
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
e7bd0ea78a9ca0750319f94f606482d55924f9ac | 13,580 | ipynb | Jupyter Notebook | site/en/2/tutorials/eager/custom_layers.ipynb | allenlavoie/docs | 2feaa86b54ad96b53bec5851e89203b201b8cbb4 | [
"Apache-2.0"
]
| 1 | 2019-06-06T22:49:00.000Z | 2019-06-06T22:49:00.000Z | site/en/2/tutorials/eager/custom_layers.ipynb | allenlavoie/docs | 2feaa86b54ad96b53bec5851e89203b201b8cbb4 | [
"Apache-2.0"
]
| 1 | 2021-02-28T07:14:03.000Z | 2021-02-28T07:14:03.000Z | site/en/2/tutorials/eager/custom_layers.ipynb | allenlavoie/docs | 2feaa86b54ad96b53bec5851e89203b201b8cbb4 | [
"Apache-2.0"
]
| null | null | null | 36.603774 | 431 | 0.538144 | [
[
[
"##### Copyright 2018 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Custom layers",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/tutorials/eager/custom_layers\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/eager/custom_layers.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/tutorials/eager/custom_layers.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"We recommend using `tf.keras` as a high-level API for building neural networks. That said, most TensorFlow APIs are usable with eager execution.\n",
"_____no_output_____"
]
],
[
[
"!pip install tf-nightly-2.0-preview\nimport tensorflow as tf",
"_____no_output_____"
]
],
[
[
"## Layers: common sets of useful operations\n\nMost of the time when writing code for machine learning models you want to operate at a higher level of abstraction than individual operations and manipulation of individual variables.\n\nMany machine learning models are expressible as the composition and stacking of relatively simple layers, and TensorFlow provides both a set of many common layers as a well as easy ways for you to write your own application-specific layers either from scratch or as the composition of existing layers.\n\nTensorFlow includes the full [Keras](https://keras.io) API in the tf.keras package, and the Keras layers are very useful when building your own models.\n",
"_____no_output_____"
]
],
[
[
"# In the tf.keras.layers package, layers are objects. To construct a layer,\n# simply construct the object. Most layers take as a first argument the number\n# of output dimensions / channels.\nlayer = tf.keras.layers.Dense(100)\n# The number of input dimensions is often unnecessary, as it can be inferred\n# the first time the layer is used, but it can be provided if you want to \n# specify it manually, which is useful in some complex models.\nlayer = tf.keras.layers.Dense(10, input_shape=(None, 5))",
"_____no_output_____"
]
],
[
[
"The full list of pre-existing layers can be seen in [the documentation](https://www.tensorflow.org/api_docs/python/tf/keras/layers). It includes Dense (a fully-connected layer),\nConv2D, LSTM, BatchNormalization, Dropout, and many others.",
"_____no_output_____"
]
],
[
[
"# To use a layer, simply call it.\nlayer(tf.zeros([10, 5]))",
"_____no_output_____"
],
[
"# Layers have many useful methods. For example, you can inspect all variables\n# in a layer by calling layer.variables. In this case a fully-connected layer\n# will have variables for weights and biases.\nlayer.variables",
"_____no_output_____"
],
[
"# The variables are also accessible through nice accessors\nlayer.kernel, layer.bias",
"_____no_output_____"
]
],
[
[
"## Implementing custom layers\nThe best way to implement your own layer is extending the tf.keras.Layer class and implementing:\n * `__init__` , where you can do all input-independent initialization\n * `build`, where you know the shapes of the input tensors and can do the rest of the initialization\n * `call`, where you do the forward computation\n\nNote that you don't have to wait until `build` is called to create your variables, you can also create them in `__init__`. However, the advantage of creating them in `build` is that it enables late variable creation based on the shape of the inputs the layer will operate on. On the other hand, creating variables in `__init__` would mean that shapes required to create the variables will need to be explicitly specified.",
"_____no_output_____"
]
],
[
[
"class MyDenseLayer(tf.keras.layers.Layer):\n def __init__(self, num_outputs):\n super(MyDenseLayer, self).__init__()\n self.num_outputs = num_outputs\n \n def build(self, input_shape):\n self.kernel = self.add_variable(\"kernel\", \n shape=[int(input_shape[-1]), \n self.num_outputs])\n \n def call(self, input):\n return tf.matmul(input, self.kernel)\n \nlayer = MyDenseLayer(10)\nprint(layer(tf.zeros([10, 5])))\nprint(layer.variables)",
"_____no_output_____"
]
],
[
[
"Note that you don't have to wait until `build` is called to create your variables, you can also create them in `__init__`.\n\nOverall code is easier to read and maintain if it uses standard layers whenever possible, as other readers will be familiar with the behavior of standard layers. If you want to use a layer which is not present in tf.keras.layers or tf.contrib.layers, consider filing a [github issue](http://github.com/tensorflow/tensorflow/issues/new) or, even better, sending us a pull request!",
"_____no_output_____"
],
[
"## Models: composing layers\n\nMany interesting layer-like things in machine learning models are implemented by composing existing layers. For example, each residual block in a resnet is a composition of convolutions, batch normalizations, and a shortcut.\n\nThe main class used when creating a layer-like thing which contains other layers is tf.keras.Model. Implementing one is done by inheriting from tf.keras.Model.",
"_____no_output_____"
]
],
[
[
"class ResnetIdentityBlock(tf.keras.Model):\n def __init__(self, kernel_size, filters):\n super(ResnetIdentityBlock, self).__init__(name='')\n filters1, filters2, filters3 = filters\n\n self.conv2a = tf.keras.layers.Conv2D(filters1, (1, 1))\n self.bn2a = tf.keras.layers.BatchNormalization()\n\n self.conv2b = tf.keras.layers.Conv2D(filters2, kernel_size, padding='same')\n self.bn2b = tf.keras.layers.BatchNormalization()\n\n self.conv2c = tf.keras.layers.Conv2D(filters3, (1, 1))\n self.bn2c = tf.keras.layers.BatchNormalization()\n\n def call(self, input_tensor, training=False):\n x = self.conv2a(input_tensor)\n x = self.bn2a(x, training=training)\n x = tf.nn.relu(x)\n\n x = self.conv2b(x)\n x = self.bn2b(x, training=training)\n x = tf.nn.relu(x)\n\n x = self.conv2c(x)\n x = self.bn2c(x, training=training)\n\n x += input_tensor\n return tf.nn.relu(x)\n\n \nblock = ResnetIdentityBlock(1, [1, 2, 3])\nprint(block(tf.zeros([1, 2, 3, 3])))\nprint([x.name for x in block.variables])",
"_____no_output_____"
]
],
[
[
"Much of the time, however, models which compose many layers simply call one layer after the other. This can be done in very little code using tf.keras.Sequential",
"_____no_output_____"
]
],
[
[
" my_seq = tf.keras.Sequential([tf.keras.layers.Conv2D(1, (1, 1)),\n tf.keras.layers.BatchNormalization(),\n tf.keras.layers.Conv2D(2, 1, \n padding='same'),\n tf.keras.layers.BatchNormalization(),\n tf.keras.layers.Conv2D(3, (1, 1)),\n tf.keras.layers.BatchNormalization()])\nmy_seq(tf.zeros([1, 2, 3, 3]))",
"_____no_output_____"
]
],
[
[
"# Next steps\n\nNow you can go back to the previous notebook and adapt the linear regression example to use layers and models to be better structured.",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7bd17e2a956c51abd89b9d852e2c9ba534ac008 | 3,727 | ipynb | Jupyter Notebook | HW2/prototyping.ipynb | dshlai/1101_P76I900 | 63c48088db03da7d7eaee262dc76ef4e811065fb | [
"MIT"
]
| null | null | null | HW2/prototyping.ipynb | dshlai/1101_P76I900 | 63c48088db03da7d7eaee262dc76ef4e811065fb | [
"MIT"
]
| null | null | null | HW2/prototyping.ipynb | dshlai/1101_P76I900 | 63c48088db03da7d7eaee262dc76ef4e811065fb | [
"MIT"
]
| null | null | null | 32.12931 | 996 | 0.574188 | [
[
[
"import pandas as pd\n\ncols_for_metadata = [\"title\", \"journal\", \"pdf_json_files\", \"pmc_json_files\", \"authors\", \"abstract\"]\n\ndf = pd.read_csv(\"~/Datasets/P76I900/HW2/CORD19/metadata.csv\", usecols=cols_for_metadata, low_memory=False)",
"_____no_output_____"
],
[
"df_abstract_empty = df[df[\"abstract\"].isnull()]\ndf_abstract = df.dropna(subset=[\"abstract\"])",
"_____no_output_____"
],
[
"print(len(df_abstract))\nprint(len(df_abstract) + len(df_abstract_empty))\nprint(len(df))",
"592272\n793502\n793502\n"
],
[
"import spacy\nfrom collections import Counter\nnlp = spacy.load(\"en_core_web_md\")\n\n",
"_____no_output_____"
],
[
"\ndoc = nlp(df_abstract.iloc[0][\"abstract\"])\n\nwords = [tk for tk in doc if tk.is_alpha]\nwords = [tk.lemma_ for tk in words]\n\ncounter = Counter(words)\n#counter = sorted([(freq, w) for w, freq in counter.items()], reverse=True)\n\nword_df = pd.DataFrame.from_dict(counter) \nword_df",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bd26512029c810ec1966902dee86dfabc9b86d | 1,779 | ipynb | Jupyter Notebook | Day5 Assignment1.ipynb | Tulasi-ummadipolu/LetsUpgrade-Python-B7 | 9972f1d2d9287ba5ac97fb0a590c746db73efcf9 | [
"Apache-2.0"
]
| null | null | null | Day5 Assignment1.ipynb | Tulasi-ummadipolu/LetsUpgrade-Python-B7 | 9972f1d2d9287ba5ac97fb0a590c746db73efcf9 | [
"Apache-2.0"
]
| null | null | null | Day5 Assignment1.ipynb | Tulasi-ummadipolu/LetsUpgrade-Python-B7 | 9972f1d2d9287ba5ac97fb0a590c746db73efcf9 | [
"Apache-2.0"
]
| null | null | null | 27.369231 | 256 | 0.468803 | [
[
[
"<a href=\"https://colab.research.google.com/github/Tulasi-ummadipolu/LetsUpgrade-Python-B7/blob/master/Day5%20Assignment1.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"check_list = [1,1,5,7,9,6,4]\nsub_list = [1,1,5]\nprint(\"original list : \" +str (check_list))\nprint(\"original sublist : \" +str (sub_list))\nflag=0\nif (set (sub_list).issubset(set (check_list))):\n flag = 1\nif (flag):\n print(\"Its a Match.\")\nelse :\n rint(\"Its Gone\")",
"original list : [1, 1, 5, 7, 9, 6, 4]\noriginal sublist : [1, 1, 5]\nIts a Match.\n"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
]
]
|
e7bd2a60e8b35f8f974f725a0b88b3f26b9387cd | 17,257 | ipynb | Jupyter Notebook | Mont Co PA 911 Calls.ipynb | larohndale/pythonfordata | 463958aa8146387a5f140eab9b7f1c07a7cd0434 | [
"MIT"
]
| null | null | null | Mont Co PA 911 Calls.ipynb | larohndale/pythonfordata | 463958aa8146387a5f140eab9b7f1c07a7cd0434 | [
"MIT"
]
| null | null | null | Mont Co PA 911 Calls.ipynb | larohndale/pythonfordata | 463958aa8146387a5f140eab9b7f1c07a7cd0434 | [
"MIT"
]
| null | null | null | 46.514825 | 7,650 | 0.694385 | [
[
[
"import numpy as np\nimport pandas as pd\nimport sqlite3",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set_style('whitegrid')\n%matplotlib inline",
"_____no_output_____"
],
[
"df = pd.read_csv('911.csv')",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 326425 entries, 0 to 326424\nData columns (total 9 columns):\nlat 326425 non-null float64\nlng 326425 non-null float64\ndesc 326425 non-null object\nzip 286835 non-null float64\ntitle 326425 non-null object\ntimeStamp 326425 non-null object\ntwp 326310 non-null object\naddr 326425 non-null object\ne 326425 non-null int64\ndtypes: float64(3), int64(1), object(5)\nmemory usage: 22.4+ MB\n"
],
[
"df['twp'].value_counts(sort=True)",
"_____no_output_____"
],
[
"#use lambda expression to create reasons column for db",
"_____no_output_____"
],
[
"df['Reason'] = df['title'].apply(lambda title: title.split(':')[0])",
"_____no_output_____"
],
[
"df['Reason'].value_counts()",
"_____no_output_____"
],
[
"conn = sqlite3.connect('911.db')",
"_____no_output_____"
],
[
"c = conn.cursor()\n#Create Table \nc.execute('''CREATE TABLE calls_final2\n (reason text, qty real)''')\nc.execute(\"INSERT INTO calls_final2 VALUES ('EMS', 161441)\")\nconn.commit()\nconn.close()",
"ERROR:root:An unexpected error occurred while tokenizing input\nThe following traceback may be corrupted or invalid\nThe error message is: ('EOF in multi-line string', (1, 36))\n\n"
],
[
"conn = sqlite3.connect('911.db')\nc = conn.cursor()\nc. fetchall()",
"_____no_output_____"
],
[
"allReasons = [('Traffic', 116065),\n ('Fire', 48919),]\nc.executemany('INSERT INTO calls_final2 VALUES (?,?)', allReasons)",
"_____no_output_____"
],
[
"for row in c.execute('SELECT * FROM calls_final2'):\n print(row)",
"('EMS', 161441.0)\n('Traffic', 116065.0)\n('Fire', 48919.0)\n"
],
[
"sns.countplot(x='Reason',data=df,palette='viridis')",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bd459f136704abb1a65ce116798ada4f906111 | 16,526 | ipynb | Jupyter Notebook | notebooks/em/FDEM_Planewave_Wholespace.ipynb | jcapriot/geosci-labs | 044a73432b9cb1187924f7761942ab329259d875 | [
"MIT"
]
| null | null | null | notebooks/em/FDEM_Planewave_Wholespace.ipynb | jcapriot/geosci-labs | 044a73432b9cb1187924f7761942ab329259d875 | [
"MIT"
]
| null | null | null | notebooks/em/FDEM_Planewave_Wholespace.ipynb | jcapriot/geosci-labs | 044a73432b9cb1187924f7761942ab329259d875 | [
"MIT"
]
| null | null | null | 23.374823 | 236 | 0.484146 | [
[
[
"%matplotlib inline\nfrom IPython.display import display\nfrom geoscilabs.em.PlanewaveWidgetFD import PlanewaveWidget, PolarEllipse, InteractivePlaneProfile\nfrom geoscilabs.em.DipoleWidgetFD import InteractiveDipoleProfile\nfrom geoscilabs.em.VolumeWidgetPlane import InteractivePlanes, plotObj3D",
"_____no_output_____"
]
],
[
[
"# Planewave propagation in a Whole-space (frequency-domain)",
"_____no_output_____"
],
[
"# Purpose\n\nWe visualizae downward propagating planewave in the homogeneous earth medium. With the three apps: a) Plane wave app, b) Profile app, and c) Polarization ellipse app, we understand fundamental concepts of planewave propagation. \n",
"_____no_output_____"
],
[
"# Set up\n\nPlanewave EM equation can be written as \n\n$$\\frac{\\partial^2 \\mathbf{E}}{\\partial z^2} + k^2 \\mathbf{E} = 0,$$\n\nFor homogeneous earth, solution can be simply derived:\n\n\n$$\\mathbf{E} = \\mathbf{E}_0 e^{ikz}$$\n\n$$\\mathbf{H} = - i \\omega \\mu \\nabla \\times (\\mathbf{E}_0 e^{ikz}).$$\n\nwhere complex wavenumber $k$ is \n\n$$ k = \\sqrt{\\mu \\epsilon \\omega^2 - i \\mu \\sigma \\omega}.$$\n\nIn time domain, the wave travelling in the negative z-direction has the form:\n\n$$ \\mathbf{e} = \\mathbf{e}_0^- e^{i(k z + \\omega t)}.$$",
"_____no_output_____"
]
],
[
[
"ax = plotObj3D()",
"_____no_output_____"
]
],
[
[
"# Planewave app\n\n## Parameters:\n\n- Field: Type of EM fields (\"Ex\": electric field, \"Hy\": magnetic field)\n- AmpDir: Type of the vectoral EM fields \n\n None: $F_x$ or $F_y$ or $F_z$\n \n Amp: $\\mathbf{F} \\cdot \\mathbf{F}^* = |\\mathbf{F}|^2$\n \n Dir: Real part of a vectoral EM fields, $\\Re[\\mathbf{F}]$\n \n- ComplexNumber: Type of complex data (\"Re\", \"Im\", \"Amp\", \"Phase\") \n- Frequency: Transmitting frequency (Hz)\n- Sigma: Conductivity of homogeneous earth (S/m)\n- Scale: Choose \"log\" or \"linear\" scale \n- Time: ",
"_____no_output_____"
]
],
[
[
"dwidget = PlanewaveWidget()\nQ = dwidget.InteractivePlaneWave()\ndisplay(Q)",
"_____no_output_____"
]
],
[
[
"# Profile app\n\nWe visualize EM fields at vertical profile (marked as red dots in the above app). \n\n## Parameters:\n\n- **Field**: Ex, Hy, and Impedance \n- ** $\\sigma$ **: Conductivity (S/m)\n- **Scale**: Log10 or Linear scale\n- **Fixed**: Fix the scale or not\n- **$f$**: Frequency\n- **$t$**: Time\n",
"_____no_output_____"
]
],
[
[
"display(InteractivePlaneProfile())",
"_____no_output_____"
]
],
[
[
"# Polarization Ellipse app",
"_____no_output_____"
]
],
[
[
"Polarwidget = PolarEllipse(); \nPolarwidget.Interactive()",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7bd4a5689e2b9803609810e10d7bdaf46142017 | 52,876 | ipynb | Jupyter Notebook | docs_src/callbacks.one_cycle.ipynb | fmgonzales/fastai | be6389ff9b61be916a8f02d575d1b15ff2c6e9ad | [
"Apache-2.0"
]
| 1 | 2020-07-01T18:55:50.000Z | 2020-07-01T18:55:50.000Z | docs_src/callbacks.one_cycle.ipynb | fmgonzales/fastai | be6389ff9b61be916a8f02d575d1b15ff2c6e9ad | [
"Apache-2.0"
]
| 1 | 2022-02-26T12:22:31.000Z | 2022-02-26T12:22:31.000Z | docs_src/callbacks.one_cycle.ipynb | fmgonzales/fastai | be6389ff9b61be916a8f02d575d1b15ff2c6e9ad | [
"Apache-2.0"
]
| 2 | 2018-09-19T09:35:09.000Z | 2018-10-03T09:08:12.000Z | 118.556054 | 28,452 | 0.869771 | [
[
[
"# The 1cycle policy",
"_____no_output_____"
]
],
[
[
"from fastai.gen_doc.nbdoc import *\nfrom fastai import *\nfrom fastai.vision import *",
"_____no_output_____"
]
],
[
[
"## What is 1cycle?",
"_____no_output_____"
],
[
"This Callback allows us to easily train a network using Leslie Smith's 1cycle policy. To learn more about the 1cycle technique for training neural networks check out [Leslie Smith's paper](https://arxiv.org/pdf/1803.09820.pdf) and for a more graphical and intuitive explanation check out [Sylvain Gugger's post](https://sgugger.github.io/the-1cycle-policy.html).\n\nTo use our 1cycle policy we will need an [optimum learning rate](https://sgugger.github.io/how-do-you-find-a-good-learning-rate.html). We can find this learning rate by using a learning rate finder which can be called by using [`lr_finder`](/callbacks.lr_finder.html#callbacks.lr_finder). It will do a mock training by going over a large range of learning rates, then plot them against the losses. We will pick a value a bit before the minimum, where the loss still improves. Our graph would look something like this:\n\n\n\nHere anything between `3x10^-2` and `10^-2` is a good idea.\n\nNext we will apply the 1cycle policy with the chosen learning rate as the maximum learning rate. The original 1cycle policy has three steps:\n\n 1. We progressively increase our learning rate from lr_max/div_factor to lr_max and at the same time we progressively decrease our momentum from mom_max to mom_min.\n 2. We do the exact opposite: we progressively decrease our learning rate from lr_max to lr_max/div_factor and at the same time we progressively increase our momentum from mom_min to mom_max.\n 3. We further decrease our learning rate from lr_max/div_factor to lr_max/(div_factor x 100) and we keep momentum steady at mom_max.\n \nThis gives the following form:\n\n<img src=\"imgs/onecycle_params.png\" alt=\"1cycle parameteres\" width=\"500\">\n\nUnpublished work has shown even better results by using only two phases: the same phase 1, followed by a second phase where we do a cosine annealing from lr_max to 0. The momentum goes from mom_min to mom_max by following the symmetric cosine (see graph a bit below).",
"_____no_output_____"
],
[
"## Basic Training",
"_____no_output_____"
],
[
"The one cycle policy allows to train very quickly, a phenomenon termed [_superconvergence_](https://arxiv.org/abs/1708.07120). To see this in practice, we will first train a CNN and see how our results compare when we use the [`OneCycleScheduler`](/callbacks.one_cycle.html#OneCycleScheduler) with [`fit_one_cycle`](/train.html#fit_one_cycle).",
"_____no_output_____"
]
],
[
[
"path = untar_data(URLs.MNIST_SAMPLE)\ndata = ImageDataBunch.from_folder(path)\nmodel = simple_cnn((3,16,16,2))\nlearn = Learner(data, model, metrics=[accuracy])",
"_____no_output_____"
]
],
[
[
"First lets find the optimum learning rate for our comparison by doing an LR range test.",
"_____no_output_____"
]
],
[
[
"learn.lr_find()",
"_____no_output_____"
],
[
"learn.recorder.plot()",
"_____no_output_____"
]
],
[
[
"Here 5e-2 looks like a good value, a tenth of the minimum of the curve. That's going to be the highest learning rate in 1cycle so let's try a constant training at that value.",
"_____no_output_____"
]
],
[
[
"learn.fit(2, 5e-2)",
"_____no_output_____"
]
],
[
[
"We can also see what happens when we train at a lower learning rate",
"_____no_output_____"
]
],
[
[
"model = simple_cnn((3,16,16,2))\nlearn = Learner(data, model, metrics=[accuracy])\nlearn.fit(2, 5e-3)",
"_____no_output_____"
]
],
[
[
"## Training with the 1cycle policy",
"_____no_output_____"
],
[
"Now to do the same thing with 1cycle, we use [`fit_one_cycle`](/train.html#fit_one_cycle).",
"_____no_output_____"
]
],
[
[
"model = simple_cnn((3,16,16,2))\nlearn = Learner(data, model, metrics=[accuracy])\nlearn.fit_one_cycle(2, 5e-2)",
"_____no_output_____"
]
],
[
[
"This gets the best of both world and we can see how we get a far better accuracy and a far lower loss in the same number of epochs. It's possible to get to the same amazing results with training at constant learning rates, that we progressively diminish, but it will take a far longer time.\n\nHere is the schedule of the lrs (left) and momentum (right) that the new 1cycle policy uses.",
"_____no_output_____"
]
],
[
[
"learn.recorder.plot_lr(show_moms=True)",
"_____no_output_____"
],
[
"show_doc(OneCycleScheduler, doc_string=False)",
"_____no_output_____"
]
],
[
[
"Create a [`Callback`](/callback.html#Callback) that handles the hyperparameters settings following the 1cycle policy for `learn`. `lr_max` should be picked with the [`lr_find`](/train.html#lr_find) test. In phase 1, the learning rates goes from `lr_max/div_factor` to `lr_max` linearly while the momentum goes from `moms[0]` to `moms[1]` linearly. In phase 2, the learning rates follows a cosine annealing from `lr_max` to 0, as the momentum goes from `moms[1]` to `moms[0]` with the same annealing.",
"_____no_output_____"
]
],
[
[
"show_doc(OneCycleScheduler.steps, doc_string=False)",
"_____no_output_____"
]
],
[
[
"Build the [`Stepper`](/callback.html#Stepper) for the [`Callback`](/callback.html#Callback) according to `steps_cfg`.",
"_____no_output_____"
]
],
[
[
"show_doc(OneCycleScheduler.on_train_begin, doc_string=False)",
"_____no_output_____"
]
],
[
[
"Initiate the parameters of a training for `n_epochs`.",
"_____no_output_____"
]
],
[
[
"show_doc(OneCycleScheduler.on_batch_end, doc_string=False)",
"_____no_output_____"
]
],
[
[
"Prepares the hyperparameters for the next batch.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7bd4b46a54027da54a92e784b9f03da79e9df71 | 247,878 | ipynb | Jupyter Notebook | ml-presentation/cx-pima-diabetes.ipynb | mgfeller/tensorflow | eae672c3547e2b9fca276a2f228a64c39ac46132 | [
"Apache-2.0"
]
| null | null | null | ml-presentation/cx-pima-diabetes.ipynb | mgfeller/tensorflow | eae672c3547e2b9fca276a2f228a64c39ac46132 | [
"Apache-2.0"
]
| null | null | null | ml-presentation/cx-pima-diabetes.ipynb | mgfeller/tensorflow | eae672c3547e2b9fca276a2f228a64c39ac46132 | [
"Apache-2.0"
]
| null | null | null | 143.447917 | 65,032 | 0.867104 | [
[
[
"## <div style=\"text-align: center\">Maskinlæring med Python</div>\n\n### <div style=\"text-align: center\">Michael Gfeller, Computasdag 3.2.2018</div>\n\n\n\n\n----\n\n_(Notebook basert på https://www.kaggle.com/futurist/pima-data-visualisation-and-machine-learning, [Apache 2.0 license](http://www.apache.org/licenses/LICENSE-2.0))_",
"_____no_output_____"
],
[
"# Definer og forstå oppgaven\n\n",
"_____no_output_____"
]
],
[
[
"from IPython.display import YouTubeVideo\nYouTubeVideo(\"pN4HqWRybwk\")",
"_____no_output_____"
]
],
[
[
"Innsikt og forutsigelse om en kvinne fra Pima-folkestammen får diabetes innen 5 år. ",
"_____no_output_____"
],
[
"# Last inn biblioteker",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"# Last inn og utforsk data",
"_____no_output_____"
]
],
[
[
"pima = pd.read_csv(\"diabetes.csv\") # pandas.core.frame.DataFrame",
"_____no_output_____"
],
[
"pima.head(4)",
"_____no_output_____"
],
[
"pima.shape",
"_____no_output_____"
],
[
"pima.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 768 entries, 0 to 767\nData columns (total 9 columns):\nPregnancies 768 non-null int64\nGlucose 768 non-null int64\nBloodPressure 768 non-null int64\nSkinThickness 768 non-null int64\nInsulin 768 non-null int64\nBMI 768 non-null float64\nDiabetesPedigreeFunction 768 non-null float64\nAge 768 non-null int64\nOutcome 768 non-null int64\ndtypes: float64(2), int64(7)\nmemory usage: 54.1 KB\n"
],
[
"pima.describe()",
"_____no_output_____"
],
[
"pima.groupby(\"Outcome\").size()",
"_____no_output_____"
]
],
[
[
"# Visualiser data",
"_____no_output_____"
],
[
"## Histogram",
"_____no_output_____"
]
],
[
[
"pima.hist(figsize=(10,10))",
"_____no_output_____"
]
],
[
[
"## Boxplot",
"_____no_output_____"
]
],
[
[
"pima.plot(kind= 'box' , subplots=True, layout=(3,3), sharex=False, sharey=False, figsize=(8,8))",
"_____no_output_____"
],
[
"X_columns = pima.columns[0:len(pima.columns) - 1]",
"_____no_output_____"
],
[
"pima[X_columns].plot(kind= 'box', subplots=False, figsize=(20,8))",
"_____no_output_____"
]
],
[
[
"## Korrelasjon mellom variablene",
"_____no_output_____"
]
],
[
[
"correlations = pima[pima.columns].corr()",
"_____no_output_____"
],
[
"sns.heatmap(correlations, annot = True)",
"_____no_output_____"
]
],
[
[
"# Velg input-variabler (features, givens, independent)",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_selection import SelectKBest\nfrom sklearn.feature_selection import chi2",
"_____no_output_____"
],
[
"X = pima.iloc[:,0:8]\nY = pima.iloc[:,8]\nselect_top_4 = SelectKBest(score_func=chi2, k = 4)",
"_____no_output_____"
],
[
"fit = select_top_4.fit(X,Y)\nfeatures = fit.transform(X)",
"_____no_output_____"
],
[
"feature_cols = pima.columns[fit.get_support('indices')]\nfeature_cols",
"_____no_output_____"
],
[
"features[0:3]",
"_____no_output_____"
],
[
"pima.head(3)",
"_____no_output_____"
],
[
"X_features = pd.DataFrame(data = features, columns = feature_cols)",
"_____no_output_____"
],
[
"X_features.head(3)",
"_____no_output_____"
]
],
[
[
"# Forbered data med standardisering ",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import StandardScaler # En av flere scalers. \nX_features_scaled = StandardScaler().fit_transform(X_features)",
"_____no_output_____"
],
[
"X = pd.DataFrame(data = X_features_scaled, columns= X_features.columns)",
"_____no_output_____"
],
[
"X.head(3)",
"_____no_output_____"
],
[
"X.hist()",
"_____no_output_____"
],
[
"X.plot(kind= 'box', subplots=False, figsize=(20,8))",
"_____no_output_____"
]
],
[
[
"# Prøv ut forskjellige modeller - binærklassifisering",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nrandom_seed = 22\nX_train,X_test,Y_train,Y_test = train_test_split(X,Y, random_state = random_seed, test_size = 0.2)",
"_____no_output_____"
],
[
"from sklearn.model_selection import KFold\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.naive_bayes import GaussianNB # Gaussian Naive Bayes\nfrom sklearn.neighbors import KNeighborsClassifier \nfrom sklearn.tree import DecisionTreeClassifier \nfrom sklearn.svm import SVC\nfrom sklearn.svm import LinearSVC",
"_____no_output_____"
],
[
"models = []\nmodels.append((\"LR\",LogisticRegression()))\nmodels.append((\"NB\",GaussianNB())) \nmodels.append((\"KNN\",KNeighborsClassifier()))\nmodels.append((\"DT\",DecisionTreeClassifier()))\nmodels.append((\"SVM\",SVC()))\nmodels.append((\"LSVM\",LinearSVC()))",
"_____no_output_____"
],
[
"results = []\nnames = []\nfor name,model in models:\n kfold = KFold(n_splits=10, random_state=random_seed)\n cv_result = cross_val_score(model,X_train,Y_train, cv = kfold,scoring = \"accuracy\")\n names.append(name)\n results.append(cv_result)\nfor i in range(len(names)):\n print(\"%-5s: %.2f%% +/- %.2f%%\" % (names[i],results[i].mean()*100,results[i].std()*100))",
"LR : 77.69% +/- 5.23%\nNB : 76.05% +/- 5.94%\nKNN : 74.59% +/- 4.68%\nDT : 70.36% +/- 3.79%\nSVM : 77.69% +/- 5.15%\nLSVM : 77.85% +/- 5.24%\n"
]
],
[
[
"# Visualiser resultatene",
"_____no_output_____"
]
],
[
[
"ax = sns.boxplot(data=results)\nax.set_xticklabels(names)",
"_____no_output_____"
]
],
[
[
"# Tren og valider de beste modeller\n\nLogistisk regresjon og (L)SVM ga de beste resultatene.",
"_____no_output_____"
]
],
[
[
"X_train.describe()",
"_____no_output_____"
],
[
"Y_train_df = pd.DataFrame(data = Y_train, columns = ['Outcome'])\nY_train_df.groupby(\"Outcome\").size()",
"_____no_output_____"
],
[
"X_test.describe()",
"_____no_output_____"
],
[
"Y_test_df = pd.DataFrame(data = Y_test, columns = ['Outcome'])\nY_test_df.groupby(\"Outcome\").size()",
"_____no_output_____"
]
],
[
[
"### Logistisk regresjon",
"_____no_output_____"
]
],
[
[
"lr = LogisticRegression()\nlr.fit(X_train,Y_train)\npredictions = lr.predict(X_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score\nfrom sklearn.metrics import classification_report\nfrom sklearn.metrics import confusion_matrix",
"_____no_output_____"
],
[
"print(\"%-5s: %.2f%%\" % (\"LR\", accuracy_score(Y_test,predictions)*100))",
"LR : 71.43%\n"
]
],
[
[
"### Support Vector Classifier",
"_____no_output_____"
]
],
[
[
"svm = SVC()\nsvm.fit(X_train,Y_train)\npredictions = svm.predict(X_test)",
"_____no_output_____"
],
[
"print(\"%-5s: %.2f%%\" % (\"SVM\", accuracy_score(Y_test,predictions)*100))",
"SVM : 73.38%\n"
],
[
"print(classification_report(Y_test,predictions))",
" precision recall f1-score support\n\n 0 0.74 0.92 0.82 100\n 1 0.72 0.39 0.51 54\n\navg / total 0.73 0.73 0.71 154\n\n"
],
[
"# https://en.wikipedia.org/wiki/Confusion_matrix\nconfusion = confusion_matrix(Y_test,predictions)\n# print(confusion)\ntn, fp, fn, tp = confusion.ravel()\nprint(\"True negatives: %4d\" % tn)\nprint(\"True positives: %4d\" % tp)\nprint(\"False negatives: %4d\" % fn)\nprint(\"False positives: %4d\" % fp)\nprint(\"Accuracy: %4.0f%%\" % (100*(tp+tn)/(tn + fp + fn + tp)))\nprint(\"Precision: %4.0f%%\" % (100*tp/(tp+fp)))\nprint(\"Recall: %4.0f%%\" % (100*tp/(tp+fn)))",
"True negatives: 92\nTrue positives: 21\nFalse negatives: 33\nFalse positives: 8\nAccuracy: 73%\nPrecision: 72%\nRecall: 39%\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
e7bd632351eb6b45fd658946bc8a0e863ce48b0f | 210,778 | ipynb | Jupyter Notebook | demo/dev_clean.ipynb | rbuerki/codebook | fee607c1bf7d6630f346d14d1f5e8835794460fd | [
"MIT"
]
| null | null | null | demo/dev_clean.ipynb | rbuerki/codebook | fee607c1bf7d6630f346d14d1f5e8835794460fd | [
"MIT"
]
| null | null | null | demo/dev_clean.ipynb | rbuerki/codebook | fee607c1bf7d6630f346d14d1f5e8835794460fd | [
"MIT"
]
| null | null | null | 293.154381 | 39,996 | 0.924209 | [
[
[
"<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Load-Data\" data-toc-modified-id=\"Load-Data-1\"><span class=\"toc-item-num\">1 </span>Load Data</a></span></li><li><span><a href=\"#Demo-of-Cleaning-Functions\" data-toc-modified-id=\"Demo-of-Cleaning-Functions-2\"><span class=\"toc-item-num\">2 </span>Demo of Cleaning Functions</a></span><ul class=\"toc-item\"><li><span><a href=\"#Columns\" data-toc-modified-id=\"Columns-2.1\"><span class=\"toc-item-num\">2.1 </span>Columns</a></span></li><li><span><a href=\"#Outliers\" data-toc-modified-id=\"Outliers-2.2\"><span class=\"toc-item-num\">2.2 </span>Outliers</a></span></li><li><span><a href=\"#Transformations\" data-toc-modified-id=\"Transformations-2.3\"><span class=\"toc-item-num\">2.3 </span>Transformations</a></span></li></ul></li></ul></div>",
"_____no_output_____"
]
],
[
[
"import datetime as dt\nimport sys\nfrom pathlib import Path\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"print(sys.executable)\nprint(sys.version)\nprint(f\"Pandas {pd.__version__}\")\nprint(f\"Seaborn {sns.__version__}\")",
"C:\\Users\\r2d4\\miniconda3\\envs\\py3\\python.exe\n3.8.3 (default, May 19 2020, 06:50:17) [MSC v.1916 64 bit (AMD64)]\nPandas 1.3.1\nSeaborn 0.11.0\n"
],
[
"sys.path.append(str(Path.cwd().parent / 'src' / 'codebook'))",
"_____no_output_____"
],
[
"%load_ext autoreload\n%autoreload 2\n\n%matplotlib inline\n# %config InlineBackend.figure_format = 'svg'\nplt.style.use('raph-base')\n\nfrom IPython.core.interactiveshell import InteractiveShell\nInteractiveShell.ast_node_interactivity = 'all'\n\npd.set_option('precision', 2)\npd.set_option('display.max_columns', 30)\npd.set_option('display.expand_frame_repr', False)\npd.set_option('max_colwidth', 800)",
"_____no_output_____"
],
[
"import src.codebook.EDA as EDA\nimport src.codebook.clean as clean",
"_____no_output_____"
]
],
[
[
"## Load Data",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(\"../data/realWorldTestData.csv\", \n low_memory=False, \n nrows=1000,\n usecols=[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 18]\n )",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 1000 entries, 0 to 999\nData columns (total 14 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 target_event 1000 non-null object \n 1 NUM_CONSEC_SERVICES 1000 non-null int64 \n 2 SUM_INVOICE_AMOUNT_IN_SERVICE 1000 non-null float64\n 3 SUM_INVOICE_AMOUNT 1000 non-null float64\n 4 NUM_EVENTS 1000 non-null int64 \n 5 FIRST_EVT 1000 non-null object \n 6 LAST_EVT 1000 non-null object \n 7 LAST_MILEAGE 1000 non-null float64\n 8 MEAN_MILEAGE_PER_MNTH 1000 non-null float64\n 9 AVG_DIFF_MNTH 1000 non-null int64 \n 10 age_mnth 1000 non-null int64 \n 11 KANTON_LICENCE_PLATE 991 non-null object \n 12 INSPECTION_INTERVAL_UID 1000 non-null object \n 13 CAR_BRAND_UID 1000 non-null object \ndtypes: float64(4), int64(4), object(6)\nmemory usage: 109.5+ KB\n"
]
],
[
[
"## Demo of Cleaning Functions \n### Columns",
"_____no_output_____"
]
],
[
[
"# Prettify the column names \n\ndf = clean.prettify_column_names(df)\n\n# Check result\ndf.columns",
"_____no_output_____"
],
[
"# Delete columns\n\ndf_del = clean.delete_columns(df, cols_to_delete=[\"target_event\", \"first_evt\"])\n\nassert df_del.shape[1] == (df.shape[1] - 2)",
"Column target_event successfully deleted.\nColumn first_evt successfully deleted.\n"
],
[
"# Downcast dtypes\n\ndf_lean = clean.downcast_dtypes(df)\n\n# Check result\ndf_lean.dtypes",
" Original df size before downcasting: 0.46 MB\n New df size after downcasting:0.16 MB\n"
]
],
[
[
"<b><font color='red'>A word of Warning:</span></b><font color='red'></font> Downcasting the numerical dtypes this way can lead to problems with the power transforms that are demonstrated below. That's why we continue with the original frame here.",
"_____no_output_____"
],
[
"### Outliers",
"_____no_output_____"
]
],
[
[
"# Count Outliers using the IQR-Method, with a distance of X\n\nclean.count_outliers_IQR_method(df, iqr_dist=2)",
"\nnum_consec_services:\n - effective upper cut-off value: 7.00\n - effective lower cut-off value: 1.00\n - Identified outliers: 6\n - of total values: 0.6%\n\nsum_invoice_amount_in_service:\n - effective upper cut-off value: 0.00\n - effective lower cut-off value: 0.00\n - Identified outliers: 69\n - of total values: 6.9%\n\nsum_invoice_amount:\n - effective upper cut-off value: 4,930.24\n - effective lower cut-off value: 0.00\n - Identified outliers: 35\n - of total values: 3.5%\n\nnum_events:\n - effective upper cut-off value: 31.75\n - effective lower cut-off value: 3.00\n - Identified outliers: 14\n - of total values: 1.4%\n\nlast_mileage:\n - effective upper cut-off value: 172,933.25\n - effective lower cut-off value: 1,296.00\n - Identified outliers: 14\n - of total values: 1.4%\n\nmean_mileage_per_mnth:\n - effective upper cut-off value: 2,912.81\n - effective lower cut-off value: 50.64\n - Identified outliers: 19\n - of total values: 1.9%\n\navg_diff_mnth:\n - effective upper cut-off value: 9.00\n - effective lower cut-off value: 1.00\n - Identified outliers: 22\n - of total values: 2.2%\n"
],
[
"# Remove outliers in two selected columns\n\noutlier_cols=[\"avg_diff_mnth\", \"mean_mileage_per_mnth\"]\n\ndf_outliers, deleted_idx = clean.remove_outliers_IQR_method(\n df,\n outlier_cols=outlier_cols,\n iqr_dist=2,\n return_idx_deleted=True\n)",
"\navg_diff_mnth: \nRows to remove: 22\n\n\nmean_mileage_per_mnth: \nRows to remove: 19\n\n\nRows removed in total: 41\n(Percentage of original DataFrame: 4.1%)\n"
],
[
"# Because we have set the `return_idx_deleted` param to true\n# We have also received a list of the removed outliers' index values\n\nprint(deleted_idx)",
"[257, 2, 3, 771, 646, 266, 527, 917, 282, 418, 550, 422, 171, 555, 180, 309, 59, 321, 836, 453, 710, 200, 841, 330, 587, 971, 75, 718, 850, 210, 596, 980, 599, 856, 739, 239, 497, 758, 887, 632, 637]\n"
],
[
"# (As a sidenote) There is also a helper function, that is simply returning the outlier values \n# with the lower, upper threshold for an interable\noutliers, lower_thx, upper_thx = clean.get_outlier_values_with_iqr_method(\n df[\"avg_diff_mnth\"], iqr_dist=2\n)\n\nprint(len(outliers))\nprint(f\"Lower threshold: {lower_thx}\")\nprint(f\"Upper threshold: {upper_thx}\")",
"22\nLower threshold: -1.0\nUpper threshold: 9.0\n"
],
[
"# Winsorize outliers in two more columns\n# (We use the IQR-Method output from above to define the quantiles)\n\nw_dict = {\n \"sum_invoice_amount\": (None, 0.035),\n \"last_mileage\": (0.0005, 0.014),\n}\n\ndf_w = clean.winsorize_outliers(df, w_dict)\n\n# Check results\nprint(list(zip(\n df_w[list(w_dict.keys())].min(),\n df_w[list(w_dict.keys())].max()\n )))",
"[(0.0, 4889.35), (1296.0, 171053.0)]\n"
]
],
[
[
"### Transformations",
"_____no_output_____"
]
],
[
[
"df_transform = df[[\"last_mileage\", \"sum_invoice_amount\", \"mean_mileage_per_mnth\"]]. copy()\n\nEDA.plot_distr_histograms(df_transform)",
"_____no_output_____"
],
[
"df_log = clean.transform_data(df_transform, method=\"log\")\n\nEDA.plot_distr_histograms(df_log)",
"Zero or negative value(s) in col sum_invoice_amount, all data is shifted by 0.1. Alternatively use method 'yeo-johnson'.\n"
],
[
"df_log10 = clean.transform_data(df_transform, method=\"log10\")\n\nEDA.plot_distr_histograms(df_log10)",
"Zero or negative value(s) in col sum_invoice_amount, all data is shifted by 0.1. Alternatively use method 'yeo-johnson'.\n"
],
[
"df_bc = clean.transform_data(df_transform, method=\"box_cox\")\n\nEDA.plot_distr_histograms(df_bc)",
"Zero or negative value(s) in col sum_invoice_amount, all data is shifted by 0.1. Alternatively use method 'yeo-johnson'.\n"
],
[
"df_jy = clean.transform_data(df_transform, method=\"yeo_johnson\")\n\nEDA.plot_distr_histograms(df_jy)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bd688e2a322594190ab4a882421d8b10d0819c | 155,616 | ipynb | Jupyter Notebook | projects/graphexplorer/submissions/RonanDariusHamilton/graphexplore.ipynb | wrgr/intersession2018 | 096dd01fc49a9ce4f95e144c90ae677adfcbb00e | [
"Apache-2.0"
]
| null | null | null | projects/graphexplorer/submissions/RonanDariusHamilton/graphexplore.ipynb | wrgr/intersession2018 | 096dd01fc49a9ce4f95e144c90ae677adfcbb00e | [
"Apache-2.0"
]
| null | null | null | projects/graphexplorer/submissions/RonanDariusHamilton/graphexplore.ipynb | wrgr/intersession2018 | 096dd01fc49a9ce4f95e144c90ae677adfcbb00e | [
"Apache-2.0"
]
| null | null | null | 342.013187 | 35,928 | 0.928709 | [
[
[
"# Getting Data\n\nFirst, we want to grab some graphs and subject covariates from a web-accessible url. We've given this to you on google drive rather than having you set up aws s3 credentials in the interest of saving time. The original data is hosted at m2g.io\n\nBelow, you will be getting the following dataset:\n\n| Property | Value |\n|:--------:|:-----:|\n| Dataset | SWU4 |\n| N-Subjects | 454 |\n| Scans-per-subjects | 2 |\n| Atlases | Desikan, CPAC200 |\n| Desikan Nodes | 70 |\n| CPAC200 Nodes | 200 |\n\nThe covariates you have are: `SUBID, SESSION, AGE_AT_SCAN_1, SEX, RESTING_STATE_INSTRUCTION, TIME_OF_DAY, SEASON, SATIETY, LMP`. There are other columns in the `.csv` file (downloaded in the next step) but they are populated with a `#` meaning that the value was not recorded.\n\nThere are several other atlases available - you can change which one you use \nRunning the cell below will get you the data. **Please note, you only have to run these two cells once!!!**",
"_____no_output_____"
],
[
"## Loading Graphs + Covariates\nRun the following cells of code to load the graphs into your computer, as well as the covariates.",
"_____no_output_____"
]
],
[
[
"!pip install networkx==1.9 #networkx broke backwards compatibility with these graph files\nimport numpy as np\nimport networkx as nx\nimport scipy as sp\nimport matplotlib.pyplot as plt\nimport os\nimport csv\nimport networkx.algorithms.centrality as nac\n\n\nfrom collections import OrderedDict",
"Requirement already satisfied: networkx==1.9 in /opt/conda/lib/python3.6/site-packages\r\nRequirement already satisfied: decorator>=3.4.0 in /opt/conda/lib/python3.6/site-packages (from networkx==1.9)\r\n"
],
[
"# Initializing dataset names\ndataset_names = ('SWU4')\n\nbasepath = 'data'\n\n# change which atlas you use, here!\n\natlas = 'desikan' # 'desikan' # or 'CPAC200', or 'Talairach'\ndir_names = basepath + '/' + dataset_names + '/' + atlas\n#basepath = \"/\"\n#dir_names = basepath\nprint(dir_names)\nfs = OrderedDict()\nfs[dataset_names] = [root + \"/\" + fl for root, dirs, files in os.walk(dir_names)\n for fl in files if fl.endswith(\".gpickle\")]\n\nps = \"data/SWU4/SWU4.csv\"\n\nprint(\"Datasets: \" + \", \".join([fkey + \" (\" + str(len(fs[fkey])) + \")\"\n for fkey in fs]))\nprint(\"Total Subjects: %d\" % (sum([len(fs[key]) for key in fs])))",
"data/SWU4/desikan\nDatasets: SWU4 (454)\nTotal Subjects: 454\n"
],
[
"def loadGraphs(filenames, verb=False):\n \"\"\"\n Given a list of files, returns a dictionary of graphs\n\n Required parameters:\n filenames:\n - List of filenames for graphs\n Optional parameters:\n verb:\n - Toggles verbose output statements\n \"\"\"\n # Initializes empty dictionary\n gstruct = OrderedDict()\n for idx, files in enumerate(filenames):\n if verb:\n print(\"Loading: \" + files)\n # Adds graphs to dictionary with key being filename\n fname = os.path.basename(files)\n gstruct[fname] = nx.read_gpickle(files)\n return gstruct\n\ndef constructGraphDict(names, fs, verb=False):\n \"\"\"\n Given a set of files and a directory to put things, loads graphs.\n\n Required parameters:\n names:\n - List of names of the datasets\n fs:\n - Dictionary of lists of files in each dataset\n Optional parameters:\n verb:\n - Toggles verbose output statements\n \"\"\"\n # Loads graphs into memory for all datasets\n graphs = OrderedDict()\n if verb:\n print(\"Loading Dataset: \" + names)\n # The key for the dictionary of graphs is the dataset name\n graphs[names] = loadGraphs(fs[names], verb=verb)\n return graphs",
"_____no_output_____"
],
[
"graphs = constructGraphDict(dataset_names, fs, verb=False)",
"_____no_output_____"
],
[
"import csv\n# This gets age and sex, respecitvely.\ntmp = csv.reader(open(ps,newline='')) # this is the whole phenotype file\npheno = OrderedDict()\ntriple = [[t[0].strip(), t[2], int(t[3] == '2')] for t in tmp\n if t[3] != '#' and t[2] != '#'][1:] # female=1->0, male=2->1\n\nfor idx, trip in enumerate(triple):\n pheno[trip[0]] = trip[1:]",
"_____no_output_____"
],
[
"## replace with this\n\nk = sorted(list(graphs['SWU4'].keys()))\nk_id = list(key[6:11] for key in k)\nk_id = k_id[0::2]\nk_g1 = k[0::2]\n\ng1 = []\nfor xx in k_g1:\n g1.append(graphs['SWU4'][xx])\n\n#Create vectors of labels\nage = list()\nsex = list()\n\nfor key in k_id:\n sex.append(pheno[key][1])\n age.append(pheno[key][0]) ",
"_____no_output_____"
]
],
[
[
"## ASSIGNMENT: \n(Code above used to get data in the correct format. Below is a simple example test string with kind of silly features)",
"_____no_output_____"
]
],
[
[
"#Combine features, separate training and test data\n\nX = []\nfor i in range(len(g1)):\n featvec = []\n \n matrix = nx.to_numpy_matrix(g1[i], nodelist=sorted(g1[i].nodes())) #this is how you go to a matrix\n \n logmatrix = np.log10(np.sum(matrix,0) + 1)\n logmatrix = np.ravel(logmatrix)\n \n covariate1 = nx.degree_centrality(g1[i])\n covariate1 = covariate1.values()\n \n covariate2 = nac.betweenness_centrality(g1[i])\n covariate2 = covariate2.values()\n #dict\n \n covariate3 = nx.average_clustering(g1[i])\n covariate3 = np.ravel(covariate3)\n #float\n \n covariate4 = nac.closeness_centrality(g1[i])\n covariate4 = covariate4.values()\n #dict\n \n covariate5 = nac.eigenvector_centrality(g1[i])\n covariate5 = covariate5.values()\n #dict\n\n \n for ii in logmatrix:\n featvec.append(ii)\n for iii in covariate1:\n featvec.append(iii)\n for iv in covariate2:\n featvec.append(iv)\n for v in covariate3:\n featvec.append(v)\n for vi in covariate4:\n featvec.append(vi)\n for vii in covariate5:\n featvec.append(vii)\n \n\n xsum = np.asarray(np.sum(matrix))\n featvec.append(xsum)\n np.shape(featvec)\n X.append(featvec)",
"_____no_output_____"
],
[
"X_train = X[0:100]\nY_train = sex[0:100]\n\nX_test = X[100:200]\nY_test = sex[100:200]\n\nfrom sklearn.ensemble import RandomForestClassifier\naccuracy = []\nfor ii in range(10): #performance will change over time\n clf = RandomForestClassifier(n_estimators=100)\n clf.fit(X_train, Y_train)\n acc = (clf.predict(X_test) == Y_test)\n #print(acc)\n accval = (float(np.sum(acc))/float(len(Y_test)))\n accuracy.append(accval)\n print('Accuracy:',accval)\n\nprint('Overall Accuracy:',str(np.mean(accuracy)))",
"Accuracy: 0.62\nAccuracy: 0.65\nAccuracy: 0.61\nAccuracy: 0.64\nAccuracy: 0.6\nAccuracy: 0.62\nAccuracy: 0.59\nAccuracy: 0.62\nAccuracy: 0.63\nAccuracy: 0.62\nOverall Accuracy: 0.62\n"
],
[
"# plot a graph\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\n# mean connectome\nmatrix = np.zeros([70, 70])\nn = 0\nfor i in range(len(g1)):\n matrix += nx.to_numpy_matrix(g1[i], nodelist=sorted(g1[i].nodes())) #this is how you go to a matrix\n n += 1\n\nmatrix /= n\n\nplt.imshow(np.log10(matrix+1))\nplt.colorbar()\nplt.title('Mean Connectome')\nplt.show()\n\n# mean female connectome\nmatrix = np.zeros([70, 70])\nn = 0\nfor i in range(len(g1)):\n if sex[i] == 0:\n matrix += nx.to_numpy_matrix(g1[i], nodelist=sorted(g1[i].nodes())) #this is how you go to a matrix\n n += 1\n\nmatrix /= n\n\nmFC = nx.DiGraph(matrix)\n\nplt.imshow(np.log10(matrix+1))\nplt.colorbar()\nplt.title('Mean Female Connectome')\nplt.show()\n\n# mean male connectome\nmatrix = np.zeros([70, 70])\nn = 0\nfor i in range(len(g1)):\n if sex[i] == 1:\n matrix += nx.to_numpy_matrix(g1[i], nodelist=sorted(g1[i].nodes())) #this is how you go to a matrix\n n += 1\n\nmatrix /= n\n\nmMC = nx.DiGraph(matrix)\n\nplt.imshow(np.log10(matrix+1))\nplt.colorbar()\nplt.title('Mean Male Connectome')\nplt.show()\n\n# mean connectome difference\ndiff = nx.algorithms.difference(mMC, mFC)\nmatrix += nx.to_numpy_matrix(diff, nodelist=sorted(diff.nodes())) #this is how you go to a matrix\n\n\nplt.imshow(np.log10(matrix+1))\nplt.colorbar()\nplt.title('Mean Connectome Difference')\nplt.show()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
e7bd74219e370e71bfcdff415312708c24f4bb29 | 51,609 | ipynb | Jupyter Notebook | Notebooks/Notebook_2.ipynb | w-meiners/rlt-rlq | 215594ebdbcc364d81d29fa620389e006864cc4d | [
"MIT"
]
| null | null | null | Notebooks/Notebook_2.ipynb | w-meiners/rlt-rlq | 215594ebdbcc364d81d29fa620389e006864cc4d | [
"MIT"
]
| null | null | null | Notebooks/Notebook_2.ipynb | w-meiners/rlt-rlq | 215594ebdbcc364d81d29fa620389e006864cc4d | [
"MIT"
]
| null | null | null | 208.100806 | 44,136 | 0.894999 | [
[
[
"# Raumluftqualität 2.0",
"_____no_output_____"
],
[
"## Zeitliche Entwicklung der CO_2-Konzentration in Räumen\n\nIn einem gut gelüfteten, leeren Raum wird sich zunächst genau so viel CO_2 befinden, wie in der Außenluft. \n\nWenn sich dann Personen in den Raum begeben und CO_2 freisetzen, wird die CO_2-Konzentration langsam zunehmen. Auf welchen Wert sie sich schließlich einstellt, hängt vom Außenluftvolumenstrom ab, mit dem der Raum belüftet wird.\n\nBei einem völlig unbelüfteten Raum wird das von den Personen produzierte CO_2 sich in der Raumluft immer stärker anreichern, wobei je Zeiteinheit die gleiche Menge an CO_2 freigesetzt wird.",
"_____no_output_____"
],
[
"### Beispiel:\n\nIn einem Raum von $15 \\rm m^2$ Grundfläche bei $2.5 \\rm m$ Geschosshöhe befinden sich 2 Personen, die je Person $30\\,{\\frac{\\ell}{h}}$ CO_2 ausatmen. Die CO_2-Konzentration der Außenluft ist 400 ppM. Im Raum sollen 1200 ppM CO_2 zulässig sein.\n\nStellen Sie die zeitliche Entwicklung der CO_2-Konzentration in einem Diagramm dar.",
"_____no_output_____"
],
[
"Gegeben: \n\nRaumvolumen: $V_{\\rm ra} = 15 {\\rm m^2}\\cdot 2.5 {\\rm m} = 37.5 {\\rm m^3}$ \n\nCO_2-Produktion: $\\dot V_{\\rm sch} = 2\\cdot 30 {\\rm \\dfrac{\\ell}{h}} = 60\\,000\\, {\\rm\\dfrac{cm^3}{h}}$\n\nDamit ergibt sich die Änderungsrate \n$\n \\dot k = \\cfrac{\\dot V_{\\rm sch}}{V_{\\rm ra}} \n = {\\rm\\dfrac{60\\,000\\,cm^3}{37.5\\, m^3\\cdot h}}\n = {\\rm 1600 \\dfrac{ppM}{h}}\n$\n\nFür das Schadstoffvolumen im Raum ergibt sich:\n\n\\begin{align}\n k(t)&= 400 {\\rm ppM} + 1600\\,{\\rm\\dfrac{ppM}{h}}\\, t\n\\end{align}",
"_____no_output_____"
],
[
"Dies Ergebnis wird in den folgenden Zeilen in einem Diagramm dargestellt:",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n%config InlineBackend.figure_format = 'retina'\n\nimport pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"lt = np.linspace(0,120,13) # 10-min Schritte\ndf = pd.DataFrame(\n {\n 't': lt,\n 'k': 400 + 1600*lt/60 # 60min = 1h\n }\n)\n\ndisplay(df.T)\nax=df.plot(x='t',y='k', label='$k = k(t)$')\nax.axhline(1200,c='r')\nax.grid()\nax.set(\n xlim=(0,120),xlabel='Zeit $t$ in $min$',\n ylabel='CO_2-Konzentration $k$ in $\\mathrm{ppM}$'\n);",
"_____no_output_____"
]
],
[
[
"Die zulässige CO_2-Konzentration wird bereits nach kurzer Zeit (etwa 30 min) erreicht. Nach etwa einer Stunde ist die Raumluftqualität inakzeptabel.",
"_____no_output_____"
],
[
"### Aufgabe\n\nIn einem Gebäude ($400 \\rm m^2$ Grundfläche, $3.50 \\rm m$ Raumhöhe) arbeiten 120 Personen körperlich mittelschwer belastet. Berechnen Sie unter der Voraussetzung, dass das Gebäude nicht belüftet wird, wie sich die CO_2-Konzentration im Raum entwickelt. Die CO_2-Konzentration der Außenluft beträgt 400 ppM.\n\nNach welcher Zeit wird die zulässige CO_2-Konzentration von 1200 ppM überschritten?\n\nStellen Sie den Vorgang in einem Diagramm dar.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
]
|
e7bd778bc35cfa10f4356cef04f2323fd7720655 | 13,347 | ipynb | Jupyter Notebook | week09_mt/homework/word_alignment_assignment.ipynb | Holemar/nlp_course | 9e17ba9e8786355a6b773b9c8c0a7cd8d841499a | [
"MIT"
]
| 2 | 2021-05-14T19:05:33.000Z | 2021-08-28T21:27:27.000Z | week09_mt/homework/word_alignment_assignment.ipynb | Holemar/nlp_course | 9e17ba9e8786355a6b773b9c8c0a7cd8d841499a | [
"MIT"
]
| null | null | null | week09_mt/homework/word_alignment_assignment.ipynb | Holemar/nlp_course | 9e17ba9e8786355a6b773b9c8c0a7cd8d841499a | [
"MIT"
]
| 1 | 2021-12-13T15:43:58.000Z | 2021-12-13T15:43:58.000Z | 43.47557 | 165 | 0.60006 | [
[
[
"__Word Alignment Assignment__\n\nYour task is to learn word alignments for the data provided with this Python Notebook. \n\nStart by running the 'train' function below and implementing the assertions which will fail. Then consider the following improvements to the baseline model:\n* Is the TranslationModel parameterized efficiently?\n* What form of PriorModel would help here? (Currently the PriorModel is uniform.)\n* How could you use a Hidden Markov Model to model word alignment indices? (There's an implementation of simple HMM below to help you start.)\n* How could you initialize more complex models from simpler ones?\n* How could you model words that are not aligned to anything?\n\nGrades will be assigned as follows:\n\n Maximum AER on dev and test | Grade \n----------|-------------\n 0.5 - 0.6 | 1 \n 0.4 - 0.5 | 2 \n 0.35 - 0.4 | 3 \n 0.3 - 0.35 | 4 \n 0.25 - 0.3 | 5 \n \nYou should save the notebook with the final scores for 'dev' and 'test' test sets.\n\n",
"_____no_output_____"
]
],
[
[
"# This cell contains the generative models that you may want to use for word alignment.\n# Currently only the TranslationModel is at all functional.\n\nimport numpy as np\nfrom collections import defaultdict\n\nclass TranslationModel:\n \"Models conditional distribution over trg words given a src word.\"\n\n def __init__(self, src_corpus, trg_corpus):\n self._trg_given_src_probs = defaultdict(lambda : defaultdict(lambda : 1.0))\n self._src_trg_counts = defaultdict(lambda : defaultdict(lambda : 0.0))\n\n def get_params(self):\n return self._trg_given_src_probs\n\n def get_conditional_prob(self, src_token, trg_token):\n \"Return the conditional probability of trg_token given src_token.\"\n return self._trg_given_src_probs[src_token][trg_token]\n\n def get_parameters_for_sentence_pair(self, src_tokens, trg_tokens):\n \"Returns matrix with t[i][j] = p(f_j|e_i).\"\n return np.array([[self._trg_given_src_probs[src_token][trg_token]\n for trg_token in trg_tokens] for src_token in src_tokens])\n\n def collect_statistics(self, src_tokens, trg_tokens, posterior_matrix):\n \"Accumulate counts of translations from: posterior_matrix[j][i] = p(a_j=i|e, f)\"\n assert posterior_matrix.shape == (len(src_tokens), len(trg_tokens))\n assert False, \"Implement collection of statistics here.\"\n \n def recompute_parameters(self):\n \"Reestimate parameters and reset counters.\"\n self._trg_given_src_probs = defaultdict(lambda : defaultdict(lambda : 0.0))\n assert False, \"Implement reestimation of parameters from counters here.\"\n\n\nclass PriorModel:\n \"Models the prior probability of an alignment given only the sentence lengths and token indices.\"\n\n def __init__(self, src_corpus, trg_corpus):\n \"Add counters and parameters here for more sophisticated models.\"\n self._distance_counts = {}\n self._distance_probs = {}\n\n def get_parameters_for_sentence_pair(self, src_length, trg_length):\n return np.ones((src_length, trg_length)) * 1.0 / src_length\n \n def get_prior_prob(self, src_index, trg_index, src_length, trg_length):\n \"Returns a uniform prior probability.\"\n return 1.0 / src_length\n\n def collect_statistics(self, src_length, trg_length, posterior_matrix):\n \"Extract the necessary statistics from this matrix if needed.\"\n pass\n\n def recompute_parameters(self):\n \"Reestimate the parameters and reset counters.\"\n pass\n \n\nclass TransitionModel:\n \"Models the prior probability of an alignment conditioned on previous alignment.\"\n\n def __init__(self, src_corpus, trg_corpus):\n \"Add counters and parameters here for more sophisticated models.\"\n pass\n\n def get_parameters_for_sentence_pair(self, src_length):\n \"Retrieve the parameters for this sentence pair: A[k, i] = p(a_{j} = i|a_{j-1} = k)\"\n pass\n\n def collect_statistics(self, src_length, bigram_posteriors):\n \"Extract statistics from the bigram posterior[i][j]: p(a_{t-1} = i, a_{t} = j| e, f)\"\n pass\n \n def recompute_parameters(self):\n \"Recompute the transition matrix\"\n pass\n\n\n",
"_____no_output_____"
],
[
"# This cell contains the framework for training and evaluating a model using EM.\n\nfrom utils import read_parallel_corpus, extract_test_set_alignments, score_alignments, write_aligned_corpus\n\ndef infer_posteriors(src_tokens, trg_tokens, prior_model, translation_model):\n \"Compute the posterior probability p(a_j=i | f, e) for each target token f_j given e and f.\"\n # HINT: An HMM will require more complex statistics over the hidden alignments.\n P = prior_model.get_parameters_for_sentence_pair(len(src_tokens), len(trg_tokens))\n T = translation_model.get_parameters_for_sentence_pair(src_tokens, trg_tokens) # t[i][j] = P(f_j|e_i)\n assert False, \"Compute the posterior distribution over src indices for each trg word.\"\n \n # log_likelihood = np.sum(np.log(marginals))\n return posteriors, log_likelihood\n\ndef collect_expected_statistics(src_corpus, trg_corpus, prior_model, translation_model):\n \"E-step: infer posterior distribution over each sentence pair and collect statistics.\"\n corpus_log_likelihood = 0.0\n for src_tokens, trg_tokens in zip(src_corpus, trg_corpus):\n # Infer posterior\n posteriors, log_likelihood = infer_posteriors(src_tokens, trg_tokens, prior_model, translation_model)\n # Collect statistics in each model.\n prior_model.collect_statistics(src_tokens, trg_tokens, posteriors)\n translation_model.collect_statistics(src_tokens, trg_tokens, posteriors)\n # Update log prob\n corpus_log_likelihood += log_likelihood\n return corpus_log_likelihood\n\ndef estimate_models(src_corpus, trg_corpus, prior_model, translation_model, num_iterations):\n \"Estimate models iteratively using EM.\"\n for iteration in range(num_iterations):\n # E-step\n corpus_log_likelihood = collect_expected_statistics(src_corpus, trg_corpus, prior_model, translation_model)\n # M-step\n prior_model.recompute_parameters()\n translation_model.recompute_parameters()\n if iteration > 0:\n print(\"corpus log likelihood: %1.3f\" % corpus_log_likelihood)\n return prior_model, translation_model\n\ndef get_alignments_from_posterior(posteriors):\n \"Returns the MAP alignment for each target word given the posteriors.\"\n # HINT: If you implement an HMM, you may want to implement a better algorithm here.\n alignments = {}\n for trg_index, src_index in enumerate(np.argmax(posteriors, axis=0)):\n if trg_index not in alignments:\n alignments[trg_index] = {}\n alignments[trg_index][src_index] = '*'\n return alignments\n\ndef align_corpus(src_corpus, trg_corpus, prior_model, translation_model):\n \"Align each sentence pair in the corpus in turn.\"\n aligned_corpus = []\n for src_tokens, trg_tokens in zip(src_corpus, trg_corpus):\n posteriors, _ = infer_posteriors(src_tokens, trg_tokens, prior_model, translation_model)\n alignments = get_alignments_from_posterior(posteriors)\n aligned_corpus.append((src_tokens, trg_tokens, alignments))\n return aligned_corpus\n\ndef initialize_models(src_corpus, trg_corpus):\n prior_model = PriorModel(src_corpus, trg_corpus)\n translation_model = TranslationModel(src_corpus, trg_corpus)\n return prior_model, translation_model\n\ndef normalize(src_corpus, trg_corpus):\n assert False, \"Apply some normalization here to reduce the numbers of parameters.\"\n return normalized_src, normalized_trg\n\ndef train(num_iterations):\n src_corpus, trg_corpus, _ = read_parallel_corpus('en-cs.all')\n src_corpus, trg_corpus = normalize(src_corpus, trg_corpus)\n prior_model, translation_model = initialize_models(src_corpus, trg_corpus)\n prior_model, translation_model = estimate_models(src_corpus, trg_corpus, prior_model, translation_model, num_iterations) \n aligned_corpus = align_corpus(src_corpus, trg_corpus, prior_model, translation_model)\n return aligned_corpus, extract_test_set_alignments(aligned_corpus)\n\ndef evaluate(candidate_alignments):\n src_dev, trg_dev, wa_dev = read_parallel_corpus('en-cs-wa.dev', has_alignments=True)\n src_test, trg_test, wa_test = read_parallel_corpus('en-cs-wa.test', has_alignments=True)\n print('recall %1.3f; precision %1.3f; aer %1.3f' % score_alignments(wa_dev, candidate_alignments['dev']))\n print('recall %1.3f; precision %1.3f; aer %1.3f' % score_alignments(wa_test, candidate_alignments['test'])) ",
"_____no_output_____"
],
[
"aligned_corpus, test_alignments = train(5)\nevaluate(test_alignments)",
"_____no_output_____"
],
[
"# To visualize aligned corpus:\n# 1. call write_aligned_corpus(aligned_corpus, 'out')\n# 2. run python corpus_browser.py en-cs-wa.out (in working directory)",
"_____no_output_____"
],
[
"# Discrete HMM with scaling. You may want to use this if you decide to implement an HMM.\n# The parameters for this HMM will still need to be provided by the models above.\n\ndef forward(pi, A, O):\n S, T = O.shape\n alpha = np.zeros((S, T))\n scaling_factors = np.zeros(T)\n \n # base case\n alpha[:, 0] = pi * O[:, 0]\n scaling_factors[0] = np.sum(alpha[:, 0])\n alpha[:, 0] /= scaling_factors[0] \n \n # recursive case\n for t in range(1, T):\n alpha[:, t] = np.dot(alpha[:, t-1], A[:, :]) * O[:, t]\n\n # Normalize at each step to prevent underflow.\n scaling_factors[t] = np.sum(alpha[:, t])\n alpha[:, t] /= scaling_factors[t]\n\n return (alpha, scaling_factors)\n\ndef backward(pi, A, O, forward_scaling_factors):\n S, T = O.shape\n beta = np.zeros((S, T))\n\n # base case\n beta[:, T-1] = 1 / forward_scaling_factors[T-1]\n \n # recursive case\n for t in range(T-2, -1, -1):\n beta[:, t] = np.sum(beta[:, t+1] * A[:, :] * O[:, t+1], 1) / forward_scaling_factors[t]\n\n return beta\n\ndef forward_backward(pi, A, O):\n alpha, forward_scaling_factors = forward(pi, A, O)\n beta = backward(pi, A, O, forward_scaling_factors)\n return alpha, beta, np.sum(np.log(forward_scaling_factors))\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bd8429302171867b199b9e9e45e5e40635b36d | 45,259 | ipynb | Jupyter Notebook | day 2/day_2_classwork.ipynb | koroteevmv/ML_course | 3d8d964bb8df760a111e42e02972b796a1c04585 | [
"CC0-1.0"
]
| 1 | 2022-01-31T09:06:07.000Z | 2022-01-31T09:06:07.000Z | day 2/day_2_classwork.ipynb | koroteevmv/ML_course | 3d8d964bb8df760a111e42e02972b796a1c04585 | [
"CC0-1.0"
]
| null | null | null | day 2/day_2_classwork.ipynb | koroteevmv/ML_course | 3d8d964bb8df760a111e42e02972b796a1c04585 | [
"CC0-1.0"
]
| null | null | null | 43.983479 | 11,026 | 0.516052 | [
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"pima = pd.read_csv('https://raw.githubusercontent.com/koroteevmv/ML_course/main/day%202/diabetes.csv')",
"_____no_output_____"
],
[
"pima.head()",
"_____no_output_____"
],
[
"Y = pima.Outcome\nX = pima.drop(['Outcome'], axis=1)",
"_____no_output_____"
],
[
"X.shape, Y.shape",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nx_train, x_test, y_train, y_test = train_test_split(X, Y, \n test_size=0.2,\n random_state=True)",
"_____no_output_____"
],
[
"x_train.shape, x_test.shape",
"_____no_output_____"
],
[
"from sklearn.linear_model import LogisticRegression\ncls = LogisticRegression().fit(x_train, y_train)",
"/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_logistic.py:818: ConvergenceWarning: lbfgs failed to converge (status=1):\nSTOP: TOTAL NO. of ITERATIONS REACHED LIMIT.\n\nIncrease the number of iterations (max_iter) or scale the data as shown in:\n https://scikit-learn.org/stable/modules/preprocessing.html\nPlease also refer to the documentation for alternative solver options:\n https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression\n extra_warning_msg=_LOGISTIC_SOLVER_CONVERGENCE_MSG,\n"
],
[
"y_pred = cls.predict(x_train)\ny_pred[:10], y_train[:10]",
"_____no_output_____"
],
[
"from sklearn import metrics",
"_____no_output_____"
],
[
"metrics.confusion_matrix(y_train, y_pred)",
"_____no_output_____"
],
[
"y_pred = cls.predict(x_test)\nmetrics.confusion_matrix(y_test, y_pred)",
"_____no_output_____"
],
[
"import seaborn as sns\n%matplotlib inline\n\nclass_names = [0, 1]\nfig, ax = plt.subplots()\nticks = np.arange(len(class_names))\nplt.xticks(ticks, class_names)\nplt.yticks(ticks, class_names)\n \nsns.heatmap(pd.DataFrame(\n metrics.confusion_matrix(y_test, y_pred)),\n annot=True)\nplt.ylabel('Действительные значения')\nplt.xlabel('Предсказанные значения')",
"_____no_output_____"
],
[
"metrics.accuracy_score(y_test, y_pred)",
"_____no_output_____"
],
[
"metrics.precision_score(y_test, y_pred)",
"_____no_output_____"
],
[
"metrics.recall_score(y_test, y_pred)",
"_____no_output_____"
],
[
"print(metrics.classification_report(y_test, y_pred))",
" precision recall f1-score support\n\n 0 0.79 0.90 0.84 99\n 1 0.76 0.56 0.65 55\n\n accuracy 0.78 154\n macro avg 0.77 0.73 0.74 154\nweighted avg 0.78 0.78 0.77 154\n\n"
],
[
"from sklearn import svm\nclf = svm.SVC(kernel='rbf').fit(x_train, y_train)\ny_pred = clf.predict(x_test)\nprint(metrics.classification_report(y_test, y_pred))",
" precision recall f1-score support\n\n 0 0.78 0.94 0.85 99\n 1 0.82 0.51 0.63 55\n\n accuracy 0.79 154\n macro avg 0.80 0.72 0.74 154\nweighted avg 0.79 0.79 0.77 154\n\n"
],
[
"metrics.accuracy_score(y_test, y_pred)",
"_____no_output_____"
],
[
"from sklearn.ensemble import RandomForestClassifier\nclf = RandomForestClassifier().fit(x_train, y_train)\ny_pred = clf.predict(x_test)\nprint(metrics.classification_report(y_test, y_pred))",
" precision recall f1-score support\n\n 0 0.82 0.87 0.84 99\n 1 0.73 0.65 0.69 55\n\n accuracy 0.79 154\n macro avg 0.78 0.76 0.77 154\nweighted avg 0.79 0.79 0.79 154\n\n"
],
[
"from sklearn.neural_network import MLPClassifier\nclf = MLPClassifier().fit(x_train, y_train)\ny_pred = clf.predict(x_test)\nprint(metrics.classification_report(y_test, y_pred))",
" precision recall f1-score support\n\n 0 0.78 0.78 0.78 99\n 1 0.60 0.60 0.60 55\n\n accuracy 0.71 154\n macro avg 0.69 0.69 0.69 154\nweighted avg 0.71 0.71 0.71 154\n\n"
],
[
"y_pred[:20], y_test[:20]",
"_____no_output_____"
],
[
"from sklearn.datasets import fetch_20newsgroups\nnews = fetch_20newsgroups(subset='all')",
"_____no_output_____"
],
[
"print(news.data[0])\nprint(news.target[0], news.target_names[news.target[0]])",
"From: Mamatha Devineni Ratnam <[email protected]>\nSubject: Pens fans reactions\nOrganization: Post Office, Carnegie Mellon, Pittsburgh, PA\nLines: 12\nNNTP-Posting-Host: po4.andrew.cmu.edu\n\n\n\nI am sure some bashers of Pens fans are pretty confused about the lack\nof any kind of posts about the recent Pens massacre of the Devils. Actually,\nI am bit puzzled too and a bit relieved. However, I am going to put an end\nto non-PIttsburghers' relief with a bit of praise for the Pens. Man, they\nare killing those Devils worse than I thought. Jagr just showed you why\nhe is much better than his regular season stats. He is also a lot\nfo fun to watch in the playoffs. Bowman should let JAgr have a lot of\nfun in the next couple of games since the Pens are going to beat the pulp out of Jersey anyway. I was very disappointed not to see the Islanders lose the final\nregular season game. PENS RULE!!!\n\n\n10 rec.sport.hockey\n"
],
[
"SPLIT_PERC = 0.75\nsplit_size = int(len(news.data)*SPLIT_PERC)\nX_train = news.data[:split_size]\nX_test = news.data[split_size:]\ny_train = news.target[:split_size]\ny_test = news.target[split_size:]",
"_____no_output_____"
],
[
"from sklearn.naive_bayes import MultinomialNB\nfrom sklearn.feature_extraction.text import TfidfVectorizer, HashingVectorizer, CountVectorizer",
"_____no_output_____"
],
[
"vectorizer = CountVectorizer()\nX = vectorizer.fit_transform(X_train)\nX.shape",
"_____no_output_____"
],
[
"clf = MultinomialNB().fit(X, y_train)\n\nprint(\"Accuracy on training set:\")\nprint(clf.score(X, y_train))\n\nX_test_vec = vectorizer.transform(X_test)\nprint(\"Accuracy on testing set:\")\nprint(clf.score(X_test_vec, y_test))\n\ny_pred = clf.predict(X_test_vec)\n\nprint(\"Classification Report:\")\nprint(metrics.classification_report(y_test, y_pred))\nprint(\"Confusion Matrix:\")\nprint(metrics.confusion_matrix(y_test, y_pred))",
"Accuracy on training set:\n0.9267015706806283\nAccuracy on testing set:\n0.8425297113752123\nClassification Report:\n precision recall f1-score support\n\n 0 0.90 0.87 0.88 216\n 1 0.61 0.85 0.71 246\n 2 0.94 0.12 0.21 274\n 3 0.61 0.85 0.71 235\n 4 0.89 0.87 0.88 231\n 5 0.75 0.90 0.82 225\n 6 0.88 0.68 0.77 248\n 7 0.90 0.88 0.89 275\n 8 0.94 0.94 0.94 226\n 9 0.97 0.94 0.96 250\n 10 0.97 0.98 0.98 257\n 11 0.87 0.98 0.92 261\n 12 0.85 0.86 0.85 216\n 13 0.90 0.92 0.91 257\n 14 0.91 0.93 0.92 246\n 15 0.81 0.95 0.87 234\n 16 0.82 0.94 0.88 218\n 17 0.90 0.99 0.94 236\n 18 0.84 0.85 0.84 213\n 19 0.94 0.54 0.69 148\n\n accuracy 0.84 4712\n macro avg 0.86 0.84 0.83 4712\nweighted avg 0.86 0.84 0.83 4712\n\nConfusion Matrix:\n[[187 1 0 0 0 0 0 0 0 0 1 0 2 2 0 16 1 2\n 1 3]\n [ 0 210 0 6 0 11 4 0 1 1 0 4 1 2 1 0 0 1\n 4 0]\n [ 0 69 32 90 11 42 0 1 1 1 0 9 4 1 4 3 0 0\n 5 1]\n [ 0 10 1 199 5 6 4 0 0 1 0 3 3 0 1 0 1 0\n 1 0]\n [ 0 5 0 8 200 2 4 0 0 0 0 4 6 1 1 0 0 0\n 0 0]\n [ 0 15 0 2 1 203 0 1 0 1 0 0 0 1 1 0 0 0\n 0 0]\n [ 0 9 0 11 4 1 169 19 2 1 3 5 9 3 1 1 4 3\n 3 0]\n [ 1 2 0 1 0 1 7 241 4 1 0 0 2 2 1 0 5 2\n 5 0]\n [ 0 0 0 1 0 1 2 2 212 0 0 1 0 1 1 1 1 2\n 1 0]\n [ 0 1 0 0 1 0 0 1 2 235 3 0 2 2 0 1 1 1\n 0 0]\n [ 0 1 0 0 0 0 0 0 0 1 253 0 1 0 0 0 0 0\n 1 0]\n [ 0 2 0 0 0 0 0 0 0 0 0 255 0 0 0 0 2 1\n 1 0]\n [ 0 8 0 3 2 1 0 1 0 0 1 4 185 3 7 0 0 0\n 1 0]\n [ 1 3 0 0 0 0 0 1 1 0 0 1 1 236 3 4 4 1\n 1 0]\n [ 0 7 0 0 1 1 2 0 0 0 0 0 0 1 230 0 2 1\n 1 0]\n [ 1 3 0 2 0 0 0 1 0 0 0 1 0 2 0 223 0 1\n 0 0]\n [ 0 0 1 0 0 0 1 0 2 0 0 2 0 0 0 0 206 3\n 3 0]\n [ 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 234\n 1 0]\n [ 1 0 0 1 0 0 0 1 1 0 0 3 1 1 1 2 13 7\n 180 1]\n [ 17 0 0 0 0 1 0 0 0 0 0 0 1 3 1 26 11 2\n 6 80]]\n"
],
[
"",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bd9189e2a2f9d7dc67f214b77efd3b263e540c | 48,380 | ipynb | Jupyter Notebook | lstm-ashare-live.ipynb | sillyemperor/mypynotebook | 27a3847764a422fee05590e6d2ef145256f558de | [
"MIT"
]
| null | null | null | lstm-ashare-live.ipynb | sillyemperor/mypynotebook | 27a3847764a422fee05590e6d2ef145256f558de | [
"MIT"
]
| null | null | null | lstm-ashare-live.ipynb | sillyemperor/mypynotebook | 27a3847764a422fee05590e6d2ef145256f558de | [
"MIT"
]
| null | null | null | 180.522388 | 24,428 | 0.898057 | [
[
[
"数据网站,http://quotes.money.163.com/stock\n\n下载交易历史数据:http://quotes.money.163.com/cjmx/2019/20191120/1300127.xls\n,获得一个SCV文件。结构如下:\n成交时间,成交价,价格变动,成交量(手),成交额(元),性质\n09:30:06,17.2,-0.05,50,86011,卖盘\n09:30:09,17.21,0.01,887,1525626,买盘\n大概每3秒一条记录。",
"_____no_output_____"
],
[
"## Library",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport torch\nimport torch.nn as nn\nfrom torch.autograd import Variable\nfrom sklearn.preprocessing import MinMaxScaler\nfrom datetime import datetime\n",
"_____no_output_____"
]
],
[
[
"## Data Plot",
"_____no_output_____"
]
],
[
[
"data = pd.read_csv('data/ashare/30012720191120.csv', usecols = [0, 1, 3], converters={\n 0:lambda x:datetime.strptime(x, '%H:%M:%S')\n})\n# print(data)\n\ntraining_set = data.iloc[:,1].values\ntimeline = data.iloc[:,0].values\n\nplt.plot(timeline, training_set, )\n\nplt.show()",
"/Users/wj/项目/langstudy/python/py3study/venv/lib/python3.7/site-packages/pandas/plotting/_matplotlib/converter.py:103: FutureWarning: Using an implicitly registered datetime converter for a matplotlib plotting method. The converter was registered by pandas on import. Future versions of pandas will require you to explicitly register matplotlib converters.\n\nTo register the converters:\n\t>>> from pandas.plotting import register_matplotlib_converters\n\t>>> register_matplotlib_converters()\n warnings.warn(msg, FutureWarning)\n"
],
[
"def local_price(file):\n data = pd.read_csv(file, usecols=[0, 1, 3], converters={\n 0: lambda x: datetime.strptime(x, '%H:%M:%S')\n })\n\n for i in data.iloc[:,1].values:\n yield i",
"_____no_output_____"
],
[
"from stock import train, sliding_windows, predict, LSTM\nimport time\n\nloader = local_price('data/ashare/30012720191120.csv')\n\nnum_epochs = 100\n\nnum_classes = 3\nseq_length = 12\n\ninput_size = 1\nhidden_size = 2\nnum_layers = 1\n\nlstm = LSTM(num_classes, input_size, hidden_size, num_layers, seq_length)\n\nsc = MinMaxScaler()\n\nbucket = []\ndata = []\npredict_y = None\naloss_list = []\nloss_list = []\nx_list = []\ny_list = []\nfor price in loader:\n\n bucket.append([float(price)])\n # print(bucket, data)\n if len(bucket) >= seq_length:\n data.append(bucket)\n \n if len(data) > 1:\n if predict_y is not None:\n x = torch.tensor(predict_y)\n y = torch.tensor(bucket[:num_classes]).view(-1)\n loss = y - x\n aloss = loss.sum()/num_classes\n \n loss_list += list(loss.view(-1).numpy())\n x_list += list(x.view(-1).numpy())\n y_list += list(y.view(-1).numpy())\n aloss_list.append(aloss)\n\n # print(x)\n# print(y)\n# print(aloss, elapsed)\n# print()\n\n t1 = time.time()\n training_data = torch.Tensor(data)\n training_data = sc.fit_transform(training_data.view(-1, 1))\n # training_data = torch.Tensor([training_data])\n\n x, y = sliding_windows(training_data, seq_length, num_classes)\n trainX = torch.Tensor(np.array(x))\n trainY = torch.Tensor(np.array(y))\n\n loss = train(lstm, num_epochs, num_classes, trainX, trainY)\n elapsed = time.time() - t1\n\n predict_data = data[-1]\n predict_y = predict(lstm, predict_data)\n# print(predict_y)\n\n bucket = bucket[num_classes:]\n",
"_____no_output_____"
],
[
"plt.subplot(2,1,1)\nplt.plot(loss_list, )\nplt.subplot(2,1,2)\nplt.plot(x_list, )\nplt.plot(y_list, )\nplt.show()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
e7bd9eec423cfbc853045e88912bc4a04ae73813 | 2,660 | ipynb | Jupyter Notebook | Coursera/Data Visualization with Python-IBM/Week-2/Quiz/Basic-Visualization-Tools.ipynb | manipiradi/Online-Courses-Learning | 2a4ce7590d1f6d1dfa5cfde632660b562fcff596 | [
"MIT"
]
| 331 | 2019-10-22T09:06:28.000Z | 2022-03-27T13:36:03.000Z | Coursera/Data Visualization with Python-IBM/Week-2/Quiz/Basic-Visualization-Tools.ipynb | manipiradi/Online-Courses-Learning | 2a4ce7590d1f6d1dfa5cfde632660b562fcff596 | [
"MIT"
]
| 8 | 2020-04-10T07:59:06.000Z | 2022-02-06T11:36:47.000Z | Coursera/Data Visualization with Python-IBM/Week-2/Quiz/Basic-Visualization-Tools.ipynb | manipiradi/Online-Courses-Learning | 2a4ce7590d1f6d1dfa5cfde632660b562fcff596 | [
"MIT"
]
| 572 | 2019-07-28T23:43:35.000Z | 2022-03-27T22:40:08.000Z | 20.305344 | 148 | 0.521805 | [
[
[
"#### 1. Area plots are stacked by default.",
"_____no_output_____"
],
[
"##### Ans: True.",
"_____no_output_____"
],
[
"#### 2. The following code uses the artist layer to create a stacked area plot of the data in the pandas dataframe, area_df.",
"_____no_output_____"
]
],
[
[
"ax = series_df.plot(kind='area', figsize=(20, 10))\n\nax.title('Plot Title')\nax.ylabel('Vertical Axis Label')\nax.xlabel('Horizontal Axis Label')",
"_____no_output_____"
]
],
[
[
"#### Ans: False.",
"_____no_output_____"
],
[
"#### 3. The following code will create an unstacked area plot of the data in the pandas dataframe, area_df, with a transparency value of 0.35?",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n\ntransparency = 0.35 \narea_df.plot(kind='area', alpha=transparency, figsize=(20, 10))\n\nplt.title('Plot Title')\nplt.ylabel('Vertical Axis Label')\nplt.xlabel('Horizontal Axis Label')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"##### Ans: False",
"_____no_output_____"
],
[
"#### 4. The following code will create a histogram of a pandas series, series_data, and align the bin edges with the horizontal tick marks.",
"_____no_output_____"
]
],
[
[
"count, bin_edges = np.histogram(series_data)\nseries_data.plot(kind='hist', xticks = bin_edges)",
"_____no_output_____"
]
],
[
[
"##### Ans: True.",
"_____no_output_____"
],
[
"#### 5. question.plot(type='bar', rot=90)",
"_____no_output_____"
],
[
"##### Ans: False.",
"_____no_output_____"
]
]
]
| [
"markdown",
"raw",
"markdown",
"raw",
"markdown",
"raw",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"raw"
],
[
"markdown",
"markdown"
],
[
"raw"
],
[
"markdown",
"markdown"
],
[
"raw"
],
[
"markdown",
"markdown",
"markdown"
]
]
|
e7bda6d5deb7228ef8f3365511a4ce39df43ad6d | 32,636 | ipynb | Jupyter Notebook | notebooks/dbnl_remove_notes.ipynb | KBNLresearch/ochre | a62bf3b31df83784c017d30a83ed8e01d454bf1c | [
"Apache-2.0"
]
| 113 | 2017-10-22T20:50:43.000Z | 2022-03-26T22:51:26.000Z | notebooks/dbnl_remove_notes.ipynb | KBNLresearch/ochre | a62bf3b31df83784c017d30a83ed8e01d454bf1c | [
"Apache-2.0"
]
| 16 | 2017-10-23T13:33:37.000Z | 2021-05-06T12:28:43.000Z | notebooks/dbnl_remove_notes.ipynb | KBNLresearch/Ochre | a62bf3b31df83784c017d30a83ed8e01d454bf1c | [
"Apache-2.0"
]
| 22 | 2018-01-21T03:43:00.000Z | 2021-11-09T07:14:18.000Z | 26.08793 | 138 | 0.465927 | [
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"%matplotlib inline\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"import os\nfrom tqdm import tqdm_notebook as tqdm\n#from codecs import open\nfrom lxml import etree\n\nfrom nlppln.utils import out_file_name, create_dirs",
"_____no_output_____"
],
[
"with open('/home/jvdzwaan/data/dbnl_ocr/raw/ocr-with-title-page/_aio001jver01_01.txt') as f:\n ls = f.readlines()\n\nwith open('/home/jvdzwaan/data/dbnl_ocr/raw/notes/_aio001jver01_01.txt') as f:\n notes = f.readlines()\n\nprint(len(ls))\nprint(len(notes))",
"_____no_output_____"
],
[
"# remove empty lines from lines\nlines = []\n\nfor line in ls:\n if line.strip() != '':\n lines.append(line)\nprint(len(lines))",
"_____no_output_____"
],
[
"lines = ls",
"_____no_output_____"
],
[
"lines[3239]",
"_____no_output_____"
],
[
"# filter notes shorter than threshold\nt = 6\n\nnotes = [n for n in filter(lambda s: len(s.strip())>t, notes)]\nprint(len(notes))",
"_____no_output_____"
],
[
"# unique notes with the repeated notes\nprint(len(set(notes)))",
"_____no_output_____"
],
[
"# identieke notes die meerdere keren voorkomen\nfrom collections import Counter\n\nc = Counter()\nnum_lines = 0\n\nfor note in notes:\n c[note] += 1\n\nrepeated = []\nns = []\nfor k, v in c.most_common():\n if v > 1:\n num_lines += v\n print(repr(k), v)\n repeated.append(k)\n else:\n ns.append(k)\nprint('total number of lines:', num_lines)",
"_____no_output_____"
],
[
"# unique notes without the repeated notes\nprint(len(ns))",
"_____no_output_____"
],
[
"%%time\n# Calculate edit distance between repeated notes and lines\nimport edlib\n\n# get initial edit distances per line\nline_data = pd.DataFrame()\nfor i, n in enumerate(repeated):\n line_data[i] = [edlib.align(n, line)['editDistance'] for line in lines]",
"_____no_output_____"
],
[
"%%time\n# delete lines that have sufficient overlap with note text\n\ndef get_lines(column, t):\n #print(list(column[column < t].index))\n return list(column[column < t].index)\n\nt = 0.3\n\nlengths = [len(x) for x in lines]\nld = line_data.apply(lambda c: c/lengths)",
"_____no_output_____"
],
[
"ld",
"_____no_output_____"
],
[
"c = 0\nt = 0.4\nld[ld[c] < t][c]",
"_____no_output_____"
],
[
"to_remove = [ids for ids in ld.apply(lambda c: get_lines(c, t))]\nto_remove = list(set([item for sublist in to_remove for item in sublist]))\nprint(len(to_remove))",
"_____no_output_____"
],
[
"to_remove.sort()\nprint(to_remove)",
"_____no_output_____"
],
[
"ls = lines\nlines = []\nfor i, line in enumerate(ls):\n if i not in to_remove:\n lines.append(line)\nprint(len(lines))",
"_____no_output_____"
],
[
"%%time\n# Calculate edit distance between remaining notes and lines\nimport edlib\n\nnotes = ns\n\n# get initial edit distances per line\nline_data = pd.DataFrame()\nfor i, n in enumerate(notes):\n line_data[i] = [edlib.align(n, line)['editDistance'] for line in lines]",
"_____no_output_____"
],
[
"line_data",
"_____no_output_____"
],
[
"%%time\nimport math\nimport copy\nimport edlib\n\nns = [{'note': n, 'ed': line_data[i].min(), 'fragment': lines[i], 'l': 1, \n 'lines': line_data[i].sort_values().index[:100]} for i, n in enumerate(notes)]\nl = 2\nnum_changed = len(ns)",
"_____no_output_____"
],
[
"def ngrams(tokens, n=3):\n ngrams = zip(*[tokens[i:] for i in range(n)]) \n return [ngram for ngram in ngrams]\n\nngrams(['1', '2', '3', '4', '5', '6'])",
"_____no_output_____"
],
[
"%%time\nimport math\nimport copy\nimport edlib\n\nl = 2\nnum_changed = len(ns)\n\nwhile num_changed >= 1:\n num_changed = 0\n num_checked = 0\n print(l)\n for n in ns:\n if n['l']+1 >= l:\n num_checked += 1\n note = n['note']\n \n for ngram in ngrams(range(len(lines)), n=l):\n test = False\n for lineno in ngram:\n if lineno in n['lines']:\n test = True\n if test:\n #print(ngram)\n #print(n)\n #print(txt)\n txt = ''.join([lines[i] for i in ngram])\n res = edlib.align(note, txt)\n ed = res['editDistance']\n #print(ed)\n if ed < n['ed']:\n n['ed'] = ed\n n['fragment'] = txt\n n['l'] = l\n num_changed += 1\n \n #print(ngram)\n #print(res['editDistance'])\n #print('---')\n\n #import sys\n #sys.exit()\n #print('note:', note)\n #print('fragment:', fragment)\n #print('editdistance:', min_val)\n #print('-----')\n print('num checked', num_checked)\n print('num changed', num_changed)\n l += 1",
"_____no_output_____"
],
[
"lines.index('1) Hs. u met eene o er boven. \\n')",
"_____no_output_____"
],
[
"for n in ns:\n if n['l'] == 27:\n print(n['note'])\n print('---')\n print(n['fragment'])\n print('---')\n print(n['ed'])\n print(n['l'])\n print(n['lines'])\n print('-----')",
"_____no_output_____"
],
[
"for n in ns:\n if n['ed'] > 200:\n print(n['note'])\n print('---')\n print(n['fragment'])\n print('---')\n print(n['ed'])\n print(n['l'])\n print('-----')",
"_____no_output_____"
],
[
"eds = [n['ed'] for n in ns]\n#print(eds)\nplt.figure(figsize=(15,10))\nplt.hist(eds, 100)",
"_____no_output_____"
]
],
[
[
"## Using fuzzy wuzzy",
"_____no_output_____"
]
],
[
[
"# identieke notes die meerdere keren voorkomen\nfrom collections import Counter\n\nc = Counter()\nnum_lines = 0\n\nfor note in notes:\n c[note] += 1\n\nrepeated = []\nns = []\nfor k, v in c.most_common():\n if v > 1:\n num_lines += v\n print(repr(k), v)\n repeated.append(k)\n else:\n ns.append(k)\nprint('total number of lines:', num_lines)",
"_____no_output_____"
],
[
"%%time\n# Calculate overlap between repeated notes and lines\nfrom fuzzywuzzy import fuzz\n\nline_data = pd.DataFrame()\nfor i, n in enumerate(repeated):\n line_data[i] = [fuzz.partial_ratio(line, n) for line in lines]",
"_____no_output_____"
],
[
"line_data",
"_____no_output_____"
],
[
"for i in line_data.columns:\n print(i)\n print(line_data[line_data[i].sort_values(ascending=False) > 90].shape)",
"_____no_output_____"
],
[
"def get_lines(column, t):\n #print(list(column[column < t].index))\n return list(column[column > t].index)\n\nt = 90\n\nto_remove = line_data.apply(lambda c: get_lines(c, t))\nprint(to_remove)",
"_____no_output_____"
],
[
"to_remove = list(set([item for sublist in to_remove for item in sublist]))\nprint(len(to_remove))",
"_____no_output_____"
],
[
"print(len(lines))",
"_____no_output_____"
],
[
"ls = lines\nlines = []\nfor i, line in enumerate(ls):\n if i not in to_remove:\n lines.append(line)\nprint(len(lines))",
"_____no_output_____"
],
[
"%%time\n# Calculate overlap between remaining notes and lines\nfrom fuzzywuzzy import fuzz\n\nline_data = pd.DataFrame()\nfor i, n in enumerate(notes):\n line_data[i] = [fuzz.partial_ratio(line, n) for line in lines]",
"_____no_output_____"
],
[
"%%time\n# Calculate overlap between remaining notes and lines\nfrom py_stringmatching.similarity_measure.partial_ratio import PartialRatio\npr = PartialRatio()\n\nline_data = pd.DataFrame()\nfor i, n in enumerate(notes):\n line_data[i] = [pr.get_raw_score(line, n) for line in lines]",
"_____no_output_____"
],
[
"%%time\n# Calculate edit distance between remaining notes and lines\nimport edlib\n\n# get initial edit distances per line\nline_data = pd.DataFrame()\nfor i, n in enumerate(notes):\n line_data[i] = [edlib.align(n, line)['editDistance'] for line in lines]",
"_____no_output_____"
],
[
"def extend_lines(indexes, length, num=3):\n #print('start')\n #print(indexes)\n #print('num:', num)\n result = []\n for i in indexes:\n #print('i', i)\n result.append(i)\n # lines before i\n start = max(0, i-num) \n to_add = list(range(start, i))\n for n in to_add:\n result.append(n)\n #print(to_add)\n \n # lines after i\n end = min(length, i+num+1)\n #print('end', end)\n to_add = list(range(i, end))\n for n in to_add:\n result.append(n)\n #print(to_add)\n #print('---')\n \n result = list(set(result))\n result.sort()\n \n return(result)\n \nextend_lines([5], 6)",
"_____no_output_____"
],
[
"extend_lines([1, 5], 10, 1)",
"_____no_output_____"
],
[
"list(range(4,3))",
"_____no_output_____"
],
[
"l = list(line_data[0].sort_values().index[:100])\nr = extend_lines(l, len(lines))\nprint(len(l), len(r))",
"_____no_output_____"
],
[
"%%time\nns = [{'note': n, 'lines': extend_lines(list(line_data[i].sort_values().index[:100]), len(lines)), 'selected': [], 'scores': []} \n for i, n in enumerate(notes)]",
"_____no_output_____"
],
[
"for n in ns:\n print(len(n['lines']))",
"_____no_output_____"
],
[
"%%time\n\nfor n in ns:\n ls = n['lines']\n ls.sort()\n note = n['note']\n for idx in ls:\n r = fuzz.partial_ratio(lines[idx], note)\n n['scores'].append(r)\n \n if r > 90:\n n['selected'].append(idx)",
"_____no_output_____"
],
[
"added = 0\nfor i, note in enumerate(ns):\n #print(note['selected'])\n #print(note['lines'])\n\n if note['selected'] != []:\n n = note['selected'][-1] + 1\n add = range(n, n+3)\n for a in add:\n if a in note['lines']:\n idx = note['lines'].index(a)\n #print(idx)\n #print(note['scores'][idx], lines[add])\n #print(note['scores'][idx+1], lines[add+1])\n #print(note['scores'][idx+2], lines[add+2])\n if note['scores'][idx] > 80:\n note['selected'].append(a)\n print(i)\n added += 1\nprint(added)",
"_____no_output_____"
],
[
"ns[173]",
"_____no_output_____"
],
[
"lines[2456]",
"_____no_output_____"
],
[
"for i, n in enumerate(ns):\n print(i)\n print(n['note'])\n print('---')\n print(n['selected'])\n for idx in n['selected']:\n print(lines[idx])\n print('-'*80)",
"_____no_output_____"
],
[
"plt.figure(figsize=(15,10))\nplt.plot(ns[11]['lines'][:100], ns[11]['scores'][:100], 100)",
"_____no_output_____"
],
[
"note = ns[11]\n#print(note['selected'])\n#print(note['lines'])\n\nadd = note['selected'][-1] + 1\nif add in note['lines']:\n idx = note['lines'].index(add)\n #print(idx)\n #print(note['scores'][idx], lines[add])\n #print(note['scores'][idx+1], lines[add+1])\n #print(note['scores'][idx+2], lines[add+2])\n if note['scores'][idx] > 80:\n note['selected'].append(add)",
"_____no_output_____"
],
[
"print(note['selected'])",
"_____no_output_____"
],
[
"fuzz.partial_ratio('hooren van Aiols naam (Fransche tekst vs. 7190 vlgg.). ', \n 'hooren van Aiols naam (Fransche tekst vs. 7190 vlgg.).')",
"_____no_output_____"
],
[
"fuzz.partial_ratio('side. - 179 Hs. IIII.', \n 'side. — 179 GIs. IIII.')",
"_____no_output_____"
]
],
[
[
"## Using fuzzy wuzzy on all the notes at the same time",
"_____no_output_____"
]
],
[
[
"notes_text = ''.join(notes)\nprint(notes_text)",
"_____no_output_____"
],
[
"%%time\nfrom fuzzywuzzy import fuzz\n\nresult = pd.DataFrame()\nresult['pratio'] = [fuzz.partial_ratio(l, notes_text) for l in lines]",
"_____no_output_____"
],
[
"result.head()",
"_____no_output_____"
],
[
"result.hist(bins=100)",
"_____no_output_____"
],
[
"n = 42\nprint(lines[n])\nprint(result.loc[n])",
"_____no_output_____"
],
[
"print(notes[0])",
"_____no_output_____"
],
[
"fuzz.partial_ratio(lines[42], notes[0])",
"_____no_output_____"
],
[
"fuzz.partial_ratio(lines[42], notes_text)",
"_____no_output_____"
],
[
"from fuzzywuzzy import fuzz, StringMatcher\nimport difflib\n\n#As long as python-Levenshtein is available, that will be used for the following:\nprint(fuzz.partial_ratio(lines[42], notes[0]))\nprint(fuzz.partial_ratio(lines[42], notes_text))\n\n#Switch to difflib:\nfuzz.SequenceMatcher = difflib.SequenceMatcher\nprint(fuzz.partial_ratio(lines[42], notes[0]))\nprint(fuzz.partial_ratio(lines[42], notes_text))\n",
"_____no_output_____"
],
[
"for idx in list(result[result['pratio'] > 80].index):\n print(idx, lines[idx])",
"_____no_output_____"
]
],
[
[
"## Putting it all together",
"_____no_output_____"
]
],
[
[
"%%time\nfrom nlppln.utils import create_dirs, out_file_name\n\nin_file = '/home/jvdzwaan/data/dbnl_ocr/raw/ocr-with-title-page/_aio001jver01_01.txt'\n\n# remove selected lines\nwith open(in_file) as f:\n text = f.read()\n\nfor n in ns:\n for idx in n['selected']:\n #print(idx)\n l = lines[idx]\n \n text = text.replace(l, '')\n\nout_dir = '/home/jvdzwaan/data/dbnl_ocr/raw/ocr'\ncreate_dirs(out_dir)\nout = out_file_name(out_dir, in_file)\nprint(out)\nwith open(out, 'w') as f:\n f.write(text)",
"_____no_output_____"
],
[
"print(to_remove)",
"_____no_output_____"
],
[
"lines[43]",
"_____no_output_____"
],
[
"%%time\nimport edlib\n\nimport pandas as pd\n\nfrom collections import Counter\nfrom fuzzywuzzy import fuzz\n\ndef split_notes(notes):\n c = Counter()\n num_lines = 0\n\n for note in notes:\n c[note] += 1\n\n repeated = []\n ns = []\n for k, v in c.most_common():\n if v > 1:\n num_lines += v\n #print(repr(k), v)\n repeated.append(k)\n else:\n ns.append(k)\n #print('total number of lines:', num_lines)\n \n return ns, repeated\n\ndef get_lines(column, threshold):\n return list(column[column > threshold].index)\n\n\ndef extend_lines(indexes, length, num=3):\n #print('start')\n #print(indexes)\n #print('num:', num)\n result = []\n for i in indexes:\n #print('i', i)\n result.append(i)\n # lines before i\n start = max(0, i-num) \n to_add = list(range(start, i))\n for n in to_add:\n result.append(n)\n #print(to_add)\n \n # lines after i\n end = min(length, i+num+1)\n #print('end', end)\n to_add = list(range(i, end))\n for n in to_add:\n result.append(n)\n #print(to_add)\n #print('---')\n \n result = list(set(result))\n result.sort()\n \n return(result)\n\n\ndef remove_notes(ocr_file, notes_file, out_dir, topn=100):\n with open(ocr_file) as f:\n ls = f.readlines()\n\n with open(notes_file) as f:\n notes = f.readlines()\n \n # remove empty lines\n lines = []\n\n for line in ls:\n if line.strip() != '':\n lines.append(line)\n print('The text contains {} lines.'.format(len(lines)))\n \n # get repeated notes\n ns, repeated = split_notes(notes)\n \n print('Processing repeated notes ({})'.format(len(repeated)))\n\n # Calculate overlap between repeated notes and lines\n line_data = pd.DataFrame()\n for i, n in enumerate(repeated):\n line_data[i] = [fuzz.partial_ratio(line, n) for line in lines]\n\n # get the line numbers of the repeated notes that should be removed\n t = 90\n to_remove_repeated = line_data.apply(lambda c: get_lines(c, t))\n to_remove_repeated = list(set([item for sublist in to_remove_repeated for item in sublist]))\n\n print('Processing other notes ({})'.format(len(ns)))\n \n # get initial edit distances per line\n # uses edlib for speed\n print('Calculating distances with edlib')\n line_data = pd.DataFrame()\n for i, n in enumerate(notes):\n line_data[i] = [edlib.align(n, line)['editDistance'] for line in lines]\n \n # select the topn lines with smallest edit distances for further processing \n ns = [{'note': n, \n 'lines': extend_lines(list(line_data[i].sort_values().index[:topn]), len(lines)), \n 'selected': [], \n 'scores': []} \n for i, n in enumerate(notes)]\n \n num_lines = 0\n for i, n in enumerate(ns):\n num_lines += len(n['lines'])\n #print(n['note'])\n #print('-')\n #r = list(line_data[i].sort_values().index[:topn])\n #for j in r:\n # print(j, lines[j])\n #print('-')\n #print(r)\n #print(n['lines'])\n #print('---')\n \n \n print('Calculating distances with fuzzywuzzy ({} lines)'.format(num_lines))\n # use partial_ratio to select the lines that should be deleted\n for n in ns:\n ls = n['lines']\n ls.sort()\n note = n['note']\n for idx in ls:\n r = fuzz.partial_ratio(lines[idx], note)\n n['scores'].append(r)\n \n if r > 90:\n n['selected'].append(idx)\n \n print('Adding missing lines')\n # add missing (usually short) lines at the end of selected pieces of text\n added = 0\n for i, note in enumerate(ns):\n #print(note['selected'])\n #print(note['lines'])\n\n if note['selected'] != []:\n n = note['selected'][-1] + 1\n add = range(n, n+3)\n for a in add:\n if a in note['lines']:\n idx = note['lines'].index(a)\n #print(idx)\n #print(note['scores'][idx], lines[add])\n #print(note['scores'][idx+1], lines[add+1])\n #print(note['scores'][idx+2], lines[add+2])\n if note['scores'][idx] > 80:\n note['selected'].append(a)\n #print(i)\n added += 1\n if added > 0:\n print('{} lines added to be removed.'.format(added))\n \n print('Removing notes')\n removed = []\n \n for idx in to_remove_repeated:\n removed.append(idx)\n\n for n in ns:\n for idx in n['selected']:\n removed.append(idx)\n \n # get the ocr text\n with open(ocr_file) as f:\n text = f.read()\n \n removed = list(set(removed))\n for idx in removed:\n l = lines[idx]\n text = text.replace(l, '')\n\n # save result\n create_dirs(out_dir)\n out = out_file_name(out_dir, ocr_file)\n #print(out)\n with open(out, 'w') as f:\n f.write(text)\n \n return removed\n\nr = remove_notes('/home/jvdzwaan/data/dbnl_ocr/raw/ocr-with-title-page/_aio001jver01_01.txt', \n '/home/jvdzwaan/data/dbnl_ocr/raw/notes/_aio001jver01_01.txt',\n '/home/jvdzwaan/data/dbnl_ocr/raw/ocr', 5)\n#print(r)",
"_____no_output_____"
],
[
"import random\nimport os\n\nfrom nlppln.utils import get_files, out_file_name\n\nin_dir = '/home/jvdzwaan/data/dbnl_ocr/raw/ocr-without-title-page/'\nnotes_dir = '/home/jvdzwaan/data/dbnl_ocr/raw/notes/'\nout_dir = '/home/jvdzwaan/data/dbnl_ocr/raw/ocr'\n\nin_files = get_files(notes_dir)\nrandom.shuffle(in_files)\nin_files = [os.path.basename(f) for f in in_files[:15]]\nin_files",
"_____no_output_____"
],
[
"import os\n\nfrom tqdm import tqdm_notebook as tqdm\n\nfrom nlppln.utils import get_files, out_file_name\n\nin_dir = '/home/jvdzwaan/data/dbnl_ocr/raw/ocr-without-title-page/'\nnotes_dir = '/home/jvdzwaan/data/dbnl_ocr/raw/notes/'\nout_dir = '/home/jvdzwaan/data/dbnl_ocr/raw/ocr'\n\nin_files = ['rade001gera01_01.txt', '_zev001198901_01.txt', '_tir001196201_01.txt',\n 'looy001wond03_01.txt', 'potg001jczi10_01.txt', 'berg050jaro01_01.txt',\n '_tsj002195001_01.txt', '_jaa006199901_01.txt', '_taa006189101_01.txt',\n '_sep001197201_01.txt', 'oltm003memo05_01.txt', '_noo001189201_01.txt',\n 'koni057heil01_01.txt', '_vla016197401_01.txt', '_bij005195501_01.txt']\nin_files = [os.path.join(in_dir, f) for f in in_files]\n\nfor in_file in tqdm(in_files):\n # needs to be prcessed?\n out = out_file_name(out_dir, in_file)\n if not os.path.isfile(out):\n # is there a notes file?\n notes_file = os.path.join(notes_dir, os.path.basename(in_file))\n if os.path.isfile(notes_file):\n print('processing', in_file)\n with open('lines_removed_100.txt', 'a') as f:\n removed = remove_notes(in_file, notes_file, out_dir, 100)\n f.write(os.path.basename(out))\n f.write('\\t')\n removed = [str(r) for r in removed]\n f.write(','.join(removed))\n f.write('\\n')",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bdae032a5e196b5d367b7da7981a6252884082 | 19,757 | ipynb | Jupyter Notebook | RL/Grid World-Function.ipynb | PinmanHuang/CrashCourseML | b59ebf138d42fc9a1669735c6363d50938200e69 | [
"MIT"
]
| 16 | 2019-09-09T06:47:01.000Z | 2021-06-10T01:53:58.000Z | RL/Grid World-Function.ipynb | PinmanHuang/CrashCourseML | b59ebf138d42fc9a1669735c6363d50938200e69 | [
"MIT"
]
| 1 | 2019-09-09T15:52:32.000Z | 2019-09-09T15:53:47.000Z | RL/Grid World-Function.ipynb | PinmanHuang/CrashCourseML | b59ebf138d42fc9a1669735c6363d50938200e69 | [
"MIT"
]
| 8 | 2019-02-14T02:51:26.000Z | 2019-10-07T07:44:24.000Z | 54.728532 | 5,172 | 0.582983 | [
[
[
"# 用函數取代表格\n\n用簡單的神經網路來取代 V",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom keras.models import Sequential\nfrom keras.layers import Dense",
"_____no_output_____"
],
[
"from gridworld import GridWorld",
"_____no_output_____"
],
[
"blocks={(1,1), (3,3)}\ngw = GridWorld(size=(5,5), start=(0,0), exit=(4,4), blocks=blocks)",
"_____no_output_____"
],
[
"from ipywidgets import widgets as W\nfrom IPython.display import display",
"_____no_output_____"
],
[
"gw_html = W.HTML(value=gw._repr_html_())\ngw.restart()\n\ndef gw_move(i):\n def func(b=None):\n gw_html.value = gw.move(i)._repr_html_()\n return func\n\ndef gw_restart(b=None):\n gw.restart()\n gw_html.value = gw._repr_html_()\nbuttons = [] \nfor i, bn in enumerate(['arrow-right', 'arrow-up', \n 'arrow-left', 'arrow-down', 'refresh']):\n b = W.Button(icon='fa-'+bn, layout=W.Layout(width='5em'))\n b.on_click(gw_move(i) if i<4 else gw_restart)\n buttons.append(b)\n\nW.HBox([gw_html, W.VBox(buttons)])\n",
"_____no_output_____"
]
],
[
[
"## 使用 Q learning\n\nQ 用簡單的神經網路來定義",
"_____no_output_____"
]
],
[
[
"Q = Sequential()\nQ.add(Dense(128, input_shape=((gw.size[0]+2)*(gw.size[1]+2)+4,), activation=\"relu\" )) # 輸入是 i, j 座標和 a\nQ.add(Dense(1, activation=\"tanh\")) # 因為輸出是 +-1\nQ.compile(loss='mse',optimizer='sgd', metrics=['accuracy'])\n\navectors = [[0]* 4 for i in range(4)]\nfor i in range(4):\n avectors[i][i]=1\ndef Qfunc(i,j):\n ij = np.zeros( (gw.size[0]+2, gw.size[1]+2))\n ij[i, j]=1\n ij = list(ij.ravel())\n return np.array([Q.predict(np.array([ij+avectors[a]]))[0,0] for a in range(4)])\n\n\ndef Qupdate(i, j, a, v):\n ij = np.zeros( (gw.size[0]+2, gw.size[1]+2))\n ij[i, j]=1\n ij = list(ij.ravel())\n return Q.train_on_batch(np.array([ij+avectors[a]]), np.array([[v]]))\n\nQfunc(1,3)\n",
"_____no_output_____"
],
[
"from random import randint, random, shuffle, choice\nfrom time import sleep\ngw_html = W.HTML()\ndisplay(gw_html)\n\ndef update_VA(gw, Qfunc):\n if gw.A is None:\n gw.A = np.full( (gw.size[0]+2, gw.size[1]+2), -1)\n if gw.V is None:\n gw.V = np.full( (gw.size[0]+2, gw.size[1]+2), 2.)\n for i in range(gw.size[0]):\n for j in range(gw.size[1]):\n Qij = Qfunc(i,j)\n if Qij.min() == 2:\n gw.A[i,j]=-1\n gw.V[i,j]= 2\n else:\n gw.A[i,j] = np.argmax(np.where( Qij > 1, -2, Qij))\n gw.V[i,j] = np.max(np.where( Qij > 1, -2, Qij))\n gw_html.value = gw._repr_html_()\n\ndef Qlearn(g):\n actions = [0,1,2,3]\n while True:\n gw_html.value = g._repr_html_()\n if g.is_end():\n break\n sleep(0.02)\n src_pos = g.pos\n Q_src = Qfunc(*src_pos)\n if random()< ϵ:\n a = choice(actions)\n else:\n a = np.argmax(Q_src) \n g.move(a) \n dst_pos = g.pos\n r = g.score\n if r:\n v=r\n else:\n v=r+γ*Qfunc(*dst_pos).max()\n Qupdate(*src_pos, a, v) \n\nα = 0.1\nγ = 0.95\nϵ = 5.\nfor i in range(500):\n gw.restart()\n gw_html.value = gw._repr_html_()\n Qlearn(gw) \n update_VA(gw, Qfunc)\n ϵ *= 0.99",
"_____no_output_____"
],
[
"## 另外一種網路\n\nQ = Sequential()\nQ.add(Dense(128, input_shape=((gw.size[0]+2)*(gw.size[1]+2),), activation=\"relu\" )) # 輸入是 i, j \nQ.add(Dense(4, activation=\"tanh\")) # 因為輸出是 +-1\nQ.compile(loss='mse',optimizer='sgd', metrics=['accuracy']) # 輸出 a\n\ndef Qfunc(i,j):\n ij = np.zeros( (gw.size[0]+2, gw.size[1]+2))\n ij[i, j]=1\n ij = list(ij.ravel())\n return Q.predict(np.array([ij]))[0]\n\n\ndef Qupdate(i, j, a, v):\n ij = np.zeros( (gw.size[0]+2, gw.size[1]+2))\n ij[i, j]=1\n ij = list(ij.ravel())\n Y = Q.predict(np.array([ij]))\n Y[0][a] = v\n return Q.train_on_batch(np.array([ij]), Y)\n\nQfunc(1,3)\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
e7bdaeed53f9ac69bab74a61bcd4e6e28b0ae4fe | 137,114 | ipynb | Jupyter Notebook | FastStart/module_3_pos_tag.ipynb | Xrenya/RuCode2020 | 511a288ffc9531b39f539ac8075007f8bff9debe | [
"MIT"
]
| null | null | null | FastStart/module_3_pos_tag.ipynb | Xrenya/RuCode2020 | 511a288ffc9531b39f539ac8075007f8bff9debe | [
"MIT"
]
| null | null | null | FastStart/module_3_pos_tag.ipynb | Xrenya/RuCode2020 | 511a288ffc9531b39f539ac8075007f8bff9debe | [
"MIT"
]
| null | null | null | 76.471835 | 53,526 | 0.765305 | [
[
[
"### Задача определения частей речи, Part-Of-Speech Tagger (POS)",
"_____no_output_____"
],
[
"Мы будем решать задачу определения частей речи (POS-теггинга).",
"_____no_output_____"
]
],
[
[
"import nltk\nimport pandas as pd\nimport numpy as np\nfrom nltk.corpus import brown\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"Вам в помощь http://www.nltk.org/book/",
"_____no_output_____"
],
[
"Загрузим brown корпус",
"_____no_output_____"
]
],
[
[
"nltk.download('brown')",
"[nltk_data] Downloading package brown to /root/nltk_data...\n[nltk_data] Unzipping corpora/brown.zip.\n"
]
],
[
[
"<b>Существует не одна система тегирования, поэтому будьте внимательны, когда прогнозируете тег слов в тексте и вычисляете качество прогноза. Можете получить несправедливо низкое качество вашего решения.",
"_____no_output_____"
],
[
"Cейчас будем использовать универсальную систему тегирования universal_tagset ",
"_____no_output_____"
]
],
[
[
"nltk.download('universal_tagset')",
"[nltk_data] Downloading package universal_tagset to /root/nltk_data...\n[nltk_data] Unzipping taggers/universal_tagset.zip.\n"
]
],
[
[
"<img src=\"https://4.bp.blogspot.com/-IcFli2wljs0/WrVCw3umY_I/AAAAAAAACYM/UJ_neoUAs3wF95dj2Ouf3BzxXzB_b2TbQCLcBGAs/s1600/postags.png\">\n",
"_____no_output_____"
],
[
"Мы имеем массив предложений пар (слово-тег)",
"_____no_output_____"
]
],
[
[
"brown_tagged_sents = brown.tagged_sents(tagset=\"universal\")\nbrown_tagged_sents",
"_____no_output_____"
]
],
[
[
"Первое предложение",
"_____no_output_____"
]
],
[
[
"brown_tagged_sents[0]",
"_____no_output_____"
]
],
[
[
"Все пары (слово-тег)",
"_____no_output_____"
]
],
[
[
"brown_tagged_words = brown.tagged_words(tagset='universal')\nbrown_tagged_words",
"_____no_output_____"
]
],
[
[
"Проанализируйте данные, с которыми Вы работаете. Используйте `nltk.FreqDist()` для подсчета частоты встречаемости тега и слова в нашем корпусе. Под частой элемента подразумевается кол-во этого элемента в корпусе.",
"_____no_output_____"
]
],
[
[
"# Приведем слова к нижнему регистру\nbrown_tagged_words = list(map(lambda x: (x[0].lower(), x[1]), brown_tagged_words))",
"_____no_output_____"
],
[
"print('Кол-во предложений: ', len(brown_tagged_sents))\ntags = [tag for (word, tag) in brown_tagged_words] # наши теги\nwords = [word for (word, tag) in brown_tagged_words] # наши слова\n\ntag_num = pd.Series(nltk.FreqDist(tags)).sort_values(ascending=False) # тег - кол-во тега в корпусе\nword_num = pd.Series(nltk.FreqDist(words)).sort_values(ascending=False) # слово - кол-во слова в корпусе",
"Кол-во предложений: 57340\n"
],
[
"tag_num",
"_____no_output_____"
],
[
"plt.figure(figsize=(12, 5))\nplt.bar(tag_num.index, tag_num.values)\nplt.title(\"Tag_frequency\")\nplt.show()",
"_____no_output_____"
],
[
"word_num[:5]",
"_____no_output_____"
],
[
"plt.figure(figsize=(12, 5))\nplt.bar(word_num.index[:10], word_num.values[:10])\nplt.title(\"Word_frequency\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Вопрос 1:\n* Кол-во слова `cat` в корпусе? **(0.5 балл)**",
"_____no_output_____"
]
],
[
[
"word_num[\"cat\"]",
"_____no_output_____"
]
],
[
[
"### Вопрос 2:\n* Самое популярное слово с самым популярным тегом? **(0.5 балл)**\n",
"_____no_output_____"
]
],
[
[
"# Выбираем сначала слова с самым популярным тегом, а затем среди них выбираем самое популярное слово.\nlst = [word for (word, tag) in brown_tagged_words if tag == \"NOUN\"]\npopular = pd.Series(nltk.FreqDist(lst)).sort_values(ascending=False)\nprint(popular) # time - Самое популярное слово с самым популярным тегом \"NOUN\"",
"time 1597\nman 1203\naf 995\nyears 949\nway 899\n ... \nanti-communists 1\npeace-treaty 1\nmalinovsky 1\neleventh-floor 1\nboucle 1\nLength: 30246, dtype: int64\n"
]
],
[
[
"Cделайте разбиение выборки на обучение и контроль в отношении 9:1. **(0.5 балл)**",
"_____no_output_____"
]
],
[
[
"brown_tagged_sents = brown.tagged_sents(tagset=\"universal\")\n# Приведем слова к нижнему регистру\nmy_brown_tagged_sents = []\nfor sent in brown_tagged_sents:\n my_brown_tagged_sents.append(list(map(lambda x: (x[0].lower(), x[1]), sent)))\nmy_brown_tagged_sents = np.array(my_brown_tagged_sents)\n\nfrom sklearn.model_selection import train_test_split\ntrain_sents, test_sents = train_test_split(my_brown_tagged_sents, test_size=0.1, random_state=0)",
"_____no_output_____"
],
[
"len(train_sents), len(test_sents)",
"_____no_output_____"
]
],
[
[
"## DefaultTagger",
"_____no_output_____"
],
[
"### Вопрос 3:\n* Какое качество вы бы получили, если бы предсказывали любой тег, как самый популярный тег на выборке train(округлите до одного знака после запятой)? **(0.5 балл)**",
"_____no_output_____"
],
[
"Вы можете использовать DefaultTagger(метод tag для предсказания частей речи предложения).",
"_____no_output_____"
]
],
[
[
"from nltk.tag import DefaultTagger\ndefault_tagger = DefaultTagger(\"NOUN\")",
"_____no_output_____"
],
[
"true_pred = 0\nnum_pred = 0\n\nfor sent in test_sents:\n tags = np.array([tag for (word, tag) in sent])\n words = np.array([word for (word, tag) in sent])\n\n tagged_sent = default_tagger.tag(words)\n outputs = [tag for token, tag in tagged_sent]\n \n true_pred += sum(outputs == tags)\n num_pred += len(words)\n \nprint(\"Accuracy:\", true_pred / num_pred * 100, '%')",
"Accuracy: 23.47521651004238 %\n"
]
],
[
[
"если бы предсказывали любой тег, как самый популярный тег на выборке train: 15,86% - VERB",
"_____no_output_____"
],
[
"## LSTMTagger",
"_____no_output_____"
],
[
"### Подготовка данных",
"_____no_output_____"
],
[
"Изменим структуру данных",
"_____no_output_____"
]
],
[
[
"pos_data = [list(zip(*sent)) for sent in brown_tagged_sents]\nprint(pos_data[0])",
"[('The', 'Fulton', 'County', 'Grand', 'Jury', 'said', 'Friday', 'an', 'investigation', 'of', \"Atlanta's\", 'recent', 'primary', 'election', 'produced', '``', 'no', 'evidence', \"''\", 'that', 'any', 'irregularities', 'took', 'place', '.'), ('DET', 'NOUN', 'NOUN', 'ADJ', 'NOUN', 'VERB', 'NOUN', 'DET', 'NOUN', 'ADP', 'NOUN', 'ADJ', 'NOUN', 'NOUN', 'VERB', '.', 'DET', 'NOUN', '.', 'ADP', 'DET', 'NOUN', 'VERB', 'NOUN', '.')]\n"
]
],
[
[
"Пора эксплуатировать pytorch!",
"_____no_output_____"
]
],
[
[
"from torchtext.data import Field, BucketIterator\nimport torchtext\n\n# наши поля\nWORD = Field(lower=True)\nTAG = Field(unk_token=None) # все токены нам извсетны\n\n# создаем примеры\nexamples = []\nfor words, tags in pos_data:\n examples.append(torchtext.data.Example.fromlist([list(words), list(tags)], fields=[('words', WORD), ('tags', TAG)]))",
"_____no_output_____"
]
],
[
[
"Вот один наш пример:",
"_____no_output_____"
]
],
[
[
"print(vars(examples[0]))",
"{'words': ['the', 'fulton', 'county', 'grand', 'jury', 'said', 'friday', 'an', 'investigation', 'of', \"atlanta's\", 'recent', 'primary', 'election', 'produced', '``', 'no', 'evidence', \"''\", 'that', 'any', 'irregularities', 'took', 'place', '.'], 'tags': ['DET', 'NOUN', 'NOUN', 'ADJ', 'NOUN', 'VERB', 'NOUN', 'DET', 'NOUN', 'ADP', 'NOUN', 'ADJ', 'NOUN', 'NOUN', 'VERB', '.', 'DET', 'NOUN', '.', 'ADP', 'DET', 'NOUN', 'VERB', 'NOUN', '.']}\n"
]
],
[
[
"Теперь формируем наш датасет",
"_____no_output_____"
]
],
[
[
"# кладем примеры в наш датасет\ndataset = torchtext.data.Dataset(examples, fields=[('words', WORD), ('tags', TAG)])\n\ntrain_data, valid_data, test_data = dataset.split(split_ratio=[0.8, 0.1, 0.1])\n\nprint(f\"Number of training examples: {len(train_data.examples)}\")\nprint(f\"Number of validation examples: {len(valid_data.examples)}\")\nprint(f\"Number of testing examples: {len(test_data.examples)}\")",
"Number of training examples: 45872\nNumber of validation examples: 5734\nNumber of testing examples: 5734\n"
]
],
[
[
"Построим словари. Параметр `min_freq` выберете сами. При построении словаря испольузем только **train** **(0.5 балл)**",
"_____no_output_____"
]
],
[
[
"WORD.build_vocab(train_data, min_freq=10)\nTAG.build_vocab(train_data)\n\nprint(f\"Unique tokens in source (ru) vocabulary: {len(WORD.vocab)}\")\nprint(f\"Unique tokens in target (en) vocabulary: {len(TAG.vocab)}\")\n\nprint(WORD.vocab.itos[::200])\nprint(TAG.vocab.itos)",
"Unique tokens in source (ru) vocabulary: 7316\nUnique tokens in target (en) vocabulary: 13\n['<unk>', 'number', 'available', 'miles', 'clearly', 'corps', 'quickly', 'b.', 'resolution', 'review', 'orchestra', 'occasionally', 'warfare', 'bread', \"nation's\", 'tested', 'visitors', 'accident', 'sovereign', 'gesture', 'sharpe', '70', 'attacks', 'ada', 'workshop', 'sank', 'label', \"doctor's\", 'walker', 'mailed', 'blade', 'modernization', 'arriving', 'judged', 'adventures', 'generated', 'rolls']\n['<pad>', 'NOUN', 'VERB', '.', 'ADP', 'DET', 'ADJ', 'ADV', 'PRON', 'CONJ', 'PRT', 'NUM', 'X']\n"
]
],
[
[
"Здесь вы увидете токен `unk` и `pad`. Первый служит для обозначения слов, которых у нас нет в словаре. Второй служит для того, что объекты в одном батче были одинакового размера.",
"_____no_output_____"
]
],
[
[
"print(vars(train_data.examples[9]))",
"{'words': ['there', 'was', 'a', 'contorted', 'ugliness', 'now', ';', ';'], 'tags': ['PRT', 'VERB', 'DET', 'VERB', 'NOUN', 'ADV', '.', '.']}\n"
]
],
[
[
"Посмотрим с насколько большими предложениями мы имеем дело",
"_____no_output_____"
]
],
[
[
"length = map(len, [vars(x)['words'] for x in train_data.examples])\n\nplt.figure(figsize=[8, 4])\nplt.title(\"Length distribution in Train data\")\nplt.hist(list(length), bins=20);",
"_____no_output_____"
]
],
[
[
"Для обучения `LSTM` лучше использовать colab",
"_____no_output_____"
]
],
[
[
"import torch\nfrom torch import nn\nimport torch.nn.functional as F\nimport torch.optim as optim\n\ndevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\ndevice",
"_____no_output_____"
]
],
[
[
"Для более быстрого и устойчивого обучения сгруппируем наши данные по батчам",
"_____no_output_____"
]
],
[
[
"# бьем нашу выборку на батч, не забывая сначала отсортировать выборку по длине\ndef _len_sort_key(x):\n return len(x.words)\n\nBATCH_SIZE = 64\n\ntrain_iterator, valid_iterator, test_iterator = BucketIterator.splits(\n (train_data, valid_data, test_data), \n batch_size = BATCH_SIZE, \n device = device,\n sort_key=_len_sort_key\n)",
"_____no_output_____"
],
[
"# посморим на количество батчей\nlist(map(len, [train_iterator, valid_iterator, test_iterator]))",
"_____no_output_____"
]
],
[
[
"### Модель и её обучение",
"_____no_output_____"
],
[
"Инициализируем нашу модель. Прочитайте про dropout [тут](https://habr.com/ru/company/wunderfund/blog/330814/). **(3 балла)**",
"_____no_output_____"
]
],
[
[
"class LSTMTagger(nn.Module):\n\n def __init__(self, input_dim, emb_dim, hid_dim, output_dim, dropout):\n super().__init__()\n \n \n self.embeddings = nn.Embedding(num_embeddings=input_dim, embedding_dim=emb_dim)\n self.dropout = nn.Dropout(p=dropout)\n \n self.rnn = nn.LSTM(emb_dim, hid_dim)\n self.tag = nn.Linear(hid_dim, output_dim)\n\n def forward(self, sent):\n \n #sent = [sent len, batch size] \n \n # не забываем применить dropout к embedding\n embedded = self.dropout(self.embeddings(sent))\n\n output, _ = self.rnn(embedded)\n #output = [sent len, batch size, hid dim * n directions]\n\n prediction = self.tag(output)\n \n return prediction\n \n# параметры модели\nINPUT_DIM = len(WORD.vocab)\nOUTPUT_DIM = len(TAG.vocab)\nEMB_DIM = 10\nHID_DIM = 10\nDROPOUT = 0.5\n\nmodel = LSTMTagger(input_dim=INPUT_DIM, emb_dim=EMB_DIM, hid_dim=HID_DIM, output_dim=OUTPUT_DIM, dropout=DROPOUT).to(device)\n\n# инициализируем веса\ndef init_weights(m):\n for name, param in m.named_parameters():\n nn.init.uniform_(param, -0.08, 0.08)\n \nmodel.apply(init_weights)",
"_____no_output_____"
]
],
[
[
"Подсчитаем количество обучаемых параметров нашей модели. Используйте метод `numel()`. **(1 балл)**",
"_____no_output_____"
]
],
[
[
"def count_parameters(model):\n return sum(p.numel() for p in model.parameters() if p.requires_grad)\n\nprint(f'The model has {count_parameters(model):,} trainable parameters')",
"The model has 37,403 trainable parameters\n"
]
],
[
[
"Погнали обучать **(2 балла)**",
"_____no_output_____"
]
],
[
[
"PAD_IDX = TAG.vocab.stoi['<pad>']\noptimizer = optim.Adam(model.parameters())\ncriterion = nn.CrossEntropyLoss(ignore_index = PAD_IDX)\n\ndef train(model, iterator, optimizer, criterion, clip, train_history=None, valid_history=None):\n model.train()\n \n epoch_loss = 0\n history = []\n for i, batch in enumerate(iterator):\n \n words = batch.words\n tags = batch.tags\n \n optimizer.zero_grad()\n \n output = model(words)\n \n #tags = [sent len, batch size]\n #output = [sent len, batch size, output dim]\n \n output = output.view(-1, output.shape[-1])\n tags = tags.view(-1)\n \n #tags = [sent len * batch size]\n #output = [sent len * batch size, output dim]\n \n loss = criterion(output, tags)\n \n loss.backward()\n \n # Gradient clipping(решение проблемы взрыва граденты), clip - максимальная норма вектора\n torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=clip)\n \n optimizer.step()\n \n epoch_loss += loss.item()\n \n history.append(loss.cpu().data.numpy())\n if (i+1)%10==0:\n fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 8))\n\n clear_output(True)\n ax[0].plot(history, label='train loss')\n ax[0].set_xlabel('Batch')\n ax[0].set_title('Train loss')\n \n if train_history is not None:\n ax[1].plot(train_history, label='general train history')\n ax[1].set_xlabel('Epoch')\n if valid_history is not None:\n ax[1].plot(valid_history, label='general valid history')\n plt.legend()\n \n plt.show()\n\n \n return epoch_loss / len(iterator)\n\ndef evaluate(model, iterator, criterion):\n model.eval()\n \n epoch_loss = 0\n \n history = []\n \n with torch.no_grad():\n \n for i, batch in enumerate(iterator):\n\n words = batch.words\n tags = batch.tags\n\n output = model(words)\n\n #tags = [sent len, batch size]\n #output = [sent len, batch size, output dim]\n\n output = output.view(-1, output.shape[-1])\n tags = tags.view(-1)\n\n #tags = [sent len * batch size]\n #output = [sent len * batch size, output dim]\n\n loss = criterion(output, tags)\n \n epoch_loss += loss.item()\n \n return epoch_loss / len(iterator)\n\ndef epoch_time(start_time, end_time):\n elapsed_time = end_time - start_time\n elapsed_mins = int(elapsed_time / 60)\n elapsed_secs = int(elapsed_time - (elapsed_mins * 60))\n return elapsed_mins, elapsed_secs",
"_____no_output_____"
],
[
"import time\nimport math\nimport matplotlib\nmatplotlib.rcParams.update({'figure.figsize': (16, 12), 'font.size': 14})\nimport matplotlib.pyplot as plt\n%matplotlib inline\nfrom IPython.display import clear_output\n\ntrain_history = []\nvalid_history = []\n\nN_EPOCHS = 15\nCLIP = 32\n\nbest_valid_loss = float('inf')\n\nfor epoch in range(N_EPOCHS):\n \n start_time = time.time()\n \n train_loss = train(model, train_iterator, optimizer, criterion, CLIP, train_history, valid_history)\n valid_loss = evaluate(model, valid_iterator, criterion)\n \n end_time = time.time()\n \n epoch_mins, epoch_secs = epoch_time(start_time, end_time)\n \n if valid_loss < best_valid_loss:\n best_valid_loss = valid_loss\n torch.save(model.state_dict(), 'best-val-model.pt')\n\n train_history.append(train_loss)\n valid_history.append(valid_loss)\n print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')\n print(f'\\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')\n print(f'\\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')",
"_____no_output_____"
]
],
[
[
"### Применение модели\n **(1 балл)**",
"_____no_output_____"
]
],
[
[
"def accuracy_model(model, iterator):\n model.eval()\n \n true_pred = 0\n num_pred = 0\n \n with torch.no_grad():\n for i, batch in enumerate(iterator):\n\n words = batch.words\n tags = batch.tags\n\n output = model(words)\n \n #output = [sent len, batch size, output dim]\n # Выбираем для каждого слова индекс тэга с максимальной вероятностью\n output = output.argmax(-1)\n \n #output = [sent len, batch size]\n predict_tags = output.cpu().numpy()\n true_tags = tags.cpu().numpy()\n\n true_pred += np.sum((true_tags == predict_tags) & (true_tags != PAD_IDX))\n num_pred += np.prod(true_tags.shape) - (true_tags == PAD_IDX).sum()\n \n return round(true_pred / num_pred * 100, 3)",
"_____no_output_____"
],
[
"print(\"Accuracy:\", accuracy_model(model, test_iterator), '%')",
"Accuracy: 92.797 %\n"
]
],
[
[
"Вы можете улучшить качество, изменяя параметры модели. Вам неоходимо добиться качества не меньше, чем `accuracy = 92 %`.",
"_____no_output_____"
]
],
[
[
"best_model = LSTMTagger(INPUT_DIM, EMB_DIM, HID_DIM, OUTPUT_DIM, DROPOUT).to(device)\nbest_model.load_state_dict(torch.load('/content/best-val-model.pt'))\nassert accuracy_model(best_model, test_iterator) >= 92",
"_____no_output_____"
]
],
[
[
"### **Если качество сети меньше 92 процентов, то снимается половина от всех полученных баллов .<br> То есть максимум в этом случае 5 баллов за работу.**\n\n\n",
"_____no_output_____"
],
[
"Пример решение нашей задачи:",
"_____no_output_____"
]
],
[
[
"def print_tags(model, data):\n model.eval()\n \n with torch.no_grad():\n words, _ = data\n example = torch.LongTensor([WORD.vocab.stoi[elem] for elem in words]).unsqueeze(1).to(device)\n \n output = model(example).argmax(dim=-1).cpu().numpy()\n tags = [TAG.vocab.itos[int(elem)] for elem in output]\n\n for token, tag in zip(words, tags):\n print(f'{token:15s}{tag}')",
"_____no_output_____"
],
[
"print_tags(model, pos_data[-1])",
"From NOUN\nwhat DET\nI NOUN\nwas VERB\nable ADJ\nto PRT\ngauge NOUN\nin ADP\na DET\nswift ADJ\n, .\ngreedy NOUN\nglance NOUN\n, .\nthe DET\nfigure NOUN\ninside ADP\nthe DET\ncoral-colored NOUN\nboucle NOUN\ndress NOUN\nwas VERB\nstupefying VERB\n. .\n"
]
],
[
[
"## Вывод: \n**(0.5 балл)**\n\nПравильный подбор параметров дает большую точность, также достаточное количество эпох позволяет достичь хорошей точности, однако модель может переобучится ",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7bdb3c83409e0cfd28cacbb75a8b90bd8b3ec13 | 10,817 | ipynb | Jupyter Notebook | ui-for-ml-using-gradio.ipynb | rajtilak82/how-machines-learn | 7202d94104bd0d238ba9aa050aed26d674b8c1e1 | [
"MIT"
]
| null | null | null | ui-for-ml-using-gradio.ipynb | rajtilak82/how-machines-learn | 7202d94104bd0d238ba9aa050aed26d674b8c1e1 | [
"MIT"
]
| null | null | null | ui-for-ml-using-gradio.ipynb | rajtilak82/how-machines-learn | 7202d94104bd0d238ba9aa050aed26d674b8c1e1 | [
"MIT"
]
| null | null | null | 42.586614 | 207 | 0.613294 | [
[
[
"# UI for your Machine Learning model",
"_____no_output_____"
],
[
"## Install Gradio",
"_____no_output_____"
]
],
[
[
"pip install gradio",
"Requirement already satisfied: gradio in d:\\anaconda3\\lib\\site-packages (1.2.3)\nRequirement already satisfied: flask in d:\\anaconda3\\lib\\site-packages (from gradio) (1.1.2)\nRequirement already satisfied: numpy in d:\\anaconda3\\lib\\site-packages (from gradio) (1.18.5)\nRequirement already satisfied: analytics-python in d:\\anaconda3\\lib\\site-packages (from gradio) (1.2.9)\nRequirement already satisfied: requests in d:\\anaconda3\\lib\\site-packages (from gradio) (2.24.0)\nRequirement already satisfied: scikit-image in d:\\anaconda3\\lib\\site-packages (from gradio) (0.16.2)\nRequirement already satisfied: paramiko in d:\\anaconda3\\lib\\site-packages (from gradio) (2.7.2)\nRequirement already satisfied: pandas in d:\\anaconda3\\lib\\site-packages (from gradio) (1.1.1)\nRequirement already satisfied: IPython in d:\\anaconda3\\lib\\site-packages (from gradio) (7.18.1)\nRequirement already satisfied: scipy in d:\\anaconda3\\lib\\site-packages (from gradio) (1.5.0)\nRequirement already satisfied: itsdangerous>=0.24 in d:\\anaconda3\\lib\\site-packages (from flask->gradio) (1.1.0)\nRequirement already satisfied: click>=5.1 in d:\\anaconda3\\lib\\site-packages (from flask->gradio) (7.1.2)\nRequirement already satisfied: Werkzeug>=0.15 in d:\\anaconda3\\lib\\site-packages (from flask->gradio) (1.0.1)\nRequirement already satisfied: Jinja2>=2.10.1 in d:\\anaconda3\\lib\\site-packages (from flask->gradio) (2.11.2)\nRequirement already satisfied: six>=1.5 in d:\\anaconda3\\lib\\site-packages (from analytics-python->gradio) (1.15.0)\nRequirement already satisfied: python-dateutil>2.1 in d:\\anaconda3\\lib\\site-packages (from analytics-python->gradio) (2.8.1)\nRequirement already satisfied: certifi>=2017.4.17 in d:\\anaconda3\\lib\\site-packages (from requests->gradio) (2020.6.20)\nRequirement already satisfied: idna<3,>=2.5 in d:\\anaconda3\\lib\\site-packages (from requests->gradio) (2.10)\nRequirement already satisfied: chardet<4,>=3.0.2 in d:\\anaconda3\\lib\\site-packages (from requests->gradio) (3.0.4)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in d:\\anaconda3\\lib\\site-packages (from requests->gradio) (1.25.10)\nRequirement already satisfied: PyWavelets>=0.4.0 in d:\\anaconda3\\lib\\site-packages (from scikit-image->gradio) (1.1.1)\nRequirement already satisfied: networkx>=2.0 in d:\\anaconda3\\lib\\site-packages (from scikit-image->gradio) (2.5)\nRequirement already satisfied: matplotlib!=3.0.0,>=2.0.0 in d:\\anaconda3\\lib\\site-packages (from scikit-image->gradio) (3.3.1)\nRequirement already satisfied: pillow>=4.3.0 in d:\\anaconda3\\lib\\site-packages (from scikit-image->gradio) (7.2.0)\nRequirement already satisfied: imageio>=2.3.0 in d:\\anaconda3\\lib\\site-packages (from scikit-image->gradio) (2.9.0)\nRequirement already satisfied: cryptography>=2.5 in d:\\anaconda3\\lib\\site-packages (from paramiko->gradio) (3.1)\nRequirement already satisfied: pynacl>=1.0.1 in d:\\anaconda3\\lib\\site-packages (from paramiko->gradio) (1.4.0)\nRequirement already satisfied: bcrypt>=3.1.3 in d:\\anaconda3\\lib\\site-packages (from paramiko->gradio) (3.2.0)\nRequirement already satisfied: pytz>=2017.2 in d:\\anaconda3\\lib\\site-packages (from pandas->gradio) (2020.1)\nRequirement already satisfied: pygments in d:\\anaconda3\\lib\\site-packages (from IPython->gradio) (2.6.1)\nRequirement already satisfied: setuptools>=18.5 in d:\\anaconda3\\lib\\site-packages (from IPython->gradio) (49.6.0.post20200814)\nRequirement already satisfied: colorama; sys_platform == \"win32\" in d:\\anaconda3\\lib\\site-packages (from IPython->gradio) (0.4.3)\nRequirement already satisfied: prompt-toolkit!=3.0.0,!=3.0.1,<3.1.0,>=2.0.0 in d:\\anaconda3\\lib\\site-packages (from IPython->gradio) (3.0.7)\nRequirement already satisfied: backcall in d:\\anaconda3\\lib\\site-packages (from IPython->gradio) (0.2.0)\nRequirement already satisfied: pickleshare in d:\\anaconda3\\lib\\site-packages (from IPython->gradio) (0.7.5)\nRequirement already satisfied: traitlets>=4.2 in d:\\anaconda3\\lib\\site-packages (from IPython->gradio) (4.3.3)\nRequirement already satisfied: decorator in d:\\anaconda3\\lib\\site-packages (from IPython->gradio) (4.4.2)\nRequirement already satisfied: jedi>=0.10 in d:\\anaconda3\\lib\\site-packages (from IPython->gradio) (0.17.1)\nRequirement already satisfied: MarkupSafe>=0.23 in d:\\anaconda3\\lib\\site-packages (from Jinja2>=2.10.1->flask->gradio) (1.1.1)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.3 in d:\\anaconda3\\lib\\site-packages (from matplotlib!=3.0.0,>=2.0.0->scikit-image->gradio) (2.4.7)\nRequirement already satisfied: kiwisolver>=1.0.1 in d:\\anaconda3\\lib\\site-packages (from matplotlib!=3.0.0,>=2.0.0->scikit-image->gradio) (1.2.0)\nRequirement already satisfied: cycler>=0.10 in d:\\anaconda3\\lib\\site-packages (from matplotlib!=3.0.0,>=2.0.0->scikit-image->gradio) (0.10.0)\nRequirement already satisfied: cffi!=1.11.3,>=1.8 in d:\\anaconda3\\lib\\site-packages (from cryptography>=2.5->paramiko->gradio) (1.14.2)\nRequirement already satisfied: wcwidth in d:\\anaconda3\\lib\\site-packages (from prompt-toolkit!=3.0.0,!=3.0.1,<3.1.0,>=2.0.0->IPython->gradio) (0.2.5)\nRequirement already satisfied: ipython-genutils in d:\\anaconda3\\lib\\site-packages (from traitlets>=4.2->IPython->gradio) (0.2.0)Note: you may need to restart the kernel to use updated packages.\nRequirement already satisfied: parso<0.8.0,>=0.7.0 in d:\\anaconda3\\lib\\site-packages (from jedi>=0.10->IPython->gradio) (0.7.0)\nRequirement already satisfied: pycparser in d:\\anaconda3\\lib\\site-packages (from cffi!=1.11.3,>=1.8->cryptography>=2.5->paramiko->gradio) (2.20)\n\n"
]
],
[
[
"## Import the required libraries",
"_____no_output_____"
]
],
[
[
"import gradio as gr # for creating the UI\nimport numpy as np # for preprocessing images\nimport requests # for downloading human readable labels\nfrom keras.applications.vgg16 import VGG16 # VGG16 model\nfrom keras.applications.vgg16 import preprocess_input # VGG16 preprocessing function",
"_____no_output_____"
]
],
[
[
"## Loading the model",
"_____no_output_____"
]
],
[
[
"vgg_model = VGG16()",
"_____no_output_____"
]
],
[
[
"## Download the human readable labels",
"_____no_output_____"
]
],
[
[
"response = requests.get(\"https://raw.githubusercontent.com/gradio-app/mobilenet-example/master/labels.txt\") \nlabels = response.text.split(\"\\n\")",
"_____no_output_____"
]
],
[
[
"## Creating the classification pipeline",
"_____no_output_____"
]
],
[
[
"# this pipeline returns a dictionary with key as label and\n# values as the predicted confidence for that label\n\ndef classify_image(image):\n image = image.reshape((-1, 224, 224, 3)) # reshaping the image \n image = preprocess_input(image) # prepare the image for the VGG16 model \n prediction = vgg_model.predict(image).flatten() # predicting the output\n return {labels[i]: float(prediction[i]) for i in range(1000)} # finding the predicted labels from the 1000 labels",
"_____no_output_____"
]
],
[
[
"## Initializing the input and output components",
"_____no_output_____"
]
],
[
[
"image = gr.inputs.Image(shape = (224, 224, 3)) \nlabel = gr.outputs.Label(num_top_classes = 3) # predicts the top 3 classes",
"_____no_output_____"
]
],
[
[
"## Launching the Gradio interface with our VGG16 model",
"_____no_output_____"
]
],
[
[
"gr.Interface(fn = classify_image, inputs = image, \n outputs = label, capture_session = True).launch() ",
"Running locally at: http://127.0.0.1:7860/\nTo get a public link for a hosted model, set Share=True\nInterface loading below...\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7bdb9ca9afff0f52ba8436ab512dc9f34b47a6c | 71,856 | ipynb | Jupyter Notebook | Day_2_Activation_Function.ipynb | LukasPurbaW/100_Days_of_Deep_Learning | b171194c610639fc4574ef77708afc8e02eedf2e | [
"Apache-2.0"
]
| 4 | 2022-03-09T06:39:39.000Z | 2022-03-19T05:51:49.000Z | Day_2_Activation_Function.ipynb | LukasPurbaW/100_Days_of_Deep_Learning | b171194c610639fc4574ef77708afc8e02eedf2e | [
"Apache-2.0"
]
| null | null | null | Day_2_Activation_Function.ipynb | LukasPurbaW/100_Days_of_Deep_Learning | b171194c610639fc4574ef77708afc8e02eedf2e | [
"Apache-2.0"
]
| null | null | null | 195.26087 | 13,694 | 0.901344 | [
[
[
"<a href=\"https://colab.research.google.com/github/LukasPurbaW/100_Days_of_Deep_Learning/blob/main/Day_2_Activation_Function.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"## Activation Function",
"_____no_output_____"
]
],
[
[
"# Previous lecture we learn about neuron on action, but what actually is neuron ?\n# Every neuron have a weight, and they calculate the weight using activation function.\n# In this code, you will learn about 4 different activation function.",
"_____no_output_____"
]
],
[
[
"### Threshold Function",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport numpy as np\n\ndef binaryStep(x):\n ''' It returns '0' is the input is less then zero otherwise it returns one '''\n return np.heaviside(x,1)\n\nx = np.linspace(-10, 10)\nplt.plot(x, binaryStep(x))\nplt.axis('tight')\nplt.title('Activation Function (Threshold Function)')\nplt.show()",
"_____no_output_____"
],
[
"## Yes or no type of function, it's pretty straight function.",
"_____no_output_____"
]
],
[
[
"### Sigmoid Function",
"_____no_output_____"
]
],
[
[
"def sigmoid(x):\n ''' It returns 1/(1+exp(-x)). where the values lies between zero and one '''\n return 1/(1+np.exp(-x))\n\nx = np.linspace(-10, 10)\nplt.plot(x, sigmoid(x))\nplt.axis('tight')\nplt.title('Activation Function (Sigmoid)')\nplt.show()",
"_____no_output_____"
],
[
"## The output is equal to 1/(1+np.exp(-x)). Unlike threshold functions, this gives a smooth progression, useful in output layer.",
"_____no_output_____"
]
],
[
[
"## Rectifier or Relu",
"_____no_output_____"
]
],
[
[
"def RELU(x):\n ''' It returns zero if the input is less than zero otherwise it returns the given input. '''\n x1=[]\n for i in x:\n if i<0:\n x1.append(0)\n else:\n x1.append(i)\n return x1\n\nx = np.linspace(-10, 10)\nplt.plot(x, RELU(x))\nplt.axis('tight')\nplt.title('Activation Function (RELU)')\nplt.show()",
"_____no_output_____"
],
[
"## If the weight is 0, it stays 0, other than that, it has linear increase, the maximum value itself is infinite. Ussually used in hidden layers.",
"_____no_output_____"
]
],
[
[
"### Hyperpolic or Tanh Function",
"_____no_output_____"
]
],
[
[
"def tanh(x):\n ''' It returns the value (1-exp(-2x))/(1+exp(-2x)) and the value returned will be lies in between -1 to 1.'''\n return np.tanh(x)\nx = np.linspace(-10, 10)\nplt.plot(x, tanh(x))\nplt.axis('tight')\nplt.title('Activation Function (Tanh)')\nplt.show()",
"_____no_output_____"
],
[
"## This return the minimum value of -1 and maximum value of + 1 and the graphic is smooth like sigmoid.",
"_____no_output_____"
]
],
[
[
"### Softmax Function",
"_____no_output_____"
]
],
[
[
"def softmax(x):\n ''' Compute softmax values for each sets of scores in x. '''\n return np.exp(x) / np.sum(np.exp(x), axis=0)",
"_____no_output_____"
],
[
"x = np.linspace(-10, 10)\nplt.plot(x, softmax(x))\nplt.axis('tight')\nplt.title('Activation Function :Softmax')\nplt.show()",
"_____no_output_____"
],
[
"## Sigmoid is a smooth graphic like sigmoid. Often used in multiclass classification.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
e7bdbda8b7c65f682d40a63562d5ddb70d2caf91 | 34,625 | ipynb | Jupyter Notebook | DA0101EN/.ipynb_checkpoints/model-evaluation-and-refinement-checkpoint.ipynb | alekhaya99/IBM-CLOUD-SQL-AND-PYTHON | f005a7035b624d280ae3117e2545b049a2a492d0 | [
"MIT"
]
| null | null | null | DA0101EN/.ipynb_checkpoints/model-evaluation-and-refinement-checkpoint.ipynb | alekhaya99/IBM-CLOUD-SQL-AND-PYTHON | f005a7035b624d280ae3117e2545b049a2a492d0 | [
"MIT"
]
| null | null | null | DA0101EN/.ipynb_checkpoints/model-evaluation-and-refinement-checkpoint.ipynb | alekhaya99/IBM-CLOUD-SQL-AND-PYTHON | f005a7035b624d280ae3117e2545b049a2a492d0 | [
"MIT"
]
| null | null | null | 34,625 | 34,625 | 0.677227 | [
[
[
"<center>\n <img src=\"https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/Logos/organization_logo/organization_logo.png\" width=\"300\" alt=\"cognitiveclass.ai logo\" />\n</center>\n\n# Model Evaluation and Refinement\n\nEstimated time needed: **30** minutes\n\n## Objectives\n\nAfter completing this lab you will be able to:\n\n- Evaluate and refine prediction models\n",
"_____no_output_____"
],
[
"<h1>Table of content</h1>\n<ul>\n <li><a href=\"#ref1\">Model Evaluation </a></li>\n <li><a href=\"#ref2\">Over-fitting, Under-fitting and Model Selection </a></li>\n <li><a href=\"#ref3\">Ridge Regression </a></li>\n <li><a href=\"#ref4\">Grid Search</a></li>\n</ul>\n",
"_____no_output_____"
],
[
"This dataset was hosted on IBM Cloud object click <a href=\"https://cocl.us/DA101EN_object_storage\">HERE</a> for free storage.\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\n# Import clean data \npath = 'https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DA0101EN-SkillsNetwork/labs/Data%20files/module_5_auto.csv'\ndf = pd.read_csv(path)",
"_____no_output_____"
],
[
"df.to_csv('module_5_auto.csv')",
"_____no_output_____"
]
],
[
[
" First lets only use numeric data \n",
"_____no_output_____"
]
],
[
[
"df=df._get_numeric_data()\ndf.head()",
"_____no_output_____"
]
],
[
[
" Libraries for plotting \n",
"_____no_output_____"
]
],
[
[
"%%capture\n! pip install ipywidgets",
"_____no_output_____"
],
[
"from ipywidgets import interact, interactive, fixed, interact_manual",
"_____no_output_____"
]
],
[
[
"<h2>Functions for plotting</h2>\n",
"_____no_output_____"
]
],
[
[
"def DistributionPlot(RedFunction, BlueFunction, RedName, BlueName, Title):\n width = 12\n height = 10\n plt.figure(figsize=(width, height))\n\n ax1 = sns.distplot(RedFunction, hist=False, color=\"r\", label=RedName)\n ax2 = sns.distplot(BlueFunction, hist=False, color=\"b\", label=BlueName, ax=ax1)\n\n plt.title(Title)\n plt.xlabel('Price (in dollars)')\n plt.ylabel('Proportion of Cars')\n\n plt.show()\n plt.close()",
"_____no_output_____"
],
[
"def PollyPlot(xtrain, xtest, y_train, y_test, lr,poly_transform):\n width = 12\n height = 10\n plt.figure(figsize=(width, height))\n \n \n #training data \n #testing data \n # lr: linear regression object \n #poly_transform: polynomial transformation object \n \n xmax=max([xtrain.values.max(), xtest.values.max()])\n\n xmin=min([xtrain.values.min(), xtest.values.min()])\n\n x=np.arange(xmin, xmax, 0.1)\n\n\n plt.plot(xtrain, y_train, 'ro', label='Training Data')\n plt.plot(xtest, y_test, 'go', label='Test Data')\n plt.plot(x, lr.predict(poly_transform.fit_transform(x.reshape(-1, 1))), label='Predicted Function')\n plt.ylim([-10000, 60000])\n plt.ylabel('Price')\n plt.legend()",
"_____no_output_____"
]
],
[
[
"<h1 id=\"ref1\">Part 1: Training and Testing</h1>\n\n<p>An important step in testing your model is to split your data into training and testing data. We will place the target data <b>price</b> in a separate dataframe <b>y</b>:</p>\n",
"_____no_output_____"
]
],
[
[
"y_data = df['price']",
"_____no_output_____"
]
],
[
[
"drop price data in x data\n",
"_____no_output_____"
]
],
[
[
"x_data=df.drop('price',axis=1)",
"_____no_output_____"
]
],
[
[
"Now we randomly split our data into training and testing data using the function <b>train_test_split</b>. \n",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\n\n\nx_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.10, random_state=1)\n\n\nprint(\"number of test samples :\", x_test.shape[0])\nprint(\"number of training samples:\",x_train.shape[0])\n",
"_____no_output_____"
]
],
[
[
"The <b>test_size</b> parameter sets the proportion of data that is split into the testing set. In the above, the testing set is set to 10% of the total dataset. \n",
"_____no_output_____"
],
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #1):</h1>\n\n<b>Use the function \"train_test_split\" to split up the data set such that 40% of the data samples will be utilized for testing, set the parameter \"random_state\" equal to zero. The output of the function should be the following: \"x_train_1\" , \"x_test_1\", \"y_train_1\" and \"y_test_1\".</b>\n\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\nx_train1, x_test1, y_train1, y_test1 = train_test_split(x_data, y_data, test_size=0.4, random_state=0) \nprint(\"number of test samples :\", x_test1.shape[0])\nprint(\"number of training samples:\",x_train1.shape[0])\n```\n\n</details>\n",
"_____no_output_____"
],
[
"Let's import <b>LinearRegression</b> from the module <b>linear_model</b>.\n",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LinearRegression",
"_____no_output_____"
]
],
[
[
" We create a Linear Regression object:\n",
"_____no_output_____"
]
],
[
[
"lre=LinearRegression()",
"_____no_output_____"
]
],
[
[
"we fit the model using the feature horsepower \n",
"_____no_output_____"
]
],
[
[
"lre.fit(x_train[['horsepower']], y_train)",
"_____no_output_____"
]
],
[
[
"Let's Calculate the R^2 on the test data:\n",
"_____no_output_____"
]
],
[
[
"lre.score(x_test[['horsepower']], y_test)",
"_____no_output_____"
]
],
[
[
"we can see the R^2 is much smaller using the test data.\n",
"_____no_output_____"
]
],
[
[
"lre.score(x_train[['horsepower']], y_train)",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #2): </h1>\n<b> \nFind the R^2 on the test data using 40% of the data for training data\n</b>\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\nx_train1, x_test1, y_train1, y_test1 = train_test_split(x_data, y_data, test_size=0.4, random_state=0)\nlre.fit(x_train1[['horsepower']],y_train1)\nlre.score(x_test1[['horsepower']],y_test1)\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
" Sometimes you do not have sufficient testing data; as a result, you may want to perform Cross-validation. Let's go over several methods that you can use for Cross-validation. \n",
"_____no_output_____"
],
[
"<h2>Cross-validation Score</h2>\n",
"_____no_output_____"
],
[
"Lets import <b>model_selection</b> from the module <b>cross_val_score</b>.\n",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_score",
"_____no_output_____"
]
],
[
[
"We input the object, the feature in this case ' horsepower', the target data (y_data). The parameter 'cv' determines the number of folds; in this case 4. \n",
"_____no_output_____"
]
],
[
[
"Rcross = cross_val_score(lre, x_data[['horsepower']], y_data, cv=4)",
"_____no_output_____"
]
],
[
[
"The default scoring is R^2; each element in the array has the average R^2 value in the fold:\n",
"_____no_output_____"
]
],
[
[
"Rcross",
"_____no_output_____"
]
],
[
[
" We can calculate the average and standard deviation of our estimate:\n",
"_____no_output_____"
]
],
[
[
"print(\"The mean of the folds are\", Rcross.mean(), \"and the standard deviation is\" , Rcross.std())",
"_____no_output_____"
]
],
[
[
"We can use negative squared error as a score by setting the parameter 'scoring' metric to 'neg_mean_squared_error'. \n",
"_____no_output_____"
]
],
[
[
"-1 * cross_val_score(lre,x_data[['horsepower']], y_data,cv=4,scoring='neg_mean_squared_error')",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #3): </h1>\n<b> \nCalculate the average R^2 using two folds, find the average R^2 for the second fold utilizing the horsepower as a feature : \n</b>\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\nRc=cross_val_score(lre,x_data[['horsepower']], y_data,cv=2)\nRc.mean()\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
"You can also use the function 'cross_val_predict' to predict the output. The function splits up the data into the specified number of folds, using one fold for testing and the other folds are used for training. First import the function:\n",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_predict",
"_____no_output_____"
]
],
[
[
"We input the object, the feature in this case <b>'horsepower'</b> , the target data <b>y_data</b>. The parameter 'cv' determines the number of folds; in this case 4. We can produce an output:\n",
"_____no_output_____"
]
],
[
[
"yhat = cross_val_predict(lre,x_data[['horsepower']], y_data,cv=4)\nyhat[0:5]",
"_____no_output_____"
]
],
[
[
"<h1 id=\"ref2\">Part 2: Overfitting, Underfitting and Model Selection</h1>\n\n<p>It turns out that the test data sometimes referred to as the out of sample data is a much better measure of how well your model performs in the real world. One reason for this is overfitting; let's go over some examples. It turns out these differences are more apparent in Multiple Linear Regression and Polynomial Regression so we will explore overfitting in that context.</p>\n",
"_____no_output_____"
],
[
"Let's create Multiple linear regression objects and train the model using <b>'horsepower'</b>, <b>'curb-weight'</b>, <b>'engine-size'</b> and <b>'highway-mpg'</b> as features.\n",
"_____no_output_____"
]
],
[
[
"lr = LinearRegression()\nlr.fit(x_train[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']], y_train)",
"_____no_output_____"
]
],
[
[
"Prediction using training data:\n",
"_____no_output_____"
]
],
[
[
"yhat_train = lr.predict(x_train[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']])\nyhat_train[0:5]",
"_____no_output_____"
]
],
[
[
"Prediction using test data: \n",
"_____no_output_____"
]
],
[
[
"yhat_test = lr.predict(x_test[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']])\nyhat_test[0:5]",
"_____no_output_____"
]
],
[
[
"Let's perform some model evaluation using our training and testing data separately. First we import the seaborn and matplotlibb library for plotting.\n",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n%matplotlib inline\nimport seaborn as sns",
"_____no_output_____"
]
],
[
[
"Let's examine the distribution of the predicted values of the training data.\n",
"_____no_output_____"
]
],
[
[
"Title = 'Distribution Plot of Predicted Value Using Training Data vs Training Data Distribution'\nDistributionPlot(y_train, yhat_train, \"Actual Values (Train)\", \"Predicted Values (Train)\", Title)",
"_____no_output_____"
]
],
[
[
"Figure 1: Plot of predicted values using the training data compared to the training data. \n",
"_____no_output_____"
],
[
"So far the model seems to be doing well in learning from the training dataset. But what happens when the model encounters new data from the testing dataset? When the model generates new values from the test data, we see the distribution of the predicted values is much different from the actual target values. \n",
"_____no_output_____"
]
],
[
[
"Title='Distribution Plot of Predicted Value Using Test Data vs Data Distribution of Test Data'\nDistributionPlot(y_test,yhat_test,\"Actual Values (Test)\",\"Predicted Values (Test)\",Title)",
"_____no_output_____"
]
],
[
[
"Figur 2: Plot of predicted value using the test data compared to the test data. \n",
"_____no_output_____"
],
[
"<p>Comparing Figure 1 and Figure 2; it is evident the distribution of the test data in Figure 1 is much better at fitting the data. This difference in Figure 2 is apparent where the ranges are from 5000 to 15 000. This is where the distribution shape is exceptionally different. Let's see if polynomial regression also exhibits a drop in the prediction accuracy when analysing the test dataset.</p>\n",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import PolynomialFeatures",
"_____no_output_____"
]
],
[
[
"<h4>Overfitting</h4>\n<p>Overfitting occurs when the model fits the noise, not the underlying process. Therefore when testing your model using the test-set, your model does not perform as well as it is modelling noise, not the underlying process that generated the relationship. Let's create a degree 5 polynomial model.</p>\n",
"_____no_output_____"
],
[
"Let's use 55 percent of the data for training and the rest for testing:\n",
"_____no_output_____"
]
],
[
[
"x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.45, random_state=0)",
"_____no_output_____"
]
],
[
[
"We will perform a degree 5 polynomial transformation on the feature <b>'horse power'</b>. \n",
"_____no_output_____"
]
],
[
[
"pr = PolynomialFeatures(degree=5)\nx_train_pr = pr.fit_transform(x_train[['horsepower']])\nx_test_pr = pr.fit_transform(x_test[['horsepower']])\npr",
"_____no_output_____"
]
],
[
[
"Now let's create a linear regression model \"poly\" and train it.\n",
"_____no_output_____"
]
],
[
[
"poly = LinearRegression()\npoly.fit(x_train_pr, y_train)",
"_____no_output_____"
]
],
[
[
"We can see the output of our model using the method \"predict.\" then assign the values to \"yhat\".\n",
"_____no_output_____"
]
],
[
[
"yhat = poly.predict(x_test_pr)\nyhat[0:5]",
"_____no_output_____"
]
],
[
[
"Let's take the first five predicted values and compare it to the actual targets. \n",
"_____no_output_____"
]
],
[
[
"print(\"Predicted values:\", yhat[0:4])\nprint(\"True values:\", y_test[0:4].values)",
"_____no_output_____"
]
],
[
[
"We will use the function \"PollyPlot\" that we defined at the beginning of the lab to display the training data, testing data, and the predicted function.\n",
"_____no_output_____"
]
],
[
[
"PollyPlot(x_train[['horsepower']], x_test[['horsepower']], y_train, y_test, poly,pr)",
"_____no_output_____"
]
],
[
[
"Figur 4 A polynomial regression model, red dots represent training data, green dots represent test data, and the blue line represents the model prediction. \n",
"_____no_output_____"
],
[
"We see that the estimated function appears to track the data but around 200 horsepower, the function begins to diverge from the data points. \n",
"_____no_output_____"
],
[
" R^2 of the training data:\n",
"_____no_output_____"
]
],
[
[
"poly.score(x_train_pr, y_train)",
"_____no_output_____"
]
],
[
[
" R^2 of the test data:\n",
"_____no_output_____"
]
],
[
[
"poly.score(x_test_pr, y_test)",
"_____no_output_____"
]
],
[
[
"We see the R^2 for the training data is 0.5567 while the R^2 on the test data was -29.87. The lower the R^2, the worse the model, a Negative R^2 is a sign of overfitting.\n",
"_____no_output_____"
],
[
"Let's see how the R^2 changes on the test data for different order polynomials and plot the results:\n",
"_____no_output_____"
]
],
[
[
"Rsqu_test = []\n\norder = [1, 2, 3, 4]\nfor n in order:\n pr = PolynomialFeatures(degree=n)\n \n x_train_pr = pr.fit_transform(x_train[['horsepower']])\n \n x_test_pr = pr.fit_transform(x_test[['horsepower']]) \n \n lr.fit(x_train_pr, y_train)\n \n Rsqu_test.append(lr.score(x_test_pr, y_test))\n\nplt.plot(order, Rsqu_test)\nplt.xlabel('order')\nplt.ylabel('R^2')\nplt.title('R^2 Using Test Data')\nplt.text(3, 0.75, 'Maximum R^2 ') ",
"_____no_output_____"
]
],
[
[
"We see the R^2 gradually increases until an order three polynomial is used. Then the R^2 dramatically decreases at four.\n",
"_____no_output_____"
],
[
"The following function will be used in the next section; please run the cell.\n",
"_____no_output_____"
]
],
[
[
"def f(order, test_data):\n x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=test_data, random_state=0)\n pr = PolynomialFeatures(degree=order)\n x_train_pr = pr.fit_transform(x_train[['horsepower']])\n x_test_pr = pr.fit_transform(x_test[['horsepower']])\n poly = LinearRegression()\n poly.fit(x_train_pr,y_train)\n PollyPlot(x_train[['horsepower']], x_test[['horsepower']], y_train,y_test, poly, pr)",
"_____no_output_____"
]
],
[
[
"The following interface allows you to experiment with different polynomial orders and different amounts of data. \n",
"_____no_output_____"
]
],
[
[
"interact(f, order=(0, 6, 1), test_data=(0.05, 0.95, 0.05))",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #4a):</h1>\n\n<b>We can perform polynomial transformations with more than one feature. Create a \"PolynomialFeatures\" object \"pr1\" of degree two?</b>\n\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\npr1=PolynomialFeatures(degree=2)\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #4b): </h1>\n\n<b> \n Transform the training and testing samples for the features 'horsepower', 'curb-weight', 'engine-size' and 'highway-mpg'. Hint: use the method \"fit_transform\" \n?</b>\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\nx_train_pr1=pr1.fit_transform(x_train[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']])\n\nx_test_pr1=pr1.fit_transform(x_test[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']])\n\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
"<!-- The answer is below:\n\nx_train_pr1=pr.fit_transform(x_train[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']])\nx_test_pr1=pr.fit_transform(x_test[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']])\n\n-->\n",
"_____no_output_____"
],
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #4c): </h1>\n<b> \nHow many dimensions does the new feature have? Hint: use the attribute \"shape\"\n</b>\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\nx_train_pr1.shape #there are now 15 features\n\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #4d): </h1>\n\n<b> \nCreate a linear regression model \"poly1\" and train the object using the method \"fit\" using the polynomial features?</b>\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\npoly1=LinearRegression().fit(x_train_pr1,y_train)\n\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
" <div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #4e): </h1>\n<b>Use the method \"predict\" to predict an output on the polynomial features, then use the function \"DistributionPlot\" to display the distribution of the predicted output vs the test data?</b>\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\nyhat_test1=poly1.predict(x_test_pr1)\n\nTitle='Distribution Plot of Predicted Value Using Test Data vs Data Distribution of Test Data'\n\nDistributionPlot(y_test, yhat_test1, \"Actual Values (Test)\", \"Predicted Values (Test)\", Title)\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #4f): </h1>\n\n<b>Using the distribution plot above, explain in words about the two regions were the predicted prices are less accurate than the actual prices</b>\n\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\n#The predicted value is higher than actual value for cars where the price $10,000 range, conversely the predicted price is lower than the price cost in the $30,000 to $40,000 range. As such the model is not as accurate in these ranges.\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
"<h2 id=\"ref3\">Part 3: Ridge regression</h2> \n",
"_____no_output_____"
],
[
" In this section, we will review Ridge Regression we will see how the parameter Alfa changes the model. Just a note here our test data will be used as validation data.\n",
"_____no_output_____"
],
[
" Let's perform a degree two polynomial transformation on our data. \n",
"_____no_output_____"
]
],
[
[
"pr=PolynomialFeatures(degree=2)\nx_train_pr=pr.fit_transform(x_train[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg','normalized-losses','symboling']])\nx_test_pr=pr.fit_transform(x_test[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg','normalized-losses','symboling']])",
"_____no_output_____"
]
],
[
[
" Let's import <b>Ridge</b> from the module <b>linear models</b>.\n",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import Ridge",
"_____no_output_____"
]
],
[
[
"Let's create a Ridge regression object, setting the regularization parameter to 0.1 \n",
"_____no_output_____"
]
],
[
[
"RigeModel=Ridge(alpha=0.1)",
"_____no_output_____"
]
],
[
[
"Like regular regression, you can fit the model using the method <b>fit</b>.\n",
"_____no_output_____"
]
],
[
[
"RigeModel.fit(x_train_pr, y_train)",
"_____no_output_____"
]
],
[
[
" Similarly, you can obtain a prediction: \n",
"_____no_output_____"
]
],
[
[
"yhat = RigeModel.predict(x_test_pr)",
"_____no_output_____"
]
],
[
[
"Let's compare the first five predicted samples to our test set \n",
"_____no_output_____"
]
],
[
[
"print('predicted:', yhat[0:4])\nprint('test set :', y_test[0:4].values)",
"_____no_output_____"
]
],
[
[
"We select the value of Alpha that minimizes the test error, for example, we can use a for loop. \n",
"_____no_output_____"
]
],
[
[
"Rsqu_test = []\nRsqu_train = []\ndummy1 = []\nAlpha = 10 * np.array(range(0,1000))\nfor alpha in Alpha:\n RigeModel = Ridge(alpha=alpha) \n RigeModel.fit(x_train_pr, y_train)\n Rsqu_test.append(RigeModel.score(x_test_pr, y_test))\n Rsqu_train.append(RigeModel.score(x_train_pr, y_train))",
"_____no_output_____"
]
],
[
[
"We can plot out the value of R^2 for different Alphas \n",
"_____no_output_____"
]
],
[
[
"width = 12\nheight = 10\nplt.figure(figsize=(width, height))\n\nplt.plot(Alpha,Rsqu_test, label='validation data ')\nplt.plot(Alpha,Rsqu_train, 'r', label='training Data ')\nplt.xlabel('alpha')\nplt.ylabel('R^2')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"**Figure 6**:The blue line represents the R^2 of the validation data, and the red line represents the R^2 of the training data. The x-axis represents the different values of Alpha. \n",
"_____no_output_____"
],
[
"Here the model is built and tested on the same data. So the training and test data are the same.\n\nThe red line in figure 6 represents the R^2 of the training data. \nAs Alpha increases the R^2 decreases. \nTherefore as Alpha increases the model performs worse on the training data. \n\nThe blue line represents the R^2 on the validation data. \nAs the value for Alpha increases the R^2 increases and converges at a point \n",
"_____no_output_____"
],
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #5): </h1>\n\nPerform Ridge regression and calculate the R^2 using the polynomial features, use the training data to train the model and test data to test the model. The parameter alpha should be set to 10.\n\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\nRigeModel = Ridge(alpha=10) \nRigeModel.fit(x_train_pr, y_train)\nRigeModel.score(x_test_pr, y_test)\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
"<h2 id=\"ref4\">Part 4: Grid Search</h2>\n",
"_____no_output_____"
],
[
"The term Alfa is a hyperparameter, sklearn has the class <b>GridSearchCV</b> to make the process of finding the best hyperparameter simpler.\n",
"_____no_output_____"
],
[
"Let's import <b>GridSearchCV</b> from the module <b>model_selection</b>.\n",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import GridSearchCV",
"_____no_output_____"
]
],
[
[
"We create a dictionary of parameter values:\n",
"_____no_output_____"
]
],
[
[
"parameters1= [{'alpha': [0.001,0.1,1, 10, 100, 1000, 10000, 100000, 100000]}]\nparameters1",
"_____no_output_____"
]
],
[
[
"Create a ridge regions object:\n",
"_____no_output_____"
]
],
[
[
"RR=Ridge()\nRR",
"_____no_output_____"
]
],
[
[
"Create a ridge grid search object \n",
"_____no_output_____"
]
],
[
[
"Grid1 = GridSearchCV(RR, parameters1,cv=4)",
"_____no_output_____"
]
],
[
[
"Fit the model \n",
"_____no_output_____"
]
],
[
[
"Grid1.fit(x_data[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']], y_data)",
"_____no_output_____"
]
],
[
[
"The object finds the best parameter values on the validation data. We can obtain the estimator with the best parameters and assign it to the variable BestRR as follows:\n",
"_____no_output_____"
]
],
[
[
"BestRR=Grid1.best_estimator_\nBestRR",
"_____no_output_____"
]
],
[
[
" We now test our model on the test data \n",
"_____no_output_____"
]
],
[
[
"BestRR.score(x_test[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']], y_test)",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #6): </h1>\nPerform a grid search for the alpha parameter and the normalization parameter, then find the best values of the parameters\n</div>\n",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\nparameters2= [{'alpha': [0.001,0.1,1, 10, 100, 1000,10000,100000,100000],'normalize':[True,False]} ]\nGrid2 = GridSearchCV(Ridge(), parameters2,cv=4)\nGrid2.fit(x_data[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']],y_data)\nGrid2.best_estimator_\n\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
"### Thank you for completing this lab!\n\n## Author\n\n<a href=\"https://www.linkedin.com/in/joseph-s-50398b136/\" target=\"_blank\">Joseph Santarcangelo</a>\n\n### Other Contributors\n\n<a href=\"https://www.linkedin.com/in/mahdi-noorian-58219234/\" target=\"_blank\">Mahdi Noorian PhD</a>\n\nBahare Talayian\n\nEric Xiao\n\nSteven Dong\n\nParizad\n\nHima Vasudevan\n\n<a href=\"https://www.linkedin.com/in/fiorellawever/\" target=\"_blank\">Fiorella Wenver</a>\n\n<a href=\" https://www.linkedin.com/in/yi-leng-yao-84451275/ \" target=\"_blank\" >Yi Yao</a>.\n\n## Change Log\n\n| Date (YYYY-MM-DD) | Version | Changed By | Change Description |\n| ----------------- | ------- | ---------- | ----------------------------------- |\n| 2020-10-30 | 2.3 | Lakshmi | Changed URL of csv |\n| 2020-10-05 | 2.2 | Lakshmi | Removed unused library imports |\n| 2020-09-14 | 2.1 | Lakshmi | Made changes in OverFitting section |\n| 2020-08-27 | 2.0 | Lavanya | Moved lab to course repo in GitLab |\n\n<hr>\n\n## <h3 align=\"center\"> © IBM Corporation 2020. All rights reserved. <h3/>\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
]
|
e7bdc3de31ce18a5325ab785752b2d77ff406427 | 69,881 | ipynb | Jupyter Notebook | Introduction_to_Pandas.ipynb | Jokos-git/Covid19VaccineAesiDiagnostics | f2188e4361a6d2dcff0f029862cb0b41279c1ae7 | [
"Apache-2.0"
]
| null | null | null | Introduction_to_Pandas.ipynb | Jokos-git/Covid19VaccineAesiDiagnostics | f2188e4361a6d2dcff0f029862cb0b41279c1ae7 | [
"Apache-2.0"
]
| null | null | null | Introduction_to_Pandas.ipynb | Jokos-git/Covid19VaccineAesiDiagnostics | f2188e4361a6d2dcff0f029862cb0b41279c1ae7 | [
"Apache-2.0"
]
| null | null | null | 32.158767 | 315 | 0.337989 | [
[
[
"<a href=\"https://colab.research.google.com/github/Jokos-git/Covid19VaccineAesiDiagnostics/blob/master/Introduction_to_Pandas.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# DESU IA4 HEALH\n#Info-PROF, Introduction to Python programming for health data",
"_____no_output_____"
],
[
"#Session 2: Introduction to PANDAS\n\n#Leaning objectives\n\n\n1. Learning the different data types in pandas: Data frame and series\n2. Importing and exporting data into a data frame\n2. Subseting data frames\n5. Doing transformations with dataframes\n",
"_____no_output_____"
],
[
"##What is Pandas?\nPandas is a Python library used for working with data sets.\n\nIt has functions for analyzing, cleaning, exploring, and manipulating data.\n\nPandas on-line documentation :\n https://pandas.pydata.org/docs/reference/index.html \n\n",
"_____no_output_____"
]
],
[
[
"#Importing Pandas and verifying the version\nimport pandas as pd # as allows to create an alias\nimport numpy as np\n\nprint(pd.__version__) #allow to verify the pandas function",
"1.1.5\n"
]
],
[
[
"##Data types on Pandas :\n\n\n1. **Series :** It is a one-dimensional array holding data of any type.\n2. **Dataframes :** Multidimensional data tables holding data of any type. We can think that the series are like the columns of a dataframe whereas the whole table is the dataframe.\n\n",
"_____no_output_____"
]
],
[
[
"# Example series with labels\n\n\na = [1, 7, 2]\n\nmyvar = pd.Series(a, index = [\"x\", \"y\", \"z\"])\n\nprint(myvar)",
"x 1\ny 7\nz 2\ndtype: int64\n"
]
],
[
[
"## Dataframes \nDataframes are multidiomensional matrices that can store data of different types.",
"_____no_output_____"
]
],
[
[
"\ndata = {\n \"calories\": [420, 380, 390],\n \"duration\": [50, 40, 45],\n \"category\" : ['a','b','c']\n}\n\ndf = pd.DataFrame(data, index = [\"day1\", \"day2\", \"day3\"])\n\nprint(df) ",
" calories duration category\nday1 420 50 a\nday2 380 40 b\nday3 390 45 c\n"
],
[
"students = [ ('jack', 34, 'Sydeny') ,\n ('Riti', 30, 'Delhi' ) ,\n ('Aadi', 16, 'New York') ]\n# Create a DataFrame object\ndfObj = pd.DataFrame(students, columns = ['Name' , 'Age', 'City'], index=['a', 'b', 'c'])",
"_____no_output_____"
]
],
[
[
"**Exercise :** Create a dataframe that stores in one row the person ID, height, weight, sex and birthdate. Add at least three examples",
"_____no_output_____"
],
[
"\n##[DataFrame attributes](https://pandas.pydata.org/docs/reference/frame.html)\n",
"_____no_output_____"
],
[
"Exercise : For the dataframe previously created, go to dataframe attributes and show the following information : \n1. Number of elements\n2. Name of the columns\n3. Name of the rows\n4. Number of rows and columns\n5. Show the first rows of the dataframe\n",
"_____no_output_____"
],
[
"##Acces the elements of a dataframe :\n\nAccess by columns:\n",
"_____no_output_____"
]
],
[
[
"df['calories']\n\n",
"_____no_output_____"
]
],
[
[
"###DataFrame.loc | Select Column & Rows by Name\nDataFrame provides indexing label loc for selecting columns and rows by names \n\ndataFrame.loc[ROWS RANGE , COLUMNS RANGE]",
"_____no_output_____"
]
],
[
[
"df.loc['day1',:]",
"_____no_output_____"
],
[
"df.loc[:,'calories']",
"_____no_output_____"
]
],
[
[
"###DataFrame.iloc | Select Column Indexes & Rows Index Positions\nDataFrame provides indexing label iloc for accessing the column and rows by index positions i.e.\n*dataFrame.iloc[ROWS INDEX RANGE , COLUMNS INDEX RANGE]*\n\nIt selects the columns and rows from DataFrame by index position specified in range. If ‘:’ is given in rows or column Index Range then all entries will be included for corresponding row or column.",
"_____no_output_____"
]
],
[
[
"df.iloc[:,[0,2]]",
"_____no_output_____"
]
],
[
[
"###Variable conversion : ",
"_____no_output_____"
]
],
[
[
"df_petit = pd.DataFrame({ 'Country': ['France','Spain','Germany', 'Spain','Germany', 'France', 'Italy'], 'Age': [50,60,40,20,40,30, 20] })\ndf_petit\n\n",
"_____no_output_____"
]
],
[
[
"####Label encoding : \nLabel Encoding refers to converting the labels into a numeric form so as to convert them into the machine-readable form. Machine learning algorithms can then decide in a better way how those labels must be operated. It is an important pre-processing step for the structured dataset in supervised learning.",
"_____no_output_____"
]
],
[
[
"df_petit['Country_cat'] = df_petit['Country'].astype('category').cat.codes\ndf_petit",
"_____no_output_____"
]
],
[
[
"#### One hot encoding",
"_____no_output_____"
]
],
[
[
"help(pd.get_dummies)",
"Help on function get_dummies in module pandas.core.reshape.reshape:\n\nget_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None) -> 'DataFrame'\n Convert categorical variable into dummy/indicator variables.\n \n Parameters\n ----------\n data : array-like, Series, or DataFrame\n Data of which to get dummy indicators.\n prefix : str, list of str, or dict of str, default None\n String to append DataFrame column names.\n Pass a list with length equal to the number of columns\n when calling get_dummies on a DataFrame. Alternatively, `prefix`\n can be a dictionary mapping column names to prefixes.\n prefix_sep : str, default '_'\n If appending prefix, separator/delimiter to use. Or pass a\n list or dictionary as with `prefix`.\n dummy_na : bool, default False\n Add a column to indicate NaNs, if False NaNs are ignored.\n columns : list-like, default None\n Column names in the DataFrame to be encoded.\n If `columns` is None then all the columns with\n `object` or `category` dtype will be converted.\n sparse : bool, default False\n Whether the dummy-encoded columns should be backed by\n a :class:`SparseArray` (True) or a regular NumPy array (False).\n drop_first : bool, default False\n Whether to get k-1 dummies out of k categorical levels by removing the\n first level.\n dtype : dtype, default np.uint8\n Data type for new columns. Only a single dtype is allowed.\n \n .. versionadded:: 0.23.0\n \n Returns\n -------\n DataFrame\n Dummy-coded data.\n \n See Also\n --------\n Series.str.get_dummies : Convert Series to dummy codes.\n \n Examples\n --------\n >>> s = pd.Series(list('abca'))\n \n >>> pd.get_dummies(s)\n a b c\n 0 1 0 0\n 1 0 1 0\n 2 0 0 1\n 3 1 0 0\n \n >>> s1 = ['a', 'b', np.nan]\n \n >>> pd.get_dummies(s1)\n a b\n 0 1 0\n 1 0 1\n 2 0 0\n \n >>> pd.get_dummies(s1, dummy_na=True)\n a b NaN\n 0 1 0 0\n 1 0 1 0\n 2 0 0 1\n \n >>> df = pd.DataFrame({'A': ['a', 'b', 'a'], 'B': ['b', 'a', 'c'],\n ... 'C': [1, 2, 3]})\n \n >>> pd.get_dummies(df, prefix=['col1', 'col2'])\n C col1_a col1_b col2_a col2_b col2_c\n 0 1 1 0 0 1 0\n 1 2 0 1 1 0 0\n 2 3 1 0 0 0 1\n \n >>> pd.get_dummies(pd.Series(list('abcaa')))\n a b c\n 0 1 0 0\n 1 0 1 0\n 2 0 0 1\n 3 1 0 0\n 4 1 0 0\n \n >>> pd.get_dummies(pd.Series(list('abcaa')), drop_first=True)\n b c\n 0 0 0\n 1 1 0\n 2 0 1\n 3 0 0\n 4 0 0\n \n >>> pd.get_dummies(pd.Series(list('abc')), dtype=float)\n a b c\n 0 1.0 0.0 0.0\n 1 0.0 1.0 0.0\n 2 0.0 0.0 1.0\n\n"
],
[
"\ndf_petit = pd.get_dummies(df_petit,prefix=['Country'], columns = ['Country'], drop_first=True)\ndf_petit.head()",
"_____no_output_____"
]
],
[
[
"**Exercise :** Create a dataframe with 3 columns with the characteristics : ID, sex (M or F), frailty degree (FB, M, F). Convert the categorical variables using label encoding and one-hot-encoding.",
"_____no_output_____"
],
[
"#Dealing with dates \nhttps://pandas.pydata.org/docs/reference/api/pandas.to_datetime.html\n",
"_____no_output_____"
]
],
[
[
"#Library to deeal with dates\nimport datetime",
"_____no_output_____"
],
[
"dti = pd.to_datetime(\n [\"1/1/2018\", np.datetime64(\"2018-01-01\"), datetime.datetime(2018, 1, 1)]\n)\ndti",
"_____no_output_____"
],
[
"df = pd.DataFrame({'date': ['3/10/2000', '3/11/2000', '3/12/2000'],\n 'value': [2, 3, 4]})\ndf['date'] = pd.to_datetime(df['date'])\ndf",
"_____no_output_____"
]
],
[
[
"### Cutomize the date format",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame({'date': ['2016-6-10 20:30:0', \n '2016-7-1 19:45:30', \n '2013-10-12 4:5:1'],\n 'value': [2, 3, 4]})\ndf['date'] = pd.to_datetime(df['date'], format=\"%Y-%d-%m %H:%M:%S\")\ndf",
"_____no_output_____"
]
],
[
[
"**Exercise :** Check the Pandas documentation and create a dataframe with a columns with dates and try different datetypes.\n",
"_____no_output_____"
],
[
"###Access date elements dt. accessor :\nThe dt. accessor is an object that allows to access the different data and time elements in a datatime object.\nhttps://pandas.pydata.org/docs/reference/api/pandas.Series.dt.html",
"_____no_output_____"
]
],
[
[
"df['date_only'] = df['date'].dt.date\n\ndf['time_only'] = df['date'].dt.time\n\ndf['hour_only'] = df['date'].dt.hour\n\ndf",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"#Importing datasets\n\nhttps://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html\n\n",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(\"https://raw.githubusercontent.com/rakelup/EPICLIN2021/master/diabetes.csv\", sep=\",\",error_bad_lines=False)\ndf.head()",
"_____no_output_____"
]
],
[
[
"### Data overview",
"_____no_output_____"
]
],
[
[
"# Data overview\nprint ('Rows : ', df.shape[0])\nprint ('Coloumns : ', df.shape[1])\nprint ('\\nFeatures : \\n', df.columns.tolist())\nprint ('\\nNumber of Missing values: ', df.isnull().sum().values.sum())\nprint ('\\nNumber of unique values : \\n', df.nunique())",
"Rows : 768\nColoumns : 9\n\nFeatures : \n ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']\n\nNumber of Missing values: 0\n\nNumber of unique values : \n Pregnancies 17\nGlucose 136\nBloodPressure 47\nSkinThickness 51\nInsulin 186\nBMI 248\nDiabetesPedigreeFunction 517\nAge 52\nOutcome 2\ndtype: int64\n"
],
[
"df.describe()",
"_____no_output_____"
],
[
"df.columns",
"_____no_output_____"
]
],
[
[
"## Cleaning data in a dataframe: \n1. Dealing with missing values\n2. Data in wrong format\n3. Wrong data\n4. Duplicates\n",
"_____no_output_____"
],
[
"###Dealing with missing values : \n\nHandling missing values is an essential part of data cleaning and preparation process since almost all data in real life comes with some missing values.\n",
"_____no_output_____"
],
[
"###Check for missing values",
"_____no_output_____"
]
],
[
[
"df.info()\ndf.isnull().sum()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 768 entries, 0 to 767\nData columns (total 9 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Pregnancies 768 non-null int64 \n 1 Glucose 768 non-null int64 \n 2 BloodPressure 768 non-null int64 \n 3 SkinThickness 768 non-null int64 \n 4 Insulin 768 non-null int64 \n 5 BMI 768 non-null float64\n 6 DiabetesPedigreeFunction 768 non-null float64\n 7 Age 768 non-null int64 \n 8 Outcome 768 non-null int64 \ndtypes: float64(2), int64(7)\nmemory usage: 54.1 KB\n"
]
],
[
[
" Let's create a daframe with missing values. ",
"_____no_output_____"
]
],
[
[
"df2 = df\ndf2.Glucose.replace(99, np.nan, inplace=True)\ndf2.BloodPressure.replace(74, np.nan, inplace=True)\n\nprint ('\\nNumber of Missing values: ', df2.isnull().sum())\nprint ('\\nTotal number of missing values : ', df2.isnull().sum().values.sum())\n\n\n",
"\nValeurs manquantes: Pregnancies 0\nGlucose 17\nBloodPressure 52\nSkinThickness 0\nInsulin 0\nBMI 0\nDiabetesPedigreeFunction 0\nAge 0\nOutcome 0\ndtype: int64\n\nValeurs manquantes total: 69\n"
]
],
[
[
"###First strategy : Removing the whole row that contains a missing value",
"_____no_output_____"
]
],
[
[
"# Removing the whole row\ndf3 = df2.dropna()\n\nprint ('\\nValeurs manquantes: ', df3.isnull().sum())\nprint ('\\nValeurs manquantes total: ', df3.isnull().sum().values.sum())",
"\nValeurs manquantes: Pregnancies 0\nGlucose 0\nBloodPressure 0\nSkinThickness 0\nInsulin 0\nBMI 0\nDiabetesPedigreeFunction 0\nAge 0\nOutcome 0\ndtype: int64\n\nValeurs manquantes total: 0\n"
],
[
"\n\n##Replace the missing values\n\ndf2.Glucose.replace(np.nan, df['Glucose'].median(), inplace=True)\ndf2.BloodPressure.replace(np.nan, df['BloodPressure'].median(), inplace=True)\n",
"_____no_output_____"
]
],
[
[
"##Sorting the data\n\nhttps://pandas.pydata.org/docs/reference/api/pandas.DataFrame.sort_values.html",
"_____no_output_____"
]
],
[
[
"#Trier les données\nb = df.sort_values('Pregnancies')\nb.head()",
"_____no_output_____"
]
],
[
[
"**Exercise :** Sort the data in descending order according to the insulin level and store the data in a new Data frame. How to store the data in the same dataframe?",
"_____no_output_____"
],
[
"## Subseting the data",
"_____no_output_____"
]
],
[
[
"df[df['BloodPressure'] >70].count() # Filtrage par valeur",
"_____no_output_____"
],
[
"df_court = df[['Insulin','Glucose']]\n\ndf_court.drop('Insulin', inplace= True, axis = 1)\n\ndf_court.head()",
"/usr/local/lib/python3.7/dist-packages/pandas/core/frame.py:4174: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n errors=errors,\n"
]
],
[
[
"## Statistics applied to dataframes\n\nDataFrame.aggregate(func=None, axis=0, *args, **kwargs)\nAggregate using one or more operations over the specified axis.\n\nhttps://pandas.pydata.org/docs/reference/api/pandas.DataFrame.aggregate.html",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7bdc429f7fffa84d906b82d5ef151033a848305 | 13,661 | ipynb | Jupyter Notebook | Course 1 - Introduction to TensorFlow for AI, ML and DL/Week 4 - Using Real-world Images/Exercise4-Question.ipynb | dksifoua/TensorFlow-in-Practice | c7de142e2bb482ef31a157a1e29e165e14473376 | [
"MIT"
]
| null | null | null | Course 1 - Introduction to TensorFlow for AI, ML and DL/Week 4 - Using Real-world Images/Exercise4-Question.ipynb | dksifoua/TensorFlow-in-Practice | c7de142e2bb482ef31a157a1e29e165e14473376 | [
"MIT"
]
| null | null | null | Course 1 - Introduction to TensorFlow for AI, ML and DL/Week 4 - Using Real-world Images/Exercise4-Question.ipynb | dksifoua/TensorFlow-in-Practice | c7de142e2bb482ef31a157a1e29e165e14473376 | [
"MIT"
]
| null | null | null | 13,661 | 13,661 | 0.65288 | [
[
[
"import tensorflow as tf\nimport os\nimport zipfile\nimport urllib\nurllib.request.urlretrieve(\"https://storage.googleapis.com/laurencemoroney-blog.appspot.com/happy-or-sad.zip\",\n filename=\"/tmp/happy-or-sad.zip\")\n\nzip_ref = zipfile.ZipFile(\"/tmp/happy-or-sad.zip\", 'r')\nzip_ref.extractall(\"/tmp/h-or-s\")\nzip_ref.close()",
"_____no_output_____"
]
],
[
[
"We're going to reate a convolutional neural network that trains to 100% accuracy on these images download below and which cancels training upon hitting training accuracy of >.999",
"_____no_output_____"
]
],
[
[
"DESIRED_ACCURACY = 0.999\n\nclass StopTrainingCallback(tf.keras.callbacks.Callback):\n \n def on_epoch_end(self, epoch, logs=None):\n if logs.get('acc') >= DESIRED_ACCURACY:\n print(f'\\nReached {DESIRED_ACCURACY} accuracy so canceling training!')\n self.model.stop_training = True",
"_____no_output_____"
],
[
"model = tf.keras.models.Sequential([\n tf.keras.layers.Conv2D(16, kernel_size=(3, 3), padding='same', activation='relu', input_shape=(300, 300, 3)),\n tf.keras.layers.MaxPool2D(2),\n tf.keras.layers.Conv2D(32, kernel_size=(3, 3), padding='same', activation='relu'),\n tf.keras.layers.MaxPool2D(2),\n tf.keras.layers.Conv2D(64, kernel_size=(3, 3), padding='same', activation='relu'),\n tf.keras.layers.MaxPool2D(2),\n tf.keras.layers.Flatten(),\n tf.keras.layers.Dense(units=128, activation='relu'),\n tf.keras.layers.Dense(units=1, activation='sigmoid')\n])\nmodel.summary()",
"WARNING: Logging before flag parsing goes to stderr.\nW0819 13:47:21.340875 140518546093952 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/init_ops.py:1251: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nCall initializer instance with the dtype argument instead of passing it to the constructor\n"
],
[
"model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['accuracy'])",
"W0819 13:47:25.364413 140518546093952 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/nn_impl.py:180: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\n"
],
[
"%%time\ntrain_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)\ntrain_generator = train_datagen.flow_from_directory(\n '/tmp/h-or-s',\n target_size=(300, 300),\n batch_size=2,\n class_mode='binary')\nhistory = model.fit_generator(train_generator, steps_per_epoch=8, epochs=15, callbacks=[StopTrainingCallback()])",
"Found 80 images belonging to 2 classes.\nEpoch 1/15\n5/8 [=================>............] - ETA: 0s - loss: 0.0070 - acc: 1.0000 \nReached 0.999 accuracy so canceling training!\n8/8 [==============================] - 0s 17ms/step - loss: 0.0055 - acc: 1.0000\nCPU times: user 225 ms, sys: 23.4 ms, total: 248 ms\nWall time: 250 ms\n"
],
[
"# help(tf.keras.models.Model.fit_generator)",
"Help on function fit_generator in module tensorflow.python.keras.engine.training:\n\nfit_generator(self, generator, steps_per_epoch=None, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, validation_freq=1, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=False, shuffle=True, initial_epoch=0)\n Fits the model on data yielded batch-by-batch by a Python generator.\n \n The generator is run in parallel to the model, for efficiency.\n For instance, this allows you to do real-time data augmentation\n on images on CPU in parallel to training your model on GPU.\n \n The use of `keras.utils.Sequence` guarantees the ordering\n and guarantees the single use of every input per epoch when\n using `use_multiprocessing=True`.\n \n Arguments:\n generator: A generator or an instance of `Sequence`\n (`keras.utils.Sequence`)\n object in order to avoid duplicate data\n when using multiprocessing.\n The output of the generator must be either\n - a tuple `(inputs, targets)`\n - a tuple `(inputs, targets, sample_weights)`.\n This tuple (a single output of the generator) makes a single batch.\n Therefore, all arrays in this tuple must have the same length (equal\n to the size of this batch). Different batches may have different\n sizes.\n For example, the last batch of the epoch is commonly smaller than\n the\n others, if the size of the dataset is not divisible by the batch\n size.\n The generator is expected to loop over its data\n indefinitely. An epoch finishes when `steps_per_epoch`\n batches have been seen by the model.\n steps_per_epoch: Total number of steps (batches of samples)\n to yield from `generator` before declaring one epoch\n finished and starting the next epoch. It should typically\n be equal to the number of samples of your dataset\n divided by the batch size.\n Optional for `Sequence`: if unspecified, will use\n the `len(generator)` as a number of steps.\n epochs: Integer, total number of iterations on the data.\n verbose: Verbosity mode, 0, 1, or 2.\n callbacks: List of callbacks to be called during training.\n validation_data: This can be either\n - a generator for the validation data\n - a tuple (inputs, targets)\n - a tuple (inputs, targets, sample_weights).\n validation_steps: Only relevant if `validation_data`\n is a generator. Total number of steps (batches of samples)\n to yield from `generator` before stopping.\n Optional for `Sequence`: if unspecified, will use\n the `len(validation_data)` as a number of steps.\n validation_freq: Only relevant if validation data is provided. Integer\n or `collections.Container` instance (e.g. list, tuple, etc.). If an\n integer, specifies how many training epochs to run before a new\n validation run is performed, e.g. `validation_freq=2` runs\n validation every 2 epochs. If a Container, specifies the epochs on\n which to run validation, e.g. `validation_freq=[1, 2, 10]` runs\n validation at the end of the 1st, 2nd, and 10th epochs.\n class_weight: Dictionary mapping class indices to a weight\n for the class.\n max_queue_size: Integer. Maximum size for the generator queue.\n If unspecified, `max_queue_size` will default to 10.\n workers: Integer. Maximum number of processes to spin up\n when using process-based threading.\n If unspecified, `workers` will default to 1. If 0, will\n execute the generator on the main thread.\n use_multiprocessing: Boolean.\n If `True`, use process-based threading.\n If unspecified, `use_multiprocessing` will default to `False`.\n Note that because this implementation relies on multiprocessing,\n you should not pass non-picklable arguments to the generator\n as they can't be passed easily to children processes.\n shuffle: Boolean. Whether to shuffle the order of the batches at\n the beginning of each epoch. Only used with instances\n of `Sequence` (`keras.utils.Sequence`).\n Has no effect when `steps_per_epoch` is not `None`.\n initial_epoch: Epoch at which to start training\n (useful for resuming a previous training run)\n \n Returns:\n A `History` object.\n \n Example:\n \n ```python\n def generate_arrays_from_file(path):\n while 1:\n f = open(path)\n for line in f:\n # create numpy arrays of input data\n # and labels, from each line in the file\n x1, x2, y = process_line(line)\n yield ({'input_1': x1, 'input_2': x2}, {'output': y})\n f.close()\n \n model.fit_generator(generate_arrays_from_file('/my_file.txt'),\n steps_per_epoch=10000, epochs=10)\n ```\n Raises:\n ValueError: In case the generator yields data in an invalid format.\n\n"
],
[
"",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bdcd2ad53bd11216bb87b65b5d68c79aac8c4c | 44,534 | ipynb | Jupyter Notebook | tsp_GA.ipynb | avitomar12/TSP-using-Genetic-Algorithm | 3570b2b6454389034bbf84f007213ebd84175370 | [
"MIT"
]
| 5 | 2020-09-01T05:34:56.000Z | 2022-03-10T16:26:14.000Z | tsp_GA.ipynb | avitomar12/TSP-using-Genetic-Algorithm | 3570b2b6454389034bbf84f007213ebd84175370 | [
"MIT"
]
| null | null | null | tsp_GA.ipynb | avitomar12/TSP-using-Genetic-Algorithm | 3570b2b6454389034bbf84f007213ebd84175370 | [
"MIT"
]
| 17 | 2020-03-11T16:50:09.000Z | 2022-03-10T16:25:14.000Z | 103.808858 | 24,934 | 0.841537 | [
[
[
"import numpy as np, random, operator, pandas as pd\nimport matplotlib.pyplot as plt\n",
"_____no_output_____"
],
[
"def create_starting_population(size,Number_of_city):\n '''Method create starting population \n size= No. of the city\n Number_of_city= Total No. of the city\n '''\n population = []\n \n for i in range(0,size):\n population.append(create_new_member(Number_of_city))\n \n return population",
"_____no_output_____"
],
[
"def pick_mate(N):\n '''mates are randomaly picked \n N= no. of city '''\n i=random.randint(0,N) \n return i",
"_____no_output_____"
],
[
"def distance(i,j):\n '''\n Method calculate distance between two cities if coordinates are passed\n i=(x,y) coordinates of first city\n j=(x,y) coordinates of second city\n '''\n #returning distance of city i and j \n return np.sqrt((i[0]-j[0])**2 + (i[1]-j[1])**2)\n ",
"_____no_output_____"
],
[
"def score_population(population, CityList): \n '''\n Score of the whole population is calculated here\n population= 2 dimensional array conating all the routes\n Citylist= List of the city \n '''\n scores = []\n \n for i in population:\n #print(i)\n scores.append(fitness(i, CityList))\n #print([fitness(i, the_map)])\n return scores",
"_____no_output_____"
],
[
"def fitness(route,CityList):\n '''Individual fitness of the routes is calculated here\n route= 1d array\n CityList = List of the cities\n '''\n #Calculate the fitness and return it.\n score=0\n #N_=len(route)\n for i in range(1,len(route)):\n k=int(route[i-1])\n l=int(route[i])\n\n score = score + distance(CityList[k],CityList[l])\n \n \n return score",
"_____no_output_____"
],
[
"def create_new_member(Number_of_city):\n '''\n creating new member of the population\n '''\n pop=set(np.arange(Number_of_city,dtype=int))\n route=list(random.sample(pop,Number_of_city))\n \n return route",
"_____no_output_____"
],
[
"def crossover(a,b):\n '''\n cross over \n a=route1\n b=route2\n return child\n '''\n child=[]\n childA=[]\n childB=[]\n \n \n geneA=int(random.random()* len(a))\n geneB=int(random.random()* len(a))\n \n start_gene=min(geneA,geneB)\n end_gene=max(geneA,geneB)\n \n for i in range(start_gene,end_gene):\n childA.append(a[i])\n \n childB=[item for item in a if item not in childA]\n child=childA+childB\n \n \n \n \n return child\n",
"_____no_output_____"
],
[
"def mutate(route,probablity):\n '''\n mutation \n route= 1d array\n probablity= mutation probablity\n '''\n #for mutating shuffling of the nodes is used\n route=np.array(route)\n for swaping_p in range(len(route)):\n if(random.random() < probablity):\n swapedWith = np.random.randint(0,len(route))\n \n temp1=route[swaping_p]\n \n temp2=route[swapedWith]\n route[swapedWith]=temp1\n route[swaping_p]=temp2\n \n return route\n \n \n ",
"_____no_output_____"
],
[
"def selection(popRanked, eliteSize):\n selectionResults=[]\n result=[]\n for i in popRanked:\n result.append(i[0])\n for i in range(0,eliteSize):\n selectionResults.append(result[i])\n \n return selectionResults",
"_____no_output_____"
],
[
"def rankRoutes(population,City_List):\n fitnessResults = {}\n for i in range(0,len(population)):\n fitnessResults[i] = fitness(population[i],City_List)\n return sorted(fitnessResults.items(), key = operator.itemgetter(1), reverse = False)",
"_____no_output_____"
],
[
"def breedPopulation(mating_pool):\n children=[]\n for i in range(len(mating_pool)-1):\n children.append(crossover(mating_pool[i],mating_pool[i+1]))\n return children",
"_____no_output_____"
],
[
"def mutatePopulation(children,mutation_rate):\n new_generation=[]\n for i in children:\n muated_child=mutate(i,mutation_rate)\n new_generation.append(muated_child)\n return new_generation",
"_____no_output_____"
],
[
"def matingPool(population, selectionResults):\n matingpool = []\n for i in range(0, len(selectionResults)):\n index = selectionResults[i]\n matingpool.append(population[index])\n return matingpool",
"_____no_output_____"
],
[
"def next_generation(City_List,current_population,mutation_rate,elite_size):\n population_rank=rankRoutes(current_population,City_List)\n \n #print(f\"population rank : {population_rank}\")\n \n selection_result=selection(population_rank,elite_size)\n #print(f\"selection results {selection_result}\")\n \n mating_pool=matingPool(current_population,selection_result)\n #print(f\"mating pool {mating_pool}\")\n \n children=breedPopulation(mating_pool)\n #print(f\"childern {children}\")\n \n next_generation=mutatePopulation(children,mutation_rate)\n #print(f\"next_generation {next_generation}\")\n return next_generation",
"_____no_output_____"
],
[
"def genetic_algorithm(City_List,size_population=1000,elite_size=75,mutation_Rate=0.01,generation=2000):\n '''size_population = 1000(default) Size of population\n elite_size = 75 (default) No. of best route to choose\n mutation_Rate = 0.05 (default) probablity of Mutation rate [0,1]\n generation = 2000 (default) No. of generation \n '''\n pop=[]\n progress = []\n \n Number_of_cities=len(City_List)\n \n population=create_starting_population(size_population,Number_of_cities)\n progress.append(rankRoutes(population,City_List)[0][1])\n print(f\"initial route distance {progress[0]}\")\n print(f\"initial route {population[0]}\")\n for i in range(0,generation):\n pop = next_generation(City_List,population,mutation_Rate,elite_size)\n progress.append(rankRoutes(pop,City_List)[0][1])\n \n \n rank_=rankRoutes(pop,City_List)[0]\n \n print(f\"Best Route :{pop[rank_[0]]} \")\n print(f\"best route distance {rank_[1]}\")\n plt.plot(progress)\n plt.ylabel('Distance')\n plt.xlabel('Generation')\n plt.show()\n \n return rank_, pop\n \n ",
"_____no_output_____"
],
[
"cityList = []\n\n\nfor i in range(0,25):\n x=int(random.random() * 200)\n y=int(random.random() * 200)\n cityList.append((x,y))",
"_____no_output_____"
],
[
"rank_,pop=genetic_algorithm(City_List=cityList)",
"initial route distance 2040.384360767298\ninitial route [8, 6, 11, 2, 3, 9, 7, 10, 22, 14, 13, 4, 19, 5, 17, 12, 18, 21, 23, 24, 0, 16, 20, 15, 1]\nBest Route :[ 6 1 16 7 14 9 13 21 12 15 20 0 2 22 10 3 4 8 5 17 11 18 23 19 24] \nbest route distance 1981.5676911145292\n"
],
[
"x_axis=[]\ny_axis=[]\nfor i in cityList:\n x_axis.append(i[0])\n y_axis.append(i[1])",
"_____no_output_____"
],
[
"plt.scatter(x_axis,y_axis)\nplt.show()",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bdce63121d840f84d06b9b8ed2ff0f2e4c4be7 | 236,562 | ipynb | Jupyter Notebook | chapter_computer-vision/semantic-segmentation-and-dataset.ipynb | femj007/d2l-zh | faa3e6230fd30d56c0400fe610e7f8396fa25f8b | [
"Apache-2.0"
]
| null | null | null | chapter_computer-vision/semantic-segmentation-and-dataset.ipynb | femj007/d2l-zh | faa3e6230fd30d56c0400fe610e7f8396fa25f8b | [
"Apache-2.0"
]
| null | null | null | chapter_computer-vision/semantic-segmentation-and-dataset.ipynb | femj007/d2l-zh | faa3e6230fd30d56c0400fe610e7f8396fa25f8b | [
"Apache-2.0"
]
| null | null | null | 479.841785 | 121,576 | 0.941127 | [
[
[
"# 语义分割和数据集\n\n在前几节讨论的目标检测问题中,我们一直使用方形边界框来标注和预测图像中的目标。本节将探讨语义分割(semantic segmentation)问题,它关注如何将图像分割成属于不同语义类别的区域。值得一提的是,这些语义区域的标注和预测都是像素级的。图9.10展示了语义分割中图像有关狗、猫和背景的标签。可以看到,跟目标检测相比,语义分割标注的像素级的边框显然更加精细。\n\n\n\n\n## 图像分割和实例分割\n\n计算机视觉领域还有两个和语义分割相似的重要问题:图像分割(image segmentation)和实例分割(instance segmentation)。我们在这里将它们和语义分割简单区分一下:\n\n* 图像分割将图像分割成若干组成区域。这类问题的方法通常利用图像中像素之间的相关性。它在训练时无需有关图像像素的标签信息,在预测时也无法保证分割出的区域具有我们希望得到的语义。以图9.10的图像为输入,图像分割可能将狗分割成两个区域:一个覆盖以黑色为主的嘴巴和眼睛,而另一个覆盖以黄色为主的其余部分身体。\n* 实例分割又叫检测并分割(simultaneous detection and segmentation)。它研究如何识别图像中各个目标实例的像素级区域。与语义分割有所不同,实例分割不仅需要区分语义,还要区分不同的目标实例。如果图像中有两只狗,实例分割需要区分像素属于这两只狗中的哪一只。\n\n\n## Pascal VOC2012语义分割数据集\n\n语义分割的一个重要数据集叫做Pascal VOC2012 [1]。为了更好地了解这个数据集,我们先导入实验所需的包或模块。",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport d2lzh as d2l\nfrom mxnet import gluon, image, nd\nfrom mxnet.gluon import data as gdata, utils as gutils\nimport os\nimport sys\nimport tarfile",
"_____no_output_____"
]
],
[
[
"我们下载这个数据集的压缩包到`../data`路径下。压缩包大小是2GB,下载需要一定时间。解压之后的数据集将会放置在`../data/VOCdevkit/VOC2012`路径下。",
"_____no_output_____"
]
],
[
[
"# 本函数已保存在d2lzh包中方便以后使用\ndef download_voc_pascal(data_dir='../data'):\n voc_dir = os.path.join(data_dir, 'VOCdevkit/VOC2012')\n url = ('http://host.robots.ox.ac.uk/pascal/VOC/voc2012'\n '/VOCtrainval_11-May-2012.tar')\n sha1 = '4e443f8a2eca6b1dac8a6c57641b67dd40621a49'\n fname = gutils.download(url, data_dir, sha1_hash=sha1)\n with tarfile.open(fname, 'r') as f:\n f.extractall(data_dir)\n return voc_dir\n\nvoc_dir = download_voc_pascal()",
"_____no_output_____"
]
],
[
[
"进入`../data/VOCdevkit/VOC2012`路径后,我们可以获取数据集的不同组成部分。其中`ImageSets/Segmentation`路径包含了指定训练和测试样本的文本文件,而`JPEGImages`和`SegmentationClass`路径下分别包含了样本的输入图像和标签。这里的标签也是图像格式,其尺寸和它所标注的输入图像的尺寸相同。标签中颜色相同的像素属于同一个语义类别。下面定义`read_voc_images`函数将输入图像和标签全部读进内存。",
"_____no_output_____"
]
],
[
[
"# 本函数已保存在d2lzh包中方便以后使用\ndef read_voc_images(root=voc_dir, is_train=True):\n txt_fname = '%s/ImageSets/Segmentation/%s' % (\n root, 'train.txt' if is_train else 'val.txt')\n with open(txt_fname, 'r') as f:\n images = f.read().split()\n features, labels = [None] * len(images), [None] * len(images)\n for i, fname in enumerate(images):\n features[i] = image.imread('%s/JPEGImages/%s.jpg' % (root, fname))\n labels[i] = image.imread(\n '%s/SegmentationClass/%s.png' % (root, fname))\n return features, labels\n\ntrain_features, train_labels = read_voc_images()",
"_____no_output_____"
]
],
[
[
"我们画出前五张输入图像和它们的标签。在标签图像中,白色和黑色分别代表边框和背景,而其他不同的颜色则对应不同的类别。",
"_____no_output_____"
]
],
[
[
"n = 5\nimgs = train_features[0:n] + train_labels[0:n]\nd2l.show_images(imgs, 2, n);",
"_____no_output_____"
]
],
[
[
"接下来,我们列出标签中每个RGB颜色的值及其标注的类别。",
"_____no_output_____"
]
],
[
[
"# 该常量已保存在d2lzh包中方便以后使用\nVOC_COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],\n [0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],\n [64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],\n [64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],\n [0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],\n [0, 64, 128]]\n# 该常量已保存在d2lzh包中方便以后使用\nVOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',\n 'bottle', 'bus', 'car', 'cat', 'chair', 'cow',\n 'diningtable', 'dog', 'horse', 'motorbike', 'person',\n 'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']",
"_____no_output_____"
]
],
[
[
"有了上面定义的两个常量以后,我们可以很容易地查找标签中每个像素的类别索引。",
"_____no_output_____"
]
],
[
[
"colormap2label = nd.zeros(256 ** 3)\nfor i, colormap in enumerate(VOC_COLORMAP):\n colormap2label[(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]] = i\n\n# 本函数已保存在d2lzh包中方便以后使用\ndef voc_label_indices(colormap, colormap2label):\n colormap = colormap.astype('int32')\n idx = ((colormap[:, :, 0] * 256 + colormap[:, :, 1]) * 256\n + colormap[:, :, 2])\n return colormap2label[idx]",
"_____no_output_____"
]
],
[
[
"例如,第一张样本图像中飞机头部区域的类别索引为1,而背景全是0。",
"_____no_output_____"
]
],
[
[
"y = voc_label_indices(train_labels[0], colormap2label)\ny[105:115, 130:140], VOC_CLASSES[1]",
"_____no_output_____"
]
],
[
[
"### 预处理数据\n\n在之前的章节中,我们通过缩放图像使其符合模型的输入形状。然而在语义分割里,这样做会需要将预测的像素类别重新映射回原始尺寸的输入图像。这样的映射难以做到精确,尤其在不同语义的分割区域。为了避免这个问题,我们将图像裁剪成固定尺寸而不是缩放。具体来说,我们使用图像增广里的随机裁剪,并对输入图像和标签裁剪相同区域。",
"_____no_output_____"
]
],
[
[
"# 本函数已保存在d2lzh包中方便以后使用\ndef voc_rand_crop(feature, label, height, width):\n feature, rect = image.random_crop(feature, (width, height))\n label = image.fixed_crop(label, *rect)\n return feature, label\n\nimgs = []\nfor _ in range(n):\n imgs += voc_rand_crop(train_features[0], train_labels[0], 200, 300)\nd2l.show_images(imgs[::2] + imgs[1::2], 2, n);",
"_____no_output_____"
]
],
[
[
"### 自定义语义分割数据集类\n\n我们通过继承Gluon提供的`Dataset`类自定义了一个语义分割数据集类`VOCSegDataset`。通过实现`__getitem__`函数,我们可以任意访问数据集中索引为`idx`的输入图像及其每个像素的类别索引。由于数据集中有些图像的尺寸可能小于随机裁剪所指定的输出尺寸,这些样本需要通过自定义的`filter`函数所移除。此外,我们还定义了`normalize_image`函数,从而对输入图像的RGB三个通道的值分别做标准化。",
"_____no_output_____"
]
],
[
[
"# 本类已保存在d2lzh包中方便以后使用\nclass VOCSegDataset(gdata.Dataset):\n def __init__(self, is_train, crop_size, voc_dir, colormap2label):\n self.rgb_mean = nd.array([0.485, 0.456, 0.406])\n self.rgb_std = nd.array([0.229, 0.224, 0.225])\n self.crop_size = crop_size\n features, labels = read_voc_images(root=voc_dir, is_train=is_train)\n self.features = [self.normalize_image(feature)\n for feature in self.filter(features)]\n self.labels = self.filter(labels)\n self.colormap2label = colormap2label\n print('read ' + str(len(self.features)) + ' examples')\n\n def normalize_image(self, img):\n return (img.astype('float32') / 255 - self.rgb_mean) / self.rgb_std\n\n def filter(self, imgs):\n return [img for img in imgs if (\n img.shape[0] >= self.crop_size[0] and\n img.shape[1] >= self.crop_size[1])]\n\n def __getitem__(self, idx):\n feature, label = voc_rand_crop(self.features[idx], self.labels[idx],\n *self.crop_size)\n return (feature.transpose((2, 0, 1)),\n voc_label_indices(label, self.colormap2label))\n\n def __len__(self):\n return len(self.features)",
"_____no_output_____"
]
],
[
[
"### 读取数据集\n\n我们通过自定义的`VOCSegDataset`类来分别创建训练集和测试集的实例。假设我们指定随机裁剪的输出图像的形状为$320\\times 480$。下面我们可以查看训练集和测试集所保留的样本个数。",
"_____no_output_____"
]
],
[
[
"crop_size = (320, 480)\nvoc_train = VOCSegDataset(True, crop_size, voc_dir, colormap2label)\nvoc_test = VOCSegDataset(False, crop_size, voc_dir, colormap2label)",
"read 1114 examples\n"
]
],
[
[
"设批量大小为64,分别定义训练集和测试集的迭代器。",
"_____no_output_____"
]
],
[
[
"batch_size = 64\nnum_workers = 0 if sys.platform.startswith('win32') else 4\ntrain_iter = gdata.DataLoader(voc_train, batch_size, shuffle=True,\n last_batch='discard', num_workers=num_workers)\ntest_iter = gdata.DataLoader(voc_test, batch_size, last_batch='discard',\n num_workers=num_workers)",
"_____no_output_____"
]
],
[
[
"打印第一个小批量的形状。不同于图像分类和目标识别,这里的标签是一个三维的数组。",
"_____no_output_____"
]
],
[
[
"for X, Y in train_iter:\n print(X.shape)\n print(Y.shape)\n break",
"(64, 3, 320, 480)\n(64, 320, 480)\n"
]
],
[
[
"## 小结\n\n* 语义分割关注如何将图像分割成属于不同语义类别的区域。\n* 语义分割的一个重要数据集叫做Pascal VOC2012。\n* 由于语义分割的输入图像和标签在像素上一一对应,我们将图像随机裁剪成固定尺寸而不是缩放。\n\n## 练习\n\n* 回忆[“图像增广”](image-augmentation.md)一节中的内容。哪些在图像分类中使用的图像增广方法难以用于语义分割?\n\n## 扫码直达[讨论区](https://discuss.gluon.ai/t/topic/7218)\n\n\n\n## 参考文献\n\n[1] Pascal VOC2012数据集。http://host.robots.ox.ac.uk/pascal/VOC/voc2012/",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7bdd27f5402de96bca31c5ffab78ef5b6d5893f | 171,080 | ipynb | Jupyter Notebook | TitanicUdacity.ipynb | AllanKDeveloper/titanic_data | 632886405c0b22c84445b57738edde81801a9508 | [
"MIT"
]
| null | null | null | TitanicUdacity.ipynb | AllanKDeveloper/titanic_data | 632886405c0b22c84445b57738edde81801a9508 | [
"MIT"
]
| null | null | null | TitanicUdacity.ipynb | AllanKDeveloper/titanic_data | 632886405c0b22c84445b57738edde81801a9508 | [
"MIT"
]
| null | null | null | 142.093023 | 73,900 | 0.850842 | [
[
[
"## Questões\n\n1. **A idade determinou suas chances de sobrevivência?**\n2. **Qual o tamanho de uma família de sobreviventes?**\n3. **Baseado nas classes, comparar e identificar as relações entre elas?**\n",
"_____no_output_____"
],
[
"## Análise dos Dados",
"_____no_output_____"
],
[
"### Descrição dos dados\n\n- **survival:** Survival (0 = No; 1 = Yes)\n- **pclass:** Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd)\n- **name:** Name\n- **sex:** Sex\n- **age:** Age\n- **sibsp:** Number of Siblings/Spouses Aboard\n- **parch:** Number of Parents/Children Aboard\n- **ticket:** Ticket Number\n- **fare:** Passenger Fare\n- **cabin:** Cabin\n- **embarked:** Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)",
"_____no_output_____"
]
],
[
[
"# Matlib inline\n%matplotlib inline\n\n# Bibliotecas\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n# Lê o csv e cria o dataframe\ntitanic_data = pd.read_csv('titanic-data-6.csv')",
"_____no_output_____"
],
[
"# Print dos primeiros registros para identificação de dados\ntitanic_data.head()",
"_____no_output_____"
],
[
"# Print dos ultimos registros para identificação dos dados\ntitanic_data.tail()",
"_____no_output_____"
]
],
[
[
"**Nota:** Alguns valores para Age são NaN, enquanto os valores de ticket e cabine são alfanuméricos e também valores ausentes com NaN. Com isso, não serão necessários dados do ticket ou da cabine.",
"_____no_output_____"
],
[
"### Limpeza dos dados\n\nDesde a descrição dos dados e perguntas até a resposta, nota-se que algumas colunas não serão utilizadas na análise e por isso podem ser removidas. Isso ajudará no processamento do desempenho do conjunto de dados.\n- PassengerId\n- Name\n- Ticket\n- Cabin\n- Fare\n- Embarked\n\nPassos utilizados para a limpeza:\n1. Identifique e remova quaisquer entradas duplicadas\n2. Remova as colunas desnecessárias\n3. Corrigir problemas de formato e de dados",
"_____no_output_____"
],
[
"#### 1 - Identifique e remova quaisquer entradas duplicadas\nNão existem colunas duplicadas, como pode-se observar abaixo:",
"_____no_output_____"
]
],
[
[
"# Identifique e remova quaisquer entradas duplicadas\ntitanic_duplicados = titanic_data.duplicated()\nsum(titanic_duplicados)",
"_____no_output_____"
]
],
[
[
"#### 2 - Remova as colunas desnecessárias\nColunas do passo **limpeza de dados** removidas",
"_____no_output_____"
]
],
[
[
"# Cria um novo dataset sem as colunas\nto_drop = [\n 'PassengerId',\n 'Name',\n 'Ticket',\n 'Cabin',\n 'Fare',\n 'Embarked'\n]\n\ndef clean_data(to_drop):\n \"\"\"\n Função clean_data.\n Argumentos:\n to_drop: lista das colunas que deseja remover.\n Retorna:\n Retorna uma nova dataset sem as colunas to_drop.\n \"\"\"\n titanic_dados_limpos = titanic_data.drop(to_drop, axis=1)\n return titanic_dados_limpos\n\ntitanic_dados_limpos = clean_data(to_drop)\ntitanic_dados_limpos.head()",
"_____no_output_____"
]
],
[
[
"#### 3 - Corrigir problemas de formato e de dados",
"_____no_output_____"
]
],
[
[
"# Soma de valores faltantes\ntitanic_dados_limpos.isnull().sum()",
"_____no_output_____"
],
[
"# Review da coluna Age para verificar dados NaN\ncoluna_idade_faltante = pd.isnull(titanic_dados_limpos['Age'])\ntitanic_dados_limpos[coluna_idade_faltante].head()",
"_____no_output_____"
],
[
"# Visualização dos tipos de dados\ntitanic_dados_limpos.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 891 entries, 0 to 890\nData columns (total 6 columns):\nSurvived 891 non-null int64\nPclass 891 non-null int64\nSex 891 non-null object\nAge 714 non-null float64\nSibSp 891 non-null int64\nParch 891 non-null int64\ndtypes: float64(1), int64(4), object(1)\nmemory usage: 41.8+ KB\n"
]
],
[
[
"Pode-se observar que a coluna **Age** irá implicar nas perguntas, então, graficamente iremos tratar as idades nulas como 0.",
"_____no_output_____"
],
[
"## Exploração e Visualização dos Dados",
"_____no_output_____"
]
],
[
[
"# Descrição dos dados\ntitanic_dados_limpos.describe()",
"_____no_output_____"
]
],
[
[
"## Questão 1\nA idade determinou suas chances de sobrevivência?",
"_____no_output_____"
]
],
[
[
"# Primeiro, identifica-se o número total de dados Age nulos\nidade_feminino_vazio = titanic_dados_limpos[coluna_idade_faltante]['Sex'] == 'female'\nidade_masculino_vazio = titanic_dados_limpos[coluna_idade_faltante]['Sex'] == 'male'\n\nprint (\"Total de nulos no sexo feminino\".format(idade_feminino_vazio.sum()))\nprint (\"Total de nulos no sexo masculino\".format(idade_masculino_vazio.sum()))\n\n# Limpamos o dataset removendo os dados NaN\ntitanic_data_age_limpo = titanic_dados_limpos.dropna()\n\n# Procuramos o total de sobreviventes e o total de mortes\nnum_sobreviventes = titanic_data_age_limpo[titanic_data_age_limpo['Survived'] == True]['Survived'].count()\nnum_mortes = titanic_data_age_limpo[titanic_data_age_limpo['Survived'] == False]['Survived'].count()\n\n# Procuramos a média de sobreviventes e de mortes\nidade_media_sobreviventes = titanic_data_age_limpo[titanic_data_age_limpo['Survived'] == True]['Age'].mean()\nidade_media_mortes = titanic_data_age_limpo[titanic_data_age_limpo['Survived'] == False]['Age'].mean()\n\n# Print dos resultados encontrado\nprint (\"Total de sobreviventes: {}\".format(num_sobreviventes))\nprint (\"Total de mortes: {}\".format(num_mortes))\nprint (\"Idade aproximada da media de sobreviventes: {}\".format(round(idade_media_sobreviventes)))\nprint (\"Idade aproximada da media de mortes: {}\".format(round(idade_media_mortes)))\n\n# Gráfico - Idade dos passageiros com o sexo pela sobrevivência\ng = sns.factorplot(x=\"Survived\", y=\"Age\", hue='Sex', data=titanic_data_age_limpo, kind=\"box\", size=7, aspect=.8)\n\n# Add um título\ng.fig.suptitle('Sexo e Idade x Sobrevivência')\n\n# Renomeia os labels\n(\n g.set_axis_labels('Sobreviventes', 'Idade').set_xticklabels([\"False\", \"True\"])\n)",
"Total de nulos no sexo feminino\nTotal de nulos no sexo masculino\nTotal de sobreviventes: 290\nTotal de mortes: 424\nIdade aproximada da media de sobreviventes: 28\nIdade aproximada da media de mortes: 31\n"
],
[
"# Gráfico - Idade dos passageiros com o sexo pela sobrevivência em diferente aspecto\nh = sns.swarmplot(x=\"Survived\", y=\"Age\", hue=\"Sex\", data=titanic_data_age_limpo);\n\n# Add título\n(\n h.set_title('Sexo e Idade x Sobrevivência (gráfico 2)')\n)",
"_____no_output_____"
]
],
[
[
"Baseado nos dados visíveis acima:\n- Pode-se concluir que a **idade não é um fator deciviso para a taxa de sobrevivência**",
"_____no_output_____"
],
[
"## Questão 2\nQual o tamanho de uma família de sobreviventes?",
"_____no_output_____"
]
],
[
[
"# add Tamanho da Familia em nossa tabela\ntitanic_data_age_limpo['FamilySize'] = titanic_data_age_limpo['SibSp'] + titanic_data_age_limpo['Parch']\n# Agrupamos pelo Tamanho ordenando pela coluna Survived\ntitanic_data_age_limpo[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)",
"/home/allan/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n"
]
],
[
[
"Após análise dos dados, observa-se que as famílias com **1 a 3 membros** tem uma taxa maior de sobrevivência que as famílias com **4 a 7 membros**",
"_____no_output_____"
],
[
"## Questão 3\nBaseado nas classes, comparar e identificar as relações entre elas?",
"_____no_output_____"
]
],
[
[
"# Gráfico linar com idade x sobreviviu x classe\ng = sns.lmplot('Age','Survived',hue='Pclass',data=titanic_data_age_limpo,palette='winter')\n\n# Acessa a figura\nfig = g.fig\n\n# Add um título\nfig.suptitle(\"Classe x Sobrevivência\")\n",
"_____no_output_____"
]
],
[
[
"Como pode-se obversar no gŕafico acima, a classe **1** foi a que mais conteve sobreviventes enquanto a classe **3** a taxa de sobreviventes foi menor que 50%.",
"_____no_output_____"
],
[
"## Conclusão\n\nOs resultados da análise indicam que classe e sexo, ou seja, ser uma mulher da classe econônimica superior (classe 1), dariam uma melhor taxa de sobrevivência. A idade parece não ser um fator decisivo. Mulheres e crianças, em todas as classes, tendem a ter uma taxa de sobrevivência mais alta do que os homens, mas de forma alguma ser criança ou mulher garante a sobrevivência. Embora, no geral, as crianças acompanhadas pelos pais tenham a melhor taxa, mais de 50%.\n\n## Limitações\n- Uma parte de homens e mulheres não tinha dados de idade e foram removidos dos cálculos que poderiam ter distorcido alguns resultados.\n- A categoria de 'crianças' foi assumida como qualquer pessoa com menos de 18 anos, o que pode alterar alguns resultados se comparado com análises de outras pessoas.",
"_____no_output_____"
],
[
"## Referências\n\n- https://www.kaggle.com/c/titanic/data\n- https://github.com/prabhath6/Data-analysis-of-titanic-using-python/blob/master/Titanic%20Intro%20project.ipynb",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
]
|
e7bdea99e9acaff87259b3c4b2b80f7e20e58b76 | 96,118 | ipynb | Jupyter Notebook | 2016/tutorial_final/75/Feature Selection Tutorial.ipynb | zeromtmu/practicaldatascience.github.io | 62950a3a3e7833552b0f2269cc3ee5c34a1d6d7b | [
"MIT"
]
| 1 | 2021-07-06T17:36:24.000Z | 2021-07-06T17:36:24.000Z | 2016/tutorial_final/75/Feature Selection Tutorial.ipynb | zeromtmu/practicaldatascience.github.io | 62950a3a3e7833552b0f2269cc3ee5c34a1d6d7b | [
"MIT"
]
| null | null | null | 2016/tutorial_final/75/Feature Selection Tutorial.ipynb | zeromtmu/practicaldatascience.github.io | 62950a3a3e7833552b0f2269cc3ee5c34a1d6d7b | [
"MIT"
]
| 1 | 2021-07-06T17:36:34.000Z | 2021-07-06T17:36:34.000Z | 155.279483 | 29,346 | 0.875476 | [
[
[
"# Feature Selection Tutorial",
"_____no_output_____"
]
],
[
[
"import matplotlib\nimport matplotlib.pyplot as plt \n\nimport numpy as np\n\nfrom sklearn.feature_selection import SelectFromModel\nfrom sklearn.linear_model import Lasso, LinearRegression, lasso_path, lasso_stability_path, lars_path\n\nimport warnings\n\nfrom scipy import linalg\n\nfrom sklearn.linear_model import (RandomizedLasso, lasso_stability_path,\n LassoLarsCV)\nfrom sklearn.feature_selection import f_regression\nfrom sklearn.preprocessing import StandardScaler, scale\nfrom sklearn.metrics import auc, precision_recall_curve, mean_squared_error\nfrom sklearn.ensemble import ExtraTreesRegressor\nfrom sklearn.utils.extmath import pinvh\nfrom sklearn.exceptions import ConvergenceWarning\nfrom sklearn.svm import SVR\n\nimport pandas as pd\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## 1. Introduction to Feature Selection\n\nFeature selection is the process of selecting a subset of relevant features (variables, predictors) for use in model construction. It is used for three reasons:\n\n* simplification of models to make them easier to interpret by researchers/users,\n* shorter training times,\n* enhanced generalization by reducing overfitting\n\nThe central premise when using a feature selection technique is that the data contains many features that are either redundant or irrelevant, and can thus be removed without incurring much loss of information.\n\nThere are three main categories of feature selection algorithms: wrappers, filters and embedded methods. [1] This tutorial will mainly focuses on one of the well-known embedded methods Lasso and its variants.\n",
"_____no_output_____"
],
[
"## 2. Introduction to Lasso\n\n### 2.1 What's Lasso\nLasso is one of the embedded methods for feature selection. Embedded methods are a group of techniques which perform feature selection as part of the model construction process.\n\nLasso penalizes the regressin coefficients in a linear model with an L1 penalty. Lasso can shrinking many of coefficients to zero and leads to sparse results. From this point of view, any features which have non-zero regression coefficients are 'selected' by the Lasso.\n\n\nThe loss function of a linear model with L1 penalty will have the following form:\n\n$\\frac{1}{2} \\sum_{n=1}^{N}\\{t_n - w^T\\phi(x_n)\\}^2 + \\frac{\\alpha}{2} \\sum_{j=1}^{M} |w_j|$\n\nThe first part is the square loss function. The second part is the L1 penalty $\\frac{\\alpha}{2} \\sum_{j=1}^{M} |w_j|$, in which M is the total number of features, $w$ is the coefficient vector, $\\alpha$ controls how much L1 penalty the contributes to the overall loss and how many features will be selected. L1 penalty can also be used to improve the generalization of the model because it penalty the model complexity by $\\sum_{j=1}^{M} |w_j|$ in the loss function.",
"_____no_output_____"
],
[
"### 2.2 Why Lasso Can be Used for Feature Selection\nFirstly, if all the features are in the same scale. The coefficients of a linear model can represents how important the corresponding feature is. \n\nIn **Exp. 1**, I simulate a regression problem with three features (in the same scale). The regression target y is a linear combination of the features plus some guassion noise.\n\n$y = 0 * x_0 + 1 * x_1 + 2 * x_2 + noise$ \n\nSo from the setup of experiment 1, we can see that the importance of different features is\n\n$x_2 > x_1 > x_0$",
"_____no_output_____"
]
],
[
[
"# set the random seed\nrng = np.random.RandomState(0)",
"_____no_output_____"
]
],
[
[
"**Exp. 1**",
"_____no_output_____"
]
],
[
[
"# Exp 1\nn_samples = 10000\nn_features = 3\nnoise_level = 0.2\n\nX = rng.rand(n_samples, n_features)\ncoef = np.zeros(n_features)\ncoef[0] = 0.0\ncoef[1] = 1.0\ncoef[2] = 2.0\n\ny = np.dot(X, coef) + noise_level * rng.normal(size=n_samples)\n\nlr = LinearRegression()\nlr.fit(X, y)\nprint 'Exp. 1, coefficient of linear regression\\n%s' % str(lr.coef_)\n\nlr = Lasso(alpha=0.001)\nlr.fit(X, y)\nprint 'Exp. 1, coefficient of lasso\\n%s' % str(lr.coef_)",
"Exp. 1, coefficient of linear regression\n[-0.01119616 0.99446444 1.99559463]\nExp. 1, coefficient of lasso\n[-0. 0.98258754 1.98367942]\n"
]
],
[
[
"As we can see from **Exp. 1**, we can easily find the feature importances from the coefficient of the trained model.\nAnd an important characteristic of the L1 penalty is that it will leads to sparse models. Sparse models means the weight of unimportant/irrelevent features will shrink to 0. \n\nIn **Exp. 1**, the first feature $x_0$ is actually have nothing to do with our target. Its coefficient in the linear regression model is a very small value (still have some small contribution to the target, not exactly irrelevant). However, Lasso will directly shrink its coefficient to 0, which indicates that it's actually an irrelevant feature.\n",
"_____no_output_____"
],
[
"Here is another example shows how lasso performs when there are lots of irrelevant features. \n**Exp. 2** is also a regression problem with 50 features. However only 5 of them are relevant to the target ($x_0 - x_4$).",
"_____no_output_____"
],
[
"**Exp. 2**",
"_____no_output_____"
],
[
"Some help functions:\n* plot_sel_path: plot how will the coefficients for relevant and irrelevant features change with different $\\alpha$ setting",
"_____no_output_____"
]
],
[
[
"def plot_sel_path(X, y, coef, method='Lasso'):\n \"\"\"Plot feature selection result\n \"\"\"\n if method == 'Lasso':\n# alpha_grid, _, scores_path = lars_path(X, y, method='lasso', eps=0.05)\n alpha_grid, scores_path, _ = lasso_path(X, y, eps=0.001)\n elif method == 'Stability':\n alpha_grid, scores_path = lasso_stability_path(X, y, scaling=0.3, eps=0.001)\n \n plt.figure()\n hg = plt.plot(alpha_grid[1:] , scores_path[coef != 0].T[1:], 'r')\n hb = plt.plot(alpha_grid[1:] , scores_path[coef == 0].T[1:], 'k')\n ymin, ymax = plt.ylim()\n plt.xlabel(r'$(\\alpha / \\alpha_{max})$')\n plt.ylabel('Score for each feature')\n plt.axis('tight')\n plt.legend((hg[0], hb[0]), ('relevant features', 'irrelevant features'),\n loc='best')",
"_____no_output_____"
],
[
"# Exp. 2\nn_samples = 10000\nn_features = 50\nn_relevant_features = 5\nnoise_level = 0.2\n\nX = rng.rand(n_samples, n_features)\ncoef = np.zeros(n_features)\ncoef[:n_relevant_features] = rng.rand(n_relevant_features)\ny = np.dot(X, coef)\ny += noise_level * rng.normal(size=n_samples)\n\nprint 'Exp. 2, coefficients setting for the relevant features\\n %s' % str(coef[:n_relevant_features])\nplot_sel_path(X, y, coef, \"Lasso\")",
"Exp. 2, coefficients setting for the relevant features\n [ 0.5754498 0.93597176 0.66245048 0.32697755 0.4974818 ]\n"
]
],
[
[
"As we can see from the results, although lots of irrelevant features are given to the model. Lasso will shrink their coefficients to 0 very quickly.",
"_____no_output_____"
],
[
"### 2.4 Drawbacks of Lasso\n\nThere are some well-known limitations of Lasso, including\n1. Lasso will tend to select an individual variable out of a group of highly correlated features,\n2. even when the correlation between features is not too high, the conditions under which L1-penalized methods consistently select “good” features can be restrictive in general.\n",
"_____no_output_____"
],
[
"## 3. Variants of Lasso\n\nThere are lots of variants of Lasso that try to overcome some of the drawbacks.\n\nOne of the interesting work is Stability Selection. Sometimes, it's also called Randomized Lasso. It works by subsampling the training data and computing a Lasso estimate where the penalty of a random subset of coefficients has been scaled. Bolasso (Bootstrapped Lasso) is very similar, which using bootstraping to conduct random sampling.\n\nBy performing this double randomization several times, the method assigns high scores to features that are repeatedly selected across randomizations. In short, features selected more often are considered good features.\n",
"_____no_output_____"
],
[
"In **Exp. 3**, we generate some coherent features for a regression problem. Since there are some corelation between the features. Lasso will fail to select all relevant features.",
"_____no_output_____"
],
[
"**Exp. 3**",
"_____no_output_____"
],
[
"Some help function\n* gen_simulation_dataset: generate some coherent random features for a regression problem",
"_____no_output_____"
]
],
[
[
"def gen_simulation_dataset(n_features=50, n_relevant_features=3, \n noise_level=0.2, coef_min=0.2, n_samples=10000,\n rng=np.random.RandomState(0), conditioning=1):\n\n block_size = n_relevant_features\n\n # The coefficients of our model\n coef = np.zeros(n_features)\n coef[:n_relevant_features] = coef_min + rng.rand(n_relevant_features)\n\n # The correlation of our design: variables correlated by blocs of 3\n corr = np.zeros((n_features, n_features))\n for i in range(0, n_features, block_size):\n corr[i:i + block_size, i:i + block_size] = 1 - conditioning\n corr.flat[::n_features + 1] = 1\n corr = linalg.cholesky(corr)\n\n # \n X = rng.normal(size=(n_samples, n_features))\n X = np.dot(X, corr)\n # Keep [Wainwright2006] (26c) constant\n X[:n_relevant_features] /= np.abs(\n linalg.svdvals(X[:n_relevant_features])).max()\n X = StandardScaler().fit_transform(X.copy())\n\n # The output variable\n y = np.dot(X, coef)\n y /= np.std(y)\n # We scale the added noise as a function of the average correlation\n # between the design and the output variable\n y += noise_level * rng.normal(size=n_samples) \n \n return X, y, coef",
"_____no_output_____"
],
[
"# Exp 3 \nX, y, coef = gen_simulation_dataset(n_samples=500, rng=rng, conditioning=1e-4)\nprint 'Exp. 3, coefficients of the relevant features\\n%s' % str(coef[coef!=0])\n\nplot_sel_path(X, y, coef, 'Lasso')\n\nplot_sel_path(X, y, coef, 'Stability')",
