
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 10,111 | closed | Bug in RAG Sequence generate | IMHO there is a bug in the RAG Sequence model, in the generate function.
The shapes mismatch all the time. I looked into the code and found the issue in the following loop.
https://github.com/huggingface/transformers/blob/85395e4901f87b880f364bcd6424fe37da94574b/src/transformers/models/rag/modeling_rag.py#L936
Kindly let me know if there is indeed a bug or is it just my code problem.
Thanks. | 02-10-2021 02:09:17 | 02-10-2021 02:09:17 | Hi @krishanudb
Could you post a code snippet so we can reproduce the issue? Please post your env info, short code snippet, and stack trace if possible when reporting bugs. Thanks.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,110 | closed | Fix tokenizers training in notebooks | The `train` method has been updated in `tokenizers` v0.10, and it includes a breaking change from the previous versions (reordered arguments). This modification ensures it works for all versions.
cc @sgugger @LysandreJik | 02-10-2021 02:00:20 | 02-10-2021 02:00:20 | |
transformers | 10,109 | closed | Git does not find the model folder and does not commit model files in the hugging face | I work for Google Colab. This is how I save my training model files
````
trainer.save_model("./kvantorium-small")
tokenizer.save_pretrained("/content/For_tokenize", legacy_format=False)
````
Next, I want to commit my files to the hugging face repository. As shown in the guide (https://huggingface.co/welcome)
all these lines of code compile successfully:
````
!sudo apt-get install git-lfs
!pip install huggingface_hub
!huggingface-cli login
!huggingface-cli repo create simple-small-kvantorium
!git lfs install
!git clone https://huggingface.co/Fidlobabovic/simple-small-kvantorium
````
But when I want to make a push request to save files to the repository, I get an error that there is no such repository. How do I rewrite the request to publish the files to the repository? Is this a problem that I work for Google Colab? Thanks a lot in advance, you are helping me a lot
#9878
````
!git add .
!git commit -m "commit from $Fidlobabovic/simple-small-kvantorium"
!git push
fatal: not a git repository (or any of the parent directories): .git
fatal: not a git repository (or any of the parent directories): .git
fatal: not a git repository (or any of the parent directories): .git
```` | 02-09-2021 23:26:26 | 02-09-2021 23:26:26 | hi @IndianMLGay
You should `cd` into `simple-small-kvantorium` directory and then do `git add/commit/push` etc<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,108 | closed | Non-JSON-serializable tokenizer config with `save_pretrained` | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.1
- Platform: Linux
- Python version: 3.7.9
- PyTorch version (GPU?): 1.7.1 (GPU)
- Tensorflow version (GPU?): 2.1.2 (GPU)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): Bert
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
Using a minimal example with loading/saving a tokenizer.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
Again, this is just a minimal example.
## To reproduce
Steps to reproduce the behavior:
1. Instantiate a `BertConfig` and a `BertTokenizer` based on the config.
2. Try and save the tokenizer with `save_pretrained`
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
Minimal example:
```
from transformers import BertConfig, BertTokenizer
config = BertConfig.from_pretrained("./configs/bert-small.json", cache_dir=".")
tokenizer = BertTokenizer.from_pretrained("vocab/", cache_dir=".", config=config)
tokenizer.save_pretrained('new_save')
```
Error:
```
Traceback (most recent call last):
File "test.py", line 5, in <module>
tokenizer.save_pretrained('new_save')
File "/cluster/envs/mult/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1979, in save_pretrained
f.write(json.dumps(tokenizer_config, ensure_ascii=False))
File "/cluster/envs/mult/lib/python3.7/json/__init__.py", line 238, in dumps
**kw).encode(obj)
File "/cluster/envs/mult/lib/python3.7/json/encoder.py", line 199, in encode
chunks = self.iterencode(o, _one_shot=True)
File "/cluster/envs/mult/lib/python3.7/json/encoder.py", line 257, in iterencode
return _iterencode(o, 0)
File "/cluster/envs/mult/lib/python3.7/json/encoder.py", line 179, in default
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type BertConfig is not JSON serializable
```
## Expected behavior
Tokenizer should be saveable. I'm guessing this could be happening because the bit that's supposed to be saving the config is using the `json` library directly, instead of calling `to_json_file` on the `BertConfig`, but I'm not sure.
<!-- A clear and concise description of what you would expect to happen. -->
| 02-09-2021 22:43:47 | 02-09-2021 22:43:47 | Hi @vin-ivar
The `tokenizer` does not need the model config file, there is no need to pass it when initializing the tokenizer.<|||||>That fixes it, I was using an older script without taking that bit out. |
transformers | 10,107 | closed | Remove speed metrics from default compute objective [WIP] | # What does this PR do?
This PR removes speed metrics (e.g. `eval_runtime`) from the default compute objective (`default_compute_objective`). `default_compute_objective` is used when no `compute_objective` is passed to `Trainer.hyperparameter_search`. `Trainer` adds speed metrics such as `eval_runtime` and `eval_samples_per_second` to the metrics and `default_compute_objective` returns the sum of metrics as the objective so these speed metrics will be included in the objective.
I still need to add unit test for `default_compute_objective` to avoid having such metrics in the objective in the future.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger
| 02-09-2021 21:03:49 | 02-09-2021 21:03:49 | Oh boy, that is rather bad! Thanks a lot for fixing this!
Did you want to add the test in this PR?<|||||>> Oh boy, that is rather bad! Thanks a lot for fixing this!
> Did you want to add the test in this PR?
I can also create a follow up PR if you want to merge this asap. I can't implement the test cases right away. Maybe in ~4 days. @sgugger<|||||>In that case maybe a follow-up PR, this fix is needed badly so I will merge. Thanks again! |
transformers | 10,106 | closed | Revert "Fix TFConvBertModelIntegrationTest::test_inference_masked_lm Test" | Reverts huggingface/transformers#10104 | 02-09-2021 20:39:10 | 02-09-2021 20:39:10 | |
transformers | 10,105 | open | PruneTrain: Fast Neural Network Training by Dynamic Sparse Model Reconfiguration | # 🚀 Feature request
PruneTrain. {...} By using a structured-pruning approach and additional reconfiguration techniques we introduce, the pruned model can still be efficiently processed on a GPU accelerator. Overall, **PruneTrain achieves a reduction of 39% in the end-to-end training time of ResNet50 for ImageNet by reducing computation cost by 40% in FLOPs, memory accesses by 37% for memory bandwidth bound layers, and the inter-accelerator communication by 55%.**
## Motivation
I'm pre-training some midsize language models from scratch. If you tell me that I can pretrain a network with 1% drop in performance while cutting down the energy demand of the training by up to 40% and speeding inference time at the same time, I will buy it.
## Your contribution
https://arxiv.org/abs/1901.09290. I can not understand why the authors did not open source the code, since it could reduce the global warming, speedup experimentation and reduce energy consumption. | 02-09-2021 19:52:34 | 02-09-2021 19:52:34 | |
transformers | 10,104 | closed | Fix TFConvBertModelIntegrationTest::test_inference_masked_lm Test | 02-09-2021 19:07:39 | 02-09-2021 19:07:39 | @abhishekkrthakur - this doesn't look good to me.
Just changing the hardcoded integration test to values that make the test pass does not seem like the way to go here. The PyTorch integration test: https://github.com/huggingface/transformers/blob/7c7962ba891864f9770b9e9424f87d158b839a59/tests/test_modeling_convbert.py#L430 still has the old values and passes, which to me is an indicator that the TF implementation or the PyTorch implementation is not correct.
Also, it would be great if we could not merge PRs that have no description and that neither @sgugger, @LysandreJik or I approved. |
|
transformers | 10,103 | closed | Fix Faiss Import | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
All RAG related tests are skipped on circle ci at the moment because `faiss-cpu` is not passing the `is_faiss_available()` function. Sadly this didn't make us realize that RAG is currently broken on master. This should be merged with https://github.com/huggingface/transformers/pull/10094 to fix RAG.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-09-2021 18:24:16 | 02-09-2021 18:24:16 | As expected the two RAG tests are failing<|||||>Thanks for fixing! |
transformers | 10,102 | closed | Replace faiss cpu by faiss | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-09-2021 18:06:59 | 02-09-2021 18:06:59 | |
transformers | 10,101 | closed | Change dependency from faiss-cpu to faiss | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-09-2021 17:58:51 | 02-09-2021 17:58:51 | |
transformers | 10,100 | closed | Fix some edge cases in report_to and add deprecation warnings | # What does this PR do?
This PR adds two new values for the `report_to` TrainingArguments:
- "all" for all integrations installed
- "none" for none (necessary when using in the CLI and we can't pass an empty list)
It also starts warning the user (with an info to not be too spammy) of the upcoming change of default in v5. | 02-09-2021 15:07:34 | 02-09-2021 15:07:34 | |
transformers | 10,099 | closed | Issue training Longformer | Hello, apologies if this is the wrong place to ask for help, I'm currently trying to fine-tune longformer on a text classification task. My script is below.
When I use ```for param in model.longformer.encoder.parameters():
param.requires_grad = False``` to not train the encoder layer but just the classification head and the embeddings, training works as expected. When I don't freeze the encoder layers, the model doesn't train at all, and when I try to do inference on it, it gives constant output, regardless of what data I put in. I've been reading all the papers to find what I have done wrong, can anyone point me in the right direction? Thank you so much for your help! Tom
```import logging
import pandas as pd
from transformers import AdamW, LongformerTokenizerFast, TrainingArguments, Trainer,LongformerForSequenceClassification
import torch
from torch.utils.data import DataLoader
import numpy as np
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
# calculate accuracy using sklearn's function
acc = accuracy_score(labels, preds)
f1 = f1_score(labels,preds)
precision = precision_score(labels,preds)
recall = recall_score(labels,preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
class SupremeDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
def main():
# Setup logging:
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logging.info("*** Data processing ***")
logging.info("importing data")
data_train = pd.read_csv("../../../shared/benchmarking/supreme_train.csv").dropna()
data_val = pd.read_csv("../../../shared/benchmarking/supreme_val.csv").dropna()
tokenizer = LongformerTokenizerFast.from_pretrained('allenai/longformer-base-4096')
logging.info("tokenizing data")
train_encodings = tokenizer(list(data_train.content_decode),truncation=True,padding=True,return_tensors="pt")
val_encodings = tokenizer(list(data_val.content_decode),truncation=True,padding=True,return_tensors="pt")
train_encodings['global_attention_mask'] = torch.zeros_like(train_encodings['input_ids'])
val_encodings['global_attention_mask'] = torch.zeros_like(val_encodings['input_ids'])
train_encodings['global_attention_mask'][train_encodings['input_ids']==0] = 1
val_encodings['global_attention_mask'][val_encodings['input_ids']==0] = 1
train_labels = data_train.label.tolist()
val_labels = data_val.label.tolist()
logging.info("creating datasets")
train_dataset = SupremeDataset(train_encodings, train_labels)
val_dataset = SupremeDataset(val_encodings, val_labels)
logging.info("*** Training ***")
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=1, # batch size per device during training
per_device_eval_batch_size=1, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=200,
do_eval=True,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
evaluation_strategy = "steps",
)
logging.info("loading model")
model = LongformerForSequenceClassification.from_pretrained('allenai/longformer-base-4096')
for param in model.longformer.encoder.parameters():
param.requires_grad = False
logging.info("loading trainer")
trainer = Trainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset,
compute_metrics = compute_metrics # evaluation dataset
)
logging.info("starting training")
trainer.train()
torch.save(model, 'supremecourt_fullmodel.pt')
if __name__ == "__main__":
main()
``` | 02-09-2021 14:04:53 | 02-09-2021 14:04:53 | I've been having the same problem<|||||>Maybe @patrickvonplaten can chime in here<|||||>Hey @TomUdale-debug - thanks for reporting your issue. It's quite difficult to debug problems with training, but I'll try my best to help you here. However, I would need full access to the training data etc...Could you please make a google colab that I can just run to reproduce your error and link it here. I think this will be the easiest way to check whether there is a problem with Longformer :-) <|||||>Sure thing I will set up a Colab, thanks!<|||||>Many apologies for going slow on this, here is a [Colab](https://colab.research.google.com/drive/12ALD3gJS9rMpW7fvdIwj5mJGx1JGYgLb?usp=sharing) which demonstrates the issue. After one epoch of training (5k docs)the model logit outputs become constant, recall goes to 1 so the model if just predicting everything as 1 (binary classification task). I have the model checkpoint for that if it would be helpful. Any help on this would be great! Thanks, Tom<|||||>Hmm, at first sounds to me this sounds like the classic overfitting to one class, I'm not so sure whether this is due to using Longformer.
Some tips:
- Get more info about your dataset. Is the dataset balanced? Could it be that one class is much more present in the dataset then other classes, which would then be a reason why the model overfits to one class
- Increase the batch_size. Batch_size of 1 is too small IMO, try 8, 16 or 32
- Play around with learning_rate / weight_decay
- If nothing works, try whether you are able to fine-tune BERT well on this dataset. If BERT works well and Longformer doesn't then this is a strong indication that there is a problem with Longformer. But just from looking at the colab, I can't really draw any conclusions and it doesn't really seem to me that the problem is Longformer.
Hope this is somewhat helpful!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,098 | closed | Adding support for TFEncoderDecoderModel | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
This PR will add tf2 support for EncoderDecoderModel upon completion.
<!-- Remove if not applicable -->
Fixes #9863
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@patrickvonplaten
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-09-2021 13:31:55 | 02-09-2021 13:31:55 | Hi @patrickvonplaten,
I just realised that major step will be adding cross-attention layer to `TFDecoderLMHeadModel` for enabling this support. I will start doing that next.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,097 | closed | DeBERTa v2 throws "TypeError: stat: path should be string...", v1 not | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.1
- Platform: Linux-5.4.0-54-generic-x86_64-with-glibc2.29
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.1+cpu (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: false
- Using distributed or parallel set-up in script?: false
### Who can help
@BigBird01 @patil-suraj
## Information
Model I am using (DeBERTa v2):
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Create this file:
```
from transformers import AutoTokenizer, AutoModel
import torch
tokenizer = AutoTokenizer.from_pretrained('microsoft/deberta-xlarge-v2')
model = AutoModel.from_pretrained('microsoft/deberta-xlarge-v2')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
print(outputs)
```
2. Run the file
3. You'll get:
```
(venv) root@16gb:~/deberta# python3 index.py
Traceback (most recent call last):
File "index.py", line 4, in <module>
tokenizer = AutoTokenizer.from_pretrained('microsoft/deberta-xlarge-v2')
File "/root/deberta/venv/lib/python3.8/site-packages/transformers/models/auto/tokenization_auto.py", line 398, in from_pretrained
return tokenizer_class_py.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File "/root/deberta/venv/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1788, in from_pretrained
return cls._from_pretrained(
File "/root/deberta/venv/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1860, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/root/deberta/venv/lib/python3.8/site-packages/transformers/models/deberta/tokenization_deberta.py", line 542, in __init__
if not os.path.isfile(vocab_file):
File "/usr/lib/python3.8/genericpath.py", line 30, in isfile
st = os.stat(path)
TypeError: stat: path should be string, bytes, os.PathLike or integer, not NoneType
```
I tried this with the DeBERTa v1 models and there was no error. I've the same behavior when using `DebertaTokenizer, DebertaModel`
## Expected behavior
No error. | 02-09-2021 11:19:33 | 02-09-2021 11:19:33 | Hi @205g0
Thank you for reporting this!
`microsoft/deberta-xlarge-v2` uses `sentencepiece` vocab and it's not implemented for deberta, which is the reason for this error. <|||||>Hey Suraj, thanks for the quick response and good to know!<|||||>@BigBird01 do you think you could add the missing tokenizer, otherwise, I could add it. Thanks!<|||||>DeBERTa-v2 is not available in the library yet. We're working towards it with @BigBird01.<|||||>Thanks @205g0 for the interest in DeBERTa-v2. We are working on it with @LysandreJik, hopefully, it will be available soon. You can check our [PR](https://github.com/huggingface/transformers/pull/10018) for the progress.<|||||>Oh sorry, @BigBird01, I did not realize that this was a work in progress<|||||>> Oh sorry, @BigBird01, I did not realize that this was a work in progress
No worry, @patil-suraj. Thanks for your quick response. We are glad to integrate these SOTA NLU models with HF to benefit the community:) <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,096 | closed | Fix example in Wav2Vec2 documentation | Fixes an example in Wav2Vec2 documentation | 02-09-2021 10:48:51 | 02-09-2021 10:48:51 | |
transformers | 10,095 | closed | Fix naming in TF MobileBERT | # What does this PR do?
This PR fixes a naming issue in the `TFMobileBertForMaskedLM` model.
# Fixes
#10088 | 02-09-2021 10:27:39 | 02-09-2021 10:27:39 | |
transformers | 10,094 | closed | [RAG] fix generate | # What does this PR do?
#9984 introduced a new `encoder_no_repeat_ngram_size` `generate` param, but it was missing from `RagTokenForGeneration.generate`, it's a required argument for `_get_logits_processor` which is called inside `RagTokenForGeneration.generate`.
This PR adds the argument to `RagTokenForGeneration.generate` and passes it to `_get_logits_processor`. | 02-09-2021 10:25:17 | 02-09-2021 10:25:17 | Wow this is a huge bug actually! Thanks a lot for fixing it @patil-suraj!
@LysandreJik @sgugger - Sadly Circle CI is skipping all RAG tests at the moment -> therefore we should first fix the faiss import (#10103), then rebase this PR to see that everything is correctly solved, merge it and then do a patch |
transformers | 10,093 | closed | Pre-Training for Question Generation | Hi,
How to pre-train any of language generation models (T5, BART or GPT ) for Question Generation task where I had passage, question and answer?
| 02-09-2021 10:18:28 | 02-09-2021 10:18:28 | I guess @patil-suraj is the expert in this, check out his [repo](https://github.com/patil-suraj/question_generation) explaining all the details.<|||||>ok..
@patil-suraj , plz revert on [this](https://github.com/patil-suraj/question_generation/issues/69) issue I raised in your repo |
transformers | 10,092 | closed | Logging propagation | This PR enables logs propagation by default with transformers' logging system, in a similar fashion to https://github.com/huggingface/datasets/pull/1845.
Unlike `datasets` however, we will not remove the default handler in transformers' logging system: this handler is heavily used in all examples, and removing the default handler would prevent the formatting from being correctly applied to the examples.
Since this is the best practice shown in examples, I believe this change would be breaking for users that have copy/pasted this change across their codebases, and this change would therefore be breaking for these users.
Furthermore, any user that does not want the default handler may use the `disable_default_handler` method in order to disable that behavior. These two methods are added to the documentation in this PR.
cc @lhoestq @sgugger @patrickvonplaten | 02-09-2021 09:45:26 | 02-09-2021 09:45:26 | |
transformers | 10,091 | closed | How to run distributed training on multiple machines? | ## Environment info
- `transformers` version: 4.3.0
- Platform: PyTorch
- Python version: 3.7
- PyTorch version (GPU?): 1.7.1
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
##Who can help:
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
## Information
Model I am using (Bert, XLNet ...): Roberta
## To reproduce
The script I'm working with is https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm.py
I know that we can run the distributed training on multiple GPUs in a single machine by
`python -m torch.distributed.launch --nproc_per_node=8 run_mlm.py --sharded_dpp`
But what if I can multiple machines with multiple GPUs, let's say I have two machines and each is with 8 GPUs, what is the expected command to run on these 16 GPUs?
| 02-09-2021 08:37:34 | 02-09-2021 08:37:34 | I'm only aware that the PyTorch official documentation is using the RPC: https://pytorch.org/tutorials/intermediate/dist_pipeline_parallel_tutorial.html<|||||>This is more of a question for the PyTorch GitHub then ours since this is a question about to use `torch.distributed.launch`. That's why I'll close the issue. Still, I can share the command I run on my side:
```
python -m torch.distributed.launch --nproc_per_node 8 \
--nnodes 2 \
--node_rank rank_of_your_machine \
--master_addr main_machine_ip \
--master_port open_port_on_main_machine \
run_mlm.py \
--sharded_ddp \
--all_other_args_to_script
```
where `rank_of_your_machine` should be 0 for the main machine and 1 for the other one, `main_machine_ip` the IP of the machine of rank 0 and `open_port_on_main_machine` the port to use to communicate between the two machines.<|||||>Thanks, this is really helpful |
transformers | 10,090 | closed | [question] Are the tensorflow bert weights same as the original repo ? | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- `transformers` version: 4.2.2
- Platform: Linux-4.15.0-133-generic-x86_64-with-debian-stretch-sid
- Python version: 3.6.8
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): 2.5.0-dev20210204 (True)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: distributed
### Who can help
Models:
- albert, bert, xlm: @LysandreJik
## Information
I'm using the pretrained bert-base-chinese [here](https://huggingface.co/bert-base-chinese). I print out the pooler_output and the result is different from the tensorflow2.0 published hub saved model [here](https://tfhub.dev/tensorflow/bert_zh_L-12_H-768_A-12/3).
I want to confirm whether the two checkpoints weights are the same.
## To reproduce
Steps to reproduce the behavior:
```
from transformers import TFBert
bert = bert = TFBertModel.from_pretrained('bert-base-chinese', output_hidden_states=True)
output = bert(input_ids=tf.convert_to_tensor([[ 101, 791, 1921, 1921, 3698, 2582, 720, 3416, 102]]),
attention_mask=tf.convert_to_tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1]]), training=False)
print(output.pooler_output)
```
```
# print the beginning weights:
array([[ 0.99749047, 0.9999622 , 0.99657625, 0.96953416, 0.8489984 ,
0.06474952,
```
The tensorflow hub output can be produced from https://tfhub.dev/tensorflow/bert_zh_L-12_H-768_A-12/3.
The input text is "今天天气怎么样"
```
[[ 9.97488916e-01 9.99962687e-01 9.96489942e-01 9.69992220e-01
8.49602520e-01 6.62192404e-02 ,
```
The tensorflow part claims they use the original bert checkpoints from tf1.X.
There is no training=True/False option in tensorflow hub so I'm confused if the difference is due to this option? (I've set trainable=False in tensorflow hub)
## Expected behavior
Expect the outputs to be the same.
| 02-09-2021 08:34:43 | 02-09-2021 08:34:43 | Hi! Could you provide the code you used to get the predictions with the BERT checkpoint on TF Hub? The two should be identical.<|||||>> Hi! Could you provide the code you used to get the predictions with the BERT checkpoint on TF Hub? The two should be identical.
I copied from https://tfhub.dev/tensorflow/bert_zh_L-12_H-768_A-12/3
```python
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string)
preprocessor = hub.KerasLayer(
"https://tfhub.dev/tensorflow/bert_zh_preprocess/3")
encoder_inputs = preprocessor(text_input)
encoder = hub.KerasLayer(
"https://tfhub.dev/tensorflow/bert_zh_L-12_H-768_A-12/3",
trainable=False)
outputs = encoder(encoder_inputs)
pooled_output = outputs["pooled_output"] # [batch_size, 768].
sequence_output = outputs["sequence_output"] # [batch_size, seq_length, 768].
embedding_model = tf.keras.Model(text_input, pooled_output)
sentences = tf.constant(["今天天气怎么样"])
print(embedding_model(sentences))
```
<|||||>Any update ? @LysandreJik <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,089 | closed | Deprecate Wav2Vec2ForMaskedLM and add Wav2Vec2ForCTC | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Deprecates `Wav2Vec2ForMaskedLM` -> the name was very badly chosen since it's currently used for CTC classification which is very different from `MaskedLM`. Also `MaskedLM` is not a good name for pretraining where it should rather be something like `ForMaskedSpeechModeling`, so IMO the best idea is to deprecate the whole class.
Right after this PR is merged and there is a patch, I will update all configs.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-09-2021 08:25:54 | 02-09-2021 08:25:54 | > LGTM! Could we remove `Wav2Vec2ForMaskedLM` from the documentation?
Yes! It's better than adding a note saying that the model is deprecated? => yeah let's just remove it! |
transformers | 10,088 | closed | Language modelling head has zero weights in pretrained TFMobileBertForMaskedLM | ## Description
The `TFMobileBertForMaskedLM` example returns all zero logits while `MobileBertForMaskedLM` example works fine.
https://huggingface.co/transformers/model_doc/mobilebert.html#tfmobilebertformaskedlm
I checked language modeling head weights for both models and found that TF pretrained model has zero weights.
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.0
- Platform: Google Colab
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101
- Tensorflow version (GPU?): 2.4.1
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@jplu @patrickvonplaten
## Information
Model I am using (Bert, XLNet ...): TFMobileBertForMaskedLM
The problem arises when using:
- [x] the official example scripts: (give details below)
## To reproduce
```
from transformers import MobileBertForMaskedLM
from transformers import TFMobileBertForMaskedLM
# PyTorch
model = MobileBertForMaskedLM.from_pretrained('google/mobilebert-uncased')
print(list(model.cls.parameters())[0])
# Parameter containing:
# tensor([-7.2946, -7.4302, -7.5401, ..., -7.4850, -7.4503, -2.7798],
# requires_grad=True)
# TensorFlow
model = TFMobileBertForMaskedLM.from_pretrained('google/mobilebert-uncased')
print(model.layers[1].get_weights()[0])
# array([0., 0., 0., ..., 0., 0., 0.], dtype=float32)
```
## Expected behavior
Language modeling head for TFMobileBertForMaskedLM should have the same weights as of MobileBertForMaskedLM
| 02-09-2021 08:04:41 | 02-09-2021 08:04:41 | Hello!
Indeed there is an issue in the naming for `TFMobileBertForMaskedLM`. This will be fixed in the next release.<|||||>OK, thanks for the quick response!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,087 | closed | remove adjust_logits_during_generation method | # What does this PR do?
This PR is the first split of #9811.
This PR
1. introduces two new `generate` and `config` arguments and `LogitsProcessor`
- `forced_bos_token_id` and `forced_eos_token_id`, to force a specific start and end token. This is particularly useful for many to many and one to many translation models, so we can pass different language tokens as `forced_bos_token_id` to `generate`,
- `ForcedBOSTokenLogitsProcessor` and `ForcedEOSTokenLogitsProcessor`
2. Remove `adjust_logits_during_generation` method from all models (except `Marian`) and handle that use case using the newly introduced logits processors.
4. remove the `force_bos_token_to_be_generated` argument from `BartConfig`
For `Marian` we still need to keep the `adjust_logits_during_generation` method to force the model to not generate pad token. Adding the pad token to `bad_words_ids` does not resolve this issue, the score of `pad_token_id` needs to be set to `-inf` before calling `log_softmax` | 02-09-2021 05:52:28 | 02-09-2021 05:52:28 | All slow tests passing in PT!<|||||>@patrickvonplaten (Bart, MBart, Pegasus, Marian, Blenderbot, BlenderbotSmall) slow tests are passing in TF as well.<|||||>Applied Sylvain's suggestions. Merging! |
transformers | 10,086 | closed | doc: update W&B related doc | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Updates W&B related documentation:
* remove outdated examples
* update urls
* add config parameters
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@sgugger | 02-09-2021 05:28:38 | 02-09-2021 05:28:38 | There's also `docs/source/example.md` but I understand it is built automatically from `examples/README.md` |
transformers | 10,085 | closed | [examples/s2s] add test set predictions | # What does this PR do?
This PR adds the `do_predict` option to the `run_seq2seq.py` script for test set predictions.
Fixes #10032
cc. @stas00 | 02-09-2021 04:09:42 | 02-09-2021 04:09:42 | > I propose that the best approach would be to finish everything that is planned and then we will run tests side by side and note any small discrepancies if any and fix them in one go? Does that work?
Yes, this was the last major missing piece from this script. Now I'm going to start running both scripts side by side (manually converting the old datasets to new datasets format) and note the discrepancies, I'll also wait for your tests.
> I'm waiting for the datasets hub to port the datasets to be able to compare the old and the new.
Let's not wait for the hub, for now, we could just manually convert the datasets for tests and later upload them to the hub once it's ready. <|||||>> > I propose that the best approach would be to finish everything that is planned and then we will run tests side by side and note any small discrepancies if any and fix them in one go? Does that work?
>
> Yes, this was the last major missing piece from this script. Now I'm going to start running both scripts side by side (manually converting the old datasets to new datasets format) and note the discrepancies, I'll also wait for your tests.
That works.
> > I'm waiting for the datasets hub to port the datasets to be able to compare the old and the new.
>
> Let's not wait for the hub, for now, we could just manually convert the datasets for tests and later upload them to the hub once it's ready.
Sure - I already wrote the code for wmt en-ro https://github.com/huggingface/transformers/issues/10044#issuecomment-774413928 need to adapt to others.<|||||>Changed `eval_beams` to `num_beams`. Hopefully final name change. Merging! |
transformers | 10,084 | closed | Tapas not working with tables exceeding token limit | ## Environment info
- `transformers` version: 4.3.0
- Platform: MacOS
- Python version: 3.7
- PyTorch version (GPU?): 1.7.1
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik @sgugger @NielsRogge
## Information
Model I am using (Bert, XLNet ...): TaPas
## To reproduce
When executing the following code, using this [table](https://gist.github.com/bogdankostic/387d1c7a0e8ce25ea302395756df11b3), I get an `IndexError: index out of range in self`.
```python
from transformers import AutoTokenizer, AutoModelForTableQuestionAnswering
import pandas as pd
tokenizer = AutoTokenizer.from_pretrained("google/tapas-base-finetuned-wtq", drop_rows_to_fit=True)
model = AutoModelForTableQuestionAnswering.from_pretrained("google/tapas-base-finetuned-wtq")
df = pd.read_csv("table.tsv", sep="\t").astype(str)
queries = ["How big is Ardeen?"]
inputs = tokenizer(table=df, queries=queries, padding="max_length", truncation=True, return_tensors="pt")
outputs = model(**inputs)
```
I am not completely sure about the cause of the error but I suspect that the column rank vectors are not correctly generated. (`torch.max(token_type_ids[:, :, 4])` returns 298 and `torch.max(token_type_ids[:, :, 5])` returns 302, the Embedding Models for column rank and inverse column rank, however, allow a max value of 255)
| 02-08-2021 23:41:00 | 02-08-2021 23:41:00 | Hi,
Yes the column ranks may cause issues when a table is too big, as the vocab size is only 256. See also [my reply](https://github.com/huggingface/transformers/issues/9221#issuecomment-749093391) on #9221.
Actually, the authors of TAPAS did release a new method in a [follow-up paper](https://arxiv.org/abs/2010.00571) to prune columns that are not relevant to a question to be able to serve large tables to the BERT-like model, so this is something that maybe could be added in the future.<|||||>My suggestion would be to compute the column ranks on the truncated table. (Not sure if and how this is feasible.)
Otherwise I would suggest returning a more informative error message.<|||||>Yes, good suggestion. I've investigated this a bit and it seems that the original implementation also computes the column ranks on the original table, rather than the truncated one. I've asked the original authors [here](https://github.com/google-research/tapas/issues/106#issue-804538477). Will keep you updated.<|||||>So the author replied:
> IIRC, then we compute them before pruning the table.
That was by design so that those ranks would match the original numeric rank (pre-pruning).
It's true that the rank could thus exceed the vocab size.
We could add some trimming to prevent that.
So this is something that could be added in the future (together with the `prune_columns` option). I put it on my to-do list for now.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>@NielsRogge Thanks for the explanations above. Has there been any update on this issue? I have also run into this issue when running Tapas on the WTQ dataset, and it took me a lot of efforts to get to the bottom of this and realize that this is an issue with the `column_rank` IDs from oversized tables.
The painful part is that there is currently no guard or no warning against feeding oversized tables into the tokenizer, and the issue will only come out as a "CUDA error: device-side assert triggered" message when the Tapas forward pass is run.
I think there are several potential ways to solve this or make this less painful:
1. Computing the column rank after the table truncation (as already suggested by another comment above). This makes a ton of sense because the table will only be presented to the model after truncation in the tokenizer anyway, so there is no point to maintain a non-continuous column rank for large tables (with some ranks removed due to truncation). I understand that the original TF implementation might not handle this, but can this be added as a behavior in the Huggingface implementation?
2. Add an option to re-map all the large column ranks to the max rank value. This can be implemented in this tokenizer function: https://github.com/huggingface/transformers/blob/7fcee113c163a95d1b125ef35dc49a0a1aa13a50/src/transformers/models/tapas/tokenization_tapas.py#L1487
This is less ideal than 1, but can make sure that the model won't crash due to an index-out-of-range error.
3. The easiest fix would be to add some warning/exception in the tokenizer that reminds users about this. Or let the tokenizer return a `None` value in the output, or return a special boolean variable such as `table_oversized`. This does not solve anything, but can make the capture of this issue much easier.
Look forward to some updates on this issue.<|||||>Is there any way to bypass the token limit ?<|||||>@KML1337,
I do not have sure if you could consider the following approach:
First, you split the table into n-subtables that generate tokens under the limit tokens;
Then, process each subtable with the model;
Finally, aggregate all responses and select the one with the highest logit score.
|
transformers | 10,083 | closed | model.generate needs BART config update | ### Who can help
@patrickvonplaten @patil-suraj
```
model = BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn')
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large-cnn')
ARTICLE_TO_SUMMARIZE = "My friends are cool but they eat too many carbs."
inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors='pt')
# Generate Summary
summary_ids = model.generate(inputs['input_ids'], num_beams=4, max_length=5, early_stopping=True)
```
model.generate runs into errors. num_beam_groups, return_dict_in_generate and encoder_no_repeat_ngram_size are not defined in BART config. Should they be added? | 02-08-2021 22:21:59 | 02-08-2021 22:21:59 | Hey @swethmandava,
Sorry I don't understand the issue here - what do you mean by `model.generate` runs into errors? Your above code snippet works fine for me. Could you clarify the issue? Thank you!<|||||>`summary_ids = model.generate(inputs['input_ids'], num_beams=4, max_length=5, early_stopping=True, num_beam_groups=1, output_scores=False, return_dict_in_generate=False, encoder_no_repeat_ngram_size=0, diversity_penalty=0.0)
`
works for me. I have to define the following defaults (num_beam_groups, output_scores, return_dict_in_generate, encoder_no_repeat_ngram_size, diversity_penalty) explicitly since they are not in BARTConfig and default to None<|||||>Hey @swethmandava
You shouldn't need to define these param. All these config params have default values defined in the `PretrainedConfig` class from which all other configs inherit.
Could you try again with the newest transformers version? |
transformers | 10,082 | open | Supporting truncation from both ends of the sequence in BertTokenizerFast | # 🚀 Feature request
For `BertTokenizerFast` (inherited from `PreTrainedTokenizerFast`), it seems like `__call__` only supports truncating from the end of the sequences if we set `truncation` to be `longest_first`, `only_first` or `only_second`. For example, assuming `max_length` is 6 and `truncation` is `longest_first`:
(`I have a pen`, `I have an apple`) --> truncation --> (`I have a`, `I have an`)
However, if we take a closer look at [Google's original data-preprocessing script for BERT](https://github.com/google-research/bert/blob/master/create_pretraining_data.py#L430), truncation can happen at both ends of the sequence randomly:
(`I have a pen`, `I have an apple`) --> truncation --> (`I have a`, `have an apple`) or (`have a pen`, `I have an`) or (`I have a`, `I have an`) or (`have a pen`, `have an apple`)
For `BertTokenizer`, perhaps I could reassigned its `truncate_sequences` member function (https://github.com/huggingface/transformers/blob/master/src/transformers/tokenization_utils_base.py#L2887) with a new function that implements Google's truncation scheme; however, for `BertTokenizerFast`, truncation is handled completely in Rust, about which I can't do anything.
An alternative is to call `tokenize` first, then truncate the sequence using Google's scheme, ~~then call `__call__` and passing `is_split_into_words` as `True`~~. However, this approach has significant performance impact comparing to calling `__call__` on a batch of sequences directly (the average total tokenization latency doubled in our experiments).
> PS: Turned out `is_split_into_words` doesn't work this way (since when it sees a subword `##abc`, `__call__` would further tokenize it into `#` `#` `abc` even if `is_split_into_words==True`). Thus, the actual (but slow) alternative is to 1) call `tokenize` 2) implement the truncation scheme and making sure a subword starting with `##` won't be at the boundary 3) call `convert_tokens_to_string` 4) call `__call__`. Effectively, this alternative tokenizes the same sequence twice.
I'm wondering if's possible to add official support for random truncation from both ends of the sequence?
## Motivation
To match Google's truncation scheme exactly and minimizing artificial impacts on pretraining convergence.
## Your contribution
Unfortunately I'm not very familiar with Rust (I can read it, but I neve learned/wrote Rust before), thus I can't help much.
| 02-08-2021 21:29:32 | 02-08-2021 21:29:32 | Hi, thanks for opening an issue! We have the `padding_side` tokenizer attribute, but it doesn't work for truncation unfortunately.
@n1t0, what do you think?<|||||>@LysandreJik Thanks a lot for your response! @n1t0 I'm wondering what your thoughts are on this feature? |
transformers | 10,081 | closed | pipeline("sentiment-analysis') - index out of range in self | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.2.2
- Platform: Manjaro Linux (Feb 2021)
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.1 (GPU)
- Tensorflow version (GPU?):
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.-->
Library:
- tokenizers: @n1t0, @LysandreJik
- pipelines: @LysandreJik
## Information
Model I am using (Bert, XLNet ...): distilbert-base-uncased-finetuned-sst-2-english
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: sentiment analysis
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
My dataset consists blog articles and comments on them. Sometimes there are non-english characters, code snippets or other weird sequences.
Error occurs when:
1. Initialize the default pipeline("sentiment-analysis") with device 0 or -1
2. Run inference classifier with truncation=True of my dataset
3. After some time the classifier returns the following error:
CPU: `Index out of range in self`
GPU: ``/opt/conda/conda-bld/pytorch_1607370172916/work/aten/src/ATen/native/cuda/Indexing.cu:658: indexSelectLargeIndex: block: [56,0,0], thread: [0,0,0] Assertion `srcIndex < srcSelectDimSize` failed.``
## Expected behavior
I thought at first that my data was messing up the tokenization process or the model because sometimes there are strange sequences in the data e.g. code, links or stack traces.
