Hi @stas00,
Ya i will be happy to work more.
Actually I was looking for some issues to work on!<|||||>Awesome! Thank you, @bhadreshpsavani!
So the changes we need are:
1. use `eval` instead of `val`
2. use `predict` instead of `test`
in cl args and variable names in example scripts (only the active ones, please ignore legacy/research subdirs).
I hope this will be a last rename in awhile.
<|||||>Hi @stas00,
In the dataset we have `validation` as a key for proper conversion shall we also need to change it to `evaluation`?
For `validation_file` we can either change it to `evalution_file` or `eval_file` or keep it as it is.<|||||>No the key in the dataset dictionary is "validation", so it should be `validation_file`.<|||||>While testing my changes I come to know that few example scripts are not working fine before my changes!
Here is the List:
```
/language-modeling/run_clm.py
/language-modeling/run_plm.py
/question-answering/run_qa_beam_search.py
```
Please check/run this [colab](https://github.com/bhadreshpsavani/UnderstandingNLP/blob/master/TestingAllHuggingfaceScripts_.ipynb) for instant testing.
When I run the above script locally in ubuntu my system got freeze.<|||||>I have no luck using colab today, it doesn't connect at all, so I can't test.
I run the clm test as you posted it on my own machine and it worked just fine.
Is it only colab that it's failing on? <|||||>Hi @stas00,
It actually not giving any error but after a few epochs of training, it gives something like this ^C, and it's not doing further stages like eval and predict. <|||||>Does it silently abort the run w/o any traceback? That often means the system run out of RAM and the kernel killed the process - often you get no response. colab is notorious for giving a tiny amount of RAM.
I hope colab will start working for me again and I will see if I can reproduce this.
for hanging there is this trick, add this to the beginning of the program:
```
import faulthandler
faulthandler.dump_traceback_later(20, repeat=True)
```
now every 20 secs it will print out where each thread is (traceback). super handy!
<|||||>There is also the on demand version:
```
# register and then kill the process w/ stack trace
import faulthandler, signal
faulthandler.register(signal.SIGUSR1)
# kill the stuck process
kill -USR1 PID
```
but it often doesn't work.
`py-spy` is another handy one but it requires `sudo` so won't work on colab. Unless you start the program with it:
```
# trace a running python application - e.g. when it's hanging or very slow and you want to see the backtrace - one way is using a sighandler - but that requires killing it and already having it installed
pip install py-spy
sudo py-spy top --pid PID
# if one has no sudo, start the program via
py-spy -- python myprogram.py
# and then it will attached without sudo
# https://github.com/benfred/py-spy#when-do-you-need-to-run-as-sudo
```
<|||||>Ya, I think it silently aborted the run w/o any traceback. Might be because it is occupying the entire ram somehow.
Similar behavior I observed when I run a really big docker image locally.
I will definitely try this command and dig more!
Thanks a lot for your input. This is really insightful! I will note down this as well :)<|||||>Yes, this is almost always the case in colab. It's too bad they don't have a simple widget that shows real time memory usage.
For your personal machine, always have a huge swap file if you do ML dev. Like 100GB. It will save the day.
Also there is a way to protect your desktop from your RAM-hungry commands - you can look into `cgroups`. If you machine crashes a lot because of run away training or jupyter, this is another super useful addition. But there are other way to manage resources.<|||||>ok, so I had to disable a `Privacy Badger` firefox extension and colab started working.
First, make a habit to start colab with:
```
!free -h
```
sometimes I get 12GB RAM, other times 25GB, 12GB is typically too low for much.
So `run_clm` works just fine even on 12GB. I had to use a small bs so edited your cmd lines to limit bs:
```
!python examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 \
--dataset_name wikitext \
--max_train_samples 5 \
--max_val_samples 5 \
--dataset_config_name wikitext-2-raw-v1 \
--do_train \
--do_eval \
--output_dir /tmp/test-clm \
--per_device_eval_batch_size 2 \
--per_device_train_batch_size 2 \
--overwrite_output_dir
```
this worked too:
```
!python examples/pytorch/language-modeling/run_plm.py \
--model_name_or_path xlnet-base-cased \
--dataset_name wikitext \
--max_train_samples 5 \
--max_val_samples 5 \
--dataset_config_name wikitext-2-raw-v1 \
--do_train \
--do_eval \
--output_dir /tmp/test-clm \
--per_device_eval_batch_size 2 \
--per_device_train_batch_size 2 \
--overwrite_output_dir
```
and so did:
```
!python examples/pytorch/question-answering/run_qa.py \
--model_name_or_path distilbert-base-uncased \
--train_file tests/fixtures/tests_samples/SQUAD/sample.json \
--validation_file tests/fixtures/tests_samples/SQUAD/sample.json \
--test_file tests/fixtures/tests_samples/SQUAD/sample.json \
--do_train \
--do_eval \
--do_predict \
--max_train_samples 5 \
--max_val_samples 5 \
--max_test_samples 5 \
--learning_rate 3e-5 \
--max_seq_length 384 \
--doc_stride 128 \
--version_2_with_negative \
--output_dir /tmp/debug_squad/ \
--per_device_eval_batch_size 2 \
--per_device_train_batch_size 2 \
--overwrite_output
```
|
transformers | 10,164 | closed | [example scripts] disambiguate language specification API | Currently in example scripts like `run_seq2seq.py` we have:
1. for t5
```
--task translation_en_to_ro
--source_prefix "translate English to Romanian: "
```
2. Also these 2:
```
--target_lang ro_RO
--source_lang en_XX
```
are used only for MBart and are ignored for other models. Which means that people will unknowingly try to use these two as well when they aren't need.
The problem in both situations is that we provide error-prone API where a user wants to change the language and forgets that there is more than one of the same and changes only one of the sets of languages, but not the other, which leads to broken outcome.
If such an error is made the specification supplied by the user becomes ambiguous, because one can't tell which of the multiple inputs takes precedence.
Proposal: There should be only one way to input a set of languages and not multiple ways.
Specifically:
- in case 1, probably the easiest is to leave `--task translation_en_to_ro` and auto-generate `--source_prefix "translate English to Romanian: "`
- in case 2, assert if `--target_lang` or `--source_lang` are passed and the model is not MBart.
Thinking more about it, case 1 is a must to solve, because if a user misses `--source_prefix` or makes a typo in it - the train/eval won't fail, but will mysteriously produce really bad outcome. This is not user-friendly.
@sgugger, @patrickvonplaten, @patil-suraj | 02-13-2021 02:46:20 | 02-13-2021 02:46:20 | Regarding "case 1", only the "old" T5 models: `t5-small`, `t5-base`, `t5-large`, `t5-3b` and `t5-11b` were trained with the `source_prefix` and not the new T5 models. Also IMO, there is a very legitimate case that people might want to fine-tune `t5-small`, `t5-base`, ... on translation, but don't want to condition the model on the prefix. In the second case, I agree more that we should probably raise if `--target_lang` and/or `--source_lang` are not given. For the first case, I'm fine with adding a warning<|||||>So if it is one of the 4 models that you listed print a warning to set `--source_prefix` if it's an exact match for model name and the flag wasn't passed, right?
Is it just `run_seq2seq.py` or are there any other scripts that need these 2 special supports?<|||||>Yeah, I think this would be a good idea! Think it's only T5 so only `run_seq2seq.py`<|||||>I can take this on #10611, what I'd do is remove `source_prefix` and map `(src,tgt)` pairs to matching `source_prefix` values when the `model_name` matches the "older" T5 models.
But I'd need said mapping, do you have pointers?<|||||>Skimming through the T5 paper it seems the mapping is quite small, `en->{fr,de,ro}`?
If so no need to build an exhaustive mapping of 2 letter ISO codes to capitalized language names, and I can issue a warning when `{src,tgt}_lang` is out of "supported" language-pairs.<|||||>This is for the pre-trained models, but if a user provides their own model it could be any language.
Plus you have https://github.com/google-research/multilingual-t5.
I wonder if there is a python module that comes with such a map.<|||||>https://gist.github.com/carlopires/1262033/c52ef0f7ce4f58108619508308372edd8d0bd518<|||||>Language mapping:
Here you go: https://github.com/LuminosoInsight/langcodes
or another alternative: https://github.com/janpipek/iso639-python<|||||>Thanks, I had found a couple of mappings in json as well, should we hardcode them or use an external dependency?<|||||>we require running `pip install -r examples/seq2seq/requirements.txt` already, so why not follow suite.<|||||>This issue hasn't been resolved. @theo-m solved it initially and linked to it, but then the group didn't like the solution and it was reverted. So a user is still required to enter the language pair twice. Not a great example.<|||||>well, it looks like the overall agreement is that examples don't have to be perfect, they are just examples. |
transformers | 10,163 | closed | Increasing gradient accummulation steps significantly slows down training | When training with a batch size of 32 (grad accummulation step = 1), training speed is approximately 6 it/s, however I increase gradient accummulation step to 4 or 8 (equivalent to batch size of 128 and 256), speed reduces to 1.03 it/s.
Is this expected behaviour?
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.2.1
- Platform: Linux
- Python version: 3.7.4
- PyTorch version (GPU?): 1.7.1+cu101
- Tensorflow version (GPU?):
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Distributed
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
@sgugger
@patrickvonplaten
@LysandreJik
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): XLMR
The problem arises when using:
* [ ] the official example scripts: (give details below) Trainer script
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below) masked language model training
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| 02-13-2021 01:42:35 | 02-13-2021 01:42:35 | @sgugger
@LysandreJik
pls help<|||||>A reported step is a training step (with an optimizer pass). When you increase gradient accumulation, you take more input batches to do one step, so it's normal to have less training steps per second.
Please note that the issues are for bugs and feature requests only, general questions like this one should go on the [forums](https://discuss.huggingface.co/), which is why I'm closing this.<|||||>Yeah, I am aware that you take more input batches to do one step, so it's normal to have less training steps per second. However, the actual training time is much longer. Is this normal? Shouldn't it be faster or at least equals to a gradient accumulation step of 1. <|||||>You did not report total training it. Since there are 4 (or 8) times less batches it should stay the same even if you have a slower iteration per second total. |
transformers | 10,162 | closed | fix run_seq2seq.py; porting trainer tests to it | This PR:
- restores some of the essential dropped functionality from `finetune_trainer.py` - I'm almost sure this is far far from complete since so much was just dropped
- ports wmt_en_ro test data to `jsonlines` - I move the tests dataset into the root of examples so that it can be accessed by a variety of sub-projects.
- ports DeepSpeed tests to use `run_seq2seq.py`
- ports the other trainer script to use `run_seq2seq.py`
@sgugger | 02-13-2021 01:29:17 | 02-13-2021 01:29:17 | OK, I decided to go ahead and port the other scripts instead of waiting for merging of the first set. Had to make some more fixes in the script while at it.
|
transformers | 10,161 | closed | Seq2seq now has larger memory requirements, OOM w/Deepspeed on previously runnable models | (A continuation of #10149 , since it looks like it's a broader issue:)
It looks like seq2seq has changed in the past week, and now gives out-of-memory errors for @stas00 's impressive recent DeepSpeed work that allowed training/predicting e.g. T5-11B on a single 40GB card.
Here's a simple repeatable example using the newer scripts:
### Run script:
```
export OUTPUTDIR=tst-summarization
export BS=1; rm -rf $OUTPUTDIR; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=4 ./run_seq2seq.py \
--model_name_or_path allenai/unifiedqa-t5-11b \
--do_train \
--do_eval \
--do_predict \
--task summarization \
--dataset_name xsum \
--output_dir $OUTPUTDIR \
--per_device_train_batch_size=$BS \
--per_device_eval_batch_size=$BS \
--overwrite_output_dir \
--predict_with_generate \
--max_train_samples 500 \
--max_val_samples 100 \
--max_test_samples 100 \
```
(One note: Should I be adding a --deepspeed option as with the old finetune_trainer.py (I am not seeing it in the list of options)? And if so, should it be pointing to the new location for the config file ( ../tests/deepspeed/ds_config.json ), or does it use this location by default?)
### Conda Environment:
```
# Make new environment
conda create --name transformers-feb12-2021 python=3.8
conda activate transformers-feb12-2021
# Clone transformers
git clone https://github.com/huggingface/transformers.git
cd transformers
# Install nightly build of Pytorch
pip install --pre torch torchvision -f https://download.pytorch.org/whl/nightly/cu110/torch_nightly.html -U
# Install seq2seq transformers requirements
pip install -r examples/seq2seq/requirements.txt
# Install transformers
pip install -e .
# Install DeepSpeed from source for the A100 support
cd ..
git clone https://github.com/microsoft/DeepSpeed.git
cd DeepSpeed/
# Checkout release for DeepSpeed 0.3.10 (to avoid AMD bug in latest)
git checkout c14b839d9
./install.sh
pip install .
```
### Error:
```
...
RuntimeError: CUDA out of memory. Tried to allocate 256.00 MiB (GPU 2; 39.59 GiB total capacity; 37.87 GiB already allocated; 40.69 MiB free; 37.88 GiB reserved in total by PyTorch)
Traceback (most recent call last):
File "./run_seq2seq.py", line 629, in <module>
main()
File "./run_seq2seq.py", line 543, in main
trainer = Seq2SeqTrainer(
File "/home/pajansen/github/transformers-feb12-2021/transformers/src/transformers/trainer.py", line 276, in __init__
model = model.to(args.device)
File "/home/pajansen/anaconda3/envs/transformers-feb12-2021/lib/python3.8/site-packages/torch/nn/modules/module.py", line 673, in to
return self._apply(convert)
File "/home/pajansen/anaconda3/envs/transformers-feb12-2021/lib/python3.8/site-packages/torch/nn/modules/module.py", line 387, in _apply
module._apply(fn)
File "/home/pajansen/anaconda3/envs/transformers-feb12-2021/lib/python3.8/site-packages/torch/nn/modules/module.py", line 387, in _apply
module._apply(fn)
File "/home/pajansen/anaconda3/envs/transformers-feb12-2021/lib/python3.8/site-packages/torch/nn/modules/module.py", line 387, in _apply
module._apply(fn)
[Previous line repeated 4 more times]
File "/home/pajansen/anaconda3/envs/transformers-feb12-2021/lib/python3.8/site-packages/torch/nn/modules/module.py", line 409, in _apply
param_applied = fn(param)
File "/home/pajansen/anaconda3/envs/transformers-feb12-2021/lib/python3.8/site-packages/torch/nn/modules/module.py", line 671, in convert
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
RuntimeError: CUDA out of memory. Tried to allocate 256.00 MiB (GPU 3; 39.59 GiB total capacity; 37.87 GiB already allocated; 40.69 MiB free; 37.88 GiB reserved in total by PyTorch)
```
| 02-12-2021 21:48:04 | 02-12-2021 21:48:04 | it's there:
```
./run_seq2seq.py -h | grep deepspeed
[--sharded_ddp [SHARDED_DDP]] [--deepspeed DEEPSPEED]
--deepspeed DEEPSPEED
Enable deepspeed and pass the path to deepspeed json
```
of course, it would OOM w/o `--deepspeed` in your situation.
and you could just
```
pip install deepspeed==0.3.10
```
too ;)
And I don't know if `xsum` dataset is the same. The one we used with `finetune_trainer.py` was hand-cured, see: https://github.com/huggingface/transformers/issues/10044 I'm trying to figure out how to make these available through the dataset hub.
<|||||>> it's there:
>
> ```
> ./run_seq2seq.py -h | grep deepspeed
> [--sharded_ddp [SHARDED_DDP]] [--deepspeed DEEPSPEED]
> --deepspeed DEEPSPEED
> Enable deepspeed and pass the path to deepspeed json
> ```
>
> of course, it would OOM w/o `--deepspeed` in your situation.
>
Ugh. Sorry, my toddler didn't sleep well last night. Maybe I should just hang up my compiler for the day. Of course I just looked with my eyeballs instead of grep, and it's one of like three lines in the enormous parameter listing with a second parameter on the same line. :)
> and you could just
>
> ```
> pip install deepspeed==0.3.10
> ```
>
> too ;)
>
I use the ./install.sh script because of that issue with the A100 architecture (80) seemingly not included by default. I haven't followed up to check if that's fixed in the last few weeks.
> And I don't know if `xsum` dataset is the same. The one we used with `finetune_trainer.py` was hand-cured, see: #10044 I'm trying to figure out how to make these available through the dataset hub.
The behavior when running is a bit different -- I put xsum in the examples/seq2seq folder, but it downloaded a fresh copy from the dataset hub and used it, so that should be okay.
When running with the deepspeed option:
```
export OUTPUTDIR=tst-summarization
export BS=1; rm -rf $OUTPUTDIR; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=4 ./run_seq2seq.py \
--model_name_or_path allenai/unifiedqa-t5-11b \
--do_train \
--do_eval \
--do_predict \
--task summarization \
--dataset_name xsum \
--output_dir $OUTPUTDIR \
--per_device_train_batch_size=$BS \
--per_device_eval_batch_size=$BS \
--overwrite_output_dir \
--predict_with_generate \
--max_train_samples 500 \
--max_val_samples 100 \
--max_test_samples 100 \
--deepspeed ../tests/deepspeed/ds_config.json \
```
It gets a little further, but then still OOMs:
```
RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 2; 39.59 GiB total capacity; 36.92 GiB already allocated; 4.69 MiB free; 37.30 GiB reserved in total by PyTorch)
Traceback (most recent call last):
File "./run_seq2seq.py", line 629, in <module>
main()
File "./run_seq2seq.py", line 561, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/home/pajansen/github/transformers-feb12-2021/transformers/src/transformers/trainer.py", line 960, in train
tr_loss += self.training_step(model, inputs)
File "/home/pajansen/github/transformers-feb12-2021/transformers/src/transformers/trainer.py", line 1346, in training_step
self.deepspeed.backward(loss)
File "/home/pajansen/anaconda3/envs/transformers-feb12-2021/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 845, in backward
self.optimizer.backward(loss)
File "/home/pajansen/anaconda3/envs/transformers-feb12-2021/lib/python3.8/site-packages/deepspeed/runtime/zero/stage2.py", line 1603, in backward
buf_1 = torch.empty(int(self.reduce_bucket_size * 4.5),
RuntimeError: CUDA out of memory. Tried to allocate 1.68 GiB (GPU 1; 39.59 GiB total capacity; 35.88 GiB already allocated; 840.69 MiB free; 36.48 GiB reserved in total by PyTorch)
0%|▍ | 1/375 [00:09<58:33, 9.39s/it]
```
The ds_config.json bucket sizes are 2e8. I'm not sure I've run xsum before, so it's not clear to me if that just needs to be tinkered with (I'll try a few more values, and report back if that solves it).
<|||||>(FYI It does look like training works on:
https://github.com/huggingface/transformers/commit/c130e67dce56a092604949a8df6384a17f762189
Confirming your suggestion that the change probably happened in #10114 )<|||||>Thank your validating that, @PeterAJansen. I will research and get back to you hopefully with a better solution.<|||||>Just an update on the new script - I finally managed to get it to produce an equivalent bleu score:
Needed to convert the dataset into `jsonlines` see https://github.com/huggingface/transformers/issues/10036 and multiple other changes, the most easy to miss (as it won't fail but produce abysmal results) is the one at the end of this comment.
and then the script is:
```
export BS=16; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 python ./run_seq2seq.py \
--model_name_or_path t5-small --output_dir output_dir --adam_eps 1e-06 \
--train_file /hf/transformers-master/examples/seq2seq/wmt_en_ro/train.json \
--validation_file /hf/transformers-master/examples/seq2seq/wmt_en_ro/val.json \
--do_eval --do_train --evaluation_strategy=steps --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step \
--logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 \
--sortish_sampler --task translation_en_to_ro --val_max_target_length 128 --warmup_steps 500 \
--max_train_samples 2000 --max_val_samples 500 --source_prefix "translate English to Romanian: "
```
Note the important new addition `--source_prefix "translate English to Romanian: "` - w/o it the score is close to 0 as the new script doesn't translate for t5 automatically - I advocate to change that, but time will show.
I'm not sure if `xsum` dataset is the same - didn't get to it yet.