"Exp. 3, coefficients of the relevant features\n[ 0.42871572 0.31671741 0.69989626]\n"
]
],
[
[
"As we can see from the results, Lasso will fail to select all the relevant features if there are some corelation between the features. However, Randomized Lasso or Stability Selection will overcome such drawback and select all relevant features.",
"_____no_output_____"
],
[
"## 4. Real Dataset\n\nIn this section, we will conduct some experiments to see how Lasso and Randomized Lasso performed on a real dataset. In **Exp. 4**, I am using the same dataset in the contest for assignment 4. So you can download the dataset from the course website [link](http://www.datasciencecourse.org/hw/4/data.tar.gz). I use the tiidf as the features and them conduct feature selection on top of it using Lasso.\n",
"_____no_output_____"
],
[
"**Exp. 4**",
"_____no_output_____"
]
],
[
[
"def read(idx):\n f_X = 'data/X'+str(idx)+'.txt'\n f_Y = 'data/Y'+str(idx)+'.txt'\n\n f = open(f_X, 'r')\n x = []\n for l in f:\n x.append(l)\n f.close()\n f = open(f_Y, 'r')\n y = []\n for l in f:\n y.append(int(l))\n f.close()\n return x, y\n\nx_all = []\ny_all = []\nfor i in range(1, 9):\n x, y = read(i)\n x_all.extend(x)\n y_all.extend(y)\n\nx_true = []\nx_false = []\nfor i in range(len(y_all)):\n if y_all[i] == 1:\n x_true.append(x_all[i])\n else:\n x_false.append(x_all[i])",
"_____no_output_____"
],
[
"print len(x_all), len(y_all), len(x_true), len(x_false)",
"80000 80000 36326 43674\n"
]
],
[
[
"After loading the whole dataset, we transfer it into tfidf matrix.",
"_____no_output_____"
]
],
[
[
"from natural_language_processing import tfidf\ntfidf_all, words_all = tfidf(x_all)\nprint tfidf_all.shape",
"(80000, 1245607)\n"
]
],
[
[
"So there are about 1245607 features in total.",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_selection import SelectFromModel\nfrom sklearn.svm import LinearSVC\n\nX = tfidf_all\ny = y_all\n\nlsvc = LinearSVC(C=0.02, penalty=\"l1\", dual=False).fit(X, y)\nmodel = SelectFromModel(lsvc, prefit=True, threshold='mean')\nX_new = model.transform(X)\nprint X_new.shape\n\nmask = model.get_support()\nprint 'Number of feature selected'\nprint np.sum(mask)\n\nprint 'After feature selection'\nlsvc.fit(X_new, y)\ny_pred = lsvc.predict(X_new)\nprint np.sum(y_pred != y) / float(len(y))",
"(80000, 1307)\nNumber of feature selected\n1307\nAfter feature selection\n0.0002\n"
]
],
[
[
"As we can see from the results, although with the all 1245607 features, we may achieve 0 error rate on the training set. However, with the help of Lasso, we can select and use only 1307 features and still achieve a very low error rate. \n\nFollow up can be found at [link](https://github.com/JinyiLu/15-688-Tutorial/blob/master/Feature%20Selection%20Tutorial.ipynb)",
"_____no_output_____"
],
[
"## 5. References\n1. Guyon, Isabelle, and André Elisseeff. \"An introduction to variable and feature selection.\" Journal of machine learning research 3.Mar (2003): 1157-1182. [link](http://www.jmlr.org/papers/volume3/guyon03a/guyon03a.pdf)\n* Feature selection - Wikipedia. [link](https://en.wikipedia.org/wiki/Feature_selection)\n\n* Sklearn [link](http://scikit-learn.org/stable/modules/feature_selection.html#randomized-l1)\n* F. Bach, Model-Consistent Sparse Estimation through the Bootstrap. [link]( https://hal.inria.fr/hal-00354771/)\n* N. Meinshausen, P. Buhlmann, Stability selection, Journal of the Royal Statistical Society, 72 (2010)[link](http://arxiv.org/pdf/0809.2932.pdf)\n* http://stats.stackexchange.com/questions/45643/why-l1-norm-for-sparse-models\n* UCI Machine Learning Repository [link](http://archive.ics.uci.edu/ml/index.html)\n* http://blog.datadive.net/selecting-good-features-part-ii-linear-models-and-regularization/\n* http://scikit-learn.org/stable/auto_examples/linear_model/plot_sparse_recovery.html#sphx-glr-auto-examples-linear-model-plot-sparse-recovery-py\n* http://statistics.berkeley.edu/sites/default/files/tech-reports/709.pdf\n* https://en.wikipedia.org/wiki/Covariance",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
]
|
e7be028f78633ffd18e96f5ac6fab4d155e22b79 | 40,472 | ipynb | Jupyter Notebook | tf_keras_regression.ipynb | plum528/learn_tf2 | da2eca6b761633063c0a7e6c925e693389f70713 | [
"MIT"
]
| null | null | null | tf_keras_regression.ipynb | plum528/learn_tf2 | da2eca6b761633063c0a7e6c925e693389f70713 | [
"MIT"
]
| null | null | null | tf_keras_regression.ipynb | plum528/learn_tf2 | da2eca6b761633063c0a7e6c925e693389f70713 | [
"MIT"
]
| null | null | null | 79.669291 | 18,032 | 0.693022 | [
[
[
"import matplotlib as mpl\nimport matplotlib.pyplot as plt\n%matplotlib inline\nimport numpy as np\nimport sklearn\nimport pandas as pd\nimport os\nimport sys\nimport time\nimport tensorflow as tf\n\nfrom tensorflow import keras\n\nprint(tf.__version__)\nprint(sys.version_info)\nfor module in mpl, np, pd, sklearn, tf, keras:\n print(module.__name__, module.__version__)",
"2.0.0-alpha0\nsys.version_info(major=3, minor=7, micro=3, releaselevel='final', serial=0)\nmatplotlib 3.1.0\nnumpy 1.16.4\npandas 0.24.2\nsklearn 0.21.2\ntensorflow 2.0.0-alpha0\ntensorflow.python.keras.api._v2.keras 2.2.4-tf\n"
],
[
"from sklearn.datasets import fetch_california_housing\nhousing = fetch_california_housing()\nprint(housing.DESCR)\nprint(housing.data.shape)\nprint(housing.target.shape)",
"Downloading Cal. housing from https://ndownloader.figshare.com/files/5976036 to /root/scikit_learn_data\nWARNING: Logging before flag parsing goes to stderr.\nI0624 15:01:01.080976 139621882844928 california_housing.py:114] Downloading Cal. housing from https://ndownloader.figshare.com/files/5976036 to /root/scikit_learn_data\n"
],
[
"import pprint\npprint.pprint(housing.data[0:5])\npprint.pprint(housing.target[0:5])",
"array([[ 8.32520000e+00, 4.10000000e+01, 6.98412698e+00,\n 1.02380952e+00, 3.22000000e+02, 2.55555556e+00,\n 3.78800000e+01, -1.22230000e+02],\n [ 8.30140000e+00, 2.10000000e+01, 6.23813708e+00,\n 9.71880492e-01, 2.40100000e+03, 2.10984183e+00,\n 3.78600000e+01, -1.22220000e+02],\n [ 7.25740000e+00, 5.20000000e+01, 8.28813559e+00,\n 1.07344633e+00, 4.96000000e+02, 2.80225989e+00,\n 3.78500000e+01, -1.22240000e+02],\n [ 5.64310000e+00, 5.20000000e+01, 5.81735160e+00,\n 1.07305936e+00, 5.58000000e+02, 2.54794521e+00,\n 3.78500000e+01, -1.22250000e+02],\n [ 3.84620000e+00, 5.20000000e+01, 6.28185328e+00,\n 1.08108108e+00, 5.65000000e+02, 2.18146718e+00,\n 3.78500000e+01, -1.22250000e+02]])\narray([4.526, 3.585, 3.521, 3.413, 3.422])\n"
],
[
"from sklearn.model_selection import train_test_split\nx_train_all, x_test, y_train_all, y_test = train_test_split(\n housing.data, housing.target, random_state = 7)\nx_train, x_valid, y_train, y_valid = train_test_split(\n x_train_all, y_train_all, random_state = 11)\nprint(x_train.shape, y_train.shape)\nprint(x_valid.shape, y_valid.shape)\nprint(x_test.shape, y_test.shape)",
"(11610, 8) (11610,)\n(3870, 8) (3870,)\n(5160, 8) (5160,)\n"
],
[
"from sklearn.preprocessing import StandardScaler\n\nscaler = StandardScaler()\nx_train_scaled = scaler.fit_transform(x_train)\nx_valid_scaled = scaler.transform(x_valid)\nx_test_scaled = scaler.transform(x_test)",
"_____no_output_____"
],
[
"model = keras.models.Sequential([\n keras.layers.Dense(30, activation = 'relu',\n input_shape = x_train.shape[1:]),\n keras.layers.Dense(1),\n])\nmodel.summary()\nmodel.compile(loss = \"mean_squared_error\", optimizer = \"sgd\")\ncallbacks = [keras.callbacks.EarlyStopping(\n patience = 5, min_delta = 1e-3)]\n",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense (Dense) (None, 30) 270 \n_________________________________________________________________\ndense_1 (Dense) (None, 1) 31 \n=================================================================\nTotal params: 301\nTrainable params: 301\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"history = model.fit(x_train_scaled, y_train,\n validation_data = (x_valid_scaled, y_valid),\n epochs = 100,\n callbacks = callbacks)",
"Train on 11610 samples, validate on 3870 samples\nEpoch 1/100\n11610/11610 [==============================] - 2s 137us/sample - loss: 2.5676 - val_loss: 1.2183\nEpoch 2/100\n11610/11610 [==============================] - 1s 99us/sample - loss: 0.8789 - val_loss: 0.8375\nEpoch 3/100\n11610/11610 [==============================] - 1s 103us/sample - loss: 0.7157 - val_loss: 0.7606\nEpoch 4/100\n11610/11610 [==============================] - 1s 103us/sample - loss: 0.6625 - val_loss: 0.7160\nEpoch 5/100\n11610/11610 [==============================] - 1s 103us/sample - loss: 0.6275 - val_loss: 0.6808\nEpoch 6/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.5996 - val_loss: 0.6534\nEpoch 7/100\n11610/11610 [==============================] - 1s 98us/sample - loss: 0.5779 - val_loss: 0.6283\nEpoch 8/100\n11610/11610 [==============================] - 1s 109us/sample - loss: 0.5597 - val_loss: 0.6090\nEpoch 9/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.5453 - val_loss: 0.5928\nEpoch 10/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.5328 - val_loss: 0.5783\nEpoch 11/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.5226 - val_loss: 0.5643\nEpoch 12/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.5138 - val_loss: 0.5520\nEpoch 13/100\n11610/11610 [==============================] - 1s 103us/sample - loss: 0.5061 - val_loss: 0.5441\nEpoch 14/100\n11610/11610 [==============================] - 1s 103us/sample - loss: 0.4996 - val_loss: 0.5356\nEpoch 15/100\n11610/11610 [==============================] - 1s 105us/sample - loss: 0.4944 - val_loss: 0.5291\nEpoch 16/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4894 - val_loss: 0.5232\nEpoch 17/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.4852 - val_loss: 0.5169\nEpoch 18/100\n11610/11610 [==============================] - 1s 103us/sample - loss: 0.4815 - val_loss: 0.5130\nEpoch 19/100\n11610/11610 [==============================] - 1s 109us/sample - loss: 0.4783 - val_loss: 0.5089\nEpoch 20/100\n11610/11610 [==============================] - 1s 105us/sample - loss: 0.4750 - val_loss: 0.5059\nEpoch 21/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4725 - val_loss: 0.5020\nEpoch 22/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4697 - val_loss: 0.4981\nEpoch 23/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4674 - val_loss: 0.4952\nEpoch 24/100\n11610/11610 [==============================] - 1s 103us/sample - loss: 0.4651 - val_loss: 0.4926\nEpoch 25/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.4630 - val_loss: 0.4896\nEpoch 26/100\n11610/11610 [==============================] - 1s 103us/sample - loss: 0.4610 - val_loss: 0.4861\nEpoch 27/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4592 - val_loss: 0.4857\nEpoch 28/100\n11610/11610 [==============================] - 1s 110us/sample - loss: 0.4573 - val_loss: 0.4825\nEpoch 29/100\n11610/11610 [==============================] - 1s 105us/sample - loss: 0.4553 - val_loss: 0.4819\nEpoch 30/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4539 - val_loss: 0.4793\nEpoch 31/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4520 - val_loss: 0.4765\nEpoch 32/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4503 - val_loss: 0.4743\nEpoch 33/100\n11610/11610 [==============================] - 1s 103us/sample - loss: 0.4484 - val_loss: 0.4725\nEpoch 34/100\n11610/11610 [==============================] - 1s 103us/sample - loss: 0.4472 - val_loss: 0.4708\nEpoch 35/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4455 - val_loss: 0.4681\nEpoch 36/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4438 - val_loss: 0.4675\nEpoch 37/100\n11610/11610 [==============================] - 1s 105us/sample - loss: 0.4426 - val_loss: 0.4655\nEpoch 38/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.4410 - val_loss: 0.4646\nEpoch 39/100\n11610/11610 [==============================] - 1s 108us/sample - loss: 0.4394 - val_loss: 0.4618\nEpoch 40/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.4382 - val_loss: 0.4597\nEpoch 41/100\n11610/11610 [==============================] - 1s 110us/sample - loss: 0.4371 - val_loss: 0.4594\nEpoch 42/100\n11610/11610 [==============================] - 1s 108us/sample - loss: 0.4357 - val_loss: 0.4578\nEpoch 43/100\n11610/11610 [==============================] - 1s 111us/sample - loss: 0.4341 - val_loss: 0.4567\nEpoch 44/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.4329 - val_loss: 0.4550\nEpoch 45/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4318 - val_loss: 0.4532\nEpoch 46/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4305 - val_loss: 0.4519\nEpoch 47/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4293 - val_loss: 0.4502\nEpoch 48/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4281 - val_loss: 0.4493\nEpoch 49/100\n11610/11610 [==============================] - 1s 108us/sample - loss: 0.4271 - val_loss: 0.4480\nEpoch 50/100\n11610/11610 [==============================] - 1s 105us/sample - loss: 0.4258 - val_loss: 0.4466\nEpoch 51/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4247 - val_loss: 0.4456\nEpoch 52/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.4236 - val_loss: 0.4451\nEpoch 53/100\n11610/11610 [==============================] - 1s 105us/sample - loss: 0.4225 - val_loss: 0.4430\nEpoch 54/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4215 - val_loss: 0.4417\nEpoch 55/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4202 - val_loss: 0.4408\nEpoch 56/100\n11610/11610 [==============================] - 1s 99us/sample - loss: 0.4194 - val_loss: 0.4401\nEpoch 57/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4183 - val_loss: 0.4381\nEpoch 58/100\n11610/11610 [==============================] - 1s 105us/sample - loss: 0.4175 - val_loss: 0.4372\nEpoch 59/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.4164 - val_loss: 0.4360\nEpoch 60/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4154 - val_loss: 0.4347\nEpoch 61/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4145 - val_loss: 0.4333\nEpoch 62/100\n11610/11610 [==============================] - 1s 109us/sample - loss: 0.4136 - val_loss: 0.4338\nEpoch 63/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4126 - val_loss: 0.4313\nEpoch 64/100\n11610/11610 [==============================] - 1s 108us/sample - loss: 0.4116 - val_loss: 0.4305\nEpoch 65/100\n11610/11610 [==============================] - 1s 109us/sample - loss: 0.4108 - val_loss: 0.4296\nEpoch 66/100\n11610/11610 [==============================] - 1s 104us/sample - loss: 0.4099 - val_loss: 0.4290\nEpoch 67/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.4090 - val_loss: 0.4287\nEpoch 68/100\n11610/11610 [==============================] - 1s 107us/sample - loss: 0.4082 - val_loss: 0.4273\nEpoch 69/100\n11610/11610 [==============================] - 1s 110us/sample - loss: 0.4074 - val_loss: 0.4261\nEpoch 70/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.4064 - val_loss: 0.4244\nEpoch 71/100\n11610/11610 [==============================] - 1s 108us/sample - loss: 0.4057 - val_loss: 0.4242\nEpoch 72/100\n11610/11610 [==============================] - 1s 106us/sample - loss: 0.4049 - val_loss: 0.4224\nEpoch 73/100\n11610/11610 [==============================] - 1s 110us/sample - loss: 0.4043 - val_loss: 0.4220\nEpoch 74/100\n11610/11610 [==============================] - 1s 105us/sample - loss: 0.4035 - val_loss: 0.4209\nEpoch 75/100\n"
],
[
"def plot_learning_curves(history):\n pd.DataFrame(history.history).plot(figsize = (8, 5))\n plt.grid(True)\n plt.gca().set_ylim(0, 1)\n plt.show()\nplot_learning_curves(history)",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7be190e4c7dd80ebcc83ea1d4891f45bcc57a3f | 5,579 | ipynb | Jupyter Notebook | hw/code-review.ipynb | Victor-Palacios/msds692 | 3f159eb3203c124882e11322d64d6ee91d57d6cd | [
"MIT"
]
| 87 | 2018-08-10T23:27:24.000Z | 2022-03-29T05:07:45.000Z | hw/code-review.ipynb | Victor-Palacios/msds692 | 3f159eb3203c124882e11322d64d6ee91d57d6cd | [
"MIT"
]
| 1 | 2019-10-06T15:45:03.000Z | 2019-10-06T15:45:03.000Z | hw/code-review.ipynb | Victor-Palacios/msds692 | 3f159eb3203c124882e11322d64d6ee91d57d6cd | [
"MIT"
]
| 171 | 2018-08-20T23:59:43.000Z | 2022-03-31T16:21:52.000Z | 38.475862 | 401 | 0.640258 | [
[
[
"# Code review\n\n**Do not share code on a project until that project deadline (start of class) has passed.** All projects in this class are individual projects, not group projects. You may not look at or discuss code with others until after you have submitted your own individual effort.\n\nThis is a code review for $\\fbox{ name of partner }$\n\nThis document serves as a basic code review structure that you can use to evaluate your partner(s)'s code. Here are a couple of key points to keep in mind:\n\n1. *Code reviews do not in any way affect the grade of the person you are reviewing.*\n1. Turn in a reasonable effort reviewing your partner(s) and you get credit for this mini assignment.\n1. Be positive and use soft language with no personal attacks. The goal is to help your partner be a better programmer and also to learn from your partner's code. If the code is very good, then please say so. If the code has lots of problems, you can still provide constructive criticism by saying things like: \"Perhaps you could find a way to simplify that nested loop into a single loop.\"\n1. Submit a pdf (print then save as...) to Canvas of a copy of this notebook with your comments filled in.\n1. Spend at most 30 minutes doing these code reviews.\n\nWhen you have submitted your review, also send a PDF to your partner.",
"_____no_output_____"
],
[
"## Basic sanity checks\n\n(Place an `x` in the square brackets of the markdown to check the box.)\n\n- [ ] I received a code zip from my group partner(s)\n- [ ] Unit tests execute without syntax error\n\nNumber of unit tests that fail? $\\fbox{ num failures }$",
"_____no_output_____"
],
[
"## Review questions",
"_____no_output_____"
],
[
"### Describe the quality of the function and variable names\n\nPrograms should be readable by others and so you should name variables and functions according to their purpose. Don't name them by their type alone. For example, `df` is fine for small little scripts but `df_bulldozer` makes it clear that it's a data frame holding the bulldozer data set. \n\nIf functions or variables are named v1, v2, v3, etc..., it means that the programmer has no idea and why they are creating these or they don't understand the importance of good naming.\n\n(You can ignore functions and variables provided by the instructor.)",
"_____no_output_____"
],
[
"### Is there a lot of duplicated code?\n\nIn general, we want exactly one place in our code to compute one thing. If we need that functionality more than once, the code should be in a function and we simply call the function. Take a quick look and see if you find lots of duplicated code and give an indication here.",
"_____no_output_____"
],
[
"### How easy is it to read the code?\n\nEven with good variable and function names, code could have bad structure. Bad structure can mean too much nesting, is overly complex, has weird/useless code, etc... It's also a bad idea to leave all kinds of dead code commented out. Programmers want to see a clean piece of code, not something with a bunch of junk laying around.\n\nWere there comments and where the comments useful? For example, here is a terrible comment:\n\n```\nx = 0 # reset x\n```\n\nIt is terrible because all it does is repeat what the code says. A good comment says why you are resetting x at this point in the code. Or, it indicates what the goal is.",
"_____no_output_____"
],
[
"### How hard would it be to modify this code?\n\nIn industry, code often has a long lifetime and is continuously improved as business needs change etc... Code quality definitely affects your ability to add features to code. Imagine trying to alter this code and describe whether it would be easy or hard and why.",
"_____no_output_____"
],
[
"### Optionally, you can comment according to this code style\n\n[Google's style guide](https://google.github.io/styleguide/pyguide.html) is a good place to read more about good programming style. There is also a tool called [`pylint`](https://www.pylint.org/) that you can run for finding bugs and style problems in code.",
"_____no_output_____"
]
]
]
| [
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
e7be1b38502643ef1d0db07b5e2c6c8b1bc9bf2e | 97,421 | ipynb | Jupyter Notebook | Exercises-5.ipynb | zazke/pycon-pandas-tutorial | 7366a0ecd51170f756f07a4f6ab25d0355f73a9b | [
"MIT"
]
| null | null | null | Exercises-5.ipynb | zazke/pycon-pandas-tutorial | 7366a0ecd51170f756f07a4f6ab25d0355f73a9b | [
"MIT"
]
| null | null | null | Exercises-5.ipynb | zazke/pycon-pandas-tutorial | 7366a0ecd51170f756f07a4f6ab25d0355f73a9b | [
"MIT"
]
| null | null | null | 41.901505 | 6,776 | 0.519693 | [
[
[
"%matplotlib inline\nimport pandas as pd\nimport re",
"_____no_output_____"
],
[
"from IPython.core.display import HTML\ncss = open('style-table.css').read() + open('style-notebook.css').read()\nHTML('<style>{}</style>'.format(css))",
"_____no_output_____"
],
[
"cast = pd.read_csv('data/cast.csv')\ncast.head()",
"_____no_output_____"
],
[
"release_dates = pd.read_csv(\n 'data/release_dates.csv',\n parse_dates=['date'],\n infer_datetime_format=True,\n)\nrelease_dates.head()",
"_____no_output_____"
],
[
"# date time operations\nr = release_dates\nr.date.dt.dayofweek",
"_____no_output_____"
],
[
"release_dates.head()",
"_____no_output_____"
],
[
"# merge\nc = cast\nc[c.name == 'Ellen Page']\nc.merge(release_dates)",
"_____no_output_____"
],
[
"# Pivot\nr = release_dates\nr = r[r.title.str.startswith('Star Wars: Episode')]\nr = r[r.country.str.startswith('U')]\nr",
"_____no_output_____"
],
[
"r = r.pivot('title', 'country', 'date') # set_index and sort_index on 'title', 'country'\n # unstack on 'country'\n # show 'date'\nr",
"_____no_output_____"
],
[
"# Without pivot:\nr = release_dates\nr = r[r.title.str.startswith('Star Wars: Episode')]\nr = r[r.country.str.startswith('U')]\n\nr = r.set_index(['title', 'country']).sort_index()\nr = r.unstack()\nr['date']",
"_____no_output_____"
],
[
"# Who tends to be with Cary Grant (his co-stars)\nc = cast\nc = c[c.n <= 2]\nc = c[c.name == 'Cary Grant']\nc.head()",
"_____no_output_____"
],
[
"c = c.merge(cast, on=['title', 'year'])",
"_____no_output_____"
],
[
"c = c[c.n_y <= 2]\nc = c[c.name_y != 'Cary Grant']\nc",
"_____no_output_____"
]
],
[
[
"### Make a bar plot of the months in which movies with \"Christmas\" in their title tend to be released in the USA.",
"_____no_output_____"
]
],
[
[
"r = release_dates\nr = r[(r.title.str.contains(\"Christmas\", re.IGNORECASE, regex=True)) &\n (r.country == \"USA\")\n ]\nr = r.groupby(r.date.dt.month).size()",
"_____no_output_____"
],
[
"r.plot(kind='bar', xlabel=\"month\")",
"_____no_output_____"
]
],
[
[
"### Make a bar plot of the months in which movies whose titles start with \"The Hobbit\" are released in the USA.",
"_____no_output_____"
]
],
[
[
"r = release_dates\nr = r[(r.title.str.contains(\"The Hobbit\")) &\n (r.country == \"USA\")\n ]\nr = r.groupby(r.date.dt.month).size()\nr",
"_____no_output_____"
],
[
"r.plot(kind='bar', xlabel=\"month\")",
"_____no_output_____"
]
],
[
[
"### Make a bar plot of the day of the week on which movies with \"Romance\" in their title tend to be released in the USA.",
"_____no_output_____"
]
],
[
[
"r = release_dates\nr = r[(r.title.str.contains(\"Romance\")) &\n (r.country == \"USA\")\n ]\nr = r.groupby(r.date.dt.dayofweek).size()\nr",
"_____no_output_____"
],
[
"r.plot(kind='bar', xlabel=\"dayofweek (0=Monday)\")",
"_____no_output_____"
]
],
[
[
"### Make a bar plot of the day of the week on which movies with \"Action\" in their title tend to be released in the USA.",
"_____no_output_____"
]
],
[
[
"r = release_dates\nr = r[(r.title.str.contains(\"Action\")) &\n (r.country == \"USA\")\n ]\nr = r.groupby(r.date.dt.dayofweek).size()\nr",
"_____no_output_____"
],
[
"r.plot(kind='bar', xlabel=\"dayofweek (0=Monday)\")",
"_____no_output_____"
]
],
[
[
"### On which date was each Judi Dench movie from the 1990s released in the USA?",
"_____no_output_____"
]
],
[
[
"release_dates.columns",
"_____no_output_____"
],
[
"c = cast\nc = c[(c.name == 'Judi Dench') &\n (c.year // 10 * 10 == 1990)]\nc = c.merge(release_dates, on=['title', 'year'])\nc = c[(c.country == 'USA')]\nc",
"_____no_output_____"
],
[
"# data not available",
"_____no_output_____"
]
],
[
[
"### In which months do films with Judi Dench tend to be released in the USA?",
"_____no_output_____"
]
],
[
[
"c.groupby(c.date.dt.month).size()",
"_____no_output_____"
]
],
[
[
"November (11月) and December (12月)",
"_____no_output_____"
],
[
"### In which months do films with Tom Cruise tend to be released in the USA?",
"_____no_output_____"
]
],
[
[
"c = cast\nc = c[(c.name == 'Tom Cruise')]\nc = c.merge(release_dates, on=['title', 'year'])\nc = c[(c.country == 'USA')]\nc.head()",
"_____no_output_____"
],
[
"c.groupby(c.date.dt.month).size()",
"_____no_output_____"
]
],
[
[
"Films with Tom Cruise tend to be released in the USA in December (12月)",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
]
|
e7be1ff90e478f7a8305734b04d77fde11e04083 | 2,793 | ipynb | Jupyter Notebook | pythonUPVX32.ipynb | Coldang/pythonMoocCompanion | 51726d13caea7842cd40003990b5297193cbbb1b | [
"MIT"
]
| 8 | 2020-06-11T21:59:40.000Z | 2022-03-24T16:48:16.000Z | pythonUPVX32.ipynb | Coldang/pythonMoocCompanion | 51726d13caea7842cd40003990b5297193cbbb1b | [
"MIT"
]
| null | null | null | pythonUPVX32.ipynb | Coldang/pythonMoocCompanion | 51726d13caea7842cd40003990b5297193cbbb1b | [
"MIT"
]
| 53 | 2020-06-14T12:01:27.000Z | 2022-03-24T16:45:37.000Z | 2,793 | 2,793 | 0.700322 | [
[
[
"# TAXI!",
"_____no_output_____"
]
],
[
[
"mitexto = \"el perro de san roque no tiene rabo\"",
"_____no_output_____"
],
[
"help(str)",
"_____no_output_____"
],
[
"str.title(mitexto)",
"_____no_output_____"
]
],
[
[
"### pero **mitexto** es de tipo str podriamos tal vez...",
"_____no_output_____"
]
],
[
[
"mitexto.title()",
"_____no_output_____"
]
],
[
[
"## encadenando llamadas",
"_____no_output_____"
]
],
[
[
"mitexto.replace('san','mr').title()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7be2b918d0679b9710ab7a5ef7c2f179d881cc8 | 18,099 | ipynb | Jupyter Notebook | tutorials/Tutorial1_Basic_QA_Pipeline.ipynb | tcapilla/haystack | 0a6d361d47c60576884e412d1181fe9d88c5008e | [
"Apache-2.0"
]
| 1 | 2020-09-07T05:23:15.000Z | 2020-09-07T05:23:15.000Z | tutorials/Tutorial1_Basic_QA_Pipeline.ipynb | tcapilla/haystack | 0a6d361d47c60576884e412d1181fe9d88c5008e | [
"Apache-2.0"
]
| null | null | null | tutorials/Tutorial1_Basic_QA_Pipeline.ipynb | tcapilla/haystack | 0a6d361d47c60576884e412d1181fe9d88c5008e | [
"Apache-2.0"
]
| null | null | null | 37.240741 | 419 | 0.564506 | [
[
[
"<a href=\"https://colab.research.google.com/github/tcapilla/haystack/blob/master/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Build Your First QA System\n\n<img style=\"float: right;\" src=\"https://upload.wikimedia.org/wikipedia/en/d/d8/Game_of_Thrones_title_card.jpg\">\n\n[](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb)\n\nQuestion Answering can be used in a variety of use cases. A very common one: Using it to navigate through complex knowledge bases or long documents (\"search setting\").\n\nA \"knowledge base\" could for example be your website, an internal wiki or a collection of financial reports. \nIn this tutorial we will work on a slightly different domain: \"Game of Thrones\". \n\nLet's see how we can use a bunch of Wikipedia articles to answer a variety of questions about the \nmarvellous seven kingdoms.\n",
"_____no_output_____"
],
[
"### Prepare environment\n\n#### Colab: Enable the GPU runtime\nMake sure you enable the GPU runtime to experience decent speed in this tutorial.\n**Runtime -> Change Runtime type -> Hardware accelerator -> GPU**\n\n<img src=\"https://raw.githubusercontent.com/deepset-ai/haystack/master/docs/_src/img/colab_gpu_runtime.jpg\">",
"_____no_output_____"
]
],
[
[
"# Make sure you have a GPU running\n!nvidia-smi",
"_____no_output_____"
],
[
"# Install the latest release of Haystack in your own environment \n#! pip install farm-haystack\n\n# Install the latest master of Haystack\n!pip install grpcio-tools==1.34.1\n!pip install git+https://github.com/deepset-ai/haystack.git\n\n# If you run this notebook on Google Colab, you might need to\n# restart the runtime after installing haystack.",
"_____no_output_____"
],
[
"from haystack.preprocessor.cleaning import clean_wiki_text\nfrom haystack.preprocessor.utils import convert_files_to_dicts, fetch_archive_from_http\nfrom haystack.reader.farm import FARMReader\nfrom haystack.reader.transformers import TransformersReader\nfrom haystack.utils import print_answers",
"_____no_output_____"
]
],
[
[
"## Document Store\n\nHaystack finds answers to queries within the documents stored in a `DocumentStore`. The current implementations of `DocumentStore` include `ElasticsearchDocumentStore`, `FAISSDocumentStore`, `SQLDocumentStore`, and `InMemoryDocumentStore`.\n\n**Here:** We recommended Elasticsearch as it comes preloaded with features like [full-text queries](https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-queries.html), [BM25 retrieval](https://www.elastic.co/elasticon/conf/2016/sf/improved-text-scoring-with-bm25), and [vector storage for text embeddings](https://www.elastic.co/guide/en/elasticsearch/reference/7.6/dense-vector.html).\n\n**Alternatives:** If you are unable to setup an Elasticsearch instance, then follow the [Tutorial 3](https://github.com/deepset-ai/haystack/blob/master/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb) for using SQL/InMemory document stores.\n\n**Hint**: This tutorial creates a new document store instance with Wikipedia articles on Game of Thrones. However, you can configure Haystack to work with your existing document stores.\n\n### Start an Elasticsearch server\nYou can start Elasticsearch on your local machine instance using Docker. If Docker is not readily available in your environment (e.g. in Colab notebooks), then you can manually download and execute Elasticsearch from source.",
"_____no_output_____"
]
],
[
[
"# Recommended: Start Elasticsearch using Docker via the Haystack utility function\nfrom haystack.utils import launch_es\n\nlaunch_es()",
"_____no_output_____"
],
[
"# In Colab / No Docker environments: Start Elasticsearch from source\n! wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz -q\n! tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz\n! chown -R daemon:daemon elasticsearch-7.9.2\n\nimport os\nfrom subprocess import Popen, PIPE, STDOUT\nes_server = Popen(['elasticsearch-7.9.2/bin/elasticsearch'],\n stdout=PIPE, stderr=STDOUT,\n preexec_fn=lambda: os.setuid(1) # as daemon\n )\n# wait until ES has started\n! sleep 30",
"_____no_output_____"
],
[
"# Connect to Elasticsearch\n\nfrom haystack.document_store.elasticsearch import ElasticsearchDocumentStore\ndocument_store = ElasticsearchDocumentStore(host=\"localhost\", username=\"\", password=\"\", index=\"document\")",
"_____no_output_____"
]
],
[
[
"## Preprocessing of documents\n\nHaystack provides a customizable pipeline for:\n - converting files into texts\n - cleaning texts\n - splitting texts\n - writing them to a Document Store\n\nIn this tutorial, we download Wikipedia articles about Game of Thrones, apply a basic cleaning function, and index them in Elasticsearch.",
"_____no_output_____"
]
],
[
[
"# Let's first fetch some documents that we want to query\n# Here: 517 Wikipedia articles for Game of Thrones\ndoc_dir = \"data/article_txt_got\"\ns3_url = \"https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt.zip\"\nfetch_archive_from_http(url=s3_url, output_dir=doc_dir)\n\n# Convert files to dicts\n# You can optionally supply a cleaning function that is applied to each doc (e.g. to remove footers)\n# It must take a str as input, and return a str.\ndicts = convert_files_to_dicts(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)\n\n# We now have a list of dictionaries that we can write to our document store.\n# If your texts come from a different source (e.g. a DB), you can of course skip convert_files_to_dicts() and create the dictionaries yourself.\n# The default format here is:\n# {\n# 'text': \"<DOCUMENT_TEXT_HERE>\",\n# 'meta': {'name': \"<DOCUMENT_NAME_HERE>\", ...}\n#}\n# (Optionally: you can also add more key-value-pairs here, that will be indexed as fields in Elasticsearch and\n# can be accessed later for filtering or shown in the responses of the Pipeline)\n\n# Let's have a look at the first 3 entries:\nprint(dicts[:3])\n\n# Now, let's write the dicts containing documents to our DB.\ndocument_store.write_documents(dicts)",
"_____no_output_____"
]
],
[
[
"## Initalize Retriever, Reader, & Pipeline\n\n### Retriever\n\nRetrievers help narrowing down the scope for the Reader to smaller units of text where a given question could be answered.\nThey use some simple but fast algorithm.\n\n**Here:** We use Elasticsearch's default BM25 algorithm\n\n**Alternatives:**\n\n- Customize the `ElasticsearchRetriever`with custom queries (e.g. boosting) and filters\n- Use `TfidfRetriever` in combination with a SQL or InMemory Document store for simple prototyping and debugging\n- Use `EmbeddingRetriever` to find candidate documents based on the similarity of embeddings (e.g. created via Sentence-BERT)\n- Use `DensePassageRetriever` to use different embedding models for passage and query (see Tutorial 6)",
"_____no_output_____"
]
],
[
[
"from haystack.retriever.sparse import ElasticsearchRetriever\nretriever = ElasticsearchRetriever(document_store=document_store)",
"_____no_output_____"
],
[
"# Alternative: An in-memory TfidfRetriever based on Pandas dataframes for building quick-prototypes with SQLite document store.\n\n# from haystack.retriever.sparse import TfidfRetriever\n# retriever = TfidfRetriever(document_store=document_store)",
"_____no_output_____"
]
],
[
[
"### Reader\n\nA Reader scans the texts returned by retrievers in detail and extracts the k best answers. They are based\non powerful, but slower deep learning models.\n\nHaystack currently supports Readers based on the frameworks FARM and Transformers.\nWith both you can either load a local model or one from Hugging Face's model hub (https://huggingface.co/models).\n\n**Here:** a medium sized RoBERTa QA model using a Reader based on FARM (https://huggingface.co/deepset/roberta-base-squad2)\n\n**Alternatives (Reader):** TransformersReader (leveraging the `pipeline` of the Transformers package)\n\n**Alternatives (Models):** e.g. \"distilbert-base-uncased-distilled-squad\" (fast) or \"deepset/bert-large-uncased-whole-word-masking-squad2\" (good accuracy)\n\n**Hint:** You can adjust the model to return \"no answer possible\" with the no_ans_boost. Higher values mean the model prefers \"no answer possible\"\n\n#### FARMReader",
"_____no_output_____"
]
],
[
[
"# Load a local model or any of the QA models on\n# Hugging Face's model hub (https://huggingface.co/models)\n\nreader = FARMReader(model_name_or_path=\"deepset/roberta-base-squad2\", use_gpu=True)",
"_____no_output_____"
]
],
[
[
"#### TransformersReader",
"_____no_output_____"
]
],
[
[
"# Alternative:\n# reader = TransformersReader(model_name_or_path=\"distilbert-base-uncased-distilled-squad\", tokenizer=\"distilbert-base-uncased\", use_gpu=-1)",
"_____no_output_____"
]
],
[
[
"### Pipeline\n\nWith a Haystack `Pipeline` you can stick together your building blocks to a search pipeline.\nUnder the hood, `Pipelines` are Directed Acyclic Graphs (DAGs) that you can easily customize for your own use cases.\nTo speed things up, Haystack also comes with a few predefined Pipelines. One of them is the `ExtractiveQAPipeline` that combines a retriever and a reader to answer our questions.\nYou can learn more about `Pipelines` in the [docs](https://haystack.deepset.ai/docs/latest/pipelinesmd).",
"_____no_output_____"
]
],
[
[
"from haystack.pipeline import ExtractiveQAPipeline\npipe = ExtractiveQAPipeline(reader, retriever)",
"_____no_output_____"
]
],
[
[
"## Voilà! Ask a question!",
"_____no_output_____"
]
],
[
[
"# You can configure how many candidates the reader and retriever shall return\n# The higher top_k_retriever, the better (but also the slower) your answers. \nprediction = pipe.run(\n query=\"Who is the father of Arya Stark?\", params={\"Retriever\": {\"top_k\": 10}, \"Reader\": {\"top_k\": 5}}\n)",
"_____no_output_____"
],
[
"# prediction = pipe.run(query=\"Who created the Dothraki vocabulary?\", params={\"Reader\": {\"top_k\": 5}})\n# prediction = pipe.run(query=\"Who is the sister of Sansa?\", params={\"Reader\": {\"top_k\": 5}})",
"_____no_output_____"
],
[
"print_answers(prediction, details=\"minimal\")",
"_____no_output_____"
]
],
[
[
"## About us\n\nThis [Haystack](https://github.com/deepset-ai/haystack/) notebook was made with love by [deepset](https://deepset.ai/) in Berlin, Germany\n\nWe bring NLP to the industry via open source! \nOur focus: Industry specific language models & large scale QA systems. \n \nSome of our other work: \n- [German BERT](https://deepset.ai/german-bert)\n- [GermanQuAD and GermanDPR](https://deepset.ai/germanquad)\n- [FARM](https://github.com/deepset-ai/FARM)\n\nGet in touch:\n[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)\n\nBy the way: [we're hiring!](https://apply.workable.com/deepset/) \n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
]
|
e7be36250bfda7eb6720ac83315e02f5660962b9 | 333,025 | ipynb | Jupyter Notebook | Crash_Course_Python_Parte_2.ipynb | Adrianacms/Hello-Word | 576e498f3566a16a5c00a9889c739af06306dae6 | [
"MIT"
]
| 1 | 2021-01-13T21:59:32.000Z | 2021-01-13T21:59:32.000Z | Crash_Course_Python_Parte_2.ipynb | Adrianacms/Hello-Word | 576e498f3566a16a5c00a9889c739af06306dae6 | [
"MIT"
]
| null | null | null | Crash_Course_Python_Parte_2.ipynb | Adrianacms/Hello-Word | 576e498f3566a16a5c00a9889c739af06306dae6 | [
"MIT"
]
| null | null | null | 148.274711 | 60,706 | 0.867415 | [
[
[
"",
"_____no_output_____"
],
[
"##<font color='GreeN'>Dicas e Truques de Ciência de Dados </font>\n\n### <font color='BLUE'>Baby Steps em Ciência de Dados </font>\n \n",
"_____no_output_____"
],
[
"#**Python Crash Course**\r\n\r\n\r\n",
"_____no_output_____"
],
[
"##Strings",
"_____no_output_____"
]
],
[
[
"data = 'Cientista de Dados'\r\n",
"_____no_output_____"
],
[
"print(data)",
"Cientista de Dados\n"
],
[
"print(len(data))",
"18\n"
],
[
"data[10:]",
"_____no_output_____"
]
],
[
[
"##Números",
"_____no_output_____"
]
],
[
[
"# Numbers\r\nvalue = 123\r\nvalue\r\ntype(value)",
"_____no_output_____"
],
[
"print(value)",
"_____no_output_____"
]
],
[
[
"##Boleanos",
"_____no_output_____"
]
],
[
[
"# Boolean\r\na = True\r\nb = False\r\n",
"_____no_output_____"
],
[
"print(a,b)",
"_____no_output_____"
],
[
"# Multiple Assignment\r\na, b, c = 1, 2, 3\r\nprint(a, b,c)\r\n\r\n",
"1 2 3\n"
],
[
"# No value\r\na = None\r\nprint(a)",
"None\n"
]
],
[
[
"##Flow Control\r\nIf-Then-Else Condition Example",
"_____no_output_____"
]
],
[
[
"idade = 21",
"_____no_output_____"
],
[
"if idade >= 18:\r\n print('maior de idade')\r\nelse:\r\n print('menor de idade')",
"_____no_output_____"
],
[
"idade = 39\r\n\r\nif idade < 12:\r\n print('crianca')\r\nelif idade < 18:\r\n print('adolescente')\r\n\r\nelif idade < 39:\r\n print('maduro')\r\n\r\nelif idade < 60:\r\n print('adulto')\r\nelse:\r\n print('idoso')",
"adulto\n"
]
],
[
[
"For-Loop Example",
"_____no_output_____"
]
],
[
[
"# For-Loop\r\nfor i in range(10):\r\n\tprint(i)",
"_____no_output_____"
]
],
[
[
"While-Loop Example",
"_____no_output_____"
]
],
[
[
"# While-Loop\r\ne = 5\r\nwhile e <= 100:\r\n\tprint(e)\r\n\te += 10",
"_____no_output_____"
]
],
[
[
"##Estrutura de Dados",
"_____no_output_____"
],
[
"Tupla",
"_____no_output_____"
]
],
[
[
"tupla = (1, 2, 3)\r\nprint(tupla)",
"(1, 2, 3)\n"
],
[
"type(tupla)",
"_____no_output_____"
]
],
[
[
"Lista\r\n",
"_____no_output_____"
]
],
[
[
"\r\nmylist = [1, 2, 3]\r\n\r\nprint(\"O índice ZERO é o número: %d\" % mylist[0])",
"O índice ZERO é o número: 1\n"
],
[
"type(mylist)",
"_____no_output_____"
],
[
"mylist[0]",
"_____no_output_____"
],
[
"mylist.append(4)\r\nprint(\"List Length: %d\" % len(mylist))\r\nfor value in mylist:\r\n\tprint(value)\r\n",
"_____no_output_____"
]
],
[
[
"Dicionário",
"_____no_output_____"
]
],
[
[
"mydict = {'a': 1, 'b': 2, 'c': 3}\r\nprint(\"O valor da chave 'a' é igual: %d\" % mydict['a'])\r\n",
"O valor da chave 'a' é igual: 1\n"
],
[
"mydict['a'] = 11",
"_____no_output_____"
],
[
"mydict['a'] = 11\r\nprint(\"A value: %d\" % mydict['a'])\r\nprint(\"Keys: %s\" % mydict.keys())\r\nprint(\"Values: %s\" % mydict.values())\r\n",
"A value: 11\nKeys: dict_keys(['a', 'b', 'c'])\nValues: dict_values([11, 2, 3])\n"
],
[
"for key in mydict.keys():\r\n\tprint(mydict[key])",
"11\n2\n3\n"
]
],
[
[
"##Functions",
"_____no_output_____"
]
],
[
[
"# Sum function\r\ndef mysum(x, y):\r\n\treturn x + y\r\n \r\n",
"_____no_output_____"
],
[
"def myfun (x,y):\r\n return x+y ",
"_____no_output_____"
],
[
"print(myfun)",
"<function myfun at 0x7f274b638730>\n"
],
[
"# Test sum function\r\nmyfun(1,3)",
"_____no_output_____"
],
[
"# Sum function\r\ndef myexp(x, y):\r\n\treturn x**y\r\n \r\nmyexp(3,3)",
"_____no_output_____"
]
],
[
[
"# **NumPy Crash Course**\r\n\r\n\r\n",
"_____no_output_____"
],
[
"Create Array (matriz)\r\nmatrizes são tensores com 2 dimensões (**tensores de rank 2**).",
"_____no_output_____"
]
],
[
[
"# define an array\r\nimport numpy\r\nmylist = [1, 2, 3]\r\nmyarray = numpy.array(mylist)\r\nprint(myarray)\r\nprint(myarray.shape)",
"[1 2 3]\n(3,)\n"
]
],
[
[
"Acessando os dados do Array (matriz)",
"_____no_output_____"
]
],
[
[
"# access values\r\nimport numpy\r\nmylist = [[1, 2, 3], [3, 4, 5]]\r\nmyarray = numpy.array(mylist)\r\nprint(myarray)\r\nprint(myarray.shape)\r\n",
"[[1 2 3]\n [3 4 5]]\n(2, 3)\n"
],
[
"print(\"Primeira linha: %s\" % myarray[0])\r\n",
"Primeira linha: [1 2 3]\n"
],
[
"print(\"última linha: %s\" % myarray[-1])\r\n",
"_____no_output_____"
],
[
"print(\"Qual elemento está na Posição dessa consulta? A Resposta é %s\" % myarray[0, 2])\r\n",
"Qual elemento está na Posição dessa consulta? A Resposta é 3\n"
],
[
"print(\"Quais elementos estão na coluna dessa consulta? A Resposta é %s\" % myarray[:, 2])",
"Quais elementos estão na coluna dessa consulta? A Resposta é [3 5]\n"
]
],
[
[
"Arithmetic",
"_____no_output_____"
]
],
[
[
"# arithmetic\r\nimport numpy\r\nmyarray1 = numpy.array([2, 2, 2])\r\nmyarray2 = numpy.array([3, 3, 3])\r\nprint(\"Soma: %s\" % (myarray1 + myarray2))\r\nprint(\"Multiplicação: %s\" % (myarray1 * myarray2))",
"Soma: [5 5 5]\nMultiplicação: [6 6 6]\n"
]
],
[
[
"### O vetor n-dimensional (tensor)\r\n\r\nO NumPy é uma biblioteca para a linguagem Python com funções para se trabalhar com **computação numérica**. Seu **principal objeto é o vetor n-dimensional, ou ndarray**. Um vetor n-dimensional também é conhecido pelo nome **tensor**.\r\n\r\n A principal característica do ndarray é que ele deve ser homogêneo, ou seja, diferentemente do objeto lista, todos os seus elementos devem ser do mesmo tipo.",
"_____no_output_____"
]
],
[
[
"#cria um vetor\r\nimport numpy as np\r\nv = np.array([1,2,3,4])\r\nprint(v)",
"[1 2 3 4]\n"
],
[
"print(v.dtype)",
"int64\n"
],
[
"v = np.array([1,2,3,4], dtype='float64')\r\nprint(v.dtype)",
"float64\n"
]
],
[
[
"Os tensores NumPy também possuem um atributo chamado shape. Esse atributo indica a forma do tensor, por exemplo:",
"_____no_output_____"
]
],
[
[
"print(v.shape)",
"(4,)\n"
]
],
[
[
"Neste caso, o tensor v possui 1 dimensão (ou eixo) com 4 elementos. Um tensor unidimensional corresponde a um vetor. ",
"_____no_output_____"
],
[
"Podemos também criar um tensor bidimensional (uma matriz) usando o atributo shape:",
"_____no_output_____"
]
],
[
[
"# Alterando a dimensão do tensor\r\nv = np.array([1,2,3,4])\r\nv.shape = (2,2)\r\nprint(v)",
"[[1 2]\n [3 4]]\n"
]
],
[
[
"### Reshape\r\n\r\nOutra forma útil de mudar o shape de um tensor é simplesmente utilizando a função reshape:",
"_____no_output_____"
]
],
[
[
"v = np.array([1,2,3,4]).reshape(2,2)\r\nprint(v)\r\n",
"[[1 2]\n [3 4]]\n"
]
],
[
[
"### **ndim** (eixos ou dimensões do tensor) e **size** (total de elementos/registros)\r\nO número de eixos (ou dimensões) de um tensor é dado pelo atributo ndim, enquanto o número total de elementos é dado por size:",
"_____no_output_____"
]
],
[
[
"v = np.array(range(9)).reshape(1,3,3)\r\nv",
"_____no_output_____"
],
[
"\r\nprint('Shape = ', v.shape)\r\nprint('Número de dimensões = ', v.ndim)\r\nprint('Número de elementos = ', v.size)\r\nprint('\\n\\n Veja abaixo o Tensor v \\n\\n', v)\r\n",
"Shape = (1, 3, 3)\nNúmero de dimensões = 3\nNúmero de elementos = 9\n\n\n Veja abaixo o Tensor v \n\n [[[0 1 2]\n [3 4 5]\n [6 7 8]]]\n"
]
],
[
[
"# **Matplotlib Crash Course**\r\n",
"_____no_output_____"
],
[
"Line Plot",
"_____no_output_____"
]
],
[
[
"# basic line plot\r\nimport matplotlib.pyplot as plt\r\nimport numpy\r\n\r\nmyarray = numpy.array([1, 2, 3])\r\nplt.plot(myarray)\r\nplt.xlabel('Data')\r\nplt.ylabel('Faturamento')\r\nplt.show()",
"_____no_output_____"
]
],
[
[
"Scatter Plot",
"_____no_output_____"
]
],
[
[
"# basic scatter plot\r\nimport matplotlib.pyplot as plt\r\nimport numpy\r\nvendas = numpy.array([1, 2, 3, 4, 8, 16 ])\r\nfaturamento = numpy.array([2, 4, 6, 8, 10, 12])\r\nplt.scatter(vendas,faturamento)\r\nplt.xlabel('vendas')\r\nplt.ylabel('faturamento')\r\nplt.show()",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\r\n\r\nsize = 0.3\r\nvals = np.array([[60., 32.], [37., 40.], [29., 10.]])\r\n\r\ncmap = plt.get_cmap(\"tab20c\")\r\nouter_colors = cmap(np.arange(3)*4)\r\ninner_colors = cmap([1, 2, 5, 6, 9, 10])\r\n\r\nax.pie(vals.sum(axis=1), radius=1, colors=outer_colors,\r\n wedgeprops=dict(width=size, edgecolor='w'))\r\n\r\nax.pie(vals.flatten(), radius=1-size, colors=inner_colors,\r\n wedgeprops=dict(width=size, edgecolor='w'))\r\n\r\nax.set(aspect=\"equal\", title='Pie plot with `ax.pie`')\r\nplt.show()",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\r\nfrom matplotlib.patches import ConnectionPatch\r\nimport numpy as np\r\n\r\n# make figure and assign axis objects\r\nfig = plt.figure(figsize=(9, 5))\r\nax1 = fig.add_subplot(121)\r\nax2 = fig.add_subplot(122)\r\nfig.subplots_adjust(wspace=0)\r\n\r\n# pie chart parameters\r\nratios = [.27, .56, .17]\r\nlabels = ['Alta Renda', 'Baixa renda', 'Classe Média']\r\nexplode = [0.1, 0, 0]\r\n# rotate so that first wedge is split by the x-axis\r\nangle = -180 * ratios[0]\r\nax1.pie(ratios, autopct='%1.1f%%', startangle=angle,\r\n labels=labels, explode=explode)\r\n\r\n# bar chart parameters\r\n\r\nxpos = 0\r\nbottom = 0\r\nratios = [.33, .54, .07, .06]\r\nwidth = .2\r\ncolors = [[.1, .3, .5], [.1, .3, .3], [.1, .3, .7], [.1, .3, .9]]\r\n\r\nfor j in range(len(ratios)):\r\n height = ratios[j]\r\n ax2.bar(xpos, height, width, bottom=bottom, color=colors[j])\r\n ypos = bottom + ax2.patches[j].get_height() / 2\r\n bottom += height\r\n ax2.text(xpos, ypos, \"%d%%\" % (ax2.patches[j].get_height() * 100),\r\n ha='center')\r\n\r\nax2.set_title('Faixa Etária - Alta Renda')\r\nax2.legend(('50-65', 'acima 65', '35-49', 'abaixo 35'))\r\nax2.axis('off')\r\nax2.set_xlim(- 2.5 * width, 2.5 * width)\r\n\r\n# use ConnectionPatch to draw lines between the two plots\r\n# get the wedge data\r\ntheta1, theta2 = ax1.patches[0].theta1, ax1.patches[0].theta2\r\ncenter, r = ax1.patches[0].center, ax1.patches[0].r\r\nbar_height = sum([item.get_height() for item in ax2.patches])\r\n\r\n# draw top connecting line\r\nx = r * np.cos(np.pi / 180 * theta2) + center[0]\r\ny = r * np.sin(np.pi / 180 * theta2) + center[1]\r\ncon = ConnectionPatch(xyA=(-width / 2, bar_height), coordsA=ax2.transData,\r\n xyB=(x, y), coordsB=ax1.transData)\r\ncon.set_color([0, 0, 0])\r\ncon.set_linewidth(4)\r\nax2.add_artist(con)\r\n\r\n# draw bottom connecting line\r\nx = r * np.cos(np.pi / 180 * theta1) + center[0]\r\ny = r * np.sin(np.pi / 180 * theta1) + center[1]\r\ncon = ConnectionPatch(xyA=(-width / 2, 0), coordsA=ax2.transData,\r\n xyB=(x, y), coordsB=ax1.transData)\r\ncon.set_color([0, 0, 0])\r\nax2.add_artist(con)\r\ncon.set_linewidth(4)\r\n\r\nplt.show()",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\r\nimport numpy as np\r\n\r\n\r\nplt.style.use('fivethirtyeight')\r\n\r\nx = np.linspace(0, 10)\r\n\r\n# Fixing random state for reproducibility\r\nnp.random.seed(7)\r\n\r\nfig, ax = plt.subplots()\r\n\r\nax.plot(x, np.sin(x) + x + np.random.randn(50))\r\nax.plot(x, np.sin(x) + 0.5 * x + np.random.randn(50))\r\nax.plot(x, np.sin(x) + 2 * x + np.random.randn(50))\r\nax.plot(x, np.sin(x) - 0.5 * x + np.random.randn(50))\r\nax.plot(x, np.sin(x) - 2 * x + np.random.randn(50))\r\nax.plot(x, np.sin(x) + np.random.randn(50))\r\nax.set_title(\"'fivethirtyeight' é o Estilo do Gráfico\")\r\n\r\nplt.show()",
"_____no_output_____"
]
],
[
[
"### **Eletroencefalograma**\r\n\r\né um exame que avalia a atividade elétrica espontânea do cérebro. Para tanto, o teste, também conhecido pela abreviação EEG, amplifica os impulsos elétricos cerebrais e os registra, a fim de detectar anormalidades neurológicas.",
"_____no_output_____"
]
],
[
[
"import numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport matplotlib.cbook as cbook\r\nimport matplotlib.cm as cm\r\n\r\nfrom matplotlib.collections import LineCollection\r\nfrom matplotlib.ticker import MultipleLocator\r\n\r\nfig = plt.figure(\"MRI_with_EEG\")\r\n\r\n# Load the MRI data (256x256 16 bit integers)\r\nwith cbook.get_sample_data('s1045.ima.gz') as dfile:\r\n im = np.frombuffer(dfile.read(), np.uint16).reshape((256, 256))\r\n\r\n# Plot the MRI image\r\nax0 = fig.add_subplot(2, 2, 1)\r\nax0.imshow(im, cmap=cm.gray)\r\nax0.axis('off')\r\n\r\n# Plot the histogram of MRI intensity\r\nax1 = fig.add_subplot(2, 2, 2)\r\nim = np.ravel(im)\r\nim = im[np.nonzero(im)] # Ignore the background\r\nim = im / (2**16 - 1) # Normalize\r\nax1.hist(im, bins=100)\r\nax1.xaxis.set_major_locator(MultipleLocator(0.4))\r\nax1.minorticks_on()\r\nax1.set_yticks([])\r\nax1.set_xlabel('Intensity (a.u.)')\r\nax1.set_ylabel('MRI density')\r\n\r\n# Load the EEG data\r\nn_samples, n_rows = 800, 4\r\nwith cbook.get_sample_data('eeg.dat') as eegfile:\r\n data = np.fromfile(eegfile, dtype=float).reshape((n_samples, n_rows))\r\nt = 10 * np.arange(n_samples) / n_samples\r\n\r\n# Plot the EEG\r\nticklocs = []\r\nax2 = fig.add_subplot(2, 1, 2)\r\nax2.set_xlim(0, 10)\r\nax2.set_xticks(np.arange(10))\r\ndmin = data.min()\r\ndmax = data.max()\r\ndr = (dmax - dmin) * 0.7 # Crowd them a bit.\r\ny0 = dmin\r\ny1 = (n_rows - 1) * dr + dmax\r\nax2.set_ylim(y0, y1)\r\n\r\nsegs = []\r\nfor i in range(n_rows):\r\n segs.append(np.column_stack((t, data[:, i])))\r\n ticklocs.append(i * dr)\r\n\r\noffsets = np.zeros((n_rows, 2), dtype=float)\r\noffsets[:, 1] = ticklocs\r\n\r\nlines = LineCollection(segs, offsets=offsets, transOffset=None)\r\nax2.add_collection(lines)\r\n\r\n# Set the yticks to use axes coordinates on the y axis\r\nax2.set_yticks(ticklocs)\r\nax2.set_yticklabels(['PG3', 'PG5', 'PG7', 'PG9'])\r\n\r\nax2.set_xlabel('Time (s)')\r\n\r\n\r\nplt.tight_layout()\r\nplt.show()",
"_____no_output_____"
],
[
"from mpl_toolkits.mplot3d import axes3d\r\nimport matplotlib.pyplot as plt\r\nfrom matplotlib import cm\r\n\r\nfig = plt.figure()\r\nax = fig.gca(projection='3d')\r\nX, Y, Z = axes3d.get_test_data(0.05)\r\n\r\n# Plot the 3D surface\r\nax.plot_surface(X, Y, Z, rstride=8, cstride=8, alpha=0.3)\r\n\r\n# Plot projections of the contours for each dimension. By choosing offsets\r\n# that match the appropriate axes limits, the projected contours will sit on\r\n# the 'walls' of the graph\r\ncset = ax.contourf(X, Y, Z, zdir='z', offset=-100, cmap=cm.coolwarm)\r\ncset = ax.contourf(X, Y, Z, zdir='x', offset=-40, cmap=cm.coolwarm)\r\ncset = ax.contourf(X, Y, Z, zdir='y', offset=40, cmap=cm.coolwarm)\r\n\r\nax.set_xlim(-40, 40)\r\nax.set_ylim(-40, 40)\r\nax.set_zlim(-100, 100)\r\n\r\nax.set_xlabel('X')\r\nax.set_ylabel('Y')\r\nax.set_zlabel('Z')\r\n\r\nplt.show()",
"_____no_output_____"
]
],
[
[
"# **Pandas Crash Course**\r\n",
"_____no_output_____"
],
[
"**Series**: Uma série é um array unidimensional onde as linhas e colunas podem ser rotuladas.",
"_____no_output_____"
]
],
[
[
"# series\r\nimport numpy as np\r\nimport pandas as pd\r\nmyarray = np.array([1, 2, 3])\r\nrownames = ['Kiwi', 'Marlos', 'Bruno']\r\nmyseries = pd.Series(myarray, index=rownames)\r\nprint(myseries)",
"Kiwi 1\nMarlos 2\nBruno 3\ndtype: int64\n"
],
[
"print(myseries['Marlos'])\r\n",
"_____no_output_____"
]
],
[
[
"**Dataframe**",
"_____no_output_____"
]
],
[
[
"# dataframe\r\nimport numpy as np\r\nimport pandas as pd\r\n\r\nmyarray = np.array([[10, 9, 7], [5, 5, 8], [1,1,1]])\r\nrownames = ['Marlos', 'Kiwi','Oliveira']\r\ncolnames = ['Geografia', 'Matemática', 'Biologia']\r\nmydataframe = pd.DataFrame(myarray, index=rownames, columns=colnames)\r\nprint(mydataframe)",
" Geografia Matemática Biologia\nMarlos 10 9 7\nKiwi 5 5 8\nOliveira 1 1 1\n"
],
[
"#Quantidade de linhas\r\nmydataframe.value_counts().sum()",
"_____no_output_____"
],
[
"mydataframe.Biologia.mean()\r\n",
"_____no_output_____"
],
[
"mydataframe.Biologia.median()",
"_____no_output_____"
],
[
"df = pd.read_csv('/content/bank-full.csv',delimiter=';' )\r\ndf",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
],
[
"df.balance.sum()",
"_____no_output_____"
],
[
"df.y.value_counts()",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"#**Resumão**\r\n",
"_____no_output_____"
],
[
"Você acaba de colocar o pé nesse MAR que é o **Python**. \r\n\r\nVocê descobriu a sintaxe básica e o uso do Python e 3 bibliotecas Python principais usadas para inicira os trabalhos de aprendizado de máquina:\r\n\r\n* **NumPy**\r\n* **Matplotlib**\r\n* **Pandas** \r\n\r\nAgora você conhece sintaxe e informações de uso suficientes para ler e entender o código Python para aprendizado de máquina e para começar a criar seus próprios scripts.\r\n\r\nSimbóra!\r\n\r\n",
"_____no_output_____"
],
[
"# Fim",
"_____no_output_____"
],
[
"## Valeu!",
"_____no_output_____"
],
[
"### #Links - Ciência dos Dados <a href=\"https://linktr.ee/cienciadosdados\">https://linktr.ee/cienciadosdados</a>",
"_____no_output_____"
],
[
"### #YouTube - Mais Aulas como essa no YouTube <a href=\"https://www.youtube.com/watch?v=IaIc5oHd3II&t=1569s\">https://www.youtube.com/watch?v=IaIc5oHd3II&t=1569s</a>",
"_____no_output_____"
]
],
[
[
"from IPython.core.display import HTML\nHTML('<iframe width=\"380\" height=\"200\" src=\"https://www.youtube.com/embed/W9iktBS67Iw\" frameborder=\"0\" allow=\"accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture\" allowfullscreen></iframe>')",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
]
|
e7be5166901a66ecb3c67365c9d4cf3cba236c78 | 38,089 | ipynb | Jupyter Notebook | Starter_Code/credit_risk_ensemble.ipynb | willhua531/HW-Classification | 6c609d59d7a8b4bda5118880c01b09596d1ce0af | [
"ADSL"
]
| null | null | null | Starter_Code/credit_risk_ensemble.ipynb | willhua531/HW-Classification | 6c609d59d7a8b4bda5118880c01b09596d1ce0af | [
"ADSL"
]
| null | null | null | Starter_Code/credit_risk_ensemble.ipynb | willhua531/HW-Classification | 6c609d59d7a8b4bda5118880c01b09596d1ce0af | [
"ADSL"
]
| null | null | null | 34.314414 | 275 | 0.434141 | [
[
[
"# Ensemble Learning\n\n## Initial Imports",
"_____no_output_____"
]
],
[
[
"import warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd\nfrom pathlib import Path\nfrom collections import Counter",
"_____no_output_____"
],
[
"from sklearn.metrics import balanced_accuracy_score\nfrom sklearn.metrics import confusion_matrix\nfrom imblearn.metrics import classification_report_imbalanced",
"_____no_output_____"
]
],
[
[
"## Read the CSV and Perform Basic Data Cleaning",
"_____no_output_____"
]
],
[
[
"# Load the data\nfile_path = Path('Resources/LoanStats_2019Q1.csv')\ndf = pd.read_csv(file_path)\n\n# Preview the data\ndf.head()",
"_____no_output_____"
]
],
[
[
"## Split the Data into Training and Testing",
"_____no_output_____"
]
],
[
[
"# Create our features\ndf_encoded = pd.get_dummies(df, columns = ['home_ownership', 'verification_status', 'issue_d', \n 'pymnt_plan', 'hardship_flag', 'debt_settlement_flag', \n 'initial_list_status', 'next_pymnt_d', 'application_type'])\ndf_encoded\nX = df_encoded.drop(columns = 'loan_status')\n\n# Create our target\ny = df_encoded['loan_status']",
"_____no_output_____"
],
[
"X.describe()",
"_____no_output_____"
],
[
"# Check the balance of our target values\n# YOUR CODE HERE\ny.value_counts()",
"_____no_output_____"
],
[
"# Split the X and y into X_train, X_test, y_train, y_test\n# YOUR CODE HERE\nfrom sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X, y, random_state =1, stratify =y)\nCounter(y_train)",
"_____no_output_____"
]
],
[
[
"## Data Pre-Processing\n\nScale the training and testing data using the `StandardScaler` from `sklearn`. Remember that when scaling the data, you only scale the features data (`X_train` and `X_testing`).",
"_____no_output_____"
]
],
[
[
"# Create the StandardScaler instance\nfrom sklearn.preprocessing import StandardScaler\n# YOUR CODE HERE\nscaler = StandardScaler()",
"_____no_output_____"
],
[
"# Fit the Standard Scaler with the training data\n# When fitting scaling functions, only train on the training dataset\n# YOUR CODE HERE\nX_scaler = scaler.fit(X_train)",
"_____no_output_____"
],
[
"# Scale the training and testing data\n# YOUR CODE HERE\nX_train_scaled = X_scaler.transform(X_train)\nX_test_scaled = X_scaler.transform(X_test)",
"_____no_output_____"
]
],
[
[
"## Ensemble Learners\n\nIn this section, you will compare two ensemble algorithms to determine which algorithm results in the best performance. You will train a Balanced Random Forest Classifier and an Easy Ensemble classifier . For each algorithm, be sure to complete the folliowing steps:\n\n1. Train the model using the training data. \n2. Calculate the balanced accuracy score from sklearn.metrics.\n3. Display the confusion matrix from sklearn.metrics.\n4. Generate a classication report using the `imbalanced_classification_report` from imbalanced-learn.\n5. For the Balanced Random Forest Classifier only, print the feature importance sorted in descending order (most important feature to least important) along with the feature score\n\nNote: Use a random state of 1 for each algorithm to ensure consistency between tests",
"_____no_output_____"
],
[
"### Balanced Random Forest Classifier",
"_____no_output_____"
]
],
[
[
"# Resample the training data with the BalancedRandomForestClassifier\n# YOUR CODE HERE\nfrom imblearn.ensemble import BalancedRandomForestClassifier\nbrf = BalancedRandomForestClassifier(n_estimators=100, random_state=1)\nbrf.fit(X_train, y_train)",
"_____no_output_____"
],
[
"# Calculated the balanced accuracy score\n# YOUR CODE HERE\ny_pred = brf.predict(X_test)\nbalanced_accuracy_score(y_test, y_pred)",
"_____no_output_____"
],
[
"# Display the confusion matrix\n# YOUR CODE HERE\nconfusion_matrix(y_test, y_pred)",
"_____no_output_____"
],
[
"# Print the imbalanced classification report\n# YOUR CODE HERE\nfrom imblearn.metrics import classification_report_imbalanced\nprint(classification_report_imbalanced(y_test, y_pred))",
" pre rec spe f1 geo iba sup\n\n high_risk 0.03 0.68 0.89 0.06 0.78 0.59 87\n low_risk 1.00 0.89 0.68 0.94 0.78 0.62 17118\n\navg / total 0.99 0.89 0.68 0.94 0.78 0.62 17205\n\n"
],
[
"# List the features sorted in descending order by feature importance\n# YOUR CODE HERE\nimportances = brf.feature_importances_\nsorted(zip(importances, X.columns), reverse = True)\n\n",
"_____no_output_____"
]
],
[
[
"### Easy Ensemble Classifier",
"_____no_output_____"
]
],
[
[
"# Train the Classifier\n# YOUR CODE HERE\nfrom imblearn.ensemble import EasyEnsembleClassifier\neec = EasyEnsembleClassifier(random_state = 0)\neec.fit(X_train, y_train)\n",
"_____no_output_____"
],
[
"# Calculated the balanced accuracy score\n# YOUR CODE HERE\ny_pred_eec = eec.predict(X_test)\nbalanced_accuracy_score(y_test, y_pred_eec)",
"_____no_output_____"
],
[
"# Display the confusion matrix\n# YOUR CODE HERE\nconfusion_matrix(y_test, y_pred_eec)",
"_____no_output_____"
],
[
"# Print the imbalanced classification report\n# YOUR CODE HERE\nprint(classification_report_imbalanced(y_test, y_pred_eec))",
" pre rec spe f1 geo iba sup\n\n high_risk 0.06 0.91 0.93 0.12 0.92 0.84 87\n low_risk 1.00 0.93 0.91 0.96 0.92 0.85 17118\n\navg / total 0.99 0.93 0.91 0.96 0.92 0.85 17205\n\n"
]
],
[
[
"### Final Questions\n\n1. Which model had the best balanced accuracy score?\n\n Easy Ensemble Classifier\n\n2. Which model had the best recall score?\n\n Easy Ensemble Classifier\n\n3. Which model had the best geometric mean score?\n\n Easy Ensemble Classifier\n\n4. What are the top three features?\n\n 'total_rec_prncp', 'total_pymnt', 'last_pymnt_amnt'",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
]
|
e7be51d0a5b06ca960ae204af6baa561d50a5993 | 127,466 | ipynb | Jupyter Notebook | notebooks/hydrogenic_atom.ipynb | akey7/basic-quantum-models | b2f7edd2fdd15b6f85ee3708f8c2dae24686fd07 | [
"BSD-2-Clause"
]
| null | null | null | notebooks/hydrogenic_atom.ipynb | akey7/basic-quantum-models | b2f7edd2fdd15b6f85ee3708f8c2dae24686fd07 | [
"BSD-2-Clause"
]
| 3 | 2021-07-12T15:49:00.000Z | 2021-07-12T15:54:55.000Z | notebooks/hydrogenic_atom.ipynb | akey7/basic-quantum-models | b2f7edd2fdd15b6f85ee3708f8c2dae24686fd07 | [
"BSD-2-Clause"
]
| null | null | null | 169.728362 | 82,412 | 0.867965 | [
[
[
"In this post, I define a class to model the behavior of ahydrogen atom. In the process, I get to solve integrals like the following numerically to test my code:\n\n$$ \\int_0^{\\pi} \\int_0^{2\\pi} \\lvert Y_{l, m_l} \\rvert ^2 \\sin \\theta d \\theta d \\phi = 1 $$\n\nThis post consists of a arge block of Python code up front, and then explanations and plots below. Let's get started!\n\n## Define a class for the hydrogenic atom\n\nThis Python class has wavefunctions and energies. It is based on Chapter 10 of *Physical Chemistry, 8th Ed* by Atkins and De Paula. The goal of the Python class is to reproduce some of the plots and reproduce results with numeric integration found in Chapter 10.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib import cm\nfrom math import exp, sqrt, pi, cos, sin\nfrom scipy.integrate import dblquad, tplquad, quad\nimport cmath\n\nclass HydrogenicAtom:\n \"\"\"\n This class models the wavefunctions and energy levels of a hydrogenic atom.\n \n It assumes an infinitely heavy nucleus, so the mass is that of the\n electron.\n \n Masses are in kg, distances are in m\n \n This whole class uses complex numbers and math functions.\n \"\"\"\n \n def __init__(self, n=1, l=0, ml=0, z=1):\n \"\"\"\n This sets some instance attributes and a few constant used throughout the\n class.\n \n Leave z at 1 for hydrogen.\n \n Parameters\n ---------- \n n: int\n Principal quantum number.\n \n l: int\n Orbital angular momentum quantum number.\n \n ml: int\n Magnetic quantum number.\n \n z: int\n Number of protons in the nucleus. Defaults to 1.\n \"\"\"\n self.a0 = 5.29e-11 # m\n self.me = 9.10938356e-31 # kg\n self.e0 = 8.85418782e-12 # Permitivity of free space\n self.e_charge = 1.60217662e-19 # Coulombs, charge of electron\n self.hbar = 1.054571817e-34 # Reduced Planck's constant\n self.n = n\n self.l = l\n self.ml = ml\n self.z = z\n \n def rho(self, r):\n \"\"\"\n Calculates the rho part of the radial function. It assumes an infinitely\n heavy nucleus.\n \n From Atkins and de Paula, Table 10.1, page 324\n \n Parameters\n ----------\n r: float\n The distance, in meters being calculated\n \n Returns\n -------\n float\n The value of rho.\n \"\"\"\n return (2 * self.z / self.n / self.a0) * r\n \n def radial(self, r):\n \"\"\"\n The radial part of the wavefunction\n \n Parameters\n ----------\n r: float\n Radius, in meters\n \n Returns\n -------\n complex\n The value of the radial wavefunction, which only uses the real\n part of the complex value.\n \n Raises\n ------\n Exception\n Raises an exception for invalid n and l\n \"\"\"\n za32 = (self.z / self.a0) ** (3/2)\n rho = self.rho(r)\n exp_rho = exp(-rho / 2.0)\n \n if self.n == 1 and self.l == 0: # 1s orbital\n return 2 * za32 * exp_rho\n elif self.n == 2 and self.l == 0: # 2s orbital\n return (1.0 / sqrt(8)) * za32 * (2.0 - rho) * exp_rho\n elif self.n == 2 and self.l == 1: # 2p orbital\n return (1.0 / sqrt(24)) * za32 * rho * exp_rho\n elif self.n == 3 and self.l == 0:\n return (1.0 / sqrt(243)) * za32 * (6.0 - 6 * rho + rho ** 2) * exp_rho\n elif self.n == 3 and self.l == 1:\n return (1.0 / sqrt(486)) * za32 * (4.0 - rho) * rho * exp_rho\n elif self.n == 3 and self.l == 2:\n return (1.0 / sqrt(2430)) * za32 * rho ** 2 * exp_rho\n else:\n raise Exception(f'No radial function for {self.n} and {self.l}')\n \n def spherical_harmonic(self, theta, phi):\n \"\"\"\n Find the value of the spherical harmonic given an quantum numbers\n l, ml and coordinates theta, phi.\n \n From Atkins and de Paula, Table 9.3, page 302\n \n Parameters\n ---------- \n theta: float\n Theta coordinate, from 0 to pi\n\n phi: float\n Phi coordinate, from 0 to 2*pi\n \n Returns\n -------\n complex\n The value of the spherical harmonic, which is a complex value\n \n Raises\n ------\n Exception\n Raises an Exception for an invalid combination of l and ml\n \"\"\"\n if self.l == 0 and self.ml == 0:\n return sqrt(1 / 4.0 / pi)\n \n elif self.l == 1 and self.ml == 0:\n return sqrt(3.0 / 4.0 / pi) * cos(theta)\n elif self.l == 1 and self.ml == 1:\n return -sqrt(3.0 / 8.0 / pi) * sin(theta) * cmath.exp(1j * phi)\n elif self.l == 1 and self.ml == -1:\n return -sqrt(3.0 / 8.0 / pi) * sin(theta) * cmath.exp(-1j * phi)\n \n elif self.l == 2 and self.ml == 0:\n return sqrt(5.0 / 16.0 / pi) * (3 * cos(theta)** 2 - 1)\n elif self.l == 2 and self.ml == 1:\n return -sqrt(15.0 / 8.0 / pi) * cos(theta) * sin(theta) * cmath.exp(1j * phi)\n elif self.l == 2 and self.ml == -1:\n return sqrt(15.0 / 8.0 / pi) * cos(theta) * sin(theta) * cmath.exp(-1j * phi)\n elif self.l == 2 and self.ml == 2:\n return sqrt(15.0 / 32.0 / pi) * sin(theta) ** 2 * cmath.exp(2j * phi)\n elif self.l == 2 and self.ml == -2:\n return sqrt(15.0 / 32.0 / pi) * sin(theta) ** 2 * cmath.exp(-2j * phi)\n \n elif self.l == 3 and self.ml == 0:\n return sqrt(7.0 / 16.0 / pi) * (5 * cos(theta) ** 3 - 3 * cos(theta))\n elif self.l == 3 and self.ml == 1:\n return -sqrt(21.0 / 64.0 / pi) * (5 * cos(theta) ** 2 - 1) * sin(theta) * cmath.exp(1j * phi)\n elif self.l == 3 and self.ml == -1:\n return sqrt(21.0 / 64.0 / pi) * (5 * cos(theta) ** 2 - 1) * sin(theta) * cmath.exp(-1j * phi)\n elif self.l == 3 and self.ml == 2:\n return sqrt(105.0 / 32.0 / pi) * sin(theta) ** 2 * cos(theta) * cmath.exp(2j * phi)\n elif self.l == 3 and self.ml == -2:\n return sqrt(105.0 / 32.0 / pi) * sin(theta) ** 2 * cos(theta) * cmath.exp(-2j * phi)\n elif self.l == 3 and self.ml == 3:\n return -sqrt(35.0 / 64.0 / pi) * sin(theta) ** 3 * cmath.exp(3j * phi)\n elif self.l == 3 and self.ml == -3:\n return sqrt(35.0 / 64.0 / pi) * sin(theta) ** 3 * cmath.exp(-3j * phi)\n \n else:\n raise Exception(f'No equation for l={self.l} and ml={self.ml}')\n \n def wavefunction(self, r, theta, phi):\n \"\"\"\n Returns the value of the wavefunction at the given location.\n \n Parameters\n ----------\n r: float\n The r value, from 0 to infinity\n \n theta: float\n The theta value, from 0 to pi\n \n phi: float\n The phi value, from 0 to 2*pi\n \n Returns\n -------\n complex\n The complex value of the wavefunction.\n \"\"\"\n return self.radial(r) * self.spherical_harmonic(theta, phi)\n \n def energy(self):\n \"\"\"\n This calcuates the energy in Joules of the electron at the n level of this\n atoms configuration.\n \n It makes the infinite mas approximation for the nucleus, so the mass in\n the expression is that of the electron.\n \n From page 324 of Atkins and de Paula\n \n Returns\n -------\n float, float\n First float is energy level in joules, second float is energy level in eV\n \"\"\"\n ev_per_joule = 6.242e+18\n numerator = self.z**2 * self.me * self.e_charge**4\n denominator = 32 * pi**2 * self.e0**2 * self.hbar**2 * self.n**2\n value = numerator / denominator\n joules = -value\n ev = joules * ev_per_joule\n return joules, ev\n \n def mean_orbital_radius(self):\n \"\"\"\n Returns the mean orbital radius of the given state of this atom.\n It does this by integration.\n \n Returns\n -------\n float\n The mean orbital radius\n \"\"\"\n second_point_guess = 10 * self.n * self.a0\n def integrand(r):\n return r**3 * self.radial(r)**2\n radius, _ = quad(integrand, 0, 1, points=[0, second_point_guess])\n return radius",
"_____no_output_____"
]
],
[
[
"## Check the spherical harmonics\n\nMake sure all the spherical harmonics are normalized. That means each of the the spherical harmonic functions must stasify the following expression:\n\n$$ \\int_0^{\\pi} \\int_0^{2\\pi} \\lvert Y_{l, m_l} \\rvert ^2 \\sin \\theta d \\theta d \\phi = 1 $$\n\nThe next block of code takes the spherical harmonic for each parameter set of l and ml and numerically integrates it to ensure that the result is 1.0, within floating point precision. A report of the parameters and the results follows, and they all integrate to approximately 1.0! Success!",
"_____no_output_____"
]
],
[
[
"parameters = [\n { 'n': 3, 'l': 0, 'ml': 0 },\n { 'n': 3, 'l': 1, 'ml': 0 },\n { 'n': 3, 'l': 1, 'ml': 1 },\n { 'n': 3, 'l': 1, 'ml': -1 },\n { 'n': 3, 'l': 2, 'ml': 0 },\n { 'n': 3, 'l': 2, 'ml': 1 },\n { 'n': 3, 'l': 2, 'ml': -1 },\n { 'n': 3, 'l': 2, 'ml': 2 },\n { 'n': 3, 'l': 2, 'ml': -2 },\n { 'n': 3, 'l': 3, 'ml': 0 },\n { 'n': 3, 'l': 3, 'ml': 1 },\n { 'n': 3, 'l': 3, 'ml': -1 },\n { 'n': 3, 'l': 3, 'ml': 2 },\n { 'n': 3, 'l': 3, 'ml': -2 },\n { 'n': 3, 'l': 3, 'ml': 3 },\n { 'n': 3, 'l': 3, 'ml': -3 }\n]\n\nfor p in parameters:\n ha = HydrogenicAtom(n=p['n'], l=p['l'], ml=p['ml'])\n def integrand(phi,theta):\n value = ha.spherical_harmonic(theta, phi)\n return abs(value) ** 2 * sin(theta).real\n p['result'], _ = dblquad(integrand, 0, pi, 0, 2 * pi)\n \nfor p in parameters:\n print(p)",
"{'n': 3, 'l': 0, 'ml': 0, 'result': 0.9999999999999999}\n{'n': 3, 'l': 1, 'ml': 0, 'result': 1.0}\n{'n': 3, 'l': 1, 'ml': 1, 'result': 0.9999999999999999}\n{'n': 3, 'l': 1, 'ml': -1, 'result': 0.9999999999999999}\n{'n': 3, 'l': 2, 'ml': 0, 'result': 1.0000000000000002}\n{'n': 3, 'l': 2, 'ml': 1, 'result': 1.0}\n{'n': 3, 'l': 2, 'ml': -1, 'result': 1.0}\n{'n': 3, 'l': 2, 'ml': 2, 'result': 1.0}\n{'n': 3, 'l': 2, 'ml': -2, 'result': 1.0}\n{'n': 3, 'l': 3, 'ml': 0, 'result': 1.0}\n{'n': 3, 'l': 3, 'ml': 1, 'result': 1.0000000000000002}\n{'n': 3, 'l': 3, 'ml': -1, 'result': 1.0000000000000002}\n{'n': 3, 'l': 3, 'ml': 2, 'result': 0.9999999999999998}\n{'n': 3, 'l': 3, 'ml': -2, 'result': 0.9999999999999998}\n{'n': 3, 'l': 3, 'ml': 3, 'result': 1.0000000000000004}\n{'n': 3, 'l': 3, 'ml': -3, 'result': 1.0000000000000004}\n"
]
],
[
[
"## Plots of the radial functions\n\nFigure 1 has plots of the radial functions for various combinations of n and l. Some of the subplots are blank because there is no corresponding radial function for their position on the chart.",
"_____no_output_____"
]
],
[
[
"fig, axs = plt.subplots(nrows=3, ncols=3, figsize=(12, 15))\n\n# Just so I can access instance variables in an instance to make the dictionary.\nha = HydrogenicAtom()\nyscaler = (ha.z / ha.a0)**(3/2)\n\nparameters = [\n {'n': 1, 'l': 0, 'x_scaler': 5, 'yscaler': yscaler },\n {'n': 2, 'l': 0, 'x_scaler': 15, 'yscaler': yscaler },\n {'n': 3, 'l': 0, 'x_scaler': 20, 'yscaler': yscaler },\n {'n': 2, 'l': 1, 'x_scaler': 15, 'yscaler': yscaler },\n {'n': 3, 'l': 1, 'x_scaler': 30, 'yscaler': yscaler },\n {'n': 3, 'l': 2, 'x_scaler': 30, 'yscaler': yscaler }\n]\n\nfor p in parameters:\n row = p['n'] - 1\n col = p['l']\n ha = HydrogenicAtom(n=p['n'], l=p['l'])\n xs = np.linspace(0, ha.a0 * p['x_scaler'], 100)\n xs_labels = xs / ha.a0 # so that the x axis is labeled in units of a0\n ys = [ha.radial(r) / p['yscaler'] for r in xs]\n ax = axs[row, col]\n ax.set_title(f'n={p[\"n\"]}, l={p[\"l\"]}', color='b')\n ax.set_xlim(min(xs_labels), max(xs_labels))\n if col == 0:\n ax.set_ylabel('r/((Z/a0)**(3/2))', color='b')\n ax.set_xlabel('r/a0')\n ax.axhline(0.0, color='r')\n ax.plot(xs_labels, ys)\n \naxs[0, 1].set_title('intentionally blank')\naxs[0, 2].set_title('intentionally blank')\naxs[1, 2].set_title('intentionally blank')",
"_____no_output_____"
]
],
[
[
"## Hydrogen energy levels\n\nNote how the levels pack closer together at higher energy levels. The lowest energy, -13.6 eV, is the ground state of the hydrogen atom. All the energies are negative, which means they refer to bound states where the nucleus holds the electron.",
"_____no_output_____"
]
],
[
[
"ys = []\nfor n in range(1, 10):\n ha = HydrogenicAtom(n=n)\n _, ev = ha.energy()\n ys.append((n, round(ev, 2)))\n\nfig, ax = plt.subplots(nrows=1, ncols=1, figsize=(2, 10))\nax.set_ylim(-14.0, 0.0)\nax.set_xticks([])\nax.set_ylabel('eV', size=20, color='b')\nax.set_title('Hydrogen Energy Levels, n=1 to n=9', size=20, color='b')\nfor y in ys:\n ax.axhline(y[1], color='r')",
"_____no_output_____"
]
],
[
[
"## By numeric integration, what is the mean radius of 1s orbital?\n\nIn this section, I follow the integral given in Example 10.2 that will find the mean radius of an orbital: \n\n$$ \\langle r \\rangle = \\int_0^{\\infty} r^3 R_{n,l}^2 dr $$\n\nI integrate it numerically with the `quad` function from `scipy.integrate`. The `points` argument to `quad` tells the function the r values that the value ies within. To help the `quad` numeri integration function out, I took a guess that the mean radius is going to be within \\\\(10 \\times a_0 \\times n\\\\) radii of the nucleus. Also, I took 1 meter as the \"infinity\" for integration in this case.",
"_____no_output_____"
]
],
[
[
"ha = HydrogenicAtom(n=1, l=0, ml=0)\n\ndef integrand(r):\n return r**3 * ha.radial(r)**2\n\nquad(integrand, 0, 1, points=[0, 10 * ha.a0 * ha.n])",
"_____no_output_____"
]
],
[
[
"The first element of the tuple above is the result of the integration, and the second element is the estimated error of the integration. Below is the solution to the analytical integration solution given by the book. It matches the numeric integration!",
"_____no_output_____"
]
],
[
[
"3 * ha.a0 / 2",
"_____no_output_____"
]
],
[
[
"What about the 3s orbital? First numeric integration, then the numeric solution from the book.",
"_____no_output_____"
]
],
[
[
"ha = HydrogenicAtom(n=3, l=0, ml=0)\n\ndef integrand(r):\n return r**3 * ha.radial(r)**2\n\nquad(integrand, 0, 1, points=[0, 10 * ha.a0 * ha.n])",
"_____no_output_____"
],
[
"27 * ha.a0 / 2",
"_____no_output_____"
]
],
[
[
"What about the 3p orbital?",
"_____no_output_____"
]
],
[
[
"ha = HydrogenicAtom(n=3, l=1, ml=0)\n\ndef integrand(r):\n return r**3 * ha.radial(r)**2\n\nquad(integrand, 0, 1, points=[0, 10 * ha.a0 * ha.n])",
"_____no_output_____"
],
[
"25 * ha.a0 / 2",
"_____no_output_____"
]
],
[
[
"Overall, the numerical integration and the guess about where the interesting parts of the integration are worked out fairly well for these examples.",
"_____no_output_____"
],
[
"## What is the mean radius of each orbital?\n\nMake some plots of the mean radius of each orbital. Red circles are s orbitals, green squares are p orbitals, blue diamonds are d orbitals. Note that the radii of d < p < s for each level n.",
"_____no_output_____"
]
],
[
[
"parameters = [\n {'n': 1, 'l': 0 },\n {'n': 2, 'l': 0 },\n {'n': 2, 'l': 1 },\n {'n': 3, 'l': 0 },\n {'n': 3, 'l': 1 },\n {'n': 3, 'l': 2 }\n]\n\nfor p in parameters:\n ha = HydrogenicAtom(n=p['n'], l=p['l'])\n p['mean_radius_a0'] = ha.mean_orbital_radius() / ha.a0\n \nfig, ax = plt.subplots(nrows=1, ncols=1, figsize=(5, 5))\nfor p in parameters:\n x = p['n']\n y = p['mean_radius_a0']\n if p['l'] == 0:\n color = 'r'\n marker = 'o'\n label = 's'\n elif p['l'] == 1:\n color = 'g'\n marker = 's'\n label = 'p'\n else:\n color = 'b'\n marker = 'd'\n label = 'd'\n ax.scatter(x, y, marker=marker, color=color, s=200)\nax.set_xticks([1, 2, 3])\nax.set_xlabel('n')\nax.set_ylabel('r / a0')\nax.set_title('Relative mean orbital radii')",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
]
|
e7be55e81f6f3637b0c7a1422ee1583f0bd22f3d | 25,486 | ipynb | Jupyter Notebook | Untitled.ipynb | Voja026/Chef-de-ouvre | f6890e4df55e2c292265cc285c8389a5b1c9a6a1 | [
"MIT"
]
| null | null | null | Untitled.ipynb | Voja026/Chef-de-ouvre | f6890e4df55e2c292265cc285c8389a5b1c9a6a1 | [
"MIT"
]
| null | null | null | Untitled.ipynb | Voja026/Chef-de-ouvre | f6890e4df55e2c292265cc285c8389a5b1c9a6a1 | [
"MIT"
]
| null | null | null | 36.356633 | 149 | 0.384211 | [
[
[
"import pandas as pd\nimport numpy as np\n",
"_____no_output_____"
],
[
"data = pd.read_csv('powerplant.csv')\ndata.columns",
"_____no_output_____"
],
[
"data1 = data[['country_long', 'name', 'capacity_mw', 'latitude', 'longitude', 'primary_fuel','commissioning_year', 'owner']]\ndata1",
"_____no_output_____"
],
[
"data1['commissioning_year'] = data1['commissioning_year'].fillna('non_communique')\ndata1.head(10)",
"<ipython-input-12-ecfaa5378db5>:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n data1['commissioning_year'] = data1['commissioning_year'].fillna('non_communique')\n"
],
[
"data1['owner'] = data1['owner'].fillna('state')\ndata1",
"<ipython-input-13-2d71bf98f26d>:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n data1['owner'] = data1['owner'].fillna('state')\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7be5d1b835ab51d667251ffeac394ccd2c10971 | 207,726 | ipynb | Jupyter Notebook | samples/notebooks/week04-03-using-a-pretrained-convnet.ipynb | gu-ma/ba_218_comppx_h1901 | 7e9a32e44b152c928698657b6699e13a8edd0492 | [
"MIT"
]
| null | null | null | samples/notebooks/week04-03-using-a-pretrained-convnet.ipynb | gu-ma/ba_218_comppx_h1901 | 7e9a32e44b152c928698657b6699e13a8edd0492 | [
"MIT"
]
| null | null | null | samples/notebooks/week04-03-using-a-pretrained-convnet.ipynb | gu-ma/ba_218_comppx_h1901 | 7e9a32e44b152c928698657b6699e13a8edd0492 | [
"MIT"
]
| null | null | null | 159.177011 | 31,178 | 0.828341 | [
[
[
"# Reference\n\nThis example is taken from the book [DL with Python](https://www.manning.com/books/deep-learning-with-python) by F. Chollet. It explains how to retrain a pre-trained CNN classifier\n\nAll the notebooks from the book are available for free on [Github](https://github.com/fchollet/deep-learning-with-python-notebooks)\n\nIf you like to run the example locally follow the instructions provided on [Keras website](https://keras.io/#installation)\n\n---",
"_____no_output_____"
]
],
[
[
"import keras\nkeras.__version__",
"Using TensorFlow backend.\n"
]
],
[
[
"# Using a pre-trained convnet\n\nThis notebook contains the code sample found in Chapter 5, Section 3 of [Deep Learning with Python](https://www.manning.com/books/deep-learning-with-python?a_aid=keras&a_bid=76564dff). Note that the original text features far more content, in particular further explanations and figures: in this notebook, you will only find source code and related comments.\n\n----\n\nA common and highly effective approach to deep learning on small image datasets is to leverage a pre-trained network. A pre-trained network \nis simply a saved network previously trained on a large dataset, typically on a large-scale image classification task. If this original \ndataset is large enough and general enough, then the spatial feature hierarchy learned by the pre-trained network can effectively act as a \ngeneric model of our visual world, and hence its features can prove useful for many different computer vision problems, even though these \nnew problems might involve completely different classes from those of the original task. For instance, one might train a network on \nImageNet (where classes are mostly animals and everyday objects) and then re-purpose this trained network for something as remote as \nidentifying furniture items in images. Such portability of learned features across different problems is a key advantage of deep learning \ncompared to many older shallow learning approaches, and it makes deep learning very effective for small-data problems.\n\nIn our case, we will consider a large convnet trained on the ImageNet dataset (1.4 million labeled images and 1000 different classes). \nImageNet contains many animal classes, including different species of cats and dogs, and we can thus expect to perform very well on our cat \nvs. dog classification problem.\n\nWe will use the VGG16 architecture, developed by Karen Simonyan and Andrew Zisserman in 2014, a simple and widely used convnet architecture \nfor ImageNet. Although it is a bit of an older model, far from the current state of the art and somewhat heavier than many other recent \nmodels, we chose it because its architecture is similar to what you are already familiar with, and easy to understand without introducing \nany new concepts. This may be your first encounter with one of these cutesie model names -- VGG, ResNet, Inception, Inception-ResNet, \nXception... you will get used to them, as they will come up frequently if you keep doing deep learning for computer vision.\n\nThere are two ways to leverage a pre-trained network: *feature extraction* and *fine-tuning*. We will cover both of them. Let's start with \nfeature extraction.",
"_____no_output_____"
],
[
"## Feature extraction\n\nFeature extraction consists of using the representations learned by a previous network to extract interesting features from new samples. \nThese features are then run through a new classifier, which is trained from scratch.\n\nAs we saw previously, convnets used for image classification comprise two parts: they start with a series of pooling and convolution \nlayers, and they end with a densely-connected classifier. The first part is called the \"convolutional base\" of the model. In the case of \nconvnets, \"feature extraction\" will simply consist of taking the convolutional base of a previously-trained network, running the new data \nthrough it, and training a new classifier on top of the output.\n\n\n\nWhy only reuse the convolutional base? Could we reuse the densely-connected classifier as well? In general, it should be avoided. The \nreason is simply that the representations learned by the convolutional base are likely to be more generic and therefore more reusable: the \nfeature maps of a convnet are presence maps of generic concepts over a picture, which is likely to be useful regardless of the computer \nvision problem at hand. On the other end, the representations learned by the classifier will necessarily be very specific to the set of \nclasses that the model was trained on -- they will only contain information about the presence probability of this or that class in the \nentire picture. Additionally, representations found in densely-connected layers no longer contain any information about _where_ objects are \nlocated in the input image: these layers get rid of the notion of space, whereas the object location is still described by convolutional \nfeature maps. For problems where object location matters, densely-connected features would be largely useless.\n\nNote that the level of generality (and therefore reusability) of the representations extracted by specific convolution layers depends on \nthe depth of the layer in the model. Layers that come earlier in the model extract local, highly generic feature maps (such as visual \nedges, colors, and textures), while layers higher-up extract more abstract concepts (such as \"cat ear\" or \"dog eye\"). So if your new \ndataset differs a lot from the dataset that the original model was trained on, you may be better off using only the first few layers of the \nmodel to do feature extraction, rather than using the entire convolutional base.\n\nIn our case, since the ImageNet class set did contain multiple dog and cat classes, it is likely that it would be beneficial to reuse the \ninformation contained in the densely-connected layers of the original model. However, we will chose not to, in order to cover the more \ngeneral case where the class set of the new problem does not overlap with the class set of the original model.",
"_____no_output_____"
],
[
"Let's put this in practice by using the convolutional base of the VGG16 network, trained on ImageNet, to extract interesting features from \nour cat and dog images, and then training a cat vs. dog classifier on top of these features.\n\nThe VGG16 model, among others, comes pre-packaged with Keras. You can import it from the `keras.applications` module. Here's the list of \nimage classification models (all pre-trained on the ImageNet dataset) that are available as part of `keras.applications`:\n\n* Xception\n* InceptionV3\n* ResNet50\n* VGG16\n* VGG19\n* MobileNet\n\nLet's instantiate the VGG16 model:",
"_____no_output_____"
]
],
[
[
"from keras.applications import VGG16\n\nconv_base = VGG16(weights='imagenet',\n include_top=False,\n input_shape=(150, 150, 3))",
"_____no_output_____"
]
],
[
[
"We passed three arguments to the constructor:\n\n* `weights`, to specify which weight checkpoint to initialize the model from\n* `include_top`, which refers to including or not the densely-connected classifier on top of the network. By default, this \ndensely-connected classifier would correspond to the 1000 classes from ImageNet. Since we intend to use our own densely-connected \nclassifier (with only two classes, cat and dog), we don't need to include it.\n* `input_shape`, the shape of the image tensors that we will feed to the network. This argument is purely optional: if we don't pass it, \nthen the network will be able to process inputs of any size.\n\nHere's the detail of the architecture of the VGG16 convolutional base: it's very similar to the simple convnets that you are already \nfamiliar with.",
"_____no_output_____"
]
],
[
[
"conv_base.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) (None, 150, 150, 3) 0 \n_________________________________________________________________\nblock1_conv1 (Conv2D) (None, 150, 150, 64) 1792 \n_________________________________________________________________\nblock1_conv2 (Conv2D) (None, 150, 150, 64) 36928 \n_________________________________________________________________\nblock1_pool (MaxPooling2D) (None, 75, 75, 64) 0 \n_________________________________________________________________\nblock2_conv1 (Conv2D) (None, 75, 75, 128) 73856 \n_________________________________________________________________\nblock2_conv2 (Conv2D) (None, 75, 75, 128) 147584 \n_________________________________________________________________\nblock2_pool (MaxPooling2D) (None, 37, 37, 128) 0 \n_________________________________________________________________\nblock3_conv1 (Conv2D) (None, 37, 37, 256) 295168 \n_________________________________________________________________\nblock3_conv2 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_conv3 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_pool (MaxPooling2D) (None, 18, 18, 256) 0 \n_________________________________________________________________\nblock4_conv1 (Conv2D) (None, 18, 18, 512) 1180160 \n_________________________________________________________________\nblock4_conv2 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_conv3 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_pool (MaxPooling2D) (None, 9, 9, 512) 0 \n_________________________________________________________________\nblock5_conv1 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv2 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv3 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_pool (MaxPooling2D) (None, 4, 4, 512) 0 \n=================================================================\nTotal params: 14,714,688\nTrainable params: 14,714,688\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"The final feature map has shape `(4, 4, 512)`. That's the feature on top of which we will stick a densely-connected classifier.\n\nAt this point, there are two ways we could proceed: \n\n* Running the convolutional base over our dataset, recording its output to a Numpy array on disk, then using this data as input to a \nstandalone densely-connected classifier similar to those you have seen in the first chapters of this book. This solution is very fast and \ncheap to run, because it only requires running the convolutional base once for every input image, and the convolutional base is by far the \nmost expensive part of the pipeline. However, for the exact same reason, this technique would not allow us to leverage data augmentation at \nall.\n* Extending the model we have (`conv_base`) by adding `Dense` layers on top, and running the whole thing end-to-end on the input data. This \nallows us to use data augmentation, because every input image is going through the convolutional base every time it is seen by the model. \nHowever, for this same reason, this technique is far more expensive than the first one.\n\nWe will cover both techniques. Let's walk through the code required to set-up the first one: recording the output of `conv_base` on our \ndata and using these outputs as inputs to a new model.\n\nWe will start by simply running instances of the previously-introduced `ImageDataGenerator` to extract images as Numpy arrays as well as \ntheir labels. We will extract features from these images simply by calling the `predict` method of the `conv_base` model.",
"_____no_output_____"
]
],
[
[
"import os\nimport numpy as np\nfrom keras.preprocessing.image import ImageDataGenerator\n\nbase_dir = '/Users/guillaume/Downloads/datasets/small/'\n\ntrain_dir = os.path.join(base_dir, 'train')\nvalidation_dir = os.path.join(base_dir, 'validation')\ntest_dir = os.path.join(base_dir, 'test')\n\ndatagen = ImageDataGenerator(rescale=1./255)\nbatch_size = 20\n\ndef extract_features(directory, sample_count):\n features = np.zeros(shape=(sample_count, 4, 4, 512))\n labels = np.zeros(shape=(sample_count))\n generator = datagen.flow_from_directory(\n directory,\n target_size=(150, 150),\n batch_size=batch_size,\n class_mode='binary')\n i = 0\n for inputs_batch, labels_batch in generator:\n features_batch = conv_base.predict(inputs_batch)\n features[i * batch_size : (i + 1) * batch_size] = features_batch\n labels[i * batch_size : (i + 1) * batch_size] = labels_batch\n i += 1\n if i * batch_size >= sample_count:\n # Note that since generators yield data indefinitely in a loop,\n # we must `break` after every image has been seen once.\n break\n return features, labels\n\ntrain_features, train_labels = extract_features(train_dir, 2000)\nvalidation_features, validation_labels = extract_features(validation_dir, 1000)\ntest_features, test_labels = extract_features(test_dir, 1000)",
"Found 2000 images belonging to 2 classes.\nFound 1000 images belonging to 2 classes.\nFound 1000 images belonging to 2 classes.\n"
]
],
[
[
"The extracted features are currently of shape `(samples, 4, 4, 512)`. We will feed them to a densely-connected classifier, so first we must \nflatten them to `(samples, 8192)`:",
"_____no_output_____"
]
],
[
[
"train_features = np.reshape(train_features, (2000, 4 * 4 * 512))\nvalidation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))\ntest_features = np.reshape(test_features, (1000, 4 * 4 * 512))",
"_____no_output_____"
]
],
[
[
"At this point, we can define our densely-connected classifier (note the use of dropout for regularization), and train it on the data and \nlabels that we just recorded:",
"_____no_output_____"
]
],
[
[
"from keras import models\nfrom keras import layers\nfrom keras import optimizers\n\nmodel = models.Sequential()\nmodel.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))\nmodel.add(layers.Dropout(0.5))\nmodel.add(layers.Dense(1, activation='sigmoid'))\n\nmodel.compile(optimizer=optimizers.RMSprop(lr=2e-5),\n loss='binary_crossentropy',\n metrics=['acc'])\n\nhistory = model.fit(train_features, train_labels,\n epochs=30,\n batch_size=20,\n validation_data=(validation_features, validation_labels))",
"_____no_output_____"
]
],
[
[
"Training is very fast, since we only have to deal with two `Dense` layers -- an epoch takes less than one second even on CPU.\n\nLet's take a look at the loss and accuracy curves during training:",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n\nacc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"\nWe reach a validation accuracy of about 90%, much better than what we could achieve in the previous section with our small model trained from \nscratch. However, our plots also indicate that we are overfitting almost from the start -- despite using dropout with a fairly large rate. \nThis is because this technique does not leverage data augmentation, which is essential to preventing overfitting with small image datasets.\n\nNow, let's review the second technique we mentioned for doing feature extraction, which is much slower and more expensive, but which allows \nus to leverage data augmentation during training: extending the `conv_base` model and running it end-to-end on the inputs. Note that this \ntechnique is in fact so expensive that you should only attempt it if you have access to a GPU: it is absolutely intractable on CPU. If you \ncannot run your code on GPU, then the previous technique is the way to go.\n\nBecause models behave just like layers, you can add a model (like our `conv_base`) to a `Sequential` model just like you would add a layer. \nSo you can do the following:",
"_____no_output_____"
]
],
[
[
"from keras import models\nfrom keras import layers\n\nmodel = models.Sequential()\nmodel.add(conv_base)\nmodel.add(layers.Flatten())\nmodel.add(layers.Dense(256, activation='relu'))\nmodel.add(layers.Dense(1, activation='sigmoid'))",
"_____no_output_____"
]
],
[
[
"This is what our model looks like now:",
"_____no_output_____"
]
],
[
[
"model.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nvgg16 (Model) (None, 4, 4, 512) 14714688 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 8192) 0 \n_________________________________________________________________\ndense_3 (Dense) (None, 256) 2097408 \n_________________________________________________________________\ndense_4 (Dense) (None, 1) 257 \n=================================================================\nTotal params: 16,812,353\nTrainable params: 16,812,353\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"As you can see, the convolutional base of VGG16 has 14,714,688 parameters, which is very large. The classifier we are adding on top has 2 \nmillion parameters.\n\nBefore we compile and train our model, a very important thing to do is to freeze the convolutional base. \"Freezing\" a layer or set of \nlayers means preventing their weights from getting updated during training. If we don't do this, then the representations that were \npreviously learned by the convolutional base would get modified during training. Since the `Dense` layers on top are randomly initialized, \nvery large weight updates would be propagated through the network, effectively destroying the representations previously learned.\n\nIn Keras, freezing a network is done by setting its `trainable` attribute to `False`:",
"_____no_output_____"
]
],
[
[
"print('This is the number of trainable weights '\n 'before freezing the conv base:', len(model.trainable_weights))",
"This is the number of trainable weights before freezing the conv base: 30\n"
],
[
"conv_base.trainable = False",
"_____no_output_____"
],
[
"print('This is the number of trainable weights '\n 'after freezing the conv base:', len(model.trainable_weights))",
"This is the number of trainable weights after freezing the conv base: 4\n"
]
],
[
[
"With this setup, only the weights from the two `Dense` layers that we added will be trained. That's a total of four weight tensors: two per \nlayer (the main weight matrix and the bias vector). Note that in order for these changes to take effect, we must first compile the model. \nIf you ever modify weight trainability after compilation, you should then re-compile the model, or these changes would be ignored.\n\nNow we can start training our model, with the same data augmentation configuration that we used in our previous example:",
"_____no_output_____"
]
],
[
[
"from keras.preprocessing.image import ImageDataGenerator\n\ntrain_datagen = ImageDataGenerator(\n rescale=1./255,\n rotation_range=40,\n width_shift_range=0.2,\n height_shift_range=0.2,\n shear_range=0.2,\n zoom_range=0.2,\n horizontal_flip=True,\n fill_mode='nearest')\n\n# Note that the validation data should not be augmented!\ntest_datagen = ImageDataGenerator(rescale=1./255)\n\ntrain_generator = train_datagen.flow_from_directory(\n # This is the target directory\n train_dir,\n # All images will be resized to 150x150\n target_size=(150, 150),\n batch_size=20,\n # Since we use binary_crossentropy loss, we need binary labels\n class_mode='binary')\n\nvalidation_generator = test_datagen.flow_from_directory(\n validation_dir,\n target_size=(150, 150),\n batch_size=20,\n class_mode='binary')\n\nmodel.compile(loss='binary_crossentropy',\n optimizer=optimizers.RMSprop(lr=2e-5),\n metrics=['acc'])\n\nhistory = model.fit_generator(\n train_generator,\n steps_per_epoch=100,\n epochs=30,\n validation_data=validation_generator,\n validation_steps=50,\n verbose=2)",
"_____no_output_____"
],
[
"model.save('cats_and_dogs_small_3.h5')",
"_____no_output_____"
]
],
[
[
"Let's plot our results again:",
"_____no_output_____"
]
],
[
[
"acc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"As you can see, we reach a validation accuracy of about 96%. This is much better than our small convnet trained from scratch.",
"_____no_output_____"
],
[
"## Fine-tuning\n\nAnother widely used technique for model reuse, complementary to feature extraction, is _fine-tuning_. \nFine-tuning consists in unfreezing a few of the top layers \nof a frozen model base used for feature extraction, and jointly training both the newly added part of the model (in our case, the \nfully-connected classifier) and these top layers. This is called \"fine-tuning\" because it slightly adjusts the more abstract \nrepresentations of the model being reused, in order to make them more relevant for the problem at hand.\n\n",
"_____no_output_____"
],
[
"We have stated before that it was necessary to freeze the convolution base of VGG16 in order to be able to train a randomly initialized \nclassifier on top. For the same reason, it is only possible to fine-tune the top layers of the convolutional base once the classifier on \ntop has already been trained. If the classified wasn't already trained, then the error signal propagating through the network during \ntraining would be too large, and the representations previously learned by the layers being fine-tuned would be destroyed. Thus the steps \nfor fine-tuning a network are as follow:\n\n* 1) Add your custom network on top of an already trained base network.\n* 2) Freeze the base network.\n* 3) Train the part you added.\n* 4) Unfreeze some layers in the base network.\n* 5) Jointly train both these layers and the part you added.\n\nWe have already completed the first 3 steps when doing feature extraction. Let's proceed with the 4th step: we will unfreeze our `conv_base`, \nand then freeze individual layers inside of it.\n\nAs a reminder, this is what our convolutional base looks like:",
"_____no_output_____"
]
],
[
[
"conv_base.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) (None, 150, 150, 3) 0 \n_________________________________________________________________\nblock1_conv1 (Conv2D) (None, 150, 150, 64) 1792 \n_________________________________________________________________\nblock1_conv2 (Conv2D) (None, 150, 150, 64) 36928 \n_________________________________________________________________\nblock1_pool (MaxPooling2D) (None, 75, 75, 64) 0 \n_________________________________________________________________\nblock2_conv1 (Conv2D) (None, 75, 75, 128) 73856 \n_________________________________________________________________\nblock2_conv2 (Conv2D) (None, 75, 75, 128) 147584 \n_________________________________________________________________\nblock2_pool (MaxPooling2D) (None, 37, 37, 128) 0 \n_________________________________________________________________\nblock3_conv1 (Conv2D) (None, 37, 37, 256) 295168 \n_________________________________________________________________\nblock3_conv2 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_conv3 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_pool (MaxPooling2D) (None, 18, 18, 256) 0 \n_________________________________________________________________\nblock4_conv1 (Conv2D) (None, 18, 18, 512) 1180160 \n_________________________________________________________________\nblock4_conv2 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_conv3 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_pool (MaxPooling2D) (None, 9, 9, 512) 0 \n_________________________________________________________________\nblock5_conv1 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv2 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv3 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_pool (MaxPooling2D) (None, 4, 4, 512) 0 \n=================================================================\nTotal params: 14,714,688\nTrainable params: 0\nNon-trainable params: 14,714,688\n_________________________________________________________________\n"
]
],
[
[
"\nWe will fine-tune the last 3 convolutional layers, which means that all layers up until `block4_pool` should be frozen, and the layers \n`block5_conv1`, `block5_conv2` and `block5_conv3` should be trainable.\n\nWhy not fine-tune more layers? Why not fine-tune the entire convolutional base? We could. However, we need to consider that:\n\n* Earlier layers in the convolutional base encode more generic, reusable features, while layers higher up encode more specialized features. It is \nmore useful to fine-tune the more specialized features, as these are the ones that need to be repurposed on our new problem. There would \nbe fast-decreasing returns in fine-tuning lower layers.\n* The more parameters we are training, the more we are at risk of overfitting. The convolutional base has 15M parameters, so it would be \nrisky to attempt to train it on our small dataset.\n\nThus, in our situation, it is a good strategy to only fine-tune the top 2 to 3 layers in the convolutional base.\n\nLet's set this up, starting from where we left off in the previous example:",
"_____no_output_____"
]
],
[
[
"conv_base.trainable = True\n\nset_trainable = False\nfor layer in conv_base.layers:\n if layer.name == 'block5_conv1':\n set_trainable = True\n if set_trainable:\n layer.trainable = True\n else:\n layer.trainable = False",
"_____no_output_____"
]
],
[
[
"Now we can start fine-tuning our network. We will do this with the RMSprop optimizer, using a very low learning rate. The reason for using \na low learning rate is that we want to limit the magnitude of the modifications we make to the representations of the 3 layers that we are \nfine-tuning. Updates that are too large may harm these representations.\n\nNow let's proceed with fine-tuning:",
"_____no_output_____"
]
],
[
[
"model.compile(loss='binary_crossentropy',\n optimizer=optimizers.RMSprop(lr=1e-5),\n metrics=['acc'])\n\nhistory = model.fit_generator(\n train_generator,\n steps_per_epoch=100,\n epochs=100,\n validation_data=validation_generator,\n validation_steps=50)",
"Epoch 1/100\n100/100 [==============================] - 32s - loss: 0.0215 - acc: 0.9935 - val_loss: 0.0980 - val_acc: 0.9720\nEpoch 2/100\n100/100 [==============================] - 32s - loss: 0.0131 - acc: 0.9960 - val_loss: 0.1247 - val_acc: 0.9700\nEpoch 3/100\n100/100 [==============================] - 32s - loss: 0.0140 - acc: 0.9940 - val_loss: 0.1044 - val_acc: 0.9790\nEpoch 4/100\n100/100 [==============================] - 33s - loss: 0.0102 - acc: 0.9965 - val_loss: 0.1259 - val_acc: 0.9770\nEpoch 5/100\n100/100 [==============================] - 33s - loss: 0.0137 - acc: 0.9945 - val_loss: 0.1036 - val_acc: 0.9800\nEpoch 6/100\n100/100 [==============================] - 33s - loss: 0.0183 - acc: 0.9935 - val_loss: 0.1260 - val_acc: 0.9750\nEpoch 7/100\n100/100 [==============================] - 33s - loss: 0.0141 - acc: 0.9945 - val_loss: 0.1575 - val_acc: 0.9690\nEpoch 8/100\n100/100 [==============================] - 33s - loss: 0.0094 - acc: 0.9965 - val_loss: 0.0935 - val_acc: 0.9780\nEpoch 9/100\n100/100 [==============================] - 33s - loss: 0.0079 - acc: 0.9985 - val_loss: 0.1452 - val_acc: 0.9760\nEpoch 10/100\n100/100 [==============================] - 33s - loss: 0.0127 - acc: 0.9970 - val_loss: 0.1027 - val_acc: 0.9790\nEpoch 11/100\n100/100 [==============================] - 33s - loss: 0.0097 - acc: 0.9965 - val_loss: 0.1463 - val_acc: 0.9720\nEpoch 12/100\n100/100 [==============================] - 33s - loss: 0.0055 - acc: 0.9980 - val_loss: 0.1361 - val_acc: 0.9720\nEpoch 13/100\n100/100 [==============================] - 33s - loss: 0.0274 - acc: 0.9955 - val_loss: 0.1446 - val_acc: 0.9740\nEpoch 14/100\n100/100 [==============================] - 33s - loss: 0.0043 - acc: 0.9985 - val_loss: 0.1123 - val_acc: 0.9790\nEpoch 15/100\n100/100 [==============================] - 33s - loss: 0.0057 - acc: 0.9975 - val_loss: 0.1912 - val_acc: 0.9700\nEpoch 16/100\n100/100 [==============================] - 33s - loss: 0.0144 - acc: 0.9960 - val_loss: 0.1415 - val_acc: 0.9780\nEpoch 17/100\n100/100 [==============================] - 33s - loss: 0.0048 - acc: 0.9990 - val_loss: 0.1231 - val_acc: 0.9780\nEpoch 18/100\n100/100 [==============================] - 33s - loss: 0.0188 - acc: 0.9965 - val_loss: 0.1551 - val_acc: 0.9720\nEpoch 19/100\n100/100 [==============================] - 33s - loss: 0.0160 - acc: 0.9970 - val_loss: 0.2155 - val_acc: 0.9740\nEpoch 20/100\n100/100 [==============================] - 33s - loss: 0.0047 - acc: 0.9965 - val_loss: 0.1559 - val_acc: 0.9730\nEpoch 21/100\n100/100 [==============================] - 33s - loss: 0.0132 - acc: 0.9980 - val_loss: 0.1518 - val_acc: 0.9740\nEpoch 22/100\n100/100 [==============================] - 33s - loss: 0.0086 - acc: 0.9965 - val_loss: 0.1517 - val_acc: 0.9790\nEpoch 23/100\n100/100 [==============================] - 33s - loss: 0.0070 - acc: 0.9980 - val_loss: 0.1887 - val_acc: 0.9670\nEpoch 24/100\n100/100 [==============================] - 33s - loss: 0.0044 - acc: 0.9985 - val_loss: 0.1818 - val_acc: 0.9740\nEpoch 25/100\n100/100 [==============================] - 33s - loss: 0.0159 - acc: 0.9970 - val_loss: 0.1860 - val_acc: 0.9680\nEpoch 26/100\n100/100 [==============================] - 33s - loss: 0.0056 - acc: 0.9980 - val_loss: 0.1657 - val_acc: 0.9740\nEpoch 27/100\n100/100 [==============================] - 33s - loss: 0.0118 - acc: 0.9980 - val_loss: 0.1542 - val_acc: 0.9760\nEpoch 28/100\n100/100 [==============================] - 33s - loss: 0.0031 - acc: 0.9990 - val_loss: 0.1493 - val_acc: 0.9770\nEpoch 29/100\n100/100 [==============================] - 33s - loss: 0.0114 - acc: 0.9965 - val_loss: 0.1921 - val_acc: 0.9680\nEpoch 30/100\n100/100 [==============================] - 33s - loss: 0.0031 - acc: 0.9990 - val_loss: 0.1188 - val_acc: 0.9830\nEpoch 31/100\n100/100 [==============================] - 33s - loss: 0.0068 - acc: 0.9985 - val_loss: 0.1814 - val_acc: 0.9740\nEpoch 32/100\n100/100 [==============================] - 33s - loss: 0.0096 - acc: 0.9985 - val_loss: 0.2034 - val_acc: 0.9760\nEpoch 33/100\n100/100 [==============================] - 33s - loss: 0.0072 - acc: 0.9985 - val_loss: 0.1970 - val_acc: 0.9730\nEpoch 34/100\n100/100 [==============================] - 33s - loss: 0.0047 - acc: 0.9990 - val_loss: 0.2349 - val_acc: 0.9680\nEpoch 35/100\n100/100 [==============================] - 33s - loss: 0.0066 - acc: 0.9990 - val_loss: 0.1865 - val_acc: 0.9740\nEpoch 36/100\n100/100 [==============================] - 33s - loss: 0.0115 - acc: 0.9975 - val_loss: 0.1933 - val_acc: 0.9750\nEpoch 37/100\n100/100 [==============================] - 33s - loss: 0.0101 - acc: 0.9980 - val_loss: 0.1779 - val_acc: 0.9780\nEpoch 38/100\n100/100 [==============================] - 33s - loss: 0.0101 - acc: 0.9975 - val_loss: 0.1887 - val_acc: 0.9700\nEpoch 39/100\n100/100 [==============================] - 33s - loss: 0.0093 - acc: 0.9980 - val_loss: 0.2159 - val_acc: 0.9720\nEpoch 40/100\n100/100 [==============================] - 33s - loss: 0.0049 - acc: 0.9990 - val_loss: 0.1412 - val_acc: 0.9790\nEpoch 41/100\n100/100 [==============================] - 33s - loss: 0.0052 - acc: 0.9985 - val_loss: 0.2066 - val_acc: 0.9690\nEpoch 42/100\n100/100 [==============================] - 33s - loss: 0.0043 - acc: 0.9990 - val_loss: 0.1860 - val_acc: 0.9770\nEpoch 43/100\n100/100 [==============================] - 33s - loss: 0.0031 - acc: 0.9985 - val_loss: 0.2361 - val_acc: 0.9680\nEpoch 44/100\n100/100 [==============================] - 33s - loss: 0.0012 - acc: 0.9995 - val_loss: 0.2440 - val_acc: 0.9680\nEpoch 45/100\n100/100 [==============================] - 33s - loss: 0.0035 - acc: 0.9985 - val_loss: 0.1428 - val_acc: 0.9820\nEpoch 46/100\n100/100 [==============================] - 33s - loss: 0.0111 - acc: 0.9970 - val_loss: 0.1822 - val_acc: 0.9720\nEpoch 47/100\n100/100 [==============================] - 33s - loss: 0.0047 - acc: 0.9990 - val_loss: 0.1726 - val_acc: 0.9720\nEpoch 48/100\n100/100 [==============================] - 33s - loss: 0.0039 - acc: 0.9995 - val_loss: 0.2164 - val_acc: 0.9730\nEpoch 49/100\n100/100 [==============================] - 33s - loss: 0.0060 - acc: 0.9970 - val_loss: 0.1856 - val_acc: 0.9810\nEpoch 50/100\n100/100 [==============================] - 33s - loss: 0.0126 - acc: 0.9980 - val_loss: 0.1824 - val_acc: 0.9720\nEpoch 51/100\n100/100 [==============================] - 33s - loss: 0.0155 - acc: 0.9965 - val_loss: 0.1867 - val_acc: 0.9710\nEpoch 52/100\n100/100 [==============================] - 33s - loss: 0.0059 - acc: 0.9985 - val_loss: 0.2287 - val_acc: 0.9700\nEpoch 53/100\n100/100 [==============================] - 33s - loss: 0.0046 - acc: 0.9980 - val_loss: 0.2337 - val_acc: 0.9650\nEpoch 54/100\n100/100 [==============================] - 33s - loss: 0.0087 - acc: 0.9970 - val_loss: 0.1168 - val_acc: 0.9820\nEpoch 55/100\n100/100 [==============================] - 33s - loss: 0.0046 - acc: 0.9985 - val_loss: 0.1496 - val_acc: 0.9790\nEpoch 56/100\n100/100 [==============================] - 33s - loss: 0.0067 - acc: 0.9985 - val_loss: 0.1615 - val_acc: 0.9750\nEpoch 57/100\n100/100 [==============================] - 33s - loss: 0.0066 - acc: 0.9975 - val_loss: 0.2520 - val_acc: 0.9630\nEpoch 58/100\n100/100 [==============================] - 33s - loss: 0.0017 - acc: 0.9990 - val_loss: 0.1899 - val_acc: 0.9740\nEpoch 59/100\n100/100 [==============================] - 33s - loss: 0.0022 - acc: 0.9990 - val_loss: 0.2321 - val_acc: 0.9680\nEpoch 60/100\n100/100 [==============================] - 33s - loss: 0.0091 - acc: 0.9975 - val_loss: 0.1416 - val_acc: 0.9790\nEpoch 61/100\n100/100 [==============================] - 33s - loss: 0.0054 - acc: 0.9985 - val_loss: 0.1749 - val_acc: 0.9720\nEpoch 62/100\n100/100 [==============================] - 33s - loss: 0.0028 - acc: 0.9995 - val_loss: 0.2065 - val_acc: 0.9740\nEpoch 63/100\n100/100 [==============================] - 33s - loss: 0.0058 - acc: 0.9985 - val_loss: 0.1749 - val_acc: 0.9750\nEpoch 64/100\n100/100 [==============================] - 33s - loss: 0.0076 - acc: 0.9980 - val_loss: 0.1542 - val_acc: 0.9760\nEpoch 65/100\n100/100 [==============================] - 33s - loss: 0.0081 - acc: 0.9980 - val_loss: 0.2627 - val_acc: 0.9660\nEpoch 66/100\n"
],
[
"model.save('cats_and_dogs_small_4.h5')",
"_____no_output_____"
]
],
[
[
"Let's plot our results using the same plotting code as before:",
"_____no_output_____"
]
],
[
[
"acc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"\nThese curves look very noisy. To make them more readable, we can smooth them by replacing every loss and accuracy with exponential moving \naverages of these quantities. Here's a trivial utility function to do this:",
"_____no_output_____"
]
],
[
[
"def smooth_curve(points, factor=0.8):\n smoothed_points = []\n for point in points:\n if smoothed_points:\n previous = smoothed_points[-1]\n smoothed_points.append(previous * factor + point * (1 - factor))\n else:\n smoothed_points.append(point)\n return smoothed_points\n\nplt.plot(epochs,\n smooth_curve(acc), 'bo', label='Smoothed training acc')\nplt.plot(epochs,\n smooth_curve(val_acc), 'b', label='Smoothed validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs,\n smooth_curve(loss), 'bo', label='Smoothed training loss')\nplt.plot(epochs,\n smooth_curve(val_loss), 'b', label='Smoothed validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"\nThese curves look much cleaner and more stable. We are seeing a nice 1% absolute improvement.\n\nNote that the loss curve does not show any real improvement (in fact, it is deteriorating). You may wonder, how could accuracy improve if the \nloss isn't decreasing? The answer is simple: what we display is an average of pointwise loss values, but what actually matters for accuracy \nis the distribution of the loss values, not their average, since accuracy is the result of a binary thresholding of the class probability \npredicted by the model. The model may still be improving even if this isn't reflected in the average loss.\n\nWe can now finally evaluate this model on the test data:",
"_____no_output_____"
]
],
[
[
"test_generator = test_datagen.flow_from_directory(\n test_dir,\n target_size=(150, 150),\n batch_size=20,\n class_mode='binary')\n\ntest_loss, test_acc = model.evaluate_generator(test_generator, steps=50)\nprint('test acc:', test_acc)",
"Found 1000 images belonging to 2 classes.\ntest acc: 0.967999992371\n"
]
],
[
[
"\nHere we get a test accuracy of 97%. In the original Kaggle competition around this dataset, this would have been one of the top results. \nHowever, using modern deep learning techniques, we managed to reach this result using only a very small fraction of the training data \navailable (about 10%). There is a huge difference between being able to train on 20,000 samples compared to 2,000 samples!",
"_____no_output_____"
],
[
"## Take-aways: using convnets with small datasets\n\nHere's what you should take away from the exercises of these past two sections:\n\n* Convnets are the best type of machine learning models for computer vision tasks. It is possible to train one from scratch even on a very \nsmall dataset, with decent results.\n* On a small dataset, overfitting will be the main issue. Data augmentation is a powerful way to fight overfitting when working with image \ndata.\n* It is easy to reuse an existing convnet on a new dataset, via feature extraction. This is a very valuable technique for working with \nsmall image datasets.\n* As a complement to feature extraction, one may use fine-tuning, which adapts to a new problem some of the representations previously \nlearned by an existing model. This pushes performance a bit further.\n\nNow you have a solid set of tools for dealing with image classification problems, in particular with small datasets.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
]
|
e7be5e20581628f921e5d2c57719e2796d3d44e9 | 169,631 | ipynb | Jupyter Notebook | covid19/covid19dynstat-dash.ipynb | FZJ-JSC/jupyter-jsc-dashboads | 149764a5d1a4a84583b34b805c7e55509bb56608 | [
"BSD-3-Clause"
]
| 1 | 2020-10-21T09:09:39.000Z | 2020-10-21T09:09:39.000Z | covid19/covid19dynstat-dash.ipynb | FZJ-JSC/jupyter-jsc-dashboads | 149764a5d1a4a84583b34b805c7e55509bb56608 | [
"BSD-3-Clause"
]
| null | null | null | covid19/covid19dynstat-dash.ipynb | FZJ-JSC/jupyter-jsc-dashboads | 149764a5d1a4a84583b34b805c7e55509bb56608 | [
"BSD-3-Clause"
]
| 1 | 2020-09-28T10:53:38.000Z | 2020-09-28T10:53:38.000Z | 61.150324 | 1,004 | 0.509683 | [
[
[
"# WebApp Covid19dynstat - using Dash/JupyterDash\n@author: Jens Henrik Göbbert \n@mail: [email protected]",
"_____no_output_____"
],
[
"The `jupyter-dash` package makes it easy to develop Plotly Dash apps from the Jupyter Notebook and JupyterLab.\nJust replace the standard `dash.Dash` class with the `jupyter_dash.JupyterDash` subclass.",
"_____no_output_____"
],
[
"### before publish\n- set correct asset_url\n- set cache_time=86400\n- use app.run_server(mode=\"external\")",
"_____no_output_____"
]
],
[
[
"import dash\nimport dash_core_components as dcc\nimport dash_html_components as html\nimport dash_bootstrap_components as dbc\nfrom dash.dependencies import Input, Output, State\nimport dash_player\nfrom flask_caching import Cache\n\nimport os\nimport pandas as pd",
"_____no_output_____"
],
[
"#print(dcc.__version__)",
"_____no_output_____"
]
],
[
[
"When running in JupyterHub (or Binder), call the `infer_jupyter_config` function to detect the proxy configuration. This will detect the proper request_pathname_prefix and server_url values to use when displaying Dash apps. \nFor example: \n- server_url = `https://jupyter-jsc.fz-juelich.de` \n- request_pathname_prefix = `/user/[email protected]/jureca_login/` \n\nFor details please check the source here https://github.com/plotly/jupyter-dash/blob/v0.2.1.post1/jupyter_dash/comms.py#L33",
"_____no_output_____"
]
],
[
[
"from jupyter_dash import JupyterDash\nJupyterDash.infer_jupyter_proxy_config()",
"_____no_output_____"
]
],
[
[
"**Attention:** I have to run this cell twice: first press play, wait a bit and hit play again while it still shows `[*]`",
"_____no_output_____"
],
[
"#### Create a Dash Flask server\nRequests the browser to load Bootstrap ",
"_____no_output_____"
]
],
[
[
"from pathlib import Path\n\n# create app\napp = JupyterDash(__name__,\n external_stylesheets=[dbc.themes.BOOTSTRAP],\n update_title=None,\n suppress_callback_exceptions=True, # because of multi-page setup\n )\n\n# config app\napp.title = 'Covid-19-Interaktionsmodell'\n\ncache_dir = \"./cache\"\nPath(cache_dir).mkdir(parents=True, exist_ok=True)\ncache = Cache(app.server, config={\n 'CACHE_TYPE': 'filesystem',\n 'CACHE_DIR': cache_dir,\n #'CACHE_THRESHOLD': 10000, # max. no. items stored before deletion starts (only for SimpleCache and FileSystemCache)\n ## try 'redis' if you want to use a database for caching\n #'CACHE_TYPE': 'redis'\n #'CACHE_REDIS_URL': os.environ.get('REDIS_URL', '')\n})\ncache_timeout=1 #86400 # on day in secounds\n\n# clear cache to avoid any strange behaviour on restart while developing\ncache.clear()\n \n# start the server\nserver = app.server",
"_____no_output_____"
],
[
"from datetime import datetime as dt, timedelta\n\n# set the base-url to the assets directory\nasset_url=\"https://jupyter-jsc.fz-juelich.de\" + os.environ['JUPYTERHUB_SERVICE_PREFIX'] + \"proxy/8050/assets/\"\n#asset_url=app.get_asset_url('assets') + \"/\"\nprint(asset_url)\n\nmetadata = pd.read_csv(\"assets/metadata.csv\")\n#for index, row in metadata.iterrows():\n# print(row['countyId'])\n\ndeltadays = 25\n\nmin_date=dt(2020, 3, 26).date()\nmax_date=dt(2020, 3, 31).date() # dt.today().date()\n\ninit_date=dt(2020, 3, 26).date() # dt.today().date()\ninit_date=init_date -timedelta(days=deltadays)\n\ninit_assets_dir = init_date.strftime('%Y_%m_%d') + \"/\"\n#print(init_assets_dir)\n\ninit_countyid=11001\n\ndef get_assets_dir(date):\n date = dt.strptime(date.split(' ')[0], '%Y-%m-%d')\n assets_dir = (date -timedelta(days=deltadays)).strftime('%Y_%m_%d') + \"/\"\n return assets_dir",
"_____no_output_____"
]
],
[
[
"#### Create interactive map of Germany",
"_____no_output_____"
]
],
[
[
"## load & initialize static data\n# => tuple-list 'counties_geojson'\n# => dataframe 'counties_metadf'\nimport json\n\n# Landkreis-Geometrie vom RKI:\n# https://npgeo-corona-npgeo-de.hub.arcgis.com/datasets/917fc37a709542548cc3be077a786c17_0 -> ShapeFile\n# https://mapshaper.org -> GEOJSON\n\nwith open('assets/DE-Landkreise_RKI.geojson.json') as json_file:\n counties_geojson = json.load(json_file)\n\n# 'id' must be the unique identifier of the shapes (required by plotly.Choroplethmapbox)\nfor i, feat in enumerate(counties_geojson['features']):\n feat['id'] = i\n\ncounties_metadf = pd.DataFrame(data={\n # geoid must match county-shape-ids in json file (must start with 0 and increase with no missing one)\n 'geoids' : [feat['id'] for feat in counties_geojson['features']],\n 'names' : [feat['properties'].get('GEN') for feat in counties_geojson['features']],\n 'cca' : [feat['properties'].get('RS') for feat in counties_geojson['features']],\n })\n\n# test \n#counties_metadf.loc[counties_metadf['cca']=='03159'] # data of Göttingen\n#counties_metadf.to_csv('counties_metadata.csv', index=False)",
"_____no_output_____"
],
[
"## load dynamic data\n# => dataframe 'inf'\nimport plotly.graph_objects as go\nfrom numpy import nan\n\ndef create_map(mapcsv_path, colName):\n\n infArr=[]\n try:\n # read number of infections from csv file \n mapcsv = pd.read_csv(mapcsv_path)\n #print(mapcsv.loc[mapcsv['countyID'] == 3159]) # test with Göttingen\n\n # create (correctly sorted) dataframe from no.infections\n # loop over all counties and read no.infections from mapcsv \n for feat in counties_geojson['features']: # same loop as for df (important)\n cca_str = feat['properties'].get('RS')\n if cca_str is not None:\n # read model value for this county from mapcsv\n cca_valuedf = mapcsv.loc[mapcsv['countyID']==int(cca_str), colName] #'newInf100k']\n cca_value = next(iter(cca_valuedf), 0.0)\n infArr.append(cca_value) \n else:\n infArr.append(0.0)\n except: #IOError as e:\n print(\"File not found: \" + mapcsv_path)\n for feat in counties_geojson['features']:\n infArr.append(nan)\n\n counties_infdf = pd.DataFrame(data={'infections': infArr})\n\n # test\n #print(inf['infections'][91]) # data of Freiburg\n #inf.to_csv('countyInfections_metadata.csv', index=False)\n\n # create figure\n mapfig = go.Figure(go.Choroplethmapbox(\n geojson=counties_geojson,\n locations=counties_metadf.geoids,\n z=counties_infdf.infections,\n text=counties_metadf.names,\n colorscale=\"Jet\",\n colorbar=dict(thickness=20, ticklen=3, title=\"Neuinfektionen pro 100.000 Einwohner und Tag\", titleside=\"right\"),\n zmin=0, zmax=10,\n marker_opacity=0.5, marker_line_width=0,\n hovertemplate=\n \"<b>%{text}</b><br>\" +\n \"%{z:.2f}<br>\" +\n \"<extra></extra>\",)\n )\n mapfig.update_layout(\n uirevision=True, # keep zoom,panning, etc. when updating\n autosize=True,\n #legend=dict(\n # # Adjust click behavior\n # itemclick=\"toggleothers\",\n # itemdoubleclick=\"toggle\",\n #),\n #xaxis=dict(\n # autorange='reversed',\n # fixedrange=True\n #),\n #yaxis=dict(\n # autorange='reversed',\n # fixedrange=True\n #),\n width=500, height=450,\n mapbox_style=\"carto-positron\", # https://plotly.com/python/mapbox-layers/\n mapbox_zoom=4.5,\n mapbox_center = {\"lat\": 51.30, \"lon\": 10.45},\n margin={\"r\":0,\"t\":0,\"l\":0,\"b\":0})\n return mapfig\n\ninit_mapfig_bstim = create_map(\"assets/figures/\" + init_assets_dir + \"map.csv\", 'newInf100k')\ninit_mapfig_rki = create_map(\"assets/figures/\" + init_assets_dir + \"map.csv\", 'newInf100k_RKI')\ninit_mapfig_bstim.show(config={\"displayModeBar\": False, \"showTips\": False, \"modeBarButtonsToRemove\": ['toImage']}) # \"staticPlot\": True})",
"_____no_output_____"
]
],
[
[
"#### Define the top navigation bar",
"_____no_output_____"
]
],
[
[
"#####################\n# Disclaimer\n#####################\ndisclaimer_modal = html.Div(\n [\n dcc.Markdown(\n f\"\"\"\n -----\n ##### BSTIM-Covid19 \n -----\n Aktuelle Daten und Vorhersage der täglich gemeldeten Neuinfektionen mit COVID-19 für Landkreise in Deutschland.\n Das Model beschreibt die zeitliche Entwicklung der Neuinfektionen in einen Zeitraum von mehreren Wochen.\n Es betrachtet dazu nicht nur die wahrscheinlichste Entwicklung oder die mittlere Entwicklung, sondern schätzt die Wahrscheinlichkeit für verschiedene Szenarien ab, die mit der aktuellen Datenlage kompatibel sind.\n Zudem wird die räumlich-zeitliche Komponente des Infektionsgeschehens geschätzt und als sogenannter \"Interaktionskernel\" dargestellt.\n Die Arbeit basiert auf einer Adaption des [BSTIM Models](https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0225838#pone.0225838.ref009), angepasst an die COVID-19 Situation.\n Das Model beschreibt die tagesaktuellen Meldedaten basierend auf den [Daten](https://npgeo-corona-npgeo-de.hub.arcgis.com/datasets/dd4580c810204019a7b8eb3e0b329dd6_0/data?orderBy=Meldedatum) des RKI.\n \n Alle hier präsentierten Ergebnisse resultieren aus einer Modellierung basierend auf statistischen Methoden.\n Sie bilden damit nicht das reale Geschehen, sondern Schätzungen ab, die von der wirklichen Situation abweichen können.\n Dies ist bei der Interpretation der Ergebnisse zu berücksichtigen.\n Ebenso ist zu beachten, dass die Qualität dieser statistischen Methoden maßgeblich von der Qualität der zugrunde liegenden Daten abhängt.\n \"\"\"\n ),\n html.Span(\n children=[\n dbc.Button(\"Disclaimer\", id=\"disclaimer_modal_open\", outline=True, color=\"secondary\", className=\"mt-0\"),\n ],\n style={\n \"float\": 'right',\n \"marginTop\": 0,\n \"marginBottom\": 10,\n },\n ),\n dbc.Modal(\n id=\"disclaimer_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"Disclaimer\"),\n dbc.ModalBody(\n children=[\n dcc.Markdown(\n f\"\"\"\n Für die Gesamtzahl der Infektionen pro Bundesland/Landkreis werden die den Gesundheitsämtern nach Infektionsschutzgesetz gemeldeten Fälle verwendet,\n die dem RKI bis zum jeweiligen Tag um 0 Uhr übermittelt wurden.\n Für die Analyse wird das Meldedatum verwendet, s. [Details zu den Daten](https://experience.arcgis.com/experience/478220a4c454480e823b17327b2bf1d4)\n Da es in dem Verfahren zu Differenzen zwischen Erkrankungsdatum und Meldedatum, sowie Verzögerungen in dem Meldeprozess geben kann,\n ist die Analyse der Fallzahlen der letzten Woche bereits eine Vorhersage, die auf einer Schätzung basiert.\n Alle hier präsentierten Ergebnisse basieren auf statistischen Methoden und bilden damit nicht das reale Geschehen, sondern Schätzungen ab, die von der wirklichen Situation abweichen können.\n Dies ist bei der Interpretation der Ergebnisse zu berücksichtigen. \n Die hier präsentierten Forschungsergebnisse basieren auf einer neuen Methodik die bisher nicht für COVID-19 eingesetzt wurde. \n Die Validierung der Ergebnisse wird mit wachsender Menge an Daten in den kommenden Monaten fortgeführt. \n Für eine detailliertere Analyse der COVID-19-Fälle verweisen wir auf den [täglichen Lagebericht des RKI](https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Situationsberichte/Gesamt.html).\n \"\"\"\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"disclaimer_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n)\[email protected](\n Output(\"disclaimer_modal\", \"is_open\"),\n [Input(\"disclaimer_modal_open\", \"n_clicks\"), Input(\"disclaimer_modal_close\", \"n_clicks\")],\n [State(\"disclaimer_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, is_open):\n if n1 or n2:\n return not is_open\n return is_open",
"_____no_output_____"
],
[
"#####################\n# Impressum\n#####################\nimpressum_modal = html.Div(\n [\n dbc.Button(\"Impressum\", id=\"impressum_modal_open\", outline=True, color=\"secondary\", className=\"mr-1\"),\n dbc.Modal(\n id=\"impressum_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"Impressum und Haftungsausschluss\"),\n dbc.ModalBody(\n children=[\n dcc.Markdown(\n f\"\"\"\n ## Impressum\n Das Projekt covid19dynstat ist ein gemeinsames Projekt des Institutes für Kognitionswissenschaft der Universität Osnabrück und des Jülich Supercomputing Centre am Forschungszentrum Jülich.\n\n ### Inhaltlicher und wissenschaftlicher Kontakt\n \n Prof. Dr. Gordon Pipa\n\n Institut für Kognitionswissenschaft \n Wachsbleiche 27 \n 49090 Osnabrück \n \n Mailadresse: [email protected]\n\n ## Haftungsausschluss\n\n ### Inhalt der eigenen Seiten\n Wir haben die Internet-Seiten des Projektes covid19dynstat sorgfältig zusammengestellt.\n Allerdings übernehmen wir keine Gewähr oder Haftung für die Aktualität, Vollständigkeit und Richtigkeit der angebotenen Informationen.\n\n ### Links auf externe Web-Seiten\n Die Internet-Seiten des Projektes covid19dynstat enthalten Links auf die Web-Seiten Dritter.\n Diese Links auf die Web-Seiten Dritter stellen keine Zustimmung zu deren Inhalt dar.\n Das Projekt covid19dynstat hat keinen Einfluss auf die aktuelle oder zukünftige Gestaltung dieser Seiten.\n Wir übernehmen daher keine Haftung für die Verfügbarkeit oder den Inhalt solcher Web-Seiten und keine Haftung für Schäden, die aus der Nutzung solcher Inhalte entstehen.\n\n ## Hoster\n Die Webseiten des Projektes covid19dynstat werden gehostet am\n\n Forschungszentrum Jülich GmbH \n Wilhelm-Johnen-Straße \n 52428 Jülich \n\n #### Postanschrift:\n 52425 Jülich\n\n #### Lieferanschrift:\n Leo-Brandt-Straße \n 52428 Jülich \n\n Eingetragen im Handelsregister des Amtsgerichts Düren Nr. HR B 3498 \n Umsatzsteuer-Id-Nr. gem. § 27 a Umsatzsteuergesetz: DE 122624631 \n Steuer-Nr.: 213/5700/0033 \n\n #### Geschäftsführung:\n - Prof. Dr.-Ing. Wolfgang Marquardt (Vorsitzender) \n - Karsten Beneke (Stellvertr. Vorsitzender) \n - Prof. Dr. Harald Bolt \n\n #### Vorsitzender des Aufsichtsrats:\n Ministerialdirektor Volker Rieke\n\n #### Kontakt:\n Telefon-Sammel-Nr. 02461 61-0 \n Telefax-Sammel-Nr. 02461 61-8100 \n\n Internet: http://www.fz-juelich.de \n Mailadresse: [email protected] \n \"\"\"\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"impressum_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n)\[email protected](\n Output(\"impressum_modal\", \"is_open\"),\n [Input(\"impressum_modal_open\", \"n_clicks\"), Input(\"impressum_modal_close\", \"n_clicks\")],\n [State(\"impressum_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, is_open):\n if n1 or n2:\n return not is_open\n return is_open",
"_____no_output_____"
],
[
"#####################\n# Datenschutzerklärung\n#####################\ndatenschutz_modal = html.Div(\n [\n dbc.Button(\"Datenschutz\", id=\"datenschutz_modal_open\", outline=True, color=\"secondary\", className=\"mr-1\"),\n dbc.Modal(\n id=\"datenschutz_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"Datenschutzerklärung\"),\n dbc.ModalBody(\n children=[\n dcc.Markdown(\n f\"\"\"\n## Datenschutzerklärung\n\nWir freuen uns sehr über Ihr Interesse an unserem Projekt.\nDatenschutz hat einen besonders hohen Stellenwert für das Projekt BSTIM-Covid19.\nEine Nutzung der Internetseiten des Projekts BSTIM-Covid19 ist grundsätzlich ohne jede Angabe personenbezogener Daten möglich.\nSofern eine betroffene Person besondere Services unseres Projekts über unsere Internetseite in Anspruch nehmen möchte, könnte jedoch eine Verarbeitung personenbezogener Daten erforderlich werden.\nIst die Verarbeitung personenbezogener Daten erforderlich und besteht für eine solche Verarbeitung keine gesetzliche Grundlage, holen wir generell eine Einwilligung der betroffenen Person ein.\n\nDie Verarbeitung personenbezogener Daten, beispielsweise des Namens, der Anschrift, E-Mail-Adresse oder Telefonnummer einer betroffenen Person, erfolgt stets im Einklang mit der Datenschutz-Grundverordnung und in Übereinstimmung mit den für das Projekt BSTIM-Covid19 geltenden landesspezifischen Datenschutzbestimmungen.\nMittels dieser Datenschutzerklärung möchte unser Projekt die Öffentlichkeit über Art, Umfang und Zweck der von uns erhobenen, genutzten und verarbeiteten personenbezogenen Daten informieren.\nFerner werden betroffene Personen mittels dieser Datenschutzerklärung über die ihnen zustehenden Rechte aufgeklärt.\n\nDas Projekt BSTIM-Covid19 hat als für die Verarbeitung Verantwortlicher zahlreiche technische und organisatorische Maßnahmen umgesetzt, um einen möglichst lückenlosen Schutz der über diese Internetseite verarbeiteten personenbezogenen Daten sicherzustellen.\nDennoch können Internetbasierte Datenübertragungen grundsätzlich Sicherheitslücken aufweisen, sodass ein absoluter Schutz nicht gewährleistet werden kann. Aus diesem Grund steht es jeder betroffenen Person frei, personenbezogene Daten auch auf alternativen Wegen, beispielsweise telefonisch, an uns zu übermitteln.\n\n### 1. Begriffsbestimmungen\nDie Datenschutzerklärung des Projekts BSTIM-Covid19 beruht auf den Begrifflichkeiten, die durch den Europäischen Richtlinien- und Verordnungsgeber beim Erlass der Datenschutz-Grundverordnung (DSGVO) verwendet wurden.\nUnsere Datenschutzerklärung soll sowohl für die Öffentlichkeit als auch für unsere Kunden und Geschäftspartner einfach lesbar und verständlich sein. Um dies zu gewährleisten, möchten wir vorab die verwendeten Begrifflichkeiten erläutern.\n\nWir verwenden in dieser Datenschutzerklärung unter anderem die folgenden Begriffe:\n#### a) personenbezogene Daten\nPersonenbezogene Daten sind alle Informationen, die sich auf eine identifizierte oder identifizierbare natürliche Person (im Folgenden „betroffene Person“) beziehen.\nAls identifizierbar wird eine natürliche Person angesehen, die direkt oder indirekt, insbesondere mittels Zuordnung zu einer Kennung wie einem Namen, zu einer Kennnummer, zu Standortdaten, zu einer Online-Kennung oder zu einem oder mehreren besonderen Merkmalen, die Ausdruck der physischen, physiologischen, genetischen, psychischen, wirtschaftlichen, kulturellen oder sozialen Identität dieser natürlichen Person sind, identifiziert werden kann.\n#### b) betroffene Person\nBetroffene Person ist jede identifizierte oder identifizierbare natürliche Person, deren personenbezogene Daten von dem für die Verarbeitung Verantwortlichen verarbeitet werden.\n#### c) Verarbeitung\nVerarbeitung ist jeder mit oder ohne Hilfe automatisierter Verfahren ausgeführte Vorgang oder jede solche Vorgangsreihe im Zusammenhang mit personenbezogenen Daten wie das Erheben, das Erfassen, die Organisation, das Ordnen, die Speicherung, die Anpassung oder Veränderung, das Auslesen, das Abfragen, die Verwendung, die Offenlegung durch Übermittlung, Verbreitung oder eine andere Form der Bereitstellung, den Abgleich oder die Verknüpfung, die Einschränkung, das Löschen oder die Vernichtung.\n#### d) Einschränkung der Verarbeitung\nEinschränkung der Verarbeitung ist die Markierung gespeicherter personenbezogener Daten mit dem Ziel, ihre künftige Verarbeitung einzuschränken.\n#### e) Profiling\nProfiling ist jede Art der automatisierten Verarbeitung personenbezogener Daten, die darin besteht, dass diese personenbezogenen Daten verwendet werden, um bestimmte persönliche Aspekte, die sich auf eine natürliche Person beziehen, zu bewerten, insbesondere, um Aspekte bezüglich Arbeitsleistung, wirtschaftlicher Lage, Gesundheit, persönlicher Vorlieben, Interessen, Zuverlässigkeit, Verhalten, Aufenthaltsort oder Ortswechsel dieser natürlichen Person zu analysieren oder vorherzusagen.\n#### f) Pseudonymisierung\nPseudonymisierung ist die Verarbeitung personenbezogener Daten in einer Weise, auf welche die personenbezogenen Daten ohne Hinzuziehung zusätzlicher Informationen nicht mehr einer spezifischen betroffenen Person zugeordnet werden können, sofern diese zusätzlichen Informationen gesondert aufbewahrt werden und technischen und organisatorischen Maßnahmen unterliegen, die gewährleisten, dass die personenbezogenen Daten nicht einer identifizierten oder identifizierbaren natürlichen Person zugewiesen werden.\n#### g) Verantwortlicher oder für die Verarbeitung Verantwortlicher\nVerantwortlicher oder für die Verarbeitung Verantwortlicher ist die natürliche oder juristische Person, Behörde, Einrichtung oder andere Stelle, die allein oder gemeinsam mit anderen über die Zwecke und Mittel der Verarbeitung von personenbezogenen Daten entscheidet.\nSind die Zwecke und Mittel dieser Verarbeitung durch das Unionsrecht oder das Recht der Mitgliedstaaten vorgegeben, so kann der Verantwortliche beziehungsweise können die bestimmten Kriterien seiner Benennung nach dem Unionsrecht oder dem Recht der Mitgliedstaaten vorgesehen werden.\n#### h) Auftragsverarbeiter\nAuftragsverarbeiter ist eine natürliche oder juristische Person, Behörde, Einrichtung oder andere Stelle, die personenbezogene Daten im Auftrag des Verantwortlichen verarbeitet.\n#### i) Empfänger\nEmpfänger ist eine natürliche oder juristische Person, Behörde, Einrichtung oder andere Stelle, der personenbezogene Daten offengelegt werden, unabhängig davon, ob es sich bei ihr um einen Dritten handelt oder nicht.\nBehörden, die im Rahmen eines bestimmten Untersuchungsauftrags nach dem Unionsrecht oder dem Recht der Mitgliedstaaten möglicherweise personenbezogene Daten erhalten, gelten jedoch nicht als Empfänger.\n#### j) Dritter\nDritter ist eine natürliche oder juristische Person, Behörde, Einrichtung oder andere Stelle außer der betroffenen Person, dem Verantwortlichen, dem Auftragsverarbeiter und den Personen, die unter der unmittelbaren Verantwortung des Verantwortlichen oder des Auftragsverarbeiters befugt sind, die personenbezogenen Daten zu verarbeiten.\n#### k) Einwilligung\nEinwilligung ist jede von der betroffenen Person freiwillig für den bestimmten Fall in informierter Weise und unmissverständlich abgegebene Willensbekundung in Form einer Erklärung oder einer sonstigen eindeutigen bestätigenden Handlung, mit der die betroffene Person zu verstehen gibt, dass sie mit der Verarbeitung der sie betreffenden personenbezogenen Daten einverstanden ist.\n\n### 2. Name und Anschrift des für die Verarbeitung Verantwortlichen \nVerantwortlicher im Sinne der Datenschutz-Grundverordnung, sonstiger in den Mitgliedstaaten der Europäischen Union geltenden Datenschutzgesetze und anderer Bestimmungen mit datenschutzrechtlichem Charakter ist:\n\nProjekt BSTIM-Covid19 \nProf. Dr. Gordon Pipa\n\nInstitut für Kognitionswissenschaft \nWachsbleiche 27 \n49090 Osnabrück \n\nMailadresse: [email protected]\n\n#### a) Hoster\nDie Webseiten des Projekts BSTIM-Covid19 werden gehostet von der\n\nForschungszentrum Jülich GmbH \nWilhelm-Johnen-Straße \n52428 Jülich \nGermany\n\n### 3. Name und Anschrift des Datenschutzbeauftragten\nDer Datenschutzbeauftragte des für die Verarbeitung Verantwortlichen ist:\n\nFrank Rinkens \nForschungszentrum Jülich GmbH \nWilhelm-Johnen-Strasse \n52428 Jülich \n\nDeutschland\n\nTel.: +49 2461 61-9005\n\nWebsite: [www.fz-juelich.de](https://www.fz-juelich.de) \nE-Mail: [email protected] \n\nJede betroffene Person kann sich jederzeit bei allen Fragen und Anregungen zum Datenschutz direkt an unseren Datenschutzbeauftragten wenden.\n\n### 4. Cookies\nDie Internetseiten des Projekts BSTIM-Covid19 verwenden Cookies.\nCookies sind Textdateien, welche über einen Internetbrowser auf einem Computersystem abgelegt und gespeichert werden.\n\nZahlreiche Internetseiten und Server verwenden Cookies. Viele Cookies enthalten eine sogenannte Cookie-ID. Eine Cookie-ID ist eine eindeutige Kennung des Cookies.\nSie besteht aus einer Zeichenfolge, durch welche Internetseiten und Server dem konkreten Internetbrowser zugeordnet werden können, in dem das Cookie gespeichert wurde.\nDies ermöglicht es den besuchten Internetseiten und Servern, den individuellen Browser der betroffenen Person von anderen Internetbrowsern, die andere Cookies enthalten, zu unterscheiden.\nEin bestimmter Internetbrowser kann über die eindeutige Cookie-ID wiedererkannt und identifiziert werden.\n\nDurch den Einsatz von Cookies kann das Projekt BSTIM-Covid19 den Nutzern dieser Internetseite nutzerfreundlichere Services bereitstellen, die ohne die Cookie-Setzung nicht möglich wären.\n\nMittels eines Cookies können die Informationen und Angebote auf unserer Internetseite im Sinne des Benutzers optimiert werden. Cookies ermöglichen uns, wie bereits erwähnt, die Benutzer unserer Internetseite wiederzuerkennen.\nZweck dieser Wiedererkennung ist es, den Nutzern die Verwendung unserer Internetseite zu erleichtern.\nDer Benutzer einer Internetseite, die Cookies verwendet, muss beispielsweise nicht bei jedem Besuch der Internetseite erneut seine Zugangsdaten eingeben, weil dies von der Internetseite und dem auf dem Computersystem des Benutzers abgelegten Cookie übernommen wird.\nEin weiteres Beispiel ist das Cookie eines Warenkorbes im Online-Shop. Der Online-Shop merkt sich die Artikel, die ein Kunde in den virtuellen Warenkorb gelegt hat, über ein Cookie.\n\nDie betroffene Person kann die Setzung von Cookies durch unsere Internetseite jederzeit mittels einer entsprechenden Einstellung des genutzten Internetbrowsers verhindern und damit der Setzung von Cookies dauerhaft widersprechen.\nFerner können bereits gesetzte Cookies jederzeit über einen Internetbrowser oder andere Softwareprogramme gelöscht werden.\nDies ist in allen gängigen Internetbrowsern möglich. Deaktiviert die betroffene Person die Setzung von Cookies in dem genutzten Internetbrowser, sind unter Umständen nicht alle Funktionen unserer Internetseite vollumfänglich nutzbar.\n\n### 5. Erfassung von allgemeinen Daten und Informationen\nDie Internetseite des Projekts BSTIM-Covid19 erfasst mit jedem Aufruf der Internetseite durch eine betroffene Person oder ein automatisiertes System eine Reihe von allgemeinen Daten und Informationen.\nDiese allgemeinen Daten und Informationen werden in den Logfiles des Servers gespeichert.\nErfasst werden können die \n(1) verwendeten Browsertypen und Versionen, \n(2) das vom zugreifenden System verwendete Betriebssystem, \n(3) die Internetseite, von welcher ein zugreifendes System auf unsere Internetseite gelangt (sogenannte Referrer), \n(4) die Unterwebseiten, welche über ein zugreifendes System auf unserer Internetseite angesteuert werden, \n(5) das Datum und die Uhrzeit eines Zugriffs auf die Internetseite, \n(6) eine Internet-Protokoll-Adresse (IP-Adresse), \n(7) der Internet-Service-Provider des zugreifenden Systems und \n(8) sonstige ähnliche Daten und Informationen, die der Gefahrenabwehr im Falle von Angriffen auf unsere informationstechnologischen Systeme dienen.\n\nBei der Nutzung dieser allgemeinen Daten und Informationen zieht das Projekt BSTIM-Covid19 keine Rückschlüsse auf die betroffene Person.\nDiese Informationen werden vielmehr benötigt, um\n(1) die Inhalte unserer Internetseite korrekt auszuliefern,\n(2) die dauerhafte Funktionsfähigkeit unserer informationstechnologischen Systeme und der Technik unserer Internetseite zu gewährleisten sowie\n(3) um Strafverfolgungsbehörden im Falle eines Cyberangriffes die zur Strafverfolgung notwendigen Informationen bereitzustellen.\nDiese anonym erhobenen Daten und Informationen werden durch das Projekt BSTIM-Covid19 daher einerseits statistisch und ferner mit dem Ziel ausgewertet, den Datenschutz und die Datensicherheit in unserem Projekt zu erhöhen, um letztlich ein optimales Schutzniveau für die von uns verarbeiteten personenbezogenen Daten sicherzustellen.\nDie anonymen Daten der Server-Logfiles werden getrennt von allen durch eine betroffene Person angegebenen personenbezogenen Daten gespeichert.\n\n### 6. Kontaktmöglichkeit über die Internetseite\nDie Internetseite des Projekts BSTIM-Covid19 enthält aufgrund von gesetzlichen Vorschriften Angaben, die eine schnelle elektronische Kontaktaufnahme zu unserem Projekt sowie eine unmittelbare Kommunikation mit uns ermöglichen, was ebenfalls eine allgemeine Adresse der sogenannten elektronischen Post (E-Mail-Adresse) umfasst.\nSofern eine betroffene Person per E-Mail oder über ein Kontaktformular den Kontakt mit dem für die Verarbeitung Verantwortlichen aufnimmt, werden die von der betroffenen Person übermittelten personenbezogenen Daten automatisch gespeichert.\nSolche auf freiwilliger Basis von einer betroffenen Person an den für die Verarbeitung Verantwortlichen übermittelten personenbezogenen Daten werden für Zwecke der Bearbeitung oder der Kontaktaufnahme zur betroffenen Person gespeichert.\nEs erfolgt keine Weitergabe dieser personenbezogenen Daten an Dritte.\n\n### 7. Routinemäßige Löschung und Sperrung von personenbezogenen Daten\nDer für die Verarbeitung Verantwortliche verarbeitet und speichert personenbezogene Daten der betroffenen Person nur für den Zeitraum, der zur Erreichung des Speicherungszwecks erforderlich ist oder sofern dies durch den Europäischen Richtlinien- und Verordnungsgeber oder einen anderen Gesetzgeber in Gesetzen oder Vorschriften, welchen der für die Verarbeitung Verantwortliche unterliegt, vorgesehen wurde.\n\nEntfällt der Speicherungszweck oder läuft eine vom Europäischen Richtlinien- und Verordnungsgeber oder einem anderen zuständigen Gesetzgeber vorgeschriebene Speicherfrist ab, werden die personenbezogenen Daten routinemäßig und entsprechend den gesetzlichen Vorschriften gesperrt oder gelöscht.\n\n### 8. Rechte der betroffenen Person\n#### a) Recht auf Bestätigung\nJede betroffene Person hat das vom Europäischen Richtlinien- und Verordnungsgeber eingeräumte Recht, von dem für die Verarbeitung Verantwortlichen eine Bestätigung darüber zu verlangen, ob sie betreffende personenbezogene Daten verarbeitet werden.\nMöchte eine betroffene Person dieses Bestätigungsrecht in Anspruch nehmen, kann sie sich hierzu jederzeit an den für die Verarbeitung Verantwortlichen wenden.\n\n#### b) Recht auf Auskunft\nJede von der Verarbeitung personenbezogener Daten betroffene Person hat das vom Europäischen Richtlinien- und Verordnungsgeber gewährte Recht, jederzeit von dem für die Verarbeitung Verantwortlichen unentgeltliche Auskunft über die zu seiner Person gespeicherten personenbezogenen Daten und eine Kopie dieser Auskunft zu erhalten.\nFerner hat der Europäische Richtlinien- und Verordnungsgeber der betroffenen Person Auskunft über folgende Informationen zugestanden:\n - die Verarbeitungszwecke\n - die Kategorien personenbezogener Daten, die verarbeitet werden\n - die Empfänger oder Kategorien von Empfängern, gegenüber denen die personenbezogenen Daten offengelegt worden sind oder noch offengelegt werden, insbesondere bei Empfängern in Drittländern oder bei internationalen Organisationen\n - falls möglich die geplante Dauer, für die die personenbezogenen Daten gespeichert werden, oder, falls dies nicht möglich ist, die Kriterien für die Festlegung dieser Dauer\n - das Bestehen eines Rechts auf Berichtigung oder Löschung der sie betreffenden personenbezogenen Daten oder auf Einschränkung der Verarbeitung durch den Verantwortlichen oder eines Widerspruchsrechts gegen diese Verarbeitung\n - das Bestehen eines Beschwerderechts bei einer Aufsichtsbehörde\n - wenn die personenbezogenen Daten nicht bei der betroffenen Person erhoben werden: Alle verfügbaren Informationen über die Herkunft der Daten\n - das Bestehen einer automatisierten Entscheidungsfindung einschließlich Profiling gemäß Artikel 22 Abs.1 und 4 DSGVO und — zumindest in diesen Fällen — aussagekräftige Informationen über die involvierte Logik sowie die Tragweite und die angestrebten Auswirkungen einer derartigen Verarbeitung für die betroffene Person\n\nFerner steht der betroffenen Person ein Auskunftsrecht darüber zu, ob personenbezogene Daten an ein Drittland oder an eine internationale Organisation übermittelt wurden.\nSofern dies der Fall ist, so steht der betroffenen Person im Übrigen das Recht zu, Auskunft über die geeigneten Garantien im Zusammenhang mit der Übermittlung zu erhalten.\n\nMöchte eine betroffene Person dieses Auskunftsrecht in Anspruch nehmen, kann sie sich hierzu jederzeit an den für die Verarbeitung Verantwortlichen wenden.\n\n#### c) Recht auf Berichtigung\nJede von der Verarbeitung personenbezogener Daten betroffene Person hat das, vom Europäischen Richtlinien- und Verordnungsgeber gewährte Recht, die unverzügliche Berichtigung sie betreffender unrichtiger personenbezogener Daten zu verlangen.\nFerner steht der betroffenen Person das Recht zu, unter Berücksichtigung der Zwecke der Verarbeitung, die Vervollständigung unvollständiger personenbezogener Daten — auch mittels einer ergänzenden Erklärung — zu verlangen.\n\nMöchte eine betroffene Person dieses Berichtigungsrecht in Anspruch nehmen, kann sie sich hierzu jederzeit an den für die Verarbeitung Verantwortlichen wenden.\n\n#### d) Recht auf Löschung (Recht auf Vergessen werden)\nJede von der Verarbeitung personenbezogener Daten betroffene Person hat das vom Europäischen Richtlinien- und Verordnungsgeber gewährte Recht, von dem Verantwortlichen zu verlangen, dass die sie betreffenden personenbezogenen Daten unverzüglich gelöscht werden, sofern einer der folgenden Gründe zutrifft und soweit die Verarbeitung nicht erforderlich ist:\n - Die personenbezogenen Daten wurden für solche Zwecke erhoben oder auf sonstige Weise verarbeitet, für welche sie nicht mehr notwendig sind.\n - Die betroffene Person widerruft ihre Einwilligung, auf die sich die Verarbeitung gemäß Art. 6 Abs. 1 Buchstabe a DSGVO oder Art. 9 Abs. 2 Buchstabe a DSGVO stützte, und es fehlt an einer anderweitigen Rechtsgrundlage für die Verarbeitung.\n - Die betroffene Person legt gemäß Art. 21 Abs. 1 DSGVO Widerspruch gegen die Verarbeitung ein, und es liegen keine vorrangigen berechtigten Gründe für die Verarbeitung vor, oder die betroffene Person legt gemäß Art. 21 Abs. 2 DSGVO Widerspruch gegen die Verarbeitung ein.\n - Die personenbezogenen Daten wurden unrechtmäßig verarbeitet.\n - Die Löschung der personenbezogenen Daten ist zur Erfüllung einer rechtlichen Verpflichtung nach dem Unionsrecht oder dem Recht der Mitgliedstaaten erforderlich, dem der Verantwortliche unterliegt.\n - Die personenbezogenen Daten wurden in Bezug auf angebotene Dienste der Informationsgesellschaft gemäß Art. 8 Abs. 1 DSGVO erhoben.\n\nSofern einer der oben genannten Gründe zutrifft und eine betroffene Person die Löschung von personenbezogenen Daten, die beim Projekt BSTIM-Covid19 gespeichert sind, veranlassen möchte, kann sie sich hierzu jederzeit an den für die Verarbeitung Verantwortlichen wenden.\nEin Mitarbeiter des Projekts BSTIM-Covid19 wird veranlassen, dass dem Löschverlangen unverzüglich nachgekommen wird.\n\nWurden die personenbezogenen Daten vom Projekt BSTIM-Covid19 öffentlich gemacht und ist unser Projekt als Verantwortlicher gemäß Art. 17 Abs. 1 DSGVO zur Löschung der personenbezogenen Daten verpflichtet, so trifft das Projekt BSTIM-Covid19 unter Berücksichtigung der verfügbaren Technologie und der Implementierungskosten angemessene Maßnahmen, auch technischer Art, um andere für die Datenverarbeitung Verantwortliche, welche die veröffentlichten personenbezogenen Daten verarbeiten, darüber in Kenntnis zu setzen, dass die betroffene Person von diesen anderen für die Datenverarbeitung Verantwortlichen die Löschung sämtlicher Links zu diesen personenbezogenen Daten oder von Kopien oder Replikationen dieser personenbezogenen Daten verlangt hat, soweit die Verarbeitung nicht erforderlich ist. Ein Mitarbeiter des Projekts BSTIM-Covid19 wird im Einzelfall das Notwendige veranlassen.\n\n#### e) Recht auf Einschränkung der Verarbeitung\nJede von der Verarbeitung personenbezogener Daten betroffene Person hat das vom Europäischen Richtlinien- und Verordnungsgeber gewährte Recht, von dem Verantwortlichen die Einschränkung der Verarbeitung zu verlangen, wenn eine der folgenden Voraussetzungen gegeben ist:\n - Die Richtigkeit der personenbezogenen Daten wird von der betroffenen Person bestritten, und zwar für eine Dauer, die es dem Verantwortlichen ermöglicht, die Richtigkeit der personenbezogenen Daten zu überprüfen.\n - Die Verarbeitung ist unrechtmäßig, die betroffene Person lehnt die Löschung der personenbezogenen Daten ab und verlangt stattdessen die Einschränkung der Nutzung der personenbezogenen Daten.\n - Der Verantwortliche benötigt die personenbezogenen Daten für die Zwecke der Verarbeitung nicht länger, die betroffene Person benötigt sie jedoch zur Geltendmachung, Ausübung oder Verteidigung von Rechtsansprüchen.\n - Die betroffene Person hat Widerspruch gegen die Verarbeitung gem. Art. 21 Abs. 1 DSGVO eingelegt und es steht noch nicht fest, ob die berechtigten Gründe des Verantwortlichen gegenüber denen der betroffenen Person überwiegen.\n\nSofern eine der oben genannten Voraussetzungen gegeben ist und eine betroffene Person die Einschränkung von personenbezogenen Daten, die beim Projekt BSTIM-Covid19 gespeichert sind, verlangen möchte, kann sie sich hierzu jederzeit an den für die Verarbeitung Verantwortlichen wenden. Ein Mitarbeiter des Projekts BSTIM-Covid19 wird die Einschränkung der Verarbeitung veranlassen.\n\n#### f) Recht auf Datenübertragbarkeit\nJede von der Verarbeitung personenbezogener Daten betroffene Person hat das vom Europäischen Richtlinien- und Verordnungsgeber gewährte Recht, die sie betreffenden personenbezogenen Daten, welche durch die betroffene Person einem Verantwortlichen bereitgestellt wurden, in einem strukturierten, gängigen und maschinenlesbaren Format zu erhalten. Sie hat außerdem das Recht, diese Daten einem anderen Verantwortlichen ohne Behinderung durch den Verantwortlichen, dem die personenbezogenen Daten bereitgestellt wurden, zu übermitteln, sofern die Verarbeitung auf der Einwilligung gemäß Art. 6 Abs. 1 Buchstabe a DSGVO oder Art. 9 Abs. 2 Buchstabe a DSGVO oder auf einem Vertrag gemäß Art. 6 Abs. 1 Buchstabe b DSGVO beruht und die Verarbeitung mithilfe automatisierter Verfahren erfolgt, sofern die Verarbeitung nicht für die Wahrnehmung einer Aufgabe erforderlich ist, die im öffentlichen Interesse liegt oder in Ausübung öffentlicher Gewalt erfolgt, welche dem Verantwortlichen übertragen wurde.\n\nFerner hat die betroffene Person bei der Ausübung ihres Rechts auf Datenübertragbarkeit gemäß Art. 20 Abs. 1 DSGVO das Recht, zu erwirken, dass die personenbezogenen Daten direkt von einem Verantwortlichen an einen anderen Verantwortlichen übermittelt werden, soweit dies technisch machbar ist und sofern hiervon nicht die Rechte und Freiheiten anderer Personen beeinträchtigt werden. \nZur Geltendmachung des Rechts auf Datenübertragbarkeit kann sich die betroffene Person jederzeit an den für die Verarbeitung Verantwortlichen des Projekts BSTIM-Covid19 wenden.\n\n#### g) Recht auf Widerspruch\nJede von der Verarbeitung personenbezogener Daten betroffene Person hat das vom Europäischen Richtlinien- und Verordnungsgeber gewährte Recht, aus Gründen, die sich aus ihrer besonderen Situation ergeben, jederzeit gegen die Verarbeitung sie betreffender personenbezogener Daten, die aufgrund von Art. 6 Abs. 1 Buchstaben e oder f DSGVO erfolgt, Widerspruch einzulegen. Dies gilt auch für ein auf diese Bestimmungen gestütztes Profiling.\n\nDas Projekt BSTIM-Covid19 verarbeitet die personenbezogenen Daten im Falle des Widerspruchs nicht mehr, es sei denn, wir können zwingende schutzwürdige Gründe für die Verarbeitung nachweisen, die den Interessen, Rechten und Freiheiten der betroffenen Person überwiegen, oder die Verarbeitung dient der Geltendmachung, Ausübung oder Verteidigung von Rechtsansprüchen.\n\nZudem hat die betroffene Person das Recht, aus Gründen, die sich aus ihrer besonderen Situation ergeben, gegen die sie betreffende Verarbeitung personenbezogener Daten, die beim Projekt BSTIM-Covid19 zu wissenschaftlichen oder historischen Forschungszwecken oder zu statistischen Zwecken gemäß Art. 89 Abs. 1 DSGVO erfolgen, Widerspruch einzulegen, es sei denn, eine solche Verarbeitung ist zur Erfüllung einer im öffentlichen Interesse liegenden Aufgabe erforderlich.\n\nZur Ausübung des Rechts auf Widerspruch kann sich die betroffene Person direkt an den für die Verarbeitung Verantwortlichen des Projekts BSTIM-Covid19 wenden.\nDer betroffenen Person steht es ferner frei, im Zusammenhang mit der Nutzung von Diensten der Informationsgesellschaft, ungeachtet der Richtlinie 2002/58/EG, ihr Widerspruchsrecht mittels automatisierter Verfahren auszuüben, bei denen technische Spezifikationen verwendet werden.\n\n#### h) Automatisierte Entscheidungen im Einzelfall einschließlich Profiling\nJede von der Verarbeitung personenbezogener Daten betroffene Person hat das vom Europäischen Richtlinien- und Verordnungsgeber gewährte Recht, nicht einer ausschließlich auf einer automatisierten Verarbeitung — einschließlich Profiling — beruhenden Entscheidung unterworfen zu werden, die ihr gegenüber rechtliche Wirkung entfaltet oder sie in ähnlicher Weise erheblich beeinträchtigt, sofern die Entscheidung \n(1) nicht für den Abschluss oder die Erfüllung eines Vertrags zwischen der betroffenen Person und dem Verantwortlichen erforderlich ist, oder \n(2) aufgrund von Rechtsvorschriften der Union oder der Mitgliedstaaten, denen der Verantwortliche unterliegt, zulässig ist und diese Rechtsvorschriften angemessene Maßnahmen zur Wahrung der Rechte und Freiheiten sowie der berechtigten Interessen der betroffenen Person enthalten oder \n(3) mit ausdrücklicher Einwilligung der betroffenen Person erfolgt.\n\nIst die Entscheidung \n(1) für den Abschluss oder die Erfüllung eines Vertrags zwischen der betroffenen Person und dem Verantwortlichen erforderlich oder \n(2) erfolgt sie mit ausdrücklicher Einwilligung der betroffenen Person, trifft das Projekt BSTIM-Covid19 angemessene Maßnahmen, um die Rechte und Freiheiten sowie die berechtigten Interessen der betroffenen Person zu wahren, wozu mindestens das Recht auf Erwirkung des Eingreifens einer Person seitens des Verantwortlichen, auf Darlegung des eigenen Standpunkts und auf Anfechtung der Entscheidung gehört.\n\nMöchte die betroffene Person Rechte mit Bezug auf automatisierte Entscheidungen geltend machen, kann sie sich hierzu jederzeit an den für die Verarbeitung Verantwortlichen wenden.\n\n#### i) Recht auf Widerruf einer datenschutzrechtlichen Einwilligung\nJede von der Verarbeitung personenbezogener Daten betroffene Person hat das vom Europäischen Richtlinien- und Verordnungsgeber gewährte Recht, eine Einwilligung zur Verarbeitung personenbezogener Daten jederzeit zu widerrufen.\n\nMöchte die betroffene Person ihr Recht auf Widerruf einer Einwilligung geltend machen, kann sie sich hierzu jederzeit an den für die Verarbeitung Verantwortlichen wenden.\n\nUnbeschadet eines anderweitigen verwaltungsrechtlichen oder gerichtlichen Rechtsbehelfs steht Ihnen das Recht auf Beschwerde bei einer Aufsichtsbehörde, insbesondere in dem Mitgliedstaat ihres Aufenthaltsorts, ihres Arbeitsplatzes oder des Orts des mutmaßlichen Verstoßes, zu, wenn Sie der Ansicht sind, dass die Verarbeitung der Sie betreffenden personenbezogenen Daten gegen die DSGVO verstößt.\n\n### 9. Rechtsgrundlage der Verarbeitung\nArt. 6 I lit. a DSGVO dient unserem Projekt als Rechtsgrundlage für Verarbeitungsvorgänge, bei denen wir eine Einwilligung für einen bestimmten Verarbeitungszweck einholen.\nIst die Verarbeitung personenbezogener Daten zur Erfüllung eines Vertrags, dessen Vertragspartei die betroffene Person ist, erforderlich, wie dies beispielsweise bei Verarbeitungsvorgängen der Fall ist, die für eine Lieferung von Waren oder die Erbringung einer sonstigen Leistung oder Gegenleistung notwendig sind, so beruht die Verarbeitung auf Art. 6 I lit. b DSGVO. Gleiches gilt für solche Verarbeitungsvorgänge die zur Durchführung vorvertraglicher Maßnahmen erforderlich sind, etwa in Fällen von Anfragen zur unseren Produkten oder Leistungen.\nUnterliegt unser Projekt einer rechtlichen Verpflichtung durch welche eine Verarbeitung von personenbezogenen Daten erforderlich wird, wie beispielsweise zur Erfüllung steuerlicher Pflichten, so basiert die Verarbeitung auf Art. 6 I lit. c DSGVO.\nIn seltenen Fällen könnte die Verarbeitung von personenbezogenen Daten erforderlich werden, um lebenswichtige Interessen der betroffenen Person oder einer anderen natürlichen Person zu schützen.\nDies wäre beispielsweise der Fall, wenn ein Besucher in unserem Betrieb verletzt werden würde und daraufhin sein Name, sein Alter, seine Krankenkassendaten oder sonstige lebenswichtige Informationen an einen Arzt, ein Krankenhaus oder sonstige Dritte weitergegeben werden müssten.\nDann würde die Verarbeitung auf Art. 6 I lit. d DSGVO beruhen. Letztlich könnten Verarbeitungsvorgänge auf Art. 6 I lit. f DSGVO beruhen.\nAuf dieser Rechtsgrundlage basieren Verarbeitungsvorgänge, die von keiner der vorgenannten Rechtsgrundlagen erfasst werden, wenn die Verarbeitung zur Wahrung eines berechtigten Interesses unseres Projekts oder eines Dritten erforderlich ist, sofern die Interessen, Grundrechte und Grundfreiheiten des Betroffenen nicht überwiegen. Solche Verarbeitungsvorgänge sind uns insbesondere deshalb gestattet, weil sie durch den Europäischen Gesetzgeber besonders erwähnt wurden.\nEr vertrat insoweit die Auffassung, dass ein berechtigtes Interesse anzunehmen sein könnte, wenn die betroffene Person ein Kunde des Verantwortlichen ist (Erwägungsgrund 47 Satz 2 DSGVO).\n\n### 10. Berechtigte Interessen an der Verarbeitung, die von dem Verantwortlichen oder einem Dritten verfolgt werden\nBasiert die Verarbeitung personenbezogener Daten auf Artikel 6 I lit. f DSGVO ist unser berechtigtes Interesse die Durchführung unserer Geschäftstätigkeit zugunsten des Wohlergehens all unserer Mitarbeiter und unserer Anteilseigner.\n\n### 11. Dauer, für die die personenbezogenen Daten gespeichert werden\nDas Kriterium für die Dauer der Speicherung von personenbezogenen Daten ist die jeweilige gesetzliche Aufbewahrungsfrist. Nach Ablauf der Frist werden die entsprechenden Daten routinemäßig gelöscht, sofern sie nicht mehr zur Vertragserfüllung oder Vertragsanbahnung erforderlich sind.\n\n### 12. Gesetzliche oder vertragliche Vorschriften zur Bereitstellung der personenbezogenen Daten; Erforderlichkeit für den Vertragsabschluss; Verpflichtung der betroffenen Person, die personenbezogenen Daten bereitzustellen; mögliche Folgen der Nichtbereitstellung\nWir klären Sie darüber auf, dass die Bereitstellung personenbezogener Daten zum Teil gesetzlich vorgeschrieben ist (z.B. Steuervorschriften) oder sich auch aus vertraglichen Regelungen (z.B. Angaben zum Vertragspartner) ergeben kann.\nMitunter kann es zu einem Vertragsschluss erforderlich sein, dass eine betroffene Person uns personenbezogene Daten zur Verfügung stellt, die in der Folge durch uns verarbeitet werden müssen.\nDie betroffene Person ist beispielsweise verpflichtet uns personenbezogene Daten bereitzustellen, wenn unser Projekt mit ihr einen Vertrag abschließt. Eine Nichtbereitstellung der personenbezogenen Daten hätte zur Folge, dass der Vertrag mit dem Betroffenen nicht geschlossen werden könnte.\nVor einer Bereitstellung personenbezogener Daten durch den Betroffenen muss sich der Betroffene an einen unserer Mitarbeiter wenden.\nUnser Mitarbeiter klärt den Betroffenen einzelfallbezogen darüber auf, ob die Bereitstellung der personenbezogenen Daten gesetzlich oder vertraglich vorgeschrieben oder für den Vertragsabschluss erforderlich ist, ob eine Verpflichtung besteht, die personenbezogenen Daten bereitzustellen, und welche Folgen die Nichtbereitstellung der personenbezogenen Daten hätte. \n\n### 13. Datenschutzbestimmungen zu Einsatz und Verwendung von YouTube\nDer für die Verarbeitung Verantwortliche hat auf dieser Internetseite Komponenten von YouTube integriert. YouTube ist ein Internet-Videoportal, dass Video-Publishern das kostenlose Einstellen von Videoclips und anderen Nutzern die ebenfalls kostenfreie Betrachtung, Bewertung und Kommentierung dieser ermöglicht.\nYouTube gestattet die Publikation aller Arten von Videos, weshalb sowohl komplette Film- und Fernsehsendungen, aber auch Musikvideos, Trailer oder von Nutzern selbst angefertigte Videos über das Internetportal abrufbar sind.\nBetreibergesellschaft von YouTube ist die YouTube, LLC, 901 Cherry Ave., San Bruno, CA 94066, USA. Die YouTube, LLC ist einer Tochtergesellschaft der Google Inc., 1600 Amphitheatre Pkwy, Mountain View, CA 94043-1351, USA.\n\nDurch jeden Aufruf einer der Einzelseiten dieser Internetseite, die durch den für die Verarbeitung Verantwortlichen betrieben wird und auf welcher eine YouTube-Komponente (YouTube-Video) integriert wurde, wird der Internetbrowser auf dem informationstechnologischen System der betroffenen Person automatisch durch die jeweilige YouTube-Komponente veranlasst, eine Darstellung der entsprechenden YouTube-Komponente von YouTube herunterzuladen. Weitere Informationen zu YouTube können unter [https://www.youtube.com/yt/about/de/](https://www.youtube.com/yt/about/de/) abgerufen werden.\nIm Rahmen dieses technischen Verfahrens erhalten YouTube und Google Kenntnis darüber, welche konkrete Unterseite unserer Internetseite durch die betroffene Person besucht wird.\n\nSofern die betroffene Person gleichzeitig bei YouTube eingeloggt ist, erkennt YouTube mit dem Aufruf einer Unterseite, die ein YouTube-Video enthält, welche konkrete Unterseite unserer Internetseite die betroffene Person besucht.\nDiese Informationen werden durch YouTube und Google gesammelt und dem jeweiligen YouTube-Account der betroffenen Person zugeordnet.\n\nYouTube und Google erhalten über die YouTube-Komponente immer dann eine Information darüber, dass die betroffene Person unsere Internetseite besucht hat, wenn die betroffene Person zum Zeitpunkt des Aufrufs unserer Internetseite gleichzeitig bei YouTube eingeloggt ist; dies findet unabhängig davon statt, ob die betroffene Person ein YouTube-Video anklickt oder nicht.\nIst eine derartige Übermittlung dieser Informationen an YouTube und Google von der betroffenen Person nicht gewollt, kann diese die Übermittlung dadurch verhindern, dass sie sich vor einem Aufruf unserer Internetseite aus ihrem YouTube-Account ausloggt.\n\nDie von YouTube veröffentlichten Datenschutzbestimmungen, die unter [https://www.google.de/intl/de/policies/privacy/](https://www.google.de/intl/de/policies/privacy/) abrufbar sind, geben Aufschluss über die Erhebung, Verarbeitung und Nutzung personenbezogener Daten durch YouTube und Google.\n\n### 14. Bestehen einer automatisierten Entscheidungsfindung\nAls verantwortungsbewusstes Projekt verzichten wir auf eine automatische Entscheidungsfindung oder ein Profiling.\n\n### 15. Anpassung der Datenschutzerklärung\nWir behalten uns vor, diese Datenschutzerklärung von Zeit zu Zeit zu aktualisieren. Aktualisierungen dieser Datenschutzerklärung werden auf unserer Website veröffentlicht.\nÄnderungen gelten ab ihrer Publikation auf unserer Website. Wir empfehlen Ihnen daher, diese Seite regelmäßig zu besuchen, um sich über gegebenenfalls erfolgte Aktualisierungen zu informieren. \nDiese Datenschutzerklärung wurde durch den Datenschutzerklärungs-Generator von [\"Datenschutzbeauftragter Dresden\"](https://dg-datenschutz.de/) in Kooperation mit der [RC GmbH](http://remarketing.company), die gebrauchte Notebooks wiederverwertet und den [Filesharing Rechtsanwälten von WBS-LAW](https://www.wbs-law.de/abmahnung-filesharing/) erstellt. \n \"\"\"\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"datenschutz_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n)\[email protected](\n Output(\"datenschutz_modal\", \"is_open\"),\n [Input(\"datenschutz_modal_open\", \"n_clicks\"), Input(\"datenschutz_modal_close\", \"n_clicks\")],\n [State(\"datenschutz_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, is_open):\n if n1 or n2:\n return not is_open\n return is_open",
"_____no_output_____"
],
[
"#####################\n# Header and Footer (main)\n#####################\n# https://dash-bootstrap-components.opensource.faculty.ai/docs/components/navbar/\n\nnavbar = dbc.NavbarSimple(\n brand=\"Bayessches räumlich-zeitliches Interaktionsmodell für Covid-19\",\n brand_href=\"#\",\n color=\"dark\",\n fixed=\"top\",\n dark=True,\n children=[\n dbc.NavItem(\n dbc.Button(\n \"Fragen & Antworten\",\n color=\"primary\",\n href=\"/faq\" #\"https://jupyter-jsc.fz-juelich.de/nbviewer/github/neuroinfo-os/BSTIM-Covid19/blob/master/notebooks/FragenAntworten.ipynb\"\n )\n ),\n dbc.NavItem(\n dbc.NavLink(\n \"Quellcode\",\n href=\"https://github.com/neuroinfo-os/BSTIM-Covid19\",\n )\n ),\n ])\n\nfaq_navbar = dbc.NavbarSimple(\n brand=\"Bayessches räumlich-zeitliches Interaktionsmodell für Covid-19\",\n brand_href=\"#\",\n color=\"dark\",\n fixed=\"top\",\n dark=True,\n children=[\n dbc.NavItem(\n dbc.Button(\n \"Dashboard\",\n color=\"primary\",\n href=\"/\" #\"https://jupyter-jsc.fz-juelich.de/nbviewer/github/neuroinfo-os/BSTIM-Covid19/blob/master/notebooks/FragenAntworten.ipynb\"\n )\n ),\n dbc.NavItem(\n dbc.NavLink(\n \"Quellcode\",\n href=\"https://github.com/neuroinfo-os/BSTIM-Covid19\",\n )\n ),\n ])\n\nnavbar_footer = dbc.NavbarSimple(\n #brand=\"\",\n brand_href=\"#\",\n color=\"light\",\n #fixed=\"bottom\",\n #sticky=True,\n #dark=True,\n children=[\n dbc.NavItem(impressum_modal),\n dbc.NavItem(datenschutz_modal),\n ])",
"_____no_output_____"
],
[
"#####################\n# Interpretationshilfen\n#####################\nikernel_inter1_modal = html.Div(\n [\n dbc.Modal(\n id=\"ikernel_inter1_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"Interpretationshilfe\"),\n dbc.ModalBody(\n children=[\n dbc.Col(\n children = [\n html.Img(\n src=asset_url + \"ikernel-1.png\",\n style={'width':'80%', 'height':'80%'},\n ),\n ],\n width={\"size\": 4, \"offset\": 8},\n ), \n dcc.Markdown(\n f\"\"\"\n ### Eigenschaften des Bildes \n Eine rote intensive Farbe zeigt einen deutlichen Einfluss von Infektionen auf die Infektionsrate an.\n \n Die rote Farbe zeigt, dass es sich um eine verstärkende Interaktion handelt, die die Infektionsrate anhebt.\n Dieser Effekt ist hier räumlich auf die direkte Umgebung mit 0-10km und zeitlich auf eine Zeitspanne von 2-4 Tagen Verzögerung begrenzt.\n \n ### Interpretationshilfe\n Solch ein Muster kann auf eine starke lokale Ausbreitung hindeuten, bei der Menschen sich verstärkt in der direkten Umgebung (0-10km) anstecken und diese Ansteckung mit einer Verzögerung von 2-4 Tagen zu einer gemeldeten Erkrankung führt.\n \n **Achtung:** \n Die Farbe zeigt nicht an, ob die Anzahl an Infektionen in der Region tatsächlich zu oder abnimmt, sondern einen lokalen Effekt der Beeinflussung.\n Um die absolute Zu- oder Abnahme erkennen zu können muss zusätzlich die Vorhersage im Nowcast und Forecast genutzt werden.\n \"\"\"\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"ikernel_inter1_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n)\n\nikernel_inter2_modal = html.Div(\n [\n dbc.Modal(\n id=\"ikernel_inter2_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"Interpretationshilfe\"),\n dbc.ModalBody(\n children=[\n dbc.Col(\n children = [\n html.Img(\n src=asset_url + \"ikernel-2.png\",\n style={'width':'80%', 'height':'80%'},\n ),\n ],\n width={\"size\": 4, \"offset\": 8},\n ), \n dcc.Markdown(\n f\"\"\"\n ### Eigenschaften des Bildes\n Eine schwache rote Farbe zeigt einen schwachen Einfluss von Infektionen auf die Infektionsrate an.\n \n Die schwache Farbe zeigt, dass es sich um eine schwache Interaktion handelt, die die Infektionsrate nur schwach beeinflusst.\n Dieser Effekt ist hier räumlich auf eine weitere Umgebung mit bis zu 0-30km begrenzt und tritt zeitlich durchgehen in der Zeitspanne von 0-5 Tagen auf.\n \n ### Interpretationshilfe\n Die schwache Farbe zeigt eine schwache Anhebung der Infektionszahlen durch Menschen in der Umgebung an.\n Die große Breite und der andauernde Effekt über die gesamten 5 Tage deuten auf eine Anhebung hin, die sich über einige Landkreise hinweg erstreckt und stärker als der Bundesdurchschnitt ist.\n \n **Achtung:** \n Die Farbe zeigt nicht an, ob die Anzahl an Infektionen tatsächlich zu oder abnimmt, sondern eine lokalen Effekt der Beeinflussung.\n Um die absolute Zu- oder Abnahme erkennen zu können muss zusätzlich die Vorhersage im Nowcast und Forecast genutzt werden.\n \"\"\"\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"ikernel_inter2_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n)\n\nikernel_inter3_modal = html.Div(\n [\n dbc.Modal(\n id=\"ikernel_inter3_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"Interpretationshilfe\"),\n dbc.ModalBody(\n children=[\n dbc.Col(\n children = [\n html.Img(\n src=asset_url + \"ikernel-3.png\",\n style={'width':'100%', 'height':'100%'},\n ),\n ],\n width={\"size\": 4, \"offset\": 8},\n ), \n dcc.Markdown(\n f\"\"\"\n ### Eigenschaften des Bildes\n Mittlere rote Farben und blaue Farben zeigen einen kleineren Einfluss von Infektionen auf die Infektionsrate an.\n \n Die mittlere rote Farbe zeigt an, dass Infektionen in der Umgebung die Infektionsrate lokal anheben.\n Die mittlere blaue Farbe zeigt an, dass die Infektionen in der Umgebung die Infektionsrate lokal absenken.\n Beide Effekte sind lokal auf 0-10km begrenzt und treten mit einer zeitlichen Verzögerung auf.\n \n ### Interpretationshilfe\n Die mittlere Farbe zeigt eine schwache Anhebung bzw. Absenkung der Infektionszahlen durch Menschen in der Umgebung an.\n Aufeinanderfolgende rote und blaue Bereich können auf eine Kette von Ereignissen hindeuten.\n So kann zum Beispiel dieses Muster auf eine lokalen Verzögerung oder Verschiebung der Meldeergebnisse zurückgeführt werden.\n Die erhöhte rote Infektionsrate kann also das Ergebnis von „Nachmeldungen“ sein.\n \n **Achtung:** \n Die Farbe zeigt nicht an, ob die tatsächliche Anzahl an Infektionen zu oder abnimmt, sondern eine lokalen Effekt der Beeinflussung.\n Um die absolute Zu- oder Abnahme erkennen zu können muss zusätzlich die Vorhersage im Nowcast und Forecast genutzt werden.\n \"\"\"\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"ikernel_inter3_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n)",
"_____no_output_____"
],
[
"#####################\n# Date-Tabs (left)\n#####################\nleft_date_tab1 = dbc.Card(\n outline=True,\n color=\"light\",\n className=\"mt-3\",\n children=[ dbc.CardBody(\n style={ 'padding': 0, },\n children=[\n html.Div(\n id=\"left_date_tab1_img_div\",\n children=[\n dcc.Loading(\n id = \"left_date_tab1_loading_graph\", \n children=[html.Div(children=[\n dcc.Graph(id='left_date_tab1_graph', figure=init_mapfig_bstim, style={'width':'100%', 'height':'100%','display':'inline-block'}),\n ])],\n type=\"circle\", # 'graph', 'cube', 'circle', 'dot', 'default'\n color=\"#343A40\",\n style={'hight':'450px'},\n ),\n ]),\n ]),\n ])\n\nleft_date_tab2_modal = html.Div(\n [\n dbc.Button(\"Vergrößern\", id=\"left_date_tab2_modal_open\", outline=True, color=\"secondary\", className=\"mr-1\"),\n dbc.Modal(\n id=\"left_date_tab2_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"Interaktionskernel\"),\n dbc.ModalBody(\n children=[\n html.Img(\n id=\"left_date_modal2_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/interaction_kernel.png\",\n style={'width':'100%', 'height':'100%'},\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"left_date_tab2_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n) \nleft_date_tab2 = dbc.Card(\n outline=True,\n color=\"light\",\n className=\"mt-3\", \n children=[ dbc.CardBody(\n children=[\n html.Div(\n id=\"left_date_tab2_img_div\",\n children=[\n left_date_tab2_modal,\n dcc.Loading(\n id = \"left_date_tab2_loading_img\", \n children=[html.Div(children=[\n html.Img(\n id=\"left_date_tab2_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/interaction_kernel.png\",\n style={'width':'100%', 'height':'100%'},\n ),\n ])],\n type=\"circle\", # 'graph', 'cube', 'circle', 'dot', 'default'\n color=\"#343A40\",\n style={'hight':'450px'},\n ),\n dbc.Tooltip(\n \"Der Interaktionskernel schätzt ab um wie stark eine gemeldete Infektion eine Neuansteckung in den nächsten Tagen \"\n \"in einem Umkreis von bis zu 50km beeinflusst. \"\n \"Diese Interaktion ist ein zusätzlicher Faktor der den Trend in einem Landkreis verstärkt oder abschwächt. \"\n \"Eine warme Farbe indiziert, dass eine Covid-19 Meldung eine erhöhte Wahrscheinlichkeit einer Neuinfektion \"\n \"im Verhältnis zum Trend zur Folge hat. \"\n \"Eine starke Farben in der Nähe kleiner Radien bedeutet, dass das Infektionsgeschehen vor allem Auswirkungen \"\n \"in der direkten Nähe der gemeldeten Fälle zur Folge hat. \"\n \"Die Interaktion basiert auf einer Schätzung der Bevölkerungsdichte und der Form der Landkreise. \"\n \"Daten zu den Wohnorten der Infizierten werden in dem Model nicht genutzt. \"\n \"Alle hier genutzten Daten sind vollständig anonymisiert (siehe Erklärvideo). \"\n \"Bei der Interpretation der Interaktionskernel ist dies zu berücksichtigen, und wir weisen darauf hin, dass dies nur eine Schätzung ist \"\n \"die von der Realität abweichen kann.\",\n target=\"left_date_tab2_img\",\n style={\"width\": \"200%\"},\n placement=\"left\",\n ),\n ]),\n html.Div(\n children = [\n dbc.Row(\n dbc.Col(\n html.Div(\"Klick ähnliche Darstellung für Interpretationshilfe:\"),\n width={\"size\": 11, \"offset\": 1},\n )\n ),\n dbc.Row(\n children = [\n dbc.Col(\n children = [\n html.Div(\n id=\"left_date_tab2_ikernel1_div\",\n children = [\n html.Img(\n id=\"left_date_tab2_ikernel1\",\n src=asset_url + \"ikernel-1-border.png\",\n style={'width':'80%', 'height':'80%'},\n ),\n ],\n ),\n ],\n width={\"size\": 3, \"offset\": 1},\n ),\n dbc.Col(\n children = [\n html.Div(\n id=\"left_date_tab2_ikernel2_div\",\n children = [\n html.Img(\n id=\"left_date_tab2_ikernel2\",\n src=asset_url + \"ikernel-2-border.png\",\n style={'width':'80%', 'height':'80%'},\n ),\n ],\n ),\n ],\n width={\"size\": 3, \"offset\": 1},\n ),\n dbc.Col(\n children = [\n html.Div(\n id=\"left_date_tab2_ikernel3_div\",\n children = [\n html.Img(\n id=\"left_date_tab2_ikernel3\",\n src=asset_url + \"ikernel-3-border.png\",\n style={'width':'80%', 'height':'80%'},\n ),\n ],\n ),\n ],\n width={\"size\": 3, \"offset\": 1},\n ),\n ],\n ),\n ],\n ),\n ]),\n ])\n\nleft_date_tab3 = dbc.Card(\n outline=True,\n color=\"light\",\n className=\"mt-3\",\n children=[ dbc.CardBody(\n style={ 'padding': 0, },\n children=[\n html.Div(\n id=\"left_date_tab3_img_div\",\n children=[\n dcc.Loading(\n id = \"left_date_tab3_loading_graph\", \n children=[html.Div(children=[\n dcc.Graph(id='left_date_tab3_graph', figure=init_mapfig_rki, style={'width':'100%', 'height':'100%','display':'inline-block'}),\n ])],\n type=\"circle\", # 'graph', 'cube', 'circle', 'dot', 'default'\n color=\"#343A40\",\n style={'hight':'450px'},\n ),\n ]),\n ]),\n ])\n\[email protected](\n Output(\"left_date_tab2_modal\", \"is_open\"),\n [Input(\"left_date_tab2_img_div\", \"n_clicks\"), Input(\"left_date_tab2_modal_open\", \"n_clicks\"), Input(\"left_date_tab2_modal_close\", \"n_clicks\")],\n [State(\"left_date_tab2_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, n3, is_open):\n if n1 or n2 or n3:\n return not is_open\n return is_open",
"_____no_output_____"
],
[
"#####################\n# Date-Window Picker (left)\n#####################\nleft_date_controls = dbc.FormGroup(\n children=[\n dbc.Label(\n id='left_date-label',\n children=[\"Vorhersagebeginn:\"],\n ),\n html.Div(\n children=[\n dcc.DatePickerSingle(\n id='left_date-picker',\n style={'width':'100%'},\n display_format='DD. MMM YYYY',\n min_date_allowed=min_date,\n max_date_allowed=max_date,\n initial_visible_month=init_date,\n date=init_date +timedelta(days=deltadays),\n ),\n html.Div(\n id='left_output-container-date-picker',\n style={'display': 'none'},\n children=[(init_date +timedelta(days=deltadays)).strftime('%Y_%m_%d')],\n ),\n ]),\n dbc.Label(\n id='left_date-label2',\n children=[\"(auf Basis der Daten des vorherigen 3-Wochenfensters)\"],\n ),\n ])\n\n# Date Picker\[email protected](\n Output(component_id='left_output-container-date-picker', component_property='children'),\n [Input(component_id='left_date-picker', component_property='date')])\ndef update_left_date_picker(date):\n if date is not None:\n return get_assets_dir(date)\n else:\n return init_assets_dir\n\n# Interactive Map\[email protected](\n Output(component_id='left_date_tab1_graph', component_property='figure'),\n [Input(component_id='left_date-picker', component_property='date')])\[email protected](timeout=cache_timeout)\ndef update_left_date_tab1_map(date):\n if date is not None:\n assets_dir = get_assets_dir(date)\n mapfig = create_map(\"assets/figures/\" + assets_dir + \"/map.csv\", 'newInf100k')\n else:\n mapfig = create_map(\"assets/placeholders/map_empty.csv\", 'newInf100k')\n return mapfig\n\n# Interaction Kernel\[email protected](\n [Output(component_id='left_date_tab2_img', component_property='src'),\n Output(component_id='left_date_modal2_img', component_property='src')],\n [Input(component_id='left_date-picker', component_property='date')])\ndef update_left_date_tab2_img(date):\n imgUrl=\"\"\n if date is not None:\n assets_dir = get_assets_dir(date)\n imgUrl = \"figures/\" + assets_dir + \"interaction_kernel.png\"\n if not os.path.isfile(\"assets/\" + imgUrl): \n imgUrl = \"placeholders/plot_not_found.png\"\n imgUrl = asset_url + imgUrl\n return imgUrl, imgUrl\n\n# Interactive Map - RKI\[email protected](\n Output(component_id='left_date_tab3_graph', component_property='figure'),\n [Input(component_id='left_date-picker', component_property='date')])\[email protected](timeout=cache_timeout)\ndef update_left_date_tab3_map(date):\n if date is not None:\n assets_dir = get_assets_dir(date)\n mapfig = create_map(\"assets/figures/\" + assets_dir + \"/map.csv\", 'newInf100k_RKI') \n else:\n mapfig = create_map(\"assets/placeholders/map_empty.csv\", 'newInf100k')\n return mapfig",
"_____no_output_____"
],
[
"#####################\n# Date-Tabs (right)\n#####################\nright_date_tab1 = dbc.Card(\n outline=True,\n color=\"light\", \n className=\"mt-3\",\n children=[ dbc.CardBody(\n style={ 'padding': 0, },\n children=[\n html.Div(\n id=\"right_date_tab1_img_div\",\n children=[\n dcc.Loading(\n id = \"right_date_tab1_loading_graph\", \n children=[html.Div(children=[\n dcc.Graph(id='right_date_tab1_graph', figure=init_mapfig_bstim, style={'width':'100%', 'height':'100%','display':'inline-block'}),\n ])],\n type=\"circle\", # 'graph', 'cube', 'circle', 'dot', 'default'\n color=\"#343A40\",\n style={'hight':'450px'},\n ),\n ]),\n ]),\n ])\n\nright_date_tab2_modal = html.Div(\n [\n dbc.Button(\"Vergrößern\", id=\"right_date_tab2_modal_open\", outline=True, color=\"secondary\", className=\"mr-1\"),\n dbc.Modal(\n id=\"right_date_tab2_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"Interaktionskernel\"),\n dbc.ModalBody(\n children=[\n html.Img(\n id=\"right_date_modal2_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/interaction_kernel.png\",\n style={'width':'100%', 'height':'100%'},\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"right_date_tab2_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n) \nright_date_tab2 = dbc.Card(\n outline=True,\n color=\"light\", \n className=\"mt-3\", \n children=[ dbc.CardBody(\n children=[\n html.Div(\n id=\"right_date_tab2_img_div\",\n children=[\n right_date_tab2_modal,\n dcc.Loading(\n id = \"right_date_tab2_loading_img\", \n children=[html.Div(children=[\n html.Img(\n id=\"right_date_tab2_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/interaction_kernel.png\",\n style={'width':'100%', 'height':'100%'},\n ),\n ])],\n type=\"circle\", # 'graph', 'cube', 'circle', 'dot', 'default'\n color=\"#343A40\",\n style={'hight':'450px'},\n ), \n dbc.Tooltip(\n \"Der Interaktionskernel schätzt ab um wie stark eine gemeldete Infektion eine Neuansteckung in den nächsten Tagen \"\n \"in einem Umkreis von bis zu 50km beeinflusst. \"\n \"Diese Interaktion ist ein zusätzlicher Faktor der den Trend in einem Landkreis verstärkt oder abschwächt. \"\n \"Eine warme Farbe indiziert, dass eine Covid-19 Meldung eine erhöhte Wahrscheinlichkeit einer Neuinfektion \"\n \"im Verhältnis zum Trend zur Folge hat. \"\n \"Eine starke Farben in der Nähe kleiner Radien bedeutet, dass das Infektionsgeschehen vor allem Auswirkungen \"\n \"in der direkten Nähe der gemeldeten Fälle zur Folge hat. \"\n \"Die Interaktion basiert auf einer Schätzung der Bevölkerungsdichte und der Form der Landkreise. \"\n \"Daten zu den Wohnorten der Infizierten werden in dem Model nicht genutzt. \"\n \"Alle hier genutzten Daten sind vollständig anonymisiert (siehe Erklärvideo). \"\n \"Bei der Interpretation der Interaktionskernel ist dies zu berücksichtigen, und wir weisen darauf hin, dass dies nur eine Schätzung ist \"\n \"die von der Realität abweichen kann.\",\n target=\"right_date_tab2_img\",\n style={\"width\": \"200%\"},\n placement=\"right\",\n ),\n ]),\n html.Div(\n children = [\n dbc.Row(\n dbc.Col(\n html.Div(\"Klick ähnliche Darstellung für Interpretationshilfe:\"),\n width={\"size\": 11, \"offset\": 1},\n )\n ),\n dbc.Row(\n children = [\n dbc.Col(\n children = [\n html.Div(\n id=\"right_date_tab2_ikernel1_div\",\n children = [\n html.Img(\n id=\"right_date_tab2_ikernel1\",\n src=asset_url + \"ikernel-1-border.png\",\n style={'width':'80%', 'height':'80%'},\n ),\n ],\n ),\n ],\n width={\"size\": 3, \"offset\": 1},\n ),\n dbc.Col(\n children = [\n html.Div(\n id=\"right_date_tab2_ikernel2_div\",\n children = [\n html.Img(\n id=\"right_date_tab2_ikernel2\",\n src=asset_url + \"ikernel-2-border.png\",\n style={'width':'80%', 'height':'80%'},\n ),\n ],\n ),\n ],\n width={\"size\": 3, \"offset\": 1},\n ),\n dbc.Col(\n children = [\n html.Div(\n id=\"right_date_tab2_ikernel3_div\",\n children = [\n html.Img(\n id=\"right_date_tab2_ikernel3\",\n src=asset_url + \"ikernel-3-border.png\",\n style={'width':'80%', 'height':'80%'},\n ),\n ],\n ),\n ],\n width={\"size\": 3, \"offset\": 1},\n ),\n ],\n ),\n ],\n ),\n ]),\n ])\n\nright_date_tab3 = dbc.Card(\n outline=True,\n color=\"light\", \n className=\"mt-3\",\n children=[ dbc.CardBody(\n style={ 'padding': 0, },\n children=[\n html.Div(\n id=\"right_date_tab3_img_div\",\n children=[\n dcc.Loading(\n id = \"right_date_tab3_loading_graph\", \n children=[html.Div(children=[\n dcc.Graph(id='right_date_tab3_graph', figure=init_mapfig_rki, style={'width':'100%', 'height':'100%','display':'inline-block'}),\n ])],\n type=\"circle\", # 'graph', 'cube', 'circle', 'dot', 'default'\n color=\"#343A40\",\n style={'hight':'450px'},\n ),\n ]),\n ]),\n ])\n\[email protected](\n Output(\"right_date_tab2_modal\", \"is_open\"),\n [Input(\"right_date_tab2_img_div\", \"n_clicks\"), Input(\"right_date_tab2_modal_open\", \"n_clicks\"), Input(\"right_date_tab2_modal_close\", \"n_clicks\")],\n [State(\"right_date_tab2_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, n3, is_open):\n if n1 or n2 or n3:\n return not is_open\n return is_open",
"_____no_output_____"
],
[
"#####################\n# callbacks für Interpretationshilfen\n#####################\[email protected](\n Output(\"ikernel_inter1_modal\", \"is_open\"),\n [Input(\"left_date_tab2_ikernel1_div\", \"n_clicks\"), Input(\"right_date_tab2_ikernel1_div\", \"n_clicks\"), Input(\"ikernel_inter1_modal_close\", \"n_clicks\")],\n [State(\"ikernel_inter1_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, n3, is_open):\n if n1 or n2 or n3:\n return not is_open\n return is_open\n\[email protected](\n Output(\"ikernel_inter2_modal\", \"is_open\"),\n [Input(\"left_date_tab2_ikernel2_div\", \"n_clicks\"), Input(\"right_date_tab2_ikernel2_div\", \"n_clicks\"), Input(\"ikernel_inter2_modal_close\", \"n_clicks\")],\n [State(\"ikernel_inter2_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, n3, is_open):\n if n1 or n2 or n3:\n return not is_open\n return is_open\n\[email protected](\n Output(\"ikernel_inter3_modal\", \"is_open\"),\n [Input(\"left_date_tab2_ikernel3_div\", \"n_clicks\"), Input(\"right_date_tab2_ikernel3_div\", \"n_clicks\"), Input(\"ikernel_inter3_modal_close\", \"n_clicks\")],\n [State(\"ikernel_inter3_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, n3, is_open):\n if n1 or n2 or n3:\n return not is_open\n return is_open",
"_____no_output_____"
],
[
"#####################\n# Date-Window Picker (right)\n#####################\nright_date_controls = dbc.FormGroup(\n children=[\n dbc.Label(\n id='right_date-label',\n children=[\"Vorhersagebeginn:\"],\n ),\n html.Div(\n children=[\n dcc.DatePickerSingle(\n id='right_date-picker',\n style={'width':'100%'}, #150px'},\n display_format='DD. MMM YYYY',\n min_date_allowed=min_date,\n max_date_allowed=max_date,\n initial_visible_month=init_date,\n date=init_date +timedelta(days=deltadays),\n ),\n html.Div(\n id='right_output-container-date-picker',\n style={'display': 'none'},\n children=[(init_date +timedelta(days=deltadays)).strftime('%Y_%m_%d')],\n ),\n ]),\n dbc.Label(\n id='right_date-label2',\n children=[\"(auf Basis der Daten des vorherigen 3-Wochenfensters)\"],\n ),\n ])\n\n# Date Picker\[email protected](\n Output(component_id='right_output-container-date-picker', component_property='children'),\n [Input(component_id='right_date-picker', component_property='date')])\ndef update_right_date_picker(date):\n if date is not None:\n return get_assets_dir(date)\n else:\n return init_assets_dir\n\n# Interactive Map - BSTIM\[email protected](\n Output(component_id='right_date_tab1_graph', component_property='figure'),\n [Input(component_id='right_date-picker', component_property='date')])\[email protected](timeout=cache_timeout)\ndef update_right_date_tab1_map(date):\n if date is not None:\n assets_dir = get_assets_dir(date)\n mapfig = create_map(\"assets/figures/\" + assets_dir + \"/map.csv\", 'newInf100k') \n else:\n mapfig = create_map(\"assets/placeholders/map_empty.csv\", 'newInf100k')\n return mapfig\n \n# Interaction Kernel\[email protected](\n [Output(component_id='right_date_tab2_img', component_property='src'),\n Output(component_id='right_date_modal2_img', component_property='src')],\n [Input(component_id='right_date-picker', component_property='date')])\ndef update_right_date_tab2_img(date):\n imgUrl=\"\"\n if date is not None:\n assets_dir = get_assets_dir(date)\n imgUrl = \"figures/\" + assets_dir + \"interaction_kernel.png\"\n if not os.path.isfile(\"assets/\" + imgUrl): \n imgUrl = \"placeholders/plot_not_found.png\"\n imgUrl = asset_url + imgUrl\n return imgUrl, imgUrl\n\n# Interactive Map - RKI\[email protected](\n Output(component_id='right_date_tab3_graph', component_property='figure'),\n [Input(component_id='right_date-picker', component_property='date')])\[email protected](timeout=cache_timeout)\ndef update_right_date_tab3_map(date):\n if date is not None:\n assets_dir = get_assets_dir(date)\n mapfig = create_map(\"assets/figures/\" + assets_dir + \"/map.csv\", 'newInf100k_RKI') \n else:\n mapfig = create_map(\"assets/placeholders/map_empty.csv\", 'newInf100k')\n return mapfig",
"_____no_output_____"
],
[
"#####################\n# County-Tabs (left)\n#####################\nleft_pos_tab1_modal = html.Div(\n [\n dbc.Button(\"Vergrößern\", id=\"left_pos_tab1_modal_open\", outline=True, color=\"secondary\", className=\"mr-1\"),\n dbc.Modal(\n id=\"left_pos_tab1_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"geglättet\"),\n dbc.ModalBody(\n children=[\n html.Img(\n id=\"left_pos_modal1_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/curve_{0:05d}.png\".format(init_countyid),\n style={'width':'100%', 'height':'100%'},\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"left_pos_tab1_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n) \nleft_pos_tab1 = dbc.Card(\n outline=True,\n color=\"light\",\n className=\"mt-3\",\n children=[ dbc.CardBody(\n children=[\n html.Div(\n id=\"left_pos_tab1_img_div\",\n children=[\n left_pos_tab1_modal,\n dcc.Loading(\n id = \"left_pos_tab1_loading_img\", \n children=[html.Div(children=[\n html.Img(\n id=\"left_pos_tab1_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/curve_{0:05d}.png\".format(init_countyid),\n style={'width':'100%', 'height':'100%'},\n ),\n ])],\n type=\"circle\", # 'graph', 'cube', 'circle', 'dot', 'default'\n color=\"#343A40\",\n style={'hight':'340px'},\n ), \n html.Div(\n dcc.Markdown(\n id=\"left_pos_tab1_txt\",\n children=[\"\"],\n )\n ),\n dbc.Tooltip(\n \"Analyse und Vorhersage der Infektionszahlen für den ausgewählten Landkreis. \"\n \"Der Nowcast entspricht der Schätzung der realen aktuellen Neuinfektionen für den angegebenden Tag. \"\n \"Diese Schätzung korrigiert die gemeldeten Zahlen, die aufgrund von Verzögerungen im Meldeprozess \"\n \"und einem unbekannten Erkrankungsdatum kleiner als die tatsächlichen Zahlen sein können, auf der Basis einer Vorhersage. \"\n \"Die Vorhersage nutzt das gleiche Modell um den Verlauf der kommenden 5 Tage, für die noch keine Zahlen vorliegen, vorherzusagen. \"\n \"Das geglättete Model korrigiert die Ergebnisse bezüglich eines Wochenrhythmusses bei den Meldeverzögerungen (siehe Erklärvideo). \",\n target=\"left_pos_tab1_img\",\n style={\"width\": \"600px\"},\n placement=\"left\",\n ),\n ]),\n ]),\n ])\[email protected](\n Output(\"left_pos_tab1_modal\", \"is_open\"),\n [Input(\"left_pos_tab1_img_div\", \"n_clicks\"), Input(\"left_pos_tab1_modal_open\", \"n_clicks\"), Input(\"left_pos_tab1_modal_close\", \"n_clicks\")],\n [State(\"left_pos_tab1_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, n3, is_open):\n if n1 or n2 or n3:\n return not is_open\n return is_open\n\n#####################\n\nleft_pos_tab2_modal = html.Div(\n [\n dbc.Button(\"Vergrößern\", id=\"left_pos_tab2_modal_open\", outline=True, color=\"secondary\", className=\"mr-1\"),\n dbc.Modal(\n id=\"left_pos_tab2_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"ungeglättet\"),\n dbc.ModalBody(\n children=[\n html.Img(\n id=\"left_pos_modal2_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/curve_trend_{0:05d}.png\".format(init_countyid),\n style={'width':'100%', 'height':'100%'},\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"left_pos_tab2_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n)\nleft_pos_tab2 = dbc.Card(\n outline=True,\n color=\"light\",\n className=\"mt-3\",\n children=[ dbc.CardBody(\n children=[\n html.Div(\n id=\"left_pos_tab2_img_div\",\n children=[\n left_pos_tab2_modal,\n dcc.Loading(\n id = \"left_pos_tab2_loading_img\", \n children=[html.Div(children=[\n html.Img(\n id=\"left_pos_tab2_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/curve_trend_{0:05d}.png\".format(init_countyid),\n style={'width':'100%', 'height':'100%'},\n ),\n ])],\n type=\"circle\", # 'graph', 'cube', 'circle', 'dot', 'default'\n color=\"#343A40\",\n style={'hight':'340px'},\n ), \n html.Div(\n dcc.Markdown(\n id=\"left_pos_tab2_txt\",\n children=[\"\"],\n )\n ),\n dbc.Tooltip(\n \"Analyse und Vorhersage der Infektionszahlen für den ausgewählten Landkreis. \"\n \"Der Nowcast entspricht der Schätzung der realen aktuellen Neuinfektionen für den angegebenden Tag. \"\n \"Diese Schätzung korrigiert die gemeldeten Zahlen, die aufgrund von Verzögerungen im Meldeprozess \"\n \"und einem unbekannten Erkrankungsdatum kleiner als die tatsächlichen Zahlen sein können, auf der Basis einer Vorhersage. \"\n \"Die Vorhersage nutzt das gleiche Modell um den Verlauf der kommenden 5 Tage, für die noch keine Zahlen vorliegen, vorherzusagen. \"\n \"Das geglättete Model korrigiert die Ergebnisse bezüglich eines Wochenrhythmusses bei den Meldeverzögerungen (siehe Erklärvideo). \",\n target=\"left_pos_tab2_img\",\n style={\"width\": \"200%\"},\n placement=\"left\",\n ),\n ]),\n ]),\n ])\[email protected](\n Output(\"left_pos_tab2_modal\", \"is_open\"),\n [Input(\"left_pos_tab2_img_div\", \"n_clicks\"), Input(\"left_pos_tab2_modal_open\", \"n_clicks\"), Input(\"left_pos_tab2_modal_close\", \"n_clicks\")],\n [State(\"left_pos_tab2_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, n3, is_open):\n if n1 or n2 or n3:\n return not is_open\n return is_open",
"_____no_output_____"
],
[
"#####################\n# County Picker (left)\n#####################\nleft_pos_controls = dbc.FormGroup(\n children=[\n dbc.Label(\n id='left_pos-label',\n children=[\"Wähle Landkreis:\"],\n ),\n html.Div(\n children=[\n dcc.Dropdown(\n id=\"left_pos-variable\",\n value=init_countyid,\n options=[\n {\"label\": row['LKName'] + \" (\" + row['LKType'] + \")\", \"value\": row['countyID']} for index, row in metadata.iterrows()\n ]),\n #html.Div(id='left_output-container-pos-variable', style={'display': 'none'}),\n ]), \n ])\n\n# County Picker\n#@app.callback(\n# Output(component_id='left_output-container-pos-variable', component_property='children'),\n# [Input(component_id='left_pos-variable', component_property='value'),\n# Input(component_id='left_output-container-date-picker', component_property='children')])\n#def update_left_pos_variable(value, assets_dir):\n# if value is not None:\n# return asset_url + \"figures/\" + assets_dir + \"curve_trend_{0:05d}.png\".format(value)\n\n# change dropbox on map-click\[email protected](\n Output(component_id='left_pos-variable', component_property='value'),\n # Output(component_id='left_date_tab1_txt', component_property='children')],\n [Input(component_id='left_date_tab1_graph', component_property='clickData'),\n Input(component_id='left_date_tab3_graph', component_property='clickData')]\n)\ndef update_left_date_mapclick(choro1_click, choro3_click):\n ctx = dash.callback_context\n if not ctx.triggered:\n id_str = init_countyid\n else:\n cid = ctx.triggered[0]['value']['points'][0]['location']\n id_str = counties_metadf['cca'][cid]\n #print(\"update_right_date1_mapclick - cid={}, id_str={}\".format(cid,id_str))\n return int(id_str) #, id_str\n\n# geglättet\[email protected](\n [Output(component_id='left_pos_tab1_img', component_property='src'),\n Output(component_id='left_pos_modal1_img', component_property='src')],\n [Input(component_id='left_pos-variable', component_property='value'),\n Input(component_id='left_output-container-date-picker', component_property='children')])\ndef update_left_pos_tab1_img(value, assets_dir):\n imgUrl=\"\"\n if value is not None:\n imgUrl = \"figures/\" + assets_dir + \"curve_trend_{0:05d}.png\".format(value)\n if not os.path.isfile(\"assets/\" + imgUrl): \n imgUrl = \"placeholders/plot_not_found.png\"\n imgUrl = asset_url + imgUrl\n return imgUrl, imgUrl\n\n# ungeglättet\[email protected](\n [Output(component_id='left_pos_tab2_img', component_property='src'),\n Output(component_id='left_pos_modal2_img', component_property='src')],\n [Input(component_id='left_pos-variable', component_property='value'),\n Input(component_id='left_output-container-date-picker', component_property='children')])\ndef update_left_pos_tab2_img(value, assets_dir):\n imgUrl=\"\"\n if value is not None:\n imgUrl = \"figures/\" + assets_dir + \"curve_{0:05d}.png\".format(value)\n if not os.path.isfile(\"assets/\" + imgUrl): \n imgUrl = \"placeholders/plot_not_found.png\"\n imgUrl = asset_url + imgUrl\n return imgUrl, imgUrl\n\n# print meta-information\[email protected](\n [Output(component_id='left_pos_tab1_txt', component_property='children'),\n Output(component_id='left_pos_tab2_txt', component_property='children')], \n [Input(component_id='left_pos-variable', component_property='value'),\n Input(component_id='left_output-container-date-picker', component_property='children')])\ndef update_left_pos_txt(value, assets_dir):\n msg = \" \"\n if value is not None:\n try:\n mdat = pd.read_csv(\"./assets/figures/\" + assets_dir + \"/metadata.csv\")\n msg = mdat.loc[mdat['countyID'] == value]['probText'].to_string(index=False)\n try:\n val = float(msg)\n absVal = abs(val)\n if val<0.0:\n if 95.0 < absVal <= 100.0:\n msg = 'Es gibt eine deutliche Tendenz von **fallenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **95%**.'\n elif 75.0 < absVal <= 95.0:\n msg = 'Es gibt eine Tendenz von **fallenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **75%**.'\n elif 50.0 < absVal <= 75.0:\n msg = 'Es gibt eine Tendenz von **fallenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **50%**.'\n else:\n msg = 'Die Infektioneszahlen werden mit einer Wahrscheinlichkeit von **{:.1f}%** fallen.'.format(absVal)\n else:\n if 95.0 < absVal <= 100.0:\n msg = 'Es gibt eine deutliche Tendenz von **steigenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **95%**.'\n elif 75.0 < absVal <= 95.0:\n msg = 'Es gibt eine Tendenz von **steigenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **75%**.'\n elif 50.0 < absVal <= 75.0:\n msg = 'Es gibt eine Tendenz von **steigenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **50%**.'\n else:\n msg = 'Die Infektioneszahlen werden mit einer Wahrscheinlichkeit von **{:.1f}%** fallen.'.format(absVal)\n except:\n print(\"Exception in update_right_pos_txt\")\n pass\n except:\n pass\n return msg, msg",
"_____no_output_____"
],
[
"#####################\n# County-Tabs (right)\n#####################\nright_pos_tab1_modal = html.Div(\n [\n dbc.Button(\"Vergrößern\", id=\"right_pos_tab1_modal_open\", outline=True, color=\"secondary\", className=\"mr-1\"),\n dbc.Modal(\n id=\"right_pos_tab1_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"geglättet\"),\n dbc.ModalBody(\n children=[\n html.Img(\n id=\"right_pos_modal1_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/curve_{0:05d}.png\".format(init_countyid),\n style={'width':'100%', 'height':'100%'},\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"right_pos_tab1_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n) \nright_pos_tab1 = dbc.Card(\n outline=True,\n color=\"light\",\n className=\"mt-3\",\n children=[ dbc.CardBody(\n children=[\n html.Div(\n id=\"right_pos_tab1_img_div\",\n children=[\n right_pos_tab1_modal,\n dcc.Loading(\n id = \"right_pos_tab1_loading_img\", \n children=[html.Div(children=[\n html.Img(\n id=\"right_pos_tab1_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/curve_{0:05d}.png\".format(init_countyid),\n style={'width':'100%', 'height':'100%'},\n ),\n ])],\n type=\"circle\", # 'graph', 'cube', 'circle', 'dot', 'default'\n color=\"#343A40\",\n style={'hight':'340px'},\n ), \n html.Div(\n dcc.Markdown(\n id=\"right_pos_tab1_txt\",\n children=[\"\"],\n )\n ),\n dbc.Tooltip(\n \"Analyse und Vorhersage der Infektionszahlen für den ausgewählten Landkreis. \"\n \"Der Nowcast entspricht der Schätzung der realen aktuellen Neuinfektionen für den angegebenden Tag. \"\n \"Diese Schätzung korrigiert die gemeldeten Zahlen, die aufgrund von Verzögerungen im Meldeprozess \"\n \"und einem unbekannten Erkrankungsdatum kleiner als die tatsächlichen Zahlen sein können, auf der Basis einer Vorhersage. \"\n \"Die Vorhersage nutzt das gleiche Modell um den Verlauf der kommenden 5 Tage, für die noch keine Zahlen vorliegen, vorherzusagen. \"\n \"Das geglättete Model korrigiert die Ergebnisse bezüglich eines Wochenrhythmusses bei den Meldeverzögerungen (siehe Erklärvideo). \",\n target=\"right_pos_tab1_img\",\n style={\"width\": \"200%\"},\n placement=\"right\",\n ),\n ]),\n ]),\n ])\[email protected](\n Output(\"right_pos_tab1_modal\", \"is_open\"),\n [Input(\"right_pos_tab1_img_div\", \"n_clicks\"), Input(\"right_pos_tab1_modal_open\", \"n_clicks\"), Input(\"right_pos_tab1_modal_close\", \"n_clicks\")],\n [State(\"right_pos_tab1_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, n3, is_open):\n if n1 or n2 or n3:\n return not is_open\n return is_open\n\n#####################\n\nright_pos_tab2_modal = html.Div(\n [\n dbc.Button(\"Vergrößern\", id=\"right_pos_tab2_modal_open\", outline=True, color=\"secondary\", className=\"mr-1\"),\n dbc.Modal(\n id=\"right_pos_tab2_modal\",\n size=\"xl\",\n children=[\n dbc.ModalHeader(\"ungeglättet\"),\n dbc.ModalBody(\n children=[\n html.Img(\n id=\"right_pos_modal2_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/curve_trend_{0:05d}.png\".format(init_countyid),\n style={'width':'100%', 'height':'100%'},\n ),\n ]\n ),\n dbc.ModalFooter(\n dbc.Button(\"Schließen\", id=\"right_pos_tab2_modal_close\", className=\"ml-auto\")\n ),\n ],\n ),\n ]\n)\nright_pos_tab2 = dbc.Card(\n outline=True,\n color=\"light\",\n className=\"mt-3\",\n children=[ dbc.CardBody(\n children=[\n html.Div(\n id=\"right_pos_tab2_img_div\",\n children=[\n right_pos_tab2_modal,\n dcc.Loading(\n id = \"right_pos_tab2_loading_img\", \n children=[html.Div(children=[\n html.Img(\n id=\"right_pos_tab2_img\",\n src=asset_url + \"figures/\" + init_date.strftime('%Y_%m_%d') + \"/curve_trend_{0:05d}.png\".format(init_countyid),\n style={'width':'100%', 'height':'100%'},\n ),\n ])],\n type=\"circle\", # 'graph', 'cube', 'circle', 'dot', 'default'\n color=\"#343A40\",\n style={'hight':'340px'},\n ), \n html.Div(\n dcc.Markdown(\n id=\"right_pos_tab2_txt\",\n children=[\"\"],\n )\n ),\n dbc.Tooltip(\n \"Analyse und Vorhersage der Infektionszahlen für den ausgewählten Landkreis. \"\n \"Der Nowcast entspricht der Schätzung der realen aktuellen Neuinfektionen für den angegebenden Tag. \"\n \"Diese Schätzung korrigiert die gemeldeten Zahlen, die aufgrund von Verzögerungen im Meldeprozess \"\n \"und einem unbekannten Erkrankungsdatum kleiner als die tatsächlichen Zahlen sein können, auf der Basis einer Vorhersage. \"\n \"Die Vorhersage nutzt das gleiche Modell um den Verlauf der kommenden 5 Tage, für die noch keine Zahlen vorliegen, vorherzusagen. \"\n \"Das geglättete Model korrigiert die Ergebnisse bezüglich eines Wochenrhythmusses bei den Meldeverzögerungen (siehe Erklärvideo). \",\n target=\"right_pos_tab2_img\",\n style={\"width\": \"200%\"},\n placement=\"right\",\n ),\n ]),\n ]),\n ])\[email protected](\n Output(\"right_pos_tab2_modal\", \"is_open\"),\n [Input(\"right_pos_tab2_img\", \"n_clicks\"), Input(\"right_pos_tab2_modal_open\", \"n_clicks\"), Input(\"right_pos_tab2_modal_close\", \"n_clicks\")],\n [State(\"right_pos_tab2_modal\", \"is_open\")],\n)\ndef toggle_modal(n1, n2, n3, is_open):\n if n1 or n2 or n3:\n return not is_open\n return is_open",
"_____no_output_____"
],
[
"#####################\n# County Picker (right)\n#####################\nright_pos_controls = dbc.FormGroup(\n children=[\n dbc.Label(\n id='right_pos-label',\n children=[\"Wähle Landkreis:\"],\n ),\n html.Div(\n children=[\n dcc.Dropdown(\n id=\"right_pos-variable\",\n value=init_countyid,\n options=[\n {\"label\": row['LKName'] + \" (\" + row['LKType'] + \")\", \"value\": row['countyID']} for index, row in metadata.iterrows()\n ]),\n #html.Div(id='right_output-container-pos-variable', style={'display': 'none'}),\n ]), \n ])\n\n# County Picker\n#@app.callback(\n# Output(component_id='right_output-container-pos-variable', component_property='children'),\n# [Input(component_id='right_pos-variable', component_property='value'),\n# Input(component_id='right_output-container-date-picker', component_property='children')])\n#def update_right_pos_variable(value, assets_dir):\n# if value is not None:\n# return asset_url + \"figures/\" + assets_dir + \"curve_trend_{0:05d}.png\".format(value)\n\n# change dropbox on map-click\[email protected](\n Output(component_id='right_pos-variable', component_property='value'),\n # Output(component_id='right_date_tab1_txt', component_property='children')],\n [Input(component_id='right_date_tab1_graph', component_property='clickData'),\n Input(component_id='right_date_tab3_graph', component_property='clickData')]\n)\ndef update_right_date_mapclick(choro1_click, choro3_click):\n ctx = dash.callback_context\n if not ctx.triggered:\n id_str = init_countyid\n else:\n cid = ctx.triggered[0]['value']['points'][0]['location']\n id_str = counties_metadf['cca'][cid]\n #print(\"update_right_date1_mapclick - cid={}, id_str={}\".format(cid,id_str))\n return int(id_str) #, id_str\n\n# geglättet\[email protected](\n [Output(component_id='right_pos_tab1_img', component_property='src'),\n Output(component_id='right_pos_modal1_img', component_property='src')],\n [Input(component_id='right_pos-variable', component_property='value'),\n Input(component_id='right_output-container-date-picker', component_property='children')])\ndef update_right_pos_tab1_img(value, assets_dir):\n imgUrl=\"\"\n if value is not None:\n imgUrl = \"figures/\" + assets_dir + \"curve_trend_{0:05d}.png\".format(value)\n if not os.path.isfile(\"assets/\" + imgUrl): \n imgUrl = \"placeholders/plot_not_found.png\"\n imgUrl = asset_url + imgUrl\n return imgUrl, imgUrl\n \n# ungeglättet\[email protected](\n [Output(component_id='right_pos_tab2_img', component_property='src'),\n Output(component_id='right_pos_modal2_img', component_property='src')],\n [Input(component_id='right_pos-variable', component_property='value'),\n Input(component_id='right_output-container-date-picker', component_property='children')])\ndef update_right_pos_tab2_img(value, assets_dir):\n imgUrl=\"\"\n if value is not None:\n imgUrl = \"figures/\" + assets_dir + \"curve_{0:05d}.png\".format(value)\n if not os.path.isfile(\"assets/\" + imgUrl): \n imgUrl = \"placeholders/plot_not_found.png\"\n imgUrl = asset_url + imgUrl\n return imgUrl, imgUrl\n\n# print meta-information\[email protected](\n [Output(component_id='right_pos_tab1_txt', component_property='children'),\n Output(component_id='right_pos_tab2_txt', component_property='children')], \n [Input(component_id='right_pos-variable', component_property='value'),\n Input(component_id='right_output-container-date-picker', component_property='children')])\ndef update_right_pos_txt(value, assets_dir):\n msg = \" \"\n if value is not None:\n try:\n mdat = pd.read_csv(\"./assets/figures/\" + assets_dir + \"/metadata.csv\")\n msg = mdat.loc[mdat['countyID'] == value]['probText'].to_string(index=False)\n try:\n val = float(msg)\n absVal = abs(val)\n if val<0.0:\n if 95.0 < absVal <= 100.0:\n msg = 'Es gibt eine deutliche Tendenz von **fallenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **95%**.'\n elif 75.0 < absVal <= 95.0:\n msg = 'Es gibt eine Tendenz von **fallenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **75%**.'\n elif 50.0 < absVal <= 75.0:\n msg = 'Es gibt eine Tendenz von **fallenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **50%**.'\n else:\n msg = 'Die Infektioneszahlen werden mit einer Wahrscheinlichkeit von **{:.1f}%** fallen.'.format(absVal)\n else:\n if 95.0 < absVal <= 100.0:\n msg = 'Es gibt eine deutliche Tendenz von **steigenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **95%**.'\n elif 75.0 < absVal <= 95.0:\n msg = 'Es gibt eine Tendenz von **steigenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **75%**.'\n elif 50.0 < absVal <= 75.0:\n msg = 'Es gibt eine Tendenz von **steigenden** Infektionszahlen mit einer Wahrscheinlichkeit von grösser **50%**.'\n else:\n msg = 'Die Infektioneszahlen werden mit einer Wahrscheinlichkeit von **{:.1f}%** fallen.'.format(absVal)\n except:\n print(\"Exception in update_right_pos_txt\")\n pass\n except:\n pass\n return msg, msg",
