
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 2,291 | closed | Fix F841 flake8 warning | This PR completes the "fix all flake8 warnings" effort of the last few days.
There's a lot of judgment in the fixes here: when the result of an expression is assigned to a variable that isn't used:
- if the expression has no side effect, then it can safely be removed
- if the expression has side effects, then it must be kept and only the assignment to a variable must be removed
- or it may be a coding / refactoring mistake that results in a badly named variable
I'm not sure I made the right call in all cases, so I would appreciate a review.
E203, E501, W503 are still ignored because they're debatable, black disagrees with flake8, and black wins (by not being configurable). | 12-23-2019 21:42:39 | 12-23-2019 21:42:39 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2291?src=pr&el=h1) Report
> Merging [#2291](https://codecov.io/gh/huggingface/transformers/pull/2291?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/072750f4dc4f586cb53f0face4b4a448bb0cdcac?src=pr&el=desc) will **decrease** coverage by `1.18%`.
> The diff coverage is `50%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2291?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2291 +/- ##
==========================================
- Coverage 74.45% 73.26% -1.19%
==========================================
Files 85 85
Lines 14608 14603 -5
==========================================
- Hits 10876 10699 -177
- Misses 3732 3904 +172
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2291?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [...c/transformers/modeling\_tf\_transfo\_xl\_utilities.py](https://codecov.io/gh/huggingface/transformers/pull/2291/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl90cmFuc2ZvX3hsX3V0aWxpdGllcy5weQ==) | `86.13% <ø> (+0.84%)` | :arrow_up: |
| [src/transformers/modeling\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/2291/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19hbGJlcnQucHk=) | `78.86% <ø> (-0.18%)` | :arrow_down: |
| [src/transformers/data/metrics/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/2291/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL21ldHJpY3MvX19pbml0X18ucHk=) | `27.9% <ø> (ø)` | :arrow_up: |
| [src/transformers/modeling\_tf\_pytorch\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2291/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9weXRvcmNoX3V0aWxzLnB5) | `8.72% <0%> (-81.28%)` | :arrow_down: |
| [src/transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/2291/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190NS5weQ==) | `81.05% <100%> (ø)` | :arrow_up: |
| [src/transformers/modeling\_tf\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/2291/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl90NS5weQ==) | `96.54% <100%> (ø)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2291/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `93.12% <66.66%> (ø)` | :arrow_up: |
| [src/transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2291/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19yb2JlcnRhLnB5) | `54.1% <0%> (-10.15%)` | :arrow_down: |
| [src/transformers/modeling\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2291/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ194bG5ldC5weQ==) | `71.19% <0%> (-2.32%)` | :arrow_down: |
| ... and [5 more](https://codecov.io/gh/huggingface/transformers/pull/2291/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2291?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2291?src=pr&el=footer). Last update [072750f...3e0cf49](https://codecov.io/gh/huggingface/transformers/pull/2291?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,290 | closed | duplicated line for repeating_words_penalty_for_language_generation | length_penalty has a duplicated wrong documentation for language generation -> delete two lines | 12-23-2019 20:51:17 | 12-23-2019 20:51:17 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2290?src=pr&el=h1) Report
> Merging [#2290](https://codecov.io/gh/huggingface/transformers/pull/2290?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/aeef4823ab6099249679756182700e6800024c36?src=pr&el=desc) will **decrease** coverage by `<.01%`.
> The diff coverage is `0%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2290?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2290 +/- ##
==========================================
- Coverage 73.49% 73.48% -0.01%
==========================================
Files 87 87
Lines 14793 14794 +1
==========================================
Hits 10872 10872
- Misses 3921 3922 +1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2290?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2290/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `63.34% <0%> (-0.12%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2290?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2290?src=pr&el=footer). Last update [aeef482...0f6017b](https://codecov.io/gh/huggingface/transformers/pull/2290?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Yes, actually the doc is still not complete for this new feature.
We should add some examples and double-check all. Feel free to clean this up if you feel like it.<|||||>clean up documentation, add examples for documentation and rename some variables<|||||>checked example generation for openai-gpt, gpt2, xlnet and xlm in combination with #2289.
<|||||>Also checked for ctrl<|||||>also checked for transfo-xl<|||||>Awesome, merging! |
transformers | 2,289 | closed | fix bug in prepare inputs for language generation for xlm for effective batch_size > 1 | if multiple sentence are to be generated the masked tokens to be appended have to equal the effective batch size | 12-23-2019 20:46:49 | 12-23-2019 20:46:49 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2289?src=pr&el=h1) Report
> Merging [#2289](https://codecov.io/gh/huggingface/transformers/pull/2289?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/81db12c3ba0c2067f43c4a63edf5e45f54161042?src=pr&el=desc) will **decrease** coverage by `0.01%`.
> The diff coverage is `0%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2289?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2289 +/- ##
==========================================
- Coverage 73.54% 73.52% -0.02%
==========================================
Files 87 87
Lines 14789 14792 +3
==========================================
Hits 10876 10876
- Misses 3913 3916 +3
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2289?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/2289/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ194bG0ucHk=) | `86.23% <0%> (-0.23%)` | :arrow_down: |
| [src/transformers/modeling\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2289/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ194bG5ldC5weQ==) | `73.26% <0%> (-0.25%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2289?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2289?src=pr&el=footer). Last update [81db12c...f18ac4c](https://codecov.io/gh/huggingface/transformers/pull/2289?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Indeed, thanks @patrickvonplaten |
transformers | 2,288 | closed | Improve handling of optional imports | 12-23-2019 20:30:53 | 12-23-2019 20:30:53 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2288?src=pr&el=h1) Report
> Merging [#2288](https://codecov.io/gh/huggingface/transformers/pull/2288?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/23dad8447c8db53682abc3c53d1b90f85d222e4b?src=pr&el=desc) will **increase** coverage by `0.2%`.
> The diff coverage is `100%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2288?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2288 +/- ##
=========================================
+ Coverage 74.27% 74.47% +0.2%
=========================================
Files 85 85
Lines 14610 14608 -2
=========================================
+ Hits 10851 10879 +28
+ Misses 3759 3729 -30
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2288?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/tokenization\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdDUucHk=) | `93.93% <ø> (ø)` | :arrow_up: |
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `63.91% <ø> (ø)` | :arrow_up: |
| [src/transformers/commands/train.py](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb21tYW5kcy90cmFpbi5weQ==) | `0% <ø> (ø)` | :arrow_up: |
| [src/transformers/tokenization\_albert.py](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYWxiZXJ0LnB5) | `89.1% <ø> (ø)` | :arrow_up: |
| [src/transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9waXBlbGluZXMucHk=) | `68.31% <ø> (+2.32%)` | :arrow_up: |
| [src/transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL3Byb2Nlc3NvcnMvc3F1YWQucHk=) | `29.37% <ø> (ø)` | :arrow_up: |
| [src/transformers/data/processors/utils.py](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL3Byb2Nlc3NvcnMvdXRpbHMucHk=) | `19.6% <ø> (ø)` | :arrow_up: |
| [src/transformers/tokenization\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25feGxtLnB5) | `83.26% <ø> (ø)` | :arrow_up: |
| [src/transformers/data/metrics/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL21ldHJpY3MvX19pbml0X18ucHk=) | `27.9% <ø> (-3.21%)` | :arrow_down: |
| [src/transformers/tokenization\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25feGxuZXQucHk=) | `89.9% <ø> (ø)` | :arrow_up: |
| ... and [7 more](https://codecov.io/gh/huggingface/transformers/pull/2288/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2288?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2288?src=pr&el=footer). Last update [23dad84...4621ad6](https://codecov.io/gh/huggingface/transformers/pull/2288?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
|
transformers | 2,287 | closed | Do Hugging Face GPT-2 Transformer Models Automatically Does the Absolute Position Embedding for Users? | Hello,
According to Hugging Face ```GPT2DoubleHeadsModel``` documentation (https://huggingface.co/transformers/model_doc/gpt2.html#gpt2doubleheadsmodel)
```
"Indices of input sequence tokens in the vocabulary.
GPT-2 is a model with absolute position embeddings"
```
So does this mean that, when we implement any Hugging Face GPT-2 Models (```GPT2DoubleHeadsModel```,```GPT2LMHeadsModel```, etc.) via the ```model( )``` statement, the 'absolute position embedding' is _automatically_ done for the user, so that the user actually does not need to specify anything in the ```model( )``` statement to ensure the absolute position embedding?
If the answer is 'yes', then why do we have an option of specifying ```position_ids``` in the ```model( )``` statement?
Thank you,
| 12-23-2019 18:42:50 | 12-23-2019 18:42:50 | Indeed, as you can see from the source code [here](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_gpt2.py#L414-L417), when no position ids are passed, they are created as absolute position embeddings.
You could have trained a model with a GPT-2 architecture that was using an other type of position embeddings, in which case passing your specific embeddings would be necessary. I'm sure several other use-cases would make sure of specific position embeddings.<|||||>Ooohh, ok,
so to clarify, absolute position embedding _**is automatically done**_ by the ```model( )``` statement, but if we want to use our custom position embedding (i.e. other than the absolute position embedding), we can use the ```position_ids``` option inside the ```model( )``` statement......is what I said above correct?
Thank you,<|||||>Yes, that is correct!<|||||>Thank you :) ! |
transformers | 2,286 | closed | Typo in tokenization_utils.py | avoir -> avoid | 12-23-2019 17:15:01 | 12-23-2019 17:15:01 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2286?src=pr&el=h1) Report
> Merging [#2286](https://codecov.io/gh/huggingface/transformers/pull/2286?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/23dad8447c8db53682abc3c53d1b90f85d222e4b?src=pr&el=desc) will **increase** coverage by `0.18%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2286?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2286 +/- ##
==========================================
+ Coverage 74.27% 74.45% +0.18%
==========================================
Files 85 85
Lines 14610 14610
==========================================
+ Hits 10851 10878 +27
+ Misses 3759 3732 -27
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2286?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2286/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `92.08% <ø> (+0.77%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2286/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `93.12% <0%> (+1.58%)` | :arrow_up: |
| [src/transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/2286/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9waXBlbGluZXMucHk=) | `68.31% <0%> (+2.32%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2286/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hdXRvLnB5) | `32.14% <0%> (+7.14%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2286?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2286?src=pr&el=footer). Last update [23dad84...7cef764](https://codecov.io/gh/huggingface/transformers/pull/2286?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,285 | closed | BertTokenizer custom UNK unexpected behavior | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [X] my own modified scripts: (give details)
Importing transformers to my own project but using BertTokenizer and BertModel with pretrained weights, using 'bert-base-multilingual-cased' for both tokenizer and model.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details)
Fine tuning BERT for English NER on a custom news dataset.
## To Reproduce
Steps to reproduce the behavior:
1. Initialize a tokenizer with custom UNK
2. Try to convert the custom UNK to ID
3. Receive None as
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
```
>>>tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased', do_lower_case=False, pad_token="<pad>", unk_token="<unk>")
>>> tokenizer.tokenize("<unk>")
['<unk>']
>>> tokenizer.convert_tokens_to_ids(["<unk>"])
[None]
```
## Expected behavior
My custom UNK should have an ID. (instead, I get None)
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Mac OSX
* Python version: 3.7.3
* PyTorch version: 1.1.0.post2
* PyTorch Transformers version (or branch): 2.1.1
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| 12-23-2019 15:12:29 | 12-23-2019 15:12:29 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>I actually have the same problem with GPT-2 tokenizer. Is this the expected behavior? |
transformers | 2,284 | closed | [ALBERT]: Albert base model itself consuming 32 GB GPU memory.. | ## 🐛 Bug
<!-- Important information -->
Model I am using TFALBERT:
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts:
`from transformers import TFAlbertForSequenceClassification`
`model = TFAlbertForSequenceClassification.from_pretrained('albert-base-v2')`
After this GPU memory is consumed almost 32 GB.... base V2 is model is roughly around 50 MB which is occupying 32 GB on GPU

## Environment
* OS: Linux
* Python version: 3.7
| 12-23-2019 14:48:14 | 12-23-2019 14:48:14 | i have similar situation.
https://github.com/dsindex/iclassifier#emb_classalbert
in the paper( https://arxiv.org/pdf/1909.11942.pdf ), ALBERT xlarge has just 60M parameters which is much less than BERT large(334M)'s.
but, we are unable to load albert-xlarge-v2 on 32G GPU memory.
(no problem on bert-large-uncased, bert-large-cased)<|||||>A similar situation happened to me too.
While fine-tuning Albert base on SQuAD 2.0, I had to lower the train batch size to manage to fit the model on 2x NVIDIA 1080 Ti, for a total of about 19 GB used.
I find it quite interesting and weird as the same time, as I managed to fine-tune BERT base on the same dataset and the same GPUs using less memory...<|||||>Same for the pytorch version of ALBERT, where my 8/11GB GPU could run BERT_base and RoBERTa.<|||||>Interesting, I started to hesitate on using this ALBERT implementation but hope it will be fixed soon.<|||||>Indeed, I can reproduce for the TensorFlow version. I'm looking into it, thanks for raising this issue.<|||||>@jonanem, if you do this at the beginning of your script, does it change the amount of memory used?
```py
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_virtual_device_configuration(
gpus[0],
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=1024)]
)
```
This should keep the amount of memory allocated to the model to 1024MB, with possibility to grow if need be. Initializing the model after this only uses 1.3GB of VRAM on my side. Can you reproduce?
See this for more information: [limiting gpu memory growth](https://www.tensorflow.org/guide/gpu#limiting_gpu_memory_growth)<|||||>@LysandreJik I just did some investigation and I found a similar problem with the Pytorch implementation.
Model: ALBERT base v2, fine tuning on SQuAD v2 task
I used the official code from Google Tensorflow repository and I managed to fine tune it on a single GTX 1080 Ti, with batch size 16 and memory consumption of about 10 GB.
Then, I used transformers Pytorch implementation and did the same task on 4x V100 on AWS, with total batch size 48 and memory consumption of 52 GB (about 13 GB per GPU).
Now, putting it in perspective, I guess the memory consumption of the Pytorch implementation is 10/15 GB above what I was expecting. Is this normal?
In particular, where in the code is there the Embedding Factorization technique proposed in the official paper?<|||||>Hi @matteodelv, I ran a fine-tuning task on ALBERT (base-v2) with the parameters you mentioned: batch size of 16. I end up with a VRAM usage of 11.4GB, which is slightly more than the official Google Tensorflow implementation you mention. The usage is lower than when using BERT, which has a total usage of 14GB.
However, when loading the model on its own without any other tensors, taking into account the pytorch memory overhead, it only takes about 66MB of VRAM.
Concerning your second question, here is the definition of the Embedding Factorization technique proposed in the official paper: `[...] The first one is a factorized embedding parameterization. By decomposing
the large vocabulary embedding matrix into two small matrices, we separate the size of the hidden
layers from the size of vocabulary embedding.`
In this PyTorch implementation, there are indeed two smaller matrices so that the two sizes may be separate. The first embedding layer is visible in [the `AlbertEmbeddings` class](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_albert.py#L172), and is of size `(vocab_size, embedding_size)`, whereas the second layer is visible in [the `AlbertTransformer` class](https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_albert.py#L317), with size `(embedding_size, hidden_size)`.<|||||>Thanks for your comment @LysandreJik... I haven't looked in the `AlbertTransformer` class for the embedding factorization.
However, regarding the VRAM consumption, I'm still a bit confused about it.
I don't get why the same model with a batch size 16 consumes about 10/11 GB on a single GPU while the same training, on 4 GPUs (total batch size 48, so it's 12 per GPUs) requires more memory.
Could you please check this? May it be related to Pytorch's `DataParallel`?<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Did @matteodelv @LysandreJik find any issue or solution for this? The memory consumption given the parameter is insane<|||||>Unfortunately not. I had to tune hyperparameters or use other hardware with more memory. But I was using an older version... I haven't checked if the situation has changed since then.<|||||>Hey,
I tried running on GTX 1080 (10GB) bert-base-uncased with **sucess** on IMDB dataset with a batch-size equal to 16 and sequence length equal to 128.
Running albert-base-v2 with the same sequence length and same batch size is giving me Out-of-memory issues.
I am using pytorch, so I guess I have the same problem as you guys here.<|||||>Same issue. ALBERT raises OOM requiring 32G. <|||||>ALBERT repeats the same parameters for each layer but increases each layer size, so even though it have fewer parameters than BERT, the memory needs are greater due to the much larger activations in each layer.<|||||>> ALBERT repeats the same parameters for each layer but increases each layer size, so even though it have fewer parameters than BERT, the memory needs are greater due to the much larger activations in each layer.
That is true, still there is need for more computation, but BERT can fit into 16G memory. I had my albert reimplemented differently and I could fit its weights on a 24G gpu.<|||||>> ALBERT repeats the same parameters for each layer but increases each layer size, so even though it have fewer parameters than BERT, the memory needs are greater due to the much larger activations in each layer.
Thanks for this explanation, which saves my life. |
transformers | 2,283 | closed | Loading sciBERT failed | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I am trying to compare the effect of different pre-trained models on RE, the code to load bert is:
`self.bert = BertModel.from_pretrained(pretrain_path)`
When the "pretrain_path" is "pretrain/bert-base-uncased" , everything is fine, but after i changed it to "pretrain/scibert-uncased", i got error:
`-OSError: Model name 'pretrain/scibert-uncased' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese, bert-base-german-cased, bert-large-uncased-whole-word-masking, bert-large-cased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad, bert-large-cased-whole-word-masking-finetuned-squad, bert-base-cased-finetuned-mrpc, bert-base-german-dbmdz-cased, bert-base-german-dbmdz-uncased). We assumed 'pretrain/scibert-uncased/config.json' was a path or url to a configuration file named config.json or a directory containing such a file but couldn't find any such file at this path or url.`
The scibert is pytorch model and the two directories are same in structure.
It seems that if the model name is not in the name list, it won't work.
Thank you very much! | 12-23-2019 14:20:53 | 12-23-2019 14:20:53 | Try to use the following commands:
```bash
$ wget "https://s3-us-west-2.amazonaws.com/ai2-s2-research/scibert/huggingface_pytorch/scibert_scivocab_uncased.tar"
$ tar -xf scibert_scivocab_uncased.tar
The sciBERT model is now extracted and located under: `./scibert_scivocab_uncased`.
To load it:
```python
from transformers import BertModel
model = BertModel.from_pretrained("./scibert_scivocab_uncased")
model.eval()
```
This should work 🤗<|||||>> Try to use the following commands:
>
> ```shell
> $ wget "https://s3-us-west-2.amazonaws.com/ai2-s2-research/scibert/huggingface_pytorch/scibert_scivocab_uncased.tar"
> $ tar -xf scibert_scivocab_uncased.tar
>
> The sciBERT model is now extracted and located under: `./scibert_scivocab_uncased`.
>
> To load it:
>
> ```python
> from transformers import BertModel
>
> model = BertModel.from_pretrained("./scibert_scivocab_uncased")
> model.eval()
> ```
>
> This should work 🤗
It works! Thank you very much! |
transformers | 2,282 | closed | Maybe some parameters are error in document for distributed training ? | Based on [Distributed training document](https://huggingface.co/transformers/examples.html#id1) , one can use `bert-base-cased` model to fine-tune MR model and reaches very high score.
> Here is an example using distributed training on 8 V100 GPUs and Bert Whole Word Masking uncased model to reach a F1 > 93 on SQuAD1.0:
```
python -m torch.distributed.launch --nproc_per_node=8 run_squad.py \
--model_type bert \
--model_name_or_path bert-base-cased \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v1.1.json \
--predict_file $SQUAD_DIR/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ../models/wwm_uncased_finetuned_squad/ \
--per_gpu_train_batch_size 24 \
--gradient_accumulation_steps 12
```
```
f1 = 93.15
exact_match = 86.91
```
**But based on [google bert repo](https://github.com/google-research/bert#squad-11) , the model `bert-base-cased` perfermance is**
```
{"f1": 88.41249612335034, "exact_match": 81.2488174077578}
```
Maybe the right pretrained model is `bert-large-uncased` ?
Thanks~ | 12-23-2019 13:08:03 | 12-23-2019 13:08:03 | |
transformers | 2,281 | closed | Add Dutch pre-trained BERT model | We trained a Dutch cased BERT model at the University of Groningen.
Details are on [Github](https://github.com/wietsedv/bertje/) and [Arxiv](https://arxiv.org/abs/1912.09582). | 12-23-2019 12:40:56 | 12-23-2019 12:40:56 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2281?src=pr&el=h1) Report
> Merging [#2281](https://codecov.io/gh/huggingface/transformers/pull/2281?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ba2378ced560c12f8ee97ca7998fd28b93fcfb47?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2281?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2281 +/- ##
=======================================
Coverage 74.45% 74.45%
=======================================
Files 85 85
Lines 14610 14610
=======================================
Hits 10878 10878
Misses 3732 3732
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2281?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/tokenization\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2281/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYmVydC5weQ==) | `96.34% <ø> (ø)` | :arrow_up: |
| [src/transformers/configuration\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2281/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2JlcnQucHk=) | `100% <ø> (ø)` | :arrow_up: |
| [src/transformers/modeling\_tf\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2281/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9iZXJ0LnB5) | `96.26% <ø> (ø)` | :arrow_up: |
| [src/transformers/modeling\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2281/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19iZXJ0LnB5) | `87.7% <ø> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2281?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2281?src=pr&el=footer). Last update [ba2378c...5eb71e6](https://codecov.io/gh/huggingface/transformers/pull/2281?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Hi @wietsedv! Did you try loading your tokenizer/model directly, cf. https://huggingface.co/wietsedv/bert-base-dutch-cased
i.e. It should work out-of-the-box using:
```python
tokenizer = AutoTokenizer.from_pretrained("wietsedv/bert-base-dutch-cased")
model = AutoModel.from_pretrained("wietsedv/bert-base-dutch-cased")
tf_model = TFAutoModel.from_pretrained("wietsedv/bert-base-dutch-cased")
```
Let us know if it's not the case (we can still merge this PR to have a nice shortcut inside the code but feature-wise it should be equivalent)<|||||>Hi! Thanks for your response. I did notice that I can use that snippet and I can confirm it works. I am however not sure whether cased tokenization works correctly that way. Correct me if I am wrong, but it seems that Transformers always lowercases unless that is explicitly disabled. I did disable it in this PR, which makes it work correctly out of the box. But I think lowercasing is enabled by default if people use the snippet above.
Please correct my if I am wrong.<|||||>We'll check, thanks for the report.<|||||>Just a note: I absolutely love seeing a Dutch version of BERT but this isn't the only BERT model out there. As you mention in your paper, there's also [BERT-NL](http://textdata.nl/). You seem to claim that it performs a lot worse than your version and that it is even outperformed by multilingual BERT. At first glance I don't see any written-down experiments confirming that claim - a comparison between BERTje, BERT-NL, and multilingual BERT on down-stream tasks would've been much more informative. (BERT-NL will be presented at the largest computational linguistics conference on Dutch (Computational Linguistics in the Netherlands; CLIN) at the end of the month, so presumably it does carry some weight.)
All this to say: why does your version deserve to be "the" `bert-base-dutch-cased` model if there is an alternative? Don't get me wrong, I really value your research, but a fair and full comparison is missing.<|||||>It is correct that there is another Dutch model and we do full fine-tuning results of this model. These numbers were included in an earlier draft of our paper, but we removed it since they did not add any value. For instance for named entity recognition (conll2002), multilingual BERT achieves about 80% accuracy, our BERT model about 88% and their BERT model just 41%.
More detailed comparison with their model would therefore not add any value since the scores are too low. The authors have not made any claims about model performance yet, so it would have been unfair to be too negative about their model before they have even released any paper.
Someone at Leiden has confirmed that their experiments also showed that they were outperformed by multilingual BERT. Therefore I think that our BERT model is the only _effective_ Dutch BERT model.
PS: The entry barrier for CLIN is not extremely high. The reason we are not presenting at CLIN is that we missed the deadline. <|||||>I think it is in fact very useful information to see such huge difference. This way readers are not confronted with the same question that I posed before: there are two Dutch BERT models - but which one should I use/which one is better? You now clarify it to me, for which I am grateful, but a broader audience won't know. I think the added value is great. However, I do agree that is hard and perhaps unfair to compare to a model that hasn't been published/discussed yet. (Then again, their model is available online so they should be open to criticism.)
The CLIN acceptance rate is indeed high, and the follow-up CLIN Journal is also not bad. Still, what I was aiming for is peer review. If I were to review the BERT-NL (assuming they will submit after conference and assuming I was a reviewer this year), then I would also mention your model and ask for a comparison. To be honest, I put more faith in a peer reviewed journal/conference than arXiv papers.
I really don't want to come off as arrogant and I very much value your work, but I am trying to approach this from a person who is just getting started with this kind of stuff and doesn't follow the trends or what is going on in the field. They might find this model easily available in the Transformers hub, but then they might read in a journal (possibly) about BERT-NL - which then is apparently different from the version in Transformers. On top of that, neither paper (presumably) refers or compares to the other! Those people _must be confused_ by that.
The above wall of text just to say that I have no problem with your model being "the" Dutch BERT model because it seems to clearly be the best one, but that I would very much like to see reference/comparison to the other model in your paper so that it is clear to the community what is going on with these two models. I hope that the authors of BERT-NL do the same. Do you have any plans to submit a paper somewhere?<|||||>Thanks for your feedback and clear explanation. We do indeed intend to submit a long paper somewhere. The short paper on arxiv is mainly intended for reference and to demonstrate that the model is effective with some benchmarks. Further evaluation would be included in a longer paper.<|||||>The authors of BERT-NL have reported results which can be compared to Bertje, see https://twitter.com/suzan/status/1200361620398125056
Also see the results in this thread https://twitter.com/danieldekok/status/1213378688563253249 and https://twitter.com/danieldekok/status/1213741132863156224
In both cases, Bertje does outperform BERT-NL. On the other hand, the results about Bertje vs multilingual BERT are different, so this needs to be investigated further.<|||||>I think @BramVanroy raises some good points about naming convention.
In my opinion the organization name or author name should come after the "bert-base-<language>" skeleton.
So it seems that BERTje is current SOTA now. But: on the next conference maybe another BERT model for Dutch is better... I'm not a fan of the "First come, first served" principle here 😅
/cc @thomwolf , @julien-c <|||||>> On the other hand, the results about Bertje vs multilingual BERT are different, so this needs to be investigated further.
Agreed. Tweeting results of doing "tests" is one thing, but actual thorough investigating and reporting is something else. It has happened to all of us that you quickly wanted to check something and only later realized that you made a silly mistake. (My last one was forgetting the `-` in my learning rate and not noticing it, oh boy what a day.) As I said before I would really like to a see a thorough, reproducible comparison of BERTje, BERT-NL, and multilingual BERT, and I believe that that should be the basis of any new model. Many new models sprout from the community grounds - and that's great! - but without having at least _some_ reference and comparison, it is guess-work trying to figure out which one is best or which one you should use.
> I think @BramVanroy raises some good points about naming convention.
>
> In my opinion the organization name or author name should come after the "bert-base-" skeleton.
>
> So it seems that BERTje is current SOTA now. But: on the next conference maybe another BERT model for Dutch is better... I'm not a fan of the "First come, first served" principle here 😅
>
> /cc @thomwolf , @julien-c
Perhaps it's better to just make the model available through the user and that's all? In this case, only make it available through `wietsedv/bert-base-dutch-cased` and not `bert-base-dutch-cased`? That being said, where do you draw the line of course. Hypothetical question: why does _a Google_ get the rights to make its weights available without a `google/` prefix, acting as a "standard"? I don't know how to answer that question, so ultimately it's up to the HuggingFace people.
I'm also not sure how diverging models would then work. If for instance you bring out a German BERT-derivative that has a slightly different architecture, or e.g. a different tokenizer, how would that then get integrated in Transformers? (For example, IIRC BERTje uses SOP instead of NSP, so that may lead to more structural changing in the available heads than just different weights.)
<|||||>I inherently completely agree with your points. I think the people at Huggingface are trying to figure out how to do this, but they have not been really consistent. Initially, the "official" models within Transformers were only original models (Google/Facebook) and it is unlikely that there would be competetition for better models with exactly the same architecture in English. But for other monolingual models this is different.
I prefer a curated list with pre-trained general models that has more structure than the long community models list. But existing shortcuts should be renamed to be consistent. German for instance has a regular named german and there is one with the `dbmdz` infix. And Finnish has for some reason the `v1` suffix?
My preference would be to always use `institution/` or `institution-` prefixes in the curated list. In Transformers 2.x, the current shortcuts could be kept for backward compatibility but a structured format should be used in the documentation. I think this may prevent many frustrations if even more non-english models are trained and even more people are wanting to use and trust (!) these models.<|||||>200% agree with that. That would be the fairest and probably clearest way of doing this. Curating the list might not be easy, though, unless it is curated by the community (like a wiki)? Perhaps requiring a description, website, paper, any other meta information might help to distinguish models as well, giving the authors a chance to explain, e.g., which data their model was trained on, which hyperparameters were used, and how their model differs from others.
I really like http://nlpprogress.com/ which "tracks" the SOTA across different NLP tasks. It is an open source list and anyone can contribute through github. Some kind of lists like this might be useful, but instead discussing the models. <|||||>You all raise excellent questions, many (most?) of which we don’t have a definitive answer to right now 🤗
Some kind of structured evaluation results (declarative or automated) could be a part of the solution. In addition to nlpprogress, sotabench/paperswithcode is also a good source of inspiration.
<|||||>On the previous point of being able to load the tokenizer's (remote) config correctly:
- I've added a `tokenizer_config.json` to your user namespace on S3: https://s3.amazonaws.com/models.huggingface.co/bert/wietsedv/bert-base-dutch-cased/tokenizer_config.json
- We're fixing the support for those remote tokenizer configs in https://github.com/huggingface/transformers/pull/2535 (you'll see that the unit test uses your model). Feedback welcome.<|||||>Merging this as we haven't seen other "better" BERT models for Dutch (coincidentally, [`RobBERT`](https://people.cs.kuleuven.be/~pieter.delobelle/robbert/) from @iPieter looks like a great RoBERTa-like model)
Please see [this discussion on model descriptions/README.md](https://github.com/huggingface/transformers/issues/2520#issuecomment-579009439). If you can upload a README.md with eval results/training methods, that'd be awesome.
Thanks! |
transformers | 2,280 | closed | Do anyone have solution for this | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
| 12-23-2019 10:50:38 | 12-23-2019 10:50:38 | |
transformers | 2,279 | closed | Help with finetune BERT pretraining | Hi
could you please assist me how I can pretrain the BERT model, so not like SNLI/MNLI when we finetune a pretrained model, but doing pretraining objective.
thanks a lot
and Merry Christmas and happy new year in advance to the team | 12-23-2019 10:35:49 | 12-23-2019 10:35:49 | I suggest you follow the [run_lm_finetuning.py](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py) script. Instead of downloading a pretrained model, simply start with a fresh one. Here's an example:
```
from transformers import BertModel, BertConfig, BertTokenizer
model = BertModel(BertConfig())
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
```
I personally don't have a reason to write my own tokenizer, but if you do feel free to do that as well. All you need to do is generate a vocab.txt file from your corpus.<|||||>You can now leave `--model_name_or_path` to None in `run_language_modeling.py` to train a model from scratch.
See also https://huggingface.co/blog/how-to-train |
transformers | 2,278 | closed | where is the script of a second step of knwoledge distillation on SQuAD 1.0? | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
In Distil part, there is a paragraph description which is "distilbert-base-uncased-distilled-squad: A finetuned version of distilbert-base-uncased finetuned using (a second step of) knwoledge distillation on SQuAD 1.0. This model reaches a F1 score of 86.9 on the dev set (for comparison, Bert bert-base-uncased version reaches a 88.5 F1 score)."
so where is the script of "a second step of knwoledge distillation on SQuAD 1.0" mentioned above?
Thanks a lot, it will be very helpful to me!
| 12-23-2019 09:13:26 | 12-23-2019 09:13:26 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>Check here: https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py |
transformers | 2,277 | closed | Does the calling order need to be changed? | ## ❓ Questions & Help
pytorch: 1.3.0
torch/optim/lr_scheduler.py:100: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule.See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
"https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
| 12-23-2019 08:30:10 | 12-23-2019 08:30:10 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,276 | closed | fix error due to wrong argument name to Tensor.scatter() | The named argument is called "source", not "src" in the out of place version for some reason, despite it being called "src" in the in-place version of the same Pytorch function. This causes an error. | 12-23-2019 07:19:41 | 12-23-2019 07:19:41 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2276?src=pr&el=h1) Report
> Merging [#2276](https://codecov.io/gh/huggingface/transformers/pull/2276?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ce50305e5b8c8748b81b0c8f5539a337b6a995b9?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `0%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2276?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2276 +/- ##
=======================================
Coverage 74.45% 74.45%
=======================================
Files 85 85
Lines 14610 14610
=======================================
Hits 10878 10878
Misses 3732 3732
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2276?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2276/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ191dGlscy5weQ==) | `63.91% <0%> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2276?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2276?src=pr&el=footer). Last update [ce50305...398bb03](https://codecov.io/gh/huggingface/transformers/pull/2276?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Thanks a lot for catching that @ShnitzelKiller!<|||||>I just realized that despite the official (current) documentation saying that the argument name is "source", after upgrading my pytorch version, this code is what throws an error saying the argument name is "src"! I should probably notify you to revert this pull request then. |
transformers | 2,275 | closed | Gpt2/xl Broken on "Write With Transformer" site | If you navigate to the [GPT-2 section of the Write With Transformer site](https://transformer.huggingface.co/doc/gpt2-large), select gpt2/xl, and try to generate text, the process will not generate anything. | 12-23-2019 05:26:28 | 12-23-2019 05:26:28 | Same problem. And it seems not fixed yet.<|||||>It should be fixed now. Thank you for raising this issue. |
transformers | 2,274 | closed | AttributeError: 'GPT2LMHeadModel' object has no attribute 'generate' | ## 🐛 Bug
<!-- Important information -->
The example script `run_generation.py` is broken with the error message `AttributeError: 'GPT2LMHeadModel' object has no attribute 'generate'`
## To Reproduce
Steps to reproduce the behavior:
1. In a terminal, cd to `transformers/examples` and then `python run_generation.py --model_type=gpt2 --model_name_or_path=gpt2`
2. After the model binary is downloaded to cache, enter anything when prompted "`Model prompt >>>`"
3. And then you will see the error:
```
Traceback (most recent call last):
File "run_generation.py", line 236, in <module>
main()
File "run_generation.py", line 216, in main
output_sequences = model.generate(
File "C:\Anaconda3\lib\site-packages\torch\nn\modules\module.py", line 585, in __getattr__
type(self).__name__, name))
AttributeError: 'GPT2LMHeadModel' object has no attribute 'generate'
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Windows 10
* Python version: 3.7.3
* PyTorch version: 1.3.1
* PyTorch Transformers version (or branch): 2.2.2
* Using GPU ? N/A
* Distributed of parallel setup ? N/A
* Any other relevant information:
I'm running the latest version of `run_generation.py`. Here is the permanent link: https://github.com/huggingface/transformers/blob/ce50305e5b8c8748b81b0c8f5539a337b6a995b9/examples/run_generation.py
## Additional context
<!-- Add any other context about the problem here. -->
| 12-23-2019 03:05:15 | 12-23-2019 03:05:15 | Same problem<|||||>I have found the reason.