So with summarization you most likely need to add --source_prefix "summarize: "<|||||>Further update: I ported the wmt pre-processed data to HF `datasets`, so now the dataset fetching is automated:
```
export BS=16; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 python ./run_seq2seq.py \
--model_name_or_path t5-small --output_dir output_dir --adam_eps 1e-06 \
--do_eval --do_train --evaluation_strategy=steps --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step \
--logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 \
--sortish_sampler --task translation_en_to_ro --val_max_target_length 128 --warmup_steps 500 \
--max_train_samples 2000 --max_val_samples 500 --source_prefix "translate English to Romanian: " \
--dataset_name wmt16-en-ro-pre-processed
```<|||||>@PeterAJansen, so I have been thinking about that change that I introduced that you discovered made it impossible to eval the 45GB model on 40GB card. But the thing is, before the change, you were using an fp16 version remaining from train - during eval, which from what I understand may not give good accuracy - have you run evaluation and received good results?
I'm trying to see whether the Trainer should support fp16 in eval.
The tricky issue is that currently we switch `.to(device)` in trainer's init, so this will have to be re-worked somehow. But first I would love to hear if that work on t5-11b quality-wise. `model.half()` will require only 22GB
As a quick test if you're doing `eval` only and no training it could be hacked by putting it before switching to gpu:
https://github.com/huggingface/transformers/blob/1c8c2d9ab34b8c8d326db9e0608f8e54cfccb885/src/transformers/trainer.py#L271-L276
<|||||>Hmmm, that's a good question. I've been doing exploration on new data, and the generations looked okay by eye, but I don't have a solid metric to automatically evaluate them right now -- so I can't immediately answer the question of whether the results look good.
I've had a long run going for about 5 days that should be done in about 10 hours. Is there a test run that one of us could try then to verify that things look good before I stick the next 5-day batch on? :) (perhaps one of the standard t5 evaluation datasets with known performance?). <|||||>What task and language are you training/finetuning for, so that we can find a way to compare apples to apples, and might be indicative.
And of course the ultimate test is to compare the scores for the same model before and after the finetuning/training on the same test data.<|||||>Mine is a big can of worms (a complex inference task, with the data currently being generated by annotators, with no current automated metrics for evaluation) so we should use something different.
Maybe the WMT task, since it's one of the examples shown in the huggingface seq2seq readme (and the one I used for the example script above to show the bug)? There are published expected results on Table 14 (page 39) in the T5 paper we can use as a guide:
https://arxiv.org/pdf/1910.10683.pdf<|||||>So if you're running many days of training and you have no way of evaluating the quality improvement what is then the point of this exercise? Just to first know that it can be trained? Which is a totally valid exercise.
Surely you could establish at least some baseline, to know even roughly if there is an improvement.
If the data/task is similar to WMT then yes, it'd be useful.
e.g. eval en2ro translation:
```
export BS=16; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 CUDA_VISIBLE_DEVICES=0 python ./run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir --adam_eps 1e-06 --do_eval --evaluation_strategy=steps --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --val_max_target_length 128 --warmup_steps 500 --max_val_samples 500 --dataset_name wmt16 --dataset_config "ro-en" --source_prefix "translate English to Romanian: "
...
02/16/2021 10:45:50 - INFO - __main__ - ***** val metrics *****
02/16/2021 10:45:50 - INFO - __main__ - val_bleu = 24.1257
02/16/2021 10:45:50 - INFO - __main__ - val_gen_len = 39.554
02/16/2021 10:45:50 - INFO - __main__ - val_loss = 3.7917
02/16/2021 10:45:50 - INFO - __main__ - val_runtime = 18.2931
02/16/2021 10:45:50 - INFO - __main__ - val_samples = 500
02/16/2021 10:45:50 - INFO - __main__ - val_samples_per_second = 27.333
```
note that the eval scores are very language pair-specific - the variations between various pairs can be huge.<|||||>The short answer is, I work in an area that doesn't yet have good automated metrics for evaluating generation quality, and so we typically evaluate them manually (which takes a lot of time, typically from research assistants -- part of what we're working on right now is figuring out reasonable automated metrics). But we still know from other earlier work and analyses that we've done that pre-training on related data helps, so that's what I'm doing now (the long early tail of pre-training). While I know that pre-training helps from past work, I can't easily evaluate it online -- I have to run the set, then evaluate it manually.
But all that is unrelated to the original question, whether T5-11B fp16 evaluation (in general, not paired to a specific dataset) has an issue or works okay relative to fp32:
> @PeterAJansen, so I have been thinking about that change that I introduced that you discovered made it impossible to eval the 45GB model on 40GB card. But the thing is, before the change, you were using an fp16 version remaining from train - during eval, which from what I understand may not give good accuracy - have you run evaluation and received good results?
>
> I'm trying to see whether the Trainer should support fp16 in eval.
To figure that out, we won't be able to use my lab's dataset for various technical reasons, so if there's some minimum benchmarking dataset that helps measure this that works well with automated evaluation, then that would be best to use. :)
<|||||>Thank you for elucidating your particular situation, @PeterAJansen
I'm going to run some experiments on fp16 eval against fp32 for t5 w/ wmt and we shall see. If it works well, then we can make fp16-eval available in the Trainer for those who want to try it.<|||||>Interesting and possibly related bug (on c130e67):
1) Fune-tuning T5-11B from the model hub (and saving it as. e.g. Model2) works
2) Subsequently further fine-tuning Model 2 (loaded from disk) on different data appears to OOM.
<|||||>Yes, there are a few places where `model.to(self.args.device)` is called, does the OOM go away if you disable them all - I think there 2 more that aren't conditioned on `deepspeed`.
Most likely I need to go over and replicated each place where it's done for `self.is_model_parallel` since it's the same circumstances where we don't want the model to be on device right away.
Also what was the specific 2nd command line? so that I can add a test
Thank you.<|||||>This:
```
diff --git a/src/transformers/trainer.py b/src/transformers/trainer.py
index 8afae0720..cda1a2822 100755
--- a/src/transformers/trainer.py
+++ b/src/transformers/trainer.py
@@ -792,7 +792,7 @@ class Trainer:
# If model was re-initialized, put it on the right device and update self.model_wrapped
if model_reloaded:
- if not self.is_model_parallel and self.args.place_model_on_device:
+ if not (self.is_model_parallel or (args.deepspeed and args.do_train)) and self.args.place_model_on_device:
self.model = self.model.to(self.args.device)
self.model_wrapped = self.model
@@ -1045,7 +1045,7 @@ class Trainer:
)
if isinstance(self.model, PreTrainedModel):
self.model = self.model.from_pretrained(self.state.best_model_checkpoint)
- if not self.is_model_parallel and self.args.place_model_on_device:
+ if not (self.is_model_parallel or (args.deepspeed and args.do_train)) and self.args.place_model_on_device:
self.model = self.model.to(self.args.device)
else:
state_dict = torch.load(os.path.join(self.state.best_model_checkpoint, WEIGHTS_NAME))
```<|||||>Thanks! I hope to be able to give this diff a test tonight when the current run is done (about 10h left).
> Also what was the specific 2nd command line? so that I can add a test
Here are two cases (my exact script, but a distilled version that matches the WMT example at the top of this issue from the readme):
1. Here is my exact script that I'm using for my experment (the two MODELDIR exports at the top being the critical difference between it working or not working -- the one currently selected is just the output of a past run of this script pointing to different training data):
```
#!/bin/bash
export DATADIR=/home/pajansen/github/compositional-expl/pretrain/min-6-max-8/ \
export MODELDIR=allenai/unifiedqa-t5-11b
#export MODELDIR=output_dir_compexpl-feb8-epoch3-uqa-11b-pretrain-teacher-min4-max5
export SEQLEN=256 \
export EPOCHS=3 \
export OUTPUTDIR=output_dir_compexpl-feb16-epoch$EPOCHSS-uqa-11b-pretrain-teacher-min6-max8 \
export BS=1; rm -rf $OUTPUTDIR; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=4 ./finetune_trainer.py --model_name_or_path $MODELDIR --output_dir $OUTPUTDIR --adam_eps 1e-06 --data_dir $DATADIR \
--do_eval --do_predict --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 \
--logging_first_step --logging_steps 5000 --max_source_length $SEQLEN --max_target_length $SEQLEN --num_train_epochs $EPOCHS \
--overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--predict_with_generate --sortish_sampler \
--test_max_target_length $SEQLEN --val_max_target_length $SEQLEN \
--warmup_steps 5 \
--deepspeed ../tests/deepspeed/ds_config.json --fp16 \
--save_total_limit 2 \
--save_steps 5000 \
```
2. But, here's a distilled version, using the WMT example, that should illustrate the issue (but I haven't run this one). The call is identical here, it's just the OUTPUTDIRx and MODELDIRx environment variables that change (though in practice, like above, you'd want to change the data you're fine tuning with, too):
```
# Step 1: Fine-tune base model with dataset 1
export OUTPUTDIR1=tst-summarization-step1
export MODELDIR1=allenai/unifiedqa-t5-11b
export BS=1; rm -rf $OUTPUTDIR1; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=4 ./run_seq2seq.py \
--model_name_or_path $MODELDIR1 \
--do_train \
--do_eval \
--do_predict \
--task summarization \
--dataset_name xsum \
--output_dir $OUTPUTDIR \
--per_device_train_batch_size=$BS \
--per_device_eval_batch_size=$BS \
--overwrite_output_dir \
--predict_with_generate \
--max_train_samples 500 \
--max_val_samples 100 \
--max_test_samples 100 \
# Step 2: Further fine-tune model saved in Step 1 with new data
# Also pretend that the dataset_name is different here (suggesting fine-tuning the model from Step 1 using a different dataset -- but just for the test, fine-tuning twice on the same dataset should illustrate the OOM issue)
export OUTPUTDIR2=tst-summarization-step2
export MODELDIR2=$OUTPUTDIR1
export BS=1; rm -rf $OUTPUTDIR2; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=4 ./run_seq2seq.py \
--model_name_or_path $MODELDIR2 \
--do_train \
--do_eval \
--do_predict \
--task summarization \
--dataset_name xsum \
--output_dir $OUTPUTDIR \
--per_device_train_batch_size=$BS \
--per_device_eval_batch_size=$BS \
--overwrite_output_dir \
--predict_with_generate \
--max_train_samples 500 \
--max_val_samples 100 \
--max_test_samples 100 \
```
<|||||>Thank you for the details, @PeterAJansen - hoping to validate later in the day, but meanwhile this PR should solve it https://github.com/huggingface/transformers/pull/10243 (i.e. instead of the patch I sent last night).
**edit** PR merged, so master should be OK.
<|||||>Questions:
1. This is with non-master version but then one before the fateful PR of mine, correct? since `eval` currently won't fit 45GB onto 22GB - I'm working on a solution.
2. can you check if the saved model is bigger than the original? my feeling is that something else gets tacked onto the model that wasn't there in the original.
I developed a new memory usage metrics feature: https://github.com/huggingface/transformers/pull/10225 so that should make it possible to identify and debug such problems on a much smaller model. You will probably find it useful too.
So I should be well equipped to run your failing scenario now.<|||||>FYI, master has a new Trainer flag `--fp16_full_eval` https://github.com/huggingface/transformers/pull/10268 so now you should be able to eval at fp16 and be able to fit t5-11b onto 40gb gpu. It may or may not do what you want quality-wise, since `model.half()` doesn't always produce the desired results. But it does restore the original deepspeed/trainer non-deepspeed eval ability to fit in fp16.
Still need to check on your 2 step scenario OOM report, @PeterAJansen <|||||>another update: DS currently locks one in if one wants to be able to access the fp32 model, see https://github.com/microsoft/DeepSpeed/issues/797
once they add a method to extract the fp32 model https://github.com/microsoft/DeepSpeed/issues/800 then we can sort this out.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,160 | closed | past_key_values tuple index out of range error when using text2text-generation pipeline with encoder-decoder model | ## Environment info
- `transformers` version: 4.3.0
- Platform: Linux-5.4.0-65-generic-x86_64-with-Ubuntu-20.04-focal
- Python version: 3.7.9
- PyTorch version (GPU?): 1.7.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik
## Information
Model I am using (Bert, XLNet ...): I am using the encoder-decoder model with a Roberta encoder and RobertaForCausalLM decoder.
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
In my real code I am using custom pre-trained models and tokenizers, but the error and behavior is the same as that produced by the demo script below.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
I am trying to use a pipeline to generate results from an encoder-decoder model that was trained on a custom text2text dataset.
## To reproduce
Steps to reproduce the behavior:
You can just run the script below, or:
1. Load an encoder-decoder model with RoBERTa encoder and decoder
2. Create a text2text-generation pipeline with an appropriate tokenizer
3. Use the pipeline to generate a result
```python
import transformers
encoder = transformers.RobertaModel.from_pretrained(pretrained_model_name_or_path='roberta-base')
decoder = transformers.RobertaForCausalLM.from_pretrained(pretrained_model_name_or_path='roberta-base')
encoder_decoder_model = transformers.EncoderDecoderModel(encoder=encoder, decoder=decoder)
tokenizer = transformers.AutoTokenizer.from_pretrained('google/roberta2roberta_L-24_bbc')
text2text = transformers.pipeline('text2text-generation', model=encoder_decoder_model, tokenizer=tokenizer)
output = text2text('This is a test sentence.')
print(output)
```
Output:
```
If you want to use `RobertaLMHeadModel` as a standalone, add `is_decoder=True.`
normalizer.cc(51) LOG(INFO) precompiled_charsmap is empty. use identity normalization.
Traceback (most recent call last):
File "demo.py", line 12, in <module>
output = text2text('This is a test sentence.')
File "/home/james/Code/demo/.env/lib/python3.7/site-packages/transformers/pipelines/text2text_generation.py", line 125, in __call__
**generate_kwargs,
File "/home/james/Code/demo/.env/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 26, in decorate_context
return func(*args, **kwargs)
File "/home/james/Code/demo/.env/lib/python3.7/site-packages/transformers/generation_utils.py", line 913, in generate
**model_kwargs,
File "/home/james/Code/demo/.env/lib/python3.7/site-packages/transformers/generation_utils.py", line 1177, in greedy_search
output_hidden_states=output_hidden_states,
File "/home/james/Code/demo/.env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/james/Code/demo/.env/lib/python3.7/site-packages/transformers/models/encoder_decoder/modeling_encoder_decoder.py", line 430, in forward
**kwargs_decoder,
File "/home/james/Code/demo/.env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/james/Code/demo/.env/lib/python3.7/site-packages/transformers/models/roberta/modeling_roberta.py", line 937, in forward
return_dict=return_dict,
File "/home/james/Code/demo/.env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/james/Code/demo/.env/lib/python3.7/site-packages/transformers/models/roberta/modeling_roberta.py", line 771, in forward
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
IndexError: tuple index out of range
```
## Expected behavior
I expect the pipeline to generate an output string.
| 02-12-2021 21:24:54 | 02-12-2021 21:24:54 | I have been digging into this a little bit more and found some information that might be helpful. It looks like the underlying problem is in the EncoderDecoderModel or one of its dependencies, not the pipeline.
- When I replaced the pipeline call with a manual tokenization and call to the model's generate method, I got the same `tuple index out of range` error for past_key_values.
- When I created the encoder_decoder_model using `transformers.EncoderDecoderModel.from_encoder_decoder_pretrained('roberta-base', 'roberta-base')`, the pipeline prediction worked.
- If I use the AutoModel and AutoModelForCausulLM `from_pretrained` methods to create the encoder and decoder (mirroring the way that `from_encoder_decoder_pretrained` works) and then pass them to the EncoderDecoderModel constructor, I still get the `index out of range` error.
- If I use the `AutoModel.from_pretrained()` methods to create the encoder and decoder, then call `save_pretrained()` on them to save in a local directory, then load them using `EncoderDecoderModel.from_encoder_decoder_pretrained()`, the pipeline prediction works.
I believe there is some difference between the ways that EncoderDecoderModel's `init()` and `from_encoder_decoder_pretrained()` functions work that is leading to this error, but I haven't been able to figure out what the difference is, or why it is happening.<|||||>@thominj can you try with `decoder = transformers.RobertaForCausalLM.from_pretrained(pretrained_model_name_or_path='roberta-base', add_cross_attention=True, is_decoder=True, bos_token_id=<bos-id>, eos_token_id=<eos-id>)`?<|||||>> @thominj can you try with `decoder = transformers.RobertaForCausalLM.from_pretrained(pretrained_model_name_or_path='roberta-base', add_cross_attention=True, is_decoder=True, bos_token_id=<bos-id>, eos_token_id=<eos-id>)`?
That worked!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Is this considered to be expected behavior? If so, are add_cross_attention, is_decoder, bos_token_id, and eos_token_id all required for every decoder that can be used in EncoderDecoderModel?<|||||>HI @thominj
Yes, `add_cross_attention` and `is_decoder` is required if you are initializing the model as a decoder yourself.
But if you do
```python
model = EncoderDecoderModel. from_encoder_decoder_pretrained("roberta-base", "roberta-base")
```
then it'll happen automatically, the `from_encoder_decoder_pretrained` method takes care of this.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>The same exception may also be raised when model is in train mode, call model.eval() before may solve this problem. It happened when I use model `BartForConditionalGeneration`. |
transformers | 10,159 | closed | [hf_api] delete deprecated methods and tests | 02-12-2021 20:30:39 | 02-12-2021 20:30:39 | ||
transformers | 10,158 | open | Multiple Mask support in Pipeline | # 🚀 Feature request
The [fill mask](https://huggingface.co/bert-base-uncased?text=Paris+is+the+capital+of+%5BMASK%5D+%3F) feature as a part of the pipeline currently only supports a single mask for the inputs. It could be expanded to predict and return the results for multiple masks in the same sentence too.
## Motivation
There are use cases where one would ideally have more than just a single mask where they would need a prediction from the model. For example, smarter template filling in outputs returned to users etc. Could also be used in better study of the implicit knowledge that BERT models have accumulated during pre-training.
## Your contribution
I should be able to raise a PR for the same. The output JSON schema would have to be slightly modified, but I can go ahead and complete the same if there is no other obvious issue that slipped my mind as to why only a single [MASK] token needs to be supported. | 02-12-2021 19:26:25 | 02-12-2021 19:26:25 | @LysandreJik
The current implementation for a single mask returns the data as a list of
```
{
"sequence" : "the final sequence with the mask added",
"score" : "the softmax score",
"token" : "the token ID used in filling the MASK",
"token_str" : "the token string used in filling the MASK"
}
```
When returning the results for sentences with multiple masks, it is not possible to maintain the same return format of the JSON. I propose to have a different pipeline call for this 'fill-mask-multiple' or something along those lines. The return format I have proceeded with is
```
{
"sequence" : "the final sequence with all the masks filled by the model,
"scores" : ["the softmax score of mask 1", "the softmax score of mask 2", ...]
"tokens" : ["the token ID used in filling mask 1", "the token ID used in filling mask 2", ...]
"token_strs" : ["the token string used in filling mask 1", "the token string used in filling mask 2", ...]
}
```
Some minor changes will be made to the input param "targets" to support optional targets for each of the mask.
If having 2 separate pipelines does not seem a great idea, we could just club them both right now into one single pipeline call irrespective of whether it is a single mask or multiple mask. The return json type would change, I am not sure about the impact/how feasible it would be to bring that across in minor version updates.
Would really benefit from some expert advice since I am sort of new here.
PS: I have currently implemented the functionality for the pytorch framework, getting the same done in tf too.<|||||>This change seems okay to me. Since you have already some functionality for PyTorch, do you mind opening a PR (even a draft PR), so that we may play around with it and talk about the potential improvements? Thanks! Pinging @Narsil too |
transformers | 10,157 | closed | Fix typo in comments | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-12-2021 17:44:50 | 02-12-2021 17:44:50 | |
transformers | 10,156 | closed | Fix typo in comment | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-12-2021 17:43:03 | 02-12-2021 17:43:03 | |
transformers | 10,155 | closed | rfc: integration tests need non-example application for testing | # 🚀 Feature request
We have an ongoing conflict with some of the core integration tests needing a serious program to be tested with. The only place these can be found is under `examples/` - and so the tests - e.g. deepspeed/apex/fairscale reside under `examples/` because of that.
The problem is that because they are under `examples/` they are being treated as such, but they are not examples.
I propose we have at least one complex representative example turned into a serious program that is being supported like any other core function. Such program or programs can then be used for integration testing and what we keep on discussing but not getting to do is performance regression. You can't do performance regression on mock ups.
