
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 8,502 | closed | TF T5-small with output hidden state and attention not owrking | - `transformers` version: 2.11
- Platform: Multiple
- Python version: multiple
### Who can help
T5: @patrickvonplaten
tensorflow: @jplu
## Information
Model I am using (Bert, XLNet ...): T5
The problem arises when t5-small is loaded from pretrain with output_hidden_states=True, output_attentions=True
sample script https://colab.research.google.com/drive/1oF8hMaQg1yl2fE6QPUYKSTZcer4Mlk6S?usp=sharing
if these parameter is removed script works
I am getting following error.
```python
/usr/local/lib/python3.6/dist-packages/transformers/modeling_tf_utils.py in generate(self, input_ids, max_length, min_length, do_sample, early_stopping, num_beams, temperature, top_k, top_p, repetition_penalty, bad_words_ids, bos_token_id, pad_token_id, eos_token_id, length_penalty, no_repeat_ngram_size, num_return_sequences, attention_mask, decoder_start_token_id, use_cache)
780 encoder_outputs=encoder_outputs,
781 attention_mask=attention_mask,
--> 782 use_cache=use_cache,
783 )
784 else:
/usr/local/lib/python3.6/dist-packages/transformers/modeling_tf_utils.py in _generate_beam_search(self, input_ids, cur_len, max_length, min_length, do_sample, early_stopping, temperature, top_k, top_p, repetition_penalty, no_repeat_ngram_size, bad_words_ids, bos_token_id, pad_token_id, decoder_start_token_id, eos_token_id, batch_size, num_return_sequences, length_penalty, num_beams, vocab_size, encoder_outputs, attention_mask, use_cache)
1027 input_ids, past=past, attention_mask=attention_mask, use_cache=use_cache
1028 )
-> 1029 outputs = self(**model_inputs) # (batch_size * num_beams, cur_len, vocab_size)
1030 next_token_logits = outputs[0][:, -1, :] # (batch_size * num_beams, vocab_size)
1031
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in __call__(self, *args, **kwargs)
983
984 with ops.enable_auto_cast_variables(self._compute_dtype_object):
--> 985 outputs = call_fn(inputs, *args, **kwargs)
986
987 if self._activity_regularizer:
/usr/local/lib/python3.6/dist-packages/transformers/modeling_tf_t5.py in call(self, inputs, **kwargs)
1061 encoder_attention_mask=attention_mask,
1062 head_mask=head_mask,
-> 1063 use_cache=use_cache,
1064 )
1065
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in __call__(self, *args, **kwargs)
983
984 with ops.enable_auto_cast_variables(self._compute_dtype_object):
--> 985 outputs = call_fn(inputs, *args, **kwargs)
986
987 if self._activity_regularizer:
/usr/local/lib/python3.6/dist-packages/transformers/modeling_tf_t5.py in call(self, inputs, attention_mask, encoder_hidden_states, encoder_attention_mask, inputs_embeds, head_mask, past_key_value_states, use_cache, training)
572 # required mask seq length can be calculated via length of past
573 # key value states and seq_length = 1 for the last token
--> 574 mask_seq_length = shape_list(past_key_value_states[0][0])[2] + seq_length
575 else:
576 mask_seq_length = seq_length
IndexError: list index out of range
```
## Expected behavior
how to get the attention and hidden states as output?
Even if you can share a sample for pytorch I would be able to make it work for TF. | 11-12-2020 16:21:00 | 11-12-2020 16:21:00 | Hello!
Unfortunately this is a known bug we have with few of the TF models. We are currently reworking all the TF models to solve this issue among others.<|||||>@jplu I tried the same thing with Pytorch model also. It is also giving error. Any idea if I can get the attentions with pytorch?<|||||>You get the same error with PyTorch? For PyTorch I will let @patrickvonplaten take the lead to help you, he knows better than me.<|||||>The error is the same instead of list it just says tuple<|||||>Hey @pathikchamaria - is it possible to update your version? 2.11 is very outdated by now. Could you try again with the current version of transformers (3.5) ? <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>@jplu are there any updates on this on the tensorflow side? |
transformers | 8,501 | closed | Why is the XLM-RoBERTa sometimes producing a standalone start of the word character (the special underscore with ord = 9601) | I'm using the `transformers` library 3.4.0.
The XLM-RoBERTa tokenizer produces in certain cases standalone start of the word characters. Is that intended?
For example:
```
tokenizer.tokenize('amerikanische')
['▁', 'amerikanische']
```
while
```
tokenizer.tokenize('englische')
['▁englische']
```
| 11-12-2020 15:56:00 | 11-12-2020 15:56:00 | Ah, I guess I figured that out. Does it happen when the training data set of the tokenizer never had this token at the beginning of a word but only inside a word? |
transformers | 8,500 | closed | Fix doc bug | Fix the example of Trainer, hope it help.
@sgugger
| 11-12-2020 15:48:03 | 11-12-2020 15:48:03 | Thanks for the fix! |
transformers | 8,499 | closed | Unable to install Transformers | Hi all - I'm unable to install transformers from source. I need this for a project, it's really annoying not be able to use your amazing work. Could you please help me? :) Thank you so much.
**Issue**
pip install is blocked at **sentencepiece-0.1.91** install and crashes
**What I tried**
- I tried to find a workaround by installing the latest version of sentencepiece 0.1.94 but it doesn't solve the issue
- I tried to download the repository locally and change the version requirement in setup.py and requirement.txt it doesn't solve neither
- My system: MacOS 10.15.7 / Python 3.9.0 / Pip 20.2.4 / Anaconda3 with PyTorch
**The error messages and pip list to show you I installed latest sentencepiece**
```
(env) (base) Cecilias-MacBook-Air:transformers mymacos$ pip3 install -e .
Obtaining file:///Users/mymacos/Documents/OpenAI/transformers
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Collecting filelock
Using cached filelock-3.0.12-py3-none-any.whl (7.6 kB)
Collecting sentencepiece==0.1.91
Using cached sentencepiece-0.1.91.tar.gz (500 kB)
ERROR: Command errored out with exit status 1:
command: /Users/mymacos/Documents/OpenAI/env/bin/python3 -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/private/var/folders/s7/73dlmpfj3253cpbpl6v96rbm0000gn/T/pip-install-5ceji0j1/sentencepiece/setup.py'"'"'; __file__='"'"'/private/var/folders/s7/73dlmpfj3253cpbpl6v96rbm0000gn/T/pip-install-5ceji0j1/sentencepiece/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /private/var/folders/s7/73dlmpfj3253cpbpl6v96rbm0000gn/T/pip-pip-egg-info-svt86xy8
cwd: /private/var/folders/s7/73dlmpfj3253cpbpl6v96rbm0000gn/T/pip-install-5ceji0j1/sentencepiece/
Complete output (5 lines):
Package sentencepiece was not found in the pkg-config search path.
Perhaps you should add the directory containing `sentencepiece.pc'
to the PKG_CONFIG_PATH environment variable
No package 'sentencepiece' found
Failed to find sentencepiece pkgconfig
----------------------------------------
ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.
(env) (base) Cecilias-MacBook-Air:transformers mymacos$ pip list
Package Version
----------------- -------
astroid 2.4.2
isort 5.6.4
lazy-object-proxy 1.4.3
mccabe 0.6.1
numpy 1.19.4
pip 20.2.4
pylint 2.6.0
PyYAML 5.3.1
**sentencepiece 0.1.94**
setuptools 50.3.2
six 1.15.0
toml 0.10.2
wheel 0.35.1
wrapt 1.12.1
``` | 11-12-2020 15:33:12 | 11-12-2020 15:33:12 | I guess the issue is that you're using `anaconda` here. Until version v4.0.0, we're not entirely compatible with anaconda as SentencePiece is not on a conda channel.
In the meantime, we recommend installing `transformers` in a pip virtual env:
```shell-script
python -m venv .env
source .env/bin/activate
pip install -e .
```<|||||>@LysandreJik Thanks for your answer! Actually it was not an `anaconda` issue.
I found the solution! There're 2 version issues in the install requirements.
See below the steps - but I had to reinstall Python back to 3.8 as Torch/TorchVision don't support 3.9 yet.
1. Copy content of GitHub repo in a “transformers” folder: https://github.com/huggingface/transformers
2. `cd transformers`
3. Change all the `tokenizers` 0.9.3 reference to 0.9.4 in transformers files
4. Change all the `sentencepiece` 0.1.91 reference to 0.1.94 in transformers files
5. `brew install pkgconfig`
6. `python3.8 setup.py install`
And voila! I hope it helps lots of folks struggling. 👍
<|||||>@MoonshotQuest - what are "transformers files" in the reply above? |
transformers | 8,498 | closed | Model sharing doc | # What does this PR do?
This PR expands the model sharing doc with some instructions specific to colab.
Unrelated: some fixes in marian.rst that I thought I had pushed directly to master but had not. | 11-12-2020 15:23:33 | 11-12-2020 15:23:33 | |
transformers | 8,497 | closed | Error when loading a model cloned without git-lfs is quite cryptic | # 🚀 Error message request
If you forget to install git-LFS (e.g. on Google Colab) and you just do:
```python
!git clone https://huggingface.co/facebook/bart-base
from transformers import AutoModel
model = AutoModel.from_pretrained('./bart-base')
```
The cloning seems to work well but the model weights are not downloaded. The error message is then quite cryptic and could probably be tailored to this (probably) common failure case:
```
loading weights file ./bart-large-cnn/pytorch_model.bin
---------------------------------------------------------------------------
UnpicklingError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
950 try:
--> 951 state_dict = torch.load(resolved_archive_file, map_location="cpu")
952 except Exception:
4 frames
UnpicklingError: invalid load key, 'v'.
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
952 except Exception:
953 raise OSError(
--> 954 f"Unable to load weights from pytorch checkpoint file for '{pretrained_model_name_or_path}' "
955 f"at '{resolved_archive_file}'"
956 "If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True. "
OSError: Unable to load weights from pytorch checkpoint file for './bart-large-cnn' at './bart-large-cnn/pytorch_model.bin'If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True.
```
git-LFS specification files are pretty simple to parse and typically look like this:
```
version https://git-lfs.github.com/spec/v1
oid sha256:097417381d6c7230bd9e3557456d726de6e83245ec8b24f529f60198a67b203a
size 440473133
```
The first *key* is always `version`: https://github.com/git-lfs/git-lfs/blob/master/docs/spec.md | 11-12-2020 15:20:15 | 11-12-2020 15:20:15 | Yep, they way I would go about this would be to programmatically check whether the file is text-only (non-binary) and between 100 and 200 bytes. If it is (and we expected a weights file), it's probably a lfs pointer file.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>unstale |
transformers | 8,496 | closed | Created ModelCard for Hel-ach-en MT model | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-12-2020 15:00:59 | 11-12-2020 15:00:59 | This is really cool @Pogayo, thanks for sharing.
If you can, please consider adding sample inputs for the inference widget, either in DefaultWidget.ts (see https://huggingface.co/docs#how-can-i-control-my-models-widgets-example-inputs) or in this model card.
Will also add Acholi to the list in https://huggingface.co/languages<|||||>I don't know if this is the right place to ask, apologies in advance - I am trying to translate on the model page and getting this error:

I have not been able to figure out what causes it so if you can guide me, I would really love to see this model accessible for people.
Unrecognized configuration class for this kind of AutoModel: AutoModelForCausalLM. Model type should be one of CamembertConfig, XLMRobertaConfig, RobertaConfig, BertConfig, OpenAIGPTConfig, GPT2Config, TransfoXLConfig, XLNetConfig, XLMConfig, CTRLConfig, ReformerConfig, BertGenerationConfig, XLMProphetNetConfig, ProphetNetConfig.
<|||||>Did you change the `pipeline_tag` in the meantime ? It's working now:
https://huggingface.co/Helsinki-NLP/opus-mt-luo-en?text=Ariyo
The error seemed to point it wanted to do text-generation with your model which it can't.<|||||>It is still not working @Narsil. I get a different error now, do you know what might be causing it?

The model you referenced is a different one- A Luo -English model- This one is Acholi -English |
transformers | 8,495 | closed | Allow tensorflow tensors as input to Tokenizer | Firstly thanks so much for all the amazing work!
I'm trying to package a model for use in TF Serving. The problem is that everywhere I see this done, the tokenisation step happens outside of the server. I want to include this step inside the server so the user can just provide raw text as the input and not need to know anything about tokenization.
Here's how I'm trying to do it
```
def save_model(model, tokenizer, output_path):
@tf.function(input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string)])
def serving(input_text):
inputs = tokenizer(input_text, padding='longest', truncation=True, return_tensors="tf")
outputs = model(inputs)
logits = outputs[0]
probs = tf.nn.softmax(logits, axis=1).numpy()[:, 1]
predictions = tf.cast(tf.math.round(probs), tf.int32)
return {
'classes': predictions,
'probabilities': probs
}
print(f'Exporting model for TF Serving in {tf_serving_output}')
tf.saved_model.save(model, export_dir=output_path, signatures=serving)
```
where e.g.
```
model = TFAlbertForSequenceClassification.from_pretrained('albert-base-v2', num_labels=num_classes)
tokenizer`= = AutoTokenizer.from_pretrained('albert-base-v2')
```
The problem is that the tokenization step results in
```
AssertionError: text input must of type `str` (single example), `List[str]` (batch or single pretokenized example) or `List[List[str]]` (batch of pretokenized examples).
```
clearly it wants plain python strings, not tensorflow tensors.
Would appreciate any help, workarounds, or ideally of course, this to be supported.
-----
Running:
transformers==3.4.0
tensorflow==2.3.0 | 11-12-2020 14:29:01 | 11-12-2020 14:29:01 | I believe @jplu has already used TF Serving. Do you know if it's possible to include tokenization in it?<|||||>Hello!
Unfortunately it is currently not possible to integrate our tokenizer directly inside a model due to some TensorFlow limitations. Nevertheless, there might be a solution by trying to create your own Tokenization layer such as the one the TF team is [working on](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/TextVectorization).<|||||>Thanks for response and for the link.
Ya, it's a shame that there is still no way to use plain python in the signature.
I'll likely just find a different work around e.g. converting to PyTorch and serving with TorchServe.
I'll close this for now.<|||||>I found a working soltuion that doesn't require any changes to Tensorflow or Transformers.
Commenting because I came across this trying to do something similar. I actually think the issue here is not tensorflow but the transformer type checking for the tokenizer call which doesn't allow for the tensorflow objects.
I made the following implementation which appears to be working and doesn't rely on anything due to tensorflow limitations:
```python
# NOTE: the specific model here will need to be overwritten because AutoModel doesn't work
class CustomModel(transformers.TFDistilBertForSequenceClassification):
def call_tokenizer(self, input):
if type(input) == list:
return self.tokenizer([str(x) for x in input], return_tensors='tf')
else:
return self.tokenizer(str(input), return_tensors='tf')
@tf.function(input_signature=[tf.TensorSpec(shape=(1, ), dtype=tf.string)])
def serving(self, content: str):
batch = self.call_tokenizer(content)
batch = dict(batch)
batch = [batch]
output = self.call(batch)
return self.serving_output(output)
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_path,
use_fast=True
)
config = transformers.AutoConfig.from_pretrained(
model_path,
num_labels=2,
from_pt=True
)
model = CustomModel.from_pretrained(
model_path,
config=config,
from_pt=True
)
model.tokenizer = tokenizer
model.id2label = config.id2label
model.save_pretrained("model", saved_model=True)
```<|||||>Hi @maxzzze
I was also working on including hf tokenizer into tf model. However, I found that inside call_tokenizer, the results tokenizer return would always be the same despites the text input you passed in.
Have you also encounter such issue? I am thinking save_pretrained wasn't including the tokenizer appropriately.
> I found a working soltuion that doesn't require any changes to Tensorflow or Transformers.
>
> Commenting because I came across this trying to do something similar. I actually think the issue here is not tensorflow but the transformer type checking for the tokenizer call which doesn't allow for the tensorflow objects.
>
> I made the following implementation which appears to be working and doesn't rely on anything due to tensorflow limitations:
>
> ```python
> # NOTE: the specific model here will need to be overwritten because AutoModel doesn't work
> class CustomModel(transformers.TFDistilBertForSequenceClassification):
>
> def call_tokenizer(self, input):
> if type(input) == list:
> return self.tokenizer([str(x) for x in input], return_tensors='tf')
>
> else:
> return self.tokenizer(str(input), return_tensors='tf')
>
>
>
> @tf.function(input_signature=[tf.TensorSpec(shape=(1, ), dtype=tf.string)])
> def serving(self, content: str):
> batch = self.call_tokenizer(content)
> batch = dict(batch)
> batch = [batch]
> output = self.call(batch)
> return self.serving_output(output)
>
>
> tokenizer = transformers.AutoTokenizer.from_pretrained(
> model_path,
> use_fast=True
> )
>
> config = transformers.AutoConfig.from_pretrained(
> model_path,
> num_labels=2,
> from_pt=True
> )
>
> model = CustomModel.from_pretrained(
> model_path,
> config=config,
> from_pt=True
> )
>
> model.tokenizer = tokenizer
> model.id2label = config.id2label
> model.save_pretrained("model", saved_model=True)
> ```
|
transformers | 8,494 | closed | error occurs when trainning transformer-xl by ddp | my env is as below:
- `transformers` version: 3.4.0
- Platform: 1Ubuntu-18.04
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0+cu101 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
I am trainning the transformer-xl on one machine with multi-gpus by ddp.
my script is as below:
python -m torch.distributed.launch --nproc_per_node 4 run_language_modeling.py --output_dir ${model_dir}
--tokenizer_name $data_dir/wordpiece-custom.json
--config_name $data_dir/$config_file
--train_data_files "$data_dir/train*.txt"
--eval_data_file $data_dir/valid.txt
--block_size=128
--do_train
--do_eval
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--learning_rate 6e-4
--weight_decay 0.01
--adam_epsilon 1e-6
--adam_beta1 0.9
--adam_beta2 0.98
--max_steps 500_000
--warmup_steps 24_000
--fp16
--logging_dir ${model_dir}/tensorboard
--save_steps 5000
--save_total_limit 20
--seed 108
--max_steps -1
--num_train_epochs 20
--dataloader_num_workers 0
--overwrite_output_dir
occur error:
[INFO|language_modeling.py:242] 2020-11-11 11:54:46,363 >> Loading features from cached file /opt/ml/input/data/training/kyzhan/huggingface/data/train40G/cached_lm_PreTrainedTokenizerFast_126_train3.txt [took 116.431 s]
/ th_index_copy
main()
File "run_hf_train_lm_ti.py", line 338, in main
trainer.train(model_path=model_path)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 758, in train
tr_loss += self.training_step(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1056, in training_step
loss = self.compute_loss(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1082, in compute_loss
outputs = model(**inputs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/distributed.py", line 511, in forward
output = self.module(*inputs[0], **kwargs[0])
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_transfo_xl.py", line 1056, in forward
return_dict=return_dict,
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_transfo_xl.py", line 888, in forward
word_emb = self.word_emb(input_ids)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 722, in call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_transfo_xl.py", line 448, in forward
emb_flat.index_copy(0, indices_i, emb_i)
RuntimeError: Expected object of scalar type Float but got scalar type Half for argument #4 'source' in call to th_index_copy
@TevenLeScao | 11-12-2020 12:16:58 | 11-12-2020 12:16:58 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,493 | closed | I meet the zero gradient descent | I want use transformers to do text classification, I want code myself rather than use `TFBertForSequenceClassification`,so I write the model with `TFBertModel` and `tf.keras.laters.Dense`,but this is no gradient descent in my code, I try to find what wrong with my code but I can't. So I submit this issues to ask for some help.
my code is here:
Model:
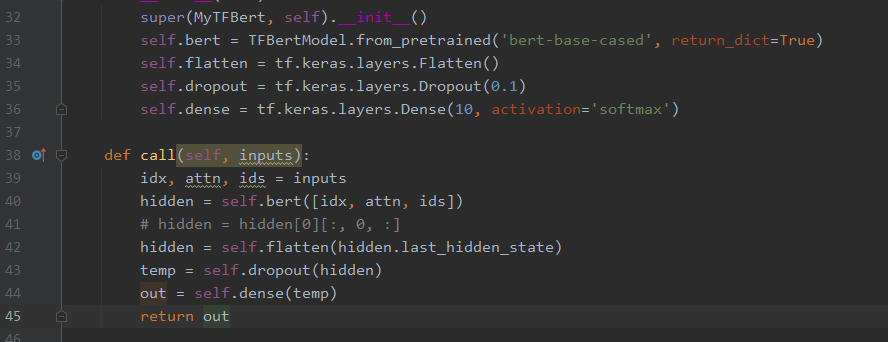

and I know train data is test data,just for quick debug.
and when I train this model ,

| 11-12-2020 11:29:45 | 11-12-2020 11:29:45 | Hi @Sniper970119 do you mind posting this on the forum rather? It's here: https://discuss.huggingface.co
We are trying to focus the issues on bug reports and features/model requests.
Thanks a lot.<|||||>>
>
> Hi @Sniper970119 do you mind posting this on the forum rather? It's here: https://discuss.huggingface.co
>
> We are trying to focus the issues on bug reports and features/model requests.
>
> Thanks a lot.
ok,I just post it on the forum.Thank for your reply. |
transformers | 8,492 | closed | Rework some TF tests | # What does this PR do?
Rework some TF tests to make them compliant with dict returns, and simplify some of them. | 11-12-2020 11:15:28 | 11-12-2020 11:15:28 | |
transformers | 8,491 | closed | Fix check scripts for Windows | # What does this PR do?
The current check-X scripts are reading/writing with `os.linesep` as the newline separator. On Windows it makes the overwritten files in CRLF instead of LF. Same logic is applied on Mac with CR. Now, Python will always use LF to read and write in the files. | 11-12-2020 10:47:05 | 11-12-2020 10:47:05 | It doesn't make any change on Linux, and you've tested it on Windows. Could we get someone using MacOS to double-check it doesn't break anything for them before merging?<|||||>I think @LysandreJik is on MacOS?<|||||>I'm actually between Manjaro and EndeavourOS, but I'll check on a Mac. |
transformers | 8,490 | closed | New TF loading weights | # What does this PR do?
This PR improves the way we load the TensorFlow weights. Before we had to go through the instantiated model + the checkpoint twice:
- once for loading the weights from the checkpoints into the instantiated model
- once for computing the missing and unexpected keys
Now both are done simultaneously which makes the loading faster. | 11-12-2020 10:23:37 | 11-12-2020 10:23:37 | I have added a lot of comments in the method to make it clearer, I removed a small part of the code that was due to the moment where I was updating to the new names in same time. @LysandreJik @sgugger it should be easier to understand now.<|||||>It's a lot clearer, thanks. There are still unaddressed comments however, and I can't comment on line 259 but it should be removed now (since the dict is create two lines below).<|||||>What is missing now?<|||||>There is Lysandre's comments at line 283 and mine about the loop line 277. Like I said in my previous comments, doing the two functions in one is great, I just don't get the added complexity of the new `model_layers_name_value` variable when we could stick to the previous loop in the function `load_tf_weights` while adding the behavior of `detect_tf_missing_unexpected_layers`.
The comments are a great addition, thanks a lot for adding those!<|||||>I have addressed the Lysandre's comment at line 283 and yours for the loop at line 277. Do you see anything else?<|||||>The typos should be fixed now. Sorry for that.<|||||>Good to merge for me too! |
transformers | 8,489 | closed | Fix typo in roberta-base-squad2-v2 model card | # What does this PR do?
Simply adding `-v2` for Haystack API model loading. Furthermore, I've also changed `model` in `model_name_or_path` due to breaking change in Haystack (https://github.com/deepset-ai/haystack/pull/510).
## Who can review?
Model Cards: @julien-c | 11-12-2020 10:15:46 | 11-12-2020 10:15:46 | |
transformers | 8,488 | closed | [WIP] T5v1.1 & MT5 | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-12-2020 09:46:23 | 11-12-2020 09:46:23 | Maybe wrong model config for T5.1.1. For instance, T5.1.1.small should have num_layers=8 and num_heads=6.
See https://github.com/google-research/text-to-text-transfer-transformer/blob/master/t5/models/gin/models/t5.1.1.small.gin<|||||>> Maybe wrong model config for T5.1.1. For instance, T5.1.1.small should have num_layers=8 and num_heads=6.
>
> See https://github.com/google-research/text-to-text-transfer-transformer/blob/master/t5/models/gin/models/t5.1.1.small.gin
Thanks yeah, I implemented that.
The new model structure is now equal to mesh t5 v1.1.
If you download the t5v1.1 `t5-small` checkpoint and replace the corresponding path in `check_t5_against_hf.py` you can see that the models are equal.
There is still quite some work to do: write more tests, lots of cleaning and better design, and check if mT5 works with it.<|||||>> If you download the t5v1.1 `t5-small` checkpoint and replace the corresponding path in `check_t5_against_hf.py` you can see that the models are equal.
Hi, `check_t5_against_hf.py` still fails if I use a longer input text instead of `Hello there`, like `Hello there. Let's put more words in more languages than I originally thought.`
<|||||>> > If you download the t5v1.1 `t5-small` checkpoint and replace the corresponding path in `check_t5_against_hf.py` you can see that the models are equal.
>
> Hi, `check_t5_against_hf.py` still fails if I use a longer input text instead of `Hello there`, like `Hello there. Let's put more words in more languages than I originally thought.`
Hmm, it works for me - do you experience that for T5v1.1 or mT5?<|||||>> > > If you download the t5v1.1 `t5-small` checkpoint and replace the corresponding path in `check_t5_against_hf.py` you can see that the models are equal.
> >
> >
> > Hi, `check_t5_against_hf.py` still fails if I use a longer input text instead of `Hello there`, like `Hello there. Let's put more words in more languages than I originally thought.`
>
> Hmm, it works for me - do you experience that for T5v1.1 or mT5?
Aha, the checking is OK now. Yesterday I made a mistake that when I changed the test input sentence in the check script, I didn't update the input length for MTF model from 4 to a longer value like 128. So actually the MTF model and PyTorch model received different inputs, and of course got different results.
Besides, if I add the z-loss to the CE loss at last, it differs from MTF score again. I just found MTF ignores z-loss when not training ([code](https://github.com/tensorflow/mesh/blob/4f82ba1275e4c335348019fee7974d11ac0c9649/mesh_tensorflow/transformer/transformer.py#L781)). So I think MTF model score does not include z-loss, but its training does, which is absent from HF T5 training. Well, this is absolutely not a blocking issue now.
Appreciate your great work :) <|||||>closing in favor of https://github.com/huggingface/transformers/pull/8552. |
transformers | 8,487 | closed | `log_history` does not contain metrics anymore | Since version 3.5.0 the `log_history` of the trainer does not contain the metrics anymore. Version 3.4.0 works...
My trainer uses a `compute_metrics` callback. It avaluates after each epoch. At version 3.4.0 after the training I am extracting the last epoch results: `trainer.state.log_history[-1]` to log the metrics.
At version 3.5.0 the dict only contains loss and epoch number but not the computed metrics.
I think anything was changed that broke the metric logging. I can not provide example code. Sorry...
| 11-12-2020 09:28:09 | 11-12-2020 09:28:09 | `evaluate` calls `log` which appends the results to `log_history`. So the code is there. Without a reproducer to investigate, there is nothing we can do to help.<|||||>Here is the demo code that shows the bug: https://colab.research.google.com/drive/1dEzkDoMampL-VVrQeO924HQmHXffya0Z?usp=sharing
The last line should print all metrics and does that with version 3.4.0 but not with 3.5.0
Output of 3.4.0 (which is correct):
```
{'eval_loss': 0.5401068925857544, 'eval_f1_OTHER': 0.8642232403165347, 'eval_f1_OFFENSE': 0.6730190571715146, 'eval_recall_OTHER': 0.9230427046263345, 'eval_recall_OFFENSE': 0.5834782608695652, 'eval_acc': 0.8081224249558564, 'eval_bac': 0.7532604827479499, 'eval_mcc': 0.5547059570919702, 'eval_f1_macro': 0.7686211487440247, 'epoch': 2.0, 'total_flos': 668448673730400, 'step': 628}
```
Bug in 3.5.0:
```
{'total_flos': 668448673730400, 'epoch': 2.0, 'step': 628}
```<|||||>Ah it's not a bug. In 3.5.0 there is one final log entry for the total_flos (instead of logging them during training as it's only useful at the end). So you can still access all your metrics but with the second-to-last entry (`trainer.state.log_history[-2]`).<|||||>Hi @sgugger ok thanks for the info.
It might be no bug but honestly. This logging "API" is very fragile. What happens if I do a `[-2]` now and in the next release the final log entry for the total_flos is moved to an other list. Then I am getting the result of the 2nd last epoch instead of the last one.
IMO this logging "API" needs a clean and better redesign. Or do I just use it in a wrong way?<|||||>There are plenty of things that could log more info: a callback, some other tweak in training performed at the end. IMO you shouldn't rely on a hard-coded index but loop from the end of the `log_history` until you find a dict with the metric values.<|||||>Ok. Closing this. |
transformers | 8,486 | closed | Gradient accumulation averages over gradients | https://github.com/huggingface/transformers/blob/121c24efa4453e4e726b5f0b2cf7095b14b7e74e/src/transformers/trainer.py#L1118
So I have been looking at this for the past day and a half. Please explain to me. Gradient accumulation should accumulate the gradient, not average it, right? That makes this scaling plain wrong? Am I missing something? | 11-12-2020 08:28:47 | 11-12-2020 08:28:47 | Hi @MarktHart do you mind posting this on the forum rather? It's here: https://discuss.huggingface.co
We are trying to focus the issues on bug reports and features/model requests.
Thanks a lot.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,485 | closed | Prediction loop: work with batches of variable length (fixed per batch) | In the current form, the `prediction_loop` doesn't handle batches with samples of varying lengths (but fixed length per batch). This patch adds this capability.
This is great because it can save a lot of time during training and inference, where using the full length every time is a big sacrifice, knowing self-attention scales in n**2.
Disclaimer: This is a strictly personal contribution, not linked to my professional affiliation in any way.
@sgugger
https://github.com/huggingface/transformers/issues/8483
| 11-12-2020 05:49:02 | 11-12-2020 05:49:02 | Please feel free to modify this in any shape or form of course.<|||||>This will cause a regression for code expecting a NumPy output, obviously :/<|||||>I don't have much time, if any, to dedicate to this. If you're not interested by the idea, it's completely fine, I will close.<|||||>I think @jplu is redesigning the TFTrainer. Maybe this should be reopened once that design has been merged in master?<|||||>This won't be compliant anymore because the redisign doesn't use custom loops.<|||||>Do you support different batch lengths in the new one? @jplu <|||||>It is not on top of the list but, yes for sure, we plan to support it, including for training. |
transformers | 8,484 | closed | automodel | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten @TevenLeScao
Blenderbot: @patrickvonplaten
Bart: @patrickvonplaten
Marian: @patrickvonplaten
Pegasus: @patrickvonplaten
mBART: @patrickvonplaten
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
RAG: @patrickvonplaten, @lhoestq
FSMT: @stas00
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| 11-12-2020 05:15:54 | 11-12-2020 05:15:54 | |
transformers | 8,483 | closed | transformers.TFTrainer: Does not support batches with sequences of variable lengths? | Hello,
It seems like `np.append` in `TFTrainer.prediction_loop` is the only thing that prevent TFTrainer from being able to deal with batches of variable sequence length (between the batches, not inside the batches themselves). Indeed, `np.append` requires the batches to be of the same sequence length.
Alternatives: as this is in tensorflow, an easy alternative would be to convert the batches to `tf.RaggedTensor` with `tf.ragged.constant`, and to concatenate them (the usual way) with `tf.concat`.
You could also ofc just make `preds` and `label_ids` into lists. There doesn't seem to be any big computation going on on these objects.
| 11-12-2020 05:14:14 | 11-12-2020 05:14:14 | Created pull request https://github.com/huggingface/transformers/pull/8485<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Hello @JulesGM
Regarding [#8483](https://github.com/huggingface/transformers/pull/8485)
I went through the code and I found this helpful. But I'm facing issues to convert my training tf.data.Dataset to tf.RaggedTensor format. if possible can you share resources regarding this? |
transformers | 8,482 | closed | TAPAS tokenizer & tokenizer tests | This PR aims to implement the tokenizer API for the TAPAS model, as well as the tests. It is based on `tapas-style` which contains all the changes done by black & isort on top of the `nielsrogge/tapas_v3` branch in https://github.com/huggingface/transformers/pull/8113.
The API is akin to our other tokenizers': it is based on the `__call__` method which dispatches to `encode_plus` or `batch_encode_plus` according to the inputs.
These two methods then dispatch to `_encode_plus` and `_batch_encode_plus`, which themselves dispatch to `prepare_for_model` and `_batch_prepare_for_model`.
Here are the remaining tasks for the tokenizers, from what I could observe:
- Two tokenizer tests are failing. This is only due to the fact that there is no checkpoint currently available.
- The truncation is *not* the same as it was before these changes. Before these changes, if a row of the dataframe was to be truncated, the whole row was removed. Right now only the overflowing tokens will be removed. This is probably an important change that will need to be reverted (implemented in the new API).
- The tokenizer is based on `pd.DataFrame`s. It should be very simple to switch from these to `datasets.Dataset`, which serve the same purpose.
Once this PR is merged, I'll open a PR from `tapas-style` to `nielsrogge/tapas_v3` as explained in https://github.com/huggingface/transformers/pull/8113#issuecomment-725818087 | 11-12-2020 04:10:49 | 11-12-2020 04:10:49 | Thank you!
❗ This is a preliminary review, I'm not finished with it. 2 important things for now:
1) I am also testing the Colab demo's with this branch. Currently I'm getting an error when providing `answer_coordinates` and `answer_texts` to the tokenizer:
SQA: https://colab.research.google.com/drive/1BNxrKkrwpWuE2TthZL5qQlERtcK4ZbIt?usp=sharing
WTQ: https://colab.research.google.com/drive/1K8ZeNQyBqo-A03D8RL8_j34n-Ubggb9U?usp=sharing
Normally, the `label_ids`, `numeric_values` and `numeric_values_scale` should also be padded when I set padding='max_length'.
2) I've got an updated version of the creation of the numeric values (they are currently not performed correctly) in a branch named `tapas_v3_up_to_date_with_master`. Either you could incorporate these changes in your branch before making a PR, or I make them after the PR is merged (what you like best - the latter is probably easier). <|||||>Great, thanks for your great preliminary review. I've fixed a few of the issues, just pushed a commit. There's a few things you mention that definitely need a deeper look. I can do so in the coming days, but I'll let you finish your review first so that I may batch everything. Thank you!<|||||>@LysandreJik I have finished reviewing, I've added more (mostly documentation-related) comments.
The most important thing is that when `label_ids`, `answer_coordinates` and `answer_text` are provided to the tokenizer, an error is currently thrown due to the fact that padding is not working.
Besides this, the other important things are:
* a correct implementation of the creation of the `prev_label_ids` when a batch of table-question pairs is provided
* a correct implementation of `drop_rows_to_fit` and `cell_trim_length` |
transformers | 8,481 | closed | TAPAS Tokenizer & tokenizer tests | 11-12-2020 04:03:21 | 11-12-2020 04:03:21 | ||
transformers | 8,480 | closed | Error when upload models: "LFS: Client error" | I am using the most recent release to upload a model.
Like the new instructions suggested, I am using git to upload my files:
```bash
$ git add --all
Encountered 1 file(s) that may not have been copied correctly on Windows:
pytorch_model.bin
$ git status
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: pytorch_model.bin
$ git commit -m 'update'
[main 820bb7e] update
1 file changed, 3 insertions(+)
create mode 100644 pytorch_model.bin
$ git push
Username for 'https://huggingface.co': danyaljj
Password for 'https://[email protected]':
LFS: Client error: https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T015933Z&X-Amz-Expires=900&X-Amz-Signature=0115d52aa41e4a5e80315f03689f278c36f3f1d4961ee5544e8bb9b427d0ba7c&X-Amz-SignedHeaders=host
Uploading LFS objects: 0% (0/1), 33 KB | 169 KB/s, done.
error: failed to push some refs to 'https://huggingface.co/allenai/unifiedqa-t5-3b'
```
FYI, here are my versions:
```bash
$ pip list | grep transformers
transformers 3.5.0
```
@julien-c | 11-12-2020 02:05:49 | 11-12-2020 02:05:49 | Since `git push` by itself is not so informative, I retried it with more verbose output (sorry for the long output):
```
$ GIT_TRACE=1 GIT_CURL_VERBOSE=1 git push
18:07:20.246678 git.c:440 trace: built-in: git push
18:07:20.247908 run-command.c:663 trace: run_command: GIT_DIR=.git git-remote-https origin https://huggingface.co/allenai/unifiedqa-t5-3b
* Couldn't find host huggingface.co in the .netrc file; using defaults
* Trying 192.99.39.165...
* TCP_NODELAY set
* Connected to huggingface.co (192.99.39.165) port 443 (#0)
* ALPN, offering h2
* ALPN, offering http/1.1
* successfully set certificate verify locations:
* CAfile: /etc/ssl/cert.pem
CApath: none
* SSL connection using TLSv1.2 / ECDHE-RSA-AES256-GCM-SHA384
* ALPN, server accepted to use http/1.1
* Server certificate:
* subject: CN=huggingface.co
* start date: Nov 10 08:05:46 2020 GMT
* expire date: Feb 8 08:05:46 2021 GMT
* subjectAltName: host "huggingface.co" matched cert's "huggingface.co"
* issuer: C=US; O=Let's Encrypt; CN=Let's Encrypt Authority X3
* SSL certificate verify ok.