However, if you name the model and tokenizer during pipeline initialization, inference from the model works fine for the same data:
`classifier = pipeline('sentiment-analysis', model='distilbert-base-uncased-finetuned-sst-2-english', tokenizer='distilbert-base-uncased', device=0)`
| 02-08-2021 21:07:10 | 02-08-2021 21:07:10 | Hello! Do you mind giving us a reproducible example, for example the sequence that makes this pipeline crash? Without such an example we won't be able to find out what's wrong. Thank you for your understanding<|||||>Hello! Thank you very much for your quick reply. While there are many entities in my dataset that cause the error, I just found the following entry and reproduced the error in a seperate script:
> Hi Jan! Nice post and I’m jealous that you get to go to both the SAP sessions and the AppleDevCon. But I think you inadvertent discovery of the aging of the SAP developer population vs the non-enterprise developers is a telling one. SAP tools and platforms remain a niche area that are only utilised by SAP developers. They may be brilliant, indeed I think in some area SAP is well ahead of the rest of the pack. The problem is I am 1 in 10,000 in thinking this (conservative estimate I fear). Those with plenty of experience in enterprise development (hence older) appreciate the ways that SAPs tools work with an enterprise way of doing things (translatable, solid, standard, accessible, enhanceable, etc). Whereas those that are used to pushing code changes to production every few hours just don’t understand. Why would you want your app to look like it is an SAP app? (Hello UI5 I can see you from across the room, you can’t hide.) Of course if you’re using this as an enterprise-wide approach, it makes sense. Thankfully for the livelihood of all of us aging SAP developers, enterprises have architects that insist on standards and enterprise-wide approaches. In the meantime, however, our younger, and likely less well paid, colleagues in the non SAP developer space will continue to use whatever framework offers the best(fastest/easiest) result and most jobs. Since to get a job in the SAP space customers are used to asking for a minimum of multiple years of experience, it’s hard to get a gig – so it’s much more profitable to just develop in Firebase, Angular, etc and get a job. After all, having a paying job is quite often more important that working with your framework of choice. I am sure that many of us older SAP devs will hire many people and teach them the minor cross-over skills to be proficient in the SAP iOS SDK, and we’ll probably make a decent amount of money from the companies that have architects that insist on SAP UI5 looking applications. But I don’t think this will change the overall conversation. In another 3 years, the developers in SAP will have aged another 3 years (there will still be a huge demand and the pay will be too good to move on). A bunch of new talent will have been trained in the new tools and will by now have 3 years experience and will be able to find enterprise SAP jobs of their own, but we will be no closer to getting anyone to adopt SAP tools for anything other than SAP customer usage. Grim outlook – sorry. The alternative (as I see it) is that SAP gives up on building its own (even if open source and rather excellent) frameworks and just starts adding to some existing ones. All of a sudden instead of trying to convince people to use a new framework, you ask them to use a variant of one they already know. At the same time SAP invests some serious money into “public API first” development and makes everything in S4 and their other cloud products able to be accessed and updated via well documented APIs. (Thus the end of the need for ABAP developers and those who understand the black arts of the SAP APIs.) The costs per developer hour plummet and then we see a new group of developers helping customers realise their dreams. And some very happy customers. As for the SAP iOS SDK, I think it has a very niche area, even more so than standard UI5 development. Not only is it specific to a requirement that only a large SAP customer would have, it’s also mobile platform specific. Given that it will not translate to Android devices I fear that it will not interest the generic mobile app developer. Due to being quite SAP specific quite probably not the iOS only developer either. We’ll see SAP devs training up or being hired & trained for specific tasks, not adopting the platform just because it’s cool. Perhaps I’m just being too much of a grumpy old git (meant in the non-awesome code sharing/management/versioning way) and we will find that these open frameworks are adopted. That would be awesome. It would make a lot of SAP customers a lot happier too to be able to have some decent choice as to who to do their work. Cheers, Chris<|||||>Hello! There were two issues here:
- The configuration for the tokenizer of `distilbert-base-uncased-finetuned-sst-2-english` was ill-configured and was lacking the `max_length`. I've manually fixed this in [huggingface#03b4d1](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english/commit/03b4d196c19d0a73c7e0322684e97db1ec397613)
- You should truncate your sequences by setting `truncation=True` so that your sequences don't overflow in the pipeline:
```py
classifier = pipeline('sentiment-analysis')
classifier(text, truncation=True)
```
Let me know if this fixes your issue!<|||||>Hello!
Thank you so much! That fixed the issue. I already thought the missing `max_length` could be the issue but it did not help to pass `max_length = 512` to the _call_ function of the pipeline.
I used the truncation flag before but I guess it did not work due to the missing `max_length` value.
Anyway, works perfectly now! Thank you!<|||||>Unfortunately this was due to the ill-configured tokenizer on the hub. We're working on a more general fix to prevent this from happening in the future.
Happy to help! |
transformers | 10,080 | closed | [deepspeed tests] transition to new tests dir | as discussed at https://github.com/huggingface/transformers/issues/10076 relocating deepspeed tests a dedicated area and out of the scripts area.
I went right ahead and create a dedicated sub-folder for deepspeed tests.
I no longer can use the libraries from `seq2seq` since I can't do a relative import from the script.
The only thing is that I will need to update all of my comments/posts to mention that `ds_config.json` has moved.
fairscale will be probably next if this looks good.
Fixes: https://github.com/huggingface/transformers/issues/10076
@sgugger | 02-08-2021 18:56:14 | 02-08-2021 18:56:14 | > I no longer can use the libraries from seq2seq since I can't do a relative import from the script.
We can add things to the sys path if needed (see the [general text examples](https://github.com/huggingface/transformers/blob/master/examples/test_examples.py)).
Thanks for doing this, it looks good to me!<|||||>Indeed, that's what we have been doing, but having a library named "`utils.py`" and importing it from far away is too ambiguous. So will probably need to rename such libraries, or start moving their functionality into a more central area. |
transformers | 10,079 | closed | Unclear error "NotImplementedError: "while saving tokenizer. How fix it? | Here is my tokenizer code and how I save it to a json file" /content/bert-datas7.json"
````
from tokenizers import normalizers
from tokenizers.normalizers import Lowercase, NFD, StripAccents
bert_tokenizer.pre_tokenizer = Whitespace()
from tokenizers.processors import TemplateProcessing
bert_tokenizer.post_processor = TemplateProcessing(
single="[CLS] $A [SEP]",
pair="[CLS] $A [SEP] $B:1 [SEP]:1",
special_tokens=[
("[CLS]", 1),
("[SEP]", 2),
("[PAD]", 3),
],
)
from tokenizers.trainers import WordPieceTrainer
trainer = WordPieceTrainer(
vocab_size=30522, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"], pad_to_max_length=True
)
files = [f"/content/For_ITMO.txt" for split in ["test", "train", "valid"]]
bert_tokenizer.train(trainer, files)
model_files = bert_tokenizer.model.save("data", "/content/For_ITMO.txt")
bert_tokenizer.model = WordPiece.from_file(*model_files, unk_token="[UNK]", pad_to_max_length=True)
bert_tokenizer.save("/content/bert-datas7.json")
````
When I output tokenizer name_or_path = nothing is displayed. This is normal?
````
tokenizer = PreTrainedTokenizerFast(tokenizer_file='/content/bert-datas7.json')
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
print(tokenizer)
>>> PreTrainedTokenizerFast(name_or_path='', vocab_size=1435, model_max_len=1000000000000000019884624838656, is_fast=True, padding_side='right', special_tokens={'pad_token': '[PAD]'})
````
Also, when I try to save my tokenizer, I get an error without explanation. How can I rewrite the code so that all this???
#9658
#10039
[For_ITMO.txt-vocab (1) (1).txt](https://github.com/huggingface/transformers/files/5945659/For_ITMO.txt-vocab.1.1.txt)
````
tokenizer.save_pretrained("/content/tokennizerrrr")
NotImplementedError Traceback (most recent call last)
<ipython-input-11-efc48254a528> in <module>()
----> 1 tokenizer.save_pretrained("/content/tokennizerrrr")
2 frames
/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py in save_vocabulary(self, save_directory, filename_prefix)
2042 :obj:`Tuple(str)`: Paths to the files saved.
2043 """
-> 2044 raise NotImplementedError
2045
2046 def tokenize(self, text: str, pair: Optional[str] = None, add_special_tokens: bool = False, **kwargs) -> List[str]:
NotImplementedError:
````
| 02-08-2021 17:49:49 | 02-08-2021 17:49:49 | Maybe @n1t0 can chime in here!<|||||>> When I output tokenizer name_or_path = nothing is displayed. This is normal?
I think it is yes, you are loading using `tokenizer_file=` instead of using the normal path with `from_pretrained`. No need to worry about this.
Concerning the error, I think the way to avoid it is by specifying `legacy_format=False`:
```python
tokenizer.save_pretrained("/content/tokennizerrrr", legacy_format=False)
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,078 | closed | Replace strided slice with tf.expand_dims | # What does this PR do?
This PR aims to replace the strided slice notation by its TF operator counterpart. As proposed by @mfuntowicz https://github.com/huggingface/transformers/pull/9890#discussion_r571939682 | 02-08-2021 17:15:56 | 02-08-2021 17:15:56 | > When two new dimensions are need, can we use a different operator to make the code more readable? Suggested tf.reshape but there might be something else available?
Yes, this is doable with `tf.reshape`.<|||||>All the slow tests of the concerned models are ok! |
transformers | 10,077 | closed | Update tokenizers requirement | Bump `tokenizers` version requirement to use the latest release, and also accept any new version before the next one possibly breaking. | 02-08-2021 17:15:02 | 02-08-2021 17:15:02 | |
transformers | 10,076 | closed | [tests] where to put deepspeed + fairscale tests | As a split off from this comment https://github.com/huggingface/transformers/pull/10039#pullrequestreview-585482462 we need to find a new home for deepspeed + fairscale tests.
Currently there are under `examples/seq2seq` because they rely on `finetune_trainer.py` ( `run_seq2seq.py` once the transition is over).
@sgugger suggests to keep the `seq2seq` folder as simple as possible. We also have `ds_config.json` there that could be moved too.
Seeing what's happening in the fairscale land - I think we will need a bunch of various tests there in the future too.
So where should we put the deepspeed + fairscale tests?
Ideally they should be put under main `tests`, since they are part of the trainer core, but I'm not sure whether reaching across the tests suite is a clean approach.
My fantasy is that one day transformers will have a few essential tools that aren't examples, and those will then leave somewhere in the main tree, perhaps `src/transformers/apps` and then it'd be easy to have such tests under `tests`.
So suggestions for now:
1. create `examples/deepspeed` and `examples/fairscale`
2. create `examples/distributed` and perhaps have all those extensions tested in one folder
3. create a new 3rd test suite for integrations
4. create `tests/deepspeed` - but as voiced earlier I'm not sure how reaching across a test suite will work - need to try - also this proposes to change the current flat structure of `tests`.
Perhaps you have other ideas.
@sgugger, @patrickvonplaten, @LysandreJik, @patil-suraj | 02-08-2021 16:51:39 | 02-08-2021 16:51:39 | The examples are not tests, so `examples/deepspeed` should not be created to host some deepspeed tests. I'm wondering why we would need an `examples/deepspeed` since the base concept of having deepspeed integrating in our `Trainer` is to have it work out of the box for **all** our examples.
My suggestion was to create an `examples/tests` folder where all tests should go (so `test_examples`, and all `seq2seq/test_xxx`), to keep the examples folder themselves clean so that user can easily use them.<|||||>> The examples are not tests, so `examples/deepspeed` should not be created to host some deepspeed tests. I'm wondering why we would need an `examples/deepspeed` since the base concept of having deepspeed integrating in our `Trainer` is to have it work out of the box for **all** our examples.
I only meant it as a grouping, same as we did for models. first it was all flat and then we grouped them together under `models`.
> My suggestion was to create an `examples/tests` folder where all tests should go (so `test_examples`, and all `seq2seq/test_xxx`), to keep the examples folder themselves clean so that user can easily use them.
Sure, as long as you feel that it's OK that we test core integrations under `examples` (as it is now) that works for me.
Could you pelase clarify, do you prefer most/all of the `examples/tests` to be flat, or would grouping make things easier to make sense of - I'm asking since some tests come with extra files (as is the case with ds_config files) - so `examples/tests/deepspeed`, ...
<|||||>I agree with Sylvain, fairscale/deepspeed is supposed to work with all of our existing examples, so IMO we shouldn’t add `examples/deepspeed`.
`examples/tests` makes sense to me.<|||||>> Could you pelase clarify, do you prefer most/all of the examples/tests to be flat, or would grouping make things easier to make sense of - I'm asking since some tests come with extra files (as is the case with ds_config files) - so examples/tests/deepspeed, ...
We can certainly have several files once they are all together in one folder. I'd just like the examples subfolders to be clean, our internal testing should be setup so it's the easiest for us to understand/debug.<|||||>Thank you for the clarification, @sgugger. I will start working on that transition. |
transformers | 10,075 | closed | assertion failed: [predictions must be >= 0] | Trying to train a binary classifier over sentence pairs with custom dataset throws a Tensroflow error.
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: `4.2.2`
- Platform: Ubuntu 18.04
- Python version: `3.7.5`
- PyTorch version (GPU?):
- Tensorflow version (GPU): `2.3.1`
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Nope
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (TFRoberta, TFXLMRoberta...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: https://huggingface.co/transformers/training.html#fine-tuning-in-native-tensorflow-2
* [x] my own task or dataset:
## To reproduce
Steps to reproduce the behavior:
```python
from transformers import TFAutoModelForSequenceClassification, AutoTokenizer
from keras.metrics import Precision, Recall
import tensorflow as tf
def build_dataset(tokenizer, filename):
data = [[], [], []]
with open(filename, 'r') as file_:
for line in file_:
fields = line.split('\t')
data[0].append(fields[0].strip())
data[1].append(fields[1].strip())
data[2].append(int(fields[2].strip()))
sentences = tokenizer(data[0], data[1],
padding=True,
truncation=True)
return tf.data.Dataset.from_tensor_slices((dict(sentences),
data[2]))
settings = {
"model": 'roberta-base',
"batch_size": 8,
"n_classes": 1,
"epochs": 10,
"steps_per_epoch": 128,
"patience": 5,
"loss": "binary_crossentropy",
"lr": 5e7,
"clipnorm": 1.0,
}
tokenizer = AutoTokenizer.from_pretrained(settings["model"])
train_dataset = build_dataset(tokenizer, 'train.head')
train_dataset = train_dataset.shuffle(
len(train_dataset)).batch(settings["batch_size"])
dev_dataset = build_dataset(tokenizer, 'dev.head').batch(
settings["batch_size"])
model = TFAutoModelForSequenceClassification.from_pretrained(
settings['model'],
num_labels=1)
model.compile(optimizer='adam',
#loss='binary_crossentropy',
loss=model.compute_loss,
metrics=[Precision(name='p'), Recall(name='r')])
model.summary()
model.fit(train_dataset,
epochs=settings["epochs"],
#steps_per_epoch=steps_per_epoch,
validation_data=dev_dataset,
batch_size=settings["batch_size"],
verbose=1)
```
Gives the following output
```
Some layers of TFRobertaForSequenceClassification were not initialized from the model checkpoint at roberta-base and are newly initialized: ['classifier']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Model: "tf_roberta_for_sequence_classification"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
roberta (TFRobertaMainLayer) multiple 124055040
_________________________________________________________________
classifier (TFRobertaClassif multiple 591361
=================================================================
Total params: 124,646,401
Trainable params: 124,646,401
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
The parameters `output_attentions`, `output_hidden_states` and `use_cache` cannot be updated when calling a model.They have to be set to True/False in the config object (i.e.: `config=XConfig.from_pretrained('name', output_attentions=True)`).
The parameter `return_dict` cannot be set in graph mode and will always be set to `True`.
The parameters `output_attentions`, `output_hidden_states` and `use_cache` cannot be updated when calling a model.They have to be set to True/False in the config object (i.e.: `config=XConfig.from_pretrained('name', output_attentions=True)`).
The parameter `return_dict` cannot be set in graph mode and will always be set to `True`.
Traceback (most recent call last):
File "finetune.py", line 52, in <module>
verbose=1)
File "/work/user/bicleaner-neural/venv/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py", line 108, in _method_wrapper
return method(self, *args, **kwargs)
File "/work/user/bicleaner-neural/venv/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py", line 1098, in fit
tmp_logs = train_function(iterator)
File "/work/user/bicleaner-neural/venv/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 780, in __call__
result = self._call(*args, **kwds)
File "/work/user/bicleaner-neural/venv/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 840, in _call
return self._stateless_fn(*args, **kwds)
File "/work/user/bicleaner-neural/venv/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 2829, in __call__
return graph_function._filtered_call(args, kwargs) # pylint: disable=protected-access
File "/work/user/bicleaner-neural/venv/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 1848, in _filtered_call
cancellation_manager=cancellation_manager)
File "/work/user/bicleaner-neural/venv/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 1924, in _call_flat
ctx, args, cancellation_manager=cancellation_manager))
File "/work/user/bicleaner-neural/venv/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 550, in call
ctx=ctx)
File "/work/user/bicleaner-neural/venv/lib/python3.7/site-packages/tensorflow/python/eager/execute.py", line 60, in quick_execute
inputs, attrs, num_outputs)
tensorflow.python.framework.errors_impl.InvalidArgumentError: 2 root error(s) found.
(0) Invalid argument: assertion failed: [predictions must be >= 0] [Condition x >= y did not hold element-wise:] [x (tf_roberta_for_sequence_classification/classifier/out_proj/BiasAdd:0) = ] [[0.153356239][0.171548933][0.121127911]...] [y (Cast_3/x:0) = ] [0]
[[{{node assert_greater_equal/Assert/AssertGuard/else/_1/assert_greater_equal/Assert/AssertGuard/Assert}}]]
[[assert_greater_equal_1/Assert/AssertGuard/pivot_f/_31/_205]]
(1) Invalid argument: assertion failed: [predictions must be >= 0] [Condition x >= y did not hold element-wise:] [x (tf_roberta_for_sequence_classification/classifier/out_proj/BiasAdd:0) = ] [[0.153356239][0.171548933][0.121127911]...] [y (Cast_3/x:0) = ] [0]
[[{{node assert_greater_equal/Assert/AssertGuard/else/_1/assert_greater_equal/Assert/AssertGuard/Assert}}]]
0 successful operations.
0 derived errors ignored. [Op:__inference_train_function_20780]
Function call stack:
train_function -> train_function
```
The dataset examples look like this:
```python
print(list(train_dataset.take(1).as_numpy_iterator()))
```
```
[({'input_ids': array([[ 0, 133, 864, ..., 1, 1, 1],
[ 0, 133, 382, ..., 1, 1, 1],
[ 0, 1121, 645, ..., 1, 1, 1],
...,
[ 0, 133, 864, ..., 1, 1, 1],
[ 0, 1121, 144, ..., 1, 1, 1],
[ 0, 495, 21046, ..., 1, 1, 1]], dtype=int32), 'attention_mask': array([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]], dtype=int32)}, array([0, 0, 0, 0, 1, 0, 0, 0], dtype=int32))]
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| 02-08-2021 16:41:28 | 02-08-2021 16:41:28 | Maybe @jplu has an idea!<|||||>I dug up a bit into the model and it seems that the activation is `tanh`. Shouldn't it be a `sigmoid` or a `softmax`? That's why it is producing predictions lower than 0.
```python
In [2]: model.classifier.dense
Out[2]: <tensorflow.python.keras.layers.core.Dense at 0x7f6f70357350>
In [3]: model.classifier.dense.activation
Out[3]: <function tensorflow.python.keras.activations.tanh(x)>
```<|||||>Hello!
From what I can see from your dataset example, you have two labels `0` and `1` and not one so that's might be why you get this issue. For regression task, (single label output), they all have to have a float value between `0` and `1`. You can have an example with the `stsb` glue task in our example here https://github.com/huggingface/transformers/blob/master/examples/text-classification/run_tf_glue.py<|||||>Alright, I'll take a look then. Predicting a binary classification with 2 neurons and `linear` or `tanh` activations seemed strange to me. I've always used a single neuron with `sigmoid`.<|||||>For binary classification, you have two labels and then neurons, it is more intuitive to proceed that way :) but yes you can also do what you propose and round the float value to 0 or 1 depending of the output of your sigmoid activation. Nevertheless, our models don't propose such approach.<|||||>Figured out that the error was thrown by the `Precision` and `Recall` classes because they require values between 0 and 1. In case someone wants to use them when training with native TensowFlow I managed to add the `argmax` to the the classes with this:
```python
from tensorflow.python.keras.utils import metrics_utils
class PrecisionArgmax(Precision):
def update_state(self, y_true, y_pred, sample_weight=None):
y_pred = tf.math.argmax(y_pred, -1)
return metrics_utils.update_confusion_matrix_variables(
{
metrics_utils.ConfusionMatrix.TRUE_POSITIVES: self.true_positives,
metrics_utils.ConfusionMatrix.FALSE_POSITIVES: self.false_positives
},
y_true,
y_pred,
thresholds=self.thresholds,
top_k=self.top_k,
class_id=self.class_id,
sample_weight=sample_weight)
```
So the code that I posted works with `num_classes=2` and using the the overridden classes as metrics. |
transformers | 10,074 | closed | AttributeError: 'tensorflow.python.framework.ops.EagerTensor' object has no attribute 'new_ones' | I have environment with following
```
torch=1.7.1+cpu
tensorflow=2.2.0
transformers=4.2.2
Python=3.6.12
```
and I am using below command
```
input_ids = tokenizer.encode('accident', return_tensors='tf')
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
```
but I get the error below
```
File "/home/anaconda3/envs/myenv/lib/python3.6/site-packages/transformers/generation_utils.py", line 368, in _prepare_attention_mask_for_generation
return input_ids.new_ones(input_ids.shape)
AttributeError: 'tensorflow.python.framework.ops.EagerTensor' object has no attribute 'new_ones'
```
Earlier, until October, the same was working perfectly. May I ask help which error or conflict I am making./?
| 02-08-2021 15:05:35 | 02-08-2021 15:05:35 | Did you fix this, and if so, how? I'm having the same problem and nothing's working for me so far.
**EDIT**: Fixed it, I was using `tf` tensors with a (PyTorch) `AutoModel` instead of a `TFAutoModel`. |
transformers | 10,073 | closed | Added integration tests for Pytorch implementation of the ELECTRA model | Added integration tests for Pytorch implementation of the ELECTRA model
Fixes #9949
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
@LysandreJik | 02-08-2021 14:22:43 | 02-08-2021 14:22:43 | |
transformers | 10,072 | closed | Fixing model templates | 02-08-2021 13:55:31 | 02-08-2021 13:55:31 | One of the model templates test (the pull request target) will fail because it doesn't take into account the changes made in the PR. Following this in https://github.com/huggingface/transformers/issues/10065<|||||>Thanks for fixing! |
|
transformers | 10,071 | closed | Fix mlflow param overflow clean | # What does this PR do?
This PR fixes the issue #8849 where MLflow logging failed due to parameters logged being too long. Now the MLflow logger also fetches the limits directly from MLflow validation utility.
Fixes #8849
An example using run_seq2seq.py: https://colab.research.google.com/drive/1Sof7YtueI5MNcm9rn0wOKkFvWSeqK-Sy?usp=sharing
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@sgugger | 02-08-2021 13:38:40 | 02-08-2021 13:38:40 | |
transformers | 10,070 | closed | remove token_type_ids from TokenizerBertGeneration output | # What does this PR do?
this PR fixes #10045 removes `token_type_ids` as it's not needed for `BertGenerationModel`
@LysandreJik | 02-08-2021 13:32:06 | 02-08-2021 13:32:06 | |
transformers | 10,069 | closed | Fix TF template | # What does this PR do?
Fix the TF template. | 02-08-2021 12:27:03 | 02-08-2021 12:27:03 | @LysandreJik I think there is a problem with the Template test. It doesn't seem to take into account the changes in the current PR.<|||||>Good catch @jplu, thanks for fixing! Yes indeed, this test needs to be reworked. Tracking it in https://github.com/huggingface/transformers/issues/10065 |
transformers | 10,068 | closed | Integrating GPT-2 model with Web page | Hi,
I would like to integrate GPT-2 model with web technology such as html, and javascript in order to build a similar editor https://transformer.huggingface.co/doc/gpt2-large
Can you please guide me how can I achieve it? | 02-08-2021 11:54:17 | 02-08-2021 11:54:17 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,067 | closed | "Connection error, and we cannot find the requested files in the cached path." ValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on. | I am trying to execute this command after installing all the required modules and I ran into this error:
NOTE : We are running this on HPC cluster.
`python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
`
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/civil/phd/cez198233/anaconda3/envs/lang2/lib/python3.7/site-packages/transformers/pipelines/__init__.py", line 340, in pipeline
framework = framework or get_framework(model)
File "/home/civil/phd/cez198233/anaconda3/envs/lang2/lib/python3.7/site-packages/transformers/pipelines/base.py", line 66, in get_framework
model = AutoModel.from_pretrained(model, revision=revision)
File "/home/civil/phd/cez198233/anaconda3/envs/lang2/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py", line 724, in from_pretrained
pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
File "/home/civil/phd/cez198233/anaconda3/envs/lang2/lib/python3.7/site-packages/transformers/models/auto/configuration_auto.py", line 360, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/civil/phd/cez198233/anaconda3/envs/lang2/lib/python3.7/site-packages/transformers/configuration_utils.py", line 420, in get_config_dict
use_auth_token=use_auth_token,
File "/home/civil/phd/cez198233/anaconda3/envs/lang2/lib/python3.7/site-packages/transformers/file_utils.py", line 1056, in cached_path
local_files_only=local_files_only,
File "/home/civil/phd/cez198233/anaconda3/envs/lang2/lib/python3.7/site-packages/transformers/file_utils.py", line 1235, in get_from_cache
"Connection error, and we cannot find the requested files in the cached path."
ValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on.
**#CONDA LIST OUTPUT**
conda list
# packages in environment at /home/civil/phd/cez198233/anaconda3/envs/lang2:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
blas 1.0 mkl
brotlipy 0.7.0 py37hb5d75c8_1001 conda-forge
ca-certificates 2020.12.5 ha878542_0 conda-forge
certifi 2020.12.5 py37h89c1867_1 conda-forge
cffi 1.14.4 py37h261ae71_0
chardet 4.0.0 py37h89c1867_1 conda-forge
click 7.1.2 pyh9f0ad1d_0 conda-forge
cryptography 2.9.2 py37hb09aad4_0 conda-forge
cudatoolkit 10.0.130 0
dataclasses 0.7 pyhb2cacf7_7 conda-forge
filelock 3.0.12 pyh9f0ad1d_0 conda-forge
freetype 2.10.4 h5ab3b9f_0
gperftools 2.7 h767d802_2 conda-forge
idna 2.10 pyh9f0ad1d_0 conda-forge
importlib-metadata 3.4.0 py37h89c1867_0 conda-forge
intel-openmp 2020.2 254
joblib 1.0.0 pyhd8ed1ab_0 conda-forge
jpeg 9b h024ee3a_2
lcms2 2.11 h396b838_0
ld_impl_linux-64 2.33.1 h53a641e_7
libedit 3.1.20191231 h14c3975_1
libffi 3.3 he6710b0_2
libgcc-ng 9.1.0 hdf63c60_0
libpng 1.6.37 hbc83047_0
libstdcxx-ng 9.1.0 hdf63c60_0
libtiff 4.1.0 h2733197_1
lz4-c 1.9.3 h2531618_0
mkl 2020.2 256
mkl-service 2.3.0 py37he8ac12f_0
mkl_fft 1.2.0 py37h23d657b_0
mkl_random 1.1.1 py37h0573a6f_0
ncurses 6.2 he6710b0_1
ninja 1.10.2 py37hff7bd54_0
numpy 1.19.2 py37h54aff64_0
numpy-base 1.19.2 py37hfa32c7d_0
olefile 0.46 py37_0
openssl 1.1.1i h27cfd23_0
packaging 20.9 pyh44b312d_0 conda-forge
perl 5.32.0 h36c2ea0_0 conda-forge
pillow 8.1.0 py37he98fc37_0
pip 20.3.3 py37h06a4308_0
pycparser 2.20 py_2
pyopenssl 19.1.0 py37_0 conda-forge
pyparsing 2.4.7 pyh9f0ad1d_0 conda-forge
pysocks 1.7.1 py37h89c1867_3 conda-forge
python 3.7.9 h7579374_0
python_abi 3.7 1_cp37m conda-forge
pytorch 1.1.0 py3.7_cuda10.0.130_cudnn7.5.1_0 pytorch
readline 8.1 h27cfd23_0
regex 2020.11.13 py37h4abf009_0 conda-forge
requests 2.25.1 pyhd3deb0d_0 conda-forge
sacremoses 0.0.43 pyh9f0ad1d_0 conda-forge
sentencepiece 0.1.92 py37h99015e2_0 conda-forge
setuptools 52.0.0 py37h06a4308_0
six 1.15.0 py37h06a4308_0
sqlite 3.33.0 h62c20be_0
tk 8.6.10 hbc83047_0
tokenizers 0.9.4 py37h17e0dd7_1 conda-forge
torchvision 0.3.0 py37_cu10.0.130_1 pytorch
tqdm 4.56.0 pyhd8ed1ab_0 conda-forge
transformers 4.2.2 pyhd8ed1ab_0 conda-forge
typing_extensions 3.7.4.3 py_0 conda-forge
urllib3 1.26.3 pyhd8ed1ab_0 conda-forge
wheel 0.36.2 pyhd3eb1b0_0
xz 5.2.5 h7b6447c_0
zipp 3.4.0 py_0 conda-forge
zlib 1.2.11 h7b6447c_3
zstd 1.4.5 h9ceee32_0
**conda info --all output**
conda info --all
active environment : lang2
active env location : /home/civil/phd/cez198233/anaconda3/envs/lang2
shell level : 1
user config file : /home/civil/phd/cez198233/.condarc
populated config files : /home/civil/phd/cez198233/.condarc
conda version : 4.8.3
conda-build version : 3.18.11
python version : 3.7.6.final.0
virtual packages : __glibc=2.17
base environment : /home/civil/phd/cez198233/anaconda3 (writable)
channel URLs : https://repo.anaconda.com/pkgs/main/linux-64
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/r/linux-64
https://repo.anaconda.com/pkgs/r/noarch
package cache : /home/civil/phd/cez198233/anaconda3/pkgs
/home/civil/phd/cez198233/.conda/pkgs
envs directories : /home/civil/phd/cez198233/anaconda3/envs
/home/civil/phd/cez198233/.conda/envs
platform : linux-64
user-agent : conda/4.8.3 requests/2.22.0 CPython/3.7.6 Linux/3.10.0-957.el7.x86_64 centos/7.6.1810 glibc/2.17
UID:GID : 86941:11302
netrc file : None
offline mode : False
# conda environments:
#
base /home/civil/phd/cez198233/anaconda3
9pytorch /home/civil/phd/cez198233/anaconda3/envs/9pytorch
lang2 * /home/civil/phd/cez198233/anaconda3/envs/lang2
tf-gpu /home/civil/phd/cez198233/anaconda3/envs/tf-gpu
sys.version: 3.7.6 (default, Jan 8 2020, 19:59:22)
...
sys.prefix: /home/civil/phd/cez198233/anaconda3
sys.executable: /home/civil/phd/cez198233/anaconda3/bin/python
conda location: /home/civil/phd/cez198233/anaconda3/lib/python3.7/site-packages/conda
conda-build: /home/civil/phd/cez198233/anaconda3/bin/conda-build
conda-convert: /home/civil/phd/cez198233/anaconda3/bin/conda-convert
conda-debug: /home/civil/phd/cez198233/anaconda3/bin/conda-debug
conda-develop: /home/civil/phd/cez198233/anaconda3/bin/conda-develop
conda-env: /home/civil/phd/cez198233/anaconda3/bin/conda-env
conda-index: /home/civil/phd/cez198233/anaconda3/bin/conda-index
conda-inspect: /home/civil/phd/cez198233/anaconda3/bin/conda-inspect
conda-metapackage: /home/civil/phd/cez198233/anaconda3/bin/conda-metapackage
conda-render: /home/civil/phd/cez198233/anaconda3/bin/conda-render
conda-server: /home/civil/phd/cez198233/anaconda3/bin/conda-server
conda-skeleton: /home/civil/phd/cez198233/anaconda3/bin/conda-skeleton
conda-verify: /home/civil/phd/cez198233/anaconda3/bin/conda-verify
user site dirs: ~/.local/lib/python3.6
~/.local/lib/python3.7
CIO_TEST: <not set>
CONDA_DEFAULT_ENV: lang2
CONDA_EXE: /home/civil/phd/cez198233/anaconda3/bin/conda
CONDA_PREFIX: /home/civil/phd/cez198233/anaconda3/envs/lang2
CONDA_PROMPT_MODIFIER: (lang2)
CONDA_PYTHON_EXE: /home/civil/phd/cez198233/anaconda3/bin/python
CONDA_ROOT: /home/civil/phd/cez198233/anaconda3
CONDA_SHLVL: 1
HTTPS_PROXY: <set>
HTTP_PROXY: <set>
MANPATH: /usr/share/Modules/3.2.10/share/man::/opt/pbs/19.2.4/share/man
MODULEPATH: /home/soft/modules
PATH: /home/civil/phd/cez198233/anaconda3/bin:/home/civil/phd/cez198233/anaconda3/envs/lang2/bin:/home/civil/phd/cez198233/anaconda3/bin:/home/civil/phd/cez198233/anaconda3/bin:/home/civil/phd/cez198233/anaconda3/condabin:/opt/am/bin:/opt/am/sbin:/opt/pbs/default/bin:/opt/pbs/default/sbin:/usr/share/Modules/3.2.10/bin:/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/ibutils/bin:/root/bin:/opt/pbs/19.2.4/bin:/home/civil/phd/cez198233/bin
REQUESTS_CA_BUNDLE: <not set>
SSL_CERT_FILE: <not set>
ftp_proxy: <set>
http_proxy: <set>
https_proxy: <set> | 02-08-2021 11:36:32 | 02-08-2021 11:36:32 | Hello! Can you try installing the brand new v4.3.0 to see if it resolves your issue?<|||||>same problem here and my transformers is v4.3.0, still not working<|||||>Could you try to load the model/tokenizer and specify the `local_files_only=True` kwarg to the `from_pretrained` method, before passing them to the pipeline directly?
i.e., instead of:
```py
pipeline('sentiment-analysis')('I love you')
```
try:
```py
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english", local_files_only=True)
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english", local_files_only=True)
pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)('I love you')
```<|||||>Thanks @LysandreJik.
Tried your suggestions.
Not working. Tried by keeping local_files_only both True and False while loading the model. It did not work.<|||||>@PrinceMohdZaki were you able to find a solution for this error?<|||||>Can anyone having those kind of issues, please try #10235, and let us know if it provides more insight into the cause (networking issue, proxy error, etc.)?
Thanks!<|||||>> @PrinceMohdZaki were you able to find a solution for this error?
Yeah. Finally we resolved it by exporting the https_proxy same as http_proxy as shown here : https://stackoverflow.com/questions/56628194/sslerror-installing-with-pip/56628419 <|||||>I am facing the same issue when trying to do `spacy.load`. Is there an obvious solution to that?
I am following [this](https://turbolab.in/build-a-custom-ner-model-using-spacy-3-0/) tutorial to build a custom NER pipeline on an HPC cluster where the compute nodes do not have access to the internet.
Here's the log:
```
python3 -m spacy train data/config.cfg --paths.train ./train.spacy --paths.dev ./valid.spacy --output ./models/output --gpu-id 0
ℹ Saving to output directory: models/output
ℹ Using GPU: 0
=========================== Initializing pipeline ===========================
[2022-11-18 15:12:08,973] [INFO] Set up nlp object from config
[2022-11-18 15:12:08,982] [INFO] Pipeline: ['transformer', 'ner']
[2022-11-18 15:12:08,984] [INFO] Created vocabulary
[2022-11-18 15:12:08,986] [INFO] Finished initializing nlp object
Traceback (most recent call last):
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/spacy/__main__.py", line 4, in <module>
setup_cli()
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/spacy/cli/_util.py", line 71, in setup_cli
command(prog_name=COMMAND)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/click/core.py", line 1128, in __call__
return self.main(*args, **kwargs)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/click/core.py", line 1053, in main
rv = self.invoke(ctx)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/click/core.py", line 1659, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/click/core.py", line 1395, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/click/core.py", line 754, in invoke
return __callback(*args, **kwargs)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/typer/main.py", line 500, in wrapper
return callback(**use_params) # type: ignore
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/spacy/cli/train.py", line 45, in train_cli
train(config_path, output_path, use_gpu=use_gpu, overrides=overrides)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/spacy/cli/train.py", line 72, in train
nlp = init_nlp(config, use_gpu=use_gpu)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/spacy/training/initialize.py", line 84, in init_nlp
nlp.initialize(lambda: train_corpus(nlp), sgd=optimizer)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/spacy/language.py", line 1317, in initialize
proc.initialize(get_examples, nlp=self, **p_settings)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/spacy_transformers/pipeline_component.py", line 355, in initialize
self.model.initialize(X=docs)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/thinc/model.py", line 299, in initialize
self.init(self, X=X, Y=Y)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/spacy_transformers/layers/transformer_model.py", line 131, in init
hf_model = huggingface_from_pretrained(name, tok_cfg, trf_cfg)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/spacy_transformers/layers/transformer_model.py", line 251, in huggingface_from_pretrained
tokenizer = AutoTokenizer.from_pretrained(str_path, **tok_config)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/transformers/models/auto/tokenization_auto.py", line 471, in from_pretrained
tokenizer_config = get_tokenizer_config(pretrained_model_name_or_path, **kwargs)
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/transformers/models/auto/tokenization_auto.py", line 332, in get_tokenizer_config
resolved_config_file = get_file_from_repo(
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/transformers/file_utils.py", line 2310, in get_file_from_repo
resolved_file = cached_path(
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/transformers/file_utils.py", line 1921, in cached_path
output_path = get_from_cache(
File "/home/hyadav/.conda/envs/spacy_venv/lib/python3.10/site-packages/transformers/file_utils.py", line 2177, in get_from_cache
raise ValueError(
ValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on.
```
<|||||>First you need to run internet on the hpc. Read your hpc's documentation or ask system administrator about it.<|||||>> First you need to run internet on the hpc. Read your hpc's documentation or ask system administrator about it.
We have access to the internet on the login nodes but not on the compute nodes. So, I can download everything on the login nodes I need before I finally start computations on the compute nodes.<|||||>Follow the same protocol to run internet on the compute nodes. If you are
running the script by submitting a job on compute nodes, insert the
commands to run internet in the job script before the python command.
If proxies are also required to be exported, you can either export them
before the python command or export proxies within the code using os module.
On Sat, 19 Nov 2022, 00:27 Himanshi Yadav, ***@***.***> wrote:
> First you need to run internet on the hpc. Read your hpc's documentation
> or ask system administrator about it.
>
> We have access to the internet on the login nodes but not on the compute
> nodes. So, I can download everything on the login nodes I need before I
> finally start computations on the compute nodes.
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/10067#issuecomment-1320540933>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AFATXOFCQS2LFR2I2KNVXN3WI7YFFANCNFSM4XI2ROIA>
> .
> You are receiving this because you modified the open/close state.Message
> ID: ***@***.***>
>
<|||||>> Follow the same protocol to run internet on the compute nodes. If you are running the script by submitting a job on compute nodes, insert the commands to run internet in the job script before the python command. If proxies are also required to be exported, you can either export them before the python command or export proxies within the code using os module.
> […](#)
> On Sat, 19 Nov 2022, 00:27 Himanshi Yadav, ***@***.***> wrote: First you need to run internet on the hpc. Read your hpc's documentation or ask system administrator about it. We have access to the internet on the login nodes but not on the compute nodes. So, I can download everything on the login nodes I need before I finally start computations on the compute nodes. — Reply to this email directly, view it on GitHub <[#10067 (comment)](https://github.com/huggingface/transformers/issues/10067#issuecomment-1320540933)>, or unsubscribe <https://github.com/notifications/unsubscribe-auth/AFATXOFCQS2LFR2I2KNVXN3WI7YFFANCNFSM4XI2ROIA> . You are receiving this because you modified the open/close state.Message ID: ***@***.***>
There is no protocol to run the internet on the compute nodes, you **can not** use internet on the compute nodes. <|||||>Getting this error, and found out today that **HuggingFace is down** so this is likely not because of the issues mentioned above at the moment<|||||>Thank you !
I solved the problem when I set export HTTPS_PROXY and https_proxy<|||||>changing the default value of force_download=True
in cached_path line 1037
\home\username\anaconda3\envs\punct\lib\python3.8\site-packages\transformers\file_utils.py solved it for me
|
transformers | 10,066 | closed | Removing run_pl_glue.py from text classification docs, include run_xnli.py & run_tf_text_classification.py | # What does this PR do?
Since `run_pl_glue.py` is not part of `text-classification` examples after #9010, this PR removes it from the text-classification docs. Also, it adds `run_xnli.py` and `run_tf_text_classification.py` scripts, which are in that folder now.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Before submitting
- [X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger may be interested in the PR, he's responsible for docs and the author of #9010
| 02-08-2021 11:34:17 | 02-08-2021 11:34:17 | Sure! Change applied<|||||>Done, command `make style` applied. Thanks for the guidance<|||||>Build still not succeeding. I will check <|||||>Ah yes, those links don't need the underscores! Good catch and sorry for giving you the wrong example to follow. Just waiting for the last tests and we can merge :-)<|||||>No worries, @sgugger. Thanks for the guidance :) |
transformers | 10,065 | closed | Model templates tests are run twice | The CI currently runs the model template tests twice when opening a PR from a branch of the huggingface/transformers repo.
The `pull_request_target` should only trigger on external pull requests, or we should remove the `push` target so that the suite only runs once.
Additionally, the `pull_request_target` suite doesn't take into account the changes the PR is doing.