The few attempts to measure bleu scores are being killed as well with the current `seq2seq` wipeout. How can one do regression testing if there is nothing to measure. The regressions can be subtle and not detected by general common tests. It's a way easier to know that this input should give this bleu score on this model and if it doesn't then something is wrong.
@patrickvonplaten, @sgugger, @LysandreJik, @patil-suraj | 02-12-2021 17:40:33 | 02-12-2021 17:40:33 | I'm all for having core integration tests to do regression testing. As you have said, these tests should not be under `examples/` as that is a dedicated `examples/` folder, but should be under `tests/`.
I'm not 100% sure whether we would want that in existing testing files (for example a BART regression test in `test_modeling_bart.py`), or if we would want to create new files.
We could also create a new file `test_modeling_common_integration.py` that would serve a similar purpose to `test_modeling_common.py`, but for integration tests, if these can be shared among models simply.
---
Regarding how to approach this, these would be quite heavy tests to run, and take a long time. Do we want to run them daily, like other slow tests, or should we create a weekly suite? We'll need to create a weekly suite eventually, as some TensorFlow tests take 3+ hours *per* model to test `saved_models` (cc @jplu)
---
I believe you've proposed a similar approach to the registry system you've built for fastai, I think this would be a good approach to tackle the issue. Happy to help set this up/work with you on that front to keep the current performance regression tests you have created.<|||||>Thank you for your feedback, @LysandreJik
I think one thing that was missing is that this need is not only for performance regression testing, but also for normal testing of deepspeed/apex/fairscale which are part of the core. So I think I wasn't clear at communicating that for that I need a real program, such as the ones we have under examples. So the tests run this program. As compared to a normal test that has all the logic contained within. This is for functionality testing. So we have 2 unrelated things:
1. performance+quality regression testing - is our core getting slower? is it delivering worse quality?
2. 3rd party component integration functionality testing - can we run HF Trainer w/ DeepSpeed on a gpu with only 3 legs?
They are common only as such that they should be placed somewhere under the core tests.
Wrt number 1 - yes, we started discussing at how to implement that practically (there was an idea of reusing the registry), but again I'm returning to the main need which is not that, but perhaps adapting one of the example scripts to be a testing tool and not an example:
- not facing users - clean refactored code
- probably needs to have several different functionalities - so that different aspects can be tested - probably it needs to cover all the main NLP tasks (not exhaustively, but say one translation, one summarization, etc.) So that the different main logic paths can be tested.
Once we have the tool then we can see how to start recording and validating results. Of course, it can be an organically need-based grown tool, and my first question is where such tool would live.
It'll also be used for posting public benchmarks - so users should be able to use it too to reproduce reported results, but not try to read its code as they would with an example, just as an opaque tool.
I won't worry at the moment at how often we run those things, the schedule will evolve once we have something in place and then we can see what the requirements are.
We don't need to do one hour training to detect a quality or performance regression, while we can - we should instead design optimized scenarios where bad things are detected within a much quicker time span.
At the moment these are just feeler notes, I'd be happy to start compiling a detailed proposal once others get a chance to voice their inspirations and of course we need to see if there is a group's desire to go in that direction.<|||||>we agreed to copy what's needed for the benchmarking/testing which may happen down the road. |
transformers | 10,154 | closed | Add mBART-50 | # What does this PR do?
This is the second part of splitting #9811
This PR adds the mBART-50 models.
- Add `MBart50Tokenizer` and `MBart50TokenizerFast`. A new tokenizer is needed because it adds extra languages and the encoding format is different than `MBartTokenizer`. The difference is that for `mbart-50` both source and target language text begin with the `<language token>`, whereas for `mbart-cc25` `<language_token>` is used as suffix token.
- The new tokenizers use `src_lang` as a `getter` and `setter` property. This is needed because for many-to-many translation models whenever we change the `src_lang` we need to set special tokens for that language. The `src_lang.setter` calls `set_src_lang_special_tokens` method whenever a we set a new `src_lang` to handle this.
- A new model class is not necessary as mBART-50 is similar to our existing mBART-25 model, the only difference being `relu` activation instead of `gelu` and emb size of 250054 instead of 250027
All model checkpoints are uploaded on hub https://huggingface.co/models?filter=mbart-50 | 02-12-2021 15:31:26 | 02-12-2021 15:31:26 | > As a follow-up, is mBART aligned with mBART-50? We should have the same setter there. It would make a nice first issue I believe, once this PR is merged and provides a good model.
Yes. Here the setter was necessary because of the many to many models. But yes mBART can also be used for multilingual fine-tuning so the tokenizers should also be aligned.<|||||>Hi, I want to use MBart-Large-50 for finetuning, but I get the error:
`File "/home/michael/anaconda3/envs/paraphrases/lib/python3.9/site-packages/transformers/models/mbart/tokenization_mbart.py", line 199, in set_src_lang_special_tokens
self.cur_lang_code = self.lang_code_to_id[src_lang]
KeyError: None
`
It was working with the previous version of the model. Is it correct, that this PR adresses this issue that MBartTokenizer is used and not MBart50Tokenizer?<|||||>Hey @MichaelJanz
For mBART-50 you should use the `MBart50Tokenizer`. Also when fine-tuning make sure that you either pass or set the `src_lang` and `tgt_lang` attributes<|||||>Hi @patil-suraj and thanks for answering!
I am using the script under examples/seq2seq run_seq2seq.py, which has no reference to the `MBart50Tokenizer`, but I think it should have. `src_lang` and `tgt_lang` are set. I suspect that the base class of `MBart50Tokenizer` is used, which is simply `MBartTokenizer`. Will the script work when this commit is merged, or are there further changes neccesary, or am I executing the script wrong?<|||||>`MBart50Tokenizer` does not inherit from `MBartTokenizer` and for now, the script does not support mBART-50, but you could easily modify the script for mBART-50. I think the only necessary change is to use the correct tokenizer class. This PR will be merged today, please open an issue if you have more questions after the PR is merged. Happy to answer :)<|||||>Thanks for your help!
If I can get it to work, I will create a PR. Thanks for your great work :)<|||||>Thanks a lot, everyone! Merging! |
transformers | 10,153 | closed | I-BERT model support | # What does this PR do?
This PR implements [I-BERT](https://arxiv.org/abs/2101.01321), an integer-only quantization scheme for Transformer architectures. I-BERT is based on the model architecture and the pre-trained parameters of RoBERTa (this can be extended to other architectures as a future task), except that it calls custom integer-only operations instead of the normal ones. (The custom kernels are implemented in `ibert/quant_modules.py`.) Therefore, under the current implementation, I-BERT inherits its tokenizer and configuration from the RoBERTa’s, and pulls the model parameter from the `roberta-base/large` repo.
The model can be finetuned on a specific task in 2-pass,
1) Finetune the model on a given task with the normal mode (`config.quant_mode = False`) before quantizing it. The model will then take the normal non-quantized pass.
2) Once the model achieves the best accuracy, do another finetuning with the quantization mode (`config.quant_mode = True`). The model will then take the integer-only quantized pass to recover the accuracy degradation through quantization-aware training.
You can skip the first pass and do task-specific finetuning and quantization-aware training at the same time, but it normally results in lower accuracy.
Here are some missing features and TODOs:
- [x] Static quantization: activation ranges (min/max) must be fixed in evaluation time.
- [x] `ibert-roberta-large` support
- [ ] Test on different types of tasks
- [ ] More intuitive APIs?
## Results on the GLUE tasks
* RTE, MRPC, SST2, and QNLI with `ibert-roberta-base`
* Without extensive hyperparameter tuning (the results, both the baseline and I-BERT, could be improved)
Task | RTE | MRPC | SST2 | QNLI
--- | --- | --- | --- |---
Baseline(FP32) | 74.37 | 90.75 | 92.15 | 92.89
I-BERT(INT8) | 79.78 | 91.18 | 93.81 | 91.83
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
<!--
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-12-2021 15:26:19 | 02-12-2021 15:26:19 | Actually as @patrickvonplaten correctly mentioned, we really need some test files before we can merge this.<|||||>@kssteven418,
Thanks a mille for your PR - that's an amazing contribution!
I think before merging we still do need to do a couple of things:
1) **Tests** - it seems that currently no tests were added to the PR. It would be nice to add tests here. Besides the standard model tests, that are usually directly generated by the cookie-cutter, we should definitely also add some tests for the new quantization functionality
2) **Remove the Encoder-Decoder logic** I don't think that this model is ready to be used in an Encoder-Decoder setting yet -> so it would be better to remove all things related to Encoder-Decoder I think. This corresponds to *fully* removing the logic of `encoder_hidden_states`, `encoder_attention_mask`, `past_key_values`, `cross_attention`, ...
3) **CPU - compatible** - To me it seems that the model is only compatible on GPU at the moment - there are some `cuda()` call hardcoded in the utils functions. I think it would be nice to remove those<|||||>It seems that some failures appear in the automatic tests. Could you help me out resolving them?<|||||>@LysandreJik I let you merge when you think it's ready |
transformers | 10,152 | closed | Reduce the time spent for the TF slow tests | # What does this PR do?
This PR reduces by half the time spent on running the all the tests (including the slow tests). Here are the time comparison (time recorded on my machine with the models already downloaded):
- albert: from 13mins to 6mins
- bart: from 19mins to 9mins
- bert: from 17mins to 9mins
- blenderbot_small: from 19mins to 9mins
- blenderbot: from 19mins to 9mins
- convbert: from 21mins to 11mins
- ctrl: from 10mins to 7mins
- distilbert: from 13mins to 7mins
- dpr: from 6mins to 3mins
- electra: from 15mins to 7mins
- flaubert: from 13mins to 7mins
- funnel: from 28mins to 13mins
- gpt2: from 8mins to 4mins
- led: from 44mins to 20mins
- longformer: from 1h30mins to 40mins
- lxmert: from 6mins to 3mins
- marian: from 19mins to 9mins
- mbart: from 19mins to 9mins
- mobilebert: from 33mins to 16mins
- mpnet: from 13mins to 7mins
- openai gpt: from 8mins to 4mins
- pegasus: from 19mins to 9mins
- roberta: from 10mins to 6mins
- t5: from 12mins to 7mins
- transfo_xl: from 8mins to 5mins
- xlm: from 13mins to 7mins
- xlnet: from 9mins to 5mins
Total: from 8h5mins to 4h8mins
The total time spent on running the entire tests has been reduced by half by merging three tests about the SavedModel into a single one. | 02-12-2021 14:20:11 | 02-12-2021 14:20:11 | @sgugger Yes, this is exactly that. There was an important overlap across these three tests (all based on creating a saved model and two on testing the output), so merging them was IMO the best way to keep the coverage and reduce the time.
@patrickvonplaten feel free to merge if the PR looks ok for you! |
transformers | 10,151 | closed | Model Parallelism for Bert Models | Hi,
I'm trying to implement Model parallelism for BERT models by splitting and assigning layers across GPUs. I took DeBERTa as an example for this.
For DeBERTa, I'm able to split entire model into 'embedding', 'encoder', 'pooler', 'classifier' and 'dropout' layers as shown in below pic.
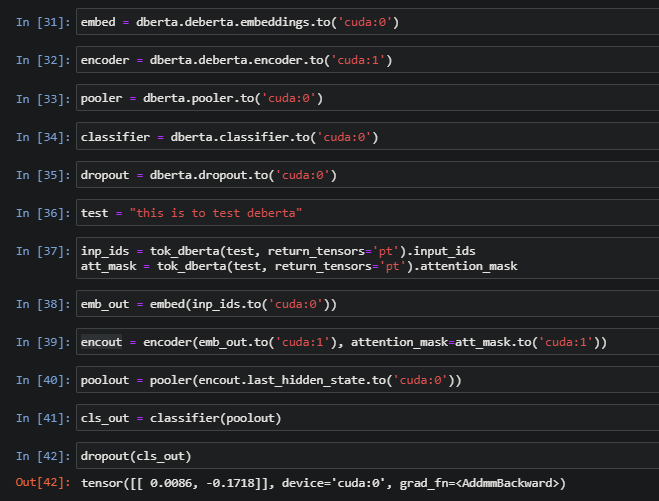
With this approach, I trained on IMDB classification task by assigning 'encoder' to second GPU and others to first 'GPU'. At the end of the training, second GPU consumed lot of memory when compared to first GPU and this resulted in 20-80 split of the entire model.
So, I tried splitting encoder layers also as shown below but getting this error - **"TypeError: forward() takes 1 positional argument but 2 were given"**
```
embed = dberta.deberta.embeddings.to('cuda:0')
f6e = dberta.deberta.encoder.layer[:6].to('cuda:0')
l6e = dberta.deberta.encoder.layer[6:].to('cuda:1')
pooler = dberta.pooler.to('cuda:0')
classifier = dberta.classifier.to('cuda:0')
dropout = dberta.dropout.to('cuda:0')
test = "this is to test deberta"
inp_ids = tok_dberta(test, return_tensors='pt').input_ids
att_mask = tok_dberta(test, return_tensors='pt').attention_mask
emb_out = embed(inp_ids.to('cuda:0'))
first_6_enc_lay_out = f6e(emb_out)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-15-379d948e5ba5> in <module>
----> 1 first_6_enc_lay_out = f6e(emb_out)
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
TypeError: forward() takes 1 positional argument but 2 were given
```
Plz suggest how to proceed further.. | 02-12-2021 12:22:20 | 02-12-2021 12:22:20 | We already have naive vertical MP implemented in t5 and gpt, and there is a much easier version of Bart MP - but it's not merged (https://github.com/huggingface/transformers/pull/9384).
The problem with naive MP is that it's very inefficient. That's why at the moment the rest of transformers isn't being ported.
Until then try HF Trainer DeepSpeed integration: https://huggingface.co/blog/zero-deepspeed-fairscale
Pipeline is the next in line, but it's very complicated.
Naive vertical MP is Pipeline with chunks=1.
See my work in progress notes on Parallelism: https://github.com/huggingface/transformers/issues/9766
<|||||>Thanks @stas00 for sharing your work. I'll implement DeepSpeed with HF..<|||||>Hi @stas00 ,
As mentioned above, I installed deepspeed and used HF Trainer to train instead of native pytorch. Without DeepSpeed, I'm able to complete the training but with DeepSpeed, execution is stuck at -
**[2021-02-17 15:05:24,441] [INFO] [distributed.py:40:init_distributed] Initializing torch distributed with backend: nccl** .
complete log is -
```
[2021-02-17 15:05:06,621] [WARNING] [runner.py:117:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
[2021-02-17 15:05:06,736] [INFO] [runner.py:355:main] cmd = /usr/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMF19 --master_addr=127.0.0.1 --master_port=29500 ./Deepspeed.py --output_dir test1 --overwrite_output_dir --do_train --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --learning_rate 3e-5 --weight_decay 0.01 --num_train_epochs 1 --load_best_model_at_end --deepspeed ds_config.json
[2021-02-17 15:05:08,344] [INFO] [launch.py:78:main] WORLD INFO DICT: {'localhost': [0]}
[2021-02-17 15:05:08,344] [INFO] [launch.py:87:main] nnodes=1, num_local_procs=1, node_rank=0
[2021-02-17 15:05:08,345] [INFO] [launch.py:99:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0]})
[2021-02-17 15:05:08,345] [INFO] [launch.py:100:main] dist_world_size=1
[2021-02-17 15:05:08,345] [INFO] [launch.py:103:main] Setting CUDA_VISIBLE_DEVICES=0
2021-02-17 15:05:10.792753: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
Some weights of the model checkpoint at /home/jovyan/models/roberta-large/ were not used when initializing RobertaForSequenceClassification: ['lm_head.bias', 'lm_head.dense.weight', 'lm_head.dense.bias', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.decoder.weight', 'roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
- This IS expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of RobertaForSequenceClassification were not initialized from the model checkpoint at /home/jovyan/models/roberta-large/ and are newly initialized: ['classifier.dense.weight', 'classifier.dense.bias', 'classifier.out_proj.weight', 'classifier.out_proj.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
loaded df
Encoding done
parser created
[2021-02-17 15:05:24,441] [INFO] [distributed.py:40:init_distributed] Initializing torch distributed with backend: nccl
```
I'm passing below in cmd -
```
!deepspeed ./Deepspeed.py --output_dir test1 --overwrite_output_dir --do_train \
--per_device_train_batch_size 8 --per_device_eval_batch_size 8 --learning_rate 3e-5 --weight_decay 0.01 --num_train_epochs 1 \
--load_best_model_at_end --deepspeed ds_config.json
```
Here's my simple script -
```
from transformers import RobertaForSequenceClassification, RobertaTokenizerFast, Trainer, TrainingArguments, HfArgumentParser
import pandas as pd
import numpy as np
import torch
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
tok = RobertaTokenizerFast.from_pretrained('/home/jovyan/models/roberta-large/')
model = RobertaForSequenceClassification.from_pretrained('/home/jovyan/models/roberta-large/', num_labels=2)
df_full = pd.read_csv('IMDB_Dataset.csv')
print("loaded df")
df_full = df_full.sample(frac=1).reset_index(drop=True)
df_req = df_full.head(1000)
df_train = df_req.head(800)
df_eval = df_req.tail(200)
train_text, train_labels_raw, val_text, val_labels_raw = df_train.review.values.tolist(), df_train.sentiment.values.tolist(), df_eval.review.values.tolist(), df_eval.sentiment.values.tolist()
train_encodings = tok(train_text, padding=True, truncation=True, max_length=512)
val_encodings = tok(val_text, padding=True, truncation=True, max_length=512)
train_labels = [1 if i=='positive' else 0 for i in train_labels_raw]
val_labels = [1 if i=='positive' else 0 for i in val_labels_raw]
class IMDbDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_dataset = IMDbDataset(train_encodings, train_labels)
val_dataset = IMDbDataset(val_encodings, val_labels)
print("Encoding done")
parser = HfArgumentParser(TrainingArguments)
print('parser created')
train_args = parser.parse_args_into_dataclasses()
print('got training')
print(train_args[0])
trainer = Trainer(
model=model,
args=train_args[0],
train_dataset=train_dataset,
eval_dataset=val_dataset
)
print('------------TRAINING-------------')
trainer.train()
```
Plz let me know if I missed anything..<|||||>This looks like a pytorch distributed issue, can you launch your script as following?
```
python -m torch.distributed.launch --nproc_per_node=1 ./Deepspeed.py --output_dir test1 --overwrite_output_dir --do_train \
--per_device_train_batch_size 8 --per_device_eval_batch_size 8 --learning_rate 3e-5 --weight_decay 0.01 --num_train_epochs 1 \
--load_best_model_at_end
```
Deespeed requires a distributed env even with one gpu. so in this experiment we remove DeepSpeed completely but launch a similar distributed environment for a single process.
What's the output of: `python -m torch.utils.collect_env` on that system? Are you running on a recent pytorch version? I'm noticing that I have a different `distributed.py`, since the logger reports a different line number on my side:
```
[2021-02-17 09:36:01,176] [INFO] [distributed.py:46:init_distributed] Initializing torch distributed with backend: nccl
```
Also, I'm noticing your trying to run it from a notebook. This could be related as well. Any reason why you're not using a normal console? Are you on colab or some restricted environment?
Though I checked I can launch deepspeed just fine from the notebook. via `!deepspeed` or `%%bash cell`.
Alternatively you can launch your script via the native notebook, i.e. no script, using this:
https://huggingface.co/transformers/master/main_classes/trainer.html#deployment-in-notebooks
But let's see if we can resolve the distributed hanging, by first ensuring your are on a recent pytorch. I see bug reports for this in older pytorch versions (from 2018-2019)<|||||>Hi @stas00 ,
Thanks for reverting. Here are the results for above experiment -
1.
```
!python -m torch.distributed.launch --nproc_per_node=1 ./Deepspeed.py --output_dir test1 --overwrite_output_dir --do_train \
--per_device_train_batch_size 8 --per_device_eval_batch_size 8 --learning_rate 3e-5 --weight_decay 0.01 --num_train_epochs 1 \
--load_best_model_at_end
```
with the above command, execution got hanged and below is the output -
```
2021-02-18 01:29:23.513697: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
Some weights of the model checkpoint at /home/jovyan/models/roberta-large/ were not used when initializing RobertaForSequenceClassification: ['lm_head.bias', 'lm_head.dense.weight', 'lm_head.dense.bias', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.decoder.weight', 'roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
- This IS expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of RobertaForSequenceClassification were not initialized from the model checkpoint at /home/jovyan/models/roberta-large/ and are newly initialized: ['classifier.dense.weight', 'classifier.dense.bias', 'classifier.out_proj.weight', 'classifier.out_proj.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
loaded df
Encoding done
parser created
```
2.