> GET /allenai/unifiedqa-t5-3b/info/refs?service=git-receive-pack HTTP/1.1
Host: huggingface.co
User-Agent: git/2.23.0
Accept: */*
Accept-Encoding: deflate, gzip
Accept-Language: en-US, *;q=0.9
Pragma: no-cache
< HTTP/1.1 401 Unauthorized
< Server: nginx/1.14.2
< Date: Thu, 12 Nov 2020 02:07:21 GMT
< Content-Type: text/plain; charset=utf-8
< Content-Length: 12
< Connection: keep-alive
< X-Powered-By: huggingface-moon
< WWW-Authenticate: Basic realm="Authentication required", charset="UTF-8"
< ETag: W/"c-dAuDFQrdjS3hezqxDTNgW7AOlYk"
<
* Connection #0 to host huggingface.co left intact
18:07:20.859025 run-command.c:663 trace: run_command: 'git credential-osxkeychain get'
18:07:20.876285 git.c:703 trace: exec: git-credential-osxkeychain get
18:07:20.877309 run-command.c:663 trace: run_command: git-credential-osxkeychain get
* Found bundle for host huggingface.co: 0x7f89a65048d0 [can pipeline]
* Could pipeline, but not asked to!
* Re-using existing connection! (#0) with host huggingface.co
* Connected to huggingface.co (192.99.39.165) port 443 (#0)
* Server auth using Basic with user 'danyaljj'
> GET /allenai/unifiedqa-t5-3b/info/refs?service=git-receive-pack HTTP/1.1
Host: huggingface.co
Authorization: Basic ZGFueWFsamo6UmVuZGNyYXp5MQ==
User-Agent: git/2.23.0
Accept: */*
Accept-Encoding: deflate, gzip
Accept-Language: en-US, *;q=0.9
Pragma: no-cache
< HTTP/1.1 200 OK
< Server: nginx/1.14.2
< Date: Thu, 12 Nov 2020 02:07:21 GMT
< Content-Type: application/x-git-receive-pack-advertisement
< Transfer-Encoding: chunked
< Connection: keep-alive
< X-Powered-By: huggingface-moon
<
* Connection #0 to host huggingface.co left intact
18:07:21.159144 run-command.c:663 trace: run_command: 'git credential-osxkeychain store'
18:07:21.175886 git.c:703 trace: exec: git-credential-osxkeychain store
18:07:21.176867 run-command.c:663 trace: run_command: git-credential-osxkeychain store
18:07:21.240597 run-command.c:663 trace: run_command: .git/hooks/pre-push origin https://huggingface.co/allenai/unifiedqa-t5-3b
18:07:21.258423 git.c:703 trace: exec: git-lfs pre-push origin https://huggingface.co/allenai/unifiedqa-t5-3b
18:07:21.259618 run-command.c:663 trace: run_command: git-lfs pre-push origin https://huggingface.co/allenai/unifiedqa-t5-3b
18:07:21.280328 trace git-lfs: exec: git 'version'
18:07:21.305769 trace git-lfs: exec: git '-c' 'filter.lfs.smudge=' '-c' 'filter.lfs.clean=' '-c' 'filter.lfs.process=' '-c' 'filter.lfs.required=false' 'rev-parse' 'HEAD' '--symbolic-full-name' 'HEAD'
18:07:21.330148 trace git-lfs: exec: git 'config' '-l'
18:07:21.341551 trace git-lfs: pre-push: refs/heads/main 820bb7e936e2e5665ea9c4ac3016456b3ce55bc7 refs/heads/main 4d2dae1e804fc041975dc40c06e3ab902b6c3f38
18:07:21.829857 trace git-lfs: tq: running as batched queue, batch size of 100
18:07:21.830328 trace git-lfs: run_command: git rev-list --stdin --objects --not --remotes=origin --
18:07:21.848139 trace git-lfs: tq: sending batch of size 1
18:07:21.848726 trace git-lfs: api: batch 1 files
18:07:21.848996 trace git-lfs: creds: git credential fill ("https", "huggingface.co", "")
18:07:21.859568 git.c:440 trace: built-in: git credential fill
18:07:21.861149 run-command.c:663 trace: run_command: 'git credential-osxkeychain get'
18:07:21.877936 git.c:703 trace: exec: git-credential-osxkeychain get
18:07:21.879004 run-command.c:663 trace: run_command: git-credential-osxkeychain get
18:07:21.920056 trace git-lfs: Filled credentials for https://huggingface.co/allenai/unifiedqa-t5-3b
18:07:21.989068 trace git-lfs: HTTP: POST https://huggingface.co/allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch
> POST /allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch HTTP/1.1
> Host: huggingface.co
> Accept: application/vnd.git-lfs+json; charset=utf-8
> Authorization: Basic * * * * *
> Content-Length: 205
> Content-Type: application/vnd.git-lfs+json; charset=utf-8
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
{"operation":"upload","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119}],"transfers":["lfs-standalone-file","basic"],"ref":{"name":"refs/heads/main"}}18:07:23.102074 trace git-lfs: HTTP: 200
< HTTP/1.1 200 OK
< Content-Length: 578
< Connection: keep-alive
< Content-Type: application/vnd.git-lfs+json; charset=utf-8
< Date: Thu, 12 Nov 2020 02:07:23 GMT
< Etag: W/"242-LFg/omWZFm9SxeMWd5EiIfG1JTM"
< Server: nginx/1.14.2
< X-Powered-By: huggingface-moon
<
18:07:23.102239 trace git-lfs: creds: git credential approve ("https", "huggingface.co", "")
18:07:23.112995 git.c:440 trace: built-in: git credential approve
18:07:23.114213 run-command.c:663 trace: run_command: 'git credential-osxkeychain store'
18:07:23.129607 git.c:703 trace: exec: git-credential-osxkeychain store
18:07:23.130582 run-command.c:663 trace: run_command: git-credential-osxkeychain store
18:07:23.195094 trace git-lfs: HTTP: {"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020723Z&X-Amz-Expires=900&X-Amz-Signature=2d3c1762e44b21f78c89a7c5a5f41
{"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020723Z&X-Amz-Expires=900&X-Amz-Signature=2d3c1762e44b21f78c89a7c5a5f4118:07:23.195387 trace git-lfs: HTTP: 655333c901abeb466effd6f1d61bd110f6a&X-Amz-SignedHeaders=host"}}}]}
655333c901abeb466effd6f1d61bd110f6a&X-Amz-SignedHeaders=host"}}}]}Uploading LFS objects: 0% (0/1), 0 B | 0 B/s 18:07:23.195588 trace git-lfs: tq: starting transfer adapter "basic"
18:07:23.195998 trace git-lfs: xfer: adapter "basic" Begin() with 8 workers
18:07:23.196062 trace git-lfs: xfer: adapter "basic" started
18:07:23.196099 trace git-lfs: xfer: adapter "basic" worker 2 starting
18:07:23.196118 trace git-lfs: xfer: adapter "basic" worker 0 starting
18:07:23.196169 trace git-lfs: xfer: adapter "basic" worker 2 waiting for Auth
18:07:23.196185 trace git-lfs: xfer: adapter "basic" worker 1 starting
18:07:23.196151 trace git-lfs: xfer: adapter "basic" worker 4 starting
18:07:23.196216 trace git-lfs: xfer: adapter "basic" worker 5 starting
18:07:23.196257 trace git-lfs: xfer: adapter "basic" worker 5 waiting for Auth
18:07:23.196248 trace git-lfs: xfer: adapter "basic" worker 4 waiting for Auth
18:07:23.196288 trace git-lfs: xfer: adapter "basic" worker 0 processing job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:07:23.196293 trace git-lfs: xfer: adapter "basic" worker 1 waiting for Auth
18:07:23.196255 trace git-lfs: xfer: adapter "basic" worker 3 starting
18:07:23.196290 trace git-lfs: xfer: adapter "basic" worker 6 starting
18:07:23.196423 trace git-lfs: xfer: adapter "basic" worker 6 waiting for Auth
18:07:23.196380 trace git-lfs: xfer: adapter "basic" worker 7 starting
18:07:23.196458 trace git-lfs: xfer: adapter "basic" worker 7 waiting for Auth
18:07:23.196420 trace git-lfs: xfer: adapter "basic" worker 3 waiting for Auth
18:07:23.261193 trace git-lfs: HTTP: PUT https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386
> PUT /lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020723Z&X-Amz-Expires=900&X-Amz-Signature=2d3c1762e44b21f78c89a7c5a5f41655333c901abeb466effd6f1d61bd110f6a&X-Amz-SignedHeaders=host HTTP/1.1
> Host: s3.amazonaws.com
> Content-Length: 11406640119
> Content-Type: application/zip
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
18:07:23.499247 trace git-lfs: xfer: adapter "basic" worker 4 auth signal received
18:07:23.499298 trace git-lfs: xfer: adapter "basic" worker 5 auth signal received
18:07:23.499281 trace git-lfs: xfer: adapter "basic" worker 2 auth signal received
18:07:23.499315 trace git-lfs: xfer: adapter "basic" worker 6 auth signal received
18:07:23.499324 trace git-lfs: xfer: adapter "basic" worker 7 auth signal received
18:07:23.499353 trace git-lfs: xfer: adapter "basic" worker 1 auth signal received
18:07:23.499412 trace git-lfs: xfer: adapter "basic" worker 3 auth signal received
18:07:34.596626 trace git-lfs: xfer: adapter "basic" worker 0 finished job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:07:34.596706 trace git-lfs: tq: retrying object 7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386: LFS: Put https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020723Z&X-Amz-Expires=900&X-Amz-Signature=2d3c1762e44b21f78c89a7c5a5f41655333c901abeb466effd6f1d61bd110f6a&X-Amz-SignedHeaders=host: write tcp 192.168.0.6:57346->52.216.242.102:443: write: broken pipe
18:07:34.596761 trace git-lfs: tq: enqueue retry #1 for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386" (size: 11406640119)
18:07:34.596823 trace git-lfs: tq: sending batch of size 1
18:07:34.596995 trace git-lfs: api: batch 1 files
18:07:34.597180 trace git-lfs: creds: git credential cache ("https", "huggingface.co", "")
18:07:34.597193 trace git-lfs: Filled credentials for https://huggingface.co/allenai/unifiedqa-t5-3b
18:07:34.597208 trace git-lfs: HTTP: POST https://huggingface.co/allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch
> POST /allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch HTTP/1.1
> Host: huggingface.co
> Accept: application/vnd.git-lfs+json; charset=utf-8
> Authorization: Basic * * * * *
> Content-Length: 205
> Content-Type: application/vnd.git-lfs+json; charset=utf-8
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
{"operation":"upload","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119}],"transfers":["lfs-standalone-file","basic"],"ref":{"name":"refs/heads/main"}}18:07:34.925848 trace git-lfs: HTTP: 200
< HTTP/1.1 200 OK
< Content-Length: 578
< Connection: keep-alive
< Content-Type: application/vnd.git-lfs+json; charset=utf-8
< Date: Thu, 12 Nov 2020 02:07:35 GMT
< Etag: W/"242-5zNHypYie/0vI3rttL7+btltlmQ"
< Server: nginx/1.14.2
< X-Powered-By: huggingface-moon
<
18:07:34.926039 trace git-lfs: HTTP: {"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020735Z&X-Amz-Expires=900&X-Amz-Signature=602be765be6206f6363a93f156b88
{"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020735Z&X-Amz-Expires=900&X-Amz-Signature=602be765be6206f6363a93f156b8818:07:34.926220 trace git-lfs: HTTP: 37884d95b5a8f27d14e254dd7108b845cb7&X-Amz-SignedHeaders=host"}}}]}
37884d95b5a8f27d14e254dd7108b845cb7&X-Amz-SignedHeaders=host"}}}]}Uploading LFS objects: 0% (0/1), 9.7 MB | 742 KB/s 18:07:34.926411 trace git-lfs: xfer: adapter "basic" worker 4 processing job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:07:34.926793 trace git-lfs: HTTP: PUT https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386
> PUT /lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020735Z&X-Amz-Expires=900&X-Amz-Signature=602be765be6206f6363a93f156b8837884d95b5a8f27d14e254dd7108b845cb7&X-Amz-SignedHeaders=host HTTP/1.1
> Host: s3.amazonaws.com
> Content-Length: 11406640119
> Content-Type: application/zip
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
18:07:44.835908 trace git-lfs: HTTP: 400 | 752 KB/s
< HTTP/1.1 400 Bad Request
< Connection: close
< Transfer-Encoding: chunked
< Content-Type: application/xml
< Date: Thu, 12 Nov 2020 02:07:44 GMT
< Server: AmazonS3
< X-Amz-Id-2: mDWWLDn2SM2srJXwqsVkEIAue+9F8wnupyuGkTAD4lcLKmDSSBa75zgKY7NXUC0X7QEMVwmPSVk=
< X-Amz-Request-Id: B971E21D6254F404
<
18:07:44.836114 trace git-lfs: xfer: adapter "basic" worker 4 finished job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:07:44.836157 trace git-lfs: tq: retrying object 7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386: LFS: Client error: https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020735Z&X-Amz-Expires=900&X-Amz-Signature=602be765be6206f6363a93f156b8837884d95b5a8f27d14e254dd7108b845cb7&X-Amz-SignedHeaders=host
18:07:44.836199 trace git-lfs: tq: enqueue retry #2 for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386" (size: 11406640119)
18:07:44.836238 trace git-lfs: tq: sending batch of size 1
18:07:44.836355 trace git-lfs: api: batch 1 files
18:07:44.836546 trace git-lfs: creds: git credential cache ("https", "huggingface.co", "")
18:07:44.836556 trace git-lfs: Filled credentials for https://huggingface.co/allenai/unifiedqa-t5-3b
18:07:44.836585 trace git-lfs: HTTP: POST https://huggingface.co/allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch
> POST /allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch HTTP/1.1
> Host: huggingface.co
> Accept: application/vnd.git-lfs+json; charset=utf-8
> Authorization: Basic * * * * *
> Content-Length: 205
> Content-Type: application/vnd.git-lfs+json; charset=utf-8
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
{"operation":"upload","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119}],"transfers":["lfs-standalone-file","basic"],"ref":{"name":"refs/heads/main"}}18:07:45.158001 trace git-lfs: HTTP: 200
< HTTP/1.1 200 OK
< Content-Length: 578
< Connection: keep-alive
< Content-Type: application/vnd.git-lfs+json; charset=utf-8
< Date: Thu, 12 Nov 2020 02:07:45 GMT
< Etag: W/"242-m4CvhzTDqQPlc75+BedrFERvkE0"
< Server: nginx/1.14.2
< X-Powered-By: huggingface-moon
<
18:07:45.158145 trace git-lfs: HTTP: {"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020745Z&X-Amz-Expires=900&X-Amz-Signature=82592319178cff3f2a02f404e3540
{"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020745Z&X-Amz-Expires=900&X-Amz-Signature=82592319178cff3f2a02f404e354018:07:45.158254 trace git-lfs: HTTP: 89a6ef22b79fe75e6f544e1786faf3e8f5e&X-Amz-SignedHeaders=host"}}}]}
89a6ef22b79fe75e6f544e1786faf3e8f5e&X-Amz-SignedHeaders=host"}}}]}Uploading LFS objects: 0% (0/1), 9.7 MB | 752 KB/s 18:07:45.158419 trace git-lfs: xfer: adapter "basic" worker 5 processing job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:07:45.158794 trace git-lfs: HTTP: PUT https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386
> PUT /lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020745Z&X-Amz-Expires=900&X-Amz-Signature=82592319178cff3f2a02f404e354089a6ef22b79fe75e6f544e1786faf3e8f5e&X-Amz-SignedHeaders=host HTTP/1.1
> Host: s3.amazonaws.com
> Content-Length: 11406640119
> Content-Type: application/zip
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
18:07:55.959066 trace git-lfs: HTTP: 400 | 665 KB/s
< HTTP/1.1 400 Bad Request
< Connection: close
< Transfer-Encoding: chunked
< Content-Type: application/xml
< Date: Thu, 12 Nov 2020 02:07:54 GMT
< Server: AmazonS3
< X-Amz-Id-2: YPk1ZSL19/lW1Z7WxE/pTAyDK0Ny2ryDVCi1TZXtuT8Bh6itRmL4qO163dKG+s9yBSl8jyKRD7Y=
< X-Amz-Request-Id: D0E50DEEB73DFA43
<
18:07:55.959368 trace git-lfs: xfer: adapter "basic" worker 5 finished job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:07:55.959409 trace git-lfs: tq: retrying object 7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386: LFS: Client error: https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020745Z&X-Amz-Expires=900&X-Amz-Signature=82592319178cff3f2a02f404e354089a6ef22b79fe75e6f544e1786faf3e8f5e&X-Amz-SignedHeaders=host
18:07:55.959458 trace git-lfs: tq: enqueue retry #3 for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386" (size: 11406640119)
18:07:55.959490 trace git-lfs: tq: sending batch of size 1
18:07:55.959582 trace git-lfs: api: batch 1 files
18:07:55.959750 trace git-lfs: creds: git credential cache ("https", "huggingface.co", "")
18:07:55.959768 trace git-lfs: Filled credentials for https://huggingface.co/allenai/unifiedqa-t5-3b
18:07:55.959786 trace git-lfs: HTTP: POST https://huggingface.co/allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch
> POST /allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch HTTP/1.1
> Host: huggingface.co
> Accept: application/vnd.git-lfs+json; charset=utf-8
> Authorization: Basic * * * * *
> Content-Length: 205
> Content-Type: application/vnd.git-lfs+json; charset=utf-8
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
{"operation":"upload","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119}],"transfers":["basic","lfs-standalone-file"],"ref":{"name":"refs/heads/main"}}18:07:56.260024 trace git-lfs: HTTP: 200
< HTTP/1.1 200 OK
< Content-Length: 578
< Connection: keep-alive
< Content-Type: application/vnd.git-lfs+json; charset=utf-8
< Date: Thu, 12 Nov 2020 02:07:56 GMT
< Etag: W/"242-31cowPk91NvaIaX84tjI/gLbdvo"
< Server: nginx/1.14.2
< X-Powered-By: huggingface-moon
<
18:07:56.260224 trace git-lfs: HTTP: {"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020756Z&X-Amz-Expires=900&X-Amz-Signature=1c194a7990031e65288f0e7c59507
{"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020756Z&X-Amz-Expires=900&X-Amz-Signature=1c194a7990031e65288f0e7c5950718:07:56.260428 trace git-lfs: HTTP: 8387ee098bd5b3f3708e02085e3e9f6601a&X-Amz-SignedHeaders=host"}}}]}
8387ee098bd5b3f3708e02085e3e9f6601a&X-Amz-SignedHeaders=host"}}}]}Uploading LFS objects: 0% (0/1), 9.7 MB | 665 KB/s 18:07:56.260674 trace git-lfs: xfer: adapter "basic" worker 2 processing job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:07:56.261037 trace git-lfs: HTTP: PUT https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386
> PUT /lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020756Z&X-Amz-Expires=900&X-Amz-Signature=1c194a7990031e65288f0e7c595078387ee098bd5b3f3708e02085e3e9f6601a&X-Amz-SignedHeaders=host HTTP/1.1
> Host: s3.amazonaws.com
> Content-Length: 11406640119
> Content-Type: application/zip
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
18:08:07.099441 trace git-lfs: HTTP: 400 | 567 KB/s
< HTTP/1.1 400 Bad Request
< Connection: close
< Transfer-Encoding: chunked
< Content-Type: application/xml
< Date: Thu, 12 Nov 2020 02:08:06 GMT
< Server: AmazonS3
< X-Amz-Id-2: e9blPqVAV5CVfFOylV29AzDODso+WNBEVIhJKKQc6NbEAMDeUCyJ5NKumhuM5P3i67O58fmm31g=
< X-Amz-Request-Id: DFED315EE7523BFE
<
18:08:07.099632 trace git-lfs: xfer: adapter "basic" worker 2 finished job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:07.099659 trace git-lfs: tq: retrying object 7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386: LFS: Client error: https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020756Z&X-Amz-Expires=900&X-Amz-Signature=1c194a7990031e65288f0e7c595078387ee098bd5b3f3708e02085e3e9f6601a&X-Amz-SignedHeaders=host
18:08:07.099701 trace git-lfs: tq: enqueue retry #4 for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386" (size: 11406640119)
18:08:07.099742 trace git-lfs: tq: sending batch of size 1
18:08:07.099832 trace git-lfs: api: batch 1 files
18:08:07.099999 trace git-lfs: creds: git credential cache ("https", "huggingface.co", "")
18:08:07.100008 trace git-lfs: Filled credentials for https://huggingface.co/allenai/unifiedqa-t5-3b
18:08:07.100024 trace git-lfs: HTTP: POST https://huggingface.co/allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch
> POST /allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch HTTP/1.1
> Host: huggingface.co
> Accept: application/vnd.git-lfs+json; charset=utf-8
> Authorization: Basic * * * * *
> Content-Length: 205
> Content-Type: application/vnd.git-lfs+json; charset=utf-8
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
{"operation":"upload","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119}],"transfers":["lfs-standalone-file","basic"],"ref":{"name":"refs/heads/main"}}18:08:07.441913 trace git-lfs: HTTP: 200
< HTTP/1.1 200 OK
< Content-Length: 578
< Connection: keep-alive
< Content-Type: application/vnd.git-lfs+json; charset=utf-8
< Date: Thu, 12 Nov 2020 02:08:07 GMT
< Etag: W/"242-aR0wlUnNkp2RbtWgiEkJ7LUjpW0"
< Server: nginx/1.14.2
< X-Powered-By: huggingface-moon
<
18:08:07.442095 trace git-lfs: HTTP: {"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020807Z&X-Amz-Expires=900&X-Amz-Signature=126779f211c325c10aba6be7bfc4b
{"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020807Z&X-Amz-Expires=900&X-Amz-Signature=126779f211c325c10aba6be7bfc4b18:08:07.442300 trace git-lfs: HTTP: 32fc8b2d03b037c48b35a864f81d0c3f11f&X-Amz-SignedHeaders=host"}}}]}
32fc8b2d03b037c48b35a864f81d0c3f11f&X-Amz-SignedHeaders=host"}}}]}Uploading LFS objects: 0% (0/1), 9.7 MB | 673 KB/s 18:08:07.442493 trace git-lfs: xfer: adapter "basic" worker 6 processing job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:07.442893 trace git-lfs: HTTP: PUT https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386
> PUT /lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020807Z&X-Amz-Expires=900&X-Amz-Signature=126779f211c325c10aba6be7bfc4b32fc8b2d03b037c48b35a864f81d0c3f11f&X-Amz-SignedHeaders=host HTTP/1.1
> Host: s3.amazonaws.com
> Content-Length: 11406640119
> Content-Type: application/zip
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
18:08:18.357156 trace git-lfs: HTTP: 400 | 549 KB/s
< HTTP/1.1 400 Bad Request
< Connection: close
< Transfer-Encoding: chunked
< Content-Type: application/xml
< Date: Thu, 12 Nov 2020 02:08:17 GMT
< Server: AmazonS3
< X-Amz-Id-2: 18NzY2b209RdCK3nCS9J1AwpWxSPw7jRub8DLEosfO4JcG33iZ00V59ZRf/CwwCpEFS/G7xHPsI=
< X-Amz-Request-Id: 8M6V1WEG2N8R8YAT
<
18:08:18.357367 trace git-lfs: xfer: adapter "basic" worker 6 finished job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:18.357394 trace git-lfs: tq: retrying object 7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386: LFS: Client error: https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020807Z&X-Amz-Expires=900&X-Amz-Signature=126779f211c325c10aba6be7bfc4b32fc8b2d03b037c48b35a864f81d0c3f11f&X-Amz-SignedHeaders=host
18:08:18.357453 trace git-lfs: tq: enqueue retry #5 for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386" (size: 11406640119)
18:08:18.357489 trace git-lfs: tq: sending batch of size 1
18:08:18.357602 trace git-lfs: api: batch 1 files
18:08:18.357764 trace git-lfs: creds: git credential cache ("https", "huggingface.co", "")
18:08:18.357773 trace git-lfs: Filled credentials for https://huggingface.co/allenai/unifiedqa-t5-3b
18:08:18.357788 trace git-lfs: HTTP: POST https://huggingface.co/allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch
> POST /allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch HTTP/1.1
> Host: huggingface.co
> Accept: application/vnd.git-lfs+json; charset=utf-8
> Authorization: Basic * * * * *
> Content-Length: 205
> Content-Type: application/vnd.git-lfs+json; charset=utf-8
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
{"operation":"upload","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119}],"transfers":["basic","lfs-standalone-file"],"ref":{"name":"refs/heads/main"}}18:08:18.659856 trace git-lfs: HTTP: 200
< HTTP/1.1 200 OK
< Content-Length: 578
< Connection: keep-alive
< Content-Type: application/vnd.git-lfs+json; charset=utf-8
< Date: Thu, 12 Nov 2020 02:08:18 GMT
< Etag: W/"242-wt34qjjMKH3OaOLKkwsE5YY47Uo"
< Server: nginx/1.14.2
< X-Powered-By: huggingface-moon
<
18:08:18.659952 trace git-lfs: HTTP: {"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020818Z&X-Amz-Expires=900&X-Amz-Signature=4f4be5d714bb7cb2270c3c9934412
{"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020818Z&X-Amz-Expires=900&X-Amz-Signature=4f4be5d714bb7cb2270c3c993441218:08:18.660061 trace git-lfs: HTTP: cf1f62357f5a3fcde898603508194a423f1&X-Amz-SignedHeaders=host"}}}]}
cf1f62357f5a3fcde898603508194a423f1&X-Amz-SignedHeaders=host"}}}]}Uploading LFS objects: 0% (0/1), 9.7 MB | 549 KB/s 18:08:18.660225 trace git-lfs: xfer: adapter "basic" worker 7 processing job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:18.660511 trace git-lfs: HTTP: PUT https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386
> PUT /lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020818Z&X-Amz-Expires=900&X-Amz-Signature=4f4be5d714bb7cb2270c3c9934412cf1f62357f5a3fcde898603508194a423f1&X-Amz-SignedHeaders=host HTTP/1.1
> Host: s3.amazonaws.com
> Content-Length: 11406640119
> Content-Type: application/zip
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
18:08:31.284958 trace git-lfs: HTTP: 400 | 415 KB/s
< HTTP/1.1 400 Bad Request
< Connection: close
< Transfer-Encoding: chunked
< Content-Type: application/xml
< Date: Thu, 12 Nov 2020 02:08:30 GMT
< Server: AmazonS3
< X-Amz-Id-2: EilC4w16RhqwexN8CgO2pXC5Vf5T7PUWS5lsntHalCkp603MmhbpjBtHiITw8NIYifaMK5cuY6U=
< X-Amz-Request-Id: A0585EE068BDEB73
<
18:08:31.285190 trace git-lfs: xfer: adapter "basic" worker 7 finished job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:31.285198 trace git-lfs: tq: retrying object 7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386: LFS: Client error: https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020818Z&X-Amz-Expires=900&X-Amz-Signature=4f4be5d714bb7cb2270c3c9934412cf1f62357f5a3fcde898603508194a423f1&X-Amz-SignedHeaders=host
18:08:31.285250 trace git-lfs: tq: enqueue retry #6 for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386" (size: 11406640119)
18:08:31.285284 trace git-lfs: tq: sending batch of size 1
18:08:31.285391 trace git-lfs: api: batch 1 files
18:08:31.285539 trace git-lfs: creds: git credential cache ("https", "huggingface.co", "")
18:08:31.285549 trace git-lfs: Filled credentials for https://huggingface.co/allenai/unifiedqa-t5-3b
18:08:31.285566 trace git-lfs: HTTP: POST https://huggingface.co/allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch
> POST /allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch HTTP/1.1
> Host: huggingface.co
> Accept: application/vnd.git-lfs+json; charset=utf-8
> Authorization: Basic * * * * *
> Content-Length: 205
> Content-Type: application/vnd.git-lfs+json; charset=utf-8
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
{"operation":"upload","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119}],"transfers":["lfs-standalone-file","basic"],"ref":{"name":"refs/heads/main"}}18:08:31.638814 trace git-lfs: HTTP: 200
< HTTP/1.1 200 OK
< Content-Length: 578
< Connection: keep-alive
< Content-Type: application/vnd.git-lfs+json; charset=utf-8
< Date: Thu, 12 Nov 2020 02:08:31 GMT
< Etag: W/"242-7CB890z2UIC8LfHHmFvE0XNO8co"
< Server: nginx/1.14.2
< X-Powered-By: huggingface-moon
<
18:08:31.639032 trace git-lfs: HTTP: {"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020831Z&X-Amz-Expires=900&X-Amz-Signature=577f945c7c793130dc45581c51367
{"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020831Z&X-Amz-Expires=900&X-Amz-Signature=577f945c7c793130dc45581c5136718:08:31.639183 trace git-lfs: HTTP: 2755ab7636ad209ef6755d542a332673930&X-Amz-SignedHeaders=host"}}}]}
2755ab7636ad209ef6755d542a332673930&X-Amz-SignedHeaders=host"}}}]}Uploading LFS objects: 0% (0/1), 9.7 MB | 415 KB/s 18:08:31.639442 trace git-lfs: xfer: adapter "basic" worker 1 processing job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:31.639795 trace git-lfs: HTTP: PUT https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386
> PUT /lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020831Z&X-Amz-Expires=900&X-Amz-Signature=577f945c7c793130dc45581c513672755ab7636ad209ef6755d542a332673930&X-Amz-SignedHeaders=host HTTP/1.1
> Host: s3.amazonaws.com
> Content-Length: 11406640119
> Content-Type: application/zip
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
18:08:35.670792 trace git-lfs: HTTP: 400 | 442 KB/s
< HTTP/1.1 400 Bad Request
< Connection: close
< Transfer-Encoding: chunked
< Content-Type: application/xml
< Date: Thu, 12 Nov 2020 02:08:34 GMT
< Server: AmazonS3
< X-Amz-Id-2: 37wPu8zcJ6igY2DAtJ27Oaf5vcLhzCJStEw6bBpHK4QIwUFxcriAuVDuPgfYsUp5mOIqpGXYd5g=
< X-Amz-Request-Id: 4040905E813EF937
<
18:08:35.670992 trace git-lfs: xfer: adapter "basic" worker 1 finished job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:35.671009 trace git-lfs: tq: retrying object 7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386: LFS: Client error: https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020831Z&X-Amz-Expires=900&X-Amz-Signature=577f945c7c793130dc45581c513672755ab7636ad209ef6755d542a332673930&X-Amz-SignedHeaders=host
18:08:35.671057 trace git-lfs: tq: enqueue retry #7 for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386" (size: 11406640119)
18:08:35.671169 trace git-lfs: tq: sending batch of size 1
18:08:35.671270 trace git-lfs: api: batch 1 files
18:08:35.671422 trace git-lfs: creds: git credential cache ("https", "huggingface.co", "")
18:08:35.671434 trace git-lfs: Filled credentials for https://huggingface.co/allenai/unifiedqa-t5-3b
18:08:35.671449 trace git-lfs: HTTP: POST https://huggingface.co/allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch
> POST /allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch HTTP/1.1
> Host: huggingface.co
> Accept: application/vnd.git-lfs+json; charset=utf-8
> Authorization: Basic * * * * *
> Content-Length: 205
> Content-Type: application/vnd.git-lfs+json; charset=utf-8
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
{"operation":"upload","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119}],"transfers":["lfs-standalone-file","basic"],"ref":{"name":"refs/heads/main"}}18:08:35.978219 trace git-lfs: HTTP: 200
< HTTP/1.1 200 OK
< Content-Length: 578
< Connection: keep-alive
< Content-Type: application/vnd.git-lfs+json; charset=utf-8
< Date: Thu, 12 Nov 2020 02:08:36 GMT
< Etag: W/"242-aBj4kp6nW/vZfASETDB6DUEmP80"
< Server: nginx/1.14.2
< X-Powered-By: huggingface-moon
<
18:08:35.978365 trace git-lfs: HTTP: {"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020836Z&X-Amz-Expires=900&X-Amz-Signature=25e0ceea23657b4711a66397bf0e4
{"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020836Z&X-Amz-Expires=900&X-Amz-Signature=25e0ceea23657b4711a66397bf0e418:08:35.978471 trace git-lfs: HTTP: 274d53934c669794d8f31e5be4472d27493&X-Amz-SignedHeaders=host"}}}]}
274d53934c669794d8f31e5be4472d27493&X-Amz-SignedHeaders=host"}}}]}Uploading LFS objects: 0% (0/1), 9.7 MB | 442 KB/s 18:08:35.978651 trace git-lfs: xfer: adapter "basic" worker 3 processing job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:35.978961 trace git-lfs: HTTP: PUT https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386
> PUT /lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020836Z&X-Amz-Expires=900&X-Amz-Signature=25e0ceea23657b4711a66397bf0e4274d53934c669794d8f31e5be4472d27493&X-Amz-SignedHeaders=host HTTP/1.1
> Host: s3.amazonaws.com
> Content-Length: 11406640119
> Content-Type: application/zip
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
18:08:47.217142 trace git-lfs: HTTP: 400 | 382 KB/s
< HTTP/1.1 400 Bad Request
< Connection: close
< Transfer-Encoding: chunked
< Content-Type: application/xml
< Date: Thu, 12 Nov 2020 02:08:46 GMT
< Server: AmazonS3
< X-Amz-Id-2: 5AEyU9ANTZA6eG2d4Y1XW5KAQ5XX9TsO5IKpThwbwvYh2x2neejx+SxYlt7ysbZ5ZZKRtOQhp0k=
< X-Amz-Request-Id: CF55ABCF55095CE9
<
18:08:47.217330 trace git-lfs: xfer: adapter "basic" worker 3 finished job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:47.217349 trace git-lfs: tq: retrying object 7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386: LFS: Client error: https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020836Z&X-Amz-Expires=900&X-Amz-Signature=25e0ceea23657b4711a66397bf0e4274d53934c669794d8f31e5be4472d27493&X-Amz-SignedHeaders=host
18:08:47.217399 trace git-lfs: tq: enqueue retry #8 for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386" (size: 11406640119)
18:08:47.217432 trace git-lfs: tq: sending batch of size 1
18:08:47.217524 trace git-lfs: api: batch 1 files
18:08:47.217666 trace git-lfs: creds: git credential cache ("https", "huggingface.co", "")
18:08:47.217675 trace git-lfs: Filled credentials for https://huggingface.co/allenai/unifiedqa-t5-3b
18:08:47.217689 trace git-lfs: HTTP: POST https://huggingface.co/allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch
> POST /allenai/unifiedqa-t5-3b.git/info/lfs/objects/batch HTTP/1.1
> Host: huggingface.co
> Accept: application/vnd.git-lfs+json; charset=utf-8
> Authorization: Basic * * * * *
> Content-Length: 205
> Content-Type: application/vnd.git-lfs+json; charset=utf-8
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
{"operation":"upload","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119}],"transfers":["lfs-standalone-file","basic"],"ref":{"name":"refs/heads/main"}}18:08:47.576518 trace git-lfs: HTTP: 200
< HTTP/1.1 200 OK
< Content-Length: 578
< Connection: keep-alive
< Content-Type: application/vnd.git-lfs+json; charset=utf-8
< Date: Thu, 12 Nov 2020 02:08:47 GMT
< Etag: W/"242-I6sTx/9B2Dp11gS7wtbjrP1c3lQ"
< Server: nginx/1.14.2
< X-Powered-By: huggingface-moon
<
18:08:47.576645 trace git-lfs: HTTP: {"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020847Z&X-Amz-Expires=900&X-Amz-Signature=81eab82a86449f39b5dc223fbdf2b
{"transfer":"basic","objects":[{"oid":"7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386","size":11406640119,"authenticated":true,"actions":{"upload":{"href":"https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020847Z&X-Amz-Expires=900&X-Amz-Signature=81eab82a86449f39b5dc223fbdf2b18:08:47.576740 trace git-lfs: HTTP: d23ecd4834899033d6a896742ea480a1985&X-Amz-SignedHeaders=host"}}}]}
d23ecd4834899033d6a896742ea480a1985&X-Amz-SignedHeaders=host"}}}]}Uploading LFS objects: 0% (0/1), 9.7 MB | 382 KB/s 18:08:47.576910 trace git-lfs: xfer: adapter "basic" worker 0 processing job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:47.577223 trace git-lfs: HTTP: PUT https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386
> PUT /lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020847Z&X-Amz-Expires=900&X-Amz-Signature=81eab82a86449f39b5dc223fbdf2bd23ecd4834899033d6a896742ea480a1985&X-Amz-SignedHeaders=host HTTP/1.1
> Host: s3.amazonaws.com
> Content-Length: 11406640119
> Content-Type: application/zip
> User-Agent: git-lfs/2.10.0 (GitHub; darwin amd64; go 1.13.6)
>
18:08:50.864302 trace git-lfs: HTTP: 400 | 278 KB/s
< HTTP/1.1 400 Bad Request
< Connection: close
< Transfer-Encoding: chunked
< Content-Type: application/xml
< Date: Thu, 12 Nov 2020 02:08:49 GMT
< Server: AmazonS3
< X-Amz-Id-2: hV+PVm+Jl6JpvptNirGJM1ZhxunLPQcDUc0z0Ea053vMhwpgNMGs57y/qnEQFaL5ffAzrTmcfOI=
< X-Amz-Request-Id: 7Z1MEY0MAV4T5NCY
<
18:08:50.864739 trace git-lfs: xfer: adapter "basic" worker 0 finished job for "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386"
18:08:50.864774 trace git-lfs: tq: refusing to retry "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386", too many retries (8)
18:08:50.864842 trace git-lfs: tq: refusing to retry "7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386", too many retries (8)
18:08:50.864891 trace git-lfs: xfer: adapter "basic" End()
18:08:50.864903 trace git-lfs: xfer: adapter "basic" worker 4 stopping
18:08:50.864910 trace git-lfs: xfer: adapter "basic" worker 0 stopping
18:08:50.864929 trace git-lfs: xfer: adapter "basic" worker 3 stopping
18:08:50.864935 trace git-lfs: xfer: adapter "basic" worker 1 stopping
18:08:50.864940 trace git-lfs: xfer: adapter "basic" worker 7 stopping
18:08:50.864946 trace git-lfs: xfer: adapter "basic" worker 6 stopping
18:08:50.864954 trace git-lfs: xfer: adapter "basic" worker 2 stopping
18:08:50.864956 trace git-lfs: xfer: adapter "basic" worker 5 stopping
18:08:50.865017 trace git-lfs: xfer: adapter "basic" stopped
LFS: Client error: https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020847Z&X-Amz-Expires=900&X-Amz-Signature=81eab82a86449f39b5dc223fbdf2bd23ecd4834899033d6a896742ea480a1985&X-Amz-SignedHeaders=host
Uploading LFS objects: 0% (0/1), 9.7 MB | 278 KB/s, done.
error: failed to push some refs to 'https://huggingface.co/allenai/unifiedqa-t5-3b'
* Closing connection 0
```
I see lines like this that contain error messages, but not sure what they mean:
```
18:08:47.217349 trace git-lfs: tq: retrying object 7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386: LFS: Client error: https://s3.amazonaws.com/lfs.huggingface.co/allenai/unifiedqa-t5-3b/7e295e01528dc6a361211884f82daac33c422089644d0f5b2ddb2d96166aa386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20201112%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20201112T020836Z&X-Amz-Expires=900&X-Amz-Signature=25e0ceea23657b4711a66397bf0e4274d53934c669794d8f31e5be4472d27493&X-Amz-SignedHeaders=host
```
I also tried tweaking the git config parameters a bit, just in case they matter; but did not help.