So it turns out that the `generate()` method of the `PreTrainedModel` class is newly added, even newer than the latest release (2.3.0). Quite understandable since this library is iterating very fast.
So to make `run_generation.py` work, you can install this library like this:
- Clone the repo to your computer
- cd into the repo
- Run `pip install -e .` (don't forget the dot)
- Re-run `run_generation.py`
I'll leave this ticket open until the `generate()` method is incorporated into the latest release.<|||||>@jsh9's solution worked for me!
Also, if you want to avoid doing the manual steps, you can just `pip install` directly from the `master` branch by running:
```bash
pip install git+https://github.com/huggingface/transformers.git@master#egg=transformers
```
<|||||>i was getting the same error then i used repository before 7days which is working fine for me
`!wget https://github.com/huggingface/transformers/archive/f09d9996413f2b265f1c672d7a4b438e4c5099c4.zip`
then unzip with
`!unzip file_name.zip`
there is some bugs in recent update, hope they fix it soon<|||||>@Weenkus's way worked for me. In `requirements.txt` you can use;
```
-e git+https://github.com/huggingface/transformers.git@master#egg=transformers
```
(all on one line)<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,273 | closed | adding special tokens after truncating in run_lm_finetuning.py | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details)
In `run_lm_finetuning.py`, we have the following
```
for i in range(0, len(tokenized_text) - block_size + 1, block_size): # Truncate in block of block_size
self.examples.append(tokenizer.build_inputs_with_special_tokens(tokenized_text[i : i + block_size]))
```
If we add special tokens after truncating to `block_size`, the example is no longer of length `block_size`, but longer.
In the help information for `block_size` as an input argument, it says "Optional input sequence length after tokenization. The training dataset will be truncated in block of this size for training. Default to the model max input length for single sentence inputs (**take into account special tokens**)." This may be confusing, because the `block_size` written as the default input is 512, but if you use BERT-base as the model you're pretraining from, the `block_size` input in that function is actually 510.
The [original BERT code](https://github.com/google-research/bert/blob/master/extract_features.py) makes sure all examples are `block_size` after adding special tokens:
```
if tokens_b:
# Modifies `tokens_a` and `tokens_b` in place so that the total
# length is less than the specified length.
# Account for [CLS], [SEP], [SEP] with "- 3"
_truncate_seq_pair(tokens_a, tokens_b, seq_length - 3)
else:
# Account for [CLS] and [SEP] with "- 2"
if len(tokens_a) > seq_length - 2:
tokens_a = tokens_a[0:(seq_length - 2)]
``` | 12-22-2019 23:28:49 | 12-22-2019 23:28:49 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,272 | closed | Run_tf_ner.py error on TPU | ## 🐛 Bug
run_tf_ner.py does not work with TPU. The first error is:
`File system scheme '[local]' not implemented `
When the script is changed and .tfrecord file is moved to gs:// address (and also hardcoded "/tmp/mylogs" is replaced with gs:/// dir) there is an error with optimiser:
`AttributeError: 'device_map' not accessible within a TPU context.`
## To Reproduce
Steps to reproduce the behaviour:
python run_tf_ner.py.1 --tpu grpc://10.240.1.2:8470 --data_dir gs://nomentech/datadir --labels ./datasets/labels.txt --output_dir gs://nomentech/model1 --max_seq_length 40 --model_type bert --model_name_or_path bert-base-multilingual-cased --do_train --do_eval --cache_dir gs://nomentech/cachedir --num_train_epochs 5 --per_device_train_batch_size 96
## Environment
* OS: Ubuntu 18
* Python version: 3.7
* Tensorflow version: 2.1.0-dev20191222 (tf-nightly)
* PyTorch Transformers version (or branch): 2.3.0
* Distributed of parallel setup ? TPU
| 12-22-2019 23:19:29 | 12-22-2019 23:19:29 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>I have the same issue on Colab TPU with tf-nightly 2.2.0. @dlauc did you solve the problem?<|||||>Hi @BOUALILILila, I've switched to the TF/Keras - it works well with TPU-s<|||||>Hi @dlauc. Could you elaborate how you fixed this? I am having the same problem. |
transformers | 2,271 | closed | Improve setup and requirements | - Clean up several requirements files generated with pip freeze, with no clear update process
- Rely on extra_requires for managing optional requirements
- Update contribution instructions | 12-22-2019 19:39:04 | 12-22-2019 19:39:04 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2271?src=pr&el=h1) Report
> Merging [#2271](https://codecov.io/gh/huggingface/transformers/pull/2271?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/23dad8447c8db53682abc3c53d1b90f85d222e4b?src=pr&el=desc) will **decrease** coverage by `0.58%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2271?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2271 +/- ##
==========================================
- Coverage 74.27% 73.68% -0.59%
==========================================
Files 85 87 +2
Lines 14610 14791 +181
==========================================
+ Hits 10851 10899 +48
- Misses 3759 3892 +133
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2271?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/commands/user.py](https://codecov.io/gh/huggingface/transformers/pull/2271/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb21tYW5kcy91c2VyLnB5) | `0% <0%> (ø)` | |
| [src/transformers/commands/serving.py](https://codecov.io/gh/huggingface/transformers/pull/2271/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb21tYW5kcy9zZXJ2aW5nLnB5) | `0% <0%> (ø)` | |
| [src/transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2271/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `92.27% <0%> (+0.96%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2271/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `93.12% <0%> (+1.58%)` | :arrow_up: |
| [src/transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/2271/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9waXBlbGluZXMucHk=) | `68.31% <0%> (+2.32%)` | :arrow_up: |
| [src/transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/2271/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL3Byb2Nlc3NvcnMvc3F1YWQucHk=) | `35.97% <0%> (+6.6%)` | :arrow_up: |
| [src/transformers/modeling\_tf\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2271/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hdXRvLnB5) | `32.14% <0%> (+7.14%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2271?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2271?src=pr&el=footer). Last update [23dad84...10724a8](https://codecov.io/gh/huggingface/transformers/pull/2271?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,270 | closed | Remove support for Python 2 | 12-22-2019 17:23:35 | 12-22-2019 17:23:35 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2270?src=pr&el=h1) Report
> Merging [#2270](https://codecov.io/gh/huggingface/transformers/pull/2270?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b6ea0f43aeb7ff1dcb03658e38bacae1130abd91?src=pr&el=desc) will **increase** coverage by `1.2%`.
> The diff coverage is `86.66%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2270?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2270 +/- ##
=========================================
+ Coverage 73.25% 74.45% +1.2%
=========================================
Files 85 85
Lines 14779 14610 -169
=========================================
+ Hits 10826 10878 +52
+ Misses 3953 3732 -221
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2270?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/modeling\_camembert.py](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ19jYW1lbWJlcnQucHk=) | `100% <ø> (ø)` | :arrow_up: |
| [src/transformers/configuration\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX3JvYmVydGEucHk=) | `100% <ø> (ø)` | :arrow_up: |
| [src/transformers/tokenization\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZGlzdGlsYmVydC5weQ==) | `100% <ø> (ø)` | :arrow_up: |
| [src/transformers/modeling\_tf\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl9hdXRvLnB5) | `32.14% <ø> (-0.41%)` | :arrow_down: |
| [src/transformers/configuration\_distilbert.py](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2Rpc3RpbGJlcnQucHk=) | `100% <ø> (ø)` | :arrow_up: |
| [src/transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl91dGlscy5weQ==) | `93.12% <ø> (-0.04%)` | :arrow_down: |
| [src/transformers/configuration\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9jb25maWd1cmF0aW9uX2N0cmwucHk=) | `97.05% <ø> (-0.09%)` | :arrow_down: |
| [src/transformers/tokenization\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fcm9iZXJ0YS5weQ==) | `100% <ø> (ø)` | :arrow_up: |
| [src/transformers/tokenization\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fY3RybC5weQ==) | `96.11% <ø> (-0.08%)` | :arrow_down: |
| [src/transformers/modeling\_tf\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9tb2RlbGluZ190Zl90NS5weQ==) | `96.54% <ø> (-0.01%)` | :arrow_down: |
| ... and [66 more](https://codecov.io/gh/huggingface/transformers/pull/2270/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2270?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2270?src=pr&el=footer). Last update [b6ea0f4...1a948d7](https://codecov.io/gh/huggingface/transformers/pull/2270?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
|
transformers | 2,269 | closed | Bad F1 Score for run_squad.py on SQuAD2.0 | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
When I run the run_squad.py for SQuAD2.0 like this
python3 run_squad.py \
--model_type bert \
--model_name_or_path bert-base-cased \
--do_train \
--do_eval \
--train_file /share/nas165/Wendy/transformers/examples/tests_samples/SQUAD/train-v2.0.json \
--predict_file /share/nas165/Wendy/transformers/examples/tests_samples/SQUAD/dev-v2.0.json \
--per_gpu_train_batch_size 4 \
--learning_rate 4e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /share/nas165/Wendy/transformers/examples/SQuAD2.0_debug_bert/
--version_2_with_negative=True \
--null_score_diff_threshold=-1.967471694946289
It runs very fast and the f1 score only 7.9% What is wrong with it
The log message like this
<img width="960" alt="擷取" src="https://user-images.githubusercontent.com/32416416/71322341-939daa80-2501-11ea-9313-e179d1760b99.PNG">
Thanks a lot for your help.By the way I clone it today so it is the new version
| 12-22-2019 13:22:27 | 12-22-2019 13:22:27 | |
transformers | 2,268 | closed | Improve repository structure | This PR builds on top of #2255 (which should be merged first).
Since it changes the location of the source code, once it's merged, contributors must update their local development environment with:
$ pip uninstall transformers
$ pip install -e .
I'll clarify this when I update the contributor documentation (later).
I checked that:
- `python setup.py sdist` packages the right files (only from `src`)
- I didn't lose any tests — the baseline for `run_tests_py3_torch_and_tf` is `691 passed, 68 skipped, 50 warnings`, see [here](https://app.circleci.com/jobs/github/huggingface/transformers/10684))
| 12-22-2019 13:00:05 | 12-22-2019 13:00:05 | Last test run failed only because of a flaky test — this is #2240. |
transformers | 2,267 | closed | Does Pre-Trained Weights Work Internally in pytorch? | I am using bert’s pretrained model in from_pretrained and coming across it’s fine tuning code we can save the new model weights and other hyper params in save_pretrained.
My doubt is in there modeling_bert code there is no explicit code that takes the pre-trained weights in acount and then trains as it generally takes attention matrices and puts it in a feed forward network in the class `BertPredictionHeadTransform`
```
class BertPredictionHeadTransform(nn.Module):
def __init__(self, config):
super(BertPredictionHeadTransform, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
if isinstance(config.hidden_act, str) or (sys.version_info[0] == 2 and isinstance(config.hidden_act, unicode)):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
print('BertPredictionHeadTransform', hidden_states.shape)
return hidden_states
```
And here i do not see any kind of “inheritance” of the pre-trained weights…
So is it internally handled by pytorch or am i missing something in the code itself?
| 12-22-2019 10:26:42 | 12-22-2019 10:26:42 | `BertPredictionHeadTransform` is never used in itself AFAIK, and is only part of the full scale models (e.g. `BertModel`). As such, the weights for the prediction head are loaded when you run BertModel.from_pretrained(), since the `BertPredictionHeadTransform` is only a module in the whole model.<|||||>> `BertPredictionHeadTransform` is never used in itself AFAIK, and is only part of the full scale models (e.g. `BertModel`). As such, the weights for the prediction head are loaded when you run BertModel.from_pretrained(), since the `BertPredictionHeadTransform` is only a module in the whole model.
Thanks, Bram. As you said `BertModel` does take `BertPreTrainedModel` in `super`. I did notice it, But It's just that my mind doesn't get around how/where and when those weights are getting used exactly.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,266 | closed | Imports likely broken in examples | ## 🐛 Bug
While cleaning up imports with isort, I classified them all. I failed to identify the following four imports:
1. model_bertabs
2. utils_squad
3. utils_squad_evaluate
4. models.model_builder
These modules aren't available on PyPI or in the transformers code repository.
I think they will result in ImportError (I didn't check).
I suspect they used to be in transformers, but they were renamed or removed.
| 12-22-2019 10:24:04 | 12-22-2019 10:24:04 | @aaugustin it seems like that i met the same problem when i use convert_bertabs_original_pytorch_checkpoint.py ,have you ever fixed it or find any way to make it work.
Appriciate it if you can tell me!<|||||>I didn't attempt to fix this issue. I merely noticed it while I was working on the overall quality of the `transformers` code base.
I suspect these modules used to exist in `transformers` and were removed in a refactoring, but I don't know for sure.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,265 | closed | Only the Bert model is currently supported | ## 🐛 Bug
<!-- Important information -->
Model I am using Model2Model and BertTokenizer:
Language I am using the model on English:
The problem arise when using:
* the official example scripts: (give details)
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
```
# Let's re-use the previous question
question = "Who was Jim Henson?"
encoded_question = tokenizer.encode(question)
question_tensor = torch.tensor([encoded_question])
# This time we try to generate the answer, so we start with an empty sequence
answer = "[CLS]"
encoded_answer = tokenizer.encode(answer, add_special_tokens=False)
answer_tensor = torch.tensor([encoded_answer])
# Load pre-trained model (weights)
model = Model2Model.from_pretrained('fine-tuned-weights')
model.eval()
# If you have a GPU, put everything on cuda
question_tensor = encoded_question.to('cuda')
answer_tensor = encoded_answer.to('cuda')
model.to('cuda')
# Predict all tokens
with torch.no_grad():
outputs = model(question_tensor, answer_tensor)
predictions = outputs[0]
# confirm we were able to predict 'jim'
predicted_index = torch.argmax(predictions[0, -1]).item()
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
```
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Colab
* Python version:
* PyTorch version:
* PyTorch Transformers version (or branch):
* Using GPU ? Yes
* Distributed of parallel setup ? No
* Any other relevant information:
| 12-22-2019 09:24:32 | 12-22-2019 09:24:32 | You need to give more information. What are you trying to do, what is the code that you use for it, what does not work the way you intended to?<|||||>> You need to give more information. What are you trying to do, what is the code that you use for it, what does not work the way you intended to?
I am learning how to use this repo.
I use the example of the official website model2model, the link is as follows
https://huggingface.co/transformers/quickstart.html
And I use google colab to install the transformer and copy and run the official website code<|||||>I mean, which error are you getting or what is not working as expected? <|||||>> I mean, which error are you getting or what is not working as expected?
this is my issue topic
Only the Bert model is currently supported
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-18-58aac9aa944f> in <module>()
9
10 # Load pre-trained model (weights)
---> 11 model = Model2Model.from_pretrained('fine-tuned-weights')
12 model.eval()
13
/usr/local/lib/python3.6/dist-packages/transformers/modeling_encoder_decoder.py in from_pretrained(cls, pretrained_model_name_or_path, *args, **kwargs)
281 or "distilbert" in pretrained_model_name_or_path
282 ):
--> 283 raise ValueError("Only the Bert model is currently supported.")
284
285 model = super(Model2Model, cls).from_pretrained(
ValueError: Only the Bert model is currently supported.
```<|||||>That wasn't clear. In the future, please post the trace so it is clear what your error is, like so:
```
Traceback (most recent call last):
File "C:/Users/bramv/.PyCharm2019.2/config/scratches/scratch_16.py", line 62, in <module>
model = Model2Model.from_pretrained('fine-tuned-weights')
File "C:\Users\bramv\.virtualenvs\semeval-task7-Z5pypsxD\lib\site-packages\transformers\modeling_encoder_decoder.py", line 315, in from_pretrained
raise ValueError("Only the Bert model is currently supported.")
ValueError: Only the Bert model is currently supported.
```
This is not a bug, then of course. In the example, where "fine-tuned-weights" is used, you can load your own fine-tuned model. So if you tuned a model and saved it as "checkpoint.pth" you can use that.<|||||>> This is not a bug, then of course. In the example, where "fine-tuned-weights" is used, you can load your own fine-tuned model. So if you tuned a model and saved it as "checkpoint.pth" you can use that.
thanks<|||||>Please close this question. |
transformers | 2,264 | closed | Fix doc link in README | close https://github.com/huggingface/transformers/issues/2252
- [x] Update `.circleci/deploy.sh`
- [x] Update `deploy_multi_version_doc.sh`
Set commit hash before "Release: v2.3.0".
| 12-22-2019 07:12:24 | 12-22-2019 07:12:24 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2264?src=pr&el=h1) Report
> Merging [#2264](https://codecov.io/gh/huggingface/transformers/pull/2264?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/645713e2cb8307e41febb2b7c9f6036f6645efce?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2264?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2264 +/- ##
=======================================
Coverage 78.35% 78.35%
=======================================
Files 133 133
Lines 19878 19878
=======================================
Hits 15576 15576
Misses 4302 4302
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2264?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2264?src=pr&el=footer). Last update [645713e...9d00f78](https://codecov.io/gh/huggingface/transformers/pull/2264?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Thanks @upura! |
transformers | 2,263 | closed | BertModel sometimes produces the same output during evaluation | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I finetune BertModel as a part of my model to produce word embeddings. I found sometimes the performance was very bad, then i run the code again without any change, the performance was normal. It is very strange. I check my code to try to find the bug. I found the word embeddings produced by BertModel were all the same. Then I followed the code of BertModel, and found the BertEncoder would make the output become similar gradually which was consisted of 12 BertLayers. I have no idea about this situation. | 12-22-2019 07:00:45 | 12-22-2019 07:00:45 | Did you set a fixed seed? If you want deterministic results, you should set a fixed seed. <|||||>> Did you set a fixed seed? If you want deterministic results, you should set a fixed seed.
No, I didn't. My problem seems that the model finetuned is totally wrong sometimes. Is it a problem related to random seed?<|||||>What do you mean by "bad"? Post some code to better help you.<|||||>> What do you mean by "bad"? Post some code to better help you.
For example, the normal performance is 140.1, but the bad performance is 1.0. As I mentioned before, this situation happened sometimes and I found the word embeddings produced by BertModel were all the same when the performance was bad.
The text encoding part of my code is as follows:

<|||||>I think you are accessing the CLS token embeddings and It is constant as the model you are using is trained on MLM objective. <|||||>> I think you are accessing the CLS token embeddings and It is constant as the model you are using is trained on MLM objective.
If I change the out to self.bert(text)[0][:,1,:], the output is the same as self.bert(text)[0][:,0,:]. It seems I get the same output no matter the input that I put in.<|||||>I saved the checkpoint when this situation happened. I multiplied all the parameter values of bert by 10 and found the outputs were different, while I divided all parameter values by 10 and found the outputs were almost same. So I think the reason is that the parameter values are too small.<|||||>@xuesong0309 https://github.com/huggingface/transformers/issues/1465,Could you look at this problem?<|||||>> @xuesong0309 https://github.com/huggingface/transformers/issues/1465,Could you look at this problem?
Did you always get same output? I suggest outputing the parameter values of your model as I mentioned above.<|||||>> > @xuesong0309 [https://github.com/huggingface/transformers/issues/1465,Could](https://github.com/huggingface/transformers/issues/1465%EF%BC%8CCould) you look at this problem?
>
> Did you always get same output? I suggest outputing the parameter values of your model as I mentioned above.
It may not be the problem you mentioned, because the model is normal for multi-class classification, and this happens only for multi-label classification.<|||||>> @xuesong0309 https://github.com/huggingface/transformers/issues/1465,Could you look at this problem?
>
> Did you always get same output? I suggest outputing the parameter values of your model as I mentioned above.
>
> It may not be the problem you mentioned, because the model is normal for multi-class classification, and this happens only for multi-label classification.
You could open a new issue to describe your problem in detail.<|||||>Have you solved this issue? I have facing the same issue. Output same results during evaluation.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,262 | closed | How to do_predict on run_glue? | ## ❓ Questions & Help
I have fine-tuned BERT for sequence classification task by running run_glue script. Now I have trained and evaluated model. My question is how do I make prediction with it on new instances (test set)? Thanks! | 12-22-2019 02:45:02 | 12-22-2019 02:45:02 | #2198 Same here. A predict script can be really helpful to researchers.<|||||>same here<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,261 | closed | AlbertTokenizer behavior doesn't match docs | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): AlbertForQuestionAnswering
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Run the code sample from the docs: https://huggingface.co/transformers/v2.2.0/model_doc/albert.html#albertforquestionanswering
```
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
model = AlbertForQuestionAnswering.from_pretrained('albert-base-v2')
question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
input_text = "[CLS] " + question + " [SEP] " + text + " [SEP]"
input_ids = tokenizer.encode(input_text)
token_type_ids = [0 if i <= input_ids.index(102) else 1 for i in range(len(input_ids))]
start_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))
all_tokens = tokenizer.convert_ids_to_tokens(input_ids)
print(' '.join(all_tokens[torch.argmax(start_scores) : torch.argmax(end_scores)+1]))
# a nice puppet
```
2. Getting the following error:
---------------------------------------------------------------------------
```
ValueError Traceback (most recent call last)
<ipython-input-16-2185be87fe39> in <module>
5 input_text = "[CLS] " + question + " [SEP] " + text + " [SEP]"
6 input_ids = tokenizer.encode(input_text)
----> 7 token_type_ids = [0 if i <= input_ids.index(102) else 1 for i in range(len(input_ids))]
8 start_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))
9 all_tokens = tokenizer.convert_ids_to_tokens(input_ids)
<ipython-input-16-2185be87fe39> in <listcomp>(.0)
5 input_text = "[CLS] " + question + " [SEP] " + text + " [SEP]"
6 input_ids = tokenizer.encode(input_text)
----> 7 token_type_ids = [0 if i <= input_ids.index(102) else 1 for i in range(len(input_ids))]
8 start_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))
9 all_tokens = tokenizer.convert_ids_to_tokens(input_ids)
ValueError: 102 is not in list
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
Code says expected output is "a nice puppet"
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Kaggle kernel, no GPU
* Python version: 3.6.6
* PyTorch version: 1.3.0
* PyTorch Transformers version (or branch): 2.3.0
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information:
Some debugging info:
```
print(input_ids)
[2, 2, 72, 23, 2170, 27674, 60, 3, 2170, 27674, 23, 21, 2210, 10956, 3, 3]
tokenizer.decode(input_ids)
'[CLS][CLS] who was jim henson?[SEP] jim henson was a nice puppet[SEP][SEP]'
```
## Additional context
<!-- Add any other context about the problem here. -->
| 12-22-2019 00:59:49 | 12-22-2019 00:59:49 | The encoder itself would automatically add the [CLS] and [SEP] tokens so if you've done that during preprocessing, you would need to change the `add_special_tokens` parameter to `False`. So your code should probably be like this:
```
input_ids = tokenizer.encode(input_text, add_special_tokens=False)
```<|||||>Thanks, but that does not fix the error. The problem is there is no [102] token in the list. Maybe because we're using AlbertTokenizer?
```
input_ids = tokenizer.encode(input_text, add_special_tokens=False)
print(input_ids)
[2, 72, 23, 2170, 27674, 60, 3, 2170, 27674, 23, 21, 2210, 10956, 3]
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,260 | closed | Fixing incorrect link in model docstring | The docstring contains a link to Salesforce/CTRL repo, while the model itself is Facebookresearch/mmbt. It may be the wrong copy\paste. | 12-21-2019 21:02:07 | 12-21-2019 21:02:07 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2260?src=pr&el=h1) Report
> Merging [#2260](https://codecov.io/gh/huggingface/transformers/pull/2260?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/645713e2cb8307e41febb2b7c9f6036f6645efce?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2260?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2260 +/- ##
=======================================
Coverage 78.35% 78.35%
=======================================
Files 133 133
Lines 19878 19878
=======================================
Hits 15576 15576
Misses 4302 4302
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2260?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/modeling\_mmbt.py](https://codecov.io/gh/huggingface/transformers/pull/2260/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX21tYnQucHk=) | `18.25% <ø> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2260?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2260?src=pr&el=footer). Last update [645713e...b668a74](https://codecov.io/gh/huggingface/transformers/pull/2260?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Thanks |
transformers | 2,259 | closed | problem in the doc, in the "Quick Start" GPT2 example | I am going through the GPT2 example in the doc. Is there a mistake in the "Using the past" code. The main loop to generate text is:
```python
for i in range(100):
print(i)
output, past = model(context, past=past)
token = torch.argmax(output[0, :])
generated += [token.tolist()]
context = token.unsqueeze(0)
```
At the first iteration the tensor output as shape [1, 3, 50257], and at all the following iterations it has size [1,50257]. Should the code be:
```python
for i in range(100):
print(i)
output, past = model(context, past=past)
if i==0:
token = torch.argmax(output[0,-1,:])
else:
token = torch.argmax(output[0, :])
generated += [token.tolist()]
context = token.unsqueeze(0)
```
| 12-21-2019 20:20:17 | 12-21-2019 20:20:17 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,258 | closed | run_ner.py load checkpoint issue | Hi,
I just launched the **transformers/examples/run_ner.py** script with my custom model:
`python3 transformers/examples/run_ner.py --data_dir $INPUT_DATA_DIR \
--tokenizer_name $TOKENIZER_FILE_PATH --output_dir $OUTPUT_DIR --model_type camembert --labels $LABELS_DIR --model_name_or_path $BERT_MODEL --max_seq_length $MAX_LENGTH --num_train_epochs $NUM_EPOCHS --gradient_accumulation_steps $ACCUMULATION_STEPS --per_gpu_train_batch_size $BATCH_SIZE --save_steps $SAVE_STEPS --do_lower_case --do_train --do_eval --do_predict`
Once the data for the train has been loaded, an error appear:
`Traceback (most recent call last):
File "transformers/examples/run_ner.py", line 567, in <module>
main()
File "transformers/examples/run_ner.py", line 496, in main
global_step, tr_loss = train(args, train_dataset, model, tokenizer, labels, pad_token_label_id)
File "transformers/examples/run_ner.py", line 132, in train
global_step = int(args.model_name_or_path.split('-')[-1].split('/')[0])
ValueError: invalid literal for int() with base 10: 'pytorch_dump_folder'`
Launching the same script a few hours ago the error did not appear, is it something related to the last updates #2134 ?
Thanks in advance. | 12-21-2019 19:27:54 | 12-21-2019 19:27:54 | Can confirm this issue -> a temporary workaround would be to change the line to:
```python
if os.path.exists(args.model_name_or_path) and "checkpoint" in args.model_name_or_path:
```<|||||>See also related (recent) fix on master: https://github.com/huggingface/transformers/commit/4d36472b96d144887cbe95b083f0d2091fd5ff03<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,257 | closed | HuggingFace transformers documentation webpage is blank? | Hello,
Is HuggingFace updating their transformers documentation site (https://huggingface.co/transformers/)?
I looked there to get some information about the HugginFace GPT-2, but for some reason all the contents of the website are gone.
Thank you,
| 12-21-2019 19:09:36 | 12-21-2019 19:09:36 | Having the same issue.<|||||>May be related to this:
https://twitter.com/Thom_Wolf/status/1208365367493636096
<|||||>Are you still having an issue or is it fixed (if it is, please close the issue)?<|||||>Hello,
I am still having the same issue.
<|||||>Ok, we are in the process of fixing it. Thanks for the report<|||||>It works now, thank you for the help |
transformers | 2,256 | closed | Untrainable dense layer in TFBert. "WARNING:tensorflow:Gradients do not exist for variables ['tf_bert_model/bert/pooler/dense/kernel:0', 'tf_bert_model/bert/pooler/dense/bias:0'] when minimizing the loss." | ## 🐛 Bug
<!-- Important information -->
I am getting
> WARNING:tensorflow:Gradients do not exist for variables ['tf_bert_model/bert/pooler/dense/kernel:0', 'tf_bert_model/bert/pooler/dense/bias:0'] when minimizing the loss.
> WARNING:tensorflow:Gradients do not exist for variables ['tf_bert_model/bert/pooler/dense/kernel:0', 'tf_bert_model/bert/pooler/dense/bias:0'] when minimizing the loss.
> WARNING:tensorflow:Gradients do not exist for variables ['tf_bert_model/bert/pooler/dense/kernel:0', 'tf_bert_model/bert/pooler/dense/bias:0'] when minimizing the loss.
> WARNING:tensorflow:Gradients do not exist for variables ['tf_bert_model/bert/pooler/dense/kernel:0', 'tf_bert_model/bert/pooler/dense/bias:0'] when minimizing the loss.
Errors when using the Tensorflow Bert.
For convenience, here is a colab notebook that reproduces the error
https://colab.research.google.com/drive/1fh8l43Mm7g4-yjlun7nTilmuP0SOMOx-
It looks like there's an operation in the TF Bert that does not allow gradients to flow, judging from goolging this issue
https://github.com/tensorflow/probability/issues/467
https://github.com/tensorflow/tensorflow/issues/27949
https://stackoverflow.com/questions/55434653/batch-normalization-doesnt-have-gradient-in-tensorflow-2-0
https://stackoverflow.com/questions/57144586/tensorflow-gradienttape-gradients-does-not-exist-for-variables-intermittently
Model I am using (Bert, XLNet....):
TFBertModel
Language I am using the model on (English, Chinese....):
English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [X ] my own modified scripts: (give details)
```
!pip install transformers --quiet
%tensorflow_version 2.x
try:
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
import os
from tensorflow import keras
from tensorflow.keras.layers import Lambda
from tensorflow.keras import backend as K
from keras.preprocessing.sequence import pad_sequences
from transformers import TFBertModel, BertTokenizer, BertConfig
import numpy as np
from glob import glob
from tqdm import tqdm_notebook
print('TensorFlow:', tf.__version__)
posCites = tf.random.uniform(shape=(3, 4, 768), minval=-1, maxval=1, dtype=tf.dtypes.float32)
negCites = tf.random.uniform(shape=(3, 16, 768), minval=-1, maxval=1, dtype=tf.dtypes.float32)
textInputsIds = tf.random.uniform(shape=(3, 8), minval=0, maxval=200, dtype=tf.dtypes.int32)
dataset = (textInputsIds, posCites, negCites)
batch_size = 3
post_size = 4
neg_size = 16
posLabels = keras.backend.ones(batch_size*post_size)
negLabels = keras.backend.zeros(batch_size*neg_size)
totalLabels = keras.backend.concatenate((posLabels, negLabels), axis=-1)
totalLabels = tf.convert_to_tensor([[totalLabels] * 3])
totalLabels = tf.squeeze(totalLabels)
model = TFBertModel.from_pretrained('bert-base-uncased')
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='binary_crossentropy',
metrics=['acc'])
labels = tf.constant(np.array([1,0,1]))
model(textInputsIds)[0]
def create_model():
textInputs = tf.keras.Input(shape=(8,), dtype=tf.int32)
bert_model = TFBertModel.from_pretrained('bert-base-uncased')
textOut = bert_model(textInputs)
textOutMean = tf.reduce_mean(textOut[0], axis=1)
logits = tf.reduce_sum(textOutMean, axis=-1)
return tf.keras.Model(inputs=[textInputs], outputs=[logits])
model = create_model()
# model = TFBertModel.from_pretrained('bert-base-uncased')
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='binary_crossentropy',
metrics=['acc'])
labels = tf.constant(np.array([1,0,1]))
model.fit(textInputsIds, labels, epochs=100)
```
WARNING:tensorflow:Gradients do not exist for variables ['tf_bert_model_1/bert/pooler/dense/kernel:0', 'tf_bert_model_1/bert/pooler/dense/bias:0'] when minimizing the loss.
WARNING:tensorflow:Gradients do not exist for variables ['tf_bert_model_1/bert/pooler/dense/kernel:0', 'tf_bert_model_1/bert/pooler/dense/bias:0'] when minimizing the loss.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ X] my own task or dataset: (give details)
Using Bert as a text encoder, and matching output embeddings with a target.
## To Reproduce
Steps to reproduce the behavior:
Here is a ColabNotebook which contains the code posted above, to recreate the error
https://colab.research.google.com/drive/1fh8l43Mm7g4-yjlun7nTilmuP0SOMOx-
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
Gradients should be calculated for all variables in tfBert.
## Environment
* OS: Linux
* Python version: 3+
* PyTorch version: 1.2+
* PyTorch Transformers version (or branch): same as Pip install
* Using GPU ? colab gpu
* Distributed of parallel setup ? no
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
Possibly related issues
https://github.com/huggingface/transformers/issues/1727
| 12-21-2019 18:53:37 | 12-21-2019 18:53:37 | After looking at
https://github.com/huggingface/transformers/issues/1727
I figured out we're getting the warning because we're not using the pooler, therefore it gets no updates. <|||||>@Santosh-Gupta can you please update your colab notebook with correct version. i am unbale to get this resolved<|||||>Hi, I have exactly the same issue with TFXLMRobertaForSequenceClassification. How did you solve the issue ?<|||||>> Hi, I have exactly the same issue with TFXLMRobertaForSequenceClassification. How did you solve the issue ?