I'm using transformers-4.3.0 and below is the detailed output for `!python -m torch.utils.collect_env` -
```
Collecting environment information...
PyTorch version: 1.7.1
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Python version: 3.6 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: 10.1.243
GPU models and configuration: GPU 0: Tesla V100-SXM2-32GB
Nvidia driver version: 450.51.06
cuDNN version: /usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] kubeflow-pytorchjob==0.1.3
[pip3] numpy==1.18.5
[pip3] torch==1.7.1
[pip3] torchvision==0.8.2
[conda] Could not collect
```
3.
I am using kubeflow notebook servers provided by my company. So that's why I'm running commands in notebook itself..
4.
I tried by setting env variables as mentioned in https://huggingface.co/transformers/master/main_classes/trainer.html#deployment-in-notebooks and execution got hanged in below cell -
<|||||>Thank you for your detailed answers, @saichandrapandraju
It feels like your environment can't run pytorch distributed. Here is a very simple test to check that the launcher + dist init works:
```
%%bash
echo 'import os, torch; print(os.environ["LOCAL_RANK"]); torch.distributed.init_process_group("nccl")' > test.py
python -m torch.distributed.launch --nproc_per_node=1 test.py
```
you can copy-n-paste it as is into a new cell including bash magic and then run it.
It should print `0` and not fail.
And if it fails, perhaps trying a different backend instead of `nccl`? what if you try `gloo`? But I don't think it'd do any good if it does work with `gloo`, as it doesn't support the same ops as `nccl` https://pytorch.org/docs/stable/distributed.html#backends
If this test fails let me know and I will ask if Deepspeed can support any other way. Normally distributed isn't needed for 1 gpu, but since the cpu acts as a sort of another gpu, they use the distributed environment to communicate between the two units.
<|||||>This looks like a potential thread to explore for the hanging " Initializing torch distributed with backend: nccl ":
https://discuss.pytorch.org/t/unexpected-hang-up-when-using-distributeddataparallel-on-two-machines/92262
See if you have any luck identifying the problem with the suggestions in that thread.<|||||>Hi @stas00 ,
with below command it got hanged again
```
%%bash
echo 'import os, torch; print(os.environ["LOCAL_RANK"]); torch.distributed.init_process_group("nccl")' > test.py
python -m torch.distributed.launch --nproc_per_node=1 test.py
```
But returned `0` with `gloo`
same after trying https://discuss.pytorch.org/t/unexpected-hang-up-when-using-distributeddataparallel-on-two-machines/92262
Below versions are different. Is it fine?
```
CUDA runtime version: 10.1.243
CUDA used to build PyTorch: 10.2
```<|||||>So this is a pure pytorch issue, you may want to file an Issue with pytorch: https://github.com/pytorch/pytorch/issues
If you can't launch distributed then DeepSpeed won't work for you.
Also I'd try pytorch-nightly - I read in one thread they have been tweaking this functionality since the last release. https://pytorch.org/get-started/locally/ - you should be able to install that locally.
> Below versions are different. Is it fine?
> ```
> CUDA runtime version: 10.1.243
> CUDA used to build PyTorch: 10.2
> ```
Shouldn't be a problem. Pytorch comes with its own toolkit.
This system-wide entry is useful for when building pytorch CPP extensions (which incidentally Deepspeed is). There ideally you want to have the same version for both, but sometimes minor version difference is not a problem.
<|||||>Thanks @stas00 ,
Raised an issue https://github.com/pytorch/pytorch/issues/52433 and https://discuss.pytorch.org/t/hanging-torch-distributed-init-process-group/112223
Even I'm thinking of nightly. Will give it a try...<|||||>If this is sorted out, I hope HFTrainer and deepspeed will work with single and multi gpu setting..<|||||>I'd help for you to augment your pytorch Issue with the information they request - at the very least the output of `python -m torch.utils.collect_env` and probably mention that you're running from a notebook and in a kubeflow container. Because as you presented it now, they won't know what to do with it, as such code works just fine on a normal setup.<|||||>Thanks @stas00 ,
I installed `1.7.1+cu101` and below returned `0`
```
%%bash
echo 'import os, torch; print(os.environ["LOCAL_RANK"]); torch.distributed.init_process_group("nccl")' > test.py
python -m torch.distributed.launch --nproc_per_node=1 test.py
```
But it got hanged again with script and below are the logs -
```
2021-02-18 19:00:28.946359: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
Some weights of the model checkpoint at /home/jovyan/models/roberta-large/ were not used when initializing RobertaForSequenceClassification: ['lm_head.bias', 'lm_head.dense.weight', 'lm_head.dense.bias', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.decoder.weight', 'roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
- This IS expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of RobertaForSequenceClassification were not initialized from the model checkpoint at /home/jovyan/models/roberta-large/ and are newly initialized: ['classifier.dense.weight', 'classifier.dense.bias', 'classifier.out_proj.weight', 'classifier.out_proj.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
loaded df
Encoding done
fastai-c2-0:13993:13993 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to eth0
fastai-c2-0:13993:13993 [0] NCCL INFO NCCL_SOCKET_IFNAME set to eth0
fastai-c2-0:13993:13993 [0] NCCL INFO Bootstrap : Using [0]eth0:10.244.2.134<0>
fastai-c2-0:13993:13993 [0] NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
fastai-c2-0:13993:13993 [0] misc/ibvwrap.cc:63 NCCL WARN Failed to open libibverbs.so[.1]
fastai-c2-0:13993:13993 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to eth0
fastai-c2-0:13993:13993 [0] NCCL INFO NCCL_SOCKET_IFNAME set to eth0
fastai-c2-0:13993:13993 [0] NCCL INFO NET/Socket : Using [0]eth0:10.244.2.134<0>
fastai-c2-0:13993:13993 [0] NCCL INFO Using network Socket
NCCL version 2.7.8+cuda10.1
```
Also tried with nightly build(`1.9.0.dev20210218+cu101`) and got `0` for that bash command, but now it hanged at trainer.train() and below are the logs -
```
2021-02-18 19:28:13.170701: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
Some weights of the model checkpoint at /home/jovyan/models/roberta-large/ were not used when initializing RobertaForSequenceClassification: ['lm_head.bias', 'lm_head.dense.weight', 'lm_head.dense.bias', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.decoder.weight', 'roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
- This IS expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of RobertaForSequenceClassification were not initialized from the model checkpoint at /home/jovyan/models/roberta-large/ and are newly initialized: ['classifier.dense.weight', 'classifier.dense.bias', 'classifier.out_proj.weight', 'classifier.out_proj.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
loaded df
Encoding done
parser and args created
------------TRAINING-------------
fastai-c2-0:14431:14431 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to eth0
fastai-c2-0:14431:14431 [0] NCCL INFO NCCL_SOCKET_IFNAME set to eth0
fastai-c2-0:14431:14431 [0] NCCL INFO Bootstrap : Using [0]eth0:10.244.2.134<0>
fastai-c2-0:14431:14431 [0] NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
fastai-c2-0:14431:14431 [0] misc/ibvwrap.cc:63 NCCL WARN Failed to open libibverbs.so[.1]
fastai-c2-0:14431:14431 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to eth0
fastai-c2-0:14431:14431 [0] NCCL INFO NCCL_SOCKET_IFNAME set to eth0
fastai-c2-0:14431:14431 [0] NCCL INFO NET/Socket : Using [0]eth0:10.244.2.134<0>
fastai-c2-0:14431:14431 [0] NCCL INFO Using network Socket
NCCL version 2.7.8+cuda10.1
```
used the same script for both -
```
from transformers import RobertaForSequenceClassification, RobertaTokenizerFast, Trainer, TrainingArguments, HfArgumentParser
import pandas as pd
import numpy as np
import torch
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ['NCCL_DEBUG']='INFO'
os.environ['NCCL_DEBUG_SUBSYS']='ALL'
os.environ['NCCL_IB_DISABLE']='1'
os.environ['NCCL_SOCKET_IFNAME']='eth0'
tok = RobertaTokenizerFast.from_pretrained('/home/jovyan/models/roberta-large/')
model = RobertaForSequenceClassification.from_pretrained('/home/jovyan/models/roberta-large/', num_labels=2)
df_full = pd.read_csv('IMDB_Dataset.csv')
print("loaded df")
df_full = df_full.sample(frac=1).reset_index(drop=True)
df_req = df_full.head(1000)
df_train = df_req.head(800)
df_eval = df_req.tail(200)
train_text, train_labels_raw, val_text, val_labels_raw = df_train.review.values.tolist(), df_train.sentiment.values.tolist(), df_eval.review.values.tolist(), df_eval.sentiment.values.tolist(),
train_encodings = tok(train_text, padding=True, truncation=True, max_length=512)
val_encodings = tok(val_text, padding=True, truncation=True, max_length=512)
train_labels = [1 if i=='positive' else 0 for i in train_labels_raw]
val_labels = [1 if i=='positive' else 0 for i in val_labels_raw]
class IMDbDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_dataset = IMDbDataset(train_encodings, train_labels)
val_dataset = IMDbDataset(val_encodings, val_labels)
print("Encoding done")
parser = HfArgumentParser(TrainingArguments)
train_args = parser.parse_args_into_dataclasses()
print('parser and args created')
trainer = Trainer(
model=model,
args=train_args[0],
train_dataset=train_dataset,
eval_dataset=val_dataset
)
if train_args[0].do_train:
print('------------TRAINING-------------')
trainer.train()
if train_args[0].do_eval:
print('------------EVALUATING-------------')
trainer.evaluate()
```
Updated same in pytorch issues and forums as well ...
Wanted to let you know about the progress.
<|||||>> I installed `1.7.1+cu101` and below returned `0`
>
> ```
> %%bash
> echo 'import os, torch; print(os.environ["LOCAL_RANK"]); torch.distributed.init_process_group("nccl")' > test.py
> python -m torch.distributed.launch --nproc_per_node=1 test.py
> ```
That's a good step forward, I'm glad it worked. From what I understand system-wide cuda shouldn't have impact on whether distributed works or not, but clearly in your case it did.
How can I reproduce your setup? I don't know where you got your dataset from. As suggested earlier if you want to save my time, please setup a public google colab notebook (free) and then me and others can easily look at the situation without needing to figure out how to set up our own.<|||||>Hi @stas00 ,
[Here](https://colab.research.google.com/drive/1u0QHP8kdjlEqv85IyB98KVlVLBcddhMi?usp=sharing) is the colab version of my script. I used [IMDB from kaggle](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews) in local but in colab I gave a download and extractable version. Also, I included torch and transformers versions that I'm using.<|||||>Thank you, but have you tried running it? It fails in many cells, perhaps I wasn't clear but the idea was to give us a working notebook and then it's easier to spend the time trying to understand the problem, rather than trying to figure out how to make it run - does it make sense?<|||||>Hmm, you're running on a system with multi-gpus, correct? In one threads I found out that if a vm is used and NVLink they may not work unless properly configured, and that person solved the problem with:
```
export NCCL_P2P_DISABLE=1
```
which disables NVLink between the 2 cards and switches to the slower PCIe bridge connection.
Could you try and check that this is not your case?
<|||||>So sorry for that..
But in colab everything works just fine with same library versions that I'm using. [Here](https://colab.research.google.com/drive/1u0QHP8kdjlEqv85IyB98KVlVLBcddhMi?usp=sharing) is the updated one along with outputs.
I have 3 VM's where 1 is having 2 GPU's and rest with single GPU. Currently I'm trying in one of the VM with single GPU and if everything is fine we'll replicate this to 2 GPU VM or combine all 4 V100-32GB GPU's for bigger models. This is the higher level roadmap.
1. with deepspeed :
I tried exact colab that I shared in my notebook server and it is hanging here -

2. normal torch.distributed :
Same with script using torch.distributed.launch and it also hangs at trainer.train() with below log -
```
parser and args created
fastai-c2-0:22177:22177 [0] NCCL INFO Bootstrap : Using [0]eth0:10.244.2.134<0>
fastai-c2-0:22177:22177 [0] NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
fastai-c2-0:22177:22177 [0] misc/ibvwrap.cc:63 NCCL WARN Failed to open libibverbs.so[.1]
fastai-c2-0:22177:22177 [0] NCCL INFO NET/Socket : Using [0]eth0:10.244.2.134<0>
fastai-c2-0:22177:22177 [0] NCCL INFO Using network Socket
NCCL version 2.7.8+cuda10.1
```
same with `export NCCL_P2P_DISABLE=1`
But now it's not hanging at ' Initializing torch distributed with backend: nccl ' anymore -

<|||||>Will there be any potential configuration issue..?
But I think everything should work with 1 GPU. Correct me if I'm wrong.<|||||>Hi @stas00 ,
It's working with `NCCL_SOCKET_IFNAME=lo` from [this](https://github.com/NVIDIA/nccl/issues/352) thread.
both of the below were working now -
```
!NCCL_SOCKET_IFNAME=lo python -m torch.distributed.launch --nproc_per_node=1 ./Seq2Seq.py --output_dir ./out_dir/results --overwrite_output_dir --do_train \
--do_eval --per_device_train_batch_size 4 --per_device_eval_batch_size 4 --learning_rate 3e-5 --weight_decay 0.01 \
--num_train_epochs 1 --load_best_model_at_end --local_rank 0
```
and
```
!NCCL_SOCKET_IFNAME=lo deepspeed ./Seq2Seq.py --output_dir ./out_dir/results --overwrite_output_dir --do_train \
--do_eval --per_device_train_batch_size 12 --per_device_eval_batch_size 12 --learning_rate 3e-5 --weight_decay 0.01 \
--num_train_epochs 1 --load_best_model_at_end --local_rank 0 --deepspeed ds_config.json
```
Not sure exactly what it's doing internally. I will check in other scenarios like multi-GPU and let you know...<|||||>Yay, so glad to hear you found a solution, @saichandrapandraju!
Thank you for updating the notebook too!
If the issue has been fully resolved for you please don't hesitate to close this Issue.
If some new problem occurs, please open a new dedicated issue. Thank you.<|||||>Tested DeepSpeed on multi-GPU as well and it worked !!
By setting `NCCL_SOCKET_IFNAME=lo`, everything worked as expected.
Thanks a lot @stas00 |
transformers | 10,150 | closed | Problem with evaluation_strategy | Hi everyone!
I have a problem (i think is a bug but i'm not sure) with the parameter "evaluation_strategy" in TFTrainingArguments.
I created a script for finetuning a transfomers model, based on the example "run_tf_text_classification.py" file.
In "TFTrainingArguments" i put the parameter "evaluation_strategy="epoch"", to see how the eval_loss change after each epoch.
Unfortunately, the eval_loss is not printed after each epoch, but if a change from "epoch" to "steps", actually the eval_loss is printed after each steps. | 02-12-2021 10:42:58 | 02-12-2021 10:42:58 | `evaluation_strategy` is not an argument fully implemented in `TFTrainer`, it only supports "steps". (The PyTorch counterpart supports all the possibilities.)
To evaluate every epoch, the best is to use the native Keras fit method.<|||||>Thanks a lot!! |
transformers | 10,149 | closed | Issue using num_beams parameter for T5 / DeepSpeed | Using a fine-turned seq2seq model, I'd like to generate some number of possible different generations for a given input. One way of typically doing this is using beam search.
Using @stas00 's amazing DeepSpeed additions so that T5-11B will fit in my GPUs, I'm calling the trainer ( finetune_trainer.py
) with only the --do_predict (no train/eval) and (critically) the --num_beams parameter, but this is throwing an error.
I think the issue is likely one of the following:
1) That this is an unexpected bug/error
2) That this is normal/expected, and that beam search isn't supported on trainer prediction, but rather normally accomplished using run_distributed_eval.py (as described in https://github.com/huggingface/transformers/blob/master/examples/seq2seq/README.md ). But if I remember correctly I don't think run_distributed_eval.py currently works with DeepSpeed (though I could be wrong?).
I am using a pull from around Feb 4th, so if things have changed in the past week, it's possible that's my issue, too.
### Run Script
```
export BS=1; rm -rf $OUTPUTDIR; PYTHONPATH=../../src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus=4 ./finetune_trainer.py --model_name_or_path allenai/unifiedqa-t5-11b --output_dir $OUTPUTDIR --adam_eps 1e-06 --data_dir $DATADIR \
--do_predict \
--num_beams 8 \
--evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 \
--logging_first_step --logging_steps 1000 --max_source_length $SEQLEN --max_target_length $SEQLEN --num_train_epochs $EPOCHS \
--overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--predict_with_generate --sortish_sampler \
--test_max_target_length $SEQLEN --val_max_target_length $SEQLEN \
--warmup_steps 5 \
--deepspeed ds_config.json --fp16 \
```
### Error
```
[2021-02-12 01:02:55,207] [WARNING] [runner.py:117:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
[2021-02-12 01:02:55,861] [INFO] [runner.py:355:main] cmd = /home/pajansen/anaconda3/envs/transformers-feb4-2020/bin/python -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMCwgMSwgMiwgM119 --master_addr=127.0.0.1 --master_port=29500 ./finetune_trainer.py --model_name_or_path allenai/unifiedqa-t5-11b --output_dir output_dir_compexpl-feb10-epoch1-uqa-11b-pretrain-teacher-min6-max8-step2-beam --adam_eps 1e-06 --data_dir /home/pajansen/github/compositional-expl/pretrain/min-6-max-8-noduptest/ --do_predict --num_beams 8 --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 256 --max_target_length 256 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size 1 --per_device_train_batch_size 1 --predict_with_generate --sortish_sampler --test_max_target_length 256 --val_max_target_length 256 --warmup_steps 5 --deepspeed ds_config.json --fp16
[2021-02-12 01:02:56,753] [INFO] [launch.py:78:main] WORLD INFO DICT: {'localhost': [0, 1, 2, 3]}
[2021-02-12 01:02:56,753] [INFO] [launch.py:84:main] nnodes=1, num_local_procs=4, node_rank=0
[2021-02-12 01:02:56,753] [INFO] [launch.py:99:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0, 1, 2, 3]})
[2021-02-12 01:02:56,753] [INFO] [launch.py:100:main] dist_world_size=4
[2021-02-12 01:02:56,753] [INFO] [launch.py:102:main] Setting CUDA_VISIBLE_DEVICES=0,1,2,3
[2021-02-12 01:02:59,580] [INFO] [distributed.py:39:init_distributed] Initializing torch distributed with backend: nccl
[2021-02-12 01:02:59,723] [INFO] [distributed.py:39:init_distributed] Initializing torch distributed with backend: nccl
[2021-02-12 01:02:59,828] [INFO] [distributed.py:39:init_distributed] Initializing torch distributed with backend: nccl
[2021-02-12 01:02:59,976] [INFO] [distributed.py:39:init_distributed] Initializing torch distributed with backend: nccl
Traceback (most recent call last):
File "./finetune_trainer.py", line 367, in <module>
main()
File "./finetune_trainer.py", line 160, in main
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
File "/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/hf_argparser.py", line 189, in parse_args_into_dataclasses
raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
ValueError: Some specified arguments are not used by the HfArgumentParser: ['--num_beams', '8']
Traceback (most recent call last):
File "./finetune_trainer.py", line 367, in <module>
main()
File "./finetune_trainer.py", line 160, in main
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
File "/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/hf_argparser.py", line 189, in parse_args_into_dataclasses
raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
ValueError: Some specified arguments are not used by the HfArgumentParser: ['--num_beams', '8']
Traceback (most recent call last):
File "./finetune_trainer.py", line 367, in <module>
Traceback (most recent call last):
File "./finetune_trainer.py", line 367, in <module>
main()
File "./finetune_trainer.py", line 160, in main
main()
File "./finetune_trainer.py", line 160, in main
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
model_args, data_args, training_args = parser.parse_args_into_dataclasses() File "/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/hf_argparser.py", line 189, in parse_args_into_dataclasses
File "/home/pajansen/github/transformers-feb4-2021/transformers/src/transformers/hf_argparser.py", line 189, in parse_args_into_dataclasses
raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
ValueErrorValueError: : Some specified arguments are not used by the HfArgumentParser: ['--num_beams', '8']Some specified arguments are not used by the HfArgumentParser: ['--num_beams', '8']
```
| 02-12-2021 08:16:07 | 02-12-2021 08:16:07 | It's `--eval_beams` in that particular script:
```
./finetune_trainer.py -h | grep beams
[--tgt_lang TGT_LANG] [--eval_beams EVAL_BEAMS]
--eval_beams EVAL_BEAMS
# num_beams to use for evaluation.
```
This script is going to be retired soon and `run_seq2seq.py` is the replacement, and there by my suggestions we switched to `num_beams` to match the `model.config.num_beams`<|||||>Thanks -- I was doing it the complex way and looking through the seqtrainer to verify the num_beams was being passed, when really I should have started with funetune_trainer.py to verify the name was the same. :)
That did get rid of the argument error. But I am now seeing different errors:
1) I received the "RuntimeError: Input, output and indices must be on the current device" error, but then realized that was fixed in #10039 , so I did a pull of master.