```
$ git config --global lfs.transfer.maxretries 10
$ git config --global lfs.dialtimeout 600000
```
<|||||>Very weird, and unfortunately error messages from S3 aren't very informative (we're generating presigned upload urls to S3, in your log git-lfs actually tries to upload to S3).
What kind of upload bandwidth do you have? (cc @pierrci) Can you share your pytorch_model.bin somewhere so that I can try pushing it in a clone of your model?
The one thing I'm thinking about is maybe if S3 presigned URLs expire while the upload is still underway, does it reject the download.<|||||>@julien-c The model files are here: https://console.cloud.google.com/storage/browser/unifiedqa/tmp;tab=objects
> What kind of upload bandwidth do you have?
I am actually not sure how to answer this question. But my internet is quite reliable; never had any major issues with download/uploads.
<|||||>Ok @danyaljj, we can reproduce and will be working on a fix in the coming weeks.
In the meantime, do you want me to upload your models manually?<|||||>> In the meantime, do you want me to upload your models manually?
That would be great! 🙏 <|||||>⚠️⚠️ For anyone else in the Hugging Face team (@patrickvonplaten notably) who might have to upload large models before we improve native support for large files (ETA = about 2 weeks), here's the current workaround (Reminder: previous workaround was simply `aws s3 cp` as the `transformers-cli` already had the same issue):
- compute sha256 of large file with e.g. `sha256sum` (takes 3 mins on a beefy machine for 42GB t5-11b checkpoint)
- copy the file to our lfs bucket, named with the sha256: `aws s3 cp pytorch_model.bin s3://lfs.huggingface.co/{model_id}/{sha256_from_above}`
- clone the model repo you want to push to (with `GIT_LFS_SKIP_SMUDGE=1`) and write an LFS pointer file manually at the file's place, replacing the sha256 and the file size: example for t5-3b is https://huggingface.co/allenai/unifiedqa-t5-3b/blob/main/pytorch_model.bin
- commit and push
You can then check that it worked, with (with lfs installed):
```
git clone https://huggingface.co/{model_id}
```
cc @Pierrci @Narsil @thomwolf <|||||>Ok @danyaljj thanks for your patience 😄
Files are uploaded at
https://huggingface.co/allenai/unifiedqa-t5-11b/commits/main
and
https://huggingface.co/allenai/unifiedqa-t5-3b/commits/main
I've checked that git clones work, though the clone takes a pretty long time for the 11b model :)
Let me know if any issue.<|||||>Appreciate the help, @julien-c 🙏 <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,479 | closed | Fix SqueezeBERT for masked language model | # What does this PR do?
This corrects a mistake in the implementation of SqueezeBertForMaskedLM.
Fixes #8277
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Yes: https://github.com/huggingface/transformers/issues/8277
- [x] Did you make sure to update the documentation with your changes? Here are the
- [ ] Did you write any new necessary tests? _No tests added._
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
@sgugger @LysandreJik @ontocord
| 11-12-2020 01:12:38 | 11-12-2020 01:12:38 | |
transformers | 8,478 | closed | [s2s] finetune.py: specifying generation min_length | # What does this PR do?
Adds an argument to `finetune.py` to specify min length for text generation.
Related to:
https://github.com/huggingface/transformers/issues/5142#issuecomment-724938595
https://github.com/huggingface/transformers/issues/7796#issuecomment-709348940
## Who can review?
@patrickvonplaten @patil-suraj | 11-12-2020 00:53:22 | 11-12-2020 00:53:22 | LGTM, but will break CI. no idea why it's not running.
You will need to update the tests. I bet `pytest examples/seq2seq/test_seq2seq_examples.py` will fail ( you should fix that).
<|||||>Yeah, here is the error I am seeing.
```
$ pytest examples/seq2seq/test_seq2seq_examples.py
comet_ml is installed but `COMET_API_KEY` is not set.
Traceback (most recent call last):
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 430, in _importconftest
return self._conftestpath2mod[conftestpath]
KeyError: local('/Users/danielk/ideaProjects/transformers/examples/conftest.py')
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/danielk/opt/anaconda3/bin/pytest", line 10, in <module>
sys.exit(main())
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 58, in main
config = _prepareconfig(args, plugins)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 196, in _prepareconfig
pluginmanager=pluginmanager, args=args
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/hooks.py", line 286, in __call__
return self._hookexec(self, self.get_hookimpls(), kwargs)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/manager.py", line 92, in _hookexec
return self._inner_hookexec(hook, methods, kwargs)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/manager.py", line 86, in <lambda>
firstresult=hook.spec.opts.get("firstresult") if hook.spec else False,
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/callers.py", line 203, in _multicall
gen.send(outcome)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/helpconfig.py", line 93, in pytest_cmdline_parse
config = outcome.get_result()
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/callers.py", line 80, in get_result
raise ex[1].with_traceback(ex[2])
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/callers.py", line 187, in _multicall
res = hook_impl.function(*args)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 675, in pytest_cmdline_parse
self.parse(args)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 845, in parse
self._preparse(args, addopts=addopts)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 809, in _preparse
early_config=self, args=args, parser=self._parser
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/hooks.py", line 286, in __call__
return self._hookexec(self, self.get_hookimpls(), kwargs)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/manager.py", line 92, in _hookexec
return self._inner_hookexec(hook, methods, kwargs)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/manager.py", line 86, in <lambda>
firstresult=hook.spec.opts.get("firstresult") if hook.spec else False,
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/callers.py", line 208, in _multicall
return outcome.get_result()
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/callers.py", line 80, in get_result
raise ex[1].with_traceback(ex[2])
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/callers.py", line 187, in _multicall
res = hook_impl.function(*args)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 719, in pytest_load_initial_conftests
self.pluginmanager._set_initial_conftests(early_config.known_args_namespace)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 379, in _set_initial_conftests
self._try_load_conftest(current)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 382, in _try_load_conftest
self._getconftestmodules(anchor)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 414, in _getconftestmodules
mod = self._importconftest(conftestpath)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 464, in _importconftest
self.consider_conftest(mod)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 492, in consider_conftest
self.register(conftestmodule, name=conftestmodule.__file__)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/_pytest/config/__init__.py", line 306, in register
ret = super(PytestPluginManager, self).register(plugin, name)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/manager.py", line 126, in register
hook._maybe_apply_history(hookimpl)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/hooks.py", line 333, in _maybe_apply_history
res = self._hookexec(self, [method], kwargs)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/manager.py", line 92, in _hookexec
return self._inner_hookexec(hook, methods, kwargs)
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/manager.py", line 86, in <lambda>
firstresult=hook.spec.opts.get("firstresult") if hook.spec else False,
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/callers.py", line 208, in _multicall
return outcome.get_result()
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/callers.py", line 80, in get_result
raise ex[1].with_traceback(ex[2])
File "/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/pluggy/callers.py", line 187, in _multicall
res = hook_impl.function(*args)
File "/Users/danielk/ideaProjects/transformers/examples/conftest.py", line 20, in pytest_addoption
from transformers.testing_utils import pytest_addoption_shared
File "/Users/danielk/ideaProjects/transformers/src/transformers/__init__.py", line 135, in <module>
from .pipelines import (
File "/Users/danielk/ideaProjects/transformers/src/transformers/pipelines.py", line 38, in <module>
from .tokenization_auto import AutoTokenizer
File "/Users/danielk/ideaProjects/transformers/src/transformers/tokenization_auto.py", line 119, in <module>
from .tokenization_albert_fast import AlbertTokenizerFast
File "/Users/danielk/ideaProjects/transformers/src/transformers/tokenization_albert_fast.py", line 23, in <module>
from .tokenization_utils_fast import PreTrainedTokenizerFast
File "/Users/danielk/ideaProjects/transformers/src/transformers/tokenization_utils_fast.py", line 30, in <module>
from .convert_slow_tokenizer import convert_slow_tokenizer
File "/Users/danielk/ideaProjects/transformers/src/transformers/convert_slow_tokenizer.py", line 25, in <module>
from tokenizers.models import BPE, Unigram, WordPiece
ImportError: cannot import name 'Unigram' from 'tokenizers.models' (/Users/danielk/opt/anaconda3/lib/python3.7/site-packages/tokenizers/models/__init__.py)
```
Likely caused by previous changes?
<|||||>The above error comes from a wrong version of `tokenizers` being installed.
Could you
```
pip install --upgrade tokenizers
```
and re-run the tests? <|||||>Have updated the branch now and I *think* the previous error has gone away. <|||||>Looks good to me. @patil-suraj can you take a final look and merge if you want?<|||||>Something is wrong with this PR,
1) didn't go through autoformatters
2) failing CI on current master. e.g. see: https://app.circleci.com/pipelines/github/huggingface/transformers/16336/workflows/09f5b053-9f0e-4f70-aae8-3b31c79227f0/jobs/125984 (from unrelated recent PR https://github.com/huggingface/transformers/pull/8798)
3) It looks like CI has never passed on this PR yet was merged - odd
<|||||>Hey @danyaljj - sorry we merged your PR too early without exactly checking whether everything was fine or not. A couple of tests were actually failing on master due to the merge of this PR and I just reverted the PR.
Could you maybe open a new PR and we'll all make sure this time that all tests pass? :-)
Sorry for the inconvenience! The mistake is definitely on us here!<|||||>post mortem - for some reason this PR had no indication of CI pass/fail - one can only see its status in the merge https://github.com/huggingface/transformers/commit/5aa361f3e56de0f65720f291bb3975bfc98f2837, which fails 3 CIs.
So this was definitely an odd situation and probably some bug in CI software itself.<|||||>The tests are failing because in s2s tests the `args` are directly passed to `finetune.py`'s `main` function and the newly added `eval_min_gen_length` is not included in it.
Two changes to make the tests pass
1. add `eval_min_gen_length` in `CHEAP_ARGS` `dict` here https://github.com/huggingface/transformers/blob/master/examples/seq2seq/test_seq2seq_examples.py#L30
2. run `make style` |
transformers | 8,477 | closed | How to print out the probability for each bean search result in gpt2 text generator? | # 🚀 I want to see the probability for the text result generated by gpt2 model
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
See a sample code as below, when we used a pre-trained model, can we also print out the probability outcome with each beam_output?
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
for i, beam_output in enumerate(beam_outputs):
**print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))**
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| 11-12-2020 00:21:14 | 11-12-2020 00:21:14 | Take a look at https://github.com/huggingface/transformers/issues/5164<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,476 | closed | Trainer runs out of memory when computing eval score | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.5.0
- Platform: Linux-3.10.0-1127.19.1.el7.x86_64-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.4.0 (False)
- Tensorflow version (GPU?): 2.3.0 (False)
- Using GPU in script?: NO
- Using distributed or parallel set-up in script?: NO
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
-->
Trainer: @sgugger
## Information
Model I am using (Bert, XLNet ...): Camembert
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
I am trying to finetune a Camembert Model for a mlm task.
This is the configuration i am using:
```python
training_args = TrainingArguments(
seed=92,
output_dir='./results', # output directory
disable_tqdm=False,
prediction_loss_only=False,
num_train_epochs=3, # total number of training epochs
learning_rate=1e-4,
evaluation_strategy='steps',
per_device_train_batch_size=8, # batch size per device during training
per_device_eval_batch_size=16, # batch size for evaluation
eval_steps = 25,
logging_dir='./logs', # directory for storing logs
logging_steps=5,
)
data_collator = DataCollatorForLanguageModeling(tokenizer=TOKENIZER, mlm=True, mlm_probability=0.15)
trainer = Trainer(
model=MODEL,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics = compute_metrics
)
```
Steps to reproduce the behavior:
1. Load a train and validation dataset.
2. Define a compute_metrics function for evaluation.
3. evaluation works at the beginning but it raises a ```RuntimeError: [enforce fail at CPUAllocator.cpp:64] . DefaultCPUAllocator: can't allocate memory: you tried to allocate 57680691200 bytes. Error code 12 (Cannot allocate memory)``` when trying to run the ```nested_concat``` function inside the ```prediction_loop```.
```
/usr/local/lib/python3.6/dist-packages/transformers/trainer.py in prediction_loop(self, dataloader, description, prediction_loss_only)
1420 losses_host = losses if losses_host is None else torch.cat((losses_host, losses), dim=0)
1421 if logits is not None:
-> 1422 preds_host = logits if preds_host is None else nested_concat(preds_host, logits, padding_index=-100)
1423 if labels is not None:
1424 labels_host = labels if labels_host is None else nested_concat(labels_host, labels, padding_index=-100)
/usr/local/lib/python3.6/dist-packages/transformers/trainer_pt_utils.py in nested_concat(tensors, new_tensors, padding_index)
84 return type(tensors)(nested_concat(t, n, padding_index=padding_index) for t, n in zip(tensors, new_tensors))
85 elif isinstance(tensors, torch.Tensor):
---> 86 return torch_pad_and_concatenate(tensors, new_tensors, padding_index=padding_index)
87 elif isinstance(tensors, np.ndarray):
88 return numpy_pad_and_concatenate(tensors, new_tensors, padding_index=padding_index)
/usr/local/lib/python3.6/dist-packages/transformers/trainer_pt_utils.py in torch_pad_and_concatenate(tensor1, tensor2, padding_index)
52
53 # Now let's fill the result tensor
---> 54 result = tensor1.new_full(new_shape, padding_index)
55 result[: tensor1.shape[0], : tensor1.shape[1]] = tensor1
56 result[tensor1.shape[0] :, : tensor2.shape[1]] = tensor2
RuntimeError: [enforce fail at CPUAllocator.cpp:64] . DefaultCPUAllocator: can't allocate memory: you tried to allocate 57680691200 bytes. Error code 12 (Cannot allocate memory)
```
The machine i am using has 120Gb of RAM.
The data contains 20355 sentences with the max number of words in a sentence inferior to 200. The dataset fits easily in the RAM.
The subset used for evaluation contains 4057 examples with the same structure as the training dataset.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
It seems that setting ```prediction_loss_only=True``` avoids the problem as it does not compute evaluation metrics and only loss metric, so it costs much lower RAM to compute. The downside obviously is that you dont get any evaluation metrics.
The Trainer should be able to handle the workload as we go further in evaluation steps. Maybe clearing heavy variables in the evaluation process might help avoid blowing up RAM by storing values that are too large.
<!-- A clear and concise description of what you would expect to happen. -->
| 11-12-2020 00:09:50 | 11-12-2020 00:09:50 | I'm not sure what the bug is: by requiring the complete predictions for your `compute_metrics` function, you are asking for an array of 4,057 by 200 by vocab_size (which for the base CamemBERT model is 30,522 I believe). This does not fit easily in RAM.
<|||||>Is there another way to compute the metrics (or an estimation) without having to build such a huge vector ?<|||||>You haven't shared what metric you are using so I have no idea.<|||||>This the function i'm using:
```python
from sklearn.metrics import precision_recall_fscore_support
def compute_metrics(p: EvalPrediction) -> Dict:
#print('raw_predictions: ', p.predictions, '\n')
#print('labels: ', p.label_ids,'\n')
preds = np.argmax(p.predictions, axis=-1)
#print('shape:', preds.shape, '\n')
precision, recall, f1, _ = precision_recall_fscore_support(p.label_ids.flatten(), preds.flatten(), average='weighted', zero_division=0)
return {
'accuracy': (preds == p.label_ids).mean(),
'f1': f1,
'precision': precision,
'recall': recall
}
```<|||||>I guess you could write your custom loop to store the predictions after the argmax together, this won't blow up memory the same way.<|||||>Great, thanks a lot for the tip !
I ll mark the issue as closed.<|||||>@soufianeelalami Did you come up with a solution for this issue? Our team has run into the same issue with `nested_conat` while evaluating on a fairly large dataset.<|||||>@gphillips-ema Hello, basically what you need to do is create your trainer class (which inherits from the trainer class) then override the ```prediction_loop```method to change one particular behavior:
```python
if logits is not None:
#preds_host = logits if preds_host is None else nested_concat(preds_host, logits, padding_index=-100)
logits_reduced = np.argmax(logits, axis=-1)
preds_host = logits_reduced if preds_host is None else nested_concat(preds_host, logits_reduced, padding_index=-100)
```
You need to do a ```np.argmax(logits, axis=-1)``` to reduce the dimension of the output logit vector.
If you are using accumulation, then you need to do the same thing in that part of the code (always in the ```prediction_loop```method).
Please let me know if this solves your problem or if you need any help.<|||||>I was facing a related issues with `nested_concat` that caused GPU memory errors. Using the `Seq2SeqTrainer` instead of the default Trainer solved the issue for me, since does not rely on concatenating the logits over the vocabulary. <|||||>Same issue, I got an A5000 gpu for training, but I can't even eval with batch_size=8. |
transformers | 8,475 | closed | Update deploy-docs dependencies on CI to enable Flax | Signed-off-by: Morgan Funtowicz <[email protected]> | 11-11-2020 23:13:10 | 11-11-2020 23:13:10 | |
transformers | 8,474 | closed | Fix on "examples/language-modeling" to support more datasets | # What does this PR do?
Fix on "run_clm.py", "run_mlm.py", "run_plm.py", so that they can support datasets with more than one features. Before they will fail on datasets with more than one features.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
@sgugger
| 11-11-2020 22:05:39 | 11-11-2020 22:05:39 | Great fix, thanks! |
transformers | 8,473 | closed | Support fp16 for inference | # 🚀 Feature request - support fp16 inference
Right now most models support mixed precision for model training, but not for inference. Naively calling `model= model.haf()` makes the model generate junk instead of valid results for text generation, even though mixed-precision works fine in training.
If there's a way to make the model produce stable behavior at 16-bit precision at inference, the throughput can potentially double on most modern GPUS.
## Motivation
Double the speed is always attractive, especially since transformers are compute-intensive.
| 11-11-2020 21:06:59 | 11-11-2020 21:06:59 | I imagine this only happens when the `generate()` method is used under the hood? <|||||>Hi there! It's true you can't just do `model.half()` for generation. There is nothing in Trainer/Seq2SeqTrainer right now for FP16-inference, only training, but we're looking at it right now through #8403. So stay tuned!<|||||>Thanks for the input @sgugger. Good to know we're not missing something here and it's actually unsupported somehow. <|||||>Hi,
I've noticed the same issue of the model randomly generating junk when using autocast within a custom generate() method with the only change below (fp16 is a boolean). From the above comments I thought this approach should've worked.
```
if fp16:
with torch.cuda.amp.autocast():
outputs = self(**model_inputs)
else:
outputs = self(**model_inputs)
```
The current model I've tested it on is a huggingface gpt2 model finetuned on a personal dataset. Without fp16 the generate works perfectly. The dataset is very specific and the model is supposed to generate symbols+numbers, so it's clear when it starts spitting out words during fp16 inference.
<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread.<|||||>has this been solved? |
transformers | 8,472 | closed | GPT2 (pre-trained not fine-tuned) only generates additional special tokens | ## Environment info
- `transformers` version: 3.5.0
- Platform: Darwin-19.6.0-x86_64-i386-64bit
- Python version: 3.6.3
- PyTorch version (GPU?): 1.7.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@patrickvonplaten
## Information
Model I am using (GPT2 / DistilGPT2):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
I'm using GPT2 or DistilGPT2 on MetalWOZ and the issue I'm having is when I add special tokens (even bos, eos, etc) and prompt the model, it only generates those special tokens - no other token. For example, if I add the tokens <USER> and <SYSTEM> and prompt the model with:
"I want a pepperoni pizza with mushroom"
I get:
"I want a pepperoni pizza with mushroom <USER> <USER> <USER> <SYSTEM> <USER> <USER> <USER> <SYSTEM> <USER> <USER>"
## To reproduce
Steps to reproduce the behavior:
1. Add special tokens to a GPT2 model (example below with distilgpt2 but I get the same behavior with gpt2)
2. Resize embeddings
3. Prompt model
```
import torch
import torch.nn.functional as F
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('distilgpt2')
tokenizer.add_special_tokens(
{'additional_special_tokens': ['<USER>', '<SYSTEM>']}
)
model = GPT2LMHeadModel.from_pretrained('distilgpt2')
model.resize_token_embeddings(len(tokenizer))
inp_tok_ids = tokenizer.encode('I want a pepperoni pizza with mushroom')
inp_tensor = torch.LongTensor(inp_tok_ids).unsqueeze(0)
model.eval()
with torch.no_grad():
for i in range(10):
outputs = model(inp_tensor)
logits = outputs[0][:, -1, :]
probs = F.softmax(logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1).squeeze(1)
inp_tensor = torch.cat([inp_tensor, next_token.unsqueeze(-1)], dim=-1)
print(tokenizer.decode(inp_tensor[0]))
```
## Expected behavior
I would expect a mix of the new special tokens and other tokens.
| 11-11-2020 21:03:11 | 11-11-2020 21:03:11 | @g-karthik <|||||>Was able to reproduce this as well.
From the observation, I suspect the random weights being initialized for the added tokens in the final `Linear` and/or `SequenceSummary` head are such that no matter what hidden state is sent in, a special token gets the highest final scalar score. Haven't dived in to check how the random initialization is done, but if it's done from a standard unit Gaussian, I would imagine this cannot happen at every single time-step.<|||||>You should fine-tune your model on a dataset containing your added tokens, otherwise the model will very probably generate gibberish.<|||||>@LysandreJik The model is only generating special tokens. It does not generate any of the original tokens in the pre-trained model's vocabulary. I'd understand if there were special tokens generated occasionally, but that's not the case.<|||||>I understand. By adding new tokens, you're resizing the token embedding layer with some *randomly initialized values*. These values can be of an entirely different dimension to the ones currently initialized in your token embedding layer, which can lead to these tokens being overly generated.
As I said before: you should fine-tune your model on a dataset containing your added tokens, otherwise the model will very probably generate gibberish.<|||||>I'm aware that fine-tuning on a dataset containing the added tokens will bring those "entirely different dimension" (as you call them) values back to the "same dimension". But that's besides the point here. We're talking about expected behavior.
> By adding new tokens, you're resizing the token embedding layer with some randomly initialized values
It's not just the token embedding layer that'll get resized though, right? There's the final `Linear` that outputs the distribution over the vocabulary as well that would have to be adjusted to account for the new vocabulary size.
> These values can be of an entirely different dimension to the ones currently initialized in your token embedding layer
Can you please point me to the code that does this "entirely different dimension" random initialization for the added tokens? If the argument you're making is that a pre-trained model *should* generate *only-special-tokens* gibberish if special tokens were added to its vocabulary and it were resized accordingly, then I disagree with it. I would expect a mix of both, and if the random initialization can be altered to ensure the pre-trained model's behavior with and without added special tokens is *mostly* similar, that would be the best outcome for consistency. That's why I brought up the point about random initialization from a unit Gaussian earlier in this issue.<|||||>> It's not just the token embedding layer that'll get resized though, right? There's the final Linear that outputs the distribution over the vocabulary as well that would have to be adjusted to account for the new vocabulary size.
Yes, you are right. However, the embedding layer and output linear layer are shared. They have the same values, as they are tied. Resizing the embedding layer resizes the output layer at the same time.
This is done in the [_tie_or_clone_weights method](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_utils.py#L571), which is called by the [init_weights method](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_gpt2.py#L705).
> Can you please point me to the code that does this "entirely different dimension" random initialization for the added tokens?
[Here it is](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_gpt2.py#L341-L351).
> If the argument you're making is that a pre-trained model should generate only-special-tokens gibberish if special tokens were added to its vocabulary and it were resized accordingly, then I disagree with it.
I am not making this argument. The argument I'm making is that if you're adding *any* token to an embedding matrix **without** training the model afterwards, you will obtain gibberish.<|||||>> The argument I'm making is that if you're adding any token to an embedding matrix without training the model afterwards, you will obtain gibberish.
What @al3xpapangelis and I are saying is that a pre-trained model's behavior *before* and *after* adding *any* new token, with no *further* training done beyond the original pre-training, should be the same *on average* for the same input. We're talking about expected behavior vs. actual behavior, and what can be done to make them the same. Your argument makes sense to me, but only in the scenario where the model's not been trained originally at all.
Thanks for the pointers! Looks like the random initialization for `Linear` is from a 0-centered, 0.02 std. deviation Gaussian. I'll do some analysis to see how vectors from this distribution "vary" on average from a pre-trained embedding for a regular token.<|||||>Hey @g-karthik and hey @al3xpapangelis (cool to see you here again :-) ),
The reason for this behavior is mainly because `lm_head` is tied to the word_embedding matrix and therefore the softmax over the output logit vectors seems to give very high values to the randomly init tokens. So this seems to suggest the distribution of trained logit vectors is very different from the rnd init ones.
I'd also suggest to play around with changing the init scheme for new tokens or just setting the newly added tokens manually to some better value:
```python
model.lm_head.weight[:, -2] = # good init vector for <USER>
model.lm_head.weight[:, -1] = # good init vector for <SYSTEM>
```
If you do this for example, the tokens won't be generated.
```python
import torch
import torch.nn.functional as F
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('distilgpt2')
tokenizer.add_special_tokens(
{'additional_special_tokens': ['<USER>', '<SYSTEM>']}
)
model = GPT2LMHeadModel.from_pretrained('distilgpt2')
model.resize_token_embeddings(len(tokenizer))
inp_tok_ids = tokenizer.encode('I want a pepperoni pizza with mushroom')
inp_tensor = torch.LongTensor(inp_tok_ids).unsqueeze(0)
model.eval()
model.lm_head.weight[-2, :] = (torch.zeros((768,)) - 10000.0)
model.lm_head.weight[-1, :] = (torch.zeros((768,)) - 10000.0)
with torch.no_grad():
for i in range(10):
outputs = model(inp_tensor)
logits = outputs[0][:, -1, :]
probs = F.softmax(logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1).squeeze(1)
inp_tensor = torch.cat([inp_tensor, next_token.unsqueeze(-1)], dim=-1)
print(tokenizer.decode(inp_tensor[0]))
```<|||||>@patrickvonplaten yes, I was thinking I'll try and estimate the mean and covariance of the set of values in GPT-2's pre-trained embeddings (across all of its 4 model sizes), assuming a Gaussian distribution. And then update the random initialization's mean and std. dev. accordingly in the model's [`_init_weights()`](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_gpt2.py#L346). That way, the random initialization comes from a distribution that's effectively "similar" to that of the pre-trained vectors, and hence decoding sequences would result in a mixture of the original tokens and added tokens.<|||||>Thanks @LysandreJik and @patrickvonplaten! I like @g-karthik suggestion, it would be nice for this bevahiour to happen automatically |
transformers | 8,471 | closed | TFBertForTokenClassification scoring only O labels on a NER task | I'm using TFBertForTokenClassification to perform a NER task on the annotated corpus fo NER:
[https://www.kaggle.com/abhinavwalia95/entity-annotated-corpus](https://www.kaggle.com/abhinavwalia95/entity-annotated-corpus).
The problem is that the O-Labels are the majority of all labels, then the accuracy is quite high as the model correctly predicts most of them.
So, when I try to predict the labels of a simple sentence, the network predict only the O Label for each token of the sentence, however in several tutorials in which it is used Pytorch (I am using Tensorflow), the predictions are good.
Probably there is a problem in my code, but I cannot figure out where is it.
The code is the following:
```python
# Import libraries
import tensorflow as tf
import pandas as pd
from sklearn.model_selection import train_test_split
import math
import numpy as np
from transformers import (
TF2_WEIGHTS_NAME,
BertConfig,
BertTokenizer,
TFBertForTokenClassification,
create_optimizer)
```
```python
# Config
MAX_LEN= 128
TRAIN_BATCH_SIZE = 32
VALID_BTCH_SIZE = 8
EPOCHS = 10
BERT_MODEL = 'bert-base-uncased'
MODEL_PATH = "model.bin"
TRAINING_FILE = "../input/entity-annotated-corpus/ner_dataset.csv"
TOKENIZER = BertTokenizer.from_pretrained(BERT_MODEL, do_lower_case=True)
```
```python
# Create the padded input, attention masks, token type and labels
def get_train_data(text, tags):
tokenized_text = []
target_tags = []
for index, token in enumerate(text):
encoded_token = TOKENIZER.encode(
token,
add_special_tokens = False
)
encoded_token_len = len(encoded_token)
tokenized_text.extend(encoded_token)
target_tags.extend([tags[index]] * encoded_token_len)
#truncation
tokenized_text = tokenized_text[: MAX_LEN - 2]
target_tags = target_tags[: MAX_LEN - 2]
#[101] = [CLS] , [102] = [SEP]
tokenized_text = [101] + tokenized_text + [102]
target_tags = [0] + target_tags + [0]
attention_mask = [1] * len(tokenized_text)
token_type_ids = [0] * len(tokenized_text)
#padding
padding_len = int(MAX_LEN - len(tokenized_text))
tokenized_text = tokenized_text + ([0] * padding_len)
target_tags = target_tags + ([0] * padding_len)
attention_mask = attention_mask + ([0] * padding_len)
token_type_ids = token_type_ids + ([0] * padding_len)
return (tokenized_text, target_tags, attention_mask, token_type_ids)
```
```python
# Extract sentences from dataset
class RetrieveSentence(object):
def __init__(self, data):
self.n_sent = 1
self.data = data
self.empty = False
function = lambda s: [(w, p, t) for w, p, t in zip(s["Word"].values.tolist(),
s["POS"].values.tolist(),
s["Tag"].values.tolist())]
self.grouped = self.data.groupby("Sentence #").apply(function)
self.sentences = [s for s in self.grouped]
def retrieve(self):
try:
s = self.grouped["Sentence: {}".format(self.n_sent)]
self.n_sent += 1
return s
except:
return None
```
```python
# Load dataset and create one hot encoding for labels
df_data = pd.read_csv(TRAINING_FILE,sep=",",encoding="latin1").fillna(method='ffill')
Sentences = RetrieveSentence(df_data)
sentences_list = [" ".join([s[0] for s in sent]) for sent in Sentences.sentences]
labels = [ [s[2] for s in sent] for sent in Sentences.sentences]
tags_2_val = list(set(df_data["Tag"]))
tag_2_idx = {t: i for i, t in enumerate(tags_2_val)}
id_labels = [[tag_2_idx.get(l) for l in lab] for lab in labels]
sentences_list = [sent.split() for sent in sentences_list]
# I removed the sentence n 41770 because it gave index problems
del labels[41770]
del sentences_list[41770]
del id_labels[41770]
```
```python
encoded_text = []
encoded_labels = []
attention_masks = []
token_type_ids = []
for i in range(len(sentences_list)):
text, labels, att_mask, tok_type = get_train_data(text = sentences_list[i], tags = id_labels[i])
encoded_text.append(text)
encoded_labels.append(labels)
attention_masks.append(att_mask)
token_type_ids.append(tok_type)
```
```python
# Convert from list to np array
encoded_text = np.array(encoded_text)
encoded_labels = np.array(encoded_labels)
attention_masks = np.array(attention_masks)
token_type_ids = np.array(token_type_ids)
```
```python
# Train Test split
X_train, X_valid, Y_train, Y_valid = train_test_split(encoded_text, encoded_labels, random_state=20, test_size=0.1)
Mask_train, Mask_valid, Token_ids_train, Token_ids_valid = train_test_split(attention_masks,token_type_ids ,random_state=20, test_size=0.1)
```
```python
# Aggregate the train and test set, then shuffle and batch the train set
def example_to_features(input_ids,attention_masks,token_type_ids,y):
return {"input_ids": input_ids,
"attention_mask": attention_masks,
"token_type_ids": token_type_ids},y
train_ds = tf.data.Dataset.from_tensor_slices((X_train,Mask_train,Token_ids_train,Y_train)).map(example_to_features).shuffle(1000).batch(32)
test_ds=tf.data.Dataset.from_tensor_slices((X_valid,Mask_valid,Token_ids_valid,Y_valid)).map(example_to_features).batch(1)
```
```python
# Load TFBertForTokenClassification with default config
config = BertConfig.from_pretrained(BERT_MODEL,num_labels=len(tags_2_val))
model = TFBertForTokenClassification.from_pretrained(BERT_MODEL, from_pt=bool(".bin" in BERT_MODEL), config=config)
```
```python
# Add softmax layer, compute loss, optimizer and fit
model.layers[-1].activation = tf.keras.activations.softmax
model.summary()
optimizer = tf.keras.optimizers.Adam()
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
history = model.fit(train_ds, epochs=3, validation_data=test_ds)
```
```python
# Prediction. Spoiler: the label predicted are O-Label
sentence = "Hi , my name is Bob and I live in England"
inputs = TOKENIZER(sentence, return_tensors="tf")
input_ids = inputs["input_ids"]
inputs["labels"] = tf.reshape(tf.constant([1] * tf.size(input_ids).numpy()), (-1, tf.size(input_ids))) # Batch size 1
output = model(inputs)
```
The code is executed on a Kaggle notebook.
The transformer library version is 3.4.0
I include also a ipynb file which shows the output.
[BERT_NERT_Tensorflow.zip](https://github.com/huggingface/transformers/files/5525652/BERT_NERT_Tensorflow.zip)
Many thanks in advance. | 11-11-2020 17:20:09 | 11-11-2020 17:20:09 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discusss.huggingface.co) instead?
Thanks! |
transformers | 8,470 | closed | Add pretraining loss computation for TF Bert pretraining | # What does this PR do?
This PR adds the loss computation for the pretraining TF BERT model. The loss computation test is also more robust on variable call signature lengths. | 11-11-2020 16:32:09 | 11-11-2020 16:32:09 | |
transformers | 8,469 | closed | Pegasus models load very slowly or do not load at all on initial execution of from_pretrained() when Python is spawned from within a Node.js process | ## Description
We are using Node.js to coordinate processes, including a Python web server that loads a pretrained model in CPU mode.
The model files are downloaded and cached prior to execution during a container build process.
On initial execution, it appears the model stalls while loading the primary weights file from the local cache. Subsequent executions do not stall at this point and load successfully.
Are there any threading caveats we should be aware of when using a coordinating process? Issue #7516 noticed problems with Celery outside of single-pool mode.
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.4.0
- Platform: Docker, RHEL8 UBI Base Image
- Python version: Python 3.8.0 (default, Mar 9 2020, 18:02:46), [GCC 8.3.1 20191121 (Red Hat 8.3.1-5)] on linux
- PyTorch version (GPU?): 1.7.0+cpu, no GPU
- Tensorflow version (GPU?): N/A
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
- System: AWS t3.large image running Docker
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people. -->
Pegasus: @patrickvonplaten
documentation: @sgugger
### Thank you!
Thank you to the Hugging Face team and contributors to this project. The barriers to entry on complex NLP tasks have been lowered substantially, and it's been a huge amount of fun exploring with these models.
