
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
d0604a8ef3c4efaa3345b4e152ffb03ab00a4160 | 62,735 | ipynb | Jupyter Notebook | scratch/working/2.2.NoVPC-EFS-Train-Model.ipynb | gonsoomoon-ml/SageMaker-With-Secure-VPC | b3ccdede952e8a32a256cb1aab53d196e519f401 | [
"MIT"
]
| 2 | 2021-02-01T00:48:25.000Z | 2021-08-02T09:43:27.000Z | scratch/working/2.2.NoVPC-EFS-Train-Model.ipynb | gonsoomoon-ml/SageMaker-With-Secure-VPC | b3ccdede952e8a32a256cb1aab53d196e519f401 | [
"MIT"
]
| 1 | 2021-02-08T06:18:25.000Z | 2021-02-08T06:18:25.000Z | scratch/working/2.2.NoVPC-EFS-Train-Model.ipynb | gonsoomoon-ml/SageMaker-With-Secure-VPC | b3ccdede952e8a32a256cb1aab53d196e519f401 | [
"MIT"
]
| 2 | 2021-02-04T08:23:14.000Z | 2021-02-25T07:13:11.000Z | 116.175926 | 19,813 | 0.635259 | [
[
[
"# [모듈 2.1] SageMaker 클러스터에서 훈련 (No VPC에서 실행)\n\n이 노트북은 아래의 작업을 실행 합니다.\n- SageMaker Hosting Cluster 에서 훈련을 실행\n- 훈련한 Job 이름을 저장 \n - 다음 노트북에서 모델 배포 및 추론시에 사용 합니다.\n---",
"_____no_output_____"
],
[
"SageMaker의 세션을 얻고, role 정보를 가져옵니다.\n- 위의 두 정보를 통해서 SageMaker Hosting Cluster에 연결합니다.",
"_____no_output_____"
]
],
[
[
"import os\nimport sagemaker\nfrom sagemaker import get_execution_role\n\nsagemaker_session = sagemaker.Session()\n\nrole = get_execution_role()",
"_____no_output_____"
]
],
[
[
"## 로컬의 데이터 S3 업로딩\n로컬의 데이터를 S3에 업로딩하여 훈련시에 Input으로 사용 합니다.",
"_____no_output_____"
]
],
[
[
"# dataset_location = sagemaker_session.upload_data(path='data', key_prefix='data/DEMO-cifar10')\n# display(dataset_location)\ndataset_location = 's3://sagemaker-ap-northeast-2-057716757052/data/DEMO-cifar10'\ndataset_location",
"_____no_output_____"
],
[
"# efs_dir = '/home/ec2-user/efs/data'\n\n# ! ls {efs_dir} -al\n# ! aws s3 cp {dataset_location} {efs_dir} --recursive",
"_____no_output_____"
],
[
"from sagemaker.inputs import FileSystemInput\n\n# Specify EFS ile system id.\nfile_system_id = 'fs-38dc1558' # 'fs-xxxxxxxx'\nprint(f\"EFS file-system-id: {file_system_id}\")\n\n# Specify directory path for input data on the file system. \n# You need to provide normalized and absolute path below.\ntrain_file_system_directory_path = '/data/train'\neval_file_system_directory_path = '/data/eval'\nvalidation_file_system_directory_path = '/data/validation'\nprint(f'EFS file-system data input path: {train_file_system_directory_path}')\nprint(f'EFS file-system data input path: {eval_file_system_directory_path}')\nprint(f'EFS file-system data input path: {validation_file_system_directory_path}')\n\n# Specify the access mode of the mount of the directory associated with the file system. \n# Directory must be mounted 'ro'(read-only).\nfile_system_access_mode = 'ro'\n\n# Specify your file system type\nfile_system_type = 'EFS'\n\ntrain = FileSystemInput(file_system_id=file_system_id,\n file_system_type=file_system_type,\n directory_path=train_file_system_directory_path,\n file_system_access_mode=file_system_access_mode)\n\neval = FileSystemInput(file_system_id=file_system_id,\n file_system_type=file_system_type,\n directory_path=eval_file_system_directory_path,\n file_system_access_mode=file_system_access_mode)\n\nvalidation = FileSystemInput(file_system_id=file_system_id,\n file_system_type=file_system_type,\n directory_path=validation_file_system_directory_path,\n file_system_access_mode=file_system_access_mode)",
"EFS file-system-id: fs-38dc1558\nEFS file-system data input path: /data/train\nEFS file-system data input path: /data/eval\nEFS file-system data input path: /data/validation\n"
],
[
"aws_region = 'ap-northeast-2'# aws-region-code e.g. us-east-1\ns3_bucket = 'sagemaker-ap-northeast-2-057716757052'# your-s3-bucket-name",
"_____no_output_____"
],
[
"prefix = \"cifar10/efs\" #prefix in your bucket\ns3_output_location = f's3://{s3_bucket}/{prefix}/output'\nprint(f'S3 model output location: {s3_output_location}')",
"S3 model output location: s3://sagemaker-ap-northeast-2-057716757052/cifar10/efs/output\n"
],
[
"security_group_ids = ['sg-0192524ef63ec6138'] # ['sg-xxxxxxxx'] \n# subnets = ['subnet-0a84bcfa36d3981e6','subnet-0304abaaefc2b1c34','subnet-0a2204b79f378b178'] # [ 'subnet-xxxxxxx', 'subnet-xxxxxxx', 'subnet-xxxxxxx']\nsubnets = ['subnet-0a84bcfa36d3981e6'] # [ 'subnet-xxxxxxx', 'subnet-xxxxxxx', 'subnet-xxxxxxx']\n\n\n",
"_____no_output_____"
],
[
"from sagemaker.tensorflow import TensorFlow\nestimator = TensorFlow(base_job_name='cifar10',\n entry_point='cifar10_keras_sm_tf2.py',\n source_dir='training_script',\n role=role,\n framework_version='2.0.0',\n py_version='py3',\n script_mode=True,\n hyperparameters={'epochs' : 1},\n train_instance_count=1, \n train_instance_type='ml.p3.2xlarge',\n output_path=s3_output_location, \n subnets=subnets,\n security_group_ids=security_group_ids, \n session = sagemaker.Session()\n )\n\nestimator.fit({'train': train,\n 'validation': validation,\n 'eval': eval,\n })\n# estimator.fit({'train': 'file://data/train',\n# 'validation': 'file://data/validation',\n# 'eval': 'file://data/eval'})",
"train_instance_type has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\ntrain_instance_count has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\ntrain_instance_type has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\n"
]
],
[
[
"# VPC_Mode를 True, False 선택\n#### **[중요] VPC_Mode에서 실행시에 True로 변경해주세요**",
"_____no_output_____"
]
],
[
[
"VPC_Mode = False",
"_____no_output_____"
],
[
"from sagemaker.tensorflow import TensorFlow\n\ndef retrieve_estimator(VPC_Mode):\n if VPC_Mode:\n # VPC 모드 경우에 subnets, security_group을 기술 합니다.\n estimator = TensorFlow(base_job_name='cifar10',\n entry_point='cifar10_keras_sm_tf2.py',\n source_dir='training_script',\n role=role,\n framework_version='2.0.0',\n py_version='py3',\n script_mode=True, \n hyperparameters={'epochs': 2},\n train_instance_count=1, \n train_instance_type='ml.p3.8xlarge',\n subnets = ['subnet-090c1fad32165b0fa','subnet-0bd7cff3909c55018'],\n security_group_ids = ['sg-0f45d634d80aef27e'] \n ) \n else:\n estimator = TensorFlow(base_job_name='cifar10',\n entry_point='cifar10_keras_sm_tf2.py',\n source_dir='training_script',\n role=role,\n framework_version='2.0.0',\n py_version='py3',\n script_mode=True, \n hyperparameters={'epochs': 2},\n train_instance_count=1, \n train_instance_type='ml.p3.8xlarge')\n return estimator\n\nestimator = retrieve_estimator(VPC_Mode)",
"train_instance_type has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\ntrain_instance_count has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\ntrain_instance_type has been renamed in sagemaker>=2.\nSee: https://sagemaker.readthedocs.io/en/stable/v2.html for details.\n"
]
],
[
[
"학습을 수행합니다. 이번에는 각각의 채널(`train, validation, eval`)에 S3의 데이터 저장 위치를 지정합니다.<br>\n학습 완료 후 Billable seconds도 확인해 보세요. Billable seconds는 실제로 학습 수행 시 과금되는 시간입니다.\n```\nBillable seconds: <time>\n```\n\n참고로, `ml.p2.xlarge` 인스턴스로 5 epoch 학습 시 전체 6분-7분이 소요되고, 실제 학습에 소요되는 시간은 3분-4분이 소요됩니다.",
"_____no_output_____"
]
],
[
[
"%%time\nestimator.fit({'train':'{}/train'.format(dataset_location),\n 'validation':'{}/validation'.format(dataset_location),\n 'eval':'{}/eval'.format(dataset_location)})",
"2021-01-27 04:02:44 Starting - Starting the training job...\n2021-01-27 04:03:08 Starting - Launching requested ML instancesProfilerReport-1611720164: InProgress\n.........\n2021-01-27 04:04:29 Starting - Preparing the instances for training......\n2021-01-27 04:05:44 Downloading - Downloading input data\n2021-01-27 04:05:44 Training - Downloading the training image...\n2021-01-27 04:06:11 Training - Training image download completed. Training in progress..\u001b[34m2021-01-27 04:06:06,541 sagemaker-containers INFO Imported framework sagemaker_tensorflow_container.training\u001b[0m\n\u001b[34m2021-01-27 04:06:07,035 sagemaker-containers INFO Invoking user script\n\u001b[0m\n\u001b[34mTraining Env:\n\u001b[0m\n\u001b[34m{\n \"additional_framework_parameters\": {},\n \"channel_input_dirs\": {\n \"eval\": \"/opt/ml/input/data/eval\",\n \"validation\": \"/opt/ml/input/data/validation\",\n \"train\": \"/opt/ml/input/data/train\"\n },\n \"current_host\": \"algo-1\",\n \"framework_module\": \"sagemaker_tensorflow_container.training:main\",\n \"hosts\": [\n \"algo-1\"\n ],\n \"hyperparameters\": {\n \"model_dir\": \"s3://sagemaker-ap-northeast-2-057716757052/cifar10-2021-01-27-04-02-44-183/model\",\n \"epochs\": 2\n },\n \"input_config_dir\": \"/opt/ml/input/config\",\n \"input_data_config\": {\n \"eval\": {\n \"TrainingInputMode\": \"File\",\n \"S3DistributionType\": \"FullyReplicated\",\n \"RecordWrapperType\": \"None\"\n },\n \"validation\": {\n \"TrainingInputMode\": \"File\",\n \"S3DistributionType\": \"FullyReplicated\",\n \"RecordWrapperType\": \"None\"\n },\n \"train\": {\n \"TrainingInputMode\": \"File\",\n \"S3DistributionType\": \"FullyReplicated\",\n \"RecordWrapperType\": \"None\"\n }\n },\n \"input_dir\": \"/opt/ml/input\",\n \"is_master\": true,\n \"job_name\": \"cifar10-2021-01-27-04-02-44-183\",\n \"log_level\": 20,\n \"master_hostname\": \"algo-1\",\n \"model_dir\": \"/opt/ml/model\",\n \"module_dir\": \"s3://sagemaker-ap-northeast-2-057716757052/cifar10-2021-01-27-04-02-44-183/source/sourcedir.tar.gz\",\n \"module_name\": \"cifar10_keras_sm_tf2\",\n \"network_interface_name\": \"eth0\",\n \"num_cpus\": 32,\n \"num_gpus\": 4,\n \"output_data_dir\": \"/opt/ml/output/data\",\n \"output_dir\": \"/opt/ml/output\",\n \"output_intermediate_dir\": \"/opt/ml/output/intermediate\",\n \"resource_config\": {\n \"current_host\": \"algo-1\",\n \"hosts\": [\n \"algo-1\"\n ],\n \"network_interface_name\": \"eth0\"\n },\n \"user_entry_point\": \"cifar10_keras_sm_tf2.py\"\u001b[0m\n\u001b[34m}\n\u001b[0m\n\u001b[34mEnvironment variables:\n\u001b[0m\n\u001b[34mSM_HOSTS=[\"algo-1\"]\u001b[0m\n\u001b[34mSM_NETWORK_INTERFACE_NAME=eth0\u001b[0m\n\u001b[34mSM_HPS={\"epochs\":2,\"model_dir\":\"s3://sagemaker-ap-northeast-2-057716757052/cifar10-2021-01-27-04-02-44-183/model\"}\u001b[0m\n\u001b[34mSM_USER_ENTRY_POINT=cifar10_keras_sm_tf2.py\u001b[0m\n\u001b[34mSM_FRAMEWORK_PARAMS={}\u001b[0m\n\u001b[34mSM_RESOURCE_CONFIG={\"current_host\":\"algo-1\",\"hosts\":[\"algo-1\"],\"network_interface_name\":\"eth0\"}\u001b[0m\n\u001b[34mSM_INPUT_DATA_CONFIG={\"eval\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"},\"train\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"},\"validation\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"}}\u001b[0m\n\u001b[34mSM_OUTPUT_DATA_DIR=/opt/ml/output/data\u001b[0m\n\u001b[34mSM_CHANNELS=[\"eval\",\"train\",\"validation\"]\u001b[0m\n\u001b[34mSM_CURRENT_HOST=algo-1\u001b[0m\n\u001b[34mSM_MODULE_NAME=cifar10_keras_sm_tf2\u001b[0m\n\u001b[34mSM_LOG_LEVEL=20\u001b[0m\n\u001b[34mSM_FRAMEWORK_MODULE=sagemaker_tensorflow_container.training:main\u001b[0m\n\u001b[34mSM_INPUT_DIR=/opt/ml/input\u001b[0m\n\u001b[34mSM_INPUT_CONFIG_DIR=/opt/ml/input/config\u001b[0m\n\u001b[34mSM_OUTPUT_DIR=/opt/ml/output\u001b[0m\n\u001b[34mSM_NUM_CPUS=32\u001b[0m\n\u001b[34mSM_NUM_GPUS=4\u001b[0m\n\u001b[34mSM_MODEL_DIR=/opt/ml/model\u001b[0m\n\u001b[34mSM_MODULE_DIR=s3://sagemaker-ap-northeast-2-057716757052/cifar10-2021-01-27-04-02-44-183/source/sourcedir.tar.gz\u001b[0m\n\u001b[34mSM_TRAINING_ENV={\"additional_framework_parameters\":{},\"channel_input_dirs\":{\"eval\":\"/opt/ml/input/data/eval\",\"train\":\"/opt/ml/input/data/train\",\"validation\":\"/opt/ml/input/data/validation\"},\"current_host\":\"algo-1\",\"framework_module\":\"sagemaker_tensorflow_container.training:main\",\"hosts\":[\"algo-1\"],\"hyperparameters\":{\"epochs\":2,\"model_dir\":\"s3://sagemaker-ap-northeast-2-057716757052/cifar10-2021-01-27-04-02-44-183/model\"},\"input_config_dir\":\"/opt/ml/input/config\",\"input_data_config\":{\"eval\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"},\"train\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"},\"validation\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"}},\"input_dir\":\"/opt/ml/input\",\"is_master\":true,\"job_name\":\"cifar10-2021-01-27-04-02-44-183\",\"log_level\":20,\"master_hostname\":\"algo-1\",\"model_dir\":\"/opt/ml/model\",\"module_dir\":\"s3://sagemaker-ap-northeast-2-057716757052/cifar10-2021-01-27-04-02-44-183/source/sourcedir.tar.gz\",\"module_name\":\"cifar10_keras_sm_tf2\",\"network_interface_name\":\"eth0\",\"num_cpus\":32,\"num_gpus\":4,\"output_data_dir\":\"/opt/ml/output/data\",\"output_dir\":\"/opt/ml/output\",\"output_intermediate_dir\":\"/opt/ml/output/intermediate\",\"resource_config\":{\"current_host\":\"algo-1\",\"hosts\":[\"algo-1\"],\"network_interface_name\":\"eth0\"},\"user_entry_point\":\"cifar10_keras_sm_tf2.py\"}\u001b[0m\n\u001b[34mSM_USER_ARGS=[\"--epochs\",\"2\",\"--model_dir\",\"s3://sagemaker-ap-northeast-2-057716757052/cifar10-2021-01-27-04-02-44-183/model\"]\u001b[0m\n\u001b[34mSM_OUTPUT_INTERMEDIATE_DIR=/opt/ml/output/intermediate\u001b[0m\n\u001b[34mSM_CHANNEL_EVAL=/opt/ml/input/data/eval\u001b[0m\n\u001b[34mSM_CHANNEL_VALIDATION=/opt/ml/input/data/validation\u001b[0m\n\u001b[34mSM_CHANNEL_TRAIN=/opt/ml/input/data/train\u001b[0m\n\u001b[34mSM_HP_MODEL_DIR=s3://sagemaker-ap-northeast-2-057716757052/cifar10-2021-01-27-04-02-44-183/model\u001b[0m\n\u001b[34mSM_HP_EPOCHS=2\u001b[0m\n\u001b[34mPYTHONPATH=/opt/ml/code:/usr/local/bin:/usr/lib/python36.zip:/usr/lib/python3.6:/usr/lib/python3.6/lib-dynload:/usr/local/lib/python3.6/dist-packages:/usr/lib/python3/dist-packages\n\u001b[0m\n\u001b[34mInvoking script with the following command:\n\u001b[0m\n\u001b[34m/usr/bin/python3 cifar10_keras_sm_tf2.py --epochs 2 --model_dir s3://sagemaker-ap-northeast-2-057716757052/cifar10-2021-01-27-04-02-44-183/model\n\n\u001b[0m\n\u001b[34mTrain for 312 steps, validate for 78 steps\u001b[0m\n\u001b[34mEpoch 1/2\u001b[0m\n\u001b[34m#015 1/312 [..............................] - ETA: 34:31 - loss: 3.5045 - accuracy: 0.1094#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 7/312 [..............................] - ETA: 4:52 - loss: 3.1433 - accuracy: 0.1462 #010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 13/312 [>.............................] - ETA: 2:35 - loss: 2.9194 - accuracy: 0.1587#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 19/312 [>.............................] - ETA: 1:45 - loss: 2.7623 - accuracy: 0.1641#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 26/312 [=>............................] - ETA: 1:15 - loss: 2.6259 - accuracy: 0.1683#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 32/312 [==>...........................] - ETA: 1:00 - loss: 2.5445 - accuracy: 0.1753#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 39/312 [==>...........................] - ETA: 48s - loss: 2.4627 - accuracy: 0.1873 #010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 45/312 [===>..........................] - ETA: 41s - loss: 2.4148 - accuracy: 0.1951#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 51/312 [===>..........................] - ETA: 36s - loss: 2.3721 - accuracy: 0.2028#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 57/312 [====>.........................] - ETA: 31s - loss: 2.3383 - accuracy: 0.2057#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 64/312 [=====>........................] - ETA: 27s - loss: 2.2982 - accuracy: 0.2120#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 71/312 [=====>........................] - ETA: 24s - loss: 2.2635 - accuracy: 0.2171#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 78/312 [======>.......................] - ETA: 21s - loss: 2.2315 - accuracy: 0.2229#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 85/312 [=======>......................] - ETA: 19s - loss: 2.2051 - accuracy: 0.2268#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 92/312 [=======>......................] - ETA: 17s - loss: 2.1798 - accuracy: 0.2320#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 99/312 [========>.....................] - ETA: 16s - loss: 2.1550 - accuracy: 0.2371#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015106/312 [=========>....................] - ETA: 14s - loss: 2.1355 - accuracy: 0.2412#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015113/312 [=========>....................] - ETA: 13s - loss: 2.1166 - accuracy: 0.2458#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015120/312 [==========>...................] - ETA: 12s - loss: 2.0997 - accuracy: 0.2493#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015127/312 [===========>..................] - ETA: 11s - loss: 2.0852 - accuracy: 0.2542#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015134/312 [===========>..................] - ETA: 10s - loss: 2.0716 - accuracy: 0.2577#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015140/312 [============>.................] - ETA: 9s - loss: 2.0586 - accuracy: 0.2616 #010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015147/312 [=============>................] - ETA: 8s - loss: 2.0466 - accuracy: 0.2645#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015154/312 [=============>................] - ETA: 8s - loss: 2.0331 - accuracy: 0.2677#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015161/312 [==============>...............] - ETA: 7s - loss: 2.0210 - accuracy: 0.2723#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015168/312 [===============>..............] - ETA: 6s - loss: 2.0082 - accuracy: 0.2766#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015175/312 [===============>..............] - ETA: 6s - loss: 1.9988 - accuracy: 0.2790#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015181/312 [================>.............] - ETA: 5s - loss: 1.9901 - accuracy: 0.2804#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015188/312 [=================>............] - ETA: 5s - loss: 1.9790 - accuracy: 0.2836#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015195/312 [=================>............] - ETA: 4s - loss: 1.9695 - accuracy: 0.2856#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015202/312 [==================>...........] - ETA: 4s - loss: 1.9605 - accuracy: 0.2881#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015209/312 [===================>..........] - ETA: 4s - loss: 1.9531 - accuracy: 0.2906#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015216/312 [===================>..........] - ETA: 3s - loss: 1.9457 - accuracy: 0.2930#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015223/312 [====================>.........] - ETA: 3s - loss: 1.9350 - accuracy: 0.2959#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015230/312 [=====================>........] - ETA: 3s - loss: 1.9290 - accuracy: 0.2975#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015237/312 [=====================>........] - ETA: 2s - loss: 1.9219 - accuracy: 0.2991#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015244/312 [======================>.......] - ETA: 2s - loss: 1.9130 - accuracy: 0.3024#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015251/312 [=======================>......] - ETA: 2s - loss: 1.9066 - accuracy: 0.3046#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015258/312 [=======================>......] - ETA: 1s - loss: 1.9006 - accuracy: 0.3065#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015264/312 [========================>.....] - ETA: 1s - loss: 1.8959 - accuracy: 0.3079#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015271/312 [=========================>....] - ETA: 1s - loss: 1.8884 - accuracy: 0.3104#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015278/312 [=========================>....] - ETA: 1s - loss: 1.8834 - accuracy: 0.3122#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015285/312 [==========================>...] - ETA: 0s - loss: 1.8764 - accuracy: 0.3148#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015292/312 [===========================>..] - ETA: 0s - loss: 1.8714 - accuracy: 0.3172#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015299/312 [===========================>..] - ETA: 0s - loss: 1.8642 - accuracy: 0.3197#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015305/312 [============================>.] - ETA: 0s - loss: 1.8589 - accuracy: 0.3213#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015312/312 [==============================] - 10s 32ms/step - loss: 1.8530 - accuracy: 0.3232 - val_loss: 2.0282 - val_accuracy: 0.3226\u001b[0m\n\u001b[34mEpoch 2/2\u001b[0m\n\u001b[34m#015 1/312 [..............................] - ETA: 2s - loss: 1.4358 - accuracy: 0.4531#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 8/312 [..............................] - ETA: 2s - loss: 1.5428 - accuracy: 0.4131#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 15/312 [>.............................] - ETA: 2s - loss: 1.5658 - accuracy: 0.4026#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 22/312 [=>............................] - ETA: 2s - loss: 1.5621 - accuracy: 0.4116#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 29/312 [=>............................] - ETA: 2s - loss: 1.5536 - accuracy: 0.4181#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 36/312 [==>...........................] - ETA: 2s - loss: 1.5312 - accuracy: 0.4316#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 43/312 [===>..........................] - ETA: 2s - loss: 1.5190 - accuracy: 0.4391#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 50/312 [===>..........................] - ETA: 2s - loss: 1.5194 - accuracy: 0.4364#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 56/312 [====>.........................] - ETA: 2s - loss: 1.5234 - accuracy: 0.4351#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 63/312 [=====>........................] - ETA: 1s - loss: 1.5260 - accuracy: 0.4339#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 70/312 [=====>........................] - ETA: 1s - loss: 1.5249 - accuracy: 0.4376#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 77/312 [======>.......................] - ETA: 1s - loss: 1.5162 - accuracy: 0.4421#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 84/312 [=======>......................] - ETA: 1s - loss: 1.5111 - accuracy: 0.4443#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 91/312 [=======>......................] - ETA: 1s - loss: 1.5092 - accuracy: 0.4439#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015 98/312 [========>.....................] - ETA: 1s - loss: 1.5105 - accuracy: 0.4430#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015105/312 [=========>....................] - ETA: 1s - loss: 1.5119 - accuracy: 0.4424#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015112/312 [=========>....................] - ETA: 1s - loss: 1.5089 - accuracy: 0.4440#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015119/312 [==========>...................] - ETA: 1s - loss: 1.5087 - accuracy: 0.4458#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015126/312 [===========>..................] - ETA: 1s - loss: 1.5124 - accuracy: 0.4441#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015132/312 [===========>..................] - ETA: 1s - loss: 1.5132 - accuracy: 0.4441#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015139/312 [============>.................] - ETA: 1s - loss: 1.5099 - accuracy: 0.4453#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015146/312 [=============>................] - ETA: 1s - loss: 1.5104 - accuracy: 0.4464#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015153/312 [=============>................] - ETA: 1s - loss: 1.5065 - accuracy: 0.4489#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015160/312 [==============>...............] - ETA: 1s - loss: 1.5054 - accuracy: 0.4499#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015166/312 [==============>...............] - ETA: 1s - loss: 1.5030 - accuracy: 0.4507#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015172/312 [===============>..............] - ETA: 1s - loss: 1.5006 - accuracy: 0.4514#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015179/312 [================>.............] - ETA: 1s - loss: 1.4972 - accuracy: 0.4527#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015186/312 [================>.............] - ETA: 0s - loss: 1.4946 - accuracy: 0.4536#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015193/312 [=================>............] - ETA: 0s - loss: 1.4922 - accuracy: 0.4547#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015200/312 [==================>...........] - ETA: 0s - loss: 1.4917 - accuracy: 0.4553#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015207/312 [==================>...........] - ETA: 0s - loss: 1.4904 - accuracy: 0.4556#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015214/312 [===================>..........] - ETA: 0s - loss: 1.4877 - accuracy: 0.4567#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015221/312 [====================>.........] - ETA: 0s - loss: 1.4865 - accuracy: 0.4576#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015228/312 [====================>.........] - ETA: 0s - loss: 1.4846 - accuracy: 0.4582#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015235/312 [=====================>........] - ETA: 0s - loss: 1.4813 - accuracy: 0.4593#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015242/312 [======================>.......] - ETA: 0s - loss: 1.4780 - accuracy: 0.4611#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015249/312 [======================>.......] - ETA: 0s - loss: 1.4757 - accuracy: 0.4621#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015255/312 [=======================>......] - ETA: 0s - loss: 1.4742 - accuracy: 0.4624#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015262/312 [========================>.....] - ETA: 0s - loss: 1.4709 - accuracy: 0.4642#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015268/312 [========================>.....] - ETA: 0s - loss: 1.4689 - accuracy: 0.4651#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015275/312 [=========================>....] - ETA: 0s - loss: 1.4664 - accuracy: 0.4662#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015282/312 [==========================>...] - ETA: 0s - loss: 1.4634 - accuracy: 0.4671#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015289/312 [==========================>...] - ETA: 0s - loss: 1.4600 - accuracy: 0.4679#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015296/312 [===========================>..] - ETA: 0s - loss: 1.4562 - accuracy: 0.4693#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015303/312 [============================>.] - ETA: 0s - loss: 1.4529 - accuracy: 0.4707#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015310/312 [============================>.] - ETA: 0s - loss: 1.4507 - accuracy: 0.4713#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#015312/312 [==============================] - 3s 10ms/step - loss: 1.4498 - accuracy: 0.4717 - val_loss: 1.6843 - val_accuracy: 0.4161\u001b[0m\n\n2021-01-27 04:12:46 Uploading - Uploading generated training model\u001b[34m2021-01-27 04:12:39.226548: W tensorflow/python/util/util.cc:299] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.\u001b[0m\n\u001b[34mWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/ops/resource_variable_ops.py:1781: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.\u001b[0m\n\u001b[34mInstructions for updating:\u001b[0m\n\u001b[34mIf using Keras pass *_constraint arguments to layers.\u001b[0m\n\u001b[34mWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/ops/resource_variable_ops.py:1781: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.\u001b[0m\n\u001b[34mInstructions for updating:\u001b[0m\n\u001b[34mIf using Keras pass *_constraint arguments to layers.\u001b[0m\n\u001b[34mINFO:tensorflow:Assets written to: /opt/ml/model/1/assets\u001b[0m\n\u001b[34mINFO:tensorflow:Assets written to: /opt/ml/model/1/assets\u001b[0m\n\u001b[34m2021-01-27 04:12:42,835 sagemaker-containers INFO Reporting training SUCCESS\u001b[0m\n\n2021-01-27 04:13:16 Completed - Training job completed\nProfilerReport-1611720164: NoIssuesFound\nTraining seconds: 452\nBillable seconds: 452\nCPU times: user 1.59 s, sys: 1.44 ms, total: 1.59 s\nWall time: 10min 46s\n"