"_____no_output_____"
]
],
[
[
"#### Define the main body of the webpage \nhttps://dash-bootstrap-components.opensource.faculty.ai/docs/components/layout/ \nLayout in Bootstrap is controlled using the grid system.\nThe Bootstrap grid has **twelve** columns, and **five** responsive tiers (allowing you to specify different behaviours on different screen sizes, see below).",
"_____no_output_____"
]
],
[
[
"#####################\n# Main Structure\n#####################\ntab_height = '5vh'\nbody_layout = dbc.Container(\n style={\"marginTop\": 100, \"marginBottom\": 20},\n #fluid=True,\n children=[\n \n #####################\n # Introduction\n #####################\n \n dbc.Row(\n children=[\n dbc.Col(\n style={\n \"marginBottom\": 10,\n \"width\": 12,\n }, \n children=[\n dcc.Markdown(\n f\"\"\"\n ##### **Ein Gemeinschaftsprojekt der Arbeitsgruppe [Neuroinformatik an der Universität Osnabrück](https://www.ikw.uni-osnabrueck.de/en/research_groups/neuroinformatics)** \n ##### **und des [Jülich Supercomputing Centre](https://www.fz-juelich.de/jsc), auf Basis der Daten des [RKI](https://www.rki.de/DE/Content/Infekt/IfSG/Signale/Projekte/Signale_Projekte_node.html;jsessionid=C61DE534E8208B0D69BEAD299FC753F9.internet091)**\n \"\"\"\n ),\n ]), \n ]),\n dbc.Row(\n children=[\n dbc.Col(\n width=4,\n children=[\n html.A([\n html.Img(\n src=asset_url + 'uniosnab-logo.png',\n height='48', # width='500',\n style={\n 'display':'block',\n 'margin-left': 'auto',\n 'margin-right': 'auto'\n },\n ),\n ], href='https://www.ikw.uni-osnabrueck.de/en/research_groups/neuroinformatics'),\n ]),\n dbc.Col(\n width=4,\n children=[\n # html.A([\n # html.Img(\n # src=asset_url + 'rki-logo.png', #'https://www.rki.de/SiteGlobals/StyleBundles/Bilder/Farbschema_A/logo_a.jpg?__blob=normal&v=7',\n # height='48', # width='500',\n # style={\n # 'display':'block',\n # 'margin-left': 'auto',\n # 'margin-right': 'auto'\n # },\n # ),\n # ], href='https://www.rki.de'),\n ]), \n dbc.Col(\n width=4,\n children=[\n html.A([ \n html.Img(\n src=asset_url + 'jsc-logo.png',\n height='48', # width='500',\n style={\n 'display':'block',\n 'margin-left': 'auto',\n 'margin-right': 'auto'\n },\n ),\n ], href='https://www.fz-juelich.de/jsc'),\n ]),\n ]),\n dbc.Row(\n children=[\n dbc.Col(\n style={\n \"marginTop\": 30,\n \"width\": 6,\n },\n children=[\n disclaimer_modal,\n ]),\n dbc.Col(\n style={\n \"marginTop\": 30,\n \"width\": 6,\n },\n children=[\n dcc.Markdown(\n f\"\"\"\n -----\n ##### Wie funktioniert die Vorhersage und Analyse\n -----\n \"\"\"\n ),\n html.Div(\n style={\n 'width': '100%',\n 'float': 'left',\n 'margin': '0% 0% 5% 0%' # top, right, bottom, left\n },\n children=[\n dash_player.DashPlayer(\n id='video-player',\n url='https://youtu.be/0jvH3nkjR9I',\n controls=True,\n width='100%'\n ),\n dcc.Markdown(\n f\"\"\"\n Das Video ist unter folgendem Link auch unter YouTube verfügbar: \n [\"BSTIM Covid-19 Model zur Analyse der Ausbreitung der Infektion\"](https://youtu.be/0jvH3nkjR9I)\n \"\"\",\n style={\n 'margin': '5% 0% 0% 0%' # top, right, bottom, left\n },\n ), \n ]), \n ]),\n ]),\n \n #####################\n # Plots Section\n ##################### \n \n dbc.Row(\n children=[\n dbc.Col(\n dbc.Alert(\"Basisauswahl\", color=\"primary\")\n ),\n dbc.Col(\n dbc.Alert(\"Vergleichsauswahl\", color=\"primary\")\n ),\n ]\n ),\n\n ikernel_inter1_modal,\n ikernel_inter2_modal,\n ikernel_inter3_modal,\n \n dbc.Row(\n children=[\n \n ##### left plots\n dbc.Col(\n children=[\n dbc.Card(\n style={\n 'margin': '0% 0% 0% 0%', # top, right, bottom, left\n 'padding': '0',\n },\n body=True, \n children=[\n \n # --- Zeitangabe (left) ---\n dbc.CardHeader(\n left_date_controls,\n ),\n dbc.CardBody(\n className=\"mt-3\",\n children=[\n dbc.Tabs(\n id=\"left_date-card-tabs\",\n active_tab=\"tab-0\", \n children=[\n dbc.Tab(left_date_tab3, label=\"Meldedaten RKI\", style={'padding': '0', 'height': '450px'}),\n dbc.Tab(left_date_tab1, label=\"Nowcast BSTIM\", style={'padding': '0', 'height': '450px'}),\n dbc.Tab(left_date_tab2, label=\"Interaktionskernel\", style={'padding': '0', 'height': '450px'}), \n ]),\n \n html.P(\n id=\"left_pos-card-separator\",\n className=\"card-text\",\n ),\n \n # --- Ortsangabe (left) ---\n dbc.Card(\n style={\n 'margin': '0% 0% 0% 0%', # top, right, bottom, leftleft\n 'padding': '0',\n }, \n children=[\n dbc.CardHeader(\n left_pos_controls,\n ),\n dbc.CardBody(\n className=\"mt-3\",\n children=[\n dbc.Tabs(\n id=\"left_pos-card-tabs\",\n active_tab=\"tab-0\", \n children=[\n dbc.Tab(left_pos_tab1, label=\"geglättet\", style={'padding': '0', 'height': '340px'}),\n dbc.Tab(left_pos_tab2, label=\"ungeglättet\", style={'padding': '0', 'height': '340px'}),\n ]),\n\n html.P(\n id=\"left_pos-card-content\",\n className=\"card-text\",\n ),\n ]),\n ]), \n ]),\n ]),\n ]),\n\n ##### right plots\n dbc.Col(\n children=[\n dbc.Card(\n style={\n 'margin': '0% 0% 0% 0%', # top, right, bottom, left\n 'padding': '0',\n },\n body=True, \n children=[\n \n # --- Zeitangabe (left) ---\n dbc.CardHeader(\n right_date_controls,\n ),\n dbc.CardBody(\n className=\"mt-3\",\n children=[\n dbc.Tabs(\n id=\"right_date-card-tabs\",\n active_tab=\"tab-0\",\n children=[\n dbc.Tab(right_date_tab3, label=\"Meldedaten RKI\", style={'padding': '0', 'height': '450px'}),\n dbc.Tab(right_date_tab1, label=\"Nowcast BSTIM\", style={'padding': '0', 'height': '450px'}),\n dbc.Tab(right_date_tab2, label=\"Interaktionskernel\", style={'padding': '0', 'height': '450px'}),\n ]),\n \n html.P(\n id=\"right_pos-card-separator\",\n className=\"card-text\",\n ),\n html.P(id='right_pos-card-hidden', style={'display':'none'}, children=[\"init\"]),\n \n # --- Ortsangabe (left) ---\n dbc.Card(\n style={\n 'margin': '0% 0% 0% 0%', # top, right, bottom, left\n 'padding': '0',\n }, \n children=[\n dbc.CardHeader(\n right_pos_controls,\n ),\n dbc.CardBody(\n className=\"mt-3\",\n children=[\n dbc.Tabs(\n id=\"right_pos-card-tabs\",\n active_tab=\"tab-0\", \n children=[\n dbc.Tab(right_pos_tab1, label=\"geglättet\", style={'padding': '0', 'height': '340px'}),\n dbc.Tab(right_pos_tab2, label=\"ungeglättet\", style={'padding': '0', 'height': '340px'}),\n ]),\n\n html.P(\n id=\"right_pos-card-content\",\n className=\"card-text\",\n ),\n ]),\n ]), \n ]),\n ]),\n ]),\n ]),\n ])\n\n# Note that if the container itself is resizable, the graph will not be replotted/resized.\n# There isn’t a reliable way to tell if a graph’s container has changed size in JavaScript yet, so we’re just checking if the window is resized.\n# We have to call a synthetic resize event to ensure, the graph is informed.\n# Solution found here: https://community.plotly.com/t/update-div-size-with-graph-in-it/22671\napp.clientside_callback(\n \"\"\"\n function syntheticResize() {\n var evt = window.document.createEvent('UIEvents');\n evt.initUIEvent('resize', true, false, window, 0);\n window.dispatchEvent(evt);\n return \"updated\";\n }\n \"\"\",\n Output('right_pos-card-hidden', 'children'),\n [Input('left_date-card-tabs', 'active_tab'),\n Input('right_date-card-tabs', 'active_tab')]\n)",
"_____no_output_____"
],
[
"#####################\n# Fragen & Anworten Structure\n#####################\nfaq_body_layout = dbc.Container(\n style={\"marginTop\": 100, \"marginBottom\": 20},\n #fluid=True,\n children=[\n \n #####################\n # Introduction\n #####################\n \n dbc.Row(\n children=[\n dbc.Col(\n style={\n \"marginBottom\": 10,\n \"width\": 12,\n }, \n children=[\n dcc.Markdown(\n f\"\"\"\n ##### **Ein Gemeinschaftsprojekt der Arbeitsgruppe [Neuroinformatik an der Universität Osnabrück](https://www.ikw.uni-osnabrueck.de/en/research_groups/neuroinformatics)** \n ##### **und des [Jülich Supercomputing Centre](https://www.fz-juelich.de/jsc), auf Basis der Daten des [RKI](https://www.rki.de/DE/Content/Infekt/IfSG/Signale/Projekte/Signale_Projekte_node.html;jsessionid=C61DE534E8208B0D69BEAD299FC753F9.internet091)**\n \"\"\"\n ),\n ]), \n ]),\n dbc.Row(\n children=[\n dbc.Col(\n width=4,\n children=[\n html.Img(\n src=asset_url + 'uniosnab-logo.png',\n height='48', # width='500',\n style={\n 'display':'block',\n 'margin-left': 'auto',\n 'margin-right': 'auto'\n },\n ),\n ]),\n dbc.Col(\n width=4,\n children=[\n # html.Img(\n # src=asset_url + 'rki-logo.png', #'https://www.rki.de/SiteGlobals/StyleBundles/Bilder/Farbschema_A/logo_a.jpg?__blob=normal&v=7',\n # height='48', # width='500',\n # style={\n # 'display':'block',\n # 'margin-left': 'auto',\n # 'margin-right': 'auto'\n # },\n # ),\n ]), \n dbc.Col(\n width=4,\n children=[\n html.Img(\n src=asset_url + 'jsc-logo.png',\n height='48', # width='500',\n style={\n 'display':'block',\n 'margin-left': 'auto',\n 'margin-right': 'auto'\n },\n ),\n ]),\n ]),\n dbc.Row(\n style={ \"marginTop\": 30 },\n children=[\n dcc.Markdown(\n f\"\"\"\n ------------------------\n ### Fragen & Antworten\n ##### Bayessches räumlich-zeitliches Interaktionsmodell für Covid-19 \n ------------------------\n\n #### Was ist ein Nowcast?\n Aufgrund von verschiedenen Verzögerungen in der Erfassung von Infektionen entsprechen die aktuellen Meldezahlen nicht den tatsächlichen des heutigen Tages.\n Das Nowcasting schätzt wie viele Fälle noch nicht berücksichtigt wurden und korrigiert Zahlen so, dass sie möglichst nah an den echten Zahlen sind.\n Für weitere Informationen siehe das [FAQ des Robert Koch-Instituts](https://www.rki.de/SharedDocs/FAQ/NCOV2019/gesamt.html) und den [Erklärfilm](https://youtu.be/8-AfYeosBW8) .\n\n ------------------------\n\n #### Woher kommen die Daten?\n Die Zahlen der Positiv-Tests beziehen wir vom offiziellen [Dashboard des RKIs](https://experience.arcgis.com/experience/478220a4c454480e823b17327b2bf1d4), bzw. dem dahinterliegenden ArcGIS-System.\n Eine Zusammenfassung dieser Zahlen wird auch im [Wochenbericht des RKI](https://ars.rki.de/Content/COVID19/Main.aspx) veröffentlicht. \n\n ------------------------\n\n #### Worin unterscheidet sich diese Analyse von anderen Vorhersagen?\n Dieses Modell modelliert nicht nur den wahrscheinlichsten Verlauf, sondern zeigt eine Vielzahl von mit den Daten kompatiblen Verläufen und berechnet deren Wahrscheinlichkeit (Bayesian Analyse, siehe auch [Konfidenzintervall](https://de.wikipedia.org/wiki/Konfidenzintervall)).\n Dies erlaubt es die Wahrscheinlichkeit für eine Zu- oder Abnahme zu bestimmen, und zudem auch seltene aber eventuell extreme Vorhersagen in die Bewertung einfließen zu lassen.\n\n ------------------------\n\n #### Was ist ein Konfidenzintervall?\n Ein Konfidenzintervall gibt an wie groß der Bereich der Modell-Entwicklung ist, der mit einer bestimmten Wahrscheinlichkeit vorhergesagt wird.\n In unserem Fall haben wir für die Vorhersage zwei Konfidenzintervalle genutzt, die wie folgt interpretiert werden können. \n - 25%-75% Quantil: Dieses dunkelgrüne/-orange Intervall beinhaltet 50% der Vorhersagen.\n Das heißt man kann erwarten, dass für eine Vorhersage die echten zukünftigen Daten mit einer Wahrscheinlichkeit von 50% in dem dunkelgrünen/-orangen Intervall liegen. \n - 5%-95% Quantil: Dieses hellgrüne/-orange Intervall beinhaltet 90% der Vorhersagen.\n Das heißt man kann erwarten, dass für eine Vorhersage die echten zukünftigen Daten mit einer Wahrscheinlichkeit von 90 % in dem hellgrünen/-orangen Intervall liegen. \n\n ------------------------\n\n #### Was ist der Interaktionskernel?\n Der Interaktionskernel schätzt ab um wie stark eine gemeldete Infektion eine Neuansteckung in den nächsten Tagen in einem Umkreis von bis zu 50km beeinflusst.\n Diese Interaktion ist ein zusätzlicher Faktor der den Trend in einem Landkreis verstärkt oder abschwächt.\n Eine warme Farbe indiziert, dass eine Covid-19 Meldung eine erhöhte Wahrscheinlichkeit einer Neuinfektion im Verhältnis zum Trend zur Folge hat.\n Eine starke Farben in der Nähe kleiner Radien bedeutet, dass das Infektionsgeschehen vor allem Auswirkungen in der direkten Nähe der gemeldeten Fälle zur Folge hat.\n Die Interaktion basiert auf einer Schätzung der Bevölkerungsdichte und der Form der Landkreise.\n Daten zu den Wohnorten der Infizierten werden in dem Model nicht genutzt.\n Alle hier genutzten Daten sind vollständig anonymisiert (siehe Erklärvideo).\n Bei der Interpretation der Interaktionskernel ist dies zu berücksichtigen, und wir weisen darauf hin, dass dies nur eine Schätzung ist die von der Realität abweichen kann.\n\n ------------------------\n\n #### Nach welchen Regeln werden die Farben des Interaktionskernels gewählt?\n Die Farben des Interaktionskernel geben die Stärke des lokalen und zeitlichen Einflusses der Umgebung an.\n Die Farben wurden so gewählt, dass starke Farben den größten Effekten seit dem Beginn der Analyse entsprechen.\n Schwache Farben indizieren, dass der Effekt deutlich kleiner ist. \n\n ------------------------\n\n #### Welche Schwächen hat die Methode?\n Alle hier präsentierten Ergebnisse basieren auf statistischen Methoden und bilden damit nicht das tatsächliche Geschehen ab, sondern Schätzungen, die von der wirklichen Situation abweichen können.\n Dies ist bei der Interpretation der Ergebnisse zu berücksichtigen.\n Die hier präsentierten Forschungsergebnisse basieren auf einer neuen Methodik, die bisher nicht für COVID-19 sondern für Campylobacteriosis-, Rotavirus- und Borreliose-Infektionen eingesetzt wurde (siehe Veröffentlichung).\n Die Validierung der Ergebnisse für COVID-19 wird mit der wachsenden Menge an Daten in den kommenden Monaten fortgeführt. \n\n ------------------------\n\n #### Was ist das geglättete und ungeglättete Modell?\n Die Daten des RKI zeigen eine Modulation im Wochenrhythmus, mit einer typischerweise niedrigeren Rate an Neuinfektionen am Wochenende.\n Die Modulation lässt sich durch systematische Verzögerungen im Meldeprozess erklären.\n Um die wirklichen Fallzahlen zu schätzen, nutzen wir ein Modell, welches diese Modulation im Wochenrhythmus korrigiert.\n Diese korrigierte Version entspricht den geglätteten Daten und dem wahrscheinlichsten wirklichen Infektionsgeschehen. \n Um die Modulation zu korrigieren, verfolgen wir den Ansatz, den Wochenrhythmus zunächst im Modell zu beschreiben und anschließend diesen Teil aus dem Modell zur Vorhersage zu entfernen.\n Eine Alternative zu unserem Verfahren wäre es, die Daten zunächst zu filtern.\n Im Vergleich bietet das von uns eingesetzte Model die Möglichkeit, die Güte der Beschreibung der Daten sowohl für die geglätteten als auch ungeglätteten Daten durchzuführen und so auch die Qualität der Glättung selbst zu bestimmen. \n\n ------------------------\n\n #### Wer hat zu diesem Modell beigetragen?\n - Luke Effenberger (Uni Osnabrück) (Umsetzung, Daten Analyse und Konzeption, Darstellung der Ergebnisse)\n - [Jens Henrik Göbbert](https://www.fz-juelich.de/SharedDocs/Personen/IAS/JSC/EN/staff/goebbert_j_h.html) (Jülich Supercomputing Centre) (Umsetzung und Konzeption der Webapplikation sowie des wissenschaftlichen Rechnens) \n - [Dr. Kai Krajsek](https://www.fz-juelich.de/SharedDocs/Personen/IAS/JSC/EN/staff/krajsek_k.html) (Jülich Supercomputing Centre) (Performance-Analyse und -Optimierung durch Nutzung von GPU) \n - [Tim Kreuzer](https://www.fz-juelich.de/SharedDocs/Personen/IAS/JSC/EN/staff/kreuzer_t.html) (Jülich Supercomputing Centre) (Infrastruktur für das wissenschaftliche Rechens, Webapplikation, Automatisierung der Rechnungen) \n - [Prof. Dr. Gordon Pipa](https://www.ikw.uni-osnabrueck.de/en/research_groups/neuroinformatics/people/prof_dr_gordon_pipa.html) (Uni Osnabrück) (Konzeption und wissenschaftliche Leitung)\n - [Pascal Nieters](https://www.ikw.uni-osnabrueck.de/en/research_groups/neuroinformatics/people/msc_pascal_nieters.html) (Uni Osnabrück) (Umsetzung, Daten Analyse und Konzeption, Darstellung der Ergebnisse)\n - Dr. Daniel Rohe (Jülich Supercomputing Centre) (Organisation und Diskussion)\n \"\"\"\n ),\n ],\n ),\n ],\n) ",
"_____no_output_____"
],
[
"main_page = html.Div(children=[\n html.P('4.5', id='version', style={'display':'none'}),\n navbar, body_layout, navbar_footer\n ])\nfaq_page = html.Div(children=[faq_navbar, faq_body_layout, navbar_footer])\n\napp.layout = html.Div([\n dcc.Location(id='url', refresh=False),\n html.Div(id='page-content')\n])\n\n# Update the visible page\[email protected](dash.dependencies.Output('page-content', 'children'),\n [dash.dependencies.Input('url', 'pathname')])\ndef display_page(pathname):\n if pathname == '/faq':\n return faq_page\n else:\n return main_page",
"_____no_output_____"
]
],
[
[
"#### Start the app",
"_____no_output_____"
]
],
[
[
"app.run_server(mode=\"jupyterlab\", debug=True) #,port=8052,debug=True)\n# mode=\"jupyterlab\" -> will open the app in a tab in JupyterLab\n# mode=\"inline\" -> will open the app below this cell\n# mode=\"external\" -> will displays a URL that you can click on to open the app in a browser tab",
"_____no_output_____"
]
],
[
[
"--------------------------\n**Attention** \nIf you get the error \"adress in use\" this can also be the case because simply your layout has an error so that a dash-app could not been started. Open the app in a new browser-tab with the url\n`<base-url>/proxy/<port>` where \\<base-url\\> derives from the url of your jupyterlab and \\<port\\> is by default 8050. \nFor example: `https://jupyter-jsc.fz-juelich.de/user/[email protected]/jureca_login/proxy/8050` \nThis will show the full error log.\n\n--------------------------",
"_____no_output_____"
],
[
"Show the Dash Flask server is listening",
"_____no_output_____"
]
],
[
[
"!echo \"COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME\"\n!lsof -i -P -n | grep LISTEN",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
]
|
e7be6c1078cd3e35678425a9a89df6c5d84dbacd | 13,919 | ipynb | Jupyter Notebook | Topic Modeling/Step 4 - Topic Modeling Method Testing.ipynb | autodidact-m/Projects | f4c0473adba42f3a629b62eb09d3b1df91982f46 | [
"Apache-2.0"
]
| null | null | null | Topic Modeling/Step 4 - Topic Modeling Method Testing.ipynb | autodidact-m/Projects | f4c0473adba42f3a629b62eb09d3b1df91982f46 | [
"Apache-2.0"
]
| null | null | null | Topic Modeling/Step 4 - Topic Modeling Method Testing.ipynb | autodidact-m/Projects | f4c0473adba42f3a629b62eb09d3b1df91982f46 | [
"Apache-2.0"
]
| null | null | null | 29.427061 | 548 | 0.599971 | [
[
[
"# Topic Modeling Methods",
"_____no_output_____"
],
[
"Topic modeling is a powerful tool for quickly sorting through a lot of text and documents without having to read every one. There are several methods available for this using python, as well as several libraries. Topic modeling is extremely challenging to get meaningful results. \"Garbage in, garbage out\" is a phrase that applies well to this - we have to do a significant amount of text preprocessing to extract the right information to feed into a model. On this sheet, I will be topic modeling supreme court cases with the following:\n\n- SKlearn\n\n- LDA (with TF)\n\n- LSA - AKA TruncatedSVD (with TF and TFIDF)\n\n- NMF (with TFIDF)",
"_____no_output_____"
],
[
"## Reminder of Full Project Workflow\n\nExtracting text using beautiful soup --> processing the text --> fitting text to a model --> applying model to other text",
"_____no_output_____"
],
[
"### Software Package & Built in Function Documentation\n- textblob - http://textblob.readthedocs.io/en/dev/",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport re\nfrom sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer, TfidfTransformer\nfrom sklearn.decomposition import NMF, LatentDirichletAllocation, TruncatedSVD\nfrom textblob import TextBlob\nfrom sklearn.preprocessing import Normalizer",
"_____no_output_____"
],
[
"doc_list.read_pickle(\"full_proj_lemmatized3.pickle\") #always save your work!",
"_____no_output_____"
],
[
"doc_list.shape #checking to make sure we have the info we expected to have",
"_____no_output_____"
]
],
[
[
"## Testing Models\n\nTry LDA, NMF and LSA as well as adjusting # of features, # topics, and overlap for best results.",
"_____no_output_____"
]
],
[
[
"def print_top_words(model, feature_names, n_top_words):\n for topic_idx, topic in enumerate(model.components_):\n print(\"Topic #%d:\" % topic_idx)\n print(\" \".join([feature_names[i]\n for i in topic.argsort()[:-n_top_words - 1:-1]]))\n print()\n \n \ndef modeler(corp, n_topics, n_top_words, clf, vect):\n df = .80\n str_vect = str(vect).split(\"(\")[0]\n str_clf = str(clf).split(\"(\")[0]\n\n print(\"Extracting {} features for {}...\".format(str_vect, str_clf))\n vect_trans = vect.fit_transform(corp)\n\n\n # Fit the model\n print(\"Fitting the {} model with {} features, \"\n \"n_topics= {}, n_topic_words= {}, n_features= {}...\"\n .format(str_clf, str_vect, n_topics, n_top_words, n_features))\n\n clf = clf.fit(vect_trans)\n if str_clf == \"TruncatedSVD\":\n print(\"\\nExplained variance ratio\", clf.explained_variance_ratio_)\n \n print(\"\\nTopics in {} model:\".format(str_clf))\n feature_names = vect.get_feature_names()\n return print_top_words(clf, feature_names, n_top_words)",
"_____no_output_____"
]
],
[
[
"### Latent Dirchlet Allocation Model\nIn natural language processing, Latent Dirichlet Allocation (LDA) is a generative statistical model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"#### Improving Accuracy of Topic Modeling\n1. Frequency Filter\n2. Part of Speech Tag Filter \n3. Batch Wise LDA",
"_____no_output_____"
],
[
"The results of topic models are completely dependent on the features (terms) present in the corpus. The corpus is represented as document term matrix, which in general is very sparse in nature. Reducing the dimensionality of the matrix can improve the results of topic modelling. Based on my practical experience, there are few approaches which do the trick.",
"_____no_output_____"
],
[
"**Frequency Filter**\n\nArrange every term according to its frequency. Terms with higher frequencies are more likely to appear in the results as compared ones with low frequency. The low frequency terms are essentially weak features of the corpus, hence it is a good practice to get rid of all those weak features. An exploratory analysis of terms and their frequency can help to decide what frequency value should be considered as the threshold.",
"_____no_output_____"
],
[
"**Part of Speech Tag Filter**\n\nPOS tag filter is more about the context of the features than frequencies of features. Topic Modelling tries to map out the recurring patterns of terms into topics. However, every term might not be equally important contextually. For example, POS tag IN contain terms such as – “within”, “upon”, “except”. “CD” contains – “one”,”two”, “hundred” etc. “MD” contains “may”, “must” etc. These terms are the supporting words of a language and can be removed by studying their post tags.\n",
"_____no_output_____"
],
[
"**Batch Wise LDA**\n\nIn order to retrieve most important topic terms, a corpus can be divided into batches of fixed sizes. Running LDA multiple times on these batches will provide different results, however, the best topic terms will be the intersection of all batches.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"modeler(doc_list.lem, 30, 30, LatentDirichletAllocation(n_topics=30, max_iter=5, learning_method='online', \\\n learning_offset=50.,random_state=0), CountVectorizer(max_df=.80, min_df=2, \n stop_words='english'))",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"LDA_mod(doc_list.lem, .95, 2, 2000,10) #df is a way to extract 'meaningful text' in this case",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"#### Notes about LDA model performance\n\nLDA is the most frequently used model in conversations about topic modeling. LDA has proven ineffective for this project, it performs poorly at picking up subtle differences in a corpus about the same subject (as in, if I wanted to find the difference between Apple products and apple the fruit, LDA would probably work, but not if I need to find the difference between cases where the majority of the text is about the law). \n\nLikely because LDA can only use a count vectorizer rather than a tfidf, so this bag of words is a serious limitation to finding how these documents relate.",
"_____no_output_____"
],
[
"### Truncated SVD (LSA) Model\nThis transformer performs linear dimensionality reduction by means of truncated singular value decomposition (SVD). It is very similar to PCA, but operates on sample vectors directly, instead of on a covariance matrix. This means it can work with scipy.sparse matrices efficiently.\n\nNotes: SVD suffers from a problem called “sign indeterminancy”, which means the sign of the components_ and the output from transform depend on the algorithm and random state. To work around this, fit instances of this class to data once, then keep the instance around to do transformations.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"modeler(doc_list.lem, 100, 30, TruncatedSVD(2, algorithm = 'arpack'), TfidfVectorizer(max_df=.8, min_df=2,stop_words='english'))",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"#### Notes about LSA performance\n\nIssues similar to LDA - it's good at pulling out the law themes, but that's not really what we need. We need the law terms to not play a role at all in modeling for these topics - we know that this entire corpus is about the law, but we need to know what KIND of law each case within the corpus is about.",
"_____no_output_____"
],
[
"### NMF model\nFind two non-negative matrices (W, H) whose product approximates the non- negative matrix X. This factorization can be used for example for dimensionality reduction, source separation or topic extraction.",
"_____no_output_____"
],
[
"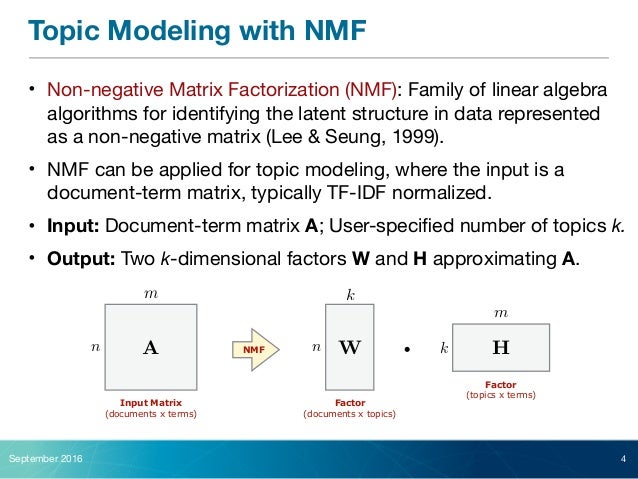",
"_____no_output_____"
]
],
[
[
"modeler(doc_list.lem, 30, 30, NMF(n_components=30, random_state=1, alpha=.1, l1_ratio=.5), \\ \n TfidfVectorizer(max_df=.98, min_df=2,stop_words='english'))",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"#### Notes about NMF performance\nSeeing these results should make you happy. Being able to use tf-idf is very important for modeling the kind of law each case within the corpus is about.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
]
|
e7be7a64dfd32ab215c7690d1194a86b68b5adf8 | 139,705 | ipynb | Jupyter Notebook | Combinatoria.ipynb | santiavenda2/notebooks | 248307f0be5269b4ee0b2c119e56334ae11cca88 | [
"Apache-2.0"
]
| null | null | null | Combinatoria.ipynb | santiavenda2/notebooks | 248307f0be5269b4ee0b2c119e56334ae11cca88 | [
"Apache-2.0"
]
| null | null | null | Combinatoria.ipynb | santiavenda2/notebooks | 248307f0be5269b4ee0b2c119e56334ae11cca88 | [
"Apache-2.0"
]
| null | null | null | 37.707152 | 130 | 0.279238 | [
[
[
"import itertools",
"_____no_output_____"
],
[
"dir(itertools)",
"_____no_output_____"
],
[
"itertools.combinations?",
"_____no_output_____"
],
[
"itertools.combinations_with_replacement?",
"_____no_output_____"
],
[
"list(x for x in itertools.combinations_with_replacement(range(1,11), 2) if sum(x) < 10)",
"_____no_output_____"
],
[
"list(x for x in itertools.combinations_with_replacement(range(1,11), 5) if sum(x) < 10)",
"_____no_output_____"
],
[
"combinations = list(x for c in range(2,11) for x in itertools.combinations_with_replacement(range(1,11), c) if sum(x) <= 10)",
"_____no_output_____"
],
[
"len(combinations)",
"_____no_output_____"
],
[
"%timeit list(x for c in range(2,11) for x in itertools.combinations_with_replacement(range(1,11), c) if sum(x) <= 10)",
"10 loops, best of 3: 29.6 ms per loop\n"
],
[
"itertools.permutations?",
"_____no_output_____"
],
[
"%time len(set(itertools.permutations((1, 1, 1, 1, 1, 1, 1, 1, 2, 0), 10)))",
"CPU times: user 273 ms, sys: 0 ns, total: 273 ms\nWall time: 272 ms\n"
],
[
"from math import factorial",
"_____no_output_____"
],
[
"factorial(9)",
"_____no_output_____"
],
[
"def pack_def(permutations, b):\n packs = []\n for p in permutations:\n p_units = list(p)\n p_units.extend([0] * (b-len(p)))\n new_packs = set(itertools.permutations(p_units, b))\n packs.extend(new_packs)\n return packs",
"_____no_output_____"
],
[
"packs = pack_def(combinations, 10)",
"_____no_output_____"
],
[
"len(packs)",
"_____no_output_____"
],
[
"any(sum(p) > 10 for p in packs)",
"_____no_output_____"
],
[
"def list_with_sum_generator(tope, n, suma):\n if 1 < n:\n return ([h] + tail for h in range(1, tope + 1) for tail in list_with_sum_generator(tope, n - 1, suma - h))\n else:\n return ([x] for x in xrange(1, suma + 1))",
"_____no_output_____"
],
[
"def list_with_sum(n, max_suma):\n \"\"\"Devuelve todas las listas l de enteros >0 de tamanio n tal que sum(l) <= max_suma \"\"\"\n if max_suma >= n:\n tope = max_suma - (n - 1)\n return list(list_with_sum_generator(tope, n, max_suma))\n else:\n return []",
"_____no_output_____"
],
[
"len(list_with_sum(10, 15))",
"_____no_output_____"
],
[
"def list_with_sum2(n, max_suma):\n return list(x for x in itertools.product(range(1, max_suma + 1), repeat=n) if sum(x) <= max_suma)",
"_____no_output_____"
],
[
"len(list_with_sum2(4, 7))",
"_____no_output_____"
],
[
"%timeit list_with_sum2(6,10)",
"10 loops, best of 3: 135 ms per loop\n"
],
[
"len(list_with_sum(11, 15))",
"_____no_output_____"
],
[
"def lists_with_sum_iterable(n, max_suma):\n vector = [1] * n\n i = 0\n suma = n\n \n while i < n: \n while suma <= max_suma:\n yield tuple(vector)\n vector[0] += 1\n suma += 1\n \n i = 0\n while suma >= max_suma and i < n:\n suma -= vector[i] - 1\n vector[i] = 1\n i += 1\n \n if i < n:\n vector[i] += 1\n suma += 1 ",
"_____no_output_____"
],
[
"len(list(lists_with_sum_iterable(4, 7)))",
"_____no_output_____"
],
[
"sum(1 for x in lists_with_sum_iterable(15, 30))",
"_____no_output_____"
],
[
"all(len(list(lists_with_sum_iterable(n, s))) == len(list_with_sum(n, s)) for s in range(1,16) for n in range(1, s+1))",
"_____no_output_____"
],
[
"def lists_with_sum_generator_inversed(n, max_suma):\n vector = [1] * n\n i = n - 1\n suma = n\n \n while i >= 0: \n while suma <= max_suma:\n yield tuple(vector)\n vector[-1] += 1\n suma += 1\n \n i = n - 1\n while suma >= max_suma and i >= 0:\n suma -= vector[i] - 1\n vector[i] = 1\n i -= 1\n \n if i >= 0:\n vector[i] += 1\n suma += 1",
"_____no_output_____"
],
[
"len(list(lists_with_sum_generator_inversed(4, 7)))",
"_____no_output_____"
],
[
"%timeit lists_with_sum_generator_inversed(6, 10)",
"The slowest run took 12.25 times longer than the fastest. This could mean that an intermediate result is being cached \n1000000 loops, best of 3: 253 ns per loop\n"
],
[
"for x in lists_with_sum_generator_inversed(10, 15):\n print x ",
"(1, 1, 1, 1, 1, 1, 1, 1, 1, 1)\n(1, 1, 1, 1, 1, 1, 1, 1, 1, 2)\n(1, 1, 1, 1, 1, 1, 1, 1, 1, 3)\n(1, 1, 1, 1, 1, 1, 1, 1, 1, 4)\n(1, 1, 1, 1, 1, 1, 1, 1, 1, 5)\n(1, 1, 1, 1, 1, 1, 1, 1, 1, 6)\n(1, 1, 1, 1, 1, 1, 1, 1, 2, 1)\n(1, 1, 1, 1, 1, 1, 1, 1, 2, 2)\n(1, 1, 1, 1, 1, 1, 1, 1, 2, 3)\n(1, 1, 1, 1, 1, 1, 1, 1, 2, 4)\n(1, 1, 1, 1, 1, 1, 1, 1, 2, 5)\n(1, 1, 1, 1, 1, 1, 1, 1, 3, 1)\n(1, 1, 1, 1, 1, 1, 1, 1, 3, 2)\n(1, 1, 1, 1, 1, 1, 1, 1, 3, 3)\n(1, 1, 1, 1, 1, 1, 1, 1, 3, 4)\n(1, 1, 1, 1, 1, 1, 1, 1, 4, 1)\n(1, 1, 1, 1, 1, 1, 1, 1, 4, 2)\n(1, 1, 1, 1, 1, 1, 1, 1, 4, 3)\n(1, 1, 1, 1, 1, 1, 1, 1, 5, 1)\n(1, 1, 1, 1, 1, 1, 1, 1, 5, 2)\n(1, 1, 1, 1, 1, 1, 1, 1, 6, 1)\n(1, 1, 1, 1, 1, 1, 1, 2, 1, 1)\n(1, 1, 1, 1, 1, 1, 1, 2, 1, 2)\n(1, 1, 1, 1, 1, 1, 1, 2, 1, 3)\n(1, 1, 1, 1, 1, 1, 1, 2, 1, 4)\n(1, 1, 1, 1, 1, 1, 1, 2, 1, 5)\n(1, 1, 1, 1, 1, 1, 1, 2, 2, 1)\n(1, 1, 1, 1, 1, 1, 1, 2, 2, 2)\n(1, 1, 1, 1, 1, 1, 1, 2, 2, 3)\n(1, 1, 1, 1, 1, 1, 1, 2, 2, 4)\n(1, 1, 1, 1, 1, 1, 1, 2, 3, 1)\n(1, 1, 1, 1, 1, 1, 1, 2, 3, 2)\n(1, 1, 1, 1, 1, 1, 1, 2, 3, 3)\n(1, 1, 1, 1, 1, 1, 1, 2, 4, 1)\n(1, 1, 1, 1, 1, 1, 1, 2, 4, 2)\n(1, 1, 1, 1, 1, 1, 1, 2, 5, 1)\n(1, 1, 1, 1, 1, 1, 1, 3, 1, 1)\n(1, 1, 1, 1, 1, 1, 1, 3, 1, 2)\n(1, 1, 1, 1, 1, 1, 1, 3, 1, 3)\n(1, 1, 1, 1, 1, 1, 1, 3, 1, 4)\n(1, 1, 1, 1, 1, 1, 1, 3, 2, 1)\n(1, 1, 1, 1, 1, 1, 1, 3, 2, 2)\n(1, 1, 1, 1, 1, 1, 1, 3, 2, 3)\n(1, 1, 1, 1, 1, 1, 1, 3, 3, 1)\n(1, 1, 1, 1, 1, 1, 1, 3, 3, 2)\n(1, 1, 1, 1, 1, 1, 1, 3, 4, 1)\n(1, 1, 1, 1, 1, 1, 1, 4, 1, 1)\n(1, 1, 1, 1, 1, 1, 1, 4, 1, 2)\n(1, 1, 1, 1, 1, 1, 1, 4, 1, 3)\n(1, 1, 1, 1, 1, 1, 1, 4, 2, 1)\n(1, 1, 1, 1, 1, 1, 1, 4, 2, 2)\n(1, 1, 1, 1, 1, 1, 1, 4, 3, 1)\n(1, 1, 1, 1, 1, 1, 1, 5, 1, 1)\n(1, 1, 1, 1, 1, 1, 1, 5, 1, 2)\n(1, 1, 1, 1, 1, 1, 1, 5, 2, 1)\n(1, 1, 1, 1, 1, 1, 1, 6, 1, 1)\n(1, 1, 1, 1, 1, 1, 2, 1, 1, 1)\n(1, 1, 1, 1, 1, 1, 2, 1, 1, 2)\n(1, 1, 1, 1, 1, 1, 2, 1, 1, 3)\n(1, 1, 1, 1, 1, 1, 2, 1, 1, 4)\n(1, 1, 1, 1, 1, 1, 2, 1, 1, 5)\n(1, 1, 1, 1, 1, 1, 2, 1, 2, 1)\n(1, 1, 1, 1, 1, 1, 2, 1, 2, 2)\n(1, 1, 1, 1, 1, 1, 2, 1, 2, 3)\n(1, 1, 1, 1, 1, 1, 2, 1, 2, 4)\n(1, 1, 1, 1, 1, 1, 2, 1, 3, 1)\n(1, 1, 1, 1, 1, 1, 2, 1, 3, 2)\n(1, 1, 1, 1, 1, 1, 2, 1, 3, 3)\n(1, 1, 1, 1, 1, 1, 2, 1, 4, 1)\n(1, 1, 1, 1, 1, 1, 2, 1, 4, 2)\n(1, 1, 1, 1, 1, 1, 2, 1, 5, 1)\n(1, 1, 1, 1, 1, 1, 2, 2, 1, 1)\n(1, 1, 1, 1, 1, 1, 2, 2, 1, 2)\n(1, 1, 1, 1, 1, 1, 2, 2, 1, 3)\n(1, 1, 1, 1, 1, 1, 2, 2, 1, 4)\n(1, 1, 1, 1, 1, 1, 2, 2, 2, 1)\n(1, 1, 1, 1, 1, 1, 2, 2, 2, 2)\n(1, 1, 1, 1, 1, 1, 2, 2, 2, 3)\n(1, 1, 1, 1, 1, 1, 2, 2, 3, 1)\n(1, 1, 1, 1, 1, 1, 2, 2, 3, 2)\n(1, 1, 1, 1, 1, 1, 2, 2, 4, 1)\n(1, 1, 1, 1, 1, 1, 2, 3, 1, 1)\n(1, 1, 1, 1, 1, 1, 2, 3, 1, 2)\n(1, 1, 1, 1, 1, 1, 2, 3, 1, 3)\n(1, 1, 1, 1, 1, 1, 2, 3, 2, 1)\n(1, 1, 1, 1, 1, 1, 2, 3, 2, 2)\n(1, 1, 1, 1, 1, 1, 2, 3, 3, 1)\n(1, 1, 1, 1, 1, 1, 2, 4, 1, 1)\n(1, 1, 1, 1, 1, 1, 2, 4, 1, 2)\n(1, 1, 1, 1, 1, 1, 2, 4, 2, 1)\n(1, 1, 1, 1, 1, 1, 2, 5, 1, 1)\n(1, 1, 1, 1, 1, 1, 3, 1, 1, 1)\n(1, 1, 1, 1, 1, 1, 3, 1, 1, 2)\n(1, 1, 1, 1, 1, 1, 3, 1, 1, 3)\n(1, 1, 1, 1, 1, 1, 3, 1, 1, 4)\n(1, 1, 1, 1, 1, 1, 3, 1, 2, 1)\n(1, 1, 1, 1, 1, 1, 3, 1, 2, 2)\n(1, 1, 1, 1, 1, 1, 3, 1, 2, 3)\n(1, 1, 1, 1, 1, 1, 3, 1, 3, 1)\n(1, 1, 1, 1, 1, 1, 3, 1, 3, 2)\n(1, 1, 1, 1, 1, 1, 3, 1, 4, 1)\n(1, 1, 1, 1, 1, 1, 3, 2, 1, 1)\n(1, 1, 1, 1, 1, 1, 3, 2, 1, 2)\n(1, 1, 1, 1, 1, 1, 3, 2, 1, 3)\n(1, 1, 1, 1, 1, 1, 3, 2, 2, 1)\n(1, 1, 1, 1, 1, 1, 3, 2, 2, 2)\n(1, 1, 1, 1, 1, 1, 3, 2, 3, 1)\n(1, 1, 1, 1, 1, 1, 3, 3, 1, 1)\n(1, 1, 1, 1, 1, 1, 3, 3, 1, 2)\n(1, 1, 1, 1, 1, 1, 3, 3, 2, 1)\n(1, 1, 1, 1, 1, 1, 3, 4, 1, 1)\n(1, 1, 1, 1, 1, 1, 4, 1, 1, 1)\n(1, 1, 1, 1, 1, 1, 4, 1, 1, 2)\n(1, 1, 1, 1, 1, 1, 4, 1, 1, 3)\n(1, 1, 1, 1, 1, 1, 4, 1, 2, 1)\n(1, 1, 1, 1, 1, 1, 4, 1, 2, 2)\n(1, 1, 1, 1, 1, 1, 4, 1, 3, 1)\n(1, 1, 1, 1, 1, 1, 4, 2, 1, 1)\n(1, 1, 1, 1, 1, 1, 4, 2, 1, 2)\n(1, 1, 1, 1, 1, 1, 4, 2, 2, 1)\n(1, 1, 1, 1, 1, 1, 4, 3, 1, 1)\n(1, 1, 1, 1, 1, 1, 5, 1, 1, 1)\n(1, 1, 1, 1, 1, 1, 5, 1, 1, 2)\n(1, 1, 1, 1, 1, 1, 5, 1, 2, 1)\n(1, 1, 1, 1, 1, 1, 5, 2, 1, 1)\n(1, 1, 1, 1, 1, 1, 6, 1, 1, 1)\n(1, 1, 1, 1, 1, 2, 1, 1, 1, 1)\n(1, 1, 1, 1, 1, 2, 1, 1, 1, 2)\n(1, 1, 1, 1, 1, 2, 1, 1, 1, 3)\n(1, 1, 1, 1, 1, 2, 1, 1, 1, 4)\n(1, 1, 1, 1, 1, 2, 1, 1, 1, 5)\n(1, 1, 1, 1, 1, 2, 1, 1, 2, 1)\n(1, 1, 1, 1, 1, 2, 1, 1, 2, 2)\n(1, 1, 1, 1, 1, 2, 1, 1, 2, 3)\n(1, 1, 1, 1, 1, 2, 1, 1, 2, 4)\n(1, 1, 1, 1, 1, 2, 1, 1, 3, 1)\n(1, 1, 1, 1, 1, 2, 1, 1, 3, 2)\n(1, 1, 1, 1, 1, 2, 1, 1, 3, 3)\n(1, 1, 1, 1, 1, 2, 1, 1, 4, 1)\n(1, 1, 1, 1, 1, 2, 1, 1, 4, 2)\n(1, 1, 1, 1, 1, 2, 1, 1, 5, 1)\n(1, 1, 1, 1, 1, 2, 1, 2, 1, 1)\n(1, 1, 1, 1, 1, 2, 1, 2, 1, 2)\n(1, 1, 1, 1, 1, 2, 1, 2, 1, 3)\n(1, 1, 1, 1, 1, 2, 1, 2, 1, 4)\n(1, 1, 1, 1, 1, 2, 1, 2, 2, 1)\n(1, 1, 1, 1, 1, 2, 1, 2, 2, 2)\n(1, 1, 1, 1, 1, 2, 1, 2, 2, 3)\n(1, 1, 1, 1, 1, 2, 1, 2, 3, 1)\n(1, 1, 1, 1, 1, 2, 1, 2, 3, 2)\n(1, 1, 1, 1, 1, 2, 1, 2, 4, 1)\n(1, 1, 1, 1, 1, 2, 1, 3, 1, 1)\n(1, 1, 1, 1, 1, 2, 1, 3, 1, 2)\n(1, 1, 1, 1, 1, 2, 1, 3, 1, 3)\n(1, 1, 1, 1, 1, 2, 1, 3, 2, 1)\n(1, 1, 1, 1, 1, 2, 1, 3, 2, 2)\n(1, 1, 1, 1, 1, 2, 1, 3, 3, 1)\n(1, 1, 1, 1, 1, 2, 1, 4, 1, 1)\n(1, 1, 1, 1, 1, 2, 1, 4, 1, 2)\n(1, 1, 1, 1, 1, 2, 1, 4, 2, 1)\n(1, 1, 1, 1, 1, 2, 1, 5, 1, 1)\n(1, 1, 1, 1, 1, 2, 2, 1, 1, 1)\n(1, 1, 1, 1, 1, 2, 2, 1, 1, 2)\n(1, 1, 1, 1, 1, 2, 2, 1, 1, 3)\n(1, 1, 1, 1, 1, 2, 2, 1, 1, 4)\n(1, 1, 1, 1, 1, 2, 2, 1, 2, 1)\n(1, 1, 1, 1, 1, 2, 2, 1, 2, 2)\n(1, 1, 1, 1, 1, 2, 2, 1, 2, 3)\n(1, 1, 1, 1, 1, 2, 2, 1, 3, 1)\n(1, 1, 1, 1, 1, 2, 2, 1, 3, 2)\n(1, 1, 1, 1, 1, 2, 2, 1, 4, 1)\n(1, 1, 1, 1, 1, 2, 2, 2, 1, 1)\n(1, 1, 1, 1, 1, 2, 2, 2, 1, 2)\n(1, 1, 1, 1, 1, 2, 2, 2, 1, 3)\n(1, 1, 1, 1, 1, 2, 2, 2, 2, 1)\n(1, 1, 1, 1, 1, 2, 2, 2, 2, 2)\n(1, 1, 1, 1, 1, 2, 2, 2, 3, 1)\n(1, 1, 1, 1, 1, 2, 2, 3, 1, 1)\n(1, 1, 1, 1, 1, 2, 2, 3, 1, 2)\n(1, 1, 1, 1, 1, 2, 2, 3, 2, 1)\n(1, 1, 1, 1, 1, 2, 2, 4, 1, 1)\n(1, 1, 1, 1, 1, 2, 3, 1, 1, 1)\n(1, 1, 1, 1, 1, 2, 3, 1, 1, 2)\n(1, 1, 1, 1, 1, 2, 3, 1, 1, 3)\n(1, 1, 1, 1, 1, 2, 3, 1, 2, 1)\n(1, 1, 1, 1, 1, 2, 3, 1, 2, 2)\n(1, 1, 1, 1, 1, 2, 3, 1, 3, 1)\n(1, 1, 1, 1, 1, 2, 3, 2, 1, 1)\n(1, 1, 1, 1, 1, 2, 3, 2, 1, 2)\n(1, 1, 1, 1, 1, 2, 3, 2, 2, 1)\n(1, 1, 1, 1, 1, 2, 3, 3, 1, 1)\n(1, 1, 1, 1, 1, 2, 4, 1, 1, 1)\n(1, 1, 1, 1, 1, 2, 4, 1, 1, 2)\n(1, 1, 1, 1, 1, 2, 4, 1, 2, 1)\n(1, 1, 1, 1, 1, 2, 4, 2, 1, 1)\n(1, 1, 1, 1, 1, 2, 5, 1, 1, 1)\n(1, 1, 1, 1, 1, 3, 1, 1, 1, 1)\n(1, 1, 1, 1, 1, 3, 1, 1, 1, 2)\n(1, 1, 1, 1, 1, 3, 1, 1, 1, 3)\n(1, 1, 1, 1, 1, 3, 1, 1, 1, 4)\n(1, 1, 1, 1, 1, 3, 1, 1, 2, 1)\n(1, 1, 1, 1, 1, 3, 1, 1, 2, 2)\n(1, 1, 1, 1, 1, 3, 1, 1, 2, 3)\n(1, 1, 1, 1, 1, 3, 1, 1, 3, 1)\n(1, 1, 1, 1, 1, 3, 1, 1, 3, 2)\n(1, 1, 1, 1, 1, 3, 1, 1, 4, 1)\n(1, 1, 1, 1, 1, 3, 1, 2, 1, 1)\n(1, 1, 1, 1, 1, 3, 1, 2, 1, 2)\n(1, 1, 1, 1, 1, 3, 1, 2, 1, 3)\n(1, 1, 1, 1, 1, 3, 1, 2, 2, 1)\n(1, 1, 1, 1, 1, 3, 1, 2, 2, 2)\n(1, 1, 1, 1, 1, 3, 1, 2, 3, 1)\n(1, 1, 1, 1, 1, 3, 1, 3, 1, 1)\n(1, 1, 1, 1, 1, 3, 1, 3, 1, 2)\n(1, 1, 1, 1, 1, 3, 1, 3, 2, 1)\n(1, 1, 1, 1, 1, 3, 1, 4, 1, 1)\n(1, 1, 1, 1, 1, 3, 2, 1, 1, 1)\n(1, 1, 1, 1, 1, 3, 2, 1, 1, 2)\n(1, 1, 1, 1, 1, 3, 2, 1, 1, 3)\n(1, 1, 1, 1, 1, 3, 2, 1, 2, 1)\n(1, 1, 1, 1, 1, 3, 2, 1, 2, 2)\n(1, 1, 1, 1, 1, 3, 2, 1, 3, 1)\n(1, 1, 1, 1, 1, 3, 2, 2, 1, 1)\n(1, 1, 1, 1, 1, 3, 2, 2, 1, 2)\n(1, 1, 1, 1, 1, 3, 2, 2, 2, 1)\n(1, 1, 1, 1, 1, 3, 2, 3, 1, 1)\n(1, 1, 1, 1, 1, 3, 3, 1, 1, 1)\n(1, 1, 1, 1, 1, 3, 3, 1, 1, 2)\n(1, 1, 1, 1, 1, 3, 3, 1, 2, 1)\n(1, 1, 1, 1, 1, 3, 3, 2, 1, 1)\n(1, 1, 1, 1, 1, 3, 4, 1, 1, 1)\n(1, 1, 1, 1, 1, 4, 1, 1, 1, 1)\n(1, 1, 1, 1, 1, 4, 1, 1, 1, 2)\n(1, 1, 1, 1, 1, 4, 1, 1, 1, 3)\n(1, 1, 1, 1, 1, 4, 1, 1, 2, 1)\n(1, 1, 1, 1, 1, 4, 1, 1, 2, 2)\n(1, 1, 1, 1, 1, 4, 1, 1, 3, 1)\n(1, 1, 1, 1, 1, 4, 1, 2, 1, 1)\n(1, 1, 1, 1, 1, 4, 1, 2, 1, 2)\n(1, 1, 1, 1, 1, 4, 1, 2, 2, 1)\n(1, 1, 1, 1, 1, 4, 1, 3, 1, 1)\n(1, 1, 1, 1, 1, 4, 2, 1, 1, 1)\n(1, 1, 1, 1, 1, 4, 2, 1, 1, 2)\n(1, 1, 1, 1, 1, 4, 2, 1, 2, 1)\n(1, 1, 1, 1, 1, 4, 2, 2, 1, 1)\n(1, 1, 1, 1, 1, 4, 3, 1, 1, 1)\n(1, 1, 1, 1, 1, 5, 1, 1, 1, 1)\n(1, 1, 1, 1, 1, 5, 1, 1, 1, 2)\n(1, 1, 1, 1, 1, 5, 1, 1, 2, 1)\n(1, 1, 1, 1, 1, 5, 1, 2, 1, 1)\n(1, 1, 1, 1, 1, 5, 2, 1, 1, 1)\n(1, 1, 1, 1, 1, 6, 1, 1, 1, 1)\n(1, 1, 1, 1, 2, 1, 1, 1, 1, 1)\n(1, 1, 1, 1, 2, 1, 1, 1, 1, 2)\n(1, 1, 1, 1, 2, 1, 1, 1, 1, 3)\n(1, 1, 1, 1, 2, 1, 1, 1, 1, 4)\n(1, 1, 1, 1, 2, 1, 1, 1, 1, 5)\n(1, 1, 1, 1, 2, 1, 1, 1, 2, 1)\n(1, 1, 1, 1, 2, 1, 1, 1, 2, 2)\n(1, 1, 1, 1, 2, 1, 1, 1, 2, 3)\n(1, 1, 1, 1, 2, 1, 1, 1, 2, 4)\n(1, 1, 1, 1, 2, 1, 1, 1, 3, 1)\n(1, 1, 1, 1, 2, 1, 1, 1, 3, 2)\n(1, 1, 1, 1, 2, 1, 1, 1, 3, 3)\n(1, 1, 1, 1, 2, 1, 1, 1, 4, 1)\n(1, 1, 1, 1, 2, 1, 1, 1, 4, 2)\n(1, 1, 1, 1, 2, 1, 1, 1, 5, 1)\n(1, 1, 1, 1, 2, 1, 1, 2, 1, 1)\n(1, 1, 1, 1, 2, 1, 1, 2, 1, 2)\n(1, 1, 1, 1, 2, 1, 1, 2, 1, 3)\n(1, 1, 1, 1, 2, 1, 1, 2, 1, 4)\n(1, 1, 1, 1, 2, 1, 1, 2, 2, 1)\n(1, 1, 1, 1, 2, 1, 1, 2, 2, 2)\n(1, 1, 1, 1, 2, 1, 1, 2, 2, 3)\n(1, 1, 1, 1, 2, 1, 1, 2, 3, 1)\n(1, 1, 1, 1, 2, 1, 1, 2, 3, 2)\n(1, 1, 1, 1, 2, 1, 1, 2, 4, 1)\n(1, 1, 1, 1, 2, 1, 1, 3, 1, 1)\n(1, 1, 1, 1, 2, 1, 1, 3, 1, 2)\n(1, 1, 1, 1, 2, 1, 1, 3, 1, 3)\n(1, 1, 1, 1, 2, 1, 1, 3, 2, 1)\n(1, 1, 1, 1, 2, 1, 1, 3, 2, 2)\n(1, 1, 1, 1, 2, 1, 1, 3, 3, 1)\n(1, 1, 1, 1, 2, 1, 1, 4, 1, 1)\n(1, 1, 1, 1, 2, 1, 1, 4, 1, 2)\n(1, 1, 1, 1, 2, 1, 1, 4, 2, 1)\n(1, 1, 1, 1, 2, 1, 1, 5, 1, 1)\n(1, 1, 1, 1, 2, 1, 2, 1, 1, 1)\n(1, 1, 1, 1, 2, 1, 2, 1, 1, 2)\n(1, 1, 1, 1, 2, 1, 2, 1, 1, 3)\n(1, 1, 1, 1, 2, 1, 2, 1, 1, 4)\n(1, 1, 1, 1, 2, 1, 2, 1, 2, 1)\n(1, 1, 1, 1, 2, 1, 2, 1, 2, 2)\n(1, 1, 1, 1, 2, 1, 2, 1, 2, 3)\n(1, 1, 1, 1, 2, 1, 2, 1, 3, 1)\n(1, 1, 1, 1, 2, 1, 2, 1, 3, 2)\n(1, 1, 1, 1, 2, 1, 2, 1, 4, 1)\n(1, 1, 1, 1, 2, 1, 2, 2, 1, 1)\n(1, 1, 1, 1, 2, 1, 2, 2, 1, 2)\n(1, 1, 1, 1, 2, 1, 2, 2, 1, 3)\n(1, 1, 1, 1, 2, 1, 2, 2, 2, 1)\n(1, 1, 1, 1, 2, 1, 2, 2, 2, 2)\n(1, 1, 1, 1, 2, 1, 2, 2, 3, 1)\n(1, 1, 1, 1, 2, 1, 2, 3, 1, 1)\n(1, 1, 1, 1, 2, 1, 2, 3, 1, 2)\n(1, 1, 1, 1, 2, 1, 2, 3, 2, 1)\n(1, 1, 1, 1, 2, 1, 2, 4, 1, 1)\n(1, 1, 1, 1, 2, 1, 3, 1, 1, 1)\n(1, 1, 1, 1, 2, 1, 3, 1, 1, 2)\n(1, 1, 1, 1, 2, 1, 3, 1, 1, 3)\n(1, 1, 1, 1, 2, 1, 3, 1, 2, 1)\n(1, 1, 1, 1, 2, 1, 3, 1, 2, 2)\n(1, 1, 1, 1, 2, 1, 3, 1, 3, 1)\n(1, 1, 1, 1, 2, 1, 3, 2, 1, 1)\n(1, 1, 1, 1, 2, 1, 3, 2, 1, 2)\n(1, 1, 1, 1, 2, 1, 3, 2, 2, 1)\n(1, 1, 1, 1, 2, 1, 3, 3, 1, 1)\n(1, 1, 1, 1, 2, 1, 4, 1, 1, 1)\n(1, 1, 1, 1, 2, 1, 4, 1, 1, 2)\n(1, 1, 1, 1, 2, 1, 4, 1, 2, 1)\n(1, 1, 1, 1, 2, 1, 4, 2, 1, 1)\n(1, 1, 1, 1, 2, 1, 5, 1, 1, 1)\n(1, 1, 1, 1, 2, 2, 1, 1, 1, 1)\n(1, 1, 1, 1, 2, 2, 1, 1, 1, 2)\n(1, 1, 1, 1, 2, 2, 1, 1, 1, 3)\n(1, 1, 1, 1, 2, 2, 1, 1, 1, 4)\n(1, 1, 1, 1, 2, 2, 1, 1, 2, 1)\n(1, 1, 1, 1, 2, 2, 1, 1, 2, 2)\n(1, 1, 1, 1, 2, 2, 1, 1, 2, 3)\n(1, 1, 1, 1, 2, 2, 1, 1, 3, 1)\n(1, 1, 1, 1, 2, 2, 1, 1, 3, 2)\n(1, 1, 1, 1, 2, 2, 1, 1, 4, 1)\n(1, 1, 1, 1, 2, 2, 1, 2, 1, 1)\n(1, 1, 1, 1, 2, 2, 1, 2, 1, 2)\n(1, 1, 1, 1, 2, 2, 1, 2, 1, 3)\n(1, 1, 1, 1, 2, 2, 1, 2, 2, 1)\n(1, 1, 1, 1, 2, 2, 1, 2, 2, 2)\n(1, 1, 1, 1, 2, 2, 1, 2, 3, 1)\n(1, 1, 1, 1, 2, 2, 1, 3, 1, 1)\n(1, 1, 1, 1, 2, 2, 1, 3, 1, 2)\n(1, 1, 1, 1, 2, 2, 1, 3, 2, 1)\n(1, 1, 1, 1, 2, 2, 1, 4, 1, 1)\n(1, 1, 1, 1, 2, 2, 2, 1, 1, 1)\n(1, 1, 1, 1, 2, 2, 2, 1, 1, 2)\n(1, 1, 1, 1, 2, 2, 2, 1, 1, 3)\n(1, 1, 1, 1, 2, 2, 2, 1, 2, 1)\n(1, 1, 1, 1, 2, 2, 2, 1, 2, 2)\n(1, 1, 1, 1, 2, 2, 2, 1, 3, 1)\n(1, 1, 1, 1, 2, 2, 2, 2, 1, 1)\n(1, 1, 1, 1, 2, 2, 2, 2, 1, 2)\n(1, 1, 1, 1, 2, 2, 2, 2, 2, 1)\n(1, 1, 1, 1, 2, 2, 2, 3, 1, 1)\n(1, 1, 1, 1, 2, 2, 3, 1, 1, 1)\n(1, 1, 1, 1, 2, 2, 3, 1, 1, 2)\n(1, 1, 1, 1, 2, 2, 3, 1, 2, 1)\n(1, 1, 1, 1, 2, 2, 3, 2, 1, 1)\n(1, 1, 1, 1, 2, 2, 4, 1, 1, 1)\n(1, 1, 1, 1, 2, 3, 1, 1, 1, 1)\n(1, 1, 1, 1, 2, 3, 1, 1, 1, 2)\n(1, 1, 1, 1, 2, 3, 1, 1, 1, 3)\n(1, 1, 1, 1, 2, 3, 1, 1, 2, 1)\n(1, 1, 1, 1, 2, 3, 1, 1, 2, 2)\n(1, 1, 1, 1, 2, 3, 1, 1, 3, 1)\n(1, 1, 1, 1, 2, 3, 1, 2, 1, 1)\n(1, 1, 1, 1, 2, 3, 1, 2, 1, 2)\n(1, 1, 1, 1, 2, 3, 1, 2, 2, 1)\n(1, 1, 1, 1, 2, 3, 1, 3, 1, 1)\n(1, 1, 1, 1, 2, 3, 2, 1, 1, 1)\n(1, 1, 1, 1, 2, 3, 2, 1, 1, 2)\n(1, 1, 1, 1, 2, 3, 2, 1, 2, 1)\n(1, 1, 1, 1, 2, 3, 2, 2, 1, 1)\n(1, 1, 1, 1, 2, 3, 3, 1, 1, 1)\n(1, 1, 1, 1, 2, 4, 1, 1, 1, 1)\n(1, 1, 1, 1, 2, 4, 1, 1, 1, 2)\n(1, 1, 1, 1, 2, 4, 1, 1, 2, 1)\n(1, 1, 1, 1, 2, 4, 1, 2, 1, 1)\n(1, 1, 1, 1, 2, 4, 2, 1, 1, 1)\n(1, 1, 1, 1, 2, 5, 1, 1, 1, 1)\n(1, 1, 1, 1, 3, 1, 1, 1, 1, 1)\n(1, 1, 1, 1, 3, 1, 1, 1, 1, 2)\n(1, 1, 1, 1, 3, 1, 1, 1, 1, 3)\n(1, 1, 1, 1, 3, 1, 1, 1, 1, 4)\n(1, 1, 1, 1, 3, 1, 1, 1, 2, 1)\n(1, 1, 1, 1, 3, 1, 1, 1, 2, 2)\n(1, 1, 1, 1, 3, 1, 1, 1, 2, 3)\n(1, 1, 1, 1, 3, 1, 1, 1, 3, 1)\n(1, 1, 1, 1, 3, 1, 1, 1, 3, 2)\n(1, 1, 1, 1, 3, 1, 1, 1, 4, 1)\n(1, 1, 1, 1, 3, 1, 1, 2, 1, 1)\n(1, 1, 1, 1, 3, 1, 1, 2, 1, 2)\n(1, 1, 1, 1, 3, 1, 1, 2, 1, 3)\n(1, 1, 1, 1, 3, 1, 1, 2, 2, 1)\n(1, 1, 1, 1, 3, 1, 1, 2, 2, 2)\n(1, 1, 1, 1, 3, 1, 1, 2, 3, 1)\n(1, 1, 1, 1, 3, 1, 1, 3, 1, 1)\n(1, 1, 1, 1, 3, 1, 1, 3, 1, 2)\n(1, 1, 1, 1, 3, 1, 1, 3, 2, 1)\n(1, 1, 1, 1, 3, 1, 1, 4, 1, 1)\n(1, 1, 1, 1, 3, 1, 2, 1, 1, 1)\n(1, 1, 1, 1, 3, 1, 2, 1, 1, 2)\n(1, 1, 1, 1, 3, 1, 2, 1, 1, 3)\n(1, 1, 1, 1, 3, 1, 2, 1, 2, 1)\n(1, 1, 1, 1, 3, 1, 2, 1, 2, 2)\n(1, 1, 1, 1, 3, 1, 2, 1, 3, 1)\n(1, 1, 1, 1, 3, 1, 2, 2, 1, 1)\n(1, 1, 1, 1, 3, 1, 2, 2, 1, 2)\n(1, 1, 1, 1, 3, 1, 2, 2, 2, 1)\n(1, 1, 1, 1, 3, 1, 2, 3, 1, 1)\n(1, 1, 1, 1, 3, 1, 3, 1, 1, 1)\n(1, 1, 1, 1, 3, 1, 3, 1, 1, 2)\n(1, 1, 1, 1, 3, 1, 3, 1, 2, 1)\n(1, 1, 1, 1, 3, 1, 3, 2, 1, 1)\n(1, 1, 1, 1, 3, 1, 4, 1, 1, 1)\n(1, 1, 1, 1, 3, 2, 1, 1, 1, 1)\n(1, 1, 1, 1, 3, 2, 1, 1, 1, 2)\n(1, 1, 1, 1, 3, 2, 1, 1, 1, 3)\n(1, 1, 1, 1, 3, 2, 1, 1, 2, 1)\n(1, 1, 1, 1, 3, 2, 1, 1, 2, 2)\n(1, 1, 1, 1, 3, 2, 1, 1, 3, 1)\n(1, 1, 1, 1, 3, 2, 1, 2, 1, 1)\n(1, 1, 1, 1, 3, 2, 1, 2, 1, 2)\n(1, 1, 1, 1, 3, 2, 1, 2, 2, 1)\n(1, 1, 1, 1, 3, 2, 1, 3, 1, 1)\n(1, 1, 1, 1, 3, 2, 2, 1, 1, 1)\n(1, 1, 1, 1, 3, 2, 2, 1, 1, 2)\n(1, 1, 1, 1, 3, 2, 2, 1, 2, 1)\n(1, 1, 1, 1, 3, 2, 2, 2, 1, 1)\n(1, 1, 1, 1, 3, 2, 3, 1, 1, 1)\n(1, 1, 1, 1, 3, 3, 1, 1, 1, 1)\n(1, 1, 1, 1, 3, 3, 1, 1, 1, 2)\n(1, 1, 1, 1, 3, 3, 1, 1, 2, 1)\n(1, 1, 1, 1, 3, 3, 1, 2, 1, 1)\n(1, 1, 1, 1, 3, 3, 2, 1, 1, 1)\n(1, 1, 1, 1, 3, 4, 1, 1, 1, 1)\n(1, 1, 1, 1, 4, 1, 1, 1, 1, 1)\n(1, 1, 1, 1, 4, 1, 1, 1, 1, 2)\n(1, 1, 1, 1, 4, 1, 1, 1, 1, 3)\n(1, 1, 1, 1, 4, 1, 1, 1, 2, 1)\n(1, 1, 1, 1, 4, 1, 1, 1, 2, 2)\n(1, 1, 1, 1, 4, 1, 1, 1, 3, 1)\n(1, 1, 1, 1, 4, 1, 1, 2, 1, 1)\n(1, 1, 1, 1, 4, 1, 1, 2, 1, 2)\n(1, 1, 1, 1, 4, 1, 1, 2, 2, 1)\n(1, 1, 1, 1, 4, 1, 1, 3, 1, 1)\n(1, 1, 1, 1, 4, 1, 2, 1, 1, 1)\n(1, 1, 1, 1, 4, 1, 2, 1, 1, 2)\n(1, 1, 1, 1, 4, 1, 2, 1, 2, 1)\n(1, 1, 1, 1, 4, 1, 2, 2, 1, 1)\n(1, 1, 1, 1, 4, 1, 3, 1, 1, 1)\n(1, 1, 1, 1, 4, 2, 1, 1, 1, 1)\n(1, 1, 1, 1, 4, 2, 1, 1, 1, 2)\n(1, 1, 1, 1, 4, 2, 1, 1, 2, 1)\n(1, 1, 1, 1, 4, 2, 1, 2, 1, 1)\n(1, 1, 1, 1, 4, 2, 2, 1, 1, 1)\n(1, 1, 1, 1, 4, 3, 1, 1, 1, 1)\n(1, 1, 1, 1, 5, 1, 1, 1, 1, 1)\n(1, 1, 1, 1, 5, 1, 1, 1, 1, 2)\n(1, 1, 1, 1, 5, 1, 1, 1, 2, 1)\n(1, 1, 1, 1, 5, 1, 1, 2, 1, 1)\n(1, 1, 1, 1, 5, 1, 2, 1, 1, 1)\n(1, 1, 1, 1, 5, 2, 1, 1, 1, 1)\n(1, 1, 1, 1, 6, 1, 1, 1, 1, 1)\n(1, 1, 1, 2, 1, 1, 1, 1, 1, 1)\n(1, 1, 1, 2, 1, 1, 1, 1, 1, 2)\n(1, 1, 1, 2, 1, 1, 1, 1, 1, 3)\n(1, 1, 1, 2, 1, 1, 1, 1, 1, 4)\n(1, 1, 1, 2, 1, 1, 1, 1, 1, 5)\n(1, 1, 1, 2, 1, 1, 1, 1, 2, 1)\n(1, 1, 1, 2, 1, 1, 1, 1, 2, 2)\n(1, 1, 1, 2, 1, 1, 1, 1, 2, 3)\n(1, 1, 1, 2, 1, 1, 1, 1, 2, 4)\n(1, 1, 1, 2, 1, 1, 1, 1, 3, 1)\n(1, 1, 1, 2, 1, 1, 1, 1, 3, 2)\n(1, 1, 1, 2, 1, 1, 1, 1, 3, 3)\n(1, 1, 1, 2, 1, 1, 1, 1, 4, 1)\n(1, 1, 1, 2, 1, 1, 1, 1, 4, 2)\n(1, 1, 1, 2, 1, 1, 1, 1, 5, 1)\n(1, 1, 1, 2, 1, 1, 1, 2, 1, 1)\n(1, 1, 1, 2, 1, 1, 1, 2, 1, 2)\n(1, 1, 1, 2, 1, 1, 1, 2, 1, 3)\n(1, 1, 1, 2, 1, 1, 1, 2, 1, 4)\n(1, 1, 1, 2, 1, 1, 1, 2, 2, 1)\n(1, 1, 1, 2, 1, 1, 1, 2, 2, 2)\n(1, 1, 1, 2, 1, 1, 1, 2, 2, 3)\n(1, 1, 1, 2, 1, 1, 1, 2, 3, 1)\n(1, 1, 1, 2, 1, 1, 1, 2, 3, 2)\n(1, 1, 1, 2, 1, 1, 1, 2, 4, 1)\n(1, 1, 1, 2, 1, 1, 1, 3, 1, 1)\n(1, 1, 1, 2, 1, 1, 1, 3, 1, 2)\n(1, 1, 1, 2, 1, 1, 1, 3, 1, 3)\n(1, 1, 1, 2, 1, 1, 1, 3, 2, 1)\n(1, 1, 1, 2, 1, 1, 1, 3, 2, 2)\n(1, 1, 1, 2, 1, 1, 1, 3, 3, 1)\n(1, 1, 1, 2, 1, 1, 1, 4, 1, 1)\n(1, 1, 1, 2, 1, 1, 1, 4, 1, 2)\n(1, 1, 1, 2, 1, 1, 1, 4, 2, 1)\n(1, 1, 1, 2, 1, 1, 1, 5, 1, 1)\n(1, 1, 1, 2, 1, 1, 2, 1, 1, 1)\n(1, 1, 1, 2, 1, 1, 2, 1, 1, 2)\n(1, 1, 1, 2, 1, 1, 2, 1, 1, 3)\n(1, 1, 1, 2, 1, 1, 2, 1, 1, 4)\n(1, 1, 1, 2, 1, 1, 2, 1, 2, 1)\n(1, 1, 1, 2, 1, 1, 2, 1, 2, 2)\n(1, 1, 1, 2, 1, 1, 2, 1, 2, 3)\n(1, 1, 1, 2, 1, 1, 2, 1, 3, 1)\n(1, 1, 1, 2, 1, 1, 2, 1, 3, 2)\n(1, 1, 1, 2, 1, 1, 2, 1, 4, 1)\n(1, 1, 1, 2, 1, 1, 2, 2, 1, 1)\n(1, 1, 1, 2, 1, 1, 2, 2, 1, 2)\n(1, 1, 1, 2, 1, 1, 2, 2, 1, 3)\n(1, 1, 1, 2, 1, 1, 2, 2, 2, 1)\n(1, 1, 1, 2, 1, 1, 2, 2, 2, 2)\n(1, 1, 1, 2, 1, 1, 2, 2, 3, 1)\n(1, 1, 1, 2, 1, 1, 2, 3, 1, 1)\n(1, 1, 1, 2, 1, 1, 2, 3, 1, 2)\n(1, 1, 1, 2, 1, 1, 2, 3, 2, 1)\n(1, 1, 1, 2, 1, 1, 2, 4, 1, 1)\n(1, 1, 1, 2, 1, 1, 3, 1, 1, 1)\n(1, 1, 1, 2, 1, 1, 3, 1, 1, 2)\n(1, 1, 1, 2, 1, 1, 3, 1, 1, 3)\n(1, 1, 1, 2, 1, 1, 3, 1, 2, 1)\n(1, 1, 1, 2, 1, 1, 3, 1, 2, 2)\n(1, 1, 1, 2, 1, 1, 3, 1, 3, 1)\n(1, 1, 1, 2, 1, 1, 3, 2, 1, 1)\n(1, 1, 1, 2, 1, 1, 3, 2, 1, 2)\n(1, 1, 1, 2, 1, 1, 3, 2, 2, 1)\n(1, 1, 1, 2, 1, 1, 3, 3, 1, 1)\n(1, 1, 1, 2, 1, 1, 4, 1, 1, 1)\n(1, 1, 1, 2, 1, 1, 4, 1, 1, 2)\n(1, 1, 1, 2, 1, 1, 4, 1, 2, 1)\n(1, 1, 1, 2, 1, 1, 4, 2, 1, 1)\n(1, 1, 1, 2, 1, 1, 5, 1, 1, 1)\n(1, 1, 1, 2, 1, 2, 1, 1, 1, 1)\n(1, 1, 1, 2, 1, 2, 1, 1, 1, 2)\n(1, 1, 1, 2, 1, 2, 1, 1, 1, 3)\n(1, 1, 1, 2, 1, 2, 1, 1, 1, 4)\n(1, 1, 1, 2, 1, 2, 1, 1, 2, 1)\n(1, 1, 1, 2, 1, 2, 1, 1, 2, 2)\n(1, 1, 1, 2, 1, 2, 1, 1, 2, 3)\n(1, 1, 1, 2, 1, 2, 1, 1, 3, 1)\n(1, 1, 1, 2, 1, 2, 1, 1, 3, 2)\n(1, 1, 1, 2, 1, 2, 1, 1, 4, 1)\n(1, 1, 1, 2, 1, 2, 1, 2, 1, 1)\n(1, 1, 1, 2, 1, 2, 1, 2, 1, 2)\n(1, 1, 1, 2, 1, 2, 1, 2, 1, 3)\n(1, 1, 1, 2, 1, 2, 1, 2, 2, 1)\n(1, 1, 1, 2, 1, 2, 1, 2, 2, 2)\n(1, 1, 1, 2, 1, 2, 1, 2, 3, 1)\n(1, 1, 1, 2, 1, 2, 1, 3, 1, 1)\n(1, 1, 1, 2, 1, 2, 1, 3, 1, 2)\n(1, 1, 1, 2, 1, 2, 1, 3, 2, 1)\n(1, 1, 1, 2, 1, 2, 1, 4, 1, 1)\n(1, 1, 1, 2, 1, 2, 2, 1, 1, 1)\n(1, 1, 1, 2, 1, 2, 2, 1, 1, 2)\n(1, 1, 1, 2, 1, 2, 2, 1, 1, 3)\n(1, 1, 1, 2, 1, 2, 2, 1, 2, 1)\n(1, 1, 1, 2, 1, 2, 2, 1, 2, 2)\n(1, 1, 1, 2, 1, 2, 2, 1, 3, 1)\n(1, 1, 1, 2, 1, 2, 2, 2, 1, 1)\n(1, 1, 1, 2, 1, 2, 2, 2, 1, 2)\n(1, 1, 1, 2, 1, 2, 2, 2, 2, 1)\n(1, 1, 1, 2, 1, 2, 2, 3, 1, 1)\n(1, 1, 1, 2, 1, 2, 3, 1, 1, 1)\n(1, 1, 1, 2, 1, 2, 3, 1, 1, 2)\n(1, 1, 1, 2, 1, 2, 3, 1, 2, 1)\n(1, 1, 1, 2, 1, 2, 3, 2, 1, 1)\n(1, 1, 1, 2, 1, 2, 4, 1, 1, 1)\n(1, 1, 1, 2, 1, 3, 1, 1, 1, 1)\n(1, 1, 1, 2, 1, 3, 1, 1, 1, 2)\n(1, 1, 1, 2, 1, 3, 1, 1, 1, 3)\n(1, 1, 1, 2, 1, 3, 1, 1, 2, 1)\n(1, 1, 1, 2, 1, 3, 1, 1, 2, 2)\n(1, 1, 1, 2, 1, 3, 1, 1, 3, 1)\n(1, 1, 1, 2, 1, 3, 1, 2, 1, 1)\n(1, 1, 1, 2, 1, 3, 1, 2, 1, 2)\n(1, 1, 1, 2, 1, 3, 1, 2, 2, 1)\n(1, 1, 1, 2, 1, 3, 1, 3, 1, 1)\n(1, 1, 1, 2, 1, 3, 2, 1, 1, 1)\n(1, 1, 1, 2, 1, 3, 2, 1, 1, 2)\n(1, 1, 1, 2, 1, 3, 2, 1, 2, 1)\n(1, 1, 1, 2, 1, 3, 2, 2, 1, 1)\n(1, 1, 1, 2, 1, 3, 3, 1, 1, 1)\n(1, 1, 1, 2, 1, 4, 1, 1, 1, 1)\n(1, 1, 1, 2, 1, 4, 1, 1, 1, 2)\n(1, 1, 1, 2, 1, 4, 1, 1, 2, 1)\n(1, 1, 1, 2, 1, 4, 1, 2, 1, 1)\n(1, 1, 1, 2, 1, 4, 2, 1, 1, 1)\n(1, 1, 1, 2, 1, 5, 1, 1, 1, 1)\n(1, 1, 1, 2, 2, 1, 1, 1, 1, 1)\n(1, 1, 1, 2, 2, 1, 1, 1, 1, 2)\n(1, 1, 1, 2, 2, 1, 1, 1, 1, 3)\n(1, 1, 1, 2, 2, 1, 1, 1, 1, 4)\n(1, 1, 1, 2, 2, 1, 1, 1, 2, 1)\n(1, 1, 1, 2, 2, 1, 1, 1, 2, 2)\n(1, 1, 1, 2, 2, 1, 1, 1, 2, 3)\n(1, 1, 1, 2, 2, 1, 1, 1, 3, 1)\n(1, 1, 1, 2, 2, 1, 1, 1, 3, 2)\n(1, 1, 1, 2, 2, 1, 1, 1, 4, 1)\n(1, 1, 1, 2, 2, 1, 1, 2, 1, 1)\n(1, 1, 1, 2, 2, 1, 1, 2, 1, 2)\n(1, 1, 1, 2, 2, 1, 1, 2, 1, 3)\n(1, 1, 1, 2, 2, 1, 1, 2, 2, 1)\n(1, 1, 1, 2, 2, 1, 1, 2, 2, 2)\n(1, 1, 1, 2, 2, 1, 1, 2, 3, 1)\n(1, 1, 1, 2, 2, 1, 1, 3, 1, 1)\n(1, 1, 1, 2, 2, 1, 1, 3, 1, 2)\n(1, 1, 1, 2, 2, 1, 1, 3, 2, 1)\n(1, 1, 1, 2, 2, 1, 1, 4, 1, 1)\n(1, 1, 1, 2, 2, 1, 2, 1, 1, 1)\n(1, 1, 1, 2, 2, 1, 2, 1, 1, 2)\n(1, 1, 1, 2, 2, 1, 2, 1, 1, 3)\n(1, 1, 1, 2, 2, 1, 2, 1, 2, 1)\n(1, 1, 1, 2, 2, 1, 2, 1, 2, 2)\n(1, 1, 1, 2, 2, 1, 2, 1, 3, 1)\n(1, 1, 1, 2, 2, 1, 2, 2, 1, 1)\n(1, 1, 1, 2, 2, 1, 2, 2, 1, 2)\n(1, 1, 1, 2, 2, 1, 2, 2, 2, 1)\n(1, 1, 1, 2, 2, 1, 2, 3, 1, 1)\n(1, 1, 1, 2, 2, 1, 3, 1, 1, 1)\n(1, 1, 1, 2, 2, 1, 3, 1, 1, 2)\n(1, 1, 1, 2, 2, 1, 3, 1, 2, 1)\n(1, 1, 1, 2, 2, 1, 3, 2, 1, 1)\n(1, 1, 1, 2, 2, 1, 4, 1, 1, 1)\n(1, 1, 1, 2, 2, 2, 1, 1, 1, 1)\n(1, 1, 1, 2, 2, 2, 1, 1, 1, 2)\n(1, 1, 1, 2, 2, 2, 1, 1, 1, 3)\n(1, 1, 1, 2, 2, 2, 1, 1, 2, 1)\n(1, 1, 1, 2, 2, 2, 1, 1, 2, 2)\n(1, 1, 1, 2, 2, 2, 1, 1, 3, 1)\n(1, 1, 1, 2, 2, 2, 1, 2, 1, 1)\n(1, 1, 1, 2, 2, 2, 1, 2, 1, 2)\n(1, 1, 1, 2, 2, 2, 1, 2, 2, 1)\n(1, 1, 1, 2, 2, 2, 1, 3, 1, 1)\n(1, 1, 1, 2, 2, 2, 2, 1, 1, 1)\n(1, 1, 1, 2, 2, 2, 2, 1, 1, 2)\n(1, 1, 1, 2, 2, 2, 2, 1, 2, 1)\n(1, 1, 1, 2, 2, 2, 2, 2, 1, 1)\n(1, 1, 1, 2, 2, 2, 3, 1, 1, 1)\n(1, 1, 1, 2, 2, 3, 1, 1, 1, 1)\n(1, 1, 1, 2, 2, 3, 1, 1, 1, 2)\n(1, 1, 1, 2, 2, 3, 1, 1, 2, 1)\n(1, 1, 1, 2, 2, 3, 1, 2, 1, 1)\n(1, 1, 1, 2, 2, 3, 2, 1, 1, 1)\n(1, 1, 1, 2, 2, 4, 1, 1, 1, 1)\n(1, 1, 1, 2, 3, 1, 1, 1, 1, 1)\n(1, 1, 1, 2, 3, 1, 1, 1, 1, 2)\n(1, 1, 1, 2, 3, 1, 1, 1, 1, 3)\n(1, 1, 1, 2, 3, 1, 1, 1, 2, 1)\n(1, 1, 1, 2, 3, 1, 1, 1, 2, 2)\n(1, 1, 1, 2, 3, 1, 1, 1, 3, 1)\n(1, 1, 1, 2, 3, 1, 1, 2, 1, 1)\n(1, 1, 1, 2, 3, 1, 1, 2, 1, 2)\n(1, 1, 1, 2, 3, 1, 1, 2, 2, 1)\n(1, 1, 1, 2, 3, 1, 1, 3, 1, 1)\n(1, 1, 1, 2, 3, 1, 2, 1, 1, 1)\n(1, 1, 1, 2, 3, 1, 2, 1, 1, 2)\n(1, 1, 1, 2, 3, 1, 2, 1, 2, 1)\n(1, 1, 1, 2, 3, 1, 2, 2, 1, 1)\n(1, 1, 1, 2, 3, 1, 3, 1, 1, 1)\n(1, 1, 1, 2, 3, 2, 1, 1, 1, 1)\n(1, 1, 1, 2, 3, 2, 1, 1, 1, 2)\n(1, 1, 1, 2, 3, 2, 1, 1, 2, 1)\n(1, 1, 1, 2, 3, 2, 1, 2, 1, 1)\n(1, 1, 1, 2, 3, 2, 2, 1, 1, 1)\n(1, 1, 1, 2, 3, 3, 1, 1, 1, 1)\n(1, 1, 1, 2, 4, 1, 1, 1, 1, 1)\n(1, 1, 1, 2, 4, 1, 1, 1, 1, 2)\n(1, 1, 1, 2, 4, 1, 1, 1, 2, 1)\n(1, 1, 1, 2, 4, 1, 1, 2, 1, 1)\n(1, 1, 1, 2, 4, 1, 2, 1, 1, 1)\n(1, 1, 1, 2, 4, 2, 1, 1, 1, 1)\n(1, 1, 1, 2, 5, 1, 1, 1, 1, 1)\n(1, 1, 1, 3, 1, 1, 1, 1, 1, 1)\n(1, 1, 1, 3, 1, 1, 1, 1, 1, 2)\n(1, 1, 1, 3, 1, 1, 1, 1, 1, 3)\n(1, 1, 1, 3, 1, 1, 1, 1, 1, 4)\n(1, 1, 1, 3, 1, 1, 1, 1, 2, 1)\n(1, 1, 1, 3, 1, 1, 1, 1, 2, 2)\n(1, 1, 1, 3, 1, 1, 1, 1, 2, 3)\n(1, 1, 1, 3, 1, 1, 1, 1, 3, 1)\n(1, 1, 1, 3, 1, 1, 1, 1, 3, 2)\n(1, 1, 1, 3, 1, 1, 1, 1, 4, 1)\n(1, 1, 1, 3, 1, 1, 1, 2, 1, 1)\n(1, 1, 1, 3, 1, 1, 1, 2, 1, 2)\n(1, 1, 1, 3, 1, 1, 1, 2, 1, 3)\n(1, 1, 1, 3, 1, 1, 1, 2, 2, 1)\n(1, 1, 1, 3, 1, 1, 1, 2, 2, 2)\n(1, 1, 1, 3, 1, 1, 1, 2, 3, 1)\n(1, 1, 1, 3, 1, 1, 1, 3, 1, 1)\n(1, 1, 1, 3, 1, 1, 1, 3, 1, 2)\n(1, 1, 1, 3, 1, 1, 1, 3, 2, 1)\n(1, 1, 1, 3, 1, 1, 1, 4, 1, 1)\n(1, 1, 1, 3, 1, 1, 2, 1, 1, 1)\n(1, 1, 1, 3, 1, 1, 2, 1, 1, 2)\n(1, 1, 1, 3, 1, 1, 2, 1, 1, 3)\n(1, 1, 1, 3, 1, 1, 2, 1, 2, 1)\n(1, 1, 1, 3, 1, 1, 2, 1, 2, 2)\n(1, 1, 1, 3, 1, 1, 2, 1, 3, 1)\n(1, 1, 1, 3, 1, 1, 2, 2, 1, 1)\n(1, 1, 1, 3, 1, 1, 2, 2, 1, 2)\n(1, 1, 1, 3, 1, 1, 2, 2, 2, 1)\n(1, 1, 1, 3, 1, 1, 2, 3, 1, 1)\n(1, 1, 1, 3, 1, 1, 3, 1, 1, 1)\n(1, 1, 1, 3, 1, 1, 3, 1, 1, 2)\n(1, 1, 1, 3, 1, 1, 3, 1, 2, 1)\n(1, 1, 1, 3, 1, 1, 3, 2, 1, 1)\n(1, 1, 1, 3, 1, 1, 4, 1, 1, 1)\n(1, 1, 1, 3, 1, 2, 1, 1, 1, 1)\n(1, 1, 1, 3, 1, 2, 1, 1, 1, 2)\n(1, 1, 1, 3, 1, 2, 1, 1, 1, 3)\n(1, 1, 1, 3, 1, 2, 1, 1, 2, 1)\n(1, 1, 1, 3, 1, 2, 1, 1, 2, 2)\n(1, 1, 1, 3, 1, 2, 1, 1, 3, 1)\n(1, 1, 1, 3, 1, 2, 1, 2, 1, 1)\n(1, 1, 1, 3, 1, 2, 1, 2, 1, 2)\n(1, 1, 1, 3, 1, 2, 1, 2, 2, 1)\n(1, 1, 1, 3, 1, 2, 1, 3, 1, 1)\n(1, 1, 1, 3, 1, 2, 2, 1, 1, 1)\n(1, 1, 1, 3, 1, 2, 2, 1, 1, 2)\n(1, 1, 1, 3, 1, 2, 2, 1, 2, 1)\n(1, 1, 1, 3, 1, 2, 2, 2, 1, 1)\n(1, 1, 1, 3, 1, 2, 3, 1, 1, 1)\n(1, 1, 1, 3, 1, 3, 1, 1, 1, 1)\n(1, 1, 1, 3, 1, 3, 1, 1, 1, 2)\n(1, 1, 1, 3, 1, 3, 1, 1, 2, 1)\n(1, 1, 1, 3, 1, 3, 1, 2, 1, 1)\n(1, 1, 1, 3, 1, 3, 2, 1, 1, 1)\n(1, 1, 1, 3, 1, 4, 1, 1, 1, 1)\n(1, 1, 1, 3, 2, 1, 1, 1, 1, 1)\n(1, 1, 1, 3, 2, 1, 1, 1, 1, 2)\n(1, 1, 1, 3, 2, 1, 1, 1, 1, 3)\n(1, 1, 1, 3, 2, 1, 1, 1, 2, 1)\n(1, 1, 1, 3, 2, 1, 1, 1, 2, 2)\n(1, 1, 1, 3, 2, 1, 1, 1, 3, 1)\n(1, 1, 1, 3, 2, 1, 1, 2, 1, 1)\n(1, 1, 1, 3, 2, 1, 1, 2, 1, 2)\n(1, 1, 1, 3, 2, 1, 1, 2, 2, 1)\n(1, 1, 1, 3, 2, 1, 1, 3, 1, 1)\n(1, 1, 1, 3, 2, 1, 2, 1, 1, 1)\n(1, 1, 1, 3, 2, 1, 2, 1, 1, 2)\n(1, 1, 1, 3, 2, 1, 2, 1, 2, 1)\n(1, 1, 1, 3, 2, 1, 2, 2, 1, 1)\n(1, 1, 1, 3, 2, 1, 3, 1, 1, 1)\n(1, 1, 1, 3, 2, 2, 1, 1, 1, 1)\n(1, 1, 1, 3, 2, 2, 1, 1, 1, 2)\n(1, 1, 1, 3, 2, 2, 1, 1, 2, 1)\n(1, 1, 1, 3, 2, 2, 1, 2, 1, 1)\n(1, 1, 1, 3, 2, 2, 2, 1, 1, 1)\n(1, 1, 1, 3, 2, 3, 1, 1, 1, 1)\n(1, 1, 1, 3, 3, 1, 1, 1, 1, 1)\n(1, 1, 1, 3, 3, 1, 1, 1, 1, 2)\n(1, 1, 1, 3, 3, 1, 1, 1, 2, 1)\n(1, 1, 1, 3, 3, 1, 1, 2, 1, 1)\n(1, 1, 1, 3, 3, 1, 2, 1, 1, 1)\n(1, 1, 1, 3, 3, 2, 1, 1, 1, 1)\n(1, 1, 1, 3, 4, 1, 1, 1, 1, 1)\n(1, 1, 1, 4, 1, 1, 1, 1, 1, 1)\n(1, 1, 1, 4, 1, 1, 1, 1, 1, 2)\n(1, 1, 1, 4, 1, 1, 1, 1, 1, 3)\n(1, 1, 1, 4, 1, 1, 1, 1, 2, 1)\n(1, 1, 1, 4, 1, 1, 1, 1, 2, 2)\n(1, 1, 1, 4, 1, 1, 1, 1, 3, 1)\n(1, 1, 1, 4, 1, 1, 1, 2, 1, 1)\n(1, 1, 1, 4, 1, 1, 1, 2, 1, 2)\n(1, 1, 1, 4, 1, 1, 1, 2, 2, 1)\n(1, 1, 1, 4, 1, 1, 1, 3, 1, 1)\n(1, 1, 1, 4, 1, 1, 2, 1, 1, 1)\n(1, 1, 1, 4, 1, 1, 2, 1, 1, 2)\n(1, 1, 1, 4, 1, 1, 2, 1, 2, 1)\n(1, 1, 1, 4, 1, 1, 2, 2, 1, 1)\n(1, 1, 1, 4, 1, 1, 3, 1, 1, 1)\n(1, 1, 1, 4, 1, 2, 1, 1, 1, 1)\n(1, 1, 1, 4, 1, 2, 1, 1, 1, 2)\n(1, 1, 1, 4, 1, 2, 1, 1, 2, 1)\n(1, 1, 1, 4, 1, 2, 1, 2, 1, 1)\n(1, 1, 1, 4, 1, 2, 2, 1, 1, 1)\n(1, 1, 1, 4, 1, 3, 1, 1, 1, 1)\n(1, 1, 1, 4, 2, 1, 1, 1, 1, 1)\n(1, 1, 1, 4, 2, 1, 1, 1, 1, 2)\n(1, 1, 1, 4, 2, 1, 1, 1, 2, 1)\n(1, 1, 1, 4, 2, 1, 1, 2, 1, 1)\n(1, 1, 1, 4, 2, 1, 2, 1, 1, 1)\n(1, 1, 1, 4, 2, 2, 1, 1, 1, 1)\n(1, 1, 1, 4, 3, 1, 1, 1, 1, 1)\n(1, 1, 1, 5, 1, 1, 1, 1, 1, 1)\n(1, 1, 1, 5, 1, 1, 1, 1, 1, 2)\n(1, 1, 1, 5, 1, 1, 1, 1, 2, 1)\n(1, 1, 1, 5, 1, 1, 1, 2, 1, 1)\n(1, 1, 1, 5, 1, 1, 2, 1, 1, 1)\n(1, 1, 1, 5, 1, 2, 1, 1, 1, 1)\n(1, 1, 1, 5, 2, 1, 1, 1, 1, 1)\n(1, 1, 1, 6, 1, 1, 1, 1, 1, 1)\n(1, 1, 2, 1, 1, 1, 1, 1, 1, 1)\n(1, 1, 2, 1, 1, 1, 1, 1, 1, 2)\n(1, 1, 2, 1, 1, 1, 1, 1, 1, 3)\n(1, 1, 2, 1, 1, 1, 1, 1, 1, 4)\n(1, 1, 2, 1, 1, 1, 1, 1, 1, 5)\n(1, 1, 2, 1, 1, 1, 1, 1, 2, 1)\n(1, 1, 2, 1, 1, 1, 1, 1, 2, 2)\n(1, 1, 2, 1, 1, 1, 1, 1, 2, 3)\n(1, 1, 2, 1, 1, 1, 1, 1, 2, 4)\n(1, 1, 2, 1, 1, 1, 1, 1, 3, 1)\n(1, 1, 2, 1, 1, 1, 1, 1, 3, 2)\n(1, 1, 2, 1, 1, 1, 1, 1, 3, 3)\n(1, 1, 2, 1, 1, 1, 1, 1, 4, 1)\n(1, 1, 2, 1, 1, 1, 1, 1, 4, 2)\n(1, 1, 2, 1, 1, 1, 1, 1, 5, 1)\n(1, 1, 2, 1, 1, 1, 1, 2, 1, 1)\n(1, 1, 2, 1, 1, 1, 1, 2, 1, 2)\n(1, 1, 2, 1, 1, 1, 1, 2, 1, 3)\n(1, 1, 2, 1, 1, 1, 1, 2, 1, 4)\n(1, 1, 2, 1, 1, 1, 1, 2, 2, 1)\n(1, 1, 2, 1, 1, 1, 1, 2, 2, 2)\n(1, 1, 2, 1, 1, 1, 1, 2, 2, 3)\n(1, 1, 2, 1, 1, 1, 1, 2, 3, 1)\n(1, 1, 2, 1, 1, 1, 1, 2, 3, 2)\n(1, 1, 2, 1, 1, 1, 1, 2, 4, 1)\n(1, 1, 2, 1, 1, 1, 1, 3, 1, 1)\n(1, 1, 2, 1, 1, 1, 1, 3, 1, 2)\n(1, 1, 2, 1, 1, 1, 1, 3, 1, 3)\n(1, 1, 2, 1, 1, 1, 1, 3, 2, 1)\n(1, 1, 2, 1, 1, 1, 1, 3, 2, 2)\n(1, 1, 2, 1, 1, 1, 1, 3, 3, 1)\n(1, 1, 2, 1, 1, 1, 1, 4, 1, 1)\n(1, 1, 2, 1, 1, 1, 1, 4, 1, 2)\n(1, 1, 2, 1, 1, 1, 1, 4, 2, 1)\n(1, 1, 2, 1, 1, 1, 1, 5, 1, 1)\n(1, 1, 2, 1, 1, 1, 2, 1, 1, 1)\n(1, 1, 2, 1, 1, 1, 2, 1, 1, 2)\n(1, 1, 2, 1, 1, 1, 2, 1, 1, 3)\n(1, 1, 2, 1, 1, 1, 2, 1, 1, 4)\n(1, 1, 2, 1, 1, 1, 2, 1, 2, 1)\n(1, 1, 2, 1, 1, 1, 2, 1, 2, 2)\n(1, 1, 2, 1, 1, 1, 2, 1, 2, 3)\n(1, 1, 2, 1, 1, 1, 2, 1, 3, 1)\n(1, 1, 2, 1, 1, 1, 2, 1, 3, 2)\n(1, 1, 2, 1, 1, 1, 2, 1, 4, 1)\n(1, 1, 2, 1, 1, 1, 2, 2, 1, 1)\n(1, 1, 2, 1, 1, 1, 2, 2, 1, 2)\n(1, 1, 2, 1, 1, 1, 2, 2, 1, 3)\n(1, 1, 2, 1, 1, 1, 2, 2, 2, 1)\n(1, 1, 2, 1, 1, 1, 2, 2, 2, 2)\n(1, 1, 2, 1, 1, 1, 2, 2, 3, 1)\n(1, 1, 2, 1, 1, 1, 2, 3, 1, 1)\n(1, 1, 2, 1, 1, 1, 2, 3, 1, 2)\n(1, 1, 2, 1, 1, 1, 2, 3, 2, 1)\n(1, 1, 2, 1, 1, 1, 2, 4, 1, 1)\n(1, 1, 2, 1, 1, 1, 3, 1, 1, 1)\n(1, 1, 2, 1, 1, 1, 3, 1, 1, 2)\n(1, 1, 2, 1, 1, 1, 3, 1, 1, 3)\n(1, 1, 2, 1, 1, 1, 3, 1, 2, 1)\n(1, 1, 2, 1, 1, 1, 3, 1, 2, 2)\n(1, 1, 2, 1, 1, 1, 3, 1, 3, 1)\n(1, 1, 2, 1, 1, 1, 3, 2, 1, 1)\n(1, 1, 2, 1, 1, 1, 3, 2, 1, 2)\n(1, 1, 2, 1, 1, 1, 3, 2, 2, 1)\n(1, 1, 2, 1, 1, 1, 3, 3, 1, 1)\n(1, 1, 2, 1, 1, 1, 4, 1, 1, 1)\n(1, 1, 2, 1, 1, 1, 4, 1, 1, 2)\n(1, 1, 2, 1, 1, 1, 4, 1, 2, 1)\n(1, 1, 2, 1, 1, 1, 4, 2, 1, 1)\n(1, 1, 2, 1, 1, 1, 5, 1, 1, 1)\n(1, 1, 2, 1, 1, 2, 1, 1, 1, 1)\n(1, 1, 2, 1, 1, 2, 1, 1, 1, 2)\n(1, 1, 2, 1, 1, 2, 1, 1, 1, 3)\n(1, 1, 2, 1, 1, 2, 1, 1, 1, 4)\n(1, 1, 2, 1, 1, 2, 1, 1, 2, 1)\n(1, 1, 2, 1, 1, 2, 1, 1, 2, 2)\n(1, 1, 2, 1, 1, 2, 1, 1, 2, 3)\n(1, 1, 2, 1, 1, 2, 1, 1, 3, 1)\n(1, 1, 2, 1, 1, 2, 1, 1, 3, 2)\n(1, 1, 2, 1, 1, 2, 1, 1, 4, 1)\n(1, 1, 2, 1, 1, 2, 1, 2, 1, 1)\n(1, 1, 2, 1, 1, 2, 1, 2, 1, 2)\n(1, 1, 2, 1, 1, 2, 1, 2, 1, 3)\n(1, 1, 2, 1, 1, 2, 1, 2, 2, 1)\n(1, 1, 2, 1, 1, 2, 1, 2, 2, 2)\n(1, 1, 2, 1, 1, 2, 1, 2, 3, 1)\n(1, 1, 2, 1, 1, 2, 1, 3, 1, 1)\n(1, 1, 2, 1, 1, 2, 1, 3, 1, 2)\n(1, 1, 2, 1, 1, 2, 1, 3, 2, 1)\n(1, 1, 2, 1, 1, 2, 1, 4, 1, 1)\n(1, 1, 2, 1, 1, 2, 2, 1, 1, 1)\n(1, 1, 2, 1, 1, 2, 2, 1, 1, 2)\n(1, 1, 2, 1, 1, 2, 2, 1, 1, 3)\n(1, 1, 2, 1, 1, 2, 2, 1, 2, 1)\n(1, 1, 2, 1, 1, 2, 2, 1, 2, 2)\n(1, 1, 2, 1, 1, 2, 2, 1, 3, 1)\n(1, 1, 2, 1, 1, 2, 2, 2, 1, 1)\n(1, 1, 2, 1, 1, 2, 2, 2, 1, 2)\n(1, 1, 2, 1, 1, 2, 2, 2, 2, 1)\n(1, 1, 2, 1, 1, 2, 2, 3, 1, 1)\n(1, 1, 2, 1, 1, 2, 3, 1, 1, 1)\n(1, 1, 2, 1, 1, 2, 3, 1, 1, 2)\n(1, 1, 2, 1, 1, 2, 3, 1, 2, 1)\n(1, 1, 2, 1, 1, 2, 3, 2, 1, 1)\n(1, 1, 2, 1, 1, 2, 4, 1, 1, 1)\n(1, 1, 2, 1, 1, 3, 1, 1, 1, 1)\n(1, 1, 2, 1, 1, 3, 1, 1, 1, 2)\n(1, 1, 2, 1, 1, 3, 1, 1, 1, 3)\n(1, 1, 2, 1, 1, 3, 1, 1, 2, 1)\n(1, 1, 2, 1, 1, 3, 1, 1, 2, 2)\n(1, 1, 2, 1, 1, 3, 1, 1, 3, 1)\n(1, 1, 2, 1, 1, 3, 1, 2, 1, 1)\n(1, 1, 2, 1, 1, 3, 1, 2, 1, 2)\n(1, 1, 2, 1, 1, 3, 1, 2, 2, 1)\n(1, 1, 2, 1, 1, 3, 1, 3, 1, 1)\n(1, 1, 2, 1, 1, 3, 2, 1, 1, 1)\n(1, 1, 2, 1, 1, 3, 2, 1, 1, 2)\n(1, 1, 2, 1, 1, 3, 2, 1, 2, 1)\n(1, 1, 2, 1, 1, 3, 2, 2, 1, 1)\n(1, 1, 2, 1, 1, 3, 3, 1, 1, 1)\n(1, 1, 2, 1, 1, 4, 1, 1, 1, 1)\n(1, 1, 2, 1, 1, 4, 1, 1, 1, 2)\n(1, 1, 2, 1, 1, 4, 1, 1, 2, 1)\n(1, 1, 2, 1, 1, 4, 1, 2, 1, 1)\n(1, 1, 2, 1, 1, 4, 2, 1, 1, 1)\n(1, 1, 2, 1, 1, 5, 1, 1, 1, 1)\n(1, 1, 2, 1, 2, 1, 1, 1, 1, 1)\n(1, 1, 2, 1, 2, 1, 1, 1, 1, 2)\n(1, 1, 2, 1, 2, 1, 1, 1, 1, 3)\n(1, 1, 2, 1, 2, 1, 1, 1, 1, 4)\n(1, 1, 2, 1, 2, 1, 1, 1, 2, 1)\n(1, 1, 2, 1, 2, 1, 1, 1, 2, 2)\n(1, 1, 2, 1, 2, 1, 1, 1, 2, 3)\n(1, 1, 2, 1, 2, 1, 1, 1, 3, 1)\n(1, 1, 2, 1, 2, 1, 1, 1, 3, 2)\n(1, 1, 2, 1, 2, 1, 1, 1, 4, 1)\n(1, 1, 2, 1, 2, 1, 1, 2, 1, 1)\n(1, 1, 2, 1, 2, 1, 1, 2, 1, 2)\n(1, 1, 2, 1, 2, 1, 1, 2, 1, 3)\n(1, 1, 2, 1, 2, 1, 1, 2, 2, 1)\n(1, 1, 2, 1, 2, 1, 1, 2, 2, 2)\n(1, 1, 2, 1, 2, 1, 1, 2, 3, 1)\n(1, 1, 2, 1, 2, 1, 1, 3, 1, 1)\n(1, 1, 2, 1, 2, 1, 1, 3, 1, 2)\n(1, 1, 2, 1, 2, 1, 1, 3, 2, 1)\n(1, 1, 2, 1, 2, 1, 1, 4, 1, 1)\n(1, 1, 2, 1, 2, 1, 2, 1, 1, 1)\n(1, 1, 2, 1, 2, 1, 2, 1, 1, 2)\n(1, 1, 2, 1, 2, 1, 2, 1, 1, 3)\n(1, 1, 2, 1, 2, 1, 2, 1, 2, 1)\n(1, 1, 2, 1, 2, 1, 2, 1, 2, 2)\n(1, 1, 2, 1, 2, 1, 2, 1, 3, 1)\n(1, 1, 2, 1, 2, 1, 2, 2, 1, 1)\n(1, 1, 2, 1, 2, 1, 2, 2, 1, 2)\n(1, 1, 2, 1, 2, 1, 2, 2, 2, 1)\n(1, 1, 2, 1, 2, 1, 2, 3, 1, 1)\n(1, 1, 2, 1, 2, 1, 3, 1, 1, 1)\n(1, 1, 2, 1, 2, 1, 3, 1, 1, 2)\n(1, 1, 2, 1, 2, 1, 3, 1, 2, 1)\n(1, 1, 2, 1, 2, 1, 3, 2, 1, 1)\n(1, 1, 2, 1, 2, 1, 4, 1, 1, 1)\n(1, 1, 2, 1, 2, 2, 1, 1, 1, 1)\n(1, 1, 2, 1, 2, 2, 1, 1, 1, 2)\n(1, 1, 2, 1, 2, 2, 1, 1, 1, 3)\n(1, 1, 2, 1, 2, 2, 1, 1, 2, 1)\n(1, 1, 2, 1, 2, 2, 1, 1, 2, 2)\n(1, 1, 2, 1, 2, 2, 1, 1, 3, 1)\n(1, 1, 2, 1, 2, 2, 1, 2, 1, 1)\n(1, 1, 2, 1, 2, 2, 1, 2, 1, 2)\n(1, 1, 2, 1, 2, 2, 1, 2, 2, 1)\n(1, 1, 2, 1, 2, 2, 1, 3, 1, 1)\n(1, 1, 2, 1, 2, 2, 2, 1, 1, 1)\n(1, 1, 2, 1, 2, 2, 2, 1, 1, 2)\n(1, 1, 2, 1, 2, 2, 2, 1, 2, 1)\n(1, 1, 2, 1, 2, 2, 2, 2, 1, 1)\n(1, 1, 2, 1, 2, 2, 3, 1, 1, 1)\n(1, 1, 2, 1, 2, 3, 1, 1, 1, 1)\n(1, 1, 2, 1, 2, 3, 1, 1, 1, 2)\n(1, 1, 2, 1, 2, 3, 1, 1, 2, 1)\n(1, 1, 2, 1, 2, 3, 1, 2, 1, 1)\n(1, 1, 2, 1, 2, 3, 2, 1, 1, 1)\n(1, 1, 2, 1, 2, 4, 1, 1, 1, 1)\n(1, 1, 2, 1, 3, 1, 1, 1, 1, 1)\n(1, 1, 2, 1, 3, 1, 1, 1, 1, 2)\n(1, 1, 2, 1, 3, 1, 1, 1, 1, 3)\n(1, 1, 2, 1, 3, 1, 1, 1, 2, 1)\n(1, 1, 2, 1, 3, 1, 1, 1, 2, 2)\n(1, 1, 2, 1, 3, 1, 1, 1, 3, 1)\n(1, 1, 2, 1, 3, 1, 1, 2, 1, 1)\n(1, 1, 2, 1, 3, 1, 1, 2, 1, 2)\n(1, 1, 2, 1, 3, 1, 1, 2, 2, 1)\n(1, 1, 2, 1, 3, 1, 1, 3, 1, 1)\n(1, 1, 2, 1, 3, 1, 2, 1, 1, 1)\n(1, 1, 2, 1, 3, 1, 2, 1, 1, 2)\n(1, 1, 2, 1, 3, 1, 2, 1, 2, 1)\n(1, 1, 2, 1, 3, 1, 2, 2, 1, 1)\n(1, 1, 2, 1, 3, 1, 3, 1, 1, 1)\n(1, 1, 2, 1, 3, 2, 1, 1, 1, 1)\n(1, 1, 2, 1, 3, 2, 1, 1, 1, 2)\n(1, 1, 2, 1, 3, 2, 1, 1, 2, 1)\n(1, 1, 2, 1, 3, 2, 1, 2, 1, 1)\n(1, 1, 2, 1, 3, 2, 2, 1, 1, 1)\n(1, 1, 2, 1, 3, 3, 1, 1, 1, 1)\n(1, 1, 2, 1, 4, 1, 1, 1, 1, 1)\n(1, 1, 2, 1, 4, 1, 1, 1, 1, 2)\n(1, 1, 2, 1, 4, 1, 1, 1, 2, 1)\n(1, 1, 2, 1, 4, 1, 1, 2, 1, 1)\n(1, 1, 2, 1, 4, 1, 2, 1, 1, 1)\n(1, 1, 2, 1, 4, 2, 1, 1, 1, 1)\n(1, 1, 2, 1, 5, 1, 1, 1, 1, 1)\n(1, 1, 2, 2, 1, 1, 1, 1, 1, 1)\n(1, 1, 2, 2, 1, 1, 1, 1, 1, 2)\n(1, 1, 2, 2, 1, 1, 1, 1, 1, 3)\n(1, 1, 2, 2, 1, 1, 1, 1, 1, 4)\n(1, 1, 2, 2, 1, 1, 1, 1, 2, 1)\n(1, 1, 2, 2, 1, 1, 1, 1, 2, 2)\n(1, 1, 2, 2, 1, 1, 1, 1, 2, 3)\n(1, 1, 2, 2, 1, 1, 1, 1, 3, 1)\n(1, 1, 2, 2, 1, 1, 1, 1, 3, 2)\n(1, 1, 2, 2, 1, 1, 1, 1, 4, 1)\n(1, 1, 2, 2, 1, 1, 1, 2, 1, 1)\n(1, 1, 2, 2, 1, 1, 1, 2, 1, 2)\n(1, 1, 2, 2, 1, 1, 1, 2, 1, 3)\n(1, 1, 2, 2, 1, 1, 1, 2, 2, 1)\n(1, 1, 2, 2, 1, 1, 1, 2, 2, 2)\n(1, 1, 2, 2, 1, 1, 1, 2, 3, 1)\n(1, 1, 2, 2, 1, 1, 1, 3, 1, 1)\n(1, 1, 2, 2, 1, 1, 1, 3, 1, 2)\n(1, 1, 2, 2, 1, 1, 1, 3, 2, 1)\n(1, 1, 2, 2, 1, 1, 1, 4, 1, 1)\n(1, 1, 2, 2, 1, 1, 2, 1, 1, 1)\n(1, 1, 2, 2, 1, 1, 2, 1, 1, 2)\n(1, 1, 2, 2, 1, 1, 2, 1, 1, 3)\n(1, 1, 2, 2, 1, 1, 2, 1, 2, 1)\n(1, 1, 2, 2, 1, 1, 2, 1, 2, 2)\n(1, 1, 2, 2, 1, 1, 2, 1, 3, 1)\n(1, 1, 2, 2, 1, 1, 2, 2, 1, 1)\n(1, 1, 2, 2, 1, 1, 2, 2, 1, 2)\n(1, 1, 2, 2, 1, 1, 2, 2, 2, 1)\n(1, 1, 2, 2, 1, 1, 2, 3, 1, 1)\n(1, 1, 2, 2, 1, 1, 3, 1, 1, 1)\n(1, 1, 2, 2, 1, 1, 3, 1, 1, 2)\n(1, 1, 2, 2, 1, 1, 3, 1, 2, 1)\n(1, 1, 2, 2, 1, 1, 3, 2, 1, 1)\n(1, 1, 2, 2, 1, 1, 4, 1, 1, 1)\n(1, 1, 2, 2, 1, 2, 1, 1, 1, 1)\n(1, 1, 2, 2, 1, 2, 1, 1, 1, 2)\n(1, 1, 2, 2, 1, 2, 1, 1, 1, 3)\n(1, 1, 2, 2, 1, 2, 1, 1, 2, 1)\n(1, 1, 2, 2, 1, 2, 1, 1, 2, 2)\n(1, 1, 2, 2, 1, 2, 1, 1, 3, 1)\n(1, 1, 2, 2, 1, 2, 1, 2, 1, 1)\n(1, 1, 2, 2, 1, 2, 1, 2, 1, 2)\n(1, 1, 2, 2, 1, 2, 1, 2, 2, 1)\n(1, 1, 2, 2, 1, 2, 1, 3, 1, 1)\n(1, 1, 2, 2, 1, 2, 2, 1, 1, 1)\n(1, 1, 2, 2, 1, 2, 2, 1, 1, 2)\n(1, 1, 2, 2, 1, 2, 2, 1, 2, 1)\n(1, 1, 2, 2, 1, 2, 2, 2, 1, 1)\n(1, 1, 2, 2, 1, 2, 3, 1, 1, 1)\n(1, 1, 2, 2, 1, 3, 1, 1, 1, 1)\n(1, 1, 2, 2, 1, 3, 1, 1, 1, 2)\n(1, 1, 2, 2, 1, 3, 1, 1, 2, 1)\n(1, 1, 2, 2, 1, 3, 1, 2, 1, 1)\n(1, 1, 2, 2, 1, 3, 2, 1, 1, 1)\n(1, 1, 2, 2, 1, 4, 1, 1, 1, 1)\n(1, 1, 2, 2, 2, 1, 1, 1, 1, 1)\n(1, 1, 2, 2, 2, 1, 1, 1, 1, 2)\n(1, 1, 2, 2, 2, 1, 1, 1, 1, 3)\n(1, 1, 2, 2, 2, 1, 1, 1, 2, 1)\n(1, 1, 2, 2, 2, 1, 1, 1, 2, 2)\n(1, 1, 2, 2, 2, 1, 1, 1, 3, 1)\n(1, 1, 2, 2, 2, 1, 1, 2, 1, 1)\n(1, 1, 2, 2, 2, 1, 1, 2, 1, 2)\n(1, 1, 2, 2, 2, 1, 1, 2, 2, 1)\n(1, 1, 2, 2, 2, 1, 1, 3, 1, 1)\n(1, 1, 2, 2, 2, 1, 2, 1, 1, 1)\n(1, 1, 2, 2, 2, 1, 2, 1, 1, 2)\n(1, 1, 2, 2, 2, 1, 2, 1, 2, 1)\n(1, 1, 2, 2, 2, 1, 2, 2, 1, 1)\n(1, 1, 2, 2, 2, 1, 3, 1, 1, 1)\n(1, 1, 2, 2, 2, 2, 1, 1, 1, 1)\n(1, 1, 2, 2, 2, 2, 1, 1, 1, 2)\n(1, 1, 2, 2, 2, 2, 1, 1, 2, 1)\n(1, 1, 2, 2, 2, 2, 1, 2, 1, 1)\n(1, 1, 2, 2, 2, 2, 2, 1, 1, 1)\n(1, 1, 2, 2, 2, 3, 1, 1, 1, 1)\n(1, 1, 2, 2, 3, 1, 1, 1, 1, 1)\n(1, 1, 2, 2, 3, 1, 1, 1, 1, 2)\n(1, 1, 2, 2, 3, 1, 1, 1, 2, 1)\n(1, 1, 2, 2, 3, 1, 1, 2, 1, 1)\n(1, 1, 2, 2, 3, 1, 2, 1, 1, 1)\n(1, 1, 2, 2, 3, 2, 1, 1, 1, 1)\n(1, 1, 2, 2, 4, 1, 1, 1, 1, 1)\n(1, 1, 2, 3, 1, 1, 1, 1, 1, 1)\n(1, 1, 2, 3, 1, 1, 1, 1, 1, 2)\n(1, 1, 2, 3, 1, 1, 1, 1, 1, 3)\n(1, 1, 2, 3, 1, 1, 1, 1, 2, 1)\n(1, 1, 2, 3, 1, 1, 1, 1, 2, 2)\n(1, 1, 2, 3, 1, 1, 1, 1, 3, 1)\n(1, 1, 2, 3, 1, 1, 1, 2, 1, 1)\n(1, 1, 2, 3, 1, 1, 1, 2, 1, 2)\n(1, 1, 2, 3, 1, 1, 1, 2, 2, 1)\n(1, 1, 2, 3, 1, 1, 1, 3, 1, 1)\n(1, 1, 2, 3, 1, 1, 2, 1, 1, 1)\n(1, 1, 2, 3, 1, 1, 2, 1, 1, 2)\n(1, 1, 2, 3, 1, 1, 2, 1, 2, 1)\n(1, 1, 2, 3, 1, 1, 2, 2, 1, 1)\n(1, 1, 2, 3, 1, 1, 3, 1, 1, 1)\n(1, 1, 2, 3, 1, 2, 1, 1, 1, 1)\n(1, 1, 2, 3, 1, 2, 1, 1, 1, 2)\n(1, 1, 2, 3, 1, 2, 1, 1, 2, 1)\n(1, 1, 2, 3, 1, 2, 1, 2, 1, 1)\n(1, 1, 2, 3, 1, 2, 2, 1, 1, 1)\n(1, 1, 2, 3, 1, 3, 1, 1, 1, 1)\n(1, 1, 2, 3, 2, 1, 1, 1, 1, 1)\n(1, 1, 2, 3, 2, 1, 1, 1, 1, 2)\n(1, 1, 2, 3, 2, 1, 1, 1, 2, 1)\n(1, 1, 2, 3, 2, 1, 1, 2, 1, 1)\n(1, 1, 2, 3, 2, 1, 2, 1, 1, 1)\n(1, 1, 2, 3, 2, 2, 1, 1, 1, 1)\n(1, 1, 2, 3, 3, 1, 1, 1, 1, 1)\n(1, 1, 2, 4, 1, 1, 1, 1, 1, 1)\n(1, 1, 2, 4, 1, 1, 1, 1, 1, 2)\n(1, 1, 2, 4, 1, 1, 1, 1, 2, 1)\n(1, 1, 2, 4, 1, 1, 1, 2, 1, 1)\n(1, 1, 2, 4, 1, 1, 2, 1, 1, 1)\n(1, 1, 2, 4, 1, 2, 1, 1, 1, 1)\n(1, 1, 2, 4, 2, 1, 1, 1, 1, 1)\n(1, 1, 2, 5, 1, 1, 1, 1, 1, 1)\n(1, 1, 3, 1, 1, 1, 1, 1, 1, 1)\n(1, 1, 3, 1, 1, 1, 1, 1, 1, 2)\n(1, 1, 3, 1, 1, 1, 1, 1, 1, 3)\n(1, 1, 3, 1, 1, 1, 1, 1, 1, 4)\n(1, 1, 3, 1, 1, 1, 1, 1, 2, 1)\n(1, 1, 3, 1, 1, 1, 1, 1, 2, 2)\n(1, 1, 3, 1, 1, 1, 1, 1, 2, 3)\n(1, 1, 3, 1, 1, 1, 1, 1, 3, 1)\n(1, 1, 3, 1, 1, 1, 1, 1, 3, 2)\n(1, 1, 3, 1, 1, 1, 1, 1, 4, 1)\n(1, 1, 3, 1, 1, 1, 1, 2, 1, 1)\n(1, 1, 3, 1, 1, 1, 1, 2, 1, 2)\n(1, 1, 3, 1, 1, 1, 1, 2, 1, 3)\n(1, 1, 3, 1, 1, 1, 1, 2, 2, 1)\n(1, 1, 3, 1, 1, 1, 1, 2, 2, 2)\n(1, 1, 3, 1, 1, 1, 1, 2, 3, 1)\n(1, 1, 3, 1, 1, 1, 1, 3, 1, 1)\n(1, 1, 3, 1, 1, 1, 1, 3, 1, 2)\n(1, 1, 3, 1, 1, 1, 1, 3, 2, 1)\n(1, 1, 3, 1, 1, 1, 1, 4, 1, 1)\n(1, 1, 3, 1, 1, 1, 2, 1, 1, 1)\n(1, 1, 3, 1, 1, 1, 2, 1, 1, 2)\n(1, 1, 3, 1, 1, 1, 2, 1, 1, 3)\n(1, 1, 3, 1, 1, 1, 2, 1, 2, 1)\n(1, 1, 3, 1, 1, 1, 2, 1, 2, 2)\n(1, 1, 3, 1, 1, 1, 2, 1, 3, 1)\n(1, 1, 3, 1, 1, 1, 2, 2, 1, 1)\n(1, 1, 3, 1, 1, 1, 2, 2, 1, 2)\n(1, 1, 3, 1, 1, 1, 2, 2, 2, 1)\n(1, 1, 3, 1, 1, 1, 2, 3, 1, 1)\n(1, 1, 3, 1, 1, 1, 3, 1, 1, 1)\n(1, 1, 3, 1, 1, 1, 3, 1, 1, 2)\n(1, 1, 3, 1, 1, 1, 3, 1, 2, 1)\n(1, 1, 3, 1, 1, 1, 3, 2, 1, 1)\n(1, 1, 3, 1, 1, 1, 4, 1, 1, 1)\n(1, 1, 3, 1, 1, 2, 1, 1, 1, 1)\n(1, 1, 3, 1, 1, 2, 1, 1, 1, 2)\n(1, 1, 3, 1, 1, 2, 1, 1, 1, 3)\n(1, 1, 3, 1, 1, 2, 1, 1, 2, 1)\n(1, 1, 3, 1, 1, 2, 1, 1, 2, 2)\n(1, 1, 3, 1, 1, 2, 1, 1, 3, 1)\n(1, 1, 3, 1, 1, 2, 1, 2, 1, 1)\n(1, 1, 3, 1, 1, 2, 1, 2, 1, 2)\n(1, 1, 3, 1, 1, 2, 1, 2, 2, 1)\n(1, 1, 3, 1, 1, 2, 1, 3, 1, 1)\n(1, 1, 3, 1, 1, 2, 2, 1, 1, 1)\n(1, 1, 3, 1, 1, 2, 2, 1, 1, 2)\n(1, 1, 3, 1, 1, 2, 2, 1, 2, 1)\n(1, 1, 3, 1, 1, 2, 2, 2, 1, 1)\n(1, 1, 3, 1, 1, 2, 3, 1, 1, 1)\n(1, 1, 3, 1, 1, 3, 1, 1, 1, 1)\n(1, 1, 3, 1, 1, 3, 1, 1, 1, 2)\n(1, 1, 3, 1, 1, 3, 1, 1, 2, 1)\n(1, 1, 3, 1, 1, 3, 1, 2, 1, 1)\n(1, 1, 3, 1, 1, 3, 2, 1, 1, 1)\n(1, 1, 3, 1, 1, 4, 1, 1, 1, 1)\n(1, 1, 3, 1, 2, 1, 1, 1, 1, 1)\n(1, 1, 3, 1, 2, 1, 1, 1, 1, 2)\n(1, 1, 3, 1, 2, 1, 1, 1, 1, 3)\n(1, 1, 3, 1, 2, 1, 1, 1, 2, 1)\n(1, 1, 3, 1, 2, 1, 1, 1, 2, 2)\n(1, 1, 3, 1, 2, 1, 1, 1, 3, 1)\n(1, 1, 3, 1, 2, 1, 1, 2, 1, 1)\n(1, 1, 3, 1, 2, 1, 1, 2, 1, 2)\n(1, 1, 3, 1, 2, 1, 1, 2, 2, 1)\n(1, 1, 3, 1, 2, 1, 1, 3, 1, 1)\n(1, 1, 3, 1, 2, 1, 2, 1, 1, 1)\n(1, 1, 3, 1, 2, 1, 2, 1, 1, 2)\n(1, 1, 3, 1, 2, 1, 2, 1, 2, 1)\n(1, 1, 3, 1, 2, 1, 2, 2, 1, 1)\n(1, 1, 3, 1, 2, 1, 3, 1, 1, 1)\n(1, 1, 3, 1, 2, 2, 1, 1, 1, 1)\n(1, 1, 3, 1, 2, 2, 1, 1, 1, 2)\n(1, 1, 3, 1, 2, 2, 1, 1, 2, 1)\n(1, 1, 3, 1, 2, 2, 1, 2, 1, 1)\n(1, 1, 3, 1, 2, 2, 2, 1, 1, 1)\n(1, 1, 3, 1, 2, 3, 1, 1, 1, 1)\n(1, 1, 3, 1, 3, 1, 1, 1, 1, 1)\n(1, 1, 3, 1, 3, 1, 1, 1, 1, 2)\n(1, 1, 3, 1, 3, 1, 1, 1, 2, 1)\n(1, 1, 3, 1, 3, 1, 1, 2, 1, 1)\n(1, 1, 3, 1, 3, 1, 2, 1, 1, 1)\n(1, 1, 3, 1, 3, 2, 1, 1, 1, 1)\n(1, 1, 3, 1, 4, 1, 1, 1, 1, 1)\n(1, 1, 3, 2, 1, 1, 1, 1, 1, 1)\n(1, 1, 3, 2, 1, 1, 1, 1, 1, 2)\n(1, 1, 3, 2, 1, 1, 1, 1, 1, 3)\n(1, 1, 3, 2, 1, 1, 1, 1, 2, 1)\n(1, 1, 3, 2, 1, 1, 1, 1, 2, 2)\n(1, 1, 3, 2, 1, 1, 1, 1, 3, 1)\n(1, 1, 3, 2, 1, 1, 1, 2, 1, 1)\n(1, 1, 3, 2, 1, 1, 1, 2, 1, 2)\n(1, 1, 3, 2, 1, 1, 1, 2, 2, 1)\n(1, 1, 3, 2, 1, 1, 1, 3, 1, 1)\n(1, 1, 3, 2, 1, 1, 2, 1, 1, 1)\n(1, 1, 3, 2, 1, 1, 2, 1, 1, 2)\n(1, 1, 3, 2, 1, 1, 2, 1, 2, 1)\n(1, 1, 3, 2, 1, 1, 2, 2, 1, 1)\n(1, 1, 3, 2, 1, 1, 3, 1, 1, 1)\n(1, 1, 3, 2, 1, 2, 1, 1, 1, 1)\n(1, 1, 3, 2, 1, 2, 1, 1, 1, 2)\n(1, 1, 3, 2, 1, 2, 1, 1, 2, 1)\n(1, 1, 3, 2, 1, 2, 1, 2, 1, 1)\n(1, 1, 3, 2, 1, 2, 2, 1, 1, 1)\n(1, 1, 3, 2, 1, 3, 1, 1, 1, 1)\n(1, 1, 3, 2, 2, 1, 1, 1, 1, 1)\n(1, 1, 3, 2, 2, 1, 1, 1, 1, 2)\n(1, 1, 3, 2, 2, 1, 1, 1, 2, 1)\n(1, 1, 3, 2, 2, 1, 1, 2, 1, 1)\n(1, 1, 3, 2, 2, 1, 2, 1, 1, 1)\n(1, 1, 3, 2, 2, 2, 1, 1, 1, 1)\n(1, 1, 3, 2, 3, 1, 1, 1, 1, 1)\n(1, 1, 3, 3, 1, 1, 1, 1, 1, 1)\n(1, 1, 3, 3, 1, 1, 1, 1, 1, 2)\n(1, 1, 3, 3, 1, 1, 1, 1, 2, 1)\n(1, 1, 3, 3, 1, 1, 1, 2, 1, 1)\n(1, 1, 3, 3, 1, 1, 2, 1, 1, 1)\n(1, 1, 3, 3, 1, 2, 1, 1, 1, 1)\n(1, 1, 3, 3, 2, 1, 1, 1, 1, 1)\n(1, 1, 3, 4, 1, 1, 1, 1, 1, 1)\n(1, 1, 4, 1, 1, 1, 1, 1, 1, 1)\n(1, 1, 4, 1, 1, 1, 1, 1, 1, 2)\n(1, 1, 4, 1, 1, 1, 1, 1, 1, 3)\n(1, 1, 4, 1, 1, 1, 1, 1, 2, 1)\n(1, 1, 4, 1, 1, 1, 1, 1, 2, 2)\n(1, 1, 4, 1, 1, 1, 1, 1, 3, 1)\n(1, 1, 4, 1, 1, 1, 1, 2, 1, 1)\n(1, 1, 4, 1, 1, 1, 1, 2, 1, 2)\n(1, 1, 4, 1, 1, 1, 1, 2, 2, 1)\n(1, 1, 4, 1, 1, 1, 1, 3, 1, 1)\n(1, 1, 4, 1, 1, 1, 2, 1, 1, 1)\n(1, 1, 4, 1, 1, 1, 2, 1, 1, 2)\n(1, 1, 4, 1, 1, 1, 2, 1, 2, 1)\n(1, 1, 4, 1, 1, 1, 2, 2, 1, 1)\n(1, 1, 4, 1, 1, 1, 3, 1, 1, 1)\n(1, 1, 4, 1, 1, 2, 1, 1, 1, 1)\n(1, 1, 4, 1, 1, 2, 1, 1, 1, 2)\n(1, 1, 4, 1, 1, 2, 1, 1, 2, 1)\n(1, 1, 4, 1, 1, 2, 1, 2, 1, 1)\n(1, 1, 4, 1, 1, 2, 2, 1, 1, 1)\n(1, 1, 4, 1, 1, 3, 1, 1, 1, 1)\n(1, 1, 4, 1, 2, 1, 1, 1, 1, 1)\n(1, 1, 4, 1, 2, 1, 1, 1, 1, 2)\n(1, 1, 4, 1, 2, 1, 1, 1, 2, 1)\n(1, 1, 4, 1, 2, 1, 1, 2, 1, 1)\n(1, 1, 4, 1, 2, 1, 2, 1, 1, 1)\n(1, 1, 4, 1, 2, 2, 1, 1, 1, 1)\n(1, 1, 4, 1, 3, 1, 1, 1, 1, 1)\n(1, 1, 4, 2, 1, 1, 1, 1, 1, 1)\n(1, 1, 4, 2, 1, 1, 1, 1, 1, 2)\n(1, 1, 4, 2, 1, 1, 1, 1, 2, 1)\n(1, 1, 4, 2, 1, 1, 1, 2, 1, 1)\n(1, 1, 4, 2, 1, 1, 2, 1, 1, 1)\n(1, 1, 4, 2, 1, 2, 1, 1, 1, 1)\n(1, 1, 4, 2, 2, 1, 1, 1, 1, 1)\n(1, 1, 4, 3, 1, 1, 1, 1, 1, 1)\n(1, 1, 5, 1, 1, 1, 1, 1, 1, 1)\n(1, 1, 5, 1, 1, 1, 1, 1, 1, 2)\n(1, 1, 5, 1, 1, 1, 1, 1, 2, 1)\n(1, 1, 5, 1, 1, 1, 1, 2, 1, 1)\n(1, 1, 5, 1, 1, 1, 2, 1, 1, 1)\n(1, 1, 5, 1, 1, 2, 1, 1, 1, 1)\n(1, 1, 5, 1, 2, 1, 1, 1, 1, 1)\n(1, 1, 5, 2, 1, 1, 1, 1, 1, 1)\n(1, 1, 6, 1, 1, 1, 1, 1, 1, 1)\n(1, 2, 1, 1, 1, 1, 1, 1, 1, 1)\n(1, 2, 1, 1, 1, 1, 1, 1, 1, 2)\n(1, 2, 1, 1, 1, 1, 1, 1, 1, 3)\n(1, 2, 1, 1, 1, 1, 1, 1, 1, 4)\n(1, 2, 1, 1, 1, 1, 1, 1, 1, 5)\n(1, 2, 1, 1, 1, 1, 1, 1, 2, 1)\n(1, 2, 1, 1, 1, 1, 1, 1, 2, 2)\n(1, 2, 1, 1, 1, 1, 1, 1, 2, 3)\n(1, 2, 1, 1, 1, 1, 1, 1, 2, 4)\n(1, 2, 1, 1, 1, 1, 1, 1, 3, 1)\n(1, 2, 1, 1, 1, 1, 1, 1, 3, 2)\n(1, 2, 1, 1, 1, 1, 1, 1, 3, 3)\n(1, 2, 1, 1, 1, 1, 1, 1, 4, 1)\n(1, 2, 1, 1, 1, 1, 1, 1, 4, 2)\n(1, 2, 1, 1, 1, 1, 1, 1, 5, 1)\n(1, 2, 1, 1, 1, 1, 1, 2, 1, 1)\n(1, 2, 1, 1, 1, 1, 1, 2, 1, 2)\n(1, 2, 1, 1, 1, 1, 1, 2, 1, 3)\n(1, 2, 1, 1, 1, 1, 1, 2, 1, 4)\n(1, 2, 1, 1, 1, 1, 1, 2, 2, 1)\n(1, 2, 1, 1, 1, 1, 1, 2, 2, 2)\n(1, 2, 1, 1, 1, 1, 1, 2, 2, 3)\n(1, 2, 1, 1, 1, 1, 1, 2, 3, 1)\n(1, 2, 1, 1, 1, 1, 1, 2, 3, 2)\n(1, 2, 1, 1, 1, 1, 1, 2, 4, 1)\n(1, 2, 1, 1, 1, 1, 1, 3, 1, 1)\n(1, 2, 1, 1, 1, 1, 1, 3, 1, 2)\n(1, 2, 1, 1, 1, 1, 1, 3, 1, 3)\n(1, 2, 1, 1, 1, 1, 1, 3, 2, 1)\n(1, 2, 1, 1, 1, 1, 1, 3, 2, 2)\n(1, 2, 1, 1, 1, 1, 1, 3, 3, 1)\n(1, 2, 1, 1, 1, 1, 1, 4, 1, 1)\n(1, 2, 1, 1, 1, 1, 1, 4, 1, 2)\n(1, 2, 1, 1, 1, 1, 1, 4, 2, 1)\n(1, 2, 1, 1, 1, 1, 1, 5, 1, 1)\n(1, 2, 1, 1, 1, 1, 2, 1, 1, 1)\n(1, 2, 1, 1, 1, 1, 2, 1, 1, 2)\n(1, 2, 1, 1, 1, 1, 2, 1, 1, 3)\n(1, 2, 1, 1, 1, 1, 2, 1, 1, 4)\n(1, 2, 1, 1, 1, 1, 2, 1, 2, 1)\n(1, 2, 1, 1, 1, 1, 2, 1, 2, 2)\n(1, 2, 1, 1, 1, 1, 2, 1, 2, 3)\n(1, 2, 1, 1, 1, 1, 2, 1, 3, 1)\n(1, 2, 1, 1, 1, 1, 2, 1, 3, 2)\n(1, 2, 1, 1, 1, 1, 2, 1, 4, 1)\n(1, 2, 1, 1, 1, 1, 2, 2, 1, 1)\n(1, 2, 1, 1, 1, 1, 2, 2, 1, 2)\n(1, 2, 1, 1, 1, 1, 2, 2, 1, 3)\n(1, 2, 1, 1, 1, 1, 2, 2, 2, 1)\n(1, 2, 1, 1, 1, 1, 2, 2, 2, 2)\n(1, 2, 1, 1, 1, 1, 2, 2, 3, 1)\n(1, 2, 1, 1, 1, 1, 2, 3, 1, 1)\n(1, 2, 1, 1, 1, 1, 2, 3, 1, 2)\n(1, 2, 1, 1, 1, 1, 2, 3, 2, 1)\n(1, 2, 1, 1, 1, 1, 2, 4, 1, 1)\n(1, 2, 1, 1, 1, 1, 3, 1, 1, 1)\n(1, 2, 1, 1, 1, 1, 3, 1, 1, 2)\n(1, 2, 1, 1, 1, 1, 3, 1, 1, 3)\n(1, 2, 1, 1, 1, 1, 3, 1, 2, 1)\n(1, 2, 1, 1, 1, 1, 3, 1, 2, 2)\n(1, 2, 1, 1, 1, 1, 3, 1, 3, 1)\n(1, 2, 1, 1, 1, 1, 3, 2, 1, 1)\n(1, 2, 1, 1, 1, 1, 3, 2, 1, 2)\n(1, 2, 1, 1, 1, 1, 3, 2, 2, 1)\n(1, 2, 1, 1, 1, 1, 3, 3, 1, 1)\n(1, 2, 1, 1, 1, 1, 4, 1, 1, 1)\n(1, 2, 1, 1, 1, 1, 4, 1, 1, 2)\n(1, 2, 1, 1, 1, 1, 4, 1, 2, 1)\n(1, 2, 1, 1, 1, 1, 4, 2, 1, 1)\n(1, 2, 1, 1, 1, 1, 5, 1, 1, 1)\n(1, 2, 1, 1, 1, 2, 1, 1, 1, 1)\n(1, 2, 1, 1, 1, 2, 1, 1, 1, 2)\n(1, 2, 1, 1, 1, 2, 1, 1, 1, 3)\n(1, 2, 1, 1, 1, 2, 1, 1, 1, 4)\n(1, 2, 1, 1, 1, 2, 1, 1, 2, 1)\n(1, 2, 1, 1, 1, 2, 1, 1, 2, 2)\n(1, 2, 1, 1, 1, 2, 1, 1, 2, 3)\n(1, 2, 1, 1, 1, 2, 1, 1, 3, 1)\n(1, 2, 1, 1, 1, 2, 1, 1, 3, 2)\n(1, 2, 1, 1, 1, 2, 1, 1, 4, 1)\n(1, 2, 1, 1, 1, 2, 1, 2, 1, 1)\n(1, 2, 1, 1, 1, 2, 1, 2, 1, 2)\n(1, 2, 1, 1, 1, 2, 1, 2, 1, 3)\n(1, 2, 1, 1, 1, 2, 1, 2, 2, 1)\n(1, 2, 1, 1, 1, 2, 1, 2, 2, 2)\n(1, 2, 1, 1, 1, 2, 1, 2, 3, 1)\n(1, 2, 1, 1, 1, 2, 1, 3, 1, 1)\n(1, 2, 1, 1, 1, 2, 1, 3, 1, 2)\n(1, 2, 1, 1, 1, 2, 1, 3, 2, 1)\n(1, 2, 1, 1, 1, 2, 1, 4, 1, 1)\n(1, 2, 1, 1, 1, 2, 2, 1, 1, 1)\n(1, 2, 1, 1, 1, 2, 2, 1, 1, 2)\n(1, 2, 1, 1, 1, 2, 2, 1, 1, 3)\n(1, 2, 1, 1, 1, 2, 2, 1, 2, 1)\n(1, 2, 1, 1, 1, 2, 2, 1, 2, 2)\n(1, 2, 1, 1, 1, 2, 2, 1, 3, 1)\n(1, 2, 1, 1, 1, 2, 2, 2, 1, 1)\n(1, 2, 1, 1, 1, 2, 2, 2, 1, 2)\n(1, 2, 1, 1, 1, 2, 2, 2, 2, 1)\n(1, 2, 1, 1, 1, 2, 2, 3, 1, 1)\n(1, 2, 1, 1, 1, 2, 3, 1, 1, 1)\n(1, 2, 1, 1, 1, 2, 3, 1, 1, 2)\n(1, 2, 1, 1, 1, 2, 3, 1, 2, 1)\n(1, 2, 1, 1, 1, 2, 3, 2, 1, 1)\n(1, 2, 1, 1, 1, 2, 4, 1, 1, 1)\n(1, 2, 1, 1, 1, 3, 1, 1, 1, 1)\n(1, 2, 1, 1, 1, 3, 1, 1, 1, 2)\n(1, 2, 1, 1, 1, 3, 1, 1, 1, 3)\n(1, 2, 1, 1, 1, 3, 1, 1, 2, 1)\n(1, 2, 1, 1, 1, 3, 1, 1, 2, 2)\n(1, 2, 1, 1, 1, 3, 1, 1, 3, 1)\n(1, 2, 1, 1, 1, 3, 1, 2, 1, 1)\n(1, 2, 1, 1, 1, 3, 1, 2, 1, 2)\n(1, 2, 1, 1, 1, 3, 1, 2, 2, 1)\n(1, 2, 1, 1, 1, 3, 1, 3, 1, 1)\n(1, 2, 1, 1, 1, 3, 2, 1, 1, 1)\n(1, 2, 1, 1, 1, 3, 2, 1, 1, 2)\n(1, 2, 1, 1, 1, 3, 2, 1, 2, 1)\n(1, 2, 1, 1, 1, 3, 2, 2, 1, 1)\n(1, 2, 1, 1, 1, 3, 3, 1, 1, 1)\n(1, 2, 1, 1, 1, 4, 1, 1, 1, 1)\n(1, 2, 1, 1, 1, 4, 1, 1, 1, 2)\n(1, 2, 1, 1, 1, 4, 1, 1, 2, 1)\n(1, 2, 1, 1, 1, 4, 1, 2, 1, 1)\n(1, 2, 1, 1, 1, 4, 2, 1, 1, 1)\n(1, 2, 1, 1, 1, 5, 1, 1, 1, 1)\n(1, 2, 1, 1, 2, 1, 1, 1, 1, 1)\n(1, 2, 1, 1, 2, 1, 1, 1, 1, 2)\n(1, 2, 1, 1, 2, 1, 1, 1, 1, 3)\n(1, 2, 1, 1, 2, 1, 1, 1, 1, 4)\n(1, 2, 1, 1, 2, 1, 1, 1, 2, 1)\n(1, 2, 1, 1, 2, 1, 1, 1, 2, 2)\n(1, 2, 1, 1, 2, 1, 1, 1, 2, 3)\n(1, 2, 1, 1, 2, 1, 1, 1, 3, 1)\n(1, 2, 1, 1, 2, 1, 1, 1, 3, 2)\n(1, 2, 1, 1, 2, 1, 1, 1, 4, 1)\n(1, 2, 1, 1, 2, 1, 1, 2, 1, 1)\n(1, 2, 1, 1, 2, 1, 1, 2, 1, 2)\n(1, 2, 1, 1, 2, 1, 1, 2, 1, 3)\n(1, 2, 1, 1, 2, 1, 1, 2, 2, 1)\n(1, 2, 1, 1, 2, 1, 1, 2, 2, 2)\n(1, 2, 1, 1, 2, 1, 1, 2, 3, 1)\n(1, 2, 1, 1, 2, 1, 1, 3, 1, 1)\n(1, 2, 1, 1, 2, 1, 1, 3, 1, 2)\n(1, 2, 1, 1, 2, 1, 1, 3, 2, 1)\n(1, 2, 1, 1, 2, 1, 1, 4, 1, 1)\n(1, 2, 1, 1, 2, 1, 2, 1, 1, 1)\n(1, 2, 1, 1, 2, 1, 2, 1, 1, 2)\n(1, 2, 1, 1, 2, 1, 2, 1, 1, 3)\n(1, 2, 1, 1, 2, 1, 2, 1, 2, 1)\n(1, 2, 1, 1, 2, 1, 2, 1, 2, 2)\n(1, 2, 1, 1, 2, 1, 2, 1, 3, 1)\n(1, 2, 1, 1, 2, 1, 2, 2, 1, 1)\n(1, 2, 1, 1, 2, 1, 2, 2, 1, 2)\n(1, 2, 1, 1, 2, 1, 2, 2, 2, 1)\n(1, 2, 1, 1, 2, 1, 2, 3, 1, 1)\n(1, 2, 1, 1, 2, 1, 3, 1, 1, 1)\n(1, 2, 1, 1, 2, 1, 3, 1, 1, 2)\n(1, 2, 1, 1, 2, 1, 3, 1, 2, 1)\n(1, 2, 1, 1, 2, 1, 3, 2, 1, 1)\n(1, 2, 1, 1, 2, 1, 4, 1, 1, 1)\n(1, 2, 1, 1, 2, 2, 1, 1, 1, 1)\n(1, 2, 1, 1, 2, 2, 1, 1, 1, 2)\n(1, 2, 1, 1, 2, 2, 1, 1, 1, 3)\n(1, 2, 1, 1, 2, 2, 1, 1, 2, 1)\n(1, 2, 1, 1, 2, 2, 1, 1, 2, 2)\n(1, 2, 1, 1, 2, 2, 1, 1, 3, 1)\n(1, 2, 1, 1, 2, 2, 1, 2, 1, 1)\n(1, 2, 1, 1, 2, 2, 1, 2, 1, 2)\n(1, 2, 1, 1, 2, 2, 1, 2, 2, 1)\n(1, 2, 1, 1, 2, 2, 1, 3, 1, 1)\n(1, 2, 1, 1, 2, 2, 2, 1, 1, 1)\n(1, 2, 1, 1, 2, 2, 2, 1, 1, 2)\n(1, 2, 1, 1, 2, 2, 2, 1, 2, 1)\n(1, 2, 1, 1, 2, 2, 2, 2, 1, 1)\n(1, 2, 1, 1, 2, 2, 3, 1, 1, 1)\n(1, 2, 1, 1, 2, 3, 1, 1, 1, 1)\n(1, 2, 1, 1, 2, 3, 1, 1, 1, 2)\n(1, 2, 1, 1, 2, 3, 1, 1, 2, 1)\n(1, 2, 1, 1, 2, 3, 1, 2, 1, 1)\n(1, 2, 1, 1, 2, 3, 2, 1, 1, 1)\n(1, 2, 1, 1, 2, 4, 1, 1, 1, 1)\n(1, 2, 1, 1, 3, 1, 1, 1, 1, 1)\n(1, 2, 1, 1, 3, 1, 1, 1, 1, 2)\n(1, 2, 1, 1, 3, 1, 1, 1, 1, 3)\n(1, 2, 1, 1, 3, 1, 1, 1, 2, 1)\n(1, 2, 1, 1, 3, 1, 1, 1, 2, 2)\n(1, 2, 1, 1, 3, 1, 1, 1, 3, 1)\n(1, 2, 1, 1, 3, 1, 1, 2, 1, 1)\n(1, 2, 1, 1, 3, 1, 1, 2, 1, 2)\n(1, 2, 1, 1, 3, 1, 1, 2, 2, 1)\n(1, 2, 1, 1, 3, 1, 1, 3, 1, 1)\n(1, 2, 1, 1, 3, 1, 2, 1, 1, 1)\n(1, 2, 1, 1, 3, 1, 2, 1, 1, 2)\n(1, 2, 1, 1, 3, 1, 2, 1, 2, 1)\n(1, 2, 1, 1, 3, 1, 2, 2, 1, 1)\n(1, 2, 1, 1, 3, 1, 3, 1, 1, 1)\n(1, 2, 1, 1, 3, 2, 1, 1, 1, 1)\n(1, 2, 1, 1, 3, 2, 1, 1, 1, 2)\n(1, 2, 1, 1, 3, 2, 1, 1, 2, 1)\n(1, 2, 1, 1, 3, 2, 1, 2, 1, 1)\n(1, 2, 1, 1, 3, 2, 2, 1, 1, 1)\n(1, 2, 1, 1, 3, 3, 1, 1, 1, 1)\n(1, 2, 1, 1, 4, 1, 1, 1, 1, 1)\n(1, 2, 1, 1, 4, 1, 1, 1, 1, 2)\n(1, 2, 1, 1, 4, 1, 1, 1, 2, 1)\n(1, 2, 1, 1, 4, 1, 1, 2, 1, 1)\n(1, 2, 1, 1, 4, 1, 2, 1, 1, 1)\n(1, 2, 1, 1, 4, 2, 1, 1, 1, 1)\n(1, 2, 1, 1, 5, 1, 1, 1, 1, 1)\n(1, 2, 1, 2, 1, 1, 1, 1, 1, 1)\n(1, 2, 1, 2, 1, 1, 1, 1, 1, 2)\n(1, 2, 1, 2, 1, 1, 1, 1, 1, 3)\n(1, 2, 1, 2, 1, 1, 1, 1, 1, 4)\n(1, 2, 1, 2, 1, 1, 1, 1, 2, 1)\n(1, 2, 1, 2, 1, 1, 1, 1, 2, 2)\n(1, 2, 1, 2, 1, 1, 1, 1, 2, 3)\n(1, 2, 1, 2, 1, 1, 1, 1, 3, 1)\n(1, 2, 1, 2, 1, 1, 1, 1, 3, 2)\n(1, 2, 1, 2, 1, 1, 1, 1, 4, 1)\n(1, 2, 1, 2, 1, 1, 1, 2, 1, 1)\n(1, 2, 1, 2, 1, 1, 1, 2, 1, 2)\n(1, 2, 1, 2, 1, 1, 1, 2, 1, 3)\n(1, 2, 1, 2, 1, 1, 1, 2, 2, 1)\n(1, 2, 1, 2, 1, 1, 1, 2, 2, 2)\n(1, 2, 1, 2, 1, 1, 1, 2, 3, 1)\n(1, 2, 1, 2, 1, 1, 1, 3, 1, 1)\n(1, 2, 1, 2, 1, 1, 1, 3, 1, 2)\n(1, 2, 1, 2, 1, 1, 1, 3, 2, 1)\n(1, 2, 1, 2, 1, 1, 1, 4, 1, 1)\n(1, 2, 1, 2, 1, 1, 2, 1, 1, 1)\n(1, 2, 1, 2, 1, 1, 2, 1, 1, 2)\n(1, 2, 1, 2, 1, 1, 2, 1, 1, 3)\n(1, 2, 1, 2, 1, 1, 2, 1, 2, 1)\n(1, 2, 1, 2, 1, 1, 2, 1, 2, 2)\n(1, 2, 1, 2, 1, 1, 2, 1, 3, 1)\n(1, 2, 1, 2, 1, 1, 2, 2, 1, 1)\n(1, 2, 1, 2, 1, 1, 2, 2, 1, 2)\n(1, 2, 1, 2, 1, 1, 2, 2, 2, 1)\n(1, 2, 1, 2, 1, 1, 2, 3, 1, 1)\n(1, 2, 1, 2, 1, 1, 3, 1, 1, 1)\n(1, 2, 1, 2, 1, 1, 3, 1, 1, 2)\n(1, 2, 1, 2, 1, 1, 3, 1, 2, 1)\n(1, 2, 1, 2, 1, 1, 3, 2, 1, 1)\n(1, 2, 1, 2, 1, 1, 4, 1, 1, 1)\n(1, 2, 1, 2, 1, 2, 1, 1, 1, 1)\n(1, 2, 1, 2, 1, 2, 1, 1, 1, 2)\n(1, 2, 1, 2, 1, 2, 1, 1, 1, 3)\n(1, 2, 1, 2, 1, 2, 1, 1, 2, 1)\n(1, 2, 1, 2, 1, 2, 1, 1, 2, 2)\n(1, 2, 1, 2, 1, 2, 1, 1, 3, 1)\n(1, 2, 1, 2, 1, 2, 1, 2, 1, 1)\n(1, 2, 1, 2, 1, 2, 1, 2, 1, 2)\n(1, 2, 1, 2, 1, 2, 1, 2, 2, 1)\n(1, 2, 1, 2, 1, 2, 1, 3, 1, 1)\n(1, 2, 1, 2, 1, 2, 2, 1, 1, 1)\n(1, 2, 1, 2, 1, 2, 2, 1, 1, 2)\n(1, 2, 1, 2, 1, 2, 2, 1, 2, 1)\n(1, 2, 1, 2, 1, 2, 2, 2, 1, 1)\n(1, 2, 1, 2, 1, 2, 3, 1, 1, 1)\n(1, 2, 1, 2, 1, 3, 1, 1, 1, 1)\n(1, 2, 1, 2, 1, 3, 1, 1, 1, 2)\n(1, 2, 1, 2, 1, 3, 1, 1, 2, 1)\n(1, 2, 1, 2, 1, 3, 1, 2, 1, 1)\n(1, 2, 1, 2, 1, 3, 2, 1, 1, 1)\n(1, 2, 1, 2, 1, 4, 1, 1, 1, 1)\n(1, 2, 1, 2, 2, 1, 1, 1, 1, 1)\n(1, 2, 1, 2, 2, 1, 1, 1, 1, 2)\n(1, 2, 1, 2, 2, 1, 1, 1, 1, 3)\n(1, 2, 1, 2, 2, 1, 1, 1, 2, 1)\n(1, 2, 1, 2, 2, 1, 1, 1, 2, 2)\n(1, 2, 1, 2, 2, 1, 1, 1, 3, 1)\n(1, 2, 1, 2, 2, 1, 1, 2, 1, 1)\n(1, 2, 1, 2, 2, 1, 1, 2, 1, 2)\n(1, 2, 1, 2, 2, 1, 1, 2, 2, 1)\n(1, 2, 1, 2, 2, 1, 1, 3, 1, 1)\n(1, 2, 1, 2, 2, 1, 2, 1, 1, 1)\n(1, 2, 1, 2, 2, 1, 2, 1, 1, 2)\n(1, 2, 1, 2, 2, 1, 2, 1, 2, 1)\n(1, 2, 1, 2, 2, 1, 2, 2, 1, 1)\n(1, 2, 1, 2, 2, 1, 3, 1, 1, 1)\n(1, 2, 1, 2, 2, 2, 1, 1, 1, 1)\n(1, 2, 1, 2, 2, 2, 1, 1, 1, 2)\n(1, 2, 1, 2, 2, 2, 1, 1, 2, 1)\n(1, 2, 1, 2, 2, 2, 1, 2, 1, 1)\n(1, 2, 1, 2, 2, 2, 2, 1, 1, 1)\n(1, 2, 1, 2, 2, 3, 1, 1, 1, 1)\n(1, 2, 1, 2, 3, 1, 1, 1, 1, 1)\n(1, 2, 1, 2, 3, 1, 1, 1, 1, 2)\n(1, 2, 1, 2, 3, 1, 1, 1, 2, 1)\n(1, 2, 1, 2, 3, 1, 1, 2, 1, 1)\n(1, 2, 1, 2, 3, 1, 2, 1, 1, 1)\n(1, 2, 1, 2, 3, 2, 1, 1, 1, 1)\n(1, 2, 1, 2, 4, 1, 1, 1, 1, 1)\n(1, 2, 1, 3, 1, 1, 1, 1, 1, 1)\n(1, 2, 1, 3, 1, 1, 1, 1, 1, 2)\n(1, 2, 1, 3, 1, 1, 1, 1, 1, 3)\n(1, 2, 1, 3, 1, 1, 1, 1, 2, 1)\n(1, 2, 1, 3, 1, 1, 1, 1, 2, 2)\n(1, 2, 1, 3, 1, 1, 1, 1, 3, 1)\n(1, 2, 1, 3, 1, 1, 1, 2, 1, 1)\n(1, 2, 1, 3, 1, 1, 1, 2, 1, 2)\n(1, 2, 1, 3, 1, 1, 1, 2, 2, 1)\n(1, 2, 1, 3, 1, 1, 1, 3, 1, 1)\n(1, 2, 1, 3, 1, 1, 2, 1, 1, 1)\n(1, 2, 1, 3, 1, 1, 2, 1, 1, 2)\n(1, 2, 1, 3, 1, 1, 2, 1, 2, 1)\n(1, 2, 1, 3, 1, 1, 2, 2, 1, 1)\n(1, 2, 1, 3, 1, 1, 3, 1, 1, 1)\n(1, 2, 1, 3, 1, 2, 1, 1, 1, 1)\n(1, 2, 1, 3, 1, 2, 1, 1, 1, 2)\n(1, 2, 1, 3, 1, 2, 1, 1, 2, 1)\n(1, 2, 1, 3, 1, 2, 1, 2, 1, 1)\n(1, 2, 1, 3, 1, 2, 2, 1, 1, 1)\n(1, 2, 1, 3, 1, 3, 1, 1, 1, 1)\n(1, 2, 1, 3, 2, 1, 1, 1, 1, 1)\n(1, 2, 1, 3, 2, 1, 1, 1, 1, 2)\n(1, 2, 1, 3, 2, 1, 1, 1, 2, 1)\n(1, 2, 1, 3, 2, 1, 1, 2, 1, 1)\n(1, 2, 1, 3, 2, 1, 2, 1, 1, 1)\n(1, 2, 1, 3, 2, 2, 1, 1, 1, 1)\n(1, 2, 1, 3, 3, 1, 1, 1, 1, 1)\n(1, 2, 1, 4, 1, 1, 1, 1, 1, 1)\n(1, 2, 1, 4, 1, 1, 1, 1, 1, 2)\n(1, 2, 1, 4, 1, 1, 1, 1, 2, 1)\n(1, 2, 1, 4, 1, 1, 1, 2, 1, 1)\n(1, 2, 1, 4, 1, 1, 2, 1, 1, 1)\n(1, 2, 1, 4, 1, 2, 1, 1, 1, 1)\n(1, 2, 1, 4, 2, 1, 1, 1, 1, 1)\n(1, 2, 1, 5, 1, 1, 1, 1, 1, 1)\n(1, 2, 2, 1, 1, 1, 1, 1, 1, 1)\n(1, 2, 2, 1, 1, 1, 1, 1, 1, 2)\n(1, 2, 2, 1, 1, 1, 1, 1, 1, 3)\n(1, 2, 2, 1, 1, 1, 1, 1, 1, 4)\n(1, 2, 2, 1, 1, 1, 1, 1, 2, 1)\n(1, 2, 2, 1, 1, 1, 1, 1, 2, 2)\n(1, 2, 2, 1, 1, 1, 1, 1, 2, 3)\n(1, 2, 2, 1, 1, 1, 1, 1, 3, 1)\n(1, 2, 2, 1, 1, 1, 1, 1, 3, 2)\n(1, 2, 2, 1, 1, 1, 1, 1, 4, 1)\n(1, 2, 2, 1, 1, 1, 1, 2, 1, 1)\n(1, 2, 2, 1, 1, 1, 1, 2, 1, 2)\n(1, 2, 2, 1, 1, 1, 1, 2, 1, 3)\n(1, 2, 2, 1, 1, 1, 1, 2, 2, 1)\n(1, 2, 2, 1, 1, 1, 1, 2, 2, 2)\n(1, 2, 2, 1, 1, 1, 1, 2, 3, 1)\n(1, 2, 2, 1, 1, 1, 1, 3, 1, 1)\n(1, 2, 2, 1, 1, 1, 1, 3, 1, 2)\n(1, 2, 2, 1, 1, 1, 1, 3, 2, 1)\n(1, 2, 2, 1, 1, 1, 1, 4, 1, 1)\n(1, 2, 2, 1, 1, 1, 2, 1, 1, 1)\n(1, 2, 2, 1, 1, 1, 2, 1, 1, 2)\n(1, 2, 2, 1, 1, 1, 2, 1, 1, 3)\n(1, 2, 2, 1, 1, 1, 2, 1, 2, 1)\n(1, 2, 2, 1, 1, 1, 2, 1, 2, 2)\n(1, 2, 2, 1, 1, 1, 2, 1, 3, 1)\n(1, 2, 2, 1, 1, 1, 2, 2, 1, 1)\n(1, 2, 2, 1, 1, 1, 2, 2, 1, 2)\n(1, 2, 2, 1, 1, 1, 2, 2, 2, 1)\n(1, 2, 2, 1, 1, 1, 2, 3, 1, 1)\n(1, 2, 2, 1, 1, 1, 3, 1, 1, 1)\n(1, 2, 2, 1, 1, 1, 3, 1, 1, 2)\n(1, 2, 2, 1, 1, 1, 3, 1, 2, 1)\n(1, 2, 2, 1, 1, 1, 3, 2, 1, 1)\n(1, 2, 2, 1, 1, 1, 4, 1, 1, 1)\n(1, 2, 2, 1, 1, 2, 1, 1, 1, 1)\n(1, 2, 2, 1, 1, 2, 1, 1, 1, 2)\n(1, 2, 2, 1, 1, 2, 1, 1, 1, 3)\n(1, 2, 2, 1, 1, 2, 1, 1, 2, 1)\n(1, 2, 2, 1, 1, 2, 1, 1, 2, 2)\n(1, 2, 2, 1, 1, 2, 1, 1, 3, 1)\n(1, 2, 2, 1, 1, 2, 1, 2, 1, 1)\n(1, 2, 2, 1, 1, 2, 1, 2, 1, 2)\n(1, 2, 2, 1, 1, 2, 1, 2, 2, 1)\n(1, 2, 2, 1, 1, 2, 1, 3, 1, 1)\n(1, 2, 2, 1, 1, 2, 2, 1, 1, 1)\n(1, 2, 2, 1, 1, 2, 2, 1, 1, 2)\n(1, 2, 2, 1, 1, 2, 2, 1, 2, 1)\n(1, 2, 2, 1, 1, 2, 2, 2, 1, 1)\n(1, 2, 2, 1, 1, 2, 3, 1, 1, 1)\n(1, 2, 2, 1, 1, 3, 1, 1, 1, 1)\n(1, 2, 2, 1, 1, 3, 1, 1, 1, 2)\n(1, 2, 2, 1, 1, 3, 1, 1, 2, 1)\n(1, 2, 2, 1, 1, 3, 1, 2, 1, 1)\n(1, 2, 2, 1, 1, 3, 2, 1, 1, 1)\n(1, 2, 2, 1, 1, 4, 1, 1, 1, 1)\n(1, 2, 2, 1, 2, 1, 1, 1, 1, 1)\n(1, 2, 2, 1, 2, 1, 1, 1, 1, 2)\n(1, 2, 2, 1, 2, 1, 1, 1, 1, 3)\n(1, 2, 2, 1, 2, 1, 1, 1, 2, 1)\n(1, 2, 2, 1, 2, 1, 1, 1, 2, 2)\n(1, 2, 2, 1, 2, 1, 1, 1, 3, 1)\n(1, 2, 2, 1, 2, 1, 1, 2, 1, 1)\n(1, 2, 2, 1, 2, 1, 1, 2, 1, 2)\n(1, 2, 2, 1, 2, 1, 1, 2, 2, 1)\n(1, 2, 2, 1, 2, 1, 1, 3, 1, 1)\n(1, 2, 2, 1, 2, 1, 2, 1, 1, 1)\n(1, 2, 2, 1, 2, 1, 2, 1, 1, 2)\n(1, 2, 2, 1, 2, 1, 2, 1, 2, 1)\n(1, 2, 2, 1, 2, 1, 2, 2, 1, 1)\n(1, 2, 2, 1, 2, 1, 3, 1, 1, 1)\n(1, 2, 2, 1, 2, 2, 1, 1, 1, 1)\n(1, 2, 2, 1, 2, 2, 1, 1, 1, 2)\n(1, 2, 2, 1, 2, 2, 1, 1, 2, 1)\n(1, 2, 2, 1, 2, 2, 1, 2, 1, 1)\n(1, 2, 2, 1, 2, 2, 2, 1, 1, 1)\n(1, 2, 2, 1, 2, 3, 1, 1, 1, 1)\n(1, 2, 2, 1, 3, 1, 1, 1, 1, 1)\n(1, 2, 2, 1, 3, 1, 1, 1, 1, 2)\n(1, 2, 2, 1, 3, 1, 1, 1, 2, 1)\n(1, 2, 2, 1, 3, 1, 1, 2, 1, 1)\n(1, 2, 2, 1, 3, 1, 2, 1, 1, 1)\n(1, 2, 2, 1, 3, 2, 1, 1, 1, 1)\n(1, 2, 2, 1, 4, 1, 1, 1, 1, 1)\n(1, 2, 2, 2, 1, 1, 1, 1, 1, 1)\n(1, 2, 2, 2, 1, 1, 1, 1, 1, 2)\n(1, 2, 2, 2, 1, 1, 1, 1, 1, 3)\n(1, 2, 2, 2, 1, 1, 1, 1, 2, 1)\n(1, 2, 2, 2, 1, 1, 1, 1, 2, 2)\n(1, 2, 2, 2, 1, 1, 1, 1, 3, 1)\n(1, 2, 2, 2, 1, 1, 1, 2, 1, 1)\n(1, 2, 2, 2, 1, 1, 1, 2, 1, 2)\n(1, 2, 2, 2, 1, 1, 1, 2, 2, 1)\n(1, 2, 2, 2, 1, 1, 1, 3, 1, 1)\n(1, 2, 2, 2, 1, 1, 2, 1, 1, 1)\n(1, 2, 2, 2, 1, 1, 2, 1, 1, 2)\n(1, 2, 2, 2, 1, 1, 2, 1, 2, 1)\n(1, 2, 2, 2, 1, 1, 2, 2, 1, 1)\n(1, 2, 2, 2, 1, 1, 3, 1, 1, 1)\n(1, 2, 2, 2, 1, 2, 1, 1, 1, 1)\n(1, 2, 2, 2, 1, 2, 1, 1, 1, 2)\n(1, 2, 2, 2, 1, 2, 1, 1, 2, 1)\n(1, 2, 2, 2, 1, 2, 1, 2, 1, 1)\n(1, 2, 2, 2, 1, 2, 2, 1, 1, 1)\n(1, 2, 2, 2, 1, 3, 1, 1, 1, 1)\n(1, 2, 2, 2, 2, 1, 1, 1, 1, 1)\n(1, 2, 2, 2, 2, 1, 1, 1, 1, 2)\n(1, 2, 2, 2, 2, 1, 1, 1, 2, 1)\n(1, 2, 2, 2, 2, 1, 1, 2, 1, 1)\n(1, 2, 2, 2, 2, 1, 2, 1, 1, 1)\n(1, 2, 2, 2, 2, 2, 1, 1, 1, 1)\n(1, 2, 2, 2, 3, 1, 1, 1, 1, 1)\n(1, 2, 2, 3, 1, 1, 1, 1, 1, 1)\n(1, 2, 2, 3, 1, 1, 1, 1, 1, 2)\n(1, 2, 2, 3, 1, 1, 1, 1, 2, 1)\n(1, 2, 2, 3, 1, 1, 1, 2, 1, 1)\n(1, 2, 2, 3, 1, 1, 2, 1, 1, 1)\n(1, 2, 2, 3, 1, 2, 1, 1, 1, 1)\n(1, 2, 2, 3, 2, 1, 1, 1, 1, 1)\n(1, 2, 2, 4, 1, 1, 1, 1, 1, 1)\n(1, 2, 3, 1, 1, 1, 1, 1, 1, 1)\n(1, 2, 3, 1, 1, 1, 1, 1, 1, 2)\n(1, 2, 3, 1, 1, 1, 1, 1, 1, 3)\n(1, 2, 3, 1, 1, 1, 1, 1, 2, 1)\n(1, 2, 3, 1, 1, 1, 1, 1, 2, 2)\n(1, 2, 3, 1, 1, 1, 1, 1, 3, 1)\n(1, 2, 3, 1, 1, 1, 1, 2, 1, 1)\n(1, 2, 3, 1, 1, 1, 1, 2, 1, 2)\n(1, 2, 3, 1, 1, 1, 1, 2, 2, 1)\n(1, 2, 3, 1, 1, 1, 1, 3, 1, 1)\n(1, 2, 3, 1, 1, 1, 2, 1, 1, 1)\n(1, 2, 3, 1, 1, 1, 2, 1, 1, 2)\n(1, 2, 3, 1, 1, 1, 2, 1, 2, 1)\n(1, 2, 3, 1, 1, 1, 2, 2, 1, 1)\n(1, 2, 3, 1, 1, 1, 3, 1, 1, 1)\n(1, 2, 3, 1, 1, 2, 1, 1, 1, 1)\n(1, 2, 3, 1, 1, 2, 1, 1, 1, 2)\n(1, 2, 3, 1, 1, 2, 1, 1, 2, 1)\n(1, 2, 3, 1, 1, 2, 1, 2, 1, 1)\n(1, 2, 3, 1, 1, 2, 2, 1, 1, 1)\n(1, 2, 3, 1, 1, 3, 1, 1, 1, 1)\n(1, 2, 3, 1, 2, 1, 1, 1, 1, 1)\n(1, 2, 3, 1, 2, 1, 1, 1, 1, 2)\n(1, 2, 3, 1, 2, 1, 1, 1, 2, 1)\n(1, 2, 3, 1, 2, 1, 1, 2, 1, 1)\n(1, 2, 3, 1, 2, 1, 2, 1, 1, 1)\n(1, 2, 3, 1, 2, 2, 1, 1, 1, 1)\n(1, 2, 3, 1, 3, 1, 1, 1, 1, 1)\n(1, 2, 3, 2, 1, 1, 1, 1, 1, 1)\n(1, 2, 3, 2, 1, 1, 1, 1, 1, 2)\n(1, 2, 3, 2, 1, 1, 1, 1, 2, 1)\n(1, 2, 3, 2, 1, 1, 1, 2, 1, 1)\n(1, 2, 3, 2, 1, 1, 2, 1, 1, 1)\n(1, 2, 3, 2, 1, 2, 1, 1, 1, 1)\n(1, 2, 3, 2, 2, 1, 1, 1, 1, 1)\n(1, 2, 3, 3, 1, 1, 1, 1, 1, 1)\n(1, 2, 4, 1, 1, 1, 1, 1, 1, 1)\n(1, 2, 4, 1, 1, 1, 1, 1, 1, 2)\n(1, 2, 4, 1, 1, 1, 1, 1, 2, 1)\n(1, 2, 4, 1, 1, 1, 1, 2, 1, 1)\n(1, 2, 4, 1, 1, 1, 2, 1, 1, 1)\n(1, 2, 4, 1, 1, 2, 1, 1, 1, 1)\n(1, 2, 4, 1, 2, 1, 1, 1, 1, 1)\n(1, 2, 4, 2, 1, 1, 1, 1, 1, 1)\n(1, 2, 5, 1, 1, 1, 1, 1, 1, 1)\n(1, 3, 1, 1, 1, 1, 1, 1, 1, 1)\n(1, 3, 1, 1, 1, 1, 1, 1, 1, 2)\n(1, 3, 1, 1, 1, 1, 1, 1, 1, 3)\n(1, 3, 1, 1, 1, 1, 1, 1, 1, 4)\n(1, 3, 1, 1, 1, 1, 1, 1, 2, 1)\n(1, 3, 1, 1, 1, 1, 1, 1, 2, 2)\n(1, 3, 1, 1, 1, 1, 1, 1, 2, 3)\n(1, 3, 1, 1, 1, 1, 1, 1, 3, 1)\n(1, 3, 1, 1, 1, 1, 1, 1, 3, 2)\n(1, 3, 1, 1, 1, 1, 1, 1, 4, 1)\n(1, 3, 1, 1, 1, 1, 1, 2, 1, 1)\n(1, 3, 1, 1, 1, 1, 1, 2, 1, 2)\n(1, 3, 1, 1, 1, 1, 1, 2, 1, 3)\n(1, 3, 1, 1, 1, 1, 1, 2, 2, 1)\n(1, 3, 1, 1, 1, 1, 1, 2, 2, 2)\n(1, 3, 1, 1, 1, 1, 1, 2, 3, 1)\n(1, 3, 1, 1, 1, 1, 1, 3, 1, 1)\n(1, 3, 1, 1, 1, 1, 1, 3, 1, 2)\n(1, 3, 1, 1, 1, 1, 1, 3, 2, 1)\n(1, 3, 1, 1, 1, 1, 1, 4, 1, 1)\n(1, 3, 1, 1, 1, 1, 2, 1, 1, 1)\n(1, 3, 1, 1, 1, 1, 2, 1, 1, 2)\n(1, 3, 1, 1, 1, 1, 2, 1, 1, 3)\n(1, 3, 1, 1, 1, 1, 2, 1, 2, 1)\n(1, 3, 1, 1, 1, 1, 2, 1, 2, 2)\n(1, 3, 1, 1, 1, 1, 2, 1, 3, 1)\n(1, 3, 1, 1, 1, 1, 2, 2, 1, 1)\n(1, 3, 1, 1, 1, 1, 2, 2, 1, 2)\n(1, 3, 1, 1, 1, 1, 2, 2, 2, 1)\n(1, 3, 1, 1, 1, 1, 2, 3, 1, 1)\n(1, 3, 1, 1, 1, 1, 3, 1, 1, 1)\n(1, 3, 1, 1, 1, 1, 3, 1, 1, 2)\n(1, 3, 1, 1, 1, 1, 3, 1, 2, 1)\n(1, 3, 1, 1, 1, 1, 3, 2, 1, 1)\n(1, 3, 1, 1, 1, 1, 4, 1, 1, 1)\n(1, 3, 1, 1, 1, 2, 1, 1, 1, 1)\n(1, 3, 1, 1, 1, 2, 1, 1, 1, 2)\n(1, 3, 1, 1, 1, 2, 1, 1, 1, 3)\n(1, 3, 1, 1, 1, 2, 1, 1, 2, 1)\n(1, 3, 1, 1, 1, 2, 1, 1, 2, 2)\n(1, 3, 1, 1, 1, 2, 1, 1, 3, 1)\n(1, 3, 1, 1, 1, 2, 1, 2, 1, 1)\n(1, 3, 1, 1, 1, 2, 1, 2, 1, 2)\n(1, 3, 1, 1, 1, 2, 1, 2, 2, 1)\n(1, 3, 1, 1, 1, 2, 1, 3, 1, 1)\n(1, 3, 1, 1, 1, 2, 2, 1, 1, 1)\n(1, 3, 1, 1, 1, 2, 2, 1, 1, 2)\n(1, 3, 1, 1, 1, 2, 2, 1, 2, 1)\n(1, 3, 1, 1, 1, 2, 2, 2, 1, 1)\n(1, 3, 1, 1, 1, 2, 3, 1, 1, 1)\n(1, 3, 1, 1, 1, 3, 1, 1, 1, 1)\n(1, 3, 1, 1, 1, 3, 1, 1, 1, 2)\n(1, 3, 1, 1, 1, 3, 1, 1, 2, 1)\n(1, 3, 1, 1, 1, 3, 1, 2, 1, 1)\n(1, 3, 1, 1, 1, 3, 2, 1, 1, 1)\n(1, 3, 1, 1, 1, 4, 1, 1, 1, 1)\n(1, 3, 1, 1, 2, 1, 1, 1, 1, 1)\n(1, 3, 1, 1, 2, 1, 1, 1, 1, 2)\n(1, 3, 1, 1, 2, 1, 1, 1, 1, 3)\n(1, 3, 1, 1, 2, 1, 1, 1, 2, 1)\n(1, 3, 1, 1, 2, 1, 1, 1, 2, 2)\n(1, 3, 1, 1, 2, 1, 1, 1, 3, 1)\n(1, 3, 1, 1, 2, 1, 1, 2, 1, 1)\n(1, 3, 1, 1, 2, 1, 1, 2, 1, 2)\n(1, 3, 1, 1, 2, 1, 1, 2, 2, 1)\n(1, 3, 1, 1, 2, 1, 1, 3, 1, 1)\n(1, 3, 1, 1, 2, 1, 2, 1, 1, 1)\n(1, 3, 1, 1, 2, 1, 2, 1, 1, 2)\n(1, 3, 1, 1, 2, 1, 2, 1, 2, 1)\n(1, 3, 1, 1, 2, 1, 2, 2, 1, 1)\n(1, 3, 1, 1, 2, 1, 3, 1, 1, 1)\n(1, 3, 1, 1, 2, 2, 1, 1, 1, 1)\n(1, 3, 1, 1, 2, 2, 1, 1, 1, 2)\n(1, 3, 1, 1, 2, 2, 1, 1, 2, 1)\n(1, 3, 1, 1, 2, 2, 1, 2, 1, 1)\n(1, 3, 1, 1, 2, 2, 2, 1, 1, 1)\n(1, 3, 1, 1, 2, 3, 1, 1, 1, 1)\n(1, 3, 1, 1, 3, 1, 1, 1, 1, 1)\n(1, 3, 1, 1, 3, 1, 1, 1, 1, 2)\n(1, 3, 1, 1, 3, 1, 1, 1, 2, 1)\n(1, 3, 1, 1, 3, 1, 1, 2, 1, 1)\n(1, 3, 1, 1, 3, 1, 2, 1, 1, 1)\n(1, 3, 1, 1, 3, 2, 1, 1, 1, 1)\n(1, 3, 1, 1, 4, 1, 1, 1, 1, 1)\n(1, 3, 1, 2, 1, 1, 1, 1, 1, 1)\n(1, 3, 1, 2, 1, 1, 1, 1, 1, 2)\n(1, 3, 1, 2, 1, 1, 1, 1, 1, 3)\n(1, 3, 1, 2, 1, 1, 1, 1, 2, 1)\n(1, 3, 1, 2, 1, 1, 1, 1, 2, 2)\n(1, 3, 1, 2, 1, 1, 1, 1, 3, 1)\n(1, 3, 1, 2, 1, 1, 1, 2, 1, 1)\n(1, 3, 1, 2, 1, 1, 1, 2, 1, 2)\n(1, 3, 1, 2, 1, 1, 1, 2, 2, 1)\n(1, 3, 1, 2, 1, 1, 1, 3, 1, 1)\n(1, 3, 1, 2, 1, 1, 2, 1, 1, 1)\n(1, 3, 1, 2, 1, 1, 2, 1, 1, 2)\n(1, 3, 1, 2, 1, 1, 2, 1, 2, 1)\n(1, 3, 1, 2, 1, 1, 2, 2, 1, 1)\n(1, 3, 1, 2, 1, 1, 3, 1, 1, 1)\n(1, 3, 1, 2, 1, 2, 1, 1, 1, 1)\n(1, 3, 1, 2, 1, 2, 1, 1, 1, 2)\n(1, 3, 1, 2, 1, 2, 1, 1, 2, 1)\n(1, 3, 1, 2, 1, 2, 1, 2, 1, 1)\n(1, 3, 1, 2, 1, 2, 2, 1, 1, 1)\n(1, 3, 1, 2, 1, 3, 1, 1, 1, 1)\n(1, 3, 1, 2, 2, 1, 1, 1, 1, 1)\n(1, 3, 1, 2, 2, 1, 1, 1, 1, 2)\n(1, 3, 1, 2, 2, 1, 1, 1, 2, 1)\n(1, 3, 1, 2, 2, 1, 1, 2, 1, 1)\n(1, 3, 1, 2, 2, 1, 2, 1, 1, 1)\n(1, 3, 1, 2, 2, 2, 1, 1, 1, 1)\n(1, 3, 1, 2, 3, 1, 1, 1, 1, 1)\n(1, 3, 1, 3, 1, 1, 1, 1, 1, 1)\n(1, 3, 1, 3, 1, 1, 1, 1, 1, 2)\n(1, 3, 1, 3, 1, 1, 1, 1, 2, 1)\n(1, 3, 1, 3, 1, 1, 1, 2, 1, 1)\n(1, 3, 1, 3, 1, 1, 2, 1, 1, 1)\n(1, 3, 1, 3, 1, 2, 1, 1, 1, 1)\n(1, 3, 1, 3, 2, 1, 1, 1, 1, 1)\n(1, 3, 1, 4, 1, 1, 1, 1, 1, 1)\n(1, 3, 2, 1, 1, 1, 1, 1, 1, 1)\n(1, 3, 2, 1, 1, 1, 1, 1, 1, 2)\n(1, 3, 2, 1, 1, 1, 1, 1, 1, 3)\n(1, 3, 2, 1, 1, 1, 1, 1, 2, 1)\n(1, 3, 2, 1, 1, 1, 1, 1, 2, 2)\n(1, 3, 2, 1, 1, 1, 1, 1, 3, 1)\n(1, 3, 2, 1, 1, 1, 1, 2, 1, 1)\n(1, 3, 2, 1, 1, 1, 1, 2, 1, 2)\n(1, 3, 2, 1, 1, 1, 1, 2, 2, 1)\n(1, 3, 2, 1, 1, 1, 1, 3, 1, 1)\n(1, 3, 2, 1, 1, 1, 2, 1, 1, 1)\n(1, 3, 2, 1, 1, 1, 2, 1, 1, 2)\n(1, 3, 2, 1, 1, 1, 2, 1, 2, 1)\n(1, 3, 2, 1, 1, 1, 2, 2, 1, 1)\n(1, 3, 2, 1, 1, 1, 3, 1, 1, 1)\n(1, 3, 2, 1, 1, 2, 1, 1, 1, 1)\n(1, 3, 2, 1, 1, 2, 1, 1, 1, 2)\n(1, 3, 2, 1, 1, 2, 1, 1, 2, 1)\n(1, 3, 2, 1, 1, 2, 1, 2, 1, 1)\n(1, 3, 2, 1, 1, 2, 2, 1, 1, 1)\n(1, 3, 2, 1, 1, 3, 1, 1, 1, 1)\n(1, 3, 2, 1, 2, 1, 1, 1, 1, 1)\n(1, 3, 2, 1, 2, 1, 1, 1, 1, 2)\n(1, 3, 2, 1, 2, 1, 1, 1, 2, 1)\n(1, 3, 2, 1, 2, 1, 1, 2, 1, 1)\n(1, 3, 2, 1, 2, 1, 2, 1, 1, 1)\n(1, 3, 2, 1, 2, 2, 1, 1, 1, 1)\n(1, 3, 2, 1, 3, 1, 1, 1, 1, 1)\n(1, 3, 2, 2, 1, 1, 1, 1, 1, 1)\n(1, 3, 2, 2, 1, 1, 1, 1, 1, 2)\n(1, 3, 2, 2, 1, 1, 1, 1, 2, 1)\n(1, 3, 2, 2, 1, 1, 1, 2, 1, 1)\n(1, 3, 2, 2, 1, 1, 2, 1, 1, 1)\n(1, 3, 2, 2, 1, 2, 1, 1, 1, 1)\n(1, 3, 2, 2, 2, 1, 1, 1, 1, 1)\n(1, 3, 2, 3, 1, 1, 1, 1, 1, 1)\n(1, 3, 3, 1, 1, 1, 1, 1, 1, 1)\n(1, 3, 3, 1, 1, 1, 1, 1, 1, 2)\n(1, 3, 3, 1, 1, 1, 1, 1, 2, 1)\n(1, 3, 3, 1, 1, 1, 1, 2, 1, 1)\n(1, 3, 3, 1, 1, 1, 2, 1, 1, 1)\n(1, 3, 3, 1, 1, 2, 1, 1, 1, 1)\n(1, 3, 3, 1, 2, 1, 1, 1, 1, 1)\n(1, 3, 3, 2, 1, 1, 1, 1, 1, 1)\n(1, 3, 4, 1, 1, 1, 1, 1, 1, 1)\n(1, 4, 1, 1, 1, 1, 1, 1, 1, 1)\n(1, 4, 1, 1, 1, 1, 1, 1, 1, 2)\n(1, 4, 1, 1, 1, 1, 1, 1, 1, 3)\n(1, 4, 1, 1, 1, 1, 1, 1, 2, 1)\n(1, 4, 1, 1, 1, 1, 1, 1, 2, 2)\n(1, 4, 1, 1, 1, 1, 1, 1, 3, 1)\n(1, 4, 1, 1, 1, 1, 1, 2, 1, 1)\n(1, 4, 1, 1, 1, 1, 1, 2, 1, 2)\n(1, 4, 1, 1, 1, 1, 1, 2, 2, 1)\n(1, 4, 1, 1, 1, 1, 1, 3, 1, 1)\n(1, 4, 1, 1, 1, 1, 2, 1, 1, 1)\n(1, 4, 1, 1, 1, 1, 2, 1, 1, 2)\n(1, 4, 1, 1, 1, 1, 2, 1, 2, 1)\n(1, 4, 1, 1, 1, 1, 2, 2, 1, 1)\n(1, 4, 1, 1, 1, 1, 3, 1, 1, 1)\n(1, 4, 1, 1, 1, 2, 1, 1, 1, 1)\n(1, 4, 1, 1, 1, 2, 1, 1, 1, 2)\n(1, 4, 1, 1, 1, 2, 1, 1, 2, 1)\n(1, 4, 1, 1, 1, 2, 1, 2, 1, 1)\n(1, 4, 1, 1, 1, 2, 2, 1, 1, 1)\n(1, 4, 1, 1, 1, 3, 1, 1, 1, 1)\n(1, 4, 1, 1, 2, 1, 1, 1, 1, 1)\n(1, 4, 1, 1, 2, 1, 1, 1, 1, 2)\n(1, 4, 1, 1, 2, 1, 1, 1, 2, 1)\n(1, 4, 1, 1, 2, 1, 1, 2, 1, 1)\n(1, 4, 1, 1, 2, 1, 2, 1, 1, 1)\n(1, 4, 1, 1, 2, 2, 1, 1, 1, 1)\n(1, 4, 1, 1, 3, 1, 1, 1, 1, 1)\n(1, 4, 1, 2, 1, 1, 1, 1, 1, 1)\n(1, 4, 1, 2, 1, 1, 1, 1, 1, 2)\n(1, 4, 1, 2, 1, 1, 1, 1, 2, 1)\n(1, 4, 1, 2, 1, 1, 1, 2, 1, 1)\n(1, 4, 1, 2, 1, 1, 2, 1, 1, 1)\n(1, 4, 1, 2, 1, 2, 1, 1, 1, 1)\n(1, 4, 1, 2, 2, 1, 1, 1, 1, 1)\n(1, 4, 1, 3, 1, 1, 1, 1, 1, 1)\n(1, 4, 2, 1, 1, 1, 1, 1, 1, 1)\n(1, 4, 2, 1, 1, 1, 1, 1, 1, 2)\n(1, 4, 2, 1, 1, 1, 1, 1, 2, 1)\n(1, 4, 2, 1, 1, 1, 1, 2, 1, 1)\n(1, 4, 2, 1, 1, 1, 2, 1, 1, 1)\n(1, 4, 2, 1, 1, 2, 1, 1, 1, 1)\n(1, 4, 2, 1, 2, 1, 1, 1, 1, 1)\n(1, 4, 2, 2, 1, 1, 1, 1, 1, 1)\n(1, 4, 3, 1, 1, 1, 1, 1, 1, 1)\n(1, 5, 1, 1, 1, 1, 1, 1, 1, 1)\n(1, 5, 1, 1, 1, 1, 1, 1, 1, 2)\n(1, 5, 1, 1, 1, 1, 1, 1, 2, 1)\n(1, 5, 1, 1, 1, 1, 1, 2, 1, 1)\n(1, 5, 1, 1, 1, 1, 2, 1, 1, 1)\n(1, 5, 1, 1, 1, 2, 1, 1, 1, 1)\n(1, 5, 1, 1, 2, 1, 1, 1, 1, 1)\n(1, 5, 1, 2, 1, 1, 1, 1, 1, 1)\n(1, 5, 2, 1, 1, 1, 1, 1, 1, 1)\n(1, 6, 1, 1, 1, 1, 1, 1, 1, 1)\n(2, 1, 1, 1, 1, 1, 1, 1, 1, 1)\n(2, 1, 1, 1, 1, 1, 1, 1, 1, 2)\n(2, 1, 1, 1, 1, 1, 1, 1, 1, 3)\n(2, 1, 1, 1, 1, 1, 1, 1, 1, 4)\n(2, 1, 1, 1, 1, 1, 1, 1, 1, 5)\n(2, 1, 1, 1, 1, 1, 1, 1, 2, 1)\n(2, 1, 1, 1, 1, 1, 1, 1, 2, 2)\n(2, 1, 1, 1, 1, 1, 1, 1, 2, 3)\n(2, 1, 1, 1, 1, 1, 1, 1, 2, 4)\n(2, 1, 1, 1, 1, 1, 1, 1, 3, 1)\n(2, 1, 1, 1, 1, 1, 1, 1, 3, 2)\n(2, 1, 1, 1, 1, 1, 1, 1, 3, 3)\n(2, 1, 1, 1, 1, 1, 1, 1, 4, 1)\n(2, 1, 1, 1, 1, 1, 1, 1, 4, 2)\n(2, 1, 1, 1, 1, 1, 1, 1, 5, 1)\n(2, 1, 1, 1, 1, 1, 1, 2, 1, 1)\n(2, 1, 1, 1, 1, 1, 1, 2, 1, 2)\n(2, 1, 1, 1, 1, 1, 1, 2, 1, 3)\n(2, 1, 1, 1, 1, 1, 1, 2, 1, 4)\n(2, 1, 1, 1, 1, 1, 1, 2, 2, 1)\n(2, 1, 1, 1, 1, 1, 1, 2, 2, 2)\n(2, 1, 1, 1, 1, 1, 1, 2, 2, 3)\n(2, 1, 1, 1, 1, 1, 1, 2, 3, 1)\n(2, 1, 1, 1, 1, 1, 1, 2, 3, 2)\n(2, 1, 1, 1, 1, 1, 1, 2, 4, 1)\n(2, 1, 1, 1, 1, 1, 1, 3, 1, 1)\n(2, 1, 1, 1, 1, 1, 1, 3, 1, 2)\n(2, 1, 1, 1, 1, 1, 1, 3, 1, 3)\n(2, 1, 1, 1, 1, 1, 1, 3, 2, 1)\n(2, 1, 1, 1, 1, 1, 1, 3, 2, 2)\n(2, 1, 1, 1, 1, 1, 1, 3, 3, 1)\n(2, 1, 1, 1, 1, 1, 1, 4, 1, 1)\n(2, 1, 1, 1, 1, 1, 1, 4, 1, 2)\n(2, 1, 1, 1, 1, 1, 1, 4, 2, 1)\n(2, 1, 1, 1, 1, 1, 1, 5, 1, 1)\n(2, 1, 1, 1, 1, 1, 2, 1, 1, 1)\n(2, 1, 1, 1, 1, 1, 2, 1, 1, 2)\n(2, 1, 1, 1, 1, 1, 2, 1, 1, 3)\n(2, 1, 1, 1, 1, 1, 2, 1, 1, 4)\n(2, 1, 1, 1, 1, 1, 2, 1, 2, 1)\n(2, 1, 1, 1, 1, 1, 2, 1, 2, 2)\n(2, 1, 1, 1, 1, 1, 2, 1, 2, 3)\n(2, 1, 1, 1, 1, 1, 2, 1, 3, 1)\n(2, 1, 1, 1, 1, 1, 2, 1, 3, 2)\n(2, 1, 1, 1, 1, 1, 2, 1, 4, 1)\n(2, 1, 1, 1, 1, 1, 2, 2, 1, 1)\n(2, 1, 1, 1, 1, 1, 2, 2, 1, 2)\n(2, 1, 1, 1, 1, 1, 2, 2, 1, 3)\n(2, 1, 1, 1, 1, 1, 2, 2, 2, 1)\n(2, 1, 1, 1, 1, 1, 2, 2, 2, 2)\n(2, 1, 1, 1, 1, 1, 2, 2, 3, 1)\n(2, 1, 1, 1, 1, 1, 2, 3, 1, 1)\n(2, 1, 1, 1, 1, 1, 2, 3, 1, 2)\n(2, 1, 1, 1, 1, 1, 2, 3, 2, 1)\n(2, 1, 1, 1, 1, 1, 2, 4, 1, 1)\n(2, 1, 1, 1, 1, 1, 3, 1, 1, 1)\n(2, 1, 1, 1, 1, 1, 3, 1, 1, 2)\n(2, 1, 1, 1, 1, 1, 3, 1, 1, 3)\n(2, 1, 1, 1, 1, 1, 3, 1, 2, 1)\n(2, 1, 1, 1, 1, 1, 3, 1, 2, 2)\n(2, 1, 1, 1, 1, 1, 3, 1, 3, 1)\n(2, 1, 1, 1, 1, 1, 3, 2, 1, 1)\n(2, 1, 1, 1, 1, 1, 3, 2, 1, 2)\n(2, 1, 1, 1, 1, 1, 3, 2, 2, 1)\n(2, 1, 1, 1, 1, 1, 3, 3, 1, 1)\n(2, 1, 1, 1, 1, 1, 4, 1, 1, 1)\n(2, 1, 1, 1, 1, 1, 4, 1, 1, 2)\n(2, 1, 1, 1, 1, 1, 4, 1, 2, 1)\n(2, 1, 1, 1, 1, 1, 4, 2, 1, 1)\n(2, 1, 1, 1, 1, 1, 5, 1, 1, 1)\n(2, 1, 1, 1, 1, 2, 1, 1, 1, 1)\n(2, 1, 1, 1, 1, 2, 1, 1, 1, 2)\n(2, 1, 1, 1, 1, 2, 1, 1, 1, 3)\n(2, 1, 1, 1, 1, 2, 1, 1, 1, 4)\n(2, 1, 1, 1, 1, 2, 1, 1, 2, 1)\n(2, 1, 1, 1, 1, 2, 1, 1, 2, 2)\n(2, 1, 1, 1, 1, 2, 1, 1, 2, 3)\n(2, 1, 1, 1, 1, 2, 1, 1, 3, 1)\n(2, 1, 1, 1, 1, 2, 1, 1, 3, 2)\n(2, 1, 1, 1, 1, 2, 1, 1, 4, 1)\n(2, 1, 1, 1, 1, 2, 1, 2, 1, 1)\n(2, 1, 1, 1, 1, 2, 1, 2, 1, 2)\n(2, 1, 1, 1, 1, 2, 1, 2, 1, 3)\n(2, 1, 1, 1, 1, 2, 1, 2, 2, 1)\n(2, 1, 1, 1, 1, 2, 1, 2, 2, 2)\n(2, 1, 1, 1, 1, 2, 1, 2, 3, 1)\n(2, 1, 1, 1, 1, 2, 1, 3, 1, 1)\n(2, 1, 1, 1, 1, 2, 1, 3, 1, 2)\n(2, 1, 1, 1, 1, 2, 1, 3, 2, 1)\n(2, 1, 1, 1, 1, 2, 1, 4, 1, 1)\n(2, 1, 1, 1, 1, 2, 2, 1, 1, 1)\n(2, 1, 1, 1, 1, 2, 2, 1, 1, 2)\n(2, 1, 1, 1, 1, 2, 2, 1, 1, 3)\n(2, 1, 1, 1, 1, 2, 2, 1, 2, 1)\n(2, 1, 1, 1, 1, 2, 2, 1, 2, 2)\n(2, 1, 1, 1, 1, 2, 2, 1, 3, 1)\n(2, 1, 1, 1, 1, 2, 2, 2, 1, 1)\n(2, 1, 1, 1, 1, 2, 2, 2, 1, 2)\n(2, 1, 1, 1, 1, 2, 2, 2, 2, 1)\n(2, 1, 1, 1, 1, 2, 2, 3, 1, 1)\n(2, 1, 1, 1, 1, 2, 3, 1, 1, 1)\n(2, 1, 1, 1, 1, 2, 3, 1, 1, 2)\n(2, 1, 1, 1, 1, 2, 3, 1, 2, 1)\n(2, 1, 1, 1, 1, 2, 3, 2, 1, 1)\n(2, 1, 1, 1, 1, 2, 4, 1, 1, 1)\n(2, 1, 1, 1, 1, 3, 1, 1, 1, 1)\n(2, 1, 1, 1, 1, 3, 1, 1, 1, 2)\n(2, 1, 1, 1, 1, 3, 1, 1, 1, 3)\n(2, 1, 1, 1, 1, 3, 1, 1, 2, 1)\n(2, 1, 1, 1, 1, 3, 1, 1, 2, 2)\n(2, 1, 1, 1, 1, 3, 1, 1, 3, 1)\n(2, 1, 1, 1, 1, 3, 1, 2, 1, 1)\n(2, 1, 1, 1, 1, 3, 1, 2, 1, 2)\n(2, 1, 1, 1, 1, 3, 1, 2, 2, 1)\n(2, 1, 1, 1, 1, 3, 1, 3, 1, 1)\n(2, 1, 1, 1, 1, 3, 2, 1, 1, 1)\n(2, 1, 1, 1, 1, 3, 2, 1, 1, 2)\n(2, 1, 1, 1, 1, 3, 2, 1, 2, 1)\n(2, 1, 1, 1, 1, 3, 2, 2, 1, 1)\n(2, 1, 1, 1, 1, 3, 3, 1, 1, 1)\n(2, 1, 1, 1, 1, 4, 1, 1, 1, 1)\n(2, 1, 1, 1, 1, 4, 1, 1, 1, 2)\n(2, 1, 1, 1, 1, 4, 1, 1, 2, 1)\n(2, 1, 1, 1, 1, 4, 1, 2, 1, 1)\n(2, 1, 1, 1, 1, 4, 2, 1, 1, 1)\n(2, 1, 1, 1, 1, 5, 1, 1, 1, 1)\n(2, 1, 1, 1, 2, 1, 1, 1, 1, 1)\n(2, 1, 1, 1, 2, 1, 1, 1, 1, 2)\n(2, 1, 1, 1, 2, 1, 1, 1, 1, 3)\n(2, 1, 1, 1, 2, 1, 1, 1, 1, 4)\n(2, 1, 1, 1, 2, 1, 1, 1, 2, 1)\n(2, 1, 1, 1, 2, 1, 1, 1, 2, 2)\n(2, 1, 1, 1, 2, 1, 1, 1, 2, 3)\n(2, 1, 1, 1, 2, 1, 1, 1, 3, 1)\n(2, 1, 1, 1, 2, 1, 1, 1, 3, 2)\n(2, 1, 1, 1, 2, 1, 1, 1, 4, 1)\n(2, 1, 1, 1, 2, 1, 1, 2, 1, 1)\n(2, 1, 1, 1, 2, 1, 1, 2, 1, 2)\n(2, 1, 1, 1, 2, 1, 1, 2, 1, 3)\n(2, 1, 1, 1, 2, 1, 1, 2, 2, 1)\n(2, 1, 1, 1, 2, 1, 1, 2, 2, 2)\n(2, 1, 1, 1, 2, 1, 1, 2, 3, 1)\n(2, 1, 1, 1, 2, 1, 1, 3, 1, 1)\n(2, 1, 1, 1, 2, 1, 1, 3, 1, 2)\n(2, 1, 1, 1, 2, 1, 1, 3, 2, 1)\n(2, 1, 1, 1, 2, 1, 1, 4, 1, 1)\n(2, 1, 1, 1, 2, 1, 2, 1, 1, 1)\n(2, 1, 1, 1, 2, 1, 2, 1, 1, 2)\n(2, 1, 1, 1, 2, 1, 2, 1, 1, 3)\n(2, 1, 1, 1, 2, 1, 2, 1, 2, 1)\n(2, 1, 1, 1, 2, 1, 2, 1, 2, 2)\n(2, 1, 1, 1, 2, 1, 2, 1, 3, 1)\n(2, 1, 1, 1, 2, 1, 2, 2, 1, 1)\n(2, 1, 1, 1, 2, 1, 2, 2, 1, 2)\n(2, 1, 1, 1, 2, 1, 2, 2, 2, 1)\n(2, 1, 1, 1, 2, 1, 2, 3, 1, 1)\n(2, 1, 1, 1, 2, 1, 3, 1, 1, 1)\n(2, 1, 1, 1, 2, 1, 3, 1, 1, 2)\n(2, 1, 1, 1, 2, 1, 3, 1, 2, 1)\n(2, 1, 1, 1, 2, 1, 3, 2, 1, 1)\n(2, 1, 1, 1, 2, 1, 4, 1, 1, 1)\n(2, 1, 1, 1, 2, 2, 1, 1, 1, 1)\n(2, 1, 1, 1, 2, 2, 1, 1, 1, 2)\n(2, 1, 1, 1, 2, 2, 1, 1, 1, 3)\n(2, 1, 1, 1, 2, 2, 1, 1, 2, 1)\n(2, 1, 1, 1, 2, 2, 1, 1, 2, 2)\n(2, 1, 1, 1, 2, 2, 1, 1, 3, 1)\n(2, 1, 1, 1, 2, 2, 1, 2, 1, 1)\n(2, 1, 1, 1, 2, 2, 1, 2, 1, 2)\n(2, 1, 1, 1, 2, 2, 1, 2, 2, 1)\n(2, 1, 1, 1, 2, 2, 1, 3, 1, 1)\n(2, 1, 1, 1, 2, 2, 2, 1, 1, 1)\n(2, 1, 1, 1, 2, 2, 2, 1, 1, 2)\n(2, 1, 1, 1, 2, 2, 2, 1, 2, 1)\n(2, 1, 1, 1, 2, 2, 2, 2, 1, 1)\n(2, 1, 1, 1, 2, 2, 3, 1, 1, 1)\n(2, 1, 1, 1, 2, 3, 1, 1, 1, 1)\n(2, 1, 1, 1, 2, 3, 1, 1, 1, 2)\n(2, 1, 1, 1, 2, 3, 1, 1, 2, 1)\n(2, 1, 1, 1, 2, 3, 1, 2, 1, 1)\n(2, 1, 1, 1, 2, 3, 2, 1, 1, 1)\n(2, 1, 1, 1, 2, 4, 1, 1, 1, 1)\n(2, 1, 1, 1, 3, 1, 1, 1, 1, 1)\n(2, 1, 1, 1, 3, 1, 1, 1, 1, 2)\n(2, 1, 1, 1, 3, 1, 1, 1, 1, 3)\n(2, 1, 1, 1, 3, 1, 1, 1, 2, 1)\n(2, 1, 1, 1, 3, 1, 1, 1, 2, 2)\n(2, 1, 1, 1, 3, 1, 1, 1, 3, 1)\n(2, 1, 1, 1, 3, 1, 1, 2, 1, 1)\n(2, 1, 1, 1, 3, 1, 1, 2, 1, 2)\n(2, 1, 1, 1, 3, 1, 1, 2, 2, 1)\n(2, 1, 1, 1, 3, 1, 1, 3, 1, 1)\n(2, 1, 1, 1, 3, 1, 2, 1, 1, 1)\n(2, 1, 1, 1, 3, 1, 2, 1, 1, 2)\n(2, 1, 1, 1, 3, 1, 2, 1, 2, 1)\n(2, 1, 1, 1, 3, 1, 2, 2, 1, 1)\n(2, 1, 1, 1, 3, 1, 3, 1, 1, 1)\n(2, 1, 1, 1, 3, 2, 1, 1, 1, 1)\n(2, 1, 1, 1, 3, 2, 1, 1, 1, 2)\n(2, 1, 1, 1, 3, 2, 1, 1, 2, 1)\n(2, 1, 1, 1, 3, 2, 1, 2, 1, 1)\n(2, 1, 1, 1, 3, 2, 2, 1, 1, 1)\n(2, 1, 1, 1, 3, 3, 1, 1, 1, 1)\n(2, 1, 1, 1, 4, 1, 1, 1, 1, 1)\n(2, 1, 1, 1, 4, 1, 1, 1, 1, 2)\n(2, 1, 1, 1, 4, 1, 1, 1, 2, 1)\n(2, 1, 1, 1, 4, 1, 1, 2, 1, 1)\n(2, 1, 1, 1, 4, 1, 2, 1, 1, 1)\n(2, 1, 1, 1, 4, 2, 1, 1, 1, 1)\n(2, 1, 1, 1, 5, 1, 1, 1, 1, 1)\n(2, 1, 1, 2, 1, 1, 1, 1, 1, 1)\n(2, 1, 1, 2, 1, 1, 1, 1, 1, 2)\n(2, 1, 1, 2, 1, 1, 1, 1, 1, 3)\n(2, 1, 1, 2, 1, 1, 1, 1, 1, 4)\n(2, 1, 1, 2, 1, 1, 1, 1, 2, 1)\n(2, 1, 1, 2, 1, 1, 1, 1, 2, 2)\n(2, 1, 1, 2, 1, 1, 1, 1, 2, 3)\n(2, 1, 1, 2, 1, 1, 1, 1, 3, 1)\n(2, 1, 1, 2, 1, 1, 1, 1, 3, 2)\n(2, 1, 1, 2, 1, 1, 1, 1, 4, 1)\n(2, 1, 1, 2, 1, 1, 1, 2, 1, 1)\n(2, 1, 1, 2, 1, 1, 1, 2, 1, 2)\n(2, 1, 1, 2, 1, 1, 1, 2, 1, 3)\n(2, 1, 1, 2, 1, 1, 1, 2, 2, 1)\n(2, 1, 1, 2, 1, 1, 1, 2, 2, 2)\n(2, 1, 1, 2, 1, 1, 1, 2, 3, 1)\n(2, 1, 1, 2, 1, 1, 1, 3, 1, 1)\n(2, 1, 1, 2, 1, 1, 1, 3, 1, 2)\n(2, 1, 1, 2, 1, 1, 1, 3, 2, 1)\n(2, 1, 1, 2, 1, 1, 1, 4, 1, 1)\n(2, 1, 1, 2, 1, 1, 2, 1, 1, 1)\n(2, 1, 1, 2, 1, 1, 2, 1, 1, 2)\n(2, 1, 1, 2, 1, 1, 2, 1, 1, 3)\n(2, 1, 1, 2, 1, 1, 2, 1, 2, 1)\n(2, 1, 1, 2, 1, 1, 2, 1, 2, 2)\n(2, 1, 1, 2, 1, 1, 2, 1, 3, 1)\n(2, 1, 1, 2, 1, 1, 2, 2, 1, 1)\n(2, 1, 1, 2, 1, 1, 2, 2, 1, 2)\n(2, 1, 1, 2, 1, 1, 2, 2, 2, 1)\n(2, 1, 1, 2, 1, 1, 2, 3, 1, 1)\n(2, 1, 1, 2, 1, 1, 3, 1, 1, 1)\n(2, 1, 1, 2, 1, 1, 3, 1, 1, 2)\n(2, 1, 1, 2, 1, 1, 3, 1, 2, 1)\n(2, 1, 1, 2, 1, 1, 3, 2, 1, 1)\n(2, 1, 1, 2, 1, 1, 4, 1, 1, 1)\n(2, 1, 1, 2, 1, 2, 1, 1, 1, 1)\n(2, 1, 1, 2, 1, 2, 1, 1, 1, 2)\n(2, 1, 1, 2, 1, 2, 1, 1, 1, 3)\n(2, 1, 1, 2, 1, 2, 1, 1, 2, 1)\n(2, 1, 1, 2, 1, 2, 1, 1, 2, 2)\n(2, 1, 1, 2, 1, 2, 1, 1, 3, 1)\n(2, 1, 1, 2, 1, 2, 1, 2, 1, 1)\n(2, 1, 1, 2, 1, 2, 1, 2, 1, 2)\n(2, 1, 1, 2, 1, 2, 1, 2, 2, 1)\n(2, 1, 1, 2, 1, 2, 1, 3, 1, 1)\n(2, 1, 1, 2, 1, 2, 2, 1, 1, 1)\n(2, 1, 1, 2, 1, 2, 2, 1, 1, 2)\n(2, 1, 1, 2, 1, 2, 2, 1, 2, 1)\n(2, 1, 1, 2, 1, 2, 2, 2, 1, 1)\n(2, 1, 1, 2, 1, 2, 3, 1, 1, 1)\n(2, 1, 1, 2, 1, 3, 1, 1, 1, 1)\n(2, 1, 1, 2, 1, 3, 1, 1, 1, 2)\n(2, 1, 1, 2, 1, 3, 1, 1, 2, 1)\n(2, 1, 1, 2, 1, 3, 1, 2, 1, 1)\n(2, 1, 1, 2, 1, 3, 2, 1, 1, 1)\n(2, 1, 1, 2, 1, 4, 1, 1, 1, 1)\n(2, 1, 1, 2, 2, 1, 1, 1, 1, 1)\n(2, 1, 1, 2, 2, 1, 1, 1, 1, 2)\n(2, 1, 1, 2, 2, 1, 1, 1, 1, 3)\n(2, 1, 1, 2, 2, 1, 1, 1, 2, 1)\n(2, 1, 1, 2, 2, 1, 1, 1, 2, 2)\n(2, 1, 1, 2, 2, 1, 1, 1, 3, 1)\n(2, 1, 1, 2, 2, 1, 1, 2, 1, 1)\n(2, 1, 1, 2, 2, 1, 1, 2, 1, 2)\n(2, 1, 1, 2, 2, 1, 1, 2, 2, 1)\n(2, 1, 1, 2, 2, 1, 1, 3, 1, 1)\n(2, 1, 1, 2, 2, 1, 2, 1, 1, 1)\n(2, 1, 1, 2, 2, 1, 2, 1, 1, 2)\n(2, 1, 1, 2, 2, 1, 2, 1, 2, 1)\n(2, 1, 1, 2, 2, 1, 2, 2, 1, 1)\n(2, 1, 1, 2, 2, 1, 3, 1, 1, 1)\n(2, 1, 1, 2, 2, 2, 1, 1, 1, 1)\n(2, 1, 1, 2, 2, 2, 1, 1, 1, 2)\n(2, 1, 1, 2, 2, 2, 1, 1, 2, 1)\n(2, 1, 1, 2, 2, 2, 1, 2, 1, 1)\n(2, 1, 1, 2, 2, 2, 2, 1, 1, 1)\n(2, 1, 1, 2, 2, 3, 1, 1, 1, 1)\n(2, 1, 1, 2, 3, 1, 1, 1, 1, 1)\n(2, 1, 1, 2, 3, 1, 1, 1, 1, 2)\n(2, 1, 1, 2, 3, 1, 1, 1, 2, 1)\n(2, 1, 1, 2, 3, 1, 1, 2, 1, 1)\n(2, 1, 1, 2, 3, 1, 2, 1, 1, 1)\n(2, 1, 1, 2, 3, 2, 1, 1, 1, 1)\n(2, 1, 1, 2, 4, 1, 1, 1, 1, 1)\n(2, 1, 1, 3, 1, 1, 1, 1, 1, 1)\n(2, 1, 1, 3, 1, 1, 1, 1, 1, 2)\n(2, 1, 1, 3, 1, 1, 1, 1, 1, 3)\n(2, 1, 1, 3, 1, 1, 1, 1, 2, 1)\n(2, 1, 1, 3, 1, 1, 1, 1, 2, 2)\n(2, 1, 1, 3, 1, 1, 1, 1, 3, 1)\n(2, 1, 1, 3, 1, 1, 1, 2, 1, 1)\n(2, 1, 1, 3, 1, 1, 1, 2, 1, 2)\n(2, 1, 1, 3, 1, 1, 1, 2, 2, 1)\n(2, 1, 1, 3, 1, 1, 1, 3, 1, 1)\n(2, 1, 1, 3, 1, 1, 2, 1, 1, 1)\n(2, 1, 1, 3, 1, 1, 2, 1, 1, 2)\n(2, 1, 1, 3, 1, 1, 2, 1, 2, 1)\n(2, 1, 1, 3, 1, 1, 2, 2, 1, 1)\n(2, 1, 1, 3, 1, 1, 3, 1, 1, 1)\n(2, 1, 1, 3, 1, 2, 1, 1, 1, 1)\n(2, 1, 1, 3, 1, 2, 1, 1, 1, 2)\n(2, 1, 1, 3, 1, 2, 1, 1, 2, 1)\n(2, 1, 1, 3, 1, 2, 1, 2, 1, 1)\n(2, 1, 1, 3, 1, 2, 2, 1, 1, 1)\n(2, 1, 1, 3, 1, 3, 1, 1, 1, 1)\n(2, 1, 1, 3, 2, 1, 1, 1, 1, 1)\n(2, 1, 1, 3, 2, 1, 1, 1, 1, 2)\n(2, 1, 1, 3, 2, 1, 1, 1, 2, 1)\n(2, 1, 1, 3, 2, 1, 1, 2, 1, 1)\n(2, 1, 1, 3, 2, 1, 2, 1, 1, 1)\n(2, 1, 1, 3, 2, 2, 1, 1, 1, 1)\n(2, 1, 1, 3, 3, 1, 1, 1, 1, 1)\n(2, 1, 1, 4, 1, 1, 1, 1, 1, 1)\n(2, 1, 1, 4, 1, 1, 1, 1, 1, 2)\n(2, 1, 1, 4, 1, 1, 1, 1, 2, 1)\n(2, 1, 1, 4, 1, 1, 1, 2, 1, 1)\n(2, 1, 1, 4, 1, 1, 2, 1, 1, 1)\n(2, 1, 1, 4, 1, 2, 1, 1, 1, 1)\n(2, 1, 1, 4, 2, 1, 1, 1, 1, 1)\n(2, 1, 1, 5, 1, 1, 1, 1, 1, 1)\n(2, 1, 2, 1, 1, 1, 1, 1, 1, 1)\n(2, 1, 2, 1, 1, 1, 1, 1, 1, 2)\n(2, 1, 2, 1, 1, 1, 1, 1, 1, 3)\n(2, 1, 2, 1, 1, 1, 1, 1, 1, 4)\n(2, 1, 2, 1, 1, 1, 1, 1, 2, 1)\n(2, 1, 2, 1, 1, 1, 1, 1, 2, 2)\n(2, 1, 2, 1, 1, 1, 1, 1, 2, 3)\n(2, 1, 2, 1, 1, 1, 1, 1, 3, 1)\n(2, 1, 2, 1, 1, 1, 1, 1, 3, 2)\n(2, 1, 2, 1, 1, 1, 1, 1, 4, 1)\n(2, 1, 2, 1, 1, 1, 1, 2, 1, 1)\n(2, 1, 2, 1, 1, 1, 1, 2, 1, 2)\n(2, 1, 2, 1, 1, 1, 1, 2, 1, 3)\n(2, 1, 2, 1, 1, 1, 1, 2, 2, 1)\n(2, 1, 2, 1, 1, 1, 1, 2, 2, 2)\n(2, 1, 2, 1, 1, 1, 1, 2, 3, 1)\n(2, 1, 2, 1, 1, 1, 1, 3, 1, 1)\n(2, 1, 2, 1, 1, 1, 1, 3, 1, 2)\n(2, 1, 2, 1, 1, 1, 1, 3, 2, 1)\n(2, 1, 2, 1, 1, 1, 1, 4, 1, 1)\n(2, 1, 2, 1, 1, 1, 2, 1, 1, 1)\n(2, 1, 2, 1, 1, 1, 2, 1, 1, 2)\n(2, 1, 2, 1, 1, 1, 2, 1, 1, 3)\n(2, 1, 2, 1, 1, 1, 2, 1, 2, 1)\n(2, 1, 2, 1, 1, 1, 2, 1, 2, 2)\n(2, 1, 2, 1, 1, 1, 2, 1, 3, 1)\n(2, 1, 2, 1, 1, 1, 2, 2, 1, 1)\n(2, 1, 2, 1, 1, 1, 2, 2, 1, 2)\n(2, 1, 2, 1, 1, 1, 2, 2, 2, 1)\n(2, 1, 2, 1, 1, 1, 2, 3, 1, 1)\n(2, 1, 2, 1, 1, 1, 3, 1, 1, 1)\n(2, 1, 2, 1, 1, 1, 3, 1, 1, 2)\n(2, 1, 2, 1, 1, 1, 3, 1, 2, 1)\n(2, 1, 2, 1, 1, 1, 3, 2, 1, 1)\n(2, 1, 2, 1, 1, 1, 4, 1, 1, 1)\n(2, 1, 2, 1, 1, 2, 1, 1, 1, 1)\n(2, 1, 2, 1, 1, 2, 1, 1, 1, 2)\n(2, 1, 2, 1, 1, 2, 1, 1, 1, 3)\n(2, 1, 2, 1, 1, 2, 1, 1, 2, 1)\n(2, 1, 2, 1, 1, 2, 1, 1, 2, 2)\n(2, 1, 2, 1, 1, 2, 1, 1, 3, 1)\n(2, 1, 2, 1, 1, 2, 1, 2, 1, 1)\n(2, 1, 2, 1, 1, 2, 1, 2, 1, 2)\n(2, 1, 2, 1, 1, 2, 1, 2, 2, 1)\n(2, 1, 2, 1, 1, 2, 1, 3, 1, 1)\n(2, 1, 2, 1, 1, 2, 2, 1, 1, 1)\n(2, 1, 2, 1, 1, 2, 2, 1, 1, 2)\n(2, 1, 2, 1, 1, 2, 2, 1, 2, 1)\n(2, 1, 2, 1, 1, 2, 2, 2, 1, 1)\n(2, 1, 2, 1, 1, 2, 3, 1, 1, 1)\n(2, 1, 2, 1, 1, 3, 1, 1, 1, 1)\n(2, 1, 2, 1, 1, 3, 1, 1, 1, 2)\n(2, 1, 2, 1, 1, 3, 1, 1, 2, 1)\n(2, 1, 2, 1, 1, 3, 1, 2, 1, 1)\n(2, 1, 2, 1, 1, 3, 2, 1, 1, 1)\n(2, 1, 2, 1, 1, 4, 1, 1, 1, 1)\n(2, 1, 2, 1, 2, 1, 1, 1, 1, 1)\n(2, 1, 2, 1, 2, 1, 1, 1, 1, 2)\n(2, 1, 2, 1, 2, 1, 1, 1, 1, 3)\n(2, 1, 2, 1, 2, 1, 1, 1, 2, 1)\n(2, 1, 2, 1, 2, 1, 1, 1, 2, 2)\n(2, 1, 2, 1, 2, 1, 1, 1, 3, 1)\n(2, 1, 2, 1, 2, 1, 1, 2, 1, 1)\n(2, 1, 2, 1, 2, 1, 1, 2, 1, 2)\n(2, 1, 2, 1, 2, 1, 1, 2, 2, 1)\n(2, 1, 2, 1, 2, 1, 1, 3, 1, 1)\n(2, 1, 2, 1, 2, 1, 2, 1, 1, 1)\n(2, 1, 2, 1, 2, 1, 2, 1, 1, 2)\n(2, 1, 2, 1, 2, 1, 2, 1, 2, 1)\n(2, 1, 2, 1, 2, 1, 2, 2, 1, 1)\n(2, 1, 2, 1, 2, 1, 3, 1, 1, 1)\n(2, 1, 2, 1, 2, 2, 1, 1, 1, 1)\n(2, 1, 2, 1, 2, 2, 1, 1, 1, 2)\n(2, 1, 2, 1, 2, 2, 1, 1, 2, 1)\n(2, 1, 2, 1, 2, 2, 1, 2, 1, 1)\n(2, 1, 2, 1, 2, 2, 2, 1, 1, 1)\n(2, 1, 2, 1, 2, 3, 1, 1, 1, 1)\n(2, 1, 2, 1, 3, 1, 1, 1, 1, 1)\n(2, 1, 2, 1, 3, 1, 1, 1, 1, 2)\n(2, 1, 2, 1, 3, 1, 1, 1, 2, 1)\n(2, 1, 2, 1, 3, 1, 1, 2, 1, 1)\n(2, 1, 2, 1, 3, 1, 2, 1, 1, 1)\n(2, 1, 2, 1, 3, 2, 1, 1, 1, 1)\n(2, 1, 2, 1, 4, 1, 1, 1, 1, 1)\n(2, 1, 2, 2, 1, 1, 1, 1, 1, 1)\n(2, 1, 2, 2, 1, 1, 1, 1, 1, 2)\n(2, 1, 2, 2, 1, 1, 1, 1, 1, 3)\n(2, 1, 2, 2, 1, 1, 1, 1, 2, 1)\n(2, 1, 2, 2, 1, 1, 1, 1, 2, 2)\n(2, 1, 2, 2, 1, 1, 1, 1, 3, 1)\n(2, 1, 2, 2, 1, 1, 1, 2, 1, 1)\n(2, 1, 2, 2, 1, 1, 1, 2, 1, 2)\n(2, 1, 2, 2, 1, 1, 1, 2, 2, 1)\n(2, 1, 2, 2, 1, 1, 1, 3, 1, 1)\n(2, 1, 2, 2, 1, 1, 2, 1, 1, 1)\n(2, 1, 2, 2, 1, 1, 2, 1, 1, 2)\n(2, 1, 2, 2, 1, 1, 2, 1, 2, 1)\n(2, 1, 2, 2, 1, 1, 2, 2, 1, 1)\n(2, 1, 2, 2, 1, 1, 3, 1, 1, 1)\n(2, 1, 2, 2, 1, 2, 1, 1, 1, 1)\n(2, 1, 2, 2, 1, 2, 1, 1, 1, 2)\n(2, 1, 2, 2, 1, 2, 1, 1, 2, 1)\n(2, 1, 2, 2, 1, 2, 1, 2, 1, 1)\n(2, 1, 2, 2, 1, 2, 2, 1, 1, 1)\n(2, 1, 2, 2, 1, 3, 1, 1, 1, 1)\n(2, 1, 2, 2, 2, 1, 1, 1, 1, 1)\n(2, 1, 2, 2, 2, 1, 1, 1, 1, 2)\n(2, 1, 2, 2, 2, 1, 1, 1, 2, 1)\n(2, 1, 2, 2, 2, 1, 1, 2, 1, 1)\n(2, 1, 2, 2, 2, 1, 2, 1, 1, 1)\n(2, 1, 2, 2, 2, 2, 1, 1, 1, 1)\n(2, 1, 2, 2, 3, 1, 1, 1, 1, 1)\n(2, 1, 2, 3, 1, 1, 1, 1, 1, 1)\n(2, 1, 2, 3, 1, 1, 1, 1, 1, 2)\n(2, 1, 2, 3, 1, 1, 1, 1, 2, 1)\n(2, 1, 2, 3, 1, 1, 1, 2, 1, 1)\n(2, 1, 2, 3, 1, 1, 2, 1, 1, 1)\n(2, 1, 2, 3, 1, 2, 1, 1, 1, 1)\n(2, 1, 2, 3, 2, 1, 1, 1, 1, 1)\n(2, 1, 2, 4, 1, 1, 1, 1, 1, 1)\n(2, 1, 3, 1, 1, 1, 1, 1, 1, 1)\n(2, 1, 3, 1, 1, 1, 1, 1, 1, 2)\n(2, 1, 3, 1, 1, 1, 1, 1, 1, 3)\n(2, 1, 3, 1, 1, 1, 1, 1, 2, 1)\n(2, 1, 3, 1, 1, 1, 1, 1, 2, 2)\n(2, 1, 3, 1, 1, 1, 1, 1, 3, 1)\n(2, 1, 3, 1, 1, 1, 1, 2, 1, 1)\n(2, 1, 3, 1, 1, 1, 1, 2, 1, 2)\n(2, 1, 3, 1, 1, 1, 1, 2, 2, 1)\n(2, 1, 3, 1, 1, 1, 1, 3, 1, 1)\n(2, 1, 3, 1, 1, 1, 2, 1, 1, 1)\n(2, 1, 3, 1, 1, 1, 2, 1, 1, 2)\n(2, 1, 3, 1, 1, 1, 2, 1, 2, 1)\n(2, 1, 3, 1, 1, 1, 2, 2, 1, 1)\n(2, 1, 3, 1, 1, 1, 3, 1, 1, 1)\n(2, 1, 3, 1, 1, 2, 1, 1, 1, 1)\n(2, 1, 3, 1, 1, 2, 1, 1, 1, 2)\n(2, 1, 3, 1, 1, 2, 1, 1, 2, 1)\n(2, 1, 3, 1, 1, 2, 1, 2, 1, 1)\n(2, 1, 3, 1, 1, 2, 2, 1, 1, 1)\n(2, 1, 3, 1, 1, 3, 1, 1, 1, 1)\n(2, 1, 3, 1, 2, 1, 1, 1, 1, 1)\n(2, 1, 3, 1, 2, 1, 1, 1, 1, 2)\n(2, 1, 3, 1, 2, 1, 1, 1, 2, 1)\n(2, 1, 3, 1, 2, 1, 1, 2, 1, 1)\n(2, 1, 3, 1, 2, 1, 2, 1, 1, 1)\n(2, 1, 3, 1, 2, 2, 1, 1, 1, 1)\n(2, 1, 3, 1, 3, 1, 1, 1, 1, 1)\n(2, 1, 3, 2, 1, 1, 1, 1, 1, 1)\n(2, 1, 3, 2, 1, 1, 1, 1, 1, 2)\n(2, 1, 3, 2, 1, 1, 1, 1, 2, 1)\n(2, 1, 3, 2, 1, 1, 1, 2, 1, 1)\n(2, 1, 3, 2, 1, 1, 2, 1, 1, 1)\n(2, 1, 3, 2, 1, 2, 1, 1, 1, 1)\n(2, 1, 3, 2, 2, 1, 1, 1, 1, 1)\n(2, 1, 3, 3, 1, 1, 1, 1, 1, 1)\n(2, 1, 4, 1, 1, 1, 1, 1, 1, 1)\n(2, 1, 4, 1, 1, 1, 1, 1, 1, 2)\n(2, 1, 4, 1, 1, 1, 1, 1, 2, 1)\n(2, 1, 4, 1, 1, 1, 1, 2, 1, 1)\n(2, 1, 4, 1, 1, 1, 2, 1, 1, 1)\n(2, 1, 4, 1, 1, 2, 1, 1, 1, 1)\n(2, 1, 4, 1, 2, 1, 1, 1, 1, 1)\n(2, 1, 4, 2, 1, 1, 1, 1, 1, 1)\n(2, 1, 5, 1, 1, 1, 1, 1, 1, 1)\n(2, 2, 1, 1, 1, 1, 1, 1, 1, 1)\n(2, 2, 1, 1, 1, 1, 1, 1, 1, 2)\n(2, 2, 1, 1, 1, 1, 1, 1, 1, 3)\n(2, 2, 1, 1, 1, 1, 1, 1, 1, 4)\n(2, 2, 1, 1, 1, 1, 1, 1, 2, 1)\n(2, 2, 1, 1, 1, 1, 1, 1, 2, 2)\n(2, 2, 1, 1, 1, 1, 1, 1, 2, 3)\n(2, 2, 1, 1, 1, 1, 1, 1, 3, 1)\n(2, 2, 1, 1, 1, 1, 1, 1, 3, 2)\n(2, 2, 1, 1, 1, 1, 1, 1, 4, 1)\n(2, 2, 1, 1, 1, 1, 1, 2, 1, 1)\n(2, 2, 1, 1, 1, 1, 1, 2, 1, 2)\n(2, 2, 1, 1, 1, 1, 1, 2, 1, 3)\n(2, 2, 1, 1, 1, 1, 1, 2, 2, 1)\n(2, 2, 1, 1, 1, 1, 1, 2, 2, 2)\n(2, 2, 1, 1, 1, 1, 1, 2, 3, 1)\n(2, 2, 1, 1, 1, 1, 1, 3, 1, 1)\n(2, 2, 1, 1, 1, 1, 1, 3, 1, 2)\n(2, 2, 1, 1, 1, 1, 1, 3, 2, 1)\n(2, 2, 1, 1, 1, 1, 1, 4, 1, 1)\n(2, 2, 1, 1, 1, 1, 2, 1, 1, 1)\n(2, 2, 1, 1, 1, 1, 2, 1, 1, 2)\n(2, 2, 1, 1, 1, 1, 2, 1, 1, 3)\n(2, 2, 1, 1, 1, 1, 2, 1, 2, 1)\n(2, 2, 1, 1, 1, 1, 2, 1, 2, 2)\n(2, 2, 1, 1, 1, 1, 2, 1, 3, 1)\n(2, 2, 1, 1, 1, 1, 2, 2, 1, 1)\n(2, 2, 1, 1, 1, 1, 2, 2, 1, 2)\n(2, 2, 1, 1, 1, 1, 2, 2, 2, 1)\n(2, 2, 1, 1, 1, 1, 2, 3, 1, 1)\n(2, 2, 1, 1, 1, 1, 3, 1, 1, 1)\n(2, 2, 1, 1, 1, 1, 3, 1, 1, 2)\n(2, 2, 1, 1, 1, 1, 3, 1, 2, 1)\n(2, 2, 1, 1, 1, 1, 3, 2, 1, 1)\n(2, 2, 1, 1, 1, 1, 4, 1, 1, 1)\n(2, 2, 1, 1, 1, 2, 1, 1, 1, 1)\n(2, 2, 1, 1, 1, 2, 1, 1, 1, 2)\n(2, 2, 1, 1, 1, 2, 1, 1, 1, 3)\n(2, 2, 1, 1, 1, 2, 1, 1, 2, 1)\n(2, 2, 1, 1, 1, 2, 1, 1, 2, 2)\n(2, 2, 1, 1, 1, 2, 1, 1, 3, 1)\n(2, 2, 1, 1, 1, 2, 1, 2, 1, 1)\n(2, 2, 1, 1, 1, 2, 1, 2, 1, 2)\n(2, 2, 1, 1, 1, 2, 1, 2, 2, 1)\n(2, 2, 1, 1, 1, 2, 1, 3, 1, 1)\n(2, 2, 1, 1, 1, 2, 2, 1, 1, 1)\n(2, 2, 1, 1, 1, 2, 2, 1, 1, 2)\n(2, 2, 1, 1, 1, 2, 2, 1, 2, 1)\n(2, 2, 1, 1, 1, 2, 2, 2, 1, 1)\n(2, 2, 1, 1, 1, 2, 3, 1, 1, 1)\n(2, 2, 1, 1, 1, 3, 1, 1, 1, 1)\n(2, 2, 1, 1, 1, 3, 1, 1, 1, 2)\n(2, 2, 1, 1, 1, 3, 1, 1, 2, 1)\n(2, 2, 1, 1, 1, 3, 1, 2, 1, 1)\n(2, 2, 1, 1, 1, 3, 2, 1, 1, 1)\n(2, 2, 1, 1, 1, 4, 1, 1, 1, 1)\n(2, 2, 1, 1, 2, 1, 1, 1, 1, 1)\n(2, 2, 1, 1, 2, 1, 1, 1, 1, 2)\n(2, 2, 1, 1, 2, 1, 1, 1, 1, 3)\n(2, 2, 1, 1, 2, 1, 1, 1, 2, 1)\n(2, 2, 1, 1, 2, 1, 1, 1, 2, 2)\n(2, 2, 1, 1, 2, 1, 1, 1, 3, 1)\n(2, 2, 1, 1, 2, 1, 1, 2, 1, 1)\n(2, 2, 1, 1, 2, 1, 1, 2, 1, 2)\n(2, 2, 1, 1, 2, 1, 1, 2, 2, 1)\n(2, 2, 1, 1, 2, 1, 1, 3, 1, 1)\n(2, 2, 1, 1, 2, 1, 2, 1, 1, 1)\n(2, 2, 1, 1, 2, 1, 2, 1, 1, 2)\n(2, 2, 1, 1, 2, 1, 2, 1, 2, 1)\n(2, 2, 1, 1, 2, 1, 2, 2, 1, 1)\n(2, 2, 1, 1, 2, 1, 3, 1, 1, 1)\n(2, 2, 1, 1, 2, 2, 1, 1, 1, 1)\n(2, 2, 1, 1, 2, 2, 1, 1, 1, 2)\n(2, 2, 1, 1, 2, 2, 1, 1, 2, 1)\n(2, 2, 1, 1, 2, 2, 1, 2, 1, 1)\n(2, 2, 1, 1, 2, 2, 2, 1, 1, 1)\n(2, 2, 1, 1, 2, 3, 1, 1, 1, 1)\n(2, 2, 1, 1, 3, 1, 1, 1, 1, 1)\n(2, 2, 1, 1, 3, 1, 1, 1, 1, 2)\n(2, 2, 1, 1, 3, 1, 1, 1, 2, 1)\n(2, 2, 1, 1, 3, 1, 1, 2, 1, 1)\n(2, 2, 1, 1, 3, 1, 2, 1, 1, 1)\n(2, 2, 1, 1, 3, 2, 1, 1, 1, 1)\n(2, 2, 1, 1, 4, 1, 1, 1, 1, 1)\n(2, 2, 1, 2, 1, 1, 1, 1, 1, 1)\n(2, 2, 1, 2, 1, 1, 1, 1, 1, 2)\n(2, 2, 1, 2, 1, 1, 1, 1, 1, 3)\n(2, 2, 1, 2, 1, 1, 1, 1, 2, 1)\n(2, 2, 1, 2, 1, 1, 1, 1, 2, 2)\n(2, 2, 1, 2, 1, 1, 1, 1, 3, 1)\n(2, 2, 1, 2, 1, 1, 1, 2, 1, 1)\n(2, 2, 1, 2, 1, 1, 1, 2, 1, 2)\n(2, 2, 1, 2, 1, 1, 1, 2, 2, 1)\n(2, 2, 1, 2, 1, 1, 1, 3, 1, 1)\n(2, 2, 1, 2, 1, 1, 2, 1, 1, 1)\n(2, 2, 1, 2, 1, 1, 2, 1, 1, 2)\n(2, 2, 1, 2, 1, 1, 2, 1, 2, 1)\n(2, 2, 1, 2, 1, 1, 2, 2, 1, 1)\n(2, 2, 1, 2, 1, 1, 3, 1, 1, 1)\n(2, 2, 1, 2, 1, 2, 1, 1, 1, 1)\n(2, 2, 1, 2, 1, 2, 1, 1, 1, 2)\n(2, 2, 1, 2, 1, 2, 1, 1, 2, 1)\n(2, 2, 1, 2, 1, 2, 1, 2, 1, 1)\n(2, 2, 1, 2, 1, 2, 2, 1, 1, 1)\n(2, 2, 1, 2, 1, 3, 1, 1, 1, 1)\n(2, 2, 1, 2, 2, 1, 1, 1, 1, 1)\n(2, 2, 1, 2, 2, 1, 1, 1, 1, 2)\n(2, 2, 1, 2, 2, 1, 1, 1, 2, 1)\n(2, 2, 1, 2, 2, 1, 1, 2, 1, 1)\n(2, 2, 1, 2, 2, 1, 2, 1, 1, 1)\n(2, 2, 1, 2, 2, 2, 1, 1, 1, 1)\n(2, 2, 1, 2, 3, 1, 1, 1, 1, 1)\n(2, 2, 1, 3, 1, 1, 1, 1, 1, 1)\n(2, 2, 1, 3, 1, 1, 1, 1, 1, 2)\n(2, 2, 1, 3, 1, 1, 1, 1, 2, 1)\n(2, 2, 1, 3, 1, 1, 1, 2, 1, 1)\n(2, 2, 1, 3, 1, 1, 2, 1, 1, 1)\n(2, 2, 1, 3, 1, 2, 1, 1, 1, 1)\n(2, 2, 1, 3, 2, 1, 1, 1, 1, 1)\n(2, 2, 1, 4, 1, 1, 1, 1, 1, 1)\n(2, 2, 2, 1, 1, 1, 1, 1, 1, 1)\n(2, 2, 2, 1, 1, 1, 1, 1, 1, 2)\n(2, 2, 2, 1, 1, 1, 1, 1, 1, 3)\n(2, 2, 2, 1, 1, 1, 1, 1, 2, 1)\n(2, 2, 2, 1, 1, 1, 1, 1, 2, 2)\n(2, 2, 2, 1, 1, 1, 1, 1, 3, 1)\n(2, 2, 2, 1, 1, 1, 1, 2, 1, 1)\n(2, 2, 2, 1, 1, 1, 1, 2, 1, 2)\n(2, 2, 2, 1, 1, 1, 1, 2, 2, 1)\n(2, 2, 2, 1, 1, 1, 1, 3, 1, 1)\n(2, 2, 2, 1, 1, 1, 2, 1, 1, 1)\n(2, 2, 2, 1, 1, 1, 2, 1, 1, 2)\n(2, 2, 2, 1, 1, 1, 2, 1, 2, 1)\n(2, 2, 2, 1, 1, 1, 2, 2, 1, 1)\n(2, 2, 2, 1, 1, 1, 3, 1, 1, 1)\n(2, 2, 2, 1, 1, 2, 1, 1, 1, 1)\n(2, 2, 2, 1, 1, 2, 1, 1, 1, 2)\n(2, 2, 2, 1, 1, 2, 1, 1, 2, 1)\n(2, 2, 2, 1, 1, 2, 1, 2, 1, 1)\n(2, 2, 2, 1, 1, 2, 2, 1, 1, 1)\n(2, 2, 2, 1, 1, 3, 1, 1, 1, 1)\n(2, 2, 2, 1, 2, 1, 1, 1, 1, 1)\n(2, 2, 2, 1, 2, 1, 1, 1, 1, 2)\n(2, 2, 2, 1, 2, 1, 1, 1, 2, 1)\n(2, 2, 2, 1, 2, 1, 1, 2, 1, 1)\n(2, 2, 2, 1, 2, 1, 2, 1, 1, 1)\n(2, 2, 2, 1, 2, 2, 1, 1, 1, 1)\n(2, 2, 2, 1, 3, 1, 1, 1, 1, 1)\n(2, 2, 2, 2, 1, 1, 1, 1, 1, 1)\n(2, 2, 2, 2, 1, 1, 1, 1, 1, 2)\n(2, 2, 2, 2, 1, 1, 1, 1, 2, 1)\n(2, 2, 2, 2, 1, 1, 1, 2, 1, 1)\n(2, 2, 2, 2, 1, 1, 2, 1, 1, 1)\n(2, 2, 2, 2, 1, 2, 1, 1, 1, 1)\n(2, 2, 2, 2, 2, 1, 1, 1, 1, 1)\n(2, 2, 2, 3, 1, 1, 1, 1, 1, 1)\n(2, 2, 3, 1, 1, 1, 1, 1, 1, 1)\n(2, 2, 3, 1, 1, 1, 1, 1, 1, 2)\n(2, 2, 3, 1, 1, 1, 1, 1, 2, 1)\n(2, 2, 3, 1, 1, 1, 1, 2, 1, 1)\n(2, 2, 3, 1, 1, 1, 2, 1, 1, 1)\n(2, 2, 3, 1, 1, 2, 1, 1, 1, 1)\n(2, 2, 3, 1, 2, 1, 1, 1, 1, 1)\n(2, 2, 3, 2, 1, 1, 1, 1, 1, 1)\n(2, 2, 4, 1, 1, 1, 1, 1, 1, 1)\n(2, 3, 1, 1, 1, 1, 1, 1, 1, 1)\n(2, 3, 1, 1, 1, 1, 1, 1, 1, 2)\n(2, 3, 1, 1, 1, 1, 1, 1, 1, 3)\n(2, 3, 1, 1, 1, 1, 1, 1, 2, 1)\n(2, 3, 1, 1, 1, 1, 1, 1, 2, 2)\n(2, 3, 1, 1, 1, 1, 1, 1, 3, 1)\n(2, 3, 1, 1, 1, 1, 1, 2, 1, 1)\n(2, 3, 1, 1, 1, 1, 1, 2, 1, 2)\n(2, 3, 1, 1, 1, 1, 1, 2, 2, 1)\n(2, 3, 1, 1, 1, 1, 1, 3, 1, 1)\n(2, 3, 1, 1, 1, 1, 2, 1, 1, 1)\n(2, 3, 1, 1, 1, 1, 2, 1, 1, 2)\n(2, 3, 1, 1, 1, 1, 2, 1, 2, 1)\n(2, 3, 1, 1, 1, 1, 2, 2, 1, 1)\n(2, 3, 1, 1, 1, 1, 3, 1, 1, 1)\n(2, 3, 1, 1, 1, 2, 1, 1, 1, 1)\n(2, 3, 1, 1, 1, 2, 1, 1, 1, 2)\n(2, 3, 1, 1, 1, 2, 1, 1, 2, 1)\n(2, 3, 1, 1, 1, 2, 1, 2, 1, 1)\n(2, 3, 1, 1, 1, 2, 2, 1, 1, 1)\n(2, 3, 1, 1, 1, 3, 1, 1, 1, 1)\n(2, 3, 1, 1, 2, 1, 1, 1, 1, 1)\n(2, 3, 1, 1, 2, 1, 1, 1, 1, 2)\n(2, 3, 1, 1, 2, 1, 1, 1, 2, 1)\n(2, 3, 1, 1, 2, 1, 1, 2, 1, 1)\n(2, 3, 1, 1, 2, 1, 2, 1, 1, 1)\n(2, 3, 1, 1, 2, 2, 1, 1, 1, 1)\n(2, 3, 1, 1, 3, 1, 1, 1, 1, 1)\n(2, 3, 1, 2, 1, 1, 1, 1, 1, 1)\n(2, 3, 1, 2, 1, 1, 1, 1, 1, 2)\n(2, 3, 1, 2, 1, 1, 1, 1, 2, 1)\n(2, 3, 1, 2, 1, 1, 1, 2, 1, 1)\n(2, 3, 1, 2, 1, 1, 2, 1, 1, 1)\n(2, 3, 1, 2, 1, 2, 1, 1, 1, 1)\n(2, 3, 1, 2, 2, 1, 1, 1, 1, 1)\n(2, 3, 1, 3, 1, 1, 1, 1, 1, 1)\n(2, 3, 2, 1, 1, 1, 1, 1, 1, 1)\n(2, 3, 2, 1, 1, 1, 1, 1, 1, 2)\n(2, 3, 2, 1, 1, 1, 1, 1, 2, 1)\n(2, 3, 2, 1, 1, 1, 1, 2, 1, 1)\n(2, 3, 2, 1, 1, 1, 2, 1, 1, 1)\n(2, 3, 2, 1, 1, 2, 1, 1, 1, 1)\n(2, 3, 2, 1, 2, 1, 1, 1, 1, 1)\n(2, 3, 2, 2, 1, 1, 1, 1, 1, 1)\n(2, 3, 3, 1, 1, 1, 1, 1, 1, 1)\n(2, 4, 1, 1, 1, 1, 1, 1, 1, 1)\n(2, 4, 1, 1, 1, 1, 1, 1, 1, 2)\n(2, 4, 1, 1, 1, 1, 1, 1, 2, 1)\n(2, 4, 1, 1, 1, 1, 1, 2, 1, 1)\n(2, 4, 1, 1, 1, 1, 2, 1, 1, 1)\n(2, 4, 1, 1, 1, 2, 1, 1, 1, 1)\n(2, 4, 1, 1, 2, 1, 1, 1, 1, 1)\n(2, 4, 1, 2, 1, 1, 1, 1, 1, 1)\n(2, 4, 2, 1, 1, 1, 1, 1, 1, 1)\n(2, 5, 1, 1, 1, 1, 1, 1, 1, 1)\n(3, 1, 1, 1, 1, 1, 1, 1, 1, 1)\n(3, 1, 1, 1, 1, 1, 1, 1, 1, 2)\n(3, 1, 1, 1, 1, 1, 1, 1, 1, 3)\n(3, 1, 1, 1, 1, 1, 1, 1, 1, 4)\n(3, 1, 1, 1, 1, 1, 1, 1, 2, 1)\n(3, 1, 1, 1, 1, 1, 1, 1, 2, 2)\n(3, 1, 1, 1, 1, 1, 1, 1, 2, 3)\n(3, 1, 1, 1, 1, 1, 1, 1, 3, 1)\n(3, 1, 1, 1, 1, 1, 1, 1, 3, 2)\n(3, 1, 1, 1, 1, 1, 1, 1, 4, 1)\n(3, 1, 1, 1, 1, 1, 1, 2, 1, 1)\n(3, 1, 1, 1, 1, 1, 1, 2, 1, 2)\n(3, 1, 1, 1, 1, 1, 1, 2, 1, 3)\n(3, 1, 1, 1, 1, 1, 1, 2, 2, 1)\n(3, 1, 1, 1, 1, 1, 1, 2, 2, 2)\n(3, 1, 1, 1, 1, 1, 1, 2, 3, 1)\n(3, 1, 1, 1, 1, 1, 1, 3, 1, 1)\n(3, 1, 1, 1, 1, 1, 1, 3, 1, 2)\n(3, 1, 1, 1, 1, 1, 1, 3, 2, 1)\n(3, 1, 1, 1, 1, 1, 1, 4, 1, 1)\n(3, 1, 1, 1, 1, 1, 2, 1, 1, 1)\n(3, 1, 1, 1, 1, 1, 2, 1, 1, 2)\n(3, 1, 1, 1, 1, 1, 2, 1, 1, 3)\n(3, 1, 1, 1, 1, 1, 2, 1, 2, 1)\n(3, 1, 1, 1, 1, 1, 2, 1, 2, 2)\n(3, 1, 1, 1, 1, 1, 2, 1, 3, 1)\n(3, 1, 1, 1, 1, 1, 2, 2, 1, 1)\n(3, 1, 1, 1, 1, 1, 2, 2, 1, 2)\n(3, 1, 1, 1, 1, 1, 2, 2, 2, 1)\n(3, 1, 1, 1, 1, 1, 2, 3, 1, 1)\n(3, 1, 1, 1, 1, 1, 3, 1, 1, 1)\n(3, 1, 1, 1, 1, 1, 3, 1, 1, 2)\n(3, 1, 1, 1, 1, 1, 3, 1, 2, 1)\n(3, 1, 1, 1, 1, 1, 3, 2, 1, 1)\n(3, 1, 1, 1, 1, 1, 4, 1, 1, 1)\n(3, 1, 1, 1, 1, 2, 1, 1, 1, 1)\n(3, 1, 1, 1, 1, 2, 1, 1, 1, 2)\n(3, 1, 1, 1, 1, 2, 1, 1, 1, 3)\n(3, 1, 1, 1, 1, 2, 1, 1, 2, 1)\n(3, 1, 1, 1, 1, 2, 1, 1, 2, 2)\n(3, 1, 1, 1, 1, 2, 1, 1, 3, 1)\n(3, 1, 1, 1, 1, 2, 1, 2, 1, 1)\n(3, 1, 1, 1, 1, 2, 1, 2, 1, 2)\n(3, 1, 1, 1, 1, 2, 1, 2, 2, 1)\n(3, 1, 1, 1, 1, 2, 1, 3, 1, 1)\n(3, 1, 1, 1, 1, 2, 2, 1, 1, 1)\n(3, 1, 1, 1, 1, 2, 2, 1, 1, 2)\n(3, 1, 1, 1, 1, 2, 2, 1, 2, 1)\n(3, 1, 1, 1, 1, 2, 2, 2, 1, 1)\n(3, 1, 1, 1, 1, 2, 3, 1, 1, 1)\n(3, 1, 1, 1, 1, 3, 1, 1, 1, 1)\n(3, 1, 1, 1, 1, 3, 1, 1, 1, 2)\n(3, 1, 1, 1, 1, 3, 1, 1, 2, 1)\n(3, 1, 1, 1, 1, 3, 1, 2, 1, 1)\n(3, 1, 1, 1, 1, 3, 2, 1, 1, 1)\n(3, 1, 1, 1, 1, 4, 1, 1, 1, 1)\n(3, 1, 1, 1, 2, 1, 1, 1, 1, 1)\n(3, 1, 1, 1, 2, 1, 1, 1, 1, 2)\n(3, 1, 1, 1, 2, 1, 1, 1, 1, 3)\n(3, 1, 1, 1, 2, 1, 1, 1, 2, 1)\n(3, 1, 1, 1, 2, 1, 1, 1, 2, 2)\n(3, 1, 1, 1, 2, 1, 1, 1, 3, 1)\n(3, 1, 1, 1, 2, 1, 1, 2, 1, 1)\n(3, 1, 1, 1, 2, 1, 1, 2, 1, 2)\n(3, 1, 1, 1, 2, 1, 1, 2, 2, 1)\n(3, 1, 1, 1, 2, 1, 1, 3, 1, 1)\n(3, 1, 1, 1, 2, 1, 2, 1, 1, 1)\n(3, 1, 1, 1, 2, 1, 2, 1, 1, 2)\n(3, 1, 1, 1, 2, 1, 2, 1, 2, 1)\n(3, 1, 1, 1, 2, 1, 2, 2, 1, 1)\n(3, 1, 1, 1, 2, 1, 3, 1, 1, 1)\n(3, 1, 1, 1, 2, 2, 1, 1, 1, 1)\n(3, 1, 1, 1, 2, 2, 1, 1, 1, 2)\n(3, 1, 1, 1, 2, 2, 1, 1, 2, 1)\n(3, 1, 1, 1, 2, 2, 1, 2, 1, 1)\n(3, 1, 1, 1, 2, 2, 2, 1, 1, 1)\n(3, 1, 1, 1, 2, 3, 1, 1, 1, 1)\n(3, 1, 1, 1, 3, 1, 1, 1, 1, 1)\n(3, 1, 1, 1, 3, 1, 1, 1, 1, 2)\n(3, 1, 1, 1, 3, 1, 1, 1, 2, 1)\n(3, 1, 1, 1, 3, 1, 1, 2, 1, 1)\n(3, 1, 1, 1, 3, 1, 2, 1, 1, 1)\n(3, 1, 1, 1, 3, 2, 1, 1, 1, 1)\n(3, 1, 1, 1, 4, 1, 1, 1, 1, 1)\n(3, 1, 1, 2, 1, 1, 1, 1, 1, 1)\n(3, 1, 1, 2, 1, 1, 1, 1, 1, 2)\n(3, 1, 1, 2, 1, 1, 1, 1, 1, 3)\n(3, 1, 1, 2, 1, 1, 1, 1, 2, 1)\n(3, 1, 1, 2, 1, 1, 1, 1, 2, 2)\n(3, 1, 1, 2, 1, 1, 1, 1, 3, 1)\n(3, 1, 1, 2, 1, 1, 1, 2, 1, 1)\n(3, 1, 1, 2, 1, 1, 1, 2, 1, 2)\n(3, 1, 1, 2, 1, 1, 1, 2, 2, 1)\n(3, 1, 1, 2, 1, 1, 1, 3, 1, 1)\n(3, 1, 1, 2, 1, 1, 2, 1, 1, 1)\n(3, 1, 1, 2, 1, 1, 2, 1, 1, 2)\n(3, 1, 1, 2, 1, 1, 2, 1, 2, 1)\n(3, 1, 1, 2, 1, 1, 2, 2, 1, 1)\n(3, 1, 1, 2, 1, 1, 3, 1, 1, 1)\n(3, 1, 1, 2, 1, 2, 1, 1, 1, 1)\n(3, 1, 1, 2, 1, 2, 1, 1, 1, 2)\n(3, 1, 1, 2, 1, 2, 1, 1, 2, 1)\n(3, 1, 1, 2, 1, 2, 1, 2, 1, 1)\n(3, 1, 1, 2, 1, 2, 2, 1, 1, 1)\n(3, 1, 1, 2, 1, 3, 1, 1, 1, 1)\n(3, 1, 1, 2, 2, 1, 1, 1, 1, 1)\n(3, 1, 1, 2, 2, 1, 1, 1, 1, 2)\n(3, 1, 1, 2, 2, 1, 1, 1, 2, 1)\n(3, 1, 1, 2, 2, 1, 1, 2, 1, 1)\n(3, 1, 1, 2, 2, 1, 2, 1, 1, 1)\n(3, 1, 1, 2, 2, 2, 1, 1, 1, 1)\n(3, 1, 1, 2, 3, 1, 1, 1, 1, 1)\n(3, 1, 1, 3, 1, 1, 1, 1, 1, 1)\n(3, 1, 1, 3, 1, 1, 1, 1, 1, 2)\n(3, 1, 1, 3, 1, 1, 1, 1, 2, 1)\n(3, 1, 1, 3, 1, 1, 1, 2, 1, 1)\n(3, 1, 1, 3, 1, 1, 2, 1, 1, 1)\n(3, 1, 1, 3, 1, 2, 1, 1, 1, 1)\n(3, 1, 1, 3, 2, 1, 1, 1, 1, 1)\n(3, 1, 1, 4, 1, 1, 1, 1, 1, 1)\n(3, 1, 2, 1, 1, 1, 1, 1, 1, 1)\n(3, 1, 2, 1, 1, 1, 1, 1, 1, 2)\n(3, 1, 2, 1, 1, 1, 1, 1, 1, 3)\n(3, 1, 2, 1, 1, 1, 1, 1, 2, 1)\n(3, 1, 2, 1, 1, 1, 1, 1, 2, 2)\n(3, 1, 2, 1, 1, 1, 1, 1, 3, 1)\n(3, 1, 2, 1, 1, 1, 1, 2, 1, 1)\n(3, 1, 2, 1, 1, 1, 1, 2, 1, 2)\n(3, 1, 2, 1, 1, 1, 1, 2, 2, 1)\n(3, 1, 2, 1, 1, 1, 1, 3, 1, 1)\n(3, 1, 2, 1, 1, 1, 2, 1, 1, 1)\n(3, 1, 2, 1, 1, 1, 2, 1, 1, 2)\n(3, 1, 2, 1, 1, 1, 2, 1, 2, 1)\n(3, 1, 2, 1, 1, 1, 2, 2, 1, 1)\n(3, 1, 2, 1, 1, 1, 3, 1, 1, 1)\n(3, 1, 2, 1, 1, 2, 1, 1, 1, 1)\n(3, 1, 2, 1, 1, 2, 1, 1, 1, 2)\n(3, 1, 2, 1, 1, 2, 1, 1, 2, 1)\n(3, 1, 2, 1, 1, 2, 1, 2, 1, 1)\n(3, 1, 2, 1, 1, 2, 2, 1, 1, 1)\n(3, 1, 2, 1, 1, 3, 1, 1, 1, 1)\n(3, 1, 2, 1, 2, 1, 1, 1, 1, 1)\n(3, 1, 2, 1, 2, 1, 1, 1, 1, 2)\n(3, 1, 2, 1, 2, 1, 1, 1, 2, 1)\n(3, 1, 2, 1, 2, 1, 1, 2, 1, 1)\n(3, 1, 2, 1, 2, 1, 2, 1, 1, 1)\n(3, 1, 2, 1, 2, 2, 1, 1, 1, 1)\n(3, 1, 2, 1, 3, 1, 1, 1, 1, 1)\n(3, 1, 2, 2, 1, 1, 1, 1, 1, 1)\n(3, 1, 2, 2, 1, 1, 1, 1, 1, 2)\n(3, 1, 2, 2, 1, 1, 1, 1, 2, 1)\n(3, 1, 2, 2, 1, 1, 1, 2, 1, 1)\n(3, 1, 2, 2, 1, 1, 2, 1, 1, 1)\n(3, 1, 2, 2, 1, 2, 1, 1, 1, 1)\n(3, 1, 2, 2, 2, 1, 1, 1, 1, 1)\n(3, 1, 2, 3, 1, 1, 1, 1, 1, 1)\n(3, 1, 3, 1, 1, 1, 1, 1, 1, 1)\n(3, 1, 3, 1, 1, 1, 1, 1, 1, 2)\n(3, 1, 3, 1, 1, 1, 1, 1, 2, 1)\n(3, 1, 3, 1, 1, 1, 1, 2, 1, 1)\n(3, 1, 3, 1, 1, 1, 2, 1, 1, 1)\n(3, 1, 3, 1, 1, 2, 1, 1, 1, 1)\n(3, 1, 3, 1, 2, 1, 1, 1, 1, 1)\n(3, 1, 3, 2, 1, 1, 1, 1, 1, 1)\n(3, 1, 4, 1, 1, 1, 1, 1, 1, 1)\n(3, 2, 1, 1, 1, 1, 1, 1, 1, 1)\n(3, 2, 1, 1, 1, 1, 1, 1, 1, 2)\n(3, 2, 1, 1, 1, 1, 1, 1, 1, 3)\n(3, 2, 1, 1, 1, 1, 1, 1, 2, 1)\n(3, 2, 1, 1, 1, 1, 1, 1, 2, 2)\n(3, 2, 1, 1, 1, 1, 1, 1, 3, 1)\n(3, 2, 1, 1, 1, 1, 1, 2, 1, 1)\n(3, 2, 1, 1, 1, 1, 1, 2, 1, 2)\n(3, 2, 1, 1, 1, 1, 1, 2, 2, 1)\n(3, 2, 1, 1, 1, 1, 1, 3, 1, 1)\n(3, 2, 1, 1, 1, 1, 2, 1, 1, 1)\n(3, 2, 1, 1, 1, 1, 2, 1, 1, 2)\n(3, 2, 1, 1, 1, 1, 2, 1, 2, 1)\n(3, 2, 1, 1, 1, 1, 2, 2, 1, 1)\n(3, 2, 1, 1, 1, 1, 3, 1, 1, 1)\n(3, 2, 1, 1, 1, 2, 1, 1, 1, 1)\n(3, 2, 1, 1, 1, 2, 1, 1, 1, 2)\n(3, 2, 1, 1, 1, 2, 1, 1, 2, 1)\n(3, 2, 1, 1, 1, 2, 1, 2, 1, 1)\n(3, 2, 1, 1, 1, 2, 2, 1, 1, 1)\n(3, 2, 1, 1, 1, 3, 1, 1, 1, 1)\n(3, 2, 1, 1, 2, 1, 1, 1, 1, 1)\n(3, 2, 1, 1, 2, 1, 1, 1, 1, 2)\n(3, 2, 1, 1, 2, 1, 1, 1, 2, 1)\n(3, 2, 1, 1, 2, 1, 1, 2, 1, 1)\n(3, 2, 1, 1, 2, 1, 2, 1, 1, 1)\n(3, 2, 1, 1, 2, 2, 1, 1, 1, 1)\n(3, 2, 1, 1, 3, 1, 1, 1, 1, 1)\n(3, 2, 1, 2, 1, 1, 1, 1, 1, 1)\n(3, 2, 1, 2, 1, 1, 1, 1, 1, 2)\n(3, 2, 1, 2, 1, 1, 1, 1, 2, 1)\n(3, 2, 1, 2, 1, 1, 1, 2, 1, 1)\n(3, 2, 1, 2, 1, 1, 2, 1, 1, 1)\n(3, 2, 1, 2, 1, 2, 1, 1, 1, 1)\n(3, 2, 1, 2, 2, 1, 1, 1, 1, 1)\n(3, 2, 1, 3, 1, 1, 1, 1, 1, 1)\n(3, 2, 2, 1, 1, 1, 1, 1, 1, 1)\n(3, 2, 2, 1, 1, 1, 1, 1, 1, 2)\n(3, 2, 2, 1, 1, 1, 1, 1, 2, 1)\n(3, 2, 2, 1, 1, 1, 1, 2, 1, 1)\n(3, 2, 2, 1, 1, 1, 2, 1, 1, 1)\n(3, 2, 2, 1, 1, 2, 1, 1, 1, 1)\n(3, 2, 2, 1, 2, 1, 1, 1, 1, 1)\n(3, 2, 2, 2, 1, 1, 1, 1, 1, 1)\n(3, 2, 3, 1, 1, 1, 1, 1, 1, 1)\n(3, 3, 1, 1, 1, 1, 1, 1, 1, 1)\n(3, 3, 1, 1, 1, 1, 1, 1, 1, 2)\n(3, 3, 1, 1, 1, 1, 1, 1, 2, 1)\n(3, 3, 1, 1, 1, 1, 1, 2, 1, 1)\n(3, 3, 1, 1, 1, 1, 2, 1, 1, 1)\n(3, 3, 1, 1, 1, 2, 1, 1, 1, 1)\n(3, 3, 1, 1, 2, 1, 1, 1, 1, 1)\n(3, 3, 1, 2, 1, 1, 1, 1, 1, 1)\n(3, 3, 2, 1, 1, 1, 1, 1, 1, 1)\n(3, 4, 1, 1, 1, 1, 1, 1, 1, 1)\n(4, 1, 1, 1, 1, 1, 1, 1, 1, 1)\n(4, 1, 1, 1, 1, 1, 1, 1, 1, 2)\n(4, 1, 1, 1, 1, 1, 1, 1, 1, 3)\n(4, 1, 1, 1, 1, 1, 1, 1, 2, 1)\n(4, 1, 1, 1, 1, 1, 1, 1, 2, 2)\n(4, 1, 1, 1, 1, 1, 1, 1, 3, 1)\n(4, 1, 1, 1, 1, 1, 1, 2, 1, 1)\n(4, 1, 1, 1, 1, 1, 1, 2, 1, 2)\n(4, 1, 1, 1, 1, 1, 1, 2, 2, 1)\n(4, 1, 1, 1, 1, 1, 1, 3, 1, 1)\n(4, 1, 1, 1, 1, 1, 2, 1, 1, 1)\n(4, 1, 1, 1, 1, 1, 2, 1, 1, 2)\n(4, 1, 1, 1, 1, 1, 2, 1, 2, 1)\n(4, 1, 1, 1, 1, 1, 2, 2, 1, 1)\n(4, 1, 1, 1, 1, 1, 3, 1, 1, 1)\n(4, 1, 1, 1, 1, 2, 1, 1, 1, 1)\n(4, 1, 1, 1, 1, 2, 1, 1, 1, 2)\n(4, 1, 1, 1, 1, 2, 1, 1, 2, 1)\n(4, 1, 1, 1, 1, 2, 1, 2, 1, 1)\n(4, 1, 1, 1, 1, 2, 2, 1, 1, 1)\n(4, 1, 1, 1, 1, 3, 1, 1, 1, 1)\n(4, 1, 1, 1, 2, 1, 1, 1, 1, 1)\n(4, 1, 1, 1, 2, 1, 1, 1, 1, 2)\n(4, 1, 1, 1, 2, 1, 1, 1, 2, 1)\n(4, 1, 1, 1, 2, 1, 1, 2, 1, 1)\n(4, 1, 1, 1, 2, 1, 2, 1, 1, 1)\n(4, 1, 1, 1, 2, 2, 1, 1, 1, 1)\n(4, 1, 1, 1, 3, 1, 1, 1, 1, 1)\n(4, 1, 1, 2, 1, 1, 1, 1, 1, 1)\n(4, 1, 1, 2, 1, 1, 1, 1, 1, 2)\n(4, 1, 1, 2, 1, 1, 1, 1, 2, 1)\n(4, 1, 1, 2, 1, 1, 1, 2, 1, 1)\n(4, 1, 1, 2, 1, 1, 2, 1, 1, 1)\n(4, 1, 1, 2, 1, 2, 1, 1, 1, 1)\n(4, 1, 1, 2, 2, 1, 1, 1, 1, 1)\n(4, 1, 1, 3, 1, 1, 1, 1, 1, 1)\n(4, 1, 2, 1, 1, 1, 1, 1, 1, 1)\n(4, 1, 2, 1, 1, 1, 1, 1, 1, 2)\n(4, 1, 2, 1, 1, 1, 1, 1, 2, 1)\n(4, 1, 2, 1, 1, 1, 1, 2, 1, 1)\n(4, 1, 2, 1, 1, 1, 2, 1, 1, 1)\n(4, 1, 2, 1, 1, 2, 1, 1, 1, 1)\n(4, 1, 2, 1, 2, 1, 1, 1, 1, 1)\n(4, 1, 2, 2, 1, 1, 1, 1, 1, 1)\n(4, 1, 3, 1, 1, 1, 1, 1, 1, 1)\n(4, 2, 1, 1, 1, 1, 1, 1, 1, 1)\n(4, 2, 1, 1, 1, 1, 1, 1, 1, 2)\n(4, 2, 1, 1, 1, 1, 1, 1, 2, 1)\n(4, 2, 1, 1, 1, 1, 1, 2, 1, 1)\n(4, 2, 1, 1, 1, 1, 2, 1, 1, 1)\n(4, 2, 1, 1, 1, 2, 1, 1, 1, 1)\n(4, 2, 1, 1, 2, 1, 1, 1, 1, 1)\n(4, 2, 1, 2, 1, 1, 1, 1, 1, 1)\n(4, 2, 2, 1, 1, 1, 1, 1, 1, 1)\n(4, 3, 1, 1, 1, 1, 1, 1, 1, 1)\n(5, 1, 1, 1, 1, 1, 1, 1, 1, 1)\n(5, 1, 1, 1, 1, 1, 1, 1, 1, 2)\n(5, 1, 1, 1, 1, 1, 1, 1, 2, 1)\n(5, 1, 1, 1, 1, 1, 1, 2, 1, 1)\n(5, 1, 1, 1, 1, 1, 2, 1, 1, 1)\n(5, 1, 1, 1, 1, 2, 1, 1, 1, 1)\n(5, 1, 1, 1, 2, 1, 1, 1, 1, 1)\n(5, 1, 1, 2, 1, 1, 1, 1, 1, 1)\n(5, 1, 2, 1, 1, 1, 1, 1, 1, 1)\n(5, 2, 1, 1, 1, 1, 1, 1, 1, 1)\n(6, 1, 1, 1, 1, 1, 1, 1, 1, 1)\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bea0a9468684d58a8f50f6f60b7955bc8ce257 | 11,824 | ipynb | Jupyter Notebook | docs/source/getting_started/using_entitysets.ipynb | Laezerus/FeatureTools | aaa84e3634988b2e6d2c528ff240a397655024d7 | [
"BSD-3-Clause"
]
| 4,299 | 2017-09-09T02:41:29.000Z | 2019-10-10T05:41:11.000Z | docs/source/getting_started/using_entitysets.ipynb | Laezerus/FeatureTools | aaa84e3634988b2e6d2c528ff240a397655024d7 | [
"BSD-3-Clause"
]
| 729 | 2017-09-22T01:54:48.000Z | 2019-10-09T15:36:17.000Z | docs/source/getting_started/using_entitysets.ipynb | Laezerus/FeatureTools | aaa84e3634988b2e6d2c528ff240a397655024d7 | [
"BSD-3-Clause"
]
| 532 | 2017-09-13T14:18:22.000Z | 2019-10-08T06:13:46.000Z | 32.573003 | 562 | 0.609269 | [
[
[
"# Representing Data with EntitySets\n\nAn ``EntitySet`` is a collection of dataframes and the relationships between them. They are useful for preparing raw, structured datasets for feature engineering. While many functions in Featuretools take ``dataframes`` and ``relationships`` as separate arguments, it is recommended to create an ``EntitySet``, so you can more easily manipulate your data as needed.\n\n## The Raw Data\n\nBelow we have two tables of data (represented as Pandas DataFrames) related to customer transactions. The first is a merge of transactions, sessions, and customers so that the result looks like something you might see in a log file:",
"_____no_output_____"
]
],
[
[
"import featuretools as ft\ndata = ft.demo.load_mock_customer()\ntransactions_df = data[\"transactions\"].merge(data[\"sessions\"]).merge(data[\"customers\"])\n\ntransactions_df.sample(10)",
"_____no_output_____"
]
],
[
[
"And the second dataframe is a list of products involved in those transactions.",
"_____no_output_____"
]
],
[
[
"products_df = data[\"products\"]\nproducts_df",
"_____no_output_____"
]
],
[
[
"## Creating an EntitySet\n\nFirst, we initialize an ``EntitySet``. If you'd like to give it a name, you can optionally provide an ``id`` to the constructor.",
"_____no_output_____"
]
],
[
[
"es = ft.EntitySet(id=\"customer_data\")",
"_____no_output_____"
]
],
[
[
"## Adding dataframes\n\nTo get started, we add the transactions dataframe to the `EntitySet`. In the call to ``add_dataframe``, we specify three important parameters:\n\n* The ``index`` parameter specifies the column that uniquely identifies rows in the dataframe.\n* The ``time_index`` parameter tells Featuretools when the data was created.\n* The ``logical_types`` parameter indicates that \"product_id\" should be interpreted as a Categorical column, even though it is just an integer in the underlying data.",
"_____no_output_____"
]
],
[
[
"from woodwork.logical_types import Categorical, PostalCode\n\nes = es.add_dataframe(\n dataframe_name=\"transactions\",\n dataframe=transactions_df,\n index=\"transaction_id\",\n time_index=\"transaction_time\",\n logical_types={\n \"product_id\": Categorical,\n \"zip_code\": PostalCode,\n },\n)\n\nes",
"_____no_output_____"
]
],
[
[
"You can also use a setter on the ``EntitySet`` object to add dataframes",
"_____no_output_____"
]
],
[
[
".. currentmodule:: featuretools\n\n\n.. note ::\n\n You can also use a setter on the ``EntitySet`` object to add dataframes\n\n ``es[\"transactions\"] = transactions_df``\n\n that this will use the default implementation of `add_dataframe`, notably the following:\n\n * if the DataFrame does not have `Woodwork <https://woodwork.alteryx.com/>`_ initialized, the first column will be the index column\n * if the DataFrame does not have Woodwork initialized, all columns will be inferred by Woodwork.\n * if control over the time index column and logical types is needed, Woodwork should be initialized before adding the dataframe.\n\n.. note ::\n\n You can also display your `EntitySet` structure graphically by calling :meth:`.EntitySet.plot`.",
"_____no_output_____"
]
],
[
[
"This method associates each column in the dataframe to a [Woodwork](https://woodwork.alteryx.com/) logical type. Each logical type can have an associated standard semantic tag that helps define the column data type. If you don't specify the logical type for a column, it gets inferred based on the underlying data. The logical types and semantic tags are listed in the schema of the dataframe. For more information on working with logical types and semantic tags, take a look at the [Woodwork documention](https://woodwork.alteryx.com/).",
"_____no_output_____"
]
],
[
[
"es[\"transactions\"].ww.schema",
"_____no_output_____"
]
],
[
[
"Now, we can do that same thing with our products dataframe.",
"_____no_output_____"
]
],
[
[
"es = es.add_dataframe(\n dataframe_name=\"products\",\n dataframe=products_df,\n index=\"product_id\")\n\nes",
"_____no_output_____"
]
],
[
[
"With two dataframes in our `EntitySet`, we can add a relationship between them.\n\n## Adding a Relationship\n\nWe want to relate these two dataframes by the columns called \"product_id\" in each dataframe. Each product has multiple transactions associated with it, so it is called the **parent dataframe**, while the transactions dataframe is known as the **child dataframe**. When specifying relationships, we need four parameters: the parent dataframe name, the parent column name, the child dataframe name, and the child column name. Note that each relationship must denote a one-to-many relationship rather than a relationship which is one-to-one or many-to-many.",
"_____no_output_____"
]
],
[
[
"es = es.add_relationship(\"products\", \"product_id\", \"transactions\", \"product_id\")\nes",
"_____no_output_____"
]
],
[
[
"Now, we see the relationship has been added to our `EntitySet`.\n\n## Creating a dataframe from an existing table\n\nWhen working with raw data, it is common to have sufficient information to justify the creation of new dataframes. In order to create a new dataframe and relationship for sessions, we \"normalize\" the transaction dataframe.",
"_____no_output_____"
]
],
[
[
"es = es.normalize_dataframe(\n base_dataframe_name=\"transactions\",\n new_dataframe_name=\"sessions\",\n index=\"session_id\",\n make_time_index=\"session_start\",\n additional_columns=[\n \"device\",\n \"customer_id\",\n \"zip_code\",\n \"session_start\",\n \"join_date\",\n ],\n)\nes",
"_____no_output_____"
]
],
[
[
"Looking at the output above, we see this method did two operations:\n\n1. It created a new dataframe called \"sessions\" based on the \"session_id\" and \"session_start\" columns in \"transactions\"\n2. It added a relationship connecting \"transactions\" and \"sessions\"\n\nIf we look at the schema from the transactions dataframe and the new sessions dataframe, we see two more operations that were performed automatically:",
"_____no_output_____"
]
],
[
[
"es[\"transactions\"].ww.schema",
"_____no_output_____"
],
[
"es[\"sessions\"].ww.schema",
"_____no_output_____"
]
],
[
[
"1. It removed \"device\", \"customer_id\", \"zip_code\" and \"join_date\" from \"transactions\" and created a new columns in the sessions dataframe. This reduces redundant information as the those properties of a session don't change between transactions.\n2. It copied and marked \"session_start\" as a time index column into the new sessions dataframe to indicate the beginning of a session. If the base dataframe has a time index and ``make_time_index`` is not set, ``normalize_dataframe`` will create a time index for the new dataframe. In this case it would create a new time index called \"first_transactions_time\" using the time of the first transaction of each session. If we don't want this time index to be created, we can set ``make_time_index=False``.\n\nIf we look at the dataframes, we can see what ``normalize_dataframe`` did to the actual data.",
"_____no_output_____"
]
],
[
[
"es[\"sessions\"].head(5)",
"_____no_output_____"
],
[
"es[\"transactions\"].head(5)",
"_____no_output_____"
]
],
[
[
"To finish preparing this dataset, create a \"customers\" dataframe using the same method call.",
"_____no_output_____"
]
],
[
[
"es = es.normalize_dataframe(\n base_dataframe_name=\"sessions\",\n new_dataframe_name=\"customers\",\n index=\"customer_id\",\n make_time_index=\"join_date\",\n additional_columns=[\"zip_code\", \"join_date\"],\n)\n\nes",
"_____no_output_____"
]
],
[
[
"## Using the EntitySet\n\nFinally, we are ready to use this EntitySet with any functionality within Featuretools. For example, let's build a feature matrix for each product in our dataset.",
"_____no_output_____"
]
],
[
[
"feature_matrix, feature_defs = ft.dfs(entityset=es, target_dataframe_name=\"products\")\n\nfeature_matrix",
"_____no_output_____"
]
],
[
[
"As we can see, the features from DFS use the relational structure of our `EntitySet`. Therefore it is important to think carefully about the dataframes that we create.\n\nDask and Spark EntitySets\n~~~~~~~~~~~~~~~~~~~~~~~~~~\n\nEntitySets can also be created using Dask dataframes or Spark dataframes. For more information refer to :doc:`../guides/using_dask_entitysets` and :doc:`../guides/using_spark_entitysets`.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"raw"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"raw"
]
]
|
e7bea2de6704eb7f9815a7e06e43412678a8a4ca | 40,301 | ipynb | Jupyter Notebook | Week 2 - SQL/jupyter-labs-eda-sql-coursera.ipynb | pFontanilla/ibm-applied-datascience-capstone | 6acbe86b73eb9f5381ceef9bbde8fd5fc6a0b4e0 | [
"MIT"
]
| null | null | null | Week 2 - SQL/jupyter-labs-eda-sql-coursera.ipynb | pFontanilla/ibm-applied-datascience-capstone | 6acbe86b73eb9f5381ceef9bbde8fd5fc6a0b4e0 | [
"MIT"
]
| null | null | null | Week 2 - SQL/jupyter-labs-eda-sql-coursera.ipynb | pFontanilla/ibm-applied-datascience-capstone | 6acbe86b73eb9f5381ceef9bbde8fd5fc6a0b4e0 | [
"MIT"
]
| null | null | null | 35.105401 | 587 | 0.521997 | [
[
[
"<center>\n <img src=\"https://gitlab.com/ibm/skills-network/courses/placeholder101/-/raw/master/labs/module%201/images/IDSNlogo.png\" width=\"300\" alt=\"cognitiveclass.ai logo\" />\n</center>\n\n<h1 align=center><font size = 5>Assignment: SQL Notebook for Peer Assignment</font></h1>\n\nEstimated time needed: **60** minutes.\n\n## Introduction\n\nUsing this Python notebook you will:\n\n1. Understand the Spacex DataSet\n2. Load the dataset into the corresponding table in a Db2 database\n3. Execute SQL queries to answer assignment questions\n",
"_____no_output_____"
],
[
"## Overview of the DataSet\n\nSpaceX has gained worldwide attention for a series of historic milestones.\n\nIt is the only private company ever to return a spacecraft from low-earth orbit, which it first accomplished in December 2010.\nSpaceX advertises Falcon 9 rocket launches on its website with a cost of 62 million dollars wheras other providers cost upward of 165 million dollars each, much of the savings is because Space X can reuse the first stage.\n\nTherefore if we can determine if the first stage will land, we can determine the cost of a launch.\n\nThis information can be used if an alternate company wants to bid against SpaceX for a rocket launch.\n\nThis dataset includes a record for each payload carried during a SpaceX mission into outer space.\n",
"_____no_output_____"
],
[
"### Download the datasets\n\nThis assignment requires you to load the spacex dataset.\n\nIn many cases the dataset to be analyzed is available as a .CSV (comma separated values) file, perhaps on the internet. Click on the link below to download and save the dataset (.CSV file):\n\n<a href=\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/labs/module_2/data/Spacex.csv?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork26802033-2021-01-01\" target=\"_blank\">Spacex DataSet</a>\n",
"_____no_output_____"
],
[
"### Store the dataset in database table\n\n**it is highly recommended to manually load the table using the database console LOAD tool in DB2**.\n\n<img src = \"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/labs/module_2/images/spacexload.png\">\n\nNow open the Db2 console, open the LOAD tool, Select / Drag the .CSV file for the dataset, Next create a New Table, and then follow the steps on-screen instructions to load the data. Name the new table as follows:\n\n**SPACEXDATASET**\n\n**Follow these steps while using old DB2 UI which is having Open Console Screen**\n\n**Note:While loading Spacex dataset, ensure that detect datatypes is disabled. Later click on the pencil icon(edit option).**\n\n1. Change the Date Format by manually typing DD-MM-YYYY and timestamp format as DD-MM-YYYY HH\\:MM:SS\n\n2. Change the PAYLOAD_MASS\\_\\_KG\\_ datatype to INTEGER.\n\n<img src = \"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/labs/module_2/images/spacexload2.png\">\n",
"_____no_output_____"
],
[
"**Changes to be considered when having DB2 instance with the new UI having Go to UI screen**\n\n* Refer to this insruction in this <a href=\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DB0201EN-SkillsNetwork/labs/Labs_Coursera_V5/labs/Lab%20-%20Sign%20up%20for%20IBM%20Cloud%20-%20Create%20Db2%20service%20instance%20-%20Get%20started%20with%20the%20Db2%20console/instructional-labs.md.html?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork26802033-2021-01-01\">link</a> for viewing the new Go to UI screen.\n\n* Later click on **Data link(below SQL)** in the Go to UI screen and click on **Load Data** tab.\n\n* Later browse for the downloaded spacex file.\n\n<img src=\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/labs/module_2/images/browsefile.png\" width=\"800\"/>\n\n* Once done select the schema andload the file.\n\n <img src=\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/labs/module_2/images/spacexload3.png\" width=\"800\"/>\n",
"_____no_output_____"
]
],
[
[
"!pip install sqlalchemy==1.3.9\n!pip install ibm_db_sa\n!pip install ipython-sql",
"Collecting sqlalchemy==1.3.9\n Downloading SQLAlchemy-1.3.9.tar.gz (6.0 MB)\nUsing legacy 'setup.py install' for sqlalchemy, since package 'wheel' is not installed.\nInstalling collected packages: sqlalchemy\n Running setup.py install for sqlalchemy: started\n Running setup.py install for sqlalchemy: finished with status 'done'\nSuccessfully installed sqlalchemy-1.3.9\n"
]
],
[
[
"### Connect to the database\n\nLet us first load the SQL extension and establish a connection with the database\n",
"_____no_output_____"
]
],
[
[
"%load_ext sql",
"_____no_output_____"
]
],
[
[
"**DB2 magic in case of old UI service credentials.**\n\nIn the next cell enter your db2 connection string. Recall you created Service Credentials for your Db2 instance before. From the **uri** field of your Db2 service credentials copy everything after db2:// (except the double quote at the end) and paste it in the cell below after ibm_db_sa://\n\n<img src =\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DB0201EN-SkillsNetwork/labs/FinalModule_edX/images/URI.jpg\">\n\nin the following format\n\n**%sql ibm_db_sa://my-username:my-password\\@my-hostname:my-port/my-db-name**\n\n**DB2 magic in case of new UI service credentials.**\n\n<img src =\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/labs/module_2/images/servicecredentials.png\" width=600> \n\n* Use the following format.\n\n* Add security=SSL at the end\n\n**%sql ibm_db_sa://my-username:my-password\\@my-hostname:my-port/my-db-name?security=SSL**\n",
"_____no_output_____"
]
],
[
[
"%sql ibm_db_sa://gmb99703:n8jwm8hlw2k7hr^[email protected]:50000/BLUDB",
"_____no_output_____"
],
[
"%sql select TABSCHEMA, TABNAME, CREATE_TIME from SYSCAT.TABLES where TABSCHEMA='GMB99703'",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
],
[
"%sql SELECT * FROM SPACEXDATASET LIMIT 20",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"## Tasks\n\nNow write and execute SQL queries to solve the assignment tasks.\n\n### Task 1\n\n##### Display the names of the unique launch sites in the space mission\n",
"_____no_output_____"
]
],
[
[
"%sql SELECT UNIQUE LAUNCH_SITE FROM SPACEXDATASET",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"### Task 2\n\n##### Display 5 records where launch sites begin with the string 'CCA'\n",
"_____no_output_____"
]
],
[
[
"%sql SELECT * FROM SPACEXDATASET WHERE LAUNCH_SITE LIKE 'CCA%' LIMIT 5",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"### Task 3\n\n##### Display the total payload mass carried by boosters launched by NASA (CRS)\n",
"_____no_output_____"
]
],
[
[
"%sql SELECT SUM(PAYLOAD_MASS__KG_) FROM SPACEXDATASET WHERE PAYLOAD LIKE '%CRS%'",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"### Task 4\n\n##### Display average payload mass carried by booster version F9 v1.1\n",
"_____no_output_____"
]
],
[
[
"%sql SELECT AVG(PAYLOAD_MASS__KG_) FROM SPACEXDATASET WHERE booster_version LIKE '%F9 v1.1%'",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"### Task 5\n\n##### List the date when the first successful landing outcome in ground pad was acheived.\n\n*Hint:Use min function*\n",
"_____no_output_____"
]
],
[
[
"%sql SELECT MIN(DATE) FROM SPACEXDATASET WHERE landing__outcome = 'Success (ground pad)'",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"### Task 6\n\n##### List the names of the boosters which have success in drone ship and have payload mass greater than 4000 but less than 6000\n",
"_____no_output_____"
]
],
[
[
"%sql SELECT BOOSTER_VERSION FROM SPACEXDATASET WHERE landing__outcome = 'Success (drone ship)' AND 4000 < PAYLOAD_MASS__KG_ < 6000",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"### Task 7\n\n##### List the total number of successful and failure mission outcomes\n",
"_____no_output_____"
]
],
[
[
"%sql SELECT MISSION_OUTCOME, COUNT(MISSION_OUTCOME) FROM SPACEXDATASET GROUP BY MISSION_OUTCOME",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"### Task 8\n\n##### List the names of the booster_versions which have carried the maximum payload mass. Use a subquery\n",
"_____no_output_____"
]
],
[
[
"%sql SELECT UNIQUE BOOSTER_VERSION FROM SPACEXDATASET WHERE PAYLOAD_MASS__KG_ = (SELECT MAX(PAYLOAD_MASS__KG_) FROM SPACEXDATASET)",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"### Task 9\n\n##### List the failed landing_outcomes in drone ship, their booster versions, and launch site names for in year 2015\n",
"_____no_output_____"
]
],
[
[
"%sql SELECT BOOSTER_VERSION, launch_site, landing__outcome FROM SPACEXDATASET WHERE LANDING__OUTCOME = 'Failure (drone ship)' AND YEAR(DATE) = 2015",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"### Task 10\n\n##### Rank the count of landing outcomes (such as Failure (drone ship) or Success (ground pad)) between the date 2010-06-04 and 2017-03-20, in descending order\n",
"_____no_output_____"
]
],
[
[
"%sql SELECT LANDING__OUTCOME, COUNT(LANDING__OUTCOME) FROM SPACEXDATASET WHERE DATE BETWEEN '2010-06-04' AND '2017-03-20' GROUP BY LANDING__OUTCOME ORDER BY COUNT(LANDING__OUTCOME) DESC",
" * ibm_db_sa://gmb99703:***@dashdb-txn-sbox-yp-dal09-04.services.dal.bluemix.net:50000/BLUDB\nDone.\n"
]
],
[
[
"### Reference Links\n\n* <a href =\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DB0201EN-SkillsNetwork/labs/Labs_Coursera_V5/labs/Lab%20-%20String%20Patterns%20-%20Sorting%20-%20Grouping/instructional-labs.md.html?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork26802033-2021-01-01&origin=www.coursera.org\">Hands-on Lab : String Patterns, Sorting and Grouping</a>\n\n* <a href=\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DB0201EN-SkillsNetwork/labs/Labs_Coursera_V5/labs/Lab%20-%20Built-in%20functions%20/Hands-on_Lab__Built-in_Functions.md.html?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork26802033-2021-01-01&origin=www.coursera.org\">Hands-on Lab: Built-in functions</a>\n\n* <a href=\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DB0201EN-SkillsNetwork/labs/Labs_Coursera_V5/labs/Lab%20-%20Sub-queries%20and%20Nested%20SELECTs%20/instructional-labs.md.html?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork26802033-2021-01-01&origin=www.coursera.org\">Hands-on Lab : Sub-queries and Nested SELECT Statements</a>\n\n* <a href=\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DB0201EN-SkillsNetwork/labs/Module%205/DB0201EN-Week3-1-3-SQLmagic.ipynb?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork26802033-2021-01-01\">Hands-on Tutorial: Accessing Databases with SQL magic</a>\n\n* <a href= \"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DB0201EN-SkillsNetwork/labs/Module%205/DB0201EN-Week3-1-4-Analyzing.ipynb?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork26802033-2021-01-01\">Hands-on Lab: Analyzing a real World Data Set</a>\n",
"_____no_output_____"
],
[
"## Author(s)\n\n<h4> Lakshmi Holla </h4>\n",
"_____no_output_____"
],
[
"## Other Contributors\n\n<h4> Rav Ahuja </h4>\n",
"_____no_output_____"
],
[
"## Change log\n\n| Date | Version | Changed by | Change Description |\n| ---------- | ------- | ------------- | ------------------------- |\n| 2021-08-24 | 0.3 | Lakshmi Holla | Added library update |\n| 2021-07-09 | 0.2 | Lakshmi Holla | Changes made in magic sql |\n| 2021-05-20 | 0.1 | Lakshmi Holla | Created Initial Version |\n",
"_____no_output_____"
],
[
"## <h3 align=\"center\"> © IBM Corporation 2021. All rights reserved. <h3/>\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
e7bea7b908eebce61458a135b18b83652531d014 | 3,264 | ipynb | Jupyter Notebook | solutions/S0012.ipynb | trabdlkarim/UrkelOs | cb40609083fc5f0b22edc40e827cab0238040c1e | [
"MIT"
]
| 2 | 2018-10-09T07:46:21.000Z | 2018-10-09T07:46:35.000Z | solutions/S0012.ipynb | trabdlkarim/UrkelOs | cb40609083fc5f0b22edc40e827cab0238040c1e | [
"MIT"
]
| null | null | null | solutions/S0012.ipynb | trabdlkarim/UrkelOs | cb40609083fc5f0b22edc40e827cab0238040c1e | [
"MIT"
]
| null | null | null | 19.428571 | 183 | 0.458027 | [
[
[
"# Highly divisible triangular number\n\n# Problem 12\nThe sequence of triangle numbers is generated by adding the natural numbers. So the 7th triangle number would be 1 + 2 + 3 + 4 + 5 + 6 + 7 = 28. The first ten terms would be:\n\n1, 3, 6, 10, 15, 21, 28, 36, 45, 55, ...\n\nLet us list the factors of the first seven triangle numbers:\n\n 1: 1\n \n 3: 1,3\n \n 6: 1,2,3,6\n \n10: 1,2,5,10\n\n15: 1,3,5,15\n\n21: 1,3,7,21\n\n28: 1,2,4,7,14,28\n\nWe can see that 28 is the first triangle number to have over five divisors.\n\nWhat is the value of the first triangle number to have over five hundred divisors?",
"_____no_output_____"
],
[
"# Solution 12",
"_____no_output_____"
]
],
[
[
"def factors(n):\n f = []\n for i in range(1,n+1):\n if (n%i) == 0:\n f.append(i)\n return f",
"_____no_output_____"
],
[
"len(factors(25200))",
"_____no_output_____"
],
[
"def triangle_number(n):\n tri_num = 0\n for i in range(1,n+1):\n tri_num += i\n return tri_num",
"_____no_output_____"
],
[
"triangle_number(125150)",
"_____no_output_____"
],
[
"def find_tri_num_div(n):\n x = 1\n while(1):\n t = triangle_number(x)\n f = factors(t)\n if len(f) > n:\n return t\n x += 1",
"_____no_output_____"
],
[
"find_tri_num_div(100)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7beab1a8130deef253f7300c37cea37806263ff | 2,635 | ipynb | Jupyter Notebook | python/join_data.ipynb | cvalenzuela/modernflags | f5da737a56971950f0fa1a498c05119b50d36564 | [
"MIT"
]
| null | null | null | python/join_data.ipynb | cvalenzuela/modernflags | f5da737a56971950f0fa1a498c05119b50d36564 | [
"MIT"
]
| null | null | null | python/join_data.ipynb | cvalenzuela/modernflags | f5da737a56971950f0fa1a498c05119b50d36564 | [
"MIT"
]
| null | null | null | 16.783439 | 81 | 0.495636 | [
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"ginidata = pd.read_csv(\"data/gini.csv\", delimiter=\";\")",
"_____no_output_____"
],
[
"hdidata = pd.read_csv(\"data/hdi.csv\", delimiter=\";\")",
"_____no_output_____"
],
[
"co2data = pd.read_csv(\"data/co2.csv\", delimiter=\";\")",
"_____no_output_____"
],
[
"population_data = pd.read_csv(\"data/population.csv\", delimiter=\";\")",
"_____no_output_____"
],
[
"merged_data = ginidata.merge(hdidata).merge(co2data).merge(population_data)",
"_____no_output_____"
],
[
"merged_data.to_csv(\"data/merged_data.csv\", index=False)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7beb7f3ff46be0dd669586657862631efd8bac9 | 172,324 | ipynb | Jupyter Notebook | Notebook/Employee_Attrition_Prediction.ipynb | rjparkk/rjparkk.github.io | ea60711424d5530e1bd6d1db0ca1266eebf06796 | [
"MIT"
]
| null | null | null | Notebook/Employee_Attrition_Prediction.ipynb | rjparkk/rjparkk.github.io | ea60711424d5530e1bd6d1db0ca1266eebf06796 | [
"MIT"
]
| null | null | null | Notebook/Employee_Attrition_Prediction.ipynb | rjparkk/rjparkk.github.io | ea60711424d5530e1bd6d1db0ca1266eebf06796 | [
"MIT"
]
| null | null | null | 119.669444 | 73,008 | 0.790575 | [
[
[
"Load the data and perform EDA.\n\nhttps://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset\n\n1. Evaluate missing values\n2. Assess target class distribution\n3. Assess information value of individual features (correlation analysis and pairlot).\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\nibm = pd.read_csv('WA_Fn-UseC_-HR-Employee-Attrition.csv',index_col=0)\n\n# Evaluate missing values\nibm.isnull().sum()",
"_____no_output_____"
],
[
"ibm.describe().transpose()",
"_____no_output_____"
],
[
"# Change data types for categorical variables\n# Dummy code categorical features\n\n# Recoding \n\nibm['BusinessTravel'][ibm['BusinessTravel'] == 'Non-Travel'] = 'Never'\nibm['BusinessTravel'][ibm['BusinessTravel'] == 'Travel_Rarely'] = 'Rarely'\nibm['BusinessTravel'][ibm['BusinessTravel'] == 'Travel_Frequently'] = 'Frequently'\n\n\n\nibm['Attrition'].replace('No',0,inplace=True)\nibm['Attrition'].replace('Yes',1,inplace=True)\n\nibm = pd.get_dummies(ibm)\n\nibm.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 1470 entries, 41 to 34\nData columns (total 55 columns):\n # Column Non-Null Count Dtype\n--- ------ -------------- -----\n 0 Attrition 1470 non-null int64\n 1 DailyRate 1470 non-null int64\n 2 DistanceFromHome 1470 non-null int64\n 3 Education 1470 non-null int64\n 4 EmployeeCount 1470 non-null int64\n 5 EmployeeNumber 1470 non-null int64\n 6 EnvironmentSatisfaction 1470 non-null int64\n 7 HourlyRate 1470 non-null int64\n 8 JobInvolvement 1470 non-null int64\n 9 JobLevel 1470 non-null int64\n 10 JobSatisfaction 1470 non-null int64\n 11 MonthlyIncome 1470 non-null int64\n 12 MonthlyRate 1470 non-null int64\n 13 NumCompaniesWorked 1470 non-null int64\n 14 PercentSalaryHike 1470 non-null int64\n 15 PerformanceRating 1470 non-null int64\n 16 RelationshipSatisfaction 1470 non-null int64\n 17 StandardHours 1470 non-null int64\n 18 StockOptionLevel 1470 non-null int64\n 19 TotalWorkingYears 1470 non-null int64\n 20 TrainingTimesLastYear 1470 non-null int64\n 21 WorkLifeBalance 1470 non-null int64\n 22 YearsAtCompany 1470 non-null int64\n 23 YearsInCurrentRole 1470 non-null int64\n 24 YearsSinceLastPromotion 1470 non-null int64\n 25 YearsWithCurrManager 1470 non-null int64\n 26 BusinessTravel_Frequently 1470 non-null uint8\n 27 BusinessTravel_Never 1470 non-null uint8\n 28 BusinessTravel_Rarely 1470 non-null uint8\n 29 Department_Human Resources 1470 non-null uint8\n 30 Department_Research & Development 1470 non-null uint8\n 31 Department_Sales 1470 non-null uint8\n 32 EducationField_Human Resources 1470 non-null uint8\n 33 EducationField_Life Sciences 1470 non-null uint8\n 34 EducationField_Marketing 1470 non-null uint8\n 35 EducationField_Medical 1470 non-null uint8\n 36 EducationField_Other 1470 non-null uint8\n 37 EducationField_Technical Degree 1470 non-null uint8\n 38 Gender_Female 1470 non-null uint8\n 39 Gender_Male 1470 non-null uint8\n 40 JobRole_Healthcare Representative 1470 non-null uint8\n 41 JobRole_Human Resources 1470 non-null uint8\n 42 JobRole_Laboratory Technician 1470 non-null uint8\n 43 JobRole_Manager 1470 non-null uint8\n 44 JobRole_Manufacturing Director 1470 non-null uint8\n 45 JobRole_Research Director 1470 non-null uint8\n 46 JobRole_Research Scientist 1470 non-null uint8\n 47 JobRole_Sales Executive 1470 non-null uint8\n 48 JobRole_Sales Representative 1470 non-null uint8\n 49 MaritalStatus_Divorced 1470 non-null uint8\n 50 MaritalStatus_Married 1470 non-null uint8\n 51 MaritalStatus_Single 1470 non-null uint8\n 52 Over18_Y 1470 non-null uint8\n 53 OverTime_No 1470 non-null uint8\n 54 OverTime_Yes 1470 non-null uint8\ndtypes: int64(26), uint8(29)\nmemory usage: 351.7 KB\n"
],
[
"# Accessing target varaible distribution\n\nprint(ibm['Attrition'].mean())\nibm['Attrition'].hist(xrot=45.0)",
"0.16122448979591836\n"
],
[
"# Pair Plot\n\nfrom IPython.display import Image\nimport seaborn as sns\nimport matplotlib.pyplot as plt \n\nsns_plot = sns.pairplot(ibm, hue = 'Attrition')\nsns_plot.savefig(\"pairplot.png\")\n\nplt.clf() # Clean parirplot figure from sns \n\nImage(filename='pairplot.png') # Show pairplot as image",
"_____no_output_____"
],
[
"# Correlation Analysis \n\nsns.heatmap(ibm.corr(), cmap=\"Spectral\")",
"_____no_output_____"
],
[
"# Correlation Analysis \n\nibm.corr()['Attrition'].sort_values(ascending=False)",
"_____no_output_____"
]
],
[
[
"4. Pre-process the dataset\n5. Split the data into training/test datasets (70/30)\n\n4 pts.",
"_____no_output_____"
]
],
[
[
"#Dropping variables\n\n# ibm.drop(['Over18_Y'], axis=1, inplace=True)\n# ibm.drop(['EmployeeCount'], axis=1, inplace=True)\n# ibm.drop(['StandardHours'], axis=1, inplace=True)\n\n# Preparing features and labels\n\nX = ibm.drop('Attrition',axis=1).values\ny = ibm['Attrition'].values\n",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\n\nX_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=1)",
"_____no_output_____"
],
[
"from sklearn.preprocessing import MinMaxScaler\n\nscaler = MinMaxScaler()\nscaler.fit(X_train)\n\nX_train = scaler.transform(X_train)\nX_test = scaler.transform(X_test)",
"_____no_output_____"
]
],
[
[
"6. Build a sequential neural network with the following parameters: 3 hidden dense layers - 100, 50, 25 nodes respectively, activation function = 'relu', dropout = 0.5 for each layer).\n7. Use early stopping callback to prevent overfitting.\n\n",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Dense,Activation,Dropout",
"_____no_output_____"
],
[
"model = Sequential()\n\nmodel.add(Dense(units=100,activation='relu'))\nmodel.add(Dense(units=50,activation='relu'))\nmodel.add(Dense(units=25,activation='relu'))\nmodel.add(Dense(units=1,activation='sigmoid'))\n# For a binary classification problem\nmodel.compile(loss='binary_crossentropy', optimizer='adam')",
"_____no_output_____"
],
[
"model.fit(x=X_train, \n y=y_train,\n batch_size=128, \n epochs=100,\n validation_data=(X_test, y_test), verbose=1\n )",
"Epoch 1/100\n9/9 [==============================] - 0s 12ms/step - loss: 0.6206 - val_loss: 0.5047\nEpoch 2/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.4449 - val_loss: 0.4384\nEpoch 3/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.4050 - val_loss: 0.4446\nEpoch 4/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3983 - val_loss: 0.4251\nEpoch 5/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3836 - val_loss: 0.4141\nEpoch 6/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3731 - val_loss: 0.4061\nEpoch 7/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3626 - val_loss: 0.3982\nEpoch 8/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3526 - val_loss: 0.3913\nEpoch 9/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3477 - val_loss: 0.3883\nEpoch 10/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3405 - val_loss: 0.3834\nEpoch 11/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3309 - val_loss: 0.3811\nEpoch 12/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3244 - val_loss: 0.3764\nEpoch 13/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3172 - val_loss: 0.3693\nEpoch 14/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3106 - val_loss: 0.3662\nEpoch 15/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3052 - val_loss: 0.3653\nEpoch 16/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.3029 - val_loss: 0.3638\nEpoch 17/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2909 - val_loss: 0.3721\nEpoch 18/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2907 - val_loss: 0.3616\nEpoch 19/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2842 - val_loss: 0.3607\nEpoch 20/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2771 - val_loss: 0.3579\nEpoch 21/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2752 - val_loss: 0.3539\nEpoch 22/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2652 - val_loss: 0.3531\nEpoch 23/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2608 - val_loss: 0.3564\nEpoch 24/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2539 - val_loss: 0.3599\nEpoch 25/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2473 - val_loss: 0.3608\nEpoch 26/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2405 - val_loss: 0.3678\nEpoch 27/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2359 - val_loss: 0.3690\nEpoch 28/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2277 - val_loss: 0.3771\nEpoch 29/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2231 - val_loss: 0.3824\nEpoch 30/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2197 - val_loss: 0.3811\nEpoch 31/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2226 - val_loss: 0.3844\nEpoch 32/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2107 - val_loss: 0.3866\nEpoch 33/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2250 - val_loss: 0.3812\nEpoch 34/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.2045 - val_loss: 0.3840\nEpoch 35/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1992 - val_loss: 0.3831\nEpoch 36/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1838 - val_loss: 0.3894\nEpoch 37/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1763 - val_loss: 0.3945\nEpoch 38/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1669 - val_loss: 0.4016\nEpoch 39/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1650 - val_loss: 0.4206\nEpoch 40/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1835 - val_loss: 0.4356\nEpoch 41/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1779 - val_loss: 0.4149\nEpoch 42/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1619 - val_loss: 0.4220\nEpoch 43/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1497 - val_loss: 0.4221\nEpoch 44/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1370 - val_loss: 0.4334\nEpoch 45/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1302 - val_loss: 0.4387\nEpoch 46/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1272 - val_loss: 0.4537\nEpoch 47/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1227 - val_loss: 0.4525\nEpoch 48/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1267 - val_loss: 0.4700\nEpoch 49/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1329 - val_loss: 0.4683\nEpoch 50/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1184 - val_loss: 0.4694\nEpoch 51/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1062 - val_loss: 0.4899\nEpoch 52/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1023 - val_loss: 0.4893\nEpoch 53/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0938 - val_loss: 0.4954\nEpoch 54/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0992 - val_loss: 0.5353\nEpoch 55/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.1150 - val_loss: 0.5232\nEpoch 56/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0961 - val_loss: 0.5228\nEpoch 57/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0902 - val_loss: 0.5294\nEpoch 58/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0895 - val_loss: 0.5398\nEpoch 59/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0790 - val_loss: 0.5374\nEpoch 60/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0809 - val_loss: 0.5736\nEpoch 61/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0799 - val_loss: 0.5639\nEpoch 62/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0785 - val_loss: 0.5815\nEpoch 63/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0748 - val_loss: 0.5737\nEpoch 64/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0630 - val_loss: 0.5816\nEpoch 65/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0624 - val_loss: 0.6182\nEpoch 66/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0741 - val_loss: 0.6116\nEpoch 67/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0582 - val_loss: 0.6305\nEpoch 68/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0543 - val_loss: 0.6173\nEpoch 69/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0471 - val_loss: 0.6169\nEpoch 70/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0462 - val_loss: 0.6218\nEpoch 71/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0402 - val_loss: 0.6338\nEpoch 72/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0377 - val_loss: 0.6504\nEpoch 73/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0347 - val_loss: 0.6626\nEpoch 74/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0321 - val_loss: 0.6754\nEpoch 75/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0305 - val_loss: 0.6815\nEpoch 76/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0293 - val_loss: 0.6959\nEpoch 77/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0286 - val_loss: 0.7075\nEpoch 78/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0294 - val_loss: 0.7130\nEpoch 79/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0269 - val_loss: 0.7256\nEpoch 80/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0238 - val_loss: 0.7345\nEpoch 81/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0243 - val_loss: 0.7529\nEpoch 82/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0249 - val_loss: 0.7595\nEpoch 83/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0211 - val_loss: 0.7841\nEpoch 84/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0224 - val_loss: 0.7887\nEpoch 85/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0224 - val_loss: 0.8029\nEpoch 86/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0199 - val_loss: 0.7925\nEpoch 87/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0164 - val_loss: 0.8088\nEpoch 88/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0166 - val_loss: 0.8126\nEpoch 89/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0137 - val_loss: 0.8208\nEpoch 90/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0135 - val_loss: 0.8228\nEpoch 91/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0130 - val_loss: 0.8390\nEpoch 92/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0119 - val_loss: 0.8557\nEpoch 93/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0110 - val_loss: 0.8705\nEpoch 94/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0113 - val_loss: 0.8725\nEpoch 95/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0107 - val_loss: 0.8759\nEpoch 96/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0097 - val_loss: 0.8829\nEpoch 97/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0088 - val_loss: 0.8968\nEpoch 98/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0098 - val_loss: 0.9060\nEpoch 99/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0090 - val_loss: 0.9155\nEpoch 100/100\n9/9 [==============================] - 0s 3ms/step - loss: 0.0079 - val_loss: 0.9204\n"
]
],
[
[
"8. Plot training and validation losses versus epochs.\n9. Print out model confusion matrix.\n10. Print out model classification report.\n11. Print out model ROC AUC.\n\n",
"_____no_output_____"
]
],
[
[
"model_loss = pd.DataFrame(model.history.history)\nmodel_loss.plot()",
"_____no_output_____"
],
[
"# with Dropout\n\nfrom tensorflow.keras.layers import Dropout\n\nmodel = Sequential()\nmodel.add(Dense(units=100,activation='relu'))\nmodel.add(Dropout(0.5))\n\nmodel.add(Dense(units=50,activation='relu'))\nmodel.add(Dropout(0.5))\n\nmodel.add(Dense(units=25,activation='relu'))\nmodel.add(Dropout(0.5))\n\nmodel.add(Dense(units=1,activation='sigmoid'))\n\nmodel.compile(loss='binary_crossentropy', optimizer='adam')",
"_____no_output_____"
],
[
"model.fit(x=X_train, \n y=y_train, \n batch_size=128,\n epochs=200,\n validation_data=(X_test, y_test), verbose=1,\n callbacks=[early_stop]\n )",
"Epoch 1/200\n9/9 [==============================] - 0s 11ms/step - loss: 0.6368 - val_loss: 0.4970\nEpoch 2/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.5146 - val_loss: 0.4447\nEpoch 3/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4929 - val_loss: 0.4389\nEpoch 4/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.5047 - val_loss: 0.4339\nEpoch 5/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4842 - val_loss: 0.4270\nEpoch 6/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4566 - val_loss: 0.4215\nEpoch 7/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4679 - val_loss: 0.4189\nEpoch 8/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4646 - val_loss: 0.4139\nEpoch 9/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4436 - val_loss: 0.4091\nEpoch 10/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4246 - val_loss: 0.4049\nEpoch 11/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4200 - val_loss: 0.3979\nEpoch 12/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4099 - val_loss: 0.3930\nEpoch 13/200\n9/9 [==============================] - 0s 4ms/step - loss: 0.4208 - val_loss: 0.3890\nEpoch 14/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4169 - val_loss: 0.3858\nEpoch 15/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4136 - val_loss: 0.3845\nEpoch 16/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4142 - val_loss: 0.3847\nEpoch 17/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4067 - val_loss: 0.3842\nEpoch 18/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4091 - val_loss: 0.3822\nEpoch 19/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4223 - val_loss: 0.3770\nEpoch 20/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3925 - val_loss: 0.3761\nEpoch 21/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4116 - val_loss: 0.3762\nEpoch 22/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3969 - val_loss: 0.3748\nEpoch 23/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3928 - val_loss: 0.3753\nEpoch 24/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3875 - val_loss: 0.3728\nEpoch 25/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.4078 - val_loss: 0.3722\nEpoch 26/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3905 - val_loss: 0.3718\nEpoch 27/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3687 - val_loss: 0.3716\nEpoch 28/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3779 - val_loss: 0.3695\nEpoch 29/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3756 - val_loss: 0.3702\nEpoch 30/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3906 - val_loss: 0.3674\nEpoch 31/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3651 - val_loss: 0.3668\nEpoch 32/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3799 - val_loss: 0.3659\nEpoch 33/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3799 - val_loss: 0.3651\nEpoch 34/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3761 - val_loss: 0.3638\nEpoch 35/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3696 - val_loss: 0.3631\nEpoch 36/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3699 - val_loss: 0.3626\nEpoch 37/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3541 - val_loss: 0.3660\nEpoch 38/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3597 - val_loss: 0.3656\nEpoch 39/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3685 - val_loss: 0.3636\nEpoch 40/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3664 - val_loss: 0.3616\nEpoch 41/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3500 - val_loss: 0.3604\nEpoch 42/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3453 - val_loss: 0.3611\nEpoch 43/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3572 - val_loss: 0.3607\nEpoch 44/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3643 - val_loss: 0.3607\nEpoch 45/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3448 - val_loss: 0.3607\nEpoch 46/200\n9/9 [==============================] - 0s 3ms/step - loss: 0.3603 - val_loss: 0.3615\nEpoch 00046: early stopping\n"
],
[
"model_loss = pd.DataFrame(model.history.history)\nmodel_loss.plot()",
"_____no_output_____"
],
[
"y_pred = model.predict_classes(X_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import classification_report,confusion_matrix, roc_auc_score\n\nprint(classification_report(y_test,y_pred))",
" precision recall f1-score support\n\n 0 0.83 1.00 0.91 364\n 1 0.83 0.06 0.12 77\n\n accuracy 0.83 441\n macro avg 0.83 0.53 0.51 441\nweighted avg 0.83 0.83 0.77 441\n\n"
],
[
"print(confusion_matrix(y_test,y_pred))\nprint('ROC AUC: ', roc_auc_score(y_test,y_pred))",
"[[363 1]\n [ 72 5]]\nROC AUC: 0.531093906093906\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7becdc1e716190c500b8bc00035c86145f27399 | 24,015 | ipynb | Jupyter Notebook | py_notebooks/RawDataAnalysis.ipynb | GeoFelpave/MResDissertation_Aug2021 | 340261d5a533a8235048554fe99df7e11fd06334 | [
"MIT"
]
| 4 | 2022-01-15T04:02:43.000Z | 2022-01-27T11:38:58.000Z | py_notebooks/RawDataAnalysis.ipynb | GeoFelpave/MResDissertation_Aug2021 | 340261d5a533a8235048554fe99df7e11fd06334 | [
"MIT"
]
| null | null | null | py_notebooks/RawDataAnalysis.ipynb | GeoFelpave/MResDissertation_Aug2021 | 340261d5a533a8235048554fe99df7e11fd06334 | [
"MIT"
]
| null | null | null | 37.003082 | 221 | 0.580929 | [
[
[
"# Raw Data visualisation and analysis\n\nThis notebook was designed to carry out the visualisation and analysis of the raw data\n\n---\n\n - Author: \n Luis F Patino Velasquez - MA\n - Date: \n Jun 2020\n - Version: \n 1.0\n - Notes: \n Files used in this notebook are in netCDF format\n - Jupyter version: \n jupyter core : 4.7.1\n jupyter-notebook : 6.4.0\n qtconsole : 5.1.1\n ipython : 7.25.0\n ipykernel : 6.0.3\n jupyter client : 6.1.12\n jupyter lab : 3.0.16\n nbconvert : 6.1.0\n ipywidgets : 7.6.3\n nbformat : 5.1.3\n traitlets : 5.0.5\n - Python version: \n 3.8.5 \n\n---\n\n### Setting Python Modules",
"_____no_output_____"
]
],
[
[
"# Imports for xclim and xarray\nimport xclim as xc\nimport pandas as pd\nimport numpy as np\nimport xarray as xr\nimport functools\n# from functools import reduce\n\n# File handling libraries\nimport time\nimport tempfile\nfrom pathlib import Path\n\n# Geospatial libraries\nimport geopandas\nimport rioxarray\nfrom shapely.geometry import mapping\n\n# import plotting stuff\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nfrom matplotlib import cm\nimport matplotlib.mlab as mlab\nimport seaborn as sns\n# set colours\n# plt.style.use('default')\nplt.style.use(\"~/.local/lib/python3.8/site-packages/matplotlib/mpl-data/stylelib/lfpv.mplstyle\")\n\n%matplotlib inline\n# Set some plotting defaults\nplt.rcParams['figure.figsize'] = (15, 11)\nplt.rcParams['figure.dpi'] = 50\n\n# Mapping libraries\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.basemap import Basemap\n\nfldr_images = Path('/mnt/d/MRes_dataset/Images/Others')\n\nsep = '-----------\\n-----------'\nprint(sep)",
"_____no_output_____"
],
[
"def UK_clip(xarray_dataset, coord_lon_name, coord_lat_name, xarray_dataset_crs):\n # Setting spatial dimmension in nc data\n xarray_dataset.rio.set_spatial_dims(x_dim=coord_lon_name, y_dim=coord_lat_name, inplace=True)\n xarray_dataset.rio.write_crs(xarray_dataset_crs, inplace=True)\n\n # Set mask based on boundary\n uk_admn = geopandas.read_file('/mnt/d/MRes_dataset/active_data/101_admin/uk_admin_boundary_py_nasa_pp_countryOutlineFromGiovanni.shp', crs=\"epsg:4326\")\n # Data for UK\n uk_clipData = xarray_dataset.rio.clip(uk_admn.geometry.apply(mapping), uk_admn.crs, drop=False)\n \n return(uk_clipData)",
"_____no_output_____"
]
],
[
[
"### 1. Reading the raw data\n\n#### 1.1. ERA5",
"_____no_output_____"
]
],
[
[
"# Set directory to read and for outputs\nfldr_src = Path('/mnt/d/MRes_dataset/search_data/era_copernicus_uk/')\n\n# Create list with files\nfls_lst = fldr_src.glob('**/era5_copernicus_DAY_prcp_*')\n\n# Load multiple NetCDFs into a single xarray.Dataset\ndataset_ERA = xr.open_mfdataset(paths=fls_lst, combine='by_coords', parallel=True)\ndataset_ERA",
"_____no_output_____"
]
],
[
[
"#### 1.2. GPM-IMERG",
"_____no_output_____"
]
],
[
[
"# Set directory to read and for outputs\nfldr_src = Path('/mnt/d/MRes_dataset/search_data/gpm_imerg_nasa_uk/')\n\n# Create list with files\nfls_lst = fldr_src.glob('**/*')\n\n\n# Load multiple NetCDFs into a single xarray.Dataset\ndataset_GPM = xr.open_mfdataset(paths=fls_lst, combine='by_coords', parallel=True)\ndataset_GPM",
"_____no_output_____"
]
],
[
[
"#### 1.3. HadUK-Grid",
"_____no_output_____"
]
],
[
[
"# Set directory to read and for outputs\nfldr_src = Path('/mnt/d/MRes_dataset/search_data/haduk_cedac_uk/')\n\n# Create list with files\nfls_lst = fldr_src.glob('**/*')\n\n\n# Load multiple NetCDFs into a single xarray.Dataset\ndataset_HAD = xr.open_mfdataset(paths=fls_lst, combine='by_coords', parallel=True)\ndataset_HAD",
"_____no_output_____"
]
],
[
[
"### 2. Data Analysis",
"_____no_output_____"
],
[
"#### 2.1. Functions",
"_____no_output_____"
]
],
[
[
"def UK_clip(xarray_dataset, coord_lon_name, coord_lat_name, xarray_dataset_crs):\n \"\"\"\n Return xarray with data for the UK only\n :xarray_dataset: xarray\n :coord_lon_name: string\n :coord_lat_name: string\n :xarray_dataset_crs: dictionary\n :return: xarray\n \"\"\"\n # Setting spatial dimmension in nc data\n xarray_dataset.rio.set_spatial_dims(x_dim=coord_lon_name, y_dim=coord_lat_name, inplace=True)\n xarray_dataset.rio.write_crs(xarray_dataset_crs, inplace=True)\n\n # Set mask based on boundary\n uk_admn = geopandas.read_file('/mnt/d/MRes_dataset/active_data/101_admin/uk_admin_boundary_py_nasa_pp_countryOutlineFromGiovanni.shp', crs=\"epsg:4326\")\n # Data for UK\n uk_clipData = xarray_dataset.rio.clip(uk_admn.geometry.apply(mapping), uk_admn.crs, drop=False)\n \n return(uk_clipData)\n\ndef plot_setup(subplot_ref, data_source1, data_source2):\n \"\"\"\n Return mapplotlib figure\n :subplot_ref: list of integers\n :data_source1: string\n :data_source2: string\n :return: mapplotlib figure\n \"\"\"\n # x-axis labels\n subplot_ref.grid(b=True, which='major', color='grey', linestyle='-', alpha=0.3)\n subplot_ref.set_xticks(x)\n subplot_ref.set_xticklabels([*range(2001,2020,1)])\n \n # Set the tick positions\n subplot_ref.set_xticks(x)\n # Set the tick labels\n subplot_ref.xaxis.set_tick_params(labelsize='x-large')\n subplot_ref.yaxis.set_tick_params(labelsize='x-large')\n # Set title and axis\n subplot_ref.grid(b=True, which='major', color='grey', linestyle='-', alpha=0.3)\n subplot_ref.set_ylabel('Precipitation (mm)', fontdict={'fontsize': 20, 'fontweight': 'normal'})\n subplot_ref.set_xlabel('Years', fontdict={'fontsize': 20, 'fontweight': 'normal'})\n # Set text\n subplot_ref.text(0.95, 0.95, 'HadUK-Grid', horizontalalignment='center', verticalalignment='top',\\\n transform=subplot_ref.transAxes, fontsize='x-large', fontweight='bold',\\\n bbox=dict(facecolor='none', edgecolor='#a65628', boxstyle='round', linewidth=5.0))\n if data_source2 == 'ERA':\n subplot_ref.text(0.95, 0.92, ' ERA5 ', horizontalalignment='center', verticalalignment='top',\\\n transform=subplot_ref.transAxes, fontsize='x-large', fontweight='bold',\\\n bbox=dict(facecolor='none', edgecolor='#377eb8', boxstyle='round', linewidth=5.0))\n else:\n subplot_ref.text(0.95, 0.92, 'GPM-IMERG', horizontalalignment='center', verticalalignment='top',\\\n transform=subplot_ref.transAxes, fontsize='x-large', fontweight='bold',\\\n bbox=dict(facecolor='none', edgecolor='#4daf4a', boxstyle='round', linewidth=5.0))\n\ndef violin_clr(figure, colour):\n for vp in figure['bodies']:\n vp.set_facecolor(colour)\n for partname in ('cbars','cmins','cmaxes','cmeans'):\n vp = figure[partname]\n vp.set_edgecolor(colour)\n vp.set_linewidth(1)\n\ndef saving_image(subplot_ref, fldr_plot, file_name):\n \"\"\"\n Save image output in folder\n :subplot_ref: list of integers\n :fldr_plot: pathlib folder path\n :file_name: string\n \"\"\"\n extent = subplot_ref.get_window_extent().transformed(fig.dpi_scale_trans.inverted())\n fig.savefig((Path(fldr_plot / file_name)), bbox_inches=extent)\n # Pad the saved area by 10% in the x-direction and 20% in the y-direction\n fig.savefig((Path(fldr_plot / file_name)), bbox_inches=extent.expanded(1.1, 1.2))",
"_____no_output_____"
]
],
[
[
"#### 2.2. Yearly Average Analysis\nHere we are plotting the mean yearly value for each of the datasets for the whole UK",
"_____no_output_____"
]
],
[
[
"# Get annual value from daily data\narr_yearPrcp_ERA = dataset_ERA.groupby('time.year').sum(dim='time')\narr_yearPrcp_GPM = dataset_GPM.groupby('time.year').sum(dim='time')\narr_yearPrcp_HAD = dataset_HAD.groupby('time.year').sum(dim='time')\n\n# only use mainland UK data\narr_yearPrcp_ERAUK = UK_clip(arr_yearPrcp_ERA, 'longitude', 'latitude', \"epsg:4326\")\narr_yearPrcp_GPMUK = UK_clip(arr_yearPrcp_GPM, 'lon', 'lat', \"epsg:4326\")\n\n# Convert data to pandas dataframe\ndf_yearPrcp_ERA = arr_yearPrcp_ERA.to_dataframe().reset_index()\ndf_yearPrcp_GPM = arr_yearPrcp_GPM.to_dataframe().reset_index()\ndf_yearPrcp_HAD = arr_yearPrcp_HAD.to_dataframe().reset_index()\n\n####################################################\n#I NEED TO ADD THE FUNCTION THAT JOINS THE DATAFRAMES\n#####################################################\n\n# For HADGrid-UK replace zero for NaN to avoid using zero in the mean value\ndf_yearPrcp_HAD = df_yearPrcp_HAD.replace(0, np.NaN)\ndf_yearPrcp_ERA\n\n\n# Get the mean yearly value new = df_yearPrcp_ERA.groupby(['year']).agg({'tp': ['mean']}).reset_index()\ndf_MeanyearPrcp_ERA = df_yearPrcp_ERA.groupby('year', as_index=False)['tp'].mean()\ndf_MeanyearPrcp_GPM = df_yearPrcp_GPM.groupby('year', as_index=False)['precipitationCal'].mean()\ndf_MeanyearPrcp_HAD = df_yearPrcp_HAD.groupby('year', as_index=False)['rainfall'].mean()\n\n# create dataframe with mean yearly value\ndfs_lst = [df_MeanyearPrcp_ERA, df_MeanyearPrcp_GPM, df_MeanyearPrcp_HAD]\ndf_final = functools.reduce(lambda left,right: pd.merge(left,right,on='year'), dfs_lst)\ndf_final",
"_____no_output_____"
]
],
[
[
"* **Plotting the yearly average for the UK using all datasets**",
"_____no_output_____"
]
],
[
[
"# Create copy of dataframe\ndf_plot = df_final\n\n\n# Rename columns\ndf_plot.rename(columns = {'tp':'prcp_ERA5', 'precipitationCal':'prcp_IMERG',\n 'rainfall':'prcp_HadGrid-UK'}, inplace = True)\n\n# change year column to date format\ndf_plot['year'] = pd.to_datetime(df_plot['year'], format='%Y')\n\n# Plot data\nERA = df_plot['prcp_ERA5'].tolist()\nGPM = df_plot['prcp_IMERG'].tolist()\nHAD = df_plot['prcp_HadGrid-UK'].tolist()\nyrs = df_plot['year'].tolist()\n\n# Create plot\nfig, axs = plt.subplots(figsize=(15, 11))\naxs.plot(yrs, ERA, label = 'prcp ERA5', marker='D')\naxs.plot(yrs, GPM, label = 'prcp GPM-IMERG', marker='v')\naxs.plot(yrs, HAD, label = 'prcp HadGrid-UK', marker='o')\n\naxs.xaxis.set_tick_params(labelsize='large')\naxs.yaxis.set_tick_params(labelsize='large')\n# Set title and axis\naxs.grid(b=True, which='major', color='grey', linestyle='-', alpha=0.3)\naxs.set_ylabel('precipitation (mm)', fontdict={'fontsize': 18, 'fontweight': 'normal'})\naxs.set_xlabel('years', fontdict={'fontsize': 18, 'fontweight': 'normal'})\n# Set legend\naxs.legend(bbox_to_anchor=(0, 1, 1, 0), loc='best', fontsize='large', ncol=3)",
"_____no_output_____"
]
],
[
[
"* **Creating climatology map for all datasets**",
"_____no_output_____"
]
],
[
[
"# Summ data by year\nyear_dataset = dataset_GPM.groupby('time.year').sum(dim='time')\n# year_dataset_climat = UK_clip(year_dataset, 'longitude', 'latitude', \"epsg:4326\")\n# year_dataset_climat = dataset_HAD.groupby('time.year').sum(dim='time')\n# Change to pandas dataframe\ndf = year_dataset.to_dataframe().reset_index()\n# Group by coordinate and average\ngrouped_df=df.groupby(['latitude','longitude']).mean()\ngrouped_df1 = grouped_df.reset_index()\ngrouped_prcp = grouped_df1.drop(['year'], axis = 1)\n\n# Pivot dataframe ready for the plot\nval_pivot_df = grouped_prcp.pivot(index='latitude', columns='longitude', values='tp')\n\n \n# Plot\nfrom mpl_toolkits.axes_grid1 import make_axes_locatable\nfig, axs = plt.subplots(figsize=(8,15))\nmm = Basemap(resolution='i',projection='merc',ellps='WGS84',llcrnrlat=49,urcrnrlat=61,llcrnrlon=-9,urcrnrlon=2,lat_ts=20,ax=axs)\nlons = val_pivot_df.columns.values\nlats = val_pivot_df.index.values\ndata_values = val_pivot_df.values\nmasked_data = np.ma.masked_invalid(data_values)\nlon, lat = np.meshgrid(lons, lats)\nxi, yi = mm(lon, lat)\ncs = mm.pcolor(xi,yi,masked_data,shading='auto')\nfig.colorbar(cs, ax=axs, shrink=0.8, pad=0.15, label='any_text')\n# add shp file as coastline\n# mm.readshapefile('/mnt/c/Users/C0060017/Documents/Taught_Material/MRes_Dissertation/Dissertation/MRes_dataset/active_data/101_admin/uk_admin_boundary_py_nasa_pp_countryOutlineFromGiovanni', 'uk_admin_boundary')\n# Map properties set up\nmerid = mm.drawmeridians(\n np.arange(-180, 180, 2), \n labels=[False, False, False, True])\nparall = mm.drawparallels(\n np.arange(0, 160), \n labels=[True, True, False, False])\n\nplt.show()\n\n\n# filterinfDataframe = df[(df['longitude'] == -9.0) & (df['latitude'] == 61.0) ]\n# filterinfDataframe\n",
"_____no_output_____"
]
],
[
[
"#### 2.3. Data distribution\n\nHere we are plotting the distribution of the mean daily precipitation for each year - *The plotted dataset contains the daily mean value for each year at each grid cell*",
"_____no_output_____"
]
],
[
[
"# Get average value by season\nERA_season_mean = dataset_ERA.groupby('time.season').mean('time')\n\n# Change to dataframe\ndf_era_season = ERA_season_mean.to_dataframe().reset_index()\n\ntest = df_era_season[(df_era_season[\"season\"] == 'DJF')]\ntest2 = df_era_season[(df_era_season[\"season\"] == 'MAM')]\ntest3 = df_era_season[(df_era_season[\"season\"] == 'JJA')]\ntest4 = df_era_season[(df_era_season[\"season\"] == 'SON')]\ntest_data = [test['tp'], test2['tp'], test3['tp'], test4['tp']]\nx = [1,2,3,4]\n\nprint(df_era_season.shape[0])\n\nfig, axes = plt.subplots(figsize=(30,15))\n# axes.violinplot(dataset = [test['tp'],test2['tp'], test3['tp'], test4['tp']])\naxes.violinplot([test['tp'],test2['tp'], test3['tp'], test4['tp']], showmeans=True, showmedians=False, showextrema=True, points=10000)\n\n# x-axis labels\naxes.set_xticks(x)\naxes.set_xticklabels(['DJF', 'MAM','JJA', 'SON'])\n\nplt.show()\n\n\n\n# df = df_era_season.set_index(['season'])\n# df\n# grouped = df['tp'].groupby(level='season')\n# grouped.boxplot(rot=45, fontsize=12, figsize=(8,10))",
"_____no_output_____"
],
[
"# Get average value by season\nERA_yearly_mean = dataset_ERA.groupby('time.year').mean('time')\nGPM_yearly_mean = dataset_GPM.groupby('time.year').mean('time')\nHAD_yearly_mean = dataset_HAD.groupby('time.year').mean('time')\n\n# Change to dataframe\ndf_era_yearly = ERA_yearly_mean.to_dataframe().reset_index()\ndf_gpm_yearly = GPM_yearly_mean.to_dataframe().reset_index()\ndf_had_yearly = HAD_yearly_mean.to_dataframe().reset_index()\n\n# For HadUK NaN values need to be removed\ndf_had_yearly_final = df_had_yearly.dropna(subset=['rainfall'], how='all')\n\n# integer for x axis\nx = [*range(1,len(df_era_yearly['year'].unique()) +1, 1)]\n\n# Create list to store data for the graph\ndataset_lst_ERA=[]\ndataset_lst_GPM=[]\ndataset_lst_HAD=[]\n\n# Create graph datasets\nfor yr in [*range(2001,2020,1)]:\n dataset_lst_ERA.append(df_era_yearly[(df_era_yearly[\"year\"] == yr)]['tp'])\n dataset_lst_GPM.append(df_gpm_yearly[(df_gpm_yearly[\"year\"] == yr)]['precipitationCal'])\n dataset_lst_HAD.append(df_had_yearly_final[(df_had_yearly_final[\"year\"] == yr)]['rainfall'])\n\n# Create plots\nfig, axs = plt.subplots(2, 1, figsize=(50,50))\n\n# HadUK-Grid and ERA5\nvp_era = axs[0].violinplot(dataset=dataset_lst_ERA, showmeans=True, showmedians=False, showextrema=True)\nvp_had = axs[0].violinplot(dataset=dataset_lst_HAD, showmeans=True, showmedians=False, showextrema=True)\nplot_setup(axs[0],'HAD','ERA')\n# change colour of violin o match other graphs\nviolin_clr(vp_had, '#a65628')\nviolin_clr(vp_era, '#377eb8')\n# # saving image\n# file_name = 'HADUK-ERA5_Year_Mean_Daily_Distribution.png'\n# saving_image(axs[0], fldr_images, file_name)\n\n# HadUK-Grid and GPM-IMERG\nvp_gpm = axs[1].violinplot(dataset=dataset_lst_GPM, showmeans=True, showmedians=False, showextrema=True)\nvp_had = axs[1].violinplot(dataset=dataset_lst_HAD, showmeans=True, showmedians=False, showextrema=True)\n\nplot_setup(axs[1],'HAD','GPM-IMERG')\n# change colour of violin o match other graphs\nviolin_clr(vp_had, '#a65628')\nviolin_clr(vp_gpm, '#4daf4a')\n# # saving image\n# file_name = 'HADUK-GPM-IMERG_Year_Mean_Daily_Distribution.png'\n# saving_image(axs[1], fldr_images, file_name)\n\n\nplt.show()\n# Make sure it show a nice layout avoiding overlapping\nplt.tight_layout()",
"_____no_output_____"
]
],
[
[
"#### 2.3.1. Descriptive statistics\n\nHere we get the individual tables showing the descriptive characteristics.",
"_____no_output_____"
]
],
[
[
"# Create dataframe using the data for each year - These data was used in the violin plots\ndataset_lst_ERA\ndataset_lst_GPM\ndataset_lst_HAD\n\n# Conver to pandas dataframe\nERA = pd.DataFrame(list(map(np.ravel, dataset_lst_ERA)))\nGPM = pd.DataFrame(list(map(np.ravel, dataset_lst_GPM)))\nHAD = pd.DataFrame(list(map(np.ravel, dataset_lst_HAD)))\n\n# Get descriptive statistics for each year and all datasets\nERA_stats = ERA.apply(pd.Series.describe, axis=1)\nGPM_stats = GPM.apply(pd.Series.describe, axis=1)\nHAD_stats = HAD.apply(pd.Series.describe, axis=1)\n\ndfs = [ERA_stats, GPM_stats, HAD_stats]\n\nfor df in dfs:\n # Add years as column\n df['years'] = [*range(2001,2020,1)]\n # Shift column 'year' to first position\n first_column = df.pop('years')\n # insert column using insert(position,column_name,first_column) function\n df.insert(0, 'years', first_column)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7bef223ffc338e7bc4c36c120c098de9670b59f | 20,983 | ipynb | Jupyter Notebook | lecture13_numpy_5/lecture13-demos.ipynb | alexhuth/ndap-fa2018 | c4ba67ccabb77a844172c0ec14f877e25a3efded | [
"BSD-3-Clause"
]
| 29 | 2018-08-28T15:54:52.000Z | 2021-10-08T22:52:53.000Z | lecture13_numpy_5/lecture13-demos.ipynb | alexhuth/ndap-fa2018 | c4ba67ccabb77a844172c0ec14f877e25a3efded | [
"BSD-3-Clause"
]
| null | null | null | lecture13_numpy_5/lecture13-demos.ipynb | alexhuth/ndap-fa2018 | c4ba67ccabb77a844172c0ec14f877e25a3efded | [
"BSD-3-Clause"
]
| 27 | 2018-09-15T22:57:23.000Z | 2020-07-22T21:09:07.000Z | 30.147989 | 245 | 0.421246 | [
[
[
"import numpy as np",
"_____no_output_____"
],
[
"a = np.ones(10)\nb = np.arange(10)\nprint(a)\nprint(b)",
"[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]\n[0 1 2 3 4 5 6 7 8 9]\n"
],
[
"(a + b).shape",
"_____no_output_____"
],
[
"(a + b)[0] == a[0] + b[0]",
"_____no_output_____"
],
[
"a + b",
"_____no_output_____"
],
[
"np.set_printoptions(precision=2)",
"_____no_output_____"
],
[
"arr = np.random.rand(50,10)\nto_add = np.arange(10)\nprint(arr)",
"[[0.16 0.64 0.47 0.72 0.81 0.05 0.74 0.2 0.84 0. ]\n [0.61 0.5 0.15 0.59 0.11 0.45 0.45 0.24 0.27 0.26]\n [0.03 0.05 0.76 0.89 0.38 0.33 0.67 0.63 0.14 0.06]\n [0.02 0.15 0.04 0.7 0.89 0.52 0.52 0.48 0.41 0.69]\n [0.62 0.58 0.01 0.39 0.24 0.73 0.87 0.66 0.84 0.12]\n [0.2 0.6 0.84 0.74 0.99 0.78 0.51 0.33 0.93 0.34]\n [0.27 0.25 0.94 0.08 0.22 0.28 0.19 0.38 0.02 0.5 ]\n [0.13 0.92 0.93 0.78 0.44 0.88 0.7 0.29 0.19 0.54]\n [0.8 0.67 0.64 0.01 0.79 0.77 0.02 0.31 0.78 0.03]\n [0.26 0.38 0.91 0.93 0.88 0.15 0.89 0.32 0.51 0.42]\n [0.59 0.72 0.43 0.34 0.56 0.4 0.46 0.99 0.42 0.12]\n [0.19 0.39 0.71 0.78 0.05 0.46 0.78 0.27 0.48 0.49]\n [0.14 0.36 0.85 0.72 0.24 0.29 0.97 0.01 0.86 0.26]\n [0.26 0.63 0.77 0.64 0.67 0.59 0.85 0.78 0.12 0.93]\n [0.33 0.23 0.83 0.08 0.87 0.1 0.21 0.57 0.41 0.96]\n [0.83 0.49 0.18 0.91 0.82 0.78 0.82 0.41 0.8 0.15]\n [0.53 0.36 0.86 0.25 0.58 0.91 0.76 0.13 0.16 0.94]\n [0.57 0.41 0.55 0.62 0.24 0.91 0.08 0.44 0.36 0.55]\n [0.24 0.86 0.95 0.06 0.27 0.85 0.88 0.51 0.5 0.06]\n [0.14 0.34 0.26 0.91 0.43 0.61 0.53 0.31 0.48 0.44]\n [0.99 0.09 0.01 0.58 0.97 0.45 0.93 0.69 1. 0.68]\n [0.44 0.42 0.63 0.55 0.44 0.38 0.94 0.85 0.27 0.66]\n [0.61 0.52 0.2 0.93 0.04 0.29 0.45 0.51 0.3 0.52]\n [0.45 0.09 0.13 0.09 0.69 0.83 0.01 0.43 0.55 0.16]\n [0.61 0.86 0.59 0.49 0.42 0.46 0.39 0.45 0.42 0.57]\n [0.67 0.88 0.94 0.8 0.12 0.93 0.39 0.58 0.78 0.77]\n [0.42 0.82 0.23 0.96 0.54 0.9 0.6 0.77 0.01 0.63]\n [0.65 0.81 0.3 0.9 0.31 0.1 0.8 0.24 0.05 0.56]\n [0.45 0.3 0.16 0.91 0.05 0.59 0.68 0.62 0.23 0.89]\n [0.55 0.41 0.11 0.89 0.52 0.68 0.19 0.06 0.65 0.21]\n [0.37 0.99 0.46 0.08 0.5 0.8 0.72 0.87 0.05 0.16]\n [0.64 0.58 0.32 0.38 0.42 1. 0.4 0.61 0.75 0.42]\n [0.63 0.33 0.12 0.69 0.17 0.98 0.46 0.73 0.46 0.16]\n [0.67 0.39 0.08 0.45 0.87 0.78 0.25 0.32 0.95 0.32]\n [0.78 0.28 0.32 0.35 0.17 0.26 0.16 0.66 0.15 0.01]\n [0.93 0.5 0.48 0.57 0.95 0.39 0.98 0.41 0.47 0.32]\n [0.65 0.87 0.84 0.32 0.61 0.29 0.91 0.26 0.67 0.46]\n [0.83 0.42 0.27 0.46 0.77 0.2 0.4 0.5 0.19 0.96]\n [0.81 0.83 0.54 0.91 0.86 0.22 0.48 0.38 0.38 0.62]\n [0.65 0.72 0.18 0.52 0.54 0.59 0.59 0.68 0.22 0.81]\n [0.12 0.34 0.45 0.74 0. 0.62 0.8 0.04 0.11 0.15]\n [0.71 0.95 0.63 0.23 0.51 0.5 0.33 0.28 0.38 0.69]\n [0.12 0.31 0.31 0.39 0.85 0.42 0.51 0.1 0.04 0.45]\n [0.63 0.04 0.22 0.83 0.12 0.76 0.85 0.57 0.81 0.04]\n [0.66 0.87 0.28 0.91 0.92 0.74 0.62 0.38 0.1 0.62]\n [0.98 0.71 0.36 0.23 0.5 0.36 0.38 0.7 0.82 0.79]\n [0.93 0.52 0.37 0.17 0.91 0.13 0.86 0.49 0.77 0.13]\n [0.58 0.26 0.53 0.15 0.12 0.64 0.48 0.53 0.75 0.48]\n [0.67 0.22 0.5 0.57 0.15 0.3 0.21 0.65 0.03 0.09]\n [0.13 0.66 0.84 0.24 0.7 0.9 0.43 0.99 0.85 0.18]]\n"
],
[
"print(to_add)",
"[0 1 2 3 4 5 6 7 8 9]\n"
],
[
"arr[0]",
"_____no_output_____"
],
[
"# first row should be\narr[0] + to_add",
"_____no_output_____"
],
[
"# we could write a for loop\nresult = np.zeros((50,10))\nfor ii in range(50):\n result[ii] = arr[ii] + to_add\n\n# this suuuucks",
"_____no_output_____"
],
[
"print(result)",
"[[0.16 1.64 2.47 3.72 4.81 5.05 6.74 7.2 8.84 9. ]\n [0.61 1.5 2.15 3.59 4.11 5.45 6.45 7.24 8.27 9.26]\n [0.03 1.05 2.76 3.89 4.38 5.33 6.67 7.63 8.14 9.06]\n [0.02 1.15 2.04 3.7 4.89 5.52 6.52 7.48 8.41 9.69]\n [0.62 1.58 2.01 3.39 4.24 5.73 6.87 7.66 8.84 9.12]\n [0.2 1.6 2.84 3.74 4.99 5.78 6.51 7.33 8.93 9.34]\n [0.27 1.25 2.94 3.08 4.22 5.28 6.19 7.38 8.02 9.5 ]\n [0.13 1.92 2.93 3.78 4.44 5.88 6.7 7.29 8.19 9.54]\n [0.8 1.67 2.64 3.01 4.79 5.77 6.02 7.31 8.78 9.03]\n [0.26 1.38 2.91 3.93 4.88 5.15 6.89 7.32 8.51 9.42]\n [0.59 1.72 2.43 3.34 4.56 5.4 6.46 7.99 8.42 9.12]\n [0.19 1.39 2.71 3.78 4.05 5.46 6.78 7.27 8.48 9.49]\n [0.14 1.36 2.85 3.72 4.24 5.29 6.97 7.01 8.86 9.26]\n [0.26 1.63 2.77 3.64 4.67 5.59 6.85 7.78 8.12 9.93]\n [0.33 1.23 2.83 3.08 4.87 5.1 6.21 7.57 8.41 9.96]\n [0.83 1.49 2.18 3.91 4.82 5.78 6.82 7.41 8.8 9.15]\n [0.53 1.36 2.86 3.25 4.58 5.91 6.76 7.13 8.16 9.94]\n [0.57 1.41 2.55 3.62 4.24 5.91 6.08 7.44 8.36 9.55]\n [0.24 1.86 2.95 3.06 4.27 5.85 6.88 7.51 8.5 9.06]\n [0.14 1.34 2.26 3.91 4.43 5.61 6.53 7.31 8.48 9.44]\n [0.99 1.09 2.01 3.58 4.97 5.45 6.93 7.69 9. 9.68]\n [0.44 1.42 2.63 3.55 4.44 5.38 6.94 7.85 8.27 9.66]\n [0.61 1.52 2.2 3.93 4.04 5.29 6.45 7.51 8.3 9.52]\n [0.45 1.09 2.13 3.09 4.69 5.83 6.01 7.43 8.55 9.16]\n [0.61 1.86 2.59 3.49 4.42 5.46 6.39 7.45 8.42 9.57]\n [0.67 1.88 2.94 3.8 4.12 5.93 6.39 7.58 8.78 9.77]\n [0.42 1.82 2.23 3.96 4.54 5.9 6.6 7.77 8.01 9.63]\n [0.65 1.81 2.3 3.9 4.31 5.1 6.8 7.24 8.05 9.56]\n [0.45 1.3 2.16 3.91 4.05 5.59 6.68 7.62 8.23 9.89]\n [0.55 1.41 2.11 3.89 4.52 5.68 6.19 7.06 8.65 9.21]\n [0.37 1.99 2.46 3.08 4.5 5.8 6.72 7.87 8.05 9.16]\n [0.64 1.58 2.32 3.38 4.42 6. 6.4 7.61 8.75 9.42]\n [0.63 1.33 2.12 3.69 4.17 5.98 6.46 7.73 8.46 9.16]\n [0.67 1.39 2.08 3.45 4.87 5.78 6.25 7.32 8.95 9.32]\n [0.78 1.28 2.32 3.35 4.17 5.26 6.16 7.66 8.15 9.01]\n [0.93 1.5 2.48 3.57 4.95 5.39 6.98 7.41 8.47 9.32]\n [0.65 1.87 2.84 3.32 4.61 5.29 6.91 7.26 8.67 9.46]\n [0.83 1.42 2.27 3.46 4.77 5.2 6.4 7.5 8.19 9.96]\n [0.81 1.83 2.54 3.91 4.86 5.22 6.48 7.38 8.38 9.62]\n [0.65 1.72 2.18 3.52 4.54 5.59 6.59 7.68 8.22 9.81]\n [0.12 1.34 2.45 3.74 4. 5.62 6.8 7.04 8.11 9.15]\n [0.71 1.95 2.63 3.23 4.51 5.5 6.33 7.28 8.38 9.69]\n [0.12 1.31 2.31 3.39 4.85 5.42 6.51 7.1 8.04 9.45]\n [0.63 1.04 2.22 3.83 4.12 5.76 6.85 7.57 8.81 9.04]\n [0.66 1.87 2.28 3.91 4.92 5.74 6.62 7.38 8.1 9.62]\n [0.98 1.71 2.36 3.23 4.5 5.36 6.38 7.7 8.82 9.79]\n [0.93 1.52 2.37 3.17 4.91 5.13 6.86 7.49 8.77 9.13]\n [0.58 1.26 2.53 3.15 4.12 5.64 6.48 7.53 8.75 9.48]\n [0.67 1.22 2.5 3.57 4.15 5.3 6.21 7.65 8.03 9.09]\n [0.13 1.66 2.84 3.24 4.7 5.9 6.43 7.99 8.85 9.18]]\n"
],
[
"# with broadcasting\narr + to_add",
"_____no_output_____"
],
[
"a = np.ones((2,3,4))\nprint(a)",
"[[[1. 1. 1. 1.]\n [1. 1. 1. 1.]\n [1. 1. 1. 1.]]\n\n [[1. 1. 1. 1.]\n [1. 1. 1. 1.]\n [1. 1. 1. 1.]]]\n"
],
[
"b = np.arange(4)\nprint(b)\nprint(b.shape)",
"[0 1 2 3]\n(4,)\n"
],
[
"padded_b = b.reshape((1,1,4))\nprint(padded_b.shape)\nprint(a.shape)",
"(1, 1, 4)\n(2, 3, 4)\n"
],
[
"a + b",
"_____no_output_____"
],
[
"c = np.arange(3)\nprint(c)",
"[0 1 2]\n"
],
[
"padded_c = c.reshape((1,3,1))\nprint(padded_c.shape)\nprint(a.shape)",
"(1, 3, 1)\n(2, 3, 4)\n"
],
[
"a + padded_c",
"_____no_output_____"
],
[
"a + c",
"_____no_output_____"
],
[
"d = np.arange(2)\nprint(d)\nprint(d.shape)",
"[0 1]\n(2,)\n"
],
[
"a + d",
"_____no_output_____"
],
[
"a + d.reshape((2,1,1))",
"_____no_output_____"
],
[
"a + d[:,np.newaxis,np.newaxis]",
"_____no_output_____"
],
[
"d[:,np.newaxis,np.newaxis].shape",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bef9efcd5af63f7b7f5b4c89a97eb246265bca | 52,592 | ipynb | Jupyter Notebook | notebooks/Fusion_Basics/Dispersion Relation.ipynb | Hash--/documents | 86a2ba249a3a478cba9bdcd511d02c4f4302d6fc | [
"MIT"
]
| null | null | null | notebooks/Fusion_Basics/Dispersion Relation.ipynb | Hash--/documents | 86a2ba249a3a478cba9bdcd511d02c4f4302d6fc | [
"MIT"
]
| null | null | null | notebooks/Fusion_Basics/Dispersion Relation.ipynb | Hash--/documents | 86a2ba249a3a478cba9bdcd511d02c4f4302d6fc | [
"MIT"
]
| null | null | null | 136.958333 | 33,164 | 0.872186 | [
[
[
"%pylab\n%matplotlib inline",
"Using matplotlib backend: Qt5Agg\nPopulating the interactive namespace from numpy and matplotlib\n"
],
[
"from scipy.constants import epsilon_0, electron_mass, elementary_charge, physical_constants",
"_____no_output_____"
]
],
[
[
"# The Dispersion Relation\nThe _dispersion relation_ is the function that relates the frequency $\\omega$ and the wavevector $k$. It characterizes each wave type and leads to the labels for the various type.\n",
"_____no_output_____"
],
[
" - CMA diagram\n - phase velocity vs normalized frequency\n - normalized or not\n - density\n - angle\n - field strength\n \n - transverse motions of the electrons on cyclotron resonance sec.2.9.3",
"_____no_output_____"
],
[
"The plasma pulsation is :\n$$\n\\omega_{p_s} = \\sqrt{\\frac{n_s q_s^2}{m_s \\varepsilon_0}}\n$$",
"_____no_output_____"
]
],
[
[
"def plasma_frequency(n, q, m):\n '''\n Returns the plasma angular frequency for a given species.\n '''\n omega_p = sqrt(n*q**2/(m*epsilon_0))\n return omega_p\n\ndef cyclotron_frequency(q, m, B0):\n '''\n Returns the cyclotron angular frequency for a given species.\n '''\n omega_c = np.abs(q)*B0/m\n return omega_c",
"_____no_output_____"
]
],
[
[
"Let's define a convenient object: a particle species.",
"_____no_output_____"
]
],
[
[
"class Species:\n def __init__(self, m, q, description=None):\n self.m = m\n self.q = q\n self.description = description\n def omega_p(self, n):\n return plasma_frequency(n, self.q, self.m)\n def omega_c(self, B0):\n return cyclotron_frequency(self.q, self.m, B0)\n def __repr__(self):\n return 'Specie:{}. Mass:{} kg, charge:{} C'.format(self.description, self.m, self.q)",
"_____no_output_____"
],
[
"electron = Species(electron_mass, -elementary_charge, description='Electron')\nprint(electron)\n\ndeuterium = Species(physical_constants['deuteron mass'][0], +elementary_charge, description='Deuterium')\nprint(deuterium)",
"Specie:Electron. Mass:9.10938356e-31 kg, charge:-1.6021766208e-19 C\nSpecie:Deuterium. Mass:3.343583719e-27 kg, charge:1.6021766208e-19 C\n"
]
],
[
[
"## The cold plasma tensor\nThe cold plasma tensor is given by:\n$$\n\\mathbf{K} = \\left(\n\\begin{matrix}\nK_\\perp & K_\\times & 0 \\\\\n-K_\\times & K_\\perp & 0 \\\\\n0 & 0 & K_\\parallel\n\\end{matrix}\n\\right)\n$$\nwith\n$$\n\\begin{array}{lcl}\nK_\\perp = S &=& 1 - \\displaystyle \\sum_k \\frac{\\omega_{pk}^2}{\\omega^2 - \\omega_{ck}^2}\n\\\\\ni K_\\times = D &=& \\displaystyle \\sum_k \\frac{\\epsilon_k \\omega_{ck} \\omega_{pk}^2}\n{\\omega \\left( \\omega^2 - \\omega_{ck}^2\\right)}\n\\\\\nK_\\parallel = P &=& 1 - \\displaystyle \\sum_k \\frac{\\omega_{pk}^2}{\\omega^2}\n\\end{array}\n$$",
"_____no_output_____"
]
],
[
[
"def K_perp(species, n, B0, f):\n K_perp = 1\n omega = 2*np.pi*f\n\n for k, specie in enumerate(species):\n K_perp -= specie.omega_p(n[k])**2 / (omega**2 - specie.omega_c(B0)**2) \n return K_perp\n\ndef K_parallel(species, n, f):\n K_parallel = 1\n omega = 2*np.pi*f\n for k,specie in enumerate(species):\n K_parallel -= specie.omega_p(n[k])**2 / omega**2\n return K_parallel\n\ndef K_cross(species, n, B0, f):\n K_cross = 0\n omega = 2*np.pi*f\n\n for k, specie in enumerate(species):\n K_cross += np.sign(specie.q) * specie.omega_c(B0) * specie.omega_p(n[k])**2 / (omega*(omega**2 - specie.omega_c(B0)**2)) \n return -1j*K_cross",
"_____no_output_____"
],
[
"plasma = (electron, deuterium)\nn_e = 1e17 # m^-3\nn_D = 1e17 # m^-3\nn = (n_e, n_D)\nB0 = 1 # T\nf = 5e9 # Hz\nprint(K_perp(plasma, n, B0, f))\nprint(K_parallel(plasma, n, f))\nprint(K_cross(plasma, n, B0, f))\nnp.sign(electron.q)",
"1.01053942851\n0.677446602595\n-0.05949695354234114j\n"
],
[
"freqs = np.logspace(6, 11, 1001)\nloglog(freqs, abs(K_parallel(plasma, n, freqs)), lw=2)\nloglog(freqs, abs(K_perp(plasma, n, B0, freqs)), lw=2)\nloglog(freqs, abs(1j*K_cross(plasma, n, B0, freqs)), lw=2)\nxlabel('f [Hz]', fontsize=16)\nyticks(fontsize=16)\nxticks(fontsize=16)\ngrid(True)\nlegend(('$K_\\parallel$', '$K_\\perp$', '$K_X$' ), fontsize=16)\n\naxvline(deuterium.omega_c(B0)/(2*pi), lw=2, ls='--', color='k')\ntext(x=2.5e6, y=1e4, s='$\\omega_{c,D}$', fontsize=16)\naxvline(deuterium.omega_p(n_e)/(2*pi), lw=2, ls='--', color='g')\ntext(x=1e8, y=1e5, s='$\\omega_{p,D}$', fontsize=16)\naxvline(electron.omega_p(n_e)/(2*pi), lw=2, ls='--', color='g')\ntext(x=1e9, y=1e5, s='$\\omega_{p,e}$', fontsize=16)\naxvline(electron.omega_c(B0)/(2*pi), lw=2, ls='--', color='k')\ntext(x=1e10, y=1e1, s='$\\omega_{c,e}$', fontsize=16)",
"_____no_output_____"
],
[
"def solve_dispersion_relation(plasma, n, B0, f, theta):\n S = K_perp(plasma, n, B0, f)\n P = K_parallel(plasma, n, f)\n D = 1j*K_cross(plasma, n, B0, f)\n \n R = S+D\n L = S-D\n \n A = S*np.sin(theta)**2 + P*np.cos(theta)**2\n B = R*L*np.sin(theta)**2 + P*S*(1+np.cos(theta)**2)\n C = P*R*L\n p = (A,B,C)\n n = np.roots(p)\n \n return n",
"_____no_output_____"
],
[
"diel_index = np.array([solve_dispersion_relation(plasma, n, B0=3, f=f, theta=0) for f in freqs])\n\nloglog(freqs, real(diel_index[:,0]), lw=2)\nloglog(freqs, real(diel_index[:,1]), lw=2)\ngrid(True)\nxlabel('f [Hz]', fontsize=16)",
"_____no_output_____"
]
],
[
[
"# References\n - Swanson, Plasma Waves, chap.2",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
]
|
e7bf04b9c723237111e63b9637c4d71a1ae9012e | 37,633 | ipynb | Jupyter Notebook | Modelos_sem_reducao/CNN_IDS/ModelosCodigo2D/CNN2DosIDS(16-02-2018).ipynb | AfonsoSeguro/IDS_Comportamental | 83145f815b67b2d501eb3744367aaea9b5d11cba | [
"MIT"
]
| null | null | null | Modelos_sem_reducao/CNN_IDS/ModelosCodigo2D/CNN2DosIDS(16-02-2018).ipynb | AfonsoSeguro/IDS_Comportamental | 83145f815b67b2d501eb3744367aaea9b5d11cba | [
"MIT"
]
| null | null | null | Modelos_sem_reducao/CNN_IDS/ModelosCodigo2D/CNN2DosIDS(16-02-2018).ipynb | AfonsoSeguro/IDS_Comportamental | 83145f815b67b2d501eb3744367aaea9b5d11cba | [
"MIT"
]
| null | null | null | 117.971787 | 19,960 | 0.812558 | [
[
[
"import os\nimport tensorflow as tf\nimport numpy as np\nimport itertools\nimport matplotlib.pyplot as plt\nimport gc\nfrom datetime import datetime\nfrom sklearn.utils import shuffle\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.model_selection import train_test_split\nfrom tensorflow import keras\nfrom tensorflow.keras import layers\nfrom sklearn.metrics import confusion_matrix",
"_____no_output_____"
],
[
"input_label = []\noutput_label = []",
"_____no_output_____"
],
[
"a,b = 0,0\n\nficheiro = open(\"..\\\\Dataset\\\\16-02-2018.csv\", \"r\")\n\nficheiro.readline()\nficheiro.readline()\nficheiro.readline()\n\nlinha = ficheiro.readline()\nwhile(linha != \"\"):\n linha = linha.split(\",\")\n out = linha.pop(19)\n if(out == \"Benign\"): \n out = 0\n b += 1\n else: \n out = 1\n a += 1\n output_label.append(out)\n input_label.append(linha)\n linha = ficheiro.readline()\n \nficheiro.close()\nprint(str(a) + \" \" + str(b))",
"286191 758334\n"
],
[
"scaler = MinMaxScaler(feature_range=(0,1))\nscaler.fit(input_label)\ninput_label = scaler.transform(input_label)",
"_____no_output_____"
],
[
"input_label = np.array(input_label).reshape(len(input_label), 6, 13, 1)\noutput_label = np.array(output_label)",
"_____no_output_____"
],
[
"input_label, output_label = shuffle(input_label, output_label)",
"_____no_output_____"
],
[
"inp_train, inp_test, out_train, out_test = train_test_split(input_label, output_label, test_size = 0.2)",
"_____no_output_____"
],
[
"model = keras.Sequential([\n layers.Conv2D(filters = 128, kernel_size = ((3,3)), input_shape=(6, 13, 1), padding = \"same\", activation = \"relu\", use_bias = True), \n layers.MaxPool2D(pool_size=(3, 3), padding='same'),\n layers.Conv2D(filters = 64, kernel_size = ((3,3)), padding = \"same\", activation = \"relu\", use_bias = True),\n layers.MaxPool2D(pool_size=(3, 3), padding='same'),\n layers.Conv2D(filters = 32, kernel_size = ((3,3)), padding = \"same\", activation = \"relu\", use_bias = True),\n layers.MaxPool2D(pool_size=(3, 3), padding='same'),\n layers.Flatten(),\n layers.Dense(units = 2, activation = \"softmax\")\n])",
"_____no_output_____"
],
[
"model.compile(optimizer= keras.optimizers.SGD(learning_rate= 0.08), loss=\"sparse_categorical_crossentropy\", metrics=['accuracy'])",
"_____no_output_____"
],
[
"treino = model.fit(x = inp_train, y = out_train, validation_split= 0.1, epochs = 10, shuffle = True,verbose = 1)",
"Epoch 1/10\n 1177/23502 [>.............................] - ETA: 1:52 - loss: 0.2901 - accuracy: 0.8615"
],
[
"plt.plot(treino.history[\"loss\"])\nplt.show()",
"_____no_output_____"
],
[
"plt.plot(treino.history[\"accuracy\"])\nplt.show()",
"_____no_output_____"
],
[
"model.save(\"CNN2DosNet(16-02-2018).h5\")",
"_____no_output_____"
],
[
"res = [np.argmax(resu) for resu in model.predict(inp_test)]",
"_____no_output_____"
],
[
"cm = confusion_matrix(y_true = out_test.reshape(len(out_test)), y_pred = np.array(res))",
"_____no_output_____"
],
[
"def plot_confusion_matrix(cm, classes, normaliza = False, title = \"Confusion matrix\", cmap = plt.cm.Blues):\n plt.imshow(cm, interpolation='nearest', cmap=cmap)\n plt.title(title)\n plt.colorbar()\n tick_marks = np.arange(len(classes))\n plt.xticks(tick_marks, classes, rotation=45)\n plt.yticks(tick_marks, classes)\n if normaliza:\n cm = cm.astype('float') / cm.sum(axis = 1)[:, np.newaxis]\n print(\"Normalized confusion matrix\")\n else:\n print(\"Confusion matrix, without normalization\")\n \n print(cm)\n \n thresh = cm.max() / 2\n for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):\n plt.text(j, i, cm[i, j],\n horizontalalignment=\"center\",\n color=\"white\" if cm[i,j] > thresh else \"black\")\n \n plt.tight_layout()\n plt.ylabel('True label')\n plt.xlabel('Predicted label')",
"_____no_output_____"
],
[
"labels = [\"Benign\", \"Dos\"]\nplot_confusion_matrix(cm = cm, classes = labels, title = \"Dos IDS\")",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bf4a3b09cd271625810f9c902fa26a53b4d8d5 | 13,082 | ipynb | Jupyter Notebook | a7-final.ipynb | tejusk/hcde410-final | b133eb91f4f1e98d969f7c29d6558b7effd6bdde | [
"MIT"
]
| null | null | null | a7-final.ipynb | tejusk/hcde410-final | b133eb91f4f1e98d969f7c29d6558b7effd6bdde | [
"MIT"
]
| null | null | null | a7-final.ipynb | tejusk/hcde410-final | b133eb91f4f1e98d969f7c29d6558b7effd6bdde | [
"MIT"
]
| null | null | null | 99.106061 | 1,390 | 0.750879 | [
[
[
"# HCDE 410 - Final Project\n### Tejus Krishnan",
"_____no_output_____"
],
[
"## Introduction\n\nI'm interested in tracking worldwide progress on the COVID-19 vaccine. I'm personally drawn to the topic because I feel I have not kept myself as up-to-date on COVID data (on a societal level) as I should, and because I have friends and relatives living overseas. On a broader level, it is valuable to understand the different rates of vaccination progress between world regions in order to root out potential inequities in vaccine distribution. I am comparing vaccination data with economic and population statistics on each country to identify correlations with vaccine progress. \n\n### Background\n\nWorld progress on the COVID vaccine is currently being studied by a number of research and news organizations, including [Our World in Data](https://ourworldindata.org/covid-vaccinations), [Johns Hopkins University](https://coronavirus.jhu.edu/vaccines/international), and [CNN](https://www.cnn.com/interactive/2021/health/global-covid-vaccinations/). However, these public vaccine trackers simply provide information similar to what is described in my first dataset (see below), whereas I am more interested in correlating this data with a country's economic and demographic profile to discover potential correlations. I am mainly doing so to find the quantitative basis behind existing inequities in vaccine distribution, which have been covered in more policy-based reporting such as [this article by NPR](https://www.npr.org/2021/04/17/988302407/what-can-wealthy-nations-do-to-address-global-vaccine-inequity).\n\n### Hypotheses / Research Questions\n\n* A country's GDP per capita will be positively correlated with its vaccine progress.\n* What effect does migration rate have on vaccination progress?\n",
"_____no_output_____"
],
[