## Information
Model I am using: tuner007/pegasus_paraphrase
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Spawn a Python webserver that loads a Pegasus model using `from_pretrained(...)`
2. The initial load takes upwards of 300 seconds or fails
3. Subsequent loads take 60 seconds but succeed
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Load time of Pegasus models should be consistent.
<!-- A clear and concise description of what you would expect to happen. -->
Docker runs in privileged mode with full access to host memory and network.
## Source Code and Logs
```bash
sudo docker run -d \
-u 0:0 \
--ipc=host \
--privileged \
--network host \
--restart always \
--log-driver json-file \
--log-opt max-size=100m \
--log-opt max-file=5 \
-v /root/.example:/root/.example \
--name example \
example:1.0
```
Node.js management script spawns a detached Python process.
```js
// @flow
const uuid = require('uuid');
const { spawn } = require('child_process');
const superagent = require('superagent');
const makeLogger = require('../logger');
const killProcess = require('../lib/kill-process');
const commandExists = require('command-exists');
const pythonWebserverExistsPromise = new Promise((resolve, reject) => {
commandExists('python3.8', (error:Error, exists:boolean) => {
if (error) {
reject(error);
} else {
resolve(exists);
}
});
});
class PythonWebserverDoesNotExistError extends Error {}
module.exports.PythonWebserverDoesNotExistError = PythonWebserverDoesNotExistError;
module.exports.startPythonWebserver = async (port:number, path:string) => {
const logger = makeLogger(`Python Webserver ${path}`);
const exists = await pythonWebserverExistsPromise;
if (!exists) {
logger.error('python3.8 does not exist on path');
throw new PythonWebserverDoesNotExistError('python3.8 does not exist on path');
}
const pythonWebserverArgs = [path, `${port}`];
let isManuallyClosed = false;
let mainProcess;
let pid;
let isReadyPromise = Promise.resolve();
const spawnPythonWebserver = () => {
logger.info(`Spawning ${path}`);
mainProcess = spawn('python3.8', pythonWebserverArgs, { windowsHide: true, detached: true, shell: true, env: Object.assign({}, {}, process.env) });
pid = mainProcess.pid;
if (!pid) {
logger.error('Process did not spawn with PID');
try {
mainProcess.kill();
} catch (error) {
logger.error('Unable to kill process');
logger.errorStack(error);
}
throw new Error('Python webserver process did not spawn');
}
let isClosed = false;
isManuallyClosed = false;
mainProcess.stdout.on('data', (data) => {
data.toString('utf8').trim().split('\n').forEach((line) => logger.info(line));
});
mainProcess.stderr.on('data', (data) => {
data.toString('utf8').trim().split('\n').forEach((line) => logger.error(line));
});
mainProcess.on('error', (error) => {
logger.errorStack(error);
});
mainProcess.on('close', (code:number) => {
if (code === 0 || code === null) {
logger.info('Process closed');
} else {
logger.error(`Failed with exit code ${code}`);
}
isClosed = true;
if (!isManuallyClosed) {
spawnPythonWebserver();
}
});
logger.info('Listening');
isReadyPromise = (async () => {
let lastError;
const connectionTimeout = Date.now() + 300000;
const start = Date.now();
while (true) {
if (isManuallyClosed && isClosed) {
return;
}
if (isClosed || Date.now() > connectionTimeout) {
await close();
logger.error(`Unable to conect to ${path} at http://127.0.0.1:${port} after 300 seconds`);
if (lastError) {
logger.errorStack(lastError);
throw new Error(`Unable to conect to python webserver ${path} at http://127.0.0.1:${port} after 300 seconds: ${lastError.message}`);
} else {
throw new Error(`Unable to conect to python webserver ${path} at http://127.0.0.1:${port} after 300 seconds`);
}
}
try {
await superagent.get(`http://127.0.0.1:${port}/${uuid.v4()}`).timeout({ response: 3000, deadline: 3000 });
break;
} catch (error) {
if (error && error.response && error.response.statusCode === 404) {
break;
} else {
lastError = error;
}
}
await new Promise((resolve) => setTimeout(resolve, 1000));
}
logger.info(`Connected to ${path} at http://127.0.0.1:${port} after ${Math.round(10 * (Date.now() - start) / 1000) / 10} seconds`);
})();
};
spawnPythonWebserver();
const close = async () => {
isManuallyClosed = true;
logger.info('Shutting down');
if (pid) {
await killProcess(pid, 'python webserver');
} else {
logger.warn('PID not found');
}
logger.info('Shut down');
};
const checkIsReady = () => isReadyPromise;
return [close, checkIsReady];
};
```
Python uses a Tornado web server to host an inference API.
```python
import tornado.ioloop
import tornado.web
import sys
import gc
import json
import numpy as np
from os.path import expanduser
from transformers import PegasusForConditionalGeneration, PegasusTokenizer, logging
import torch
from multiprocessing import cpu_count
executor = tornado.concurrent.futures.ThreadPoolExecutor(max_workers=2)
def chunks(lst, n):
"""Yield successive n-sized chunks from lst."""
for i in range(0, len(lst), n):
yield lst[i:i + n]
class NumpyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.ndarray):
return obj.tolist()
return json.JSONEncoder.default(self, obj)
@torch.no_grad()
def generate(tokenizer, model, sentences):
batch = tokenizer.prepare_seq2seq_batch(sentences, truncation=True, padding='longest', max_length=60)
translated = model.generate(**batch, num_beams=3, repetition_penalty=2.0, length_penalty=0.4, do_sample=True, temperature=0.8)
return tokenizer.batch_decode(translated, skip_special_tokens=True)
class Summarization(tornado.web.RequestHandler):
def initialize(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
def set_default_headers(self):
self.set_header('Content-Type', 'application/json')
@tornado.gen.coroutine
def post(self):
body = json.loads(self.request.body.decode())
if not isinstance(body, list):
raise web.HTTPError(400, 'Invalid request body. A valid JSON document containing an array of strings is required.')
for sentence in body:
if not isinstance(sentence, str):
raise web.HTTPError(400, 'Invalid request body. A valid JSON document containing an array of strings is required.')
result = []
sentence_groups = list(chunks(body, 20))
for sentence_group in sentence_groups:
decoded = yield executor.submit(generate, self.tokenizer, self.model, sentence_group)
result = result + decoded
gc.collect()
self.finish(json.dumps(result, cls=NumpyEncoder))
def make_app(model, tokenizer):
return tornado.web.Application([
(r"/summarization", Summarization, dict(model=model, tokenizer=tokenizer))
])
if __name__ == "__main__":
torch.set_grad_enabled(False)
logging.set_verbosity_debug()
torch_device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = PegasusForConditionalGeneration.from_pretrained('tuner007/pegasus_paraphrase').to(torch_device)
tokenizer = PegasusTokenizer.from_pretrained('tuner007/pegasus_paraphrase')
model.share_memory()
app = make_app(model, tokenizer)
app.listen(sys.argv[1])
gc.collect()
tornado.ioloop.IOLoop.current().start()
```
Debug output on initial execution, model fails to load after 300s.
```
Python Webserver /example/python/nlp-tornado-summarization.py - error - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/tuner007/pegasus_paraphrase/config.json from cache at /root/.cache/torch/transformers/6aa2f0999c84ce856faa292c839572741e6591fae603fe7245e31c2420c621b1.2e89bfaa32f367525ed659d47352d25c26f87f779656ee16db23d056fe7cfc78
Python Webserver /example/python/nlp-tornado-summarization.py - error - Model config PegasusConfig {
Python Webserver /example/python/nlp-tornado-summarization.py - error - "activation_dropout": 0.1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "activation_function": "relu",
Python Webserver /example/python/nlp-tornado-summarization.py - error - "add_bias_logits": false,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "add_final_layer_norm": true,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "architectures": [
Python Webserver /example/python/nlp-tornado-summarization.py - error - "PegasusForConditionalGeneration"
Python Webserver /example/python/nlp-tornado-summarization.py - error - ],
Python Webserver /example/python/nlp-tornado-summarization.py - error - "attention_dropout": 0.1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "bos_token_id": 0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "classif_dropout": 0.0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "classifier_dropout": 0.0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "d_model": 1024,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "decoder_attention_heads": 16,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "decoder_ffn_dim": 4096,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "decoder_layerdrop": 0.0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "decoder_layers": 16,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "do_blenderbot_90_layernorm": false,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "dropout": 0.1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "encoder_attention_heads": 16,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "encoder_ffn_dim": 4096,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "encoder_layerdrop": 0.0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "encoder_layers": 16,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "eos_token_id": 1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "extra_pos_embeddings": 1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "force_bos_token_to_be_generated": false,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "id2label": {
Python Webserver /example/python/nlp-tornado-summarization.py - error - "0": "LABEL_0",
Python Webserver /example/python/nlp-tornado-summarization.py - error - "1": "LABEL_1",
Python Webserver /example/python/nlp-tornado-summarization.py - error - "2": "LABEL_2"
Python Webserver /example/python/nlp-tornado-summarization.py - error - },
Python Webserver /example/python/nlp-tornado-summarization.py - error - "init_std": 0.02,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "is_encoder_decoder": true,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "label2id": {
Python Webserver /example/python/nlp-tornado-summarization.py - error - "LABEL_0": 0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "LABEL_1": 1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "LABEL_2": 2
Python Webserver /example/python/nlp-tornado-summarization.py - error - },
Python Webserver /example/python/nlp-tornado-summarization.py - error - "length_penalty": 0.8,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "max_length": 60,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "max_position_embeddings": 60,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "model_type": "pegasus",
Python Webserver /example/python/nlp-tornado-summarization.py - error - "normalize_before": true,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "normalize_embedding": false,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "num_beams": 8,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "num_hidden_layers": 16,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "pad_token_id": 0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "scale_embedding": true,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "static_position_embeddings": true,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "vocab_size": 96103
Python Webserver /example/python/nlp-tornado-summarization.py - error - }
Python Webserver /example/python/nlp-tornado-summarization.py - error - loading weights file https://cdn.huggingface.co/tuner007/pegasus_paraphrase/pytorch_model.bin from cache at /root/.cache/torch/transformers/387ce6aee5feafa70429f4659a02b7433a17ea8b0a6c5cad24e894cc46c7b88e.37d8caa66cfa802d672246ab9f2f72b886c1a58ac1ba12892a05c17d8b0d421f
Python Webserver /example/python/nlp-tornado-summarization.py - info - Shutting down
Process Killer - info - Sending SIGTERM to python webserver process 38
Python Webserver /example/python/nlp-tornado-summarization.py - info - Process closed
Process Killer - info - Stopped python webserver process 38 with SIGTERM
Python Webserver /example/python/nlp-tornado-summarization.py - info - Shut down
Python Webserver /example/python/nlp-tornado-summarization.py - error - Unable to conect to /example/python/nlp-tornado-summarization.py at http://127.0.0.1:43777 after 300 seconds
Python Webserver /example/python/nlp-tornado-summarization.py - error - Error: connect ECONNREFUSED 127.0.0.1:43777
Python Webserver /example/python/nlp-tornado-summarization.py - error - at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1145:16)
Python Webserver /example/python/nlp-tornado-summarization.py - error - errno: "ECONNREFUSED"
Python Webserver /example/python/nlp-tornado-summarization.py - error - code: "ECONNREFUSED"
Python Webserver /example/python/nlp-tornado-summarization.py - error - syscall: "connect"
Python Webserver /example/python/nlp-tornado-summarization.py - error - address: "127.0.0.1"
Python Webserver /example/python/nlp-tornado-summarization.py - error - port: 43777
Python Webserver /example/python/nlp-tornado-summarization.py - error - response: undefined
```
Debug output on second execution, model loads after 60s.
```
Python Webserver /example/python/nlp-tornado-summarization.py - info - Spawning /example/python/nlp-tornado-summarization.py
Python Webserver /example/python/nlp-tornado-summarization.py - info - Listening
Python Webserver /example/python/nlp-tornado-summarization.py - error - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/tuner007/pegasus_paraphrase/config.json from cache at /root/.cache/torch/transformers/6aa2f0999c84ce856faa292c839572741e6591fae603fe7245e31c2420c621b1.2e89bfaa32f367525ed659d47352d25c26f87f779656ee16db23d056fe7cfc78
Python Webserver /example/python/nlp-tornado-summarization.py - error - Model config PegasusConfig {
Python Webserver /example/python/nlp-tornado-summarization.py - error - "activation_dropout": 0.1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "activation_function": "relu",
Python Webserver /example/python/nlp-tornado-summarization.py - error - "add_bias_logits": false,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "add_final_layer_norm": true,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "architectures": [
Python Webserver /example/python/nlp-tornado-summarization.py - error - "PegasusForConditionalGeneration"
Python Webserver /example/python/nlp-tornado-summarization.py - error - ],
Python Webserver /example/python/nlp-tornado-summarization.py - error - "attention_dropout": 0.1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "bos_token_id": 0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "classif_dropout": 0.0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "classifier_dropout": 0.0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "d_model": 1024,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "decoder_attention_heads": 16,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "decoder_ffn_dim": 4096,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "decoder_layerdrop": 0.0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "decoder_layers": 16,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "do_blenderbot_90_layernorm": false,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "dropout": 0.1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "encoder_attention_heads": 16,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "encoder_ffn_dim": 4096,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "encoder_layerdrop": 0.0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "encoder_layers": 16,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "eos_token_id": 1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "extra_pos_embeddings": 1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "force_bos_token_to_be_generated": false,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "id2label": {
Python Webserver /example/python/nlp-tornado-summarization.py - error - "0": "LABEL_0",
Python Webserver /example/python/nlp-tornado-summarization.py - error - "1": "LABEL_1",
Python Webserver /example/python/nlp-tornado-summarization.py - error - "2": "LABEL_2"
Python Webserver /example/python/nlp-tornado-summarization.py - error - },
Python Webserver /example/python/nlp-tornado-summarization.py - error - "init_std": 0.02,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "is_encoder_decoder": true,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "label2id": {
Python Webserver /example/python/nlp-tornado-summarization.py - error - "LABEL_0": 0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "LABEL_1": 1,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "LABEL_2": 2
Python Webserver /example/python/nlp-tornado-summarization.py - error - },
Python Webserver /example/python/nlp-tornado-summarization.py - error - "length_penalty": 0.8,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "max_length": 60,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "max_position_embeddings": 60,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "model_type": "pegasus",
Python Webserver /example/python/nlp-tornado-summarization.py - error - "normalize_before": true,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "normalize_embedding": false,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "num_beams": 8,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "num_hidden_layers": 16,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "pad_token_id": 0,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "scale_embedding": true,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "static_position_embeddings": true,
Python Webserver /example/python/nlp-tornado-summarization.py - error - "vocab_size": 96103
Python Webserver /example/python/nlp-tornado-summarization.py - error - }
Python Webserver /example/python/nlp-tornado-summarization.py - error - loading weights file https://cdn.huggingface.co/tuner007/pegasus_paraphrase/pytorch_model.bin from cache at /root/.cache/torch/transformers/387ce6aee5feafa70429f4659a02b7433a17ea8b0a6c5cad24e894cc46c7b88e.37d8caa66cfa802d672246ab9f2f72b886c1a58ac1ba12892a05c17d8b0d421f
Python Webserver /example/python/nlp-tornado-summarization.py - error - All model checkpoint weights were used when initializing PegasusForConditionalGeneration.
Python Webserver /example/python/nlp-tornado-summarization.py - error - All the weights of PegasusForConditionalGeneration were initialized from the model checkpoint at tuner007/pegasus_paraphrase.
Python Webserver /example/python/nlp-tornado-summarization.py - error - If your task is similar to the task the model of the checkpoint was trained on, you can already use PegasusForConditionalGeneration for predictions without further training.
Python Webserver /example/python/nlp-tornado-summarization.py - error - Model name 'tuner007/pegasus_paraphrase' not found in model shortcut name list (google/pegasus-xsum). Assuming 'tuner007/pegasus_paraphrase' is a path, a model identifier, or url to a directory containing tokenizer files.
Python Webserver /example/python/nlp-tornado-summarization.py - error - loading file https://s3.amazonaws.com/models.huggingface.co/bert/tuner007/pegasus_paraphrase/spiece.model from cache at /root/.cache/torch/transformers/fa4532c0035b101d7abcd5c0c9c34a83288902b66c5616034db1a47643e05c75.efce77b8dcd2c57b109b0d10170fcdcd53f23c21286974d4f66706536758ab6e
Python Webserver /example/python/nlp-tornado-summarization.py - error - loading file https://s3.amazonaws.com/models.huggingface.co/bert/tuner007/pegasus_paraphrase/added_tokens.json from cache at None
Python Webserver /example/python/nlp-tornado-summarization.py - error - loading file https://s3.amazonaws.com/models.huggingface.co/bert/tuner007/pegasus_paraphrase/special_tokens_map.json from cache at /root/.cache/torch/transformers/87ea1eeb171e0c2b3d4a7c9dbef4cb9aa4a7251e3673777ff8b756af93bb1e65.d142dfa55f201f5033fe9ee40eb8fe1ca965dcb0f38b175386020492986d507f
Python Webserver /example/python/nlp-tornado-summarization.py - error - loading file https://s3.amazonaws.com/models.huggingface.co/bert/tuner007/pegasus_paraphrase/tokenizer_config.json from cache at /root/.cache/torch/transformers/9ee22427dfb233033bc52ded6b335bbd3dd17b3698f3349e8aecb3c0ec0a99aa.1598fab009ce003f8802a6055c13134aa3be28abc2cca8db6a881bdc1ef0164e
Python Webserver /example/python/nlp-tornado-summarization.py - error - loading file https://s3.amazonaws.com/models.huggingface.co/bert/tuner007/pegasus_paraphrase/tokenizer.json from cache at None
Python Webserver /example/python/nlp-tornado-summarization.py - info - Connected to /example/python/nlp-tornado-summarization.py at http://127.0.0.1:43777 after 282.4 seconds
Python Webserver /example/python/nlp-tornado-encoding.py - info - Spawning /example/python/nlp-tornado-encoding.py
Python Webserver /example/python/nlp-tornado-encoding.py - info - Listening
Python Webserver /example/python/nlp-tornado-summarization.py - error - WARNING:tornado.access:404 GET /458e8657-7e9f-468c-9b87-4d7383e42df8 (127.0.0.1) 0.54ms
Python Webserver /example/python/nlp-tornado-encoding.py - info - Connected to /example/python/nlp-tornado-encoding.py at http://127.0.0.1:43778 after 65.1 seconds
Python Webserver /example/python/nlp-tornado-encoding.py - error - WARNING:tornado.access:404 GET /77f8c1da-9c3d-4ef0-934a-b95f434349f6 (127.0.0.1) 0.54ms
``` | 11-11-2020 16:24:27 | 11-11-2020 16:24:27 | maybe @julien-c or @Pierrci can answer this question better<|||||>This seems very environment-specific. @wehriam in case paid support is an option, we have a technical support program in beta at [email protected] (cc @clmnt @jeffboudier)<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,468 | closed | Example NER script predicts on tokenized dataset | The new run_ner.py script (relying on datasets) tries to run prediction on the input test set `datasets["test"]`, but it should really input the tokenized set `tokenized_datasets["test"]`
# What does this PR do?
Fix an error with run_ner.py at the prediction step on a custom dataset
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-11-2020 15:14:39 | 11-11-2020 15:14:39 | |
transformers | 8,467 | closed | Fine tuning a classification model with engineered features | # 🚀 Feature request
When fine-tuning a BERT model for text classification, it would be useful to be able to add some engineered features to improve accuracy.
## Motivation
For example:
- if there are any dates on the text (based on NER);
- if the text starts with a punctuation;
- if the font size is larger or smaller than the rest of the document, etc.
These things can help the model make better predictions as to the class of the text.
## Contribution
At the moment, I've been adding these features as custom tokens to the end of the text. E.g "\<DATES\>", "\<PUNCT\>"
| 11-11-2020 15:04:46 | 11-11-2020 15:04:46 | Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.
Could you ask your question on the [forum](https://discuss.huggingface.co) instead?
Thanks! |
transformers | 8,466 | closed | Fix TF next sentence output | # What does this PR do?
Make the loss optional in the TF next sentence prediction output. | 11-11-2020 14:28:44 | 11-11-2020 14:28:44 | |
transformers | 8,465 | closed | Pytorch Vs Onnx: Pytorch is faster and provides different output | ## Environment info
- `transformers` version: 3.5.0
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): 2.3.0 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
albert, bert, GPT2, XLM: @LysandreJik
Onnx: @mfuntowicz
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
https://colab.research.google.com/drive/1UwgWgUF4k_GPJ5TcziHo4eH_rRFQeNVL?usp=sharing
## Expected behavior
I have followed the the onnx export tutorial:
https://github.com/huggingface/transformers/blob/master/notebooks/04-onnx-export.ipynb
However, I have found 2 issues:
1. Pytorch is faster than Onnx.
2. Onnx produce different embedding output than Pytorch.
Could anyone help me to figure out the issue ? | 11-11-2020 14:15:08 | 11-11-2020 14:15:08 | I also got different results 🤦<|||||>I have figured out the problem, but I don't have the solution.
When you use a single sample per batch it works correctly, but when you use more than one sample per batch, the results are totally different.<|||||>@mfuntowicz and @LysandreJik , it will be great if you could show us an example for how to correctly use batch processing for onnx inference.<|||||>Hey @agemagician! I have exactly the same problem, great inference time with onnx when batch size = 1 but when batch size is increased, raw pytorch wins over onnx. Did you find any solution for the issue?<|||||>unfortunately, not.<|||||>That's unfortunate..<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,464 | closed | Add model card for ai4bharat/indic-bert | # What does this PR do?
This PR adds model card for IndicBERT model (shortcut name: `ai4bharat/indic-bert`)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Also: @julien-c (model cards)
| 11-11-2020 14:06:51 | 11-11-2020 14:06:51 | really cool, thanks for sharing |
transformers | 8,463 | closed | Better regex expression for extracting language code in tokenization_marian.py | # Better regex expression for extracting language code in tokenization_marian.py
In `tokenization_marian.py`, the regex `>>.+<<` is used to extract the language token from the sentences leading to the following incorrect tokenization.
```
Example Sentence:
>>hin<< We use cout<< function to print a line in C++.
Current Tokenizer gives:
['<unk>', '▁function', '▁to', '▁print', '▁a', '▁line', '▁in', '▁C', '++', '.', '</s>']
Expected Tokenization:
['>>hin<<', '▁We', '▁use', '▁c', 'out', '<', '<', '▁function', '▁to', '▁print', '▁a', '▁line', '▁in', '▁C', '++', '.', '</s>']
```
This pull request changes the regex to `>>.{3}<<|>>.{3}\_.{4}<<` which covers the 194 language tags in the en-mul model.
@sshleifer | 11-11-2020 13:34:25 | 11-11-2020 13:34:25 | cc @patrickvonplaten <|||||>No, 2 character language codes are not covered. However `>>.{2}<<|>>.{3}<<|>>.{3}\_.{4}<<` can be used.
I can try writing tests. Is these somewhere where I could find an exhaustive set of language codes? I had written the regex to cover the 194 language code in `'Helsinki-NLP/opus-mt-en-mul'`.
```python
def test_language_codes(self):
tok = MarianTokenizer.from_pretrained(f"{ORG_NAME}opus-mt-en-mul")
batch = tok.prepare_seq2seq_batch([">>hin<< I am a small frog", ">>zlm_Latn<< I am a small frog", ">>fr<< I am a small frog"], return_tensors=FRAMEWORK)
expected = [[[888, 21, 437, 9, 2613, 37565, 0], [770, 21, 437, 9, 2613, 37565, 0], [1, 21, 437, 9, 2613, 37565, 0]]
for i in range(3):
self.assertListEqual(expected[i], batch.input_ids[i])
```
The above will need some changes since `>>fr<<` is not in the vocabulary and the sentences also do not have another `<<` in them (maybe a different test for that?).<|||||>> Is there somewhere where I could find an exhaustive set of language codes?
Not easily, you can find the supported codes for any model by looking for `tgt_languages` or `tgt_constituents` on a model card e.g. https://huggingface.co/Helsinki-NLP/opus-mt-en-ROMANCE or https://huggingface.co/Helsinki-NLP/opus-mt-en-roa?text=%3E%3Efra%3C%3C+My+name+is+Sarah+and+I+live+in+London
Here are some more:
```python
tgt_constituents= {'ita', 'cat', 'roh', 'spa', 'pap', 'lmo', 'mwl', 'lij', 'lad_Latn', 'ext', 'ron', 'ast', 'glg', 'pms', 'zsm_Latn', 'gcf_Latn', 'lld_Latn', 'min', 'tmw_Latn', 'cos', 'wln', 'zlm_Latn', 'por', 'egl', 'oci', 'vec', 'arg', 'ind', 'fra', 'hat', 'lad', 'max_Latn', 'frm_Latn', 'scn', 'mfe'}
tgt_constituents: {'cmn_Hans', 'nan', 'nan_Hani', 'gan', 'yue', 'cmn_Kana', 'yue_Hani', 'wuu_Bopo', 'cmn_Latn', 'yue_Hira', 'cmn_Hani', 'cjy_Hans', 'cmn', 'lzh_Hang', 'lzh_Hira', 'cmn_Hant', 'lzh_Bopo', 'zho', 'zho_Hans', 'zho_Hant', 'lzh_Hani', 'yue_Hang', 'wuu', 'yue_Kana', 'wuu_Latn', 'yue_Bopo', 'cjy_Hant', 'yue_Hans', 'lzh', 'cmn_Hira', 'lzh_Yiii', 'lzh_Hans', 'cmn_Bopo', 'cmn_Hang', 'hak_Hani', 'cmn_Yiii', 'yue_Hant', 'lzh_Kana', 'wuu_Hani'}
```
I think we should accept any number of alphabet characters or '_' inside the `>>` or at least up to 8.
<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,462 | closed | Add next sentence prediction loss computation | # What does this PR do?
This PR adds the loss computation for the next sentence prediction task in TF BERT and MobileBERT. | 11-11-2020 13:00:10 | 11-11-2020 13:00:10 | |
transformers | 8,461 | closed | multiple hard-coded paths in transformers/file_utils.py | Hi
I need to run the codes on a machine not having access to internet, I am running finetune_trainer.py on a dataset from datasets repo, due to these hardcoded paths I cannot get the code running without access to internet, could you please make any hard-coded path a parameter, so if user do not have access to internet, they could download the data and set the paths? here is the full path to the file I am mentioning
/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/utils/file_utils.py
thanks.
Best
Rabeeh | 11-11-2020 11:55:40 | 11-11-2020 11:55:40 | will report this in datasets repo. |
transformers | 8,460 | closed | Fix TF Longformer | # What does this PR do?
Fix TF Longformer model outputs. | 11-11-2020 11:48:08 | 11-11-2020 11:48:08 | |
transformers | 8,459 | closed | Question Answering Documentation Example Bug | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.5.0
- Platform: Darwin-19.6.0-x86_64-i386-64bit
- Python version: 3.6.12
- PyTorch version (GPU?): 1.7.0 (False)
- Tensorflow version (GPU?): 2.3.1 (False)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: parallel
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten @TevenLeScao
Blenderbot: @patrickvonplaten
Bart: @patrickvonplaten
Marian: @patrickvonplaten
Pegasus: @patrickvonplaten
mBART: @patrickvonplaten
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
RAG: @patrickvonplaten, @lhoestq
FSMT: @stas00
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
--> @sgugger
## Information
Model I am using (Bert, XLNet ...): bert-large-uncased-whole-word-masking-finetuned-squad
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
Trying to run this [example script](https://huggingface.co/transformers/task_summary.html#extractive-question-answering) for TF, I kept on getting error:
```
InvalidArgumentError: Value for attr 'T' of string is not in the list of allowed values: float, double, int32, uint8, int16, int8, complex64, int64, qint8, quint8, qint32, bfloat16, uint16, complex128, half, uint32, uint64, bool
; NodeDef: {{node ArgMax}}; Op<name=ArgMax; signature=input:T, dimension:Tidx -> output:output_type; attr=T:type,allowed=[DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT16, ..., DT_COMPLEX128, DT_HALF, DT_UINT32, DT_UINT64, DT_BOOL]; attr=Tidx:type,default=DT_INT32,allowed=[DT_INT32, DT_INT64]; attr=output_type:type,default=DT_INT64,allowed=[DT_INT32, DT_INT64]> [Op:ArgMax]
```
at the line where` tf.argmax()` is called on `answer_start_scores` and `answer_end_scores`
## Expected behavior
This error is normal since `type(answer_start_scores)` is `str`, so I propose the following amendment to the documentation:
from transformers import AutoTokenizer, TFAutoModelForQuestionAnswering
```
import tensorflow as tf
tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
model = TFAutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad", return_dict=True)
text = r"""
🤗 Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides general-purpose
architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural
Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between
TensorFlow 2.0 and PyTorch.
"""
questions = [
"How many pretrained models are available in 🤗 Transformers?",
"What does 🤗 Transformers provide?",
"🤗 Transformers provides interoperability between which frameworks?",
]
for question in questions:
inputs = tokenizer(question, text, add_special_tokens=True, return_tensors="tf")
input_ids = inputs["input_ids"].numpy()[0]
text_tokens = tokenizer.convert_ids_to_tokens(input_ids)
output = model(inputs)
answer_start = tf.argmax(
output.start_logits, axis=1
).numpy()[0] # Get the most likely beginning of answer with the argmax of the score
answer_end = (
tf.argmax(output.end_logits, axis=1) + 1
).numpy()[0] # Get the most likely end of answer with the argmax of the score
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
print(f"Question: {question}")
print(f"Answer: {answer}")
```
Best,
Irem | 11-11-2020 11:07:19 | 11-11-2020 11:07:19 | Hi! That sounds good, do you want to open a PR?<|||||>Yes, I am on it. Thanks!
<|||||>+1
any updates?<|||||>@iremnasir can you please let me know how exactly you managed to solve it? I am having the same issue.

<|||||>Hi, you can see my answer above for the solution in Expected Behavior section<|||||>Got it. Thanks
As got the error for AutoTokenizer: `NameError: name 'AutoTokenizer' is not defined `
Just imported all:
`from transformers import * ` earlier I was only importing `pipeline` from transformers<|||||>This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread.<|||||>Thanks @iremnasir, it worked. Why hasn't this been merged yet? |
transformers | 8,458 | closed | Fix logging in the examples | # What does this PR do?
This PR updates all the examples to use the Transformers logging util. Before no logs was displayed. | 11-11-2020 10:18:46 | 11-11-2020 10:18:46 | The five examples scripts mentioned above all already use the huggingface logger, and already set it to the correct verbosity level. Seeing as the example scripts are *examples*, they really should be as straightforward as possible, and should not repeat unnecessary statements.
Please update the following files: `run_clm.py`, `run_mlm.py`, `run_glue.py`, `run_mlm_wwm.py`, `run_plm.py` so that they do not have useless statements.
@sgugger pointed you towards the correct area, you should be able to find it if you look for "logging".<|||||>I don't see the import neither the usage. Can you link it please?<|||||>https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_clm.py#L170<|||||>Ok got it I was looking at my own updated file ahah.<|||||>It is also in your file, below https://github.com/huggingface/transformers/blob/d410b83111238f7b949b7c9c6a4c3f689d29519b/examples/language-modeling/run_clm.py#L176<|||||>Ok I have removed the duplicate import and add only the two missing calls.<|||||>Already done the changes 👍 <|||||>No, the changes are not done:
1. in the scripts like the new `run_glue.py`, the code for logging is duplicated and executed once for every process, then once for the main process.
2. in all the other scripts, the code is executed on all processes.
This is also added in util files or test files where it's just not necessary.<|||||>I really don't get what you mean, sorry. What are the exact changes I have to make for each file?<|||||>@sgugger Please check the last commit and let me know if it was what you meant. Otherwise, please, can you be more specific in what you want me to change. |
transformers | 8,457 | closed | Correct mark down grammar in readme file | I correct the mark down grammar about WWM readme, in order to keep all things right. | 11-11-2020 09:12:17 | 11-11-2020 09:12:17 | This issue has been automatically marked as stale and been closed because it has not had recent activity. Thank you for your contributions.
If you think this still needs to be addressed please comment on this thread. |
transformers | 8,456 | closed | ValueError: No gradients provided for any variable: ['tf_bert_for_masked_lm_6/bert/embeddings/word_embeddings/weight:0', 'tf_bert_for_masked_lm_6/bert/embeddings/position_embeddings/embeddings:0'...... | Hi! Everyone.
I encounter some problems with TFBertForMaskedLM.
I modify TFBertForMaskedLM layer according to "Condition-Bert Contextual Augmentation" paper.
In short, my dataset sentences have 5 labels, then change type_token_ids to label_ids.
so, i change bert.embeddings.token_type_embeddings .
my model code as follows:
```python
from_pretrain = 'bert-base-chinese'
def create_model():
mlm_model = TFBertForMaskedLM.from_pretrained(from_pretrain, return_dict=True)
mlm_model.bert.embeddings.token_type_embeddings = tf.keras.layers.Embedding(6, 768)
return tf_bert_mlm_model
model = create_model()
```
then, my tf dataset tensor as follows(batch_size=2):
```
{'input_ids': <tf.Tensor: shape=(2, 128), dtype=int32, numpy=
array([[ 101, 103, 103, 928, 6249, 6244, 103, 7361, 4534,
5022, 3300, 3126, 511, 6313, 4825, 6291, 5206, 7514,
6352, 1162, 103, 100, 6745, 1057, 5080, 6244, 103,
6349, 4826, 103, 9039, 8599, 1564, 4500, 6257, 991,
6291, 6349, 3302, 1243, 103, 6313, 1257, 2200, 7710,
6349, 4826, 6752, 4761, 800, 103, 8024, 7344, 3632,
3300, 2552, 782, 1894, 4671, 4500, 511, 102, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 101, 523, 791, 8532, 677, 5221, 524, 1920, 686,
103, 6240, 4634, 2466, 103, 2695, 103, 519, 5064,
1918, 736, 2336, 520, 4158, 2695, 1564, 4923, 8013,
678, 6734, 8038, 8532, 131, 120, 120, 8373, 119,
103, 9989, 119, 8450, 103, 100, 120, 12990, 8921,
8165, 102, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0]], dtype=int32)>,
'attention_mask': <tf.Tensor: shape=(2, 128), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int32)>,
'token_type_ids': <tf.Tensor: shape=(2, 128), dtype=int32, numpy=
array([[3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int32)>,
'labels': <tf.Tensor: shape=(2, 128), dtype=int32, numpy=
array([[ -100, 704, 1751, -100, -100, -100, 2622, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, 4826, -100, 6745, -100, -100, -100, 7710,
-100, -100, 10873, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, 8024, -100, -100, -100, -100,
-100, -100, -100, -100, -100, 782, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100],
[ -100, -100, -100, 3189, -100, -100, -100, -100, -100,
4518, -100, -100, -100, 2204, -100, 100, -100, -100,
-100, -100, -100, -100, -100, 2695, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
8429, -100, -100, -100, 120, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100]], dtype=int32)>}
```
and model.compile() and model.fit() as follows:
```python
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer=optimizer, loss=loss)
model.fit(tf_sms_dataset, epochs=2)
```
But I always get the error message of
```
ValueError: in user code:
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py:806 train_function *
return step_function(self, iterator)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py:796 step_function **
outputs = model.distribute_strategy.run(run_step, args=(data,))
/opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/distribute_lib.py:1211 run
return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/distribute_lib.py:2585 call_for_each_replica
return self._call_for_each_replica(fn, args, kwargs)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/distribute/distribute_lib.py:2945 _call_for_each_replica
return fn(*args, **kwargs)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py:789 run_step **
outputs = model.train_step(data)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py:757 train_step
self.trainable_variables)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py:2737 _minimize
trainable_variables))
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/optimizer_v2/optimizer_v2.py:562 _aggregate_gradients
filtered_grads_and_vars = _filter_grads(grads_and_vars)
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/optimizer_v2/optimizer_v2.py:1271 _filter_grads
([v.name for _, v in grads_and_vars],))
ValueError: No gradients provided for any variable: ['tf_bert_for_masked_lm_6/bert/embeddings/word_embeddings/weight:0', 'tf_bert_for_masked_lm_6/bert/embeddings/position_embeddings/embeddings:0', 'tf_bert_for_masked_lm_6/bert/embeddings/LayerNorm/gamma:0', ..........]
```
How to solve the problem? Thanks
| 11-11-2020 07:05:15 | 11-11-2020 07:05:15 | change other questions.<|||||>How did u solve this issue?<|||||>How did u solve this problem? I got same problem like yours |
transformers | 8,455 | closed | Can't down models from huggingface.cn! | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten @TevenLeScao
Blenderbot: @patrickvonplaten
Bart: @patrickvonplaten
Marian: @patrickvonplaten
Pegasus: @patrickvonplaten
mBART: @patrickvonplaten
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
RAG: @patrickvonplaten, @lhoestq
FSMT: @stas00
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
I want to down model from huggingface.cn, but I can't find the models to down.

But I found the model had been download many times in noverber 9. Something happened I didn't know about? And what should I do to get models that I need?