ETA until resolved ~ 2 weeks. | 02-08-2021 10:52:41 | 02-08-2021 10:52:41 | |
transformers | 10,064 | closed | Fix model template typo | Fix typo introduced in https://github.com/huggingface/transformers/pull/10033 | 02-08-2021 10:49:52 | 02-08-2021 10:49:52 | Thanks for fixing! |
transformers | 10,063 | closed | [Finetune Seq2Seq Trainer] fix bert2bert test | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR fixes the slow test: `tests/test_trainer_seq2seq.py::Seq2seqTrainerTester::test_finetune_bert2bert` which was failing because `rouge_score` was not added to the dependencies. In this PR I remove the usage of `datasets.load("rouge")` since it is very much unnecessary here => we are only testing whether training does not throw an error and for this it doesn't matter whether we use the rouge metric or accuracy. Removing `rouge` removes a dependency, which is the better way here IMO.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-08-2021 10:25:41 | 02-08-2021 10:25:41 | failing test is unrelated -> waiting for @sgugger's approval before merging though. |
transformers | 10,062 | closed | Disable temporarily too slow tests (Longformer/LED) | # What does this PR do?
The tests about SavedModel takes way too long for Longformer and LED. To do not timeout the CI, we disable them and will see how to better handle them. | 02-08-2021 10:14:27 | 02-08-2021 10:14:27 | @jplu feel free to merge after fixing the style! |
transformers | 10,061 | closed | Dimension error while finetuning longformer with roberta-large EncoderDecoderModel | ## Environment info
- `transformers` version: 4.2.2
- Platform: Linux-3.10.0-1160.6.1.el7.x86_64-x86_64-with-debian-buster-sid
- Python version: 3.6.11
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): 2.2.0 (True)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
- maintained examples (not research project or legacy): @patrickvonplaten
Models:
- allenai/longformer-base-4096 with roberta-large
- allenai/longformer-base-4096 with xlm-roberta-large
## To reproduce
Steps to reproduce the behavior:
I have follow the steps on https://huggingface.co/patrickvonplaten/longformer2roberta-cnn_dailymail-fp16
but switched model roberta-base to roberta-large
**CODE:-**
```
model = EncoderDecoderModel.from_encoder_decoder_pretrained("allenai/longformer-base-4096", "roberta-large")
tokenizer = LongformerTokenizer.from_pretrained("allenai/longformer-base-4096")
```
model params
```
# enable gradient checkpointing for longformer encoder
model.encoder.config.gradient_checkpointing = True
# set decoding params
model.config.decoder_start_token_id = tokenizer.bos_token_id
model.config.eos_token_id = tokenizer.eos_token_id
model.config.max_length = 142
model.config.min_length = 56
model.config.no_repeat_ngram_size = 3
model.early_stopping = True
model.length_penalty = 2.0
model.num_beams = 4
encoder_length = 2048
decoder_length = 128
batch_size = 16
```
training parms
```
training_args = TrainingArguments(
output_dir="./",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
#predict_from_generate=True,
#evaluate_during_training=True,
do_train=True,
do_eval=True,
logging_steps=1000,
save_steps=1000,
eval_steps=1000,
overwrite_output_dir=True,
warmup_steps=2000,
save_total_limit=3,
fp16=True,
)
# instantiate trainer
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_dataset,
eval_dataset=val_dataset,
)
# start training
trainer.train()
```
**ERROR:-**
```
RuntimeError: Caught RuntimeError in replica 0 on device 0.
Original Traceback (most recent call last):
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker
output = module(*input, **kwargs)
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jovyan/.local/lib/python3.6/site-packages/transformers/models/encoder_decoder/modeling_encoder_decoder.py", line 430, in forward
**kwargs_decoder,
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jovyan/.local/lib/python3.6/site-packages/transformers/models/roberta/modeling_roberta.py", line 928, in forward
return_dict=return_dict,
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jovyan/.local/lib/python3.6/site-packages/transformers/models/roberta/modeling_roberta.py", line 808, in forward
return_dict=return_dict,
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jovyan/.local/lib/python3.6/site-packages/transformers/models/roberta/modeling_roberta.py", line 505, in forward
output_attentions,
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jovyan/.local/lib/python3.6/site-packages/transformers/models/roberta/modeling_roberta.py", line 424, in forward
output_attentions,
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jovyan/.local/lib/python3.6/site-packages/transformers/models/roberta/modeling_roberta.py", line 328, in forward
output_attentions,
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jovyan/.local/lib/python3.6/site-packages/transformers/models/roberta/modeling_roberta.py", line 198, in forward
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/modules/linear.py", line 93, in forward
return F.linear(input, self.weight, self.bias)
File "/home/jovyan/.local/lib/python3.6/site-packages/torch/nn/functional.py", line 1692, in linear
output = input.matmul(weight.t())
RuntimeError: mat1 dim 1 must match mat2 dim 0
```
| 02-08-2021 10:06:59 | 02-08-2021 10:06:59 | Hey @amiyamandal-dev, you can only combine `longformer-base-4096` with `roberta-base` since those two models have the same `hidden_size`. Combining `longformer-base-4096` with `roberta-large` will necessarily lead to errors.<|||||>Thank you for your reply @patrickvonplaten,
Able to understand why it's not working. If I want to run train a model with Encoder `longformer` and Decoder some big model like `roberta-large` , so what steps to follow. That would be a great help.<|||||>I think you should be able to use longformer-large, e.g. https://huggingface.co/allenai/longformer-large-4096-finetuned-triviaqa for your case<|||||>Thanks @patrickvonplaten it worked |
transformers | 10,060 | closed | [BART Tests] Fix Bart mask filling pipeline tests | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Following the PR: https://github.com/huggingface/transformers/pull/9783/ some slow Bart tests were not updated. This PR updates the mask-filling bart tests accordingly.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-08-2021 10:03:21 | 02-08-2021 10:03:21 | Test failure is unrelated. Merging |
transformers | 10,059 | closed | Fix slow dpr test | 02-08-2021 09:42:11 | 02-08-2021 09:42:11 | ||
transformers | 10,058 | closed | When encoding text to feature vectors - Would be awesome to be able to use the simplest tokenizer with a split on spaces | # 🚀 Feature request
When using the `DistilBertTokenizer` (or `BertTokenizer`) I would love to tokenize my text by simply splitting it on spaces:
```
['also', 'du', 'fängst', 'an', 'mit', 'der', 'Stadtrundfahrt']
```
instead of the default behavior, which is splitting it into sub-parts:
```
['also', 'du', 'f', '##ängst', 'an', 'mit', 'der', 'Stadt', '##rund', '##fahrt']
```
## Motivation
That's needed in order to have feature vector length to be the same as the number of words in the text, so that we can have 1-to-1 correspondence between words and their features
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
## Your contribution
I have seen that such tokenization can be done using `tokenizer.basic_tokenizer` and I have tried to use it to encode the text:
```
from transformers import DistilBertModel, DistilBertTokenizer
import torch
text_str = "also du fängst an mit der Stadtrundfahrt"
# create DistilBERT tokenizer and model
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-german-cased')
model = DistilBertModel.from_pretrained('distilbert-base-german-cased')
# check if tokens are correct
tokens = tokenizer.basic_tokenizer.tokenize(text_str)
print("Tokens: ", tokens)
# Encode the curent text
input_ids = torch.tensor(tokenizer.basic_tokenizer.encode(text_str)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
```
But this code raises an error because `BasicTokenizer` does not have attribute 'encode' yet:
```
Traceback (most recent call last):
File "/home/tarask/Desktop/Work/Code/Git/probabilistic-gesticulator/my_code/data_processing/annotations/feat/test.py", line 15, in <module>
input_ids = torch.tensor(tokenizer.basic_tokenizer.encode(text_str)).unsqueeze(0)
AttributeError: 'BasicTokenizer' object has no attribute 'encode'
```
| 02-08-2021 08:27:28 | 02-08-2021 08:27:28 | This solution seems to be working:
```
from transformers import DistilBertModel, DistilBertTokenizer
import torch
text_str = "also du fängst an mit der Stadtrundfahrt"
# create DistilBERT tokenizer and model
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-german-cased')
model = DistilBertModel.from_pretrained('distilbert-base-german-cased')
# check if tokens are correct
tokens = tokenizer.basic_tokenizer.tokenize(text_str)
print("Tokens: ", tokens)
# Encode the curent text
input_ids = torch.tensor(tokenizer.encode(tokens)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
print(last_hidden_states[0,1:-1].shape)
```
What do you think? Is it correct usage?<|||||>I just realized it was not correct. [Users of StackOverflow](https://stackoverflow.com/questions/66064503/in-huggingface-tokenizers-how-can-i-split-a-sequence-simply-on-spaces/) indicated that.
Running the following command: `tokenizer.convert_ids_to_tokens(input_ids.tolist()[0])` indicates that "fängst" and "Stadtrundfahrt" are encoded with the same id because they are not part of the dictionary :( <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,057 | closed | Fixed docs for the shape of `scores` in `generate()` | # What does this PR do?
Fixed the shape of `scores` from `generate()` outputs to be `max_length-1` for all output classes. The first token `decoder_start_token_id` is not generated and thus no scores.
[Scores in generate()](https://discuss.huggingface.co/t/scores-in-generate/3450)
[Generation Probabilities: How to compute probabilities of output scores for GPT2](https://discuss.huggingface.co/t/generation-probabilities-how-to-compute-probabilities-of-output-scores-for-gpt2/3175)
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@patrickvonplaten
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-08-2021 07:08:55 | 02-08-2021 07:08:55 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Hey @kylie-box,
Could you run `make style` to fix a problem with the code quality. I think we can merge afterward :-)<|||||>Hey @patrickvonplaten,
It's fixed now. :)
<|||||>Thanks a lot! |
transformers | 10,056 | closed | Play around with mask-filling of original model | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-07-2021 20:57:31 | 02-07-2021 20:57:31 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,055 | closed | Cannnot train Roberta: 2 different errors | ## Environment info
- `transformers` version: 4.4.0.dev0
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No (Single GPU) --> **COLAB**
### Who can help
I am not sure, since the error is very vague and untraceable
## Information
Model I am using (Bert, XLNet ...): Roberta
The problem arises when using:
* [ ] the official example scripts: (give details below)
The tasks I am working on is:
* [x] my own task or dataset: (give details below)
It is a private dataset, so I am not at liberty to share it. However, I can provide a clue as to how the `csv` looks like:-
,ID,Text,Label
......................
> I do not think there can be anything wrong with the DataFrame as I am taking data from specific columns and converting them to numpy arrays for the rest of the steps in the HF "Fine-tuning" guide.
## To reproduce
Steps to reproduce the behavior:
```
!git clone https://github.com/huggingface/transformers.git
!cd transformers
!pip install -e .
train_text = list(train['Text'].values)
train_label = list(train['Label'].values)
val_text = list(val['Text'].values)
val_label = list(val['Label'].values)
from transformers import RobertaTokenizer, TFRobertaForSequenceClassification
import tensorflow as tf
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = TFRobertaForSequenceClassification.from_pretrained('roberta-base')
train_encodings = tokenizer(train_text, truncation=True, padding=True)
val_encodings = tokenizer(val_text, truncation=True, padding=True)
train_dataset = tf.data.Dataset.from_tensor_slices((
dict(train_encodings),
train_label
))
val_dataset = tf.data.Dataset.from_tensor_slices((
dict(val_encodings),
val_label
))
```
All this code is common. Howver, now there is a difference in errors depending upon the training method.
###Training using `trainer`
Code:
```
from transformers import TFTrainingArguments, TFTrainer
training_args = TFTrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
)
with training_args.strategy.scope():
model = TFRobertaForSequenceClassification.from_pretrained("roberta-base")
trainer = TFTrainer(
model=model, # the instantiated Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset # evaluation dataset
)
trainer.train()
```
**ERROR:-**
```
All model checkpoint layers were used when initializing TFRobertaForSequenceClassification.
Some layers of TFRobertaForSequenceClassification were not initialized from the model checkpoint at roberta-base and are newly initialized: ['classifier']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-52-f86f69d7497b> in <module>()
22 )
23
---> 24 trainer.train()
10 frames
/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py in train(self)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py in __call__(self, *args, **kwds)
826 tracing_count = self.experimental_get_tracing_count()
827 with trace.Trace(self._name) as tm:
--> 828 result = self._call(*args, **kwds)
829 compiler = "xla" if self._experimental_compile else "nonXla"
830 new_tracing_count = self.experimental_get_tracing_count()
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py in _call(self, *args, **kwds)
869 # This is the first call of __call__, so we have to initialize.
870 initializers = []
--> 871 self._initialize(args, kwds, add_initializers_to=initializers)
872 finally:
873 # At this point we know that the initialization is complete (or less
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py in _initialize(self, args, kwds, add_initializers_to)
724 self._concrete_stateful_fn = (
725 self._stateful_fn._get_concrete_function_internal_garbage_collected( # pylint: disable=protected-access
--> 726 *args, **kwds))
727
728 def invalid_creator_scope(*unused_args, **unused_kwds):
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py in _get_concrete_function_internal_garbage_collected(self, *args, **kwargs)
2967 args, kwargs = None, None
2968 with self._lock:
-> 2969 graph_function, _ = self._maybe_define_function(args, kwargs)
2970 return graph_function
2971
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py in _maybe_define_function(self, args, kwargs)
3359
3360 self._function_cache.missed.add(call_context_key)
-> 3361 graph_function = self._create_graph_function(args, kwargs)
3362 self._function_cache.primary[cache_key] = graph_function
3363
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py in _create_graph_function(self, args, kwargs, override_flat_arg_shapes)
3204 arg_names=arg_names,
3205 override_flat_arg_shapes=override_flat_arg_shapes,
-> 3206 capture_by_value=self._capture_by_value),
3207 self._function_attributes,
3208 function_spec=self.function_spec,
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/func_graph.py in func_graph_from_py_func(name, python_func, args, kwargs, signature, func_graph, autograph, autograph_options, add_control_dependencies, arg_names, op_return_value, collections, capture_by_value, override_flat_arg_shapes)
988 _, original_func = tf_decorator.unwrap(python_func)
989
--> 990 func_outputs = python_func(*func_args, **func_kwargs)
991
992 # invariant: `func_outputs` contains only Tensors, CompositeTensors,
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py in wrapped_fn(*args, **kwds)
632 xla_context.Exit()
633 else:
--> 634 out = weak_wrapped_fn().__wrapped__(*args, **kwds)
635 return out
636
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py in bound_method_wrapper(*args, **kwargs)
3885 # However, the replacer is still responsible for attaching self properly.
3886 # TODO(mdan): Is it possible to do it here instead?
-> 3887 return wrapped_fn(*args, **kwargs)
3888 weak_bound_method_wrapper = weakref.ref(bound_method_wrapper)
3889
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/func_graph.py in wrapper(*args, **kwargs)
975 except Exception as e: # pylint:disable=broad-except
976 if hasattr(e, "ag_error_metadata"):
--> 977 raise e.ag_error_metadata.to_exception(e)
978 else:
979 raise
TypeError: in user code:
/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py:669 distributed_training_steps *
nb_instances_in_batch = self._compute_nb_instances(batch)
/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py:681 _compute_nb_instances *
nb_instances = tf.reduce_sum(tf.cast(labels != -100, dtype=tf.int32))
/usr/local/lib/python3.6/dist-packages/tensorflow/python/util/dispatch.py:201 wrapper
return target(*args, **kwargs)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:1786 tensor_not_equals
return gen_math_ops.not_equal(self, other, incompatible_shape_error=False)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/gen_math_ops.py:6412 not_equal
name=name)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:531 _apply_op_helper
repr(values), type(values).__name__, err))
TypeError: Expected string passed to parameter 'y' of op 'NotEqual', got -100 of type 'int' instead. Error: Expected string, got -100 of type 'int' instead.
```
###Using Native `Tensorflow` code (from official example)
CODE:
from transformers import TFRobertaForSequenceClassification
```
model = TFRobertaForSequenceClassification.from_pretrained('roberta-base')
optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
model.compile(optimizer=optimizer, loss=model.compute_loss) # can also use any keras loss fn
model.fit(train_dataset.shuffle(1000).batch(16), validation_data=val.shuffle(1000).batch(16), epochs=3, batch_size=16)
```
**ERROR:-**
```
All model checkpoint layers were used when initializing TFRobertaForSequenceClassification.
Some layers of TFRobertaForSequenceClassification were not initialized from the model checkpoint at roberta-base and are newly initialized: ['classifier']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-51-a13d177c752e> in <module>()
5 optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
6 model.compile(optimizer=optimizer, loss=model.compute_loss) # can also use any keras loss fn
----> 7 model.fit(train_dataset.shuffle(1000).batch(16), validation_data=val.shuffle(1000).batch(16), epochs=3, batch_size=16)
/usr/local/lib/python3.6/dist-packages/pandas/core/generic.py in __getattr__(self, name)
5139 if self._info_axis._can_hold_identifiers_and_holds_name(name):
5140 return self[name]
-> 5141 return object.__getattribute__(self, name)
5142
5143 def __setattr__(self, name: str, value) -> None:
AttributeError: 'DataFrame' object has no attribute 'shuffle'
```
This is very surprising since the error are pretty different and I can't find many fixes online. I tested the datatypes of the input data and it seems to check out.
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
The model to start training on this `SequenceClassification` task and achieve good accuracy on it. | 02-07-2021 20:24:24 | 02-07-2021 20:24:24 | Please follow the instructions in the template and do not tag more than three people. In this case you are sending notifications to seven different persons for a problem no one can help you solve since you did not give enough information. Let's see why:
The first error seems to indicate your labels are strings, which cannot be known for sure since you did not provide an example of what your data look like. Just saying "My data is private so I can't share it with you" is not helpful. You could give us the first line of the dataset, potentially masking some private content.
If your labels indeed are strings, you need to convert them to some IDs (going from 0 to your number of labels) before trying to train your model with them. You model should also be instantiated with the correct number of labels by passing along `num_labels=xxx` (otherwise you will get other errors down the line).
The second error has nothing to do with transformers, you are passing `val.shuffle` as validation data where `val` is a pandas DataFrame and therefore as no `shuffle` method.<|||||>Sorry for tagging more than 3 people :( my bad
About the labels, it is actually a string, and there are about 20 unique labels. Does that mean I should hot encode them (like 20 columns and the value `1` in the correct column) or just simple like:-
```
ID_UNiqe_23, "Lorem Ipsum .....", 2
ID_UNiqe_2314, "Lorem Lorem .....", 13
```
Note that I want to do simple classification, NOT multi-label classification. I shall update you with the problem regarding the `shuffle` method because the error was before I added `validation_data` argument in the fit function.
Lastly, where should the `num_labels` argument be put, since I can't find any reference to that for `TFTrainingArguments`.
Thanx a ton for your help!
<|||||>Hello @neel04!
Yes, all your labels have to be ids and not strings. You can find a complete example among the examples, and more precisely the text classification one, https://github.com/huggingface/transformers/blob/master/examples/text-classification/run_tf_text_classification.py I suggest you to thoroughly read it as it contains what you need to know for the labels :)
For you second example, you cannot call `compille` and `fit` directly on the models, you have to re-create a model by specifying the inputs and output. Such as:
```
r_model = TFRobertForSequenceClassification(....)
input_ids = tf.keras.layers.Input([None,], dtype=tf.int32, name="input_ids")
attention_mask = tf.keras.layers.Input([None,], dtype=tf.int32, name="attention_mask")
token_type_ids = tf.keras.layers.Input([None,], dtype=tf.int32, name="token_type_ids")
output = model([input_ids, attention_mask, token_type_ids])
model = tf.keras.models.Model(inputs=[input_ids, attention_mask, token_type_ids], output=output)
model.compile(....)
model.fit(....)
``` <|||||>So I converted the labels to Python Integers and tried using the `Trainer()` method but I am getting this error:-
```
Some weights of the model checkpoint at Roberta-base were not used when initializing TFRobertaForSequenceClassification: ['lm_head']
- This IS expected if you are initializing TFRobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing TFRobertaForSequenceClassification from the checkpoint of a model that you expect to be identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of TFRobertaForSequenceClassification were not initialized from the model checkpoint at Roberta-base and are newly initialized: ['classifier']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-54-f86f69d7497b> in <module>()
22 )
23
---> 24 trainer.train()
11 frames
/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py in train(self)
410 if self.args.past_index >= 0:
411 self._past = None
--> 412 for step, training_loss in enumerate(self._training_steps(train_ds, optimizer)):
413 self.global_step = iterations.numpy()
414 self.epoch_logging = epoch_iter - 1 + (step + 1) / steps_per_epoch
/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py in _training_steps(self, ds, optimizer)
457 Returns a generator over training steps (i.e. parameters update).
458 """
--> 459 for i, loss in enumerate(self._accumulate_next_gradients(ds)):
460 if i % self.args.gradient_accumulation_steps == 0:
461 self._apply_gradients(optimizer)
/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py in _accumulate_next_gradients(self, ds)
490 while True:
491 try:
--> 492 yield _accumulate_next()
493 except tf.errors.OutOfRangeError:
494 break
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py in __call__(self, *args, **kwds)
826 tracing_count = self.experimental_get_tracing_count()
827 with trace.Trace(self._name) as tm:
--> 828 result = self._call(*args, **kwds)
829 compiler = "xla" if self._experimental_compile else "nonXla"
830 new_tracing_count = self.experimental_get_tracing_count()
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py in _call(self, *args, **kwds)
869 # This is the first call of __call__, so we have to initialize.
870 initializers = []
--> 871 self._initialize(args, kwds, add_initializers_to=initializers)
872 finally:
873 # At this point we know that the initialization is complete (or less
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py in _initialize(self, args, kwds, add_initializers_to)
724 self._concrete_stateful_fn = (
725 self._stateful_fn._get_concrete_function_internal_garbage_collected( # pylint: disable=protected-access
--> 726 *args, **kwds))
727
728 def invalid_creator_scope(*unused_args, **unused_kwds):
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py in _get_concrete_function_internal_garbage_collected(self, *args, **kwargs)
2967 args, kwargs = None, None
2968 with self._lock:
-> 2969 graph_function, _ = self._maybe_define_function(args, kwargs)
2970 return graph_function
2971
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py in _maybe_define_function(self, args, kwargs)
3359
3360 self._function_cache.missed.add(call_context_key)
-> 3361 graph_function = self._create_graph_function(args, kwargs)
3362 self._function_cache.primary[cache_key] = graph_function
3363
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py in _create_graph_function(self, args, kwargs, override_flat_arg_shapes)
3204 arg_names=arg_names,
3205 override_flat_arg_shapes=override_flat_arg_shapes,
-> 3206 capture_by_value=self._capture_by_value),
3207 self._function_attributes,
3208 function_spec=self.function_spec,
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/func_graph.py in func_graph_from_py_func(name, python_func, args, kwargs, signature, func_graph, autograph, autograph_options, add_control_dependencies, arg_names, op_return_value, collections, capture_by_value, override_flat_arg_shapes)
988 _, original_func = tf_decorator.unwrap(python_func)
989
--> 990 func_outputs = python_func(*func_args, **func_kwargs)
991
992 # invariant: `func_outputs` contains only Tensors, CompositeTensors,
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py in wrapped_fn(*args, **kwds)
632 xla_context.Exit()
633 else:
--> 634 out = weak_wrapped_fn().__wrapped__(*args, **kwds)
635 return out
636
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/func_graph.py in wrapper(*args, **kwargs)
975 except Exception as e: # pylint:disable=broad-except
976 if hasattr(e, "ag_error_metadata"):
--> 977 raise e.ag_error_metadata.to_exception(e)
978 else:
979 raise
AttributeError: in user code:
/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py:488 _accumulate_next *
return self._accumulate_gradients(per_replica_features, per_replica_labels)
/usr/local/lib/python3.6/dist-packages/transformers/trainer_tf.py:498 _accumulate_gradients *
per_replica_loss = self.args.strategy.experimental_run_v2(
AttributeError: 'OneDeviceStrategy' object has no attribute 'experimental_run_v2'
```
Any Idea what it might be? code is still the same.
```
from transformers import TFTrainingArguments, TFTrainer
training_args = TFTrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
)
with training_args.strategy.scope():
model = TFRobertaForSequenceClassification.from_pretrained("roberta-base")
trainer = TFTrainer(
model=model, # the instantiated Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset # evaluation dataset
)
trainer.train()
```<|||||>This error should be fixed if you use the latest trainer 4.3.1 version of transformers :) <|||||>I am on `4.4.0.dev0`. Downgrade?<|||||>from what I can see you have the error ` AttributeError: 'OneDeviceStrategy' object has no attribute 'experimental_run_v2'`. This error has been fixed in 4.2. So this tells me that you are using an outdated version of transformers.<|||||>Shouldn't the latest "Bleeding-edge" version at `4.4.0` be better than that of `4.2`?
Or is this just a bug in the latest?
**EDIT:-** I used the specific version (`4.3.1`) from Pypi and ran the code. This time it just produced some warnings and stopped (i.e the cell completed execution). It didn't start training despite calling `trainer.train()`.
This is the output:-
All model checkpoint layers were used when initializing TFRobertaForSequenceClassification.
```
Some layers of TFRobertaForSequenceClassification were not initialized from the model checkpoint at roberta-base and are newly initialized: ['classifier']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
WARNING:tensorflow:The parameters `output_attentions`, `output_hidden_states` and `use_cache` cannot be updated when calling a model.They have to be set to True/False in the config object (i.e.: `config=XConfig.from_pretrained('name', output_attentions=True)`).
WARNING:tensorflow:The parameter `return_dict` cannot be set in graph mode and will always be set to `True`.
WARNING:tensorflow:The parameters `output_attentions`, `output_hidden_states` and `use_cache` cannot be updated when calling a model.They have to be set to True/False in the config object (i.e.: `config=XConfig.from_pretrained('name', output_attentions=True)`).
WARNING:tensorflow:The parameter `return_dict` cannot be set in graph mode and will always be set to `True`.
```
GPU memory is still occupied but Usage drops to `0%`. Any Idea what causes it not to train? @jplu <|||||>That was a bug in the versions < 4.2. So you might have some conflicts in your env with multiple versions installed.<|||||>So the bug still remains - **I cannot train the model with `Trainer()`** but using native Tensorflow+edit for instantiating the number of labels, it's now training alright. Thanx a lot @jplu and @sgugger for your help! :+1: :1st_place_medal:
Now its just to figure out how to get Trainer to work - I want to do a Hyperparameter search which apparently Trainer can be used for interfacing. Let's see how that's gonna be resolved<|||||>> Now its just to figure out how to get Trainer to work - I want to do a Hyperparameter search which apparently Trainer can be used for interfacing.
This isn't implemented on the TensorFlow side, only PyTorch.<|||||>Well that's bad. Any other way I could use HypSearch in TF?<|||||>> > Now its just to figure out how to get Trainer to work - I want to do a Hyperparameter search which apparently Trainer can be used for interfacing.
>
> This isn't implemented on the TensorFlow side, only PyTorch.
Also, if this isn't implemented on TF side, then why is there a toggle button for TF version, and why don't the docs tell that?
https://huggingface.co/transformers/training.html?highlight=fine%20tune#trainer<|||||>Fine-tuning is implemented for both PyTorch and TF. You were talking about hyper-parameter search.<|||||>I am talking about using `Trainer()`. I can't use it - the cell executes successfully but it never starts training
<|||||>Also, I found that the model has pretty low validation accuracy (~1-2%) and it doesn't go any further (this was achieved in 1 epoch). I suspect that the problem could be the activation function not being `Sigmoid` which is required for `Categorical Crossentropy loss`. Should I post my questions here or should I make a new issue? @jplu @sgugger |
transformers | 10,054 | closed | Error: "Transformers CLI tool: error: unrecognized arguments: kvantorium-small" while deploying machine learning model to hugging face profile | I work with hugging face on Google Colab
My process of training and tuning the model looks like this. The model is successfully trained and saved in the models folder, but when I am going to upload it to my huggingface repository, an error occurs
````
tokenizer = `PreTrainedTokenizerFast(tokenizer_file='/content/bert-datas7.json')
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
dataset = LineByLineTextDataset(tokenizer=tokenizer, file_path="/content/For_ITMO (1).txt",block_size=128)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=mlm, mlm_probability=0.15
)
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="models/kvantorium-small",
overwrite_output_dir=True,
num_train_epochs=1000,
per_gpu_train_batch_size=64,
save_steps=10_000,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset)
trainer.train()
````
#8480
When I am going to upload it to my huggingface repository, an error occurs, why is it displayed for me? And how to specify the correct documentation? My folder in the Google Colab directory is called "/ content / models / kvantorium-small" This is the folder where I save the model after training
````
!transformers-cli login
!transformers-cli upload "/content/models/kvantorium-small"
2021-02-07 16:56:32.089450: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
usage: transformers-cli <command> [<args>]
Transformers CLI tool: error: unrecognized arguments: /content/models/kvantorium-small
````
Is this a google collab problem and how can I rewrite the request or fix the error?
Sorry in advance if my issue seems to be incorrect to you, I'm new to git.
I also attached my data and my tokenizer file
[For_ITMO (1).txt](https://github.com/huggingface/transformers/files/5939713/For_ITMO.1.txt)
[For_ITMO.txt-vocab (1) (1).txt](https://github.com/huggingface/transformers/files/5939719/For_ITMO.txt-vocab.1.1.txt)
| 02-07-2021 18:26:36 | 02-07-2021 18:26:36 | Hello! Since version v4.0.0, we recommend using git and git-lfs to upload your models. Could you take a look at the following documentation page: [Model sharing and uploading](https://huggingface.co/transformers/model_sharing.html) and try what is shown in that document? Thank you!<|||||>> Hello! Since version v4.0.0, we recommend using git and git-lfs to upload your models. Could you take a look at the following documentation page: [Model sharing and uploading](https://huggingface.co/transformers/model_sharing.html) and try what is shown in that document? Thank you!
@LysandreJik That is, I first need to connect github to my google colab and only then upload my model files to the hugging face? Thank you very much in advance
<|||||>No, you'll only need a huggingface hub account to upload to it.<|||||>@LysandreJik Error Again
````
!transformers-cli upload https://huggingface.co/Fidlobabovic/your-model-name
2021-02-08 19:24:21.906281: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
usage: transformers-cli <command> [<args>]
Transformers CLI tool: error: unrecognized arguments: Fidlobabovic/your-model-name
````<|||||>Hi @IndianMLGay. I'm sorry but I don't understand what is the issue. Nowhere in the file I linked is there a `transformers-cli upload` command.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,053 | open | Add CharacterBERT model [WIP] | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #9061
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the [documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
*I'm still missing the updates in the general documentation.*
- [x] Did you write any new necessary tests?
*Some of the tests are currently failing. This is due to CharacterBERT having a different input shape than bert (batch size, seq length, token length) instead of (batch size, seq length). Also, there are some other tests that are related to reshaping the embedding which fail for the same reason. I did not fix these test as that would mean changing things in the way the common tests are currently working. For all other cases, I tried my best to implement tests that by adapting those from the BERT suite (these pass).*
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag members/contributors which may be interested in your PR.
@LysandreJik please have a look at this PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-07-2021 17:50:10 | 02-07-2021 17:50:10 | I will, thanks for the ping @helboukkouri!<|||||>Hi @helboukkouri, how are you doing? What do you think of the proposed changes above? Would you like us to take over from here?<|||||>> Hi @helboukkouri, how are you doing? What do you think of the proposed changes above? Would you like us to take over from here?
Hi @LysandreJik, sorry for the delay. No need to take over, I have been working on another topic (pre-training code for CharacterBERT) but I'll go back to the PR as soon as possible (beginning of next week at the latest).
I will fix the documentation then move on to the tests - about which I wanted to know if it is okay to change some of the code that is common to all models. I think that most tests that do not pass with CharacterBERT don't because they expect the input to be shaped as `(batch size, seq length)` instead of `(batch size, seq length, token length)`.
Cheers!<|||||>Really cool, looking forward to it!
For tests in the common tests that you believe don't apply to CharacterBERT, I would recommend you override them in the CharacterBERT test file directly. For example TAPAS's tokenizer didn't fit to most common tests as it is a table-based model/tokenizer, so we reimplemented most tests in the test file directly:
https://github.com/huggingface/transformers/blob/master/tests/test_tokenization_tapas.py#L49
This is an example for the tokenizer, but you can apply the same for the model!<|||||>I still need to fix the tests. I'll try to progress on that asap 😊<|||||>Not a bug, just a general comment:
This is perfectly working when using a (potential future) CharacterBERT model, that is cased:
Tokenizer config:
```json
{
"do_lower_case": false,
"strip_accents":false
}
```
(place it under a folder e.g. `./convbert-tokenizer-test`.
Then:
```python
In [1]: from transformers import CharacterBertTokenizer
In [2]: tokenizer = CharacterBertTokenizer.from_pretrained("./convbert-tokenizer-test")
In [3]: tokenizer.tokenize("Nice weather in Munich töday!")
Out[3]: ['Nice', 'weather', 'in', 'Munich', 'töday', '!']
```
is perfectly working: no lowercasing and accent stripping (as defined in tokenizer configuration) is done.<|||||>Hi @LysandreJik, so I made sure all the tests in `tests/test_modeling_character_bert.py` pass by:
- Fixing some issues regarding the input shape
- Removing the inheritance to ModelTesterMixin
The command I used to run the tests was:
```python
python -m pytest ./tests/test_modeling_character_bert.py
```
Now I guess I could copy/paste and adapt the tests from `ModelTesterMixin` to include them back. But this seems against the whole point of having common tests (and will make the test file for CharacterBERT pretty verbose). Should I do it anyway ? Is it necessary ?
Wanted your input before moving forward. 😊
Also, at some point I will probably need to add the hardcoded hyperparameters like the maximum token length and the character embedding dimension (basically all of [this](https://github.com/helboukkouri/transformers/blob/add-character-bert/src/transformers/models/character_bert/modeling_character_bert.py#L232-L249)) to the `CharacterBertConfig` class.<|||||>Hi @helboukkouri, that's fantastic news!!
Regarding the `ModelTesterMixin`, a better approach would be to keep your class as a child of it, but to re-implement directly in that class the tests that need to receive changes. By overriding those tests, you can choose what happens in them.
Regarding the configuration, by all means do! You can add as many CharacterBERT specific configuration properties as you need, and remove the ones that you don't need, of course.
<|||||>> Regarding the `ModelTesterMixin`, a better approach would be to keep your class as a child of it, but to re-implement directly in that class the tests that need to receive changes.
Of course! Should've thought of that :)
So, I added the tests from `ModelTesterMixin`. They all pass with the exception of those related to embedding tying which I bypass as `CharacterBERT` does not have a WordPiece embedding layer.
I will now complete `CharacterBertConfig` to include the parameters from the CharacterCNN module.
Is there anything else to do ? Please let me know 😊<|||||>Hey @helboukkouri ,
do you think it makes sense to add the `max_word_length` value to that configuration :thinking:
As we discussed this parameter in the corresponding CharacterBERT issue, I'm not sure if it ever will be changed/adjusted :thinking:
On the other side it is included in the ELMo [configuration files](https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway_5.5B/elmo_2x4096_512_2048cnn_2xhighway_5.5B_options.json) and it also can be seen as a "magic number" in the code...<|||||>> do you think it makes sense to add the `max_word_length` value to that configuration 🤔
Hi @stefan-it,
I'm actually working on it right now. It will be a parameter in `tokenizer_config.json` as well as a possible argument for `CharacterBertTokenizer`. This way, it possible for anybody to choose to train models that handle shorter or longer words.
I'm also adding a whole bunch of parameters in the model configuration like the character embeddings dimension and number of highway layers in the `CharacterCnn` module. The only fixed value will be the character "vocabulary size". This will stay at 263 for the 256 possible utf-8 bytes (I'm not sure I'm using the right term here) + the special symbols for [CLS], [SEP], [MASK], [PAD], Beginning/EndOfWord, CharacterPadding.<|||||>@LysandreJik Please let me know if there is anything else I can do. 😊<|||||>It seems most of the tests failing are solved on `master`, do you mind rebasing on `master`? I'll give a deeper look ASAP!<|||||>Sorry Lysandre, I'm not really used to doing merges and rebases. I guess this is good practice ^^
Please let me know if I somehow managed to do what you needed me to do 😊<|||||>Flair team here 😅
This is currently not working:
```python
from transformers import CharacterBertTokenizer
tokenizer = CharacterBertTokenizer()
tokenized_string = tokenizer.tokenize("Hello from Munich!")
encoded_inputs = tokenizer.encode_plus(tokenized_string, max_length=1024,
truncation=True, stride=512, return_overflowing_tokens=True)
```
Problem comes with the `return_overflowing_tokens` argument, it throws the following error message:
```
/mnt/character-bert-pretraining/external/transformers/src/transformers/tokenization_utils_base.py in encode_plus(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
2357 )
2358
-> 2359 return self._encode_plus(
2360 text=text,
2361 text_pair=text_pair,
/mnt/character-bert-pretraining/external/transformers/src/transformers/tokenization_utils.py in _encode_plus(self, text, text_pair, add_special_tokens, padding_strategy, truncation_strategy, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
440 second_ids = get_input_ids(text_pair) if text_pair is not None else None
441
--> 442 return self.prepare_for_model(
443 first_ids,
444 pair_ids=second_ids,
/mnt/character-bert-pretraining/external/transformers/src/transformers/tokenization_utils_base.py in prepare_for_model(self, ids, pair_ids, add_special_tokens, padding, truncation, max_length, stride, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, prepend_batch_axis, **kwargs)
2807 # Padding
2808 if padding_strategy != PaddingStrategy.DO_NOT_PAD or return_attention_mask:
-> 2809 encoded_inputs = self.pad(
2810 encoded_inputs,
2811 max_length=max_length,
/mnt/character-bert-pretraining/external/transformers/src/transformers/tokenization_utils_base.py in pad(self, encoded_inputs, padding, max_length, pad_to_multiple_of, return_attention_mask, return_tensors, verbose)
2635
2636 batch_size = len(required_input)
-> 2637 assert all(
2638 len(v) == batch_size for v in encoded_inputs.values()
2639 ), "Some items in the output dictionary have a different batch size than others."
AssertionError: Some items in the output dictionary have a different batch size than others.
```
When a user wants to use the `encode_plus` function we should maybe add some additional checks to avoid these errors :thinking:
<|||||>It seems that `attention_scores` and `attention_mask` have different shapes, I just tried the following example from the PR:
```python
from transformers import CharacterBertTokenizer, CharacterBertForNextSentencePrediction
import torch
tokenizer = CharacterBertTokenizer.from_pretrained('helboukkouri/character-bert')
model = CharacterBertForNextSentencePrediction.from_pretrained('helboukkouri/character-bert')
prompt = "In Italy, pizza served in formal settings, such as at a restaurant, is presented unsliced."
next_sentence = "The sky is blue due to the shorter wavelength of blue light."
encoding = tokenizer(prompt, next_sentence, return_tensors='pt')
outputs = model(**encoding, labels=torch.LongTensor([1]))
logits = outputs.logits
assert logits[0, 0] < logits[0, 1] # next sentence was random
```
This throws:
```bash
File "nsp.py", line 11, in <module>
outputs = model(**encoding, labels=torch.LongTensor([1]))
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 744, in _call_impl
result = self.forward(*input, **kwargs)
File "/mnt/character-bert-pretraining/external/transformers/src/transformers/models/character_bert/modeling_character_bert.py", line 1611, in forward
outputs = self.character_bert(
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 744, in _call_impl
result = self.forward(*input, **kwargs)
File "/mnt/character-bert-pretraining/external/transformers/src/transformers/models/character_bert/modeling_character_bert.py", line 1149, in forward
encoder_outputs = self.encoder(
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 744, in _call_impl
result = self.forward(*input, **kwargs)
File "/mnt/character-bert-pretraining/external/transformers/src/transformers/models/character_bert/modeling_character_bert.py", line 742, in forward
layer_outputs = layer_module(
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 744, in _call_impl
result = self.forward(*input, **kwargs)
File "/mnt/character-bert-pretraining/external/transformers/src/transformers/models/character_bert/modeling_character_bert.py", line 629, in forward
self_attention_outputs = self.attention(
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 744, in _call_impl
result = self.forward(*input, **kwargs)
File "/mnt/character-bert-pretraining/external/transformers/src/transformers/models/character_bert/modeling_character_bert.py", line 557, in forward
self_outputs = self.self(
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 744, in _call_impl
result = self.forward(*input, **kwargs)
File "/mnt/character-bert-pretraining/external/transformers/src/transformers/models/character_bert/modeling_character_bert.py", line 480, in forward
attention_scores = attention_scores + attention_mask
RuntimeError: The size of tensor a (35) must match the size of tensor b (50) at non-singleton dimension 3
```<|||||>Hi @helboukkouri, the rebase was exactly what I wanted you to do, so that's great! How is it going? Can we help in any way regarding the failing tests/Stefan's comments?<|||||>> Hi @helboukkouri, the rebase was exactly what I wanted you to do, so that's great! How is it going? Can we help in any way regarding the failing tests/Stefan's comments?