2) Then I was getting OOM errors when calling trainer with just --do_predict. I tried reducing eval_beams to 1, then excluding the argument all together, and the OOM is still thrown.
3) To figure out if this was a broader issue from the pull, I've went back to rerunning my fine tuning script, but it's also now throwing OOM on T5-11B (but worked okay on my pull from ~Feb 4th). I'm running a few more tests to try to rule out if it's something I accidentally changed (so far nothing). I should probably start a fresh issue.
<|||||>You probably need to start transitioning to `run_seq2seq.py` as `funetune_trainer.py` is about to be demoted into the legacy underworld.
I haven't full figured out how to do it as not everything was ported, but I'm updating notes here: https://github.com/huggingface/transformers/issues/10036 as I learn new nuances - one of the main changes is that datasets are now done in a complete different way.
----
> To figure out if this was a broader issue from the pull, I've went back to rerunning my fine tuning script, but it's also now throwing OOM on T5-11B
Yes, I remember I had encountered that too - I went back to the original scripts that I know worked (https://github.com/huggingface/transformers/issues/9996) and then started comparing what changes I have done and then discovered which differences I made that led to more GPU usage.
Also note that since the merge of https://github.com/huggingface/transformers/pull/10114 the DeepSpeed process is completely contained in the `train()` stage (since it doesn't have anything to offer during eval at the moment). I think this then would impact the ability to load t5-11b 45GB model onto 40GB gpu, because DeepSpeed was loading it in fp16 (22GB), but HF trainer can't do that. But this is a very recent change. I started looking at doing fp16 during eval in HF Trainer, but it looks like this is a wildcard and many models fail to deliver when `.half`ed.
Before this PR was merged, if you were to train and then eval then the smaller model would avail itself to eval. Not yet sure how to best to proceed - surely if one can train a model, they should be able to eval it too.
**edit**: looking closer, `self.model` will remain as it were in `train` anyway, so actually this PR shouldn't have affected the eval stage - i.e. should remain in fp16 if the trainer set the model. But if `train` wasn't run it surely won't be able to load in fp32 (45GB>40GB).<|||||>Thanks -- I migrated to ```run_seq2seq.py``` and I'm now able to replicate the OOM error on the README examples (assuming I have DeepSpeed configured correctly). So it does seem like it's a broader issue, and we may back to not being able to train T5-11B on the 40gb cards on the current master (though I can always go back and try to see if there's a commit from the past week that's post-eval-issue fix and pre-new issue).
Since this is unrelated to the ```--num_beams`` argument, I put it in a new issue: #10161 and we can probably close this one. |
transformers | 10,148 | closed | Fix typo in GPT2DoubleHeadsModel docs | If I'm not mistaken, masked label ids should be set to `-100` not `-1`
| 02-12-2021 05:27:17 | 02-12-2021 05:27:17 | |
transformers | 10,147 | closed | BERT with regression head cannot fit one datapoint | Hi, I am trying to use BERT for a token-level regression task (predict a continuous value for each token), and I'm having trouble getting my model to train. As a debugging strategy, I'm trying to get it to overfit one datapoint, which should be easy, but it's failing that also.
Here is a minimal reproducing source code. The model is BERT which feeds into a ``nn.Linear(768, 1)``. To keep things simple, I am feeding it a sequence of length 1, and training it to output 0.5.
```
import torch
import transformers
class RegressionModel(torch.nn.Module):
def __init__(self):
super(RegressionModel, self).__init__()
self.bert = transformers.BertModel.from_pretrained('bert-base-uncased')
self.linear = torch.nn.Linear(768, 1)
def forward(self, X_ids):
return self.linear(self.bert(X_ids).last_hidden_state)
model = RegressionModel().cuda()
model.train()
opt = torch.optim.Adam(model.parameters())
X_ids = torch.LongTensor([[12345]]).cuda()
Y_true = torch.Tensor([[0.5]]).cuda()
steps = 0
while True:
opt.zero_grad()
Y_pred = model(X_ids)
loss = (Y_true - Y_pred)**2
loss.backward()
print(steps, Y_pred, float(loss))
steps += 1
opt.step()
```
After a few thousand iterations, it predicts around 0.5 but not exactly:
```
2315 tensor([[[0.4669]]], device='cuda:0', grad_fn=<AddBackward0>) 0.0010972624877467752
2316 tensor([[[0.5115]]], device='cuda:0', grad_fn=<AddBackward0>) 0.00013136999041307718
2317 tensor([[[0.4788]]], device='cuda:0', grad_fn=<AddBackward0>) 0.00045129822683520615
2318 tensor([[[0.4658]]], device='cuda:0', grad_fn=<AddBackward0>) 0.0011675604619085789
```
Note that if I set `model.eval()` instead of `model.train()`, then the model is able to fit as expected (predicts 0.5000 after about 200 iterations). The problem exists in the RoBERTa model as well.
## Version information
- `transformers` version: 4.3.2
- Platform: Linux-4.15.0-112-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.5
- PyTorch version (GPU?): 1.4.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no | 02-11-2021 20:07:01 | 02-11-2021 20:07:01 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discusss.huggingface.co) instead?
Thanks! |
transformers | 10,146 | closed | Model not training beyond 1st epoch | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.0.dev0
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No (Single GPU) --> **COLAB**
### Who can help
Models:
- albert, bert, xlm: @LysandreJik
- tensorflow: @jplu
- trainer: @sgugger
## Information
Model I am using (Bert, XLNet ...): RoBERTa
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
First off, this issue is basically a continuation of #10055 but since that error was mostly resolved, I have thus opened another issue. I am using a private dataset, so I am not at liberty to share it. However, I can provide a clue as to how the `csv` looks like:-
```
,ID,Text,Label
......................
Id_1, "Lorem Ipsum", 14
```
This is the code:-
```
!git clone https://github.com/huggingface/transformers.git
!cd transformers
!pip install -e .
train_text = list(train['Text'].values)
train_label = list(train['Label'].values)
val_text = list(val['Text'].values)
val_label = list(val['Label'].values)
from transformers import RobertaTokenizer, TFRobertaForSequenceClassification
import tensorflow as tf
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = TFRobertaForSequenceClassification.from_pretrained('roberta-base')
train_encodings = tokenizer(train_text, truncation=True, padding=True)
val_encodings = tokenizer(val_text, truncation=True, padding=True)
train_dataset = tf.data.Dataset.from_tensor_slices((
dict(train_encodings),
train_label
))
val_dataset = tf.data.Dataset.from_tensor_slices((
dict(val_encodings),
val_label
))
#----------------------------------------------------------------------------------------------------------------------
#Since The trainer does not work, I will use the native one
from transformers import TFTrainingArguments, TFTrainer
training_args = TFTrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
)
with training_args.strategy.scope():
model = TFRobertaForSequenceClassification.from_pretrained("roberta-base")
trainer = TFTrainer(
model=model, # the instantiated Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset # evaluation dataset
)
trainer.train()
#----------------------------------------------------------------------------------------------------------------------
#Using Native Tensorflow
from transformers import TFRobertaForSequenceClassification
import tensorflow as tf
model = TFRobertaForSequenceClassification.from_pretrained('roberta-base', num_labels=1)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-18)
loss_fn = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
model.compile(optimizer=optimizer, loss=loss_fn, metrics=['accuracy']) # can also use any keras loss fn
model.fit(train_dataset.batch(8), validation_data = val_dataset.batch(64), epochs=15, batch_size=8)
```
**The Problems:**
- [ ] Cannot train using the `Trainer()` method. The cell successfully executes, but it does nothing - does not start training at all. This is not much of a major issue but it may be a factor in this problem.
- [x] Model does not train more than 1 epoch :---> I have shared this log for you, where you can clearly see that the model does not train beyond 1st epoch; The rest of epochs just do what the first accomplished:-
```
All model checkpoint layers were used when initializing TFRobertaForSequenceClassification.
Some layers of TFRobertaForSequenceClassification were not initialized from the model checkpoint at roberta-base and are newly initialized: ['classifier']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Epoch 1/5
WARNING:tensorflow:The parameters `output_attentions`, `output_hidden_states` and `use_cache` cannot be updated when calling a model.They have to be set to True/False in the config object (i.e.: `config=XConfig.from_pretrained('name', output_attentions=True)`).WARNING:tensorflow:AutoGraph could not transform <bound method Socket.send of <zmq.sugar.socket.Socket object at 0x7f5b14f1b6c8>> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: <cyfunction Socket.send at 0x7f5b323fb2a0> is not a module, class, method, function, traceback, frame, or code object
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <bound method Socket.send of <zmq.sugar.socket.Socket object at 0x7f5b14f1b6c8>> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: <cyfunction Socket.send at 0x7f5b323fb2a0> is not a module, class, method, function, traceback, frame, or code object
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:tensorflow:AutoGraph could not transform <function wrap at 0x7f5b301d3c80> and will run it as-is.
Cause: while/else statement not yet supported
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <function wrap at 0x7f5b301d3c80> and will run it as-is.
Cause: while/else statement not yet supported
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:tensorflow:The parameter `return_dict` cannot be set in graph mode and will always be set to `True`.
WARNING:tensorflow:The parameters `output_attentions`, `output_hidden_states` and `use_cache` cannot be updated when calling a model.They have to be set to True/False in the config object (i.e.: `config=XConfig.from_pretrained('name', output_attentions=True)`).
WARNING:tensorflow:The parameter `return_dict` cannot be set in graph mode and will always be set to `True`.
180/180 [==============================] - ETA: 0s - loss: 0.0000e+00 - accuracy: 0.0022WARNING:tensorflow:The parameters `output_attentions`, `output_hidden_states` and `use_cache` cannot be updated when calling a model.They have to be set to True/False in the config object (i.e.: `config=XConfig.from_pretrained('name', output_attentions=True)`).
WARNING:tensorflow:The parameter `return_dict` cannot be set in graph mode and will always be set to `True`.
180/180 [==============================] - 150s 589ms/step - loss: 0.0000e+00 - accuracy: 0.0022 - val_loss: 0.0000e+00 - val_accuracy: 0.0077
Epoch 2/5
180/180 [==============================] - 105s 582ms/step - loss: 0.0000e+00 - accuracy: 0.0022 - val_loss: 0.0000e+00 - val_accuracy: 0.0077
Epoch 3/5
180/180 [==============================] - 105s 582ms/step - loss: 0.0000e+00 - accuracy: 0.0022 - val_loss: 0.0000e+00 - val_accuracy: 0.0077
```
> I think the problem may be that the `activation function` may be wrong. For `CategoricalCrossentropy` we need a `Sigmoid` loss but maybe the activation used in my code is not that.
Can anyone tell me how exactly to change the activation function, or maybe other thoughts on the potential problem? I have tried changing the learning rate with no effect. | 02-11-2021 19:19:08 | 02-11-2021 19:19:08 | Could you please post this on the [forum](https://discuss.huggingface.co/), rather than here? The authors of HuggingFace like to keep this place for bugs or feature requests, and they're more than happy to help you on the forum.
Looking at your code, this seems more like an issue with preparing the data correctly for the model.
Take a look at [this example in the docs](https://huggingface.co/transformers/custom_datasets.html#sequence-classification-with-imdb-reviews) on how to perform text classification with the Trainer.
<|||||>@NielsRogge Not very pleased with your reply, please ask someone a question if you are unclear about something rather than trying to just close an issue.
As regards the data, I can assure you it is in the format specified by your guide - It is in NumPy arrays converted to list and then made into a TFDataset object and has all the correct parts. The conversion was made to list because an error clearly specified that lists are to be passed.
This **is** a bug because the model does appear to be training, just having extremely low accuracy (Which may be because of the activation function, but I am not sure) and it won't train any further than the 1st epoch, where subsequent epochs don't pick up where the previous epoch left.<|||||>I've created a Google Colab that will hopefully resolve your issue:
https://colab.research.google.com/drive/1azTvNc0AZeN5JMyzPnOGic53jddIS-QK?usp=sharing
What I did was create some dummy data based on the format of your data, and then see if the model is able to overfit them (as this is [one of the most common things to do first when debugging a neural network](http://karpathy.github.io/2019/04/25/recipe/)). As you can see in the notebook, it appears to do, so everything seems to be working fine. Let me know if this helps.
UPDATE: looking at your code, it appears that the learning rate is way too low in your case. A typical value for Transformers is 5e-5. <|||||>@NielsRogge Thanx a lot for the advice, I will surely update you regarding any solution.
I have been trying to apply this to my own code, but I am still reproducing the bug - the warnings are there (unlike yours) I am using the latest version of `transformers`. The problem is that it doesn't learn - whatever progress it has made in 1st epoch is replicated in the rest of them. As an example, using this dummy dataset:-
```
train_text = ['a', 'b']
train_label = [0,1]
val_text = ['b']
val_label = [1]
```
even after 35 epochs, the model does not overfit. the same accuracy/loss is maintained irrespective of the loss function.
```
from transformers import TFRobertaForSequenceClassification
import tensorflow as tf
model = TFRobertaForSequenceClassification.from_pretrained('roberta-base', num_labels=1)
optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
loss_fn = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
model.compile(optimizer=optimizer, loss=loss_fn, metrics=['accuracy']) # can also use any keras loss fn
model.fit(train_dataset.batch(16), validation_data = val_dataset.batch(64), epochs=5, batch_size=1)
```
**UPDATE:** You might have missed this line @NeilsRogge about using the Keras loss function rather than the default one
`loss_fn = tf.keras.losses.CategoricalCrossentropy(from_logits=True)`
can you try reproduce the issue with that?<|||||>> Not very pleased with your reply, please ask someone a question if you are unclear about something rather than trying to just close an issue.
I want to jump in here and let you know that this kind of behavior is inappropriate. @NielsRogge is doing his best to help you here and he is doing this on his own free time. "My model is not training" is very vague and doesn't seem like a bug, so suggesting to take this on the forums is very appropriate: more people will be able to help you there.
Please respect that this is an open-source project. No one has to help you solve your bug so staying open-mined and kind will go a long way into getting the help you need.<|||||>@sgugger with all due respect, My model was training; just that it lost all progress it had made in an epoch for the next one - starting and ending with the exact number. And this is very much a bug.
And about the open-source project, I do understand that this is voluntary **but**, someday if you need help and someone else tells you without reading your question that whatever you have done (without any prior proof) and suggests you to ask your question somewhere else that I know for a fact is not that active, I would like to see your response.
We have many projects that are not backed by a company - look at `TPOT` for instance. its maintainer (weixuanfu) does this mostly as a hobby and for learning but if there is something he does not know, he wouldn't say "ask your question somewhere else" and not fully try to solve the problem.
If you don't want to spend time solving my problem, that's fine. I have no issue with that. But if you do not want to solve my problem just to close down the list of issues **then**, it feels pretty bad. I do know that I don't understand ML very deeply and certainly not enough to make a project of mine, but I do know the difference between someone actually trying to help me versus just trying to reduce the number of open GIthub issues.<|||||>I do think there's a bit of a misunderstanding with what we mean by a _bug_.
Of course, since your model isn't training properly, there's a bug in your code. But in this case, it's a bug probably caused by the user (these bugs include setting hyperparameters like learning rate too low, not setting your model in training mode, improper use of the Trainer, etc.). These things are bugs, but they are caused by the user. And for such cases, the forum is the ideal place to seek help.
Github issues are mostly for bugs caused by the Transformers library itself, i.e. caused by the authors (these bugs include implementations of models which are incorrect, a bug in the implementation of the Trainer, etc.).
So the issue you're posting here is a perfect use case for the forum! It's not that we want to close issues as soon as possible, and it's also not the case that we don't want to help you. It's just a difference between bugs due to the user/bugs due to the library itself, and there are 2 different places for this.<|||||>What said @NielsRogge is correct, your way of training your model is not correct (and your data might also be malformed). As far as I can see, if your data really looks like:
```
ID,Text,Label
......................
Id_1, "Lorem Ipsum", 14
```
I guess that if you have label id up to at least 14, it certainly means that you have more than one label, then the line
`model = TFRobertaForSequenceClassification.from_pretrained('roberta-base', num_labels=1)` is wrong and `1` should be replaced by the proper number.
Nevertheless, if you really have only one label, your loss must be `tf.keras.losses.MeanSquaredError` and not `tf.keras.losses.CategoricalCrossentropy`. But, if you have more than one label your loss must be `tf.keras.losses.SparseCategoricalCrossentropy`.
So as far as I can say, I second what has been said before and this post should be on the forum, not here.<|||||> @jplu Hmm.. I had thought that num_labels was the number labels to be predicted by the model (Like if it is multi-label classification) and about the data, I am importing it in NumPy arrays after preprocessing so I don't see why the structure of the data frame might be a problem.
@NielsRogge You may be right that the bug may be hyperparameter (I tried using all sorts of LR but it didn't work) but the reason why I think it is a bug in `transformers` is that if the loss starts from `100` and ends at `70` in 1st epoch, it is the exact same story in the rest of the epochs (They start and end with the same numbers):
```
.................
accuracy: 0.0025 - val_loss: 87.4479 - val_accuracy: 0.0077
accuracy: 0.0047 - val_loss: 87.4479 - val_accuracy: 0.0077
accuracy: 0.0049 - val_loss: 87.4479 - val_accuracy: 0.0077
accuracy: 0.0043 - val_loss: 87.4479 - val_accuracy: 0.0077
accuracy: 0.0052 - val_loss: 87.4479 - val_accuracy: 0.0077
.................
```
Another reason was that trying to train the model using `Trainer()` did not work (the cell executes successfully) but does not start training nor report an error. Can you tell me whether this is a bug or not? I had put it in the list above, and this is the output of the cell:- [just normal warnings, but does not start training]
```
All model checkpoint layers were used when initializing TFRobertaForSequenceClassification.
Some layers of TFRobertaForSequenceClassification were not initialized from the model checkpoint at roberta-base and are newly initialized: ['classifier']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
WARNING:tensorflow:The parameters `output_attentions`, `output_hidden_states` and `use_cache` cannot be updated when calling a model.They have to be set to True/False in the config object (i.e.: `config=XConfig.from_pretrained('name', output_attentions=True)`).
WARNING:tensorflow:The parameter `return_dict` cannot be set in graph mode and will always be set to `True`.
WARNING:tensorflow:The parameters `output_attentions`, `output_hidden_states` and `use_cache` cannot be updated when calling a model.They have to be set to True/False in the config object (i.e.: `config=XConfig.from_pretrained('name', output_attentions=True)`).
WARNING:tensorflow:The parameter `return_dict` cannot be set in graph mode and will always be set to `True`.
```
UPDATE: After quite some fixing, the model is now training and seems to be learning (I am still confused about what exactly `num_labels` is supposed to mean - number of total labels present in data OR labels that the model has to predict [multi-label classification]). Anyways, It still **doesn't** train with `Trainer()` which means I can't do Hyperparameter tuning :(<|||||>> Anyways, It still doesn't train with Trainer() which means I can't do Hyperparameter tuning :(
As mentioned before `TFTrainer` does not have hyper-parameter tuning. You should try the Keras one.<|||||>@sgugger I don't get what you mean - I should use PyTorch trainer? because I can't find any trainer for Keras in docs, only for native Tensorflow. In the example, [here](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/text_classification.ipynb#scrollTo=ttfT0CqaIrJm) they just use `Trainer`. Is there any way to do Htuning with keras/TF only, and not use pytorch?<|||||>This example is using PyTorch, not TensorFlow. There is no hyper-parameter tuning implemented in Transformers in TensorFlow, which is why I was recommending [Keras Tuner](https://blog.tensorflow.org/2020/01/hyperparameter-tuning-with-keras-tuner.html).<|||||>Alright. Thanx a ton!<|||||>> > Anyways, It still doesn't train with Trainer() which means I can't do Hyperparameter tuning :(
>
> As mentioned before `TFTrainer` does not have hyper-parameter tuning. You should try the Keras one.