| 11-11-2020 06:49:07 | 11-11-2020 06:49:07 | Duplicate of #8449 |
transformers | 8,454 | open | Add POINTER model | # 🌟 New model addition
## Model description
[POINTER](https://github.com/dreasysnail/POINTER) is a progressive and non-autoregressive text generation pre-training approach, published on EMNLP 2020 by Microsoft Research. POINTER generates fluent text in a progressive and parallel manner. With empirical logarithmic time, POINTER outperforms existing non-autoregressive text generation approaches in hard-constrained text generation.
The model uses basically BERT-large architecture. However, an additional token is added to the vocab. The inference is performed by passing the input iteratively to the model. Since there is no existing model architecture in Huggingface that is compatible, I am not sure how to incorporate this into the model card.
## Open source status
* [x] the model implementation is available: (https://github.com/dreasysnail/POINTER)
* [x] the model weights are available: [here](https://yizzhang.blob.core.windows.net/insertiont/ckpt.tar.gz?st=2020-08-18T20%3A49%3A02Z&se=2024-01-16T20%3A49%3A00Z&sp=rl&sv=2018-03-28&sr=b&sig=PKrSJt38cmY0P%2FBcZuyK%2Btm3bXyYzzfazaqTu1%2F%2FDtc%3D)
* [x] who are the authors: @dreasysnail
| 11-11-2020 06:35:13 | 11-11-2020 06:35:13 | Thanks @patrickvonplaten for taking this. It's nice to work with you again :)<|||||>Really interesting approach :hugs:
@dreasysnail Do you think it is possible to pre-train a model from scratch on **one** GPU in a reasonable time? Could you say something about your used hardware setup and training time for the pre-training phase :thinking: <|||||>Thanks @stefan-it ! Regarding your question:
> @dreasysnail Do you think it is possible to pre-train a model from scratch on **one** GPU in a reasonable time? Could you say something about your used hardware setup and training time for the pre-training phase 🤔
The speed advantage of this algorithm is more on the decoding side. For the training time, you can expect this takes roughly similar amount of time comparing to, say, fine-tuning a BERT. One GPU is possible but if your dataset is large the training could be slow. So I would recommend you fine-tune from what we have already pretrained for fast convergence and better quality.
For your reference, we were using 8/16*V100 GPUs to pretrain and fine-tune the models. The pretraining takes roughly one week and the fine-tuning takes 1-2 days.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,453 | closed | _pickle.PicklingError: Can't pickle typing.Union[str, NoneType]: it's not the same object as typing.Union | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:3.4.0
- Platform:linux
- Python version:3.6
- PyTorch version (GPU?):1.6 cuda10
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
When I try to train roberta-wwm from scratch for my dataset , I get this error when I follow transformers' run_mlm_wwm.py code
```
!python run_mlm_wwm.py --model_name_or_path hfl/chinese-roberta-wwm-ext --train_file ../../../../pretrain_data/pretrain_train.txt --validation_file ../../../../pretrain_data/pretrain_val.txt --train_ref_file ../../../../pretrain_data/ref_train.txt --validation_ref_file ../../../../pretrain_data/ref_val.txt --do_train --do_eval --output_dir ./output
```
```
All the weights of BertForMaskedLM were initialized from the model checkpoint at hfl/chinese-roberta-wwm-ext.
If your task is similar to the task the model of the checkpoint was trained on, you can already use BertForMaskedLM for predictions without further training.
Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.
Traceback (most recent call last):
File "run_mlm_wwm.py", line 333, in <module>
main()
File "run_mlm_wwm.py", line 274, in main
load_from_cache_file=not data_args.overwrite_cache,
File "/usr/local/lib/python3.6/dist-packages/datasets/dataset_dict.py", line 300, in map
for k, dataset in self.items()
File "/usr/local/lib/python3.6/dist-packages/datasets/dataset_dict.py", line 300, in <dictcomp>
for k, dataset in self.items()
File "/usr/local/lib/python3.6/dist-packages/datasets/arrow_dataset.py", line 1256, in map
update_data=update_data,
File "/usr/local/lib/python3.6/dist-packages/datasets/arrow_dataset.py", line 156, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/datasets/fingerprint.py", line 158, in wrapper
self._fingerprint, transform, kwargs_for_fingerprint
File "/usr/local/lib/python3.6/dist-packages/datasets/fingerprint.py", line 105, in update_fingerprint
hasher.update(transform_args[key])
File "/usr/local/lib/python3.6/dist-packages/datasets/fingerprint.py", line 57, in update
self.m.update(self.hash(value).encode("utf-8"))
File "/usr/local/lib/python3.6/dist-packages/datasets/fingerprint.py", line 53, in hash
return cls.hash_default(value)
File "/usr/local/lib/python3.6/dist-packages/datasets/fingerprint.py", line 46, in hash_default
return cls.hash_bytes(dumps(value))
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/py_utils.py", line 367, in dumps
dump(obj, file)
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/py_utils.py", line 339, in dump
Pickler(file, recurse=True).dump(obj)
File "/usr/local/lib/python3.6/dist-packages/dill/_dill.py", line 454, in dump
StockPickler.dump(self, obj)
File "/usr/lib/python3.6/pickle.py", line 409, in dump
self.save(obj)
File "/usr/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/usr/local/lib/python3.6/dist-packages/dill/_dill.py", line 1447, in save_function
obj.__dict__, fkwdefaults), obj=obj)
File "/usr/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/usr/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/usr/lib/python3.6/pickle.py", line 751, in save_tuple
save(element)
File "/usr/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/usr/lib/python3.6/pickle.py", line 736, in save_tuple
save(element)
File "/usr/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/usr/local/lib/python3.6/dist-packages/dill/_dill.py", line 1178, in save_cell
pickler.save_reduce(_create_cell, (f,), obj=obj)
File "/usr/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/usr/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/usr/lib/python3.6/pickle.py", line 736, in save_tuple
save(element)
File "/usr/lib/python3.6/pickle.py", line 521, in save
self.save_reduce(obj=obj, *rv)
File "/usr/lib/python3.6/pickle.py", line 605, in save_reduce
save(cls)
File "/usr/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/usr/local/lib/python3.6/dist-packages/dill/_dill.py", line 1374, in save_type
obj.__bases__, _dict), obj=obj)
File "/usr/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/usr/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/usr/lib/python3.6/pickle.py", line 751, in save_tuple
save(element)
File "/usr/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/usr/local/lib/python3.6/dist-packages/dill/_dill.py", line 941, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/usr/lib/python3.6/pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File "/usr/lib/python3.6/pickle.py", line 847, in _batch_setitems
save(v)
File "/usr/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/usr/local/lib/python3.6/dist-packages/dill/_dill.py", line 941, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/usr/lib/python3.6/pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File "/usr/lib/python3.6/pickle.py", line 847, in _batch_setitems
save(v)
File "/usr/lib/python3.6/pickle.py", line 507, in save
self.save_global(obj, rv)
File "/usr/lib/python3.6/pickle.py", line 927, in save_global
(obj, module_name, name))
**_pickle.PicklingError: Can't pickle typing.Union[str, NoneType]: it's not the same object as typing.Union**
```
please help me.
<!-- A clear and concise description of what you would expect to happen. -->
| 11-11-2020 04:48:13 | 11-11-2020 04:48:13 | Maybe @sgugger has an idea<|||||>This is a duplicate of #8212 which gives the workaround (install python 3.7) while waiting for the new release of datasets, which will fix that bug.<|||||>Maybe we should do a quick patch release of `datasets` just for this one @lhoestq?<|||||>It seems an issue ´till Python 3.6 on Pickle (I´m exactly on 3.6). As I´m (really) on a hurry, just commented the error on Pickle and It run normally.<|||||>> This is a duplicate of #8212 which gives the workaround (install python 3.7) while waiting for the new release of datasets, which will fix that bug.
**Thank you very much. 🌹**
I did run the above code correctly in Python 3.7.9, but it's strange that the following error occurred. This didn't happen in my previous Python 3.6.9 environment.
Traceback (most recent call last):
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\urllib3\connectionpool.py", line 696, in urlopen
self._prepare_proxy(conn)
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\urllib3\connectionpool.py", line 964, in _prepare_proxy
conn.connect()
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\urllib3\connection.py", line 359, in connect
conn = self._connect_tls_proxy(hostname, conn)
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\urllib3\connection.py", line 502, in _connect_tls_proxy
ssl_context=ssl_context,
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\urllib3\util\ssl_.py", line 424, in ssl_wrap_socket
ssl_sock = _ssl_wrap_socket_impl(sock, context, tls_in_tls)
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\urllib3\util\ssl_.py", line 466, in _ssl_wrap_socket_impl
return ssl_context.wrap_socket(sock)
File "D:\Anaconda3\envs\RobertaWWMExt\lib\ssl.py", line 423, in wrap_socket
session=session
File "D:\Anaconda3\envs\RobertaWWMExt\lib\ssl.py", line 870, in _create
self.do_handshake()
File "D:\Anaconda3\envs\RobertaWWMExt\lib\ssl.py", line 1139, in do_handshake
self._sslobj.do_handshake()
**ssl.SSLError: [SSL: WRONG_VERSION_NUMBER] wrong version number (_ssl.c:1091)**
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\requests\adapters.py", line 449, in send
timeout=timeout
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\urllib3\connectionpool.py", line 756, in urlopen
method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\urllib3\util\retry.py", line 573, in increment
raise MaxRetryError(_pool, url, error or ResponseError(cause))
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/text/text.py (Caused by SSLError(SSLError(1, '[SSL: WRONG_VERSION_NUMBER] wrong version number (_ssl.c:1091)')))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "./run_mlm_wwm.py", line 336, in <module>
main()
File "./run_mlm_wwm.py", line 213, in main
datasets = load_dataset(extension, data_files=data_files)
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\datasets\load.py", line 590, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\datasets\load.py", line 264, in prepare_module
head_hf_s3(path, filename=name, dataset=dataset)
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\datasets\utils\file_utils.py", line 200, in head_hf_s3
return requests.head(hf_bucket_url(identifier=identifier, filename=filename, use_cdn=use_cdn, dataset=dataset))
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\requests\api.py", line 104, in head
return request('head', url, **kwargs)
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\requests\api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\requests\sessions.py", line 542, in request
resp = self.send(prep, **send_kwargs)
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\requests\sessions.py", line 655, in send
r = adapter.send(request, **kwargs)
File "D:\Anaconda3\envs\RobertaWWMExt\lib\site-packages\requests\adapters.py", line 514, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/text/text.py **(Caused by SSLError(SSLError(1, '[SSL: WRONG_VERSION_NUMBER] wrong version number (_ssl.c:1091)')))**
Could you give me a suggestion about this bug, please.<|||||>Pinging @julien-c and @Pierrci here additionally (connection to S3)<|||||>> Maybe we should do a quick patch release of `datasets` just for this one @lhoestq?
Yes will do a patch release soon<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,452 | closed | Fine-tuning GPT: problems with padding | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.4.0
- Platform: Linux-3.10.0-957.el7.x86_64-x86_64-with-glibc2.10
- Python version: 3.8.3
- PyTorch version (GPU?): 1.5.1+cu101 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@LysandreJik
tokenizers: @mfuntowicz
## Information
Model I am using openai-gpt:
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The scripts are my own scripts inspired by the glue examples.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
Simple binary text classification, nothing fancy, inspired by the glue example files.
## To reproduce
Steps to reproduce the behavior:
As reported in other issues, padding is not done for GPT* models. One workaround for this issue is to set the padding token to the eos token. This seems to work fine for the GPT2 models (I tried GPT2 and DistilGPT2), but creates some issues for the GPT model. Comparing the outputs of the two models, it looks like the config file for the GPT2 models contains ids for bos and eos tokens, while these are missing from the GPT config file (not sure this is the real problem).
Some other interesting bits from the outputs:
```
ftfy or spacy is not installed using BERT BasicTokenizer instead of SpaCy & ftfy.
Using eos_token, but it is not set yet.
```
Bottom line, it crashes with ValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})` - despite the fact that I have `tokenizer.pad_token = tokenizer.eos_token` in the code.
I'm expecting some issue with the tokenizer/missing ids for the special tokens. Wondering if there is something missing in the config file for the model.
## Expected behavior
No error? :) I don't see any of these issues after setting the padding token to the eos token for the GPT2 model. As I briefly mentioned above, the only difference that I see in the config file is the ids for the eos/bos tokens, which seem to be missing from the GPT model config.
Thanks for your help!
| 11-11-2020 04:17:35 | 11-11-2020 04:17:35 | Another suspicious flag in the config for GPT is `predict_special_tokens` which is set to `True` (no such thing for GPT2 config). I did a grep on this flag and it seems to be present only in the config class and not used anywhere else. Somewhat strange. <|||||>I might have found a problem in my scripts/code. I've been using BERT-based models so far and when examples are converted to features, the batch encoder is initialized with padding set to max_length; I'm trying to initialize it to do_not_pad. In theory, this should fix it. In practice... we shall see :) <|||||>Indeed, the root of the issue seems to be that you're asking your tokenizer to pad the sequences, but it does not have a padding token, and therefore cannot do so.
If setting the tokenizer's pad token to the eos token doesn't work, you can try adding a new token to the tokenizer with the `add_special_tokens()` method, and then resize the model embedding layer.
Seeing as you should use the attention mask when padding, these tokens should have close to zero influence on your training.
See the docs about the aforementioned methods [here](https://huggingface.co/transformers/internal/tokenization_utils.html?highlight=resize_token_embeddings#transformers.tokenization_utils_base.SpecialTokensMixin.add_special_tokens)<|||||>Isn't it more straightforward to ask the tokenizer to not pad the sequence (for gpt* models)?
The confusion came from the fact that setting the padding token to eos works for GPT2* models (because eos is defined in the config of the pretrained model), but doesn't for GPT (because eos is not defined)<|||||>So no padding seems to work looking at a few samples (but no batching possible). I'll start a few training jobs, I'll know tomorrow if it really trained properly (large dataset). <|||||>Yes, it is more straightforward, but as you've said, no batching can be made. This is quite limiting and would tremendously slow down the training; if your training is small enough then that might still be enough!<|||||>@LysandreJik It's slow indeed, but I think I can live with it. I can't recall what the problem was, even fro gpt2 where I could assigned pad = eos, I got an error when I tried to batch. <|||||>Ah, this is weird. If you ever stumble upon this issue again, please let us know so that we may see what's wrong. Thanks!<|||||>To get GPT2 to work, you'll also need to update the config's pad token to be the eos token:
`config.pad_token_id = config.eos_token_id`
For example, in `examples/lightning_base.py`, I've added the below lines right after loading the tokenizer in BaseTransformer().\_\_init\_\_():
```py
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
self.config.pad_token_id = self.config.eos_token_id
```<|||||>@ethanjperez thanks for the tip, I'll give it a try!
<|||||>I think this works. I managed to train gpt and gpt2. I have an issue during evaluation with gpt2, but I don't think it's related. Closing this one, thanks @ethanjperez <|||||>```
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
self.config.pad_token_id = self.config.eos_token_id
```
Using this can train, but save will meet so many problems!
https://github.com/huggingface/transformers/issues/5571
|
transformers | 8,451 | closed | config.attention_head_size for structured pruning out-of-box | # 🚀 Feature request
## Motivation
for structured pruning like `fastformers`, https://github.com/microsoft/fastformers#pruning-models ,
we should modify the source code of transformers for `attention_head_size.
for example,
1. configuration_bert.py
https://github.com/microsoft/fastformers/blob/main/src/transformers/configuration_bert.py#L128
2. modeling_bert.py
https://github.com/microsoft/fastformers/blob/main/src/transformers/modeling_bert.py#L192
https://github.com/microsoft/fastformers/blob/main/src/transformers/modeling_bert.py#L263
is it possible to set `attention_head_size` from outside(config.json) ?
## Your contribution
| 11-11-2020 04:10:38 | 11-11-2020 04:10:38 | @dsindex FYI, I am working on creating a PR including this feature for the effort of #8083 .<|||||>@ykim362 great! closing issue here. |
transformers | 8,450 | closed | A layman wants to train DistilBERT | I want to train DistilBERT, but I don't know how to get the training data.
In the article, it describes the training data as a concatenation of Toronto Book Corpus and English Wikipedia (same training data as the English version of BERT). So how can I get it?

[https://github.com/huggingface/transformers/blob/1ab8dc44b3d84ed1894f5b6a6fab58fb39298fc7/examples/distillation/README.md](url) | 11-11-2020 03:12:00 | 11-11-2020 03:12:00 | [https://github.com/google-research/bert](url)
In this url, I find some files.

But I don't whether they are the data which used to be the training data of distilbert.
And the distilbert model need "dump.txt ", not ".json", whether the data we need is included in it?<|||||>I find a text in the goole project bert.
[https://github.com/google-research/bert/blob/master/sample_text.txt](url)
Is it the training data of this project?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,449 | closed | Can't find model to down | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
## Your contribution
I can't find any model to down in "huggingface.cn", so what happened?

but I find many people downed the model in Noverber 9, so why I can't find model today?
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| 11-11-2020 02:52:56 | 11-11-2020 02:52:56 | I encountered the same problem<|||||>Will release a new version of that UX tomorrow<|||||>We just added file sizes, and download links, to the lists of model files, see for instance:
<img width="1592" alt="Screenshot 2020-11-13 at 22 55 23" src="https://user-images.githubusercontent.com/326577/99125288-be896500-25d1-11eb-84f5-03eb9b44f29d.png">
https://huggingface.co/dbmdz/bert-base-turkish-cased/tree/main
Let us know if this solves your use case @havetry @xlxwalex.<|||||>> We just added file sizes, and download links, to the lists of model files, see for instance:
>
> <img alt="Screenshot 2020-11-13 at 22 55 23" width="1592" src="https://user-images.githubusercontent.com/326577/99125288-be896500-25d1-11eb-84f5-03eb9b44f29d.png">
>
> https://huggingface.co/dbmdz/bert-base-turkish-cased/tree/main
>
> Let us know if this solves your use case @havetry @xlxwalex.
Good job, thanks!<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,448 | closed | Make sure the slot variables are created under the same strategy scope. | - `transformers` version: 3.5.0
- Platform: jupyter notebook
- Python version: 3.6.9
- Tensorflow version (GPU?): 2.3.1
- Using GPU in script?: Single RTX 2080TI
- Model: "distilbert-base-multilingual-cased"
with tf.device('/device:GPU:0'):
model.compile(optimizer=optimizer, loss=loss_fn)
model.fit(train_dataset.batch(batch_size_train), epochs=1)
Code above works fine. Using TFtrainer with code below produces strategy error.
Note:
tf.config.list_physical_devices('GPU') gives [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Steps to reproduce the behavior:
from transformers import BertTokenizer, TFBertForTokenClassification
from transformers import __version__
from transformers import TFTrainer, TFTrainingArguments
label2id = {"False": 0, "True": 1}
bert_model = "distilbert-base-multilingual-cased"
cache_dir = "cache/distilbert"
model = TFBertForTokenClassification.from_pretrained(
bert_model,
cache_dir = cache_dir,
num_labels = len(label2id),
label2id = label2id,
id2label = {v:k for k,v in label2id.items()}
)
training_args = TFTrainingArguments(
output_dir='cp',
num_train_epochs=1,
per_device_train_batch_size=16,
warmup_steps=500,
weight_decay=0.05,
)
trainer = TFTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
)
trainer.train()
ValueError: Trying to create optimizer slot variable under the scope for tf.distribute.Strategy (<tensorflow.python.distribute.one_device_strategy.OneDeviceStrategy object at 0x7effe7039588>), which is different from the scope used for the original variable (<tf.Variable 'tf_bert_for_token_classification/bert/embeddings/word_embeddings/weight:0' shape=(119547, 768) dtype=float32, numpy=
array([[ 0.01447453, -0.03549159, 0.03377417, ..., -0.01235564,
0.00624704, -0.01201372],
[ 0.00689944, 0.00139387, -0.00716509, ..., 0.02127312,
-0.00164859, -0.02350472],
[ 0.00123599, -0.02220839, -0.01472212, ..., -0.02844208,
-0.01958628, 0.01139562],
...,
[ 0.03488934, 0.00115632, 0.0073231 , ..., 0.00768381,
-0.02942067, -0.00667366],
[ 0.00224815, -0.00895759, 0.0046453 , ..., 0.00379816,
0.00176853, -0.01759749],
[-0.02521203, -0.03274821, -0.00520367, ..., -0.01396327,
0.0071948 , -0.01428833]], dtype=float32)>). Make sure the slot variables are created under the same strategy scope. This may happen if you're restoring from a checkpoint outside the scope | 11-10-2020 19:52:15 | 11-10-2020 19:52:15 | I think i already got an answer to my question from this page https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_tf_ner.py :)
with training_args.strategy.scope():
model = TFBertForTokenClassification.from_pretrained(bert_model,
cache_dir=cache_dir,
num_labels=len(label2id),
label2id=label2id,
id2label={v:k for k,v in label2id.items()}
)
model.summary() |
transformers | 8,447 | closed | Model name 'facebook/rag-sequence-base/*' not found when running examples/rag/finetune.sh | ## Environment info
- `transformers` version: 3.3.1
- Platform: Linux-4.15.0-38-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: True (Retriever is distributed)
### Who can help
@patrickvonplaten, @lhoestq
## Information
Model I am using (Bert, XLNet ...):
**facebook/rag-sequence-base**
The problem arises when using:
* [x ] the official example scripts: (give details below)
examples/rag/finetune.sh
The tasks I am working on is:
* [x ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
run `sh finetune.sh`
with
```
DATA_DIR=data_dir
OUTPUT_DIR=output_dir
MODEL_NAME_OR_PATH="facebook/rag-sequence-base"
```
gives:
**Model name 'facebook/rag-sequence-base/question_encoder_tokenizer' not found in model shortcut name list (facebook/dpr-question_encoder-single-nq-base). Assuming 'facebook/rag-sequence-base/question_encoder_tokenizer' is a path, a model identifier, or url to a directory containing tokenizer files**.
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/question_encoder_tokenizer/vocab.txt from cache at /h/asabet/.cache/torch/transformers/14d599f015518cd5b95b5d567b8c06b265dbbf04047e44b3654efd7cbbacb697.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/question_encoder_tokenizer/added_tokens.json from cache at None
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/question_encoder_tokenizer/special_tokens_map.json from cache at /h/asabet/.cache/torch/transformers/70614c7a84151409876eaaaecb3b5185213aa5c560926855e35753b9909f1116.275045728fbf41c11d3dae08b8742c054377e18d92cc7b72b6351152a99b64e4
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/question_encoder_tokenizer/tokenizer_config.json from cache at /h/asabet/.cache/torch/transformers/8ade9cf561f8c0a47d1c3785e850c57414d776b3795e21bd01e58483399d2de4.11f57497ee659e26f830788489816dbcb678d91ae48c06c50c9dc0e4438ec05b
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/question_encoder_tokenizer/tokenizer.json from cache at None
**Model name 'facebook/rag-sequence-base/generator_tokenizer' not found in model shortcut name list (facebook/bart-base, facebook/bart-large, facebook/bart-large-mnli, facebook/bart-large-cnn, facebook/bart-large-xsum, yjernite/bart_eli5). Assuming 'facebook/rag-sequence-base/generator_tokenizer' is a path, a model identifier, or url to a directory containing tokenizer files.**
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/generator_tokenizer/vocab.json from cache at /h/asabet/.cache/torch/transformers/3b9637b6eab4a48cf2bc596e5992aebb74de6e32c9ee660a27366a63a8020557.6a4061e8fc00057d21d80413635a86fdcf55b6e7594ad9e25257d2f99a02f4be
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/generator_tokenizer/merges.txt from cache at /h/asabet/.cache/torch/transformers/b2a6adcb3b8a4c39e056d80a133951b99a56010158602cf85dee775936690c6a.70bec105b4158ed9a1747fea67a43f5dee97855c64d62b6ec3742f4cfdb5feda
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/generator_tokenizer/added_tokens.json from cache at None
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/generator_tokenizer/special_tokens_map.json from cache at /h/asabet/.cache/torch/transformers/342599872fb2f45f954699d3c67790c33b574cc552a4b433fedddc97e6a3c58e.6e217123a3ada61145de1f20b1443a1ec9aac93492a4bd1ce6a695935f0fd97a
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/generator_tokenizer/tokenizer_config.json from cache at /h/asabet/.cache/torch/transformers/e5f72dc4c0b1ba585d7afb7fa5e3e52ff0e1f101e49572e2caaf38fab070d4d6.d596a549211eb890d3bb341f3a03307b199bc2d5ed81b3451618cbcb04d1f1bc
loading file https://s3.amazonaws.com/models.huggingface.co/bert/facebook/rag-sequence-base/generator_tokenizer/tokenizer.json from cache at None
Traceback (most recent call last):
File "finetune.py", line 499, in <module>
main(args)
File "finetune.py", line 439, in main
model: GenerativeQAModule = GenerativeQAModule(args)
File "finetune.py", line 105, in __init__
retriever = RagPyTorchDistributedRetriever.from_pretrained(hparams.model_name_or_path, config=config)
File "/h/asabet/.local/lib/python3.6/site-packages/transformers/retrieval_rag.py", line 308, in from_pretrained
config, question_encoder_tokenizer=question_encoder_tokenizer, generator_tokenizer=generator_tokenizer
File "/scratch/ssd001/home/asabet/transformers/examples/rag/distributed_retriever.py", line 41, in __init__
index=index,
**TypeError: __init__() got an unexpected keyword argument 'index'**
## Expected behavior
finetune.sh should launch and run
| 11-10-2020 19:06:07 | 11-10-2020 19:06:07 | Hi, I have a related issue. This happen to `"facebook/rag-token-base"` and `"facebook/rag-token-nq"` and `"facebook/rag-sequence-nq"` as well.
Basic loading failed (was able to do it until around 2 days ago -- I use version 3.5.0)
Both
`tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq")`
and
`retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)`
result in the same error message:
`OSError: Can't load tokenizer for 'facebook/rag-sequence-nq/question_encoder_tokenizer'.`
<<< Seem like it add the wrong path `question_encoder_tokenizer` at the end.
<|||||>to add to @ratthachat's comment: I observe the same problem when loading the model with:
`model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq") `
<|||||>Tagging @julien-c @Pierrci here. Maybe an issue related to the migration to git/git-lfs<|||||>Initial poster seems to be running `transformers version: 3.3.1` which makes me suspect it might not be related to the git/git-lfs migration
Update: @lhoestq is looking into it<|||||>@lhoestq @julien-c @thomwolf
Sorry to ask, but I am translating TFRag and would really love to continue before long hollidays.
Could it be possible to fix only the wrong file path (the last `question_encoder_tokenizer`) in
`OSError: Can't load tokenizer for 'facebook/rag-sequence-nq/question_encoder_tokenizer'.`
to fix error of basic loading
```
tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq")
or
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
or
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq")
```<|||||>Apologies for any duplicate comments, but experiencing the same issue as @ratthachat.
Any updates or fixes on this? Currently running transformers-3.5.1<|||||>Hello, feel free to open a PR with your proposed fix and we'll take a look. Thanks!<|||||>Can confirm that this error is eliminated when downgrading to:
```
transformers==3.3.1
tokenizers==0.9.2
datasets==1.1.2
```
Looks very likely that something went wrong in the transition to git-lfs for this use case.
@thomwolf @julien-c <|||||>Thanks for the detailed reports everyone, this should now be fixed on `master`.<|||||>@julien-c
Hi I am trying to run [use_own_knowledge_dataset.py](https://github.com/huggingface/transformers/blob/master/examples/rag/use_own_knowledge_dataset.py) with **Transformers Version: 3.5.1**. But it gives the following error.
```
OSError: Can't load tokenizer for 'facebook/rag-sequence-nq/question_encoder_tokenizer'. Make sure that:
- 'facebook/rag-sequence-nq/question_encoder_tokenizer' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'facebook/rag-seq
```uence-nq/question_encoder_tokenizer' is the correct path to a directory containing relevant tokenizer files
<|||||>> @julien-c
>
> Hi I am trying to run [use_own_knowledge_dataset.py](https://github.com/huggingface/transformers/blob/master/examples/rag/use_own_knowledge_dataset.py) with **Transformers Version: 3.5.1**. But it gives the following error.
>
> ```
>
> OSError: Can't load tokenizer for 'facebook/rag-sequence-nq/question_encoder_tokenizer'. Make sure that:
>
> - 'facebook/rag-sequence-nq/question_encoder_tokenizer' is a correct model identifier listed on 'https://huggingface.co/models'
>
> - or 'facebook/rag-seq
> ```uence-nq/question_encoder_tokenizer' is the correct path to a directory containing relevant tokenizer files
> ```
Hey @shamanez - could you open a separate issue for this and tag @lhoestq ? :-) <|||||>Sure :) <|||||>The fix is not yet in a released version only on `master`, so you need to install from master for now.<|||||>so shall I install from sources?<|||||>Thank you! When will the fixed version be released? |
transformers | 8,446 | closed | using multi_gpu consistently | As discussed [here](https://github.com/huggingface/transformers/pull/8341#issuecomment-722705833) this PR replaces
* `multiple_gpu`
* `multigpu`
with `multi_gpu` for consistency
There is no functionality change otherwise.
I did repo-wide:
```
find . -type d -name ".git" -prune -o -type f -exec perl -pi -e 's#(multiple_gpu|multigpu)#multi_gpu#g' {} \;
```
@LysandreJik, @sgugger | 11-10-2020 18:03:14 | 11-10-2020 18:03:14 | |
transformers | 8,445 | closed | [marian.rst] remove combined lines | 11-10-2020 18:03:09 | 11-10-2020 18:03:09 | I already did that in a commit to master, thanks for fixing too! :-) |
|
transformers | 8,444 | closed | Add missing import | # What does this PR do?
Fix a missing import for TF auto. | 11-10-2020 16:44:36 | 11-10-2020 16:44:36 | |
transformers | 8,443 | closed | Dropout p is changing after loading | ## Environment info
- `transformers` version: 3.5.0
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.7.0+cu101 (True)
- Tensorflow version (GPU?): 2.3.0 (True)
- Using GPU in script?:
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik, @sgugger
## Information
Model I am using (Bert, XLNet ...): Bert, Roberta
The problem arises when using:
* [ *] the official example scripts: Using information given in this link: https://huggingface.co/transformers/master/custom_datasets.html
The tasks I am working on is:
* [ *] my own task or dataset: text classification
## To reproduce
Steps to reproduce the behavior:
1. I'm trying to change dropout probability. I'm using one of these methods for Bert instance:
```python
model.classifier.dropout.p=0.7
model.classifier.dropout = nn.Dropout(0.7)
```
2. After training is completed, model is saved
```python
model.save_pretrained('xxx/bert')
```
3. Model is loaded in another session using this code snippet. But after loading, model.classifier.dropout.p is changing to 0.1 which is in the config file.
```python
model = BertForSequenceClassification.from_pretrained("xxx/bert",
num_labels = 3,
output_attentions = False,
output_hidden_states = False,
)
```
## Expected behavior
Dropout p is changing to default value after loading the model. But the model is modified so that it shouldn't do that behavior
| 11-10-2020 16:15:40 | 11-10-2020 16:15:40 | Hi, this is not the best way to update the dropout value as it will get overridden by the configuration value on load.
The classifier in `BertForSequenceClassification` is a linear layer, that has no dropout. If you want to change the dropout which is applied before the linear layer, you should update the `config.hidden_dropout_prob`. You can see the source code [here](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bert.py#L1319).
The code is made to be easy to read and easy to tweak, so feel free to directly modify the source code to fit your needs.<|||||>Hi,
I've already tried it but it changes all of the output dropout layers value since each layer is using same config as you can see below. I think it'd be better to have a different dropout config for the last layer since bert official example is suggesting to optimize it with changing(https://github.com/google-research/bert/blob/master/predicting_movie_reviews_with_bert_on_tf_hub.ipynb). This also applies to roberta as well. I guess I need to modify the source code accordingly.
```python
config = BertConfig.from_pretrained('bert-base-uncased')
config.hidden_dropout_prob=0.7
model = BertForSequenceClassification.from_pretrained(
"bert-base-uncased",
config = config
)
model.cuda()
```
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.7, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.7, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.7, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.7, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.7, inplace=False)
)
)
(2): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.7, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.7, inplace=False)
)
)
....
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.7, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.7, inplace=False)
(classifier): Linear(in_features=768, out_features=2, bias=True)
)<|||||>Yes, the model files are completely independent of each other for that purpose: it should be very easy to modify each independent model file.
Feel free to modify the model file so that it fits your needs.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,442 | closed | Models fine-tuned with gradient checkpointing (=True) fails to export to ONXX | ## Environment info
- `transformers` version: 3.5.0
- Platform: Linux-5.4.0-52-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.9
- PyTorch version (GPU?): 1.7.0 (True)
- Tensorflow version (GPU?): 2.3.1 (False)
- Using GPU in script?: False
- Using distributed or parallel set-up in script?: False
### Who can help
Hi @LysandreJik and @patrickvonplaten, I hope I have tagged the right person. If not please untag yourself and tag the right person.
## Information
Model I am using (Bert):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
It's a super simple script that uses gradient check-pointing with BERT.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
A dummy data
## To reproduce
I have made a reproducible google collab here -> https://colab.research.google.com/drive/1tUpIzbugZ4xPz6eAOJtZT-fGww9LemwN?usp=sharing
Steps to reproduce the behavior:
1. Open the notebook
2. Runtime->Run all
Error thrown:
```python
RuntimeError Traceback (most recent call last)
<ipython-input-5-2702a59a9c3e> in <module>()
7 tokenizer=tokenizer, # <-- CHANGED: add tokenizer
8 output=Path("onnx/bert-base-cased.onnx"),
----> 9 opset=11)
10
11 # Tensorflow
4 frames
/usr/local/lib/python3.6/dist-packages/torch/onnx/utils.py in _export(model, args, f, export_params, verbose, training, input_names, output_names, operator_export_type, export_type, example_outputs, opset_version, _retain_param_name, do_constant_folding, strip_doc_string, dynamic_axes, keep_initializers_as_inputs, fixed_batch_size, custom_opsets, add_node_names, enable_onnx_checker, use_external_data_format, onnx_shape_inference, use_new_jit_passes)
648 params_dict, opset_version, dynamic_axes, defer_weight_export,
649 operator_export_type, strip_doc_string, val_keep_init_as_ip, custom_opsets,
--> 650 val_add_node_names, val_use_external_data_format, model_file_location)
651 else:
652 proto, export_map = graph._export_onnx(
RuntimeError: ONNX export failed: Couldn't export Python operator CheckpointFunction
```
| 11-10-2020 15:20:38 | 11-10-2020 15:20:38 | Indeed, I see why this would fail. I don't have access to your notebook, but as a temporary workaround you could do:
```py
model.save_pretrained("here")
model = ModelClass.from_pretrained("here", gradient_checkpointing=False)
```
You should be able to convert that model to ONNX then.<|||||>I made it public now, my bad. Another work around I found was to edit the `config.json` by setting `"gradient_checkpointing": false`. I did this because the convert script looks for the model in a path and not in memory.<|||||>Yes, this works too!<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,441 | closed | CUDA out of memory (ALBERT)!! | # ❓ Questions & Help
While using `albert-base-v2` to train my model, I got the following problem:
```
#first call
outputs = self.albert(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds)
sequence_output = outputs[0]
context_mask = token_type_ids * attention_mask
question_mask = ((1 - context_mask) * attention_mask)
#second call
question, _ = self.albert(input_ids, attention_mask=question_mask, token_type_ids=token_type_ids)
#third call
context, _ = self.albert(input_ids, attention_mask=context_mask, token_type_ids=token_type_ids)
```
While calling `self.albert()` thrice, the memory it consumes will multiply by 3.
So that I must change my batch_size to 4, it's so bad!
Is it a BUG or a feature?
Even `albert-base` so large?
| 11-10-2020 14:25:00 | 11-10-2020 14:25:00 | Hi there. Questions like this should be asked on the forum. In your code example, you are using different variable names for each of your three call, so it's logical to get more memory consumption. Python will only release the memory if you reuse the same variable name.<|||||>Hi,friends.
`you are using different variable names for each of your three call`
what do you mean?
My problem is that:
when I first call `outputs = self.albert()` , the memory is almost 4G
And I second call `question, _ = self.albert()` , the memory increase to almost 8G.
But the variable `question` should not take up so much memory.<|||||>> Hi there. Questions like this should be asked on the forum. In your code example, you are using different variable names for each of your three call, so it's logical to get more memory consumption. Python will only release the memory if you reuse the same variable name.
Hi,friends.
`you are using different variable names for each of your three call`
what do you mean?
My problem is that:
when I first call `outputs = self.albert()` , the memory is almost 4G
And I second call `question, _ = self.albert()` , the memory increase to almost 8G.
But the variable `question` should not take up so much memory.<|||||>Agree with @sgugger. Question like this should be asked on https://discuss.huggingface.co
We are tying to keep the issues for bug reports and new features/model requests.
Closing this for now. |
transformers | 8,440 | closed | Question template | # What does this PR do?