From what understand, this is not a bug. You won't get gradients calculated for variables (kernel and bias) of the layer tf_bert_model/bert/pooler/dense if you don't use it. As such, if you indeed don't use the pooler, you can simply ignore this warning. <|||||>> @Santosh-Gupta can you please update your colab notebook with correct version. i am unbale to get this resolved
It's not a bug, the forward pass doesn't go through the pooler, so the backwards pass doesn't go through it either. <|||||>I'm having the same issue, although I am using the pooling layer.
my model is like this one
```
class TFAlbertForNaturalQuestionAnswering(TFAlbertPreTrainedModel):
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.albert = TFAlbertMainLayer(config)
self.initializer = get_initializer(config.initializer_range)
self.start = tf.keras.layers.Dense(1,
kernel_initializer=self.initializer, name='start')
self.end = tf.keras.layers.Dense(1,
kernel_initializer=self.initializer, name='end')
self.long_outputs = tf.keras.layers.Dense(1, kernel_initializer=self.initializer,
name='long')
self.answerable = tf.keras.layers.Dense(1, kernel_initializer=self.initializer,
name='answerable', activation = "sigmoid")
def call(self, inputs, **kwargs):
outputs = self.albert(inputs, **kwargs)
sequence_output = outputs[0]
# tf.print(outputs[0].shape) (batch, len->0, hidden) 1->0
# tf.print(outputs[1].shape) (batch, hidden_size)
start_logits = tf.squeeze(self.start(sequence_output), -1)
end_logits = tf.squeeze(self.end(sequence_output), -1)
long_logits = tf.squeeze(self.long_outputs(sequence_output), -1)
answerable = tf.squeeze(self.answerable(outputs[1]), -1)
```<|||||>Hey ! i'm getting the same issue with attention model and embedding layer, the weights of both layers are not updating .
```
embd=Embedding(input_dim=len(vocab),output_dim=100,name="embd")
lstm1=Bidirectional(LSTM(units=100,return_sequences=True,name="lstm1"),name="bd1")
lstm2=Bidirectional(LSTM(units=100,return_sequences=True,name="lstm2"),name="bd2")
attention_layer=Attention_Model(21,200)
dense1=Dense(units=80,name="dense1",kernel_regularizer="l2")
dropout1=Dropout(0.5)
act1=Activation('sigmoid')
dense2=Dense(units=50,name="dense2",kernel_regularizer="l2")
dropout2=Dropout(0.4)
act2=Activation('sigmoid')
dense3=Dense(units=30,name="dense3",kernel_regularizer="l2")
dropout3=Dropout(0.3)
act3=Activation('sigmoid')
dense4=Dense(units=len(classes),name="dense4")
dropout4=Dropout(0.2)
output=Activation('softmax')
```
Forward Pass :
```
def forward_pass(X):
t=embd(X)
t=lstm1(t)
t=lstm2(t)
t=attention_layer(t)
t=dense1(t)
t=dropout1(t)
t=act1(t)
t=dense2(t)
t=dropout2(t)
t=act2(t)
t=dense3(t)
t=dropout3(t)
t=act3(t)
t=dense4(t)
t=dropout4(t)
t=output(t)
return t
```
Attention Model :
```
class Attention_Model():
def __init__(self,seq_length,units):
self.seq_length=seq_length
self.units=units
self.lstm=LSTM(units=units,return_sequences=True,return_state=True)
def get_lstm_s(self,seq_no):
input_lstm=tf.expand_dims(tf.reduce_sum(self.X*(self.alphas[:,:,seq_no:seq_no+1]),axis=1),axis=1)
a,b,c=self.lstm(input_lstm)
self.output[:,seq_no,:]=a[:,0,:]
return b
def __call__(self,X):
self.X=X
self.output=np.zeros(shape=(self.X.shape[0],self.seq_length,self.units))
self.dense=Dense(units=self.seq_length)
self.softmax=Softmax(axis=1)
for i in range(self.seq_length+1):
if i==0 :
s=np.zeros(shape=(self.X.shape[0],self.units))
else :
s=self.get_lstm_s(i-1)
if(i==self.seq_length):
break
s=RepeatVector(self.X.shape[1])(s)
concate_X=np.concatenate([self.X,s],axis=-1)
self.alphas=self.softmax(self.dense(concate_X))
return self.output
```
is anything wrong with implementation or something else ?<|||||>@MarioBonse , your forward pass isn't going through the pooling layer
'''sequence_output = outputs[0]'''
@gajeshladhar
Is that code from the hf library? Where are the classes defined?
<|||||>pooler_output of transformers TFRobertaModel have tf_roberta_model/roberta/pooler/dense/kernel:0. if you have not use pooler_output,tf_roberta_model/roberta/pooler/dense/kernel:0 do not update Gradients |
transformers | 2,255 | closed | Implement some Python best practices | Improve source code quality with black, isort & flake8. | 12-21-2019 14:53:02 | 12-21-2019 14:53:02 | This is in reasonably good shape. There are two tasks left:
1. Figure out why isort doesn't behave the same locally and on Circle CI. Most likely this has to do with how it classifies first-party / third-party / unknown libraries. Then enable it on Circle CI. **EDIT - fixed** - this was a matter of installing optional dependencies, not listed in setup.py, on Circle CI so that isort can classify them correctly.
2. Fix flake8 F841 warnings and stop ignoring them.
Assuming tests pass, I think it would be best to merge this PR and deal with these two items later. I'd like to do the repository structure changes first, so we're done with the large changes.<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2255?src=pr&el=h1) Report
> Merging [#2255](https://codecov.io/gh/huggingface/transformers/pull/2255?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/645713e2cb8307e41febb2b7c9f6036f6645efce?src=pr&el=desc) will **decrease** coverage by `0.24%`.
> The diff coverage is `44.23%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2255?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2255 +/- ##
==========================================
- Coverage 78.35% 78.11% -0.25%
==========================================
Files 133 133
Lines 19878 19655 -223
==========================================
- Hits 15576 15354 -222
+ Misses 4302 4301 -1
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2255?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/modeling\_tf\_xlm.py](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3hsbS5weQ==) | `90.44% <ø> (-0.04%)` | :arrow_down: |
| [transformers/configuration\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25feGxuZXQucHk=) | `93.47% <ø> (-0.4%)` | :arrow_down: |
| [transformers/modeling\_mmbt.py](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX21tYnQucHk=) | `18.25% <ø> (ø)` | :arrow_up: |
| [transformers/modelcard.py](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsY2FyZC5weQ==) | `87.8% <ø> (ø)` | :arrow_up: |
| [transformers/tests/modeling\_bert\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2JlcnRfdGVzdC5weQ==) | `98% <ø> (-0.02%)` | :arrow_down: |
| [transformers/modeling\_tf\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3JvYmVydGEucHk=) | `90.9% <ø> (ø)` | :arrow_up: |
| [transformers/tests/modeling\_tf\_ctrl\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2N0cmxfdGVzdC5weQ==) | `95.74% <ø> (-0.18%)` | :arrow_down: |
| [transformers/configuration\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fb3BlbmFpLnB5) | `97.22% <ø> (-0.22%)` | :arrow_down: |
| [transformers/tests/tokenization\_xlm\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3Rva2VuaXphdGlvbl94bG1fdGVzdC5weQ==) | `82.22% <ø> (ø)` | :arrow_up: |
| [transformers/commands/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbW1hbmRzL19faW5pdF9fLnB5) | `0% <ø> (ø)` | :arrow_up: |
| ... and [237 more](https://codecov.io/gh/huggingface/transformers/pull/2255/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2255?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2255?src=pr&el=footer). Last update [645713e...c11b3e2](https://codecov.io/gh/huggingface/transformers/pull/2255?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>`pyproject.toml` is supposed to be The Future (tm). `setup.cfg`was supposed to be The Future as well. That didn't quite work, but it gained some support.
Unfortunately, in the Python packaging ecosystem, some futures never became the present. That's why I'm conservative, at least until this changes: https://packaging.python.org/specifications/distribution-formats/
I'm happy to try converting setup.py to pyproject.toml if you're feeling adventurous. Let me know.
We can move the isort configuration there, but not the flake8 configuration until [this PR](https://gitlab.com/pycqa/flake8/issues/428) is merged. I like setup.cfg because we can put both in the same file.<|||||>Alright thanks for the context! |
transformers | 2,254 | closed | adding positional embeds masking to TFRoBERTa | Adding positional embeds masking to TFRoBERTa following its addition to the PT model in #1764 to fix PT <=> TF equivalence test | 12-21-2019 14:27:11 | 12-21-2019 14:27:11 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2254?src=pr&el=h1) Report
> Merging [#2254](https://codecov.io/gh/huggingface/transformers/pull/2254?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/73f6e9817c744caae0b73fa343ceaf95ba76f9f8?src=pr&el=desc) will **increase** coverage by `1.46%`.
> The diff coverage is `100%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2254?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2254 +/- ##
==========================================
+ Coverage 77.28% 78.75% +1.46%
==========================================
Files 133 131 -2
Lines 19872 19742 -130
==========================================
+ Hits 15358 15547 +189
+ Misses 4514 4195 -319
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2254?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/modeling\_tf\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3JvYmVydGEucHk=) | `90.9% <100%> (+0.47%)` | :arrow_up: |
| [transformers/modeling\_mmbt.py](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX21tYnQucHk=) | | |
| [transformers/configuration\_mmbt.py](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbmZpZ3VyYXRpb25fbW1idC5weQ==) | | |
| [transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3BpcGVsaW5lcy5weQ==) | `67.94% <0%> (+0.58%)` | :arrow_up: |
| [transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `64.29% <0%> (+0.71%)` | :arrow_up: |
| [transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `81.51% <0%> (+1.32%)` | :arrow_up: |
| [transformers/modeling\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `96.47% <0%> (+2.2%)` | :arrow_up: |
| [transformers/modeling\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `73.72% <0%> (+2.29%)` | :arrow_up: |
| [transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `64.42% <0%> (+10.09%)` | :arrow_up: |
| [transformers/tests/modeling\_tf\_common\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `94.39% <0%> (+17.24%)` | :arrow_up: |
| ... and [1 more](https://codecov.io/gh/huggingface/transformers/pull/2254/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2254?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2254?src=pr&el=footer). Last update [73f6e98...77676c2](https://codecov.io/gh/huggingface/transformers/pull/2254?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Yeepee! |
transformers | 2,253 | closed | bias weights not used in T5Model | ## 🐛 Bug
Running the T5Model on v2.3.0 can show the info message that all bias weights are not used:
> Weights from pretrained model not used in T5Model: ['encoder.block.0.layer.0.layer_norm.bias', 'encoder.block.0.layer.1.layer_norm.bias', 'encoder.block.1.layer.0.layer_norm.bias', 'encoder.block.1.layer.1.layer_norm.bias', 'encoder.block.2.layer.0.layer_norm.bias', 'encoder.block.2.layer.1.layer_norm.bias', 'encoder.block.3.layer.0.layer_norm.bias', 'encoder.block.3.layer.1.layer_norm.bias', 'encoder.block.4.layer.0.layer_norm.bias', 'encoder.block.4.layer.1.layer_norm.bias', 'encoder.block.5.layer.0.layer_norm.bias', 'encoder.block.5.layer.1.layer_norm.bias', 'encoder.final_layer_norm.bias', 'decoder.block.0.layer.0.layer_norm.bias', 'decoder.block.0.layer.1.layer_norm.bias', 'decoder.block.0.layer.2.layer_norm.bias', 'decoder.block.1.layer.0.layer_norm.bias', 'decoder.block.1.layer.1.layer_norm.bias', 'decoder.block.1.layer.2.layer_norm.bias', 'decoder.block.2.layer.0.layer_norm.bias', 'decoder.block.2.layer.1.layer_norm.bias', 'decoder.block.2.layer.2.layer_norm.bias', 'decoder.block.3.layer.0.layer_norm.bias', 'decoder.block.3.layer.1.layer_norm.bias', 'decoder.block.3.layer.2.layer_norm.bias', 'decoder.block.4.layer.0.layer_norm.bias', 'decoder.block.4.layer.1.layer_norm.bias', 'decoder.block.4.layer.2.layer_norm.bias', 'decoder.block.5.layer.0.layer_norm.bias', 'decoder.block.5.layer.1.layer_norm.bias', 'decoder.block.5.layer.2.layer_norm.bias', 'decoder.final_layer_norm.bias']
I think these are to be expected (and that this is actually not a bug), but I'm not sure. https://github.com/huggingface/transformers/issues/180#issuecomment-453937845 mentions that in some cases like this an additional message could be shown indicating whether this is expected behaviour or not but that has not been implemented here.
```python
from transformers import T5Model
import logging
logging.basicConfig(format='%(asctime)s - [%(levelname)s]: %(message)s',
datefmt='%d-%b %H:%M:%S',
level=logging.INFO)
model = T5Model.from_pretrained('t5-small')
for name, _ in model.named_parameters():
print(name)
``` | 12-21-2019 11:02:53 | 12-21-2019 11:02:53 | Yes, all the layer norms in T5 have no bias (so we keep the default value of 0) |
transformers | 2,252 | closed | Documentation link broken | The README shows strange formatting (where 'Documentation' is put between brackets) for the links to documentation. More importantly, the link to the v2.3.0 documentation is broken (404 not found).
| 12-21-2019 10:42:14 | 12-21-2019 10:42:14 | |
transformers | 2,251 | closed | AttributeError: 'Sst2Processor' object has no attribute 'tfds_map' | ## 🐛 Bug
<!-- Important information -->
hey I just wanted to test BERT for sst2. I have just changed official example script to this:
```
import tensorflow as tf
import tensorflow_datasets
from transformers import *
# Load dataset, tokenizer, model from pretrained model/vocabulary
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = TFBertForSequenceClassification.from_pretrained('bert-base-cased')
data = tensorflow_datasets.load('glue/sst2')
# Prepare dataset for GLUE as a tf.data.Dataset instance
train_dataset = glue_convert_examples_to_features(data['train'], tokenizer, max_length=128, task='sst-2')
valid_dataset = glue_convert_examples_to_features(data['validation'], tokenizer, max_length=128, task='sst-2')
train_dataset = train_dataset.shuffle(100).batch(32).repeat(2)
valid_dataset = valid_dataset.batch(64)
# Prepare training: Compile tf.keras model with optimizer, loss and learning rate schedule
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
# Train and evaluate using tf.keras.Model.fit()
history = model.fit(train_dataset, epochs=2, steps_per_epoch=115,
validation_data=valid_dataset, validation_steps=7)
# Load the TensorFlow model in PyTorch for inspection
model.save_pretrained('./save/')
pytorch_model = BertForSequenceClassification.from_pretrained('./save/', from_tf=True)
# Quickly test a few predictions - MRPC is a paraphrasing task, let's see if our model learned the task
sentence_0 = "I didn't think this was as absolutely horrible."
inputs_1 = tokenizer.encode_plus(sentence_0, add_special_tokens=True, return_tensors='pt')
pred_1 = pytorch_model(inputs_1['input_ids'], token_type_ids=inputs_1['token_type_ids'])[0].argmax().item()
print("sentence_1 is", pred_1)
```
I'm using google colab with tensorflow2.0 . the error is :
AttributeError: 'Sst2Processor' object has no attribute 'tfds_map'
| 12-21-2019 08:31:11 | 12-21-2019 08:31:11 | @abb4s A workaround would be downgrading `transformers` to `2.2.0`. It worked for me that way.<|||||>Indeed, this was an error introduced by #1548. It was patched by 1efc208. Thank you for raising this issue! <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,250 | closed | Four tests fail when running the full test suite | ## 🐛 Bug
```
RUN_SLOW=1 python -m unittest discover -s transformers/tests -p '*_test.py' -t . -v
```
```
======================================================================
ERROR: test_model_from_pretrained (transformers.tests.modeling_tf_albert_test.TFAlbertModelTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File ".../transformers/transformers/configuration_utils.py", line 160, in from_pretrained
config = cls.from_json_file(resolved_config_file)
File ".../transformers/transformers/configuration_utils.py", line 213, in from_json_file
with open(json_file, "r", encoding='utf-8') as reader:
FileNotFoundError: [Errno 2] No such file or directory: '/var/folders/pq/hzv7wgqs5fq0hf1bwzy4mlzr0000gn/T/transformers_test/5b4c66df217ea00b14f607787de616bbff332ae36147a92cd94219160006685a'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File ".../transformers/transformers/tests/modeling_tf_albert_test.py", line 221, in test_model_from_pretrained
model = TFAlbertModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
File ".../transformers/transformers/modeling_tf_utils.py", line 249, in from_pretrained
**kwargs
File ".../transformers/transformers/configuration_utils.py", line 173, in from_pretrained
raise EnvironmentError(msg)
OSError: Model name 'albert-base-uncased' was not found in model name list (albert-xxlarge-v2, albert-large-v1, albert-xlarge-v1, albert-base-v2, albert-base-v1, albert-large-v2, albert-xlarge-v2, albert-xxlarge-v1). We assumed 'https://s3.amazonaws.com/models.huggingface.co/bert/albert-base-uncased/config.json' was a path or url to a configuration file named config.json or a directory containing such a file but couldn't find any such file at this path or url.
======================================================================
ERROR: test_model_from_pretrained (transformers.tests.modeling_tf_xlm_test.TFXLMModelTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File ".../transformers/transformers/tests/modeling_tf_xlm_test.py", line 255, in test_model_from_pretrained
model = XLMModel.from_pretrained(model_name, cache_dir=CACHE_DIR)
NameError: name 'XLMModel' is not defined
======================================================================
FAIL: test_inference_masked_lm (transformers.tests.modeling_roberta_test.RobertaModelIntegrationTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File ".../transformers/transformers/tests/modeling_roberta_test.py", line 227, in test_inference_masked_lm
torch.allclose(output[:, :3, :3], expected_slice, atol=1e-3)
AssertionError: False is not true
======================================================================
FAIL: test_inference_masked_lm (transformers.tests.modeling_tf_roberta_test.TFRobertaModelIntegrationTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File ".../transformers/transformers/tests/modeling_tf_roberta_test.py", line 220, in test_inference_masked_lm
numpy.allclose(output[:, :3, :3].numpy(), expected_slice.numpy(), atol=1e-3)
AssertionError: False is not true
----------------------------------------------------------------------
```
| 12-21-2019 07:41:53 | 12-21-2019 07:41:53 | The first two are easy fixes. I put fixes in the test parallelization PR.
The last two are likely the same bug, but I'm out of my depth there.<|||||>I guess this has been fixed by now |
transformers | 2,249 | closed | bert(+lstm)+crf | add crf layer for better performance in NER tasks | 12-21-2019 06:24:43 | 12-21-2019 06:24:43 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2249?src=pr&el=h1) Report
> Merging [#2249](https://codecov.io/gh/huggingface/transformers/pull/2249?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ac1b449cc938bb34bc9021feff599cfd3b2376ae?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2249?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2249 +/- ##
=======================================
Coverage 79.82% 79.82%
=======================================
Files 131 131
Lines 19496 19496
=======================================
Hits 15562 15562
Misses 3934 3934
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2249?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2249?src=pr&el=footer). Last update [ac1b449...ea25498](https://codecov.io/gh/huggingface/transformers/pull/2249?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>@michael-wzhu did this increase f1 on CoNLL?<|||||>> add crf layer for better performance in NER tasks
Hi. How do you solve the tokens with "##..." when they are fed into the crf layer?
e.g. De ##duct ##ive reasoning
Do "##duct" and ""##ive" are fed into the crf layer? If they are, do they have chance to be transfered in the transition matrix?<|||||>> e" are fed into the crf layer? If they are, do they have chance to be transfered in the transition matrix?
I have used this to develop my own version. To answer your quesiton, ## sub word tokens are treated as padding, as suggested by the original BERT authors. This code relies on The padding label token being "X", at the first position (to get0th index) from the output of get_labels function in crf_utils_ner.py
The pad token label id might need to be 0 for calculations in CRF, but you should be careful in declaring your mask so your model does not confuse padding with one of the tokens. <|||||>If ## sub word tokens are treated as padding, it will break the tag-tag dependencies, so definitely not ideal.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>@srush @mezig351 What did you find after your work on this issue? Why didn't you merge it?<|||||>I think you should add it, it's not trivial, and I myself spent 2 days to make it work...
and then I just found this thread... |
transformers | 2,248 | closed | Extract features aligned to tokens from a BertForQuestionAnswering model | ## ❓ Questions & Help
I have a finetuned Bert model on a custom Question Answering task (follow original Tensorflow source), I've successful converted this model and loaded it with `BertForQuestionAnswering`
<!-- A clear and concise description of the question. -->
My question is how to get feature embedding aligned to each token from a pretrained `BertForQuestionAnswering`
| 12-21-2019 05:00:37 | 12-21-2019 05:00:37 | >My question is how to get feature embedding aligned to each token from a pretrained BertForQuestionAnswering
Could you elaborate on what this means? I am currently working with BertForQuestionAnswering but haven't encountered this area before. |
transformers | 2,247 | closed | NER pipeline missing start/end | ## 🚀 Feature
2.3 is a great release! Really excited for pipelines.
The feature to add is the start/end positions of the entities.
Additionally, the option to show the recognized entity rather than in subword form would be more user-friendly as an API.
## Motivation
[The release mentions including positions of the entities](https://github.com/huggingface/transformers/releases/tag/v2.3.0). The start/end positions are not in `transformers.py`
## Additional context
This is really exciting and motivated me to use your module. I hope to make a PR in the future.
| 12-21-2019 02:46:41 | 12-21-2019 02:46:41 | That would be a great feature, +1.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,246 | closed | Recently added pipelines tests should be marked as slow | ## 🐛 Bug
Starting today, when running tests, some very large files are downloaded even though I don't enable RUN_SLOW=true.
Some tests in pipelines_test.py should be marked with `@slow` so they don't run unless RUN_SLOW=True. | 12-20-2019 20:28:32 | 12-20-2019 20:28:32 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,245 | closed | Training dataset is not available | ## ❓ Questions & Help
As stated [here](https://github.com/huggingface/transformers/blob/1ab8dc44b3d84ed1894f5b6a6fab58fb39298fc7/examples/distillation/README.md), the model was trained using Toronto Book Corpus and English Wikipedia. Neither this repository or BERT repository provides links to obtain this data. Upon further investigation the Toronto Book Corpus is no longer public. Please advise on how to get this data. | 12-20-2019 20:07:56 | 12-20-2019 20:07:56 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>paging @LysandreJik <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,244 | closed | Fix Camembert and XLM-R `decode` method- Fix NER pipeline alignement | Fix `decode` method for Camembert and XLM-R
Simplify alignement method for NER pipeline | 12-20-2019 19:45:09 | 12-20-2019 19:45:09 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2244?src=pr&el=h1) Report
> Merging [#2244](https://codecov.io/gh/huggingface/transformers/pull/2244?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ceae85ad60da38cacb14eca49f752669a4fe31dc?src=pr&el=desc) will **decrease** coverage by `0.04%`.
> The diff coverage is `58.82%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2244?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2244 +/- ##
==========================================
- Coverage 79.92% 79.88% -0.05%
==========================================
Files 131 131
Lines 19469 19480 +11
==========================================
Hits 15561 15561
- Misses 3908 3919 +11
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2244?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/commands/run.py](https://codecov.io/gh/huggingface/transformers/pull/2244/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbW1hbmRzL3J1bi5weQ==) | `0% <0%> (ø)` | :arrow_up: |
| [transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2244/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `67.1% <100%> (-1.76%)` | :arrow_down: |
| [transformers/tokenization\_camembert.py](https://codecov.io/gh/huggingface/transformers/pull/2244/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl9jYW1lbWJlcnQucHk=) | `36.61% <50%> (+0.79%)` | :arrow_up: |
| [transformers/tokenization\_xlm\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2244/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl94bG1fcm9iZXJ0YS5weQ==) | `37.68% <50%> (+0.75%)` | :arrow_up: |
| [transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/2244/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3BpcGVsaW5lcy5weQ==) | `67.94% <71.42%> (+0.09%)` | :arrow_up: |
| [transformers/tests/pipelines\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2244/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3BpcGVsaW5lc190ZXN0LnB5) | `98.03% <0%> (-0.99%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2244?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2244?src=pr&el=footer). Last update [ceae85a...655fd06](https://codecov.io/gh/huggingface/transformers/pull/2244?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,243 | closed | fixing xlm-roberta tokenizer max_length and automodels | Fix missing max token num in XLM-Roberta | 12-20-2019 18:02:20 | 12-20-2019 18:02:20 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2243?src=pr&el=h1) Report
> Merging [#2243](https://codecov.io/gh/huggingface/transformers/pull/2243?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/65c75fc58796b278d58b0ce2c8d2031594ef0f64?src=pr&el=desc) will **decrease** coverage by `0.02%`.
> The diff coverage is `21.42%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2243?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2243 +/- ##
==========================================
- Coverage 79.9% 79.88% -0.03%
==========================================
Files 131 131
Lines 19451 19467 +16
==========================================
+ Hits 15543 15551 +8
- Misses 3908 3916 +8
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2243?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2243/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `94.1% <ø> (+1.07%)` | :arrow_up: |
| [transformers/commands/run.py](https://codecov.io/gh/huggingface/transformers/pull/2243/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2NvbW1hbmRzL3J1bi5weQ==) | `0% <0%> (ø)` | :arrow_up: |
| [transformers/tokenization\_xlm\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2243/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl94bG1fcm9iZXJ0YS5weQ==) | `36.92% <0%> (ø)` | :arrow_up: |
| [transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2243/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `92.08% <100%> (+0.01%)` | :arrow_up: |
| [transformers/modeling\_auto.py](https://codecov.io/gh/huggingface/transformers/pull/2243/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2F1dG8ucHk=) | `31.92% <18.18%> (-1.09%)` | :arrow_down: |
| [transformers/pipelines.py](https://codecov.io/gh/huggingface/transformers/pull/2243/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3BpcGVsaW5lcy5weQ==) | `67.65% <27.58%> (+0.49%)` | :arrow_up: |
| [transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2243/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3V0aWxzLnB5) | `93.15% <0%> (-0.53%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2243?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2243?src=pr&el=footer). Last update [65c75fc...bbaaec0](https://codecov.io/gh/huggingface/transformers/pull/2243?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,242 | closed | BertTokenizer / CamemBERTokenizer `decode` behaviour ? | ## 🐛 Bug
Thank you for CamemBERT, it's a great work 😃
Model I am using (Bert, XLNet....): CamemBERT
Language I am using the model on (English, Chinese....): French
The problem arise when using:
* [ ] the official example scripts:
* [x] my own modified scripts: followed by the official documentation at https://huggingface.co/transformers/main_classes/tokenizer.html#
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task:
* [x] my own task or dataset: Show the tokens from the CamemBERT tokenizer.
## To Reproduce
Steps to reproduce the behavior:
1. Tokenize (`encode`) a sentence.
2. Try to `decode` the ids but not working (`TypeError` thrown)
```
tokenizer = CamembertTokenizer.from_pretrained('camembert-base')
ids = tokenizer.encode(sentence)
print(tokenizer.decode(ids))
```
I just followed the documentation for decode which explains :
Converts a sequence of ids (integer) in a string, using the tokenizer and vocabulary with options to remove special tokens and clean up tokenization spaces. Similar to doing self.convert_tokens_to_string(self.convert_ids_to_tokens(token_ids)).
Traceback :
```
File "/d/Workspaces/camembert-test/main.py", line 51, in <module>
tokens_with_transformers_error(sentence)
File "/d/Workspaces/camembert-test/main.py", line 32, in tokens_with_transformers_error
print(tokenizer.decode(ids))
File "/d/Workspaces/camembert-test/.venv/lib/python3.7/site-packages/transformers/tokenization_utils.py", line 1187, in decode
sub_texts.append(self.convert_tokens_to_string(current_sub_text))
File "/d/Workspaces/camembert-test/.venv/lib/python3.7/site-packages/transformers/tokenization_utils.py", line 1156, in convert_tokens_to_string
return ' '.join(self.convert_ids_to_tokens(tokens))
File "/d/Workspaces/camembert-test/.venv/lib/python3.7/site-packages/transformers/tokenization_utils.py", line 1145, in convert_ids_to_tokens
tokens.append(self._convert_id_to_token(index))
File "/d/Workspaces/camembert-test/.venv/lib/python3.7/site-packages/transformers/tokenization_camembert.py", line 146, in _convert_id_to_token
return self.sp_model.IdToPiece(index - self.fairseq_offset)
TypeError: unsupported operand type(s) for -: 'str' and 'int'
```
Here, convert_tokens_to_string seems to call convert_ids_to_tokens ? Why ?
## Expected behavior
Have the same return statement (or anything else) as this code which seems to works but don't have to...? I am not sure though 😃
```
tokenizer = CamembertTokenizer.from_pretrained('camembert-base')
ids = tokenizer.encode(sentence)
print(tokenizer.convert_tokens_to_string(ids)) # I give list of ids, not list of tokens
```
## Environment
* OS: Linux
* Python version: 3.7
* PyTorch version: 1.3.1
* PyTorch Transformers version (or branch): 2.2.2
* Using GPU ? no
* Distributed of parallel setup ? no
* Any other relevant information: /
## Additional context
<!-- Add any other context about the problem here. -->
| 12-20-2019 15:19:10 | 12-20-2019 15:19:10 | > tokenizer.decode(ids)
I've made some tests, and this problem occurs also with `BertTokenizer`.
<|||||>Should be fixed by #2244, can you check that you get the expected behaviour on master?
Thanks!<|||||>I confirm with the version with the merge commit and new version 2.3.0, it works.
Thank you !<|||||>Thanks for checking! |
transformers | 2,241 | closed | How to load the finetuned model for retraining from checkpoints in run_squad.py? | Because of bad internet connection and computational issues its hard for us to train a large number of epochs. We're trying to use the run_squad.py script for bangla QA system training. We have trained the model before and have the checkpoints.
```
!python run_squad.py \
--model_type distilbert \
--model_name_or_path ../data/tmp/attempt_with_dataset_v3/checkpoint-5000/ \
--do_train \
--do_eval \
--do_lower_case \
--train_file ../data/dataset_v_3/train_bangla_samples.json \
--predict_file ../data/dataset_v_3/valid_bangla_samples.json \
--version_2_with_negative \
--per_gpu_train_batch_size 12 \
--learning_rate 5e-5 \
--num_train_epochs 1.0 \
--max_seq_length 384 \
--doc_stride 128 \
--logging_steps 100 \
--save_steps 100 \
--fp16 \
--evaluate_during_training \
--output_dir ../data/mytrial
```
command produces this error :
```
12/20/2019 14:06:45 - WARNING - __main__ - Process rank: -1, device: cuda, n_gpu: 1, distributed training: False, 16-bits training: True
12/20/2019 14:06:47 - INFO - transformers.configuration_utils - loading configuration file ../data/tmp/attempt_with_dataset_v3/checkpoint-5000/config.json
12/20/2019 14:06:47 - INFO - transformers.configuration_utils - Model config {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"finetuning_task": null,
"hidden_dim": 3072,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"is_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"max_position_embeddings": 512,
"n_heads": 12,
"n_layers": 6,
"num_labels": 2,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pruned_heads": {},
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"tie_weights_": true,
"torchscript": false,
"use_bfloat16": false,
"vocab_size": 30522
}
12/20/2019 14:06:47 - INFO - transformers.tokenization_utils - Model name '../data/tmp/attempt_with_dataset_v3/checkpoint-5000/' not found in model shortcut name list (distilbert-base-uncased, distilbert-base-uncased-distilled-squad, distilbert-base-german-cased, distilbert-base-multilingual-cased). Assuming '../data/tmp/attempt_with_dataset_v3/checkpoint-5000/' is a path or url to a directory containing tokenizer files.
12/20/2019 14:06:47 - INFO - transformers.tokenization_utils - Didn't find file ../data/tmp/attempt_with_dataset_v3/checkpoint-5000/vocab.txt. We won't load it.
12/20/2019 14:06:47 - INFO - transformers.tokenization_utils - Didn't find file ../data/tmp/attempt_with_dataset_v3/checkpoint-5000/added_tokens.json. We won't load it.
12/20/2019 14:06:47 - INFO - transformers.tokenization_utils - Didn't find file ../data/tmp/attempt_with_dataset_v3/checkpoint-5000/special_tokens_map.json. We won't load it.
12/20/2019 14:06:47 - INFO - transformers.tokenization_utils - Didn't find file ../data/tmp/attempt_with_dataset_v3/checkpoint-5000/tokenizer_config.json. We won't load it.
Traceback (most recent call last):
File "run_squad.py", line 614, in <module>
main()
File "run_squad.py", line 528, in main
cache_dir=args.cache_dir if args.cache_dir else None)
File "/content/gdrive/My Drive/huggingfaceattempt/transformers/transformers/tokenization_utils.py", line 302, in from_pretrained
return cls._from_pretrained(*inputs, **kwargs)
File "/content/gdrive/My Drive/huggingfaceattempt/transformers/transformers/tokenization_utils.py", line 370, in _from_pretrained
list(cls.vocab_files_names.values())))
OSError: Model name '../data/tmp/attempt_with_dataset_v3/checkpoint-5000/' was not found in tokenizers model name list (distilbert-base-uncased, distilbert-base-uncased-distilled-squad, distilbert-base-german-cased, distilbert-base-multilingual-cased). We assumed '../data/tmp/attempt_with_dataset_v3/checkpoint-5000/' was a path or url to a directory containing vocabulary files named ['vocab.txt'] but couldn't find such vocabulary files at this path or url.
```
but none of the checkpoint folders have any vocabulary stored. Are we supposed to pass the checkpoint folder path to the model_name_or_path for training again from that checkpoint? | 12-20-2019 14:33:32 | 12-20-2019 14:33:32 | Ah, turns out to run from a pretrained model we have to specify the output_dir as the previous checkpoint. I feel like its quite unintuitive. <|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,240 | closed | TFDistilBertModelTest.test_pt_tf_model_equivalence thrown while merging after PR | ## 🐛 Bug
I've seen that some PRs failed because of the same error, such as #2239 (today) and #2237 (today). If I'm not remember wrong, there is also another PR in the last days involved @rlouf that he had the same error. Even if the changes made not affect `DistilBertModel` such as #2237, this error occurs!