Do you plan to add this support for TFTrainer?<|||||>@liaocs2008 the `TFTrainer` is not deprecated in favor of `Keras` which is now the default in all of our examples.<|||||>> After quite some fixing, the model is now training and seems to be learning
@neel04 I am facing the same issue, the model seems to be resetting after each epoch. Could you please share what fixes you implemented? |
transformers | 10,145 | closed | Add Fine-Tuning for Wav2Vec2 | # What does this PR do?
This PR adds the possibility to finetune Wav2Vec2 on a downstream task. I ran a couple of experiments and I think the training is pretty stable now, see this training run *e.g.*:
https://wandb.ai/patrickvonplaten/huggingface/reports/Project-Dashboard--Vmlldzo0OTI0OTc?accessToken=8azw8iyxnbiqd4ytxcgm4hbnfh3x1b2c9l2eyfqfzdqw7l0icreljc9qpx0rkl6f
Once this is merged, I will make a nice forum post and link 1,2 notebooks.
## Who can review?
Would be great if @sgugger @LysandreJik and @patil-suraj could review. | 02-11-2021 17:36:51 | 02-11-2021 17:36:51 | This is really nice, and the piece that will make the wav2vec 2.0 stuff awesome and more readily available! let me know if I can assist in testing/whatnot :) |
transformers | 10,144 | closed | T5 Base length of Tokenizer not equal config vocab_size | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: Installed from git
## Issue
The `len(AutoTokenizer.from_pretrained("t5-base"))` is `32100` but the `T5ForConditionalGeneration.from_pretrained("t5-base").config.vocab_size` is `32128`. Seems to be a similar issue to that of : https://github.com/huggingface/transformers/issues/2020
| 02-11-2021 16:35:31 | 02-11-2021 16:35:31 | duplicate of https://github.com/huggingface/transformers/issues/4875 I think<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,143 | closed | context manager for seeding, or generating fixed random tensor. | # 🚀 Feature request
context manager for torch random seed, where the seed is fixed only inside
## Motivation
in some integration test, an input required is very large to be hardcoded, and the ids_tensor provide only int32 examples.
However to fix this input either we can use NumPy seed, but probably it will compromise the randomness of other parts of the test.
I think a context manager where the seed is fixed only inside, it would benefit alot.
example of issues needing large fixed tensors as input #9951 #9954
if there's any alternative please suggest? | 02-11-2021 16:10:42 | 02-11-2021 16:10:42 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,142 | closed | T5 GPU Runtime Degradation | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.2.1 VS 3.4.0
- Platform: Colab (K80 GPU)
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101
- Tensorflow version (GPU?): N.A.
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@patrickvonplaten, @patil-suraj
## Information
Model I am using (Bert, XLNet ...): T5
The problem arises when using:
* [x] the official example scripts: (give details below)
* [] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
Hello,
I’ve noticed that the running time of T5 on a GPU has increased between v3.4.0 and the current version (v4.2.1). When running inference on a single example on a K80 GPU (Google Colab), the average runtime of a generate() call for a single example (the one in the transformers documentation) with t5-base in v3.4.0 is 539 ± 13 ms, while the runtime for v4.2.1 is 627 ± 13 ms.
On t5-large, the difference is 1004 ± 22 ms, compared to 1242 ± 15 ms.
I made two colab notebooks that compare the two versions:
https://colab.research.google.com/drive/1Rm9RFdfLUFFHOvjAOg816-6oXw8zm_tE?usp=sharing#scrollTo=eeJ0sS_g7-X2
https://colab.research.google.com/drive/1U2QPA4MR48xPCpn4XiG5KBk3qZGYeoIJ?usp=sharing
I’m aware of a at least one bug fix that was made to the attention mechanism of T5 in v4.0.0 (#8158), but I don’t think this change should have caused such a degradation.
Any idea why such a degradation occurred?
Thanks!
## To reproduce
See Colab notebooks attached. See the following code snippet as well:
```
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
print(f"Using device: {device}")
t5_tokenizer = T5TokenizerFast.from_pretrained('t5-base')
t5_model = T5ForConditionalGeneration.from_pretrained('t5-base')
t5_model = t5_model.to(device)
t5_input_ids = t5_tokenizer("summarize: studies have shown that owning a dog is good for you ", return_tensors="pt").input_ids # Batch size 1
t5_input_ids = t5_input_ids.to(device)
import time
import numpy as np
N = 100
times = []
for _ in range(N):
start = time.time()
t5_outputs = t5_model.generate(t5_input_ids)
end = time.time()
times.append(end-start)
print(f"transformers version: {transformers_version}")
print(f"torch version: {torch_version}")
print(f"{1000*np.mean(times):.0f} ms \u00B1 {1000*np.std(times):.2f} ms per loop (mean \u00B1 std of {N} runs)")
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
| 02-11-2021 13:48:50 | 02-11-2021 13:48:50 | Thanks a lot for this issue @dsgissin! Will take a look this week!<|||||>Hey!
Did you get a chance to look into the runtime degradation?
Thanks<|||||>Looking now! Sorry for the delay<|||||>Okey, I can reproduce the degradation! Will try to fix it today<|||||>I think this PR should fix it: https://github.com/huggingface/transformers/pull/10496
Let me know if you still encounter a degradation!
Thanks a mille for spotting this degradation - you probably now made T5 faster for the whole community :-)<|||||>Great, thanks a lot for the quick fix! |
transformers | 10,141 | closed | Add AMP for TF Albert | # What does this PR do?
This PR adds the following features to TF Albert:
- AMP compliancy
- Loss computation for TFAlbertForPreTraining
- Cleaning source code | 02-11-2021 12:58:16 | 02-11-2021 12:58:16 | I can split this PR into two different ones, but the one on AMP will be very short (only two single line to update, see the review above). Are you agree with a that tiny PR? If it is still ok, I will split this one^^<|||||>It's ok, thanks for showing me the changes!<|||||>@patrickvonplaten feel free to merge if it looks ok for you! |
transformers | 10,140 | closed | Direct way to apply different learning rate for different group of parameters in Trainer. | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
For now, if I want to specify learning rate to different parameter groups, I need to define an AdamW optimizer in my main function like the following:
```
optimizer = AdamW([{'params': model.classifier.parameters(), 'lr': 0.03 }],
model.bert.parameters(), lr=5e-5
)
```
and new a lr_schedule like the following:
```
lr_scheduler = get_linear_schedule_with_warmup(
self.optimizer, num_warmup_steps=self.args.warmup_steps, num_training_steps=num_training_steps
)
```
I believe that adding the feature of specifying different learning rates to `Trainer` for networks is quite convenient for fine-tuning processing.
Like the following:
```
trainer = Trainer(
...
grouped_parameters={
"params": ..,
},
{
"params": ..,
},
]
```
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
I am not a professional Github user, but I think a can make a PR if necessary.
| 02-11-2021 12:20:02 | 02-11-2021 12:20:02 | What if instead you derive from `Trainer` and override `create_optimizer_and_scheduler()` and have that function set your different learning rates? |
transformers | 10,139 | closed | ValueError: `Checkpoint` was expecting a trackable object (an object derived from `TrackableBase`), got GPT2LMHeadModel | I'm having this issue, and I think it's my fault, but can someone, please, advise me in case this is a bug rather than a mistake:
```
from transformers import TFTrainer, TFTrainingArguments, GPT2Tokenizer, GPT2LMHeadModel
training_args = TFTrainingArguments(
do_train=True,
output_dir="results",
overwrite_output_dir=True,
num_train_epochs=4,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
logging_dir="logs",
)
model = GPT2LMHeadModel.from_pretrained("distilgpt2")
trainer = TFTrainer(model=model,args=training_args,train_dataset=data)
trainer.train()
```
which returns the error:
```
Traceback (most recent call last):
File ".\train-tf.py", line 52, in <module>
trainer.train()
File "C:\Anaconda3\lib\site-packages\transformers\trainer_tf.py", line 492, in train
ckpt = tf.train.Checkpoint(optimizer=self.optimizer, model=self.model)
File "C:\Anaconda3\lib\site-packages\tensorflow\python\training\tracking\util.py", line 1929, in __init__
_assert_trackable(converted_v)
File "C:\Anaconda3\lib\site-packages\tensorflow\python\training\tracking\util.py", line 1410, in _assert_trackable
raise ValueError(
ValueError: `Checkpoint` was expecting a trackable object (an object derived from `TrackableBase`), got GPT2LMHeadModel(
```
and then it displays the model data.
Thanks for anything that you can add. | 02-11-2021 11:09:07 | 02-11-2021 11:09:07 | Oh no! I was using the PyTorch model with the TF trainer! I have fixed it now. |
transformers | 10,138 | closed | Back Translation | # 🚀 Feature request
I want to perform Back translation as a text data augmentation technique using TensorFlow
I want to augment data using translation techniques. I want to perform the below operation English ---> French ---> English. so that resulting english statement might be a new one. These sentences can be part of test data and will help to perform Behavioral Testing of NLP models.
## Motivation
I want to perform above operation using tensorflow. Currently there is no implementation of OPUS models for <any source text> to English. All the models are available in pytorch and not in tensorflow. This is really irritating.
## Your contribution
I am not sure, if I can. But you can assign me simple tasks
| 02-11-2021 10:55:30 | 02-11-2021 10:55:30 | Hi @chaituValKanO
Please use the [forum](https://discuss.huggingface.co/) to ask such questions. Issues are for bugs, feature requests etc.
And to answer your question you could use the `MarianMT` models for this purpose. Here's a nice blog-post about that
https://amitness.com/back-translation/.
Will close this issue. Thanks!<|||||>Hello Suraj,
But the issue is that there are no Pre trained models for MarianMT under
Tensorflow framework where target is English language.
Nevertheless, I will check with people in forum.
Thanks and regards,
Chaitanya Kanth.
On Fri, 12 Feb 2021 at 5:46 PM, Suraj Patil <[email protected]>
wrote:
> Closed #10138 <https://github.com/huggingface/transformers/issues/10138>.
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/10138#event-4324522055>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AB6VJCAIPJNM36CXVKH37QDS6UL2XANCNFSM4XOTUU4A>
> .
>
--
Sent from my iphone
<|||||>Marian is available in TF as well, you'll just need to pass `from_pt=True` to `from_pretrained` when loading the TF modle
<|||||>Thanks Suraj 😁
On Fri, Feb 12, 2021 at 6:22 PM Suraj Patil <[email protected]>
wrote:
> Marian is available in TF as well, you'll just need to pass from_pt=True
> to from_pretrained when loading the TF modle
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/10138#issuecomment-778177918>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AB6VJCAC53RGMVY5OCVVYRLS6UQCXANCNFSM4XOTUU4A>
> .
>
|
transformers | 10,137 | open | Text to Speech Generalized End-To-End Loss for Speaker Verification, Real Time Voice Cloning | # 🌟 New model addition
## Model description
Generalized End-To-End Loss for Speaker Verification implements Real time voice cloning, a way to generate a Text-To-Speech model adapted to a certain speaker with a short audio sample. The model implements the following paper.
https://arxiv.org/pdf/1806.04558.pdf and the code is available on github.
https://github.com/CorentinJ/Real-Time-Voice-Cloning
<!-- Important information -->
## Open source status
* [ ] the model implementation is available: (give details)
https://colab.research.google.com/drive/1SUq5RLOI0TIMkrBzMHMms01aaVNgkO7c?usp=sharing
The model can be run through Colaboratory. Here is an example of a generated voice.
https://soundcloud.com/birger-mo-ll/generated-voice
* [ ] the model weights are available: (give details)
Here are the model weights that are used.
encoder.load_model(project_name / Path("encoder/saved_models/pretrained.pt"))
synthesizer = Synthesizer(project_name / Path("synthesizer/saved_models/logs-pretrained/taco_pretrained"))
vocoder.load_model(project_name / Path("vocoder/saved_models/pretrained/pretrained.pt"))
* [ ] who are the authors: @CorentinJ
The author is not currently working on the repo, but since it is a fairly popular repo (25.000 stars) it might be reasonable to take the time to explore how to recreate / adapt the model to work with Huggingface transformer.
| 02-11-2021 10:31:55 | 02-11-2021 10:31:55 | @patrickvonplaten This is a suggestion but there are several models available and I think the best first step would be to look into getting a Text-To-Speech model working.
I explored the Real-Time-Voice-Cloning the other day and noticed it had several issues (since the project is no longer maintained) so it might be good to look into other speech models.
Here are some examples of repos that might be useful.
https://github.com/mozilla/TTS
https://github.com/as-ideas/ForwardTacotron
<|||||>Hey @BirgerMoell - thanks a lot for the links I will take a look soon :-)<|||||>@BirgerMoell
Thank you for resource sharing. I also want to add [TransformerTTS](https://github.com/as-ideas/TransformerTTS) to the list since it makes more sense to me to have transformers involved :P
I'd love to see this addition to huggingface though<|||||>I think it'd make a lot of sense to add FastSpeech2 to the library - happy to help with a PR if someone is interested. See: https://github.com/huggingface/transformers/pull/11135<|||||>Also, we started integrating https://github.com/as-ideas/TransformerTTS to the model hub so that people have easier access to TensorflowTTS models :-)
https://huggingface.co/tensorspeech/tts-fastspeech2-baker-ch<|||||>Hello
To avoid duplication, I just wanted to check if anyone is working on this or if this is still relevant. If someone is still needed for this, I will be interested to take this up. |
transformers | 10,136 | closed | [WIP][examples/seq2seq] move old s2s scripts to legacy | # What does this PR do?
Move the `finetune_trainer.py` and related utils, tests, bash scripts to `examples/legacy/seq2seq` | 02-11-2021 09:18:12 | 02-11-2021 09:18:12 | Thanks a lot Stas and Sylvain :) |
transformers | 10,135 | closed | Adding end-to-end retriever training to RAG with RAY implementation. | # 🚀 Feature request
Use of RAY to run separate processes for retrieve document indexes, training the system, and re-initialize the indexes with an updated context encoder.
## Motivation
Recent [papers](https://arxiv.org/abs/2101.00408) have shown that fine-tuning the entire retriever gives huge gains for QA tasks. Also having able to fine-tune end-end manner can give better results in different domains.
The idea is to train the RAG as is, but we keep updating the gradients of the context encoder with the supervised loss function (doc score mentioned in the RAG). Then in every n-steps, we re-initialize the embedding and indexes with updated context encoder weights.
REALM [does this with a back-and-forth process ](https://github.com/google-research/language/tree/master/language/realm#running-the-code)which is only run on a single GPU.
As discussed in this [issue](https://github.com/huggingface/transformers/issues/9646#issuecomment-775309123), @lhoestq suggested it would be easier to complete this with RAY since we can have separate actors.
@richardliaw
@amogkam | 02-11-2021 08:50:04 | 02-11-2021 08:50:04 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,134 | closed | cant install from source | ## Environment info
transformers-cli env
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 3.3.1
- Platform: Linux-4.19.0-13-cloud-amd64-x86_64-with-debian-10.7
- Python version: 3.7.8
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
## To reproduce
pip install git+https://github.com/huggingface/transformers
Collecting git+https://github.com/huggingface/transformers
Cloning https://github.com/huggingface/transformers to /tmp/pip-req-build-BEpAl9
Installing build dependencies ... done
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-req-build-BEpAl9/setup.py", line 192
entries = "\n".join([f' "{k}": "{v}",' for k, v in deps.items()])
^
SyntaxError: invalid syntax
| 02-11-2021 08:46:29 | 02-11-2021 08:46:29 | Hi,
maybe `pip` is not connected to a proper Python version (f-strings work in >= 3.6). To make sure that the right version gets called, you can execute the following command:
```
python -m pip install git+https://github.com/huggingface/transformers
```
This is why it's a good idea to use a virtual env.
Let me know if this helps.<|||||>this was issue with the wrong pip version |
transformers | 10,133 | closed | [examples/run_s2s] remove task_specific_params and update rouge computation | # What does this PR do?
- correctly handle `task_specific_params` and `prefix`
The current script tries to access the `prefix` from `config.task_specific_params.prefix`, which is always going to be `None` as `task_specific_params` is a nested `dict` with each key being a task name. This PR retrieves the `task_specific_params` from `config` using the task name (`data_args.task`), updates the `config` with the retrieved params (this is needed for `T5`), and access `prefix` using `config.prefix`
@stas00 as you reported offline, the bleu score for the new script was different from the old script for `T5` on the `en-ro` task. This was because the old script was using the `task_specific_params` and the new script wasn't. This update should resolve that issue.
- Update `rouge` score computation.
The `rougeLsum` metric expects newlines between each sentence, this is usually the score reported in papers. This PR
1. adds newlines to each sentence in `preds` and `labels` using `nltk` to correctly compute `rougeLsum`
2. pass `use_stemmer=True` to `metric.compute` to match the metrics with old script.
- Add `test_file` argument to `DataTrainingArguments` to load custom test dataset. | 02-11-2021 08:17:06 | 02-11-2021 08:17:06 | **Context:**
Here some context on the `task_specific_params` config param. In the beginning, we had T5 as the only model that was used for both the translation and summarization pipeline. The problem was that we had **one** model that we used as a default for both pipelines. At that time @thomwolf and I thought about a nice general design that - depending on the specific task (e.g. summarization, translation) - automatically sets the correct parameter set, so we started adding a `task_specific_params` parameter to the config that depending on the task sets the correct parameters. This is why the config of T5 is so long and looks like this:
```
{
...
"task_specific_params": {
"summarization": {
"early_stopping": true,
"length_penalty": 2.0,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
},
...
}
```
=> So this design was chosen only for the pipelines and essentially only for T5 version 1 since T5 version 1, is the only model we have that needs task-specific params (especially due to the different required prefixes depending on the task). Up until now, there were too many problems with this mechanism IMO so that the benefit of having it is IMO outweighed by its disadvantages, which are:
**1)** It blows up the config a lot and is not scalable (what do you do with many-to-many translation models? you can have each combination of `translation_..._to_...`)
**2)** No one understood anymore what was happening under the hood. IMO, having such a mechanism is a bit too "magical" because it creates a whole other logical layer to the already complicated mechanism that we have for the config params. In short, we currently have the following logic in pipelines:
i) The function argument is used (such as `max_length`), if not given, then
ii) the config's `task_specific_params` (such as `config.task_specific_params["summarization"]["max_length"]` is used, if not set, then
iii) the normal config's param is used such as `config.max_length`, if not set, then
iiii) the default `PretrainedConfig` param is used.
=> It is obvious that this a very complicated and somewhat "magical" logic and lot of people internally didn't even really understand it. This is why I really would like to remove the second step. It's confusing to see multiple `max_length` parameters in the config IMO and it's just not worth it.
**3)** So far `T5` is the only model that really requires this "magical" mechanism and that's mostly because it has a very special constraint in the sense that it was primed during training on cues such as `translation from X to Y: ...` which is definitely not something general that we would expect future models to have as well. We might very well have models in the future that have task-specific params like `max_length` and `beam_search` (It can very well be that a GPT3-like model that can do everything wants to adapt those params depending on the task), but those params are usually things that people are aware of and adjust themselves during evaluation IMO. E.g. if one is evaluating a model on `summarization`, setting the correct `max_length`, `num_beams` and maybe `repetition_penalty` is IMO something people should do themselves and not expect to be set correctly automatically.