]
],
[
[
"## training_job_name 저장\n\n현재의 training_job_name을 저장 합니다.\n- training_job_name을 에는 훈련에 관련 내용 및 훈련 결과인 **Model Artifact** 파일의 S3 경로를 제공 합니다.",
"_____no_output_____"
]
],
[
[
"train_job_name = estimator._current_job_name",
"_____no_output_____"
],
[
"%store train_job_name",
"Stored 'train_job_name' (str)\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
d06051dceb9e7c3e4941d98bb5860c0cd4d1b728 | 66,639 | ipynb | Jupyter Notebook | notebooks/test_0_lstm_shell_colab.ipynb | SPRACE/track-ml | 3af95fd014e98a5b11261dc5d618f34f82fdf84d | [
"MIT"
]
| null | null | null | notebooks/test_0_lstm_shell_colab.ipynb | SPRACE/track-ml | 3af95fd014e98a5b11261dc5d618f34f82fdf84d | [
"MIT"
]
| 10 | 2019-04-15T21:44:31.000Z | 2020-08-26T21:05:00.000Z | notebooks/test_0_lstm_shell_colab.ipynb | SPRACE/track-ml | 3af95fd014e98a5b11261dc5d618f34f82fdf84d | [
"MIT"
]
| 4 | 2019-04-12T19:04:16.000Z | 2020-01-14T13:30:44.000Z | 213.586538 | 47,300 | 0.647204 | [
[
[
"!pip install git+https://github.com/LAL/trackml-library.git\n!pip install plotly.express\n!pip install shortuuid",
"_____no_output_____"
],
[
"# Clonning the repository you can get the lastest code from dev branch \n#!git clone https://github.com/SPRACE/track-ml.git cloned-repo\n!git clone https://github.com/stonescenter/track-ml.git\n!ls",
"_____no_output_____"
],
[
"%cd track-ml/",
"/content/track-ml\n"
]
],
[
[
"# Running scripts with python shell #",
"_____no_output_____"
]
],
[
[
"#!pip install tensorflow==1.14.0\n#!pip install tensorflow-base==1.14.0\n#!pip install tensorflow-gpu==1.14.0\n\n%tensorflow_version 1.x",
"_____no_output_____"
],
[
"\n! python main_train.py --config config_default.json",
"_____no_output_____"
]
],
[
[
"# Plot Predicted Data #\n",
"_____no_output_____"
]
],
[
[
"import os\nimport json\nimport numpy as np\nimport pandas as pd\n\nconfigs = json.load(open('config_default.json', 'r'))\n\ncylindrical = configs['data']['cylindrical'] # set to polar or cartesian coordenates\nnormalise = configs['data']['normalise'] \nname = configs['model']['name']\n\nif cylindrical:\n coord = 'cylin'\nelse:\n coord = 'xyz'\n\npath1 = 'results/x_true_%s_%s.csv' % (name, coord)\npath2 = 'results/y_true_%s_%s.csv' % (name, coord)\npath3 = 'results/y_pred_%s_%s.csv' % (name, coord)\n\nprint('loading from .. %s' % path1)\nprint('loading from .. %s' % path2)\nprint('loading from .. %s' % path3)\n\ndf_test = pd.read_csv(path1, header=None)\ndf_true = pd.read_csv(path2, header=None)\ndf_pred = pd.read_csv(path3, header=None)\n\nprint('shape df_test ', df_test.shape)\nprint('shape df_true ', df_true.shape)\nprint('shape df_pred ', df_pred.shape)\n# concat\n#y_true = pd.concat([df_test, df_true], axis = 1, ignore_index = True)\n#y_pred = pd.concat([df_test, df_pred], axis = 1, ignore_index = True)\n\ny_true = np.concatenate([df_test, df_true], axis = 1)\ny_pred = np.concatenate([df_test, df_pred], axis = 1)\ny_true = pd.DataFrame(y_true)\ny_pred = pd.DataFrame(y_pred)\n#y_true.name = 'real'\n#y_pred.name = 'pred'\ny_pred.columns.name = 'pred'\ny_true.columns.name = 'real'\n\nprint('size y_true ', y_true.shape)\nprint('size y_pred ', y_pred.shape)",
"loading from .. results/x_true_lstm_xyz.csv\nloading from .. results/y_true_lstm_xyz.csv\nloading from .. results/y_pred_lstm_xyz.csv\nshape df_test (528, 12)\nshape df_true (528, 18)\nshape df_pred (528, 18)\nsize y_true (528, 30)\nsize y_pred (528, 30)\n"
],
[
"from core.utils.utils import *\nimport warnings\n\nN_tracks = 30\npath_html = ''\nname = configs['model']['name']\n\nfig = track_plot_xyz([y_true, y_pred], n_hits = 10, cylindrical = cylindrical, n_tracks = N_tracks, \n title='Track Prediction #10 Hit - Model %s (Nearest hits)' % name.upper())\n\nfig.show()",
"/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning:\n\npandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.\n\n"
],
[
"",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
d06051e608c2bfcf56c74a60dc9f350d0d1b7d14 | 137,607 | ipynb | Jupyter Notebook | code/preprocessing_and_decomposition/Matrix_Profile.ipynb | iotanalytics/IoTTutorial | 33666ca918cdece60df4684f0a2ec3465e9663b6 | [
"MIT"
]
| 3 | 2021-07-20T18:02:51.000Z | 2021-08-18T13:26:57.000Z | code/preprocessing_and_decomposition/Matrix_Profile.ipynb | iotanalytics/IoTTutorial | 33666ca918cdece60df4684f0a2ec3465e9663b6 | [
"MIT"
]
| null | null | null | code/preprocessing_and_decomposition/Matrix_Profile.ipynb | iotanalytics/IoTTutorial | 33666ca918cdece60df4684f0a2ec3465e9663b6 | [
"MIT"
]
| null | null | null | 539.635294 | 128,352 | 0.946311 | [
[
[
"<a href=\"https://colab.research.google.com/github/iotanalytics/IoTTutorial/blob/main/code/preprocessing_and_decomposition/Matrix_Profile.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"## Matrix Profile\n",
"_____no_output_____"
],
[
"## Introduction\n\nThe matrix profile (MP) is a data structure and associated algorithms that helps solve the dual problem of anomaly detection and motif discovery. It is robust, scalable and largely parameter-free.\n\nMP can be combined with other algorithms to accomplish:\n\n* Motif discovery\n* Time series chains\n* Anomaly discovery\n* Joins\n* Semantic segmentation\n\nmatrixprofile-ts offers 3 different algorithms to compute Matrix Profile:\n* STAMP (Scalable Time Series Anytime Matrix Profile) - Each distance profile is independent of other distance profiles, the order in which they are computed can be random. It is an anytime algorithm.\n* STOMP (Scalable Time Series Ordered Matrix Profile) - This algorithm is an exact ordered algorithm. It is significantly faster than STAMP.\n* SCRIMP++ (Scalable Column Independent Matrix Profile) - This algorithm combines the anytime component of STAMP with the speed of STOMP.\n\n\nSee: https://towardsdatascience.com/introduction-to-matrix-profiles-5568f3375d90",
"_____no_output_____"
],
[
"## Code Example\n",
"_____no_output_____"
]
],
[
[
"!pip install matrixprofile-ts",
"Collecting matrixprofile-ts\n Downloading matrixprofile_ts-0.0.9-py2.py3-none-any.whl (24 kB)\nRequirement already satisfied: numpy>=1.11.3 in /usr/local/lib/python3.7/dist-packages (from matrixprofile-ts) (1.19.5)\nInstalling collected packages: matrixprofile-ts\nSuccessfully installed matrixprofile-ts-0.0.9\n"
],
[
"import pandas as pd\n## example data importing\ndata = pd.read_csv('https://raw.githubusercontent.com/iotanalytics/IoTTutorial/main/data/SCG_data.csv').drop('Unnamed: 0',1).to_numpy()[0:20,:1000]",
"_____no_output_____"
],
[
"import operator\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matrixprofile import *\n\nimport numpy as np\nfrom datetime import datetime\n\nimport matplotlib.pyplot as plt\nfrom matplotlib.colors import ListedColormap\nfrom sklearn import neighbors, datasets\n\n# Pull a portion of the data\npattern = data[10,:] + max(abs(data[10,:]))\n\n# Compute Matrix Profile\nm = 10\nmp = matrixProfile.stomp(pattern,m)\n\n#Append np.nan to Matrix profile to enable plotting against raw data\nmp_adj = np.append(mp[0],np.zeros(m-1)+np.nan)\n\n#Plot the signal data\nfig, (ax1, ax2) = plt.subplots(2,1,sharex=True,figsize=(20,10))\nax1.plot(np.arange(len(pattern)),pattern)\nax1.set_ylabel('Signal', size=22)\n\n#Plot the Matrix Profile\nax2.plot(np.arange(len(mp_adj)),mp_adj, label=\"Matrix Profile\", color='red')\nax2.set_ylabel('Matrix Profile', size=22)\nax2.set_xlabel('Time', size=22);",
"_____no_output_____"
]
],
[
[
"## Discussion\n\n\nPros:\n* It is exact: For motif discovery, discord discovery, time series joins etc., the Matrix Profile based methods provide no false positives or false dismissals.\n* It is simple and parameter-free: In contrast, the more general algorithms in this space\nthat typically require building and tuning spatial access methods and/or hash functions.\n* It is space efficient: Matrix Profile construction algorithms requires an inconsequential\nspace overhead, just linear in the time series length with a small constant factor, allowing\nmassive datasets to be processed in main memory (for most data mining, disk is death).\n* It allows anytime algorithms: While exact MP algorithms are extremely scalable, for\nextremely large datasets we can compute the Matrix Profile in an anytime fashion, allowing\nultra-fast approximate solutions and real-time data interaction.\n* It is incrementally maintainable: Having computed the Matrix Profile for a dataset,\nwe can incrementally update it very efficiently. In many domains this means we can effectively\nmaintain exact joins, motifs, discords on streaming data forever.\n* It can leverage hardware: Matrix Profile construction is embarrassingly parallelizable,\nboth on multicore processors, GPUs, distributed systems etc.\n* It is free of the curse of dimensionality: That is to say, It has time complexity that is\nconstant in subsequence length: This is a very unusual and desirable property; virtually all\nexisting algorithms in the time series scale poorly as the subsequence length grows.\n* It can be constructed in deterministic time: Almost all algorithms for time series\ndata mining can take radically different times to finish on two (even slightly) different datasets.\nIn contrast, given only the length of the time series, we can precisely predict in advance how\nlong it will take to compute the Matrix Profile. (this allows resource planning)\n* It can handle missing data: Even in the presence of missing data, we can provide\nanswers which are guaranteed to have no false negatives.\n* Finally, and subjectively: Simplicity and Intuitiveness: Seeing the world through\nthe MP lens often invites/suggests simple and elegant solutions. \n\nCons:\n* Larger datasets can take a long time to compute. Scalability needs to be addressed.\n* Cannot be used with Dynamic time Warping as of now.\n * DTW is used for one-to-all matching whereas MP is used for all-to-all matching.\n * DTW is used for smaller datasets rather than large.\n* Need to adjust window size manually for different datasets.\n\n*How to read MP* :\n* Where you see relatively low values, you know that the subsequence in the original time\nseries must have (at least one) relatively similar subsequence elsewhere in the data (such\nregions are “motifs” or reoccurring patterns)\n* Where you see relatively high values, you know that the subsequence in the original time\nseries must be unique in its shape (such areas are “discords” or anomalies). In fact, the highest point is exactly the definition of Time\nSeries Discord, perhaps the best anomaly detector for time series.\n",
"_____no_output_____"
],
[
"##References:\n\nhttps://www.cs.ucr.edu/~eamonn/MatrixProfile.html (powerpoints on this site - a lot of examples)\n\nhttps://towardsdatascience.com/introduction-to-matrix-profiles-5568f3375d90\n\nPython implementation: https://github.com/TDAmeritrade/stumpy",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
]
|
d06059853171785ee6baaefaab157274881917e4 | 41,007 | ipynb | Jupyter Notebook | day37_ML_ANN_RNN.ipynb | DynamicEngine2001/Programming-Codes | 6f19cbca47eef4b059b723703b261545ab08fc5d | [
"MIT"
]
| null | null | null | day37_ML_ANN_RNN.ipynb | DynamicEngine2001/Programming-Codes | 6f19cbca47eef4b059b723703b261545ab08fc5d | [
"MIT"
]
| 1 | 2020-10-15T14:33:30.000Z | 2020-10-15T14:33:30.000Z | day37_ML_ANN_RNN.ipynb | DynamicEngine2001/Programming-Codes | 6f19cbca47eef4b059b723703b261545ab08fc5d | [
"MIT"
]
| 7 | 2020-10-05T13:05:35.000Z | 2021-10-18T17:06:50.000Z | 35.596354 | 6,416 | 0.472797 | [
[
[
"### Steps to build a Neural Network\n\n1. Empty Model (sequential/Model)\n2",
"_____no_output_____"
]
],
[
[
"import tensorflow.keras.datasets as kd",
"_____no_output_____"
],
[
"data = kd.fashion_mnist.load_data()",
"Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz\n32768/29515 [=================================] - 0s 7us/step\nDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz\n26427392/26421880 [==============================] - 13s 1us/step\nDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz\n8192/5148 [===============================================] - 0s 0us/step\nDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz\n4423680/4422102 [==============================] - 2s 0us/step\n"
],
[
"(xtrain,ytrain),(xtest,ytest) = data",
"_____no_output_____"
],
[
"xtrain.shape",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"plt.imshow(xtrain[0,:,:],cmap='gray_r')",
"_____no_output_____"
],
[
"ytrain[0]",
"_____no_output_____"
],
[
"xtrain1 = xtrain.reshape(-1,28*28)\nxtest1 = xtest.reshape(-1,28*28)",
"_____no_output_____"
],
[
"xtrain1.shape",
"_____no_output_____"
],
[
"from tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Dense",
"_____no_output_____"
],
[
"model_ann = Sequential()\nmodel_ann.add(Dense(units=128, input_shape=(784,), activation='relu'))\nmodel_ann.add(Dense(units=128, activation='relu'))\nmodel_ann.add(Dense(units=10, activation='softmax'))\nmodel_ann.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])",
"_____no_output_____"
],
[
"model_ann.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense (Dense) (None, 128) 100480 \n_________________________________________________________________\ndense_1 (Dense) (None, 128) 16512 \n_________________________________________________________________\ndense_2 (Dense) (None, 10) 1290 \n=================================================================\nTotal params: 118,282\nTrainable params: 118,282\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"1st layer = ",
"_____no_output_____"
],
[
"history = model_ann.fit(xtrain1,ytrain,epochs=10)",
"Epoch 1/10\n1875/1875 [==============================] - 8s 3ms/step - loss: 2.0255 - accuracy: 0.7341\nEpoch 2/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.6520 - accuracy: 0.7857\nEpoch 3/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.6020 - accuracy: 0.8008\nEpoch 4/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.5439 - accuracy: 0.8156\nEpoch 5/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.5079 - accuracy: 0.8259\nEpoch 6/10\n1875/1875 [==============================] - 7s 4ms/step - loss: 0.4657 - accuracy: 0.8365\nEpoch 7/10\n1875/1875 [==============================] - 7s 4ms/step - loss: 0.4380 - accuracy: 0.8442\nEpoch 8/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.4248 - accuracy: 0.8483\nEpoch 9/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.4050 - accuracy: 0.8524\nEpoch 10/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.3999 - accuracy: 0.8567\n"
],
[
"plt.plot(history.history['loss'])\nplt.plot(history.history['accuracy'])\nplt.grid()\nplt.\nplt.xticks(range(1,11))\nplt.xlabel('Epochs-->')\nplt.show()",
"_____no_output_____"
],
[
"ypred = model_ann.predict(xtest1)",
"_____no_output_____"
],
[
"labels.get(ytest[0])",
"_____no_output_____"
],
[
"ypred[0].argmax()",
"_____no_output_____"
],
[
"model_ann.evaluate(xtest1,ytest)",
"313/313 [==============================] - 1s 2ms/step - loss: 0.4793 - accuracy: 0.8335\n"
]
],
[
[
"### Churn Modelling",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"df = pd.read_csv('Churn_Modelling.csv')\ndf",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 10000 entries, 0 to 9999\nData columns (total 14 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 RowNumber 10000 non-null int64 \n 1 CustomerId 10000 non-null int64 \n 2 Surname 10000 non-null object \n 3 CreditScore 10000 non-null int64 \n 4 Geography 10000 non-null object \n 5 Gender 10000 non-null object \n 6 Age 10000 non-null int64 \n 7 Tenure 10000 non-null int64 \n 8 Balance 10000 non-null float64\n 9 NumOfProducts 10000 non-null int64 \n 10 HasCrCard 10000 non-null int64 \n 11 IsActiveMember 10000 non-null int64 \n 12 EstimatedSalary 10000 non-null float64\n 13 Exited 10000 non-null int64 \ndtypes: float64(2), int64(9), object(3)\nmemory usage: 1.1+ MB\n"
],
[
"df1 = pd.get_dummies(df)",
"_____no_output_____"
],
[
"df1.head()",
"_____no_output_____"
]
],
[
[
"### Recurrent Neural Network",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"stock_data = pd.read_csv('stock_data.csv')",
"_____no_output_____"
],
[
"fb = stock_data[['Open']] [stock_data['Stock']=='FB'].copy()",
"_____no_output_____"
],
[
"fb.head()",
"_____no_output_____"
],
[
"fb = fb.values",
"_____no_output_____"
],
[
"fb.shape",
"_____no_output_____"
],
[
"x = []\ny = []\nfor i in range(20, len(fb)):\n x.append(fb['Open'].valuesfb[i-20:1].tolist())\n y.append(fb[i].tolist())\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d0605f7486d4b21270c84051e4665d2a8b65650a | 16,303 | ipynb | Jupyter Notebook | Python_Core/Python Modules and Imports.ipynb | ValRCS/RCS_Python_11 | 157c8e08aaf9849341cadb50077fe65dead536fa | [
"MIT"
]
| 1 | 2019-07-11T16:25:15.000Z | 2019-07-11T16:25:15.000Z | Python_Core/Python Modules and Imports.ipynb | ValRCS/RCS_Python_11 | 157c8e08aaf9849341cadb50077fe65dead536fa | [
"MIT"
]
| 8 | 2020-01-28T22:54:14.000Z | 2022-02-10T00:17:47.000Z | Python Modules and Imports.ipynb | ValRCS/RCS_Data_Analysis_Python_2019_July | 19e2f8310f41b697f9c86d7a085a9ff19390eeac | [
"MIT"
]
| 2 | 2019-12-11T14:39:36.000Z | 2019-12-13T14:29:09.000Z | 22.674548 | 463 | 0.497577 | [
[
[
"## Python Modules",
"_____no_output_____"
]
],
[
[
"%%writefile weather.py\ndef prognosis():\n print(\"It will rain today\")",
"Writing weather.py\n"
],
[
"import weather\n",
"_____no_output_____"
],
[
"weather.prognosis()",
"It will rain today\n"
]
],
[
[
"## How does Python know from where to import packages/modules from?",
"_____no_output_____"
]
],
[
[
"# Python imports work by searching the directories listed in sys.path.",
"_____no_output_____"
],
[
"import sys\nsys.path\n",
"_____no_output_____"
],
[
"## \"__main__\" usage\n# A module can discover whether or not it is running in the main scope by checking its own __name__, \n# which allows a common idiom for conditionally executing code in a module when it is run as a script or with python -m \n# but not when it is imported:",
"_____no_output_____"
],
[
"%%writefile hw.py\n#!/usr/bin/env python\ndef hw():\n print(\"Running Main\")\n\ndef hw2():\n print(\"Hello 2\")\n\nif __name__ == \"__main__\":\n # execute only if run as a script\n print(\"Running as script\")\n hw()\n hw2()",
"Overwriting hw.py\n"
],
[
"import main\nimport hw",
"_____no_output_____"
],
[
"main.main()\nhw.hw2()",
"Running Main\nHello 2\n"
],
[
"# Running on all 3 OSes from command line:\n\npython main.py",
"_____no_output_____"
]
],
[
[
"## Make main.py self running on Linux (also should work on MacOS):\n \nAdd \n#!/usr/bin/env python to first line of script\n\nmark it executable using\n\n### need to change permissions too!\n$ chmod +x main.py",
"_____no_output_____"
],
[
"## Making Standalone .EXEs for Python in Windows \n\n* http://www.py2exe.org/ used to be for Python 2 , now supposedly Python 3 as well\n* http://www.pyinstaller.org/\n Tutorial: https://medium.com/dreamcatcher-its-blog/making-an-stand-alone-executable-from-a-python-script-using-pyinstaller-d1df9170e263\n\n Need to create exe on a similar system as target system! ",
"_____no_output_____"
]
],
[
[
"# Exercise Write a function which returns a list of fibonacci numbers up to starting with 1, 1, 2, 3, 5 up to the nth.\nSo Fib(4) would return [1,1,2,3]",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"%%writefile fibo.py\n# Fibonacci numbers module\n\ndef fib(n): # write Fibonacci series up to n\n a, b = 1 1\n while b < n:\n print(b, end=' ')\n a, b = b, a+b\n print()\n\ndef fib2(n): # return Fibonacci series up to n\n result = []\n a, b = 1, 1\n while b < n:\n result.append(b)\n a, b = b, a+b\n return result",
"Writing fibo.py\n"
],
[
"import fibo",
"_____no_output_____"
],
[
"fibo.fib(100)",
"1 1 2 3 5 8 13 21 34 55 89 \n"
],
[
"fibo.fib2(100)",
"_____no_output_____"
],
[
"fib=fibo.fib",
"_____no_output_____"
]
],
[
[
"If you intend to use a function often you can assign it to a local name:",
"_____no_output_____"
]
],
[
[
"fib(300)",
"1 1 2 3 5 8 13 21 34 55 89 144 233 \n"
]
],
[
[
"#### There is a variant of the import statement that imports names from a module directly into the importing module’s symbol table. ",
"_____no_output_____"
]
],
[
[
"from fibo import fib, fib2 # we overwrote fib=fibo.fib",
"_____no_output_____"
],
[
"fib(100)",
"1 1 2 3 5 8 13 21 34 55 89 \n"
],
[
"fib2(200)",
"_____no_output_____"
]
],
[
[
"This does not introduce the module name from which the imports are taken in the local symbol table (so in the example, fibo is not defined).",
"_____no_output_____"
],
[
"There is even a variant to import all names that a module defines: **NOT RECOMMENDED**",
"_____no_output_____"
]
],
[
[
"## DO not do this Namespace collission possible!!",
"_____no_output_____"
],
[
"from fibo import *",
"_____no_output_____"
],
[
"fib(400)",
"1 1 2 3 5 8 13 21 34 55 89 144 233 377 \n"
]
],
[
[
"### If the module name is followed by as, then the name following as is bound directly to the imported module.",
"_____no_output_____"
]
],
[
[
"import fibo as fib",
"_____no_output_____"
],
[
"dir(fib)",
"_____no_output_____"
],
[
"fib.fib(50)",
"1 1 2 3 5 8 13 21 34 \n"
],
[
"### It can also be used when utilising from with similar effects:",
"_____no_output_____"
],
[
" from fibo import fib as fibonacci",
"_____no_output_____"
],
[
"fibonacci(200)",
"1 1 2 3 5 8 13 21 34 55 89 144 \n"
]
],
[
[
"### Executing modules as scripts¶",
"_____no_output_____"
],
[
"When you run a Python module with\n\npython fibo.py <arguments>\n \nthe code in the module will be executed, just as if you imported it, but with the \\_\\_name\\_\\_ set to \"\\_\\_main\\_\\_\". That means that by adding this code at the end of your module:",
"_____no_output_____"
]
],
[
[
"%%writefile fibbo.py \n \n# Fibonacci numbers module\n\ndef fib(n): # write Fibonacci series up to n\n a, b = 0, 1\n while b < n:\n print(b, end=' ')\n a, b = b, a+b\n print()\n\ndef fib2(n): # return Fibonacci series up to n\n result = []\n a, b = 0, 1\n while b < n:\n result.append(b)\n a, b = b, a+b\n return result\n\nif __name__ == \"__main__\":\n import sys\n fib(int(sys.argv[1], 10))",
"Overwriting fibbo.py\n"
],
[
"import fibbo as fi\nfi.fib(200)",
"1 1 2 3 5 8 13 21 34 55 89 144 \n"
]
],
[
[
"#### This is often used either to provide a convenient user interface to a module, or for testing purposes (running the module as a script executes a test suite).",
"_____no_output_____"
],
[
"### The Module Search Path\n\nWhen a module named spam is imported, the interpreter first searches for a built-in module with that name. If not found, it then searches for a file named spam.py in a list of directories given by the variable sys.path. sys.path is initialized from these locations:\n\n* The directory containing the input script (or the current directory when no file is specified).\n* PYTHONPATH (a list of directory names, with the same syntax as the shell variable PATH).\n* The installation-dependent default.",
"_____no_output_____"
],
[
"Packages are a way of structuring Python’s module namespace by using “dotted module names”. For example, the module name A.B designates a submodule named B in a package named A. Just like the use of modules saves the authors of different modules from having to worry about each other’s global variable names, the use of dotted module names saves the authors of multi-module packages like NumPy or Pillow from having to worry about each other’s module names.",
"_____no_output_____"
]
],
[
[
"sound/ Top-level package\n __init__.py Initialize the sound package\n formats/ Subpackage for file format conversions\n __init__.py\n wavread.py\n wavwrite.py\n aiffread.py\n aiffwrite.py\n auread.py\n auwrite.py\n ...\n effects/ Subpackage for sound effects\n __init__.py\n echo.py\n surround.py\n reverse.py\n ...\n filters/ Subpackage for filters\n __init__.py\n equalizer.py\n vocoder.py\n karaoke.py\n ...",
"_____no_output_____"
]
],
[
[
"The \\_\\_init\\_\\_.py files are required to make Python treat the directories as containing packages; this is done to prevent directories with a common name, such as string, from unintentionally hiding valid modules that occur later on the module search path. In the simplest case, \\_\\_init\\_\\_.py can just be an empty file",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
d060798bb49284e8cdc2d12caf2fd61bd056185e | 237,327 | ipynb | Jupyter Notebook | notebooks/testing_multitask.ipynb | GJBoth/MultiTaskPINN | 8a9bb23b8bfc0d0f678090e015316dbd0cfbf024 | [
"MIT"
]
| null | null | null | notebooks/testing_multitask.ipynb | GJBoth/MultiTaskPINN | 8a9bb23b8bfc0d0f678090e015316dbd0cfbf024 | [
"MIT"
]
| null | null | null | notebooks/testing_multitask.ipynb | GJBoth/MultiTaskPINN | 8a9bb23b8bfc0d0f678090e015316dbd0cfbf024 | [
"MIT"
]
| 1 | 2022-02-24T04:27:25.000Z | 2022-02-24T04:27:25.000Z | 40.72186 | 198 | 0.505539 | [
[
[
"# General imports\nimport numpy as np\nimport torch\n\n# DeepMoD stuff\nfrom multitaskpinn import DeepMoD\nfrom multitaskpinn.model.func_approx import NN\nfrom multitaskpinn.model.library import Library1D\nfrom multitaskpinn.model.constraint import LeastSquares\nfrom multitaskpinn.model.sparse_estimators import Threshold\nfrom multitaskpinn.training import train, train_multitask\nfrom multitaskpinn.training.sparsity_scheduler import TrainTestPeriodic\n\nfrom phimal_utilities.data import Dataset\nfrom phimal_utilities.data.burgers import BurgersDelta\n\nif torch.cuda.is_available():\n device ='cuda'\nelse:\n device = 'cpu'\ndevice = 'cpu'\n\n# Settings for reproducibility\nnp.random.seed(0)\ntorch.manual_seed(0)\ntorch.backends.cudnn.deterministic = True\ntorch.backends.cudnn.benchmark = False\n\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"device",
"_____no_output_____"
],
[
"# Making dataset\nv = 0.1\nA = 1.0\n\nx = np.linspace(-3, 4, 100)\nt = np.linspace(0.5, 5.0, 50)\nx_grid, t_grid = np.meshgrid(x, t, indexing='ij')\ndataset = Dataset(BurgersDelta, v=v, A=A)\n\nX, y = dataset.create_dataset(x_grid.reshape(-1, 1), t_grid.reshape(-1, 1), n_samples=1000, noise=0.2, random=True, normalize=False)\nX, y = X.to(device), y.to(device)",
"_____no_output_____"
],
[
"network = NN(2, [30, 30, 30, 30, 30], 1)\nlibrary = Library1D(poly_order=2, diff_order=3) # Library function\nestimator = Threshold(0.1) # Sparse estimator \nconstraint = LeastSquares() # How to constrain\nmodel = DeepMoD(network, library, estimator, constraint).to(device) # Putting it all in the model",
"_____no_output_____"
],
[
"sparsity_scheduler = TrainTestPeriodic(patience=8, delta=1e-5, periodicity=50)\noptimizer = torch.optim.Adam(model.parameters(), betas=(0.99, 0.999), amsgrad=True, lr=2e-3) # Defining optimizer",
"_____no_output_____"
],
[
"train_multitask(model, X, y, optimizer, sparsity_scheduler, write_iterations=25, log_dir='runs/testing_multitask_unnormalized/', max_iterations=15000, delta=1e-3, patience=8) # Running",
"| Iteration | Progress | Time remaining | Loss | MSE | Reg | L1 norm |\n 2150 14.33% 396s -1.56e+01 1.40e-03 1.12e-07 1.55e+00 Algorithm converged. Stopping training.\n"
],
[