"## Data\nI am primarily using a Kaggle dataset called [COVID-19 World Vaccination Progress](https://www.kaggle.com/gpreda/covid-world-vaccination-progress). The dataset is a compilation (updated daily) of entries from the [Our World in Data](https://ourworldindata.org/) GitHub repository, which tracks vaccinations by country. The dataset is licensed to the public domain under the Creative Commons CC0 1.0 dedication. I find the dataset suitable for my research given its thoroughness and detail: it sorts its entries by a number of relevant variables including (but not limited to) country, date, and vaccination counts sorted by daily rate, usage, and various population proportions. I don't anticipate any privacy violations given that the data is just a series of counts and averages across countries rather than information about individuals.\n\nI am comparing this data to the [Countries of the World](https://www.kaggle.com/fernandol/countries-of-the-world) dataset, which compiles various general facts about each world nation (including GDP per capita, population, population density, and net migration). This dataset is also licensed to the public domain under Creative Commons. Cross-referencing my first dataset with this one will allow me to investigate my hypotheses and research questions.",
"_____no_output_____"
],
[
"## Methodology",
"_____no_output_____"
],
[
"#### Data Cleaning\n\nAll management of data was done through Microsoft Excel. My first step was to isolate the ``country_vaccinations`` dataset to only include the most recent total vaccinations for each country. I did this by first eliminating all blank rows from the ``total_vaccinations`` column, and saving that sheet in a separate file. I then isolated only the most recent entries for each country from this sheet and copied those entries to a second page on the sheet titled ``most_recent_total_vaccinations``, which gave me 214 entries to work with. This was 14 short of the 228 countries on the ``countries of the world`` dataset, which meant that there are 14 countries for which COVID vaccination data has not been recorded.\n\nUnfortunately, this meant that I could not perform analyses on these 14 countries since there was no way for me to cross-reference information between datasets without the countries directly matching. Hence, I combined the two datasets (``most_recent_total_vaccinations`` and ``countries of the world``) into a single sheet, selected the columns representing country names for each respective dataset, and then highlighted unique values between the two to identify the mismatching countries. Controlling for spelling differences (ex: \"Boznia **and** Herzegovina\" as opposed to \"Bosnia **&** Herzegovina\"), I deleted the data from the rows where a country was not represented in both datasets. This ensured that the data between the two sets was aligned to the same countries. To verify, I added an extra column in the combined sheet and entered the formula `=A1=L1`, then applied it down the entire sheet. The formula returned `TRUE` for every row, which meant that the country data between the two datasets was correctly aligned.\n\nOne additional piece of cleaning was to express all decimals in American notation so that Excel would recognize the values as numbers. The ``countries of the world`` dataset writes out the decimals using a comma, which is European notation. I used Excel's Find & Replace tool to adjust this.\n\n#### Data Analysis\n\nNow that I had a combined spreadsheet with data aligned to each country, it was simply a matter of isolating my columns of interest and generating linear regression graphs based on that data. I believe linear regression analysis is the optimal approach for this research given that it is the most intuitive way to depict correlational relationships. Based on my research questions/hypotheses, the column pairs I compared were ``total_vaccinations`` vs. ``GDP ($ per capita)`` and ``total vaccinations`` vs. ``Net Migration``.",
"_____no_output_____"
],
[
"## Findings\n#### GDP Per Capita vs. Vaccination Rate\n\n\n#### Net Migration vs. Vaccination Rate\n\n\nAs we can see, GDP per capita does indeed predict vaccination progress, with an R-squared value of 0.3604. There were two significant outliers: one was Gibraltar, which had a GDP per capita of only $\\$$17,500 but had a per-hundred vaccination rate of 116. The other was Luxembourg, with an opposite situation: a high GDP per capita ($\\$$55,100), but only 36.43 people vaccinated per hundred. \n\nAs for the effect of net migration, there does appear to be a positive correlation, albeit a weak one, with an R-squared of 0.0977. Most of the data points seem to be concentrated around the Y-axis, which appears to reflect reduced rates of migration during COVID-19.",
"_____no_output_____"
],
[
"## Discussion\nBased on my data visualizations, it appears clear that a country's economic health predicts its ongoing progress with administering the COVID-19 vaccine. This is consistent with [ongoing reporting](https://www.news-medical.net/news/20210217/GDP-significantly-associated-with-greater-COVID-19-vaccine-distribution.aspx) on vaccine distribution, which surmises that high GDPs promote the creation, testing and distribution of vaccines. It also underscores the need for wealthier countries to use their power and resources to help poorer countries immunize at a faster rate. However, one interesting point of possible cause for the economic disparities in vaccine distribution could have to do with the deals reached by wealthier countries for vaccine doses, as [investigated in this report from *The New York Times*](https://www.nytimes.com/interactive/2021/03/31/world/global-vaccine-supply-inequity.html). The report discusses how richer countries had the means to order multiple vaccines, absorbing doses that smaller countries may have otherwise purchased (essentially turning immunization into a race to \"pre-order\" vaccines). This is obviously not the sole cause for inequities in vaccine distribution, but it is notable to observe how countries already endowed with vast resources still exploit their power to fast-track their immunization at the expense of smaller nations.\n\nThat said, certain outliers exist, such as Gibraltar, which [vaccinated most of its adults by April](https://www.nytimes.com/interactive/2021/03/31/world/global-vaccine-supply-inequity.html) and has since enjoyed a resurgence in public life. Given the relatively small population of the territory, it's no surprise that its \"people vaccinated per hundred\" score would be disproportionately high. However, its staggeringly effective vaccine rollout is still a notable achievement - a possible explanation is that the territory is not an independent economy but rather a British territory.\n\nAs for the migration data, the relationship was less clear than with GDP, so I believe my analysis alone presents fewer opportunities for discussion. However, it is worth noting the [various barriers](https://www.nilc.org/2021/04/12/immigrant-access-to-the-covid-19-vaccines/) that exist for immigrants' access to healthcare and immunization, and what role this may have played in the statistics I observed. Perhaps there are vast disparities across the world for how much access is afforded to migrants to get vaccinated. The other possible causal thread is reduced rates of migration during the pandemic.\n\nThis study had a number of limitations, most notably the mismatch between the datasets and the resulting omissions I was forced to make in order to standardize the data. At least ten nations were missed in the analysis as a result; there was also Palestine, which was reported as a single entity in the ``country_vaccinations`` dataset but split into the West Bank and the Gaza Strip in the ``countries of the world`` set. Because I could not simply \"combine\" the data from those two rows, I was also forced to count Palestine as a mismatch even though both datasets technically accounted for it. If I were to iterate on this project, I would certainly find alternative means to analyze COVID data for the countries omitted from this analysis.",
"_____no_output_____"
],
[
"## Conclusion\nWith this project, I set out to get a sharper quantitative understanding of vaccination progress worldwide, as I felt I was solely focusing on vaccine rollout within my own community and was insufficiently informed of the wider global picture. I'm happy to have made good on that opportunity here, at least to the extent to which I analyzed my data for this project. Given the complexity of the subject and the various dimensions along which a country's profile can be constructed (in relation to its vaccine progress), I stuck to two simple research questions given that the paradigm for performing the analysis was the same regardless of what variables I was analyzing. However, based on the limitations I encountered in the study, I would certainly collect more data, either in the form of actual datasets or more external research (particularly to account for the nations I was unable to analyze in this project). Furthermore, I would iterate on this study by conducting a deeper *qualitative* exploration of vaccine progress in the countries whose data points particularly stood out to me, including the outliers I named in the discussion section. I believe the project as it stands to be a stepping stone for a broader analysis on the differences in how various parts of the world are fighting the pandemic.",
"_____no_output_____"
]
]
]
| [
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
e7bf63324450e4749ab4805367059acdf4bddcf0 | 81,499 | ipynb | Jupyter Notebook | notebooks/keras_lesson1.ipynb | AmanDaVinci/DeepLabs | 2c9adef1baaed06c908e94f457dbdf3fd9f1b200 | [
"MIT"
]
| null | null | null | notebooks/keras_lesson1.ipynb | AmanDaVinci/DeepLabs | 2c9adef1baaed06c908e94f457dbdf3fd9f1b200 | [
"MIT"
]
| null | null | null | notebooks/keras_lesson1.ipynb | AmanDaVinci/DeepLabs | 2c9adef1baaed06c908e94f457dbdf3fd9f1b200 | [
"MIT"
]
| null | null | null | 86.242328 | 27,948 | 0.749653 | [
[
[
"# Dogs vs Cats with Keras\n---",
"_____no_output_____"
],
[
"# Import Libraries",
"_____no_output_____"
]
],
[
[
"%reload_ext autoreload\n%autoreload 2\n%matplotlib inline",
"_____no_output_____"
],
[
"PATH = \"../data/dogscats/dogscats/\"\nsz=224\nbatch_size=64",
"_____no_output_____"
],
[
"import numpy as np\nfrom keras.preprocessing.image import ImageDataGenerator\nfrom keras.preprocessing import image\nfrom keras.layers import Dropout, Flatten, Dense\nfrom keras.applications import ResNet50\nfrom keras.models import Model, Sequential\nfrom keras.layers import Dense, GlobalAveragePooling2D\nfrom keras import backend as K\nfrom keras.applications.resnet50 import preprocess_input",
"/home/ainsteinx/anaconda3/envs/fastai/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\nUsing TensorFlow backend.\n"
],
[
"import matplotlib.pyplot as plt\n",
"_____no_output_____"
]
],
[
[
"# Load Data",
"_____no_output_____"
]
],
[
[
"train_data_dir = f'{PATH}train'\nvalidation_data_dir = f'{PATH}valid'",
"_____no_output_____"
],
[
"train_datagen = ImageDataGenerator(preprocessing_function=preprocess_input, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)\n\ntest_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)",
"_____no_output_____"
],
[
"train_generator = train_datagen.flow_from_directory(train_data_dir, target_size=(sz, sz),\n batch_size=batch_size, class_mode='binary')\n\nvalidation_generator = test_datagen.flow_from_directory(validation_data_dir, shuffle=False, target_size=(sz, sz),\n batch_size=batch_size, class_mode='binary')",
"Found 23000 images belonging to 2 classes.\nFound 2000 images belonging to 2 classes.\n"
]
],
[
[
"# Build Model ",
"_____no_output_____"
]
],
[
[
"base_model = ResNet50(weights='imagenet', include_top=False)",
"Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5\n94658560/94653016 [==============================] - 12s 0us/step\n"
],
[
"base_model.summary()",
"__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_1 (InputLayer) (None, None, None, 3 0 \n__________________________________________________________________________________________________\nconv1_pad (ZeroPadding2D) (None, None, None, 3 0 input_1[0][0] \n__________________________________________________________________________________________________\nconv1 (Conv2D) (None, None, None, 6 9472 conv1_pad[0][0] \n__________________________________________________________________________________________________\nbn_conv1 (BatchNormalization) (None, None, None, 6 256 conv1[0][0] \n__________________________________________________________________________________________________\nactivation_1 (Activation) (None, None, None, 6 0 bn_conv1[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_1 (MaxPooling2D) (None, None, None, 6 0 activation_1[0][0] \n__________________________________________________________________________________________________\nres2a_branch2a (Conv2D) (None, None, None, 6 4160 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nbn2a_branch2a (BatchNormalizati (None, None, None, 6 256 res2a_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_2 (Activation) (None, None, None, 6 0 bn2a_branch2a[0][0] \n__________________________________________________________________________________________________\nres2a_branch2b (Conv2D) (None, None, None, 6 36928 activation_2[0][0] \n__________________________________________________________________________________________________\nbn2a_branch2b (BatchNormalizati (None, None, None, 6 256 res2a_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_3 (Activation) (None, None, None, 6 0 bn2a_branch2b[0][0] \n__________________________________________________________________________________________________\nres2a_branch2c (Conv2D) (None, None, None, 2 16640 activation_3[0][0] \n__________________________________________________________________________________________________\nres2a_branch1 (Conv2D) (None, None, None, 2 16640 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nbn2a_branch2c (BatchNormalizati (None, None, None, 2 1024 res2a_branch2c[0][0] \n__________________________________________________________________________________________________\nbn2a_branch1 (BatchNormalizatio (None, None, None, 2 1024 res2a_branch1[0][0] \n__________________________________________________________________________________________________\nadd_1 (Add) (None, None, None, 2 0 bn2a_branch2c[0][0] \n bn2a_branch1[0][0] \n__________________________________________________________________________________________________\nactivation_4 (Activation) (None, None, None, 2 0 add_1[0][0] \n__________________________________________________________________________________________________\nres2b_branch2a (Conv2D) (None, None, None, 6 16448 activation_4[0][0] \n__________________________________________________________________________________________________\nbn2b_branch2a (BatchNormalizati (None, None, None, 6 256 res2b_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_5 (Activation) (None, None, None, 6 0 bn2b_branch2a[0][0] \n__________________________________________________________________________________________________\nres2b_branch2b (Conv2D) (None, None, None, 6 36928 activation_5[0][0] \n__________________________________________________________________________________________________\nbn2b_branch2b (BatchNormalizati (None, None, None, 6 256 res2b_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_6 (Activation) (None, None, None, 6 0 bn2b_branch2b[0][0] \n__________________________________________________________________________________________________\nres2b_branch2c (Conv2D) (None, None, None, 2 16640 activation_6[0][0] \n__________________________________________________________________________________________________\nbn2b_branch2c (BatchNormalizati (None, None, None, 2 1024 res2b_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_2 (Add) (None, None, None, 2 0 bn2b_branch2c[0][0] \n activation_4[0][0] \n__________________________________________________________________________________________________\nactivation_7 (Activation) (None, None, None, 2 0 add_2[0][0] \n__________________________________________________________________________________________________\nres2c_branch2a (Conv2D) (None, None, None, 6 16448 activation_7[0][0] \n__________________________________________________________________________________________________\nbn2c_branch2a (BatchNormalizati (None, None, None, 6 256 res2c_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_8 (Activation) (None, None, None, 6 0 bn2c_branch2a[0][0] \n__________________________________________________________________________________________________\nres2c_branch2b (Conv2D) (None, None, None, 6 36928 activation_8[0][0] \n__________________________________________________________________________________________________\nbn2c_branch2b (BatchNormalizati (None, None, None, 6 256 res2c_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_9 (Activation) (None, None, None, 6 0 bn2c_branch2b[0][0] \n__________________________________________________________________________________________________\nres2c_branch2c (Conv2D) (None, None, None, 2 16640 activation_9[0][0] \n__________________________________________________________________________________________________\nbn2c_branch2c (BatchNormalizati (None, None, None, 2 1024 res2c_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_3 (Add) (None, None, None, 2 0 bn2c_branch2c[0][0] \n activation_7[0][0] \n__________________________________________________________________________________________________\nactivation_10 (Activation) (None, None, None, 2 0 add_3[0][0] \n__________________________________________________________________________________________________\nres3a_branch2a (Conv2D) (None, None, None, 1 32896 activation_10[0][0] \n__________________________________________________________________________________________________\nbn3a_branch2a (BatchNormalizati (None, None, None, 1 512 res3a_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_11 (Activation) (None, None, None, 1 0 bn3a_branch2a[0][0] \n__________________________________________________________________________________________________\nres3a_branch2b (Conv2D) (None, None, None, 1 147584 activation_11[0][0] \n__________________________________________________________________________________________________\nbn3a_branch2b (BatchNormalizati (None, None, None, 1 512 res3a_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_12 (Activation) (None, None, None, 1 0 bn3a_branch2b[0][0] \n__________________________________________________________________________________________________\nres3a_branch2c (Conv2D) (None, None, None, 5 66048 activation_12[0][0] \n__________________________________________________________________________________________________\nres3a_branch1 (Conv2D) (None, None, None, 5 131584 activation_10[0][0] \n__________________________________________________________________________________________________\nbn3a_branch2c (BatchNormalizati (None, None, None, 5 2048 res3a_branch2c[0][0] \n__________________________________________________________________________________________________\nbn3a_branch1 (BatchNormalizatio (None, None, None, 5 2048 res3a_branch1[0][0] \n__________________________________________________________________________________________________\nadd_4 (Add) (None, None, None, 5 0 bn3a_branch2c[0][0] \n bn3a_branch1[0][0] \n__________________________________________________________________________________________________\nactivation_13 (Activation) (None, None, None, 5 0 add_4[0][0] \n__________________________________________________________________________________________________\nres3b_branch2a (Conv2D) (None, None, None, 1 65664 activation_13[0][0] \n__________________________________________________________________________________________________\nbn3b_branch2a (BatchNormalizati (None, None, None, 1 512 res3b_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_14 (Activation) (None, None, None, 1 0 bn3b_branch2a[0][0] \n__________________________________________________________________________________________________\nres3b_branch2b (Conv2D) (None, None, None, 1 147584 activation_14[0][0] \n__________________________________________________________________________________________________\nbn3b_branch2b (BatchNormalizati (None, None, None, 1 512 res3b_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_15 (Activation) (None, None, None, 1 0 bn3b_branch2b[0][0] \n__________________________________________________________________________________________________\nres3b_branch2c (Conv2D) (None, None, None, 5 66048 activation_15[0][0] \n__________________________________________________________________________________________________\nbn3b_branch2c (BatchNormalizati (None, None, None, 5 2048 res3b_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_5 (Add) (None, None, None, 5 0 bn3b_branch2c[0][0] \n activation_13[0][0] \n__________________________________________________________________________________________________\nactivation_16 (Activation) (None, None, None, 5 0 add_5[0][0] \n__________________________________________________________________________________________________\nres3c_branch2a (Conv2D) (None, None, None, 1 65664 activation_16[0][0] \n__________________________________________________________________________________________________\nbn3c_branch2a (BatchNormalizati (None, None, None, 1 512 res3c_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_17 (Activation) (None, None, None, 1 0 bn3c_branch2a[0][0] \n__________________________________________________________________________________________________\nres3c_branch2b (Conv2D) (None, None, None, 1 147584 activation_17[0][0] \n__________________________________________________________________________________________________\nbn3c_branch2b (BatchNormalizati (None, None, None, 1 512 res3c_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_18 (Activation) (None, None, None, 1 0 bn3c_branch2b[0][0] \n__________________________________________________________________________________________________\nres3c_branch2c (Conv2D) (None, None, None, 5 66048 activation_18[0][0] \n__________________________________________________________________________________________________\nbn3c_branch2c (BatchNormalizati (None, None, None, 5 2048 res3c_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_6 (Add) (None, None, None, 5 0 bn3c_branch2c[0][0] \n activation_16[0][0] \n__________________________________________________________________________________________________\nactivation_19 (Activation) (None, None, None, 5 0 add_6[0][0] \n__________________________________________________________________________________________________\nres3d_branch2a (Conv2D) (None, None, None, 1 65664 activation_19[0][0] \n__________________________________________________________________________________________________\nbn3d_branch2a (BatchNormalizati (None, None, None, 1 512 res3d_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_20 (Activation) (None, None, None, 1 0 bn3d_branch2a[0][0] \n__________________________________________________________________________________________________\nres3d_branch2b (Conv2D) (None, None, None, 1 147584 activation_20[0][0] \n__________________________________________________________________________________________________\nbn3d_branch2b (BatchNormalizati (None, None, None, 1 512 res3d_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_21 (Activation) (None, None, None, 1 0 bn3d_branch2b[0][0] \n__________________________________________________________________________________________________\nres3d_branch2c (Conv2D) (None, None, None, 5 66048 activation_21[0][0] \n__________________________________________________________________________________________________\nbn3d_branch2c (BatchNormalizati (None, None, None, 5 2048 res3d_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_7 (Add) (None, None, None, 5 0 bn3d_branch2c[0][0] \n activation_19[0][0] \n__________________________________________________________________________________________________\nactivation_22 (Activation) (None, None, None, 5 0 add_7[0][0] \n__________________________________________________________________________________________________\nres4a_branch2a (Conv2D) (None, None, None, 2 131328 activation_22[0][0] \n__________________________________________________________________________________________________\nbn4a_branch2a (BatchNormalizati (None, None, None, 2 1024 res4a_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_23 (Activation) (None, None, None, 2 0 bn4a_branch2a[0][0] \n__________________________________________________________________________________________________\nres4a_branch2b (Conv2D) (None, None, None, 2 590080 activation_23[0][0] \n__________________________________________________________________________________________________\nbn4a_branch2b (BatchNormalizati (None, None, None, 2 1024 res4a_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_24 (Activation) (None, None, None, 2 0 bn4a_branch2b[0][0] \n__________________________________________________________________________________________________\nres4a_branch2c (Conv2D) (None, None, None, 1 263168 activation_24[0][0] \n__________________________________________________________________________________________________\nres4a_branch1 (Conv2D) (None, None, None, 1 525312 activation_22[0][0] \n__________________________________________________________________________________________________\nbn4a_branch2c (BatchNormalizati (None, None, None, 1 4096 res4a_branch2c[0][0] \n__________________________________________________________________________________________________\nbn4a_branch1 (BatchNormalizatio (None, None, None, 1 4096 res4a_branch1[0][0] \n__________________________________________________________________________________________________\nadd_8 (Add) (None, None, None, 1 0 bn4a_branch2c[0][0] \n bn4a_branch1[0][0] \n__________________________________________________________________________________________________\nactivation_25 (Activation) (None, None, None, 1 0 add_8[0][0] \n__________________________________________________________________________________________________\nres4b_branch2a (Conv2D) (None, None, None, 2 262400 activation_25[0][0] \n__________________________________________________________________________________________________\nbn4b_branch2a (BatchNormalizati (None, None, None, 2 1024 res4b_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_26 (Activation) (None, None, None, 2 0 bn4b_branch2a[0][0] \n__________________________________________________________________________________________________\nres4b_branch2b (Conv2D) (None, None, None, 2 590080 activation_26[0][0] \n__________________________________________________________________________________________________\nbn4b_branch2b (BatchNormalizati (None, None, None, 2 1024 res4b_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_27 (Activation) (None, None, None, 2 0 bn4b_branch2b[0][0] \n__________________________________________________________________________________________________\nres4b_branch2c (Conv2D) (None, None, None, 1 263168 activation_27[0][0] \n__________________________________________________________________________________________________\nbn4b_branch2c (BatchNormalizati (None, None, None, 1 4096 res4b_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_9 (Add) (None, None, None, 1 0 bn4b_branch2c[0][0] \n activation_25[0][0] \n__________________________________________________________________________________________________\nactivation_28 (Activation) (None, None, None, 1 0 add_9[0][0] \n__________________________________________________________________________________________________\nres4c_branch2a (Conv2D) (None, None, None, 2 262400 activation_28[0][0] \n__________________________________________________________________________________________________\nbn4c_branch2a (BatchNormalizati (None, None, None, 2 1024 res4c_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_29 (Activation) (None, None, None, 2 0 bn4c_branch2a[0][0] \n__________________________________________________________________________________________________\nres4c_branch2b (Conv2D) (None, None, None, 2 590080 activation_29[0][0] \n__________________________________________________________________________________________________\nbn4c_branch2b (BatchNormalizati (None, None, None, 2 1024 res4c_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_30 (Activation) (None, None, None, 2 0 bn4c_branch2b[0][0] \n__________________________________________________________________________________________________\nres4c_branch2c (Conv2D) (None, None, None, 1 263168 activation_30[0][0] \n__________________________________________________________________________________________________\nbn4c_branch2c (BatchNormalizati (None, None, None, 1 4096 res4c_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_10 (Add) (None, None, None, 1 0 bn4c_branch2c[0][0] \n activation_28[0][0] \n__________________________________________________________________________________________________\nactivation_31 (Activation) (None, None, None, 1 0 add_10[0][0] \n__________________________________________________________________________________________________\nres4d_branch2a (Conv2D) (None, None, None, 2 262400 activation_31[0][0] \n__________________________________________________________________________________________________\nbn4d_branch2a (BatchNormalizati (None, None, None, 2 1024 res4d_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_32 (Activation) (None, None, None, 2 0 bn4d_branch2a[0][0] \n__________________________________________________________________________________________________\nres4d_branch2b (Conv2D) (None, None, None, 2 590080 activation_32[0][0] \n__________________________________________________________________________________________________\nbn4d_branch2b (BatchNormalizati (None, None, None, 2 1024 res4d_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_33 (Activation) (None, None, None, 2 0 bn4d_branch2b[0][0] \n__________________________________________________________________________________________________\nres4d_branch2c (Conv2D) (None, None, None, 1 263168 activation_33[0][0] \n__________________________________________________________________________________________________\nbn4d_branch2c (BatchNormalizati (None, None, None, 1 4096 res4d_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_11 (Add) (None, None, None, 1 0 bn4d_branch2c[0][0] \n activation_31[0][0] \n__________________________________________________________________________________________________\nactivation_34 (Activation) (None, None, None, 1 0 add_11[0][0] \n__________________________________________________________________________________________________\nres4e_branch2a (Conv2D) (None, None, None, 2 262400 activation_34[0][0] \n__________________________________________________________________________________________________\nbn4e_branch2a (BatchNormalizati (None, None, None, 2 1024 res4e_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_35 (Activation) (None, None, None, 2 0 bn4e_branch2a[0][0] \n__________________________________________________________________________________________________\nres4e_branch2b (Conv2D) (None, None, None, 2 590080 activation_35[0][0] \n__________________________________________________________________________________________________\nbn4e_branch2b (BatchNormalizati (None, None, None, 2 1024 res4e_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_36 (Activation) (None, None, None, 2 0 bn4e_branch2b[0][0] \n__________________________________________________________________________________________________\nres4e_branch2c (Conv2D) (None, None, None, 1 263168 activation_36[0][0] \n__________________________________________________________________________________________________\nbn4e_branch2c (BatchNormalizati (None, None, None, 1 4096 res4e_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_12 (Add) (None, None, None, 1 0 bn4e_branch2c[0][0] \n activation_34[0][0] \n__________________________________________________________________________________________________\nactivation_37 (Activation) (None, None, None, 1 0 add_12[0][0] \n__________________________________________________________________________________________________\nres4f_branch2a (Conv2D) (None, None, None, 2 262400 activation_37[0][0] \n__________________________________________________________________________________________________\nbn4f_branch2a (BatchNormalizati (None, None, None, 2 1024 res4f_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_38 (Activation) (None, None, None, 2 0 bn4f_branch2a[0][0] \n__________________________________________________________________________________________________\nres4f_branch2b (Conv2D) (None, None, None, 2 590080 activation_38[0][0] \n__________________________________________________________________________________________________\nbn4f_branch2b (BatchNormalizati (None, None, None, 2 1024 res4f_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_39 (Activation) (None, None, None, 2 0 bn4f_branch2b[0][0] \n__________________________________________________________________________________________________\nres4f_branch2c (Conv2D) (None, None, None, 1 263168 activation_39[0][0] \n__________________________________________________________________________________________________\nbn4f_branch2c (BatchNormalizati (None, None, None, 1 4096 res4f_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_13 (Add) (None, None, None, 1 0 bn4f_branch2c[0][0] \n activation_37[0][0] \n__________________________________________________________________________________________________\nactivation_40 (Activation) (None, None, None, 1 0 add_13[0][0] \n__________________________________________________________________________________________________\nres5a_branch2a (Conv2D) (None, None, None, 5 524800 activation_40[0][0] \n__________________________________________________________________________________________________\nbn5a_branch2a (BatchNormalizati (None, None, None, 5 2048 res5a_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_41 (Activation) (None, None, None, 5 0 bn5a_branch2a[0][0] \n__________________________________________________________________________________________________\nres5a_branch2b (Conv2D) (None, None, None, 5 2359808 activation_41[0][0] \n__________________________________________________________________________________________________\nbn5a_branch2b (BatchNormalizati (None, None, None, 5 2048 res5a_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_42 (Activation) (None, None, None, 5 0 bn5a_branch2b[0][0] \n__________________________________________________________________________________________________\nres5a_branch2c (Conv2D) (None, None, None, 2 1050624 activation_42[0][0] \n__________________________________________________________________________________________________\nres5a_branch1 (Conv2D) (None, None, None, 2 2099200 activation_40[0][0] \n__________________________________________________________________________________________________\nbn5a_branch2c (BatchNormalizati (None, None, None, 2 8192 res5a_branch2c[0][0] \n__________________________________________________________________________________________________\nbn5a_branch1 (BatchNormalizatio (None, None, None, 2 8192 res5a_branch1[0][0] \n__________________________________________________________________________________________________\nadd_14 (Add) (None, None, None, 2 0 bn5a_branch2c[0][0] \n bn5a_branch1[0][0] \n__________________________________________________________________________________________________\nactivation_43 (Activation) (None, None, None, 2 0 add_14[0][0] \n__________________________________________________________________________________________________\nres5b_branch2a (Conv2D) (None, None, None, 5 1049088 activation_43[0][0] \n__________________________________________________________________________________________________\nbn5b_branch2a (BatchNormalizati (None, None, None, 5 2048 res5b_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_44 (Activation) (None, None, None, 5 0 bn5b_branch2a[0][0] \n__________________________________________________________________________________________________\nres5b_branch2b (Conv2D) (None, None, None, 5 2359808 activation_44[0][0] \n__________________________________________________________________________________________________\nbn5b_branch2b (BatchNormalizati (None, None, None, 5 2048 res5b_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_45 (Activation) (None, None, None, 5 0 bn5b_branch2b[0][0] \n__________________________________________________________________________________________________\nres5b_branch2c (Conv2D) (None, None, None, 2 1050624 activation_45[0][0] \n__________________________________________________________________________________________________\nbn5b_branch2c (BatchNormalizati (None, None, None, 2 8192 res5b_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_15 (Add) (None, None, None, 2 0 bn5b_branch2c[0][0] \n activation_43[0][0] \n__________________________________________________________________________________________________\nactivation_46 (Activation) (None, None, None, 2 0 add_15[0][0] \n__________________________________________________________________________________________________\nres5c_branch2a (Conv2D) (None, None, None, 5 1049088 activation_46[0][0] \n__________________________________________________________________________________________________\nbn5c_branch2a (BatchNormalizati (None, None, None, 5 2048 res5c_branch2a[0][0] \n__________________________________________________________________________________________________\nactivation_47 (Activation) (None, None, None, 5 0 bn5c_branch2a[0][0] \n__________________________________________________________________________________________________\nres5c_branch2b (Conv2D) (None, None, None, 5 2359808 activation_47[0][0] \n__________________________________________________________________________________________________\nbn5c_branch2b (BatchNormalizati (None, None, None, 5 2048 res5c_branch2b[0][0] \n__________________________________________________________________________________________________\nactivation_48 (Activation) (None, None, None, 5 0 bn5c_branch2b[0][0] \n__________________________________________________________________________________________________\nres5c_branch2c (Conv2D) (None, None, None, 2 1050624 activation_48[0][0] \n__________________________________________________________________________________________________\nbn5c_branch2c (BatchNormalizati (None, None, None, 2 8192 res5c_branch2c[0][0] \n__________________________________________________________________________________________________\nadd_16 (Add) (None, None, None, 2 0 bn5c_branch2c[0][0] \n activation_46[0][0] \n__________________________________________________________________________________________________\nactivation_49 (Activation) (None, None, None, 2 0 add_16[0][0] \n__________________________________________________________________________________________________\navg_pool (AveragePooling2D) (None, None, None, 2 0 activation_49[0][0] \n==================================================================================================\nTotal params: 23,587,712\nTrainable params: 23,534,592\nNon-trainable params: 53,120\n__________________________________________________________________________________________________\n"
],
[
"x = base_model.output\nx = GlobalAveragePooling2D()(x)\nx = Dense(1024, activation='relu')(x)\npredictions = Dense(1, activation='sigmoid')(x)",
"_____no_output_____"
],
[
"model = Model(inputs=base_model.input, outputs=predictions)\nfor layer in base_model.layers: layer.trainable = False\nmodel.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"# Train Model",
"_____no_output_____"
]
],
[
[
"%%time\nmodel.fit_generator(train_generator, train_generator.n // batch_size, epochs=3, workers=4,\n validation_data=validation_generator, validation_steps=validation_generator.n // batch_size)",
"Epoch 1/3\n359/359 [==============================] - 254s 707ms/step - loss: 0.1787 - acc: 0.9486 - val_loss: 0.0590 - val_acc: 0.9834\nEpoch 2/3\n359/359 [==============================] - 207s 576ms/step - loss: 0.0854 - acc: 0.9705 - val_loss: 0.0873 - val_acc: 0.9793\nEpoch 3/3\n359/359 [==============================] - 207s 576ms/step - loss: 0.0670 - acc: 0.9766 - val_loss: 0.0652 - val_acc: 0.9859\nCPU times: user 24min 34s, sys: 1min 24s, total: 25min 59s\nWall time: 11min 7s\n"
],
[
"len(model.layers)",
"_____no_output_____"
],
[
"split_at = 140\nfor layer in model.layers[:split_at]: layer.trainable = False\nfor layer in model.layers[split_at:]: layer.trainable = True\nmodel.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) ",
"_____no_output_____"
],
[
"%%time\nmodel.fit_generator(train_generator, train_generator.n // batch_size, epochs=1, workers=3,\n validation_data=validation_generator, validation_steps=validation_generator.n // batch_size)",
"Epoch 1/1\n359/359 [==============================] - 263s 733ms/step - loss: 0.0779 - acc: 0.9739 - val_loss: 0.2162 - val_acc: 0.9718\nCPU times: user 9min 54s, sys: 38.2 s, total: 10min 33s\nWall time: 4min 25s\n"
]
],
[
[
"# Model Evaluation",
"_____no_output_____"
]
],
[
[
"test_data_dir = f'{PATH}valid'",
"_____no_output_____"
],
[
"test_generator = test_datagen.flow_from_directory(test_data_dir, target_size=(sz,sz),\n batch_size=batch_size, class_mode='binary')",
"Found 2000 images belonging to 2 classes.\n"
],
[
"test_generator.n",
"_____no_output_____"
],
[
"sample_x, sample_y = test_generator.next()\n",
"_____no_output_____"
],
[
"sample_x.shape, sample_y.shape",
"_____no_output_____"
],
[
"sample_pred = model.predict(x=sample_x, batch_size=32, verbose=1)",
"64/64 [==============================] - 1s 18ms/step\n"
],
[
"acc = np.array(sample_pred==sample_y)",
"_____no_output_____"
],
[
"sample_pred.shape, sample_y.shape",
"_____no_output_____"
],
[
"sample_pred = sample_pred.astype(int).flatten()",
"_____no_output_____"
],
[
"acc = (sample_pred == sample_y)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nax.plot(sample_pred[:32].astype(int), c='r')\nax.plot(sample_y[:32], c='b')",
"_____no_output_____"
],
[
"acc.mean()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bf6bffff9b4708ad73665619349729ee570d25 | 1,248 | ipynb | Jupyter Notebook | turtle practice with small projects.ipynb | sushilkanathia/turtle-graphics | d06592fb7b16d926553ff7598e2dce8422bdcb68 | [
"BSL-1.0"
]
| null | null | null | turtle practice with small projects.ipynb | sushilkanathia/turtle-graphics | d06592fb7b16d926553ff7598e2dce8422bdcb68 | [
"BSL-1.0"
]
| null | null | null | turtle practice with small projects.ipynb | sushilkanathia/turtle-graphics | d06592fb7b16d926553ff7598e2dce8422bdcb68 | [
"BSL-1.0"
]
| null | null | null | 16.421053 | 34 | 0.471955 | [
[
[
"from turtle import *",
"_____no_output_____"
],
[
"color('red','yellow')",
"_____no_output_____"
],
[
"begin_fill()",
"_____no_output_____"
],
[
"while True:\n forward(200)\n left(170)\n if abs(pos()) < 1:\n break",
"_____no_output_____"
],
[
"end_fill()\ndone()",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bf884cd1de9daf8d2a117bde2f8c6fdb4e4add | 674,660 | ipynb | Jupyter Notebook | top5brand_classification.ipynb | auliakhalqillah/top5brand-classification | c244bdbed280389db9864fae7f40f35a80866053 | [
"MIT"
]
| null | null | null | top5brand_classification.ipynb | auliakhalqillah/top5brand-classification | c244bdbed280389db9864fae7f40f35a80866053 | [
"MIT"
]
| null | null | null | top5brand_classification.ipynb | auliakhalqillah/top5brand-classification | c244bdbed280389db9864fae7f40f35a80866053 | [
"MIT"
]
| null | null | null | 782.668213 | 113,243 | 0.725182 | [
[
[
"# Brand Classification\n\nSource : https://www.dqlab.id/\n\nTyped by : Aulia Khalqillah",
"_____no_output_____"
],
[
"## Import Libraries",
"_____no_output_____"
]
],
[
[
"import datetime\nimport pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"### Load data",
"_____no_output_____"
]
],
[
[
"dataset = pd.read_csv('retail_raw_reduced.csv')\ndataset",
"_____no_output_____"
]
],
[
[
"## Info data",
"_____no_output_____"
]
],
[
[
"dataset.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 5000 entries, 0 to 4999\nData columns (total 9 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 order_id 5000 non-null int64 \n 1 order_date 5000 non-null object\n 2 customer_id 5000 non-null int64 \n 3 city 5000 non-null object\n 4 province 5000 non-null object\n 5 product_id 5000 non-null object\n 6 brand 5000 non-null object\n 7 quantity 5000 non-null int64 \n 8 item_price 5000 non-null int64 \ndtypes: int64(4), object(5)\nmemory usage: 351.7+ KB\n"
]
],
[
[
"## Exploratory Data Analysis",
"_____no_output_____"
],
[
"Generate new columns of order_month and Gross Marchendise Volume (GMV)",
"_____no_output_____"
]
],
[
[
"dataset['order_month'] = dataset['order_date'].apply(lambda x: datetime.datetime.strptime(x, \"%Y-%m-%d\").strftime('%Y-%m'))",
"_____no_output_____"
],
[
"dataset['gmv'] = dataset['item_price']*dataset['quantity']\ndataset",
"_____no_output_____"
]
],
[
[
"Select top 5 brands based on its total of quantity in December 2019",
"_____no_output_____"
]
],
[
[
"top_brands = (dataset[dataset['order_month']=='2019-12'].groupby('brand')['quantity']\n .sum()\n .reset_index()\n .sort_values(by='quantity',ascending=False)\n .reset_index()\n .drop('index',axis=1)\n .head(5))\ntop_brands",
"_____no_output_____"
]
],
[
[
"Generate new dataframe for top 5 brands in December 2019",
"_____no_output_____"
]
],
[
[
"dataset_top5brand_dec = dataset[\n (dataset['order_month']=='2019-12') & (dataset['brand'].isin(top_brands['brand'].to_list()))\n ].reset_index().drop('index',axis=1)\ndataset_top5brand_dec",
"_____no_output_____"
]
],
[
[
"High value",
"_____no_output_____"
]
],
[
[
"max_brand = dataset_top5brand_dec.groupby(['order_date','brand'])['quantity'].sum().unstack().idxmax().index\nmax_order_date = dataset_top5brand_dec.groupby(['order_date','brand'])['quantity'].sum().unstack().idxmax().values\nmax_quantity = dataset_top5brand_dec.groupby(['order_date','brand'])['quantity'].sum().unstack().max().values\nmax_quantity_value = ({\n 'brand' : max_brand,\n 'order_date': max_order_date,\n 'max_quantity': max_quantity\n})\nmax_quantity_datset = pd.DataFrame(max_quantity_value)\nidx_max_qty = max_quantity_datset['max_quantity'].argmax()\nmax_quantity_datset",
"_____no_output_____"
],
[
"max_quantity_datset.iloc[idx_max_qty]",
"_____no_output_____"
]
],
[
[
"A total of quantity of brands in December 2019",
"_____no_output_____"
]
],
[
[
"dataset_top5brand_dec.groupby(['order_date','brand'])['quantity'].sum().unstack()",
"_____no_output_____"
],
[
"dataset_top5brand_dec.groupby(['order_date','brand'])['quantity'].sum().unstack().plot(marker='.', cmap='plasma', figsize=(10,5))\nplt.title('Daily Sold Quantity Dec 2019 Breakdown by Brands',loc='center',pad=30, fontsize=15, color='blue')\nplt.xlabel('Order Date', fontsize = 12)\nplt.ylabel('Quantity',fontsize = 12)\nplt.grid(color='darkgray', linestyle=':', linewidth=0.5)\nplt.ylim(ymin=0)\nplt.legend(loc='best', bbox_to_anchor=(1.2, 1), shadow=True, ncol=1)\nplt.annotate('Highest Quantity', xy=(7, 310), xytext=(8, 300),\n weight='bold', color='red',\n arrowprops=dict(arrowstyle='->',\n connectionstyle=\"arc3\",\n color='red'))\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Plot number of sold products for each brand in December 2019",
"_____no_output_____"
]
],
[
[
"dataset_top5brand_dec.groupby('brand')['product_id'].nunique().sort_values(ascending=False).plot(kind='bar', color='green', figsize=(10,5))\nplt.title('Number of Sold Products per Brand, December 2019',loc='center',pad=30, fontsize=15, color='blue')\nplt.xlabel('Brand', fontsize = 15)\nplt.ylabel('Number of Products',fontsize = 15)\nplt.ylim(ymin=0)\nplt.xticks(rotation=0)\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Generate new data frame of total of quantity for each product",
"_____no_output_____"
]
],
[
[
"dataset_top5brand_dec_per_product = dataset_top5brand_dec.groupby(['brand','product_id'])['quantity'].sum().reset_index()\ndataset_top5brand_dec_per_product",
"_____no_output_____"
]
],
[
[
"Add a columns for quantity group (>=100 or < 100)",
"_____no_output_____"
]
],
[
[
"dataset_top5brand_dec_per_product['quantity_group'] = dataset_top5brand_dec_per_product['quantity'].apply(\n lambda x: '>= 100' if x>=100 else '< 100'\n )\ndataset_top5brand_dec_per_product.sort_values('quantity',ascending=False,inplace=True)\ndataset_top5brand_dec_per_product",
"_____no_output_____"
]
],
[
[
"How much products in each brand?",
"_____no_output_____"
]
],
[
[
"s_sort = dataset_top5brand_dec_per_product.groupby('brand')['product_id'].nunique().sort_values(ascending=False)\ns_sort",
"_____no_output_____"
],
[
"dataset_top5brand_dec_per_product_by_quantity = dataset_top5brand_dec_per_product.groupby(['brand','quantity_group'])['product_id'].nunique().reindex(index=s_sort.index, level='brand').unstack()\ndataset_top5brand_dec_per_product_by_quantity",
"_____no_output_____"
],
[
"dataset_top5brand_dec_per_product_by_quantity.plot(kind='bar', stacked=True, figsize=(10,5))\nplt.title('Number of Sold Products per Brand, December 2019',loc='center',pad=30, fontsize=15, color='blue')\nplt.xlabel('Brand', fontsize = 15)\nplt.ylabel('Number of Products',fontsize = 15)\nplt.ylim(ymin=0)\nplt.xticks(rotation=0)\nplt.show()",
"_____no_output_____"
]
],
[
[
"6 products of Brand P were sold more than 100 pcs, which is the highest sales number compared others products and brands. Otherwise, the Brand C was sold less than 100 pcs.",
"_____no_output_____"
]
],
[
[
"plt.hist(dataset_top5brand_dec.groupby('product_id')['item_price'].median(), bins=20, stacked=True, range=(1,2000000), color='green', edgecolor='black')\nplt.title('Distribution of Price Median per Product\\nTop 5 Brands in Dec 2019', fontsize=15, color='blue')\nplt.xlabel('Price Median (1000000)', fontsize = 12)\nplt.ylabel('Number of Products', fontsize = 12)\nplt.xlim(xmin=0,xmax=2000000)\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Based on median calculation, a lot of selling products has range of price from 250000 - 750000. That means, many products from various brands are purchased less than 1000000.",
"_____no_output_____"
],
[
"Calculate total of quantity, total of GMV, and median of item price for each product.",
"_____no_output_____"
]
],
[
[
"data_per_product_top5brand_dec = dataset_top5brand_dec.groupby('product_id').agg({'quantity': 'sum', 'gmv':'sum', 'item_price':'median'}).reset_index()\ndata_per_product_top5brand_dec",
"_____no_output_____"
],
[
"plt.scatter(data_per_product_top5brand_dec['quantity'],data_per_product_top5brand_dec['gmv'], marker='+', color='red')\nplt.title('Correlation of Quantity and GMV per Product\\nTop 5 Brands in December 2019',fontsize=15, color='blue')\nplt.xlabel('Quantity', fontsize = 12)\nplt.ylabel('GMV (in Millions)',fontsize = 12)\nplt.xlim(xmin=0,xmax=300)\nplt.ylim(ymin=0,ymax=200000000)\nlabels, locations = plt.yticks()\nplt.yticks(labels, (labels/1000000).astype(int))\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"The correlation between quantity number of product was purchased and GMV from top 5 brands in December 2019, a lot of products were sold less than 50 pcs. It indicates the GMV is not high enough for each brand. However, there are some quantities of products were sold more than 50 pcs.",
"_____no_output_____"
]
],
[
[
"plt.scatter(data_per_product_top5brand_dec['item_price'],data_per_product_top5brand_dec['quantity'], marker='o', color='green')\nplt.title('Correlation of Price Median and Quantity\\nTop 5 Brands in December 2019',fontsize=15, color='blue')\nplt.xlabel('Price Median (1000000)', fontsize = 12)\nplt.ylabel('Quantity',fontsize = 12)\nplt.xlim(xmin=0,xmax=2000000)\nplt.ylim(ymin=0,ymax=250)\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"The correlation between median price and its quantity is various. The products were sold less than 50 pcs that have various price in range 250000 to 1750000. Also, there are more than 100 pcs of products were sold less than 1000000 of price. Overall, many products were purchased with high number of quantity have low price.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7bf984b5fe3111638b8c28bf7876ded7a5d196c | 14,103 | ipynb | Jupyter Notebook | notebooks/create-nyc-tlc-parquet-polars.ipynb | ncclementi/mrpowers-benchmarks | 54534af98806a867f6eea9dc9d085ed377d6737e | [
"BSD-3-Clause"
]
| null | null | null | notebooks/create-nyc-tlc-parquet-polars.ipynb | ncclementi/mrpowers-benchmarks | 54534af98806a867f6eea9dc9d085ed377d6737e | [
"BSD-3-Clause"
]
| null | null | null | notebooks/create-nyc-tlc-parquet-polars.ipynb | ncclementi/mrpowers-benchmarks | 54534af98806a867f6eea9dc9d085ed377d6737e | [
"BSD-3-Clause"
]
| null | null | null | 106.037594 | 4,775 | 0.672623 | [
[
[
"import glob\nimport polars as pl",
"_____no_output_____"
],
[
"all_files = glob.glob(\"../data/nyc-tlc/*.csv\")",
"_____no_output_____"
],
[
"all_files",
"_____no_output_____"
],
[
"dtypes = {'vendor_name': pl.Utf8,\n 'Trip_Pickup_DateTime': pl.Utf8,\n 'Trip_Dropoff_DateTime': pl.Utf8,\n 'Passenger_Count': pl.Int64,\n 'Trip_Distance': pl.Float64,\n 'Start_Lon': pl.Float64,\n 'Start_Lat': pl.Float64,\n 'Rate_Code': pl.Utf8,\n 'store_and_forward': pl.Utf8,\n 'End_Lon': pl.Float64,\n 'End_Lat': pl.Float64,\n 'Payment_Type': pl.Utf8,\n 'Fare_Amt': pl.Float64,\n 'surcharge': pl.Float64,\n 'mta_tax': pl.Utf8,\n 'Tip_Amt': pl.Float64,\n 'Tolls_Amt': pl.Float64,\n 'Total_Amt': pl.Float64}",
"_____no_output_____"
],
[
"for file in all_files:\n df = pl.read_csv(file, dtype=dtypes, null_values=\"*\")\n new_filename = file.split(\"/\")[-1].replace(\"csv\", \"parquet\")\n df.to_parquet(f\"../data/nyc-tlc/polars/{new_filename}\")",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bf985edc4f3e61831f5dc30f751ff420c079b0 | 7,713 | ipynb | Jupyter Notebook | 2020/selection/fuels.ipynb | jandolezal/balances | 9cf77bba33e7315c113748a9da414ab5e5dc1f90 | [
"MIT"
]
| 1 | 2021-02-27T15:21:16.000Z | 2021-02-27T15:21:16.000Z | 2020/selection/fuels.ipynb | jandolezal/balances | 9cf77bba33e7315c113748a9da414ab5e5dc1f90 | [
"MIT"
]
| null | null | null | 2020/selection/fuels.ipynb | jandolezal/balances | 9cf77bba33e7315c113748a9da414ab5e5dc1f90 | [
"MIT"
]
| null | null | null | 55.891304 | 3,307 | 0.47971 | [
[
[
"# Bioenergy consumption for each fuel\n\nGross inland consumption from Eurostat energy balances",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport os\nimport datetime",
"_____no_output_____"
],
[
"csv_input_dir = 'data'\ncsv_output_dir = datetime.datetime.today().strftime('%Y-%m-%d')\n\nif not os.path.exists(csv_output_dir):\n os.mkdir(csv_output_dir)\n\ndf = pd.read_csv(os.path.join(os.path.abspath(csv_input_dir), 'eurostat_2002_2018_tj.csv'), decimal=',')",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"for country in ['CZ', 'AT', 'DK', 'NL', 'PL', 'SK']:\n label = country.lower()\n cdf = df.loc[df['country'] == country, ['country', 'year', 'fuel', 'gross_inland_consumption']].pivot_table(values='gross_inland_consumption', index='year', columns='fuel')\n cdf.to_csv(os.path.join(os.path.abspath(csv_output_dir), f'{label}_selected_fuels_consumption_tj.csv'), decimal=',')",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
e7bfb9c82732843ae6f11dc50bf800fbce97c88b | 7,154 | ipynb | Jupyter Notebook | Week12/Examples_python_12.ipynb | Tgordon523/linkedin-learning | e4cd04820fe1eee36c1988d5f1e1b3691a4f5398 | [
"MIT"
]
| 1 | 2021-04-06T06:20:16.000Z | 2021-04-06T06:20:16.000Z | Week12/Examples_python_12.ipynb | Tgordon523/linkedin-learning | e4cd04820fe1eee36c1988d5f1e1b3691a4f5398 | [
"MIT"
]
| null | null | null | Week12/Examples_python_12.ipynb | Tgordon523/linkedin-learning | e4cd04820fe1eee36c1988d5f1e1b3691a4f5398 | [
"MIT"
]
| 1 | 2021-07-06T10:09:23.000Z | 2021-07-06T10:09:23.000Z | 52.992593 | 2,042 | 0.49329 | [
[
[
"### Load in libraries\nimport pandas as pd \nimport numpy as np\nfrom pathlib import Path",
"_____no_output_____"
],
[
"df = pd.read_excel(Path.cwd()/'test.xlsx', engine=\"openpyxl\")",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"### regex pattern to extract the given code and number from unstructured text\npat = r'(?P<Code>[A-Z]{3})(?P<Number>\\d)'\n### extract from the text and separate\ndf_extract = df.line.str.extract(pat)",
"_____no_output_____"
],
[
"df_extract",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bfc3740374f3337602fbb6b3f67f01f38d3337 | 77,617 | ipynb | Jupyter Notebook | notebook/speed_note/nb_speed_note.ipynb | xyise/xyise | e2bc1c2e824da4fc5cd1d81aaef76a1ad147fb01 | [
"Apache-2.0"
]
| null | null | null | notebook/speed_note/nb_speed_note.ipynb | xyise/xyise | e2bc1c2e824da4fc5cd1d81aaef76a1ad147fb01 | [
"Apache-2.0"
]
| null | null | null | notebook/speed_note/nb_speed_note.ipynb | xyise/xyise | e2bc1c2e824da4fc5cd1d81aaef76a1ad147fb01 | [
"Apache-2.0"
]
| null | null | null | 40.362454 | 7,516 | 0.50887 | [
[
[
"import numpy as np\nimport jax.numpy as jnp\nimport jax.random as jrandom\nimport random\nfrom numba import njit, jit\n",
"_____no_output_____"
],
[
"\n\n@njit\ndef n_g(N, M):\n# print(N)\n for n in range(N):\n np.random.standard_normal(M)\n# for m in range(M):\n# np.random.normal()\n# print(n)\n return N * M",
"_____no_output_____"
],
[
"M = 10\nN = 10000000",
"_____no_output_____"
],
[
"%%time\nn_g(N,M)",
"CPU times: user 4.73 s, sys: 12.1 ms, total: 4.74 s\nWall time: 4.72 s\n"
],
[
"def n_n(N, M, K):\n# print(N)\n for n in range(int(N/K)):\n np.random.standard_normal(M*K)\n# for m in range(M):\n# np.random.normal()\n# print(n)\n return N * M",
"_____no_output_____"
],
[
"%%time\nn_n(N,M,10)",
"CPU times: user 4.41 s, sys: 0 ns, total: 4.41 s\nWall time: 4.42 s\n"
],
[
"from joblib import Parallel, delayed",
"_____no_output_____"
],
[
"%%time\nres = Parallel(n_jobs=4)(delayed(n_g)(N/4,M) for i in range(4))\nnp.sum(res)",
"CPU times: user 21.9 ms, sys: 23.9 ms, total: 45.8 ms\nWall time: 7.51 s\n"
],
[
"%%time\nres = Parallel(n_jobs=4)(delayed(n_n)(N/4,M,10) for i in range(4))\nnp.sum(res)",
"CPU times: user 10.6 ms, sys: 0 ns, total: 10.6 ms\nWall time: 45.3 s\n"
],
[
"(1e6 * 5000) * 8 / 1000 / 1000 / 1000",
"_____no_output_____"
],
[
"def pi(npoints): \n n_in_circle = 0 \n for i in range(npoints):\n x = random.random()\n y = random.random()\n if (x**2+y**2 < 1):\n n_in_circle += 1\n return 4*n_in_circle / npoints\n\n@jit(nopython=True, parallel=True)\ndef nb_pi(npoints): \n rng = np.random\n n_in_circle = 0 \n for i in range(npoints):\n x = rng.random()\n y = rng.random() \n if (x**2+y**2 < 1):\n n_in_circle += 1\n return 4*n_in_circle / npoints\n\ndef np_pi(npoints): \n rng = np.random\n x = rng.random(npoints)\n y = rng.random(npoints)\n n_in_circle = np.sum(x**2 + y**2 < 1)\n return 4*n_in_circle / npoints",
"_____no_output_____"
],
[
"%%time\npi(1000000)",
"CPU times: user 336 ms, sys: 0 ns, total: 336 ms\nWall time: 336 ms\n"
],
[
"%timeit nb_pi(int(1e6))",
"/home/youngsuklee/miniconda3/envs/anylox/lib/python3.7/site-packages/numba/core/typed_passes.py:316: NumbaPerformanceWarning: \nThe keyword argument 'parallel=True' was specified but no transformation for parallel execution was possible.\n\nTo find out why, try turning on parallel diagnostics, see https://numba.pydata.org/numba-doc/latest/user/parallel.html#diagnostics for help.\n\nFile \"<ipython-input-19-893bb5deb967>\", line 11:\n@jit(nopython=True, parallel=True)\ndef nb_pi(npoints): \n^\n\n state.func_ir.loc))\n"
],
[
"%timeit np_pi(int(1e6))",
"20.6 ms ± 137 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)\n"
],
[
"import numpy as np\nimport numba\nimport time as time\n\[email protected]([\"float64(float64,float64)\"],\n nopython=True,target='parallel')\ndef add2_par(x, y):\n return x + 2 * y\nn = np.array( int(4e8))# number of data points\n\nX = np.ones(n, dtype=np.float)\nY = np.ones(n, dtype=np.float)\nt0 = time.time()\nadd2_par(X, Y, out=X)\nt1 = time.time()\nrun_time = t1 - t0",
"_____no_output_____"
],
[
"from numpy.random import PCG64, Philox\nfrom numpy.random import MT19937, SFC64\n\n\nmy_prng = PCG64\n\nrng = my_prng(12345)\narng = []\nfor i in range(10000):\n arng.append(rng.jumped(100*i))",
"_____no_output_____"
],
[
"for i in range(int(1e6)):\n rng.jumped()\n #rng.random_raw()",
"_____no_output_____"
],
[
"rng = np.random.PCG64(12345)\n\nrandom_raw = rng.cffi.next_double\n@njit\ndef nb_rdn(rng, npoints): \n for i in range(npoints):\n x = random_raw(())\n return x",
"_____no_output_____"
],
[
"np.__version__",
"_____no_output_____"
],
[
"normal_d = bit_gen.cffi",
"_____no_output_____"
],
[
"normal_d",
"_____no_output_____"
],
[
"rg.random()",
"_____no_output_____"
],
[
"import numpy as np\nimport numba as nb\n\nfrom numpy.random import PCG64\nfrom timeit import timeit\n\nbit_gen = PCG64(0)\nnext_d = bit_gen.cffi.next_double\nstate_addr = bit_gen.cffi.state_address\nprint(state_addr)\n\ndef normals(n, state):\n out = np.empty(n)\n for i in range((n + 1) // 2):\n x1 = 2.0 * next_d(state) - 1.0\n x2 = 2.0 * next_d(state) - 1.0\n r2 = x1 * x1 + x2 * x2\n while r2 >= 1.0 or r2 == 0.0:\n x1 = 2.0 * next_d(state) - 1.0\n x2 = 2.0 * next_d(state) - 1.0\n r2 = x1 * x1 + x2 * x2\n f = np.sqrt(-2.0 * np.log(r2) / r2)\n out[2 * i] = f * x1\n if 2 * i + 1 < n:\n out[2 * i + 1] = f * x2\n return out\n\n# Compile using Numba\nnormalsj = nb.jit(normals, nopython=True)\n# Must use state address not state with numba\nn = 1000\n\ndef numbacall():\n return normalsj(n, state_addr)\n\nbit_gen = PCG64(0)\nnext_d = bit_gen.cffi.next_double\nstate_addr = bit_gen.cffi.state_address\nprint(state_addr)\nrg = np.random.Generator(bit_gen)\n\ndef numpycall():\n return rg.normal(size=n)\n\n# Check that the functions work\nr1 = numbacall()\nr2 = numpycall()\nassert r1.shape == (n,)\nassert r1.shape == r2.shape\n\nt1 = timeit(numbacall, number=1000)\nprint('{:.2f} secs for {} PCG64 (Numba/PCG64) gaussian randoms'.format(t1, n))\nt2 = timeit(numpycall, number=1000)\nprint('{:.2f} secs for {} PCG64 (NumPy/PCG64) gaussian randoms'.format(t2, n))\n",
"139810588200888\n139810588198584\n0.03 secs for 1000 PCG64 (Numba/PCG64) gaussian randoms\n0.02 secs for 1000 PCG64 (NumPy/PCG64) gaussian randoms\n"
],
[
"r1 - r2",
"_____no_output_____"
],
[
"\"\"\"\nUse cffi to access any of the underlying C functions from distributions.h\n\"\"\"\nimport os\nimport numpy as np\nimport cffi\nfrom parse import parse_distributions_h\nffi = cffi.FFI()\n\ninc_dir = os.path.join(np.get_include(), 'numpy')\n\n# Basic numpy types\nffi.cdef('''\n typedef intptr_t npy_intp;\n typedef unsigned char npy_bool;\n\n''')\n\nparse_distributions_h(ffi, inc_dir)\n",
"_____no_output_____"
],
[
"# Compare the distributions.h random_standard_normal_fill to\n# Generator.standard_random\nbit_gen = np.random.PCG64()\nrng = np.random.Generator(bit_gen)\nstate = bit_gen.state\n\ninterface = rng.bit_generator.cffi\nn = 100\nvals_cffi = ffi.new('double[%d]' % n)\nlib.random_standard_normal_fill(interface.bit_generator, n, vals_cffi)\n\n# reset the state\nbit_gen.state = state\n\nvals = rng.standard_normal(n)\n\nfor i in range(n):\n assert vals[i] == vals_cffi[i]",
"_____no_output_____"
],
[
"rng.advance(10)\nx1 = rng.random_raw(10)\nrng.advance(10)\nx2 = rng.random_raw(10)",
"_____no_output_____"
],
[
"import os\nos.chdir(r'/home/youngsuklee/miniconda3/envs/anylox/lib/python3.7/site-packages/numpy/random/_examples/cffi')",
"_____no_output_____"
],
[
"x2",
"_____no_output_____"
],
[
"njumps = int(1e7)\nN = 2**128",
"_____no_output_____"
],
[
"x = np.mod(np.arange(0, njumps) * (gr - 1) * N, N)\nx = np.sort(x)",
"_____no_output_____"
],
[
"np.diff(x).min()",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nplt.figure()\nplt.plot(x, x, '.')\nplt.show()",
"_____no_output_____"
],
[
"x",
"_____no_output_____"
],
[
"rng.state",
"_____no_output_____"
],
[
"from numpy.random import SeedSequence, default_rng\n\nss = SeedSequence(12345)\n\n# Spawn off 10 child SeedSequences to pass to child processes.\nchild_seeds = ss.spawn(10)\nstreams = [default_rng(s) for s in child_seeds]",
"_____no_output_____"
],
[
"child_seeds",
"_____no_output_____"
],
[
"file = r'/mnt/c/Users/youngsuk/Downloads/iShares-Listed-Private-Equity-UCITS-ETF-USD-Dist_fund.xls'",
"_____no_output_____"
],
[
"f = open(file, 'r')\nf.write()",
"_____no_output_____"
],
[
"subprocess.run(['ls', '-l'])",
"_____no_output_____"
],
[
"subprocess.run(['python', '--version'])",
"_____no_output_____"
],
[
"subprocess.run(['python', r'/home/youngsuk/repos/fortyfive/py_ufo/drops/test1.py'], capture_output=True)",
"_____no_output_____"
],
[
"os.getcwd()",
"_____no_output_____"
],
[
"os.getlogin()",
"_____no_output_____"
],
[
"os.getpid()",
"_____no_output_____"
],
[
"import pathlib",
"_____no_output_____"
],
[
"pathlib.Path.home()",
"_____no_output_____"
],
[
"import pandas as pd",
"_____no_output_____"
],
[
"table=pd.read_html('https://en.wikipedia.org/wiki/COVID-19_pandemic_by_country_and_territory')",
"_____no_output_____"
],
[
"df = table[3]\ndf",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"table[1]",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bfe11a4ef43c851941701112a0222977598a68 | 869,201 | ipynb | Jupyter Notebook | VAE_TimeSeries/VAE_TimeSeries.ipynb | MugiPham/MEDIUM_NoteBook | 799b146469c99d8a94ab8684beb78271eec73cfb | [
"MIT"
]
| 1 | 2022-03-02T14:31:08.000Z | 2022-03-02T14:31:08.000Z | VAE_TimeSeries/VAE_TimeSeries.ipynb | MugiPham/MEDIUM_NoteBook | 799b146469c99d8a94ab8684beb78271eec73cfb | [
"MIT"
]
| null | null | null | VAE_TimeSeries/VAE_TimeSeries.ipynb | MugiPham/MEDIUM_NoteBook | 799b146469c99d8a94ab8684beb78271eec73cfb | [
"MIT"
]
| null | null | null | 732.26706 | 172,216 | 0.946672 | [
[
[
"import os\nimport random\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\nfrom sklearn.metrics import mean_squared_error as mse\n\nimport tensorflow as tf\nfrom tensorflow.keras.layers import *\nfrom tensorflow.keras.models import *\nfrom tensorflow.keras.optimizers import *\nfrom tensorflow.keras import backend as K\nfrom tensorflow.keras.callbacks import EarlyStopping",
"_____no_output_____"
],
[
"### READ DATA ###\n\ndf = pd.read_csv('Metro_Interstate_Traffic_Volume.csv.gz')\ndf['date_time'] = pd.to_datetime(df['date_time'])\ndf.drop_duplicates('date_time', inplace=True)\ndf.set_index('date_time', inplace=True)\n\nprint(df.shape)\ndf.head()",
"(40575, 8)\n"
],
[
"### INSERT MISSING DATES ###\n\ndf = df.reindex(pd.date_range(df.head(1).index[0], df.tail(1).index[0], freq='H'))\n\ndf.shape",
"_____no_output_____"
],
[
"### PLOT TRAFFIC SAMPLE ###\n\ndf.traffic_volume.tail(2000).plot(figsize=(18,5))\nplt.ylabel('traffic_volume')",
"_____no_output_____"
],
[
"### PLOT MISSING VALUES OVER TIME ###\n\nplt.figure(figsize=(18,5))\nsns.heatmap(df[['traffic_volume']].isna().T, cbar=False, cmap='plasma', \n xticklabels=False, yticklabels=['traffic NaNs'])\nplt.xticks(range(0,len(df), 24*180), list(df.index.year[::24*180]))\nnp.set_printoptions(False)",
"_____no_output_____"
],
[
"### FILL MISSING VALUES ###\n\ndf = df[df.index.year.isin([2016,2017,2018])].copy()\n\ndf = pd.concat([df.select_dtypes(include=['object']).fillna(method='backfill'),\n df.select_dtypes(include=['float']).interpolate()], axis=1)\n\ndf.shape",
"_____no_output_____"
],
[
"### PLOT TRAFFIC DISTRIBUTION IN EACH MONTH ###\n\nplt.figure(figsize=(9,5))\nsns.boxplot(x=df.index.month, y=df.traffic_volume, palette='plasma')\n\nplt.ylabel('traffic_volume'); plt.xlabel('month')",
"_____no_output_____"
],
[
"### PLOT TRAFFIC DISTRIBUTION IN EACH WEEKDAY ###\n\nplt.figure(figsize=(9,5))\nsns.boxplot(x=df.index.weekday, y=df.traffic_volume, palette='plasma')\n\nplt.ylabel('traffic_volume'); plt.xlabel('weekday')",
"_____no_output_____"
],
[
"### PLOT TRAFFIC DISTRIBUTION IN EACH HOUR ###\n\nplt.figure(figsize=(9,5))\nsns.boxplot(x=df.index.hour, y=df.traffic_volume, palette='plasma')\n\nplt.ylabel('traffic_volume'); plt.xlabel('hour')",
"_____no_output_____"
],
[
"### NUMERICAL ENCODE CATEGORICAL COLUMNS ###\n\nmap_col = dict()\n\nX = df.select_dtypes(include=['object']).copy()\nfor i,cat in enumerate(X):\n X[cat] = df[cat].factorize()[0]\n map_col[cat] = i\n\nX['month'] = df.index.month; i += 1; map_col['month'] = i\nX['weekday'] = df.index.weekday; i += 1; map_col['weekday'] = i\nX['hour'] = df.index.hour; i += 1; map_col['hour'] = i\nX.shape",
"_____no_output_____"
],
[
"### UTILITY FUNCTION FOR 3D SEQUENCE GENERATION ###\n\ndef gen_seq(id_df, seq_length, seq_cols):\n\n data_matrix = id_df[seq_cols]\n num_elements = data_matrix.shape[0]\n\n for start, stop in zip(range(0, num_elements-seq_length, 1), range(seq_length, num_elements, 1)):\n \n yield data_matrix[stop-sequence_length:stop].values.reshape((-1,len(seq_cols)))",
"_____no_output_____"
],
[
"### GENERATE 3D SEQUENCES ###\n\nsequence_length = 24*7\n\nsequence_input = []\nsequence_target = []\n\nfor seq in gen_seq(X, sequence_length, X.columns):\n sequence_input.append(seq)\n \nfor seq in gen_seq(df, sequence_length, ['traffic_volume']):\n sequence_target.append(seq)\n \nsequence_input = np.asarray(sequence_input)\nsequence_target = np.asarray(sequence_target)\n\nsequence_input.shape, sequence_target.shape",
"_____no_output_____"
],
[
"### UTILITY FUNCTION TO INSERT RANDOM MISSING INTERVALS ###\n\ndef drop_fill_pieces(sequence_input, sequence_target, missing_len, missing_val=np.nan, size=0.2):\n \n sequence_input = np.copy(sequence_input)\n sequence_target = np.copy(sequence_target)\n \n _id_seq = np.random.choice(range(len(sequence_target)), int(len(sequence_target)*size), replace=False)\n _id_time = np.random.randint(0,sequence_length-missing_len, int(len(sequence_target)*size))\n \n for i,t in zip(_id_seq, _id_time):\n sequence_input[i, t:t+missing_len, \n [map_col['holiday'], \n map_col['weather_main'],\n map_col['weather_description']]] = -1\n sequence_target[i, t:t+missing_len, :] = missing_val\n \n sequence_input[:,:, \n [map_col['holiday'], \n map_col['weather_main'],\n map_col['weather_description']]] += 1\n \n return sequence_input, sequence_target",
"_____no_output_____"
],
[
"### INSERT MISSING INTERVALS AT RANDOM ###\n\nnp.random.seed(33)\n\nmissing_len = 24\nsequence_input, sequence_target_drop = drop_fill_pieces(sequence_input, sequence_target,\n missing_len=missing_len, size=0.6)\n\nsequence_input.shape, sequence_target_drop.shape",
"_____no_output_____"
],
[
"### TRAIN TEST SPLIT ###\n\ntrain_size = 0.8\n\nsequence_input_train = sequence_input[:int(len(sequence_input)*train_size)]\nsequence_input_test = sequence_input[int(len(sequence_input)*train_size):]\nprint(sequence_input_train.shape, sequence_input_test.shape)\n\nsequence_target_train = sequence_target[:int(len(sequence_target)*train_size)]\nsequence_target_test = sequence_target[int(len(sequence_target)*train_size):]\nprint(sequence_target_train.shape, sequence_target_test.shape)\n\nsequence_target_drop_train = sequence_target_drop[:int(len(sequence_target_drop)*train_size)]\nsequence_target_drop_test = sequence_target_drop[int(len(sequence_target_drop)*train_size):]\nprint(sequence_target_drop_train.shape, sequence_target_drop_test.shape)",
"(19142, 168, 6) (4786, 168, 6)\n(19142, 168, 1) (4786, 168, 1)\n(19142, 168, 1) (4786, 168, 1)\n"
],
[
"### UTILITY CLASS FOR SEQUENCES SCALING ###\n\nclass Scaler1D:\n \n def fit(self, X):\n self.mean = np.nanmean(np.asarray(X).ravel())\n self.std = np.nanstd(np.asarray(X).ravel())\n return self\n \n def transform(self, X):\n return (X - self.mean)/self.std\n \n def inverse_transform(self, X):\n return (X*self.std) + self.mean",
"_____no_output_____"
],
[
"### SCALE SEQUENCES AND MASK NANs ###\n\nscaler_target = Scaler1D().fit(sequence_target_train)\n\nsequence_target_train = scaler_target.transform(sequence_target_train)\nsequence_target_test = scaler_target.transform(sequence_target_test)\n\nsequence_target_drop_train = scaler_target.transform(sequence_target_drop_train)\nsequence_target_drop_test = scaler_target.transform(sequence_target_drop_test)\n\nmask_value = -999.\nsequence_target_drop_train[np.isnan(sequence_target_drop_train)] = mask_value\nsequence_target_drop_test[np.isnan(sequence_target_drop_test)] = mask_value",
"_____no_output_____"
],
[
"### UTILITY FUNCTIONS FOR VAE CREATION ###\n\nlatent_dim = 2\n\ndef set_seed(seed):\n \n tf.random.set_seed(seed)\n os.environ['PYTHONHASHSEED'] = str(seed)\n np.random.seed(seed)\n random.seed(seed)\n\ndef sampling(args):\n \n z_mean, z_log_sigma = args\n batch_size = tf.shape(z_mean)[0]\n epsilon = K.random_normal(shape=(batch_size, latent_dim), mean=0., stddev=1.)\n \n return z_mean + K.exp(0.5 * z_log_sigma) * epsilon\n\ndef vae_loss(inp, original, out, z_log_sigma, z_mean):\n \n reconstruction = K.mean(K.square(original - out)) * sequence_length\n kl = -0.5 * K.mean(1 + z_log_sigma - K.square(z_mean) - K.exp(z_log_sigma))\n\n return reconstruction + kl\n\ndef get_model():\n \n set_seed(33)\n \n ### encoder ###\n \n inp = Input(shape=(sequence_length, 1))\n inp_original = Input(shape=(sequence_length, 1))\n \n cat_inp = []\n cat_emb = []\n for cat,i in map_col.items():\n inp_c = Input(shape=(sequence_length,))\n if cat in ['holiday', 'weather_main', 'weather_description']:\n emb = Embedding(X[cat].max()+2, 6)(inp_c)\n else:\n emb = Embedding(X[cat].max()+1, 6)(inp_c)\n cat_inp.append(inp_c)\n cat_emb.append(emb)\n \n concat = Concatenate()(cat_emb + [inp])\n enc = LSTM(64)(concat)\n \n z = Dense(32, activation=\"relu\")(enc)\n \n z_mean = Dense(latent_dim)(z)\n z_log_sigma = Dense(latent_dim)(z)\n \n encoder = Model(cat_inp + [inp], [z_mean, z_log_sigma])\n \n ### decoder ###\n \n inp_z = Input(shape=(latent_dim,))\n\n dec = RepeatVector(sequence_length)(inp_z)\n dec = Concatenate()([dec] + cat_emb)\n dec = LSTM(64, return_sequences=True)(dec)\n \n out = TimeDistributed(Dense(1))(dec)\n \n decoder = Model([inp_z] + cat_inp, out) \n \n ### encoder + decoder ###\n \n z_mean, z_log_sigma = encoder(cat_inp + [inp])\n z = Lambda(sampling)([z_mean, z_log_sigma])\n pred = decoder([z] + cat_inp)\n \n vae = Model(cat_inp + [inp, inp_original], pred)\n vae.add_loss(vae_loss(inp, inp_original, pred, z_log_sigma, z_mean))\n vae.compile(loss=None, optimizer=Adam(lr=1e-3))\n \n return vae, encoder, decoder",
"_____no_output_____"
],
[
"es = EarlyStopping(patience=10, verbose=1, min_delta=0.001, monitor='val_loss', mode='auto', restore_best_weights=True)\nvae, enc, dec = get_model()\nvae.fit([sequence_input_train[:,:,i] for cat,i in map_col.items()] + [sequence_target_drop_train, sequence_target_train], \n batch_size=128, epochs=100, validation_split=0.2, shuffle=False, callbacks=[es])",
"Epoch 1/100\n120/120 [==============================] - 36s 302ms/step - loss: 80.3598 - val_loss: 37.5229\nEpoch 2/100\n120/120 [==============================] - 36s 300ms/step - loss: 22.6669 - val_loss: 23.1471\nEpoch 3/100\n120/120 [==============================] - 40s 332ms/step - loss: 15.4416 - val_loss: 23.8763\nEpoch 4/100\n120/120 [==============================] - 32s 269ms/step - loss: 13.6259 - val_loss: 24.1615\nEpoch 5/100\n120/120 [==============================] - 32s 265ms/step - loss: 13.2095 - val_loss: 23.7290\nEpoch 6/100\n120/120 [==============================] - 32s 265ms/step - loss: 12.1795 - val_loss: 27.4268\nEpoch 7/100\n120/120 [==============================] - 32s 265ms/step - loss: 11.7454 - val_loss: 19.7928\nEpoch 8/100\n120/120 [==============================] - 32s 265ms/step - loss: 10.6105 - val_loss: 19.4873\nEpoch 9/100\n120/120 [==============================] - 32s 264ms/step - loss: 10.2637 - val_loss: 18.9843\nEpoch 10/100\n120/120 [==============================] - 32s 266ms/step - loss: 10.0790 - val_loss: 18.6886\nEpoch 11/100\n120/120 [==============================] - 32s 267ms/step - loss: 9.9261 - val_loss: 18.1589\nEpoch 12/100\n120/120 [==============================] - 37s 312ms/step - loss: 9.7807 - val_loss: 17.6899\nEpoch 13/100\n120/120 [==============================] - 37s 308ms/step - loss: 9.6459 - val_loss: 16.9676\nEpoch 14/100\n120/120 [==============================] - 33s 277ms/step - loss: 9.4534 - val_loss: 16.7162\nEpoch 15/100\n120/120 [==============================] - 32s 269ms/step - loss: 9.3133 - val_loss: 16.0207\nEpoch 16/100\n120/120 [==============================] - 33s 276ms/step - loss: 9.1466 - val_loss: 15.0431\nEpoch 17/100\n120/120 [==============================] - 34s 285ms/step - loss: 8.9959 - val_loss: 16.3769\nEpoch 18/100\n120/120 [==============================] - 33s 279ms/step - loss: 8.8482 - val_loss: 15.2331\nEpoch 19/100\n120/120 [==============================] - 33s 274ms/step - loss: 8.1891 - val_loss: 15.0140\nEpoch 20/100\n120/120 [==============================] - 33s 275ms/step - loss: 8.0029 - val_loss: 15.2483\nEpoch 21/100\n120/120 [==============================] - 33s 274ms/step - loss: 7.7745 - val_loss: 14.3563\nEpoch 22/100\n120/120 [==============================] - 33s 279ms/step - loss: 7.4886 - val_loss: 15.4906\nEpoch 23/100\n120/120 [==============================] - 35s 289ms/step - loss: 7.4733 - val_loss: 13.3267\nEpoch 24/100\n120/120 [==============================] - 33s 274ms/step - loss: 7.1292 - val_loss: 14.3210\nEpoch 25/100\n120/120 [==============================] - 33s 275ms/step - loss: 6.9960 - val_loss: 14.0886\nEpoch 26/100\n120/120 [==============================] - 33s 276ms/step - loss: 6.9587 - val_loss: 13.9111\nEpoch 27/100\n120/120 [==============================] - 35s 289ms/step - loss: 7.0121 - val_loss: 14.6882\nEpoch 28/100\n120/120 [==============================] - 35s 294ms/step - loss: 7.0252 - val_loss: 15.6209\nEpoch 29/100\n120/120 [==============================] - 35s 290ms/step - loss: 6.9910 - val_loss: 16.4013\nEpoch 30/100\n120/120 [==============================] - 36s 297ms/step - loss: 7.1385 - val_loss: 14.3325\nEpoch 31/100\n120/120 [==============================] - 33s 275ms/step - loss: 6.7943 - val_loss: 13.5026\nEpoch 32/100\n120/120 [==============================] - 33s 275ms/step - loss: 6.6017 - val_loss: 13.2601\nEpoch 33/100\n120/120 [==============================] - 33s 278ms/step - loss: 6.4953 - val_loss: 12.9813\nEpoch 34/100\n120/120 [==============================] - 33s 277ms/step - loss: 6.5000 - val_loss: 13.9200\nEpoch 35/100\n120/120 [==============================] - 34s 282ms/step - loss: 6.5001 - val_loss: 13.6677\nEpoch 36/100\n120/120 [==============================] - 34s 280ms/step - loss: 6.4192 - val_loss: 12.8832\nEpoch 37/100\n120/120 [==============================] - 34s 286ms/step - loss: 6.3106 - val_loss: 12.5372\nEpoch 38/100\n120/120 [==============================] - 32s 268ms/step - loss: 6.1377 - val_loss: 12.9336\nEpoch 39/100\n120/120 [==============================] - 33s 272ms/step - loss: 6.1189 - val_loss: 13.6871\nEpoch 40/100\n120/120 [==============================] - 33s 278ms/step - loss: 6.1300 - val_loss: 14.3407\nEpoch 41/100\n120/120 [==============================] - 33s 273ms/step - loss: 6.0424 - val_loss: 13.8931\nEpoch 42/100\n120/120 [==============================] - 33s 275ms/step - loss: 6.1732 - val_loss: 14.3399\nEpoch 43/100\n120/120 [==============================] - 33s 274ms/step - loss: 5.9348 - val_loss: 14.6929\nEpoch 44/100\n120/120 [==============================] - 33s 277ms/step - loss: 6.0805 - val_loss: 15.0564\nEpoch 45/100\n120/120 [==============================] - 34s 280ms/step - loss: 5.9597 - val_loss: 13.1424\nEpoch 46/100\n120/120 [==============================] - 33s 278ms/step - loss: 5.9404 - val_loss: 15.0520\nEpoch 47/100\n120/120 [==============================] - ETA: 0s - loss: 5.6088Restoring model weights from the end of the best epoch.\n120/120 [==============================] - 34s 282ms/step - loss: 5.6088 - val_loss: 16.8258\nEpoch 00047: early stopping\n"
],
[
"### COMPUTE RECONSTRUCTION ###\n\nvae = Model(vae.input[:-1], vae.output)\n\nreconstruc_train = scaler_target.inverse_transform(\n vae.predict([sequence_input_train[:,:,i] for cat,i in map_col.items()] + [sequence_target_drop_train]))\nreconstruc_test = scaler_target.inverse_transform(\n vae.predict([sequence_input_test[:,:,i] for cat,i in map_col.items()] + [sequence_target_drop_test]))\n\nreconstruc_train.shape, reconstruc_test.shape",
"_____no_output_____"
],
[
"### PLOT REAL vs RECONSTRUCTION ###\n\nid_seq = 100\n\nseq = np.copy(sequence_target_drop_test[id_seq])\nseq[seq == mask_value] = np.nan\nseq = scaler_target.inverse_transform(seq)\n\nplt.figure(figsize=(9,5))\nplt.plot(reconstruc_test[id_seq], label='reconstructed', c='red')\nplt.plot(seq, c='blue', label='original', alpha=0.6)\nplt.legend()",
"_____no_output_____"
],
[
"### PLOT REAL vs RECONSTRUCTION ###\n\nid_seq = 800\n\nseq = np.copy(sequence_target_drop_test[id_seq])\nseq[seq == mask_value] = np.nan\nseq = scaler_target.inverse_transform(seq)\n\nplt.figure(figsize=(9,5))\nplt.plot(reconstruc_test[id_seq], label='reconstructed', c='red')\nplt.plot(seq, c='blue', label='original', alpha=0.6)\nplt.legend()",
"_____no_output_____"
],
[
"### COMPUTE PERFORMANCES ON TRAIN ###\n\nmask = (sequence_target_drop_train == mask_value)\n\nprint('reconstruction error on entire sequences:',\n mse(np.squeeze(reconstruc_train, -1), np.squeeze(sequence_target_train, -1), squared=False))\nprint('reconstruction error on missing sequences:',\n mse(reconstruc_train[mask].reshape(-1,missing_len), sequence_target_train[mask].reshape(-1,missing_len), squared=False))",
"reconstruction error on entire sequences: 4045.475900775017\nreconstruction error on missing sequences: 4049.877372703149\n"
],
[
"### COMPUTE PERFORMANCES ON TEST ###\n\nmask = (sequence_target_drop_test == mask_value)\n\nprint('reconstruction error on entire sequences:',\n mse(np.squeeze(reconstruc_test, -1), np.squeeze(sequence_target_test, -1), squared=False))\nprint('reconstruction error on missing sequences:',\n mse(reconstruc_test[mask].reshape(-1,missing_len), sequence_target_test[mask].reshape(-1,missing_len), squared=False))",
"reconstruction error on entire sequences: 4064.68189234263\nreconstruction error on missing sequences: 4069.3574954226733\n"
],
[
"### GET LATENT REPRESENTATION ON TRAIN DATA ###\n\nenc_pred, _ = enc.predict([sequence_input_train[:,:,i] for cat,i in map_col.items()] + [sequence_target_drop_train])\nenc_pred.shape",
"_____no_output_____"
],
[
"### PLOT LATENT REPRESENTATION ###\n\nfor cat,i in map_col.items():\n plt.scatter(enc_pred[:,0], enc_pred[:,1], c=sequence_input_train[:,sequence_length//2,i], cmap='plasma')\n plt.title(cat); plt.show()",
"_____no_output_____"
],
[
"### GENERATE RANDOM PERMUTATION ###\n\nnp.random.seed(33)\n\nid_seq = 3333\n\n_X = np.random.normal(enc_pred[id_seq,0], 3, 10)\n_Y = np.random.normal(enc_pred[id_seq,1], 3, 10)\n_cat_input = [sequence_input_train[[id_seq],:,i] for cat,i in map_col.items()]",
"_____no_output_____"
],
[
"### PLOT RANDOM PERMUTATION ###\n\nplt.figure(figsize=(9,5))\n \nfor x in _X:\n for y in _Y:\n dec_pred = dec.predict([np.asarray([[x,y]])] + _cat_input)\n plt.plot(scaler_target.inverse_transform(dec_pred[0]), c='orange', alpha=0.6)\nplt.plot(scaler_target.inverse_transform(sequence_target_train[id_seq]), c='blue')",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7bfe4535341b5f20e900de0558baf494b28d55e | 2,850 | ipynb | Jupyter Notebook | 6_combine_trajectory_data_for_modeling.ipynb | riffelllab/Mosquito-larval-analyses-2 | 8aefa6bf6bc32c5936ce00eb1b7c8ff12ccf071c | [
"MIT"
]
| 1 | 2019-06-30T08:44:06.000Z | 2019-06-30T08:44:06.000Z | 6_combine_trajectory_data_for_modeling.ipynb | eleanorlutz/aedes-aegypti-2019 | 8aefa6bf6bc32c5936ce00eb1b7c8ff12ccf071c | [
"MIT"
]
| null | null | null | 6_combine_trajectory_data_for_modeling.ipynb | eleanorlutz/aedes-aegypti-2019 | 8aefa6bf6bc32c5936ce00eb1b7c8ff12ccf071c | [
"MIT"
]
| null | null | null | 28.787879 | 194 | 0.509123 | [
[
[
"### Combine trajectory data\n#### List of tasks accomplished in this Jupyter Notebook:\n- Output 4 dataframe combining all animal trajectories: Fed animals acclimation phase, Fed animals experiment phase, Starved animals acclimation phase, and Starved animals experiment phase",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport eleanor_constants as EL",
"_____no_output_____"
],
[
"df = pd.read_csv(\"./data/experiment_IDs/cleaned_static_data.csv\")\n\nfor val in [\"acclimate\", \"experiment\"]:\n for food, tag in EL.fed.items():\n df_food = df[df['starved'] == tag]\n master_df = pd.DataFrame()\n\n for index, row in df_food.iterrows():\n animal = row[\"animal_ID\"]\n readname = \"./data/trajectories/video_calculations/\"+animal+\"-\"+val+\".csv\"\n temp = pd.read_csv(readname)\n temp[\"animal_ID\"] = animal\n temp[\"treatment_odor\"] = row[\"treatment_odor\"]\n master_df = pd.concat([master_df, temp], sort=False)\n\n master_df.drop([\"interpolated\", \"manual_tracker_fix\", \"objid\", \"pixel_height\", \"pixel_width\",\n \"measurement_x\", \"measurement_y\", \"position_x\", \"position_y\", \"bin_ID\", \n \"turn\", \"larvae_length_mm\", \n \"pos_x_mm\", \"pos_y_mm\"],\n axis=1, inplace=True)\n master_df.to_csv(\"./data/trajectories/summary/modeling_\"+\\\n food+\"_\"+val+\"_all_animals.csv\", index=None)\n\nprint(\"--- All files finished ---\")",
"--- All files finished ---\n"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
]
]
|
e7c004552d182fab2c26317e774cfc2982e05a06 | 4,616 | ipynb | Jupyter Notebook | source/training10.ipynb | hskm07/pybeginner_training100 | 4196dd33781d41fa733a671c73fa45d041d20b0f | [
"MIT"
]
| null | null | null | source/training10.ipynb | hskm07/pybeginner_training100 | 4196dd33781d41fa733a671c73fa45d041d20b0f | [
"MIT"
]
| null | null | null | source/training10.ipynb | hskm07/pybeginner_training100 | 4196dd33781d41fa733a671c73fa45d041d20b0f | [
"MIT"
]
| null | null | null | 20.069565 | 112 | 0.473354 | [
[
[
"## **問10 format()関数について**",
"_____no_output_____"
],
[
"複数の変数定義と、`format()`関数について学びましょう。以下のコードを実行してみましょう。\n<br>\n`format()`関数も使用する組み込み関数の一つです。慣れておきましょう。\n<br>\nとりあえず、プログラムを実行してみましょう。\n<br>\n<br>\nスクリプト名:training10.py",
"_____no_output_____"
]
],
[
[
"# 複数の変数を定義する方法\nx_data, y_data = 100, 1000\nprint(\"x_data:\", x_data, \"y_data : \", y_data)",
"x_data: 100 y_data : 1000\n"
]
],
[
[
"上記の例では、`変数1, 変数2, ... = 値1, 値2, ...`と定義すると、\n<br>\n変数1には値1、変数2には値2、...という感じで値が代入されます。\n",
"_____no_output_____"
]
],
[
[
"# 複数の変数を定義する方法\nx_string, y_string, z_number = \"python\", \"vba\", 10*10\nprint(\"x_string:\", x_string, \"y_string : \", y_string, \"z_number : \", z_number)",
"x_string: python y_string : vba z_number : 100\n"
]
],
[
[
"******",
"_____no_output_____"
],
[
"## format()関数の使い方",
"_____no_output_____"
]
],
[
[
"# 練習1\nmsg = \"私の年齢は{0}歳で、出身地は{1}です。趣味は{2}です。\".format(29,\"東京都\",\"釣り\")\nprint(msg)",
"私の年齢は29歳で、出身地は東京都です。趣味は釣りです。\n"
]
],
[
[
"***フォーマット関数 : `文字列{}.format(引数...)`***\n<br>波カッコで囲まれた{}部分は、置換フィールドと呼ばれ、引数で{}の部分を置換します。\n<br>上記の例は、\"私の年齢は{0}歳で、出身地は{1}です。趣味は{2}です。\".format(29,\"東京都\",\"釣り\")\n<br>{0} --> 引数1: 29\n<br>{1} --> 引数2: \"東京都\"\n<br>{2} --> 引数3: \"釣り\"\n<br>という感じで値が置換されます。",
"_____no_output_____"
]
],
[
[
"# 練習2\nhello = \"私は株式会社サンプルに{0}年に入社しました。職種は{1}です。得意なことは{2}と{3}です。\".format(2020, \"営業\", \"走ること\", \"Python\")\nprint(hello)",
"私は株式会社サンプルに2020年に入社しました。職種は営業です。得意なことは走ることとPythonです。\n"
]
],
[
[
"******",
"_____no_output_____"
],
[
"for文を使って、文字を一文字ずつ取り出す",
"_____no_output_____"
]
],
[
[
"print(\"\\\"for文\\\"で文字を一文字ずつ取り出します\")\n\n# len()関数で変数msgの長さを取得\nln = len(msg)\nfor i in range(ln):\n print(\"{0}番目の文字は、{1}です。\".format(i, msg[i]))",
"\"for文\"で文字を一文字ずつ取り出します\n0番目の文字は、私です。\n1番目の文字は、のです。\n2番目の文字は、年です。\n3番目の文字は、齢です。\n4番目の文字は、はです。\n5番目の文字は、2です。\n6番目の文字は、9です。\n7番目の文字は、歳です。\n8番目の文字は、でです。\n9番目の文字は、、です。\n10番目の文字は、出です。\n11番目の文字は、身です。\n12番目の文字は、地です。\n13番目の文字は、はです。\n14番目の文字は、東です。\n15番目の文字は、京です。\n16番目の文字は、都です。\n17番目の文字は、でです。\n18番目の文字は、すです。\n19番目の文字は、。です。\n20番目の文字は、趣です。\n21番目の文字は、味です。\n22番目の文字は、はです。\n23番目の文字は、釣です。\n24番目の文字は、りです。\n25番目の文字は、でです。\n26番目の文字は、すです。\n27番目の文字は、。です。\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
]
|
e7c0090ac16b0b321c54fa46919ba380d8949cee | 218,773 | ipynb | Jupyter Notebook | DS_Unit_1_Sprint_Challenge_2.ipynb | aapte11/DS-Sprint-02-Storytelling-With-Data | 1d51302f0c309bdb6371648b84695137d1b24e19 | [
"MIT"
]
| null | null | null | DS_Unit_1_Sprint_Challenge_2.ipynb | aapte11/DS-Sprint-02-Storytelling-With-Data | 1d51302f0c309bdb6371648b84695137d1b24e19 | [
"MIT"
]
| null | null | null | DS_Unit_1_Sprint_Challenge_2.ipynb | aapte11/DS-Sprint-02-Storytelling-With-Data | 1d51302f0c309bdb6371648b84695137d1b24e19 | [
"MIT"
]
| null | null | null | 225.77193 | 57,954 | 0.866007 | [
[
[
"<a href=\"https://colab.research.google.com/github/aapte11/DS-Sprint-02-Storytelling-With-Data/blob/master/DS_Unit_1_Sprint_Challenge_2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Data Science Unit 1 Sprint Challenge 2\n\n# Storytelling with Data\n\nIn this sprint challenge you'll work with a dataset from **FiveThirtyEight's article, [Every Guest Jon Stewart Ever Had On ‘The Daily Show’](https://fivethirtyeight.com/features/every-guest-jon-stewart-ever-had-on-the-daily-show/)**!",
"_____no_output_____"
],
[
"# Part 0 — Run this starter code\n\nYou don't need to add or change anything here. Just run this cell and it loads the data for you, into a dataframe named `df`.\n\n(You can explore the data if you want, but it's not required to pass the Sprint Challenge.)",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\n\ndf = pd.read_csv('https://raw.githubusercontent.com/fivethirtyeight/data/master/daily-show-guests/daily_show_guests.csv')\ndf.rename(columns={'YEAR': 'Year', 'Raw_Guest_List': 'Guest'}, inplace=True)\n\ndef get_occupation(group):\n if group in ['Acting', 'Comedy', 'Musician']:\n return 'Acting, Comedy & Music'\n elif group in ['Media', 'media']:\n return 'Media'\n elif group in ['Government', 'Politician', 'Political Aide']:\n return 'Government and Politics'\n else:\n return 'Other'\n \ndf['Occupation'] = df['Group'].apply(get_occupation)",
"_____no_output_____"
]
],
[
[
"# Part 1 — What's the breakdown of guests’ occupations per year?\n\nFor example, in 1999, what percentage of guests were actors, comedians, or musicians? What percentage were in the media? What percentage were in politics? What percentage were from another occupation?\n\nThen, what about in 2000? In 2001? And so on, up through 2015.\n\nSo, **for each year of _The Daily Show_, calculate the percentage of guests from each occupation:**\n- Acting, Comedy & Music\n- Government and Politics\n- Media\n- Other\n\n#### Hints:\n1. Use pandas to make a **crosstab** of **`Year`** & **`Occupation`**. ([This documentation](http://pandas.pydata.org/pandas-docs/stable/reshaping.html#cross-tabulations) has examples and explanation.)\n2. To get percentages instead of counts, use crosstab's **`normalize`** parameter to normalize over each _row._ ([This documentation](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.crosstab.html) describes the parameter and its options.)\n3. You'll know you've calculated the crosstab correctly when the percentage of \"Acting, Comedy & Music\" guests is 90.36% in 1999, and 45% in 2015.",
"_____no_output_____"
]
],
[
[
"df.head()",
"_____no_output_____"
]
],
[
[
"**PART 1: CROSSTAB**",
"_____no_output_____"
]
],
[
[
"cross = pd.crosstab(df.Year, df.Occupation, normalize = 'index') \n\ncross\n\n",
"_____no_output_____"
]
],
[
[
"# Part 2 — Recreate this explanatory visualization:",
"_____no_output_____"
]
],
[
[
"from IPython.display import display, Image\nurl = 'https://fivethirtyeight.com/wp-content/uploads/2015/08/hickey-datalab-dailyshow.png'\nexample = Image(url, width=500)\ndisplay(example)",
"_____no_output_____"
]
],
[
[
"**Hint:** use the crosstab you calculated in part 1!\n\n**Expectations:** Your plot should include:\n- 3 lines visualizing \"occupation of guests, by year.\" The shapes of the lines should look roughly identical to 538's example. Each line should be a different color. (But you don't need to use the _same_ colors as 538.)\n- Legend or labels for the lines. (But you don't need each label positioned next to its line or colored like 538.)\n- Title in the upper left: _\"Who Got To Be On 'The Daily Show'?\"_ with more visual emphasis than the subtitle. (Bolder and/or larger font.)\n- Subtitle underneath the title: _\"Occupation of guests, by year\"_\n\nAny visual element not specifically mentioned in the expectations is an optional bonus, but it's _not_ required to pass the Sprint Challenge.\n\n\n\n\n",
"_____no_output_____"
]
],
[
[
"cross.index",
"_____no_output_____"
],
[
"import matplotlib.style as style\nstyle.available",
"_____no_output_____"
],
[
"cross100 = 100*cross\n\nfig, ax = plt.subplots(facecolor = 'white', figsize = (8,6)) \n\nstyle.use(\"fivethirtyeight\") # Doesn't work\n\nyear = cross100.index\nmedia = cross100['Media']\ngov = cross100['Government and Politics']\nentertainment = cross100['Acting, Comedy & Music']\n\nax.plot(year, media, color = 'purple', linewidth = 3, label = 'Media' )\nax.plot(year, gov, color = 'orangered', linewidth = 3)\nax.plot(year, entertainment, color = 'dodgerblue', linewidth = 3)\n\nax.tick_params(axis = 'x', labelrotation = 0, colors = 'black', pad = 4)\nx_ticks = [2000,2004,2008,2012]\nax.set_xticks(x_ticks)\n\n\nax.tick_params(axis = 'y', labelrotation = 0, colors = 'black')\ny_ticks = [0,25,50,75,100]\nax.set_yticks(y_ticks)\n\nax.legend().set_visible(True)\n\n# plt.annotate()\n\nplt.annotate(\"Media\", xy = (25,25))\n\nplt.title(\"Who Got To Be On 'The Daily Show'?\", fontweight='bold', loc = 'left')\n\n\n# plt.xlabel('Guest', fontweight='bold')\n# plt.ylabel('Number of Appearances', fontweight='bold') \n\n# ax.text(0,50,s=\"Who Got To Be On 'The Daily Show'?\", fontsize=18, weight='bold') #Doesn't work\n# ax.text(-1.5,42,s=\"Occupation of guests, by year\", fontsize=16) #Doesn't work\n\n# plt.figtext(20,20,s=\"Media\", color = 'purple') #Doesn't work\n\n\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"**plt.text and plt.style did not work in this case so I couldn't place text as needed. **",
"_____no_output_____"
]
],
[
[
"!pip install --upgrade seaborn",
"Collecting seaborn\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/a8/76/220ba4420459d9c4c9c9587c6ce607bf56c25b3d3d2de62056efe482dadc/seaborn-0.9.0-py3-none-any.whl (208kB)\n\r\u001b[K 4% |█▋ | 10kB 19.0MB/s eta 0:00:01\r\u001b[K 9% |███▏ | 20kB 2.9MB/s eta 0:00:01\r\u001b[K 14% |████▊ | 30kB 3.3MB/s eta 0:00:01\r\u001b[K 19% |██████▎ | 40kB 3.0MB/s eta 0:00:01\r\u001b[K 24% |███████▉ | 51kB 3.4MB/s eta 0:00:01\r\u001b[K 29% |█████████▌ | 61kB 4.0MB/s eta 0:00:01\r\u001b[K 34% |███████████ | 71kB 4.2MB/s eta 0:00:01\r\u001b[K 39% |████████████▋ | 81kB 4.0MB/s eta 0:00:01\r\u001b[K 44% |██████████████▏ | 92kB 4.4MB/s eta 0:00:01\r\u001b[K 49% |███████████████▊ | 102kB 4.5MB/s eta 0:00:01\r\u001b[K 54% |█████████████████▎ | 112kB 4.5MB/s eta 0:00:01\r\u001b[K 59% |███████████████████ | 122kB 5.6MB/s eta 0:00:01\r\u001b[K 63% |████████████████████▌ | 133kB 5.4MB/s eta 0:00:01\r\u001b[K 68% |██████████████████████ | 143kB 6.9MB/s eta 0:00:01\r\u001b[K 73% |███████████████████████▋ | 153kB 6.5MB/s eta 0:00:01\r\u001b[K 78% |█████████████████████████▏ | 163kB 6.0MB/s eta 0:00:01\r\u001b[K 83% |██████████████████████████▊ | 174kB 6.6MB/s eta 0:00:01\r\u001b[K 88% |████████████████████████████▍ | 184kB 7.5MB/s eta 0:00:01\r\u001b[K 93% |██████████████████████████████ | 194kB 7.5MB/s eta 0:00:01\r\u001b[K 98% |███████████████████████████████▌| 204kB 7.1MB/s eta 0:00:01\r\u001b[K 100% |████████████████████████████████| 215kB 6.4MB/s \n\u001b[?25hRequirement already satisfied, skipping upgrade: pandas>=0.15.2 in /usr/local/lib/python3.6/dist-packages (from seaborn) (0.22.0)\nRequirement already satisfied, skipping upgrade: scipy>=0.14.0 in /usr/local/lib/python3.6/dist-packages (from seaborn) (1.1.0)\nRequirement already satisfied, skipping upgrade: numpy>=1.9.3 in /usr/local/lib/python3.6/dist-packages (from seaborn) (1.14.6)\nRequirement already satisfied, skipping upgrade: matplotlib>=1.4.3 in /usr/local/lib/python3.6/dist-packages (from seaborn) (2.1.2)\nRequirement already satisfied, skipping upgrade: python-dateutil>=2 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.15.2->seaborn) (2.5.3)\nRequirement already satisfied, skipping upgrade: pytz>=2011k in /usr/local/lib/python3.6/dist-packages (from pandas>=0.15.2->seaborn) (2018.7)\nRequirement already satisfied, skipping upgrade: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=1.4.3->seaborn) (0.10.0)\nRequirement already satisfied, skipping upgrade: six>=1.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=1.4.3->seaborn) (1.11.0)\nRequirement already satisfied, skipping upgrade: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=1.4.3->seaborn) (2.3.0)\nInstalling collected packages: seaborn\n Found existing installation: seaborn 0.7.1\n Uninstalling seaborn-0.7.1:\n Successfully uninstalled seaborn-0.7.1\nSuccessfully installed seaborn-0.9.0\n"
],
[
"import seaborn as sns\nsns.__version__",
"_____no_output_____"
],
[
"\nimport matplotlib.pyplot as plt\n\nfive_thirty_eight = [\n \"#30a2da\",\n \"#fc4f30\",\n \"#e5ae38\",\n \"#6d904f\",\n \"#8b8b8b\",\n]\n\nsns.set_palette(five_thirty_eight)\nsns.palplot(sns.color_palette())\nplt.show()",
"_____no_output_____"
]
],
[
[
"**Attempting the problem in Seaborn**\n\n**UPDATE: Same text issues with seaborn**",
"_____no_output_____"
]
],
[
[
"year = cross100.index\nmedia = cross100['Media']\ngov = cross100['Government and Politics']\nentertainment = cross100['Acting, Comedy & Music']\n\nax1 = sns.lineplot(x=year, y=media, color = 'purple')\nax2 = sns.lineplot(x=year, y=gov, color = 'orangered')\nax3 = sns.lineplot(x=year, y=entertainment, color = 'dodgerblue')\n\nax1.set(xticks=[2000, 2004, 2008, 2012])\nax2.set(yticks=[0,25,50,75,100])\n\n\nax1.set(ylabel = '')\nax3.set(xlabel = '')\n\n\nplt.show()\n\n",
"_____no_output_____"
]
],
[
[
"# Part 3 — Who were the top 10 guests on _The Daily Show_?\n\n**Make a plot** that shows their names and number of appearances.\n\n**Hint:** you can use the pandas `value_counts` method.\n\n**Expectations:** This can be a simple, quick plot: exploratory, not explanatory. \n\nIf you want, you can add titles and change aesthetics, but it's _not_ required to pass the Sprint Challenge.",
"_____no_output_____"
]
],
[
[
"top_ten = df.Guest.value_counts()[0:10]\n",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(facecolor = 'white', figsize = (8,6)) \n\n\nax = top_ten.plot.bar(width = 0.9, color = 'limegreen')\n\nax.tick_params(axis = 'x', labelrotation = 90, colors = 'black', pad = 2, bottom = 'on')\n\nax.tick_params(axis = 'y', labelrotation = 0, colors = 'black')\ny_ticks = [0,5,10,15,20,25]\nax.set_yticks(y_ticks)\nax.legend().set_visible(False)\nax.set_facecolor(\"cornsilk\")\n\nplt.title('Top Ten Guest Apperances on the Daily Show', fontweight='bold')\nplt.xlabel('Guest', fontweight='bold')\nplt.ylabel('Number of Appearances', fontweight='bold')\n\n# plt.axhline(y = -0.25, color = 'black', linewidth = 1.3, alpha = .7)\n# plt.axvline(x = -0.5, color = 'black', linewidth = 1.3, alpha = .7)\n\nfor x, y in enumerate(top_ten):\n ax.text(x-.15, y+.3, str(y), color = 'blue') # str(y) \n\n\n\n\nplt.show()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7c0178176329078acb15d693c9b298b31bfac52 | 12,910 | ipynb | Jupyter Notebook | 24_distribucion_de_software.ipynb | jasant00/servidores | 50f23b7a3e0d9b2e1e78ebe75d6137b7efb5f97a | [
"MIT"
]
| 11 | 2019-03-04T23:03:08.000Z | 2021-10-14T23:08:41.000Z | 24_distribucion_de_software.ipynb | jasant00/servidores | 50f23b7a3e0d9b2e1e78ebe75d6137b7efb5f97a | [
"MIT"
]
| null | null | null | 24_distribucion_de_software.ipynb | jasant00/servidores | 50f23b7a3e0d9b2e1e78ebe75d6137b7efb5f97a | [
"MIT"
]
| 7 | 2019-03-06T03:36:51.000Z | 2021-07-08T14:55:10.000Z | 27.763441 | 405 | 0.590395 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
e7c01f5b37f3e5ac3ee3c50f1538fd1e94426c7e | 19,523 | ipynb | Jupyter Notebook | practicas/introduccion-sympy.ipynb | maprieto/CalculoMultivariable | 6bd7839803d696c6cd0e3536c0631453eacded70 | [
"MIT"
]
| 1 | 2021-01-09T18:30:54.000Z | 2021-01-09T18:30:54.000Z | practicas/introduccion-sympy.ipynb | maprieto/CalculoMultivariable | 6bd7839803d696c6cd0e3536c0631453eacded70 | [
"MIT"
]
| null | null | null | practicas/introduccion-sympy.ipynb | maprieto/CalculoMultivariable | 6bd7839803d696c6cd0e3536c0631453eacded70 | [
"MIT"
]
| null | null | null | 63.386364 | 4,109 | 0.622036 | [
[
[
"# Introducción a Sympy\n\nAdemais das variables numéricas existen as variables simbólicas que permiten calcular\nlímites, derivadas, integrais etc., como se fai habitualmente nas clases de matemáticas.\nPara poder facer estas operacións, habituais nun curso de Cálculo, é preciso ter instalada a libraría **Sympy**.\n\nAo contrario que o módulo **Math** ou o módulo **Numpy** que acabamos de revisar na práctica anterior, o módulo **Sympy** non traballa cunha estrutura de datos baseado en números (xa sexan de tipo enteiro ou dobre) senón que traballa con obxectos que posúen atributos e métodos que tratan de reproducir o comportamento matemático de variables, funcións, rexións, ecuacións, etc. coas que se traballa habitualmente nas disciplinas da álxebra e o cálculo diferencial e integral.\n\nPara empregar directamente este guión de prácticas dende unha instalación de Python con *Anaconda*, basta con facer clic na aplicación 'Jupyter notebook' que xa está instalada por defecto (para máis detalles: https://jupyter-notebook-beginner-guide.readthedocs.io/en/latest/execute.html).\n\n### Obxectivos:\n\n- Uso de variables simbólicas\n- Suposicións e requerimentos das variables \n- Manipulación de expresións sinxelas en varias variables\n\n\n## Instalación e carga do módulo\nPara facer que estea dispoñible o módulo **Sympy**, hai que instalalo usando a ferramente `pip` (ou `conda` se estades a usar entornos de traballo diferenciados). No caso do uso de *Microsoft Azute Notebooks* (https://notebooks.azure.com/), empregaríase a seguinte instalación:",
"_____no_output_____"
]
],
[
[
"!pip -q install sympy",
"\u001b[33mYou are using pip version 19.3.1, however version 20.0.2 is available.\r\nYou should consider upgrading via the 'pip install --upgrade pip' command.\u001b[0m\r\n"
]
],
[
[
"Para dispoñer do módulo **Sympy** e importalo para o resto do guión de prácticas, usaremos:",
"_____no_output_____"
]
],
[
[
"import sympy as sp",
"_____no_output_____"
]
],
[
[
"## Variables simbólicas\nPara traballar en modo simbólico é necesario definir variables simbólicas e para facer\nisto usaremos o función `sp.Symbol`. Vexamos algúns exemplos do seu uso:",
"_____no_output_____"
]
],
[
[
"x = sp.Symbol('x') # define a variable simbólica x\ny = sp.Symbol('y') # define a variable simbólica y\nf = 3*x + 5*y # agora temos definida a expresion simbólica f\nprint(f)\n\na, b, c = sp.symbols('a:c') # define como simbólicas as variables a, b, c.\nexpresion = a**3 + b**2 + c\nprint(expresion)",
"3*x + 5*y\na**3 + b**2 + c\n"
]
],
[
[
"Por claridade na implementación e nos cálculos, será habitual que o nome da variable simbólica e o nome do obxecto **Sympy** no que se alamacena coincidan, pero isto non ter porque ser así:",
"_____no_output_____"
]
],
[
[
"a = sp.Symbol('x')\nprint(a)\na.name",
"x\n"
]
],
[
[
"Debemos ter claso que agora as variables `x` ou `y` definidas antes non son números, nin tampouco pertencen aos obxectos definidos co módulo **Numpy** revisado na práctica anterior. Todas as variables simbólicas son obxectos da clase `sp.Symbol` e os seus atributos e métodos son completamente diferentes aos que aparecían ás variables numéricas e vectores de **Numpy**:",
"_____no_output_____"
]
],
[
[
"print(type(x))\ndir(x)",
"<class 'sympy.core.symbol.Symbol'>\n"
]
],
[
[
"Con **Sympy** pódense definir constantes enteiras ou números racioanais (todas de forma simbólica) de xeito doado usando o comando `sp.Integer` ou `sp.Rational`. Por exemplo, podemos definir a constante simbólica $1/3$. Se fixeramos o mesmo con números representados por defecto en Python, obteríamos resultados moi diferentes. Observa tamén a diferenza que existe entre o tipo\nde dato asignado no espazo de traballo",
"_____no_output_____"
]
],
[
[
"a = sp.Rational('1/3')\nb = sp.Integer('6')/sp.Integer('3')\nc = 1/3\nd = 1.0/3.0\nprint(a)\nprint(b)\nprint(c)\nprint(d)\nprint(type(a))\nprint(type(b))\nprint(type(c))\nprint(type(d))\nprint(a)\nprint(b)",
"1/3\n2\n0\n0.333333333333\n<class 'sympy.core.numbers.Rational'>\n<class 'sympy.core.numbers.Integer'>\n<type 'int'>\n<type 'float'>\n1/3\n2\n"
]
],
[
[
"Outra forma sinxela de manexar valores constante mediante obxectos do módulo **Sympy** é usar a función `sp.S`. Unha vez feitos todos os cálculos simbólicos, se precisamos obter o valor numérico, empregaríase a función `sp.N` ou ben directamente `float`:",
"_____no_output_____"
]
],
[
[
"a = sp.S(2)\nb = sp.S(6)\nc = a/b\nd = sp.N(c)\ne = float(c)\nprint(type(a))\nprint(type(b))\nprint(type(c))\nprint(type(d))\nprint(type(e))\nprint(c)\nprint(d)\nprint('{0:.15f}'.format(e))",
"<class 'sympy.core.numbers.Integer'>\n<class 'sympy.core.numbers.Integer'>\n<class 'sympy.core.numbers.Rational'>\n<class 'sympy.core.numbers.Float'>\n<type 'float'>\n1/3\n0.333333333333333\n0.333333333333333\n"
]
],
[
[
"Ao longo do curso usaremos asiduamente dous números reais que podes definir como constantes simbólicas: $\\pi$ e o numéro $e$. Do mesmo xeito, para operar con variables ou constantes simbólicas, debemos empregar funcións que sexan capaces de manipular este tipo de obxectos, todas elas implementadas no módulo **Sympy** (por exemplo, `sp.sin`, `sp.cos`, `sp.log`, etc)",
"_____no_output_____"
]
],
[
[
"import numpy as np\nprint(np.pi)\nprint(type(np.pi))\n\np=sp.pi # definición da constante pi\nprint(sp.cos(p))\n\ne = sp.E # definición do número e\nprint(sp.log(e))\n\nprint(sp.N(sp.pi,1000))\nprint(type(sp.N(sp.pi,100)))",
"3.14159265359\n<type 'float'>\n-1\n1\n3.141592653589793238462643383279502884197169399375105820974944592307816406286208998628034825342117067982148086513282306647093844609550582231725359408128481117450284102701938521105559644622948954930381964428810975665933446128475648233786783165271201909145648566923460348610454326648213393607260249141273724587006606315588174881520920962829254091715364367892590360011330530548820466521384146951941511609433057270365759591953092186117381932611793105118548074462379962749567351885752724891227938183011949129833673362440656643086021394946395224737190702179860943702770539217176293176752384674818467669405132000568127145263560827785771342757789609173637178721468440901224953430146549585371050792279689258923542019956112129021960864034418159813629774771309960518707211349999998372978049951059731732816096318595024459455346908302642522308253344685035261931188171010003137838752886587533208381420617177669147303598253490428755468731159562863882353787593751957781857780532171226806613001927876611195909216420198\n<class 'sympy.core.numbers.Float'>\n"
]
],
[
[
"## Suposicións sobre as variables\n\nCando se define unha variable simbólica se lle pode asignar certa información adicional sobre o tipo de valores que pode acadar, ou as suposicións que se lle van a aplicar. Por exemplo, podemos decidir antes de facer calquera cálculo se a variable toma valores enteiros ou reais, se é positiva ou negativa, maior que un certo número, etc. Este tipo de información engádese no momento da definición da variable simbólica como un argumento opcional.",
"_____no_output_____"
]
],
[
[
"x = sp.Symbol('x', nonnegative = True) # A raíz cadrada dun número non negativo é real\ny = sp.sqrt(x)\nprint(y.is_real)\n\nx = sp.Symbol('x', integer = True) # A potencia dun número enteiro é enteira\ny = x**sp.S(2)\nprint(y.is_integer)\n\na = sp.Symbol('a')\nb = sp.sqrt(a)\nprint(b.is_real)\n\na = sp.Symbol('a')\nb = a**sp.S(2)\nprint(b.is_integer)",
"True\nTrue\nNone\nNone\n"
]
],
[
[
"Posto que os cálculos simbólicos son consistentes en **Sympy**, se poden tamén facer comprobacións sobre se algunhas desigualdades son certas ou non, sempre e cando se teña coidado nas suposicións que se fagan ao definir as variables simbólicas",
"_____no_output_____"
]
],
[
[
"x = sp.Symbol('x', real = True)\np = sp.Symbol('p', positive = True)\nq = sp.Symbol('q', real = True)\ny = sp.Abs(x) + p # O valor absoluto\nz = sp.Abs(x) + q\nprint(y > 0)\nprint(z > 0)",
"True\nq + Abs(x) > 0\n"
]
],
[
[
"## Manipulación de expresións simbólicas",
"_____no_output_____"
],
[
"Do mesmo xeito que o módulo **Sympy** nos permite definir variables simbólicas, tamén podemos definir expresións matemáticas a partir destas e manipulalas, factorizándoas, expandíndoas, simplificalas, ou mesmo imprimilas dun xeito similar a como o faríamos con lápiz e papel",
"_____no_output_____"
]
],
[
[
"x,y = sp.symbols('x,y', real=True)\nexpr = (x-3)*(x-3)**2*(y-2)\nexpr_long = sp.expand(expr) # Expandir expresión\n\nprint(expr_long) # Imprimir de forma estándar\nsp.pprint(expr_long) # Imprimir de forma semellante a con lápiz e papel\n\nexpr_short = sp.factor(expr)\nprint(expr_short) # Factorizar expresión\n\nexpr = -3+(x**2-6*x+9)/(x-3)\nexpr_simple = sp.simplify(expr) # Simplificar expresión\nsp.pprint(expr)\nprint(expr_simple)",
"x**3*y - 2*x**3 - 9*x**2*y + 18*x**2 + 27*x*y - 54*x - 27*y + 54\n 3 3 2 2 \nx ⋅y - 2⋅x - 9⋅x ⋅y + 18⋅x + 27⋅x⋅y - 54⋅x - 27⋅y + 54\n(x - 3)**3*(y - 2)\n 2 \n x - 6⋅x + 9\n-3 + ────────────\n x - 3 \nx - 6\n"
]
],
[
[
"Dada unha expresión en **Sympy** tamén se pode manipulala, substituindo unhas variables simbólica por outras ou mesmo reemprazando as variables simbólicas por constantes. Para facer este tipo de substitucións emprégase a función `subs` e os valores a utilizar na substitución veñen definidos por un diccionario de Python:",
"_____no_output_____"
]
],
[
[
"x,y = sp.symbols('x,y', real=True)\nexpr = x*x + x*y + y*x + y*y\nres = expr.subs({x:1, y:2}) # Substitutición das variables simbólicas por constantes\nprint(res)\n\nexpr_sub = expr.subs({x:1-y}) # Subsitución de variable simbólica por unha expresión\nsp.pprint(expr_sub)\nprint(sp.simplify(expr_sub))",
"9\n 2 2\ny + 2⋅y⋅(-y + 1) + (-y + 1) \n1\n"
]
],
[
[
"### **Exercicio 2.1** \nDefine a expresión dada pola suma dos termos seguintes:\n$$\na+a^2+a^3+\\ldots+a^N,\n$$\nonde $a$ é unha variable real arbitraria e $N$ e un valor enteiro positivo.",
"_____no_output_____"
]
],
[
[
"# O TEU CÓDIGO AQUÍ",
"_____no_output_____"
]
],
[
[
"### **Exercicio 2.2** \nCal é o valor exacto da anterior expresión cando $N=15$ e $a=5/6$? Cal é valor numérico en coma flotante?",
"_____no_output_____"
]
],
[
[
"# O TEU CÓDIGO AQUÍ",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7c02150eb68b8add081fa7bc7954027e169b7f5 | 261,815 | ipynb | Jupyter Notebook | Models/Kartikay/notes_model.ipynb | badrinath-reddy/Notes-Separator | dee751e7ebfc58c79dfbafb9890554ce8c9878af | [
"MIT"
]
| 1 | 2019-07-21T20:44:58.000Z | 2019-07-21T20:44:58.000Z | Models/Kartikay/notes_model.ipynb | badrinath-reddy/Notes-Separator | dee751e7ebfc58c79dfbafb9890554ce8c9878af | [
"MIT"
]
| null | null | null | Models/Kartikay/notes_model.ipynb | badrinath-reddy/Notes-Separator | dee751e7ebfc58c79dfbafb9890554ce8c9878af | [
"MIT"
]
| 1 | 2019-06-12T18:39:15.000Z | 2019-06-12T18:39:15.000Z | 364.137691 | 107,500 | 0.924137 | [
[
[
"# import the requiered libraries\n\n\nimport numpy as np\nimport tensorflow as tf\nimport keras\nfrom keras import layers\nfrom keras.layers import Input, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D\nfrom keras.layers import AveragePooling2D, MaxPooling2D, Dropout, GlobalMaxPooling2D, GlobalAveragePooling2D\nfrom keras.models import Model\nfrom keras.preprocessing import image\nfrom keras.utils import layer_utils\nfrom keras.utils.data_utils import get_file\nfrom keras.applications.imagenet_utils import preprocess_input\nfrom IPython.display import SVG\nfrom keras.utils.vis_utils import model_to_dot\nfrom keras.utils import plot_model\n\nimport keras.backend as K\nK.set_image_data_format('channels_last')\nimport matplotlib.pyplot as plt\nfrom matplotlib.pyplot import imshow\n\n%matplotlib inline\nimport os\nimport cv2",
"Using TensorFlow backend.\n"
],
[
"#loading training and validation data\n\n\nDATADIR = \"D:/dataset1/train\"\nCATEGORIES = [\"non-notes\",\"notes\"]\nIMG_SIZE = 300\n\nfor category in CATEGORIES:\n path=os.path.join(DATADIR,category) #path to notes or non-notes dir\n for img in os.listdir(path):\n img_array=cv2.imread(os.path.join(path,img))\n plt.imshow(img_array)\n plt.show()\n break\n break\n \n\nprint(img_array.shape)\n\ntraining_data=[]\ndef create_training_data():\n for category in CATEGORIES:\n path=os.path.join(DATADIR,category) #path to notes or non-notes dir\n class_num=CATEGORIES.index(category)\n for img in os.listdir(path):\n try:\n img_array=cv2.imread(os.path.join(path,img), cv2.IMREAD_COLOR)\n new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))\n training_data.append([img_array, class_num])\n except Exception as e:\n pass\n \ncreate_training_data()\n\nprint(len(training_data))\n\n\n\nX_train=[]\nY_train=[]\n\nfor features,label in training_data:\n X_train.append(features)\n Y_train.append(label)\n \nX_train=np.array(X_train).reshape(-1,300,300,3)\nY_train=np.array(Y_train).reshape(-1)\n\nimport pickle\n\npickle_out = open(\"X_train.pickle\",\"wb\")\npickle.dump(X_train,pickle_out)\npickle_out.close()\n\npickle_out = open(\"Y_train.pickle\",\"wb\")\npickle.dump(Y_train,pickle_out)\npickle_out.close()\n\npickle_in=open(\"X_train.pickle\",\"rb\")\nX_train=pickle.load(pickle_in)\n\nX_train[8]\n\npickle_in=open(\"Y_train.pickle\",\"rb\")\nY_train=pickle.load(pickle_in)\n\nY_train.shape\n\n\nDATADIR = \"D:/dataset1/val\"\nCATEGORIES = [\"non-notes\",\"notes\"]\nIMG_SIZE = 300\n\nfor category in CATEGORIES:\n path=os.path.join(DATADIR,category) #path to notes or non-notes dir\n for img in os.listdir(path):\n img_array=cv2.imread(os.path.join(path,img))\n plt.imshow(img_array)\n plt.show()\n break\n break\n \n\nprint(img_array.shape)\n\nval_data=[]\ndef create_val_data():\n for category in CATEGORIES:\n path=os.path.join(DATADIR,category) #path to notes or non-notes dir\n class_num=CATEGORIES.index(category)\n for img in os.listdir(path):\n try:\n img_array=cv2.imread(os.path.join(path,img), cv2.IMREAD_COLOR)\n new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))\n training_data.append([img_array, class_num])\n except Exception as e:\n pass\n \ncreate_val_data()\n\nprint(len(val_data))\n\n\n\nX_val=[]\nY_val=[]\n\nfor features,label in training_data:\n X_val.append(features)\n Y_val.append(label)\n \nX_val=np.array(X_val).reshape(-1,300,300,3)\nY_val=np.array(Y_val).reshape(-1)\n\nimport pickle\n\npickle_out = open(\"X_val.pickle\",\"wb\")\npickle.dump(X_val,pickle_out)\npickle_out.close()\n\npickle_out = open(\"Y_val.pickle\",\"wb\")\npickle.dump(Y_val,pickle_out)\npickle_out.close()\n\npickle_in=open(\"X_val.pickle\",\"rb\")\nX_val=pickle.load(pickle_in)\n\nX_val[8]\n\npickle_in=open(\"Y_val.pickle\",\"rb\")\nY_val=pickle.load(pickle_in)\n\nY_val.shape",
"_____no_output_____"
],
[
"#loading test data\n\nDATADIR = \"D:/dataset1/test\"\nCATEGORIES = [\"testset\"]\nIMG_SIZE=300\n\nfor category in CATEGORIES:\n path=os.path.join(DATADIR,category) #path to test dir\n for img in os.listdir(path):\n img_array=cv2.imread(os.path.join(path,img))\n plt.imshow(img_array)\n plt.show()\n break\n break\n \n\nprint(img_array.shape)\n\ntest_data=[]\ndef create_test_data():\n for category in CATEGORIES:\n path=os.path.join(DATADIR,category) #path to test dir\n class_num=CATEGORIES.index(category)\n for img in os.listdir(path):\n try:\n img_array=cv2.imread(os.path.join(path,img), cv2.IMREAD_COLOR)\n new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))\n test_data.append([img_array, class_num])\n except Exception as e:\n pass\n \ncreate_test_data()\n\nprint(len(test_data))\n\n\n\nX_test=[]\nY_test=[]\n\nfor features,label in test_data:\n X_test.append(features)\n Y_test.append(label)\n \nX_test=np.array(X_test).reshape(-1,300,300,3)\nY_test=np.array(Y_test).reshape(-1)\nimport pickle\n\npickle_out = open(\"X_test.pickle\",\"wb\")\npickle.dump(X_test,pickle_out)\npickle_out.close()\n\npickle_out = open(\"Y_test.pickle\",\"wb\")\npickle.dump(Y_test,pickle_out)\npickle_out.close()\n\npickle_in=open(\"X_test.pickle\",\"rb\")\nX_test=pickle.load(pickle_in)\nX_test.shape\n\npickle_in=open(\"Y_test.pickle\",\"rb\")\nY_test=pickle.load(pickle_in)\nY_test.shape",
"_____no_output_____"
],
[
"#model architecture....\n\nmodel = tf.keras.models.Sequential([\n # Note the input shape is the desired size of the image 300x300 with 3 bytes color\n # This is the first convolution\n tf.keras.layers.Conv2D(32, (3,3), activation='relu',kernel_regularizer=tf.keras.regularizers.l2(0.01), input_shape=(300, 300, 3)),\n tf.keras.layers.MaxPooling2D(2, 2),\n # The second convolution\n tf.keras.layers.Conv2D(64, (3,3), activation='relu',kernel_regularizer=tf.keras.regularizers.l2(0.01)),\n tf.keras.layers.MaxPooling2D(2,2),\n # The third convolution\n tf.keras.layers.Conv2D(128, (3,3), activation='relu',kernel_regularizer=tf.keras.regularizers.l2(0.01)),\n tf.keras.layers.MaxPooling2D(2,2),\n # The fourth convolution\n tf.keras.layers.Conv2D(256, (3,3), activation='relu',kernel_regularizer=tf.keras.regularizers.l2(0.01)),\n tf.keras.layers.MaxPooling2D(2,2),\n # The fifth convolution\n tf.keras.layers.Conv2D(512, (3,3), activation='relu',kernel_regularizer=tf.keras.regularizers.l2(0.01)),\n tf.keras.layers.MaxPooling2D(2,2),\n # Flatten the results to feed into a DNN\n tf.keras.layers.Flatten(),\n tf.keras.layers.Dense(50, activation='relu'),\n tf.keras.layers.Dense(50, activation='relu'),\n # Only 1 output neuron. It will contain a value from 0-1 where 0 for 1 class ('horses') and 1 for the other ('humans')\n tf.keras.layers.Dense(1, activation='sigmoid')\n])",
"_____no_output_____"
],
[
"# model summary....\n\nmodel.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d_5 (Conv2D) (None, 298, 298, 32) 896 \n_________________________________________________________________\nmax_pooling2d_5 (MaxPooling2 (None, 149, 149, 32) 0 \n_________________________________________________________________\nconv2d_6 (Conv2D) (None, 147, 147, 64) 18496 \n_________________________________________________________________\nmax_pooling2d_6 (MaxPooling2 (None, 73, 73, 64) 0 \n_________________________________________________________________\nconv2d_7 (Conv2D) (None, 71, 71, 128) 73856 \n_________________________________________________________________\nmax_pooling2d_7 (MaxPooling2 (None, 35, 35, 128) 0 \n_________________________________________________________________\nconv2d_8 (Conv2D) (None, 33, 33, 256) 295168 \n_________________________________________________________________\nmax_pooling2d_8 (MaxPooling2 (None, 16, 16, 256) 0 \n_________________________________________________________________\nconv2d_9 (Conv2D) (None, 14, 14, 512) 1180160 \n_________________________________________________________________\nmax_pooling2d_9 (MaxPooling2 (None, 7, 7, 512) 0 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 25088) 0 \n_________________________________________________________________\ndense_3 (Dense) (None, 50) 1254450 \n_________________________________________________________________\ndense_4 (Dense) (None, 50) 2550 \n_________________________________________________________________\ndense_5 (Dense) (None, 1) 51 \n=================================================================\nTotal params: 2,825,627\nTrainable params: 2,825,627\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"from tensorflow.keras.optimizers import RMSprop\n\n# compiling model\n\nmodel.compile(loss='binary_crossentropy',\n optimizer=RMSprop(lr=0.001),\n metrics=['acc'])",
"_____no_output_____"
],
[
"from tensorflow.keras.preprocessing.image import ImageDataGenerator\n\n# Define our example directories and files\ntrain_dir = \"D:/dataset1/train\"\nvalidation_dir = \"D:/dataset1/val\"\n\n# Add our data-augmentation parameters to ImageDataGenerator\ntrain_datagen = ImageDataGenerator(rescale = 1./255.,\n width_shift_range = 0.2,\n height_shift_range = 0.2,\n shear_range = 0.2,\n zoom_range = 0.2,\n horizontal_flip = True)\n\n# Note that the validation data should not be augmented!\ntest_datagen = ImageDataGenerator( rescale = 1.0/255. )\n\n# Flow training images in batches of 20 using train_datagen generator\ntrain_generator = train_datagen.flow_from_directory(train_dir,\n batch_size = 50,\n class_mode = 'binary', \n target_size = (300, 300)) \n\n# Flow validation images in batches of 20 using test_datagen generator\nvalidation_generator = test_datagen.flow_from_directory( validation_dir,\n batch_size = 20,\n class_mode = 'binary', \n target_size = (300, 300))",
"Found 1416 images belonging to 2 classes.\nFound 126 images belonging to 2 classes.\n"
],
[
"# Define a Callback class that stops training once accuracy reaches 98.5%\n# in this model it never reached that accuracy\n\n\nclass myCallback(tf.keras.callbacks.Callback):\n def on_epoch_end(self, epoch, logs={}):\n if(logs.get('acc')>0.985):\n print(\"\\nReached 98.5% accuracy so cancelling training!\")\n self.model.stop_training = True\n",
"_____no_output_____"
],
[
"# had to import this since cell below was not getting excuted\n\nfrom IPython.display import display\nfrom PIL import Image",
"_____no_output_____"
],
[
"callbacks = myCallback()\n\n\n#training the model\n\nhistory = model.fit_generator(\n train_generator,\n validation_data = validation_generator,\n steps_per_epoch = 20,\n epochs = 20,\n validation_steps = 20,\n verbose = 2,\n callbacks=[callbacks])",
"Epoch 1/20\n7/7 [==============================] - 7s 986ms/step - loss: 1.2925 - acc: 0.8968\n - 142s - loss: 3.0327 - acc: 0.5897 - val_loss: 1.2925 - val_acc: 0.8968\nEpoch 2/20\n7/7 [==============================] - 7s 1s/step - loss: 0.8137 - acc: 0.9048\n - 128s - loss: 0.9963 - acc: 0.8835 - val_loss: 0.8137 - val_acc: 0.9048\nEpoch 3/20\n7/7 [==============================] - 8s 1s/step - loss: 0.4858 - acc: 0.9444\n - 204s - loss: 0.6893 - acc: 0.8856 - val_loss: 0.4858 - val_acc: 0.9444\nEpoch 4/20\n7/7 [==============================] - 9s 1s/step - loss: 0.4432 - acc: 0.9683\n - 196s - loss: 0.5361 - acc: 0.8997 - val_loss: 0.4432 - val_acc: 0.9683\nEpoch 5/20\n7/7 [==============================] - 9s 1s/step - loss: 0.3450 - acc: 0.9683\n - 226s - loss: 0.4715 - acc: 0.9145 - val_loss: 0.3450 - val_acc: 0.9683\nEpoch 6/20\n7/7 [==============================] - 10s 1s/step - loss: 0.3733 - acc: 0.9206\n - 221s - loss: 0.3766 - acc: 0.9280 - val_loss: 0.3733 - val_acc: 0.9206\nEpoch 7/20\n7/7 [==============================] - 9s 1s/step - loss: 0.2942 - acc: 0.9524\n - 227s - loss: 0.3507 - acc: 0.9329 - val_loss: 0.2942 - val_acc: 0.9524\nEpoch 8/20\n7/7 [==============================] - 9s 1s/step - loss: 0.2849 - acc: 0.9603\n - 223s - loss: 0.3354 - acc: 0.9301 - val_loss: 0.2849 - val_acc: 0.9603\nEpoch 9/20\n7/7 [==============================] - 9s 1s/step - loss: 0.2307 - acc: 0.9603\n - 214s - loss: 0.2928 - acc: 0.9442 - val_loss: 0.2307 - val_acc: 0.9603\nEpoch 10/20\n7/7 [==============================] - 9s 1s/step - loss: 0.6554 - acc: 0.6587\n - 216s - loss: 0.2996 - acc: 0.9343 - val_loss: 0.6554 - val_acc: 0.6587\nEpoch 11/20\n7/7 [==============================] - 9s 1s/step - loss: 0.4164 - acc: 0.8810\n - 283s - loss: 0.2726 - acc: 0.9400 - val_loss: 0.4164 - val_acc: 0.8810\nEpoch 12/20\n7/7 [==============================] - 7s 1s/step - loss: 0.3650 - acc: 0.9683\n - 151s - loss: 0.2479 - acc: 0.9506 - val_loss: 0.3650 - val_acc: 0.9683\nEpoch 13/20\n7/7 [==============================] - 6s 876ms/step - loss: 0.2087 - acc: 0.9603\n - 136s - loss: 0.2475 - acc: 0.9541 - val_loss: 0.2087 - val_acc: 0.9603\nEpoch 14/20\n7/7 [==============================] - 8s 1s/step - loss: 3.2777 - acc: 0.5000\n - 131s - loss: 0.2355 - acc: 0.9506 - val_loss: 3.2777 - val_acc: 0.5000\nEpoch 15/20\n7/7 [==============================] - 9s 1s/step - loss: 0.2306 - acc: 0.9603\n - 208s - loss: 0.3457 - acc: 0.9343 - val_loss: 0.2306 - val_acc: 0.9603\nEpoch 16/20\n7/7 [==============================] - 9s 1s/step - loss: 0.1793 - acc: 0.9683\n - 231s - loss: 0.2022 - acc: 0.9590 - val_loss: 0.1793 - val_acc: 0.9683\nEpoch 17/20\n7/7 [==============================] - 6s 901ms/step - loss: 0.1908 - acc: 0.9603\n - 147s - loss: 0.1912 - acc: 0.9576 - val_loss: 0.1908 - val_acc: 0.9603\nEpoch 18/20\n7/7 [==============================] - 8s 1s/step - loss: 0.1980 - acc: 0.9603\n - 135s - loss: 0.2809 - acc: 0.9520 - val_loss: 0.1980 - val_acc: 0.9603\nEpoch 19/20\n7/7 [==============================] - 8s 1s/step - loss: 0.1795 - acc: 0.9603\n - 158s - loss: 0.2125 - acc: 0.9463 - val_loss: 0.1795 - val_acc: 0.9603\nEpoch 20/20\n7/7 [==============================] - 7s 1s/step - loss: 0.1662 - acc: 0.9762\n - 142s - loss: 0.2286 - acc: 0.9492 - val_loss: 0.1662 - val_acc: 0.9762\n"
],
[
"#saving the entire model\n#which includes saving model architecture ,model weights, training configuration( ie, optimizers, loss)\n\nmodel.save('notes_model.h5')",
"_____no_output_____"
],
[
"\n#testing model on testset\n\nval_loss,val_acc=model.evaluate(X_test,Y_test)\nprint(val_loss,val_acc)",
"51/51 [==============================] - 2s 35ms/sample - loss: 0.6320 - acc: 0.8627\n0.6320489300232307 0.8627451\n"
],
[
"# saving model weights...individually also\n\nmodel.save_weights('notes_model_weights.h5')",
"_____no_output_____"
],
[
"from sklearn.metrics import confusion_matrix",
"_____no_output_____"
],
[
"y_pred = model.predict(X_test)\ny_pred = (y_pred > 0.80)\nc_matrix = confusion_matrix(Y_test, y_pred)",
"_____no_output_____"
],
[
"c_matrix",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c0279e9ffdb20223238af907476a6cdae03dbb | 13,389 | ipynb | Jupyter Notebook | .ipynb_checkpoints/Solution Properties-checkpoint.ipynb | amosonabike/CRC-Solution-Properties- | 5eb7053b37d9291906293878851a44ae93fd08aa | [
"MIT"
]
| null | null | null | .ipynb_checkpoints/Solution Properties-checkpoint.ipynb | amosonabike/CRC-Solution-Properties- | 5eb7053b37d9291906293878851a44ae93fd08aa | [
"MIT"
]
| null | null | null | .ipynb_checkpoints/Solution Properties-checkpoint.ipynb | amosonabike/CRC-Solution-Properties- | 5eb7053b37d9291906293878851a44ae93fd08aa | [
"MIT"
]
| null | null | null | 39.26393 | 206 | 0.534917 | [
[
[
"import numpy as np\nimport pandas as pd\npd.set_option('display.max_rows', 500)\nimport matplotlib.pyplot as plt\nfrom scipy.optimize import curve_fit\nimport ipywidgets as widgets\nimport IPython\nfrom IPython.display import display, clear_output\nimport warnings\n\n\nresolution = 300 #dpi\ntick_size = 18\nfontlabel_size = 18\n\nfigure_width = 233 / 25.4 #conversion to mm is 25.4\nfigure_height = 144 / 25.4 #conversion to mm is 25.4\nfigure_size = (figure_width, figure_height)\n\nparams = {\n 'lines.markersize' : 2,\n 'axes.labelsize': fontlabel_size,\n 'legend.fontsize': fontlabel_size,\n 'xtick.labelsize': tick_size,\n 'ytick.labelsize': tick_size,\n 'figure.figsize': figure_size,\n 'xtick.direction': 'in', # direction: {in, out, inout}\n 'ytick.direction': 'in', # direction: {in, out, inout}\n 'axes.spines.top': False,\n 'axes.spines.right': False,\n 'xtick.major.pad': 8,\n 'ytick.major.pad': 8,\n 'font.family' : 'serif,',\n 'ytick.labelsize' : fontlabel_size,\n 'xtick.labelsize' : fontlabel_size,\n 'axes.linewidth' : 1.2\n}\nplt.rcParams.update(params)",
"_____no_output_____"
],
[
"mfs_range = np.linspace(0,1,1000)\n\nfilepath_CRC_data = 'src/CRC Solution Properties.txt'\ndf_CRC_data = pd.read_csv(filepath_CRC_data, sep = '\\t', comment= '#', encoding='latin-1').drop('Row',axis=1)\n\n#df_CRC_data.fillna('Empty', inplace=True)\n\nCAS_numbers = df_CRC_data.CAS_Reg_No.unique()\n\ngrouped_CRC_data = df_CRC_data.groupby('CAS_Reg_No')\n",
"_____no_output_____"
],
[
"#Descriptors of solutes\nsolutions = ['SubHeader',\n 'Solute',\n 'Synonym',\n 'CAS_Reg_No',\n 'Mol_wt',\n 'data',\n 'MFS_molal',\n 'MFS_molar']\n\n#Different ways of expressing concentration\nconc_measurements = ['Mass_prct',\n 'Mass_fraction',\n 'Molality_m',\n 'Molarity_c']\n\n#Concentrative properties of solution\nsolution_properties = ['Density',\n 'Refractive_index_n',\n 'T_freeze_supression',\n 'Viscosity_dynamic']\n\nthree_lists = [solutions,\n conc_measurements,\n solution_properties]\n\n#turn lists into dicts\nsolutions = dict.fromkeys(solutions)\nconc_measurements = dict.fromkeys(conc_measurements)\nsolution_properties = dict.fromkeys(solution_properties)\n\nconc_measurements['Mass_prct'] = 'W/W Mass / %'\nconc_measurements['Mass_fraction'] = 'Mass Fraction Solute'\nconc_measurements['Molality_m'] = 'Molality / mol/kg'\nconc_measurements['Molarity_c'] = 'Molarity / mol/L'\n\nsolution_properties['Density'] = 'Density / kg/L'\nsolution_properties['Refractive_index_n'] = 'Refractive Index'\nsolution_properties['T_freeze_supression'] = '-$\\delta$T / K'\nsolution_properties['Viscosity_dynamic'] = 'Dynamic Viscosity / Pas'\n\n",
"_____no_output_____"
],
[
"for key in solutions:\n solutions[key] = []\n if key == 'data':\n for number in CAS_numbers:\n solutions[key].append(grouped_CRC_data.get_group(number))\n continue\n if key == 'MFS_molal' or key == 'MFS_molar':\n solutions[key] = [None] * len(solutions['CAS_Reg_No'])\n continue\n for number in CAS_numbers:\n solutions[key].append(grouped_CRC_data.get_group(number).iloc[0][key])",
"_____no_output_____"
],
[
"def GUI():\n\n solute_dropdown = widgets.Dropdown(options = solutions['Solute'], value = 'Sodium chloride')\n conc_dropdown = widgets.Dropdown(options = conc_measurements.keys(), value = 'Mass_fraction')\n property_dropdown = widgets.Dropdown(options = solution_properties.keys(), value = 'Density')\n\n output = widgets.Output()\n\n def show_poly_fit(solute_name, x_series , y_series, order = 3):\n '''\n Takes the solute name and chosen poperties to plot and performs a poly fit\n '''\n data = solutions['data'][solutions['Solute'].index(solute_name)]\n mfs_to_molal = solutions['MFS_molal'][solutions['Solute'].index(solute_name)]\n mfs_to_molar = solutions['MFS_molar'][solutions['Solute'].index(solute_name)]\n\n with output:\n\n fig, ax = plt.subplots(constrained_layout=True)\n\n '''# move the toolbar to the bottom\n fig.canvas.toolbar_position = 'bottom'''\n ax.grid(True) \n line_data, = ax.plot(data[x_series], data[y_series], color = 'k', lw = 4, label = \"Reference Data\")\n\n #get a poly fit to ratio\n try:\n poly_fit = np.polyfit(data['Mass_fraction'],\n data[y_series],\n order)\n\n poly_function = np.poly1d(poly_fit)\n\n #showing fit to mfs molal or molar ratio\n if x_series == 'Mass_prct':\n line_fit, = ax.plot(100 * mfs_range, poly_function(mfs_range), ls = ':', lw = 3, color = 'b', label = 'Mass % Fit')\n elif x_series == 'Molality_m':\n line_fit, = ax.plot(mfs_to_molal(mfs_range), poly_function(mfs_range), ls = ':', lw = 3, color = 'magenta', label = 'Molality Fit')\n elif x_series == 'Molarity_c':\n line_fit, = ax.plot(mfs_to_molar(mfs_range), poly_function(mfs_range), ls = ':', lw = 3, color = 'cyan', label = 'Molarity Fit')\n elif x_series == 'Mass_fraction':\n line_fit, = ax.plot(mfs_range, poly_function(mfs_range), ls = ':', lw = 3, color = 'r', label = 'MFS Fit')\n\n except Exception as e: \n print(e)\n warnings.warn('Failed to parameterise data}')\n pass\n\n plt.legend()\n ax.set_xlabel(x_series)\n ax.set_ylabel(y_series)\n plt.show()\n\n return\n\n def show_mol_ratio(solute_name, order = 3):\n\n data = solutions['data'][solutions['Solute'].index(solute_name)]\n\n with output:\n fig, (ax0, ax1) = plt.subplots( 1, 2, constrained_layout=True)\n ax0.set_xlabel(conc_measurements['Mass_fraction'])\n ax1.set_xlabel(conc_measurements['Mass_fraction'])\n ax0.set_ylabel(conc_measurements['Molality_m'])\n ax1.set_ylabel(conc_measurements['Molarity_c'])\n\n line_a, = ax0.plot(data.Mass_fraction, data.Molality_m, color = 'k', lw = 4)\n line_b, = ax1.plot(data.Mass_fraction, data.Molarity_c, color = 'k', lw = 4)\n\n try:\n molal_fit = np.poly1d(np.polyfit(data.Mass_fraction, data.Molality_m, order))\n molar_fit = np.poly1d(np.polyfit(data.Mass_fraction, data.Molarity_c, order))\n\n line_fit_a, = ax0.plot(mfs_range, molal_fit(mfs_range), ls = ':', lw = 3, color = 'dodgerblue', label = 'MFS to Molality Fit')\n #solution_properties['MFS_molal'] = np.poly1d(np.polyfit(data.Mass_fraction, data.Molality_m, order))\n line_fit_b, = ax1.plot(mfs_range, molar_fit(mfs_range), ls = ':', lw = 3, color = 'dodgerblue', label = 'MFS to Molarity Fit')\n #solution_properties['MFS_molar'] = np.poly1d(np.polyfit(data.Mass_fraction, data.Molarity_c, order))\n plt.legend()\n plt.show()\n\n return molal_fit, molar_fit\n\n except:\n plt.show()\n warnings.warn(\"Failed to parameterise MFS to either Molality or Molarity. Consider interpolating from experimental data if possible\")\n return None, None\n\n return\n\n def solute_dropdown_handler(change):\n #output.clear_output()\n with output:\n\n #data = solutions['data'][solutions['Solute'].index(change.new)]\n solutions['MFS_molal'][solutions['Solute'].index(solute_dropdown.value)],solutions['MFS_molar'][solutions['Solute'].index(solute_dropdown.value)] = show_mol_ratio(change.new)\n show_poly_fit(change.new, conc_dropdown.value, property_dropdown.value)\n IPython.display.clear_output(wait=True)\n\n return\n\n def conc_dropdown_handler(change):\n with output:\n #data = solutions['data'][solutions['Solute'].index(solute_dropdown.value)]\n solutions['MFS_molal'][solutions['Solute'].index(solute_dropdown.value)],solutions['MFS_molar'][solutions['Solute'].index(solute_dropdown.value)] = show_mol_ratio(solute_dropdown.value)\n show_poly_fit(solute_dropdown.value, conc_dropdown.value, property_dropdown.value)\n IPython.display.clear_output(wait=True)\n\n return\n\n def property_dropdown_handler(change):\n #output.clear_output()\n with output:\n #data = solutions['data'][solutions['Solute'].index(solute_dropdown.value)]\n solutions['MFS_molal'][solutions['Solute'].index(solute_dropdown.value)],solutions['MFS_molar'][solutions['Solute'].index(solute_dropdown.value)] = show_mol_ratio(solute_dropdown.value)\n show_poly_fit(solute_dropdown.value, conc_dropdown.value, property_dropdown.value)\n IPython.display.clear_output(wait=True)\n return\n\n solute_dropdown.observe(solute_dropdown_handler, names = 'value')\n conc_dropdown.observe(conc_dropdown_handler, names = 'value')\n property_dropdown.observe(property_dropdown_handler, names = 'value')\n\n input_widgets = widgets.HBox([solute_dropdown, conc_dropdown, property_dropdown])\n\n display(input_widgets)\n display(output)\n #IPython.display.clear_output(wait=True) \n\n",
"_____no_output_____"
],
[
"GUI()",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c035e7bea1a880ac760ae2cc9c92d417318c14 | 6,518 | ipynb | Jupyter Notebook | Course/Data structures and algorithms/3.Basic algorithm/1.Basic algorithms/5.First and last index.ipynb | IulianOctavianPreda/Udacity | 4349f4c12c838bcf3e53409f943ca8aacd58c94b | [
"MIT"
]
| null | null | null | Course/Data structures and algorithms/3.Basic algorithm/1.Basic algorithms/5.First and last index.ipynb | IulianOctavianPreda/Udacity | 4349f4c12c838bcf3e53409f943ca8aacd58c94b | [
"MIT"
]
| null | null | null | Course/Data structures and algorithms/3.Basic algorithm/1.Basic algorithms/5.First and last index.ipynb | IulianOctavianPreda/Udacity | 4349f4c12c838bcf3e53409f943ca8aacd58c94b | [
"MIT"
]
| null | null | null | 28.587719 | 218 | 0.541577 | [
[
[
"## Problem statement\n\nGiven a sorted array that may have duplicate values, use *binary search* to find the **first** and **last** indexes of a given value.\n\nFor example, if you have the array `[0, 1, 2, 2, 3, 3, 3, 4, 5, 6]` and the given value is `3`, the answer will be `[4, 6]` (because the value `3` occurs first at index `4` and last at index `6` in the array).\n\nThe expected complexity of the problem is $O(log(n))$.",
"_____no_output_____"
]
],
[
[
"def first_and_last_index(arr, number):\n \"\"\"\n Given a sorted array that may have duplicate values, use binary \n search to find the first and last indexes of a given value.\n\n Args:\n arr(list): Sorted array (or Python list) that may have duplicate values\n number(int): Value to search for in the array\n Returns:\n a list containing the first and last indexes of the given value\n \"\"\"\n \n # TODO: Write your first_and_last function here\n # Note that you may want to write helper functions to find the start \n # index and the end index\n \n pass",
"_____no_output_____"
]
],
[
[
"<span class=\"graffiti-highlight graffiti-id_y3lxp1x-id_fkngaks\"><i></i><button>Hide Solution</button></span>",
"_____no_output_____"
]
],
[
[
"def first_and_last_index(arr, number):\n # search first occurence\n first_index = find_start_index(arr, number, 0, len(arr) - 1)\n \n # search last occurence\n last_index = find_end_index(arr, number, 0, len(arr) - 1)\n return [first_index, last_index]\n\n\ndef find_start_index(arr, number, start_index, end_index):\n # binary search solution to search for the first index of the array\n if start_index > end_index:\n return -1\n\n mid_index = start_index + (end_index - start_index)//2\n\n if arr[mid_index] == number:\n current_start_pos = find_start_index(arr, number, start_index, mid_index - 1)\n if current_start_pos != -1:\n start_pos = current_start_pos\n else:\n start_pos = mid_index\n return start_pos\n\n elif arr[mid_index] < number:\n return find_start_index(arr, number, mid_index + 1, end_index)\n else:\n return find_start_index(arr, number, start_index, mid_index - 1)\n\n\ndef find_end_index(arr, number, start_index, end_index):\n # binary search solution to search for the last index of the array\n if start_index > end_index:\n return -1\n\n mid_index = start_index + (end_index - start_index)//2\n\n if arr[mid_index] == number:\n current_end_pos = find_end_index(arr, number, mid_index + 1, end_index)\n if current_end_pos != -1:\n end_pos = current_end_pos\n else:\n end_pos = mid_index\n return end_pos\n elif arr[mid_index] < number:\n return find_end_index(arr, number, mid_index + 1, end_index)\n else:\n return find_end_index(arr, number, start_index, mid_index - 1)\n",
"_____no_output_____"
]
],
[
[
"Below are several different test cases you can use to check your solution.",
"_____no_output_____"
]
],
[
[
"def test_function(test_case):\n input_list = test_case[0]\n number = test_case[1]\n solution = test_case[2]\n output = first_and_last_index(input_list, number)\n if output == solution:\n print(\"Pass\")\n else:\n print(\"Fail\")",
"_____no_output_____"
],
[
"input_list = [1]\nnumber = 1\nsolution = [0, 0]\ntest_case_1 = [input_list, number, solution]\ntest_function(test_case_1)",
"_____no_output_____"
],
[
"input_list = [0, 1, 2, 3, 3, 3, 3, 4, 5, 6]\nnumber = 3\nsolution = [3, 6]\ntest_case_2 = [input_list, number, solution]\ntest_function(test_case_2)",
"_____no_output_____"
],
[
"input_list = [0, 1, 2, 3, 4, 5]\nnumber = 5\nsolution = [5, 5]\ntest_case_3 = [input_list, number, solution]\ntest_function(test_case_3)",
"_____no_output_____"
],
[
"input_list = [0, 1, 2, 3, 4, 5]\nnumber = 6\nsolution = [-1, -1]\ntest_case_4 = [input_list, number, solution]\ntest_function(test_case_4)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c03abc522ae5faa43e31199199b6e72b3cc2fb | 1,019 | ipynb | Jupyter Notebook | Untitled2.ipynb | mohamadhayeri9/tensorflow_example | f9cafa7a52a3a3d9b67ed9ece9a149f7fd9a8e86 | [
"MIT"
]
| 2 | 2020-05-13T22:34:12.000Z | 2020-05-13T22:34:17.000Z | Untitled2.ipynb | mohamadhayeri9/tensorflow_example | f9cafa7a52a3a3d9b67ed9ece9a149f7fd9a8e86 | [
"MIT"
]
| null | null | null | Untitled2.ipynb | mohamadhayeri9/tensorflow_example | f9cafa7a52a3a3d9b67ed9ece9a149f7fd9a8e86 | [
"MIT"
]
| null | null | null | 24.261905 | 241 | 0.509323 | [
[
[
"<a href=\"https://colab.research.google.com/github/mohamadhayeri9/tensorflow_example/blob/master/Untitled2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"print(\"ssss213\")",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
]
]
|
e7c043abd3a38b5b8aa07c1e46491cb4ae0d8dda | 2,946 | ipynb | Jupyter Notebook | examples/julia/Julia.ipynb | dfinke/qsharp-server | ff09855561fa38fb3aa3312a1245e99dea420f4c | [
"MIT"
]
| 1 | 2021-11-12T10:00:14.000Z | 2021-11-12T10:00:14.000Z | examples/julia/Julia.ipynb | dfinke/qsharp-server | ff09855561fa38fb3aa3312a1245e99dea420f4c | [
"MIT"
]
| null | null | null | examples/julia/Julia.ipynb | dfinke/qsharp-server | ff09855561fa38fb3aa3312a1245e99dea420f4c | [
"MIT"
]
| 1 | 2021-11-19T17:15:15.000Z | 2021-11-19T17:15:15.000Z | 21.194245 | 243 | 0.447047 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
e7c04a017320a33c674a230672487ad74e63f4a9 | 147,756 | ipynb | Jupyter Notebook | Midas_A_1.ipynb | pksenpai/Midas | 3a61fb9c8be67cd3b2a601867601b28ff6b9ea4f | [
"MIT"
]
| 1 | 2021-04-06T19:12:23.000Z | 2021-04-06T19:12:23.000Z | Midas_A_1.ipynb | pksenpai/Midas | 3a61fb9c8be67cd3b2a601867601b28ff6b9ea4f | [
"MIT"
]
| null | null | null | Midas_A_1.ipynb | pksenpai/Midas | 3a61fb9c8be67cd3b2a601867601b28ff6b9ea4f | [
"MIT"
]
| null | null | null | 125.110923 | 39,722 | 0.8066 | [
[
[
"!unzip /content/train.zip",
"Archive: /content/train.zip\n creating: train/\n creating: train/Sample002/\n inflating: train/Sample002/img002-048.png \n inflating: train/Sample002/img002-050.png \n inflating: train/Sample002/img002-006.png \n inflating: train/Sample002/img002-004.png \n inflating: train/Sample002/img002-053.png \n inflating: train/Sample002/img002-045.png \n inflating: train/Sample002/img002-052.png \n inflating: train/Sample002/img002-047.png \n inflating: train/Sample002/img002-020.png \n inflating: train/Sample002/img002-009.png \n inflating: train/Sample002/img002-011.png \n inflating: train/Sample002/img002-013.png \n inflating: train/Sample002/img002-034.png \n inflating: train/Sample002/img002-038.png \n inflating: train/Sample002/img002-024.png \n inflating: train/Sample002/img002-025.png \n inflating: train/Sample002/img002-018.png \n inflating: train/Sample002/img002-032.png \n inflating: train/Sample002/img002-028.png \n inflating: train/Sample002/img002-001.png \n inflating: train/Sample002/img002-019.png \n inflating: train/Sample002/img002-041.png \n inflating: train/Sample002/img002-042.png \n inflating: train/Sample002/img002-007.png \n inflating: train/Sample002/img002-043.png \n inflating: train/Sample002/img002-031.png \n inflating: train/Sample002/img002-040.png \n inflating: train/Sample002/img002-026.png \n inflating: train/Sample002/img002-003.png \n inflating: train/Sample002/img002-037.png \n inflating: train/Sample002/img002-046.png \n inflating: train/Sample002/img002-010.png \n inflating: train/Sample002/img002-049.png \n inflating: train/Sample002/img002-017.png \n inflating: train/Sample002/img002-035.png \n inflating: train/Sample002/img002-008.png \n inflating: train/Sample002/img002-002.png \n inflating: train/Sample002/img002-021.png \n inflating: train/Sample002/img002-012.png \n inflating: train/Sample002/img002-055.png \n creating: train/Sample004/\n inflating: train/Sample004/img004-048.png \n inflating: train/Sample004/img004-012.png \n inflating: train/Sample004/img004-049.png \n inflating: train/Sample004/img004-002.png \n inflating: train/Sample004/img004-029.png \n inflating: train/Sample004/img004-018.png \n inflating: train/Sample004/img004-040.png \n inflating: train/Sample004/img004-039.png \n inflating: train/Sample004/img004-022.png \n inflating: train/Sample004/img004-035.png \n inflating: train/Sample004/img004-014.png \n inflating: train/Sample004/img004-023.png \n inflating: train/Sample004/img004-009.png \n inflating: train/Sample004/img004-020.png \n inflating: train/Sample004/img004-024.png \n inflating: train/Sample004/img004-026.png \n inflating: train/Sample004/img004-011.png \n inflating: train/Sample004/img004-055.png \n inflating: train/Sample004/img004-042.png \n inflating: train/Sample004/img004-044.png \n inflating: train/Sample004/img004-033.png \n inflating: train/Sample004/img004-016.png \n inflating: train/Sample004/img004-001.png \n inflating: train/Sample004/img004-006.png \n inflating: train/Sample004/img004-038.png \n inflating: train/Sample004/img004-007.png \n inflating: train/Sample004/img004-036.png \n inflating: train/Sample004/img004-047.png \n inflating: train/Sample004/img004-027.png \n inflating: train/Sample004/img004-021.png \n inflating: train/Sample004/img004-050.png \n inflating: train/Sample004/img004-003.png \n inflating: train/Sample004/img004-025.png \n inflating: train/Sample004/img004-034.png \n inflating: train/Sample004/img004-041.png \n inflating: train/Sample004/img004-030.png \n inflating: train/Sample004/img004-013.png \n inflating: train/Sample004/img004-028.png \n inflating: train/Sample004/img004-008.png \n inflating: train/Sample004/img004-031.png \n creating: train/Sample003/\n inflating: train/Sample003/img003-022.png \n inflating: train/Sample003/img003-003.png \n inflating: train/Sample003/img003-002.png \n inflating: train/Sample003/img003-054.png \n inflating: train/Sample003/img003-016.png \n inflating: train/Sample003/img003-004.png \n inflating: train/Sample003/img003-031.png \n inflating: train/Sample003/img003-027.png \n inflating: train/Sample003/img003-023.png \n inflating: train/Sample003/img003-055.png \n inflating: train/Sample003/img003-033.png \n inflating: train/Sample003/img003-042.png \n inflating: train/Sample003/img003-009.png \n inflating: train/Sample003/img003-025.png \n inflating: train/Sample003/img003-010.png \n inflating: train/Sample003/img003-040.png \n inflating: train/Sample003/img003-039.png \n inflating: train/Sample003/img003-026.png \n inflating: train/Sample003/img003-012.png \n inflating: train/Sample003/img003-050.png \n inflating: train/Sample003/img003-048.png \n inflating: train/Sample003/img003-019.png \n inflating: train/Sample003/img003-005.png \n inflating: train/Sample003/img003-037.png \n inflating: train/Sample003/img003-008.png \n inflating: train/Sample003/img003-041.png \n inflating: train/Sample003/img003-044.png \n inflating: train/Sample003/img003-011.png \n inflating: train/Sample003/img003-047.png \n inflating: train/Sample003/img003-049.png \n inflating: train/Sample003/img003-045.png \n inflating: train/Sample003/img003-028.png \n inflating: train/Sample003/img003-015.png \n inflating: train/Sample003/img003-053.png \n inflating: train/Sample003/img003-020.png \n inflating: train/Sample003/img003-032.png \n inflating: train/Sample003/img003-036.png \n inflating: train/Sample003/img003-006.png \n inflating: train/Sample003/img003-017.png \n inflating: train/Sample003/img003-030.png \n creating: train/Sample010/\n inflating: train/Sample010/img010-012.png \n inflating: train/Sample010/img010-033.png \n inflating: train/Sample010/img010-017.png \n inflating: train/Sample010/img010-018.png \n inflating: train/Sample010/img010-022.png \n inflating: train/Sample010/img010-019.png \n inflating: train/Sample010/img010-025.png \n inflating: train/Sample010/img010-028.png \n inflating: train/Sample010/img010-040.png \n inflating: train/Sample010/img010-046.png \n inflating: train/Sample010/img010-036.png \n inflating: train/Sample010/img010-043.png \n inflating: train/Sample010/img010-004.png \n inflating: train/Sample010/img010-055.png \n inflating: train/Sample010/img010-032.png \n inflating: train/Sample010/img010-014.png \n inflating: train/Sample010/img010-034.png \n inflating: train/Sample010/img010-054.png \n inflating: train/Sample010/img010-007.png \n inflating: train/Sample010/img010-005.png \n inflating: train/Sample010/img010-037.png \n inflating: train/Sample010/img010-002.png \n inflating: train/Sample010/img010-023.png \n inflating: train/Sample010/img010-049.png \n inflating: train/Sample010/img010-003.png \n inflating: train/Sample010/img010-020.png \n inflating: train/Sample010/img010-039.png \n inflating: train/Sample010/img010-013.png \n inflating: train/Sample010/img010-041.png \n inflating: train/Sample010/img010-031.png \n inflating: train/Sample010/img010-051.png \n inflating: train/Sample010/img010-010.png \n inflating: train/Sample010/img010-008.png \n inflating: train/Sample010/img010-050.png \n inflating: train/Sample010/img010-052.png \n inflating: train/Sample010/img010-011.png \n inflating: train/Sample010/img010-047.png \n inflating: train/Sample010/img010-024.png \n inflating: train/Sample010/img010-042.png \n inflating: train/Sample010/img010-029.png \n creating: train/Sample001/\n inflating: train/Sample001/img001-054.png \n inflating: train/Sample001/img001-045.png \n inflating: train/Sample001/img001-043.png \n inflating: train/Sample001/img001-002.png \n inflating: train/Sample001/img001-034.png \n inflating: train/Sample001/img001-037.png \n inflating: train/Sample001/img001-012.png \n inflating: train/Sample001/img001-019.png \n inflating: train/Sample001/img001-047.png \n inflating: train/Sample001/img001-003.png \n inflating: train/Sample001/img001-027.png \n inflating: train/Sample001/img001-004.png \n inflating: train/Sample001/img001-007.png \n inflating: train/Sample001/img001-008.png \n inflating: train/Sample001/img001-033.png \n inflating: train/Sample001/img001-016.png \n inflating: train/Sample001/img001-053.png \n inflating: train/Sample001/img001-014.png \n inflating: train/Sample001/img001-011.png \n inflating: train/Sample001/img001-013.png \n inflating: train/Sample001/img001-001.png \n inflating: train/Sample001/img001-051.png \n inflating: train/Sample001/img001-010.png \n inflating: train/Sample001/img001-025.png \n inflating: train/Sample001/img001-029.png \n inflating: train/Sample001/img001-052.png \n inflating: train/Sample001/img001-018.png \n inflating: train/Sample001/img001-046.png \n inflating: train/Sample001/img001-050.png \n inflating: train/Sample001/img001-036.png \n inflating: train/Sample001/img001-049.png \n inflating: train/Sample001/img001-017.png \n inflating: train/Sample001/img001-026.png \n inflating: train/Sample001/img001-042.png \n inflating: train/Sample001/img001-009.png \n inflating: train/Sample001/img001-030.png \n inflating: train/Sample001/img001-021.png \n inflating: train/Sample001/img001-055.png \n inflating: train/Sample001/img001-044.png \n inflating: train/Sample001/img001-024.png \n creating: train/Sample008/\n inflating: train/Sample008/img008-042.png \n inflating: train/Sample008/img008-005.png \n inflating: train/Sample008/img008-040.png \n inflating: train/Sample008/img008-041.png \n inflating: train/Sample008/img008-039.png \n inflating: train/Sample008/img008-009.png \n inflating: train/Sample008/img008-016.png \n inflating: train/Sample008/img008-014.png \n inflating: train/Sample008/img008-013.png \n inflating: train/Sample008/img008-053.png \n inflating: train/Sample008/img008-033.png \n inflating: train/Sample008/img008-047.png \n inflating: train/Sample008/img008-046.png \n inflating: train/Sample008/img008-010.png \n inflating: train/Sample008/img008-017.png \n inflating: train/Sample008/img008-044.png \n inflating: train/Sample008/img008-012.png \n inflating: train/Sample008/img008-019.png \n inflating: train/Sample008/img008-003.png \n inflating: train/Sample008/img008-011.png \n inflating: train/Sample008/img008-007.png \n inflating: train/Sample008/img008-023.png \n inflating: train/Sample008/img008-029.png \n inflating: train/Sample008/img008-034.png \n inflating: train/Sample008/img008-027.png \n inflating: train/Sample008/img008-018.png \n inflating: train/Sample008/img008-038.png \n inflating: train/Sample008/img008-052.png \n inflating: train/Sample008/img008-055.png \n inflating: train/Sample008/img008-015.png \n inflating: train/Sample008/img008-024.png \n inflating: train/Sample008/img008-026.png \n inflating: train/Sample008/img008-032.png \n inflating: train/Sample008/img008-028.png \n inflating: train/Sample008/img008-008.png \n inflating: train/Sample008/img008-049.png \n inflating: train/Sample008/img008-021.png \n inflating: train/Sample008/img008-035.png \n inflating: train/Sample008/img008-031.png \n inflating: train/Sample008/img008-002.png \n creating: train/Sample006/\n inflating: train/Sample006/img006-032.png \n inflating: train/Sample006/img006-015.png \n inflating: train/Sample006/img006-010.png \n inflating: train/Sample006/img006-005.png \n inflating: train/Sample006/img006-045.png \n inflating: train/Sample006/img006-018.png \n inflating: train/Sample006/img006-042.png \n inflating: train/Sample006/img006-014.png \n inflating: train/Sample006/img006-021.png \n inflating: train/Sample006/img006-036.png \n inflating: train/Sample006/img006-050.png \n inflating: train/Sample006/img006-030.png \n inflating: train/Sample006/img006-049.png \n inflating: train/Sample006/img006-038.png \n inflating: train/Sample006/img006-039.png \n inflating: train/Sample006/img006-006.png \n inflating: train/Sample006/img006-041.png \n inflating: train/Sample006/img006-026.png \n inflating: train/Sample006/img006-055.png \n inflating: train/Sample006/img006-004.png \n inflating: train/Sample006/img006-003.png \n inflating: train/Sample006/img006-052.png \n inflating: train/Sample006/img006-008.png \n inflating: train/Sample006/img006-001.png \n inflating: train/Sample006/img006-029.png \n inflating: train/Sample006/img006-035.png \n inflating: train/Sample006/img006-022.png \n inflating: train/Sample006/img006-007.png \n inflating: train/Sample006/img006-027.png \n inflating: train/Sample006/img006-043.png \n inflating: train/Sample006/img006-012.png \n inflating: train/Sample006/img006-053.png \n inflating: train/Sample006/img006-024.png \n inflating: train/Sample006/img006-009.png \n inflating: train/Sample006/img006-020.png \n inflating: train/Sample006/img006-011.png \n inflating: train/Sample006/img006-017.png \n inflating: train/Sample006/img006-025.png \n inflating: train/Sample006/img006-051.png \n inflating: train/Sample006/img006-023.png \n creating: train/Sample007/\n inflating: train/Sample007/img007-026.png \n inflating: train/Sample007/img007-012.png \n inflating: train/Sample007/img007-001.png \n inflating: train/Sample007/img007-017.png \n inflating: train/Sample007/img007-011.png \n inflating: train/Sample007/img007-005.png \n inflating: train/Sample007/img007-041.png \n inflating: train/Sample007/img007-002.png \n inflating: train/Sample007/img007-034.png \n inflating: train/Sample007/img007-024.png \n inflating: train/Sample007/img007-023.png \n inflating: train/Sample007/img007-014.png \n inflating: train/Sample007/img007-047.png \n inflating: train/Sample007/img007-003.png \n inflating: train/Sample007/img007-013.png \n inflating: train/Sample007/img007-018.png \n inflating: train/Sample007/img007-040.png \n inflating: train/Sample007/img007-031.png \n inflating: train/Sample007/img007-045.png \n inflating: train/Sample007/img007-033.png \n inflating: train/Sample007/img007-032.png \n inflating: train/Sample007/img007-029.png \n inflating: train/Sample007/img007-004.png \n inflating: train/Sample007/img007-042.png \n inflating: train/Sample007/img007-039.png \n inflating: train/Sample007/img007-049.png \n inflating: train/Sample007/img007-025.png \n inflating: train/Sample007/img007-038.png \n inflating: train/Sample007/img007-015.png \n inflating: train/Sample007/img007-052.png \n inflating: train/Sample007/img007-008.png \n inflating: train/Sample007/img007-054.png \n inflating: train/Sample007/img007-019.png \n inflating: train/Sample007/img007-044.png \n inflating: train/Sample007/img007-027.png \n inflating: train/Sample007/img007-010.png \n inflating: train/Sample007/img007-036.png \n inflating: train/Sample007/img007-046.png \n inflating: train/Sample007/img007-022.png \n inflating: train/Sample007/img007-050.png \n creating: train/Sample005/\n inflating: train/Sample005/img005-045.png \n inflating: train/Sample005/img005-037.png \n inflating: train/Sample005/img005-027.png \n inflating: train/Sample005/img005-038.png \n inflating: train/Sample005/img005-029.png \n inflating: train/Sample005/img005-012.png \n inflating: train/Sample005/img005-004.png \n inflating: train/Sample005/img005-002.png \n inflating: train/Sample005/img005-017.png \n inflating: train/Sample005/img005-013.png \n inflating: train/Sample005/img005-009.png \n inflating: train/Sample005/img005-001.png \n inflating: train/Sample005/img005-016.png \n inflating: train/Sample005/img005-005.png \n inflating: train/Sample005/img005-007.png \n inflating: train/Sample005/img005-048.png \n inflating: train/Sample005/img005-033.png \n inflating: train/Sample005/img005-055.png \n inflating: train/Sample005/img005-034.png \n inflating: train/Sample005/img005-011.png \n inflating: train/Sample005/img005-036.png \n inflating: train/Sample005/img005-050.png \n inflating: train/Sample005/img005-051.png \n inflating: train/Sample005/img005-014.png \n inflating: train/Sample005/img005-024.png \n inflating: train/Sample005/img005-049.png \n inflating: train/Sample005/img005-008.png \n inflating: train/Sample005/img005-021.png \n inflating: train/Sample005/img005-025.png \n inflating: train/Sample005/img005-020.png \n inflating: train/Sample005/img005-031.png \n inflating: train/Sample005/img005-052.png \n inflating: train/Sample005/img005-054.png \n inflating: train/Sample005/img005-044.png \n inflating: train/Sample005/img005-046.png \n inflating: train/Sample005/img005-023.png \n inflating: train/Sample005/img005-047.png \n inflating: train/Sample005/img005-032.png \n inflating: train/Sample005/img005-022.png \n inflating: train/Sample005/img005-042.png \n creating: train/Sample009/\n inflating: train/Sample009/img009-023.png \n inflating: train/Sample009/img009-049.png \n inflating: train/Sample009/img009-020.png \n inflating: train/Sample009/img009-012.png \n inflating: train/Sample009/img009-045.png \n inflating: train/Sample009/img009-017.png \n inflating: train/Sample009/img009-037.png \n inflating: train/Sample009/img009-001.png \n inflating: train/Sample009/img009-035.png \n inflating: train/Sample009/img009-030.png \n inflating: train/Sample009/img009-047.png \n inflating: train/Sample009/img009-026.png \n inflating: train/Sample009/img009-008.png \n inflating: train/Sample009/img009-028.png \n inflating: train/Sample009/img009-006.png \n inflating: train/Sample009/img009-038.png \n inflating: train/Sample009/img009-042.png \n inflating: train/Sample009/img009-016.png \n inflating: train/Sample009/img009-022.png \n inflating: train/Sample009/img009-003.png \n inflating: train/Sample009/img009-029.png \n inflating: train/Sample009/img009-015.png \n inflating: train/Sample009/img009-010.png \n inflating: train/Sample009/img009-041.png \n inflating: train/Sample009/img009-046.png \n inflating: train/Sample009/img009-040.png \n inflating: train/Sample009/img009-011.png \n inflating: train/Sample009/img009-024.png \n inflating: train/Sample009/img009-018.png \n inflating: train/Sample009/img009-032.png \n inflating: train/Sample009/img009-005.png \n inflating: train/Sample009/img009-009.png \n inflating: train/Sample009/img009-034.png \n inflating: train/Sample009/img009-039.png \n inflating: train/Sample009/img009-054.png \n inflating: train/Sample009/img009-007.png \n inflating: train/Sample009/img009-051.png \n inflating: train/Sample009/img009-036.png \n inflating: train/Sample009/img009-052.png \n inflating: train/Sample009/img009-013.png \n"
],
[
"import os\nimport torch\nimport torchvision\nimport torch.nn as nn\nimport numpy as np\nimport torch.nn.functional as F\nfrom torchvision.datasets import ImageFolder\nfrom torch.utils.data import DataLoader\nimport torchvision.transforms as tt\nfrom torch.utils.data import random_split\nfrom torchvision.utils import make_grid\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"data_dir = '/content/train'\nclasses = os.listdir(data_dir)\nprint(classes)",
"['Sample001', 'Sample003', 'Sample005', 'Sample004', 'Sample002', 'Sample010', 'Sample008', 'Sample006', 'Sample009', 'Sample007']\n"
],
[
"tfms = tt.Compose([tt.Resize((32,32)),\n tt.ToTensor(),tt.Grayscale(num_output_channels=1)])",
"_____no_output_____"
],
[
"dataset = ImageFolder(data_dir,tfms)\n",
"_____no_output_____"
],
[
"val_size = 50\ntrain_size = len(dataset) - val_size\n\ntrain_ds, val_ds = random_split(dataset, [train_size, val_size])\nlen(train_ds), len(val_ds)",
"_____no_output_____"
],
[
"img_tensor, label = dataset[0]\nprint(img_tensor.shape, label)",
"torch.Size([1, 32, 32]) 0\n"
],
[
"batch_size = 16\n\ntrain_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=3, pin_memory=True)\nvalid_dl = DataLoader(val_ds, batch_size*2, num_workers=3, pin_memory=True)\n",
"/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py:477: UserWarning: This DataLoader will create 3 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.\n cpuset_checked))\n"
],
[
"\ndef show_batch(dl):\n for images, labels in dl:\n fig, ax = plt.subplots(figsize=(12, 12))\n ax.set_xticks([]); ax.set_yticks([])\n ax.imshow(make_grid(images[:64], nrow=8).permute(1, 2, 0))\n break",
"_____no_output_____"
],
[
"show_batch(train_dl)\n",
"/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py:477: UserWarning: This DataLoader will create 3 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.\n cpuset_checked))\n"
],
[
"def get_default_device():\n \"\"\"Pick GPU if available, else CPU\"\"\"\n if torch.cuda.is_available():\n return torch.device('cuda')\n else:\n return torch.device('cpu')\n \ndef to_device(data, device):\n \"\"\"Move tensor(s) to chosen device\"\"\"\n if isinstance(data, (list,tuple)):\n return [to_device(x, device) for x in data]\n return data.to(device, non_blocking=True)\n\nclass DeviceDataLoader():\n \"\"\"Wrap a dataloader to move data to a device\"\"\"\n def __init__(self, dl, device):\n self.dl = dl\n self.device = device\n \n def __iter__(self):\n \"\"\"Yield a batch of data after moving it to device\"\"\"\n for b in self.dl: \n yield to_device(b, self.device)\n\n def __len__(self):\n \"\"\"Number of batches\"\"\"\n return len(self.dl)",
"_____no_output_____"
],
[
"device = get_default_device()\ndevice\n",
"_____no_output_____"
],
[
"train_dl = DeviceDataLoader(train_dl, device)\nvalid_dl = DeviceDataLoader(valid_dl, device)",
"_____no_output_____"
],
[
"def accuracy(outputs, labels):\n _, preds = torch.max(outputs, dim=1)\n return torch.tensor(torch.sum(preds == labels).item() / len(preds))\n\nclass ImageClassificationBase(nn.Module):\n def training_step(self, batch):\n images, labels = batch \n out = self(images) # Generate predictions\n loss = F.cross_entropy(out, labels) # Calculate loss\n return loss\n \n def validation_step(self, batch):\n images, labels = batch \n out = self(images) # Generate predictions\n loss = F.cross_entropy(out, labels) # Calculate loss\n acc = accuracy(out, labels) # Calculate accuracy\n return {'val_loss': loss.detach(), 'val_acc': acc}\n \n def validation_epoch_end(self, outputs):\n batch_losses = [x['val_loss'] for x in outputs]\n epoch_loss = torch.stack(batch_losses).mean() # Combine losses\n batch_accs = [x['val_acc'] for x in outputs]\n epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies\n return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}\n \n def epoch_end(self, epoch, result):\n print(\"Epoch [{}], last_lr: {:.5f}, train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}\".format(\n epoch, result['lrs'][-1], result['train_loss'], result['val_loss'], result['val_acc']))",
"_____no_output_____"
],
[
"def conv_block(in_channels, out_channels, pool=False):\n layers = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), \n nn.BatchNorm2d(out_channels), \n nn.ReLU(inplace=True)]\n if pool: layers.append(nn.MaxPool2d(2))\n return nn.Sequential(*layers)\n\nclass ResNet9(ImageClassificationBase):\n def __init__(self, in_channels, num_classes):\n super().__init__()\n \n self.conv1 = conv_block(in_channels, 64)\n self.conv2 = conv_block(64, 128, pool=True)\n self.res1 = nn.Sequential(conv_block(128, 128), conv_block(128, 128))\n \n self.conv3 = conv_block(128, 256, pool=True)\n self.conv4 = conv_block(256, 512, pool=True)\n self.res2 = nn.Sequential(conv_block(512, 512), conv_block(512, 512))\n \n self.classifier = nn.Sequential(nn.MaxPool2d(4), \n nn.Flatten(), \n nn.Linear(512, num_classes))\n \n def forward(self, xb):\n out = self.conv1(xb)\n out = self.conv2(out)\n out = self.res1(out) + out\n out = self.conv3(out)\n out = self.conv4(out)\n out = self.res2(out) + out\n out = self.classifier(out)\n return out",
"_____no_output_____"
],
[
"model = to_device(ResNet9(1, 10), device)\nmodel",
"_____no_output_____"
],
[
"@torch.no_grad()\ndef evaluate(model, val_loader):\n model.eval()\n outputs = [model.validation_step(batch) for batch in val_loader]\n return model.validation_epoch_end(outputs)\n\ndef get_lr(optimizer):\n for param_group in optimizer.param_groups:\n return param_group['lr']\n\ndef fit_one_cycle(epochs, max_lr, model, train_loader, val_loader, \n weight_decay=0, grad_clip=None, opt_func=torch.optim.SGD):\n torch.cuda.empty_cache()\n history = []\n \n # Set up cutom optimizer with weight decay\n optimizer = opt_func(model.parameters(), max_lr, weight_decay=weight_decay)\n # Set up one-cycle learning rate scheduler\n sched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epochs, \n steps_per_epoch=len(train_loader))\n \n for epoch in range(epochs):\n # Training Phase \n model.train()\n train_losses = []\n lrs = []\n for batch in train_loader:\n loss = model.training_step(batch)\n train_losses.append(loss)\n loss.backward()\n \n # Gradient clipping\n if grad_clip: \n nn.utils.clip_grad_value_(model.parameters(), grad_clip)\n \n optimizer.step()\n optimizer.zero_grad()\n \n # Record & update learning rate\n lrs.append(get_lr(optimizer))\n sched.step()\n \n # Validation phase\n result = evaluate(model, val_loader)\n result['train_loss'] = torch.stack(train_losses).mean().item()\n result['lrs'] = lrs\n model.epoch_end(epoch, result)\n history.append(result)\n return history",
"_____no_output_____"
],
[
"history = [evaluate(model, valid_dl)]\nhistory",
"/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py:477: UserWarning: This DataLoader will create 3 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.\n cpuset_checked))\n"
],
[
"epochs = 10\nmax_lr = 0.01\ngrad_clip = 0.1\nweight_decay = 1e-4\nopt_func = torch.optim.Adam",
"_____no_output_____"
],
[
"%%time\nhistory += fit_one_cycle(epochs, max_lr, model, train_dl, valid_dl, \n grad_clip=grad_clip, \n weight_decay=weight_decay, \n opt_func=opt_func)\n",
"/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py:477: UserWarning: This DataLoader will create 3 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.\n cpuset_checked))\n"
],
[
"def plot_accuracies(history):\n accuracies = [x['val_acc'] for x in history]\n plt.plot(accuracies, '-x')\n plt.xlabel('epoch')\n plt.ylabel('accuracy')\n plt.title('Accuracy vs. No. of epochs');\n\nplot_accuracies(history)",
"_____no_output_____"
],
[
"def plot_losses(history):\n train_losses = [x.get('train_loss') for x in history]\n val_losses = [x['val_loss'] for x in history]\n plt.plot(train_losses, '-bx')\n plt.plot(val_losses, '-rx')\n plt.xlabel('epoch')\n plt.ylabel('loss')\n plt.legend(['Training', 'Validation'])\n plt.title('Loss vs. No. of epochs');\n\nplot_losses(history)",
"_____no_output_____"
],
[
"def plot_lrs(history):\n lrs = np.concatenate([x.get('lrs', []) for x in history])\n plt.plot(lrs)\n plt.xlabel('Batch no.')\n plt.ylabel('Learning rate')\n plt.title('Learning Rate vs. Batch no.');\nplot_lrs(history)",
"_____no_output_____"
],
[
"torch.save(model, '/content/Midas_A.1')\n\n",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c053482993ac8b0f7191ed75a45affd86343db | 136,724 | ipynb | Jupyter Notebook | ventilation/mode_analysis.ipynb | cosgriffc/mimic-ccu | c23098f3df7788191adb269c8f304a5b417205f2 | [
"MIT"
]
| 1 | 2019-04-10T13:43:55.000Z | 2019-04-10T13:43:55.000Z | ventilation/mode_analysis.ipynb | cosgriffc/mimic-ccu | c23098f3df7788191adb269c8f304a5b417205f2 | [
"MIT"
]
| null | null | null | ventilation/mode_analysis.ipynb | cosgriffc/mimic-ccu | c23098f3df7788191adb269c8f304a5b417205f2 | [
"MIT"
]
| null | null | null | 226.364238 | 118,140 | 0.892791 | [
[
[
"## Project: Ventilation in the CCU\n### EDA: Ventilator Mode in the CCU Cohort\n### C.V. Cosgriff\n#### NYU CCU Data Science Group\n\n\n__Question:__ Can you guys please see how many of the 756 patients received receive SIMV or IMV as the mode of mechanical ventilation. A very interesting (and relatively simple) analysis would be to compare length of stay, mortality, ventilator free days and MV duration between those undergoing SIMV/IMV and other modes.\n\n### Analysis Plan\n* Extract the CCU Metavision Cohort with basic demographic data\n* Identify the `itemid` for ventilator mode\n* Extract the ventilator mode items for each patient on the first day\n* Decide how to summarise if multiple modes exist\n* Assign patients to each group and compare unadjusted mortality\n* Build logistic regression model for hospital mortality\n* Build Poisson model for length of stay\n\n## 0 - Environment",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\n\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set()\n%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport psycopg2\ndbname = 'mimic'\nschema_name = 'mimiciii'\ndb_schema = 'SET search_path TO {0};'.format(schema_name)\ncon = psycopg2.connect(database=dbname)",
"_____no_output_____"
]
],
[
[
"## 1 - CCU Cohort Extraction",
"_____no_output_____"
]
],
[
[
"query = db_schema + '''\nSELECT ie.icustay_id, ie.hadm_id, ie.subject_id, ie.dbsource\n , ie.first_careunit, ie.intime, ie.outtime, ie.los\n , ied.admission_age, ied.gender, ied.ethnicity\n , ied.first_icu_stay, oa.oasis AS oasis_score\n , elix.elixhauser_vanwalraven AS elixhauser_score\n , vd.starttime AS vent_start, vd.endtime AS vent_end\n , ad.hospital_expire_flag\nFROM icustays ie\nLEFT JOIN icustay_detail ied\n ON ie.icustay_id = ied.icustay_id\nLEFT JOIN admissions ad\n ON ie.hadm_id = ad.hadm_id\nLEFT JOIN elixhauser_ahrq_score elix\n ON ie.hadm_id = elix.hadm_id\nLEFT JOIN oasis oa\n ON ie.icustay_id = oa.icustay_id\nLEFT JOIN ventdurations vd\n ON ie.icustay_id = vd.icustay_id;\n'''\ncohort_df = pd.read_sql(query, con)\nprint(cohort_df.shape)\ndisplay(cohort_df.head())",
"(73298, 17)\n"
],
[
"cohort_df = cohort_df.loc[cohort_df.dbsource == 'metavision', :]\ncohort_df = cohort_df.loc[cohort_df.first_careunit == 'CCU', :]\ncohort_df = cohort_df.loc[cohort_df.admission_age >= 16, :]\ncohort_df = cohort_df.drop('dbsource', axis=1)",
"_____no_output_____"
],
[
"cohort_df.drop_duplicates(subset='icustay_id').shape",
"_____no_output_____"
]
],
[
[
"## 2 - Identify Ventilator Mode Items",
"_____no_output_____"
]
],
[
[
"query = db_schema + '''\nSELECT itemid, label, dbsource, linksto \nFROM d_items \nWHERE LOWER(label) LIKE '%mode%'\nAND dbsource='metavision';\n'''\n\nd_search = pd.read_sql_query(query, con)\ndisplay(d_search)",
"_____no_output_____"
]
],
[
[
"It appears the `itemid` is __223849__.",
"_____no_output_____"
],
[
"## 3 - Extract Ventilation Modes",
"_____no_output_____"
]
],
[
[
"query = db_schema + '''\nWITH vent_mode_day1 AS (\n SELECT ce.icustay_id, ce.charttime - ie.intime AS offset\n , ce.value\n FROM icustays ie\n LEFT JOIN chartevents ce\n ON ie.icustay_id = ce.icustay_id\n WHERE ce.itemid = 223849\n)\nSELECT vm.icustay_id, vm.value AS vent_mode_24h\nFROM vent_mode_day1 vm\nWHERE vm.offset <= interval '24' hour;\n'''\n\nvm_df = pd.read_sql(query, con)\ndisplay(vm_df.head())",
"_____no_output_____"
]
],
[
[
"Lets look at the distribution of different ventilation modes in this data.",
"_____no_output_____"
]
],
[
[
"vm_df.groupby(vm_df.vent_mode_24h).count().plot(kind='bar', figsize=(12,6))",
"_____no_output_____"
]
],
[
[
"Will stop here for now to consult with team about these modes.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
e7c05c9e3791b72982b81de0799d35522d1a0403 | 7,712 | ipynb | Jupyter Notebook | notebooks/.ipynb_checkpoints/0_format_BRATS_data-checkpoint.ipynb | neurips2021vat/Variance-Aware-Training | 2dcd017ef06e81e299448bdd9da65fa682835127 | [
"BSD-2-Clause"
]
| null | null | null | notebooks/.ipynb_checkpoints/0_format_BRATS_data-checkpoint.ipynb | neurips2021vat/Variance-Aware-Training | 2dcd017ef06e81e299448bdd9da65fa682835127 | [
"BSD-2-Clause"
]
| null | null | null | notebooks/.ipynb_checkpoints/0_format_BRATS_data-checkpoint.ipynb | neurips2021vat/Variance-Aware-Training | 2dcd017ef06e81e299448bdd9da65fa682835127 | [
"BSD-2-Clause"
]
| null | null | null | 26.965035 | 115 | 0.514652 | [
[
[
"import os\nimport numpy as np\nimport nibabel as nib\nimport matplotlib.pyplot as plt\nimport torch\nfrom tqdm import tqdm\nimport json\nfrom sklearn.model_selection import GroupKFold",
"_____no_output_____"
]
],
[
[
"# Format Data",
"_____no_output_____"
]
],
[
[
"def permute(image):\n image = torch.Tensor(image)\n image = image.permute(3,0,1,2).numpy()\n return image",
"_____no_output_____"
],
[
"DATA_PATH = '../data/brats_dataset/raw_data/'\nOUT_PATH = '../data/brats_dataset/processed_data_2d/'\nTABLE_PATH = '../data/split_tables/brats_2d/'\nos.makedirs(TABLE_PATH,exist_ok=True)",
"_____no_output_____"
],
[
"patient_list = [i for i in os.listdir(DATA_PATH) if i.find('g_')!=-1]\nn_slices_width = 128",
"_____no_output_____"
],
[
"for patient in tqdm(patient_list):\n img_flair = np.array(nib.load(DATA_PATH+patient+'/'+patient+'_flair.nii.gz').dataobj)\n img_t1 = np.array(nib.load(DATA_PATH+patient+'/'+patient+'_t1.nii.gz').dataobj)\n img_t1ce = np.array(nib.load(DATA_PATH+patient+'/'+patient+'_t1ce.nii.gz').dataobj)\n img_t2 = np.array(nib.load(DATA_PATH+patient+'/'+patient+'_t2.nii.gz').dataobj)\n seg = np.array(nib.load(DATA_PATH+patient+'/'+patient+'_seg.nii.gz').dataobj)\n \n img = np.stack([img_flair,img_t1,img_t1ce,img_t2],axis=0)\n \n seg = seg.reshape(1,seg.shape[0],seg.shape[1],seg.shape[2])\n seg[seg==4] = 3\n\n os.makedirs(OUT_PATH+patient,exist_ok=True)\n \n \n \n for i in range(img.shape[-1]):\n temp = img[:,:,:,i]\n temp_y = seg[:,:,:,i]\n\n \n #save\n np.save(OUT_PATH+patient+f'/{i}_voxels.npy',temp)\n np.save(OUT_PATH+patient+f'/{i}_labels.npy',temp_y)\n \n",
" 93%|█████████▎| 342/369 [22:45<01:42, 3.78s/it]"
]
],
[
[
"# Prepare split tables",
"_____no_output_____"
]
],
[
[
"patient_list = [OUT_PATH[1:]+i for i in os.listdir(OUT_PATH) if i.find('.')==-1]\nprint(f'Total number of patients: {len(patient_list)}')",
"Total number of patients: 22\n"
],
[
"patient_arr = []\nrecords = []\nfor patient in patient_list:\n records += [patient+'/'+i for i in os.listdir('.'+patient) if i.find('voxels')!=-1]\n patient_arr += [patient]*len([patient+'/'+i for i in os.listdir('.'+patient) if i.find('voxels')!=-1])\n \nrecords = np.array(records)\npatient_arr = np.array(patient_arr)",
"_____no_output_____"
],
[
"#create test\nkf = GroupKFold(n_splits=2)\n\nfor (train,test) in kf.split(records,records,patient_arr):\n \n records_test = records[test]\n \n \n #create test\n split = {\n 'test': records_test.tolist(),\n }\n \n with open(f'{TABLE_PATH}test_split_table.json', 'w') as outfile:\n json.dump(split, outfile)\n break\n\npatient_arr = patient_arr[train]\nrecords = records[train]",
"_____no_output_____"
],
[
"#create train and validation\nkf = GroupKFold(n_splits=2)\n\nfor (train,test) in kf.split(records,records,patient_arr):\n \n records_test = records[test]\n \n \n #create test\n split = {\n 'test': records_test.tolist(),\n }\n \n with open(f'{TABLE_PATH}test_split_table.json', 'w') as outfile:\n json.dump(split, outfile)\n break\n\npatient_arr = patient_arr[train]\nrecords = records[train]",
"_____no_output_____"
],
[
"#create train and validation\nn_patients = [1,2,4,8]\n\npatients_unique = np.unique(patient_arr)\n\nfor i in n_patients:\n \n train_patients = patients_unique[:i]\n train_records = np.empty(0)\n for patient in train_patients.tolist():\n train_records = np.append(train_records,records[patient_arr==patient],axis=0)\n \n val_patients = patients_unique[-2:]\n val_records = np.empty(0)\n for patient in val_patients.tolist():\n val_records = np.append(val_records,records[patient_arr==patient],axis=0)\n \n \n \n split = {\n 'train': train_records.tolist(),\n 'val': val_records.tolist(),\n 'pretrain': records.tolist(),\n }\n with open(f'{TABLE_PATH}{i}_split_table.json', 'w') as outfile:\n json.dump(split, outfile)\n",
"_____no_output_____"
],
[
"#create UB\n\ntrain_patients = patients_unique[:patients_unique.shape[0]//2]\ntrain_records = np.empty(0)\nfor patient in train_patients.tolist():\n train_records = np.append(train_records,records[patient_arr==patient],axis=0)\n\nval_patients = patients_unique[patients_unique.shape[0]//2:]\nval_records = np.empty(0)\nfor patient in val_patients.tolist():\n val_records = np.append(val_records,records[patient_arr==patient],axis=0)\n\nsplit = {\n 'train': train_records.tolist(),\n 'val': val_records.tolist(),\n }\nwith open(f'{TABLE_PATH}UB_split_table.json', 'w') as outfile:\n json.dump(split, outfile)\n",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c08437407da1dd3e1fa79f6dfa62a7b755631b | 38,414 | ipynb | Jupyter Notebook | res/Python-for-Data-Analysis/Pandas/Merging, Joining, and Concatenating .ipynb | Calvibert/machine-learning-exercises | 8184a8338505ea8075992f419385620be6522d14 | [
"MIT"
]
| 25 | 2020-10-01T05:44:04.000Z | 2020-10-30T17:30:26.000Z | res/Python-for-Data-Analysis/Pandas/Merging, Joining, and Concatenating .ipynb | Calvibert/machine-learning-exercises | 8184a8338505ea8075992f419385620be6522d14 | [
"MIT"
]
| 14 | 2020-10-01T09:32:47.000Z | 2020-11-05T16:17:12.000Z | res/Python-for-Data-Analysis/Pandas/Merging, Joining, and Concatenating .ipynb | Calvibert/machine-learning-exercises | 8184a8338505ea8075992f419385620be6522d14 | [
"MIT"
]
| 143 | 2020-10-01T05:47:04.000Z | 2021-10-03T04:25:42.000Z | 25.729404 | 223 | 0.296559 | [
[
[
"___\n\n<a href='http://www.pieriandata.com'> <img src='../Pierian_Data_Logo.png' /></a>\n___",
"_____no_output_____"
],
[
"# Merging, Joining, and Concatenating\n\nThere are 3 main ways of combining DataFrames together: Merging, Joining and Concatenating. In this lecture we will discuss these 3 methods with examples.\n\n____",
"_____no_output_____"
],
[
"### Example DataFrames",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],\n 'B': ['B0', 'B1', 'B2', 'B3'],\n 'C': ['C0', 'C1', 'C2', 'C3'],\n 'D': ['D0', 'D1', 'D2', 'D3']},\n index=[0, 1, 2, 3])",
"_____no_output_____"
],
[
"df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],\n 'B': ['B4', 'B5', 'B6', 'B7'],\n 'C': ['C4', 'C5', 'C6', 'C7'],\n 'D': ['D4', 'D5', 'D6', 'D7']},\n index=[4, 5, 6, 7]) ",
"_____no_output_____"
],
[
"df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],\n 'B': ['B8', 'B9', 'B10', 'B11'],\n 'C': ['C8', 'C9', 'C10', 'C11'],\n 'D': ['D8', 'D9', 'D10', 'D11']},\n index=[8, 9, 10, 11])",
"_____no_output_____"
],
[
"df1",
"_____no_output_____"
],
[
"df2",
"_____no_output_____"
],
[
"df3",
"_____no_output_____"
]
],
[
[
"## Concatenation\n\nConcatenation basically glues together DataFrames. Keep in mind that dimensions should match along the axis you are concatenating on. You can use **pd.concat** and pass in a list of DataFrames to concatenate together:",
"_____no_output_____"
]
],
[
[
"pd.concat([df1,df2,df3])",
"_____no_output_____"
],
[
"pd.concat([df1,df2,df3],axis=1)",
"_____no_output_____"
]
],
[
[
"_____\n## Example DataFrames",
"_____no_output_____"
]
],
[
[
"left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],\n 'A': ['A0', 'A1', 'A2', 'A3'],\n 'B': ['B0', 'B1', 'B2', 'B3']})\n \nright = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],\n 'C': ['C0', 'C1', 'C2', 'C3'],\n 'D': ['D0', 'D1', 'D2', 'D3']}) ",
"_____no_output_____"
],
[
"left",
"_____no_output_____"
],
[
"right",
"_____no_output_____"
]
],
[
[
"___",
"_____no_output_____"
],
[
"## Merging\n\nThe **merge** function allows you to merge DataFrames together using a similar logic as merging SQL Tables together. For example:",
"_____no_output_____"
]
],
[
[
"pd.merge(left,right,how='inner',on='key')",
"_____no_output_____"
]
],
[
[
"Or to show a more complicated example:",
"_____no_output_____"
]
],
[
[
"left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],\n 'key2': ['K0', 'K1', 'K0', 'K1'],\n 'A': ['A0', 'A1', 'A2', 'A3'],\n 'B': ['B0', 'B1', 'B2', 'B3']})\n \nright = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],\n 'key2': ['K0', 'K0', 'K0', 'K0'],\n 'C': ['C0', 'C1', 'C2', 'C3'],\n 'D': ['D0', 'D1', 'D2', 'D3']})",
"_____no_output_____"
],
[
"pd.merge(left, right, on=['key1', 'key2'])",
"_____no_output_____"
],
[
"pd.merge(left, right, how='outer', on=['key1', 'key2'])",
"_____no_output_____"
],
[
"pd.merge(left, right, how='right', on=['key1', 'key2'])",
"_____no_output_____"
],
[
"pd.merge(left, right, how='left', on=['key1', 'key2'])",
"_____no_output_____"
]
],
[
[
"## Joining\nJoining is a convenient method for combining the columns of two potentially differently-indexed DataFrames into a single result DataFrame.",
"_____no_output_____"
]
],
[
[
"left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],\n 'B': ['B0', 'B1', 'B2']},\n index=['K0', 'K1', 'K2']) \n\nright = pd.DataFrame({'C': ['C0', 'C2', 'C3'],\n 'D': ['D0', 'D2', 'D3']},\n index=['K0', 'K2', 'K3'])",
"_____no_output_____"
],
[
"left.join(right)",
"_____no_output_____"
],
[
"left.join(right, how='outer')",
"_____no_output_____"
]
],
[
[
"# Great Job!",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
]
|
e7c087360721c1f1201fe5f4cddd77d093cd1715 | 484,076 | ipynb | Jupyter Notebook | 3rd rush.ipynb | sunnyCUD/PannyClass | b99c7ff80d2e4593a91ccdc0688472e8f6329651 | [
"MIT"
]
| null | null | null | 3rd rush.ipynb | sunnyCUD/PannyClass | b99c7ff80d2e4593a91ccdc0688472e8f6329651 | [
"MIT"
]
| null | null | null | 3rd rush.ipynb | sunnyCUD/PannyClass | b99c7ff80d2e4593a91ccdc0688472e8f6329651 | [
"MIT"
]
| null | null | null | 800.12562 | 25,028 | 0.950576 | [
[
[
"import cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom PIL import Image\nimport glob\nimport math",
"_____no_output_____"
],
[
"def select_Filter(name):\n if name == 0:\n matrix = [\n [1,1,1,1,1],\n [1,1,1,1,1],\n [1,1,1,1,1],\n [1,1,1,1,1],\n [1,1,1,1,1]\n ]\n s= 1/25\n if name == 1:\n matrix = [\n [0,1,2,1,0],\n [1,3,5,3,1],\n [2,5,9,5,2],\n [1,3,5,3,1],\n [0,1,2,1,0]\n ]\n s=1/57\n if name == 2:\n matrix = [\n [0,0,-1,0,0],\n [0,-1,-2,-1,0],\n [-1,-2,16,-2,-1],\n [0,-1,-2,-1,0],\n [0,0,-1,0,0]\n ]\n s=1/16\n return int(len(matrix)/2),int(len(matrix[0])/2),matrix,s\n ",
"_____no_output_____"
],
[
"'''under construction'''\ndef image_Filter(img,filter_type):\n img_H,img_W = img.shape\n if filter_type == 0:\n mask_H,mask_W,matrix,s = select_Filter(0)\n if filter_type == 1:\n mask_H,mask_W,matrix,s = select_Filter(1)\n if filter_type == 2:\n mask_H,mask_W,matrix,s = select_Filter(2)\n \n \n img_copy = img\n for v in range(0,img_H):\n for u in range(0,img_W):\n summy =0\n for j in range(-mask_H,mask_H):\n for i in range(-mask_W,mask_W):\n if v+j < 0 or v+j > img_H-1 or u+i <0 or u+i> img_W-1:\n summy = summy + 0\n else:\n p = img_copy[v+j,u+i]\n c = matrix[j+mask_H][i+mask_W]\n summy = summy + c*p \n q = round(s*summy)\n if (q < 0) :\n q = 0\n if (q > 255):\n q = 255\n img[v][u] = q\n \n return img",
"_____no_output_____"
],
[
"def rescale(img,scale):\n scale_percent = scale # percent of original size\n width = int(img.shape[1] * scale_percent / 100)\n height = int(img.shape[0] * scale_percent / 100)\n dim = (width, height)\n # resize image\n resized = cv2.resize(img, dim, interpolation = cv2.INTER_AREA)\n return resized",
"_____no_output_____"
],
[
"#import images from a folder into list\nimage_list = []\nfor filename in glob.glob('TU_pic/*.jpg'):\n image_list.append(filename)\n print(filename)",
"TU_pic\\0645133-18878.jpg\nTU_pic\\0645133-18879.jpg\nTU_pic\\0645133-18880.jpg\nTU_pic\\0645133-18924.jpg\nTU_pic\\0645133-18925.jpg\nTU_pic\\0645133-18926.jpg\nTU_pic\\0645133-18927.jpg\nTU_pic\\0704716-18939.jpg\nTU_pic\\0704716-18940.jpg\nTU_pic\\0922091-18941.jpg\nTU_pic\\0922091-18942.jpg\n"
],
[
"for pic_name in image_list:\n img = cv2.imread(pic_name,0)\n img1 = rescale(img,5)\n img2 = image_Filter(img1,0)\n plt.figure()\n plt.imshow(img2,cmap =\"gray\")",
"_____no_output_____"
],
[
"for pic_name in image_list:\n img = cv2.imread(pic_name,0)\n img1 = rescale(img,5)\n img2 = image_Filter(img1,1)\n plt.figure()\n plt.imshow(img2,cmap =\"gray\")",
"_____no_output_____"
],
[
"for pic_name in image_list:\n img = cv2.imread(pic_name,0)\n img1 = rescale(img,5)\n img2 = image_Filter(img1,2)\n plt.figure()\n plt.imshow(img2,cmap =\"gray\")",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c0943acf5dda9e336126d8431236c72138cdfd | 619,377 | ipynb | Jupyter Notebook | huggingface_t5_6_3.ipynb | skywalker00001/Conterfactual-Reasoning-Project | 48464dcd073507801fdea50dbb3baac10644470f | [
"MIT"
]
| null | null | null | huggingface_t5_6_3.ipynb | skywalker00001/Conterfactual-Reasoning-Project | 48464dcd073507801fdea50dbb3baac10644470f | [
"MIT"
]
| null | null | null | huggingface_t5_6_3.ipynb | skywalker00001/Conterfactual-Reasoning-Project | 48464dcd073507801fdea50dbb3baac10644470f | [
"MIT"
]
| null | null | null | 199.734602 | 257,114 | 0.504032 | [
[
[
"<a href=\"https://colab.research.google.com/github/skywalker00001/Conterfactual-Reasoning-Project/blob/main/huggingface_t5_6_3.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"Version 6.0\n\nground truth using \"denosing\"\n\nfind out the different pairs and only output those different things",
"_____no_output_____"
],
[
"# 1. Preparation",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')\nroot = 'drive/MyDrive/LM/'",
"Mounted at /content/drive\n"
],
[
"!pip install sentencepiece\n!pip install transformers -q\n!pip install wandb -q",
"Collecting sentencepiece\n Downloading sentencepiece-0.1.96-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.2 MB)\n\u001b[K |████████████████████████████████| 1.2 MB 3.2 MB/s \n\u001b[?25hInstalling collected packages: sentencepiece\nSuccessfully installed sentencepiece-0.1.96\n\u001b[K |████████████████████████████████| 3.8 MB 2.1 MB/s \n\u001b[K |████████████████████████████████| 67 kB 4.7 MB/s \n\u001b[K |████████████████████████████████| 596 kB 59.1 MB/s \n\u001b[K |████████████████████████████████| 895 kB 47.0 MB/s \n\u001b[K |████████████████████████████████| 6.5 MB 50.3 MB/s \n\u001b[K |████████████████████████████████| 1.7 MB 3.2 MB/s \n\u001b[K |████████████████████████████████| 181 kB 58.4 MB/s \n\u001b[K |████████████████████████████████| 144 kB 36.5 MB/s \n\u001b[K |████████████████████████████████| 63 kB 1.6 MB/s \n\u001b[?25h Building wheel for pathtools (setup.py) ... \u001b[?25l\u001b[?25hdone\n"
],
[
"# Importing stock libraries\nimport numpy as np\nimport pandas as pd\nimport time\nfrom tqdm import tqdm\nimport os\nimport regex as re\nimport sys\nsys.path.append('/content/drive/MyDrive/LM/')\nfrom global_param import MyConfig\nimport nltk\nnltk.download(\"punkt\")\nfrom nltk.tokenize.treebank import TreebankWordDetokenizer\ndetokenizer = TreebankWordDetokenizer()\n\nimport torch\nfrom torch import cuda\nimport torch.nn.functional as F\nfrom torch.utils.data import Dataset, DataLoader, RandomSampler, SequentialSampler\n# Importing the T5 modules from huggingface/transformers\nfrom transformers import T5Tokenizer, T5ForConditionalGeneration\n\n# WandB – Import the wandb library\nimport wandb",
"[nltk_data] Downloading package punkt to /root/nltk_data...\n[nltk_data] Unzipping tokenizers/punkt.zip.\n"
],
[
"# Login to wandb to log the model run and all the parameters\n# 7229adacb32965027d73056a6927efd0365a00bc\n!wandb login",
"\u001b[34m\u001b[1mwandb\u001b[0m: You can find your API key in your browser here: https://wandb.ai/authorize\n\u001b[34m\u001b[1mwandb\u001b[0m: Paste an API key from your profile and hit enter, or press ctrl+c to quit: \n\u001b[34m\u001b[1mwandb\u001b[0m: Appending key for api.wandb.ai to your netrc file: /root/.netrc\n"
],
[
"myconfig = MyConfig()",
"_____no_output_____"
],
[
"# Checking out the GPU we have access to. This is output is from the google colab version. \n!nvidia-smi",
"Thu Mar 10 20:16:34 2022 \n+-----------------------------------------------------------------------------+\n| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |\n|-------------------------------+----------------------+----------------------+\n| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |\n| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |\n| | | MIG M. |\n|===============================+======================+======================|\n| 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 |\n| N/A 40C P0 26W / 250W | 0MiB / 16280MiB | 0% Default |\n| | | N/A |\n+-------------------------------+----------------------+----------------------+\n \n+-----------------------------------------------------------------------------+\n| Processes: |\n| GPU GI CI PID Type Process name GPU Memory |\n| ID ID Usage |\n|=============================================================================|\n| No running processes found |\n+-----------------------------------------------------------------------------+\n"
],
[
"# # Setting up the device for GPU usage\n\ndevice = 'cuda' if cuda.is_available() else 'cpu'\nprint(\"Device is: \", device)\n\n# Set random seeds and deterministic pytorch for reproducibility\n#SEED = 42\nSEED = myconfig.SEED\ntorch.manual_seed(SEED) # pytorch random seed\nnp.random.seed(SEED) # numpy random seed\ntorch.backends.cudnn.deterministic = True",
"Device is: cuda\n"
],
[
"# Global Parameter\nmodel_version = \"6.3\"\n\nload_version = \"6.2\"\ninitial_epoch = 0\n\n# WandB – Initialize a new run\nwandb.init(project=\"counterfactual\"+model_version)\n\n# WandB – Config is a variable that holds and saves hyperparameters and inputs\n# Defining some key variables that will be used later on in the training \n# config = wandb.config # Initialize config\n# config.TRAIN_BATCH_SIZE = 16 # input batch size for training (default: 64)\n# config.VALID_BATCH_SIZE = 32 # input batch size for testing (default: 1000)\n# config.TRAIN_EPOCHS = 51 # number of epochs to train (default: 10)\n# config.VAL_EPOCHS = 1 \n# config.LEARNING_RATE = 1e-4 # learning rate (default: 0.01)\n# config.SEED = 42 # random seed (default: 42)\n# config.SOURCE_LEN = 150\n# config.TARGET_LEN = 110\n\n# WandB – Config is a variable that holds and saves hyperparameters and inputs\n# Defining some key variables that will be used later on in the training \nconfig = wandb.config # Initialize config\nconfig.TRAIN_BATCH_SIZE = 16 # input batch size for training (default: 64)\nconfig.VALID_BATCH_SIZE = 32 # input batch size for testing (default: 1000)\n#config.TRAIN_EPOCHS = myconfig.TRAIN_EPOCHS # number of epochs to train (default: 10)\nconfig.TRAIN_EPOCHS = 41\nconfig.VAL_EPOCHS = myconfig.VAL_EPOCHS \nconfig.LEARNING_RATE = myconfig.LEARNING_RATE # learning rate (default: 0.01)\nconfig.SEED = myconfig.SEED # random seed (default: 42)\nconfig.SOURCE_LEN = 150\nconfig.TARGET_LEN = 70\nconfig.LOAD_PATH = root+'models/model'+load_version+'.tar'\nconfig.SAVE_PATH = root+'models/model'+model_version+'.tar'",
"\u001b[34m\u001b[1mwandb\u001b[0m: Currently logged in as: \u001b[33mskywalk3r\u001b[0m (use `wandb login --relogin` to force relogin)\n"
],
[
"PRETRAINED_MODEL_NAME = myconfig.PRETRAINED_MODEL_NAME\n# tokenzier for encoding the text\nt5_tokenizer = T5Tokenizer.from_pretrained(PRETRAINED_MODEL_NAME)\n# Defining the model. We are using t5-base model and added a Language model layer on top for generation of Summary. \n# Further this model is sent to device (GPU/TPU) for using the hardware.\nmodel = T5ForConditionalGeneration.from_pretrained(PRETRAINED_MODEL_NAME)\nmodel = model.to(device)",
"_____no_output_____"
],
[
"# Defining the optimizer that will be used to tune the weights of the network in the training session. \noptimizer = torch.optim.Adam(params = model.parameters(), lr=config.LEARNING_RATE)",
"_____no_output_____"
]
],
[
[
"# 2. Load dataframe",
"_____no_output_____"
]
],
[
[
"#training df\nsmall_path = root + '/TimeTravel/cleaned_small_2.0.xlsx'\nsmall_df = pd.read_excel(small_path)\n#small_df.head()\nprint(len(small_df))",
"_____no_output_____"
],
[
"small_df.head(3)",
"_____no_output_____"
],
[
"#valid df\nlarge_path = root + '/TimeTravel/cleaned_large_2.0.xlsx'\nlarge_df = pd.read_excel(large_path)\n#large_df.head()\nprint(len(large_df))",
"_____no_output_____"
],
[
"small_ids = []\nfor i in range(len(small_df)):\n small_ids.append(small_df.loc[i, 'story_id'])\n\nprint(len(small_ids))",
"_____no_output_____"
],
[
"large_df = large_df[~large_df.story_id.isin(small_ids)]\nlarge_df = large_df.reset_index(drop=True) # must reset index after delete rows\nprint(len(large_df))",
"_____no_output_____"
],
[
"# select data not in training set\npart_large_cleaned_df = large_df[0:100]\n#part_large_cleaned_df = large_cleaned_df[0:1000]\npart_large_cleaned_df = part_large_cleaned_df.reset_index(drop=True)\nprint(len(part_large_cleaned_df))",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"# 3. Dataset and Dataloader",
"_____no_output_____"
]
],
[
[
"# Creating a custom dataset for reading the dataframe and loading it into the dataloader to pass it to the neural network at a later stage for finetuning the model and to prepare it for predictions\n\nclass CustomDataset(Dataset):\n\n def __init__(self, dataframe, tokenizer, input_len, output_len):\n self.tokenizer = tokenizer\n self.data = dataframe\n self.input_len = input_len\n self.output_len = output_len\n self.input = self.data.input1\n self.output = self.data.output1\n \n\n def __len__(self):\n return len(self.data)\n\n def __getitem__(self, index):\n input = str(self.input[index])\n # input = ' '.join(input.split())\n\n output = str(self.output[index])\n # output = ' '.join(output.split())\n\n source = self.tokenizer.encode_plus(input, max_length= self.input_len, padding='max_length', return_tensors='pt')\n target = self.tokenizer.encode_plus(output, max_length= self.output_len, padding='max_length', return_tensors='pt')\n\n source_ids = source['input_ids'].squeeze()\n source_mask = source['attention_mask'].squeeze()\n target_ids = target['input_ids'].squeeze()\n target_mask = target['attention_mask'].squeeze()\n\n return {\n 'source_ids': source_ids.to(dtype=torch.long), \n 'source_mask': source_mask.to(dtype=torch.long), \n 'target_ids': target_ids.to(dtype=torch.long),\n 'target_ids_y': target_ids.to(dtype=torch.long)\n }",
"_____no_output_____"
],
[
"train_df = small_df\nvalid_df = part_large_cleaned_df\n\ntrainingset = CustomDataset(dataframe=train_df, tokenizer=t5_tokenizer, input_len=config.SOURCE_LEN , output_len=config.TARGET_LEN )\nvalidset = CustomDataset(dataframe=valid_df, tokenizer=t5_tokenizer, input_len=config.SOURCE_LEN , output_len=config.TARGET_LEN )",
"_____no_output_____"
],
[
"# max_sou_len = 0\n# max_tar_len = 0\n# for i in range(len(small_df)):\n# input = small_df.loc[i, 'input1']\n# output = small_df.loc[i, 'output1']\n# source = t5_tokenizer.encode_plus(input, return_tensors='pt')['input_ids'].squeeze()\n# target = t5_tokenizer.encode_plus(output, return_tensors='pt')['input_ids'].squeeze()\n# max_sou_len = max(max_sou_len, len(source))\n# max_tar_len = max(max_tar_len, len(target))\n\n\n# print(max_sou_len)\n# print(max_tar_len)",
"_____no_output_____"
],
[
"# max_sou_len = 0\n# max_tar_len = 0\n# for i in range(len(large_df)):\n# input = large_df.loc[i, 'input1']\n# output = large_df.loc[i, 'output1']\n# source = t5_tokenizer.encode_plus(input, return_tensors='pt')['input_ids'].squeeze()\n# target = t5_tokenizer.encode_plus(output, return_tensors='pt')['input_ids'].squeeze()\n# max_sou_len = max(max_sou_len, len(source))\n# max_tar_len = max(max_tar_len, len(target))\n\n\n# print(max_sou_len)\n# print(max_tar_len)",
"_____no_output_____"
],
[
"# pick up a data sample\nsample_idx = 4\nsample = trainingset[sample_idx]\n\nsource_ids = sample[\"source_ids\"]\nsource_mask = sample[\"source_mask\"]\ntarget_ids = sample[\"target_ids\"]\ntarget_ids_y = sample[\"target_ids_y\"]\n\nprint(source_ids)",
"_____no_output_____"
],
[
"print(train_df.loc[sample_idx, 'output1'])\n\nsen = t5_tokenizer.decode(target_ids, skip_special_tokens=False) # skip_special_tokens=True will be completely same.\nprint(sen)\nsen = t5_tokenizer.decode(source_ids, skip_special_tokens=False) # skip_special_tokens=True will be completely same.\nprint(sen)\n",
"_____no_output_____"
],
[
"# DataLoader\n\ntrain_params = {\n 'batch_size': config.TRAIN_BATCH_SIZE,\n 'shuffle': True,\n 'num_workers': 2\n }\n\nval_params = {\n 'batch_size': config.VALID_BATCH_SIZE,\n 'shuffle': False,\n 'num_workers': 2\n }\n\ntraining_loader = DataLoader(trainingset, **train_params)\nval_loader = DataLoader(validset, **val_params)\nprint(len(training_loader))\nprint(len(val_loader))",
"_____no_output_____"
]
],
[
[
"# 4. Define train() and val()",
"_____no_output_____"
]
],
[
[
"def save_model(epoch, model, optimizer, loss, PATH):\n torch.save({\n 'epoch': epoch,\n 'model_state_dict': model.state_dict(),\n 'optimizer_state_dict': optimizer.state_dict(),\n 'loss': loss\n }, PATH)",
"_____no_output_____"
],
[
"def load_model(PATH):\n checkpoint = torch.load(PATH)\n model.load_state_dict(checkpoint['model_state_dict'])\n optimizer.load_state_dict(checkpoint['optimizer_state_dict'])\n epoch = checkpoint['epoch']\n loss = checkpoint['loss']\n return model, optimizer, epoch, loss",
"_____no_output_____"
],
[
"# Creating the training function. This will be called in the main function. It is run depending on the epoch value.\n# The model is put into train mode and then we wnumerate over the training loader and passed to the defined network \n\ndef train(epoch, tokenizer, model, device, loader, optimizer):\n model.train()\n for i,data in enumerate(loader):\n #len(loader)=10xx\n ids = data['source_ids'].to(device, dtype = torch.long)\n mask = data['source_mask'].to(device, dtype = torch.long)\n y = data['target_ids'].to(device, dtype = torch.long)\n\n # padded ids (pad=0) are set to -100, which means ignore for loss calculation\n y[y[: ,:] == tokenizer.pad_token_id ] = -100\n label_ids = y.to(device)\n\n outputs = model(input_ids = ids, attention_mask = mask, labels=label_ids)\n loss = outputs[0]\n #logit = outputs[1]\n \n if i%50 == 0:\n wandb.log({\"Training Loss\": loss.item()})\n\n if i%600==0:\n print(f'Epoch: {epoch}, Loss: {loss.item()}')\n \n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n \n # xm.optimizer_step(optimizer)\n # xm.mark_step()\n \n if (epoch % 5 == 0):\n save_model(epoch, model, optimizer, loss.item(), config.SAVE_PATH)\n ",
"_____no_output_____"
],
[
"def validate(tokenizer, model, device, loader):\n model.eval()\n predictions = []\n actuals = []\n raws = []\n final_loss = 0\n with torch.no_grad():\n for i, data in enumerate(loader):\n y = data['target_ids'].to(device, dtype = torch.long)\n ids = data['source_ids'].to(device, dtype = torch.long)\n mask = data['source_mask'].to(device, dtype = torch.long)\n\n '''\n generated_ids = model.generate(\n input_ids = ids,\n attention_mask = mask, \n num_beams=2,\n max_length=config.TARGET_LEN, \n repetition_penalty=2.5, \n length_penalty=1.0, \n early_stopping=True\n )\n '''\n generated_ids = model.generate(\n input_ids = ids,\n attention_mask = mask, \n num_beams=2,\n max_length=config.TARGET_LEN, \n repetition_penalty=2.5, \n length_penalty=1.0, \n early_stopping=True\n )\n loss = model(input_ids=ids, attention_mask=mask, labels=y).loss\n final_loss += loss\n\n raw = [tokenizer.decode(i, skip_special_tokens=False) for i in ids]\n preds = [tokenizer.decode(i, skip_special_tokens=False) for i in generated_ids]\n target = [tokenizer.decode(i, skip_special_tokens=False)for i in y]\n if i%3==0:\n print(f'valid Completed {(i+1)* config.VALID_BATCH_SIZE}')\n\n raws.extend(raw)\n predictions.extend(preds)\n actuals.extend(target)\n return raws, predictions, actuals, final_loss",
"_____no_output_____"
]
],
[
[
"# 5. main()",
"_____no_output_____"
]
],
[
[
"import time\n# Helper function to print time between epochs\ndef epoch_time(start_time, end_time):\n elapsed_time = end_time - start_time\n elapsed_mins = int(elapsed_time / 60)\n elapsed_secs = int(elapsed_time - (elapsed_mins * 60))\n return elapsed_mins, elapsed_secs",
"_____no_output_____"
],
[
"# if need, load model\n\nloss = 0\nif (load_version != None and load_version != \"\"):\n model, optimizer, initial_epoch, loss = load_model(config.LOAD_PATH)\nprint(loss)",
"_____no_output_____"
],
[
"# Log metrics with wandb\n#wandb.watch(model, log=\"all\")\n\n# Training loop\nprint('Initiating Fine-Tuning for the model on counterfactual dataset:')\n\nfor epoch in range(initial_epoch, initial_epoch+config.TRAIN_EPOCHS):\n#for epoch in tqdm(range(config.TRAIN_EPOCHS)):\n start_time = time.time()\n train(epoch, t5_tokenizer, model, device, training_loader, optimizer)\n end_time = time.time()\n epoch_mins, epoch_secs = epoch_time(start_time, end_time)\n print(f'Epoch: {epoch:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')\n\n# Mark the run as finished\nwandb.finish()",
"_____no_output_____"
],
[
"# Load model\n# model = T5ForConditionalGeneration.from_pretrained(PRETRAINED_MODEL_NAME)\n# model = model.to(device)\n# optimizer = torch.optim.Adam(params = model.parameters(), lr=config.LEARNING_RATE)\n\n# model, optimizer, epoch, loss = load_model(config.LOAD_PATH)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"# 6. Inference",
"_____no_output_____"
]
],
[
[
"# # load model\n# model, optimizer, initial_epoch, loss = load_model(config.LOAD_PATH)\n# print(loss)",
"_____no_output_____"
],
[
"# Validation loop and saving the resulting file with predictions and acutals in a dataframe.\n# Saving the dataframe as predictions.csv\nprint('Now inferecing:')\nstart_time = time.time()\nraws, predictions, actuals,final_loss = validate(t5_tokenizer, model, device, val_loader)\nend_time = time.time()\nepoch_mins, epoch_secs = epoch_time(start_time, end_time)\nprint(f'Time: {epoch_mins}m {epoch_secs}s')\n\nfinal_df = pd.DataFrame({'input_text': raws, 'ground_truth': actuals, 'generated_text': predictions})\n#final_df.to_csv(root + 'results/' + 'output' + model_version + '.csv')\nfinal_df.to_excel(root + 'results/' + 'output' + model_version + '.xlsx')\nprint('Output Files generated for review')\nprint(f'Final Loss is: {final_loss:.5f}')",
"_____no_output_____"
],
[
"print(len(actuals))",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"# 7. check the samples with same original ending and edited ending",
"_____no_output_____"
]
],
[
[
"# import pandas as pd\n# import regex as re\n\nresult_df = pd.read_excel(root + 'results/' + 'output_beam1' + model_version + '.xlsx')\nresult_df.head()\nprint(len(result_df))",
"1000\n"
],
[
"or_pat = re.compile(r'(original_ending: )(.*)$') \ned_pat = re.compile(r'(edited_ending: )(.*)$') \npipei = re.search(ed_pat, result_df.iloc[0].generated_text)\n# pipei = re.search(or_pat, result_df.iloc[0].raw_text)\nprint(pipei.group(2))",
"Soon, they wanted to spend time with her. She reflected on why she was so nice. She decided she needed to be a more loving person.\n"
],
[
"re_pat = re.compile(r'(original_ending: )(.*)$') # regular expression, pick the text after \"original_ending: \"\n#orig = = re.search(re_pat, te).group(2)\nor_text = [] # or for original_ending\ned_text = [] # ed for edited_ending\n\nfor i in range(len(result_df)):\n or_text.append(re.search(or_pat, result_df.loc[i, \"raw_text\"]).group(2))\n ed_text.append(re.search(ed_pat, result_df.loc[i, \"generated_text\"]).group(2))\nprint(len(or_text))\nprint(len(ed_text))",
"1000\n1000\n"
],
[
"comparison = [i==j for i, j in zip(or_text, ed_text)]\nprint(comparison)",
"[False, False, False, False, False, True, False, False, False, True, False, False, False, False, False, False, False, False, False, True, True, False, True, False, True, False, False, False, True, False, False, True, False, False, False, False, True, True, False, False, False, False, False, False, False, False, True, True, False, False, True, False, True, True, True, False, False, False, True, True, False, False, True, True, False, True, False, False, True, True, True, False, True, True, False, False, True, False, False, False, False, False, False, True, False, True, True, False, False, True, False, False, False, False, False, False, False, True, False, True, False, True, False, False, False, False, False, False, True, False, False, True, True, False, False, False, False, False, False, False, False, True, False, True, True, True, True, False, False, False, True, False, False, False, False, False, False, False, False, False, False, False, False, False, True, True, False, False, False, False, False, False, False, True, False, False, True, False, False, True, False, True, True, False, True, True, False, False, False, False, True, False, True, False, False, False, False, True, False, False, False, True, True, False, False, False, False, True, False, False, False, False, False, True, False, False, True, False, False, False, False, False, False, True, True, True, False, True, False, True, False, False, True, False, False, True, True, True, False, False, False, False, False, False, True, False, False, True, False, True, False, True, True, True, False, True, False, False, False, True, True, False, True, False, False, False, False, False, False, True, False, True, False, False, False, False, True, True, False, False, False, False, False, False, True, True, False, False, False, False, False, False, False, True, False, False, True, False, False, False, False, False, True, False, True, False, False, False, False, False, True, True, False, False, False, True, False, False, False, False, True, False, False, False, False, False, False, False, False, False, False, False, True, True, False, False, False, True, True, False, False, False, False, True, False, True, False, False, False, False, False, True, False, False, True, False, False, False, False, True, False, True, True, False, False, True, False, True, False, False, True, True, True, False, False, True, False, True, False, False, True, True, False, False, True, True, False, False, True, False, False, False, True, False, False, False, False, False, False, False, True, False, False, False, True, False, True, True, True, False, False, True, True, False, False, False, True, True, False, False, False, False, False, False, False, False, False, False, False, False, True, True, False, True, False, False, True, False, False, False, True, False, False, True, True, True, False, False, False, False, False, True, True, False, False, False, False, False, False, False, False, False, False, False, True, False, False, False, False, False, False, False, True, False, True, True, False, False, False, False, True, True, True, False, False, True, False, True, False, False, False, False, True, False, False, False, False, False, True, False, True, False, False, False, True, True, False, True, False, False, True, False, True, False, False, False, False, True, False, False, True, False, True, False, False, False, True, True, False, True, False, True, False, True, False, True, True, True, True, False, False, False, True, False, True, False, True, False, True, True, False, True, False, False, True, False, False, False, False, False, False, False, False, True, True, False, False, True, True, False, False, False, False, False, False, False, False, False, False, False, False, False, True, True, False, False, False, True, False, True, False, False, True, False, False, False, False, True, False, True, False, True, True, False, False, False, True, False, False, False, True, False, False, False, False, True, False, True, False, False, False, False, False, False, False, False, False, False, False, False, False, True, False, False, False, False, False, False, False, False, True, False, False, False, False, False, False, True, False, False, True, False, True, False, False, True, True, False, False, False, False, False, True, False, False, True, False, True, False, False, True, False, True, True, True, False, False, True, False, False, False, False, False, False, True, False, False, False, False, False, True, False, False, False, False, True, False, False, True, False, True, False, False, True, True, False, False, False, True, True, False, True, False, True, False, False, False, False, True, False, False, False, True, False, False, True, False, False, False, True, False, False, False, True, True, False, True, False, False, True, True, False, False, False, True, True, False, False, True, False, True, True, False, False, False, True, False, False, False, False, True, True, True, True, False, False, True, False, True, True, False, True, False, False, False, False, False, False, False, True, False, False, True, False, False, False, True, False, False, True, False, True, True, False, False, False, False, False, True, False, True, False, False, False, True, True, False, True, False, True, True, False, False, False, False, False, True, False, False, False, False, True, False, False, False, False, False, False, False, False, False, False, False, False, True, False, False, False, True, False, True, True, False, True, False, True, False, False, False, False, True, False, False, True, False, False, False, False, False, False, True, False, False, False, True, False, False, True, True, False, False, False, False, False, False, True, False, True, True, False, True, False, False, False, True, False, False, False, False, False, False, True, False, True, True, True, False, False, True, True, True, True, False, False, False, True, True, True, False, False, False, True, True, False, False, True, True, True, False, True, False, True, False, False, False, False, False, True, True, False, False, False, False, False, False, True, False, True, False, True, False, True, False, True, False, True, True, True, False, False, False, True, False, False, False, False, True, False, True, False, False, True, True, False, False, False, True, True, True, False, True, True, False, False, False, False, False, True, False, False, True, False, False, True, False, True, False, True, True, True, True, False, False, False, False, False, False, False, False, False, False, False, True, False, False, False, False, True, False, False, False, False, False, True, True, True, True, False, False, False]\n"