This PR updates the question template to insist a bit more on users using the forum for questions. | 11-10-2020 14:17:50 | 11-10-2020 14:17:50 | <img width="1402" alt="image" src="https://user-images.githubusercontent.com/7353373/98936078-c3bcb600-24e4-11eb-9ae3-6894af553004.png">
For some reason I don't see the "Question and Help" option when I try to open an issue @sgugger @LysandreJik <|||||>Mmm, guess the metadata at the top doesn't like the link. |
transformers | 8,439 | closed | Model sharing rst | Update the model sharing RST for the new model versioning. | 11-10-2020 13:25:45 | 11-10-2020 13:25:45 | Merging it now with Julien's offline approval. |
transformers | 8,438 | closed | login to huggingface forum | hey.
I'm not sure where to post it, so my apologise in advance.
I'm trying to login to huggingface forum, but it return me the message: "Unauthorized".
what can I do?
(I created a user..)
thanks. | 11-10-2020 13:06:20 | 11-10-2020 13:06:20 | Maybe @julien-c or @Pierrci knows!<|||||>can you try again, just in case it was an intermittent issue?<|||||>Wonderful, i login with another email and it works. Thanks. |
transformers | 8,437 | closed | [T5Tokenizer] fix t5 token type ids | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #7840
T5 does not use token type ids. Nevertheless, the T5Tokenizer should analogs to RobertaTokenizer return all [0] for the `token_type_ids`.
Functions and Tests are added for T5TokenizerFast and T5Tokenizer.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-10-2020 11:58:31 | 11-10-2020 11:58:31 | |
transformers | 8,436 | closed | Windows dev section in the contributing file | # What does this PR do?
This PR adds a section for people who wants to contribute from a Windows environment. | 11-10-2020 11:16:03 | 11-10-2020 11:16:03 | |
transformers | 8,435 | closed | [T5 Tokenizer] Fix t5 special tokens | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #5142, #8109
T5FastToeknzier and T5SlowTokenizer have different behaviors for special tokens as shown in the issue above.
This PR fixes the slow T5 tokenizer and adds a test making sure that Fast and Slow tokenizer have the same behavior.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @patrickvonplaten
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @patil-suraj
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-10-2020 11:10:09 | 11-10-2020 11:10:09 | Fixes #7796 |
transformers | 8,434 | closed | Support serialized tokenizer in AutoTokenizer | # What does this PR do?
Addresses issue: https://github.com/huggingface/transformers/issues/7293
With these changes, the `AutoTokenizer.from_pretrained()` supports also loading a tokenizer, which was saved with [🤗 Tokenizers](https://github.com/huggingface/tokenizers) library.
Example:
```python
from tokenizers import CharBPETokenizer
tokenizer = CharBPETokenizer()
tokenizer.save('./char-bpe.json')
from transformers import AutoTokenizer
my_tokenizer = AutoTokenizer.from_pretrained('./char-bpe.json', use_fast=True)
```
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed.
Also: @mfuntowicz (tokenizers), @thomwolf (due to https://github.com/huggingface/transformers/pull/7659) | 11-10-2020 10:54:03 | 11-10-2020 10:54:03 | I'm having an issue that could be fixed by this PR. I trained a BPETokinizer using the Tokenizers library, uploaded the tokenizer generated JSON file to [my HF repository](https://huggingface.co/jonatasgrosman/bartuque-bart-large-mefmt/blob/main/vocab.json) and this command:
```python
from transformers import AutoTokenizer
AutoTokenizer.from_pretrained("jonatasgrosman/bartuque-bart-large-mefmt")
```
... Results on this error:
```python
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/Users/jonatas/projects/github/bartuque/venv/lib/python3.7/site-packages/transformers/models/auto/tokenization_auto.py", line 385, in from_pretrained
return tokenizer_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File "/Users/jonatas/projects/github/bartuque/venv/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1769, in from_pretrained
resolved_vocab_files, pretrained_model_name_or_path, init_configuration, *init_inputs, **kwargs
File "/Users/jonatas/projects/github/bartuque/venv/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1787, in _from_pretrained
**(copy.deepcopy(kwargs)),
File "/Users/jonatas/projects/github/bartuque/venv/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1841, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/Users/jonatas/projects/github/bartuque/venv/lib/python3.7/site-packages/transformers/models/roberta/tokenization_roberta.py", line 171, in __init__
**kwargs,
File "/Users/jonatas/projects/github/bartuque/venv/lib/python3.7/site-packages/transformers/models/gpt2/tokenization_gpt2.py", line 178, in __init__
self.decoder = {v: k for k, v in self.encoder.items()}
File "/Users/jonatas/projects/github/bartuque/venv/lib/python3.7/site-packages/transformers/models/gpt2/tokenization_gpt2.py", line 178, in <dictcomp>
self.decoder = {v: k for k, v in self.encoder.items()}
TypeError: unhashable type: 'list'
```
I hope this PR will be merged soon.
<|||||>Just an update... after renaming my tokenizer file from `vocab.json` to `tokenizer.json`, the AutoTokenizer stop to crash and is working well now.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,433 | closed | Replaced unnecessary iadd operations on lists in tokenization_utils.py with proper list methods | # Replaced unnecessary iadd operations on lists in tokenization_utils.py with proper list methods
@mfuntowicz
Previously, unnecessarily many list objects are created because of list updates through iadd operations.
This is bad for the following reasons.
* It slows down the program.
* It's a substandard style.
Regarding the slowing down, please see the following snippets.
```
l = []
for i in range(10**6):
l.append(i)
# Takes 0.13282 seconds, on average, on my machine
```
```
l = []
for i in range(10**6):
l += [i] # this creates a new list [i] every iteration
# Takes 0.14698 seconds, on average, on my machine
```
The previous style is considered bad since it's confusing. It is easy to think that `l += [i]` has the same semantics as `l = l + [i]`, which is not at all the case. To see this, run the following code.
```
l = []
for i in range(10**6):
l = l + [i] # This replaces the existing list with a new list (l + [i]) every iteration
```
The fact that the existing list is mutated is more clearly expressed in the new code, and, to my best knowledge, all the python standard library code prefer the style of the new code.
| 11-10-2020 10:20:07 | 11-10-2020 10:20:07 | Thanks for the quick reviews both of you!
@LysandreJik
I just searched the whole code and I found many more list append operations than updates through `__iadd__`. So I actually think that for consistency over the whole project scope, it may be better to use list append whenever it's applicable. If you approve, I would like to fix the other similar cases, too.
Regarding tuples, the current style seems perfectly okay. Tuples are immutable and `__iadd__` does not update existing tuple but replace it with a newly created one, i.e., `tup += ('a',)` is equivalent to `tup = tup + ('a',)`. So they should be treated differently from lists.
Here is a demonstration that shows the different effects of `__iadd__` on lists and tuples.
```
l = ['a']
print(id(l)) # 4327718256
l += ['b']
print(id(l)) # 4327718256
tup = ('a',)
print(id(tup)) # 4326480784
tup += ('b',)
print(id(l)) # 4327718256 (ID changed!)
``` |
transformers | 8,432 | closed | Add auto next sentence prediction | # What does this PR do?
This PR adds auto models for the next sentence prediction task.
| 11-10-2020 09:39:30 | 11-10-2020 09:39:30 | |
transformers | 8,431 | closed | Get Scores for each NE Label | I'm running the run_ner.py script to use the bert-base-german-cased transformer model in the token classification task to train it on custom NE labels and make predictions for German documents. I have 11 labels in total.
I wondered if there is any way to get prediction results (meaning loss, accuracy, precision, etc.) not only for the whole task, but for each label individually. This would make it easier to compare the real perfomance of the model. So that each label has results like:
```
eval_loss = 0.07476427406072617
eval_accuracy_score = 0.9818217086485438
eval_precision = 0.6756756756756757
eval_recall = 0.676378772112383
eval_f1 = 0.6760270410816434
```
Reason I'm asking: the O-Labels (the only thing I kept from BIO tagging) are of course the majority of all labels, therefore the accuracy is quite high as the model correctly predicts most of them, but as a consequence the scores for the real labels get lost in the statistical noise.
Is there any way to achieve this?
Thanks in advance.
| 11-10-2020 08:55:21 | 11-10-2020 08:55:21 | Maybe @sgugger or @jplu have an idea<|||||>`seqeval` can return you more information, for instance the version in the Datasets library returns all the metrics per label IIRC. The code is [here](https://github.com/huggingface/datasets/blob/8005fed0887236804a07bfdc7dc69298e15dac7c/metrics/seqeval/seqeval.py#L96), you just need to adapt what's inside the `compute_metrics` function to fit your needs.<|||||>Hi @sgugger - that did the trick, thank you! |
transformers | 8,430 | closed | RAG: Explanation on Retriever Variables. | Can you please explain what these terms in the RAG retrieval mean?
1. config.index_name
2. config.index_path | 11-10-2020 03:10:56 | 11-10-2020 03:10:56 | Hey @shamanez - could you please forward this question to the forum: https://discuss.huggingface.co/ . We try to keep the issues for bug reports. |
transformers | 8,429 | closed | [examples] better PL version check | `pkg_resources.require(f"{pkg}>={min_ver}")` does a great job of checking the minimal required versions at runtime, but I wasn't aware that it checks that the dependencies meet their requirements too! So I started getting a false alarm about needing `pytorch-lightning=1.0.4` when I already had a higher version.
The problem was in:
```
$ python -c 'import pkg_resources; pkg_resources.require("pytorch_lightning>=1.0.4")'
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pkg_resources/__init__.py", line 884, in require
needed = self.resolve(parse_requirements(requirements))
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pkg_resources/__init__.py", line 775, in resolve
raise VersionConflict(dist, req).with_context(dependent_req)
pkg_resources.ContextualVersionConflict: (torch 1.8.0.dev20201106+cu110 (/mnt/nvme1/anaconda3/envs/main-38/lib/python3.8/site-packages), Requirement.parse('torch<1.8,>=1.3'), {'pytorch-lightning'})
```
Long story short, currently PL explicitly excludes pytorch-1.8 in its dependency list: https://github.com/PyTorchLightning/pytorch-lightning/issues/4596 - which leads to this problem. When I upgrade PL pip uninstalls `pytorch-1.8` - thanks, but no thanks - rtx-3090 doesn't work with pytorch < 1.8. So I install it back and now I get the failure above. Except in the current code it's masked by the `try/except` block which hides the actual problem. So this is not good.
This PR rewrites the check in a way that doesn't check whether the dependencies of the package in questions are in order, and only checks that the minimal version is correct.
@sshleifer | 11-10-2020 03:04:33 | 11-10-2020 03:04:33 | |
transformers | 8,428 | closed | Add missing tasks to `pipeline` docstring | I added missing tasks to `pipeline` docstring.
Also, I fixed some typos I found. | 11-10-2020 02:08:40 | 11-10-2020 02:08:40 | |
transformers | 8,427 | closed | Set num_beams=4 for all Helsinki-NLP models | Currently it is 6. Empirically, I tested 77 random models and num_beams=4 was about 50% faster and on average slightly higher BLEU (22.5 vs 22.4).
We also have @jorgtied 's approval for the change.
On slack, he wrote
> Again, no systematic evaluation - more like a feeling. I had the impression that 1 or 2 is worse and I didn’t want to set 10 or 12 that I have seen otherwise, because it may slow down things quite substantially. If you make some more tests then let me know what you will find … Thanks!
There are about 1300 affected model's, so this feels like the type of thing @patrickvonplaten 's script could do well. | 11-09-2020 21:09:56 | 11-09-2020 21:09:56 | I can do the change! Will wait until the new git model hub is merged and then apply it :-) <|||||>Thanks!
<|||||>Should be decently easy to do it @patrickvonplaten let me know when you get to it :)<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>@julien-c, @jorgtied - sorry forgot about this issue...changing `num_beams=4` for all opus models now. |
transformers | 8,426 | closed | Wrong files names in model list for "xlm-roberta-large-finetuned-conll03-german" | Hi, the names of the model files for "xlm-roberta-large-finetuned-conll03-german" are incorrect and have to model name as prefix.
Example:
xlm-roberta-large-finetuned-conll03-german-config.json instead of config.json
| 11-09-2020 19:38:25 | 11-09-2020 19:38:25 | Hi, what do you mean they're incorrect? Are you having issues loading the files in your `transformers` objects?<|||||>Hi, click on [https://huggingface.co/xlm-roberta-large-finetuned-conll03-german](https://huggingface.co/xlm-roberta-large-finetuned-conll03-german) and then on _List all files in model_ and move the mouse over each link. You will see that the files have a prefix (namely the name of the model). This is not allowed by the transformers api, since it expects to find e.g. config.json instead of xlm-roberta-large-finetuned-conll03-german-config.json. Hope this explaination helps.<|||||>~I cannot see the prefix in the link you've given, and~ I can correctly load the models in the library:
```py
from transformers import XLMRobertaModel
XLMRobertaModel.from_pretrained("xlm-roberta-large-finetuned-conll03-german")
```
works correctly.
The legacy models (e.g. `bert-base-cased`, this one too) had the prefix, but we've changed the approach since and only keep them that way for backwards compatibility.<|||||>I can confirm this is intended<|||||>Okay, I only experience this error when downloading the files and load from local storage instead of providing a name. But when this is working as intended, it is fine for me. |
transformers | 8,425 | closed | Check all models are in an auto class | # What does this PR do?
Following up from @patrickvonplaten fixes, this PR adds a script to check all models are in an auto class. This way we will get a CI error if a newly added model ends up forgotten :-) | 11-09-2020 19:34:49 | 11-09-2020 19:34:49 | |
transformers | 8,424 | closed | Electra multi-gpu pretraining. | Hi, I am pretraining the Electra model with my own data, for now, I am pretraining using one GPU in my machine. Can we use multi GPUs to pretrain Electra? Thanks for your reply
| 11-09-2020 19:21:07 | 11-09-2020 19:21:07 | That would depend of the training script. All of our models are `nn.Module`s so all can be trained on multi-GPU, it just depends on the script. What script are you using?<|||||>@LysandreJik Hi, thanks for your reply, i am not pretty sure about script, what I am doing now is using TensorFlow google Electra, but it seems I haven't figure out how to use multi gpu in TensorFlow, that's why i am here, Do u have any advice, I mean maybe I can just use Electra in this project to achieve multi-gpu pretraining?<|||||>Yes, you could check [this thread](https://discuss.huggingface.co/t/electra-training-reimplementation-and-discussion/1004) and use their project to train ELECTRA, which is based on this repository.<|||||>@LysandreJik thanks, however, according to this issue https://github.com/richarddwang/electra_pytorch/issues/5 , I guess they haven't figure out how to use multigpu yet,<|||||>Ah, then I don't think I can help you further, unfortunately.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 8,423 | closed | Fix bart shape comment | fixes #8384
Before transpose , shape of x and encoder_hidden_states are both (BS, seq_len, model_dim) to me.
| 11-09-2020 18:04:26 | 11-09-2020 18:04:26 | |
transformers | 8,422 | closed | [docs] [testing] gpu decorators table | This PR adds a table of gpu requirement decorators that perhaps is easier to grasp quickly in addition to the prose version.
(based on the discussion [here](https://github.com/huggingface/transformers/pull/8341#issuecomment-723705104))
@sgugger | 11-09-2020 17:59:20 | 11-09-2020 17:59:20 | Thanks Stas! |
transformers | 8,421 | closed | [docs] improve bart/marian/mBART/pegasus docs | + Give example of bart mask filling
+ Link to training scripts where applicable
+ Clarify Marian naming scheme a bit. | 11-09-2020 17:11:52 | 11-09-2020 17:11:52 | |
transformers | 8,420 | closed | Deprecate old data/metrics functions | # What does this PR do?
This PR deprecates the old data/metrics utils we used now that we have some examples of scripts leveraging the Datasets library to point at. The idea is to eventually remove those from the library but keep them somewhere in the examples folder as utilities, so the old scripts can still be run. | 11-09-2020 16:23:19 | 11-09-2020 16:23:19 | |
transformers | 8,419 | closed | Bump tokenizers | # What does this PR do?
Bump the version of tokenizers to the last release. This fixes some bugs in `XLNetTokenizerFast`. | 11-09-2020 15:56:26 | 11-09-2020 15:56:26 | |
transformers | 8,418 | closed | [docs] remove sshleifer from issue-template :( | + Removes sshleifer from issue-templates :(
+ For previous @sshleifer stuff, if it's in `src/` I put @patrickvonplaten, if it's `examples/seq2seq` I put @patil-suraj.
+ @stas00 if you want to take over any thing or feel comfortable being the point person for certain things, feel free to suggest.
| 11-09-2020 14:22:46 | 11-09-2020 14:22:46 | Thank you for the invitation, @sshleifer.
My feeling is that a person in charge of any domain should have commit rights to that domain. Since I don't have those I'd be happy to be delegated to. (with the exception of fsmt since I wrote it) |
transformers | 8,417 | closed | Changing XLNet default from not using memories to 512 context size following paper | In #8317, we found out that calling `XLNetLMHeadModel.from_pretrained(mem_len=384)` still produced the FutureWarning that announces that the default configuration will change in 3.5.0, as the config first gets initialized with `mem_len=0` then `mem_len` gets changed. This PR moves the warning to the `forward` pass in the model to avoid this. | 11-09-2020 13:11:57 | 11-09-2020 13:11:57 | Ha yeah I saw your message on Slack just afterwards, I'll just change the default :)<|||||>It's changed !<|||||>Merging now so that it's in v3.5.0! |
transformers | 8,416 | closed | Does MBartTokenizer remove the parameter decoder_input_ids? | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:3.4.0
- Platform:Google Colab
- Python version:3.7
- PyTorch version (GPU?):1.7.0+cu101
- Tensorflow version (GPU?):2.x
- Using GPU in script?: no
- Using distributed or parallel set-up in script?:no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten @TevenLeScao
blenderbot: @mariamabarham
Bart: @sshleifer
Marian: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
RAG: @patrickvonplaten, @lhoestq
FSTM: @stas00
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Model I am using (Bert, XLNet ...): mbart
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
```python
example_english_phrase = "UN Chief Says There Is No Military Solution in Syria"
expected_translation_romanian = "Şeful ONU declară că nu există o soluţie militară în Siria"
batch = MBartTokenizer.from_pretrained('facebook/mbart-large-cc25').prepare_seq2seq_batch(example_english_phrase, src_lang="en_XX", tgt_lang="ro_RO", tgt_texts=expected_translation_romanian)
input_ids = batch["input_ids"]
target_ids = batch["decoder_input_ids"]
```
Steps to reproduce the behavior:
```python
KeyError Traceback (most recent call last)
<ipython-input-11-b3eedaf10c3e> in <module>()
3 batch = MBartTokenizer.from_pretrained('facebook/mbart-large-en-ro').prepare_seq2seq_batch(example_english_phrase, src_lang="en_XX", tgt_lang="ro_RO", tgt_texts=expected_translation_romanian)
4 input_ids = batch["input_ids"]
----> 5 target_ids = batch["decoder_input_ids"]
/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py in __getitem__(self, item)
232 """
233 if isinstance(item, str):
--> 234 return self.data[item]
235 elif self._encodings is not None:
236 return self._encodings[item]
KeyError: 'decoder_input_ids'
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
<!-- A clear and concise description of what you would expect to happen. -->
| 11-09-2020 12:51:58 | 11-09-2020 12:51:58 | The docs are incorrect, sorry about that.
Try
```python
from transformers import MBartForConditionalGeneration, MBartTokenizer
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-en-ro")
tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-en-ro")
article = "UN Chief Says There Is No Military Solution in Syria"
batch = tokenizer.prepare_seq2seq_batch(src_texts=[article], src_lang="en_XX")
translated_tokens = model.generate(**batch, decoder_start_token_id=tokenizer.lang_code_to_id["ro_RO"])
translation = tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
assert translation == "Şeful ONU declară că nu există o soluţie militară în Siria"
```<|||||>> The docs are incorrect, sorry about that.
>
> Try
>
> ```python
> from transformers import MBartForConditionalGeneration, MBartTokenizer
> model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-en-ro")
> tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-en-ro")
> article = "UN Chief Says There Is No Military Solution in Syria"
> batch = tokenizer.prepare_seq2seq_batch(src_texts=[article], src_lang="en_XX")
> translated_tokens = model.generate(**batch, decoder_start_token_id=tokenizer.lang_code_to_id["ro_RO"])
> translation = tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
> assert translation == "Şeful ONU declară că nu există o soluţie militară în Siria"
> ```
thank you for your reply, If I don't want to generate, I just want to train. How should I change it?
```python
example_english_phrase = "UN Chief Says There Is No Military Solution in Syria"
expected_translation_romanian = "Şeful ONU declară că nu există o soluţie militară în Siria"
batch = tokenizer.prepare_seq2seq_batch(example_english_phrase, src_lang="en_XX", tgt_lang="ro_RO", tgt_texts=expected_translation_romanian)
input_ids = batch["input_ids"]
target_ids = batch["decoder_input_ids"] # Error
decoder_input_ids = target_ids[:, :-1].contiguous()
labels = target_ids[:, 1:].clone()
model(input_ids=input_ids, decoder_input_ids=decoder_input_ids, labels=labels) #forward
```<|||||>See this https://github.com/huggingface/transformers/blob/master/examples/seq2seq/finetune.py#L138
the `batch` argument to that fn is the same as your `batch` (the output of `prepare_seq2seq_batch`) |
transformers | 8,415 | closed | [Tests] Add Common Test for Training + Fix a couple of bugs | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR adds an aggressive test to check that all models that should be trainable can perform a backward pass of their loss output. In addition, a test for training with gradient checkpointing is added as well. The motivation comes from this error: https://github.com/huggingface/transformers/pull/7562#issuecomment-723887221 - the PR introduced broke gradient checkpointing without any test noticing it.
To make the test applicable for all models, some `ModelTests` have to overwrite the `_prepare_for_class` function.
In addition, some cleaning was done `ForPretraining` was renamed to `ForPreTraining`; an `AutoModelForNextSentencePredicition` was added, ...
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-09-2020 09:26:38 | 11-09-2020 09:26:38 | |
transformers | 8,414 | closed | [seq2seq] translation tpu example doesnt work | Hi im trying to run the `train_distil_marian_enro_tpu.sh` example in collab/kaggle tpus and for some reason it gives me the following output:
@sshleifer
```
Exception in device=TPU:0: Cannot access data pointer of Tensor that doesn't have storage
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/torch_xla/distributed/xla_multiprocessing.py", line 330, in _mp_start_fn
_start_fn(index, pf_cfg, fn, args)
File "/usr/local/lib/python3.6/dist-packages/torch_xla/distributed/xla_multiprocessing.py", line 324, in _start_fn
fn(gindex, *args)
File "/content/transformers/examples/seq2seq/finetune_trainer.py", line 300, in _mp_fn
main()
File "/content/transformers/examples/seq2seq/finetune_trainer.py", line 249, in main
model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 776, in train
tr_loss += self.training_step(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1128, in training_step
loss.backward()
File "/usr/local/lib/python3.6/dist-packages/torch/tensor.py", line 221, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/usr/local/lib/python3.6/dist-packages/torch/autograd/__init__.py", line 132, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: Cannot access data pointer of Tensor that doesn't have storage
0% 0/7158 [00:44<?, ?it/s]
Traceback (most recent call last):
File "xla_spawn.py", line 72, in <module>
main()
File "xla_spawn.py", line 68, in main
xmp.spawn(mod._mp_fn, args=(), nprocs=args.num_cores)
File "/usr/local/lib/python3.6/dist-packages/torch_xla/distributed/xla_multiprocessing.py", line 395, in spawn
start_method=start_method)
File "/usr/local/lib/python3.6/dist-packages/torch/multiprocessing/spawn.py", line 157, in start_processes
while not context.join():
File "/usr/local/lib/python3.6/dist-packages/torch/multiprocessing/spawn.py", line 112, in join
(error_index, exitcode)
Exception: process 0 terminated with exit code
```
Related to this issue #https://github.com/pytorch/xla/issues/929
Not sure how to solve it. Thanks! | 11-09-2020 05:51:18 | 11-09-2020 05:51:18 | Hi,
I'm experiencing the same issue while fine-tuning on TPU for marianMT. Code works well on GPU. On TPU, it throws similar exception:
```python
RuntimeError: Cannot access data pointer of Tensor that doesn't have storage
```
Thanks!<|||||>Hi @chris-tng ,
could you post your env info, and the script/command that you are running ?<|||||>Sure, I'm using
```shell
transformers 4.0.1
torch 1.7.0+cu101
torch-xla 1.7
torchsummary 1.5.1
torchtext 0.3.1
torchvision 0.8.1+cu101
```
- command
```shell
!python xla_spawn.py --num_cores 8 finetune_trainer.py \
--tokenizer_name "Helsinki-NLP/opus-mt-es-en" \
--model_name_or_path "Helsinki-NLP/opus-mt-es-en" \
--data_dir "/content/data" \
--output_dir "/content/marian_es_en" --overwrite_output_dir \
--learning_rate=3e-4 \
--warmup_steps 500 \
--per_device_train_batch_size=256 --per_device_eval_batch_size=256 \
--freeze_encoder --freeze_embeds \
--num_train_epochs=6 \
--save_steps 3000 --eval_steps 3000 \
--logging_first_step --logging_steps 200 \
--max_source_length 128 \
--max_target_length 128 --val_max_target_length 128 --test_max_target_length 128 \
--do_train --do_eval --do_predict \
--n_val 5000 --n_test 10000 --evaluation_strategy steps \
--prediction_loss_only \
--task translation --label_smoothing 0.1 \
"$@"
```
Here is the error
```
[INFO|trainer.py:666] 2020-12-11 05:56:11,550 >> Total train batch size (w. parallel, distributed & accumulation) = 2048
[INFO|trainer.py:667] 2020-12-11 05:56:11,550 >> Gradient Accumulation steps = 1
[INFO|trainer.py:668] 2020-12-11 05:56:11,550 >> Total optimization steps = 1830
0% 0/1830 [00:00<?, ?it/s]Exception in device=TPU:0: Cannot access data pointer of Tensor that doesn't have storage
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/torch_xla/distributed/xla_multiprocessing.py", line 330, in _mp_start_fn
_start_fn(index, pf_cfg, fn, args)
File "/usr/local/lib/python3.6/dist-packages/torch_xla/distributed/xla_multiprocessing.py", line 324, in _start_fn
fn(gindex, *args)
File "/content/transformers/examples/seq2seq/finetune_trainer.py", line 309, in _mp_fn
main()
File "/content/transformers/examples/seq2seq/finetune_trainer.py", line 258, in main
model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 747, in train
tr_loss += self.training_step(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1089, in training_step
loss.backward()
File "/usr/local/lib/python3.6/dist-packages/torch/tensor.py", line 221, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/usr/local/lib/python3.6/dist-packages/torch/autograd/__init__.py", line 132, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: Cannot access data pointer of Tensor that doesn't have storage
0% 0/1830 [03:34<?, ?it/s]
Traceback (most recent call last):
File "xla_spawn.py", line 72, in <module>
main()
File "xla_spawn.py", line 68, in main
xmp.spawn(mod._mp_fn, args=(), nprocs=args.num_cores)
File "/usr/local/lib/python3.6/dist-packages/torch_xla/distributed/xla_multiprocessing.py", line 395, in spawn
start_method=start_method)
File "/usr/local/lib/python3.6/dist-packages/torch/multiprocessing/spawn.py", line 157, in start_processes
while not context.join():
File "/usr/local/lib/python3.6/dist-packages/torch/multiprocessing/spawn.py", line 112, in join
(error_index, exitcode)
Exception: process 0 terminated with exit code 17
```
<|||||>Hi @patil-suraj , any idea why it happens? <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored. |
transformers | 8,413 | closed | continuing fine-tuning from the last checkpoint | Hello,
While fine-tuning BERT on the custom data using "run_language_modeling.py" script, due to memory issue the fine-tuning stopped in the middle. However, I tried to resume the fine-tuning from the last checkpoint. But, I came across with the following error:
```
python run_language_modeling.py --output_dir=/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results --model_type=bert --model_name_or_path=/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results/result_dir/checkpoint_37000/ --do_train --train_data_file=$TRAIN_FILE --do_eval --eval_data_file=$TEST_FILE --mlm --per_gpu_train_batch_size=4
/home/ai-students/.local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/home/ai-students/.local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:517: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/home/ai-students/.local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:518: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/home/ai-students/.local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:519: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/home/ai-students/.local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:520: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/home/ai-students/.local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:525: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
11/08/2020 22:40:18 - WARNING - __main__ - Process rank: -1, device: cuda:0, n_gpu: 2, distributed training: False, 16-bits training: False
11/08/2020 22:40:18 - INFO - __main__ - Training/evaluation parameters TrainingArguments(output_dir='/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results', overwrite_output_dir=False, do_train=True, do_eval=True, do_predict=False, evaluate_during_training=False, evaluation_strategy=<EvaluationStrategy.NO: 'no'>, prediction_loss_only=False, per_device_train_batch_size=8, per_device_eval_batch_size=8, per_gpu_train_batch_size=4, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, eval_accumulation_steps=None, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=-1, warmup_steps=0, logging_dir='runs/Nov08_22-40-18_aistudents-msi', logging_first_step=False, logging_steps=500, save_steps=500, save_total_limit=None, no_cuda=False, seed=42, fp16=False, fp16_opt_level='O1', local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=500, dataloader_num_workers=0, past_index=-1, run_name='/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results', disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None)
Traceback (most recent call last):
File "/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/transformers/configuration_utils.py", line 387, in get_config_dict
raise EnvironmentError
OSError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_language_modeling.py", line 355, in <module>
main()
File "run_language_modeling.py", line 236, in main
config = AutoConfig.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
File "/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/transformers/configuration_auto.py", line 329, in from_pretrained
config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/transformers/configuration_utils.py", line 396, in get_config_dict
raise EnvironmentError(msg)
OSError: Can't load config for '/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results/result_dir/checkpoint_37000/'. Make sure that:
- '/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results/result_dir/checkpoint_37000/' is a correct model identifier listed on 'https://huggingface.co/models'
- or '/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results/result_dir/checkpoint_37000/' is the correct path to a directory containing a config.json file
```
Command used to fine-tune from the last checkpoint is as follows:
```
python run_language_modeling.py --output_dir=/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results --model_type=bert --model_name_or_path=/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results/result_dir/checkpoint_37000/ --do_train --train_data_file=$TRAIN_FILE --do_eval --eval_data_file=$TEST_FILE --mlm --per_gpu_train_batch_size=4
```
Here is the command used to fine-tune BERT earlier:
```
python run_language_modeling.py --output_dir=/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/result_dir --model_type=bert --model_name_or_path=bert-base-cased --do_train --train_data_file=$TRAIN_FILE --do_eval --eval_data_file=$TEST_FILE --mlm --per_gpu_train_batch_size=4
```
@sgugger Could anyone please let me know on how to resume fine-tuning from the last checkpoint?
Thanks in advance :) | 11-08-2020 22:09:33 | 11-08-2020 22:09:33 | It looks like the config was not saved in the checkpoint folder you are passing. Double-check its contents, but apparently, the model was not properly saved inside it.<|||||>> It looks like the config was not saved in the checkpoint folder you are passing. Double-check its contents, but apparently, the model was not properly saved inside it.
Thanks for replying @sgugger
I have the following files in my checkpoint folder:
```
config.json optimizer.pt pytorch_model.bin scheduler.pt trainer_state.json training_args.bin
```
and inside the "config.json" it looks like this:
```
{
"_name_or_path": "bert-base-cased",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"type_vocab_size": 2,
"vocab_size": 28996
}
```
Do you have any idea where exactly I am going wrong?<|||||>Oh, I think you just have a typo in your path:
```
/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results/result_dir/checkpoint_37000/
```
should be
```
/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results/result_dir/checkpoint-37000/
```
(a dash instead of the underscore).<|||||>Ahhhh my bad!
Thanks a lot @sgugger
I had encountered one more problem (vocab.txt is missing):
```
Traceback (most recent call last):
File "run_language_modeling.py", line 355, in <module>
main()
File "run_language_modeling.py", line 244, in main
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
File "/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/transformers/tokenization_auto.py", line 336, in from_pretrained
return tokenizer_class_py.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File "/home/ai-students/anaconda3/envs/env_nesara/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 1649, in from_pretrained
list(cls.vocab_files_names.values()),
OSError: Model name '/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/result_dir/checkpoint-37000' was not found in tokenizers model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc, bert-base-german-dbmdz-cased, bert-base-german-dbmdz-uncased, TurkuNLP/bert-base-finnish-cased-v1, TurkuNLP/bert-base-finnish-uncased-v1, wietsedv/bert-base-dutch-cased). We assumed '/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/result_dir/checkpoint-37000' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.txt'] but couldn't find such vocabulary files at this path or url.
```
After adding the parameter --tokenizer_name I could resolve the issue and now the fine-tuning resumes as expected
Below is the command:
```
python run_language_modeling.py --output_dir=/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/new_results --model_type=bert --model_name_or_path=/media/ai-students/Data/Nesara/Bert_MLM_fine_tune/result_dir/checkpoint-37000 --do_train --train_data_file=$TRAIN_FILE --do_eval --eval_data_file=$TEST_FILE --mlm --per_gpu_train_batch_size=4 --tokenizer_name=bert-base-cased
``` |
transformers | 8,412 | closed | [s2s/distill] remove run_distiller.sh, fix xsum script | 11-08-2020 21:56:53 | 11-08-2020 21:56:53 | ||
transformers | 8,411 | closed | Tokenizer return nothing instead of unk for certain token? | ## Environment info
- `transformers` version: 3.1.0
- Platform: pytorch
- Python version: python 3.6.9
- PyTorch version (GPU?): 1.6.0
- Tensorflow version (GPU?): na
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
## Information
Model I am using (tokenizer && model == google/electra-large-generator):
The problem arises when using:
* [x ] my own modified scripts: (give details below)
self.fill_mask = pipeline("fill-mask", model="google/electra-large-generator",\
tokenizer="google/electra-large-generator")
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x ] my own task or dataset: (give details below)
a simple fill mask type of task with transformer pipline
## To reproduce
Steps to reproduce the behavior:
1. fill_mask = pipeline("fill-mask", model="google/electra-large-generator",\
tokenizer="google/electra-large-generator")
2. fill_mask.tokenizer.tokenize(""" ̈ """)
3. output is []
## Expected behavior
In this case the missing of this punctuation would cause some downstream usage to fail due to IndexError. The problem might be intrinsic to this particular tokenizer, maybe it is worthwhile to raise a warning/error or returning a unk token? Thanks!
| 11-08-2020 20:16:59 | 11-08-2020 20:16:59 | Similar error at [1662]https://github.com/huggingface/transformers/issues/1662
The problem could be solved by switching to multilingual tokenizer(if present), else it would require some hot fix. |
transformers | 8,410 | closed | comet_ml init weirdness | Using a slightly bogus invocation of the following
```
cd examples/seq2seq
PYTHONPATH="../../src" BS=2 python finetune.py --data_dir cnn_dm --do_predict --do_train --eval_batch_size $BS --fp16 --fp16_opt_level O1--freeze_embeds --freeze_encoder --gpus 1 --gradient_accumulation_steps 1 --learning_rate 3e-5 --max_target_length 142 --model_name_or_path sshleifer/student_cnn_12_6 --n_val 500 --num_train_epochs 2 --output_dir distilbart-cnn-12-6 --tokenizer_name facebook/bart-large --train_batch_size $BS --val_check_interval 0.25 --val_max_target_length 142 --warmup_steps 500
```
I get:
```
Traceback (most recent call last):
File "finetune.py", line 18, in <module>
from callbacks import Seq2SeqLoggingCallback, get_checkpoint_callback, get_early_stopping_callback
File "/mnt/nvme1/code/huggingface/transformers-comet_ml/examples/seq2seq/callbacks.py", line 11, in <module>
from utils import save_json
File "/mnt/nvme1/code/huggingface/transformers-comet_ml/examples/seq2seq/utils.py", line 22, in <module>
from transformers import BartTokenizer, EvalPrediction, PreTrainedTokenizer, T5Tokenizer
File "/mnt/nvme1/code/huggingface/transformers-master/src/transformers/__init__.py", line 22, in <module>
from .integrations import ( # isort:skip
File "/mnt/nvme1/code/huggingface/transformers-master/src/transformers/integrations.py", line 17, in <module>
if comet_ml.config.get_config("comet.api_key"):
AttributeError: module 'comet_ml' has no attribute 'config'
```
no idea why this happens. this PR adds a band-aid - and then once I apply it - the real error shows up `$BS` wasn't defined - i.e. my args had an issue. But I need to see the real error and not some totally unrelated `comet_ml` error.
perhaps something else needs to be fixed.
While we are at it, once again I ended up with `comet_ml` w/o explicitly installing it.
So I again get to enjoy the incessant:
```
comet_ml is installed but `COMET_API_KEY` is not set.
```
:(
```
pipdeptree --reverse --packages comet_ml
```
doesn't give me the parent who pulled it in which is very odd, since it works for other packages.
Is there a different way to trace what pulled in a certain package?
If I install/update it explicitly it appears I already have the latest version:
```
pip install comet_ml -U
Requirement already up-to-date: comet_ml in /mnt/nvme1/anaconda3/envs/main-38/lib/python3.8/site-packages (3.2.5)
```
@sgugger, @dsblank
| 11-08-2020 19:53:02 | 11-08-2020 19:53:02 | Thanks for the report... I'll take a look at this.<|||||>Again, if you find out how comet_ml got installed, that would be helpful.<|||||>> Again, if you find out how comet_ml got installed, that would be helpful.