"network = NN(2, [30, 30, 30, 30, 30], 1)\nlibrary = Library1D(poly_order=2, diff_order=3) # Library function\nestimator = Threshold(0.1) # Sparse estimator \nconstraint = LeastSquares() # How to constrain\nmodel = DeepMoD(network, library, estimator, constraint).to(device) # Putting it all in the model",
"_____no_output_____"
],
[
"sparsity_scheduler = TrainTestPeriodic(patience=8, delta=1e-5, periodicity=50)\noptimizer = torch.optim.Adam(model.parameters(), betas=(0.99, 0.999), amsgrad=True, lr=2e-3) # Defining optimizer",
"_____no_output_____"
],
[
"train(model, X, y, optimizer, sparsity_scheduler, write_iterations=25, log_dir='runs/testing_normal_unnormalized/', max_iterations=15000, delta=1e-3, patience=8) # Running",
"| Iteration | Progress | Time remaining | Loss | MSE | Reg | L1 norm |\n 11300 75.33% 108s 1.38e-03 1.36e-03 1.72e-05 1.63e+00 Algorithm converged. Stopping training.\n"
]
],
[
[
"# Quick analysis",
"_____no_output_____"
]
],
[
[
"from phimal_utilities.analysis import Results\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set(context='notebook', style='white')\n\n%config InlineBackend.figure_format = 'svg'",
"_____no_output_____"
],
[
"data_mt = Results('runs/testing_multitask_unnormalized//')\ndata_bl = Results('runs/testing_normal_unnormalized//')\n\nkeys = data_mt.keys",
"_____no_output_____"
],
[
"fig, axes = plt.subplots(figsize=(10, 3), constrained_layout=True, ncols=2)\n\nax = axes[0]\nax.semilogy(data_bl.df.index, data_bl.df[keys['mse']], label='Baseline')\nax.semilogy(data_mt.df.index, data_mt.df[keys['mse']], label='Multitask')\nax.set_title('MSE')\nax.set_xlabel('Epoch', weight='bold')\nax.set_ylabel('Cost', weight='bold')\nax.legend()\n#ax.set_xlim([0, 8000])\n\n\nax = axes[1]\nax.semilogy(data_bl.df.index, data_bl.df[keys['reg']], label='Baseline')\nax.semilogy(data_mt.df.index, data_mt.df[keys['reg']], label='Multitask')\nax.set_title('Regression')\nax.set_xlabel('Epoch', weight='bold')\nax.set_ylabel('Cost', weight='bold')\nax.legend()\n#ax.set_xlim([0, 8000])\n\nfig.show()",
"_____no_output_____"
],
[
"fig, axes = plt.subplots(ncols=3, constrained_layout=True, figsize=(15, 4))\n\nax = axes[0]\nax.plot(data_bl.df.index, data_bl.df[keys['coeffs']])\nax.plot(data_bl.df.index, data_bl.df[keys['coeffs'][2]], lw=3)\nax.plot(data_bl.df.index, data_bl.df[keys['coeffs'][5]], lw=3)\nax.set_ylim([-2, 2])\nax.set_title('Coefficients baseline')\nax.set_xlabel('Epoch', weight='bold')\nax.set_ylabel('Cost', weight='bold')\n#ax.set_xlim([0, 8000])\n\nax = axes[1]\nax.plot(data_mt.df.index, data_mt.df[keys['coeffs']])\nax.plot(data_mt.df.index, data_mt.df[keys['coeffs'][2]], lw=3)\nax.plot(data_mt.df.index, data_mt.df[keys['coeffs'][5]], lw=3)\nax.set_ylim([-2, 2])\nax.set_title('Coefficients Multitask')\nax.set_xlabel('Epoch', weight='bold')\nax.set_ylabel('Cost', weight='bold')\n#ax.set_xlim([0, 8000])\n\nax = axes[2]\ntrue_coeffs = np.zeros(len(keys['unscaled_coeffs']))\ntrue_coeffs[2] = 0.1\ntrue_coeffs[5] = -1\n\nax.semilogy(data_bl.df.index, np.mean(np.abs(data_bl.df[keys['unscaled_coeffs']] - true_coeffs), axis=1), label='Baseline')\nax.semilogy(data_mt.df.index, np.mean(np.abs(data_mt.df[keys['unscaled_coeffs']] - true_coeffs), axis=1), label='Baseline')\nax.set_ylim([-5, 2])\nax.legend()\n\nfig.show()",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
d06079be15478f4e2f794b8f7c80c271870f6724 | 47,640 | ipynb | Jupyter Notebook | notebook/pytorch/nn_tutorial.ipynb | mengwangk/myinvestor-toolkit | 3dca9e1accfccf1583dcdbec80d1a0fe9dae2e81 | [
"MIT"
]
| 7 | 2019-10-13T18:58:33.000Z | 2021-08-07T12:46:22.000Z | notebook/pytorch/nn_tutorial.ipynb | mengwangk/myinvestor-toolkit | 3dca9e1accfccf1583dcdbec80d1a0fe9dae2e81 | [
"MIT"
]
| 7 | 2019-12-16T21:25:34.000Z | 2022-02-10T00:11:22.000Z | notebook/pytorch/nn_tutorial.ipynb | mengwangk/myinvestor-toolkit | 3dca9e1accfccf1583dcdbec80d1a0fe9dae2e81 | [
"MIT"
]
| 4 | 2020-02-01T11:23:51.000Z | 2021-12-13T12:27:18.000Z | 29.849624 | 124 | 0.558858 | [
[
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"\nWhat is `torch.nn` *really*?\n============================\nby Jeremy Howard, `fast.ai <https://www.fast.ai>`_. Thanks to Rachel Thomas and Francisco Ingham.\n\n",
"_____no_output_____"
],
[
"We recommend running this tutorial as a notebook, not a script. To download the notebook (.ipynb) file,\nclick `here <https://pytorch.org/tutorials/beginner/nn_tutorial.html#sphx-glr-download-beginner-nn-tutorial-py>`_ .\n\nPyTorch provides the elegantly designed modules and classes `torch.nn <https://pytorch.org/docs/stable/nn.html>`_ ,\n`torch.optim <https://pytorch.org/docs/stable/optim.html>`_ ,\n`Dataset <https://pytorch.org/docs/stable/data.html?highlight=dataset#torch.utils.data.Dataset>`_ ,\nand `DataLoader <https://pytorch.org/docs/stable/data.html?highlight=dataloader#torch.utils.data.DataLoader>`_\nto help you create and train neural networks.\nIn order to fully utilize their power and customize\nthem for your problem, you need to really understand exactly what they're\ndoing. To develop this understanding, we will first train basic neural net\non the MNIST data set without using any features from these models; we will\ninitially only use the most basic PyTorch tensor functionality. Then, we will\nincrementally add one feature from ``torch.nn``, ``torch.optim``, ``Dataset``, or\n``DataLoader`` at a time, showing exactly what each piece does, and how it\nworks to make the code either more concise, or more flexible.\n\n**This tutorial assumes you already have PyTorch installed, and are familiar\nwith the basics of tensor operations.** (If you're familiar with Numpy array\noperations, you'll find the PyTorch tensor operations used here nearly identical).\n\nMNIST data setup\n----------------\n\nWe will use the classic `MNIST <http://deeplearning.net/data/mnist/>`_ dataset,\nwhich consists of black-and-white images of hand-drawn digits (between 0 and 9).\n\nWe will use `pathlib <https://docs.python.org/3/library/pathlib.html>`_\nfor dealing with paths (part of the Python 3 standard library), and will\ndownload the dataset using\n`requests <http://docs.python-requests.org/en/master/>`_. We will only\nimport modules when we use them, so you can see exactly what's being\nused at each point.\n\n",
"_____no_output_____"
]
],
[
[
"from pathlib import Path\nimport requests\n\nDATA_PATH = Path(\"data\")\nPATH = DATA_PATH / \"mnist\"\n\nPATH.mkdir(parents=True, exist_ok=True)\n\nURL = \"http://deeplearning.net/data/mnist/\"\nFILENAME = \"mnist.pkl.gz\"\n\nif not (PATH / FILENAME).exists():\n content = requests.get(URL + FILENAME).content\n (PATH / FILENAME).open(\"wb\").write(content)",
"_____no_output_____"
]
],
[
[
"This dataset is in numpy array format, and has been stored using pickle,\na python-specific format for serializing data.\n\n",
"_____no_output_____"
]
],
[
[
"import pickle\nimport gzip\n\nwith gzip.open((PATH / FILENAME).as_posix(), \"rb\") as f:\n ((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding=\"latin-1\")",
"_____no_output_____"
]
],
[
[
"Each image is 28 x 28, and is being stored as a flattened row of length\n784 (=28x28). Let's take a look at one; we need to reshape it to 2d\nfirst.\n\n",
"_____no_output_____"
]
],
[
[
"from matplotlib import pyplot\nimport numpy as np\n\npyplot.imshow(x_train[0].reshape((28, 28)), cmap=\"gray\")\nprint(x_train.shape)",
"_____no_output_____"
]
],
[
[
"PyTorch uses ``torch.tensor``, rather than numpy arrays, so we need to\nconvert our data.\n\n",
"_____no_output_____"
]
],
[
[
"import torch\n\nx_train, y_train, x_valid, y_valid = map(\n torch.tensor, (x_train, y_train, x_valid, y_valid)\n)\nn, c = x_train.shape\nx_train, x_train.shape, y_train.min(), y_train.max()\nprint(x_train, y_train)\nprint(x_train.shape)\nprint(y_train.min(), y_train.max())",
"_____no_output_____"
]
],
[
[
"Neural net from scratch (no torch.nn)\n---------------------------------------------\n\nLet's first create a model using nothing but PyTorch tensor operations. We're assuming\nyou're already familiar with the basics of neural networks. (If you're not, you can\nlearn them at `course.fast.ai <https://course.fast.ai>`_).\n\nPyTorch provides methods to create random or zero-filled tensors, which we will\nuse to create our weights and bias for a simple linear model. These are just regular\ntensors, with one very special addition: we tell PyTorch that they require a\ngradient. This causes PyTorch to record all of the operations done on the tensor,\nso that it can calculate the gradient during back-propagation *automatically*!\n\nFor the weights, we set ``requires_grad`` **after** the initialization, since we\ndon't want that step included in the gradient. (Note that a trailling ``_`` in\nPyTorch signifies that the operation is performed in-place.)\n\n<div class=\"alert alert-info\"><h4>Note</h4><p>We are initializing the weights here with\n `Xavier initialisation <http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf>`_\n (by multiplying with 1/sqrt(n)).</p></div>\n\n",
"_____no_output_____"
]
],
[
[
"import math\n\nweights = torch.randn(784, 10) / math.sqrt(784)\nweights.requires_grad_()\nbias = torch.zeros(10, requires_grad=True)",
"_____no_output_____"
]
],
[
[
"Thanks to PyTorch's ability to calculate gradients automatically, we can\nuse any standard Python function (or callable object) as a model! So\nlet's just write a plain matrix multiplication and broadcasted addition\nto create a simple linear model. We also need an activation function, so\nwe'll write `log_softmax` and use it. Remember: although PyTorch\nprovides lots of pre-written loss functions, activation functions, and\nso forth, you can easily write your own using plain python. PyTorch will\neven create fast GPU or vectorized CPU code for your function\nautomatically.\n\n",
"_____no_output_____"
]
],
[
[
"def log_softmax(x):\n return x - x.exp().sum(-1).log().unsqueeze(-1)\n\ndef model(xb):\n return log_softmax(xb @ weights + bias)",
"_____no_output_____"
]
],
[
[
"In the above, the ``@`` stands for the dot product operation. We will call\nour function on one batch of data (in this case, 64 images). This is\none *forward pass*. Note that our predictions won't be any better than\nrandom at this stage, since we start with random weights.\n\n",
"_____no_output_____"
]
],
[
[
"bs = 64 # batch size\n\nxb = x_train[0:bs] # a mini-batch from x\npreds = model(xb) # predictions\npreds[0], preds.shape\nprint(preds[0], preds.shape)",
"_____no_output_____"
]
],
[
[
"As you see, the ``preds`` tensor contains not only the tensor values, but also a\ngradient function. We'll use this later to do backprop.\n\nLet's implement negative log-likelihood to use as the loss function\n(again, we can just use standard Python):\n\n",
"_____no_output_____"
]
],
[
[
"def nll(input, target):\n return -input[range(target.shape[0]), target].mean()\n\nloss_func = nll",
"_____no_output_____"
]
],
[
[
"Let's check our loss with our random model, so we can see if we improve\nafter a backprop pass later.\n\n",
"_____no_output_____"
]
],
[
[
"yb = y_train[0:bs]\nprint(loss_func(preds, yb))",
"_____no_output_____"
]
],
[
[
"Let's also implement a function to calculate the accuracy of our model.\nFor each prediction, if the index with the largest value matches the\ntarget value, then the prediction was correct.\n\n",
"_____no_output_____"
]
],
[
[
"def accuracy(out, yb):\n preds = torch.argmax(out, dim=1)\n return (preds == yb).float().mean()",
"_____no_output_____"
]
],
[
[
"Let's check the accuracy of our random model, so we can see if our\naccuracy improves as our loss improves.\n\n",
"_____no_output_____"
]
],
[
[
"print(accuracy(preds, yb))",
"_____no_output_____"
]
],
[
[
"We can now run a training loop. For each iteration, we will:\n\n- select a mini-batch of data (of size ``bs``)\n- use the model to make predictions\n- calculate the loss\n- ``loss.backward()`` updates the gradients of the model, in this case, ``weights``\n and ``bias``.\n\nWe now use these gradients to update the weights and bias. We do this\nwithin the ``torch.no_grad()`` context manager, because we do not want these\nactions to be recorded for our next calculation of the gradient. You can read\nmore about how PyTorch's Autograd records operations\n`here <https://pytorch.org/docs/stable/notes/autograd.html>`_.\n\nWe then set the\ngradients to zero, so that we are ready for the next loop.\nOtherwise, our gradients would record a running tally of all the operations\nthat had happened (i.e. ``loss.backward()`` *adds* the gradients to whatever is\nalready stored, rather than replacing them).\n\n.. tip:: You can use the standard python debugger to step through PyTorch\n code, allowing you to check the various variable values at each step.\n Uncomment ``set_trace()`` below to try it out.\n\n\n",
"_____no_output_____"
]
],
[
[
"from IPython.core.debugger import set_trace\n\nlr = 0.5 # learning rate\nepochs = 2 # how many epochs to train for\n\nfor epoch in range(epochs):\n for i in range((n - 1) // bs + 1):\n # set_trace()\n start_i = i * bs\n end_i = start_i + bs\n xb = x_train[start_i:end_i]\n yb = y_train[start_i:end_i]\n pred = model(xb)\n loss = loss_func(pred, yb)\n\n loss.backward()\n with torch.no_grad():\n weights -= weights.grad * lr\n bias -= bias.grad * lr\n weights.grad.zero_()\n bias.grad.zero_()",
"_____no_output_____"
]
],
[
[
"That's it: we've created and trained a minimal neural network (in this case, a\nlogistic regression, since we have no hidden layers) entirely from scratch!\n\nLet's check the loss and accuracy and compare those to what we got\nearlier. We expect that the loss will have decreased and accuracy to\nhave increased, and they have.\n\n",
"_____no_output_____"
]
],
[
[
"print(loss_func(model(xb), yb), accuracy(model(xb), yb))",
"_____no_output_____"
]
],
[
[
"Using torch.nn.functional\n------------------------------\n\nWe will now refactor our code, so that it does the same thing as before, only\nwe'll start taking advantage of PyTorch's ``nn`` classes to make it more concise\nand flexible. At each step from here, we should be making our code one or more\nof: shorter, more understandable, and/or more flexible.\n\nThe first and easiest step is to make our code shorter by replacing our\nhand-written activation and loss functions with those from ``torch.nn.functional``\n(which is generally imported into the namespace ``F`` by convention). This module\ncontains all the functions in the ``torch.nn`` library (whereas other parts of the\nlibrary contain classes). As well as a wide range of loss and activation\nfunctions, you'll also find here some convenient functions for creating neural\nnets, such as pooling functions. (There are also functions for doing convolutions,\nlinear layers, etc, but as we'll see, these are usually better handled using\nother parts of the library.)\n\nIf you're using negative log likelihood loss and log softmax activation,\nthen Pytorch provides a single function ``F.cross_entropy`` that combines\nthe two. So we can even remove the activation function from our model.\n\n",
"_____no_output_____"
]
],
[
[
"import torch.nn.functional as F\n\nloss_func = F.cross_entropy\n\ndef model(xb):\n return xb @ weights + bias",
"_____no_output_____"
]
],
[
[
"Note that we no longer call ``log_softmax`` in the ``model`` function. Let's\nconfirm that our loss and accuracy are the same as before:\n\n",
"_____no_output_____"
]
],
[
[
"print(loss_func(model(xb), yb), accuracy(model(xb), yb))",
"_____no_output_____"
]
],
[
[
"Refactor using nn.Module\n-----------------------------\nNext up, we'll use ``nn.Module`` and ``nn.Parameter``, for a clearer and more\nconcise training loop. We subclass ``nn.Module`` (which itself is a class and\nable to keep track of state). In this case, we want to create a class that\nholds our weights, bias, and method for the forward step. ``nn.Module`` has a\nnumber of attributes and methods (such as ``.parameters()`` and ``.zero_grad()``)\nwhich we will be using.\n\n<div class=\"alert alert-info\"><h4>Note</h4><p>``nn.Module`` (uppercase M) is a PyTorch specific concept, and is a\n class we'll be using a lot. ``nn.Module`` is not to be confused with the Python\n concept of a (lowercase ``m``) `module <https://docs.python.org/3/tutorial/modules.html>`_,\n which is a file of Python code that can be imported.</p></div>\n\n",
"_____no_output_____"
]
],
[
[
"from torch import nn\n\nclass Mnist_Logistic(nn.Module):\n def __init__(self):\n super().__init__()\n self.weights = nn.Parameter(torch.randn(784, 10) / math.sqrt(784))\n self.bias = nn.Parameter(torch.zeros(10))\n\n def forward(self, xb):\n return xb @ self.weights + self.bias",
"_____no_output_____"
]
],
[
[
"Since we're now using an object instead of just using a function, we\nfirst have to instantiate our model:\n\n",
"_____no_output_____"
]
],
[
[
"model = Mnist_Logistic()",
"_____no_output_____"
]
],
[
[
"Now we can calculate the loss in the same way as before. Note that\n``nn.Module`` objects are used as if they are functions (i.e they are\n*callable*), but behind the scenes Pytorch will call our ``forward``\nmethod automatically.\n\n",
"_____no_output_____"
]
],
[
[
"print(loss_func(model(xb), yb))",
"_____no_output_____"
]
],
[
[
"Previously for our training loop we had to update the values for each parameter\nby name, and manually zero out the grads for each parameter separately, like this:\n::\n with torch.no_grad():\n weights -= weights.grad * lr\n bias -= bias.grad * lr\n weights.grad.zero_()\n bias.grad.zero_()\n\n\nNow we can take advantage of model.parameters() and model.zero_grad() (which\nare both defined by PyTorch for ``nn.Module``) to make those steps more concise\nand less prone to the error of forgetting some of our parameters, particularly\nif we had a more complicated model:\n::\n with torch.no_grad():\n for p in model.parameters(): p -= p.grad * lr\n model.zero_grad()\n\n\nWe'll wrap our little training loop in a ``fit`` function so we can run it\nagain later.\n\n",
"_____no_output_____"
]
],
[
[
"def fit():\n for epoch in range(epochs):\n for i in range((n - 1) // bs + 1):\n start_i = i * bs\n end_i = start_i + bs\n xb = x_train[start_i:end_i]\n yb = y_train[start_i:end_i]\n pred = model(xb)\n loss = loss_func(pred, yb)\n\n loss.backward()\n with torch.no_grad():\n for p in model.parameters():\n p -= p.grad * lr\n model.zero_grad()\n\nfit()",
"_____no_output_____"
]
],
[
[
"Let's double-check that our loss has gone down:\n\n",
"_____no_output_____"
]
],
[
[
"print(loss_func(model(xb), yb))",
"_____no_output_____"
]
],
[
[
"Refactor using nn.Linear\n-------------------------\n\nWe continue to refactor our code. Instead of manually defining and\ninitializing ``self.weights`` and ``self.bias``, and calculating ``xb @\nself.weights + self.bias``, we will instead use the Pytorch class\n`nn.Linear <https://pytorch.org/docs/stable/nn.html#linear-layers>`_ for a\nlinear layer, which does all that for us. Pytorch has many types of\npredefined layers that can greatly simplify our code, and often makes it\nfaster too.\n\n",
"_____no_output_____"
]
],
[
[
"class Mnist_Logistic(nn.Module):\n def __init__(self):\n super().__init__()\n self.lin = nn.Linear(784, 10)\n\n def forward(self, xb):\n return self.lin(xb)",
"_____no_output_____"
]
],
[
[
"We instantiate our model and calculate the loss in the same way as before:\n\n",
"_____no_output_____"
]
],
[
[
"model = Mnist_Logistic()\nprint(loss_func(model(xb), yb))",
"_____no_output_____"
]
],
[
[
"We are still able to use our same ``fit`` method as before.\n\n",
"_____no_output_____"
]
],
[
[
"fit()\n\nprint(loss_func(model(xb), yb))",
"_____no_output_____"
]
],
[
[
"Refactor using optim\n------------------------------\n\nPytorch also has a package with various optimization algorithms, ``torch.optim``.\nWe can use the ``step`` method from our optimizer to take a forward step, instead\nof manually updating each parameter.\n\nThis will let us replace our previous manually coded optimization step:\n::\n with torch.no_grad():\n for p in model.parameters(): p -= p.grad * lr\n model.zero_grad()\n\nand instead use just:\n::\n opt.step()\n opt.zero_grad()\n\n(``optim.zero_grad()`` resets the gradient to 0 and we need to call it before\ncomputing the gradient for the next minibatch.)\n\n",
"_____no_output_____"
]
],
[
[
"from torch import optim",
"_____no_output_____"
]
],
[
[
"We'll define a little function to create our model and optimizer so we\ncan reuse it in the future.\n\n",
"_____no_output_____"
]
],
[
[
"def get_model():\n model = Mnist_Logistic()\n return model, optim.SGD(model.parameters(), lr=lr)\n\nmodel, opt = get_model()\nprint(loss_func(model(xb), yb))\n\nfor epoch in range(epochs):\n for i in range((n - 1) // bs + 1):\n start_i = i * bs\n end_i = start_i + bs\n xb = x_train[start_i:end_i]\n yb = y_train[start_i:end_i]\n pred = model(xb)\n loss = loss_func(pred, yb)\n\n loss.backward()\n opt.step()\n opt.zero_grad()\n\nprint(loss_func(model(xb), yb))",
"_____no_output_____"
]
],
[
[
"Refactor using Dataset\n------------------------------\n\nPyTorch has an abstract Dataset class. A Dataset can be anything that has\na ``__len__`` function (called by Python's standard ``len`` function) and\na ``__getitem__`` function as a way of indexing into it.\n`This tutorial <https://pytorch.org/tutorials/beginner/data_loading_tutorial.html>`_\nwalks through a nice example of creating a custom ``FacialLandmarkDataset`` class\nas a subclass of ``Dataset``.\n\nPyTorch's `TensorDataset <https://pytorch.org/docs/stable/_modules/torch/utils/data/dataset.html#TensorDataset>`_\nis a Dataset wrapping tensors. By defining a length and way of indexing,\nthis also gives us a way to iterate, index, and slice along the first\ndimension of a tensor. This will make it easier to access both the\nindependent and dependent variables in the same line as we train.\n\n",
"_____no_output_____"
]
],
[
[
"from torch.utils.data import TensorDataset",
"_____no_output_____"
]
],
[
[
"Both ``x_train`` and ``y_train`` can be combined in a single ``TensorDataset``,\nwhich will be easier to iterate over and slice.\n\n",
"_____no_output_____"
]
],
[
[
"train_ds = TensorDataset(x_train, y_train)",
"_____no_output_____"
]
],
[
[
"Previously, we had to iterate through minibatches of x and y values separately:\n::\n xb = x_train[start_i:end_i]\n yb = y_train[start_i:end_i]\n\n\nNow, we can do these two steps together:\n::\n xb,yb = train_ds[i*bs : i*bs+bs]\n\n\n",
"_____no_output_____"
]
],
[
[
"model, opt = get_model()\n\nfor epoch in range(epochs):\n for i in range((n - 1) // bs + 1):\n xb, yb = train_ds[i * bs: i * bs + bs]\n pred = model(xb)\n loss = loss_func(pred, yb)\n\n loss.backward()\n opt.step()\n opt.zero_grad()\n\nprint(loss_func(model(xb), yb))",
"_____no_output_____"
]
],
[
[
"Refactor using DataLoader\n------------------------------\n\nPytorch's ``DataLoader`` is responsible for managing batches. You can\ncreate a ``DataLoader`` from any ``Dataset``. ``DataLoader`` makes it easier\nto iterate over batches. Rather than having to use ``train_ds[i*bs : i*bs+bs]``,\nthe DataLoader gives us each minibatch automatically.\n\n",
"_____no_output_____"
]
],
[
[
"from torch.utils.data import DataLoader\n\ntrain_ds = TensorDataset(x_train, y_train)\ntrain_dl = DataLoader(train_ds, batch_size=bs)",
"_____no_output_____"
]
],
[
[
"Previously, our loop iterated over batches (xb, yb) like this:\n::\n for i in range((n-1)//bs + 1):\n xb,yb = train_ds[i*bs : i*bs+bs]\n pred = model(xb)\n\nNow, our loop is much cleaner, as (xb, yb) are loaded automatically from the data loader:\n::\n for xb,yb in train_dl:\n pred = model(xb)\n\n",
"_____no_output_____"
]
],
[
[
"model, opt = get_model()\n\nfor epoch in range(epochs):\n for xb, yb in train_dl:\n pred = model(xb)\n loss = loss_func(pred, yb)\n\n loss.backward()\n opt.step()\n opt.zero_grad()\n\nprint(loss_func(model(xb), yb))",
"_____no_output_____"
]
],
[
[
"Thanks to Pytorch's ``nn.Module``, ``nn.Parameter``, ``Dataset``, and ``DataLoader``,\nour training loop is now dramatically smaller and easier to understand. Let's\nnow try to add the basic features necessary to create effecive models in practice.\n\nAdd validation\n-----------------------\n\nIn section 1, we were just trying to get a reasonable training loop set up for\nuse on our training data. In reality, you **always** should also have\na `validation set <https://www.fast.ai/2017/11/13/validation-sets/>`_, in order\nto identify if you are overfitting.\n\nShuffling the training data is\n`important <https://www.quora.com/Does-the-order-of-training-data-matter-when-training-neural-networks>`_\nto prevent correlation between batches and overfitting. On the other hand, the\nvalidation loss will be identical whether we shuffle the validation set or not.\nSince shuffling takes extra time, it makes no sense to shuffle the validation data.\n\nWe'll use a batch size for the validation set that is twice as large as\nthat for the training set. This is because the validation set does not\nneed backpropagation and thus takes less memory (it doesn't need to\nstore the gradients). We take advantage of this to use a larger batch\nsize and compute the loss more quickly.\n\n",
"_____no_output_____"
]
],
[
[
"train_ds = TensorDataset(x_train, y_train)\ntrain_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)\n\nvalid_ds = TensorDataset(x_valid, y_valid)\nvalid_dl = DataLoader(valid_ds, batch_size=bs * 2)",
"_____no_output_____"
]
],
[
[
"We will calculate and print the validation loss at the end of each epoch.\n\n(Note that we always call ``model.train()`` before training, and ``model.eval()``\nbefore inference, because these are used by layers such as ``nn.BatchNorm2d``\nand ``nn.Dropout`` to ensure appropriate behaviour for these different phases.)\n\n",
"_____no_output_____"
]
],
[
[
"model, opt = get_model()\n\nfor epoch in range(epochs):\n model.train()\n for xb, yb in train_dl:\n pred = model(xb)\n loss = loss_func(pred, yb)\n\n loss.backward()\n opt.step()\n opt.zero_grad()\n\n model.eval()\n with torch.no_grad():\n valid_loss = sum(loss_func(model(xb), yb) for xb, yb in valid_dl)\n\n print(epoch, valid_loss / len(valid_dl))",
"_____no_output_____"
]
],
[
[
"Create fit() and get_data()\n----------------------------------\n\nWe'll now do a little refactoring of our own. Since we go through a similar\nprocess twice of calculating the loss for both the training set and the\nvalidation set, let's make that into its own function, ``loss_batch``, which\ncomputes the loss for one batch.\n\nWe pass an optimizer in for the training set, and use it to perform\nbackprop. For the validation set, we don't pass an optimizer, so the\nmethod doesn't perform backprop.\n\n",
"_____no_output_____"
]
],
[
[
"def loss_batch(model, loss_func, xb, yb, opt=None):\n loss = loss_func(model(xb), yb)\n\n if opt is not None:\n loss.backward()\n opt.step()\n opt.zero_grad()\n\n return loss.item(), len(xb)",
"_____no_output_____"
]
],
[
[
"``fit`` runs the necessary operations to train our model and compute the\ntraining and validation losses for each epoch.\n\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\ndef fit(epochs, model, loss_func, opt, train_dl, valid_dl):\n for epoch in range(epochs):\n model.train()\n for xb, yb in train_dl:\n loss_batch(model, loss_func, xb, yb, opt)\n\n model.eval()\n with torch.no_grad():\n losses, nums = zip(\n *[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl]\n )\n val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)\n\n print(epoch, val_loss)",
"_____no_output_____"
]
],
[
[
"``get_data`` returns dataloaders for the training and validation sets.\n\n",
"_____no_output_____"
]
],
[
[