],
[
"count = pd.value_counts(comparison)\nprint(count)",
"False 678\nTrue 322\ndtype: int64\n"
],
[
"result_df[comparison].head(10)",
"_____no_output_____"
],
[
"same_df = result_df[comparison]\nsame_df.reset_index(drop=True)",
"_____no_output_____"
],
[
"same_df.to_excel(root + 'results/' + 'output_same_b1' + model_version + '.xlsx')",
"_____no_output_____"
]
],
[
[
"## pick some samples to test\n",
"_____no_output_____"
]
],
[
[
"model.eval()\nwith torch.no_grad():\n text = 'premise: I am supposed to take food to a party tomorrow. initial: I had bought all the ingredients for it last week. counterfactual: I need to buy all the ingredients for it after work today. original_ending: I spent all day yesterday cooking the food. Unfortunately, I burnt the food. I won\\'t be able to get new ingredients in time for tomorrow\\'s party.'\n\n input_ids = tokenizer(text, return_tensors=\"pt\").input_ids.to(device)\n outputs = model.generate(input_ids, max_length=config.TARGET_LEN, num_beams=2)\n print(tokenizer.decode(outputs[0], skip_special_tokens=True))",
"edited_ending: I spent all day yesterday cooking the food. Unfortunately, I burnt the food. I won't be able to get new ingredients in time for tomorrow's party.\n"
]
],
[
[
"# 8. Evalutation\n",
"_____no_output_____"
],
[
"## 7.1 Blue score",
"_____no_output_____"
]
],
[
[
"# predicitions: y', actuals: y\nfrom torchtext.data.metrics import bleu_score",
"_____no_output_____"
],
[
"pre_corpus = [i.split(\" \") for i in predictions]\nact_corpus = [i.split(\" \") for i in actuals]",
"_____no_output_____"
],
[
"print(act_corpus)",
"[['edited_ending:', 'Soon,everyone', 'wanted', 'to', 'spend', 'time', 'with', 'her.', 'She', 'reflected', 'on', 'if', 'she', 'could', 'be', 'nicer.', 'She', 'decided', 'she', 'needed', 'to', 'atleast', 'try', 'to', 'be', 'the', 'best', 'person', 'she', 'could', 'be.'], ['edited_ending:', 'Bill', 'congratulated', 'the', 'other', 'team.', 'He', 'also', 'went', 'into', 'the', 'locker', 'room', 'to', 'cry.', 'He', \"didn't\", 'tell', 'anyone', 'until', 'the', 'next', 'day.'], ['edited_ending:', 'She', 'jumped', 'over', 'the', 'fence', 'and', 'vanished.', 'Without', 'a', 'spare,', 'the', 'game', 'was', 'done.', 'They', 'were', 'forced', 'to', 'quit.'], ['edited_ending:', 'She', 'was', 'nervous', 'about', 'helping', 'the', 'people', 'and', 'making', 'them', 'feel', 'more', 'comfortable.', 'One', 'day', 'she', 'witnessed', 'something', 'that', 'she', 'could', 'never', 'forget.', 'She', 'decided', 'she', 'could', 'not', 'live', 'with', 'the', 'memories', 'and', 'quit', 'her', 'job.'], ['edited_ending:', 'I', 'tried', 'to', 'stay', 'quiet', 'and', 'busy.', 'I', 'knew', 'I', 'could', 'find', 'something', 'to', 'keep', 'myself', 'occupied.', 'I', 'kept', 'kept', 'to', 'myself', 'and', 'did', 'some', 'busy', 'work.'], ['edited_ending:', 'Jeff', 'then', 'became', 'distant', 'and', \"wasn't\", 'the', 'same', 'person', 'anymore.', 'Pam', 'decided', 'she', \"can't\", 'do', 'the', 'marriage', 'anymore', 'and', 'leaves.', 'Pam', 'and', 'Jeff', 'got', 'a', 'divorce', 'and', 'went', 'their', 'own', 'ways.'], ['edited_ending:', 'Then', 'the', 'salesman', 'took', 'my', 'measurements.', 'After', 'taking', 'my', 'measurements', 'I', 'picked', 'out', 'a', 'nice', 'green', 'suit.', 'I', 'paid', 'for', 'the', 'suit', 'and', 'now', 'I', \"can't\", 'wait', 'to', 'wear', 'it!'], ['edited_ending:', 'It', 'landed', 'on', 'a', \"pedestrian's\", 'foot.', 'The', 'pedestrian', 'thought', 'it', 'was', 'on', 'purpose.', 'He', 'punched', 'the', 'band', 'member.'], ['edited_ending:', 'She', 'felt', 'obliged,', 'but', 'she', 'chose', 'not', 'to', 'go.', 'All', 'of', 'the', 'sudden,', 'she', 'got', 'sick', 'when', 'she', 'woke', 'up', 'in', 'the', 'morning.', 'Kelley', 'would', 'have', 'been', 'very', 'embarrassed', 'if', 'that', 'had', 'happened', 'at', 'the', 'party.'], ['edited_ending:', 'I', 'will', 'have', 'to', 'spend', 'all', 'day', 'cooking', 'the', 'food.', 'I', 'hope', 'I', \"don't\", 'burn', 'the', 'food.', 'If', 'I', 'ruin', 'anything', 'I', \"won't\", 'have', 'time', 'to', 'get', 'new', 'ingredients', 'and', 'cook', 'anything', 'else', 'before', 'tomorrow.'], ['edited_ending:', 'On', 'this', 'day,', 'a', 'man', 'jumped', 'from', 'behind', 'the', 'trees', 'and', 'Ligeti', 'laughed', 'at', 'him.', 'The', 'boy', 'ran', 'all', 'the', 'way', 'home,', 'laughing.', 'The', 'boy', 'grew', 'up', 'to', 'be', 'ready', 'to', 'face', 'the', 'unknown.'], ['edited_ending:', 'All', 'of', 'a', 'sudden', 'she', 'freaked', 'out.', 'She', 'thought', 'her', 'earrings', 'were', 'lost.', 'It', 'took', 'Kate', 'one', 'hour', 'to', 'realized', 'she', 'had', 'already', 'taken', 'her', 'jewelry', 'off', 'before', 'swimming', 'and', 'they', 'were', 'in', 'her', 'purse.'], ['edited_ending:', 'The', 'day', 'of', 'prom,', 'Hannah', 'put', 'on', 'her', \"sister's\", 'old', 'dress.', 'When', 'she', 'arrived', 'to', 'prom,', 'she', 'saw', 'another', 'girl', 'had', 'the', 'same', 'dress!', 'Hannah', 'was', 'disappointed', 'and', 'wished', 'she', 'had', 'found', 'a', 'different', 'dress.'], ['edited_ending:', 'Liz', 'had', 'a', 'new', 'car', 'but', \"didn't\", 'want', 'Kate', 'to', 'get', 'sick', 'inside.', 'She', 'refused', 'to', 'take', 'her', 'car.', 'In', 'the', 'end', 'they', 'decided', 'to', 'take', \"Kate's\", 'car.'], ['edited_ending:', 'Calling', 'his', 'name,', 'he', \"didn't\", 'respond', 'to', 'his', 'mother', 'until', 'she', 'pulled', 'him', 'into', 'the', 'car.', 'They', 'were', 'off', 'to', 'see', 'the', 'the', 'doctor.', 'The', 'doctor', 'checked', 'his', 'ear', 'and', 'said', '\"You', 'have', 'a', 'lot', 'of', 'ear', 'wax!\"'], ['edited_ending:', 'Finally', 'Sam', 'saw', 'there', 'was', 'a', 'car', 'accident.', 'That', 'explained', 'why', 'the', 'traffic', 'was', 'so', 'heavy.', 'Once', 'Sam', 'bypassed', 'it,', 'she', 'was', 'in', 'her', 'way.'], ['edited_ending:', 'The', 'cat', 'sat', 'on', 'the', 'car.', 'Shanelle', 'knew', 'there', 'would', 'have', 'been', 'paw', 'prints', 'on', 'her', 'car', 'if', 'she', \"hadn't\", 'put', 'on', 'the', 'car', 'cover.', 'She', 'was', 'glad', 'the', 'cat', \"wasn't\", 'making', 'her', 'car', 'dirty.'], ['edited_ending:', 'He', 'loved', 'the', 'look', 'of', 'them.', 'Fred', 'wished', 'he', 'could', 'buy', 'one', 'for', 'himself.', 'A', 'juke', 'box', 'would', 'have', 'been', 'a', 'fitting', 'addition', 'to', 'his', 'home', 'theater', 'room.'], ['edited_ending:', 'It', 'was', 'a', 'big', 'job', 'so', 'he', 'hired', 'someone', 'to', 'do', 'it.', 'When', 'it', 'was', 'done,', 'his', 'car', 'looked', 'great.', 'John', 'was', 'glad', 'he', 'had', 'someone', 'clean', 'out', 'his', 'car.'], ['edited_ending:', \"Eli's\", 'mother', 'constantly', 'tried', 'to', 'get', 'him', 'to', 'stay', 'inside', 'but', 'he', 'refused.', 'One', 'day,', 'he', 'snuck', 'out', 'and', 'fell', 'off', 'a', 'tree', 'he', 'was', 'climbing.', 'Eli', 'broke', 'his', 'leg', 'and', 'had', 'to', 'get', 'a', 'cast', 'put', 'on.'], ['edited_ending:', 'It', 'was', 'a', 'normal', 'day', 'of', 'work.', 'Jane', 'left', 'her', 'badge', 'at', 'work.', 'She', 'forgot', 'where', 'it', 'was.'], ['edited_ending:', 'She', 'held', 'the', 'dog', 'to', 'make', 'sure', 'he', \"didn't\", 'move.', 'She', 'turned', 'around', 'and', 'began', 'walking', 'home.', 'Eventually', 'she', 'turned', 'to', 'see', 'the', \"dog's\", 'owner', 'was', 'following', 'not', 'far', 'behind.'], ['edited_ending:', 'A', 'snake', 'had', 'struck', 'her!', 'Her', 'hand', 'swelled', 'up', 'and', 'hurt.', 'She', 'stopped', 'gardening', 'and', 'iced', 'her', 'hand.'], ['edited_ending:', 'He', 'got', 'out', 'of', 'the', 'shower.', 'His', 'roommate', 'came', 'home.', 'His', 'roommate', 'could', 'not', 'take', 'a', 'shower.'], ['edited_ending:', 'A', 'car', 'tried', 'to', 'park', 'near', 'hers,', 'did', 'not', 'stop,', 'and', 'hit', 'her', 'car.', \"Jenny's\", 'car', 'was', 'taken', 'to', 'a', 'shop', 'by', 'a', 'tow', 'truck.', 'Luckily', 'the', 'car', 'only', 'had', 'a', 'few', 'minor', 'dents.'], ['edited_ending:', 'But', 'then', 'his', 'mom', 'got', 'sick', 'and', 'had', 'to', 'stay', 'in', 'the', 'hospital.', 'Adam', 'was', 'forced', 'to', 'study', 'and', 'write', 'on', 'his', 'own.', 'But', 'luckily', 'he', 'learned', 'quickly', 'and', 'improved', 'his', 'knowledge.'], ['edited_ending:', 'One', 'of', 'her', 'friends', 'bumped', 'into', 'her', 'elbow.', 'Lisa', 'spilled', 'water', 'all', 'over', 'her', 'new', 'white', 'dress.', 'Lisa', 'was', 'thankful', 'it', \"wouldn't\", 'stain', 'her', 'dress.'], ['edited_ending:', 'She', 'accidentally', 'tipped', 'the', 'plastic', 'cup', 'over,', 'wine', 'spilled', 'all', 'over.', 'Allison', 'sighed.', 'She', 'had', 'to', 'clean', 'it', 'up', 'quickly.'], ['edited_ending:', 'People', 'thought', 'Alex', 'was', 'dumb.', 'Alex', 'disagreed', 'with', 'them.', 'But', 'he', 'never', 'did', 'anything', 'to', 'demonstrate', 'he', 'was', 'smart.'], ['edited_ending:', 'The', 'hot', 'filling', 'overflowed', 'on', 'bottom', 'of', 'the', 'oven.', 'Gretchen', 'got', 'cleaning', 'supplies.', 'She', 'dropped', 'to', 'her', 'knees,', 'on', 'the', 'ground.'], ['edited_ending:', 'My', 'son', 'said', 'there', 'was', 'bone', 'in', 'his', 'burger', 'and', 'I', 'thought', 'it', 'was', 'a', 'little', 'gristle.', 'I', 'told', 'him', 'to', 'quit', 'whining', 'about', 'every', 'little', 'thing.', 'I', 'looked', 'at', 'the', 'bone.', 'It', 'was', 'a', 'half', 'inch', 'thick', 'and', 'two', 'inches', 'wide.'], ['edited_ending:', 'The', 'two', 'of', 'them', 'became', 'very', 'close', 'friends.', 'They', 'would', 'help', 'each', 'other', 'study,', 'eat', 'together,', 'and', 'hang', 'out', 'too.', 'Tiffany', 'missed', 'her', 'roommate', 'terribly', 'on', 'her', 'first', 'trip', 'home', 'for', 'winter', 'break.'], ['edited_ending:', 'Finally', 'the', 'day', 'came', 'when', 'Dave', 'closed', 'his', 'restaurant.', 'The', 'food', 'had', 'always', 'had', 'terrible', 'reviews.', 'Now', 'Dave', 'is', 'an', 'unknown', 'chef', 'without', 'his', 'own', 'dream', 'TV', 'show.'], ['edited_ending:', 'She', 'prepared', 'the', 'pan', 'for', 'cake', 'and', 'got', 'the', 'ingredients', 'ready.', 'She', 'layered', 'the', 'cherries', 'and', 'cake', 'mix,', 'but', 'forgot', 'the', 'butter.', 'The', 'cake', 'cooked', 'and', 'the', 'family', 'was', 'horrified', 'at', 'how', 'it', 'turned', 'out.'], ['edited_ending:', 'She', 'chased', 'them', 'around,', 'trying', 'to', 'catch', 'them.', 'She', 'snapped', 'the', 'lamp', 'shade', 'by', 'running', 'into', 'it.', 'I', 'fixed', 'it', 'and', 'luckily', 'my', 'dog', 'was', 'tired.'], ['edited_ending:', 'One', 'chapter', 'was', 'about', 'Christmas.', 'She', 'liked', 'that', 'kind', 'of', 'book,', 'but', 'not', 'at', 'this', 'time', 'of', 'year.', 'To', 'be', 'thinking', 'of', 'Christmas', 'in', 'July', 'made', 'her', 'feel', 'very', 'depressed.'], ['edited_ending:', 'Bob', \"couldn't\", 'believe', \"he'd\", 'told', 'so', 'many', 'stories.', 'Bob', 'really', 'hoped', 'his', 'friends', 'enjoyed', 'them.', 'He', 'made', 'a', 'mental', 'note', 'to', 'send', 'them', 'their', 'favorite', 'movies', 'for', 'Christmas.'], ['edited_ending:', 'She', 'was', 'carried', 'away', 'on', 'a', 'stretcher', 'to', 'the', \"coroner's\", 'vehicle.', 'Fortunately', 'the', 'driver', 'was', 'okay,', 'just', 'a', 'little', 'bruised.', 'Her', \"parents'\", 'were', 'very', 'upset', 'and', 'saddened', 'that', 'she', 'was', 'fatally', 'injured.'], ['edited_ending:', 'Omar', 'was', 'upset', 'because', 'he', 'just', 'wanted', 'to', 'know', 'the', 'weather', 'forecast', 'But', 'he', 'quickly', 'became', 'absorbed', 'with', 'the', 'fire.', 'He', 'celebrated', 'when', 'he', 'watched', 'a', 'fireman', 'rescue', 'someone.'], ['edited_ending:', 'She', 'keeps', 'up', 'with', 'all', 'gaming', 'news.', 'Priya', 'decided', 'to', 'use', 'her', 'time', 'for', 'something', 'more', 'fruitful.', 'Now', 'she', 'makes', 'money', 'working', 'for', 'a', 'fortune', '500', 'company.'], ['edited_ending:', 'He', \"couldn't\", 'pick', 'a', 'favorite', 'candidate.', 'When', 'the', 'election', 'was', 'done', 'one', 'of', 'the', 'candidates', 'won.', 'Elijah', \"couldn't\", 'have', 'cared', 'less.'], ['edited_ending:', 'The', 'line', 'was', 'empty.', 'After', '5', 'minutes,', 'I', 'got', 'through', 'security.', 'I', 'knew', 'I', 'would', 'always', 'go', 'back', 'to', 'this', 'airport.'], ['edited_ending:', 'The', 'apple', 'pie', 'turned', 'out', 'perfect.', 'She', 'used', 'just', 'the', 'right', 'amount', 'of', 'butter.', 'The', 'apple', 'pie', 'ended', 'up', 'being', 'delicious,', 'and', 'the', 'shell', 'held', 'very', 'well.'], ['edited_ending:', 'When', 'I', 'got', 'there', 'I', 'I', 'was', 'hesitant', 'about', 'eating.', 'I', 'ate', 'some', 'of', 'the', 'food.', 'It', 'made', 'me', 'feel', 'sick', 'the', 'rest', 'of', 'the', 'day.'], ['edited_ending:', 'He', 'decided', 'to', 'get', 'one', 'on', 'his', 'arm', 'insead.', 'Steve', 'kept', 'his', 'tattoo', 'hidden', 'from', 'his', 'parents.', \"Steve's\", 'parents', 'still', \"don't\", 'know.'], ['edited_ending:', 'It', 'was', 'a', 'hotly', 'contested', 'issue.', 'People', 'protested', 'until', 'they', 'were', 'able', 'to', 'change', 'the', 'pipeline', 'plans.', 'The', 'protest', 'took', 'hours', 'to', 'conclude.'], ['edited_ending:', 'She', 'quickly', 'turned', 'the', 'television', 'drama', 'back', 'on', 'as', 'it', 'was', 'reaching', 'the', 'climax', 'of', 'the', 'episode.', 'When', 'the', 'twist', 'was', 'revealed,', 'Martha', 'let', 'out', 'a', 'scream.', 'She', 'immediately', 'called', 'her', 'best', 'friend.'], ['edited_ending:', 'She', 'downloaded', 'her', 'music', 'through', 'a', 'different', 'app.', 'One', 'album', 'had', '13', 'songs,', 'but', 'only', '7', 'were', 'downloaded.', 'She', 'sent', 'an', 'email', 'to', 'tech', 'support.'], ['edited_ending:', 'She', 'was', 'long', 'and', 'pudgy,', 'and', 'loved', 'running', 'around', 'the', 'room.', 'She', 'begged', 'for', 'a', 'piece', 'of', 'pumpkin', 'pie', 'when', 'I', 'first', 'met', 'her.', 'Because', 'of', 'this,', 'I', 'named', 'her', 'Pumpkin.'], ['edited_ending:', 'Jean', 'bought', 'clothing', 'appropriate', 'for', 'the', 'weather', 'in', 'Namibia.', 'She', 'travelled', 'on', 'a', 'bus', 'and', 'stayed', 'for', 'one', 'week.', \"Jean's\", 'trip', 'to', 'Africa', 'was', 'better', 'than', 'she', 'had', 'hoped.'], ['edited_ending:', 'Finding', 'the', 'scenery', 'to', 'be', 'very', 'calming,', 'he', 'began', 'to', 'fall', 'asleep.', 'It', \"wasn't\", 'long', 'before', 'he', 'had', 'completely', 'passed', 'out.', 'He', 'was', 'awoken', 'later', 'by', 'his', 'boss,', 'who', 'was', 'angry', 'with', 'him.'], ['edited_ending:', 'After', 'researching,', 'Gary', 'saw', 'cheaper', 'alternatives.', 'Gary', 'saw', 'that', 'dental', 'work', 'in', 'Mexico', 'was', 'much', 'cheaper', 'than', 'the', 'U.S..', 'Gary', 'decided', 'he', 'was', 'happy', 'to', 'stay', 'with', 'his', 'dentist', 'and', 'not', 'go', 'to', 'Mexico', 'to', 'get', 'his', 'dental', 'work', 'done.'], ['edited_ending:', \"Denise's\", 'friend', 'Dan', 'knew', 'about', 'this,', 'and', 'decided', 'to', 'get', 'her', 'a', 'cake.', 'On', 'her', 'birthday,', 'Dan', 'surprised', 'Denise', 'with', 'her', 'usual', 'birthday', 'cake.', 'Denise', 'cried', 'tears', 'of', 'joy', 'that', 'Dan', 'remembered', 'her', 'birthday', 'tradition.'], ['edited_ending:', 'They', 'all', 'told', 'stories', 'about', 'when', 'I', 'was', 'growing', 'up.', 'Some', 'of', 'them', 'were', 'very', 'embarrassing.', 'I', 'do', 'not', 'really', 'like', 'those', 'stories.'], ['edited_ending:', 'On', 'top', 'of', 'that', 'my', 'nails', 'chipped', 'today.', 'I', 'was', 'relieved', 'at', 'the', 'opportunity', 'to', 'change', 'my', 'nail', 'color', 'Next', 'time', 'I', 'will', 'make', 'sure', 'to', 'clarify', 'what', 'color', 'I', 'want.'], ['edited_ending:', 'I', 'went', 'to', 'the', 'store', 'just', 'to', 'get', 'some', 'shampoo', 'and', 'conditioner.', 'I', 'got', 'the', 'shampoo', 'and', 'lathered', 'my', 'hair.', 'I', 'really', 'think', 'washing', 'my', 'hair', 'helped', 'me', 'get', 'a', 'job.'], ['edited_ending:', 'She', 'felt', 'like', 'she', 'was', 'going', 'to', 'be', 'happy.', 'There', 'was', 'no', 'turbulence.', 'Thankfully', 'she', 'drank', 'tea', 'and', 'felt', 'even', 'better.'], ['edited_ending:', 'The', 'kids', 'looked', 'at', 'all', 'the', 'paintings.', 'At', 'the', 'end', 'of', 'the', 'trip,', 'they', 'had', 'learned', 'a', 'lot.', 'The', 'kids', 'now', 'understood', 'a', 'lot', 'about', 'art!'], ['edited_ending:', 'He', 'gave', 'his', 'friend', 'the', 'present', 'on', 'his', 'birthday.', 'His', 'friend', 'complained', 'that', 'it', \"wasn't\", 'Christmas.', 'Zach', 'reminded', 'him', 'that', 'gifts', 'can', 'be', 'given', 'any', 'time', 'of', 'year.'], ['edited_ending:', 'As', 'expected,', 'something', 'bad', 'happened.', 'The', 'couch', 'fell', 'apart.', 'I', 'was', 'rather', 'upset', 'about', 'it.'], ['edited_ending:', 'She', 'got', 'scared', 'and', 'tried', 'to', 'swim', 'as', 'fast', 'as', 'she', 'can', 'to', 'the', 'shore.', 'Jenny', 'had', 'to', 'help', 'her', 'get', 'up', 'since', 'she', 'had', 'breathing', 'problems.', 'Terry', 'rose', 'from', 'the', 'water', 'and', 'ran.'], ['edited_ending:', 'She', 'wore', 'them', 'as', 'a', 'bracelet', 'instead,', 'classic', 'dress.', 'Whenever', 'she', 'wore', 'them', 'together,', 'she', 'felt', 'classy', 'and', 'pretty.', \"Emma's\", 'accessories', 'always', 'made', 'her', 'feel', 'put', 'together.'], ['edited_ending:', 'The', 'championship', 'game', 'was', 'next', 'month.', 'The', 'team', 'was', 'counting', 'on', 'Kareem', 'to', 'help', 'their', 'morale.', 'Kareem', 'broke', 'his', 'wrist', 'the', 'day', 'before', 'the', 'game', 'and', 'the', 'team', 'lost.'], ['edited_ending:', 'Hannah', 'desperately', 'wants', 'to', 'get', 'engaged.', 'Nate', 'does', 'not', 'want', 'to', 'get', 'married', 'to', 'her.', 'Hannah', 'breaks', 'up', 'with', 'Nate', 'because', 'he', \"didn't\", 'want', 'marriage.'], ['edited_ending:', 'He', 'had', 'trouble', 'getting', 'out', 'of', 'the', 'cab.', 'He', 'felt', 'that', 'the', 'day', 'was', 'never', 'going', 'to', 'end.', 'The', 'cabdriver', 'helped', 'him', 'with', 'the', 'door', 'and', \"Chet's\", 'day', 'got', 'better.'], ['edited_ending:', 'Her', 'family', 'told', 'her', 'that', 'she', 'was', 'making', 'too', 'many', 'swans.', 'They', 'said', 'that', 'she', 'would', 'have', 'nowhere', 'to', 'store', 'them', 'all.', 'Yoshiye', 'started', 'folding', 'some', 'paper', 'storage', 'boxes', 'for', 'her', 'swans.'], ['edited_ending:', 'When', 'an', 'acquaintance', 'asked', 'him', 'for', 'a', 'house,', 'he', 'pretended', 'he', \"didn't\", 'know', 'what', 'they', 'were', 'talking', 'about.', 'He', 'never', 'built', 'the', 'house.', 'His', 'acquaintance', 'was', 'speechless', 'as', 'he', 'knew', 'Jamie', 'was', 'lying.'], ['edited_ending:', 'He', 'started', 'putting', 'together', 'his', 'resume.', 'The', 'next', 'day', 'he', 'applied', 'to', 'all', 'the', 'jobs', 'he', 'could.', 'A', 'week', 'later', 'and', 'Scott', 'had', 'a', 'new', 'job.'], ['edited_ending:', 'He', 'was', 'charged', 'with', 'fixing', 'it', 'because', 'he', 'is', 'the', 'manager.', 'Ben', 'decided', 'to', 'sue', 'the', 'printer', 'maker', 'due', 'to', 'the', 'break.', 'Ben', 'won', 'because', 'of', 'a', 'lack', 'of', 'evidence.'], ['edited_ending:', 'However', 'when', 'she', 'arrived', 'she', 'had', 'a', 'flat', 'tire.', 'I', 'used', 'the', 'spare', 'tire', 'in', 'the', 'trunk', 'to', 'replace', 'the', 'bad', 'one.', 'The', 'girl', 'I', 'was', 'with', 'was', 'very', 'impressed', 'that', 'I', 'changed', 'the', 'tire.'], ['edited_ending:', 'The', 'deer', 'was', 'eating', 'and', 'moved', 'when', 'he', 'heard', 'their', 'voices.', 'The', 'deer', 'looked', 'at', 'Jack', 'and', 'Diane', 'for', 'a', 'moment', 'and', 'bolted.', 'Jack', 'and', 'Diane', 'tried', 'to', 'follow', 'it', 'but', 'they', 'were', 'not', 'able', 'to', 'find', 'him.'], ['edited_ending:', 'He', 'thought', 'for', 'two', 'minutes', 'before', 'each', 'move', 'when', 'she', 'moved', 'quickly.', 'And', 'he', 'took', 'more', 'pieces', 'than', 'her', 'to', 'win.', 'But', 'in', 'the', 'end,', 'with', 'experienced', 'he', 'won', 'and', 'cheered.'], ['edited_ending:', 'Cal', \"didn't\", 'understand', 'the', 'point', 'of', 'that.', 'Mike', 'said', 'he', 'already', 'had', 'everything', 'else.', 'Cal', 'sold', 'off', 'the', 'chainsaw', 'to', 'Mike.'], ['edited_ending:', 'His', 'boss', 'approached', 'John', 'and', 'told', 'him', 'to', 'go', 'home.', 'John', \"didn't\", 'get', 'to', 'work', 'on', 'any', 'new', 'assignments', 'at', 'all.', 'John', 'ended', 'up', 'only', 'working', '40', 'hours', 'that', 'week.'], ['edited_ending:', 'He', 'took', 'the', 'portable', 'system', 'to', 'the', 'nearest', 'trail.', 'He', 'had', 'a', 'lot', 'of', 'fun', 'walking', 'the', 'trail', 'while', 'playing.', 'Tom', 'knew', 'he', 'had', 'found', 'his', 'new', 'hobby.'], ['edited_ending:', 'Phil', 'practiced', 'with', 'his', 'piano', 'every', 'day', 'and', 'improved', 'his', 'skills.', 'Phil', 'decided', 'to', 'try', 'to', 'become', 'a', 'musician.', 'He', 'recently', 'performed', 'his', 'first', 'concert.'], ['edited_ending:', 'No', 'one', 'had,', 'so', 'I', 'put', 'up', 'posters', 'around', 'town', 'with', 'his', 'name', 'and', 'picture.', 'Someone', 'called', 'me', 'about', 'an', 'hour', 'later', 'to', 'say', 'he', 'was', 'in', 'her', 'yard.', 'When', 'I', 'went', 'to', 'pick', 'him', 'up,', 'it', \"wasn't\", 'my', 'dog', 'that', 'jumped', 'all', 'over', 'me', 'and', 'gave', 'me', 'doggy', 'kisses.'], ['edited_ending:', 'Tommy', 'wanted', 'to', 'explore.', 'Unfortunately,', 'during', 'his', 'exploring', 'he', 'would', 'have', 'got', 'lost.', 'He', 'was', 'rewarded', 'for', 'listening.'], ['edited_ending:', 'When', 'the', 'delivery', 'man', 'arrived', 'he', 'took', 'their', 'money', 'The', 'boys', 'knew', 'their', 'order', 'was', 'plain.', 'But', 'they', \"didn't\", 'care', '-', 'because', 'the', 'pie', 'was', 'delicious'], ['edited_ending:', 'So', 'he', 'read', 'every', 'letter', 'he', 'found.', 'No', 'one', 'caught', 'him', 'reading', 'the', 'mail.', 'Roy', 'felt', 'very', 'guilty', 'afterward.'], ['edited_ending:', 'In', 'my', 'excitement', 'I', 'opened', 'it', 'wide', 'and', 'stuck', 'my', 'head', 'out.', 'My', 'mother', 'came', 'in', 'yelling', 'at', 'me', 'to', 'shut', 'it', 'so', 'as', 'not', 'to', 'let', 'the', 'heat', 'in.', 'She', 'said', 'she', 'already', 'laid', 'out', 'my', 'summer', 'clothes', 'and', 'I', 'should', 'go', 'play.'], ['edited_ending:', 'Joey', 'went', 'home', 'feeling', 'giddy.', 'He', 'ate', 'a', 'whole', 'container', 'of', 'ice', 'cream.', 'He', 'went', 'to', 'bed', 'feeling', 'excited', 'for', 'the', 'future.'], ['edited_ending:', 'The', 'editors', 'told', 'me', 'to', 'just', 'try', 'my', 'best', 'since', 'they', \"didn't\", 'want', 'to', 'be', 'there', 'either.', 'I', 'sat', 'down', 'on', 'the', 'last', 'night', 'possible', 'and', 'wrote', 'as', 'much', 'as', 'I', 'could.', 'The', 'newspaper', 'turned', 'out', 'pretty', 'good', 'but', 'I', 'was', 'still', 'very', 'nervous.'], ['edited_ending:', 'She', 'then', 'bought', 'a', 'puppet', 'theater', 'at', 'a', 'new', 'store.', 'She', 'invited', 'her', 'parents', 'and', 'two', 'brothers', 'to', 'the', 'show.', 'Her', 'family', 'clapped', 'and', 'hollered', 'for', 'an', 'encore', 'after', 'the', 'show', 'was', 'over.'], ['edited_ending:', 'She', 'was', 'concerned', 'the', 'pregnancy', 'would', 'ruin', 'her', 'academic', 'career.', 'She', 'decided', 'not', 'to', 'have', 'the', 'baby', 'and', 'give', 'it', 'up', 'for', 'adoption.', 'Years', 'later,', 'Carey', 'felt', 'that', 'abortion', 'was', 'a', 'small', 'price', 'to', 'pay.'], ['edited_ending:', 'It', 'made', 'me', 'feel', 'great.', 'I', \"couldn't\", 'wait', 'to', 'get', 'more.', 'I', 'immediately', 'asked', 'my', 'doctor', 'for', 'ten', 'more', 'bottles.'], ['edited_ending:', 'Then', 'people', \"couldn't\", 'make', 'fun', 'of', 'his', 'antics', 'and', 'cause', 'him', 'pain.', 'He', \"didn't\", 'have', 'to', 'pay', 'so', 'much', 'attention', 'to', 'what', 'he', 'was', 'doing.', 'In', 'the', 'end,', 'it', 'was', 'easier', 'to', 'accept', 'who', 'he', 'was.'], ['edited_ending:', 'And', 'he', 'ran', 'out', 'with', 'a', 'bunch', 'of', 'the', \"library's\", 'computers', 'that', 'were', 'worth', 'quite', 'a', 'few', 'dollars.', 'He', 'tried', 'to', 'steal', 'from', 'the', 'library', 'again', 'a', 'week', 'later', 'but', 'was', 'caught.', 'And', 'he', 'realized', 'it', \"wasn't\", 'worth', 'the', 'money.'], ['edited_ending:', 'He', 'had', 'waited', 'for', 'hours,', 'and', 'nobody', 'else', 'had', 'yet', 'showed', 'up.', 'So', 'they', 'ended', 'eating', 'all', 'the', 'food', 'he', 'brought', 'by', 'themselves.', 'When', 'Joe', 'got', 'into', 'his', 'car,', 'he', 'saw', 'another', 'friend', 'arriving', 'but', 'left', 'anyway.'], ['edited_ending:', 'Finally,', 'he', 'decided', 'on', 'a', 'motel', 'within', 'his', 'price', 'range.', 'Days', 'later,', 'he', 'arrived', 'at', 'the', 'motel,', 'ready', 'to', 'start', 'his', 'vacation.', 'He', 'was', 'surprised', 'when', 'the', 'motel', 'room', 'was', 'even', 'worse', 'in', 'person.'], ['edited_ending:', 'Lars', 'decides', 'to', 'try', 'anyway', 'and', 'buys', 'avocado,', 'onion,', 'lime,', 'and', 'cilantro.', 'He', 'mixes', 'it', 'up', 'into', 'a', 'delicious', 'guacamole.', 'Lars', 'is', 'very', 'happy', 'that', 'he', 'decided', 'to', 'make', 'guacamole', 'at', 'home.'], ['edited_ending:', 'The', 'refused', 'to', 'offer', 'him', 'a', 'residence.', 'He', 'accepted', 'that', 'as', 'his', 'punishment.', 'Toby', 'kept', 'his', 'items', 'at', 'his', 'old', 'apartment.'], ['edited_ending:', 'She', 'was', 'scared', 'she', 'would', 'do', 'poorly.', 'But', 'the', 'next', 'day,', 'the', 'captain', 'gave', 'her', 'great', 'news.', 'Not', 'enough', 'girls', 'tried', 'out', 'for', 'the', 'team,', 'so', 'Anna', 'had', 'made', 'the', 'school', 'tennis', 'team', 'without', 'even', 'trying', 'out.'], ['edited_ending:', 'When', 'he', 'saw', 'it', 'he', 'jumped.', 'He', 'slipped', 'and', 'fell', 'into', 'the', 'stream.', 'He', 'had', 'to', 'walk', 'back', 'home', 'soaking', 'wet'], ['edited_ending:', 'The', 'people', 'around', 'her', 'talked', 'and', 'chatted', 'loudly.', 'They', 'even', 'excluded', 'her', 'from', 'the', 'conversation.', 'Janet', 'decided', 'she', 'would', 'ride', 'the', 'bus', 'again.'], ['edited_ending:', 'Jenny', 'never', 'wanted', 'to', 'trip', 'over', 'a', 'rock.', 'She', 'protected', 'her', 'elbows.', 'Jenny', 'wants', 'to', 'play', 'hopscotch', 'every', 'day.'], ['edited_ending:', 'He', 'decided', 'to', 'try', 'it', 'out', 'on', 'the', 'sidewalk', 'anyway.', 'The', 'boy', 'fell', 'and', 'broke', 'his', 'arm.', 'His', 'parents', 'felt', 'guilty', 'and', 'got', 'him', 'a', 'tablet.'], ['edited_ending:', 'She', 'slept', 'everyday', 'in', 'a', 'new', 'place.', 'The', 'day', 'finally', 'arrived', 'for', 'her', 'to', 'go', 'home.', 'All', 'her', 'kids', 'and', 'grandchildren', 'came', 'to', 'welcome', 'her.'], ['edited_ending:', 'The', 'chemotherapy', 'was', 'a', 'success', 'but', 'left', 'him', 'balding.', 'Derek', 'worried', 'his', 'classmate', 'would', 'make', 'fun', 'of', 'him.', 'So', 'he', 'dad', 'went', 'and', 'shaved', 'his', 'head', 'to', 'match', \"Derek's\", 'baldness.'], ['edited_ending:', 'The', 'revolver', 'went', 'off', 'when', 'it', 'hit', 'the', 'ground', 'and', 'made', 'a', 'deafening', 'roar', 'howled', 'through', 'the', 'canyon.', 'When', 'he', 'looked', 'at', 'the', 'target,', 'no', 'bullet', 'holes', 'were', 'there.', 'However,', 'his', 'trusted', 'donkey,', 'Fred,', 'was', 'dead.'], ['edited_ending:', 'However,', 'his', 'bottom', 'teeth', 'started', 'to', 'get', 'discolored.', 'He', 'decided', 'it', 'was', 'time', 'to', 'start', 'brushing.', 'He', 'brushed', 'his', 'teeth', 'and', 'set', 'up', 'an', 'appointment', 'with', 'a', 'dentist.'], ['edited_ending:', 'His', 'mom', 'yelled', 'at', 'him', 'to', 'take', 'better', 'care', 'of', 'his', 'things.', 'To', 'make', 'it', 'up', 'to', 'her', 'he', 'went', 'to', 'the', 'store', 'and', 'bought', 'a', 'new', 'shirt.', 'She', 'told', 'him', 'it', 'was', 'very', 'thoughtful.'], ['edited_ending:', 'He', 'hit', 'the', 'water', 'on', 'his', 'head.', 'The', 'lifeguard', 'watched.', 'The', 'lifeguard', 'jumped', 'into', 'the', 'pool', 'to', 'congratulate', 'Nathan.'], ['edited_ending:', 'He', 'worked', 'very', 'hard', 'every', 'day', 'to', 'save', 'money.', 'He', 'added', 'a', 'substantial', 'amount', 'of', 'money', 'to', 'a', 'vacation', 'fund.', 'He', 'eventually', 'took', 'the', 'vacation', 'of', 'his', 'dreams.'], ['edited_ending:', 'The', 'man', 'got', 'a', 'cone', 'with', 'chocolate', 'and', 'strawberry', 'ice', 'cream.', 'He', 'also', 'added', 'sprinkles', 'and', 'whipped', 'cream.', 'The', 'boy', \"couldn't\", 'even', 'look', 'at', 'the', 'ice', 'cream.'], ['edited_ending:', 'When', 'the', 'test', 'was', 'handed', 'out,', 'she', 'drew', 'a', 'deep', 'breath.', 'She', 'was', 'happy', 'to', 'see', 'she', 'knew', 'all', 'the', 'answers', 'anyway.', 'Annie', 'did', 'great', 'on', 'the', 'test.'], ['edited_ending:', 'I', 'handled', 'all', 'kinds', 'of', 'sensitive', 'information', 'on', 'my', 'computer', 'server.', 'When', 'I', 'ran', 'for', 'president,', 'many', 'questioned', 'my', 'use', 'of', 'the', 'server.', 'They', 'tried', 'to', 'indict', 'me', 'and', 'were', 'successful.'], ['edited_ending:', 'They', 'went', 'to', 'the', 'thrift', 'store', 'they', 'tried', 'multiple', 'pairs.', 'Tina', 'ended', 'up', 'liking', 'the', 'first', 'pair', 'that', 'fit.', 'Her', 'mother', 'bought', 'that', 'first', 'pair.'], ['edited_ending:', 'When', 'his', 'friends', 'proposed', 'to', 'meet', 'at', 'a', 'local', 'bar,', 'Cy', 'accepted.', 'He', 'could', 'handle', 'people', 'online', 'and', 'in', 'real', 'life.', 'He', 'accepted', 'the', 'offer', 'and', 'met', 'his', 'friends', 'at', 'the', 'bar.'], ['edited_ending:', 'I', 'was', 'very', 'skeptical', 'that', 'I', 'could', 'win.', 'I', 'was', 'so', 'nervous', 'about', 'winning', 'that', 'I', 'stopped', 'playing', 'as', 'well.', 'I', 'ended', 'up', 'losing', 'the', 'game.'], ['edited_ending:', 'We', 'went', 'to', 'our', 'seats', 'and', 'got', 'the', 'snacks', 'ready', 'to', 'eat.', 'We', 'started', 'to', 'watch', 'the', 'movie', 'and', 'the', 'kids', 'loved', 'it.', 'But', 'by', 'the', 'time', 'the', 'second', 'movie', 'started', 'they', 'were', 'asleep.'], ['edited_ending:', 'I', 'picked', 'a', 'steady', 'pace', 'to', 'start', 'with', 'at', 'which', 'I', 'felt', 'comfortable.', 'Near', 'the', 'end', 'I', 'tried', 'to', 'speed', 'up', 'to', 'beat', 'another', 'runner.', 'I', 'trailed', 'him', 'badly', 'and', 'threw', 'up.'], ['edited_ending:', 'I', 'drove', 'over', 'to', 'see', 'what', 'it', 'was', 'about.', 'The', 'line', 'was', 'incredibly', 'long.', 'I', 'still', 'waited', 'to', 'try', 'it.'], ['edited_ending:', 'One', 'of', 'the', 'friends', 'checked', 'his', 'phone', 'for', 'meal', 'ideas.', 'They', 'saw', 'new', 'pizza', 'recipe', 'that', 'looked', 'good.', 'Seeing', 'all', 'the', 'ingredients', 'in', 'their', 'kitchen,', 'the', 'group', 'got', 'to', 'work', 'cooking.'], ['edited_ending:', 'He', 'was', 'too', 'stubborn', 'to', 'ask', 'for', 'help', 'from', 'his', 'friends.', 'He', 'never', 'decided', 'to', 'ask', 'any', 'of', 'his', 'friends', 'for', 'help.', 'Without', 'his', \"friends'\", 'help,', 'he', 'moved', 'out', 'very', 'slowly.'], ['edited_ending:', 'She', 'answered', 'the', 'phone', 'and', 'heard', 'his', 'prank', 'call.', 'She', 'screamed', 'at', 'him', 'because', 'she', 'was', 'very', 'upset.', 'He', 'was', 'easily', 'found', 'out', 'and', 'got', 'into', 'a', 'lot', 'of', 'trouble.'], ['edited_ending:', 'Judy', 'worked', 'extra', 'hard', 'to', 'make', 'up', 'for', 'her', 'size.', 'She', 'managed', 'to', 'be', 'accepted', 'for', 'the', 'next', 'semester.', 'Now', 'Judy', 'is', 'one', 'of', 'the', 'best', 'cops'], ['edited_ending:', 'Thankfully,', 'he', 'allowed', 'me', 'to', 'do', 'it.', 'He', 'stroked', 'me', 'across', 'the', 'face.', 'I', 'decided', 'that', 'he', 'was', 'a', 'true', 'friend', 'so', 'I', 'hugged', 'him.'], ['edited_ending:', 'She', 'was', 'at', 'a', 'bar', 'one', 'night', 'and', 'met', 'a', 'woman', 'she', 'began', 'to', 'be', 'interested', 'in.', 'They', 'began', 'dating.', 'Nicole', 'just', 'got', 'engaged', 'to', 'be', 'married.'], ['edited_ending:', 'She', 'wanted', 'to', 'go', 'to', 'games', 'for', 'a', 'long', 'time', 'and', 'now', 'could', 'afford', 'tickets.', 'She', 'entered', 'a', 'radio', 'contest', 'for', 'more', 'baseball', 'tickets.', 'Allison', 'won', 'the', 'contest', 'and', 'invited', 'her', 'friends', 'to', 'her', 'favorite', \"team's\", 'game.'], ['edited_ending:', 'She', 'saw', 'a', 'cute', 'boy', 'walk', 'in.', 'Kathy', 'hoped', 'he', 'would', 'notice', 'her.', 'He', 'did', 'and', 'winked.'], ['edited_ending:', 'The', 'policeman', 'showed', 'us', 'his', 'gun', 'and', 'nightstick', 'menacingly.', 'Policemen', 'are', 'really', 'scary.', 'I', \"don't\", 'want', 'to', 'be', 'one', 'when', 'I', 'grow', 'up!'], ['edited_ending:', 'Then,', 'Anthony', 'learned', 'that', 'he', 'had', 'a', 'lot', 'in', 'common', 'with', 'women.', 'He', 'became', 'involved', 'in', 'a', 'brief', 'romance', 'with', 'his', 'female', 'coworker.', 'From', 'this', 'romance,', 'Anthony', 'gained', 'more', 'confident', 'with', 'women.'], ['edited_ending:', 'She', 'had', 'to', 'go', 'to', 'the', 'emergency', 'room.', 'After', 'that,', 'Amy', 'was', 'late', 'for', 'work!', 'Amy', 'felt', 'sad', 'and', 'angry', 'about', 'the', 'bad', 'things', 'in', 'her', 'day.'], ['edited_ending:', 'She', 'said', 'she', 'would', 'contact', 'me', 'if', 'the', 'old', 'work', 'group', 'went', 'out.', 'Her', 'last', 'Facebook', 'post', 'was', 'a', 'photo', 'of', 'the', 'old', 'group', 'at', 'dinner.', \"I'm\", 'sad', 'she', 'neglected', 'to', 'contact', 'me.'], ['edited_ending:', 'Joe', 'also', 'needed', 'to', 'dig', 'a', 'trench', 'for', 'the', 'sprinkler', 'system.', 'He', 'worked', 'tirelessly', 'from', 'dawn', 'to', 'dusk.', 'He', 'had', 'the', 'sprinklers', 'installed', 'the', 'next', 'day.'], ['edited_ending:', 'One', 'day,', 'he', 'started', 'working', 'for', 'the', 'government.', 'Rekindling', 'his', 'love', 'of', 'hacking,', 'he', 'leaked', 'secret', 'documents.', 'But', 'he', 'was', 'caught', 'and', 'spent', 'many', 'years', 'afterward', 'in', 'prison.'], ['edited_ending:', 'She', \"didn't\", 'fear', 'the', 'vines', 'would', 'die', 'before', 'they', 'could', 'grow.', 'She', 'planted', 'them', 'and', 'to', 'her', 'delight', 'they', 'climbed', 'easily!', 'Soon', 'her', 'whole', 'brick', 'wall', 'was', 'covered', 'with', 'lush', 'greenery!'], ['edited_ending:', 'She', 'had', 'chased', 'him', 'outside', 'with', 'a', 'cup', 'of', 'water.', 'My', 'dad', 'then', 'sat', 'down', 'and', 'held', 'his', 'nose.', 'My', 'sister', 'and', 'I', 'called', 'the', 'ambulance.'], ['edited_ending:', 'He', 'took', 'the', 'pizza', 'home.', 'His', 'wife', 'took', 'a', 'bite.', 'She', 'kept', 'eating', 'the', 'slice', 'as', 'normal.'], ['edited_ending:', 'Everybody', 'in', 'the', 'room', 'seemed', 'to', 'be', 'glaring', 'at', 'him.', 'The', 'man', 'set', 'the', 'ketchup', 'down', 'gently,', 'self-conscious', 'about', 'the', 'stares.', 'The', 'crowed', 'shouted', 'angrily.'], ['edited_ending:', 'While', 'at', 'lunch', 'they', 'brought', 'out', 'a', 'special', 'cake.', 'The', 'cake', 'was', 'decorated', 'with', 'baby', 'items.', 'They', 'announced', 'to', 'their', 'friends', 'they', 'were', 'pregnant.'], ['edited_ending:', 'While', 'I', 'was', 'standing', 'there,', 'I', 'saw', 'a', 'very', 'pretty', 'girl', 'cleaning', 'the', 'counter', 'in', 'the', 'coffee', 'shop.', 'I', 'tapped', 'on', 'the', 'door', 'and', 'asked', 'for', 'her', 'phone', 'number.', 'She', 'gave', 'it', 'to', 'me', 'and', 'we', 'talked', 'for', 'a', 'long', 'time!'], ['edited_ending:', 'Nancy', 'just', 'had', 'to', 'have', 'this', 'one.', 'Nancy', 'started', 'to', 'bid', 'but', 'was', 'quickly', 'outbid.', 'Nancy', 'decided', 'she', 'had', 'to', 'have', 'it', 'and', 'outbid', 'everyone', 'for', 'the', 'glass', 'bowl.'], ['edited_ending:', 'She', 'turned', '10', 'just', 'before', 'the', 'vet', 'told', 'us', 'she', 'was', 'sick.', 'The', 'last', 'thing', 'I', 'remember', 'was', 'her', 'looking', 'at', 'me', 'while', 'I', 'petted', 'her', 'head.', 'She', 'fell', 'over', 'sideways', 'just', 'before', 'she', 'closed', 'her', 'eyes', 'for', 'the', 'last', 'time.'], ['edited_ending:', 'She', 'mastered', 'her', 'song,', 'and', 'made', 'a', 'recording.', 'The', 'recording', 'did', 'not', 'play', 'correctly.', 'Cyrus', 'went', 'and', 'spent', 'three', 'hundred', 'dollars', 'for', 'new', 'recording', 'software.'], ['edited_ending:', 'Until', 'one', 'day', 'she', 'realized', 'she', 'missed', 'a', 'voice', 'mail.', 'A', 'day', 'later', 'she', 'called', 'back.', 'Tina', 'got', 'hired.'], ['edited_ending:', \"Dan's\", 'co-worker', 'told', 'him', 'he', 'needed', 'to', 'stop', 'this', 'habit.', 'He', 'locked', 'his', 'drawer', 'shut', 'to', 'make', 'it', 'harder', 'to', 'open.', 'Dan', 'was', 'dismayed', 'when', 'it', \"didn't\", 'help.'], ['edited_ending:', 'She', \"didn't\", 'even', 'realize', 'she', 'was', 'so', 'thirsty.', 'She', \"didn't\", 'drink', 'water.', 'Soon', 'she', 'got', 'a', 'headache', 'because', 'she', 'was', 'dehydrated.'], ['edited_ending:', \"She'd\", 'used', 'some', 'baking', 'soda', 'and', 'a', 'paper', 'towel', 'to', 'attempt', 'some', 'basic', 'hygiene.', 'Mandy', \"didn't\", 'think', 'it', 'was', 'enough.', 'She', 'knew', \"she'd\", 'be', 'humiliated', 'if', 'anyone', 'thought', 'she', 'was', 'classless.'], ['edited_ending:', 'His', 'daughter', 'was', 'happy', 'to', 'join', 'him', 'in', 'the', 'effort.', 'They', 'spent', 'weeks', 'putting', 'it', 'together', 'in', 'intricate', 'detail', 'because', 'it', 'was', 'too', 'intricate', 'to', 'finish', 'in', 'a', 'day.', 'They', 'were', 'both', 'very', 'proud', 'when', 'the', 'elaborate', 'set', 'up', 'was', 'all', 'done'], ['edited_ending:', 'He', 'was', 'sad', 'at', 'first,', 'since', 'he', 'loved', 'his', 'motorcycle.', 'He', 'called', 'the', 'motorcycle', 'dealership', 'and', 'inquired', 'about', 'their', 'bikes.', 'He', 'was', 'shocked', 'to', 'learn', 'how', 'cheap', 'they', 'were', 'compared', 'to', 'the', 'one', \"he'd\", 'just', 'sold.'], ['edited_ending:', 'Caleb', 'found', 'a', 'game', 'and', 'got', 'ready', 'to', 'play.', 'The', 'game', 'was', 'boring', 'and', 'not', 'entertaining', 'at', 'all.', 'Caleb', 'fell', 'asleep', 'in', 'the', 'arcade.'], ['edited_ending:', 'When', 'she', 'made', 'a', 'statement,', 'no', 'one', 'laughed.', 'Finally', 'she', 'laughed', 'awkwardly.', 'Tina', 'was', 'embarrassed.'], ['edited_ending:', 'After', 'it', 'was', 'released,', 'it', 'did', 'amazing.', 'He', 'was', 'driving', 'when', 'he', 'heard', 'it', 'come', 'on', 'the', 'radio.', 'He', 'pulled', 'over', 'and', 'started', 'dancing', 'to', 'it.'], ['edited_ending:', 'The', 'toy', 'came', 'with', 'a', 'tiny', 'stuffed', 'baby', 'in', 'her', 'arms.', 'The', 'baby', 'had', 'a', 'twig', 'of', 'purple', 'curly', 'hair.', 'The', 'two', 'came', 'as', 'a', 'pair,', 'and', 'are', 'very', 'cute.'], ['edited_ending:', 'Jess', 'never', 'laughed', 'at', \"Dara's\", 'jokes.', 'Dara', 'asked', 'if', 'they', 'could', 'go', 'on', 'another', 'date.', 'Jess', 'said', 'no', 'and', \"that's\", 'when', 'they', 'broke', 'up.'], ['edited_ending:', 'I', 'decided', 'to', 'throw', 'my', 'own,', 'but', 'could', 'not', 'find', 'a', 'good', 'costume', 'in', 'time.', 'I', 'decided', 'to', 'design', 'the', 'perfect', 'mask.', 'I', 'ended', 'up', 'having', 'the', 'best', 'disguise', 'at', 'the', 'party.'], ['edited_ending:', 'Instead,', 'at', 'night', 'they', 'gathered', 'for', 'a', 'talk', 'about', 'sea', 'lions.', 'The', 'ranger', 'got', 'a', 'call', 'about', 'a', 'sea', 'lion', 'on', 'the', 'beach.', 'They', 'all', 'raced', 'together', 'to', 'watch', 'the', 'sea', 'lion', 'give', 'birth', 'on', 'the', 'beach.'], ['edited_ending:', 'That', 'same', 'day', 'she', 'had', 'complained', 'of', 'chest', 'pain', 'and', 'wheezing.', 'She', 'had', 'just', 'found', 'out', 'she', 'had', 'asthma.', 'Thanks', 'to', 'her', 'new', 'inhaler', 'she', 'quit', 'coughing', 'and', 'now', 'feels', 'better.'], ['edited_ending:', 'The', 'couple', 'left', 'right', 'after', 'the', 'sermon.', 'They', 'looked', 'for', 'another', 'mass', 'during', 'the', 'week.', 'There', 'was', 'none.'], ['edited_ending:', 'Toby', 'tried', 'his', 'best', 'to', 'get', 'rid', 'of', 'bees', 'all', 'day', 'with', 'poison.', 'But', 'when', 'he', 'went', 'home', 'and', 'smelled', 'like', 'poison,', 'he', 'quit', 'the', 'job.', 'He', 'found', 'another', 'elsewhere', 'where', 'no', 'bees', 'or', 'poison', 'was', 'involved.'], ['edited_ending:', 'It', 'was', 'okay', 'but', 'she', 'was', 'really', 'strange.', 'He', 'always', 'had', 'to', 'pick', 'her', 'up', 'at', 'funerals.', 'He', 'ended', 'up', 'getting', 'married', 'to', 'her', 'at', 'the', 'first', 'attempt.'], ['edited_ending:', 'She', 'stopped', 'working', 'hard', 'at', 'it,', 'and', 'people', 'noticed.', 'One', 'day', 'she', 'upset', 'she', \"wasn't\", 'invited', 'to', 'attend', 'the', 'City', \"Taggers'\", 'Meeting.', 'Sky', 'was', 'disappointed', 'that', 'her', 'work', 'had', 'been', 'dismissed.'], ['edited_ending:', 'Suddenly', 'a', 'large', 'male', 'silverback', 'walked', 'out', 'of', 'an', 'entryway.', 'He', 'glared', 'angrily', 'at', 'me', 'the', 'entire', 'time', 'I', 'was', 'there.', 'I', 'felt', 'very', 'guilty,', 'like', 'I', \"shouldn't\", 'be', 'there', 'looking', 'at', 'him.'], ['edited_ending:', \"Vicky's\", 'family', 'tries', 'to', 'give', 'her', 'a', 'gun', 'and', 'lessons.', 'She', 'refuses', 'to', 'practice.', 'Vicky', 'never', 'goes', 'hunting', 'with', 'her', 'family.'], ['edited_ending:', 'His', 'ex-wife', 'heard', 'a', 'knock', 'on', 'the', 'door', 'one', 'day.', 'She', 'saw', 'a', 'large', 'bouquet', 'of', 'flowers', 'through', 'the', 'peep', 'hole.', 'She', 'threw', 'open', 'the', 'door', 'to', 'see', 'Grant', 'trying', 'to', 'win', 'her', 'back.'], ['edited_ending:', 'Geoffrey', 'had', 'considered', 'sneaking', 'his', 'calculator', 'into', 'the', 'exam.', 'Geoffrey', 'knew', 'he', 'might', 'get', 'caught', 'using', 'the', 'calculator', 'by', 'his', 'teacher.', 'Geoffrey', 'was', 'glad', 'to', 'have', 'more', 'time', 'to', 'study', 'for', 'the', 'test.'], ['edited_ending:', 'Suddenly,', 'the', 'wind', 'blew', 'it', 'out', 'of', 'her', 'hand.', 'She', 'tried', 'her', 'hardest', 'to', 'catch', 'it.', 'But', 'unfortunately', 'it', 'fell', 'in', 'the', 'mud.'], ['edited_ending:', 'Even', 'thought', 'it', 'was', 'a', 'school', 'night,', 'he', 'decided', 'to', 'steal', 'all', 'of', 'it.', 'He', 'crept', 'into', 'the', 'kitchen', 'quietly', 'and', 'opened', 'the', 'jar.', 'As', 'he', 'reached', 'in,', 'he', 'heard', 'his', 'mother', 'ask', 'him', 'what', 'he', 'was', 'doing.'], ['edited_ending:', 'The', 'store', 'only', 'had', 'red', 'peppers.', 'She', 'bought', 'them', 'anyway.', 'Her', 'salsa', 'was', 'still', 'good,', 'even', 'with', 'the', 'red', 'peppers.'], ['edited_ending:', 'Today', 'the', 'fish', 'died.', 'My', 'daughter', 'pretended', 'that', 'nothing', 'happened.', 'So', 'far,', 'her', 'daughter', 'thinks', 'the', 'fish', 'is', 'sleeping.'], ['edited_ending:', 'I', 'bought', 'her', 'dinner', 'and', 'a', 'small', 'chocolate', 'cake.', 'I', 'felt', 'bad', 'for', 'not', 'remembering', \"Mother's\", 'Day.', 'She', 'loved', 'the', 'company', 'and', 'cake', 'though!'], ['edited_ending:', 'He', 'had', 'a', 'very', 'important', 'food', 'magazine', 'coming', 'to', 'do', 'an', 'interview.', 'He', 'had', 'just', 'found', 'out', 'his', 'chef', 'had', 'an', 'std.', 'He', 'knew', 'the', 'right', 'thing', 'to', 'do', 'was', 'to', 'cancel', 'the', 'interview.'], ['edited_ending:', 'They', 'camped', 'next', 'to', 'the', 'rapid', 'river.', 'They', 'spent', 'the', 'whole', 'time', 'in', 'the', 'camper,', 'telling', 'stories.', 'Mike', 'still', 'had', 'a', 'great', 'time,', 'and', 'cherished', 'the', 'time', 'with', 'family.'], ['edited_ending:', 'They', 'never', 'tell', 'each', 'other', 'Happy', 'Anniversary.', 'Neither', 'of', 'them', 'seemed', 'to', 'think', 'it', 'was', 'a', 'special', 'day', 'to', 'acknowledge.', 'Now', \"they're\", 'both', 'anxious', 'to', 'get', 'the', 'divorce', 'process', 'started.'], ['edited_ending:', 'Jason', 'wanted', 'to', 'make', 'sure', 'they', 'did', 'something', 'all', 'three', 'of', 'them', 'would', 'like.', 'He', 'planned', 'a', 'hunting', 'trip.', 'Jason,', 'his', 'mom,', 'and', 'his', 'father', 'went', 'and', 'had', 'a', 'great', 'time', 'together.'], ['edited_ending:', 'Claire', 'drove', 'home', 'without', 'any', 'fruit.', 'She', 'used', 'canned', 'apples', 'to', 'cook', 'a', 'homemade', 'apple', 'pie.', 'Claire', \"couldn't\", 'believe', 'how', 'tasteless', 'her', 'pie', 'was.'], ['edited_ending:', 'Her', 'sister', 'told', 'her', 'that', 'she', 'once', 'cut', 'through', 'the', \"frog's\", 'chest', 'and', 'produced', 'its', 'still', 'beating', 'heart.', 'Her', 'teacher', 'was', 'annoyed,', 'because', 'the', \"frog's\", 'were', 'already', 'dead.', 'Miley', 'shrugged', 'and', 'told', 'everyone', 'that', 'she', 'cut', 'up', 'a', 'frog.'], ['edited_ending:', 'She', 'would', 'often', 'spend', 'her', 'entire', 'check', 'in', 'a', 'single', 'night.', 'She', 'forgot', 'to', 'pay', 'rent', 'one', 'day', 'and', 'was', 'evicted.', 'Terry', 'had', 'to', 'sell', 'herself', 'on', 'the', 'corner', 'for', 'some', 'cash.'], ['edited_ending:', 'The', 'message', 'said', 'to', 'make', 'a', 'donation', 'by', 'texting', 'a', 'number.', 'Jack', 'made', 'a', '$10', 'donation,', 'and', 'on', 'his', 'bill', '$10', 'was', 'charged.', 'Jack', 'decided', 'to', 'make', 'sure', 'to', 'continue', 'donating', 'to', 'this', 'charity.'], ['edited_ending:', 'One', 'day', 'she', 'let', 'the', 'rabbit', 'out', 'and', 'it', 'ran', 'off.', 'She', 'looked', 'everywhere.', 'Finally', 'she', 'found', 'it', 'in', 'the', 'cupboard.'], ['edited_ending:', 'By', 'the', 'time', 'he', 'climbed', 'out', 'again,', 'I', 'had', 'caught', 'a', 'big', 'fish.', 'When', 'he', 'saw', 'my', 'fish,', 'he', 'made', 'sure', 'he', 'was', 'not', 'distracted', 'anymore.', 'Soon', 'after,', 'he', 'too', 'caught', 'a', 'fish.'], ['edited_ending:', 'Then', 'they', 'ran', 'away', 'from', 'the', 'door,', 'breathing', 'heavily.', 'They', 'went', 'back', 'the', 'next', 'day,', 'and', 'both', 'reached', 'the', 'top,', 'but', 'it', 'was', 'hard!', 'They', 'agreed', 'that', 'they', 'both', 'needed', 'to', 'be', 'a', 'little', 'more', 'fit!'], ['edited_ending:', 'He', 'went', 'to', 'the', 'State', 'Prison', 'in', 'his', 'town.', 'Paris', 'was', 'able', 'to', 'receive', 'money', 'from', 'his', 'family.', 'This', 'allowed', 'him', 'to', 'have', 'a', 'better', 'life', 'in', 'prison.'], ['edited_ending:', 'They', 'ordered', 'champagne', 'and', 'caviar.', 'Paul', 'presented', 'Martha', 'with', 'a', 'beautiful', 'necklace.', 'It', 'was', 'a', 'special', 'trip', 'for', 'a', 'special', 'couple', 'and', 'it', 'showed', 'in', 'the', 'video!'], ['edited_ending:', 'The', 'cat', 'played', 'in', \"it's\", 'bed.', 'He', 'came', 'back', 'with', 'a', 'toy', 'mouse.', 'The', 'cat', 'gave', 'the', 'toy', 'mouse', 'to', 'the', 'owner.'], ['edited_ending:', 'Mitzi', 'eventually', 'snuggled', 'up', 'to', 'the', 'cat,', 'and', 'when', 'I', 'saw', 'her', 'later,', 'I', 'giggled', 'and', 'she', 'heard', 'me', 'and', 'woke', 'up.', 'She', 'jumped', 'up', 'and', 'snarled', 'at', 'the', 'cat', 'like', 'a', 'ferocious', 'cat-hater.', 'The', 'cat', 'yawned', 'and', 'went', 'back', 'to', 'sleep.'], ['edited_ending:', 'Dan', 'informed', 'the', 'guests', 'of', 'the', 'theme.', 'In', 'addition,', 'Dan', 'wanted', 'the', 'guest', 'to', 'wear', 'cute', 'rodeo', 'costumes.', 'Dan', 'could', 'not', 'wait', 'to', 'have', 'fun', 'with', 'his', 'guests', 'at', 'his', 'rodeo', 'party.'], ['edited_ending:', 'Miley', 'was', 'so', 'mad.', 'Miley', 'began', 'to', 'spend', 'much', 'more', 'time', 'on', 'her', 'studying', 'and', 'homework.', 'Her', 'grades', 'improved,', 'and', 'the', 'whole', 'family', 'was', 'pleased!'], ['edited_ending:', 'When', 'she', 'was', 'done,', 'the', 'audience', 'hated', 'her.', 'It', 'took', 'about', 'one', 'hour.', 'Kelley', 'was', 'asked', 'not', 'to', 'come', 'back.'], ['edited_ending:', 'I', 'needed', 'to', 'feel', 'inspired.', 'I', 'decided', 'to', 'search', 'for', 'new', 'music', 'online', 'that', 'was', 'similar', 'to', 'what', 'my', 'favorite', 'artist', 'played.', 'The', 'new', 'music', 'gave', 'me', 'the', 'refreshing', 'feel', 'I', 'needed.'], ['edited_ending:', 'He', \"doesn't\", 'like', 'working', 'at', 'home', 'as', 'a', 'job.', 'He', 'decides', 'to', 'get', 'a', 'normal', 'job.', 'Before', 'he', 'started,', 'he', 'went', 'and', 'talked', 'to', 'his', 'new', 'boss.'], ['edited_ending:', 'Over', 'the', 'weekend', 'she', 'went', 'to', 'the', 'animal', 'shelter.', 'She', 'fell', 'in', 'love', 'with', 'a', 'little', 'brown', 'terrier', 'and', 'named', 'him', 'Breadie.', 'She', 'took', 'the', 'puppy', 'home', 'and', 'he', 'is', 'now', 'part', 'of', 'the', 'family.'], ['edited_ending:', 'In', 'the', 'second', 'half,', 'the', 'blue', 'team', 'barely', 'tried', 'to', 'compete.', 'They', 'lost', 'the', 'game', 'by', '17', 'points.', 'The', 'red', 'team', 'was', 'so', 'proud!'], ['edited_ending:', 'He', 'would', 'often', 'go', 'visit', 'them', 'since', 'he', \"didn't\", 'have', 'to', 'leave', 'for', 'war', 'immediately.', 'Finally', 'it', 'was', 'time', 'for', 'him', 'to', 'go', 'to', 'war.', 'Eduardo', 'steps', 'on', 'the', 'plane', 'after', 'hugging', 'his', 'family.'], ['edited_ending:', 'They', 'had', 'to', 'walk', 'through', 'a', 'bad', 'part', 'of', 'town.', 'They', 'were', 'all', 'robbed', 'at', 'gunpoint.', 'Yanna', 'had', 'emotional', 'problems', 'and', 'depression', 'after', 'the', 'attack.'], ['edited_ending:', 'Because', 'the', 'engine', 'had', 'roared', 'loudly.', 'We', 'had', 'been', 'worried', 'the', 'axle', 'would', 'snap.', 'And', 'then', 'we', 'would', 'have', 'had', 'to', 'tow', 'it', 'out.'], ['edited_ending:', 'I', 'ended', 'up', 'having', 'to', 'walk', 'home.', 'The', 'walk', 'home', 'lasted', 'about', '2-3', 'hours', 'When', 'I', 'got', 'home', 'my', 'mom', 'was', 'upset', 'about', 'her', 'accident'], ['edited_ending:', 'He', 'created', 'a', 'taco', 'dinner', 'for', 'one.', 'Fred', 'was', 'pretty', 'into', 'it.', 'He', 'ended', 'up', 'doing', 'this', 'every', 'Tuesday.'], ['edited_ending:', 'He', 'liked', 'to', 'hang', 'out', 'with', 'a', 'lot', 'of', 'people.', 'He', 'started', 'hanging', 'out', 'with', 'my', 'boyfriend.', 'Sam', 'and', 'I', 'are', 'no', 'longer', 'friends.'], ['edited_ending:', 'I', 'did', 'every', 'homework', 'assignment,', 'even', 'the', 'difficult', 'ones', 'I', 'was', 'happy', 'to', 'be', 'in', 'the', 'class', 'and', 'liked', 'it', 'through', 'the', 'end.', \"I'm\", 'proud', 'of', 'my', 'grade'], ['edited_ending:', 'We', 'stooed', 'in', 'a', 'line', 'along', 'the', 'highway.', 'They', 'explained', 'that', 'help', 'was', 'on', 'the', 'way,', 'but', 'nobody', 'was', 'listening.', 'We', 'were', 'all', 'so', 'bored', 'by', 'the', 'waiting', 'that', 'we', \"didn't\", 'pay', 'attention.'], ['edited_ending:', 'She', 'loves', 'her', 'cat', 'so', 'she', 'hides', 'it', 'during', 'the', 'inspection.', 'Unfortunately', 'the', 'landlord', 'smells', 'the', 'cat', 'due', 'to', 'his', 'allergies.', 'She', 'is', 'having', 'a', 'hard', 'time', 'coping', 'with', 'having', 'to', 'give', 'away', 'her', 'cat.'], ['edited_ending:', 'One', 'night,', 'he', 'heard', 'his', 'garage', 'can', 'get', 'knocked', 'over.', 'And', 'he', 'looked', 'out', 'his', 'window', 'to', 'see', 'what', 'is', 'was.', 'He', 'snuggled', 'up', 'with', 'his', 'mom', 'so', 'he', \"wouldn't\", 'be', 'scared.'], ['edited_ending:', 'We', 'are', 'flying', 'out', 'in', 'a', 'few', 'hours.', 'He', 'is', 'taking', 'me', 'to', 'Disney', 'World', 'to', 'see', 'Mickey.', 'It', 'will', 'be', 'so', 'unpleasant', 'to', 'endure', 'the', 'Florida', 'sun!'], ['edited_ending:', 'Back', 'on', 'the', 'road', 'she', 'was', 'eating', 'her', 'nuts.', 'One', 'person', 'finished', 'all', 'his', 'snacks', 'and', 'kept', 'mooching', 'nuts', 'from', 'Kate.', 'Kate', 'was', 'fuming', 'over', 'having', 'to', 'share', 'all', 'over', 'again', 'with', 'the', 'greedy', 'moocher.'], ['edited_ending:', 'She', 'dumped', 'sand', 'on', 'the', 'floor', 'from', 'her', 'shoes.', 'An', 'hour', 'later', 'her', 'mother', 'called', 'her', 'to', 'the', 'living', 'room.', 'Amy', 'got', 'in', 'trouble', 'because', 'sand', 'had', 'been', 'tracked', 'through', 'the', 'house.'], ['edited_ending:', 'I', 'couldnt', 'even', 'look', 'at', 'the', 'sight', 'of', 'a', 'ham', 'and', 'cheese', 'sandwich.', 'I', 'bought', 'nothing.', 'A', 'week', 'later', 'I', 'was', 'starving.'], ['edited_ending:', 'He', 'went', 'into', 'the', 'bank', 'to', 'ask', 'for', 'an', 'application.', 'The', 'teller', 'finished', 'with', 'another', 'customer', 'before', 'giving', 'Boris', 'an', 'application.', 'Boris', 'is', 'now', 'waiting', 'to', 'hear', 'back', 'from', 'the', 'bank.'], ['edited_ending:', 'Surprised,', 'he', 'rushed', 'indoors.', 'He', 'researched', 'how', 'to', 'safely', 'dispose', 'of', 'the', 'nest.', 'Later', 'that', 'day', 'he', 'took', 'the', 'proper', 'measures', 'to', 'get', 'rid', 'of', 'it.'], ['edited_ending:', 'He', 'tries', 'on', 'a', 'pair', 'of', 'the', 'contacts.', 'Marco', 'loves', 'his', 'new', 'contacts.', 'He', 'is', 'happy', 'that', 'he', 'is', 'able', 'to', 'see', 'well', 'again', 'without', 'glasses.'], ['edited_ending:', 'She', 'was', 'thinking', 'about', 'moving', 'but', 'her', 'lease', \"wasn't\", 'over.', 'But', 'she', 'was', 'able', 'to', 'make', 'money', 'by', 'posting', 'her', 'apartment', 'on', 'Airbnb.', 'She', 'recently', 'signed', 'another', 'lease.'], ['edited_ending:', 'I', 'tried', 'to', 'take', 'the', 'new', 'batteries', 'out', 'to', 'keep', 'them,', 'but', 'the', 'screws', 'were', 'too', 'tight.', 'Finally', 'I', 'took', 'the', 'thing', 'to', 'an', 'electronics', 'store.', 'It', 'turns', 'out', 'I', 'had', 'put', 'the', 'batteries', 'in', 'backwards!'], ['edited_ending:', 'Now', 'that', \"it's\", 'under', 'control,', 'he', 'loves', 'riding', 'his', 'bike', 'on', 'long,', '2', 'or', 'three', 'hour', 'trips.', 'Yesterday', 'he', 'left', 'to', 'go', 'to', 'Toledo.', 'He', 'just', 'called', 'me', 'from', 'Detroit.'], ['edited_ending:', 'Before', 'they', 'left,', 'Alex', 'hit', 'an', 'incredible', 'shot', 'over', 'a', 'lake.', 'His', 'dad', 'praised', 'him', 'and', 'wished', 'he', 'was', 'still', 'young', 'After', 'they', 'left', 'the', 'golf', 'course,', 'Alex', 'and', 'his', 'dad', 'got', 'drunk', 'at', 'the', 'bar.'], ['edited_ending:', 'They', 'had', 'a', 'famous', 'ancient', 'fire', 'walk', 'every', 'weekend.', 'Still,', 'Liam', 'took', 'off', 'his', 'shoes', 'and', 'socks', 'and', 'walked', 'across', 'hot', 'coals.', 'He', 'feel', 'within', 'seconds', 'and', 'burned', 'his', 'elbows', 'and', 'knees.'], ['edited_ending:', 'She', 'would', 'stay', 'up', 'tonight', 'to', 'play', 'games,', 'but', 'she', 'is', 'too', 'tired', 'too.', 'Instead', 'she', 'will', 'just', 'go', 'to', 'bed', 'early', 'so', 'she', 'gets', 'a', 'good', 'grade.', 'Sally', 'is', 'so', 'very', 'responsible.'], ['edited_ending:', 'Amelia', \"didn't\", 'always', 'trust', 'her', 'mother,', 'and', \"didn't\", 'want', 'to', 'be', 'so', 'plump.', 'She', 'went', 'on', 'a', 'diet', 'and', 'lost', 'a', 'few', 'pounds.', 'But', 'when', 'she', \"didn't\", 'find', 'a', 'husband,', 'she', 'went', 'back', 'to', 'eating', 'normally.'], ['edited_ending:', 'I', 'would', 'never', 'put', 'my', 'cat', 'near', 'a', 'mouse.', 'I', 'took', 'my', 'cat', 'to', 'the', 'park', 'and', 'let', 'her', 'play.', 'Within', '10', 'minutes,', 'she', 'had', 'made', 'two', 'new', 'cat', 'friends.'], ['edited_ending:', 'Greg', 'gave', 'his', 'dog', 'a', 'bath.', 'Since', 'his', 'dog', 'stayed', 'inside', 'he', \"wouldn't\", 'need', 'a', 'bath', 'for', 'a', 'while.', 'Greg', 'loved', 'that', 'his', 'dog', 'stayed', 'clean'], ['edited_ending:', 'The', 'food', 'had', 'almost', 'started', 'to', 'burn.', 'But', 'the', 'smoke', 'alarm', \"didn't\", 'go', 'off.', 'Ani', 'turned', 'the', 'burner', 'off', 'and', 'enjoyed', 'her', 'dinner.'], ['edited_ending:', 'Eventually', 'they', 'were', 'able', 'to,', 'but', 'on', 'the', 'way', 'back', 'they', 'took', 'a', 'bend', 'too', 'fast', 'with', 'the', 'boat.', 'The', 'axle', 'missed', 'the', 'turn', 'and', 'broke', 'in', 'half.', 'The', 'trailer', 'and', 'boat', 'tipped', 'onto', 'the', 'road.'], ['edited_ending:', 'Jill', 'decided', 'to', 'find', 'a', 'part', 'time', 'job', 'to', 'make', 'up', 'for', 'the', 'money', 'she', 'spent.', 'She', 'started', 'working', 'as', 'a', 'waitress', 'to', 'save', 'up', 'again.', 'Jill', 'finally', 'was', 'able', 'to', 'get', 'back', 'to', 'her', 'old', 'balance.'], ['edited_ending:', 'Jack', 'leaned', 'back', 'and', 'gently', 'stretched', 'his', 'arm', 'overhead.', 'He', 'then', 'got', 'up', 'and', 'left', 'the', 'theater.', 'Within', 'minutes,', 'he', 'was', 'in', 'a', 'taxi', 'on', 'his', 'way', 'home', 'alone.'], ['edited_ending:', 'The', 'orders', 'never', 'came.', 'When', 'Matt', 'left', 'to', 'use', 'the', 'bathroom,', 'Derek', 'asked', 'the', 'waiter', 'about', 'the', 'food.', 'The', 'waiter', 'ignored', 'him', 'and', 'left', 'the', 'dining', 'room.'], ['edited_ending:', 'The', 'lemonade', 'seemed', 'rather', 'interesting.', 'I', 'wanted', 'to', 'see', 'what', 'it', 'tasted', 'like.', 'I', 'wish', 'I', 'could', 'have', 'bought', 'some.'], ['edited_ending:', 'He', 'realized', 'the', 'table', 'had', 'a', 'dip', 'in', 'it.', 'Dan', 'did', 'not', 'like', 'the', 'way', 'the', 'table', 'was', 'now.', 'He', 'sanded', 'the', 'rest', 'of', 'the', 'table', 'to', 'make', 'it', 'even.'], ['edited_ending:', 'They', 'got', 'to', 'the', 'park', 'and', 'started', 'flying', 'the', 'kite.', 'All', 'of', 'them', 'were', 'having', 'a', 'wonderful', 'time.', 'Afterwards', 'they', 'were', 'all', 'happy', 'they', 'went', 'to', 'the', 'park', 'that', 'day.'], ['edited_ending:', 'Gary', 'immediately', 'went', 'to', 'the', 'store', 'and', 'purchased', 'a', 'car', 'charger', 'for', 'his', 'laptop.', 'While', 'skeptical,', 'Gary', 'plugged', 'the', 'laptop', 'in,', 'and', 'then', 'his', 'phone.', 'Gary', 'was', 'amazed', 'to', 'see', 'that', 'his', 'cell', 'phone', 'was', 'charging!'], ['edited_ending:', 'He', 'bought', 'a', 'big', 'selection', 'of', 'paintings', 'with', 'some', 'of', 'his', 'money.', 'Beautiful', 'women', 'were', 'impressed', 'by', 'this', 'feat', 'and', 'married', 'him.', 'Donald', 'divorced', 'all', 'but', 'one', 'of', 'them.'], ['edited_ending:', 'Because', 'of', 'this,', 'Alan', 'was', 'a', 'very', 'poor', 'shot.', 'But', 'as', 'he', 'practiced,', 'his', 'aim', 'improved.', 'Soon', 'Alan', 'a', 'better', 'shot', 'than', 'even', 'his', 'dad!'], ['edited_ending:', 'One', 'day', 'he', 'accidentally', 'slammed', 'a', 'vase', 'on', 'the', 'fireplace.', 'His', 'dad,', 'furious,', 'came', 'in', 'yelling', 'and', 'told', 'him', 'wrestling', 'was', 'fake.', 'Mitt', 'was', 'so', 'crushed', 'that', 'he', 'could', 'never', 'watch', 'wrestling', 'again.'], ['edited_ending:', 'The', 'young', 'woman', 'said', 'she', 'wanted', 'a', 'balloon', 'animal.', 'Levon', 'made', 'the', 'young', 'woman', 'a', 'balloon', 'giraffe.', 'The', 'young', 'woman', 'left', 'the', 'park', 'overjoyed.'], ['edited_ending:', 'Tom', 'began', 'eating', 'onlyfruit', 'and', 'lean', 'protein.', 'Soon', 'he', 'lost', 'weight.', 'Tom', 'was', 'happy', 'that', 'he', 'was', 'dieting.'], ['edited_ending:', 'When', 'he', 'came', 'out', 'of', 'the', 'store', 'he', 'thought', 'his', 'bike', 'was', 'gone.', 'Devan', 'looked', 'around', 'frantically.', 'He', 'reported', 'his', 'bike', 'stolen', 'to', 'the', 'police', 'but', 'soon', 'realized', 'the', 'bike', 'was', 'right', 'behind', 'him,', 'locked', 'in', 'front', 'of', 'the', 'store.'], ['edited_ending:', 'His', 'neighbor', 'saw', 'Harold', 'throw', 'out', 'the', 'trash.', 'He', 'yelled', 'at', 'Harold', 'from', 'the', 'porch.', 'His', 'neighbor', 'was', 'really', 'upset.'], ['edited_ending:', 'The', 'next', 'night,', 'I', 'lost', 'track', 'of', 'time', 'again', 'and', 'I', 'forgot', 'to', 'sleep', 'completely.', 'The', 'next', 'day', 'I', 'was', 'too', 'tired', 'to', 'move.', \"I'll\", 'never', 'do', 'that', 'again.'], ['edited_ending:', 'She', 'also', 'bought', 'chicken', 'from', 'the', 'deli.', 'She', 'loved', 'the', 'chicken', 'and', 'pizza', 'from', 'the', 'first', 'bite.', 'She', 'knew', 'she', 'could', 'eat', 'this', 'everyday.'], ['edited_ending:', 'The', 'sauce', 'was', 'only', 'a', 'base', 'and', 'needed', 'an', 'extra', 'touch.', 'She', 'mixed', 'the', 'sauce', 'with', 'additional', 'herbs', 'and', 'spices.', \"Anna's\", 'family', 'all', 'complimented', 'her', 'delicious', 'homemade', 'sauce!'], ['edited_ending:', 'His', \"friend's\", 'boss', 'read', 'the', 'joke.', 'The', 'boss', 'chuckled', 'to', 'himself.', 'Gustaf', 'received', 'an', 'offer', 'to', 'tell', 'jokes', 'at', 'the', \"company's\", 'employee', 'appreciation', 'day.'], ['edited_ending:', 'He', 'needed', 'to', 'get', 'the', 'truck', 'packed', 'up', 'before', 'the', 'morning', 'was', 'over.', 'He', 'threw', 'his', 'smaller', 'bag', 'into', 'the', 'truck.', 'He', 'raced', 'to', 'make', 'it', 'to', 'the', 'bus', 'station', 'on', 'time.'], ['edited_ending:', 'Soon,', 'emergencies', 'mounted', 'up.', 'Stacey', 'needed', 'another', 'credit', 'card', 'just', 'to', 'deal', 'with', 'all', 'her', 'expenses.', 'Stacey', 'now', 'has', '$15,000', 'of', 'credit', 'card', 'debt.'], ['edited_ending:', 'When', 'I', 'woke', 'up', 'for', 'work,', 'the', 'sun', 'had', 'not', 'come', 'up.', 'I', 'wound', 'up', 'going', 'in', 'early', 'and', 'getting', 'overtime.', 'I', 'found', 'a', 'new', 'favorite', 'shift', 'between', 'and', 'noon,', 'now', 'I', 'have', 'a', 'new', 'shift!'], ['edited_ending:', 'The', 'ball', 'never', 'went', 'in.', 'He', 'tried', 'many', 'different', 'foot', 'techniques.', 'He', 'was', 'able', 'to', 'miss', '11', 'baskets', 'in', 'a', 'row', 'doing', 'this.f'], ['edited_ending:', 'The', 'power', 'then', 'went', 'out.', 'I', 'was', 'afraid', 'we', 'would', 'hurt.', 'Luckily', 'after', 'ten', 'minutes', 'it', 'stopped.'], ['edited_ending:', 'The', 'new', 'erasable', 'pens', 'were', 'a', 'big', 'hit.', 'He', 'made', 'a', 'lot', 'of', 'money', 'under', 'this', 'scheme.', 'To', 'celebrate', 'his', 'wealth', 'he', 'took', 'a', 'day', 'off', 'and', 'went', 'to', 'the', 'beach.'], ['edited_ending:', 'He', 'walked', 'into', 'the', 'gym', 'to', 'ask', 'the', 'drama', 'teacher', 'for', 'an', 'audition.', 'The', 'drama', 'teacher', 'agreed', 'to', 'let', 'Jake', 'try', 'out.', 'Jake', 'tried', 'out', 'and', 'actually', 'got', 'a', 'part.'], ['edited_ending:', 'The', 'day', 'of', 'the', 'test', 'arrived', 'and', 'I', 'was', 'sure', \"I'd\", 'do', 'well.', 'I', 'also', 'sat', 'next', 'to', 'the', 'smartest', 'person', 'in', 'class.', 'To', 'be', 'sure,', 'I', 'used', 'his', 'answers', 'to', 'double', 'check', 'mine.'], ['edited_ending:', 'His', 'dad', 'led', 'him', 'down', 'to', 'the', 'river.', 'His', 'dad', 'showed', 'him', 'how', 'to', 'cast', 'his', 'line.', 'His', 'dad', 'showed', 'him', 'how', 'to', 'cast', 'his', 'line.'], ['edited_ending:', 'Fred', 'decided', 'to', 'try', 'recreating', 'it', 'at', 'home.', 'He', 'found', 'recipes', 'online', 'for', 'homemade', 'dough', 'and', 'sauce.', 'It', 'was', 'the', 'best', 'pizza', 'Fred', 'had', 'ever', 'eaten!'], ['edited_ending:', 'He', 'began', 'to', 'try', 'to', 'find', 'his', 'way', 'home.', 'After', 'a', 'little', 'wandering,', 'Tommy', 'found', 'his', 'backyard.', 'It', 'turns', 'out', 'that', 'his', 'house', 'was', 'not', 'so', 'far', 'away!'], ['edited_ending:', 'He', 'started', 'by', 'visiting', 'all', 'the', 'ancient', 'Roman', 'buildings', 'still', 'standing.', 'He', 'also', 'made', 'sure', 'to', 'take', 'in', 'as', 'much', 'local', 'cuisine', 'as', 'he', 'could.', 'He', 'came', 'home', 'with', 'a', 'few', 'pictures', 'but', 'nothing', 'interesting.'], ['edited_ending:', 'The', 'next', 'day,', 'I', 'purchased', 'another', 'bottle', 'and', 'it', 'took', 'me', 'ten', 'minutes.', 'Afterwards', 'I', 'felt', 'very', 'content.', 'I', 'went', 'out', 'to', 'buy', 'some', 'more.'], ['edited_ending:', 'Unfortunately', 'they', \"couldn't\", 'fix', 'it', 'themselves', 'without', 'the', 'proper', 'tools.', 'Robert', 'asked', 'his', 'neighbor', 'for', 'some', 'help', 'and', 'he', 'accepted.', 'His', 'neighbor', 'was', 'able', 'to', 'fix', 'the', 'car', 'and', 'solve', 'his', \"friend's\", 'issue.'], ['edited_ending:', 'He', 'crashes', 'into', 'a', 'tree.', 'The', 'engine', 'is', 'smoking', 'very', 'badly.', 'His', 'car', 'engine', 'is', 'blown', 'up!'], ['edited_ending:', 'After', 'saving', 'for', 'months,', 'he', 'went', 'down', 'to', 'the', 'dealership', 'looking', 'for', 'a', 'new', 'car.', 'He', 'went', 'back', 'and', 'forth', 'but', 'finally', 'decided', 'on', 'a', 'Mustang.', 'Joe', 'was', 'so', 'happy', 'with', 'his', 'new', 'car', 'and', 'never', 'looked', 'back.'], ['edited_ending:', 'The', 'kitten', 'dreamed', 'about', 'something', 'brown', 'and', 'squishy.', 'The', 'kitten', 'was', 'content', 'in', 'her', 'sleep.', 'The', 'kitten', 'imagined', 'it', 'was', 'asleep', 'on', 'the', 'lab.'], ['edited_ending:', 'Lacys', 'boss', 'warned', 'her', 'it', 'was', 'a', 'dead', 'end', 'job.', 'Lacy', 'worked', 'even', 'harder.', 'In', 'the', 'end,', 'she', 'was', 'stuck.'], ['edited_ending:', 'I', 'instantly', 'fell', 'in', 'love', 'with', 'Suki.', 'I', 'asked', 'her', 'to', 'marry', 'me', 'and', 'stay', 'in', 'Spain.', 'Unbelievably,', 'she', 'said', 'yes!'], ['edited_ending:', 'She', 'looked', 'through', 'magazines', 'for', 'ideas.', 'She', 'went', 'to', 'her', 'hairstylist', 'with', 'a', 'picture', 'of', 'the', 'exact', 'shade', 'she', 'wanted.', 'Kim', 'now', 'has', 'long', 'brown', 'hair.'], ['edited_ending:', 'Jay', 'picked', 'his', 'favorite', 'flowers', 'from', 'the', 'store.', 'He', 'passed', 'the', 'flowers', 'off', 'to', 'Mary.', 'Mary', 'chuckled', 'and', 'told', 'Chris', 'those', 'was', 'her', 'favorite', 'flowers.'], ['edited_ending:', 'His', 'friend', \"didn't\", 'want', 'to', 'help', 'so', 'he', 'had', 'to', 'find', 'someone', 'else.', 'He', 'went', 'on', 'a', 'site', 'called', \"Angie's\", 'List.', 'They', 'gave', 'a', 'great', 'review', 'of', 'a', 'plumber', 'for', 'him', 'to', 'hire.'], ['edited_ending:', 'He', 'asked', 'her', 'out', 'online', 'and', 'she', 'said', 'no.', 'Fred', 'was', 'devastated.', 'He', 'lost', 'his', 'confidence.'], ['edited_ending:', 'Jeff', 'was', 'sad', 'because', 'the', 'rug', 'really', 'tied', 'the', 'room', 'together.', 'Jeff', 'asked', 'his', 'friends', 'why', 'they', \"didn't\", 'like', 'the', 'rug.', 'The', 'people', 'said', 'they', \"didn't\", 'like', 'the', 'colors.'], ['edited_ending:', 'He', 'told', 'his', 'wife', 'that', 'the', 'neighbors', 'were', 'moaning', 'really', 'loud.', 'His', 'wife', 'told', 'him', 'to', 'mind', 'his', 'own', 'business.', 'The', 'neighbor', 'turned', 'on', 'some', 'music', 'to', 'drown', 'out', 'the', 'noise.'], ['edited_ending:', 'She', 'got', 'distracted', 'with', 'work.', 'Mel', 'remembered', 'the', 'turtle', 'when', 'she', 'finished', 'working.', \"Mel's\", 'turtle', 'had', 'cooled', 'down', 'and', 'she', 'painted', 'it.'], ['edited_ending:', 'Although', 'sore,', 'she', 'was', 'determined', 'and', 'decided', 'to', 'keep', 'going.', 'But,', 'the', 'next', 'day', 'the', 'pain', 'was', 'so', 'bad', 'she', 'collapsed', 'in', 'the', 'gym.', 'At', 'the', 'hospital', 'they', 'told', 'her', 'since', 'she', 'kept', 'pushing', 'herself', 'and', 'now', 'had', 'a', 'bad', 'injury.'], ['edited_ending:', 'Marco', 'took', 'small', 'sips', 'until', 'the', 'coffee', 'was', 'done.', 'He', 'was', 'happy', 'to', 'have', 'coffee.', 'Marco', 'was', 'glad', 'that', 'he', 'was', 'no', 'longer', 'bored.'], ['edited_ending:', 'Donna', 'challenged', 'Lisa', 'to', 'a', 'friendly', 'match.', 'Donna', 'practiced', 'every', 'day', 'for', 'hours.', 'Donna', 'easily', 'beat', 'Lisa.'], ['edited_ending:', 'They', 'cleaned', 'it', 'up', 'and', 'took', 'it', 'home.', 'One', \"kid's\", 'dad', 'said', 'that', 'it', 'looked', 'like', 'a', 'rare', 'species.', 'They', 'took', 'it', 'to', 'their', 'biology', 'teacher', 'to', 'find', 'out.'], ['edited_ending:', 'He', 'never', 'had', 'any', 'luck', 'bay', 'fishing,', 'but', 'it', 'was', 'worth', 'a', 'try.', 'Almost', 'immediately,', 'he', 'felt', 'a', 'big', 'tug', 'on', 'his', 'small', 'hook.', 'He', 'pulled', 'up', 'the', 'biggest,', 'heaviest', 'fish', 'he', 'had', 'ever', 'caught.'], ['edited_ending:', 'After', 'checking,', 'Dan', 'noticed', 'that', 'there', 'were', 'no', 'more', 'bananas.', 'Dan', 'decided', 'to', 'make', 'more', 'but', 'he', 'was', 'without', 'bananas', 'now.', 'Dan', 'was', 'not', 'happy', 'with', 'the', 'consequence,', 'as', 'he', 'knew', 'he', 'needed', 'bananas.'], ['edited_ending:', 'Over', 'time,', 'we', 'starting', 'falling', 'for', 'each', 'other.', 'We', 'decided', 'to', 'move', 'in', 'together.', 'We', 'moved', 'across', 'two', 'states', 'to', 'be', 'together.'], ['edited_ending:', 'He', 'saw', 'a', 'beautiful', 'painting', 'of', 'a', 'tucan', 'in', 'the', 'trees.', 'He', 'took', 'dozens', 'of', 'photos', 'of', 'it.', 'Of', 'all', 'the', 'paintings', 'he', 'saw,', 'the', 'toucan', 'was', 'his', 'favorite!'], ['edited_ending:', 'She', 'did', 'everything', 'for', 'him', 'and', 'did', 'it', 'in', 'a', 'lackluster', 'manner.', 'Then', 'one', 'day', 'her', 'son', 'Randy', 'passed', 'away.', 'Dorothy', 'was', 'heartbroken', 'and', 'felt', 'guilty.'], ['edited_ending:', 'When', 'she', 'finally', 'got', 'to', 'work', 'she', 'bought', 'some', 'Gatorade.', 'She', 'drank', 'a', 'lot', 'of', 'it', 'up.', 'When', 'she', 'finished', 'it', 'up', 'she', 'was', 'sad', 'she', 'had', 'none', 'left.'], ['edited_ending:', 'She', 'has', 'used', 'public', 'transit', 'exclusively', 'for', 'over', 'a', 'year.', 'Fortunately,', 'this', 'has', 'not', 'caused', 'her', 'any', 'major', 'problems.', 'Jody', 'is', 'very', 'happy', 'with', 'her', 'new', 'bus', 'and', 'train', 'passes.'], ['edited_ending:', 'She', 'got', 'up', 'in', 'ten', 'minutes.', 'Lucy', 'missed', 'her', 'ride.', 'She', 'had', 'to', 'walk', 'to', 'school.'], ['edited_ending:', 'I', 'kept', 'my', 'eyes', 'opened', 'the', 'entire', 'time.', 'I', 'wanted', 'to', 'see', 'what', 'was', 'going', 'on.', 'When', 'it', 'was', 'done', 'I', 'wanted', 'to', 'do', 'it', 'again.'], ['edited_ending:', 'He', 'told', 'Toni', 'he', 'was', 'there', 'first.', 'Toni', 'was', 'very', 'upset.', 'She', 'ended', 'up', 'throwing', 'something', 'at', 'the', 'man.'], ['edited_ending:', 'There', 'was', 'an', 'important', 'race', 'coming', 'up', 'at', 'the', 'end', 'of', 'the', 'month.', 'Anthony', 'trained', 'diligently', 'every', 'day.', 'On', 'the', 'day', 'of', 'the', 'race,', 'Anthony', 'was', 'unable', 'to', 'set', 'a', 'new', 'course', 'record.'], ['edited_ending:', 'The', 'family', 'talked', 'about', 'adopting', 'another', 'kid.', 'Their', 'adopted', 'child', 'felt', 'nervous', 'about', 'that.', 'The', 'family', 'decided', 'not', 'to', 'adopt', 'another', 'kid.'], ['edited_ending:', 'In', 'addition,', 'he', 'was', 'working', 'so', 'much', 'he', 'barely', 'had', 'time', 'for', 'her.', 'Denise', 'decided', 'it', 'was', 'best', 'that', 'she', 'propose', 'to', 'him.', 'Denise', 'was', 'ecstatic', 'that', 'he', 'agreed', 'to', 'marry', 'her.'], ['edited_ending:', 'She', 'then', 'went', 'over', 'to', 'greet', 'them.', 'They', 'greeted', 'her', 'with', 'open', 'arms.', 'Kelley', 'was', 'happy', 'to', 'see', 'them.'], ['edited_ending:', 'After', 'two', \"Year's\", 'of', 'school', 'she', 'decided', 'to', 'switch', 'schools.', 'Now', 'she', 'has', 'the', 'debt', 'from', 'law', 'school', 'and', 'a', 'better', 'degree.', 'Now', 'Carla', 'is', 'glad', 'she', 'had', 'ever', 'wanted', 'to', 'be', 'a', 'lawyer.'], ['edited_ending:', 'She', 'aspired', 'to', 'be', 'a', 'model', 'but', 'knew', 'it', \"wasn't\", 'realistic.', 'Reva', 'got', 'an', 'office', 'job.', 'Reva', 'was', 'proud', 'to', 'be', 'the', 'way', 'she', 'was.'], ['edited_ending:', 'Barney', 'bought', 'a', 'new', 'costume', 'with', 'his', 'money.', 'Barney', 'danced', 'for', 'the', 'crowd', 'with', 'the', 'new', 'costume.', 'The', 'crowd', 'threw', 'even', 'more', 'money', 'into', \"Barney's\", 'hat.'], ['edited_ending:', 'One', 'day', 'he', 'met', 'a', 'wonderful', 'girl', 'that', 'seemed', 'to', 'like', 'him.', 'James', 'fell', 'in', 'love', 'with', 'her', 'and', 'proposed', 'to', 'her.', 'James', 'and', 'his', 'new', 'wife', 'became', 'a', 'family'], ['edited_ending:', 'At', 'two', 'months,', 'my', 'ears', 'started', 'to', 'swell.', 'I', 'began', 'to', 'get', 'nervous.', 'Unfortunately', 'I', 'got', 'an', 'infection', 'and', 'had', 'to', 'take', 'them', 'out.'], ['edited_ending:', 'Becky', 'went', 'to', 'her', 'computer.', 'Becky', 'calls', 'soon', 'came', 'in.', 'Becky', 'found', 'that', 'she', 'needed', 'help', 'to', 'understand', 'everything.'], ['edited_ending:', 'It', 'was', 'a', 'close', 'game', 'and', 'the', 'other', 'team', 'lost.', 'We', 'were', 'very', 'glad', 'that', 'they', 'won.', 'We', 'hope', 'that', \"they'll\", 'win', 'again', 'tonight.'], ['edited_ending:', 'She', 'found', 'lots', 'of', 'great', 'outfits', 'in', 'her', \"sister's\", 'closet.', 'When', 'school', 'began,', 'she', 'was', 'dressed', 'to', 'the', 'nines.', 'Zoe', 'felt', 'very', 'confident', 'in', 'her', \"sister's\", 'wardrobe.'], ['edited_ending:', 'a', 'friend', 'went', 'to', 'the', 'lot', 'for', 'me.', 'they', 'told', 'me', \"I'd\", 'like', 'it,', 'so', 'I', 'talked', 'to', 'the', 'salesperson', 'about', 'financing.', 'After', 'the', 'paperwork', 'was', 'done,', 'the', 'car', 'was', 'mine!'], ['edited_ending:', 'One', 'day,', 'Sharon', 'noticed', 'Tommy', \"wasn't\", 'picking', 'up', 'his', 'phone', 'when', 'she', 'was', 'trying', 'to', 'call', 'and', 'break', 'up.', 'Sharon', 'went', 'to', \"Tommy's\", 'House', 'to', 'do', 'it', 'in', 'person.', 'Found', 'him', 'with', 'another', 'Woman', 'and', 'dumped', 'him.'], ['edited_ending:', 'Her', 'friend', 'had', 'never', 'been', 'boating', 'before.', 'They', 'sped', 'around', 'the', 'lake', 'and', 'enjoyed', 'the', 'sunshine.', 'It', 'was', 'a', 'great', 'day', 'on', 'the', 'water!'], ['edited_ending:', 'We', 'begged', 'our', 'parents', 'to', 'take', 'us', 'back', 'the', 'next', 'day,', 'but', 'they', 'said', 'no.', 'Eventually,', 'we', 'wore', 'them', 'down', 'and', 'they', 'said', 'yes.', 'That', 'was', 'another', 'great', 'trip', 'to', 'the', 'candy', 'store.'], ['edited_ending:', 'He', 'moved', 'onto', 'his', 'land', 'with', 'his', 'dog.', 'Jake', 'laided', 'down', 'seeds', 'with', 'his', 'own', 'hands.', 'Jake', 'lived', 'on', 'the', 'land,', 'away', 'from', 'civilization.'], ['edited_ending:', 'On', 'the', 'first', 'day,', 'I', 'was', 'shy', 'but', 'I', 'did', 'say', 'hello', 'to', 'some', 'kids.', 'None', 'of', 'them', 'invited', 'me', 'to', 'sit', 'with', 'them', 'at', 'lunch.', 'Now,', '10', 'years', 'later,', 'I', 'still', \"don't\", 'have', 'any', 'friends.'], ['edited_ending:', 'I', 'borrowed', 'some', 'books', 'about', 'cameras', 'from', 'the', 'library.', 'Unfortunately', 'I', 'lost', 'one', 'of', 'them.', 'I', 'had', 'to', 'pay', 'the', 'school', 'for', 'the', 'book', 'I', 'lost.'], ['edited_ending:', 'Then', 'a', 'thaw', 'came', 'overnight.', 'In', 'the', 'morning', 'all', 'that', 'remained', 'was', 'a', 'carrot', 'nose.', 'They', 'were', 'very', 'disappointed', 'there', 'was', 'no', 'more', 'snow', 'to', 'build', 'another', 'snowman', 'today.'], ['edited_ending:', 'As', 'he', 'was', 'leaving', 'for', 'work,', 'he', 'realized', 'that', 'he', \"didn't\", 'have', 'his', 'keys.', 'He', 'had', 'to', 'look', 'for', 'them', 'to', 'no', 'avail.', 'Tom', 'was', 'late', 'to', 'work', 'because', 'he', 'had', 'to', 'walk', 'to', 'the', 'bus', 'station.'], ['edited_ending:', 'While', 'looking', 'for', 'a', 'job', 'in', 'the', 'newspaper', 'he', 'gets', 'a', 'call.', 'His', 'boss', 'told', 'him', 'he', 'was', 'fired.', 'Ken', 'was', 'now', 'desperate.'], ['edited_ending:', 'My', 'mom', 'began', 'to', 'choke', 'on', 'a', 'hair.', 'She', 'soothed', 'herself', 'by', 'swallowing', 'an', 'entire', 'glass', 'of', 'water.', 'The', 'hair', 'will', 'never', 'win.'], ['edited_ending:', 'I', 'got', 'angry', 'at', 'him', 'for', 'ruining', 'my', 'clothes.', 'I', 'shooed', 'him', 'away.', 'I', 'spent', 'all', 'day', 'cleaning', 'the', 'clothes', 'again.'], ['edited_ending:', 'Lucy', 'was', 'not', 'worried', 'she', 'would', 'mess', 'up.', 'When', 'she', 'got', 'up', 'on', 'stage', 'she', 'was', 'relaxed.', 'Thankfully', 'she', 'did', 'wonderful', 'like', 'she', 'knew', 'she', 'would.'], ['edited_ending:', 'I', 'calmed', 'down', 'and', 'the', 'two', 'of', 'us', 'developed', 'a', 'plan', 'for', 'her', 'to', 'beat', 'this.', 'Surgery', 'was', 'scheduled', 'for', 'the', 'next', 'week.', 'She', 'is', 'now', 'missing', 'a', 'breast,', 'but', 'she', 'is', 'also', 'cancer', 'free!'], ['edited_ending:', 'He', 'was', 'sitting', 'at', 'the', 'very', 'top', 'row', 'but', 'he', \"didn't\", 'care.', 'He', 'was', 'just', 'happy', 'to', 'be', 'there!', 'The', 'Patriots', 'won', 'and', 'Angelo', 'was', 'thrilled!'], ['edited_ending:', 'He', 'was', 'going', 'to', 'relax', 'on', 'the', 'beach.', 'When', 'he', 'arrived', 'at', 'the', 'airport,', 'his', 'flight', 'was', 'delayed.', 'He', 'waited', 'for', 'six', 'hours', 'before', 'his', 'flight', 'could', 'leave.'], ['edited_ending:', 'Today,', 'she', 'brought', 'a', 'large', 'loaf', 'of', 'bread.', 'She', 'can', 'feed', 'the', 'squirrels', 'all', 'day.', 'One', 'large', 'squirrel', 'tried', 'to', 'steal', 'the', 'whole', 'loaf.'], ['edited_ending:', 'She', 'decided', 'to', 'ask', 'him', 'out', 'on', 'a', 'date.', 'He', 'was', 'very', 'surprised', 'and', \"didn't\", 'agree', 'to', 'date', 'her.', 'Alyssa', 'and', 'Sam', 'are', 'now', 'friends.'], ['edited_ending:', 'She', 'was', 'texting', 'when', 'she', \"didn't\", 'see', 'her', 'teacher', 'coming', 'to', 'her', 'desk.', 'Her', 'teacher', 'yelled', 'at', 'her', 'in', 'front', 'of', 'everyone.', 'Today,', 'she', 'still', 'texts', 'her', 'friends', 'while', 'in', 'class,', 'but', 'looks', 'around', 'for', 'the', 'teacher.'], ['edited_ending:', 'We', 'showed', 'him', 'a', 'lot', 'of', 'love', 'and', 'affection', 'He', 'is', 'a', 'happy', 'dog', 'now.', 'He', 'is', 'no', 'longer', 'mean.'], ['edited_ending:', 'Jason', 'ran', 'for', 'city', 'councilman', 'in', 'the', 'new', 'city.', 'He', 'ran', 'a', 'good', 'campaign', 'and', 'told', 'people', 'he', 'really', 'wanted', 'to', 'help.', 'Jason', \"didn't\", 'win', 'the', 'election', 'because', 'they', 'found', 'out', 'he', 'abandoned', 'his', 'old', 'community.'], ['edited_ending:', 'After', 'six', 'months', 'he', 'cheated', 'on', 'her', 'and', 'stole', 'things.', 'Synthia', 'had', 'had', 'enough', 'and', 'called', 'the', 'police.', 'Synthia', 'was', 'able', 'to', 'live', 'happily', 'after', 'that', 'despite', 'losing', 'her', 'stuff.'], ['edited_ending:', 'He', 'flipped', 'the', 'burgers', 'at', 'the', 'perfect', 'time.', 'He', 'cooked', 'each', 'burger', 'for', 'the', 'perfect', 'amount', 'of', 'time.', 'The', 'burgers', 'were', 'perfect.'], ['edited_ending:', 'Martha', 'walked', 'to', 'work', 'under', 'dangerous', 'conditions.', 'She', 'dodged', 'hail', 'the', 'size', 'of', 'baseballs.', 'Luckily', 'she', 'made', 'it', 'to', 'work', 'without', 'getting', 'killed.'], ['edited_ending:', 'He', 'borrowed', 'some', 'money', 'from', 'his', 'brother', 'to', 'buy', 'his', 'ticket.', 'The', 'night', 'before', 'the', 'concert,', 'he', 'could', 'barely', 'sleep.', 'Finally', 'the', 'day', 'came', 'and', 'Ian', 'had', 'an', 'incredible', 'time!'], ['edited_ending:', 'There', 'were', 'no', 'more', 'nuts.', 'The', 'squirrel', 'chewed', 'on', 'some', 'grass.', 'The', 'squirrel', 'climbed', 'back', 'up', 'the', 'tree.'], ['edited_ending:', 'They', \"wouldn't\", 'wait', 'until', 'the', 'lease', 'was', 'over.', 'Unfortunately', 'it', 'was', 'expensive.', 'They', 'wound', 'up', 'paying', 'a', 'break', 'lease', 'fee.'], ['edited_ending:', 'It', 'was', 'slightly', 'shorter', 'than', 'the', 'other', 'tables.', 'Anna', 'was', 'able', 'to', 'secure', 'an', 'bottle', 'of', 'wood', 'finish', 'to', 'even', 'out', 'the', 'finish.', 'She', 'was', 'proud', 'of', 'her', 'handy', 'craftsmanship!'], ['edited_ending:', 'She', 'felt', 'totally', 'humiliated.', 'She', 'ended', 'up', 'having', 'to', 'wait', 'ten', 'minutes', 'for', 'her', 'bus', 'to', 'arrive.', 'It', 'was', 'so', 'embarrassing', 'for', 'her.'], ['edited_ending:', 'He', 'reached', 'the', 'nest', 'and', 'all', 'of', 'his', 'efforts', 'were', 'successful.', 'The', 'nest', 'stayed', 'up', 'and', 'all', 'of', 'the', 'eggs', 'stayed', 'whole.', 'He', 'was', 'very', 'happy', 'with', 'all', 'his', 'effort.'], ['edited_ending:', 'The', 'gradually', 'got', 'smaller.', 'Eventually', 'it', 'was', 'hardly', 'noticeable.', 'I', 'was', 'glad', 'that', 'I', 'took', 'it', 'easy.'], ['edited_ending:', 'Throughout', 'high', 'school,', 'Kevin', 'parents', \"didn't\", 'want', 'him', 'getting', 'into', 'sports', 'He', 'dreamed', 'of', 'receiving', 'a', 'scholarship', 'to', 'play', 'for', 'The', 'University', 'of', 'Kentucky.', 'Now,', 'Kevin', 'plays', 'in', 'a', 'neighborhood', 'ball', 'league', 'and', 'gets', 'to', 'somewhat', 'live', 'out', 'his', 'dream.'], ['edited_ending:', 'It', \"didn't\", 'look', 'the', 'same', 'at', 'all.', 'One', 'day', 'the', 'bear', 'was', 'gone.', 'She', 'searched', 'through', 'the', 'dump', 'for', 'hours', 'and', 'found', 'it', 'as', 'dirty', 'as', 'it', 'used', 'to', 'be.'], ['edited_ending:', 'Gary', 'immediately', 'rushed', 'to', 'the', 'store', 'to', 'buy', 'some', 'book.', 'They', 'were', 'having', 'a', 'big', 'clearance.', 'Gary', 'was', 'pleased', 'when', 'he', 'got', 'home', 'he', 'started', 'reading', 'one', 'of', 'the', 'books', 'he', 'bought.'], ['edited_ending:', 'He', 'tried', 'to', 'give', 'it', 'food', 'and', 'walk', 'it', 'outside', 'with', 'no', 'success.', 'He', 'went', 'to', 'bed', 'exhausted', 'and', 'the', 'dog', 'was', 'still', 'sleeping.', 'Only', 'when', 'he', 'fell', 'asleep', 'would', 'the', 'dog', 'decide', 'to', 'wake', 'up.'], ['edited_ending:', 'He', 'accepted', 'the', 'return', 'without', 'hesitation.', 'The', 'man', 'offered', 'him', 'a', 'full', 'refund.', 'The', 'customer', 'gladly', 'took', 'it.'], ['edited_ending:', 'He', 'broke', 'many', 'traffic', 'laws', 'during', 'his', 'test.', 'Afterwards,', 'he', 'sadly', 'turned', 'to', 'his', 'tester.', 'The', 'tester', 'told', 'him', 'he', 'had', 'failed', 'the', 'test.'], ['edited_ending:', 'She', 'went', 'to', 'the', 'doctor', 'complaining', 'of', 'a', 'stomach', 'ache.', 'The', 'doctor', 'told', 'her', 'to', 'eat', 'slower', 'and', 'masticate', 'her', 'food', 'so', 'it', 'would', 'digest', 'more', 'easily.', 'Nina', 'listened', 'to', 'the', 'doctor', 'and', 'ate', 'her', 'food', 'at', 'a', 'slower', 'pace.'], ['edited_ending:', 'Dan', 'was', 'about', 'to', 'purchase', 'a', 'lot', 'near', 'the', 'beach', 'in', 'Florida', 'to', 'build', 'his', 'house.', 'Dan', 'was', 'told', 'construction', 'would', 'begin', 'during', 'the', 'winter', 'season.', 'Now', 'Dan', 'will', 'have', 'to', 'start', 'over', 'in', 'his', 'goal', 'to', 'attain', 'home', 'ownership.'], ['edited_ending:', 'She', 'tried', 'to', 'make', 'this', 'relationship', 'last.', 'Luckily', \"Sam's\", 'new', 'boyfriend', 'was', 'very', 'compatible.', 'He', 'always', 'took', \"Sam's\", 'feelings', 'into', 'consideration.'], ['edited_ending:', 'Stan', 'tipped', 'her', 'fifty', 'dollars', 'one', 'day.', 'Debbie', \"didn't\", 'stop', 'Stan,', 'even', 'though', 'it', 'had', 'to', 'be', 'a', 'mistake.', 'Stan', 'came', 'in', 'later', 'looking', 'for', 'the', 'money,', 'but', 'Debbie', 'denied', 'it.'], ['edited_ending:', 'I', 'had', 'spilled', 'juice', 'all', 'over', 'the', 'old', 'one.', 'I', 'was', 'devastated.', 'I', 'budgeted', 'to', 'buy', 'another', 'one', 'later', 'in', 'the', 'month.'], ['edited_ending:', 'She', 'thought', 'she', 'looked', 'more', 'natural', 'that', 'way.', 'She', 'never', 'replaced', 'the', 'contacts.', 'She', 'thought', 'her', 'eyes', 'looked', 'better', 'blue', 'than', 'brown.'], ['edited_ending:', 'At', 'the', 'bus', 'stop', 'the', 'wind', 'blew', 'her', 'skirt', 'up.', 'She', 'was', 'embarrassed.', 'She', 'could', 'not', 'keep', 'it', 'down.'], ['edited_ending:', 'Kelly', \"didn't\", 'do', 'very', 'well', 'in', 'English', 'though.', 'Her', 'grade', 'point', 'average', 'was', 'going', 'to', 'drop', 'if', 'she', 'got', 'a', 'bad', 'grade.', 'Kelly', 'joined', 'the', 'poetry', 'team', 'to', 'make', 'up', 'for', 'a', 'C', 'in', 'English.'], ['edited_ending:', 'During', 'treatment,', 'he', 'went', 'to', 'stay', 'at', 'Ronald', 'McDonald', 'House', 'in', 'Memphis.', 'I', 'visited', 'him', 'all', 'day', 'long.', 'We', 'played', 'with', 'his', 'fire', 'truck.'], ['edited_ending:', 'I', 'placed', 'her', 'on', 'the', 'mantel', 'of', 'my', 'fireplace', 'to', 'be', 'polite.', 'When', 'people', 'come', 'over', 'they', 'often', 'comment', 'on', 'her', 'shiny', 'porcelain', 'skin.', 'She', 'sits', 'on', 'the', 'mantel', 'every', 'day', 'looking', 'ugly', 'and', 'never', 'being', 'moved', 'from', 'position.'], ['edited_ending:', 'She', 'went', 'back', 'home', 'to', 'get', 'it.', 'As', 'she', 'picked', 'it', 'up,', 'it', 'slipped', 'and', 'landed', 'on', 'the', 'ground.', 'When', 'Janny', 'picked', 'it', 'up,', 'the', 'screen', 'was', 'cracked.'], ['edited_ending:', 'He', 'was', 'scared,', 'but', 'decided', 'to', 'face', 'his', 'fear.', 'It', 'turned', 'out', 'that', 'the', 'bully', 'just', 'wanted', 'to', 'play,', 'and', 'Jack', 'changed', 'his', 'mind', 'about', 'never', 'being', 'friends', 'with', 'him.', 'He', 'and', 'Jack', 'became', 'best', 'friends.'], ['edited_ending:', 'On', 'her', 'birthday,', \"Gidget's\", 'dad', 'got', 'her', 'a', 'nice', 'camera', 'with', 'great', 'zooming', 'abilities.', 'Gidget', 'could', 'now', 'take', 'pictures', 'of', 'little', 'birds', 'who', 'roosted', 'in', 'high', 'trees.', 'Gidget', 'quickly', 'became', 'very', 'knowledgable', 'about', 'bird', 'habitats.'], ['edited_ending:', 'She', 'was', 'in', 'the', 'final', 'seconds', 'on', 'a', 'game', 'against', 'a', 'rival', 'school.', 'She', 'had', 'one', 'shot', 'to', 'get', 'the', 'ball', 'and', 'make', 'the', 'shot.', 'Amanda', 'shot', 'an', 'air', 'ball.'], ['edited_ending:', 'This', 'year', 'he', 'dressed', 'up', 'as', 'a', 'scary', 'hot', 'dog,', 'a', 'Halloweeny.', 'None', 'of', 'the', 'kids', 'thought', 'his', 'costume', 'was', 'scary.', 'It', 'turned', 'out', 'the', 'costume', 'was', 'not', 'as', 'scary', 'as', 'Rashad', 'expected.'], ['edited_ending:', 'She', 'decided', 'to', 'make', 'some', 'lasagna.', 'She', 'left', 'it', 'on', 'the', 'counter', 'while', 'she', 'ducked', 'outside.', 'The', 'dog', 'ran', 'in', 'and', 'gobbled', 'it', 'up.'], ['edited_ending:', 'When', 'she', 'checked', 'on', 'him,', 'she', 'saw', 'that', 'he', 'had', 'peas', 'in', 'his', 'nose.', 'She', 'and', 'her', 'husband', 'put', 'the', 'baby', 'in', 'the', 'shower.', 'Then', 'they', 'cleaned', 'him', 'and', 'his', 'nose', 'up.'], ['edited_ending:', 'She', 'was', 'glad', 'rashes', 'never', 'developed', 'on', 'her', 'skin.', 'Ellen', \"didn't\", 'need', 'to', 'see', 'her', 'doctor.', 'The', 'previous', 'doctor', 'determined', 'she', 'was', 'allergic', 'to', 'her', 'old', 'soap.'], ['edited_ending:', 'The', 'nest', 'made', 'too', 'much', 'noise.', 'The', 'predator', 'hunted', 'them', 'down.', 'It', 'was', 'a', 'nice', 'snack.'], ['edited_ending:', 'He', 'decided', 'to', 'teach', 'another', 'painting', 'class', 'in', 'school.', 'Shane', 'created', 'many', 'beautiful', 'paintings.', 'Now', 'Shane', 'is', 'able', 'to', 'sell', 'his', 'artwork.'], ['edited_ending:', 'Thinking', 'of', 'where', 'to', 'go', 'next,', 'she', 'scratched', 'her', 'head.', 'Her', 'brother', 'scratched', 'his', 'head,', 'too.', 'She', 'realized', 'they', 'should', 'go', 'see', 'the', 'cats!'], ['edited_ending:', 'He', 'said', 'I', 'could', 'no', 'longer', 'use', 'it', 'to', 'pay', 'for', 'anything.', 'I', 'got', 'really', 'mad', 'because', 'he', 'told', 'me', 'to', 'be', 'responsible.', 'I', 'hung', 'up', 'the', 'phone', 'on', 'him.'], ['edited_ending:', 'Heather', 'was', 'able', 'to', 'drive', 'to', 'work', 'even', 'though', 'her', 'daughter', 'offered', 'to', 'drive', 'her.', 'Heather', 'went', 'the', 'very', 'next', 'day', 'to', 'buy', 'a', 'new', 'case.', 'Heather', 'called', 'her', 'daughter', 'and', 'told', 'her', 'she', 'did', 'not', 'have', 'to', 'go', 'to', 'the', 'store', 'with', 'her.'], ['edited_ending:', 'He', 'watched', 'a', 'tv', 'program', 'on', 'the', 'Hebrides', 'islands.', 'He', 'found', 'them', 'even', 'more', 'remote', 'and', 'wonderful.', 'The', 'Hebrides', 'became', \"Neil's\", 'new', 'favorite', 'islands!'], ['edited_ending:', 'Today', 'would', 'be', 'his', 'first', 'egg', 'harvest', 'of', 'the', 'season.', 'Noah', 'picked', 'up', 'the', 'first', 'egg', 'he', 'saw.', 'After', 'one', 'look,', 'he', 'knew', 'this', 'was', 'the', 'best', 'egg', 'yet.'], ['edited_ending:', 'We', 'ended', 'up', 'breaking', 'up', 'after', 'that', 'year.', 'I', 'was', 'very', 'upset', 'at', 'first', 'but', 'eventually', 'got', 'over', 'it.', 'I', 'learned', 'a', 'lot', 'from', 'that', 'relationship', 'and', 'feel', 'better', 'because', 'of', 'it.'], ['edited_ending:', 'The', 'train', 'broken', 'down', 'and', 'I', 'had', 'to', 'stand', 'around', 'and', 'wait', 'an', 'extra', '15', 'minutes', 'for', 'the', 'next', 'one.', 'Eventually,', 'another', 'train', 'came', 'and', 'I', 'got', 'on', 'it.', 'I', 'was', 'very', 'late', 'for', 'work', 'and', 'my', 'boss', 'was', 'mad', 'at', 'me.'], ['edited_ending:', 'The', 'runner', 'kept', 'his', 'foot', 'firmly', 'on', 'the', 'base.', 'He', 'watched', 'the', 'catcher', 'in', 'front', 'of', 'home', 'plate.', 'The', 'catcher', 'threw', 'the', 'ball', 'to', 'the', 'pitcher.'], ['edited_ending:', 'Until', 'he', 'had', 'find', 'a', 'new', 'job,', 'where', 'despite', 'not', 'receiving', 'much,', 'he', 'still', 'managed', 'to', 'send', 'money', 'home.', 'His', 'struggles', 'were', 'noticed', 'by', 'his', 'new', 'employer.', 'His', 'new', 'employer', 'raised', 'his', 'wages', 'which', 'helped', 'his', 'living', 'conditions.'], ['edited_ending:', 'The', 'characters', 'looked', 'like', 'professional', 'dancers', 'and', 'were', 'very', 'good.', 'They', 'taught', 'me', 'everything', 'about', 'dancing.', 'It', 'made', 'me', 'better', 'and', 'now', 'I', 'am', 'also', 'a', 'really', 'good', 'dancer.'], ['edited_ending:', 'One', 'day,', 'she', 'saw', 'someone', 'sending', 'a', 'text', 'and', 'run', 'a', 'stop', 'light.', 'Rachel', 'was', 'ejected', 'from', 'their', 'car', 'after', 'the', 'other', 'vehicle', 'hit', 'her.', 'Rachel', 'lost', 'a', 'leg', 'as', 'a', 'result', 'and', 'gave', 'speeches', 'about', 'never', 'texting', 'while', 'driving.'], ['edited_ending:', 'One', 'day', 'some', 'bigger', 'kids', 'were', 'picking', 'on', 'Tim.', 'Tims', 'cousins', 'chased', 'them', 'away.', 'Tim', 'tried', 'not', 'to', 'dislike', 'his', 'cousins', 'anymore.'], ['edited_ending:', 'He', 'wrote', 'himself', 'a', 'note', 'to', 'remember', 'to', 'get', 'her', 'flowers', 'to', 'thank', 'her', 'for', 'the', 'favor.', 'He', 'saw', 'the', 'note', 'and', 'remembered', 'to', 'get', 'the', 'flowers.', \"Freddy's\", 'wife', 'was', 'happy', 'to', 'receive', 'them.'], ['edited_ending:', 'He', 'fell', 'asleep', 'in', 'the', 'trees.', 'Gun', 'fire', 'happened', 'during', 'his', 'sleep.', 'He', 'never', 'woke', 'up.'], ['edited_ending:', 'She', 'picked', 'out', 'a', 'stuffed', 'animal', 'She', 'chose', 'to', 'get', 'a', 'snake', 'Jan', 'loved', 'her', 'stuffed', 'animal', 'snake', 'very', 'much'], ['edited_ending:', 'The', 'radio', 'in', 'the', 'cab', 'played', \"Kate's\", 'favorite', 'song.', 'She', 'wanted', 'to', 'hold', 'the', \"guy's\", 'hand', 'for', 'just', 'this', 'one', 'song.', 'They', 'ended', 'up', 'spending', 'an', 'hour', 'holding', 'hands.'], ['edited_ending:', 'His', 'guests', \"weren't\", 'wowed', 'by', 'the', 'presentation.', 'After', 'the', 'dinner', 'party,', 'Norman', 'was', 'embarassed', 'of', 'his', 'hosting', 'skills.', 'Everyone', 'talked', 'about', 'what', 'a', 'boring', 'party', 'it', 'had', 'been.'], ['edited_ending:', 'She', 'was', 'excited', 'to', 'get', 'a', 'lot', 'of', 'work', 'done.', 'From', 'the', 'plane,', 'she', 'saw', 'the', 'Hollywood', 'Hills', 'and', 'lots', 'of', 'celebrity', 'homes.', 'Chelsea', 'was', 'happy', 'she', 'had', 'finally', 'gotten', 'to', 'fly', 'over', 'California', 'landmarks.'], ['edited_ending:', 'She', 'went', 'to', 'sleep', 'happy', 'and', 'hot.', 'At', '4', 'AM', 'she', 'was', 'awakened', 'by', 'the', 'sounds', 'of', 'rain', 'and', 'a', 'breeze.', 'She', 'was', 'sad', 'to', 'see', 'the', 'heat', 'had', 'finally', 'broke.'], ['edited_ending:', 'They', 'ignored', 'a', 'car', 'that', 'followed', 'them,', 'but', 'it', 'came', 'back', 'again.', 'This', 'time,', 'they', 'ran', 'away', 'and', 'called', 'the', 'police.', 'The', 'police', 'arrived', 'later', 'and', 'Tiffany', 'and', 'her', 'husband', 'went', 'home.'], ['edited_ending:', 'A', 'network', 'decided', 'it', 'was', 'time', 'for', 'him', 'to', 'get', 'his', 'own', 'show.', 'Conan', 'was', 'ready', 'to', 'take', 'on', 'the', 'role.', 'Conan', 'loved', 'his', 'new', 'job', 'and', 'show.'], ['edited_ending:', 'I', 'gave', 'him', 'a', 'ball', 'yesterday', 'and', 'he', 'tossed', 'it', 'back', 'to', 'me.', 'I', 'picked', 'it', 'up', 'and', 'he', 'opened', 'his', 'mouth', 'slightly.', 'I', 'tossed', 'it', 'into', 'his', 'mouth', 'and', 'he', 'threw', 'it', 'back,', 'happy.'], ['edited_ending:', 'Unfortunately', 'yesterday', 'she', 'started', 'feeling', 'irritated.', 'As', 'she', 'was', 'walking,', 'she', 'realized', 'her', 'shirt', 'gave', 'her', 'a', 'huge', 'rash.', 'Kelley', 'no', 'longer', 'wanted', 'to', 'wear', 'them.'], ['edited_ending:', 'But', 'one', 'day', 'he', 'was', 'finally', 'getting', 'to', 'leave', 'home', 'in', 'two', 'days.', 'When', 'he', 'arrived,', 'he', 'was', 'very', 'nervous.', 'When', 'Sam', 'stepped', 'out', 'the', 'airplane,', 'he', 'realized', 'it', 'was', 'the', 'first', 'time', 'he', 'was', 'without', 'his', 'family.'], ['edited_ending:', 'Nita', 'followed', 'the', 'directions', 'given', 'through', 'her', 'devices', 'GPS.', 'Nita', \"couldn't\", 'find', 'the', 'house.', 'Nita', 'had', 'to', 'call', 'her', 'friend', 'to', 'direct', 'her.'], ['edited_ending:', 'It', 'tasted', 'like', 'soggy', 'warm', 'bread.', 'Jill', 'ordered', 'pizza', 'delivered', 'from', 'a', 'different', 'pizzeria.', 'She', 'threw', 'out', 'the', 'pizza', 'that', 'tasted', 'like', 'soggy', 'bread.'], ['edited_ending:', 'They', 'were', 'so', 'excited.', 'Then', 'Tina', 'discovered', 'she', 'the', 'triplets', 'were', 'all', 'boys!', 'She', 'knew', 'she', 'had', 'a', 'lot', 'of', 'work', 'ahead', 'of', 'her!'], ['edited_ending:', 'Her', 'mother', 'told', 'her', 'to', 'put', 'the', 'tooth', 'under', 'her', 'pillow', 'when', 'she', 'was', 'younger.', 'Jill', 'did', 'as', 'her', 'mother', 'instructed.', 'The', 'next', 'day', 'Jill', 'found', 'five', 'dollars', 'under', 'her', 'pillow.'], ['edited_ending:', 'In', 'the', 'store', 'she', 'saw', 'RIT', 'dye', 'and', 'decided', 'to', 'die', 'her', 'jacket', 'that', 'was', 'starting', 'to', 'fade.', 'She', 'decided', 'she', 'would', 'dye', 'the', 'jacket', 'blue', 'again.', 'She', 'wondered', 'why', 'she', \"hadn't\", 'thought', 'of', 'it', 'sooner.'], ['edited_ending:', 'They', 'kept', 'awake', 'all', 'night', 'trying', 'to', 'find', 'their', 'way.', 'They', 'never', 'got', 'up', 'the', 'next', 'day', 'and', 'were', 'never', 'seen', 'again.', 'They', 'never', 'got', 'the', 'revenge', 'they', 'wanted', 'on', 'their', 'annoying', 'neighbors.'], ['edited_ending:', 'He', 'ignored', 'his', 'phone', 'when', 'the', 'principal', 'called.', 'The', 'school', 'sent', 'a', 'truant', 'officer', 'to', 'his', 'house.', 'Everybody', 'noticed', 'that', 'Bernie', 'was', 'late', 'for', 'class.'], ['edited_ending:', 'Denise', 'decided', 'to', 'try', 'waxing.', 'After', 'locating', 'a', 'clinic,', 'Denise', 'tried', 'the', 'facial', 'waxing.', 'Denise', 'was', 'so', 'satisfied', 'with', 'the', 'results', 'of', 'her', 'first', 'facial', 'waxing.'], ['edited_ending:', 'Someone', 'handed', 'him', 'a', 'bagged', 'lunch', 'for', 'his', 'meal!', 'He', 'was', 'very', 'grateful.', 'This', 'small', 'kind', 'act', 'really', 'improved', 'his', 'mood!'], ['edited_ending:', 'She', 'decided', 'to', 'get', 'a', 'buzz', 'cut.', 'When', 'she', 'went', 'to', 'get', 'it', 'done,', 'it', 'went', 'quickly.', 'When', 'it', 'was', 'done', 'it', 'looked', 'great.'], ['edited_ending:', 'When', 'they', 'returned', 'home,', 'Maya', 'had', 'hot', 'cocoa', 'ready!', 'The', 'three', 'males', 'eagerly', 'sipped', 'the', 'warm', 'drink.', 'As', 'Maya', 'had', 'suspected,', 'they', 'were', 'frozen', 'to', 'the', 'bone!'], ['edited_ending:', 'The', 'kids', 'had', 'put', 'on', 'their', 'swimsuits', 'and', 'were', 'ready', 'to', 'splash', 'in', 'the', 'water', 'all', 'evening!', 'Everyone', 'was', 'greatly', 'disappointed.', \"We'll\", 'have', 'to', 'be', 'coming', 'back', 'to', 'the', 'pool', 'this', 'Sunday.'], ['edited_ending:', 'When', 'a', 'starving', 'dog', 'came', 'to', 'her', 'door', 'and', 'barked,', 'she', 'froze.', 'She', \"didn't\", 'want', 'to', 'let', 'it', 'in.', 'But', 'in', 'the', 'end,', 'he', 'heart', 'melted,', 'she', 'fed', 'the', 'dog', 'and', 'kept', 'it', 'with', 'her.'], ['edited_ending:', 'When', 'he', 'stepped', 'over', 'it,', 'the', 'rubber', 'band', 'snagged', 'on', 'the', 'sole', 'of', 'his', 'shoe.', 'The', 'rubber', 'band', 'snapped', 'and', 'broke.', 'Steve', 'threw', 'the', 'remains', 'in', 'the', 'trash.'], ['edited_ending:', 'The', 'attendant', 'rang', 'up', 'her', 'groceries', 'and', 'asked', 'for', 'payment.', \"Sarah's\", 'wallet', 'was', 'lost', 'and', 'she', 'was', 'so', 'embarrassed.', 'The', 'person', 'behind', 'her', 'paid', 'for', 'her', 'groceries', 'and', 'Sarah', 'was', 'so', 'grateful.'], ['edited_ending:', 'He', 'was', 'not', 'worried', 'if', 'he', 'would', 'not', 'make', 'any', 'friends.', 'When', 'he', 'got', 'there', 'some', 'nice', 'kids', 'started', 'talking', 'to', 'him', 'anyway.', 'Fred', 'was', 'happy', 'he', 'made', 'some', 'friends', 'afterall.'], ['edited_ending:', 'He', 'served', 'a', 'different', 'version', 'to', 'his', 'family', 'at', 'his', 'party.', 'They', 'all', 'begged', 'for', 'the', 'recipe.', 'Miguel', 'was', 'proud', 'that', 'they', 'loved', 'it', 'so', 'much.'], ['edited_ending:', 'Suddenly', 'I', 'had', 'a', 'yank', 'on', 'my', 'line!', 'I', 'was', 'very', 'excited', 'except', 'the', 'fish', 'got', 'away.', 'We', 'went', 'home', 'disappointed', 'that', 'day.'], ['edited_ending:', 'He', 'never', 'applies', 'for', 'other', 'jobs.', 'He', 'gets', 'a', 'call', 'the', 'next', 'day', 'from', 'a', 'place', 'offering', 'a', 'better', 'job.', 'Jeff', 'takes', 'the', 'Job.'], ['edited_ending:', 'When', 'he', 'has', 'tried', 'all', 'of', 'them,', 'he', 'was', 'hungry', 'again.', 'He', 'bought', 'another', 'corn', 'dog', 'and', 'drank', 'a', 'soda.', 'Rodney', \"didn't\", 'think', 'twice', 'and', 'went', 'back', 'in', 'a', 'ride', 'and', 'was', 'sick.'], ['edited_ending:', 'He', 'had', 'begged', 'his', 'parents', 'constantly', 'for', 'the', 'camera.', 'Then', 'one', 'day', 'they', 'finally', 'gave', 'in', 'and', 'told', 'him', 'to', 'buy', 'it.', 'He', 'was', 'so', 'happy', 'that', 'he', 'accidentally', 'ended', 'up', 'breaking', 'it.'], ['edited_ending:', 'Cornelia', 'enjoys', 'a', 'weekend', 'of', 'sunbathing.', 'She', 'returns', 'home.', 'She', 'is', 'satisfied', 'that', 'she', 'got', 'out', 'of', 'her', 'house.'], ['edited_ending:', 'He', 'should', 'have', 'undergone', 'months', 'of', 'chemo,', 'but', 'he', 'stayed', 'positive.', 'Then', 'he', 'went', 'to', 'his', 'follow-up', 'appointment', 'for', 'the', 'news.', 'The', 'doctor', 'told', 'Bob', 'his', 'cancer', 'was', 'fully', 'stage', 'four.'], ['edited_ending:', 'She', 'tried', 'other', 'things', 'on', 'the', 'menu.', 'But', 'she', 'always', 'ended', 'up', 'returning', 'to', 'the', 'Rollitini.', 'She', 'was', 'hooked', 'and', 'ate', 'it', 'at', 'least', 'once', 'a', 'week', 'for', 'months.'], ['edited_ending:', 'Todd', 'could', 'not', 'wait', 'to', 'get', 'his', 'grade.', 'He', 'went', 'to', 'his', 'teacher', 'and', 'asked', 'how', 'it', 'was.', 'Todd', 'was', 'glad', 'to', 'get', 'an', 'A', 'later', 'that', 'afternoon.'], ['edited_ending:', 'At', 'the', 'proceedings', 'Gary', 'waited', 'for', 'his', 'wife.', 'After', 'the', 'proceedings,', 'Gary', 'called', 'his', 'wife', 'to', 'tell', 'her', 'they', 'were', 'divorced.', 'Gary', 'was', 'sad,', 'because', 'she', 'yelled', 'and', 'cried', 'on', 'the', 'phone.'], ['edited_ending:', 'His', \"boss's\", 'desk', 'caught', 'on', 'fire.', 'His', 'boss', 'watched', 'the', 'flames', 'dance', 'over', 'the', 'work.', 'His', 'boss', 'extinguished', 'it', 'before', 'it', 'got', 'too', 'big.'], ['edited_ending:', 'She', 'saw', 'it', \"wasn't\", 'her', 'glasses.', 'She', 'called', 'her', 'sister', 'for', 'help.', 'Her', 'sister', 'drove', 'over', 'to', 'help', 'her', 'look', 'that', 'afternoon.'], ['edited_ending:', 'In', 'his', 'bunk,', 'he', 'dreamt.', 'He', 'imagined', 'the', 'boat', 'breaking', 'apart', 'and', 'him', 'falling', 'into', 'the', 'sea.', 'As', 'he', 'woke', 'up', 'he', 'thought', 'at', 'least', 'he', \"isn't\", 'having', 'the', 'bad', 'dream', 'anymore.'], ['edited_ending:', 'Tim', 'decided', 'to', 'sing', 'in', 'a', 'busy', 'street', 'corner', 'for', 'some', 'cash.', 'A', 'talent', 'scout', 'noticed', \"Tim's\", 'horrible', 'singing', 'voice.', 'The', 'talent', 'scout', 'offered', 'Tim', 'some', 'money', 'to', 'be', 'quiet.'], ['edited_ending:', 'The', 'vet', 'rehabilitated', 'the', 'little', 'crow.', 'The', 'crow', 'comes', 'and', 'goes', 'as', 'it', 'pleases.', 'Every', 'time', 'it', 'returns,', 'the', 'crow', 'brings', 'the', 'vet', 'a', 'trinket.'], ['edited_ending:', 'I', 'used', 'other', \"friend's\", 'putter.', 'It', 'was', 'the', 'only', 'club', 'I', 'knew', 'how', 'to', 'use.', 'I', 'ended', 'up', 'losing', 'horribly.'], ['edited_ending:', 'He', 'had', 'always', 'thought', 'he', 'would', 'get', 'second', 'place', 'if', 'he', 'tried.', 'The', 'day', 'of', 'the', 'competition', 'he', 'nervously', 'competed.', 'John', 'ended', 'up', 'just', 'barely', 'getting', '1st', 'place,', 'he', 'was', 'so', 'proud!'], ['edited_ending:', 'They', 'told', 'him', 'he', 'still', 'had', 'to', 'improve,', 'though.', 'John', 'lifted', 'weights', 'every', 'day', 'at', 'the', 'school', 'gym.', 'Soon', 'he', 'had', 'improved', 'drastically', 'and', 'was', 'still', 'one', 'of', 'the', 'best', 'on', 'the', 'team!'], ['edited_ending:', 'Harland', 'and', 'his', 'boss', 'were', 'not', 'friends.', 'They', 'never', 'decided', 'to', 'start', 'a', 'business', 'together.', 'They', 'never', 'built', 'a', 'business', 'into', 'a', 'huge', 'success.'], ['edited_ending:', 'The', 'dog', 'walked', 'around', 'the', 'house', 'then', 'returned', 'to', 'the', 'door.', 'It', 'then', 'gave', 'up', 'and', 'walked', 'away.', 'The', 'dog', 'went', 'to', 'lie', 'down', 'in', 'his', 'bed.'], ['edited_ending:', 'George', 'graduated', 'high', 'school.', 'He', 'was', 'happy', 'he', 'made', 'the', 'decision', 'to', 'make', 'his', 'dream', 'come', 'true.', 'Later,', 'George', 'decided', 'to', 'join', 'a', 'wrestling', 'league', 'instead', 'to', 'see', 'what', 'he', 'was', 'made', 'of.'], ['edited_ending:', 'She', 'was', 'so', 'embarrassed', 'and', 'went', 'to', 'the', 'restroom.', 'Sara', 'vowed', 'to', 'go', 'on', 'buy', 'bigger', 'pants.', 'She', 'ended', 'up', 'buying', '5', 'pairs', 'that', 'fit', 'her', 'well', 'and', 'felt', 'great.'], ['edited_ending:', 'She', 'got', 'the', 'ingredients', 'together', 'for', 'pudding.', 'It', 'turned', 'out', 'great.', 'She', 'made', 'it', 'for', 'the', 'neighborhood', 'and', 'they', 'all', 'loved', 'it.'], ['edited_ending:', 'We', 'gave', 'her', 'soothing', 'aloe', 'vera', 'lotion.', 'After', 'half', 'an', 'hour', 'she', 'was', 'still', 'not', 'itchy.', 'I', 'am', 'glad', 'she', 'did', 'not', 'have', 'an', 'allergic', 'reaction', 'to', 'the', 'cake.'], ['edited_ending:', 'Eventually', 'he', 'settled', 'on', 'a', 'restaurant.', 'He', 'drove', 'to', 'the', 'restaurant.', 'He', 'was', 'satisfied', 'with', 'the', 'selection', 'of', 'pancakes'], ['edited_ending:', 'There', 'was', 'a', 'new', 'kid', 'in', 'the', 'school.', 'Tom', 'greeted', 'him', 'and', 'punched', 'him.', 'The', 'new', 'kid', 'beat', 'him.'], ['edited_ending:', 'A', 'neighbor', 'lady', 'made', 'fun', 'of', 't', 'his', 'legs.', 'Terry', 'stopped', 'to', 'talk', 'to', 'his', 'neighbor.', 'She', 'made', 'a', 'joke', 'at', 'his', 'expense.'], ['edited_ending:', 'After', 'forty', 'five', 'minutes,', 'he', 'was', 'told', 'to', 'wait', 'another', 'half', 'hour.', 'Joseph', 'was', 'starting', 'to', 'be', 'impatient', 'but', 'waited', 'anyway.', 'After', 'two', 'hours', 'his', 'car', 'was', 'repaired', 'and', 'he', 'could', 'go', 'home.'], ['edited_ending:', 'When', 'she', 'opened', 'the', 'gift', 'it', 'was', 'an', 'ugly', 'sweater.', 'Toni', 'love', 'it.', 'However', 'to', 'her', 'surprise,', 'her', 'parents', \"didn't!\"], ['edited_ending:', 'When', 'we', 'I', 'arrived,', 'he', 'got', 'us', 'a', 'cozy', 'table.', 'Mike', 'had', 'flowers', 'waiting', 'at', 'the', 'table.', 'I', 'could', 'not', 'go', 'wrong', 'dating', 'Mike.'], ['edited_ending:', 'When', 'her', 'friends', 'saw', 'it', 'was', 'healthy', 'food,', 'they', 'praised', 'her.', 'Joanna', 'blushed', 'deeply', 'but', 'ate', 'her', 'lunch', 'in', 'silence.', 'Only', 'when', 'her', 'friends', 'were', 'gone', 'did', 'she', 'call', 'her', 'mom', 'to', 'thank', 'her.'], ['edited_ending:', 'Once', 'Gary', 'caught', 'a', 'ground', 'squirrel', 'and', 'fed', 'it', 'some', 'of', 'his', 'snacks.', 'Gary', \"didn't\", 'know', 'the', 'squirrel', 'had', 'rabies.', 'Gary', 'had', 'to', 'get', 'rabies', 'shots', 'after', 'the', 'squirrel', 'bit', 'him.'], ['edited_ending:', 'While', 'in', 'the', 'mountains', 'my', 'brother', 'swallowed', 'a', 'large', 'bug.', 'He', 'felt', 'very', 'sick', 'after', 'eating', 'the', 'bug.', 'We', 'decided', 'that', 'we', 'will', 'not', 'go', 'to', 'the', 'mountains', 'next', 'year.'], ['edited_ending:', 'The', 'concert', 'proceeded', 'despite', 'concerns', 'about', 'rain.', 'Sue', 'ended', 'up', 'staying', 'late', 'to', 'talk', 'with', 'her', 'friends.', 'All', 'the', 'money', 'she', 'spent', 'was', 'spent', 'well.'], ['edited_ending:', 'But', 'then', 'his', 'mom', 'saw', 'that', 'he', 'had', 'spent', 'fifty', 'hours', 'on', 'the', 'app.', 'She', 'shut', \"Carl's\", 'phone', 'off', 'for', 'an', 'entire', 'month.', 'Carl', 'learned', 'his', 'lesson', 'during', 'that', 'miserable', 'month!'], ['edited_ending:', 'The', 'cat', 'had', 'never', 'seen', 'a', 'rat.', 'The', 'cat', 'got', 'down', 'and', 'swatted', 'the', 'rat.', 'The', 'cat', 'liked', 'playing', 'with', 'the', 'rat.'], ['edited_ending:', 'Gary', 'knew', 'he', 'was', 'much', 'healthier', 'than', 'before.', 'Gary', 'knew', 'he', 'had', 'to', 'continue', 'on', 'his', 'healthy', 'path.', 'Gary', 'was', 'glad', 'his', 'weight', 'loss', 'gave', 'him', 'a', 'new', 'attitude', 'on', 'life.'], ['edited_ending:', 'I', 'made', 'a', 'lot', 'of', 'songs', 'and', 'practiced', 'them', 'a', 'lot.', 'I', 'would', 'play', 'shows', 'at', 'houses', 'around', 'the', 'neighborhood.', 'All', 'my', 'friends', 'and', 'family', 'would', 'come', 'to', 'watch', 'me', 'play', 'music.'], ['edited_ending:', 'I', 'had', 'checked', 'my', 'pants', 'in', 'the', 'washing', 'machine.', 'I', 'found', 'my', 'pants', 'and', 'they', 'were', 'all', 'wet.', \"I'm\", 'glad', 'my', 'cellphone', \"wasn't\", 'in', 'there.'], ['edited_ending:', 'Three', 'of', 'the', 'students', 'had', 'refused', 'an', 'assignment', 'to', 'write', 'a', 'summary', 'about', 'Trump.', 'The', 'Professor', 'told', 'them', 'if', 'they', 'want', 'to', 'pass', 'they', 'must', 'do', 'the', 'work.', \"That's\", 'when', 'the', 'Dean', 'begrudgingly', 'stepped', 'in.'], ['edited_ending:', 'One', 'evening', 'after', 'eating', 'his', 'dinner', 'of', 'steak', 'and', 'potatoes.', 'Larry', 'went', 'for', 'a', 'run.', 'He', 'burned', 'off', 'the', 'calories', 'quick.'], ['edited_ending:', 'One', 'of', 'the', 'eggs', 'was', 'dropped', 'and', 'forgotten.', 'The', 'egg', 'rotted', 'for', 'two', 'months.', 'The', 'family', 'found', 'the', 'egg', 'from', 'the', 'smell.'], ['edited_ending:', 'The', 'man', 'dug', 'through', 'his', 'pockets', 'and', \"couldn't\", 'find', 'his', 'phone.', 'The', 'man', 'sighed', 'and', 'realized', 'he', 'forgot', 'it', 'in', 'the', 'car.', 'The', 'man', 'went', 'to', 'his', 'car', 'and', 'got', 'his', 'phone.'], ['edited_ending:', 'He', 'was', 'smelly', 'to', 'other', 'people.', 'Richard', 'decided', 'to', 'try', 'and', 'be', 'less', 'smelly.', 'He', 'showered', 'everyday', 'for', 'a', 'whole', 'week', 'and', 'received', 'compliments', 'from', 'his', 'coworkers.'], ['edited_ending:', 'so', 'he', 'sat', 'down', 'and', 'started', 'to', 'write', 'the', 'perfect', 'song', 'for', 'his', 'next', 'record', 'When', 'he', 'was', 'done', 'he', 'recorded', 'it.', 'The', 'song', 'became', 'his', 'second', 'huge', 'hit', 'in', 'a', 'short', 'period', 'of', 'time.'], ['edited_ending:', 'She', 'added', 'more', 'water', 'and', 'hoped', 'for', 'the', 'best.', 'The', 'kids', 'loved', 'it,', 'to', 'her', 'shock!', 'Anna', 'had', 'that', 'her', 'kids', \"weren't\", 'too', 'picky', 'when', 'it', 'came', 'to', 'drinks.'], ['edited_ending:', 'He', 'floated', 'over', 'a', 'current.', 'He', 'screamed', 'for', 'help.', 'Eventually', 'the', 'river', 'dumped', 'him', 'on', 'shore.'], ['edited_ending:', 'When', 'the', 'rain', 'stopped,', 'I', 'wanted', 'to', 'go', 'swimming', 'so', 'I', 'went', 'outside', 'and', 'realized', 'the', 'air', 'was', 'heavy', 'and', 'my', 'asthma', 'acted', 'up.', 'I', 'quickly', 'went', 'back', 'inside', 'to', 'decide', 'if', 'I', 'wanted', 'to', 'go', 'for', 'a', 'swim.', 'I', 'decided', 'not', 'to', 'go', 'swimming', 'and', 'watch', 'a', 'movie', 'in', 'the', 'a/c', 'instead.'], ['edited_ending:', 'Two', 'board', 'members', 'requested', 'a', 'report.', 'The', 'report', 'said', 'they', 'had', 'made', 'the', 'money', 'back.', 'The', 'report', 'suggested', 'other', 'companies', 'to', 'do', 'this.'], ['edited_ending:', 'He', 'waved', 'for', 'someone', 'to', 'stop.', 'A', 'big', 'truck', 'stopped', 'and', 'took', 'him', 'along.', 'He', 'had', 'the', 'car', 'towed', 'to', 'an', 'auto', 'shop', 'that', 'specialized', 'in', 'computer', 'malfunctions.'], ['edited_ending:', 'He', \"didn't\", 'need', 'to', 'get', 'to', 'the', 'store.', 'Gary', 'looked', 'on', 'a', 'recipe', 'app.', 'He', 'was', 'thrilled', 'to', 'see', 'a', 'real', 'Italian', 'dish', 'that', 'he', 'could', 'make.'], ['edited_ending:', 'A', 'trumpet', 'sounded', 'as', 'the', 'scout', 'rapidly', 'made', 'his', 'way', 'to', 'the', 'leader.', 'He', 'had', 'found', 'enough', 'water', 'for', 'everyone', 'and', 'it', 'was', 'very', 'close.', 'The', 'group', 'would', 'not', 'need', 'their', 'canteens', 'after', 'all.'], ['edited_ending:', 'Her', 'boyfriend', 'Sam', 'did', 'not', 'enjoy', 'when', 'Emilia', 'cried.', 'At', 'the', 'end', 'of', 'one', 'of', 'these', 'movies,', 'Sam', 'rolled', 'his', 'eyes', 'at', 'her', 'crying.', 'Emilia', 'got', 'mad', 'and', \"wouldn't\", 'speak', 'to', 'Sam', 'for', 'an', 'hour.'], ['edited_ending:', 'A', 'neighbor', 'in', 'the', 'building', 'worked', 'for', 'the', 'Italian', 'consulate.', 'She', 'arranged', 'for', 'him', 'to', 'get', 'amedal.', 'The', 'local', 'television', 'news', 'covered', 'the', 'ceremony.'], ['edited_ending:', 'She', 'was', 'offered', 'a', 'small', 'role', 'in', 'the', 'Nutcracker.', 'She', 'was', 'nervous', 'about', 'her', 'performance.', 'She', 'performed', 'adequately.'], ['edited_ending:', 'I', 'tried', 'to', 'plug', 'them', 'in', 'but', 'the', 'jack', 'would', 'not', 'fit.', 'I', 'downloaded', 'the', 'computer', 'manual', 'to', 'find', 'an', 'adapter.', 'I', 'found', 'out', 'I', 'was', 'putting', 'the', 'jack', 'into', 'the', 'wrong', 'hole!'], ['edited_ending:', 'She', 'had', 'searched', 'her', \"brother's\", 'room', 'first.', 'She', 'thought', 'she', 'would', 'find', 'the', 'doll', 'completely', 'destroyed.', 'She', 'was', 'relieved', 'and', 'she', \"didn't\", 'have', 'to', 'tell', 'her', 'mom', 'and', 'get', 'her', 'brother', 'in', 'big', 'trouble.'], ['edited_ending:', 'Towards', 'the', 'end', 'of', 'the', 'dance', 'I', 'started', 'to', 'get', 'fairly', 'hungry.', 'My', 'friends', 'and', 'I', 'decided', 'that', 'we', 'wanted', 'some', 'pizza,', 'hunger', 'was', 'taking', 'over', 'the', 'though', 'of', 'an', 'upset', 'stomach.', 'When', 'we', 'got', 'to', 'it', 'they', 'were', 'all', 'out', 'of', 'pizza', 'and', 'we', 'were', 'upset.'], ['edited_ending:', 'He', 'had', 'never', 'seen', 'them', 'before,', 'as', 'they', 'are', 'rare', 'in', 'the', 'Arctic.', 'There', 'were', '2', 'of', 'them,', 'sitting', 'near', 'the', 'rocks', 'behind', 'the', 'glass.', 'The', 'other', 'customers', \"didn't\", 'even', 'look', 'up', 'at', 'us', 'the', 'entire', 'time', 'we', 'were', 'there.'], ['edited_ending:', 'He', 'also', 'gave', 'her', 'a', 'pair', 'of', 'keys', 'and', 'told', 'her', 'to', 'look', 'at', 'the', 'parking', 'lot.', 'She', 'saw', 'a', 'new,', 'shiny', 'cars.', 'She', 'became', 'happy', 'and', 'gave', 'him', 'a', 'hug.'], ['edited_ending:', 'She', 'put', 'the', 'wallet', 'in', 'her', 'purse.', 'Her', 'bosses', 'checked', 'cameras', 'after', 'someone', 'reported', 'her.', 'Joy', 'was', 'arrested.'], ['edited_ending:', 'Once', 'the', 'pills', 'were', 'no', 'longer', 'effective', 'he', 'went', 'to', 'the', 'doctor.', 'The', 'doctor', 'said', 'Nick', 'needed', 'surgery', 'to', 'replace', 'his', 'old,', 'worn-out', 'hip.', 'They', 'scheduled', 'an', 'operation', 'for', 'the', 'next', 'month,', 'and', 'it', 'was', 'a', 'success.'], ['edited_ending:', 'After', 'much', 'deliberation,', 'we', 'pulled', 'out', 'our', 'fishing', 'sticks.', 'Almost', 'immediately,', 'Tom', 'caught', 'a', 'fish.', 'I', 'was', 'cheering', 'while', 'he', 'reeled', 'it', 'in.'], ['edited_ending:', 'He', 'wanted', 'to', 'be', 'able', 'to', 'help', 'the', 'president.', 'He', 'looks', 'in', 'the', 'mirror', 'and', 'is', 'proud', 'of', 'himself.', 'Joe', 'is', 'a', 'great', 'chief', 'of', 'staff'], ['edited_ending:', 'I', 'was', 'two', 'blocks', 'away', 'from', 'the', 'bus', 'stop', 'when', 'I', 'saw', 'the', 'bus', 'leave.', 'It', 'had', 'arrived', '10', 'minutes', 'early.', 'I', 'had', 'to', 'wait', 'thirty', 'minutes', 'for', 'the', 'next', 'bus.'], ['edited_ending:', 'She', 'went', 'to', 'her', 'teacher', 'and', 'told', 'him', \"she'd\", 'work', 'alone.', 'The', 'teacher', 'refused.', 'So', 'Silvia', 'hardly', 'had', 'to', 'do', 'any', 'work', 'to', 'pass', 'her', 'class.'], ['edited_ending:', 'He', 'bought', 'a', 'bunch', 'of', 'wine', 'grapes', 'to', 'do', 'so.', 'Leonardo', 'ate', 'all', 'the', 'grapes.', 'There', 'was', 'nothing', 'left', 'to', 'make', 'wine.'], ['edited_ending:', 'I', 'was', 'very', 'nervous', 'about', 'my', 'new', 'schedule.', 'When', 'my', 'new', 'schedule', 'started,', 'I', 'was', 'angry.', 'It', 'was', 'as', 'bad', 'as', 'I', 'had', 'thought.'], ['edited_ending:', 'All', 'of', 'sudden', 'a', 'girl', 'with', 'blonde', 'hair', 'and', 'ripped', 'jeans', 'stepped', 'out.', 'Allen', 'fell', 'in', 'love', 'with', 'her', 'jeans', 'instantly', 'as', 'she', 'walked', 'past.', 'He', 'was', 'so', 'shocked', 'he', 'went', 'to', 'say', 'hi', 'and', 'complimented', 'her', 'outfit', 'before', 'she', 'walked', 'away.'], ['edited_ending:', 'Emma', \"didn't\", 'have', 'to', 'ask', 'her', 'friends', 'and', 'family', 'to', 'babysit.', 'Emma', 'was', 'able', 'to', 'babysit', 'her', 'own', 'child.', 'Emma', \"didn't\", 'need', 'to', 'find', 'a', 'substitute', 'for', 'her', 'shift.'], ['edited_ending:', 'It', 'came', 'out', 'very', 'bad.', 'Charles', 'instead', 'now', 'enjoyed', 'drinking', 'tea.', 'He', 'decided', 'to', 'continue', 'to', 'make', 'tea', 'each', 'day.'], ['edited_ending:', 'They', 'had', 'settle', 'this', 'by', 'playing', 'a', 'game.', 'The', 'winner', 'had', 'gotten', 'to', 'choose', 'all', 'the', 'toppings.', 'The', 'winner', 'had', 'been', 'excited', 'to', 'get', 'the', 'honor', 'of', 'pizza', 'toppings,', 'but', 'decided', 'they', 'would', 'both', 'agree', 'upon', 'the', 'toppings', 'together.'], ['edited_ending:', 'Cam', 'got', 'a', 'job.', 'With', 'the', 'money', 'saved', 'from', 'the', 'job', 'he', 'was', 'able', 'to', 'pay', 'for', 'it.', 'Cam', 'had', 'really', 'straight', 'teeth.'], ['edited_ending:', 'Billy', 'had', 'done', 'great', 'in', 'school.', 'He', 'told', 'his', 'mother', 'he', 'needed', 'to', 'attend', 'summer', 'school.', 'Billy', 'loved', 'studying', 'in', 'his', 'room.'], ['edited_ending:', 'One', 'day', 'Billy', 'asked', 'her', 'a', 'question', 'about', 'class.', 'She', 'realized', 'he', 'needed', 'help,', 'and', 'offered', 'to', 'tutor', 'him.', 'Amanda', 'and', 'Billy', 'formed', 'a', 'stronger', 'relationship.'], ['edited_ending:', 'He', 'finished', 'in', 'a', 'few', 'minutes', 'and', 'confidently', 'turned', 'in', 'his', 'test.', 'And', 'he', 'was', 'in', 'a', 'good', 'mood', 'the', 'whole', 'day.', 'When', 'he', 'got', 'his', 'test', 'score', 'back,', 'he', 'was', 'ecstatic.'], ['edited_ending:', 'Jeff', 'looked', 'straight', 'ahead', 'in', 'concentration.', 'A', 'young', 'girl', 'caught', 'his', 'eye.', 'She', 'was', 'diligently', 'taking', 'notes', 'and', 'appeared', 'captured', 'by', 'the', 'lesson.'], ['edited_ending:', 'Dan', 'was', 'interested', 'because', 'he', 'never', 'encountered', 'an', 'inflatable', 'tube', 'before.', 'Dan', 'wondered', 'whether', 'he', 'should', 'stay', 'and', 'play', 'with', 'the', 'inflatable', 'tube', 'or', 'drag', 'it', 'to', 'shore.', 'Dan', 'chose', 'to', 'drag', 'it', 'to', 'shore.'], ['edited_ending:', 'Her', 'blog', 'started', 'to', 'become', 'popular.', 'Eventually', 'she', 'wished', 'she', \"hadn't\", 'revealed', 'her', 'identity.', 'Rachel', 'is', 'now', 'famous', 'because', 'of', 'her', 'blog.'], ['edited_ending:', 'Unfortunately', 'however', 'there', 'was', 'a', 'big', 'fight', 'about', 'it.', 'Penelope', 'had', 'to', 'ask', 'everyone', 'to', 'never', 'contact', 'her.', 'She', 'realized', 'she', \"couldn't\", 'have', 'friends', 'any', 'more.'], ['edited_ending:', 'I', 'thought', 'I', 'was', 'taking', 'pictures', 'but', 'I', 'was', 'drunk.', 'I', 'had', 'been', 'taking', 'pictures', 'with', 'a', 'fake', 'camera.', 'That', 'was', 'a', 'very', 'embarrassing', 'realization.'], ['edited_ending:', 'She', 'still', 'kept', 'a', 'box', 'of', 'chocolates', 'under', 'her', 'bed', 'to', 'nibble', 'on', 'at', 'night.', 'After', 'a', 'week,', 'she', 'came', 'to', 'the', 'conclusion', 'that', 'diets', \"weren't\", 'for', 'her.', 'Now', 'Karen', 'goes', 'out', 'and', \"doesn't\", 'worry', 'about', 'what', 'she', 'orders.'], ['edited_ending:', 'They', 'tried', 'to', 'climb', 'the', 'great', 'wall', 'quickly.', 'But', \"David's\", 'girlfriend', 'wanted', 'to', 'stop', 'to', 'rest', 'after', '20', 'minutes.', 'They', 'ended', 'up', 'leaving.'], ['edited_ending:', 'She', 'was', 'happy,', 'because', 'she', \"didn't\", 'like', 'to', 'use', 'her', 'air', 'conditioner.', 'it', 'was', 'the', 'perfect', 'temperature', 'to', 'just', 'use', 'just', 'the', 'fans.', 'She', 'decided', 'to', 'run', 'the', 'fans', 'on', 'high', 'and', 'not', 'use', 'her', 'AC.'], ['edited_ending:', 'She', 'knew', 'she', 'was', 'probably', 'going', 'to', 'the', 'vet', 'and', \"didn't\", 'really', 'have', 'a', 'choice', 'about', 'it.', 'When', 'she', 'saw', 'the', \"vet's\", 'office,', 'she', 'knew', 'it', 'was', 'going', 'to', 'be', 'a', 'bad', 'day.', 'The', 'vet', \"wasn't\", 'as', 'bad', 'as', 'she', 'thought,', 'and', 'they', 'went', 'to', 'the', 'park', 'after.'], ['edited_ending:', 'She', \"wasn't\", 'popular', 'and', 'her', 'grandparents', 'talking', 'to', 'her', 'made', 'her', 'happy.', 'She', 'told', 'her', 'friends', 'they', 'could', 'come', 'over', 'if', 'they', 'kept', 'it', 'calm', 'and', 'quiet.', 'Within', 'hours', 'her', 'friends', 'were', 'there', 'and', 'her', 'grandparents', 'were', 'glad', 'to', 'see', 'them.'], ['edited_ending:', 'Lauren', 'told', 'her', 'mom', 'he', 'was', 'ignoring', 'her.', 'Her', 'mom', 'grounded', 'her', 'brother.', 'Her', 'brother', 'felt', 'indignant', 'at', 'being', 'grounded.'], ['edited_ending:', 'Anna', 'opened', 'the', 'refrigerator.', 'She', 'took', 'out', 'the', 'milk.', 'She', 'poured', 'milk', 'into', 'a', 'bowl', 'of', 'cereal.'], ['edited_ending:', 'Lebowski', 'asked', 'Jeff', 'to', 'deliver', 'the', 'contract', 'money.', 'Jeff', 'said', 'no', 'at', 'first,', 'but', 'Lebowski', 'offered', 'to', 'pay', 'him.', 'Jeff', 'agreed', 'to', 'deliver', 'the', 'money', 'to', 'the', 'hitmen.'], ['edited_ending:', 'I', 'looked', 'in', 'several', 'stores', 'online.', 'I', 'finally', 'settled', 'for', 'one', 'that', 'was', 'solid', 'blue.', 'I', 'purchased', 'it', 'and', 'am', 'waiting', 'for', 'it', 'to', 'arrive.'], ['edited_ending:', 'Carlos', 'was', 'never', 'pulled', 'over', 'for', 'speeding.', 'The', 'officer', 'never', 'got', 'the', 'chance', 'to', 'write', 'up', 'a', 'speeding', 'ticket.', 'Carlos', 'never', 'had', 'to', 'go', 'to', 'court.'], ['edited_ending:', 'Every', 'day', 'for', 'the', 'previous', 'year,', 'Casey', 'had', 'asked', 'about', 'having', 'a', 'puppy.', 'Finally', 'Christmas', 'day', 'came.', 'That', 'morning,', 'Casey', 'cried', 'when', 'her', 'gift', 'was', 'a', 'new', 'puppy!'], ['edited_ending:', 'When', 'he', 'went', 'to', 'lunch', 'he', 'would', 'walk', 'around', 'talking', 'to', 'everyone.', 'Many', 'kids', 'would', 'come', 'up', 'and', 'introduce', 'themselves.', 'Joe', 'had', 'many', 'friends', 'because', 'he', 'talked', 'to', 'everyone.'], ['edited_ending:', 'After', 'almost', 'tripping,', 'it', 'was', 'just', 'my', 'luck', 'and', 'I', 'stepped', 'in', 'a', 'pothole', 'and', 'fell', 'and', 'hurt', 'my', 'ankle', 'very', 'badly.', 'It', 'so', 'bad', 'I', \"couldn't\", 'walk', 'and', 'called', 'my', 'friend', 'to', 'come', 'get', 'me.', 'My', 'friend', 'picked', 'me', 'up', 'and', 'brought', 'me', 'back', 'home!'], ['edited_ending:', 'At', 'first', 'she', 'had', 'trouble', 'fitting', 'in,', 'but', 'then', 'she', 'started', 'making', 'friends.', 'By', 'the', 'fifth', 'week,', 'she', 'had', 'lots', 'of', 'new', 'friends.', 'Isabelle', 'is', 'one', 'of', 'the', 'most', 'popular', 'people', 'in', 'her', 'club', 'now.'], ['edited_ending:', 'She', 'fed', 'it', 'a', 'carrot.', 'The', 'duck', 'swam', 'away.', 'She', 'looked', 'for', 'it', 'every', 'day', 'but', 'never', 'saw', 'it', 'again.'], ['edited_ending:', 'Someone', 'ordered', 'beef', 'tongue,', 'and', 'I', 'was', 'very', 'nervous.', 'I', 'tried', 'it.', 'It', 'was', 'surprisingly', 'disgusting!'], ['edited_ending:', 'So', 'the', 'pie', 'turned', 'out', 'horrible.', 'She', 'figured', 'out', 'she', 'used', 'salt', 'when', 'she', 'went', 'to', 'taste', 'it', 'and', 'it', 'tasted', 'terrible.', 'Tina', 'had', 'to', 'throw', 'it', 'out.'], ['edited_ending:', 'Matt', 'looked', 'for', 'his', 'cat.', 'He', 'put', 'posters', 'up', 'to', 'find', 'his', 'cat.', 'Someone', 'called', 'him', 'to', 'tell', 'him', 'his', 'cat', 'was', 'stuck', 'outside', 'the', 'window.'], ['edited_ending:', 'He', 'was', 'lassoing', 'things,', 'and', 'next', 'thing', 'I', 'knew,', 'I', 'felt', 'a', 'tug.', 'My', 'friend', 'had', 'lassoed', 'me!', 'I', 'had', 'rope', 'burns', 'for', 'months', 'after', 'that!'], ['edited_ending:', 'Jerome', 'decided', 'to', 'buy', 'a', 'video', 'game', 'system', 'in', 'his', 'honor', 'He', 'would', 'play', 'video', 'games', 'online', 'with', \"Jerome's\", 'friends.', 'He', 'formed', 'a', 'team', 'with', \"Jerome's\", 'friends', 'and', 'named', 'it', 'after', 'him.'], ['edited_ending:', 'When', 'they', 'sat', 'at', 'their', 'seats,', 'they', 'were', 'harassed.', 'Disgusted', 'by', 'this,', 'the', 'usher', 'told', 'the', 'manager.', 'Justin', 'and', 'Josh', 'got', 'to', 'enjoy', 'their', 'anniversary', 'the', 'rest', 'of', 'the', 'night.'], ['edited_ending:', 'After', 'the', 'track', 'meet', 'Kaleb', 'found', 'a', 'rerun', 'of', 'the', 'show', 'at', '11:30pm.', 'He', 'did', 'everything', 'in', 'his', 'power', 'to', 'stay', 'up', 'to', 'watch', 'the', 'show.', 'After', 'finally', 'watching', 'the', 'show,', 'he', 'felt', 'amazed', 'that', 'he', 'could', 'stay', 'up.'], ['edited_ending:', 'Nothing', 'seemed', 'quite', 'suitable', 'at', 'the', 'mall.', 'Then', 'she', 'asked', 'her', 'mom', 'if', 'she', 'could', 'borrow', 'a', 'necklace.', \"Cay's\", 'mom', 'lent', 'her', 'a', 'perfect', 'diamond', 'necklace!'], ['edited_ending:', 'It', 'took', 'me', 'a', 'short', 'time', 'to', 'accept', 'the', 'fact', 'that', 'she', 'died.', 'When', 'I', 'did', 'accept', 'her', 'death,', 'a', 'weight', 'was', 'lifted', 'off', 'my', 'shoulders.', 'I', 'am', 'glad', 'that', 'I', 'have', 'come', 'to', 'terms', 'with', 'her', 'dying.'], ['edited_ending:', 'I', 'had', 'been', 'careful', 'with', 'the', 'cable', 'running', 'to', 'my', 'house.', 'The', 'cable', 'turned', 'out', 'to', 'be', 'my', 'internet', 'connection.', 'I', 'was', 'glad', 'I', \"didn't\", 'have', 'to', 'go', 'without', 'internet', 'because', 'I', 'had', 'been', 'careful.'], ['edited_ending:', 'I', 'accepted', 'the', 'challenged', 'and', 'he', 'laid', 'out', 'the', 'pies.', 'When', 'he', 'won,', 'he', 'ended', 'up', 'breaking', 'his', 'chair.', 'His', 'back', 'landed', 'on', 'the', 'floor', 'first.'], ['edited_ending:', 'She', 'asked', 'her', 'dad', 'to', 'drive', 'me', 'to', 'the', 'ER', 'at', '3', 'in', 'the', 'morning', 'when', 'I', 'threw', 'up.', 'He', 'did,', 'and', 'it', 'turned', 'out', 'I', 'had', 'pneumonia.', 'They', 'sent', 'me', 'home', 'after', 'around', '13', 'hours', 'with', 'medication.'], ['edited_ending:', 'Peter', \"couldn't\", 'find', 'Sally', 'and', 'he', 'had', 'looked', 'everywhere', 'Peter', 'remembered', 'that', 'Sally', 'was', 'out', 'of', 'town', 'all', 'weekend', 'Peter', 'was', 'patient', 'and', 'decided', 'he', 'could', 'wait', 'and', 'show', 'Sally', 'on', 'Monday'], ['edited_ending:', 'One', 'night', 'Jimmy', 'was', 'racing', 'and', 'had', 'almost', 'won.', 'A', 'bicycle', 'rolled', 'out', 'onto', 'the', 'road', 'in', 'front', 'of', 'him.', 'Jimmy', 'slammed', 'into', 'the', 'bicycle', 'and', 'flew', 'from', 'his', 'car', 'and', 'hit', 'the', 'pavement.'], ['edited_ending:', 'Carlos', 'noticed', 'a', 'kid', 'pick', 'up', 'an', 'apple', 'and', 'pocketed', 'it.', 'As', 'the', 'kid', 'walked', 'away,', 'Carlos', 'ignored', 'him.', 'The', 'kid', 'just', 'kept', 'walking.'], ['edited_ending:', 'And', 'his', 'car', 'was', 'gone!', 'He', 'called', 'the', 'police', 'in', 'a', 'panic.', 'The', 'police', 'came', 'out', 'to', 'stop', 'the', 'burglar.'], ['edited_ending:', 'Then', 'during', 'the', 'test', 'I', 'accidentally', 'side-swiped', 'an', 'old', 'car', 'while', 'parking.', 'My', 'tester', 'got', 'very', 'mad', 'at', 'me', 'and', 'we', 'had', 'to', 'stop.', 'He', 'told', 'me', 'I', 'failed', 'my', 'test,', \"I'd\", 'have', 'to', 'go', 'home', 'and', 'try', 'again', 'later.'], ['edited_ending:', 'He', 'was', 'having', 'a', 'lot', 'of', 'fun.', 'A', 'cop', 'pulled', 'him', 'over', 'for', 'speeding.', 'Jerry', 'drove', 'more', 'carefully', 'the', 'rest', 'of', 'the', 'way.'], ['edited_ending:', 'We', 'heard', 'that', 'others', 'were', 'stunned', 'by', 'how', 'awesome', 'it', 'was.', 'I', \"can't\", 'wait', 'until', 'I', 'am', 'older', 'and', 'can', 'fly', 'one.', 'Since', 'we', 'missed', 'it', 'I', 'am', 'going', 'to', 'fly', 'in', 'an', 'air', 'show', 'for', 'my', 'dad', 'one', 'day.'], ['edited_ending:', 'One', 'day', 'it', 'rained', 'and', 'Colin', 'forgot', 'his', 'shovel', 'outside.', 'The', 'shovel', 'became', 'buried', 'under', 'mud', 'and', 'Colin', \"couldn't\", 'find', 'it.', 'Colin', 'cried', 'until', 'his', 'mother', 'bought', 'him', 'a', 'new', 'shovel.'], ['edited_ending:', 'Joe', 'read', 'a', 'magazine', 'while', 'he', 'waited', 'at', 'the', 'barber.', 'Joe', 'took', 'his', 'turn', 'to', 'get', 'his', 'hair', 'cut.', 'He', 'loved', 'his', 'new', 'cut.'], ['edited_ending:', 'One', 'family', 'was', 'interested', 'in', 'helping', 'him.', 'The', 'family', 'joined', 'Don', 'in', 'cleaning', 'up', 'the', 'car.', 'Don', 'reported', 'the', 'crime', 'to', 'the', 'local', 'police', 'station.'], ['edited_ending:', 'Henry', 'chose', 'to', 'eat', 'a', 'burger', 'during', 'lunch.', 'He', 'spilled', 'ketchup', 'on', 'his', 'suit.', 'Henry', 'vowed', 'never', 'to', 'eat', 'messy', 'food', 'at', 'a', 'company', 'event', 'again'], ['edited_ending:', 'One', 'day', 'she', 'made', 'them', 'some', 'new', 'snacks', 'she', 'had', 'never', 'tried', 'before.', 'She', 'fed', 'them', 'to', 'her', 'dogs.', 'The', 'treats', 'were', 'no', 'good', 'and', 'none', 'of', 'the', 'dogs', 'would', 'eat', 'them.'], ['edited_ending:', 'When', 'she', 'finally', 'ended', 'up', 'walking', 'to', 'her', 'car,', 'she', 'tried', 'to', 'keep', 'her', 'head', 'down.', 'Just', 'then', 'the', 'wind', 'swept', 'a', 'gust', 'of', 'sand', 'into', \"Kim's\", 'face.', 'She', 'stood', 'on', 'the', 'sidewalk', 'coughing', 'out', 'the', 'sand.'], ['edited_ending:', 'I', \"didn't\", 'have', 'a', 'job', 'but', 'I', 'wanted', 'to', 'be', 'out', 'on', 'my', 'own.', 'I', 'tried', 'to', 'look', 'for', 'a', 'job', 'but', 'my', 'luck', 'was', 'down.', 'I', 'ended', 'up', 'homeless.'], ['edited_ending:', 'It', 'was', 'a', 'new', 'grill!', 'He', 'assembled', 'it', 'and', 'started', 'grilling.', 'Dennis', 'cooked', 'for', 'his', 'family', 'every', 'night', 'on', 'his', 'new', 'grill.'], ['edited_ending:', 'She', 'worried', 'that', 'none', 'of', 'her', 'friends', 'would', 'show', 'up.', 'Maybe', 'they', 'were', 'worrying', 'the', 'same', 'thing?', 'She', 'decided', 'it', 'really', \"didn't\", 'matter.'], ['edited_ending:', 'Nate', 'decided', 'to', 'go', 'back', 'in', 'and', 'cheat', 'to', 'improve', 'his', 'grade.', 'But', 'Nate', 'just', \"couldn't\", 'bring', 'himself', 'to', 'cheat', 'off', 'another', 'student.', 'He', 'turned', 'in', 'his', 'exam,', 'knowing', 'he', 'would', 'fail', 'but', 'did', 'the', 'right', 'thing.'], ['edited_ending:', 'He', 'found', 'a', 'letter', 'under', 'it', 'that', 'was', 'dated', '60', 'years', 'ago', 'to', 'an', 'address', 'that', 'no', 'longer', 'existed.', 'He', 'opened', 'the', 'letter', 'and', 'read', 'it.', 'It', 'was', 'a', 'confession', 'from', 'one', 'friend', 'to', 'another.'], ['edited_ending:', 'Tony', 'met', 'an', 'old', 'girlfriend', 'at', 'the', 'grocery', 'store', 'right', 'after', 'the', 'wedding.', 'She', 'asked', 'how', 'the', 'wedding', 'was.', 'Tony', 'and', 'his', 'ex', 'had', 'a', 'nice', 'chat.'], ['edited_ending:', 'He', 'had', 'looked', 'every', 'where', 'for', 'a', 'cheap', 'saxophone.', 'One', 'day', 'he', 'had', 'finally', 'found', 'one', 'he', 'could', 'afford.', 'He', 'became', 'a', 'great', 'player.'], ['edited_ending:', 'Her', 'daughter', 'was', 'wondering', 'what', 'happened', 'to', 'the', 'books.', 'She', 'had', 'used', 'them', 'as', 'a', 'secret', 'diary.', 'All', 'of', 'her', 'thoughts', 'were', 'lost.'], ['edited_ending:', 'She', \"didn't\", 'believe', 'her', 'and', 'wanted', 'a', 'horse', 'with', 'a', 'pretty', 'horn', 'on', 'its', 'head', 'She', 'begged', 'her', 'mom', 'all', 'day', 'before', 'Christmas', 'Sasha', 'woke', 'up', 'to', 'her', 'horse', 'having', 'a', 'horn', 'taped', 'to', 'its', 'temple'], ['edited_ending:', 'His', 'sister', 'is', 'packing', 'the', 'tent', 'in', 'the', 'truck.', 'Lew', 'is', 'helping', 'her.', 'Soon', 'they', 'arrive', 'at', 'the', 'campsite.'], ['edited_ending:', 'Trying', 'to', 'get', 'his', 'luck', 'going,', 'Mel', 'made', 'another', 'bet.', 'He', 'held', 'the', 'dice', 'and', 'let', 'his', 'companion', 'blow', 'on', 'them.', 'He', 'let', 'the', 'dice', 'fly', 'one', 'more', 'time,', 'hoping', 'for', 'a', 'big', 'payout.'], ['edited_ending:', 'When', 'his', 'mother', 'died,', 'she', 'left', 'her', 'house', 'to', 'him.', 'Charles', 'wanted', 'to', 'live', 'in', 'the', 'house', 'with', 'his', 'sister.', 'But', 'the', 'will', 'stated', 'not', 'to', 'let', 'his', 'Sister', 'in', 'because', 'she', 'hated', 'his', 'dad.'], ['edited_ending:', 'His', 'teacher', 'took', 'his', 'temperature.', 'She', 'told', 'him', 'that', 'he', 'could', 'not', 'stay', 'at', 'school', 'today', 'because', 'you', 'are', 'sick.', 'When', 'he', 'went', 'home,', 'his', 'mom', 'gave', 'him', 'some', 'medicine', 'and', 'by', 'morning', 'he', 'was', 'well', 'again.'], ['edited_ending:', 'He', 'was', 'her', 'only', 'child.', 'Alex', 'made', 'arrangements', 'to', 'bury', 'him.', 'She', 'was', 'going', 'to', 'miss', 'her', 'son', 'so', 'badly.'], ['edited_ending:', 'She', 'considered', 'waiting', 'for', 'her', 'family,', 'but', \"couldn't\", 'help', 'herself.', 'She', 'searched', 'the', 'house', 'for', 'a', 'gift', 'with', 'her', 'name', 'on', 'it.', 'By', 'the', 'time', 'her', 'family', 'woke', 'up,', 'there', 'still', 'were', 'no', 'gifts.'], ['edited_ending:', 'He', 'closed', 'his', 'eyes', 'to', 'imagine', 'himself', 'running.', 'An', 'hour', 'had', 'passed', 'when', 'he', 'next', 'opened', 'them.', 'Bob', 'was', 'even', 'more', 'anxious', 'now.'], ['edited_ending:', 'He', 'ordered', 'a', 'drink', 'from', 'the', 'bartender', 'while', 'he', 'waited.', 'The', 'man', 'took', 'a', 'sip', 'and', 'spat', 'it', 'out.', 'He', 'threatened', 'to', 'call', 'the', 'police', 'on', 'the', 'bartender.'], ['edited_ending:', 'Tina', 'was', 'terrified.', 'She', 'started', 'crying.', 'Then', 'she', 'realized', 'she', 'was', 'unhurt.'], ['edited_ending:', 'He', 'worked', 'harder', 'at', 'his', 'job', 'help', 'support', 'his', 'dream.', 'After', 'hours', 'and', 'hours', 'of', 'work', 'he', 'finally', 'had', 'his', 'money.', 'He', 'quit', 'his', 'job', 'and', 'went', 'on', 'his', 'way', 'happier', 'than', 'ever.'], ['edited_ending:', 'It', 'had', 'seemed', 'so', 'great', 'and', 'so', 'she', 'bought', 'it!', 'She', 'got', 'home', 'and', 'took', 'the', 'tags', 'off', 'to', 'try', 'it', 'on', 'one', 'more', 'time.', 'She', 'tried', 'it', 'on', 'and', 'was', 'very', 'disappointed', 'that', 'it', \"didn't\", 'fit', 'her.'], ['edited_ending:', 'When', 'we', 'finally', 'got', 'to', 'the', 'zoo', 'it', 'was', 'hot', 'and', 'crowded', 'with', 'families.', 'We', 'walked', 'around', 'for', 'a', 'bit', 'and', 'she', 'got', 'to', 'ride', 'the', 'elephant!', 'When', 'we', 'were', 'leaving', 'the', 'zoo', 'she', 'said', 'she', 'had', 'a', 'great', 'time!'], ['edited_ending:', 'Alex', \"wasn't\", 'sure', 'what', 'it', 'was', 'because', 'she', 'had', 'been', 'sound', 'asleep.', 'He', 'noticed', 'a', 'dog', 'that', 'kept', 'licking.', 'His', 'face', 'was', 'soaked', 'when', 'he', 'got', 'up', 'from', 'his', 'nap.'], ['edited_ending:', 'Thomas', 'got', 'some', 'firewood', 'from', 'outside.', 'He', 'put', 'it', 'in', 'the', 'fireplace', 'and', 'they', 'all', 'sat', 'around', 'it', 'together.', 'After', 'hours', 'he', 'spent', 'with', 'his', 'family,', 'he', 'was', 'truly', 'thankful.'], ['edited_ending:', 'The', 'encouragement', 'from', 'the', 'doctors', 'and', 'her', 'husband', 'also', 'helped.', 'Finally,', 'the', 'baby', 'was', 'born.', 'It', 'was', 'a', 'girl.'], ['edited_ending:', 'Her', 'husband', 'decided', 'to', 'use', 'good', 'manners.', 'He', 'went', 'to', 'an', 'etiquette', 'class', 'Now', 'he', 'drinks', 'tea', 'with', 'his', 'pinky', 'out', 'like', 'a', 'gentleman', 'but', 'Wilma', \"won't\", 'take', 'him', 'back'], ['edited_ending:', 'Then', 'she', 'saw', 'Tom', 'at', 'a', 'store.', 'He', 'was', 'with', 'another', 'girl.', 'Lucy', 'immediately', 'went', 'up', 'to', 'him', 'and', 'screamed', 'at', 'him.'], ['edited_ending:', 'It', 'was', 'the', 'most', 'beautiful', 'thing', 'Eric', 'had', 'ever', 'seen.', 'When', 'it', 'was', 'over', 'he', 'headed', 'back', 'to', 'bed.', 'It', 'was', 'late', 'at', 'night,', 'but', 'it', 'was', 'worth', 'it.'], ['edited_ending:', 'Without', 'warning,', 'a', 'storm', 'came', 'in', 'and', 'Martin', 'scampered', 'to', 'a', 'nearby', 'tree', 'to', 'take', 'cover.', 'He', 'began', 'to', 'beg', 'God', 'to', 'preserve', 'his', 'life.', 'Just', 'at', 'that', 'moment,', 'the', 'clouds', 'parted', 'and', 'Martin', 'felt', 'relieved!'], ['edited_ending:', 'She', 'was', 'about', 'to', 'leave', 'when', 'she', 'saw', 'a', 'bird', 'on', 'the', 'ground.', 'She', 'took', 'a', 'picture', 'and', 'it', 'turned', 'out', 'to', 'be', 'the', 'best', 'one.', 'Barbara', 'delivered', 'it', 'to', 'the', 'local', 'museum', 'and', 'they', 'loved', 'this', 'one', 'above', 'all.'], ['edited_ending:', 'Fortunately,', 'after', 'a', 'few', 'days', 'it', 'stopped', 'hurting', 'so', 'bad.', 'I', 'will', 'be', 'able', 'to', 'play', 'again', 'soon.', 'That', 'is', 'a', 'really', 'lucky', 'turn', 'of', 'events.'], ['edited_ending:', 'He', 'found', 'the', 'mouse', 'was', 'dead.', 'Cody', 'threw', 'the', 'dead', 'mouse', 'in', 'the', 'trash', 'His', 'cat', 'dug', 'the', 'mouse', 'out', 'of', 'the', 'trash', 'can'], ['edited_ending:', 'I', 'was', 'so', 'nervous', 'before', 'the', 'scrimmage.', 'I', 'was', 'so', 'nervous', 'that', 'I', \"couldn't\", 'sleep.', 'I', \"don't\", 'know', 'why', 'I', 'was', 'nervous', 'because', 'we', 'ended', 'up', 'winning', 'the', 'scrimmage.'], ['edited_ending:', 'He', \"couldn't\", 'even', 'do', 'five', 'push', 'ups', 'a', 'week.', 'He', 'was', 'furious', 'that', 'he', \"hadn't\", 'lost', 'a', 'pound.', 'He', 'then', 'decided', 'that', 'his', 'body', 'was', 'fine', 'the', 'way', 'it', 'was.'], ['edited_ending:', 'Somebody', 'suggested', 'that', 'Chuck', 'stop', 'beating', 'his', 'dog.', 'That', 'turned', 'out', 'to', 'be', 'an', 'excellent', 'idea.', 'The', 'dog', 'now', 'responds', 'when', 'told', 'to', 'come,', 'sit,', 'stay', 'and', 'lie', 'down.'], ['edited_ending:', 'His', 'daughter', 'refused', 'the', 'sandwich.', 'The', 'man', 'ate', 'it', 'instead.', 'The', 'man', 'gave', 'his', 'daughter', 'an', 'apple.'], ['edited_ending:', 'During', 'the', 'test', 'I', 'knew', 'if', 'I', 'cheated', 'I', 'would', 'make', 'a', 'good', 'grade.', 'I', 'decided', 'to', 'cheat.', 'Even', 'though', 'it', \"wasn't\", 'ethical,', \"I'm\", 'happy', 'with', 'my', 'choice.'], ['edited_ending:', 'I', 'asked', 'the', 'neighbors', 'about', 'the', 'source', 'of', 'the', 'noise.', 'They', 'said', 'it', 'seemed', 'to', 'be', 'coming', 'from', 'the', 'AC.', 'They', 'opened', 'the', 'blinds', 'to', 'see', 'a', 'group', 'of', 'birds', 'hopping', 'around', 'on', 'the', 'AC.'], ['edited_ending:', 'After', 'half', 'an', 'hour', 'my', 'neighbor', \"didn't\", 'open', 'her', 'door.', 'As', 'the', 'dog', 'was', 'still', 'screaming', 'for', 'help,', 'I', 'went', 'downstairs.', 'My', 'neighbor', 'opened', 'the', 'door,', 'she', 'screamed', 'at', 'me,', 'and', 'left', 'the', 'dog', 'out.'], ['edited_ending:', 'She', 'looked', 'in', 'the', 'refrigerator.', 'She', 'took', 'some', 'cheese', 'out', 'of', 'the', 'refrigerator.', 'Hannah', 'ate', 'the', 'cheese', 'while', 'she', 'waited.'], ['edited_ending:', 'I', 'called', 'the', 'stores', 'in', 'my', 'area', 'and', 'they', 'did', 'not', 'carry', 'it', 'any', 'more.', 'One', 'clerk', 'thought', 'I', 'wanted', 'a', 'Red', 'Sorghum', 'mix.', 'I', 'said', 'she', 'was', 'totally', 'off', 'base.'], ['edited_ending:', 'When', 'I', 'was', 'hungry', 'I', 'had', 'a', 'salad', 'It', 'tasted', 'amazing.', 'The', 'salad', 'was', 'the', 'winner', 'of', 'the', 'night.'], ['edited_ending:', 'When', 'she', 'was', 'done', 'she', 'cleaned', 'up', 'the', 'paint.', 'There', 'was', 'paint', 'all', 'over', 'the', 'floor.', 'Kate', 'knew', 'she', 'was', 'in', 'a', 'lot', 'of', 'trouble'], ['edited_ending:', 'One', 'day', 'we', 'had', 'to', 'practice', 'kissing', 'in', 'front', 'of', 'the', 'director.', 'My', 'boyfriend', 'slipped', 'me', 'the', 'tongue!', 'I', 'was', 'embarrassed', 'but', 'I', 'slipped', 'mine', 'in', 'as', 'well.'], ['edited_ending:', 'He', 'frowned', 'and', 'kept', 'away.', 'She', 'looked', 'sad', 'and', 'walked', 'away.', 'It', 'hurt', 'her', 'feelings', 'and', 'he', 'walked', 'away', 'with', 'guilt.'], ['edited_ending:', 'She', 'got', 'her', 'friends', 'together', 'to', 'have', 'a', 'party.', 'They', 'got', 'the', 'soda', 'and', 'chips', 'out.', 'It', 'was', 'the', 'party', 'of', 'the', 'year.'], ['edited_ending:', 'He', 'felt', 'something', 'pull', 'his', 'fishing', 'rod', 'strongly.', 'And', 'it', 'was', 'a', 'fish', 'with', 'three', 'eyes.', 'Fred', 'was', 'did', 'not', 'worry', 'about', 'it', 'and', 'threw', 'it', 'back', 'and', 'continued', 'you', 'fishing', 'immediately.'], ['edited_ending:', 'They', 'were', 'going', 'swimming', 'at', 'the', 'pool.', 'All', 'of', 'his', 'friends', 'came', 'and', 'brought', 'no', 'gifts.', 'When', 'the', 'party', 'was', 'over,', 'he', 'handed', 'out', 'goodie', 'bags.'], ['edited_ending:', 'She', 'told', 'me', 'she', 'loved', 'water.', 'I', 'told', 'her', 'it', 'was', 'ok.', 'I', 'put', 'on', 'my', 'swim', 'trunks', 'and', 'dove', 'in.'], ['edited_ending:', 'There', 'has', 'been', 'a', 'marked', 'lack', 'of', 'warmth.', 'The', 'only', 'warmth', 'the', 'plants', 'have', 'gotten', 'is', 'when', 'one', 'day', 'it', 'broke', '50', 'degrees.', 'We', 'have', 'now', 'mostly', 'given', 'up', 'on', 'getting', 'much', 'produce.'], ['edited_ending:', 'The', 'year', 'of', 'my', '12th', 'birthday', 'she', 'sent', 'a', 'fruitcake.', 'unfortunately,', 'my', 'dad', 'made', 'me', 'eat', 'the', 'entire', 'cake', 'on', 'my', 'own.', 'When', 'Aunt', 'Irma', 'found', 'out', 'she', 'graciously', 'sent', 'another', 'for', 'Xmas!'], ['edited_ending:', 'The', 'man', 'tried', 'to', 'back', 'away', 'from', 'it', 'but', 'it', 'saw', 'him.', 'He', 'picked', 'up', 'a', 'rock', 'and', 'tossed', 'it', 'over.', 'The', 'rock', 'hit', 'the', 'ground', 'and', 'the', 'mountain', 'lion', 'growled.'], ['edited_ending:', 'She', 'had', 'created', 'a', 'recipe', 'for', 'banana', 'flan.', 'After', 'her', 'family', 'tasted', 'it,', 'they', 'gave', 'her', 'a', 'round', 'of', 'applause.', 'Barb', 'was', 'so', 'proud!'], ['edited_ending:', 'He', 'started', 'talking', 'to', 'me', 'and', 'I', 'had', 'a', 'great', 'time.', 'We', 'eventually', 'parted', 'ways', 'but', 'not', 'before', 'I', 'was', 'able', 'to', 'hug', 'him.', 'He', 'started', 'laughing', 'and', 'has', 'since', 'kept', 'being', 'nice', 'to', 'anyone', 'that', \"I'm\", 'aware', 'of.'], ['edited_ending:', 'He', 'made', 'a', 'elaborate', 'demonstration', 'of', 'how', 'fun', 'they', 'were', 'to', 'use.', 'The', 'only', 'person', 'watching', 'him', 'was', 'hypnotized', 'by', 'his', 'enthusiasm.', 'The', 'an', 'gave', 'his', 'product', 'for', 'free', 'to', 'his', 'single', 'fan', 'before', 'the', 'fair', 'was', 'over.'], ['edited_ending:', 'He', 'hopped', 'in', 'their', 'tubes', 'and', 'started', 'floating.', 'He', 'went', 'several', 'miles,', 'having', 'a', 'good', 'time', 'all', 'the', 'while.', 'It', 'was', 'a', 'great', 'trip', 'down', 'the', 'river,', 'he', 'thought', 'to', 'himself.'], ['edited_ending:', 'There', \"wasn't\", 'enough', 'chicken', 'in', 'my', 'house', 'so', 'I', 'used', 'tofu.', 'I', 'ate', 'the', 'tofu', 'bowl', 'quickly.', 'My', 'new', 'food', 'invention', 'satisfied', 'my', 'hunger.'], ['edited_ending:', 'She', 'would', 'make', 'one', 'every', 'week.', 'Last', 'week', 'she', 'added', 'fresh', 'vegetables.', 'Everyone', 'said', 'they', 'could', 'taste', 'the', 'difference!'], ['edited_ending:', 'The', 'mom', 'thought', 'her', 'daughter', 'was', 'trustworthy.', 'Her', 'daughter', 'knew', 'she', \"wasn't\", 'going', 'to', 'be', 'caught.', 'She', 'never', 'returned', 'the', 'money', 'to', 'her', 'mom.'], ['edited_ending:', 'Kate', 'played', 'with', 'and', 'sang', 'to', 'the', 'baby.', 'Kate', 'loved', 'when', 'her', 'cousin', 'came', 'visiting.', 'Today', 'her', 'cousin', 'won', 'over', 'the', 'baby', 'with', 'her', 'singing', 'and', 'smile.'], ['edited_ending:', 'The', \"Smith's\", 'house', 'was', 'the', 'perfect', 'place.', 'All', 'of', 'the', 'kids', 'gathered', 'there', 'and', 'played', 'video', 'games.', 'It', 'was', 'a', 'wonderful', 'first', 'day', 'of', 'summer', 'break.'], ['edited_ending:', 'Joey', 'skipped', 'practicing', 'his', 'pitch', 'and', 'went', 'clubbing', 'instead.', 'The', 'client', 'arrived', 'early', 'to', 'the', 'meeting.', 'Joey', 'was', 'so', 'tired', 'he', 'failed', 'to', 'sign', 'the', 'client.'], ['edited_ending:', 'Eventually', 'his', 'youthful', 'foolishness', 'got', 'the', 'better', 'of', 'him.', 'He', 'decided', 'to', 'race', 'and', 'lost', 'control', 'of', 'the', 'car', 'and', 'landed', 'in', 'a', 'ditch.', 'Everyone', 'was', 'okay,', 'but', 'he', \"doesn't\", 'have', 'a', 'car', 'to', 'race', 'in', 'now.'], ['edited_ending:', 'It', 'was', 'the', 'day', 'of', 'the', 'party', 'and', 'she', \"couldn't\", 'wait', 'for', 'the', 'surprise.', \"That's\", 'when', 'her', 'parents', 'showed', 'her', 'a', 'beautiful', 'puppy', 'in', 'the', 'yard.', 'She', 'played', 'with', 'it', 'for', 'the', 'whole', 'day.'], ['edited_ending:', 'During', 'this', 'ride', 'I', 'listened', 'to', 'a', 'lot', 'of', 'music', 'and', 'got', 'some', 'food', 'I', 'took', 'my', 'time', 'on', 'the', 'highway', 'and', 'enjoyed', 'the', 'scenery', 'When', 'I', 'was', 'on', 'my', 'way', 'home', 'I', 'stopped', 'and', 'got', 'food', 'for', 'my', 'mom'], ['edited_ending:', 'The', 'list', 'started', 'small', 'but', 'grew', 'as', 'he', 'remembered', 'more', 'people', 'for', 'his', 'list.', 'Harry', 'realized', 'that', 'he', 'could', 'no', 'longer', 'have', 'a', 'small', 'party.', 'He', 'decided', 'to', 'change', 'the', 'venue', 'to', 'a', 'bigger', 'place', 'to', 'hold', 'his', 'friends.'], ['edited_ending:', 'She', 'worked', 'hard', 'to', 'memorize', 'her', 'lines', 'for', 'the', 'play', 'anyway.', 'When', 'the', 'show', 'opened,', 'she', 'stood', 'in', 'the', 'audience', 'and', 'took', 'it', 'all', 'in.', 'She', 'missed', 'the', 'feeling', 'of', 'performing.'], ['edited_ending:', 'The', 'guest', 'reconsidered', 'his', 'order', 'and', 'asked', 'for', 'more', 'time.', 'The', 'guest', 'asked', 'about', 'the', 'specials', 'again.', 'The', 'waiter', 'sighed', 'loudly.'], ['edited_ending:', 'She', 'was', 'so', 'tall', 'that', 'we', 'played', 'with', 'her', 'in', 'silly', 'ways.', 'We', 'put', 'a', 'large', 'trash', 'bag', 'over', 'her', 'and', 'spun', 'her', 'around.', 'We', 'could', 'hear', 'her', 'laughing', 'inside', 'the', 'bag.'], ['edited_ending:', 'His', 'girlfriend', 'fussed', 'because', 'she', 'knew', 'his', 'shoes', 'were', 'too', 'expensive.', 'Danny', 'denied', 'the', 'price', 'of', 'the', 'shoes', 'but', \"Danny's\", 'girlfriend', 'called', 'the', 'bank.', 'He', 'returned', 'the', 'shoes', 'but', 'said', 'he', \"didn't\", 'overpay.'], ['edited_ending:', 'It', 'was', 'an', 'extremely', 'hot', 'day.', 'Mike', 'went', 'to', 'a', 'festival.', 'Mike', \"didn't\", 'think', 'it', 'was', 'worth', 'coming.'], ['edited_ending:', 'He', 'was', 'more', 'excited', 'to', 'be', 'visiting', 'the', 'Flaming', 'Cliffs', 'while', 'there.', 'In', 'addition,', 'he', 'could', 'not', 'wait', 'to', 'go', 'to', 'the', 'monasteries', 'as', 'well.', 'Gary', 'was', 'in', 'high', 'anticipation', 'for', 'his', 'annual', 'summer', 'vacation', 'trip.'], ['edited_ending:', 'He', 'recognized', 'the', 'special', 'seal', 'on', 'it.', 'Nervously', 'he', 'opened', 'the', 'package.', 'He', 'got', 'accepted', 'into', 'college.'], ['edited_ending:', 'Most', 'of', 'her', 'family', 'could', 'always', 'make', 'it', 'to', 'her', 'recitals.', 'Her', 'mom', 'said', 'she', 'would', 'come', 'and', 'was', 'in', 'the', 'front', 'row.', 'Stacy', 'felt', 'ecstatic.'], ['edited_ending:', 'It', 'wasn’t', 'as', 'good', 'as', 'the', 'ones', 'my', 'friends', 'made.', 'I', 'asked', 'my', 'friends', 'to', 'make', 'them', 'for', 'me,', 'I', 'bought', 'all', 'the', 'things', 'I', 'needed', 'to', 'make', 'a', 'lot', 'of', 'sandwiches.', 'It', 'turns', 'out', 'that', 'my', 'friends', 'make', 'a', 'great', 'grilled', 'cheese.'], ['edited_ending:', 'So', 'she', 'was', 'unable', 'to', 'follow', 'the', 'steps', 'exactly.', 'She', \"didn't\", 'like', 'the', 'situation.', 'The', 'lady', 'looked', 'for', 'the', 'English', 'manual', 'again.'], ['edited_ending:', 'Tom', 'and', 'his', 'friends', 'overindulged', 'in', 'driks.', 'Slowly', 'Tom', 'started', 'to', 'feel', 'bad.', 'He', 'realized', 'he', 'drink', 'too', 'much'], ['edited_ending:', 'Anna', 'thought', 'this', 'was', 'a', 'good', 'way', 'to', 'make', 'her', 'hobby', 'useful,', 'as', 'a', 'career.', 'After', 'she', 'finished', 'school', 'she', 'got', 'a', 'job', 'as', 'a', 'movie', 'director.', 'That', 'made', 'Anna', 'and', 'her', 'parents', 'both', 'very', 'happy!'], ['edited_ending:', 'So', 'instead', 'of', 'arguing,', 'they', 'decided', 'on', 'Italian', 'food.', 'They', 'decided', 'to', 'play', 'rock,', 'paper,', 'scissors.', 'Jennifer', 'won', 'rock', 'over', 'scissors,', 'and', 'got', 'a', 'free', 'meal.'], ['edited_ending:', 'As', 'I', 'was', 'opening', 'the', 'door', 'I', 'stepped', 'on', 'a', 'cicada', 'who', 'began', 'to', 'screech.', 'I', 'instantly', 'ran', 'inside.', 'To', 'this', 'day', 'I', 'hate', 'cicadas!'], ['edited_ending:', 'I', 'was', 'very', 'nervous', 'about', 'playing', 'with', 'my', 'cast.', 'Everyone', 'told', 'me', 'not', 'to', 'worry', 'about', 'it.', 'We', 'ended', 'up', 'losing', 'the', 'game.'], ['edited_ending:', 'His', 'daughter', 'praised', 'his', 'outfits.', 'She', 'asked', 'him', 'to', 'help', 'her', 'shop', 'for', 'some', 'new', 'clothes.', 'Hank', 'was', 'happy', 'to', 'help', 'his', 'daughter', 'look', 'for', 'new', 'clothes.'], ['edited_ending:', 'He', 'pulls', 'over', 'to', 'check', 'out', 'the', 'problem.', 'He', 'crouches', 'down', 'and', 'looks', 'at', 'the', 'tire.', 'He', 'calls', 'a', 'tow', 'truck', 'and', 'waits', 'for', 'help.'], ['edited_ending:', 'She', 'placed', 'the', 'big', 'white', 'pot', 'on', 'her', 'front', 'porch.', 'Her', 'house', 'looked', 'very', 'modern.', 'She', 'liked', 'the', 'new', 'addition', 'to', 'her', 'front', 'porch.'], ['edited_ending:', 'She', 'studied', 'interest', 'rates,', 'fees,', 'and', 'benefits.', 'He', 'had', 'a', 'card', 'that', 'was', 'perfect', 'for', 'her.', 'Francine', 'is', 'happy', 'that', 'she', 'has', 'such', 'good', 'credit.'], ['edited_ending:', 'Then', 'Natalie', 'went', 'to', 'the', 'pet', 'store', 'that', 'was', 'closest', 'to', 'her', 'home.', 'At', 'the', 'store', 'she', 'chose', 'several', 'fish', 'and', 'hired', 'someone', 'to', 'set', 'up', 'a', 'tank.', 'Natalie', 'then', 'went', 'home', 'with', 'the', 'man', 'so', 'he', 'could', 'set', 'up', 'the', 'tank', 'with', 'her', 'fish.'], ['edited_ending:', 'Their', 'oldest', 'child', 'was', 'scheduled', 'to', 'marry', 'in', 'November.', 'Ginger', 'demanded', 'they', 'renew', 'their', 'vows', 'before', 'their', 'child', 'gives', 'birth.', 'John', 'finally', 'proposed', 'and', 'they', 'got', 'remarried', 'in', 'June.'], ['edited_ending:', 'Finally', 'I', 'found', 'one', 'in', 'red.', 'I', 'was', 'thankful', 'that', 'I', 'did.', 'I', 'ended', 'up', 'carrying', 'around', 'with', 'me', 'everywhere.'], ['edited_ending:', 'He', 'wondered', 'one', 'day', 'what', 'would', 'have', 'happend', 'if', 'he', 'had,', 'acted', 'on', 'that', 'crazy', 'idea', 'and', 'ran', 'for', 'President.', 'He', 'dreamed', 'that', 'he', 'would', 'have', 'had', 'a', 'good', 'turnout', 'and', 'became', 'the', 'Republican', 'Nominee.', 'Donald', 'started', 'to', 'regret', 'his', 'decision,', 'and', 'believed', 'he', 'would', 'have', 'went', 'on', 'to', 'become', 'The', 'President', 'of', 'the', 'United', 'States', 'of', 'America.'], ['edited_ending:', 'Rachel', 'and', 'her', 'dog', 'got', 'caught', 'in', 'the', 'snow.', 'It', 'was', 'snowing', 'very', 'hard', 'so', 'they', 'had', 'to', 'take', 'cover.', 'They', 'went', 'to', 'a', 'local', 'shop', 'and', 'stayed', 'until', 'it', 'stopped', 'snowing.'], ['edited_ending:', 'But', 'the', 'neighbor', 'always', 'smiles.', 'One', 'day', 'Rene', 'worked', 'up', 'the', 'nerve', 'to', 'ask', 'her', 'why', 'she', 'smiles', 'like', 'that.', 'The', 'neighbor', 'just', 'gave', 'her', 'a', 'weird', 'look', 'and', 'walked', 'away.'], ['edited_ending:', 'She', 'thought', 'a', 'fish', 'swam', 'into', 'her', 'mouth', 'but', 'it', 'was', 'seaweed.', 'She', 'spit', 'it', 'out', 'and', 'screeched.', 'She', 'never', 'wanted', 'to', 'swim', 'again.'], ['edited_ending:', 'One', 'day', 'they', 'decided', 'to', 'have', 'a', 'race.', 'Timmy', 'and', 'Jason', 'both', 'lined', 'up', 'their', 'bikes', 'and', 'sped', 'off', 'They', 'both', 'ended', 'up', 'riding', 'slow', 'and', 'crossed', 'the', 'line', 'at', 'the', 'same', 'time.'], ['edited_ending:', 'Kate', 'was', 'not', 'fond', 'of', 'doing', 'accounting.', 'Kate', 'was', 'hesitant', 'to', 'help.', 'But', 'she', 'agreed', 'to', 'help', 'since', 'he', 'was', 'family.'], ['edited_ending:', 'There', 'were', 'silly', 'noises', 'everywhere.', 'I', 'was', 'too', 'bored', 'to', 'be', 'scared.', 'I', 'would', 'never', 'ever', 'do', 'that', 'again.'], ['edited_ending:', 'He', 'ate', 'the', 'salad.', 'The', 'next', 'week', 'he', 'went', 'back', 'to', 'the', 'garden.', 'The', 'weeds', 'were', 'dried', 'and', 'brown.'], ['edited_ending:', 'One', 'day', 'while', 'her', 'mom', 'was', 'gone,', 'Sara', 'decided', 'to', 'clean.', 'She', 'was', 'cautious', 'not', 'to', 'find', 'her', 'presents.', 'She', 'avoided', 'her', \"mom's\", 'room', 'and', \"didn't\", 'find', 'anything.'], ['edited_ending:', 'Tim', 'asked', 'his', 'parents', 'for', 'help.', 'They', 'recommended', 'he', 'start', 'a', 'career', 'in', 'the', 'military.', 'Tim', 'just', 'finished', 'basic', 'training', 'for', 'the', 'Army.'], ['edited_ending:', 'Olly', 'was', 'practicing', 'a', 'jump', 'on', 'the', 'track.', 'The', 'bike', 'went', 'high', 'in', 'the', 'air', 'and', 'Ollie', 'skillfully', 'stayed', 'on.', 'Ollie', 'landed', 'safely', 'and', 'kept', 'riding', 'successfully', 'for', 'months.'], ['edited_ending:', 'She', 'also', 'had', 'solar', 'panels', 'installed', 'on', 'her', 'new', 'house.', 'Her', 'electricity', 'bill', 'became', 'nonexistent.', 'Martha', 'was', 'extremely', 'happy', 'with', 'her', 'purchases.'], ['edited_ending:', 'I', \"couldn't\", 'stop', 'sweating,', 'so', 'I', 'went', 'to', 'the', 'bathroom', 'to', 'cool', 'down.', 'I', 'ran', 'cold', 'water', 'on', 'my', 'hands,', 'turning', 'them', 'cool', 'white.', 'When', 'I', 'came', 'out,', 'he', 'yelled', 'at', 'me', 'for', 'missing', 'the', 'game.'], ['edited_ending:', 'I', 'had', 'to', 'climb', 'up', 'and', 'down', 'the', 'ladder', 'while', 'carrying', 'bags', 'of', 'cherries.', 'Eventually,', 'I', 'made', 'only', 'about', '$15', 'an', 'hour', 'since', 'I', 'was', 'so', 'slow.', 'The', 'only', 'thing', 'I', 'liked', 'about', 'it', 'were', 'the', 'free', 'cherries', 'I', 'received.'], ['edited_ending:', 'She', 'walked', 'across', 'the', 'stage', 'and', 'got', 'her', 'diploma.', 'She', \"didn't\", 'feel', 'a', 'huge', 'sense', 'of', 'accomplishment.', 'She', 'hung', 'the', 'diploma', 'on', 'her', 'wall', 'and', 'sighed.'], ['edited_ending:', 'He', 'tried', 'to', 'remove', 'the', 'bug', 'but', 'could', 'not,', 'so', 'the', 'man', 'called', 'the', 'doctor', 'office', 'to', 'make', 'an', 'appointment.', 'The', 'man', 'went', 'into', 'his', 'appointment', 'with', 'the', 'doctor.', 'The', 'doctor', 'removed', 'the', 'bug', 'and', 'gave', 'him', 'a', 'prescription.'], ['edited_ending:', 'He', 'had', 'bounced', 'up', 'and', 'down', 'in', 'the', 'car', 'the', 'entire', 'way', 'there.', 'He', 'was', 'finally', 'going', 'to', 'meet', 'Santa.', 'As', 'they', 'met', 'the', 'elves,', 'he', 'recited', 'to', 'himself', 'the', 'list', 'one', 'last', 'time.'], ['edited_ending:', 'Ben', 'spent', 'all', 'his', 'money', 'at', 'the', 'casino.', 'With', 'his', 'last', 'dollar', 'he', 'hit', 'the', 'jackpot!', 'Ben', 'forgot', 'all', 'about', 'basketball.'], ['edited_ending:', 'He', 'arrived', 'at', 'his', 'other', 'friends', 'door', 'just', 'as', 'they', 'were', 'walking', 'out.', 'Both', 'ready,', 'they', 'started', 'toward', 'to', 'their', 'destination', 'of', 'foot.', 'The', 'air', 'was', 'balmy,', 'and', 'they', 'remarked', 'on', 'it', 'upon', 'arriving', 'at', 'the', 'boat.'], ['edited_ending:', 'He', 'has', 'to', 'take', 'a', 'taxis', 'to', 'get', 'to', 'the', 'park', 'with', 'the', 'benches.', 'I', 'asked', 'him', 'why', 'he', \"didn't\", 'take', 'the', 'bus,', 'He', 'said', \"it's\", 'dangerous', 'and', 'he', \"doesn't\", 'feel', 'safe.'], ['edited_ending:', 'When', 'she', 'finally', 'saved', 'up', 'enough', 'money', 'she', 'ordered', 'a', 'protective', 'case', 'for', 'it.', 'It', 'came', 'to', 'her', 'house', 'and', 'she', 'opened', 'the', 'box', 'and', 'put', 'her', 'new', 'phone', 'in', 'the', 'case.', 'To', \"Sue's\", 'surprise,', 'she', 'dropped', 'it', 'and', 'the', 'new', 'phone', 'was', 'shattered.'], ['edited_ending:', 'Everyday,', 'she', 'took', 'care', 'of', 'children', 'inside', 'a', 'daycare.', 'And', 'they', 'developed', 'a', 'close', 'relationship.', 'Cindy', 'was', 'glad', 'she', 'chose', 'such', 'a', 'rewarding', 'job.'], ['edited_ending:', 'But', 'she', 'did', 'have', 'a', 'waffle', 'iron!', 'Nora', 'had', 'to', 'drive', 'four', 'miles', 'to', 'the', 'store', 'for', 'waffle', 'mix.', 'There,', 'she', 'finally', 'made', 'the', 'cone', 'she', 'craved!'], ['edited_ending:', 'I', 'love', 'modern', 'more', 'unique', 'homes.', 'I', 'am', 'hoping', 'I', 'can', 'find', 'one', 'of', 'those', 'in', 'my', 'price', 'range.', 'When', 'we', 'finally', 'decide', 'on', 'a', 'place', 'I', \"can't\", 'wait', 'to', 'build', 'it!'], ['edited_ending:', 'As', 'he', 'hiked,', 'Cody', 'spotted', 'some', 'wolves', 'in', 'the', 'distance.', 'If', 'it', \"weren't\", 'for', 'his', 'sharp', 'senses,', 'Cody', 'would', 'have', 'missed', 'the', 'pack.', 'He', 'reluctantly', 'told', 'Adam', 'he', 'wished', 'he', 'had', 'come', 'along', 'when', 'he', 'got', 'home.'], ['edited_ending:', 'He', 'was', 'a', 'member', 'of', 'their', 'political', 'party,', 'but', 'they', \"didn't\", 'support', 'him.', 'Jim', 'made', 'some', 'rather', 'stupid', 'decisions', 'that', 'election', 'year.', 'People', 'could', 'not', 'deal', 'with', 'those', 'decisions', 'and', 'voted', 'him', 'out.'], ['edited_ending:', 'Billy', 'was', 'very', 'upset.', 'The', 'class', 'arrived', 'at', 'the', 'firehouse.', 'Billy', 'had', 'an', 'awful', 'time', 'that', 'day', 'at', 'home', 'while', 'seeing', 'pictures', 'of', 'his', 'friends', 'at', 'the', 'firehouse.'], ['edited_ending:', 'She', 'read', 'his', 'favorite', 'poem.', \"Megan's\", 'phone', 'lost', \"it's\", 'connection.', 'They', 'talked', 'later.'], ['edited_ending:', 'Alex', 'loved', 'looking', 'at', 'the', 'old', 'games', 'on', 'display.', 'She', 'tried', 'on', 'an', 'old', 'retro', 'gaming', 'glove.', 'She', 'purchased', 'it', 'and', 'wore', 'it', 'out', 'of', 'the', 'store.'], ['edited_ending:', 'Unfortunately', 'I', 'made', 'an', 'enemy', 'and', 'they', 'hated', 'me.', 'They', 'reported', 'me', 'and', 'had', 'false', 'evidence', 'against', 'me.', 'I', 'am', 'now', 'serving', 'time', 'in', 'prison.'], ['edited_ending:', 'Suddenly', 'it', 'opened', 'with', 'a', 'loud', 'BANG', 'and', 'she', 'fell', 'to', 'the', 'floor', 'with', 'the', 'food', 'on', 'top', 'of', 'her.', 'The', 'avalanche', 'had', 'fallen', 'out', 'and', 'broken', 'her', 'foot!', 'Liz', 'had', 'ice', 'cream', 'for', 'dinner', 'at', 'the', 'hospital', 'instead.'], ['edited_ending:', 'During', 'the', 'weather', 'report', 'on', 'the', 'news', 'he', 'gave', 'a', 'great', 'forecast.', 'The', 'weatherman', 'said', 'it', 'would', 'snow', 'on', 'Christmas.', 'Many', 'happy', 'viewers', 'called', 'into', 'the', 'station.'], ['edited_ending:', 'His', 'family', 'was', 'angry', 'but', 'there', 'was', 'nothing', 'they', 'could', 'do.', 'He', 'made', 'a', 'satisfied', 'smile.', 'And', 'died', 'leaving', 'a', 'whole', 'mess', 'behind.'], ['edited_ending:', 'Once', 'we', 'got', 'there', 'we', 'decided', 'to', 'buy', 'her', 'a', 'mini', 'dinosaur.', 'She', 'spent', 'the', 'rest', 'of', 'the', 'trip', 'playing', 'with', 'it.', 'It', 'was', 'one', 'of', 'the', 'most', 'fun', 'vacations', 'we', 'have', 'ever', 'been', 'on.'], ['edited_ending:', 'I', 'had', 'a', 'boring', 'time.', 'Im', 'not', 'sure', 'why', 'I', 'even', 'went', 'to', 'Florida.', 'it', 'wasnt', 'a', 'vacation', 'at', 'all'], ['edited_ending:', 'He', 'was', 'expecting', 'a', 'small', 'yacht,', 'but', 'the', 'boat', 'was', 'actually', 'quite', 'big.', 'Jack', 'was', 'too', 'busy', 'looking', 'at', 'everything', 'on', 'the', 'boat', 'to', 'even', 'fish.', 'Jack', 'decided', 'he', 'wanted', 'to', 'buy', 'a', 'boat', 'when', 'he', 'got', 'older.'], ['edited_ending:', 'The', 'repairman', 'tried', 'fix', 'it', 'himself.', 'After', 'hours', 'of', 'frustration,', 'the', 'faucet', \"wasn't\", 'fixed.', \"Andy's\", 'repairman', 'called', 'another', 'repairman.'], ['edited_ending:', 'She', 'decides', 'to', 'get', 'out', 'of', 'the', 'house.', 'She', 'goes', 'out', 'to', 'dance.', 'Vicky', 'really', 'enjoys', 'her', 'time', 'out', 'on', 'the', 'dance', 'floor.'], ['edited_ending:', 'He', 'saw', 'a', 'black', 'car', 'with', 'tinted', 'windows', 'driving', 'along', 'side', 'them.', 'And', 'the', 'person', 'yelled', 'and', 'asked', 'for', 'directions.', 'Kevin', 'decided', 'to', 'grab', 'Kelly’s', 'hand', 'and', 'run', 'away.'], ['edited_ending:', 'Even', 'as', 'an', 'adult,', 'I', 'long', 'to', 'have', 'childlike', 'excitement.', 'I', 'want', 'to', 'open', 'presents', 'and', 'eat', 'too', 'much', 'food.', 'Then', 'maybe', 'watch', 'old', 'Christmas', 'movies', 'and', 'nap.'], ['edited_ending:', 'She', 'also', 'took', 'up', 'cooking', 'lessons', 'but', 'she', 'was', 'not', 'satisfied.', 'She', 'took', 'up', 'yoga', 'but', 'that', 'was', 'not', 'for', 'her.', 'She', 'took', 'up', 'karate,', 'and', 'realized', 'she', 'was', 'also', 'that', 'kind', 'of', 'person.'], ['edited_ending:', 'He', 'would', 'often', 'get', 'creepy', 'messages', 'from', 'him.', 'Jimmy', 'got', 'bothered', 'when', 'the', 'man', 'discovered', 'his', 'home', 'address.', 'He', 'told', 'his', 'parents', 'and', 'they', 'called', 'the', 'cops,', 'the', 'man', 'was', 'never', 'heard', 'from', 'again.'], ['edited_ending:', 'One', 'day', 'Tina', 'found', 'it', 'at', 'CVS.', 'It', 'was', 'a', 'godsend.', 'Now', 'Tina', 'could', 'have', 'all', 'the', 'yogurt', 'she', 'wanted.'], ['edited_ending:', 'Darren', 'called', 'for', 'help.', \"Darren's\", 'son', 'drove', 'him', 'to', 'the', 'hospital.', 'His', 'son', 'bought', 'a', 'gallon', 'of', 'milk', 'from', 'the', 'store.'], ['edited_ending:', 'The', 'babysitter', 'is', 'a', 'friend', 'to', 'the', 'family', 'and', 'they', 'love', 'her.', 'After', 'her', 'lunch', 'was', 'fed', 'to', 'her', 'Zoe', 'fell', 'asleep.', 'She', 'would', 'not', 'wake', 'up', 'from', 'her', 'nap', 'and', 'went', 'home', 'still', 'sleeping.'], ['edited_ending:', 'The', 'price', 'of', 'the', 'model', 'he', 'bought', 'fell', 'and', 'it', 'seemed', 'like', 'he', 'made', 'the', 'wrong', 'decision.', 'Carl', 'was', 'patient', 'and', 'the', 'price', 'of', 'his', 'car', 'went', 'up', 'again.', 'Carl', 'now', 'looks', 'like', 'he', 'made', 'a', 'smart', 'decision.'], ['edited_ending:', 'Carrie', 'tried', 'anyway', 'and', 'brought', 'a', 'list', 'of', 'reasons', 'to', 'her', 'parents.', 'Her', 'parents', 'read', 'the', 'entire', 'list,', 'impressed.', 'They', 'agreed', 'that', 'a', 'dog', 'would', 'be', 'great', 'for', 'Carrie.'], ['edited_ending:', 'Eventually,', 'I', 'began', 'getting', 'poorer', 'grades', 'because', 'I', \"wasn't\", 'studying.', 'Then,', 'I', 'decided', 'to', 'study', 'every', 'time', 'I', 'went', 'to', 'school.', 'On', 'my', 'next', 'report', 'card', 'my', 'grades', 'went', 'up', 'significantly!'], ['edited_ending:', 'Her', 'older', 'brother', 'plays', 'violin.', 'Tanya', 'borrows', 'his', 'violin', 'every', 'other', 'day.', 'Tanya', 'continues', 'to', 'practice', 'diligently.'], ['edited_ending:', 'She', 'got', 'on', 'her', 'surfboard', 'and', 'immediately', 'fell', 'hard', 'on', 'her', 'tushy.', 'Laura', \"couldn't\", 'believe', 'how', 'hard', 'it', 'was.', 'She', 'could', 'not', 'wait', 'to', 'go', 'home.'], ['edited_ending:', 'Andy', 'tried', 'to', 'tell', 'the', 'joke', 'to', 'Bob.', 'Bob', 'was', 'confused', 'about', 'the', 'joke.', 'He', \"didn't\", 'laugh.'], ['edited_ending:', 'I', 'named', 'the', 'kitten', 'Spot', 'and', 'took', 'him', 'home', 'I', 'nursed', 'Spot', 'back', 'to', 'health.', 'Now', 'Spot', 'and', 'I', 'are', 'best', 'friends'], ['edited_ending:', 'As', 'Lydia', 'was', 'vain,', 'she', 'liked', 'the', 'attention', 'very', 'much.', 'Until', 'someone', 'came', 'along', 'and', 'unsuccessfully', 'tried', 'to', 'snatch', 'the', 'purse', 'and', 'run', 'away.', 'Lydia', 'since', 'then', 'buys', 'simple', 'purses', 'and', 'no', 'one', 'notices', 'them.'], ['edited_ending:', 'They', 'stood', 'on', 'chairs', 'to', 'see', 'the', 'stage', 'even', 'better', 'The', 'ushers', 'told', 'them', 'to', 'get', 'down.', 'Sara', 'understood', 'that', 'others', 'could', 'not', 'see', 'the', 'stage.'], ['edited_ending:', 'They', 'rented', 'bikes', 'and', 'rode', 'through', 'the', 'town', 'until', 'they', 'got', 'to', 'a', 'steep', 'road.', 'The', 'small', 'bikes', 'would', 'not', 'go', 'up', 'the', 'hill', 'so', 'they', 'backed', 'down.', 'They', 'returned', 'the', 'bikes', 'to', 'the', 'agency', 'and', 'took', 'the', 'cab', 'to', 'the', 'beach.'], ['edited_ending:', 'Justin', 'started', 'to', 'smile.', 'Abby', 'hugged', 'him.', 'Abby', 'put', 'his', 'hand', 'in', 'hers.'], ['edited_ending:', 'I', 'had', 'never', 'ridden', 'before', 'but', 'I', 'was', 'excited.', 'That', 'day,', 'Jen', 'was', 'so', 'happy,', 'up', 'on', 'her', 'horse.', 'I', 'smiled', 'as', 'I', 'rode', 'next', 'to', 'her.'], ['edited_ending:', 'Hidden', 'in', 'the', 'branches', 'was', 'a', 'large', 'beehive.', 'The', 'beehive', 'crashed', 'onto', 'the', 'ground.', 'Suddenly', 'hundreds', 'of', 'bees', 'flew', 'out', 'and', 'stung', 'him', 'all', 'over', 'his', 'body!'], ['edited_ending:', 'Suddenly', 'a', 'flock', 'of', 'birds', 'flew', 'over', 'his', 'house.', 'Luckily,', 'the', 'hamburgers', 'were', 'safe', 'from', 'bird', 'droppings.', 'Fred,', 'vindicated,', 'grilled', 'hamburgers', 'for', 'everyone.'], ['edited_ending:', 'He', 'trained', 'and', 'trained', 'and', 'passed', 'all', 'of', 'his', 'tests', 'to', 'be', 'a', 'firefighter.', 'He', 'was', 'extremely', 'nervous', 'the', 'entire', 'time.', 'When', 'he', 'graduated', 'he', 'was', 'very', 'proud', 'of', 'himself', 'and', 'his', 'family', 'was', 'too.'], ['edited_ending:', 'The', 'supplies', 'stayed', 'fresh.', 'The', 'next', 'owner', 'found', 'them.', 'The', 'next', 'owner', 'kept', 'it.'], ['edited_ending:', 'The', 'boss', 'was', 'annoyed', 'with', 'his', 'lack', 'of', 'progress.', 'The', 'boss', 'requested', 'a', 'pay', 'decrease', 'for', 'the', 'man.', 'The', 'pay', 'decrease', 'request', 'was', 'denied.'], ['edited_ending:', 'So', 'he', 'stole', 'the', 'paint', 'and', 'brushes', 'and', 'started', 'to', 'draw', 'paintings', 'of', 'still', 'life.', 'He', 'eventually', 'became', 'good', 'at', 'painting.', 'He', 'sold', 'his', 'work', 'for', 'thousands', 'of', 'dollars.'], ['edited_ending:', 'She', 'figured', 'then', 'it', 'would', 'be', 'best', 'to', 'ask', 'her', 'doctor.', 'Her', 'doctor', 'told', 'her', 'it', 'could', 'be', 'signs', 'of', 'depression', 'or', 'anxiety.', 'Kathy', 'decided', 'to', 'seek', 'therapy', 'and', 'began', 'to', 'sleep', 'at', 'night', 'again.'], ['edited_ending:', 'Susan', 'was', 'several', 'years', 'older', 'than', 'Robbie.', 'She', 'always', 'flirted', 'with', 'strange', 'men.', 'Robbie', 'was', 'crushed', 'when', 'Susan', 'admitted', 'that', 'she', 'found', 'him', 'ugly.'], ['edited_ending:', 'When', 'she', 'woke', 'up,', 'it', 'was', 'raining', 'so', 'Marjorie', 'put', 'on', 'her', 'hat', 'after', 'straightening', 'her', 'hair.', 'As', 'soon', 'as', 'she', 'arrived', 'at', 'work,', 'she', 'took', 'her', 'hat', 'off.', 'She', 'went', 'to', 'the', 'bathroom', 'to', 'try', 'to', 'straighten', 'her', 'hair', 'again.'], ['edited_ending:', 'The', 'police', 'takes', 'a', 'look', 'at', 'his', 'truck.', 'There', 'is', 'a', 'flat', 'tire.', 'They', 'call', 'a', 'towing', 'service', 'to', 'come', 'get', 'the', 'truck.'], ['edited_ending:', 'He', 'tried', 'to', 'buy', 'a', 'house', 'at', 'auction', 'for', 'half', 'its', 'value.', 'Randy', 'lost', 'the', 'bid.', 'He', 'heard', 'the', 'house', 'was', 'sold', 'for', 'a', 'huge', 'profit.'], ['edited_ending:', 'A', 'man', 'came', 'to', 'her', 'door', 'and', 'pointed', 'to', 'her', 'earphones', 'which', 'had', 'fallen', 'on', 'the', 'ground', 'in', 'front', 'of', 'her', 'house.', 'She', 'bent', 'down', 'to', 'retrieve', 'them', 'but', 'hit', 'her', 'head', 'on', 'the', \"man's\", 'head.', 'When', 'she', 'looked', 'up,', 'she', 'felt', 'her', 'heartbeat', 'and', 'smiled', 'to', 'him.'], ['edited_ending:', 'I', 'tried', 'to', 'teach', 'him', 'my', 'name.', 'I', 'hope', 'someday', 'he', 'would', 'say', 'my', 'name', 'when', 'I', 'walked', 'in.', 'I', 'would', 'say', 'hello,', 'and', 'he', \"wouldn't\", 'say', 'anything.'], ['edited_ending:', 'He', 'paid', 'for', 'it', 'and', 'drove', 'to', 'pick', 'it', 'up', 'right', 'away.', 'He', 'paid', 'for', 'it', 'and', 'drove', 'to', 'pick', 'it', 'up', 'right', 'away.', 'Jimmy', 'rushed', 'it', 'back', 'and', 'exchanged', 'the', 'camera', 'locally.'], ['edited_ending:', 'A', 'store', 'clerk', 'gave', 'me', 'some', 'cash', 'and', 'let', 'me', 'sit', 'outside.', 'The', 'clerk', 'emptied', 'the', 'cash', 'drawer', 'into', 'my', 'bag.', 'I', 'was', 'able', 'to', 'pay', 'my', 'rent', 'but', 'the', 'store', 'clerk', 'was', 'fired.'], ['edited_ending:', 'He', 'was', 'very', 'happy', 'with', 'my', 'decision.', 'I', 'went', 'ahead', 'and', 'converted', 'to', 'his', 'religion.', 'We', 'study', 'this', 'religion', 'every', 'chance', 'we', 'get.'], ['edited_ending:', 'Irene', 'took', 'the', 'class', 'before', 'and', 'did', 'not', 'like', 'the', 'class', 'at', 'all!', 'She', 'decided', 'it', 'was', 'okay', 'to', 'be', 'different', 'than', 'Cammy.', 'Cammy', 'could', 'be', 'the', 'family', 'dancer', '-', 'not', 'Irene!'], ['edited_ending:', 'She', 'played', 'a', 'practice', 'game', 'with', 'the', 'other', 'tryout', 'people.', 'Her', 'team', 'lost', 'the', 'game.', 'Julie', 'is', 'off', 'the', 'basketball', 'team', 'now.'], ['edited_ending:', 'It', 'was', 'very', 'difficult', 'at', 'first.', 'Carlos', 'eventually', 'learned', 'more', 'and', 'more', 'words', 'in', 'Spanish.', 'He', 'was', 'happy', 'to', 'be', 'learning', 'a', 'new', 'language.'], ['edited_ending:', 'Luke', 'noticed', 'a', 'man', 'in', 'the', 'building', 'had', 'attacked', 'someone.', 'Luke', \"didn't\", 'like', 'that', 'so', 'he', 'knocked', 'the', 'man', 'down.', 'He', 'noticed', 'his', 'friend', 'come', 'out', 'of', 'the', 'building', 'and', 'told', 'him', 'to', 'call', 'the', 'police.'], ['edited_ending:', 'They', 'thought', 'it', 'would', 'be', 'fun', 'to', 'see', 'how', 'much', 'popcorn', 'they', 'could', 'eat.', 'They', 'spent', 'the', 'whole', 'movie', 'drinking', 'soda', 'and', 'eating', 'popcorn.', 'The', 'next', 'morning', 'they', 'had', 'terrible', 'stomach', 'aches.'], ['edited_ending:', 'Shari', 'tried', 'to', 'take', 'the', 'children', 'to', 'fun', 'events', 'with', 'Jay.', 'But', 'Jay', 'was', 'one', 'step', 'ahead', 'of', 'her', 'and', 'already', 'brought', 'them', 'to', 'a', 'movie.', 'They', 'went', 'to', 'the', 'park', 'and', 'Jay', 'won', 'a', 'football', 'game', 'against', 'both', 'children.'], ['edited_ending:', 'So', 'he', 'calls', 'everyone', 'he', 'knows', 'to', 'see', 'if', 'anyone', 'wants', 'to', 'play.', 'Most', 'times', 'no', 'one', 'wants', 'to', 'play', 'with', 'him.', 'But', 'that', \"doesn't\", 'stop', 'Zyah', 'from', 'calling', 'every', '30', 'minutes'], ['edited_ending:', 'The', 'surgeon', 'smiled', 'and', 'said', 'he', \"wouldn't\", 'do', 'a', 'lot.', 'But', 'Fiona', 'was', 'firm', 'and', 'hold', 'her', 'ground.', 'After', 'the', 'surgery,', 'she', 'looked', 'different,', 'but', 'she', 'liked', 'it.'], ['edited_ending:', 'Mia', 'joined', 'him', 'and', 'smiled', 'while', 'gently', 'touching', 'his', 'muscle.', 'Their', 'weekly', 'challenge', 'would', 'have', 'to', 'wait,', 'he', 'thought,', 'as', 'she', 'helped', 'him', 'to', 'the', 'locker', 'room.', 'He', 'dressed', 'and', 'Mia', 'took', 'him', 'to', 'the', 'doctor.'], ['edited_ending:', 'Her', 'mother', 'felt', 'sorry', 'for', 'her.', 'One', 'day,', 'her', 'mom', 'noticed', 'her', 'shoelaces', 'were', 'untied.', 'She', 'quickly', 'tied', 'her', 'shoes', 'so', 'it', \"wouldn't\", 'cause', 'any', 'danger.'], ['edited_ending:', 'His', 'phone', 'stayed', 'quiet', 'as', 'they', 'talked.', 'Jim', 'found', 'it', 'incredibly', 'awkward.', 'He', 'made', 'an', 'effort', 'to', 'get', 'off', 'the', 'phone', 'as', 'quickly', 'as', 'possible.'], ['edited_ending:', 'She', 'practiced', 'everyday', 'for', 'hours', 'after', 'school', 'Eventually', 'she', 'realized', 'it', \"wasn't\", 'helping', 'and', \"she'd\", 'never', 'be', 'good.', 'Jill', 'gave', 'up', 'on', 'her', 'music', 'dream'], ['edited_ending:', 'She', 'always', 'wanted', 'a', 'sweet', 'sixteen', 'party', 'like', 'the', 'celebrities', 'have.', 'She', 'felt', 'the', 'ship', 'had', 'sailed,', 'but', 'she', \"didn't\", 'care', 'much.', 'Her', 'friends', 'threw', 'her', 'a', 'surprise', 'sweet', '16', 'themed', 'party.'], ['edited_ending:', 'Misty', 'took', 'her', 'time', 'making', 'the', 'drink', 'beautiful.', 'The', 'customer', 'appreciated', 'the', 'extra', 'care', 'taken.', 'The', 'customer', 'tipped', 'Misty', 'dollars.'], ['edited_ending:', 'A', 'couple', 'of', 'months', 'later,', 'I', 'read', 'that', 'it', 'was', 'a', 'Ponzi', 'scheme.', 'I', 'was', 'glad', 'I', \"hadn't\", 'invest', 'money', 'in', 'it.', 'The', 'person', 'running', 'the', 'company', 'went', 'to', 'prison.'], ['edited_ending:', 'He', 'bought', 'a', 'pocket', 'protector,', 'hair', 'grease,', 'and', 'a', 'pack', 'of', 'MTG', 'cards.', 'Steffan', 'decided', 'he', 'was', 'going', 'to', 'become', 'a', 'dungeon', 'master.', 'First', 'campaign', 'made', 'him', 'quickly', 'realize', 'he', 'was', 'bad', 'being', 'a', 'dungeon', 'master.'], ['edited_ending:', 'I', 'tried', 'to', 'take', 'a', 'photo', 'in', 'the', 'photobooth.', 'I', 'tried', 'so', 'many', 'times', 'but', 'I', 'never', 'did', 'get', 'a', 'photo.', 'I', 'hope', 'I', 'can', 'get', 'a', 'photo', 'the', 'next', 'time', 'I', 'go.'], ['edited_ending:', 'A', 'rescue', 'group', 'tried', 'to', 'help', 'her', 'but', 'she', 'ran', 'away.', 'If', 'they', 'could', 'have', 'caught', 'her,', 'they', 'might', 'have', 'made', 'her', 'better.', 'Maybe', 'she', 'would', 'have', 'had', 'a', 'haircut', 'and', 'a', 'new', 'home.'], ['edited_ending:', 'The', 'store', 'was', 'out', 'of', 'cakes', 'so', 'she', 'gathered', 'all', 'of', 'the', 'ingredients', 'on', 'the', 'counter.', 'Then', 'she', 'realized', 'she', 'had', 'no', 'idea', 'how', 'to', 'make', 'a', 'cake', 'from', 'scratch.', 'She', 'decided', 'to', 'go', 'online', 'to', 'find', 'a', 'recipe.'], ['edited_ending:', 'Katie', 'was', 'going', 'to', 'pick', 'out', 'which', 'park', 'to', 'go', 'to.', 'She', 'decided', 'to', 'go', 'to', 'Smith', 'Park,', 'looking', 'for', 'the', 'basketball', 'hoop.', 'Katie', 'brought', 'a', 'basketball', 'and', 'had', 'a', 'great', 'birthday!'], ['edited_ending:', 'He', 'was', 'really', 'nervous', 'about', 'playing.', 'He', 'made', 'sure', 'to', 'get', 'a', 'good', \"night's\", 'sleep', 'before', 'the', 'game.', 'Peter', 'was', 'surprised', 'and', 'played', 'well', 'in', 'the', 'game.'], ['edited_ending:', \"Linda's\", 'first', 'assignment', 'was', 'to', 'photograph', 'a', 'local', 'celebrity.', 'She', 'took', 'his', 'picture', 'by', 'bushes,', 'standing', 'in', 'concrete', 'and', 'off', 'the', 'curb.', 'Linda', 'was', 'shocked', 'and', 'when', 'the', 'editor', 'fired', 'her,', 'and', \"didn't\", 'like', 'her', 'photos.'], ['edited_ending:', 'He', 'had', 'heard', 'a', 'loud', 'crack', 'and', 'had', 'looked', 'up.', 'There', 'it', 'was', 'now,', 'coming', 'right', 'at', 'him.', 'He', 'held', 'his', 'arm', 'up', 'high', 'and', 'caught', 'it!'], ['edited_ending:', 'Suddenly,', 'Ellie', 'heard', 'a', 'loud', 'ringing', 'noise.', 'Ellie', 'had', 'won', 'five', 'thousand', 'dollars!', 'Ellie', 'was', 'excited', 'to', 'tell', 'Joe', 'as', 'he', 'returned.'], ['edited_ending:', 'He', 'finds', 'a', 'new', 'job', 'to', 'help', 'him', 'earn', 'money.', 'After', 'a', 'few', 'months', 'of', 'working,', 'Ben', 'saves', 'enough', 'for', 'the', 'perfect', 'home.', 'Bes', 'is', 'able', 'to', 'buy', 'his', 'dream', 'home.'], ['edited_ending:', 'While', 'waiting,', 'they', 'saw', 'a', 'rat.', 'Reece', 'screamed.', 'She', 'was', 'terrified.'], ['edited_ending:', 'Chris', 'was', 'trying', 'to', 'find', 'higher', 'end', 'boots.', 'After', 'hours,', 'he', \"couldn't\", 'find', 'a', 'thing', 'they', 'wanted.', 'He', 'decided', 'to', 'go', 'home', 'to', 'shop', 'online.'], ['edited_ending:', 'He', \"didn't\", 'dare', 'turn', 'on', 'the', 'television', 'and', 'the', 'air', 'conditioner.', 'He', 'knew', 'if', 'he', 'did,', 'a', 'fuse', 'would', 'blow', 'out', 'in', 'the', 'generator.', 'And', 'he', 'would', 'have', 'to', 'sit', 'in', 'the', 'silence', 'without', 'a', 'working', 'fridge.'], ['edited_ending:', 'Ida', 'called', 'her', 'husband.', \"Ida's\", 'husband', 'was', 'proud', 'of', 'her', 'hard', 'work,', \"Ida's\", 'husband', 'presented', 'Ida', 'with', 'a', 'beautiful', 'bouquet', 'of', 'flowers', 'two', 'hours', 'later.'], ['edited_ending:', 'She', 'asked', 'her', 'friend', 'to', 'switch', 'work', 'shifts', 'with', 'her.', 'This', 'gave', 'Sally', 'time', 'to', 'study.', 'To', 'her', 'surprise,', 'Sally', 'ended', 'up', 'passing', 'the', 'test', 'and', 'even', 'got', 'an', 'A.'], ['edited_ending:', 'She', 'called', 'the', 'dogs', 'back', 'inside', 'before', 'they', 'killed', 'each', 'other.', 'Once', 'inside,', 'the', 'dogs', 'saw', 'a', 'groundhog', 'and', 'started', 'barking.', 'The', 'little', 'groundhog', 'ran', 'under', 'the', 'fence', 'to', 'the', \"neighbor's\", 'yard.'], ['edited_ending:', 'Finally', 'she', 'screamed', 'for', 'help.', 'All', 'of', 'the', 'sudden,', 'it', 'broke', 'off.', 'They', 'had', 'to', 'wait', 'an', 'hour', 'to', 'be', 'rescued.'], ['edited_ending:', \"That's\", 'why', 'he', \"didn't\", 'like', 'his', \"neighbor's\", 'dog', 'who', 'peed', 'on', 'the', 'fence.', 'He', 'booed', 'him', 'away', 'and', \"didn't\", 'often', 'succeed', 'Until', 'he', 'gave', 'him', 'food', 'and', 'kept', 'him', 'at', 'bay'], ['edited_ending:', 'I', 'stayed', 'and', 'studied', 'even', 'though', 'I', 'really', 'wanted', 'to', 'go', 'with', 'them', 'instead.', 'I', 'got', 'a', 'perfect', 'grade', 'on', 'my', 'test.', \"I'm\", 'glad', 'I', 'stayed', 'in', 'and', 'studied.'], ['edited_ending:', 'He', 'discovered', 'his', 'PC', \"couldn't\", 'handle', 'the', \"game's\", 'advanced', 'graphics.', 'He', 'decided', 'he', \"didn't\", 'need', 'a', 'new', 'graphics', 'card', 'for', 'a', 'game', 'that', \"wasn't\", 'that', 'good.', 'He', 'installed', 'another', 'new', 'game', 'instead', 'that', 'played', 'beautifully.'], ['edited_ending:', 'Last', 'Sunday', 'Elisa', 'dressed', 'up', 'in', 'a', 'pretty', 'sundress,', 'gloves', 'and', 'a', 'elegant', 'hat.', 'One', 'guy', 'stared', 'at', 'her', 'while', 'they', 'were', 'singing', 'choir', 'songs.', \"Elisa's\", 'lyrics', 'pages', 'were', 'torn', 'and', 'the', 'guy', 'brought', 'her', 'another', 'one.'], ['edited_ending:', 'Sara', 'really', 'wanted', 'a', 'thermos', 'instead.', 'Therefore,', 'she', 'bought', 'an', 'inexpensive', 'one.', 'Her', 'drink', 'stayed', 'cold', 'all', 'day', 'long', 'like', 'everyone', \"else's.\"], ['edited_ending:', 'He', 'told', 'Stef', 'how', 'to', 'spot', 'a', 'fake', 'check.', 'Stef', \"didn't\", 'know', 'what', 'to', 'do', 'but', 'she', 'awkwardly', 'thanked', 'him.', 'She', 'left', 'and', 'went', 'straight', 'home', 'to', 'cry.'], ['edited_ending:', 'Dan', 'listened', 'with', 'his', 'daughter,', 'and', 'she', 'loved', 'it.', 'She', 'loved', 'the', 'audiobook', 'so', 'much,', 'Dan', 'listened', 'to', 'the', 'audiobook', 'another', 'two', 'times.', 'Dan', 'loved', 'the', 'fact', 'that', 'his', 'daughter', 'loved', 'the', 'audiobook', 'he', 'bought.'], ['edited_ending:', 'One', 'day', 'she', 'lost', 'the', 'safebox.', 'Laura', 'cried', 'and', 'cried', 'when', 'she', 'realized', 'it', 'was', 'not', 'in', 'her', 'room.', 'The', 'next', 'day,', 'the', 'safebox', 'was', 'found', 'and', 'returned', 'safely', 'to', 'her.'], ['edited_ending:', 'They', 'sent', 'her', 'to', 'culinary', 'camp', 'at', 'age', 'eleven.', 'There,', 'Anna', 'learned', 'all', 'kinds', 'of', 'cooking', 'techniques.', 'She', 'came', 'home', 'with', 'more', 'skills', 'than', 'they', 'expected', 'and', 'they', 'were', 'impressed.'], ['edited_ending:', 'He', 'never', 'got', 'up', 'and', 'hit', 'on', 'them', 'like', 'he', 'used', 'to.', 'Eventually', 'he', 'got', 'drunk', 'with', 'his', 'friends.', 'He', 'avoided', 'the', 'girls', 'as', 'planned', 'and', 'still', 'had', 'fun.'], ['edited_ending:', 'Jason', 'sits', 'on', 'the', 'sand', 'and', 'enjoys', 'the', 'sea', 'breeze.', 'Afterwards', 'he', 'feels', 'less', 'bored.', 'Jason', 'is', 'glad', 'he', 'went', 'to', 'the', 'beach.'], ['edited_ending:', 'She', 'worked', 'every', 'and', 'was', 'too', 'busy', 'to', 'attend.', 'Julia', 'bought', 'a', 'new', 'party', 'dress', 'for', 'herself,', 'instead.', 'Wherever', 'she', 'went', 'in', 'it,', 'she', 'was', 'a', 'knockout,', 'and', 'turned', 'many', 'heads.'], ['edited_ending:', 'I', 'spent', 'the', 'weekends', 'catching', 'fly', 'balls', 'with', 'my', 'dad.', 'All', 'that', 'practice', 'really', 'helped', 'me', 'out.', 'I', 'feel', 'like', 'I', 'had', 'developed', 'into', 'a', 'great', 'right', 'fielder.'], ['edited_ending:', 'He', 'decided', 'to', 'work', 'with', 'his', 'physical', 'therapist.', 'He', 'ended', 'up', 'healing', 'in', 'time', 'to', 'win', 'the', 'competition.', 'Unfortunately,', 'his', 'doctor', 'told', 'him', 'he', 'should', 'never', 'play', 'again.'], ['edited_ending:', 'It', 'filled', 'the', 'buckets', 'for', 'us', 'to', 'feed', 'to', 'the', 'animals.', 'We', 'drove', 'through', 'the', 'safari', 'feeding', 'all', 'of', 'the', 'exotic', 'animals.', 'The', 'ostriches', 'snapped', 'and', 'bit', 'my', 'fingers.'], ['edited_ending:', 'He', 'was', 'shocked', 'it', 'was', 'ready', 'so', 'quickly.', 'He', 'handed', 'her', 'the', 'payment.', 'He', 'ate', 'his', 'ice', 'cream.'], ['edited_ending:', 'He', 'went', 'to', 'a', 'new', 'salon.', 'The', 'stylist', 'made', 'a', 'mistake', 'and', 'cut', 'his', 'hair', 'much', 'too', 'short.', 'He', 'sighed', 'and', 'asked', 'for', 'his', 'money', 'back.'], ['edited_ending:', 'Jane', 'searches', 'on', 'the', 'dealership', 'site', 'to', 'see', 'what', 'they', 'have.', 'Jane', 'has', 'an', 'online', 'chat', 'with', 'a', 'very', 'nice', 'salesman.', 'He', 'sells', 'Jane', 'a', 'brand', 'new', 'Car', 'and', 'Jane', 'totally', 'loves', 'it.'], ['edited_ending:', 'On', 'the', 'way', 'to', 'the', 'house', 'she', 'dropped', 'the', 'peppers.', 'She', 'made', 'a', 'salad', 'with', 'no', 'peppers.', 'Her', 'guests', \"didn't\", 'suspect', 'a', 'thing.'], ['edited_ending:', 'After', 'he', 'saw', 'the', 'price,', 'he', 'was', 'so', 'annoyed.', 'Then,', 'Tim', 'got', 'into', 'a', 'huge', 'car', 'crash.', 'Tim', 'was', 'so', 'glad', 'he', 'had', 'insurance.'], ['edited_ending:', 'And', 'he', 'always', 'got', 'in', 'trouble', 'in', 'school.', 'He', 'was', 'told', 'by', 'the', 'school', 'that', 'bad', 'kids', \"don't\", 'get', 'presents.', \"Mike's\", 'parents', 'did', 'get', 'him', 'presents', 'that', 'year.'], ['edited_ending:', 'This', 'time,', 'his', 'girlfriend', 'decided', 'to', 'make', 'them', 'herself.', 'She', 'was', 'trying', 'to', 'shape', 'them', 'but', 'they', \"wouldn't\", 'stay', 'together.', 'Alex', 'gave', 'her', 'some', 'tips.'], ['edited_ending:', 'He', 'gets', 'to', 'the', 'airport', 'and', 'through', 'security', 'rather', 'quickly.', 'He', 'strolls', 'to', 'the', 'gate', 'and', 'is', 'very', 'early.', 'John', 'relaxes', 'for', 'an', 'hour', 'before', 'it', 'is', 'time', 'to', 'board', 'his', 'plane.'], ['edited_ending:', 'The', 'move', 'had', 'exstinguished', 'her', 'smile.', 'She', 'opened', 'the', 'door', 'to', 'see', 'her', 'old,', 'tiny,', 'overpriced', 'apartment.', 'She', 'wondered', 'if', 'it', 'was', 'worth', 'it.'], ['edited_ending:', 'Her', 'yard', 'was', 'covered', 'in', 'mud.', 'Kelley', 'walked', 'through', 'it', 'on', 'her', 'way', 'back', 'from', 'the', 'mailbox.', 'She', 'got', 'stuck.'], ['edited_ending:', 'That', 'one', 'had', 'a', 'clue', 'to', 'the', 'kitchen', 'so', 'they', 'went', 'there.', 'The', 'parents', 'said', 'that', 'was', 'it', 'so', 'they', 'ended', 'the', 'egg', 'hunt.', 'They', 'gave', 'the', 'kids', 'their', 'basket', 'of', 'candy', 'for', 'Easter.'], ['edited_ending:', 'He', 'decided', 'to', 'attend', 'culinary', 'school', 'after', 'high', 'school.', 'Ethan', 'graduated', 'at', 'the', 'top', 'of', 'his', 'class', 'at', 'his', \"mother's\", 'surprise.', 'He', 'is', 'now', 'the', 'chef', 'at', 'a', 'popular', 'restaurant', 'in', 'the', 'city.'], ['edited_ending:', 'People', 'were', 'standing', 'around', 'it', 'They', 'were', 'talking', 'about', 'how', 'creative', 'and', 'big', 'it', 'was.before', 'it', 'fell.', 'Joy', 'and', 'Robbie', 'felt', 'very', 'sad', 'about', 'their', 'creation.'], ['edited_ending:', 'She', 'decided', 'to', 'brush', 'up', 'on', 'her', 'political', 'knowledge', 'online.', 'She', 'read', 'many', 'news', 'articles', 'after', 'she', 'missed', 'the', 'election.', 'She', 'voted', 'on', 'the', 'next', 'election', 'day', 'and', 'felt', 'good', 'about', 'her', 'choice.'], ['edited_ending:', 'Dogs', 'were', 'expensive', 'so', 'he', 'decided', 'to', 'rescue', 'one.', 'Oswald', 'was', 'happy', 'to', 'get', 'his', 'new', 'puppy', 'Oswald', 'decided', 'you', 'should', 'never', 'buy', 'a', 'dog.'], ['edited_ending:', 'But', 'Dan', 'knew', 'he', 'was', 'expected', 'to', 'speak,', 'and', 'he', 'prepared', 'a', 'speech', 'about', 'his', 'experience', 'with', 'the', 'company.', 'In', 'addition,', 'Dan', 'talked', 'about', 'his', 'relationship', 'with', 'his', 'co', 'workers.', 'After', 'writing,', 'Dan', 'felt', 'confident', 'about', 'his', 'acceptance', 'speech.'], ['edited_ending:', 'Not', 'paying', 'attention,', 'five', 'minutes', 'later', 'he', 'did', 'cut', 'his', 'finger', 'and', 'the', 'manager', 'sent', 'Peter', 'to', 'get', 'medical', 'help.', 'Peter', 'saw', 'a', 'doctor', 'who', 'tended', 'to', \"Peter's\", 'wound.', 'Peter', 'was', 'back', 'to', 'work', 'within', 'a', 'few', 'days.'], ['edited_ending:', 'His', 'son', 'grew', 'up', 'to', 'be', 'much', 'slower', 'than', 'him.', 'When', 'he', 'finally', 'raced', 'his', 'son,', 'he', 'easily', 'won.', 'He', 'felt', 'awful', 'in', 'the', 'end.'], ['edited_ending:', 'He', 'snored', 'into', 'his', 'pillow', 'and', 'got', 'snot', 'all', 'over', 'it.', 'He', 'cuddled', 'his', 'pillow', 'close,', 'wanting', 'lots', 'of', 'attention.', 'He', 'also', 'tried', 'to', 'wake', 'me', 'up', 'the', 'next', 'morning.'], ['edited_ending:', 'Irene', 'could', 'not', 'sit', 'still', 'for', 'the', 'lecture.', 'The', 'doctor', 'was', 'patient.', 'Eventually', 'the', 'doctor', 'made', 'her', 'understand', 'what', 'she', 'needed.'], ['edited_ending:', 'Denise', 'asked', 'if', 'ducks', 'were', 'birds.', \"Denise's\", 'boyfriend', 'could', 'not', 'believe', 'she', 'had', 'asked', 'that', 'question.', 'Denise', 'immediately', 'knew', 'she', 'was', 'having', 'a', 'blonde', 'moment.'], ['edited_ending:', 'She', 'sold', 'copies', 'to', 'her', 'classmates.', 'The', 'notes', 'helped', 'everybody', 'learned.', 'The', 'whole', 'class', 'got', 'good', 'grades.'], ['edited_ending:', 'He', 'wished', 'he', 'had', 'practiced', 'the', 'harp', 'to', 'be', 'good', 'at', 'it.', 'There', 'was', 'a', 'harp', 'audition', 'for', 'the', 'local', 'symphony.', 'The', 'judges', 'might', 'have', 'been', 'very', 'impressed', 'if', 'Quincy', 'had', 'tried.'], ['edited_ending:', 'It', \"didn't\", 'change', 'when', 'they', 'went', 'on', 'their', 'overnight', 'camping', 'trip.', 'Harper', 'explained', 'he', 'needed', 'no', 'compass', 'and', 'hiked', 'alone', 'without', 'it.', 'They', 'found', 'him', 'hours', 'later,', 'crying', 'and', 'embarrassed', 'under', 'a', 'tree.'], ['edited_ending:', 'He', 'realized', 'all', 'the', 'time', 'spent', 'working', 'out,', 'he', \"wasn't\", 'eating.', 'He', 'was', 'also', 'up', 'running', 'around', 'when', 'he', 'exercised.', 'He', 'lost', 'thirty', 'pounds', 'by', 'following', 'his', 'own', 'diet.'], ['edited_ending:', 'They', 'sold', 'wine', 'and', 'fruit', 'cakes', 'locally,', 'so', 'I', 'purchased', 'a', 'cake', 'because', 'I', 'felt', 'bad', 'for', 'not', 'fixing', 'the', 'computer.', 'It', 'was', 'the', 'most', 'delicious', 'cake', \"I'd\", 'ever', 'had,', 'and', 'I', 'hate', 'fruit', 'cake.', 'I', 'realized', 'that', 'day', 'that', 'commercial', 'fruit', 'cakes', 'are', 'not', 'the', 'real', 'thing.'], ['edited_ending:', 'After', 'pondering', 'for', 'a', 'few', 'days', 'she', 'chose', 'the', 'banjo', 'but', 'at', 'first', 'it', 'was', 'difficult.', 'Over', 'time', 'she', 'improved.', 'Freda', 'was', 'happy', 'that', 'she', 'was', 'playing', 'a', 'musical', 'instrument.'], ['edited_ending:', 'Suddenly,', 'he', 'heard', 'a', 'noise.', 'It', 'was', 'someone', 'whistling', 'and', 'they', 'were', 'getting', 'closer.', 'Jack', 'ran', 'to', 'see', 'who', 'it', 'was.'], ['edited_ending:', 'He', 'had', 'wanted', 'the', 'debut', 'to', 'be', 'perfect.', 'When', 'it', 'was', 'time', 'for', 'the', 'showing,', 'Daniel', 'was', 'not', 'there', 'to', 'introduce', 'the', 'movie.', 'After', 'it', \"didn't\", 'show,', 'the', 'audience', 'had', 'a', 'lot', 'of', 'questions', 'about', 'it.'], ['edited_ending:', 'When', 'I', 'woke', 'up,', 'I', 'became', 'very', 'sick,', 'vomiting', 'and', 'staying', 'in', 'bed', 'for', 'days.', 'It', 'took', 'over', 'a', 'week', 'to', 'feel', 'better.', 'By', 'the', 'time', 'it', 'was', 'over,', 'I', 'could', 'no', 'longer', 'stand', 'the', 'sight', 'of', 'pizza.'], ['edited_ending:', 'She', 'went', 'to', 'watch', 'nature', 'while', 'there.', 'She', 'watched', 'a', 'deer', 'for', 'a', 'long', 'time.', 'After', 'a', 'while', 'she', 'went', 'inside', 'because', 'she', 'was', 'hungry.'], ['edited_ending:', 'I', 'worked', 'right', 'through', 'my', 'lunch', 'break.', 'When', 'I', 'realized', 'that,', 'I', 'was', 'so', 'hungry', 'I', 'thought', 'I', \"couldn't\", 'work', 'anymore.', 'But', 'when', 'my', 'boss', 'asked', 'me', 'to', 'take', 'a', 'break', 'and', 'I', 'said', 'no.'], ['edited_ending:', 'Emily', 'went', 'to', 'the', 'kitchen.', 'She', 'got', 'a', 'mug.', 'She', 'filled', 'the', 'mug', 'with', 'coffee.'], ['edited_ending:', 'Her', 'neighbor,', 'who', 'knew', 'this,', 'liked', 'to', 'tease', 'her.', 'He', 'shined', 'a', 'flashlight', 'outside', 'her', 'window', 'in', 'the', 'middle', 'of', 'the', 'night.', 'And', 'every', 'time', 'Suzanne', 'would', 'scream', 'and', 'be', 'afraid', 'even', 'more.'], ['edited_ending:', 'She', 'got', 'on', 'Apple', 'chat', 'tech', 'support', 'when', 'her', 'iPad', \"wasn't\", 'getting', 'the', 'photos.', 'They', 'were', 'unable', 'to', 'help', 'her.', 'We', 'finally', 'found', 'out', 'that', 'it', 'was', 'our', 'internet', 'that', 'was', 'not', 'working', 'well.'], ['edited_ending:', 'He', 'decided', 'he', 'could', 'play', 'better', 'than', 'them,', 'and', 'learned', 'to', 'play', 'the', 'drums.', 'He', 'took', 'lessons', 'and', 'practiced', 'often.', 'He', 'soon', 'became', 'a', 'drummer', 'in', 'a', 'local', 'band.'], ['edited_ending:', 'To', 'her', 'surprise', 'however,', 'on', \"Tamar's\", 'turn', 'the', 'machine', 'was', 'broken.', 'She', 'looked', 'down', 'and', \"couldn't\", 'see', 'the', 'words', 'to', 'the', 'song.', 'Tamar', 'quickly', 'had', 'to', 'leave', 'the', 'stage.'], ['edited_ending:', 'She', 'got', 'home', 'from', 'work', 'and', 'notice', 'a', 'particularly', 'horrible', 'odor.', 'She', 'could', 'not', 'figure', 'out', 'what', 'it', 'was.', 'The', 'dumpster', 'had', 'not', 'been', 'emptied', 'for', 'a', 'whole', 'month.'], ['edited_ending:', 'The', 'regular', 'customers', 'loved', 'the', 'changes.', 'They', 'always', 'wanted', 'a', 'local', 'bar.', 'Business', 'was', 'better', 'than', 'ever'], ['edited_ending:', 'Near', 'a', 'boat,', 'we', 'saw', 'jellyfish.', 'It', 'was', 'amazing.', 'I', 'made', 'sure', 'to', 'take', 'a', 'photo.'], ['edited_ending:', 'She', 'poured', 'all', 'the', 'ingredients', 'in', 'the', 'blender.', 'She', 'pushed', 'the', 'button', 'and', 'waited.', 'As', 'she', \"didn't\", 'use', 'a', 'recipe,', 'she', 'used', 'too', 'much', 'milk.'], ['edited_ending:', 'Lana', 'looked', 'for', 'the', 'chicken.', 'She', 'was', 'frustrated', 'she', 'had', 'thrown', 'the', 'money', 'away.', 'She', 'resolved', 'her', 'dog', 'had', 'eaten', 'the', 'chicken.'], ['edited_ending:', 'Ronald', 'patiently', 'explained', 'things', 'to', 'each', 'person', 'until', 'they', 'were', 'pleased.', 'The', 'next', 'day,', 'his', 'boss', 'called', 'him', 'into', 'his', 'office.', 'His', 'boss', 'praised', 'him', 'for', 'the', 'things', 'he', 'said', 'on', 'Twitter.'], ['edited_ending:', 'So', 'they', 'called', 'an', 'exterminator', 'and', 'he', 'came', 'out', 'to', 'take', 'a', 'look', 'at', 'the', 'nest.', 'It', 'ends', 'up', 'being', 'their', 'was', 'a', 'nest', 'and', 'they', 'had', 'hibernated.', 'The', 'exterminators', 'were', 'able', 'to', 'take', 'care', 'of', 'the', 'nest', 'immediately.'], ['edited_ending:', 'We', 'also', 'watch', 'the', 'big', 'sports', 'game', 'on', 'TV.', 'We', 'all', 'root', 'for', 'opposite', 'teams', 'though.', 'We', 'usually', 'get', 'into', 'a', 'big', 'argument', 'about', 'who', 'was', 'the', 'better', 'team.'], ['edited_ending:', 'My', 'mom', 'got', 'angry', 'with', 'me', 'She', 'looked', 'over', 'my', 'room', 'and', 'was', 'unhappy', 'with', 'the', 'work', 'I', 'did.', 'I', 'was', 'punished', 'from', 'being', 'able', 'to', 'go', 'outside', 'and', 'play', 'with', 'my', 'friends.'], ['edited_ending:', 'She', 'was', 'also', 'upset', 'by', 'the', 'expensive', 'prices.', 'She', \"didn't\", 'think', 'the', 'chocolate', 'there', 'would', 'be', 'worth', 'it.', 'She', 'bought', 'a', 'salad', 'for', '$11', 'and', 'instantly', 'felt', 'better.'], ['edited_ending:', 'He', 'got', 'a', 'temp', 'job', 'for', 'the', 'day.', 'Max', 'did', 'a', 'good', 'job', 'The', 'temp', 'agency', 'asked', 'Max', 'to', 'work', 'the', 'next', 'day', 'as', 'well'], ['edited_ending:', 'The', 'alarm', 'system', 'failed', 'to', 'detect', 'the', 'smoke.', 'It', 'was', 'supposed', 'to', 'trigger', 'a', 'response', 'to', 'release', 'the', 'sprinklers.', 'The', 'smoke', 'and', 'fire', 'would', 'then', 'be', 'eliminated.'], ['edited_ending:', 'I', 'bought', 'a', 'really', 'intense', 'energy', 'drink.', 'I', 'drank', 'it', 'all', 'and', 'end', 'up', 'not', 'sleeping', 'for', 'two', 'days', 'straight.', 'I', 'still', \"didn't\", 'get', 'all', 'of', 'the', 'work', 'done.'], ['edited_ending:', 'They', \"didn't\", 'have', 'a', 'lot', 'of', 'turkey', 'and', 'stuffing.', 'He', 'only', 'ate', '1', 'plate.', 'He', 'was', 'glad', 'he', \"didn't\", 'end', 'up', 'with', 'a', 'stomach', 'ache.'], ['edited_ending:', 'He', 'was', 'diagnosed', 'with', 'a', 'brain', 'injury', 'and', 'became', 'very', 'ill.', 'Deb', 'was', 'worried', 'and', 'knew', 'that', 'she', 'would', 'have', 'to', 'take', 'care', 'of', 'him.', 'Still,', 'she', 'would', 'never', 'leave', 'her', 'husband', 'because', 'of', 'the', 'stress', 'of', 'the', 'accident.'], ['edited_ending:', 'As', 'she', 'was', 'walking', 'off', 'the', 'court,', 'she', 'fainted.', 'Sandy', 'was', 'rushed', 'to', 'the', 'ER.', 'Sandy', 'was', 'extremely', 'dehydrated.'], ['edited_ending:', 'She', 'got', 'all', 'the', 'stuff', 'ready', 'to', 'be', 'shipped.', 'Many', 'people', 'bought', 'the', 'items.', 'She', 'made', 'a', 'thousand', 'at', 'the', 'end', 'of', 'the', 'week.'], ['edited_ending:', 'Kay', 'was', 'working', 'on', 'a', 'piece', 'to', 'perform', 'at', 'the', 'annual', 'recital.', 'She', 'learned', 'nothing', 'from', 'her', 'teacher.', 'She', 'was', 'totally', 'unprepared!'], ['edited_ending:', 'Ellie', \"didn't\", 'take', 'the', 'day', 'off', 'and', 'go', 'to', 'the', 'doctor.', 'The', 'doctor', 'would', 'have', 'told', 'Ellie', 'she', 'had', 'the', 'beginning', 'of', 'the', 'flu.', 'Ellie', 'would', 'have', 'had', 'to', 'miss', 'the', 'next', 'few', 'days', 'of', 'work.'], ['edited_ending:', 'He', 'carefully', 'planned', 'the', 'salad.', 'His', 'patrons', 'loved', 'the', 'new', 'dish.', 'The', 'fresh', 'salad', 'had', 'made', 'all', 'the', 'difference!'], ['edited_ending:', 'Joe', 'grew', 'up', 'helping', 'his', 'mothers', 'best', 'friend', 'work', 'there.', 'One', 'day', 'Joe', 'went', 'to', 'the', 'restaurant', 'and', 'found', 'out', 'it', 'was', 'on', 'fire.', 'Joe', 'and', 'his', 'mothers', 'friends', 'family', 'have', 'now', 'lost', 'their', \"life's\", 'work.'], ['edited_ending:', 'I', 'thought', 'about', 'different', 'colors', 'for', 'the', 'car.', 'When', 'I', 'woke', 'up,', 'there', 'was', 'a', 'horse', 'outside.', 'I', 'wanted', 'a', 'car.'], ['edited_ending:', 'Abby', 'told', 'her', 'that', 'Claire', 'was', 'taking', 'a', 'tap', 'dancing', 'class', 'Susie', 'was', 'amused.', 'She', 'immediately', 'made', 'fun', 'of', 'Claire.'], ['edited_ending:', 'One', 'morning,', 'she', 'looked', 'in', 'her', 'purse', 'and', \"couldn't\", 'find', 'them.', 'Her', 'husband', 'had', 'taken', 'them', 'out', 'and', \"didn't\", 'put', 'them', 'back', 'in.', 'They', \"weren't\", 'diamonds', 'but', 'it', 'still', 'scared', 'her', 'when', 'she', 'thought', 'she', 'lost', 'them.'], ['edited_ending:', 'Dave', 'was', 'now', 'very', 'fit', 'for', 'a', 'grandfather.', 'He', 'even', 'could', 'keep', 'up', 'with', 'his', 'grandchildren.', 'Dave', 'felt', 'like', 'he', 'was', 'young', 'again.'], ['edited_ending:', 'His', 'doctor', 'prescribed', 'a', 'migraine', 'medication.', 'Adam', 'felt', 'better', 'very', 'soon.', 'He', 'was', 'thrilled', 'to', 'finally', 'have', 'some', 'relief,', 'even', 'after', 'he', 'claimed', 'he', 'would', 'never', 'feel', 'better.'], ['edited_ending:', 'I', 'usually', 'brew', 'my', 'first', 'cup', 'in', 'my', 'machine', 'at', '5', 'AM.', 'As', 'soon', 'as', 'that', 'black', 'gold', 'touches', 'my', 'lips', 'I', 'come', 'alive.', 'I', 'am', 'in', 'a', 'happy', 'mood', 'and', 'ready', 'to', 'start', 'the', 'day.'], ['edited_ending:', 'She', 'met', 'a', 'man', 'at', 'the', 'show.', 'They', 'flirted', 'all', 'night', 'and', 'she', 'ignored', 'her', 'friends.', 'Gwen', 'went', 'home', 'with', 'the', 'man', 'after', 'the', 'show.'], ['edited_ending:', 'It', 'ignored', 'all', 'the', 'fish', 'that', 'were', 'swimming', 'around', 'it', 'a', 'small', 'pond.', 'Then', 'the', \"bird's\", 'head', 'peeked', 'out', 'from', 'under', 'its', 'wing.', 'It', 'had', 'been', 'sleeping', 'with', 'its', 'head', 'tucked', 'under', 'its', 'wing.'], ['edited_ending:', 'A', 'student', 'was', 'screaming', 'and', 'Earl', 'told', 'them', 'to', 'be', 'quiet.', 'The', 'student', 'refused', 'and', 'continued', 'to', 'scream', 'loudly', 'Earl', 'decided', 'it', 'was', 'best', 'to', 'leave', 'the', 'library,', 'and', 'study', 'elsewhere'], ['edited_ending:', 'I', 'decided', 'to', 'give', 'it', 'another', 'try,', 'and', 'I', 'practiced', 'dancing', 'in', 'my', 'room', 'for', 'years', 'and', 'years.', 'I', 'even', 'took', 'lessons', 'from', 'a', 'professional.', 'Now', 'I', 'am', 'a', 'very', 'good', 'dancer.'], ['edited_ending:', 'He', 'has', 'a', 'lot', 'of', 'other', 'obligations', 'right', 'now.', 'Mike', 'decided', 'to', 'put', 'his', 'dream', 'aside', 'for', 'now', 'and', 'focus', 'on', 'other', 'things.', 'Mike', 'is', 'a', 'bit', 'uncertain', 'about', 'his', 'future', 'as', 'a', 'guitar', 'teacher.'], ['edited_ending:', 'It', 'went', 'drift', 'behind', 'her', 'and', 'she', 'almost', 'lost', 'it.', 'Luckily,', 'the', 'wind', 'stopped', 'and', 'she', 'regained', 'her', 'grip.', 'Tia', 'was', 'thankful', 'that', 'she', \"didn't\", 'have', 'to', 'chase', 'her', 'umbrella.'], ['edited_ending:', 'I', 'handed', 'her', 'the', 'yo-yo', 'and', 'she', 'giggled', 'again', 'loudly', 'with', 'joy.', 'She', 'kissed', 'the', 'yo-yo', 'on', 'the', 'and', 'left', 'the', 'room', 'hugging', 'the', 'it.', 'I', 'was', 'happy', 'knowing', 'that', 'the', 'yo-yo', 'was', 'going', 'to', 'be', 'played', 'with', 'again.'], ['edited_ending:', 'All', 'of', 'a', 'sudden', 'the', 'gardener', 'quit!', 'Brian', 'quickly', 'got', 'out', 'his', 'own', 'lawnmower', 'to', 'do', 'the', 'work.', 'Brian', 'finished', 'his', 'lawn', 'work', 'and', 'was', 'rewarded', 'with', 'twenty', 'dollars', 'by', 'his', 'parents.'], ['edited_ending:', 'His', 'old', 'boss', 'asked', 'him', 'to', 'come', 'back.', 'He', 'offered', 'him', 'a', 'different', 'position', 'with', 'less', 'hours.', 'The', 'man', 'accepted', 'the', 'new', 'job.'], ['edited_ending:', 'The', 'road', 'was', 'of', 'course', 'covered', 'in', 'potholes', 'but', 'he', 'dodged', 'them.', 'He', 'hit', 'a', 'giant', 'hole', 'causing', 'him', 'to', 'lose', 'control', 'and', 'go', 'off', 'the', 'road.', 'Craig', 'would', 'have', 'panicked', 'but', 'he', 'noticed', 'he', 'was', 'uninjured', 'and', 'the', 'car', 'was', 'okay.'], ['edited_ending:', 'When', 'the', 'earnings', 'were', 'out', 'they', 'were', 'awful.', 'Tina', 'thought', 'she', 'would', 'make', 'money.', 'Unfortunately', 'she', 'lost', 'big', 'time.'], ['edited_ending:', 'Kim', 'hated', 'cheese,', 'but', 'knew', 'it', 'would', 'be', 'rude', 'to', 'not', 'eat.', 'She', 'tried', 'some', 'cheese', 'dishes', 'at', 'home,', 'but', 'still', 'hated', 'them', 'all.', 'At', 'the', 'party,', 'she', 'told', \"Jim's\", 'mom', 'she', 'was', 'allergic', 'and', 'all', 'was', 'fine.'], ['edited_ending:', 'It', 'was', 'not', 'salty', 'enough', 'for', 'him.', 'He', 'added', 'a', 'whole', 'lot', 'of', 'salt.', 'It', 'still', 'tasted', 'too', 'bland.'], ['edited_ending:', 'Mindy', 'decided', 'to', 'hire', 'a', 'personal', 'trainer', 'and', 'not', 'try', 'to', 'lose', 'weight.', 'This', 'has', 'been', 'a', 'superb', 'decision', 'on', \"Mindy's\", 'part.', 'She', \"hasn't\", 'lost', 'the', 'extra', 'weight,', 'but', 'she', 'feels', 'better', 'and', 'enjoys', 'the', 'sessions.'], ['edited_ending:', 'He', \"didn't\", 'have', 'to', 'apply', 'an', 'ice', 'pack', 'and', 'compression', 'bandage', 'to', 'his', 'knee', 'this', 'time.', 'He', \"didn't\", 'even', 'need', 'to', 'elevate', 'it.', \"Hydro's\", 'knee', 'felt', 'great.'], ['edited_ending:', 'He', 'danced', 'to', 'his', 'favorite', 'song', 'first.', 'Then', 'he', 'danced', 'to', 'his', \"fiance's\", 'favorite', 'song.', 'The', 'audience', 'applauded', 'loudly', 'as', 'he', 'left', 'the', 'stage.'], ['edited_ending:', 'It', 'took', 'us', 'just', 'ten', 'minutes.', 'When', 'we', 'got', 'there', 'we', 'were', 'excited.', 'It', 'was', 'worth', 'it.'], ['edited_ending:', 'Donald', 'ran', 'into', 'the', 'room', 'and', 'saw', 'her', 'dancing', 'and', 'singing.', 'He', 'quickly', 'grabbed', 'a', 'broom', 'and', 'started', 'dancing.', 'Now', 'Donald', 'no', 'longer', 'fears', 'performing!'], ['edited_ending:', 'When', 'he', 'decided', 'to', 'leave,', 'the', 'man', 'had', 'a', 'thought.', 'As', 'he', 'walked', 'down,', 'he', 'remembered', 'rolling', 'down', 'hills', 'as', 'a', 'child.', 'The', 'man', 'felt', 'old', 'as', 'he', 'decided', 'not', 'to', 'roll', 'down.'], ['edited_ending:', 'The', 'chair', \"wasn't\", 'sturdy', 'at', 'all,', 'but', 'was', 'actually', 'a', 'little', 'wobbly.', 'I', 'put', 'the', 'computer', 'underneath,', 'and', 'sat', 'on', 'the', 'chair.', 'Now', 'I', 'have', 'a', 'work', 'station,', 'even', 'though', 'it', \"isn't\", 'a', 'very', 'good', 'one.'], ['edited_ending:', 'Once', 'he', 'was', 'dressed,', 'he', 'walked', 'out', 'of', 'the', 'closet.', 'When', 'he', 'walked', 'out,', 'he', 'shut', 'the', 'closet', 'door.', 'The', 'knob,', 'however,', 'was', 'broken', 'and', 'now', 'the', 'door', \"won't\", 'open.'], ['edited_ending:', 'The', 'boss', 'tells', 'Steve', 'it', \"won't\", 'rain.', '30', 'minutes', 'after', 'he', 'said', 'that', 'it', 'starts', 'to', 'rain.', 'Steve', 'is', 'stuck', 'working', 'in', 'the', 'rain.'], ['edited_ending:', 'On', 'the', 'way,', 'she', 'decided', 'to', 'listen', 'to', 'some', 'music.', 'She', 'got', 'preoccupied', 'trying', 'to', 'put', 'a', 'cd', 'in', 'the', 'stereo.', 'She', 'missed', 'the', 'red', 'light', 'and', 'ran', 'straight', 'into', 'another', 'car,', 'killing', 'her.'], ['edited_ending:', 'She', 'opened', 'it', 'intending', 'to', 'close', 'it', 'hard.', 'But', 'the', 'gravity', 'began', 'to', 'pull', 'her', 'out', 'of', 'the', 'car.', 'Finally', 'her', 'mom', 'turned', 'and', 'the', 'door', 'closed', 'and', 'pushed', 'Kate', 'in', 'the', 'car.'], ['edited_ending:', 'Max', 'had', 'to', 'give', 'the', 'puppy', 'a', 'bath', 'first.', 'Max', 'fed', 'him', 'and', 'gave', 'him', 'to', 'his', 'new', 'owners.', 'Max', 'was', 'happy', 'he', 'helped', 'the', 'puppy.'], ['edited_ending:', 'The', 'pedicurist', 'carefully', 'clips', 'each', 'toenail.', 'Finally', 'they', 'are', 'perfect.', 'She', 'is', 'happy', 'that', 'she', 'finally', 'has', 'clipped', 'toenails.'], ['edited_ending:', 'His', 'dad', 'told', 'him', 'igloos', 'had', 'to', 'be', 'made', 'from', 'snow.', \"Tom's\", 'igloo', 'was', 'made', 'from', 'ice.', 'Tom', 'happily', 'decided', 'it', 'would', 'now', 'be', 'called', 'an', 'ice', 'hut.'], ['edited_ending:', 'The', 'tunnel', 'kept', 'the', 'man', 'shielded', 'from', 'debris.', 'The', 'storm', 'passed.', 'The', 'man', 'continued', 'on', 'his', 'adventure.'], ['edited_ending:', 'He', 'held', 'onto', 'his', 'briefcase', 'as', 'he', 'walked.', 'Suddenly', 'he', 'ran', 'into', 'a', 'woman,', 'both', 'of', 'them', 'falling', 'to', 'the', 'ground.', 'Luckily', 'since', 'his', 'paperwork', 'was', 'secured,', 'his', 'stayed', 'inside', 'the', 'briefcase.'], ['edited_ending:', 'Keith', 'is', 'the', 'first', 'in', 'his', 'family', 'to', 'be', 'an', 'apprentice.', 'His', 'parents', 'are', 'so', 'proud!', 'Keith', 'hopes', 'he', 'does', 'well', 'at', 'the', 'apprenticeship', 'and', 'is', 'successful.'], ['edited_ending:', 'After', 'listening', 'to', 'the', 'concert,', 'he', 'got', 'on', 'one', 'knee', 'and', 'proposed', 'to', 'her!', 'Kyla', 'was', 'ecstatic', 'and', 'agreed', 'at', 'once!', 'She', 'and', 'Ron', 'were', 'both', 'so', 'happy,', 'they', 'almost', 'cried!'], ['edited_ending:', 'He', 'took', 'an', 'uber', 'but', 'they', 'got', 'lost.', 'Eventually', 'he', 'made', 'it', 'to', 'the', 'front', 'desk', 'and', 'got', 'the', 'room.', 'When', 'he', 'opened', 'the', 'door', 'to', 'the', 'room', 'no', 'one', 'was', 'there.'], ['edited_ending:', 'I', 'walked', 'to', 'my', 'favorite', 'place', 'to', 'eat', 'fried', 'chicken.', 'I', 'stayed', 'there', 'for', 'hours', 'eating', 'and', 'reading.', 'I', 'had', 'a', 'great', 'time', 'by', 'myself.'], ['edited_ending:', 'I', 'bought', 'the', 'pool', 'supplies', 'and', 'some', 'floating', 'chairs.', 'I', 'worked', 'on', 'the', 'pool', 'for', 'a', 'weekend.', 'When', 'I', 'was', 'done,', 'I', 'had', 'a', 'nice', 'swim.'], ['edited_ending:', 'She', 'found', 'a', 'house', 'she', 'really', 'likes', 'in', 'Coos', 'Bay,', 'Oregon.', 'She', 'was', 'sad', 'she', \"couldn't\", 'afford', 'it.', 'Turns', 'out', 'the', 'house', 'was', 'in', 'much', 'worse', 'shape', 'than', 'shown.'], ['edited_ending:', 'I', 'checked', 'in', 'my', 'basement.', 'When', 'I', 'looked', 'down', 'there', 'I', 'got', 'very', 'spooked.', 'My', 'friend', 'had', 'been', 'hiding', 'down', 'there', 'the', 'whole', 'time.'], ['edited_ending:', 'Wendy', 'rushed', 'home', 'to', 'tend', 'to', 'her.', 'It', 'looked', 'way', 'worse', 'than', 'it', 'was,', 'with', 'lots', 'of', 'blood.', 'Wendy', 'breathed', 'a', 'sign', 'of', 'grief', 'for', 'her', 'girls', 'foot.'], ['edited_ending:', 'I', 'was', 'asked', 'to', 'take', 'the', 'last', 'shot.', 'I', 'went', 'got', 'the', 'ball', 'and', 'took', 'the', 'shot.', 'I', \"didn't\", 'make', 'it', 'and', 'we', 'lost.'], ['edited_ending:', 'She', 'planted', 'her', 'own', 'raspberries', 'in', 'her', 'garden.', 'As', 'a', 'result', 'she', 'started', 'picking', 'the', 'garden', 'every', 'day.', 'Susie', 'decided', 'to', 'then', 'sell', 'the', 'berries', 'to', 'her', \"neighbor's.