Question: **Is it a bug in Transformers or a bug in our code submitted?**
## To Reproduce
Steps to reproduce the behavior: after submitting a PR to Transformers library, it occurs
```
=================================== FAILURES ===================================
______________ TFDistilBertModelTest.test_pt_tf_model_equivalence ______________
self = <transformers.tests.modeling_tf_distilbert_test.TFDistilBertModelTest testMethod=test_pt_tf_model_equivalence>
def test_pt_tf_model_equivalence(self):
if not is_torch_available():
return
import torch
import transformers
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
pt_model_class_name = model_class.__name__[2:] # Skip the "TF" at the beggining
pt_model_class = getattr(transformers, pt_model_class_name)
config.output_hidden_states = True
tf_model = model_class(config)
pt_model = pt_model_class(config)
# Check we can load pt model in tf and vice-versa with model => model functions
tf_model = transformers.load_pytorch_model_in_tf2_model(tf_model, pt_model, tf_inputs=inputs_dict)
pt_model = transformers.load_tf2_model_in_pytorch_model(pt_model, tf_model)
# Check predictions on first output (logits/hidden-states) are close enought given low-level computational differences
pt_model.eval()
pt_inputs_dict = dict((name, torch.from_numpy(key.numpy()).to(torch.long))
for name, key in inputs_dict.items())
with torch.no_grad():
pto = pt_model(**pt_inputs_dict)
tfo = tf_model(inputs_dict, training=False)
tf_hidden_states = tfo[0].numpy()
pt_hidden_states = pto[0].numpy()
tf_hidden_states[np.isnan(tf_hidden_states)] = 0
pt_hidden_states[np.isnan(pt_hidden_states)] = 0
max_diff = np.amax(np.abs(tf_hidden_states - pt_hidden_states))
> self.assertLessEqual(max_diff, 2e-2)
E AssertionError: 3.107201 not less than or equal to 0.02
transformers/tests/modeling_tf_common_test.py:139: AssertionError
```
## Expected behavior
No error was thrown.
## Environment
* OS: **Ubuntu 16.04**
* Python version: **3.6.9**
* PyTorch version: **1.3.1**
* PyTorch Transformers version (or branch): **master**
* Using GPU ? **Indifferent**
* Distributed of parallel setup ? **Indifferent**
* Any other relevant information: | 12-20-2019 14:25:51 | 12-20-2019 14:25:51 | I've seen the same error when running the test suite locally.<|||||>I know how to reproduce/debug this particular failure so I'll take a look on monday (unless someone beats me to it)<|||||>aaarg, I can't reproduce it locally anymore.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,239 | closed | HANS evaluation | Adding the evaluation on the HANS dataset in examples | 12-20-2019 13:38:01 | 12-20-2019 13:38:01 | Thanks a lot for that Nafise!
I've started to update the readme.
Do you think you would have an example of a command to run the script together with associated results?<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2239?src=pr&el=h1) Report
> Merging [#2239](https://codecov.io/gh/huggingface/transformers/pull/2239?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/dc17f2a1110aed8d1729e77b0619601e3d96b84e?src=pr&el=desc) will **decrease** coverage by `0.01%`.
> The diff coverage is `0%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2239?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2239 +/- ##
==========================================
- Coverage 74.67% 74.66% -0.02%
==========================================
Files 87 87
Lines 14800 14802 +2
==========================================
Hits 11052 11052
- Misses 3748 3750 +2
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2239?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/data/metrics/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/2239/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9kYXRhL21ldHJpY3MvX19pbml0X18ucHk=) | `26.66% <0%> (-1.25%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2239?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2239?src=pr&el=footer). Last update [dc17f2a...258ed2e](https://codecov.io/gh/huggingface/transformers/pull/2239?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Hi Thomas,
This is an example of using test_hans.py:
```
export HANS_DIR=path-to-hans
export MODEL_TYPE=type-of-the-model-e.g.-bert-roberta-xlnet-etc
export MODEL_PATH=path-to-the-model-directory-that-is-trained-on-NLI-e.g.-by-using-run_glue.py
python examples/test_hans.py \
--task_name hans \
--model_type $MODEL_TYPE \
--do_eval \
--do_lower_case \
--data_dir $HANS_DIR \
--model_name_or_path $MODEL_PATH \
--max_seq_length 128 \
-output_dir $MODEL_PATH \
```
This will create the hans_predictions.txt file in MODEL_PATH, which can then be evaluated using hans/evaluate_heur_output.py from the HANS dataset.
The results of the BERT-base model that is trained on MNLI using batch size 8 and the random seed 42 on the HANS dataset is as follows:
```
Heuristic entailed results:
lexical_overlap: 0.9702
subsequence: 0.9942
constituent: 0.9962
Heuristic non-entailed results:
lexical_overlap: 0.199
subsequence: 0.0396
constituent: 0.118
```
<|||||>Great thanks a lot @ns-moosavi, merging this.
So happy to welcome HANS in the examples! |
transformers | 2,238 | closed | Readme installation/test order can lead to confusion when running example unit tests | ## ❓ Questions & Help
When following the main readme installation/testing instructions in order, it is not mentioned that in order to let the examples tests pass, the separate examples/requirements.txt must be installed.
Thus, `pip install -r ./examples/requirements.txt` should come before `python -m pytest -sv ./transformers/tests/` in the main readme to avoid confusion.
Additionally, the readme line `python -m unittest discover -s examples -p "*test.py" -t examples` cannot find any tests, and produces the following output;
`Ran 0 tests in 0.000s
OK`
I don't think this is the intended behavior - is the line redundant? | 12-20-2019 11:19:33 | 12-20-2019 11:19:33 | related to what @aaugustin is working on<|||||>Yes I'm planning to rework the contributor documentation. Currently it's a bit haphazard, sorry.<|||||>This is now clarified. The general README points to the README for examples which is unambiguous. |
transformers | 2,237 | closed | Fix out-of-date comments in Transformers examples directory | 12-20-2019 10:55:06 | 12-20-2019 10:55:06 | ||
transformers | 2,236 | closed | Removing redundant model weights | ## 🐛 This is not a bug, more like implemetation detail
I am using BertForTokenClassification model for my binary token classification problem. If my understanding is right, BertForTokenClassification has one layer on top with num_classes output neurons (one for each class) with softmax activation function + CrossEntropyLoss().
Now, if your problem has >2 classes this is completely fine, but if num_classes=2 you are both modeling P(input = 0) and P(input = 1), and it's easy to see why this is redunant.
num_classes=2 is special case and it should be implemented with only one output neuron with sigmoid activation function + binary cross-entopy.
Please correct me if I am wrong :)
| 12-20-2019 10:55:05 | 12-20-2019 10:55:05 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,235 | closed | add example for Model2Model in quickstart | As per discussed @LysandreJik | 12-20-2019 10:14:34 | 12-20-2019 10:14:34 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2235?src=pr&el=h1) Report
> Merging [#2235](https://codecov.io/gh/huggingface/transformers/pull/2235?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ff36e6d8d713901af807719fa604518c451ff2e5?src=pr&el=desc) will **decrease** coverage by `1.09%`.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2235?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2235 +/- ##
=========================================
- Coverage 81.42% 80.32% -1.1%
=========================================
Files 122 122
Lines 18348 18344 -4
=========================================
- Hits 14940 14735 -205
- Misses 3408 3609 +201
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2235?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/modeling\_tf\_pytorch\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2235/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `9.15% <0%> (-80.92%)` | :arrow_down: |
| [transformers/tests/modeling\_tf\_common\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2235/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `80.17% <0%> (-17.25%)` | :arrow_down: |
| [transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2235/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `59.41% <0%> (-12.36%)` | :arrow_down: |
| [transformers/modeling\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2235/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `72.21% <0%> (-2.33%)` | :arrow_down: |
| [transformers/modeling\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2235/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `94.27% <0%> (-2.21%)` | :arrow_down: |
| [transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2235/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `80.19% <0%> (-1.33%)` | :arrow_down: |
| [transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/2235/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvcHJvY2Vzc29ycy9zcXVhZC5weQ==) | `14.18% <0%> (ø)` | :arrow_up: |
| [transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2235/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `71.42% <0%> (+0.06%)` | :arrow_up: |
| [transformers/modeling\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2235/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3V0aWxzLnB5) | `91.46% <0%> (+1.17%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2235?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2235?src=pr&el=footer). Last update [ff36e6d...a3245dd](https://codecov.io/gh/huggingface/transformers/pull/2235?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,234 | closed | Supoort loading model weights from a single file. | So far, transformers package supports loading a model from a directory, such as
```python
model = BertModel.from_pretrained('./test/saved_model/') # E.g. model was saved using save_pretrained('./test/saved_model/')
```
Actually, it loads model weight from $directory/pytorch_model.bin.
Is it possible to load model weights from a file?
such as
```python
tokenizer = BertTokenizer.from_pretrained('./test/saved_model/my_vocab.txt')
```
Because my network is too slow to download models from amazon server.
I have to download the model files manually and put them to transformers.
It is more convenient to load the downloaded model weights from a file than a directory.
```python
model = BertModel.from_pretrained('./test/model_zoo/bert-base-multilingual-cased-pytorch_model.bin')
```
Thank you. | 12-20-2019 07:41:59 | 12-20-2019 07:41:59 | As my best knowledge, you **can't** load a model _directly_ from a file. As said in #2094 by @LysandreJik, if you saved using the `save_pretrained` method, then the directory already should have a `config.json` file specifying the shape of the model, so you can simply load it using:
```
>>> import transformers
>>> from transformers import BertModel
>>> model = BertModel.from_pretrained("./test/saved_model/")
```
> So far, transformers package supports loading a model from a directory, such as
>
> ```python
> model = BertModel.from_pretrained('./test/saved_model/') # E.g. model was saved using save_pretrained('./test/saved_model/')
> ```
>
> Actually, it loads model weight from $directory/pytorch_model.bin.
> Is it possible to load model weights from a file?
> such as
>
> ```python
> tokenizer = BertTokenizer.from_pretrained('./test/saved_model/my_vocab.txt')
> ```
>
> Because my network is too slow to download models from amazon server.
> I have to download the model files manually and put them to transformers.
> It is more convenient to load the downloaded model weights from a file than a directory.
>
> ```python
> model = BertModel.from_pretrained('./test/model_zoo/bert-base-multilingual-cased-pytorch_model.bin')
> ```
>
> Thank you.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,233 | closed | The code used to be clean... | Hi, thanks to all contributors!
From my point of view, recent changes in examples codes, especially run_squad script, are kinda confusing.
May I know what is the reason that we delete old utils_squad.py and store all data processing and evaluating scripts under the transformer/data folder? This makes code look quite messy. Particularly, the example and features classes have been changed a lot.
I was reading the old version scripts for a long long time, and I think it was easy for me to change any components in the whole structure, no matter data preprocessing or introducing new LM. I can easily change the input format of examples, so I could run codes on other datasets with few lines.
I believe many people have already made task-specific changes on their own codes, and sometimes some people just want to run codes on new released LMs for testing, so they come here and check. If luckily new LM is available, we would prefer update code by hands instead of the direct downloading whole package again.
But anyway, if changes are compulsory, I am definitely willing to go through it deeply. | 12-20-2019 06:59:42 | 12-20-2019 06:59:42 | Updating code by hand seems a very messy way of working. Can't you just make a copy of the (old version of the) examples directory, and make your changes there - regardless of the current installation of `transformers` itself? |
transformers | 2,232 | closed | Keep even the first of the special tokens intact while lowercasing | This fixes #2220. The order of `all_special_tokens` is random, and the first one of these will get broken by the lowercasing. There are 5 special tokens, so you have a 1 in 5 chance of hitting the problem. | 12-20-2019 01:05:39 | 12-20-2019 01:05:39 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2232?src=pr&el=h1) Report
> Merging [#2232](https://codecov.io/gh/huggingface/transformers/pull/2232?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a5a06a851e1da79138e53978aa079a093f243dde?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `100%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2232?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2232 +/- ##
=======================================
Coverage 81.43% 81.43%
=======================================
Files 122 122
Lines 18338 18338
=======================================
Hits 14933 14933
Misses 3405 3405
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2232?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2232/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rva2VuaXphdGlvbl91dGlscy5weQ==) | `90.49% <100%> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2232?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2232?src=pr&el=footer). Last update [a5a06a8...06b022d](https://codecov.io/gh/huggingface/transformers/pull/2232?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>> This fixes #2220. The order of `all_special_tokens` is random, and the first one of these will get broken by the lowercasing. There are 5 special tokens, so you have a 1 in 5 chance of hitting the problem.
You're right! Good job @dirkgr :-)<|||||>Great, thanks a lot for that @dirkgr. I've added a test in fb393ad9945f66b081f88b81b90a2974d81e9601 to make sure this doesn't happen again. |
transformers | 2,231 | closed | [http] customizable requests user-agent | 12-19-2019 23:30:04 | 12-19-2019 23:30:04 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2231?src=pr&el=h1) Report
> Merging [#2231](https://codecov.io/gh/huggingface/transformers/pull/2231?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a5a06a851e1da79138e53978aa079a093f243dde?src=pr&el=desc) will **decrease** coverage by `<.01%`.
> The diff coverage is `77.77%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2231?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2231 +/- ##
==========================================
- Coverage 81.43% 81.42% -0.01%
==========================================
Files 122 122
Lines 18338 18348 +10
==========================================
+ Hits 14933 14940 +7
- Misses 3405 3408 +3
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2231?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2231/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `71.36% <77.77%> (-0.07%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2231?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2231?src=pr&el=footer). Last update [a5a06a8...15d897f](https://codecov.io/gh/huggingface/transformers/pull/2231?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
|
transformers | 2,230 | closed | what is the most efficient way to store all hidden layers' weights? | Hi,
I am following this [post](https://mccormickml.com/2019/05/14/BERT-word-embeddings-tutorial/) for getting all 12 hidden layers' weights for every token in a sentence.
Consider I have a short text with 2 sentences: `He stole money today. He is fishing on the Mississippi riverbank.`
I want to store 5 + 8 = 13 tokens - all 12 hidden layers weights where each tensor's size=768. So, I will have 13 x 12 = 156 tensors.
I want to save all the weights in a file and I am wondering if I should use `pickle` or `hd5` format (I am working with long text documents.) I am planning to separate two sentences by a blank line, please suggest if any better ways to do it.
Thanks! | 12-19-2019 19:41:00 | 12-19-2019 19:41:00 | PyTorch has its [own saving utility](https://pytorch.org/tutorials/beginner/saving_loading_models.html): `torch.save`, which sounds good for your use case as you can easily save/load the tensors. It's based on pickle.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,229 | closed | Minor/basic text fixes | 12-19-2019 17:37:00 | 12-19-2019 17:37:00 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2229?src=pr&el=h1) Report
> Merging [#2229](https://codecov.io/gh/huggingface/transformers/pull/2229?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a1f1dce0ae511ef7766c6b6a8f5ebf9118279e73?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2229?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2229 +/- ##
=======================================
Coverage 81.47% 81.47%
=======================================
Files 122 122
Lines 18344 18344
=======================================
Hits 14946 14946
Misses 3398 3398
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2229?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/data/processors/squad.py](https://codecov.io/gh/huggingface/transformers/pull/2229/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2RhdGEvcHJvY2Vzc29ycy9zcXVhZC5weQ==) | `14.18% <0%> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2229?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2229?src=pr&el=footer). Last update [a1f1dce...70dbca5](https://codecov.io/gh/huggingface/transformers/pull/2229?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Thanks! |
|
transformers | 2,228 | closed | Trouble loading Albert model | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Albert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details):
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details)
Using example from docs: https://huggingface.co/transformers/model_doc/albert.html
## To Reproduce
Trying to load the Albert model using the code below:
```
import tensorflow as tf
from transformers import AlbertTokenizer
tokenizer = AlbertTokenizer.from_pretrained('bert-base-uncased')
```
Getting the following error:
```
Traceback (most recent call last):
File "<ipython-input-4-56254e5f4b51>", line 3, in <module>
tokenizer = AlbertTokenizer.from_pretrained('bert-base-uncased')
File "c:\users\admin\appdata\local\programs\python\python37\lib\site-packages\transformers\tokenization_utils.py", line 302, in from_pretrained
return cls._from_pretrained(*inputs, **kwargs)
File "c:\users\admin\appdata\local\programs\python\python37\lib\site-packages\transformers\tokenization_utils.py", line 437, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "c:\users\admin\appdata\local\programs\python\python37\lib\site-packages\transformers\tokenization_albert.py", line 90, in __init__
self.sp_model.Load(vocab_file)
File "c:\users\admin\appdata\local\programs\python\python37\lib\site-packages\sentencepiece.py", line 118, in Load
return _sentencepiece.SentencePieceProcessor_Load(self, filename)
RuntimeError: Internal: C:\projects\sentencepiece\src\sentencepiece_processor.cc(73) [model_proto->ParseFromArray(serialized.data(), serialized.size())]
```
Note, the same code works for bert instead of albert:
> from transformers import *
> tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
>
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
Looking for albert model to load without errors
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Windows 10
* Python version: 3.7
* PyTorch version: 1.3.1
* PyTorch Transformers version (or branch): pip install transformers (fresh install today 12/19/2019)
* Using GPU ?: Yes
* Distributed of parallel setup ?: N/A
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| 12-19-2019 16:47:23 | 12-19-2019 16:47:23 | Indeed, that's an error from the docs! I just fixed it with 33adab2. The doc should be updated now, thanks for raising this issue.<|||||>Wow, that was fast. Thank you! |
transformers | 2,227 | closed | Add "Train on Valohai" buttons to README | This pull request adds two "Train on Valohai" buttons to README:

and...

When clicked, it will automatically create a project on Valohai and let you run the project examples without any further setup. Effectively the same as "Deploy to Heroku" button if you are familiar with that.
## The flow looks like this (after login):



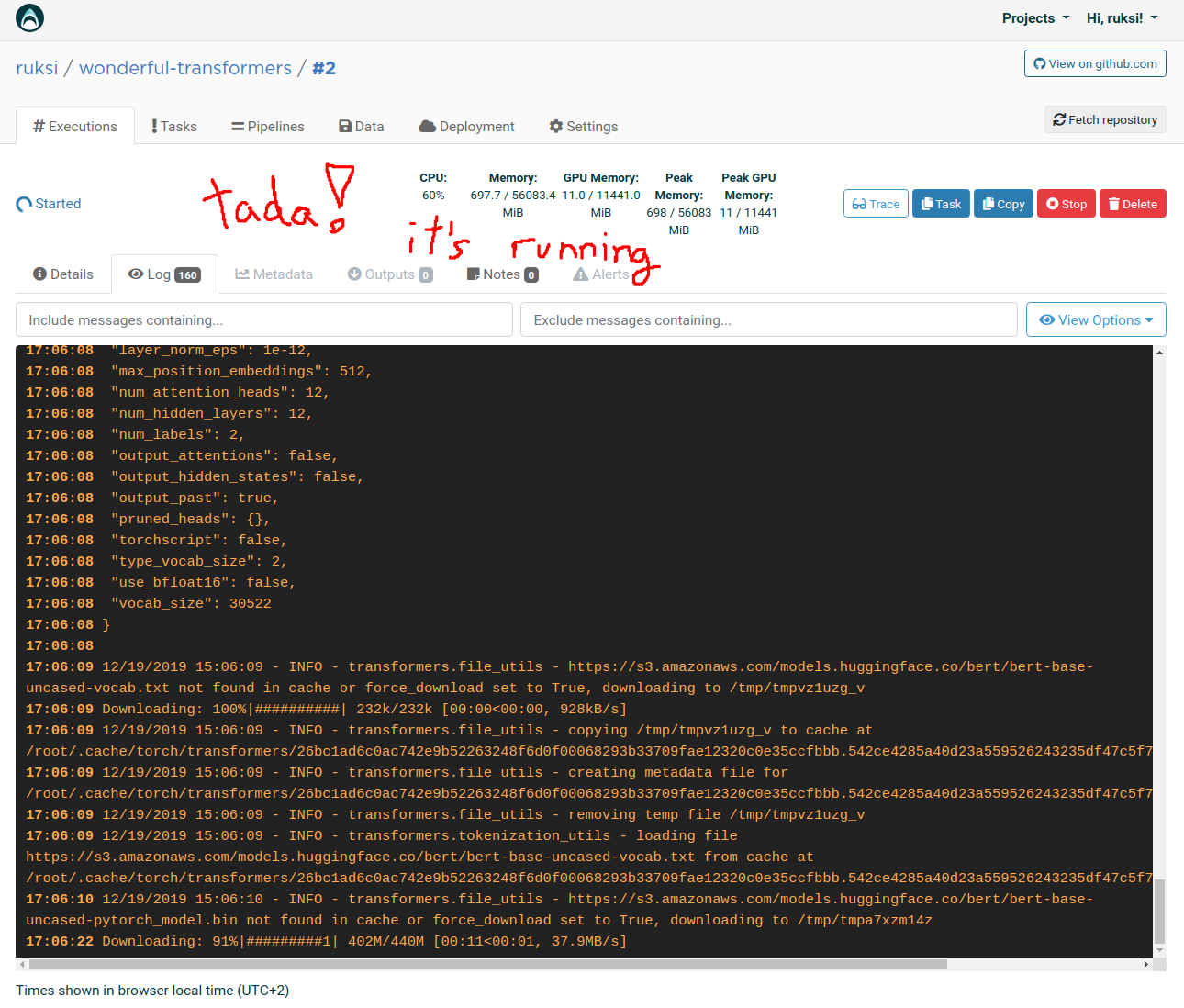
| 12-19-2019 15:12:55 | 12-19-2019 15:12:55 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2227?src=pr&el=h1) Report
> Merging [#2227](https://codecov.io/gh/huggingface/transformers/pull/2227?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/62c1fc3c1ecdfab787ee3c34d1ec1eba65c18877?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2227?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2227 +/- ##
=======================================
Coverage 81.47% 81.47%
=======================================
Files 122 122
Lines 18344 18344
=======================================
Hits 14946 14946
Misses 3398 3398
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2227?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2227?src=pr&el=footer). Last update [62c1fc3...6bfc181](https://codecov.io/gh/huggingface/transformers/pull/2227?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Big fan of the images explaining the usage :)<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,226 | closed | [REVIEW] Updated a out-of-date comment in run_lm_finetuning.py | 12-19-2019 14:24:42 | 12-19-2019 14:24:42 | ||
transformers | 2,225 | closed | [REVIEW] Updated comments in run_lm_finetuning.py | I've added DistilBERT and CamemBERT models in the description of the models that can be used for fine-tuning a LM model on a custom dataset. | 12-19-2019 14:02:39 | 12-19-2019 14:02:39 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2225?src=pr&el=h1) Report
> Merging [#2225](https://codecov.io/gh/huggingface/transformers/pull/2225?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8efc6dd544bf1a30d99d4b5abfc5e214699eab2b?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2225?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2225 +/- ##
=======================================
Coverage 81.47% 81.47%
=======================================
Files 122 122
Lines 18344 18344
=======================================
Hits 14946 14946
Misses 3398 3398
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2225?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2225?src=pr&el=footer). Last update [8efc6dd...035bfd9](https://codecov.io/gh/huggingface/transformers/pull/2225?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
|
transformers | 2,224 | closed | [REVIEW] Removed duplicate XLMConfig, XLMForQuestionAnswering and XLMTokenizer in run_squad.py | Before this PR, in run_squad.py at lines 58-65 were the following:
```
MODEL_CLASSES = {
'bert': (BertConfig, BertForQuestionAnswering, BertTokenizer),
'xlnet': (XLNetConfig, XLNetForQuestionAnswering, XLNetTokenizer),
'xlm': (XLMConfig, XLMForQuestionAnswering, XLMTokenizer),
'distilbert': (DistilBertConfig, DistilBertForQuestionAnswering, DistilBertTokenizer),
'albert': (AlbertConfig, AlbertForQuestionAnswering, AlbertTokenizer),
'xlm': (XLMConfig, XLMForQuestionAnswering, XLMTokenizer)
}
```
After this PR, I've **removed** the last (key, value) pair in the `MODEL_CLASSES` dictionary because it contains _xlm_ as key **two** times. | 12-19-2019 13:49:37 | 12-19-2019 13:49:37 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2224?src=pr&el=h1) Report
> Merging [#2224](https://codecov.io/gh/huggingface/transformers/pull/2224?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8efc6dd544bf1a30d99d4b5abfc5e214699eab2b?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2224?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2224 +/- ##
=======================================
Coverage 81.47% 81.47%
=======================================
Files 122 122
Lines 18344 18344
=======================================
Hits 14946 14946
Misses 3398 3398
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2224?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2224?src=pr&el=footer). Last update [8efc6dd...e6a7670](https://codecov.io/gh/huggingface/transformers/pull/2224?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Great, thanks @TheEdoardo93 ! |
transformers | 2,223 | closed | Need pretrained XLNET on Squad which can be loaded from_pre_trained | ## ❓ Questions & Help
It will be great ,if someone could share their username/model for XLNET pretrained on squad
<!-- A clear and concise description of the question. -->
| 12-19-2019 12:21:10 | 12-19-2019 12:21:10 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,222 | closed | Can we remove force_download=True from tests? | ## 🚀 Feature
I would like to remove `force_download=True` from tests and rely on the cache to keep cached files up to date.
## Motivation
Currently, several tests use `force_download=True` on large model files, e.g.:
https://github.com/huggingface/transformers/blob/9c58b236ef5fbbe5d0cbde4932eb342a73eaa0dc/transformers/tests/modeling_tf_auto_test.py#L49
This prevents caching large models within a test run and across test runs, which is very painful when working on these tests in a local environment. This is the main reason why I'm filing this issue.
In fact, it's so painful that these tests are marked as slow and skipped by default. As a consequence, we're not getting as much value from them as we could. If we downloaded each model only once, perhaps we could run them in CI.
I assume that `force_download=True` was added for robustness, to make sure the cache doesn't contain stale files.
If that's correct, then I believe I can be safely removed, because the current implementation of the cache in `file_utils.py` is sufficiently robust to keep the cache up to date.
The entry point is here:
https://github.com/huggingface/transformers/blob/8efc6dd544bf1a30d99d4b5abfc5e214699eab2b/transformers/configuration_utils.py#L157-L158
which goes here:
https://github.com/huggingface/transformers/blob/8efc6dd544bf1a30d99d4b5abfc5e214699eab2b/transformers/file_utils.py#L192-L196
which always gets an ETag (and, I guess, fails without an Internet connection):
https://github.com/huggingface/transformers/blob/8efc6dd544bf1a30d99d4b5abfc5e214699eab2b/transformers/file_utils.py#L288-L289
As a consequence, you never hit the only situation where the cache may use stale files: if it cannot get an ETag (either because there's no Internet connection, or because the HTTP server doesn't provide an ETag).
(As a side note, file_utils.py is needlessly complex, given that all transformers files are stored on S3.)
Am I missing a reason for `force_download=True`? Did you add it because you encountered another issue? | 12-19-2019 08:36:39 | 12-19-2019 08:36:39 | After further research, I'm seeing two possible issues.
**transformers gets files from S3 with https:// URLs, not s3:// URLs.**
I think we want to preserve the capability to use the library offline; we don't want to require an Internet connection to check the ETag in all cases. So we have two possibilities here:
1. Accept that, on a machine without access to the Internet, tests may use stale files. I think that's acceptable.
2. Add a `force_check` option; if it's `True` and we can't fetch the ETag, raise an exception instead of using a possibly stale file. I don't think that's worth the effort.
**files may be truncated if shutil.copyfileobj is interrupted**
The whole point of downloading to a temp file and then moving to the final location is to prevent truncation. By using shutil.copyfileobj, you're reducing the risk of truncation, but not eliminating it.
Here's what I would do:
- download to a temp file with a random name in the destination folder — to ensure it's on the same disk partition and to prevent an expensive copy
- rename it — renaming is atomic in a practical sense in this context
I'm not proposing to fetch the Content-Length and compare it with the file on disk because I can't see a situation where we'd get a truncated file.
----
**Summary of proposal**
- harden the "download to temp file then move" process as described just above
- remove the `force_download=True` option from tests<|||||>see related https://github.com/huggingface/transformers/issues/1678 |
transformers | 2,221 | closed | Updated typo on the link | Updated documentation due to typo | 12-19-2019 08:14:33 | 12-19-2019 08:14:33 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2221?src=pr&el=h1) Report
> Merging [#2221](https://codecov.io/gh/huggingface/transformers/pull/2221?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8efc6dd544bf1a30d99d4b5abfc5e214699eab2b?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2221?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2221 +/- ##
=======================================
Coverage 81.47% 81.47%
=======================================
Files 122 122
Lines 18344 18344
=======================================
Hits 14946 14946
Misses 3398 3398
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2221?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2221?src=pr&el=footer). Last update [8efc6dd...f9dbf62](https://codecov.io/gh/huggingface/transformers/pull/2221?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Great, nice catch! |
transformers | 2,220 | closed | tokenizer of bert-base-uncased gives an incorrect split | I found the following code gives an incorrect split
`tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')`
`text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"`
`tokenized_text = tokenizer.tokenize(text)`
`print(' '.join(tokenized_text))`
> [ cl ##s ] who was jim henson ? [ sep ] jim henson was a puppet ##eer [ sep ]
The correct one, based on the Quick tour example, seems to be
> [CLS] who was jim henson ? [SEP] jim heson was a puppet ##eer [SEP] | 12-19-2019 01:40:57 | 12-19-2019 01:40:57 | As you can see, I'm not able to reproduce your bug, therefore **in my environment it works as expected without bugs**. Here the source code I've used (the same as you):
```
Python 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import transformers
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
>>> text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
>>> tokenized_text = tokenizer.tokenize(text)
>>> tokenized_text
['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', 'henson', 'was', 'a', 'puppet', '##eer', '[SEP]']
>>> ' '.join(tokenized_text)
'[CLS] who was jim henson ? [SEP] jim henson was a puppet ##eer [SEP]'
```
My environment specifications are the following:
- Python: **3.6.9**
- OS: **Ubuntu 16.04**
- Transformers: **2.2.2** (installed with `pip install --upgrade transformers`)
- PyTorch: **1.3.1**
- TensorFlow: **2.0**
Please specify your environment in order to understand why in your case it doesn't work.
UPDATE: I've just tested also with Transformers **2.1.1** and **2.0.0** and it works! Are you using `pytorch-transformers` or even `pytorch-pretrained-bert`?
> I found the following code gives an incorrect split
>
> `tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')`
> `text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"`
> `tokenized_text = tokenizer.tokenize(text)`
> `print(' '.join(tokenized_text))`
>
> > [ cl ##s ] who was jim henson ? [ sep ] jim henson was a puppet ##eer [ sep ]
>
> The correct one, based on the Quick tour example, seems to be
>
> > [CLS] who was jim henson ? [SEP] jim heson was a puppet ##eer [SEP]<|||||>This is an issue that is fixed in 2.2.2. It was present in earlier 2.2.1. If you update to the latest versions, it should be fixed. See https://github.com/huggingface/transformers/issues/2155<|||||>I am actually seeing that the behavior is now non-deterministic:
```
$ python -c 'import transformers; print(len(transformers.BertTokenizer.from_pretrained("bert-base-uncased").tokenize("A, [MASK] AllenNLP sentence.")))'
8
$ python -c 'import transformers; print(len(transformers.BertTokenizer.from_pretrained("bert-base-uncased").tokenize("A, [MASK] AllenNLP sentence.")))'
8
$ python -c 'import transformers; print(len(transformers.BertTokenizer.from_pretrained("bert-base-uncased").tokenize("A, [MASK] AllenNLP sentence.")))'
10
$ pip freeze | fgrep transformer
transformers==2.2.2
```<|||||>I proposed a fix in #2232. |
transformers | 2,219 | closed | When i run the script run_tf_ner.py, i got ValueError: Expected floating point type, got <dtype: 'int32'>. | I have tried tf 2.0.0a0, 2.0.0b0, 2.0.0b1, but the same error was reported.
## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Traceback (most recent call last):
File "run_tf_ner.py", line 615, in <module>
app.run(main)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/absl/app.py", line 299, in run
_run_main(main, args)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/absl/app.py", line 250, in _run_main
sys.exit(main(argv))
File "run_tf_ner.py", line 517, in main
cache_dir=args['cache_dir'] if args['cache_dir'] else None)
File "/home/zpchen/transformers-master/transformers/modeling_tf_utils.py", line 303, in from_pretrained
ret = model(model.dummy_inputs, training=False) # build the network with dummy inputs
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 712, in __call__
outputs = self.call(inputs, *args, **kwargs)
File "/home/zpchen/transformers-master/transformers/modeling_tf_bert.py", line 1011, in call
outputs = self.bert(inputs, **kwargs)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 712, in __call__
outputs = self.call(inputs, *args, **kwargs)
File "/home/zpchen/transformers-master/transformers/modeling_tf_bert.py", line 547, in call
embedding_output = self.embeddings([input_ids, position_ids, token_type_ids, inputs_embeds], training=training)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 709, in __call__
self._maybe_build(inputs)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 1966, in _maybe_build
self.build(input_shapes)
File "/home/zpchen/transformers-master/transformers/modeling_tf_bert.py", line 122, in build
initializer=get_initializer(self.initializer_range))
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 389, in add_weight
aggregation=aggregation)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/training/tracking/base.py", line 713, in _add_variable_with_custom_getter
**kwargs_for_getter)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer_utils.py", line 154, in make_variable
shape=variable_shape if variable_shape else None)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variables.py", line 260, in __call__
return cls._variable_v1_call(*args, **kwargs)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variables.py", line 221, in _variable_v1_call
shape=shape)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variables.py", line 60, in getter
return captured_getter(captured_previous, **kwargs)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/distribute/distribute_lib.py", line 1250, in creator_with_resource_vars
return self._create_variable(*args, **kwargs)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/distribute/one_device_strategy.py", line 76, in _create_variable
return next_creator(*args, **kwargs)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variables.py", line 199, in <lambda>
previous_getter = lambda **kwargs: default_variable_creator(None, **kwargs)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variable_scope.py", line 2502, in default_variable_creator
shape=shape)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variables.py", line 264, in __call__
return super(VariableMetaclass, cls).__call__(*args, **kwargs)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/resource_variable_ops.py", line 464, in __init__
shape=shape)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/resource_variable_ops.py", line 608, in _init_from_args
initial_value() if init_from_fn else initial_value,
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer_utils.py", line 134, in <lambda>
init_val = lambda: initializer(shape, dtype=dtype)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/init_ops_v2.py", line 341, in __call__
dtype = _assert_float_dtype(dtype)
File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/init_ops_v2.py", line 769, in _assert_float_dtype
raise ValueError("Expected floating point type, got %s." % dtype)
ValueError: Expected floating point type, got <dtype: 'int32'>.
| 12-19-2019 01:10:09 | 12-19-2019 01:10:09 | > I have tried tf 2.0.0a0, 2.0.0b0, 2.0.0b1, but the same error was reported.