"def get_data(train_ds, valid_ds, bs):\n return (\n DataLoader(train_ds, batch_size=bs, shuffle=True),\n DataLoader(valid_ds, batch_size=bs * 2),\n )",
"_____no_output_____"
]
],
[
[
"Now, our whole process of obtaining the data loaders and fitting the\nmodel can be run in 3 lines of code:\n\n",
"_____no_output_____"
]
],
[
[
"train_dl, valid_dl = get_data(train_ds, valid_ds, bs)\nmodel, opt = get_model()\nfit(epochs, model, loss_func, opt, train_dl, valid_dl)",
"_____no_output_____"
]
],
[
[
"You can use these basic 3 lines of code to train a wide variety of models.\nLet's see if we can use them to train a convolutional neural network (CNN)!\n\nSwitch to CNN\n-------------\n\nWe are now going to build our neural network with three convolutional layers.\nBecause none of the functions in the previous section assume anything about\nthe model form, we'll be able to use them to train a CNN without any modification.\n\nWe will use Pytorch's predefined\n`Conv2d <https://pytorch.org/docs/stable/nn.html#torch.nn.Conv2d>`_ class\nas our convolutional layer. We define a CNN with 3 convolutional layers.\nEach convolution is followed by a ReLU. At the end, we perform an\naverage pooling. (Note that ``view`` is PyTorch's version of numpy's\n``reshape``)\n\n",
"_____no_output_____"
]
],
[
[
"class Mnist_CNN(nn.Module):\n def __init__(self):\n super().__init__()\n self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1)\n self.conv2 = nn.Conv2d(16, 16, kernel_size=3, stride=2, padding=1)\n self.conv3 = nn.Conv2d(16, 10, kernel_size=3, stride=2, padding=1)\n\n def forward(self, xb):\n xb = xb.view(-1, 1, 28, 28)\n xb = F.relu(self.conv1(xb))\n xb = F.relu(self.conv2(xb))\n xb = F.relu(self.conv3(xb))\n xb = F.avg_pool2d(xb, 4)\n return xb.view(-1, xb.size(1))\n\nlr = 0.1",
"_____no_output_____"
]
],
[
[
"`Momentum <https://cs231n.github.io/neural-networks-3/#sgd>`_ is a variation on\nstochastic gradient descent that takes previous updates into account as well\nand generally leads to faster training.\n\n",
"_____no_output_____"
]
],
[
[
"model = Mnist_CNN()\nopt = optim.SGD(model.parameters(), lr=lr, momentum=0.9)\n\nfit(epochs, model, loss_func, opt, train_dl, valid_dl)",
"_____no_output_____"
]
],
[
[
"nn.Sequential\n------------------------\n\n``torch.nn`` has another handy class we can use to simply our code:\n`Sequential <https://pytorch.org/docs/stable/nn.html#torch.nn.Sequential>`_ .\nA ``Sequential`` object runs each of the modules contained within it, in a\nsequential manner. This is a simpler way of writing our neural network.\n\nTo take advantage of this, we need to be able to easily define a\n**custom layer** from a given function. For instance, PyTorch doesn't\nhave a `view` layer, and we need to create one for our network. ``Lambda``\nwill create a layer that we can then use when defining a network with\n``Sequential``.\n\n",
"_____no_output_____"
]
],
[
[
"class Lambda(nn.Module):\n def __init__(self, func):\n super().__init__()\n self.func = func\n\n def forward(self, x):\n return self.func(x)\n\n\ndef preprocess(x):\n return x.view(-1, 1, 28, 28)",
"_____no_output_____"
]
],
[
[
"The model created with ``Sequential`` is simply:\n\n",
"_____no_output_____"
]
],
[
[
"model = nn.Sequential(\n Lambda(preprocess),\n nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1),\n nn.ReLU(),\n nn.Conv2d(16, 16, kernel_size=3, stride=2, padding=1),\n nn.ReLU(),\n nn.Conv2d(16, 10, kernel_size=3, stride=2, padding=1),\n nn.ReLU(),\n nn.AvgPool2d(4),\n Lambda(lambda x: x.view(x.size(0), -1)),\n)\n\nopt = optim.SGD(model.parameters(), lr=lr, momentum=0.9)\n\nfit(epochs, model, loss_func, opt, train_dl, valid_dl)",
"_____no_output_____"
]
],
[
[
"Wrapping DataLoader\n-----------------------------\n\nOur CNN is fairly concise, but it only works with MNIST, because:\n - It assumes the input is a 28\\*28 long vector\n - It assumes that the final CNN grid size is 4\\*4 (since that's the average\npooling kernel size we used)\n\nLet's get rid of these two assumptions, so our model works with any 2d\nsingle channel image. First, we can remove the initial Lambda layer but\nmoving the data preprocessing into a generator:\n\n",
"_____no_output_____"
]
],
[
[
"def preprocess(x, y):\n return x.view(-1, 1, 28, 28), y\n\n\nclass WrappedDataLoader:\n def __init__(self, dl, func):\n self.dl = dl\n self.func = func\n\n def __len__(self):\n return len(self.dl)\n\n def __iter__(self):\n batches = iter(self.dl)\n for b in batches:\n yield (self.func(*b))\n\ntrain_dl, valid_dl = get_data(train_ds, valid_ds, bs)\ntrain_dl = WrappedDataLoader(train_dl, preprocess)\nvalid_dl = WrappedDataLoader(valid_dl, preprocess)",
"_____no_output_____"
]
],
[
[
"Next, we can replace ``nn.AvgPool2d`` with ``nn.AdaptiveAvgPool2d``, which\nallows us to define the size of the *output* tensor we want, rather than\nthe *input* tensor we have. As a result, our model will work with any\nsize input.\n\n",
"_____no_output_____"
]
],
[
[
"model = nn.Sequential(\n nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1),\n nn.ReLU(),\n nn.Conv2d(16, 16, kernel_size=3, stride=2, padding=1),\n nn.ReLU(),\n nn.Conv2d(16, 10, kernel_size=3, stride=2, padding=1),\n nn.ReLU(),\n nn.AdaptiveAvgPool2d(1),\n Lambda(lambda x: x.view(x.size(0), -1)),\n)\n\nopt = optim.SGD(model.parameters(), lr=lr, momentum=0.9)",
"_____no_output_____"
]
],
[
[
"Let's try it out:\n\n",
"_____no_output_____"
]
],
[
[
"fit(epochs, model, loss_func, opt, train_dl, valid_dl)",
"_____no_output_____"
]
],
[
[
"Using your GPU\n---------------\n\nIf you're lucky enough to have access to a CUDA-capable GPU (you can\nrent one for about $0.50/hour from most cloud providers) you can\nuse it to speed up your code. First check that your GPU is working in\nPytorch:\n\n",
"_____no_output_____"
]
],
[
[
"print(torch.cuda.is_available())",
"_____no_output_____"
]
],
[
[
"And then create a device object for it:\n\n",
"_____no_output_____"
]
],
[
[
"dev = torch.device(\n \"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\")",
"_____no_output_____"
]
],
[
[
"Let's update ``preprocess`` to move batches to the GPU:\n\n",
"_____no_output_____"
]
],
[
[
"def preprocess(x, y):\n return x.view(-1, 1, 28, 28).to(dev), y.to(dev)\n\n\ntrain_dl, valid_dl = get_data(train_ds, valid_ds, bs)\ntrain_dl = WrappedDataLoader(train_dl, preprocess)\nvalid_dl = WrappedDataLoader(valid_dl, preprocess)",
"_____no_output_____"
]
],
[
[
"Finally, we can move our model to the GPU.\n\n",
"_____no_output_____"
]
],
[
[
"model.to(dev)\nopt = optim.SGD(model.parameters(), lr=lr, momentum=0.9)",
"_____no_output_____"
]
],
[
[
"You should find it runs faster now:\n\n",
"_____no_output_____"
]
],
[
[
"fit(epochs, model, loss_func, opt, train_dl, valid_dl)",
"_____no_output_____"
]
],
[
[
"Closing thoughts\n-----------------\n\nWe now have a general data pipeline and training loop which you can use for\ntraining many types of models using Pytorch. To see how simple training a model\ncan now be, take a look at the `mnist_sample` sample notebook.\n\nOf course, there are many things you'll want to add, such as data augmentation,\nhyperparameter tuning, monitoring training, transfer learning, and so forth.\nThese features are available in the fastai library, which has been developed\nusing the same design approach shown in this tutorial, providing a natural\nnext step for practitioners looking to take their models further.\n\nWe promised at the start of this tutorial we'd explain through example each of\n``torch.nn``, ``torch.optim``, ``Dataset``, and ``DataLoader``. So let's summarize\nwhat we've seen:\n\n - **torch.nn**\n\n + ``Module``: creates a callable which behaves like a function, but can also\n contain state(such as neural net layer weights). It knows what ``Parameter`` (s) it\n contains and can zero all their gradients, loop through them for weight updates, etc.\n + ``Parameter``: a wrapper for a tensor that tells a ``Module`` that it has weights\n that need updating during backprop. Only tensors with the `requires_grad` attribute set are updated\n + ``functional``: a module(usually imported into the ``F`` namespace by convention)\n which contains activation functions, loss functions, etc, as well as non-stateful\n versions of layers such as convolutional and linear layers.\n - ``torch.optim``: Contains optimizers such as ``SGD``, which update the weights\n of ``Parameter`` during the backward step\n - ``Dataset``: An abstract interface of objects with a ``__len__`` and a ``__getitem__``,\n including classes provided with Pytorch such as ``TensorDataset``\n - ``DataLoader``: Takes any ``Dataset`` and creates an iterator which returns batches of data.\n\n",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
d0609a652c7b452c6379d7bee3d565c6749ab9c6 | 107,761 | ipynb | Jupyter Notebook | 2. CNN/5D_doubleip.ipynb | nikhil-mathews/MastersPr_Predicting-Human-Pathogen-PPIs-using-Natural-Language-Processing-methods | 78bbaaf5e4e52939a522fe14aedbf5acfd29e10c | [
"MIT"
]
| null | null | null | 2. CNN/5D_doubleip.ipynb | nikhil-mathews/MastersPr_Predicting-Human-Pathogen-PPIs-using-Natural-Language-Processing-methods | 78bbaaf5e4e52939a522fe14aedbf5acfd29e10c | [
"MIT"
]
| null | null | null | 2. CNN/5D_doubleip.ipynb | nikhil-mathews/MastersPr_Predicting-Human-Pathogen-PPIs-using-Natural-Language-Processing-methods | 78bbaaf5e4e52939a522fe14aedbf5acfd29e10c | [
"MIT"
]
| null | null | null | 107,761 | 107,761 | 0.918152 | [
[
[
"import pandas as pd\n#Google colab does not have pickle\ntry:\n import pickle5 as pickle\nexcept:\n !pip install pickle5\n import pickle5 as pickle\nimport os\nimport seaborn as sns\nimport sys\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom keras.preprocessing.text import Tokenizer\nfrom keras.preprocessing.sequence import pad_sequences\nfrom keras.layers import Dense, Input, GlobalMaxPooling1D,Flatten\nfrom keras.layers import Conv1D, MaxPooling1D, Embedding, Concatenate, Lambda\nfrom keras.models import Model\nfrom sklearn.metrics import roc_auc_score,confusion_matrix,roc_curve, auc\nfrom numpy import random\nfrom keras.layers import LSTM, Bidirectional, GlobalMaxPool1D, Dropout\nfrom keras.optimizers import Adam\nfrom keras.utils.vis_utils import plot_model\n\nimport sys\nsys.path.insert(0,'/content/drive/MyDrive/ML_Data/')\nimport functions as f",
"Collecting pickle5\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/f7/4c/5c4dd0462c8d3a6bc4af500a6af240763c2ebd1efdc736fc2c946d44b70a/pickle5-0.0.11.tar.gz (132kB)\n\r\u001b[K |██▌ | 10kB 17.2MB/s eta 0:00:01\r\u001b[K |█████ | 20kB 12.3MB/s eta 0:00:01\r\u001b[K |███████▍ | 30kB 8.9MB/s eta 0:00:01\r\u001b[K |██████████ | 40kB 7.9MB/s eta 0:00:01\r\u001b[K |████████████▍ | 51kB 3.5MB/s eta 0:00:01\r\u001b[K |██████████████▉ | 61kB 4.1MB/s eta 0:00:01\r\u001b[K |█████████████████▍ | 71kB 4.7MB/s eta 0:00:01\r\u001b[K |███████████████████▉ | 81kB 5.3MB/s eta 0:00:01\r\u001b[K |██████████████████████▎ | 92kB 5.0MB/s eta 0:00:01\r\u001b[K |████████████████████████▉ | 102kB 5.5MB/s eta 0:00:01\r\u001b[K |███████████████████████████▎ | 112kB 5.5MB/s eta 0:00:01\r\u001b[K |█████████████████████████████▊ | 122kB 5.5MB/s eta 0:00:01\r\u001b[K |████████████████████████████████| 133kB 5.5MB/s \n\u001b[?25hBuilding wheels for collected packages: pickle5\n Building wheel for pickle5 (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for pickle5: filename=pickle5-0.0.11-cp37-cp37m-linux_x86_64.whl size=219265 sha256=4db361ac18314b7f73b02e1617744cb0e9d5f6acde8a0877a30a5f2c9fdfcbcb\n Stored in directory: /root/.cache/pip/wheels/a6/90/95/f889ca4aa8b0e0c7f21c8470b6f5d6032f0390a3a141a9a3bd\nSuccessfully built pickle5\nInstalling collected packages: pickle5\nSuccessfully installed pickle5-0.0.11\n"
],
[
"def load_data(D=1,randomize=False):\n try:\n with open('/content/drive/MyDrive/ML_Data/df_train_'+str(D)+'D.pickle', 'rb') as handle:\n df_train = pickle.load(handle)\n except:\n df_train = pd.read_pickle(\"C:/Users/nik00/py/proj/hyppi-train.pkl\")\n try:\n with open('/content/drive/MyDrive/ML_Data/df_test_'+str(D)+'D.pickle', 'rb') as handle:\n df_test = pickle.load(handle)\n except:\n df_test = pd.read_pickle(\"C:/Users/nik00/py/proj/hyppi-independent.pkl\")\n if randomize:\n return shuff_together(df_train,df_test)\n else:\n return df_train,df_test\n\ndf_train,df_test = load_data(5)\nprint('The data used will be:')\ndf_train[['Human','Yersinia']]",
"The data used will be:\n"
],
[
"lengths = sorted(len(s) for s in df_train['Human'])\nprint(\"Median length of Human sequence is\",lengths[len(lengths)//2])\n_ = sns.displot(lengths)\n_=plt.title(\"Most Human sequences seem to be less than 2000 in length\")",
"Median length of Human sequence is 477\n"
],
[
"lengths = sorted(len(s) for s in df_train['Yersinia'])\nprint(\"Median length of Yersinia sequence is\",lengths[len(lengths)//2])\n_ = sns.displot(lengths)\n_=plt.title(\"Most Yersinia sequences seem to be less than 1000 in length\")",
"Median length of Yersinia sequence is 334\n"
],
[
"data1_5D_doubleip_pre,data2_5D_doubleip_pre,data1_test_5D_doubleip_pre,data2_test_5D_doubleip_pre,num_words_5D,MAX_SEQUENCE_LENGTH_5D,MAX_VOCAB_SIZE_5D = f.get_seq_data_doubleip(500000,1000,df_train,df_test,pad = 'pre',show = True)",
"MAX_VOCAB_SIZE is 500000\nMAX_SEQUENCE_LENGTH is 1000\nmax sequences1_train length: 5301\nmin sequences1_train length: 12\nmedian sequences1_train length: 327\n"
],
[
"EMBEDDING_DIM_5D = 15\nVALIDATION_SPLIT = 0.2\nBATCH_SIZE = 128\nEPOCHS = 5\nDROP=0.7\n\nx1 = f.conv_model(MAX_SEQUENCE_LENGTH_5D,EMBEDDING_DIM_5D,num_words_5D,DROP)\nx2 = f.conv_model(MAX_SEQUENCE_LENGTH_5D,EMBEDDING_DIM_5D,num_words_5D,DROP)\n\nconcatenator = Concatenate(axis=1)\nx = concatenator([x1.output, x2.output])\nx = Dense(128)(x)\nx = Dropout(DROP)(x)\noutput = Dense(1, activation=\"sigmoid\",name=\"Final\")(x)\nmodel5D_CNN_doubleip = Model(inputs=[x1.input, x2.input], outputs=output)\n\nmodel5D_CNN_doubleip.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n#plot_model(model5D_CNN_doubleip, to_file='model_plot.png', show_shapes=True, show_layer_names=False)\n\ntrains = [data1_5D_doubleip_pre,data2_5D_doubleip_pre]\ntests = [data1_test_5D_doubleip_pre,data2_test_5D_doubleip_pre]\n\n\nmodel5D_CNN_doubleip.fit(trains, df_train['label'].values, epochs=EPOCHS, batch_size=BATCH_SIZE,validation_data=(tests, df_test['label'].values))\nprint(roc_auc_score(df_test['label'].values, model5D_CNN_doubleip.predict(tests)))\n\n#asd\n",
"Epoch 1/5\n49/49 [==============================] - 9s 165ms/step - loss: 0.6156 - accuracy: 0.6580 - val_loss: 0.5116 - val_accuracy: 0.7761\nEpoch 2/5\n49/49 [==============================] - 8s 160ms/step - loss: 0.4532 - accuracy: 0.7840 - val_loss: 0.4213 - val_accuracy: 0.8210\nEpoch 3/5\n49/49 [==============================] - 8s 159ms/step - loss: 0.2253 - accuracy: 0.9179 - val_loss: 0.4269 - val_accuracy: 0.8223\nEpoch 4/5\n49/49 [==============================] - 8s 157ms/step - loss: 0.1099 - accuracy: 0.9620 - val_loss: 0.4274 - val_accuracy: 0.8296\nEpoch 5/5\n49/49 [==============================] - 8s 159ms/step - loss: 0.0653 - accuracy: 0.9793 - val_loss: 0.4897 - val_accuracy: 0.8236\n0.8995234264434628\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d0609b9a0781386f0d189721804704e4449abfe0 | 255,014 | ipynb | Jupyter Notebook | Decision_tree_C5.O_CART.ipynb | anagha0397/Decision-Tree | 745b3ca72ac52a93ef947c130bf5cb60ddc20f65 | [
"MIT"
]
| null | null | null | Decision_tree_C5.O_CART.ipynb | anagha0397/Decision-Tree | 745b3ca72ac52a93ef947c130bf5cb60ddc20f65 | [
"MIT"
]
| null | null | null | Decision_tree_C5.O_CART.ipynb | anagha0397/Decision-Tree | 745b3ca72ac52a93ef947c130bf5cb60ddc20f65 | [
"MIT"
]
| null | null | null | 158.788294 | 169,820 | 0.860051 | [
[
[
"import pandas as pd \nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom sklearn.datasets import load_iris\nfrom sklearn.model_selection import train_test_split # for spliting the data into train and test \nfrom sklearn.tree import DecisionTreeClassifier # For creating a decision a tree\nfrom sklearn import tree # for displaying the tree\nfrom sklearn.metrics import classification_report # for calculating accuracy\nfrom sklearn import preprocessing # As we have applied encoding technique we have used this preprocessing library ",
"_____no_output_____"
],
[
"iris = pd.read_csv(\"iris.csv\", index_col = 0) # In order to set the index to 0 we have mentioned that index_col = 0",
"_____no_output_____"
],
[
"iris.head()",
"_____no_output_____"
],
[
"# Converting the species column to numbers so we will use encoding technique called as label encoder\n\nlabel_encoder = preprocessing.LabelEncoder() # This is called function calling\niris['Species'] = label_encoder.fit_transform(iris['Species'])",
"_____no_output_____"
],
[
"iris.head()",
"_____no_output_____"
],
[
"# Splitting the data in x and y for classification purpose, for performing any classification we are required to split the data first in input and output\n\nx = iris.iloc[:,0:4]\ny = iris['Species']",
"_____no_output_____"
],
[
"x",
"_____no_output_____"
],
[
"y",
"_____no_output_____"
],
[
"iris['Species'].unique() # for determining unique values",
"_____no_output_____"
],
[
"iris.Species.value_counts()",
"_____no_output_____"
],
[
"# Splitting the data into training and test dataset\n\nx_train, x_test, y_train, y_test = train_test_split(x,y,\n test_size=0.2,\n random_state=40)",
"_____no_output_____"
]
],
[
[
"### Building decision tree classifier using entropy criteria (c5.o)",
"_____no_output_____"
]
],
[
[
"model = DecisionTreeClassifier(criterion = 'entropy',max_depth = 3)\n",
"_____no_output_____"
],
[
"model.fit(x_train,y_train)",
"_____no_output_____"
]
],
[
[
"### Plotting the decision tree",
"_____no_output_____"
]
],
[
[
"tree.plot_tree(model);",
"_____no_output_____"
],
[
"model.get_n_leaves()",
"_____no_output_____"
],
[
"## As this tree is not visible so we will display it with some another technique",
"_____no_output_____"
],
[
"# we will extract the feature names, class names and we will define the figure size so that our tree will be visible in a better way",
"_____no_output_____"
],
[
"fn = ['SepalLengthCm',\t'SepalWidthCm',\t'PetalLengthCm',\t'PetalWidthCm']\ncn = ['Iris-setosa', 'Iris-versicolar', 'Iris-virginica']\nfig,axes = plt.subplots(nrows = 1, ncols =1, figsize =(4,4), dpi = 300) #dpi is the no. of pixels\ntree.plot_tree(model, feature_names = fn, class_names = cn, filled = True); # filled = true will fill the values inside the boxes",
"_____no_output_____"
],
[
"# Predicting the builded model on our x-test data",
"_____no_output_____"
],
[
"preds = model.predict(x_test)\npd.Series(preds).value_counts()",
"_____no_output_____"
],
[
"preds",
"_____no_output_____"
],
[
"# In order to check whether the predictions are correct or wrong we will create a cross tab on y_test data",
"_____no_output_____"
],
[
"crosstable = pd.crosstab(y_test,preds)\ncrosstable",
"_____no_output_____"
],
[
"# Final step we will calculate the accuracy of our model",
"_____no_output_____"
],
[
"np.mean(preds==y_test) # We are comparing the predicted values with the actual values and calculating mean for the matches",
"_____no_output_____"
],
[
"print(classification_report(preds,y_test))",
" precision recall f1-score support\n\n 0 1.00 1.00 1.00 8\n 1 1.00 0.92 0.96 13\n 2 0.90 1.00 0.95 9\n\n accuracy 0.97 30\n macro avg 0.97 0.97 0.97 30\nweighted avg 0.97 0.97 0.97 30\n\n"
]
],
[
[
"## Building a decision tree using CART method (Classifier model)",
"_____no_output_____"
]
],
[
[
"model_1 = DecisionTreeClassifier(criterion = 'gini',max_depth = 3)",
"_____no_output_____"
],
[
"model_1.fit(x_train,y_train)",
"_____no_output_____"
],
[
"tree.plot_tree(model_1);",
"_____no_output_____"
],
[
"# predicting the values on xtest data\n\npreds = model_1.predict(x_test)",
"_____no_output_____"
],
[
"preds",
"_____no_output_____"
],
[
"pd.Series(preds).value_counts()",
"_____no_output_____"
],
[
"# calculating accuracy of the model using the actual values",
"_____no_output_____"
],
[
"np.mean(preds==y_test)",
"_____no_output_____"
]
],
[
[
"## Decision tree Regressor using CART",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeRegressor",
"_____no_output_____"
],
[
"# Just converting the iris data into the following way as I want my Y to be numeric\n\nX = iris.iloc[:,0:3]\nY = iris.iloc[:,3]",
"_____no_output_____"
],
[
"X_train,X_test,Y_train,Y_test = train_test_split(X,Y, test_size = 0.33, random_state = 1)",
"_____no_output_____"
],
[
"model_reg = DecisionTreeRegressor()\nmodel_reg.fit(X_train,Y_train)",
"_____no_output_____"
],
[
"preds1 = model_reg.predict(X_test)\npreds1",
"_____no_output_____"
],
[
"# Will see the correct and wrong matches",
"_____no_output_____"
],
[
"pd.crosstab(Y_test,preds1)",
"_____no_output_____"
],
[
"## We will calculate the accuracy by using score method,this is an either way to calculate the accuracy of the model",
"_____no_output_____"
],
[
"model_reg.score(X_test,Y_test) # THis model.score function will first calculate the predicted values using the X_test data and then internaly only it will compare those values with the y_test data which is our actual data",
"_____no_output_____"
]
],
[
[
"model_reg.score calculates r squared value and Aic value in background",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
]
|
d0609e31ed6dc92d0a56a47774098cabc15e3d07 | 17,609 | ipynb | Jupyter Notebook | Lectures/Lecture6/Intro to Machine Learning Homework.ipynb | alaymodi/Spring-2019-Career-Exploration-master | 2ca9b4466090d57702e97e70fa772535b2dc00f3 | [
"MIT"
]
| null | null | null | Lectures/Lecture6/Intro to Machine Learning Homework.ipynb | alaymodi/Spring-2019-Career-Exploration-master | 2ca9b4466090d57702e97e70fa772535b2dc00f3 | [
"MIT"
]
| null | null | null | Lectures/Lecture6/Intro to Machine Learning Homework.ipynb | alaymodi/Spring-2019-Career-Exploration-master | 2ca9b4466090d57702e97e70fa772535b2dc00f3 | [
"MIT"
]
| null | null | null | 43.803483 | 1,777 | 0.61991 | [
[
[
"# Homework",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n%matplotlib inline\nimport random\nimport numpy as np\nimport pandas as pd\nfrom sklearn.model_selection import train_test_split\nfrom plotting import overfittingDemo, plot_multiple_linear_regression, overlay_simple_linear_model,plot_simple_residuals\nfrom scipy.optimize import curve_fit",
"_____no_output_____"
]
],
[
[
"**Exercise 1:** What are the two \"specialities\" of machine learning? Pick one and in your own words, explain what it means. `",
"_____no_output_____"
],
[
"Your Answer Here",
"_____no_output_____"
],
[
"**Exercise 2:** What is the difference between a regression task and a classification task?",
"_____no_output_____"
],
[
"Your Answer Here",
"_____no_output_____"
],
[
"**Exercise 3:** \n1. What is parametric fitting in your understanding?\n2. Given the data $x = 1,2,3,4,5, y_1 = 2,4,6,8,10, y_2 = 2,4,8,16,32,$ what function $f_1, f_2$ will you use to fit $y_1, y_2$? Why do you choose those?\n3. Why is parametric fitting somehow not machine learning?",
"_____no_output_____"
],
[
"Your Answer Here",
"_____no_output_____"
],
[
"**Exercise 4:** Take a look at the following residual plots. Residuals can be helpful in assessing if our model is overpredicting or underpredicting certain values. Assign the variable bestplot to the letter corresponding to which residual plot indicates a good fit for a linear model.\n\n<img src='residplots.png' width=\"600\" height=\"600\">",
"_____no_output_____"
]
],
[
[
"bestplot = 'Put your letter answer between these quotes'",
"_____no_output_____"
]
],
[
[
"**Exercise 5:** Observe the following graphs. Assign each graph variable to one of the following strings: 'overfitting', 'underfitting', or 'bestfit'.\n<img src='overfit-underfit.png' width=\"800\" height=\"800\">",
"_____no_output_____"
]
],
[
[
"graph1 = \"Put answer here\"\ngraph2 = \"Put answer here\"\ngraph3 = \"Put answer here\"",
"_____no_output_____"
]
],
[
[
"**Exercise 6:** What are the 3 sets we split our initial data set into?",
"_____no_output_____"
],
[
"Your Answer Here",
"_____no_output_____"
],
[
"**Exercise 7:** Refer to the graphs below when answering the following questions (Exercise 6 and 7).\n<img src='training_vs_test_error.png' width=\"800\" height=\"800\">\nAs we increase the degree of our model, what happens to the training error and what happens to the test error? ",
"_____no_output_____"
],
[
"Your Answer Here",
"_____no_output_____"
],
[
"**Exercise 8:** What is the issue with just increasing the degree of our model to get the lowest training error possible?",
"_____no_output_____"
],
[
"Your Answer Here",
"_____no_output_____"
],
[
"**Exercise 9:** Find the gradient for ridge loss, most concretely, when $L(\\theta, \\textbf{y}, \\alpha)\n= (\\frac{1}{n} \\sum_{i = 1}^{n}(y_i - \\theta)^2) + \\frac{\\alpha }{2}\\sum_{i = 1}^{n}\\theta ^2$\nfind $\\frac{\\partial}{\\partial \\hat{\\theta}} L(\\theta, \\textbf{y},\\alpha)$, you can have a look at the class example, they are really similar.",
"_____no_output_____"
],
[
"Your Answer Here",
"_____no_output_____"
],
[
"**Exercise 10:** Following the last part of the exercise, you've already fitted your model, now let's test the performance. Make sure you check the code for the previous example we went through in class.\n\n1. copy what you had from the exercise here.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\nmpg = pd.read_csv(\"./mpg_category.csv\", index_col=\"name\")\n\n#exercise part 1\nmpg['Old?'] = ... \n\n#exercise part 2\nmpg_train, mpg_test = ..., ...\n\n#exercise part 3\nfrom sklearn.linear_model import LogisticRegression\nsoftmax_reg = LogisticRegression(multi_class=\"multinomial\",solver=\"lbfgs\", C=10)\nX = ...\nY = ...\nsoftmax_reg.fit(X, Y)",
"_____no_output_____"
]
],
[
[
"2. create the test data set and make the prediction on test dataset",
"_____no_output_____"
]
],
[
[
"X_test = ...\nY_test = ...\npred = softmax_reg.predict(...)",
"_____no_output_____"
]
],
[
[
"3. Make the confusion matrix and tell me how you interpret each of the cell in the confusion matrix. What does different depth of blue means. You can just run the cell below, assumed what you did above is correct. You just have to answer your understanding.",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import confusion_matrix\nconfusion_matrix = confusion_matrix(Y_test, pred)\nX_label = ['old', 'new']\ndef plot_confusion_matrix(cm, title='Confusion matrix', cmap=plt.cm.Blues):\n plt.imshow(cm, interpolation='nearest', cmap=cmap)\n plt.title(title)\n plt.colorbar()\n tick_marks = np.arange(len(X_label))\n plt.xticks(tick_marks, X_label, rotation=45)\n plt.yticks(tick_marks, X_label,)\n plt.tight_layout()\n plt.ylabel('True label')\n plt.xlabel('Predicted label')\nplot_confusion_matrix(confusion_matrix)\n# confusion_matrix",
"_____no_output_____"
]
],
[
[
"Your Answer Here",
"_____no_output_____"
]
],
[
[
"# be sure to hit save (File > Save and Checkpoint) or Ctrl/Command-S before you run the cell!\nfrom submit import create_and_submit\n\ncreate_and_submit(['Intro to Machine Learning Homework.ipynb'], verbose=True)",