Hi @LysandreJik, so right now `CharacterBertTokenizer` works well if you simply do tokenize/convert_token_to_ids, but I still need to make sure other methods work well (e.g. encode_plus - i.e. stefan's comments). I'll work on it when I get the chance. 😊
Other than that I'm not really sure why there are still tests that do not pass. After rebasing, only:
- run_tests_templates
- build_doc
- check_code_quality
had issues. But now I see that more tests break... I'll try to investigate the other tests but in the meantime, do you have any pointers for solving the three tests listed above ?
Cheers!<|||||>> I'll try to investigate the other tests
Is there any chance that I need to rebase again ? There seems to be some conflicts in
- src/transformers/__init__.py
- src/transformers/models/auto/configuration_auto.py
- src/transformers/models/auto/modeling_auto.py<|||||>You might have to rebase once again indeed, the issue here is because of torch 1.8.0. Let me know if you would want me to handle it, happy to!
- Regarding the templates, that's actually the same issue as the code quality, so you can ignore that
- The build_doc gives you a bit of information when you open the failure:
```
/home/circleci/transformers/src/transformers/models/character_bert/configuration_character_bert.py:docstring of transformers.CharacterBertConfig:17:Unexpected indentation.
```
- And finally, you have some code quality issues. In order to do that, you should:
- Install the code quality tools with `pip install -e .[quality]` at the root of the repo
- Run `make fixup` which should tell you the issues with the style in your code
Please let me know if I can be of any help, happy to!<|||||>Hi, I've been playing around with the implementation as well, specifically the `CharacterBertForMaskedLM`. I keep running into issues with the decoding, which (as I've read in the code) is not currently implemented. Specifically, I'm having a hard time to understand how you are aligning the MLM vocab size (100k in the available model snapshot) with the character-level representations, and how you would (schematically) re-label predictions from your model.
If there is any way to help out with the MLM setup specifically, let me know!<|||||>> I'm having a hard time to understand how you are aligning the MLM vocab size (100k in the available model snapshot) with the character-level representations
Hi @dennlinger, glad to hear you're interested in CharacterBERT. I added a MLM vocabulary just as a workaround to allow me to do masked language modeling since CharacterBERT does not have a wordpiece vocab, which in the case of BERT is re-used at the output layer during MLM. So in my case, it is only used for this purpose.
How are you trying to use CharacterBERT ? In a seq2seq context ? When do you need decoding ? <|||||>The specific use case is literally just to predict masked tokens, which I'm using in the following example right now:
```python
from transformers import CharacterBertTokenizer, CharacterBertForMaskedLM, BertTokenizer
import torch
if __name__ == "__main__":
tokenizer = CharacterBertTokenizer.from_pretrained("helboukkouri/character-bert")
model = CharacterBertForMaskedLM.from_pretrained("helboukkouri/character-bert")
tokens = tokenizer.tokenize("[CLS] This is a [MASK] [SEP]")
input_tensor = torch.tensor(tokenizer.convert_tokens_to_ids(tokens)).unsqueeze(0)
with torch.no_grad():
outputs = model(input_tensor)
predictions = outputs[0]
# How can we interpret the output idx from this?
predicted_index = torch.argmax(predictions[0, 4, :]).item()
# This fails currently with NotImplementedError
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
```
I think the main issue I have is the [empty vocab file](https://huggingface.co/helboukkouri/character-bert/blob/main/vocab.txt), since I am assuming that you had a specific 100k vocab during your training, right?<|||||>> I am assuming that you had a specific 100k vocab during your training, right?
Oh I see now. So, the first thing to know is that the checkpoint in "helboukkouri/character-bert" only has weights for the `CharacterBertModel` part. So, no pre-trained weights for the MLM/NSP parts. So, even if the tokenizer worked properly, you would have had meaningless outputs 😊
On the other hand, the `convert_ids_to_tokens` method from the tokenizer is indeed "missing", and that is because there are no "token ids" with CharacterBERT as each token is seen as a sequence of character/byte ids. However, I think I should implement anyway but in a way where it takes a tensor `(batch, token sequence, character ids)` and returns `(batch, token sequence)`. I'll add it to my todo list :)
Also, I think I can manage to recover the mlm vocab / checkpoints and add them at some point to "helboukkouri/character-bert" so that the entire `CharacterBertForPretraining` model can be loaded and give meaningful output. I'll also need to find a solution for easily recovering the tokens from the predicted MLM ids (maybe add a `convert_mlm_ids_to_tokens` to the tokenizer ?)
Hope this is helpful<|||||>Ah, it's making more sense now, the detailed explanation did help a lot! :)
Maybe as a last question: It seems the MLMHead is only able to return `(batch, seq_len, MLM_vocab_size)`, and (as far as I can tell) not the required `(batch, seq_len,character_ids)`. How would one acquire the necessary character predictions from the MLM model?
I'll continue to watch the PR, thanks for all the effort!<|||||>> Please let me know if I can be of any help, happy to!
Thanks @LysandreJik! I don't mind continuing to work on PR but since I have some pressing things to handle first, progress may be slow for some time. If you think you can help solve any issues in the meantime please don't hesitate 😊<|||||>Here's my conversion script that I've used to convert my pre-trained model into a masked lm model:
```python
import torch
from transformers import CharacterBertConfig, CharacterBertForMaskedLM
orig_model = torch.load("./ckpt_1184.pt")
orig_state_dict = orig_model["model"]
# wget https://huggingface.co/helboukkouri/character-bert/resolve/main/config.json
config = CharacterBertConfig.from_pretrained("./")
model = CharacterBertForMaskedLM(config)
ignore_keys = ["character_bert.pooler.dense.weight",
"character_bert.pooler.dense.bias",
"cls.seq_relationship.weight",
"cls.seq_relationship.bias"]
for key in ignore_keys:
del orig_model["model"][key]
model.load_state_dict(orig_model["model"], strict=True)
model.half()
model.save_pretrained("./export")
```
However, when I pass a (masked) sequence to the model, it returns always the same predictions. Here's some example code:
```python
from transformers import CharacterBertTokenizer, CharacterBertForMaskedLM
import torch
model_name = "./export"
tokenizer = CharacterBertTokenizer.from_pretrained(model_name)
model = CharacterBertForMaskedLM.from_pretrained(model_name)
sentence = "Heute ist ein [MASK] Tag"
encoding = tokenizer.encode_plus(sentence, return_tensors="pt")
masked_index = 4
predictions = model(input_ids=encoding["input_ids"])[0]
predicted_index = torch.argmax(predictions[0, masked_index]).item()
mlm_vocabulary = [line.strip().split()[-1] for line in open("mlm_vocab.txt", "rt")]
print("Predicted token:", mlm_vocabulary[predicted_index])
```
I'm currently trying to figure out, where the problem could be :)<|||||>> How would one acquire the necessary character predictions from the MLM model?
It's not possible. The MLM task is at the word level, where each word has an index. If you want to convert these indices into tokens, you need the MLM vocabulary for a lookup. The character_id stuff is only at the input level. Both are dissociated, which I understand is a bit weird since both are essentially the same thing in BERT (but that's more of a convenience thing than a necessary aspect).<|||||>> How would one acquire the necessary character predictions from the MLM model?
Actually, there might be a way but it's not very natural : you could take the MLM ids -> lookup the token in the MLM vocab -> tokenize it with the CharacterBertTokenizer -> get character ids.
If you repeat this too much it may become very slow. But you may be able to cache some things and make some optimizations :)<|||||>Hey @helboukkouri, please let me know if there remains some issues and you don't have time to work on them - happy to unblock you if that's so!<|||||>> Hey @helboukkouri, please let me know if there remains some issues and you don't have time to work on them - happy to unblock you if that's so!
Hi @LysandreJik . I think the most important things right now are to fix the `encode_plus` method of the tokenizer then to rebase in order (I guess ) so that the tests can pass again. Then, there is also the code quality which needs to be improved but maybe that's less important. And finally, at some point, there will be a need for methods to handle MLM ids and convert them back into tokens using a MLM vocabulary which I guess will have to be an additional (optional) attribute of the tokenizer class. In this same context, I will also need to add the MLM model checkpoints in the hub and make sure they can load fine (by the way there are medical versions of CharacterBERT - but I'll add those later).
I don't know if you can help on any with any of these remaining topics. If not, I'll handle them but I need to finish working on some other stuff first 😊
Hope the PR is not taking too long!
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Almost ready 🥳! Only a few things left:
- Add MLM checkpoints to the model hub
- Add MLM vocabulary as an optional attribute of the tokenizer class (only needed for pretraining/MLM)
- Add a method for converting the MLM ids into tokens using the MLM vocabulary<|||||>> I'm currently trying to figure out, where the problem could be :)
@stefan-it I just found out that the tokenizer was splitting the special tokens (e.g. "[MASK]" -> "[", "mask", "]"). Maybe this is why you were having your issue (or maybe not, by anyway it was a bug). I didn't realise that before because I tend to handle token sequences and inject mask tokens directly in there instead of tokenizing from a raw string like you did 😊<|||||>> The specific use case is literally just to predict masked tokens, which I'm using in the following example right now:
>
> ```python
> from transformers import CharacterBertTokenizer, CharacterBertForMaskedLM, BertTokenizer
> import torch
>
> if __name__ == "__main__":
> tokenizer = CharacterBertTokenizer.from_pretrained("helboukkouri/character-bert")
> model = CharacterBertForMaskedLM.from_pretrained("helboukkouri/character-bert")
>
> tokens = tokenizer.tokenize("[CLS] This is a [MASK] [SEP]")
> input_tensor = torch.tensor(tokenizer.convert_tokens_to_ids(tokens)).unsqueeze(0)
>
> with torch.no_grad():
> outputs = model(input_tensor)
> predictions = outputs[0]
>
> # How can we interpret the output idx from this?
> predicted_index = torch.argmax(predictions[0, 4, :]).item()
> # This fails currently with NotImplementedError
> predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
> ```
>
> I think the main issue I have is the [empty vocab file](https://huggingface.co/helboukkouri/character-bert/blob/main/vocab.txt), since I am assuming that you had a specific 100k vocab during your training, right?
Hey @dennlinger 👋🏼, I added support for the MLM vocabulary. You can now do things like:
```python
from transformers import CharacterBertForPreTraining, CharacterBertTokenizer
# NOTE: loading a "pretrained" tokenizer is necessary for loading the MLM vocabulary
tokenizer = CharacterBertTokenizer.from_pretrained('helboukkouri/character-bert')
model = CharacterBertForPreTraining.from_pretrained('helboukkouri/character-bert')
text = 'My name is [MASK]. Nice to meet you!'
encoding = tokenizer.encode_plus(text, return_tensors="pt")
predicted_mlm_id = model(**encoding).prediction_logits[0][4].argmax().item()
predicted_token = tokenizer.convert_mlm_id_to_token(predicted_mlm_id) # outputs: "chris"
```<|||||>@LysandreJik I think that everything is ready. Please let me know if there is anything else that I can do 😊<|||||>Fantastic @helboukkouri! I'll take a look, thanks for the ping :)<|||||>@LysandreJik just in case you missed my ping, everything should be good now. Please let me know if there is anything else I can do for this PR. 😊<|||||>@LysandreJik I did the rebase (correctly I hope) and I removed some imports from the `__init__.py`, namely:
- `CharacterBertLMHeadModel`
- `CharacterBertPreTrainedModel`
- `load_tf_weights_in_character_bert`
- `CharacterCnn`
- `CharacterBertLayer`
But I kept `CharacterBertModel` since I think it can be convenient to be able to import it directly. I can remove it if necessary 😊
Can't wait for the PR to be merged!<|||||>Great work @helboukkouri ! After the PR is merged, I can finally upload my German Wikipedia CharacterBERT model 😍<|||||>> Great work @helboukkouri ! After the PR is merged, I can finally upload my German Wikipedia CharacterBERT model 😍
Looking forward to it!<|||||>@sgugger I made all the changes you suggested, rebased and ran `make style` and `make fix-copies`. Is there anything else I can do ? 😊<|||||>As you can see, there are several failures in the CI that need to be addressed:
1. You still have some formatting errors, run `make quality` locally so they are printed and fix them if you can.
2. The documentation can't build because there is no `CharacterBertLMHeadModel` in this PR but you are trying to document it
3. A lot of tests are failing because there is an import error with `from transformers import CharacterCnn` in test_modeling_common<|||||>Thanks, I'll fix the things you mentioned. I'll try and look at the CI logs if there are any more errors after that 😊<|||||>Hey guys 😊 Sorry for the long period of inactivity. However, I am still unable to dedicate time to finishing this pull request. I was actually wondering wether somebody could take it from here ? Thanks.<|||||>Hey @helboukkouri, thanks for letting us know! We'll take a look :)<|||||>Hey @LysandreJik , I'd be happy to help on this PR, too. If someone could help me with some of the more ambiguous merge conflicts, I _should_ be able to make progress on the rest of the issues.<|||||>Hey @jaminsore, how about I take care of the rebase, and then we can take a look at the failing tests?
@helboukkouri could you invite us both as collaborators to your fork so that we may commit on the PR directly?<|||||>> Hey @jaminsore, how about I take care of the rebase, and then we can take a look at the failing tests?
>
> @helboukkouri could you invite us both as collaborators to your fork so that we may commit on the PR directly?
Done! Thanks a lot for the help 😊<|||||>> Hey @jaminsore, how about I take care of the rebase, and then we can take a look at the failing tests?
>
> @helboukkouri could you invite us both as collaborators to your fork so that we may commit on the PR directly?
@LysandreJik Sounds good to me.<|||||>It should be good to go now - let's take a look at the tests now :)<|||||>@LysandreJik FYI, I took a new job in December, and I'm not sure when I'll have the to work on this again.
<|||||>@LysandreJik I'm pretty sure I've mangled the history of this branch. Locally, I've reset hard to cfdadd27ae3711d57f0a19aba980543eac3cc669, and I'd like to take another crack at it. How would you like me to handle this? A new PR? A force push? Something else?<|||||>Hey @jaminsore, if your local branch looks fine, feel free to open a new PR with it directly. GitHub sometimes messes up the history when the git history is actually perfectly fine.
What is important here is that the authors keep their authorship - so if the commits get somehow mixed up, I would squash them all into one single commit and add all users that contributed to this PR as co-authors manually. I'm happy to take care of that if you're unaware of how to do so, once you have opened the new PR!<|||||>@LysandreJik Thanks! The issue was that I mixed up "ours" and "theirs" in my rebases so everything got mangled and I was stuck in an endless cycle of large rebases. This also resulted in changes from `master` not making it at all or only partially making it into this branch. After resetting and rebasing (correctly) onto `master` things are sane again :smiley:.
Once I fix up the documentation, I'll open a new PR. <|||||>That sounds great, thanks a lot @jaminsore! |
transformers | 10,052 | closed | implementing tflxmertmodel integration test | # What does this PR do?
this PR implement an integration test for TFLxmertmodel as requested in #9954
@LysandreJik | 02-07-2021 16:46:54 | 02-07-2021 16:46:54 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>@LysandreJik <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi @LysandreJik what about this one <|||||>Sure! It seems there is no branch linked to this PR, however. The changes are still visible here https://github.com/huggingface/transformers/pull/10052/files but I am unable to reopen. |
transformers | 10,051 | closed | [example] run_ner.py raised error: IndexError: Target 3 is out of bounds. | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.0.dev0 or 4.2.2
- Platform: MacOS
- Python version: 3.6
- PyTorch version (GPU?): 1.7.1
- Tensorflow version (GPU?): 2.4.1
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
## To reproduce
Steps to reproduce the behavior:
1. bash [run.sh](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run.sh) to [run_ner.py](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner.py)
## Error
```
[INFO|trainer.py:837] 2021-02-07 22:22:31,755 >> ***** Running training *****
[INFO|trainer.py:838] 2021-02-07 22:22:31,755 >> Num examples = 14041
[INFO|trainer.py:839] 2021-02-07 22:22:31,755 >> Num Epochs = 3
[INFO|trainer.py:840] 2021-02-07 22:22:31,755 >> Instantaneous batch size per device = 8
[INFO|trainer.py:841] 2021-02-07 22:22:31,755 >> Total train batch size (w. parallel, distributed & accumulation) = 8
[INFO|trainer.py:842] 2021-02-07 22:22:31,755 >> Gradient Accumulation steps = 1
[INFO|trainer.py:843] 2021-02-07 22:22:31,755 >> Total optimization steps = 5268
0%| | 0/5268 [00:00<?, ?it/s]Traceback (most recent call last):
File "run_ner.py", line 443, in <module>
main()
File "run_ner.py", line 377, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/Users/bytedance/transformers/src/transformers/trainer.py", line 940, in train
tr_loss += self.training_step(model, inputs)
File "/Users/bytedance/transformers/src/transformers/trainer.py", line 1304, in training_step
loss = self.compute_loss(model, inputs)
File "/Users/bytedance/transformers/src/transformers/trainer.py", line 1334, in compute_loss
outputs = model(**inputs)
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/Users/bytedance/transformers/src/transformers/models/bert/modeling_bert.py", line 1701, in forward
loss = loss_fct(active_logits, active_labels)
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/torch/nn/modules/loss.py", line 962, in forward
ignore_index=self.ignore_index, reduction=self.reduction)
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/torch/nn/functional.py", line 2468, in cross_entropy
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/torch/nn/functional.py", line 2264, in nll_loss
ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
IndexError: Target 3 is out of bounds.
Exception ignored in: <bound method tqdm.__del__ of 0%| | 0/5268 [00:01<?, ?it/s]>
Traceback (most recent call last):
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/tqdm/std.py", line 1086, in __del__
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/tqdm/std.py", line 1270, in close
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/tqdm/std.py", line 572, in _decr_instances
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/tqdm/_monitor.py", line 51, in exit
File "/Users/bytedance/opt/anaconda3/lib/python3.6/threading.py", line 521, in set
File "/Users/bytedance/opt/anaconda3/lib/python3.6/threading.py", line 364, in notify_all
File "/Users/bytedance/opt/anaconda3/lib/python3.6/threading.py", line 347, in notify
TypeError: 'NoneType' object is not callable
``` | 02-07-2021 14:24:12 | 02-07-2021 14:24:12 | Which version of the datasets library are you using? The script runs fine on my side.<|||||>Hi @sgugger,
I use Version 1.2.1 of the datasets library.<|||||>I tried the different version of the datasets library. It seems that it is not due to the version of the datasets library.
- Version 1.2.1, 1.2.0, 1.1.3
```
Traceback (most recent call last):
File "run_ner.py", line 443, in <module>
main()
File "run_ner.py", line 377, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/Users/bytedance/transformers/src/transformers/trainer.py", line 940, in train
tr_loss += self.training_step(model, inputs)
File "/Users/bytedance/transformers/src/transformers/trainer.py", line 1304, in training_step
loss = self.compute_loss(model, inputs)
File "/Users/bytedance/transformers/src/transformers/trainer.py", line 1334, in compute_loss
outputs = model(**inputs)
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/Users/bytedance/transformers/src/transformers/models/bert/modeling_bert.py", line 1701, in forward
loss = loss_fct(active_logits, active_labels)
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/torch/nn/modules/loss.py", line 962, in forward
ignore_index=self.ignore_index, reduction=self.reduction)
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/torch/nn/functional.py", line 2468, in cross_entropy
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
File "/Users/bytedance/opt/anaconda3/lib/python3.6/site-packages/torch/nn/functional.py", line 2264, in nll_loss
ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
IndexError: Target 3 is out of bounds.
```
- Version 1.1.2, 1.1.1, 1.1.0
```
Traceback (most recent call last):
File "run_ner.py", line 443, in <module>
main()
File "run_ner.py", line 230, in main
if isinstance(features[label_column_name].feature, ClassLabel):
AttributeError: 'Value' object has no attribute 'feature'
```
<|||||>And to be clear you are just running the non-modified version of `token-classification/run.sh`?<|||||>> And to be clear you are just running the non-modified version of `token-classification/run.sh`?
Yes, I am just running the non-modified version of token-classification/run.sh.<|||||>Hi! The error you have for versions 1.2.1, 1.2.0 and 1.1.3 is probably the same as #10050.
See https://github.com/huggingface/transformers/issues/10050#issuecomment-775034308 for how to resolve it.<|||||>> Hi! The error you have for versions 1.2.1, 1.2.0 and 1.1.3 is probably the same as #10050.
> See [#10050 (comment)](https://github.com/huggingface/transformers/issues/10050#issuecomment-775034308) for how to resolve it.
I tried. It doesn't work.😭<|||||>I am trying to perform token classification task through fine tuning pretrained model. My input data is in conll format in which first column consist token and second column indicate it's grammatical category (value is separated by tab). I am passing these info
from transformers import DistilBertForTokenClassification, Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=16, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
)
model = DistilBertForTokenClassification.from_pretrained("distilbert-base-uncased")
trainer = Trainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset # evaluation dataset
)
trainer.train()
after running the trainer.train() in google colab with GPU runtime I am getting index error
"IndexError: Target 6 is out of bounds."
How to get rid of this problem, Can anyone help me to get rid from this issue.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>> I am trying to perform token classification task through fine tuning pretrained model. My input data is in conll format in which first column consist token and second column indicate it's grammatical category (value is separated by tab). I am passing these info
>
> from transformers import DistilBertForTokenClassification, Trainer, TrainingArguments
>
> training_args = TrainingArguments(
> output_dir='./results', # output directory
> num_train_epochs=3, # total number of training epochs
> per_device_train_batch_size=16, # batch size per device during training
> per_device_eval_batch_size=16, # batch size for evaluation
> warmup_steps=500, # number of warmup steps for learning rate scheduler
> weight_decay=0.01, # strength of weight decay
> logging_dir='./logs', # directory for storing logs
> logging_steps=10,
> )
>
> model = DistilBertForTokenClassification.from_pretrained("distilbert-base-uncased")
>
> trainer = Trainer(
> model=model, # the instantiated 🤗 Transformers model to be trained
> args=training_args, # training arguments, defined above
> train_dataset=train_dataset, # training dataset
> eval_dataset=val_dataset # evaluation dataset
> )
>
> trainer.train()
>
> after running the trainer.train() in google colab with GPU runtime I am getting index error
> "IndexError: Target 6 is out of bounds."
>
> How to get rid of this problem, Can anyone help me to get rid from this issue.
Hi HuggingFace,
I am having exact same issue. While `running trainer.train()` in Google Colab using GPU I get this error. I tried with TPU as well, get the same issue.
Running on my own data with 10 classes. My classes are labelled from 0 to 9. There are 297 training items, 97 testing and 75 Validation items. Please help us me to fix this error. <|||||>By the way, I solved it..
Solution:
While creating the model, pass `num_labels` arugment
Something like this
```
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=n_labels)
``` |
transformers | 10,050 | closed | run_ner.py fails when loading a model/checkpoint from a directory | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.0.dev0
- Platform: Linux-3.10.0-957.1.3.el7.x86_64-x86_64-with-centos-7.6.1810-Core
- Python version: 3.6.8
- PyTorch version (GPU?): 1.7.1+cu101 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
--> @sgugger, @patil-suraj
## Information
Model I am using (Bert, XLNet ...): XLMRobertaModel
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behaviour:
The run_ner.py seems to be unable to load models from a directory. The following command works as expected:
```
python transformers/examples/token-classification/run_ner.py --dataset_name conll2003 --model_name_or_path xlm-roberta-base --output_dir output --num_train_epochs 10 --per_device_train_batch_size 32 --per_device_eval_batch_size 32 --learning_rate 5e-05 --seed 29 --save_steps 9223372036854775807 --do_train --do_eval --overwrite_cache --overwrite_output_dir --fp16
```
However, if we load 'xlm-roberta-base', we save the model to a directory, and we try to run the script with the directory set as the model path, the script fails. (Same behaviour if we use XLMRobertaForTokenClassification instead of XLMRobertaModel in step 1)
1.
```
from transformers import XLMRobertaTokenizer, XLMRobertaModel
tokenizer = XLMRobertaTokenizer.from_pretrained('xlm-roberta-base')
model = XLMRobertaModel.from_pretrained('xlm-roberta-base')
spath = "models/xlmroberta"
tokenizer.save_pretrained(spath)
model.save_pretrained(spath)
```
2.
```
python transformers/examples/token-classification/run_ner.py --dataset_name conll2003 --model_name_or_path models/xlmroberta --cache_dir models/xlmroberta --output_dir output --num_train_epochs 10 --per_device_train_batch_size 32 --per_device_eval_batch_size 32 --learning_rate 5e-05 --seed 29 --do_train --do_eval --overwrite_cache --overwrite_output_dir
```
Error message (Running the command in CPU to be able to see it):
```
INFO|tokenization_utils_base.py:1688] 2021-02-07 14:38:00,146 >> Model name 'models/xlmroberta' not found in model shortcut name list (xlm-roberta-base, xlm-roberta-large, xlm-roberta-large-finetuned-conll02-dutch, xlm-roberta-large-finetuned-conll02-spanish, xlm-roberta-large-finetuned-conll03-english, xlm-roberta-large-finetuned-conll03-german). Assuming 'models/xlmroberta' is a path, a model identifier, or url to a directory containing tokenizer files.
[INFO|tokenization_utils_base.py:1721] 2021-02-07 14:38:00,146 >> Didn't find file models/xlmroberta/tokenizer.json. We won't load it.
[INFO|tokenization_utils_base.py:1721] 2021-02-07 14:38:00,147 >> Didn't find file models/xlmroberta/added_tokens.json. We won't load it.
[INFO|tokenization_utils_base.py:1784] 2021-02-07 14:38:00,147 >> loading file models/xlmroberta/sentencepiece.bpe.model
[INFO|tokenization_utils_base.py:1784] 2021-02-07 14:38:00,148 >> loading file None
[INFO|tokenization_utils_base.py:1784] 2021-02-07 14:38:00,148 >> loading file None
[INFO|tokenization_utils_base.py:1784] 2021-02-07 14:38:00,148 >> loading file models/xlmroberta/special_tokens_map.json
[INFO|tokenization_utils_base.py:1784] 2021-02-07 14:38:00,148 >> loading file models/xlmroberta/tokenizer_config.json
[INFO|modeling_utils.py:1025] 2021-02-07 14:38:02,120 >> loading weights file models/xlmroberta/pytorch_model.bin
[INFO|modeling_utils.py:1143] 2021-02-07 14:38:13,379 >> All model checkpoint weights were used when initializing XLMRobertaForTokenClassification.
[WARNING|modeling_utils.py:1146] 2021-02-07 14:38:13,380 >> Some weights of XLMRobertaForTokenClassification were not initialized from the model checkpoint at models/xlmroberta and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
100%|###################################################################################################################################################################################################################################################################################################################################################################################################| 15/15 [00:01<00:00, 7.55ba/s]
100%|#####################################################################################################################################################################################################################################################################################################################################################################################################| 4/4 [00:00<00:00, 8.69ba/s]
100%|#####################################################################################################################################################################################################################################################################################################################################################################################################| 4/4 [00:00<00:00, 8.25ba/s]
[INFO|trainer.py:429] 2021-02-07 14:38:18,120 >> The following columns in the training set don't have a corresponding argument in `XLMRobertaForTokenClassification.forward` and have been ignored: tokens, ner_tags, chunk_tags, id, pos_tags.
[INFO|trainer.py:429] 2021-02-07 14:38:18,121 >> The following columns in the evaluation set don't have a corresponding argument in `XLMRobertaForTokenClassification.forward` and have been ignored: tokens, ner_tags, chunk_tags, id, pos_tags.
[INFO|trainer.py:721] 2021-02-07 14:38:18,122 >> Loading model from models/xlmroberta).
[INFO|configuration_utils.py:443] 2021-02-07 14:38:18,123 >> loading configuration file models/xlmroberta/config.json
[INFO|configuration_utils.py:481] 2021-02-07 14:38:18,125 >> Model config XLMRobertaConfig {
"architectures": [
"XLMRobertaModel"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "xlm-roberta",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"output_past": true,
"pad_token_id": 1,
"position_embedding_type": "absolute",
"transformers_version": "4.3.0.dev0",
"type_vocab_size": 1,
"use_cache": true,
"vocab_size": 250002
}
[INFO|modeling_utils.py:1025] 2021-02-07 14:38:18,126 >> loading weights file models/xlmroberta/pytorch_model.bin
[INFO|modeling_utils.py:1143] 2021-02-07 14:38:30,381 >> All model checkpoint weights were used when initializing XLMRobertaForTokenClassification.
[WARNING|modeling_utils.py:1146] 2021-02-07 14:38:30,381 >> Some weights of XLMRobertaForTokenClassification were not initialized from the model checkpoint at models/xlmroberta and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
[INFO|trainer.py:832] 2021-02-07 14:38:30,394 >> ***** Running training *****
[INFO|trainer.py:833] 2021-02-07 14:38:30,394 >> Num examples = 14041
[INFO|trainer.py:834] 2021-02-07 14:38:30,394 >> Num Epochs = 10
[INFO|trainer.py:835] 2021-02-07 14:38:30,394 >> Instantaneous batch size per device = 32
[INFO|trainer.py:836] 2021-02-07 14:38:30,394 >> Total train batch size (w. parallel, distributed & accumulation) = 32
[INFO|trainer.py:837] 2021-02-07 14:38:30,395 >> Gradient Accumulation steps = 1
[INFO|trainer.py:838] 2021-02-07 14:38:30,395 >> Total optimization steps = 4390
0%| | 0/4390 [00:00<?, ?it/s]Traceback (most recent call last):
File "third_party/transformers/examples/token-classification/run_ner.py", line 454, in <module>
main()
File "third_party/transformers/examples/token-classification/run_ner.py", line 388, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/ikerlariak/igarcia945/envs/transformers422/lib/python3.6/site-packages/transformers/trainer.py", line 931, in train
tr_loss += self.training_step(model, inputs)
File "/ikerlariak/igarcia945/envs/transformers422/lib/python3.6/site-packages/transformers/trainer.py", line 1295, in training_step
loss = self.compute_loss(model, inputs)
File "/ikerlariak/igarcia945/envs/transformers422/lib/python3.6/site-packages/transformers/trainer.py", line 1325, in compute_loss
outputs = model(**inputs)
File "/ikerlariak/igarcia945/envs/transformers422/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/ikerlariak/igarcia945/envs/transformers422/lib/python3.6/site-packages/transformers/models/roberta/modeling_roberta.py", line 1349, in forward
loss = loss_fct(active_logits, active_labels)
File "/ikerlariak/igarcia945/envs/transformers422/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/ikerlariak/igarcia945/envs/transformers422/lib/python3.6/site-packages/torch/nn/modules/loss.py", line 962, in forward
ignore_index=self.ignore_index, reduction=self.reduction)
File "/ikerlariak/igarcia945/envs/transformers422/lib/python3.6/site-packages/torch/nn/functional.py", line 2468, in cross_entropy
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
File "/ikerlariak/igarcia945/envs/transformers422/lib/python3.6/site-packages/torch/nn/functional.py", line 2264, in nll_loss
ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
IndexError: Target 3 is out of bounds.
```
| 02-07-2021 13:47:41 | 02-07-2021 13:47:41 | Same [issue](https://github.com/huggingface/transformers/issues/10051) as me 😄 <|||||>I'm guessing this has to do with the number of labels your model has. When doing the following:
```py
model = XLMRobertaModel.from_pretrained('xlm-roberta-base')
spath = "models/xlmroberta"
model.save_pretrained(spath)
```
you're saving a model to disk that has no classification head, and the script will therefore use the default number of labels when loading it. I would advise you do the following instead, with `NUM_LABELS` your number of labels:
```py
model = XLMRobertaForTokenClassification.from_pretrained('xlm-roberta-base', num_labels=NUM_LABELS)
spath = "models/xlmroberta"
model.save_pretrained(spath)
```
Please let me know if this fixes your issue.<|||||>@LysandreJik problem solved. Thank you!! |
transformers | 10,049 | closed | Installing tf2.0 in my env but still get ImportError in my code | Hi, I have installed tf2.0 in my env and I followed the readme which says if you have installed the tf2.0 you can just run pip install transformers. But I got Error: "ImportError: cannot import name 'TFBertForSequenceClassification' from 'transformers' (unknown location)"
My code:
from transformers import BertTokenizer, TFBertForSequenceClassification
import tensorflow as tf
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = TFBertForSequenceClassification.from_pretrained('bert-base-cased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
inputs["labels"] = tf.reshape(tf.constant(1), (-1, 1)) # Batch size 1
outputs = model(inputs)
loss = outputs.loss
logits = outputs.logits
Picture(I have tf2.0 and transformers):

And I also used conda install -c huggingface transformers but it still doesn't work. Could you help me, Thanks!
| 02-07-2021 13:35:34 | 02-07-2021 13:35:34 | I tried BertForSequenceClassification instead of TFBertForSequenceClassification and it works, I'm confused now<|||||>Hi! Version v4.2.2 supports pytorch >=1.3.0 and TensorFlow >=2.3.0. Could you install TensorFlow 2.3.0 and let me know if it fixes your issue?
You can import `BertForSequenceClassification` because that's a PyTorch model and you have your environment correctly setup for torch, but not `TFBertForSequenceClassification` as you have TensorFlow <2.3.0.<|||||>After updating tensorflow from 2.0.0 to 2.4.1, it works! Thanks a lot! And I also want to know where can I find version correspondence between huggingface-transformers and tensorflow(or pytorch), for example, if I have tf2.0.0 which version of transformers I should install. Thanks!<|||||>This is a good question, and unfortunately we don't have an answer for that except checking the history of the `setup.py`. @jplu can you chime in on what is the last version that was working with the version v2.0.0 of TensorFlow?<|||||>The last was v4.1.1<|||||>I install the transformers v4.1.1 and my tf is v2.0.0, but when I run the demo, I got an error which says "AttributeError: module 'tensorflow_core.keras.activations' has no attribute 'swish'"

First I went to view the official documentation transformers v4.1.1 but got 404

<|||||>Hello, could you try loading the doc again? It should be back up. Thanks!<|||||>Ah yes, the `swish` activation needs at least TF 2.1. Then you should be able to run 2.0 with at least Transformers v3.1.0<|||||>> Hello, could you try loading the doc again? It should be back up. Thanks!
I tried in my iPhone and it could be loaded but when I tried it in my mac, it failed...<|||||>> Ah yes, the `swish` activation needs at least TF 2.1. Then you should be able to run 2.0 with at least Transformers v3.1.0
TF2.0 and Transformers3.1.0 and there are another Error happend: "ImportError: cannot import name 'Parallel' from 'joblib' (unknown location)"<|||||>I think you have to downgrade your version of joblib as well.<|||||>Now I can import it correctly but still got an error that "OSError: Unable to load weights from h5 file. If you tried to load a TF 2.0 model from a PyTorch checkpoint, please set from_pt=True."
I downloaded the file "bert-base-uncased" from the official website but there is only tf_model.h5 instead of tf_model.hdf5.
My code:
from transformers import BertTokenizer, TFBertForSequenceClassification
import tensorflow as tf
pretrain_path = "/root/huggingface-pretrain/bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(pretrain_path)
model = TFBertForSequenceClassification.from_pretrained(pretrain_path)
inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
inputs["labels"] = tf.reshape(tf.constant(1), (-1, 1)) # Batch size 1
outputs = model(inputs)
loss = outputs.loss
logits = outputs.logits<|||||>Did you try with `TFBertForSequenceClassification.from_pretrained("bert-base-uncased")` instead? What is the content of your `/root/huggingface-pretrain/bert-base-uncased` folder?<|||||>I have tried but it didn't work<|||||>I suggest that you can open multiple version including the Code and Model Format so that everyone can use them just using their TensorFlow version.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,048 | closed | ImportError: cannot import name 'list_datasets' | I'm having an unusual issue on one computer and I'm hoping that someone out there has seen something like this before. This issue does not exist on another computer. Both computers are windows 10 machines, using python 3.6.4, virtualenv, and visual studio code as the ide
I have created a clean virtualenv and installed only datasets. I get an import error when I try to import any of the built in functions, list_datasets, load_dataset, etc.
I have tried installing different versions of datasets and I have tried installing datasets from source instead of through pip with no success.
Has anyone seen anything like this? Any suggestions for something I can try to help debug?
Here's the code:
import sys
```
print (sys.version)
from datasets import list_datasets
for i, ds in enumerate(list_datasets()):
print (f"{i}: {ds}")
```
Here is the output:
3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:54:40) [MSC v.1900 64 bit (AMD64)]
Traceback (most recent call last):
File "c:\code\dataset_test\main.py", line 5, in <module>
from datasets import list_datasets
ImportError: cannot import name 'list_datasets'
Here is the pip list:
Package Version
------------------ ---------
certifi 2020.12.5
chardet 4.0.0
dataclasses 0.8
datasets 1.2.1
dill 0.3.3
idna 2.10
importlib-metadata 3.4.0
multiprocess 0.70.11.1
numpy 1.19.5
object-detection 0.1
pandas 1.1.5
pip 21.0.1
pyarrow 3.0.0
python-dateutil 2.8.1
pytz 2021.1
requests 2.25.1
setuptools 53.0.0
six 1.15.0
tqdm 4.49.0
typing-extensions 3.7.4.3
urllib3 1.26.3
wheel 0.36.2
xxhash 2.0.0
zipp 3.4.0 | 02-07-2021 12:44:56 | 02-07-2021 12:44:56 | Maybe @lhoestq can chime in here!<|||||>Hi ! It might come from a conflict. Somehow python is loading a bad `datasets` module. Can you check that you don't have a folder named "datasets" in your working directory or in a directory of you python path ?
Can you try to run this as well ?
```python
# if `datasets` points to the right `datasets` module, this should print the location of the module
print(datasets.__file__)
# if `datasets` points to a bad `datasets` module, this should print the location of the folder named "datasets"
print(datasets.__path__)
```<|||||>Thanks for the quick response. I had something in my python path from a long time ago with a 'datasets' folder. I was able to find it thanks to your suggestions (and learned something new :) ) so this problem is solved. |
transformers | 10,047 | closed | Can you give some suggestion about add features with input_ids to token-classification model ? | Hi, I want to add POS TAG labels as input with input_ids as auxiliary feature feature in NER model.
How can i get the entry in the forward function ?
And i review some implementations about model use bert model to perform NER such as
https://github.com/monologg/JointBERT/blob/master/model/modeling_jointbert.py
It seems if i want to ad this feature (POS TAG) i must rewrite the forward function in BertModel
and seems i should train the edit model from scratch.
Can you give some suggestions about edit model structure and partial weights load from
huggingface pre-trained-models ?
| 02-07-2021 02:30:33 | 02-07-2021 02:30:33 | The more general question is that dose huggingface model support some interface about
add other char level feature as auxiliary features ?<|||||>And i search some bert with ner implementations, they all not use pos tag features.
But when i view the following code :
**https://github.com/sberbank-ai/ner-bert/blob/master/modules/models/bert_models.py**
i think if add pos tag feature in lstm level (use bert embedding as input)
it seems more suitable.
Do you think this is a general solution to combine token level feature with huggingface features.
Or the future releases will support some feature combination model above bert constructions
as options ? <|||||>Or i can use set_input_embeddings and
https://github.com/plasticityai/magnitude
Additional Featurization
to the original embedding?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,046 | closed | [s2s examples] Replace -100 token ids with the tokenizer pad_id for compute_metrics | # What does this PR do?