>
> ## Questions & Help
> Traceback (most recent call last):
> File "run_tf_ner.py", line 615, in
> app.run(main)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/absl/app.py", line 299, in run
> _run_main(main, args)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/absl/app.py", line 250, in _run_main
> sys.exit(main(argv))
> File "run_tf_ner.py", line 517, in main
> cache_dir=args['cache_dir'] if args['cache_dir'] else None)
> File "/home/zpchen/transformers-master/transformers/modeling_tf_utils.py", line 303, in from_pretrained
> ret = model(model.dummy_inputs, training=False) # build the network with dummy inputs
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 712, in **call**
> outputs = self.call(inputs, *args, **kwargs)
> File "/home/zpchen/transformers-master/transformers/modeling_tf_bert.py", line 1011, in call
> outputs = self.bert(inputs, **kwargs)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 712, in **call**
> outputs = self.call(inputs, *args, **kwargs)
> File "/home/zpchen/transformers-master/transformers/modeling_tf_bert.py", line 547, in call
> embedding_output = self.embeddings([input_ids, position_ids, token_type_ids, inputs_embeds], training=training)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 709, in **call**
> self._maybe_build(inputs)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 1966, in _maybe_build
> self.build(input_shapes)
> File "/home/zpchen/transformers-master/transformers/modeling_tf_bert.py", line 122, in build
> initializer=get_initializer(self.initializer_range))
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer.py", line 389, in add_weight
> aggregation=aggregation)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/training/tracking/base.py", line 713, in _add_variable_with_custom_getter
> **kwargs_for_getter)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer_utils.py", line 154, in make_variable
> shape=variable_shape if variable_shape else None)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variables.py", line 260, in **call**
> return cls._variable_v1_call(*args, **kwargs)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variables.py", line 221, in _variable_v1_call
> shape=shape)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variables.py", line 60, in getter
> return captured_getter(captured_previous, **kwargs)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/distribute/distribute_lib.py", line 1250, in creator_with_resource_vars
> return self._create_variable(*args, **kwargs)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/distribute/one_device_strategy.py", line 76, in _create_variable
> return next_creator(*args, **kwargs)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variables.py", line 199, in
> previous_getter = lambda **kwargs: default_variable_creator(None, **kwargs)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variable_scope.py", line 2502, in default_variable_creator
> shape=shape)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/variables.py", line 264, in **call**
> return super(VariableMetaclass, cls).**call**(*args, **kwargs)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/resource_variable_ops.py", line 464, in **init**
> shape=shape)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/resource_variable_ops.py", line 608, in _init_from_args
> initial_value() if init_from_fn else initial_value,
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/keras/engine/base_layer_utils.py", line 134, in
> init_val = lambda: initializer(shape, dtype=dtype)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/init_ops_v2.py", line 341, in **call**
> dtype = _assert_float_dtype(dtype)
> File "/home/zpchen/anaconda7/lib/python3.6/site-packages/tensorflow/python/ops/init_ops_v2.py", line 769, in _assert_float_dtype
> raise ValueError("Expected floating point type, got %s." % dtype)
> ValueError: Expected floating point type, got <dtype: 'int32'>.
Do you try to look into [this StackOverflow question](https://stackoverflow.com/questions/43798817/tensorflow-valueerror-expected-non-integer-got-dtype-int32) and #1780 ?<|||||>Yes, But I also get this error 'AttributeError: module 'tensorflow.python.keras.api._v2.keras.layers' has no attribute 'LayerNormalization'. <|||||>> Yes, But I also get this error 'AttributeError: module 'tensorflow.python.keras.api._v2.keras.layers' has no attribute 'LayerNormalization'.
[Here](https://github.com/bryanlimy/tf2-transformer-chatbot/issues/4) they say to update TensorFlow 2.0 version from `alpha-0` to `beta-0`. But I remember that when you update TF you encounter another problem. Can you give a try? `pip install tensorflow==2.0.0-beta0`<|||||>> > Yes, But I also get this error 'AttributeError: module 'tensorflow.python.keras.api._v2.keras.layers' has no attribute 'LayerNormalization'.
>
> [Here](https://github.com/bryanlimy/tf2-transformer-chatbot/issues/4) they say to update TensorFlow 2.0 version from `alpha-0` to `beta-0`. But I remember that when you update TF you encounter another problem. Can you give a try? `pip install tensorflow==2.0.0-beta0`
I can try. But I got "ValueError: Expected floating point type, got <dtype: 'int32'>." previously when i use 2.0.0-beta0.<|||||>You can try with the **latest** version of TensorFlow 2.X. You can install it through `pip install tensorflow==2.1.0-rc1`. Keep us updated
> > > Yes, But I also get this error 'AttributeError: module 'tensorflow.python.keras.api._v2.keras.layers' has no attribute 'LayerNormalization'.
> >
> >
> > [Here](https://github.com/bryanlimy/tf2-transformer-chatbot/issues/4) they say to update TensorFlow 2.0 version from `alpha-0` to `beta-0`. But I remember that when you update TF you encounter another problem. Can you give a try? `pip install tensorflow==2.0.0-beta0`
>
> I can try. But I got "ValueError: Expected floating point type, got <dtype: 'int32'>." previously when i use 2.0.0-beta0.<|||||>Thank you. I will try.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>> Thank you. I will try.
have you solved this "ValueError: Expected floating point type, got <dtype: 'int32'>." problem? |
transformers | 2,218 | closed | corrected typo in example for t5 model input argument | For the T5Model the argument name of the input has to be specified explicitly since the forward function is defined as
`def forward(self, **kwargs):`
and can therefore only handle keyworded arguments such as `input_ids=inputs_ids`. | 12-19-2019 00:36:25 | 12-19-2019 00:36:25 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2218?src=pr&el=h1) Report
> Merging [#2218](https://codecov.io/gh/huggingface/transformers/pull/2218?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8efc6dd544bf1a30d99d4b5abfc5e214699eab2b?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2218?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2218 +/- ##
=======================================
Coverage 81.47% 81.47%
=======================================
Files 122 122
Lines 18344 18344
=======================================
Hits 14946 14946
Misses 3398 3398
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2218?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/modeling\_tf\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/2218/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3Q1LnB5) | `96.55% <ø> (ø)` | :arrow_up: |
| [transformers/modeling\_t5.py](https://codecov.io/gh/huggingface/transformers/pull/2218/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3Q1LnB5) | `81.22% <ø> (ø)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2218?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2218?src=pr&el=footer). Last update [8efc6dd...e280aa8](https://codecov.io/gh/huggingface/transformers/pull/2218?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Indeed, nice catch! |
transformers | 2,217 | closed | Support running tests in parallel | At this point, after `pip install pytest-xdist`, I'm getting a **2.5x speedup** running tests locally on my 2016 MBP (2,9 GHz Quad-Core Intel Core i7):
- `python -m pytest -n auto -s -v ./transformers/tests/` runs in slightly less than 2 minutes
- `python -m pytest -s -v ./transformers/tests/` takes slightly more than 5 minutes
Furthermore, Circle CI gets a **2,15x speedup**, going from [7:30 minutes](https://circleci.com/workflow-run/4ca98875-2d5c-438b-951f-4939d2f3cfc9) to [3:30 minutes](https://circleci.com/workflow-run/ad7094bb-0a0b-404d-ba3f-bd18b37f98bd).
The bottleneck is now the examples, which take a bit less than 3:30 to run, even with parallelization.
This PR adds a new dependency: filelock. You'll need to `pip install -e .` for local development again after it's merged.
This is now ready for review.
----
EDIT - test run time jumped up after I rebased on top of master mostly because of #2246. | 12-18-2019 21:58:06 | 12-18-2019 21:58:06 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2217?src=pr&el=h1) Report
> Merging [#2217](https://codecov.io/gh/huggingface/transformers/pull/2217?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ac1b449cc938bb34bc9021feff599cfd3b2376ae?src=pr&el=desc) will **increase** coverage by `0.15%`.
> The diff coverage is `59.43%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2217?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2217 +/- ##
==========================================
+ Coverage 79.82% 79.97% +0.15%
==========================================
Files 131 131
Lines 19496 19427 -69
==========================================
- Hits 15562 15537 -25
+ Misses 3934 3890 -44
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2217?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/tests/utils.py](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL3V0aWxzLnB5) | `94.11% <100%> (+0.36%)` | :arrow_up: |
| [transformers/tests/modeling\_distilbert\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX2Rpc3RpbGJlcnRfdGVzdC5weQ==) | `99.21% <100%> (ø)` | :arrow_up: |
| [transformers/tests/modeling\_tf\_distilbert\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2Rpc3RpbGJlcnRfdGVzdC5weQ==) | `99.08% <100%> (ø)` | :arrow_up: |
| [transformers/tests/modeling\_tf\_auto\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2F1dG9fdGVzdC5weQ==) | `40.67% <11.11%> (ø)` | :arrow_up: |
| [transformers/tests/modeling\_tf\_albert\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2FsYmVydF90ZXN0LnB5) | `96.19% <33.33%> (+1.74%)` | :arrow_up: |
| [transformers/tests/modeling\_tf\_transfo\_xl\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX3RyYW5zZm9feGxfdGVzdC5weQ==) | `95.87% <50%> (+1.87%)` | :arrow_up: |
| [transformers/tests/modeling\_tf\_openai\_gpt\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX29wZW5haV9ncHRfdGVzdC5weQ==) | `96.39% <50%> (+1.65%)` | :arrow_up: |
| [transformers/tests/modeling\_transfo\_xl\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RyYW5zZm9feGxfdGVzdC5weQ==) | `96.26% <50%> (+1.71%)` | :arrow_up: |
| [transformers/tests/modeling\_xlm\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3hsbV90ZXN0LnB5) | `97.36% <50%> (+1.23%)` | :arrow_up: |
| [transformers/tests/modeling\_roberta\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3JvYmVydGFfdGVzdC5weQ==) | `76.15% <50%> (+0.96%)` | :arrow_up: |
| ... and [16 more](https://codecov.io/gh/huggingface/transformers/pull/2217/diff?src=pr&el=tree-more) | |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2217?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2217?src=pr&el=footer). Last update [ac1b449...b8e924e](https://codecov.io/gh/huggingface/transformers/pull/2217?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>I'm getting an unexpected result on Circle CI:
- TensorFlow tests are about 4 times faster, which makes sense
- PyTorch tests are about 4 times **slower?!**
I'm talking about the time spent in pytest here, which is shown at the bottom of each test run.
**Before parallelization**
https://circleci.com/workflow-run/4ca98875-2d5c-438b-951f-4939d2f3cfc9
04:08 build_py3_tf
00:59 build_py3_torch
05:21 build_py3_torch_and_tf
04:30 build_py2_tf
01:12 build_py2_torch
**After parallelization**
https://circleci.com/workflow-run/5d273bdb-0b4d-4e71-b0f1-272d3f9f72da
00:56 build_py3_tf
04:02 build_py3_torch
04:53 build_py3_torch_and_tf
01:25 build_py2_tf
05:39 build_py2_torch
----
EDIT - I thought this might happen if the PyTorch tests do expensive calculations in setUp / setUpClass. Due to how pytest-xdist works, setUp / setUpClass may run multiple times on different CPUs. However, the `--dist=loadfile` option of pytest-xdist doesn't seem to help, so it must be something else.
----
EDIT 2 - setting OMP_NUM_THREADS=1 solves this, thanks @mfuntowicz!<|||||>I'm also facing an issue with `hf_api_test.py`. I'm hitting a HTTP 401 error when running tests in parallel, and so does Circle CI. Are we blocked by a security rule protecting against excessive login requests?
I'm not a big fan of tests that depend on network services. Often they're flaky.
EDIT -- this is solved by the `--dist=loadfile` option of pytest-xdist.<|||||>For future reference, I logged all filesystem read/writes with:
```
sudo opensnoop -F -n python \
| grep -v "$HOME/\.pyenv" \
| grep -v "$HOME/\.virtualenvs" \
| grep -v "__pycache__" \
| grep -v "$TMPDIR" \
| grep -v "0x00000000 \." \
> open.log
```
while running the full test suite:
```
RUN_SLOW=1 python -m unittest discover -s transformers/tests -p '*_test.py' -t . -v
```
This doesn't reveal anything that could collide between tests. |
transformers | 2,216 | closed | Error while loading Pretrained Enocder and Decoder transformers | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [ ] the official example scripts: (give details)
* [X ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ X] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Define a model and save it.
when you try to save the model initially you'll get the following error #2196 (create a folder manually encoder and decoder)
2. And try to load the model.
you'll get following error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/guest_1/anaconda3/envs/my_env/lib/python3.6/site-packages/transformers/modeling_encoder_decoder.py", line 146, in from_pretrained
encoder_pretrained_model_name_or_path, *model_args, **kwargs_encoder
File "/home/guest_1/anaconda3/envs/my_env/lib/python3.6/site-packages/transformers/modeling_auto.py", line 159, in from_pretrained
"'xlm', 'roberta, 'ctrl'".format(pretrained_model_name_or_path))
ValueError: Unrecognized model identifier in /models/m2m/. Should contains one of 'bert', 'openai-gpt', 'gpt2', 'transfo-xl', 'xlnet', 'xlm', 'roberta, 'ctrl'
```
This is because [here](https://github.com/huggingface/transformers/blob/8efc6dd544bf1a30d99d4b5abfc5e214699eab2b/transformers/modeling_auto.py#L170) the model prefix is checked to load the pre-trained model. So rather than just saving the directory as encoder and decoder save it with model prefix.
You could do something like this
```
encoder_dir = self.encoder.base_model_prefix + "encoder"
decoder_dir = self.encoder.base_model_prefix + "decoder"
self.encoder.save_pretrained(os.path.join(save_directory, encoder_dir))
self.decoder.save_pretrained(os.path.join(save_directory, decoder_dir))
```
But another potential bug the above code will lead to is that almost all the transformers has the same prefix. You need to rename all the transformers with their respective transformers prefix.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: ubuntu
* Python version: 3.6
* PyTorch version: 1.3.1
* PyTorch Transformers version (or branch): 2.2.0
* Using GPU ? doesn't matter
* Distributed of parallel setup ? doesn't matter
* Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| 12-18-2019 18:52:37 | 12-18-2019 18:52:37 | How we can solve this problem you've highlighted? Do you want to open a separate PR? If you want, we can work together on this problem!<|||||>Sure. Drop me a mail at [email protected]<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,215 | closed | Return overflowing tokens if max_length is not given | ## 🚀 Feature
The tokenizer can return overflowing tokens in the `encode_plus` method if 1. `return_overflowing_tokens=True`; and 2. if `max_length` is given. I imagine that it could also be useful to allow to return the overflowing tokens when a max_length is not given but when the input is longer than the model's max_seq_len. As an example: if the input is 600 tokens long, and the model supports up to 512, then the tokenizer will cut down the input to 512 anyway, so the superfluous 88 tokens can then be returned.
Example showing that the overflowing tokens are not returned, even though the input is trimmed. Would expect the trimmed tokens to be returned in the `overflowing_tokens` field.
```python
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = 'I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas. I like bananas.'
encoded_inputs = tokenizer.encode_plus(text,
return_tensors='pt',
pad_to_max_length=True,
return_overflowing_tokens=True,
return_special_tokens_mask=True)
print(encoded_inputs.keys())
print(encoded_inputs['input_ids'].size())
# dict_keys(['special_tokens_mask', 'input_ids', 'token_type_ids', 'attention_mask'])
# torch.Size([1, 512])
``` | 12-18-2019 16:55:21 | 12-18-2019 16:55:21 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,214 | closed | XLM run_squad errors with size mismatch | ## 🐛 Bug
<!-- Important information -->
Model: XLM_mlm_ende_1024
Language: English
Using: the official example scripts: ``run_squad.py``
## To Reproduce
Steps to reproduce the behavior:
1. install dependecies and download squad v1.1 data; pull, install transformers from github master.
2. run ``run_squad.py`` with the following args
```
--model_type xlm --model_name_or_path xlm-mlm-ende-1024 --do_train --do_eval --train_file ./squad_data/train-v1.1.json --predict_file ./squad_data/dev-v1.1.json --per_gpu_train_batch_size 12 --learning_rate 3e-5 --num_train_epochs 2.0 --max_seq_length 384 --doc_stride 128 --output_dir ./debug_xlm
```
Ultimate error:
```
size mismatch for transformer.embeddings.weight: copying a param with shape torch.Size([64699, 1024]) from checkpoint, the shape in current model is torch.Size([30145, 1024]).
```
Full inout ouput below.
Expected behavior: finetune xlm for squad.
## Environment
* OS: OpenSuse 15.0
* Python version: 3.6
* PyTorch version: torch.__version__ = '1.3.1+cpu'
* PyTorch Transformers version (or branch): (just transformers now?) 2.2.2
* Using GPU ? nope
* Distributed of parallel setup ? Ummm n/a
Relates to previous issues (possibly):
* [I've had with XLM](https://github.com/huggingface/transformers/issues/2038)
* Similar looking [error](https://github.com/huggingface/transformers/issues/594)
## Additional context
```python ./transformers/examples/run_squad.py --model_type xlm --model_name_or_path xlm-mlm-ende-1024 --do_train --do_eval --train_file ./squad_data/train-v1.1.json --predict_file ./squad_data/dev-v1.1.json --per_gpu_train_batch_size 12 --learning_rate 3e-5 --num_train_epochs 2.0 --max_seq_length 384 --doc_stride 128 --output_dir ./debug_xlm
12/18/2019 15:47:23 - WARNING - __main__ - Process rank: -1, device: cpu, n_gpu: 0, distributed training: False, 16-bits training: False
12/18/2019 15:47:23 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-ende-1024-config.json from cache at /HOME/.cache/torch/transformers/8f689e7cdf34bbebea67ad44ad6a142c9c5144e5c19d989839139e0d47d1ed74.0038e5c2b48fc777632fc95c3d3422203693750b1d0845a511b3bb84ad6d8c29
12/18/2019 15:47:23 - INFO - transformers.configuration_utils - Model config {
"asm": false,
"attention_dropout": 0.1,
"bos_index": 0,
"causal": false,
"dropout": 0.1,
"emb_dim": 1024,
"embed_init_std": 0.02209708691207961,
"end_n_top": 5,
"eos_index": 1,
"finetuning_task": null,
"gelu_activation": true,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"id2lang": {
"0": "de",
"1": "en"
},
"init_std": 0.02,
"is_decoder": false,
"is_encoder": true,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"lang2id": {
"de": 0,
"en": 1
},
"layer_norm_eps": 1e-12,
"mask_index": 5,
"max_position_embeddings": 512,
"max_vocab": -1,
"min_count": 0,
"n_heads": 8,
"n_langs": 2,
"n_layers": 6,
"num_labels": 2,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pad_index": 2,
"pruned_heads": {},
"same_enc_dec": true,
"share_inout_emb": true,
"sinusoidal_embeddings": false,
"start_n_top": 5,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "first",
"summary_use_proj": true,
"torchscript": false,
"unk_index": 3,
"use_bfloat16": false,
"use_lang_emb": true,
"vocab_size": 30145
}
12/18/2019 15:47:24 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-ende-1024-vocab.json from cache at /HOME/.cache/torch/transformers/6771b710c1daf9d51643260fdf576f6353369c3563bf0fb12176c692778dca3f.2c29a4b393decdd458e6a9744fa1d6b533212e4003a4012731d2bc2261dc35f3
12/18/2019 15:47:24 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-ende-1024-merges.txt from cache at /HOME/.cache/torch/transformers/85d878ffb1bc2c3395b785d10ce7fc91452780316140d7a26201d7a912483e44.42fa32826c068642fdcf24adbf3ef8158b3b81e210a3d03f3102cf5a899f92a0
12/18/2019 15:47:25 - INFO - transformers.modeling_utils - loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-ende-1024-pytorch_model.bin from cache at /HOME/.cache/torch/transformers/ea4c0bbee310b490decb2b608a4dbc8ed9f2e4a103dd729ce183770b0fef698b.119d74257b953e5d50d73555a430ced11b1c149a7c17583219935ec1bd37d948
12/18/2019 15:47:28 - INFO - transformers.modeling_utils - Weights of XLMForQuestionAnswering not initialized from pretrained model: ['qa_outputs.start_logits.dense.weight', 'qa_outputs.start_logits.dense.bias', 'qa_outputs.end_logits.dense_0.weight', 'qa_outputs.end_logits.dense_0.bias', 'qa_outputs.end_logits.LayerNorm.weight', 'qa_outputs.end_logits.LayerNorm.bias', 'qa_outputs.end_logits.dense_1.weight', 'qa_outputs.end_logits.dense_1.bias', 'qa_outputs.answer_class.dense_0.weight', 'qa_outputs.answer_class.dense_0.bias', 'qa_outputs.answer_class.dense_1.weight']
12/18/2019 15:47:28 - INFO - transformers.modeling_utils - Weights from pretrained model not used in XLMForQuestionAnswering: ['pred_layer.proj.weight', 'pred_layer.proj.bias']
Traceback (most recent call last):
File "./transformers/examples/run_squad.py", line 614, in <module>
main()
File "./transformers/examples/run_squad.py", line 532, in main
cache_dir=args.cache_dir if args.cache_dir else None)
File "/HOME/sandpit/transformers/transformers/modeling_utils.py", line 486, in from_pretrained
model.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for XLMForQuestionAnswering:
size mismatch for transformer.embeddings.weight: copying a param with shape torch.Size([64699, 1024]) from checkpoint, the shape in current model is torch.Size([30145, 1024]).
```
| 12-18-2019 15:07:40 | 12-18-2019 15:07:40 | I've tried different `XLM*` models with and I've obtained the same error you've. I suspect it's broken something into the implementation of `XLM*` models or the .bin file uploaded to AWS S3.
N.B: I've tried to load `xlm-mlm-17-1280` with the usual procedure (i.e. by using `from_pretrained` method) which works as expected in #2043 (about 15 days ago), but now it doesn't work (same error). Therefore, there's something broken for sure.
N.B: **it's not a download problem** itself, I've tried also with `force_download=True` parameter.
The stack trace is the following:
```
Python 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import transformers
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained('xlm-mlm-ende-1024')
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.44M/1.44M [00:00<00:00, 2.06MB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.00M/1.00M [00:00<00:00, 1.71MB/s]
>>> model = XLMWithLMHeadModel.from_pretrained('xlm-mlm-ende-1024')
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 396/396 [00:00<00:00, 177kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 835M/835M [01:13<00:00, 11.3MB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/<user>/Desktop/transformers/transformers/transformers/modeling_utils.py", line 486, in from_pretrained
model.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for XLMWithLMHeadModel:
size mismatch for transformer.embeddings.weight: copying a param with shape torch.Size([64699, 1024]) from checkpoint, the shape in current model is torch.Size([30145, 1024]).
size mismatch for pred_layer.proj.weight: copying a param with shape torch.Size([64699, 1024]) from checkpoint, the shape in current model is torch.Size([30145, 1024]).
size mismatch for pred_layer.proj.bias: copying a param with shape torch.Size([64699]) from checkpoint, the shape in current model is torch.Size([30145]).
>>> from transformers import XLMTokenizer, XLMForQuestionAnswering
>>> model = XLMForQuestionAnswering.from_pretrained('xlm-mlm-ende-1024')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/<user>/Desktop/transformers/transformers/transformers/modeling_utils.py", line 486, in from_pretrained
model.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for XLMForQuestionAnswering:
size mismatch for transformer.embeddings.weight: copying a param with shape torch.Size([64699, 1024]) from checkpoint, the shape in current model is torch.Size([30145, 1024]).
>>> model = XLMForQuestionAnswering.from_pretrained('xlm-clm-ende-1024')
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 396/396 [00:00<00:00, 164kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 835M/835M [01:11<00:00, 11.7MB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/<user>/Desktop/transformers/transformers/transformers/modeling_utils.py", line 486, in from_pretrained
model.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for XLMForQuestionAnswering:
size mismatch for transformer.embeddings.weight: copying a param with shape torch.Size([64699, 1024]) from checkpoint, the shape in current model is torch.Size([30145, 1024]).
```
> ## Bug
> Model: XLM_mlm_ende_1024
>
> Language: English
>
> Using: the official example scripts: `run_squad.py`
>
> ## To Reproduce
> Steps to reproduce the behavior:
>
> 1. install dependecies and download squad v1.1 data; pull, install transformers from github master.
> 2. run `run_squad.py` with the following args
>
> ```
> --model_type xlm --model_name_or_path xlm-mlm-ende-1024 --do_train --do_eval --train_file ./squad_data/train-v1.1.json --predict_file ./squad_data/dev-v1.1.json --per_gpu_train_batch_size 12 --learning_rate 3e-5 --num_train_epochs 2.0 --max_seq_length 384 --doc_stride 128 --output_dir ./debug_xlm
> ```
>
> Ultimate error:
>
> ```
> size mismatch for transformer.embeddings.weight: copying a param with shape torch.Size([64699, 1024]) from checkpoint, the shape in current model is torch.Size([30145, 1024]).
> ```
>
> Full inout ouput below.
>
> Expected behavior: finetune xlm for squad.
>
> ## Environment
> * OS: OpenSuse 15.0
> * Python version: 3.6
> * PyTorch version: torch.**version** = '1.3.1+cpu'
> * PyTorch Transformers version (or branch): (just transformers now?) 2.2.2
> * Using GPU ? nope
> * Distributed of parallel setup ? Ummm n/a
>
> Relates to previous issues (possibly):
>
> * [I've had with XLM](https://github.com/huggingface/transformers/issues/2038)
> * Similar looking [error](https://github.com/huggingface/transformers/issues/594)
>
> ## Additional context
> ```python
> 12/18/2019 15:47:23 - WARNING - __main__ - Process rank: -1, device: cpu, n_gpu: 0, distributed training: False, 16-bits training: False
> 12/18/2019 15:47:23 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-ende-1024-config.json from cache at /HOME/.cache/torch/transformers/8f689e7cdf34bbebea67ad44ad6a142c9c5144e5c19d989839139e0d47d1ed74.0038e5c2b48fc777632fc95c3d3422203693750b1d0845a511b3bb84ad6d8c29
> 12/18/2019 15:47:23 - INFO - transformers.configuration_utils - Model config {
> "asm": false,
> "attention_dropout": 0.1,
> "bos_index": 0,
> "causal": false,
> "dropout": 0.1,
> "emb_dim": 1024,
> "embed_init_std": 0.02209708691207961,
> "end_n_top": 5,
> "eos_index": 1,
> "finetuning_task": null,
> "gelu_activation": true,
> "id2label": {
> "0": "LABEL_0",
> "1": "LABEL_1"
> },
> "id2lang": {
> "0": "de",
> "1": "en"
> },
> "init_std": 0.02,
> "is_decoder": false,
> "is_encoder": true,
> "label2id": {
> "LABEL_0": 0,
> "LABEL_1": 1
> },
> "lang2id": {
> "de": 0,
> "en": 1
> },
> "layer_norm_eps": 1e-12,
> "mask_index": 5,
> "max_position_embeddings": 512,
> "max_vocab": -1,
> "min_count": 0,
> "n_heads": 8,
> "n_langs": 2,
> "n_layers": 6,
> "num_labels": 2,
> "output_attentions": false,
> "output_hidden_states": false,
> "output_past": true,
> "pad_index": 2,
> "pruned_heads": {},
> "same_enc_dec": true,
> "share_inout_emb": true,
> "sinusoidal_embeddings": false,
> "start_n_top": 5,
> "summary_activation": null,
> "summary_first_dropout": 0.1,
> "summary_proj_to_labels": true,
> "summary_type": "first",
> "summary_use_proj": true,
> "torchscript": false,
> "unk_index": 3,
> "use_bfloat16": false,
> "use_lang_emb": true,
> "vocab_size": 30145
> }
>
> 12/18/2019 15:47:24 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-ende-1024-vocab.json from cache at /HOME/.cache/torch/transformers/6771b710c1daf9d51643260fdf576f6353369c3563bf0fb12176c692778dca3f.2c29a4b393decdd458e6a9744fa1d6b533212e4003a4012731d2bc2261dc35f3
> 12/18/2019 15:47:24 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-ende-1024-merges.txt from cache at /HOME/.cache/torch/transformers/85d878ffb1bc2c3395b785d10ce7fc91452780316140d7a26201d7a912483e44.42fa32826c068642fdcf24adbf3ef8158b3b81e210a3d03f3102cf5a899f92a0
> 12/18/2019 15:47:25 - INFO - transformers.modeling_utils - loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-ende-1024-pytorch_model.bin from cache at /HOME/.cache/torch/transformers/ea4c0bbee310b490decb2b608a4dbc8ed9f2e4a103dd729ce183770b0fef698b.119d74257b953e5d50d73555a430ced11b1c149a7c17583219935ec1bd37d948
> 12/18/2019 15:47:28 - INFO - transformers.modeling_utils - Weights of XLMForQuestionAnswering not initialized from pretrained model: ['qa_outputs.start_logits.dense.weight', 'qa_outputs.start_logits.dense.bias', 'qa_outputs.end_logits.dense_0.weight', 'qa_outputs.end_logits.dense_0.bias', 'qa_outputs.end_logits.LayerNorm.weight', 'qa_outputs.end_logits.LayerNorm.bias', 'qa_outputs.end_logits.dense_1.weight', 'qa_outputs.end_logits.dense_1.bias', 'qa_outputs.answer_class.dense_0.weight', 'qa_outputs.answer_class.dense_0.bias', 'qa_outputs.answer_class.dense_1.weight']
> 12/18/2019 15:47:28 - INFO - transformers.modeling_utils - Weights from pretrained model not used in XLMForQuestionAnswering: ['pred_layer.proj.weight', 'pred_layer.proj.bias']
> Traceback (most recent call last):
> File "./transformers/examples/run_squad.py", line 614, in <module>
> main()
> File "./transformers/examples/run_squad.py", line 532, in main
> cache_dir=args.cache_dir if args.cache_dir else None)
> File "/HOME/sandpit/transformers/transformers/modeling_utils.py", line 486, in from_pretrained
> model.__class__.__name__, "\n\t".join(error_msgs)))
> RuntimeError: Error(s) in loading state_dict for XLMForQuestionAnswering:
> size mismatch for transformer.embeddings.weight: copying a param with shape torch.Size([64699, 1024]) from checkpoint, the shape in current model is torch.Size([30145, 1024]).
> ```<|||||>Indeed, there seems to be an error that was introduced by #2164. I'm looking into it now. Thanks for raising an issue!<|||||>Please let me know if 8efc6dd fixes this issue!<|||||>I've installed Transformers from source (`master` branch) with `pip install git+https://github.com/huggingface/transformers.git` right now, but **it seems to be the same bug**. Is it possible? The stack trace is the same as before. @LysandreJik
> Please let me know if [8efc6dd](https://github.com/huggingface/transformers/commit/8efc6dd544bf1a30d99d4b5abfc5e214699eab2b) fixes this issue!<|||||>Hmm could you post a short snippet to reproduce? Running your initial script in my environment doesn't raise any error:
```py
from transformers import XLMWithLMHeadModel
XLMWithLMHeadModel.from_pretrained("xlm-mlm-17-1280")
```
The error seems to be fixed on my side<|||||>I'm trying to use `XLMForQuestionAnswering` model, is it right for `run_squad.py` correct?
```
>>> import transformers
>>> from transformers import XLMForQuestionAnswering
>>> model = XLMForQuestionAnswering.from_pretrained('xlm-mlm-ende-1024', force_download=True)
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 396/396 [00:00<00:00, 146kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 835M/835M [01:16<00:00, 10.9MB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/vidiemme/Desktop/transformers/transformers/transformers/modeling_utils.py", line 486, in from_pretrained
model.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for XLMForQuestionAnswering:
size mismatch for transformer.embeddings.weight: copying a param with shape torch.Size([64699, 1024]) from checkpoint, the shape in current model is torch.Size([30145, 1024]).
```
N.B: I've tried also your piece of code in my environment but it doesn't work (the same bug as before). How is it possible? I'm using Python 3.6.9, OS Ubuntu 16.04, PyTorch 1.3.1 and TensorFlow 2.0.
> Hmm could you post a short snippet to reproduce? Running your initial script in my environment doesn't raise any error:
>
> ```python
> from transformers import XLMWithLMHeadModel
> XLMWithLMHeadModel.from_pretrained("xlm-mlm-17-1280")
> ```
>
> The error seems to be fixed on my side<|||||>Indeed, it doesn't fail on my side either. Is there any way you could go check in your environment, I guess (according to your error trace) following the path:
```
/home/vidiemme/Desktop/transformers/transformers/transformers/configuration_xlm.py
```
and telling me if the following lines:
```py
if "n_words" in kwargs:
self.n_words = kwargs["n_words"]
```
Are on lines 147-148? Just to make sure the install from source worked correctly. Thank you @TheEdoardo93 <|||||>> N.B: I've tried also your piece of code in my environment but it doesn't work (the same bug as before). How is it possible? I'm using Python 3.6.9, OS Ubuntu 16.04, PyTorch 1.3.1 and TensorFlow 2.0.
Hmm okay, I'm looking into it.<|||||>In the file you've said to me at line 147-148 I've got the following lines:
```
@property
def n_words(self): # For backward compatibility
return self.vocab_size
```
I don't have the lines you've posted above. Therefore, I can say that I haven't installed the Transformers library correctly. How can I do (i.e. install from master after your fix)? Usually I do the following: `pip install git+https://github.com/huggingface/transformers.git`
> Indeed, it doesn't fail on my side either. Is there any way you could go check in your environment, I guess (according to your error trace) following the path:
>
> ```
> /home/vidiemme/Desktop/transformers/transformers/transformers/configuration_xlm.py
> ```
>
> and telling me if the following lines:
>
> ```python
> if "n_words" in kwargs:
> self.n_words = kwargs["n_words"]
> ```
>
> Are on lines 147-148? Just to make sure the install from source worked correctly. Thank you @TheEdoardo93 <|||||>Hmm it seems your install from source didn't work. I don't exactly know how your environment is setup, but it looks like you've cloned the repository and the code is running from this clone rather than from the library installed in your environment/virtual environment.
If you did clone it in `/home/vidiemme/Desktop/transformers/`, I would just do a `git pull` to update it.<|||||>**Now it works as expected**! Your [fix](https://github.com/huggingface/transformers/commit/8efc6dd544bf1a30d99d4b5abfc5e214699eab2b) fixes the bug! Great work! You can close this issue for me ;)
Now we can import both `XLMForQuestionAnswering.from_pretrained('xlm-mlm-ende-1024')` and `XLMWithLMHeadModel.from_pretrained("xlm-mlm-17-1280")` correctly.
> Hmm it seems your install from source didn't work. I don't exactly know how your environment is setup, but it looks like you've cloned the repository and the code is running from this clone rather than from the library installed in your environment/virtual environment.