"Parsed Intro to Machine Learning Homework.ipynb\nEnter your Berkeley email address: [email protected]\nPosting answers for Intro to Machine Learning Homework\nYour submission: {'exercise-1': 'Your Answer Here', 'exercise-1_output': None, 'exercise-2': 'Your Answer Here', 'exercise-2_output': None, 'exercise-3': 'Your Answer Here', 'exercise-3_output': None, 'exercise-4': \"bestplot = 'Put your letter answer between these quotes'\", 'exercise-4_output': None, 'exercise-5': 'graph1 = \"Put answer here\"\\ngraph2 = \"Put answer here\"\\ngraph3 = \"Put answer here\"', 'exercise-5_output': None, 'exercise-6': 'Your Answer Here', 'exercise-6_output': None, 'exercise-7': 'Your Answer Here', 'exercise-7_output': None, 'exercise-8': 'Your Answer Here', 'exercise-8_output': None, 'exercise-9': 'Your Answer Here', 'exercise-9_output': None, 'exercise-10-1': 'import pandas as pd\\n\\nmpg = pd.read_csv(\"./mpg_category.csv\", index_col=\"name\")\\n\\n#exercise part 1\\nmpg[\\'Old?\\'] = ... \\n\\n#exercise part 2\\nmpg_train, mpg_test = ..., ...\\n\\n#exercise part 3\\nfrom sklearn.linear_model import LogisticRegression\\nsoftmax_reg = LogisticRegression(multi_class=\"multinomial\",solver=\"lbfgs\", C=...)\\nX = ...\\nY = ...\\nsoftmax_reg.fit(X, Y)', 'exercise-10-1_output': None, 'exercise-10-2': '2. create the test data set and make the prediction on test dataset', 'exercise-10-2_output': None, 'exercise-10-3': '3. Make the confusion matrix and tell me how you interpret each of the cell in the confusion matrix. What does different depth of blue means. You can just run the cell below, assumed what you did above is correct. You just have to answer your understanding.', 'exercise-10-3_output': None, 'exercise-10-4': 'Your Answer Here', 'exercise-10-4_output': None, 'email': '[email protected]', 'sheet': 'Intro to Machine Learning Homework', 'timestamp': datetime.datetime(2019, 3, 18, 16, 46, 54, 7302)}\n\nSubmitted!\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d060a7328730ae52269f71692aeaffba9f64d9a6 | 15,673 | ipynb | Jupyter Notebook | _notebooks/2022-01-03-cs231n.ipynb | star77sa/TIL-Blog | 782a24bf0b2324a66024e984dd1c7f3536cd17b9 | [
"Apache-2.0"
]
| null | null | null | _notebooks/2022-01-03-cs231n.ipynb | star77sa/TIL-Blog | 782a24bf0b2324a66024e984dd1c7f3536cd17b9 | [
"Apache-2.0"
]
| 1 | 2021-07-24T16:33:20.000Z | 2021-07-24T16:43:02.000Z | _notebooks/2022-01-03-cs231n.ipynb | star77sa/TIL-Blog | 782a24bf0b2324a66024e984dd1c7f3536cd17b9 | [
"Apache-2.0"
]
| null | null | null | 36.79108 | 722 | 0.617559 | [
[
[
"# CS231n_CNN for Visual Recognition\n> Stanford University CS231n\n\n- toc: true \n- badges: true\n- comments: true\n- categories: [CNN]\n- image: images/",
"_____no_output_____"
],
[
"---",
"_____no_output_____"
],
[
"- http://cs231n.stanford.edu/",
"_____no_output_____"
],
[
"---\n# Image Classification\n\n",
"_____no_output_____"
],
[
"- **Image Classification:** We are given a **Training Set** of labeled images, asked to predict labels on **Test Set.** Common to report the **Accuracy** of predictions(fraction of correctly predicted images)\n\n- We introduced the **k-Nearest Neighbor Classifier**, which predicts the labels based on nearest images in the training set\n\n- We saw that the choice of distance and the value of k are **hyperparameters** that are tuned using a **validation set**, or through **cross-validation** if the size of the data is small.\n\n- Once the best set of hyperparameters is chosen, the classifier is evaluated once on the test set, and reported as the performance of kNN on that data.",
"_____no_output_____"
],
[
"- Nearest Neighbor 분류기는 CIFAR-10 데이터셋에서 약 40% 정도의 정확도를 보이는 것을 확인하였다. 이 방법은 구현이 매우 간단하지만, 학습 데이터셋 전체를 메모리에 저장해야 하고, 새로운 테스트 이미지를 분류하고 평가할 때 계산량이 매우 많다.\n\n- 단순히 픽셀 값들의 L1이나 L2 거리는 이미지의 클래스보다 배경이나 이미지의 전체적인 색깔 분포 등에 더 큰 영향을 받기 때문에 이미지 분류 문제에 있어서 충분하지 못하다는 점을 보았다.",
"_____no_output_____"
],
[
"---\n# Linear Classification",
"_____no_output_____"
],
[
"- We defined a **score function** from image pixels to class scores (in this section, a linear function that depends on weights **W** and biases **b**).\n\n- Unlike kNN classifier, the advantage of this **parametric approach** is that once we learn the parameters we can discard the training data. Additionally, the prediction for a new test image is fast since it requires a single matrix multiplication with **W**, not an exhaustive comparison to every single training example.\n\n- We introduced the **bias trick**, which allows us to fold the bias vector into the weight matrix for convenience of only having to keep track of one parameter matrix.\n하나의 매개변수 행렬만 추적해야 하는 편의를 위해 편향 벡터를 가중치 행렬로 접을 수 있는 편향 트릭을 도입했습니다 .\n\n- We defined a **loss function** (we introduced two commonly used losses for linear classifiers: the **SVM** and the **Softmax**) that measures how compatible a given set of parameters is with respect to the ground truth labels in the training dataset. We also saw that the loss function was defined in such way that making good predictions on the training data is equivalent to having a small loss.",
"_____no_output_____"
],
[
"---",
"_____no_output_____"
],
[
"# Optimization",
"_____no_output_____"
],
[
"- We developed the intuition of the loss function as a **high-dimensional optimization landscape** in which we are trying to reach the bottom. The working analogy we developed was that of a blindfolded hiker who wishes to reach the bottom. In particular, we saw that the SVM cost function is piece-wise linear and bowl-shaped.\n\n- We motivated the idea of optimizing the loss function with **iterative refinement**, where we start with a random set of weights and refine them step by step until the loss is minimized.\n\n- We saw that the **gradient** of a function gives the steepest ascent direction and we discussed a simple but inefficient way of computing it numerically using the finite difference approximation (the finite difference being the value of h used in computing the numerical gradient).\n\n- We saw that the parameter update requires a tricky setting of the **step size** (or the **learning rate**) that must be set just right: if it is too low the progress is steady but slow. If it is too high the progress can be faster, but more risky. We will explore this tradeoff in much more detail in future sections.\n\n- We discussed the tradeoffs between computing the **numerical** and **analytic** gradient. The numerical gradient is simple but it is approximate and expensive to compute. The analytic gradient is exact, fast to compute but more error-prone since it requires the derivation of the gradient with math. Hence, in practice we always use the analytic gradient and then perform a **gradient check**, in which its implementation is compared to the numerical gradient.\n\n- We introduced the **Gradient Descent** algorithm which iteratively computes the gradient and performs a parameter update in loop.",
"_____no_output_____"
],
[
"---",
"_____no_output_____"
],
[
"# Backprop",
"_____no_output_____"
],
[
"- We developed intuition for what the gradients mean, how they flow backwards in the circuit, and how they communicate which part of the circuit should increase or decrease and with what force to make the final output higher.\n\n- We discussed the importance of **staged computation** for practical implementations of backpropagation. You always want to break up your function into modules for which you can easily derive local gradients, and then chain them with chain rule. Crucially, you almost never want to write out these expressions on paper and differentiate them symbolically in full, because you never need an explicit mathematical equation for the gradient of the input variables. Hence, decompose your expressions into stages such that you can differentiate every stage independently (the stages will be matrix vector multiplies, or max operations, or sum operations, etc.) and then backprop through the variables one step at a time.",
"_____no_output_____"
],
[
"---\n# Neural Network - 1",
"_____no_output_____"
],
[
"- We introduced a very coarse model of a biological **neuron**\n\n- 실제 사용되는 몇몇 **활성화 함수** 에 대해 논의하였고, ReLU가 가장 일반적인 선택이다.\n - 활성화 함수 쓰는 이유 : 데이터를 비선형으로 바꾸기 위해서. 선형이면 은닉층이 1개밖에 안나옴\n\n\n- We introduced **Neural Networks** where neurons are connected with **Fully-Connected layers** where neurons in adjacent layers have full pair-wise connections, but neurons within a layer are not connected.\n\n- 우리는 layered architecture를 통해 활성화 함수의 기능 적용과 결합된 행렬 곱을 기반으로 신경망을 매우 효율적으로 평가할 수 있음을 보았다.\n\n- 우리는 Neural Networks가 **universal function approximators**(NN으로 어떠한 함수든 근사시킬 수 있다)임을 보았지만, 우리는 또한 이 특성이 그들의 편재적인 사용과 거의 관련이 없다는 사실에 대해 논의하였다. They are used because they make certain “right” assumptions about the functional forms of functions that come up in practice.\n\n- 우리는 큰 network가 작은 network보다 항상 더 잘 작동하지만, 더 높은 model capacity는 더 강력한 정규화(높은 가중치 감소같은)로 적절히 해결되어야 하며, 그렇지 않으면 오버핏될 수 있다는 사실에 대해 논의하였다. 이후 섹션에서 더 많은 형태의 정규화(특히 dropout)를 볼 수 있을 것이다.",
"_____no_output_____"
],
[
"---\n# Neural Network - 2",
"_____no_output_____"
],
[
"- 권장되는 전처리는 데이터의 중앙에 평균이 0이 되도록 하고 (zero centered), 스케일을 [-1, 1]로 정규화 하는 것 입니다.\n - 올바른 전처리 방법 : 예를들어 평균차감 기법을 쓸 때 학습, 검증, 테스트를 위한 데이터를 먼저 나눈 후 학습 데이터를 대상으로 평균값을 구한 후에 평균차감 전처리를 모든 데이터군(학습, 검증, 테스트)에 적용하는 것이다.\n\n- ReLU를 사용하고 초기화는 $\\sqrt{2/n}$ 의 표준 편차를 갖는 정규 분포에서 가중치를 가져와 초기화합니다. 여기서 $n$은 뉴런에 대한 입력 수입니다. E.g. in numpy: `w = np.random.randn(n) * sqrt(2.0/n)`.\n\n- L2 regularization과 드랍아웃을 사용 (the inverted version)\n\n- Batch normalization 사용 (이걸쓰면 드랍아웃은 잘 안씀)\n\n- 실제로 수행할 수 있는 다양한 작업과 각 작업에 대한 가장 일반적인 손실 함수에 대해 논의했다.",
"_____no_output_____"
],
[
"---\n# Neural Network - 3",
"_____no_output_____"
],
[
"신경망(neural network)를 훈련하기 위하여:\n\n- 코드를 짜는 중간중간에 작은 배치로 그라디언트를 체크하고, 뜻하지 않게 튀어나올 위험을 인지하고 있어야 한다.\n\n- 코드가 제대로 돌아가는지 확인하는 방법으로, 손실함수값의 초기값이 합리적인지 그리고 데이터의 일부분으로 100%의 훈련 정확도를 달성할 수 있는지 확인해야한다.\n\n- 훈련 동안, 손실함수와 train/validation 정확도를 계속 살펴보고, (이게 좀 더 멋져 보이면) 현재 파라미터 값 대비 업데이트 값 또한 살펴보라 (대충 ~ 1e-3 정도 되어야 한다). 만약 ConvNet을 다루고 있다면, 첫 층의 웨이트값도 살펴보라.\n\n- 업데이트 방법으로 추천하는 건 SGD+Nesterov Momentum 혹은 Adam이다.\n\n- 학습 속도를 훈련 동안 계속 하강시켜라. 예를 들면, 정해진 에폭 수 뒤에 (혹은 검증 정확도가 상승하다가 하강세로 꺾이면) 학습 속도를 반으로 깎아라.\n\n- Hyper parameter 검색은 grid search가 아닌 random search으로 수행하라. 처음에는 성긴 규모에서 탐색하다가 (넓은 hyper parameter 범위, 1-5 epoch 정도만 학습), 점점 촘촘하게 검색하라. (좁은 범위, 더 많은 에폭에서 학습)\n- 추가적인 개선을 위하여 모형 앙상블을 구축하라.",
"_____no_output_____"
],
[
"---\n# CNN",
"_____no_output_____"
],
[
"- ConvNet 아키텍쳐는 여러 레이어를 통해 입력 이미지 볼륨을 출력 볼륨 (클래스 점수)으로 변환시켜 준다.\n\n- ConvNet은 몇 가지 종류의 레이어로 구성되어 있다. CONV/FC/RELU/POOL 레이어가 현재 가장 많이 쓰인다.\n\n- 각 레이어는 3차원의 입력 볼륨을 미분 가능한 함수를 통해 3차원 출력 볼륨으로 변환시킨다.\n\n- parameter가 있는 레이어도 있고 그렇지 않은 레이어도 있다 (FC/CONV는 parameter를 갖고 있고, RELU/POOL 등은 parameter가 없음).\n\n- hyperparameter가 있는 레이어도 있고 그렇지 않은 레이어도 있다 (CONV/FC/POOL 레이어는 hyperparameter를 가지며 ReLU는 가지지 않음).\n\n- stride, zero-padding ...",
"_____no_output_____"
],
[
"---\n# Spatial Localization and Detection",
"_____no_output_____"
],
[
"<img src='img/cs231/detect.png' width=\"500\" height=\"500\">",
"_____no_output_____"
],
[
"- Classification : 사진에 대한 라벨이 아웃풋\n- Localization : 사진에 대한 상자가 아웃풋 (x, y, w, h)\n- Detection : 사진에 대한 여러개의 상자가 아웃풋 DOG(x, y, w, h), CAT(x, y, w, h), ...\n- Segmentation : 상자가 아니라 객체의 이미지 형상을 그대로.",
"_____no_output_____"
],
[
"- Localization method : localization as Regression, Sliding Window : Overfeat\n\n- Region Proposals : 비슷한 색깔, 텍스쳐를 기준으로 박스를 생성\n\n- Detection :\n - R-CNN : Region-based CNN. Region -> CNN\n - 문제점 : Region proposal 마다 CNN을 돌려서 시간이 매우 많이든다.\n - Fast R-CNN : CNN -> Region\n - 문제점 : Region Proposal 과정에서 시간이 든다.\n - Faster R-CNN : Region Proposals도 CNN을 이용해서 해보자.\n \n - YOLO(You Only Look Once) : Detection as Regression\n - 성능은 Faster R-CNN보다 떨어지지만, 속도가 매우 빠르다.",
"_____no_output_____"
],
[
"---\n# CNNs in practice",
"_____no_output_____"
],
[
"- Data Augmentation\n - Change the pixels without changing the label\n - Train on transformed data\n - VERY widely used\n \n .....\n \n 1. Horizontal flips\n 2. Random crops/scales\n 3. Color jitter",
"_____no_output_____"
],
[
"- Transfer learning\n\n 이미지넷의 클래스와 관련있는 데이터라면 사전학습시 성능이 좋아지는게 이해가되는데 관련없는 이미지 (e.g. mri같은 의료이미지)의 경우도 성능이 좋아지는데 그 이유는 무엇인가?\n\n -> 앞단에선 엣지, 컬러같은 low level의 feature를 인식, 뒤로갈수록 상위레벨을 인식. lowlevel을 미리 학습해놓는다는 것은 그 어떤 이미지를 분석할 때도 도움이된다!",
"_____no_output_____"
],
[
"- How to stack convolutions:\n\n - Replace large convolutions (5x5, 7x7) with stacks of 3x3 convolutions\n - 1x1 \"bottleneck\" convolutions are very efficient\n - Can factor NxN convolutions into 1xN and Nx1\n - All of the above give fewer parameters, less compute, more nonlinearity\n \n 더 적은 파라미터, 더 적은 컴퓨팅연산, 더 많은 nonlinearity(필터 사이사이 ReLU등이 들어가기에)",
"_____no_output_____"
],
[
"- Computing Convolutions:\n - im2col : Easy to implement, but big memory overhead.\n - FFT : Big speedups for small kernels\n - \"Fast Algorithms\" : seem promising, not widely used yet",
"_____no_output_____"
],
[
"---\n# Segmentaion",
"_____no_output_____"
],
[
"- Semantic Segmentation\n - Classify all pixels\n - Fully convolutional models, downsample then upsample\n - Learnable upsampling: fractionally strided convolution\n - Skip connections can help\n\n...\n\n- Instance Segmentation\n - Detect instance, generate mask\n - Similar pipelines to object detection",
"_____no_output_____"
]
]
]
| [
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
d060b12257f61ab276eae7b6126d23a80f820034 | 196,953 | ipynb | Jupyter Notebook | colab/resnet.ipynb | WindQAQ/iree | 68fc75cbe6e4bdf175885c17d41f4d61a55c3537 | [
"Apache-2.0"
]
| null | null | null | colab/resnet.ipynb | WindQAQ/iree | 68fc75cbe6e4bdf175885c17d41f4d61a55c3537 | [
"Apache-2.0"
]
| null | null | null | colab/resnet.ipynb | WindQAQ/iree | 68fc75cbe6e4bdf175885c17d41f4d61a55c3537 | [
"Apache-2.0"
]
| null | null | null | 501.152672 | 185,484 | 0.926038 | [
[
[
"##### Copyright 2020 Google LLC.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");",
"_____no_output_____"
]
],
[
[
"#@title License header\n# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# ResNet\n\n[ResNet](https://arxiv.org/abs/1512.03385) is a deep neural network architecture for image recognition.\n\nThis notebook\n\n* Constructs a [ResNet50](https://www.tensorflow.org/api_docs/python/tf/keras/applications/ResNet50) model using `tf.keras`, with weights pretrained using the[ImageNet](http://www.image-net.org/) dataset\n* Compiles that model with IREE\n* Tests TensorFlow and IREE execution of the model on a sample image",
"_____no_output_____"
]
],
[
[
"#@title Imports and common setup\n\nfrom pyiree import rt as ireert\nfrom pyiree.tf import compiler as ireec\nfrom pyiree.tf.support import tf_utils\n\nimport tensorflow as tf\nfrom matplotlib import pyplot as plt",
"_____no_output_____"
],
[
"#@title Construct a pretrained ResNet model with ImageNet weights\n\ntf.keras.backend.set_learning_phase(False)\n\n# Static shape, including batch size (1).\n# Can be dynamic once dynamic shape support is ready.\nINPUT_SHAPE = [1, 224, 224, 3]\n\ntf_model = tf.keras.applications.resnet50.ResNet50(\n weights=\"imagenet\", include_top=True, input_shape=tuple(INPUT_SHAPE[1:]))\n\n# Wrap the model in a tf.Module to compile it with IREE.\nclass ResNetModule(tf.Module):\n\n def __init__(self):\n super(ResNetModule, self).__init__()\n self.m = tf_model\n self.predict = tf.function(\n input_signature=[tf.TensorSpec(INPUT_SHAPE, tf.float32)])(tf_model.call)",
"_____no_output_____"
],
[
"#@markdown ### Backend Configuration\n\nbackend_choice = \"iree_vmla (CPU)\" #@param [ \"iree_vmla (CPU)\", \"iree_llvmjit (CPU)\", \"iree_vulkan (GPU/SwiftShader)\" ]\nbackend_choice = backend_choice.split(\" \")[0]\nbackend = tf_utils.BackendInfo(backend_choice)",
"_____no_output_____"
],
[
"#@title Compile ResNet with IREE\n# This may take a few minutes.\niree_module = backend.compile(ResNetModule, [\"predict\"])",
"Created IREE driver vmla: <iree.bindings.python.pyiree.rt.binding.HalDriver object at 0x7fef48c98298>\nSystemContext driver=<iree.bindings.python.pyiree.rt.binding.HalDriver object at 0x7fef48c98298>\n"
],
[
"#@title Load a test image of a [labrador](https://commons.wikimedia.org/wiki/File:YellowLabradorLooking_new.jpg)\n\ndef load_image(path_to_image):\n image = tf.io.read_file(path_to_image)\n image = tf.image.decode_image(image, channels=3)\n image = tf.image.resize(image, (224, 224))\n image = image[tf.newaxis, :]\n return image\n\ncontent_path = tf.keras.utils.get_file(\n 'YellowLabradorLooking_new.jpg',\n 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')\ncontent_image = load_image(content_path)\n\nprint(\"Test image:\")\nplt.imshow(content_image.numpy().reshape(224, 224, 3) / 255.0)\nplt.axis(\"off\")\nplt.tight_layout()",
"Test image:\n"
],
[
"#@title Model pre- and post-processing\ninput_data = tf.keras.applications.resnet50.preprocess_input(content_image)\n\ndef decode_result(result):\n return tf.keras.applications.resnet50.decode_predictions(result, top=3)[0]",
"_____no_output_____"
],
[
"#@title Run TF model\n\nprint(\"TF prediction:\")\ntf_result = tf_model.predict(input_data)\nprint(decode_result(tf_result))",
"TF prediction:\n[('n02091244', 'Ibizan_hound', 0.12879108), ('n02099712', 'Labrador_retriever', 0.12632962), ('n02091831', 'Saluki', 0.09625229)]\n"
],
[
"#@title Run the model compiled with IREE\n\nprint(\"IREE prediction:\")\niree_result = iree_module.predict(input_data)\nprint(decode_result(iree_result))",
"IREE prediction:\n[('n02091244', 'Ibizan_hound', 0.12879075), ('n02099712', 'Labrador_retriever', 0.1263297), ('n02091831', 'Saluki', 0.09625255)]\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d060b4c997abb26f63478a8f14b093cdba70911a | 20,118 | ipynb | Jupyter Notebook | notebooks/art-for-tensorflow-v2-keras.ipynb | changx03/adversarial-robustness-toolbox | e21e0ff8ec5a88441da164c90376d63e07193242 | [
"MIT"
]
| 1,350 | 2020-07-14T08:06:55.000Z | 2022-03-31T19:22:25.000Z | notebooks/art-for-tensorflow-v2-keras.ipynb | bochengC/adversarial-robustness-toolbox | 031ffe4426678487de0cbcec5ad13f355e570bc8 | [
"MIT"
]
| 936 | 2020-07-14T03:33:00.000Z | 2022-03-31T23:05:29.000Z | notebooks/art-for-tensorflow-v2-keras.ipynb | bochengC/adversarial-robustness-toolbox | 031ffe4426678487de0cbcec5ad13f355e570bc8 | [
"MIT"
]
| 413 | 2020-07-16T16:00:16.000Z | 2022-03-29T10:31:12.000Z | 50.295 | 5,712 | 0.772641 | [
[
[
"# ART for TensorFlow v2 - Keras API",
"_____no_output_____"
],
[
"This notebook demonstrate applying ART with the new TensorFlow v2 using the Keras API. The code follows and extends the examples on www.tensorflow.org.",
"_____no_output_____"
]
],
[
[
"import warnings\nwarnings.filterwarnings('ignore')\nimport tensorflow as tf\ntf.compat.v1.disable_eager_execution()\nimport numpy as np\nfrom matplotlib import pyplot as plt\n\nfrom art.estimators.classification import KerasClassifier\nfrom art.attacks.evasion import FastGradientMethod, CarliniLInfMethod",
"_____no_output_____"
],
[
"if tf.__version__[0] != '2':\n raise ImportError('This notebook requires TensorFlow v2.')",
"_____no_output_____"
]
],
[
[
"# Load MNIST dataset",
"_____no_output_____"
]
],
[
[
"(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()\nx_train, x_test = x_train / 255.0, x_test / 255.0\n\nx_test = x_test[0:100]\ny_test = y_test[0:100]",
"_____no_output_____"
]
],
[
[
"# TensorFlow with Keras API",
"_____no_output_____"
],
[
"Create a model using Keras API. Here we use the Keras Sequential model and add a sequence of layers. Afterwards the model is compiles with optimizer, loss function and metrics.",
"_____no_output_____"
]
],
[
[
"model = tf.keras.models.Sequential([\n tf.keras.layers.InputLayer(input_shape=(28, 28)),\n tf.keras.layers.Flatten(),\n tf.keras.layers.Dense(128, activation='relu'),\n tf.keras.layers.Dropout(0.2),\n tf.keras.layers.Dense(10, activation='softmax')\n])\n\nmodel.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy']);",
"_____no_output_____"
]
],
[
[
"Fit the model on training data.",
"_____no_output_____"
]
],
[
[
"model.fit(x_train, y_train, epochs=3);",
"Train on 60000 samples\nEpoch 1/3\n60000/60000 [==============================] - 3s 46us/sample - loss: 0.2968 - accuracy: 0.9131\nEpoch 2/3\n60000/60000 [==============================] - 3s 46us/sample - loss: 0.1435 - accuracy: 0.9575\nEpoch 3/3\n60000/60000 [==============================] - 3s 46us/sample - loss: 0.1102 - accuracy: 0.9664\n"
]
],
[
[
"Evaluate model accuracy on test data.",
"_____no_output_____"
]
],
[
[
"loss_test, accuracy_test = model.evaluate(x_test, y_test)\nprint('Accuracy on test data: {:4.2f}%'.format(accuracy_test * 100))",
"Accuracy on test data: 100.00%\n"
]
],
[
[
"Create a ART Keras classifier for the TensorFlow Keras model.",
"_____no_output_____"
]
],
[
[
"classifier = KerasClassifier(model=model, clip_values=(0, 1))",
"_____no_output_____"
]
],
[
[
"## Fast Gradient Sign Method attack",
"_____no_output_____"
],
[
"Create a ART Fast Gradient Sign Method attack.",
"_____no_output_____"
]
],
[
[
"attack_fgsm = FastGradientMethod(estimator=classifier, eps=0.3)",
"_____no_output_____"
]
],
[
[
"Generate adversarial test data.",
"_____no_output_____"
]
],
[
[
"x_test_adv = attack_fgsm.generate(x_test)",
"_____no_output_____"
]
],
[
[
"Evaluate accuracy on adversarial test data and calculate average perturbation.",
"_____no_output_____"
]
],
[
[
"loss_test, accuracy_test = model.evaluate(x_test_adv, y_test)\nperturbation = np.mean(np.abs((x_test_adv - x_test)))\nprint('Accuracy on adversarial test data: {:4.2f}%'.format(accuracy_test * 100))\nprint('Average perturbation: {:4.2f}'.format(perturbation))",
"Accuracy on adversarial test data: 0.00%\nAverage perturbation: 0.18\n"
]
],
[
[
"Visualise the first adversarial test sample.",
"_____no_output_____"
]
],
[
[
"plt.matshow(x_test_adv[0])\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Carlini&Wagner Infinity-norm attack",
"_____no_output_____"
],
[
"Create a ART Carlini&Wagner Infinity-norm attack.",
"_____no_output_____"
]
],
[
[
"attack_cw = CarliniLInfMethod(classifier=classifier, eps=0.3, max_iter=100, learning_rate=0.01)",
"_____no_output_____"
]
],
[
[
"Generate adversarial test data.",
"_____no_output_____"
]
],
[
[
"x_test_adv = attack_cw.generate(x_test)",
"C&W L_inf: 100%|██████████| 1/1 [00:04<00:00, 4.23s/it]\n"
]
],
[
[
"Evaluate accuracy on adversarial test data and calculate average perturbation.",
"_____no_output_____"
]
],
[
[
"loss_test, accuracy_test = model.evaluate(x_test_adv, y_test)\nperturbation = np.mean(np.abs((x_test_adv - x_test)))\nprint('Accuracy on adversarial test data: {:4.2f}%'.format(accuracy_test * 100))\nprint('Average perturbation: {:4.2f}'.format(perturbation))",
"Accuracy on adversarial test data: 10.00%\nAverage perturbation: 0.03\n"
]
],
[
[
"Visualise the first adversarial test sample.",
"_____no_output_____"
]
],
[
[
"plt.matshow(x_test_adv[0, :, :])\nplt.show()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d060c2786199cbceb6556c2ec911dc0cd631e0d6 | 913,950 | ipynb | Jupyter Notebook | English/9_time_series_prediction/Prophet.ipynb | JeyDi/DataScienceCourse | 905a37bf3e9f77ea00b3678f7ddbdd78d5c3361a | [
"MIT"
]
| 6 | 2020-04-11T18:02:57.000Z | 2021-11-26T09:40:12.000Z | English/9_time_series_prediction/Prophet.ipynb | JeyDi/DataScienceCourse | 905a37bf3e9f77ea00b3678f7ddbdd78d5c3361a | [
"MIT"
]
| 1 | 2020-05-08T15:30:02.000Z | 2020-05-10T09:23:15.000Z | English/9_time_series_prediction/Prophet.ipynb | JeyDi/DataScienceCourse | 905a37bf3e9f77ea00b3678f7ddbdd78d5c3361a | [
"MIT"
]
| 3 | 2019-12-05T16:02:50.000Z | 2020-05-03T07:43:26.000Z | 891.658537 | 316,048 | 0.944994 | [
[
[
"# Prophet",
"_____no_output_____"
],
[
"Time serie forecasting using Prophet\n\nOfficial documentation: https://facebook.github.io/prophet/docs/quick_start.html",
"_____no_output_____"
],
[
"Procedure for forecasting time series data based on an additive model where non-linear trends are fit with yearly, weekly, and daily seasonality, plus holiday effects. It is released by Facebook’s Core Data Science team.\n\nAdditive model is a model like: \n$Data = seasonal\\space effect + trend + residual$\n\nand, multiplicative model: \n$Data = seasonal\\space effect * trend * residual$\n\nThe algorithm provides useful statistics that help visualize the tuning process, e.g. trend, week trend, year trend and their max and min errors.",
"_____no_output_____"
],
[
"### Data\n\nThe data on which the algorithms will be trained and tested upon comes from Kaggle Hourly Energy Consumption database. It is collected by PJM Interconnection, a company coordinating the continuous buying, selling, and delivery of wholesale electricity through the Energy Market from suppliers to customers in the reagon of South Carolina, USA. All .csv files contains rows with a timestamp and a value. The name of the value column corresponds to the name of the contractor. the timestamp represents a single hour and the value represents the total energy, cunsumed during that hour.\n\nThe data we will be using is hourly power consumption data from PJM. Energy consumtion has some unique charachteristics. It will be interesting to see how prophet picks them up.\n\nhttps://www.kaggle.com/robikscube/hourly-energy-consumption\n\nPulling the PJM East which has data from 2002-2018 for the entire east region.\n\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom fbprophet import Prophet\nfrom sklearn.metrics import mean_squared_error, mean_absolute_error\nplt.style.use('fivethirtyeight') # For plots",
"_____no_output_____"
],
[
"dataset_path = './data/hourly-energy-consumption/PJME_hourly.csv'\ndf = pd.read_csv(dataset_path, index_col=[0], parse_dates=[0])\nprint(\"Dataset path:\",df.shape)\ndf.head(10)",
"Dataset path: (145366, 1)\n"
],
[
"# VISUALIZE DATA\n# Color pallete for plotting\ncolor_pal = [\"#F8766D\", \"#D39200\", \"#93AA00\",\n \"#00BA38\", \"#00C19F\", \"#00B9E3\",\n \"#619CFF\", \"#DB72FB\"]\ndf.plot(style='.', figsize=(20,10), color=color_pal[0], title='PJM East Dataset TS')\nplt.show()",
"_____no_output_____"
],
[
"#Decompose the seasonal data\n\ndef create_features(df, label=None):\n \"\"\"\n Creates time series features from datetime index.\n \"\"\"\n df = df.copy()\n df['date'] = df.index\n df['hour'] = df['date'].dt.hour\n df['dayofweek'] = df['date'].dt.dayofweek\n df['quarter'] = df['date'].dt.quarter\n df['month'] = df['date'].dt.month\n df['year'] = df['date'].dt.year\n df['dayofyear'] = df['date'].dt.dayofyear\n df['dayofmonth'] = df['date'].dt.day\n df['weekofyear'] = df['date'].dt.weekofyear\n \n X = df[['hour','dayofweek','quarter','month','year',\n 'dayofyear','dayofmonth','weekofyear']]\n if label:\n y = df[label]\n return X, y\n return X",
"_____no_output_____"
],
[
"df.columns",
"_____no_output_____"
],
[
"X, y = create_features(df, label='PJME_MW')\n\nfeatures_and_target = pd.concat([X, y], axis=1)\n\nprint(\"Shape\",features_and_target.shape)\nfeatures_and_target.head(10)",
"Shape (145366, 9)\n"
],
[
"sns.pairplot(features_and_target.dropna(),\n hue='hour',\n x_vars=['hour','dayofweek',\n 'year','weekofyear'],\n y_vars='PJME_MW',\n height=5,\n plot_kws={'alpha':0.15, 'linewidth':0}\n )\nplt.suptitle('Power Use MW by Hour, Day of Week, Year and Week of Year')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Train and Test Split",
"_____no_output_____"
],
[
"We use a temporal split, keeping old data and use only new period to do the prediction",
"_____no_output_____"
]
],
[
[
"split_date = '01-Jan-2015'\npjme_train = df.loc[df.index <= split_date].copy()\npjme_test = df.loc[df.index > split_date].copy()",
"_____no_output_____"
],
[
"# Plot train and test so you can see where we have split\npjme_test \\\n .rename(columns={'PJME_MW': 'TEST SET'}) \\\n .join(pjme_train.rename(columns={'PJME_MW': 'TRAINING SET'}),\n how='outer') \\\n .plot(figsize=(15,5), title='PJM East', style='.')\nplt.show()",
"_____no_output_____"
]
],
[
[
"To use prophet you need to correctly rename features and label to correctly pass the input to the engine.",
"_____no_output_____"
]
],
[
[
"# Format data for prophet model using ds and y\npjme_train.reset_index() \\\n .rename(columns={'Datetime':'ds',\n 'PJME_MW':'y'})\n\nprint(pjme_train.columns)\npjme_train.head(5)",