This PR is a small fix that replaces the -100 token ids with the tokenizer pad_id when decoding sequences to compute metrics as was done in [this HF blog post](https://huggingface.co/blog/warm-starting-encoder-decoder)
## When does this problem occur?
When running `examples/seq2seq/finetune_trainer.py` with padding to the `max_seq_len`, an error is thrown at the evaluation step:
```
File "/opt/conda/lib/python3.8/site-packages/transformers/trainer.py", line 1004, in _maybe_log_save_evaluate
metrics = self.evaluate()
File "/opt/conda/lib/python3.8/site-packages/transformers/trainer_seq2seq.py", line 96, in evaluate
return super().evaluate(eval_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
File "/opt/conda/lib/python3.8/site-packages/transformers/trainer.py", line 1442, in evaluate
output = self.prediction_loop(
File "/opt/conda/lib/python3.8/site-packages/transformers/trainer.py", line 1601, in prediction_loop
metrics = self.compute_metrics(EvalPrediction(predictions=preds, label_ids=label_ids))
File "/eai/transformers/examples/seq2seq/utils.py", line 98, in translation_metrics
pred_str, label_str = decode_pred(pred)
File "/eai/transformers/examples/seq2seq/utils.py", line 85, in decode_pred
label_str = tokenizer.batch_decode(pred.label_ids, skip_special_tokens=True)
File "/opt/conda/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 3070, in batch_decode
return [
File "/opt/conda/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 3071, in <listcomp>
self.decode(
File "/opt/conda/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 3109, in decode
return self._decode(
File "/opt/conda/lib/python3.8/site-packages/transformers/tokenization_utils_fast.py", line 495, in _decode
text = self._tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
OverflowError: out of range integral type conversion attempted
```
This is because in the prediction loop, the labels will be padded with -100 if the prediction or labels have different sequence length https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py#L1637.
| 02-06-2021 23:42:55 | 02-06-2021 23:42:55 | Hi,
Still running into this issue here with the run_summarization.py file -
```Traceback (most recent call last):
File "run_summarization.py", line 674, in <module>
main()
File "run_summarization.py", line 628, in main
predict_results = trainer.predict(
File "/Users/aiswarya.s/Desktop/transformers_fudge/src/transformers/trainer_seq2seq.py", line 125, in predict
return super().predict(test_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
File "/Users/aiswarya.s/Desktop/transformers_fudge/src/transformers/trainer.py", line 2133, in predict
output = eval_loop(
File "/Users/aiswarya.s/Desktop/transformers_fudge/src/transformers/trainer.py", line 2235, in evaluation_loop
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)
File "/Users/aiswarya.s/Desktop/transformers_fudge/src/transformers/trainer_seq2seq.py", line 180, in prediction_step
print(self.tokenizer_t5.batch_decode(inputs["labels"], skip_special_tokens=True, clean_up_tokenization_spaces=True))
File "/Users/aiswarya.s/Desktop/transformers_fudge/src/transformers/tokenization_utils_base.py", line 3047, in batch_decode
return [
File "/Users/aiswarya.s/Desktop/transformers_fudge/src/transformers/tokenization_utils_base.py", line 3048, in <listcomp>
self.decode(
File "/Users/aiswarya.s/Desktop/transformers_fudge/src/transformers/tokenization_utils_base.py", line 3086, in decode
return self._decode(
File "/Users/aiswarya.s/Desktop/transformers_fudge/src/transformers/tokenization_utils_fast.py", line 507, in _decode
text = self._tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
OverflowError: out of range integral type conversion attempted```
Has this been addressed in that script - it relies on the trainer_seq2seq.py file, not sure if this issue has been fixed there. Thanks cc @patil-suraj
|
transformers | 10,045 | closed | BertGenerationTokenizer provides an unexpected value for BertGenerationModel | - `transformers` version: 4.2.2
- PyTorch version (GPU?): 1.7.0+cu101
- tokenizers: @n1t0, @LysandreJik
## Information
in both models BertGenerationEncoder, BertGenerationDecoder, there's no need for `token_type_ids` however the BertGenerationTokenizer provides it, this issue will be raised if you want to input the tokenizer results directly with `**`,
and if it meant to be like this, and the user should be aware of this behaviour, I think a change should be in the documentation.
Note: Another issue with BertGenerationTokenizer is the necessity of sentencepiece module, do you prefer that it should for the user to install it separately or it should be included in transformers dependencies.
| 02-06-2021 08:01:29 | 02-06-2021 08:01:29 | Hi @sadakmed!
You're right, there's no need for token type IDs in this tokenizer. The workaround for this is to remove `token_type_ids` from the model input names, as it is done in the DistilBERT tokenizer:
https://github.com/huggingface/transformers/blob/cdd86592317e7db3bab75555c3837fabc74e3429/src/transformers/models/distilbert/tokenization_distilbert.py#L71
Do you want to open a PR to fix this?
Regarding the necessity of sentencepiece module, yes it is necessary. It was previously in the transformers dependencies and we removed it because it was causing compilation issues on some hardware. The error should be straightforward and mention a `sentencepiece` installation is necessary in order to use that tokenizer, so no problem there. |
transformers | 10,044 | closed | [s2s examples] dataset porting | We need to port these to jsonlines and ideally make them part of dataset hub:
https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
https://cdn-datasets.huggingface.co/translation/wmt_en_de.tgz
https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
The problem is that nobody knows how these came to be - they are pre-processed but it's unclear how.
@sshleifer, do you by chance remember how these were created? If we put those on the new datasets hub - it'd be good to explain how these are different from normal wmt datasets.
Also do you remember which wmtXX they came from?
Thank you!
----
The resolution is here: https://github.com/huggingface/transformers/issues/10044#issuecomment-779555741 | 02-06-2021 06:53:09 | 02-06-2021 06:53:09 | Here is a script to convert these:
```
import io
import json
import re
src_lang, tgt_lang = ["en", "ro"]
for split in ["train", "val", "test"]:
recs = []
fout = f"{split}.json"
with io.open(fout, "w", encoding="utf-8") as f:
for type in ["source", "target"]:
fin = f"{split}.{type}"
recs.append([line.strip() for line in open(fin)])
for src, tgt in zip(*recs):
out = {"translation": { src_lang: src, tgt_lang: tgt } }
x = json.dumps(out, indent=0, ensure_ascii=False)
x = re.sub(r'\n', ' ', x, 0, re.M)
f.write(x + "\n")
```<|||||>The short answer is I don't recall, but my best guess is:
[en-de](https://github.com/pytorch/fairseq/blob/master/examples/translation/prepare-wmt14en2de.sh#L1)
[en-ro](https://github.com/rsennrich/wmt16-scripts/blob/master/sample/download_files.sh)
[cnn_dm](https://github.com/abisee/cnn-dailymail#option-1-download-the-processed-data)<|||||>That's perfect, @sshleifer! Thanks a lot!
I missed one more entry: https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
I found the main source at https://github.com/EdinburghNLP/XSum/tree/master/XSum-Dataset but not sure about what pre-processing if any went in.
Thank you!<|||||>Preprocessing: I don't actually know. The author sent me a link (in a github issue I can't find) which leads me to predict with high confidence that the preprocessing is the same as whatever is in the repo.
There is a larger *scraping wherever they are scraping is not deterministic* issue discussed in this thread https://github.com/huggingface/datasets/issues/672 (quentin and I run same code get different numbers)
which I was far too lazy to do anything more than complain about :)
<|||||>OK, for xsum this is as good as it gets, and so I will document what you shared. Thank you!
I was able to to reproduce 100% the datasets you created with the instructions you provided:
- [en-de](https://github.com/pytorch/fairseq/blob/master/examples/translation/prepare-wmt14en2de.sh#L1)
- [en-ro](https://github.com/rsennrich/wmt16-scripts/blob/master/sample/download_files.sh)
This one doesn't match the instructions on the page you linked to:
- [cnn_dm](https://github.com/abisee/cnn-dailymail#option-1-download-the-processed-data)
the content is the same but the format is quite different after all the pre-processing steps were applied. Their results are all lower-cased and tagged with `<s></s>`, and it's word-level tokenized. Yours is just clean normal text. So you must have used a different process.
If I dig into it, it looks like your source is for sure just the original with new lines removed - in fact this is what it says in the README.md:
```
wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
tar -xzvf cnn_dm_v2.tgz # empty lines removed
```
target looks like a combination of `@highlight` entries into the abstract. So little pre-processing here, but I think I sorted it out.
I'm trying to preserve these datasets you created since they are awesome for monitoring any regressions in the code, because they avail themselves to a high bleu scores on even a small sample, so I constantly use them as a reference and I can quickly detect any problems if the score drops. Thank you for creating those in first place, @sshleifer!
With all datasets or pretty much any data I make, I include the scripts that created it (or a link to where it can be found), so that it's easy to know how things came to be. Mainly doing it for myself, since I am not good at remembering such details. And I don't like researching the same thing more than once.
<|||||>To substitute the old datasets directories with new ones, replace:
* [x] `--data_dir wmt_en_de` => `--dataset_name wmt14 --dataset_config "de-en"` or if you want the highest score use: `--dataset_name stas/wmt14-en-de-pre-processed`
* [x] `--data_dir wmt_en_ro` => `--dataset_name wmt16 --dataset_config "ro-en"`
* [x] `--data_dir cnn_dm` => `--dataset_name cnn_dailymail --dataset_config "3.0.0"`
* [x] `--data_dir xsum` => `--dataset_name xsum`
conversion to `datasets` status:
* [x] `stas/wmt14-en-de-pre-processed` https://huggingface.co/datasets/stas/wmt14-en-de-pre-processed (this dataset version scores about twice as good as the unprocessed one)
* [x] `stas/wmt16-en-ro-pre-processed` https://huggingface.co/datasets/stas/wmt16-en-ro-pre-processed (this dataset version scores identical to the unprocessed one)
I didn't bother porting the following 2, since their score is just slightly better than the unprocessed versions. So just use the following:
* [x] `--data_dir cnn_dm` is just slightly better than `--dataset_name cnn_dailymail --dataset_config "3.0.0"`
* [x] `--data_dir xsum` is just slightly better than `--dataset_name xsum`
Here are the full benchmarks where I verified that all but wmt14 are OK with unprocessed dataset versions:
```
### wmt16-en-ro-pre-processed
export BS=16; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 python examples/seq2seq/run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir \
--adam_eps 1e-06 --do_eval --do_train --evaluation_strategy=steps \
--label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 \
--max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS \
--per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler \
--task translation_en_to_ro --val_max_target_length 128 --warmup_steps 500 \
--max_train_samples 2000 --max_val_samples 500 \
--dataset_name stas/wmt16-en-ro-pre-processed --source_prefix "translate English to Romanian: "
02/16/2021 00:01:55 - INFO - __main__ - val_bleu = 24.1319
vs normal wmt16-en-ro dataset:
export BS=16; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 python examples/seq2seq/run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir --adam_eps 1e-06 --do_eval --do_train --evaluation_strategy=steps --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --val_max_target_length 128 --warmup_steps 500 --max_train_samples 2000 --max_val_samples 500 --dataset_name wmt16 --dataset_config "ro-en" --source_prefix "translate English to Romanian: "
02/15/2021 23:59:56 - INFO - __main__ - val_bleu = 24.1319
results: the preprocessed scores identically as the non-preprocessed one
### wmt14-en-de-pre-processed
export BS=16; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 python examples/seq2seq/run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir \
--adam_eps 1e-06 --do_eval --do_train --evaluation_strategy=steps \
--label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 \
--max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS \
--per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler \
--task translation_en_to_de --val_max_target_length 128 --warmup_steps 500 \
--max_train_samples 2000 --max_val_samples 500 \
--dataset_name stas/wmt14-en-de-pre-processed --source_prefix "translate English to English: "
02/19/2021 11:53:46 - INFO - __main__ - eval_bleu = 22.2348
vs normal wmt14-en-de dataset:
export BS=16; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 python examples/seq2seq/run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir --adam_eps 1e-06 --do_eval --do_train --evaluation_strategy=steps --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_de --val_max_target_length 128 --warmup_steps 500 --max_train_samples 2000 --max_val_samples 500 --dataset_name wmt14 --dataset_config "de-en"
02/19/2021 11:55:37 - INFO - __main__ - eval_bleu = 10.5513
results: the preprocessed one scores significantly better
# cnn_dailymail
wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
tar -xzvf cnn_dm_v2.tgz # empty lines removed
mv cnn_cln cnn_dm
export BS=16 MODEL=t5-small; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 examples/legacy/seq2seq/finetune_trainer.py --model_name_or_path $MODEL --output_dir output_dir --adam_eps 1e-06 --data_dir cnn_dm --do_eval --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --eval_steps 25000 --sortish_sampler --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 50 --n_train 2000 --n_val 500 --predict_with_generate --task summarization
2021-02-19 15:16:41 | INFO | __main__ | ***** val metrics *****
2021-02-19 15:16:41 | INFO | __main__ | val_gen_len = 54.3
2021-02-19 15:16:41 | INFO | __main__ | val_loss = 3432.908
2021-02-19 15:16:41 | INFO | __main__ | val_n_objs = 500
2021-02-19 15:16:41 | INFO | __main__ | val_rouge1 = 30.2151
2021-02-19 15:16:41 | INFO | __main__ | val_rouge2 = 11.1576
2021-02-19 15:16:41 | INFO | __main__ | val_rougeL = 21.545
2021-02-19 15:16:41 | INFO | __main__ | val_rougeLsum = 27.1914
2021-02-19 15:16:41 | INFO | __main__ | val_runtime = 70.1847
2021-02-19 15:16:41 | INFO | __main__ | val_samples_per_second = 7.124
vs normal cnn_dailymail 3.0.0 dataset
export BS=16; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 python examples/seq2seq/run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir \
--adam_eps 1e-06 --do_eval --do_train --evaluation_strategy=steps \
--label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 \
--max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS \
--per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler \
--task summarization --val_max_target_length 128 --warmup_steps 500 \
--max_train_samples 2000 --max_val_samples 500 \
--dataset_name cnn_dailymail --dataset_config "3.0.0"
02/19/2021 15:02:13 - INFO - __main__ - ***** val metrics *****
02/19/2021 15:02:13 - INFO - __main__ - eval_gen_len = 74.902
02/19/2021 15:02:13 - INFO - __main__ - eval_loss = 4.7365
02/19/2021 15:02:13 - INFO - __main__ - eval_rouge1 = 28.3215
02/19/2021 15:02:13 - INFO - __main__ - eval_rouge2 = 9.8609
02/19/2021 15:02:13 - INFO - __main__ - eval_rougeL = 20.1687
02/19/2021 15:02:13 - INFO - __main__ - eval_rougeLsum = 25.0959
02/19/2021 15:02:13 - INFO - __main__ - eval_runtime = 37.8969
02/19/2021 15:02:13 - INFO - __main__ - eval_samples = 500
02/19/2021 15:02:13 - INFO - __main__ - eval_samples_per_second = 13.194
results: the preprocessed one scores slightly better
# xsum
wget https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
tar -xzvf xsum.tar.gz
export BS=16 MODEL=t5-small; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 examples/legacy/seq2seq/finetune_trainer.py --model_name_or_path $MODEL --output_dir output_dir --adam_eps 1e-06 --data_dir xsum --do_eval --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --eval_steps 25000 --sortish_sampler --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 50 --n_train 2000 --n_val 500 --predict_with_generate --task summarization
2021-02-19 15:25:32 | INFO | __main__ | val_gen_len = 42.7
2021-02-19 15:25:32 | INFO | __main__ | val_loss = 2272.3525
2021-02-19 15:25:32 | INFO | __main__ | val_n_objs = 500
2021-02-19 15:25:32 | INFO | __main__ | val_rouge1 = 20.6343
2021-02-19 15:25:32 | INFO | __main__ | val_rouge2 = 2.8416
2021-02-19 15:25:32 | INFO | __main__ | val_rougeL = 14.3483
2021-02-19 15:25:32 | INFO | __main__ | val_rougeLsum = 14.8529
2021-02-19 15:25:32 | INFO | __main__ | val_runtime = 51.8796
2021-02-19 15:25:32 | INFO | __main__ | val_samples_per_second = 9.638
vs normal cnn_dailymail 3.0.0 dataset
export BS=16; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0 python examples/seq2seq/run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir \
--adam_eps 1e-06 --do_eval --do_train --evaluation_strategy=steps \
--label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 \
--max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS \
--per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler \
--task summarization --val_max_target_length 128 --warmup_steps 500 \
--max_train_samples 2000 --max_val_samples 500 \
--dataset_name xsum
02/19/2021 15:23:38 - INFO - __main__ - epoch = 1.0
02/19/2021 15:23:38 - INFO - __main__ - eval_gen_len = 56.858
02/19/2021 15:23:38 - INFO - __main__ - eval_loss = 5.2487
02/19/2021 15:23:38 - INFO - __main__ - eval_rouge1 = 18.0063
02/19/2021 15:23:38 - INFO - __main__ - eval_rouge2 = 2.276
02/19/2021 15:23:38 - INFO - __main__ - eval_rougeL = 12.8842
02/19/2021 15:23:38 - INFO - __main__ - eval_rougeLsum = 13.9633
02/19/2021 15:23:38 - INFO - __main__ - eval_runtime = 31.2343
02/19/2021 15:23:38 - INFO - __main__ - eval_samples = 500
02/19/2021 15:23:38 - INFO - __main__ - eval_samples_per_second = 16.008
results: the preprocessed one scores slightly better
``` |
transformers | 10,043 | closed | [s2s examples] README.md fixes | This PR:
* fixes a cl arg typo
* clarifies that it's jsonlines format and not json that's expected
* adds a link explaining jsonlines
@sgugger, how do we apply the auto-re-wrapping to examples README.md files? Currently the new file is all very long lines. Thank you!
@patil-suraj, @sgugger | 02-06-2021 06:13:23 | 02-06-2021 06:13:23 | |
transformers | 10,042 | closed | Pegasus ONNX format? | I tried to convert Pegasus to the ONNX format using [this ](https://colab.research.google.com/github/huggingface/transformers/blob/master/notebooks/04-onnx-export.ipynb#scrollTo=foYlXrSksR_v) guide but it failed. Can Pegasus be converted to the ONNX format or is that not possible yet? | 02-06-2021 06:06:01 | 02-06-2021 06:06:01 | follow this [answer](https://stackoverflow.com/a/66117248/13273054), posted on StackOverflow.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,041 | closed | [s2s] Can't mix --fp16 and --device cpu | This PR fixes this user-side error:
```
RuntimeError: "threshold_cpu" not implemented for 'Half'
```
reported at https://github.com/huggingface/transformers/issues/10040
This combination `--fp16 --device cpu` is not possible, as explained here: https://github.com/pytorch/pytorch/issues/48245#issuecomment-730714723
and it's not really usable anyway - it takes minutes to run fp16 on cpu while it takes a split second on the gpu.
full trace:
```
export DATA_DIR=wmt_en_ro; PYTHONPATH=../../src ./run_eval.py t5-base $DATA_DIR/val.source t5_val_generations.txt --reference_path $DATA_DIR/val.target --score_path enro_bleu.json --task translation_en_to_ro --n_obs 100 --device cpu --fp16 --bs 32
Traceback (most recent call last):
File "./run_eval.py", line 176, in <module>
run_generate(verbose=True)
File "./run_eval.py", line 137, in run_generate
runtime_metrics = generate_summaries_or_translations(
File "./run_eval.py", line 67, in generate_summaries_or_translations
summaries = model.generate(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/mnt/nvme1/code/huggingface/transformers-cpu-no-fp16/src/transformers/generation_utils.py", line 847, in generate
model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(input_ids, model_kwargs)
File "/mnt/nvme1/code/huggingface/transformers-cpu-no-fp16/src/transformers/generation_utils.py", line 379, in _prepare_encoder_decoder_kwargs_for_generation
model_kwargs["encoder_outputs"]: ModelOutput = encoder(input_ids, return_dict=True, **encoder_kwargs)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/mnt/nvme1/code/huggingface/transformers-cpu-no-fp16/src/transformers/models/t5/modeling_t5.py", line 946, in forward
layer_outputs = layer_module(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/mnt/nvme1/code/huggingface/transformers-cpu-no-fp16/src/transformers/models/t5/modeling_t5.py", line 683, in forward
hidden_states = self.layer[-1](hidden_states)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/mnt/nvme1/code/huggingface/transformers-cpu-no-fp16/src/transformers/models/t5/modeling_t5.py", line 299, in forward
forwarded_states = self.DenseReluDense(forwarded_states)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/mnt/nvme1/code/huggingface/transformers-cpu-no-fp16/src/transformers/models/t5/modeling_t5.py", line 258, in forward
hidden_states = F.relu(hidden_states)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/nn/functional.py", line 1206, in relu
result = torch.relu(input)
RuntimeError: "threshold_cpu" not implemented for 'Half'
```
@sgugger, @patil-suraj
Fixes: https://github.com/huggingface/transformers/issues/10040 | 02-06-2021 03:58:52 | 02-06-2021 03:58:52 | I'm not following, `finetune_trainer.py` is replaced by `run_seq2seq.py`.
What replaces these 3?
```
run_distributed_eval.py
run_eval.py
run_eval_search.py
```<|||||>Not familiar with `run_eval_search` but the new `run_seq2seq` is supposed to run the right evaluation (so no need for `run_eval`) and can do it in a distributed fashion (so no need for `run_eval_distributed`). But I may have missed something.<|||||>`run_eval_search` uses `run_eval` to find the best hparams. It's not an example, but a real tool to pick the best initial model config hparams when a new model is ported. Written by yours truly.
So it probably needs to be ported to use `run_seq2seq` then.
|
transformers | 10,040 | closed | seq2seq: fail gracefully when predicting using --device cpu and --fp16 | When using the recommended seq2seq evaluation procedure in https://github.com/huggingface/transformers/blob/master/examples/seq2seq/README.md :
```
export DATA_DIR=wmt_en_ro
./run_eval.py t5-base \
$DATA_DIR/val.source t5_val_generations.txt \
--reference_path $DATA_DIR/val.target \
--score_path enro_bleu.json \
--task translation_en_to_ro \
--n_obs 100 \
--device cuda \
--fp16 \
--bs 32
```
If `--device cuda` is switched to `--device cpu` then it eventually fails with a pytorch error if `--fp16` is also enabled:
```
"threshold_cpu" not implemented for 'Half'
```
It seems that fp16 and cpu evaluation may currently be incompatible.
| 02-06-2021 03:07:33 | 02-06-2021 03:07:33 | |
transformers | 10,039 | closed | [trainer] deepspeed bug fixes and tests | This PR:
* fixes a bug with `model.no_sync()` which is not supported by DeepSpeed - we had the test but it's not running on CI
* fixes a bug with when `--train` is not used - have to `.to(device)` in that case - reported here (https://github.com/huggingface/transformers/issues/9996#issuecomment-774232901)
* splits the deepspeed tests into its own dedicated file and will slowly start to build it up - but it's good enough for now - especially since we are going to switch over `run_seq2seq.py`, except it's not fully ready yet for adoption.
* adds a new test which doesn't use `--train`
@sgugger | 02-06-2021 01:34:02 | 02-06-2021 01:34:02 | > Thanks for the PR. Concerning the new `test_deepspeed.py` file, the goal is to remove things from the seq2seq folder to make it less intimidating to new users, not add stuff in it ;-)
>
> Maybe we should put all tests in examples/tests/, that would be easier.
I'm open to suggestions, this is not really an addition but a split or a larger test file as it was becoming unnecessarily complicated.
This PR is a bug fix and the scene will evolve to be more user-friendly, but let's discuss this post merge to enable users to do their work.
I will start a new issue discussing your suggestion. https://github.com/huggingface/transformers/issues/10076<|||||>Well it's not just a bug fix since you split the test file with it ;-) But I agree we can do the regrouping in another PR.<|||||>Because I had to add new tests and the previous situation would make things too complicated, so that bug fix required a new test which was the last straw that triggered a need for a dedicated test file. That is, I couldn't easily add a test to the way things were and the test was needed to go with the bug fix. So the split was done out of necessity. |
transformers | 10,038 | closed | [examples s2s] run_seq2seq.py tweaks | Would it be possible to sync the new `run_seq2seq.py` with `./finetune_trainer.py` outputs?
Before:
```
2021-02-05 12:59:55 | INFO | __main__ | ***** train metrics *****
2021-02-05 12:59:55 | INFO | __main__ | epoch = 1.0
2021-02-05 12:59:55 | INFO | __main__ | train_n_objs = 60
2021-02-05 12:59:55 | INFO | __main__ | train_runtime = 9.7768
2021-02-05 12:59:55 | INFO | __main__ | train_samples_per_second = 6.137
2021-02-05 12:59:55 | INFO | __main__ | *** Evaluate ***
[INFO|trainer.py:1600] 2021-02-05 12:59:55,434 >> ***** Running Evaluation *****
[INFO|trainer.py:1601] 2021-02-05 12:59:55,434 >> Num examples = 10
[INFO|trainer.py:1602] 2021-02-05 12:59:55,434 >> Batch size = 1
2021-02-05 13:00:00 | INFO | __main__ | ***** val metrics *****
2021-02-05 13:00:00 | INFO | __main__ | epoch = 1.0
2021-02-05 13:00:00 | INFO | __main__ | val_bleu = 33.3125
2021-02-05 13:00:00 | INFO | __main__ | val_gen_len = 50.1
2021-02-05 13:00:00 | INFO | __main__ | val_loss = inf
2021-02-05 13:00:00 | INFO | __main__ | val_n_objs = 10
2021-02-05 13:00:00 | INFO | __main__ | val_runtime = 4.7266
2021-02-05 13:00:00 | INFO | __main__ | val_samples_per_second = 2.116
2021-02-05 13:00:00 | INFO | __main__ | *** Predict ***
```
With the new script:
```
02/05/2021 13:00:41 - INFO - __main__ - ***** Train results *****
02/05/2021 13:00:41 - INFO - __main__ - epoch = 1.0
02/05/2021 13:00:41 - INFO - __main__ - train_runtime = 1.33
02/05/2021 13:00:41 - INFO - __main__ - train_samples_per_second = 3.008
02/05/2021 13:00:41 - INFO - __main__ - *** Evaluate ***
***** Running Evaluation *****
Num examples = 100
Batch size = 32
02/05/2021 13:00:42 - INFO - __main__ - ***** Eval results *****
02/05/2021 13:00:42 - INFO - __main__ - epoch = 1.0
02/05/2021 13:00:42 - INFO - __main__ - eval_bleu = 1.3059269919149237
02/05/2021 13:00:42 - INFO - __main__ - eval_gen_len = 17.66
02/05/2021 13:00:42 - INFO - __main__ - eval_loss = 5.084951400756836
02/05/2021 13:00:42 - INFO - __main__ - eval_runtime = 0.7079
02/05/2021 13:00:42 - INFO - __main__ - eval_samples_per_second = 141.261
```
As you can see:
1. the metrics numbers aren't rounded up
2. missing `*_n_obj` in metrics
3. logging is inconsistent.
the old script has its own issues with log consistency, this one introduces its own inconsistencies.
To make it easy to read the results - the user-targeted output should ideally be aligned on one side and not in 2 columns - i.e. left column date, etc. right column information. In the new script `***** Running Evaluation *****` is missing the logger prefix.
Thank you!
@patil-suraj, @sgugger | 02-05-2021 22:20:31 | 02-05-2021 22:20:31 | this has been resolved in various PRs. It's looking even better than before. |
transformers | 10,037 | closed | [examples] make run scripts executable | For consistently and convenience of not needing to type `python` to run a script this PR adds to all `examples/*/run_*py` scripts a python shebang and make the scripts executable.
Was done with:
```
perl -0777 -pi -e 's|^|#!/usr/bin/env python\n|' */run_*.py
chmod a+x */run_*.py
```
@patil-suraj , @sgugger | 02-05-2021 22:12:39 | 02-05-2021 22:12:39 | Totally!
Just this one:
```
/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py
```
correct?
Any other scripts that I didn't catch with `examples/*/run_*.py`?
<|||||>I don't think so, we should be good. |
transformers | 10,036 | closed | [s2s examples] convert existing scripts to run_seq2seq.py from finetune_trainer.py | As `transformers` examples are evolving it seems that the good old `finetune_trainer.py` is going to be moved into unmaintained `examples/legacy/` area, and `run_seq2seq.py` is to be the new king, so let's automate this process
Assuming your cmd script is `process.txt` (and replace with the file names that you have (one or many), let's auto-adjust it:
1. Renames
```
# main name and args rename
perl -pi -e 's|finetune_trainer|run_seq2seq|g; s#--n_(train|val)#--max_$1_samples#g; \
s|--src_lang|--source_lang|g; s|--tgt_lang|--target_lang|g; s|--eval_beams|--num_beams|' process.txt
# drop no longer supported args
perl -pi -e 's|--freeze_embeds||; s|--test_max_target_length[ =]+\d+||;' process.txt
```
2. t5 auto-adding prefix has been dropped, so you need to add it manually, e.g.:
```
--source_prefix "translate English to Romanian: "
```
otherwise the results would be terrible.
3. Datasets are different
a. need to convert the normal dataset into jsonlines (unless the data is already on datasets hub)
instructions are: https://huggingface.co/docs/datasets/loading_datasets.html#json-files
b. new arguments:
instead of
```
--data_dir {data_dir}
```
now you need:
```
--train_file {data_dir}/train.json
--validation_file {data_dir}/val.json
```
Here's is an example conversion script for the `wmt_en_ro` dataset:
```
# convert.py
import io
import json
import re
src_lang, tgt_lang = ["en", "ro"]
for split in ["train", "val", "test"]:
recs = []
fout = f"{split}.json"
with io.open(fout, "w", encoding="utf-8") as f:
for type in ["source", "target"]:
fin = f"{split}.{type}"
recs.append([line.strip() for line in open(fin)])
for src, tgt in zip(*recs):
out = {"translation": { src_lang: src, tgt_lang: tgt } }
x = json.dumps(out, indent=0, ensure_ascii=False)
x = re.sub(r'\n', ' ', x, 0, re.M)
f.write(x + "\n")
```
Or if you find an existing dataset in `datasets`, you can supply it instead of the `--data_dir` arg as following:
```
--dataset_name wmt16 --dataset_config_name ro-en
```
Here is the full conversion table from the previously recommended 4 datasets in the `examples/seq2seq` folder:
* [x] `--data_dir wmt_en_de` => `--dataset_name wmt14 --dataset_config "de-en"` or if you want the highest score use: `--dataset_name wmt14-en-de-pre-processed`
* [x] `--data_dir wmt_en_ro` => --dataset_name wmt16 --dataset_config "ro-en"`
* [x] `--data_dir cnn_dm` => `--dataset_name cnn_dailymail --dataset_config "3.0.0"`
* [x] `--data_dir xsum` => `--dataset_name xsum`
You will find more details [here](https://github.com/huggingface/transformers/issues/10044#issuecomment-779555741)
----
t5-specific changes: from https://github.com/huggingface/transformers/pull/10133#issuecomment-778071812
1. Use the same dataset
2. if using T5 manually pass the `prefix` argument,
3. manually copy the `task_specific_parms` to `config`
| 02-05-2021 21:35:27 | 02-05-2021 21:35:27 | `run_seq2seq.py` didn't survive for long, it's no more in master, so yet another automatic conversion for translation scripts is:
```
perl -pi -e 's|run_seq2seq.py|run_translation.py|g; s|--task translation_(\w\w)_to_(\w\w)|--source_lang $1 --target_lang $2|;' process.txt
```
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,035 | closed | Cannot import DataCollatorForSeq2Seq from Transformers library | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.2.2
- Platform: Ubuntu
- Python version: 3.7
- PyTorch version (GPU?):
- Tensorflow version (GPU?): 1.7.1 - GPU : T4
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?:
### Who can help
@patil-suraj
@sgugger
## Information
Model I am using (Bert, XLNet ...): mT5
The problem arises when using:
* [ ] the official example scripts: run_seq2seq.py
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: Translation
* [ ] my own task or dataset: My own json dataset
## To reproduce
Steps to reproduce the behavior:
```
python run_seq2seq.py \
--model_name_or_path google/mt5-small \
--do_train \
--do_eval \
--task translation_en_to_fa \
--train_file Persian/seq2seq_train.json \
--validation_file Persian/seq2seq_val.json \
--output_dir translation_task_output \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate \
--text_column text_column_name \
--max_source_length 64 \
--max_target_length 64 \
--max_train_samples 10240 \
--max_val_samples 512 \
--source_lang en \
--target_lang fa \
--eval_beams 1 \
--source_prefix "translate English to Persian: "
```
## Error:
```
File "run_seq2seq.py", line 31, in <module>
from transformers import (
ImportError: cannot import name 'DataCollatorForSeq2Seq' from 'transformers' (unknown location)
```
| 02-05-2021 17:16:31 | 02-05-2021 17:16:31 | Could you try running this on master ? I just ran this script on master and it's working fine.<|||||>As mentioned in the README of the [examples folder](https://github.com/huggingface/transformers/tree/master/examples#important-note), all examples require a [source install](https://huggingface.co/transformers/installation.html#installing-from-source).
`DataCollatorForSeq2Seq` is not in the last release, it was introduced since then.<|||||>@sgugger @patil-suraj Thanks :) |
transformers | 10,034 | closed | Truncate max length if needed in all examples | # What does this PR do?
As pointed out in #10015, most examples will let the tokenzation and training run when `tokenizer.model_max_length < max_seq_length` and the default value is sometimes bigger than the max length for some models (like BertTweet). This PR addresses that.
Fixes #10015 | 02-05-2021 16:17:20 | 02-05-2021 16:17:20 | @sgugger Thanks for fixing this. I made this mistake again (running many jobs at once with different models) and my jobs didn't crash (meanwhile I had upgraded to the latest transformers 🚀 ) |
transformers | 10,033 | closed | A few fixes in the documentation | # What does this PR do?
This PR fixes a few things in the documentation mainly:
- version tags to reflect the latest patch-release (4.2.2
- documents decode and batch_decode in `PreTrainedTokenizer` and `PreTrainedTokenizerFast`.
Fixes #10019
| 02-05-2021 15:46:53 | 02-05-2021 15:46:53 | |
transformers | 10,032 | closed | generation length always equal to 20 when using run_seq2seq.py script | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.0.dev0
- Platform: Linux-4.4.0-197-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@patrickvonplaten @LysandreJik
Model I am using : any seq2seq model
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: cnn-dailymail / xsum
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```
python examples/seq2seq/run_seq2seq.py --model_name_or_path t5-small --do_train --do_eval --task summarization --dataset_name cnn_dailymail --dataset_config_name 3.0.0 --output_dir tmp --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --max_steps 250 --eval_steps 249 --save_steps 249 --max_val_samples 250 --max_target_length 100 --val_max_target_length 100 --predict_with_generate
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
```
02/05/2021 16:36:34 - INFO - __main__ - ***** Eval results *****
02/05/2021 16:36:34 - INFO - __main__ - epoch = 0.01
02/05/2021 16:36:34 - INFO - __main__ - eval_gen_len = 19.0
02/05/2021 16:36:34 - INFO - __main__ - eval_loss = 2.064879894256592
02/05/2021 16:36:34 - INFO - __main__ - eval_rouge1 = 21.837379907220157
02/05/2021 16:36:34 - INFO - __main__ - eval_rouge2 = 7.506564948396541
02/05/2021 16:36:34 - INFO - __main__ - eval_rougeL = 18.074704390199546
02/05/2021 16:36:34 - INFO - __main__ - eval_rougeLsum = 17.99211046381146
02/05/2021 16:36:34 - INFO - __main__ - eval_runtime = 19.079
02/05/2021 16:36:34 - INFO - __main__ - eval_samples_per_second = 13.103
```
`eval_gen_len` is never exceeding 20 for some reason. I tried with several models and datasets
| 02-05-2021 15:37:53 | 02-05-2021 15:37:53 | Hi @moussaKam
Thank you for reporting this.
Could you try evaluating directly using the generate method and calculate `avg eval_gen_len` ?<|||||>Hi @patil-suraj
I tried with the `generate` method, the model is well trained and can generate sequences with more than 20 tokens. Apparently the problem is in the prediction in the `run_seq2seq.py` script.<|||||>The issue was that the argument `val_max_target_length ` was never passed to `evaluate`, so `generate` used the default value for `max_length` which is 20. It'll be fixed after #10085 <|||||>Thanks @patil-suraj |
transformers | 10,031 | closed | AttributeError: module 'transformers' has no attribute 'PegasusForCausalLM' | ## Environment info
- `transformers` version: 4.2.2
- Platform: Linux-5.8.0-40-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@sgugger @patil-suraj
Models:
-tuner007/pegasus_paraphrase
## Information
trying to import "PegasusForCausalLM" from transformers and I got AttributeError: module 'transformers' has no attribute 'PegasusForCausalLM'
## To reproduce
```python
from transformers import PegasusForCausalLM, AutoConfig
model_name = "tuner007/pegasus_paraphrase"
output_logits = True
output_hidden_states = True
p_config =AutoConfig.from_pretrained(
model_name,
output_hidden_states=output_hidden_states,
output_logits=output_logits)
pegasus = PegasusForCausalLM.from_pretrained(model_name, config=p_config)
```
```
AttributeError: module transformers has no attribute PegasusForCausalLM
```
| 02-05-2021 15:03:29 | 02-05-2021 15:03:29 | Yes, this model was only added recently, it's not in v4.2.1 (check the [documentation](https://huggingface.co/transformers/model_doc/pegasus.html)).
You need to install the pre-release:
```
pip install transformers --pre
```
or [install from source](https://huggingface.co/transformers/installation.html#installing-from-source) to use it.
|
transformers | 10,030 | closed | Check copies match full class/function names | # What does this PR do?
@LysandreJik pointed out a failure in the `check_copies` script that came from the fact that when looking for the code of an object, the script was matching the first line it found that begun with the name of the object. So it would match `DebertaLayer` with `DebertaLayerNorm` and compare those.
This PR fixes that. | 02-05-2021 14:53:03 | 02-05-2021 14:53:03 | |
transformers | 10,029 | closed | Override Default Params on QnA Pipeline | How should we override the default params of QnA Model in Pipelines?
I tried the below but it throws an error?!
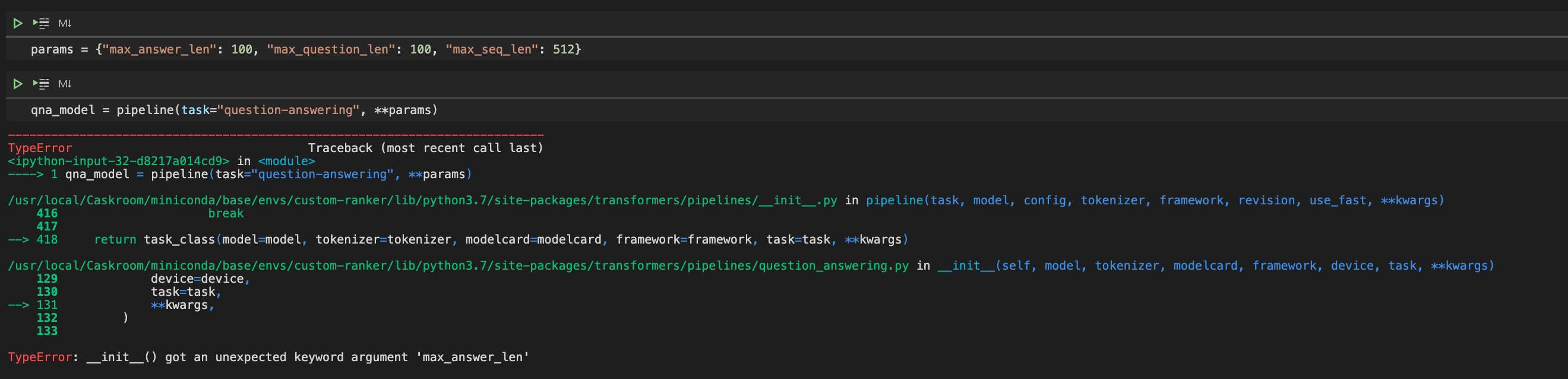 | 02-05-2021 14:48:36 | 02-05-2021 14:48:36 | I think you first need to initialize the pipeline, and then call it with any parameters you like. Example:
```
from transformers import pipeline
nlp = pipeline("question-answering")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text given a question. An example of a
question answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune
a model on a SQuAD task, you may leverage the examples/question-answering/run_squad.py script.
result = nlp(question="What is extractive question answering?", context=context, max_answer_len=100)
```
For the documentation of the `__call__` method of `QuestionAnsweringPipeline`, see [here](https://huggingface.co/transformers/main_classes/pipelines.html#transformers.QuestionAnsweringPipeline.__call__).<|||||>This solved my issue. Thank you very much. |
transformers | 10,028 | closed | custom JSON data breaks run_seq2seq.py | ## Environment info
- `transformers` version: 4.4.0.dev0
- Platform: Linux-4.19.0-11-amd64-x86_64-with-debian-10.6
- Python version: 3.7.3
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
@sgugger, @patil-suraj
## Information
I'm trying to use mt5 model (but same happens with the example t5-small)
The problem arises when using:
* [ x ] the official example scripts: (give details below)
## To reproduce
When I try to run example/seq2se1/run_seq2seq.py with my own data files, the following error occurs:
```Downloading and preparing dataset json/default-f1b6ef8723ed4d49 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/xxxxxx/.cache/huggingface/datasets/json/default-f1b6ef8723ed4d49/0.0.0/70d89ed4db1394f028c651589fcab6d6b28dddcabbe39d3b21b4d41f9a708514...