Yay, I found at least one of them `pytorch-lightning`. https://github.com/PyTorchLightning/pytorch-lightning/blob/master/environment.yml#L49
I have a feeling `pipdeptree` misses packages not installed directly via pypi deps, but via a local `pip install -e .[dev]`
I probably should just go ahead and create the key - though I have no use for it - please let me know whether it'd serve better if I didn't and continued reporting any related problems.<|||||>Thanks for tracking down pytorch's dependencies. I see that that is for conda. What is weird though is that I can't figure out how `comet_ml.config` wouldn't be defined. In any event, this PR seems fine. (I'd like to get to the bottom of this at some point).
Remember that you don't have to set a `COMET_API_KEY` (unless you really want to log stuff). You can also set `COMET_MODE="DISABLED"`. <|||||>I think it could be some fragile error handling. As I mentioned the crash happened when I mistakenly provided a bogus value to one of the pytorch-lightening clargs - so it was supposed to fail telling me that the argument was wrong, but instead failed with the error posted in OP. Once the band-aid was added it reported the error properly w/o crashing. <|||||>I still have it re-producable w/o rebasing to this fix:
```
cd examples/seq2seq
BS=2; PYTHONPATH="../../src" python finetune.py --data_dir cnn_dm --do_predict --do_train --eval_batch_size $BS --fp16 --fp16_opt_level O1 --freeze_embeds --freeze_encoder --gpus 1 --gradient_accumulation_steps 1 --learning_rate 3e-5 --max_target_length 142 --model_name_or_path sshleifer/student_cnn_12_6 --n_val 500 --num_train_epochs 2 --output_dir distilbart-cnn-12-6 --tokenizer_name facebook/bart-large --train_batch_size $BS --val_check_interval 0.25 --val_max_target_length 142 --warmup_steps 500
```
giving:
```
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/wandb/util.py:36: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
from collections import namedtuple, Mapping, Sequence
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/wandb/vendor/graphql-core-1.1/graphql/type/directives.py:55: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
assert isinstance(locations, collections.Iterable), 'Must provide locations for directive.'
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/monkey_patching.py:19: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
Traceback (most recent call last):
File "finetune.py", line 18, in <module>
from callbacks import Seq2SeqLoggingCallback, get_checkpoint_callback, get_early_stopping_callback
File "/mnt/nvme1/code/huggingface/transformers-master-stas00/examples/seq2seq/callbacks.py", line 11, in <module>
from utils import save_json
File "/mnt/nvme1/code/huggingface/transformers-master-stas00/examples/seq2seq/utils.py", line 22, in <module>
from transformers import BartTokenizer, EvalPrediction, PreTrainedTokenizer, T5Tokenizer
File "/mnt/nvme1/code/huggingface/transformers-master-stas00/src/transformers/__init__.py", line 22, in <module>
from .integrations import ( # isort:skip
File "/mnt/nvme1/code/huggingface/transformers-master-stas00/src/transformers/integrations.py", line 17, in <module>
if comet_ml.config.get_config("comet.api_key"):
AttributeError: module 'comet_ml' has no attribute 'config'
```
See if you get it yourself (pre-this PR)? or if you want me to try something let me know
<|||||>Hmm, actually the crash described in the OP happens all the time pre this PR. I even uninstalled and reinstalled `comet_ml` via `pip`.<|||||>I figured it out:
```
python -c "import comet_ml; print(comet_ml.config)"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/__init__.py", line 34, in <module>
from .api import API, APIExperiment
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/api.py", line 28, in <module>
from .experiment import CommonExperiment
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/experiment.py", line 97, in <module>
from .gpu_logging import (
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/gpu_logging.py", line 27, in <module>
import pynvml
ModuleNotFoundError: No module named 'pynvml'
```
If I install `pynvml` the error disappers.
So basically `comet_ml` fails to load and the try: block ignores the exception.<|||||>The bug is somewhere in seq2seq utils (**edit**: doesn't seem to be the case)
Following the trace in https://github.com/huggingface/transformers/pull/8410#issuecomment-724281982
This does the right thing:
```
cd examples/seq2seq
PYTHONPATH="../../src" python -c "import utils"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/mnt/nvme1/code/huggingface/transformers-master-stas00/examples/seq2seq/utils.py", line 22, in <module>
from transformers import BartTokenizer, EvalPrediction, PreTrainedTokenizer, T5Tokenizer
File "/mnt/nvme1/code/huggingface/transformers-master-stas00/src/transformers/__init__.py", line 22, in <module>
from .integrations import ( # isort:skip
File "/mnt/nvme1/code/huggingface/transformers-master-stas00/src/transformers/integrations.py", line 16, in <module>
import comet_ml # noqa: F401
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/__init__.py", line 34, in <module>
from .api import API, APIExperiment
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/api.py", line 28, in <module>
from .experiment import CommonExperiment
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/experiment.py", line 97, in <module>
from .gpu_logging import (
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/gpu_logging.py", line 27, in <module>
import pynvml
ModuleNotFoundError: No module named 'pynvml'
```
but one above that imports `utils` eats the exception:
```
PYTHONPATH="../../src" python -c "import callbacks"
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/wandb/util.py:36: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
from collections import namedtuple, Mapping, Sequence
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/wandb/vendor/graphql-core-1.1/graphql/type/directives.py:55: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
assert isinstance(locations, collections.Iterable), 'Must provide locations for directive.'
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/monkey_patching.py:19: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
2020-11-09 14:15:06.573247: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
/mnt/nvme1/code/github/00nlp/fairseq/fairseq/optim/adam.py:8: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
from collections import Collection
(main-38) /mnt/nvme1/code/huggingface/transformers-master-stas00/examples/seq2seq [stas00/transformers|patch-3|+1?8]> PYTHONPATH="../../src" python -c "import callbacks"
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/wandb/util.py:36: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
from collections import namedtuple, Mapping, Sequence
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/wandb/vendor/graphql-core-1.1/graphql/type/directives.py:55: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
assert isinstance(locations, collections.Iterable), 'Must provide locations for directive.'
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/monkey_patching.py:19: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
2020-11-09 14:15:31.366275: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
/mnt/nvme1/code/github/00nlp/fairseq/fairseq/optim/adam.py:8: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
from collections import Collection
```
<|||||>Oh, great find! Thanks for this... we'll take a further look on our end and get something out soon.<|||||>This is very odd, since I don't see any `try` blocks around this sequence of imports - except at the end inside `integrations.py` and even if I remove it there, the exception is still suppressed. `import utils` catches the error, but `import callbacks` which imports `utils` suppresses it (see https://github.com/huggingface/transformers/pull/8410#issuecomment-724312036).
Could this somehow be related to this:
```
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/monkey_patching.py:19: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
```
Do you by chance mess something up with the importer there? it feels like something overrides `import` because suddenly it ignores import errors. (**edit**: ruled that out too - see the next comment)<|||||>It's possibly the doings of `PL`, observe this:
```
PYTHONPATH="../../src" python -c "import utils"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/mnt/nvme1/code/huggingface/transformers-master-stas00/examples/seq2seq/utils.py", line 22, in <module>
from transformers import BartTokenizer, EvalPrediction, PreTrainedTokenizer, T5Tokenizer
File "/mnt/nvme1/code/huggingface/transformers-master-stas00/src/transformers/__init__.py", line 22, in <module>
from .integrations import ( # isort:skip
File "/mnt/nvme1/code/huggingface/transformers-master-stas00/src/transformers/integrations.py", line 16, in <module>
import comet_ml # noqa: F401
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/__init__.py", line 34, in <module>
from .api import API, APIExperiment
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/api.py", line 28, in <module>
from .experiment import CommonExperiment
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/experiment.py", line 97, in <module>
from .gpu_logging import (
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/gpu_logging.py", line 27, in <module>
import pynvml
ModuleNotFoundError: No module named 'pynvml'
```
and now let's add `import pytorch_lightning` first:
```
PYTHONPATH="../../src" python -c "import pytorch_lightning; import utils"
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/wandb/util.py:36: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
from collections import namedtuple, Mapping, Sequence
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/wandb/vendor/graphql-core-1.1/graphql/type/directives.py:55: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
assert isinstance(locations, collections.Iterable), 'Must provide locations for directive.'
/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/monkey_patching.py:19: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
2020-11-09 14:35:24.485463: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
/mnt/nvme1/code/github/00nlp/fairseq/fairseq/optim/adam.py:8: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
from collections import Collection
```
The exception was suppressed - so most likely it's PL's doing - most likely `import` functionality gets modified incorrectly.
Do you have enough @dsblank to proceed from here? this is no longer `transformers`-related.<|||||>Yes, I'll take it from here. We have a fix, and I'll test some more tomorrow and probably have a new comet_ml release out shortly. Thanks again!<|||||>Oh, and I forgot to give the fully isolated command that reproduces the problem:
```
python -c "import pytorch_lightning; import comet_ml"
```
doesn't fail and it should
whereas:
```
python -c "import comet_ml"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/__init__.py", line 34, in <module>
from .api import API, APIExperiment
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/api.py", line 28, in <module>
from .experiment import CommonExperiment
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/experiment.py", line 97, in <module>
from .gpu_logging import (
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/comet_ml/gpu_logging.py", line 27, in <module>
import pynvml
ModuleNotFoundError: No module named 'pynvml'
```
as it should. |
transformers | 8,409 | closed | Bug fix for permutation language modelling | Addresses a bug in permutation language modelling data collator, where `&` is used instead of `|` to compute the non-functional token mask (tokens excluding [PAD], [SEP], [CLS]). For verification, may refer to original XLNet code (https://github.com/zihangdai/xlnet/blob/master/data_utils.py#L602).
Addresses #6812 (further investigation needed, however)
@patrickvonplaten @LysandreJik | 11-08-2020 19:23:25 | 11-08-2020 19:23:25 | |
transformers | 8,408 | closed | updating tag for exbert viz | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-08-2020 15:36:14 | 11-08-2020 15:36:14 | Note that `exbert` integration is unfortunately not automatic. The authors from Exbert (@bhoov @HendrikStrobelt) need to re-deploy manually to add support for a new model. We've discussed with @Narsil @mfuntowicz hooking this into the hosted Inference API, so this might be automatic in the future.
cc'ing @JetRunner
To help us understand, what's your use case for ExBERT @smanjil?<|||||>> Note that `exbert` integration is unfortunately not automatic. The authors from Exbert (@bhoov @HendrikStrobelt) need to re-deploy manually to add support for a new model. We've discussed with @Narsil @mfuntowicz hooking this into the hosted Inference API, so this might be automatic in the future.
>
> cc'ing @JetRunner
>
> To help us understand, what's your use case for ExBERT @smanjil?
@julien-c I did not know that.
As this model is a fine-tuned model for German medical domain texts, I wanted to see the attention distribution as done in German BERT.
I believe this will be helpful for me as well as others to understand the effects of fine-tuning. Lastly, I tried with jessevig in colab, but, I have to fire it up in colab everytime. And, it was difficult to load the fine-tuned model there.
So, I am looking for a possibility here, and hope it will be done.<|||||>@julien-c Oh I thought the model was already added to ExBERT. Good to know! |
transformers | 8,407 | closed | All the weights of the model checkpoint at roberta-base were not used when initializing | # How to use the model checkpoint to initializing my own roberta?
**I wrote a class named `MyRoberta` at `modeling_roberta.py`, the main code is just like below:**
```python
class MyRoberta(RobertaPreTrainedModel):
def __init__(self, config):
super(MyRoberta, self).__init__(config)
# self.bert = RobertaModel.from_pretrained("model/roberta_base/", config=config)
self.bert = RobertaModel(config)
self.cls = RobertaLMHead(config)
# ...
```
**and then I initialized it using the code below:**
```python
config = RobertaConfig.from_pretrained("roberta-base")
logging("Model config {}".format(config))
model = MyRoberta.from_pretrained("roberta-base", mirror="tuna", cache_dir="./model/", config=config)
```
**however, one warning message shows that i didn't using the pretrained parameters.**
```
Some weights of the model checkpoint at roberta-base were not used when initializing MyRoberta: ['roberta.embeddings.word_embeddings.weight', 'roberta.embeddings.position_embeddings.weight', 'roberta.embeddings.token_type_embeddings.weight', 'roberta.embeddings.LayerNorm.weight', 'roberta.embeddings.LayerNorm.bias', 'roberta.encoder.layer.0.attention.self.query.weight', 'roberta.encoder.layer.0.attention.self.query.bias', 'roberta.encoder.layer.0.attention.self.key.weight', 'roberta.encoder.layer.0.attention.self.key.bias', 'roberta.encoder.layer.0.attention.self.value.weight', 'roberta.encoder.layer.0.attention.self.value.bias', 'roberta.encoder.layer.0.attention.output.dense.weight', 'roberta.encoder.layer.0.attention.output.dense.bias', 'roberta.encoder.layer.0.attention.output.LayerNorm.weight', 'roberta.encoder.layer.0.attention.output.LayerNorm.bias', 'roberta.encoder.layer.0.intermediate.dense.weight', 'roberta.encoder.layer.0.intermediate.dense.bias', 'roberta.encoder.layer.0.output.dense.weight', 'roberta.encoder.layer.0.output.dense.bias', 'roberta.encoder.layer.0.output.LayerNorm.weight', 'roberta.encoder.layer.0.output.LayerNorm.bias', 'roberta.encoder.layer.1.attention.self.query.weight', 'roberta.encoder.layer.1.attention.self.query.bias', 'roberta.encoder.layer.1.attention.self.key.weight', 'roberta.encoder.layer.1.attention.self.key.bias', 'roberta.encoder.layer.1.attention.self.value.weight', 'roberta.encoder.layer.1.attention.self.value.bias', 'roberta.encoder.layer.1.attention.output.dense.weight', 'roberta.encoder.layer.1.attention.output.dense.bias', 'roberta.encoder.layer.1.attention.output.LayerNorm.weight', 'roberta.encoder.layer.1.attention.output.LayerNorm.bias', 'roberta.encoder.layer.1.intermediate.dense.weight', 'roberta.encoder.layer.1.intermediate.dense.bias', 'roberta.encoder.layer.1.output.dense.weight', 'roberta.encoder.layer.1.output.dense.bias', 'roberta.encoder.layer.1.output.LayerNorm.weight', 'roberta.encoder.layer.1.output.LayerNorm.bias', 'roberta.encoder.layer.2.attention.self.query.weight', 'roberta.encoder.layer.2.attention.self.query.bias', 'roberta.encoder.layer.2.attention.self.key.weight', 'roberta.encoder.layer.2.attention.self.key.bias', 'roberta.encoder.layer.2.attention.self.value.weight', 'roberta.encoder.layer.2.attention.self.value.bias', 'roberta.encoder.layer.2.attention.output.dense.weight', 'roberta.encoder.layer.2.attention.output.dense.bias', 'roberta.encoder.layer.2.attention.output.LayerNorm.weight', 'roberta.encoder.layer.2.attention.output.LayerNorm.bias', 'roberta.encoder.layer.2.intermediate.dense.weight', 'roberta.encoder.layer.2.intermediate.dense.bias', 'roberta.encoder.layer.2.output.dense.weight', 'roberta.encoder.layer.2.output.dense.bias', 'roberta.encoder.layer.2.output.LayerNorm.weight', 'roberta.encoder.layer.2.output.LayerNorm.bias', 'roberta.encoder.layer.3.attention.self.query.weight', 'roberta.encoder.layer.3.attention.self.query.bias', 'roberta.encoder.layer.3.attention.self.key.weight', 'roberta.encoder.layer.3.attention.self.key.bias', 'roberta.encoder.layer.3.attention.self.value.weight', 'roberta.encoder.layer.3.attention.self.value.bias', 'roberta.encoder.layer.3.attention.output.dense.weight', 'roberta.encoder.layer.3.attention.output.dense.bias', 'roberta.encoder.layer.3.attention.output.LayerNorm.weight', 'roberta.encoder.layer.3.attention.output.LayerNorm.bias', 'roberta.encoder.layer.3.intermediate.dense.weight', 'roberta.encoder.layer.3.intermediate.dense.bias', 'roberta.encoder.layer.3.output.dense.weight', 'roberta.encoder.layer.3.output.dense.bias', 'roberta.encoder.layer.3.output.LayerNorm.weight', 'roberta.encoder.layer.3.output.LayerNorm.bias', 'roberta.encoder.layer.4.attention.self.query.weight', 'roberta.encoder.layer.4.attention.self.query.bias', 'roberta.encoder.layer.4.attention.self.key.weight', 'roberta.encoder.layer.4.attention.self.key.bias', 'roberta.encoder.layer.4.attention.self.value.weight', 'roberta.encoder.layer.4.attention.self.value.bias', 'roberta.encoder.layer.4.attention.output.dense.weight', 'roberta.encoder.layer.4.attention.output.dense.bias', 'roberta.encoder.layer.4.attention.output.LayerNorm.weight', 'roberta.encoder.layer.4.attention.output.LayerNorm.bias', 'roberta.encoder.layer.4.intermediate.dense.weight', 'roberta.encoder.layer.4.intermediate.dense.bias', 'roberta.encoder.layer.4.output.dense.weight', 'roberta.encoder.layer.4.output.dense.bias', 'roberta.encoder.layer.4.output.LayerNorm.weight', 'roberta.encoder.layer.4.output.LayerNorm.bias', 'roberta.encoder.layer.5.attention.self.query.weight', 'roberta.encoder.layer.5.attention.self.query.bias', 'roberta.encoder.layer.5.attention.self.key.weight', 'roberta.encoder.layer.5.attention.self.key.bias', 'roberta.encoder.layer.5.attention.self.value.weight', 'roberta.encoder.layer.5.attention.self.value.bias', 'roberta.encoder.layer.5.attention.output.dense.weight', 'roberta.encoder.layer.5.attention.output.dense.bias', 'roberta.encoder.layer.5.attention.output.LayerNorm.weight', 'roberta.encoder.layer.5.attention.output.LayerNorm.bias', 'roberta.encoder.layer.5.intermediate.dense.weight', 'roberta.encoder.layer.5.intermediate.dense.bias', 'roberta.encoder.layer.5.output.dense.weight', 'roberta.encoder.layer.5.output.dense.bias', 'roberta.encoder.layer.5.output.LayerNorm.weight', 'roberta.encoder.layer.5.output.LayerNorm.bias', 'roberta.encoder.layer.6.attention.self.query.weight', 'roberta.encoder.layer.6.attention.self.query.bias', 'roberta.encoder.layer.6.attention.self.key.weight', 'roberta.encoder.layer.6.attention.self.key.bias', 'roberta.encoder.layer.6.attention.self.value.weight', 'roberta.encoder.layer.6.attention.self.value.bias', 'roberta.encoder.layer.6.attention.output.dense.weight', 'roberta.encoder.layer.6.attention.output.dense.bias', 'roberta.encoder.layer.6.attention.output.LayerNorm.weight', 'roberta.encoder.layer.6.attention.output.LayerNorm.bias', 'roberta.encoder.layer.6.intermediate.dense.weight', 'roberta.encoder.layer.6.intermediate.dense.bias', 'roberta.encoder.layer.6.output.dense.weight', 'roberta.encoder.layer.6.output.dense.bias', 'roberta.encoder.layer.6.output.LayerNorm.weight', 'roberta.encoder.layer.6.output.LayerNorm.bias', 'roberta.encoder.layer.7.attention.self.query.weight', 'roberta.encoder.layer.7.attention.self.query.bias', 'roberta.encoder.layer.7.attention.self.key.weight', 'roberta.encoder.layer.7.attention.self.key.bias', 'roberta.encoder.layer.7.attention.self.value.weight', 'roberta.encoder.layer.7.attention.self.value.bias', 'roberta.encoder.layer.7.attention.output.dense.weight', 'roberta.encoder.layer.7.attention.output.dense.bias', 'roberta.encoder.layer.7.attention.output.LayerNorm.weight', 'roberta.encoder.layer.7.attention.output.LayerNorm.bias', 'roberta.encoder.layer.7.intermediate.dense.weight', 'roberta.encoder.layer.7.intermediate.dense.bias', 'roberta.encoder.layer.7.output.dense.weight', 'roberta.encoder.layer.7.output.dense.bias', 'roberta.encoder.layer.7.output.LayerNorm.weight', 'roberta.encoder.layer.7.output.LayerNorm.bias', 'roberta.encoder.layer.8.attention.self.query.weight', 'roberta.encoder.layer.8.attention.self.query.bias', 'roberta.encoder.layer.8.attention.self.key.weight', 'roberta.encoder.layer.8.attention.self.key.bias', 'roberta.encoder.layer.8.attention.self.value.weight', 'roberta.encoder.layer.8.attention.self.value.bias', 'roberta.encoder.layer.8.attention.output.dense.weight', 'roberta.encoder.layer.8.attention.output.dense.bias', 'roberta.encoder.layer.8.attention.output.LayerNorm.weight', 'roberta.encoder.layer.8.attention.output.LayerNorm.bias', 'roberta.encoder.layer.8.intermediate.dense.weight', 'roberta.encoder.layer.8.intermediate.dense.bias', 'roberta.encoder.layer.8.output.dense.weight', 'roberta.encoder.layer.8.output.dense.bias', 'roberta.encoder.layer.8.output.LayerNorm.weight', 'roberta.encoder.layer.8.output.LayerNorm.bias', 'roberta.encoder.layer.9.attention.self.query.weight', 'roberta.encoder.layer.9.attention.self.query.bias', 'roberta.encoder.layer.9.attention.self.key.weight', 'roberta.encoder.layer.9.attention.self.key.bias', 'roberta.encoder.layer.9.attention.self.value.weight', 'roberta.encoder.layer.9.attention.self.value.bias', 'roberta.encoder.layer.9.attention.output.dense.weight', 'roberta.encoder.layer.9.attention.output.dense.bias', 'roberta.encoder.layer.9.attention.output.LayerNorm.weight', 'roberta.encoder.layer.9.attention.output.LayerNorm.bias', 'roberta.encoder.layer.9.intermediate.dense.weight', 'roberta.encoder.layer.9.intermediate.dense.bias', 'roberta.encoder.layer.9.output.dense.weight', 'roberta.encoder.layer.9.output.dense.bias', 'roberta.encoder.layer.9.output.LayerNorm.weight', 'roberta.encoder.layer.9.output.LayerNorm.bias', 'roberta.encoder.layer.10.attention.self.query.weight', 'roberta.encoder.layer.10.attention.self.query.bias', 'roberta.encoder.layer.10.attention.self.key.weight', 'roberta.encoder.layer.10.attention.self.key.bias', 'roberta.encoder.layer.10.attention.self.value.weight', 'roberta.encoder.layer.10.attention.self.value.bias', 'roberta.encoder.layer.10.attention.output.dense.weight', 'roberta.encoder.layer.10.attention.output.dense.bias', 'roberta.encoder.layer.10.attention.output.LayerNorm.weight', 'roberta.encoder.layer.10.attention.output.LayerNorm.bias', 'roberta.encoder.layer.10.intermediate.dense.weight', 'roberta.encoder.layer.10.intermediate.dense.bias', 'roberta.encoder.layer.10.output.dense.weight', 'roberta.encoder.layer.10.output.dense.bias', 'roberta.encoder.layer.10.output.LayerNorm.weight', 'roberta.encoder.layer.10.output.LayerNorm.bias', 'roberta.encoder.layer.11.attention.self.query.weight', 'roberta.encoder.layer.11.attention.self.query.bias', 'roberta.encoder.layer.11.attention.self.key.weight', 'roberta.encoder.layer.11.attention.self.key.bias', 'roberta.encoder.layer.11.attention.self.value.weight', 'roberta.encoder.layer.11.attention.self.value.bias', 'roberta.encoder.layer.11.attention.output.dense.weight', 'roberta.encoder.layer.11.attention.output.dense.bias', 'roberta.encoder.layer.11.attention.output.LayerNorm.weight', 'roberta.encoder.layer.11.attention.output.LayerNorm.bias', 'roberta.encoder.layer.11.intermediate.dense.weight', 'roberta.encoder.layer.11.intermediate.dense.bias', 'roberta.encoder.layer.11.output.dense.weight', 'roberta.encoder.layer.11.output.dense.bias', 'roberta.encoder.layer.11.output.LayerNorm.weight', 'roberta.encoder.layer.11.output.LayerNorm.bias', 'roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
- This IS expected if you are initializing MyRoberta from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing MyRoberta from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of MyRoberta were not initialized from the model checkpoint at roberta-base and are newly initialized: ['roberta.bert.embeddings.position_ids', 'roberta.bert.embeddings.word_embeddings.weight', 'roberta.bert.embeddings.position_embeddings.weight', 'roberta.bert.embeddings.token_type_embeddings.weight', 'roberta.bert.embeddings.LayerNorm.weight', 'roberta.bert.embeddings.LayerNorm.bias', 'roberta.bert.encoder.layer.0.attention.self.query.weight', 'roberta.bert.encoder.layer.0.attention.self.query.bias', 'roberta.bert.encoder.layer.0.attention.self.key.weight', 'roberta.bert.encoder.layer.0.attention.self.key.bias', 'roberta.bert.encoder.layer.0.attention.self.value.weight', 'roberta.bert.encoder.layer.0.attention.self.value.bias', 'roberta.bert.encoder.layer.0.attention.output.dense.weight', 'roberta.bert.encoder.layer.0.attention.output.dense.bias', 'roberta.bert.encoder.layer.0.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.0.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.0.intermediate.dense.weight', 'roberta.bert.encoder.layer.0.intermediate.dense.bias', 'roberta.bert.encoder.layer.0.output.dense.weight', 'roberta.bert.encoder.layer.0.output.dense.bias', 'roberta.bert.encoder.layer.0.output.LayerNorm.weight', 'roberta.bert.encoder.layer.0.output.LayerNorm.bias', 'roberta.bert.encoder.layer.1.attention.self.query.weight', 'roberta.bert.encoder.layer.1.attention.self.query.bias', 'roberta.bert.encoder.layer.1.attention.self.key.weight', 'roberta.bert.encoder.layer.1.attention.self.key.bias', 'roberta.bert.encoder.layer.1.attention.self.value.weight', 'roberta.bert.encoder.layer.1.attention.self.value.bias', 'roberta.bert.encoder.layer.1.attention.output.dense.weight', 'roberta.bert.encoder.layer.1.attention.output.dense.bias', 'roberta.bert.encoder.layer.1.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.1.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.1.intermediate.dense.weight', 'roberta.bert.encoder.layer.1.intermediate.dense.bias', 'roberta.bert.encoder.layer.1.output.dense.weight', 'roberta.bert.encoder.layer.1.output.dense.bias', 'roberta.bert.encoder.layer.1.output.LayerNorm.weight', 'roberta.bert.encoder.layer.1.output.LayerNorm.bias', 'roberta.bert.encoder.layer.2.attention.self.query.weight', 'roberta.bert.encoder.layer.2.attention.self.query.bias', 'roberta.bert.encoder.layer.2.attention.self.key.weight', 'roberta.bert.encoder.layer.2.attention.self.key.bias', 'roberta.bert.encoder.layer.2.attention.self.value.weight', 'roberta.bert.encoder.layer.2.attention.self.value.bias', 'roberta.bert.encoder.layer.2.attention.output.dense.weight', 'roberta.bert.encoder.layer.2.attention.output.dense.bias', 'roberta.bert.encoder.layer.2.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.2.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.2.intermediate.dense.weight', 'roberta.bert.encoder.layer.2.intermediate.dense.bias', 'roberta.bert.encoder.layer.2.output.dense.weight', 'roberta.bert.encoder.layer.2.output.dense.bias', 'roberta.bert.encoder.layer.2.output.LayerNorm.weight', 'roberta.bert.encoder.layer.2.output.LayerNorm.bias', 'roberta.bert.encoder.layer.3.attention.self.query.weight', 'roberta.bert.encoder.layer.3.attention.self.query.bias', 'roberta.bert.encoder.layer.3.attention.self.key.weight', 'roberta.bert.encoder.layer.3.attention.self.key.bias', 'roberta.bert.encoder.layer.3.attention.self.value.weight', 'roberta.bert.encoder.layer.3.attention.self.value.bias', 'roberta.bert.encoder.layer.3.attention.output.dense.weight', 'roberta.bert.encoder.layer.3.attention.output.dense.bias', 'roberta.bert.encoder.layer.3.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.3.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.3.intermediate.dense.weight', 'roberta.bert.encoder.layer.3.intermediate.dense.bias', 'roberta.bert.encoder.layer.3.output.dense.weight', 'roberta.bert.encoder.layer.3.output.dense.bias', 'roberta.bert.encoder.layer.3.output.LayerNorm.weight', 'roberta.bert.encoder.layer.3.output.LayerNorm.bias', 'roberta.bert.encoder.layer.4.attention.self.query.weight', 'roberta.bert.encoder.layer.4.attention.self.query.bias', 'roberta.bert.encoder.layer.4.attention.self.key.weight', 'roberta.bert.encoder.layer.4.attention.self.key.bias', 'roberta.bert.encoder.layer.4.attention.self.value.weight', 'roberta.bert.encoder.layer.4.attention.self.value.bias', 'roberta.bert.encoder.layer.4.attention.output.dense.weight', 'roberta.bert.encoder.layer.4.attention.output.dense.bias', 'roberta.bert.encoder.layer.4.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.4.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.4.intermediate.dense.weight', 'roberta.bert.encoder.layer.4.intermediate.dense.bias', 'roberta.bert.encoder.layer.4.output.dense.weight', 'roberta.bert.encoder.layer.4.output.dense.bias', 'roberta.bert.encoder.layer.4.output.LayerNorm.weight', 'roberta.bert.encoder.layer.4.output.LayerNorm.bias', 'roberta.bert.encoder.layer.5.attention.self.query.weight', 'roberta.bert.encoder.layer.5.attention.self.query.bias', 'roberta.bert.encoder.layer.5.attention.self.key.weight', 'roberta.bert.encoder.layer.5.attention.self.key.bias', 'roberta.bert.encoder.layer.5.attention.self.value.weight', 'roberta.bert.encoder.layer.5.attention.self.value.bias', 'roberta.bert.encoder.layer.5.attention.output.dense.weight', 'roberta.bert.encoder.layer.5.attention.output.dense.bias', 'roberta.bert.encoder.layer.5.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.5.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.5.intermediate.dense.weight', 'roberta.bert.encoder.layer.5.intermediate.dense.bias', 'roberta.bert.encoder.layer.5.output.dense.weight', 'roberta.bert.encoder.layer.5.output.dense.bias', 'roberta.bert.encoder.layer.5.output.LayerNorm.weight', 'roberta.bert.encoder.layer.5.output.LayerNorm.bias', 'roberta.bert.encoder.layer.6.attention.self.query.weight', 'roberta.bert.encoder.layer.6.attention.self.query.bias', 'roberta.bert.encoder.layer.6.attention.self.key.weight', 'roberta.bert.encoder.layer.6.attention.self.key.bias', 'roberta.bert.encoder.layer.6.attention.self.value.weight', 'roberta.bert.encoder.layer.6.attention.self.value.bias', 'roberta.bert.encoder.layer.6.attention.output.dense.weight', 'roberta.bert.encoder.layer.6.attention.output.dense.bias', 'roberta.bert.encoder.layer.6.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.6.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.6.intermediate.dense.weight', 'roberta.bert.encoder.layer.6.intermediate.dense.bias', 'roberta.bert.encoder.layer.6.output.dense.weight', 'roberta.bert.encoder.layer.6.output.dense.bias', 'roberta.bert.encoder.layer.6.output.LayerNorm.weight', 'roberta.bert.encoder.layer.6.output.LayerNorm.bias', 'roberta.bert.encoder.layer.7.attention.self.query.weight', 'roberta.bert.encoder.layer.7.attention.self.query.bias', 'roberta.bert.encoder.layer.7.attention.self.key.weight', 'roberta.bert.encoder.layer.7.attention.self.key.bias', 'roberta.bert.encoder.layer.7.attention.self.value.weight', 'roberta.bert.encoder.layer.7.attention.self.value.bias', 'roberta.bert.encoder.layer.7.attention.output.dense.weight', 'roberta.bert.encoder.layer.7.attention.output.dense.bias', 'roberta.bert.encoder.layer.7.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.7.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.7.intermediate.dense.weight', 'roberta.bert.encoder.layer.7.intermediate.dense.bias', 'roberta.bert.encoder.layer.7.output.dense.weight', 'roberta.bert.encoder.layer.7.output.dense.bias', 'roberta.bert.encoder.layer.7.output.LayerNorm.weight', 'roberta.bert.encoder.layer.7.output.LayerNorm.bias', 'roberta.bert.encoder.layer.8.attention.self.query.weight', 'roberta.bert.encoder.layer.8.attention.self.query.bias', 'roberta.bert.encoder.layer.8.attention.self.key.weight', 'roberta.bert.encoder.layer.8.attention.self.key.bias', 'roberta.bert.encoder.layer.8.attention.self.value.weight', 'roberta.bert.encoder.layer.8.attention.self.value.bias', 'roberta.bert.encoder.layer.8.attention.output.dense.weight', 'roberta.bert.encoder.layer.8.attention.output.dense.bias', 'roberta.bert.encoder.layer.8.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.8.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.8.intermediate.dense.weight', 'roberta.bert.encoder.layer.8.intermediate.dense.bias', 'roberta.bert.encoder.layer.8.output.dense.weight', 'roberta.bert.encoder.layer.8.output.dense.bias', 'roberta.bert.encoder.layer.8.output.LayerNorm.weight', 'roberta.bert.encoder.layer.8.output.LayerNorm.bias', 'roberta.bert.encoder.layer.9.attention.self.query.weight', 'roberta.bert.encoder.layer.9.attention.self.query.bias', 'roberta.bert.encoder.layer.9.attention.self.key.weight', 'roberta.bert.encoder.layer.9.attention.self.key.bias', 'roberta.bert.encoder.layer.9.attention.self.value.weight', 'roberta.bert.encoder.layer.9.attention.self.value.bias', 'roberta.bert.encoder.layer.9.attention.output.dense.weight', 'roberta.bert.encoder.layer.9.attention.output.dense.bias', 'roberta.bert.encoder.layer.9.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.9.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.9.intermediate.dense.weight', 'roberta.bert.encoder.layer.9.intermediate.dense.bias', 'roberta.bert.encoder.layer.9.output.dense.weight', 'roberta.bert.encoder.layer.9.output.dense.bias', 'roberta.bert.encoder.layer.9.output.LayerNorm.weight', 'roberta.bert.encoder.layer.9.output.LayerNorm.bias', 'roberta.bert.encoder.layer.10.attention.self.query.weight', 'roberta.bert.encoder.layer.10.attention.self.query.bias', 'roberta.bert.encoder.layer.10.attention.self.key.weight', 'roberta.bert.encoder.layer.10.attention.self.key.bias', 'roberta.bert.encoder.layer.10.attention.self.value.weight', 'roberta.bert.encoder.layer.10.attention.self.value.bias', 'roberta.bert.encoder.layer.10.attention.output.dense.weight', 'roberta.bert.encoder.layer.10.attention.output.dense.bias', 'roberta.bert.encoder.layer.10.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.10.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.10.intermediate.dense.weight', 'roberta.bert.encoder.layer.10.intermediate.dense.bias', 'roberta.bert.encoder.layer.10.output.dense.weight', 'roberta.bert.encoder.layer.10.output.dense.bias', 'roberta.bert.encoder.layer.10.output.LayerNorm.weight', 'roberta.bert.encoder.layer.10.output.LayerNorm.bias', 'roberta.bert.encoder.layer.11.attention.self.query.weight', 'roberta.bert.encoder.layer.11.attention.self.query.bias', 'roberta.bert.encoder.layer.11.attention.self.key.weight', 'roberta.bert.encoder.layer.11.attention.self.key.bias', 'roberta.bert.encoder.layer.11.attention.self.value.weight', 'roberta.bert.encoder.layer.11.attention.self.value.bias', 'roberta.bert.encoder.layer.11.attention.output.dense.weight', 'roberta.bert.encoder.layer.11.attention.output.dense.bias', 'roberta.bert.encoder.layer.11.attention.output.LayerNorm.weight', 'roberta.bert.encoder.layer.11.attention.output.LayerNorm.bias', 'roberta.bert.encoder.layer.11.intermediate.dense.weight', 'roberta.bert.encoder.layer.11.intermediate.dense.bias', 'roberta.bert.encoder.layer.11.output.dense.weight', 'roberta.bert.encoder.layer.11.output.dense.bias', 'roberta.bert.encoder.layer.11.output.LayerNorm.weight', 'roberta.bert.encoder.layer.11.output.LayerNorm.bias', 'roberta.bert.pooler.dense.weight', 'roberta.bert.pooler.dense.bias', 'roberta.cls.bias', 'roberta.cls.dense.weight', 'roberta.cls.dense.bias', 'roberta.cls.layer_norm.weight', 'roberta.cls.layer_norm.bias', 'roberta.cls.decoder.weight', 'roberta.cls.decoder.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
| 11-08-2020 13:53:04 | 11-08-2020 13:53:04 | but when i use the same way to initializing `MyBert` which is based on the `BertModel`, it works and have a good result.<|||||>This is probably because you put `self.bert = RobertaModel(config)`. It's looking for the identifier `roberta`, which isn't in your model.