\"], ['edited_ending:', 'She', 'and', 'her', 'friends', 'worked', 'on', 'cleaning', 'the', 'shorelines.', 'They', 'set', 'up', 'recycling', 'stations', 'in', 'the', 'along', 'the', 'beach.', 'Bea', 'was', 'so', 'happy', 'to', 'help', 'out', 'by', 'starting', 'the', 'clean', 'up', 'effort', 'on', 'the', 'shorelines.'], ['edited_ending:', 'The', 'kids', 'would', 'glare', 'when', 'she', 'would', 'walk', 'by.', 'Nicolette', 'felt', 'bad', 'and', 'wanted', 'to', 'try', 'and', 'win', 'them', 'over.', 'She', 'delivered', 'cookies', 'to', 'all', 'of', 'the', 'kids.'], ['edited_ending:', 'Harris', 'said', 'he', 'liked', 'her.', 'They', 'talked', 'during', 'the', 'entire', 'ride.', 'Now', \"they're\", 'a', 'couple.'], ['edited_ending:', 'The', 'man', 'was', 'strict', 'but', 'fair', 'and', 'treated', 'Annie', 'well.', 'One', 'day', 'Annie', 'offered', 'the', 'old', 'man', 'an', 'extra', 'job', 'to', 'make', 'more', 'money', 'The', 'old', 'man', 'took', 'the', 'job', 'and', 'became', 'richer', 'than', 'Annie'], ['edited_ending:', 'He', \"didn't\", 'need', 'to', 'go', 'to', 'the', 'store.', 'So', 'he', 'searched', 'his', 'pantry', 'and', 'found', 'cereal.', 'Ricky', 'made', 'and', 'ate', 'cereal.'], ['edited_ending:', 'John', \"didn't\", 'want', 'to', 'lose', 'weight', 'prior', 'to', 'the', 'reunion,', 'to', 'look', 'good.', 'He', \"didn't\", 'want', 'to', 'diet', 'and', 'work', 'out.', 'John', \"wouldn't\", 'have', 'looked', 'good', 'at', 'the', 'reunion', 'and', 'would', 'have', 'tuned', 'heads', 'for', 'the', 'wrong', 'reason.'], ['edited_ending:', 'Desperately,', 'she', 'asked', 'her', 'best', 'friend', 'to', 'borrow', 'a', 'tampon.', 'Her', 'friend', 'rummaged', 'through', 'her', 'backpack', 'and', 'produced', 'a', 'tampon.', 'Kelly', 'gratefully', 'thanked', 'her', 'friend!'], ['edited_ending:', 'Kyle', 'had', 'put', 'hot', 'sauce', 'in', 'his', 'soda.', 'Wes', 'reached', 'over', 'and', 'took', 'a', 'sip.', 'Wes', 'ran', 'and', 'spit', 'his', 'drink', 'into', 'the', 'sink.'], ['edited_ending:', 'He', 'put', 'out', 'posters', 'and', 'flyers', 'seeking', 'out', 'a', 'new', 'puppy.', 'One', 'of', 'his', 'neighbors', 'found', 'him', 'a', 'new', 'dog.', \"Johnny's\", 'neighbor', 'gave', 'him', 'his', 'new', 'puppy.'], ['edited_ending:', \"It's\", 'been', 'two', 'years', 'and', 'we', \"haven't\", 'even', 'gotten', 'into', 'it.', 'I', 'show', 'him', 'an', 'asana', 'when', 'he', 'was', 'healed', 'and', 'he', 'just', \"can't\", 'move', 'that', 'way.', 'It', 'will', 'be', 'awhile', 'before', 'his', 'body', 'loosens', 'up', 'enough.'], ['edited_ending:', 'He', 'talked', 'to', 'a', 'psychologist', 'but', 'it', \"didn't\", 'help', 'him', 'much.', 'Joseph', 'moved', 'to', 'a', 'new', 'town', 'to', 'start', 'fresh.', 'With', 'their', 'love', 'and', 'understanding,', 'he', 'left.'], ['edited_ending:', 'Her', 'doctor', 'warned', 'her', 'she', 'needed', 'to', 'cut', 'back.', 'She', 'started', 'eating', 'more', 'fruit.', 'Kelley', 'lost', '20', 'pounds', 'in', 'a', 'year.'], ['edited_ending:', 'He', 'planned', 'to', 'go', 'behind', 'her', 'back', 'and', 'started', 'getting', 'really', 'nervous', 'about', 'it.', 'He', 'woke', 'up', 'ready', 'to', 'fight', 'but', 'decided', 'he', 'really', \"didn't\", 'want', 'to.', 'He', 'asked', 'his', 'friend', 'and', 'they', 'decided', 'not', 'to', 'fight.'], ['edited_ending:', 'My', 'hair', 'was', 'all', 'slimy', 'and', 'greasy.', 'It', 'was', 'horrible.', 'I', 'had', 'to', 'reapply', 'it', 'immediately.'], ['edited_ending:', 'Hector', 'was', 'running', 'next', 'to', 'him', 'cheering', 'him', 'along.', 'When', 'the', 'kid', 'tripped', 'on', 'a', 'shell,', 'the', 'kite', 'fell', 'down.', 'So', 'Hector', 'took', 'over', 'and', 'made', 'the', 'kite', 'fly', 'high', 'again.'], ['edited_ending:', 'Donna', 'stayed', 'behind', 'to', 'look', 'for', 'the', 'frisbee', 'that', 'was', 'thrown', 'deep', 'into', 'the', 'woods.', 'Donna', 'went', 'in', 'after', 'it', 'but', 'the', 'foliage', 'was', 'very', 'thick.', 'After', 'searching', 'for', 'awhile,', 'she', 'finally', 'left', 'without', 'their', 'frisbee.'], ['edited_ending:', 'There', 'was', 'a', 'wallet', 'in', 'the', 'puddle.', 'which', 'she', 'immediately', 'picked', 'it', 'up', 'and', 'looked', 'inside.', 'As', 'soon', 'as', 'she', 'found', 'who', 'it', 'was,', 'she', 'took', 'it', 'into', 'the', 'store.', 'She', 'hoped', 'the', 'store', 'would', 'help', 'find', 'the', 'owner.'], ['edited_ending:', 'She', 'ended', 'up', 'sleeping', '10', 'hours.', 'She', 'was', 'so', 'tired.', 'It', 'ended', 'up', 'being', 'a', 'peaceful', 'night.'], ['edited_ending:', 'He', 'bought', 'bigger', 'kibble', 'and', 'put', 'the', 'bowl', 'on', 'a', 'mat.', 'The', 'dog', \"didn't\", 'make', 'a', 'mess', 'anymore!', 'Max', 'was', 'happy', 'he', \"didn't\", 'have', 'to', 'clean', 'up', 'spills', 'anymore.'], ['edited_ending:', 'He', 'seemed', 'injured.', 'Mike', \"didn't\", 'want', 'to', 'call', 'a', 'wildlife', 'rescue', 'group.', 'Mike', 'checked', 'out', 'the', 'internet', 'on', 'how', 'to', 'give', 'the', 'duck', 'some', 'help.'], ['edited_ending:', 'Everyone', 'else', 'played', 'a', 'lot', 'of', 'games', 'that', 'night.', 'They', 'was', 'a', 'lot', 'of', 'food', 'to', 'eat.', 'I', \"don't\", 'know', 'why', 'I', \"didn't\", 'have', 'a', 'good', 'time.'], ['edited_ending:', 'His', 'brother', 'set', 'him', 'up', 'on', 'a', 'blind', 'date', 'and', 'they', 'made', 'plans', 'to', 'have', 'dinner', 'on', 'Saturday', 'at', 'a', 'fancy', 'restaurant.', \"Ron's\", 'paycheck', 'was', 'typed', 'incorrectly', 'and', \"didn't\", 'clear', 'so', 'he', 'was', 'broke!', 'He', 'took', 'the', 'girl', 'to', 'a', 'park', 'for', 'a', 'picnic', 'instead', 'and', 'she', 'loved', 'it.'], ['edited_ending:', 'Every', 'problem', 'in', 'class', 'simply', 'led', 'to', 'a', 'new', 'problem.', 'He', 'spent', '5', 'hours', 'on', 'the', 'phone', 'trying', 'to', 'retrieve', 'his', 'assignments.', 'He', 'was', 'so', 'frustrated', 'he', 'threw', 'his', 'laptop', 'out', 'the', 'window.'], ['edited_ending:', 'I', 'was', 'invited', 'to', 'go', 'swimming', 'at', 'a', \"friend's\", 'house', 'but', 'I', 'never', 'really', 'liked', 'him.', 'I', 'lied', 'to', 'him', 'by', 'saying', 'I', 'was', 'busy.', 'I', \"didn't\", 'feel', 'bad', 'for', 'lying.'], ['edited_ending:', 'One', 'day', 'his', 'friend', 'invited', 'him', 'to', 'run', 'in', 'a', 'charity', 'race.', 'He', 'decided', 'to', 'train', 'hard', 'and', 'run', 'in', 'the', 'race.', 'Alister', 'came', 'in', 'the', 'top', '10', 'for', 'the', 'charity', 'race', 'and', 'his', 'love', 'for', 'running', 'was', 'rejuvenated.'], ['edited_ending:', 'Earlier,', 'he', 'even', 'saw', 'a', 'cow', 'being', 'milked!', 'When', 'he', 'got', 'home,', 'all', 'he', 'could', 'talk', 'about', 'was', 'the', 'zoo!', 'Ida', 'was', 'glad', \"she'd\", 'given', 'her', 'son', 'such', 'a', 'wonderful', 'time', 'anyhow.'], ['edited_ending:', 'They', 'tried', 'to', 'talk', 'out', 'all', 'their', 'problems.', 'Their', 'communication', 'skills', 'improved.', 'But,', 'soon,', 'they', 'were', 'ready', 'to', 'get', 'a', 'divorce.'], ['edited_ending:', 'He', \"didn't\", 'like', 'corn', 'and', \"didn't\", 'know', 'anyone', 'he', 'could', 'give', 'it', 'to.', 'The', 'crops', 'grew', 'tall', 'and', 'healthy.', 'He', 'harvested', 'them', 'and', 'made', 'some', 'delicious', 'food.'], ['edited_ending:', 'The', 'girls', 'yelled', 'when', 'a', 'car', 'drove', 'too', 'close', 'to', 'the', 'sidewalk.', 'The', 'driver', 'looked', 'at', 'them,', 'surprised.', 'In', 'anger,', 'Beth', 'threw', 'her', 'M&Ms', 'at', 'the', 'windshield.'], ['edited_ending:', 'At', 'which', 'point', 'he', 'stumbled', 'upon', 'a', 'flock', 'of', 'turkeys.', 'Since', 'it', 'was', 'so', 'late', 'he', 'decided', 'the', 'first', 'turkey', 'he', 'could', 'shoot', 'would', 'suffice.', 'So', 'he', 'shot', 'the', 'nearest', 'turkey', 'and', 'had', 'a', 'Thanksgiving', 'turkey', 'dinner.'], ['edited_ending:', 'He', 'discovered', 'that', 'a', 'game-creation', 'tournament', 'was', 'coming', 'to', 'his', 'city.', 'He', 'entered', 'his', 'design', 'in', 'the', 'event', 'and', 'won.', 'Eventually', 'he', 'put', 'this', 'skill', 'to', 'use', 'and', 'is', 'a', 'big', 'CEO', 'now.'], ['edited_ending:', 'After', 'ambushing', 'him,', 'I', 'ran', 'some', 'errands,', 'eventually', 'going', 'home.', 'When', 'I', 'pulled', 'up', 'to', 'my', 'apartment', 'I', 'knew', 'something', 'was', 'fishy.', 'I', 'walked', 'to', 'my', 'door', 'to', 'find', 'some', 'granny', 'panties', 'hanging', 'on', 'the', 'knob.'], ['edited_ending:', 'Sal', 'ignored', 'their', 'requests.', 'He', 'actually', 'started', 'taking', 'medication', 'behind', 'their', 'backs.', 'So', 'his', 'parents', 'had', 'no', 'choice', 'but', 'to', 'ground', 'him.'], ['edited_ending:', 'They', 'turned', 'black', 'in', 'the', 'pan.', 'He', 'checked', 'the', 'stove.', 'The', 'stove', 'was', 'on', 'too', 'high.'], ['edited_ending:', 'He', 'gave', 'them', 'lots', 'of', 'love', 'and', 'attention.', 'They', 'could', 'not', 'produce', 'babies.', 'John', 'was', 'wondering', 'why', 'he', 'did', 'get', 'so', 'many', 'babies', 'from', 'them.'], ['edited_ending:', 'To', 'her', 'dismay', 'her', 'flight', 'was', 'leaving', 'earlier', 'than', 'expected.', 'Allison', 'did', 'not', 'know', 'what', 'to', 'do.', 'She', 'ended', 'up', 'having', 'to', 'take', 'a', 'different', 'flight.'], ['edited_ending:', 'At', 'lunch,', 'Fred', 'eats', 'carrots', 'and', 'celery.', 'He', 'finds', 'the', 'carrots', 'and', 'celery', 'an', 'acceptable', 'lunch.', 'Fred', 'is', 'happy', 'to', 'be', 'eating', 'more', 'healthy', 'food.'], ['edited_ending:', 'Every', 'day', \"we'd\", 'water', 'the', 'dirt', 'and', 'check', 'the', 'ground', 'for', 'weeds.', 'We', \"didn't\", 'understand', 'why', 'no', 'little', 'sprouts', 'began', 'to', 'emerge', 'from', 'the', 'ground.', 'Our', 'family', 'was', 'confused', 'about', 'how', 'our', 'hard', 'work', 'had', 'produced', 'nothing.'], ['edited_ending:', 'It', 'said', 'it', 'was', 'from', 'an', 'enemy.', 'Jane', \"couldn't\", 'figure', 'out', 'who', 'it', 'was.', 'She', 'was', 'scared', 'and', 'sad.'], ['edited_ending:', 'She', 'grounded', 'the', 'boy.', 'The', 'boy', 'went', 'to', 'his', 'room.', 'His', 'mother', 'hugged', 'the', 'father.'], ['edited_ending:', 'They', 'promised', 'that', 'they', 'would', 'remain', 'in', 'touch.', 'Jordan', 'wrote', 'her', 'a', 'letter', 'as', 'soon', 'as', 'she', 'got', 'home.', 'But', 'she', 'had', 'forgot', 'to', 'get', 'her', 'pen', \"pal's\", 'address.'], ['edited_ending:', 'She', 'was', 'hosting', 'the', 'show', 'for', 'the', 'first', 'time.', 'She', 'felt', 'anxious', 'as', 'she', 'walked', 'onto', 'the', 'studio', 'She', 'was', 'excited', 'to', 'give', 'it', 'a', 'shot!'], ['edited_ending:', 'He', 'was', 'glad', 'he', 'could', 'trust', 'the', 'new', 'maid.', 'He', 'gave', 'her', 'a', 'good', 'review', 'on', 'Yelp', 'simply', 'because', 'she', \"didn't\", 'steal.', 'That', 'night', 'Charlie', 'left', 'his', 'wallet', 'in', 'the', 'kitchen,', 'and', 'it', 'was', 'still', 'there', 'the', 'next', 'day.'], ['edited_ending:', 'Her', 'parents', 'warned', 'her', 'not', 'too.', 'They', 'thought', 'she', 'would', 'never', 'get', 'in.', 'Unfortunately', 'they', 'were', 'right,', 'she', 'never', 'got', 'in.'], ['edited_ending:', 'He', 'was', 'off', 'the', 'target', 'due', 'to', 'his', 'nervousness.', 'He', 'acclimated', 'and', 'adjusted', 'the', 'sights.', 'The', 'gun', 'fired', 'right', 'on', 'target', 'after', 'that.'], ['edited_ending:', 'Don', 'got', 'up', 'on', 'the', 'counter', 'at', 'the', 'edge', 'and', 'walked', 'on', 'his', 'hands.', 'The', 'counter', 'broke', 'under', 'his', 'weight.', 'Don', 'plummeted', 'to', 'the', 'floor', 'and', 'hurt', 'himself.'], ['edited_ending:', 'She', 'would', 'care', 'for', 'each', 'of', 'them', 'as', 'much', 'as', 'she', 'could.', 'She', 'would', 'feed', 'them,', 'wash', 'them,', 'and', 'love', 'them.', 'So', 'she', 'took', 'that', 'passion', 'and', 'made', 'it', 'into', 'her', 'profession.'], ['edited_ending:', 'But', 'after', 'he', 'got', 'it', 'fixed,', 'the', 'smell', 'was', 'still', 'there', 'outside.', 'Later,', 'he', 'found', 'a', 'dead', 'raccoon', 'in', 'the', 'yard.', 'And', 'the', 'smell', 'went', 'away', 'after', 'he', 'cleaned', 'it', 'up.'], ['edited_ending:', 'She', 'thought', 'the', 'right', 'thing', 'was', 'to', 'break', 'up', 'with', 'him.', 'Her', 'wealthy', 'parents', 'never', 'approved', 'of', 'her', 'boyfriend.', 'Ruth', 'then', 'knew', 'that', 'her', 'parents', 'would', 'win', 'out', 'over', 'her', 'cheating', 'boyfriend.'], ['edited_ending:', 'She', 'also', 'started', 'her', 'own', 'business.', 'The', 'business', 'was', 'a', 'success.', 'She', 'franchised', 'the', 'concept', 'and', 'quit', 'her', 'job.'], ['edited_ending:', 'The', 'people', 'he', 'was', 'able', 'to', 'invite', 'gathered', 'in', 'the', 'backyard.', 'Food', 'and', 'drinks', 'were', 'served', 'to', 'all', 'in', 'attendance.', 'Everyone', 'left', 'happy.'], ['edited_ending:', \"I'm\", 'trying', 'not', 'to', 'feel', 'awkward,', 'but', \"it's\", 'a', 'little', 'hard', 'for', 'me,', 'as', 'everyone', 'is', 'staring', 'at', 'me.', 'They', 'surprised', 'me', 'with', 'one', 'last', 'present,', 'and', 'my', 'eyes', 'light', 'up', 'as', 'I', 'see', 'my', 'brand', 'new', 'iPod', 'in', 'the', 'packaging.', 'I', 'run', 'over', 'to', 'my', 'mom,', 'and', 'hug', 'her', 'for', 'the', 'gift.'], ['edited_ending:', 'I', 'was', 'very', 'nervous', 'as', \"I've\", 'never', 'been', 'there', 'before.', 'When', 'the', 'bus', 'route', 'ended,', 'I', 'asked', 'the', 'driver', 'where', 'to', 'go.', 'He', 'told', 'me', 'to', 'stay', 'on', 'the', 'bus', 'and', 'he', 'would', 'take', 'me', 'back', 'home.'], ['edited_ending:', 'He', 'knew', 'that', 'the', 'car', 'had', 'been', 'submerged', 'in', 'a', 'flood.', 'When', 'the', 'heat', 'of', 'summer', 'came,', 'the', 'car', 'began', 'to', 'smell', 'bad.', 'Bill', \"wasn't\", 'worried,', 'because', 'he', 'had', 'paid', 'very', 'little', 'for', 'the', 'car.'], ['edited_ending:', 'Kenny', 'was', 'happybecause', 'he', 'wanted', 'his', 'grandfather', 'to', 'come.', 'He', 'talked', 'to', 'his', 'mother', 'about', 'also', 'moving', 'to', 'the', 'neighborhood.', 'The', 'whole', 'family', 'was', 'living', 'in', \"Kenny's\", 'neighborhood.'], ['edited_ending:', 'She', 'promised', 'Anna', 'she', 'would', 'buy', 'her', 'some', 'new', 'makeup', 'before', 'her', 'sixteenth', 'birthday.', 'Anna', 'counted', 'down', 'the', 'days', 'til', 'she', 'got', 'her', 'new', 'makeup.', 'Her', 'mom', 'took', 'her', 'shopping', 'for', 'eye', 'shadow', 'and', 'lip', 'gloss.'], ['edited_ending:', 'She', 'looked', 'at', 'all', 'her', 'items', 'in', 'storage', 'one', 'by', 'one.', 'Then', 'unfortunately', 'an', 'ornament', 'broke.', 'Miranda', 'was', 'devastated.'], ['edited_ending:', 'The', 'woman', 'told', 'him', 'to', 'stop.', 'The', 'man', 'brought', 'some', 'wine', 'as', 'an', 'apology.', 'The', 'two', 'became', 'great', 'friends.'], ['edited_ending:', 'She', 'started', 'cooking.', 'She', 'and', 'her', 'boyfriend', 'ended', 'up', 'eating', 'numerous', 'tacos.', 'They', 'thought', 'they', 'were', 'delicious.'], ['edited_ending:', 'The', 'band', 'was', 'set', 'to', 'play', 'a', 'big', 'game', 'at', 'halftime.', 'She', 'suddenly', 'wished', 'she', 'could', 'go', 'out', 'onto', 'the', 'field', 'too.', 'Playing', 'in', 'the', 'marching', 'band', 'was', 'starting', 'to', 'look', 'more', 'desirable', 'than', 'she', 'thought', 'it', 'would', 'be.'], ['edited_ending:', 'Betty', 'went', 'to', 'the', 'casino', 'with', 'her', 'friend', 'Jane.', 'Betty', 'told', 'her', 'husband', 'she', 'would', 'just', 'watch', 'Jane.', 'Her', 'husband', \"didn't\", 'mind', 'as', 'long', 'as', 'she', \"didn't\", 'lose', 'money'], ['edited_ending:', 'He', 'tried', 'playing', 'sports', 'but', 'it', \"wasn't\", 'his', 'thing.', 'He', 'tried', 'reading', 'but', 'it', 'bored', 'him.', 'Finally,', 'he', 'watched', 'many', 'movies', 'and', 'he', 'found', 'out', 'that', 'he', 'wanted', 'to', 'be', 'a', 'film', 'critic.'], ['edited_ending:', 'The', 'teachers', 'followed', 'the', 'principals', 'instructions.', 'The', 'principal', 'appreciated', 'that.', 'The', 'principal', 'gave', 'the', 'teachers', 'an', 'extra', 'half', 'hour', 'for', 'lunch', 'break.'], ['edited_ending:', 'The', 'donkey', 'was', 'added', 'to', 'his', 'collection.', 'He', 'refused', 'to', 'walk', 'at', 'the', 'park,', 'no', 'matter', 'what', 'Hank', 'did.', 'Hank', 'took', 'his', 'dogs', 'out', 'for', 'a', 'walk,', 'instead.'], ['edited_ending:', 'He', 'would', 'finish', 'in', 'just', '12', 'months.', 'Henry', 'loved', 'being', 'an', 'apprectice.', 'Henry', 'is', 'now', 'the', 'headliner', 'for', 'his', 'own', 'show', 'in', 'Las', 'Vegas.'], ['edited_ending:', 'A', 'sign', 'was', 'posted', 'that', 'said', 'swimming', 'was', 'banned', 'due', 'to', 'the', 'cold.', 'Amy', 'and', 'her', 'friends', 'did', 'not', 'want', 'to', 'get', 'sick!', 'They', 'sadly', 'decided', 'to', 'just', 'lay', 'on', 'the', 'couch', 'and', 'watch', 'TV', 'instead.'], ['edited_ending:', 'I', 'was', 'scared', 'that', 'I', 'would', 'throw', 'up', 'on', 'my', 'friends.', 'Luckily,', 'it', 'was', 'a', 'burp.', 'Alas,', 'my', 'friends', 'still', 'made', 'fun', 'of', 'me', 'for', 'burping.'], ['edited_ending:', 'I', 'would', 'never', 'become', 'muscular', 'and', 'ripped.', 'or', 'apply', 'for', 'modeling', 'jobs', 'in', 'New', 'York', 'City.', 'In', 'the', 'end', 'I', 'never', 'became', 'a', 'model.'], ['edited_ending:', 'I', 'never', 'wanted', 'to', 'wear', 'black', 'heels', 'again.', 'Then', 'one', 'day', 'I', 'saw', 'nicer', 'ones.', 'I', 'was', 'thrilled.'], ['edited_ending:', 'Cornelius', 'decided', 'maybe', 'he', 'should', 'try', 'eating', 'pickles.', 'He', 'bought', 'a', 'wide', 'variety', 'of', 'pickles', 'and', 'tasted', 'them', 'all.', 'While', 'he', \"didn't\", 'love', 'the', 'pickles,', 'he', 'was', 'happy', 'to', 'have', 'tried', 'them.'], ['edited_ending:', 'Sue', 'found', 'out', 'that', 'Kathy', 'was', 'telling', 'people', 'what', 'she', 'did.', 'Kathy', 'and', 'Sue', 'got', 'into', 'an', 'argument.', 'Kathy', 'never', 'talked', 'to', 'Sue', 'again.'], ['edited_ending:', 'Her', 'nosy', 'friend', 'found', 'out', 'and', 'took', 'a', 'picture.', 'Her', 'friend', 'posted', 'the', 'picture', 'on', 'the', 'internet.', 'Somebody', 'made', 'glasses', 'from', 'the', 'picture', 'on', 'the', 'internet.'], ['edited_ending:', 'Macy', 'studied', 'very', 'for', 'only', 'a', 'few', 'hours', 'and', 'was', 'really', 'scared.', 'Macy', 'wonder', 'whether', 'she', 'would', 'do', 'okay.', 'Finally', 'Macy', 'did', 'terrible', 'when', 'she', 'ended', 'up', 'taking', 'it.'], ['edited_ending:', 'Tanner', \"didn't\", 'move', 'in', 'and', 'live', 'in', 'the', 'home.', 'Suddenly', 'he', 'received', 'a', 'letter', 'saying', 'he', 'could', 'move', 'in', 'within', '30', 'days.', 'The', 'homeowner', 'decided', 'to', 'sell', 'the', 'home', 'to', 'Tanner', 'and', 'Tanner', 'was', 'no', 'longer', 'homeless.'], ['edited_ending:', 'She', 'had', 'gone', 'to', 'the', 'store', 'earlier', 'and', 'bought', 'some', 'snacks.', 'She', 'gobbled', 'them', 'up.', 'She', 'was', 'full', 'but', \"wasn't\", 'sure', 'what', \"she'd\", 'eat', 'later.'], ['edited_ending:', 'Gary', 'forgot', 'most', 'of', 'his', 'magic', 'equipment.', 'For', 'his', 'only', 'trick,', 'Gary', 'made', 'the', 'doll', 'house', 'that', 'his', 'niece', 'wanted', 'appear.', 'Gary', 'was', 'glad', 'to', 'see', 'how', 'excited', 'his', 'niece', 'was', 'because', 'of', 'his', 'magic', 'trick.'], ['edited_ending:', 'The', 'fact', 'that', 'it', 'was', 'closed', 'unnerved', 'her.', 'But', 'then', 'one', 'escaped', 'and', 'landed', 'on', 'her', 'hand', 'and', 'flapped', 'its', 'delicate', 'wings.', 'Kim,', 'enchanted,', 'immediately', 'fell', 'in', 'love', 'with', 'the', 'butterflies!'], ['edited_ending:', 'Willy', 'tried', 'gluing', 'the', 'broken', 'vase', 'together.', 'When', 'his', 'mother', 'came', 'in,', 'she', 'saw', 'the', 'identical', 'vase', 'and', \"didn't\", 'see', 'anything', 'wrong.', 'Willy', 'never', 'did', 'fix', 'the', 'old', 'vase.'], ['edited_ending:', 'She', 'made', 'ten', 'different', 'cakes', 'instead.', 'It', 'was', 'great.', 'Lisa', 'loved', 'it.'], ['edited_ending:', 'It', 'was', 'so', 'expensive,', 'they', 'all', 'were.', 'He', 'had', 'thought', 'about', 'getting', 'a', 'cheap', 'one', 'from', 'a', 'Chinese', 'website.', 'But', 'he', 'thought', 'it', 'would', 'fall', 'apart', 'after', 'a', 'few', 'weeks.'], ['edited_ending:', 'They', 'had', 'a', 'great', 'time', 'dancing', 'together.', 'A', 'few', 'months', 'later', 'Erik', 'and', 'Carl', 'got', 'married.', 'They', 'go', 'dancing', 'every', 'weekend.'], ['edited_ending:', 'Joe', 'missed', 'the', 'first', 'shot.', 'Joe', 'cocked', 'back', 'quickly', 'and', 'let', 'this', 'second', 'shot', 'fly.', 'The', 'shot', 'went', 'in', 'and', 'Joe', 'helped', 'his', 'team', 'win', 'the', 'game.'], ['edited_ending:', 'The', 'next', 'month,', 'he', 'took', 'his', 'kites', 'out', 'of', 'storage', 'and', 'walked', 'to', 'an', 'empty', 'field.', 'Soon', 'his', 'kite', 'was', 'soaring', 'high', 'in', 'the', 'sky.', 'Adam', 'felt', 'at', 'home,', 'to', 'his', 'surprise.'], ['edited_ending:', 'She', 'took', 'him', 'to', 'the', 'zoo', 'instead.', 'She', 'bought', 'him', 'a', 'stuffed', 'giraffe.', 'She', 'let', 'him', 'touch', 'the', 'stingrays.'], ['edited_ending:', 'His', 'favorite', 'cake', 'was', 'chocolate', 'with', 'peanut-butter', 'frosting.', 'Jason', 'noticed', 'that', 'he', 'had', 'all', 'the', 'needed', 'ingredients', 'in', 'his', 'kitchen.', 'Jason', 'baked', 'the', 'cake', 'and', 'ate', 'it', 'after', 'having', 'dinner.'], ['edited_ending:', 'He', 'still', 'took', 'more', 'risks', 'in', 'the', 'future.', 'They', 'all', 'turned', 'out', 'well.', 'He', 'called', 'himself', 'lucky.'], ['edited_ending:', 'She', 'made', 'six', 'dishes', 'for', 'herself', 'the', 'week.', 'Her', 'co', 'workers', 'all', 'brought', 'their', 'own', 'food,', 'too.', 'They', 'all', 'ate', 'and', 'drank', 'during', 'lunch.'], ['edited_ending:', 'The', 'boy', 'continued', 'to', 'play', 'with', 'the', 'frisbee', 'inside.', 'He', 'bounced', 'it', 'off', 'a', 'wall', 'and', 'tried', 'to', 'catch', 'it.', 'He', 'missed', 'badly', 'and', 'the', 'frisbee', 'took', 'out', 'a', 'lamp.'], ['edited_ending:', 'The', 'doctor', 'makes', 'the', 'decision', 'to', 'get', 'the', 'baby', 'out', 'immediately.', 'I', 'wake', 'up', 'my', 'wife,', 'and', 'get', 'her', 'to', 'the', 'car', 'in', 'a', 'hurry.', 'I', 'storm', 'off', 'quickly,', 'until', 'the', 'hospital', 'lights', 'shimmer', 'in', 'the', 'distance.'], ['edited_ending:', 'Simon', 'was', 'glad', 'because', 'he', \"didn't\", 'have', 'a', 'good', 'hand', 'either.', 'Scott', 'really', 'needed', 'money', 'so', \"wasn't\", 'going', 'to', 'chance', 'everything', 'on', 'a', 'band', 'hand.', 'Scott', 'refused', 'to', 'lose', 'more', 'money', 'than', 'necessary.'], ['edited_ending:', 'She', 'decided', 'she', 'would', 'check', 'it', 'out.', 'Kelly', 'realized', 'it', 'was', 'more', 'for', 'younger', 'kids.', 'It', \"didn't\", 'matter', 'to', 'her', 'because', 'she', 'had', 'a', 'great', 'time', 'watching', 'it.'], ['edited_ending:', 'Everyday', 'he', 'asks', 'me', 'if', 'I', 'want', 'more', 'children,', 'and', 'I', 'tell', 'him.', 'Yesterday', 'he', 'asked', 'him', 'how', 'my', 'two', 'kids', 'were', 'doing.', 'I', 'was', 'surprised,', 'and', 'pleased.'], ['edited_ending:', 'She', 'watched', 'as', 'it', 'crept', 'down', 'the', 'street.', 'She', 'called', 'her', 'dad', 'to', 'ask', 'what', 'he', 'was', 'doing.', 'He', 'said', 'he', 'was', 'keeping', 'an', 'eye', 'out', 'for', 'her.'], ['edited_ending:', 'I', 'have', 'always', 'won', 'against', 'her.', 'Today,', 'my', 'sister', 'won.', 'I', 'do', 'not', 'love', 'to', 'play', 'checkers', 'any', 'more.'], ['edited_ending:', 'I', 'also', 'spent', 'little', 'time', 'baking', 'it.', 'The', 'cake', 'looked', 'like', 'garbage.', 'He', 'ended', 'up', 'hating', 'how', 'it', 'tasted.'], ['edited_ending:', 'He', 'docked', 'his', 'boat', 'at', 'the', 'local', 'marina.', 'Harry', \"didn't\", 'know', 'the', 'laws', 'of', 'scuba', 'diving,', 'but', 'dove', 'anyway.', 'He', 'loved', 'scuba', 'diving!'], ['edited_ending:', 'They', 'held', 'signs', 'and', 'chanted.', 'They', 'were', 'passionate', 'about', 'their', 'cause.', 'The', 'media', 'agreed', 'they', 'were', 'great.'], ['edited_ending:', 'The', 'assistant', 'came', 'prepared', 'with', 'a', 'shotgun.', 'The', 'assistant', 'pointed', 'the', 'shotgun', 'and', 'asked', 'him', 'to', 'leave.', 'John', 'was', 'scared', 'and', 'so', 'he', 'left', 'and', 'the', 'clerk', 'called', 'the', 'police.'], ['edited_ending:', 'When', 'they', 'got', 'there', 'it', 'was', 'okay.', 'Yet', 'unfortunately', \"Eric's\", 'daughter', 'started', 'to', 'cry.', 'The', 'big', 'slide', 'was', 'too', 'scary', 'for', 'her.'], ['edited_ending:', 'Despite', 'her', 'caution,', 'she', 'shook', 'the', 'floorboards.', 'The', 'room', 'shook,', 'and', 'a', 'vase', 'toppled', 'to', 'the', 'floor.', 'Luckily,', 'it', 'remained', 'intact,', 'much', 'to', 'her', 'relief.'], ['edited_ending:', 'He', 'was', 'sick', 'all', 'that', 'night', 'and', 'had', 'to', 'call', 'in', 'sick', 'to', 'work.', 'He', 'feels', 'better', 'now,', 'fortunately.', 'He', 'will', 'never', 'go', 'back', 'to', 'that', 'specific', 'restaurant', 'ever', 'again.'], ['edited_ending:', 'He', 'fell', 'with', 'a', 'thud', 'as', 'he', 'tripped', 'leaving.', 'She', 'yelled', 'at', 'him,', 'telling', 'him', 'to', 'clean', 'up', 'the', 'mess', 'he', 'made.', 'Mike', \"didn't\", 'say', 'anything,', 'but', 'barely', 'seemed', 'affected', 'by', 'the', 'incident.'], ['edited_ending:', 'Sandy', 'kept', 'an', 'eye', 'on', 'the', 'water', 'in', 'case', 'it', 'inched', 'closer', 'to', 'her', 'home.', 'She', 'knew', 'if', 'it', 'did', 'they', 'would', 'need', 'to', 'evacuate', 'before', 'they', 'had', 'no', 'way', 'out.', 'Packing', 'all', 'their', 'things,', 'they', 'watched', 'in', 'case', 'water', 'seeped', 'into', 'their', 'home.'], ['edited_ending:', 'She', 'was', 'given', 'tickets', 'to', 'the', 'symphony,', 'and', 'luckily', 'her', 'friend', 'wanted', 'to', 'go.', 'Miranda', 'and', 'her', 'friend', 'then', 'attended', 'on', 'Saturday.', 'It', 'was', 'impeccable.'], ['edited_ending:', 'The', 'chainsaw', 'had', 'caused', 'the', 'tree', 'to', 'vibrate', 'so', 'they', \"couldn't\", 'control', 'it.', 'A', 'different', 'branch', 'that', 'the', 'one', 'they', 'caught', 'was', 'about', 'to', 'fall.', 'Disgusted', 'about', 'the', 'damage', 'they', 'already', 'caused', 'they', 'put', 'the', 'chainsaw', 'away', 'and', 'decided', 'to', 'finish', 'later'], ['edited_ending:', 'She', 'also', 'went', 'on', 'a', 'diet', 'that', 'only', 'included', 'healthy', 'food.', 'She', 'ended', 'up', 'losing', '10', 'pounds', 'in', '2months.', 'Roxy', 'is', 'now', 'happy', 'with', 'the', 'way', 'her', 'body', 'looks.'], ['edited_ending:', 'The', 'day', 'of', 'the', 'meeting,', 'Dan', 'arrived', 'early.', 'Dan', 'decided', 'to', 'call', 'his', 'banker', 'and', 'let', 'them', 'know', 'they', 'were', 'there.', 'Dan', 'felt', 'great', 'about', 'attending', 'a', 'very', 'important', 'meeting', 'with', 'his', 'banker.'], ['edited_ending:', 'Nick', 'called', 'his', 'dad', 'and', 'asked', 'him', 'to', 'meet', 'him', 'at', 'the', 'rental', 'company.', 'His', 'dad', 'agreed.', 'They', 'went', 'to', 'return', 'the', 'car', 'and', 'Nick', 'appreciated', 'the', 'help.'], ['edited_ending:', 'The', 'librarian', 'told', 'him', 'that', 'the', 'book', 'was', 'made', 'into', 'a', 'movie.', 'The', 'librarian', 'tried', 'to', 'sing', 'the', 'movie', 'theme', 'song', 'to', 'the', 'man.', 'The', 'man', 'quickly', 'left', 'the', 'library', 'with', 'the', 'book.'], ['edited_ending:', 'She', 'went', 'outside', 'but', 'it', 'was', 'night', 'time.', 'Sarah', 'decided', 'to', 'go', 'for', 'a', 'walk', 'while', 'eating.', 'She', 'went', 'down', 'the', 'local', 'roads', 'at', 'night.'], ['edited_ending:', 'Lilly', 'got', 'a', 'free', 'one', 'and', 'practiced', 'very', 'consistently.', 'Lilly', 'learned', 'some', 'really', 'tough', 'pieces.', 'In', 'six', 'months,', 'Lilly', 'was', 'auditioning', 'for', 'the', 'state', 'orchestra!'], ['edited_ending:', 'When', 'he', 'got', 'there,', 'no', 'one', 'was', 'waiting.', 'Gabe', 'called', 'the', 'dispatcher.', 'He', 'was', 'at', 'the', 'wrong', 'airport!'], ['edited_ending:', 'The', 'men', 'had', 'very', 'little', 'else', 'to', 'do', 'so', 'Alex', \"couldn't.\", 'They', 'assigned', 'watching', 'shifts', 'for', 'each', 'man.', 'On', 'one', 'shift,', 'Alex', 'had', 'to', 'work', 'all', 'day.'], ['edited_ending:', 'Miles', 'orders', 'asparagus', 'one', 'night', 'for', 'dinner.', 'He', 'is', 'glad', 'to', 'be', 'eating', 'more', 'vegetables.', 'Miles', 'is', 'proud', 'he', 'did', 'not', 'order', 'red', 'meat.'], ['edited_ending:', 'She', 'agreed', 'so', 'we', 'got', 'in', 'the', 'car', 'and', 'were', 'on', 'our', 'way.', 'When', 'I', 'reached', 'the', 'destination', 'we', 'said', 'our', 'goodbyes', 'and', 'I', 'got', 'out.', 'Later,', 'I', 'called', 'her', 'at', 'her', 'hotel', 'to', 'tell', 'her', 'everything', 'was', 'going', 'fine.'], ['edited_ending:', 'He', 'never', 'found', 'Joe,', 'so', 'he', 'thought', 'he', 'must', 'have', 'found', 'the', 'perfect', 'spot.', 'He', 'finally', 'went', 'back', 'inside', 'the', 'house', 'to', 'find', 'Joe', 'at', 'the', 'table.', 'He', 'was', 'eating', 'cookies', 'and', 'had', 'got', 'tired', 'of', 'hiding.'], ['edited_ending:', 'When', 'she', 'got', 'back', 'to', 'work', 'she', 'noticed', 'that', 'the', 'tip', 'from', 'another', 'customer', 'included', 'a', 'ring.', 'She', 'realized', 'that', 'the', 'person', 'had', 'accidentally', 'given', 'their', 'diamond', 'ring.', 'Shannon', 'returned', 'the', 'ring', 'to', 'the', 'ever', 'so', 'thankful', 'pizza', 'eater.'], ['edited_ending:', 'He', 'decided', 'to', 'go', 'get', 'salad.', 'He', 'went', 'to', 'a', 'local', 'restaurant', 'and', 'ordered', 'one.', 'He', 'gobbled', 'it', 'up', 'in', 'record', 'time.'], ['edited_ending:', 'He', 'was', 'worried', 'about', 'paying', 'too', 'much', 'for', 'insurance', 'on', 'a', 'great', 'house.', 'His', 'friend', 'recommended', 'he', 'check', 'his', 'cheap', \"homeowner's\", 'insurance.', 'Fortunately,', 'the', 'cost', 'of', 'insurance', 'was', 'covered', 'by', \"Michael's\", 'salary.'], ['edited_ending:', 'Mark', 'loves', 'his', 'new', 'fish.', 'He', 'feels', 'less', 'lonely', 'now', 'that', 'he', 'has', 'a', 'fish.', 'He', 'is', 'glad', 'that', 'he', 'got', 'a', 'pet.'], ['edited_ending:', 'He', 'still', 'needed', 'a', 'change,', 'so', 'he', 'sold', 'the', 'big', 'house.', 'He', 'also', 'sold', 'his', 'large', 'scale', 'items', 'and', 'bought', 'a', 'tiny', 'house.', 'Surprisingly,', 'Sergio', 'was', 'happy', 'with', 'his', 'new', 'digs', 'and', 'settled', 'in.'], ['edited_ending:', 'Of', 'course,', 'that', 'was', 'only', 'until', 'she', 'was', 'pushed', 'to', 'learn', 'about', 'computers', 'and', 'technology.', 'The', 'transfer', 'complete,', 'she', 'yanked', 'the', 'thumb', 'drive.', 'Tomorrow', 'she', 'would', 'be', 'wealthy', 'and', 'beyond', 'redemption.'], ['edited_ending:', 'She', 'had', 'beat', 'cancer.', 'Seeing', 'her', 'healthy', 'was', 'wonderful.', 'We', 'looked', 'forward', 'to', 'seeing', 'her', 'again.'], ['edited_ending:', 'Later', \"Luke's\", 'dad', 'found', 'him', 'climbing', 'the', 'ladder', 'to', 'find', 'the', 'cat.', 'His', 'dad', 'stopped', 'Luke', 'just', 'as', 'he', 'was', 'about', 'to', 'fall.', 'Luke', 'was', 'sad', 'that', 'the', 'cat', 'was', 'not', 'on', 'the', 'roof.'], ['edited_ending:', 'Joan', 'ordered', 'the', 'same', 'thing', 'from', 'the', 'same', 'barista', 'everyday.', 'Joan', 'had', 'always', 'thought', 'he', 'looked', 'goofy.', 'He', 'finally', 'worked', 'up', 'the', 'courage', 'to', 'ask', 'her', 'on', 'a', 'date', 'and', 'she', 'said', 'no.'], ['edited_ending:', 'I', 'felt', 'I', 'would', 'connect', 'with', 'everyone', 'and', 'make', 'friends.', 'I', 'met', 'David', 'while', 'practicing', 'a', 'play.', 'David', 'and', 'I', 'have', 'been', 'great', 'friends', 'all', 'summer.'], ['edited_ending:', 'She', \"didn't\", 'have', 'to', 'work', 'at', 'night', 'any', 'more.', 'She', 'was', 'full', 'of', 'energy', 'every', 'day.', 'She', 'was', 'happy', 'to', 'find', 'such', 'a', 'great', 'paying', 'job.'], ['edited_ending:', 'The', 'shop', 'teacher', 'nodded', 'on', 'in', 'approval.', 'Will', 'continued', 'refurbishing', 'diligently', 'for', 'the', 'whole', 'period.', 'He', 'was', 'happy', 'that', 'he', 'decided', 'to', 'take', 'shop', 'class', 'instead', 'of', 'art.'], ['edited_ending:', 'Mark', 'finally', 'cleaned', 'up', 'and', 'told', 'his', 'landlord', 'about', 'the', 'leak', 'because', 'he', 'did', 'a', 'bad', 'job.', 'A', 'plumber', 'came', 'over', 'and', 'Mark', 'was', 'glad', 'to', 'finally', 'have', 'it', 'fixed.', 'But', 'a', 'week', 'later', 'when', 'Mark', 'did', 'dishes', 'the', 'leak', 'came', 'back', 'even', 'worse.'], ['edited_ending:', 'Then', 'she', 'mopped', 'her', 'floors.', 'After', 'that', 'she', 'started', 'cooking', 'dinner.', 'Within', 'a', 'few', 'hours,', 'the', 'house', 'was', 'spotless.'], ['edited_ending:', 'Marcy', 'watched', 'the', 'clock.', 'It', 'said', 'three', \"o'clock.\", 'Marcy', 'knew', 'how', 'to', 'tell', 'time!'], ['edited_ending:', 'The', 'womman', 'ran', 'a', 'small', 'newspaper,', 'and', 'she', 'trained', 'David', 'to', 'be', 'a', 'reporter.', 'David', 'lived', 'at', 'the', \"woman's\", 'house', 'while', 'he', 'was', 'learning', 'the', 'business.', 'The', 'woman', 'had', 'a', 'daughter', 'around', \"David's\", 'age,', 'and', 'they', 'fell', 'in', 'love.'], ['edited_ending:', 'I', 'had', 'been', 'afraid', 'I', \"wouldn't\", 'like', 'it', 'once', 'I', 'got', 'home.', 'I', 'was', 'glad', 'I', \"didn't\", 'have', 'to', 'go', 'back', 'and', 'return', 'it.', 'Thankfully', 'I', 'wanted', 'to', 'keep', 'it.'], ['edited_ending:', 'People', 'kept', 'looking', 'at', 'her.', 'She', 'found', 'a', 'man', 'with', 'a', 'longer', 'nose', 'and', 'married', 'him.', 'Since', 'then,', 'people', 'look', 'at', 'both', 'of', 'them', 'and', 'Josephine', 'still', \"doesn't\", 'care.'], ['edited_ending:', 'She', 'met', 'her', 'date', 'James', 'at', 'a', 'restaurant', 'for', 'dinner,', 'then', 'a', 'movie.', 'Both', 'people', 'had', 'an', 'awful', 'time!', 'They', 'had', 'no', 'intentions', 'on', 'planning', 'a', 'second', 'date!'], ['edited_ending:', 'Within', 'two', 'weeks', 'he', 'received', 'a', 'message', 'that', 'stated', 'he', 'used', 'a', 'lot', 'of', 'data.', 'He', 'was', 'not', 'disappointed', 'because', 'he', 'could', 'still', 'get', 'on', 'the', 'internet.', 'He', \"didn't\", 'have', 'to', 'add', 'more', 'data', 'to', 'his', 'plan,', 'he', 'can', 'use', 'it', 'again.'], ['edited_ending:', 'George', 'gave', 'the', 'collection', 'of', 'celebrity', 'paintings', 'to', 'Marie', 'as', 'a', 'present.', 'An', 'art', 'collector', 'offered', 'Marie', '$15,000', 'for', 'the', 'paintings.', 'Marie', 'loved', 'the', 'paintings', 'too', 'much', 'to', 'sell', 'any', 'of', 'them.'], ['edited_ending:', 'She', 'was', 'pulling', 'and', 'pulling', 'but', 'the', 'zipper', \"wouldn't\", 'close.', 'She', 'tugged', 'hard', 'at', 'the', 'zipper.', 'She', 'was', 'shocked', 'to', 'see', 'that', 'one', 'of', 'her', 'few', 'pieces', 'of', 'clothing', 'got', 'stuck', 'in', 'the', 'zipper.'], ['edited_ending:', 'His', 'car', 'was', 'stolen,', 'but', 'at', 'least', 'he', 'had', 'the', 'suitcase.', 'Jeff', 'was', 'relieved', 'because', 'of', 'how', 'much', 'money', 'was', 'in', 'the', 'suitcase.', 'Jeff', 'went', 'to', 'the', 'police', 'about', 'the', 'car,', 'but', 'they', \"couldn't\", 'help', 'him.'], ['edited_ending:', 'It', 'took', 'a', 'long', 'time', 'to', 'make', 'the', 'orange', 'juice,', 'very', 'little', 'juice', 'was', 'coming', 'out.', 'but', 'it', 'was', 'worth', 'it', 'though', 'because', 'the', 'juice', 'was', 'delicious.', 'I', 'will', 'make', 'my', 'own', 'juice', 'tomorrow', 'morning', 'as', 'well.'], ['edited_ending:', 'The', 'master', 'caught', 'up', 'to', 'him.', 'The', 'master', 'berated', 'the', 'slave', 'for', 'his', 'slacking', 'off', 'and', 'running', 'away.', 'The', 'master', 'said', \"he'll\", 'reduce', 'the', 'water', 'ration', 'from', '35', 'to', '23', 'ounces.'], ['edited_ending:', 'She', 'decided', 'she', 'needed', 'a', 'break', 'and', 'would', 'head', 'to', 'Las', 'Vegas.', 'She', 'had', 'a', 'lot', 'of', 'fun', 'in', 'Las', 'Vegas.', 'She', 'will', 'never', 'forget', 'all', 'the', 'fun', 'she', 'had', 'in', 'Las', 'Vegas.'], ['edited_ending:', 'At', 'the', 'beer', 'tasting,', 'he', \"didn't\", 'sample', 'any', 'beers.', 'It', 'was', 'one', 'of', 'the', 'most', 'boring', 'days', 'of', 'his', 'life.', 'Hubert', 'decided', 'he', 'wanted', 'to', 'sample', 'beer', 'as', 'soon', 'as', 'possible.'], ['edited_ending:', 'The', 'entire', 'front', 'end', 'of', 'the', 'car', 'was', 'damaged', 'so', 'she', 'had', 'to', 'call', 'a', 'wrecker.', 'The', 'wrecker', 'took', 'her', 'to', 'the', 'nearest', 'store', 'so', 'she', 'could', 'fix', 'the', 'car.', 'She', 'made', 'it', 'to', 'the', 'store', 'but', 'not', 'how', 'she', 'had', 'hoped.'], ['edited_ending:', 'It', 'had', 'been', 'a', 'harsh', 'spring,', 'so', 'they', 'were', 'very', 'active', 'looking', 'for', 'food.', 'Margaret', 'spotted', 'several', 'of', 'each', 'species.', 'She', 'wrote', 'about', 'it', 'in', 'her', 'field', 'journal.'], ['edited_ending:', 'It', 'has', 'problems', 'again,', 'so', 'she', 'decided', 'to', 'bring', 'it', 'into', 'a', 'shop', 'to', 'be', 'fixed.', 'After', 'two', 'hours', 'of', 'waiting,', 'she', 'was', 'called', 'back', 'to', 'the', 'store.', 'Her', 'computer', 'had', 'been', 'repaired,', 'and', 'she', 'happily', 'continued', 'her', 'day.'], ['edited_ending:', 'Lauren', 'then', 'asked', 'her', 'husband', 'if', 'they', 'could', 'alternate', 'every', 'week.', 'He', 'disagreed', 'and', 'said', 'it', 'was', 'a', 'bad', 'idea.', 'Household', 'chores', 'are', 'still', 'distributed', 'unevenly.'], ['edited_ending:', 'She', 'was', 'waiting', 'for', 'the', 'divorce', 'for', 'a', 'long', 'time.', 'She', 'gathered', 'up', 'the', 'papers', 'and', 'shook', 'hands', 'with', 'her', 'lawyer.', 'Walking', 'out', 'of', 'the', \"attorney's\", 'office,', 'Meg', 'was', 'on', 'cloud', 'nine.'], ['edited_ending:', 'She', 'brought', 'a', 'lot', 'of', 'gifts.', 'She', 'filled', 'her', 'suitcase', 'up', 'and', 'tried', 'to', 'close', 'it.', 'To', 'her', 'horror', 'her', 'suitcase', \"wouldn't\", 'close.'], ['edited_ending:', 'When', 'he', 'gave', 'them', 'away,', 'he', 'saw', 'a', 'lot', 'of', 'people', 'already', 'waiting', 'for', 'them.', 'Nigel', 'was', 'apprehensive', 'about', 'giving', 'them', 'away', 'because', 'of', 'this.', 'Nigel', 'actually', 'had', 'a', 'tough', 'time', 'giving', 'them', 'away.'], ['edited_ending:', 'They', 'walked', 'up', 'and', 'through', 'the', 'hill.', 'After', 'a', 'while', 'they', 'made', 'it', 'to', 'a', 'canyon', 'where', 'they', 'sat', 'for', 'a', 'while.', 'When', 'they', 'were', 'done', 'they', 'hiked', 'back', 'to', 'their', 'car.'], ['edited_ending:', 'He', 'bought', 'all', 'the', 'materials', 'that', 'he', 'imagined', 'he', 'would', 'need.', 'As', 'he', 'began', 'to', 'start,', 'he', 'noticed', 'he', 'had', 'forgotten', 'to', 'buy', 'paint.', 'He', 'wondered', 'aloud', 'how', 'he', 'could', 'forget', 'such', 'a', 'crucial', 'item.'], ['edited_ending:', 'Jax', 'started', 'dating', 'Tommy', 'as', 'well.', 'Jax', 'decided', 'he', 'liked', 'Tommy', 'more.', 'So', 'Jax', 'broke', 'up', 'with', 'Carmen.'], ['edited_ending:', 'The', 'wind', 'blew', 'the', 'umbrella', 'over', 'when', 'she', 'was', 'asleep.', 'She', 'woke', 'up', 'with', 'a', 'sunburn.', 'She', 'put', 'lotion', 'all', 'over', 'her', 'sunburn.'], ['edited_ending:', 'We', 'found', 'some', 'very', 'cute', 'puppies', 'that', 'we', 'both', 'wanted.', 'Unfortunately', 'they', 'were', 'both', 'already', 'sold', 'so', 'we', \"didn't\", 'get', 'any.', 'The', 'next', 'day', 'we', 'went', 'back', 'and', 'got', 'the', 'cutest', 'puppy', 'ever.'], ['edited_ending:', 'He', 'watched', 'the', 'man.', 'The', 'man', 'noticed', 'him', 'watching.', 'He', 'called', 'the', 'police.'], ['edited_ending:', 'His', 'friend', 'forced', 'him', 'to', 'try', 'the', 'claw', 'machine', 'and', 'he', 'lined', 'the', 'claw', 'up', 'over', 'a', 'giant', 'stuffed', 'pig.', 'The', 'claw', 'dropped', 'down', 'and', 'squeezed', 'the', 'pig.', 'As', 'Jack', 'expected,', 'the', 'pig', 'slipped', 'from', 'the', 'claw', 'just', 'as', 'it', 'reached', 'the', 'chute.'], ['edited_ending:', 'Oil', 'got', 'all', 'over', 'his', 'boots.', 'Clay', 'slipped', 'on', 'the', 'wet', 'pavement', 'latter', 'with', 'his', 'oily', 'boots.', 'Clay', 'broke', 'his', 'arm', 'in', 'the', 'fall.'], ['edited_ending:', 'He', 'interviewed', 'for', 'a', 'position', 'at', 'the', 'local', 'skating', 'rink.', 'He', 'was', 'selected', 'by', 'the', 'dj', 'of', 'the', 'rink.', 'Harold', 'was', 'eager', 'to', 'get', 'to', 'work', 'in', 'the', 'new', 'field!'], ['edited_ending:', 'A', 'nice', 'cop', 'stopped', 'traffic', 'to', 'pick', 'up', 'the', 'dead', 'mother', 'duck', 'and', 'escort', 'the', 'other', 'ducklings', 'to', 'safety.', 'After', 'a', 'few', 'minutes,', 'the', 'surviving', 'ducklings', 'made', 'it', 'across.', 'Everyone', 'cheered', 'for', 'the', 'cop', 'from', 'their', 'cars.'], ['edited_ending:', 'She', 'spoke', 'to', 'everyone', 'she', 'saw', 'to', 'ask', 'them', 'who', 'left', 'the', 'door', 'open.', 'Finally', 'her', 'brother', 'said', 'that', 'he', 'had.', 'Beth', 'was', 'mad', 'at', 'her', 'brother', 'but', 'glad', 'to', 'have', 'her', 'kitten', 'again.'], ['edited_ending:', 'During', 'a', 'test,', 'another', 'student', 'tried', 'to', 'look', 'at', \"Jane's\", 'paper.', 'Jane', 'and', 'the', 'other', 'student', 'got', 'in', 'trouble.', 'Jane', 'cried', 'because', 'she', 'always', 'got', 'in', 'trouble.'], ['edited_ending:', 'She', 'asked', 'her', 'mother', 'if', 'she', 'could', 'buy', 'it', 'for', 'her.', 'Her', 'mother', 'told', 'her', 'to', 'wait', 'a', 'minute', 'and', 'paid', 'for', 'her', 'prescription.', 'Afterward,', 'her', 'mother', 'bought', 'Sally', 'the', 'makeup', 'and', 'they', 'left.'], ['edited_ending:', 'Conner', 'took', 'a', 'ride', 'down', 'the', 'hill', 'on', 'his', 'scooter.', 'He', \"couldn't\", 'handle', 'the', 'speed', 'and', 'he', 'crashed', 'into', 'the', 'stop', 'sign', 'His', 'mother', 'quickly', 'learned', 'she', 'was', 'wrong', 'to', 'let', 'him', 'go', 'down', 'the', 'hill'], ['edited_ending:', 'Mark', 'decided', 'to', 'spend', 'more', 'time', 'reading', 'and', 'doing', 'puzzles.', 'He', 'saved', 'a', 'lot', 'of', 'money', 'every', 'month.', 'Mark', 'used', 'the', 'money', 'he', 'saved', 'to', 'take', 'his', 'girlfriend', 'out.'], ['edited_ending:', 'He', 'wrote', 'the', 'song', 'for', 'her.', 'He', 'decided', 'she', 'could', 'never', 'hear', 'the', 'song.', 'He', 'was', 'too', 'shy.'], ['edited_ending:', 'She', 'thought', \"it'd\", 'be', 'hard,', 'but', 'the', 'presentation', 'was', 'easy', 'to', 'make.', 'She', 'presented', 'it', 'well', 'to', 'her', 'class.', 'Anna', 'got', 'a', 'grade', 'of', 'A+!'], ['edited_ending:', 'One', 'day', 'while', 'walking', 'he', 'gets', 'stopped', 'by', 'an', 'old', 'man', 'on', 'the', 'street.', 'The', 'old', 'man', 'compliments', 'him', 'on', 'his', 'new', 'shoes.', 'The', 'old', 'man', 'asks', 'to', 'buy', \"Rodney's\", 'shoes.'], ['edited_ending:', 'He', 'waited', 'for', 'everybody', 'to', 'get', 'home.', 'He', 'read', 'the', 'letter', 'a', 'second', 'time,', 'but', 'this', 'time', 'in', 'front', 'of', 'his', 'family.', 'Everyone', 'was', 'proud', 'that', 'he', 'was', 'accepted.'], ['edited_ending:', 'James', 'put', 'on', 'his', 'uniform', 'and', 'headed', 'out', 'the', 'door.', 'During', 'the', 'drive,', 'he', 'was', 'tired', 'but', 'nervous', 'about', 'his', 'last', 'day.', 'When', 'he', 'arrived', 'at', 'work,', 'he', 'realized', 'his', 'shirt', 'was', 'on', 'backwards.'], ['edited_ending:', 'The', 'teacher', 'called', 'home', 'to', 'tell', 'his', 'parents', 'how', 'well', 'he', 'did', 'on', 'his', 'test.', 'He', 'asked', 'his', 'parents', 'when', 'he', 'got', 'home', 'to', 'if', 'he', 'can', 'go', 'play', 'ball.', 'His', 'parents', 'let', 'him', 'play', 'because', 'he', 'did', 'so', 'great', 'on', 'his', 'test.'], ['edited_ending:', 'He', 'decides', 'to', 'buy', 'a', 'ticket.', 'He', 'spends', 'all', 'day', 'there,', 'then', 'goes', 'home', 'and', 'goes', 'to', 'sleep.', 'The', 'next', 'day', 'he', 'wakes', 'up', 'and', 'sees', 'that', 'his', 'ticket', 'allows', 'admission', 'for', 'a', 'second', 'day!'], ['edited_ending:', 'Her', 'GPS', 'was', 'useless', 'and', 'her', 'map', 'was', 'gibberish', 'to', 'her!', 'Finally', 'she', 'asked', 'an', 'old', 'man', 'at', 'a', 'corner', 'store', 'for', 'directions.', 'He', 'helped', 'her', 'get', 'home,', 'which', 'luckily', 'was', 'not', 'far!'], ['edited_ending:', 'He', 'went', 'online', 'and', 'found', 'a', 'flirting', 'method.', 'Empowered', 'with', 'confidence,', 'he', 'tried', 'a', 'line', 'on', 'his', 'date.', 'She', 'kissed', 'him', 'on', 'the', 'face', 'and', 'Robert', 'ended', 'up', 'marrying', 'her.'], ['edited_ending:', 'She', 'picked', 'a', 'plan', 'that', 'sent', 'all', 'the', 'workouts', 'each', 'week.', 'She', 'stuck', 'to', 'the', 'plan', 'for', 'a', 'month', 'and', 'never', 'cheated.', 'That', 'month,', 'Diane', 'lost', 'twelve', 'pounds.'], ['edited_ending:', 'The', 'brakes', 'got', 'stuck', 'in', 'his', 'bike.', 'The', 'man', 'could', 'not', 'stop.', 'He', 'crashed', 'his', 'bike', 'into', 'a', 'tree.'], ['edited_ending:', 'I', 'never', 'learned', 'the', 'importance', 'of', 'practicing.', 'Now', 'I', 'hate', 'to', 'practice', 'things.', 'I', \"don't\", 'know', 'how', 'to', 'get', 'better', 'at', 'the', 'thing', 'I', 'like', 'to', 'do.'], ['edited_ending:', 'So', 'I', \"didn't\", 'need', 'to', 'remember', 'to', 'spray', 'it.', 'I', 'immediately', 'spread', 'the', 'oil', 'around.', 'As', 'soon', 'as', 'I', 'did', 'that,', 'flames', 'erupted.'], ['edited_ending:', 'After', 'I', 'got', 'out', 'of', 'jail,', 'I', 'decided', 'to', 'prove', 'to', 'that', 'teacher', 'that', 'I', 'would', 'amount', 'to', 'something.', 'I', 'went', 'to', 'law', 'school', 'and', 'studied', 'hard.', 'I', 'became', 'the', 'best', 'attorney', 'in', 'the', 'country.'], ['edited_ending:', 'One', 'night', 'she', 'decides', 'to', 'knit', 'a', 'sweater', 'and', 'got', 'a', 'call', 'from', 'her', 'sister.', 'Her', 'sister', 'called', 'to', 'ask', 'her', 'to', 'dinner.', 'Mary', 'is', 'actually', 'happy', 'that', 'her', 'sister', 'wants', 'to', 'speak', 'to', 'her', 'again.'], ['edited_ending:', 'When', 'the', 'teacher', 'got', 'mad', 'at', 'Peter', 'he', 'would', 'make', 'Peter', 'run', 'laps.', 'Peter', 'figured', 'that', 'he', 'just', 'had', 'to', 'skip', 'class.', 'Peter', 'skipped', 'class', 'and', 'the', 'teacher', \"doesn't\", 'get', 'mad', 'at', 'him!'], ['edited_ending:', 'She', 'quickly', 'picked', 'it', 'up', 'and', 'examined', 'it.', 'The', 'screen', 'was', 'fine,', 'and', 'the', 'rest', 'appeared', 'to', 'work.', 'Kelly', 'decided', 'that', 'she', 'had', 'been', 'lucky.'], ['edited_ending:', 'She', 'had', 'gotten', 'a', 'full', 'scholarship', 'to', 'a', 'University.', 'Now', 'Samira', 'is', 'studying', 'to', 'become', 'an', 'Engineer.', \"She's\", 'very', 'thankful', 'for', 'all', 'of', 'her', 'natural', 'gifts.'], ['edited_ending:', 'Then', 'she', 'remembered', 'that', 'one', 'time', 'she', 'faked', 'being', 'happy.', 'To', 'her', 'surprise', 'it', 'actually', 'helped', 'her', 'to', 'feel', 'even', 'better.', 'Now', 'she', 'fakes', 'to', 'be', 'happy', 'anytime', \"she's\", 'feeling', 'sad.'], ['edited_ending:', 'Five', 'years', 'later', 'he', 'went', 'back', 'to', 'the', 'bank.', 'He', 'asked', 'to', 'withdraw', 'the', 'rest', 'of', 'the', 'money', 'in', 'his', 'account.', 'The', 'bank', 'teller', 'told', 'him', 'the', 'account', 'was', 'empty'], ['edited_ending:', 'The', 'mosquito', 'was', 'biting', 'and', 'the', 'pain', 'pulled', 'her', 'fully', 'awake.', 'Eyes', 'now', 'open,', 'Mia,', 'threw', 'the', 'blankets', 'off', 'of', 'her.', 'She', 'slapped', 'on', 'her', 'arm', 'and', 'killed', 'the', 'mosquito.'], ['edited_ending:', 'She', 'was', 'so', 'in', 'love', 'with', 'him', 'so', 'she', 'cherished', 'their', 'marriage.', 'Unfortunately,', 'her', 'husband', \"didn't\", 'think', 'that', 'highly', 'of', 'their', 'marriage.', 'He', \"didn't\", 'treat', 'Raquel', 'well,', 'the', 'same', 'way', 'he', 'treated', 'the', 'girl', 'before', 'her.'], ['edited_ending:', 'People', 'began', 'yelling', 'and', 'making', 'demands', 'from', 'outside', 'his', 'door.', 'Eventually', 'security', 'came', 'and', 'took', 'them', 'away.', 'The', 'executive', 'was', 'not', 'interested', 'in', 'hearing', 'their', 'grievanaces'], ['edited_ending:', 'They', 'never', 'argued', 'about', 'when', 'to', 'stop.', 'Now', 'they', \"weren't\", 'talking', 'for', 'a', 'bit.', 'They', 'drove', 'down', 'the', 'highway', 'in', 'silence', 'as', 'a', 'couple', 'of', 'them', 'slept.']]\n"
],
[
"print(pre_corpus)",
"[['edited_ending:', 'Soon,', 'they', 'wanted', 'to', 'spend', 'time', 'with', 'her.', 'She', 'reflected', 'on', 'why', 'she', 'was', 'so', 'kind.', 'She', 'decided', 'she', 'needed', 'to', 'be', 'a', 'nicer', 'person.'], ['edited_ending:', 'Bill', 'congratulated', 'the', 'opposing', 'team.', 'He', 'also', 'went', 'into', 'the', 'locker', 'room', 'to', 'cry.', 'He', \"didn't\", 'tell', 'anyone', 'until', 'the', 'next', 'day.'], ['edited_ending:', 'Then', 'she', 'flew', 'over', 'the', 'fence', 'and', 'vanished.', 'Without', 'a', 'spare,', 'the', 'game', 'was', 'done.', 'They', 'were', 'forced', 'to', 'quit.'], ['edited_ending:', 'She', 'hated', 'helping', 'the', 'people', 'and', 'making', 'them', 'feel', 'more', 'comfortable.', 'One', 'day', 'she', 'witnessed', 'something', 'that', 'she', 'could', 'never', 'forget.', 'She', 'decided', 'she', 'could', 'live', 'with', 'the', 'memories', 'and', 'quit', 'her', 'job.'], ['edited_ending:', 'I', 'tried', 'to', 'stay', 'quiet', 'and', 'not', 'start', 'a', 'problem.', 'I', 'knew', 'what', 'would', 'happen', 'if', 'I', 'did.', 'I', 'kept', 'very', 'still', 'and', 'quiet', 'and', 'it', \"didn't\", 'blow', 'over.'], ['edited_ending:', 'Jeff', \"isn't\", 'the', 'same', 'person', 'anymore.', 'Pam', 'decides', 'she', \"can't\", 'do', 'the', 'marriage', 'anymore', 'and', 'leaves.', 'Pam', 'and', 'Jeff', 'get', 'a', 'divorce', 'and', 'go', 'their', 'own', 'ways.'], ['edited_ending:', 'Then', 'the', 'salesman', 'took', 'my', 'measurements.', 'After', 'taking', 'my', 'measurements', 'I', 'picked', 'out', 'a', 'nice', 'green', 'suit.', 'I', 'paid', 'for', 'the', 'suit', 'and', 'now', 'I', \"can't\", 'wait', 'to', 'wear', 'it!'], ['edited_ending:', 'He', 'ran', 'into', 'a', 'pedestrian.', 'The', 'pedestrian', 'thought', 'he', 'was', 'hurt.', 'He', 'punched', 'the', 'band', 'member.'], ['edited_ending:', 'She', 'decided', 'to', 'go', 'to', 'a', 'party', 'but', \"couldn't\", 'sleep.', 'All', 'of', 'the', 'sudden', 'she', 'got', 'sick', 'on', 'the', 'dance', 'floor.', 'Kelley', 'was', 'very', 'embarrassed.'], ['edited_ending:', 'I', 'spent', 'all', 'day', 'yesterday', 'cooking', 'the', 'food.', 'Unfortunately,', 'I', 'burnt', 'the', 'food.', 'I', \"won't\", 'be', 'able', 'to', 'get', 'new', 'ingredients', 'in', 'time', 'for', \"tomorrow's\", 'party.'], ['edited_ending:', 'On', 'this', 'day,', 'a', 'man', 'jumped', 'from', 'behind', 'the', 'trees', 'and', 'scared', 'him.', 'The', 'boy', 'ran', 'all', 'the', 'way', 'home,', 'crying.', 'The', 'boy', 'grew', 'up', 'to', 'be', 'frightened', 'of', 'the', 'unknown.'], ['edited_ending:', 'All', 'of', 'the', 'sudden', 'she', 'freaked', 'out.', 'She', 'realized', 'her', 'necklace', 'was', 'lost.', 'It', 'took', 'Kate', 'one', 'hour', 'to', 'find', 'it.'], ['edited_ending:', 'The', 'day', 'of', 'prom,', 'Hannah', 'decided', 'to', 'try', 'anyway', 'and', 'put', 'on', 'her', 'perfect', 'dress.', 'When', 'she', 'arrived', 'to', 'prom,', 'she', 'saw', 'another', 'girl', 'had', 'the', 'same', 'dress!', 'Hannah', 'was', 'disappointed', 'and', 'wished', 'she', 'had', 'found', 'a', 'different', 'dress.'], ['edited_ending:', 'Liz', 'had', 'a', 'new', 'car', 'but', \"didn't\", 'want', 'to', 'put', 'a', 'lot', 'of', 'miles', 'on', 'it.', 'She', 'refused', 'to', 'reconsider.', 'In', 'the', 'end', 'they', 'decided', 'to', 'take', \"Kate's\", 'car', 'because', 'it', 'was', 'cheaper.'], ['edited_ending:', 'He', 'did', 'not', 'respond,', 'until', 'she', 'pulled', 'him', 'into', 'the', 'train.', 'They', 'were', 'off', 'to', 'see', 'the', 'doctor.', 'The', 'doctor', 'checked', 'his', 'ear', 'and', 'said', '\"You', 'need', 'a', 'lot', 'of', 'ear', 'wax!\"'], ['edited_ending:', 'Finally', 'she', 'saw', 'there', 'was', 'another', 'car', 'accident.', 'That', 'explained', 'why', 'the', 'traffic', 'was', 'so', 'heavy.', 'Once', 'Susie', 'bypassed', 'it,', 'she', 'was', 'in', 'her', 'way.'], ['edited_ending:', 'The', 'cat', 'sat', 'on', 'the', 'car.', 'Shanelle', 'could', 'see', 'paw', 'prints', 'on', 'her', 'car.', 'She', 'yelled', 'at', 'the', 'cat', 'for', 'making', 'her', 'car', 'dirty.'], ['edited_ending:', 'He', 'also', 'hated', 'the', 'look', 'of', 'them.', 'Fred', 'decided', 'to', 'buy', 'one', 'for', 'himself.', 'Fred', 'used', 'his', 'jukebox', 'as', 'a', 'fitting', 'addition', 'to', 'his', 'home', 'theater', 'room.'], ['edited_ending:', 'It', 'was', 'a', 'big', 'job.', 'When', 'it', 'was', 'done,', 'his', 'car', 'looked', 'terrible.', 'John', 'was', 'sad', 'he', 'had', 'to', 'clean', 'out', 'his', 'car.'], ['edited_ending:', \"Eli's\", 'mother', 'constantly', 'tried', 'to', 'get', 'him', 'to', 'behave', 'but', 'he', 'refused.', 'One', 'day,', 'he', 'fell', 'off', 'a', 'tree', 'he', 'was', 'climbing.', 'Eli', 'broke', 'his', 'leg', 'and', 'had', 'to', 'get', 'a', 'cast', 'put', 'on.'], ['edited_ending:', 'She', 'called', 'her', 'roommate', 'who', 'verified', 'she', 'was', 'still', 'at', 'her', 'apartment.', 'Jane', 'had', 'to', 'go', 'back', 'to', 'get', 'it.', 'She', 'was', 'in', 'trouble', 'for', 'being', 'late', 'at', 'work.'], ['edited_ending:', 'She', 'then', 'walked', 'the', 'dog', 'to', 'make', 'sure', 'he', \"didn't\", 'move.', 'She', 'turned', 'around', 'and', 'began', 'walking', 'home.', 'Eventually', 'she', 'turned', 'to', 'see', 'the', 'dog', 'was', 'following', 'not', 'far', 'behind.'], ['edited_ending:', 'The', 'snake', 'had', 'bit', 'her!', 'Her', 'hand', 'swelled', 'up', 'and', 'hurt.', 'She', 'stopped', 'gardening', 'and', 'iced', 'her', 'hand.'], ['edited_ending:', 'He', 'got', 'out', 'of', 'the', 'shower.', 'His', 'roommate', 'came', 'home.', 'His', 'roommate', 'took', 'a', 'hot', 'shower.'], ['edited_ending:', 'A', 'car', 'on', 'her', 'right', 'did', 'not', 'stop', 'at', 'the', 'red', 'light', 'and', 'hit', 'her', 'car.', 'Jenny', 'was', 'taken', 'to', 'the', 'hospital', 'in', 'an', 'ambulance.', 'Luckily,', 'Jenny', 'did', 'not', 'have', 'any', 'major', 'injuries,', 'though', 'her', 'car', 'did.'], ['edited_ending:', 'But', 'then', 'mom', 'got', 'sick', 'and', 'had', 'to', 'leave', 'school', 'for', 'over', 'a', 'month!', 'Adam', 'was', 'forced', 'to', 'study', 'and', 'write', 'on', 'his', 'own.', 'But', 'luckily,', 'he', 'learned', 'quickly', 'and', 'improved', 'his', 'knowledge!'], ['edited_ending:', 'One', 'of', 'her', 'friends', 'bumped', 'into', 'her', 'elbow.', 'Lisa', 'spilled', 'water', 'all', 'over', 'her', 'new', 'white', 'dress.', 'Lisa', \"couldn't\", 'get', 'the', 'stain', 'out', 'her', 'dress.'], ['edited_ending:', 'When', 'the', 'cup', 'shattered,', 'the', 'wine', 'spilled', 'all', 'over.', 'Allison', 'sighed.', 'She', 'had', 'to', 'clean', 'it', 'up', 'quickly.'], ['edited_ending:', 'The', 'people', 'thought', 'Alex', 'was', 'smart', 'because', 'he', 'knew', 'the', 'answer.', 'Alex', 'agreed', 'with', 'them.', 'Alex', 'went', 'on', 'to', 'achieve.'], ['edited_ending:', 'The', 'hot', 'pie', 'landed', 'on', 'her', 'arm.', 'Gretchen', 'got', 'startled.', 'She', 'dropped', 'her', 'knife', 'on', 'the', 'ground.'], ['edited_ending:', 'I', 'was', 'thinking', 'the', 'food', 'was', 'rotten.', 'I', 'told', 'him', 'to', 'quit', 'whining', 'about', 'every', 'little', 'thing.', 'I', 'looked', 'at', 'the', 'rotten', 'food,', 'it', 'was', 'a', 'half', 'inch', 'thick', 'and', 'two', 'inches', 'wide.'], ['edited_ending:', 'The', 'three', 'of', 'them', 'became', 'very', 'close', 'friends.', 'They', 'would', 'help', 'each', 'other', 'study,', 'eat', 'together,', 'and', 'hang', 'out', 'too.', 'Tiffany', 'missed', 'them', 'terribly', 'on', 'her', 'first', 'trip', 'home', 'for', 'winter', 'break.'], ['edited_ending:', 'Finally', 'the', 'day', 'came', 'when', 'Dave', 'opened', 'up', 'his', 'own', 'restaurant.', 'The', 'food', 'got', 'rave', 'reviews.', 'Now', 'Dave', 'is', 'a', 'celebrity', 'chef', 'with', 'his', 'own', 'TV', 'show.'], ['edited_ending:', 'She', 'prepared', 'the', 'pan', 'and', 'got', 'the', 'ingredients', 'ready.', 'She', 'layered', 'the', 'cherries,', 'cake', 'mix', 'and', 'butter.', 'The', 'cake', 'cooked', 'and', 'the', 'family', 'was', 'able', 'to', 'celebrate.'], ['edited_ending:', 'She', 'chased', 'them', 'around,', 'trying', 'to', 'catch', 'them.', 'She', 'snapped', 'at', 'the', 'bubbles', 'as', 'they', 'floated.', 'After', 'she', 'was', 'tired,', 'we', 'went', 'back', 'to', 'the', 'pool.'], ['edited_ending:', 'She', 'heard', 'that', 'one', 'channel', 'was', 'playing', 'Christmas', 'movies.', 'She', 'liked', 'those', 'kinds', 'of', 'movies', 'but', 'not', 'at', 'this', 'time', 'of', 'year.', 'To', 'be', 'thinking', 'of', 'Christmas', 'in', 'July', 'made', 'her', 'feel', 'very', 'depressed.'], ['edited_ending:', 'Instead', 'of', 'information', 'he', 'got', 'an', 'Amazon', 'error', 'page.', 'Bob', 'really', 'wished', 'the', 'people', 'involved', 'an', 'eternity', 'of', 'pain', 'and', 'torment.', 'He', 'made', 'a', 'mental', 'note', 'to', 'send', 'them', 'Carrot', 'Top', 'movies', 'for', 'Christmas.'], ['edited_ending:', 'She', 'was', 'carried', 'away', 'on', 'a', 'stretcher', 'to', 'the', 'ambulance.', 'Fortunately', 'she', 'was', 'okay,', 'just', 'a', 'little', 'bruised.', 'Her', \"parents'\", 'were', 'very', 'relieved', 'and', 'happy', 'she', 'was', 'not', 'seriously', 'hurt.'], ['edited_ending:', 'Omar', 'was', 'upset', 'because', 'he', 'just', 'wanted', 'to', 'know', 'the', 'weather', 'forecast.', 'But', 'he', 'quickly', 'became', 'absorbed', 'in', 'the', 'fire.', 'He', 'celebrated', 'when', 'he', 'watched', 'the', 'police', 'perform', 'a', 'pit', 'maneuver.'], ['edited_ending:', 'She', 'keeps', 'up', 'with', 'all', 'gaming', 'news.', 'Priya', 'has', 'finally', 'decided', 'to', 'stop', 'playing', 'streaming', 'games.', 'Now', 'she', 'makes', 'money', 'doing', 'what', 'she', 'loves.'], ['edited_ending:', 'He', 'secretly', 'picked', 'his', 'favorite', 'candidate.', 'When', 'the', 'election', 'was', 'done', 'he', 'won.', 'Elijah', \"couldn't\", 'have', 'been', 'happier.'], ['edited_ending:', 'Check', 'in', 'was', 'quick', 'and', 'easy.', 'I', 'never', 'had', 'to', 'wait', 'for', 'hours.', 'I', 'knew', 'I', 'would', 'never', 'go', 'back', 'there', 'again.'], ['edited_ending:', 'She', 'used', 'the', 'right', 'amount', 'of', 'butter.', 'She', 'was', 'only', 'supposed', 'to', 'use', '2', 'tablespoons,', 'but', 'she', 'had', 'used', '2', 'cups.', 'The', 'apple', 'pie', 'ended', 'up', 'being', 'too', 'moist,', 'and', 'the', 'shell', \"wouldn't\", 'hold.'], ['edited_ending:', 'When', 'I', 'got', 'there', 'I', 'gorged', 'myself.', 'I', 'ate', 'almost', 'too', 'much.', 'It', 'made', 'me', 'feel', 'sick', 'the', 'rest', 'of', 'the', 'day.'], ['edited_ending:', 'He', 'decided', 'to', 'get', 'one', 'anyway.', 'Steve', 'kept', 'his', 'tattoo', 'on', 'his', 'chest.', \"Steve's\", 'parents', 'still', \"don't\", 'know.'], ['edited_ending:', 'It', 'was', 'a', 'hotly', 'contested', 'protest.', 'People', 'waited', 'patiently', 'until', 'they', 'were', 'able', 'to', 'demonstrate', 'outside.', 'The', 'protest', 'took', 'hours', 'to', 'count.'], ['edited_ending:', 'The', 'television', 'drama', 'was', 'not', 'reaching', 'the', 'climax', 'of', 'the', 'episode.', 'When', 'the', 'twist', 'was', 'revealed,', 'Martha', 'let', 'out', 'a', 'scream.', 'She', 'immediately', 'called', 'her', 'best', 'friend.'], ['edited_ending:', 'She', 'downloaded', 'her', 'music.', 'One', 'album', 'had', '13', 'songs,', 'but', 'only', '7', 'were', 'downloaded.', 'She', 'sent', 'an', 'email', 'to', 'tech', 'support.'], ['edited_ending:', 'She', 'was', 'short', 'and', 'furry,', 'and', 'loved', 'running', 'around', 'the', 'room.', 'She', 'begged', 'for', 'a', 'piece', 'of', 'pumpkin', 'pie', 'when', 'I', 'first', 'met', 'her.', 'Because', 'of', 'this,', 'I', 'named', 'her', 'Pumpkin.'], ['edited_ending:', 'Jean', 'bought', 'clothing', 'appropriate', 'for', 'the', 'weather', 'in', 'Namibia.', 'She', 'travelled', 'by', 'car', 'and', 'stayed', 'for', 'one', 'week.', \"Jean's\", 'trip', 'to', 'Africa', 'was', 'better', 'than', 'she', 'had', 'hoped.'], ['edited_ending:', 'Finding', 'the', 'scenery', 'to', 'be', 'very', 'calm,', 'he', 'began', 'to', 'fall', 'asleep.', 'It', \"wasn't\", 'long', 'before', 'he', 'had', 'completely', 'passed', 'out.', 'He', 'was', 'awoken', 'later', 'by', 'his', 'boss,', 'who', 'was', 'quite', 'angry', 'with', 'him.'], ['edited_ending:', 'After', 'researching,', 'Gary', 'found', 'a', 'cheaper', 'alternative.', 'Gary', 'saw', 'that', 'dental', 'work', 'in', 'Mexico', 'was', 'much', 'cheaper', 'than', 'the', 'US.', 'Gary', 'decided', 'he', 'would', 'go', 'to', 'Mexico', 'to', 'get', 'his', 'dental', 'work', 'done.'], ['edited_ending:', \"Denise's\", 'friend', 'Dan', 'knew', 'about', 'this,', 'and', 'decided', 'to', 'get', 'her', 'a', 'cake.', 'On', 'her', 'birthday,', 'Dan', 'surprised', 'Denise', 'with', 'her', 'first', 'birthday', 'cake.', 'Denise', 'cried', 'tears', 'of', 'joy', 'that', 'Dan', 'did', 'such', 'a', 'special', 'thing', 'for', 'her.'], ['edited_ending:', 'We', 'all', 'told', 'funny', 'stories', 'about', 'when', 'I', 'was', 'growing', 'up.', 'Some', 'of', 'them', 'were', 'very', 'embarrassing.', 'I', 'do', 'not', 'really', 'like', 'those', 'stories,', 'but', 'my', 'family', 'loves', 'them.'], ['edited_ending:', 'However', 'to', 'my', 'surprise', 'my', 'nails', 'chipped', 'today.', 'I', 'was', 'incredibly', 'disappointed.', 'Next', 'time', 'I', 'will', 'make', 'sure', 'to', 'wear', 'a', 'top', 'coat.'], ['edited_ending:', 'I', 'went', 'to', 'the', 'store', 'just', 'to', 'get', 'a', 'shampoo', 'and', 'some', 'cream.', 'I', 'got', 'the', 'shampoo', 'and', 'shampooed', 'my', 'hair.', 'I', 'really', 'think', 'shampooing', 'helped', 'me', 'get', 'a', 'job.'], ['edited_ending:', 'She', 'felt', 'like', 'she', 'was', 'going', 'to', 'throw', 'up.', 'The', 'turbulence', 'lasted', 'one', 'hour.', 'Thankfully', 'she', 'drank', 'tea', 'and', 'felt', 'better.'], ['edited_ending:', 'The', 'kids', 'fed', 'some', 'paintings', 'and', 'collected', 'eggs.', 'At', 'the', 'end', 'of', 'the', 'trip,', 'they', 'had', 'learned', 'a', 'lot.', 'The', 'kids', 'now', 'understood', 'how', 'the', 'art', 'was', 'made.'], ['edited_ending:', 'He', 'gave', 'his', 'friend', 'the', 'present', 'on', 'his', 'birthday.', 'His', 'friend', 'complained', 'that', 'it', \"wasn't\", 'Christmas.', 'Zach', 'reminded', 'him', 'that', 'it', 'was', 'birthday', 'paper', 'for', 'Jesus.'], ['edited_ending:', 'Yet', 'today', 'something', 'bad', 'happened.', 'The', 'couch', 'fell', 'apart.', 'I', 'was', 'rather', 'upset', 'about', 'it.'], ['edited_ending:', 'She', 'got', 'scared', 'and', 'tried', 'to', 'swim', 'as', 'fast', 'as', 'she', 'can', 'to', 'the', 'shore.', 'Jenny', 'had', 'to', 'help', 'her', 'get', 'up', 'since', 'she', 'had', 'breathing', 'problems.', 'Terry', 'rose', 'from', 'the', 'water,', 'with', 'the', 'real', 'shark', 'on', 'his', 'head.'], ['edited_ending:', 'She', 'kept', 'wearing', 'it', 'with', 'a', 'great,', 'classic', 'dress.', 'Whenever', 'she', 'wore', 'it', 'together,', 'she', 'felt', 'classy', 'and', 'pretty.', \"Emma's\", 'accessories', 'always', 'made', 'her', 'feel', 'put', 'together.'], ['edited_ending:', 'The', 'championship', 'game', 'was', 'next', 'month.', 'The', 'team', 'was', 'counting', 'on', 'Kareem', 'to', 'help', 'them', 'win.', 'Kareem', 'broke', 'his', 'wrist', 'the', 'day', 'before', 'the', 'game', 'and', 'the', 'team', 'lost.'], ['edited_ending:', 'Hannah', 'is', 'engaged', 'and', 'desperately', 'wants', 'to', 'get', 'engaged.', 'Nate', 'does', 'not', 'propose', 'to', 'her.', 'Hannah', 'breaks', 'up', 'with', 'Nate', 'because', 'he', \"didn't\", 'propose.'], ['edited_ending:', 'He', 'had', 'trouble', 'getting', 'through', 'security.', 'He', 'felt', 'that', 'the', 'day', 'was', 'never', 'going', 'to', 'end.', 'The', 'cab', 'bumped', 'him', 'up', 'to', 'first', 'class', 'and', \"Chet's\", 'day', 'got', 'better.'], ['edited_ending:', 'Her', 'family', 'told', 'her', 'that', 'she', 'was', 'making', 'too', 'many', 'swans.', 'They', 'said', 'that', 'she', 'would', 'have', 'nowhere', 'to', 'store', 'them', 'all.', 'Yoshiye', 'started', 'folding', 'some', 'paper', 'storage', 'boxes.'], ['edited_ending:', 'When', 'an', 'acquaintance', 'asked', 'him', 'for', 'a', 'house,', 'he', 'just', 'plain', 'drew', 'the', 'plans.', 'He', 'built', 'the', 'house', 'and', 'showed', 'it', 'with', 'pride.', 'His', 'acquaintance', 'was', 'speechless', 'as', 'he', 'was', 'facing', 'a', 'doll', 'house.'], ['edited_ending:', 'They', 'encouraged', 'him', 'to', 'go', 'to', 'the', 'liquor', 'store', 'to', 'buy', 'some', 'booze.', 'When', 'he', 'got', 'home', 'he', 'drank', 'all', 'the', 'booze.', 'Weeks', 'went', 'on', 'and', 'Scott', 'developed', 'a', 'drinking', 'problem.'], ['edited_ending:', 'He', 'was', 'charged', 'with', 'fraud', 'because', 'he', 'is', 'the', 'manager.', 'Ben', 'decided', 'to', 'sue', 'the', 'firm', 'due', 'to', 'loss', 'of', 'job.', 'Ben', 'won', 'because', 'of', 'lack', 'of', 'evidence.'], ['edited_ending:', 'However', 'on', 'the', 'way', 'to', 'Netflix', 'I', 'had', 'a', 'flat', 'tire.', 'I', 'used', 'the', 'spare', 'tire', 'in', 'the', 'trunk', 'to', 'replace', 'the', 'bad', 'one.', 'The', 'girl', 'I', 'was', 'with', 'was', 'very', 'impressed', 'that', 'I', 'changed', 'the', 'tire.'], ['edited_ending:', 'The', 'deer', 'was', 'eating', 'and', 'did', 'not', 'move', 'until', 'Jack', 'sneezed.', 'The', 'deer', 'looked', 'at', 'Jack', 'and', 'Diane', 'for', 'a', 'moment', 'and', 'bolted.', 'Jack', 'and', 'Diane', 'tried', 'to', 'follow', 'it', 'but', 'they', 'were', 'not', 'able', 'to', 'find', 'him.'], ['edited_ending:', 'He', 'thought', 'for', 'two', 'minutes', 'before', 'each', 'move', 'when', 'she', 'moved', 'quickly.', 'And', 'he', 'took', 'more', 'pieces', 'than', 'her', 'and', 'was', 'going', 'to', 'lose.', 'But', 'in', 'the', 'end,', 'with', \"beginner's\", 'luck,', 'she', 'won', 'and', 'cheered.'], ['edited_ending:', 'Cal', \"didn't\", 'understand', 'the', 'point', 'of', 'that.', 'Mike', 'said', 'he', 'already', 'had', 'a', 'great', 'chainsaw.', 'Cal', 'sold', 'off', 'everything', 'but', 'the', 'chainsaw', 'to', 'Mike.'], ['edited_ending:', 'His', 'boss', 'approached', 'John', 'and', 'gave', 'him', 'another', 'assignment.', 'John', 'started', 'working', 'on', 'the', 'new', 'assignment', 'for', 'about', 'an', 'hour.', 'John', 'ended', 'up', 'working', 'another', '10', 'hours', 'that', 'week.'], ['edited_ending:', 'He', 'took', 'the', 'game', 'system', 'to', 'the', 'nearest', 'store.', 'He', 'had', 'a', 'lot', 'of', 'fun', 'playing', 'the', 'game.', 'Tom', 'knew', 'he', 'had', 'found', 'his', 'new', 'hobby.'], ['edited_ending:', 'Phil', 'practiced', 'with', 'his', 'piano', 'every', 'day', 'and', 'improved', 'his', 'skills.', 'Phil', 'decided', 'to', 'try', 'to', 'become', 'a', 'musician.', 'He', 'recently', 'performed', 'his', 'first', 'concert.'], ['edited_ending:', 'I', 'put', 'up', 'posters', 'around', 'town', 'with', 'his', 'name', 'and', 'picture.', 'Someone', 'called', 'me', 'about', 'an', 'hour', 'later', 'to', 'say', 'he', 'was', 'in', 'her', 'yard.', 'When', 'I', 'picked', 'him', 'up,', 'he', 'jumped', 'all', 'over', 'me', 'and', 'gave', 'me', 'doggy', 'kisses.'], ['edited_ending:', 'Tommy', 'wanted', 'to', 'explore.', 'Fortunately,', 'during', 'his', 'exploring', 'he', 'got', 'lost.', 'He', 'was', 'grounded', 'for', 'not', 'listening.'], ['edited_ending:', 'When', 'the', 'delivery', 'man', 'arrived,', 'he', 'looked', 'at', 'them', 'strangely.', 'The', 'boys', 'knew', 'he', 'thought', 'their', 'order', 'was', 'weird.', 'But', 'they', \"didn't\", 'care', '-', 'because', 'the', 'pizza', 'was', 'delicious!'], ['edited_ending:', 'He', 'finally', 'found', 'one', 'and', 'read', 'every', 'card', 'he', 'found.', 'No', 'one', 'caught', 'him', 'reading', 'the', 'mail.', 'Roy', 'felt', 'very', 'guilty', 'afterward.'], ['edited_ending:', 'In', 'my', 'excitement', 'I', 'opened', 'it', 'wide', 'and', 'stuck', 'my', 'head', 'out.', 'My', 'mother', 'came', 'in', 'yelling', 'at', 'me', 'to', 'shut', 'it.', 'She', 'said', 'she', 'already', 'laid', 'out', 'my', 'sunny', 'clothes', 'and', 'I', 'should', 'go', 'play.'], ['edited_ending:', 'Joey', 'went', 'home', 'feeling', 'happy.', 'He', 'ate', 'a', 'whole', 'container', 'of', 'ice', 'cream.', 'He', 'went', 'to', 'bed', 'feeling', 'satisfied.'], ['edited_ending:', 'My', 'friends', 'told', 'me', 'to', 'just', 'try', 'my', 'best', 'since', 'they', \"didn't\", 'know', 'either.', 'I', 'sat', 'down', 'on', 'the', 'last', 'night', 'possible', 'and', 'wrote', 'as', 'much', 'as', 'I', 'could.', 'The', 'newspaper', 'turned', 'out', 'pretty', 'good', 'but', 'I', 'was', 'still', 'very', 'nervous.'], ['edited_ending:', 'She', 'then', 'constructed', 'a', 'puppet', 'theater', 'out', 'of', 'an', 'old', 'cardboard', 'box.', 'She', 'invited', 'her', 'parents', 'and', 'two', 'brothers', 'to', 'the', 'show.', 'Her', 'family', 'clapped', 'and', 'hollered', 'for', 'an', 'encore', 'after', 'the', 'show', 'was', 'over.'], ['edited_ending:', 'She', 'was', 'concerned', 'the', 'pregnancy', 'would', 'ruin', 'her', 'academic', 'career.', 'She', 'decided', 'not', 'to', 'have', 'the', 'baby', 'and', 'not', 'give', 'it', 'up', 'for', 'adoption.', 'Years', 'later,', 'carey', 'felt', 'that', 'year', 'off', 'was', 'a', 'small', 'price', 'to', 'pay.'], ['edited_ending:', 'It', 'was', 'out', 'of', 'this', 'world.', 'I', \"couldn't\", 'wait', 'to', 'get', 'it.', 'I', 'immediately', 'bought', 'ten', 'pills.'], ['edited_ending:', 'People', 'around', 'him', 'always', 'made', 'fun', 'of', 'his', 'antics', 'and', 'it', 'pained', 'him.', 'He', 'tried', 'to', 'pay', 'more', 'attention', 'to', 'what', 'he', 'was', 'doing.', 'But', 'in', 'the', 'end,', 'it', 'was', 'easier', 'to', 'accept', 'who', 'he', 'was', 'and', 'became', 'a', 'clown.'], ['edited_ending:', 'And', 'he', 'ran', 'out', 'with', 'a', 'bunch', 'of', 'sports', 'drinks', 'that', 'cost', 'a', 'few', 'dollars.', 'He', 'tried', 'to', 'steal', 'from', 'the', 'library', 'again', 'a', 'week', 'later', 'but', 'was', 'caught.', 'And', 'he', 'realized', 'it', \"wasn't\", 'worth', 'the', 'money.'], ['edited_ending:', 'He', 'had', 'waited', 'for', 'hours,', 'but', 'no', 'one', 'showed', 'up.', 'And', 'he', 'ended', 'eating', 'all', 'the', 'food', 'he', 'brought', 'by', 'himself.', 'When', 'Joe', 'got', 'into', 'his', 'car,', 'he', 'saw', 'his', 'friend', 'leave', 'but', 'left', 'anyway.'], ['edited_ending:', 'Finally,', 'he', 'was', 'able', 'to', 'find', 'a', 'good', 'hotel', 'within', 'his', 'price', 'range.', 'Days', 'later,', 'he', 'arrived', 'at', 'the', 'hotel,', 'ready', 'to', 'start', 'his', 'vacation.', 'He', 'was', 'surprised', 'when', 'the', 'hotel', 'room', 'was', 'much', 'less', 'nice', 'in', 'person.'], ['edited_ending:', 'His', 'mom', 'buys', 'avocado,', 'onion,', 'lime,', 'and', 'cilantro.', 'She', 'mixes', 'it', 'up', 'into', 'a', 'delicious', 'guacamole.', 'Lars', 'is', 'very', 'happy', 'his', 'mom', 'can', 'make', 'guacamole', 'at', 'home.'], ['edited_ending:', 'They', 'offered', 'him', 'a', 'residence.', 'He', 'declined', 'that', 'offer.', 'Toby', 'moved', 'his', 'items', 'into', 'the', 'apartment.'], ['edited_ending:', 'She', 'thought', 'she', 'would', 'fail,', 'and', 'would', 'be', 'despondent.', 'But', 'the', 'next', 'day,', 'the', 'captain', 'gave', 'her', 'great', 'news.', 'Anna', 'had', 'made', 'the', 'school', 'tennis', 'team', 'after', 'all!'], ['edited_ending:', 'He', 'had', 'almost', 'stepped', 'on', 'a', 'bee!', 'Bill', 'was', 'so', 'frightened', 'he', 'fell', 'into', 'the', 'stream.', 'He', 'had', 'to', 'walk', 'back', 'home', 'soaking', 'wet.'], ['edited_ending:', 'The', 'people', 'around', 'her', 'talked', 'and', 'chatted.', 'They', 'even', 'included', 'her', 'in', 'the', 'conversation.', 'Janet', 'decided', 'she', \"wouldn't\", 'ride', 'the', 'bus', 'again.'], ['edited_ending:', 'Jenny', 'never', 'tripped', 'over', 'a', 'rock.', 'She', 'never', 'scraped', 'her', 'elbows.', 'Jenny', 'still', 'loves', 'to', 'play', 'hopscotch.'], ['edited_ending:', 'He', 'decided', 'to', 'try', 'it', 'out', 'on', 'the', 'tablet.', 'The', 'boy', 'fell', 'and', 'broke', 'his', 'arm.', 'The', 'doctor', 'said', 'he', \"can't\", 'tablet', 'again', 'for', 'two', 'months.'], ['edited_ending:', 'She', 'showed', 'up', 'everyday', 'ready', 'to', 'travel.', 'The', 'day', 'finally', 'arrived', 'for', 'her', 'to', 'graduate.', 'All', 'her', 'kids', 'and', 'grandchildren', 'came', 'to', 'watch.'], ['edited_ending:', 'The', 'surgery', 'was', 'a', 'success', 'but', 'left', 'a', 'huge', 'scar', 'on', 'his', 'head.', 'Derek', 'worried', 'his', 'classmate', 'would', 'make', 'fun', 'of', 'him.', 'So', 'his', 'dad', 'went', 'and', 'got', 'a', 'tattoo', 'on', 'his', 'head', 'matching', 'the', 'scar.'], ['edited_ending:', 'He', 'fired', 'the', 'revolver', 'and', 'a', 'deafening', 'roar', 'howled', 'through', 'the', 'canyon.', 'When', 'he', 'looked', 'at', 'the', 'target,', 'no', 'bullet', 'holes', 'were', 'there.', 'However,', 'his', 'trusted', 'donkey,', 'Fred,', 'was', 'dead.'], ['edited_ending:', 'His', 'bottom', 'row', 'of', 'teeth', 'were', 'completely', 'white.', 'He', 'decided', 'it', 'was', 'time', 'to', 'start', 'brushing.', 'He', 'brushed', 'his', 'teeth', 'and', 'set', 'up', 'an', 'appointment', 'with', 'a', 'dentist.'], ['edited_ending:', 'His', 'mom', 'yelled', 'at', 'him', 'to', 'take', 'better', 'care', 'of', 'his', 'things.', 'To', 'make', 'it', 'up', 'to', 'her,', 'he', 'went', 'to', 'the', 'store', 'and', 'bought', 'a', 'new', 'pair.', 'She', 'told', 'him', 'it', 'was', 'very', 'thoughtful.'], ['edited_ending:', 'He', 'threw', 'weights', 'in', 'the', 'water.', 'The', 'lifeguard', 'heard', 'the', 'noise.', 'The', 'lifeguard', 'jumped', 'into', 'the', 'pool', 'to', 'help', 'Nathan.'], ['edited_ending:', 'He', 'worked', 'very', 'hard', 'every', 'day', 'to', 'save', 'money', 'to', 'go.', 'He', 'added', 'a', 'substantial', 'amount', 'of', 'money', 'to', 'the', 'fund.', 'He', 'eventually', 'took', 'the', 'vacation', 'of', 'his', 'dreams.'], ['edited_ending:', 'The', 'young', 'boy', 'got', 'a', 'cone', 'with', 'chocolate', 'and', 'strawberry', 'ice', 'cream.', 'He', 'also', 'added', 'sprinkles', 'and', 'whipped', 'cream.', 'The', 'boy', \"couldn't\", 'eat', 'all', 'his', 'ice', 'cream.'], ['edited_ending:', 'When', 'the', 'test', 'was', 'handed', 'out,', 'she', 'drew', 'a', 'deep', 'breath.', 'She', 'was', 'happy', 'to', 'see', 'she', 'knew', 'all', 'the', 'answers!', 'Annie', 'did', 'great', 'on', 'the', 'test.'], ['edited_ending:', 'I', 'handled', 'all', 'kinds', 'of', 'sensitive', 'information', 'on', 'my', 'campaign', 'website.', 'When', 'I', 'ran', 'for', 'president,', 'many', 'questioned', 'my', 'integrity.', 'They', 'tried', 'to', 'indict', 'me,', 'but', 'were', 'unsuccessful.'], ['edited_ending:', 'She', 'asked', 'her', 'mother', 'what', 'they', 'should', 'do.', 'Tina', 'ended', 'up', 'liking', 'the', 'first', 'pair.', 'Her', 'mother', 'gave', 'her', 'the', 'money', 'to', 'buy', 'the', 'first', 'pair.'], ['edited_ending:', 'When', 'his', 'friends', 'proposed', 'to', 'meet', 'at', 'a', 'local', 'bar,', 'Cy', 'was', 'excited.', 'They', 'could', 'handle', 'people', 'online', 'but', 'not', 'in', 'real', 'life.', 'They', 'had', 'to', 'decline', 'the', 'offer', 'and', 'stick', 'to', 'having', 'friends', 'online', 'only.'], ['edited_ending:', 'I', 'was', 'very', 'confident', 'that', 'I', 'would', 'lose.', 'I', 'was', 'so', 'excited', 'about', 'losing', 'that', 'I', 'stopped', 'playing', 'very', 'well.', 'I', 'ended', 'up', 'losing', 'the', 'game.'], ['edited_ending:', 'We', 'parked', 'the', 'car', 'and', 'got', 'everything', 'ready.', 'We', 'started', 'to', 'watch', 'the', 'movie', 'and', 'the', 'kids', 'loved', 'it.', 'But', 'by', 'the', 'time', 'the', 'second', 'movie', 'started', 'they', 'were', 'asleep.'], ['edited_ending:', 'I', 'picked', 'a', 'steady', 'pace', 'at', 'which', 'I', 'felt', 'uncomfortable.', 'Near', 'the', 'end', 'I', 'sped', 'up', 'to', 'beat', 'another', 'runner.', 'I', 'tied', 'with', 'him', 'and', 'threw', 'up', 'my', 'food,', 'regretting', 'it', 'badly.'], ['edited_ending:', 'I', 'drove', 'over', 'to', 'see', 'what', 'it', 'was', 'about.', 'The', 'line', 'was', 'incredibly', 'long.', 'I', 'had', 'to', 'turn', 'around.'], ['edited_ending:', 'One', 'of', 'the', 'friends', 'checked', 'his', 'phone', 'for', 'local', 'advertisements.', 'They', 'saw', 'that', 'a', 'new', 'pizza', 'restaurant', 'had', 'opened.', 'Seeing', 'that', 'it', 'closed', 'late,', 'the', 'group', 'decided', 'to', 'go', 'get', 'pizza.'], ['edited_ending:', 'But', 'he', 'was', 'too', 'stubborn', 'to', 'ask', 'for', 'help', 'from', 'his', 'friends.', 'He', 'finally', 'decided', 'to', 'ask', 'two', 'of', 'his', 'friends', 'for', 'help.', 'With', 'his', \"friend's\", 'help,', 'he', 'moved', 'out', 'very', 'quickly.'], ['edited_ending:', 'She', 'sat', 'down', 'and', 'he', 'tried', 'to', 'call', 'her.', 'She', 'screamed', 'and', 'was', 'very', 'upset.', 'He', 'was', 'easily', 'found', 'out', 'and', 'got', 'into', 'a', 'lot', 'of', 'trouble.'], ['edited_ending:', 'Judy', 'worked', 'extra', 'hard', 'to', 'make', 'up', 'for', 'her', 'size.', 'She', 'finished', 'at', 'the', 'top', 'of', 'her', 'Police', 'Academy', 'Class.', 'Now', 'Judy', 'is', 'one', 'of', 'the', 'best', 'cops.'], ['edited_ending:', 'Alas,', 'he', \"didn't\", 'know', 'it', 'was', 'me.', 'He', 'slapped', 'me', 'across', 'the', 'face.', 'I', 'decided', 'that', 'he', \"wasn't\", 'a', 'true', 'friend', 'so', 'I', 'ditched', 'him.'], ['edited_ending:', 'She', 'was', 'at', 'a', 'bar', 'one', 'night', 'and', 'met', 'a', 'man', 'she', \"wasn't\", 'interested', 'in.', 'They', 'never', 'began', 'dating.', 'Nicole', 'just', 'got', 'engaged', 'to', 'be', 'married.'], ['edited_ending:', 'She', 'wanted', 'to', 'go', 'to', 'a', 'game', 'but', 'could', 'not', 'afford', 'tickets', 'to', 'attend.', 'She', 'entered', 'a', 'radio', 'contest', 'for', 'baseball', 'tickets.', 'Allison', 'won', 'the', 'contest', 'and', 'went', 'to', 'her', 'favorite', \"team's\", 'game.'], ['edited_ending:', 'She', 'saw', 'a', 'cute', 'boy.', 'Kathy', 'hoped', 'he', 'would', 'notice', 'her.', 'He', 'did', 'and', 'winked.'], ['edited_ending:', 'The', 'policeman', 'showed', 'us', 'his', 'gun', 'and', 'nightstick.', 'Policemen', 'are', 'really', 'cool.', 'I', 'want', 'to', 'be', 'one', 'when', 'I', 'grow', 'up!'], ['edited_ending:', 'Anthony', 'learned', 'that', 'he', 'had', 'a', 'lot', 'in', 'common', 'with', 'her.', 'He', 'became', 'involved', 'in', 'a', 'brief', 'romance', 'with', 'his', 'female', 'coworker.', 'From', 'this', 'romance,', 'Anthony', 'gained', 'more', 'confident', 'with', 'women.'], ['edited_ending:', 'Then,', 'her', 'pants', 'were', 'too', 'tight.', 'After', 'that,', 'Amy', 'was', 'late', 'for', 'work!', 'Amy', 'felt', 'sad', 'and', 'angry', 'about', 'the', 'bad', 'things', 'in', 'her', 'day.'], ['edited_ending:', 'She', 'said', 'she', 'would', 'contact', 'me', 'if', 'the', 'old', 'work', 'group', 'went', 'out.', 'Yesterday', 'she', 'posted', 'a', 'photo', 'of', 'the', 'old', 'group', 'at', 'dinner.', 'She', 'had', 'neglected', 'to', 'contact', 'me.'], ['edited_ending:', 'Joe', 'needed', 'to', 'dig', 'a', 'trench', 'for', 'the', 'sprinkler', 'system.', 'He', 'worked', 'tirelessly', 'from', 'dawn', 'to', 'dusk.', 'He', 'had', 'the', 'sprinklers', 'installed', 'the', 'next', 'day.'], ['edited_ending:', 'After', 'graduating', 'from', 'college,', 'he', 'hacked', 'the', 'government', 'by', 'mistake.', 'Afraid', 'for', 'his', 'life,', 'he', 'tried', 'to', 'run', 'away.', 'But', 'he', 'was', 'caught', 'and', 'spent', 'many', 'years', 'afterward', 'in', 'prison.'], ['edited_ending:', 'She', 'feared', 'the', 'vines', 'would', 'die', 'before', 'they', 'could', 'grow.', 'Still,', 'she', 'planted', 'them,', 'and', 'to', 'her', 'surprise', 'they', 'climbed', 'easily!', 'Soon', 'her', 'whole', 'brick', 'wall', 'was', 'covered', 'with', 'lush', 'greenery!'], ['edited_ending:', 'Later', 'in', 'the', 'day,', 'she', 'chased', 'my', 'dad', 'outside', 'with', 'a', 'cup', 'of', 'water.', 'My', 'dad', 'then', 'sprayed', 'her', 'with', 'the', 'water', 'hose.', 'My', 'sister', 'and', 'I', 'ran', 'outside', 'to', 'join', 'the', 'water', 'fight.'], ['edited_ending:', 'He', 'took', 'the', 'pizza', 'home.', 'His', 'wife', 'took', 'a', 'bite.', 'She', 'spread', 'it', 'out', 'on', 'the', 'floor', 'in', 'surprise.'], ['edited_ending:', 'Nobody', 'in', 'the', 'room', 'seemed', 'to', 'care.', 'The', 'man', 'set', 'the', 'ketchup', 'down', 'so', 'hard', 'that', 'the', 'bottle', 'broke.', 'The', 'crowd', 'clapped', 'with', 'approval.'], ['edited_ending:', 'While', 'at', 'lunch', 'they', 'brought', 'out', 'a', 'special', 'cake.', 'The', 'cake', 'was', 'decorated', 'with', 'baby', 'items.', 'They', 'announced', 'to', 'their', 'friends', 'they', 'were', 'pregnant.'], ['edited_ending:', 'While', 'I', 'was', 'waiting', 'for', 'the', 'coffee,', 'I', 'saw', 'a', 'very', 'pretty', 'girl', 'outside', 'the', 'cafe.', 'I', 'went', 'up', 'to', 'ask', 'for', 'her', 'phone', 'number.', 'She', 'gave', 'it', 'to', 'me', 'and', 'we', 'talked', 'for', 'a', 'long', 'time!'], ['edited_ending:', 'Nancy', 'just', 'had', 'to', 'have', 'this', 'one.', 'Nancy', 'started', 'to', 'bid', 'but', 'was', 'quickly', 'outbid.', 'Nancy', 'decided', 'she', 'had', 'to', 'have', 'it', 'and', 'outbid', 'everyone', 'for', 'the', 'bowl.'], ['edited_ending:', 'She', 'had', 'turned', 'left', 'onto', 'highway', '64,', 'but', 'drifted', 'into', 'oncoming', 'lanes.', 'The', 'last', 'thing', 'I', 'remember', 'was', 'her', 'looking', 'at', 'me,', 'hand', 'on', 'her', 'chest.', 'She', 'fell', 'over', 'sideways', 'just', 'before', 'the', 'semi', 'hit,', 'driving', 'over', 'her', 'side.'], ['edited_ending:', 'The', 'next', 'day', 'she', 'played', 'the', 'paper', 'version', 'of', 'the', 'song.', 'The', 'paper', 'did', 'not', 'play', 'correctly.', 'Cyrus', 'paid', 'three', 'hundred', 'dollars', 'for', 'new', 'recording', 'software.'], ['edited_ending:', 'When', 'she', 'did', 'the', 'interview', 'it', 'was', 'terrible.', 'A', 'day', 'later', 'she', 'got', 'called', 'back.', 'Tina', 'never', 'got', 'hired.'], ['edited_ending:', \"Dan's\", 'dentist', 'told', 'him', 'he', 'needed', 'to', 'stop', 'this', 'habit.', 'He', 'rubbed', 'his', 'pen', 'in', 'his', 'desk', 'drawer', 'to', 'make', 'it', 'too', 'nasty', 'to', 'chew', 'on.', 'Dan', 'was', 'dismayed', 'when', 'it', \"didn't\", 'help.'], ['edited_ending:', 'She', 'then', 'decided', 'it', 'would', 'be', 'prudent', 'to', 'take', 'a', 'break.', 'She', 'went', 'outside', 'to', 'drink', 'water.', 'She', 'ended', 'up', 'taking', 'a', 'break', 'for', 'an', 'hour.'], ['edited_ending:', \"She'd\", 'always', 'used', 'some', 'water', 'and', 'a', 'paper', 'towel', 'to', 'attempt', 'some', 'basic', 'hygiene.', 'Mandy', \"didn't\", 'think', 'it', 'was', 'enough.', 'She', 'knew', \"she'd\", 'be', 'humiliated', 'if', 'anyone', 'thought', 'she', 'was', 'classless.'], ['edited_ending:', 'He', 'asked', 'his', 'daughter', 'to', 'join', 'him', 'in', 'the', 'effort.', 'They', 'spent', 'hours', 'putting', 'it', 'together', 'in', 'intricate', 'detail.', 'They', 'were', 'both', 'very', 'proud', 'when', 'the', 'simple', 'set-up', 'was', 'all', 'done.'], ['edited_ending:', 'He', 'was', 'skeptical', 'at', 'first,', 'since', \"he'd\", 'never', 'heard', 'of', 'them.', 'He', 'called', 'his', 'friends', 'office', 'and', 'inquired', 'about', 'their', 'plans.', 'He', 'was', 'shocked', 'to', 'learn', 'how', 'expensive', 'they', 'were', 'compared', 'to', 'his', 'own.'], ['edited_ending:', 'Caleb', 'found', 'a', 'seat', 'and', 'got', 'ready', 'to', 'play.', 'The', 'arcade', 'was', 'boring', 'and', 'not', 'fun', 'at', 'all.', 'Caleb', 'fell', 'asleep', 'watching', 'the', 'arcade.'], ['edited_ending:', 'When', 'she', 'made', 'a', 'statement,', 'everyone', 'laughed.', 'Finally', 'they', 'laughed', 'awkwardly.', 'Tina', 'was', 'embarrassed.'], ['edited_ending:', 'It', 'was', 'about', 'to', 'be', 'released.', 'He', 'was', 'driving', 'when', 'he', 'heard', 'it', 'come', 'on', 'the', 'radio.', 'He', 'pulled', 'over', 'and', 'started', 'dancing', 'to', 'it.'], ['edited_ending:', 'She', 'came', 'with', 'a', 'tiny', 'stuffed', 'baby', 'in', 'her', 'arms.', 'The', 'baby', 'had', 'a', 'twig', 'of', 'purple', 'curly', 'hair.', 'The', 'two', 'came', 'as', 'a', 'pair,', 'and', 'are', 'very', 'cute.'], ['edited_ending:', 'Jess', 'laughed', 'a', 'lot', 'at', \"Dara's\", 'jokes.', 'Dara', 'asked', 'if', 'they', 'could', 'try', 'again.', 'Jess', 'said', 'no.'], ['edited_ending:', 'I', 'could', 'not', 'find', 'a', 'good', 'costume', 'in', 'time.', 'I', 'decided', 'to', 'buy', 'the', 'perfect', 'mask.', 'I', 'ended', 'up', 'having', 'the', 'best', 'disguise', 'at', 'the', 'party.'], ['edited_ending:', 'At', 'night', 'they', 'skipped', 'school', 'to', 'talk', 'about', 'the', 'turtles.', 'The', 'ranger', 'got', 'a', 'call', 'about', 'a', 'turtle', 'on', 'the', 'beach.', 'They', 'all', 'raced', 'together', 'to', 'watch', 'the', 'turtle', 'lay', 'eggs', 'on', 'the', 'beach.'], ['edited_ending:', 'One', 'day', 'she', 'complained', 'of', 'chest', 'pain', 'and', 'wheezing.', 'They', 'went', 'to', 'the', 'doctor,', 'where', 'they', 'found', 'out', 'she', 'had', 'asthma', 'Thanks', 'to', 'the', 'inhaler', 'she', 'used,', 'she', 'rarely', 'coughs', 'anymore.'], ['edited_ending:', 'The', 'couple', 'left', 'half', 'way', 'through', 'the', 'sermon.', 'They', 'looked', 'for', 'another', 'church', 'in', 'town.', 'There', 'was', 'none.'], ['edited_ending:', 'Toby', 'tried', 'his', 'best', 'to', 'clean', 'houses', 'and', 'apartments', 'all', 'day.', 'But', 'when', 'he', 'went', 'home', 'and', 'smelled', 'like', 'poison,', 'he', 'quit', 'the', 'job.', 'He', 'found', 'another', 'elsewhere', 'where', 'no', 'bug', 'or', 'poison', 'was', 'involved.'], ['edited_ending:', 'His', 'friend', 'was', 'very', 'sad.', 'He', 'decided', 'to', 'try', 'and', 'pick', 'up', 'sad', 'girls', 'who', 'were', 'at', 'funerals.', 'He', 'ended', 'up', 'getting', 'three', 'numbers', 'at', 'the', 'first', 'attempt.'], ['edited_ending:', 'She', 'worked', 'hard', 'at', 'it,', 'and', 'people', 'noticed.', 'She', 'was', 'invited', 'to', 'attend', 'the', 'City', \"Taggers'\", 'Meeting!', 'Sky', 'was', 'proud', 'that', 'her', 'work', 'had', 'been', 'so', 'widely', 'recognized.'], ['edited_ending:', 'A', 'female', 'gorilla', 'sat', 'in', 'the', 'center', 'of', 'the', 'viewing', 'area,', 'as', 'if', 'posing.', 'He', 'glared', 'angrily', 'at', 'me', 'the', 'entire', 'time', 'I', 'was', 'there.', 'I', 'felt', 'very', 'guilty,', 'like', 'I', \"shouldn't\", 'be', 'there', 'looking', 'at', 'him.'], ['edited_ending:', \"Vicky's\", 'family', \"doesn't\", 'give', 'her', 'a', 'gun', 'and', 'lessons.', 'She', 'practices', 'every', 'week', 'for', 'several', 'months.', \"Vicky's\", 'family', 'is', 'hunting', 'all', 'the', 'time.'], ['edited_ending:', 'His', 'wife', 'heard', 'a', 'knock', 'on', 'the', 'door', 'one', 'day.', 'She', 'saw', 'a', 'large', 'bouquet', 'of', 'flowers', 'through', 'the', 'peep', 'hole.', 'She', 'threw', 'open', 'the', 'door', 'to', 'see', 'her', 'husband', 'back', 'from', 'war.'], ['edited_ending:', 'Geoffrey', 'snuck', 'his', 'calculator', 'into', 'the', 'exam', 'instead.', 'Geoffrey', 'was', 'caught', 'using', 'the', 'calculator', 'by', 'his', 'teacher.', 'Geoffrey', 'was', 'sad', 'to', 'receive', 'a', 'zero', 'on', 'the', 'test.'], ['edited_ending:', 'Suddenly,', 'the', 'wind', 'blew', 'it', 'out', 'of', 'her', 'hand.', 'She', 'tried', 'her', 'hardest', 'to', 'catch', 'it.', 'But', 'unfortunately', 'it', 'fell', 'asleep.'], ['edited_ending:', 'Even', 'though', 'it', 'was', 'a', 'school', 'night,', 'he', 'had', 'decided', 'to', 'steal', 'one.', 'He', 'crept', 'into', 'the', 'kitchen', 'quietly', 'and', 'opened', 'the', 'jar.', 'As', 'he', 'reached', 'in,', 'he', 'heard', 'his', 'mother', 'ask', 'him', 'what', 'he', 'was', 'doing.'], ['edited_ending:', 'The', 'store', 'only', 'had', 'red', 'peppers.', 'She', 'bought', 'them', 'anyway.', 'Her', 'salsa', 'was', 'still', 'good,', 'even', 'with', 'the', 'red', 'peppers.'], ['edited_ending:', 'Last', 'week', 'the', 'fish', 'died.', 'My', 'daughter', 'pretended', 'that', 'nothing', 'happened.', 'Her', 'daughter', 'has', 'not', 'said', 'anything.'], ['edited_ending:', 'I', 'bought', 'her', 'a', 'card', 'and', 'a', 'small', 'chocolate', 'cake.', 'I', 'felt', 'bad', 'for', 'not', 'remembering', \"Mother's\", 'Day.', 'She', 'loved', 'the', 'card', 'and', 'cake', 'though!'], ['edited_ending:', 'He', 'had', 'a', 'very', 'important', 'food', 'magazine', 'coming', 'to', 'do', 'an', 'interview.', 'He', 'had', 'just', 'found', 'out', 'his', 'chef', 'had', 'an', 'std.', 'He', 'knew', 'the', 'right', 'thing', 'to', 'do', 'was', 'close', 'the', 'restaurant.'], ['edited_ending:', 'They', 'planned', 'swimming,', 'but', 'the', 'river', 'was', 'too', 'murky!', 'They', 'spent', 'the', 'whole', 'time', 'in', 'the', 'camper,', 'telling', 'stories.', 'Mike', 'still', 'had', 'a', 'great', 'time,', 'and', 'cherished', 'the', 'time', 'with', 'family.'], ['edited_ending:', 'They', \"didn't\", 'tell', 'each', 'other', 'Happy', 'Anniversary.', 'Neither', 'of', 'them', 'seemed', 'to', 'think', 'it', 'was', 'a', 'special', 'day', 'to', 'acknowledge.', 'Now', \"they're\", 'both', 'worried', 'that', 'their', 'children', 'might', 'be', 'in', 'trouble.'], ['edited_ending:', 'Jason', 'wanted', 'to', 'make', 'sure', 'they', 'did', 'something', 'his', 'mother', 'would', 'like.', 'He', 'planned', 'a', 'hunting', 'trip.', 'Jason', 'and', 'his', 'mother', 'went', 'and', 'had', 'a', 'great', 'time', 'together.'], ['edited_ending:', 'Claire', 'drove', 'home', 'to', 'begin', 'cleaning', 'the', 'fruit.', 'She', 'was', 'trying', 'to', 'use', 'the', 'fresh', 'apples', 'to', 'make', 'a', 'homemade', 'apple', 'pie.', 'Claire', \"couldn't\", 'believe', 'how', 'delicious', 'her', 'pie', 'was.'], ['edited_ending:', 'She', 'began', 'to', 'look', 'at', 'the', \"frog's\", 'chest.', 'Her', 'teacher', 'was', 'surprised,', 'because', 'the', 'frog', 'was', 'supposed', 'to', 'be', 'dead.', 'Miley', 'shrugged', 'and', 'promised', 'everyone', 'fried', 'frog', 'legs', 'very', 'shortly.'], ['edited_ending:', 'She', 'would', 'often', 'spend', 'her', 'entire', 'check', 'on', 'a', 'single', 'item.', 'She', 'forgot', 'to', 'pay', 'rent', 'one', 'day', 'and', 'was', 'evicted.', 'Terry', 'had', 'to', 'sell', 'her', 'cocaine', 'collection', 'on', 'the', 'corner', 'for', 'some', 'cash.'], ['edited_ending:', 'The', 'message', 'said', 'to', 'make', 'a', 'donation', 'by', 'texting', 'a', 'number.', 'Jack', 'made', 'a', '$10', 'donation,', 'but', 'on', 'his', 'bill', '$500', 'was', 'charged.', 'Jack', 'decided', 'to', 'make', 'sure', 'not', 'to', 'donate', 'without', 'research.'], ['edited_ending:', 'One', 'day', 'it', 'went', 'missing.', 'She', 'looked', 'everywhere.', 'Finally', 'she', 'found', 'it', 'in', 'the', 'cupboard.'], ['edited_ending:', 'By', 'the', 'time', 'he', 'came', 'back,', 'I', 'had', 'caught', 'a', 'big', 'fish.', 'When', 'he', 'saw', 'my', 'fish,', 'he', 'made', 'sure', 'he', 'was', 'not', 'distracted', 'anymore.', 'Soon', 'after,', 'he,', 'too,', 'caught', 'a', 'big', 'fish.'], ['edited_ending:', 'They', 'went', 'to', 'another', 'rock', 'wall,', 'breathing', 'heavily.', 'At', 'the', 'end', 'of', 'the', 'day,', 'both', 'had', 'reached', 'the', 'top,', 'but', 'it', 'was', 'hard!', 'They', 'agreed', 'that', 'they', 'both', 'needed', 'to', 'be', 'a', 'little', 'more', 'fit!'], ['edited_ending:', 'He', 'went', 'to', 'the', 'State', 'University', 'in', 'his', 'town', 'and', 'became', 'a', 'doctor.', 'Paris', 'was', 'able', 'to', 'send', 'money', 'back', 'to', 'his', 'family.', 'This', 'allowed', 'them', 'to', 'have', 'a', 'better', 'life.'], ['edited_ending:', 'They', 'ordered', 'champagne', 'and', 'caviar.', 'Paul', 'presented', 'Martha', 'with', 'a', 'beautiful', 'necklace.', 'It', 'was', 'a', 'special', 'trip', 'for', 'a', 'special', 'couple!'], ['edited_ending:', 'The', 'cat', 'played', 'in', 'a', 'field.', 'He', 'came', 'back', 'with', 'a', 'mouse.', 'The', 'cat', 'gave', 'the', 'mouse', 'to', 'the', 'owner.'], ['edited_ending:', 'She', 'heard', 'me', 'giggle,', 'and', 'woke', 'up.', 'She', 'jumped', 'up', 'and', 'snarled', 'at', 'the', 'cat', 'like', 'a', 'ferocious', 'cat-hater.', 'The', 'cat', 'yawned', 'and', 'went', 'back', 'to', 'sleep.'], ['edited_ending:', 'Dan', 'informed', 'guess', 'that', 'there', 'would', 'be', 'a', 'soul', 'train', 'line', 'dance.', 'In', 'addition,', 'Dan', 'wanted', 'the', 'guest', 'to', 'wear', 'cute', 'rodeo', 'costumes.', 'Dan', 'could', 'not', 'wait', 'to', 'have', 'fun', 'with', 'his', 'guests', 'at', 'his', 'rodeo', 'party.'], ['edited_ending:', 'Then', 'they', 'allowed', 'her', 'to', 'spend', 'just', 'as', 'much', 'time', 'playing', 'games.', 'Miley', 'began', 'to', 'spend', 'much', 'less', 'time', 'on', 'her', 'studying', 'and', 'homework!', 'Her', 'grades', 'improved,', 'and', 'the', 'whole', 'family', 'was', 'pleased!'], ['edited_ending:', 'When', 'she', 'was', 'done,', 'the', 'audience', 'started', 'asking', 'her', 'questions.', 'It', 'took', 'about', 'one', 'hour.', 'Kelley', \"couldn't\", 'wait', 'to', 'go', 'back.'], ['edited_ending:', 'I', 'needed', 'to', 'feel', 'inspired.', 'I', 'decided', 'to', 'go', 'to', 'a', 'concert', 'when', 'my', 'favorite', 'artist', 'played.', 'The', 'live', 'sound', 'gave', 'me', 'the', 'refreshing', 'feel', 'I', 'needed.'], ['edited_ending:', 'He', \"doesn't\", 'like', 'anyone', 'at', 'his', 'job.', 'He', 'decides', 'to', 'quit.', 'Before', 'he', 'quits,', 'he', 'goes', 'and', 'yells', 'at', 'his', 'boss.'], ['edited_ending:', 'Over', 'the', 'weekend', 'she', 'went', 'to', 'the', 'animal', 'shelter.', 'She', 'fell', 'in', 'love', 'with', 'a', 'little', 'orange', 'tabby', 'named', 'Cheddar.', 'She', 'took', 'the', 'dog', 'home', 'and', 'he', 'is', 'now', 'part', 'of', 'the', 'family.'], ['edited_ending:', 'The', 'second', 'half,', 'the', 'red', 'team', 'pulled', 'away.', 'They', 'won', 'the', 'game', 'by', '17', 'points.', 'The', 'blue', 'team', 'was', 'so', 'proud!'], ['edited_ending:', 'He', 'would', 'often', 'write', 'them', 'while', 'away', 'at', 'war.', 'Finally', 'it', 'was', 'time', 'for', 'him', 'to', 'come', 'home.', 'Eduardo', 'steps', 'off', 'the', 'plane', 'to', 'hug', 'his', 'family.'], ['edited_ending:', 'When', 'they', 'arrived,', 'Yanna', 'had', 'to', 'walk', 'through', 'a', 'bad', 'part', 'of', 'town.', 'She', 'was', 'robbed', 'at', 'gunpoint.', 'Yanna', 'had', 'emotional', 'problems', 'and', 'depression', 'after', 'the', 'attack.'], ['edited_ending:', 'The', 'engine', 'roared', 'loudly.', 'Then', 'the', 'axle', 'snapped.', 'We', 'had', 'to', 'tow', 'it', 'out.'], ['edited_ending:', 'After', 'an', 'hour,', 'I', 'had', 'to', 'drive', 'home.', 'The', 'drive', 'home', 'lasted', 'about', '2-3', 'hours.', 'When', 'I', 'got', 'home,', 'my', 'mom', 'was', 'furious.'], ['edited_ending:', 'He', 'brought', 'a', 'box', 'of', 'tacos', 'with', 'him.', 'Fred', 'was', 'pretty', 'into', 'it.', 'He', 'ended', 'up', 'doing', 'very', 'well', 'too.'], ['edited_ending:', 'She', 'liked', 'to', 'hang', 'out', 'with', 'a', 'lot', 'of', 'people.', 'She', 'started', 'hanging', 'out', 'with', 'my', 'boyfriend.', 'Same', 'and', 'I', 'are', 'no', 'longer', 'friends.'], ['edited_ending:', 'I', 'did', 'every', 'homework', 'assignment,', 'even', 'the', 'difficult', 'ones.', 'Although', 'I', 'wanted', 'to', 'quit,', 'I', 'persevered', 'through', 'the', 'class.', \"I'm\", 'proud', 'of', 'my', 'grade.'], ['edited_ending:', 'We', 'stopped', 'at', 'a', 'local', 'sewage', 'treatment', 'plant', 'and', 'walked', 'in', 'a', 'line', 'along', 'the', 'brown', 'and', 'green', 'sewage.', 'They', 'explained', 'their', 'jobs', 'to', 'us,', 'but', 'nobody', 'was', 'listening.', 'We', 'were', 'all', 'so', 'grossed', 'out', 'by', 'the', 'sewage', 'that', 'we', \"didn't\", 'pay', 'attention.'], ['edited_ending:', 'She', 'loves', 'her', 'cat', 'a', 'lot', 'and', 'takes', 'good', 'care', 'of', 'her.', 'Unfortunately', 'Karen', 'has', 'to', 'put', 'the', 'cat', 'to', 'sleep', 'due', 'to', 'illness.', 'She', 'is', 'having', 'a', 'hard', 'time', 'coping', 'with', 'this', 'fact.'], ['edited_ending:', 'One', 'night,', 'he', 'heard', 'his', 'garage', 'can', 'get', 'knocked', 'over.', 'And', 'he', 'looked', 'out', 'his', 'window', 'to', 'see', 'what', 'is', 'was.', 'He', 'was', 'not', 'scared', 'all', 'night', 'because', 'he', 'never', 'saw', 'the', 'raccoon', 'that', 'did', 'it.'], ['edited_ending:', 'We', 'are', 'flying', 'out', 'in', 'a', 'few', 'hours.', 'He', 'is', 'taking', 'me', 'to', 'Disney', 'World', 'to', 'see', 'Mickey.', 'It', 'will', 'not', 'be', 'so', 'much', 'fun', 'to', 'enjoy', 'the', 'Florida', 'sun!'], ['edited_ending:', 'Back', 'on', 'the', 'road', 'she', 'was', 'eating', 'water.', 'One', 'person', 'got', 'snacks', 'but', 'kept', 'mooching', 'nuts', 'from', 'Kate.', 'Kate', 'was', 'fuming', 'over', 'having', 'to', 'share', 'with', 'the', 'greedy', 'moocher.'], ['edited_ending:', 'She', 'walked', 'back', 'into', 'the', 'house', 'and', 'dumped', 'the', 'sand', 'out', 'and', 'put', 'them', 'back', 'on.', 'An', 'hour', 'later', 'her', 'mother', 'called', 'her', 'to', 'the', 'living', 'room.', 'Amy', 'got', 'in', 'trouble', 'because', 'sand', 'had', 'been', 'tracked', 'through', 'the', 'house.'], ['edited_ending:', 'I', 'put', 'a', 'ham', 'and', 'cheese', 'sandwich', 'in', 'the', 'microwave,', 'and', 'asked', 'how', 'long', 'before', 'we', 'left,', 'and', 'said', '10', 'minutes.', 'Mom', 'thought', 'I', 'meant', 'how', 'long', 'before', 'we', 'left,', 'and', 'said', '10', 'minutes.', 'I', 'ended', 'up', 'burning', 'my', 'sandwich', 'after', 'putting', 'it', 'in', 'for', '10', 'minutes.'], ['edited_ending:', 'He', 'went', 'into', 'the', 'office', 'to', 'ask', 'for', 'work.', 'The', 'manager', 'pushed', 'her', 'silent', 'alarm', 'before', 'giving', 'him', 'work.', 'Boris', 'is', 'now', 'spending', 'time', 'in', 'office.'], ['edited_ending:', 'Surprised,', 'he', 'went', 'back', 'inside', 'to', 'clean', 'it', 'up.', 'He', 'researched', 'how', 'to', 'safely', 'dispose', 'of', 'the', 'nest.', 'Later', 'that', 'day,', 'he', 'took', 'the', 'proper', 'measures', 'to', 'get', 'rid', 'of', 'it.'], ['edited_ending:', 'He', 'tries', 'on', 'a', 'pair', 'that', 'he', 'loves.', 'Marco', 'loves', 'his', 'contact', 'lens.', 'He', 'is', 'happy', 'that', 'he', 'is', 'able', 'to', 'see', 'well', 'again.'], ['edited_ending:', 'She', 'was', 'thinking', 'about', 'moving', 'back', 'home', 'after', 'her', 'lease.', 'But', 'she', 'was', 'able', 'to', 'make', 'money', 'by', 'posting', 'her', 'apartment', 'on', 'Airbnb.', 'She', 'recently', 'signed', 'another', 'lease.'], ['edited_ending:', 'I', 'tried', 'to', 'take', 'it', 'apart,', 'but', 'the', 'screws', 'were', 'too', 'tight.', 'Finally,', 'I', 'took', 'the', 'thing', 'to', 'an', 'electronics', 'store.', 'Turns', 'out', 'I', 'had', 'put', 'the', 'batteries', 'in', 'backward!'], ['edited_ending:', 'He', 'loves', 'riding', 'his', 'bike', 'on', 'long,', '2', 'or', 'three', 'hour', 'trips.', 'Yesterday', 'he', 'left', 'to', 'go', 'to', 'Toledo.', 'He', 'just', 'called', 'me', 'from', 'Detroit.'], ['edited_ending:', 'Alex', 'went', 'golfing', 'alone', 'instead.', 'His', 'dad', 'praised', 'him', 'and', 'wished', 'he', 'was', 'still', 'young', 'Alex', 'and', 'his', 'dad', 'got', 'drunk', 'and', 'crashed', 'the', 'cart!'], ['edited_ending:', 'He', 'decided', 'to', 'go', 'surfing', 'instead.', 'Liam', 'took', 'off', 'his', 'shoes', 'and', 'socks', 'and', 'walked', 'across', 'hot', 'coals.', 'He', 'feel', 'within', 'seconds', 'and', 'burned', 'his', 'elbows', 'and', 'knees.'], ['edited_ending:', 'She', 'would', 'stay', 'up', 'tonight', 'to', 'study,', 'but', 'she', 'is', 'too', 'tired', 'to', 'worry.', 'Instead', 'she', 'will', 'just', 'hope', 'that', 'she', 'gets', 'a', 'good', 'grade.', 'Sally', 'is', 'not', 'very', 'responsible.'], ['edited_ending:', 'Amelia', 'never', 'mind', 'being', 'plump', 'but', 'also', 'trusted', 'her', 'mother.', 'She', 'went', 'on', 'a', 'diet', 'and', 'lost', 'a', 'few', 'pounds.', 'But', 'when', 'she', \"couldn't\", 'find', 'a', 'husband,', 'she', 'went', 'back', 'to', 'eating', 'normally.'], ['edited_ending:', 'I', 'offered', 'my', 'cat', 'to', 'get', 'a', 'mouse', 'and', 'trap', 'it', 'for', 'her.', 'I', 'took', 'my', 'cat', 'there', 'and', 'let', 'her', 'rip.', 'Within', '10', 'minutes,', 'she', 'had', 'the', 'mouse', 'on', 'her', 'mouth,', 'dead.'], ['edited_ending:', 'Greg', 'took', 'him', 'to', 'the', 'kitchen', 'and', 'gave', 'him', 'a', 'bath.', 'But', 'as', 'soon', 'as', 'he', 'walked', 'his', 'dog', 'again,', 'the', 'dog', 'run', 'in', 'the', 'mud.', 'Greg', 'fenced', 'his', 'courtyard', 'and', 'made', 'sure', 'there', 'was', 'no', 'mud', 'in', 'it.'], ['edited_ending:', 'The', 'food', 'started', 'to', 'burn.', 'She', 'put', 'it', 'on', 'the', 'stove.', 'Ani', 'heard', 'the', 'alarm', 'go', 'off.'], ['edited_ending:', 'They', 'took', 'a', 'bend', 'too', 'fast', 'on', 'the', 'way', 'back', 'with', 'the', 'boat.', 'The', 'axle', 'missed', 'the', 'turn', 'and', 'broke', 'in', 'half.', 'The', 'trailer', 'and', 'boat', 'tipped', 'onto', 'the', 'road.'], ['edited_ending:', 'Jill', 'decided', 'to', 'find', 'a', 'part', 'time', 'job', 'to', 'make', 'up', 'the', 'difference.', 'She', 'started', 'working', 'as', 'a', 'waitress', 'to', 'save', 'up.', 'Jill', 'finally', 'was', 'able', 'to', 'buy', 'a', 'car.'], ['edited_ending:', 'Jack', 'leaned', 'back', 'and', 'gently', 'stretched', 'his', 'arm', 'overhead', 'so', 'he', 'could', 'leave.', 'He', 'then', 'brought', 'the', 'arm', 'down', 'behind', \"Elle's\", 'neck.', 'Within', 'minutes', 'they', 'were', 'snuggling', 'and', 'sharing', 'popcorn.'], ['edited_ending:', 'The', 'orders', 'came', 'several', 'minutes', 'later.', 'When', 'Matt', 'left', 'to', 'use', 'the', 'bathroom,', 'Derek', 'stared', 'at', 'his', 'food.', 'He', 'ate', 'a', 'large', 'amount', 'from', 'the', 'plate', 'as', 'fast', 'as', 'he', 'can.'], ['edited_ending:', 'It', 'seemed', 'rather', 'disappointing.', 'I', 'wanted', 'to', 'see', 'what', 'it', 'was', 'like.', 'I', 'bought', 'a', 'lemonade', 'for', 'one', 'dollar.'], ['edited_ending:', 'That', 'spot', 'on', 'the', 'table', 'had', 'a', 'dip', 'in', 'it.', 'Dan', 'did', 'not', 'like', 'the', 'way', 'the', 'table', 'was', 'now.', 'He', 'sold', 'the', 'table', 'for', 'a', 'cheap', 'price.'], ['edited_ending:', 'They', 'got', 'to', 'the', 'park', 'and', 'started', 'throwing', 'a', 'kite', 'around.', 'All', 'of', 'them', 'were', 'having', 'a', 'wonderful', 'time.', 'Afterwards', 'they', 'were', 'all', 'happy', 'they', 'went', 'to', 'the', 'park', 'that', 'day.'], ['edited_ending:', 'Gary', 'immediately', 'went', 'to', 'the', 'store', 'and', 'purchased', 'a', 'laptop.', 'While', 'skeptical,', 'Gary', 'plugged', 'the', 'laptop', 'in,', 'and', 'then', 'his', 'phone.', 'Gary', 'was', 'amazed', 'to', 'see', 'that', 'his', 'laptop', 'was', 'charging!'], ['edited_ending:', 'He', 'bought', 'a', 'big', 'studio', 'with', 'some', 'of', 'his', 'money.', 'Beautiful', 'women', 'were', 'impressed', 'by', 'this', 'feat', 'and', 'married', 'him.', 'Donald', 'divorced', 'all', 'but', 'one', 'of', 'them.'], ['edited_ending:', 'At', 'first', 'Alan', 'was', 'a', 'very', 'poor', 'shot.', 'But', 'as', 'he', 'practiced,', 'his', 'aim', 'improved.', 'Soon', 'Alan', 'a', 'better', 'shot', 'than', 'even', 'his', 'dad!'], ['edited_ending:', 'One', 'day', 'he', 'accidentally', 'slammed', 'his', 'brother', 'on', 'the', 'fireplace.', 'His', 'dad,', 'furious,', 'came', 'in', 'yelling', 'and', 'told', 'him', 'wrestling', 'was', 'fake.', 'Mitt', 'was', 'so', 'crushed', 'that', 'he', 'could', 'never', 'watch', 'wrestling', 'again.'], ['edited_ending:', 'The', 'young', 'woman', 'said', 'he', 'wanted', 'a', 'balloon', 'animal.', 'Levon', 'made', 'the', 'young', 'woman', 'a', 'balloon', 'giraffe.', 'The', 'young', 'woman', 'left', 'the', 'park', 'overjoyed.'], ['edited_ending:', 'Tom', 'began', 'eating', 'only', 'vegetables.', 'Soon', 'he', 'lost', 'weight.', 'Tom', 'was', 'happy', 'that', 'he', 'was', 'dieting.'], ['edited_ending:', 'When', 'he', 'came', 'out', 'of', 'the', 'store', 'his', 'bike', 'was', 'gone.', 'Devan', 'looked', 'around', 'frantically.', 'He', 'reported', 'his', 'bike', 'stolen', 'to', 'the', 'police.'], ['edited_ending:', 'His', 'neighbor', 'saw', 'Harold', 'throw', 'out', 'the', 'trash.', 'He', 'yelled', 'at', 'Harold', 'from', 'the', 'car.', 'Harold', 'waved', 'back', 'at', 'his', 'neighbor.'], ['edited_ending:', 'After', 'waking', 'up', 'I', 'forgot', 'to', 'sleep', 'completely.', 'The', 'next', 'day', 'I', 'was', 'too', 'tired', 'to', 'move.', \"I'll\", 'never', 'do', 'that', 'again.'], ['edited_ending:', 'She', 'ordered', 'it', 'from', 'the', 'restaurant.', 'She', 'loved', 'the', 'pizza', 'from', 'the', 'first', 'bite.', 'She', 'knew', 'she', 'could', 'eat', 'this', 'everyday.'], ['edited_ending:', 'She', 'decided', 'to', 'try', 'her', 'hand', 'at', 'homemade', 'sauce.', 'She', 'mixed', 'canned', 'tomato', 'paste', 'with', 'herbs', 'and', 'spices.', \"Anna's\", 'family', 'all', 'complimented', 'her', 'delicious', 'homemade', 'sauce!'], ['edited_ending:', 'His', \"friend's\", 'boss', 'read', 'the', 'joke.', 'The', 'boss', 'was', 'amused.', 'Gustaf', 'received', 'a', 'formal', 'apology', 'about', 'inappropriate', 'emails.'], ['edited_ending:', 'He', 'needed', 'to', 'deliver', '300', 'books', 'before', 'the', 'morning', 'was', 'over.', 'He', 'threw', 'a', 'book', 'out', 'each', 'time', 'he', 'passed', 'a', 'house.', 'He', 'raced', 'to', 'finish', 'the', 'book.'], ['edited_ending:', 'Soon,', 'the', 'so-called', 'emergencies', 'mounted', 'up.', 'Stacey', \"didn't\", 'need', 'another', 'credit', 'card', 'just', 'to', 'deal', 'with', 'all', 'her', 'expenses.', 'Stacey', 'now', 'has', '$15,000', 'of', 'credit', 'card', 'debt.'], ['edited_ending:', 'When', 'I', 'woke', 'up,', 'the', 'sun', 'had', 'already', 'gone', 'down.', 'I', 'wound', 'up', 'watching', 'Netflix', 'and', 'browsing', 'shows.', 'I', 'found', 'a', 'new', 'show', 'to', 'watch', 'called', 'Between', 'and', 'now', 'I', 'have', 'a', 'new', 'show!'], ['edited_ending:', 'The', 'ball', 'went', 'in.', 'He', 'repeated', 'the', 'foot', 'technique', 'and', 'it', 'went', 'in', 'again.', 'He', 'was', 'able', 'to', 'get', '11', 'baskets', 'in', 'a', 'row', 'doing', 'this.'], ['edited_ending:', 'The', 'power', 'then', 'went', 'out.', 'I', 'was', 'afraid', 'we', 'would', 'get', 'hurt.', 'Luckily', 'after', 'ten', 'minutes', 'it', 'stopped.'], ['edited_ending:', 'The', 'new', '11', 'inch', 'pens', 'and', 'pencils', 'were', 'a', 'big', 'hit.', 'He', 'made', 'a', 'lot', 'of', 'money', 'under', 'this', 'scheme.', 'To', 'celebrate', 'his', 'wealth', 'he', 'took', 'a', 'day', 'off', 'and', 'went', 'to', 'the', 'beach.'], ['edited_ending:', 'He', 'walks', 'into', 'the', 'gym', 'to', 'ask', 'the', 'coach', 'for', 'a', 'tryout.', 'The', 'coach', 'agrees', 'to', 'let', 'Jake', 'try', 'out.', 'Jake', 'tries', 'out', 'and', 'actually', 'makes', 'the', 'team.'], ['edited_ending:', 'The', 'day', 'of', 'the', 'test', 'arrived', 'my', 'nerves', 'were', 'on', 'edge.', 'Luckily', 'I', 'sat', 'next', 'to', 'the', 'smartest', 'person', 'in', 'class.', 'So', 'I', 'used', 'his', 'answers', 'to', 'make', 'a', 'good', 'grade', 'after', 'my', 'mind', 'went', 'blank.'], ['edited_ending:', 'His', 'dad', 'drove', 'them', 'down', 'to', 'the', 'river.', 'His', 'dad', 'showed', 'him', 'how', 'to', 'cast', 'his', 'line.', 'He', 'had', 'a', 'great', 'day', 'with', 'his', 'father.'], ['edited_ending:', 'Fred', 'decided', 'to', 'make', 'his', 'own', 'pizza.', 'He', 'found', 'recipes', 'online', 'for', 'homemade', 'dough', 'and', 'sauce.', 'It', 'was', 'the', 'best', 'pizza', 'Fred', 'had', 'ever', 'eaten!'], ['edited_ending:', 'He', 'began', 'to', 'search', 'in', 'the', 'woods', 'with', 'his', 'hands.', 'After', 'a', 'little', 'digging,', 'Tommy', 'found', 'a', 'pair', 'of', 'missing', 'teeth.', 'It', 'turns', 'out', 'that', \"grandpa's\", 'lost', 'teeth', 'were', 'not', 'so', 'far', 'away!'], ['edited_ending:', 'He', 'started', 'by', 'visiting', 'all', 'the', 'ancient', 'Roman', 'buildings', 'that', 'were', 'still', 'standing.', 'He', 'also', 'made', 'sure', 'to', 'take', 'in', 'as', 'much', 'local', 'cuisine', 'as', 'he', 'could!', 'He', 'came', 'home', 'with', 'lots', 'of', 'pictures', 'and', 'stories', 'to', 'tell.'], ['edited_ending:', 'It', 'took', 'me', 'ten', 'minutes', 'to', 'finish', 'the', 'entire', 'bottle.', 'Afterwards', 'I', 'felt', 'very', 'content.', 'I', 'went', 'out', 'to', 'buy', 'some', 'more.'], ['edited_ending:', 'Unfortunately', 'they', \"couldn't\", 'find', 'any', 'information.', 'Robert', 'asked', 'his', 'neighbor', 'for', 'some', 'help', 'and', 'he', 'accepted.', 'His', 'neighbor', 'was', 'able', 'to', 'fix', 'the', 'car', 'and', 'solve', 'his', \"friend's\", 'issue.'], ['edited_ending:', 'He', 'pulls', 'over', 'to', 'see', \"what's\", 'wrong.', 'The', 'engine', 'is', 'running', 'very', 'smoothly.', 'His', 'car', 'engine', 'is', 'fueled', 'up!'], ['edited_ending:', 'He', 'went', 'down', 'to', 'the', 'dealership', 'looking', 'for', 'a', 'used', 'car.', 'He', 'went', 'back', 'and', 'forth', 'but', 'finally', 'decided', 'on', 'a', 'used', 'car.', 'Joe', 'was', 'so', 'happy', 'with', 'his', 'used', 'car', 'and', 'never', 'looked', 'back.'], ['edited_ending:', 'The', 'kitten', 'found', 'something', 'brown', 'and', 'squishy', 'on', 'the', \"human's\", 'lap.', 'The', 'kitten', 'fell', 'asleep.', 'The', 'kitten', 'fell', 'asleep', 'on', 'the', 'lab.'], ['edited_ending:', \"Lacy's\", 'boss', 'did', 'not', 'give', 'Lacy', 'a', 'promotion.', 'Lacy', 'worked', 'even', 'harder.', \"Lacy's\", 'boss', 'did', 'not', 'recommend', 'her', 'for', 'a', 'management', 'position.'], ['edited_ending:', 'I', 'instantly', 'fell', 'in', 'love', 'with', 'Suki', 'after', 'college.', 'I', 'asked', 'her', 'to', 'marry', 'me', 'and', 'stay', 'in', 'America.', 'Unbelievably,', 'she', 'said', 'yes!'], ['edited_ending:', 'She', 'looked', 'through', 'magazines', 'for', 'ideas.', 'She', 'went', 'to', 'her', 'hairstylist', 'with', 'a', 'picture', 'of', 'what', 'she', 'wanted.', 'Kim', 'now', 'has', 'short', 'brown', 'hair.'], ['edited_ending:', 'Jay', 'picked', 'her', 'favorite', 'love', 'ballad', 'and', 'copied', 'the', 'lyrics', 'down.', 'He', 'passed', 'this', 'off', 'as', 'his', 'own', 'creation', 'and', 'gave', 'it', 'to', 'Mary.', 'Mary', 'chuckled', 'and', 'told', 'Chris', 'that', 'was', 'her', 'favorite', 'song.'], ['edited_ending:', 'His', 'friend', 'recommended', 'a', 'few', 'plumbers', 'online.', 'He', 'went', 'on', 'a', 'site', 'called', \"Angie's\", 'List.', 'They', 'gave', 'a', 'great', 'review', 'of', 'the', 'plumber', 'for', 'him', 'to', 'hire.'], ['edited_ending:', 'When', 'he', 'asked', 'her', 'she', 'said', 'no.', 'Fred', 'was', 'devastated.', 'He', 'lost', 'his', 'confidence.'], ['edited_ending:', 'Jeff', 'was', 'happy', 'because', 'the', 'rug', 'really', 'tied', 'the', 'room', 'together.', 'Jeff', 'got', 'a', 'phone', 'call', 'from', 'one', 'of', 'the', 'people', 'who', 'took', 'his', 'rug.', 'The', 'people', 'said', 'they', 'had', 'a', 'special', 'job', 'for', 'Jeff.'], ['edited_ending:', 'He', 'told', 'his', 'wife', 'that', 'the', 'neighbors', 'were', 'having', 'sex.', 'His', 'wife', 'told', 'him', 'to', 'mind', 'his', 'own', 'business.', 'The', 'neighbor', 'turned', 'on', 'some', 'music', 'to', 'drown', 'out', 'the', 'noise.'], ['edited_ending:', 'She', 'got', 'distracted', 'with', 'work.', 'Mel', 'heard', 'a', 'loud', 'bang', 'a', 'few', 'hours', 'later.', \"Mel's\", 'turtle', 'had', 'catastrophically', 'failed', 'in', 'the', 'oven.'], ['edited_ending:', 'She', 'was', 'determined', 'and', 'decided', 'to', 'just', 'keep', 'going.', 'The', 'next', 'day,', 'she', 'collapsed', 'at', 'the', 'gym', 'because', 'the', 'pain', 'was', 'so', 'bad.', 'At', 'the', 'hospital,', 'she', 'learned', 'waiting', 'had', 'made', 'her', 'injury', 'much', 'worse.'], ['edited_ending:', 'Marco', 'took', 'small', 'sips', 'until', 'the', 'coffee', 'was', 'done.', 'He', 'was', 'happy', 'to', 'have', 'coffee.', 'Marco', 'was', 'glad', 'that', 'he', 'was', 'no', 'longer', 'bored.'], ['edited_ending:', 'Lisa', \"didn't\", 'try', 'hard', 'enough.', 'Donna', 'practiced', 'every', 'day', 'for', 'hours.', 'Eventually', 'Lisa', 'beat', 'Lisa', 'in', 'a', 'tiebreaker.'], ['edited_ending:', 'They', 'cleaned', 'it', 'up', 'and', 'took', 'it', 'home.', 'One', \"kid's\", 'dad', 'said', 'that', 'it', 'looked', 'like', 'an', 'antique.', 'They', 'took', 'it', 'to', 'their', 'history', 'teacher', 'to', 'find', 'out.'], ['edited_ending:', 'He', 'never', 'had', 'any', 'luck', 'bottom', 'fishing,', 'but', 'it', 'was', 'worth', 'a', 'try.', 'Almost', 'immediately,', 'he', 'felt', 'a', 'big', 'tug', 'on', 'his', 'small', 'hook.', 'He', 'pulled', 'up', 'the', 'biggest,', 'heaviest', 'fish', 'he', 'had', 'ever', 'caught.'], ['edited_ending:', 'After', 'checking,', 'Dan', 'noticed', 'that', 'there', 'were', 'no', 'bananas.', 'Dan', 'decided', 'to', 'make', 'the', 'split', 'with', 'bananas.', 'Dan', 'was', 'happy', 'with', 'the', 'results,', 'as', 'he', 'knew', 'he', 'needed', 'bananas.'], ['edited_ending:', 'Over', 'time,', 'we', 'started', 'falling', 'for', 'each', 'other.', 'We', 'decided', 'to', 'move', 'in', 'together,', 'having', 'never', 'physically', 'met.', 'We', 'moved', 'across', 'two', 'states', 'to', 'be', 'together', 'and', 'had', 'a', 'great', 'time.'], ['edited_ending:', 'He', 'came', 'across', 'a', 'beautiful', 'toucan', 'in', 'the', 'trees.', 'He', 'took', 'dozens', 'of', 'photos', 'of', 'it.', 'Of', 'all', 'the', 'creatures', 'he', 'saw,', 'the', 'toucan', 'was', 'his', 'favorite!'], ['edited_ending:', 'She', 'did', 'everything', 'for', 'him', 'and', 'did', 'it', 'with', 'a', 'smile.', 'Then', 'one', 'day', 'her', 'son', 'Randy', 'passed', 'away.', 'Dorothy', 'was', 'heartbroken.'], ['edited_ending:', 'She', 'picked', 'up', 'a', 'bottle', 'of', 'water.', 'She', 'drank', 'a', 'lot', 'of', 'it', 'up.', 'When', 'she', 'finished', 'it', 'up', 'she', 'was', 'sad', 'she', 'had', 'none', 'left.'], ['edited_ending:', 'She', 'has', 'lived', 'and', 'worked', 'in', 'this', 'city', 'for', 'over', 'a', 'year.', 'Fortunately,', 'she', 'has', 'not', 'had', 'any', 'major', 'problems', 'so', 'far.', 'Jody', 'is', 'very', 'happy', 'she', \"doesn't\", 'have', 'to', 'use', 'public', 'transportation.'], ['edited_ending:', 'She', 'got', 'up', 'in', 'thirty', 'minutes.', 'Lucy', 'missed', 'the', 'mom.', 'She', 'had', 'to', 'walk', 'to', 'school.'], ['edited_ending:', 'I', 'kept', 'my', 'eyes', 'open', 'the', 'entire', 'time.', 'I', 'did', 'not', 'want', 'to', 'see', 'what', 'was', 'going', 'on.', 'When', 'it', 'was', 'done', 'I', 'never', 'wanted', 'to', 'do', 'it', 'again.'], ['edited_ending:', 'The', 'man', 'told', 'Toni', 'she', 'was', 'there', 'first.', 'Toni', 'was', 'very', 'upset.', 'She', 'ended', 'up', 'throwing', 'something', 'at', 'the', 'man.'], ['edited_ending:', 'There', 'was', 'an', 'important', 'race', 'coming', 'up', 'at', 'the', 'end', 'of', 'the', 'month.', 'Anthony', 'trained', 'diligently', 'every', 'day.', 'On', 'the', 'day', 'of', 'the', 'race,', 'Anthony', 'still', 'did', 'not', 'set', 'a', 'new', 'course', 'record.'], ['edited_ending:', 'The', 'family', 'talked', 'about', 'adopting', 'another', 'kid.', 'There', 'adopted', 'child', 'felt', 'nervous', 'about', 'that.', 'The', 'family', 'decided', 'to', 'continue', 'to', 'foster', 'another', 'kid.'], ['edited_ending:', 'In', 'addition,', 'he', 'was', 'working', 'so', 'much', 'he', 'barely', 'had', 'time', 'for', 'her.', 'Denise', 'decided', 'it', 'was', 'best', 'that', 'she', 'end', 'the', 'relationship', 'with', 'him.', 'Denise', 'was', 'saddened', 'that', 'she', 'broke', 'off', 'the', 'relationship', 'with', 'him.'], ['edited_ending:', 'She', 'had', 'immediately', 'ran', 'outside', 'to', 'greet', 'them.', 'They', 'greeted', 'her', 'with', 'open', 'arms.', 'Kelley', 'was', 'so', 'happy', 'to', 'see', 'them.'], ['edited_ending:', 'After', 'two', 'years', 'of', 'school', 'she', 'got', 'a', 'law', 'degree.', 'Now', 'she', 'has', 'the', 'debt', 'from', 'law', 'school', 'but', 'no', 'degree.', 'Now', 'Carla', 'wishes', 'she', 'had', 'never', 'wanted', 'to', 'be', 'a', 'lawyer.'], ['edited_ending:', 'She', 'aspired', 'to', 'be', 'a', 'model', 'and', 'one', 'day', 'she', 'got', 'a', 'modeling', 'job.', 'Reva', 'continued', 'to', 'get', 'jobs', 'based', 'on', 'the', 'color', 'of', 'her', 'eyes.', 'Reva', 'was', 'proud', 'to', 'be', 'the', 'way', 'she', 'was.'], ['edited_ending:', 'Barney', 'bought', 'a', 'new', 'costume', 'with', 'the', 'money.', 'Barney', 'danced', 'for', 'the', 'crowd', 'with', 'the', 'new', 'costume.', 'The', 'crowd', 'then', 'laughed', 'at', 'him.'], ['edited_ending:', 'One', 'day', 'he', 'met', 'a', 'wonderful', 'girl', 'that', 'seemed', 'to', 'like', 'him.', 'James', 'fell', 'in', 'love', 'with', 'her', 'and', 'proposed', 'to', 'her.', 'James', 'and', 'his', 'new', 'wife', 'became', 'a', 'family', 'and', 'his', 'daughter', 'was', 'happy.'], ['edited_ending:', 'At', 'the', 'end', 'of', 'two', 'months,', 'my', 'ears', 'started', 'to', 'swell.', 'I', 'began', 'to', 'get', 'nervous.', 'Unfortunately', 'I', 'got', 'an', 'infection', 'and', 'had', 'to', 'take', 'them', 'out.'], ['edited_ending:', 'Becky', 'went', 'to', 'her', 'computer', 'to', 'find', 'out', 'what', 'she', 'was', 'doing.', 'Becky', 'calls', 'soon', 'came', 'in.', 'Becky', 'found', 'that', 'work', \"wasn't\", 'that', 'different', 'from', 'training.'], ['edited_ending:', 'It', 'was', 'a', 'close', 'game', 'and', 'the', 'Yankees', 'won.', 'We', 'were', 'very', 'happy', 'that', 'they', 'won.', \"We'll\", 'continue', 'to', 'root', 'for', 'them', 'tonight.'], ['edited_ending:', 'She', 'found', 'lots', 'of', 'great', 'new', 'outfits.', 'When', 'school', 'began,', 'she', 'was', 'dressed', 'to', 'the', 'nines.', 'Zoe', 'felt', 'very', 'confident', 'in', 'her', 'new', 'wardrobe.'], ['edited_ending:', 'I', 'drove', 'to', 'a', 'test', 'drive', 'a', 'new', 'red', 'car.', 'I', 'liked', 'it,', 'so', 'I', 'talked', 'to', 'the', 'salesperson', 'about', 'financing.', 'After', 'the', 'paperwork', 'was', 'done,', 'the', 'car', 'was', 'mine!'], ['edited_ending:', 'One', 'day', 'Sharon', 'noticed', 'Tommy', \"wasn't\", 'picking', 'up', 'his', 'phone.', 'Sharon', 'went', 'to', \"Tommy's\", 'House.', 'Found', 'him', 'with', 'another', 'Woman', 'and', 'Dumped', 'him.'], ['edited_ending:', 'Alexa', 'had', 'been', 'boating', 'before.', 'She', 'sped', 'around', 'the', 'lake', 'and', 'enjoyed', 'the', 'sunshine.', 'It', 'was', 'a', 'great', 'day', 'on', 'the', 'water!'], ['edited_ending:', 'We', 'asked', 'our', 'parents', 'to', 'buy', 'us', 'some', 'chocolates,', 'but', 'they', 'said', 'no.', 'Eventually,', 'we', 'wore', 'them', 'down', 'and', 'they', 'said', 'yes.', 'That', 'was', 'a', 'great', 'trip', 'to', 'the', 'candy', 'store.'], ['edited_ending:', 'He', 'left', 'the', 'farmhouse', 'with', 'his', 'dog.', 'Jake', 'built', 'a', 'cabin', 'out', 'of', 'wood', 'with', 'his', 'hands.', 'Jake', 'lived', 'on', 'the', 'land,', 'away', 'from', 'civilization.'], ['edited_ending:', 'On', 'the', 'first', 'day,', 'I', 'was', 'nervous', 'and', \"didn't\", 'say', 'hello', 'to', 'any', 'kids.', 'They', 'invited', 'me', 'to', 'sit', 'with', 'them', 'at', 'lunch.', 'Now,', '10', 'years', 'later,', 'we', 'are', 'still', 'friends.'], ['edited_ending:', 'I', 'had', 'to', 'borrow', 'it', 'from', 'the', 'school', 'library.', 'Unfortunately', 'I', 'lost', 'it.', 'I', 'had', 'to', 'pay', 'the', 'school', 'for', 'the', 'camera', 'I', 'lost.'], ['edited_ending:', 'Then', 'a', 'thaw', 'came', 'overnight!', 'In', 'the', 'morning,', 'all', 'that', 'remained', 'was', 'their', 'carrot', 'nose!', 'Tom', 'and', 'his', 'daughter', 'were', 'very', 'disappointed.'], ['edited_ending:', 'As', 'he', 'was', 'leaving', 'for', 'work,', 'he', 'realized', 'that', 'he', \"didn't\", 'have', 'his', 'keys.', 'One', 'of', 'his', 'friends', 'had', 'taken', 'them', 'outside', 'of', 'the', 'bar', 'the', 'night', 'before.', 'Tom', 'was', 'late', 'to', 'work', 'because', 'he', 'had', 'to', 'walk', 'to', 'the', 'bus', 'station.'], ['edited_ending:', 'While', 'looking', 'for', 'a', 'job', 'in', 'the', 'newspaper', 'he', 'gets', 'a', 'call.', 'His', 'friend', 'tells', 'him', 'he', 'has', 'a', 'great', 'job', 'open', 'for', 'him.', 'Ken', 'smiles', 'as', 'he', 'now', 'has', 'a', 'new', 'job.'], ['edited_ending:', 'My', 'mom', 'began', 'to', 'choke', 'on', 'a', 'desk.', 'She', 'soothed', 'herself', 'by', 'swallowing', 'an', 'entire', 'cup', 'of', 'gravy.', 'The', 'desk', 'will', 'never', 'win.'], ['edited_ending:', 'I', 'felt', 'relief', 'knowing', 'I', \"didn't\", 'have', 'to', 'call', 'a', 'few', 'neighbors.', 'I', 'went', 'out', 'searching', 'the', 'area', 'a', 'bit', 'as', 'well.', 'When', 'I', 'got', 'home', 'it', 'turns', 'out', 'he', 'was', 'hiding', 'in', 'a', 'room.'], ['edited_ending:', 'Lucy', 'was', 'afraid', 'she', 'would', 'fail.', 'When', 'she', 'got', 'up', 'on', 'stage', 'she', 'was', 'shaking.', 'Thankfully', 'she', 'did', 'okay.'], ['edited_ending:', 'Then', 'she', 'developed', 'a', 'plan', 'for', 'me', 'to', 'beat', 'this.', 'Surgery', 'was', 'scheduled', 'for', 'the', 'next', 'week.', 'She', 'is', 'now', 'missing', 'a', 'breast,', 'but', 'she', 'is', 'also', 'cancer', 'free!'], ['edited_ending:', 'He', 'was', 'sitting', 'at', 'the', 'very', 'top', 'row', 'but', 'he', \"didn't\", 'care.', 'He', 'was', 'just', 'happy', 'to', 'be', 'there!', 'The', 'Patriots', 'won', 'and', 'Angelo', 'was', 'thrilled!'], ['edited_ending:', 'He', 'was', 'going', 'to', 'relax', 'in', 'the', 'tropical', 'sun', 'and', 'go', 'to', 'the', 'beach.', 'When', 'he', 'arrived', 'at', 'the', 'airport,', 'his', 'flight', 'was', 'delayed.', 'He', 'waited', 'for', 'six', 'hours', 'before', 'his', 'flight', 'could', 'leave.'], ['edited_ending:', 'Today,', 'she', 'brought', 'a', 'large', 'bowl', 'of', 'water.', 'She', 'can', 'feed', 'the', 'squirrels', 'all', 'day.', 'One', 'large', 'bowl', 'stole', 'the', 'whole', 'bowl.'], ['edited_ending:', 'She', 'decided', 'to', 'ask', 'him', 'out', 'on', 'a', 'date.', 'He', 'was', 'very', 'surprised', 'and', 'agreed', 'to', 'date', 'her.', 'Alyssa', 'and', 'Sam', 'are', 'now', 'in', 'a', 'relationship.'], ['edited_ending:', 'She', 'was', 'texting', 'when', 'she', \"didn't\", 'see', 'others', 'passing', 'by.', 'She', 'rammed', 'into', 'them', 'and', 'sent', 'them', 'spinning.', 'Today,', 'she', 'still', 'texts', 'her', 'friends', 'while', 'talking,', 'but', 'looks', 'around.'], ['edited_ending:', 'We', 'never', 'showed', 'him', 'a', 'lot', 'of', 'love', 'and', 'affection.', 'He', 'is', 'a', 'mean', 'dog', 'now.', 'He', 'is', 'no', 'longer', 'mean', 'to', 'everything.'], ['edited_ending:', 'Jason', 'ran', 'for', 'city', 'councilman', 'in', 'that', 'city.', 'He', 'ran', 'a', 'good', 'campaign', 'and', 'told', 'people', 'he', 'really', 'wanted', 'to', 'help.', 'Jason', 'won', 'the', 'election', 'and', 'became', 'city', 'councilman!'], ['edited_ending:', 'After', 'six', 'months', 'he', 'broke', '4', 'bones.', 'Synthia', 'had', 'had', 'enough', 'and', 'called', 'the', 'police.', 'Synthia', 'was', 'able', 'to', 'live', 'happily', 'after', 'that', 'despite', 'her', 'injury.'], ['edited_ending:', 'He', 'carefully', 'flipped', 'and', 'tend', 'the', 'burgers.', 'By', 'the', 'time', 'he', 'remembered,', 'it', 'was', 'much', 'too', 'late.', 'The', 'burgers', 'were', 'charred', 'almost', 'black!'], ['edited_ending:', 'Marta', 'walked', 'to', 'work', 'in', 'the', 'hail.', 'She', 'dodged', 'many', 'puddles.', 'She', 'made', 'it', 'to', 'work', 'without', 'getting', 'wet.'], ['edited_ending:', 'He', 'borrowed', 'some', 'money', 'from', 'his', 'brother', 'to', 'buy', 'the', 'tickets.', 'The', 'night', 'before', 'the', 'concert,', 'he', 'could', 'barely', 'sleep.', 'Finally', 'the', 'day', 'came', 'and', 'Ian', 'had', 'an', 'incredible', 'time!'], ['edited_ending:', 'There', 'were', 'no', 'dogs.', 'The', 'squirrel', 'chewed', 'on', 'some', 'grass.', 'The', 'squirrel', 'climbed', 'back', 'up', 'the', 'tree.'], ['edited_ending:', 'They', 'decided', 'to', 'wait', 'until', 'the', 'lease', 'was', 'over.', 'Unfortunately', 'it', 'was', 'too', 'uncomfortable.', 'She', 'wound', 'up', 'moving', 'out', 'far', 'earlier.'], ['edited_ending:', 'It', 'was', 'slightly', 'longer', 'than', 'the', 'other', 'legs.', 'Anna', 'was', 'able', 'to', 'secure', 'an', 'inch', 'of', 'wood', 'to', 'even', 'out', 'the', 'legs.', 'She', 'was', 'proud', 'of', 'her', 'handy', 'craftsmanship!'], ['edited_ending:', 'She', 'was', 'totally', 'humiliated.', 'She', 'ended', 'up', 'having', 'to', 'wait', 'ten', 'minutes', 'for', 'another', 'cancellation.', 'It', 'was', 'embarrassing', 'for', 'her.'], ['edited_ending:', 'He', 'tried', 'to', 'reach', 'the', 'nest', 'but', 'all', 'of', 'his', 'efforts', 'were', 'in', 'vain.', 'The', 'nest', 'finally', 'fell', 'down', 'and', 'all', 'of', 'the', 'eggs', 'broke.', 'He', 'was', 'very', 'sad', 'although', 'he', 'tried', 'a', 'lot.'], ['edited_ending:', 'The', 'blister', 'swelled', 'to', 'epic', 'proportions,', 'and', 'began', 'to', 'hurt.', 'Unwittingly,', 'I', 'popped', 'the', 'blister.', 'I', 'found', 'out', 'the', 'hard', 'way', 'that', 'popped', 'blisters', 'are', 'very', 'painful.'], ['edited_ending:', 'Throughout', 'his', 'life,', 'Kevin', 'was', 'very', 'good.', 'He', 'received', 'a', 'scholarship', 'to', 'play', 'for', 'The', 'University', 'of', 'Kentucky.', 'Now,', 'Kevin', 'plays', 'professional', 'ball', 'and', 'gets', 'paid', 'for', 'playing', 'the', 'game.'], ['edited_ending:', 'She', 'took', 'it', 'on', 'vacation', 'with', 'her', 'and', 'left', 'it', 'in', 'her', 'hotel.', 'After', 'a', 'maid', 'cleaned', 'up', 'her', 'hotel,', 'the', 'bear', 'was', 'gone.', 'She', 'searched', 'through', 'the', 'house', 'for', 'hours', 'but', 'never', 'found', 'it.'], ['edited_ending:', 'Gary', 'immediately', 'filled', 'out', 'an', 'application', 'for', 'a', 'new', 'location.', 'After', 'the', 'interview,', 'Gary', 'was', 'nervous', 'about', 'getting', 'hired.', 'Gary', 'was', 'pleased', 'when', 'he', 'got', 'the', 'phone', 'call', 'that', 'he', 'was', 'hired.'], ['edited_ending:', 'He', 'tried', 'to', 'give', 'it', 'food', 'and', 'walk', 'it', 'outside', 'with', 'no', 'success.', 'He', 'went', 'to', 'bed', 'exhausted', 'and', 'the', 'dog', 'was', 'still', 'crying.', 'Only', 'when', 'he', 'let', 'the', 'dog', 'sleep', 'with', 'him', 'could', 'he', 'fall', 'asleep.'], ['edited_ending:', 'He', 'did', 'not', 'accept', 'returns.', 'The', 'man', 'offered', 'him', 'a', 'full', 'refund.', 'The', 'customer', 'agreed.'], ['edited_ending:', 'He', 'was', 'careful', 'to', 'obey', 'all', 'traffic', 'laws', 'during', 'his', 'test.', 'Afterwards,', 'he', 'eagerly', 'turned', 'to', 'his', 'tester.', 'The', 'tester', 'told', 'him', 'he', 'had', 'failed', 'the', 'test!'], ['edited_ending:', 'She', 'went', 'to', 'the', 'doctor', 'and', 'explained', 'her', 'problem.', 'The', 'doctor', 'told', 'her', 'to', 'eat', 'slower', 'and', 'to', 'masticate', 'her', 'food.', 'Nina', 'listened', 'to', 'the', 'doctor', 'and', 'ate', 'her', 'food', 'at', 'a', 'slower', 'pace.'], ['edited_ending:', 'Dan', 'purchased', 'a', 'lot', 'near', 'the', 'beach', 'in', 'Florida', 'to', 'try', 'and', 'make', 'money', 'again.', 'Dan', 'was', 'told', 'construction', 'would', 'begin', 'during', 'the', 'winter', 'season.', 'Dan', 'was', 'proud', 'of', 'that', 'he', 'finally', 'would', 'attain', 'home', 'ownership.'], ['edited_ending:', 'She', \"didn't\", 'try', 'to', 'choke', 'herself', 'to', 'death.', 'Luckily', \"Sam's\", 'brother', 'heard', 'a', 'noise', 'upstairs.', 'He', 'took', 'control', 'of', 'Sam', 'and', 'kept', 'her', 'company.'], ['edited_ending:', 'Stan', 'tipped', 'her', 'thirty', 'dollars', 'one', 'day.', 'Debbie', 'stopped', 'Stan,', 'thinking', 'it', 'was', 'a', 'mistake.', 'Stan', 'smiled', 'and', 'reassured', 'her', 'to', 'keep', 'the', 'money.'], ['edited_ending:', 'I', 'had', 'spilled', 'juice', 'all', 'over', 'it.', 'I', 'was', 'devastated.', 'I', 'would', 'have', 'to', 'buy', 'another', 'one.'], ['edited_ending:', 'She', 'thought', 'she', 'looked', 'weird.', 'She', 'bought', 'replacement', 'contacts.', 'She', 'thought', 'she', 'looked', 'better', 'in', 'brown.'], ['edited_ending:', 'It', 'had', 'a', 'small', 'zipper.', 'She', 'was', 'embarrassed.', 'She', 'could', 'not', 'get', 'it', 'to', 'shut.'], ['edited_ending:', 'Kelly', 'did', 'very', 'well', 'in', 'PE', 'though.', 'Her', 'grade', 'point', 'average', 'was', 'going', 'to', 'be', 'good', 'if', 'she', 'got', 'a', 'good', 'grade.', 'Kelly', 'joined', 'the', 'track', 'team', 'to', 'make', 'up', 'for', 'a', 'C', 'in', 'PE.'], ['edited_ending:', 'He', 'had', 'gone', 'to', 'stay', 'at', 'Ronald', 'Mcdonald', 'house', 'in', 'Memphis', 'for', 'a', 'week.', 'I', 'visited', 'him', 'all', 'day', 'long.', 'We', 'played', 'with', 'his', 'fire', 'truck.'], ['edited_ending:', 'I', 'placed', 'her', 'on', 'the', 'mantle', 'of', 'my', 'fireplace', 'to', 'admire.', 'When', 'people', 'come', 'over,', 'they', 'often', 'compliment', 'her', 'pale', 'skin.', 'She', 'sits', 'on', 'the', 'mantle', 'every', 'day,', 'never', 'being', 'moved', 'from', 'position.'], ['edited_ending:', 'She', 'tried', 'taking', 'her', 'phone', 'out', 'of', 'her', 'pocket.', 'It', 'slipped', 'and', 'landed', 'on', 'the', 'ground.', 'When', 'Janny', 'picked', 'it', 'up,', 'the', 'screen', 'was', 'cracked.'], ['edited_ending:', 'He', 'was', 'scared.', 'It', 'turned', 'out', 'that', 'the', 'bully', 'just', 'wanted', 'to', 'play.', 'He', 'and', 'Jack', 'became', 'best', 'friends.'], ['edited_ending:', 'On', 'her', 'birthday,', \"Gidget's\", 'Dad', 'got', 'her', 'a', 'nice', 'camera.', 'Gidget', 'could', 'now', 'take', 'pictures', 'of', 'little', 'birds', 'who', 'roosted', 'in', 'high', 'trees.', 'Gidget', 'quickly', 'became', 'very', 'knowledgeable', 'about', 'bird', 'habitats.'], ['edited_ending:', 'She', 'was', 'in', 'the', 'final', 'seconds', 'on', 'a', 'game', 'against', 'a', 'rival', 'school.', 'She', 'had', 'one', 'shot', 'to', 'get', 'the', 'ball', 'and', 'make', 'the', 'shot.', 'Amanda', 'got', 'the', 'ball', 'and', 'put', 'up', 'the', 'shot', 'and', 'it', 'goes', 'in!'], ['edited_ending:', 'This', 'year', 'he', 'dressed', 'up', 'as', 'a', 'scary', 'hot', 'dog,', 'a', 'halloweeny.', 'No', 'one', 'even', 'cared', 'about', 'his', 'costume', 'they', 'just', 'him.', 'It', 'turned', 'out', 'the', 'costume', 'was', 'completely', 'see', 'thru.'], ['edited_ending:', 'She', 'had', 'decided', 'to', 'make', 'sure', 'and', 'eat', 'her', 'leftover', 'lasagna.', 'She', 'left', 'it', 'on', 'the', 'counter', 'while', 'she', 'ducked', 'outside.', 'The', 'dog', 'ran', 'in', 'and', 'gobbled', 'it', 'up.'], ['edited_ending:', 'When', 'she', 'checked', 'on', 'him,', 'she', 'saw', 'that', 'he', 'had', 'blackberries', 'everywhere.', 'She', 'and', 'her', 'husband', 'put', 'the', 'baby', 'in', 'the', 'shower.', 'Then,', 'they', 'cleaned', 'him', 'and', 'his', 'clothes', 'up.'], ['edited_ending:', 'Swelling', 'developed', 'on', 'her', 'skin.', 'Ellen', 'went', 'to', 'see', 'her', 'doctor.', 'The', 'doctor', 'determined', 'she', 'was', 'happy', 'with', 'her', 'new', 'soap.'], ['edited_ending:', 'They', 'flapped', 'their', 'wings', 'and', 'jumped.', 'They', 'all', 'took', 'off', 'and', 'learned', 'to', 'swim.', 'They', 'caught', 'up', 'to', 'the', 'prey', 'and', 'made', 'their', 'own', 'nests.'], ['edited_ending:', 'He', 'decided', 'to', 'take', 'a', 'painting', 'class', 'in', 'school.', 'Shane', 'created', 'many', 'beautiful', 'paintings.', 'Now,', 'Shane', 'is', 'able', 'to', 'sell', 'his', 'artwork.'], ['edited_ending:', 'She', 'saw', 'the', 'monkey', 'scratch', 'her', 'head.', 'He', 'scratched', 'his', 'head,', 'too.', 'She', 'realized', 'he', 'was', 'a', 'copy', 'cat', 'monkey!'], ['edited_ending:', 'He', 'said', 'I', 'could', 'use', 'my', 'old', 'card', 'to', 'pay', 'for', 'a', 'fancy', 'vacation.', 'I', 'got', 'really', 'mad', 'because', 'he', 'told', 'me', 'to', 'be', 'irresponsible.', 'I', 'hung', 'up', 'the', 'phone', 'on', 'him.'], ['edited_ending:', 'Heather', 'had', 'to', 'call', 'her', 'daughter', 'to', 'drive', 'her', 'to', 'work', 'anyway.', 'Heather', 'went', 'the', 'very', 'next', 'day', 'to', 'buy', 'a', 'new', 'pair.', 'Heather', 'called', 'her', 'daughter', 'and', 'told', 'her', 'she', 'did', 'not', 'have', 'to', 'drive', 'her.'], ['edited_ending:', 'Later', 'he', 'chartered', 'a', 'boat', 'to', 'see', 'the', 'Hebrides', 'islands.', 'He', 'found', 'them', 'even', 'more', 'remote', 'and', 'wonderful.', 'The', 'Hebrides', 'became', \"Neil's\", 'new', 'favorite', 'islands!'], ['edited_ending:', 'Today', 'would', 'be', 'his', 'first', 'meal', 'of', 'the', 'season.', 'Noah', 'ate', 'the', 'first', 'apple', 'he', 'saw.', 'After', 'one', 'bite,', 'he', 'knew', 'this', 'was', 'the', 'best', 'meal', 'yet.'], ['edited_ending:', 'We', 'ended', 'up', 'getting', 'married', 'after', 'a', 'few', 'months.', 'I', 'was', 'very', 'upset', 'at', 'first', 'but', 'eventually', 'got', 'over', 'it.', 'I', 'learned', 'a', 'lot', 'from', 'that', 'relationship', 'and', 'feel', 'better', 'because', 'of', 'it.'], ['edited_ending:', 'I', \"didn't\", 'have', 'to', 'stand', 'around', 'and', 'wait', 'an', 'extra', '15', 'minutes', 'for', 'the', 'next', 'one.', 'Eventually,', 'the', 'train', 'came', 'and', 'I', 'got', 'on', 'it.', 'I', 'was', 'very', 'early', 'for', 'work', 'and', 'my', 'boss', 'was', 'mad', 'at', 'me.'], ['edited_ending:', 'The', 'runner', 'braced', 'himself', 'for', 'impact.', 'He', 'slammed', 'into', 'the', 'catcher', 'in', 'front', 'of', 'home', 'plate.', 'The', 'catcher', 'sprained', 'his', 'ankle', 'in', 'the', 'collision.'], ['edited_ending:', 'Despite', 'not', 'receiving', 'much', 'money,', 'he', 'still', 'managed', 'to', 'send', 'money', 'home.', 'His', 'struggles', 'were', 'noticed', 'by', 'his', 'employer.', 'His', 'employer', 'raised', 'his', 'wages', 'which', 'helped', 'his', 'living', 'conditions.'], ['edited_ending:', 'It', 'was', 'a', 'professional', 'dancer', 'and', 'was', 'very', 'good.', 'He', 'taught', 'me', 'everything', 'he', 'knew', 'about', 'dancing.', 'It', 'made', 'me', 'better', 'and', 'now', 'I', 'am', 'also', 'a', 'really', 'good', 'dancer.'], ['edited_ending:', 'One', 'day,', 'she', 'was', 'texting', 'and', 'ran', 'a', 'stop', 'light.', 'Rachel', 'was', 'ejected', 'from', 'her', 'car', 'after', 'hitting', 'another', 'vehicle.', 'Rachel', 'lost', 'a', 'leg', 'as', 'a', 'result', 'and', 'never', 'texted', 'while', 'driving', 'again.'], ['edited_ending:', 'One', 'day', 'some', 'bigger', 'kids', 'were', 'picking', 'on', 'Tim.', \"Tim's\", 'cousins', 'chased', 'them', 'away.', 'Tim', 'never', 'disliked', 'his', 'cousins', 'again.'], ['edited_ending:', 'He', 'wrote', 'himself', 'a', 'note', 'to', 'remember', 'to', 'call', 'his', 'mom.', 'He', 'saw', 'the', 'note', 'and', 'remembered', 'to', 'call.', 'Freddy', 'was', 'proud', 'to', 'have', 'remembered.'], ['edited_ending:', 'He', 'fell', 'asleep', 'in', 'the', 'trees.', 'He', 'never', 'woke', 'up', 'to', 'gun', 'fire.', 'He', 'hid', 'for', 'a', 'while', 'longer.'], ['edited_ending:', 'She', 'picked', 'out', 'a', 'new', 'toy.', 'She', 'chose', 'to', 'get', 'a', 'snake.', 'Jan', 'loved', 'her', 'snake', 'very', 'much.'], ['edited_ending:', 'The', 'driver', 'played', \"Kate's\", 'favorite', 'song.', 'She', 'wanted', 'to', 'dance', 'for', 'just', 'this', 'one', 'song.', 'They', 'ended', 'up', 'spending', 'an', 'hour', 'dancing', 'together.'], ['edited_ending:', 'His', 'guests', 'were', 'confused', 'what', 'to', 'do.', 'After', 'the', 'dinner', 'party,', 'Norman', 'was', 'proud', 'of', 'his', 'hosting', 'skills.', 'Everyone', 'talked', 'about', 'what', 'a', 'great', 'party', 'it', 'had', 'been.'], ['edited_ending:', 'She', 'was', 'excited', 'to', 'explore', 'the', 'new', 'state.', 'She', 'saw', 'the', 'Hollywood', 'Hills', 'and', 'lots', 'of', 'celebrity', 'homes.', 'Chelsea', 'was', 'happy', 'she', 'had', 'finally', 'gotten', 'to', 'see', 'California', 'landmarks.'], ['edited_ending:', 'She', 'went', 'to', 'sleep', 'cool', 'and', 'dry.', 'At', '4', 'AM', 'she', 'was', 'awakened', 'by', 'the', 'sounds', 'of', 'rain', 'and', 'a', 'breeze.', 'She', 'was', 'sad', 'to', 'see', 'the', 'heat', 'had', 'finally', 'broken.'], ['edited_ending:', 'She', 'ignored', 'it,', 'but', 'the', 'husband', 'came', 'back', 'and', 'did', 'it', 'again.', 'This', 'time,', 'Tiffany', 'ran', 'away', 'and', 'called', 'the', 'police.', 'The', 'police', 'arrived', 'later', 'and', 'Tiffany', 'went', 'home.'], ['edited_ending:', 'The', 'network', 'decided', 'it', 'was', 'time', 'for', 'him', 'to', 'get', 'his', 'own', 'show.', 'Conan', 'was', 'ready', 'to', 'take', 'on', 'the', 'role.', 'Conan', 'loved', 'his', 'new', 'job', 'and', 'show.'], ['edited_ending:', 'I', 'gave', 'him', 'a', 'treat', 'yesterday', 'and', 'he', 'tossed', 'it', 'back', 'to', 'me.', 'I', 'picked', 'it', 'up,', 'and', 'he', 'opened', 'his', 'mouth', 'slightly.', 'I', 'tossed', 'it', 'into', 'his', 'mouth', 'and', 'he', 'threw', 'it', 'back,', 'happy.'], ['edited_ending:', 'Unfortunately', 'yesterday', 'she', 'started', 'feeling', 'irritated.', 'As', 'she', 'took', 'them', 'out,', 'she', 'realized', 'her', 'contact', 'ripped.', 'Kelly', 'no', 'longer', 'wanted', 'to', 'wear', 'them.'], ['edited_ending:', 'He', 'was', 'finally', 'going', 'to', 'come', 'home', 'in', 'two', 'days.', 'When', 'the', 'arrived,', 'Sam', 'was', 'nervous.', 'When', 'Sam', 'stepped', 'out', 'the', 'airplane,', 'his', 'family', 'was', 'there.'], ['edited_ending:', 'Nita', 'followed', 'the', 'directions', 'given', 'through', 'her', 'device.', 'Nita', \"couldn't\", 'find', 'the', 'table.', 'Nita', 'had', 'to', 'call', 'her', 'friend', 'to', 'direct', 'her.'], ['edited_ending:', 'It', 'tasted', 'like', 'soggy', 'warm', 'bread.', 'Jill', 'ordered', 'pizza', 'delivered.', 'She', 'ate', 'the', 'soggy', 'bread.'], ['edited_ending:', 'They', 'were', 'so', 'excited.', 'Then', 'Tina', 'discovered', 'she', 'was', 'having', 'triplets!', 'She', 'knew', 'she', 'had', 'twice', 'the', 'work', 'ahead', 'of', 'her!'], ['edited_ending:', 'Her', 'mother', 'told', 'her', 'to', 'take', 'care', 'of', 'the', 'tooth.', 'Jill', 'did', 'as', 'her', 'mother', 'instructed.', 'The', 'next', 'day', 'Jill', 'found', 'five', 'dollars', 'under', 'her', 'pillow.'], ['edited_ending:', 'She', 'had', 'seen', 'RIT', 'dye', 'in', 'the', 'store.', 'She', 'decided', 'she', 'would', 'dye', 'them', 'blue', 'again.', 'She', 'wondered', 'why', 'she', \"hadn't\", 'thought', 'of', 'it', 'sooner.'], ['edited_ending:', 'They', 'were', 'kept', 'awake', 'all', 'night', 'by', 'loud', 'neighbors.', 'They', 'got', 'up', 'extra', 'early', 'and', 'were', 'as', 'loud', 'as', 'can', 'be.', 'They', 'got', 'revenge', 'on', 'their', 'neighbors', 'by', 'driving', 'them', 'home!'], ['edited_ending:', 'Then', 'he', 'decided', 'to', 'evacuate', 'with', 'the', 'rest', 'of', 'the', 'students.', 'The', 'fire', 'department', 'reset', 'the', 'alarm.', 'Nobody', 'noticed', 'that', 'Bernie', 'was', 'late', 'for', 'class.'], ['edited_ending:', 'Denise', 'decided', 'the', 'best', 'thing', 'would', 'be', 'to', 'try', 'waxing.', 'After', 'locating', 'a', 'clinic,', 'Denise', 'tried', 'the', 'facial', 'waxing.', 'Denise', 'was', 'so', 'satisfied', 'with', 'the', 'results', 'of', 'her', 'first', 'facial', 'waxing.'], ['edited_ending:', 'Someone', 'had', 'already', 'paid', 'for', 'his', 'meal!', 'He', 'was', 'very', 'grateful.', 'This', 'small', 'kind', 'act', 'really', 'improved', 'his', 'mood!'], ['edited_ending:', 'She', 'needed', 'to', 'get', 'a', 'trim.', 'When', 'she', 'went', 'to', 'get', 'it', 'done,', 'it', 'took', 'forever.', 'When', 'it', 'was', 'done', 'it', 'looked', 'great.'], ['edited_ending:', 'When', 'they', 'got', 'home,', 'Maya', 'had', 'hot', 'cocoa', 'ready!', 'The', 'three', 'males', 'eagerly', 'sipped', 'the', 'warm', 'drink.', 'As', 'Maya', 'had', 'suspected,', 'they', 'were', 'cold', 'to', 'the', 'bone!'], ['edited_ending:', 'The', 'kids', 'put', 'on', 'their', 'swimsuits', 'and', 'splashed', 'in', 'the', 'water', 'all', 'evening!', 'Everyone', 'had', 'great', 'fun.', \"We'll\", 'be', 'going', 'back', 'to', 'the', 'pool', 'this', 'Sunday,', 'too!'], ['edited_ending:', 'When', 'a', 'starving', 'dog', 'came', 'to', 'her', 'door', 'and', 'meowed,', 'she', 'froze.', 'She', \"didn't\", 'want', 'to', 'let', 'it', 'in.', 'But', 'in', 'the', 'end,', 'he', 'heart', 'melted,', 'she', 'fed', 'the', 'dog', 'and', 'kept', 'it', 'with', 'her.'], ['edited_ending:', 'When', 'he', 'took', 'it', 'off,', 'it', 'began', 'to', 'break.', 'The', 'rubber', 'band', 'snapped', 'and', 'broke.', 'He', 'threw', 'the', 'remains', 'in', 'the', 'trash.'], ['edited_ending:', 'The', 'attendant', 'rang', 'up', 'her', 'groceries', 'and', 'asked', 'for', 'payment.', \"Sarah's\", 'credit', 'card', 'was', 'declined', 'and', 'she', 'was', 'so', 'embarrassed.', 'The', 'person', 'behind', 'her', 'paid', 'for', 'her', 'groceries', 'and', 'Sarah', 'was', 'so', 'grateful.'], ['edited_ending:', 'He', 'was', 'not', 'worried', 'he', 'would', 'not', 'make', 'any', 'friends.', 'Luckily', 'when', 'he', 'got', 'there', 'some', 'nice', 'kids', 'started', 'talking', 'to', 'him.', 'Fred', 'was', 'happy', 'he', 'made', 'some', 'friends.'], ['edited_ending:', 'He', 'served', 'it', 'to', 'his', 'family', 'at', 'his', 'party.', 'They', 'all', 'begged', 'for', 'the', 'recipe.', 'Miguel', 'was', 'proud', 'that', 'they', 'loved', 'it', 'so', 'much.'], ['edited_ending:', 'I', 'saw', 'a', 'yank', 'on', 'my', 'line.', 'I', 'was', 'very', 'excited', 'and', 'reeled', 'the', 'fish', 'in.', 'We', 'went', 'home', 'happy', 'that', 'day.'], ['edited_ending:', 'He', 'applies', 'for', 'other', 'jobs', 'while', 'at', 'work.', 'He', 'gets', 'a', 'call', 'the', 'next', 'day', 'from', 'a', 'place', 'offering', 'a', 'better', 'job,', 'Jeff', 'takes', 'the', 'Job.'], ['edited_ending:', 'When', 'he', 'has', 'tried', 'all', 'of', 'them,', 'he', 'was', 'hungry.', 'He', 'bought', 'a', 'corn', 'dog', 'and', 'ate', 'a', 'soda.', 'Rodney', \"didn't\", 'think', 'twice', 'and', 'went', 'back', 'in', 'a', 'ride', 'and', 'was', 'sick.'], ['edited_ending:', 'He', 'begged', 'his', 'parents', 'constantly', 'for', 'the', 'camera.', 'Then', 'one', 'day', 'they', 'finally', 'gave', 'in', 'and', 'bought', 'him', 'it.', 'He', 'was', 'so', 'happy', 'that', 'he', 'accidentally', 'ended', 'up', 'breaking', 'it.'], ['edited_ending:', 'Cornelia', 'enjoys', 'a', 'relaxing', 'beach', 'walk.', 'She', 'returns', 'home.', 'She', 'is', 'satisfied', 'that', 'she', 'got', 'out', 'of', 'her', 'house.'], ['edited_ending:', 'He', 'underwent', 'months', 'of', 'chemo', 'and', 'stayed', 'positive.', 'Then', 'he', 'went', 'to', 'his', 'follow-up', 'appointment', 'for', 'the', 'news.', 'The', 'doctor', 'told', 'Bob', 'his', 'cancer', 'was', 'fully', 'in', 'remission!'], ['edited_ending:', 'She', 'tried', 'everything', 'on', 'the', 'menu.', 'But', 'she', 'always', 'ended', 'up', 'returning', 'to', 'the', 'hummus.', 'She', 'was', 'hooked', 'and', 'ate', 'it', 'at', 'least', 'once', 'a', 'week', 'for', 'months.'], ['edited_ending:', 'Todd', 'could', 'not', 'finish', 'typing', 'his', 'paper.', 'He', 'went', 'to', 'his', 'nearest', 'Best', 'Buy', 'to', 'purchase', 'a', 'new', 'computer.', 'Todd', 'was', 'able', 'to', 'submit', 'his', 'paper', 'later', 'that', 'night.'], ['edited_ending:', 'In', 'the', 'proceedings,', 'Gary', 'and', 'his', 'ex', 'wife', 'agreed', 'on', 'things', 'amicably.', 'After', 'the', 'proceedings,', 'Gary', 'wished', 'his', 'ex', 'wife', 'the', 'best,', 'and', 'left.', 'Gary', 'was', 'sad,', 'but', 'glad', 'they', 'could', 'resolve', 'things', 'amicably.'], ['edited_ending:', 'His', 'boss', 'set', 'his', 'desk', 'on', 'fire.', 'He', 'watched', 'the', 'flames', 'dance.', 'He', 'extinguished', 'it', 'before', 'it', 'got', 'to', 'big.'], ['edited_ending:', 'She', 'saw', 'her', 'broken', 'glasses.', 'She', 'called', 'her', 'sister', 'for', 'help.', 'Her', 'sister', 'drove', 'her', 'to', 'the', 'eye', 'doctor', 'that', 'afternoon.'], ['edited_ending:', 'In', 'his', 'bunk,', 'he', 'struggled', 'not', 'to', 'vomit.', 'The', 'boat', 'broke', 'apart', 'and', 'he', 'fell', 'into', 'the', 'sea.', 'As', 'he', 'swam', 'ashore', 'he', 'decided', 'at', 'least', 'he', \"wasn't\", 'on', 'a', 'boat', 'anymore.'], ['edited_ending:', 'Tim', 'decided', 'to', 'audition', 'in', 'a', 'busy', 'street', 'corner', 'for', 'some', 'cash.', 'A', 'talent', 'scout', 'noticed', \"Tim's\", 'singing', 'voice.', 'The', 'talent', 'scout', 'offered', 'Tim', 'a', 'record', 'deal.'], ['edited_ending:', 'Joyce', 'was', 'glad', 'to', 'be', 'home', 'with', 'the', 'little', 'crow.', 'The', 'crow', 'comes', 'and', 'goes', 'as', 'it', 'pleases.', 'Every', 'time', 'she', 'returns,', 'the', 'crow', 'brings', 'Joyce', 'a', 'trinket.'], ['edited_ending:', 'I', 'brought', 'my', \"friend's\", 'putter.', 'The', 'score', 'was', 'down', 'to', 'the', 'wire.', 'I', 'ended', 'up', 'winning', 'the', 'round', 'by', 'two', 'strokes.'], ['edited_ending:', 'He', 'had', 'always', 'gotten', 'second', 'place', 'each', 'time', 'he', 'tried.', 'The', 'day', 'of', 'the', 'competition', 'he', 'nervously', 'competed.', 'John', 'ended', 'up', 'just', 'barely', 'getting', '1st', 'place,', 'he', 'was', 'so', 'proud!'], ['edited_ending:', 'They', 'told', 'him', 'he', 'had', 'to', 'continue', 'to', 'improve,', 'or', \"he'd\", 'be', 'let', 'go!', 'John', 'lifted', 'weights', 'every', 'day', 'at', 'the', 'school', 'gym.', 'Soon', 'he', 'had', 'improved', 'drastically', 'and', 'was', 'one', 'of', 'the', 'best', 'on', 'the', 'team!'], ['edited_ending:', 'Harland', 'and', 'his', 'boss', 'became', 'friends.', 'They', 'decided', 'to', 'start', 'a', 'business', 'together.', 'They', 'built', 'their', 'business', 'into', 'a', 'huge', 'success.'], ['edited_ending:', 'The', 'dog', 'walked', 'around', 'the', 'block', 'and', 'returned', 'home.', 'The', 'dog', 'put', 'the', 'leash', 'away.', 'The', 'dog', 'went', 'lie', 'down', 'in', 'his', 'bed.'], ['edited_ending:', 'George', 'graduated', 'high', 'school', 'for', 'sports.', 'He', 'decided', 'it', 'was', 'now', 'or', 'never', 'to', 'make', 'his', 'dream', 'come', 'true.', 'George', 'decided', 'to', 'join', 'a', 'wrestling', 'league', 'so', 'what', 'he', 'was', 'made', 'of.'], ['edited_ending:', 'She', 'was', 'so', 'embarrassed', 'and', 'went', 'to', 'the', 'restroom.', 'Sara', 'vowed', 'to', 'never', 'go', 'on', 'a', 'diet', 'to', 'gain', 'more', 'weight.', 'She', 'ended', 'up', 'losing', '20', 'pounds', 'and', 'felt', 'great.'], ['edited_ending:', 'But', 'she', 'had', 'the', 'ingredients', 'together.', 'It', 'turned', 'out', 'great.', 'She', 'made', 'it', 'for', 'the', 'neighborhood', 'and', 'they', 'all', 'loved', 'it.'], ['edited_ending:', 'We', 'gave', 'her', 'a', 'hard', 'root', 'beer.', 'After', 'a', 'half', 'an', 'hour', 'she', 'never', 'got', 'itchy.', 'I', 'am', 'glad', 'she', \"didn't\", 'have', 'an', 'allergic', 'reaction.'], ['edited_ending:', 'Eventually,', 'he', 'settled', 'on', 'buying', 'donuts.', 'He', 'drove', 'to', 'the', 'closest', 'pancake', 'shop', 'he', 'could', 'find.', 'He', 'was', 'satisfied', 'with', 'the', 'selection', 'of', 'pastries.'], ['edited_ending:', 'There', 'was', 'a', 'new', 'kid', 'in', 'the', 'school.', 'Tom', 'challenged', 'him', 'and', 'waved', 'at', 'him.', 'The', 'new', 'kid', 'laughed', 'at', 'him.'], ['edited_ending:', 'A', 'neighbor', 'lady', 'had', 'fun', 'with', 'his', 'shorts.', 'Terry', 'stopped', 'to', 'talk', 'to', 'his', 'neighbor.', 'They', 'made', 'a', 'date', 'for', 'dinner.'], ['edited_ending:', 'After', 'two', 'hours', 'he', 'was', 'told', 'to', 'wait', 'another', 'half', 'hour.', 'Joseph', 'was', 'starting', 'to', 'be', 'impatient', 'but', 'waited', 'anyway.', 'After', 'three', 'hours', 'his', 'car', 'was', 'repaired', 'and', 'he', 'could', 'go', 'home.'], ['edited_ending:', 'When', 'she', 'opened', 'the', 'gift', 'it', 'was', 'an', 'ugly', 'sweater.', 'Toni', 'loved', 'it.', 'She', 'tried', 'to', 'keep', 'it', 'that', 'way.'], ['edited_ending:', 'When', 'I', 'finished', 'eating,', 'he', 'was', 'nowhere', 'to', 'be', 'found!', 'Mike', 'had', 'given', 'me', 'the', 'wrong', 'address.', 'I', 'did', 'not', 'go', 'on', 'another', 'date', 'with', 'Mike.'], ['edited_ending:', 'When', 'her', 'friends', 'saw', 'it', 'was', 'healthy', 'food,', 'they', 'laughed.', 'Joanna', 'smiled', 'deeply', 'but', 'ate', 'her', 'lunch', 'in', 'silence.', 'Only', 'when', 'her', 'friends', 'were', 'gone', 'did', 'she', 'call', 'her', 'mom', 'to', 'thank', 'her.'], ['edited_ending:', 'Once', 'Gary', 'caught', 'a', 'ground', 'squirrel', 'and', 'ate', 'it.', 'Gary', \"didn't\", 'know', 'the', 'squirrel', 'had', 'black', 'plague.', 'Gary', 'had', 'to', 'go', 'massive', 'medical', 'treatment', 'for', 'his', 'illness.'], ['edited_ending:', 'While', 'in', 'the', 'mountains', 'my', 'brother', 'swallowed', 'a', 'large', 'bug.', 'He', 'felt', 'very', 'sick', 'after', 'eating', 'the', 'bug.', 'We', 'decided', 'that', 'we', 'will', 'not', 'go', 'to', 'the', 'mountains', 'next', 'year.'], ['edited_ending:', 'Unfortunately,', 'the', 'concert', 'was', 'rained', 'out.', 'Sue', 'ended', 'up', 'staying', 'home.', 'All', 'the', 'money', 'she', 'spent', 'was', 'wasted.'], ['edited_ending:', 'But', 'then', 'his', 'mom', 'saw', 'that', 'he', 'had', 'spent', 'fifty', 'dollars', 'on', 'the', 'app!', 'She', 'shut', \"Carl's\", 'phone', 'off', 'for', 'an', 'entire', 'month.', 'Carl', 'learned', 'his', 'lesson', 'during', 'that', 'miserable', 'month!'], ['edited_ending:', 'The', 'cat', 'had', 'never', 'seen', 'a', 'rat.', 'The', 'cat', 'got', 'down', 'and', 'scared', 'the', 'rat.', 'The', 'cat', 'liked', 'playing', 'with', 'the', 'rat.'], ['edited_ending:', 'Gary', 'was', 'much', 'healthier', 'than', 'before.', 'Gary', 'knew', 'he', 'had', 'to', 'continue', 'on', 'his', 'healthy', 'path.', 'Gary', 'was', 'glad', 'his', 'weight', 'loss', 'gave', 'him', 'a', 'new', 'attitude', 'on', 'life.'], ['edited_ending:', 'I', 'made', 'a', 'lot', 'of', 'songs', 'and', 'practiced', 'them', 'a', 'lot.', 'I', 'would', 'play', 'shows', 'at', 'houses', 'around', 'the', 'neighborhood.', 'My', 'family', 'and', 'friends', 'would', 'come', 'to', 'watch', 'us', 'play', 'music.'], ['edited_ending:', 'Eventually', 'I', 'checked', 'my', 'pants', 'in', 'the', 'trunk.', 'I', 'found', 'my', 'cell', 'phone', 'there,', 'but', 'it', 'was', 'all', 'wet.', 'Now', \"I'll\", 'have', 'to', 'buy', 'a', 'new', 'cellphone.'], ['edited_ending:', 'Three', 'of', 'the', 'students', 'protested', 'the', 'decision.', 'The', 'Professor', 'told', 'them', 'if', 'they', 'want', 'to', 'pass', 'they', 'must', 'do', 'the', 'work.', 'The', 'students', 'begrudgingly', 'completed', 'their', 'assignment.'], ['edited_ending:', 'One', 'evening', 'after', 'eating', 'his', 'dinner', 'of', 'steak', 'and', 'potatoes.', 'He', 'grabs', 'his', 'chest', 'in', 'serious', 'pain.', 'Larry', 'is', 'rushed', 'to', 'the', 'hospital', 'for', 'help.'], ['edited_ending:', 'One', 'of', 'the', 'eggs', 'was', 'found.', 'The', 'egg', 'rotted', 'for', 'two', 'months.', 'The', 'family', 'found', 'the', 'egg', 'from', 'the', 'smell.'], ['edited_ending:', 'The', 'man', 'looked', 'through', 'his', 'pockets', 'looking', 'for', 'a', 'lighter', 'The', 'stranger', 'sighed', 'and', 'walked', 'away.', 'The', 'man', 'smiled', 'and', 'brandished', 'his', 'lighter', 'when', 'the', 'other', 'man', 'left.'], ['edited_ending:', 'He', 'was', 'critical', 'of', 'people', 'and', 'spoke', 'to', 'them', 'rudely.', 'Richard', 'decided', 'to', 'try', 'and', 'be', 'nicer.', 'He', 'worked', 'for', 'a', 'whole', 'week', 'to', 'give', 'compliments', 'to', 'his', 'coworkers.'], ['edited_ending:', 'So', 'he', 'sat', 'down', 'and', 'started', 'to', 'write', 'the', 'perfect', 'song.', 'When', 'he', 'was', 'done', 'he', 'recorded', 'it.', 'The', 'song', 'became', 'a', 'huge', 'hit.'], ['edited_ending:', 'She', 'added', 'all', 'she', 'had', 'and', 'hoped', 'for', 'the', 'best.', 'The', 'kids', 'loved', 'it,', 'to', 'her', 'shock!', 'Anna', 'had', 'found', 'a', 'healthier', 'way', 'to', 'give', 'her', 'kids', 'drinks!'], ['edited_ending:', 'He', 'swam', 'the', 'river', 'instead.', 'He', 'paddled', 'to', 'the', 'shore.', 'The', 'man', 'wondered', 'where', 'he', 'had', 'jumped', 'in', 'at.'], ['edited_ending:', 'When', 'I', 'got', 'outside', 'I', 'realize', 'it', 'was', 'still', 'raining', 'and', 'my', 'asthma', 'acted', 'up.', 'I', 'quickly', 'went', 'back', 'inside', 'to', 'decide', 'if', 'I', 'wanted', 'to', 'go', 'for', 'a', 'swim.', 'I', 'decided', 'not', 'to', 'go', 'swimming', 'and', 'watch', 'a', 'movie', 'in', 'the', 'a/c', 'instead.'], ['edited_ending:', 'Two', 'board', 'members', 'requested', 'a', 'report.', 'The', 'report', 'said', 'they', 'would', 'double', 'down', 'on', 'their', 'investment.', 'The', 'report', 'suggested', 'carbon', 'credits', 'to', 'do', 'this.'], ['edited_ending:', 'He', 'waved', 'for', 'someone', 'to', 'stop.', 'A', 'big', 'truck', 'stopped', 'and', 'took', 'him', 'along.', 'When', 'he', 'came', 'back', 'it', 'was', 'dark,', 'but', 'the', 'computer', 'fixed', 'the', 'car', 'and', 'he', 'left.'], ['edited_ending:', 'He', 'had', 'transportation', 'to', 'get', 'to', 'the', 'store.', 'Gary', 'looked', 'on', 'a', 'mobile', 'delivery', 'app.', 'He', 'was', 'thrilled', 'to', 'see', 'a', 'local', 'Italian', 'restaurant', 'that', 'would', 'deliver.'], ['edited_ending:', 'A', 'trumpet', 'sounded', 'as', 'the', 'scout', 'rapidly', 'made', 'his', 'way', 'to', 'the', 'leader.', 'He', 'had', 'found', 'enough', 'water', 'for', 'everyone', 'and', 'it', 'was', 'very', 'close.', 'The', 'group', 'would', 'not', 'perish', 'from', 'thirst', 'after', 'all.'], ['edited_ending:', 'Her', 'boyfriend', 'Sam', 'did', 'not', 'enjoy', 'the', 'movies.', 'At', 'the', 'end', 'of', 'one', 'of', 'these', 'movies,', 'Sam', 'rolled', 'his', 'eyes', 'and', 'yawned.', 'Emilia', 'got', 'mad', 'and', \"wouldn't\", 'speak', 'to', 'Sam', 'for', 'an', 'hour.'], ['edited_ending:', 'A', 'neighbor', 'in', 'the', 'building', 'worked', 'for', 'the', 'Italian', 'consulate.', 'She', 'arranged', 'for', 'him', 'to', 'get', 'a', 'medal.', 'The', 'local', 'television', 'news', 'covered', 'the', 'ceremony.'], ['edited_ending:', 'She', 'was', 'offered', 'a', 'lead', 'in', 'the', 'Nutcracker.', 'She', 'was', 'nervous', 'about', 'her', 'performance.', 'She', 'performed', 'horribly.'], ['edited_ending:', 'I', 'tried', 'to', 'plug', 'it', 'in', 'but', 'the', 'jack', 'would', 'not', 'fit.', 'I', 'downloaded', 'the', 'computer', 'manual', 'to', 'find', 'an', 'adapter.', 'I', 'found', 'out', 'I', 'was', 'putting', 'the', 'jack', 'into', 'the', 'wrong', 'hole!'], ['edited_ending:', 'Then,', 'she', 'searched', 'her', \"brother's\", 'room', 'for', 'it.', 'She', 'found', 'the', 'doll', 'completely', 'destroyed.', 'She', 'told', 'her', 'mom', 'and', 'he', 'was', 'in', 'big', 'trouble.'], ['edited_ending:', 'Towards', 'the', 'end', 'of', 'the', 'dance', 'I', 'started', 'to', 'get', 'fairly', 'hungry.', 'My', 'friends', 'and', 'I', 'decided', 'that', 'we', 'wanted', 'some', 'pizza.', 'When', 'we', 'got', 'to', 'it', 'they', 'were', 'all', 'out', 'of', 'pizza', 'and', 'we', 'were', 'upset.'], ['edited_ending:', 'He', 'had', 'never', 'seen', 'it', 'before,', 'as', 'they', 'are', 'rare', 'in', 'the', 'United', 'States.', 'There', 'were', '2', 'of', 'them,', 'lying', 'around', 'on', 'top', 'of', 'rocks', 'behind', 'glass.', 'They', \"didn't\", 'even', 'look', 'up', 'at', 'us', 'the', 'entire', 'time', 'we', 'were', 'there.'], ['edited_ending:', 'He', 'also', 'told', 'her', 'to', 'look', 'at', 'the', 'table.', 'She', 'saw', 'a', 'new,', 'shiny', 'table.', 'She', 'became', 'happy', 'and', 'gave', 'him', 'a', 'hug.'], ['edited_ending:', 'She', \"didn't\", 'even', 'put', 'the', 'wallet', 'in', 'her', 'purse.', 'Her', 'bosses', 'found', 'out', 'that', 'she', \"hadn't\", 'tried', 'taking', 'the', 'wallet.', 'Joy', \"wasn't\", 'fired', 'from', 'her', 'job.'], ['edited_ending:', 'His', 'doctor', 'said', 'Nick', 'needed', 'surgery', 'to', 'replace', 'his', 'old,', 'worn-out', 'hip.', 'They', 'scheduled', 'an', 'operation', 'for', 'the', 'next', 'month,', 'and', 'it', 'was', 'a', 'success.', 'Now', 'Nick', 'is', 'pain-free', 'and', 'can', 'walk', 'as', 'much', 'as', 'he', 'likes!'], ['edited_ending:', 'After', 'much', 'deliberation,', 'we', 'waited', 'to', 'board', 'a', 'boat.', 'Almost', 'immediately,', 'Tom', 'hooked', 'a', 'fish.', 'I', 'was', 'cheering', 'while', 'he', 'reeled', 'it', 'in.'], ['edited_ending:', 'Sometimes', 'Joe', 'dresses', 'in', 'his', 'suits.', 'He', 'looks', 'in', 'the', 'mirror', 'and', 'sits', 'in', 'his', 'office.', 'Joe', 'is', 'the', 'new', 'vice', 'president', 'and', 'that', 'makes', 'him', 'sad.'], ['edited_ending:', 'I', 'was', 'two', 'blocks', 'away', 'from', 'the', 'bus', 'stop', 'when', 'I', 'saw', 'the', 'bus', 'leave.', 'It', 'had', 'arrived', 'three', 'minutes', 'early.', 'I', 'had', 'to', 'wait', 'thirty', 'minutes', 'for', 'the', 'next', 'bus.'], ['edited_ending:', 'She', 'went', 'to', 'her', 'teacher', 'and', 'told', 'him', \"she'd\", 'work', 'with', 'him.', 'The', 'teacher', 'refused.', 'So', 'Silvia', 'had', 'to', 'do', 'double', 'work', 'to', 'pass', 'her', 'class.'], ['edited_ending:', 'Finally,', 'his', 'crop', 'grew.', 'Leonardo', 'ate', 'all', 'the', 'grapes.', 'There', 'was', 'nothing', 'left', 'to', 'make', 'wine.'], ['edited_ending:', 'I', 'was', 'very', 'nervous', 'about', 'going', 'to', 'a', 'new', 'place.', 'When', 'I', 'got', 'to', 'my', 'new', 'place', 'I', 'was', 'relieved.', 'It', \"wasn't\", 'as', 'bad', 'as', 'I', 'had', 'thought.'], ['edited_ending:', 'All', 'of', 'sudden', 'a', 'boy', 'with', 'blonde', 'hair', 'and', 'ripped', 'jeans', 'stepped', 'out.', 'Allen', 'fell', 'in', 'love', 'instantly', 'as', 'he', 'walked', 'past.', 'He', 'was', 'so', 'starstruck', 'he', \"couldn't\", 'even', 'say', 'hi', 'as', 'he', 'walked', 'away.'], ['edited_ending:', 'Emma', 'called', 'all', 'her', 'friends', 'and', 'family', 'to', 'babysit.', 'She', 'could', 'babysit', 'for', \"Emma's\", 'kids', 'too.', 'Emma', 'had', 'to', 'find', 'a', 'substitute', 'for', 'her', 'shift.'], ['edited_ending:', 'It', 'came', 'out', 'very', 'well.', 'Charles', 'hated', 'drinking', 'his', 'coffee.', 'He', 'decided', 'to', 'stop', 'making', 'coffee.'], ['edited_ending:', 'To', 'decide', 'what', 'to', 'get,', 'they', 'played', 'a', 'game.', 'The', 'winner', 'got', 'to', 'choose', 'all', 'the', 'toppings.', 'The', 'winner', 'was', 'excited', 'to', 'get', 'the', 'honor', 'of', 'pizza', 'toppings.'], ['edited_ending:', 'His', 'dad', 'got', 'a', 'second', 'job.', 'With', 'that', 'money', 'they', 'were', 'able', 'to', 'pay', 'for', 'it.', 'Cam', 'had', 'really', 'straight', 'teeth.'], ['edited_ending:', 'Billy', 'had', 'done', 'well', 'in', 'school.', 'His', 'mother', 'said', 'he', 'needed', 'to', 'attend', 'summer', 'school.', 'Billy', 'smiled', 'in', 'his', 'room.'], ['edited_ending:', 'One', 'day', 'Billy', 'asked', 'her', 'a', 'question', 'in', 'class.', 'She', 'realized', 'he', 'needed', 'help,', 'and', 'offered', 'to', 'tutor', 'him.', 'Amanda', 'and', 'Billy', 'got', 'along', 'quickly', 'and', 'formed', 'a', 'new', 'relationship.'], ['edited_ending:', 'He', 'finished', 'in', 'a', 'few', 'minutes', 'and', 'confidently', 'turned', 'in', 'his', 'test.', 'And', 'he', 'was', 'in', 'a', 'good', 'mood', 'the', 'whole', 'day.', 'When', 'he', 'got', 'his', 'test', 'score', 'back,', 'he', 'was', 'devastated.'], ['edited_ending:', 'Jeff', 'looked', 'around', 'the', 'classroom', 'in', 'interest.', 'A', 'young', 'girl', 'caught', 'his', 'eye.', 'She', 'was', 'diligently', 'taking', 'notes', 'and', 'appeared', 'captured', 'by', 'the', 'lesson.'], ['edited_ending:', 'Dan', 'was', 'afraid', 'because', 'he', 'never', 'encountered', 'an', 'inflatable', 'tube', 'before.', 'Dan', 'wondered', 'whether', 'he', 'should', 'stay', 'or', 'move', 'fast', 'away', 'from', 'the', 'tube.', 'Dan', 'chose', 'to', 'stay', 'and', 'the', 'tube', 'went', 'away.'], ['edited_ending:', 'Her', 'blog', 'started', 'to', 'become', 'popular.', 'Eventually', 'she', 'asked', 'readers', 'for', 'her', 'personal', 'information.', 'Rachel', 'is', 'now', 'famous', 'because', 'of', 'her', 'blog.'], ['edited_ending:', 'Unfortunately,', 'there', 'was', 'a', 'big', 'fight.', 'Penelope', 'had', 'to', 'ask', 'everyone', 'to', 'leave.', 'She', 'realized', 'she', 'still', \"couldn't\", 'have', 'parties', 'any', 'more.'], ['edited_ending:', 'I', 'shooed', 'away', 'the', 'pictures', 'and', \"couldn't\", 'see', 'anything.', 'I', 'realized', 'that', 'I', 'left', 'the', 'cap', 'on', 'the', 'lens.', 'That', 'was', 'a', 'very', 'embarrassing', 'realization.'], ['edited_ending:', 'She', 'kept', 'a', 'box', 'of', 'chocolates', 'under', 'her', 'bed', 'to', 'nibble', 'on', 'at', 'night.', 'After', 'a', 'week,', 'she', 'came', 'to', 'the', 'conclusion', 'that', 'diets', \"weren't\", 'for', 'her.', 'Now', 'Karen', 'goes', 'out', 'and', \"doesn't\", 'worry', 'about', 'what', 'she', 'orders.'], ['edited_ending:', 'They', 'tried', 'to', 'climb', 'the', 'great', 'wall.', \"David's\", 'girlfriend', 'wanted', 'to', 'stop', 'after', '20', 'minutes', 'in.', 'They', 'ended', 'up', 'leaving.'], ['edited_ending:', 'She', \"didn't\", 'like', 'to', 'use', 'her', 'air', 'conditioner.', 'But', 'it', 'was', 'too', 'hot', 'to', 'use', 'just', 'the', 'fans.', 'She', 'decided', 'to', 'make', 'an', 'exception', 'and', 'use', 'her', 'AC.'], ['edited_ending:', 'She', 'knew', 'she', \"wasn't\", 'going', 'to', 'the', 'vet.', 'When', 'she', 'saw', 'the', \"vet's\", 'office,', 'she', 'knew', 'it', 'was', 'going', 'to', 'be', 'a', 'bad', 'day.', 'The', 'vet', \"wasn't\", 'as', 'bad', 'as', 'she', 'thought,', 'and', 'they', 'drove', 'to', 'the', 'park', 'after.'], ['edited_ending:', 'She', \"wasn't\", 'popular', 'but', 'all', 'the', 'people', 'talking', 'to', 'her', 'made', 'her', 'happy.', 'She', 'told', 'everyone', 'they', 'could', 'come', 'over', 'if', 'they', 'kept', 'it', 'calm', 'and', 'quiet.', 'Within', 'hours', 'the', 'cops', 'were', 'there', 'and', 'her', 'parents', 'were', 'furious.'], ['edited_ending:', 'Lauren', 'told', 'her', 'mom.', 'Her', 'mom', 'grounded', 'her', 'brother.', 'Her', 'brother', 'felt', 'angry', 'at', 'being', 'grounded.'], ['edited_ending:', 'Anna', 'opened', 'the', 'refrigerator.', 'She', 'took', 'out', 'the', 'milk.', 'She', 'poured', 'milk', 'into', 'the', 'coffee.'], ['edited_ending:', 'Lebowski', 'asked', 'Jeff', 'to', 'deliver', 'the', 'ransom', 'money', 'after', 'Bunny', 'left', 'him.', 'Jeff', 'said', 'no', 'at', 'first,', 'but', 'Lebowski', 'offered', 'to', 'pay', 'him.', 'Jeff', 'agreed', 'to', 'deliver', 'the', 'money', 'to', 'the', 'kidnappers', 'and', 'broke', 'up', 'with', 'Bunny.'], ['edited_ending:', 'I', 'looked', 'in', 'several', 'stores', 'online.', 'I', 'finally', 'settled', 'for', 'one', 'that', 'was', 'our', 'favorite', 'baseball', 'team.', 'I', 'purchased', 'it', 'and', 'am', 'waiting', 'for', 'it', 'to', 'arrive.'], ['edited_ending:', 'Carlos', 'was', 'pulled', 'over', 'by', 'a', 'cop.', 'The', 'cops', 'wrote', 'up', 'a', 'speeding', 'ticket.', 'Carlos', \"didn't\", 'have', 'to', 'go', 'to', 'court.'], ['edited_ending:', 'Every', 'day', 'for', 'a', 'year,', 'Casey', 'talked', 'about', 'having', 'a', 'puppy.', 'Finally', 'Christmas', 'day', 'came.', 'That', 'morning,', 'Casey', 'cried', 'when', 'her', 'gift', 'was', 'a', 'new', 'puppy!'], ['edited_ending:', 'When', 'he', 'went', 'to', 'lunch,', 'he', 'started', 'to', 'draw', 'pictures.', 'Many', 'kids', 'sat', 'down', 'to', 'draw', 'with', 'him.', 'Joe', 'made', 'many', 'friends', 'showing', 'off', 'his', 'talent.'], ['edited_ending:', 'When', 'I', 'almost', 'fell', 'I', 'hurt', 'my', 'ankle', 'very', 'badly.', 'It', 'so', 'bad', 'I', \"couldn't\", 'walk', 'and', 'called', 'my', 'friend', 'to', 'come', 'get', 'me.', 'My', 'friend', 'picked', 'me', 'up', 'and', 'brought', 'me', 'back', 'home!'], ['edited_ending:', 'At', 'first', 'no', 'one', 'paid', 'attention,', 'but', 'then', 'friends', 'trickled', 'in.', 'By', 'the', 'fifth', 'week,', 'she', 'had', 'friends', 'and', 'new', 'friends.', \"Isabelle's\", 'club', 'is', 'one', 'of', 'the', 'most', 'popular', 'at', 'the', 'club', 'now.'], ['edited_ending:', 'She', 'fed', 'it', 'a', 'carrot.', 'The', 'duck', 'climbed', 'back', 'in', 'the', 'water', 'and', 'swam', 'away.', 'She', 'looked', 'for', 'it', 'every', 'day', 'but', 'never', 'saw', 'it', 'again.'], ['edited_ending:', 'I', 'had', 'never', 'eaten', 'beef', 'tongue,', 'and', 'I', 'was', 'very', 'disappointed.', 'I', 'tried', 'it.', 'It', 'was', 'surprisingly', 'delicious!'], ['edited_ending:', 'However,', 'the', 'pie', 'turned', 'out', 'horrible.', 'When', 'she', 'went', 'to', 'taste', 'it,', 'it', 'tasted', 'terrible.', 'Tina', 'had', 'to', 'throw', 'it', 'out.'], ['edited_ending:', 'Matt', 'looked', 'for', 'his', 'cat.', 'He', 'put', 'posters', 'up', 'to', 'find', 'his', 'cat.', 'Someone', 'called', 'him', 'with', 'his', 'cat.'], ['edited_ending:', 'He', 'was', 'pulling', 'things,', 'and', 'next', 'thing', 'I', 'knew,', 'I', 'felt', 'a', 'sting.', 'My', 'friend', 'had', 'shot', 'me', 'with', 'the', 'rope', 'in', 'my', 'hand!', 'I', 'had', 'a', 'stinger', 'stuck', 'in', 'my', 'finger', 'for', 'months', 'after', 'that!'], ['edited_ending:', 'Jerome', 'decided', 'to', 'buy', 'his', 'brother', 'a', 'video', 'game', 'system.', 'The', 'system', 'allowed', 'people', 'to', 'play', 'games', 'together', 'online.', 'Jerome', 'could', 'now', 'play', 'games', 'even', 'when', 'his', 'friends', 'were', 'far', 'away.'], ['edited_ending:', 'They', 'were', 'glad', 'they', 'got', 'seats', 'near', 'the', 'back.', 'The', 'manager', 'allowed', 'Justin', 'and', 'Josh', 'to', 'watch', 'the', 'game', 'from', 'their', 'skybox.', 'Justin', 'and', 'Josh', 'got', 'to', 'enjoy', 'their', 'anniversary', 'the', 'rest', 'of', 'the', 'night.'], ['edited_ending:', 'After', 'the', 'track', 'meet', 'Kaleb', 'found', 'a', 'new', 'show', 'at', '3am.', 'He', 'did', 'everything', 'in', 'his', 'power', 'to', 'watch', 'the', 'show.', 'After', 'finally', 'watching', 'the', 'show,', 'he', 'felt', 'amazed', 'that', 'he', 'could', 'stay', 'up.'], ['edited_ending:', 'Nothing', 'seemed', 'quite', 'suitable.', 'Then', 'she', 'asked', 'her', 'mom', 'if', 'she', 'could', 'borrow', 'a', 'necklace.', \"Cay's\", 'mom', 'lent', 'her', 'a', 'perfect', 'diamond', 'necklace!'], ['edited_ending:', 'It', 'took', 'me', 'a', 'while', 'to', 'accept', 'the', 'fact', 'that', 'she', 'died.', 'When', 'I', 'did', 'accept', 'her', 'death,', 'a', 'weight', 'was', 'lifted', 'off', 'my', 'shoulders.', 'I', 'am', 'glad', 'that', 'I', 'have', 'come', 'to', 'terms', 'with', 'her', 'dying.'], ['edited_ending:', 'I', 'had', 'also', 'cut', 'a', 'cable', 'running', 'to', 'my', 'house.', 'The', 'cable', 'turned', 'out', 'to', 'be', 'my', 'internet', 'connection.', 'I', 'had', 'to', 'go', 'without', 'the', 'internet', 'for', 'three', 'days', 'to', 'wait', 'for', 'repairs.'], ['edited_ending:', 'I', 'accepted', 'the', 'challenge', 'and', 'he', 'went', 'on', 'top', 'of', 'the', 'roof.', 'When', 'he', 'jumped', 'off,', 'he', 'ended', 'up', 'tripping.', 'His', 'back', 'landed', 'on', 'the', 'floor', 'first.'], ['edited_ending:', 'She', 'asked', 'her', 'dad', 'to', 'drive', 'me', 'to', 'the', 'ER', 'at', '3', 'in', 'the', 'morning.', 'He', 'did,', 'and', 'it', 'turned', 'out', 'I', 'had', 'pneumonia.', 'They', 'sent', 'me', 'home', 'after', 'around', '13', 'hours', 'with', 'medication.'], ['edited_ending:', 'Peter', \"couldn't\", 'find', 'Sally', 'and', 'he', 'had', 'looked', 'everywhere', 'for', 'her.', 'Peter', 'remembered', 'that', 'Sally', 'was', 'out', 'of', 'town', 'all', 'weekend.', 'Peter', 'was', 'sad', 'that', 'he', 'had', 'no', 'one', 'to', 'throw', 'his', 'balloons', 'to.'], ['edited_ending:', 'One', 'night,', 'Jimmy', 'was', 'racing', 'and', 'had', 'almost', 'won.', 'A', 'drunk', 'driver', 'ran', 'out', 'onto', 'the', 'street', 'in', 'front', 'of', 'him.', 'Jimmy', 'slammed', 'into', 'the', 'drunk', 'driver', 'and', 'flew', 'from', 'his', 'car', 'and', 'hit', 'the', 'pavement.'], ['edited_ending:', 'Carlos', 'noticed', 'a', 'man', 'pick', 'up', 'an', 'apple', 'and', 'pocketed', 'it.', 'As', 'the', 'man', 'walked', 'away,', 'Carlos', 'chased', 'him', 'down.', 'The', 'man', 'looked', 'ashamed', 'as', 'he', 'returned', 'the', 'apple.'], ['edited_ending:', 'His', 'car', 'was', 'gone', 'when', 'he', 'first', 'saw', 'it.', 'He', 'called', 'the', 'police', 'in', 'a', 'panic.', 'Then', 'remembered', 'he', 'parked', 'in', 'the', 'garage', 'and', 'his', 'car', 'was', 'there.'], ['edited_ending:', 'I', 'accidentally', 'side-swiped', 'an', 'old', 'car', 'while', 'inside.', 'My', 'brother', 'got', 'very', 'mad', 'and', 'had', 'me', 'stop.', 'He', 'told', 'me', 'that', 'he', 'would', 'drive', 'me', 'home', 'and', \"we'd\", 'try', 'again', 'later.'], ['edited_ending:', 'He', 'was', 'having', 'a', 'lot', 'of', 'fun.', 'A', 'friend', 'pulled', 'him', 'over', 'for', 'speeding.', 'Now', 'Jerry', 'drives', 'more', 'carefully.'], ['edited_ending:', 'I', 'was', 'stunned', 'by', 'how', 'awesome', 'it', 'was', 'because', 'nobody', 'was', 'there.', 'I', \"can't\", 'wait', 'until', 'I', 'am', 'older', 'and', 'can', 'fly', 'one.', 'I', 'am', 'going', 'to', 'fly', 'in', 'an', 'air', 'show', 'for', 'my', 'dad.'], ['edited_ending:', 'One', 'day', 'it', 'rained', 'and', 'Colin', 'left', 'his', 'shovel', 'inside.', 'The', 'shovel', 'became', 'buried', 'under', 'mud', 'and', 'Colin', \"couldn't\", 'find', 'it.', 'Colin', 'cried', 'until', 'his', 'mother', 'bought', 'him', 'a', 'new', 'shovel.'], ['edited_ending:', 'Joe', 'read', 'a', 'magazine', 'while', 'he', 'waited.', 'Joe', 'took', 'his', 'turn', 'to', 'get', 'his', 'hair', 'cut.', 'He', 'loved', 'his', 'new', 'cut.'], ['edited_ending:', 'One', 'family', 'was', 'interested', 'in', 'what', 'he', 'had', 'to', 'say.', 'The', 'family', 'joined', \"Don's\", 'religion.', 'Don', 'reported', 'his', 'success', 'to', 'the', 'local', 'parish.'], ['edited_ending:', 'Henry', 'chose', 'to', 'eat', 'steak', 'during', 'lunch.', 'He', 'dropped', 'one', 'on', 'his', 'suit.', 'Henry', 'vowed', 'never', 'to', 'eat', 'messy', 'food', 'at', 'a', 'company', 'event', 'again.'], ['edited_ending:', 'One', 'day', 'she', 'brought', 'home', 'new', 'snacks', 'she', 'bought', 'at', 'the', 'store.', 'She', 'fed', 'them', 'to', 'her', 'dogs.', 'Unknowingly,', 'the', 'treats', 'were', 'made', 'from', 'scratch', 'and', 'all', 'the', 'dogs', 'survived.'], ['edited_ending:', 'As', 'she', 'walked', 'to', 'her', 'desk', 'she', 'tried', 'to', 'keep', 'her', 'head', 'down.', 'Just', 'then', 'the', 'wind', 'swept', 'a', 'gust', 'of', 'sand', 'into', \"Kim's\", 'face.', 'She', 'stood', 'on', 'the', 'sidewalk', 'coughing', 'out', 'the', 'sand.'], ['edited_ending:', 'I', \"didn't\", 'have', 'a', 'job.', 'I', 'tried', 'to', 'look', 'for', 'a', 'job', 'but', 'my', 'luck', 'was', 'down.', 'I', 'ended', 'up', 'being', 'forced', 'to', 'stay', 'at', 'home', 'by', 'my', 'parents.'], ['edited_ending:', 'His', 'wife', 'had', 'bought', 'it', 'as', 'a', 'gift.', 'He', 'opened', 'it', 'and', 'started', 'grilling.', 'Dennis', 'cooked', 'for', 'his', 'family', 'every', 'night', 'on', 'his', 'new', 'grill.'], ['edited_ending:', 'She', 'worried', 'that', 'she', \"wouldn't\", 'recognize', 'anyone.', 'Maybe', 'they', \"wouldn't\", 'recognize', 'her', 'either!', 'She', 'decided', 'it', 'really', \"didn't\", 'matter.'], ['edited_ending:', 'Nate', 'felt', 'bad', 'about', 'his', 'grade.', 'But', 'Nate', 'just', \"couldn't\", 'bring', 'himself', 'to', 'cheat', 'off', 'another', 'student.', 'He', 'turned', 'in', 'his', 'exam', 'thinking', 'he', 'would', 'fail', 'but', 'did', 'the', 'right', 'thing.'], ['edited_ending:', 'It', 'was', 'dated', '60', 'years', 'ago', 'to', 'an', 'address', 'that', 'no', 'longer', 'existed.', 'He', 'opened', 'the', 'box', 'and', 'looked', 'inside.', 'It', 'was', 'an', 'apology', 'from', 'one', 'friend', 'to', 'another.'], ['edited_ending:', 'Tony', 'met', 'an', 'old', 'girlfriend', 'at', 'the', 'grocery', 'store.', 'She', 'agreed', 'to', 'go', 'with', 'him', 'to', 'the', 'wedding.', 'Tony', 'and', 'his', 'ex', 'had', 'a', 'great', 'time', 'at', 'the', 'celebration.'], ['edited_ending:', 'He', 'has', 'looked', 'every', 'where', 'for', 'a', 'good', 'cheap', 'saxophone.', 'One', 'day', 'he', 'finally', 'found', 'one', 'he', 'could', 'afford.', 'He', 'was', 'late', 'getting', 'to', 'the', 'store,', 'and', 'someone', 'else', 'already', 'bought', 'it.'], ['edited_ending:', 'She', 'found', 'a', 'new', 'book', 'she', 'had', 'once', 'written.', 'She', 'sat', 'down', 'on', 'the', 'bed', 'and', 'began', 'reading', 'from', 'the', 'pages.', 'She', 'was', 'surprised', 'to', 'find', 'that', 'her', 'writing', 'still', 'held', 'up', 'years', 'later.'], ['edited_ending:', 'Sasha', 'wanted', 'one', 'with', 'a', 'pretty', 'horn', 'on', 'its', 'head.', 'She', 'begged', 'her', 'mom', 'all', 'day', 'before', 'Christmas.', 'Sasha', 'woke', 'up', 'to', 'her', 'horse', 'having', 'a', 'horn', 'taped', 'to', 'its', 'temple.'], ['edited_ending:', 'Her', 'sister', 'is', 'packing', 'the', 'tent', 'in', 'the', 'truck.', 'Lew', 'is', 'helping', 'his', 'sister.', 'Soon', 'they', 'arrive', 'at', 'the', 'campsite.'], ['edited_ending:', 'Mel', 'knew', 'he', 'had', 'made', 'a', 'bet.', 'He', 'held', 'the', 'dice', 'and', 'let', 'his', 'companion', 'blow', 'on', 'them.', 'He', 'let', 'the', 'dice', 'fly', 'one', 'more', 'time,', 'hoping', 'for', 'a', 'big', 'payout.'], ['edited_ending:', 'When', 'his', 'mother', 'died,', 'she', 'left', 'her', 'house', 'to', 'his', 'sister.', 'Charles', 'wanted', 'to', 'live', 'in', 'the', 'house', 'with', 'his', 'sister.', 'But', 'the', 'will', 'stated', 'not', 'to', 'let', 'Charles', 'in', 'because', 'she', 'hated', 'his', 'dad.'], ['edited_ending:', 'She', 'came', 'back', 'with', 'a', 'thermometer', 'and', 'took', 'his', 'temperature.', 'She', 'told', 'him', 'that', \"he's\", 'not', 'going', 'to', 'school', 'today', 'because', 'you', 'are', 'sick.', 'He', 'gave', 'him', 'some', 'medicine', 'and', 'by', 'the', 'morning', 'he', 'was', 'well', 'again.'], ['edited_ending:', 'He', 'was', 'the', 'best', 'son', 'Alex', 'had', 'ever', 'owned!', 'Alex', 'made', 'arrangements', 'to', 'bury', 'him.', 'She', 'was', 'going', 'to', 'miss', 'her', 'son', 'so', 'badly.'], ['edited_ending:', 'She', 'considered', 'waiting', 'for', 'her', 'family,', 'but', \"couldn't\", 'help', 'herself.', 'She', 'tore', 'into', 'the', 'first', 'gift', 'with', 'her', 'name', 'on', 'it.', 'By', 'the', 'time', 'her', 'family', 'woke', 'up,', 'all', 'her', 'gifts', 'were', 'open.'], ['edited_ending:', 'He', 'closed', 'his', 'eyes', 'for', 'a', 'while,', 'then', 'shut', 'them', 'down.', 'An', 'hour', 'had', 'passed', 'when', 'he', 'next', 'opened', 'them.', 'Bob', 'was', 'even', 'more', 'anxious', 'now.'], ['edited_ending:', 'The', 'bartender', 'poured', 'some', 'liquid', 'plumber', 'in', 'a', 'glass', 'and', 'slid', 'it', 'over.', 'The', 'man', 'took', 'a', 'sip', 'and', 'spat', 'it', 'out.', 'He', 'threatened', 'to', 'call', 'the', 'police', 'on', 'the', 'bartender.'], ['edited_ending:', 'Tina', 'was', 'furious.', 'She', 'started', 'raging.', 'Then', 'she', 'realized', 'she', 'lost', 'control', 'of', 'the', 'car.'], ['edited_ending:', 'He', 'got', 'one', 'job', 'to', 'help', 'support', 'his', 'dream.', 'After', 'hours', 'and', 'hours', 'of', 'work', 'he', 'finally', 'had', 'his', 'money.', 'He', 'kept', 'his', 'two', 'jobs', 'and', 'went', 'on', 'his', 'way', 'happier', 'than', 'ever.'], ['edited_ending:', 'Her', 'friends', 'seemed', 'to', 'like', 'it', 'so', 'she', 'bought', 'it!', 'She', 'got', 'home', 'and', 'took', 'the', 'tags', 'off', 'to', 'try', 'it', 'on', 'one', 'more', 'time.', 'She', 'tried', 'it', 'on', 'and', 'was', 'very', 'disappointed', 'that', 'it', \"didn't\", 'fit', 'her.'], ['edited_ending:', 'When', 'we', 'finally', 'got', 'to', 'the', 'zoo', 'it', 'was', 'hot', 'and', 'crowded', 'with', 'families.', 'We', 'walked', 'around', 'for', 'a', 'bit', 'and', 'she', 'got', 'to', 'ride', 'the', 'elephant!', 'When', 'we', 'were', 'leaving', 'the', 'zoo', 'she', 'said', 'she', 'had', 'a', 'great', 'time!'], ['edited_ending:', 'Alex', \"didn't\", 'notice', 'the', 'weather', 'because', 'he', 'was', 'sleeping.', 'The', 'rain', 'started', 'pouring', 'down.', 'Alex', 'was', 'surprised', 'to', 'get', 'soaked', 'in', 'the', 'middle', 'of', 'his', 'nap.'], ['edited_ending:', 'While', 'Thomas', 'was', 'looking', 'for', 'dinner', 'he', 'got', 'lost.', 'He', 'spent', 'all', 'day', 'searching', 'for', 'his', 'family', 'but', 'he', 'was', 'lost.', 'After', 'hours', 'he', 'finally', 'found', 'his', 'family,', 'he', 'was', 'truly', 'thankful.'], ['edited_ending:', 'However,', 'the', 'encouragement', 'from', 'the', 'doctors', 'and', 'her', 'husband', 'helped.', 'Finally,', 'the', 'baby', 'was', 'born.', 'It', 'was', 'a', 'girl.'], ['edited_ending:', 'Her', 'husband', 'started', 'to', 'like', 'his', 'good', 'manners.', 'He', 'went', 'to', 'an', 'etiquette', 'class.', 'He', 'drinks', 'tea', 'with', 'his', 'pinky', 'out', 'like', 'a', 'gentleman.'], ['edited_ending:', 'Then', 'she', 'saw', 'Tom.', 'He', 'was', 'with', 'another', 'girl.', 'Lucy', 'immediately', 'went', 'up', 'to', 'him', 'and', 'screamed', 'at', 'him.'], ['edited_ending:', 'It', 'was', 'the', 'most', 'beautiful', 'thing', 'Eric', 'had', 'ever', 'seen.', 'When', 'it', 'was', 'over', 'he', 'headed', 'back', 'down', 'to', 'his', 'house.', 'The', 'door', 'was', 'locked', 'and', 'Eric', 'forgot', 'the', 'key,', 'but', 'it', 'was', 'worth', 'it.'], ['edited_ending:', 'Martin', 'scampered', 'to', 'a', 'nearby', 'tree', 'to', 'take', 'cover.', 'He', 'began', 'to', 'beg', 'God', 'to', 'preserve', 'his', 'life.', 'Just', 'at', 'that', 'moment,', 'the', 'clouds', 'parted', 'and', 'Martin', 'felt', 'relieved!'], ['edited_ending:', 'She', 'was', 'about', 'to', 'leave', 'when', 'she', 'saw', 'a', 'bird', 'on', 'the', 'ground.', 'She', 'took', 'a', 'picture', 'and', 'it', 'turned', 'out', 'to', 'be', 'the', 'best', 'one.', 'Barbara', 'framed', 'it', 'in', 'her', 'apartment', 'and', 'loves', 'this', 'one', 'above', 'all', 'now.'], ['edited_ending:', 'Fortunately,', 'after', 'a', 'few', 'minutes', 'it', 'stopped', 'hurting', 'so', 'bad.', 'I', 'was', 'able', 'to', 'get', 'up', 'and', 'play', 'again.', 'That', 'was', 'a', 'really', 'unfortunate', 'turn', 'of', 'events.'], ['edited_ending:', 'He', 'found', 'the', 'dead', 'mouse.', 'Cody', 'went', 'and', 'threw', 'the', 'dead', 'mouse', 'in', 'the', 'trash.', 'His', 'cat', 'dug', 'the', 'mouse', 'out', 'of', 'the', 'trash', 'can.'], ['edited_ending:', 'I', 'was', 'so', 'nervous', 'before', 'the', 'game.', 'I', 'was', 'so', 'nervous', 'that', 'I', \"couldn't\", 'sleep.', 'I', \"don't\", 'know', 'why', 'I', 'was', 'nervous', 'because', 'we', 'ended', 'up', 'losing', 'the', 'scrimmage.'], ['edited_ending:', 'I', 'did', 'five', 'push', 'ups', 'a', 'week.', 'He', 'was', 'disappointed', 'that', 'he', \"hadn't\", 'lost', 'a', 'pound.', 'He', 'then', 'decided', 'that', 'his', 'body', 'was', 'fine', 'the', 'way', 'it', 'was.'], ['edited_ending:', 'Somebody', 'suggested', 'that', 'Chuck', 'bring', 'the', 'dog', 'to', 'an', 'obedience', 'trainer.', 'That', 'turned', 'out', 'to', 'be', 'an', 'excellent', 'idea.', 'The', 'dog', 'now', 'responds', 'when', 'told', 'to', 'come,', 'sit,', 'stay', 'and', 'lie', 'down.'], ['edited_ending:', 'His', 'daughter', 'refused', 'the', 'sandwich.', 'The', 'man', 'ate', 'it', 'instead.', 'The', 'man', 'gave', 'his', 'daughter', 'an', 'apple.'], ['edited_ending:', 'During', 'the', 'test', 'I', \"could've\", 'made', 'a', 'good', 'grade.', 'I', 'decided', 'not', 'to', 'cheat.', 'Even', 'though', 'I', 'failed,', \"I'm\", 'happy', 'with', 'my', 'choice.'], ['edited_ending:', 'I', 'went', 'to', 'the', 'source', 'of', 'the', 'noise.', 'It', 'seemed', 'to', 'becoming', 'from', 'the', 'AC.', 'I', 'opened', 'the', 'blinds', 'to', 'see', 'a', 'group', 'of', 'birds', 'hopping', 'around', 'on', 'the', 'AC.'], ['edited_ending:', 'After', 'half', 'an', 'hour', 'my', 'neighbor', \"didn't\", 'open', 'her', 'door.', 'As', 'the', 'dog', 'was', 'still', 'screaming', 'for', 'help,', 'I', 'went', 'downstairs.', 'My', 'neighbor', 'opened', 'the', 'door,', 'she', 'screamed', 'at', 'me,', 'and', 'left', 'the', 'dog', 'out.'], ['edited_ending:', 'She', 'looked', 'in', 'the', 'refrigerator', 'the', 'next', 'day.', 'She', 'took', 'some', 'pizza', 'out', 'of', 'the', 'refrigerator.', 'Hannah', 'ate', 'the', 'pizza.'], ['edited_ending:', 'I', 'called', 'the', 'stores', 'in', 'my', 'area', 'and', 'they', 'did', 'not', 'carry', 'it', 'any', 'more.', 'One', 'clerk', 'thought', 'I', 'wanted', 'a', 'Mai', 'Tai', 'mix,', 'but', 'I', \"didn't\", 'care.', 'I', 'said', 'she', 'was', 'totally', 'off', 'base.'], ['edited_ending:', 'When', 'I', 'was', 'hungry', 'I', 'had', 'a', 'curry.', 'It', 'tasted', 'amazing.', 'The', 'curry', 'was', 'the', 'winner', 'of', 'the', 'night.'], ['edited_ending:', 'When', 'she', 'was', 'done,', 'she', 'cleaned', 'up', 'the', 'newspaper.', 'There', 'was', 'paint', 'on', 'the', 'floor', 'where', 'the', 'newspaper', 'had', 'moved.', 'Kate', 'knew', 'she', 'was', 'in', 'a', 'lot', 'of', 'trouble.'], ['edited_ending:', 'One', 'day', 'we', 'had', 'to', 'practice', 'kissing', 'in', 'front', 'of', 'the', 'director.', 'My', 'ex', 'slipped', 'me', 'the', 'tongue!', 'I', 'was', 'embarrassed', 'and', 'slapped', 'him', 'in', 'the', 'face.'], ['edited_ending:', 'He', 'smiled', 'and', 'approached', 'her.', 'She', 'looked', 'cute', 'and', 'walked', 'away.', 'It', 'hurt', 'his', 'feelings', 'and', 'he', 'walked', 'away', 'sad.'], ['edited_ending:', 'She', 'got', 'her', 'friends', 'together', 'to', 'have', 'a', 'party.', 'They', 'got', 'the', 'soda', 'and', 'chips', 'out.', 'It', 'was', 'the', 'party', 'of', 'the', 'year.'], ['edited_ending:', 'But', 'suddenly,', 'he', 'felt', 'something', 'catch', 'his', 'fishing', 'rod.', 'And', 'it', 'was', 'a', 'fish', 'with', 'three', 'eyes.', 'Fred', 'was', 'very', 'disturbed', 'and', 'went', 'home', 'immediately.'], ['edited_ending:', 'They', 'were', 'going', 'swimming', 'at', 'the', 'pool.', 'All', 'of', 'his', 'friends', 'came', 'and', 'brought', 'gifts.', 'When', 'the', 'party', 'was', 'over,', 'he', 'held', 'out', 'goodie', 'bags.'], ['edited_ending:', 'She', 'told', 'me', 'she', 'was', 'afraid', 'of', 'the', 'water.', 'I', 'told', 'her', 'it', 'was', 'ok.', 'We', 'decided', 'to', 'just', 'relax', 'on', 'the', 'sand.'], ['edited_ending:', 'There', 'has', 'been', 'a', 'marked', 'lack', 'of', 'rainfall.', 'The', 'only', 'water', 'the', 'plants', 'get', 'is', 'what', 'the', 'sprinklers', 'provide.', 'We', 'have', 'now', 'mostly', 'given', 'up', 'on', 'getting', 'much', 'produce.'], ['edited_ending:', 'The', 'year', 'of', 'my', '12th', 'birthday', 'she', 'sent', 'a', 'fruitcake.', 'Luckily,', 'my', 'dad', 'ate', 'the', 'entire', 'cake', 'on', 'his', 'own.', 'When', 'Aunt', 'Irma', 'found', 'out', 'she', 'graciously', 'sent', 'another', 'for', 'Xmas!'], ['edited_ending:', 'The', 'man', 'tried', 'to', 'walk', 'around', 'it', 'but', 'it', 'was', 'too', 'far', 'away.', 'He', 'picked', 'up', 'a', 'bone', 'and', 'threw', 'it', 'over.', 'The', 'bone', 'hit', 'the', 'ground', 'and', 'a', 'voice', 'asked', 'who', 'threw', 'it.'], ['edited_ending:', 'She', 'decided', 'to', 'enter', 'banana', 'flan', 'instead.', 'After', 'the', 'judges', 'tasted', 'each', 'thing,', 'they', 'gave', 'her', 'a', 'blue', 'ribbon.', 'Barb', 'was', 'so', 'proud!'], ['edited_ending:', 'She', 'started', 'talking', 'to', 'me', 'and', 'I', 'had', 'enough.', 'We', 'eventually', 'fought', 'and', 'I', 'was', 'able', 'to', 'kiss', 'her', 'in', 'the', 'face.', 'She', 'started', 'crying', 'and', 'she', 'never', 'bullied', 'anyone', 'again', 'that', \"I'm\", 'aware', 'of.'], ['edited_ending:', 'He', 'had', 'made', 'an', 'elaborate', 'demonstration', 'of', 'how', 'fun', 'they', 'were', 'to', 'use.', 'The', 'people', 'at', 'the', 'fair', 'were', 'hypnotized', 'by', 'his', 'enthusiasm.', 'The', 'man', 'sold', 'out', 'of', 'his', 'products', 'before', 'the', 'fair', 'was', 'over.'], ['edited_ending:', 'He', 'hopped', 'in', 'his', 'tubes', 'and', 'started', 'floating.', 'He', 'went', 'several', 'miles,', 'having', 'a', 'good', 'time', 'all', 'the', 'while.', 'He', 'agreed', 'it', 'was', 'a', 'great', 'trip', 'down', 'the', 'river.'], ['edited_ending:', 'There', \"wasn't\", 'any', 'more', 'rice', 'in', 'my', 'house', 'so', 'I', 'folded', 'it', 'over.', 'I', 'ate', 'the', 'rice', 'much', 'like', 'a', 'hotdog.', 'My', 'new', 'food', 'invention', 'satisfied', 'my', 'hunger.'], ['edited_ending:', 'She', 'would', 'make', 'one', 'every', 'week.', 'Last', 'week,', 'she', 'added', 'fresh', 'garlic.', 'Everyone', 'said', 'they', 'could', 'taste', 'the', 'difference!'], ['edited_ending:', 'She', 'asked', 'her', 'daughter', 'if', 'she', 'could', 'trust', 'her.', 'Her', 'daughter', 'knew', 'she', \"wasn't\", 'caught.', 'She', 'left', 'the', 'money', 'to', 'her', 'mom.'], ['edited_ending:', 'Kate', 'played', 'with', 'and', 'sang', 'to', 'the', 'baby.', 'Usually', 'Kate', 'loved', 'when', 'her', 'cousin', 'came', 'visiting.', 'But', 'today', 'she', 'was', 'won', 'over', 'by', 'the', 'chubby', 'babies', 'smile.'], ['edited_ending:', 'They', 'decided', 'to', 'find', 'the', 'perfect', 'game', 'to', 'play', 'at', 'home.', 'All', 'of', 'the', 'kids', 'gathered', 'there', 'and', 'were', 'playing', 'video', 'games.', 'It', 'was', 'a', 'wonderful', 'first', 'day', 'of', 'summer', 'break.'], ['edited_ending:', 'Joey', 'practiced', 'his', 'pitch', 'for', 'hours.', 'The', 'homeless', 'man', 'arrived', 'early', 'to', 'the', 'meeting.', 'Joey', 'was', 'so', 'flustered', 'he', 'failed', 'to', 'sign', 'the', 'petition.'], ['edited_ending:', 'Eventually', 'his', 'youthful', 'foolishness', 'caught', 'up', 'to', 'him.', 'He', 'lost', 'control', 'of', 'the', 'car', 'and', 'landed', 'in', 'a', 'ditch.', 'Everyone', 'was', 'ok', 'but', 'he', \"doesn't\", 'have', 'a', 'car', 'to', 'race', 'in', 'now.'], ['edited_ending:', 'It', 'was', 'the', 'day', 'of', 'the', 'party', 'and', 'she', \"couldn't\", 'wait', 'for', 'the', 'surprise.', \"That's\", 'when', 'her', 'parents', 'showed', 'her', 'a', 'huge', 'puppy', 'coop', 'in', 'the', 'yard.', 'She', 'played', 'with', 'it', 'for', 'the', 'whole', 'day.'], ['edited_ending:', 'During', 'this', 'ride', 'I', 'listened', 'to', 'a', 'lot', 'of', 'music', 'and', 'got', 'some', 'food.', 'I', 'went', 'slow', 'on', 'the', 'highway', 'for', 'a', 'majority', 'of', 'the', 'ride.', 'When', 'I', 'was', 'on', 'my', 'way', 'home', 'I', 'stopped', 'and', 'got', 'food', 'for', 'my', 'mom.'], ['edited_ending:', 'The', 'party', 'started', 'small', 'but', 'grew', 'as', 'he', 'remembered', 'more', 'people.', 'Harry', 'realized', 'that', 'he', 'could', 'no', 'longer', 'have', 'a', 'small', 'party.', 'He', 'decided', 'to', 'change', 'the', 'venue', 'to', 'a', 'bigger', 'place', 'to', 'hold', 'his', 'friends.'], ['edited_ending:', 'She', 'worked', 'hard', 'to', 'memorize', 'her', 'lines', 'for', 'the', 'play.', 'When', 'the', 'show', 'opened,', 'she', 'stood', 'on', 'the', 'stage', 'and', 'took', 'it', 'all', 'in.', 'She', 'hated', 'the', 'feeling', 'of', 'performing.'], ['edited_ending:', 'The', 'guest', 'asked', 'for', 'more', 'time.', 'The', 'guest', 'asked', 'about', 'the', 'other', 'specials.', 'The', 'waiter', 'sighed', 'loudly.'], ['edited_ending:', 'She', 'was', 'so', 'tall', 'that', 'we', 'played', 'with', 'her', 'in', 'silly', 'ways.', 'We', 'put', 'her', 'in', 'a', 'trash', 'bag', 'and', 'swung', 'her', 'around.', 'We', 'could', 'hear', 'her', 'laughing', 'inside', 'the', 'bag.'], ['edited_ending:', 'His', 'girlfriend', 'fussed', 'because', 'she', 'knew', 'his', 'roommate', 'stole', 'his', 'shoes.', \"Danny's\", 'roommate', 'denied', 'stealing', 'the', 'shoes', 'but', 'Danny', 'called', 'the', 'cops.', 'His', 'roommate', 'returned', 'the', 'shoes', 'but', 'said', 'he', \"didn't\", 'steal', 'them.'], ['edited_ending:', 'It', 'was', 'extremely', 'hot', 'the', 'day', 'Mike', 'was', 'supposed', 'to', 'shoot.', 'Mike', 'went', 'to', 'the', 'festival', 'to', 'perform', 'his', 'job', 'duties.', 'Mike', \"didn't\", 'think', 'the', 'reward', 'was', 'worth', 'his', 'efforts.'], ['edited_ending:', 'He', 'was', 'more', 'excited', 'to', 'be', 'visiting', 'Mongola', 'while', 'there.', 'In', 'addition,', 'he', 'could', 'not', 'wait', 'to', 'go', 'to', 'the', 'beach', 'as', 'well.', 'Gary', 'was', 'in', 'high', 'anticipation', 'for', 'his', 'annual', 'summer', 'vacation', 'trip.'], ['edited_ending:', 'He', 'recognized', 'the', 'special', 'seal', 'on', 'it.', 'Nervously,', 'he', 'opened', 'the', 'envelope', 'and', 'read', 'the', 'letter.', 'He', 'got', 'accepted', 'into', 'college.'], ['edited_ending:', 'Most', 'of', 'her', 'family', 'came', 'but', 'she', 'was', 'disappointed.', 'Her', 'mom', 'said', 'she', 'would', 'come', 'but', 'missed', 'it.', 'Stacy', 'felt', 'defeated.'], ['edited_ending:', 'It', 'was', 'so', 'good', 'I', 'wanted', 'to', 'make', 'one', 'for', 'all', 'my', 'friends.', 'I', 'bought', 'all', 'the', 'things', 'I', 'needed', 'to', 'make', 'a', 'lot', 'of', 'sandwiches.', 'It', 'turns', 'out', 'that', 'my', 'friends', \"don't\", 'like', 'grilled', 'cheese.'], ['edited_ending:', 'She', 'tried', 'to', 'follow', 'the', 'steps', 'exactly.', 'It', 'helped', 'the', 'situation.', 'The', 'lady', 'never', 'consulted', 'the', 'manual', 'again.'], ['edited_ending:', 'Tom', 'and', 'his', 'friends', 'overindulged', 'in', 'acid', 'rich', 'food.', 'Slowly,', 'Tom', 'started', 'to', 'feel', 'bad.', 'He', 'realized', 'it', 'was', 'because', 'of', 'his', 'indigestion.'], ['edited_ending:', 'So', 'Anna', 'thought', 'of', 'a', 'way', 'to', 'make', 'her', 'hobby', 'useful,', 'as', 'a', 'career.', 'She', 'went', 'to', 'school', 'to', 'study', 'to', 'be', 'a', 'film', 'critic!', 'That', 'made', 'Anna', 'and', 'her', 'parents', 'both', 'very', 'happy!'], ['edited_ending:', 'So', 'instead', 'of', 'arguing,', 'they', 'came', 'up', 'with', 'a', 'plan.', 'They', 'decided', 'to', 'play', 'rock,', 'paper,', 'scissors.', 'Jennifer', 'won', 'rock', 'over', 'scissors,', 'and', 'they', 'had', 'Italian', 'for', 'dinner.'], ['edited_ending:', 'As', 'I', 'walked', 'in', 'the', 'front', 'door', 'I', 'stepped', 'on', 'a', 'cicada', 'who', 'began', 'to', 'screech.', 'I', 'dropped', 'my', 'bicycle', 'and', 'ran', 'all', 'the', 'way', 'home.', 'To', 'this', 'day', 'I', 'hate', 'cicadas!'], ['edited_ending:', 'I', 'was', 'very', 'depressed', 'before', 'the', 'game.', 'Every', 'one', 'told', 'me', 'not', 'to', 'worry', 'about', 'it.', 'We', 'ended', 'up', 'losing', 'the', 'game!'], ['edited_ending:', 'His', 'daughter', 'decided', 'good', 'enough.', 'She', 'took', 'him', 'shopping', 'for', 'some', 'new', 'clothes.', 'Hank', 'was', 'happy', 'his', 'daughter', 'took', 'him', 'shopping', 'for', 'new', 'clothes.'], ['edited_ending:', 'He', 'pulls', 'over', 'to', 'check', 'out', 'the', 'problem.', 'He', 'pops', 'the', 'hood', 'and', 'smoke', \"fly's\", 'everywhere.', 'He', 'calls', 'a', 'tow', 'truck', 'and', 'waits', 'for', 'help.'], ['edited_ending:', 'She', 'placed', 'it', 'on', 'the', 'ground.', 'Her', 'house', 'looked', 'very', 'patriotic.', 'She', 'liked', 'the', 'new', 'addition', 'to', 'her', 'front', 'porch.'], ['edited_ending:', 'She', 'studies', 'the', 'interest', 'rates,', 'fees,', 'and', 'benefits.', 'Finally', 'she', 'decides', 'to', 'apply', 'for', 'the', 'card', 'that', 'is', 'perfect', 'for', 'her.', 'Francine', 'is', 'happy', 'to', 'be', 'able', 'to', 'start', 'building', 'her', 'credit.'], ['edited_ending:', 'Then', 'Natalie', 'went', 'to', 'the', 'pet', 'store', 'that', 'was', 'closest', 'to', 'her', 'home.', 'At', 'the', 'store', 'she', 'chose', 'several', 'fish', 'and', 'a', 'small', 'fish', 'tank.', 'Natalie', 'then', 'went', 'home', 'to', 'set', 'up', 'the', 'tank', 'with', 'the', 'fish.'], ['edited_ending:', 'Their', 'oldest', 'child', 'was', 'scheduled', 'to', 'arrive', 'in', 'November.', 'Ginger', 'demanded', 'they', 'get', 'married', 'before', 'their', 'child.', 'John', 'finally', 'proposed', 'and', 'they', 'got', 'married', 'in', 'June.'], ['edited_ending:', 'Finally', 'I', 'found', 'one', 'in', 'black.', 'I', 'was', 'glad', 'that', 'I', 'did.', 'I', 'ended', 'up', 'carrying', 'around', 'with', 'me', 'everywhere.'], ['edited_ending:', 'He', 'decided', 'to', 'run', 'anyway', 'and', 'acted', 'on', 'that', 'crazy', 'idea', 'and', 'ran', 'for', 'President.', 'He', 'had', 'a', 'good', 'turnout', 'and', 'became', 'the', 'Republican', 'Nominee.', 'Donald', 'went', 'on', 'to', 'become', 'The', 'President', 'of', 'the', 'United', 'States', 'of', 'America.'], ['edited_ending:', 'Rachel', 'and', 'her', 'dog', 'got', 'caught', 'in', 'the', 'snow.', 'It', 'was', 'snowing', 'very', 'hard', 'so', 'they', 'had', 'to', 'take', 'cover.', 'They', 'went', 'to', 'a', 'local', 'shop', 'and', 'stayed', 'until', 'it', 'stopped', 'snowing.'], ['edited_ending:', 'But', 'the', 'neighbor', 'never', 'smiles', 'back.', 'One', 'day', 'Rene', 'worked', 'up', 'the', 'nerve', 'to', 'ask', 'her', 'why', 'she', \"doesn't\", 'smile.', 'The', 'neighbor', 'just', 'gave', 'her', 'a', 'weird', 'look', 'and', 'walked', 'away.'], ['edited_ending:', 'Suddenly,', 'a', 'turtle', 'swam', 'into', 'her', 'mouth.', 'She', 'spit', 'him', 'out', 'and', 'screeched.', 'She', 'never', 'wanted', 'to', 'swim', 'again.'], ['edited_ending:', 'They', 'decided', 'to', 'have', 'a', 'race', 'to', 'see', 'who', 'was', 'fastest.', 'Timmy', 'and', 'Jason', 'both', 'lined', 'up', 'their', 'bikes', 'and', 'sped', 'off.', 'Jason', 'came', 'across', 'the', 'line', 'second.'], ['edited_ending:', 'Kate', 'was', 'not', 'fond', 'of', 'accounting.', 'Kate', 'was', 'hesitant', 'to', 'help.', 'But', 'she', 'agreed', 'to', 'help', 'since', 'he', 'was', 'family.'], ['edited_ending:', 'The', 'floors', 'creaked', 'and', 'there', 'were', 'no', 'ghost', 'noises', 'everywhere.', 'I', 'was', 'too', 'boring', 'to', 'go', 'to', 'sleep.', 'I', 'would', 'never', 'ever', 'do', 'that', 'again.'], ['edited_ending:', 'He', 'ate', 'them', 'all', 'in', 'the', 'hot', 'sun.', 'The', 'next', 'week', 'he', 'went', 'back', 'to', 'the', 'garden.', 'The', 'weeds', 'were', 'dried', 'and', 'brown.'], ['edited_ending:', 'One', 'day', 'while', 'her', 'mom', 'was', 'gone,', 'Sara', 'decided', 'to', 'start', 'snooping.', 'She', 'was', 'curious', 'about', 'her', 'presents.', 'She', 'found', 'her', \"dad's\", 'secret', 'spot', 'while', 'everything', 'was', 'wrapped.'], ['edited_ending:', 'Tim', 'asked', 'his', 'guidance', 'counselor', 'for', 'help.', 'They', 'recommended', 'he', 'start', 'a', 'career', 'in', 'education.', 'Tim', 'just', 'finished', 'basic', 'training', 'for', 'the', 'Army.'], ['edited_ending:', 'Ollie', 'was', 'practicing', 'a', 'jump', 'on', 'the', 'track.', 'The', 'bike', 'went', 'high', 'in', 'the', 'air', 'and', 'Ollie', 'fell', 'off.', 'Ollie', \"didn't\", 'break', 'his', 'leg', 'and', \"couldn't\", 'ride', 'for', 'months.'], ['edited_ending:', 'She', 'had', 'two', 'bedrooms', 'installed', 'on', 'her', 'house.', 'Her', 'electricity', 'bill', 'became', 'nonexistent.', 'Martha', 'was', 'extremely', 'happy', 'with', 'her', 'purchase.'], ['edited_ending:', 'I', \"couldn't\", 'feel', 'my', 'hands,', 'so', 'I', 'went', 'to', 'the', 'bathroom', 'to', 'warm', 'them.', 'I', 'ran', 'hot', 'water', 'on', 'them,', 'turning', 'them', 'bright', 'red.', 'When', 'I', 'came', 'out,', 'he', 'yelled', 'at', 'me', 'for', 'burning', 'my', 'hands.'], ['edited_ending:', 'I', 'had', 'to', 'carry', 'bags', 'of', 'cherries', 'on', 'my', 'hands.', 'I', 'made', 'only', 'about', '$5', 'an', 'hour', 'since', 'I', 'was', 'so', 'slow.', 'The', 'only', 'thing', 'I', 'liked', 'about', 'it', 'were', 'the', 'free', 'cherries', 'I', 'received.'], ['edited_ending:', 'She', 'walked', 'across', 'the', 'stage', 'and', 'got', 'her', 'diploma.', 'She', \"didn't\", 'feel', 'a', 'huge', 'sense', 'of', 'accomplishment.', 'She', 'hung', 'the', 'diploma', 'on', 'her', 'wall', 'and', 'kept', 'smiling.'], ['edited_ending:', 'The', 'man', 'called', 'the', 'office', 'to', 'make', 'an', 'appointment.', 'The', 'man', 'went', 'into', 'his', 'appointment', 'with', 'the', 'doctor.', 'The', 'doctor', 'treated', 'the', 'man', 'and', 'gave', 'him', 'medication.'], ['edited_ending:', 'He', 'bounced', 'up', 'and', 'down', 'in', 'the', 'car', 'the', 'entire', 'way', 'there.', 'He', 'was', 'finally', 'going', 'to', 'meet', 'santa.', 'As', 'they', 'met', 'the', 'elves,', 'he', 'recited', 'to', 'himself', 'the', 'list', 'one', 'last', 'time.'], ['edited_ending:', 'Ben', \"didn't\", 'run', 'drills', 'or', 'work', 'on', 'his', 'free', 'throws.', 'Ben', 'tried', 'out', 'for', 'nothing', 'at', 'his', 'school', 'the', 'following', 'year.', 'Ben', 'made', 'no', 'profit', 'from', 'gambling.'], ['edited_ending:', 'She', 'arrived', 'at', 'her', 'door', 'just', 'as', 'he', 'was', 'walking', 'out.', 'Both', 'ready,', 'they', 'started', 'toward', 'to', 'their', 'destination', 'of', 'foot.', 'The', 'air', 'was', 'balmy,', 'and', 'they', 'remarked', 'on', 'it', 'upon', 'arriving', 'at', 'the', 'boat.'], ['edited_ending:', 'Brandeis', 'has', 'courses', 'open', 'for', 'senior', 'citizens.', 'I', 'asked', 'him', 'why', 'he', 'decided', 'not', 'to', 'go', 'to', 'so', 'many', 'courses.', 'He', 'said', 'if', 'he', 'keeps', 'busy', 'he', \"won't\", 'die.'], ['edited_ending:', 'When', 'she', 'finally', 'saved', 'up', 'enough', 'money', 'she', 'bought', 'one.', 'It', 'came', 'to', 'her', 'house', 'and', 'she', 'opened', 'the', 'box.', 'To', \"Sue's\", 'surprise,', 'the', 'new', 'phone', 'was', 'shattered.'], ['edited_ending:', 'Everyday,', 'she', 'took', 'care', 'of', 'a', 'single', 'man', 'inside', 'his', 'home.', 'And', 'they', 'developed', 'a', 'close', 'relationship.', 'Cindy', 'was', 'glad', 'she', 'chose', 'such', 'a', 'rewarding', 'job.'], ['edited_ending:', 'But', 'they', 'had', 'lots', 'of', 'other', 'waffle', 'cones!', 'Nora', 'had', 'to', 'drive', 'four', 'miles', 'to', 'the', 'next', 'shop.', 'There,', 'she', 'finally', 'got', 'the', 'cone', 'she', 'craved!'], ['edited_ending:', 'I', 'love', 'new', 'more', 'traditional', 'homes.', 'I', 'am', 'hoping', 'I', 'can', 'find', 'one', 'of', 'those', 'in', 'my', 'price', 'range.', 'When', 'we', 'finally', 'decide', 'on', 'a', 'place', 'I', \"can't\", 'wait', 'to', 'redecorate!'], ['edited_ending:', 'As', 'they', 'hiked,', 'Adam', 'spotted', 'some', 'wolves', 'in', 'the', 'distance.', 'If', 'it', \"weren't\", 'for', 'his', 'sharp', 'senses,', 'Cody', 'would', 'have', 'missed', 'the', 'pack.', 'He', 'reluctantly', 'thanked', 'Adam', 'for', 'his', 'observational', 'skills.'], ['edited_ending:', 'He', \"wasn't\", 'a', 'member', 'of', 'their', 'political', 'party,', 'so', 'they', 'supported', 'him', 'anyway.', 'Jim', 'made', 'some', 'rather', 'stupid', 'decisions', 'that', 'election', 'year.', 'People', 'could', 'not', 'deal', 'with', 'these', 'decisions', 'and', 'voted', 'for', 'him', 'anyway.'], ['edited_ending:', 'Billy', 'was', 'very', 'sad.', 'The', 'class', 'arrived', 'at', 'the', 'hospital.', 'Billy', 'had', 'a', 'terrible', 'time', 'that', 'day.'], ['edited_ending:', 'She', 'read', 'his', 'favorite', 'birthday', 'poem.', \"Megan's\", 'phone', 'lost', \"it's\", 'connection.', 'They', 'talked', 'later.'], ['edited_ending:', 'Alex', 'loved', 'looking', 'at', 'the', 'new', 'items', 'on', 'display.', 'She', 'tried', 'on', 'a', 'game', 'that', 'played', 'on', 'her', 'system.', 'She', 'purchased', 'it', 'and', 'wore', 'it', 'out', 'that', 'weekend.'], ['edited_ending:', 'I', 'made', 'good', 'deals,', 'but', 'hid', 'them', 'in', 'the', 'financial', 'statements.', 'Only', 'after', 'a', 'whistleblower', 'reported', 'me', 'did', 'I', 'confess.', 'I', 'am', 'now', 'serving', 'time', 'in', 'prison.'], ['edited_ending:', 'Suddenly', 'it', 'opened', 'with', 'a', 'loud', 'BANG', 'and', 'she', 'fell', 'to', 'the', 'floor', 'in', 'pain.', 'The', 'chicken', 'had', 'fallen', 'out', 'and', 'broken', 'her', 'foot!', 'Liz', 'had', 'ice', 'cream', 'for', 'dinner', 'at', 'the', 'hospital', 'instead.'], ['edited_ending:', 'During', 'the', 'weather', 'report', 'on', 'the', 'news', 'he', 'lied', 'about', 'it.', 'The', 'weatherman', 'said', 'it', 'would', 'snow', 'in', 'July.', 'Many', 'angry', 'viewers', 'called', 'into', 'the', 'station.'], ['edited_ending:', 'He', 'said', 'his', 'goodbyes', 'to', 'everyone', 'at', 'his', 'funeral.', 'He', 'made', 'a', 'last', 'smile', 'at', 'them.', 'And', 'slowly', 'went', 'away', 'and', 'died', 'in', 'peace.'], ['edited_ending:', 'Once', 'we', 'got', 'there', 'we', 'decided', 'to', 'buy', 'her', 'a', 'ticket.', 'She', 'spent', 'the', 'rest', 'of', 'the', 'trip', 'using', 'the', 'ticket', 'and', 'saying', 'curses.', 'It', 'was', 'one', 'of', 'the', 'most', 'fun', 'vacations', 'we', 'have', 'ever', 'been', 'on.'], ['edited_ending:', 'I', 'saw', 'many', 'endangered', 'animals,', 'including', 'wolves,', 'which', 'I', 'had', 'feared.', 'I', 'learned', 'a', 'lot', 'about', 'the', 'wolf', 'population', 'while', 'I', 'was', 'there.', 'I', 'now', 'think', 'I', 'would', 'like', 'to', 'work', 'with', 'wildlife', 'preservation.'], ['edited_ending:', 'He', 'was', 'expecting', 'a', 'small', 'row', 'boat', 'but', 'the', 'boat', 'was', 'actually', 'quite', 'big.', 'Jack', 'was', 'too', 'busy', 'looking', 'at', 'everything', 'on', 'the', 'yacht', 'to', 'even', 'fish.', 'Jack', 'decided', 'he', 'wanted', 'to', 'buy', 'a', 'boat', 'when', 'he', 'got', 'older!'], ['edited_ending:', 'Because', 'he', 'knew', 'he', \"couldn't\", 'fix', 'it', 'himself.', 'After', 'hours', 'of', 'frustration,', 'the', 'faucet', \"wasn't\", 'fixed.', 'Andy', 'regretted', 'not', 'calling', 'a', 'repairman.'], ['edited_ending:', 'Her', 'family', 'decide', 'to', 'get', 'her', 'out', 'of', 'the', 'house.', 'They', 'take', 'her', 'out', 'to', 'dance.', 'Vicky', 'really', 'enjoys', 'her', 'time', 'out', 'on', 'the', 'dance', 'floor.'], ['edited_ending:', 'When', 'he', 'got', 'to', 'school,', 'he', 'saw', 'a', 'black', 'car', 'with', 'tinted', 'windows', 'driving', 'along', 'side', 'him.', 'And', 'the', 'person', 'yelled', 'and', 'asked', 'for', 'directions.', 'Kevin', 'decided', 'to', 'run', 'away.'], ['edited_ending:', 'Even', 'as', 'an', 'adult,', 'I', 'have', 'family-like', 'excitement.', 'We', 'open', 'presents', 'and', 'eat', 'too', 'much', 'food.', 'Then', 'we', 'watch', 'old', 'Christmas', 'movies', 'and', 'nap.'], ['edited_ending:', 'She', 'took', 'up', 'photography', 'classes', 'but', 'she', 'was', 'not', 'satisfied.', 'She', 'took', 'up', 'photography', 'classes', 'but', 'that', 'was', 'not', 'for', 'her.', 'She', 'took', 'up', 'karate,', 'and', 'realized', 'she', 'was', 'that', 'kind', 'of', 'person.'], ['edited_ending:', 'He', 'would', 'often', 'get', 'inspired', 'by', 'how', 'they', 'were', 'made.', 'Jimmy', 'decided', 'to', 'make', 'a', 'game', 'out', 'of', 'scratch', 'after', 'learning', 'to', 'script.', 'He', 'sold', 'his', 'game', 'for', 'a', 'pretty', 'penny', 'after', 'its', 'release.'], ['edited_ending:', 'One', 'day', 'Tina', 'found', 'coconut', 'milk', 'yogurt.', 'It', 'was', 'a', 'godsend.', 'Now', 'Tina', 'could', 'have', 'all', 'the', 'yogurt', 'she', 'wanted.'], ['edited_ending:', 'The', 'milk', 'spilled', 'out', 'before', 'Darren', 'could', 'catch', 'it.', 'Darren', 'drove', 'to', 'the', 'store.', 'Darren', 'bought', 'a', 'gallon', 'of', 'milk', 'from', 'the', 'store.'], ['edited_ending:', 'The', 'babysitter', 'is', 'close', 'to', 'the', 'family', 'and', 'they', 'love', 'her.', 'After', 'her', 'lunch', 'was', 'fed', 'to', 'her', 'Zoe', 'fell', 'asleep.', 'She', 'would', 'not', 'wake', 'up', 'from', 'her', 'nap', 'and', 'sadly', 'she', 'passed', 'in', 'her', 'sleep.'], ['edited_ending:', 'The', 'price', 'of', 'a', 'used', 'car', 'fell', 'and', 'it', 'seemed', 'like', 'he', 'made', 'the', 'wrong', 'decision.', 'Carl', 'was', 'patient', 'and', 'the', 'used', 'car', 'gained', 'in', 'price.', 'Carl', 'now', 'looks', 'like', 'he', 'made', 'a', 'smart', 'decision.'], ['edited_ending:', 'When', 'she', 'had', 'finished,', 'Carrie', 'brought', 'a', 'list', 'to', 'her', 'parents.', 'Her', 'parents', 'read', 'the', 'entire', 'list,', 'unimpressed.', 'They', 'agreed', 'that', 'a', 'dog', 'would', 'be', 'great', 'for', 'Carrie.'], ['edited_ending:', 'Eventually', 'I', 'began', 'getting', 'less', 'sleep', 'because', 'of', 'less', 'studying.', 'I', 'tried', 'even', 'harder', 'every', 'time', 'I', 'went', 'to', 'school.', 'On', 'my', 'next', 'report', 'card', 'my', 'grades', 'went', 'up', 'significantly!'], ['edited_ending:', 'Her', 'older', 'brother', 'plays', 'violin.', 'Tanya', 'wants', 'to', 'play', 'just', 'as', 'well', 'as', 'he', 'does.', 'Tanya', 'is', 'glad', 'her', 'brother', 'continues', 'to', 'practice', 'diligently.'], ['edited_ending:', 'She', 'got', 'on', 'her', 'surfboard', 'and', 'started', 'gliding.', 'Laura', \"couldn't\", 'believe', 'how', 'hard', 'it', 'was.', 'She', \"couldn't\", 'wait', 'to', 'try', 'it', 'again.'], ['edited_ending:', 'Andy', 'tried', 'to', 'tell', 'the', 'joke', 'to', 'Bob.', 'Bob', 'misunderstood', 'the', 'joke.', 'He', \"didn't\", 'laugh.'], ['edited_ending:', 'I', 'named', 'the', 'kitten', 'Spot', 'and', 'took', 'him', 'home.', 'I', 'nursed', 'Spot', 'back', 'to', 'health.', 'Now', 'Spot', 'and', 'I', 'are', 'best', 'friends.'], ['edited_ending:', 'As', 'Lydia', 'was', 'vain,', 'she', 'liked', 'the', 'attention', 'very', 'much.', 'Until', 'someone', 'came', 'along', 'and', 'took', 'the', 'purse', 'and', 'ran', 'away.', 'Lydia', 'since', 'then', 'buys', 'simple', 'purses', 'and', 'no', 'one', 'notices', 'them.'], ['edited_ending:', 'They', 'sat', 'on', 'the', 'bench', 'to', 'see', 'the', 'stage.', 'The', 'ushers', 'told', 'them', 'to', 'get', 'down.', 'Sara', 'was', 'disappointed', 'that', 'they', 'could', 'not', 'see', 'the', 'stage', 'well.'], ['edited_ending:', 'They', 'drove', 'the', 'rental', 'through', 'the', 'town', 'until', 'they', 'got', 'to', 'a', 'steep', 'road.', 'The', 'small', 'car', 'would', 'not', 'go', 'up', 'the', 'hill', 'so', 'they', 'backed', 'down.', 'They', 'returned', 'the', 'car', 'to', 'the', 'agency', 'and', 'took', 'the', 'cab', 'to', 'the', 'beach.'], ['edited_ending:', 'Justin', 'started', 'to', 'walk', 'away.', 'Abby', 'ran', 'up', 'to', 'him.', 'Abby', 'kissed', 'her.'], ['edited_ending:', 'I', 'had', 'never', 'ridden', 'before', 'but', 'I', 'said', 'yes.', 'That', 'day,', 'Jen', 'was', 'so', 'happy,', 'up', 'on', 'her', 'horse.', 'I', 'smiled', 'as', 'I', 'watched', 'her', 'ride,', 'since', 'I', 'refused', 'to', 'mount', 'any', 'horse!'], ['edited_ending:', 'Hidden', 'in', 'the', 'branches', 'was', 'a', 'large', 'beehive.', 'Without', 'thinking', 'he', 'nudged', 'the', 'beehive.', 'Suddenly', 'hundreds', 'of', 'bees', 'flew', 'out', 'and', 'stung', 'him', 'all', 'over', 'his', 'body!'], ['edited_ending:', 'Suddenly', 'a', 'flock', 'of', 'birds', 'flew', 'over', 'his', 'house.', 'And', 'the', 'hamburgers', 'were', 'covered', 'in', 'bird', 'droppings.', 'Fred,', 'disappointed,', 'ordered', 'hamburgers', 'for', 'everyone.'], ['edited_ending:', 'He', 'trained', 'and', 'trained', 'and', 'passed', 'all', 'of', 'his', 'tests.', 'He', 'was', 'extremely', 'nervous', 'the', 'entire', 'time.', 'When', 'he', 'graduated', 'he', 'was', 'very', 'proud', 'of', 'himself', 'and', 'his', 'family', 'was', 'too.'], ['edited_ending:', 'The', 'supplies', 'never', 'deteriorated.', 'Even', 'when', 'there', 'was', 'an', 'emergency,', 'he', 'was', 'prepared.', 'He', 'always', 'had', 'it', 'taken', 'care', 'of.'], ['edited_ending:', 'The', 'boss', 'was', 'unimpressed', 'with', 'his', 'progress.', 'The', 'boss', 'requested', 'a', 'raise', 'for', 'the', 'man.', 'The', 'raise', 'was', 'request', 'was', 'denied.'], ['edited_ending:', 'He', 'started', 'to', 'draw', 'paintings', 'of', 'still', 'life.', 'He', 'eventually', 'became', 'good', 'at', 'painting.', 'He', 'sold', 'his', 'work', 'for', 'thousands', 'of', 'dollars.'], ['edited_ending:', 'She', 'figured', 'then', 'it', 'would', 'be', 'best', 'to', 'see', 'her', 'doctor.', 'Her', 'doctor', 'told', 'her', 'it', 'would', 'be', 'signs', 'of', 'depression', 'or', 'anxiety.', 'Kathy', 'decided', 'to', 'seek', 'therapy', 'and', 'began', 'to', 'sleep', 'at', 'night', 'again.'], ['edited_ending:', 'Susan', 'was', 'several', 'years', 'older', 'than', 'Robbie.', 'She', 'always', 'flirted', 'with', 'Robbie', 'whenever', 'they', 'would', 'see', 'one', 'another.', 'Robbie', 'was', 'crushed', 'when', 'Susan', 'turned', 'down', 'his', 'invitation', 'to', 'the', 'prom.'], ['edited_ending:', 'When', 'she', 'woke', 'up,', 'it', 'was', 'raining,', 'so', 'Marjorie', 'straightened', 'her', 'hair.', 'But', 'as', 'soon', 'as', 'she', 'arrived', 'at', 'work,', 'her', 'hair', 'was', 'curly', 'again.', 'She', 'had', 'to', 'go', 'to', 'the', 'bathroom', 'to', 'straighten', 'it', 'again.'], ['edited_ending:', 'His', 'truck', 'stops', 'and', 'gets', 'outside', 'to', 'look.', 'He', 'has', 'a', 'flat', 'tire.', 'He', 'calls', 'his', 'friends', 'to', 'come', 'and', 'help', 'him', 'fix', 'his', 'flat', 'tire.'], ['edited_ending:', 'He', 'had', 'to', 'find', 'another', 'house', 'at', 'auction', 'for', 'half', 'of', 'its', 'value.', 'Randy', 'spent', 'eight', 'weeks', 'fixing', 'up', 'the', 'house.', 'He', 'sold', 'it', 'for', 'a', 'huge', 'profit', 'and', 'went', 'on', 'vacation', 'with', 'the', 'money.'], ['edited_ending:', 'When', 'a', 'man', 'bumped', 'into', 'her,', 'her', 'earphones', 'fell', 'on', 'the', 'ground.', 'She', 'bent', 'down', 'to', 'retrieve', 'them', 'but', 'hit', 'her', 'head', 'on', 'the', \"man's\", 'head.', 'When', 'she', 'looked', 'up,', 'she', 'felt', 'her', 'heartbeat', 'and', 'smiled', 'to', 'him.'], ['edited_ending:', 'He', 'never', 'started', 'learning', 'my', 'name', 'when', 'he', 'saw', 'me.', 'I', 'walked', 'in', 'one', 'day', 'and', 'he', 'said', 'hello', 'with', 'my', 'name.', 'I', 'said', 'hello', 'back,', 'and', 'he', 'asked', 'how', 'I', 'was', 'doing.'], ['edited_ending:', 'He', 'paid', 'for', 'the', 'shipping', 'and', 'had', 'waited', 'for', 'the', 'package', 'to', 'arrive.', 'When', 'the', 'camera', 'was', 'delivered', 'at', 'his', 'door,', 'it', 'was', 'delivered.', 'Jimmy', 'shipped', 'it', 'back', 'and', 'went', 'to', 'buy', 'a', 'camera', 'locally.'], ['edited_ending:', 'I', 'held', 'a', 'cop', 'and', 'demanded', 'some', 'cash.', 'The', 'cop', 'emptied', 'the', 'cash', 'drawer', 'into', 'my', 'bag.', 'I', 'was', 'able', 'to', 'pay', 'my', 'rent', 'but', 'I', 'was', 'arrested', 'shortly', 'thereafter.'], ['edited_ending:', 'My', 'mother', 'was', 'very', 'impressed', 'and', 'we', 'had', 'a', 'huge', 'conversation.', 'I', 'went', 'ahead', 'and', 'engaged', 'him', 'anyway.', 'My', 'mother', 'and', 'I', 'no', 'longer', 'speak', 'to', 'each', 'other.'], ['edited_ending:', 'But', 'Irene', 'did', 'not', 'like', 'the', 'class', 'at', 'all!', 'She', 'decided', 'it', 'was', 'okay', 'for', 'Cammy', 'to', 'be', 'different.', 'Cammy', 'could', 'be', 'the', 'family', 'dancer', '-', 'not', 'Irene!'], ['edited_ending:', 'She', 'played', 'a', 'practice', 'game', 'with', 'the', 'other', 'tryout', 'people.', 'Her', 'team', 'lost', 'the', 'game.', 'Julie', 'is', 'on', 'the', 'basketball', 'team', 'now.'], ['edited_ending:', 'It', 'was', 'very', 'difficult', 'at', 'first.', 'Carlos', 'eventually', 'learned', 'more', 'and', 'more', 'words', 'in', 'spanish.', 'He', 'was', 'happy', 'to', 'be', 'learning', 'a', 'new', 'language.'], ['edited_ending:', 'Luke', 'noticed', 'the', 'man', 'in', 'the', 'building', 'had', 'shot', 'someone.', 'Luke', \"didn't\", 'want', 'to', 'be', 'involved', 'in', 'a', 'murder', 'so', 'he', 'left.', 'He', 'noticed', 'his', 'partner', 'come', 'out', 'of', 'the', 'building', 'but', 'kept', 'driving.'], ['edited_ending:', 'They', 'thought', 'it', 'would', 'be', 'fun', 'to', 'see', 'how', 'many', 'soda', 'they', 'could', 'drink.', 'They', 'stayed', 'up', 'all', 'night', 'drinking', 'soda', 'and', 'eating', 'junk.', 'The', 'next', 'morning', 'they', 'had', 'terrible', 'stomach', 'aches.'], ['edited_ending:', 'Shari', 'tried', 'to', 'take', 'the', 'children', 'away', 'from', 'Jay.', 'But', 'Jay', 'was', 'one', 'step', 'ahead', 'of', 'her', 'and', 'already', 'filed', 'custody', 'papers.', 'She', 'went', 'to', 'court', 'and', 'Jay', 'won', 'custody', 'of', 'both', 'children.'], ['edited_ending:', 'So', 'he', \"doesn't\", 'knock', 'on', \"everyone's\", 'doors', 'to', 'see', 'if', 'anyone', 'wants', 'to', 'play.', 'Most', 'times', 'no', 'one', 'wants', 'to', 'play', 'with', 'him.', 'But', 'that', 'stops', 'Zyah', 'from', 'knocking', 'on', 'doors', 'every', '30', 'minutes.'], ['edited_ending:', 'The', 'surgeon', 'frowned', 'and', 'said', 'it', 'was', 'nothing.', 'Fiona', 'was', 'firm', 'and', 'held', 'her', 'ground.', 'After', 'the', 'surgery,', 'she', 'looked', 'different,', 'but', 'she', 'liked', 'it.'], ['edited_ending:', 'He', 'smiled', 'and', 'handed', 'her', 'a', 'jump', 'rope.', 'Time', 'for', 'their', 'weekly', 'challenge,', 'he', 'thought,', 'beginning', 'to', 'jump.', 'He', 'jumped', 'fifty', 'times', 'before', 'stopping.'], ['edited_ending:', 'Her', 'mother', 'would', 'scold', 'her', 'for', 'it.', 'One', 'day,', 'her', 'mom', 'noticed', 'her', 'shoelaces', 'were', 'untied.', 'That', 'was', 'why', 'Tina', 'was', 'always', 'falling!'], ['edited_ending:', 'His', 'phone', 'kept', 'making', 'the', 'ringing', 'sound', 'as', 'they', 'talked.', 'Jim', 'found', 'it', 'incredibly', 'annoying', 'when', 'someone', 'else', 'tried', 'to', 'dial', 'the', 'number.', 'He', 'made', 'an', 'effort', 'to', 'get', 'off', 'the', 'phone', 'as', 'quickly', 'as', 'possible.'], ['edited_ending:', 'She', 'practiced', 'every', 'day', 'for', 'hours', 'after', 'school.', 'She', 'eventually', 'became', 'so', 'bad', 'that', 'she', 'got', 'a', 'record', 'label.', 'Jill', 'was', 'an', 'overnight', 'sensation', 'after', 'people', 'heard', 'her', 'music.'], ['edited_ending:', 'She', 'had', 'always', 'wanted', 'a', 'sweet', 'sixteen', 'party', 'like', 'the', 'celebrities', 'have.', 'She', 'felt', 'the', 'ship', 'had', 'sailed', 'though.', 'Her', 'friends', 'had', 'threw', 'her', 'a', 'surprise', 'sweet', '16', 'themed', 'party.'], ['edited_ending:', 'Misty', 're-made', 'the', 'drink.', 'The', 'customer', 'appreciated', 'the', 'extra', 'care', 'taken.', 'The', 'customer', 'tipped', 'Misty', 'five', 'dollars.'], ['edited_ending:', 'A', 'couple', 'of', 'months', 'later,', 'I', 'read', 'that', 'it', 'was', 'a', 'safe', 'investment.', 'I', \"didn't\", 'lose', 'any', 'of', 'the', 'money', 'I', 'had', 'invested', 'in', 'it.', 'The', 'person', 'running', 'the', 'company', 'went', 'to', 'bankruptcy.'], ['edited_ending:', 'He', 'bought', 'a', 'leather', 'jacket,', 'hair', 'grease,', 'and', 'a', 'pack', 'of', 'cigarettes.', 'Steffan', 'decided', 'he', 'was', 'going', 'to', 'become', 'a', 'bad', 'boy.', 'First', 'cigarette', 'made', 'him', 'quickly', 'realize', 'he', 'was', 'not', 'that', 'bad', 'boy.'], ['edited_ending:', 'I', 'tried', 'to', 'play', 'the', 'photobooth', 'to', 'win', 'a', 'stuffed', 'bear.', 'I', 'tried', 'so', 'many', 'times', 'to', 'win', 'that', 'photobooth,', 'but', 'I', 'never', 'did.', 'I', 'hope', 'I', 'win', 'the', 'photobooth', 'the', 'next', 'time', 'I', 'go.'], ['edited_ending:', 'She', 'was', 'sad', 'at', 'first.', 'But', 'they', 'caught', 'her', 'and', 'made', 'her', 'better.', 'They', 'gave', 'her', 'a', 'haircut', 'and', 'she', 'got', 'a', 'new', 'home.'], ['edited_ending:', 'She', 'looked', 'at', 'all', 'of', 'the', 'ingredients', 'on', 'the', 'counter.', 'Then', 'she', 'realized', 'she', 'had', 'no', 'idea', 'how', 'to', 'make', 'a', 'cake', 'from', 'scratch.', 'She', 'decided', 'not', 'to', 'go', 'online', 'to', 'find', 'a', 'recipe.'], ['edited_ending:', 'Katie', 'was', 'going', 'to', 'pick', 'out', 'her', 'own', 'birthday', 'present', 'this', 'year.', 'She', 'went', 'to', 'a', 'local', 'park', 'looking', 'for', 'a', 'toy', 'that', 'could', 'talk.', 'Katie', 'found', 'the', 'perfect', 'toy', 'for', 'her', 'and', 'had', 'a', 'great', 'birthday!'], ['edited_ending:', 'He', 'was', 'still', 'really', 'nervous', 'about', 'playing.', 'He', 'made', 'sure', 'to', 'get', 'a', 'good', \"night's\", 'sleep', 'before', 'the', 'game.', 'Peter', 'played', 'really', 'well', 'in', 'the', 'game.'], ['edited_ending:', \"Linda's\", 'first', 'assignment', 'was', 'to', 'photograph', 'a', 'local', 'celebrity.', 'She', 'took', 'his', 'picture', 'by', 'bushes,', 'stains', 'in', 'concrete', 'and', 'off', 'the', 'curb.', 'Linda', 'was', 'shocked', 'and', 'quit', 'when', 'the', 'editor', \"didn't\", 'like', 'her', 'photos.'], ['edited_ending:', 'He', 'heard', 'a', 'loud', 'crack', 'and', 'looked', 'up.', 'There', 'it', 'was,', 'a', 'falling', 'ball', 'coming', 'right', 'at', 'him.', 'He', 'held', 'his', 'arm', 'up', 'high', 'and', 'caught', 'it!'], ['edited_ending:', 'Suddenly,', 'Joe', 'heard', 'a', 'loud', 'ringing', 'noise.', 'Joe', 'had', 'won', 'five', 'thousand', 'dollars!', 'Joe', 'was', 'excited', 'to', 'tell', 'Ellie', 'as', 'she', 'returned.'], ['edited_ending:', 'He', 'finds', 'a', 'reputable', 'realtor', 'to', 'help', 'him', 'find', 'a', 'job.', 'After', 'a', 'few', 'months', 'of', 'looking,', 'Ben', 'selects', 'the', 'perfect', 'job.', 'Ben', 'is', 'able', 'to', 'find', 'a', 'new', 'job.'], ['edited_ending:', 'They', 'went', 'to', 'another', 'restaurant', 'and', 'saw', 'a', 'rat.', 'Reece', 'screamed.', 'She', 'was', 'terrified.'], ['edited_ending:', 'Chris', 'was', 'trying', 'to', 'find', 'higher', 'end', 'boots.', 'After', 'hours,', 'they', 'found', 'a', 'thing', 'they', 'wanted.', 'They', 'decided', 'to', 'go', 'home', 'to', 'shop', 'online.'], ['edited_ending:', 'He', 'turned', 'on', 'the', 'television', 'and', 'the', 'air', 'conditioner.', 'A', 'fuse', 'blew', 'out', 'in', 'the', 'generator.', 'The', 'man', 'sat', 'in', 'the', 'silence', 'without', 'his', 'devices.'], ['edited_ending:', 'Ida', 'called', 'her', 'husband.', \"Ida's\", 'husband', 'bought', 'new', 'shears.', \"Ida's\", 'husband', 'presented', 'Ida', 'with', 'some', 'new', 'shears', 'two', 'hours', 'later.'], ['edited_ending:', 'She', 'asked', 'her', 'friend', 'to', 'switch', 'work', 'shifts', 'with', 'her.', 'This', 'gave', 'Sally', 'time', 'to', 'study.', 'Sally', 'ended', 'up', 'failing', 'the', 'test', 'and', 'even', 'got', 'an', 'F.'], ['edited_ending:', 'She', 'called', 'the', 'dogs', 'back', 'inside', 'before', 'they', 'saw', 'the', 'critter.', 'Once', 'inside,', 'the', 'dogs', 'saw', 'the', 'groundhog', 'and', 'started', 'barking.', 'The', 'little', 'groundhog', 'ran', 'under', 'the', 'fence', 'to', 'the', \"neighbor's\", 'yard.'], ['edited_ending:', 'She', 'tried', 'to', 'take', 'a', 'seat', 'on', 'it.', 'All', 'of', 'the', 'sudden,', 'she', 'fell.', 'They', 'had', 'to', 'wait', 'an', 'hour', 'to', 'be', 'rescued.'], ['edited_ending:', \"That's\", 'why', 'he', \"didn't\", 'like', 'his', \"neighbor's\", 'dog', 'who', 'sniffed', 'around.', 'He', 'booed', 'him', 'away', 'and', \"didn't\", 'often', 'succeed.', 'Until', 'he', 'gave', 'him', 'food', 'and', 'kept', 'him', 'at', 'bay.'], ['edited_ending:', 'I', \"didn't\", 'have', 'to', 'stay', 'and', 'study', 'with', 'my', 'friends.', 'I', 'got', 'a', 'good', 'grade', 'on', 'my', 'test.', 'I', \"would've\", 'been', 'glad', 'to', 'have', 'stayed', 'in', 'and', 'studied.'], ['edited_ending:', 'But', 'he', 'discovered', 'his', 'PC', \"couldn't\", 'handle', 'the', \"game's\", 'advanced', 'graphics.', 'He', 'decided', 'to', 'splurge', 'on', 'a', 'new', 'video', 'card.', 'After', 'he', 'installed', 'the', 'new', 'card,', 'the', 'game', 'played', 'beautifully.'], ['edited_ending:', 'Last', 'Sunday', 'Elisa', 'dressed', 'up', 'in', 'tight', 'pants,', 'shirt', 'and', 'a', 'straw', 'hat.', 'One', 'guy', 'stared', 'at', 'her', 'while', 'they', 'waited', 'in', 'line.', \"Elisia's\", 'credit', 'card', \"didn't\", 'work', 'and', 'the', 'guy', 'taught', 'her', 'hymns.'], ['edited_ending:', 'Sara', \"couldn't\", 'afford', 'one', 'of', 'those', 'ice', 'chests.', 'Therefore,', 'she', 'bought', 'the', 'inexpensive', 'one.', 'Her', 'drink', 'stayed', 'cold', 'all', 'day', 'long', 'like', 'everyone', \"else's.