Traceback (most recent call last):
File "/home/xxxxx/.cache/huggingface/modules/datasets_modules/datasets/json/70d89ed4db1394f028c651589fcab6d6b28dddcabbe39d3b21b4d41f9a708514/json.py", line 82, in _generate_tables
parse_options=self.config.pa_parse_options,
File "pyarrow/_json.pyx", line 247, in pyarrow._json.read_json
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: JSON parse error: Column() changed from object to array in row 0
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "examples/seq2seq/run_seq2seq.py", line 537, in <module>
main()
File "examples/seq2seq/run_seq2seq.py", line 287, in main
datasets = load_dataset(extension, data_files=data_files)
File "/home/xxxxx/.local/lib/python3.7/site-packages/datasets/load.py", line 612, in load_dataset
ignore_verifications=ignore_verifications,
File "/home/xxxxx/.local/lib/python3.7/site-packages/datasets/builder.py", line 527, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/xxxxx/.local/lib/python3.7/site-packages/datasets/builder.py", line 604, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/xxxx/.local/lib/python3.7/site-packages/datasets/builder.py", line 959, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False, disable=not_verbose):
File "/home/xxxx/.local/lib/python3.7/site-packages/tqdm/std.py", line 1166, in __iter__
for obj in iterable:
File "/home/xxxxxxxx/.cache/huggingface/modules/datasets_modules/datasets/json/70d89ed4db1394f028c651589fcab6d6b28dddcabbe39d3b21b4d41f9a708514/json.py", line 88, in _generate_tables
f"Not able to read records in the JSON file at {file}. "
AttributeError: 'list' object has no attribute 'keys'
```
I'm using the following json format:
```
[
{
"title": "summarised text",
"body": "text to be summarized"
},
{
"title": "summarised text",
"body": "text to be summarized"
}
]
```
I pass the --text_column body --summary_column title to the script and I can't understand why it's breaking.
| 02-05-2021 14:14:45 | 02-05-2021 14:14:45 | Hi @varna9000
The script expects jsonline format where each line is a `json` object. for ex:
```
{"title": "summarised text","body": "text to be summarized"}
{"title": "summarised text","body": "text to be summarized"}
```
You can find more info in the `datasets` doc here https://huggingface.co/docs/datasets/loading_datasets.html#json-files<|||||>Thank you! :)<|||||>Hi, I somehow encountered the same problem. Can I ask you how did you solve it?<|||||>> Hi, I somehow encountered the same problem. Can I ask you how did you solve it?
Encountered too.<|||||>@judy-jii @hihihihiwsf it has been answered. You have to pass jsonlines format, not json.<|||||>For anyone else who gets here from google, make sure your JSON lines are not wrapped in quote marks or something similar. Each line should be a valid JSON object, not a string. |
transformers | 10,027 | closed | Bump minimum Jax requirement to 2.8.0 | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
According to https://github.com/google/jax/issues/5374 this should fix #10017
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-05-2021 12:49:13 | 02-05-2021 12:49:13 | You need to run `make style` to update the table deps ;-) |
transformers | 10,026 | closed | T5 doubling training time per iteration from save_steps to save_steps (1st 100 steps 33s/it - then, 75s/it) | ## Environment info
- `transformers` version: 4.3.0.dev0
- Platform: Ubuntu 18.04
- Python version: 3.7
- PyTorch version (GPU?): 1.7.1 (YES)
- Tensorflow version (GPU?):
- Using GPU in script?: YES
- Using distributed or parallel set-up in script?:
### Who can help
@patrickvonplaten @patil-suraj @sgugger
## Information
Model I am using (Bert, XLNet ...): T5
The problem arises when using:
* [x] the official example scripts: (give details below)
The problem arises when using examples/seq2seq/run_seq2seq.py
* [ ] my own modified scripts: (give details below)
The problem arises when trying to fine-tune t5 in a text2text task using the official scripts (run_seq2seq.py). The first problem is that after the first checkpoint saved, the training becomes super slow, taking twice the time it took until that checkpoint. The second problem is that when you try to load a model from one of those checkpoints, it's like the model has increased in size (not directly, but when processing batches it uses much more memory). Let me explain myself. If you start with t5-large, in a P100 16GB gpu I can fit around 350 sequence length, 52 target length, 2 train batch size per device. However, if I start from one of the checkpoints saved (which are also t5-large, just a little bit more trained) I cannot even fit batch size 1, seq length 256, target length 50, and this is really strange.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
A summarization dataset
## To reproduce
Steps to reproduce the behavior:
1. Get any summarization or any text2text dataset.
2. Train a t5-large using examples/seq2seq/run_seq2seq.py and set save_steps to 100
3. Wait until the 100 first steps have been completed, you'll see that with a batch size of 64 (using gradient accumulation) it takes 33s/iter approx.
4. After that, when the first checkpoint is created, the training will re-start, but this time using 75s/iter, doubling its time. Over the course of the rest of the training, you'll see this same timing, it never goes back to 33s/iter.
5. Then, try to adapt this model to another dataset or to the same dataset itself, and appreciate that it's unfeasible to train with the previously specified parameters, which shouldn't happen because this model should use the same memory as the original t5. However, it's not that the model itself is bigger when loaded in the gpu, what happens is that when loading batches of tensors and processing them, memory requirements exceed significantly the ones required by the same training setup changing my trained model for t5-large (the only thing that changes is the model).
## Expected behavior
It's expected that training time (iterations /s) is approx. the same during the whole training process, it's not supposed to double due to (apparently) no reason. Moreover, it's expected that when you load a re-trained t5-large you can fine-tune it with the same training setup (batch size etc) as the one used for t5-large. | 02-05-2021 12:48:59 | 02-05-2021 12:48:59 | Hey @alexvaca0,
Could you please provide us the command you used to train `t5-large` with `run_seq2seq.py` so that we can reproduce? <|||||>Also note that the timing is just a tqdm timing, that takes into account how long each iteration takes. Since the model saving takes a long time, it's normal to see it jump around a saving step and never go back to the best score of the first iterations.<|||||>I don't intend to see it go back to the best score of the first iterations, but long after the last time it has been saved, it still takes twice as much time per iteration. Let me share with you the command used:
First, I pre-trained t5 using the concepts explained here (taken from https://huggingface.co/transformers/master/model_doc/t5.html):
```{python}
input_ids = tokenizer('The <extra_id_0> walks in <extra_id_1> park', return_tensors='pt').input_ids
labels = tokenizer('<extra_id_0> cute dog <extra_id_1> the <extra_id_2>', return_tensors='pt').input_ids
# the forward function automatically creates the correct decoder_input_ids
loss = model(input_ids=input_ids, labels=labels).loss
```
For that I used the following command:
```{bash}
nohup python transformers/examples/seq2seq/run_seq2seq.py \
--model_name_or_path t5-large \
--do_eval --do_train \
--train_file /perturbed_data/tr.csv \
--validation_file /perturbed_data/val.csv \
--output_dir t5_lm \
--overwrite_output_dir \
--per_device_train_batch_size=2 \
--per_device_eval_batch_size=16 \
--eval_accumulation_steps=10 \
--max_source_length 346 \
--max_target_length 60 \
--val_max_target_length 60 --evaluation_strategy steps \
--gradient_accumulation_steps 128 --num_train_epochs=20 --eval_beams=1 \
--load_best_model_at_end --save_steps 100 --logging_steps 100 --learning_rate 7e-5 > bart_basic.txt &
```
Then, with that model trained, I tried to fine-tune it on a summarization task with the following command:
```{bash}
python transformers/examples/seq2seq/run_seq2seq.py \
--model_name_or_path t5-lm \
--do_eval --do_train \
--train_file summary_train_df.csv \
--validation_file summary_val_df.csv \
--output_dir t5_0802 \
--overwrite_output_dir \
--per_device_train_batch_size=2 \
--per_device_eval_batch_size=16 \
--eval_accumulation_steps=10 \
--max_source_length 346 \
--max_target_length 60 \
--val_max_target_length 60 --evaluation_strategy steps \
--gradient_accumulation_steps 32 --num_train_epochs=20 --eval_beams=1 \
--load_best_model_at_end --save_steps 250 --logging_steps 250 --learning_rate 3e-5
```
This is for the second part of the issue, that is, the fact that when trying to load my lm-trained t5 from disk and re-train it on a summarization corpus the batches it processes suddenly occupy much more than when they're processed by t5-large (without re-training on the LM task).
For the other part of the issue, the only command that needs to be run is:
```{bash}
python transformers/examples/seq2seq/run_seq2seq.py \
--model_name_or_path t5-large \
--do_eval --do_train \
--train_file summary_train_df.csv \
--validation_file summary_val_df.csv \
--output_dir t5_0802 \
--overwrite_output_dir \
--per_device_train_batch_size=2 \
--per_device_eval_batch_size=16 \
--eval_accumulation_steps=10 \
--max_source_length 346 \
--max_target_length 60 \
--val_max_target_length 60 --evaluation_strategy steps \
--gradient_accumulation_steps 32 --num_train_epochs=20 --eval_beams=1 \
--load_best_model_at_end --save_steps 250 --logging_steps 250 --learning_rate 3e-5
```
@patrickvonplaten @sgugger <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,025 | closed | Check TF ops for ONNX compliance | # What does this PR do?
This PR aims to check if a model is compliant with ONNX Opset12 by adding a quick test and a script. The script is only for testing a saved model while the quick test aims to be run over a manually built graph. For now, only BERT is forced to be compliant with ONNX, but the test can be unlocked for any other model.
The logic can also be extended to any other framework/SDK we might think of, such as TFLite or NNAPI.
| 02-05-2021 12:46:23 | 02-05-2021 12:46:23 | That's the moment to create that list :)<|||||>Really like the idea of improving our ONNX compatibility in a more reliable way.
In this sense, I'm not sure this is the easiest way for approaching the problem.
May be it would be more suitable to just attempt to export the model through `keras2onnx` and report errors. This can also allow us to more easily test compatibility with various ONNX opset (10 is the minimum required).
We already have the `keras2onnx` dependency when using the optional requirements `onnxruntime`
Also, regarding the list of model to be supported I think we would like to have:
- BERT
- GPT2
- BART (cc @Narsil wdyt?)<|||||>> In this sense, I'm not sure this is the easiest way for approaching the problem.
May be it would be more suitable to just attempt to export the model through `keras2onnx` and report errors. This can also allow us to more easily test compatibility with various ONNX opset (10 is the minimum required).
I'm not in favour of running the export directly in the tests, as it is less flexible and not a compatible solution with other frameworks/SDKs. We can add any other opsets without problems with the proposed approach, but I don't think that going below the 12 is good idea. Only a few of the current models are compliant with opset < 12. Also, the default in the convert script is 11, not 10, so maybe we can propose opset 11 to be aligned. I think the proposed models below are compliant but we will largely reduce the number of compliant models with ONNX.
> Also, regarding the list of model to be supported I think we would like to have:
BERT
GPT2
BART (cc @Narsil wdyt?)
These three are ok on my side!<|||||>Add BART and GPT2 as a mandatory green test.<|||||>Testing ONNX operator support might be more complicated than this.
Each operator in itself supports a set of different shape(s) as input/output combined with different data types and various dynamic axis support ...
I would go for the easiest solution, well tested of using the official converter to report incompatibilities.<|||||>The problem with the solution to use the converter is that we cannot have the full list of incompatible operators, it will stop at the first encounter one, which would be too much annoying IMO. I think we can also assume that as long as the operator belongs to this list https://github.com/onnx/tensorflow-onnx/blob/master/support_status.md it is compliant. Until now, this assumption is true for all of our models.
Unless you know a case for which it is not true?
Also, I'm afraid to add a dependency to the onnxruntime would switch the quick test into a slow test, which reduces the traceability of a potential change that will break it.
If @LysandreJik, @sgugger and @patrickvonplaten agree on making the TF tests dependent on the two keras2onnx and onnxruntime packages, I can add a slow test that will run the following pipeline:
1. Create a SavedModel
2. Convert this SavedModel into ONNX with keras2onnx
3. Run the converted model with onnxruntime<|||||>We can add a test depending on `keras2onnx` or `onnxruntime` with a `@require_onnx` decorator. If you decide to go down this road, according to the time spent doing those tests, we'll probably put them in the slow suite (which is okay, no need to test that the model opsets on each PR)<|||||>I like the idea to add a decorator. I will add a slow test doing this in addition to the quick test.<|||||>I have reworked the quick test. Now, we can easily specify against which opset we want to test a model to be compliant. In the `onnx.json` file, all the operators are split in multiple opset, where each of them corresponds to the list of operators implemented in it. This should be way much easier to maintain and more flexible to use.
In addition to this I have added slow test that runs a complete pipeline of "keras model -> ONNX model -> optimized ONNX model -> quantized ONNX model".<|||||>As proposed by @mfuntowicz I switched the min required opset version from 12 to 10 for BERT, GPT2 and BART.<|||||>> Do you have an idea of how long the slow tests take ?
Depending of the model between 1 and 5min.
> According to the information gathered, would it be possible (in a next PR) to have a doc referencing the opset compliancy/onnx support for each model?
Do you mean to have an entire page about ONNX? Or just to add a paragraph in the doc of every model about it?
I think it is also important to mention that the model `TFGPT2ForSequenceClassification` cannot be converted into ONNX for now. The reason is because of the `tf.map_fn` function, that internally creates a `tf.while` with an iterator of type `tf.variant` which is not allowed in ONNX.<|||||>LGTM on my side!
@LysandreJik I have fixed the issue with `TFGPT2ForSequenceClassification`, so now it is compliant with ONNX.
@mfuntowicz I should have addressed your comments, please double check ^^<|||||>LGTM 👍🏻 <|||||>@LysandreJik Feel free to merge if the recent changes look ok for you!<|||||>@LysandreJik Yes, this is exactly that :) I plan to apply this update to the other causal models one by one 😉 |
transformers | 10,024 | closed | Datasets library not suitable for huge text datasets | ## Environment info
- `transformers` version: 4.3.0.dev0
- Platform: Ubuntu 18
- Python version: 3.7
- PyTorch version (GPU?): 1.7.1
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
@n1t0, @LysandreJik @patrickvonplaten @sgugger
## Information
Model I am using (Bert, XLNet ...):
BERT; but the problem arises before using it.
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Get 187GB (or other big-sized) dataset
2. Try to tokenize it.
3. Wait until your whole server crashes due to memory or disk (probably this last one).
The code used to train the tokenizer is:
```{python}
from argparse import ArgumentParser
from datasets import load_dataset
from transformers import AutoTokenizer
# luego se puede cambiar esto con load_from_disk
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--train_file", type=str, required=True, help="Train file with data.")
parser.add_argument("--val_file", type=str, required=True, help="Val file with data.")
parser.add_argument("--tokenizer_path", type=str, required=True, help="Path to tokenizer.")
parser.add_argument("--num_workers", type=int, required=False, default=40, help="Number of workers for processing.")
parser.add_argument("--save_path", type=str, required=True, help="Save path for the datasets.")
args = parser.parse_args()
data_files = {"train": args.train_file, "val": args.val_file}
print("Loading dataset...")
datasets = load_dataset("text", data_files=data_files)
print("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_path)
column_names = datasets["train"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
def tokenize_function(examples):
# Remove empty lines
examples["text"] = [line for line in examples["text"] if len(line) > 0 and not line.isspace()]
return tokenizer(
examples["text"],
padding="max_length",
truncation=True,
max_length=512,
# We use this option because DataCollatorForLanguageModeling (see below) is more efficient when it
# receives the `special_tokens_mask`.
return_special_tokens_mask=True,
)
print("Tokenizing dataset...")
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
num_proc=args.num_workers,
remove_columns=[text_column_name],
load_from_cache_file=False,
)
print("Saving to disk...")
tokenized_datasets.save_to_disk(args.save_path)
```
## Expected behavior
It's expected that the tokenized texts occupy less space than pure texts, however it uses approx 2 orders of magnitude more disk, making it unfeasible to pre-train a model using Datasets library and therefore examples scripts from Transformers.
| 02-05-2021 12:16:03 | 02-05-2021 12:16:03 | Yes, it does save the tokenization on disk to avoid loading everything in RAM.
> It's expected that the tokenized texts occupy less space than pure texts
You want the script to destroy your dataset?
The previous version of the scripts were loading every text in RAM so I would argue using Datasets makes it actually more possible to train with big datasets.
The examples are also just examples for quick fine-tuning/pre-training. If you are at the stage were your datasets don't even fit in disk space, some tweaks inside them are expected.<|||||>@sgugger The thing is that it uses soooo much disk. When it had processed 18.7GB of texts it was using 2.1TB of disk... My dataset fits in the disk, and I'm sure the tokenized dataset should fit too, as it's actually lighter than text (it's only a list of integers per text), what doesn't fit in disk are the pyarrow objects created by datasets.
Sorry if I didn't explain myself clearly before, but it's not a problem with RAM or Memory, the main problem is that even when trying to pre-tokenize the whole dataset, saving it to disk for further use, it's not possible because the objects stored in disk by datasets library use 2 orders of magnitude more disk space than the original texts.<|||||>Mmm, pinging @lhoestq as this seems indeed a huge bump in memory now that I see the numbers (I understood twice the space, not 100 times more, sorry!)<|||||>Same discussion on the `datasets` repo: https://github.com/huggingface/datasets/issues/1825
> tokenizing a dataset using map takes a lot of space since it can store input_ids but also token_type_ids, attention_mask and special_tokens_mask. Moreover if your tokenization function returns python integers then by default they'll be stored as int64 which can take a lot of space. Padding can also increase the size of the tokenized dataset.
To go forward it would be nice to optimize what we actually need to be stored on disk. If some columns are not useful maybe they can be dropped (and possibly recreated on-the-fly if needed). We should also tweak the tensors precisions.
Another approach would be to tokenize on-the-fly for pretraining.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,023 | closed | Accessing language modeling script checkpoint model and tokenizer for finetuning | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.0.dev0
- Platform: Red Hat Enterprise Linux Server 7.9 (Maipo)
- Python version:Python 3.7.9
- PyTorch version (GPU?):1.7.1
- Tensorflow version (GPU?):2.4.1
- Using GPU in script?:yes
- Using distributed or parallel set-up in script?:No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@sgugger, @patil-suraj
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. I was trying to further pretrain the xlm-roberta model on custom domain dataset using run_mlm.py. The checkpoints got saved in the checkpoint directory
2. But when I try to access the tokenizer or model. I get the error message.
3. When i tried to find the solution for the tokenizer issue it was trying to find the config.json file in the checkpoint folder but only tokenizer_config.json was available and it had parameter "name_or_path" instead of "model_type"
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
Tokenizer error:
ValueError: Unrecognized model in /output_dir/checkpoint-1000/. Should have a `model_type` key in its config.json, or contain one of the following strings in its name: led, blenderbot-small, retribert, mt5, t5, mobilebert, distilbert, albert, bert-generation, camembert, xlm-roberta, pegasus, marian, mbart, mpnet, bart, blenderbot, reformer, longformer, roberta, deberta, flaubert, fsmt, squeezebert, bert, openai-gpt, gpt2, transfo-xl, xlnet, xlm-prophetnet, prophetnet, xlm, ctrl, electra, encoder-decoder, funnel, lxmert, dpr, layoutlm, rag, tapas
Model error:
RuntimeError: Error(s) in loading state_dict for XLMRobertaForSequenceClassification:
size mismatch for roberta.embeddings.position_ids: copying a param with shape torch.Size([1, 514]) from checkpoint, the shape in current model is torch.Size([1, 512]).
size mismatch for roberta.embeddings.word_embeddings.weight: copying a param with shape torch.Size([250002, 768]) from checkpoint, the shape in current model is torch.Size([30522, 768]).
size mismatch for roberta.embeddings.position_embeddings.weight: copying a param with shape torch.Size([514, 768]) from checkpoint, the shape in current model is torch.Size([512, 768]).
size mismatch for roberta.embeddings.token_type_embeddings.weight: copying a param with shape torch.Size([1, 768]) from checkpoint, the shape in current model is torch.Size([2, 768]).
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
The tokenizer and model should load from the saved checkpoint folder | 02-05-2021 12:09:57 | 02-05-2021 12:09:57 | I'm trying to reproduce your error but not managing. Could you indicate the checkpoint you are using and the command you used to launch your training? Also, what is the exact content of your `checkpoint-1000` folder? It should have a `config.json` alongside a `pytorch_model.bin`.<|||||>Thanks @sgugger for the quick reply. I was testing using the checkpoint-1000 but all other folder checkpoints have the similar file contents. They are
1) scheduler.pt
2) tokenizer_config.json
3) optimizer.pt
4) sentencepiece.bpe.model
5) trainer_state.json
6) pytorch_model.bin
7) special_tokens_map.json
8) training_args.bin.
The checkpoints all had the tokenizer_config.json instead of config.json and the contents of the tokenizer_config.json had the following.
`{"bos_token": "<s>", "eos_token": "</s>", "sep_token": "</s>", "cls_token": "<s>", "unk_token": "<unk>", "pad_token": "<pad>", "mask_token": "<mask>", "model_max_length": 512, "name_or_path": "xlm-roberta-base"}`<|||||>I meant the checkpoint from the model hub (your model identifier). And the command that you use to run the script please. The model config should be saved along the rest, I'm trying to find out why that is not the case.<|||||>@sgugger The checkpoint folder was created by language modeling run_mlm.py script. The run_mlm.py script which I ran is with the following args.
```
python run_mlm.py \
--model_name_or_path xlm-roberta-base \
--train_file train_file \
--validation_file valid_file \
--do_train \
--do_eval \
--output_dir output_path \
--logging_dir log_path \
--logging_steps 100o \
--max_seq_length 512 \
--pad_to_max_length \
--learning_rate 2e-5 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--overwrite_output_dir \
--num_train_epochs 2 \
--eval_steps 100o \
--mlm_probability 0.15 \
--evaluation_strategy "steps"
```
And to access the model and tokenizer from the checkpoint folder I used the following commands:
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained(ckpt_path)
model = AutoModelForSequenceClassification.from_pretrained(
ckpt_path,
num_labels = 3,
output_attentions = False,
output_hidden_states = False,
)
```<|||||>Mmm, I ran the same command as you did (replacing the 100o by 100, I think it's a typo) on an env similar to yours (transformers master and PyTorch 1.7.1, Python 3.7.9). The problem does not occur, everything is properly saved and your second snippet runs without problem.<|||||>@sgugger Yes it is a typo in the code snippet above, sorry for that. Maybe I will retry the whole process in a different environment and test it out.<|||||>@sgugger I tried in in a Redhat server and the code generated the config.json without a hitch but when I ran the same code in AWS Sagemaker. The config.json file was not generated. And the log information during the AWS Sagemaker run is shared below. But not sure if this is related to the Sagemaker environment or not.
```
02/10/2021 19:34:51 - INFO - logger - Trainer.model is not a `PreTrainedModel`, only saving its state dict.
/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/_functions.py:64: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
warnings.warn('Was asked to gather along dimension 0, but all '
```
<|||||>Ah thanks, this is helpful! How are you launching the script in sagemaker exactly?<|||||>@sgugger I zipped all my transformers file into a zip file and ran the run_mlm.py script in a docker image using the configuration given in the github repo. All the hyperparameters were passed in a json format to the estimator and the logging dir was changed into the tensorboard directory in sagemaker. And may I know what is causing the above information in pretraining process?<|||||>@sgugger Something like this
```
tensorboard_logs = log_s3_path
from sagemaker.debugger import TensorBoardOutputConfig
tensorboard_output_config = TensorBoardOutputConfig(
s3_output_path=tensorboard_logs,
container_local_output_path='/opt/tensorboard/'
)
import json
# JSON encode hyperparameters.
def json_encode_hyperparameters(hyperparameters):
return {str(k): json.dumps(v) for (k, v) in hyperparameters.items()}
hyperparameters = json_encode_hyperparameters({
"sagemaker_program": "run_mlm.py",
"sagemaker_submit_directory": code_path_s3,
"model_name_or_path": "xlm-roberta-base",
"num_train_epochs": 1,
"learning_rate" : 2e-5,
"max_seq_length" : 512,
"eval_steps": 1000,
"mlm_probability": 0.15,
"logging_steps": 1000,
"save_steps": 1000,
"per_device_train_batch_size": 2,
"per_device_eval_batch_size": 2,
"output_dir": "/opt/ml/output",
"logging_dir": "/opt/tensorboard/",
"train_file": train_file,
"validation_file": validation_file,
})
from sagemaker.estimator import Estimator
estimator = Estimator(
image_uri=<docker_image_path>,
output_path=output_path,
output_kms_key=kms_key,
role=role,
tensorboard_output_config = tensorboard_output_config,
instance_count = 1,
instance_type=<instance_type>,
hyperparameters=hyperparameters,
)
estimator.fit(job_name=training_job_name, inputs ={"training":f'{training_data}',
"validation":validation_file_s3_path, })
```<|||||>Mmmm, Could you try with the latest version of Transformers (a source install of the released v4.3.2?) It seems the model that the `Trainer` saved has been wrapped by something (since it doesn't find it's a `PreTrainedModel`) but I'm not finding what. When trying on SageMaker on my side, I get a regular `PreTrainedModel` and it saves properly.
Just for my information, what kind of instance are you using (1 or several GPUs?)<|||||>@sgugger Currently I am using version 4.2.2, and I am running a multi-gpu instance (p3.8xlarge - 4 GPUs). And one more quick question, does the model checkpoint saved not possible to use for finetuning. I already know the config.json file for the XLM-Roberta architecture so it is possible to using it along with the model variables stored in every checkpoint even though the Trainer class is not able to find it as a PreTrainedModel as a backup option or the model saved in each checkpoint would not be updated from the pretrained model even though it is being pretrained.<|||||>You can load the model weights manually with something like:
```
config = AutoConfig.from_pretrained("xlm-roberta-base")
model = AutoModel.from_config(config)
model.load_state_dict(torch.load(checkpoint_file))
```
<|||||>@sgugger I tried the running with v4.3.2. But I am getting tokenizer errors, which did not occur before.
thread '<unnamed>' panicked at 'index out of bounds: the len is 300 but the index is 300', /__w/tokenizers/tokenizers/tokenizers/src/tokenizer/normalizer.rs:382:21
pyo3_runtime.PanicException: index out of bounds: the len is 300 but the index is 300
And the saved checkpoint folder has multiple files for pytorch, which one should I load using torch.load()<|||||>I can't help you if you don't show me the content of that folder. I'm also unsure of the error for your tokenizer since there is no `tokenzier` in the snippet of code I pasted above.<|||||>@sgugger I think I did not convey the error correctly. I was having confusion on what file I should you as the checkpoint file in the code which you have shared.
```
config = AutoConfig.from_pretrained("xlm-roberta-base")
model = AutoModel.from_config(config)
model.load_state_dict(torch.load(checkpoint_file))
```
As in the checkpoint directory I have these files.
1. scheduler.pt
2. tokenizer_config.json
3. optimizer.pt
4. sentencepiece.bpe.model
5. trainer_state.json
6. pytorch_model.bin
7. special_tokens_map.json
8. training_args.bin.
And the tokenizer error which I have pasted is when trying to trigger the run_mlm.py script of transformers v4.3.2 on the training dataset as you had told me to try with the latest version of transformers. The new script fails in the tokenization step itself.<|||||>I will try to reproduce your error for the tokenizer. For the checkpoint file, you have to use `pytorch_model.bin`, this is where your model weights are.<|||||>@sgugger I tried to load the model from the ```pytorch_model.bin``` But I am getting the following error.
```
--------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-4-3bd59185f8cc> in <module>
2 model = AutoModel.from_config(config)
3 model_path = "/home/ec2-user/SageMaker/samples/new_checkpoint_test/checkpoint-1000/pytorch_model.bin"
----> 4 model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
~/anaconda3/envs/pytorch_latest_p36/lib/python3.6/site-packages/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)
1050 if len(error_msgs) > 0:
1051 raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
-> 1052 self.__class__.__name__, "\n\t".join(error_msgs)))
1053 return _IncompatibleKeys(missing_keys, unexpected_keys)
1054
RuntimeError: Error(s) in loading state_dict for RobertaModel:
Missing key(s) in state_dict: "embeddings.position_ids", "embeddings.word_embeddings.weight", "embeddings.position_embeddings.weight", "embeddings.token_type_embeddings.weight", "embeddings.LayerNorm.weight", "embeddings.LayerNorm.bias", "encoder.layer.0.attention.self.query.weight", "encoder.layer.0.attention.self.query.bias", "encoder.layer.0.attention.self.key.weight", "encoder.layer.0.attention.self.key.bias", "encoder.layer.0.attention.self.value.weight", "encoder.layer.0.attention.self.value.bias", "encoder.layer.0.attention.output.dense.weight", "encoder.layer.0.attention.output.dense.bias", "encoder.layer.0.attention.output.LayerNorm.weight", "encoder.layer.0.attention.output.LayerNorm.bias", "encoder.layer.0.intermediate.dense.weight", "encoder.layer.0.intermediate.dense.bias", "encoder.layer.0.output.dense.weight", "encoder.layer.0.output.dense.bias", "encoder.layer.0.output.LayerNorm.weight", "encoder.layer.0.output.LayerNorm.bias", "encoder.layer.1.attention.self.query.weight", "encoder.layer.1.attention.self.query.bias", "encoder.layer.1.attention.self.key.weight", "encoder.layer.1.attention.self.key.bias", "encoder.layer.1.attention.self.value.weight", "encoder.layer.1.attention.self.value.bias", "encoder.layer.1.attention.output.dense.weight", "encoder.layer.1.attention.output.dense.bias", "encoder.layer.1.attention.output.LayerNorm.weight", "encoder.layer.1.attention.output.LayerNorm.bias", "encoder.layer.1.intermediate.dense.weight", "encoder.layer.1.intermediate.dense.bias", "encoder.layer.1.output.dense.weight", "encoder.layer.1.output.dense.bias", "encoder.layer.1.output.LayerNorm.weight", "encoder.layer.1.output.LayerNorm.bias", "encoder.layer.2.attention.self.query.weight", "encoder.layer.2.attention.self.query.bias", "encoder.layer.2.attention.self.key.weight", "encoder.layer.2.attention.self.key.bias", "encoder.layer.2.attention.self.value.weight", "encoder.layer.2.attention.self.value.bias", "encoder.layer.2.attention.output.dense.weight", "encoder.layer.2.attention.output.dense.bias", "encoder.layer.2.attention.output.LayerNorm.weight", "encoder.layer.2.attention.output.LayerNorm.bias", "encoder.layer.2.intermediate.dense.weight", "encoder.layer.2.intermediate.dense.bias", "encoder.layer.2.output.dense.weight", "encoder.layer.2.output.dense.bias", "encoder.layer.2.output.LayerNorm.weight", "encoder.layer.2.output.LayerNorm.bias", "encoder.layer.3.attention.self.query.weight", "encoder.layer.3.attention.self.query.bias", "encoder.layer.3.attention.self.key.weight", "encoder.layer.3.attention.self.key.bias", "encoder.layer.3.attention.self.value.weight", "encoder.layer.3.attention.self.value.bias", "encoder.layer.3.attention.output.dense.weight", "encoder.layer.3.attention.output.dense.bias", "encoder.layer.3.attention.output.LayerNorm.weight", "encoder.layer.3.attention.output.LayerNorm.bias", "encoder.layer.3.intermediate.dense.weight", "encoder.layer.3.intermediate.dense.bias", "encoder.layer.3.output.dense.weight", "encoder.layer.3.output.dense.bias", "encoder.layer.3.output.LayerNorm.weight", "encoder.layer.3.output.LayerNorm.bias", "encoder.layer.4.attention.self.query.weight", "encoder.layer.4.attention.self.query.bias", "encoder.layer.4.attention.self.key.weight", "encoder.layer.4.attention.self.key.bias", "encoder.layer.4.attention.self.value.weight", "encoder.layer.4.attention.self.value.bias", "encoder.layer.4.attention.output.dense.weight", "encoder.layer.4.attention.output.dense.bias", "encoder.layer.4.attention.output.LayerNorm.weight", "encoder.layer.4.attention.output.LayerNorm.bias", "encoder.layer.4.intermediate.dense.weight", "encoder.layer.4.intermediate.dense.bias", "encoder.layer.4.output.dense.weight", "encoder.layer.4.output.dense.bias", "encoder.layer.4.output.LayerNorm.weight", "encoder.layer.4.output.LayerNorm.bias", "encoder.layer.5.attention.self.query.weight", "encoder.layer.5.attention.self.query.bias", "encoder.layer.5.attention.self.key.weight", "encoder.layer.5.attention.self.key.bias", "encoder.layer.5.attention.self.value.weight", "encoder.layer.5.attention.self.value.bias", "encoder.layer.5.attention.output.dense.weight", "encoder.layer.5.attention.output.dense.bias", "encoder.layer.5.attention.output.LayerNorm.weight", "encoder.layer.5.attention.output.LayerNorm.bias", "encoder.layer.5.intermediate.dense.weight", "encoder.layer.5.intermediate.dense.bias", "encoder.layer.5.output.dense.weight", "encoder.layer.5.output.dense.bias", "encoder.layer.5.output.LayerNorm.weight", "encoder.layer.5.output.LayerNorm.bias", "encoder.layer.6.attention.self.query.weight", "encoder.layer.6.attention.self.query.bias", "encoder.layer.6.attention.self.key.weight", "encoder.layer.6.attention.self.key.bias", "encoder.layer.6.attention.self.value.weight", "encoder.layer.6.attention.self.value.bias", "encoder.layer.6.attention.output.dense.weight", "encoder.layer.6.attention.output.dense.bias", "encoder.layer.6.attention.output.LayerNorm.weight", "encoder.layer.6.attention.output.LayerNorm.bias", "encoder.layer.6.intermediate.dense.weight", "encoder.layer.6.intermediate.dense.bias", "encoder.layer.6.output.dense.weight", "encoder.layer.6.output.dense.bias", "encoder.layer.6.output.LayerNorm.weight", "encoder.layer.6.output.LayerNorm.bias", "encoder.layer.7.attention.self.query.weight", "encoder.layer.7.attention.self.query.bias", "encoder.layer.7.attention.self.key.weight", "encoder.layer.7.attention.self.key.bias", "encoder.layer.7.attention.self.value.weight", "encoder.layer.7.attention.self.value.bias", "encoder.layer.7.attention.output.dense.weight", "encoder.layer.7.attention.output.dense.bias", "encoder.layer.7.attention.output.LayerNorm.weight", "encoder.layer.7.attention.output.LayerNorm.bias", "encoder.layer.7.intermediate.dense.weight", "encoder.layer.7.intermediate.dense.bias", "encoder.layer.7.output.dense.weight", "encoder.layer.7.output.dense.bias", "encoder.layer.7.output.LayerNorm.weight", "encoder.layer.7.output.LayerNorm.bias", "encoder.layer.8.attention.self.query.weight", "encoder.layer.8.attention.self.query.bias", "encoder.layer.8.attention.self.key.weight", "encoder.layer.8.attention.self.key.bias", "encoder.layer.8.attention.self.value.weight", "encoder.layer.8.attention.self.value.bias", "encoder.layer.8.attention.output.dense.weight", "encoder.layer.8.attention.output.dense.bias", "encoder.layer.8.attention.output.LayerNorm.weight", "encoder.layer.8.attention.output.LayerNorm.bias", "encoder.layer.8.intermediate.dense.weight", "encoder.layer.8.intermediate.dense.bias", "encoder.layer.8.output.dense.weight", "encoder.layer.8.output.dense.bias", "encoder.layer.8.output.LayerNorm.weight", "encoder.layer.8.output.LayerNorm.bias", "encoder.layer.9.attention.self.query.weight", "encoder.layer.9.attention.self.query.bias", "encoder.layer.9.attention.self.key.weight", "encoder.layer.9.attention.self.key.bias", "encoder.layer.9.attention.self.value.weight", "encoder.layer.9.attention.self.value.bias", "encoder.layer.9.attention.output.dense.weight", "encoder.layer.9.attention.output.dense.bias", "encoder.layer.9.attention.output.LayerNorm.weight", "encoder.layer.9.attention.output.LayerNorm.bias", "encoder.layer.9.intermediate.dense.weight", "encoder.layer.9.intermediate.dense.bias", "encoder.layer.9.output.dense.weight", "encoder.layer.9.output.dense.bias", "encoder.layer.9.output.LayerNorm.weight", "encoder.layer.9.output.LayerNorm.bias", "encoder.layer.10.attention.self.query.weight", "encoder.layer.10.attention.self.query.bias", "encoder.layer.10.attention.self.key.weight", "encoder.layer.10.attention.self.key.bias", "encoder.layer.10.attention.self.value.weight", "encoder.layer.10.attention.self.value.bias", "encoder.layer.10.attention.output.dense.weight", "encoder.layer.10.attention.output.dense.bias", "encoder.layer.10.attention.output.LayerNorm.weight", "encoder.layer.10.attention.output.LayerNorm.bias", "encoder.layer.10.intermediate.dense.weight", "encoder.layer.10.intermediate.dense.bias", "encoder.layer.10.output.dense.weight", "encoder.layer.10.output.dense.bias", "encoder.layer.10.output.LayerNorm.weight", "encoder.layer.10.output.LayerNorm.bias", "encoder.layer.11.attention.self.query.weight", "encoder.layer.11.attention.self.query.bias", "encoder.layer.11.attention.self.key.weight", "encoder.layer.11.attention.self.key.bias", "encoder.layer.11.attention.self.value.weight", "encoder.layer.11.attention.self.value.bias", "encoder.layer.11.attention.output.dense.weight", "encoder.layer.11.attention.output.dense.bias", "encoder.layer.11.attention.output.LayerNorm.weight", "encoder.layer.11.attention.output.LayerNorm.bias", "encoder.layer.11.intermediate.dense.weight", "encoder.layer.11.intermediate.dense.bias", "encoder.layer.11.output.dense.weight", "encoder.layer.11.output.dense.bias", "encoder.layer.11.output.LayerNorm.weight", "encoder.layer.11.output.LayerNorm.bias", "pooler.dense.weight", "pooler.dense.bias".