"Index(['PJME_MW'], dtype='object')\n"
]
],
[
[
"### Create and train the model",
"_____no_output_____"
]
],
[
[
"# Setup and train model and fit\nmodel = Prophet()\nmodel.fit(pjme_train.reset_index() \\\n .rename(columns={'Datetime':'ds',\n 'PJME_MW':'y'}))\n",
"_____no_output_____"
],
[
"# Predict on training set with model\npjme_test_fcst = model.predict(df=pjme_test.reset_index() \\\n .rename(columns={'Datetime':'ds'}))",
"_____no_output_____"
],
[
"pjme_test_fcst.head()",
"_____no_output_____"
]
],
[
[
"### Plot the results and forecast",
"_____no_output_____"
]
],
[
[
"# Plot the forecast\nf, ax = plt.subplots(1)\nf.set_figheight(5)\nf.set_figwidth(15)\nfig = model.plot(pjme_test_fcst,\n ax=ax)\nplt.show()",
"_____no_output_____"
],
[
"# Plot the components of the model\nfig = model.plot_components(pjme_test_fcst)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
d060d44ea8124e137ea522b9965ec22ce7ada076 | 244,737 | ipynb | Jupyter Notebook | examples/nyquist_plots_examples.ipynb | EISy-as-Py/EISy-as-Py | 3086ecd043fce4d8ba49ec55004340a5444c0eb0 | [
"MIT"
]
| 5 | 2020-02-06T21:38:47.000Z | 2020-02-13T20:29:44.000Z | examples/nyquist_plots_examples.ipynb | EISy-as-Py/EISy-as-Py | 3086ecd043fce4d8ba49ec55004340a5444c0eb0 | [
"MIT"
]
| 2 | 2020-03-11T22:06:21.000Z | 2020-05-18T17:22:43.000Z | examples/nyquist_plots_examples.ipynb | EISy-as-Py/EISy-as-Py | 3086ecd043fce4d8ba49ec55004340a5444c0eb0 | [
"MIT"
]
| 4 | 2020-03-13T20:35:04.000Z | 2020-03-18T21:56:28.000Z | 715.605263 | 35,248 | 0.948516 | [
[
[
"from PyEIS import *",
"_____no_output_____"
]
],
[
[
"## Frequency range\nThe first first step needed to simulate an electrochemical impedance spectra is to generate a frequency domain, to do so, use to build-in freq_gen() function, as follows",
"_____no_output_____"
]
],
[
[
"f_range = freq_gen(f_start=10**10, f_stop=0.1, pts_decade=7)\n# print(f_range[0]) #First 5 points in the freq. array\nprint()\n# print(f_range[1]) #First 5 points in the angular freq.array",
"\n"
]
],
[
[
"Note that all functions included are described, to access these descriptions stay within () and press shift+tab. The freq_gen(), returns both the frequency, which is log seperated based on points/decade between f_start to f_stop, and the angular frequency. This function is quite useful and will be used through this tutorial",
"_____no_output_____"
],
[
"## The Equivalent Circuits\nThere exist a number of equivalent circuits that can be simulated and fitted, these functions are made as definations and can be called at any time. To find these, write: \"cir_\" and hit tab. All functions are outline in the next cell and can also be viewed in the equivalent circuit overview:",
"_____no_output_____"
]
],
[
[
"cir_RC\ncir_RQ\ncir_RsRQ\ncir_RsRQRQ\ncir_Randles\ncir_Randles_simplified\ncir_C_RC_C\ncir_Q_RQ_Q\ncir_RCRCZD\ncir_RsTLsQ\ncir_RsRQTLsQ\ncir_RsTLs\ncir_RsRQTLs\ncir_RsTLQ\ncir_RsRQTLQ\ncir_RsTL\ncir_RsRQTL\ncir_RsTL_1Dsolid\ncir_RsRQTL_1Dsolid",
"_____no_output_____"
]
],
[
[
"## Simulation of -(RC)-\n\n<img src='https://raw.githubusercontent.com/kbknudsen/PyEIS/master/pyEIS_images/RC_circuit.png' width=\"300\" />\n\n#### Input Parameters:\n- w = Angular frequency [1/s]\n- R = Resistance [Ohm]\n- C = Capacitance [F]\n- fs = summit frequency of RC circuit [Hz]",
"_____no_output_____"
]
],
[
[
"RC_example = EIS_sim(frange=f_range[0], circuit=cir_RC(w=f_range[1], R=70, C=10**-6), legend='on')",
"_____no_output_____"
]
],
[
[
"## Simulation of -Rs-(RQ)-\n\n<img src='https://raw.githubusercontent.com/kbknudsen/PyEIS/master/pyEIS_images/RsRQ_circuit.png' width=\"500\" />\n\n#### Input parameters:\n- w = Angular frequency [1/s]\n- Rs = Series resistance [Ohm]\n- R = Resistance [Ohm]\n- Q = Constant phase element [s^n/ohm]\n- n = Constant phase elelment exponent [-]\n- fs = summit frequency of RQ circuit [Hz]",
"_____no_output_____"
]
],
[
[
"RsRQ_example = EIS_sim(frange=f_range[0], circuit=cir_RsRQ(w=f_range[1], Rs=70, R=200, n=.8, Q=10**-5), legend='on')",
"_____no_output_____"
],
[
"RsRC_example = EIS_sim(frange=f_range[0], circuit=cir_RsRC(w=f_range[1], Rs=80, R=100, C=10**-5), legend='on')",
"_____no_output_____"
]
],
[
[
"## Simulation of -Rs-(RQ)-(RQ)-\n\n<img src='https://raw.githubusercontent.com/kbknudsen/PyEIS/master/pyEIS_images/RsRQRQ_circuit.png' width=\"500\" />\n\n#### Input parameters:\n- w = Angular frequency [1/s]\n- Rs = Series Resistance [Ohm]\n- R = Resistance [Ohm]\n- Q = Constant phase element [s^n/ohm]\n- n = Constant phase element exponent [-]\n- fs = summit frequency of RQ circuit [Hz]\n- R2 = Resistance [Ohm]\n- Q2 = Constant phase element [s^n/ohm]\n- n2 = Constant phase element exponent [-]\n- fs2 = summit frequency of RQ circuit [Hz]",
"_____no_output_____"
]
],
[
[
"RsRQRQ_example = EIS_sim(frange=f_range[0], circuit=cir_RsRQRQ(w=f_range[1], Rs=200, R=150, n=.872, Q=10**-4, R2=50, n2=.853, Q2=10**-6), legend='on')",
"_____no_output_____"
]
],
[
[
"## Simulation of -Rs-(Q(RW))- (Randles-circuit)\nThis circuit is often used for an experimental setup with a macrodisk working electrode with an outer-sphere heterogeneous charge transfer. This, classical, warburg element is controlled by semi-infinite linear diffusion, which is given by the geometry of the working electrode. Two Randles functions are avaliable for simulations: cir_Randles_simplified() and cir_Randles(). The former contains the Warburg constant (sigma), which summs up all mass transport constants (Dox/Dred, Cred/Cox, number of electrons (n_electron), Faradays constant (F), T, and E0) into a single constant sigma, while the latter contains all of these constants. Only cir_Randles_simplified() is avaliable for fitting, as either D$_{ox}$ or D$_{red}$ and C$_{red}$ or C$_{ox}$ are needed.\n\n<img src='https://raw.githubusercontent.com/kbknudsen/PyEIS/master/pyEIS_images/Randles_circuit.png' width=\"500\" />\n\n#### Input parameters:\n- Rs = Series resistance [ohm]\n- Rct = charge-transfer resistance [ohm]\n- Q = Constant phase element used to model the double-layer capacitance [F]\n- n = expononent of the CPE [-]\n- sigma = Warburg Constant [ohm/s^1/2]",
"_____no_output_____"
]
],
[
[
"Randles = cir_Randles_simplified(w=f_range[1], Rs=100, R=1000, n=1, sigma=300, Q=10**-5)\nRandles_example = EIS_sim(frange=f_range[0], circuit=Randles, legend='off')",
"_____no_output_____"
],
[
"Randles_example = EIS_sim(frange=f_range[0], circuit=cir_Randles_simplified(w=f_range[1], Rs=100, R=1000, n=1, sigma=300, Q='none', fs=10**3.3), legend='off')",
"_____no_output_____"
]
],
[
[
"In the following, the Randles circuit with the Warburg constant (sigma) defined is simulated where:\n- D$_{red}$/D$_{ox}$ = 10$^{-6}$ cm$^2$/s\n- C$_{red}$/C$_{ox}$ = 10 mM\n- n_electron = 1\n- T = 25 $^o$C\n\nThis function is a great tool to simulate expected impedance responses prior to starting experiments as it allows for evaluation of concentrations, diffusion constants, number of electrons, and Temp. to evaluate the feasability of obtaining information on either kinetics, mass-transport, or both.",
"_____no_output_____"
]
],
[
[
"Randles_example = EIS_sim(frange=f_range[0], circuit=cir_Randles(w=f_range[1], Rs=100, Rct=1000, Q=10**-7, n=1, T=298.15, D_ox=10**-9, D_red=10**-9, C_ox=10**-5, C_red=10**-5, n_electron=1, E=0, A=1), legend='off')",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d060eba8647218bcd5795351a84e4d41e7367041 | 155,060 | ipynb | Jupyter Notebook | nbs/examples/complex_dummy_experiment_manager.ipynb | Jaume-JCI/hpsearch | 168d81f49e1a4bd4dbab838baaa8ff183a422030 | [
"MIT"
]
| null | null | null | nbs/examples/complex_dummy_experiment_manager.ipynb | Jaume-JCI/hpsearch | 168d81f49e1a4bd4dbab838baaa8ff183a422030 | [
"MIT"
]
| 15 | 2021-12-02T15:00:37.000Z | 2022-02-22T17:53:50.000Z | nbs/examples/complex_dummy_experiment_manager.ipynb | Jaume-JCI/hpsearch | 168d81f49e1a4bd4dbab838baaa8ff183a422030 | [
"MIT"
]
| null | null | null | 197.277354 | 65,596 | 0.894589 | [
[
[
"#hide\n#default_exp examples.complex_dummy_experiment_manager\nfrom nbdev.showdoc import *\nfrom block_types.utils.nbdev_utils import nbdev_setup, TestRunner\n\nnbdev_setup ()\ntst = TestRunner (targets=['dummy'])",
"_____no_output_____"
]
],
[
[
"# Complex Dummy Experiment Manager\n\n> Dummy experiment manager with features that allow additional functionality",
"_____no_output_____"
]
],
[
[
"#export\nfrom hpsearch.examples.dummy_experiment_manager import DummyExperimentManager, FakeModel\nimport hpsearch\nimport os\nimport shutil\nimport os\n\nimport hpsearch.examples.dummy_experiment_manager as dummy_em\nfrom hpsearch.visualization import plot_utils ",
"_____no_output_____"
],
[
"#for tests\nimport pytest\nfrom block_types.utils.nbdev_utils import md",
"_____no_output_____"
]
],
[
[
"## ComplexDummyExperimentManager",
"_____no_output_____"
]
],
[
[
"#export\nclass ComplexDummyExperimentManager (DummyExperimentManager):\n \n def __init__ (self, model_file_name='model_weights.pk', **kwargs):\n super().__init__ (model_file_name=model_file_name, **kwargs)\n self.raise_error_if_run = False\n\n def run_experiment (self, parameters={}, path_results='./results'):\n \n # useful for testing: in some cases the experiment manager should not call run_experiment\n if self.raise_error_if_run:\n raise RuntimeError ('run_experiment should not be called')\n \n # extract hyper-parameters used by our model. All the parameters have default values if they are not passed.\n offset = parameters.get('offset', 0.5) # default value: 0.5\n rate = parameters.get('rate', 0.01) # default value: 0.01\n epochs = parameters.get('epochs', 10) # default value: 10\n noise = parameters.get('noise', 0.0)\n if parameters.get('actual_epochs') is not None:\n epochs = parameters.get('actual_epochs')\n \n # other parameters that do not form part of our experiment definition\n # changing the values of these other parameters, does not make the ID of the experiment change\n verbose = parameters.get('verbose', True)\n \n # build model with given hyper-parameters\n model = FakeModel (offset=offset, rate=rate, epochs=epochs, noise = noise, verbose=verbose)\n \n # load training, validation and test data (fake step)\n model.load_data()\n\n # start from previous experiment if indicated by parameters\n path_results_previous_experiment = parameters.get('prev_path_results')\n if path_results_previous_experiment is not None:\n model.load_model_and_history (path_results_previous_experiment)\n \n # fit model with training data \n model.fit ()\n \n # save model weights and evolution of accuracy metric across epochs\n model.save_model_and_history(path_results)\n \n # simulate ctrl-c\n if parameters.get ('halt', False):\n raise KeyboardInterrupt ('stopped')\n \n # evaluate model with validation and test data\n validation_accuracy, test_accuracy = model.score()\n \n # store model\n self.model = model\n \n # the function returns a dictionary with keys corresponding to the names of each metric. \n # We return result on validation and test set in this example\n dict_results = dict (validation_accuracy = validation_accuracy,\n test_accuracy = test_accuracy)\n \n return dict_results\n ",
"_____no_output_____"
]
],
[
[
"### Usage",
"_____no_output_____"
]
],
[
[
"#exports tests.examples.test_complex_dummy_experiment_manager\ndef test_complex_dummy_experiment_manager ():\n #em = generate_data ('complex_dummy_experiment_manager')\n \n md (\n'''\nExtend previous experiment by using a larger number of epochs\n\nWe see how to create a experiment that is the same as a previous experiment, \nonly increasing the number of epochs. \n\n1.a. For test purposes, we first run the full number of epochs, 30, take note of the accuracy, \nand remove the experiment\n'''\n )\n \n em = ComplexDummyExperimentManager (path_experiments='test_complex_dummy_experiment_manager', \n verbose=0)\n em.create_experiment_and_run (parameters = {'epochs': 30});\n reference_accuracy = em.model.accuracy\n reference_weight = em.model.weight\n\n from hpsearch.config.hpconfig import get_path_experiments\n import os\n import pandas as pd\n\n path_experiments = get_path_experiments ()\n print (f'experiments folders: {os.listdir(f\"{path_experiments}/experiments\")}\\n')\n\n experiments_data = pd.read_pickle (f'{path_experiments}/experiments_data.pk')\n print ('csv data')\n display (experiments_data)\n\n md ('we plot the history')\n from hpsearch.visualization.experiment_visualization import plot_multiple_histories\n\n plot_multiple_histories ([0], run_number=0, op='max', backend='matplotlib', metrics='validation_accuracy')\n\n md ('1.b. Now we run two experiments: ')\n\n md ('We run the first experiment with 20 epochs:')\n\n # a.- remove previous experiment\n em.remove_previous_experiments()\n\n # b.- create first experiment with epochs=20\n em.create_experiment_and_run (parameters = {'epochs': 20});\n\n print (f'experiments folders: {os.listdir(f\"{path_experiments}/experiments\")}\\n')\n\n experiments_data = pd.read_pickle (f'{path_experiments}/experiments_data.pk')\n print ('csv data')\n display(experiments_data)\n print (f'weight: {em.model.weight}, accuracy: {em.model.accuracy}')\n\n md ('We run the second experiment resumes from the previous one and increases the epochs to 30')\n # 4.- create second experiment with epochs=10\n em.create_experiment_and_run (parameters = {'epochs': 30}, \n other_parameters={'prev_epoch': True,\n 'name_epoch': 'epochs',\n 'previous_model_file_name': 'model_weights.pk'});\n\n experiments_data = pd.read_pickle (f'{path_experiments}/experiments_data.pk')\n print ('csv data')\n display(experiments_data)\n\n new_accuracy = em.model.accuracy\n new_weight = em.model.weight\n\n assert new_weight==reference_weight\n assert new_accuracy==reference_accuracy\n\n print (f'weight: {new_weight}, accuracy: {new_accuracy}')\n\n md ('We plot the history')\n plot_multiple_histories ([1], run_number=0, op='max', backend='matplotlib', metrics='validation_accuracy')\n \n em.remove_previous_experiments()",
"_____no_output_____"
],
[
"tst.run (test_complex_dummy_experiment_manager, tag='dummy')",
"running test_complex_dummy_experiment_manager\n"
]
],
[
[
"## Running experiments and removing experiments",
"_____no_output_____"
]
],
[
[
"# export\ndef run_multiple_experiments (**kwargs):\n dummy_em.run_multiple_experiments (EM=ComplexDummyExperimentManager, **kwargs)\n\ndef remove_previous_experiments ():\n dummy_em.remove_previous_experiments (EM=ComplexDummyExperimentManager)",
"_____no_output_____"
],
[
"#export\ndef generate_data (name_folder):\n em = ComplexDummyExperimentManager (path_experiments=f'test_{name_folder}', verbose=0)\n em.remove_previous_experiments ()\n run_multiple_experiments (em=em, nruns=5, noise=0.1, verbose=False)\n return em",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
d061077a7df45ec4c5ebf5d8df4448f6c1df44f4 | 12,842 | ipynb | Jupyter Notebook | lessons/Workshop_13_OOP.ipynb | andrewt0301/python-problems | 57338611ac631f094e3fb78a6cccab8b6fd7b442 | [
"Apache-2.0"
]
| null | null | null | lessons/Workshop_13_OOP.ipynb | andrewt0301/python-problems | 57338611ac631f094e3fb78a6cccab8b6fd7b442 | [
"Apache-2.0"
]
| null | null | null | lessons/Workshop_13_OOP.ipynb | andrewt0301/python-problems | 57338611ac631f094e3fb78a6cccab8b6fd7b442 | [
"Apache-2.0"
]
| null | null | null | 42.664452 | 1,084 | 0.531926 | [
[
[
"# Workshop 13\n## _Object-oriented programming._\n\n#### Classes and Objects\n",
"_____no_output_____"
]
],
[
[
"class MyClass:\n pass\n\n\nobj1 = MyClass()\nobj2 = MyClass()\n\nprint(obj1)\nprint(type(obj1))\n\nprint(obj2)\nprint(type(obj2))\n",
"_____no_output_____"
]
],
[
[
"##### Constructor and destructor\n",
"_____no_output_____"
]
],
[
[
"class Employee: \n \n def __init__(self): \n print('Employee created.') \n \n def __del__(self): \n print('Destructor called, Employee deleted.') \n \nobj = Employee() \ndel obj \n",
"_____no_output_____"
]
],
[
[
"##### Attributes and methods\n",
"_____no_output_____"
]
],
[
[
"class Student:\n\n def __init__(self, name, grade):\n self.name = name\n self.grade = grade\n\n def __str__(self):\n return '{' + self.name + ': ' + str(self.grade) + '}'\n\n def learn(self):\n print('My name is %s. I am learning Python! My grade is %d.' % (self.name, self.grade))\n\n\nstudents = [Student('Steve', 9), Student('Oleg', 10)]\n\nfor student in students:\n print()\n print('student.name = ' + student.name)\n print('student.grade = ' + str(student.grade))\n print('student = ' + str(student))\n student.learn()\n",
"_____no_output_____"
]
],
[
[
"##### Class and instance attributes\n",
"_____no_output_____"
]
],
[
[
"class Person:\n\n # class variable shared by all instances\n status = 'student'\n\n def __init__(self, name):\n # instance variable unique to each instance\n self.name = name\n\n\na = Person('Steve')\nb = Person('Mark')\n\nprint('')\nprint(a.name + ' : ' + a.status)\nprint(b.name + ' : ' + b.status)\n\nPerson.status = 'graduate'\n\nprint('')\nprint(a.name + ' : ' + a.status)\nprint(b.name + ' : ' + b.status)\n\nPerson.status = 'student'\n\nprint('')\nprint(a.name + ' : ' + a.status)\nprint(b.name + ' : ' + b.status)\n",
"_____no_output_____"
]
],
[
[
"##### Class and static methods\n",
"_____no_output_____"
]
],
[
[
"class Env:\n os = 'Windows'\n\n @classmethod\n def print_os(self):\n print(self.os)\n \n @staticmethod\n def print_user():\n print('guest')\n\n\nEnv.print_os()\nEnv.print_user()\n",
"_____no_output_____"
]
],
[
[
"##### Encapsulation\n",
"_____no_output_____"
]
],
[
[
"class Person:\n\n def __init__(self, name):\n self.name = name\n\n def __str__(self):\n return 'My name is ' + self.name\n\n\nperson = Person('Steve')\nprint(person.name)\n\nperson.name = 'Said' \nprint(person.name)\n",
"_____no_output_____"
],
[
"class Identity:\n\n def __init__(self, name):\n self.__name = name\n\n def __str__(self):\n return 'My name is ' + self.__name\n\n\nperson = Identity('Steve')\nprint(person.__name)\n\nperson.__name = 'Said' \nprint(person)\n",
"_____no_output_____"
]
],
[
[
"##### Operator overloading\n",
"_____no_output_____"
]
],
[
[
"class Number:\n\n def __init__(self, value):\n self.__value = value\n\n def __del__(self):\n pass\n\n def __str__(self):\n return str(self.__value)\n\n def __int__(self):\n return self.__value\n\n def __eq__(self, other):\n return self.__value == other.__value\n\n def __ne__(self, other):\n return self.__value != other.__value\n\n def __lt__(self, other):\n return self.__value < other.__value\n\n def __gt__(self, other):\n return self.__value > other.__value\n\n def __add__(self, other):\n return Number(self.__value + other.__value)\n\n def __mul__(self, other):\n return Number(self.__value * other.__value)\n\n def __neg__(self):\n return Number(-self.__value)\n\n\na = Number(10)\nb = Number(20)\nc = Number(5)\n\n# Overloaded operators\nx = -a + b * c\nprint(x)\n\nprint(a < b)\nprint(b > c)\n\n# Unsupported operators\nprint(a <= b)\nprint(b >= c)\nprint(a // c)\n",
"_____no_output_____"
]
],
[
[
"#### Inheritance and polymorphism\n",
"_____no_output_____"
]
],
[
[
"class Creature:\n def say(self):\n pass\n\n\nclass Dog(Creature):\n def say(self):\n print('Woof!')\n\n\nclass Cat(Creature):\n def say(self):\n print(\"Meow!\")\n\n\nclass Lion(Creature):\n def say(self):\n print(\"Roar!\")\n \n\nanimals = [Creature(), Dog(), Cat(), Lion()]\n\nfor animal in animals:\n print(type(animal))\n animal.say()\n\n",
"_____no_output_____"
]
],
[
[
"##### Multiple inheritance\n",
"_____no_output_____"
]
],
[
[
"class Person:\n def __init__(self, name):\n self.name = name\n\n\nclass Student(Person):\n def __init__(self, name, grade):\n super().__init__(name)\n self.grade = grade\n\n\nclass Employee:\n def __init__(self, salary):\n self.salary = salary\n\n\nclass Teacher(Person, Employee):\n def __init__(self, name, salary):\n Person.__init__(self, name)\n Employee.__init__(self, salary)\n\n\nclass TA(Student, Employee):\n def __init__(self, name, grage, salary):\n Student.__init__(self, name, grage)\n Employee.__init__(self, salary)\n\n\nx = Student('Oleg', 9)\ny = TA('Sergei', 10, 1000)\nz = Teacher('Andrei', 2000)\n\nfor person in [x, y, z]:\n print(person.name)\n if isinstance(person, Employee):\n print(person.salary)\n if isinstance(person, Student):\n print(person.grade)\n",
"_____no_output_____"
]
],
[
[
"##### Function _isinstance_\n",
"_____no_output_____"
]
],
[
[
"x = 10\nprint('')\nprint(isinstance(x, int))\nprint(isinstance(x, float))\nprint(isinstance(x, str))\n\ny = 3.14\nprint('')\nprint(isinstance(y, int))\nprint(isinstance(y, float))\nprint(isinstance(y, str))\n\n\nz = 'Hello world'\nprint('')\nprint(isinstance(z, int))\nprint(isinstance(z, float))\nprint(isinstance(z, str))\n",
"_____no_output_____"
],
[
"class A:\n pass\n\n\nclass B:\n pass\n\n\nclass C(A):\n pass\n\n\nclass D(A, B):\n pass\n\n\na = A()\nb = B()\nc = C()\nd = D()\n\nprint('')\nprint(isinstance(a, object))\nprint(isinstance(a, A))\nprint(isinstance(b, B))\n\nprint('')\nprint(isinstance(b, object))\nprint(isinstance(b, A))\nprint(isinstance(b, B))\nprint(isinstance(b, C))\n\nprint('')\nprint(isinstance(c, object))\nprint(isinstance(c, A))\nprint(isinstance(c, B))\nprint(isinstance(c, D))\n\n\nprint('')\nprint(isinstance(d, object))\nprint(isinstance(d, A))\nprint(isinstance(d, B))\nprint(isinstance(d, C))\nprint(isinstance(d, D))\n",
"_____no_output_____"
]
],
[
[
"##### Composition\n",
"_____no_output_____"
]
],
[
[
"class Teacher:\n pass\n\nclass Student:\n pass\n\nclass ClassRoom:\n def __init__(self, teacher, students):\n self.teacher = teacher\n self.students = students\n\n\ncl = ClassRoom(Teacher(), [Student(), Student(), Student()])\n",
"_____no_output_____"
],
[
"class Set:\n\n def __init__(self, values=None):\n self.dict = {}\n\n if values is not None:\n for value in values:\n self.add(value)\n\n def __repr__(self):\n return \"Set: \" + str(self.dict.keys())\n\n def add(self, value):\n self.dict[value] = True\n\n def contains(self, value):\n return value in self.dict\n\n def remove(self, value):\n del self.dict[value]\n\n\ns = Set([1,2,3])\ns.add(4)\nprint(s.contains(4))\ns.remove(3)\nprint(s.contains(3))\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
d0610aae49ed9cd42f0ff340a636706689eeaf03 | 16,728 | ipynb | Jupyter Notebook | examples/06_Scalable_GP_Classification_1D/KISSGP_Classification_1D.ipynb | phumm/gpytorch | 4e8042bcecda049956f8f9e823d82ba6340766d5 | [
"MIT"
]
| 1 | 2019-09-30T06:51:03.000Z | 2019-09-30T06:51:03.000Z | examples/06_Scalable_GP_Classification_1D/KISSGP_Classification_1D.ipynb | phumm/gpytorch | 4e8042bcecda049956f8f9e823d82ba6340766d5 | [
"MIT"
]
| null | null | null | examples/06_Scalable_GP_Classification_1D/KISSGP_Classification_1D.ipynb | phumm/gpytorch | 4e8042bcecda049956f8f9e823d82ba6340766d5 | [
"MIT"
]
| 1 | 2020-09-16T16:35:27.000Z | 2020-09-16T16:35:27.000Z | 55.026316 | 6,900 | 0.718675 | [
[
[
"# Scalable GP Classification in 1D (w/ KISS-GP)\n\nThis example shows how to use grid interpolation based variational classification with an `ApproximateGP` using a `GridInterpolationVariationalStrategy` module. This classification module is designed for when the inputs of the function you're modeling are one-dimensional.\n\nThe use of inducing points allows for scaling up the training data by making computational complexity linear instead of cubic.\n\nIn this example, we’re modeling a function that is periodically labeled cycling every 1/8 (think of a square wave with period 1/4)\n\nThis notebook doesn't use cuda, in general we recommend GPU use if possible and most of our notebooks utilize cuda as well.\n\nKernel interpolation for scalable structured Gaussian processes (KISS-GP) was introduced in this paper:\nhttp://proceedings.mlr.press/v37/wilson15.pdf\n\nKISS-GP with SVI for classification was introduced in this paper:\nhttps://papers.nips.cc/paper/6426-stochastic-variational-deep-kernel-learning.pdf",
"_____no_output_____"
]
],
[
[
"import math\nimport torch\nimport gpytorch\nfrom matplotlib import pyplot as plt\nfrom math import exp\n\n%matplotlib inline\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"train_x = torch.linspace(0, 1, 26)\ntrain_y = torch.sign(torch.cos(train_x * (2 * math.pi))).add(1).div(2)",
"_____no_output_____"
],
[
"from gpytorch.models import ApproximateGP\nfrom gpytorch.variational import CholeskyVariationalDistribution\nfrom gpytorch.variational import GridInterpolationVariationalStrategy\n\n\nclass GPClassificationModel(ApproximateGP):\n def __init__(self, grid_size=128, grid_bounds=[(0, 1)]):\n variational_distribution = CholeskyVariationalDistribution(grid_size)\n variational_strategy = GridInterpolationVariationalStrategy(self, grid_size, grid_bounds, variational_distribution)\n super(GPClassificationModel, self).__init__(variational_strategy)\n self.mean_module = gpytorch.means.ConstantMean()\n self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel())\n \n def forward(self,x):\n mean_x = self.mean_module(x)\n covar_x = self.covar_module(x)\n latent_pred = gpytorch.distributions.MultivariateNormal(mean_x, covar_x)\n return latent_pred\n\n\nmodel = GPClassificationModel()\nlikelihood = gpytorch.likelihoods.BernoulliLikelihood()",
"_____no_output_____"
],
[
"from gpytorch.mlls.variational_elbo import VariationalELBO\n\n# Find optimal model hyperparameters\nmodel.train()\nlikelihood.train()\n\n# Use the adam optimizer\noptimizer = torch.optim.Adam(model.parameters(), lr=0.01)\n\n# \"Loss\" for GPs - the marginal log likelihood\n# n_data refers to the number of training datapoints\nmll = VariationalELBO(likelihood, model, num_data=train_y.numel())\n\ndef train():\n num_iter = 100\n for i in range(num_iter):\n optimizer.zero_grad()\n output = model(train_x)\n # Calc loss and backprop gradients\n loss = -mll(output, train_y)\n loss.backward()\n print('Iter %d/%d - Loss: %.3f' % (i + 1, num_iter, loss.item()))\n optimizer.step()\n \n# Get clock time\n%time train()",
"Iter 1/100 - Loss: 0.070\nIter 2/100 - Loss: 14.834\nIter 3/100 - Loss: 0.977\nIter 4/100 - Loss: 3.547\nIter 5/100 - Loss: 8.699\nIter 6/100 - Loss: 6.352\nIter 7/100 - Loss: 1.795\nIter 8/100 - Loss: 0.188\nIter 9/100 - Loss: 2.075\nIter 10/100 - Loss: 4.160\nIter 11/100 - Loss: 3.899\nIter 12/100 - Loss: 1.941\nIter 13/100 - Loss: 0.344\nIter 14/100 - Loss: 0.360\nIter 15/100 - Loss: 1.501\nIter 16/100 - Loss: 2.298\nIter 17/100 - Loss: 1.944\nIter 18/100 - Loss: 0.904\nIter 19/100 - Loss: 0.177\nIter 20/100 - Loss: 0.297\nIter 21/100 - Loss: 0.916\nIter 22/100 - Loss: 1.281\nIter 23/100 - Loss: 1.024\nIter 24/100 - Loss: 0.451\nIter 25/100 - Loss: 0.111\nIter 26/100 - Loss: 0.246\nIter 27/100 - Loss: 0.593\nIter 28/100 - Loss: 0.733\nIter 29/100 - Loss: 0.526\nIter 30/100 - Loss: 0.206\nIter 31/100 - Loss: 0.087\nIter 32/100 - Loss: 0.225\nIter 33/100 - Loss: 0.408\nIter 34/100 - Loss: 0.413\nIter 35/100 - Loss: 0.245\nIter 36/100 - Loss: 0.091\nIter 37/100 - Loss: 0.096\nIter 38/100 - Loss: 0.210\nIter 39/100 - Loss: 0.273\nIter 40/100 - Loss: 0.210\nIter 41/100 - Loss: 0.104\nIter 42/100 - Loss: 0.064\nIter 43/100 - Loss: 0.117\nIter 44/100 - Loss: 0.173\nIter 45/100 - Loss: 0.159\nIter 46/100 - Loss: 0.093\nIter 47/100 - Loss: 0.056\nIter 48/100 - Loss: 0.077\nIter 49/100 - Loss: 0.115\nIter 50/100 - Loss: 0.115\nIter 51/100 - Loss: 0.078\nIter 52/100 - Loss: 0.050\nIter 53/100 - Loss: 0.061\nIter 54/100 - Loss: 0.083\nIter 55/100 - Loss: 0.086\nIter 56/100 - Loss: 0.062\nIter 57/100 - Loss: 0.045\nIter 58/100 - Loss: 0.053\nIter 59/100 - Loss: 0.064\nIter 60/100 - Loss: 0.065\nIter 61/100 - Loss: 0.050\nIter 62/100 - Loss: 0.040\nIter 63/100 - Loss: 0.046\nIter 64/100 - Loss: 0.052\nIter 65/100 - Loss: 0.051\nIter 66/100 - Loss: 0.041\nIter 67/100 - Loss: 0.037\nIter 68/100 - Loss: 0.041\nIter 69/100 - Loss: 0.044\nIter 70/100 - Loss: 0.042\nIter 71/100 - Loss: 0.035\nIter 72/100 - Loss: 0.034\nIter 73/100 - Loss: 0.036\nIter 74/100 - Loss: 0.037\nIter 75/100 - Loss: 0.033\nIter 76/100 - Loss: 0.030\nIter 77/100 - Loss: 0.030\nIter 78/100 - Loss: 0.033\nIter 79/100 - Loss: 0.031\nIter 80/100 - Loss: 0.029\nIter 81/100 - Loss: 0.028\nIter 82/100 - Loss: 0.028\nIter 83/100 - Loss: 0.028\nIter 84/100 - Loss: 0.026\nIter 85/100 - Loss: 0.025\nIter 86/100 - Loss: 0.025\nIter 87/100 - Loss: 0.025\nIter 88/100 - Loss: 0.025\nIter 89/100 - Loss: 0.024\nIter 90/100 - Loss: 0.022\nIter 91/100 - Loss: 0.022\nIter 92/100 - Loss: 0.022\nIter 93/100 - Loss: 0.022\nIter 94/100 - Loss: 0.020\nIter 95/100 - Loss: 0.021\nIter 96/100 - Loss: 0.020\nIter 97/100 - Loss: 0.019\nIter 98/100 - Loss: 0.018\nIter 99/100 - Loss: 0.019\nIter 100/100 - Loss: 0.017\nCPU times: user 6.33 s, sys: 9.66 s, total: 16 s\nWall time: 2.31 s\n"