Try replacing `self.roberta = RobertaModel(config)`?<|||||>> This is probably because you put `self.bert = RobertaModel(config)`. It's looking for the identifier `roberta`, which isn't in your model.
>
>
>
> Try replacing `self.roberta = RobertaModel(config)`?
Thank you very much for replying, i did as you said and replaced `self.cls = RobertaLMHead(config)` with `self.lm_head = RobertaLMHead(config)`, it worked well, Thanks!<|||||>Hi @LysandreJik, sorry for reviving this old thread, but could you point to me where can I find this info in the docs? I'm interested to know what is the identifier used for different models. |
transformers | 8,406 | closed | Update README.md | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-08-2020 11:29:37 | 11-08-2020 11:29:37 | |
transformers | 8,405 | closed | Update README.md | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to the it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, XLM: @LysandreJik
GPT2: @LysandreJik, @patrickvonplaten
tokenizers: @mfuntowicz
Trainer: @sgugger
Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten, @TevenLeScao
Blenderbot, Bart, Marian, Pegasus: @sshleifer
T5: @patrickvonplaten
Rag: @patrickvonplaten, @lhoestq
EncoderDecoder: @patrickvonplaten
Longformer, Reformer: @patrickvonplaten
TransfoXL, XLNet: @TevenLeScao, @patrickvonplaten
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
FSTM: @stas00
-->
| 11-08-2020 11:26:40 | 11-08-2020 11:26:40 | |
transformers | 8,404 | closed | Tokenizer problem for model 'patrickvonplaten/longformer-random-tiny' | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.4.0
- Platform: Ubuntu 18.04.5 LTS
- Python version: Python 3.6.9
- PyTorch version (GPU?):1.6.0
- Tensorflow version (GPU?):2.3.1
- Using GPU in script?:No
- Using distributed or parallel set-up in script?:No
### Who can help
T5: @patrickvonplaten
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
albert, bert, GPT2, XLM: @LysandreJik
tokenizers: @mfuntowicz
Trainer: @sgugger
Speed and Memory Benchmarks: @patrickvonplaten
Model Cards: @julien-c
Translation: @sshleifer
Summarization: @sshleifer
TextGeneration: @TevenLeScao
examples/distillation: @VictorSanh
nlp datasets: [different repo](https://github.com/huggingface/nlp)
rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Text Generation: @patrickvonplaten @TevenLeScao
blenderbot: @mariamabarham
Bart: @sshleifer
Marian: @sshleifer
T5: @patrickvonplaten
Longformer/Reformer: @patrickvonplaten
TransfoXL/XLNet: @TevenLeScao
RAG: @patrickvonplaten, @lhoestq
FSTM: @stas00
examples/seq2seq: @sshleifer
examples/bert-loses-patience: @JetRunner
tensorflow: @jplu
examples/token-classification: @stefan-it
documentation: @sgugger
-->
## Information
Model I am using (patrickvonplaten/longformer-random-tiny):
The problem arises when using:
* [ ] the official example scripts: (give details below)
https://huggingface.co/patrickvonplaten/longformer-random-tiny
## To reproduce
Steps to reproduce the behavior:
1. Running the script.
2. Result:
_2020-11-08 11:09:14.631646: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory
2020-11-08 11:09:14.631672: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
Traceback (most recent call last):
File "test_tiny.py", line 3, in <module>
tokenizer = AutoTokenizer.from_pretrained("patrickvonplaten/longformer-random-tiny")
File "/usr/local/lib/python3.6/dist-packages/transformers/tokenization_auto.py", line 333, in from_pretrained
return tokenizer_class_py.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py", line 1591, in from_pretrained
list(cls.vocab_files_names.values()),
OSError: Model name 'patrickvonplaten/longformer-random-tiny' was not found in tokenizers model name list (allenai/longformer-base-4096, allenai/longformer-large-4096, allenai/longformer-large-4096-finetuned-triviaqa, allenai/longformer-base-4096-extra.pos.embd.only, allenai/longformer-large-4096-extra.pos.embd.only). We assumed 'patrickvonplaten/longformer-random-tiny' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.json', 'merges.txt'] but couldn't find such vocabulary files at this path or url.
_
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
I suppose two files are needed - 'vocab.json', 'merges.txt'.
Thanks.
<!-- A clear and concise description of what you would expect to happen. -->
| 11-08-2020 08:34:47 | 11-08-2020 08:34:47 | Hey @lessenko - the model is useless for any real application as it's just randomly initialized. It's only used for testing purposes.<|||||>Hi @patrickvonplaten,
Thanks. |
transformers | 8,403 | closed | [s2s finetune] huge increase in memory demands with --fp16 native amp | While working on https://github.com/huggingface/transformers/issues/8353 I discovered that `--fp16` causes a 10x+ increase in gpu memory demands.
e.g. I can run bs=12 w/o `--fp16`
```
cd examples/seq2seq
export BS=12; rm -rf distilbart-cnn-12-6; python finetune.py --learning_rate=3e-5 --gpus 1 \
--do_train --do_predict --val_check_interval 0.25 --n_val 500 --num_train_epochs 2 --freeze_encoder \
--freeze_embeds --data_dir cnn_dm --max_target_length 142 --val_max_target_length=142 \
--train_batch_size=$BS --eval_batch_size=$BS --gradient_accumulation_steps 1 \
--model_name_or_path sshleifer/student_cnn_12_6 --tokenizer_name facebook/bart-large \
--warmup_steps 500 --output_dir distilbart-cnn-12-6
```
But if I add:
```
--fp16
```
(w/ or w/o `--fp16_opt_level O1`)
I get OOM even with bs=1 on a 8GB card and it barely manages on a 24GB card - I think the increase in memory demand is more than 10x.
The OOM either right away when it does the sanity check step, or after just 10-20 batches - so within a few secs
This is with pytorch-1.6. Same goes for pytorch-1.7 and 1.8-nightly.
I wasn't able to test `--fp16` with pytorch-1.5, since I can't build apex on ubuntu-20.04. Without `--fp16` pytorch-1.5 works the same as pytorch-1.6 gpu memory-wise.
I tested with pytorch-1.5 + apex and there is no problem there. Memory consumption is about half.
Here is the table of the batch sizes that fit into a 8gb rtx-1070 (bigger BS leads to an instant OOM):
bs | version
---|--------
12 | pt15
20 | pt15+fp16
12 | pt16
1 | pt16+fp16
If you'd like to reproduce the problem here are the full steps:
```
# prep library
git clone https://github.com/huggingface/transformers
cd transformers
pip install -e .[dev]
pip install -r examples/requirements.txt
cd examples/seq2seq
# prep data
wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
tar -xzvf cnn_dm_v2.tgz # empty lines removed
mv cnn_cln cnn_dm
# run
export BS=12;
rm -rf distilbart-cnn-12-6
python finetune.py --learning_rate=3e-5 --gpus 1 \
--do_train --do_predict --val_check_interval 0.25 --n_val 500 --num_train_epochs 2 --freeze_encoder \
--freeze_embeds --data_dir cnn_dm --max_target_length 142 --val_max_target_length=142 \
--train_batch_size=$BS --eval_batch_size=$BS --gradient_accumulation_steps 1 \
--model_name_or_path sshleifer/student_cnn_12_6 --tokenizer_name facebook/bart-large \
--warmup_steps 500 --output_dir distilbart-cnn-12-6
```
This issue is to track the problem and hopefully finding a solution.
@sshleifer | 11-08-2020 07:14:19 | 11-08-2020 07:14:19 | I managed to install `nvidia-apex` binary via conda:
```
conda install nvidia-apex -c conda-forge
```
So now I was able to validate that with pytorch-1.5 + nvdia-apex `--fp16` consumes less memory, than w/o `--fp16`.
I was able to squeeze bs=20 (!) onto a 8gb card.
So the problem has to do with pytorch's 1.6 fp16
<|||||>Found another report of memory increase with fp16:
https://discuss.pytorch.org/t/fp16-training-with-feedforward-network-slower-time-and-no-memory-reduction/95560/
<|||||>Michael Carilli suggested I add this to the top of the script to find the problem:
```
import torch
torch.cuda.amp.autocast = "hfdj"
```
rerunning gives:
```
Validation sanity check: 0it [00:00, ?it/s]Traceback (most recent call last):
File "finetune.py", line 449, in <module>
main(args)
File "finetune.py", line 416, in main
trainer: pl.Trainer = generic_train(
File "/mnt/nvme1/code/huggingface/transformers-watchdog/examples/lightning_base.py", line 395, in generic_train
trainer.fit(model)
File "/mnt/nvme1/code/github/00pytorch/pytorch-lightning/pytorch_lightning/trainer/trainer.py", line 445, in fit
results = self.accelerator_backend.train()
File "/mnt/nvme1/code/github/00pytorch/pytorch-lightning/pytorch_lightning/accelerators/gpu_accelerator.py", line 54, in train
results = self.train_or_test()
File "/mnt/nvme1/code/github/00pytorch/pytorch-lightning/pytorch_lightning/accelerators/accelerator.py", line 74, in train_or_test
results = self.trainer.train()
File "/mnt/nvme1/code/github/00pytorch/pytorch-lightning/pytorch_lightning/trainer/trainer.py", line 467, in train
self.run_sanity_check(self.get_model())
File "/mnt/nvme1/code/github/00pytorch/pytorch-lightning/pytorch_lightning/trainer/trainer.py", line 671, in run_sanity_check
_, eval_results = self.run_evaluation(test_mode=False, max_batches=self.num_sanity_val_batches)
File "/mnt/nvme1/code/github/00pytorch/pytorch-lightning/pytorch_lightning/trainer/trainer.py", line 591, in run_evaluation
output = self.evaluation_loop.evaluation_step(test_mode, batch, batch_idx, dataloader_idx)
File "/mnt/nvme1/code/github/00pytorch/pytorch-lightning/pytorch_lightning/trainer/evaluation_loop.py", line 176, in evaluation_step
output = self.trainer.accelerator_backend.validation_step(args)
File "/mnt/nvme1/code/github/00pytorch/pytorch-lightning/pytorch_lightning/accelerators/gpu_accelerator.py", line 75, in validation_step
with torch.cuda.amp.autocast():
TypeError: 'str' object is not callable
```
I am on the master of PL (pytorch-lightning), but tried bisecting on earlier versions (3 months back) with no change in behavior.<|||||>The same issue, when I run the train_distilbart_xsum.sh, in sanity check step, meet OOM in 12G card<|||||>Based on some initial debugging Lightning is calling into `trainer,model.validation_step`, which is calling `BartForConditionalGeneration` with fixed tensor sizes of:
```python
torch.Size([48, 1, 1024]) torch.Size([50264, 1024]) torch.Size([1, 50264])
```
In each iteration more tensors are allocated and never freed, which yields the OOM in the `sanity_check`.
AMP run before OOM:
```python
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 13553 MB | 13555 MB | 139840 MB | 126286 MB |
| from large pool | 13551 MB | 13551 MB | 137780 MB | 124228 MB |
| from small pool | 2 MB | 25 MB | 2059 MB | 2057 MB |
|---------------------------------------------------------------------------|
| Active memory | 13553 MB | 13555 MB | 139840 MB | 126286 MB |
| from large pool | 13551 MB | 13551 MB | 137780 MB | 124228 MB |
| from small pool | 2 MB | 25 MB | 2059 MB | 2057 MB |
|---------------------------------------------------------------------------|
| GPU reserved memory | 13888 MB | 13888 MB | 13888 MB | 0 B |
| from large pool | 13858 MB | 13858 MB | 13858 MB | 0 B |
| from small pool | 30 MB | 30 MB | 30 MB | 0 B |
|---------------------------------------------------------------------------|
| Non-releasable memory | 315554 KB | 913 MB | 109380 MB | 109072 MB |
| from large pool | 313557 KB | 912 MB | 107043 MB | 106737 MB |
| from small pool | 1997 KB | 8 MB | 2336 MB | 2334 MB |
|---------------------------------------------------------------------------|
| Allocations | 3403 | 3410 | 29885 | 26482 |
| from large pool | 3161 | 3161 | 7265 | 4104 |
| from small pool | 242 | 267 | 22620 | 22378 |
|---------------------------------------------------------------------------|
| Active allocs | 3403 | 3410 | 29885 | 26482 |
| from large pool | 3161 | 3161 | 7265 | 4104 |
| from small pool | 242 | 267 | 22620 | 22378 |
|---------------------------------------------------------------------------|
| GPU reserved segments | 368 | 368 | 368 | 0 |
| from large pool | 353 | 353 | 353 | 0 |
| from small pool | 15 | 15 | 15 | 0 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 204 | 210 | 14948 | 14744 |
| from large pool | 200 | 205 | 3772 | 3572 |
| from small pool | 4 | 20 | 11176 | 11172 |
|===========================================================================|
```
FP32 run for the same step:
```python
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 3948 MB | 4000 MB | 203229 MB | 199281 MB |
| from large pool | 3946 MB | 3998 MB | 201302 MB | 197356 MB |
| from small pool | 2 MB | 24 MB | 1927 MB | 1925 MB |
|---------------------------------------------------------------------------|
| Active memory | 3948 MB | 4000 MB | 203229 MB | 199281 MB |
| from large pool | 3946 MB | 3998 MB | 201302 MB | 197356 MB |
| from small pool | 2 MB | 24 MB | 1927 MB | 1925 MB |
|---------------------------------------------------------------------------|
| GPU reserved memory | 4226 MB | 4226 MB | 4226 MB | 0 B |
| from large pool | 4198 MB | 4198 MB | 4198 MB | 0 B |
| from small pool | 28 MB | 28 MB | 28 MB | 0 B |
|---------------------------------------------------------------------------|
| Non-releasable memory | 259725 KB | 778 MB | 118090 MB | 117836 MB |
| from large pool | 257727 KB | 777 MB | 115922 MB | 115670 MB |
| from small pool | 1997 KB | 8 MB | 2168 MB | 2166 MB |
|---------------------------------------------------------------------------|
| Allocations | 415 | 422 | 23263 | 22848 |
| from large pool | 173 | 175 | 3796 | 3623 |
| from small pool | 242 | 267 | 19467 | 19225 |
|---------------------------------------------------------------------------|
| Active allocs | 415 | 422 | 23263 | 22848 |
| from large pool | 173 | 175 | 3796 | 3623 |
| from small pool | 242 | 267 | 19467 | 19225 |
|---------------------------------------------------------------------------|
| GPU reserved segments | 85 | 85 | 85 | 0 |
| from large pool | 71 | 71 | 71 | 0 |
| from small pool | 14 | 14 | 14 | 0 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 17 | 26 | 13706 | 13689 |
| from large pool | 13 | 14 | 2264 | 2251 |
| from small pool | 4 | 21 | 11442 | 11438 |
|===========================================================================|
```
The allocations increase using `AMP` by ~50 in each iteration, while FP32 increases them sometimes by ~1.
So far I wasn't able to isolate the memory increase. <|||||>@ptrblck, and if the same is done with pt15/nvidia-apex - why doesn't the same happen there? How are the two different (native vs apex)<|||||>I don't know, why an older PyTorch version with apex/amp works, as I wasn't able to isolate the issue yet.
The native amp implementation differs in various ways from `apex/amp`.
Btw. do you only see the OOM, if you are using Lightning or also using the standalone model + amp?<|||||>@ptrblck, I have tried the hugging face trainer and the problem doesn't seem to happen there. I don't think `--fp16` makes any difference in that trainer but it doesn't increase memory requirements. So is it possible this is specifically a PL issue?
For testing I used:
setup:
```
cd examples/seq2seq
wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
tar -xzvf wmt_en_ro.tar.gz
```
and then run:
```
bs=11; rm -rf tmpdir; PYTHONPATH="../../src" python ./finetune_trainer.py \
--model_name_or_path sshleifer/distill-mbart-en-ro-12-4 --data_dir wmt_en_ro --output_dir tmpdir \
--overwrite_output_dir --max_source_length 128 --max_target_length 128 --val_max_target_length 128 \
--do_train --do_eval --do_predict --num_train_epochs 10 --per_device_train_batch_size $bs \
--per_device_eval_batch_size $bs --learning_rate 3e-4 --warmup_steps 2 --evaluate_during_training \
--predict_with_generate --logging_steps 0 --save_steps 2 --eval_steps 2 --sortish_sampler \
--label_smoothing 0.1 --adafactor --task translation --tgt_lang ro_RO --src_lang en_XX --n_train 100 \
--n_val 50 --fp16
```
(same memory consumption w/o `--fp16`)
This command also uses `BartForConditionalGeneration`.
`bs=11` is the biggest batch size I could fit onto the 8GB card, `bs=12` OOMs
<|||||>@ptrblck How did you make such a nice table?
@stas00 I will check your #s on my card. cc @patil-suraj
<|||||>I replicated the OOM and fixed by passing `--amp_backend='apex'` in my torch 1.6 environment on a 24GB card. Would still be good to see if there is any easy way to get native amp working well.<|||||>Thank you for validating that, @sshleifer. So it really has something to do with the native amp in pytorch.
Here is the summary of my experiments:
- pt15 + confa-force apex w/ `--fp16` works at the start - reduces memory consumption
- pt16 + conda-forge apex w/ `--fp16 --amp_backend='apex'` works at the start too!
but both fail at the end with:
```
File "python3.8/site-packages/apex/amp/_amp_state.py", line 32, in warn_or_err
raise RuntimeError(msg)
RuntimeError: Found param model.model.shared.weight with type torch.cuda.HalfTensor, expected torch.cuda.FloatTensor.
When using amp.initialize, you do not need to call .half() on your model
```
If I use `--fp16_opt_level O1`, the failure changes to:
```
File "python3.8/site-packages/torch/optim/lr_scheduler.py", line 56, in with_counter
instance_ref = weakref.ref(method.__self__)
AttributeError: 'function' object has no attribute '__self__'
```
both envs use the binary apex from `conda-forge`
- apex doesn't support cuda11 at the moment
- rtx-30* cards don't support cuda<11 (and really cuda<11.1).
- ubuntu-20.4 doesn't support cuda<11, since it dropped gcc7, so can't build apex from source even for cuda-10
Bottom line, apex is not a great option at the moment, but may work for some short term - need to sort out native amp.
I will poke at it with debugger today.<|||||>I'm running in parallel `pt15+apex` and `pt16+native` with debugger:
Found the first issue.
At this point in stack (we are in PL domain) - both have about 1.7GB allocated on GPU:
```
restore_weights, checkpoint_connector.py:64
setup_training, training_loop.py:174
train, gpu_accelerator.py:51
fit, trainer.py:444
generic_train, lightning_base.py:398
main, finetune.py:413
<module>, finetune.py:446
```
next step: `torch.cuda.empty_cache()` frees about 0.6GB on pt15, but 0 on pt16.
Could `GradScaler` be holding onto objects and not letting them go? I commented out its init and there is no change.
Perhaps there are some circular references preventing the objects from being cleared out.
<|||||>@sshleifer I used [`torch.cuda.memory_summary()`](https://pytorch.org/docs/stable/cuda.html#torch.cuda.memory_summary) and added it for each iteration in the `BartForConditionalGeneration` model.
After some more debugging it seems that the `autocast` cache is blowing up.
As a workaround you can add `torch.clear_autocast_cache()` in [BartForConditionalGeneration.forward](https://github.com/huggingface/transformers/blob/eb3bd73ce35bfef56eeb722d697f2d39a06a8f8d/src/transformers/modeling_bart.py#L1036), which might slow down your code but should at least work.
Based on @stas00 's debugging it seems that PL is interacting with native AMP in a way that the cache is increasing.
CC @mcarilli<|||||>The autocast cache is [cleared automatically](https://github.com/pytorch/pytorch/blob/88ec72e1c2a4b1e2a15cbe4703b9567bf9369a09/torch/cuda/amp/autocast_mode.py#L127) every time you exit an autocast context, which is one reason autocast should wrap the forward pass then exit.
@ptrblck where in `BartConditionalGeneration.forward` did you call `clear_autocast_cache()` to resolve the memory blowup?
It's also helpful to write in the following sequence:
```
torch.autocast_increment_nesting()
print(torch.autocast_decrement_nesting())
```
to see how deeply we're nested in autocast contexts at that point in forward. It should print `1`.<|||||>@ptrblck, if I use your suggestion to add `torch.clear_autocast_cache()` torch blows up:
```
Epoch 0: 50%|████████████████Traceback (most recent call last): | 1/2 [00:02<00:02, 2.37s/it, loss=2.934, v_num=156]
File "finetune.py", line 447, in <module>
main(args)
File "finetune.py", line 414, in main
trainer: pl.Trainer = generic_train(
File "/mnt/nvme1/code/huggingface/transformers-watchdog/examples/lightning_base.py", line 403, in generic_train
trainer.fit(model)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 444, in fit
results = self.accelerator_backend.train()
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pytorch_lightning/accelerators/gpu_accelerator.py", line 63, in train
results = self.train_or_test()
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pytorch_lightning/accelerators/accelerator.py", line 74, in train_or_test
results = self.trainer.train()
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 493, in train
self.train_loop.run_training_epoch()
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pytorch_lightning/trainer/training_loop.py", line 589, in run_training_epoch
self.trainer.run_evaluation(test_mode=False)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 578, in run_evaluation
output = self.evaluation_loop.evaluation_step(test_mode, batch, batch_idx, dataloader_idx)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pytorch_lightning/trainer/evaluation_loop.py", line 171, in evaluation_step
output = self.trainer.accelerator_backend.validation_step(args)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pytorch_lightning/accelerators/gpu_accelerator.py", line 85, in validation_step
output = self.__validation_step(args)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pytorch_lightning/accelerators/gpu_accelerator.py", line 95, in __validation_step
output = self.trainer.model.validation_step(*args)
File "finetune.py", line 183, in validation_step
return self._generative_step(batch)
File "finetune.py", line 216, in _generative_step
generated_ids = self.model.generate(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 26, in decorate_context
return func(*args, **kwargs)
File "/mnt/nvme1/code/huggingface/transformers-watchdog/src/transformers/generation_utils.py", line 553, in generate
return self.beam_search(
File "/mnt/nvme1/code/huggingface/transformers-watchdog/src/transformers/generation_utils.py", line 950, in beam_search
beam_scores = torch.zeros((batch_size, num_beams), dtype=torch.float, device=input_ids.device)
UnboundLocalError: local variable 'torch' referenced before assignment
Exception ignored in: <function tqdm.__del__ at 0x7f1ec3812ee0>
Traceback (most recent call last):
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/tqdm/std.py", line 1122, in __del__
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/tqdm/std.py", line 1335, in close
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/tqdm/std.py", line 1514, in display
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/tqdm/std.py", line 1125, in __repr__
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/tqdm/std.py", line 1475, in format_dict
TypeError: cannot unpack non-iterable NoneType object
```
this is on pt-nightly, the only pt version I can use rtx-3090 24G card.
**correction**: on pt-nightly it blows up with this error w/ or w/o cache clearing - it just doesn't work. I checked `torch` is imported at the point it says it's not defined.
**edit2**: some problem related to `--warmup 500` - I set it to `1` and the above failure is gone - something to deal with separately.
Let me see if I can figure out how to test this on pt16 - the problem is the 8GB card still can't fit even a single sample.<|||||>> It's also helpful to write in the following sequence:
>
> ```
> torch.autocast_increment_nesting()
> print(torch.autocast_decrement_nesting())
> ```
>
> to see how deeply we're nested in autocast contexts at that point in forward. It should print `1`.
I validated - it prints `1`.<|||||>for calling `torch.clear_autocast_cache()` how does a forward know it's in the autocast context?
```
if torch.autocast_enabled:
torch.clear_autocast_cache()
```
I don't see a public API to check that [here](https://pytorch.org/docs/stable/_modules/torch/cuda/amp/autocast_mode.html#autocast)
<|||||>`torch.is_autocast_enabled()`<|||||>Thank you, I see it now in the source code - should it be in the docs too? https://pytorch.org/docs/stable/amp.html<|||||>I'm not sure, I want people to use autocast through the context manager interface. I guess it's useful for debugging.<|||||>Oh, for sure. I don't think any of the `transformers` models should be made autocast-aware - this is the job of the trainer.<|||||>Hmm, now I'm able to use the 24GB card so it's much easier to debug as I don't hit OOM all the time. Though I can't compare with apex, as I can't build it for cuda-11 - but I hope it should still be OK.
What it appears to be is the beam search (size=4) consumes some 20GB just to search for 1 sample. It calls forward about 100 times each time allocating about 200MB - never releasing memory. I suppose because with apex the model is much more lean it requires much less memory.
If I add @ptrblck's suggestion to clear the autocast cache in forward it now consumes only 2.5GB - that's 1/8th of the same with the cache.
W/o fp16 it consumes 5GB for the same beam_seach operation.
Let's summarize:
type | memory
----------|-------
w/o fp16 | 5GB
w/ fp16 | 20GB
w/ fp16 + cache flush | 2.5GB
So definitely this is at least a huge part of the culprit. I think we are making progress. Much appreciation for your suggestion, @ptrblck~
So how do you recommend to proceed? Should PL have an option to clear the autocast cache?
Should `autocast` cache be made smarter and flush automatically if gpu ram is 90% full and be called to check when this happens ala `gc.collect()`-timing and not just in the context of its use? Since now it created an additional cache in to add to to `cuda.cache`.<|||||>If you follow along this is the command I use now: `PYTHONPATH="../../src" CUDA_VISIBLE_DEVICES=0 python finetune.py --learning_rate 3e-5 --gpus 1 --do_train --val_check_interval 1 --num_train_epochs 1 --freeze_encoder --freeze_embeds --data_dir cnn_dm --max_target_length 142 --val_max_target_length 142 --train_batch_size 1 --eval_batch_size 1 --gradient_accumulation_steps 1 --model_name_or_path sshleifer/student_cnn_12_6 --tokenizer_name facebook/bart-large --warmup_steps 1 --output_dir distilbart-cnn-12-6 --overwrite_output_dir --num_sanity_val_steps 0 --n_train 1 --n_val 1 --fp16`<|||||>Don't think this is a trainer issue, I've been able to replicate this OOM crash putting autocast directly into the forward call, wrapping the code found here with `torch.cuda.amp.autocast`:
https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bart.py#L419
and turning off `--fp16`. Haven't been able to investigate further into why memory isn't being freed in this block!<|||||>Thank you for looking into it, @SeanNaren!
> Don't think this is a trainer issue
If it's an issue of `autocast` cache then it is by definition a PL issue - since it's the one managing it - but let's see what @ptrblck and @mcarilli say about what's the correct approach of taking advantage of native amp w/ incurring unreasonable increased memory demands.
Surely there must be a way to manage it efficiently, and if caching is bad for whatever reason (application specific?) - there must be a way to turn it off in first place, rather than wasting resources/time copying/deleting it repeatedly.
> Haven't been able to investigate further into why memory isn't being freed in this block!
@ptrblck and I already did - it's the `autocast` cache (at least a huge part of it). See https://github.com/huggingface/transformers/issues/8403#issuecomment-725562117<|||||>Thanks @stas00! Any idea why within that block of code I posteted above that the autocast cache is not being freed? Btw if you wrap that particular section with `with torch.cuda.amp.autocast(enabled=False)`, the code runs (which I assume just turns off autocast functionality for that region of code). <|||||>@SeanNaren, if PL still invokes the `autocast` context then this sub-context it won't free the cache on its exit. It will only free it when the most outer context will exit. You will have to remove the `autocast` call in PL for this to work.<|||||>Updates so far:
It appears that `autocast` is not designed to handle a massive number of `forward` calls in a single context - it caches them all! If I understand it correctly, it has to be called as close as possible to the first `forward` call that actually needs the casting. Currently, in `finetune.py` we end up with PL calling `autocast` on `SummarizationModule` which has nothing to do with pytorch math (i.e. needs no casting), which then goes through a massive logic of generate/beam_search which again has nothing to do with math, and only when it hits `BartForConditionalGeneration`'s `forward` we need the `autocast`.
The problem is that `generate` (which already runs under `autocast` via PL - so caching is on) ends up calling `BartForConditionalGeneration`'s `forward` 100s of times, and every such call in the debug example was adding 200MB - so in 100 calls for beam search of size 4 it accumulated 20GB - we have a big problem.
So a workaround suggested by @ptrblck is to call
```
if torch.autocast_enabled:
torch.clear_autocast_cache()
```
inside `BartForConditionalGeneration.forward` - but ideally it should be called in a more generic way in `generation_utils` `while` loop ([here](https://github.com/huggingface/transformers/blob/121c24efa4453e4e726b5f0b2cf7095b14b7e74e/src/transformers/generation_utils.py#L954)), so that it works for any `transformers` model:
```
while cur_len < max_length:
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
if torch.is_autocast_enabled():
torch.clear_autocast_cache()
outputs = self(**model_inputs, return_dict=True)
```
but this is clearly far from optimal as a lot of resources will be wasted on filling the cache and immediately emptying it.
(Perhaps there is a way to disable the cache completely, but I don't know about its performance implications).
So a more efficient solution would be to `autocast` here instead:
```
while cur_len < max_length:
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
if somehow_we_know_autocast_should_be_used():
with autocast():
outputs = self(**model_inputs, return_dict=True)
else:
outputs = self(**model_inputs, return_dict=True)
```
but we have two issues here:
1. we have a problem if someone invoked `autocast()` sooner - e.g. as PL or HF trainer do it now. As this will defeat the purpose and the cache will blow up again. There is no cache-per-context, but only a single cache, regardless of whether the contexts are stacked. The outer call defines the scope for the cache and it'll clear only on the exit of that call. So the `autocast` call above for all means and purposes is a no-op if `autocast` has already been called in earlier frames.
2. now we are mixing trainer logic with the middle-layer (`generate` is neither a trainer nor a model - it's in between, and `SummarizationModule` in `finetune.py` is definitely not a model, but more of a trainer). How would `generation_utils` know about `somehow_we_know_autocast_should_be_used()`?
At this point since the problem is better understood I invite @LysandreJik, @patrickvonplaten, @sgugger and others to chime in and suggest how to move forward.<|||||>I found at least part of the culprit or trigger of the leak - it's `@torch.no_grad()` used for `generate` https://github.com/huggingface/transformers/blob/eb3bd73ce35bfef56eeb722d697f2d39a06a8f8d/src/transformers/generation_utils.py#L281-L282
Here is a short script that reproduces the leakage. It removes all the generate/search logic and feeds the same random input_ids to `BartForConditionalGeneration` pre-trained model.
Please first run:
```
pip install ipyexperiments
```
to get the memory tracing, but feel free to disable it if for some reason it's not working for you. (it should)
```
#!/usr/bin/env python
import os
import sys
import torch
os.environ["USE_TF"] = "0"
sys.path.insert(1, "src")
# !pip install ipyexperiments
from ipyexperiments.utils.mem import gpu_mem_get_used_mbs, gpu_mem_get_used_no_cache_mbs
from transformers import BartForConditionalGeneration
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = BartForConditionalGeneration.from_pretrained('sshleifer/student_cnn_12_6').to(device)
model.eval()
vocab_size = 50264 # model.config.vocab_size
length = 10
AUTOCAST = False if "-f" in sys.argv else True
print(f"autocast: {AUTOCAST}")
class MemReport():
def __init__(self, gc_collect=True):
self.get_mem = gpu_mem_get_used_no_cache_mbs if gc_collect else gpu_mem_get_used_mbs
self.cur = self.get_mem()
def delta(self, id):
peak = torch.cuda.memory_stats()["allocated_bytes.all.peak"]
print(f"{id}: {gpu_mem_get_used_mbs()-self.cur}MB (peak {peak>>20}MB)")
self.cur = self.get_mem()
mr = MemReport(gc_collect=False)
### reproducible code starts here ###
@torch.no_grad()
def logic():
input_ids = torch.randint(vocab_size, (1,length)).to(device)
mr.delta(0)
for i in range(1,10):
outputs = model(input_ids)
mr.delta(i)
if AUTOCAST:
with torch.cuda.amp.autocast():
logic()
else:
logic()
```
So if I run it with `-f` which disables `autocast`, I get:
```
./reproduce.py -f
autocast: False
0: 0MB (peak 1165MB)
1: 12MB (peak 1167MB)
2: 0MB (peak 1169MB)
3: 0MB (peak 1169MB)
4: 0MB (peak 1169MB)
5: 0MB (peak 1169MB)
6: 0MB (peak 1169MB)
7: 0MB (peak 1169MB)
8: 0MB (peak 1169MB)
9: 0MB (peak 1169MB)
```
no leak.
If however I remove `-f` and `autocast` gets enabled, we get:
```
./reproduce.py -f
autocast: True
0: 0MB (peak 1165MB)
1: 592MB (peak 1744MB)
2: 580MB (peak 2324MB)
3: 580MB (peak 2902MB)
4: 580MB (peak 3480MB)
5: 580MB (peak 4058MB)
6: 580MB (peak 4636MB)
7: 580MB (peak 5214MB)
8: 580MB (peak 5793MB)
9: 580MB (peak 6371MB)
```
the memory logger prints the delta for each `forward` call in the loop and the peak memory.
You can see that we are leaking 600Mb per forward call here.
If I comment out `@torch.no_grad()`, the total memory usage doubles but there is no leak:
```
autocast: True
0: 0MB (peak 1165MB)
1: 602MB (peak 1754MB)
2: 590MB (peak 2343MB)
3: 0MB (peak 2343MB)
4: 0MB (peak 2343MB)
5: 0MB (peak 2343MB)
6: 0MB (peak 2343MB)
7: 0MB (peak 2343MB)
8: 0MB (peak 2343MB)
9: 0MB (peak 2343MB)
```
I was using pycharm to debug this and to write a small script and boy it got me so delayed as it leaks gpu ram on its own, since it has to save all those variables on cuda, but I wasn't aware of it. Well, now I know not to do that. Luckily I had https://github.com/stas00/ipyexperiments handy to give me easy memory tracing.
Note I'm importing two gpu mem tracking functions - one of them clears cuda cache - but here it appears it's better not use that version. <|||||>One other issue to look into is that what happens under `autocast` to weights that are deterministic (such as positional weights [SinusoidalPositionalEmbedding](https://github.com/huggingface/transformers/blob/24184e73c441397edd51e9068e0f49c0418d25ab/src/transformers/modeling_bart.py#L1340)) as these are set with `requires_grad = False`.
Seeing how the caching logic [works](https://github.com/pytorch/pytorch/blob/21f447ee2c6ebbd72b6c3608c4df17c74edd4784/aten/src/ATen/autocast_mode.cpp#L69-L71):
```
bool can_try_cache = (to_type == at::kHalf && arg.scalar_type() == at::kFloat && arg.requires_grad() && arg.is_leaf());
```
the conversion of these to fp16 will not be cached if I read the code correctly. This probably belongs to a separate issue though.<|||||>I think for it to get the full attention of pytorch devs it's the best for us to continue this discussion at pytorch, so I opened the ticket there: https://github.com/pytorch/pytorch/issues/48049<|||||>Great, thanks a lot for your thorough investigation @stas00 !<|||||>a fix has been applied to pytorch-nightly https://github.com/pytorch/pytorch/pull/48696 which fixes
https://github.com/pytorch/pytorch/issues/48049 and I verified with pytorch-nightly this issue to no longer leak memory under native amp.
Please note that this change is going to be available in pytorch-1.8 - so until then native amp and transformers aren't going to play well at times. Until then the solution is to use apex.
**edit**: good news it seems that pytorch-1.7.1 will have this fix too! https://github.com/pytorch/pytorch/issues/48049#issuecomment-742790722
<|||||>> Thank you for validating that, @sshleifer. So it really has something to do with the native amp in pytorch.
>
> Here is the summary of my experiments:
>
> * pt15 + confa-force apex w/ `--fp16` works at the start - reduces memory consumption
> * pt16 + conda-forge apex w/ `--fp16 --amp_backend='apex'` works at the start too!
>
> but both fail at the end with:
>
> ```
> File "python3.8/site-packages/apex/amp/_amp_state.py", line 32, in warn_or_err
> raise RuntimeError(msg)
> RuntimeError: Found param model.model.shared.weight with type torch.cuda.HalfTensor, expected torch.cuda.FloatTensor.
> When using amp.initialize, you do not need to call .half() on your model
> ```
>
> If I use `--fp16_opt_level O1`, the failure changes to:
>
> ```
> File "python3.8/site-packages/torch/optim/lr_scheduler.py", line 56, in with_counter
> instance_ref = weakref.ref(method.__self__)
> AttributeError: 'function' object has no attribute '__self__'
> ```
>
> both envs use the binary apex from `conda-forge`
>
> * apex doesn't support cuda11 at the moment
> * rtx-30* cards don't support cuda<11 (and really cuda<11.1).
> * ubuntu-20.4 doesn't support cuda<11, since it dropped gcc7, so can't build apex from source even for cuda-10
>
> Bottom line, apex is not a great option at the moment, but may work for some short term - need to sort out native amp.
>
> I will poke at it with debugger today.
I encountered the same issue with "AttributeError: 'function' object has no attribute '__self__' when I tried to use "--fp16_opt_level O1" with pt15 + nvidia apex. Any solution to get around this? Or how to get it to work with nvidia-apex without installing torch-nightly? <|||||>Could you please post a new issue, @XiangLi1999 - this one already has too many comments - and you're asking a related but a totally different question. Thank you!
You can tag me on it, and we can discuss it there. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.