>
> If you did clone it in `/home/vidiemme/Desktop/transformers/`, I would just do a `git pull` to update it.<|||||>Glad to hear that @TheEdoardo93 !<|||||>A bit late to the party, but I can provide a second confirmation that this error no longer appears.
Thanks!<|||||>PS I don't know where is a useful place to put this but for anyone training XLM on squad....
The command above now runs to completion.
Its score is underwhelming but demonstrates some training has been achieved
```
Results: {'exact': 56.9441816461684, 'f1': 67.90690126118979, 'total': 10570, 'HasAns_exact': 56.9441816461684, 'HasAns_f1': 67.90690126118979, 'HasAns_total': 10570, 'best_exact': 56.9441816461684, 'best_exact_thresh': 0.0, 'best_f1': 67.90690126118979, 'best_f1_thresh': 0.0}
```
|
transformers | 2,213 | closed | T5 - Finetuning of an EncoderDecoder Model | Hello,
I know that the T5 implementation is quite new, but is there already code to finetune and lateron decode from the T5 model?
As I understand most of your models are no EncoderDecoder models, so I guess that the default pipeline / code is not working for T5, is that right?
Could you point me to a script / command / piece of code for finetuning T5? | 12-18-2019 13:10:32 | 12-18-2019 13:10:32 | As I know, there is **no** Python scripts for fine-tuning T5 model, **at the moment**.
Besides the source code you can see in this library, you can see the PR #1739 which implements T5 model.
> Hello,
>
> I know that the T5 implementation is quite new, but is there already code to finetune and lateron decode from the T5 model?
>
> As I understand most of your models are no EncoderDecoder models, so I guess that the default pipeline / code is not working for T5, is that right?
>
> Could you point me to a script / command / piece of code for finetuning T5?<|||||>The same question. #1739 was merged. First of all, In T5_INPUTS_DOCSTRING is said:
```
To match pre-training, T5 input sequence should be formatted with [CLS] and [SEP] tokens as follows:
(a) For sequence pairs:
tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
(b) For single sequences:
tokens: [CLS] the dog is hairy . [SEP]
```
At second, it looks like T5Model can work in encoder mode only. So, it's possible to treat it as usual LM:
```
tokenizer = T5Tokenizer.from_pretrained('t5-small')
model = T5Model.from_pretrained('t5-small')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
outputs = model(input_ids)
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
```
Maybe @thomwolf can clarify how better to fine-tune T5 for classification tasks<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,212 | closed | Fine-tuning TF models on Colab TPU | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
I am trying to fine-tune TF BERT on Imdb dataset on Colab TPU. Here is the full notebook:
https://colab.research.google.com/drive/16ZaJaXXd2R1gRHrmdWDkFh6U_EB0ln0z
Can anyone help me what I am doing wrong?
Thanks
| 12-18-2019 08:20:39 | 12-18-2019 08:20:39 | I've read your code, and I don't see anything strange in it (I hope). It seems to be an error due to training a (whatever) model on TPUs rather than Transformers.
Do you see [this](https://github.com/tensorflow/tensorflow/issues/29896) issue reported in TensorFlow's GitHub? It seems to be the same error, and someone gives indications about how to resolve.
> ## Questions & Help
> Hi,
>
> I am trying to fine-tune TF BERT on Imdb dataset on Colab TPU. Here is the full notebook:
>
> https://colab.research.google.com/drive/16ZaJaXXd2R1gRHrmdWDkFh6U_EB0ln0z
>
> Can anyone help me what I am doing wrong?
> Thanks<|||||>Thanks for the help. Actually my code was inspired from [this colab notebook. This](https://colab.research.google.com/github/CyberZHG/keras-bert/blob/master/demo/tune/keras_bert_classification_tpu.ipynb) notebook works perfectly but there is one major difference might be causing the problem:
- I am force installing tensorflow 2.x for transformer notebook because transformer works only for TF>=2.0 but colab uses TF 1.15 on colab for TPUs
So I went to GCP and used a TPU for TF 2.x. The error changed to this:

But yes, you are right this issue might be related to TF in general.<|||||>In the official docs of GCP [here](https://cloud.google.com/tpu/docs/supported-versions), they show the current list of supported TensorFlow and Cloud TPU versions; _only_ **TensorFlow 1.13, 1.14 and 1.15 are supported** (they don't mention TensorFlow 2.0).
I think it's why you have the problem you've highlighted.
> Thanks for the help. Actually my code was inspired from [this colab notebook. This](https://colab.research.google.com/github/CyberZHG/keras-bert/blob/master/demo/tune/keras_bert_classification_tpu.ipynb) notebook works perfectly but there is one major difference might be causing the problem:
>
> * I am force installing tensorflow 2.x for transformer notebook because transformer works only for TF>=2.0 but colab uses TF 1.15 on colab for TPUs
>
> So I went to GCP and used a TPU for TF 2.x. The error changed to this:
> 
>
> But yes, you are right this issue might be related to TF in general.<|||||>tpu supports . tf2.1<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,211 | closed | Fast tokenizers | I am opening this PR to track the integration of `tokenizers`.
At the moment, we created two new classes to represent the fast version of both GPT2 and Bert tokenizers. There are a few breaking changes compared to the current `GPT2Tokenizer` and `BertTokenizer`:
- `add_special_token` is now specified during initialization
- truncation and padding options are also setup during initialization
By default, `encode_batch` pads everything using the longest sequence, and `encode` does not pad at all. If `pad_to_max_length=True`, then we pad everything using this length.
If a `max_length` is specified, then everything is truncated according to the provided options. This should work exactly like before.
In order to try these, you must `pip install tokenizers` in your virtual env.
| 12-18-2019 00:06:40 | 12-18-2019 00:06:40 | Can you remind why you moved those options to initialization vs. at `encode` time?
Is that a hard requirement of the native implem?<|||||>Sure! The native implementation doesn't have `kwargs` so we need to define a static interface with pre-defined function arguments. This means that the configuration of the tokenizer is done by initializing its various parts and attaching them. There would be some unwanted overhead in doing this every time we `encode`.
I think we generally don't need to change the behavior of the tokenizer while using it, so this shouldn't be a problem. Plus, I think it makes the underlying functions clearer, and easier to use.<|||||># [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=h1) Report
> Merging [#2211](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/81db12c3ba0c2067f43c4a63edf5e45f54161042?src=pr&el=desc) will **increase** coverage by `<.01%`.
> The diff coverage is `74.62%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2211 +/- ##
==========================================
+ Coverage 73.54% 73.54% +<.01%
==========================================
Files 87 87
Lines 14789 14919 +130
==========================================
+ Hits 10876 10972 +96
- Misses 3913 3947 +34
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [src/transformers/\_\_init\_\_.py](https://codecov.io/gh/huggingface/transformers/pull/2211/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy9fX2luaXRfXy5weQ==) | `98.79% <100%> (ø)` | :arrow_up: |
| [src/transformers/tokenization\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2211/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fdXRpbHMucHk=) | `88.13% <67.01%> (-3.96%)` | :arrow_down: |
| [src/transformers/tokenization\_gpt2.py](https://codecov.io/gh/huggingface/transformers/pull/2211/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fZ3B0Mi5weQ==) | `96.21% <93.75%> (-0.37%)` | :arrow_down: |
| [src/transformers/tokenization\_bert.py](https://codecov.io/gh/huggingface/transformers/pull/2211/diff?src=pr&el=tree#diff-c3JjL3RyYW5zZm9ybWVycy90b2tlbml6YXRpb25fYmVydC5weQ==) | `96.2% <94.73%> (-0.15%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=footer). Last update [81db12c...e6ec24f](https://codecov.io/gh/huggingface/transformers/pull/2211?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Testing the fast tokenizers is not trivial. Doing tokenizer-specific tests is alright, but as of right now the breaking changes make it impossible to implement the fast tokenizers in the common tests pipeline.
In order to do so, and to obtain full coverage of the tokenizers, we would have to either:
- Split the current common tests in actual unit tests, rather than integration tests. As the arguments are passed in the `from_pretrained` (for the rust tokenizers) method rather than the `encode` (for the python tokenizers) method, having several chained calls to `encode` with varying arguments implies a big refactor of each test to test the rust tokenizers as well. Splitting those into unit tests would ease this task.
- Copy/Paste the common tests into a separate file (not ideal).
Currently there are some integration tests for the rust GPT-2 and rust BERT tokenizers, which may offer sufficient coverage for this PR. We would need the aforementioned refactor to have full coverage, which can be attended to in a future PR. <|||||>I really like it. Great work @n1t0
I think now we should try to work on the other (python) tokenizers and see if we can find a middle ground behavior where they can both behave rather similarly, in particular for tests.
Also an open question: should we keep the "slow" python tokenizers that are easy to inspect? Could make sense, maybe renaming them to `BertTokenizerPython` for instance.<|||||>Ok, I had to rewrite the whole history after the few restructuration PRs that have been merged.
Since Python 2 has been dropped, I added `tokenizers` as a dependency (It is working for Python 3.5+).
We should now be ready to merge!
We should clearly keep the Python tokenizers and deprecate them slowly. In the end, I don't mind keeping them, but I'd like to avoid having to maintain both, especially if their API differ.<|||||>This is ready for the final review!<|||||>Ok, this is great, merging! |
transformers | 2,210 | closed | training a new BERT tokenizer model | ## ❓ Questions & Help
I would like to train a new BERT model.
There are some way to train BERT tokenizer (a.k.a. wordpiece tokenizer) ?
| 12-17-2019 23:51:52 | 12-17-2019 23:51:52 | Follow sentencepiece github or Bert tensorflow GitHub. You will have some
feedback
On Wed, Dec 18, 2019 at 07:52 Younggyun Hahm <[email protected]>
wrote:
> ❓ Questions & Help
>
> I would like to train a new BERT model.
> There are some way to train BERT tokenizer (a.k.a. wordpiece tokenizer) ?
>
> —
> You are receiving this because you are subscribed to this thread.
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/2210?email_source=notifications&email_token=AIEAE4BMLLHVIADDR5PGZ63QZFQ27A5CNFSM4J4DE7PKYY3PNVWWK3TUL52HS4DFUVEXG43VMWVGG33NNVSW45C7NFSM4IBGFX2A>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AIEAE4CUY2ESKVEH4IPDL63QZFQ27ANCNFSM4J4DE7PA>
> .
>
<|||||>If you want to see some examples of custom implementation of **tokenizers** into Transformers' library, you can see how they have implemented [Japanese Tokenizer](https://github.com/huggingface/transformers/blob/master/transformers/tokenization_bert_japanese.py).
In general, you can read more information about adding a new model into Transformers [here](https://github.com/huggingface/transformers/blob/30968d70afedb1a9815164737cdc3779f2f058fe/templates/adding_a_new_model/README.md).
> ## Questions & Help
> I would like to train a new BERT model.
> There are some way to train BERT tokenizer (a.k.a. wordpiece tokenizer) ?<|||||>Checkout the [**`tokenizers`**](https://github.com/huggingface/tokenizers) repo.
There's an example of how to train a WordPiece tokenizer: https://github.com/huggingface/tokenizers/blob/master/bindings/python/examples/train_bert_wordpiece.py
<|||||>Hi @julien-c `tokenizers` package is great, but I found an issue when using the resulting tokenizer later with `transformers`.
Assume I have this:
```
from tokenizers import BertWordPieceTokenizer
init_tokenizer = BertWordPieceTokenizer(vocab=vocab)
init_tokenizer.save("./my_local_tokenizer")
```
When I am trying to load the file:
```
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("./my_local_tokenizer")
```
an error is thrown:
```
ValueError: Unrecognized model in .... Should have a `model_type` key in its config.json, or contain one of the following strings in its name: ...
```
Seems format used by tokenizers is a single json file, whereas when I save transformers tokenizer it creates a dir with [config.json, special tokens map.json and vocab.txt].
transformers.__version__ = '4.15.0'
tokenizers.__version__ '0.10.3'
Can you please give me some hints how to fix this? Thx in advance<|||||>@tkornuta better to open a post on the forum, but tagging @SaulLu for visibility<|||||>Thanks for the ping julien-c!
@tkornuta Indeed, for this kind of questions the [forum](https://discuss.huggingface.co/) is the best place to ask them: it also allows other users who would ask the same question as you to benefit from the answer. :relaxed:
Your use case is indeed very interesting! With your current code, you have a problem because `AutoTokenizer` has no way of knowing which Tokenizer object we want to use to load your tokenizer since you chose to create a new one from scratch.
So in particular to instantiate a new `transformers` tokenizer with the Bert-like tokenizer you created with the `tokenizers` library you can do:
```python
from transformers import BertTokenizerFast
wrapped_tokenizer = BertTokenizerFast(
tokenizer_file="./my_local_tokenizer",
do_lower_case = FILL_ME,
unk_token = FILL_ME,
sep_token = FILL_ME,
pad_token = FILL_ME,
cls_token = FILL_ME,
mask_token = FILL_ME,
tokenize_chinese_chars =FILL_ME,
strip_accents = FILL_ME
)
```
Note: You will have to manually carry over the same parameters (`unk_token`, `strip_accents`, etc) that you used to initialize `BertWordPieceTokenizer` in the initialization of `BertTokenizerFast`.
I refer you to the [section "Building a tokenizer, block by block" of the course ](https://huggingface.co/course/chapter6/9?fw=pt#building-a-wordpiece-tokenizer-from-scratch) where we explained how you can build a tokenizer from scratch with the `tokenizers` library and use it to instantiate a new tokenizer with the `transformers` library. We have even treated the example of a Bert type tokenizer in this chapter :smiley:.
Moreover, if you just want to generate a new vocabulary for BERT tokenizer by re-training it on a new dataset, the easiest way is probably to use the `train_new_from_iterator` method of a fast `transformers` tokenizer which is explained in the [section "Training a new tokenizer from an old one" of our course](https://huggingface.co/course/chapter6/2?fw=pt). :blush:
I hope this can help you!
<|||||>Hi @SaulLu thanks for the answer! I managed to find the solution here:
https://huggingface.co/docs/transformers/fast_tokenizer
```
# 1st solution: Load the HF.tokenisers tokenizer.
loaded_tokenizer = Tokenizer.from_file(decoder_tokenizer_path)
# "Wrap" it with HF.transformers tokenizer.
tokenizer = PreTrainedTokenizerFast(tokenizer_object=loaded_tokenizer)
# 2nd solution: Load from tokenizer file
tokenizer = PreTrainedTokenizerFast(tokenizer_file=decoder_tokenizer_path)
```
Now I also see that somehow I have missed the information at the bottom of the section that you mention on building tokenizer that is also stating that - sorry.
<|||||>Hey @SaulLu sorry for bothering, but struggling with yet another problem/question.
When I am loading the tokenizer created in HF.tokenizers my special tokens are "gone", i.e.
```
# Load from tokenizer file
tokenizer = PreTrainedTokenizerFast(tokenizer_file=decoder_tokenizer_path)
tokenizer.pad_token # <- this is None
```
Without this when I am using padding:
```
encoded = tokenizer.encode(input, padding=True) # <- raises error - lack of pad_token
```
I can add them to tokenizer from HF.transformers e.g. like this:
```
tokenizer.add_special_tokens({'pad_token': '[PAD]'}) # <- this works!
```
Is there a similar method for setting special tokens to tokenizer in HF.tokenizers that will enable me to load the tokenizer in HF.transformers?
I have all tokens in my vocabulary and tried the following
````
# Pass as arguments to constructor:
init_tokenizer = BertWordPieceTokenizer(vocab=vocab)
#special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"]) <- error: wrong keyword
#bos_token = "[CLS]", eos_token = "[SEP]", unk_token = "[UNK]", sep_token = "[SEP]", <- wrong keywords
#pad_token = "[PAD]", cls_token = "[CLS]", mask_token = "[MASK]", <- wrong keywords
# Use tokenizer.add_special_tokens() method:
#init_tokenizer.add_special_tokens({'pad_token': '[PAD]'}) <- error: must be a list
#init_tokenizer.add_special_tokens(["[PAD]", "[CLS]", "[SEP]", "[UNK]", "[MASK]", "[BOS]", "[EOS]"]) <- doesn't work (means error when calling encode(padding=True))
#init_tokenizer.add_special_tokens(['[PAD]']) # <- doesn't work
# Set manually.
#init_tokenizer.pad_token = "[PAD]" # <- doesn't work
init_tokenizer.pad_token_id = vocab["[PAD]"] # <- doesn't work
```
Am I missing something obvious? Thanks in advance!<|||||>@tkornuta, I'm sorry I missed your second question!
The `BertWordPieceTokenizer` class is just an helper class to build a `tokenizers.Tokenizers` object with the architecture proposed by the Bert's authors. The `tokenizers` library is used to build tokenizers and the `transformers` library to wrap these tokenizers by adding useful functionality when we wish to use them with a particular model (like identifying the padding token, the separation token, etc).
To not miss anything, I would like to comment on several of your remarks
#### Remark 1
> [@tkornuta] When I am loading the tokenizer created in HF.tokenizers my special tokens are "gone", i.e.
To carry your special tokens in your `HF.transformers` tokenizer, I refer you to this section of my previous answer
> [@SaulLu] So in particular to instantiate a new transformers tokenizer with the Bert-like tokenizer you created with the tokenizers library you can do:
> ```python
> from transformers import BertTokenizerFast
>
> wrapped_tokenizer = BertTokenizerFast(
> tokenizer_file="./my_local_tokenizer",
> do_lower_case = FILL_ME,
> unk_token = FILL_ME,
> sep_token = FILL_ME,
> pad_token = FILL_ME,
> cls_token = FILL_ME,
> mask_token = FILL_ME,
> tokenize_chinese_chars =FILL_ME,
> strip_accents = FILL_ME
> )
>```
> Note: You will have to manually carry over the same parameters (unk_token, strip_accents, etc) that you used to initialize BertWordPieceTokenizer in the initialization of BertTokenizerFast.
#### Remark 2
> [@tkornuta] Is there a similar method for setting special tokens to tokenizer in HF.tokenizers that will enable me to load the tokenizer in HF.transformers?
Nothing prevents you from overloading the `BertWordPieceTokenizer` class in order to define the properties that interest you. On the other hand, there will be no automatic porting of the values of these new properties in the `HF.transformers` tokenizer properties (you have to use the method mentioned below or the methode `.add_special_tokens({'pad_token': '[PAD]'})` after having instanciated your `HF.transformers` tokenizer ).
Does this answer your questions? :relaxed: <|||||>Hi @SaulLu yeah, I was asking about this "automatic porting of special tokens". As I set them already when training the tokenizer in HF.tokenizers, hence I am really not sure why they couldn't be imported automatically when loading tokenizer in HF.transformers...
Anyway, thanks, your answer is super useful.
Moreover, thanks for the hint pointing to forum! I will use it next time for sure! :) |
transformers | 2,209 | closed | ```glue_convert_examples_to_features``` for sequence labeling tasks | ## 🚀 Feature
<!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. -->
I would like a function like ```glue_convert_examples_to_features``` for sequence labelling tasks.
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. -->
The motivation is that I need much better flexibility for sequence labelling tasks. Its not enough to have a final, and decided for me model, for this task. I want just the features (a sequence of features/embeddings I guess).
## Additional context
This can be generalized to any dataset with a specific format.
<!-- Add any other context or screenshots about the feature request here. -->
| 12-17-2019 19:28:06 | 12-17-2019 19:28:06 | duplicate to 2208 |
transformers | 2,208 | closed | ```glue_convert_examples_to_features``` for sequence labeling tasks | ## 🚀 Feature
<!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. -->
I would like a function like ```glue_convert_examples_to_features``` for sequence labelling tasks.
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. -->
The motivation is that I need much better flexibility for sequence labelling tasks. Its not enough to have a final, and decided for me model, for this task. I want just the features (a sequence of features/embeddings I guess).
## Additional context
This can be generalized to any dataset with a specific format.
<!-- Add any other context or screenshots about the feature request here. -->
| 12-17-2019 19:17:04 | 12-17-2019 19:17:04 | Do you mean the one already into Transformers in the [glue.py](https://github.com/huggingface/transformers/blob/d46147294852694d1dc701c72b9053ff2e726265/transformers/data/processors/glue.py) at line 30 or a different function?
> glue_convert_examples_to_features<|||||>A different one. Does this proposal makes sense?<|||||>> A different one. Does this proposal makes sense?
Different in which way? Describe to us please the goal and an high-level implementation.<|||||>Thanks for the reply! First of all I just want to clarify that I am not sure that my suggestion makes indeed sense. I will try to clarify: 1) This implementation ``` def glue_convert_examples_to_features(examples, tokenizer,``` is for glue datasets, so it does not cover what I suggest 2) in line 112 we see that it can only support "classification" and "regression". The classification is in sentence level. I want classification in tokens level.
So to my understanding, this function will give back one ```features``` tensor that is 1-1 correspondence with the one label for this sentence. In my case we would like n ```features``` tensors, that will have 1-1 correspondence with the labels for this sentence, where n the number of tokens of the sentence.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,207 | closed | Fix segmentation fault | Fix segmentation fault that started happening yesterday night.
Following the fix from #2205 that could be reproduced using circle ci ssh access.
~Currently fixing the unforeseen event with Python 2.~ The error with Python 2 was due to Regex releasing a new version (2019.12.17) that couldn't be built on Python 2.7. | 12-17-2019 19:02:42 | 12-17-2019 19:02:42 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=h1) Report
> Merging [#2207](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/f061606277322a013ec2d96509d3077e865ae875?src=pr&el=desc) will **increase** coverage by `1.13%`.
> The diff coverage is `83.33%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2207 +/- ##
==========================================
+ Coverage 80.32% 81.46% +1.13%
==========================================
Files 122 122
Lines 18342 18345 +3
==========================================
+ Hits 14734 14945 +211
+ Misses 3608 3400 -208
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/file\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL2ZpbGVfdXRpbHMucHk=) | `70.42% <83.33%> (-1.01%)` | :arrow_down: |
| [transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `81.51% <0%> (+1.32%)` | :arrow_up: |
| [transformers/modeling\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `96.47% <0%> (+2.2%)` | :arrow_up: |
| [transformers/modeling\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `74.54% <0%> (+2.32%)` | :arrow_up: |
| [transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `71.76% <0%> (+12.35%)` | :arrow_up: |
| [transformers/tests/modeling\_tf\_common\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `97.41% <0%> (+17.24%)` | :arrow_up: |
| [transformers/modeling\_tf\_pytorch\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2207/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `92.15% <0%> (+83%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=footer). Last update [f061606...14cc752](https://codecov.io/gh/huggingface/transformers/pull/2207?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>is this issue related to https://github.com/scipy/scipy/issues/11237, which also started happening yesterday.<|||||>Indeed, this is related to that issue. I've just tested on the CircleCI machine directly, the segmentation fault happens when importing torch after tensorflow, when scipy is installed on the machine.<|||||>@LysandreJik I get this error on transfomers 2.2.2 on PyPi. When it will be updated?
```
>>> import transformers
Segmentation fault (core dumped)
```
```
root@261246f307ae:~/src# python --version
Python 3.6.8
```<|||||>This is due to an upstream issue related to scipy 1.4.0. Please pin your scipy version to one earlier than 1.4.0 and you should see this segmentation fault resolved.<|||||>@LysandreJik thank you this issue is destroying everything 🗡 <|||||>Did pinning the scipy version fix your issue?<|||||>@LysandreJik I'm now pinning `scipy==1.3.3` that is the latest version before RC1.4.x<|||||>I confirm that with 1.3.3 works, but they have just now pushed `scipy==1.4.1`. We have tested it and it works as well.
- https://github.com/scipy/scipy/issues/11237#issuecomment-567550894
Thank you!<|||||>Glad you could make it work! |
transformers | 2,206 | closed | Transformers Encoder and Decoder Inference | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [X ] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ X] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Error while doing inference.
```
from transformers import PreTrainedEncoderDecoder, BertTokenizer
model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased',''bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
encoder_input_ids=tokenizer.encode("Hi How are you")
import torch
ouput = model(torch.tensor( encoder_input_ids).unsqueeze(0))
```
and the error is
```
TypeError: forward() missing 1 required positional argument: 'decoder_input_ids'
```
During inference why is decoder input is expected ?
Let me know if I'm missing anything?
## Environment
OS: ubuntu
Python version: 3.6
PyTorch version:1.3.0
PyTorch Transformers version (or branch):2.2.0
Using GPU ? Yes
Distributed of parallel setup ? No
Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| 12-17-2019 17:02:57 | 12-17-2019 17:02:57 | As said in #2117 by @rlouf (an author of Transformers), **at the moment** you can use `PreTrainedEncoderDecoder` with only **BERT** model both as encoder and decoder.
In more details, he said: "_Indeed, as I specified in the article, PreTrainedEncoderDecoder only works with BERT as an encoder and BERT as a decoder. GPT2 shouldn't take too much work to adapt, but we haven't had the time to do it yet. Try PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased', 'bert-base-uncased') should work. Let me know if it doesn't._".
> ## Bug
> Model I am using (Bert, XLNet....):
>
> Language I am using the model on (English, Chinese....):
>
> The problem arise when using:
>
> * [X ] the official example scripts: (give details)
> * [ ] my own modified scripts: (give details)
>
> The tasks I am working on is:
>
> * [ ] an official GLUE/SQUaD task: (give the name)
> * [ X] my own task or dataset: (give details)
>
> ## To Reproduce
> Steps to reproduce the behavior:
>
> 1. Error while doing inference.
>
> ```
> from transformers import PreTrainedEncoderDecoder, BertTokenizer
> model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased','gpt2')
> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
> encoder_input_ids=tokenizer.encode("Hi How are you")
> import torch
> ouput = model(torch.tensor( encoder_input_ids).unsqueeze(0))
> ```
>
> and the error is
>
> ```
> TypeError: forward() missing 1 required positional argument: 'decoder_input_ids'
> ```
>
> During inference why is decoder input is expected ?
>
> Let me know if I'm missing anything?
>
> ## Environment
> OS: ubuntu
> Python version: 3.6
> PyTorch version:1.3.0
> PyTorch Transformers version (or branch):2.2.0
> Using GPU ? Yes
> Distributed of parallel setup ? No
> Any other relevant information:
>
> ## Additional context<|||||>@TheEdoardo93 it doesn't matter whether it is GPT2 or bert. Both has the same error :
I'm trying to play with GPT2 that's why I pasted my own code.
Using BERT as an Encoder and Decoder
```
>>> model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased','bert-base-uncased')
>>> ouput = model(torch.tensor( encoder_input_ids).unsqueeze(0))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/guest_1/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
TypeError: forward() missing 1 required positional argument: 'decoder_input_ids'
```<|||||>First of all, authors of Transformers are working on the implementation of `PreTrainedEncoderDecoder` object, so it's not a definitive implementation, e.g. the code lacks of the implementation of some methods. Said so, I've tested your code and I've revealed how to working with `PreTrainedEncoderDecoder` **correctly without bugs**. You can see my code below.
In brief, your problem occurs because you have not passed _all_ arguments necessary to the `forward` method. By looking at the source code [here](https://github.com/huggingface/transformers/blob/master/transformers/modeling_encoder_decoder.py), you can see that this method accepts **two** parameters: `encoder_input_ids` and `decoder_input_ids`. In your code, you've passed _only one_ parameter, and the Python interpreter associates your `encoder_input_ids` to the `encoder_input_ids` of the `forward` method, but you don't have supply a value for `decoder_input_ids` of the `forward` method, and this is the cause that raise the error.