],
[
"# Set model and likelihood into eval mode\nmodel.eval()\nlikelihood.eval()\n\n# Initialize axes\nf, ax = plt.subplots(1, 1, figsize=(4, 3))\n\nwith torch.no_grad():\n test_x = torch.linspace(0, 1, 101)\n predictions = likelihood(model(test_x))\n\nax.plot(train_x.numpy(), train_y.numpy(), 'k*')\npred_labels = predictions.mean.ge(0.5).float()\nax.plot(test_x.data.numpy(), pred_labels.numpy(), 'b')\nax.set_ylim([-1, 2])\nax.legend(['Observed Data', 'Mean', 'Confidence'])",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
d0611888d467fde28d61f6cbbf1ef43118ee3058 | 221,378 | ipynb | Jupyter Notebook | notebooks/AB_tests/Understand Splitting Fraction.ipynb | mclaughlin6464/pearce | 746f2bf4bf45e904d66996e003043661a01423ba | [
"MIT"
]
| null | null | null | notebooks/AB_tests/Understand Splitting Fraction.ipynb | mclaughlin6464/pearce | 746f2bf4bf45e904d66996e003043661a01423ba | [
"MIT"
]
| 16 | 2016-11-04T22:24:32.000Z | 2018-05-01T22:53:39.000Z | notebooks/AB_tests/Understand Splitting Fraction.ipynb | mclaughlin6464/pearce | 746f2bf4bf45e904d66996e003043661a01423ba | [
"MIT"
]
| 3 | 2016-10-04T08:07:52.000Z | 2019-05-03T23:50:01.000Z | 201.987226 | 72,772 | 0.897519 | [
[
[
"import numpy as np\nimport astropy\nfrom itertools import izip\nfrom pearce.mocks import compute_prim_haloprop_bins, cat_dict\nfrom pearce.mocks.customHODModels import *\nfrom halotools.utils.table_utils import compute_conditional_percentiles\nfrom halotools.mock_observables import hod_from_mock, wp, tpcf, tpcf_one_two_halo_decomp\nfrom math import ceil",
"_____no_output_____"
],
[
"from matplotlib import pyplot as plt\n%matplotlib inline\nimport seaborn as sns\nsns.set()",
"_____no_output_____"
],
[
"shuffle_type = ''#'sh_shuffled'\nmag_type = 'vpeak'",
"_____no_output_____"
],
[
"mag_cut = -21\nmin_ptcl = 200\nmag_key = 'halo_%s%s_mag'%(shuffle_type, mag_type)\nupid_key = 'halo_%supid'%(shuffle_type)",
"_____no_output_____"
],
[
"PMASS = 591421440.0000001 #chinchilla 400/ 2048\ncatalog = astropy.table.Table.read('abmatched_halos.hdf5', format = 'hdf5')",
"_____no_output_____"
],
[
"cosmo_params = {'simname':'chinchilla', 'Lbox':400.0, 'scale_factors':[0.658, 1.0]}\ncat = cat_dict[cosmo_params['simname']](**cosmo_params)#construct the specified catalog!\n\ncat.load_catalog(1.0)\n#cat.h = 1.0\nhalo_catalog = catalog[catalog['halo_mvir'] > min_ptcl*cat.pmass] #mass cut\ngalaxy_catalog = halo_catalog[ halo_catalog[mag_key] < mag_cut ] # mag cut",
"_____no_output_____"
],
[
"def compute_mass_bins(prim_haloprop, dlog10_prim_haloprop=0.05): \n lg10_min_prim_haloprop = np.log10(np.min(prim_haloprop))-0.001\n lg10_max_prim_haloprop = np.log10(np.max(prim_haloprop))+0.001\n num_prim_haloprop_bins = (lg10_max_prim_haloprop-lg10_min_prim_haloprop)/dlog10_prim_haloprop\n return np.logspace(\n lg10_min_prim_haloprop, lg10_max_prim_haloprop,\n num=int(ceil(num_prim_haloprop_bins)))",
"_____no_output_____"
],
[
"mass_bins = compute_mass_bins(halo_catalog['halo_mvir'], 0.2)\nmass_bin_centers = (mass_bins[1:]+mass_bins[:-1])/2.0",
"_____no_output_____"
],
[
"cen_mask = galaxy_catalog['halo_upid']==-1\ncen_hod_sham, _ = hod_from_mock(galaxy_catalog[cen_mask]['halo_mvir_host_halo'],\\\n halo_catalog['halo_mvir'],\\\n mass_bins)\n\nsat_hod_sham, _ = hod_from_mock(galaxy_catalog[~cen_mask]['halo_mvir_host_halo'],\\\n halo_catalog['halo_mvir'],\\\n mass_bins)",
"_____no_output_____"
],
[
"cat.load_model(1.0, HOD=(FSAssembiasTabulatedCens, FSAssembiasTabulatedSats), hod_kwargs = {'prim_haloprop_vals': mass_bin_centers,\n #'sec_haloprop_key': 'halo_%s'%(mag_type),\n 'cen_hod_vals':cen_hod_sham,\n 'sat_hod_vals':sat_hod_sham,\n 'split':0.5})",
"_____no_output_____"
],
[
"print cat.model.param_dict",
"{'mean_occupation_satellites_assembias_split1': 0.5, 'mean_occupation_satellites_assembias_param1': 0.5, 'mean_occupation_centrals_assembias_split1': 0.5, 'mean_occupation_centrals_assembias_param1': 0.5}\n"
],
[
"#rp_bins = np.logspace(-1,1.5,20)\n#rp_bins = np.logspace(-1.1,1.8, 25)\n#rp_bins = np.loadtxt('/nfs/slac/g/ki/ki18/des/swmclau2/AB_tests/rp_bins.npy')\nrp_bins = np.array([7.943282000000000120e-02,\n1.122018500000000057e-01,\n1.584893199999999891e-01,\n2.238721100000000130e-01,\n3.162277700000000191e-01,\n4.466835900000000192e-01,\n6.309573400000000332e-01,\n8.912509400000000470e-01,\n1.258925410000000022e+00,\n1.778279409999999894e+00,\n2.511886430000000114e+00,\n3.548133889999999901e+00,\n5.011872340000000037e+00,\n7.079457839999999891e+00,\n1.000000000000000000e+01,\n1.412537544999999994e+01,\n1.995262315000000086e+01,\n2.818382931000000013e+01,\n3.981071706000000177e+01])\n\nbin_centers = (rp_bins[:1]+rp_bins[:-1])/2",
"_____no_output_____"
],
[
"min_logmass, max_logmass = 9.0, 17.0\nnames = ['mean_occupation_centrals_assembias_param1','mean_occupation_satellites_assembias_param1',\\\n 'mean_occupation_centrals_assembias_split1','mean_occupation_satellites_assembias_split1']",
"_____no_output_____"
],
[
"#mock_wp = cat.calc_wp(rp_bins, RSD= False)\nMAP = np.array([ 0.85, -0.3,0.85,0.5])\n\nparams = dict(zip(names, MAP))\n#print params.keys()\n\nmock_wps = []\nmock_wps_1h, mock_wps_2h = [],[]\n#mock_nds = []\nsplit = np.linspace(0.1, 0.9, 4)\n#split_abcissa = [10**9, 10**13, 10**16]\n\n#cat.model._input_model_dictionary['centrals_occupation']._split_abscissa = split_abcissa\n#cat.model._input_model_dictionary['satellites_occupation']._split_abscissa = split_abcissa\nfor p in split:\n #params['mean_occupation_centrals_assembias_split1'] = p\n params['mean_occupation_satellites_assembias_split1'] = p\n #print params.keys()\n #print cat.model.param_dict\n cat.populate(params)\n #print cat.model.param_dict\n #cut_idx = cat.model.mock.galaxy_table['gal_type'] == 'centrals'\n mass_cut = np.logical_and(np.log10(cat.model.mock.galaxy_table['halo_mvir'] ) > min_logmass,\\\n np.log10(cat.model.mock.galaxy_table['halo_mvir'] ) <= max_logmass)\n #mass_cut = np.logical_and(mass_cut, cut_idx)\n #mock_nds.append(len(cut_idx)/cat.Lbox**3)\n mock_pos = np.c_[cat.model.mock.galaxy_table['x'],\\\n cat.model.mock.galaxy_table['y'],\\\n cat.model.mock.galaxy_table['z']]\n mock_wps.append(wp(mock_pos*cat.h, rp_bins ,40.0*cat.h, period=cat.Lbox*cat.h, num_threads=1))\n #oneh, twoh = tpcf_one_two_halo_decomp(mock_pos,cat.model.mock.galaxy_table[mass_cut]['halo_hostid'],\\\n # rp_bins , period=cat.Lbox, num_threads=1)\n #mock_wps_1h.append(oneh)\n #mock_wps_2h.append(twoh)\n \nmock_wps = np.array(mock_wps)\nwp_errs = np.std(mock_wps, axis = 0)\n\n#mock_wps_1h = np.array(mock_wps_1h)\n#mock_wp_no_ab_1h = np.mean(mock_wps_1h, axis = 0)\n\n#mock_wps_2h = np.array(mock_wps_2h)\n#mock_wp_no_ab_2h = np.mean(mock_wps_2h, axis = 0)\n\n#mock_nds = np.array(mock_nds)\n#mock_nd = np.mean(mock_nds)\n#nd_err = np.std(mock_nds)",
"_____no_output_____"
],
[
"params",
"_____no_output_____"
],
[
"params = dict(zip(names, [0,0,0.5,0.5])) \ncat.populate(params)\nmass_cut = np.logical_and(np.log10(cat.model.mock.galaxy_table['halo_mvir'] ) > min_logmass,\\\n np.log10(cat.model.mock.galaxy_table['halo_mvir'] ) <= max_logmass)\n\nprint cat.model.param_dict\nmock_pos = np.c_[cat.model.mock.galaxy_table['x'],\\\n cat.model.mock.galaxy_table['y'],\\\n cat.model.mock.galaxy_table['z']]\nnoab_wp = wp(mock_pos*cat.h, rp_bins ,40.0*cat.h, period=cat.Lbox*cat.h, num_threads=1)",
"{'mean_occupation_centrals_assembias_split1': 0.5, 'mean_occupation_centrals_assembias_param1': 0, 'mean_occupation_satellites_assembias_split1': 0.5, 'mean_occupation_satellites_assembias_param1': 0}\n"
],
[
"print np.log10(noab_wp)",
"[ 2.86479644 2.71375719 2.5690466 2.38344144 2.20022251 2.02959663\n 1.87899003 1.72579396 1.60715197 1.52219163 1.41551296 1.27122876\n 1.12708178 0.97127198 0.80736591 0.56640291 0.25364583 -0.18412503]\n"
],
[
"from halotools.mock_observables import return_xyz_formatted_array",
"_____no_output_____"
],
[
"sham_pos = np.c_[galaxy_catalog['halo_x'],\\\n galaxy_catalog['halo_y'],\\\n galaxy_catalog['halo_z']]\n\ndistortion_dim = 'z'\nv_distortion_dim = galaxy_catalog['halo_v%s' % distortion_dim]\n# apply redshift space distortions\n#sham_pos = return_xyz_formatted_array(sham_pos[:,0],sham_pos[:,1],sham_pos[:,2], velocity=v_distortion_dim, \\\n# velocity_distortion_dimension=distortion_dim, period=cat.Lbox)\n#sham_wp = wp(sham_pos*cat.h, rp_bins, 40.0*cat.h, period=cat.Lbox*cat.h, num_threads=1)\nsham_wp = wp(sham_pos*cat.h, rp_bins, 40.0*cat.h, period=cat.Lbox*cat.h, num_threads=1)\n\n#sham_wp = tpcf(sham_pos, rp_bins , period=cat.Lbox, num_threads=1)",
"_____no_output_____"
],
[
"sham_wp",
"_____no_output_____"
],
[
"len(galaxy_catalog)/((cat.Lbox*cat.h)**3)",
"_____no_output_____"
]
],
[
[
"np.savetxt('/nfs/slac/g/ki/ki18/des/swmclau2/AB_tests/sham_vpeak_wp.npy', sham_wp)\n#np.savetxt('/nfs/slac/g/ki/ki18/des/swmclau2/AB_tests/sham_vpeak_nd.npy', np.array([len(galaxy_catalog)/((cat.Lbox*cat.h)**3)]))",
"_____no_output_____"
],
[
"np.savetxt('/nfs/slac/g/ki/ki18/des/swmclau2/AB_tests/rp_bins_split.npy',rp_bins )",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10,8))\nfor p, mock_wp in zip(split, mock_wps):\n plt.plot(bin_centers, mock_wp, label = p)\n \n#plt.plot(bin_centers, sham_wp, ls='--', label = 'SHAM')\nplt.plot(bin_centers, noab_wp, ls=':', label = 'No AB')\n\n\nplt.loglog()\nplt.legend(loc='best',fontsize = 15)\nplt.xlim([1e-1, 30e0]);\n#plt.ylim([1,15000])\nplt.xlabel(r'$r$',fontsize = 15)\nplt.ylabel(r'$\\xi(r)$',fontsize = 15)\nplt.show()",
"_____no_output_____"
],
[
"np.log10(mock_wps[-1])",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,8))\nfor p, mock_wp in zip(split, mock_wps):\n plt.plot(bin_centers, mock_wp/sham_wp, label = p)\n \n#plt.plot(bin_centers, sham_wp, ls='--', label = 'SHAM')\n#plt.plot(bin_centers, noab_wp, ls=':', label = 'No AB')\n\n\n#plt.loglog()\nplt.xscale('log')\nplt.legend(loc='best',fontsize = 15)\nplt.xlim([1e-1, 15e0]);\nplt.ylim([0.8,1.2])\nplt.xlabel(r'$r$',fontsize = 15)\nplt.ylabel(r'$\\xi(r)$',fontsize = 15)\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,8))\n#for p, mock_wp in zip(split, mock_wps):\n# plt.plot(bin_centers, mock_wp/sham_wp, label = p)\n \n#plt.plot(bin_centers, sham_wp, ls='--', label = 'SHAM')\nplt.plot(bin_centers, noab_wp/sham_wp, label = 'No AB')\n\n\n#plt.loglog()\nplt.xscale('log')\nplt.legend(loc='best',fontsize = 15)\nplt.xlim([1e-1, 15e0]);\n#plt.ylim([1,15000])\nplt.xlabel(r'$r$',fontsize = 15)\nplt.ylabel(r'$\\xi(r)$',fontsize = 15)\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,8))\nfor p, mock_wp in zip(split, mock_wps_1h):\n plt.plot(bin_centers, mock_wp, label = p)\n \n#plt.plot(bin_centers, sham_wp, ls='--', label = 'SHAM')\n#plt.plot(bin_centers, noab_wp, ls=':', label = 'No AB')\n\n\nplt.loglog()\nplt.legend(loc='best',fontsize = 15)\nplt.xlim([1e-1, 30e0]);\n#plt.ylim([1,15000])\nplt.xlabel(r'$r$',fontsize = 15)\nplt.ylabel(r'$\\xi(r)$',fontsize = 15)\nplt.show()",
"/u/ki/swmclau2/.conda/envs/hodemulator/lib/python2.7/site-packages/matplotlib/axes/_axes.py:531: UserWarning: No labelled objects found. Use label='...' kwarg on individual plots.\n warnings.warn(\"No labelled objects found. \"\n"
],
[
"plt.figure(figsize=(10,8))\nfor p, mock_wp in zip(split, mock_wps_2h):\n plt.plot(bin_centers, mock_wp, label = p)\n \n#plt.plot(bin_centers, sham_wp, ls='--', label = 'SHAM')\nplt.plot(bin_centers, noab_wp, ls=':', label = 'No AB')\n\n\nplt.loglog()\nplt.legend(loc='best',fontsize = 15)\nplt.xlim([1e-1, 30e0]);\n#plt.ylim([1,15000])\nplt.xlabel(r'$r$',fontsize = 15)\nplt.ylabel(r'$\\xi(r)$',fontsize = 15)\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,8))\nfor p, mock_wp in zip(split, mock_wps_2h):\n plt.plot(bin_centers, mock_wp/noab_wp, label = p)\n \n#plt.plot(bin_centers, sham_wp, ls='--', label = 'SHAM')\n#plt.plot(bin_centers, noab_wp, ls=':', label = 'No AB')\n\n\nplt.loglog()\nplt.legend(loc='best',fontsize = 15)\nplt.xlim([1e-1, 30e0]);\n#plt.ylim([1,15000])\nplt.xlabel(r'$r$',fontsize = 15)\nplt.ylabel(r'$\\xi(r)$',fontsize = 15)\nplt.show()",
"_____no_output_____"
],
[
"plt.plot(bin_centers, mock_wps[0, :])\nplt.plot(bin_centers, mock_wps_1h[0, :])\nplt.plot(bin_centers, mock_wps_2h[0, :])\n\n\nplt.loglog()\nplt.legend(loc='best',fontsize = 15)\nplt.xlim([1e-1, 30e0]);\n#plt.ylim([1,15000])\nplt.xlabel(r'$r$',fontsize = 15)\nplt.ylabel(r'$\\xi(r)$',fontsize = 15)\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,8))\n#avg = mock_wps.mean(axis = 0)\nfor p, mock_wp in zip(split, mock_wps):\n plt.plot(bin_centers, mock_wp/sham_wp, label = 'p = %.2f'%p)\n \nplt.plot(bin_centers, noab_wp/sham_wp, label = 'No AB', ls = ':')\n\n#plt.loglog()\nplt.xscale('log')\nplt.legend(loc='best',fontsize = 15)\nplt.xlim([1e-1, 5e0]);\nplt.ylim([0.75,1.25]);\nplt.xlabel(r'$r$',fontsize = 15)\nplt.ylabel(r'$\\xi(r)/\\xi_{SHAM}(r)$',fontsize = 15)\nplt.show()",
"_____no_output_____"
],
[
"sats_occ = cat.model._input_model_dictionary['satellites_occupation']\nsats_occ._split_ordinates = [0.99]",
"_____no_output_____"
]
],
[
[
"cens_occ = cat.model._input_model_dictionary['centrals_occupation']\ncens_occ._split_ordinates = [0.1]",
"_____no_output_____"
]
],
[
[
"print sats_occ",
"_____no_output_____"
],
[
"baseline_lower_bound, baseline_upper_bound = 0,np.inf\nprim_haloprop = cat.model.mock.halo_table['halo_mvir']\nsec_haloprop = cat.model.mock.halo_table['halo_nfw_conc']",
"_____no_output_____"
],
[
"from halotools.utils.table_utils import compute_conditional_percentile_values",
"_____no_output_____"
],
[
"split = sats_occ.percentile_splitting_function(prim_haloprop)\n\n# Compute the baseline, undecorated result\nresult = sats_occ.baseline_mean_occupation(prim_haloprop=prim_haloprop)\n\n# We will only decorate values that are not edge cases,\n# so first compute the mask for non-edge cases\nno_edge_mask = (\n (split > 0) & (split < 1) &\n (result > baseline_lower_bound) & (result < baseline_upper_bound)\n)\n# Now create convenient references to the non-edge-case sub-arrays\nno_edge_result = result[no_edge_mask]\nno_edge_split = split[no_edge_mask]",
"_____no_output_____"
]
],
[
[
"percentiles = compute_conditional_percentiles(\n prim_haloprop=prim_haloprop,\n sec_haloprop=sec_haloprop\n )\nno_edge_percentiles = percentiles[no_edge_mask]\ntype1_mask = no_edge_percentiles > no_edge_split\n\nperturbation = sats_occ._galprop_perturbation(prim_haloprop=prim_haloprop[no_edge_mask],baseline_result=no_edge_result, splitting_result=no_edge_split)\n\nfrac_type1 = 1 - no_edge_split\nfrac_type2 = 1 - frac_type1\nperturbation[~type1_mask] *= (-frac_type1[~type1_mask] /\n(frac_type2[~type1_mask]))",
"_____no_output_____"
],
[
"# Retrieve percentile values (medians) if they've been precomputed. Else, compute them.\n\nno_edge_percentile_values = compute_conditional_percentile_values(p=no_edge_split,\n prim_haloprop=prim_haloprop[no_edge_mask],\n sec_haloprop=sec_haloprop[no_edge_mask])\n\npv_sub_sec_haloprop = sec_haloprop[no_edge_mask] - no_edge_percentile_values\n\nperturbation = sats_occ._galprop_perturbation(\n prim_haloprop=prim_haloprop[no_edge_mask],\n sec_haloprop=pv_sub_sec_haloprop/np.max(np.abs(pv_sub_sec_haloprop)),\n baseline_result=no_edge_result)",
"_____no_output_____"
]
],
[
[
"from halotools.utils.table_utils import compute_conditional_averages",
"_____no_output_____"
],
[
"strength = sats_occ.assembias_strength(prim_haloprop[no_edge_mask])\nslope = sats_occ.assembias_slope(prim_haloprop[no_edge_mask])\n\n# the average displacement acts as a normalization we need.\nmax_displacement = sats_occ._disp_func(sec_haloprop=pv_sub_sec_haloprop/np.max(np.abs(pv_sub_sec_haloprop)), slope=slope)\ndisp_average = compute_conditional_averages(vals=max_displacement,prim_haloprop=prim_haloprop[no_edge_mask])\n#disp_average = np.ones((prim_haloprop.shape[0], ))*0.5\n\nperturbation2 = np.zeros(len(prim_haloprop[no_edge_mask]))\n\ngreater_than_half_avg_idx = disp_average > 0.5\nless_than_half_avg_idx = disp_average <= 0.5\n\nif len(max_displacement[greater_than_half_avg_idx]) > 0:\n base_pos = result[no_edge_mask][greater_than_half_avg_idx]\n strength_pos = strength[greater_than_half_avg_idx]\n avg_pos = disp_average[greater_than_half_avg_idx]\n\n upper_bound1 = (base_pos - baseline_lower_bound)/avg_pos\n upper_bound2 = (baseline_upper_bound - base_pos)/(1-avg_pos)\n upper_bound = np.minimum(upper_bound1, upper_bound2)\n print upper_bound1, upper_bound2\n perturbation2[greater_than_half_avg_idx] = strength_pos*upper_bound*(max_displacement[greater_than_half_avg_idx]-avg_pos)\n \n\nif len(max_displacement[less_than_half_avg_idx]) > 0:\n base_neg = result[no_edge_mask][less_than_half_avg_idx]\n strength_neg = strength[less_than_half_avg_idx]\n avg_neg = disp_average[less_than_half_avg_idx]\n\n lower_bound1 = (base_neg-baseline_lower_bound)/avg_neg#/(1- avg_neg)\n lower_bound2 = (baseline_upper_bound - base_neg)/(1-avg_neg)#(avg_neg)\n lower_bound = np.minimum(lower_bound1, lower_bound2)\n perturbation2[less_than_half_avg_idx] = strength_neg*lower_bound*(max_displacement[less_than_half_avg_idx]-avg_neg)\n\n",
"_____no_output_____"
],
[
"print np.unique(max_displacement[indices_of_mb])\nprint np.unique(disp_average[indices_of_mb])",
"_____no_output_____"
],
[
"perturbation",
"_____no_output_____"
],
[
"mass_bins = compute_mass_bins(prim_haloprop)\nmass_bin_idxs = compute_prim_haloprop_bins(prim_haloprop_bin_boundaries=mass_bins, prim_haloprop = prim_haloprop[no_edge_mask])\nmb = 87\nindices_of_mb = np.where(mass_bin_idxs == mb)[0]",
"_____no_output_____"
],
[
"plt.hist(perturbation[indices_of_mb], bins =100);\nplt.yscale('log');\n#plt.loglog();",
"_____no_output_____"
],
[
"print max(perturbation)\nprint min(perturbation)",
"_____no_output_____"
],
[
"print max(perturbation[indices_of_mb])\nprint min(perturbation[indices_of_mb])",
"_____no_output_____"
],
[
"idxs = np.argsort(perturbation)\nprint mass_bin_idxs[idxs[-10:]]",
"_____no_output_____"
],
[
"plt.hist(perturbation2[indices_of_mb], bins =100);\nplt.yscale('log');\n#plt.loglog();",
"_____no_output_____"
],
[
"print perturbation2",
"_____no_output_____"
]
]
]
| [
"code",
"raw",
"code",
"raw",
"code",
"raw",
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"raw",
"raw"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"raw"
],
[
"code",
"code",
"code",
"code"
],
[
"raw",
"raw"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d06118eed716b8b1c5ca1cd2af9f6d246ac13bb7 | 168,149 | ipynb | Jupyter Notebook | training/cyclone_model_svm.ipynb | etassone1974/UWA-Project-3 | af5608869ff1703a93855b084fb075d20df40a4a | [
"MIT"
]
| null | null | null | training/cyclone_model_svm.ipynb | etassone1974/UWA-Project-3 | af5608869ff1703a93855b084fb075d20df40a4a | [
"MIT"
]
| null | null | null | training/cyclone_model_svm.ipynb | etassone1974/UWA-Project-3 | af5608869ff1703a93855b084fb075d20df40a4a | [
"MIT"
]
| null | null | null | 391.044186 | 51,806 | 0.676091 | [
[
[
"from sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.svm import SVC\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.metrics import accuracy_score\nimport joblib\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
" # Read data into DataFrame from CSV file\n # cyclone_df = pd.read_csv(\"Cyclone_ML.csv\")\n cyclone_df = pd.read_csv(\"../data/Cyclone_ML.csv\")\n\n # Select features for machine learning and assign to X\n selected_features = cyclone_df[[\"SURFACE_CODE\",\t\"CYC_TYPE\", \"LAT\", \"LON\", \"CENTRAL_PRES\", \"MAX_WIND_SPD\", \"CENTRAL_INDEX (CI)\", \"WAVE_HEIGHT\"]]\n X = selected_features\n\n # Set y to compass direction of cyclone based on wind direction degree\n y = cyclone_df[\"WIND_COMPASS\"]\n # y = cyclone_df[\"MAX_REP_WIND_DIR\"]\n \n\n print(X.shape, y.shape)",
"(1691, 8) (1691,)\n"
],
[
"cyclone_df",
"_____no_output_____"
],
[
"X",
"_____no_output_____"
],
[
"y",
"_____no_output_____"
],
[
" # train test split\n X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)",
"_____no_output_____"
],
[
" X_scaler = StandardScaler().fit(X_train)\n X_train_scaled = X_scaler.transform(X_train)\n X_test_scaled = X_scaler.transform(X_test)",
"_____no_output_____"
],
[
" # Support vector machine linear classifier\n model = SVC(kernel='linear')\n\n # Fit the model to the training data and calculate the scores for the training and testing data\n model.fit(X_train_scaled, y_train)",
"_____no_output_____"
],
[
" training_score = model.score(X_train_scaled, y_train)\n testing_score = model.score(X_test_scaled, y_test)\n \n print(f\"Training Data Score: {training_score}\")\n print(f\"Testing Data Score: {testing_score}\")",
"Training Data Score: 0.23186119873817035\nTesting Data Score: 0.20094562647754138\n"
],
[
" predictions = model.predict(X_test_scaled)\n acc = accuracy_score(y_test, preds)\n print(f'Model accuracy on test set: {acc:.2f}')",
"Model accuracy on test set: 0.20\n"
],
[
"from sklearn.metrics import plot_confusion_matrix\nplot_confusion_matrix(model, X_test_scaled, y_test, cmap=\"Blues\")\nplt.show()",
"_____no_output_____"
],
[
"plot_confusion_matrix(model, X_train_scaled, y_train, cmap=\"Blues\")\nplt.show()",
"_____no_output_____"
],
[
"plt.savefig('../static/images/clrep_train_svm.png')",
"_____no_output_____"
],
[
"plt.savefig('books_read.png')",
"_____no_output_____"
],
[
"from sklearn.metrics import classification_report\nprint(classification_report(y_test, predictions,\n target_names=[\"E\", \"N\", \"NE\", \"NW\", \"S\", \"SE\", \"SW\", \"W\"]))",
" precision recall f1-score support\n\n E 0.17 0.60 0.27 73\n N 0.18 0.12 0.14 60\n NE 0.00 0.00 0.00 33\n NW 0.00 0.00 0.00 48\n S 0.00 0.00 0.00 58\n SE 0.22 0.34 0.27 65\n SW 0.00 0.00 0.00 25\n W 0.34 0.20 0.25 61\n\n accuracy 0.20 423\n macro avg 0.12 0.16 0.12 423\nweighted avg 0.14 0.20 0.14 423\n\n"
],
[
"joblib.dump(model, 'cyclone_SVM.smd')\nprint(\"Model is saved.\")",
"Model is saved.\n"
],
[
"joblib.dump(model, '../cyclone_SVM.smd')\nprint(\"Model is saved.\")",
"Model is saved.\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d0611dc271fbaf941d70af46922cae2350029a02 | 415,066 | ipynb | Jupyter Notebook | _notebooks/2020-06-29-01-Showing-uncertainty.ipynb | AntonovMikhail/chans_jupyter | c2cd1675408238ad5be81ba98994611d8c4e48ae | [
"Apache-2.0"
]
| 8 | 2020-06-26T23:48:52.000Z | 2021-02-27T22:26:31.000Z | _notebooks/2020-06-29-01-Showing-uncertainty.ipynb | AntonovMikhail/chans_jupyter | c2cd1675408238ad5be81ba98994611d8c4e48ae | [
"Apache-2.0"
]
| 46 | 2020-06-30T00:45:37.000Z | 2021-03-07T14:47:10.000Z | _notebooks/2020-06-29-01-Showing-uncertainty.ipynb | AntonovMikhail/chans_jupyter | c2cd1675408238ad5be81ba98994611d8c4e48ae | [
"Apache-2.0"
]
| 26 | 2020-07-24T17:30:15.000Z | 2021-02-19T10:19:25.000Z | 275.608234 | 78,352 | 0.909212 | [
[
[
"# Showing uncertainty\n> Uncertainty occurs everywhere in data science, but it's frequently left out of visualizations where it should be included. Here, we review what a confidence interval is and how to visualize them for both single estimates and continuous functions. Additionally, we discuss the bootstrap resampling technique for assessing uncertainty and how to visualize it properly. This is the Summary of lecture \"Improving Your Data Visualizations in Python\", via datacamp.\n\n- toc: true \n- badges: true\n- comments: true\n- author: Chanseok Kang\n- categories: [Python, Datacamp, Visualization]\n- image: images/so2_compare.png",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\nplt.rcParams['figure.figsize'] = (10, 5)",
"_____no_output_____"
]
],
[
[
"### Point estimate intervals\n- When is uncertainty important?\n - Estimates from sample\n - Average of a subset\n - Linear model coefficients\n- Why is uncertainty important?\n - Helps inform confidence in estimate\n - Neccessary for decision making\n - Acknowledges limitations of data",
"_____no_output_____"
],
[
"### Basic confidence intervals\nYou are a data scientist for a fireworks manufacturer in Des Moines, Iowa. You need to make a case to the city that your company's large fireworks show has not caused any harm to the city's air. To do this, you look at the average levels for pollutants in the week after the fourth of July and how they compare to readings taken after your last show. By showing confidence intervals around the averages, you can make a case that the recent readings were well within the normal range.",
"_____no_output_____"
]
],
[
[
"average_ests = pd.read_csv('./dataset/average_ests.csv', index_col=0)\naverage_ests",
"_____no_output_____"
],
[
"# Construct CI bounds for averages\naverage_ests['lower'] = average_ests['mean'] - 1.96 * average_ests['std_err']\naverage_ests['upper'] = average_ests['mean'] + 1.96 * average_ests['std_err']\n\n# Setup a grid of plots, with non-shared x axes limits\ng = sns.FacetGrid(average_ests, row='pollutant', sharex=False, aspect=2);\n\n# Plot CI for average estimate\ng.map(plt.hlines, 'y', 'lower', 'upper');\n\n# Plot observed values for comparison and remove axes labels\ng.map(plt.scatter, 'seen', 'y', color='orangered').set_ylabels('').set_xlabels('');",
"_____no_output_____"
]
],
[
[
"This simple visualization shows that all the observed values fall well within the confidence intervals for all the pollutants except for $O_3$.",
"_____no_output_____"
],
[
"### Annotating confidence intervals\nYour data science work with pollution data is legendary, and you are now weighing job offers in both Cincinnati, Ohio and Indianapolis, Indiana. You want to see if the SO2 levels are significantly different in the two cities, and more specifically, which city has lower levels. To test this, you decide to look at the differences in the cities' SO2 values (Indianapolis' - Cincinnati's) over multiple years.\n\nInstead of just displaying a p-value for a significant difference between the cities, you decide to look at the 95% confidence intervals (columns `lower` and `upper`) of the differences. This allows you to see the magnitude of the differences along with any trends over the years.",
"_____no_output_____"
]
],
[
[
"diffs_by_year = pd.read_csv('./dataset/diffs_by_year.csv', index_col=0)\ndiffs_by_year",
"_____no_output_____"
],
[
"# Set start and ends according to intervals\n# Make intervals thicker\nplt.hlines(y='year', xmin='lower', xmax='upper', \n linewidth=5, color='steelblue', alpha=0.7,\n data=diffs_by_year);\n\n# Point estimates\nplt.plot('mean', 'year', 'k|', data=diffs_by_year);\n\n# Add a 'null' reference line at 0 and color orangered\nplt.axvline(x=0, color='orangered', linestyle='--');\n\n# Set descriptive axis labels and title\nplt.xlabel('95% CI');\nplt.title('Avg SO2 differences between Cincinnati and Indianapolis');",
"_____no_output_____"
]
],
[
[