**4)** It makes the pipelines in general very inflexible. E.g. when importing the pipeline classes directly, say the `TranslationPipeline` (which is what we did for a long time for the inference API - and maybe still do - not so sure anymore @julien-c @Narsil), there is no way of knowing that we should pass a `task="summary"` arg to the init to correctly load the `task_specific_parms`. To be more precise, imagine you want to directly import the `TranslationPipeline` here: https://github.com/huggingface/transformers/blob/31245775e5772fbded1ac07ed89fbba3b5af0cb9/src/transformers/pipelines/text2text_generation.py#L215 where you don't see any `task` param. But in order to correctly load T5 translation params for `TranslationPipeline`, you actually manually have to pass `task="translation_en_to_de"` to the init (also note here that it's not as easy as just saying - let's just add a class attribute `self.task = "translation_en_to_de"` because the same pipeline is also used for EN->RO translation in which case one could not use the class attribute... => this created a lot of problems leading to @julien-c eventually hard-coding (I think) the correct task name for T5 into the inference API code, which then kind of defeated the purpose of having this mechanism.
**Conclusion**
That being said, I see two solutions in general:
1. Eventually completely remove this mechanism (which I prefer)
2. Keep this mechanism for the `pipelines` only. Since things like the `pipelines` or `AutoNLP` are not meant to be built for researchers I'm ok with having some "under-the-hood" magic / very abstracted logic there, but I definitely don't want to have it anywhere else.
=> This means that I really don't think that should use this param in `run_seq2seq.py`. It creates more confusion than it really helps and is not in line with our motivation to have the `examples` be "easy to tweak and to understand" by the user. I think as @sgugger already said multiple times the example scripts should not follow the *"one-command-fits-all-cases"* approach, but rather should be easy to understand and to tweak for the specific task. This is why I'm quite strongly against using the `task_specific_params` here. However, @patil-suraj @stas00 I think you are completely correct that we should try to not have a regression in performance here. So I would then actually prefer to hard code T5's prefixes in the script. Something like:
```
T5_PREFIX = {
"summary": ...
"translation_en_to_de": ...
}
```
Sorry for the long text, but I think this is actually an important mechanism not too many people are aware of and we should think about a more general solution for how to continue with `task_specific_params`. Actually also pinging @LysandreJik on this one to hear his opinion.
Happy to hear your opinions on what I wrote above :-) <|||||>Thanks a lot for the context @patrickvonplaten
Regarding the script, to follow the examples philosophy, let's just remove it completely. If a model requires `prefix` it should be passed explicitly and related params should be copied to the `config` manually in case one wants to reproduce some metrics. <|||||>Thank you for the detailed explanation, @patrickvonplaten - that was very awesome of you to write it all out in such clarity.
I'm totally fine with your proposal, yet I think it'd be important to document how does one reproduce the same behavior with the new script and new t5 config then.
I already started an issue that documents the nuances of porting from `./finetune_trainer.py` https://github.com/huggingface/transformers/issues/10036 so perhaps it can belong there and once the notes have been compiled we can put them into the `seq2seq/README.md` to help users transition before `./finetune_trainer.py` is moved into the unmaintained territory.
Should you decide to remove this mechanism completely, the t5 models on the hub should probably be updated to reflect that at some future point, so that there is no baggage to carry forward. Perhaps in a few release cycles after the cut is done? Surely, users who use older `transformers` version should still be able to run their scripts normally for quite some time. I'd imagine that's where the model files versioning could come in.<|||||>@stas00
To reproduce the same behavior with the new script
1. Use the same dataset
2. if using T5 manually pass the `prefix` argument,
3. manually copy the `task_specific_parms` to `config`
Again, this is just for T5, the rest of the models should give similar results. So I'm going to merge this PR and let's update the readme in the clean-up PR #10136. |
transformers | 10,132 | closed | Where the helsinki models downloaded to? when using the pretrained models | src_text=['No, los préstamos existentes continuarán por debajo de la tasa de referencia existente.']
model_name='Helsinki-NLP/opus-mt-es-en'
tokenizer=MarianTokenizer.from_pretrained(model_name)
model=MarianMTModel.from_pretrained(model_name)
translated=model.generate(**tokenizer.prepare_seq2seq_batch(src_text, return_tensors="pt"))
tgt_text=[tokenizer.decode(t, skip_special_tokens=True) for t in translated]
when calling the MarianTokenizer and MarianMTModel, the package is automatically downloading the pre_trained model, is there a way to download and integrate it manually from https://huggingface.co/Helsinki-NLP/opus-mt-es-en.
Thank you. | 02-11-2021 07:28:54 | 02-11-2021 07:28:54 | You can also just clone the repo:
```
git clone https://huggingface.co/Helsinki-NLP/opus-mt-es-en
```
and then load the model and tokenizer locally from the cloned repo:
```python
model = MarianMTModel.from_pretrained("/path/to/cloned/repo")
tokenizer = MarianTokenizer.from_pretrained("/path/to/cloned/repo")
```<|||||>OSError: Can't load tokenizer for './model/opus-mt-en-es/'. Make sure that:
- './model/opus-mt-en-es/' is a correct model identifier listed on 'https://huggingface.co/models'
- or './model/opus-mt-en-es/' is the correct path to a directory containing relevant tokenizer files
I am getting this error, even though I am passing the correct path.<|||||>Thanks, it is working. |
transformers | 10,131 | closed | Trainer Evaluates at every step | Hi, thanks for the amazing and easy to use library. While using the Trainer with Training Arguments, the trainer is evaluating at every step, instead of eval_steps.
Version: 4.3.0
```python
training_args = TrainingArguments(output_dir='outputs', per_device_train_batch_size=1,per_device_eval_batch_size=2,
evaluation_strategy='steps', do_eval=True,do_train=True, eval_steps=6)
```
Am I passing any wrong combination of arguments? None of the training_args are getting manually changed at any place in the code.
Thank you very much. | 02-11-2021 06:02:41 | 02-11-2021 06:02:41 | It's hard to know without seeing your code. This combination of arguments should evaluate every 6 steps.
Also how do you know it's evaluation every step instead of every 6 steps?<|||||>Hi, thank you for the reply. I have actually overridden the 'evaluate' function of the trainer, and have certain print statements inside the function plus a tqdm progress bar as well. This function is executed after every training step.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,130 | closed | [DeepSpeed in notebooks] Jupyter + Colab | This PR addresses issues raised in https://github.com/huggingface/transformers/issues/10011 when the user tried to use DeepSpeed in a notebook (most likely colab).
This PR:
* forces device and distributed setup init from TrainingArguments explicitly at the beginning of Trainer's `__init__`. This is needed since until now the init was happening as a side effect of someone calling `device` or `n_gpus`, which doesn't happen if someone runs their own version of `Trainer` w/ deepspeed - which is the case with notebooks - so we are missing out on DeepSpeed init and things weren't working. Let's do it explicitly, and not as a side-effect, so everything is loud and clear.
* sets up `self.local_rank` based on LOCAL_RANK env var under deepspeed to save users a hassle - deepspeed must have `local_rank>-1`. I guess the fake launcher env setup could be folded into the init as well, but then the user loses control over the port number and they may need to edit it, so for now leaving it outside - but will ask deepspeed to provide a wrapper function to make it easy for the user. perhaps once the wrapper is available it could be automated completely. Alternatively, if they make `mpi4py` a dependency then fake launcher env setup won't be needed at all.
* documents how to run DeepSpeed in the notebook env
* adds a test that mocks a notebook environment and runs deepspeed w/o a launcher
I may wait to hear about the follow up to https://github.com/microsoft/DeepSpeed/issues/748 to merge this, if it looks quick, but otherwise I will revise the setup doc in a future PR. The main changes of this PR besides the doc are required anyway.
@sgugger | 02-11-2021 05:15:06 | 02-11-2021 05:15:06 | |
transformers | 10,129 | closed | Fix v2 model loading issue | # What does this PR do?
Fix few issues with loading deberta v2 models and deberta mnli fine-tuned model
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-11-2021 03:08:08 | 02-11-2021 03:08:08 | Hi @BigBird01, thanks a lot for fixing these issues! I'd like to prevent as much as possible from having the `pre_load_hooks` in the code. When do you expect mismatched head dimensions?<|||||>This is the case that if we want to fine-tune a task based on mnli models, e.g. MRPC, SST, QNLI. If we want to avoid this method, we need to fix the error reporting when load pretrained models.
Get Outlook for iOS<https://aka.ms/o0ukef>
________________________________
From: Lysandre Debut <[email protected]>
Sent: Saturday, February 13, 2021 5:23:53 AM
To: huggingface/transformers <[email protected]>
Cc: Pengcheng He <[email protected]>; Mention <[email protected]>
Subject: Re: [huggingface/transformers] Fix v2 model loading issue (#10129)
Hi @BigBird01<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2FBigBird01&data=04%7C01%7CPengcheng.H%40microsoft.com%7C301190f89ac34907b53408d8d0229db7%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637488194400010761%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=9%2BnuKLc3nPym5xSUhe%2Flko3Fd3jxus0WRwj3W%2Bks%2FuM%3D&reserved=0>, thanks a lot for fixing these issues! I'd like to prevent as much as possible from having the pre_load_hooks in the code. When do you expect mismatched head dimensions?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fpull%2F10129%23issuecomment-778618852&data=04%7C01%7CPengcheng.H%40microsoft.com%7C301190f89ac34907b53408d8d0229db7%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637488194400010761%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=ka8Oo2xj%2Ba0u2X6Fobb77H27KO94ePzlbCeZ7a797ww%3D&reserved=0>, or unsubscribe<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fnotifications%2Funsubscribe-auth%2FAJDNDRT5T5MFRSCQH3MXIEDS6Z4OTANCNFSM4XOC2W6A&data=04%7C01%7CPengcheng.H%40microsoft.com%7C301190f89ac34907b53408d8d0229db7%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637488194400020711%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=kdOpjyJfnJyaSLKNbPjNIMs3p2KbiceAVHHS4WCfVEA%3D&reserved=0>.
<|||||>Usually we recommend to load through the base model to lose the head:
```py
from transformers import DebertaV2Model, DebertaV2ForSequenceClassification
seq_model = DebertaV2ForSequenceClassification.from_pretrained("xxx", num_labels=4)
seq_model.save_pretrained(directory)
base = DebertaV2Model.from_pretrained(directory) # Lose the head
base.save_pretrained(directory)
seq_model = DebertaV2ForSequenceClassification.from_pretrained(directory, num_labels=8)
```
Does that work in your case? I agree you're touching to something that has a bad API, and this should be handled in the `from_pretrained` method. I don't think we should handle it model-wise, however. I'll look into it soon.<|||||>yes. but this looks a little bit tricky. And need to modify existing text classification code to benefit from mnli fine-tuned models. How about we keep current hook method, and finish current PR? After we work out a systematic solution for such scenario, we can drop the hook method.
Get Outlook for iOS<https://aka.ms/o0ukef>
________________________________
From: Lysandre Debut <[email protected]>
Sent: Saturday, February 13, 2021 6:28:34 AM
To: huggingface/transformers <[email protected]>
Cc: Pengcheng He <[email protected]>; Mention <[email protected]>
Subject: Re: [huggingface/transformers] Fix v2 model loading issue (#10129)
Usually we recommend to load through the base model to lose the head:
from transformers import DebertaV2Model, DebertaV2ForSequenceClassification
seq_model = DebertaV2ForSequenceClassification.from_pretrained("xxx", num_labels=4)
seq_model.save_pretrained(directory)
base = DebertaV2Model.from_pretrained(directory) # Lose the head
base.save_pretrained(directory)
seq_model = DebertaV2ForSequenceClassification.from_pretrained(directory, num_labels=8)
Does that work in your case? I agree you're touching to something that has a bad API, and this should be handled in the from_pretrained method. I don't think we should handle it model-wise, however. I'll look into it soon.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fpull%2F10129%23issuecomment-778627044&data=04%7C01%7CPengcheng.H%40microsoft.com%7C4e6ebb9592e84114db8908d8d02ba69b%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637488233183179214%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=6B7Tw%2BulDyc50hCWtt40Y3Eu%2F9pDhycqsFcGGlbEWJA%3D&reserved=0>, or unsubscribe<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fnotifications%2Funsubscribe-auth%2FAJDNDRSALWZ5T6MA5DFF7VDS62EBFANCNFSM4XOC2W6A&data=04%7C01%7CPengcheng.H%40microsoft.com%7C4e6ebb9592e84114db8908d8d02ba69b%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637488233183179214%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=DUoGLBFe%2Ff2Ms580JCNn5okYXrYWH9vqTIhAMve0tqE%3D&reserved=0>.
<|||||>Ok, will merge like that and we'll discuss with other team members for the main PR. Thanks! |
transformers | 10,128 | closed | Bug in numpy_pad_and_concatenate | https://github.com/huggingface/transformers/blob/77b862847b8069d57c0849ca012f48414c427d8e/src/transformers/trainer_pt_utils.py#L71
I believe this should be
`np.concatenate((array1, array2), axis=0)` | 02-11-2021 01:30:59 | 02-11-2021 01:30:59 | Indeed. Would you like to do a PR to fix this since you spotted the bug?<|||||>sure thing!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,127 | closed | XLM-R tokenizer is none | ## Environment info
- `transformers` version: 4.3.2
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
### Who can help
@LysandreJik @n1t0
## Information
I am using XLM-R:
The problem arises when using:
* the official example scripts: (give details below)
The tasks I am working on is:
* my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behaviour:
```
tokenizer = XLMRobertaTokenizer.from_pretrained('xlm-roberta-base')
model = XLMRobertaModel.from_pretrained('xlm-roberta-base')
print(tokenizer, model)
```
## Result
The xlm-r tokenizer is none but the model can be found.
I am a beginner for this model. Many thanks for your help.
| 02-10-2021 23:03:59 | 02-10-2021 23:03:59 | Hello! This is weird, it shouldn't happen. Could you try to install `sentencepiece` and let me know if it fixes your issue? Thank you!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>I'm still facing this issue.

<|||||>Do you have a reproducible colab notebook? Thanks<|||||>Not sure how but it's working today.

<|||||>This is probably because you hadn't restarted your kernel after installing the `sentencepiece` dependency! |
transformers | 10,126 | closed | Add new community notebook - Blenderbot | Updated community.md file to add new notebook, How to fine tune T5 for summarization using the Trainer API | 02-10-2021 22:02:52 | 02-10-2021 22:02:52 | Thank you for your work @lordtt13
Actually, there are already plenty of notebooks about how to fine-tune T5. It would be great if could add a notebook for missing/new models/task. Below are some of the new models which aren't used much
- T5_v1_1, mT5
- ProphetNet, xlm-prophetnet
- Blenderbot
- mBART, mBART-50
Using languages other than English would be even better, we now have so many languages in the `datasets` library after the sprint. So it's a good opportunity to use those datasets to fine-tune/evaluate multi-lingual models on them (mT5, mBART, xlm-prophetnet)
cc @patrickvonplaten <|||||>I agree with @patil-suraj that notebooks on multilingual T5 would be super useful as well!
But nevertheless, I think we can merge this notebook :-) <|||||>Thank you for the suggestions, and yes maybe T5 has been trained on too much, I will change the notebook to have it train a different model and then request for merge.<|||||>Have trained now on BlenderBotSmall, will add multilingual model training tutorial in next PR!
Please check @patil-suraj @patrickvonplaten |
transformers | 10,125 | closed | Converted pytorch model to onnx does not work correctly | I converted pretrained 'Rostlab/prot_bert_bfd' @ huggingface to onnx, then tried to convert a checkpoint from fine tuning of the pretrained model. Comparing to pretrained model, conversion of fine tuned model generated a lot of warnings. Basically the warnings said that parameters from first to last layer were not initialized. The converted model did not work correctly.
This is how I called the conversion module:
python3 -m transformers.convert_graph_to_onnx --model Rostlab/prot_bert_bfd --framework pt prot_bert_bfd.onnx
I did similarly for checkpoint model.
Does the module work on checkpoint?
| 02-10-2021 20:38:11 | 02-10-2021 20:38:11 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>> I converted pretrained 'Rostlab/prot_bert_bfd' @ huggingface to onnx, then tried to convert a checkpoint from fine tuning of the pretrained model. Comparing to pretrained model, conversion of fine tuned model generated a lot of warnings. Basically the warnings said that parameters from first to last layer were not initialized. The converted model did not work correctly.
>
> This is how I called the conversion module:
>
> python3 -m transformers.convert_graph_to_onnx --model Rostlab/prot_bert_bfd --framework pt prot_bert_bfd.onnx
> I did similarly for checkpoint model.
>
> Does the module work on checkpoint?
Hello @yzhang-github-pub ,I have used the same line of code as you did for a PEGASUS model on colab:
`!python3 -m transformers.convert_graph_to_onnx --model jpcorb20/pegasus-large-reddit_tifu-samsum-256 --framework pt pegasus-large-reddit_tifu-samsum-256.onnx`
**The following error keeps showing and the coversion fails. Can you please tell me how did you solve this problem??**
**The error:**
> Some weights of the model checkpoint at jpcorb20/pegasus-large-reddit_tifu-samsum-256 were not used when initializing PegasusModel: ['final_logits_bias', 'lm_head.weight']
> - This IS expected if you are initializing PegasusModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
> - This IS NOT expected if you are initializing PegasusModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
> Downloading: 100% 1.50k/1.50k [00:00<00:00, 1.29MB/s]
> Downloading: 100% 1.91M/1.91M [00:01<00:00, 1.12MB/s]
> Downloading: 100% 1.34k/1.34k [00:00<00:00, 1.18MB/s]
> Error while converting the model: Folder /content is not empty, aborting conversion<|||||>I wrote a script to do onnx conversion, by importing onnx and onnxruntime modules. I heard some versions of transformer have bugs in onnx conversion and model loading.
|
transformers | 10,124 | closed | [Doc] Fix version control in internal pages | # What does this PR do?
When I added the internal submenu, I didn't think of also adding it in the test that properly generates the links for another version of the doc. This PR fixes that. | 02-10-2021 20:18:10 | 02-10-2021 20:18:10 | |
transformers | 10,123 | closed | Help on training TFBERT to IntegerEncoded sequences | Hi,
My inputs are Integer Encoded vectors, like:
`[1,2,3,1,2,4,1,2,3,4,2,3,4, ...]`
Where:
`len(inputs) = 1200` & `unique values = 4` (1,2,3,4).
As you can see, this is not a common NLP problem as I have only 4 tokens, instead of a huge vocabulary.
And I could not find any pretrained vocab to tokenize this.
**What I am trying to do**:
I want to fit a BERT model to this sequence data.
**What have I tried**
I am using `tensorflow-2.4.0`, and here is my model:
```
class MyModel(Model):
def __init__(self):
super().__init__()
self._bert = _create_bert_model()
self._head = Dense(1)
def call(self, inputs):
embedding = self._bert(inputs)
return self._head(embedding)
def _create_bert_model() -> TFBertModel:
config = BertConfig(vocab_size=4+1)
return TFBertModel(config)
```
As you can see, I want to create an "embedding" using BERT, and pass this to a head (regression).
## Issue
When I put a breakpoint inside this `call` method, here is what I get:
```
# Batch Size: 4 (just for debug)
>> inputs
<tf.Tensor: shape=(4, 1200), dtype=int32, numpy=
array([[2, 4, 1, ..., 4, 3, 3],
[2, 1, 4, ..., 1, 2, 4],
[4, 2, 1, ..., 3, 1, 2],
[2, 2, 4, ..., 1, 2, 1]], dtype=int32)>
>> self._bert(inputs)
*** tensorflow.python.framework.errors_impl.InvalidArgumentError: Incompatible shapes: [512,768] vs. [4,1200,768] [Op:BroadcastTo]
```
## Help
Can anyone provide me any guidance on solving this issue, and procceed with my modelling?
And, is there any tutorial I may find on fitting a HuggingFace Tokenizer/BERT on custom vocabulary?
## Reproduce
```
from transformers import TFBertModel, BertConfig
import numpy as np
x = np.random.randint(1,5,1200)
config = BertConfig(vocab_size=4+1)
model = TFBertModel(config)
model(x)
```
Thank you! | 02-10-2021 19:15:22 | 02-10-2021 19:15:22 | I had to define the following parameters on `BertConfig`:
`config = BertConfig(vocab_size=4+1, hidden_size=len(x), max_position_embeddings=len(x))`
My issue is now:
`InvalidArgumentError: Index out of range using input dim 1; input has only 1 dims [Op:StridedSlice] name: tf_bert_model_8/bert/strided_slice/`<|||||>The input to BERT (`input_ids`) must be a tensor of shape `(batch_size, sequence_length)` = `(1, 1200)`.