```
Python 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import transformers
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
>>> from transformers import PreTrainedEncoderDecoder
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
>>> model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased', 'bert-base-uncased')
>>> text='Hi How are you'
>>> import torch
>>> input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)
>>> input_ids
tensor([[ 101, 7632, 2129, 2024, 2017, 102]])
>>> output = model(input_ids) # YOUR PROBLEM IS HERE
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/<user>/anaconda3/envs/huggingface/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
TypeError: forward() missing 1 required positional argument: 'decoder_input_ids'
>>> output = model(input_ids, input_ids) # SOLUTION TO YOUR PROBLEM
>>> output
(tensor([[[ -6.3390, -6.3664, -6.4600, ..., -5.5354, -4.1787, -5.8384],
[ -6.3550, -6.3077, -6.4661, ..., -5.3516, -4.1338, -4.0742],
[ -6.7090, -6.6050, -6.6682, ..., -5.9591, -4.7142, -3.8219],
[ -7.7608, -7.5956, -7.6634, ..., -6.8113, -5.7777, -4.1638],
[ -8.6462, -8.5767, -8.6366, ..., -7.9503, -6.5382, -5.0959],
[-12.8752, -12.3775, -12.2770, ..., -10.0880, -10.7659, -9.0092]]],
grad_fn=<AddBackward0>), tensor([[[ 0.0929, -0.0264, -0.1224, ..., -0.2106, 0.1739, 0.1725],
[ 0.4074, -0.0593, 0.5523, ..., -0.6791, 0.6556, -0.2946],
[-0.2116, -0.6859, -0.4628, ..., 0.1528, 0.5977, -0.9102],
[ 0.3992, -1.3208, -0.0801, ..., -0.3213, 0.2557, -0.5780],
[-0.0757, -1.3394, 0.1816, ..., 0.0746, 0.4032, -0.7080],
[ 0.5989, -0.2841, -0.3490, ..., 0.3042, -0.4368, -0.2097]]],
grad_fn=<NativeLayerNormBackward>), tensor([[-9.3097e-01, -3.3807e-01, -6.2162e-01, 8.4082e-01, 4.4154e-01,
-1.5889e-01, 9.3273e-01, 2.2240e-01, -4.3249e-01, -9.9998e-01,
-2.7810e-01, 8.9449e-01, 9.8638e-01, 6.4763e-02, 9.6649e-01,
-7.7835e-01, -4.4046e-01, -5.9515e-01, 2.7585e-01, -7.4638e-01,
7.4700e-01, 9.9983e-01, 4.4468e-01, 2.8673e-01, 3.6586e-01,
9.7642e-01, -8.4343e-01, 9.6599e-01, 9.7235e-01, 7.2667e-01,
-7.5785e-01, 9.2892e-02, -9.9089e-01, -1.7004e-01, -6.8200e-01,
-9.9283e-01, 2.6244e-01, -7.9871e-01, 2.3397e-02, 4.6413e-02,
-9.3371e-01, 2.7699e-01, 9.9995e-01, -3.2671e-01, 2.1108e-01,
-2.0636e-01, -1.0000e+00, 1.9622e-01, -9.3330e-01, 6.8736e-01,
6.4731e-01, 5.3773e-01, 9.2759e-02, 4.1069e-01, 4.0360e-01,
1.9002e-01, -1.7049e-01, 7.5259e-03, -2.0453e-01, -5.7574e-01,
-5.3062e-01, 3.9367e-01, -7.0627e-01, -9.2865e-01, 6.8820e-01,
3.2698e-01, -3.3506e-02, -1.2323e-01, -1.5304e-01, -1.8077e-01,
9.3398e-01, 2.6375e-01, 3.7505e-01, -8.9548e-01, 1.1777e-01,
2.2054e-01, -6.3351e-01, 1.0000e+00, -6.9228e-01, -9.8653e-01,
6.9799e-01, 4.0303e-01, 5.2453e-01, 2.3217e-01, -1.2151e-01,
-1.0000e+00, 5.6760e-01, 2.9295e-02, -9.9318e-01, 8.3171e-02,
5.2939e-01, -2.3176e-01, -1.5694e-01, 4.9278e-01, -4.2614e-01,
-3.8079e-01, -2.6060e-01, -6.9055e-01, -1.7180e-01, -1.9810e-01,
-2.7986e-02, -7.2085e-02, -3.7635e-01, -3.7743e-01, 1.3508e-01,
-4.3892e-01, -6.1321e-01, 1.7726e-01, -3.5434e-01, 6.4734e-01,
4.0373e-01, -2.8194e-01, 4.5104e-01, -9.7876e-01, 6.1044e-01,
-2.3526e-01, -9.9035e-01, -5.1350e-01, -9.9280e-01, 6.8329e-01,
-2.1623e-01, -1.4641e-01, 9.8273e-01, 3.7345e-01, 4.8171e-01,
-5.6467e-03, -7.3005e-01, -1.0000e+00, -7.2252e-01, -5.1978e-01,
7.0765e-02, -1.5036e-01, -9.8355e-01, -9.7384e-01, 5.8453e-01,
9.6710e-01, 1.4193e-01, 9.9981e-01, -2.1194e-01, 9.6675e-01,
2.3627e-02, -4.1555e-01, 1.9872e-01, -4.0593e-01, 6.5180e-01,
6.1598e-01, -6.8750e-01, 7.9808e-02, -2.0437e-01, 3.4504e-01,
-6.7176e-01, -1.3692e-01, -2.7750e-01, -9.6740e-01, -3.6698e-01,
9.6934e-01, -2.5050e-01, -6.9297e-01, 4.8327e-01, -1.4613e-01,
-5.1224e-01, 8.8387e-01, 6.9173e-01, 3.8395e-01, -1.7536e-01,
3.8873e-01, -4.3011e-03, 6.1876e-01, -8.9292e-01, 3.4243e-02,
4.5193e-01, -2.4782e-01, -4.7402e-01, -9.8375e-01, -3.1763e-01,
5.9109e-01, 9.9284e-01, 7.9634e-01, 2.4601e-01, 6.1729e-01,
-1.8376e-01, 6.8750e-01, -9.7083e-01, 9.8624e-01, -2.0573e-01,
2.0418e-01, 4.1400e-01, 1.9102e-01, -9.1718e-01, -3.5273e-01,
8.9628e-01, -5.6812e-01, -8.9552e-01, -3.5567e-02, -4.9052e-01,
-4.3559e-01, -6.2323e-01, 5.6863e-01, -2.6201e-01, -3.1324e-01,
-1.2852e-02, 9.4585e-01, 9.8664e-01, 8.3363e-01, -2.4392e-01,
7.3786e-01, -9.4466e-01, -5.2720e-01, -1.6349e-02, 2.4207e-01,
3.6905e-02, 9.9638e-01, -5.8095e-01, -7.2046e-02, -9.4418e-01,
-9.8921e-01, -1.0289e-01, -9.3301e-01, -5.3531e-02, -6.8719e-01,
5.3295e-01, 1.6390e-01, 2.3460e-01, 4.3260e-01, -9.9501e-01,
-7.7318e-01, 2.6342e-01, -3.6949e-01, 4.0245e-01, -1.6657e-01,
4.5766e-01, 7.4537e-01, -5.8549e-01, 8.4632e-01, 9.3526e-01,
-6.4963e-01, -7.8264e-01, 8.5868e-01, -2.9683e-01, 9.0246e-01,
-6.5124e-01, 9.8896e-01, 8.6732e-01, 8.7014e-01, -9.5627e-01,
-4.1195e-01, -9.1043e-01, -4.5438e-01, 5.7729e-02, -3.6862e-01,
5.7032e-01, 5.5757e-01, 3.0482e-01, 7.0850e-01, -6.6279e-01,
9.9909e-01, -5.0139e-01, -9.7001e-01, -2.2370e-01, -1.8440e-02,
-9.9107e-01, 7.2208e-01, 2.4379e-01, 6.9083e-02, -3.2313e-01,
-7.3217e-01, -9.7295e-01, 9.2268e-01, 5.0675e-02, 9.9215e-01,
-8.0247e-02, -9.5682e-01, -4.1637e-01, -9.4549e-01, -2.9790e-01,
-1.5625e-01, 2.4707e-01, -1.8468e-01, -9.7276e-01, 4.7428e-01,
5.6760e-01, 5.5919e-01, -1.9418e-01, 9.9932e-01, 1.0000e+00,
9.7844e-01, 9.3669e-01, 9.5284e-01, -9.9929e-01, -4.9083e-01,
9.9999e-01, -9.7835e-01, -1.0000e+00, -9.5292e-01, -6.5736e-01,
4.1425e-01, -1.0000e+00, -2.7896e-03, 7.0756e-02, -9.4186e-01,
2.7960e-01, 9.8389e-01, 9.9658e-01, -1.0000e+00, 8.8289e-01,
9.6828e-01, -6.2958e-01, 9.3367e-01, -3.7519e-01, 9.8027e-01,
4.2505e-01, 3.0766e-01, -3.2042e-01, 2.7469e-01, -7.8253e-01,
-8.8309e-01, -1.5604e-01, -3.6222e-01, 9.9091e-01, 3.0116e-02,
-7.8697e-01, -9.4496e-01, 2.2050e-01, -8.4521e-02, -4.8378e-01,
-9.7952e-01, -1.3446e-01, 4.2209e-01, 7.8760e-01, 6.4992e-02,
2.0492e-01, -7.8143e-01, 2.2120e-01, -5.0228e-01, 3.7149e-01,
6.5244e-01, -9.4897e-01, -6.0978e-01, -4.8976e-03, -4.6856e-01,
-2.8122e-01, -9.6984e-01, 9.8036e-01, -3.5220e-01, 7.4903e-01,
1.0000e+00, -1.0373e-01, -9.4037e-01, 6.2856e-01, 1.5745e-01,
-1.1596e-01, 1.0000e+00, 7.2891e-01, -9.8543e-01, -5.3814e-01,
4.0543e-01, -4.9501e-01, -4.8527e-01, 9.9950e-01, -1.4058e-01,
-2.3799e-01, -1.5841e-01, 9.8467e-01, -9.9180e-01, 9.7240e-01,
-9.5292e-01, -9.8022e-01, 9.8012e-01, 9.5211e-01, -6.6387e-01,
-7.2622e-01, 1.1509e-01, -3.1365e-01, 1.8487e-01, -9.7602e-01,
7.9482e-01, 5.2428e-01, -1.3540e-01, 9.1377e-01, -9.0275e-01,
-5.2769e-01, 2.8301e-01, -4.9215e-01, 3.4866e-02, 8.3573e-01,
5.0270e-01, -2.4031e-01, -6.1194e-02, -2.5558e-01, -1.3530e-01,
-9.8688e-01, 2.9877e-01, 1.0000e+00, -5.3199e-02, 4.4522e-01,
-2.4564e-01, 3.8897e-02, -3.7170e-01, 3.6843e-01, 5.1087e-01,
-1.9742e-01, -8.8481e-01, 4.5420e-01, -9.8222e-01, -9.8894e-01,
8.5417e-01, 1.4674e-01, -3.3154e-01, 9.9999e-01, 4.4333e-01,
7.1728e-02, 1.6790e-01, 9.6064e-01, 2.3267e-02, 7.2436e-01,
4.9905e-01, 9.8528e-01, -2.0286e-01, 5.2711e-01, 9.0711e-01,
-5.6147e-01, -3.4452e-01, -6.1113e-01, -8.1268e-02, -9.2887e-01,
1.0119e-01, -9.7066e-01, 9.7404e-01, 8.2025e-01, 2.9760e-01,
1.9059e-01, 3.6089e-01, 1.0000e+00, -2.7256e-01, 6.5052e-01,
-6.0092e-01, 9.0897e-01, -9.9819e-01, -9.1409e-01, -3.7810e-01,
1.2677e-02, -3.9492e-01, -3.0028e-01, 3.4323e-01, -9.7925e-01,
4.4501e-01, 3.7582e-01, -9.9622e-01, -9.9495e-01, 1.6366e-01,
9.2522e-01, -1.3063e-02, -9.5314e-01, -7.5003e-01, -6.5409e-01,
4.1526e-01, -7.6235e-02, -9.6046e-01, 3.2395e-01, -2.7184e-01,
4.7535e-01, -1.1767e-01, 5.6867e-01, 4.6844e-01, 8.3125e-01,
-2.1505e-01, -2.6495e-01, -4.4479e-02, -8.5166e-01, 8.8927e-01,
-8.9329e-01, -7.7919e-01, -1.5320e-01, 1.0000e+00, -4.3274e-01,
6.4268e-01, 7.7000e-01, 7.9197e-01, -5.4889e-02, 8.0927e-02,
7.9722e-01, 2.1034e-01, -1.9189e-01, -4.4749e-01, -8.0585e-01,
-3.5409e-01, 7.0995e-01, 1.2411e-01, 2.0604e-01, 8.3328e-01,
7.4750e-01, 1.7900e-04, 7.6917e-02, -9.1725e-02, 9.9981e-01,
-2.6801e-01, -8.3787e-02, -4.8642e-01, 1.1836e-01, -3.5603e-01,
-5.8620e-01, 1.0000e+00, 2.2691e-01, 3.2801e-01, -9.9343e-01,
-7.3298e-01, -9.5126e-01, 1.0000e+00, 8.4895e-01, -8.6216e-01,
6.9319e-01, 5.5441e-01, -1.1380e-02, 8.6958e-01, -1.2449e-01,
-2.8602e-01, 1.8517e-01, 9.2221e-02, 9.6773e-01, -4.5911e-01,
-9.7611e-01, -6.6894e-01, 3.7154e-01, -9.7862e-01, 9.9949e-01,
-5.5391e-01, -2.0926e-01, -3.9404e-01, -2.3863e-02, 6.3624e-01,
-1.0563e-01, -9.8927e-01, -1.4047e-01, 1.2247e-01, 9.7469e-01,
2.6847e-01, -6.0451e-01, -9.5354e-01, 4.5191e-01, 6.6822e-01,
-7.2218e-01, -9.6438e-01, 9.7538e-01, -9.9165e-01, 5.6641e-01,
1.0000e+00, 2.2837e-01, -2.8539e-01, 1.6956e-01, -4.6714e-01,
2.5561e-01, -2.6744e-01, 7.4301e-01, -9.7890e-01, -2.7469e-01,
-1.4162e-01, 2.7886e-01, -7.0853e-02, -5.8891e-02, 8.2879e-01,
1.9968e-01, -5.4085e-01, -6.8158e-01, 3.7584e-02, 3.5805e-01,
8.9092e-01, -1.7879e-01, -8.1491e-02, 5.0655e-02, -7.9140e-02,
-9.5114e-01, -1.4923e-01, -3.5370e-01, -9.9994e-01, 7.4321e-01,
-1.0000e+00, 2.1850e-01, -2.5182e-01, -2.2171e-01, 8.7817e-01,
2.9648e-01, 3.4926e-01, -8.2534e-01, -3.8831e-01, 7.6622e-01,
8.0938e-01, -2.1051e-01, -3.0882e-01, -7.6183e-01, 2.2523e-01,
-1.4952e-02, 1.5150e-01, -2.1056e-01, 7.3482e-01, -1.5207e-01,
1.0000e+00, 1.0631e-01, -7.7462e-01, -9.8438e-01, 1.6242e-01,
-1.6337e-01, 1.0000e+00, -9.4196e-01, -9.7149e-01, 3.9827e-01,
-7.2371e-01, -8.6582e-01, 3.0937e-01, -6.4325e-02, -8.1062e-01,
-8.8436e-01, 9.8219e-01, 9.3543e-01, -5.6058e-01, 4.5004e-01,
-3.2933e-01, -5.5851e-01, -6.9835e-02, 6.0196e-01, 9.9111e-01,
4.1170e-01, 9.1721e-01, 5.9978e-01, -9.4103e-02, 9.7966e-01,
1.5322e-01, 5.3662e-01, 4.2338e-02, 1.0000e+00, 2.8920e-01,
-9.3933e-01, 2.4383e-01, -9.8948e-01, -1.5036e-01, -9.7242e-01,
2.8053e-01, 1.1691e-01, 9.0178e-01, -2.1055e-01, 9.7547e-01,
-5.0734e-01, -8.5119e-03, -5.2189e-01, 1.1963e-01, 4.0313e-01,
-9.4529e-01, -9.8752e-01, -9.8975e-01, 4.5711e-01, -4.0753e-01,
5.8175e-02, 1.1543e-01, 8.6051e-02, 3.6199e-01, 4.3131e-01,
-1.0000e+00, 9.5818e-01, 4.0499e-01, 6.9443e-01, 9.7521e-01,
6.7153e-01, 4.3386e-01, 2.2481e-01, -9.9118e-01, -9.9126e-01,
-3.1248e-01, -1.4604e-01, 7.9951e-01, 6.1145e-01, 9.2726e-01,
4.0171e-01, -3.9375e-01, -2.0938e-01, -3.2651e-02, -4.1723e-01,
-9.9582e-01, 4.5682e-01, -9.4401e-02, -9.8150e-01, 9.6766e-01,
-5.5518e-01, -8.0481e-02, 4.4743e-01, -6.0429e-01, 9.7261e-01,
8.6633e-01, 3.7309e-01, 9.4917e-04, 4.6426e-01, 9.1590e-01,
9.6965e-01, 9.8799e-01, -4.6592e-01, 8.7146e-01, -3.1116e-01,
5.1496e-01, 6.7961e-01, -9.5609e-01, 1.3302e-03, 3.6581e-01,
-2.3789e-01, 2.6341e-01, -1.2874e-01, -9.8464e-01, 4.8621e-01,
-1.8921e-01, 6.1015e-01, -4.3986e-01, 2.1561e-01, -3.7115e-01,
-1.5832e-02, -6.9704e-01, -7.3403e-01, 5.7310e-01, 5.0895e-01,
9.4111e-01, 6.9365e-01, 6.9171e-02, -7.3277e-01, -1.1294e-01,
-4.0168e-01, -9.2587e-01, 9.6638e-01, 2.2207e-02, 1.5029e-01,
2.8954e-01, -8.5994e-02, 7.4631e-01, -1.5933e-01, -3.5710e-01,
-1.6201e-01, -7.1149e-01, 9.0602e-01, -4.2873e-01, -4.6653e-01,
-5.4765e-01, 7.4640e-01, 2.3966e-01, 9.9982e-01, -4.6795e-01,
-6.4802e-01, -4.1201e-01, -3.4984e-01, 3.5475e-01, -5.4668e-01,
-1.0000e+00, 3.6903e-01, -1.7324e-01, 4.3267e-01, -4.7206e-01,
6.3586e-01, -5.2151e-01, -9.9077e-01, -1.6597e-01, 2.6735e-01,
4.5069e-01, -4.3034e-01, -5.6321e-01, 5.7792e-01, 8.8123e-02,
9.4964e-01, 9.2798e-01, -3.3326e-01, 5.1963e-01, 6.0865e-01,
-4.4019e-01, -6.8129e-01, 9.3489e-01]], grad_fn=<TanhBackward>))
>>> len(output)
3
>>> output[0]
tensor([[[ -6.3390, -6.3664, -6.4600, ..., -5.5354, -4.1787, -5.8384],
[ -6.3550, -6.3077, -6.4661, ..., -5.3516, -4.1338, -4.0742],
[ -6.7090, -6.6050, -6.6682, ..., -5.9591, -4.7142, -3.8219],
[ -7.7608, -7.5956, -7.6634, ..., -6.8113, -5.7777, -4.1638],
[ -8.6462, -8.5767, -8.6366, ..., -7.9503, -6.5382, -5.0959],
[-12.8752, -12.3775, -12.2770, ..., -10.0880, -10.7659, -9.0092]]],
grad_fn=<AddBackward0>)
>>> output[0].shape
torch.Size([1, 6, 30522])
>>> output[1]
tensor([[[ 0.0929, -0.0264, -0.1224, ..., -0.2106, 0.1739, 0.1725],
[ 0.4074, -0.0593, 0.5523, ..., -0.6791, 0.6556, -0.2946],
[-0.2116, -0.6859, -0.4628, ..., 0.1528, 0.5977, -0.9102],
[ 0.3992, -1.3208, -0.0801, ..., -0.3213, 0.2557, -0.5780],
[-0.0757, -1.3394, 0.1816, ..., 0.0746, 0.4032, -0.7080],
[ 0.5989, -0.2841, -0.3490, ..., 0.3042, -0.4368, -0.2097]]],
grad_fn=<NativeLayerNormBackward>)
>>> output[1].shape
torch.Size([1, 6, 768])
>>> output[2]
tensor([[-9.3097e-01, -3.3807e-01, -6.2162e-01, 8.4082e-01, 4.4154e-01,
-1.5889e-01, 9.3273e-01, 2.2240e-01, -4.3249e-01, -9.9998e-01,
-2.7810e-01, 8.9449e-01, 9.8638e-01, 6.4763e-02, 9.6649e-01,
-7.7835e-01, -4.4046e-01, -5.9515e-01, 2.7585e-01, -7.4638e-01,
7.4700e-01, 9.9983e-01, 4.4468e-01, 2.8673e-01, 3.6586e-01,
9.7642e-01, -8.4343e-01, 9.6599e-01, 9.7235e-01, 7.2667e-01,
-7.5785e-01, 9.2892e-02, -9.9089e-01, -1.7004e-01, -6.8200e-01,
-9.9283e-01, 2.6244e-01, -7.9871e-01, 2.3397e-02, 4.6413e-02,
-9.3371e-01, 2.7699e-01, 9.9995e-01, -3.2671e-01, 2.1108e-01,
-2.0636e-01, -1.0000e+00, 1.9622e-01, -9.3330e-01, 6.8736e-01,
6.4731e-01, 5.3773e-01, 9.2759e-02, 4.1069e-01, 4.0360e-01,
1.9002e-01, -1.7049e-01, 7.5259e-03, -2.0453e-01, -5.7574e-01,
-5.3062e-01, 3.9367e-01, -7.0627e-01, -9.2865e-01, 6.8820e-01,
3.2698e-01, -3.3506e-02, -1.2323e-01, -1.5304e-01, -1.8077e-01,
9.3398e-01, 2.6375e-01, 3.7505e-01, -8.9548e-01, 1.1777e-01,
2.2054e-01, -6.3351e-01, 1.0000e+00, -6.9228e-01, -9.8653e-01,
6.9799e-01, 4.0303e-01, 5.2453e-01, 2.3217e-01, -1.2151e-01,
-1.0000e+00, 5.6760e-01, 2.9295e-02, -9.9318e-01, 8.3171e-02,
5.2939e-01, -2.3176e-01, -1.5694e-01, 4.9278e-01, -4.2614e-01,
-3.8079e-01, -2.6060e-01, -6.9055e-01, -1.7180e-01, -1.9810e-01,
-2.7986e-02, -7.2085e-02, -3.7635e-01, -3.7743e-01, 1.3508e-01,
-4.3892e-01, -6.1321e-01, 1.7726e-01, -3.5434e-01, 6.4734e-01,
4.0373e-01, -2.8194e-01, 4.5104e-01, -9.7876e-01, 6.1044e-01,
-2.3526e-01, -9.9035e-01, -5.1350e-01, -9.9280e-01, 6.8329e-01,
-2.1623e-01, -1.4641e-01, 9.8273e-01, 3.7345e-01, 4.8171e-01,
-5.6467e-03, -7.3005e-01, -1.0000e+00, -7.2252e-01, -5.1978e-01,
7.0765e-02, -1.5036e-01, -9.8355e-01, -9.7384e-01, 5.8453e-01,
9.6710e-01, 1.4193e-01, 9.9981e-01, -2.1194e-01, 9.6675e-01,
2.3627e-02, -4.1555e-01, 1.9872e-01, -4.0593e-01, 6.5180e-01,
6.1598e-01, -6.8750e-01, 7.9808e-02, -2.0437e-01, 3.4504e-01,
-6.7176e-01, -1.3692e-01, -2.7750e-01, -9.6740e-01, -3.6698e-01,
9.6934e-01, -2.5050e-01, -6.9297e-01, 4.8327e-01, -1.4613e-01,
-5.1224e-01, 8.8387e-01, 6.9173e-01, 3.8395e-01, -1.7536e-01,
3.8873e-01, -4.3011e-03, 6.1876e-01, -8.9292e-01, 3.4243e-02,
4.5193e-01, -2.4782e-01, -4.7402e-01, -9.8375e-01, -3.1763e-01,
5.9109e-01, 9.9284e-01, 7.9634e-01, 2.4601e-01, 6.1729e-01,
-1.8376e-01, 6.8750e-01, -9.7083e-01, 9.8624e-01, -2.0573e-01,
2.0418e-01, 4.1400e-01, 1.9102e-01, -9.1718e-01, -3.5273e-01,
8.9628e-01, -5.6812e-01, -8.9552e-01, -3.5567e-02, -4.9052e-01,
-4.3559e-01, -6.2323e-01, 5.6863e-01, -2.6201e-01, -3.1324e-01,
-1.2852e-02, 9.4585e-01, 9.8664e-01, 8.3363e-01, -2.4392e-01,
7.3786e-01, -9.4466e-01, -5.2720e-01, -1.6349e-02, 2.4207e-01,
3.6905e-02, 9.9638e-01, -5.8095e-01, -7.2046e-02, -9.4418e-01,
-9.8921e-01, -1.0289e-01, -9.3301e-01, -5.3531e-02, -6.8719e-01,
5.3295e-01, 1.6390e-01, 2.3460e-01, 4.3260e-01, -9.9501e-01,
-7.7318e-01, 2.6342e-01, -3.6949e-01, 4.0245e-01, -1.6657e-01,
4.5766e-01, 7.4537e-01, -5.8549e-01, 8.4632e-01, 9.3526e-01,
-6.4963e-01, -7.8264e-01, 8.5868e-01, -2.9683e-01, 9.0246e-01,
-6.5124e-01, 9.8896e-01, 8.6732e-01, 8.7014e-01, -9.5627e-01,
-4.1195e-01, -9.1043e-01, -4.5438e-01, 5.7729e-02, -3.6862e-01,
5.7032e-01, 5.5757e-01, 3.0482e-01, 7.0850e-01, -6.6279e-01,
9.9909e-01, -5.0139e-01, -9.7001e-01, -2.2370e-01, -1.8440e-02,
-9.9107e-01, 7.2208e-01, 2.4379e-01, 6.9083e-02, -3.2313e-01,
-7.3217e-01, -9.7295e-01, 9.2268e-01, 5.0675e-02, 9.9215e-01,
-8.0247e-02, -9.5682e-01, -4.1637e-01, -9.4549e-01, -2.9790e-01,
-1.5625e-01, 2.4707e-01, -1.8468e-01, -9.7276e-01, 4.7428e-01,
5.6760e-01, 5.5919e-01, -1.9418e-01, 9.9932e-01, 1.0000e+00,
9.7844e-01, 9.3669e-01, 9.5284e-01, -9.9929e-01, -4.9083e-01,
9.9999e-01, -9.7835e-01, -1.0000e+00, -9.5292e-01, -6.5736e-01,
4.1425e-01, -1.0000e+00, -2.7896e-03, 7.0756e-02, -9.4186e-01,
2.7960e-01, 9.8389e-01, 9.9658e-01, -1.0000e+00, 8.8289e-01,
9.6828e-01, -6.2958e-01, 9.3367e-01, -3.7519e-01, 9.8027e-01,
4.2505e-01, 3.0766e-01, -3.2042e-01, 2.7469e-01, -7.8253e-01,
-8.8309e-01, -1.5604e-01, -3.6222e-01, 9.9091e-01, 3.0116e-02,
-7.8697e-01, -9.4496e-01, 2.2050e-01, -8.4521e-02, -4.8378e-01,
-9.7952e-01, -1.3446e-01, 4.2209e-01, 7.8760e-01, 6.4992e-02,
2.0492e-01, -7.8143e-01, 2.2120e-01, -5.0228e-01, 3.7149e-01,
6.5244e-01, -9.4897e-01, -6.0978e-01, -4.8976e-03, -4.6856e-01,
-2.8122e-01, -9.6984e-01, 9.8036e-01, -3.5220e-01, 7.4903e-01,
1.0000e+00, -1.0373e-01, -9.4037e-01, 6.2856e-01, 1.5745e-01,
-1.1596e-01, 1.0000e+00, 7.2891e-01, -9.8543e-01, -5.3814e-01,
4.0543e-01, -4.9501e-01, -4.8527e-01, 9.9950e-01, -1.4058e-01,
-2.3799e-01, -1.5841e-01, 9.8467e-01, -9.9180e-01, 9.7240e-01,
-9.5292e-01, -9.8022e-01, 9.8012e-01, 9.5211e-01, -6.6387e-01,
-7.2622e-01, 1.1509e-01, -3.1365e-01, 1.8487e-01, -9.7602e-01,
7.9482e-01, 5.2428e-01, -1.3540e-01, 9.1377e-01, -9.0275e-01,
-5.2769e-01, 2.8301e-01, -4.9215e-01, 3.4866e-02, 8.3573e-01,
5.0270e-01, -2.4031e-01, -6.1194e-02, -2.5558e-01, -1.3530e-01,
-9.8688e-01, 2.9877e-01, 1.0000e+00, -5.3199e-02, 4.4522e-01,
-2.4564e-01, 3.8897e-02, -3.7170e-01, 3.6843e-01, 5.1087e-01,
-1.9742e-01, -8.8481e-01, 4.5420e-01, -9.8222e-01, -9.8894e-01,
8.5417e-01, 1.4674e-01, -3.3154e-01, 9.9999e-01, 4.4333e-01,
7.1728e-02, 1.6790e-01, 9.6064e-01, 2.3267e-02, 7.2436e-01,
4.9905e-01, 9.8528e-01, -2.0286e-01, 5.2711e-01, 9.0711e-01,
-5.6147e-01, -3.4452e-01, -6.1113e-01, -8.1268e-02, -9.2887e-01,
1.0119e-01, -9.7066e-01, 9.7404e-01, 8.2025e-01, 2.9760e-01,
1.9059e-01, 3.6089e-01, 1.0000e+00, -2.7256e-01, 6.5052e-01,
-6.0092e-01, 9.0897e-01, -9.9819e-01, -9.1409e-01, -3.7810e-01,
1.2677e-02, -3.9492e-01, -3.0028e-01, 3.4323e-01, -9.7925e-01,
4.4501e-01, 3.7582e-01, -9.9622e-01, -9.9495e-01, 1.6366e-01,
9.2522e-01, -1.3063e-02, -9.5314e-01, -7.5003e-01, -6.5409e-01,
4.1526e-01, -7.6235e-02, -9.6046e-01, 3.2395e-01, -2.7184e-01,
4.7535e-01, -1.1767e-01, 5.6867e-01, 4.6844e-01, 8.3125e-01,
-2.1505e-01, -2.6495e-01, -4.4479e-02, -8.5166e-01, 8.8927e-01,
-8.9329e-01, -7.7919e-01, -1.5320e-01, 1.0000e+00, -4.3274e-01,
6.4268e-01, 7.7000e-01, 7.9197e-01, -5.4889e-02, 8.0927e-02,
7.9722e-01, 2.1034e-01, -1.9189e-01, -4.4749e-01, -8.0585e-01,
-3.5409e-01, 7.0995e-01, 1.2411e-01, 2.0604e-01, 8.3328e-01,
7.4750e-01, 1.7900e-04, 7.6917e-02, -9.1725e-02, 9.9981e-01,
-2.6801e-01, -8.3787e-02, -4.8642e-01, 1.1836e-01, -3.5603e-01,
-5.8620e-01, 1.0000e+00, 2.2691e-01, 3.2801e-01, -9.9343e-01,
-7.3298e-01, -9.5126e-01, 1.0000e+00, 8.4895e-01, -8.6216e-01,
6.9319e-01, 5.5441e-01, -1.1380e-02, 8.6958e-01, -1.2449e-01,
-2.8602e-01, 1.8517e-01, 9.2221e-02, 9.6773e-01, -4.5911e-01,
-9.7611e-01, -6.6894e-01, 3.7154e-01, -9.7862e-01, 9.9949e-01,
-5.5391e-01, -2.0926e-01, -3.9404e-01, -2.3863e-02, 6.3624e-01,
-1.0563e-01, -9.8927e-01, -1.4047e-01, 1.2247e-01, 9.7469e-01,
2.6847e-01, -6.0451e-01, -9.5354e-01, 4.5191e-01, 6.6822e-01,
-7.2218e-01, -9.6438e-01, 9.7538e-01, -9.9165e-01, 5.6641e-01,
1.0000e+00, 2.2837e-01, -2.8539e-01, 1.6956e-01, -4.6714e-01,
2.5561e-01, -2.6744e-01, 7.4301e-01, -9.7890e-01, -2.7469e-01,
-1.4162e-01, 2.7886e-01, -7.0853e-02, -5.8891e-02, 8.2879e-01,
1.9968e-01, -5.4085e-01, -6.8158e-01, 3.7584e-02, 3.5805e-01,
8.9092e-01, -1.7879e-01, -8.1491e-02, 5.0655e-02, -7.9140e-02,
-9.5114e-01, -1.4923e-01, -3.5370e-01, -9.9994e-01, 7.4321e-01,
-1.0000e+00, 2.1850e-01, -2.5182e-01, -2.2171e-01, 8.7817e-01,
2.9648e-01, 3.4926e-01, -8.2534e-01, -3.8831e-01, 7.6622e-01,
8.0938e-01, -2.1051e-01, -3.0882e-01, -7.6183e-01, 2.2523e-01,
-1.4952e-02, 1.5150e-01, -2.1056e-01, 7.3482e-01, -1.5207e-01,
1.0000e+00, 1.0631e-01, -7.7462e-01, -9.8438e-01, 1.6242e-01,
-1.6337e-01, 1.0000e+00, -9.4196e-01, -9.7149e-01, 3.9827e-01,
-7.2371e-01, -8.6582e-01, 3.0937e-01, -6.4325e-02, -8.1062e-01,
-8.8436e-01, 9.8219e-01, 9.3543e-01, -5.6058e-01, 4.5004e-01,
-3.2933e-01, -5.5851e-01, -6.9835e-02, 6.0196e-01, 9.9111e-01,
4.1170e-01, 9.1721e-01, 5.9978e-01, -9.4103e-02, 9.7966e-01,
1.5322e-01, 5.3662e-01, 4.2338e-02, 1.0000e+00, 2.8920e-01,
-9.3933e-01, 2.4383e-01, -9.8948e-01, -1.5036e-01, -9.7242e-01,
2.8053e-01, 1.1691e-01, 9.0178e-01, -2.1055e-01, 9.7547e-01,
-5.0734e-01, -8.5119e-03, -5.2189e-01, 1.1963e-01, 4.0313e-01,
-9.4529e-01, -9.8752e-01, -9.8975e-01, 4.5711e-01, -4.0753e-01,
5.8175e-02, 1.1543e-01, 8.6051e-02, 3.6199e-01, 4.3131e-01,
-1.0000e+00, 9.5818e-01, 4.0499e-01, 6.9443e-01, 9.7521e-01,
6.7153e-01, 4.3386e-01, 2.2481e-01, -9.9118e-01, -9.9126e-01,
-3.1248e-01, -1.4604e-01, 7.9951e-01, 6.1145e-01, 9.2726e-01,
4.0171e-01, -3.9375e-01, -2.0938e-01, -3.2651e-02, -4.1723e-01,
-9.9582e-01, 4.5682e-01, -9.4401e-02, -9.8150e-01, 9.6766e-01,
-5.5518e-01, -8.0481e-02, 4.4743e-01, -6.0429e-01, 9.7261e-01,
8.6633e-01, 3.7309e-01, 9.4917e-04, 4.6426e-01, 9.1590e-01,
9.6965e-01, 9.8799e-01, -4.6592e-01, 8.7146e-01, -3.1116e-01,
5.1496e-01, 6.7961e-01, -9.5609e-01, 1.3302e-03, 3.6581e-01,
-2.3789e-01, 2.6341e-01, -1.2874e-01, -9.8464e-01, 4.8621e-01,
-1.8921e-01, 6.1015e-01, -4.3986e-01, 2.1561e-01, -3.7115e-01,
-1.5832e-02, -6.9704e-01, -7.3403e-01, 5.7310e-01, 5.0895e-01,
9.4111e-01, 6.9365e-01, 6.9171e-02, -7.3277e-01, -1.1294e-01,
-4.0168e-01, -9.2587e-01, 9.6638e-01, 2.2207e-02, 1.5029e-01,
2.8954e-01, -8.5994e-02, 7.4631e-01, -1.5933e-01, -3.5710e-01,
-1.6201e-01, -7.1149e-01, 9.0602e-01, -4.2873e-01, -4.6653e-01,
-5.4765e-01, 7.4640e-01, 2.3966e-01, 9.9982e-01, -4.6795e-01,
-6.4802e-01, -4.1201e-01, -3.4984e-01, 3.5475e-01, -5.4668e-01,
-1.0000e+00, 3.6903e-01, -1.7324e-01, 4.3267e-01, -4.7206e-01,
6.3586e-01, -5.2151e-01, -9.9077e-01, -1.6597e-01, 2.6735e-01,
4.5069e-01, -4.3034e-01, -5.6321e-01, 5.7792e-01, 8.8123e-02,
9.4964e-01, 9.2798e-01, -3.3326e-01, 5.1963e-01, 6.0865e-01,
-4.4019e-01, -6.8129e-01, 9.3489e-01]], grad_fn=<TanhBackward>)
>>> output[2].shape
torch.Size([1, 768])
>>>
```
> @TheEdoardo93 it doesn't matter whether it is GPT2 or bert. Both has the same error :
> I'm trying to play with GPT2 that's why I pasted my own code.
>
> Using BERT as an Encoder and Decoder
>
> ```
> >>> model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased','bert-base-uncased')
> >>> ouput = model(torch.tensor( encoder_input_ids).unsqueeze(0))
> Traceback (most recent call last):
> File "<stdin>", line 1, in <module>
> File "/home/guest_1/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
> result = self.forward(*input, **kwargs)
> TypeError: forward() missing 1 required positional argument: 'decoder_input_ids'
> ```<|||||>I got the same issue<|||||>Do you try to follow my suggestion reported above? In my environment, it **works as expected**.
My environment details:
- **OS**: Ubuntu 16.04
- **Python**: 3.6.9
- **Transformers**: 2.2.2 (installed with `pip install transformers`)
- **PyTorch**: 1.3.1
- **TensorFlow**: 2.0
If not, can you post your **environment** and a list of **steps** to reproduce the bug?
> I got the same issue<|||||>> Said so, I've tested your code and I've revealed how to working with PreTrainedEncoderDecoder correctly without bugs. You can see my code below.
@TheEdoardo93 that doesn't make sense you giving your encoders input as a decoder's input.
<|||||>> > Said so, I've tested your code and I've revealed how to working with PreTrainedEncoderDecoder correctly without bugs. You can see my code below.
>
> @TheEdoardo93 that doesn't make sense your giving your encoders input as a decoder's input.
> Never-mind, I know what's the issue is so closing it.
Sorry, it was my mistake. Can you share with us what was the problem and how to solve it?<|||||>@anandhperumal Could you please share how you solved the issue? did you path a ```<BOS>``` to decoder input?
Appreciate that<|||||>@anandhperumal can you let us know how you fixed the issue?<|||||>You can pass a start token to the decoder, just like a Seq2Seq Arch.
|
transformers | 2,205 | closed | Segmentation fault when GPT2-chinese import transformers | ## ❓ Questions & Help
CPU: Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz
GPU: Tesla P40
OS Platform: Ubuntu 16.04.3 LTS
transformers version: 2.2.2
TensorFlow version: 2.0.0
PyTorch version: 1.3.1
Python version: 3.6.2
Hi
When I trained the model in [GPT2-chinese](https://github.com/Morizeyao/GPT2-Chinese), it imported transformers and got an error - Segmentation fault(core dumped)
```
(python36) user@ubuntu:~/projects/GPT2-Chinese$ python -Xfaulthandler train.py
I1218 00:39:09.690756 139724474922816 file_utils.py:33] TensorFlow version 2.0.0 available.
Fatal Python error: Segmentation fault
Current thread 0x00007f1423b1b740 (most recent call first):
File "<frozen importlib._bootstrap>", line 205 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 922 in create_module
File "<frozen importlib._bootstrap>", line 560 in module_from_spec
File "<frozen importlib._bootstrap>", line 648 in _load_unlocked
File "<frozen importlib._bootstrap>", line 950 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 961 in _find_and_load
File "/home/wangjun/.conda/envs/python36/lib/python3.6/site-packages/torch/__init__.py", line 81 in <module>
File "<frozen importlib._bootstrap>", line 205 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 678 in exec_module
File "<frozen importlib._bootstrap>", line 655 in _load_unlocked
File "<frozen importlib._bootstrap>", line 950 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 961 in _find_and_load
File "/home/wangjun/.conda/envs/python36/lib/python3.6/site-packages/transformers/file_utils.py", line 38 in <module>
File "<frozen importlib._bootstrap>", line 205 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 678 in exec_module
File "<frozen importlib._bootstrap>", line 655 in _load_unlocked
File "<frozen importlib._bootstrap>", line 950 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 961 in _find_and_load
File "/home/wangjun/.conda/envs/python36/lib/python3.6/site-packages/transformers/__init__.py", line 20 in <module>
File "<frozen importlib._bootstrap>", line 205 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 678 in exec_module
File "<frozen importlib._bootstrap>", line 655 in _load_unlocked
File "<frozen importlib._bootstrap>", line 950 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 961 in _find_and_load
File "train.py", line 1 in <module>
Segmentation fault (core dumped)
```
So I found the error came from line 33 'import torch' in 'transformers/transformers/file_utils.py'.