Unexpected key(s) in state_dict: "roberta.embeddings.position_ids", "roberta.embeddings.word_embeddings.weight", "roberta.embeddings.position_embeddings.weight", "roberta.embeddings.token_type_embeddings.weight", "roberta.embeddings.LayerNorm.weight", "roberta.embeddings.LayerNorm.bias", "roberta.encoder.layer.0.attention.self.query.weight", "roberta.encoder.layer.0.attention.self.query.bias", "roberta.encoder.layer.0.attention.self.key.weight", "roberta.encoder.layer.0.attention.self.key.bias", "roberta.encoder.layer.0.attention.self.value.weight", "roberta.encoder.layer.0.attention.self.value.bias", "roberta.encoder.layer.0.attention.output.dense.weight", "roberta.encoder.layer.0.attention.output.dense.bias", "roberta.encoder.layer.0.attention.output.LayerNorm.weight", "roberta.encoder.layer.0.attention.output.LayerNorm.bias", "roberta.encoder.layer.0.intermediate.dense.weight", "roberta.encoder.layer.0.intermediate.dense.bias", "roberta.encoder.layer.0.output.dense.weight", "roberta.encoder.layer.0.output.dense.bias", "roberta.encoder.layer.0.output.LayerNorm.weight", "roberta.encoder.layer.0.output.LayerNorm.bias", "roberta.encoder.layer.1.attention.self.query.weight", "roberta.encoder.layer.1.attention.self.query.bias", "roberta.encoder.layer.1.attention.self.key.weight", "roberta.encoder.layer.1.attention.self.key.bias", "roberta.encoder.layer.1.attention.self.value.weight", "roberta.encoder.layer.1.attention.self.value.bias", "roberta.encoder.layer.1.attention.output.dense.weight", "roberta.encoder.layer.1.attention.output.dense.bias", "roberta.encoder.layer.1.attention.output.LayerNorm.weight", "roberta.encoder.layer.1.attention.output.LayerNorm.bias", "roberta.encoder.layer.1.intermediate.dense.weight", "roberta.encoder.layer.1.intermediate.dense.bias", "roberta.encoder.layer.1.output.dense.weight", "roberta.encoder.layer.1.output.dense.bias", "roberta.encoder.layer.1.output.LayerNorm.weight", "roberta.encoder.layer.1.output.LayerNorm.bias", "roberta.encoder.layer.2.attention.self.query.weight", "roberta.encoder.layer.2.attention.self.query.bias", "roberta.encoder.layer.2.attention.self.key.weight", "roberta.encoder.layer.2.attention.self.key.bias", "roberta.encoder.layer.2.attention.self.value.weight", "roberta.encoder.layer.2.attention.self.value.bias", "roberta.encoder.layer.2.attention.output.dense.weight", "roberta.encoder.layer.2.attention.output.dense.bias", "roberta.encoder.layer.2.attention.output.LayerNorm.weight", "roberta.encoder.layer.2.attention.output.LayerNorm.bias", "roberta.encoder.layer.2.intermediate.dense.weight", "roberta.encoder.layer.2.intermediate.dense.bias", "roberta.encoder.layer.2.output.dense.weight", "roberta.encoder.layer.2.output.dense.bias", "roberta.encoder.layer.2.output.LayerNorm.weight", "roberta.encoder.layer.2.output.LayerNorm.bias", "roberta.encoder.layer.3.attention.self.query.weight", "roberta.encoder.layer.3.attention.self.query.bias", "roberta.encoder.layer.3.attention.self.key.weight", "roberta.encoder.layer.3.attention.self.key.bias", "roberta.encoder.layer.3.attention.self.value.weight", "roberta.encoder.layer.3.attention.self.value.bias", "roberta.encoder.layer.3.attention.output.dense.weight", "roberta.encoder.layer.3.attention.output.dense.bias", "roberta.encoder.layer.3.attention.output.LayerNorm.weight", "roberta.encoder.layer.3.attention.output.LayerNorm.bias", "roberta.encoder.layer.3.intermediate.dense.weight", "roberta.encoder.layer.3.intermediate.dense.bias", "roberta.encoder.layer.3.output.dense.weight", "roberta.encoder.layer.3.output.dense.bias", "roberta.encoder.layer.3.output.LayerNorm.weight", "roberta.encoder.layer.3.output.LayerNorm.bias", "roberta.encoder.layer.4.attention.self.query.weight", "roberta.encoder.layer.4.attention.self.query.bias", "roberta.encoder.layer.4.attention.self.key.weight", "roberta.encoder.layer.4.attention.self.key.bias", "roberta.encoder.layer.4.attention.self.value.weight", "roberta.encoder.layer.4.attention.self.value.bias", "roberta.encoder.layer.4.attention.output.dense.weight", "roberta.encoder.layer.4.attention.output.dense.bias", "roberta.encoder.layer.4.attention.output.LayerNorm.weight", "roberta.encoder.layer.4.attention.output.LayerNorm.bias", "roberta.encoder.layer.4.intermediate.dense.weight", "roberta.encoder.layer.4.intermediate.dense.bias", "roberta.encoder.layer.4.output.dense.weight", "roberta.encoder.layer.4.output.dense.bias", "roberta.encoder.layer.4.output.LayerNorm.weight", "roberta.encoder.layer.4.output.LayerNorm.bias", "roberta.encoder.layer.5.attention.self.query.weight", "roberta.encoder.layer.5.attention.self.query.bias", "roberta.encoder.layer.5.attention.self.key.weight", "roberta.encoder.layer.5.attention.self.key.bias", "roberta.encoder.layer.5.attention.self.value.weight", "roberta.encoder.layer.5.attention.self.value.bias", "roberta.encoder.layer.5.attention.output.dense.weight", "roberta.encoder.layer.5.attention.output.dense.bias", "roberta.encoder.layer.5.attention.output.LayerNorm.weight", "roberta.encoder.layer.5.attention.output.LayerNorm.bias", "roberta.encoder.layer.5.intermediate.dense.weight", "roberta.encoder.layer.5.intermediate.dense.bias", "roberta.encoder.layer.5.output.dense.weight", "roberta.encoder.layer.5.output.dense.bias", "roberta.encoder.layer.5.output.LayerNorm.weight", "roberta.encoder.layer.5.output.LayerNorm.bias", "roberta.encoder.layer.6.attention.self.query.weight", "roberta.encoder.layer.6.attention.self.query.bias", "roberta.encoder.layer.6.attention.self.key.weight", "roberta.encoder.layer.6.attention.self.key.bias", "roberta.encoder.layer.6.attention.self.value.weight", "roberta.encoder.layer.6.attention.self.value.bias", "roberta.encoder.layer.6.attention.output.dense.weight", "roberta.encoder.layer.6.attention.output.dense.bias", "roberta.encoder.layer.6.attention.output.LayerNorm.weight", "roberta.encoder.layer.6.attention.output.LayerNorm.bias", "roberta.encoder.layer.6.intermediate.dense.weight", "roberta.encoder.layer.6.intermediate.dense.bias", "roberta.encoder.layer.6.output.dense.weight", "roberta.encoder.layer.6.output.dense.bias", "roberta.encoder.layer.6.output.LayerNorm.weight", "roberta.encoder.layer.6.output.LayerNorm.bias", "roberta.encoder.layer.7.attention.self.query.weight", "roberta.encoder.layer.7.attention.self.query.bias", "roberta.encoder.layer.7.attention.self.key.weight", "roberta.encoder.layer.7.attention.self.key.bias", "roberta.encoder.layer.7.attention.self.value.weight", "roberta.encoder.layer.7.attention.self.value.bias", "roberta.encoder.layer.7.attention.output.dense.weight", "roberta.encoder.layer.7.attention.output.dense.bias", "roberta.encoder.layer.7.attention.output.LayerNorm.weight", "roberta.encoder.layer.7.attention.output.LayerNorm.bias", "roberta.encoder.layer.7.intermediate.dense.weight", "roberta.encoder.layer.7.intermediate.dense.bias", "roberta.encoder.layer.7.output.dense.weight", "roberta.encoder.layer.7.output.dense.bias", "roberta.encoder.layer.7.output.LayerNorm.weight", "roberta.encoder.layer.7.output.LayerNorm.bias", "roberta.encoder.layer.8.attention.self.query.weight", "roberta.encoder.layer.8.attention.self.query.bias", "roberta.encoder.layer.8.attention.self.key.weight", "roberta.encoder.layer.8.attention.self.key.bias", "roberta.encoder.layer.8.attention.self.value.weight", "roberta.encoder.layer.8.attention.self.value.bias", "roberta.encoder.layer.8.attention.output.dense.weight", "roberta.encoder.layer.8.attention.output.dense.bias", "roberta.encoder.layer.8.attention.output.LayerNorm.weight", "roberta.encoder.layer.8.attention.output.LayerNorm.bias", "roberta.encoder.layer.8.intermediate.dense.weight", "roberta.encoder.layer.8.intermediate.dense.bias", "roberta.encoder.layer.8.output.dense.weight", "roberta.encoder.layer.8.output.dense.bias", "roberta.encoder.layer.8.output.LayerNorm.weight", "roberta.encoder.layer.8.output.LayerNorm.bias", "roberta.encoder.layer.9.attention.self.query.weight", "roberta.encoder.layer.9.attention.self.query.bias", "roberta.encoder.layer.9.attention.self.key.weight", "roberta.encoder.layer.9.attention.self.key.bias", "roberta.encoder.layer.9.attention.self.value.weight", "roberta.encoder.layer.9.attention.self.value.bias", "roberta.encoder.layer.9.attention.output.dense.weight", "roberta.encoder.layer.9.attention.output.dense.bias", "roberta.encoder.layer.9.attention.output.LayerNorm.weight", "roberta.encoder.layer.9.attention.output.LayerNorm.bias", "roberta.encoder.layer.9.intermediate.dense.weight", "roberta.encoder.layer.9.intermediate.dense.bias", "roberta.encoder.layer.9.output.dense.weight", "roberta.encoder.layer.9.output.dense.bias", "roberta.encoder.layer.9.output.LayerNorm.weight", "roberta.encoder.layer.9.output.LayerNorm.bias", "roberta.encoder.layer.10.attention.self.query.weight", "roberta.encoder.layer.10.attention.self.query.bias", "roberta.encoder.layer.10.attention.self.key.weight", "roberta.encoder.layer.10.attention.self.key.bias", "roberta.encoder.layer.10.attention.self.value.weight", "roberta.encoder.layer.10.attention.self.value.bias", "roberta.encoder.layer.10.attention.output.dense.weight", "roberta.encoder.layer.10.attention.output.dense.bias", "roberta.encoder.layer.10.attention.output.LayerNorm.weight", "roberta.encoder.layer.10.attention.output.LayerNorm.bias", "roberta.encoder.layer.10.intermediate.dense.weight", "roberta.encoder.layer.10.intermediate.dense.bias", "roberta.encoder.layer.10.output.dense.weight", "roberta.encoder.layer.10.output.dense.bias", "roberta.encoder.layer.10.output.LayerNorm.weight", "roberta.encoder.layer.10.output.LayerNorm.bias", "roberta.encoder.layer.11.attention.self.query.weight", "roberta.encoder.layer.11.attention.self.query.bias", "roberta.encoder.layer.11.attention.self.key.weight", "roberta.encoder.layer.11.attention.self.key.bias", "roberta.encoder.layer.11.attention.self.value.weight", "roberta.encoder.layer.11.attention.self.value.bias", "roberta.encoder.layer.11.attention.output.dense.weight", "roberta.encoder.layer.11.attention.output.dense.bias", "roberta.encoder.layer.11.attention.output.LayerNorm.weight", "roberta.encoder.layer.11.attention.output.LayerNorm.bias", "roberta.encoder.layer.11.intermediate.dense.weight", "roberta.encoder.layer.11.intermediate.dense.bias", "roberta.encoder.layer.11.output.dense.weight", "roberta.encoder.layer.11.output.dense.bias", "roberta.encoder.layer.11.output.LayerNorm.weight", "roberta.encoder.layer.11.output.LayerNorm.bias", "lm_head.bias", "lm_head.dense.weight", "lm_head.dense.bias", "lm_head.layer_norm.weight", "lm_head.layer_norm.bias", "lm_head.decoder.weight", "lm_head.decoder.bias".
```<|||||>Oh sorry, the proper class is `AutoModelForMaskedLM` (since this is your current task), not `AutoModel`.<|||||>@sgugger Thanks, I am able to read the model checkpoint now. But the v4.3.2 tokenizer issue still persists, I have tried it in various environments.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 10,022 | closed | Added integration tests for Pytorch implementation of the FlauBert model | Added integration tests for Pytorch implementation of the FlauBert model
Fixes #9950
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
@LysandreJik | 02-05-2021 11:29:58 | 02-05-2021 11:29:58 | |
transformers | 10,021 | closed | Clarify QA pipeline output based on character | Fixes https://github.com/huggingface/transformers/issues/10013 | 02-05-2021 10:30:02 | 02-05-2021 10:30:02 | |
transformers | 10,020 | closed | Protobuf | ## Environment info
- `transformers` version: 4.2.2
- Platform: aws/codebuild/amazonlinux2-x86_64-standard:3.0 AND Windows-10-10.0.17763-SP0
- Python version: 3.8.3 AND 3.8.7
- PyTorch version (GPU?): 1.7.1+cpu (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: False
- Using distributed or parallel set-up in script?: False
### Who can help
@thomwolf @LysandreJik
Models:
- T-Systems-onsite/cross-en-de-roberta-sentence-transformer
Packages:
- pipenv
- sentence-transformers
## Information
Model I am using (Bert, XLNet ...): T-Systems-onsite/cross-en-de-roberta-sentence-transformer
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Create a new empty project with pipenv
2. Install sentence-transformers
3. Call SentenceTransformer('T-Systems-onsite/cross-en-de-roberta-sentence-transformer')
```
Traceback (most recent call last):
File "C:/Source/pythonProject/main.py", line 4, in <module>
SentenceTransformer('T-Systems-onsite/cross-en-de-roberta-sentence-transformer')
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\sentence_transformers\SentenceTransformer.py", line 87, in __init__
transformer_model = Transformer(model_name_or_path)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\sentence_transformers\models\Transformer.py", line 31, in __init__
self.tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, cache_dir=cache_dir, **tokenizer_args)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\models\auto\tokenization_auto.py", line 385, in from_pretrained
return tokenizer_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\tokenization_utils_base.py", line 1768, in from_pretrained
return cls._from_pretrained(
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\tokenization_utils_base.py", line 1841, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\models\xlm_roberta\tokenization_xlm_roberta_fast.py", line 133, in __init__
super().__init__(
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\tokenization_utils_fast.py", line 89, in __init__
fast_tokenizer = convert_slow_tokenizer(slow_tokenizer)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\convert_slow_tokenizer.py", line 659, in convert_slow_tokenizer
return converter_class(transformer_tokenizer).converted()
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\convert_slow_tokenizer.py", line 301, in __init__
requires_protobuf(self)
File "C:\Users\chrs\.virtualenvs\pythonProject-WdXdK-Rq\lib\site-packages\transformers\file_utils.py", line 467, in requires_protobuf
raise ImportError(PROTOBUF_IMPORT_ERROR.format(name))
ImportError:
XLMRobertaConverter requires the protobuf library but it was not found in your environment. Checkout the instructions on the
installation page of its repo: https://github.com/protocolbuffers/protobuf/tree/master/python#installation and follow the ones
that match your environment.
```
## Expected behavior
Somehow the protobuf dependency doesn't get installed properly with Pipenv and when I try initializing a SentenceTransformer Object with the T-Systems-onsite/cross-en-de-roberta-sentence-transformer it crashes. It can be resolved by manually installing Protobuf. I saw, that it is in your dependencies. This might be a Pipenv or SentenceTransformer issue as well but I thought I would start with you folks.
The error occured on our Cloud instance as well as on my local windows machine. If you think the issue is related to another package please let me know, then I will contact them 😊
Thanks a lot
| 02-05-2021 09:25:55 | 02-05-2021 09:25:55 | Just to make sure, can you try installing sentencepiece? `pip install sentencepiece`<|||||>Pip says
`Requirement already satisfied: sentencepiece in c:\users\chrs\.virtualenvs\pythonproject-wdxdk-rq\lib\site-packages (0.1.95)`
Pipenv "installs it" (I guess it just links it) and writes it to the lock-file. Running the example again I get the same error about Protobuf.<|||||>Okay, thank you for trying. Could you show me the steps you did to get this error, seeing as you get the errors on both your cloud instance and your windows machine? I'll try it on my Windows machine and try to reproduce the issue to find out what's happening.<|||||>Yeah the steps are as follows:
1. Create a new pipenv environment
2. Install sentence-transformers
3. Create a python file with the following content
`from sentence-transformers import SentenceTransformer`
`SentenceTransformer('T-Systems-onsite/cross-en-de-roberta-sentence-transformer')`
4. Run the python file => Error<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Facing the same issue with T5. Following demo code:
```
from transformers import AutoTokenizer, T5ForConditionalGeneration
model_name = "allenai/unifiedqa-t5-small"
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
<|||||>I had the same problem. I had tried many things like here [Link](https://stackoverflow.com/questions/31308812/no-module-named-google-protobuf) but nothing fixed the problem.
With the same environment I worked with the fastai library, which installs quite a few packages. So I created a new environment without fastai and now it works.
name: [NAME]
channels:
- conda-forge
- pytorch
dependencies:
- python=3.8
- pandas
- numpy
- scikit-learn
- seaborn
- pytest
- twine
- pip
- ftfy
- xlrd
- ipykernel
- notebook
- pip
- pip:
- azureml-core==1.0.*
- azureml-sdk==1.0.*
- pandas==1.0.5
- numpy==1.17.*
- fastavro==0.22.*
- pandavro==1.5.*
- sentencepiece==0.1.95
- datasets==1.8.0
- transformers==4.7.0
- seqeval==1.2.2
- tensorflow==2.5.0
- ipywidgets==7.6.3<|||||>As mentioned over [here](https://github.com/huggingface/transformers/issues/9515#issuecomment-869188308), `pip install protobuf` could help. <|||||>This is still a problem.
On an ubuntu cloud instance, I installed in a venv:
```
torch
transformers
pandas
seaborn
jupyter
sentencepiece
protobuf==3.20.1
```
I had to downgrade protobuf to 3.20.x for it to work.
Expected behaviour would be that it works without the need to search the internet to land at this fix.<|||||>Thanks @raoulg. I had the same issue working with the pegasus model, actually from an example in huggingface's new book. Downgrading to 3.20.x was the solution. |
transformers | 10,019 | closed | Tokenizer Batch decoding of predictions obtained from model.generate in t5 | How to do batch decoding of sequences obtained from model.generate in t5? Is there a function available for batch decoding in tokenizer `tokenizer.batch_decode_plus` similar to batch enocding `tokenizer.batch_encode_plus`? | 02-05-2021 08:02:32 | 02-05-2021 08:02:32 | There is `batch_decode`, yes, the docs are [here](https://huggingface.co/transformers/internal/tokenization_utils.html?highlight=batch_decode#transformers.tokenization_utils_base.PreTrainedTokenizerBase.batch_decode).
@sgugger I wonder if we shouldn't make the docs of this method more prominent? The "Utilities for tokenizer" page mentions: "Most of those are only useful if you are studying the code of the tokenizers in the library.", but `batch_decode` and `decode` are only found here, and are very important methods of the tokenization pipeline.<|||||>We should add them to the `PreTrainedTokenizer` and `PreTrainedTokenizerFast` documentation. Or did you want to add them to all models?
<|||||>@LysandreJik `tokenizer.batch_decode` and `tokenizer.decode` in loop, both the functions take almost the same time. can you suggest something, how can I speed up the decoding in T5? why is batch_decode not as fast as batch_encode_plus? Is there a way to make decoding even faster?<|||||>Unfortunately we have no way to go faster than that.<|||||>@LysandreJik this function is used in compute_metrics. and it seems it is limited to the number of GPUs ( it uses the same number of `--nproc_per_node` when doing ddp training, how is it possible to extend that to the maximum number of cores) any guide on how to fix and maybe do a PR? |
transformers | 10,018 | closed | Integrate DeBERTa v2(the 1.5B model surpassed human performance on Su… | # What does this PR do?
Integrate DeBERTa v2
1. Add DeBERTa XLarge model, DeBERTa v2 XLarge model, XXLarge model
|Model | Parameters| MNLI-m/mm|
|----------------- |------------ | ---------------|
|Base |140M |88.8/88.6 |
|Large |400M |91.3/91.1 |
|[XLarge](https://huggingface.co/microsoft/deberta-xlarge) |750M |91.5/91.2 |
|[V2-XLarge](https://huggingface.co/microsoft/deberta-v2-xlarge) |900M |91.7/91.6 |
|**[V2-XXLarge](https://huggingface.co/microsoft/deberta-v2-xxlarge)**|1.5B |**91.7/91.9** |
The 1.5B XXLarge-V2 model is the model that surpass human performance and T5 11B on [SuperGLUE](https://super.gluebenchmark.com/leaderboard) leaderboard.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 02-04-2021 23:55:08 | 02-04-2021 23:55:08 | Hi @BigBird01, thank you for opening the PR! Can you let me know once you're satisfied with your changes so that we can take a look? Thank you!<|||||>hi, Lysandre
I already tested the code and model. I think it’s good to go. Hope we can merge it into master soon, as there are a lot of people in the community waiting for a try with it.
Thanks!
Pengcheng
Get Outlook for iOS<https://aka.ms/o0ukef>
________________________________
From: Lysandre Debut <[email protected]>
Sent: Thursday, February 4, 2021 10:21:00 PM
To: huggingface/transformers <[email protected]>
Cc: Pengcheng He <[email protected]>; Mention <[email protected]>
Subject: Re: [huggingface/transformers] Integrate DeBERTa v2(the 1.5B model surpassed human performance on Su… (#10018)
Hi @BigBird01<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2FBigBird01&data=04%7C01%7CPengcheng.H%40microsoft.com%7C4e5ccdeff6dc4cda999b08d8c99e36f9%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481028648975065%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=fqbkcIs%2FwVkKIqCXBn0NjbZUx2ws7CO6wPKIg8CbQUU%3D&reserved=0>, thank you for opening the PR! Can you let me know once you're satisfied with your changes so that we can take a look? Thank you!
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fpull%2F10018%23issuecomment-773820084&data=04%7C01%7CPengcheng.H%40microsoft.com%7C4e5ccdeff6dc4cda999b08d8c99e36f9%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481028648975065%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=UaaB2syxP0gd3AKFP%2BRkxK0TU%2Fh8kEwS8vhu%2FCFvPfQ%3D&reserved=0>, or unsubscribe<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fnotifications%2Funsubscribe-auth%2FAJDNDRRDJHJGIDNKSUGZ63TS5OE4ZANCNFSM4XDYVO7A&data=04%7C01%7CPengcheng.H%40microsoft.com%7C4e5ccdeff6dc4cda999b08d8c99e36f9%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481028648985020%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=zYLDqVBRXr3TFu%2FNXABOll%2BBPvT54RvQt1cOHRG4dT4%3D&reserved=0>.
<|||||>I see, thanks. As mentioned by e-mail, I think the correct approach here is to create a `deberta-v2` folder that contains all of the changes, rather than implementing changes in the original `deberta` folder.
Can I handle that for you?<|||||>> I see, thanks. As mentioned by e-mail, I think the correct approach here is to create a `deberta-v2` folder that contains all of the changes, rather than implementing changes in the original `deberta` folder.
>
> Can I handle that for you?
But I think the current implementation is better. First ,the current changes not only contain the new features of v2 but also some improvements to v1. Second, the change between v2 and v1 is small. I also tested all the models with current implementation, and I didn't find any regression. Third and the most important, by creating another folder for deberta-v2 we need to add redundant code and tests to cover v2. This may introduce additional maintain effort in the future.
Let me know what's your thought.
<|||||>In that case, just feel free to take over the change and follow the rule to merge it to master. Please let me know when you finish it and I will take a test over it. Thanks in advance @[email protected]<mailto:[email protected]>
Get Outlook for iOS<https://aka.ms/o0ukef>
________________________________
From: Lysandre Debut <[email protected]>
Sent: Thursday, February 4, 2021 10:55:24 PM
To: huggingface/transformers <[email protected]>
Cc: Pengcheng He <[email protected]>; Mention <[email protected]>
Subject: Re: [huggingface/transformers] Integrate DeBERTa v2(the 1.5B model surpassed human performance on Su… (#10018)
@LysandreJik commented on this pull request.
The issues with modifying the code of the first version are:
* We might inadvertently modify some of the behavior of the past model
* We don't know what is the difference between the first and second version
For example here the DisentangledSelfAttention layer gets radically changed, with some layer name changes, which makes me dubious that you can load first version checkpoints inside.
Finally, you make a good point regarding maintainability. However, we can still enforce this by building some tools which ensure that the code does not diverge. We have this setup for a multitude of models, for example BART is very similar to mBART, Pegasus, Marian.
Please take a look at the mBART code and look for the "# Copied from ..." comments, such as the following:
https://github.com/huggingface/transformers/blob/3be965c5dbee794a7a3606df6a1ae36a0d65904d/src/transformers/models/mbart/modeling_mbart.py#L96-L108<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fblob%2F3be965c5dbee794a7a3606df6a1ae36a0d65904d%2Fsrc%2Ftransformers%2Fmodels%2Fmbart%2Fmodeling_mbart.py%23L96-L108&data=04%7C01%7CPengcheng.H%40microsoft.com%7Ce6bf8235a2654c89b0bc08d8c9a30491%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481049290703674%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=pvA7y0lA326x2LKdGrnEaFbrjl7AI5tVvk3fotCeQM0%3D&reserved=0>
This ensures that the two implementations do not diverge, it helps identify where the code is different, and it is what we've chosen to go through in order to keep readability to a maximum.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fpull%2F10018%23pullrequestreview-584064416&data=04%7C01%7CPengcheng.H%40microsoft.com%7Ce6bf8235a2654c89b0bc08d8c9a30491%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481049290703674%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=6taj4jBCjpauA8sHZETQSZgUWxe7IaPYLDzorhvY4EE%3D&reserved=0>, or unsubscribe<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fnotifications%2Funsubscribe-auth%2FAJDNDRUB2E3QCL4LSA6B34TS5OI5ZANCNFSM4XDYVO7A&data=04%7C01%7CPengcheng.H%40microsoft.com%7Ce6bf8235a2654c89b0bc08d8c9a30491%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481049290713636%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=q2G2HWxOOd1Hz2KJzEAeGDm8QTVolDlkkoLFrCUyrsE%3D&reserved=0>.
<|||||>This works for me, thank you for your understanding. I'll ping you once the PR can be reviewed.<|||||>Great! Thanks!
Get Outlook for iOS<https://aka.ms/o0ukef>
________________________________
From: Lysandre Debut <[email protected]>
Sent: Thursday, February 4, 2021 11:03:05 PM
To: huggingface/transformers <[email protected]>
Cc: Pengcheng He <[email protected]>; Mention <[email protected]>
Subject: Re: [huggingface/transformers] Integrate DeBERTa v2(the 1.5B model surpassed human performance on Su… (#10018)
This works for me, thank you for your understanding. I'll ping you once the PR can be reviewed.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fpull%2F10018%23issuecomment-773838474&data=04%7C01%7CPengcheng.H%40microsoft.com%7C3092474ab5094c50311108d8c9a417aa%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481053901879595%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=N6LqcZcPYCxNOm%2BBvLmPt3ZvG%2FmegyaNZFn5AEqLz10%3D&reserved=0>, or unsubscribe<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fnotifications%2Funsubscribe-auth%2FAJDNDRQD247WMEFTE7SRXNTS5OJ2TANCNFSM4XDYVO7A&data=04%7C01%7CPengcheng.H%40microsoft.com%7C3092474ab5094c50311108d8c9a417aa%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637481053901879595%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=lL68lmcS4iGlBfZvNttTSTsXpCq8hNTWhJUDzbFMtsA%3D&reserved=0>.
<|||||>PR to split the two models is here: https://github.com/BigBird01/transformers/pull/1<|||||>@BigBird01 just wanted to ask if the new additions involve the base and large versions of v2 as well, because i saw that new base and large deberta models were added as well, or will they be just v1?<|||||>> @BigBird01 just wanted to ask if the new additions involve the base and large versions of v2 as well, because i saw that new base and large deberta models were added as well, or will they be just v1?
For v2 we don't have base and large yet. But we will add them in the future.<|||||>Are there any bottlenecks preventing this from being merged?<|||||>> @BigBird01 just wanted to ask if the new additions involve the base and large versions of v2 as well, because i saw that new base and large deberta models were added as well, or will they be just v1?
I think @LysandreJik will merge the changes to master soon.
> PR to split the two models is here: [BigBird01#1](https://github.com/BigBird01/transformers/pull/1)
Thanks @LysandreJik. I just reviewed the PR and I'm good with it
> Are there any bottlenecks preventing this from being merged?
<|||||>After playing around with the model, I don't think we need pre-load hooks after all. In order to load the MNLI checkpoints, you just need to specify to the model that it needs three labels. It can be done as follows:
```py
from transformers import DebertaV2ForSequenceClassification
model = DebertaV2ForSequenceClassification.from_pretrained("microsoft/deberta-v2-xlarge-mnli", num_labels=3)
```
But this should be taken care of in the configuration. I believe all your MNLI model configurations should have the `num_labels` field set to `3` in order to be loadable.
---
Following this, I found a few issues with the XLARGE MNLI checkpoint. When loading it in the `DebertaForSequenceClassification` model, I get the following messages:
```
Some weights of the model checkpoint at microsoft/deberta-xlarge-mnli were not used when initializing DebertaForSequenceClassification: ['deberta.encoder.layer.0.attention.self.query_proj.weight', 'deberta.encoder.layer.0.attention.self.query_proj.bias', 'deberta.encoder.layer.0.attention.self.key_proj.weight', 'deberta.encoder.layer.0.attention.self.key_proj.bias', 'deberta.encoder.layer.0.attention.self.value_proj.weight', 'deberta.encoder.layer.0.attention.self.value_proj.bias', 'deberta.encoder.layer.0.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.0.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.0.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.0.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.1.attention.self.query_proj.weight', 'deberta.encoder.layer.1.attention.self.query_proj.bias', 'deberta.encoder.layer.1.attention.self.key_proj.weight', 'deberta.encoder.layer.1.attention.self.key_proj.bias', 'deberta.encoder.layer.1.attention.self.value_proj.weight', 'deberta.encoder.layer.1.attention.self.value_proj.bias', 'deberta.encoder.layer.1.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.1.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.1.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.1.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.2.attention.self.query_proj.weight', 'deberta.encoder.layer.2.attention.self.query_proj.bias', 'deberta.encoder.layer.2.attention.self.key_proj.weight', 'deberta.encoder.layer.2.attention.self.key_proj.bias', 'deberta.encoder.layer.2.attention.self.value_proj.weight', 'deberta.encoder.layer.2.attention.self.value_proj.bias', 'deberta.encoder.layer.2.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.2.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.2.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.2.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.3.attention.self.query_proj.weight', 'deberta.encoder.layer.3.attention.self.query_proj.bias', 'deberta.encoder.layer.3.attention.self.key_proj.weight', 'deberta.encoder.layer.3.attention.self.key_proj.bias', 'deberta.encoder.layer.3.attention.self.value_proj.weight', 'deberta.encoder.layer.3.attention.self.value_proj.bias', 'deberta.encoder.layer.3.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.3.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.3.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.3.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.4.attention.self.query_proj.weight', 'deberta.encoder.layer.4.attention.self.query_proj.bias', 'deberta.encoder.layer.4.attention.self.key_proj.weight', 'deberta.encoder.layer.4.attention.self.key_proj.bias', 'deberta.encoder.layer.4.attention.self.value_proj.weight', 'deberta.encoder.layer.4.attention.self.value_proj.bias', 'deberta.encoder.layer.4.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.4.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.4.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.4.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.5.attention.self.query_proj.weight', 'deberta.encoder.layer.5.attention.self.query_proj.bias', 'deberta.encoder.layer.5.attention.self.key_proj.weight', 'deberta.encoder.layer.5.attention.self.key_proj.bias', 'deberta.encoder.layer.5.attention.self.value_proj.weight', 'deberta.encoder.layer.5.attention.self.value_proj.bias', 'deberta.encoder.layer.5.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.5.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.5.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.5.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.6.attention.self.query_proj.weight', 'deberta.encoder.layer.6.attention.self.query_proj.bias', 'deberta.encoder.layer.6.attention.self.key_proj.weight', 'deberta.encoder.layer.6.attention.self.key_proj.bias', 'deberta.encoder.layer.6.attention.self.value_proj.weight', 'deberta.encoder.layer.6.attention.self.value_proj.bias', 'deberta.encoder.layer.6.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.6.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.6.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.6.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.7.attention.self.query_proj.weight', 'deberta.encoder.layer.7.attention.self.query_proj.bias', 'deberta.encoder.layer.7.attention.self.key_proj.weight', 'deberta.encoder.layer.7.attention.self.key_proj.bias', 'deberta.encoder.layer.7.attention.self.value_proj.weight', 'deberta.encoder.layer.7.attention.self.value_proj.bias', 'deberta.encoder.layer.7.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.7.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.7.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.7.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.8.attention.self.query_proj.weight', 'deberta.encoder.layer.8.attention.self.query_proj.bias', 'deberta.encoder.layer.8.attention.self.key_proj.weight', 'deberta.encoder.layer.8.attention.self.key_proj.bias', 'deberta.encoder.layer.8.attention.self.value_proj.weight', 'deberta.encoder.layer.8.attention.self.value_proj.bias', 'deberta.encoder.layer.8.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.8.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.8.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.8.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.9.attention.self.query_proj.weight', 'deberta.encoder.layer.9.attention.self.query_proj.bias', 'deberta.encoder.layer.9.attention.self.key_proj.weight', 'deberta.encoder.layer.9.attention.self.key_proj.bias', 'deberta.encoder.layer.9.attention.self.value_proj.weight', 'deberta.encoder.layer.9.attention.self.value_proj.bias', 'deberta.encoder.layer.9.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.9.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.9.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.9.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.10.attention.self.query_proj.weight', 'deberta.encoder.layer.10.attention.self.query_proj.bias', 'deberta.encoder.layer.10.attention.self.key_proj.weight', 'deberta.encoder.layer.10.attention.self.key_proj.bias', 'deberta.encoder.layer.10.attention.self.value_proj.weight', 'deberta.encoder.layer.10.attention.self.value_proj.bias', 'deberta.encoder.layer.10.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.10.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.10.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.10.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.11.attention.self.query_proj.weight', 'deberta.encoder.layer.11.attention.self.query_proj.bias', 'deberta.encoder.layer.11.attention.self.key_proj.weight', 'deberta.encoder.layer.11.attention.self.key_proj.bias', 'deberta.encoder.layer.11.attention.self.value_proj.weight', 'deberta.encoder.layer.11.attention.self.value_proj.bias', 'deberta.encoder.layer.11.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.11.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.11.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.11.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.12.attention.self.query_proj.weight', 'deberta.encoder.layer.12.attention.self.query_proj.bias', 'deberta.encoder.layer.12.attention.self.key_proj.weight', 'deberta.encoder.layer.12.attention.self.key_proj.bias', 'deberta.encoder.layer.12.attention.self.value_proj.weight', 'deberta.encoder.layer.12.attention.self.value_proj.bias', 'deberta.encoder.layer.12.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.12.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.12.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.12.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.13.attention.self.query_proj.weight', 'deberta.encoder.layer.13.attention.self.query_proj.bias', 'deberta.encoder.layer.13.attention.self.key_proj.weight', 'deberta.encoder.layer.13.attention.self.key_proj.bias', 'deberta.encoder.layer.13.attention.self.value_proj.weight', 'deberta.encoder.layer.13.attention.self.value_proj.bias', 'deberta.encoder.layer.13.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.13.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.13.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.13.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.14.attention.self.query_proj.weight', 'deberta.encoder.layer.14.attention.self.query_proj.bias', 'deberta.encoder.layer.14.attention.self.key_proj.weight', 'deberta.encoder.layer.14.attention.self.key_proj.bias', 'deberta.encoder.layer.14.attention.self.value_proj.weight', 'deberta.encoder.layer.14.attention.self.value_proj.bias', 'deberta.encoder.layer.14.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.14.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.14.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.14.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.15.attention.self.query_proj.weight', 'deberta.encoder.layer.15.attention.self.query_proj.bias', 'deberta.encoder.layer.15.attention.self.key_proj.weight', 'deberta.encoder.layer.15.attention.self.key_proj.bias', 'deberta.encoder.layer.15.attention.self.value_proj.weight', 'deberta.encoder.layer.15.attention.self.value_proj.bias', 'deberta.encoder.layer.15.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.15.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.15.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.15.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.16.attention.self.query_proj.weight', 'deberta.encoder.layer.16.attention.self.query_proj.bias', 'deberta.encoder.layer.16.attention.self.key_proj.weight', 'deberta.encoder.layer.16.attention.self.key_proj.bias', 'deberta.encoder.layer.16.attention.self.value_proj.weight', 'deberta.encoder.layer.16.attention.self.value_proj.bias', 'deberta.encoder.layer.16.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.16.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.16.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.16.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.17.attention.self.query_proj.weight', 'deberta.encoder.layer.17.attention.self.query_proj.bias', 'deberta.encoder.layer.17.attention.self.key_proj.weight', 'deberta.encoder.layer.17.attention.self.key_proj.bias', 'deberta.encoder.layer.17.attention.self.value_proj.weight', 'deberta.encoder.layer.17.attention.self.value_proj.bias', 'deberta.encoder.layer.17.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.17.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.17.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.17.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.18.attention.self.query_proj.weight', 'deberta.encoder.layer.18.attention.self.query_proj.bias', 'deberta.encoder.layer.18.attention.self.key_proj.weight', 'deberta.encoder.layer.18.attention.self.key_proj.bias', 'deberta.encoder.layer.18.attention.self.value_proj.weight', 'deberta.encoder.layer.18.attention.self.value_proj.bias', 'deberta.encoder.layer.18.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.18.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.18.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.18.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.19.attention.self.query_proj.weight', 'deberta.encoder.layer.19.attention.self.query_proj.bias', 'deberta.encoder.layer.19.attention.self.key_proj.weight', 'deberta.encoder.layer.19.attention.self.key_proj.bias', 'deberta.encoder.layer.19.attention.self.value_proj.weight', 'deberta.encoder.layer.19.attention.self.value_proj.bias', 'deberta.encoder.layer.19.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.19.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.19.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.19.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.20.attention.self.query_proj.weight', 'deberta.encoder.layer.20.attention.self.query_proj.bias', 'deberta.encoder.layer.20.attention.self.key_proj.weight', 'deberta.encoder.layer.20.attention.self.key_proj.bias', 'deberta.encoder.layer.20.attention.self.value_proj.weight', 'deberta.encoder.layer.20.attention.self.value_proj.bias', 'deberta.encoder.layer.20.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.20.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.20.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.20.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.21.attention.self.query_proj.weight', 'deberta.encoder.layer.21.attention.self.query_proj.bias', 'deberta.encoder.layer.21.attention.self.key_proj.weight', 'deberta.encoder.layer.21.attention.self.key_proj.bias', 'deberta.encoder.layer.21.attention.self.value_proj.weight', 'deberta.encoder.layer.21.attention.self.value_proj.bias', 'deberta.encoder.layer.21.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.21.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.21.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.21.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.22.attention.self.query_proj.weight', 'deberta.encoder.layer.22.attention.self.query_proj.bias', 'deberta.encoder.layer.22.attention.self.key_proj.weight', 'deberta.encoder.layer.22.attention.self.key_proj.bias', 'deberta.encoder.layer.22.attention.self.value_proj.weight', 'deberta.encoder.layer.22.attention.self.value_proj.bias', 'deberta.encoder.layer.22.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.22.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.22.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.22.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.23.attention.self.query_proj.weight', 'deberta.encoder.layer.23.attention.self.query_proj.bias', 'deberta.encoder.layer.23.attention.self.key_proj.weight', 'deberta.encoder.layer.23.attention.self.key_proj.bias', 'deberta.encoder.layer.23.attention.self.value_proj.weight', 'deberta.encoder.layer.23.attention.self.value_proj.bias', 'deberta.encoder.layer.23.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.23.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.23.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.23.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.24.attention.self.query_proj.weight', 'deberta.encoder.layer.24.attention.self.query_proj.bias', 'deberta.encoder.layer.24.attention.self.key_proj.weight', 'deberta.encoder.layer.24.attention.self.key_proj.bias', 'deberta.encoder.layer.24.attention.self.value_proj.weight', 'deberta.encoder.layer.24.attention.self.value_proj.bias', 'deberta.encoder.layer.24.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.24.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.24.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.24.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.25.attention.self.query_proj.weight', 'deberta.encoder.layer.25.attention.self.query_proj.bias', 'deberta.encoder.layer.25.attention.self.key_proj.weight', 'deberta.encoder.layer.25.attention.self.key_proj.bias', 'deberta.encoder.layer.25.attention.self.value_proj.weight', 'deberta.encoder.layer.25.attention.self.value_proj.bias', 'deberta.encoder.layer.25.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.25.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.25.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.25.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.26.attention.self.query_proj.weight', 'deberta.encoder.layer.26.attention.self.query_proj.bias', 'deberta.encoder.layer.26.attention.self.key_proj.weight', 'deberta.encoder.layer.26.attention.self.key_proj.bias', 'deberta.encoder.layer.26.attention.self.value_proj.weight', 'deberta.encoder.layer.26.attention.self.value_proj.bias', 'deberta.encoder.layer.26.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.26.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.26.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.26.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.27.attention.self.query_proj.weight', 'deberta.encoder.layer.27.attention.self.query_proj.bias', 'deberta.encoder.layer.27.attention.self.key_proj.weight', 'deberta.encoder.layer.27.attention.self.key_proj.bias', 'deberta.encoder.layer.27.attention.self.value_proj.weight', 'deberta.encoder.layer.27.attention.self.value_proj.bias', 'deberta.encoder.layer.27.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.27.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.27.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.27.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.28.attention.self.query_proj.weight', 'deberta.encoder.layer.28.attention.self.query_proj.bias', 'deberta.encoder.layer.28.attention.self.key_proj.weight', 'deberta.encoder.layer.28.attention.self.key_proj.bias', 'deberta.encoder.layer.28.attention.self.value_proj.weight', 'deberta.encoder.layer.28.attention.self.value_proj.bias', 'deberta.encoder.layer.28.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.28.