However, currently the shape of your x is only `(1200,`). You should add a batch dimension, like so:
```
import numpy as np
x = np.random.randint(1,5,1200)
x = np.expand_dims(x, axis=0)
```
The embedding layer of BERT will then turn this into a tensor of shape `(batch_size, sequence_length, hidden_size)`, i.e. it will turn each of the 1200 integers into a vector of size `hidden_size`. As you're setting `hidden_size` equal to `len(x)`, this means that each integer will be turned into a vector of size 1200. Is this what you want (seems quite a big vector :p)?
Then the following will work:
```
from transformers import TFBertModel, BertConfig
config = BertConfig(vocab_size=4+1, max_position_embeddings=len(x))
model = TFBertModel(config)
model(x)
```
Btw, please ask questions which are not bugs or feature requests on the [forum](https://discuss.huggingface.co/) rather than here.<|||||>Thank you @NielsRogge. I must apologize. Should I cut this issue and paste into the forum?
I think I made a mistake... the vector size should not be that large and won't fit into memory :P
I managed to complete a model forward cycle. But, if you allow me another question:
Should I add an extra integer to the beginning of the sequence (of value != to the existing ones, e.g.: `5`), to act as the <CLS> token?
I am asking this because the `model(inputs)` returns a pooled `(batch_size, 1,hidden_size)` token, instead of `(batch_size, seq_length, hidden_size)`, however I am not sure if I should be passing this to the `Dense(1)` layer in the next step.<|||||>> Should I add an extra integer to the beginning of the sequence (of value != to the existing ones, e.g.: `5`), to act as the token?
Each integer acts as a token, so adding one more will increase the number of tokens by one. The `vocab_size` is the total number of tokens for which the model learns an embedding vector.
> I am asking this because the `model(inputs)` returns a pooled `(batch_size, 1,hidden_size)` token, instead of `(batch_size, seq_length, hidden_size)`, however I am not sure if I should be passing this to the `Dense(1)` layer in the next step.
If you use `TFBertModel`, then by default it returns a `TFBaseModelOutputWithPooling` object, with an attribute called `last_hidden_state`. This is a tensor of shape `(batch_size, sequence_length, hidden_size)` and this is probably what you want.
You may close the issue and if you have any further questions, feel free to ask them on the forum, we're happy to help! |
transformers | 10,122 | closed | Add SageMakerTrainer for model paralellism | # What does this PR do?
This PR adds a subclass of `Trainer` to use model parallelism in SageMaker. This new `Trainer` still retains all the functionality of the previous trainer (e.g. when not run in SageMaker it will work like the normal one) while automatically enabling model parallelism when an example script is launched via SageMaker with that option activated.
The easiest way to enable this in any example script is to replace the `Trainer` and `TrainingArguments` imports by:
```python
from transformers.sagemaker import SageMakerTrainingArguments as TrainingArguments, SageMakerTrainer as Trainer
```
Along the way, I had to refactor a few things in `Trainer` to make it easier to deal with stuff in the subclass (without having to rewrite the whole train method for instance), mainly the part that does the model wrapping. Also, there was a subtle bug coming from the fact SageMaker wrapper for the model for model parallelism changes the forward method of the model, so the `Trainer` will now store the arguments in the signature (in case that signature changes after wrapping the model). | 02-10-2021 16:29:21 | 02-10-2021 16:29:21 | |
transformers | 10,121 | open | Allow `do_lower_case=True` for any tokenizer | # 🚀 Feature request
Extract the `do_lower_case` option to make it available for any tokenizer. Not just those that initially supported this, like the `BERT` tokenizers.
## Motivation
Sometimes we want to specify `do_lower_case=True` in the `tokenizer_config.json` of a custom tokenizer to activate the lowercasing. The problem is that this obviously works only for tokenizers based on one that originally used this option.
I think we should extract this feature to make it a shared one, that could be used with any tokenizer.
Example of a model that would need this described here: https://github.com/huggingface/transformers/issues/9518
## Special care points
- Make sure the `convert_slow_tokenizer` script also handles this, to activate the option in the resulting fast tokenizer.
- Maybe some other options could have the same treatment?
cc @LysandreJik @sgugger | 02-10-2021 15:28:24 | 02-10-2021 15:28:24 | Discussed offline with @n1t0: our current decision is to wait for https://github.com/huggingface/tokenizers/issues/659 to be resolved before moving on with this issue.
This is the better tradeoff as the alternative would imply duplicating a lot of logic in `transformers` that's already present but not exposed by `tokenizers`. |
transformers | 10,120 | closed | Conversion from slow to fast for BPE spm vocabs contained an error. | # What does this PR do?
- There is only 1 test currently (tokenizers + slow) that used the modified path
and it's reformer, which does not contain any ids modification so the
bug was silent for now.
- The real issue is that vocab variable was overloaded by
SentencePieceExtractor, leading to Slow specific vocab oddities to be
completely ignored
- The bug was reported here https://github.com/huggingface/transformers/issues/9518
- Ran the complete tokenization test suite with slow without error
(`RUN_SLOW=1 pytest -sv tests/test_tokenization_*`)
- We need to keep in mind that BPE + SPM are relatively rare.
- I still need to carry out
a full sweep of the hub to check all possible variants.
Affected models (all repos containing `sentencepiece.bpe.model`):
- `Musixmatch/umberto-commoncrawl-cased-v1`
- `idb-ita/gilberto-uncased-from-camembert`
- `itsunoda/wolfbbsRoBERTa-large` (not fixed with current PR, seems linked to prefixed '_' in fast tokenizers)
- `itsunoda/wolfbbsRoBERTa-small` (not fixed with current PR)
- `mrm8488/umberto-wikipedia-uncased-v1-finetuned-squadv1-it`
- `EMBEDDIA/litlat-bert`
- `neuralspace-reverie/indic-transformers-bn-xlmroberta`
- `neuralspace-reverie/indic-transformers-hi-xlmroberta`
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@thomwolf @LysandreJik @sgugger
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | 02-10-2021 13:42:15 | 02-10-2021 13:42:15 | |
transformers | 10,119 | closed | Line endings should be LF across repo and not CRLF | Up to now we've had quite a few issues with users on Windows having their line endings be "CRLF" by default, while Linux users have "LF" line endings by default.
### Problem
This can be problematic in the following scenarios where no handling of the issue has been done on the user's side:
- When a user runs `make style`, their line endings will switch from LF to CRLF in *all* files, essentially rewriting the entire file
- When a user adds a new file to the repository, it will be in the "CRLF" format and will be committed as such.
### Resolution
The resolution is either to have the user handle that, or to handle that ourselves. Handling it ourselves is simple as it only requires adding a `.gitattributes` file at the root of the repository which will specify the line endings we're looking for, thus this is what this PR is proposing. On the other hand, we had issues handling it on the user side with the proposed `git core.autocrlf` as it seemed to have different results according to the setup.
Additionally, if users already have files in `CRLF` mode, then an additional command is required to convert these files to `LF`: `git add --renormalize .`. I believe this only impacts users that created files previous to this PR, as newly created files will already benefit from the `.gitattributes` file.
---
This PR completely reformats two files: `examples/research_projects/bertology/run_prune_gpt.py` and `tests/test_modeling_deberta.py`. These files had CRLF line endings, and will now have LF line endings.
---
Further readings:
- [🙏 Please Add .gitattributes To Your Git Repository](https://dev.to/deadlybyte/please-add-gitattributes-to-your-git-repository-1jld)
- [Why should I use core.autocrlf=true in Git?](https://stackoverflow.com/questions/2825428/why-should-i-use-core-autocrlf-true-in-git)
- [git replacing LF with CRLF](https://stackoverflow.com/questions/1967370/git-replacing-lf-with-crlf?noredirect=1&lq=1)
cc @NielsRogge | 02-10-2021 08:38:53 | 02-10-2021 08:38:53 | Thank you @LysandreJik, this will alleviate much of the pain Windows users had with git in the past!<|||||>To hack my way up the contributors list, can I change all line endings to CRLF then revert? 😂 |
transformers | 10,118 | closed | Exporting transformers models in ONNX format | I am trying to convert transformer model to ONNX by referring the article **[here](https://huggingface.co/transformers/serialization.html)** but running into below error. Can you please guide me if this is not the correct way of doing it.
Code I am using in Colab:
```
!git clone https://github.com/huggingface/transformers.git
%cd transformers
!pip install .
%cd src/transformers
!python3 convert_graph_to_onnx.py --framework pt --model bert-base-cased bert-base-cased.onnx
```
Traceback (most recent call last):
File "convert_graph_to_onnx.py", line 22, in <module>
from .file_utils import ModelOutput, is_tf_available, is_torch_available
ModuleNotFoundError: No module named '__main__.file_utils'; '__main__' is not a package | 02-10-2021 07:33:10 | 02-10-2021 07:33:10 | Hi!
Try this one, but do it from an empty folder:
`python3 -m transformers.convert_graph_to_onnx --framework pt --model bert-base-cased bert-base-cased.onnx`<|||||>@Denovitz Thanks a lot. I was able to convert the BERT model to ONNX successfully. Do you have a sample code of how the converted ONNX model can be used further for inferences? I am able to use ONNX for TF, Keras, Sklearn, Xgboost and other models but stuck with transformer model. Appreciate any inputs. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,117 | closed | [Wav2Vec2] Improve Tokenizer & Model for batched inference | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR improves batched inference for Wav2Vec2 models by:
- adding an `attention_mask`
- adding zero-mean unit-variance normalization to the tokenizer
- correctly setting returning `attention_mask` and doing normalization depending on which architecture is used
## Background
Some of Fairseq's Wav2Vec2 models apply Group Normalization over the time axis in the feature extractor. This means that the convolutional layers in the feature extractor can not 100% correctly treat padded input resulting in those models giving different results depending on whether the input is padded or not. See https://github.com/pytorch/fairseq/issues/3227 . Those models should never make use of `attention_mask` which is made sure by setting `return_attention_mask=False` in their corresponding tokenizer configs: https://huggingface.co/facebook/wav2vec2-base-960h/blob/main/tokenizer_config.json . Also some explicit warnigs have been added to both the tokenizer and model.
For the "newer" models however that have the improved layer norm architecture in the feature extraction: https://huggingface.co/facebook/wav2vec2-large-960h-lv60-self , normalization and correct padding via `attention_mask` gives some nice performance improvements and works correctly.
## Performance Evaluation
I've evaluated both `wav2vec2-large-960h-lv60-self` and `wav2vec2-large-960h-lv60` on the test set of librispeech and got some nice improvements:
- `wav2vec2-large-960h-lv60-self`: 2.2 WER -> 1.8 WER
- `wav2vec2-large-960h-lv60`: 3.4 WER -> 2.2 WER
So that the results now seem to match the paper's results very nicely.
Also, I checked that `wav2vec2-base-960h` should **not** use an `attention_mask` as the performance on librispeech test then drop heavily from ~4 WER to ~20 WER.
## TODO
Once this PR is merged, I can fully focus on adding the fine-tuning functionality and will also update the model cards with the new evaluation code & results. | 02-10-2021 07:04:51 | 02-10-2021 07:04:51 | Go Patrick!!!!! YES! someone who cares!<|||||>Merging since @LysandreJik is off today and this is blocking me a bit |
transformers | 10,116 | closed | [scheduled github CI] add deepspeed fairscale deps | This PR adds `deepspeed` +`fairscale` to pip install on multi-gpu self-hosted scheduled job - so that we can start running those tests.
@LysandreJik, @sgugger | 02-10-2021 06:17:53 | 02-10-2021 06:17:53 | Thanks! |
transformers | 10,115 | closed | [CI] build docs faster | I assume the CI machine should have at least 4 cores, so let's build docs faster.
@sgugger, @LysandreJik | 02-10-2021 06:10:48 | 02-10-2021 06:10:48 | |
transformers | 10,114 | closed | [DeepSpeed] restore memory for evaluation | I spent some time trying to see if we could gain from DeepSpeed during inference - and while in the future there will be goodies to make it useful at the moment we don't need it, so let's make DeepSpeed cleanly contained to `train` for now.
This PR has a few small tweaks:
- frees up all the memory used by DeepSpeed at the end of training
- makes a clean way of not switching `model.to()` - only for when `--do_train` is used with deepspeed (so this is the case where you @sgugger were concerned about eval before train - no problem now)
- adds a warning if a user tries to use `--deepspeed` without `--do_train`
- re-works the test suite
- applies consistent json config formatting
@sgugger, @LysandreJik | 02-10-2021 05:43:36 | 02-10-2021 05:43:36 | |
transformers | 10,113 | closed | CUDA Out of Memory After Several Epochs | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.1.1
- Platform: Linux-4.14.105-1-tlinux3-0013-x86_64-with-centos-7.2-Final
- Python version: 3.7.7
- PyTorch version (GPU?): 1.5.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: using nn.data_parallel
### Who can help
- gpt2: @patrickvonplaten
- trainer: @sgugger
## Information
Model I am using (Bert, XLNet ...): GPT2
The problem arises when using:
* [- ] the official example scripts: run_clm.py
The tasks I am working on is:
* [ -] my own task or dataset: zh_wikitext
## To reproduce
The strange thing is that the scripts runs ok in the first 12 epochs, and ends with error in the middle of 12 epochs. I have checked that the trainer doesn't cache training loss tensor, so I am quite puzzled by the error. Any help are highly appreciated.
Steps to reproduce the behavior:
1. `python run_clm.py config.json`
Several useful config in `config.json` are:
```
block_size: 512
check_point_name: "gpt2_result/checkpoint-100000"
per_device_train_batch_size: 12
learning_rate: 0.00005
weight_decay: 0
adam_beta1: 0.9
adam_beta2: 0.98
adam_epsilon: 1e-8
max_grad_norm: 1
num_train_epochs: 50
max_steps: -1
warmup_steps: 0
```
Model Config are:
```
Model config GPT2Config {
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"gradient_checkpointing": false,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 512,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 12,
"n_positions": 512,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"use_cache": true,
"vocab_size": 21128
}
```
The tokenizer used is `BertTokenizer.from_pretrained('Bert-base-chinese')`.
The error log are following:
```
[INFO|trainer.py:703] 2021-02-10 11:30:39,997 >> ***** Running training *****
[INFO|trainer.py:704] 2021-02-10 11:30:39,997 >> Num examples = 744899
[INFO|trainer.py:705] 2021-02-10 11:30:39,997 >> Num Epochs = 50
[INFO|trainer.py:706] 2021-02-10 11:30:39,997 >> Instantaneous batch size per device = 12
[INFO|trainer.py:707] 2021-02-10 11:30:39,997 >> Total train batch size (w. parallel, distributed & accumulation) = 96
[INFO|trainer.py:708] 2021-02-10 11:30:39,997 >> Gradient Accumulation steps = 1
[INFO|trainer.py:709] 2021-02-10 11:30:39,997 >> Total optimization steps = 388000
[INFO|trainer.py:725] 2021-02-10 11:30:40,011 >> Continuing training from checkpoint, will skip to saved global_step
[INFO|trainer.py:726] 2021-02-10 11:30:40,011 >> Continuing training from epoch 12
[INFO|trainer.py:727] 2021-02-10 11:30:40,011 >> Continuing training from global step 100002
0%| | 0/388000 [00:00<?, ?it/s]/data/miniconda3/lib/python3.7/site-packages/torch/nn/parallel/_functions.py:61: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
warnings.warn('Was asked to gather along dimension 0, but all '
26%|███████████████████████▋ | 100003/388000 [00:17<00:50, 5746.78it/s]Traceback (most recent call last):
File "run_clm.py", line 321, in <module>
main()
File "run_clm.py", line 291, in main
trainer.train(model_path=model_path)
File "/data/miniconda3/lib/python3.7/site-packages/transformers/trainer.py", line 799, in train
tr_loss += self.training_step(model, inputs)
File "/data/miniconda3/lib/python3.7/site-packages/transformers/trainer.py", line 1139, in training_step
loss = self.compute_loss(model, inputs)
File "/data/miniconda3/lib/python3.7/site-packages/transformers/trainer.py", line 1163, in compute_loss
outputs = model(**inputs)
File "/data/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/data/miniconda3/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 156, in forward
return self.gather(outputs, self.output_device)
File "/data/miniconda3/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 168, in gather
return gather(outputs, output_device, dim=self.dim)
File "/data/miniconda3/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 68, in gather
res = gather_map(outputs)
File "/data/miniconda3/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 62, in gather_map
for k in out))
File "<string>", line 9, in __init__
File "/data/miniconda3/lib/python3.7/site-packages/transformers/file_utils.py", line 1412, in __post_init__
for element in iterator:
File "/data/miniconda3/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 62, in <genexpr>
for k in out))
File "/data/miniconda3/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 63, in gather_map
return type(out)(map(gather_map, zip(*outputs)))
File "/data/miniconda3/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 55, in gather_map
return Gather.apply(target_device, dim, *outputs)
File "/data/miniconda3/lib/python3.7/site-packages/torch/nn/parallel/_functions.py", line 68, in forward
return comm.gather(inputs, ctx.dim, ctx.target_device)
File "/data/miniconda3/lib/python3.7/site-packages/torch/cuda/comm.py", line 165, in gather
return torch._C._gather(tensors, dim, destination)
RuntimeError: CUDA out of memory. Tried to allocate 288.00 MiB (GPU 0; 23.88 GiB total capacity; 22.53 GiB already allocated; 86.38 MiB free; 23.21 GiB reserved in total by PyTorch)
```
| 02-10-2021 03:58:06 | 02-10-2021 03:58:06 | I'm quite puzzled too, to be honest. I know that sometimes, PyTorch will trigger a CUDA OOM error even if there is enough memory in theory just because it's not able to find a contiguous chunk or has some leftovers for some reason, exactly like what your message suggests (22.53GB allocated but 23.21GB reserved by PyTorch). I don't have any suggestion apart from trying the usual strategies to lower a bit the memory footprint (slightly lower the batch size or block size).<|||||>@sgugger Appreciate your reply! I am wondering that can I resume the training processing if I change the batch size or block size of the training args. I have no idea whether it will fit the saved schedule or optimizer parameters.<|||||>> @sgugger Appreciate your reply! I am wondering that can I resume the training processing if I change the batch size or block size of the training args. I have no idea whether it will fit the saved schedule or optimizer parameters.
你好,请问你解决了这个问题了吗<|||||>@xinjicong Not yet. If you have some ideas, please shares.<|||||>> @xinjicong Not yet. If you have some ideas, please shares.
i try to make max_seq_length smaller but it can't not work. <|||||>> @xinjicong Not yet. If you have some ideas, please shares.
我检查了代码,发现是我在使用tokenizer的时候,出现了问题。tokenizer输出的维度多了一维,然后后面batch的时候就出错了。<|||||>I observe the same issue, if I train a model, save a checkpoint and reload from this, I get memory issues for the code which was training fine before. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Same Issue<|||||>+1<|||||>I have this issue as well. Model trains for 1 epoch and goes through validation step, then I get OOM somewhere in the second epoch. These are large models I am training and I often get OOM after it has been training for a couple of hours.<|||||>@dinsausti-vir Try reducing validation batch size to 1. I'm not sure how I fixed the error but batch size is usually the cause for OOM<|||||>@perceptiveshawty Thanks for the tip. I will give that a shot! |
transformers | 10,112 | closed | Possible bug in RAG Tokenizer | On this line
input_dict = tokenizer.prepare_seq2seq_batch(question, return_tensors="pt")
the following error is being generated
AttributeError: 'super' object has no attribute 'prepare_seq2seq_batch'
| 02-10-2021 02:12:21 | 02-10-2021 02:12:21 | hi @krishanudb
Thank you for reporting this @krishanudb !<|||||>Is there any update on this issue? @patil-suraj <|||||>It's fixed now on master!
see #10167<|||||>The issue persists in transformers 4.3.3
/usr/local/lib/python3.7/dist-packages/transformers/models/rag/tokenization_rag.py in prepare_seq2seq_batch(self, src_texts, tgt_texts, max_length, max_target_length, **kwargs)
75 if max_target_length is None:
76 max_target_length = self.generator.model_max_length
---> 77 return super().prepare_seq2seq_batch(
78 src_texts, tgt_texts, max_length=max_length, max_target_length=max_target_length, **kwargs
79 )
AttributeError: 'super' object has no attribute 'prepare_seq2seq_batch'<|||||>Hi @rajasekar-venkatesan
The issue is fixed on master after the `4.3.3` release. This fix will be available in the next release. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.