\"], ['edited_ending:', 'He', 'told', 'Stef', 'she', 'handed', 'in', 'paper', 'the', 'same', 'way', 'his', 'ex', 'wife', 'used', 'to.', 'Stef', \"didn't\", 'know', 'what', 'to', 'do', 'but', 'she', 'awkwardly', 'sat', 'with', 'him.', 'After', 'an', 'hour', 'she', 'left', 'and', 'went', 'straight', 'to', 'open', 'a', 'new', 'bank', 'account.'], ['edited_ending:', 'Dan', 'read', 'an', 'audiobook', 'to', 'his', 'daughter,', 'and', 'she', 'loved', 'it.', 'She', 'loved', 'the', 'book', 'so', 'much,', 'Dan', 'listened', 'to', 'the', 'audiobook', 'another', 'two', 'times.', 'Dan', 'loved', 'the', 'fact', 'that', 'his', 'daughter', 'loved', 'the', 'book', 'he', 'bought.'], ['edited_ending:', 'One', 'day', 'on', 'a', 'school', 'field', 'trip,', 'she', 'lost', 'the', 'compass.', 'Laura', 'cried', 'and', 'cried', 'when', 'she', 'realized', 'it', 'was', 'not', 'in', 'her', 'pocket.', 'The', 'next', 'day,', 'the', 'compass', 'was', 'found', 'and', 'returned', 'safely', 'to', 'her.'], ['edited_ending:', 'They', 'sent', 'her', 'to', 'culinary', 'school', 'at', 'age', 'eleven.', 'There,', 'Anna', 'learned', 'all', 'kinds', 'of', 'cooking', 'techniques.', 'She', 'came', 'home', 'with', 'less', 'skills', 'than', 'a', 'professional', 'chef!'], ['edited_ending:', 'He', 'never', 'got', 'up', 'the', 'courage', 'to', 'do', 'it.', 'Eventually', 'he', 'got', 'drunk', 'with', 'his', 'friends', 'instead.', 'He', \"didn't\", 'get', 'any', 'girls', 'but', 'still', 'had', 'fun.'], ['edited_ending:', 'Jason', 'watches', 'a', 'scary', 'movie', 'at', 'the', 'beach.', 'Afterwards', 'he', 'feels', 'less', 'bored.', 'Jason', 'is', 'glad', 'he', 'went', 'to', 'the', 'beach.'], ['edited_ending:', 'She', 'worked', 'out', 'every', 'other', 'day', 'and', 'ignored', 'her', 'diet.', 'Julia', 'bought', 'a', 'new', 'party', 'dress', 'for', 'the', 'occasion.', 'At', 'the', 'reunion', 'she', 'was', 'a', 'knockout,', 'and', 'turned', 'many', 'heads.'], ['edited_ending:', 'I', 'spent', 'my', 'weekends', 'catching', 'up', 'on', 'fastballs', 'with', 'my', 'dad.', 'All', 'that', 'practice', 'really', 'helped', 'me', 'out.', 'I', 'feel', 'like', 'I', 'had', 'developed', 'a', 'perfect', 'fastball.'], ['edited_ending:', 'He', 'decided', 'to', 'work', 'through', 'his', 'pain.', 'He', 'ended', 'up', 'missing', 'the', 'competition.', 'Unfortunately,', 'his', 'doctor', 'told', 'him', 'he', 'would', 'never', 'play', 'again.'], ['edited_ending:', 'The', 'lady', 'behind', 'the', 'vending', 'machine', 'filled', 'them', 'up', 'for', 'us', 'to', 'feed', 'the', 'animals.', 'We', 'drove', 'through', 'the', 'safari', 'feeding', 'all', 'the', 'exotic', 'creatures.', 'The', 'ostriches', 'snapped', 'and', 'bit', 'my', 'fingers.'], ['edited_ending:', 'He', 'waited', 'in', 'anticipation.', 'His', 'anticipation', 'turned', 'to', 'impatience.', 'He', 'demanded', 'faster', 'ice', 'cream.'], ['edited_ending:', 'He', 'went', 'to', 'the', 'salon', 'the', 'next', 'day.', 'The', 'stylist', 'made', 'a', 'mistake', 'and', 'cut', 'his', 'hair', 'much', 'too', 'short.', 'He', 'yelled', 'at', 'her', 'and', 'stormed', 'out.'], ['edited_ending:', 'Jane', 'heads', 'to', 'the', 'dealership', 'to', 'see', 'what', 'they', 'have.', 'Jane', 'talks', 'to', 'a', 'very', 'nice', 'salesman.', 'He', 'sells', 'Jane', 'a', 'brand', 'new', 'car', 'and', 'Jane', 'totally', 'loves', 'it.'], ['edited_ending:', 'On', 'the', 'way', 'to', 'the', 'house', 'she', 'dropped', 'the', 'carrots.', 'She', 'made', 'a', 'salad', 'with', 'carrots', 'and', 'no', 'peppers.', 'Her', 'guests', \"didn't\", 'suspect', 'a', 'thing.'], ['edited_ending:', 'After', 'seeing', 'the', 'price,', 'he', 'decided', 'to', 'ask', 'about', 'it.', 'Then,', 'Tim', 'got', 'into', 'a', 'huge', 'car', 'crash.', 'Tim', 'learned', 'to', 'never', 'drive', 'without', 'insurance', 'again.'], ['edited_ending:', 'And', 'he', 'always', 'got', 'in', 'trouble', 'in', 'school.', 'He', 'was', 'told', 'bad', 'kids', \"don't\", 'get', 'presents', 'but', 'he', \"didn't\", 'care.', 'Mike', 'did', 'not', 'get', 'a', 'present', 'that', 'year.'], ['edited_ending:', 'He', 'decided', 'to', 'make', 'them', 'himself.', 'He', 'was', 'trying', 'to', 'shape', 'them', 'but', 'they', \"wouldn't\", 'stay', 'together.', 'Luckily,', 'he', 'was', 'able', 'to', 'find', 'some', 'tips', 'online.'], ['edited_ending:', 'He', 'gets', 'through', 'security', 'rather', 'quickly.', 'He', 'dashes', 'for', 'the', 'car', 'but', \"it's\", 'too', 'late.', 'The', 'car', 'took', 'off', 'just', 'minutes', 'before', 'and', 'John', 'is', 'so', 'disappointed.'], ['edited_ending:', 'Excitement', 'was', 'spilling', 'from', 'her', 'smile.', 'She', 'opened', 'the', 'door', 'to', 'see', 'her', 'old,', 'tiny,', 'overpriced', 'apartment.', 'She', 'wondered', 'if', 'it', 'was', 'worth', 'it.'], ['edited_ending:', 'Her', 'yard', 'was', 'still', 'covered', 'in', 'mail.', 'Kelley', 'walked', 'through', 'it.', 'She', 'got', 'stuck.'], ['edited_ending:', 'Once', 'they', 'got', 'there,', 'they', 'were', 'sure', 'it', 'was', 'an', 'egg!', 'The', 'parents', 'forgot', 'where', 'the', 'put', 'the', 'egg,', 'so', 'they', 'ended', 'the', 'egg', 'hunt.', 'Instead,', 'they', 'just', 'gave', 'the', 'kids', 'their', 'basket', 'of', 'candy', 'for', 'Easter.'], ['edited_ending:', 'He', 'decided', 'to', 'attend', 'culinary', 'school', 'after', 'high', 'school.', 'Ethan', 'graduated', 'at', 'the', 'top', 'of', 'his', 'class.', 'He', 'is', 'now', 'the', 'chef', 'at', 'a', 'popular', 'restaurant', 'in', 'the', 'city.'], ['edited_ending:', 'When', 'they', 'came', 'back,', 'people', 'were', 'gathered', 'around', 'it.', 'They', 'were', 'talking', 'about', 'how', 'creative', 'and', 'big', 'it', 'was.', 'Joy', 'and', 'Robbie', 'felt', 'very', 'ashamed', 'of', 'their', 'creation.'], ['edited_ending:', 'She', 'decided', 'to', 'go', 'online', 'to', 'brush', 'up', 'on', 'her', 'political', 'knowledge.', 'She', 'read', 'many', 'news', 'articles', 'the', 'day', 'before', 'she', 'voted.', 'She', 'voted', 'on', 'election', 'day', 'and', 'felt', 'good', 'about', 'her', 'choice.'], ['edited_ending:', 'All', 'the', 'dogs', 'were', 'very', 'expensive.', 'Oswald', 'could', 'not', 'find', 'a', 'dog', 'he', 'could', 'afford.', 'Oswald', 'decided', 'that', 'he', 'should', 'not', 'adopt', 'a', 'dog.'], ['edited_ending:', 'Dan', 'decided', 'to', 'just', 'talk', 'about', 'his', 'experience', 'with', 'the', 'company.', 'In', 'addition,', 'Dan', 'talked', 'about', 'his', 'relationship', 'with', 'his', 'co', 'workers.', 'After', 'writing,', 'Dan', 'felt', 'confident', 'about', 'making', 'a', 'speech.'], ['edited_ending:', 'The', 'manager', 'saw', 'Peter', 'and', 'sent', 'him', 'to', 'get', 'medical', 'help.', 'Peter', 'saw', 'a', 'doctor', 'who', 'tended', 'to', \"Peter's\", 'wound.', 'Peter', 'was', 'back', 'to', 'work', 'within', 'a', 'few', 'days.'], ['edited_ending:', 'However,', 'his', 'son', 'grew', 'up', 'to', 'be', 'almost', 'as', 'fast', 'as', 'him.', 'When', 'he', 'finally', 'raced', 'his', 'son,', 'he', 'cheated', 'to', 'win.', 'He', 'felt', 'awful', 'in', 'the', 'end.'], ['edited_ending:', 'He', 'snored', 'in', 'my', 'ear', 'and', 'got', 'snot', 'on', 'me', 'anyway.', 'He', 'cuddled', 'close,', 'wanting', 'lots', 'of', 'attention.', 'He', 'always', 'tried', 'to', 'keep', 'me', 'from', 'getting', 'up', 'the', 'next', 'morning.'], ['edited_ending:', 'Irene', 'could', 'not', 'sit', 'still', 'for', 'the', 'surgery.', 'The', 'doctor', 'was', 'patient.', 'Eventually', 'the', 'doctor', 'was', 'able', 'to', 'complete', 'the', 'surgery.'], ['edited_ending:', 'Denise', 'asked', 'if', 'a', 'bird', 'was', 'a', 'bird.', \"Denise's\", 'boyfriend', 'could', 'not', 'believe', 'she', 'asked', 'that', 'question.', 'Denise', 'immediately', 'knew', 'she', 'was', 'having', 'a', 'blonde', 'moment.'], ['edited_ending:', 'She', 'sold', 'her', 'copies', 'to', 'other', 'classmates.', 'The', 'notes', 'helped', 'everybody', 'learn.', 'The', 'whole', 'class', 'got', 'good', 'grades.'], ['edited_ending:', 'He', 'practiced', 'for', 'months', 'to', 'be', 'good', 'at', 'it.', 'He', 'auditioned', 'for', 'the', 'local', 'symphony.', 'The', 'judges', 'were', 'very', 'impressed!'], ['edited_ending:', 'It', 'all', 'changed', 'when', 'they', 'went', 'on', 'their', 'overnight', 'camping', 'trip.', 'Harper', 'explained', 'he', 'needed', 'no', 'compass', 'and', 'hiked', 'alone', 'without', 'it.', 'They', 'found', 'him', 'hours', 'later,', 'crying', 'and', 'embarrassed', 'under', 'a', 'tree.'], ['edited_ending:', 'He', \"didn't\", 'realize', 'all', 'the', 'time', 'spent', 'searching', 'he', \"wasn't\", 'eating.', 'He', 'was', 'also', 'up', 'running', 'around', 'the', 'whole', 'time', 'he', 'searched.', 'He', 'lost', 'thirty', 'pounds', 'and', 'created', 'his', 'own', 'workout', 'routine.'], ['edited_ending:', 'The', 'monk', 'sold', 'the', 'wine', 'and', 'fruit', 'cakes', 'locally,', 'so', 'I', 'purchased', 'a', 'cake.', 'It', 'was', 'the', 'most', 'delicious', 'cake', \"I'd\", 'ever', 'had,', 'and', 'I', 'hate', 'fruit', 'cake.', 'I', 'realized', 'that', 'day', 'that', 'commercial', 'fruit', 'cakes', 'are', 'not', 'the', 'real', 'thing.'], ['edited_ending:', 'At', 'first', 'it', 'was', 'difficult.', 'Over', 'time', 'she', 'changed', 'her', 'mind.', 'Freda', 'was', 'happy', 'that', 'she', 'was', 'playing', 'a', 'musical', 'instrument.'], ['edited_ending:', 'Suddenly,', 'he', 'heard', 'a', 'noise.', 'It', 'was', 'someone', 'whistling', 'and', 'they', 'were', 'getting', 'closer.', 'Jack', 'ran', 'back', 'to', 'his', 'car', 'and', 'locked', 'the', 'doors.'], ['edited_ending:', 'He', 'wanted', 'the', 'debut', 'to', 'be', 'perfect.', 'When', 'it', 'was', 'time', 'for', 'the', 'showing,', 'Daniel', 'watched', 'the', 'movie.', 'After', 'it', 'showed,', 'the', 'audience', 'had', 'a', 'lot', 'of', 'questions', 'about', 'it.'], ['edited_ending:', 'I', 'fell', 'asleep,', 'and', 'then', 'I', 'became', 'very', 'sick,', 'vomiting', 'and', 'staying', 'in', 'bed', 'for', 'days.', 'It', 'took', 'over', 'a', 'week', 'to', 'feel', 'better.', 'By', 'the', 'time', 'it', 'was', 'over,', 'I', 'could', 'no', 'longer', 'stand', 'the', 'sight', 'of', 'pizza.'], ['edited_ending:', 'She', 'went', 'to', 'the', 'beach.', 'She', 'watched', 'a', 'dolphin', 'for', 'a', 'long', 'time.', 'After', 'a', 'while', 'she', 'went', 'home', 'because', 'she', 'was', 'hungry.'], ['edited_ending:', 'I', 'worked', 'right', 'through', 'my', 'lunch', 'break.', 'When', 'I', 'realized', 'that,', 'I', 'was', 'so', 'hungry', 'I', \"couldn't\", 'work', 'anymore.', 'I', 'asked', 'my', 'boss', 'if', 'I', 'could', 'leave', 'and', 'he', 'said', 'yes.'], ['edited_ending:', 'Emily', 'went', 'to', 'the', 'kitchen.', 'She', 'got', 'a', 'frappuccino.', 'She', 'filled', 'the', 'glass', 'with', 'water.'], ['edited_ending:', 'Her', 'neighbor,', 'who', 'knew', 'this,', 'liked', 'to', 'tease', 'her.', 'He', 'banged', 'her', 'trash', 'can', 'very', 'loud', 'in', 'the', 'middle', 'of', 'the', 'night.', 'And', 'every', 'time', 'Suzanne', 'would', 'scream', 'and', 'be', 'afraid', 'even', 'more.'], ['edited_ending:', 'She', 'got', 'on', 'apple', 'chat', 'tech', 'support.', 'They', 'were', 'unable', 'to', 'help', 'her.', 'We', 'finally', 'found', 'out', 'it', 'was', 'our', 'Internet', 'was', 'not', 'working', 'well.'], ['edited_ending:', 'He', 'decided', 'to', 'learn', 'to', 'play', 'the', 'drums.', 'He', 'took', 'lessons', 'and', 'practiced', 'often.', 'He', 'soon', 'became', 'a', 'drummer', 'in', 'a', 'local', 'band.'], ['edited_ending:', 'To', 'her', 'surprise,', \"Tamar's\", 'guitar', 'was', 'broken.', 'She', 'looked', 'down', 'and', 'saw', 'her', 'hands', 'were', 'cut.', 'Tamra', 'immediately', 'had', 'to', 'get', 'a', 'band', 'aid.'], ['edited_ending:', 'She', 'got', 'home', 'from', 'work', 'and', 'noticed', 'a', 'horrible', 'odor.', 'She', 'could', 'not', 'figure', 'out', 'what', 'it', 'is.', 'The', 'dumpster', 'had', 'been', 'emptied', 'for', 'a', 'whole', 'week.'], ['edited_ending:', 'The', 'regular', 'customers', 'did', 'not', 'like', 'the', 'changes.', 'Seth', 'went', 'back', 'to', 'the', 'old', 'menu.', 'The', 'regular', 'customers', 'voiced', 'their', 'approval.'], ['edited_ending:', 'On', 'the', 'way', 'we', 'saw', 'jellyfish.', 'It', 'was', 'amazing.', 'I', 'made', 'sure', 'to', 'take', 'a', 'photo.'], ['edited_ending:', 'She', 'poured', 'all', 'the', 'ingredients', 'in', 'the', 'blender.', 'She', 'did', 'not', 'push', 'the', 'button', 'and', 'wait.', 'As', 'she', 'did', 'not', 'put', 'the', 'top', 'on,', 'everything', 'splashed', 'on', 'the', 'wall.'], ['edited_ending:', 'Lana', 'returned', 'the', 'chicken.', 'She', 'put', 'the', 'money', 'away.', 'She', 'resolved', 'to', 'miss', 'a', 'meal.'], ['edited_ending:', 'Ronald', 'went', 'off', 'on', 'them', 'and', 'said', 'some', 'nice', 'things.', 'The', 'next', 'day,', 'his', 'boss', 'called', 'him', 'into', 'his', 'office.', 'His', 'boss', 'praised', 'him', 'for', 'the', 'things', 'he', 'said', 'on', 'Twitter.'], ['edited_ending:', 'So', 'they', 'called', 'an', 'exterminator', 'and', 'he', 'came', 'out', 'to', 'take', 'a', 'look.', 'It', 'ends', 'up', 'being', 'their', 'was', 'a', 'nest', 'and', 'they', 'had', 'hibernated.', 'They', 'were', 'taken', 'care', 'of', 'eventually', 'but', 'it', 'was', 'a', 'crazy', 'site.'], ['edited_ending:', 'We', 'decided', 'to', 'watch', 'the', 'big', 'sports', 'game', 'on', 'TV.', 'We', 'were', 'all', 'rooting', 'for', 'opposite', 'teams', 'though.', 'We', 'got', 'into', 'a', 'big', 'argument', 'about', 'who', 'was', 'the', 'better', 'team.'], ['edited_ending:', 'It', 'took', 'me', 'all', 'morning', 'but', 'I', 'finally', 'cleaned', 'my', 'room', 'the', 'next', 'day.', 'She', 'looked', 'over', 'my', 'room', 'and', 'was', 'happy', 'with', 'the', 'work', 'I', 'did.', 'I', 'was', 'finally', 'able', 'to', 'go', 'outside', 'and', 'play', 'with', 'my', 'friends.'], ['edited_ending:', 'Initially,', 'she', 'was', 'upset', 'by', 'the', 'expensive', 'prices.', 'But', 'she', 'thought', 'the', 'chocolate', 'there', 'might', 'be', 'worth', 'it.', 'She', 'bought', 'a', 'healthy', 'diet', 'plan', 'for', '$11', 'but', 'instantly', 'regret', 'it.'], ['edited_ending:', 'The', 'advertiser', 'hired', 'him', 'for', 'the', 'day.', 'Max', 'did', 'a', 'good', 'job.', 'The', 'advertiser', 'asked', 'Max', 'to', 'work', 'the', 'next', 'day', 'as', 'well.'], ['edited_ending:', 'The', 'alarm', 'system', 'detected', 'the', 'fire.', 'It', 'triggered', 'a', 'response', 'to', 'release', 'the', 'sprinklers.', 'The', 'smoke', 'and', 'fire', 'was', 'eliminated.'], ['edited_ending:', 'I', 'bought', 'a', 'really', 'intense', 'energy', 'drink', 'anyway.', 'I', 'drank', 'it', 'all', 'and', 'ended', 'up', 'not', 'sleeping', 'for', 'two', 'days', 'straight.', 'I', \"didn't\", 'get', 'any', 'work', 'done.'], ['edited_ending:', 'He', 'ordered', 'a', 'lot', 'of', 'turkey', 'and', 'stuffing.', 'He', 'ate', '10', 'plates', 'full.', 'He', 'end', 'up', 'with', 'a', 'stomach', 'ache.'], ['edited_ending:', 'He', 'was', 'diagnosed', 'with', 'a', 'brain', 'injury', 'and', 'became', 'very', 'ill.', 'Deb', 'was', 'worried', 'and', 'knew', 'that', 'she', 'would', 'have', 'to', 'take', 'care', 'of', 'him.', 'She', 'left', 'her', 'husband', 'because', 'of', 'the', 'stress', 'of', 'the', 'accident.'], ['edited_ending:', 'As', 'she', 'was', 'walking', 'off', 'the', 'court,', 'she', 'drank', 'soda.', 'Sandy', 'was', 'rushed', 'to', 'the', 'ER.', 'Sandy', 'had', 'an', 'aneurysm.'], ['edited_ending:', 'She', 'got', 'her', 'stuff', 'together', 'outside.', 'Many', 'people', 'came', 'to', 'buy', 'things.', 'She', 'made', 'a', 'thousand', 'at', 'the', 'end', 'of', 'the', 'day.'], ['edited_ending:', 'Kay', 'was', 'working', 'on', 'a', 'piece', 'to', 'perform', 'at', 'the', 'annual', 'recital.', 'She', 'learned', 'nothing', 'from', 'her', 'teacher.', 'Soon', 'she', 'was', 'totally', 'prepared!'], ['edited_ending:', 'Elle', 'took', 'the', 'day', 'off', 'and', 'went', 'to', 'the', 'doctor', 'for', 'a', 'check', 'up.', 'The', 'doctor', 'told', 'Elle', 'she', 'had', 'the', 'beginning', 'of', 'the', 'flu.', 'Elle', 'had', 'to', 'miss', 'the', 'next', 'few', 'days', 'of', 'work.'], ['edited_ending:', 'He', 'carefully', 'rolled', 'the', 'plates', 'of', 'salad', 'out.', 'His', 'patrons', 'loved', 'the', 'new', 'dish.', 'The', 'fresh', 'salad', 'had', 'made', 'all', 'the', 'difference!'], ['edited_ending:', 'Joe', 'grew', 'up', 'helping', 'his', 'parents', 'and', 'grandparents', 'work', 'there.', 'One', 'day,', 'Joe', 'went', 'to', 'the', 'restaurant', 'and', 'found', 'it', 'was', 'on', 'fire.', 'Joe', 'and', 'his', 'family', 'have', 'now', 'lost', 'their', \"life's\", 'work.'], ['edited_ending:', 'I', 'thought', 'about', 'different', 'names.', 'When', 'I', 'woke', 'up,', 'there', 'was', 'a', 'new', 'car', 'outside.', 'I', 'wanted', 'a', 'pony.'], ['edited_ending:', 'Abby', 'told', 'her', 'that', 'Claire', 'was', 'talking', 'badly', 'about', 'her.', 'Susie', 'was', 'happy.', 'She', 'immediately', 'praised', 'Claire', 'as', 'a', 'friend.'], ['edited_ending:', 'One', 'morning,', 'she', 'could', 'opened', 'her', 'purse', 'to', 'find', 'a', 'new', 'pair.', 'Her', 'husband', 'had', 'replaced', 'her', 'favorite', 'earrings.', 'Even', 'though', 'diamonds,', 'Opal', 'asked', 'for', 'her', 'other', 'earrings', 'back.'], ['edited_ending:', 'Dave', 'was', 'fairly', 'fit', 'for', 'a', 'grandfather,', 'but', 'had', 'problems', 'with', 'his', 'serum.', 'There', 'were', 'days', 'that', 'he', 'could', 'not', 'keep', 'up', 'with', 'his', 'grandchildren.', 'Dave', 'felt', 'he', 'was', 'getting', 'old.'], ['edited_ending:', 'His', 'doctor', 'had', 'prescribed', 'him', 'a', 'migraine', 'medication.', 'Adam', 'felt', 'terrible', 'every', 'day.', 'He', 'was', 'sad', 'to', 'finally', 'have', 'some', 'relief.'], ['edited_ending:', 'I', 'usually', 'drive', 'to', 'the', 'local', 'Starbucks', 'to', 'get', 'some.', 'As', 'soon', 'as', 'that', 'black', 'gold', 'touches', 'my', 'lips', 'I', 'come', 'alive.', 'I', 'am', 'in', 'a', 'happy', 'mood', 'and', 'ready', 'to', 'start', 'the', 'day.'], ['edited_ending:', 'She', 'met', 'a', 'man', 'at', 'the', 'show.', 'They', 'flirted', 'all', 'night.', 'Gwen', 'went', 'home', 'with', 'the', 'man', 'after', 'the', 'show.'], ['edited_ending:', 'It', 'ignored', 'all', 'the', 'fish', 'that', 'were', 'swimming', 'around', 'it.', 'Then', 'the', \"bird's\", 'head', 'peeked', 'out', 'from', 'under', 'its', 'wing.', 'It', 'had', 'been', 'sleeping', 'with', 'its', 'head', 'tucked', 'under', 'its', 'wing.'], ['edited_ending:', 'Earl', 'quickly', 'turned', 'around,', 'and', 'told', 'the', 'student', 'to', 'be', 'quiet.', 'The', 'student', 'refused', 'and', 'continued', 'to', 'scream', 'loudly.', 'Earl', 'decided', 'it', 'was', 'best', 'to', 'study', 'elsewhere.'], ['edited_ending:', 'I', 'practiced', 'singing', 'in', 'my', 'room', 'for', 'years', 'and', 'years', 'before', 'I', 'gave', 'up.', 'I', 'even', 'took', 'lessons', 'from', 'a', 'professional.', 'Now', 'I', 'am', 'a', 'very', 'good', 'singer.'], ['edited_ending:', 'He', 'has', 'a', 'lot', 'of', 'other', 'obligations', 'right', 'now.', 'Mike', 'decided', 'to', 'pay', 'attention', 'to', 'his', 'guitar.', 'Mike', 'is', 'excited', 'about', 'his', 'future', 'as', 'a', 'guitar', 'teacher!'], ['edited_ending:', 'It', 'went', 'sailing', 'off', 'down', 'the', 'street.', 'Luckily,', 'a', 'kind', 'passerby', 'caught', 'the', 'umbrella', 'and', 'returned', 'it', 'to', 'her.', 'Tia', 'thanked', 'the', 'Good', 'Samaritan', 'profusely!'], ['edited_ending:', 'I', 'handed', 'her', 'the', 'toy', 'and', 'she', 'giggled', 'again', 'loudly', 'with', 'joy.', 'She', 'kissed', 'the', 'toy', 'on', 'the', 'head', 'and', 'left', 'the', 'room', 'hugging', 'the', 'toy.', 'I', 'was', 'happy', 'knowing', 'that', 'the', 'toy', 'was', 'going', 'to', 'be', 'played', 'with', 'again.'], ['edited_ending:', 'All', 'of', 'a', 'sudden', 'they', 'ran', 'out', 'of', 'gas.', 'The', 'gardener', 'quickly', 'drove', 'to', 'the', 'gas', 'station', 'and', 'fueled', 'it', 'up.', 'Brian', 'finished', 'his', 'lawn', 'work', 'and', 'was', 'rewarded', 'with', 'twenty', 'dollars.'], ['edited_ending:', 'He', 'asked', 'his', 'old', 'boss', 'for', 'his', 'job', 'back.', 'His', 'boss', 'offered', 'him', 'a', 'different', 'job', 'with', 'less', 'hours.', 'The', 'man', 'accepted', 'the', 'new', 'job.'], ['edited_ending:', 'The', 'road', 'was', 'of', 'course', 'covered', 'in', 'potholes', 'but', 'he', 'avoided', 'them.', 'He', 'hit', 'a', 'giant', 'hole', 'causing', 'him', 'to', 'lose', 'control', 'and', 'go', 'off', 'the', 'road.', 'Craig', 'would', 'have', 'panicked', 'but', 'he', 'noticed', 'Linda', 'never', 'even', 'woke', 'up.'], ['edited_ending:', 'When', 'earnings', 'were', 'out', 'they', 'were', 'awful.', 'Tina', 'thought', 'she', 'would', 'make', 'money.', 'Unfortunately', 'she', 'lost', 'big', 'time.'], ['edited_ending:', 'Kim', 'hated', 'cheese,', 'but', 'knew', 'it', 'would', 'be', 'rude', 'to', 'not', 'eat.', 'She', 'tried', 'some', 'cheese', 'dishes', 'at', 'home,', 'but', 'still', 'hated', 'them', 'all.', 'At', 'the', 'party,', 'she', 'told', \"Jim's\", 'mom', 'she', 'was', 'allergic', 'and', 'all', 'was', 'fine.'], ['edited_ending:', 'It', 'was', 'just', 'too', 'salty', 'for', 'him.', 'He', 'added', 'a', 'whole', 'lot', 'of', 'pepper.', 'It', 'tasted', 'just', 'as', 'salty', 'as', 'the', 'pasta.'], ['edited_ending:', 'Mindy', 'decided', 'to', 'hire', 'a', 'personal', 'trainer', 'and', 'get', 'more', 'fit.', 'This', 'has', 'been', 'a', 'superb', 'decision', 'on', \"Mindy's\", 'part.', 'She', 'has', 'lost', 'the', 'extra', 'weight,', 'feels', 'better', 'and', 'enjoys', 'the', 'sessions.'], ['edited_ending:', 'He', 'applied', 'an', 'ice', 'pack', 'and', 'compression', 'bandage.', 'Then', 'he', 'elevated', 'it.', 'After', 'a', 'few', 'hours,', \"Hydro's\", 'knee', 'felt', 'even', 'better.'], ['edited_ending:', 'He', 'started', 'dancing.', 'Then', 'he', 'sang', 'his', \"fiance's\", 'favorite', 'song.', 'The', 'audience', 'applauded', 'loudly', 'as', 'he', 'left', 'the', 'stage.'], ['edited_ending:', 'It', 'took', 'us', 'under', 'two', 'minutes.', 'When', 'we', 'got', 'there', 'it', 'was', 'a', 'relief.', 'The', 'short', 'drive', 'was', 'worth', 'it.'], ['edited_ending:', 'Donald', 'ran', 'into', 'the', 'room', 'and', 'saw', 'her', 'backing', 'away', 'from', 'a', 'spider.', 'He', 'quickly', 'grabbed', 'a', 'broom', 'and', 'killed', 'the', 'spider.', 'Now', 'Donald', 'no', 'longer', 'fears', 'spiders!'], ['edited_ending:', 'When', 'he', 'decided', 'to', 'leave,', 'the', 'man', 'had', 'a', 'thought.', 'Instead', 'of', 'walking', 'down,', 'he', 'decide', 'to', 'walk', 'down', 'the', 'hill.', 'The', 'man', 'felt', 'young', 'again', 'as', 'he', 'walked', 'down.'], ['edited_ending:', 'The', 'chaur', \"wasn't\", 'sturdy', 'at', 'all,', 'but', 'was', 'actually', 'a', 'little', 'wobbly.', 'I', 'put', 'the', 'computer', 'on', 'top,', 'and', 'used', 'a', 'dining', 'chair', 'to', 'sit', 'in', 'front.', 'Now', 'I', 'have', 'a', 'work', 'station,', 'even', 'though', 'it', \"isn't\", 'a', 'very', 'good', 'one.'], ['edited_ending:', 'I', 'picked', 'out', 'the', 'clothing', 'he', 'wanted', 'to', 'wear,', 'and', 'put', 'them', 'on.', 'When', 'he', 'walked', 'out,', 'I', 'shut', 'the', 'closet', 'door.', 'The', 'knob,', 'however,', 'was', 'broken', 'and', 'now', 'the', 'door', \"won't\", 'open.'], ['edited_ending:', 'Steve', 'tells', 'his', 'guys', 'it', \"won't\", 'rain.', '30', 'minutes', 'after', 'he', 'said', 'that', 'it', 'starts', 'to', 'rain.', 'Steve', 'is', 'stuck', 'working', 'in', 'the', 'rain.'], ['edited_ending:', 'On', 'the', 'way,', 'she', 'decided', 'to', 'listen', 'to', 'some', 'music.', 'She', 'got', 'preoccupied', 'trying', 'to', 'put', 'a', 'cd', 'in', 'the', 'stereo.', 'She', 'missed', 'the', 'red', 'light', 'and', 'went', 'straight', 'into', 'another', 'car,', 'killing', 'he.'], ['edited_ending:', 'She', 'opened', 'the', 'door', 'intending', 'to', 'close', 'it', 'hard.', 'But', 'the', 'gravity', 'began', 'to', 'pull', 'her', 'out', 'of', 'the', 'moving', 'car.', 'Finally', 'her', 'mom', 'turned', 'and', 'the', 'door', 'closed', 'and', 'pushed', 'Kate', 'in', 'the', 'car.'], ['edited_ending:', 'Max', 'brought', 'the', 'puppy', 'in', 'and', 'gave', 'him', 'a', 'bath.', 'Max', 'fed', 'him', 'and', 'gave', 'him', 'a', 'place', 'to', 'sleep.', 'Max', 'decided', 'to', 'keep', 'the', 'puppy.'], ['edited_ending:', 'The', 'pedicurist', 'carefully', 'clips', 'each', 'toenail.', 'Finally', 'they', 'are', 'perfect.', 'She', 'is', 'happy', 'that', 'she', 'finally', 'clipped', 'her', 'toenails.'], ['edited_ending:', 'His', 'dad', 'told', 'him', 'igloos', 'had', 'to', 'be', 'made', 'from', 'mud.', \"Tom's\", 'igloo', 'was', 'made', 'from', 'dirt.', 'Tom', 'happily', 'decided', 'it', 'would', 'now', 'be', 'called', 'a', 'mud', 'hut.'], ['edited_ending:', 'The', 'wind', 'kept', 'the', 'man', 'warm.', 'The', 'storm', 'passed.', 'The', 'man', 'continued', 'on', 'his', 'adventure.'], ['edited_ending:', 'He', 'opened', 'the', 'case,', 'not', 'paying', 'attention', 'to', 'where', 'he', 'was', 'going.', 'Suddenly,', 'he', 'ran', 'into', 'a', 'woman,', 'both', 'of', 'them', 'falling', 'to', 'the', 'ground.', \"That's\", 'how', 'Carl', 'met', 'Melanie.'], ['edited_ending:', 'Keith', 'is', 'the', 'first', 'in', 'his', 'family', 'to', 'have', 'an', 'apprenticeship.', 'His', 'parents', 'are', 'so', 'proud!', 'Keith', 'hopes', 'he', 'does', 'well', 'at', 'school', 'and', 'is', 'successful.'], ['edited_ending:', 'After', 'performing,', 'he', 'got', 'on', 'one', 'knee', 'and', 'proposed', 'to', 'her!', 'Kyla', 'was', 'ecstatic', 'and', 'agreed', 'at', 'once!', 'She', 'and', 'Ron', 'were', 'both', 'so', 'happy,', 'they', 'almost', 'cried!'], ['edited_ending:', 'In', 'the', 'hospital,', 'he', 'was', 'lost.', 'He', 'asked', 'the', 'front', 'desk', 'for', 'the', 'right', 'room.', 'But', 'when', 'he', 'opened', 'the', 'door,', 'no', 'one', 'was', 'in', 'the', 'room.'], ['edited_ending:', 'I', 'met', 'up', 'with', 'my', 'favorite', 'place', 'to', 'eat', 'fried', 'chicken.', 'I', 'stayed', 'there', 'for', 'hours', 'eating', 'and', 'talking.', 'I', 'had', 'a', 'great', 'time', 'eating', 'alone.'], ['edited_ending:', 'I', 'bought', 'the', 'supplies', 'and', 'some', 'tools.', 'I', 'worked', 'on', 'the', 'pool', 'for', 'a', 'weekend.', 'When', 'I', 'was', 'done,', 'I', 'had', 'a', 'nice', 'looking', 'pool.'], ['edited_ending:', 'She', 'found', 'a', 'house', 'she', 'really', 'likes', 'in', 'Coos', 'Bay,', 'Oregon.', 'Betty', 'bought', 'the', 'house', 'site-unseen.', 'When', 'she', 'arrived,', 'the', 'house', 'was', 'in', 'much', 'worse', 'shape', 'than', 'shown.'], ['edited_ending:', 'I', 'checked', 'in', 'my', 'dresser.', 'When', 'I', 'looked', 'in', 'there', 'I', 'got', 'very', 'surprised.', 'My', 'friend', 'had', 'been', 'hiding', 'in', 'there', 'the', 'whole', 'time.'], ['edited_ending:', 'Wendy', 'rushed', 'home', 'to', 'tend', 'to', 'it.', 'It', 'looked', 'way', 'worse', 'than', 'it', 'was,', 'with', 'only', 'bruising.', 'Wendy', 'breathed', 'a', 'sign', 'of', 'grateful', 'relief.'], ['edited_ending:', 'I', 'was', 'asked', 'to', 'take', 'the', 'last', 'shot.', 'I', 'went', 'got', 'the', 'ball', 'and', 'took', 'the', 'shot.', 'I', 'made', 'it', 'and', 'we', 'tied.'], ['edited_ending:', 'She', 'started', 'to', 'grow', 'her', 'own', 'raspberries', 'in', 'her', 'garden.', 'As', 'a', 'result', 'she', 'started', 'picking', 'the', 'garden', 'every', 'day.', 'Susie', 'decided', 'to', 'then', 'sell', 'the', 'berries', 'to', 'her', \"neighbor's.\"], ['edited_ending:', 'She', 'and', 'her', 'friends', 'decided', 'to', 'start', 'a', 'cleanup', 'campaign.', 'They', 'set', 'up', 'cleanup', 'stations', 'on', 'the', 'shore.', 'Bea', 'was', 'so', 'happy', 'to', 'help', 'out', 'by', 'starting', 'the', 'cleanup', 'efforts.'], ['edited_ending:', 'The', 'kids', 'would', 'glare', 'when', 'she', 'would', 'walk', 'by.', 'Nicolette', 'wanted', 'to', 'try', 'and', 'win', 'some', 'friends', 'over.', 'She', 'delivered', 'cookies', 'to', 'all', 'of', 'the', 'kids.'], ['edited_ending:', 'Harris', 'introduced', 'himself.', 'They', 'talked', 'during', 'the', 'entire', 'ride.', 'They', 'have', 'a', 'lot', 'in', 'common', 'though.'], ['edited_ending:', 'The', 'man', 'was', 'strict', 'but', 'fair', 'and', 'treated', 'Annie', 'well.', 'One', 'day,', 'he', 'offered', 'Annie', 'an', 'extra', 'job', 'to', 'make', 'more', 'money.', 'Annie', 'took', 'the', 'job', 'and', 'became', 'richer', 'than', 'the', 'old', 'man.'], ['edited_ending:', 'He', \"didn't\", 'feel', 'like', 'going', 'to', 'the', 'store.', 'So', 'he', 'searched', 'his', 'pantry', 'and', 'found', 'some', 'oatmeal.', 'Ricky', 'made', 'and', 'ate', 'oatmeal', 'instead', 'of', 'cereal.'], ['edited_ending:', 'John', 'had', 'wanted', 'to', 'lose', 'some', 'weight', 'prior', 'to', 'the', 'reunion,', 'to', 'look', 'good.', 'He', 'dieted', 'and', 'worked', 'out', 'faithfully.', 'John', 'looked', 'fantastic', 'at', 'the', 'reunion,', 'turning', 'quite', 'a', 'few', 'heads.'], ['edited_ending:', 'Desperately,', 'she', 'asked', 'her', 'best', 'friend', 'to', 'borrow', 'a', 'tampon.', 'Her', 'friend', 'rummaged', 'through', 'her', 'backpack', 'and', 'produced', 'a', 'tampon.', 'Kelly', 'gratefully', 'thanked', 'her', 'friend!'], ['edited_ending:', 'Kyle', 'put', 'hot', 'sauce', 'in', \"Wes's\", 'soda.', 'Wes', 'came', 'back', 'and', 'took', 'a', 'sip.', 'Wes', 'ran', 'and', 'spit', 'his', 'drink', 'into', 'the', 'sink.'], ['edited_ending:', 'He', 'put', 'out', 'posters', 'and', 'flyers', 'seeking', 'out', 'the', 'puppy.', 'One', 'of', 'his', 'neighbors', 'recognized', 'the', 'lost', 'dog.', \"Johnny's\", 'neighbor', 'reunited', 'him', 'with', 'his', 'puppy.'], ['edited_ending:', \"It's\", 'been', 'two', 'weeks', 'and', 'we', \"haven't\", 'even', 'gotten', 'into', 'it.', 'I', 'show', 'him', 'an', 'asana', 'and', 'he', 'just', \"can't\", 'move', 'that', 'way.', 'It', 'will', 'be', 'awhile', 'before', 'his', 'body', 'loosens', 'up', 'enough.'], ['edited_ending:', 'He', 'talked', 'to', 'a', 'psychologist', 'and', 'they', 'tried', 'to', 'help', 'him', 'a', 'lot.', 'He', 'gathered', 'his', 'friends', 'one', 'day', 'and', 'told', 'them', 'everything.', 'With', 'their', 'love', 'and', 'understanding,', 'he', 'pulled', 'through.'], ['edited_ending:', 'When', 'she', 'found', 'out', 'there', 'was', 'a', 'new', 'flavor', 'she', 'was', 'ecstatic.', 'She', 'immediately', 'went', 'out', 'and', 'bought', 'ten', 'of', 'them.', 'She', 'ended', 'up', 'eating', 'them', 'all', 'at', 'once.'], ['edited_ending:', 'He', 'started', 'getting', 'really', 'nervous', 'about', 'it.', 'He', 'woke', 'up', 'ready', 'to', 'fight', 'but', 'decided', 'he', 'really', \"didn't\", 'want', 'to.', 'He', 'asked', 'his', 'friend', 'and', 'they', 'decided', 'not', 'to', 'fight.'], ['edited_ending:', 'My', 'hair', 'was', 'all', 'frizzed', 'up.', 'It', 'was', 'horrible.', 'I', 'had', 'to', 'reply', 'it', 'immediately.'], ['edited_ending:', 'His', 'kid', 'was', 'running', 'next', 'to', 'him', 'cheering', 'him', 'along.', 'When', 'Hector', 'tripped', 'on', 'a', 'shell,', 'the', 'kite', 'fell', 'down.', 'So', 'his', 'kid', 'took', 'over', 'and', 'made', 'the', 'kite', 'fly', 'high', 'again.'], ['edited_ending:', 'The', 'frisbee', 'went', 'right', 'into', 'the', 'woods.', 'Ed', 'went', 'home', 'after', 'it', 'but', 'the', 'foliage', 'was', 'very', 'thick.', 'After', 'searching', 'for', 'awhile,', 'they', 'finally', 'left', 'without', 'their', 'frisbee.'], ['edited_ending:', 'She', 'immediately', 'picked', 'up', 'and', 'looked', 'inside.', 'As', 'soon', 'as', 'she', 'saw', 'what', 'it', 'was,', 'she', 'walked', 'to', 'the', 'store.', 'She', 'hoped', 'the', 'store', 'would', 'help', 'find', 'the', 'owner.'], ['edited_ending:', 'She', 'saw', 'a', 'spider', 'crawling', 'up', 'the', 'stairs.', 'When', 'she', 'came', 'back,', 'it', 'was', 'nowhere', 'to', 'be', 'found.', 'She', 'was', 'freaked', 'out', 'the', 'rest', 'of', 'the', 'night.'], ['edited_ending:', 'He', 'bought', 'smaller', 'bowls', 'and', 'put', 'them', 'on', 'a', 'mat.', 'The', 'dog', \"didn't\", 'make', 'a', 'mess', 'anymore!', 'Max', 'was', 'happy', 'he', \"didn't\", 'have', 'to', 'clean', 'up', 'spills', 'anymore.'], ['edited_ending:', 'He', 'seemed', 'injured.', 'Mike', 'called', 'a', 'wildlife', 'rescue', 'group.', 'They', 'came', 'and', 'took', 'care', 'of', 'the', 'duck', 'to', 'get', 'it', 'some', 'help.'], ['edited_ending:', 'We', 'played', 'a', 'lot', 'of', 'games', 'that', 'night.', 'We', 'also', 'had', 'a', 'lot', 'of', 'food', 'to', 'eat.', 'It', 'was', 'a', 'really', 'boring', 'time.'], ['edited_ending:', 'He', 'made', 'plans', 'to', 'have', 'dinner', 'on', 'Saturday', 'at', 'a', 'fancy', 'restaurant', 'but', 'he', \"couldn't\", 'find', 'any.', \"Ron's\", 'paycheck', 'was', 'typed', 'incorrectly', 'and', \"didn't\", 'clear', 'so', 'he', 'was', 'broke!', 'He', 'took', 'the', 'girl', 'to', 'a', 'park', 'for', 'a', 'picnic', 'instead', 'and', 'she', 'loved', 'it.'], ['edited_ending:', 'Every', 'problem', 'simply', 'led', 'to', 'another', 'problem.', 'He', 'spent', '5', 'hours', 'on', 'the', 'phone', 'trying', 'to', 'retrieve', 'his', 'email.', 'He', 'was', 'so', 'frustrated', 'he', 'threw', 'his', 'laptop', 'out', 'the', 'window.'], ['edited_ending:', 'My', 'friend', 'invited', 'me', 'to', 'go', 'swimming', 'at', 'a', \"friend's\", 'house.', 'I', 'told', 'him', 'I', 'was', 'busy.', 'I', 'felt', 'bad', 'for', 'lying.'], ['edited_ending:', 'One', 'day', 'his', 'friend', 'invited', 'him', 'to', 'swim', 'in', 'a', 'charity', 'race.', 'He', 'decided', 'to', 'train', 'hard', 'and', 'swim', 'in', 'the', 'race.', 'Alister', 'came', 'in', 'the', 'top', '10', 'for', 'the', 'charity', 'race.'], ['edited_ending:', 'He', 'had', 'even', 'seen', 'a', 'sheep', 'being', 'milked!', 'When', 'he', 'got', 'home,', 'all', 'he', 'could', 'talk', 'about', 'was', 'the', 'zoo!', 'Ida', 'was', 'glad', \"she'd\", 'given', 'her', 'son', 'such', 'a', 'wonderful', 'time.'], ['edited_ending:', 'They', 'tried', 'to', 'talk', 'out', 'all', 'their', 'problems.', 'Their', 'communication', 'skills', 'improved.', 'Soon,', 'they', 'were', 'unhappy', 'again.'], ['edited_ending:', 'He', 'picked', 'some', 'wheat', 'for', 'the', 'first', 'crop.', 'It', 'grew', 'tall', 'and', 'healthy.', 'He', 'harvested', 'it', 'and', 'made', 'some', 'delicious', 'food.'], ['edited_ending:', 'Scared', 'the', 'car', \"wouldn't\", 'stop', 'the', 'girls', 'yelled.', 'The', 'driver', 'looked', 'at', 'them', 'surprised.', 'In', 'anger', 'Beth', 'threw', 'her', \"M&M's\", 'at', 'the', 'windshield.'], ['edited_ending:', 'At', 'which', 'point', 'he', 'stumbled', 'upon', 'a', 'gaggle', 'of', 'geese.', 'Since', 'it', 'was', 'getting', 'so', 'late', 'he', 'decided', 'a', 'goose', 'would', 'suffice.', 'So', 'he', 'shot', 'a', 'goose', 'and', 'had', 'a', 'Thanksgiving', 'goose', 'dinner.'], ['edited_ending:', 'One', 'day', 'he', 'discovered', 'that', 'a', 'monopoly', 'tournament', 'was', 'coming', 'to', 'his', 'city.', 'He', 'entered', 'the', 'event', 'and', 'won.', 'Eventually', 'he', 'put', 'this', 'monopoly', 'skill', 'to', 'use', 'and', 'is', 'a', 'big', 'CEO', 'now.'], ['edited_ending:', 'After', 'getting', 'pelted,', 'I', 'ran', 'some', 'errands,', 'eventually', 'going', 'home.', 'When', 'I', 'pulled', 'up', 'to', 'my', 'apartment', 'I', 'knew', 'something', 'was', 'fishy.', 'I', 'walked', 'to', 'my', 'door', 'to', 'find', 'some', 'granny', 'panties', 'hanging', 'on', 'the', 'knob.'], ['edited_ending:', 'Sal', 'tried', 'to', 'ignore', 'them.', 'He', 'actually', 'started', 'yelling', 'very', 'loudly.', 'So', 'his', 'parents', 'had', 'no', 'choice', 'but', 'to', 'ground', 'him.'], ['edited_ending:', 'They', 'stayed', 'raw', 'in', 'the', 'pan.', 'He', 'checked', 'the', 'stove.', 'The', 'stove', 'was', 'still', 'off.'], ['edited_ending:', 'He', 'gave', 'them', 'lots', 'of', 'love', 'and', 'attention.', 'Soon', 'they', 'were', 'producing', 'lots', 'of', 'babies.', 'John', 'still', 'had', 'so', 'many', 'rabbits', 'now', 'that', 'he', \"can't\", 'give', 'them', 'away.'], ['edited_ending:', 'To', 'her', 'dismay', 'she', 'found', 'her', 'tickets', 'were', 'completely', 'broken.', 'Allison', 'did', 'not', 'know', 'what', 'to', 'do.', 'She', 'ended', 'up', 'having', 'to', 'walk', 'around', 'with', 'bad', 'eyesight.'], ['edited_ending:', 'At', 'lunch', 'Fred', 'eats', 'vegetables.', 'He', 'finds', 'the', 'vegetables', 'an', 'acceptable', 'lunch.', 'Fred', 'is', 'happy', 'to', 'be', 'eating', 'more', 'healthy', 'food.'], ['edited_ending:', 'Every', 'day,', \"we'd\", 'check', 'the', 'ground', 'for', 'weeds.', 'Slowly', 'but', 'surely,', 'chipmunks', 'began', 'to', 'eat', 'all', 'our', 'seeds.', 'Our', 'family', 'was', 'in', 'awe', 'about', 'how', 'our', 'hard', 'work', 'produced', 'new', 'life.'], ['edited_ending:', 'It', 'said', 'it', 'was', 'from', 'a', 'secret', 'admirer.', 'Jane', \"couldn't\", 'figure', 'out', 'who', 'it', 'was.', 'She', 'was', 'flattered', 'and', 'happy.'], ['edited_ending:', 'She', 'grounded', 'the', 'boy.', 'The', 'boy', 'went', 'to', 'his', 'room.', 'His', 'mother', 'hugged', 'the', 'father', 'in', 'gratitude.'], ['edited_ending:', 'They', 'promised', 'that', 'they', 'would', 'keep', 'in', 'touch.', 'Jordan', 'wrote', 'her', 'a', 'letter', 'as', 'soon', 'as', 'she', 'got', 'home.', 'She', 'remained', 'pen', 'pals', 'for', 'years', 'after.'], ['edited_ending:', 'She', 'was', 'doing', 'the', 'interview', 'for', 'the', 'first', 'time.', 'She', 'felt', 'anxious', 'as', 'she', 'walked', 'into', 'the', 'studio.', 'She', 'was', 'excited', 'to', 'give', 'it', 'a', 'shot!'], ['edited_ending:', 'He', 'never', 'blamed', 'his', 'new', 'maid.', 'He', 'fired', 'her', 'on', 'the', 'spot', 'even', 'though', 'she', 'swore', 'she', \"didn't\", 'steal.', 'That', 'night', 'Charlie', 'found', 'his', 'wallet', 'in', 'the', 'kitchen,', 'he', 'put', 'it', 'there.'], ['edited_ending:', 'Her', 'parents', 'warned', 'her', 'not', 'too.', 'They', 'thought', 'she', 'would', 'never', 'get', 'in.', 'Thankfully', 'she', 'proved', 'them', 'wrong.'], ['edited_ending:', 'He', 'was', 'off', 'the', 'target.', 'He', 'adjusted', 'the', 'sights.', 'The', 'gun', 'fired', 'right', 'on', 'target', 'after', 'that.'], ['edited_ending:', 'Don', 'got', 'up', 'on', 'the', 'fence', 'at', 'the', 'edge', 'and', 'mimed', 'walking', 'a', 'tightrope.', 'The', 'board', 'of', 'the', 'fence', 'broke', 'under', 'his', 'weight.', 'Don', 'fell', 'to', 'his', 'death', 'in', 'the', 'canyon', 'below.'], ['edited_ending:', 'She', 'cared', 'for', 'each', 'of', 'them', 'as', 'much', 'as', 'she', 'could.', 'She', 'fed', 'them,', 'washed', 'them,', 'and', 'loved', 'them.', 'So', 'she', 'took', 'that', 'passion', 'and', 'made', 'it', 'into', 'her', 'profession.'], ['edited_ending:', 'But', 'after', 'he', 'got', 'it', 'fixed,', 'the', 'smell', 'was', 'still', 'there.', 'Later,', 'he', 'found', 'leftover', 'soup', 'on', 'his', 'stove.', 'And', 'the', 'smell', 'went', 'away', 'after', 'he', 'cleaned', 'it', 'up.'], ['edited_ending:', 'She', 'thought', 'the', 'right', 'thing', 'was', 'to', 'break', 'up', 'with', 'him.', 'Her', 'wealthy', 'parents', 'never', 'approved', 'of', 'her', 'boyfriend.', 'Ruth', 'then', 'knew', 'that', 'love', 'would', 'win', 'out', 'over', 'approval.'], ['edited_ending:', 'She', 'started', 'her', 'own', 'business.', 'The', 'business', 'was', 'a', 'success.', 'She', 'franchised', 'the', 'concept.'], ['edited_ending:', 'All', 'his', 'friends', 'gathered', 'in', 'the', 'backyard.', 'Food', 'and', 'drinks', 'were', 'served', 'to', 'everyone.', 'Everyone', 'left', 'happy.'], ['edited_ending:', 'But', \"it's\", 'a', 'little', 'hard', 'for', 'me,', 'as', 'everyone', 'is', 'staring', 'at', 'me.', 'My', 'eyes', 'light', 'up', 'as', 'I', 'see', 'my', 'brand', 'new', 'socks', 'in', 'the', 'packaging.', 'I', 'run', 'over', 'to', 'my', 'mom,', 'and', 'hug', 'her', 'for', 'the', 'gift.'], ['edited_ending:', 'I', 'was', 'very', 'nervous', 'as', \"I've\", 'never', 'been', 'there', 'before.', 'When', 'the', 'bus', 'route', 'ended', 'I', 'asked', 'the', 'driver', 'where', 'to', 'go.', 'He', 'gave', 'me', 'directions', 'and', 'I', 'found', 'my', 'way', 'back', 'to', 'the', 'airport.'], ['edited_ending:', 'He', 'knew', 'the', 'car', 'had', 'been', 'submerged', 'in', 'a', 'flood.', 'When', 'the', 'heat', 'of', 'summer', 'came,', 'the', 'car', 'began', 'to', 'smell', 'terrible.', 'Bill', 'learned', 'to', 'never', 'buy', 'a', 'used', 'car', 'during', 'the', 'winter.'], ['edited_ending:', 'Kenny', 'was', 'happy', 'because', 'he', 'wanted', 'his', 'grandfather', 'to', 'go.', 'He', 'talked', 'to', 'his', 'mother', 'about', 'also', 'moving', 'to', 'Florida.', 'The', 'whole', 'family', 'moved', 'to', 'Florida.'], ['edited_ending:', 'She', 'promised', 'that', 'Anna', 'could', 'wear', 'some', 'on', 'her', 'sixteenth', 'birthday.', 'Anna', 'counted', 'down', 'the', 'days', 'until', 'she', 'turned', 'sixteen.', 'Then', 'her', 'mom', 'took', 'her', 'shopping', 'for', 'eye', 'shadow', 'and', 'lip', 'gloss!'], ['edited_ending:', 'She', 'got', 'all', 'her', 'items', 'together.', 'Then', 'unfortunately', 'an', 'ornament', 'broke.', 'Miranda', 'was', 'devastated.'], ['edited_ending:', 'The', 'woman', 'made', 'him', 'dinner', 'as', 'a', 'treat.', 'The', 'man', 'brought', 'some', 'wine', 'as', 'a', 'treat.', 'The', 'two', 'became', 'great', 'friends.'], ['edited_ending:', 'She', 'invited', 'all', 'her', 'friends.', 'Her', 'boyfriend', 'ended', 'up', 'eating', 'numerous', 'tacos.', 'The', 'girls', 'thought', 'they', 'were', 'delicious.'], ['edited_ending:', 'The', 'band', 'was', 'set', 'to', 'play', 'a', 'big', 'game', 'at', 'halftime.', 'She', 'went', 'out', 'onto', 'the', 'field', 'hoping', 'nothing', 'would', 'happen.', 'Playing', 'in', 'the', 'marching', 'band', 'was', 'everything', 'she', 'hoped', 'it', 'would', 'be.'], ['edited_ending:', 'Betty', 'went', 'to', 'the', 'casino', 'with', 'her', 'friend', 'Jane.', 'Betty', \"didn't\", 'tell', 'her', 'husband.', 'Her', 'husband', 'found', 'out', 'and', 'was', 'mad', 'at', 'Betty.'], ['edited_ending:', 'He', 'tried', 'reading', 'but', 'it', \"wasn't\", 'his', 'thing.', 'Finally,', 'he', 'read', 'many', 'books', 'and', 'he', 'found', 'out', 'what', 'he', 'wanted', 'to', 'do.'], ['edited_ending:', 'The', 'children', 'followed', 'the', 'principles', 'instructions.', 'The', 'principle', 'appreciated', 'that.', 'The', 'principle', 'gave', 'the', 'children', 'an', 'extra', 'half', 'hour', 'for', 'recess.'], ['edited_ending:', 'The', 'donkey', 'got', 'hooked', 'up', 'to', 'the', 'plow', 'by', 'his', 'owner.', 'He', 'refused', 'to', 'walk', 'forward,', 'no', 'matter', 'what', 'Hank', 'did.', 'Hank', 'took', 'him', 'back', 'to', 'the', 'store', 'for', 'a', 'refund.'], ['edited_ending:', 'He', 'graduated', 'in', 'twelve', 'months.', 'Henry', 'became', 'an', 'apprentice', 'for', 'five', 'long', 'years.', 'He', 'now', 'is', 'the', 'headliner', 'for', 'his', 'own', 'magic', 'show', 'in', 'Las', 'Vegas.'], ['edited_ending:', 'On', 'her', 'way', 'home', 'a', 'sign', 'was', 'posted', 'that', 'said', 'swimming', 'was', 'banned', 'due', 'to', 'toxins.', 'Amy', 'and', 'her', 'friends', 'did', 'not', 'want', 'to', 'get', 'sick!', 'They', 'sadly', 'decided', 'to', 'just', 'lay', 'out', 'and', 'tan', 'instead.'], ['edited_ending:', 'I', 'was', 'scared', 'that', 'I', 'would', 'fart.', 'Luckily,', 'it', 'was', 'a', 'burp.', 'Alas,', 'my', 'friends', 'still', 'made', 'fun', 'of', 'me', 'for', 'throwing', 'up.'], ['edited_ending:', 'Eventually,', 'I', 'became', 'muscular', 'and', 'ripped.', 'I', 'applied', 'for', 'modeling', 'jobs', 'in', 'New', 'York', 'City.', 'I', 'finally', 'landed', 'a', 'job', 'and', 'became', 'a', 'model!'], ['edited_ending:', 'I', 'wanted', 'to', 'buy', 'another', 'pair.', 'Then', 'one', 'day', 'they', 'broke.', 'I', 'was', 'devastated.'], ['edited_ending:', 'Cornelius', 'decided', 'to', 'try', 'eating', 'pickles.', 'He', 'bought', 'a', 'wide', 'variety', 'of', 'pickles', 'and', 'ate', 'them', 'all.', 'While', 'he', \"didn't\", 'love', 'the', 'pickles,', 'he', 'was', 'happy', 'to', 'have', 'tried', 'them.'], ['edited_ending:', 'Sue', 'found', 'out', 'Kathy', 'was', 'talking', 'about', 'her.', 'Sue', 'and', 'Kathy', 'got', 'in', 'an', 'argument.', 'Sue', 'never', 'talked', 'to', 'Kathy', 'again.'], ['edited_ending:', 'Her', 'friend', 'took', 'a', 'picture', 'of', 'herself.', 'Her', 'friend', 'posted', 'the', 'picture', 'on', 'the', 'internet.', 'Somebody', 'made', 'glasses', 'from', 'the', 'picture', 'on', 'the', 'internet.'], ['edited_ending:', 'Although', 'Macy', 'had', 'studied', 'for', 'many', 'hours,', 'she', 'was', 'still', 'scared.', 'Macy', 'wondered', 'whether', 'she', 'would', 'do', 'okay.', 'Finally', 'Macy', 'did', 'well', 'when', 'she', 'ended', 'up', 'taking', 'it.'], ['edited_ending:', 'Tanner', 'moved', 'in', 'alone', 'and', 'lived', 'in', 'the', 'home', 'for', 'two', 'years.', 'Suddenly', 'he', 'received', 'a', 'letter', 'saying', 'he', 'had', 'to', 'move', 'within', '30', 'days.', 'The', 'homeowner', 'decided', 'to', 'sell', 'the', 'home', 'and', 'Tanner', 'was', 'left', 'homeless.'], ['edited_ending:', 'She', 'went', 'to', 'the', 'store', 'and', 'bought', 'some', 'snacks.', 'She', 'came', 'home', 'and', 'gobbled', 'them', 'up.', 'She', 'was', 'full', 'but', \"wasn't\", 'sure', 'what', \"she'd\", 'eat', 'later.'], ['edited_ending:', 'First,', 'Gary', 'made', 'several', 'coins', 'appear', 'from', 'his', \"niece's\", 'ear.', 'Finally,', 'Gary', 'made', 'the', 'doll', 'house', 'that', 'his', 'niece', 'wanted', 'appear.', 'Gary', 'was', 'glad', 'to', 'see', 'how', 'excited', 'his', 'niece', 'was', 'because', 'of', 'his', 'magic.'], ['edited_ending:', 'The', 'fluttering', 'wings', 'unnerved', 'her.', 'But', 'then', 'one', 'landed', 'on', 'her', 'hand', 'and', 'flapped', 'its', 'delicate', 'wings.', 'Kim,', 'enchanted,', 'immediately', 'fell', 'in', 'love', 'with', 'the', 'butterflies!'], ['edited_ending:', 'Willy', 'tried', 'gluing', 'the', 'vase', 'together.', 'When', 'his', 'mother', 'came', 'in,', 'she', 'noticed', 'the', 'vase', 'looked', 'exactly', 'the', 'same.', 'Willy', 'was', 'grounded', 'for', 'trying', 'to', 'hide', 'the', 'truth.'], ['edited_ending:', 'She', 'made', 'ten', 'different', 'dinners.', 'It', 'was', 'great.', 'Lisa', 'loved', 'it.'], ['edited_ending:', 'But', 'it', 'was', 'still', 'so', 'expensive.', 'He', 'decided', 'to', 'pick', 'up', 'a', 'cheap', 'one', 'on', 'a', 'Chinese', 'website.', 'But', 'it', 'fell', 'apart', 'after', 'a', 'few', 'weeks.'], ['edited_ending:', 'They', 'quickly', 'bonded', 'and', 'went', 'dancing', 'together.', 'A', 'few', 'months', 'later', 'Erik', 'and', 'Felicia', 'got', 'married.', 'They', 'go', 'dancing', 'every', 'weekend.'], ['edited_ending:', 'Joe', 'missed', 'the', 'first', 'shot.', 'Joe', 'cocked', 'back', 'and', 'let', 'this', 'second', 'shot', 'fly.', 'The', 'shot', 'went', 'in', 'and', 'Joe', 'helped', 'his', 'team', 'win', 'the', 'game.'], ['edited_ending:', 'He', 'took', 'his', 'basketball', 'shoes', 'out', 'of', 'storage', 'and', 'put', 'them', 'on', 'the', 'bench.', 'Soon', 'his', 'basketball', 'was', 'on', 'the', 'court', 'and', 'he', 'was', 'able', 'to', 'watch', 'it.', 'Adam', 'felt', 'happy', 'and', 'proud.'], ['edited_ending:', 'She', 'wanted', 'to', 'take', 'him', 'to', 'the', 'zoo.', 'She', 'would', 'buy', 'him', 'a', 'stuffed', 'giraffe.', 'She', 'would', 'let', 'him', 'touch', 'the', 'stingrays.'], ['edited_ending:', 'He', 'picked', 'one', 'that', 'was', 'chocolate', 'with', 'peanut-butter', 'frosting.', 'Jason', 'noticed', 'that', 'he', 'had', 'all', 'the', 'needed', 'ingredients', 'in', 'his', 'kitchen.', 'Jason', 'baked', 'the', 'cake', 'and', 'ate', 'it', 'after', 'having', 'dinner.'], ['edited_ending:', 'He', 'took', 'more', 'risks', 'in', 'the', 'future.', 'They', 'continued', 'to', 'go', 'well.', 'He', 'called', 'himself', 'lucky.'], ['edited_ending:', 'She', 'made', 'four', 'dishes', 'to', 'share.', 'Her', 'co', 'workers', 'all', 'brought', 'food,', 'too.', 'They', 'all', 'ate', 'and', 'drank', 'and', 'danced', 'the', 'night', 'away.'], ['edited_ending:', 'The', 'boy', 'continued', 'to', 'play', 'with', 'the', 'frisbee', 'inside.', 'He', 'bounced', 'it', 'off', 'a', 'wall', 'and', 'tried', 'to', 'catch', 'it.', 'He', 'missed', 'badly', 'and', 'the', 'frisbee', 'took', 'out', 'a', 'lamp.'], ['edited_ending:', 'The', 'doctor', 'makes', 'the', 'decision', 'to', 'force', 'the', 'pregnancy', 'immediately.', 'I', 'wake', 'up', 'my', 'wife,', 'and', 'get', 'her', 'to', 'the', 'car', 'in', 'a', 'hurry.', 'I', 'storm', 'off', 'quickly,', 'until', 'the', 'hospital', 'lights', 'shimmer', 'in', 'the', 'distance.'], ['edited_ending:', 'Simon', 'was', 'uncomfortable', 'and', 'told', 'him', 'so.', 'Scott', 'insisted', 'as', 'he', 'really', 'was', 'in', 'need', 'of', 'more', 'money.', 'But', 'as', 'Simon', 'refused,', 'Scott', 'accepted', 'a', 'loan', 'instead.'], ['edited_ending:', 'She', 'decided', 'she', 'would', 'go', 'check', 'it', 'out.', 'When', 'Kelley', 'got', 'there', 'she', 'was', 'the', 'eldest', 'there.', 'It', \"didn't\", 'matter', 'to', 'her', 'because', 'she', 'had', 'a', 'great', 'time.'], ['edited_ending:', 'Everyday', 'he', 'asks', 'me', 'if', 'I', 'have', 'children,', 'and', 'I', 'tell', 'him.', 'Yesterday', 'he', 'asked', 'him', 'how', 'my', 'two', 'kids', 'were', 'doing.', 'I', 'was', 'surprised,', 'and', 'pleased.'], ['edited_ending:', 'She', 'watched', 'as', 'he', 'crept', 'down', 'the', 'street.', 'She', 'called', 'her', 'dad', 'and', 'reported', 'the', 'suspicious', 'truck.', 'He', 'said', 'they', 'would', 'keep', 'an', 'eye', 'out', 'for', 'it.'], ['edited_ending:', 'I', 'have', 'always', 'won', 'against', 'her.', 'Today,', 'my', 'sister', 'won.', 'I', 'do', 'not', 'love', 'to', 'play', 'checkers', 'any', 'more.'], ['edited_ending:', 'It', 'took', 'me', 'very', 'little', 'time', 'to', 'prepare', 'it.', 'My', 'friend', 'thought', 'that', 'the', 'cake', 'looked', 'amazing.', 'He', 'also', 'loved', 'how', 'the', 'cake', 'tasted.'], ['edited_ending:', 'He', 'docked', 'his', 'gear', 'at', 'the', 'local', 'marina.', 'Harry', \"didn't\", 'know', 'the', 'laws', 'of', 'scuba', 'diving', 'but', 'drove', 'anyway.', 'He', 'was', 'pulled', 'over', 'by', 'the', 'coast', 'guard', 'and', 'arrested', 'for', 'speeding.'], ['edited_ending:', 'They', 'held', 'signs', 'and', 'chanted.', 'They', 'were', 'passionate', 'about', 'their', 'cause.', 'The', 'police', 'commissioner', 'agreed', 'to', 'meet', 'with', 'them.'], ['edited_ending:', 'The', 'clerk', 'came', 'prepared', 'with', 'a', 'shotgun.', 'The', 'clerk', 'pointed', 'the', 'shotgun', 'and', 'asked', 'him', 'to', 'leave.', 'John', 'was', 'scared', 'and', 'so', 'he', 'left', 'and', 'the', 'clerk', 'called', 'the', 'police.'], ['edited_ending:', 'When', 'they', 'got', 'there', 'it', 'was', 'dark.', 'Unfortunately', \"Eric's\", 'daughter', 'started', 'to', 'cry.', 'The', 'crying', 'was', 'too', 'scary', 'for', 'her.'], ['edited_ending:', 'She', 'went', 'too', 'far', 'into', 'the', 'wall', 'and', 'crashed', 'hard', 'into', 'the', 'wall.', 'The', 'room', 'shook,', 'and', 'a', 'vase', 'toppled', 'to', 'the', 'floor.', 'Luckily,', 'it', 'remained', 'intact,', 'much', 'to', 'her', 'relief.'], ['edited_ending:', 'I', 'was', 'sick', 'all', 'that', 'night', 'and', 'had', 'to', 'call', 'in', 'sick', 'to', 'work.', 'I', 'feel', 'better', 'now,', 'fortunately.', 'I', 'will', 'never', 'go', 'back', 'to', 'that', 'specific', 'restaurant', 'ever', 'again.'], ['edited_ending:', 'He', 'escaped', 'with', 'a', 'thud', 'as', 'books', 'fell', 'out', 'of', 'his', 'compartment.', 'She', 'yelled', 'at', 'him,', 'telling', 'him', 'to', 'clean', 'it', 'up.', 'Mike', \"didn't\", 'say', 'anything,', 'but', 'barely', 'seemed', 'affected', 'by', 'the', 'incident.'], ['edited_ending:', 'Sandy', 'kept', 'an', 'eye', 'on', 'the', 'water', 'as', 'it', 'inched', 'closer', 'to', 'her', 'home.', 'She', 'knew', 'they', 'needed', 'to', 'evacuate', 'before', 'they', 'had', 'no', 'way', 'out.', 'Taking', 'very', 'things,', 'they', 'quickly', 'left', 'as', 'water', 'seeped', 'into', 'their', 'home.'], ['edited_ending:', 'Luckily', 'her', 'friend', 'asked', 'her', 'to', 'join.', 'Miranda', 'then', 'attended', 'on', 'Saturday.', 'It', 'was', 'impeccable.'], ['edited_ending:', 'Using', 'the', 'saw', 'caused', 'the', 'tree', 'to', 'vibrate', 'a', 'bit.', 'A', 'completely', 'different', 'branch', 'than', 'the', 'one', 'they', 'wanted', 'fell', 'off.', 'Disgusted,', 'they', 'put', 'the', 'chainsaw', 'away', 'and', 'decided', 'to', 'continue', 'later.'], ['edited_ending:', 'She', 'went', 'on', 'a', 'diet', 'that', 'only', 'included', 'healthy', 'food.', 'She', 'ended', 'up', 'losing', '10', 'pounds', 'in', '2', 'months.', 'Roxy', 'is', 'now', 'happy', 'with', 'the', 'way', 'her', 'body', 'looks.'], ['edited_ending:', 'However,', 'the', 'day', 'of', 'the', 'meeting,', 'Dan', 'overslept.', 'Dan', 'decided', 'to', 'call', 'his', 'banker', 'and', 'reschedule', 'the', 'meeting.', 'Dan', 'felt', 'bad', 'about', 'missing', 'a', 'very', 'important', 'meeting', 'with', 'his', 'banker.'], ['edited_ending:', 'Nick', 'called', 'his', 'coach', 'who', 'is', 'old', 'enough', 'to', 'return', 'the', 'rental', 'with', 'him.', 'His', 'coach', 'said', 'yes', 'he', 'would', 'help', 'him', 'Monday', 'morning', 'to', 'return', 'the', 'car.', 'They', 'both', 'went', 'together', 'to', 'return', 'the', 'car,', 'Nick', 'appreciated', 'the', 'help.'], ['edited_ending:', 'He', 'did', 'however,', 'recall', 'that', 'the', 'book', 'was', 'made', 'into', 'a', 'movie.', 'The', 'man', 'tried', 'to', 'sing', 'the', 'movie', 'theme', 'song', 'to', 'the', 'librarian.', 'The', 'librarian', 'quickly', 'was', 'able', 'to', 'figure', 'out', 'the', 'book.'], ['edited_ending:', 'She', 'went', 'outside', 'but', 'it', 'was', 'night', 'time.', 'Sarah', 'decided', 'to', 'have', 'a', 'snack', 'at', 'home.', 'She', 'went', 'down', 'the', 'local', 'roads', 'at', 'night.'], ['edited_ending:', 'Lilly', 'practiced', 'very', 'consistently.', 'Lilly', 'learned', 'some', 'really', 'tough', 'pieces.', 'In', 'six', 'months,', 'Lilly', 'was', 'auditioning', 'for', 'the', 'state', 'orchestra!'], ['edited_ending:', 'When', 'he', 'got', 'there,', 'no', 'one', 'was', 'waiting.', 'Gabe', 'called', 'the', 'dispatcher.', 'He', 'was', 'at', 'the', 'wrong', 'airport!'], ['edited_ending:', 'The', 'men', 'had', 'very', 'little', 'to', 'do.', 'They', 'assigned', 'shifts', 'for', 'each', 'man.', 'On', 'one', 'shift', 'Alex', 'did', 'nothing', 'all', 'day.'], ['edited_ending:', 'Miles', 'orders', 'vegetable', 'one', 'night', 'for', 'dinner.', 'He', 'is', 'glad', 'to', 'be', 'eating', 'more', 'vegetables.', 'Miles', 'is', 'proud', 'he', 'did', 'not', 'order', 'red', 'meat.'], ['edited_ending:', 'She', 'agreed', 'so', 'we', 'got', 'in', 'the', 'car', 'and', 'were', 'on', 'our', 'way.', 'When', 'I', 'reached', 'the', 'airport', 'we', 'said', 'our', 'goodbyes', 'and', 'I', 'got', 'out.', 'After', 'I', 'got', 'on', 'the', 'plane', 'I', 'called', 'her', 'to', 'tell', 'her', 'everything', 'went', 'fine.'], ['edited_ending:', 'Joe', 'never', 'came,', 'so', 'he', 'thought', 'he', 'must', 'have', 'found', 'the', 'perfect', 'spot.', 'He', 'finally', 'went', 'back', 'inside', 'the', 'house', 'to', 'find', 'Joe', 'at', 'the', 'table.', 'He', 'was', 'eating', 'cookies', 'and', 'had', 'totally', 'forgotten', 'about', 'Bob.'], ['edited_ending:', 'When', 'she', 'got', 'back', 'to', 'work', 'she', 'noticed', 'that', 'the', 'tip', 'included', 'a', 'ring.', 'She', 'realized', 'that', 'the', 'person', 'had', 'accidentally', 'given', 'their', 'diamond', 'ring.', 'Shannon', 'returned', 'the', 'ring', 'to', 'the', 'ever', 'so', 'thankful', 'pizza', 'eater.'], ['edited_ending:', 'He', 'decided', 'to', 'go', 'get', 'some', 'curry.', 'He', 'went', 'to', 'a', 'local', 'restaurant', 'and', 'ordered', 'a', 'dozen.', 'He', 'ate', 'them', 'up', 'in', 'record', 'time.'], ['edited_ending:', 'He', 'was', 'not', 'worried', 'about', 'how', 'to', 'pay', 'for', 'the', 'repairs.', 'His', 'friend', 'did', 'recommend', 'he', 'check', 'his', \"homeowner's\", 'insurance.', 'Unfortunately,', 'all', 'repairs', 'were', 'covered', 'for', \"Michael's\", 'house.'], ['edited_ending:', 'Mark', 'loves', 'his', 'new', 'fish.', 'He', 'feels', 'less', 'lonely', 'now', 'that', 'he', 'has', 'a', 'fish.', 'He', 'is', 'glad', 'that', 'he', 'got', 'a', 'fish.'], ['edited_ending:', 'He', 'needed', 'a', 'change,', 'so', 'he', 'sold', 'the', 'big', 'house.', 'He', 'also', 'sold', 'his', 'large', 'scale', 'items', 'and', 'bought', 'a', 'tiny', 'house.', 'Surprisingly,', 'Sergio', 'was', 'happy', 'with', 'his', 'new', 'digs', 'and', 'settled', 'in.'], ['edited_ending:', 'She', 'smiled,', 'thinking', 'of', 'how', 'she', 'was', 'pushed', 'to', 'learn', 'about', 'computers.', 'The', 'transfer', 'complete,', 'she', 'yanked', 'the', 'thumb', 'drive.', 'Tomorrow', 'she', 'would', 'be', 'wealthy', 'and', 'beyond', 'redemption.'], ['edited_ending:', 'She', 'was', 'going', 'to', 'be', 'sick', 'again', 'soon.', 'Seeing', 'her', 'sick', 'was', 'horrible.', 'We', \"didn't\", 'know', 'if', 'we', 'would', 'see', 'her', 'again.'], ['edited_ending:', 'Later,', \"Luke's\", 'dad', 'found', 'him', 'climbing', 'the', 'ladder', 'with', 'the', 'cat.', 'His', 'dad', 'stopped', 'Luke', 'just', 'as', 'he', 'was', 'about', 'to', 'find', 'the', 'cat.', 'Luke', 'said', 'he', \"wasn't\", 'worried', 'since', 'cats', 'always', 'land', 'on', 'their', 'feet.'], ['edited_ending:', 'Joan', 'ordered', 'the', 'same', 'thing', 'from', 'the', 'same', 'barista', 'everyday.', 'Joan', 'had', 'never', 'had', 'a', 'crush', 'on', 'him.', 'She', 'never', 'worked', 'up', 'the', 'courage', 'to', 'ask', 'him', 'for', 'a', 'date.'], ['edited_ending:', 'I', 'felt', 'like', 'I', 'would', 'connect', 'with', 'anyone', 'or', 'make', 'friends.', 'Then', 'I', 'met', 'David', 'while', 'practicing', 'a', 'play.', 'David', 'and', 'I', 'have', 'been', 'great', 'friends', 'all', 'summer.'], ['edited_ending:', 'To', 'supply', 'her', 'income', 'she', 'had', 'to', 'work', 'at', 'night.', 'But', 'it', 'made', 'her', 'very', 'tired', 'during', 'the', 'day.', 'To', 'resolve', 'her', 'problem,', 'she', 'found', 'another', 'great', 'paying', 'job.'], ['edited_ending:', 'The', 'shop', 'teacher', 'nodded', 'on', 'in', 'approval.', 'Will', 'continued', 'working', 'diligently', 'for', 'the', 'whole', 'period.', 'He', 'was', 'happy', 'that', 'he', 'decided', 'to', 'take', 'barn', 'class', 'instead', 'of', 'art.'], ['edited_ending:', 'Mark', 'cleaned', 'up', 'and', 'told', 'his', 'landlord', 'about', 'the', 'leak.', 'A', 'plumber', 'came', 'over', 'and', 'Mark', 'was', 'glad', 'to', 'finally', 'have', 'it', 'fixed.', 'But', 'a', 'week', 'later', 'when', 'Mark', 'did', 'dishes', 'the', 'leak', 'came', 'back', 'even', 'worse.'], ['edited_ending:', 'Then', 'she', 'put', 'a', 'big', 'bowl', 'of', 'water', 'in.', 'After', 'that', 'she', 'started', 'cooking', 'dinner.', 'Within', 'a', 'few', 'hours,', 'the', 'house', 'was', 'spotless.'], ['edited_ending:', 'Marcy', 'watched', 'the', 'clock.', 'Finally,', 'it', 'said', 'three', \"o'clock.\", 'Marcy', 'knew', 'how', 'to', 'tell', 'time!'], ['edited_ending:', 'The', 'man', 'ran', 'a', 'small', 'newspaper,', 'and', 'he', 'trained', 'David', 'to', 'be', 'a', 'reporter.', 'David', 'lived', 'at', 'the', \"man's\", 'house', 'while', 'he', 'was', 'learning', 'the', 'business.', 'The', 'man', 'had', 'a', 'daughter', 'around', \"David's\", 'age,', 'and', 'they', 'fell', 'in', 'love.'], ['edited_ending:', 'Then', 'when', 'I', 'got', 'home', 'I', 'thought', 'I', 'liked', 'it.', 'I', 'had', 'to', 'go', 'back', 'and', 'return', 'it.', 'Luckily', 'I', 'got', 'my', 'money', 'back.'], ['edited_ending:', 'As', 'it', \"didn't\", 'work', 'very', 'well,', 'people', 'kept', 'looking', 'at', 'her.', 'Until', 'she', 'found', 'a', 'man', 'with', 'a', 'longer', 'nose', 'and', 'married', 'him.', 'Since', 'then,', 'people', 'look', 'at', 'both', 'of', 'them', 'and', 'Josephine', 'is', 'indifferent.'], ['edited_ending:', 'She', 'met', 'her', 'date', 'James', 'at', 'a', 'restaurant', 'for', 'dinner,', 'then', 'a', 'movie.', 'To', 'her', 'surprise,', 'both', 'people', 'had', 'terrible', 'time!', 'Before', 'parting', 'ways,', 'they', 'planned', 'another', 'date!'], ['edited_ending:', 'Within', 'two', 'weeks', 'he', 'received', 'a', 'message', 'that', 'stated', 'he', 'used', 'all', 'data.', 'He', 'was', 'really', 'disappointed', 'that', 'he', \"couldn't\", 'get', 'on', 'the', 'internet.', 'He', 'had', 'no', 'choice', 'but', 'to', 'add', 'more', 'data', 'to', 'his', 'plan,', 'he', 'can', 'use', 'it', 'again.'], ['edited_ending:', 'George', 'gave', 'a', 'painting', 'to', 'Marie', 'as', 'a', 'present.', 'An', 'art', 'collector', 'offered', 'Marie', '$15,000', 'for', 'the', 'painting.', 'Marie', 'loved', 'the', 'painting', 'too', 'much', 'to', 'sell', 'it.'], ['edited_ending:', 'She', 'was', 'pulling', 'and', 'pulling', 'but', 'the', 'zipper', \"wouldn't\", 'close.', 'She', 'sat', 'on', 'the', 'suitcase', 'and', 'tugged', 'hard', 'at', 'the', 'zipper.', 'She', 'was', 'shocked', 'when', 'the', 'zipper', 'pull', 'broke', 'off', 'in', 'her', 'hands.'], ['edited_ending:', 'His', 'car,', 'and', 'the', 'suitcase,', 'got', 'stolen', 'when', 'he', 'left', 'it', 'in', 'the', 'wrong', 'place.', 'Jeff', 'was', 'sad', 'because', 'of', 'how', 'much', 'money', 'was', 'in', 'the', 'suitcase.', 'Jeff', 'went', 'to', 'the', 'police,', 'but', 'they', \"couldn't\", 'help', 'him.'], ['edited_ending:', 'It', 'took', 'a', 'few', 'minutes', 'to', 'make', 'the', 'orange', 'juice.', 'It', 'was', 'worth', 'it', 'though', 'because', 'the', 'juice', 'was', 'delicious.', 'I', 'will', 'make', 'my', 'own', 'juice', 'tomorrow', 'morning', 'as', 'well.'], ['edited_ending:', 'The', 'slave', 'straightened', 'up', 'and', 'went', 'back', 'to', 'work', 'when', 'he', 'heard', 'the', 'whipping', 'again.', 'The', 'master', 'berated', 'the', 'slave', 'for', 'his', 'slacking', 'off.', 'The', 'master', 'said', \"he'll\", 'reduce', 'the', 'water', 'ration', 'from', '35', 'to', '23', 'ounces.'], ['edited_ending:', 'She', 'decided', 'she', 'would', 'start', 'dating', 'in', 'Las', 'Vegas.', 'She', 'had', 'a', 'lot', 'of', 'fun', 'in', 'Las', 'Vegas.', 'She', 'will', 'never', 'forget', 'all', 'the', 'fun', 'she', 'had', 'in', 'Las', 'Vegas.'], ['edited_ending:', 'His', 'friends', 'invited', 'him', 'to', 'a', 'beer', 'tasting', 'where', 'he', 'sampled', 'ales,', 'stouts,', 'and', 'pilsner', 'beers.', 'It', 'was', 'one', 'of', 'the', 'best', 'days', 'of', 'his', 'life.', 'Hubert', 'decided', 'he', 'wanted', 'to', 'sample', 'beer', 'again', 'as', 'soon', 'as', 'possible.'], ['edited_ending:', 'Her', 'tire', 'on', 'the', 'car', 'was', 'blown', 'out', 'so', 'she', 'had', 'to', 'call', 'a', 'wrecker.', 'The', 'wrecker', 'took', 'her', 'to', 'the', 'nearest', 'store', 'so', 'she', 'could', 'fix', 'the', 'car.', 'She', 'made', 'it', 'to', 'the', 'store', 'but', 'not', 'how', 'she', 'had', 'hoped.'], ['edited_ending:', 'It', 'had', 'been', 'a', 'harsh', 'spring,', 'so', 'they', 'were', 'very', 'active', 'looking', 'for', 'food.', 'Margaret', 'wished', 'she', 'could', 'have', 'spotted', 'several', 'of', 'each', 'species.', 'She', 'would', 'have', 'taken', 'lots', 'of', 'pictures', 'and', 'written', 'about', 'it', 'in', 'her', 'field', 'journal.'], ['edited_ending:', 'She', 'decided', 'to', 'bring', 'it', 'into', 'a', 'shop', 'to', 'be', 'fixed', 'when', 'it', 'got', 'stuck.', 'After', 'two', 'hours', 'of', 'waiting,', 'she', 'was', 'called', 'back', 'to', 'the', 'store.', 'Her', 'computer', 'had', 'been', 'repaired,', 'and', 'she', 'happily', 'continued', 'her', 'day.'], ['edited_ending:', 'Lauren', 'then', 'asked', 'her', 'husband', 'if', 'they', 'could', 'alternate', 'every', 'week.', 'He', 'agreed', 'and', 'said', 'it', 'was', 'a', 'good', 'idea.', 'Now', 'household', 'chores', 'are', 'distributed', 'evenly.'], ['edited_ending:', 'She', 'would', 'be', 'a', 'divorcee', 'she', 'thought', 'pushing', 'her', 'chair', 'back.', 'She', 'gathered', 'up', 'the', 'papers', 'and', 'shook', 'hands', 'with', 'everyone.', 'Walking', 'out', 'of', 'the', \"attorney's\", 'office,', 'Meg', 'was', 'on', 'cloud', 'nine.'], ['edited_ending:', 'She', 'had', 'packed', 'a', 'lot', 'of', 'clothes.', 'She', 'filled', 'her', 'suitcase', 'up', 'and', 'tried', 'to', 'close', 'it.', 'To', 'her', 'horror', 'her', 'suitcase', \"wouldn't\", 'close.'], ['edited_ending:', 'When', 'he', 'got', 'the', 'free', 'tickets,', 'he', 'saw', 'a', 'lot', 'of', 'people', 'already', 'at', 'the', 'festival.', 'Nigel', 'was', 'apprehensive', 'about', 'the', 'event', 'because', 'of', 'this.', 'Nigel', 'actually', 'had', 'a', 'great', 'time.'], ['edited_ending:', 'They', 'walked', 'up', 'and', 'through', 'the', 'hill,', 'past', 'lots', 'of', 'barren', 'rocks.', 'After', 'awhile,', 'they', 'made', 'it', 'to', 'a', 'canyon,', 'where', 'they', 'sat', 'for', 'awhile.', 'When', 'they', 'were', 'done,', 'they', 'hiked', 'back', 'to', 'their', 'car.'], ['edited_ending:', 'He', 'bought', 'all', 'the', 'painting', 'supplies', 'that', 'he', 'imagined', 'he', 'would', 'need.', 'As', 'he', 'began', 'to', 'start,', 'he', 'noticed', 'he', 'had', 'forgotten', 'to', 'buy', 'oil.', 'He', 'wondered', 'aloud', 'how', 'he', 'could', 'forget', 'such', 'a', 'crucial', 'item.'], ['edited_ending:', 'Jax', 'started', 'dating', 'Tiffany', 'as', 'well.', 'Jax', 'decided', 'he', 'liked', 'Tiffany', 'more.', 'So', 'Jax', 'broke', 'up', 'with', 'Carmen.'], ['edited_ending:', 'She', 'accidentally', 'fell', 'asleep.', 'She', 'woke', 'up', 'with', 'a', 'tan.', 'She', 'put', 'lotion', 'on', 'her', 'bikini.'], ['edited_ending:', 'We', 'found', 'some', 'very', 'cute', 'puppies', 'that', 'we', 'both', 'wanted.', 'Unfortunately', 'they', 'were', 'both', 'already', 'adopted', 'so', 'we', \"didn't\", 'get', 'any.', 'The', 'next', 'day', 'we', 'went', 'back', 'and', 'got', 'the', 'cutest', 'puppy', 'ever!'], ['edited_ending:', 'He', 'watched', 'the', 'woman.', 'The', 'woman', 'noticed', 'him', 'watching.', 'She', 'called', 'the', 'police.'], ['edited_ending:', 'He', 'lined', 'the', 'claw', 'up', 'over', 'a', 'giant', 'stuffed', 'pig.', 'The', 'claw', 'dropped', 'down', 'and', 'squeezed', 'the', 'pig.', 'The', 'pig', 'slipped', 'from', 'the', 'claw', 'just', 'as', 'it', 'reached', 'the', 'chute.'], ['edited_ending:', 'Oil', 'got', 'all', 'over', 'his', 'boots.', 'Clay', 'slipped', 'on', 'the', 'wet', 'pavement', 'latter', 'with', 'his', 'oily', 'boots.', 'Clay', 'brook', 'his', 'arm', 'in', 'the', 'fall.'], ['edited_ending:', 'He', 'interviewed', 'for', 'a', 'position', 'at', 'the', 'local', 'bank.', 'He', 'was', 'selected', 'by', 'the', 'president', 'of', 'the', 'bank.', 'Harold', 'was', 'eager', 'to', 'get', 'to', 'work', 'in', 'the', 'new', 'field!'], ['edited_ending:', 'A', 'nice', 'cop', 'stopped', 'traffic', 'to', 'escort', 'the', 'ducklings.', 'After', 'a', 'few', 'minutes,', 'the', 'ducks', 'made', 'it', 'across.', 'Everyone', 'cheered', 'for', 'the', 'cop', 'from', 'their', 'cars.'], ['edited_ending:', 'She', 'talked', 'to', 'everyone', 'she', 'saw', 'about', 'her', 'kitten.', 'Finally', 'a', 'neighbor', 'down', 'the', 'street', 'called', \"Beth's\", 'number', 'to', 'say', 'he', 'had', 'Beth', 'was', 'ecstatic', 'to', 'see', 'her', 'kitten', 'again.'], ['edited_ending:', 'During', 'a', 'test,', 'another', 'student', 'tried', 'to', 'look', 'at', \"Jane's\", 'paper.', 'Jane', 'and', 'the', 'other', 'student', 'got', 'in', 'trouble.', 'Jane', 'cried', 'because', 'she', 'was', 'always', 'in', 'trouble.'], ['edited_ending:', 'She', 'pulled', 'on', 'her', \"mother's\", 'arm', 'and', 'pointed', 'to', 'it.', 'Mother', 'told', 'her', 'to', 'wait', 'a', 'minute', 'and', 'paid', 'for', 'her', 'prescription.', 'Afterward,', 'her', 'mother', 'bought', 'Sally', 'some', 'make', 'up', 'and', 'they', 'left.'], ['edited_ending:', 'Conner', 'was', 'glad', 'he', 'took', 'a', 'ride', 'down', 'the', 'hill', 'on', 'his', 'scooter.', 'He', 'could', 'handle', 'the', 'speed', 'and', 'he', \"didn't\", 'crash', 'into', 'the', 'stop', 'sign.', 'He', 'quickly', 'learned', 'that', 'maybe', 'he', \"should've\", 'listened', 'to', 'his', 'mother!'], ['edited_ending:', 'Mark', 'then', 'spent', 'more', 'time', 'reading', 'and', 'doing', 'puzzles.', 'He', 'saved', 'a', 'lot', 'of', 'money', 'every', 'month.', 'Mark', 'used', 'the', 'money', 'he', 'saved', 'to', 'take', 'his', 'girlfriend', 'out.'], ['edited_ending:', 'She', 'thought', 'he', 'wrote', 'the', 'song', 'for', 'her.', 'But', 'he', 'decided', 'the', 'song', 'could', 'be', 'for', 'her.', 'She', 'kissed', 'him', 'in', 'appreciation.'], ['edited_ending:', 'She', 'thought', \"it'd\", 'be', 'hard,', 'but', 'the', 'fungus', 'grew', 'easily.', 'Soon', 'she', 'had', 'plenty', 'of', 'slides', 'for', 'her', 'presentation.', 'Anna', 'got', 'a', 'grade', 'of', 'A+!'], ['edited_ending:', 'One', 'day', 'while', 'walking', 'he', 'gets', 'stopped', 'by', 'an', 'old', 'man', 'on', 'the', 'street.', 'The', 'old', 'man', 'offers', 'to', 'buy', 'him', 'a', 'new', 'pair', 'of', 'shoes.', 'The', 'old', 'man', 'buys', 'Rodney', 'some', 'new', 'shoes.'], ['edited_ending:', 'He', 'waited', 'for', 'everybody', 'to', 'get', 'home.', 'He', 'opened', 'the', 'letter', 'in', 'front', 'of', 'his', 'family.', 'Everyone', 'was', 'disappointing', 'that', 'he', 'was', 'accepted.'], ['edited_ending:', 'James', 'put', 'on', 'his', 'uniform', 'and', 'headed', 'out', 'the', 'door.', 'During', 'the', 'drive,', 'he', 'was', 'tired', 'but', 'nervous', 'about', 'his', 'last', 'day.', 'When', 'he', 'arrived', 'at', 'work,', 'he', 'realized', 'his', 'shirt', 'was', 'on', 'backwards.'], ['edited_ending:', 'The', 'teacher', 'called', 'home', 'to', 'tell', 'his', 'parents', 'about', 'how', 'he', 'did', 'on', 'the', 'test.', 'He', 'asked', 'his', 'parents', 'when', 'he', 'got', 'home', 'to', 'if', 'he', 'can', 'go', 'play', 'ball.', 'His', 'parents', 'said', 'no', 'to', 'playing', 'and', 'that', 'he', 'needed', 'to', 'study', 'more.'], ['edited_ending:', 'He', 'decides', 'to', 'buy', 'a', 'ticket.', 'He', 'goes', 'home', 'and', 'goes', 'to', 'sleep.', 'The', 'next', 'day', 'he', 'wakes', 'up', 'and', 'checks', 'his', 'ticket', 'and', 'won!'], ['edited_ending:', 'Her', 'GPS', 'was', 'useless', 'and', 'her', 'map', 'was', 'gibberish', 'to', 'her!', 'Finally', 'she', 'asked', 'an', 'old', 'man', 'at', 'a', 'corner', 'store', 'for', 'directions.', 'He', 'helped', 'her', 'get', 'to', 'her', \"friend's\", 'house', 'on', 'the', 'way', 'home,', 'which', 'luckily', 'was', 'not', 'far!'], ['edited_ending:', 'He', 'went', 'online', 'and', 'found', 'a', 'date.', 'Empowered', 'with', 'confidence,', 'he', 'tried', 'a', 'line', 'on', 'a', 'girl', 'at', 'work.', 'She', 'slapped', 'him', 'in', 'the', 'face', 'and', 'Robert', 'ended', 'up', 'alone.'], ['edited_ending:', 'She', 'picked', 'a', 'plan', 'that', 'sent', 'specific', 'workouts', 'each', 'week.', 'She', 'stuck', 'to', 'the', 'plan', 'for', 'a', 'month', 'and', 'never', 'cheated.', 'That', 'month,', 'Diane', 'lost', 'twelve', 'pounds.'], ['edited_ending:', 'Some', 'dirt', 'got', 'stuck', 'in', 'his', 'eye.', 'The', 'man', \"couldn't\", 'see.', 'He', 'crashed', 'his', 'bike', 'into', 'a', 'tree.'], ['edited_ending:', 'Eventually', 'I', 'learned', 'the', 'importance', 'of', 'practicing.', 'Now', 'I', 'love', 'to', 'practice', 'things.', 'It', 'helps', 'me', 'get', 'better', 'at', 'the', 'thing', 'I', 'like', 'to', 'do.'], ['edited_ending:', 'I', 'forgot', 'to', 'spray', 'the', 'pan', 'with', 'it.', 'I', 'immediately', 'sprayed', 'it.', 'As', 'soon', 'as', 'I', 'did', 'that,', 'flames', 'erupted.'], ['edited_ending:', 'I', 'had', 'decided', 'to', 'try', 'to', 'prove', 'that', 'teacher', 'wrong.', 'I', 'went', 'to', 'law', 'school', 'and', 'studied', 'hard.', 'I', 'became', 'the', 'best', 'attorney', 'in', 'the', 'country.'], ['edited_ending:', 'One', 'night', 'she', 'decides', 'to', 'knit', 'a', 'sweater', 'and', 'send', 'it', 'to', 'her', 'sister.', 'Her', 'sister', 'calls', 'her', 'to', 'thank', 'her', 'for', 'the', 'sweater.', 'Mary', 'is', 'so', 'happy', 'that', 'she', 'and', 'her', 'sister', 'are', 'never', 'speaking', 'again.'], ['edited_ending:', 'When', 'the', 'teacher', 'got', 'mad', 'at', 'Peter', 'he', 'would', 'make', 'Peter', 'skip', 'laps.', 'Peter', 'figured', 'that', 'he', 'just', 'had', 'to', 'follow', 'the', 'rules.', 'Peter', 'followed', 'the', 'rules', 'and', 'the', 'teacher', 'gets', 'mad', 'at', 'him!'], ['edited_ending:', 'She', 'quickly', 'picked', 'it', 'up', 'and', 'examined', 'it.', 'The', 'screen', 'was', 'fine,', 'and', 'the', 'rest', 'appeared', 'to', 'work.', 'Kelly', 'decided', 'that,', 'all', 'in', 'all,', 'she', 'was', 'lucky.'], ['edited_ending:', 'She', 'got', 'a', 'full', 'scholarship', 'to', 'a', 'University.', 'Now', 'Samira', 'is', 'studying', 'to', 'become', 'an', 'Engineer.', \"She's\", 'very', 'thankful', 'for', 'all', 'of', 'her', 'hard', 'work.'], ['edited_ending:', 'Then', 'she', 'remembered', 'that', 'one', 'time', 'she', 'faked', 'being', 'happy.', 'To', 'her', 'surprise', 'it', 'actually', 'helped', 'her', 'to', 'feel', 'a', 'little', 'bit', 'better.', 'Now', 'she', 'fakes', 'to', 'be', 'happy', 'anytime', \"she's\", 'feeling', 'sad.'], ['edited_ending:', 'Five', 'years', 'later', 'he', 'went', 'back', 'to', 'the', 'bank.', 'He', 'asked', 'to', 'withdraw', 'the', 'money', 'he', 'had', 'deposited.', 'The', 'bank', 'teller', 'told', 'him', 'his', 'account', 'now', 'had', 'fifty', 'dollars.'], ['edited_ending:', 'The', 'mosquito', 'was', 'brewing', 'and', 'the', 'smell', 'pulled', 'her', 'fully', 'awake.', 'Eyes', 'now', 'open,', 'Mia,', 'threw', 'the', 'blankets', 'off', 'of', 'her.', 'She', 'slipped', 'on', 'her', 'slippers', 'and', 'ran', 'down', 'stairs.'], ['edited_ending:', 'She', 'was', 'already', 'in', 'love', 'with', 'him', 'so', 'she', 'decided', 'to', 'try', 'again.', 'Unfortunately,', 'her', 'husband', \"didn't\", 'think', 'that', 'highly', 'of', 'their', 'marriage.', 'He', 'cheated', 'on', 'Raquel', 'the', 'same', 'way', 'he', 'cheated', 'on', 'the', 'girl', 'before', 'her.'], ['edited_ending:', 'He', 'began', 'yelling', 'and', 'making', 'demands', 'all', 'at', 'once.', 'Eventually', 'security', 'came', 'in,', 'but', 'the', 'executive', 'turned', 'them', 'back.', 'He', 'listened', 'patiently', 'as', 'the', 'men', 'aired', 'their', 'grievances', 'more', 'calmly.'], ['edited_ending:', 'They', 'had', 'already', 'talked', 'about', 'the', 'frequent', 'stops.', 'Now', 'they', 'were', 'talking', 'to', 'each', 'other.', 'They', 'drove', 'down', 'the', 'highway', 'in', 'an', 'awkward,', 'uncomfortable', 'silence.']]\n"
],
[
"#bs = bleu_score([pre_corpus[0]], [act_corpus[0]], max_n=1, weights=[1])\n#bs = bleu_score([pre_corpus[0]], [act_corpus[0]], max_n=2, weights=[0.5, 0.5])\nbs_1 = bleu_score(pre_corpus, act_corpus, max_n=1, weights=[1])\n#bs_2 = bleu_score(pre_corpus, act_corpus, max_n=2, weights=[0.1, 0.9])\n#print(f'bs_1: {bs_1:.5f}, bs_2: {bs_2:.5f}')\nprint(f'bleus_1: {bs_1:.5f}')",
"bleus_1: 0.02605\n"
]
],
[
[
"## 7.2 ROUGE",
"_____no_output_____"
]
],
[
[
"!pip install rouge",
"Collecting rouge\n Downloading rouge-1.0.1-py3-none-any.whl (13 kB)\nRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from rouge) (1.15.0)\nInstalling collected packages: rouge\nSuccessfully installed rouge-1.0.1\n"
],
[
"from rouge import Rouge \ndef compute_rouge(predictions, targets):\n predictions = [\" \".join(prediction).lower() for prediction in predictions]\n predictions = [prediction if prediction else \"EMPTY\" for prediction in predictions]\n targets = [\" \".join(target).lower() for target in targets]\n targets = [target if target else \"EMPTY\" for target in targets]\n rouge = Rouge()\n scores = rouge.get_scores(hyps=predictions, refs=targets, avg=True)\n return scores['rouge-1']['f']",
"_____no_output_____"
],
[
"rouge_1 = compute_rouge(predictions, actuals)\nprint(f'rouge_1: {rouge_1:.5f}')",
"rouge_1: 0.96353\n"
]
],
[
[
"## 7.3 T5 loss (cross entropy), discussed before",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"print(final_loss / len(part_large_cleaned_df))",
"tensor(0.9354, device='cuda:0')\n"
],
[
"# source = tokenizer.encode_plus(predictions, max_length= config.SOURCE_LEN, padding='max_length', return_tensors='pt')\n# target = tokenizer.encode_plus(actuals, max_length= config.TARGET_LEN, padding='max_length', return_tensors='pt')\n\n# source_ids = source['input_ids'].squeeze()\n# target_ids = target['input_ids'].squeeze()",
"_____no_output_____"
],
[
"# encode the sources OOM\n'''\nsource_encoding = tokenizer(\n predictions, max_length= config.SOURCE_LEN, padding='max_length', return_tensors='pt'\n )\noriginal, attention_mask = source_encoding.input_ids, source_encoding.attention_mask\n\n# encode the targets\ntarget_encoding = tokenizer(\n actuals, max_length= config.TARGET_LEN, padding='max_length', return_tensors='pt'\n )\nending = target_encoding.input_ids\nending[ending == tokenizer.pad_token_id] = -100\n\noriginal, attention_mask, ending = original.to(device), attention_mask.to(device), ending.to(device)\n# forward pass\nloss = model(input_ids=original, attention_mask=attention_mask, labels=ending).loss\n'''",
"_____no_output_____"
],
[
"print(a)",
"I paid the cashier and patiently waited for my drink.\n"
],
[
"print(a.splitlines())",
"['I paid the cashier and patiently waited for my drink.']\n"
],
[
"diff = d.compare(a.splitlines(), b.splitlines())",
"_____no_output_____"
],
[
"a = \"I paid the cashier and patiently waited for my drink.\"\nb = \"I paid the cashier and patiently waited at the counter for my drink.\"\n\nfrom difflib import Differ\nd = Differ()\ndiff = d.compare(a.splitlines(), b.splitlines())\nprint('\\n'.join(list(diff)))",
"- I paid the cashier and patiently waited for my drink.\n+ I paid the cashier and patiently waited at the counter for my drink.\n? +++++++++++++++\n\n"
],
[
"import difflib\na = \"I paid the cashier and patiently waited for my drink.\"\nb = \"I paid the cashier and patiently waited at the counter for my drink.\"\ns = difflib.SequenceMatcher(None, a, b)\nfor block in s.get_matching_blocks():\n print(block)\n \n",
"Match(a=0, b=0, size=40)\nMatch(a=40, b=55, size=13)\nMatch(a=53, b=68, size=0)\n"
],
[
"import difflib\na = \"I paid the cashier and patiently waited acoorinding to for my drink.\"\nb = \"I paid the cashier and patiently waited at the counter for my drink.\"\ns = difflib.SequenceMatcher(None, a, b)\n\nmatches = []\nfor block in s.get_matching_blocks():\n #matches.append([block[0], block[1], block[2]])\n matches.append([i for i in block])\n #matches.append(block)\nprint(matches) \n\n\n# explanation: matches[i, 0] are the a index, matches[i, 1] are the b index, matches[i, 2] are the lengths of same (matched) words.",
"[[0, 0, 41], [41, 47, 2], [44, 53, 1], [54, 54, 14], [68, 68, 0]]\n"
],
[
"changes = []\nfor i in range(len(matches) - 1):\n print(matches[i])\n if ((a[i,0]+ a[i,2] < a[i+1,0]) && (b[i,0]+ b[i,2] < b[i+1,0])): # replacing\n changes.append(f\"{a[i,0]+a[i,1]}-{a[i,2]}: {}\")",
"[0, 0, 41]\n[41, 47, 2]\n[44, 53, 1]\n[54, 54, 14]\n"
],
[
"print(a)",
"_____no_output_____"
],
[
"print(len(a))",
"53\n"
],
[
"a1 = tokenizer(a)\nprint(a1)",
"{'input_ids': [27, 1866, 8, 1723, 972, 11, 1868, 120, 3, 13106, 3, 9, 509, 32, 13119, 53, 12, 21, 82, 3281, 5, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c0a11baccf3dc6852649a3c2c41c0f65290904 | 13,276 | ipynb | Jupyter Notebook | notebooks/04_global_alignment.ipynb | asabenhur/CS425 | c0d6aa7c2af3c2030ceb93996b904000059be4c3 | [
"MIT"
]
| null | null | null | notebooks/04_global_alignment.ipynb | asabenhur/CS425 | c0d6aa7c2af3c2030ceb93996b904000059be4c3 | [
"MIT"
]
| null | null | null | notebooks/04_global_alignment.ipynb | asabenhur/CS425 | c0d6aa7c2af3c2030ceb93996b904000059be4c3 | [
"MIT"
]
| null | null | null | 32.942928 | 145 | 0.392437 | [
[
[
"<a href=\"https://colab.research.google.com/github//asabenhur/CS425/blob/master/notebooks/04_global_alignment.ipynb\">\n <img align=\"left\" src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/>\n</a>",
"_____no_output_____"
],
[
"# Global Alignment: The Needleman Wunsch Algorithm\n\nThe objective of this notebook is to help you familiarize yourself with the Needleman Wunsch algorithm for pairwise alignment of sequences.",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"# to print colored arrows you will need the termcolor module\n# if you don't have it, traceback arrows will be printed \n# without color\ncolor = True\ntry :\n from termcolor import colored\nexcept :\n color = False\n\n# the three directions you can go in the traceback:\nDIAG = 0 \nUP = 1 \nLEFT = 2\n# UTF-8 representations of arrow symbols\n# arrows[DIAG] is a diagonal arrow\n# arrows[UP] is an up arrow\n# arrows[LEFT] is a left\narrows = [u\"\\u2196\", u\"\\u2191\", u\"\\u2190\"]\n\ndef needleman_wunsch_matrix(seq1, seq2, \n match=1, mismatch=-1, indel=-1):\n \"\"\"\n Fill the DP matrix according to the Needleman-Wunsch \n algorithm for two sequences seq1 and seq2.\n match: the match score\n mismatch: the mismatch score\n indel: the indel score\n \n Returns the matrix of scores and the matrix of pointers\n \"\"\"\n n = len(seq1)\n m = len(seq2)\n s = np.zeros( (n+1, m+1) ) # DP matrix\n ptr = np.zeros( (n+1, m+1), dtype=int ) # matrix of pointers\n\n ##### INITIALIZE SCORING MATRIX (base case) #####\n\n for i in range(1, n+1) :\n s[i,0] = indel * i\n for j in range(1, m+1):\n s[0,j] = indel * j\n \n ########## INITIALIZE TRACEBACK MATRIX ##########\n\n # Tag first row by LEFT, indicating initial '-'s\n ptr[0,1:] = LEFT\n \n # Tag first column by UP, indicating initial '-'s\n ptr[1:,0] = UP\n\n #####################################################\n\n for i in range(1,n+1):\n for j in range(1,m+1): \n # match\n if seq1[i-1] == seq2[j-1]:\n s[i,j] = s[i-1,j-1] + match\n ptr[i,j] = DIAG\n # mismatch\n else :\n s[i,j] = s[i-1,j-1] + mismatch\n ptr[i,j] = DIAG\n # indel penalty\n if s[i-1,j] + indel > s[i,j] :\n s[i,j] = s[i-1,j] + indel\n ptr[i,j] = UP\n # indel penalty\n if s[i, j-1] + indel > s[i,j]:\n s[i,j] = s[i, j-1] + indel\n ptr[i,j] = LEFT\n\n return s, ptr\n\ndef needleman_wunsch_trace(seq1, seq2, s, ptr) :\n\n #### TRACE BEST PATH TO GET ALIGNMENT ####\n align1 = \"\"\n align2 = \"\"\n n, m = (len(seq1), len(seq2))\n i = n\n j = m\n curr = ptr[i, j]\n while (i > 0 or j > 0): \n ptr[i,j] += 3\n if curr == DIAG : \n align1 = seq1[i-1] + align1\n align2 = seq2[j-1] + align2\n i -= 1\n j -= 1 \n elif curr == LEFT:\n align1 = '-' + align1\n align2 = seq2[j-1] + align2\n j -= 1 \n elif curr == UP:\n align1 = seq1[i-1] + align1\n align2 = '-' + align2\n i -= 1\n \n curr = ptr[i,j]\n\n return align1, align2\n",
"_____no_output_____"
],
[
"def show_ptr_matrix(ptr, seq1, seq2) :\n\n print('\\n'+'~`'*25)\n print(\"Traceback\")\n global color\n print(\" \" + \" \".join(seq2))\n for i in range(len(ptr)) :\n if (i > 0) :\n print (seq1[i-1] + \" \",end=\"\")\n if (i == 0) :\n print(\" \",end=\"\")\n for j in range(len(ptr[i])) :\n if color and ptr[i,j] >= 3 :\n print(\" \" + colored(arrows[ptr[i,j]-3], 'green' ),\n end=\"\")\n else :\n if ptr[i,j] >=3 :\n ptr[i,j] -=3\n print(\" \" + arrows[ptr[i,j]],end=\"\")\n print() \n\ndef show_dp_matrix(s, seq1, seq2) :\n\n print('\\n'+'~`'*25)\n print(\"DP matrix\")\n print(\" \" + \" \".join(seq2))\n for i in range(len(s)) :\n if (i > 0) :\n print(seq1[i-1] + \" \",end=\"\")\n if (i == 0) :\n print(\" \",end=\"\")\n for j in range(len(s[i])) :\n print(\" \" + \"% 2.1f\" % s[i,j],end=\"\")\n print() \n ",
"_____no_output_____"
],
[
"def needleman_wunsch(seq1, seq2, match=1, mismatch=-1, indel=-1,\n verbose=True) :\n \"\"\"\n computes an optimal global alignment of two sequences using \n the Needleman-Wunsch algorithm\n returns the alignment and its score\n \"\"\"\n s,ptr = needleman_wunsch_matrix(seq1, seq2, \n match, mismatch, indel)\n alignment = needleman_wunsch_trace(seq1, seq2, s, ptr)\n\n if verbose :\n show_dp_matrix(s, seq1, seq2)\n show_ptr_matrix(ptr, seq1, seq2)\n print('\\n'+'~`'*25)\n print(\"Alignment Score: %f\\n\" % (s[len(seq1),len(seq2)]))\n print(\"Alignment:\")\n print(alignment[0])\n print(alignment[1])\n \n return alignment, s[len(seq1), len(seq2)]\n",
"_____no_output_____"
],
[
"from random import randint\ndef random_DNA_sequence(length):\n \"\"\"\n Returns a random DNA of the given length.\n \"\"\"\n nucleotides = ['A','T','G','C']\n seq = [ nucleotides[randint(0,3)] for i in range(length) ]\n return ''.join(seq)",
"_____no_output_____"
],
[
"seq1 = random_DNA_sequence(10)\nseq2 = random_DNA_sequence(10)",
"_____no_output_____"
],
[
"needleman_wunsch(seq1, seq2, 1, -1, -1)",
"\n~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`\nDP matrix\n A T G T C G C T T A\n 0.0 -1.0 -2.0 -3.0 -4.0 -5.0 -6.0 -7.0 -8.0 -9.0 -10.0\nA -1.0 1.0 0.0 -1.0 -2.0 -3.0 -4.0 -5.0 -6.0 -7.0 -8.0\nT -2.0 0.0 2.0 1.0 0.0 -1.0 -2.0 -3.0 -4.0 -5.0 -6.0\nA -3.0 -1.0 1.0 1.0 0.0 -1.0 -2.0 -3.0 -4.0 -5.0 -4.0\nC -4.0 -2.0 0.0 0.0 0.0 1.0 0.0 -1.0 -2.0 -3.0 -4.0\nA -5.0 -3.0 -1.0 -1.0 -1.0 0.0 0.0 -1.0 -2.0 -3.0 -2.0\nC -6.0 -4.0 -2.0 -2.0 -2.0 0.0 -1.0 1.0 0.0 -1.0 -2.0\nT -7.0 -5.0 -3.0 -3.0 -1.0 -1.0 -1.0 0.0 2.0 1.0 0.0\nC -8.0 -6.0 -4.0 -4.0 -2.0 0.0 -1.0 0.0 1.0 1.0 0.0\nC -9.0 -7.0 -5.0 -5.0 -3.0 -1.0 -1.0 0.0 0.0 0.0 0.0\nG -10.0 -8.0 -6.0 -4.0 -4.0 -2.0 0.0 -1.0 -1.0 -1.0 -1.0\n\n~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`\nTraceback\n A T G T C G C T T A\n ↖ ← ← ← ← ← ← ← ← ← ←\nA ↑ \u001b[32m↖\u001b[0m ← ← ← ← ← ← ← ← ↖\nT ↑ ↑ \u001b[32m↖\u001b[0m \u001b[32m←\u001b[0m ↖ ← ← ← ↖ ↖ ←\nA ↑ ↖ ↑ ↖ \u001b[32m↖\u001b[0m ↖ ↖ ↖ ↖ ↖ ↖\nC ↑ ↑ ↑ ↖ ↖ \u001b[32m↖\u001b[0m ← ↖ ← ← ←\nA ↑ ↖ ↑ ↖ ↖ ↑ \u001b[32m↖\u001b[0m ↖ ↖ ↖ ↖\nC ↑ ↑ ↑ ↖ ↖ ↖ ↖ \u001b[32m↖\u001b[0m ← ← ←\nT ↑ ↑ ↖ ↖ ↖ ↑ ↖ ↑ \u001b[32m↖\u001b[0m ↖ ←\nC ↑ ↑ ↑ ↖ ↑ ↖ ← ↖ \u001b[32m↑\u001b[0m ↖ ↖\nC ↑ ↑ ↑ ↖ ↑ ↖ ↖ ↖ ↑ \u001b[32m↖\u001b[0m ↖\nG ↑ ↑ ↑ ↖ ↑ ↑ ↖ ↑ ↖ ↖ \u001b[32m↖\u001b[0m\n\n~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`\nAlignment Score: -1.000000\n\nAlignment:\nAT-ACACTCCG\nATGTCGCT-TA\n"
],
[
"needleman_wunsch(seq1, seq2, 1, -1, -0.1)",
"\n~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`\nDP matrix\n A T G T C G C T T A\n 0.0 -0.1 -0.2 -0.3 -0.4 -0.5 -0.6 -0.7 -0.8 -0.9 -1.0\nA -0.1 1.0 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1\nT -0.2 0.9 2.0 1.9 1.8 1.7 1.6 1.5 1.4 1.3 1.2\nA -0.3 0.8 1.9 1.8 1.7 1.6 1.5 1.4 1.3 1.2 2.3\nC -0.4 0.7 1.8 1.7 1.6 2.7 2.6 2.5 2.4 2.3 2.2\nA -0.5 0.6 1.7 1.6 1.5 2.6 2.5 2.4 2.3 2.2 3.3\nC -0.6 0.5 1.6 1.5 1.4 2.5 2.4 3.5 3.4 3.3 3.2\nT -0.7 0.4 1.5 1.4 2.5 2.4 2.3 3.4 4.5 4.4 4.3\nC -0.8 0.3 1.4 1.3 2.4 3.5 3.4 3.3 4.4 4.3 4.2\nC -0.9 0.2 1.3 1.2 2.3 3.4 3.3 4.4 4.3 4.2 4.1\nG -1.0 0.1 1.2 2.3 2.2 3.3 4.4 4.3 4.2 4.1 4.0\n\n~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`\nTraceback\n A T G T C G C T T A\n ↖ ← ← ← ← ← ← ← ← ← ←\nA ↑ \u001b[32m↖\u001b[0m \u001b[32m←\u001b[0m \u001b[32m←\u001b[0m ← ← ← ← ← ← ←\nT ↑ ↑ ↖ ← \u001b[32m↖\u001b[0m ← ← ← ↖ ↖ ←\nA ↑ ↖ ↑ ↑ \u001b[32m↑\u001b[0m ↑ ↑ ↑ ↑ ↑ ↖\nC ↑ ↑ ↑ ↑ ↑ \u001b[32m↖\u001b[0m \u001b[32m←\u001b[0m ↖ ← ← ↑\nA ↑ ↑ ↑ ↑ ↑ ↑ \u001b[32m↑\u001b[0m ↑ ↑ ↑ ↖\nC ↑ ↑ ↑ ↑ ↑ ↖ ↑ \u001b[32m↖\u001b[0m \u001b[32m←\u001b[0m ← ↑\nT ↑ ↑ ↖ ← ↖ ↑ ↑ ↑ ↖ \u001b[32m↖\u001b[0m \u001b[32m←\u001b[0m\nC ↑ ↑ ↑ ↑ ↑ ↖ ← ↖ ↑ ↑ \u001b[32m↑\u001b[0m\nC ↑ ↑ ↑ ↑ ↑ ↖ ↑ ↖ ↑ ↑ \u001b[32m↑\u001b[0m\nG ↑ ↑ ↑ ↖ ← ↑ ↖ ↑ ↑ ↑ \u001b[32m↑\u001b[0m\n\n~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`~`\nAlignment Score: 4.000000\n\nAlignment:\nA--TAC-AC-T-CCG\nATGT-CG-CTTA---\n"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c0aca7bfb835d1a1638da8b611ba29149ffc30 | 85,434 | ipynb | Jupyter Notebook | HW5/notebook/HW5.ipynb | okuchap/SML | 4a301293524e21d31c8cc65cdd21cf72f89ecdc5 | [
"MIT"
]
| null | null | null | HW5/notebook/HW5.ipynb | okuchap/SML | 4a301293524e21d31c8cc65cdd21cf72f89ecdc5 | [
"MIT"
]
| null | null | null | HW5/notebook/HW5.ipynb | okuchap/SML | 4a301293524e21d31c8cc65cdd21cf72f89ecdc5 | [
"MIT"
]
| null | null | null | 130.234756 | 25,380 | 0.891905 | [
[
[
"import numpy as np\nfrom scipy.linalg import sqrtm\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"N = 1000",
"_____no_output_____"
],
[
"s_gauss = np.random.randn(N)*2 + 3",
"_____no_output_____"
],
[
"s_uniform = np.random.rand(N) * 3 - 2",
"_____no_output_____"
],
[
"S = np.array([s_gauss, s_uniform])",
"_____no_output_____"
],
[
"M = np.array([[1,3],[5,1]])",
"_____no_output_____"
],
[
"X = np.dot(M, S)",
"_____no_output_____"
],
[
"X.shape",
"_____no_output_____"
],
[
"def plot(x1, line=None):\n x = x1[0]\n y = x1[1]\n plt.plot(x, y, 'ro', ms=3, label='class1')\n\n if not (line is None):\n plt.plot(line[0], line[1], 'k-', ms=5)\n \n #plt.xlim(np.min(x)-1, np.max(x)+1)\n #plt.ylim(np.min(y)-1, np.max(y)+1)\n \n plt.show()",
"_____no_output_____"
],
[
"plot(X)",
"_____no_output_____"
],
[
"def centering_sphering(X):\n '''\n X: d x n matrix\n '''\n n = X.shape[1]\n H = np.eye(n) - np.ones((n,n))/n\n XH = np.dot(X, H)\n temp = sqrtm(np.linalg.inv(np.dot(XH, XH.T)/n))\n X_tilde = np.dot(temp, XH)\n return X_tilde",
"_____no_output_____"
],
[
"X_tilde = centering_sphering(X)",
"_____no_output_____"
],
[
"X_tilde.shape",
"_____no_output_____"
],
[
"np.mean(X_tilde[0])",
"_____no_output_____"
],
[
"np.std(X_tilde[0])",
"_____no_output_____"
],
[
"A = np.array([[3,1], [1,3]])",
"_____no_output_____"
],
[
"_, lamb = np.linalg.eig(A)",
"_____no_output_____"
],
[
"lamb",
"_____no_output_____"
],
[
"np.dot(A, lamb)",
"_____no_output_____"
],
[
"1e-08",
"_____no_output_____"
],
[
"np.inf",
"_____no_output_____"
],
[
"def approx_newton(X, Nlim=50):\n '''\n X should be normalized.\n X: d x n matrix\n '''\n n = X.shape[1]\n b = np.array([1,0])\n threshold = 1e-08\n diff = np.inf\n n_loop = 1\n \n while n_loop < Nlim:\n #print(b)\n b_prev = b\n sum = 0\n for i in range(n):\n sum += X[:, i] * (np.dot(b, X[:, i]) ** 3)\n b = 3 * b - sum/n\n b = b / np.linalg.norm(b)\n diff = np.linalg.norm(b - b_prev)\n if (diff < threshold):\n break\n else:\n n_loop += 1\n \n if n_loop == Nlim:\n print('may not be converged')\n \n return b",
"_____no_output_____"
],
[
"approx_newton(X_tilde)",
"[1 0]\n[ 0.99206035 -0.12576269]\n[ 0.99465987 -0.10320727]\n[ 0.99422366 -0.10732807]\n[ 0.99430417 -0.10657966]\n[ 0.99428957 -0.10671572]\n[ 0.99429223 -0.10669099]\n[ 0.99429174 -0.10669549]\n[ 0.99429183 -0.10669467]\n[ 0.99429182 -0.10669482]\n[ 0.99429182 -0.10669479]\n"
],
[
"b = approx_newton(X_tilde)",
"_____no_output_____"
],
[
"plot(X_tilde)",
"_____no_output_____"
],
[
"def line(b, X):\n x_min = np.min(X[0])\n x_max = np.max(X[1])\n x = np.linspace(x_min, x_max, 1000)\n return [x, (b[1]/b[0])*x]",
"_____no_output_____"
],
[
"plot(X_tilde, line(b, X_tilde))",
"_____no_output_____"
]
],
[
[
"# Summary",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom scipy.linalg import sqrtm\nimport matplotlib.pyplot as plt\n\nN = 1000",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7c0b1f211d11c708fc481f605ac0a2545835a65 | 1,908 | ipynb | Jupyter Notebook | docs/_downloads/29369f7678f70a010207df843f9d0358/plot__facet_wrapping.ipynb | IKupriyanov-HORIS/lets-plot-docs | 30fd31cb03dc649a03518b0c9348639ebfe09d53 | [
"MIT"
]
| null | null | null | docs/_downloads/29369f7678f70a010207df843f9d0358/plot__facet_wrapping.ipynb | IKupriyanov-HORIS/lets-plot-docs | 30fd31cb03dc649a03518b0c9348639ebfe09d53 | [
"MIT"
]
| null | null | null | docs/_downloads/29369f7678f70a010207df843f9d0358/plot__facet_wrapping.ipynb | IKupriyanov-HORIS/lets-plot-docs | 30fd31cb03dc649a03518b0c9348639ebfe09d53 | [
"MIT"
]
| null | null | null | 21.931034 | 123 | 0.471174 | [
[
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"\n# Facet Wrapping\n\nFacets divide a plot into subplots based on the values of one or more\ndiscrete variable.\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\nfrom lets_plot import *\nLetsPlot.setup_html()",
"_____no_output_____"
],
[
"df = pd.read_csv('https://raw.githubusercontent.com/JetBrains/lets-plot-docs/master/data/mpg.csv')",
"_____no_output_____"
],
[
"p = ggplot(df, aes('cty', 'hwy')) + geom_point()\np",
"_____no_output_____"
],
[
"p + facet_wrap(facets='fl', ncol=3)",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
e7c0cca800ed484d87bd2562bf3b2a12821b133a | 11,651 | ipynb | Jupyter Notebook | Naive_Bayes/Naive_bayes_classifier.ipynb | Ajith013/Machine_learning | ec107196f7ac4a32b3060c7c2551fcb1a800f3e8 | [
"MIT"
]
| null | null | null | Naive_Bayes/Naive_bayes_classifier.ipynb | Ajith013/Machine_learning | ec107196f7ac4a32b3060c7c2551fcb1a800f3e8 | [
"MIT"
]
| null | null | null | Naive_Bayes/Naive_bayes_classifier.ipynb | Ajith013/Machine_learning | ec107196f7ac4a32b3060c7c2551fcb1a800f3e8 | [
"MIT"
]
| null | null | null | 23.924025 | 238 | 0.415329 | [
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom sklearn.model_selection import train_test_split \nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.metrics import accuracy_score",
"_____no_output_____"
],
[
"data = pd.read_csv('iris.data')",
"_____no_output_____"
]
],
[
[
"Now put heading according to the description mentioned in the dataset",
"_____no_output_____"
]
],
[
[
"data.columns = [\"sepal length\", \"sepal width\", \"petal length\", \"petal width\", \"Class\"]",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
]
],
[
[
"Make sure that all the datatypes are correct and consistent",
"_____no_output_____"
]
],
[
[
"data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 149 entries, 0 to 148\nData columns (total 5 columns):\nsepal length 149 non-null float64\nsepal width 149 non-null float64\npetal length 149 non-null float64\npetal width 149 non-null float64\nClass 149 non-null object\ndtypes: float64(4), object(1)\nmemory usage: 5.9+ KB\n"
]
],
[
[
"Dividing the dataset in X and Y (Attributes and Classes)",
"_____no_output_____"
]
],
[
[
"X = data.drop(['Class'], axis = 1)",
"_____no_output_____"
],
[
"Y = data['Class']",
"_____no_output_____"
],
[
"X.head()",
"_____no_output_____"
],
[
"Y.head()",
"_____no_output_____"
]
],
[
[
"Now split the data into training and test data",
"_____no_output_____"
]
],
[
[
"X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state = 0, test_size = 0.30)",
"_____no_output_____"
],
[
"classifier = GaussianNB()\nclassifier.fit(X_train, y_train)",
"_____no_output_____"
]
],
[
[
"__The class prior shows the probability of each class. This can be set before building the model manually. If not then it is handled by the function.In the above cas the priors are not set. So it is adjusted according to the data.__",
"_____no_output_____"
],
[
"__The priors adjusted according to the data are as follows__",
"_____no_output_____"
]
],
[
[
"classifier.class_prior_",
"_____no_output_____"
]
],
[
[
"__Var_smoothing is the portion of the largest variance of all features that is added to variances for calculation stability.In this case the parameter has been set to default.__",
"_____no_output_____"
]
],
[
[
"classifier.get_params()",
"_____no_output_____"
],
[
"y_pred = classifier.predict(X_test)",
"_____no_output_____"
],
[
"cm = confusion_matrix(y_test, y_pred)",
"_____no_output_____"
],
[
"print(\"Confusion matrix: \", cm)",
"Confusion matrix: [[16 0 0]\n [ 0 15 1]\n [ 0 4 9]]\n"
],
[
"print(\"Accuracy of the model: \" ,accuracy_score(y_test, y_pred))",
"Accuracy of the model: 0.8888888888888888\n"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c0cf174a240d0750d2d7ab3067f1218b9a0cf2 | 42,800 | ipynb | Jupyter Notebook | notebooks/Using_Cache.ipynb | madsbk/cucim | e521dd4d7669d224884f1f1274445612b70e3a61 | [
"Apache-2.0"
]
| null | null | null | notebooks/Using_Cache.ipynb | madsbk/cucim | e521dd4d7669d224884f1f1274445612b70e3a61 | [
"Apache-2.0"
]
| null | null | null | notebooks/Using_Cache.ipynb | madsbk/cucim | e521dd4d7669d224884f1f1274445612b70e3a61 | [
"Apache-2.0"
]
| null | null | null | 45.775401 | 404 | 0.58771 | [
[
[
"# Using Cache (available since v21.06.00)\n\n## Need for Cache\n\nIn many deep learning use cases, small image patches need to be extracted from the large image and they are fed into the neural network. \n\nIf the patch size doesn't align with the underlying tile layout of TIFF image (e.g., AI model such as ResNet may accept a particular size of the image [e.g., 224x224] that is smaller than the underlying tile size [256x256]), redundant image loadings for a tile are needed (See the following two figures)\n\n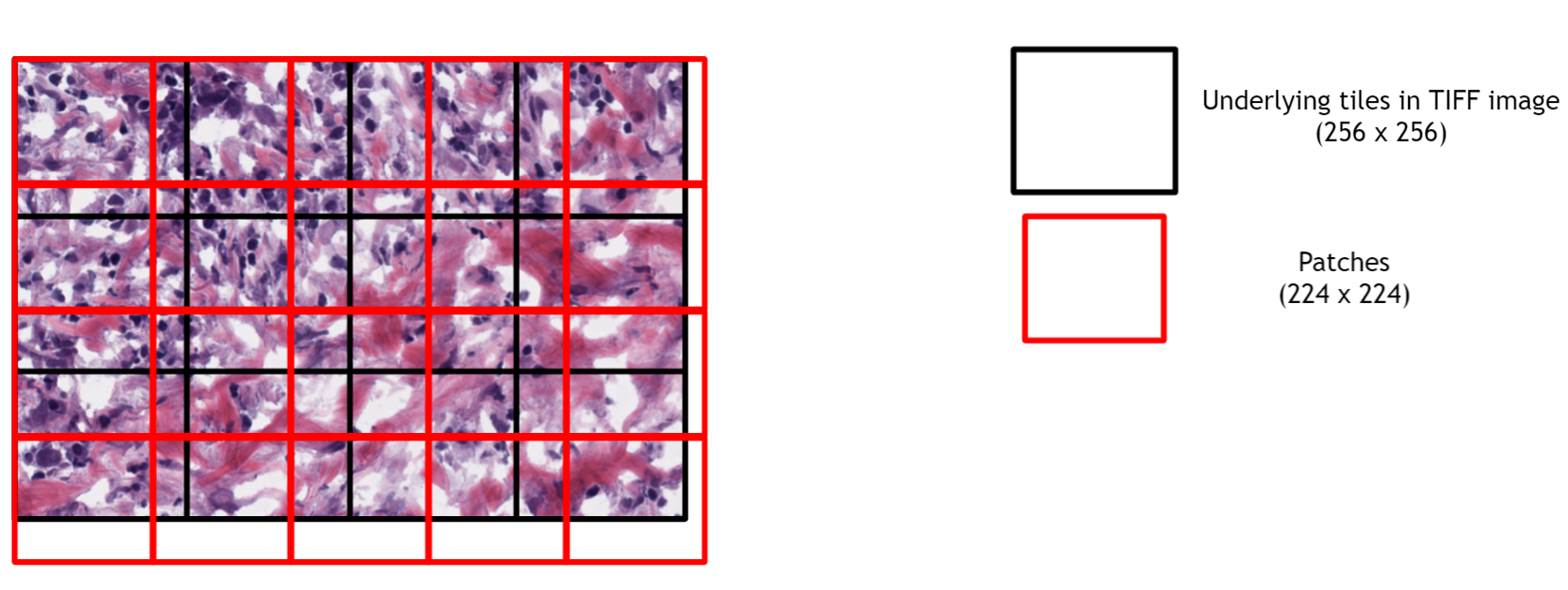\n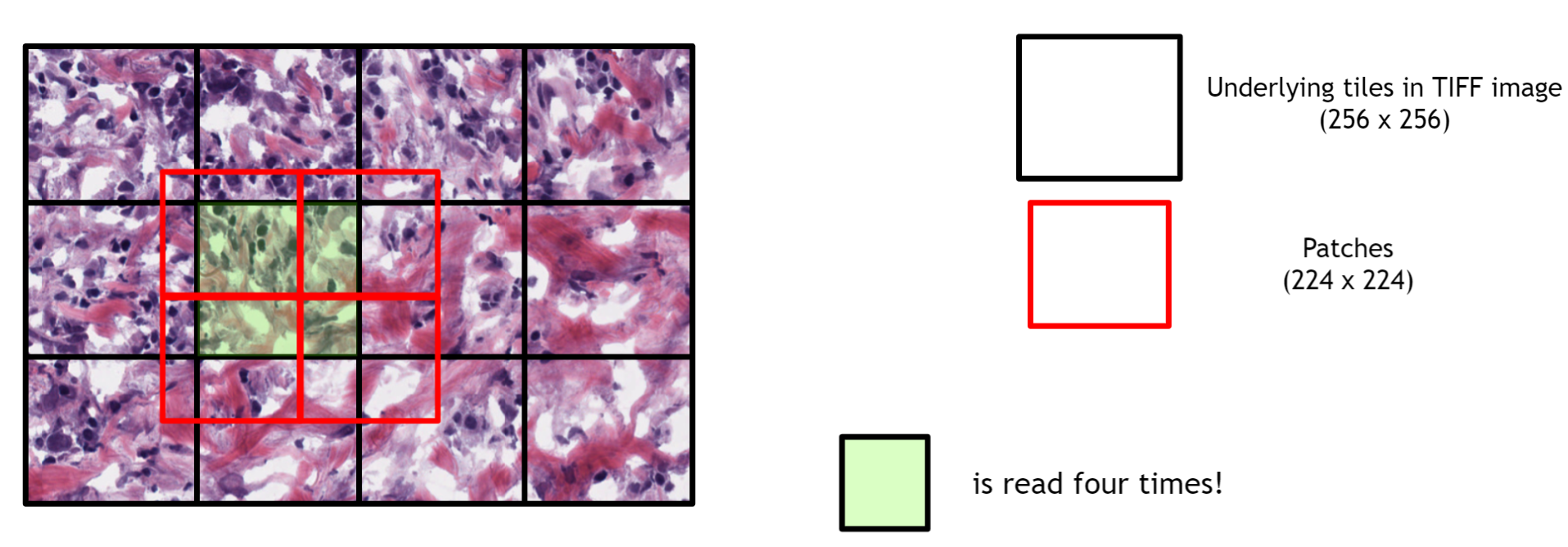\n\nWhich resulted in lower performance for unaligned cases as shown in our [GTC 2021 presentation](https://www.nvidia.com/en-us/gtc/catalog/?search=cuCIM)\n\n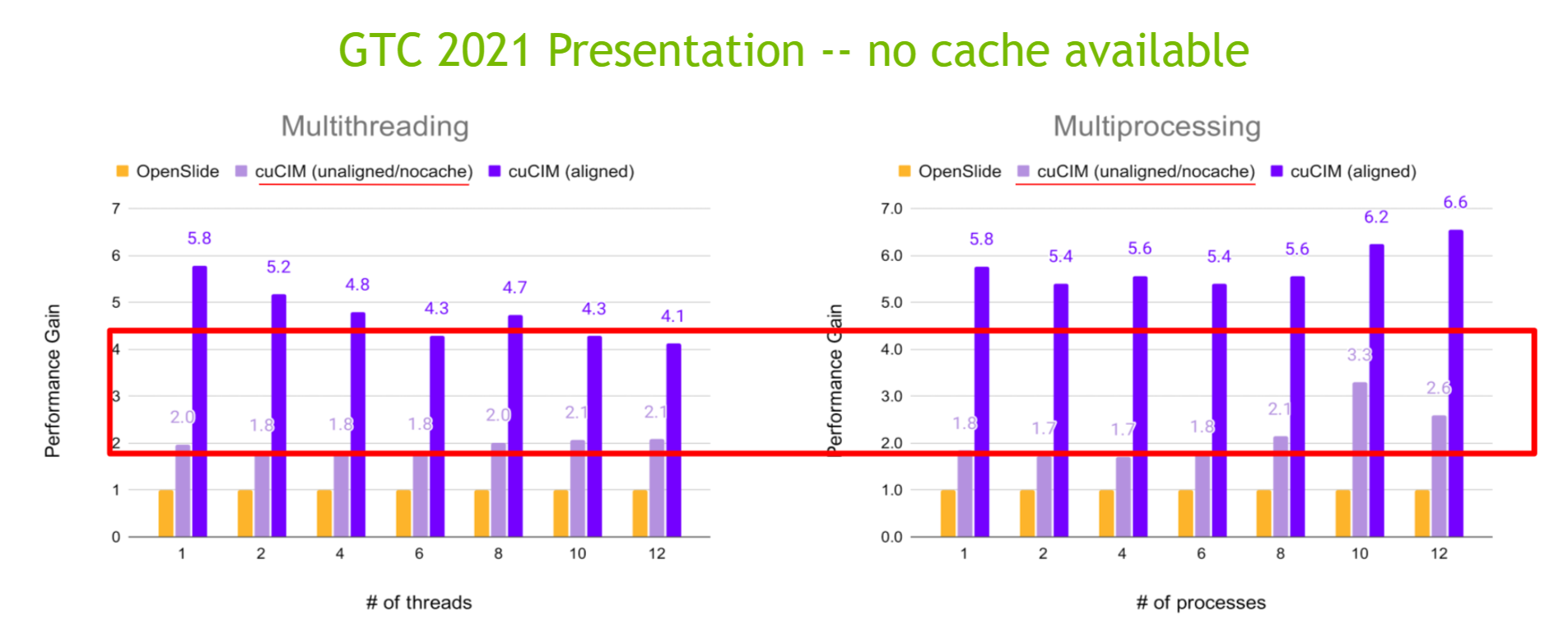\n\n\nThe proper use of cache improves the loading performance greatly, especially for **inference** use cases and when [accessing tiles sequentially (left to right, top to bottom) from one TIFF file](https://nbviewer.jupyter.org/github/rapidsai/cucim/blob/branch-21.06/notebooks/File-access_Experiments_on_TIFF.ipynb#1.-Accessing-tiles-sequentially-(left-to-right,-top-to-bottom)-from-one-TIFF-file).\n\nOn the other hand, if the application [accesses partial tiles randomly from multiple TIFF files](https://nbviewer.jupyter.org/github/rapidsai/cucim/blob/branch-21.06/notebooks/File-access_Experiments_on_TIFF.ipynb#3.-Accessing-partial-tiles-randomly-from-multiple-TIFF-files) (this usually happens for **training** use cases), using a cache could be meaningless.",
"_____no_output_____"
],
[
"## Enabling cache\n\nCurrently, cuCIM supports the following three strategies:\n\n - `nocache`\n - `per_process`\n - `shared_memory` (interprocess)\n\n\n**1) `nocache`**\n\nNo cache.\n\nBy default, this cache strategy is used.\nWith this strategy, the behavior is the same as one before `v20.06.00`.\n\n**2) `per_process`**\n\nThe cache memory is shared among threads.\n\n**3) `shared_memory`**\n\nThe cache memory is shared among processes.\n\n### Getting cache setting\n\n`CuImage.cache()` would return an object that can control the current cache. The object has the following properties:\n\n- `type`: The type (strategy) name\n- `memory_size`: The number of bytes used in the cache memory\n- `memory_capacity`: The maximum number of bytes that can be allocated (used) in the cache memory\n- `free_memory`: The number of bytes available in the cache memory\n- `size`: The number of cache items used\n- `capacity`: The maximum number of cache items that can be created\n- `hit_count`: The cache hit count\n- `miss_count`: The cache miss count\n- `config`: A configuration dictionary that was used for configuring cache.\n",
"_____no_output_____"
]
],
[
[
"from cucim import CuImage\n\ncache = CuImage.cache()\n\nprint(f' type: {cache.type}({int(cache.type)})')\nprint(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')\nprint(f'free_memory: {cache.free_memory}')\nprint(f' size: {cache.size}/{cache.capacity}')\nprint(f' hit_count: {cache.hit_count}')\nprint(f' miss_count: {cache.miss_count}')\nprint(f' config: {cache.config}')\n",
" type: CacheType.NoCache(0)\nmemory_size: 0/0\nfree_memory: 0\n size: 0/0\n hit_count: 0\n miss_count: 0\n config: {'type': 'nocache', 'memory_capacity': 1024, 'capacity': 5461, 'mutex_pool_capacity': 11117, 'list_padding': 10000, 'extra_shared_memory_size': 100, 'record_stat': False}\n"
]
],
[
[
"### Changing Cache Setting\n\nCache configuration can be changed by adding parameters to `cache()` method.\n\nThe following parameters are available:\n\n- `type`: The type (strategy) name. Default to 'no_cache'.\n- `memory_capacity`: The maximum number of mebibytes (`MiB`, 2^20) that can be allocated (used) in the cache memory. Default to `1024`.\n- `capacity`: The maximum number of cache items that can be created. Default to `5461` (= (\\<memory_capacity\\> x 2^20) / (256x256x3)).\n- `mutex_pool_capacity`: The mutex pool size. Default to `11117`.\n- `list_padding`: The number of additional items used for the internal circular queue. Default to `10000`.\n- `extra_shared_memory_size`: The size of additional memory allocation (in MiB) for shared_memory allocator in `shared_process` strategy. Default to `100`.\n- `record_stat`: If the cache statistic should be recorded or not. Default to `False`.\n\nIn most cases, `type`(required) and `memory_capacity` are used.",
"_____no_output_____"
]
],
[
[
"from cucim import CuImage\n\ncache = CuImage.cache('per_process', memory_capacity=2048)\nprint(f' type: {cache.type}({int(cache.type)})')\nprint(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')\nprint(f'free_memory: {cache.free_memory}')\nprint(f' size: {cache.size}/{cache.capacity}')\nprint(f' hit_count: {cache.hit_count}')\nprint(f' miss_count: {cache.miss_count}')\nprint(f' config: {cache.config}')",
" type: CacheType.PerProcess(1)\nmemory_size: 0/2147483648\nfree_memory: 2147483648\n size: 0/10922\n hit_count: 0\n miss_count: 0\n config: {'type': 'per_process', 'memory_capacity': 2048, 'capacity': 10922, 'mutex_pool_capacity': 11117, 'list_padding': 10000, 'extra_shared_memory_size': 100, 'record_stat': False}\n"
]
],
[
[
"## Choosing Proper Cache Memory Size\n\nIt is important to select the appropriate cache memory size (capacity). Small cache memory size results in low cache hit rates. Conversely, if the cache memory size is too large, memory is wasted.\n\nFor example, if the default tile size is 256x256 and the patch size to load is 224x224, the cache memory needs to be large enough to contain at least two rows of tiles in the image to avoid deleting the required cache entries while loading patches sequentially (left to right, top to bottom) from one TIFF file.\n\n\n\ncuCIM provide a utility method (`cucim.clara.cache.preferred_memory_capacity()`) to calculate a preferred cache memory size for the given image (image size and tile size) and the patch size.\n\nInternal logic is available at <https://godbolt.org/z/jY7G84xzT>\n",
"_____no_output_____"
]
],
[
[
"from cucim import CuImage\nfrom cucim.clara.cache import preferred_memory_capacity\n\nimg = CuImage('input/image.tif')\n\nimage_size = img.size('XY') # same with `img.resolutions[\"level_dimensions\"][0]`\ntile_size = img.resolutions['level_tile_sizes'][0] # default: (256, 256)\npatch_size = (1024, 1024) # default: (256, 256)\nbytes_per_pixel = 3 # default: 3\n\nprint(f'image size: {image_size}')\nprint(f'tile size: {tile_size}')\n\n# Below three statements are the same.\nmemory_capacity = preferred_memory_capacity(img, patch_size=patch_size)\nmemory_capacity2 = preferred_memory_capacity(None, image_size, tile_size, patch_size, bytes_per_pixel)\nmemory_capacity3 = preferred_memory_capacity(None, image_size, patch_size=patch_size)\n\nprint(f'memory_capacity : {memory_capacity} MiB')\nprint(f'memory_capacity2: {memory_capacity2} MiB')\nprint(f'memory_capacity3: {memory_capacity3} MiB')\n\ncache = CuImage.cache('per_process', memory_capacity=memory_capacity) # You can also manually set capacity` (e.g., `capacity=500`)\nprint('= Cache Info =')\nprint(f' type: {cache.type}({int(cache.type)})')\nprint(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')\nprint(f' size: {cache.size}/{cache.capacity}')\n",
"image size: [19920, 26420]\ntile size: (256, 256)\nmemory_capacity : 74 MiB\nmemory_capacity2: 74 MiB\nmemory_capacity3: 74 MiB\n= Cache Info =\n type: CacheType.PerProcess(1)\nmemory_size: 0/77594624\n size: 0/394\n"
]
],
[
[
"### Reserve More Cache Memory\n\nIf more cache memory capacity is needed in runtime, you can use `reserve()` method.\n",
"_____no_output_____"
]
],
[
[
"from cucim import CuImage\nfrom cucim.clara.cache import preferred_memory_capacity\n\nimg = CuImage('input/image.tif')\n\nmemory_capacity = preferred_memory_capacity(img, patch_size=(256, 256))\nnew_memory_capacity = preferred_memory_capacity(img, patch_size=(512, 512))\n\nprint(f'memory_capacity : {memory_capacity} MiB')\nprint(f'new_memory_capacity: {new_memory_capacity} MiB')\nprint()\n\ncache = CuImage.cache('per_process', memory_capacity=memory_capacity)\nprint('= Cache Info =')\nprint(f' type: {cache.type}({int(cache.type)})')\nprint(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')\nprint(f' size: {cache.size}/{cache.capacity}')\nprint()\n\ncache.reserve(new_memory_capacity)\nprint('= Cache Info (update memory capacity) =')\nprint(f' type: {cache.type}({int(cache.type)})')\nprint(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')\nprint(f' size: {cache.size}/{cache.capacity}')\nprint()\n\ncache.reserve(memory_capacity, capacity=500)\nprint('= Cache Info (update memory capacity & capacity) =')\nprint(f' type: {cache.type}({int(cache.type)})')\nprint(f'memory_size: {cache.memory_size}/{cache.memory_capacity} # smaller `memory_capacity` value does not change this')\nprint(f' size: {cache.size}/{cache.capacity}')\nprint()\n\ncache = CuImage.cache('no_cache')\nprint('= Cache Info (no cache) =')\nprint(f' type: {cache.type}({int(cache.type)})')\nprint(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')\nprint(f' size: {cache.size}/{cache.capacity}')\n\n",
"memory_capacity : 30 MiB\nnew_memory_capacity: 44 MiB\n\n= Cache Info =\n type: CacheType.PerProcess(1)\nmemory_size: 0/31457280\n size: 0/160\n\n= Cache Info (update memory capacity) =\n type: CacheType.PerProcess(1)\nmemory_size: 0/46137344\n size: 0/234\n\n= Cache Info (update memory capacity & capacity) =\n type: CacheType.PerProcess(1)\nmemory_size: 0/46137344 # smaller `memory_capacity` value does not change this\n size: 0/500\n\n= Cache Info (no cache) =\n type: CacheType.NoCache(0)\nmemory_size: 0/0\n size: 0/0\n"
]
],
[
[
"## Profiling Cache Hit/Miss\n\nIf you add an argument `record_stat=True` to `CuImage.cache()` method, cache statistics is recorded.\n\nCache hit/miss count is accessible through `hit_count`/`miss_count` property of the cache object.\n\nYou can get/set/unset the recording through `record()` method.\n",
"_____no_output_____"
]
],
[
[
"from cucim import CuImage\nfrom cucim.clara.cache import preferred_memory_capacity\n\nimg = CuImage('input/image.tif')\nmemory_capacity = preferred_memory_capacity(img, patch_size=(256, 256))\ncache = CuImage.cache('per_process', memory_capacity=memory_capacity, record_stat=True)\n\nimg.read_region((0,0), (100,100))\nprint(f'cache hit: {cache.hit_count}, cache miss: {cache.miss_count}')\n\nregion = img.read_region((0,0), (100,100))\nprint(f'cache hit: {cache.hit_count}, cache miss: {cache.miss_count}')\n\nregion = img.read_region((0,0), (100,100))\nprint(f'cache hit: {cache.hit_count}, cache miss: {cache.miss_count}')\n\nprint(f'Is recorded: {cache.record()}')\n\ncache.record(False)\nprint(f'Is recorded: {cache.record()}')\n\nregion = img.read_region((0,0), (100,100))\nprint(f'cache hit: {cache.hit_count}, cache miss: {cache.miss_count}')\nprint()\n\nprint(f' type: {cache.type}({int(cache.type)})')\nprint(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')\nprint(f'free_memory: {cache.free_memory}')\nprint(f' size: {cache.size}/{cache.capacity}')\nprint()\n\ncache = CuImage.cache('no_cache')\nprint(f' type: {cache.type}({int(cache.type)})')\nprint(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')\nprint(f'free_memory: {cache.free_memory}')\nprint(f' size: {cache.size}/{cache.capacity}')\n",
"cache hit: 0, cache miss: 1\ncache hit: 1, cache miss: 1\ncache hit: 2, cache miss: 1\nIs recorded: True\nIs recorded: False\ncache hit: 0, cache miss: 0\n\n type: CacheType.PerProcess(1)\nmemory_size: 196608/31457280\nfree_memory: 31260672\n size: 1/160\n\n type: CacheType.NoCache(0)\nmemory_size: 0/0\nfree_memory: 0\n size: 0/0\n"
]
],
[
[
"## Considerations in Multi-threading/processing Environment\n\n\n### `per_process` strategy\n\n#### Cache memory\n\nIf used in the multi-threading environment and each thread is reading the different part of the image sequentially, please consider increasing cache memory size than the size suggested by `cucim.clara.cache.preferred_memory_capacity()` to avoid dropping necessary cache items.\n\nIf used in the multi-processing environment, the cache memory size allocated can be `(# of processes) x (cache memory capacity)`. \n\nPlease be careful not to oversize the memory allocated by the cache.\n\n\n#### Cache Statistics\n\nIf used in the multi-processing environment (e.g, using `concurrent.futures.ProcessPoolExecutor()`), cache hit count (`hit_count`) and miss count (`miss_count`) wouldn't be recorded in the main process's cache object.\n\n\n### `shared_memory` strategy\n\nIn general, `shared_memory` strategy has more overhead than `per_process` strategy. However, it is recommended that you select this strategy if you want to use a fixed size of cache memory regardless of the number of processes.\n\nNote that, this strategy pre-allocates the cache memory in the shared memory and allocates more memory (as specified in `extra_shared_memory_size` parameter) than the requested cache memory size (capacity) for the memory allocator to handle memory segments.\n\n\n#### Cache memory\n\nSince the cache memory would be shared by multiple threads/processes, you will need to set enough cache memory to avoid dropping necessary cache items.\n",
"_____no_output_____"
],
[
"## Setting Default Cache Configuration\n\nThe configuration for cuCIM can be specified in `.cucim.json` file and user can set a default cache settings there.\n\ncuCIM finds `.cucim.json` file from the following order:\n\n1. The current folder\n2. `$HOME/.cucim.json`\n\nThe configuration for the cache can be specified like below.\n\n```jsonc\n\n{\n // This is actually JSONC file so comments are available.\n \"cache\": {\n \"type\": \"nocache\",\n \"memory_capacity\": 1024,\n \"capacity\": 5461,\n \"mutex_pool_capacity\": 11117,\n \"list_padding\": 10000,\n \"extra_shared_memory_size\": 100,\n \"record_stat\": false\n }\n}\n```\n\nYou can write the current cache configuration into the file like below:",
"_____no_output_____"
]
],
[
[
"import json\nfrom cucim import CuImage\n\ncache = CuImage.cache()\nconfig_data = {'cache': cache.config}\njson_text = json.dumps(config_data, indent=4)\nprint(json_text)\n\n# Save into the configuration file.\nwith open('.cucim.json', 'w') as fp:\n fp.write(json_text)",
"{\n \"cache\": {\n \"type\": \"nocache\",\n \"memory_capacity\": 1024,\n \"capacity\": 5461,\n \"mutex_pool_capacity\": 11117,\n \"list_padding\": 10000,\n \"extra_shared_memory_size\": 100,\n \"record_stat\": false\n }\n}\n"
]
],
[
[
"### Cache Mechanism Used in Other Libraries (OpenSlide and rasterio)\n\nOther libraries have the following strategies for the cache.\n\n- [OpenSlide](https://openslide.org/) \n - 1024 x 1024 x 30 bytes (30MiB) per file handle for cache ==> 160 (RGB) or 120 (ARGB) 256x256 tiles\n - Not configurable\n- [rasterio](https://rasterio.readthedocs.io/en/latest/)\n - 5% of available system memory per process by default (e.g., 32 GB of free memory => 1.6 GB of cache memory allocated).\n - Configurable through [environment module](https://rasterio.readthedocs.io/en/latest/api/rasterio.env.html)\n",
"_____no_output_____"
],
[
"## Results\n\ncuCIM has a similar performance gain with the aligned case when the patch and tile layout are not aligned.\n\nWe compared performance against OpenSlide and rasterio.\n\nFor the cache memory size(capacity) setting, we used a similar approach with rasterio (5% of available system memory).\n\n\n### System Information\n\n- OS: Ubuntu 18.04\n- CPU: [Intel(R) Core(TM) i7-7800X CPU @ 3.50GHz](https://www.cpubenchmark.net/cpu.php?cpu=Intel+Core+i7-7800X+%40+3.50GHz&id=3037)\n- Memory: 64GB (G-Skill DDR4 2133 16GB X 4)\n- Storage\n - SATA SSD: [Samsung SSD 850 EVO 1TB](https://www.samsung.com/us/computing/memory-storage/solid-state-drives/ssd-850-evo-2-5-sata-iii-1tb-mz-75e1t0b-am/)\n \n### Experiment Setup\n+ Use read_region() APIs to read all patches (256x256 size each) of a whole slide image (.tif) at the largest resolution level (92,344 x 81,017. Internal tile size is 256 x 256 with 95% JPEG compression quality level) on multithread/multiprocess environment.\n - Original whole slide image (.svs : 1.6GB) was converted into .tif file (3.2GB) using OpenSlide & tifffile library in this experiment (image2.tif).\n * Original image can be downloaded from here(https://drive.google.com/drive/u/0/folders/0B--ztKW0d17XYlBqOXppQmw0M2M , TUPAC-TR-488.svs)\n+ Two different job configurations\n - multithreading: spread workload into multiple threads\n - multiprocessing: spread workload into multiple processes\n+ Two different read configurations for each job configuration\n - unaligned/nocache: (256x256)-patch-reads start from (1,1). e.g., read the region (1,1)-(257,257) then, read the region (257,1)-(513,257), ...\n - aligned: (256x256)-patch-reads start from (0,0). OpenSlide's internal cache mechanism does not affect this case.\n+ Took about 10 samples due to the time to conduct the experiment so there could have some variation in the results.\n+ Note that this experiment doesn’t isolate the effect of system cache (page cache) that we excluded its effect on C++ API benchmark[discard_cache] so IO time itself could be short for both libraries.\n\n### Aligned Case (`per_process`, JPEG-compressed TIFF file)\n\n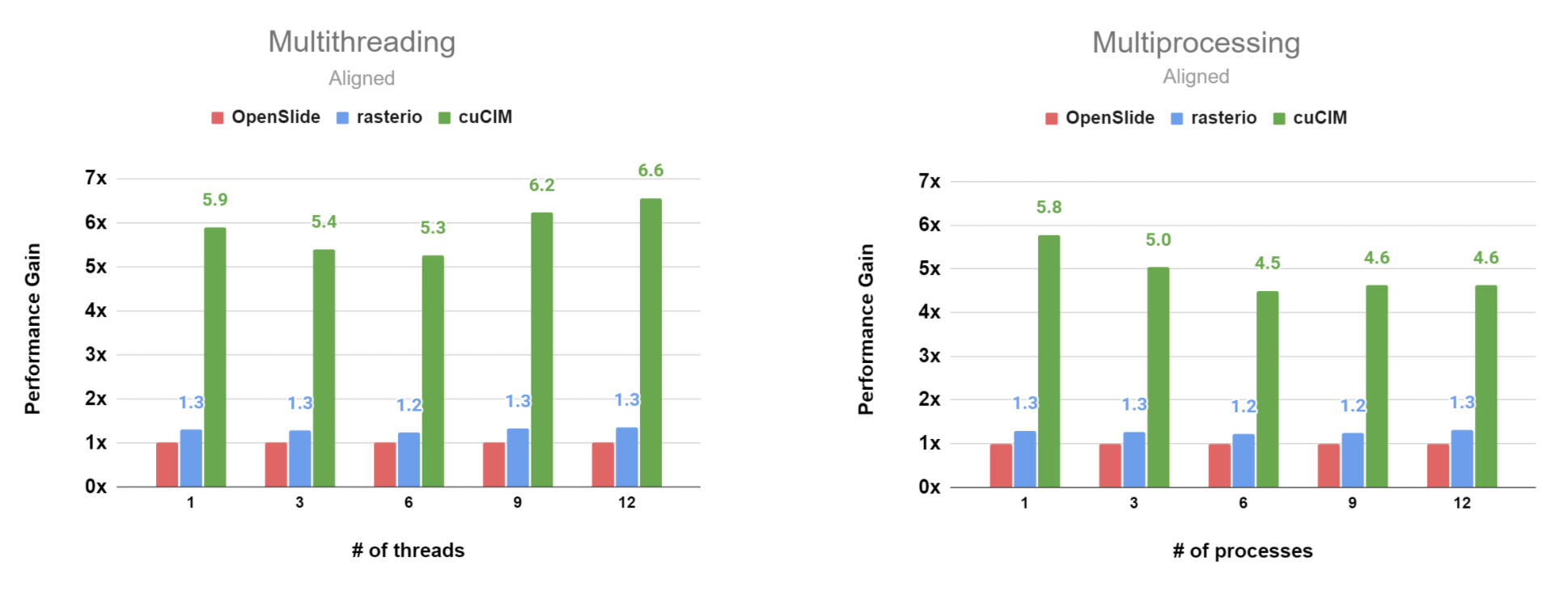\n\n\n### Unaligned Case (`per_process`, JPEG-compressed TIFF file)\n\n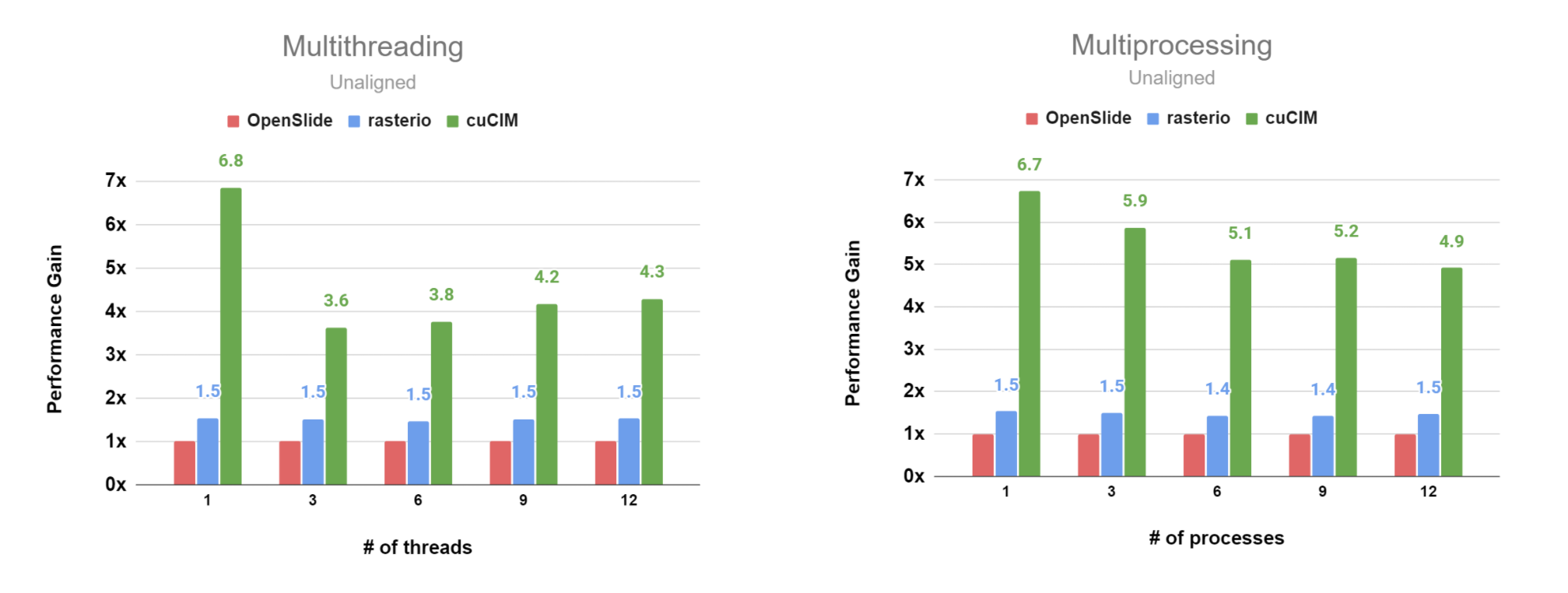\n\n### Overall Performance of `per_process` Compared with `no_cache` for Unaligned Case\n\n\n\n\nThe detailed data is available [here](https://docs.google.com/spreadsheets/d/1eAqs24p25p6iIzZdUlnWNlk_RsrdRfEkIOYB9Xgu67c/edit?usp=sharing).\n",
"_____no_output_____"
],
[
"\n## Room for Improvement\n\n### Using of a Memory Pool\n\n`per_process` strategy performs better than `shared_memory` strategy, and both strategies perform less than `nocache` strategy when underlying tiles and patches are aligned.\n- `shared_memory` strategy does some additional operations compared with `per_process` strategy, and both strategies have some overhead using cache (such as memory allocation for cache item/indirect function calls)\n\n=> All three strategies (including `nocache`) can have benefited if we allocate CPU/GPU memory for tiles from a fixed-sized cache memory pool (using [RMM](https://docs.rapids.ai/api/rmm/stable/basics.html) and/or [PMR](https://en.cppreference.com/w/cpp/memory/synchronized_pool_resource)) instead of calling malloc() to allocate memory.\n\n### Supporting Generator (iterator)\n\nWhen patches to read in an image can be determined in advance (inference use case), we can load/prefetch entire compressed/decompressed image data to the memory and provide Python generator(iterator) to get a series of patches efficiently for inference use cases. \n\n",
"_____no_output_____"
],
[
"## Appendix\n\n### Experiment Code\n\n```python\n#\n# Copyright (c) 2021, NVIDIA CORPORATION.\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\nimport concurrent.futures\nfrom contextlib import ContextDecorator\nfrom datetime import datetime\nfrom itertools import repeat\nfrom time import perf_counter\n\nimport numpy as np\nimport rasterio\nfrom cucim import CuImage\nfrom openslide import OpenSlide\nfrom rasterio.windows import Window\n\n\nclass Timer(ContextDecorator):\n def __init__(self, message):\n self.message = message\n self.end = None\n\n def elapsed_time(self):\n self.end = perf_counter()\n return self.end - self.start\n\n def __enter__(self):\n self.start = perf_counter()\n return self\n\n def __exit__(self, exc_type, exc, exc_tb):\n if not self.end:\n self.elapsed_time()\n print(\"{} : {}\".format(self.message, self.end - self.start))\n\n\ndef load_tile_openslide(slide, start_loc, patch_size):\n _ = slide.read_region(start_loc, 0, [patch_size, patch_size])\n\ndef load_tile_openslide_chunk(inp_file, start_loc_list, patch_size):\n with OpenSlide(inp_file) as slide:\n for start_loc in start_loc_list:\n region = slide.read_region(start_loc, 0, [patch_size, patch_size])\n\ndef load_tile_cucim(slide, start_loc, patch_size):\n _ = slide.read_region(start_loc, [patch_size, patch_size], 0)\n\ndef load_tile_cucim_chunk(inp_file, start_loc_list, patch_size):\n try:\n slide = CuImage(inp_file)\n for start_loc in start_loc_list:\n region = slide.read_region(start_loc, [patch_size, patch_size], 0)\n except Exception as e:\n print(e)\n\nidentity = rasterio.Affine(1, 0, 0, 0, 1, 0)\ndef load_tile_rasterio(slide, start_loc, tile_size):\n _ = np.moveaxis(slide.read([1,2,3],\n window=Window.from_slices((start_loc[0], start_loc[0] + tile_size),(start_loc[1], start_loc[1] + tile_size))), 0, -1)\n\ndef load_tile_rasterio_chunk(input_file, start_loc_list, patch_size):\n identity = rasterio.Affine(1, 0, 0, 0, 1, 0)\n slide = rasterio.open(input_file, transform = identity, num_threads=1)\n for start_loc in start_loc_list:\n _ = np.moveaxis(slide.read([1,2,3],\n window=Window.from_slices((start_loc[0], start_loc[0] + patch_size),(start_loc[1], start_loc[1] + patch_size))), 0, -1)\n\n\ndef load_tile_openslide_chunk_mp(inp_file, start_loc_list, patch_size):\n with OpenSlide(inp_file) as slide:\n for start_loc in start_loc_list:\n region = slide.read_region(start_loc, 0, [patch_size, patch_size])\n\ndef load_tile_cucim_chunk_mp(inp_file, start_loc_list, patch_size):\n slide = CuImage(inp_file)\n for start_loc in start_loc_list:\n region = slide.read_region(start_loc, [patch_size, patch_size], 0)\n\ndef load_tile_rasterio_chunk_mp(input_file, start_loc_list, patch_size):\n slide = rasterio.open(input_file, num_threads=1)\n for start_loc in start_loc_list:\n region = np.moveaxis(slide.read([1,2,3],\n window=Window.from_slices((start_loc[0], start_loc[0] + patch_size),(start_loc[1], start_loc[1] + patch_size))), 0, -1)\n\ndef experiment_thread(cache_strategy, input_file, num_threads, start_location, patch_size):\n import psutil\n print(\" \", psutil.virtual_memory())\n for num_workers in range(1, num_threads + 1): # range(1, num_threads + 1): # (num_threads,):\n openslide_time = 1\n cucim_time = 1\n rasterio_time = 1\n\n with OpenSlide(input_file) as slide:\n width, height = slide.dimensions\n\n start_loc_data = [(sx, sy)\n for sy in range(start_location, height, patch_size)\n for sx in range(start_location, width, patch_size)]\n chunk_size = len(start_loc_data) // num_workers\n start_loc_list_iter = [start_loc_data[i:i+chunk_size] for i in range(0, len(start_loc_data), chunk_size)]\n with Timer(\" Thread elapsed time (OpenSlide)\") as timer:\n with concurrent.futures.ThreadPoolExecutor(\n max_workers=num_workers\n ) as executor:\n executor.map(\n load_tile_openslide_chunk,\n repeat(input_file),\n start_loc_list_iter,\n repeat(patch_size)\n )\n openslide_time = timer.elapsed_time()\n print(\" \", psutil.virtual_memory())\n\n cache_size = psutil.virtual_memory().available // 1024 // 1024 // 20\n cache = CuImage.cache(cache_strategy, memory_capacity=cache_size, record_stat=True)\n cucim_time = 0\n slide = CuImage(input_file)\n start_loc_data = [(sx, sy)\n for sy in range(start_location, height, patch_size)\n for sx in range(start_location, width, patch_size)]\n chunk_size = len(start_loc_data) // num_workers\n start_loc_list_iter = [start_loc_data[i:i+chunk_size] for i in range(0, len(start_loc_data), chunk_size)]\n with Timer(\" Thread elapsed time (cuCIM)\") as timer:\n with concurrent.futures.ThreadPoolExecutor(\n max_workers=num_workers\n ) as executor:\n executor.map(\n load_tile_cucim_chunk,\n repeat(input_file),\n start_loc_list_iter,\n repeat(patch_size)\n )\n cucim_time = timer.elapsed_time()\n print(f\" hit: {cache.hit_count} miss: {cache.miss_count}\")\n print(\" \", psutil.virtual_memory())\n\n start_loc_data = [(sx, sy)\n for sy in range(start_location, height, patch_size)\n for sx in range(start_location, width, patch_size)]\n chunk_size = len(start_loc_data) // num_workers\n start_loc_list_iter = [start_loc_data[i:i+chunk_size] for i in range(0, len(start_loc_data), chunk_size)]\n\n with Timer(\" Thread elapsed time (rasterio)\") as timer:\n with concurrent.futures.ThreadPoolExecutor(\n max_workers=num_workers\n ) as executor:\n executor.map(\n load_tile_rasterio_chunk,\n repeat(input_file),\n start_loc_list_iter,\n repeat(patch_size)\n )\n rasterio_time = timer.elapsed_time()\n\n print(\" \", psutil.virtual_memory())\n output_text = f\"{datetime.now().strftime('%Y-%m-%d %H:%M:%S')},thread,{cache_strategy},{input_file},{start_location},{patch_size},{num_workers},{openslide_time},{cucim_time},{rasterio_time},{openslide_time / cucim_time},{rasterio_time / cucim_time},{cache_size},{cache.hit_count},{cache.miss_count}\\n\"\n with open(\"experiment.txt\", \"a+\") as f:\n f.write(output_text)\n print(output_text)\n\ndef experiment_process(cache_strategy, input_file, num_processes, start_location, patch_size):\n import psutil\n print(\" \", psutil.virtual_memory())\n for num_workers in range(1, num_processes + 1):\n openslide_time = 1\n cucim_time = 1\n rasterio_time = 1\n # (92344 x 81017)\n with OpenSlide(input_file) as slide:\n width, height = slide.dimensions\n\n start_loc_data = [(sx, sy)\n for sy in range(start_location, height, patch_size)\n for sx in range(start_location, width, patch_size)]\n chunk_size = len(start_loc_data) // num_workers\n start_loc_list_iter = [start_loc_data[i:i+chunk_size] for i in range(0, len(start_loc_data), chunk_size)]\n\n with Timer(\" Process elapsed time (OpenSlide)\") as timer:\n with concurrent.futures.ProcessPoolExecutor(\n max_workers=num_workers\n ) as executor:\n executor.map(\n load_tile_openslide_chunk_mp,\n repeat(input_file),\n start_loc_list_iter,\n repeat(patch_size)\n )\n openslide_time = timer.elapsed_time()\n print(\" \", psutil.virtual_memory())\n\n cache_size = psutil.virtual_memory().available // 1024 // 1024 // 20\n if cache_strategy == \"shared_memory\":\n cache_size = cache_size * num_workers\n cache = CuImage.cache(cache_strategy, memory_capacity=cache_size, record_stat=True)\n cucim_time = 0\n slide = CuImage(input_file)\n start_loc_data = [(sx, sy)\n for sy in range(start_location, height, patch_size)\n for sx in range(start_location, width, patch_size)]\n chunk_size = len(start_loc_data) // num_workers\n start_loc_list_iter = [start_loc_data[i:i+chunk_size] for i in range(0, len(start_loc_data), chunk_size)]\n\n with Timer(\" Process elapsed time (cuCIM)\") as timer:\n with concurrent.futures.ProcessPoolExecutor(\n max_workers=num_workers\n ) as executor:\n executor.map(\n load_tile_cucim_chunk_mp,\n repeat(input_file),\n start_loc_list_iter,\n repeat(patch_size)\n )\n cucim_time = timer.elapsed_time()\n print(\" \", psutil.virtual_memory())\n\n rasterio_time = 0\n start_loc_data = [(sx, sy)\n for sy in range(start_location, height, patch_size)\n for sx in range(start_location, width, patch_size)]\n chunk_size = len(start_loc_data) // num_workers\n start_loc_list_iter = [start_loc_data[i:i+chunk_size] for i in range(0, len(start_loc_data), chunk_size)]\n\n with Timer(\" Process elapsed time (rasterio)\") as timer:\n with concurrent.futures.ProcessPoolExecutor(\n max_workers=num_workers\n ) as executor:\n executor.map(\n load_tile_rasterio_chunk_mp,\n repeat(input_file),\n start_loc_list_iter,\n repeat(patch_size)\n )\n rasterio_time = timer.elapsed_time()\n\n print(\" \", psutil.virtual_memory())\n output_text = f\"{datetime.now().strftime('%Y-%m-%d %H:%M:%S')},process,{cache_strategy},{input_file},{start_location},{patch_size},{num_workers},{openslide_time},{cucim_time},{rasterio_time},{openslide_time / cucim_time},{rasterio_time / cucim_time},{cache_size},{cache.hit_count},{cache.miss_count}\\n\"\n with open(\"experiment.txt\", \"a+\") as f:\n f.write(output_text)\n print(output_text)\n\nexperiment_thread(\"nocache\", \"notebooks/input/image.tif\", 12, 0, 256)\nexperiment_process(\"nocache\", \"notebooks/input/image.tif\", 12, 0, 256)\nexperiment_thread(\"per_process\", \"notebooks/input/image.tif\", 12, 0, 256)\nexperiment_process(\"per_process\", \"notebooks/input/image.tif\", 12, 0, 256)\nexperiment_thread(\"shared_memory\", \"notebooks/input/image.tif\", 12, 0, 256)\nexperiment_process(\"shared_memory\", \"notebooks/input/image.tif\", 12, 0, 256)\n\nexperiment_thread(\"nocache\", \"notebooks/input/image.tif\", 12, 1, 256)\nexperiment_process(\"nocache\", \"notebooks/input/image.tif\", 12, 1, 256)\nexperiment_thread(\"per_process\", \"notebooks/input/image.tif\", 12, 1, 256)\nexperiment_process(\"per_process\", \"notebooks/input/image.tif\", 12, 1, 256)\nexperiment_thread(\"shared_memory\", \"notebooks/input/image.tif\", 12, 1, 256)\nexperiment_process(\"shared_memory\", \"notebooks/input/image.tif\", 12, 1, 256)\n\nexperiment_thread(\"nocache\", \"notebooks/input/image2.tif\", 12, 0, 256)\nexperiment_process(\"nocache\", \"notebooks/input/image2.tif\", 12, 0, 256)\nexperiment_thread(\"per_process\", \"notebooks/input/image2.tif\", 12, 0, 256)\nexperiment_process(\"per_process\", \"notebooks/input/image2.tif\", 12, 0, 256)\nexperiment_thread(\"shared_memory\", \"notebooks/input/image2.tif\", 12, 0, 256)\nexperiment_process(\"shared_memory\", \"notebooks/input/image2.tif\", 12, 0, 256)\n\nexperiment_thread(\"nocache\", \"notebooks/input/image2.tif\", 12, 1, 256)\nexperiment_process(\"nocache\", \"notebooks/input/image2.tif\", 12, 1, 256)\nexperiment_thread(\"per_process\", \"notebooks/input/image2.tif\", 12, 1, 256)\nexperiment_process(\"per_process\", \"notebooks/input/image2.tif\", 12, 1, 256)\nexperiment_thread(\"shared_memory\", \"notebooks/input/image2.tif\", 12, 1, 256)\nexperiment_process(\"shared_memory\", \"notebooks/input/image2.tif\", 12, 1, 256)\n\nexperiment_thread(\"nocache\", \"notebooks/0486052bb.tiff\", 12, 0, 1024)\nexperiment_process(\"nocache\", \"notebooks/0486052bb.tiff\", 12, 0, 1024)\nexperiment_thread(\"per_process\", \"notebooks/0486052bb.tiff\", 12, 0, 1024)\nexperiment_process(\"per_process\", \"notebooks/0486052bb.tiff\", 12, 0, 1024)\nexperiment_thread(\"shared_memory\", \"notebooks/0486052bb.tiff\", 12, 0, 1024)\nexperiment_process(\"shared_memory\", \"notebooks/0486052bb.tiff\", 12, 0, 1024)\n\nexperiment_thread(\"nocache\", \"notebooks/0486052bb.tiff\", 12, 1, 1024)\nexperiment_process(\"nocache\", \"notebooks/0486052bb.tiff\", 12, 1, 1024)\nexperiment_thread(\"per_process\", \"notebooks/0486052bb.tiff\", 12, 1, 1024)\nexperiment_process(\"per_process\", \"notebooks/0486052bb.tiff\", 12, 1, 1024)\nexperiment_thread(\"shared_memory\", \"notebooks/0486052bb.tiff\", 12, 1, 1024)\nexperiment_process(\"shared_memory\", \"notebooks/0486052bb.tiff\", 12, 1, 1024)\n```",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
e7c0f5a8523605f4090a42b98c5dbea6806fe6bf | 387,795 | ipynb | Jupyter Notebook | allesfitter/epic3752_ini.ipynb | jpdeleon/kesprint2 | a32e755c3a9f8476dfb6e45975c1018b328d25b7 | [
"MIT"
]
| null | null | null | allesfitter/epic3752_ini.ipynb | jpdeleon/kesprint2 | a32e755c3a9f8476dfb6e45975c1018b328d25b7 | [
"MIT"
]
| null | null | null | allesfitter/epic3752_ini.ipynb | jpdeleon/kesprint2 | a32e755c3a9f8476dfb6e45975c1018b328d25b7 | [
"MIT"
]
| null | null | null | 145.678062 | 55,152 | 0.814188 | [
[
[
"!mkdir epic3752",
"_____no_output_____"
]
],
[
[
"from IPython.display import HTML\n\nHTML('''<script>\ncode_show=true; \nfunction code_toggle() {\n if (code_show){\n $('div.input').hide();\n } else {\n $('div.input').show();\n }\n code_show = !code_show\n} \n$( document ).ready(code_toggle);\n</script>\n<form action=\"javascript:code_toggle()\"><input type=\"submit\" value=\"Click here to toggle on/off the raw code.\"></form>''')",
"_____no_output_____"
],
[
"%%html\n<style>\nbody {\n font-family: \"Times New Roman\";\n font-size: 12pt;\n}\n</style> ",
"_____no_output_____"
],
[
"\"\"\"\nCreated on Tue Nov 2 20:31:38 2018\n\n@author:\nMaximilian N. Günther\nMIT Kavli Institute for Astrophysics and Space Research, \nMassachusetts Institute of Technology,\n77 Massachusetts Avenue,\nCambridge, MA 02109, \nUSA\nEmail: [email protected]\nWeb: www.mnguenther.com\n\"\"\"\n\nfrom __future__ import print_function, division, absolute_import\n\n#::: plotting settings\nimport seaborn as sns\nsns.set(context='paper', style='ticks', palette='deep', font='sans-serif', font_scale=1.5, color_codes=True)\nsns.set_style({\"xtick.direction\": \"in\",\"ytick.direction\": \"in\"})\nsns.set_context(rc={'lines.markeredgewidth': 1})\n\n#::: modules\nimport numpy as np\nimport os, sys\nimport csv\nimport ipywidgets as widgets\nfrom IPython.display import display, HTML, Markdown, clear_output, Javascript\ndisplay(HTML(\"<style>.container { width:80% !important; }</style>\"))\nfrom multiprocessing import cpu_count\nif sys.version_info[0] == 3: # for Python3\n from tkinter import Tk, filedialog\nelif sys.version_info[0] == 2: # for Python2\n from Tkinter import Tk\n import tkFileDialog as filedialog\nimport warnings\ndef custom_formatwarning(msg, *args, **kwargs):\n return str(msg) + '\\n'\nwarnings.formatwarning = custom_formatwarning\n \n#::: allesfitter modules\n#::: somehow jupyter notebooks don't allow relative imports, so it needs a little hack...\nmodule_path = os.path.abspath(os.path.join('..'))\nif module_path not in sys.path: sys.path.append(module_path)\nimport allesfitter\nfrom allesfitter.utils.latex_printer import round_txt_separately\nfrom allesfitter.priors.transform_priors import get_cosi_from_i, get_Rsuma_from_a_over_Rstar, get_Rsuma_from_Rstar_over_a\nfrom allesfitter.priors.estimate_noise import estimate_noise\n\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"#::: globals\nglobal INPUT\nglobal VBOXES\nglobal BUTTONS\nglobal DROPDOWNS\nINPUT = {}\nVBOXES = {}\nBUTTONS = {}\nDROPDOWNS = {}\nlayout = {'width': '180px'}\nlayout_wide = {'width': '360px'}\nlayout_textbox = {'width': '120px'}\nlayout_checkbox = {}",
"_____no_output_____"
],
[
"#:::: clean up csv file\ndef clean_up_csv(fname, N_last_rows=0):\n \n with open(fname, \"r\") as f:\n params_csv = list(csv.reader(f))\n\n with open(fname, \"w\") as f:\n writer = csv.writer(f)\n for i in range(len(params_csv)-N_last_rows):\n row = params_csv[i]\n writer.writerow(row)\n \n\n#:::: append a row into csv file \ndef fwrite_params_line(text):\n with open(INPUT['fname_params'], 'a') as f:\n f.write(text+'\\n')\n \n \n#:::: write params into csv file \ndef fwrite_params(key, label, unit, physical_bounds, return_str=False):\n if INPUT[key+'_bounds_type'].value == 'uniform':\n bounds = 'uniform ' \\\n + str( np.max( [physical_bounds[0], float(INPUT[key+'_median'].value)-float(INPUT[key+'_lerr'].value)] ) ) + ' ' \\\n + str( np.min( [physical_bounds[1], float(INPUT[key+'_median'].value)+float(INPUT[key+'_uerr'].value)] ) )\n elif INPUT[key+'_bounds_type'].value == 'uniform * 5':\n bounds = 'uniform ' \\\n + str( np.max( [physical_bounds[0], float(INPUT[key+'_median'].value)-5*float(INPUT[key+'_lerr'].value)] ) ) + ' ' \\\n + str( np.min( [physical_bounds[1], float(INPUT[key+'_median'].value)+5*float(INPUT[key+'_uerr'].value)] ) )\n elif INPUT[key+'_bounds_type'].value == 'trunc_normal':\n bounds = 'trunc_normal ' \\\n + str(physical_bounds[0]) + ' ' \\\n + str(physical_bounds[1]) + ' ' \\\n + str(INPUT[key+'_median'].value) + ' ' \\\n + str(np.max( [ float(INPUT[key+'_lerr'].value), float(INPUT[key+'_uerr'].value) ] ))\n elif INPUT[key+'_bounds_type'].value == 'trunc_normal * 5':\n bounds = 'trunc_normal ' \\\n + str(physical_bounds[0]) + ' ' \\\n + str(physical_bounds[1]) + ' ' \\\n + str(INPUT[key+'_median'].value) + ' ' \\\n + str(5*np.max( [ float(INPUT[key+'_lerr'].value), float(INPUT[key+'_uerr'].value) ] ))\n string = key + ',' + str(INPUT[key+'_median'].value) + ',' + str(int(INPUT[key+'_fit'].value)) + ',' + bounds + ',' + label + ',' + unit\n if not return_str:\n fwrite_params_line(string) \n else:\n return string\n \n#unique\ndef unique(array):\n uniq, index = np.unique(array, return_index=True)\n return uniq[index.argsort()]",
"_____no_output_____"
]
],
[
[
"# 1. working directory",
"_____no_output_____"
],
[
"Select the working directory for this fit, for example `/Users/me/TESS-1b/`. Then you can run a fit using `allesfitter.ns_fit('/Users/me/TESS-1b/')`.",
"_____no_output_____"
]
],
[
[
"BUTTONS['datadir'] = widgets.Button(description='Select directory', button_style='')\ntext_af_directory = widgets.Text(value='', placeholder='for example: /Users/me/TESS-1b/', disable=True)\nhbox = widgets.HBox([BUTTONS['datadir'], text_af_directory])\ndisplay(hbox)\n\ndef select_datadir(change):\n root = Tk()\n root.withdraw()\n root.call('wm', 'attributes', '.', '-topmost', True)\n INPUT['datadir'] = filedialog.askdirectory()\n %gui tk\n if INPUT['datadir'] != '':\n text_af_directory.value = INPUT['datadir']\n BUTTONS['datadir'].style.button_color = 'lightgreen'\n INPUT['show_step_2a'] = True\n display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1, IPython.notebook.ncells())'))\nBUTTONS['datadir'].on_click(select_datadir)",
"_____no_output_____"
]
],
[
[
"# 2. settings",
"_____no_output_____"
]
],
[
[
"if 'show_step_2a' in INPUT and INPUT['show_step_2a'] == True:\n\n display(Markdown('### General settings'))\n \n \n DROPDOWNS['planet_or_EB'] = widgets.Dropdown(options=['Planets', 'EBs'])\n display( widgets.HBox([widgets.Label(value='Fitting planets or EBs?', layout=layout), DROPDOWNS['planet_or_EB']]) )\n \n \n display(Markdown('Give the companion letters and instruments, space-separated. Leave empty if not applicable.'))\n \n hbox_list = []\n \n text_companions_phot = widgets.Text(value='', placeholder='for example: b')\n hbox_list.append( widgets.HBox([widgets.Label(value='Companions in photometry', layout=layout), text_companions_phot]) )\n\n text_companions_rv = widgets.Text(value='', placeholder='for example: b c')\n hbox_list.append( widgets.HBox([widgets.Label(value='Companions in RV', layout=layout), text_companions_rv]) )\n\n text_inst_phot = widgets.Text(value='', placeholder='for example: TESS NGTS')\n hbox_list.append( widgets.HBox([widgets.Label(value='Instruments for photometry', layout=layout), text_inst_phot]) )\n\n text_inst_rv = widgets.Text(value='', placeholder='for example: HARPS Coralie')\n hbox_list.append( widgets.HBox([widgets.Label(value='Instruments for RV', layout=layout), text_inst_rv]) )\n\n display(widgets.VBox(hbox_list))\n \n def confirm(change):\n \n #::: set stuff\n if len(text_inst_phot.value): INPUT['inst_phot'] = str(text_inst_phot.value).split(' ')\n else: INPUT['inst_phot'] = []\n if len(text_inst_rv.value): INPUT['inst_rv'] = str(text_inst_rv.value).split(' ')\n else: INPUT['inst_rv'] = []\n\n if len(text_companions_phot.value): INPUT['companions_phot'] = str(text_companions_phot.value).split(' ')\n else: INPUT['companions_phot'] = []\n if len(text_companions_rv.value): INPUT['companions_rv'] = str(text_companions_rv.value).split(' ')\n else: INPUT['companions_rv'] = []\n\n INPUT['companions_all'] = list(np.unique(INPUT['companions_phot']+INPUT['companions_rv'])) #sorted by b, c, d...\n INPUT['inst_all'] = list(unique(INPUT['inst_phot']+INPUT['inst_rv'])) #sorted like user input\n \n button_2a.style.button_color = 'lightgreen'\n INPUT['show_step_2b'] = True\n display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1, IPython.notebook.ncells())'))\n \n button_2a = widgets.Button(description='Confirm', button_style='')\n display(button_2a)\n button_2a.on_click(confirm)",
"_____no_output_____"
],
[
"if 'show_step_2b' in INPUT and INPUT['show_step_2b'] == True:\n \n display(Markdown('### Advanced settings'))\n \n \n vbox_list = []\n \n #::: Fitting & performance\n hbox_list = []\n \n max_cores = cpu_count()\n DROPDOWNS['multiprocessing'] = widgets.Dropdown(options=['No'] + ['on '+str(i)+' of my '+str(max_cores)+' cores' for i in range(2,max_cores)] + ['always on all - 1 cores on any system'])\n hbox_list.append(widgets.HBox([widgets.Label(value='Multiprocessing', layout=layout), DROPDOWNS['multiprocessing']]))\n \n DROPDOWNS['fit_type'] = widgets.Dropdown(options=['Transit (fast)', 'Transit and occultation (fast)', 'Full lightcurve (slow)'])\n hbox_list.append(widgets.HBox([widgets.Label(value='Fit type', layout=layout), DROPDOWNS['fit_type']]))\n \n DROPDOWNS['shift_epoch'] = widgets.Dropdown(options=['Yes', 'No'])\n hbox_list.append(widgets.HBox([widgets.Label(value='Automatically shift epoch?', layout=layout), DROPDOWNS['shift_epoch']]))\n \n DROPDOWNS['mcmc_settings'] = widgets.Dropdown(options=['Default'])\n hbox_list.append(widgets.HBox([widgets.Label(value='MCMC settings', layout=layout), DROPDOWNS['mcmc_settings']]))\n \n DROPDOWNS['ns_settings'] = widgets.Dropdown(options=['Default'])\n hbox_list.append(widgets.HBox([widgets.Label(value='Nested Sampling settings', layout=layout), DROPDOWNS['ns_settings']]))\n \n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Limb darkening\n hbox_list = []\n for inst in INPUT['inst_phot']:\n DROPDOWNS['host_ld_law_'+inst] = widgets.Dropdown(options=['None','Linear','Quadratic','Sing'], value='Quadratic')\n hbox_list.append( widgets.HBox([widgets.Label(value='Host limb darkening '+inst, layout=layout), DROPDOWNS['host_ld_law_'+inst]]) )\n if DROPDOWNS['planet_or_EB'].value == 'EBs':\n for companion in INPUT['companions_all']:\n DROPDOWNS[companion+'_ld_law_'+inst] = widgets.Dropdown(options=['None','Linear','Quadratic','Sing'])\n hbox_list.append( widgets.HBox([widgets.Label(value=companion+' limb darkening '+inst, layout=layout), DROPDOWNS[companion+'_ld_law_'+inst]]) )\n vbox_list.append( widgets.VBox(hbox_list) )\n\n \n #::: Baseline settings\n hbox_list = []\n for inst in INPUT['inst_phot']:\n DROPDOWNS['baseline_flux_'+inst] = widgets.Dropdown(options=['sample_offset', 'sample_linear', 'sample_GP_Matern32', 'sample_GP_SHO', 'sample_GP_real', 'sample_GP_complex', 'hybrid_offset', 'hybrid_poly_1', 'hybrid_poly_2', 'hybrid_poly_3', 'hybrid_poly_4', 'hybrid_spline'], value='hybrid_offset')\n hbox_list.append( widgets.HBox([widgets.Label(value='Baseline flux '+inst, layout=layout), DROPDOWNS['baseline_flux_'+inst]]) )\n for inst in INPUT['inst_rv']:\n DROPDOWNS['baseline_rv_'+inst] = widgets.Dropdown(options=['sample_offset', 'sample_linear', 'sample_GP_Matern32', 'sample_GP_SHO', 'sample_GP_real', 'sample_GP_complex', 'hybrid_offset', 'hybrid_poly_1', 'hybrid_poly_2', 'hybrid_poly_3', 'hybrid_poly_4', 'hybrid_spline'], value='hybrid_offset')\n hbox_list.append( widgets.HBox([widgets.Label(value='Baseline RV '+inst, layout=layout), DROPDOWNS['baseline_rv_'+inst]]) )\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Error settings\n hbox_list = []\n for inst in INPUT['inst_phot']:\n DROPDOWNS['error_flux_'+inst] = widgets.Dropdown(options=['sample', 'hybrid'], value='sample')\n hbox_list.append( widgets.HBox([widgets.Label(value='Error flux '+inst, layout=layout), DROPDOWNS['error_flux_'+inst]]) )\n for inst in INPUT['inst_rv']:\n DROPDOWNS['error_rv_'+inst] = widgets.Dropdown(options=['sample', 'hybrid'], value='sample')\n hbox_list.append( widgets.HBox([widgets.Label(value='Error RV '+inst, layout=layout), DROPDOWNS['error_rv_'+inst]]) )\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Exposure time interpolation\n hbox_list = []\n for inst in INPUT['inst_all']:\n DROPDOWNS['t_exp_'+inst] = widgets.Text( placeholder='None' )\n hbox_list.append( widgets.HBox([widgets.Label(value='Exposure time '+inst, layout=layout), DROPDOWNS['t_exp_'+inst], widgets.Label(value='days', layout=layout)]) )\n for inst in INPUT['inst_all']:\n DROPDOWNS['t_exp_n_int_'+inst] = widgets.Text( placeholder='None' )\n hbox_list.append( widgets.HBox([widgets.Label(value='Interpolation points '+inst, layout=layout), DROPDOWNS['t_exp_n_int_'+inst], widgets.Label(value='(integer)', layout=layout)]) )\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Number of spots\n hbox_list = []\n for inst in INPUT['inst_all']:\n DROPDOWNS['host_N_spots_'+inst] = widgets.Text( placeholder='None' )\n hbox_list.append( widgets.HBox([widgets.Label(value='host: Nr. of spots '+inst, layout=layout), DROPDOWNS['host_N_spots_'+inst], widgets.Label(value='(integer)', layout=layout)]) )\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Number of flares\n hbox_list = []\n DROPDOWNS['N_flares'] = widgets.Text( placeholder='None' )\n hbox_list.append( widgets.HBox([widgets.Label(value='Nr. of flares', layout=layout), DROPDOWNS['N_flares'], widgets.Label(value='(integer)', layout=layout)]) )\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Fit TTVs?\n hbox_list = []\n DROPDOWNS['fit_ttvs'] = widgets.Dropdown(options=[\"yes\",\"no\"], value=\"no\")\n hbox_list.append( widgets.HBox([widgets.Label(value='Fit TTVs?', layout=layout), DROPDOWNS['fit_ttvs']]) )\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Stellar grid (e.g. use \"sparse\" to speed up intense spot computations) \n hbox_list = []\n for inst in INPUT['inst_all']:\n DROPDOWNS['host_grid_'+inst] = widgets.Dropdown(options=[\"very_sparse\", \"sparse\", \"default\", \"fine\", \"very_fine\"], value=\"default\")\n hbox_list.append( widgets.HBox([widgets.Label(value='Host grid '+inst, layout=layout), DROPDOWNS['host_grid_'+inst]]) )\n if DROPDOWNS['planet_or_EB'].value == 'EBs':\n for companion in INPUT['companions_all']:\n DROPDOWNS[companion+'_grid_'+inst] = widgets.Dropdown(options=[\"very_sparse\", \"sparse\", \"default\", \"fine\", \"very_fine\"], value=\"default\")\n hbox_list.append( widgets.HBox([widgets.Label(value=companion+' grid '+inst, layout=layout), DROPDOWNS[companion+'_grid_'+inst]]) )\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Stellar shape (e.g. use \"roche\" for ellipsoidal variablity)\n hbox_list = []\n for inst in INPUT['inst_all']:\n DROPDOWNS['host_shape_'+inst] = widgets.Dropdown(options=[\"roche\", \"roche_v\", \"sphere\", \"poly1p5\", \"poly3p0\", \"love\"], value=\"sphere\")\n hbox_list.append( widgets.HBox([widgets.Label(value='Host shape '+inst, layout=layout), DROPDOWNS['host_shape_'+inst]]) )\n if DROPDOWNS['planet_or_EB'].value == 'EBs':\n for companion in INPUT['companions_all']:\n DROPDOWNS[companion+'_shape_'+inst] = widgets.Dropdown(options=[\"roche\", \"roche_v\", \"sphere\", \"poly1p5\", \"poly3p0\", \"love\"], value=\"sphere\")\n hbox_list.append( widgets.HBox([widgets.Label(value=companion+' shape '+inst, layout=layout), DROPDOWNS[companion+'_shape_'+inst]]) )\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Flux weighted RVs (\"Yes\" for Rossiter-McLaughlin effect)\n hbox_list = []\n for inst in INPUT['inst_rv']:\n for companion in INPUT['companions_rv']:\n DROPDOWNS[companion+'_flux_weighted_'+inst] = widgets.Dropdown(options=['No', 'Yes'])\n hbox_list.append( widgets.HBox([widgets.Label(value=companion+' flux weighted RV '+inst, layout=layout), DROPDOWNS[companion+'_flux_weighted_'+inst]]) )\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: accordion\n accordion = widgets.Accordion(children=vbox_list)\n accordion.set_title(0, 'Fitting & performance')\n accordion.set_title(1, 'Limb darkening laws')\n accordion.set_title(2, 'Baseline sampling')\n accordion.set_title(3, 'Error sampling')\n accordion.set_title(4, 'Exposure time interpolation')\n accordion.set_title(5, 'Number of spots')\n accordion.set_title(6, 'Number of flares')\n accordion.set_title(7, 'TTVs')\n accordion.set_title(8, 'Stellar grid (e.g. use \"very_sparse\" to speed up computations)')\n accordion.set_title(9, 'Stellar shape (e.g. use \"roche\" for ellipsoidal variablity)')\n accordion.set_title(10, 'Flux weighted RVs (e.g. use \"true\" for Rossiter-McLaughlin effect)')\n display(accordion)\n \n \n #::: confirm button\n button_2b = widgets.Button(description='Confirm', button_style='')\n display(button_2b)\n\n def confirm(change):\n button_2b.style.button_color = 'lightgreen'\n INPUT['show_step_2c'] = True\n display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1, IPython.notebook.ncells())'))\n button_2b.on_click(confirm)",
"_____no_output_____"
],
[
"if 'show_step_2c' in INPUT and INPUT['show_step_2c'] == True:\n\n BUTTONS['2c'] = widgets.Button(description='Create settings.csv', button_style='')\n checkbox_2c = widgets.Checkbox(description='Overwrite old settings.csv (if existing)', value=False)\n display(widgets.HBox([BUTTONS['2c'], checkbox_2c]))\n \n \n\n def create_settings_file(change):\n clear_output()\n display(widgets.HBox([BUTTONS['2c'], checkbox_2c]))\n\n go_ahead = True\n\n if 'datadir' not in INPUT:\n warnings.warn('No allesfitter woking directory selected yet. Please go back to step 1) and fill in all fields.')\n go_ahead = False\n\n if os.path.exists(os.path.join(INPUT['datadir'],'settings.csv')) and (checkbox_2c.value==False):\n warnings.warn('The selected working directory '+os.path.join(INPUT['datadir'],'settings.csv')+' already exists. To proceed, give permission to overwrite it.')\n go_ahead = False\n\n if go_ahead:\n fname_settings = os.path.join(INPUT['datadir'], 'settings.csv')\n with open(fname_settings, 'w+') as f:\n f.write('#name,value\\n')\n\n def fwrite_settings(text):\n with open(fname_settings, 'a') as f:\n f.write(text+'\\n')\n \n\n fwrite_settings('###############################################################################,')\n fwrite_settings('# General settings,')\n fwrite_settings('###############################################################################,')\n fwrite_settings('companions_phot,'+text_companions_phot.value)\n fwrite_settings('companions_rv,'+text_companions_rv.value)\n fwrite_settings('inst_phot,'+text_inst_phot.value)\n fwrite_settings('inst_rv,'+text_inst_rv.value)\n\n \n fwrite_settings('###############################################################################,')\n fwrite_settings('# Fit performance settings,')\n fwrite_settings('###############################################################################,')\n if DROPDOWNS['multiprocessing'].value=='No':\n fwrite_settings('multiprocess,False')\n elif DROPDOWNS['multiprocessing'].value=='always on all - 1 cores on any system':\n fwrite_settings('multiprocess,True')\n fwrite_settings('multiprocess_cores,all')\n else:\n fwrite_settings('multiprocess,True')\n fwrite_settings('multiprocess_cores,'+DROPDOWNS['multiprocessing'].value.split(' ')[1])\n \n \n if DROPDOWNS['fit_type'].value=='Transit (fast)':\n fwrite_settings('fast_fit,True')\n fwrite_settings('fast_fit_width,0.3333333333333333')\n fwrite_settings('secondary_eclipse,False')\n fwrite_settings('phase_curve,False')\n elif DROPDOWNS['fit_type'].value=='Transit and occultation (fast)':\n fwrite_settings('fast_fit,True')\n fwrite_settings('fast_fit_width,0.3333333333333333')\n fwrite_settings('secondary_eclipse,True')\n fwrite_settings('phase_curve,False')\n elif DROPDOWNS['fit_type'].value=='Full lightcurve (slow)':\n fwrite_settings('fast_fit,False')\n fwrite_settings('fast_fit_width,')\n fwrite_settings('secondary_eclipse,True')\n fwrite_settings('phase_curve,True')\n fwrite_settings('phase_curve_style,GP')\n \n \n if DROPDOWNS['shift_epoch'].value=='Yes':\n fwrite_settings('shift_epoch,True')\n for companion in INPUT['companions_all']:\n fwrite_settings('inst_for_'+companion+'_epoch,all')\n \n \n fwrite_settings('###############################################################################,')\n fwrite_settings('# MCMC settings,')\n fwrite_settings('###############################################################################,')\n if DROPDOWNS['mcmc_settings'].value=='Default':\n fwrite_settings('mcmc_nwalkers,100')\n fwrite_settings('mcmc_total_steps,2000')\n fwrite_settings('mcmc_burn_steps,1000')\n fwrite_settings('mcmc_thin_by,1')\n\n \n fwrite_settings('###############################################################################,')\n fwrite_settings('# Nested Sampling settings,')\n fwrite_settings('###############################################################################,')\n if DROPDOWNS['ns_settings'].value=='Default':\n fwrite_settings('ns_modus,dynamic')\n fwrite_settings('ns_nlive,500')\n fwrite_settings('ns_bound,single')\n fwrite_settings('ns_sample,rwalk')\n fwrite_settings('ns_tol,0.01')\n\n \n fwrite_settings('###############################################################################,')\n fwrite_settings(\"# Limb darkening law per object and instrument,\")\n fwrite_settings(\"# if 'lin' one corresponding parameter called 'ldc_q1_inst' has to be given in params.csv,\")\n fwrite_settings(\"# if 'quad' two corresponding parameter called 'ldc_q1_inst' and 'ldc_q2_inst' have to be given in params.csv,\")\n fwrite_settings(\"# if 'sing' three corresponding parameter called 'ldc_q1_inst'; 'ldc_q2_inst' and 'ldc_q3_inst' have to be given in params.csv,\")\n fwrite_settings('###############################################################################,')\n def translate_ld(x):\n if x=='None': return ''\n elif x=='Linear': return 'lin'\n elif x=='Quadratic': return 'quad'\n elif x=='Sing': return 'sing'\n \n for inst in INPUT['inst_phot']:\n fwrite_settings('host_ld_law_'+inst+','+translate_ld(DROPDOWNS['host_ld_law_'+inst].value))\n \n if DROPDOWNS['planet_or_EB'].value == 'EBs':\n for companion in INPUT['companions_all']:\n fwrite_settings(companion+'_ld_law_'+inst+','+translate_ld(DROPDOWNS[companion+'_ld_law_'+inst].value))\n \n \n fwrite_settings('###############################################################################,')\n fwrite_settings(\"# Baseline settings per instrument,\")\n fwrite_settings(\"# baseline params per instrument: sample_offset / sample_linear / sample_GP / hybrid_offset / hybrid_poly_1 / hybrid_poly_2 / hybrid_poly_3 / hybrid_pol_4 / hybrid_spline / hybrid_GP,\")\n fwrite_settings(\"# if 'sample_offset' one corresponding parameter called 'baseline_offset_key_inst' has to be given in params.csv,\")\n fwrite_settings(\"# if 'sample_linear' two corresponding parameters called 'baseline_a_key_inst' and 'baseline_b_key_inst' have to be given in params.csv,\")\n fwrite_settings(\"# if 'sample_GP' two corresponding parameters called 'baseline_gp1_key_inst' and 'baseline_gp2_key_inst' have to be given in params.csv,\")\n fwrite_settings('###############################################################################,')\n for inst in INPUT['inst_phot']:\n fwrite_settings('baseline_flux_'+inst+','+DROPDOWNS['baseline_flux_'+inst].value)\n for inst in INPUT['inst_rv']:\n fwrite_settings('baseline_rv_'+inst+','+DROPDOWNS['baseline_rv_'+inst].value)\n\n \n fwrite_settings('###############################################################################,')\n fwrite_settings(\"# Error settings per instrument,\")\n fwrite_settings(\"# errors (overall scaling) per instrument: sample / hybrid,\")\n fwrite_settings(\"# if 'sample' one corresponding parameter called 'ln_err_key_inst' (photometry) or 'ln_jitter_key_inst' (RV) has to be given in params.csv,\")\n fwrite_settings('###############################################################################,')\n for inst in INPUT['inst_phot']:\n fwrite_settings('error_flux_'+inst+','+DROPDOWNS['error_flux_'+inst].value)\n for inst in INPUT['inst_rv']:\n fwrite_settings('error_rv_'+inst+','+DROPDOWNS['error_rv_'+inst].value)\n \n \n fwrite_settings('###############################################################################,')\n fwrite_settings('# Exposure times for interpolation,')\n fwrite_settings('# needs to be in the same units as the time series,')\n fwrite_settings('# if not given the observing times will not be interpolated leading to biased results,')\n fwrite_settings('###############################################################################,')\n for inst in INPUT['inst_all']:\n fwrite_settings('t_exp_'+inst+','+DROPDOWNS['t_exp_'+inst].value)\n\n \n fwrite_settings('###############################################################################,')\n fwrite_settings('# Number of points for exposure interpolation,')\n fwrite_settings('# Sample as fine as possible; generally at least with a 2 min sampling for photometry,')\n fwrite_settings('# n_int=5 was found to be a good number of interpolation points for any short photometric cadence t_exp;,')\n fwrite_settings('# increase to at least n_int=10 for 30 min phot. cadence,')\n fwrite_settings('# the impact on RV is not as drastic and generally n_int=5 is fine enough,')\n fwrite_settings('###############################################################################,')\n for inst in INPUT['inst_all']:\n fwrite_settings('t_exp_n_int_'+inst+','+DROPDOWNS['t_exp_n_int_'+inst].value)\n\n\n fwrite_settings('###############################################################################,')\n fwrite_settings('# Number of spots per object and instrument,')\n fwrite_settings('###############################################################################,')\n for inst in INPUT['inst_all']:\n fwrite_settings('host_N_spots_'+inst+','+DROPDOWNS['host_N_spots_'+inst].value)\n \n \n fwrite_settings('###############################################################################,')\n fwrite_settings('# Number of flares (in total),')\n fwrite_settings('###############################################################################,')\n fwrite_settings('N_flares'+','+DROPDOWNS['N_flares'].value)\n \n \n fwrite_settings('###############################################################################,')\n fwrite_settings('# TTVs,')\n fwrite_settings('###############################################################################,')\n if DROPDOWNS['fit_ttvs'].value == 'no':\n fwrite_settings('fit_ttvs'+',False')\n elif DROPDOWNS['fit_ttvs'].value == 'yes':\n fwrite_settings('fit_ttvs'+',True')\n \n \n fwrite_settings('###############################################################################,')\n fwrite_settings('# Stellar grid per object and instrument,')\n fwrite_settings('###############################################################################,')\n for inst in INPUT['inst_all']:\n fwrite_settings('host_grid_'+inst+','+DROPDOWNS['host_grid_'+inst].value)\n if DROPDOWNS['planet_or_EB'].value == 'EBs':\n for companion in INPUT['companions_all']:\n fwrite_settings(companion+'_grid_'+inst+','+DROPDOWNS[companion+'_grid_'+inst].value)\n \n \n fwrite_settings('###############################################################################,')\n fwrite_settings('# Stellar shape per object and instrument,')\n fwrite_settings('###############################################################################,')\n for inst in INPUT['inst_all']:\n fwrite_settings('host_shape_'+inst+','+DROPDOWNS['host_shape_'+inst].value)\n if DROPDOWNS['planet_or_EB'].value == 'EBs':\n for companion in INPUT['companions_all']:\n fwrite_settings(companion+'_shape_'+inst+','+DROPDOWNS[companion+'_shape_'+inst].value)\n \n \n fwrite_settings('###############################################################################,')\n fwrite_settings('# Flux weighted RVs per object and instrument,')\n fwrite_settings('# (\"Yes\" for Rossiter-McLaughlin effect),')\n fwrite_settings('###############################################################################,')\n for inst in INPUT['inst_rv']:\n for companion in INPUT['companions_rv']:\n fwrite_settings(companion+'_flux_weighted_'+inst+','+DROPDOWNS[companion+'_flux_weighted_'+inst].value)\n \n \n BUTTONS['2c'].style.button_color = 'lightgreen' \n print('Done.') \n INPUT['show_step_3'] = True\n display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1, IPython.notebook.ncells())'))\n\n\n BUTTONS['2c'].on_click(create_settings_file)",
"_____no_output_____"
]
],
[
[
"# 3. parameters",
"_____no_output_____"
]
],
[
[
"import chronos as cr\n\nall_campaigns = cr.get_all_campaigns(epic)\ncamps = \"c\".join([str(c).zfill(2) for c in all_campaigns])\ncamps",
"_____no_output_____"
],
[
"import pandas as pd\nfrom glob import glob\n\nfp = f\"{loc}/everest_w_limbdark_prior2_new_ini/EPIC{epic}_c{camps}\"\ncsvs = glob(f\"{fp}/*mcmc-results.csv\")\nassert len(csvs)>0\n\nds = {}\nfor i,csv in enumerate(sorted(csvs)):\n d = pd.read_csv(csv, squeeze=True, index_col=0)\n ds[i] = d\ndf = pd.concat(ds)\ndf",
"_____no_output_____"
],
[
"d.columns",
"_____no_output_____"
],
[
"for i,d in df.iterrows():\n print(i)\n for c in ['$a/R_{\\star}$', '$R_p/R_{\\star}$', '$T_{0}$', '$P$']:\n print(f\"{c}: {d.loc[c]:.4f}, {d.loc[c+'_lo']:.5f}, {d.loc[c+'_hi']:.5f}\")\n print()",
"(0, 211413752.01)\n$a/R_{\\star}$: 17.1732, 9.46289, 4.82221\n$R_p/R_{\\star}$: 0.0312, 0.00221, 0.00908\n$T_{0}$: 2457140.8467, 0.00210, 0.00213\n$P$: 9.3275, 0.00002, 0.00002\n\n(1, 211413752.02)\n$a/R_{\\star}$: 7.7601, 1.83505, 0.72033\n$R_p/R_{\\star}$: 0.0175, 0.00058, 0.00142\n$T_{0}$: 2457143.6543, 0.00252, 0.00244\n$P$: 2.1517, 0.00001, 0.00001\n\n(2, 211413752.03)\n$a/R_{\\star}$: 41.4142, 8.32664, 3.15299\n$R_p/R_{\\star}$: 0.0259, 0.00082, 0.00169\n$T_{0}$: 2457142.1917, 0.00385, 0.00396\n$P$: 26.2706, 0.00011, 0.00011\n\n(3, 211413752.04)\n$a/R_{\\star}$: 12.5696, 3.32009, 1.18490\n$R_p/R_{\\star}$: 0.0173, 0.00064, 0.00156\n$T_{0}$: 2457143.9747, 0.00330, 0.00318\n$P$: 4.5286, 0.00002, 0.00002\n\n(4, 211413752.05)\n$a/R_{\\star}$: 16.9294, 4.06068, 1.89437\n$R_p/R_{\\star}$: 0.0155, 0.00078, 0.00126\n$T_{0}$: 2457142.3440, 0.00471, 0.00485\n$P$: 6.1312, 0.00003, 0.00003\n\n"
],
[
"if 'show_step_3' in INPUT and INPUT['show_step_3'] == True:\n\n #::: placeholder\n placeholder = widgets.Label(value='', visible=False, layout=layout)\n\n \n \n #::: helper function\n def add_row(key, label, hbox_list, median=0, lerr=0, uerr=0, transform='trunc_normal * 5', fit_value=False):\n INPUT[key+'_median'] = widgets.FloatText(value=median, placeholder='NaN', layout=layout_textbox)\n INPUT[key+'_lerr'] = widgets.FloatText(value=lerr, placeholder='NaN', layout=layout_textbox)\n INPUT[key+'_uerr'] = widgets.FloatText(value=uerr, placeholder='NaN', layout=layout_textbox)\n INPUT[key+'_bounds_type'] = widgets.Dropdown(options=['uniform', 'uniform * 5', 'trunc_normal', 'trunc_normal * 5'], value=transform, layout=layout)\n INPUT[key+'_fit'] = widgets.Checkbox(value=fit_value, description='fit?', layout=layout_checkbox)\n \n buf = placeholder\n if key in [ companion+'_rsuma' for companion in INPUT['companions_all'] ]:\n INPUT[key+'_input_type'] = widgets.Dropdown(options=['(R_comp + R_host) / a', 'R_host / a', 'a / R_host'], layout=layout)\n buf = INPUT[key+'_input_type']\n elif key in [ companion+'_cosi' for companion in INPUT['companions_all'] ]:\n INPUT[key+'_input_type'] = widgets.Dropdown(options=['cos(i)', 'i (degree)', 'i (rad)'], layout=layout)\n buf = INPUT[key+'_input_type']\n \n hbox_list.append( widgets.HBox([widgets.Label(value=label, layout=layout), \n INPUT[key+'_median'], \n widgets.Label(value=\"-\"), INPUT[key+'_lerr'], \n widgets.Label(value=\"+\"), INPUT[key+'_uerr'], \n buf, \n INPUT[key+'_bounds_type'],\n INPUT[key+'_fit']]) )\n \n \n \n #::: start\n display(Markdown('### Initial guess and error bars'))\n display(Markdown('These values will be converted into either uniform or truncated normal priors (with physical boundaries). The errors can be blown up by a factor of 5.')) \n \n \n \n display(Markdown('#### Astrophysical params per companion'))\n vbox_list = []\n for companion in INPUT['companions_all']:\n \n# display(Markdown('##### Companion '+companion))\n \n hbox_list = []\n add_row(companion+'_rsuma', 'Radii & semi-major axis:', hbox_list)\n add_row(companion+'_rr', '$R_'+companion+' / R_\\star$:', hbox_list)\n add_row(companion+'_cosi', 'Inclination:', hbox_list)\n add_row(companion+'_epoch', 'Epoch (d):', hbox_list)\n add_row(companion+'_period', 'Period (d):', hbox_list)\n if companion in INPUT['companions_rv']:\n add_row(companion+'_K', 'K (km/s):', hbox_list)\n add_row(companion+'_f_c', '$\\sqrt{e} \\cos{\\omega}$:', hbox_list)\n add_row(companion+'_f_s', '$\\sqrt{e} \\sin{\\omega}$:', hbox_list)\n vbox_list.append( widgets.VBox(hbox_list) )\n \n tab = widgets.Tab(children=vbox_list)\n for i, comp in enumerate(INPUT['companions_all']):\n tab.set_title(i, 'Companion '+comp)\n display(tab)\n \n \n \n# else:\n# print('Complete previous steps first.')",
"_____no_output_____"
],
[
"from configobj import ConfigObj\n\nepic = 211413752\nloc = '/home/jp/github/research/project/kesprint/data/transit_fit'\nco = ConfigObj(f'{loc}/{epic}.ini')\nco",
"_____no_output_____"
],
[
"star = {i:list(map(float, co['star'][i]) )for i in co['star']}\nstar",
"_____no_output_____"
],
[
"from limbdark import claret\n\nu = claret('Kp', \n *star['teff'],\n *star['logg'],\n *star['feh'],\n# transform=True\n )",
"_____no_output_____"
],
[
"u",
"_____no_output_____"
],
[
"from limbdark.limbdark import u_to_q\n\nu_to_q(u[0], u[2]), u_to_q(u[1], u[3])",
"_____no_output_____"
],
[
"if 'show_step_3' in INPUT and INPUT['show_step_3'] == True:\n \n display(Markdown('### Advanced params'))\n vbox_list = []\n \n \n #::: Dilution per instrument\n hbox_list = []\n for inst in INPUT['inst_phot']:\n add_row('dil_'+inst, 'Dilution '+inst, hbox_list)\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Limb darkening per object and instrument\n hbox_list = []\n for inst in INPUT['inst_phot']:\n if DROPDOWNS['host_ld_law_'+inst].value=='None':\n pass\n elif DROPDOWNS['host_ld_law_'+inst].value=='Linear':\n add_row('host_ldc_q1_'+inst, 'host LD q1 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n elif DROPDOWNS['host_ld_law_'+inst].value=='Quadratic':\n add_row('host_ldc_q1_'+inst, 'host LD q1 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n add_row('host_ldc_q2_'+inst, 'host LD q2 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n elif DROPDOWNS['host_ld_law_'+inst].value=='Sing':\n add_row('host_ldc_q1_'+inst, 'host LD q1 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n add_row('host_ldc_q2_'+inst, 'host LD q2 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n add_row('host_ldc_q3_'+inst, 'host LD q3 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n \n if DROPDOWNS['planet_or_EB']=='EBs':\n for companion in INPUT['companions_phot']:\n if DROPDOWNS[companion+'_ld_law_'+inst].value=='None':\n pass\n elif DROPDOWNS[companion+'_ld_law_'+inst].value=='Linear':\n add_row(companion+'_ldc_q1_'+inst, companion+' LD q1 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n elif DROPDOWNS[companion+'_ld_law_'+inst].value=='Quadratic':\n add_row(companion+'_ldc_q1_'+inst, companion+' LD q1 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n add_row(companion+'_ldc_q2_'+inst, companion+' LD q2 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n elif DROPDOWNS[companion+'_ld_law_'+inst].value=='Sing':\n add_row(companion+'_ldc_q1_'+inst, companion+' LD q1 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n add_row(companion+'_ldc_q2_'+inst, companion+' LD q2 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n add_row(companion+'_ldc_q3_'+inst, companion+' LD q3 '+inst, hbox_list, median=0.5, lerr=0.5, uerr=0.5, transform='uniform', fit_value=True)\n \n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Surface brightness ratio per system and instrument\n hbox_list = []\n for inst in INPUT['inst_all']:\n for companion in INPUT['companions_all']:\n add_row(companion+'_sbratio_'+inst, companion+' sbratio '+inst, hbox_list)\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Geometric albedo per object and instrument\n hbox_list = []\n for inst in INPUT['inst_all']:\n add_row('host_geom_albedo_'+inst, 'host geom. alb. '+inst, hbox_list)\n for companion in INPUT['companions_all']:\n add_row(companion+'_geom_albedo_'+inst, companion+' geom. alb. '+inst, hbox_list)\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Gravity darkening per object and instrument\n hbox_list = []\n for inst in INPUT['inst_all']:\n add_row('host_gdc_'+inst, 'host grav. dark. '+inst, hbox_list)\n if DROPDOWNS['planet_or_EB']=='EBs':\n for companion in INPUT['companions_all']:\n add_row(companion+'_gdc_'+inst, companion+' grav. dark. '+inst, hbox_list)\n vbox_list.append( widgets.VBox(hbox_list) )\n \n\n #::: Stellar spots per object and instrument\n hbox_list = []\n for inst in INPUT['inst_all']:\n \n if len(DROPDOWNS['host_N_spots_'+inst].value):\n N_spots = int(DROPDOWNS['host_N_spots_'+inst].value)\n for i in range(1,N_spots+1):\n add_row('host_spot_'+str(i)+'_lat_'+inst, 'host spot '+str(i)+' lat. '+inst+' (deg)', hbox_list)\n add_row('host_spot_'+str(i)+'_long_'+inst, 'host spot '+str(i)+' long. '+inst+' (deg)', hbox_list)\n add_row('host_spot_'+str(i)+'_size_'+inst, 'host spot '+str(i)+' size '+inst+' (deg)', hbox_list)\n add_row('host_spot_'+str(i)+'_brightness_'+inst,'host spot '+str(i)+' brightness '+inst, hbox_list)\n\n# To keep the GUI simplistic, spots on companions are only available by manually editing the params.csv and settings.csv files\n# if DROPDOWNS['planet_or_EB'].value == 'EBs':\n# for companion in INPUT['companions_all']:\n# if len(DROPDOWNS[companion+'_N_spots_'+inst].value):\n# N_spots = int(DROPDOWNS[companion+'_N_spots_'+inst].value)\n# for i in range(1,N_spots+1):\n# add_row(companion+'_spot_'+str(i)+'_lat_'+inst, companion+' spot '+str(i)+' lat. '+inst+' (deg)', hbox_list)\n# add_row(companion+'_spot_'+str(i)+'_long_'+inst, companion+' spot '+str(i)+' long. '+inst+' (deg)', hbox_list)\n# add_row(companion+'_spot_'+str(i)+'_size_'+inst, companion+' spot '+str(i)+' size '+inst+' (deg)', hbox_list)\n# add_row(companion+'_spot_'+str(i)+'_brightness_'+inst, companion+' spot '+str(i)+' brightness '+inst, hbox_list)\n \n if len(hbox_list)==0:\n pass\n #hbox_list.append(widgets.Label(value='N_spots was set to \"None\" for all objects and instruments.'))\n vbox_list.append( widgets.VBox(hbox_list) )\n\n\n #::: Flares\n hbox_list = []\n if len(DROPDOWNS['N_flares'].value):\n N_flares = int(DROPDOWNS['N_flares'].value)\n for i in range(1,N_flares+1):\n add_row('flare_tpeak_'+str(i), 'Flare tpeak '+str(i), hbox_list)\n add_row('flare_fwhm_'+str(i), 'Flare fwhm '+str(i), hbox_list)\n add_row('flare_ampl_'+str(i), 'Flare ampl '+str(i), hbox_list)\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: TTV per transit\n hbox_list = []\n if (DROPDOWNS['fit_ttvs'].value)=='yes':\n for companion in INPUT['companions_all']:\n add_row(companion+'_ttv_per_transit', 'TTV per transit', hbox_list, median=0, lerr=0.00347222, uerr=0.00347222, transform='uniform', fit_value=True)\n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Errors per instrument\n hbox_list = []\n \n for inst in INPUT['inst_phot']:\n if DROPDOWNS['error_flux_'+inst].value == 'sample':\n add_row('ln_err_flux_'+inst, 'ln err flux '+inst, hbox_list, median=-7, lerr=8, uerr=7, transform='uniform', fit_value=True)\n else:\n pass\n #hbox_list.append(widgets.Label(value='Not applicable, error sampling was set to \"hybrid\".'))\n \n for inst in INPUT['inst_rv']:\n if DROPDOWNS['error_rv_'+inst].value == 'sample':\n add_row('ln_jitter_rv_'+inst, 'ln jitter rv '+inst, hbox_list, median=-3, lerr=12, uerr=3, transform='uniform', fit_value=True)\n else:\n pass\n #hbox_list.append(widgets.Label(value='Not applicable, error sampling was set to \"hybrid\".'))\n \n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: Baselines per instrument\n hbox_list = []\n for inst in INPUT['inst_all']:\n if inst in INPUT['inst_phot']:\n key = 'flux'\n elif inst in INPUT['inst_rv']:\n key = 'rv'\n \n if DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_GP_Matern32':\n add_row('baseline_gp_matern32_lnsigma_'+key+'_'+inst, 'baseline gp Matern32 lnsigma '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n add_row('baseline_gp_matern32_lnrho_'+key+'_'+inst, 'baseline gp Matern32 lnrho '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n elif DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_GP_SHO':\n add_row('baseline_gp_sho_lnS0_'+key+'_'+inst, 'baseline gp SHO lnS0 '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n add_row('baseline_gp_sho_lnQ_'+key+'_'+inst, 'baseline gp SHO lnQ '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n add_row('baseline_gp_sho_lnomega0_'+key+'_'+inst, 'baseline gp SHO lnomega0 '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n elif DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_GP_real':\n add_row('baseline_gp_real_lna_'+key+'_'+inst, 'baseline gp real lna '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n add_row('baseline_gp_real_lnc_'+key+'_'+inst, 'baseline gp real lnc '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n elif DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_GP_complex':\n add_row('baseline_gp_complex_lna_'+key+'_'+inst, 'baseline gp complex lna '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n add_row('baseline_gp_complex_lnc_'+key+'_'+inst, 'baseline gp complex lnc '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n add_row('baseline_gp_complex_lnb_'+key+'_'+inst, 'baseline gp complex lnb '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n add_row('baseline_gp_complex_lnd_'+key+'_'+inst, 'baseline gp complex lnd '+inst, hbox_list, median=0, lerr=15, uerr=15, transform='uniform', fit_value=True)\n elif DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_offset':\n add_row('baseline_offset_'+key+'_'+inst, 'baseline offset '+inst, hbox_list, median=0, lerr=0, uerr=0, transform='uniform', fit_value=True)\n elif DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_linear':\n add_row('baseline_offset_'+key+'_'+inst, 'baseline offset '+inst, hbox_list, median=0, lerr=0, uerr=0, transform='uniform', fit_value=True)\n add_row('baseline_slope_'+key+'_'+inst, 'baseline slope '+inst, hbox_list, median=0, lerr=0, uerr=0, transform='uniform', fit_value=True)\n \n vbox_list.append( widgets.VBox(hbox_list) )\n \n \n #::: accordion\n accordion = widgets.Accordion(children=vbox_list)\n accordion.set_title(0, 'Dilution')\n accordion.set_title(1, 'Limb darkening')\n accordion.set_title(2, 'Surface brightness ratio')\n accordion.set_title(3, 'Geometric albedo')\n accordion.set_title(4, 'Gravity darkening')\n accordion.set_title(5, 'Stellar spots')\n accordion.set_title(6, 'Flares')\n accordion.set_title(7, 'TTVs')\n accordion.set_title(8, 'Errors & jitter')\n accordion.set_title(9, 'Baselines')\n display(accordion)\n ",
"_____no_output_____"
],
[
"if 'show_step_3' in INPUT and INPUT['show_step_3'] == True:\n \n nan_fields = False\n \n button_create_params_file = widgets.Button(description='Create params.csv', button_style='')\n checkbox_overwrite_params_file = widgets.Checkbox(description='Overwrite old params.csv (if existing)', value=False)\n hbox_params_file = widgets.HBox([button_create_params_file, checkbox_overwrite_params_file])\n display(hbox_params_file)\n \n def create_params_file(change):\n \n clear_output()\n display(hbox_params_file)\n print('Calculating... this might take a few seconds. Please be patient, you will get notified once everything is completed.')\n\n go_ahead = True\n\n if 'datadir' not in INPUT:\n warnings.warn('No allesfitter woking directory selected yet. Please go back to step 1) and fill in all fields.')\n go_ahead = False\n\n if os.path.exists(os.path.join(INPUT['datadir'],'params.csv')) and (checkbox_overwrite_params_file.value==False):\n warnings.warn('The selected working directory '+os.path.join(INPUT['datadir'],'params.csv')+' already exists. To proceed, give permission to overwrite it.')\n go_ahead = False\n\n \n if go_ahead:\n INPUT['fname_params'] = os.path.join(INPUT['datadir'], 'params.csv')\n with open(INPUT['fname_params'], 'w+') as f:\n f.write('#name,value,fit,bounds,label,unit\\n')\n\n \n \n def get_median_and_error_strings(text_median, text_lerr, text_uerr):\n if (text_median.value == ''):\n median = 'NaN'\n nan_fields = True\n else:\n median = text_median.value\n if (text_lerr.value == '') or (text_uerr.value == ''):\n err = 'NaN'\n nan_fields = True\n else:\n err = str( 5.* np.max( [float(text_lerr.value), float(text_uerr.value)] ) )\n median, err, _ = round_txt_separately( float(median), float(err), float(err) )\n return median, err\n \n\n \n #:::: astrophysical parameters per system\n for companion in INPUT['companions_all']:\n fwrite_params_line('#companion '+companion+' astrophysical params,,,,,') \n \n #::: rr\n fwrite_params(companion+'_rr', '$R_'+companion+' / R_\\star$', '', [0,1])\n \n #::: rsuma\n if INPUT[companion+'_rsuma_input_type'].value=='(R_comp + R_host) / a':\n pass\n elif INPUT[companion+'_rsuma_input_type'].value=='R_host / a':\n Rstar_over_a = [ float(INPUT[companion+'_rsuma_median'].value), float(INPUT[companion+'_rsuma_lerr'].value), float(INPUT[companion+'_rsuma_uerr'].value) ]\n Rp_over_Rstar = [ float(INPUT[companion+'_rr_median'].value), float(INPUT[companion+'_rr_lerr'].value), float(INPUT[companion+'_rr_uerr'].value) ]\n INPUT[companion+'_rsuma_median'].value, INPUT[companion+'_rsuma_lerr'].value, INPUT[companion+'_rsuma_uerr'].value \\\n = get_Rsuma_from_Rstar_over_a(Rstar_over_a, Rp_over_Rstar)\n INPUT[companion+'_rsuma_input_type'].value = '(R_comp + R_host) / a'\n elif INPUT[companion+'_rsuma_input_type'].value=='a / R_host':\n a_over_Rstar = [ float(INPUT[companion+'_rsuma_median'].value), float(INPUT[companion+'_rsuma_lerr'].value), float(INPUT[companion+'_rsuma_uerr'].value) ]\n Rp_over_Rstar = [ float(INPUT[companion+'_rr_median'].value), float(INPUT[companion+'_rr_lerr'].value), float(INPUT[companion+'_rr_uerr'].value) ]\n INPUT[companion+'_rsuma_median'].value, INPUT[companion+'_rsuma_lerr'].value, INPUT[companion+'_rsuma_uerr'].value \\\n = get_Rsuma_from_a_over_Rstar(a_over_Rstar, Rp_over_Rstar)\n INPUT[companion+'_rsuma_input_type'].value = '(R_comp + R_host) / a'\n else:\n raise ValueError('Oops, something went wrong.')\n fwrite_params(companion+'_rsuma', '$(R_\\star + R_'+companion+') / a_'+companion+'$', '', [0,1])\n \n #::: cosi\n if INPUT[companion+'_cosi_input_type'].value=='cos(i)':\n pass\n elif INPUT[companion+'_cosi_input_type'].value=='i (degree)':\n incl = [ float(INPUT[companion+'_cosi_median'].value), float(INPUT[companion+'_cosi_lerr'].value), float(INPUT[companion+'_cosi_uerr'].value) ]\n INPUT[companion+'_cosi_median'].value, INPUT[companion+'_cosi_lerr'].value, INPUT[companion+'_cosi_uerr'].value \\\n = get_cosi_from_i(incl)\n INPUT[companion+'_cosi_input_type'].value = 'cos(i)'\n elif INPUT[companion+'_cosi_input_type'].value=='i (rad)':\n incl = [ float(INPUT[companion+'_cosi_median'].value)/180.*np.pi, float(INPUT[companion+'_cosi_lerr'].value)/180.*np.pi, float(INPUT[companion+'_cosi_uerr'].value)/180.*np.pi ]\n INPUT[companion+'_cosi_median'].value, INPUT[companion+'_cosi_lerr'].value, INPUT[companion+'_cosi_uerr'].value \\\n = get_cosi_from_i(incl)\n INPUT[companion+'_cosi_input_type'].value = 'cos(i)'\n fwrite_params(companion+'_cosi', '$\\cos{i_'+companion+'}$', '', [0,1])\n\n #::: epoch\n fwrite_params(companion+'_epoch', '$T_{0;'+companion+'}$', '$\\mathrm{BJD}$', [-1e12,1e12])\n\n #::: period\n fwrite_params(companion+'_period', '$P_'+companion+'$', '$\\mathrm{d}$', [-1e12,1e12])\n \n #::: RV semi-amplitude\n if companion in INPUT['companions_rv']:\n fwrite_params(companion+'_K', '$K_'+companion+'$', '$\\mathrm{km/s}$', [-1e12,1e12])\n \n #::: eccentricity f_c\n fwrite_params(companion+'_f_c', '$\\sqrt{e_'+companion+'} \\cos{\\omega_'+companion+'}$', '', [-1,1])\n \n #::: eccentricity f_s\n fwrite_params(companion+'_f_s', '$\\sqrt{e_'+companion+'} \\sin{\\omega_'+companion+'}$', '', [-1,1])\n\n \n #::: dilution per instrument\n if len(INPUT['inst_phot']):\n fwrite_params_line('#dilution per instrument,,,,,')\n for inst in INPUT['inst_phot']:\n fwrite_params('dil_'+inst, '$D_\\mathrm{0; '+inst+'}$', '', [0,1])\n #fwrite_params('dil_'+inst+',0,0,trunc_normal 0 1 0 0,$D_\\mathrm{0; '+inst+'}$,')\n\n \n #::: limb darkening coefficients per instrument\n if len(INPUT['inst_phot']):\n fwrite_params_line('#limb darkening coefficients per instrument,,,,,') \n for inst in INPUT['inst_phot']:\n \n #::: host\n if DROPDOWNS['host_ld_law_'+inst].value=='None':\n pass\n elif DROPDOWNS['host_ld_law_'+inst].value=='Linear':\n fwrite_params('host_ldc_q1_'+inst, '$q_{1; \\mathrm{'+inst+'}}$', '', [0,1]) \n elif DROPDOWNS['host_ld_law_'+inst].value=='Quadratic':\n fwrite_params('host_ldc_q1_'+inst, '$q_{1; \\mathrm{'+inst+'}}$', '', [0,1]) \n fwrite_params('host_ldc_q2_'+inst, '$q_{2; \\mathrm{'+inst+'}}$', '', [0,1]) \n elif DROPDOWNS['host_ld_law_'+inst].value=='Sing':\n fwrite_params('host_ldc_q1_'+inst, '$q_{1; \\mathrm{'+inst+'}}$', '', [0,1]) \n fwrite_params('host_ldc_q2_'+inst, '$q_{2; \\mathrm{'+inst+'}}$', '', [0,1]) \n fwrite_params('host_ldc_q3_'+inst, '$q_{3; \\mathrm{'+inst+'}}$', '', [0,1]) \n \n #::: companion (if EB)\n if DROPDOWNS['planet_or_EB']=='EBs':\n if DROPDOWNS[companion+'_ld_law_'+inst].value=='None':\n pass\n elif DROPDOWNS[companion+'_ld_law_'+inst].value=='Linear':\n fwrite_params(companion+'_ldc_q1_'+inst, '$q_{1; \\mathrm{'+inst+'}}$', '', [0,1]) \n elif DROPDOWNS[companion+'_ld_law_'+inst].value=='Quadratic':\n fwrite_params(companion+'_ldc_q1_'+inst, '$q_{1; \\mathrm{'+inst+'}}$', '', [0,1]) \n fwrite_params(companion+'_ldc_q2_'+inst, '$q_{2; \\mathrm{'+inst+'}}$', '', [0,1]) \n elif DROPDOWNS[companion+'_ld_law_'+inst].value=='Sing':\n fwrite_params(companion+'_ldc_q1_'+inst, '$q_{1; \\mathrm{'+inst+'}}$', '', [0,1]) \n fwrite_params(companion+'_ldc_q2_'+inst, '$q_{2; \\mathrm{'+inst+'}}$', '', [0,1]) \n fwrite_params(companion+'_ldc_q3_'+inst, '$q_{3; \\mathrm{'+inst+'}}$', '', [0,1]) \n \n \n #::: brightness ratio per system and instrument\n if len(INPUT['inst_all']):\n fwrite_params_line('#surface brightness per instrument and companion,,,,,')\n for companion in INPUT['companions_all']:\n for inst in INPUT['inst_all']:\n fwrite_params(companion+'_sbratio_'+inst, '$J_{'+companion+'; \\mathrm{'+inst+'}}$', '', [0,1])\n \n \n #::: geometric albedo per system and instrument\n if len(INPUT['inst_all']):\n fwrite_params_line('#albedo per instrument and companion,,,,,')\n for inst in INPUT['inst_all']:\n fwrite_params('host_geom_albedo_'+inst, '$A_{\\mathrm{geom}; host; \\mathrm{'+inst+'}}$', '', [0,1])\n for companion in INPUT['companions_all']:\n for inst in INPUT['inst_all']:\n fwrite_params(companion+'_geom_albedo_'+inst, '$A_{\\mathrm{geom}; '+companion+'; \\mathrm{'+inst+'}}$', '', [0,1])\n\n \n #::: gravity darkening per object and instrument\n if len(INPUT['inst_all']): \n fwrite_params_line('#gravity darkening per instrument and companion,,,,,')\n for inst in INPUT['inst_all']:\n #::: host\n fwrite_params('host_gdc_'+inst, '$Grav. dark._{'+companion+'; \\mathrm{'+inst+'}}$', '', [0,1])\n #::: companion (if EB)\n if DROPDOWNS['planet_or_EB']=='EBs':\n for companion in INPUT['companions_all']:\n fwrite_params(companion+'_sbratio_'+inst, '$Grav. dark._{'+companion+'; \\mathrm{'+inst+'}}$', '', [0,1])\n \n \n \n #::: spots per object and instrument\n if len(INPUT['inst_all']): \n \n fwrite_params_line('#spots per instrument and companion,,,,,')\n \n for inst in INPUT['inst_all']:\n if len(DROPDOWNS['host_N_spots_'+inst].value):\n N_spots = int(DROPDOWNS['host_N_spots_'+inst].value)\n for i in range(1,N_spots+1):\n #::: host\n fwrite_params('host_spot_'+str(i)+'_long_'+inst, '$\\mathrm{host: spot '+str(i)+' long. '+inst+'}$', '\\mathrm{deg}', [0,360])\n fwrite_params('host_spot_'+str(i)+'_lat_'+inst, '$\\mathrm{host: spot '+str(i)+' lat. '+inst+'}$', '\\mathrm{deg}', [-90,90])\n fwrite_params('host_spot_'+str(i)+'_size_'+inst, '$\\mathrm{host: spot '+str(i)+' size '+inst+'}$', '\\mathrm{deg}', [0,30])\n fwrite_params('host_spot_'+str(i)+'_brightness_'+inst, '$\\mathrm{host: spot '+str(i)+' brightness '+inst+'}$', '', [0,1])\n \n #::: companion (if EB)\n if DROPDOWNS['planet_or_EB']=='EBs':\n for companion in INPUT['companions_all']:\n if len(DROPDOWNS[companion+'_N_spots_'+inst].value):\n N_spots = int(DROPDOWNS[companion+'_N_spots_'+inst].value)\n fwrite_params(companion+'_spot_'+str(i)+'_long_'+inst, '$\\mathrm{'+companion+': spot '+str(i)+' long. '+inst+'}$', '\\mathrm{deg}', [0,360])\n fwrite_params(companion+'_spot_'+str(i)+'_lat_'+inst, '$\\mathrm{'+companion+': spot '+str(i)+' lat. '+inst+'}$', '\\mathrm{deg}', [-90,90])\n fwrite_params(companion+'_spot_'+str(i)+'_size_'+inst, '$\\mathrm{'+companion+': spot '+str(i)+' size '+inst+'}$', '\\mathrm{deg}', [0,30])\n fwrite_params(companion+'_spot_'+str(i)+'_brightness_'+inst, '$\\mathrm{'+companion+': spot '+str(i)+' brightness '+inst+'}$', '', [0,1])\n \n \n #::: flares\n if len(DROPDOWNS['N_flares'].value):\n fwrite_params_line('#flares,,,,,')\n N_flares = int(DROPDOWNS['N_flares'].value)\n for i in range(1,N_flares+1):\n fwrite_params('flare_tpeak_'+str(i), '$t_\\mathrm{peak; flare '+str(i)+'}$', '$\\mathrm{BJD}$', [-1e12,1e12])\n fwrite_params('flare_ampl_'+str(i), '$A_\\mathrm{flare '+str(i)+'}$', '$\\mathrm{rel. flux.}$', [-1e12,1e12])\n fwrite_params('flare_fwhm_'+str(i), '$FWHM_\\mathrm{flare '+str(i)+'}$', '$\\mathrm{BJD}$', [-1e12,1e12])\n \n \n \n #::: TTV per instrument\n if (DROPDOWNS['fit_ttvs'].value=='yes'):\n fwrite_params_line('#TTV per transit,,,,,')\n warnings.warn('TTV priors in params.csv will not be set until you also complete step 4 (adding the data files).')\n # for inst in INPUT['inst_phot']:\n # fwrite_params('ttv_'+inst, '$\\mathrm{TTV_'+inst+'}$', '$\\mathrm{d}$', [-1e12,1e12])\n \n \n #::: errors and baselines - keep track of rows\n INPUT['N_last_rows'] = 0\n \n \n #::: errors per instrument\n if any( [ 'sample' in DROPDOWNS['error_flux_'+inst].value for inst in INPUT['inst_phot'] ] ) \\\n or any( [ 'sample' in DROPDOWNS['error_rv_'+inst].value for inst in INPUT['inst_rv'] ] ):\n \n fwrite_params_line('#errors per instrument,')\n INPUT['N_last_rows'] += 1\n\n for inst in INPUT['inst_phot']:\n if 'hybrid' not in DROPDOWNS['error_flux_'+inst].value:\n fwrite_params('ln_err_flux_'+inst, '$\\ln{\\sigma_\\mathrm{'+inst+'}}$', '$\\ln{ \\mathrm{rel. flux.} }$', [-15,0])\n INPUT['N_last_rows'] += 1\n\n for inst in INPUT['inst_rv']:\n if 'hybrid' not in DROPDOWNS['error_rv_'+inst].value:\n fwrite_params('ln_jitter_rv_'+inst, '$\\ln{\\sigma_\\mathrm{jitter; '+inst+'}}$', '$\\ln{ \\mathrm{km/s} }$', [-15,0])\n INPUT['N_last_rows'] += 1\n \n \n #::: baseline\n if any( [ 'sample' in DROPDOWNS['baseline_flux_'+inst].value for inst in INPUT['inst_phot'] ] ) \\\n or any( [ 'sample' in DROPDOWNS['baseline_rv_'+inst].value for inst in INPUT['inst_rv'] ] ):\n \n fwrite_params_line('#baseline per instrument,')\n INPUT['N_last_rows'] += 1\n \n for inst in INPUT['inst_all']:\n if inst in INPUT['inst_phot']:\n key = 'flux'\n elif inst in INPUT['inst_rv']:\n key = 'rv'\n \n if DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_GP_Matern32':\n fwrite_params('baseline_gp_matern32_lnsigma_'+key+'_'+inst, '$\\mathrm{gp: \\ln{\\sigma} ('+inst+')}$', '', [-15,15])\n fwrite_params('baseline_gp_matern32_lnrho_'+key+'_'+inst, '$\\mathrm{gp: \\ln{\\\\rho} ('+inst+')}$', '', [-15,15])\n INPUT['N_last_rows'] += 2\n \n elif DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_GP_SHO':\n fwrite_params('baseline_gp_sho_lnS0_'+key+'_'+inst, '$\\mathrm{gp: \\ln{S_0} ('+inst+')}$', '', [-15,15])\n fwrite_params('baseline_gp_sho_lnQ_'+key+'_'+inst, '$\\mathrm{gp: \\ln{Q} ('+inst+')}$', '', [-15,15])\n fwrite_params('baseline_gp_sho_lnomega0_'+key+'_'+inst, '$\\mathrm{gp: \\ln{\\omega_0} ('+inst+')}$', '', [-15,15])\n INPUT['N_last_rows'] += 3\n\n elif DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_GP_real':\n fwrite_params('baseline_gp_real_lna_'+key+'_'+inst, '$\\mathrm{gp: \\ln{a} ('+inst+')}$', '', [-15,15])\n fwrite_params('baseline_gp_real_lnc_'+key+'_'+inst, '$\\mathrm{gp: \\ln{c} ('+inst+')}$', '', [-15,15])\n INPUT['N_last_rows'] += 2\n \n elif DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_GP_complex':\n fwrite_params('baseline_gp_real_lna_'+key+'_'+inst, '$\\mathrm{gp: \\ln{a} ('+inst+')}$', '', [-15,15])\n fwrite_params('baseline_gp_real_lnc_'+key+'_'+inst, '$\\mathrm{gp: \\ln{c} ('+inst+')}$', '', [-15,15])\n fwrite_params('baseline_gp_real_lnb_'+key+'_'+inst, '$\\mathrm{gp: \\ln{b} ('+inst+')}$', '', [-15,15])\n fwrite_params('baseline_gp_real_lnd_'+key+'_'+inst, '$\\mathrm{gp: \\ln{d} ('+inst+')}$', '', [-15,15])\n INPUT['N_last_rows'] += 4\n \n elif DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_offset':\n fwrite_params('baseline_offset_flux_'+inst, 'offset ('+inst+')', '', [-1e12,1e12])\n INPUT['N_last_rows'] += 1\n\n elif DROPDOWNS['baseline_'+key+'_'+inst].value == 'sample_linear':\n fwrite_params('baseline_a_flux_'+inst, 'lin. a ('+inst+')', '', [-1e12,1e12])\n fwrite_params('baseline_b_flux_'+inst, 'lin. b ('+inst+')', '', [-1e12,1e12])\n INPUT['N_last_rows'] += 2\n\n \n #::: continue\n button_create_params_file.style.button_color = 'lightgreen' \n print('Done.')\n INPUT['show_step_4'] = True\n display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1, IPython.notebook.ncells())'))\n \n if nan_fields:\n warnings.warn('You left some fields empty. These will be set NaN in params.csv. Make sure to fix this manually later.')\n \n\n button_create_params_file.on_click(create_params_file)",
"_____no_output_____"
],
[
"epic",
"_____no_output_____"
],
[
"pipeline = 'everest'\nsave = True\noutput_cols = 'time flux flux_err'.split()\n\nfor n,campaign in enumerate(all_campaigns):\n if pipeline=='everest':\n e = cr.Everest(epicid=epic, campaign=campaign, verbose=False)\n lc = e.get_everest_lc()\n else:\n e = cr.K2sff(epicid=epic, campaign=campaign, verbose=False)\n lc = e.get_k2sff_lc()\n lc = lc.remove_outliers()\n# if save:\n# camp = str(campaign).zfill(2)\n# fp_csv = f'../data/lc/candidate_lcs/{pipeline}_lcs/EPIC{epic}_{pipeline}_c{camp}_raw.csv'\n# raw = pd.DataFrame(np.c_[lc.time, lc.flux, lc.flux_err],\n# columns=output_cols\n# )\n# raw.to_csv(fp_csv, columns=output_cols,\n# sep=' ',\n# header=False,\n# index=False)\n# print(f'Saved: {fp_csv}')\n if n==0:\n lcs = lc.copy()\n else:\n lcs = lcs.append(lc)\n \nlcs.campaign = all_campaigns\n\nif save:\n output_cols = 'time flux flux_err'.split()\n # fp_csv = f'../data/lc/candidate_lcs/{pipeline}_lcs/EPIC{e.epicid}_{pipeline}_c{camps}_raw.csv'\n fp_csv = f'./epic{str(epic)[-4:]}/k2.csv'\n raw = pd.DataFrame(np.c_[lcs.time, lcs.flux, lcs.flux_err],\n columns=output_cols\n )\n raw.to_csv(fp_csv, columns=output_cols,\n sep=',',\n header=False,\n index=False)\n print(f'Saved: {fp_csv}')",
"Saved: ./epic3752/k2.csv\n"
]
],
[
[
"# 4. data files\nPlease put all data files into the selected directory, and click the button to confirm.",
"_____no_output_____"
]
],
[
[
"if 'show_step_4' in INPUT and INPUT['show_step_4']==True:\n\n BUTTONS['confirm_data_files'] = widgets.Button(description='Confirm', button_style='')\n display(BUTTONS['confirm_data_files'])\n \n def check_data_files(change):\n clear_output()\n display(BUTTONS['confirm_data_files'])\n \n all_data_exists = True\n for inst in INPUT['inst_all']:\n if not os.path.exists( os.path.join(INPUT['datadir'], inst+'.csv') ):\n warnings.warn('Data file '+os.path.join(INPUT['datadir'], inst+'.csv')+' does not exist. Please include the data file into the directory and then repeat this step.')\n all_data_exists = False\n if all_data_exists:\n BUTTONS['confirm_data_files'].style.button_color = 'lightgreen' \n INPUT['show_step_5'] = True\n display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1, IPython.notebook.ncells())'))\n \n BUTTONS['confirm_data_files'].on_click(check_data_files)\n \n# else: \n# print('Complete previous steps first.')",
"_____no_output_____"
],
[
"############################################################################\n#::: time to include those TTV lines into the folder!\n############################################################################\n\nif 'show_step_5' in INPUT and INPUT['show_step_5']==True and DROPDOWNS['fit_ttvs'].value=='yes':\n \n from allesfitter import config\n config.init(INPUT['datadir'])\n \n new_lines = ''\n \n for companion in INPUT['companions_all']:\n N_observed_transits = len(config.BASEMENT.data[companion+'_tmid_observed_transits'])\n for i in range(N_observed_transits):\n string = fwrite_params(companion+'_ttv_per_transit', 'TTV$_\\mathrm{'+str(i+1)+'}}$', '$\\mathrm{d}$', [-15,15], return_str=True) + '\\n'\n string = string.replace('per_transit', 'transit_'+str(i+1))\n new_lines += string\n \n with open(INPUT['fname_params'], \"r\") as f:\n contents = f.readlines()\n \n for i, line in enumerate(contents): \n line = line.rstrip() # remove '\\n' at end of line\n if line == '#TTV per transit,,,,,':\n index = i+1\n \n contents.insert(index, new_lines)\n\n with open(INPUT['fname_params'], \"w\") as f:\n contents = \"\".join(contents)\n f.write(contents)\n \n print('TTVs per transit were added to params.csv.')\n print('params.csv and settings.csv are now ready to use.')",
"_____no_output_____"
]
],
[
[
"# 5. check",
"_____no_output_____"
]
],
[
[
"if 'show_step_5' in INPUT and INPUT['show_step_5']==True:\n \n from allesfitter.general_output import show_initial_guess\n import matplotlib.pyplot as plt\n\n fig_list = show_initial_guess(INPUT['datadir'], do_logprint=False, return_figs=True)\n \n for fig in fig_list:\n plt.show(fig)",
"\r 0%| | 0/1163 [00:00<?, ?it/s]"
],
[
"if 'show_step_5' in INPUT and INPUT['show_step_5']==True:\n\n BUTTONS['confirm_plots'] = widgets.Button(description='Looks good', button_style='')\n display(BUTTONS['confirm_plots'])\n \n def check_plots(change):\n clear_output()\n display(BUTTONS['confirm_plots'])\n BUTTONS['confirm_plots'].style.button_color = 'lightgreen' \n INPUT['show_step_6'] = True\n display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1, IPython.notebook.ncells())'))\n \n BUTTONS['confirm_plots'].on_click(check_plots)\n \n# else: \n# print('Complete previous steps first.')",
"_____no_output_____"
]
],
[
[
"# 6. tighter priors on errors and baselines\nThis will take a couple of minutes. Make sure your initial guess above is very good. This will subtract the model from the data and evaluate the remaining noise patterns to estimate errors, jitter and GP baselines.",
"_____no_output_____"
]
],
[
[
"if 'show_step_6' in INPUT and INPUT['show_step_6']==True:\n\n def estimate_tighter_priors(change):\n \n print('\\nEstimating errors and baselines... this will take a couple of minutes. Please be patient, you will get notified once everything is completed.\\n')\n\n #::: run MCMC fit to estimate errors and baselines\n estimate_noise(INPUT['datadir'])\n\n #::: delete the rows containing the default (zero) errors and baselines from the params.csv file\n clean_up_csv( os.path.join( INPUT['datadir'], 'params.csv' ), N_last_rows=INPUT['N_last_rows'] )\n\n\n #::: write new rows into params.csv\n #::: errors\n fwrite_params_line('#errors per instrument,')\n\n for i, inst in enumerate(INPUT['inst_phot']): \n #::: read in the summary file\n summaryfile = os.path.join( INPUT['datadir'], 'priors', 'summary_phot.csv' )\n priors2 = np.genfromtxt(summaryfile, names=True, delimiter=',', dtype=None)\n priors = {}\n for key in priors2.dtype.names:\n priors[key] = np.atleast_1d(priors2[key])\n\n median = priors['ln_yerr_median'][i]\n err = 5.*np.max([ float(priors['ln_yerr_ll'][i]), float(priors['ln_yerr_ul'][i]) ])\n median, err, _ = round_txt_separately(median,err,err)\n fwrite_params_line('ln_err_flux_'+inst+','+median+',1,trunc_normal -15 0 '+median+' '+err+',$\\ln{\\sigma_\\mathrm{'+inst+'}}$,')\n\n for i, inst in enumerate(INPUT['inst_rv']): \n #::: read in the summary file\n summaryfile = os.path.join( INPUT['datadir'], 'priors', 'summary_rv.csv' )\n priors2 = np.genfromtxt(summaryfile, names=True, delimiter=',', dtype=None)\n priors = {}\n for key in priors2.dtype.names:\n priors[key] = np.atleast_1d(priors2[key])\n\n median = priors['ln_yerr_median'][i]\n err = 5.*np.max([ float(priors['ln_yerr_ll'][i]), float(priors['ln_yerr_ul'][i]) ])\n median, err, _ = round_txt_separately(median,err,err)\n fwrite_params('ln_jitter_rv_'+inst+','+median+',1,trunc_normal -15 0 '+median+' '+err+',$\\ln{\\sigma_\\mathrm{jitter; '+inst+'}}$,')\n\n\n #::: write new rows into params.csv\n #::: baselines\n fwrite_params_line('#baseline per instrument,')\n\n for i, inst in enumerate(INPUT['inst_phot']): \n #::: read in the summary file\n summaryfile = os.path.join( INPUT['datadir'], 'priors', 'summary_phot.csv' )\n priors2 = np.genfromtxt(summaryfile, names=True, delimiter=',', dtype=None)\n priors = {}\n for key in priors2.dtype.names:\n priors[key] = np.atleast_1d(priors2[key])\n\n median = priors['gp_ln_sigma_median'][i]\n err = 5.*np.max([ float(priors['gp_ln_sigma_ll'][i]), float(priors['gp_ln_sigma_ul'][i]) ])\n median, err, _ = round_txt_separately(median,err,err)\n fwrite_params_line('baseline_gp1_flux_'+inst+','+median+',1,trunc_normal -15 15 '+median+' '+err+',$\\mathrm{gp: \\ln{\\sigma} ('+inst+')}$,')\n\n median = priors['gp_ln_rho_median'][i]\n err = 5.*np.max([ float(priors['gp_ln_rho_ll'][i]), float(priors['gp_ln_rho_ul'][i]) ])\n median, err, _ = round_txt_separately(median,err,err)\n fwrite_params_line('baseline_gp2_flux_'+inst+','+median+',1,trunc_normal -15 15 '+median+' '+err+',$\\mathrm{gp: \\ln{\\\\rho} ('+inst+')}$,')\n\n \n #::: confirm\n BUTTONS['estimate_tighter_priors'].style.button_color = 'lightgreen' \n print('Done.')\n INPUT['show_step_7'] = True\n display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1, IPython.notebook.ncells())'))\n \n \n \n \n def skip(change):\n BUTTONS['skip'].style.button_color = 'lightgreen' \n print('Skipped.')\n INPUT['show_step_7'] = True\n display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1, IPython.notebook.ncells())'))\n \n \n# else: \n# print('Complete previous steps first.')",
"_____no_output_____"
],
[
"if 'show_step_6' in INPUT and INPUT['show_step_6']==True:\n \n BUTTONS['estimate_tighter_priors'] = widgets.Button(value=False, description='Estimate tighter priors')\n BUTTONS['skip'] = widgets.Button(value=False, description='Skip')\n display( widgets.HBox([BUTTONS['estimate_tighter_priors'],BUTTONS['skip']]))\n \n BUTTONS['estimate_tighter_priors'].on_click(estimate_tighter_priors)\n \n BUTTONS['skip'].on_click(skip)",
"_____no_output_____"
]
],
[
[
"# 7. run the fit",
"_____no_output_____"
]
],
[
[
"if 'show_step_7' in INPUT and INPUT['show_step_7']==True:\n \n try:\n from importlib import reload\n except:\n pass\n \n try:\n from imp import reload\n except:\n pass\n \n import allesfitter\n reload(allesfitter)\n \n button_run_ns_fit = widgets.Button(description='Run NS fit', button_style='')\n button_run_mcmc_fit = widgets.Button(description='Run MCMC fit', button_style='')\n hbox = widgets.HBox([button_run_ns_fit, button_run_mcmc_fit])\n display(hbox)\n \n def run_ns_fit(change):\n button_run_ns_fit.style.button_color = 'lightgreen'\n allesfitter.ns_fit(INPUT['datadir'])\n allesfitter.ns_output(INPUT['datadir'])\n \n def run_mcmc_fit(change):\n button_run_mcmc_fit.style.button_color = 'lightgreen'\n allesfitter.mcmc_fit(INPUT['datadir'])\n allesfitter.mcmc_output(INPUT['datadir'])\n \n button_run_ns_fit.on_click(run_ns_fit)\n button_run_mcmc_fit.on_click(run_mcmc_fit)\n \n \n# else:\n# print('Complete previous steps first.')",
"_____no_output_____"
]
]
]
| [
"raw",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"raw"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7c0fff203952f29721bac4130acb6c6544d2b0a | 9,496 | ipynb | Jupyter Notebook | components/gcp/ml_engine/deploy/sample.ipynb | JohnPaton/pipelines | d673a1f954ff4f5a54336cb6f9e8748a9ca5502d | [
"Apache-2.0"
]
| null | null | null | components/gcp/ml_engine/deploy/sample.ipynb | JohnPaton/pipelines | d673a1f954ff4f5a54336cb6f9e8748a9ca5502d | [
"Apache-2.0"
]
| null | null | null | components/gcp/ml_engine/deploy/sample.ipynb | JohnPaton/pipelines | d673a1f954ff4f5a54336cb6f9e8748a9ca5502d | [
"Apache-2.0"
]
| null | null | null | 39.239669 | 376 | 0.629107 | [
[
[