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.28.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.28.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.29.attention.self.query_proj.weight', 'deberta.encoder.layer.29.attention.self.query_proj.bias', 'deberta.encoder.layer.29.attention.self.key_proj.weight', 'deberta.encoder.layer.29.attention.self.key_proj.bias', 'deberta.encoder.layer.29.attention.self.value_proj.weight', 'deberta.encoder.layer.29.attention.self.value_proj.bias', 'deberta.encoder.layer.29.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.29.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.29.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.29.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.30.attention.self.query_proj.weight', 'deberta.encoder.layer.30.attention.self.query_proj.bias', 'deberta.encoder.layer.30.attention.self.key_proj.weight', 'deberta.encoder.layer.30.attention.self.key_proj.bias', 'deberta.encoder.layer.30.attention.self.value_proj.weight', 'deberta.encoder.layer.30.attention.self.value_proj.bias', 'deberta.encoder.layer.30.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.30.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.30.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.30.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.31.attention.self.query_proj.weight', 'deberta.encoder.layer.31.attention.self.query_proj.bias', 'deberta.encoder.layer.31.attention.self.key_proj.weight', 'deberta.encoder.layer.31.attention.self.key_proj.bias', 'deberta.encoder.layer.31.attention.self.value_proj.weight', 'deberta.encoder.layer.31.attention.self.value_proj.bias', 'deberta.encoder.layer.31.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.31.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.31.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.31.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.32.attention.self.query_proj.weight', 'deberta.encoder.layer.32.attention.self.query_proj.bias', 'deberta.encoder.layer.32.attention.self.key_proj.weight', 'deberta.encoder.layer.32.attention.self.key_proj.bias', 'deberta.encoder.layer.32.attention.self.value_proj.weight', 'deberta.encoder.layer.32.attention.self.value_proj.bias', 'deberta.encoder.layer.32.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.32.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.32.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.32.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.33.attention.self.query_proj.weight', 'deberta.encoder.layer.33.attention.self.query_proj.bias', 'deberta.encoder.layer.33.attention.self.key_proj.weight', 'deberta.encoder.layer.33.attention.self.key_proj.bias', 'deberta.encoder.layer.33.attention.self.value_proj.weight', 'deberta.encoder.layer.33.attention.self.value_proj.bias', 'deberta.encoder.layer.33.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.33.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.33.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.33.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.34.attention.self.query_proj.weight', 'deberta.encoder.layer.34.attention.self.query_proj.bias', 'deberta.encoder.layer.34.attention.self.key_proj.weight', 'deberta.encoder.layer.34.attention.self.key_proj.bias', 'deberta.encoder.layer.34.attention.self.value_proj.weight', 'deberta.encoder.layer.34.attention.self.value_proj.bias', 'deberta.encoder.layer.34.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.34.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.34.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.34.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.35.attention.self.query_proj.weight', 'deberta.encoder.layer.35.attention.self.query_proj.bias', 'deberta.encoder.layer.35.attention.self.key_proj.weight', 'deberta.encoder.layer.35.attention.self.key_proj.bias', 'deberta.encoder.layer.35.attention.self.value_proj.weight', 'deberta.encoder.layer.35.attention.self.value_proj.bias', 'deberta.encoder.layer.35.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.35.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.35.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.35.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.36.attention.self.query_proj.weight', 'deberta.encoder.layer.36.attention.self.query_proj.bias', 'deberta.encoder.layer.36.attention.self.key_proj.weight', 'deberta.encoder.layer.36.attention.self.key_proj.bias', 'deberta.encoder.layer.36.attention.self.value_proj.weight', 'deberta.encoder.layer.36.attention.self.value_proj.bias', 'deberta.encoder.layer.36.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.36.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.36.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.36.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.37.attention.self.query_proj.weight', 'deberta.encoder.layer.37.attention.self.query_proj.bias', 'deberta.encoder.layer.37.attention.self.key_proj.weight', 'deberta.encoder.layer.37.attention.self.key_proj.bias', 'deberta.encoder.layer.37.attention.self.value_proj.weight', 'deberta.encoder.layer.37.attention.self.value_proj.bias', 'deberta.encoder.layer.37.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.37.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.37.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.37.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.38.attention.self.query_proj.weight', 'deberta.encoder.layer.38.attention.self.query_proj.bias', 'deberta.encoder.layer.38.attention.self.key_proj.weight', 'deberta.encoder.layer.38.attention.self.key_proj.bias', 'deberta.encoder.layer.38.attention.self.value_proj.weight', 'deberta.encoder.layer.38.attention.self.value_proj.bias', 'deberta.encoder.layer.38.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.38.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.38.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.38.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.39.attention.self.query_proj.weight', 'deberta.encoder.layer.39.attention.self.query_proj.bias', 'deberta.encoder.layer.39.attention.self.key_proj.weight', 'deberta.encoder.layer.39.attention.self.key_proj.bias', 'deberta.encoder.layer.39.attention.self.value_proj.weight', 'deberta.encoder.layer.39.attention.self.value_proj.bias', 'deberta.encoder.layer.39.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.39.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.39.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.39.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.40.attention.self.query_proj.weight', 'deberta.encoder.layer.40.attention.self.query_proj.bias', 'deberta.encoder.layer.40.attention.self.key_proj.weight', 'deberta.encoder.layer.40.attention.self.key_proj.bias', 'deberta.encoder.layer.40.attention.self.value_proj.weight', 'deberta.encoder.layer.40.attention.self.value_proj.bias', 'deberta.encoder.layer.40.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.40.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.40.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.40.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.41.attention.self.query_proj.weight', 'deberta.encoder.layer.41.attention.self.query_proj.bias', 'deberta.encoder.layer.41.attention.self.key_proj.weight', 'deberta.encoder.layer.41.attention.self.key_proj.bias', 'deberta.encoder.layer.41.attention.self.value_proj.weight', 'deberta.encoder.layer.41.attention.self.value_proj.bias', 'deberta.encoder.layer.41.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.41.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.41.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.41.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.42.attention.self.query_proj.weight', 'deberta.encoder.layer.42.attention.self.query_proj.bias', 'deberta.encoder.layer.42.attention.self.key_proj.weight', 'deberta.encoder.layer.42.attention.self.key_proj.bias', 'deberta.encoder.layer.42.attention.self.value_proj.weight', 'deberta.encoder.layer.42.attention.self.value_proj.bias', 'deberta.encoder.layer.42.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.42.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.42.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.42.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.43.attention.self.query_proj.weight', 'deberta.encoder.layer.43.attention.self.query_proj.bias', 'deberta.encoder.layer.43.attention.self.key_proj.weight', 'deberta.encoder.layer.43.attention.self.key_proj.bias', 'deberta.encoder.layer.43.attention.self.value_proj.weight', 'deberta.encoder.layer.43.attention.self.value_proj.bias', 'deberta.encoder.layer.43.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.43.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.43.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.43.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.44.attention.self.query_proj.weight', 'deberta.encoder.layer.44.attention.self.query_proj.bias', 'deberta.encoder.layer.44.attention.self.key_proj.weight', 'deberta.encoder.layer.44.attention.self.key_proj.bias', 'deberta.encoder.layer.44.attention.self.value_proj.weight', 'deberta.encoder.layer.44.attention.self.value_proj.bias', 'deberta.encoder.layer.44.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.44.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.44.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.44.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.45.attention.self.query_proj.weight', 'deberta.encoder.layer.45.attention.self.query_proj.bias', 'deberta.encoder.layer.45.attention.self.key_proj.weight', 'deberta.encoder.layer.45.attention.self.key_proj.bias', 'deberta.encoder.layer.45.attention.self.value_proj.weight', 'deberta.encoder.layer.45.attention.self.value_proj.bias', 'deberta.encoder.layer.45.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.45.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.45.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.45.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.46.attention.self.query_proj.weight', 'deberta.encoder.layer.46.attention.self.query_proj.bias', 'deberta.encoder.layer.46.attention.self.key_proj.weight', 'deberta.encoder.layer.46.attention.self.key_proj.bias', 'deberta.encoder.layer.46.attention.self.value_proj.weight', 'deberta.encoder.layer.46.attention.self.value_proj.bias', 'deberta.encoder.layer.46.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.46.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.46.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.46.attention.self.pos_query_proj.bias', 'deberta.encoder.layer.47.attention.self.query_proj.weight', 'deberta.encoder.layer.47.attention.self.query_proj.bias', 'deberta.encoder.layer.47.attention.self.key_proj.weight', 'deberta.encoder.layer.47.attention.self.key_proj.bias', 'deberta.encoder.layer.47.attention.self.value_proj.weight', 'deberta.encoder.layer.47.attention.self.value_proj.bias', 'deberta.encoder.layer.47.attention.self.pos_key_proj.weight', 'deberta.encoder.layer.47.attention.self.pos_key_proj.bias', 'deberta.encoder.layer.47.attention.self.pos_query_proj.weight', 'deberta.encoder.layer.47.attention.self.pos_query_proj.bias']
- This IS expected if you are initializing DebertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DebertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DebertaForSequenceClassification were not initialized from the model checkpoint at microsoft/deberta-xlarge-mnli and are newly initialized: ['deberta.encoder.layer.0.attention.self.q_bias', 'deberta.encoder.layer.0.attention.self.v_bias', 'deberta.encoder.layer.0.attention.self.in_proj.weight', 'deberta.encoder.layer.0.attention.self.pos_proj.weight', 'deberta.encoder.layer.0.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.0.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.1.attention.self.q_bias', 'deberta.encoder.layer.1.attention.self.v_bias', 'deberta.encoder.layer.1.attention.self.in_proj.weight', 'deberta.encoder.layer.1.attention.self.pos_proj.weight', 'deberta.encoder.layer.1.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.1.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.2.attention.self.q_bias', 'deberta.encoder.layer.2.attention.self.v_bias', 'deberta.encoder.layer.2.attention.self.in_proj.weight', 'deberta.encoder.layer.2.attention.self.pos_proj.weight', 'deberta.encoder.layer.2.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.2.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.3.attention.self.q_bias', 'deberta.encoder.layer.3.attention.self.v_bias', 'deberta.encoder.layer.3.attention.self.in_proj.weight', 'deberta.encoder.layer.3.attention.self.pos_proj.weight', 'deberta.encoder.layer.3.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.3.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.4.attention.self.q_bias', 'deberta.encoder.layer.4.attention.self.v_bias', 'deberta.encoder.layer.4.attention.self.in_proj.weight', 'deberta.encoder.layer.4.attention.self.pos_proj.weight', 'deberta.encoder.layer.4.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.4.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.5.attention.self.q_bias', 'deberta.encoder.layer.5.attention.self.v_bias', 'deberta.encoder.layer.5.attention.self.in_proj.weight', 'deberta.encoder.layer.5.attention.self.pos_proj.weight', 'deberta.encoder.layer.5.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.5.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.6.attention.self.q_bias', 'deberta.encoder.layer.6.attention.self.v_bias', 'deberta.encoder.layer.6.attention.self.in_proj.weight', 'deberta.encoder.layer.6.attention.self.pos_proj.weight', 'deberta.encoder.layer.6.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.6.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.7.attention.self.q_bias', 'deberta.encoder.layer.7.attention.self.v_bias', 'deberta.encoder.layer.7.attention.self.in_proj.weight', 'deberta.encoder.layer.7.attention.self.pos_proj.weight', 'deberta.encoder.layer.7.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.7.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.8.attention.self.q_bias', 'deberta.encoder.layer.8.attention.self.v_bias', 'deberta.encoder.layer.8.attention.self.in_proj.weight', 'deberta.encoder.layer.8.attention.self.pos_proj.weight', 'deberta.encoder.layer.8.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.8.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.9.attention.self.q_bias', 'deberta.encoder.layer.9.attention.self.v_bias', 'deberta.encoder.layer.9.attention.self.in_proj.weight', 'deberta.encoder.layer.9.attention.self.pos_proj.weight', 'deberta.encoder.layer.9.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.9.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.10.attention.self.q_bias', 'deberta.encoder.layer.10.attention.self.v_bias', 'deberta.encoder.layer.10.attention.self.in_proj.weight', 'deberta.encoder.layer.10.attention.self.pos_proj.weight', 'deberta.encoder.layer.10.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.10.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.11.attention.self.q_bias', 'deberta.encoder.layer.11.attention.self.v_bias', 'deberta.encoder.layer.11.attention.self.in_proj.weight', 'deberta.encoder.layer.11.attention.self.pos_proj.weight', 'deberta.encoder.layer.11.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.11.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.12.attention.self.q_bias', 'deberta.encoder.layer.12.attention.self.v_bias', 'deberta.encoder.layer.12.attention.self.in_proj.weight', 'deberta.encoder.layer.12.attention.self.pos_proj.weight', 'deberta.encoder.layer.12.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.12.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.13.attention.self.q_bias', 'deberta.encoder.layer.13.attention.self.v_bias', 'deberta.encoder.layer.13.attention.self.in_proj.weight', 'deberta.encoder.layer.13.attention.self.pos_proj.weight', 'deberta.encoder.layer.13.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.13.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.14.attention.self.q_bias', 'deberta.encoder.layer.14.attention.self.v_bias', 'deberta.encoder.layer.14.attention.self.in_proj.weight', 'deberta.encoder.layer.14.attention.self.pos_proj.weight', 'deberta.encoder.layer.14.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.14.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.15.attention.self.q_bias', 'deberta.encoder.layer.15.attention.self.v_bias', 'deberta.encoder.layer.15.attention.self.in_proj.weight', 'deberta.encoder.layer.15.attention.self.pos_proj.weight', 'deberta.encoder.layer.15.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.15.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.16.attention.self.q_bias', 'deberta.encoder.layer.16.attention.self.v_bias', 'deberta.encoder.layer.16.attention.self.in_proj.weight', 'deberta.encoder.layer.16.attention.self.pos_proj.weight', 'deberta.encoder.layer.16.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.16.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.17.attention.self.q_bias', 'deberta.encoder.layer.17.attention.self.v_bias', 'deberta.encoder.layer.17.attention.self.in_proj.weight', 'deberta.encoder.layer.17.attention.self.pos_proj.weight', 'deberta.encoder.layer.17.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.17.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.18.attention.self.q_bias', 'deberta.encoder.layer.18.attention.self.v_bias', 'deberta.encoder.layer.18.attention.self.in_proj.weight', 'deberta.encoder.layer.18.attention.self.pos_proj.weight', 'deberta.encoder.layer.18.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.18.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.19.attention.self.q_bias', 'deberta.encoder.layer.19.attention.self.v_bias', 'deberta.encoder.layer.19.attention.self.in_proj.weight', 'deberta.encoder.layer.19.attention.self.pos_proj.weight', 'deberta.encoder.layer.19.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.19.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.20.attention.self.q_bias', 'deberta.encoder.layer.20.attention.self.v_bias', 'deberta.encoder.layer.20.attention.self.in_proj.weight', 'deberta.encoder.layer.20.attention.self.pos_proj.weight', 'deberta.encoder.layer.20.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.20.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.21.attention.self.q_bias', 'deberta.encoder.layer.21.attention.self.v_bias', 'deberta.encoder.layer.21.attention.self.in_proj.weight', 'deberta.encoder.layer.21.attention.self.pos_proj.weight', 'deberta.encoder.layer.21.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.21.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.22.attention.self.q_bias', 'deberta.encoder.layer.22.attention.self.v_bias', 'deberta.encoder.layer.22.attention.self.in_proj.weight', 'deberta.encoder.layer.22.attention.self.pos_proj.weight', 'deberta.encoder.layer.22.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.22.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.23.attention.self.q_bias', 'deberta.encoder.layer.23.attention.self.v_bias', 'deberta.encoder.layer.23.attention.self.in_proj.weight', 'deberta.encoder.layer.23.attention.self.pos_proj.weight', 'deberta.encoder.layer.23.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.23.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.24.attention.self.q_bias', 'deberta.encoder.layer.24.attention.self.v_bias', 'deberta.encoder.layer.24.attention.self.in_proj.weight', 'deberta.encoder.layer.24.attention.self.pos_proj.weight', 'deberta.encoder.layer.24.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.24.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.25.attention.self.q_bias', 'deberta.encoder.layer.25.attention.self.v_bias', 'deberta.encoder.layer.25.attention.self.in_proj.weight', 'deberta.encoder.layer.25.attention.self.pos_proj.weight', 'deberta.encoder.layer.25.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.25.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.26.attention.self.q_bias', 'deberta.encoder.layer.26.attention.self.v_bias', 'deberta.encoder.layer.26.attention.self.in_proj.weight', 'deberta.encoder.layer.26.attention.self.pos_proj.weight', 'deberta.encoder.layer.26.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.26.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.27.attention.self.q_bias', 'deberta.encoder.layer.27.attention.self.v_bias', 'deberta.encoder.layer.27.attention.self.in_proj.weight', 'deberta.encoder.layer.27.attention.self.pos_proj.weight', 'deberta.encoder.layer.27.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.27.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.28.attention.self.q_bias', 'deberta.encoder.layer.28.attention.self.v_bias', 'deberta.encoder.layer.28.attention.self.in_proj.weight', 'deberta.encoder.layer.28.attention.self.pos_proj.weight', 'deberta.encoder.layer.28.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.28.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.29.attention.self.q_bias', 'deberta.encoder.layer.29.attention.self.v_bias', 'deberta.encoder.layer.29.attention.self.in_proj.weight', 'deberta.encoder.layer.29.attention.self.pos_proj.weight', 'deberta.encoder.layer.29.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.29.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.30.attention.self.q_bias', 'deberta.encoder.layer.30.attention.self.v_bias', 'deberta.encoder.layer.30.attention.self.in_proj.weight', 'deberta.encoder.layer.30.attention.self.pos_proj.weight', 'deberta.encoder.layer.30.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.30.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.31.attention.self.q_bias', 'deberta.encoder.layer.31.attention.self.v_bias', 'deberta.encoder.layer.31.attention.self.in_proj.weight', 'deberta.encoder.layer.31.attention.self.pos_proj.weight', 'deberta.encoder.layer.31.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.31.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.32.attention.self.q_bias', 'deberta.encoder.layer.32.attention.self.v_bias', 'deberta.encoder.layer.32.attention.self.in_proj.weight', 'deberta.encoder.layer.32.attention.self.pos_proj.weight', 'deberta.encoder.layer.32.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.32.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.33.attention.self.q_bias', 'deberta.encoder.layer.33.attention.self.v_bias', 'deberta.encoder.layer.33.attention.self.in_proj.weight', 'deberta.encoder.layer.33.attention.self.pos_proj.weight', 'deberta.encoder.layer.33.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.33.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.34.attention.self.q_bias', 'deberta.encoder.layer.34.attention.self.v_bias', 'deberta.encoder.layer.34.attention.self.in_proj.weight', 'deberta.encoder.layer.34.attention.self.pos_proj.weight', 'deberta.encoder.layer.34.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.34.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.35.attention.self.q_bias', 'deberta.encoder.layer.35.attention.self.v_bias', 'deberta.encoder.layer.35.attention.self.in_proj.weight', 'deberta.encoder.layer.35.attention.self.pos_proj.weight', 'deberta.encoder.layer.35.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.35.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.36.attention.self.q_bias', 'deberta.encoder.layer.36.attention.self.v_bias', 'deberta.encoder.layer.36.attention.self.in_proj.weight', 'deberta.encoder.layer.36.attention.self.pos_proj.weight', 'deberta.encoder.layer.36.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.36.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.37.attention.self.q_bias', 'deberta.encoder.layer.37.attention.self.v_bias', 'deberta.encoder.layer.37.attention.self.in_proj.weight', 'deberta.encoder.layer.37.attention.self.pos_proj.weight', 'deberta.encoder.layer.37.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.37.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.38.attention.self.q_bias', 'deberta.encoder.layer.38.attention.self.v_bias', 'deberta.encoder.layer.38.attention.self.in_proj.weight', 'deberta.encoder.layer.38.attention.self.pos_proj.weight', 'deberta.encoder.layer.38.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.38.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.39.attention.self.q_bias', 'deberta.encoder.layer.39.attention.self.v_bias', 'deberta.encoder.layer.39.attention.self.in_proj.weight', 'deberta.encoder.layer.39.attention.self.pos_proj.weight', 'deberta.encoder.layer.39.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.39.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.40.attention.self.q_bias', 'deberta.encoder.layer.40.attention.self.v_bias', 'deberta.encoder.layer.40.attention.self.in_proj.weight', 'deberta.encoder.layer.40.attention.self.pos_proj.weight', 'deberta.encoder.layer.40.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.40.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.41.attention.self.q_bias', 'deberta.encoder.layer.41.attention.self.v_bias', 'deberta.encoder.layer.41.attention.self.in_proj.weight', 'deberta.encoder.layer.41.attention.self.pos_proj.weight', 'deberta.encoder.layer.41.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.41.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.42.attention.self.q_bias', 'deberta.encoder.layer.42.attention.self.v_bias', 'deberta.encoder.layer.42.attention.self.in_proj.weight', 'deberta.encoder.layer.42.attention.self.pos_proj.weight', 'deberta.encoder.layer.42.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.42.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.43.attention.self.q_bias', 'deberta.encoder.layer.43.attention.self.v_bias', 'deberta.encoder.layer.43.attention.self.in_proj.weight', 'deberta.encoder.layer.43.attention.self.pos_proj.weight', 'deberta.encoder.layer.43.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.43.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.44.attention.self.q_bias', 'deberta.encoder.layer.44.attention.self.v_bias', 'deberta.encoder.layer.44.attention.self.in_proj.weight', 'deberta.encoder.layer.44.attention.self.pos_proj.weight', 'deberta.encoder.layer.44.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.44.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.45.attention.self.q_bias', 'deberta.encoder.layer.45.attention.self.v_bias', 'deberta.encoder.layer.45.attention.self.in_proj.weight', 'deberta.encoder.layer.45.attention.self.pos_proj.weight', 'deberta.encoder.layer.45.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.45.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.46.attention.self.q_bias', 'deberta.encoder.layer.46.attention.self.v_bias', 'deberta.encoder.layer.46.attention.self.in_proj.weight', 'deberta.encoder.layer.46.attention.self.pos_proj.weight', 'deberta.encoder.layer.46.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.46.attention.self.pos_q_proj.bias', 'deberta.encoder.layer.47.attention.self.q_bias', 'deberta.encoder.layer.47.attention.self.v_bias', 'deberta.encoder.layer.47.attention.self.in_proj.weight', 'deberta.encoder.layer.47.attention.self.pos_proj.weight', 'deberta.encoder.layer.47.attention.self.pos_q_proj.weight', 'deberta.encoder.layer.47.attention.self.pos_q_proj.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```<|||||>Apart from the two issues mentioned above, the PR looks in a good state to me. Would you mind:
- Checking what's wrong with `microsoft/deberta-xlarge-mnli`
- Adding the `num_labels` field to the configuration of your MNLI models and removing the pre-load hooks
- Rebasing on the current `master`
I can take care of 2) and 3) if you want.<|||||>> Apart from the two issues mentioned above, the PR looks in a good state to me. Would you mind:
>
> * Checking what's wrong with `microsoft/deberta-xlarge-mnli`
> * Adding the `num_labels` field to the configuration of your MNLI models and removing the pre-load hooks
> * Rebasing on the current `master`
>
> I can take care of 2) and 3) if you want.
Thanks @LysandreJik. I just fixed the model issue and resolved the merge conflicts.
For the hook issue, add num_labels will not fix the issue. In most of the cases we want to load a mnli fine-tuned model for another task, which has 2 or 1 labels, e.g. MRPC, STS-2, SST-B. So we still need the hook unless we get the loading issue fixed in load_pretrained_model method. One possible way is to add ignore error dictionary just like ignore_unexpected keys. But I think we should fix this in another separate PR.
<|||||>Thank you for taking care of those issues.
@patrickvonplaten @sgugger, could you give this one a look?
The unresolved issue is regarding the pre-load hooks. Loading a pre-trained model that already has a classification head with a different number of labels will not work, as the weight will have the wrong numbers of parameters.
Until now, we've been doing:
```py
from transformers import DebertaV2Model, DebertaV2ForSequenceClassification
seq_model = DebertaV2ForSequenceClassification.from_pretrained("xxx", num_labels=4)
seq_model.save_pretrained(directory)
base = DebertaV2Model.from_pretrained(directory) # Lose the head
base.save_pretrained(directory)
seq_model = DebertaV2ForSequenceClassification.from_pretrained(directory, num_labels=8)
```
The pre-load hook that @BigBird01 worked on drops the head instead when it finds it is ill-loaded. I'm okay to merge it like this, and I'll work on a model-agnostic approach this week. Let me know your thoughts.<|||||>@LysandreJik Thanks for the fix.
Can you merge this PR, please?<|||||>> Awesome! Thanks so much for adding this super important model @BigBird01 ! I left a couple of comments in the `modeling_deberta_v2.py` file - it would be great if we can make the code a bit cleaner there, _e.g._:
>
> * remove the `use_conv` attribute
> * set `output_hidden_states=False` as a default
> * refactor the `MaskLayerNorm` class
>
> Those changes should be pretty trivial - thanks so much for all your work!
Thank you @patrickvonplaten! I will take a look at it soon. <|||||>As seen with @BigBird01, taking over the PR!<|||||>> As seen with @BigBird01, taking over the PR!
Thank you @LysandreJik ! <|||||>My pleasure! Thank you for your work! |
transformers | 10,017 | closed | python utils/check_repo.py fails | on master after making sure I got all the deps updated (from `make style/quality/fixup`)
```
No library .py files were modified
running deps_table_update
updating src/transformers/dependency_versions_table.py
python utils/check_copies.py
python utils/check_table.py
python utils/check_dummies.py
python utils/check_repo.py
Checking all models are properly tested.
2021-02-04 14:36:09.588141: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
Traceback (most recent call last):
File "utils/check_repo.py", line 487, in <module>
check_repo_quality()
File "utils/check_repo.py", line 479, in check_repo_quality
check_all_models_are_tested()
File "utils/check_repo.py", line 251, in check_all_models_are_tested
modules = get_model_modules()
File "utils/check_repo.py", line 165, in get_model_modules
modeling_module = getattr(model_module, submodule)
File "src/transformers/file_utils.py", line 1488, in __getattr__
value = self._get_module(name)
File "src/transformers/models/bert/__init__.py", line 134, in _get_module
return importlib.import_module("." + module_name, self.__name__)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 783, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "src/transformers/models/bert/modeling_flax_bert.py", line 20, in <module>
import flax.linen as nn
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/flax/__init__.py", line 36, in <module>
from . import core
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/flax/core/__init__.py", line 15, in <module>
from .frozen_dict import FrozenDict, freeze, unfreeze
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/flax/core/frozen_dict.py", line 19, in <module>
import jax
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jax/__init__.py", line 22, in <module>
from .api import (
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jax/api.py", line 37, in <module>
from . import core
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jax/core.py", line 31, in <module>
from . import dtypes
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jax/dtypes.py", line 31, in <module>
from .lib import xla_client
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jax/lib/__init__.py", line 60, in <module>
from jaxlib import cusolver
ImportError: cannot import name 'cusolver' from 'jaxlib' (/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/jaxlib/__init__.py)
make: *** [Makefile:28: extra_quality_checks] Error 1
```
| 02-04-2021 22:43:20 | 02-04-2021 22:43:20 | Yes there are some conflicts between a latest version of jax and an older version of flax (I think uninstalling both and reinstalling with pip install -e .[dev] will solve your problem). I had the same problem earlier.
@patrickvonplaten It seems to have appeared with the minimum version change in jax/flax if you can have a look.
<|||||>Your workaround worked, @sgugger - thank you!
> Yes there are some conflicts between a latest version of jax and an older version of flax
In which case `setup.py` needs to be updated to reflect the right combination of versions, right? I'd have sent a PR, but I don't know which min versions should be used.
I also tried `pip install -e .[dev] -U` to force update, but it seems to ignore `-U` and since the requirements are met it doesn't update these libraries automatically.
<|||||>I cannot reproduce the error on my side, but the reason seems to be a mismatch of the `jax` version and `jaxlib` as shown here: https://github.com/google/jax/issues/5374 . Currently, we support `jax>=0.2.0` and in the issues it says `jax>=0.2.8` solves the issue. So I'd recommend that we also raise our minimum allowed version of jax ot `jax>=0.2.8`. What do you think? |
transformers | 10,016 | closed | Feature-extraction pipeline to return Tensor | # 🚀 Feature request
Actually, to code of the feature-extraction pipeline
`transformers.pipelines.feature-extraction.FeatureExtractionPipeline l.82` return a `super().__call__(*args, **kwargs).tolist()`
Which gives a list[float] (or list[list[float]] if list[str] in input)
I guess it's to be framework agnostic, but we can specify `framework='pt'` in the pipeline config so I was expecting a `torch.tensor`.
Could we add some logic to return tensors ?
# Motivation
Features will be used as input of other models, so keeping them as tensors (even better on GPU) would be profitable.
Thanks in advance for the reply,
Have a great day. | 02-04-2021 22:12:05 | 02-04-2021 22:12:05 | Hello! Indeed, this is a valid request. Would you like to open a PR and take a stab at it?<|||||>@LysandreJik Hi, thanks for the fast reply !
Ok will do that :)
I will comment here when the PR will be ready<|||||>Hi @LysandreJik is there any update on this issue? If @Ierezell didn't have time, I might be able to give a shot at it in the next days<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi!
Is this issue somewhere in consideration still?
Would be awesome to be able to get tensors from the feature extraction pipeline<|||||>I think we'd still be open to that; WDYT @Narsil?<|||||>Sure !
Would adding an argument `return_type= "tensors"` be OK ? That way we can enable this feature without breaking backward compatibility ?<|||||>I'm baffled as to why returning the features as a list is the default behavior in the first place... Isn't one common usage of feature extraction to provide an input to another model, which means it is preferred to keep it as a tensor?<|||||>@ajsanjoaquin
Well it depends, not necessarily. Another very common use case is to feed it to some feature database for querying later.
Those database engines are not necessarily expecting the same kind of tensors that you are sending.
But I kind of agree that it should be at least a `numpy.array` because usually conversions between numpy and PT or TF is basically free, meaning it would be much easier to use that way.
Some `pipeline` were added a long time ago where the current situation was not as clear as today, and since we are very conservative regarding breaking changes, that can explain why some defaults are the way they are.
If/When v5 is getting prepared there would be a lot of small but breaking changes in that regard. |
transformers | 10,015 | closed | Do not allow fine tuning with sequence size larger than during training | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
I just wasted some hours chasing a problem see #10010 that I think could be avoided with the following simple solution:
Do not allow `max_seq_length` to be higher than `max_position_embeddings`.
Most models are built with 512 and, as such, this problem doesn't happen too often. It so happens that BERTweet was trained with 130. The code allows it to run with `max_seq_length` higher than 130 and it ends up with cryptic cuda errors down the pipe.
| 02-04-2021 21:42:37 | 02-04-2021 21:42:37 | Also, I for one, I find it confusing that there are two different parameters that (kind of) refer to the same thing. I was lucky that I had run my code successfully with 10+ other models from the hub and it stood out that the sizes used for embeddings during training were different. |
transformers | 10,014 | closed | Update doc for pre-release | # What does this PR do?
This PR puts the default version of the doc for the pre-release. | 02-04-2021 21:42:34 | 02-04-2021 21:42:34 | |
transformers | 10,013 | closed | [Question] Pipeline QA start_index | I got a dictionary with 'score', 'start', 'end' and 'answer'. I want to use the 'start' and 'end' index. But the index of 'start' and 'end' are usually greater than length of encoding? Code:
text = text
question = quesiton
pipeline = pipeline('question-answering' , model = model)
answers = pipeline(context = data, question = questions)
print(answers)
{'score': 0.7909670472145081, 'start': 6192, 'end': 6195, 'answer': '111'}
but the length of context + question is smaller than 6000. How can I use 'start_index' and 'end_index' to verify that the result is '111'? | 02-04-2021 20:14:49 | 02-04-2021 20:14:49 | Hi! So that we may help you, could you provide the information related to your environment as asked in the issue template?
Also, we can't understand what's happening here because we don't know what's your text, your question, and most importantly the model you used.
Finally, you instantiated a model, but you didn't do so for the tokenizer. If you have mismatched models/tokenizers, then outputs are bound to be confusing.<|||||>> Hi! So that we may help you, could you provide the information related to your environment as asked in the issue template?
>
> Also, we can't understand what's happening here because we don't know what's your text, your question, and most importantly the model you used.
>
> Finally, you instantiated a model, but you didn't do so for the tokenizer. If you have mismatched models/tokenizers, then outputs are bound to be confusing.
Oh,sorry. My enviroonment is as follows:
OS: Macos catalina
python version: python3.7.3
Package Version: transformers 3.4
The model, which I have used, is 'ktrapeznikov/biobert_v1.1_pubmed_squad_v2'. And the code is like following:
```py
data ='I live in Berkeley. I am 30 years old. And my name is Clara.'
question = 'What's my name?'
pipeline = pipeline('question-answering',model = 'ktrapeznikov/biobert_v1.1_pubmed_squad_v2')
answers = pipeline(context = data, question = question)
answer is like {'score': 0.9977871179580688, 'start': 54, 'end': 59, 'answer': 'Clara.'}
tokenizer = AutoTokenizer.from_pretrained('ktrapeznikov/biobert_v1.1_pubmed_squad_v2')
encoding = tokenizer.encode(questions,data)
len(encoding)
```
With len(encoding) I got the length of encoding 26. But from the answer I got start index as 54 and end index as 59?<|||||>Yes, the length of encoding is the length of the list of tokens. The start and end index are the start and end index of characters, not tokens. We should clarify that in the docs.<|||||>> Yes, the length of encoding is the length of the list of tokens. The start and end index are the start and end index of characters, not tokens. We should clarify that in the docs.
okay, thats what i mean. Thx |
transformers | 10,012 | closed | return_dict scores are inconsistent between sampling and beam search | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.0.dev0
- Platform: Linux-5.4.0-1035-aws-x86_64-with-debian-buster-sid
- Python version: 3.7.6
- PyTorch version (GPU?): 1.7.1+cu110 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@SBrandeis @patrickvonplaten
## Information
When generating text using `model.generate` and `return_dict_in_generate` and beam search, beam search [sets the score for the first token to be 1e-9 across all beams other than the first](https://github.com/huggingface/transformers/blob/a449ffcbd2887b936e6b70a89e533a0bb713743a/src/transformers/generation_utils.py#L1576). This is not consistent with the sampling score which maintains the same score for the same token across different generations, and results in rather confusing behavior for score when using beam search.
## To reproduce
Steps to reproduce the behavior:
```python
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
text = "How are"
input_ids = tokenizer.encode(text, return_tensors='pt')
# Beam Search
generated_outputs = model.generate(input_ids, return_dict_in_generate=True, output_scores=True, num_return_sequences=4, num_beams=4, max_length=input_ids.shape[-1] + 2)
gen_sequences = generated_outputs.sequences[:, input_ids.shape[-1]:]
# tensor([[ 345, 1804],
# [ 345, 1016],
# [ 356, 1016],
# [ 345, 4203]])
probs = torch.stack(generated_outputs.scores, dim=1).softmax(-1)
gen_probs = torch.gather(probs, 2, gen_sequences[:, :, None]).squeeze(-1)
# tensor([[3.7034e-01, 1.4759e-01],
# [1.9898e-05, 2.7981e-01],
# [1.9898e-05, 3.2767e-05],
# [1.9898e-05, 2.9494e-03]])
np.random.seed(42)
torch.manual_seed(42)
# Sampling
generated_outputs = model.generate(input_ids, return_dict_in_generate=True, output_scores=True, num_return_sequences=3, do_sample=True, top_p=.9, max_length=input_ids.shape[-1] + 2)
gen_sequences = generated_outputs.sequences[:, input_ids.shape[-1]:]
probs = torch.stack(generated_outputs.scores, dim=1).softmax(-1)
gen_probs = torch.gather(probs, 2, gen_sequences[:, :, None]).squeeze(-1)
gen_sequences
# tensor([[ 262, 1180],
# [ 345, 1016],
# [ 345, 4203]])
gen_probs[:, 0]
# tensor([0.1121, 0.5147, 0.5147])
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
When performing beam search the score from the model's logits should be output as the score rather than 1e-9.
| 02-04-2021 19:23:40 | 02-04-2021 19:23:40 | Hey @mshuffett,
I understand your concern and I think I agree with you! Would you be interested in opening a PR to fix this for `beam_search` and `group_beam_search` ? It's essentially just moving the ` + beam_scores` line further down<|||||>@patrickvonplaten I would be happy to but upon trying your suggested fix, it does solve the problem with the score of the first token, but the second token now has the same problem.
I just moved this line below the `return_dict_in_generate` block.
```python
next_token_scores = next_token_scores + beam_scores[:, None].expand_as(next_token_scores)
```
I believe this is still unexpected but I'm not yet sure why this is happening. If you have any thoughts that would be helpful.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Unstale<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>Ping
<|||||>Yeah I'm probably not going to be able to submit a PR for this, but I do
think it should be fixed.
ᐧ
On Mon, May 31, 2021 at 2:27 AM Patrick von Platen ***@***.***>
wrote:
> Ping
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/10012#issuecomment-851265135>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AAIFLUJ6IGHT52SRTDKJIKDTQM25NANCNFSM4XDNCCEQ>
> .
>
--
Michael Shuffett
Written with compose.ai
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>I had the same issue. I'm trying to replicate OpenAI's behavior when selecting "Show probabilities: Full Spectrum". I would like, at each step, for it to show the top N candidate tokens as well as all their probabilities.
I've not quite figured out how to make it select the _top_ candidates, because sampling is selecting them randomly. It seems like beam search does indeed do what I want selecting always the top probabilities, but then I can't get the true probabilities this way because of the 1e-09 issue. <|||||>@monsieurpooh,
Could you open a new issue for this one? I'm not quite sure whether you are interested in sampling, beam search, etc... :-) Happy to extend `generate()` to cover more important use cases<|||||>The only thing I was trying to do was get the top 10 tokens (and their probabilities) for the next 1 token. For example: "I went to the" -> {" store": 0.25, " park": 0.1, ...}
I do not need any beam search, sampling, etc. I used the workaround described earlier in the thread and it works perfectly.<|||||>@patrickvonplaten can you please this question [here](https://stackoverflow.com/questions/72180737/beam-search-and-generate-are-not-consistent) . If I don't miss something, I think there is a bug in beam_search. Thanks<|||||>Hey @rafikg,
Could you please open a new issue or use the forum: https://discuss.huggingface.co/ if you have a question? Thanks!<|||||>@monsieurpooh can you please elaborate how you implemented the workaround?
Looking at master during the time of your posting in posting in March 7th, the workaround you mentioned seems already implemented?
https://github.com/huggingface/transformers/blob/5c6f57ee75665499c8045a8bf7c73bf2415fba20/src/transformers/generation_utils.py#L2112
`next_token_scores` is not invoked until after the `if return_dict_in_generate` https://github.com/huggingface/transformers/blob/5c6f57ee75665499c8045a8bf7c73bf2415fba20/src/transformers/generation_utils.py#L2115
`next_token_scores_processed` is being used instead |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.