Then I swapped the position where tensorflow and torch are imported and the error disappeared.
I wonder whether it is a bug of transformer or torch and what caused it.
| 12-17-2019 16:41:27 | 12-17-2019 16:41:27 | Is it related to #2204 ?
**Segmentation fault** (usually) means that you tried to access memory that you do not have access to.<|||||>> Is it related to #2204 ?
Yes, it looks like the same bug as this. I know how to solve it but do not know why.😂
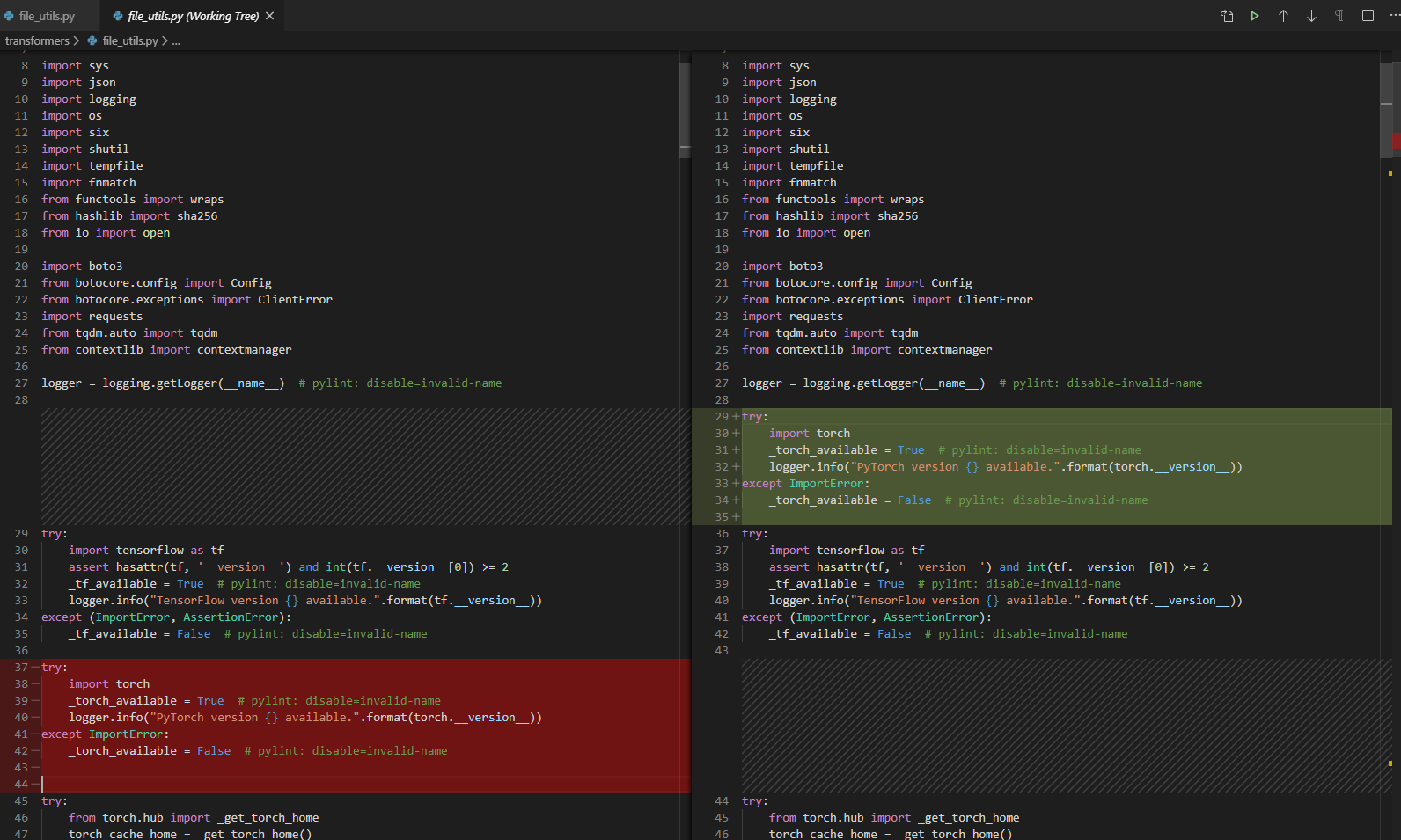
<|||||>Solved in #2207 <|||||>@jstzwj I'm still getting this issue on "transformers==2.2.2" on PyPi, how to solve it?<|||||>> @jstzwj I'm still getting this issue on "transformers==2.2.2" on PyPi, how to solve it?
#2207 |
transformers | 2,204 | closed | PRs error which occurs many times in the last days | ## 🐛 Bug
I've seen that many recent PRs (e.g. [2201](https://github.com/huggingface/transformers/pull/2201), [2203](https://github.com/huggingface/transformers/pull/2203), [2190](https://github.com/huggingface/transformers/pull/2190), [2189](https://github.com/huggingface/transformers/pull/2189), ...) have encountered the same error reported below. All the PRs I've mentioned above passed 7 different checks, but not the **`ci/circleci: build_py3_torch_and_tf`**.
```
python -m pytest -sv ./transformers/tests/ --cov
============================= test session starts ==============================
platform linux -- Python 3.5.9, pytest-5.3.2, py-1.8.0, pluggy-0.13.1 -- /usr/local/bin/python
cachedir: .pytest_cache
rootdir: /home/circleci/transformers
plugins: cov-2.8.1
collecting ... Fatal Python error: Segmentation fault
Current thread 0x00007f0afaba9740 (most recent call first):
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 938 in create_module
File "<frozen importlib._bootstrap>", line 577 in module_from_spec
File "<frozen importlib._bootstrap>", line 666 in _load_unlocked
File "<frozen importlib._bootstrap>", line 957 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "/usr/local/lib/python3.5/site-packages/torch/__init__.py", line 81 in <module>
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 697 in exec_module
File "<frozen importlib._bootstrap>", line 673 in _load_unlocked
File "<frozen importlib._bootstrap>", line 957 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "/home/circleci/transformers/transformers/file_utils.py", line 38 in <module>
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 697 in exec_module
File "<frozen importlib._bootstrap>", line 673 in _load_unlocked
File "<frozen importlib._bootstrap>", line 957 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "/home/circleci/transformers/transformers/__init__.py", line 20 in <module>
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 697 in exec_module
File "<frozen importlib._bootstrap>", line 673 in _load_unlocked
File "<frozen importlib._bootstrap>", line 957 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 943 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "<frozen importlib._bootstrap>", line 222 in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 943 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 968 in _find_and_load
File "/usr/local/lib/python3.5/site-packages/py/_path/local.py", line 701 in pyimport
File "/usr/local/lib/python3.5/site-packages/_pytest/python.py", line 492 in _importtestmodule
File "/usr/local/lib/python3.5/site-packages/_pytest/python.py", line 424 in _getobj
File "/usr/local/lib/python3.5/site-packages/_pytest/python.py", line 248 in obj
File "/usr/local/lib/python3.5/site-packages/_pytest/python.py", line 440 in _inject_setup_module_fixture
File "/usr/local/lib/python3.5/site-packages/_pytest/python.py", line 427 in collect
File "/usr/local/lib/python3.5/site-packages/_pytest/runner.py", line 254 in <lambda>
File "/usr/local/lib/python3.5/site-packages/_pytest/runner.py", line 234 in from_call
File "/usr/local/lib/python3.5/site-packages/_pytest/runner.py", line 254 in pytest_make_collect_report
File "/usr/local/lib/python3.5/site-packages/pluggy/callers.py", line 187 in _multicall
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 87 in <lambda>
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 93 in _hookexec
File "/usr/local/lib/python3.5/site-packages/pluggy/hooks.py", line 286 in __call__
File "/usr/local/lib/python3.5/site-packages/_pytest/runner.py", line 373 in collect_one_node
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 717 in genitems
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 720 in genitems
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 492 in _perform_collect
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 454 in perform_collect
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 255 in pytest_collection
File "/usr/local/lib/python3.5/site-packages/pluggy/callers.py", line 187 in _multicall
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 87 in <lambda>
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 93 in _hookexec
File "/usr/local/lib/python3.5/site-packages/pluggy/hooks.py", line 286 in __call__
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 245 in _main
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 196 in wrap_session
File "/usr/local/lib/python3.5/site-packages/_pytest/main.py", line 239 in pytest_cmdline_main
File "/usr/local/lib/python3.5/site-packages/pluggy/callers.py", line 187 in _multicall
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 87 in <lambda>
File "/usr/local/lib/python3.5/site-packages/pluggy/manager.py", line 93 in _hookexec
File "/usr/local/lib/python3.5/site-packages/pluggy/hooks.py", line 286 in __call__
File "/usr/local/lib/python3.5/site-packages/_pytest/config/__init__.py", line 92 in main
File "/usr/local/lib/python3.5/site-packages/pytest/__main__.py", line 7 in <module>
File "/usr/local/lib/python3.5/runpy.py", line 85 in _run_code
File "/usr/local/lib/python3.5/runpy.py", line 193 in _run_module_as_main
Received "segmentation fault" signal
```
## Expected behavior
When a new PR comes into Transformers, it does not generate this bug.
## Environment
* OS: **Ubuntu 16.04**
* Python version: **3.6.9**
* PyTorch version: **1.3.1**
* PyTorch Transformers version (or branch): **master** (installed with `pip install transformers`)
* Using GPU **Indifferent**
* Distributed of parallel setup **Indifferent**
* Any other relevant information: | 12-17-2019 16:36:26 | 12-17-2019 16:36:26 | #2207 <|||||>Solved by @LysandreJik yesterday (this was due to upstream dependency bug) |
transformers | 2,203 | closed | fix: wrong architecture count in README | Just say “the following” so that this intro doesn't so easily fall out of date :) | 12-17-2019 16:18:20 | 12-17-2019 16:18:20 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=h1) Report
> Merging [#2203](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/94c99db34cf9074a212c36554fb925c513d70ab1?src=pr&el=desc) will **not change** coverage.
> The diff coverage is `n/a`.
[](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2203 +/- ##
=======================================
Coverage 81.47% 81.47%
=======================================
Files 122 122
Lines 18342 18342
=======================================
Hits 14945 14945
Misses 3397 3397
```
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=footer). Last update [94c99db...a297846](https://codecov.io/gh/huggingface/transformers/pull/2203?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>This is a good idea :) @thomwolf |
transformers | 2,202 | closed | weights not initialised in pre-trained Roberta | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Robert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [X] my own modified scripts: see below
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: I am importing pre-trained models
## To Reproduce
When running the following code:
```
import logging
logging.basicConfig(level=logging.INFO)
from transformers import RobertaForMaskedLM
pt_m = RobertaForMaskedLM.from_pretrained('roberta-base')
```
I am getting the following messages in the log:
```
INFO:transformers.modeling_utils:loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-pytorch_model.bin from cache at /home/bartosz/.cache/torch/transformers/228756ed15b6d200d7cb45aaef08c087e2706f54cb912863d2efe07c89584eb7.49b88ba7ec2c26a7558dda98ca3884c3b80fa31cf43a1b1f23aef3ff81ba344e
INFO:transformers.modeling_utils:Weights of RobertaForMaskedLM not initialized from pretrained model: ['lm_head.decoder.weight']
INFO:transformers.modeling_utils:Weights from pretrained model not used in RobertaForMaskedLM: ['lm_head.weight']
```
In particular, I am concerned that the weight of the LM head were not initialised from the stored values.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
The model should load and all weights should get initialized from the pre-trained model.
<!-- A clear and concise description of what you expected to happen. -->
## Environment
* OS: Linux
* Python version: 3.7
* PyTorch version: 1.2.1
* PyTorch Transformers version (or branch): 2.2.2
* Using GPU ? No
* Distributed of parallel setup ? No
* Any other relevant information:
## Additional context
If I comment out these two lines the messages disappear:
https://github.com/huggingface/transformers/blob/f061606277322a013ec2d96509d3077e865ae875/transformers/modeling_utils.py#L445-L446
<!-- Add any other context about the problem here. -->
| 12-17-2019 14:31:54 | 12-17-2019 14:31:54 | Thanks for the bug report. Fixed on `master` in 9a399ead253e27792cbf0ef386cc39f9b7084f8f by reverting the output of #1778. |
transformers | 2,201 | closed | [WAITING YOUR REVIEW] Issue #2196: now it's possible to save PreTrainedEncoderDecoder objects correctly to file system | **Details implemented in this PR:**
- [X] Create the output directory (whose name is passed by the user in the "save_directory" parameter) where it will be saved encoder and decoder, if not exists.
- [X] Empty the output directory, if it contains any files or subdirectories.
- [X] Create the "encoder" directory inside "save_directory", if not exists.
- [X] Create the "decoder" directory inside "save_directory", if not exists.
- [X] Save the encoder and the decoder in the previous two directories, respectively. | 12-17-2019 09:33:25 | 12-17-2019 09:33:25 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=h1) Report
> Merging [#2201](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/f061606277322a013ec2d96509d3077e865ae875?src=pr&el=desc) will **decrease** coverage by `0.07%`.
> The diff coverage is `0%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2201 +/- ##
==========================================
- Coverage 80.32% 80.25% -0.08%
==========================================
Files 122 122
Lines 18342 18358 +16
==========================================
Hits 14734 14734
- Misses 3608 3624 +16
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/modeling\_encoder\_decoder.py](https://codecov.io/gh/huggingface/transformers/pull/2201/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2VuY29kZXJfZGVjb2Rlci5weQ==) | `25.92% <0%> (-6.39%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=footer). Last update [f061606...0f844f5](https://codecov.io/gh/huggingface/transformers/pull/2201?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>@julien-c @LysandreJik @thomwolf you can review my code for solving issue #2196 :)<|||||>Cool, thanks @TheEdoardo93 ! Do you mind if I clean the commits as to not have a merge commit (rebasing on master instead)? I'll push directly on your fork if that's okay. You'll still be the author of the commits.<|||||>@LysandreJik
The steps I’ve done for this PR are the following:
- make my changes on the source code
- git add/commit/push
- after that, the automatic tests start to run but an error of “segmentation fault” occurs
- i’ve changed a line only for “redo” the tests suite after the bug was solved, but my local branch was below “master”. I didn’t see this fact so I didn’t do a “git pull”. After that, I’ve done git add/commit/push and run the tests suite and now the tests suite is working without error
Said so, my changes only occurs in my first commit. The other ones are due to Transformers’ master changes. Have I answered to you? I hope yes.
Thanks for being the author of this PR yet!<|||||>I rebased your code on the current master branch so that there's only the two commits. Thanks @TheEdoardo93.<|||||>I feel like this is very verbose so let's maybe revisit when we drop Python 2 support. |
transformers | 2,200 | closed | run_ner.py example fails | I am trying to run the run_ner.py example described here: (https://huggingface.co/transformers/examples.html#named-entity-recognition)
When running the example I get the following exception:
```
I1217 09:36:10.744300 14416 file_utils.py:40] PyTorch version 1.3.1 available.
W1217 09:36:11.329299 14416 run_ner.py:422] Process rank: -1, device: cuda, n_gpu: 1, distributed training: False, 16-bits training: False
I1217 09:36:11.863193 14416 configuration_utils.py:160] loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert_base_uncased/config.json from cache at s3_cache\67674340071d93960fbc3eb74cf1d0b51de232689bfc75d63e3f4ab1c9a052f9
Traceback (most recent call last):
File ".\run_ner.py", line 531, in <module>
main()
File ".\run_ner.py", line 441, in main
cache_dir=args.cache_dir if args.cache_dir else None)
File "C:\Program Files\Python\Python37\lib\site-packages\transformers\configuration_utils.py", line 163, in from_pretrained
config = cls.from_json_file(resolved_config_file)
File "C:\Program Files\Python\Python37\lib\site-packages\transformers\configuration_utils.py", line 196, in from_json_file
return cls.from_dict(json.loads(text))
File "C:\Program Files\Python\Python37\lib\json\__init__.py", line 348, in loads
return _default_decoder.decode(s)
File "C:\Program Files\Python\Python37\lib\json\decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "C:\Program Files\Python\Python37\lib\json\decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
```
A JSON files does not seemed to be found. Can someone tell me which file this is?
| 12-17-2019 08:38:51 | 12-17-2019 08:38:51 | A few questions (the ones asked in the issue templates...):
- which version/branch of `transformers` are you using?
- which exact command line are you running?<|||||>Hi,
sorry, my bad.
I am calling run_ner.py with
```
python .\run_ner.py --data_dir ./ --model_type bert --labels .\labels.txt --model_name_or_path bert_base_uncased --output_dir pytorch_ner --max_seq_length 75 --n
um_train_epochs 5 --per_gpu_train_batch_size 12 --save_steps 750 --seed 4711 --do_train --do_eval --do_predict --cache_dir s3_cache
```
I am using transformers 2.2.2<|||||>The JSON file the Python script is trying to use is the configuration of BERT model (`config.json`)?
> I am trying to run the run_ner.py example described here: (https://huggingface.co/transformers/examples.html#named-entity-recognition)
>
> When running the example I get the following exception:
>
> ```
> I1217 09:36:10.744300 14416 file_utils.py:40] PyTorch version 1.3.1 available.
> W1217 09:36:11.329299 14416 run_ner.py:422] Process rank: -1, device: cuda, n_gpu: 1, distributed training: False, 16-bits training: False
> I1217 09:36:11.863193 14416 configuration_utils.py:160] loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/bert_base_uncased/config.json from cache at s3_cache\67674340071d93960fbc3eb74cf1d0b51de232689bfc75d63e3f4ab1c9a052f9
> Traceback (most recent call last):
> File ".\run_ner.py", line 531, in <module>
> main()
> File ".\run_ner.py", line 441, in main
> cache_dir=args.cache_dir if args.cache_dir else None)
> File "C:\Program Files\Python\Python37\lib\site-packages\transformers\configuration_utils.py", line 163, in from_pretrained
> config = cls.from_json_file(resolved_config_file)
> File "C:\Program Files\Python\Python37\lib\site-packages\transformers\configuration_utils.py", line 196, in from_json_file
> return cls.from_dict(json.loads(text))
> File "C:\Program Files\Python\Python37\lib\json\__init__.py", line 348, in loads
> return _default_decoder.decode(s)
> File "C:\Program Files\Python\Python37\lib\json\decoder.py", line 337, in decode
> obj, end = self.raw_decode(s, idx=_w(s, 0).end())
> File "C:\Program Files\Python\Python37\lib\json\decoder.py", line 355, in raw_decode
> raise JSONDecodeError("Expecting value", s, err.value) from None
> json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
> ```
>
> A JSON files does not seemed to be found. Can someone tell me which file this is?<|||||>Do I have to retrieve the file from somewhere ? I assumed everything is retrieved automatically by the script?<|||||>Reminds me of this isse: https://github.com/huggingface/transformers/issues/2154<|||||>Well, the `bert_base_uncased` for the `model_name_or_path` option is not correct. Just use: `bert-base-uncased` :)<|||||>Yes, the `bert_base_uncased` should be `bert-base-uncased`.
I've improved these error messages on the master with #2164 by the way, it should be more explicit now that the configuration file can't be found.<|||||>@Horsmann Additionally, if you want to use an uncased model, make sure that you pass `--do_lower_case` to the `run_ner.py` script!<|||||>Thanks! It is working now. The exception looked like I am missing a file so I didn't checked for the model name. |
transformers | 2,199 | closed | How to add traditional features for transformers? | ## ❓ Questions & Help
I don't know whether models like Bert can capture some traditional features or not, such as the number of nouns in a sentence, the number of words in a sentence, etc. But I want to add these features to Bert or xlnet for training. Can anyone help me?
| 12-17-2019 08:38:09 | 12-17-2019 08:38:09 | What do you mean "for training"? Training what? I imagine that you wish to do this for a downstream task. In that case you can just use BERT for feature extraction and use its features in another system. I suppose one could also fine-tune the model during training where you somewhere inject other features into the model, but you'll have to think carefully where and how you optimize the model (one optimizer for finetuning and training newly injected parameters, multiple optimizers, and so on).
I'd say you could start with feature extraction and adding other features. <|||||>As correctly said by @BramVanroy , you can see some examples of this approach [here](https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/).
> ## Questions & Help
> I don't know whether models like Bert can capture some traditional features or not, such as the number of nouns in a sentence, the number of words in a sentence, etc. But I want to add these features to Bert or xlnet for training. Can anyone help me?<|||||>Hi @TheEdoardo93 , I read the approach you told me. But I still have some confusing, since the model could output a vector of 768 for every sentence. Where I concat my feature like "the number of nouns in a sentence"? Just the end line of the vector and normalized all of them to 1? Thank you.<|||||>`BERT` gives you a feature vector of size 768 for each sentence. Besides this, you can add _N_ features to this vector in order to have at the end a vector of size 768 + _N_, in which the N features have been chosen by you, e.g. number of nouns in a sentence.
So, from 0 to 767 you have the features extracted with `BERT` model, and from 768 to 768+_N_-1 you have your **custom** features extracted by you.
N.B: remember that it's very important in Machine Learning to have the range for all features the same (or quite the same), in order to not give more importance to some rather than others. For this task, you can use e.g. StandardScaler or MinMaxScaler from [Scikit-learn](https://scikit-learn.org/stable/) or a custom scaler implemented by you.
> Hi @TheEdoardo93 , I read the approach you told me. But I still have some confusing, since the model could output a vector of 768 for every sentence. Where I concat my feature like "the number of nouns in a sentence"? Just the end line of the vector and normalized all of them to 1? Thank you.<|||||>@TheEdoardo93 Thank you very much ! |
transformers | 2,198 | closed | How to output labels for GLUE test set | ## ❓ Questions & Help
Thanks for your great work.
I have done some modification based on your library. I'd like to test it on GLUE test set (not dev set). Is there any way I can do it? Do you have a script for output GLUE submission files?
Thanks. | 12-17-2019 08:14:56 | 12-17-2019 08:14:56 | Hi, if you're working on a clone/fork of this library, then you can freely change the following lines in `transformers/data/processors/glue.py` (lines 254-262 on the current master):
```py
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
```
to read the `test.tsv` instead of the `dev.tsv`.<|||||>Hi @LysandreJik,
Thanks for your reply!
However, the format of test set is different from the dev set. It has an extra `id` field and does not have ground truth labels. Thus, the simple change you suggested wouldn't work in this case. Besides, GLUE leaderboard also requires a specific output format for submission.
I have noticed that in Huggingface's workshop paper [DistilBERT](https://arxiv.org/abs/1910.01108), you also use DEV set instead of TEST result from GLUE leaderboard. I guess it may be somehow related to the lack of a submission script. To facilitate further research, I hope you can make a script for GLUE submission. As far as I know, many researchers are using huggingface/transformers for their research. I really appreciate it if you can provide a script for the community.
Thanks!<|||||>Hi @LysandreJik,
I've just realized that you are one of the authors of DistilBERT so I suppose you know exactly what I mean. It can truly benefit the research community if you do this. Thanks.<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
<|||||>hi did u get the script? <|||||>@yuchenlin My co-author wrote one himself. I added you on Wechat but you didn't respond. <|||||>Hey, I think this would be helpful for many in the community. Can you maybe share the script you wrote for this via a pull request?<|||||>@Breakend Sure, I will verify the script and open a pull request.<|||||>Hello @JetRunner , no news about this script?
Thank you in advance<|||||>> Hello @JetRunner , no news about this script?
> Thank you in advance
Sorry, I totally forgot about this stuff. I'll notify you as soon as we upload it.
cc @michaelzhouwang<|||||>> Hello @JetRunner , no news about this script?
> Thank you in advance
Hi I have uploaded the script for prediction on GLUE benchmarks at:
https://github.com/JetRunner/BERT-of-Theseus/tree/master/glue_script
You can first replace the glue.py in src/transformers/data/processor/ and then use run_prediction.py.<|||||>> > Hello @JetRunner , no news about this script?
> > Thank you in advance
>
> Hi I have uploaded the script for prediction on GLUE benchmarks at:
> https://github.com/JetRunner/BERT-of-Theseus/tree/master/glue_script
> You can first replace the glue.py in src/transformers/data/processor/ and then use run_prediction.py.
cc @Breakend @jibay <|||||>@JetRunner @MichaelZhouwang Thank you for the quick answer, i will check asap :) |
transformers | 2,197 | closed | XLNet fine-tuning speed (Multi-label classification) | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi!
I'm wondering whether my speed of fine-tuning is normal.
Training is taking **2~3hours per epoch**.
I am using [fast-bert](https://github.com/kaushaltrivedi/fast-bert) to train multi-label classifier, with
- model = xlnet-base-cased
- max sequence length = 512 tokens
- mem states using = no
- gpu = V100 * 4
- training data amount = 110000 ~ 120000
- validation data amount = 30000 ~ 40000
- evaluation = per each epoch, per every 100 steps
- apex, f16 used
Thank you so much!
| 12-17-2019 05:46:55 | 12-17-2019 05:46:55 | This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,196 | closed | Error while saving Pretrained model for Encoder and decoder | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [ ] the official example scripts: (give details)
* [X] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details)
## To Reproduce
Steps to reproduce the behavior:
1. Define a model and try to save the model then the error occurs. This is because the encoder and decoder model is save in different directories and the directories are not created.
In order to handle this, you need to check if the given path exists then the encoder folder exists if not create a folder above this [line](https://github.com/huggingface/transformers/blob/3f5ccb183e3cfa755dea2dd2afd9abbf1a0f93b8/transformers/modeling_encoder_decoder.py#L169)
Code to reproduce:
```
from transformers import PreTrainedEncoderDecoder
model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased', 'bert-base-uncased', cache_dir='../transformers/cache')
model.save_pretrained(final_model_output)
```
Error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/guest_1/anaconda3/envs/my_env/lib/python3.6/site-packages/transformers/modeling_encoder_decoder.py", line 167, in save_pretrained
self.encoder.save_pretrained(os.path.join(save_directory, "encoder"))
File "/home/guest_1/anaconda3/envs/my_env/lib/python3.6/site-packages/transformers/modeling_utils.py", line 239, in save_pretrained
assert os.path.isdir(save_directory), "Saving path should be a directory where the model and configuration can be saved"
AssertionError: Saving path should be a directory where the model and configuration can be saved
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
OS: ubuntu
Python version: 3.6
PyTorch version:1.3.0
PyTorch Transformers version (or branch):2.2.0
Using GPU ? Yes
Distributed of parallel setup ? No
Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
| 12-17-2019 04:10:13 | 12-17-2019 04:10:13 | I resolved this issue you've raised correctly. I'll make a PR today to solve this bug! :)
UPDATE: I've made the PR: you can look [here](https://github.com/huggingface/transformers/pull/2201).
> ## Bug
> Model I am using (Bert, XLNet....):
>
> Language I am using the model on (English, Chinese....):
>
> The problem arise when using:
>
> * [ ] the official example scripts: (give details)
> * [x] my own modified scripts: (give details)
>
> The tasks I am working on is:
>
> * [ ] an official GLUE/SQUaD task: (give the name)
> * [x] my own task or dataset: (give details)
>
> ## To Reproduce
> Steps to reproduce the behavior:
>
> 1. Define a model and try to save the model then the error occurs. This is because the encoder and decoder model is save in different directories and the directories are not created.
> In order to handle this, you need to check if the given path exists then the encoder folder exists if not create a folder above this [line](https://github.com/huggingface/transformers/blob/3f5ccb183e3cfa755dea2dd2afd9abbf1a0f93b8/transformers/modeling_encoder_decoder.py#L169)
>
> Code to reproduce:
>
> ```
> from transformers import PreTrainedEncoderDecoder
> model = PreTrainedEncoderDecoder.from_pretrained('bert-base-uncased', 'bert-base-uncased', cache_dir='../transformers/cache')
> model.save_pretrained(final_model_output)
> ```
>
> Error:
>
> ```
> Traceback (most recent call last):
> File "<stdin>", line 1, in <module>
> File "/home/guest_1/anaconda3/envs/my_env/lib/python3.6/site-packages/transformers/modeling_encoder_decoder.py", line 167, in save_pretrained
> self.encoder.save_pretrained(os.path.join(save_directory, "encoder"))
> File "/home/guest_1/anaconda3/envs/my_env/lib/python3.6/site-packages/transformers/modeling_utils.py", line 239, in save_pretrained
> assert os.path.isdir(save_directory), "Saving path should be a directory where the model and configuration can be saved"
> AssertionError: Saving path should be a directory where the model and configuration can be saved
> ```
>
> ## Expected behavior
> ## Environment
> ```
> OS: ubuntu
> Python version: 3.6
> PyTorch version:1.3.0
> PyTorch Transformers version (or branch):2.2.0
> Using GPU ? Yes
> Distributed of parallel setup ? No
> Any other relevant information:
> ```
>
> ## Additional context<|||||>@TheEdoardo93 did you try doing inference ? |
transformers | 2,195 | closed | Fixing checks test pr, will be closed | 12-17-2019 04:05:25 | 12-17-2019 04:05:25 | ||
transformers | 2,194 | closed | Improve TextDataset building/tokenization (6x faster; Enable large dataset file usage) | ## This PR:
- Chunks the reading of the dataset file used to create a `TextDataset` for training, if you used a file of any larger size (for my case I had 3.5GB txt file I was able to get finish in ~45 min) the program would just hang at `f.read()` 😢
- Speeds up `lowercase_text` in the `BasicTokenizer` with a simpler regex scheme
- Add `@functools.lru_cache()` to several functions responsible for acting on individual chars
- Use multiprocessing to drastically speed up tokenization inside `TextDataset` constructor
## Checkouts & Performance Profiling
Benchmark script I used to clock speeds 👉 [gist](https://gist.github.com/mttcnnff/f192d8933f2a8d2b58e14b53841c4080)
Comparison script I used to compare results 👉 [gist](https://gist.github.com/mttcnnff/503f9facd3c317e7efc61a43295a335f)
### Performance on master with no changes on a ~16.5MB txt file (~1 min):
<img width="703" alt="image" src="https://user-images.githubusercontent.com/17532157/70959441-4aa1ae00-204a-11ea-95ad-b1d89baf2e09.png">
### Performance after all changes applied on same ~16.5MB txt file (~10 seconds):
<img width="788" alt="image" src="https://user-images.githubusercontent.com/17532157/70959476-6c9b3080-204a-11ea-9228-6bd55332fff0.png"> | 12-17-2019 02:47:00 | 12-17-2019 02:47:00 | @thomwolf or @julien-c any idea what's going on with the seg fault in the `build_py3_torch_and_tf` [run](https://circleci.com/gh/huggingface/transformers/9811?utm_campaign=vcs-integration-link&utm_medium=referral&utm_source=github-build-link)? was able to run and pass locally...

<|||||>> @thomwolf or @julien-c any idea what's going on with the seg fault in the `build_py3_torch_and_tf` [run](https://circleci.com/gh/huggingface/transformers/9811?utm_campaign=vcs-integration-link&utm_medium=referral&utm_source=github-build-link)? was able to run and pass locally...
> 
I've encountered this problem too while adding my PR some days ago. It was broken something inside Transformers library, but @LysandreJik solved this bug two days ago in #2207. Therefore, you can re-launch your tests and you'll see that now it works as expected! :)
UPDATE: you've to install transformers from source code `master` branch through `pip install git+https://github.com/huggingface/transformers.git`<|||||>This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
|
transformers | 2,193 | closed | Fine-tuning GPT2 or BERT and adding new vocabulary? | ## ❓ Questions & Help
I am fine-tuning the GPT2 on a domain-specific corpus and I was wondering if there is a way to add new vocabulary to the model. I am checking the ```vocab.json``` file after saving the model into ```output``` directory and don't find the any new vocabulary in there.
| 12-16-2019 22:11:33 | 12-16-2019 22:11:33 | Hi, you can add new vocabulary using the tokenizer's `add_tokens` method.<|||||>Thanks for the quick response! |
transformers | 2,192 | closed | Bug fix: PyTorch loading from TF and vice-versa | Fix loading a PyTorch model from TF and vice-versa when model architectures are not the same
Fix #2109 | 12-16-2019 21:33:19 | 12-16-2019 21:33:19 | # [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=h1) Report
> Merging [#2192](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/d8034092153a6850052862f154a398b88b8ba4e5?src=pr&el=desc) will **increase** coverage by `1.12%`.
> The diff coverage is `33.33%`.
[](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #2192 +/- ##
==========================================
+ Coverage 80.21% 81.33% +1.12%
==========================================
Files 120 120
Lines 18254 18261 +7
==========================================
+ Hits 14642 14853 +211
+ Misses 3612 3408 -204
```
| [Impacted Files](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=tree) | Coverage Δ | |
|---|---|---|
| [transformers/modeling\_tf\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3V0aWxzLnB5) | `92.3% <0%> (ø)` | :arrow_up: |
| [transformers/modeling\_tf\_pytorch\_utils.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3RmX3B5dG9yY2hfdXRpbHMucHk=) | `92.15% <37.5%> (+82.56%)` | :arrow_up: |
| [transformers/modeling\_openai.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX29wZW5haS5weQ==) | `81.45% <0%> (+1.32%)` | :arrow_up: |
| [transformers/modeling\_ctrl.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX2N0cmwucHk=) | `96.47% <0%> (+2.2%)` | :arrow_up: |
| [transformers/modeling\_xlnet.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3hsbmV0LnB5) | `74.54% <0%> (+2.32%)` | :arrow_up: |
| [transformers/modeling\_roberta.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL21vZGVsaW5nX3JvYmVydGEucHk=) | `71.76% <0%> (+12.35%)` | :arrow_up: |
| [transformers/tests/modeling\_tf\_common\_test.py](https://codecov.io/gh/huggingface/transformers/pull/2192/diff?src=pr&el=tree#diff-dHJhbnNmb3JtZXJzL3Rlc3RzL21vZGVsaW5nX3RmX2NvbW1vbl90ZXN0LnB5) | `97.41% <0%> (+17.24%)` | :arrow_up: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=continue).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=footer). Last update [d803409...2dd30a3](https://codecov.io/gh/huggingface/transformers/pull/2192?src=pr&el=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments).
<|||||>Great, this works! |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.