"# Deploying a trained model to Cloud Machine Learning Engine\nA Kubeflow Pipeline component to deploy a trained model from a Cloud Storage path to a Cloud Machine Learning Engine service.\n\n## Intended use\nUse the component to deploy a trained model to Cloud Machine Learning Engine service. The deployed model can serve online or batch predictions in a KFP pipeline.\n\n## Runtime arguments:\nName | Description | Type | Optional | Default\n:--- | :---------- | :--- | :------- | :------\nmodel_uri | The Cloud Storage URI which contains a model file. Commonly used TF model search paths (export/exporter) will be used. | GCSPath | No |\nproject_id | The ID of the parent project of the serving model. | GCPProjectID | No | \nmodel_id | The user-specified name of the model. If it is not provided, the operation uses a random name. | String | Yes | ` `\nversion_id | The user-specified name of the version. If it is not provided, the operation uses a random name. | String | Yes | ` `\nruntime_version | The [Cloud ML Engine runtime version](https://cloud.google.com/ml-engine/docs/tensorflow/runtime-version-list) to use for this deployment. If it is not set, the Cloud ML Engine uses the default stable version, 1.0. | String | Yes | ` ` \npython_version | The version of Python used in the prediction. If it is not set, the default version is `2.7`. Python `3.5` is available when the runtime_version is set to `1.4` and above. Python `2.7` works with all supported runtime versions. | String | Yes | ` `\nversion | The JSON payload of the new [Version](https://cloud.google.com/ml-engine/reference/rest/v1/projects.models.versions). | Dict | Yes | ` `\nreplace_existing_version | A Boolean flag that indicates whether to replace existing version in case of conflict. | Bool | Yes | False\nset_default | A Boolean flag that indicates whether to set the new version as default version in the model. | Bool | Yes | False\nwait_interval | A time-interval to wait for in case the operation has a long run time. | Integer | Yes | 30\n\n## Output:\nName | Description | Type\n:--- | :---------- | :---\nmodel_uri | The Cloud Storage URI of the trained model. | GCSPath\nmodel_name | The name of the serving model. | String\nversion_name | The name of the deployed version of the model. | String\n\n## Cautions & requirements\n\nTo use the component, you must:\n* Setup cloud environment by following the [guide](https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction#setup).\n* The component is running under a secret of [Kubeflow user service account](https://www.kubeflow.org/docs/started/getting-started-gke/#gcp-service-accounts) in a Kubeflow cluster. For example:\n\n```python\nmlengine_deploy_op(...).apply(gcp.use_gcp_secret('user-gcp-sa'))\n\n```\n* Grant Kubeflow user service account the read access to the Cloud Storage buckets which contains the trained model.\n\n\n## Detailed Description\n\nThe component does:\n* Search for the trained model from the user provided Cloud Storage path.\n* Create a new model if user provided model doesn’t exist.\n* Delete the existing model version if `replace_existing_version` is enabled.\n* Create a new model version from the trained model.\n* Set the new version as the default version of the model if ‘set_default’ is enabled.\n\nHere are the steps to use the component in a pipeline:\n1. Install KFP SDK\n",
"_____no_output_____"
]
],
[
[
"%%capture --no-stderr\n\nKFP_PACKAGE = 'https://storage.googleapis.com/ml-pipeline/release/0.1.14/kfp.tar.gz'\n!pip3 install $KFP_PACKAGE --upgrade",
"_____no_output_____"
]
],
[
[
"2. Load the component using KFP SDK",
"_____no_output_____"
]
],
[
[
"import kfp.components as comp\n\nmlengine_deploy_op = comp.load_component_from_url(\n 'https://raw.githubusercontent.com/kubeflow/pipelines/d2f5cc92a46012b9927209e2aaccab70961582dc/components/gcp/ml_engine/deploy/component.yaml')\nhelp(mlengine_deploy_op)",
"_____no_output_____"
]
],
[
[
"For more information about the component, please checkout:\n* [Component python code](https://github.com/kubeflow/pipelines/blob/master/component_sdk/python/kfp_component/google/ml_engine/_deploy.py)\n* [Component docker file](https://github.com/kubeflow/pipelines/blob/master/components/gcp/container/Dockerfile)\n* [Sample notebook](https://github.com/kubeflow/pipelines/blob/master/components/gcp/ml_engine/deploy/sample.ipynb)\n* [Cloud Machine Learning Engine Model REST API](https://cloud.google.com/ml-engine/reference/rest/v1/projects.models)\n* [Cloud Machine Learning Engine Version REST API](https://cloud.google.com/ml-engine/reference/rest/v1/projects.versions)\n\n\n### Sample\nNote: The following sample code works in IPython notebook or directly in Python code.\n\nIn this sample, we will deploy a pre-built trained model from `gs://ml-pipeline-playground/samples/ml_engine/census/trained_model/` to Cloud Machine Learning Engine service. The deployed model is named `kfp_sample_model`. A new version will be created every time when the sample is run, and the latest version will be set as the default version of the deployed model.\n\n#### Set sample parameters",
"_____no_output_____"
]
],
[
[
"# Required Parameters\nPROJECT_ID = '<Please put your project ID here>'\n\n# Optional Parameters\nEXPERIMENT_NAME = 'CLOUDML - Deploy'\nTRAINED_MODEL_PATH = 'gs://ml-pipeline-playground/samples/ml_engine/census/trained_model/'",
"_____no_output_____"
]
],
[
[
"#### Example pipeline that uses the component",
"_____no_output_____"
]
],
[
[
"import kfp.dsl as dsl\nimport kfp.gcp as gcp\nimport json\[email protected](\n name='CloudML deploy pipeline',\n description='CloudML deploy pipeline'\n)\ndef pipeline(\n model_uri = 'gs://ml-pipeline-playground/samples/ml_engine/census/trained_model/',\n project_id = PROJECT_ID,\n model_id = 'kfp_sample_model',\n version_id = '',\n runtime_version = '1.10',\n python_version = '',\n version = '',\n replace_existing_version = 'False',\n set_default = 'True',\n wait_interval = '30'):\n task = mlengine_deploy_op(\n model_uri=model_uri, \n project_id=project_id, \n model_id=model_id, \n version_id=version_id, \n runtime_version=runtime_version, \n python_version=python_version,\n version=version, \n replace_existing_version=replace_existing_version, \n set_default=set_default, \n wait_interval=wait_interval).apply(gcp.use_gcp_secret('user-gcp-sa'))",
"_____no_output_____"
]
],
[
[
"#### Compile the pipeline",
"_____no_output_____"
]
],
[
[
"pipeline_func = pipeline\npipeline_filename = pipeline_func.__name__ + '.zip'\nimport kfp.compiler as compiler\ncompiler.Compiler().compile(pipeline_func, pipeline_filename)",
"_____no_output_____"
]
],
[
[
"#### Submit the pipeline for execution",
"_____no_output_____"
]
],
[
[
"#Specify pipeline argument values\narguments = {}\n\n#Get or create an experiment and submit a pipeline run\nimport kfp\nclient = kfp.Client()\nexperiment = client.create_experiment(EXPERIMENT_NAME)\n\n#Submit a pipeline run\nrun_name = pipeline_func.__name__ + ' run'\nrun_result = client.run_pipeline(experiment.id, run_name, pipeline_filename, arguments)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7c102f46361409b82fe8f33a65f1125fed51a89 | 179,800 | ipynb | Jupyter Notebook | Cross-Validation.ipynb | JungJiBum/Do-it_DeepLearning | 942069a637d4546bd8675cfd7004cbfddf985326 | [
"MIT"
]
| null | null | null | Cross-Validation.ipynb | JungJiBum/Do-it_DeepLearning | 942069a637d4546bd8675cfd7004cbfddf985326 | [
"MIT"
]
| null | null | null | Cross-Validation.ipynb | JungJiBum/Do-it_DeepLearning | 942069a637d4546bd8675cfd7004cbfddf985326 | [
"MIT"
]
| null | null | null | 111.538462 | 20,672 | 0.831557 | [
[
[
"from sklearn.datasets import load_breast_cancer\ncancer = load_breast_cancer()",
"_____no_output_____"
],
[
"print(cancer.data.shape, cancer.target.shape)",
"(569, 30) (569,)\n"
],
[
"cancer",
"_____no_output_____"
],
[
"cancer.data[:3]",
"_____no_output_____"
],
[
"cancer.target[:]",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nimport numpy as np\n\nplt.boxplot(cancer.data)\nplt.xlabel('feature')\nplt.ylabel('value')\nplt.show()",
"_____no_output_____"
],
[
"cancer.feature_names[[3,13,23]]",
"_____no_output_____"
],
[
"np.unique(cancer.target, return_counts=True)",
"_____no_output_____"
],
[
"x = cancer.data\ny = cancer.target",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"x_train, x_test, y_train, y_test = train_test_split(x,y,stratify=y, test_size=0.2,random_state=42)",
"_____no_output_____"
],
[
"print(x_train.shape,x_test.shape)",
"(455, 30) (114, 30)\n"
],
[
"np.unique(y_train, return_counts=True)",
"_____no_output_____"
],
[
"class LogisticNeuron:\n \n def __init__(self):\n self.w = None\n self.b = None\n \n def forpass(self, x):\n z = np.sum(x * self.w) + self.b #직선 방정식을 계산\n return z\n \n def backprop(self, x, err):\n w_grad = x * err # 가중치에 대한 그레이디언트 계산\n b_grad = 1 * err # 절편에 대한 그레이디언트를 계산\n return w_grad, b_grad\n \n def activation(self, z):\n a = 1 / (1 + np.exp(-z))\n return a\n \n def fit(self, x, y, epochs=100):\n self.w = np.ones(x.shape[1]) # 가중치 초기화\n self.b = 0 # 절편 초기화\n for i in range(epochs): # epochs만큼 반복\n for x_i, y_i in zip(x, y): # 모든 샘플에 대해 반복\n z = self.forpass(x_i) # 정방향 계산\n a = self.activation(z) # 활성화 함수 적용\n err = -(y_i - a) # 오차 계산\n w_grad, b_grad = self.backprop(x_i, err) # 역방향 계산\n self.w -= w_grad # 가중치 업데이트\n self.b -= b_grad # 절편 업데이트\n\n def predict(self, x):\n z = [self.forpass(x_i) for x_i in x] # 선형 함수 적용\n a = self.activation(np.array(z)) # 활성화 함수 적용\n return a > 0.5 # 계단 함수 적용",
"_____no_output_____"
],
[
"neuron = LogisticNeuron()\nneuron.fit(x_train, y_train)",
"<ipython-input-12-36164ee85fd9>:17: RuntimeWarning: overflow encountered in exp\n a = 1 / (1 + np.exp(-z))\n"
],
[
"np.mean(neuron.predict(x_test) == y_test)",
"<ipython-input-12-36164ee85fd9>:17: RuntimeWarning: overflow encountered in exp\n a = 1 / (1 + np.exp(-z))\n"
],
[
"class SingleLayer:\n \n def __init__(self):\n self.w = None\n self.b = None\n self.losses = []\n \n def forpass(self, x):\n z = np.sum(x * self.w) + self.b # 직선 방정식 계산\n return z\n \n def backprop(self, x, err):\n w_grad = x * err # 가중치에 대한 그레이디언트를 계산\n b_grad = 1 *err # 절편에 대한 그레이디언트를 계산\n return w_grad, b_grad\n \n def activation(self, z):\n a = 1 / (1 + np.exp(-z)) # 시그모이드 계산\n return a\n \n def fit(self, x, y, epochs=100):\n self.w = np.ones(x.shape[1]) # 가중치를 초기화\n self.b = 0 # 절편 초기화\n for i in range(epochs): # epochs만큼 반복\n loss = 0\n indexes = np.random.permutation(np.arange(len(x))) # 인덱스 섞기\n for i in indexes: # 모든 샘플에 대해 반복\n z = self.forpass(x[i]) # 정방향 계산\n a = self.activation(z) # 활성화 함수 적용\n err = -(y[i] - a) # 오차 계산\n w_grad, b_grad = self.backprop(x[i], err) # 역방향 계산\n self.w -= w_grad # 가중치 업데이트\n self.b -= b_grad # 절편 업데이트\n a = np.clip(a, 1e-10, 1-1e-10) #안전한 로그 계산을 위해 클리핑한 후 손실을 누적\n loss += -(y[i]*np.log(a)+(1-y[i])*np.log(1-a)) # 에포크마다 평균 손실을 저장\n self.losses.append(loss/len(y))\n \n def predict(self, x):\n z = [self.forpass(x_i) for x_i in x] # 정방향 계산\n return np.array(z) > 0 # 스텝 함수 적용\n \n def score(self, x, y):\n return np.mean(self.predict(x) == y)",
"_____no_output_____"
],
[
"#단일층 신경망 훈련하고 정확도 출력하기\nlayer = SingleLayer()\nlayer.fit(x_train, y_train)\nlayer.score(x_test, y_test)",
"<ipython-input-15-e7a35f3e59cb>:18: RuntimeWarning: overflow encountered in exp\n a = 1 / (1 + np.exp(-z)) # 시그모이드 계산\n"
],
[
"#손실함수 누적값 확인하기\nplt.plot(layer.losses)\nplt.xlabel('epoch')\nplt.ylabel('loss')\nplt.show()",
"_____no_output_____"
],
[
"#로지스틱 손실함수 지정하기\nfrom sklearn.linear_model import SGDClassifier\nsgd = SGDClassifier(loss='log', max_iter=100, tol=1e-3, random_state=42)\n",
"_____no_output_____"
],
[
"#사이킷런으로 훈련하고 평가하기\nsgd.fit(x_train, y_train)\nsgd.score(x_test, y_test)",
"_____no_output_____"
],
[
"#사이킷런으로 예측하기\nsgd.predict(x_test[0:10])",
"_____no_output_____"
],
[
"#로지스틱 회귀로 모델 훈련하고 평가하기\nfrom sklearn.datasets import load_breast_cancer\nfrom sklearn.model_selection import train_test_split\ncancer = load_breast_cancer()\nx = cancer.data\ny = cancer.target\nx_train_all, x_test, y_train_all, y_test = train_test_split(x,y,stratify=y,test_size=0.2, random_state = 42)",
"_____no_output_____"
],
[
"from sklearn.linear_model import SGDClassifier\nsgd = SGDClassifier(loss='log',random_state=42)\nsgd.fit(x_train_all, y_train_all)\nsgd.score(x_test, y_test)",
"_____no_output_____"
],
[
"#서포트 벡터머신으로 모델 훈련하고 평가하기\nfrom sklearn.linear_model import SGDClassifier\nsgd = SGDClassifier(loss='hinge',random_state = 42)\nsgd.fit(x_train, y_train)\nsgd.score(x_test,y_test)",
"_____no_output_____"
],
[
"#데이터셋 준비하기\nfrom sklearn.datasets import load_breast_cancer\nfrom sklearn.model_selection import train_test_split\ncancer = load_breast_cancer()\nx = cancer.data\ny = cancer.target\nx_train_all, x_test, y_train_all, y_test = train_test_split(x,y,stratify=y,test_size=0.2,random_state = 42)",
"_____no_output_____"
],
[
"#검증세트 분할하기\nx_train, x_val, y_train, y_val = train_test_split(x_train_all, y_train_all,stratify=y_train_all, test_size = 0.2, random_state=42)\nprint(len(x_train), len(x_val))",
"364 91\n"
],
[
"#검증세트 사용해 모델 평가하기\nsgd = SGDClassifier(loss='log', random_state = 42)\nsgd.fit(x_train, y_train)\nsgd.score(x_val, y_val)",
"_____no_output_____"
],
[
"#스케일을 조정하지 않고 모델을 훈련해보기\n#훈련 데이터 준비하고 스케일 비교하기\n\nprint(cancer.feature_names[[2,3]])\nplt.boxplot(x_train[:,2:4])\nplt.xlabel('feature')\nplt.ylabel('value')\nplt.show()",
"['mean perimeter' 'mean area']\n"
],
[
"#가중치를 기록할 변수와 학습률 파라미터 추가하기\nclass SingleLayer2:\n def __init__(self, learning_rate =0.1):\n self.w = None\n self.b = None\n self.losses = []\n self.w_history = []\n self.lr = learning_rate\n\n def forpass(self, x):\n z = np.sum(x * self.w) + self.b # 직선 방정식 계산\n return z\n \n def backprop(self, x, err):\n w_grad = x * err # 가중치에 대한 그레이디언트를 계산\n b_grad = 1 *err # 절편에 대한 그레이디언트를 계산\n return w_grad, b_grad\n \n def activation(self, z):\n a = 1 / (1 + np.exp(-z)) # 시그모이드 계산\n return a\n\n #가중치 기록하고 업데이트양 조절하기\n def fit(self, x, y, epochs=100):\n self.w = np.ones(x.shape[1])\n self.b = 0\n self.w_history.append(self.w.copy())\n np.random.seed(42)\n for i in range(epochs):\n loss = 0\n #인덱스를 섞습니다.\n indexes = np.random.permutation(np.arange(len(x)))\n for i in indexes:\n z = self.forpass(x[i])\n a = self.activation(z)\n err = -(y[i] - a)\n w_grad, b_grad = self.backprop(x[i], err)\n self.w -= self.lr * w_grad\n self.b -= b_grad\n #가중치를 기록합니다.\n self.w_history.append(self.w.copy( ))\n #안전한 로그 계산을 위해 클리핑한 후 손실을 누적합니다.\n a = np.clip(a, 1e-10, 1-1e-10)\n loss += -(y[i]*np.log(a)+(1-y[i])*np.log(1-a))\n #에포크마다 평균 손실을 저장합니다.\n self.losses.append(loss/len(y))\n def predict(self, x):\n z = [self.forpass(x_i) for x_i in x] # 정방향 계산\n return np.array(z) > 0 # 스텝 함수 적용\n \n def score(self, x, y):\n return np.mean(self.predict(x) == y)",
"_____no_output_____"
],
[
"#모델 훈련하고 평가하기\nlayer1 = SingleLayer2()\nlayer1.fit(x_train,y_train)\nlayer1.score(x_val, y_val)",
"<ipython-input-28-b3325900082d>:20: RuntimeWarning: overflow encountered in exp\n a = 1 / (1 + np.exp(-z)) # 시그모이드 계산\n"
],
[
"w2 = []\nw3 = []\nfor w in layer1.w_history:\n w2.append(w[2])\n w3.append(w[3]) \nplt.plot(w2, w3)\nplt.plot(w2[-1], w3[-1], 'ro')\nplt.xlabel('w[2]') \nplt.ylabel('w[3]')\nplt.show()",
"_____no_output_____"
],
[
"#넘파이로 표준화 구현하기\ntrain_mean = np.mean(x_train, axis=0)\ntrain_std = np.std(x_train, axis=0)\nx_train_scaled = (x_train - train_mean) / train_std",
"_____no_output_____"
],
[
"#모델 훈련하기\nlayer2 = SingleLayer2()\nlayer2.fit(x_train_scaled, y_train)\nw2 = []\nw3 = []\nfor w in layer2.w_history:\n w2.append(w[2])\n w3.append(w[3])\nplt.plot(w2, w3)\nplt.plot(w2[-1], w3[-1], 'ro')\nplt.xlabel('w[2]')\nplt.ylabel('w[3]')\nplt.show()",
"_____no_output_____"
],
[
"#모델 성능 평가하기\nlayer2.score(x_val, y_val)",
"_____no_output_____"
],
[
"val_mean = np.mean(x_val, axis=0)\nval_std = np.std(x_val, axis=0)\nx_val_scaled = (x_val - val_mean) / val_std\nlayer2.score(x_val_scaled, y_val)",
"_____no_output_____"
],
[
"#원본 훈련 세트와 검증 세트로 산점도 그리기\nplt.plot(x_train[:50, 0], x_train[:50, 1], 'bo')\nplt.plot(x_val[:50, 0], x_val[:50, 1], 'ro')\nplt.xlabel('fature1')\nplt.ylabel('fature2')\nplt.legend(['train set', 'val.set'])\nplt.show()\n",
"_____no_output_____"
],
[
"#전처리한 훈련 세트와 검증 세트로 산점도 그리기\nplt.plot(x_train_scaled[:50, 0], x_train_scaled[:50, 1], 'bo')\nplt.plot(x_val_scaled[:50,0], x_val_scaled[:50, 1], 'ro')\nplt.xlabel('fature1')\nplt.ylabel('fature2')\nplt.legend(['train set', 'val.set'])\nplt.show()",
"_____no_output_____"
],
[
"#올바르게 검증 세트 전처리 하기\nx_val_scaled = (x_val - train_mean) / train_std\nplt.plot(x_train_scaled[:50, 0 ], x_train_scaled[:50, 1 ], 'bo')\nplt.plot(x_val_scaled[:50, 0], x_val_scaled[:50, 1], 'ro')\nplt.xlabel('fature1')\nplt.ylabel('fature2')\nplt.legend(['train set', 'val.set'])\nplt.show()",
"_____no_output_____"
],
[
"#모델 평가하기\nlayer2.score(x_val_scaled, y_val)",
"_____no_output_____"
],
[
"#가중치를 기록할 변수와 학습률 파라미터 추가하기\nclass SingleLayer3:\n def __init__(self, learning_rate =0.1):\n self.w = None\n self.b = None\n self.losses = []\n self.val_losses = []\n self.w_history = []\n self.lr = learning_rate\n\n def forpass(self, x):\n z = np.sum(x * self.w) + self.b # 직선 방정식 계산\n return z\n \n def backprop(self, x, err):\n w_grad = x * err # 가중치에 대한 그레이디언트를 계산\n b_grad = 1 *err # 절편에 대한 그레이디언트를 계산\n return w_grad, b_grad\n \n def activation(self, z):\n a = 1 / (1 + np.exp(-z)) # 시그모이드 계산\n return a\n\n #가중치 기록하고 업데이트양 조절하기\n def fit(self, x, y, epochs=100, x_val=None, y_val=None):\n self.w = np.ones(x.shape[1]) #가중치 초기화\n self.b = 0 #절편 초기화\n self.w_history.append(self.w.copy()) #가중치 기록\n np.random.seed(42) #무작위로 시드 생성\n for i in range(epochs): #epochs만큼 반복\n loss = 0\n #인덱스를 섞습니다.\n indexes = np.random.permutation(np.arange(len(x)))\n for i in indexes: #모든 샘플에 대해 반복\n z = self.forpass(x[i]) #정방향계산\n a = self.activation(z) #활성화 함수 적용\n err = -(y[i] - a) #오차 계산\n w_grad, b_grad = self.backprop(x[i], err) #역방향계산\n self.w -= self.lr * w_grad #가중치 업데이트\n self.b -= b_grad #절편 업데이트\n #가중치를 기록합니다.\n self.w_history.append(self.w.copy( ))\n #안전한 로그 계산을 위해 클리핑한 후 손실을 누적합니다.\n a = np.clip(a, 1e-10, 1-1e-10)\n loss += -(y[i]*np.log(a)+(1-y[i])*np.log(1-a))\n #에포크마다 평균 손실을 저장합니다.\n self.losses.append(loss/len(y))\n #검증 세트에 대한 손실을 계산\n self.update_val_loss(x_val, y_val)\n \n def update_val_loss(self, x_val, y_val):\n if x_val is None:\n return\n val_loss = 0\n for i in range(len(x_val)):\n z = self.forpass(x_val[i])\n a = self.activation(z)\n a = np.clip(a, 1e-10, 1-1e-10)\n val_loss += -(y_val[i]*np.log(a)+(1-y_val[i]*np.log(1-a)))\n self.val_losses.append(val_loss/len(y_val))\n \n def predict(self, x):\n z = [self.forpass(x_i) for x_i in x] # 정방향 계산\n return np.array(z) > 0 # 스텝 함수 적용\n \n def score(self, x, y):\n return np.mean(self.predict(x) == y)",
"_____no_output_____"
],
[
"#모델 훈련하기\nlayer3 = SingleLayer3()\nlayer3.fit(x_train_scaled, y_train, x_val=x_val_scaled, y_val=y_val)",
"_____no_output_____"
],
[
"plt.ylim(0, 0.3)\nplt.plot(layer3.losses)\nplt.plot(layer3.val_losses)\nplt.ylabel('loss')\nplt.xlabel('epoch')\nplt.legend(['train_loss','val_loss'])\nplt.show()\n",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c107991e62351c5cd17bcdb90817b3393a91ae | 747,818 | ipynb | Jupyter Notebook | asking_questions_inferencing/graph_opening.ipynb | rts1988/IntelligentTutoringSystem_Experiments | b2f797a5bfff18fb37c7a779a19a72a75db7eeef | [
"MIT"
]
| 1 | 2020-05-30T17:10:30.000Z | 2020-05-30T17:10:30.000Z | asking_questions_inferencing/graph_opening.ipynb | rts1988/IntelligentTutoringSystem_Experiments | b2f797a5bfff18fb37c7a779a19a72a75db7eeef | [
"MIT"
]
| null | null | null | asking_questions_inferencing/graph_opening.ipynb | rts1988/IntelligentTutoringSystem_Experiments | b2f797a5bfff18fb37c7a779a19a72a75db7eeef | [
"MIT"
]
| 1 | 2019-05-02T05:11:15.000Z | 2019-05-02T05:11:15.000Z | 436.554583 | 562,696 | 0.911036 | [
[
[
"# Asking salient questions",
"_____no_output_____"
],
[
"Now that we can generate the concept map, and calculate the cognitive load per sentence, let's display text blurbs in order of increasing cognitive load as we traverse the created learning path. Based on the blurbs, we will ask questions of the student that are multiple choice. The answers will be passed through a basic inference engine. \n\nThe questions are designed to fill general schema for different entity types in the STEM domain. Relationships are defined based on the roles these entities play. A memory map will be simulated for the student, and review and follow-up questions will be asked based on the memory map for that student. \n\nFurther work will be done for more intelligent question asking, and being able to prompt critical and creative thinking, through relationship extraction and entity detection models. Directing and/or exploring based on learning goals defined based on Bloom's taxonomy will also be done. \n",
"_____no_output_____"
]
],
[
[
"import itertools\nfrom itertools import chain\nimport nltk \n#stop_words = set(stopwords.words('english'))\n\n#filename = 'A Mind For Numbers_ How to Excel at Math and Science (Even If You Flunked Algebra)'\nfilename = 'physics_iitjee_vol1'\nconcepts = {}\nimport pickle\n# Loading extracted concepts from file (see concept_extraction.ipynb)\n#concepts = {'sents':sents,'rawtxt':rawtxt,'sent_to_npflat':sent_to_npflat,'sent_to_tags':sent_to_tags,'sent_to_ltags':sent_to_ltags,'np_to_sent':np_to_sent,'Conceptdata':Conceptdata}\nwith open('../processed_data/'+filename +'concepts.pickle', 'rb') as f:\n concepts = pickle.load(f)\n\n# Loading idf dictionary (see Build_IDF_dictionary.ipynb)\nwith open('../processed_data/'+'idf_dict.pickle','rb') as f1:\n idf_dict =pickle.load(f1)\n\nwith open('../processed_data/'+filename+'conceptimp.pickle','rb') as f2:\n dfConceptimp = pickle.load(f2)\n\nsents = concepts['sents']\nrawtxt = concepts['rawtxt']\nsent_to_npflat = concepts['sent_to_npflat']\nsent_to_tags= concepts['sent_to_tags']\nsent_to_ltags = concepts['sent_to_ltags']\nnp_to_sent = concepts['np_to_sent']\nConceptdata = concepts['Conceptdata']\n\nimport math\n\n\n\ndef get_idf(wrd,totaldocs=10788):\n wrd = wrd.lower()\n return idf_dict.get(wrd,math.log(totaldocs))\n",
"_____no_output_____"
],
[
"import pandas as pd\nwith open('../processed_data/'+filename+'conceptmap.pickle','rb') as f2:\n df = pickle.load(f2)",
"_____no_output_____"
],
[
"def calc_cl_per_sentence(sent_to_npflatsent_to_npflat,known_concepts = [], maxidf=9.1):\n sent_to_clt = []\n for i in range(len(sent_to_npflat)):\n npinsent = sent_to_npflat[i]\n npinsent = [np for np in npinsent if np not in known_concepts]\n clt= 0\n for np in npinsent:\n tokens = np.split(' ')\n idf = 0\n for t in tokens:\n idf = idf + get_idf(t)\n idf = idf*len(tokens)*1.67\n if (idf>=maxidf):\n clt = clt + 1\n sent_to_clt.append(clt)\n return sent_to_clt\n\ndef plot_clt(sent_to_clt):\n \n from matplotlib import pyplot as plt\n plt.xlabel('document sentence #')\n plt.ylabel('Load added to working memory by sentence')\n plt.title('Cognitive Load for '+filename)\n plt.plot(list(range(1,len(sent_to_npflat)+1)),sent_to_clt,drawstyle='steps')\n plt.savefig('cltfig1.png')\n return None\n\nsent_to_clt = calc_cl_per_sentence(sent_to_npflat)\nplot_clt(sent_to_clt)",
"_____no_output_____"
],
[
"def print_sents_by_target_cl(target,cl):\n return [sents[s] for s in np_to_sent[target] if sent_to_clt[s]==cl]\n\nprint_sents_by_target_cl('life',1)",
"_____no_output_____"
],
[
"sent_to_clt = calc_cl_per_sentence(sent_to_npflat)\nprint('Mininum cognitive load sentence: ',sents[sent_to_clt.index(min(sent_to_clt))])\nprint('Maximum cognitive load sentence: ',sents[sent_to_clt.index(max(sent_to_clt))])",
"Mininum cognitive load sentence: 1 of 4Dr.\nMaximum cognitive load sentence: 81.1 Introduction1.1.1 Branches of Physics1.1.2 Scope and Excitement of Physics1.1.3 Physics in Relation to Technology and Society1.2 Measurement2.1 Different Types of Measurement Systems1.2.2 Measurement of Basic Quantities1.2.3 Parallax Method1.3 Theory of Errors1.3.1 Accuracy and Precision1.3.2 Errors in Measurement1.3.3 Error Analysis1.3.4 Propagation of Errors1.4 Significant Figures1.4.1 Definition and Rules of Significant Figures1.4.2 Rounding Off1.5 Dimensional Analysis1.5.1 Dimension of Physical Quantities1.5.2 Dimensional Formula and Equation1.5.3 Principle of Homogeneity of Dimensions1.6 Multiple Choice Questions with Detailed SolutionsChapter-2: Kinematics ….662.1 Introduction2.1.1 Concept of Rest and Motion2.1.2 Point mass2.2 Types of Motion2.3 Motion in One, Two and Three Dimensions2.4 Elementary Concepts of Vector Algebra2.4.1 Different Types of Vectors2.4.2 Addition of Vectors2.4.3 Subtraction of Vectors2.4.4 Components of A Vector2.4.5 Vector Addition using Components2.4.6 Multiplication of Vector by a Scalar2.4.7 The Vector Product of Two Vectors2.4.8 Position Vector2.5 Distance and Displacement2.5.1 Displacement Vector in Cartesian Coordinate System2.6 Differential Calculus2.7 Integral Calculus2.8 Average Velocity2.9 Motion along One Dimension 2.9.1 Average velocity2.9.2 Relative Velocity in One and Two Dimensional Motion2.9.3 Accelerated Motion2.9.4 Equations of Uniformly Accelerated Motion by Calculus Method2.9.5 Kinematic Equations2.10 Equations of Motion under Gravity2.11 Projectile Motion2.11.1 Projectile in Horizontal Projection2.11.2 Projectile under an Angular Projection2.12 Introduction to Degrees and Radians2.13 Angular Displacement2.14 Circular Motion2.14.1 Centripetal Acceleration2.14.2 Non Uniform Circular Motion2.15 Multiple Choice Questions with Detailed SolutionsChapter-3: Laws of Motion ….1633.1 Introduction3.2 Newton’s Laws3.2.1 Newton’s First Law3.2.2 Newton’s Second Law3.2.3 Newton’s Third Law3.2.4 Application of Newton’s Laws3.3 Particle Moving in an Inclined Plane3.3.1 Two Bodies in Contact on a Horizontal Surface3.3.2 Motion of Connected Bodies3.4 Concurrent Forces and Lami’s Theorem3.4.1 Lami’s Theorem3.5 Law of Conservation of Total Linear Momentum3.5.1 Meaning of Law of Conservation of Momentum3.5.2 Impulse3.5.3 Friction3.6 Dynamics of Circular Motion3.6.1 Centripetal Force3.6.2 Centrifugal Force3.7 Multiple Choice Questions with Detailed SolutionsChapter- 4 : Work, Energy and Power …2384.1 Introduction4.2 Work4.2.1 Work Done by a Constant Force 4.2.2 Work Done by a Variable Force4.3.1 Kinetic Energy4.3 Energy4.3.2 Work-Kinetic Energy Theorem4.3.3 Relation between Momentum and Kinetic Energy4.4 Potential Energy4.4.1 Potential Energy near the Surface of the Earth4.4.2 Elastic Potential Energy4.4.3 Force-Displacement Graph for a Spring4.4.4 Potential Energy-Displacement Graph for a Spring4.5 Conservative and Non- Conservative Forces4.5.1 Conservative Force4.5.2 Non-Conservative Force4.5.3 Law of Conservation of Energy4.6 Power4.6.1 Definition of Power4.6.2 Unit of Power4.6.3 Relation between Power and Velocity4.7 Collisions4.7.1 Types of Collisions4.7.2 Elastic Collisions in one Dimension4.7.3 Perfect Inelastic Collision4.8 Multiple Choice Questions with Detailed SolutionsChapter-5: Rotational Motion… 3045.1 Introduction5.2 Center of Mass5.2.1 Center of Mass of a Rigid Body5.2.2 Center of Mass for Distributed Point Masses5.2.3 Center of Mass of Two Point Masses5.2.4 Center of Mass for Uniform Distribution of Mass5.3 Torque and Angular Momentum5.3.1 Definition of Torque5.3.2 Torque about an Axis5.3.3 Torque and Angular Acceleration5.3.4 Angular Momentum5.3.5 Angular Momentum and Angular Velocity5.3.6 Torque and Angular Momentum5.4 Equilibrium of Rigid Bodies5.4.1 Types of Equilibrium5.4.2 Couple5.5 Principle of Moments5.5.1 Center of Gravity5.5.2 Bending of Cyclist in Curves5.6 Moment of Inertia5.6.1 Moment of Inertia of a Uniform Rod5.6.2 Moment of Inertia of a Uniform Ring5.6.3 Moment of Inertia of a Uniform Disc5.6.4 Radius of Gyration5.7 Theorems of Moment of Inertia5.8 Rotational Dynamics5.8.1 Effect of Torque on Rigid Bodies5.8.2 Conservation of Angular Momentum5.8.3 Work Done by Torque5.8.4 Kinetic Energy in Rotation5.8.4 Relation between Rotational Kinetic Energy and Angular Momentum 5.8.5 Comparison of Translational and Rotational Quantities5.9 Rolling Motion5.9.1 Combination of Translation and Rotation5.9.2 Slipping and Sliding5.9.3 Kinetic Energy in Pure Rolling5.10 Multiple Choice Questions with Detailed SolutionsChapter -1: PHYSICS MEASURMENT1.1 PHYSICS - INTRODUCTIONThe word ‘physics’ is derived from the Greek word “Fusis”, meaning nature.\n"
],
[
"plot_clt(sent_to_clt)",
"_____no_output_____"
]
],
[
[
"Functions to get blurbs for two concepts\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\ndef calc_clt_blurb_order(tuplist):\n tup_to_clt = {}\n for tup in tuplist:\n blurb_clt = 0\n for i in range(tup[0],tup[1]+1):\n blurb_clt = blurb_clt + sent_to_clt[i]\n tup_to_clt[tup] = blurb_clt\n tup_to_clt = pd.Series(tup_to_clt)\n tup_to_clt.sort_values(ascending=True)\n return list(tup_to_clt.sort_values(ascending=True).index)\n \n ",
"_____no_output_____"
],
[
"def get_sentence_indices(np1,np2,max_distance=3):\n sents1 = np_to_sent[np1]\n sents2 = np_to_sent[np2]\n ind1 = 0\n ind2 = 0\n tuplist = []\n lensents1 = len(sents1)\n #print(lensents1)\n lensents2 = len(sents2)\n #print(lensents2)\n while(ind1<lensents1 and ind2 <lensents2):\n #print(ind1,ind2)\n if (sents1[ind1]<sents2[ind2]):\n #print('sent1 less than sent2')\n if sents2[ind2]-sents1[ind1]<=max_distance:\n tuplist.append((sents1[ind1],sents2[ind2]))\n ind1 = ind1+1\n ind2 = ind2 + 1\n else:\n #ind1 = bs.bisect_left(sents1,sents2[ind2])\n ind1 = ind1 + 1\n elif (sents1[ind1]>sents2[ind2]):\n #print('sent2 less than sent1')\n if sents1[ind1]-sents2[ind2] <= max_distance:\n tuplist.append((sents2[ind2],sents1[ind1]))\n ind1 = ind1 + 1\n ind2 = ind2 + 1\n else:\n #ind2 = bs.bisect_left(sents2,sents1[ind1])\n ind2 = ind2 + 1\n else:\n tuplist.append((sents1[ind1],sents2[ind2]))\n ind1 = ind1+1\n ind2 = ind2+1\n return tuplist\n\ndef get_blurbs(np1,np2,max_distance=3):\n blurblist = []\n tuplist = calc_clt_blurb_order(get_sentence_indices(np1,np2,max_distance))\n print(tuplist)\n for t in tuplist:\n blurb = []\n print(t)\n blurb = ' '.join(sents[t[0]:t[1]+1]).replace('\\n', ' ').replace('\\r', '')\n print(blurb)\n blurblist.append(blurb)\n return tuplist, blurblist",
"_____no_output_____"
],
[
"tuplist, blurblist = get_blurbs('speed','velocity',0)",
"[(860, 860), (1669, 1669), (737, 737), (2443, 2443), (687, 687), (668, 668), (671, 671), (919, 919), (667, 667), (646, 646), (2257, 2257), (934, 934), (1848, 1848), (682, 682), (2368, 2368), (1789, 1789), (808, 808), (887, 887)]\n(860, 860)\nIn uniform circular motion, the velocity is always changing but speed remains the same.\n(1669, 1669)\nBoth the direction and magnitude (speed) of velocity can be changed.\n(737, 737)\nCalculate the swimmer’s speed in still water and the velocity of the river flow.Solution: Let vs and vr , represent the velocities of the swimmer and river respectively with respect to ground.\n(2443, 2443)\nThen after all collision A and B are brought to rest and C takes off with velocity of...... (elastic collision)(A) 20 m/s (B) 2.5 m/s(C) 10 m/s (D) 7.5 m/s [image file=rsrcET7.jpg] Solution: A hits B head on with speed 10 m/s.\n(687, 687)\nHence, [image file=rsrcE68.jpg] The particle C has the greatest speed.Example 2.23: Two cars are travelling with respective velocities [image file=rsrcE69.jpg] =10ms-1 along east and [image file=rsrcE6A.jpg] =10ms-1 along west What are the speeds of the cars?Solution: Both cars have the same magnitude of velocity.\n(668, 668)\nThe unit of speed is also mMomentumThe linear momentum or simply momentum of a particle is defined as product of mass with velocity.\n(671, 671)\n[image file=rsrcE5Z.jpg] The direction of momentum is also in the direction of velocity, and the magnitude of momentum is equal to product of mass and speed of the particle.\n(919, 919)\nIts velocity will decrease till itreaches top and increases while coming down.Time(s)Velocity (m/s)060150240330Up word dirn42051060710820Downward dirn9301040average speed in upward dirn = {(60 + 50 + 40 + 30 + 20 + 10 + 0) / 7}= 30 m/saverage speed in downward dirn = {(0 + 10 + 20 + 30 + 40) / 5} = 20 m/saverage speed = [{(30) × (6) + (20) × (4)} / {10}] = [{260} / {10}] = 26 m/saverage velocity = [{60 + (– 40)} / {2}]= 10 m/s ----- taking downward velocity negative.\n(667, 667)\n[image file=rsrcE5V.jpg] In component form, this velocity is [image file=rsrcE5W.jpg] The magnitude of velocity v is called speed and is given by [image file=rsrcE5X.jpg] Speed is always a positive scalar.\n(646, 646)\nThe table below shows the derivatives of some common functions used in physics [image file=rsrcE54.jpg] [image file=rsrcE55.jpg] In physics, velocity, speed and acceleration are all derivatives with respect to time‘t’.\n(2257, 2257)\nThen, the fi nal velocities of the bodies can be calculated from the equation (4.53) and equation (4.54) [image file=rsrcES1.jpg] As the two speeds v1and v2 are positive, they move in the same direction with the velocities, 3.33 m s−1 and 8.33 m s−1 respectively.Example 4.21: A bullet of mass 50 g is fired from below into a suspended object of mass 450 g. The object rises through a height of 1.8 m with bullet remaining inside the object.\n(934, 934)\nvelocity after 6 sec = 90 m/saverage speed = {(2v1v2) / (v1 + v2)}= {(2vov) / (vo + v)} = [{2(30) (90)} / {30 + 90}] = 45 m/sratio {(average speed) / (instantaneous velocity)} = (45 / 90) = (1/2) PROBLEM 24: The motion of a particle along a straight line is described by the function x = (3t – 2)2.\n(1848, 1848)\n(D) A body has a constant speed but velocity is zero.Solution: a = (dv / dt)if speed is constant then acceleration = a = (d / dt) (constant) = 0PROBLEM 44: A force of 8 N acts on an object of mass 5kg in X-directionand another force of 6 N acts on it in Y-direction.\n(682, 682)\n[image file=rsrcE62.jpg] Solution [image file=rsrcE63.jpg] The average velocity is in the positive x direction.The average speed = total path length / time taken (the path is semi-circular) [image file=rsrcE64.jpg] Note that the average speed is greater than the magnitude of the average velocity.Example 2.21: The position vector of a particle is given [image file=rsrcE65.jpg] Calculate the velocity and speed of the particle at any instant t. Calculate the velocity and speed of the particle at time t = 2 sSolution [image file=rsrcE66.jpg] Note that the particle has velocity components along x and y direction.\n(2368, 2368)\nMaximum value of R for the body to successfully complete the loop is(A) 6 cm (B) (15 / 4) cm(C) (5 / 12) cm (D) (12 / 5) cm [image file=rsrcESY.jpg] Solution: let speed at bottom = VBThe minimum velocity at bottom of a body to complete verticalcircle is √5gRhence VB = √5gRP.E of body = KE in motionmgh = (1/2)mV2gh = {(VB2) / 2}VB = √2ghhence√5gR = √2ghR = (2/5)hR = (2/5) × 6R = (12 / 5) cm PROBLEM 57: If the water falls from a dam into a turbine wheel 19.6 m below, then the velocity of water at the turbine is ......(g = 9.8 m/s2)(A) 9.8 m/s (B) 19.6 m/s(C) 39.2 m/s (D) 98.0 m/sSolution: PE of water = KE of turbinemgh = (1/2) mV2V2 = 2ghV2 = (2) (9.8) (19.6)V = 19.6 m/s PROBLEM 58: A bomb of 12 kg divides in two parts whose ratio of masses is 1:4.\n(1789, 1789)\nThe value of pressure on the surface will be(A) 2 × 103 Nm–2 (B) 2 × 105 Nm–2(C) 107 Nm–2 (D) 2 × 107 Nm2Solution: No of balls = 10000mass of each ball = 1g.area = 1 cm2 = 10–4 m2pressure = {(Force) / (area)} = (ma / A) = [{no of balls × mass of each ball× change in velocity per unit time} / {Area}]Pressure = [{10000 × 10–3 × (v – (– v))} / {10–4}] = as ball rebound withsame velocity hence v2 = – v= [{10000 × 10–3 × 2 × 100} / {10–4}]= 2 × 107 N/m2 PROBLEM 10: When the speed of a moving body is doubled(A) Its acceleration is doubled(B) Its momentum is doubled(C) Its kinetic energy is doubled(D) Its potential energy is doubledSolution: momentum = mass × velocityvelocity is doubled hence momentum all get doubled.PROBLEM 11: A particle moves in the XY Plane under the action of a force F such that the components of its linear momentum P at any time t are Px = 2 cost, Py = 2sint.\n(808, 808)\n[image file=rsrcE8H.jpg] The velocity component at any t along horizontal (x-axis) is vx = ux + a x tSince, ux = u, ax = 0 , we get [image file=rsrcE8J.jpg] The component of velocity along vertical direction (y-axis) is v y = uy + a y tSince, uy = 0, ay = g, we get [image file=rsrcE8K.jpg] Hence the velocity of the particle at any instant is [image file=rsrcE8M.jpg] The speed of the particle at any instant t is given by [image file=rsrcE8N.jpg] (4) Speed of the projectile when it hits the ground: When the projectile hits the ground after initially thrown horizontally from the top of tower of height h, the time of flight is [image file=rsrcE8P.jpg] The horizontal component velocity of the projectile remains the same i.e vx= uThe vertical component velocity of the projectile at time T is [image file=rsrcE8R.jpg] The speed of the particle when it reaches the ground is [image file=rsrcE8S.jpg] 2.11.2 Projectile under an Angular ProjectionThis projectile motion takes place when the initial velocity is not horizontal, but at some angle with the vertical, as shown in Figure 2.42.Examples :Water ejected out of a hose pipe held obliquely.Cannon fired in a battle ground.\n(887, 887)\nThe angular displacement made by the particle is given by [image file=rsrcEAB.jpg] Summarya) speed = [(distance x) / (time t)]Average speed = [(Total distance) / (Total time)]b) Instantaneous speed = limΔt➙0 (Δx / Δt)c) Velocity ѵ = [(displacement) / (time)] = (Δr / Δt)Instantaneous velocity ѵ➙ = limΔt➙0 (Δr / Δt) = (Δr / dt)d) Average acceleration Gave = (Δѵ / Δt)e) Instantaneous acceleration a➙ = limΔt➙ (Δѵ➙ / Δt)= (dѵ➙ / Δt)f) Equation for Uniformly accelerated motion(1) ѵ = ѵ0 + at (3) d = ѵot + (1/2) at2(2) s = [(Vo + V) / 2] t (4) V2 = Vo2 + 2adg) Distance covered in nth Second Sn = Vo + (a/2) (2n – 1) [image file=rsrcEAC.jpg] A➙ Λ B➙ then A➙ ∙ B➙ = 0 A➙ Λ B➙ then |A➙ ' B➙ = ABA➙ || B➙ then A➙ ∙ B➙ = AB A➙ || B➙ then A➙ ' B➙ = 0|A➙| = |B➙| and A➙ and B➙ is Q the angle between(1) θ = 0 then |A➙ + B➙| = 2A(2) θ = 180 then |A➙ + B➙| = 0(3) θ = 90 then |A➙ + B➙| = √2 A(4) θ = 60 then |A➙ + B➙| = √3 A(5) θ = 120 then |A➙ + B➙| = Ai) For projectile– Time to reach the highest point tm = [(ѵo sin θ) / g]– Maximum height H = [(ѵ02 sin2 θ) / 2g]– Range R = [(ѵ02 sin2 θ) / g]– Maximum Range R = [(ѵ02) / g]– Flight time T = [(2ѵ0 sin θ) / g]– Equation of trajectory y = x tan θ – [(gx2) / (2ѵ02 cos2 θ)]– R = 4H cot θ 2.15 Multiple Choice Questions with Detailed SolutionsPROBLEM 1: A branch of physics dealing whit motion without considering its causes is known as … (A) Kinematics (B) dynamics(C) Hydrodynamics (D) mechanicsSolution: Branch of physics dealing with motion without considering causes is kinematics.PROBLEM 2: Mechanics is a branch of physics.\n"
],
[
"import networkx as nx\nimport numpy as num",
"_____no_output_____"
],
[
"bond_threshold=num.quantile(df['Bondstrength'],0.0)\ndfdir = df[(df['Direction']>=1) & (df['Bondstrength']>=bond_threshold)]\nprint(len(dfdir))",
"40848\n"
],
[
"print(bond_threshold)\nimport networkx as nx\nimport matplotlib.pyplot as plt\nG = nx.from_pandas_edgelist(dfdir,'Concept1','Concept2', create_using=nx.DiGraph())\n\n\npaths=dict(nx.all_pairs_shortest_path(G,cutoff=None))\ndef get_nodes_allpairs(concept_list):\n nodelist = [paths.get(cl1, {}).get(cl2,None) for cl1 in concept_list for cl2 in concept_list if paths.get(cl1, {}).get(cl2,None) is not None]\n nodelist = list(chain.from_iterable(nodelist))\n return list(set(nodelist))\n\nstart_concepts_number = 5 # Start drawing graph with top n concepts\n\nstart_concept_list = list(dfConceptimp.sort_values(by=['TFIDFA','Amap','SdevA','AfirstOc'],ascending=[False,False,False,True]).head(start_concepts_number)['Concept1'])\n\nprint('Including the following concepts :',start_concept_list)\n\n# now get the paths from all pairs in the concept list and the corresponding nodes \nnodelist = get_nodes_allpairs(start_concept_list)\nprint('The nodes that connect these concepts: ', nodelist)\nstart_concept_edges = dfdir[dfdir['Concept1'].isin(nodelist) & dfdir['Concept2'].isin(nodelist)]\nstart_concept_from = set(start_concept_edges['Concept1'])\nprint(start_concept_from)\nstart_concept_to = set(start_concept_edges['Concept2'])\nprint(start_concept_to)\nroots = start_concept_from - start_concept_to\nprint('Roots: ',roots)\n\nleaves = start_concept_to - start_concept_from\nprint('Leaves:',leaves)\nprint('All the longest paths in this subgraph:')\nfor r in roots:\n for l in leaves:\n if nx.has_path(G,r,l):\n print(paths[r][l])\n\nlen(start_concept_edges)\nplt.figure(figsize=(20,10))\nnx.draw_circular(G.subgraph(list(start_concept_from | start_concept_to)),with_labels=True, font_size=18,node_size=1200)",
"0.3333333333333333\nIncluding the following concepts : ['particle', 'mass', 'velocity', 'body', 'force']\nThe nodes that connect these concepts: ['velocity', 'body', 'mass', 'particle', 'force']\n{'velocity', 'particle', 'body', 'force'}\n{'body', 'velocity', 'mass'}\nRoots: {'particle', 'force'}\nLeaves: {'mass'}\nAll the longest paths in this subgraph:\n['particle', 'velocity', 'mass']\n['force', 'body', 'mass']\n"
],
[
"def in_and_out_nodes(G,concept):\n return list(G.predecessors(concept)) + list(G.successors(concept)) + [concept]\n \ndef draw_graph(G,nodes_list):\n plt.figure(figsize=(20,10))\n nx.draw_circular(G.subgraph(nodes_list),with_labels=True, font_size=18,node_size=1200)\n \ndef ",
"_____no_output_____"
],
[
"draw_graph(G,in_and_out_nodes(G,'particle'))",
"_____no_output_____"
],
[
"get_blurbs('speed','classical mechanic',10)\n",
"[(77, 82), (81, 84), (92, 98), (29, 33), (1, 9), (0, 7), (85, 92), (12, 22), (87, 97)]\n(77, 82)\nClassical mechanics also describes the more complex motions of extended non-pointlike objects. Euler's laws provide extensions to Newton's laws in this area. The concepts of angular momentum rely on the same calculus used to describe one-dimensional motion. The rocket equation extends the notion of rate of change of an object's momentum to include the effects of an object \"losing mass\". There are two important alternative formulations of classical mechanics: Lagrangian mechanics and Hamiltonian mechanics. These, and other modern formulations, usually bypass the concept of \"force\", instead referring to other physical quantities, such as energy, speed and momentum, for describing mechanical systems in generalized coordinates.\n(81, 84)\nThere are two important alternative formulations of classical mechanics: Lagrangian mechanics and Hamiltonian mechanics. These, and other modern formulations, usually bypass the concept of \"force\", instead referring to other physical quantities, such as energy, speed and momentum, for describing mechanical systems in generalized coordinates. The expressions given above for momentum and kinetic energy are only valid when there is no significant electromagnetic contribution. In electromagnetism, Newton's second law for current-carrying wires breaks down unless one includes the electromagnetic field contribution to the momentum of the system as expressed by the Poynting vector divided by c2, where c is the speed of light in free space.\n(92, 98)\nIn the case of high velocity objects approaching the speed of light, classical mechanics is enhanced by special relativity. In case that objects become extremely heavy (i.e. their Schwarzschild radius is not negligibly small for a given application), deviations from Newtonian mechanics become apparent and can be quantified by using the Parameterized post-Newtonian formalism. In that case, General relativity (GR) becomes applicable. However, until now there is no theory of Quantum gravity unifying GR and QFT in the sense that it could be used when objects become extremely small and heavy. [4] [5] In special relativity, the momentum of a particle is given by where m is the particle's rest mass, v its velocity, v is the modulus of v, and c is the speed of light. If v is very small compared to c, v2/c2 is approximately zero, and so Thus the Newtonian equation p = mv is an approximation of the relativistic equation for bodies moving with low speeds compared to the speed of light.\n(29, 33)\n[2] The velocity, or the rate of change of position with time, is defined as the derivative of the position with respect to time: In classical mechanics, velocities are directly additive and subtractive. For example, if one car travels east at 60 km/h and passes another car traveling in the same direction at 50 km/h, the slower car perceives the faster car as traveling east at 60 − 50 = 10 km/h. However, from the perspective of the faster car, the slower car is moving 10 km/h to the west, often denoted as -10 km/h where the sign implies opposite direction. Velocities are directly additive as vector quantities; they must be dealt with using vector analysis. Mathematically, if the velocity of the first object in the previous discussion is denoted by the vector u = ud and the velocity of the second object by the vector v = ve, where u is the speed of the first object, v is the speed of the second object, and d and e are unit vectors in the directions of motion of each object respectively, then the velocity of the first object as seen by the second object is Similarly, the first object sees the velocity of the second object as When both objects are moving in the same direction, this equation can be simplified to Or, by ignoring direction, the difference can be given in terms of speed only: The acceleration, or rate of change of velocity, is the derivative of the velocity with respect to time (the second derivative of the position with respect to time): Acceleration represents the velocity's change over time.\n(1, 9)\nIf the present state of an object is known it is possible to predict by the laws of classical mechanics how it will move in the future (determinism) and how it has moved in the past (reversibility). The earliest development of classical mechanics is often referred to as Newtonian mechanics. It consists of the physical concepts employed and the mathematical methods invented by Isaac Newton, Gottfried Wilhelm Leibniz and others in the 17th century to describe the motion of bodies under the influence of a system of forces. Later, more abstract methods were developed, leading to the reformulations of classical mechanics known as Lagrangian mechanics and Hamiltonian mechanics. These advances, made predominantly in the 18th and 19th centuries, extend substantially beyond Newton's work, particularly through their use of analytical mechanics. They are, with some modification, also used in all areas of modern physics. Classical mechanics provides extremely accurate results when studying large objects that are not extremely massive and speeds not approaching the speed of light. When the objects being examined have about the size of an atom diameter, it becomes necessary to introduce the other major sub-field of mechanics: quantum mechanics. To describe velocities that are not small compared to the speed of light, special relativity is needed.\n(0, 7)\n Classical mechanics describes the motion of macroscopic objects, from projectiles to parts of machinery, and astronomical objects, such as spacecraft, planets, stars and galaxies. If the present state of an object is known it is possible to predict by the laws of classical mechanics how it will move in the future (determinism) and how it has moved in the past (reversibility). The earliest development of classical mechanics is often referred to as Newtonian mechanics. It consists of the physical concepts employed and the mathematical methods invented by Isaac Newton, Gottfried Wilhelm Leibniz and others in the 17th century to describe the motion of bodies under the influence of a system of forces. Later, more abstract methods were developed, leading to the reformulations of classical mechanics known as Lagrangian mechanics and Hamiltonian mechanics. These advances, made predominantly in the 18th and 19th centuries, extend substantially beyond Newton's work, particularly through their use of analytical mechanics. They are, with some modification, also used in all areas of modern physics. Classical mechanics provides extremely accurate results when studying large objects that are not extremely massive and speeds not approaching the speed of light.\n(85, 92)\nMany branches of classical mechanics are simplifications or approximations of more accurate forms; two of the most accurate being general relativity and relativistic statistical mechanics. Geometric optics is an approximation to the quantum theory of light, and does not have a superior \"classical\" form. When both quantum mechanics and classical mechanics cannot apply, such as at the quantum level with many degrees of freedom, quantum field theory (QFT) is of use. QFT deals with small distances and large speeds with many degrees of freedom as well as the possibility of any change in the number of particles throughout the interaction. When treating large degrees of freedom at the macroscopic level, statistical mechanics becomes useful. Statistical mechanics describes the behavior of large (but countable) numbers of particles and their interactions as a whole at the macroscopic level. Statistical mechanics is mainly used in thermodynamics for systems that lie outside the bounds of the assumptions of classical thermodynamics. In the case of high velocity objects approaching the speed of light, classical mechanics is enhanced by special relativity.\n(12, 22)\n[note 1] The following introduces the basic concepts of classical mechanics. For simplicity, it often models real-world objects as point particles (objects with negligible size). The motion of a point particle is characterized by a small number of parameters: its position, mass, and the forces applied to it. Each of these parameters is discussed in turn. In reality, the kind of objects that classical mechanics can describe always have a non-zero size. (The physics of very small particles, such as the electron, is more accurately described by quantum mechanics.) Objects with non-zero size have more complicated behavior than hypothetical point particles, because of the additional degrees of freedom, e.g., a baseball can spin while it is moving. However, the results for point particles can be used to study such objects by treating them as composite objects, made of a large number of collectively acting point particles. The center of mass of a composite object behaves like a point particle. Classical mechanics uses common-sense notions of how matter and forces exist and interact. It assumes that matter and energy have definite, knowable attributes such as location in space and speed.\n(87, 97)\nWhen both quantum mechanics and classical mechanics cannot apply, such as at the quantum level with many degrees of freedom, quantum field theory (QFT) is of use. QFT deals with small distances and large speeds with many degrees of freedom as well as the possibility of any change in the number of particles throughout the interaction. When treating large degrees of freedom at the macroscopic level, statistical mechanics becomes useful. Statistical mechanics describes the behavior of large (but countable) numbers of particles and their interactions as a whole at the macroscopic level. Statistical mechanics is mainly used in thermodynamics for systems that lie outside the bounds of the assumptions of classical thermodynamics. In the case of high velocity objects approaching the speed of light, classical mechanics is enhanced by special relativity. In case that objects become extremely heavy (i.e. their Schwarzschild radius is not negligibly small for a given application), deviations from Newtonian mechanics become apparent and can be quantified by using the Parameterized post-Newtonian formalism. In that case, General relativity (GR) becomes applicable. However, until now there is no theory of Quantum gravity unifying GR and QFT in the sense that it could be used when objects become extremely small and heavy. [4] [5] In special relativity, the momentum of a particle is given by where m is the particle's rest mass, v its velocity, v is the modulus of v, and c is the speed of light.\n"
],
[
"plot_clt(calc_cl_per_sentence(sent_to_npflat))\nknown_concepts = ['geometry','orbitals','electron','atom','element','parameter','program','nucleus']\nplot_clt(calc_cl_per_sentence(sent_to_npflat,known_concepts))",
"_____no_output_____"
],
[
"print_sents_by_target_cl('life',2)",
"_____no_output_____"
],
[
"df[(df['Concept1']=='surface') & (df['Direction']>=1)].sort_values(by=['Bondstrength','dAB_dBA_diff'],ascending=[False, False]).head(41)",
"_____no_output_____"
],
[
"print_sents_by_target_cl('monte carlo method',5)",
"_____no_output_____"
],
[
"print_sents_by_target_cl('functional',2)",
"_____no_output_____"
],
[
"sents[1275:1279]",
"_____no_output_____"
],
[
"tuplist,blurblist = get_blurbs('life','woman',3)",
"[(1349, 1351)]\n(1349, 1351)\n”{ 6 }zombies everywhere:Digging Deeper to Understand the Habit of ProcrastinationIn the insightful book The Power of Habit, author Charles Duhigg describes a lost soul—Lisa Allen, a middle-aged woman who had always struggled with her weight, who had begun drinking and smoking when she was sixteen, and whose husband had left her for another woman. Lisa had never held a job for more than a year and had fallen deeply into debt. But in a four-year span, Lisa turned her life around completely.\n"
],
[
"print([sents[i] for i in np_to_sent['pes']])",
"_____no_output_____"
],
[
"fromset = set(dfdir['Concept1'])\ntoset = set(dfdir['Concept2'])\nrootset = fromset-toset\nleavesset = toset-fromset",
"_____no_output_____"
],
[
"df[df['Concept2'].isin(list(leavesset))].sort_values(by='FB',ascending=False).head(30)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c1109c31cf3d68156a9623a9cc67f4794068f3 | 376,321 | ipynb | Jupyter Notebook | Assignment1/hw1.ipynb | john850512/Deep_Learning | e438e9245c2146f8e8c758eb340fcd0adf9b8f7e | [
"MIT"
]
| 8 | 2020-11-12T13:35:34.000Z | 2022-01-21T04:20:57.000Z | Assignment1/hw1.ipynb | john850512/Deep_Learning | e438e9245c2146f8e8c758eb340fcd0adf9b8f7e | [
"MIT"
]
| null | null | null | Assignment1/hw1.ipynb | john850512/Deep_Learning | e438e9245c2146f8e8c758eb340fcd0adf9b8f7e | [
"MIT"
]
| 1 | 2020-12-15T14:23:33.000Z | 2020-12-15T14:23:33.000Z | 110.196486 | 47,228 | 0.800622 | [
[
[
"# Deep learning - hw1\n- 0756708 孫茂勛",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport random\nimport pandas as pd\nfrom sklearn.model_selection import train_test_split\nfrom keras.utils import to_categorical\nimport matplotlib.pyplot as plt\nimport copy",
"Using TensorFlow backend.\n"
]
],
[
[
"### 1. Data processing",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('./titanic.csv')",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"training_set = df[:800]\ntesting_set = df[800:]\n\nX_train = training_set[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']].values\nX_test = testing_set[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']].values\nX_train = X_train.reshape(X_train.shape[0], -1, 1)\nX_test = X_test.reshape(X_test.shape[0], -1, 1)\n\ny_train = training_set['Survived'].values\ny_test = testing_set['Survived'].values\ny_train = to_categorical(y_train).reshape(y_train.shape[0], -1, 1)\ny_test = to_categorical(y_test).reshape(y_test.shape[0], -1, 1)\n\nprint(X_train.shape, y_train.shape)\nprint(X_test.shape, y_test.shape)\n\n# combine data & labels \ntraining_data = list(zip(X_train, y_train))\ntesting_data = list(zip(X_test, y_test))",
"(800, 6, 1) (800, 2, 1)\n(91, 6, 1) (91, 2, 1)\n"
]
],
[
[
"### 2. Model Architecture",
"_____no_output_____"
]
],
[
[
"def sigmoid(z):\n return 1.0 / (1.0 + np.exp(-z))\n\ndef sigmoid_derivate(z):\n return sigmoid(z) * (1-sigmoid(z))\n\ndef cross_entropy(output, ground_truth):\n return np.sum( np.nan_to_num( -ground_truth*np.log(output) - (1-ground_truth)*np.log(1-output) ) )\n\ndef cross_entropy_derivative(output, ground_truth):\n return output - ground_truth",
"_____no_output_____"
],
[
"class NN():\n def __init__(self, neurons):\n self.num_layers = len(neurons)\n self.neurons = neurons\n # create weights & bias\n self.weights = [ np.zeros((j, i)) for i, j in zip(neurons[:-1], neurons[1:]) ]\n self.biases = [ np.zeros((i, 1)) for i in neurons[1:] ]\n # info \n self.training_loss = []\n self.training_error_rate = []\n self.testing_error_rate = []\n \n def SGD(self, training_data, testing_data, epochs, batch_size, lr):\n\n num = len(training_data)\n self.training_loss = []\n self.training_error_rate = []\n self.testing_error_rate = []\n \n evaluation_cost, evaluation_accuracy = [], []\n training_cost, training_accuracy = [], []\n \n for epoch in range(epochs):\n random.shuffle(training_data)\n mini_batch = [ training_data[i : i + batch_size] for i in range(0, num, batch_size) ] # split data into mini_batch\n for single_data in mini_batch:\n self.update_mini_batch(single_data, lr)\n \n if (epoch % 50 == 0):\n # record info\n self.training_loss.append(self.calc_loss(training_data))\n self.training_error_rate.append(self.count_error(training_data) / len(training_data))\n self.testing_error_rate.append(self.count_error(testing_data) / len(testing_data))\n print('===================================')\n print(\"【Epoch %s】\" % epoch) \n print(' training loss: %f' % self.calc_loss(training_data))\n print(' training error rate: %d / %d(%f)' % (self.count_error(training_data), len(training_data), self.count_error(training_data) / len(training_data)))\n print(' testing error rate: %d / %d(%f)' % (self.count_error(testing_data), len(testing_data), self.count_error(testing_data) / len(testing_data)))\n \n \n def update_mini_batch(self, single_data, lr):\n sum_gradient_w = [ np.zeros(w.shape) for w in self.weights ]\n sum_gradient_b = [ np.zeros(b.shape) for b in self.biases ]\n \n # cumulate gradient of each single data\n for x, y in single_data:\n gradient_w, gradient_b = self.backward(x, y)\n sum_gradient_w = [ sw + w for sw, w in zip(sum_gradient_w, gradient_w)]\n sum_gradient_b = [ sb + b for sb, b in zip(sum_gradient_b, gradient_b)]\n \n # update weights & biases with (mean of sum of gradient * learning rate)\n self.weights = [ w - lr/len(single_data) * sw for w, sw in zip(self.weights, sum_gradient_w) ]\n self.biases = [ b - lr/len(single_data) * sb for b, sb in zip(self.biases, sum_gradient_b) ]\n \n def forward(self, x):\n for w, b in zip(self.weights, self.biases):\n x = np.dot(w, x) + b\n x = sigmoid(x)\n return x\n \n def backward(self, x, y):\n # store gradient of w, b\n gradient_w = [ np.zeros(w.shape) for w in self.weights ]\n gradient_b = [ np.zeros(b.shape) for b in self.biases ]\n \n # forward\n activation = x\n zs = [] # store vectors which is input of activation function\n activations = [x] # store vectors which is output of activation function\n \n for w, b in zip(self.weights, self.biases):\n z = np.dot(w, activation) + b\n zs.append(z)\n activation = sigmoid(z)\n activations.append(activation)\n \n # backward \n # we calc last layer separately, because loss function is diff with activation funcion\n delta = cross_entropy_derivative(activations[-1], y)\n gradient_b[-1] = delta * 1\n gradient_w[-1] = np.dot(delta, activations[-2].T)\n for layer in range(2, self.num_layers):\n z = zs[-layer]\n delta = np.dot(self.weights[-layer + 1].T, delta) * sigmoid_derivate(z)\n gradient_w[-layer] = np.dot(delta, activations[-layer - 1].T)\n gradient_b[-layer] = delta\n return gradient_w, gradient_b\n \n def calc_loss(self, data):\n # calc cross entropy loss\n loss = 0\n for x, y in data:\n output = self.forward(x)\n loss += cross_entropy(output, y)/ len(data)\n return loss\n \n def count_error(self, data):\n # count error number\n compare_list = [ (np.argmax(self.forward(x)), np.argmax(y)) for x, y in data ]\n error_count = sum( int(y1 != y2) for y1, y2 in compare_list)\n return error_count ",
"_____no_output_____"
]
],
[
[
"### 3. Training",
"_____no_output_____"
],
[
"#### p1",
"_____no_output_____"
]
],
[
[
"module1 = NN([6, 32, 32, 64, 2])\nmodule1.SGD(training_data, testing_data, 3000, 100, 0.3)",
"===================================\n【Epoch 0】\n training loss: 1.347053\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 50】\n training loss: 1.344135\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 100】\n training loss: 1.339753\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 150】\n training loss: 1.329431\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 200】\n training loss: 1.279102\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 250】\n training loss: 1.219769\n training error rate: 262 / 800(0.327500)\n testing error rate: 26 / 91(0.285714)\n===================================\n【Epoch 300】\n training loss: 1.424017\n training error rate: 285 / 800(0.356250)\n testing error rate: 32 / 91(0.351648)\n===================================\n【Epoch 350】\n training loss: 1.133523\n training error rate: 237 / 800(0.296250)\n testing error rate: 24 / 91(0.263736)\n===================================\n【Epoch 400】\n training loss: 1.066066\n training error rate: 209 / 800(0.261250)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 450】\n training loss: 1.105616\n training error rate: 204 / 800(0.255000)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 500】\n training loss: 1.054994\n training error rate: 210 / 800(0.262500)\n testing error rate: 22 / 91(0.241758)\n===================================\n【Epoch 550】\n training loss: 1.122180\n training error rate: 228 / 800(0.285000)\n testing error rate: 22 / 91(0.241758)\n===================================\n【Epoch 600】\n training loss: 1.062763\n training error rate: 210 / 800(0.262500)\n testing error rate: 23 / 91(0.252747)\n===================================\n【Epoch 650】\n training loss: 1.003373\n training error rate: 183 / 800(0.228750)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 700】\n training loss: 1.249502\n training error rate: 259 / 800(0.323750)\n testing error rate: 27 / 91(0.296703)\n===================================\n【Epoch 750】\n training loss: 1.071180\n training error rate: 203 / 800(0.253750)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 800】\n training loss: 1.319083\n training error rate: 279 / 800(0.348750)\n testing error rate: 25 / 91(0.274725)\n===================================\n【Epoch 850】\n training loss: 0.971300\n training error rate: 164 / 800(0.205000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 900】\n training loss: 0.967382\n training error rate: 176 / 800(0.220000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 950】\n training loss: 0.993461\n training error rate: 180 / 800(0.225000)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 1000】\n training loss: 1.025338\n training error rate: 193 / 800(0.241250)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1050】\n training loss: 0.991202\n training error rate: 171 / 800(0.213750)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1100】\n training loss: 0.974576\n training error rate: 160 / 800(0.200000)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 1150】\n training loss: 1.205752\n training error rate: 224 / 800(0.280000)\n testing error rate: 20 / 91(0.219780)\n===================================\n【Epoch 1200】\n training loss: 0.973684\n training error rate: 167 / 800(0.208750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1250】\n training loss: 1.031579\n training error rate: 179 / 800(0.223750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1300】\n training loss: 0.967561\n training error rate: 159 / 800(0.198750)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1350】\n training loss: 1.013431\n training error rate: 178 / 800(0.222500)\n testing error rate: 20 / 91(0.219780)\n===================================\n【Epoch 1400】\n training loss: 1.036337\n training error rate: 193 / 800(0.241250)\n testing error rate: 16 / 91(0.175824)\n===================================\n【Epoch 1450】\n training loss: 0.964494\n training error rate: 156 / 800(0.195000)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1500】\n training loss: 0.957799\n training error rate: 157 / 800(0.196250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1550】\n training loss: 0.967302\n training error rate: 167 / 800(0.208750)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1600】\n training loss: 0.945280\n training error rate: 161 / 800(0.201250)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 1650】\n training loss: 1.048269\n training error rate: 192 / 800(0.240000)\n testing error rate: 16 / 91(0.175824)\n===================================\n【Epoch 1700】\n training loss: 0.948409\n training error rate: 167 / 800(0.208750)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 1750】\n training loss: 1.023371\n training error rate: 172 / 800(0.215000)\n testing error rate: 21 / 91(0.230769)\n===================================\n【Epoch 1800】\n training loss: 0.971837\n training error rate: 174 / 800(0.217500)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1850】\n training loss: 0.987515\n training error rate: 166 / 800(0.207500)\n testing error rate: 20 / 91(0.219780)\n===================================\n【Epoch 1900】\n training loss: 0.975402\n training error rate: 182 / 800(0.227500)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1950】\n training loss: 1.016586\n training error rate: 187 / 800(0.233750)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 2000】\n training loss: 0.979204\n training error rate: 183 / 800(0.228750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2050】\n training loss: 0.950838\n training error rate: 168 / 800(0.210000)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 2100】\n training loss: 0.962391\n training error rate: 159 / 800(0.198750)\n testing error rate: 21 / 91(0.230769)\n===================================\n【Epoch 2150】\n training loss: 1.022040\n training error rate: 186 / 800(0.232500)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2200】\n training loss: 0.942759\n training error rate: 157 / 800(0.196250)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 2250】\n training loss: 0.982890\n training error rate: 170 / 800(0.212500)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 2300】\n training loss: 0.942392\n training error rate: 159 / 800(0.198750)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 2350】\n training loss: 0.936544\n training error rate: 158 / 800(0.197500)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 2400】\n training loss: 0.942017\n training error rate: 155 / 800(0.193750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2450】\n training loss: 0.962886\n training error rate: 166 / 800(0.207500)\n testing error rate: 20 / 91(0.219780)\n===================================\n【Epoch 2500】\n training loss: 0.940124\n training error rate: 158 / 800(0.197500)\n testing error rate: 17 / 91(0.186813)\n"
],
[
"new_x_axis = np.arange(0,3000, 50)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 1)\nax.plot(new_x_axis, module1.training_loss)\nax.set_title('training loss')\nax.set_xlabel('Epochs')\nax.set_ylabel('Average cross entropy')",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 2)\nfig.set_size_inches(12, 4)\nax[0].plot(new_x_axis, module1.training_error_rate)\nax[0].set_title('training error rate')\nax[0].set_xlabel('Epochs')\nax[0].set_ylabel('Error rate')\n\nax[1].plot(new_x_axis, module1.testing_error_rate)\nax[1].set_title('testing error rate')\nax[1].set_xlabel('Epochs')\nax[1].set_ylabel('Error rate')",
"_____no_output_____"
]
],
[
[
"#### p2",
"_____no_output_____"
]
],
[
[
"module2 = NN([6, 3, 3, 2])",
"_____no_output_____"
],
[
"module2.SGD(training_data, testing_data, 3000, 100, 0.03)",
"===================================\n【Epoch 0】\n training loss: 1.376259\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 50】\n training loss: 1.332859\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 100】\n training loss: 1.332620\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 150】\n training loss: 1.332084\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 200】\n training loss: 1.331055\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 250】\n training loss: 1.329397\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 300】\n training loss: 1.326865\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 350】\n training loss: 1.323153\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 400】\n training loss: 1.318022\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 450】\n training loss: 1.311381\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 500】\n training loss: 1.303288\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 550】\n training loss: 1.293717\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 600】\n training loss: 1.282168\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 650】\n training loss: 1.268219\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 700】\n training loss: 1.252719\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 750】\n training loss: 1.237040\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 800】\n training loss: 1.221593\n training error rate: 267 / 800(0.333750)\n testing error rate: 25 / 91(0.274725)\n===================================\n【Epoch 850】\n training loss: 1.205503\n training error rate: 264 / 800(0.330000)\n testing error rate: 28 / 91(0.307692)\n===================================\n【Epoch 900】\n training loss: 1.189265\n training error rate: 254 / 800(0.317500)\n testing error rate: 25 / 91(0.274725)\n===================================\n【Epoch 950】\n training loss: 1.153499\n training error rate: 245 / 800(0.306250)\n testing error rate: 24 / 91(0.263736)\n===================================\n【Epoch 1000】\n training loss: 1.149745\n training error rate: 242 / 800(0.302500)\n testing error rate: 26 / 91(0.285714)\n===================================\n【Epoch 1050】\n training loss: 1.080776\n training error rate: 221 / 800(0.276250)\n testing error rate: 21 / 91(0.230769)\n===================================\n【Epoch 1100】\n training loss: 1.088000\n training error rate: 228 / 800(0.285000)\n testing error rate: 23 / 91(0.252747)\n===================================\n【Epoch 1150】\n training loss: 1.257809\n training error rate: 267 / 800(0.333750)\n testing error rate: 25 / 91(0.274725)\n===================================\n【Epoch 1200】\n training loss: 1.066339\n training error rate: 213 / 800(0.266250)\n testing error rate: 23 / 91(0.252747)\n===================================\n【Epoch 1250】\n training loss: 1.014702\n training error rate: 179 / 800(0.223750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1300】\n training loss: 1.050740\n training error rate: 202 / 800(0.252500)\n testing error rate: 22 / 91(0.241758)\n===================================\n【Epoch 1350】\n training loss: 0.995550\n training error rate: 169 / 800(0.211250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1400】\n training loss: 0.994537\n training error rate: 171 / 800(0.213750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1450】\n training loss: 1.101971\n training error rate: 214 / 800(0.267500)\n testing error rate: 23 / 91(0.252747)\n===================================\n【Epoch 1500】\n training loss: 1.045124\n training error rate: 187 / 800(0.233750)\n testing error rate: 23 / 91(0.252747)\n===================================\n【Epoch 1550】\n training loss: 0.986537\n training error rate: 170 / 800(0.212500)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1600】\n training loss: 1.023784\n training error rate: 187 / 800(0.233750)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1650】\n training loss: 1.063868\n training error rate: 201 / 800(0.251250)\n testing error rate: 21 / 91(0.230769)\n===================================\n【Epoch 1700】\n training loss: 1.004462\n training error rate: 180 / 800(0.225000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1750】\n training loss: 1.010287\n training error rate: 173 / 800(0.216250)\n testing error rate: 20 / 91(0.219780)\n===================================\n【Epoch 1800】\n training loss: 0.988561\n training error rate: 178 / 800(0.222500)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1850】\n training loss: 1.014545\n training error rate: 177 / 800(0.221250)\n testing error rate: 21 / 91(0.230769)\n===================================\n【Epoch 1900】\n training loss: 1.015103\n training error rate: 176 / 800(0.220000)\n testing error rate: 21 / 91(0.230769)\n===================================\n【Epoch 1950】\n training loss: 0.981122\n training error rate: 173 / 800(0.216250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2000】\n training loss: 1.094621\n training error rate: 219 / 800(0.273750)\n testing error rate: 28 / 91(0.307692)\n===================================\n【Epoch 2050】\n training loss: 0.976912\n training error rate: 173 / 800(0.216250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2100】\n training loss: 0.973900\n training error rate: 167 / 800(0.208750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2150】\n training loss: 0.971284\n training error rate: 168 / 800(0.210000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2200】\n training loss: 0.971122\n training error rate: 173 / 800(0.216250)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 2250】\n training loss: 0.969263\n training error rate: 163 / 800(0.203750)\n testing error rate: 16 / 91(0.175824)\n===================================\n【Epoch 2300】\n training loss: 1.016974\n training error rate: 177 / 800(0.221250)\n testing error rate: 22 / 91(0.241758)\n===================================\n【Epoch 2350】\n training loss: 0.972374\n training error rate: 164 / 800(0.205000)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 2400】\n training loss: 0.977932\n training error rate: 175 / 800(0.218750)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 2450】\n training loss: 1.030981\n training error rate: 192 / 800(0.240000)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 2500】\n training loss: 0.993527\n training error rate: 180 / 800(0.225000)\n testing error rate: 19 / 91(0.208791)\n"
],
[
"fig, ax = plt.subplots(1, 1)\nax.plot(new_x_axis, module2.training_loss)\nax.set_title('training loss')\nax.set_xlabel('Epochs')\nax.set_ylabel('Average cross entropy')",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 2)\nfig.set_size_inches(12, 4)\nax[0].plot(new_x_axis, module2.training_error_rate)\nax[0].set_title('training error rate')\nax[0].set_xlabel('Epochs')\nax[0].set_ylabel('Error rate')\n\nax[1].plot(new_x_axis, module2.testing_error_rate)\nax[1].set_title('testing error rate')\nax[1].set_xlabel('Epochs')\nax[1].set_ylabel('Error rate')",
"_____no_output_____"
]
],
[
[
"#### p4",
"_____no_output_____"
]
],
[
[
"df.head()",
"_____no_output_____"
],
[
"module2.weights[0]",
"_____no_output_____"
]
],
[
[
"#### p3.",
"_____no_output_____"
]
],
[
[
"df_new = df.copy()\ndf_new.head()",
"_____no_output_____"
],
[
"from sklearn.preprocessing import StandardScaler",
"_____no_output_____"
],
[
"fare_scaler = StandardScaler()\ndf_new['Fare'] = pd.DataFrame(fare_scaler.fit_transform(df_new['Fare'].values.reshape(-1,1)))",
"_____no_output_____"
],
[
"df_new.head()",
"_____no_output_____"
],
[
"training_set = df_new[:800]\ntesting_set = df_new[800:]\n\nX_train = training_set[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']].values\nX_test = testing_set[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']].values\nX_train = X_train.reshape(X_train.shape[0], -1, 1)\nX_test = X_test.reshape(X_test.shape[0], -1, 1)\n\ny_train = training_set['Survived'].values\ny_test = testing_set['Survived'].values\ny_train = to_categorical(y_train).reshape(y_train.shape[0], -1, 1)\ny_test = to_categorical(y_test).reshape(y_test.shape[0], -1, 1)\n\nprint(X_train.shape, y_train.shape)\nprint(X_test.shape, y_test.shape)\n\n# combine data & labels \ntraining_data = list(zip(X_train, y_train))\ntesting_data = list(zip(X_test, y_test))",
"(800, 6, 1) (800, 2, 1)\n(91, 6, 1) (91, 2, 1)\n"
],
[
"module3 = NN([6, 3, 3, 2])\nmodule3.SGD(training_data, testing_data, 3000, 100, 0.1)",
"===================================\n【Epoch 0】\n training loss: 1.359142\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 50】\n training loss: 1.332919\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 100】\n training loss: 1.332917\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 150】\n training loss: 1.332917\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 200】\n training loss: 1.332917\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 250】\n training loss: 1.332917\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 300】\n training loss: 1.332916\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 350】\n training loss: 1.332914\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 400】\n training loss: 1.332913\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 450】\n training loss: 1.332909\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 500】\n training loss: 1.332912\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 550】\n training loss: 1.332898\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 600】\n training loss: 1.332879\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 650】\n training loss: 1.332853\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 700】\n training loss: 1.332806\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 750】\n training loss: 1.332743\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 800】\n training loss: 1.332579\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 850】\n training loss: 1.332290\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 900】\n training loss: 1.331687\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 950】\n training loss: 1.330274\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1000】\n training loss: 1.326667\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1050】\n training loss: 1.317046\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1100】\n training loss: 1.294522\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1150】\n training loss: 1.268098\n training error rate: 296 / 800(0.370000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1200】\n training loss: 1.185563\n training error rate: 252 / 800(0.315000)\n testing error rate: 28 / 91(0.307692)\n===================================\n【Epoch 1250】\n training loss: 1.259664\n training error rate: 278 / 800(0.347500)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1300】\n training loss: 1.064621\n training error rate: 171 / 800(0.213750)\n testing error rate: 20 / 91(0.219780)\n===================================\n【Epoch 1350】\n training loss: 1.024573\n training error rate: 165 / 800(0.206250)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1400】\n training loss: 1.089819\n training error rate: 212 / 800(0.265000)\n testing error rate: 26 / 91(0.285714)\n===================================\n【Epoch 1450】\n training loss: 1.011925\n training error rate: 163 / 800(0.203750)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1500】\n training loss: 1.003990\n training error rate: 169 / 800(0.211250)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1550】\n training loss: 0.990625\n training error rate: 155 / 800(0.193750)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1600】\n training loss: 0.996711\n training error rate: 167 / 800(0.208750)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1650】\n training loss: 1.091725\n training error rate: 211 / 800(0.263750)\n testing error rate: 25 / 91(0.274725)\n===================================\n【Epoch 1700】\n training loss: 0.980620\n training error rate: 165 / 800(0.206250)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1750】\n training loss: 0.967489\n training error rate: 164 / 800(0.205000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1800】\n training loss: 0.980539\n training error rate: 168 / 800(0.210000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1850】\n training loss: 1.082002\n training error rate: 208 / 800(0.260000)\n testing error rate: 28 / 91(0.307692)\n===================================\n【Epoch 1900】\n training loss: 0.983616\n training error rate: 161 / 800(0.201250)\n testing error rate: 20 / 91(0.219780)\n===================================\n【Epoch 1950】\n training loss: 0.987111\n training error rate: 167 / 800(0.208750)\n testing error rate: 21 / 91(0.230769)\n===================================\n【Epoch 2000】\n training loss: 0.956379\n training error rate: 159 / 800(0.198750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2050】\n training loss: 1.119560\n training error rate: 199 / 800(0.248750)\n testing error rate: 20 / 91(0.219780)\n===================================\n【Epoch 2100】\n training loss: 0.945149\n training error rate: 156 / 800(0.195000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2150】\n training loss: 0.936270\n training error rate: 156 / 800(0.195000)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 2200】\n training loss: 1.007418\n training error rate: 181 / 800(0.226250)\n testing error rate: 20 / 91(0.219780)\n===================================\n【Epoch 2250】\n training loss: 0.986804\n training error rate: 166 / 800(0.207500)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2300】\n training loss: 0.954882\n training error rate: 157 / 800(0.196250)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 2350】\n training loss: 0.938807\n training error rate: 156 / 800(0.195000)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 2400】\n training loss: 1.033120\n training error rate: 195 / 800(0.243750)\n testing error rate: 25 / 91(0.274725)\n===================================\n【Epoch 2450】\n training loss: 0.939949\n training error rate: 155 / 800(0.193750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2500】\n training loss: 0.947014\n training error rate: 157 / 800(0.196250)\n testing error rate: 18 / 91(0.197802)\n"
],
[
"new_x_axis = np.arange(0, 3000, 50)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 1)\nax.plot(new_x_axis, module3.training_loss)\nax.set_title('training loss')\nax.set_xlabel('Epochs')\nax.set_ylabel('Average cross entropy')",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 2)\nfig.set_size_inches(12, 4)\nax[0].plot(new_x_axis, module3.training_error_rate)\nax[0].set_title('training error rate')\nax[0].set_xlabel('Epochs')\nax[0].set_ylabel('Error rate')\n\nax[1].plot(new_x_axis, module3.testing_error_rate)\nax[1].set_title('testing error rate')\nax[1].set_xlabel('Epochs')\nax[1].set_ylabel('Error rate')",
"_____no_output_____"
]
],
[
[
"#### p3-2",
"_____no_output_____"
]
],
[
[
"df_new_1 = df.copy()",
"_____no_output_____"
],
[
"fare_scaler = StandardScaler()\nage_scaler = StandardScaler()\ndf_new_1['Fare'] = pd.DataFrame(fare_scaler.fit_transform(df_new_1['Fare'].values.reshape(-1,1)))\ndf_new_1['Age'] = pd.DataFrame(age_scaler.fit_transform(df_new_1['Age'].values.reshape(-1,1)))",
"_____no_output_____"
],
[
"training_set = df_new_1[:800]\ntesting_set = df_new_1[800:]\n\nX_train = training_set[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']].values\nX_test = testing_set[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']].values\nX_train = X_train.reshape(X_train.shape[0], -1, 1)\nX_test = X_test.reshape(X_test.shape[0], -1, 1)\n\ny_train = training_set['Survived'].values\ny_test = testing_set['Survived'].values\ny_train = to_categorical(y_train).reshape(y_train.shape[0], -1, 1)\ny_test = to_categorical(y_test).reshape(y_test.shape[0], -1, 1)\n\nprint(X_train.shape, y_train.shape)\nprint(X_test.shape, y_test.shape)\n\n# combine data & labels \ntraining_data = list(zip(X_train, y_train))\ntesting_data = list(zip(X_test, y_test))",
"(800, 6, 1) (800, 2, 1)\n(91, 6, 1) (91, 2, 1)\n"
],
[
"module4 = NN([6, 3, 3, 2])\nmodule4.SGD(training_data, testing_data, 3000, 100, 0.1)",
"===================================\n【Epoch 0】\n training loss: 1.359158\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 50】\n training loss: 1.332920\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 100】\n training loss: 1.332931\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 150】\n training loss: 1.332918\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 200】\n training loss: 1.332923\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 250】\n training loss: 1.332917\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 300】\n training loss: 1.332918\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 350】\n training loss: 1.332915\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 400】\n training loss: 1.332913\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 450】\n training loss: 1.332910\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 500】\n training loss: 1.332908\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 550】\n training loss: 1.332896\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 600】\n training loss: 1.332882\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 650】\n training loss: 1.332862\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 700】\n training loss: 1.332823\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 750】\n training loss: 1.332746\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 800】\n training loss: 1.332606\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 850】\n training loss: 1.332353\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 900】\n training loss: 1.331830\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 950】\n training loss: 1.330677\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1000】\n training loss: 1.327929\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1050】\n training loss: 1.321283\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1100】\n training loss: 1.305529\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1150】\n training loss: 1.265879\n training error rate: 301 / 800(0.376250)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1200】\n training loss: 1.159046\n training error rate: 240 / 800(0.300000)\n testing error rate: 26 / 91(0.285714)\n===================================\n【Epoch 1250】\n training loss: 1.026258\n training error rate: 165 / 800(0.206250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1300】\n training loss: 0.973327\n training error rate: 162 / 800(0.202500)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1350】\n training loss: 0.948331\n training error rate: 158 / 800(0.197500)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 1400】\n training loss: 0.931660\n training error rate: 154 / 800(0.192500)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 1450】\n training loss: 0.903806\n training error rate: 150 / 800(0.187500)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1500】\n training loss: 0.891035\n training error rate: 148 / 800(0.185000)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1550】\n training loss: 0.885530\n training error rate: 148 / 800(0.185000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1600】\n training loss: 0.882308\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1650】\n training loss: 0.880577\n training error rate: 147 / 800(0.183750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1700】\n training loss: 0.879751\n training error rate: 150 / 800(0.187500)\n testing error rate: 18 / 91(0.197802)\n===================================\n【Epoch 1750】\n training loss: 0.879115\n training error rate: 148 / 800(0.185000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1800】\n training loss: 0.878299\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1850】\n training loss: 0.879082\n training error rate: 153 / 800(0.191250)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 1900】\n training loss: 0.877683\n training error rate: 148 / 800(0.185000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1950】\n training loss: 0.877821\n training error rate: 151 / 800(0.188750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2000】\n training loss: 0.877422\n training error rate: 148 / 800(0.185000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2050】\n training loss: 0.877345\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2100】\n training loss: 0.877339\n training error rate: 147 / 800(0.183750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2150】\n training loss: 0.877218\n training error rate: 151 / 800(0.188750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2200】\n training loss: 0.877174\n training error rate: 148 / 800(0.185000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2250】\n training loss: 0.877141\n training error rate: 148 / 800(0.185000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2300】\n training loss: 0.877273\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2350】\n training loss: 0.877132\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2400】\n training loss: 0.877079\n training error rate: 150 / 800(0.187500)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2450】\n training loss: 0.877069\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2500】\n training loss: 0.877145\n training error rate: 148 / 800(0.185000)\n testing error rate: 19 / 91(0.208791)\n"
],
[
"fig, ax = plt.subplots(1, 1)\nax.plot(new_x_axis, module4.training_loss)\nax.set_title('training loss')\nax.set_xlabel('Epochs')\nax.set_ylabel('Average cross entropy')",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 2)\nfig.set_size_inches(12, 4)\nax[0].plot(new_x_axis, module4.training_error_rate)\nax[0].set_title('training error rate')\nax[0].set_xlabel('Epochs')\nax[0].set_ylabel('Error rate')\n\nax[1].plot(new_x_axis, module4.testing_error_rate)\nax[1].set_title('testing error rate')\nax[1].set_xlabel('Epochs')\nax[1].set_ylabel('Error rate')",
"_____no_output_____"
]
],
[
[
"#### p5",
"_____no_output_____"
]
],
[
[
"df_new_2 = pd.get_dummies(df_new_1, columns=['Pclass'])",
"_____no_output_____"
],
[
"df_new_2.head()",
"_____no_output_____"
],
[
"training_set = df_new_2[:800]\ntesting_set = df_new_2[800:]\n\nX_train = training_set[['Pclass_1', 'Pclass_2', 'Pclass_3', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']].values\nX_test = testing_set[['Pclass_1', 'Pclass_2', 'Pclass_3', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']].values\nX_train = X_train.reshape(X_train.shape[0], -1, 1)\nX_test = X_test.reshape(X_test.shape[0], -1, 1)\n\ny_train = training_set['Survived'].values\ny_test = testing_set['Survived'].values\ny_train = to_categorical(y_train).reshape(y_train.shape[0], -1, 1)\ny_test = to_categorical(y_test).reshape(y_test.shape[0], -1, 1)\n\nprint(X_train.shape, y_train.shape)\nprint(X_test.shape, y_test.shape)\n\n# combine data & labels \ntraining_data = list(zip(X_train, y_train))\ntesting_data = list(zip(X_test, y_test))",
"(800, 8, 1) (800, 2, 1)\n(91, 8, 1) (91, 2, 1)\n"
],
[
"module5 = NN([8, 3, 3, 2])\nmodule5.SGD(training_data, testing_data, 3000, 100, 0.1)",
"===================================\n【Epoch 0】\n training loss: 1.359803\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 50】\n training loss: 1.332921\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 100】\n training loss: 1.332921\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 150】\n training loss: 1.332924\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 200】\n training loss: 1.332931\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 250】\n training loss: 1.332918\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 300】\n training loss: 1.332918\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 350】\n training loss: 1.332918\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 400】\n training loss: 1.332915\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 450】\n training loss: 1.332913\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 500】\n training loss: 1.332911\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 550】\n training loss: 1.332908\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 600】\n training loss: 1.332901\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 650】\n training loss: 1.332892\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 700】\n training loss: 1.332876\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 750】\n training loss: 1.332850\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 800】\n training loss: 1.332813\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 850】\n training loss: 1.332740\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 900】\n training loss: 1.332609\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 950】\n training loss: 1.332364\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1000】\n training loss: 1.331888\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1050】\n training loss: 1.330788\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1100】\n training loss: 1.327943\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1150】\n training loss: 1.319494\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1200】\n training loss: 1.292657\n training error rate: 308 / 800(0.385000)\n testing error rate: 34 / 91(0.373626)\n===================================\n【Epoch 1250】\n training loss: 1.213111\n training error rate: 280 / 800(0.350000)\n testing error rate: 33 / 91(0.362637)\n===================================\n【Epoch 1300】\n training loss: 1.055589\n training error rate: 186 / 800(0.232500)\n testing error rate: 17 / 91(0.186813)\n===================================\n【Epoch 1350】\n training loss: 0.947323\n training error rate: 153 / 800(0.191250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1400】\n training loss: 0.908645\n training error rate: 151 / 800(0.188750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1450】\n training loss: 0.891137\n training error rate: 147 / 800(0.183750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1500】\n training loss: 0.883982\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1550】\n training loss: 0.880665\n training error rate: 151 / 800(0.188750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1600】\n training loss: 0.878958\n training error rate: 151 / 800(0.188750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1650】\n training loss: 0.878045\n training error rate: 150 / 800(0.187500)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1700】\n training loss: 0.877457\n training error rate: 151 / 800(0.188750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1750】\n training loss: 0.877121\n training error rate: 152 / 800(0.190000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1800】\n training loss: 0.876913\n training error rate: 152 / 800(0.190000)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1850】\n training loss: 0.876770\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1900】\n training loss: 0.876671\n training error rate: 150 / 800(0.187500)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 1950】\n training loss: 0.876614\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2000】\n training loss: 0.876572\n training error rate: 150 / 800(0.187500)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2050】\n training loss: 0.876537\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2100】\n training loss: 0.876535\n training error rate: 149 / 800(0.186250)\n testing error rate: 20 / 91(0.219780)\n===================================\n【Epoch 2150】\n training loss: 0.876494\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2200】\n training loss: 0.876476\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2250】\n training loss: 0.876468\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2300】\n training loss: 0.876459\n training error rate: 150 / 800(0.187500)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2350】\n training loss: 0.876469\n training error rate: 151 / 800(0.188750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2400】\n training loss: 0.876468\n training error rate: 151 / 800(0.188750)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2450】\n training loss: 0.876450\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n===================================\n【Epoch 2500】\n training loss: 0.876446\n training error rate: 149 / 800(0.186250)\n testing error rate: 19 / 91(0.208791)\n"
],
[
"new_x_axis = np.arange(0, 3000, 50)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 1)\nax.plot(new_x_axis, module5.training_loss)\nax.set_title('training loss')\nax.set_xlabel('Epochs')\nax.set_ylabel('Average cross entropy')",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 2)\nfig.set_size_inches(12, 4)\nax[0].plot(new_x_axis, module5.training_error_rate)\nax[0].set_title('training error rate')\nax[0].set_xlabel('Epochs')\nax[0].set_ylabel('Error rate')\n\nax[1].plot(new_x_axis, module5.testing_error_rate)\nax[1].set_title('testing error rate')\nax[1].set_xlabel('Epochs')\nax[1].set_ylabel('Error rate')",
"_____no_output_____"
]
],
[
[
"#### p6.",
"_____no_output_____"
]
],
[
[
"# X_train = training_set[['Pclass_1', 'Pclass_2', 'Pclass_3', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']].values",
"_____no_output_____"
],
[
"X_train[1]",
"_____no_output_____"
],
[
"people_John = np.array([[0, 0, 1, 1, age_scaler.transform([[23]]), 2, 2, fare_scaler.transform([[0.87]])]]).reshape(-1, 1)\nprint(people_John)",
"[[ 0. ]\n [ 0. ]\n [ 1. ]\n [ 1. ]\n [-0.04545002]\n [ 2. ]\n [ 2. ]\n [-0.63090448]]\n"
],
[
"prediction_john = module5.forward(people_John)\nprint('John死亡的機率vs存活的機率:', prediction_john[0], prediction_john[1] )",
"John死亡的機率vs存活的機率: [0.87382879] [0.12617121]\n"
],
[
"people_Angela = np.array([[1, 0, 0, 0, age_scaler.transform([[18]]), 1, 2, fare_scaler.transform([[20]])]]).reshape(-1, 1)\nprint(people_Angela)",
"[[ 1. ]\n [ 0. ]\n [ 0. ]\n [ 0. ]\n [-0.3297639 ]\n [ 1. ]\n [ 2. ]\n [-0.24572791]]\n"
],
[
"prediction_Angela = module5.forward(people_Angela)\nprint('Angela死亡的機率vs存活的機率:', prediction_Angela[0], prediction_Angela[1] )",
"Angela死亡的機率vs存活的機率: [0.03808093] [0.96191907]\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c11ac4f96c9b79941001a76e8ae25f6c76abec | 296,079 | ipynb | Jupyter Notebook | BiologicalPatternFormation/WorkingReactionDiffusion.ipynb | topatomer/IntroToBiophysics | a05d0b4738de11317327c465197850918996ce08 | [
"Apache-2.0"
]
| 20 | 2015-07-29T09:52:21.000Z | 2021-10-09T04:01:18.000Z | BiologicalPatternFormation/WorkingReactionDiffusion.ipynb | mglerner/IntroToBiophysics | a05d0b4738de11317327c465197850918996ce08 | [
"Apache-2.0"
]
| null | null | null | BiologicalPatternFormation/WorkingReactionDiffusion.ipynb | mglerner/IntroToBiophysics | a05d0b4738de11317327c465197850918996ce08 | [
"Apache-2.0"
]
| 7 | 2016-01-18T06:46:40.000Z | 2021-12-13T13:11:55.000Z | 83.426036 | 300 | 0.828634 | [
[
[
"> This is one of the 100 recipes of the [IPython Cookbook](http://ipython-books.github.io/), the definitive guide to high-performance scientific computing and data science in Python.\n",
"_____no_output_____"
],
[
"Links:\n\n * http://mrob.com/pub/comp/xmorphia/F260/F260-k550.html\n * http://mrob.com/pub/comp/xmorphia/",
"_____no_output_____"
],
[
"# 12.4. Simulating a Partial Differential Equation: reaction-diffusion systems and Turing patterns",
"_____no_output_____"
],
[
"1. Let's import the packages.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"2. We will simulate the following system of partial differential equations on the domain $E=[-1,1]^2$:",
"_____no_output_____"
],
[
"\\begin{align*}\n\\frac{\\partial u}{\\partial t} &= a \\Delta u + u - u^3 - v + k\\\\\n\\tau\\frac{\\partial v}{\\partial t} &= b \\Delta v + u - v\\\\\n\\end{align*}",
"_____no_output_____"
],
[
"The variable $u$ represents the concentration of a substance favoring skin pigmentation, whereas $v$ represents another substance that reacts with the first and impedes pigmentation.\n\nAt initialization time, we assume that $u$ and $v$ contain independent random numbers on every grid point. Besides, we take **Neumann boundary conditions**: we require the spatial derivatives of the variables with respect to the normal vectors to be null on the boundaries of the domain $E$.\n\nLet's define the four parameters of the model.",
"_____no_output_____"
]
],
[
[
"#a = 2.8e-4\n#b = 5e-3\na=4e-4\nb=2e-4\nF=0.0180\nk=0.0510\n#F=0.0260\n#k=0.0550",
"_____no_output_____"
]
],
[
[
"3. We discretize time and space. The following condition ensures that the discretization scheme we use here is stable:\n\n$$dt \\leq \\frac{dx^2}{2}$$",
"_____no_output_____"
]
],
[
[
"size = 200 # size of the 2D grid\ndx = 2./size # space step",
"_____no_output_____"
],
[
"T = 10.0 # total time\ndt = .9 * dx**2/2 # time step\nn = int(T/dt)",
"_____no_output_____"
]
],
[
[
"4. We initialize the variables $u$ and $v$. The matrices $U$ and $V$ contain the values of these variables on the vertices of the 2D grid. These variables are initialized with a uniform noise between $0$ and $1$.",
"_____no_output_____"
]
],
[
[
"U = np.random.rand(size, size)\nV = np.random.rand(size, size)",
"_____no_output_____"
]
],
[
[
"5. Now, we define a function that computes the discrete Laplace operator of a 2D variable on the grid, using a five-point stencil finite difference method. This operator is defined by:\n\n$$\\Delta u(x,y) \\simeq \\frac{u(x+h,y)+u(x-h,y)+u(x,y+h)+u(x,y-h)-4u(x,y)}{dx^2}$$\n\nWe can compute the values of this operator on the grid using vectorized matrix operations. Because of side effects on the edges of the matrix, we need to remove the borders of the grid in the computation.",
"_____no_output_____"
]
],
[
[
"def laplacian(Z):\n Ztop = Z[0:-2,1:-1]\n Zleft = Z[1:-1,0:-2]\n Zbottom = Z[2:,1:-1]\n Zright = Z[1:-1,2:]\n Zcenter = Z[1:-1,1:-1]\n return (Ztop + Zleft + Zbottom + Zright - 4 * Zcenter) / dx**2",
"_____no_output_____"
]
],
[
[
"6. Now, we simulate the system of equations using the finite difference method. At each time step, we compute the right-hand sides of the two equations on the grid using discrete spatial derivatives (Laplacians). Then, we update the variables using a discrete time derivative.",
"_____no_output_____"
]
],
[
[
"plt.imshow(U,cmap=plt.cm.copper,interpolation='none')",
"_____no_output_____"
],
[
"# We simulate the PDE with the finite difference method.\nfor i in range(n):\n # We compute the Laplacian of u and v.\n deltaU = laplacian(U)\n deltaV = laplacian(V)\n # We take the values of u and v inside the grid.\n Uc = U[1:-1,1:-1]\n Vc = V[1:-1,1:-1]\n # We update the variables.\n U[1:-1,1:-1], V[1:-1,1:-1] = \\\n Uc + dt * (a * deltaU - Uc*Vc*Vc + F*(1-Uc)), \\\n Vc + dt * (b * deltaV + Uc*Vc*Vc - (F+k)*Vc)\n # Neumann conditions: derivatives at the edges\n # are null.\n for Z in (U, V):\n Z[0,:] = Z[1,:]\n Z[-1,:] = Z[-2,:]\n Z[:,0] = Z[:,1]\n Z[:,-1] = Z[:,-2]",
"_____no_output_____"
]
],
[
[
"7. Finally, we display the variable $u$ after a time $T$ of simulation.",
"_____no_output_____"
]
],
[
[
"plt.imshow(U, cmap=plt.cm.jet, extent=[-1,1,-1,1],interpolation='none');",
"_____no_output_____"
]
],
[
[
"Whereas the variables when completely random at initialization time, we observe the formation of patterns after a sufficiently long simulation time.",
"_____no_output_____"
],
[
"> You'll find all the explanations, figures, references, and much more in the book (to be released later this summer).\n\n> [IPython Cookbook](http://ipython-books.github.io/), by [Cyrille Rossant](http://cyrille.rossant.net), Packt Publishing, 2014 (500 pages).",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
]
|
e7c11f31ca596ca0b1ca40cbe12e77a710cc8dc6 | 22,337 | ipynb | Jupyter Notebook | Statistics.ipynb | Data-science-vidhya/Numpy | 77cdfd2f7374db44f4b8b91a6ae6f81dd3d6531f | [
"MIT"
]
| null | null | null | Statistics.ipynb | Data-science-vidhya/Numpy | 77cdfd2f7374db44f4b8b91a6ae6f81dd3d6531f | [
"MIT"
]
| null | null | null | Statistics.ipynb | Data-science-vidhya/Numpy | 77cdfd2f7374db44f4b8b91a6ae6f81dd3d6531f | [
"MIT"
]
| null | null | null | 40.53902 | 6,700 | 0.717106 | [
[
[
"# Statistics",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
]
],
[
[
"## Order statistics",
"_____no_output_____"
],
[
"#### Return the minimum value of x along the second axis.",
"_____no_output_____"
]
],
[
[
"x = np.arange(4).reshape((2, 2))\nprint(\"x=\\n\", x)\nprint(\"ans=\\n\", np.amin(x, 1))",
"x=\n [[0 1]\n [2 3]]\nans=\n [0 2]\n"
]
],
[
[
"#### Return the maximum value of x along the second axis. Reduce the second axis to the dimension with size one.",
"_____no_output_____"
]
],
[
[
"x = np.arange(4).reshape((2, 2))\nprint(\"x=\\n\", x)\nprint(\"ans=\\n\", np.amax(x, 1, keepdims=True))",
"x=\n [[0 1]\n [2 3]]\nans=\n [[1]\n [3]]\n"
]
],
[
[
"#### Calcuate the difference between the maximum and the minimum of x along the second axis.",
"_____no_output_____"
]
],
[
[
"x = np.arange(10).reshape((2, 5))\nprint(\"x=\\n\", x)\n\nout1 = np.ptp(x, 1)\nout2 = np.amax(x, 1) - np.amin(x, 1)\nassert np.allclose(out1, out2)\nprint(\"ans=\\n\", out1)\n",
"x=\n [[0 1 2 3 4]\n [5 6 7 8 9]]\nans=\n [4 4]\n"
]
],
[
[
"#### Compute the 75th percentile of x along the second axis.",
"_____no_output_____"
]
],
[
[
"x = np.arange(1, 11).reshape((2, 5))\nprint(\"x=\\n\", x)\n\nprint(\"ans=\\n\", np.percentile(x, 75, 1))",
"x=\n [[ 1 2 3 4 5]\n [ 6 7 8 9 10]]\nans=\n [4. 9.]\n"
]
],
[
[
"## Averages and variances",
"_____no_output_____"
],
[
"#### Compute the median of flattened x.",
"_____no_output_____"
]
],
[
[
"x = np.arange(1, 10).reshape((3, 3))\nprint(\"x=\\n\", x)\n\nprint(\"ans=\\n\", np.median(x))",
"x=\n [[1 2 3]\n [4 5 6]\n [7 8 9]]\nans=\n 5.0\n"
]
],
[
[
"#### Compute the weighted average of x.",
"_____no_output_____"
]
],
[
[
"x = np.arange(5)\nweights = np.arange(1, 6)\n\nout1 = np.average(x, weights=weights)\nout2 = (x*(weights/weights.sum())).sum()\nassert np.allclose(out1, out2)\nprint(out1)",
"2.6666666666666665\n"
]
],
[
[
"#### Compute the mean, standard deviation, and variance of x along the second axis.",
"_____no_output_____"
]
],
[
[
"x = np.arange(5)\nprint(\"x=\\n\",x)\n\nout1 = np.mean(x)\nout2 = np.average(x)\nassert np.allclose(out1, out2)\nprint(\"mean=\\n\", out1)\n\nout3 = np.std(x)\nout4 = np.sqrt(np.mean((x - np.mean(x)) ** 2 ))\nassert np.allclose(out3, out4)\nprint(\"std=\\n\", out3)\n\nout5 = np.var(x)\nout6 = np.mean((x - np.mean(x)) ** 2 )\nassert np.allclose(out5, out6)\nprint(\"variance=\\n\", out5)\n",
"x=\n [0 1 2 3 4]\nmean=\n 2.0\nstd=\n 1.4142135623730951\nvariance=\n 2.0\n"
]
],
[
[
"## Correlating",
"_____no_output_____"
],
[
"#### Compute the covariance matrix of x and y.",
"_____no_output_____"
]
],
[
[
"x = np.array([0, 1, 2])\ny = np.array([2, 1, 0])\n\nprint(\"ans=\\n\", np.cov(x, y))",
"ans=\n [[ 1. -1.]\n [-1. 1.]]\n"
]
],
[
[
"#### In the above covariance matrix, what does the -1 mean?",
"_____no_output_____"
],
[
"It means `x` and `y` correlate perfectly in opposite directions.",
"_____no_output_____"
],
[
"#### Compute Pearson product-moment correlation coefficients of x and y.",
"_____no_output_____"
]
],
[
[
"x = np.array([0, 1, 3])\ny = np.array([2, 4, 5])\n\nprint(\"ans=\\n\", np.corrcoef(x, y))",
"ans=\n [[1. 0.92857143]\n [0.92857143 1. ]]\n"
]
],
[
[
"#### Compute cross-correlation of x and y.",
"_____no_output_____"
]
],
[
[
"x = np.array([0, 1, 3])\ny = np.array([2, 4, 5])\n\nprint(\"ans=\\n\", np.correlate(x, y))",
"ans=\n [19]\n"
]
],
[
[
"## Histograms",
"_____no_output_____"
],
[
"#### Compute the histogram of x against the bins.",
"_____no_output_____"
]
],
[
[
"x = np.array([0.5, 0.7, 1.0, 1.2, 1.3, 2.1])\nbins = np.array([0, 1, 2, 3])\nprint(\"ans=\\n\", np.histogram(x, bins))\n\nimport matplotlib.pyplot as plt\n%matplotlib inline\nplt.hist(x, bins=bins)\nplt.show()",
"ans=\n (array([2, 3, 1], dtype=int64), array([0, 1, 2, 3]))\n"
]
],
[
[
"#### Compute the 2d histogram of x and y.",
"_____no_output_____"
]
],
[
[
"xedges = [0, 1, 2, 3]\nyedges = [0, 1, 2, 3, 4]\nx = np.array([0, 0.1, 0.2, 1., 1.1, 2., 2.1])\ny = np.array([0, 0.1, 0.2, 1., 1.1, 2., 3.3])\nH, xedges, yedges = np.histogram2d(x, y, bins=(xedges, yedges))\nprint(\"ans=\\n\", H)\n\nplt.scatter(x, y)\nplt.grid()",
"ans=\n [[3. 0. 0. 0.]\n [0. 2. 0. 0.]\n [0. 0. 1. 1.]]\n"
]
],
[
[
"#### Count number of occurrences of 0 through 7 in x.",
"_____no_output_____"
]
],
[
[
"x = np.array([0, 1, 1, 3, 2, 1, 7])\nprint(\"ans=\\n\", np.bincount(x))",
"ans=\n [1 3 1 1 0 0 0 1]\n"
]
],
[
[
"#### Return the indices of the bins to which each value in x belongs.",
"_____no_output_____"
]
],
[
[
"x = np.array([0.2, 6.4, 3.0, 1.6])\nbins = np.array([0.0, 1.0, 2.5, 4.0, 10.0])\n\nprint(\"ans=\\n\", np.digitize(x, bins))",
"ans=\n [1 4 3 2]\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7c1311f6f7a966aab9d70005da4ed0d3c38f9f8 | 23,074 | ipynb | Jupyter Notebook | 1. Introduction/.ipynb_checkpoints/Part 6 - Saving and Loading Models-checkpoint.ipynb | Not-A-Builder/DL-PyTorch | f2d7c03ca0292827b7d0c4de65edb59afea39e08 | [
"MIT"
]
| null | null | null | 1. Introduction/.ipynb_checkpoints/Part 6 - Saving and Loading Models-checkpoint.ipynb | Not-A-Builder/DL-PyTorch | f2d7c03ca0292827b7d0c4de65edb59afea39e08 | [
"MIT"
]
| null | null | null | 1. Introduction/.ipynb_checkpoints/Part 6 - Saving and Loading Models-checkpoint.ipynb | Not-A-Builder/DL-PyTorch | f2d7c03ca0292827b7d0c4de65edb59afea39e08 | [
"MIT"
]
| null | null | null | 56.832512 | 4,268 | 0.677082 | [
[
[
"# Saving and Loading Models\n\nIn this notebook, I'll show you how to save and load models with PyTorch. This is important because you'll often want to load previously trained models to use in making predictions or to continue training on new data.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport matplotlib.pyplot as plt\n\nimport torch\nfrom torch import nn\nfrom torch import optim\nimport torch.nn.functional as F\nfrom torchvision import datasets, transforms\n\nimport helper\nimport fc_model",
"_____no_output_____"
],
[
"# Define a transform to normalize the data\ntransform = transforms.Compose([transforms.ToTensor(),\n transforms.Normalize((0.5,), (0.5,))])\n# Download and load the training data\ntrainset = datasets.FashionMNIST('F_MNIST_data/', download=True, train=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)\n\n# Download and load the test data\ntestset = datasets.FashionMNIST('F_MNIST_data/', download=True, train=False, transform=transform)\ntestloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)",
"Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz\nDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz\nDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz\nDownloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz\nProcessing...\nDone!\n"
]
],
[
[
"Here we can see one of the images.",
"_____no_output_____"
]
],
[
[
"image, label = next(iter(trainloader))\nhelper.imshow(image[0,:]);",
"_____no_output_____"
]
],
[
[
"# Train a network\n\nTo make things more concise here, I moved the model architecture and training code from the last part to a file called `fc_model`. Importing this, we can easily create a fully-connected network with `fc_model.Network`, and train the network using `fc_model.train`. I'll use this model (once it's trained) to demonstrate how we can save and load models.",
"_____no_output_____"
]
],
[
[
"# Create the network, define the criterion and optimizer\n\nmodel = fc_model.Network(784, 10, [512, 256, 128])\ncriterion = nn.NLLLoss()\noptimizer = optim.Adam(model.parameters(), lr=0.001)",
"_____no_output_____"
],
[
"fc_model.train(model, trainloader, testloader, criterion, optimizer, epochs=2)",
"Epoch: 1/2.. Training Loss: 1.684.. Test Loss: 1.004.. Test Accuracy: 0.627\nEpoch: 1/2.. Training Loss: 1.023.. Test Loss: 0.752.. Test Accuracy: 0.719\nEpoch: 1/2.. Training Loss: 0.897.. Test Loss: 0.672.. Test Accuracy: 0.738\nEpoch: 1/2.. Training Loss: 0.773.. Test Loss: 0.655.. Test Accuracy: 0.750\nEpoch: 1/2.. Training Loss: 0.744.. Test Loss: 0.604.. Test Accuracy: 0.768\nEpoch: 1/2.. Training Loss: 0.742.. Test Loss: 0.577.. Test Accuracy: 0.772\nEpoch: 1/2.. Training Loss: 0.673.. Test Loss: 0.567.. Test Accuracy: 0.781\nEpoch: 1/2.. Training Loss: 0.672.. Test Loss: 0.565.. Test Accuracy: 0.785\nEpoch: 1/2.. Training Loss: 0.682.. Test Loss: 0.553.. Test Accuracy: 0.791\nEpoch: 1/2.. Training Loss: 0.633.. Test Loss: 0.544.. Test Accuracy: 0.798\nEpoch: 1/2.. Training Loss: 0.621.. Test Loss: 0.539.. Test Accuracy: 0.794\nEpoch: 1/2.. Training Loss: 0.598.. Test Loss: 0.539.. Test Accuracy: 0.797\nEpoch: 1/2.. Training Loss: 0.622.. Test Loss: 0.528.. Test Accuracy: 0.809\nEpoch: 1/2.. Training Loss: 0.595.. Test Loss: 0.505.. Test Accuracy: 0.816\nEpoch: 1/2.. Training Loss: 0.631.. Test Loss: 0.514.. Test Accuracy: 0.808\nEpoch: 1/2.. Training Loss: 0.589.. Test Loss: 0.513.. Test Accuracy: 0.815\nEpoch: 1/2.. Training Loss: 0.617.. Test Loss: 0.518.. Test Accuracy: 0.813\nEpoch: 1/2.. Training Loss: 0.582.. Test Loss: 0.485.. Test Accuracy: 0.816\nEpoch: 1/2.. Training Loss: 0.573.. Test Loss: 0.487.. Test Accuracy: 0.824\nEpoch: 1/2.. Training Loss: 0.590.. Test Loss: 0.501.. Test Accuracy: 0.814\nEpoch: 1/2.. Training Loss: 0.596.. Test Loss: 0.487.. Test Accuracy: 0.825\nEpoch: 1/2.. Training Loss: 0.596.. Test Loss: 0.505.. Test Accuracy: 0.808\nEpoch: 1/2.. Training Loss: 0.539.. Test Loss: 0.493.. Test Accuracy: 0.820\nEpoch: 2/2.. Training Loss: 0.581.. Test Loss: 0.487.. Test Accuracy: 0.820\nEpoch: 2/2.. Training Loss: 0.567.. Test Loss: 0.498.. Test Accuracy: 0.819\nEpoch: 2/2.. Training Loss: 0.545.. Test Loss: 0.506.. Test Accuracy: 0.822\nEpoch: 2/2.. Training Loss: 0.552.. Test Loss: 0.481.. Test Accuracy: 0.825\nEpoch: 2/2.. Training Loss: 0.558.. Test Loss: 0.480.. Test Accuracy: 0.825\nEpoch: 2/2.. Training Loss: 0.537.. Test Loss: 0.461.. Test Accuracy: 0.829\nEpoch: 2/2.. Training Loss: 0.523.. Test Loss: 0.471.. Test Accuracy: 0.831\nEpoch: 2/2.. Training Loss: 0.550.. Test Loss: 0.459.. Test Accuracy: 0.833\nEpoch: 2/2.. Training Loss: 0.522.. Test Loss: 0.457.. Test Accuracy: 0.834\nEpoch: 2/2.. Training Loss: 0.540.. Test Loss: 0.458.. Test Accuracy: 0.833\nEpoch: 2/2.. Training Loss: 0.525.. Test Loss: 0.488.. Test Accuracy: 0.821\nEpoch: 2/2.. Training Loss: 0.469.. Test Loss: 0.464.. Test Accuracy: 0.832\nEpoch: 2/2.. Training Loss: 0.509.. Test Loss: 0.481.. Test Accuracy: 0.819\nEpoch: 2/2.. Training Loss: 0.542.. Test Loss: 0.468.. Test Accuracy: 0.831\nEpoch: 2/2.. Training Loss: 0.570.. Test Loss: 0.447.. Test Accuracy: 0.838\nEpoch: 2/2.. Training Loss: 0.495.. Test Loss: 0.458.. Test Accuracy: 0.832\nEpoch: 2/2.. Training Loss: 0.512.. Test Loss: 0.449.. Test Accuracy: 0.831\nEpoch: 2/2.. Training Loss: 0.512.. Test Loss: 0.451.. Test Accuracy: 0.836\nEpoch: 2/2.. Training Loss: 0.516.. Test Loss: 0.441.. Test Accuracy: 0.837\nEpoch: 2/2.. Training Loss: 0.496.. Test Loss: 0.467.. Test Accuracy: 0.830\nEpoch: 2/2.. Training Loss: 0.486.. Test Loss: 0.461.. Test Accuracy: 0.831\nEpoch: 2/2.. Training Loss: 0.514.. Test Loss: 0.437.. Test Accuracy: 0.843\nEpoch: 2/2.. Training Loss: 0.497.. Test Loss: 0.445.. Test Accuracy: 0.836\n"
]
],
[
[
"## Saving and loading networks\n\nAs you can imagine, it's impractical to train a network every time you need to use it. Instead, we can save trained networks then load them later to train more or use them for predictions.\n\nThe parameters for PyTorch networks are stored in a model's `state_dict`. We can see the state dict contains the weight and bias matrices for each of our layers.",
"_____no_output_____"
]
],
[
[
"print(\"Our model: \\n\\n\", model, '\\n')\nprint(\"The state dict keys: \\n\\n\", model.state_dict().keys())",
"Our model: \n\n Network(\n (hidden_layers): ModuleList(\n (0): Linear(in_features=784, out_features=512, bias=True)\n (1): Linear(in_features=512, out_features=256, bias=True)\n (2): Linear(in_features=256, out_features=128, bias=True)\n )\n (output): Linear(in_features=128, out_features=10, bias=True)\n (dropout): Dropout(p=0.5)\n) \n\nThe state dict keys: \n\n odict_keys(['hidden_layers.0.weight', 'hidden_layers.0.bias', 'hidden_layers.1.weight', 'hidden_layers.1.bias', 'hidden_layers.2.weight', 'hidden_layers.2.bias', 'output.weight', 'output.bias'])\n"
]
],
[
[
"The simplest thing to do is simply save the state dict with `torch.save`. For example, we can save it to a file `'checkpoint.pth'`.",
"_____no_output_____"
]
],
[
[
"torch.save(model.state_dict(), 'checkpoint.pth')",
"_____no_output_____"
]
],
[
[
"Then we can load the state dict with `torch.load`.",
"_____no_output_____"
]
],
[
[
"state_dict = torch.load('checkpoint.pth')\nprint(state_dict.keys())",
"odict_keys(['hidden_layers.0.weight', 'hidden_layers.0.bias', 'hidden_layers.1.weight', 'hidden_layers.1.bias', 'hidden_layers.2.weight', 'hidden_layers.2.bias', 'output.weight', 'output.bias'])\n"
]
],
[
[
"And to load the state dict in to the network, you do `model.load_state_dict(state_dict)`.",
"_____no_output_____"
]
],
[
[
"model.load_state_dict(state_dict)",
"_____no_output_____"
]
],
[
[
"Seems pretty straightforward, but as usual it's a bit more complicated. Loading the state dict works only if the model architecture is exactly the same as the checkpoint architecture. If I create a model with a different architecture, this fails.",
"_____no_output_____"
]
],
[
[
"# Try this\nmodel = fc_model.Network(784, 10, [400, 200, 100])\n# This will throw an error because the tensor sizes are wrong!\nmodel.load_state_dict(state_dict)",
"_____no_output_____"
]
],
[
[
"This means we need to rebuild the model exactly as it was when trained. Information about the model architecture needs to be saved in the checkpoint, along with the state dict. To do this, you build a dictionary with all the information you need to compeletely rebuild the model.",
"_____no_output_____"
]
],
[
[
"checkpoint = {'input_size': 784,\n 'output_size': 10,\n 'hidden_layers': [each.out_features for each in model.hidden_layers],\n 'state_dict': model.state_dict()}\n\ntorch.save(checkpoint, 'checkpoint.pth')",
"_____no_output_____"
]
],
[
[
"Now the checkpoint has all the necessary information to rebuild the trained model. You can easily make that a function if you want. Similarly, we can write a function to load checkpoints. ",
"_____no_output_____"
]
],
[
[
"def load_checkpoint(filepath):\n checkpoint = torch.load(filepath)\n model = fc_model.Network(checkpoint['input_size'],\n checkpoint['output_size'],\n checkpoint['hidden_layers'])\n model.load_state_dict(checkpoint['state_dict'])\n \n return model",
"_____no_output_____"
],
[
"model = load_checkpoint('checkpoint.pth')\nprint(model)",
"Network(\n (hidden_layers): ModuleList(\n (0): Linear(in_features=784, out_features=400, bias=True)\n (1): Linear(in_features=400, out_features=200, bias=True)\n (2): Linear(in_features=200, out_features=100, bias=True)\n )\n (output): Linear(in_features=100, out_features=10, bias=True)\n (dropout): Dropout(p=0.5)\n)\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7c14168c6bfa66809affab42ac1d2732432f7aa | 16,207 | ipynb | Jupyter Notebook | 2.3_Modules_and_Packages.ipynb | estherpuyol/BHF_Python_workshop | 0992159fb0d14d9f4d7ad8428c410945356d707c | [
"Apache-2.0"
]
| null | null | null | 2.3_Modules_and_Packages.ipynb | estherpuyol/BHF_Python_workshop | 0992159fb0d14d9f4d7ad8428c410945356d707c | [
"Apache-2.0"
]
| null | null | null | 2.3_Modules_and_Packages.ipynb | estherpuyol/BHF_Python_workshop | 0992159fb0d14d9f4d7ad8428c410945356d707c | [
"Apache-2.0"
]
| null | null | null | 16,207 | 16,207 | 0.725057 | [
[
[
"!git clone https://github.com/estherpuyol/BHF_Python_workshop.git",
"fatal: destination path 'BHF_Python_workshop' already exists and is not an empty directory.\n"
]
],
[
[
"# Modules, Packages and Classes ",
"_____no_output_____"
],
[
"\nWhen working with Python interactively, as we have thus far been doing, all functions that we define are available only within that notebook. This would similarly be the case if we were to write a simple script within an IDE.\n\nThus, in order to write more complex programs it is important to be able to write code in carefully organised and structured files that can then be accessed from the main program. To support this Python has a way to put definitions in a file and use them in a script or in an interactive instance. This type of file is called a _Module_. Groups of related modules can be used to create _Packages_. As Python is open source and utlised by a broad community in research in industry a wide variety of advanced packages for Machine Learning and Statistical Packages have been developed and are well supported and documented.\n\nIn this notebook we will discuss how to create modules and call them from scripts. We will list some useful modules from the Python standard library, then introduce the names of Python packages that will be used throughout the course. At the end we will introduce the topic of Object Oriented programming in Python. ",
"_____no_output_____"
],
[
"# Python .py files",
"_____no_output_____"
],
[
"Similarly to Matlab python (.py) files can have many uses. They can be used to encapsulate modules and classes. Or they can be used to encapsulate a script that imports external modules, reads in data, then processes the data through application of inline code and functions. ",
"_____no_output_____"
],
[
"# Modules",
"_____no_output_____"
],
[
"We will start by creating our own module containing some simple math functions 'simplemath.py'. In this we will provide simple math operations on two inputs:",
"_____no_output_____"
]
],
[
[
"def mysum(x,y):\n return x+y\n\ndef mult(x,y):\n return x*y\n\ndef divide(x,y):\n return x/y",
"_____no_output_____"
]
],
[
[
"Now we will call these functions in a separate Python script 'apply_simple_functions.py'. Open these files, in your IDE. Try running 'apply_simple_functions.py'. Note the initial line which loads the module and renames it in shorthand (see also below); it is important that this module file is available in the same folder as the script you call it from, or available as part of your system path.",
"_____no_output_____"
]
],
[
[
"from BHF_Python_workshop import simplemath as sm # load module\n\n\n# define variables\nx=2\ny=5\n\nprint('output sum of x and y:', sm.mysum(x,y))\nprint('output product of x and y:', sm.mult(x,y))\nprint('output quotient of x and y:', sm.divide(x,y))\n",
"output sum of x and y: 7\noutput product of x and y: 10\noutput quotient of x and y: 0.4\n"
]
],
[
[
"The functions defined in the module are now available in the script (and this notebook) by simply prefixing with the name given to the module when it is imported. It is also possible to just load selective functions from a module using the call ",
"_____no_output_____"
]
],
[
[
"from BHF_Python_workshop.simplemath import mysum as simplesum # note use of 'as' here, allows the change of names of functions \n\nprint('output sum of x and y:', simplesum(x,y))",
"output sum of x and y: 7\n"
]
],
[
[
"Alternatively all functions can be imported using *",
"_____no_output_____"
]
],
[
[
"from simplemath import * \n\nprint('output sum of x and y:', mysum(x,y))\nprint('output product of x and y:', mult(x,y))\nprint('output quotient of x and y:', divide(x,y))\n\n",
"_____no_output_____"
]
],
[
[
"## Standard Modules",
"_____no_output_____"
],
[
"Some modules come packaged with Python as standard. Useful examples include, ```os```:",
"_____no_output_____"
]
],
[
[
"import os\n\ndirname='/some/path/to/directory'\nfilename='myfile.txt'\n\nprint('my file path is:', os.path.join(dirname,filename)) # intelligent concatenation of path components\nprint('my file path exists:', os.path.exists(os.path.join(dirname,filename))) # checks whether file exists\n",
"_____no_output_____"
]
],
[
[
"```os``` performs useful operations on filenames; for more examples see https://docs.python.org/3/library/os.path.html#module-os.path. Also, ```sys```: this allows the addition or removal of paths from your python search path (https://docs.python.org/3/library/sys.html#module-sys), and is useful when you want to add the location of new modules to your path for example: ",
"_____no_output_____"
]
],
[
[
"import sys\n\nprint('system path:', sys.path)\n\n# add path to your system\nsys.path.append('/some/path/')\nprint('after append system path:', sys.path)\n\n#remove path from your system\nsys.path.remove('/some/path/')",
"_____no_output_____"
]
],
[
[
"```random``` is a random number generator",
"_____no_output_____"
]
],
[
[
"import random\n\nmult=25\n\nrand_int = random.randint(1, 10) # random int in defined range\nrand_float = random.random() # random float between 0 and 1\nrand_float_gen = random.random()*mult # random float between 0 and 25\n\nprint('my random integer is: ', rand_int)\nprint('my random float (between 0 and 1) is: ', rand_float)\nprint('my random float (between 0 and {}) is: {}'.format(mult,rand_float_gen))\n\n",
"_____no_output_____"
]
],
[
[
"math is Python's standard math module:",
"_____no_output_____"
]
],
[
[
"import math\n\nx=2.2\ny=4\n\nprint('ceil of {} is {}'. format(x,math.ceil(x)))\nprint('{} to the power {} is {}'.format(x,y,math.pow(x,y)))\nprint('The natural log of {} is {}'.format(x,math.log(x)))",
"_____no_output_____"
]
],
[
[
"For an extensive list of all standard math operations see https://docs.python.org/3/library/math.html#module-math. Finally, copy which was introduced in the previous notebook for generation of hard copies of objects in memory (https://docs.python.org/3/library/copy.html). For more examples of standard modules see https://docs.python.org/3/py-modindex.html",
"_____no_output_____"
],
[
"# Classes and Objects",
"_____no_output_____"
],
[
"Python is an object-oriented language. This allows the structuring of code into classes, allowing a clean and efficient coding style which improves code structure and reuse. The basic structure of a Python class can be written in pseudo code as \n\n```\nclass ClassName:\n <statement-1>\n .\n .\n .\n <statement-N>\n\n```\nWhere it is generally important to start classes with an constructor (instantiation function) such as:",
"_____no_output_____"
]
],
[
[
"class MyClass:\n \"\"\"A simple example class\"\"\"\n\n def __init__(self): # constructor\n self.data = []\n \nx=MyClass() # creates new instance of class",
"_____no_output_____"
]
],
[
[
"And, in practice, the statements inside a class definition will usually be method (object function) definitions e.g. :",
"_____no_output_____"
]
],
[
[
"class MyClass:\n \"\"\"A simple example class\"\"\"\n\n def __init__(self): \n self.data = []\n \n def f(self): # method\n return 'hello world'\n \nx=MyClass() # creates new instance of class\n\nprint(x.f()) # now run the class sub function f",
"_____no_output_____"
]
],
[
[
"Understanding of the formatting of Python classes is essential knoweldge for development of advanced python packages. However, in this course we will stick to relatively simple scripting. We leave investigation of more advanced features to the reader. For more materials on Python Classes see: https://docs.python.org/3/tutorial/classes.html\n\n**Exercise: Define a class representing a point in 2D space which has members for storing x and y position, and methods for calculating cartesian length.**",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"# Packages",
"_____no_output_____"
],
[
"Python packages are collections of related classes and modules; designed to solve some umbrella task. A wide variety of externally supported and well documented packages exist to meet a variety of advanced programming requirements. Examples of some that will be key to this module include:\n\n- Numpy (library for manipulation of arrays; including powerful linear algebra implementations, http://www.numpy.org/)\n- Matplotlib (plotting library, https://matplotlib.org/)\n- Scikit learn (very power machine learning library, http://scikit-learn.org/stable/)\n- Pandas (powerful tool for creating and manipulating complex tabulated data sheets https://pandas.pydata.org/)\n- Nibabel (library for reading medical image formats, http://nipy.org/nibabel/)\n\nWe will learn about these packages as we go through the course, though a regular 'Python Package of the Week' feature. Remember always to cite these packages where you use them.",
"_____no_output_____"
],
[
"## Installing Packages",
"_____no_output_____"
],
[
"There are two ways to install packages: 1) through Anaconda; 2) Through the python installer package ```pip```.\n\nAssuming you have installed Anaconda then most packages can be installed through the system terminal (cmd in windows) and running of ```conda install <package> ```. Packages can be updated through ```conda update ``` \n\nSometimes, packages are not available to Anaconda. In these cases, and for systems where Anaconda is not used then ```pip``` is preferable. Packages are installed using ```pip install package ``` and updated with ```pip install package --upgrade``` ",
"_____no_output_____"
],
[
"# Citing",
"_____no_output_____"
],
[
"Where project code is heavily derived from existing Python Packages it is very important to cite the original projects in resulting projects and papers. This is particularly true for research derived and supported packages such as Scikit-Learn:\n\nSee https://www.scipy.org/citing.html for full citation list\n\n",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
e7c165de7ab17674f039cb683d29bc7f136a0788 | 35,257 | ipynb | Jupyter Notebook | doc/src/GradientOptim/autodiff/examples_allowed_functions.ipynb | ndavila/MachineLearningMSU | b13377424d4d982bec97bc275a1ffd265e73e138 | [
"CC0-1.0"
]
| 59 | 2019-12-06T09:24:50.000Z | 2022-02-17T03:27:28.000Z | doc/src/GradientOptim/autodiff/examples_allowed_functions.ipynb | ndavila/MachineLearningMSU | b13377424d4d982bec97bc275a1ffd265e73e138 | [
"CC0-1.0"
]
| 5 | 2020-06-16T18:24:24.000Z | 2020-07-08T21:13:56.000Z | doc/src/GradientOptim/autodiff/examples_allowed_functions.ipynb | ndavila/MachineLearningMSU | b13377424d4d982bec97bc275a1ffd265e73e138 | [
"CC0-1.0"
]
| 43 | 2019-11-30T00:37:00.000Z | 2021-12-01T21:30:09.000Z | 52.078287 | 1,635 | 0.628471 | [
[
[
"# Examples of the supported features in Autograd",
"_____no_output_____"
],
[
"Before using Autograd for more complicated calculations, it might be useful to experiment with what kind of functions Autograd is capable of finding the gradient of. The following Python functions are just meant to illustrate what Autograd can do, but please feel free to experiment with other, possibly more complicated, functions as well! ",
"_____no_output_____"
]
],
[
[
"import autograd.numpy as np\nfrom autograd import grad",
"_____no_output_____"
]
],
[
[
"## Supported functions",
"_____no_output_____"
],
[
"Here are some examples of supported function implementations that Autograd can differentiate. Keep in mind that this list over examples is not comprehensive, but rather explores which basic constructions one might often use. ",
"_____no_output_____"
],
[
"### Functions using simple arithmetics",
"_____no_output_____"
]
],
[
[
"def f1(x):\n return x**3 + 1",
"_____no_output_____"
],
[
"f1_grad = grad(f1)\n\n# Remember to send in float as argument to the computed gradient from Autograd!\na = 1.0\n\n# See the evaluated gradient at a using autograd:\nprint(\"The gradient of f1 evaluated at a = %g using autograd is: %g\"%(a,f1_grad(a)))\n\n# Compare with the analytical derivative, that is f1'(x) = 3*x**2 \ngrad_analytical = 3*a**2\nprint(\"The gradient of f1 evaluated at a = %g by finding the analytic expression is: %g\"%(a,grad_analytical))",
"The gradient of f1 evaluated at a = 1 using autograd is: 3\nThe gradient of f1 evaluated at a = 1 by finding the analytic expression is: 3\n"
]
],
[
[
"### Functions with two (or more) arguments",
"_____no_output_____"
],
[
"To differentiate with respect to two (or more) arguments of a Python function, Autograd need to know at which variable the function if being differentiated with respect to. ",
"_____no_output_____"
]
],
[
[
"def f2(x1,x2):\n return 3*x1**3 + x2*(x1 - 5) + 1",
"_____no_output_____"
],
[
"# By sending the argument 0, Autograd will compute the derivative w.r.t the first variable, in this case x1\nf2_grad_x1 = grad(f2,0)\n\n# ... and differentiate w.r.t x2 by sending 1 as an additional arugment to grad\nf2_grad_x2 = grad(f2,1)\n\nx1 = 1.0\nx2 = 3.0 \n\nprint(\"Evaluating at x1 = %g, x2 = %g\"%(x1,x2))\nprint(\"-\"*30)\n\n# Compare with the analytical derivatives:\n\n# Derivative of f2 w.r.t x1 is: 9*x1**2 + x2:\nf2_grad_x1_analytical = 9*x1**2 + x2\n\n# Derivative of f2 w.r.t x2 is: x1 - 5:\nf2_grad_x2_analytical = x1 - 5\n\n# See the evaluated derivations:\nprint(\"The derivative of f2 w.r.t x1: %g\"%( f2_grad_x1(x1,x2) ))\nprint(\"The analytical derivative of f2 w.r.t x1: %g\"%( f2_grad_x1(x1,x2) ))\n\nprint()\n\nprint(\"The derivative of f2 w.r.t x2: %g\"%( f2_grad_x2(x1,x2) ))\nprint(\"The analytical derivative of f2 w.r.t x2: %g\"%( f2_grad_x2(x1,x2) ))",
"Evaluating at x1 = 1, x2 = 3\n------------------------------\nThe derivative of f2 w.r.t x1: 12\nThe analytical derivative of f2 w.r.t x1: 12\n\nThe derivative of f2 w.r.t x2: -4\nThe analytical derivative of f2 w.r.t x2: -4\n"
]
],
[
[
"Note that the grad function will not produce the true gradient of the function. The true gradient of a function with two or more variables will produce a vector, where each element is the function differentiated w.r.t a variable. ",
"_____no_output_____"
],
[
"### Functions using the elements of its argument directly",
"_____no_output_____"
]
],
[
[
"def f3(x): # Assumes x is an array of length 5 or higher\n return 2*x[0] + 3*x[1] + 5*x[2] + 7*x[3] + 11*x[4]**2",
"_____no_output_____"
],
[
"f3_grad = grad(f3)\n\nx = np.linspace(0,4,5)\n\n# Print the computed gradient:\nprint(\"The computed gradient of f3 is: \", f3_grad(x))\n\n# The analytical gradient is: (2, 3, 5, 7, 22*x[4])\nf3_grad_analytical = np.array([2, 3, 5, 7, 22*x[4]])\n\n# Print the analytical gradient:\nprint(\"The analytical gradient of f3 is: \", f3_grad_analytical)",
"The computed gradient of f3 is: [ 2. 3. 5. 7. 88.]\nThe analytical gradient of f3 is: [ 2. 3. 5. 7. 88.]\n"
]
],
[
[
"Note that in this case, when sending an array as input argument, the output from Autograd is another array. This is the true gradient of the function, as opposed to the function in the previous example. By using arrays to represent the variables, the output from Autograd might be easier to work with, as the output is closer to what one could expect form a gradient-evaluting function. ",
"_____no_output_____"
],
[
"### Functions using mathematical functions from Numpy",
"_____no_output_____"
]
],
[
[
"def f4(x):\n return np.sqrt(1+x**2) + np.exp(x) + np.sin(2*np.pi*x)",
"_____no_output_____"
],
[
"f4_grad = grad(f4)\n\nx = 2.7\n\n# Print the computed derivative:\nprint(\"The computed derivative of f4 at x = %g is: %g\"%(x,f4_grad(x)))\n\n# The analytical derivative is: x/sqrt(1 + x**2) + exp(x) + cos(2*pi*x)*2*pi\nf4_grad_analytical = x/np.sqrt(1 + x**2) + np.exp(x) + np.cos(2*np.pi*x)*2*np.pi\n\n# Print the analytical gradient:\nprint(\"The analytical gradient of f4 at x = %g is: %g\"%(x,f4_grad_analytical))",
"The computed derivative of f4 at x = 2.7 is: 13.8759\nThe analytical gradient of f4 is: 13.87586944687107\n"
]
],
[
[
"### Functions using if-else tests",
"_____no_output_____"
]
],
[
[
"def f5(x):\n if x >= 0:\n return x**2\n else:\n return -3*x + 1",
"_____no_output_____"
],
[
"f5_grad = grad(f5)\n\nx = 2.7\n\n# Print the computed derivative:\nprint(\"The computed derivative of f5 at x = %g is: %g\"%(x,f5_grad(x)))\n\n# The analytical derivative is: \n# if x >= 0, then 2*x\n# else -3\n\nif x >= 0:\n f5_grad_analytical = 2*x\nelse:\n f5_grad_analytical = -3\n\n\n# Print the analytical derivative:\nprint(\"The analytical derivative of f5 at x = %g is: %g\"%(x,f5_grad_analytical))",
"The computed derivative of f5 is: 5.4\nThe analytical derivative of f5 is: 5.4\n"
]
],
[
[
"### Functions using for- and while loops",
"_____no_output_____"
]
],
[
[
"def f6_for(x):\n val = 0\n for i in range(10):\n val = val + x**i\n return val\n\ndef f6_while(x):\n val = 0\n i = 0\n while i < 10:\n val = val + x**i\n i = i + 1\n return val",
"_____no_output_____"
],
[
"f6_for_grad = grad(f6_for)\nf6_while_grad = grad(f6_while)\n\nx = 0.5\n\n# Print the computed derivaties of f6_for and f6_while\nprint(\"The computed derivative of f6_for at x = %g is: %g\"%(x,f6_for_grad(x)))\nprint(\"The computed derivative of f6_while at x = %g is: %g\"%(x,f6_while_grad(x)))\n\n# Both of the functions are implementation of the sum: sum(x**i) for i = 0, ..., 9\n# The analytical derivative is: sum(i*x**(i-1)) \nf6_grad_analytical = 0\nfor i in range(10):\n f6_grad_analytical += i*x**(i-1)\n\nprint(\"The analytical derivative of f6 at x = %g is: %g\"%(x,f6_grad_analytical))",
"The computed derivative of f6_for at x = 0.5 is: 3.95703\nThe computed derivative of f6_while at x = 0.5 is: 3.95703\nThe analytical derivative of f6 at x = 0.5 is: 3.95703\n"
]
],
[
[
"### Functions using recursion",
"_____no_output_____"
]
],
[
[
"def f7(n): # Assume that n is an integer\n if n == 1 or n == 0:\n return 1\n else:\n return n*f7(n-1)",
"_____no_output_____"
],
[
"f7_grad = grad(f7)\n\nn = 2.0\n\nprint(\"The computed derivative of f7 at n = %d is: %g\"%(n,f7_grad(n)))\n\n# The function f7 is an implementation of the factorial of n.\n# By using the product rule, one can find that the derivative is:\n\nf7_grad_analytical = 0\nfor i in range(int(n)-1):\n tmp = 1\n for k in range(int(n)-1):\n if k != i:\n tmp *= (n - k)\n f7_grad_analytical += tmp\n\nprint(\"The analytical derivative of f7 at n = %d is: %g\"%(n,f7_grad_analytical))",
"The computed derivative of f7 at n = 2 is: 1\nThe analytical derivative of f7 at n = 2 is: 1\n"
]
],
[
[
"Note that if n is equal to zero or one, Autograd will give an error message. This message appears when the output is independent on input. ",
"_____no_output_____"
],
[
"## Unsupported functions",
"_____no_output_____"
],
[
"Autograd supports many features. However, there are some functions that is not supported (yet) by Autograd.",
"_____no_output_____"
],
[
"### Assigning a value to the variable being differentiated with respect to",
"_____no_output_____"
]
],
[
[
"def f8(x): # Assume x is an array\n x[2] = 3\n return x*2",
"_____no_output_____"
],
[
"f8_grad = grad(f8)\n\nx = 8.4\n\nprint(\"The derivative of f8 is:\",f8_grad(x))",
"_____no_output_____"
]
],
[
[
"Here, Autograd tells us that an 'ArrayBox' does not support item assignment. The item assignment is done when the program tries to assign x[2] to the value 3. However, Autograd has implemented the computation of the derivative such that this assignment is not possible. ",
"_____no_output_____"
],
[
"### The syntax a.dot(b) when finding the dot product",
"_____no_output_____"
]
],
[
[
"def f9(a): # Assume a is an array with 2 elements\n b = np.array([1.0,2.0])\n return a.dot(b)",
"_____no_output_____"
],
[
"f9_grad = grad(f9)\n\nx = np.array([1.0,0.0])\n\nprint(\"The derivative of f9 is:\",f9_grad(x))",
"_____no_output_____"
]
],
[
[
"Here we are told that the 'dot' function does not belong to Autograd's version of a Numpy array. \nTo overcome this, an alternative syntax which also computed the dot product can be used:",
"_____no_output_____"
]
],
[
[
"def f9_alternative(x): # Assume a is an array with 2 elements\n b = np.array([1.0,2.0])\n return np.dot(x,b) # The same as x_1*b_1 + x_2*b_2",
"_____no_output_____"
],
[
"f9_alternative_grad = grad(f9_alternative)\n\nx = np.array([3.0,0.0])\n\nprint(\"The gradient of f9 is:\",f9_alternative_grad(x))\n\n# The analytical gradient of the dot product of vectors x and b with two elements (x_1,x_2) and (b_1, b_2) respectively\n# w.r.t x is (b_1, b_2).",
"The gradient of f9 is: [1. 2.]\n"
]
],
[
[
"### Recommended to avoid",
"_____no_output_____"
],
[
"The [documentation](https://github.com/HIPS/autograd/blob/master/docs/tutorial.md) recommends to avoid inplace operations such as",
"_____no_output_____"
]
],
[
[
"a += b\na -= b\na*= b\na /=b",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"raw"
]
]
|
e7c1670dd4007f08bdc7e5a8eb27978069e0fb37 | 26,762 | ipynb | Jupyter Notebook | notes/maximum_likelihood.ipynb | thbeutin/csep2 | 79bc5c77c90f4dd13dae69425d3cb39aabcec7bf | [
"MIT"
]
| null | null | null | notes/maximum_likelihood.ipynb | thbeutin/csep2 | 79bc5c77c90f4dd13dae69425d3cb39aabcec7bf | [
"MIT"
]
| null | null | null | notes/maximum_likelihood.ipynb | thbeutin/csep2 | 79bc5c77c90f4dd13dae69425d3cb39aabcec7bf | [
"MIT"
]
| null | null | null | 78.251462 | 17,080 | 0.798931 | [
[
[
"# B-Value estimates from Maximum Likelihood\n\nHere we implement the maximum likelihood method from Tinti and Mulargia [1987]. We will compute the distribution of b-values from the stochastic event set and compare with the Comcat catalog. We will filter both the stochastic event sets and the catalog above Mw 3.95.",
"_____no_output_____"
]
],
[
[
"import time\nimport os\nimport pandas as pd\nimport numpy as np\nimport scipy.stats as stats\nfrom csep.utils.plotting import plot_mfd\nimport csep\n%pylab inline",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"def bval_ml_est(mws, dmw):\n \n # compute the p term from eq 3.10 in marzocchi and sandri [2003]\n def p():\n top = dmw\n # assuming that the magnitudes are truncated above Mc (ask about this).\n bottom = np.mean(mws) - np.min(mws)\n return 1 + top / bottom\n \n bottom = np.log(10) * dmw\n return 1.0 / bottom * np.log(p())\n\ndef bval_err_est(mws, dmw):\n \n # compute the p term from eq 3.10 in marzocchi and sandri [2003]\n def p():\n top = dmw\n # assuming that the magnitudes are truncated above Mc (ask about this).\n bottom = np.mean(mws) - np.min(mws)\n return 1 + top / bottom\n\n top = 1 - p()\n bottom = np.log(10)*dmw*np.sqrt(len(mws)*p())\n return top / bottom\n\ndef discretize(data, bin_edges):\n \"\"\"\n returns array with len(bin_edges) consisting of the discretized values from each bin. \n instead of returning the counts of each bin, this will return an array with values \n modified such that any value within bin_edges[0] <= x_new < bin_edges[1] ==> x_new.\n \"\"\"\n n = data.shape[0]\n idx = digitize(data, bins=bin_edges)\n x_new = bin_edges[idx]\n return x_new",
"_____no_output_____"
],
[
"# Comcat Synthetics\nepoch_time = 709732655000\nduration_in_years = 1.0\nt0 = time.time()\ncomcat = csep.load_catalog(type='comcat', format='native',\n start_epoch=epoch_time, duration_in_years=1.0,\n min_magnitude=2.5, \n min_latitude=31.50, max_latitude=43.00,\n min_longitude=-125.40, max_longitude=-113.10,\n name='Comcat').filter('magnitude > 3.95')\nt1 = time.time()\n\n# Statements about Comcat Downloads\nprint(\"Fetched Comcat catalog in {} seconds.\\n\".format(t1-t0))\nprint(\"Downloaded Comcat Catalog with following parameters\")\nprint(\"Start Date: {}\\nEnd Date: {}\".format(str(comcat.start_time), str(comcat.end_time)))\nprint(\"Min Latitude: {} and Max Latitude: {}\".format(comcat.min_latitude, comcat.max_latitude))\nprint(\"Min Longitude: {} and Max Longitude: {}\".format(comcat.min_longitude, comcat.max_longitude))\nprint(\"Min Magnitude: {} and Max Magnitude: {}\\n\".format(comcat.min_magnitude, comcat.max_magnitude))",
"Fetched Comcat catalog in 6.098243951797485 seconds.\n\nDownloaded Comcat Catalog with following parameters\nStart Date: 1992-06-28 12:00:59.904000+00:00\nEnd Date: 1993-05-31 08:55:11.616000+00:00\nMin Latitude: 32.242000579833984 and Max Latitude: 41.52033233642578\nMin Longitude: -124.40650177001953 and Max Longitude: -113.19066619873047\nMin Magnitude: 3.9600000381469727 and Max Magnitude: 6.300000190734863\n\n"
],
[
"# read in ucerf3 simulations\nproject_root = '/Users/wsavran/Projects/CSEP2/u3etas_simulations/landers_experiment'\nfilename = os.path.join(project_root, '10-23-2018_landers-pt1/results_complete.bin')\nfilename_nofaults = os.path.join(project_root, '10-31-2018_landers-nofaults-pt1/results_complete.bin')\nu3catalogs = []\nfor cat in csep.load_stochastic_event_set(filename=filename, format='native', type='ucerf3', name='UCERF3-ETAS'):\n u3catalogs.append(cat.filter('magnitude > 3.95'))",
"_____no_output_____"
],
[
"dmw = 0.1\nb_vals = []\n\n# get b-values from stochastic event set\nfor cat in u3catalogs:\n global_max = max([max(cat.get_magnitudes()), max(comcat.get_magnitudes())])\n mws = arange(3.95, global_max+2*dmw, dmw)\n cat_mws = discretize(cat.get_magnitudes(), mws)\n b_est = bval_ml_est(cat_mws, dmw)\n b_vals.append(b_est)\nb_vals = np.array(b_vals)\n\n# get b-value for comcat catalog\ncom_mws = discretize(comcat.get_magnitudes(), mws)\ncom_bval = bval_ml_est(com_mws, dmw)\ncom_bval_err = bval_err_est(com_mws, dmw)\nprint(com_bval_err)\n\n# plot b-value estimates\nfig = hist(b_vals, bins = 60, edgecolor='black', alpha=0.7, label='Stochastic Event Set')\naxvline(x=com_bval, color='black', linestyle='-', label='Observation')\naxvline(x=com_bval-com_bval_err, color='black', linestyle='--', label='$\\pm\\hat{\\sigma_{TM}}$')\naxvline(x=com_bval+com_bval_err, color='black', linestyle='--')\nxlabel('b-value')\nylabel('Frequency')\ntitle('b-value Estimates')\nlegend(loc='upper right')",
"-0.0620467887229116\n"
]
],
[
[
"## Verifying computation of $a$ from Michael [2014]\n\n$log(N(m)) = a - bM$ <br>\n$ a = log(N(m)/T) + bM $\n\nFrom Table 2 in Michael [2014], <br>\n$T$: 1900 $-$ 2009 <br>\n$M_c:$ 7.7 <br> \n$N^{\\prime}:$ 100 <br> \n$b$ = 1.59 $\\pm$ 0.13",
"_____no_output_____"
]
],
[
[
"Np = 100\nb = 1.59\nMc = 7.7\nT = 2009-1900\nsigma = 0.13\n\ndef a_val(N, M, b, T):\n return np.log10(N/T) + M*b\n\na = a_val(Np, Mc, b, T)\nprint(a)\n\ndef a_err(a, b, sigma):\n return a*sigma/b\n\nprint(a_err(a, b, sigma))",
"12.205573502059377\n0.9979399718664899\n"
],
[
"Np = 635\nb = 1.07\nMc = 7.0\nT = 2009-1918\nsigma = 0.03\n\ndef a_val(N, M, b, T):\n return np.log10(N/T) + M*b\n\na = a_val(Np, Mc, b, T)\nprint(a)\n\ndef a_err(a, b, sigma):\n return sigma/b*a\n\nprint(a_err(a, b, sigma))",
"8.333732332970882\n0.23365604671880974\n"
],
[
"Np = 810\nb = 1.05\nMc = 6.8\nT = 2009-1940\nsigma = 0.03\n\ndef a_val(N, M, b, T):\n return np.log10(N/T) + M*b\n\na = a_val(Np, Mc, b, T)\nprint(a)\n\ndef a_err(a, b, sigma):\n return sigma/b*a\n\nprint(a_err(a, b, sigma))",
"8.209635928141394\n0.23456102651832553\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
e7c17ed995c67b9ab128453f0ae7c572e379aa43 | 27,529 | ipynb | Jupyter Notebook | examples/football-data.co.uk.ipynb | martineastwood/penaltyblog | 6e9a5af9359537556e3215ff4df58c7817d86173 | [
"MIT"
]
| 17 | 2021-06-09T15:31:37.000Z | 2022-03-11T22:17:56.000Z | examples/football-data.co.uk.ipynb | martineastwood/penaltyblog | 6e9a5af9359537556e3215ff4df58c7817d86173 | [
"MIT"
]
| 1 | 2022-03-28T20:02:02.000Z | 2022-03-28T20:02:02.000Z | examples/football-data.co.uk.ipynb | martineastwood/penaltyblog | 6e9a5af9359537556e3215ff4df58c7817d86173 | [
"MIT"
]
| 3 | 2021-08-20T07:46:11.000Z | 2022-03-09T15:02:15.000Z | 32.578698 | 91 | 0.289295 | [
[
[
"import sys\nsys.path.append(\"../\")\n\nimport penaltyblog as pb",
"_____no_output_____"
]
],
[
[
"### List the available countries to download data for",
"_____no_output_____"
]
],
[
[
"pb.footballdata.list_countries()",
"_____no_output_____"
]
],
[
[
"### Download the data for the English Premier League",
"_____no_output_____"
]
],
[
[
"pb.footballdata.fetch_data(\"England\", 2020, 0)",
"_____no_output_____"
]
],
[
[
"### Download the data for the French Ligue 2",
"_____no_output_____"
]
],
[
[
"pb.footballdata.fetch_data(\"France\", 2020, 1)",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7c18926261ac7f8569410ce3fd2ad8b8fa026ed | 2,679 | ipynb | Jupyter Notebook | curry_n_partial.ipynb | mrwizard82d1/learn_toolz | dbd2f2dc47de60ff457be00858d2127e4c1a11c4 | [
"MIT"
]
| null | null | null | curry_n_partial.ipynb | mrwizard82d1/learn_toolz | dbd2f2dc47de60ff457be00858d2127e4c1a11c4 | [
"MIT"
]
| 6 | 2021-04-03T00:17:53.000Z | 2021-08-23T21:21:11.000Z | curry_n_partial.ipynb | mrwizard82d1/learn_toolz | dbd2f2dc47de60ff457be00858d2127e4c1a11c4 | [
"MIT"
]
| null | null | null | 18.604167 | 68 | 0.48003 | [
[
[
"# Investigate behavior of `curry` and `partial`",
"_____no_output_____"
]
],
[
[
"from toolz.curried import *",
"_____no_output_____"
],
[
"def clump3(a, b, c):\n return a, b, c",
"_____no_output_____"
],
[
"@curry\ndef curried_clump3(a, b, c):\n return a, b, c",
"_____no_output_____"
],
[
"partial1_clump3=partial(clump3, 1)\npartial12_clump3=partial(clump3, 1, 2)",
"_____no_output_____"
],
[
"print(f'clump3(1, 2, 3)={clump3(1, 2, 3)}')\nprint(f'clump3(3, 1, 2)={clump3(3, 1, 2)}')\nprint()\nprint(f'curried_clump3(1)(2)(3)={curried_clump3(1)(2)(3)}')\nprint(f'curried_clump3(1)(2)(3)={curried_clump3(1)(2)(3)}')\nprint()\nprint(f'curried_clump3(3, 1)(2)={curried_clump3(3, 1)(2)}')",
"_____no_output_____"
],
[
"print()\nprint(f'partial1_clump3(2, 3)={partial1_clump3(2, 3)}')\nprint(f'partial12_clump3(2, 3)={partial12_clump3(3)}')",
"_____no_output_____"
],
[
"\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c18feca796e16eb52fa71be6ee6cd459712112 | 466,339 | ipynb | Jupyter Notebook | SAS Jupyter/Tutorial2.ipynb | juandiazmart/Biostats-II-Tutorial | 86d79550d205534f62f1879d5e8d919060dc8066 | [
"MIT"
]
| null | null | null | SAS Jupyter/Tutorial2.ipynb | juandiazmart/Biostats-II-Tutorial | 86d79550d205534f62f1879d5e8d919060dc8066 | [
"MIT"
]
| null | null | null | SAS Jupyter/Tutorial2.ipynb | juandiazmart/Biostats-II-Tutorial | 86d79550d205534f62f1879d5e8d919060dc8066 | [
"MIT"
]
| 1 | 2021-01-18T19:40:55.000Z | 2021-01-18T19:40:55.000Z | 60.064271 | 31,992 | 0.617977 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
e7c1a7aa09812ac720797b4a674f44a8f151ca10 | 177,115 | ipynb | Jupyter Notebook | CNN_Persian_DigitsClassifier.ipynb | saniaki/Digit-Image-Classifier | d8cb61ad84c5b188a907ad1b44996eb8cbb40546 | [
"MIT"
]
| null | null | null | CNN_Persian_DigitsClassifier.ipynb | saniaki/Digit-Image-Classifier | d8cb61ad84c5b188a907ad1b44996eb8cbb40546 | [
"MIT"
]
| null | null | null | CNN_Persian_DigitsClassifier.ipynb | saniaki/Digit-Image-Classifier | d8cb61ad84c5b188a907ad1b44996eb8cbb40546 | [
"MIT"
]
| null | null | null | 216.522005 | 60,948 | 0.891449 | [
[
[
"\n# Convolutional Neural Network (CNN) Image Classifier for Persian Numbers ",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom scipy.io import loadmat\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport random\nimport math\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPool2D, Dropout, BatchNormalization\nfrom tensorflow.keras.optimizers import Adam\nfrom tensorflow.keras.activations import relu, softmax\nfrom tensorflow.keras import regularizers\nfrom tensorflow.keras.losses import sparse_categorical_crossentropy\nfrom tensorflow.keras.initializers import he_uniform, glorot_normal, zeros, ones\nfrom tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint",
"_____no_output_____"
]
],
[
[
"[HODA dataset](http://farsiocr.ir/%D9%85%D8%AC%D9%85%D9%88%D8%B9%D9%87-%D8%AF%D8%A7%D8%AF%D9%87/%D9%85%D8%AC%D9%85%D9%88%D8%B9%D9%87-%D8%A7%D8%B1%D9%82%D8%A7%D9%85-%D8%AF%D8%B3%D8%AA%D9%86%D9%88%DB%8C%D8%B3-%D9%87%D8%AF%DB%8C/)<br>",
"_____no_output_____"
],
[
"HODA Daset reader from: https://github.com/amir-saniyan/HodaDatasetReader",
"_____no_output_____"
]
],
[
[
"# *-* coding: utf-8 *-*\n\n# Hoda Dataset Reader\n# Python code for reading Hoda farsi digit dataset.\n\n# Hoda Farsi Digit Dataset:\n# http://farsiocr.ir/\n# http://farsiocr.ir/مجموعه-داده/مجموعه-ارقام-دستنویس-هدی\n# http://dadegan.ir/catalog/hoda\n\n# Repository:\n# https://github.com/amir-saniyan/HodaDatasetReader\n\nimport struct\nimport numpy as np\nimport cv2\n\ndef __convert_to_one_hot(vector, num_classes):\n result = np.zeros(shape=[len(vector), num_classes])\n result[np.arange(len(vector)), vector] = 1\n return result\n\n\ndef __resize_image(src_image, dst_image_height, dst_image_width):\n src_image_height = src_image.shape[0]\n src_image_width = src_image.shape[1]\n\n if src_image_height > dst_image_height or src_image_width > dst_image_width:\n height_scale = dst_image_height / src_image_height\n width_scale = dst_image_width / src_image_width\n scale = min(height_scale, width_scale)\n img = cv2.resize(src=src_image, dsize=(0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC)\n else:\n img = src_image\n\n img_height = img.shape[0]\n img_width = img.shape[1]\n\n dst_image = np.zeros(shape=[dst_image_height, dst_image_width], dtype=np.uint8)\n\n y_offset = (dst_image_height - img_height) // 2\n x_offset = (dst_image_width - img_width) // 2\n\n dst_image[y_offset:y_offset+img_height, x_offset:x_offset+img_width] = img\n\n return dst_image\n\n\ndef read_hoda_cdb(file_name):\n with open(file_name, 'rb') as binary_file:\n\n data = binary_file.read()\n\n offset = 0\n\n # read private header\n\n yy = struct.unpack_from('H', data, offset)[0]\n offset += 2\n\n m = struct.unpack_from('B', data, offset)[0]\n offset += 1\n\n d = struct.unpack_from('B', data, offset)[0]\n offset += 1\n\n H = struct.unpack_from('B', data, offset)[0]\n offset += 1\n\n W = struct.unpack_from('B', data, offset)[0]\n offset += 1\n\n TotalRec = struct.unpack_from('I', data, offset)[0]\n offset += 4\n\n LetterCount = struct.unpack_from('128I', data, offset)\n offset += 128 * 4\n\n imgType = struct.unpack_from('B', data, offset)[0] # 0: binary, 1: gray\n offset += 1\n\n Comments = struct.unpack_from('256c', data, offset)\n offset += 256 * 1\n\n Reserved = struct.unpack_from('245c', data, offset)\n offset += 245 * 1\n\n if (W > 0) and (H > 0):\n normal = True\n else:\n normal = False\n\n images = []\n labels = []\n\n for i in range(TotalRec):\n\n StartByte = struct.unpack_from('B', data, offset)[0] # must be 0xff\n offset += 1\n\n label = struct.unpack_from('B', data, offset)[0]\n offset += 1\n\n if not normal:\n W = struct.unpack_from('B', data, offset)[0]\n offset += 1\n\n H = struct.unpack_from('B', data, offset)[0]\n offset += 1\n\n ByteCount = struct.unpack_from('H', data, offset)[0]\n offset += 2\n\n image = np.zeros(shape=[H, W], dtype=np.uint8)\n\n if imgType == 0:\n # Binary\n for y in range(H):\n bWhite = True\n counter = 0\n while counter < W:\n WBcount = struct.unpack_from('B', data, offset)[0]\n offset += 1\n # x = 0\n # while x < WBcount:\n # if bWhite:\n # image[y, x + counter] = 0 # Background\n # else:\n # image[y, x + counter] = 255 # ForeGround\n # x += 1\n if bWhite:\n image[y, counter:counter + WBcount] = 0 # Background\n else:\n image[y, counter:counter + WBcount] = 255 # ForeGround\n bWhite = not bWhite # black white black white ...\n counter += WBcount\n else:\n # GrayScale mode\n data = struct.unpack_from('{}B'.format(W * H), data, offset)\n offset += W * H\n image = np.asarray(data, dtype=np.uint8).reshape([W, H]).T\n\n images.append(image)\n labels.append(label)\n\n return images, labels\n\n\ndef read_hoda_dataset(dataset_path, images_height=32, images_width=32, one_hot=False, reshape=True):\n images, labels = read_hoda_cdb(dataset_path)\n assert len(images) == len(labels)\n\n X = np.zeros(shape=[len(images), images_height, images_width], dtype=np.float32)\n Y = np.zeros(shape=[len(labels)], dtype=np.int)\n\n for i in range(len(images)):\n image = images[i]\n # Image resizing.\n image = __resize_image(src_image=image, dst_image_height=images_height, dst_image_width=images_width)\n # Image normalization.\n image = image / 255\n # Image binarization.\n image = np.where(image >= 0.5, 1, 0)\n # Image.\n X[i] = image\n # Label.\n Y[i] = labels[i]\n\n if one_hot:\n Y = __convert_to_one_hot(Y, 10).astype(dtype=np.float32)\n else:\n Y = Y.astype(dtype=np.float32)\n\n if reshape:\n X = X.reshape(-1, images_height * images_width)\n else:\n X = X.reshape(-1, images_height, images_width, 1)\n\n return X, Y\n",
"_____no_output_____"
],
[
"# loading dataset\n# train data\ntrain_images, train_labels = read_hoda_dataset(dataset_path='data_Persian/Train 60000.cdb',\n images_height=32,\n images_width=32,\n one_hot=False,\n reshape=False)\n# test data\ntest_images, test_labels = read_hoda_dataset(dataset_path='data_Persian/Test 20000.cdb',\n images_height=32,\n images_width=32,\n one_hot=False,\n reshape=False)",
"_____no_output_____"
]
],
[
[
"## Visualization fucntions",
"_____no_output_____"
]
],
[
[
"def show_images(n,image_array,label_array, cmap=None):\n '''\n show random n number of images from image_array with corresponding label_array\n '''\n total_rows = math.floor(n/4)+1\n random_list = random.sample(range(0, image_array.shape[0]), n)\n fig, axes = plt.subplots(total_rows, 4, figsize=(16, total_rows*4))\n [axi.set_axis_off() for axi in axes.ravel()] # this line sets all axis off\n r = 0\n c = 0\n for i in random_list:\n image = image_array[i,:,:,:]\n #axes[r, c].set_axis_off()\n axes[r, c].imshow(np.squeeze(image), cmap=cmap)\n axes[r, c].set_title(f\"Label: {label_array[i]} \\n {i}th image in the dataset.\")\n c += 1\n if c % 4 == 0:\n r += 1\n c = 0\n plt.show()",
"_____no_output_____"
],
[
"def show_images_predictions(n,image_array,label_array1,label_array2, cmap=None):\n '''\n show random n number of images from image_array with corresponding label_array\n the precition of class probablity distibution from each model also would be discplayed\n '''\n random_list = random.sample(range(0, image_array.shape[0]), n)\n fig, axes = plt.subplots(n, 2, figsize=(16, n*6))\n #[axi.set_axis_off() for axi in axes.ravel()] # this line sets all axis off\n category_list1 = list(map(lambda x : x + 0.15, list(range(10)))) \n category_list2 = list(map(lambda x : x - 0.15, list(range(10)))) \n r = 0\n for i in random_list:\n image = image_array[i,:,:,:]\n axes[r, 0].set_axis_off()\n axes[r, 0].imshow(np.squeeze(image), cmap=cmap)\n #axes[r, 1].set_title(f\"{i}th image in the dataset.\")\n axes[r, 1].bar(category_list1,label_array1[i], width=0.3, label='MLP')\n axes[r, 1].bar(category_list2,label_array2[i], width=0.3, label='CNN')\n axes[r, 1].set_title(f\"Prediction from MLP model: {np.argmax(label_array1[i,:])} \\n Prediction from CNN model: {np.argmax(label_array2[i,:])} \")\n axes[r, 1].legend()\n r += 1\n plt.show()",
"_____no_output_____"
],
[
"# Functions to plot accuacy and loss\ndef plot_acc(history):\n try:\n plt.plot(history.history['accuracy'])\n plt.plot(history.history['val_accuracy'])\n except KeyError:\n plt.plot(history.history['acc'])\n plt.plot(history.history['val_acc'])\n plt.title('Accuracy vs. epochs')\n plt.ylabel('Loss')\n plt.xlabel('Epoch')\n plt.legend(['Training', 'Validation'], loc='lower right')\n plt.show() \n\n\ndef plot_loss(history):\n plt.plot(history.history['loss'])\n plt.plot(history.history['val_loss'])\n plt.title('Loss vs. epochs')\n plt.ylabel('Loss')\n plt.xlabel('Epoch')\n plt.legend(['Training', 'Validation'], loc='upper right')\n plt.show() ",
"_____no_output_____"
]
],
[
[
"## Check training images",
"_____no_output_____"
]
],
[
[
"n = 10 # number of images to show\n# showing images and correspoind labels from train set\nshow_images(n,train_images,train_labels)",
"_____no_output_____"
]
],
[
[
"## CNN neural network classifier",
"_____no_output_____"
]
],
[
[
"def CNN_NN(input_shape, dropout_rate, reg_rate):\n model = Sequential([\n Conv2D(8, (3,3), activation='relu', input_shape=input_shape, \n kernel_initializer=\"he_uniform\", bias_initializer=\"ones\", \n kernel_regularizer=regularizers.l2(reg_rate), name='CONV2D_1_1_relu'),\n BatchNormalization(),\n Conv2D(16, (3,3), activation='relu', kernel_regularizer=regularizers.l2(reg_rate), name='CONV2D_2_2_relu'),\n MaxPool2D((3,3), strides=(2, 2), name='MaxPool2D_1_2_relu'),\n Dropout(dropout_rate),\n BatchNormalization(),\n Conv2D(32, (3,3), activation='relu', kernel_regularizer=regularizers.l2(reg_rate), name='CONV2D_3_3_relu'),\n MaxPool2D((3,3), strides=(2, 2), name='MaxPool2D_2_3_relu'),\n Dropout(dropout_rate),\n BatchNormalization(),\n Flatten(),\n Dense(64, activation='relu', kernel_regularizer=regularizers.l2(reg_rate), name='Dense_1_4_relu'),\n Dense(32, activation='relu', kernel_regularizer=regularizers.l2(reg_rate), name='Dense_2_5_relu'),\n Dense(10, activation='softmax', name='Dense_3_6_softmax')\n ])\n return model",
"_____no_output_____"
],
[
"def get_checkpoint_best_only(checkpoint_path):\n '''\n save best weights of the model with monitoring validation accuract\n '''\n checkpoint = ModelCheckpoint(checkpoint_path,\n save_weights_only=True,\n monitor='val_accuracy',\n verbose=1,\n save_best_only=True)\n \n return checkpoint",
"_____no_output_____"
],
[
"def get_test_accuracy(model, x_test, y_test):\n '''\n checking the accuracy of the model on the test sets\n '''\n test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)\n print(' test accuracy: {acc:0.3f}'.format(acc=test_acc), '\\n',\n 'test loss: {loss:0.3f}'.format(loss=test_loss))",
"_____no_output_____"
],
[
"# creating CNN model for greay scale images\nmodel_CNN = CNN_NN(input_shape= (32,32,1), dropout_rate = 0.3, reg_rate=1e-3)\nmodel_CNN.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nCONV2D_1_1_relu (Conv2D) (None, 30, 30, 8) 80 \n_________________________________________________________________\nbatch_normalization (BatchNo (None, 30, 30, 8) 32 \n_________________________________________________________________\nCONV2D_2_2_relu (Conv2D) (None, 28, 28, 16) 1168 \n_________________________________________________________________\nMaxPool2D_1_2_relu (MaxPooli (None, 13, 13, 16) 0 \n_________________________________________________________________\ndropout (Dropout) (None, 13, 13, 16) 0 \n_________________________________________________________________\nbatch_normalization_1 (Batch (None, 13, 13, 16) 64 \n_________________________________________________________________\nCONV2D_3_3_relu (Conv2D) (None, 11, 11, 32) 4640 \n_________________________________________________________________\nMaxPool2D_2_3_relu (MaxPooli (None, 5, 5, 32) 0 \n_________________________________________________________________\ndropout_1 (Dropout) (None, 5, 5, 32) 0 \n_________________________________________________________________\nbatch_normalization_2 (Batch (None, 5, 5, 32) 128 \n_________________________________________________________________\nflatten (Flatten) (None, 800) 0 \n_________________________________________________________________\nDense_1_4_relu (Dense) (None, 64) 51264 \n_________________________________________________________________\nDense_2_5_relu (Dense) (None, 32) 2080 \n_________________________________________________________________\nDense_3_6_softmax (Dense) (None, 10) 330 \n=================================================================\nTotal params: 59,786\nTrainable params: 59,674\nNon-trainable params: 112\n_________________________________________________________________\n"
],
[
"model_CNN.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"checkpoint_best_only = get_checkpoint_best_only('Trained models weights_Persian\\checkpoints_best_only_CNN\\checkpoint')\n\nhistory_CNN = model_CNN.fit(train_images,\n train_labels,\n batch_size=32,\n epochs=30,\n validation_split=0.10,\n callbacks=[EarlyStopping(monitor='val_accuracy', patience=4), checkpoint_best_only]\n )",
"Epoch 1/30\n1687/1688 [============================>.] - ETA: 0s - loss: 0.3074 - accuracy: 0.9568\nEpoch 00001: val_accuracy improved from -inf to 0.98100, saving model to Trained models weights_Persian\\checkpoints_best_only_CNN\\checkpoint\n1688/1688 [==============================] - 59s 35ms/step - loss: 0.3074 - accuracy: 0.9568 - val_loss: 0.1747 - val_accuracy: 0.9810\nEpoch 2/30\n1688/1688 [==============================] - ETA: 0s - loss: 0.1406 - accuracy: 0.9858\nEpoch 00002: val_accuracy improved from 0.98100 to 0.98917, saving model to Trained models weights_Persian\\checkpoints_best_only_CNN\\checkpoint\n1688/1688 [==============================] - 74s 44ms/step - loss: 0.1406 - accuracy: 0.9858 - val_loss: 0.1132 - val_accuracy: 0.9892\nEpoch 3/30\n1688/1688 [==============================] - ETA: 0s - loss: 0.1106 - accuracy: 0.9874\nEpoch 00003: val_accuracy did not improve from 0.98917\n1688/1688 [==============================] - 52s 31ms/step - loss: 0.1106 - accuracy: 0.9874 - val_loss: 0.1051 - val_accuracy: 0.9870\nEpoch 4/30\n1687/1688 [============================>.] - ETA: 0s - loss: 0.0959 - accuracy: 0.9886\nEpoch 00004: val_accuracy did not improve from 0.98917\n1688/1688 [==============================] - 52s 31ms/step - loss: 0.0959 - accuracy: 0.9886 - val_loss: 0.0954 - val_accuracy: 0.9892\nEpoch 5/30\n1686/1688 [============================>.] - ETA: 0s - loss: 0.0921 - accuracy: 0.9883\nEpoch 00005: val_accuracy did not improve from 0.98917\n1688/1688 [==============================] - 53s 31ms/step - loss: 0.0920 - accuracy: 0.9883 - val_loss: 0.0869 - val_accuracy: 0.9890\nEpoch 6/30\n1687/1688 [============================>.] - ETA: 0s - loss: 0.0860 - accuracy: 0.9892\nEpoch 00006: val_accuracy improved from 0.98917 to 0.99383, saving model to Trained models weights_Persian\\checkpoints_best_only_CNN\\checkpoint\n1688/1688 [==============================] - 56s 33ms/step - loss: 0.0860 - accuracy: 0.9892 - val_loss: 0.0710 - val_accuracy: 0.9938\nEpoch 7/30\n1686/1688 [============================>.] - ETA: 0s - loss: 0.0822 - accuracy: 0.9896\nEpoch 00007: val_accuracy did not improve from 0.99383\n1688/1688 [==============================] - 52s 31ms/step - loss: 0.0822 - accuracy: 0.9895 - val_loss: 0.0862 - val_accuracy: 0.9877\nEpoch 8/30\n1687/1688 [============================>.] - ETA: 0s - loss: 0.0793 - accuracy: 0.9898\nEpoch 00008: val_accuracy did not improve from 0.99383\n1688/1688 [==============================] - 54s 32ms/step - loss: 0.0793 - accuracy: 0.9898 - val_loss: 0.0747 - val_accuracy: 0.9903\nEpoch 9/30\n1686/1688 [============================>.] - ETA: 0s - loss: 0.0774 - accuracy: 0.9898\nEpoch 00009: val_accuracy did not improve from 0.99383\n1688/1688 [==============================] - 52s 31ms/step - loss: 0.0774 - accuracy: 0.9899 - val_loss: 0.0745 - val_accuracy: 0.9912\nEpoch 10/30\n1687/1688 [============================>.] - ETA: 0s - loss: 0.0739 - accuracy: 0.9907\nEpoch 00010: val_accuracy did not improve from 0.99383\n1688/1688 [==============================] - 52s 31ms/step - loss: 0.0739 - accuracy: 0.9907 - val_loss: 0.0721 - val_accuracy: 0.9922\n"
],
[
"plot_acc(history_CNN)",
"_____no_output_____"
],
[
"plot_loss(history_CNN)",
"_____no_output_____"
],
[
"get_test_accuracy(model_CNN, test_images, test_labels)",
" test accuracy: 0.983 \n test loss: 0.097\n"
]
],
[
[
"## Model predictions",
"_____no_output_____"
]
],
[
[
"def get_model_best_epoch(model, checkpoint_path):\n '''\n get model saved best epoch\n '''\n model.load_weights(checkpoint_path)\n \n return model",
"_____no_output_____"
],
[
"# CNN model best epoch\nmodel_CNN = CNN_NN(input_shape= (32,32,1), dropout_rate = 0.3, reg_rate=1e-4)\nmodel_CNN = get_model_best_epoch(model_CNN, 'Trained models weights_Persian\\checkpoints_best_only_CNN\\checkpoint')",
"_____no_output_____"
],
[
"prediction_CNN = model_CNN.predict(test_images)\nprediction_CNN_final = np.argmax(prediction_CNN, axis=1) # finding the maximum category\nprediction_CNN_final = np.expand_dims(prediction_CNN_final, axis=1) # add the channel dimension",
"_____no_output_____"
],
[
"n = 5 # number of images to show\nshow_images(n,test_images,prediction_CNN_final, cmap='Greys')",
"_____no_output_____"
]
],
[
[
"## Comparison\nTo do a comparison between MLP and CNN model, the MLP model is created here and the trained wights are loaded",
"_____no_output_____"
]
],
[
[
"def MLP_NN(input_shape, reg_rate):\n '''\n Multilayer Perceptron (MLP) classification model\n '''\n model = Sequential([\n Flatten(input_shape=input_shape),\n Dense(256, activation='relu', kernel_initializer=\"he_uniform\", bias_initializer=\"ones\",\n kernel_regularizer=regularizers.l2(reg_rate), name='dense_1_relu'),\n Dense(256, activation='relu', kernel_regularizer=regularizers.l2(reg_rate), name='dense_2_relu'),\n Dense(128, activation='relu', kernel_regularizer=regularizers.l2(reg_rate), name='dense_3_relu'),\n Dense(128, activation='relu', kernel_regularizer=regularizers.l2(reg_rate), name='dense_4_relu'),\n Dense(10, activation='softmax', name='dense_5_softmax')\n ])\n return model\n\nmodel_MLP = MLP_NN(input_shape=(32,32,1), reg_rate=1e-4)\nmodel_MLP = get_model_best_epoch(model_MLP, 'Trained models weights_Persian\\checkpoints_best_only_MLP\\checkpoint')\nprediction_MLP = model_MLP.predict(test_images)\nprediction_MLP_final = np.argmax(prediction_MLP, axis=1) # finding the maximum category\nprediction_MLP_final = np.expand_dims(prediction_MLP_final, axis=1) # add the channel dimension",
"_____no_output_____"
],
[
"n = 5 # number of random images\nshow_images_predictions(n,test_images,prediction_MLP, prediction_CNN, cmap='Greys')",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
e7c1b37011a961fb50d935192fd029849fcc10ba | 146,639 | ipynb | Jupyter Notebook | notebook/bigsim/roc-separate-withscalpel.ipynb | johnsmith2077/kevlar | 3ed06dae62479e89ccd200391728c416d4df8052 | [
"MIT"
]
| 24 | 2016-12-07T07:59:09.000Z | 2019-03-11T02:05:36.000Z | notebook/bigsim/roc-separate-withscalpel.ipynb | johnsmith2077/kevlar | 3ed06dae62479e89ccd200391728c416d4df8052 | [
"MIT"
]
| 325 | 2016-12-07T07:37:17.000Z | 2019-03-12T19:01:40.000Z | notebook/bigsim/roc-separate-withscalpel.ipynb | johnsmith2077/kevlar | 3ed06dae62479e89ccd200391728c416d4df8052 | [
"MIT"
]
| 8 | 2017-08-17T01:37:39.000Z | 2019-03-01T16:17:44.000Z | 575.054902 | 136,076 | 0.933817 | [
[
[
"%matplotlib inline\nimport re\nimport sys\nimport math\nimport matplotlib\nimport seaborn\nimport numpy\nfrom matplotlib import pyplot as plt\nfrom collections import defaultdict\n\nfrom evalutils import IntervalForest, populate_index_from_bed, compact\nfrom evalutils import subset_variants_bed, load_kevlar_vcf, load_scalpel_vcf, load_gatk_mvf, load_triodenovo_vcf\nimport kevlar\n\nseaborn.set_context({'figure.figsize': (24, 12)})\nmatplotlib.rcParams['axes.labelsize'] = 16\nmatplotlib.rcParams['xtick.labelsize'] = 14\nmatplotlib.rcParams['ytick.labelsize'] = 14",
"_____no_output_____"
],
[
"def roc(calls, index, delta=10, fmt='vcf'):\n ncorrect = 0\n num_true_calls_per_false_call = list()\n for varcall in calls:\n if fmt == 'vcf':\n valid = index.query(varcall.seqid, varcall.position, delta=delta) != set()\n elif fmt == 'mvf':\n callindex, call = varcall\n valid = index.query(call['CHROM'], call['POS'], delta=delta) != set()\n else:\n raise ValueError('unknown format \"'+ fmt +'\"')\n if valid:\n ncorrect += 1\n continue\n num_true_calls_per_false_call.append(ncorrect)\n if len(num_true_calls_per_false_call) == 0 or ncorrect > num_true_calls_per_false_call[-1]:\n num_true_calls_per_false_call.append(ncorrect)\n return num_true_calls_per_false_call",
"_____no_output_____"
],
[
"def doplot(axis, data, color, label, linestyle, symbol, msize):\n if len(data) == 1:\n axis.plot(range(len(data)), data, symbol, markersize=12, color=color, label=label)\n else:\n axis.plot(range(len(data)), data, color=color, linestyle=linestyle)\n rate = 1\n if len(data) > 10:\n rate = 3\n if len(data) > 50:\n rate = 6\n if len(data) > 200:\n rate = 25\n axis.plot(range(len(data)), data, symbol, markersize=msize, color=color, markevery=rate, label=label)",
"_____no_output_____"
],
[
"delta = 10\nlinestyle = '-'\n#for cov in ('10', '20', '30', '50'):\nfor cov in (['30']):\n categories = [\n ('SNV', None, None, 'SNVs'),\n ('INDEL', 1, 10, 'INDELs 1-10bp'),\n ('INDEL', 11, 100, 'INDELs 11-100bp'),\n ('INDEL', 101, 200, 'INDELs 101-200bp'),\n ('INDEL', 201, 300, 'INDELs 201-300bp'),\n ('INDEL', 301, 400, 'INDELs 301-400bp'),\n ]\n fig, ((ax11, ax12, ax13), (ax21, ax22, ax23)) = plt.subplots(2, 3)\n axes = (ax11, ax12, ax13, ax21, ax22, ax23)\n seaborn.set_context({'figure.figsize': (24, 12)})\n \n for i, (category, axis) in enumerate(zip(categories, axes)):\n vartype, minlength, maxlength, label = category\n with kevlar.open('SimulatedVariants_chr17_hg38_markII.bed', 'r') as instream:\n variants = subset_variants_bed(instream, vartype, minlength, maxlength)\n index = populate_index_from_bed(variants)\n \n kevlar_truecalls = roc(\n load_kevlar_vcf(\n 'kevlar-calls-'+ cov +'x-nohomopoly.vcf.gz', index, delta=delta,\n vartype=vartype, minlength=minlength, maxlength=maxlength\n ),\n index, delta=delta, fmt='vcf'\n )\n scalpel_truecalls = roc(\n load_scalpel_vcf(\n 'scalpel.denovo.indel.vcf', cov=cov,\n vartype=vartype, minlength=minlength, maxlength=maxlength,\n ),\n index, delta=delta, fmt='vcf'\n )\n gatk_truecalls = roc(\n load_gatk_mvf(\n 'JointCall-'+ cov +'x-PBT.mvf',\n vartype=vartype, minlength=minlength, maxlength=maxlength\n ).iterrows(),\n index, delta=delta, fmt='mvf'\n )\n triodenovo_truecalls = roc(\n load_triodenovo_vcf(\n 'JointCall-'+ cov +'x-TDN.vcf', cov=cov,\n vartype=vartype, minlength=minlength, maxlength=maxlength,\n ),\n index, delta=delta, fmt='vcf'\n )\n doplot(axis, kevlar_truecalls, 'red', 'kevlar ({}x)'.format(cov), linestyle, 'o', 6)\n doplot(axis, scalpel_truecalls, 'purple', 'scalpel ({}x)'.format(cov), linestyle, '*', 10)\n doplot(axis, gatk_truecalls, 'blue', 'GATK PBT ({}x)'.format(cov), linestyle, '^', 8)\n doplot(axis, triodenovo_truecalls, 'green', 'triodenovo ({}x)'.format(cov), linestyle, 'D', 6)\n \n nvariants = len(index.trees['chr17'])\n ticknums = [0, math.ceil(nvariants * 0.25), int(nvariants * 0.5), math.ceil(nvariants * 0.75), nvariants]\n ticklabels = ['{:d}%\\n({:d})'.format(round(tn / nvariants * 100), tn) for tn in ticknums]\n \n _ = axis.set_xlabel('False calls', fontsize=16)\n xaxis_max = max([len(kevlar_truecalls), len(scalpel_truecalls), len(gatk_truecalls), len(triodenovo_truecalls)])\n if xaxis_max < 6:\n xticknums = list(range(xaxis_max))\n _ = axis.set_xticks(xticknums)\n _ = axis.set_yticks(ticknums)\n _ = axis.set_yticklabels(ticklabels)\n _ = axis.set_ylabel('True calls', fontsize=16)\n _ = axis.set_ylim((0, nvariants))\n _ = axis.set_title(label, fontsize=18)\n if i == 0:\n _ = axis.legend(fontsize=14)\n \n _ = plt.subplots_adjust(hspace=0.3)\n _ = plt.savefig('four-callers-'+ cov +'x-combined-sep.pdf', dpi=300)\n _ = plt.show()",
"_____no_output_____"
],
[
"with kevlar.open('SimulatedVariants_chr17_hg38_markII.bed', 'r') as instream:\n variants = subset_variants_bed(instream, 'SNV')\n index = populate_index_from_bed(variants)\n\ntriodenovo_truecalls = roc(\n load_triodenovo_vcf('JointCall-20x-TDN.vcf', cov='20', vartype='SNV'),\n index, delta=delta, fmt='vcf'\n)\nprint(triodenovo_truecalls)\nprint(len(triodenovo_truecalls))\nprint(triodenovo_truecalls[-1])\nprint(len(index.trees['chr17']))\nprint(triodenovo_truecalls[-1] / len(index.trees['chr17']))",
"[12, 23, 23, 23, 53, 54, 76, 78, 103, 106, 127, 127, 128, 146, 150, 150, 172, 175, 183, 190, 191, 198, 201, 208, 219, 221, 221, 225, 228, 229, 230, 232, 237, 241, 241, 241, 241, 241, 241, 242, 245, 245, 245, 245, 245, 245, 245, 247]\n48\n247\n263\n0.9391634980988594\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c1be2391057782f46908abba6492f87742c6b9 | 2,014 | ipynb | Jupyter Notebook | notebook/parser_debug.ipynb | xinranhe/mahjong | 8cfc6234f9c80fd11267adf06b420b63f4c8d87d | [
"MIT"
]
| null | null | null | notebook/parser_debug.ipynb | xinranhe/mahjong | 8cfc6234f9c80fd11267adf06b420b63f4c8d87d | [
"MIT"
]
| null | null | null | notebook/parser_debug.ipynb | xinranhe/mahjong | 8cfc6234f9c80fd11267adf06b420b63f4c8d87d | [
"MIT"
]
| null | null | null | 20.762887 | 165 | 0.554121 | [
[
[
"import sys\nsys.path.insert(0, \"/Users/xinran.he/GitProjects/mahjong\")",
"_____no_output_____"
],
[
"import requests\n\ntemp = requests.get('https://tenhou.net/3/mjlog2xml.cgi?2019031303gm-00e1-0000-6be36403', headers={'host': 'tenhou.net', \n 'referer': 'http://tenhou.net/3/?log=2019031303gm-00e1-0000-6be36403',\n 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Mobile Safari/537.36'})\nprint temp.text",
"_____no_output_____"
],
[
"from log_parser.discard_prediction_parser import parse_discard_prediction",
"_____no_output_____"
],
[
"games = parse_discard_prediction(temp.text)",
"_____no_output_____"
],
[
"print games[4].one_round[0]",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
e7c1c1a61c97b21bc18e6a43b2dc50c2a2704864 | 4,222 | ipynb | Jupyter Notebook | Group/Group_index.ipynb | askeyjw/2019-20_uProject_Magnetic_Nanowire_Modelling | 4eec034970fc437a5c11867499c2ca929d62e44b | [
"BSD-3-Clause"
]
| null | null | null | Group/Group_index.ipynb | askeyjw/2019-20_uProject_Magnetic_Nanowire_Modelling | 4eec034970fc437a5c11867499c2ca929d62e44b | [
"BSD-3-Clause"
]
| null | null | null | Group/Group_index.ipynb | askeyjw/2019-20_uProject_Magnetic_Nanowire_Modelling | 4eec034970fc437a5c11867499c2ca929d62e44b | [
"BSD-3-Clause"
]
| null | null | null | 47.438202 | 805 | 0.678825 | [
[
[
"\n### Session 1\n\nTest TEST TEEEEEEESSSSSSSST!!!! \n\n1. [Planar](Planar/planar_index.ipynb)\n2. [Square](Square/square_index.ipynb)\n3. [Cylindrical](Cylindrical/cylindrical_index.ipynb)\n\nWe believe we do not need much Python knowledge in order to run ubermag. However, more you feel confident writing Python, more benefits you can get from ubermag. There are many resources online you can choose from. We can recommend the online one by Hans Fangohr:\n\n- https://fangohr.github.io/teaching/python/book.html\n\n### Session 2\n\nIn the previous session, we introduced some very basic concepts of Ubermag simulations, had a look at some basic Python syntax, and familiarised ourselves with Jupyter environment. In session 2, we are going to have a look into more details of Ubermag simulations, so we can start simulating some real-world problems. In the first half of the session, we are going to analyse the skeleton of Ubermag simulation and quickly go through the three main concepts (magnetisation field, energy equation, and dynamics equation). In each tutorial, we introduce some data analysis and visualisation concepts, which are then going to be the main focus of session 3. After the break, we are going to simulate vortex dynamics, drive domain walls with a spin-polarised current, and have a look at the exercise.\n\n1. [Magnetisation field](magnetisation-field.ipynb)\n2. [Energy equation](energy-equation.ipynb)\n3. [Dynamics equation](dynamics-equation.ipynb)\n4. [Vortex dynamics](vortex-dynamics.ipynb)\n5. [Spatially varying parameters 1](spatially-varying-parameters1.ipynb)\n6. [Spatially varying parameters 2](spatially-varying-parameters2.ipynb)\n7. [Periodic boundary conditions](periodic-boundary-conditions.ipynb)\n8. [Current induced domain wall motion](driving-dw.ipynb)\n9. [Exercise](dw-pair-conversion.ipynb)\n\n### Session 3\n\nThis is the last session of our online workshop. The main topic of this session is going to be data analysis and visualisation. However, similar to the previous sessions, we are going to go through tutorials, which are going to introduce a mixture of simulation techniques and micromagnetic concepts as well.\n\n1. [Choosing runner](choosing-runner.ipynb)\n2. [Multiple energy terms of the same class](multiple-terms.ipynb)\n3. [RKKY energy term](rkky.ipynb)\n4. [Time-dependent field](time-dependent-field.ipynb)\n5. [Negative exchange energy constant](negative-A.ipynb)\n6. [Energy term computations](energy-term-computations.ipynb)\n7. [Field operations 1](field-operations1.ipynb)\n8. [Field operations 2](field-operations2.ipynb)\n9. [Field file formats](file-formats.ipynb)\n10. [Line basics and visualisation](line.ipynb)\n11. [Table basics](table-basics.ipynb)\n12. [Table visualisation](table-visualisation.ipynb)\n13. [Table interactive plots](table-interactive-plot.ipynb)\n14. [Region visualisation](region-visualisation.ipynb)\n15. [Mesh visualisation](mesh-visualisation.ipynb)\n16. [Field mpl visualisation](mpl-visualisation.ipynb)\n17. [Field k3d visualisation](k3d-visualisation.ipynb)\n18. [Interactive plotting](interactive-plotting.ipynb)\n19. [Various topics](various-topics.ipynb)",
"_____no_output_____"
]
]
]
| [
"markdown"
]
| [
[
"markdown"
]
]
|
e7c1c5b4c479242c020691e785441c01ab376920 | 11,111 | ipynb | Jupyter Notebook | notebooks/ml_intermediate/raw/ex1.ipynb | aurnik/learntools | 4d7ab1d2e2e40c60b9e277bafeaa041eacbae90b | [
"Apache-2.0"
]
| null | null | null | notebooks/ml_intermediate/raw/ex1.ipynb | aurnik/learntools | 4d7ab1d2e2e40c60b9e277bafeaa041eacbae90b | [
"Apache-2.0"
]
| null | null | null | notebooks/ml_intermediate/raw/ex1.ipynb | aurnik/learntools | 4d7ab1d2e2e40c60b9e277bafeaa041eacbae90b | [
"Apache-2.0"
]
| null | null | null | 34.940252 | 655 | 0.614706 | [
[
[
"As a warm-up, you'll review some machine learning fundamentals and submit your initial results to a Kaggle competition.\n\n# Setup\n\nThe questions below will give you feedback on your work. Run the following cell to set up the feedback system.",
"_____no_output_____"
]
],
[
[
"# Set up code checking\nimport os\nif not os.path.exists(\"../input/train.csv\"):\n os.symlink(\"../input/home-data-for-ml-course/train.csv\", \"../input/train.csv\") \n os.symlink(\"../input/home-data-for-ml-course/test.csv\", \"../input/test.csv\") \nfrom learntools.core import binder\nbinder.bind(globals())\nfrom learntools.ml_intermediate.ex1 import *\nprint(\"Setup Complete\")",
"_____no_output_____"
]
],
[
[
"You will work with data from the [Housing Prices Competition for Kaggle Learn Users](https://www.kaggle.com/c/home-data-for-ml-course) to predict home prices in Iowa using 79 explanatory variables describing (almost) every aspect of the homes. \n\n\n\nRun the next code cell without changes to load the training and validation features in `X_train` and `X_valid`, along with the prediction targets in `y_train` and `y_valid`. The test features are loaded in `X_test`. (_If you need to review **features** and **prediction targets**, please check out [this short tutorial](https://www.kaggle.com/dansbecker/your-first-machine-learning-model). To read about model **validation**, look [here](https://www.kaggle.com/dansbecker/model-validation). Alternatively, if you'd prefer to look through a full course to review all of these topics, start [here](https://www.kaggle.com/learn/machine-learning).)_",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfrom sklearn.model_selection import train_test_split\n\n# Read the data\nX_full = pd.read_csv('../input/train.csv', index_col='Id')\nX_test_full = pd.read_csv('../input/test.csv', index_col='Id')\n\n# Obtain target and predictors\ny = X_full.SalePrice\nfeatures = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']\nX = X_full[features].copy()\nX_test = X_test_full[features].copy()\n\n# Break off validation set from training data\nX_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,\n random_state=0)",
"_____no_output_____"
]
],
[
[
"Use the next cell to print the first several rows of the data. It's a nice way to get an overview of the data you will use in your price prediction model.",
"_____no_output_____"
]
],
[
[
"X_train.head()",
"_____no_output_____"
]
],
[
[
"# Step 1: Evaluate several models\n\nThe next code cell defines five different random forest models. Run this code cell without changes. (_To review **random forests**, look [here](https://www.kaggle.com/dansbecker/random-forests)._)",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import RandomForestRegressor\n\n# Define the models\nmodel_1 = RandomForestRegressor(n_estimators=50, random_state=0)\nmodel_2 = RandomForestRegressor(n_estimators=100, random_state=0)\nmodel_3 = RandomForestRegressor(n_estimators=100, criterion='mae', random_state=0)\nmodel_4 = RandomForestRegressor(n_estimators=200, min_samples_split=20, random_state=0)\nmodel_5 = RandomForestRegressor(n_estimators=100, max_depth=7, random_state=0)\n\nmodels = [model_1, model_2, model_3, model_4, model_5]",
"_____no_output_____"
]
],
[
[
"To select the best model out of the five, we define a function `score_model()` below. This function returns the mean absolute error (MAE) from the validation set. Recall that the best model will obtain the lowest MAE. (_To review **mean absolute error**, look [here](https://www.kaggle.com/dansbecker/model-validation).)_\n\nRun the code cell without changes.",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import mean_absolute_error\n\n# Function for comparing different models\ndef score_model(model, X_t=X_train, X_v=X_valid, y_t=y_train, y_v=y_valid):\n model.fit(X_t, y_t)\n preds = model.predict(X_v)\n return mean_absolute_error(y_v, preds)\n\nfor i in range(0, len(models)):\n mae = score_model(models[i])\n print(\"Model %d MAE: %d\" % (i+1, mae))",
"_____no_output_____"
]
],
[
[
"Use the above results to fill in the line below. Which model is the best model? Your answer should be one of `model_1`, `model_2`, `model_3`, `model_4`, or `model_5`.",
"_____no_output_____"
]
],
[
[
"# Fill in the best model\nbest_model = ____\n\n# Check your answer\nstep_1.check()",
"_____no_output_____"
],
[
"#%%RM_IF(PROD)%%\nbest_model = model_3\nstep_1.assert_check_passed()",
"_____no_output_____"
],
[
"# Lines below will give you a hint or solution code\n#_COMMENT_IF(PROD)_\nstep_1.hint()\n#_COMMENT_IF(PROD)_\nstep_1.solution()",
"_____no_output_____"
]
],
[
[
"# Step 2: Generate test predictions\n\nGreat. You know how to evaluate what makes an accurate model. Now it's time to go through the modeling process and make predictions. In the line below, create a Random Forest model with the variable name `my_model`.",
"_____no_output_____"
]
],
[
[
"# Define a model\nmy_model = ____ # Your code here\n\n# Check your answer\nstep_2.check()",
"_____no_output_____"
],
[
"#%%RM_IF(PROD)%%\nmy_model = 3\nstep_2.assert_check_failed()",
"_____no_output_____"
],
[
"#%%RM_IF(PROD)%%\nmy_model = best_model\nstep_2.assert_check_passed()",
"_____no_output_____"
],
[
"# Lines below will give you a hint or solution code\n#_COMMENT_IF(PROD)_\nstep_2.hint()\n#_COMMENT_IF(PROD)_\nstep_2.solution()",
"_____no_output_____"
]
],
[
[
"Run the next code cell without changes. The code fits the model to the training and validation data, and then generates test predictions that are saved to a CSV file. These test predictions can be submitted directly to the competition!",
"_____no_output_____"
]
],
[
[
"# Fit the model to the training data\nmy_model.fit(X, y)\n\n# Generate test predictions\npreds_test = my_model.predict(X_test)\n\n# Save predictions in format used for competition scoring\noutput = pd.DataFrame({'Id': X_test.index,\n 'SalePrice': preds_test})\noutput.to_csv('submission.csv', index=False)",
"_____no_output_____"
]
],
[
[
"# Step 3: Submit your results\n\nOnce you have successfully completed Step 2, you're ready to submit your results to the leaderboard! First, you'll need to join the competition if you haven't already. So open a new window by clicking on [this link](https://www.kaggle.com/c/home-data-for-ml-course). Then click on the **Join Competition** button.\n\n\n\nNext, follow the instructions below:\n1. Begin by clicking on the blue **Save Version** button in the top right corner of this window. This will generate a pop-up window. \n2. Ensure that the **Save and Run All** option is selected, and then click on the blue **Save** button.\n3. This generates a window in the bottom left corner of the notebook. After it has finished running, click on the number to the right of the **Save Version** button. This pulls up a list of versions on the right of the screen. Click on the ellipsis **(...)** to the right of the most recent version, and select **Open in Viewer**. This brings you into view mode of the same page. You will need to scroll down to get back to these instructions.\n4. Click on the **Output** tab on the right of the screen. Then, click on the **Submit to Competition** button to submit your results to the leaderboard.\n\nYou have now successfully submitted to the competition!\n\n5. If you want to keep working to improve your performance, select the blue **Edit** button in the top right of the screen. Then you can change your model and repeat the process. There's a lot of room to improve your model, and you will climb up the leaderboard as you work.",
"_____no_output_____"
],
[
"# Keep going\n\nYou've made your first model. But how can you quickly make it better?\n\nLearn how to improve your competition results by incorporating columns with **[missing values](#$NEXT_NOTEBOOK_URL$)**.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
]
|
e7c1c9c7226b10d115a99bcfdf4d8006777e8883 | 73,694 | ipynb | Jupyter Notebook | .ipynb_checkpoints/1.6 时间转换及处理-checkpoint.ipynb | Yanie1asdfg/Quant-Lectures | 4e4b84cf2aff290b715a7924277335a23f5e8168 | [
"MIT"
]
| 6 | 2020-12-29T07:53:46.000Z | 2022-01-17T07:07:54.000Z | .ipynb_checkpoints/1.6 时间转换及处理-checkpoint.ipynb | Yanie1asdfg/Quant-Lectures | 4e4b84cf2aff290b715a7924277335a23f5e8168 | [
"MIT"
]
| null | null | null | .ipynb_checkpoints/1.6 时间转换及处理-checkpoint.ipynb | Yanie1asdfg/Quant-Lectures | 4e4b84cf2aff290b715a7924277335a23f5e8168 | [
"MIT"
]
| 4 | 2020-12-28T03:11:26.000Z | 2021-02-09T06:12:51.000Z | 66.631103 | 27,260 | 0.816539 | [
[
[
"# 时间转换及处理",
"_____no_output_____"
],
[
"str类型的时间转换为datetime类型的时间",
"_____no_output_____"
]
],
[
[
"from datetime import datetime\ntime = '2010-05-01 00:00:00'\ntime = datetime.strptime(time, \"%Y-%m-%d %H:%M:%S\")\ntype(time),time",
"_____no_output_____"
]
],
[
[
"datetime类型的时间转换为str类型的时间",
"_____no_output_____"
]
],
[
[
"from datetime import datetime\ntime = datetime(2010, 5, 1, 0, 0)\ntime = datetime.strftime(time, \"%Y-%m-%d %H:%M:%S\")\ntype(time),time",
"_____no_output_____"
],
[
"import tushare as ts\ndf = ts.get_k_data('600519','2020-08-01','2020-08-05')\ndf",
"_____no_output_____"
],
[
"type(df.date[140]),df.date[140]",
"_____no_output_____"
],
[
"import pandas as pd\n#dateframe 日期数据,字符型转换成datetime日期格式\ndf.date = pd.to_datetime(df.date,format='%Y/%m/%d %H:%M:%S')\ntype(df.date[140]),df.date[140]",
"_____no_output_____"
]
],
[
[
"#获取 日期数据 的年、月、日、时、分",
"_____no_output_____"
]
],
[
[
"df.date.dt.time",
"_____no_output_____"
],
[
"df.date.dt.date",
"_____no_output_____"
],
[
"from IPython.core.interactiveshell import InteractiveShell\nInteractiveShell.ast_node_interactivity = \"all\"\n\ndf.date.dt.year\ndf.date.dt.month\ndf.date.dt.day\ndf.date.dt.hour\ndf.date.dt.minute\ndf.date.dt.second",
"_____no_output_____"
]
],
[
[
"### 时间加减",
"_____no_output_____"
]
],
[
[
"from datetime import datetime,timedelta\nstart = '2010-05-01 00:00:00'\nstart = datetime.strptime(start, \"%Y-%m-%d %H:%M:%S\")\ntime = start+timedelta(days=60)\ntime = datetime.strftime(time, \"%Y-%m-%d %H:%M:%S\")\ntime",
"_____no_output_____"
],
[
"from datetime import datetime,timedelta\nstart = '2010-05-01 00:00:00'\nstart = datetime.strptime(start, \"%Y-%m-%d %H:%M:%S\")\ntime = start+timedelta(seconds=1)\ntime = datetime.strftime(time, \"%Y-%m-%d %H:%M:%S\")\ntime",
"_____no_output_____"
],
[
"from datetime import datetime,timedelta\nstart = '2010-05-01 00:00:00'\nstart = datetime.strptime(start, \"%Y-%m-%d %H:%M:%S\")\ntime = start+timedelta(minutes=1)\ntime = datetime.strftime(time, \"%Y-%m-%d %H:%M:%S\")\ntime",
"_____no_output_____"
],
[
"from datetime import datetime,timedelta\nstart = '2010-05-01 00:00:00'\nstart = datetime.strptime(start, \"%Y-%m-%d %H:%M:%S\")\ntime = start+timedelta(hours=1)\ntime = datetime.strftime(time, \"%Y-%m-%d %H:%M:%S\")\ntime",
"_____no_output_____"
],
[
"from IPython.core.interactiveshell import InteractiveShell\nInteractiveShell.ast_node_interactivity = \"all\"\n\nstart = '2010-05-01 00:00:00'\nend = '2010-05-01 05:00:00'\nstart = datetime.strptime(start, \"%Y-%m-%d %H:%M:%S\")\nend = datetime.strptime(end, \"%Y-%m-%d %H:%M:%S\")\n(end-start).seconds\n(end-start).total_seconds()",
"_____no_output_____"
]
],
[
[
"# dateime模块",
"_____no_output_____"
],
[
"### datetime模块中包含如下类:",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"### date类",
"_____no_output_____"
],
[
"today(...):返回当前日期",
"_____no_output_____"
]
],
[
[
"import datetime\ndatetime.date.today()",
"_____no_output_____"
]
],
[
[
"#### date对象由year年份、month月份及day日期三部分构成:",
"_____no_output_____"
]
],
[
[
"import datetime\na = datetime.date.today()\na",
"_____no_output_____"
],
[
"a.year,a.month,a.day",
"_____no_output_____"
]
],
[
[
"#### 用于日期比较大小的方法",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"a=datetime.date(2020,3,1)\nb=datetime.date(2020,9,4)",
"_____no_output_____"
],
[
"a.__eq__(b)",
"_____no_output_____"
],
[
"a.__ge__(b)",
"_____no_output_____"
],
[
"a.__le__(b)",
"_____no_output_____"
]
],
[
[
"#### 获得二个日期相差多少天",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"a=datetime.date(2020,3,1)\nb=datetime.date(2020,9,4)",
"_____no_output_____"
],
[
"a.__sub__(b).days",
"_____no_output_____"
],
[
"a.__rsub__(b).days",
"_____no_output_____"
]
],
[
[
"#### 日期的字符串输出",
"_____no_output_____"
]
],
[
[
"import datetime\na = datetime.date.today()\na.__format__('%Y-%m-%d')",
"_____no_output_____"
],
[
"import datetime\na = datetime.date.today()\na.__format__('%Y/%m/%d')",
"_____no_output_____"
],
[
"import datetime\na = datetime.date.today()\na.__str__()",
"_____no_output_____"
]
],
[
[
"### time类",
"_____no_output_____"
],
[
"time类由hour小时、minute分钟、second秒、microsecond毫秒和tzinfo五部分组成",
"_____no_output_____"
]
],
[
[
"import datetime\na = datetime.time(12,20,59,899)\na.__str__()",
"_____no_output_____"
],
[
"a.__format__('%H:%M:%S')",
"_____no_output_____"
]
],
[
[
"### datetime类",
"_____no_output_____"
],
[
"datetime类其实是可以看做是date类和time类的合体,其大部分的方法和属性都继承于这二个类",
"_____no_output_____"
],
[
"#### 返回现在的时间",
"_____no_output_____"
]
],
[
[
"import datetime\na = datetime.datetime.now()\na",
"_____no_output_____"
],
[
"a.date(),a.time()",
"_____no_output_____"
]
],
[
[
"#### combine(…):将一个date对象和一个time对象合并生成一个datetime对象",
"_____no_output_____"
]
],
[
[
"datetime.datetime.combine(a.date(),a.time())",
"_____no_output_____"
]
],
[
[
"#### strptime(…):根据string, format 2个参数,返回一个对应的datetime对象:",
"_____no_output_____"
]
],
[
[
"datetime.datetime.strptime('2017-3-22 15:25','%Y-%m-%d %H:%M')",
"_____no_output_____"
]
],
[
[
"#### strftime(…):根据datetime, format 的参数,返回一个对应的str:",
"_____no_output_____"
]
],
[
[
"a = datetime.datetime.now()\ndatetime.datetime.strftime(a,'%Y-%m-%d %H:%M:%S')",
"_____no_output_____"
]
],
[
[
"### timedelta类",
"_____no_output_____"
],
[
"timedelta类是用来计算datetime对象的差值的。",
"_____no_output_____"
],
[
"#### 此类中包含如下属性:",
"_____no_output_____"
],
[
"1、days:天数\n\n2、microseconds:微秒数(>=0 并且 <1秒)\n\n3、seconds:秒数(>=0 并且 <1天)",
"_____no_output_____"
],
[
"参考:https://m.jb51.net/article/147429.htm",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
e7c1e4e10a2c925b76c31989f41117d8ef29c8fb | 7,048 | ipynb | Jupyter Notebook | Torrent_To_Google_Drive_Downloader.ipynb | l-i-e-d-j-i-6-7-8-w-d/Torrent-To-Google-Drive-Downloader | f7af902103df6a49aa0e87b3e24b45717aa7a496 | [
"MIT"
]
| null | null | null | Torrent_To_Google_Drive_Downloader.ipynb | l-i-e-d-j-i-6-7-8-w-d/Torrent-To-Google-Drive-Downloader | f7af902103df6a49aa0e87b3e24b45717aa7a496 | [
"MIT"
]
| null | null | null | Torrent_To_Google_Drive_Downloader.ipynb | l-i-e-d-j-i-6-7-8-w-d/Torrent-To-Google-Drive-Downloader | f7af902103df6a49aa0e87b3e24b45717aa7a496 | [
"MIT"
]
| null | null | null | 29.004115 | 272 | 0.456442 | [
[
[
"<a href=\"https://colab.research.google.com/github/FKLC/Torrent-To-Google-Drive-Downloader/blob/master/Torrent_To_Google_Drive_Downloader.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Torrent To Google Drive Downloader ",
"_____no_output_____"
],
[
"**Important Note:** To get more disk space:\n> Go to Runtime -> Change Runtime and give GPU as the Hardware Accelerator. You will get around 384GB to download any torrent you want.",
"_____no_output_____"
],
[
"### Install libtorrent and Initialize Session",
"_____no_output_____"
]
],
[
[
"!python -m pip install --upgrade pip setuptools wheel\n!python -m pip install lbry-libtorrent\n!apt install python3-libtorrent\n\nimport libtorrent as lt\n\nses = lt.session()\nses.listen_on(6881, 6891)\ndownloads = []",
"_____no_output_____"
]
],
[
[
"### Mount Google Drive\nTo stream files we need to mount Google Drive.",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\n\ndrive.mount(\"/content/drive\")",
"_____no_output_____"
]
],
[
[
"### Add From Torrent File\nYou can run this cell to add more files as many times as you want",
"_____no_output_____"
]
],
[
[
"from google.colab import files\n\nsource = files.upload()\nparams = {\n \"save_path\": \"/content/drive/My Drive/Torrent\",\n \"ti\": lt.torrent_info(list(source.keys())[0]),\n}\ndownloads.append(ses.add_torrent(params))",
"_____no_output_____"
]
],
[
[
"### Add From Magnet Link\nYou can run this cell to add more files as many times as you want",
"_____no_output_____"
]
],
[
[
"params = {\"save_path\": \"/content/drive/My Drive/Torrent\"}\n\nwhile True:\n magnet_link = input(\"Enter Magnet Link Or Type Exit: \")\n if magnet_link.lower() == \"exit\":\n break\n downloads.append(\n lt.add_magnet_uri(ses, magnet_link, params)\n )\n",
"_____no_output_____"
]
],
[
[
"### Start Download\nSource: https://stackoverflow.com/a/5494823/7957705 and [#3 issue](https://github.com/FKLC/Torrent-To-Google-Drive-Downloader/issues/3) which refers to this [stackoverflow question](https://stackoverflow.com/a/6053350/7957705)",
"_____no_output_____"
]
],
[
[
"import time\nfrom IPython.display import display\nimport ipywidgets as widgets\n\nstate_str = [\n \"queued\",\n \"checking\",\n \"downloading metadata\",\n \"downloading\",\n \"finished\",\n \"seeding\",\n \"allocating\",\n \"checking fastresume\",\n]\n\nlayout = widgets.Layout(width=\"auto\")\nstyle = {\"description_width\": \"initial\"}\ndownload_bars = [\n widgets.FloatSlider(\n step=0.01, disabled=True, layout=layout, style=style\n )\n for _ in downloads\n]\ndisplay(*download_bars)\n\nwhile downloads:\n next_shift = 0\n for index, download in enumerate(downloads[:]):\n bar = download_bars[index + next_shift]\n if not download.is_seed():\n s = download.status()\n\n bar.description = \" \".join(\n [\n download.name(),\n str(s.download_rate / 1000),\n \"kB/s\",\n state_str[s.state],\n ]\n )\n bar.value = s.progress * 100\n else:\n next_shift -= 1\n ses.remove_torrent(download)\n downloads.remove(download)\n bar.close() # Seems to be not working in Colab (see https://github.com/googlecolab/colabtools/issues/726#issue-486731758)\n download_bars.remove(bar)\n print(download.name(), \"complete\")\n time.sleep(1)\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
e7c1ee93a0a667b04261b64306dff7f0137b4b18 | 583,357 | ipynb | Jupyter Notebook | 2-Valued-Based Methods/monte-carlo/Monte_Carlo.ipynb | zhaolongkzz/DRL-of-Udacity | 331aeb5d61c769f94c6847a902f6a781af690bc2 | [
"MIT"
]
| null | null | null | 2-Valued-Based Methods/monte-carlo/Monte_Carlo.ipynb | zhaolongkzz/DRL-of-Udacity | 331aeb5d61c769f94c6847a902f6a781af690bc2 | [
"MIT"
]
| null | null | null | 2-Valued-Based Methods/monte-carlo/Monte_Carlo.ipynb | zhaolongkzz/DRL-of-Udacity | 331aeb5d61c769f94c6847a902f6a781af690bc2 | [
"MIT"
]
| null | null | null | 1,054.895118 | 281,544 | 0.953169 | [
[
[
"# Monte Carlo Methods\n\nIn this notebook, you will write your own implementations of many Monte Carlo (MC) algorithms. \n\nWhile we have provided some starter code, you are welcome to erase these hints and write your code from scratch.\n\n### Part 0: Explore BlackjackEnv\n\nWe begin by importing the necessary packages.",
"_____no_output_____"
]
],
[
[
"import sys\nimport gym\nimport numpy as np\nfrom collections import defaultdict\n\nfrom plot_utils import plot_blackjack_values, plot_policy",
"_____no_output_____"
]
],
[
[
"Use the code cell below to create an instance of the [Blackjack](https://github.com/openai/gym/blob/master/gym/envs/toy_text/blackjack.py) environment.",
"_____no_output_____"
]
],
[
[
"env = gym.make('Blackjack-v0')",
"_____no_output_____"
]
],
[
[
"Each state is a 3-tuple of:\n- the player's current sum $\\in \\{0, 1, \\ldots, 31\\}$,\n- the dealer's face up card $\\in \\{1, \\ldots, 10\\}$, and\n- whether or not the player has a usable ace (`no` $=0$, `yes` $=1$).\n\nThe agent has two potential actions:\n\n```\n STICK = 0\n HIT = 1\n```\nVerify this by running the code cell below.",
"_____no_output_____"
]
],
[
[
"print(env.observation_space)\nprint(env.action_space)",
"Tuple(Discrete(32), Discrete(11), Discrete(2))\nDiscrete(2)\n"
]
],
[
[
"Execute the code cell below to play Blackjack with a random policy. \n\n(_The code currently plays Blackjack three times - feel free to change this number, or to run the cell multiple times. The cell is designed for you to get some experience with the output that is returned as the agent interacts with the environment._)",
"_____no_output_____"
]
],
[
[
"for i_episode in range(3):\n state = env.reset()\n while True:\n print(state)\n action = env.action_space.sample()\n state, reward, done, info = env.step(action)\n if done:\n print('End game! Reward: ', reward)\n print('You won :)\\n') if reward > 0 else print('You lost :(\\n')\n break",
"(12, 10, False)\nEnd game! Reward: -1.0\nYou lost :(\n\n(19, 10, False)\nEnd game! Reward: -1\nYou lost :(\n\n(18, 2, False)\nEnd game! Reward: -1\nYou lost :(\n\n"
]
],
[
[
"### Part 1: MC Prediction\n\nIn this section, you will write your own implementation of MC prediction (for estimating the action-value function). \n\nWe will begin by investigating a policy where the player _almost_ always sticks if the sum of her cards exceeds 18. In particular, she selects action `STICK` with 80% probability if the sum is greater than 18; and, if the sum is 18 or below, she selects action `HIT` with 80% probability. The function `generate_episode_from_limit_stochastic` samples an episode using this policy.\n\nexceeding 18 will be `probs = [.8, .2] if state[0] > 18 else [.2, .8]`, and `np.random.choice(action, probs)` choose the action from probilities.\n\nThe function accepts as **input**:\n- `bj_env`: This is an instance of OpenAI Gym's Blackjack environment.\n\nIt returns as **output**:\n- `episode`: This is a list of (state, action, reward) tuples (of tuples) and corresponds to $(S_0, A_0, R_1, \\ldots, S_{T-1}, A_{T-1}, R_{T})$, where $T$ is the final time step. In particular, `episode[i]` returns $(S_i, A_i, R_{i+1})$, and `episode[i][0]`, `episode[i][1]`, and `episode[i][2]` return $S_i$, $A_i$, and $R_{i+1}$, respectively.",
"_____no_output_____"
]
],
[
[
"def generate_episode_from_limit_stochastic(bj_env):\n episode = []\n state = bj_env.reset()\n while True:\n probs = [0.8, 0.2] if state[0] > 18 else [0.2, 0.8]\n action = np.random.choice(np.arange(2), p=probs)\n next_state, reward, done, info = bj_env.step(action)\n episode.append((state, action, reward))\n state = next_state\n if done:\n break\n return episode",
"_____no_output_____"
]
],
[
[
"Execute the code cell below to play Blackjack with the policy. \n\n(*The code currently plays Blackjack three times - feel free to change this number, or to run the cell multiple times. The cell is designed for you to gain some familiarity with the output of the `generate_episode_from_limit_stochastic` function.*)",
"_____no_output_____"
]
],
[
[
"for i in range(3):\n print(generate_episode_from_limit_stochastic(env))",
"[((17, 9, False), 1, -1)]\n[((16, 6, False), 1, -1)]\n[((18, 8, False), 1, -1)]\n"
]
],
[
[
"Now, you are ready to write your own implementation of MC prediction. Feel free to implement either first-visit or every-visit MC prediction; in the case of the Blackjack environment, the techniques are equivalent.\n\nYour algorithm has three arguments:\n- `env`: This is an instance of an OpenAI Gym environment.\n- `num_episodes`: This is the number of episodes that are generated through agent-environment interaction.\n- `generate_episode`: This is a function that returns an episode of interaction.\n- `gamma`: This is the discount rate. It must be a value between 0 and 1, inclusive (default value: `1`).\n\nThe algorithm returns as output:\n- `Q`: This is a dictionary (of one-dimensional arrays) where `Q[s][a]` is the estimated action value corresponding to state `s` and action `a`.",
"_____no_output_____"
]
],
[
[
"def mc_prediction_q(env, num_episodes, generate_episode, gamma=1.0):\n # initialize empty dictionaries of arrays\n returns_sum = defaultdict(lambda: np.zeros(env.action_space.n))\n N = defaultdict(lambda: np.zeros(env.action_space.n))\n Q = defaultdict(lambda: np.zeros(env.action_space.n))\n # loop over episodes\n for i_episode in range(1, num_episodes+1):\n # monitor progress\n if i_episode % 1000 == 0:\n print(\"\\rEpisode {}/{}.\".format(i_episode, num_episodes), end=\"\")\n sys.stdout.flush()\n \n ## TODO: complete the function\n episode = generate_episode(env)\n # as above episode has states, actions, rewards, need extract\n states, actions, rewards = zip(*episode) # return list\n # define a list of discounts to adapt S, A, R \n discounts = np.array([gamma ** i for i in range(len(rewards) + 1)])\n \n for i, state in enumerate(states):\n N[state][actions[i]] += 1.0\n # [:-1] denote from 0 to the last, [:-2] is to the second to last \n G_t = sum(rewards[i:] * discounts[: -(1+i)])\n returns_sum[state][actions[i]] += G_t\n Q[state][actions[i]] = returns_sum[state][actions[i]] / N[state][actions[i]]\n \n return Q",
"_____no_output_____"
],
[
"episode = generate_episode_from_limit_stochastic(env)\nprint(episode)\nstates, actions, rewards = zip(*episode)\nprint('\\nstates:', states)\nprint('\\nactions:', actions)\nprint('\\nrewards:', rewards)",
"[((19, 10, False), 0, 1.0)]\n\nstates: ((19, 10, False),)\n\nactions: (0,)\n\nrewards: (1.0,)\n"
]
],
[
[
"Use the cell below to obtain the action-value function estimate $Q$. We have also plotted the corresponding state-value function.\n\nTo check the accuracy of your implementation, compare the plot below to the corresponding plot in the solutions notebook **Monte_Carlo_Solution.ipynb**.",
"_____no_output_____"
]
],
[
[
"# obtain the action-value function\nQ = mc_prediction_q(env, 500000, generate_episode_from_limit_stochastic)\n\n# obtain the corresponding state-value function\nV_to_plot = dict((k,(k[0]>18)*(np.dot([0.8, 0.2],v)) + (k[0]<=18)*(np.dot([0.2, 0.8],v))) \\\n for k, v in Q.items())\n\n# plot the state-value function\nplot_blackjack_values(V_to_plot)",
"Episode 500000/500000."
]
],
[
[
"### Part 2: MC Control\n\nIn this section, you will write your own implementation of constant-$\\alpha$ MC control. \n\nYour algorithm has four arguments:\n- `env`: This is an instance of an OpenAI Gym environment.\n- `num_episodes`: This is the number of episodes that are generated through agent-environment interaction.\n- `alpha`: This is the step-size parameter for the update step.\n- `gamma`: This is the discount rate. It must be a value between 0 and 1, inclusive (default value: `1`).\n\nThe algorithm returns as output:\n- `Q`: This is a dictionary (of one-dimensional arrays) where `Q[s][a]` is the estimated action value corresponding to state `s` and action `a`.\n- `policy`: This is a dictionary where `policy[s]` returns the action that the agent chooses after observing state `s`.\n\n(_Feel free to define additional functions to help you to organize your code._)",
"_____no_output_____"
]
],
[
[
"import random\ndef generate_episode_from_q(env, Q, nA, epsilon):\n epsidoe = []\n state = env.reset()\n while True:\n # from the reset state, we can make choice or sample randamly\n action = np.random.choice(np.arange(nA), p=get_probs(Q, nA, epsilon)) if state in Q else env.action_space.sample()\n next_state, reward, done, info = env.step(action)\n epsidoe.append((state, action, reward))\n state = next_state\n if done:\n break\n return epsidoe\n\ndef generate_episode_from_q_epsilon(env, Q, nA, epsilon):\n epsidoe = []\n state = env.reset()\n while True:\n # from the reset state, we can make choice or sample randamly\n action = epsilon_greedy(Q, nA, state, epsilon)\n next_state, reward, done, info = env.step(action)\n epsidoe.append((state, action, reward))\n state = next_state\n if done:\n break\n return epsidoe\n\ndef get_probs(Q_s, nA, epsilon):\n # build a list [nA] for policy\n policy_s = np.ones(nA) * epsilon / nA\n best_a = np.argmax(Q_s)\n policy_s[best_a] = 1 - epsilon + (epsilon / nA)\n return policy_s\n\n# we can also use epsilon-greedy, but need to return policy\ndef epsilon_greedy(Q, nA, state, epsilon):\n '''explore and explicit by epsilon-greedy, return action'''\n if random.random() > epsilon:\n return np.argmax(Q[state])\n else:\n return random.choice(np.arange(nA))",
"_____no_output_____"
],
[
"def mc_control(env, num_episodes, alpha, gamma=1.0, epsilon = 1.0, eps_decay=.99999, eps_min=.05):\n # initialize empty dictionary of arrays\n nA = env.action_space.n\n Q = defaultdict(lambda: np.zeros(nA))\n # loop over episodes\n for i_episode in range(1, num_episodes+1):\n # monitor progress\n if i_episode % 1000 == 0:\n print(\"\\rEpisode {}/{}.\".format(i_episode, num_episodes), end=\"\")\n sys.stdout.flush()\n \n ## TODO: complete the function\n # epsilon = max(epsilon*eps_decay, eps_min) # set a fixed epsilon\n # or we can generate epsiode by changing epsilon\n epsilon = 1.0 / i_episode\n \n # episode = generate_episode_from_q(env, Q, nA, epsilon)\n # or\n episode = generate_episode_from_q_epsilon(env, Q, nA, epsilon)\n \n # as above episode has states, actions, rewards, need extract\n states, actions, rewards = zip(*episode) # return list\n # define a list of discounts to adapt S, A, R \n discounts = np.array([gamma**i for i in range(len(rewards)+1)])\n \n for i, state in enumerate(states):\n G_t = sum( rewards[i:] * discounts[: -(1+i)] )\n old_Q = Q[state][actions[i]]\n Q[state][actions[i]] = old_Q + alpha * (G_t - old_Q)\n # pack state and action into dictionary for optional policy\n policy = dict((k, np.argmax(v)) for k, v in Q.items())\n return policy, Q",
"_____no_output_____"
]
],
[
[
"Use the cell below to obtain the estimated optimal policy and action-value function. Note that you should fill in your own values for the `num_episodes` and `alpha` parameters.",
"_____no_output_____"
]
],
[
[
"# obtain the estimated optimal policy and action-value function\npolicy, Q = mc_control(env, 500000, 0.02)",
"Episode 500000/500000."
]
],
[
[
"Next, we plot the corresponding state-value function.",
"_____no_output_____"
]
],
[
[
"# obtain the corresponding state-value function\nV = dict((k,np.max(v)) for k, v in Q.items())\n\n# plot the state-value function\nplot_blackjack_values(V)",
"_____no_output_____"
]
],
[
[
"Finally, we visualize the policy that is estimated to be optimal.",
"_____no_output_____"
]
],
[
[
"# plot the policy\nplot_policy(policy)",
"_____no_output_____"
]
],
[
[
"The **true** optimal policy $\\pi_*$ can be found in Figure 5.2 of the [textbook](http://go.udacity.com/rl-textbook) (and appears below). Compare your final estimate to the optimal policy - how close are you able to get? If you are not happy with the performance of your algorithm, take the time to tweak the decay rate of $\\epsilon$, change the value of $\\alpha$, and/or run the algorithm for more episodes to attain better results.\n\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.