"By looking at the confidence intervals you can see that the difference flipped from generally positive (more pollution in Cincinnati) in 2013 to negative (more pollution in Indianapolis) in 2014 and 2015. Given that every year's confidence interval contains the null value of zero, no P-Value would be significant, and a plot that only showed significance would have been entirely hidden this trend.",
"_____no_output_____"
],
[
"## Confidence bands",
"_____no_output_____"
],
[
"### Making a confidence band\nVandenberg Air Force Base is often used as a location to launch rockets into space. You have a theory that a recent increase in the pace of rocket launches could be harming the air quality in the surrounding region. To explore this, you plotted a 25-day rolling average line of the measurements of atmospheric $NO_2$. To help decide if any pattern observed is random-noise or not, you decide to add a 99% confidence band around your rolling mean. Adding a confidence band to a trend line can help shed light on the stability of the trend seen. This can either increase or decrease the confidence in the discovered trend.\n\n",
"_____no_output_____"
]
],
[
[
"vandenberg_NO2 = pd.read_csv('./dataset/vandenberg_NO2.csv', index_col=0)\nvandenberg_NO2.head()",
"_____no_output_____"
],
[
"# Draw 99% interval bands for average NO2\nvandenberg_NO2['lower'] = vandenberg_NO2['mean'] - 2.58 * vandenberg_NO2['std_err']\nvandenberg_NO2['upper'] = vandenberg_NO2['mean'] + 2.58 * vandenberg_NO2['std_err']\n\n# Plot mean estimate as a white semi-transparent line\nplt.plot('day', 'mean', data=vandenberg_NO2, color='white', alpha=0.4);\n\n# Fill between the upper and lower confidence band values\nplt.fill_between(x='day', y1='lower', y2='upper', data=vandenberg_NO2);",
"_____no_output_____"
]
],
[
[
"This plot shows that the middle of the year's $NO_2$ values are not only lower than the beginning and end of the year but also are less noisy. If just the moving average line were plotted, then this potentially interesting observation would be completely missed. (Can you think of what may cause reduced variance at the lower values of the pollutant?)",
"_____no_output_____"
],
[
"### Separating a lot of bands\nIt is relatively simple to plot a bunch of trend lines on top of each other for rapid and precise comparisons. Unfortunately, if you need to add uncertainty bands around those lines, the plot becomes very difficult to read. Figuring out whether a line corresponds to the top of one class' band or the bottom of another's can be hard due to band overlap. Luckily in Seaborn, it's not difficult to break up the overlapping bands into separate faceted plots.\n\nTo see this, explore trends in SO2 levels for a few cities in the eastern half of the US. If you plot the trends and their confidence bands on a single plot - it's a mess. To fix, use Seaborn's `FacetGrid()` function to spread out the confidence intervals to multiple panes to ease your inspection.",
"_____no_output_____"
]
],
[
[
"eastern_SO2 = pd.read_csv('./dataset/eastern_SO2.csv', index_col=0)\neastern_SO2.head()",
"_____no_output_____"
],
[
"# setup a grid of plots with columns divided by location\ng = sns.FacetGrid(eastern_SO2, col='city', col_wrap=2);\n\n# Map interval plots to each cities data with coral colored ribbons\ng.map(plt.fill_between, 'day', 'lower', 'upper', color='coral');\n\n# Map overlaid mean plots with white line\ng.map(plt.plot, 'day', 'mean', color='white');",
"_____no_output_____"
]
],
[
[
"By separating each band into its own plot you can investigate each city with ease. Here, you see that Des Moines and Houston on average have lower SO2 values for the entire year than the two cities in the Midwest. Cincinnati has a high and variable peak near the beginning of the year but is generally more stable and lower than Indianapolis.",
"_____no_output_____"
],
[
"### Cleaning up bands for overlaps\nYou are working for the city of Denver, Colorado and want to run an ad campaign about how much cleaner Denver's air is than Long Beach, California's air. To investigate this claim, you will compare the SO2 levels of both cities for the year 2014. Since you are solely interested in how the cities compare, you want to keep the bands on the same plot. To make the bands easier to compare, decrease the opacity of the confidence bands and set a clear legend.",
"_____no_output_____"
]
],
[
[
"SO2_compare = pd.read_csv('./dataset/SO2_compare.csv', index_col=0)\nSO2_compare.head()",
"_____no_output_____"
],
[
"for city, color in [('Denver', '#66c2a5'), ('Long Beach', '#fc8d62')]:\n # Filter data to desired city\n city_data = SO2_compare[SO2_compare.city == city]\n \n # Set city interval color to desired and lower opacity\n plt.fill_between(x='day', y1='lower', y2='upper', data=city_data, color=color, alpha=0.4);\n \n # Draw a faint mean line for reference and give a label for legend\n plt.plot('day', 'mean', data=city_data, label=city, color=color, alpha=0.25);\n \nplt.legend();",
"_____no_output_____"
]
],
[
[
"From these two curves you can see that during the first half of the year Long Beach generally has a higher average SO2 value than Denver, in the middle of the year they are very close, and at the end of the year Denver seems to have higher averages. However, by showing the confidence intervals, you can see however that almost none of the year shows a statistically meaningful difference in average values between the two cities.",
"_____no_output_____"
],
[
"## Beyond 95%\n",
"_____no_output_____"
],
[
"### 90, 95, and 99% intervals\nYou are a data scientist for an outdoor adventure company in Fairbanks, Alaska. Recently, customers have been having issues with SO2 pollution, leading to costly cancellations. The company has sensors for CO, NO2, and O3 but not SO2 levels.\n\nYou've built a model that predicts SO2 values based on the values of pollutants with sensors (loaded as `pollution_model`, a `statsmodels` object). You want to investigate which pollutant's value has the largest effect on your model's SO2 prediction. This will help you know which pollutant's values to pay most attention to when planning outdoor tours. To maximize the amount of information in your report, show multiple levels of uncertainty for the model estimates.",
"_____no_output_____"
]
],
[
[
"from statsmodels.formula.api import ols",
"_____no_output_____"
],
[
"pollution = pd.read_csv('./dataset/pollution_wide.csv')\npollution = pollution.query(\"city == 'Fairbanks' & year == 2014 & month == 11\")",
"_____no_output_____"
],
[
"pollution_model = ols(formula='SO2 ~ CO + NO2 + O3 + day', data=pollution)\nres = pollution_model.fit()",
"_____no_output_____"
],
[
"# Add interval percent widths\nalphas = [ 0.01, 0.05, 0.1] \nwidths = [ '99% CI', '95%', '90%']\ncolors = ['#fee08b','#fc8d59','#d53e4f']\n\nfor alpha, color, width in zip(alphas, colors, widths):\n # Grab confidence interval\n conf_ints = res.conf_int(alpha)\n \n # Pass current interval color and legend label to plot\n plt.hlines(y = conf_ints.index, xmin = conf_ints[0], xmax = conf_ints[1],\n colors = color, label = width, linewidth = 10) \n\n# Draw point estimates\nplt.plot(res.params, res.params.index, 'wo', label = 'Point Estimate')\n\nplt.legend(loc = 'upper right')",
"_____no_output_____"
]
],
[
[
"### 90 and 95% bands\nYou are looking at a 40-day rolling average of the $NO_2$ pollution levels for the city of Cincinnati in 2013. To provide as detailed a picture of the uncertainty in the trend you want to look at both the 90 and 99% intervals around this rolling estimate.\n\nTo do this, set up your two interval sizes and an orange ordinal color palette. Additionally, to enable precise readings of the bands, make them semi-transparent, so the Seaborn background grids show through.",
"_____no_output_____"
]
],
[
[
"cinci_13_no2 = pd.read_csv('./dataset/cinci_13_no2.csv', index_col=0);\ncinci_13_no2.head()",
"_____no_output_____"
],
[
"int_widths = ['90%', '99%']\nz_scores = [1.67, 2.58]\ncolors = ['#fc8d59', '#fee08b']\n\nfor percent, Z, color in zip(int_widths, z_scores, colors):\n \n # Pass lower and upper confidence bounds and lower opacity\n plt.fill_between(\n x = cinci_13_no2.day, alpha = 0.4, color = color,\n y1 = cinci_13_no2['mean'] - Z * cinci_13_no2['std_err'],\n y2 = cinci_13_no2['mean'] + Z * cinci_13_no2['std_err'],\n label = percent);\n \nplt.legend();",
"_____no_output_____"
]
],
[
[
"This plot shows us that throughout 2013, the average NO2 values in Cincinnati followed a cyclical pattern with the seasons. However, the uncertainty bands show that for most of the year you can't be sure this pattern is not noise at both a 90 and 99% confidence level.",
"_____no_output_____"
],
[
"### Using band thickness instead of coloring\nYou are a researcher investigating the elevation a rocket reaches before visual is lost and pollutant levels at Vandenberg Air Force Base. You've built a model to predict this relationship, and since you are working independently, you don't have the money to pay for color figures in your journal article. You need to make your model results plot work in black and white. To do this, you will plot the 90, 95, and 99% intervals of the effect of each pollutant as successively smaller bars.",
"_____no_output_____"
]
],
[
[
"rocket_model = pd.read_csv('./dataset/rocket_model.csv', index_col=0)\nrocket_model",
"_____no_output_____"
],
[
"# Decrase interval thickness as interval widens\nsizes = [ 15, 10, 5]\nint_widths = ['90% CI', '95%', '99%']\nz_scores = [ 1.67, 1.96, 2.58]\n\nfor percent, Z, size in zip(int_widths, z_scores, sizes):\n plt.hlines(y = rocket_model.pollutant, \n xmin = rocket_model['est'] - Z * rocket_model['std_err'],\n xmax = rocket_model['est'] + Z * rocket_model['std_err'],\n label = percent, \n # Resize lines and color them gray\n linewidth = size, \n color = 'gray'); \n \n# Add point estimate\nplt.plot('est', 'pollutant', 'wo', data = rocket_model, label = 'Point Estimate');\nplt.legend(loc = 'center left', bbox_to_anchor = (1, 0.5));",
"_____no_output_____"
]
],
[
[
"While less elegant than using color to differentiate interval sizes, this plot still clearly allows the reader to access the effect each pollutant has on rocket visibility. You can see that of all the pollutants, O3 has the largest effect and also the tightest confidence bounds",
"_____no_output_____"
],
[
"## Visualizing the bootstrap\n",
"_____no_output_____"
],
[
"### The bootstrap histogram\nYou are considering a vacation to Cincinnati in May, but you have a severe sensitivity to NO2. You pull a few years of pollution data from Cincinnati in May and look at a bootstrap estimate of the average $NO_2$ levels. You only have one estimate to look at the best way to visualize the results of your bootstrap estimates is with a histogram.\n\nWhile you like the intuition of the bootstrap histogram by itself, your partner who will be going on the vacation with you, likes seeing percent intervals. To accommodate them, you decide to highlight the 95% interval by shading the region.",
"_____no_output_____"
]
],
[
[
"# Perform bootstrapped mean on a vector\ndef bootstrap(data, n_boots):\n return [np.mean(np.random.choice(data,len(data))) for _ in range(n_boots) ]",
"_____no_output_____"
],
[
"pollution = pd.read_csv('./dataset/pollution_wide.csv')\ncinci_may_NO2 = pollution.query(\"city == 'Cincinnati' & month == 5\").NO2\n\n# Generate bootstrap samples\nboot_means = bootstrap(cinci_may_NO2, 1000)\n\n# Get lower and upper 95% interval bounds\nlower, upper = np.percentile(boot_means, [2.5, 97.5])\n\n# Plot shaded area for interval\nplt.axvspan(lower, upper, color = 'gray', alpha = 0.2);\n\n# Draw histogram of bootstrap samples\nsns.distplot(boot_means, bins = 100, kde = False);",
"_____no_output_____"
]
],
[
[
"Your bootstrap histogram looks stable and uniform. You're now confident that the average NO2 levels in Cincinnati during your vacation should be in the range of 16 to 23.",
"_____no_output_____"
],
[
"### Bootstrapped regressions\nWhile working for the Long Beach parks and recreation department investigating the relationship between $NO_2$ and $SO_2$ you noticed a cluster of potential outliers that you suspect might be throwing off the correlations.\n\nInvestigate the uncertainty of your correlations through bootstrap resampling to see how stable your fits are. For convenience, the bootstrap sampling is complete and is provided as `no2_so2_boot` along with `no2_so2` for the non-resampled data.",
"_____no_output_____"
]
],
[
[
"no2_so2 = pd.read_csv('./dataset/no2_so2.csv', index_col=0)\nno2_so2_boot = pd.read_csv('./dataset/no2_so2_boot.csv', index_col=0)",
"_____no_output_____"
],
[
"sns.lmplot('NO2', 'SO2', data = no2_so2_boot,\n # Tell seaborn to a regression line for each sample\n hue = 'sample', \n # Make lines blue and transparent\n line_kws = {'color': 'steelblue', 'alpha': 0.2},\n # Disable built-in confidence intervals\n ci = None, legend = False, scatter = False);\n\n# Draw scatter of all points\nplt.scatter('NO2', 'SO2', data = no2_so2);",
"_____no_output_____"
]
],
[
[
"The outliers appear to drag down the regression lines as evidenced by the cluster of lines with more severe slopes than average. In a single plot, you have not only gotten a good idea of the variability of your correlation estimate but also the potential effects of outliers.",
"_____no_output_____"
],
[
"### Lots of bootstraps with beeswarms\nAs a current resident of Cincinnati, you're curious to see how the average NO2 values compare to Des Moines, Indianapolis, and Houston: a few other cities you've lived in.\n\nTo look at this, you decide to use bootstrap estimation to look at the mean NO2 values for each city. Because the comparisons are of primary interest, you will use a swarm plot to compare the estimates.",
"_____no_output_____"
]
],
[
[
"pollution_may = pollution.query(\"month == 5\")\npollution_may",
"_____no_output_____"
],
[
"# Initialize a holder DataFrame for bootstrap results\ncity_boots = pd.DataFrame()\n\nfor city in ['Cincinnati', 'Des Moines', 'Indianapolis', 'Houston']:\n # Filter to city\n city_NO2 = pollution_may[pollution_may.city == city].NO2\n # Bootstrap city data & put in DataFrame\n cur_boot = pd.DataFrame({'NO2_avg': bootstrap(city_NO2, 100), 'city': city})\n # Append to other city's bootstraps\n city_boots = pd.concat([city_boots,cur_boot])\n\n# Beeswarm plot of averages with citys on y axis\nsns.swarmplot(y = \"city\", x = \"NO2_avg\", data = city_boots, color = 'coral');",
"_____no_output_____"
]
],
[
[
"The beeswarm plots show that Indianapolis and Houston both have the highest average NO2 values, with Cincinnati falling roughly in the middle. Interestingly, you can rather confidently say that Des Moines has the lowest as nearly all its sample estimates fall below those of the other cities.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
]
|
d06127bfe2404b70d73671ba48a678224d198027 | 13,667 | ipynb | Jupyter Notebook | notebooks/find_a_shakemap.ipynb | iwbailey/shakemap_lookup | 75ac2739cba2a293f95a24feb1d7f57ebc0f834b | [
"MIT"
]
| 1 | 2020-10-16T07:31:58.000Z | 2020-10-16T07:31:58.000Z | notebooks/find_a_shakemap.ipynb | iwbailey/shakemap_lookup | 75ac2739cba2a293f95a24feb1d7f57ebc0f834b | [
"MIT"
]
| null | null | null | notebooks/find_a_shakemap.ipynb | iwbailey/shakemap_lookup | 75ac2739cba2a293f95a24feb1d7f57ebc0f834b | [
"MIT"
]
| null | null | null | 33.829208 | 299 | 0.524914 | [
[
[
"from shakemap_lookup import usgs_web",
"_____no_output_____"
],
[
"help(usgs_web.search_usgsevents)",
"Help on function search_usgsevents in module shakemap_lookup.usgs_web:\n\nsearch_usgsevents(searchParams, urlEndpt='https://earthquake.usgs.gov/fdsnws/event/1/query', maxNprint=30, isQuiet=False)\n Search the USGS for events satisfying the criteria and return a list of\n events\n \n IN:\n searchParams is a dict containing the search parameters used for the query\n urlEndpt [string] is the web address used for the search.\n \n API doc here... https://earthquake.usgs.gov/fdsnws/event/1/\n \n OUT:\n A list of events satisfying the conditions in a json structure\n\n"
]
],
[
[
"## Define our search parameters and send to the USGS \nUse a dict, with same names as used by the USGS web call.\n\nSend a query to the web server. The result is a list of events also in a dict format.",
"_____no_output_____"
]
],
[
[
"search_params = {\n 'starttime': \"2018-05-01\",\n 'endtime': \"2018-05-17\",\n 'minmagnitude': 6.8,\n 'maxmagnitude': 10.0,\n 'mindepth': 0.0,\n 'maxdepth': 50.0,\n 'minlongitude': -180.0,\n 'maxlongitude': -97.0,\n 'minlatitude': 0.0,\n 'maxlatitude': 45.0,\n 'limit': 50,\n 'producttype': 'shakemap'\n}\n\nevents = usgs_web.search_usgsevents(search_params)",
"Sending query to get events...\nParsing...\n\t...1 events returned (limit of 50)\n\t\t 70116556 : M 6.9 - 19km SSW of Leilani Estates, Hawaii\n"
]
],
[
[
"## Check the metadata \nDisplay metadata including number of earthquakes returned and what url was used for the query",
"_____no_output_____"
]
],
[
[
"for k, v in events['metadata'].items():\n print(k,\":\", v)",
"generated : 1575582197000\nurl : https://earthquake.usgs.gov/fdsnws/event/1/query?starttime=2018-05-01&endtime=2018-05-17&minmagnitude=6.8&maxmagnitude=10.0&mindepth=0.0&maxdepth=50.0&minlongitude=-180.0&maxlongitude=-97.0&minlatitude=0.0&maxlatitude=45.0&limit=50&producttype=shakemap&format=geojson&jsonerror=true\ntitle : USGS Earthquakes\nstatus : 200\napi : 1.8.1\nlimit : 50\noffset : 1\ncount : 1\n"
]
],
[
[
"## Selection of event from candidates",
"_____no_output_____"
]
],
[
[
"my_event = usgs_web.choose_event(events)\nmy_event",
"\nUSER SELECTION OF EVENT:\n========================\n 0: M 6.9 - 19km SSW of Leilani Estates, Hawaii (70116556)\nNone: First on list\n -1: Exit\n\nChoice: \n\t... selected M 6.9 - 19km SSW of Leilani Estates, Hawaii (70116556)\n\n"
]
],
[
[
"## Select which ShakeMap for the selected event",
"_____no_output_____"
]
],
[
[
"smDetail = usgs_web.query_shakemapdetail(my_event['properties'])",
"Querying detailed event info for eventId=70116556...\n\t...2 shakemaps found\n\nUSER SELECTION OF SHAKEMAP:\n===========================\nOption 0:\n\t eventsourcecode: 70116556\n\t version: 1\n\t process-timestamp: 2018-09-08T02:52:24Z\nOption 1:\n\t eventsourcecode: 1000dyad\n\t version: 11\n\t process-timestamp: 2018-06-15T23:02:03Z\n\nChoice [default 0]: \n\t... selected 0\n\n"
]
],
[
[
"## Display available content for the ShakeMap",
"_____no_output_____"
]
],
[
[
"print(\"Available Content\\n=================\")\nfor k, v in smDetail['contents'].items():\n print(\"{:32s}: {} [{}]\".format(k, v['contentType'], v['length']))",
"Available Content\n=================\nabout_formats.html : text/html [28820]\ncontents.xml : application/xml [9187]\ndownload/70116556.kml : application/vnd.google-earth.kml+xml [1032]\ndownload/cont_mi.json : application/json [79388]\ndownload/cont_mi.kmz : application/vnd.google-earth.kmz [17896]\ndownload/cont_pga.json : application/json [17499]\ndownload/cont_pga.kmz : application/vnd.google-earth.kmz [4362]\ndownload/cont_pgv.json : application/json [12352]\ndownload/cont_pgv.kmz : application/vnd.google-earth.kmz [3309]\ndownload/cont_psa03.json : application/json [24669]\ndownload/cont_psa03.kmz : application/vnd.google-earth.kmz [5843]\ndownload/cont_psa10.json : application/json [15028]\ndownload/cont_psa10.kmz : application/vnd.google-earth.kmz [3843]\ndownload/cont_psa30.json : application/json [7537]\ndownload/cont_psa30.kmz : application/vnd.google-earth.kmz [2254]\ndownload/epicenter.kmz : application/vnd.google-earth.kmz [1299]\ndownload/event.txt : text/plain [125]\ndownload/grid.xml : application/xml [3423219]\ndownload/grid.xml.zip : application/zip [493382]\ndownload/grid.xyz.zip : application/zip [428668]\ndownload/hazus.zip : application/zip [329755]\ndownload/hv70116556.kml : application/vnd.google-earth.kml+xml [1032]\ndownload/hv70116556.kmz : application/vnd.google-earth.kmz [127511]\ndownload/ii_overlay.png : image/png [25259]\ndownload/ii_thumbnail.jpg : image/jpeg [3530]\ndownload/info.json : application/json [2237]\ndownload/intensity.jpg : image/jpeg [60761]\ndownload/intensity.ps.zip : application/zip [139098]\ndownload/metadata.txt : text/plain [33137]\ndownload/mi_regr.png : image/png [35160]\ndownload/overlay.kmz : application/vnd.google-earth.kmz [25245]\ndownload/pga.jpg : image/jpeg [49594]\ndownload/pga.ps.zip : application/zip [89668]\ndownload/pga_regr.png : image/png [33466]\ndownload/pgv.jpg : image/jpeg [49781]\ndownload/pgv.ps.zip : application/zip [89389]\ndownload/pgv_regr.png : image/png [17605]\ndownload/polygons_mi.kmz : application/vnd.google-earth.kmz [43271]\ndownload/psa03.jpg : image/jpeg [49354]\ndownload/psa03.ps.zip : application/zip [90027]\ndownload/psa03_regr.png : image/png [18371]\ndownload/psa10.jpg : image/jpeg [49003]\ndownload/psa10.ps.zip : application/zip [89513]\ndownload/psa10_regr.png : image/png [31310]\ndownload/psa30.jpg : image/jpeg [48956]\ndownload/psa30.ps.zip : application/zip [89113]\ndownload/psa30_regr.png : image/png [18055]\ndownload/raster.zip : application/zip [1940448]\ndownload/rock_grid.xml.zip : application/zip [403486]\ndownload/sd.jpg : image/jpeg [45869]\ndownload/shape.zip : application/zip [1029832]\ndownload/stationlist.json : application/json [55083]\ndownload/stationlist.txt : text/plain [6737]\ndownload/stationlist.xml : application/xml [32441]\ndownload/stations.kmz : application/vnd.google-earth.kmz [7343]\ndownload/tvguide.txt : text/plain [8765]\ndownload/tvmap.jpg : image/jpeg [44223]\ndownload/tvmap.ps.zip : application/zip [273000]\ndownload/tvmap_bare.jpg : image/jpeg [48640]\ndownload/tvmap_bare.ps.zip : application/zip [273146]\ndownload/uncertainty.xml.zip : application/zip [211743]\ndownload/urat_pga.jpg : image/jpeg [45869]\ndownload/urat_pga.ps.zip : application/zip [51741]\nintensity.html : text/html [19291]\npga.html : text/html [19083]\npgv.html : text/html [19083]\nproducts.html : text/html [18584]\npsa03.html : text/html [20250]\npsa10.html : text/html [20249]\npsa30.html : text/html [20249]\nstationlist.html : text/html [127947]\n"
]
],
[
[
"## Get download links\nClick on the link to download",
"_____no_output_____"
]
],
[
[
"# Extract the shakemap grid urls and version from the detail\ngrid = smDetail['contents']['download/grid.xml.zip']\nprint(grid['url'])",
"https://earthquake.usgs.gov/archive/product/shakemap/hv70116556/us/1536375199192/download/grid.xml.zip\n"
],
[
"grid = smDetail['contents']['download/uncertainty.xml.zip']\nprint(grid['url'])",
"https://earthquake.usgs.gov/archive/product/shakemap/hv70116556/us/1536375199192/download/uncertainty.xml.zip\n"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
d0613442e8a77054618c47832a0a30ce54d0c49d | 148,109 | ipynb | Jupyter Notebook | module3-permutation-boosting/LS_DS_233.ipynb | mariokart345/DS-Unit-2-Applied-Modeling | ecb7506dc3b08bb06c282937bdbc152332fb9b1b | [
"MIT"
]
| null | null | null | module3-permutation-boosting/LS_DS_233.ipynb | mariokart345/DS-Unit-2-Applied-Modeling | ecb7506dc3b08bb06c282937bdbc152332fb9b1b | [
"MIT"
]
| null | null | null | module3-permutation-boosting/LS_DS_233.ipynb | mariokart345/DS-Unit-2-Applied-Modeling | ecb7506dc3b08bb06c282937bdbc152332fb9b1b | [
"MIT"
]
| null | null | null | 68.064798 | 25,922 | 0.626633 | [
[
[
"<a href=\"https://colab.research.google.com/github/mariokart345/DS-Unit-2-Applied-Modeling/blob/master/module3-permutation-boosting/LS_DS_233.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"Lambda School Data Science\n\n*Unit 2, Sprint 3, Module 3*\n\n---",
"_____no_output_____"
],
[
"# Permutation & Boosting\n\n- Get **permutation importances** for model interpretation and feature selection\n- Use xgboost for **gradient boosting**",
"_____no_output_____"
],
[
"### Setup\n\nRun the code cell below. You can work locally (follow the [local setup instructions](https://lambdaschool.github.io/ds/unit2/local/)) or on Colab.\n\nLibraries:\n\n- category_encoders\n- [**eli5**](https://eli5.readthedocs.io/en/latest/)\n- matplotlib\n- numpy\n- pandas\n- scikit-learn\n- [**xgboost**](https://xgboost.readthedocs.io/en/latest/)",
"_____no_output_____"
]
],
[
[
"%%capture\nimport sys\n\n# If you're on Colab:\nif 'google.colab' in sys.modules:\n DATA_PATH = 'https://raw.githubusercontent.com/LambdaSchool/DS-Unit-2-Applied-Modeling/master/data/'\n !pip install category_encoders==2.*\n !pip install eli5\n\n# If you're working locally:\nelse:\n DATA_PATH = '../data/'",
"_____no_output_____"
]
],
[
[
"We'll go back to Tanzania Waterpumps for this lesson.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nfrom sklearn.model_selection import train_test_split\n\n# Merge train_features.csv & train_labels.csv\ntrain = pd.merge(pd.read_csv(DATA_PATH+'waterpumps/train_features.csv'), \n pd.read_csv(DATA_PATH+'waterpumps/train_labels.csv'))\n\n# Read test_features.csv & sample_submission.csv\ntest = pd.read_csv(DATA_PATH+'waterpumps/test_features.csv')\nsample_submission = pd.read_csv(DATA_PATH+'waterpumps/sample_submission.csv')\n\n\n# Split train into train & val\ntrain, val = train_test_split(train, train_size=0.80, test_size=0.20, \n stratify=train['status_group'], random_state=42)\n\n\ndef wrangle(X):\n \"\"\"Wrangle train, validate, and test sets in the same way\"\"\"\n \n # Prevent SettingWithCopyWarning\n X = X.copy()\n \n # About 3% of the time, latitude has small values near zero,\n # outside Tanzania, so we'll treat these values like zero.\n X['latitude'] = X['latitude'].replace(-2e-08, 0)\n \n # When columns have zeros and shouldn't, they are like null values.\n # So we will replace the zeros with nulls, and impute missing values later.\n # Also create a \"missing indicator\" column, because the fact that\n # values are missing may be a predictive signal.\n cols_with_zeros = ['longitude', 'latitude', 'construction_year', \n 'gps_height', 'population']\n for col in cols_with_zeros:\n X[col] = X[col].replace(0, np.nan)\n X[col+'_MISSING'] = X[col].isnull()\n \n # Drop duplicate columns\n duplicates = ['quantity_group', 'payment_type']\n X = X.drop(columns=duplicates)\n \n # Drop recorded_by (never varies) and id (always varies, random)\n unusable_variance = ['recorded_by', 'id']\n X = X.drop(columns=unusable_variance)\n \n # Convert date_recorded to datetime\n X['date_recorded'] = pd.to_datetime(X['date_recorded'], infer_datetime_format=True)\n \n # Extract components from date_recorded, then drop the original column\n X['year_recorded'] = X['date_recorded'].dt.year\n X['month_recorded'] = X['date_recorded'].dt.month\n X['day_recorded'] = X['date_recorded'].dt.day\n X = X.drop(columns='date_recorded')\n \n # Engineer feature: how many years from construction_year to date_recorded\n X['years'] = X['year_recorded'] - X['construction_year']\n X['years_MISSING'] = X['years'].isnull()\n \n # return the wrangled dataframe\n return X\n\ntrain = wrangle(train)\nval = wrangle(val)\ntest = wrangle(test)",
"_____no_output_____"
],
[
"# Arrange data into X features matrix and y target vector\ntarget = 'status_group'\nX_train = train.drop(columns=target)\ny_train = train[target]\nX_val = val.drop(columns=target)\ny_val = val[target]\nX_test = test",
"_____no_output_____"
],
[
"import category_encoders as ce\nfrom sklearn.impute import SimpleImputer\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.pipeline import make_pipeline\n\npipeline = make_pipeline(\n ce.OrdinalEncoder(), \n SimpleImputer(strategy='median'), \n RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)\n)\n\n# Fit on train, score on val\npipeline.fit(X_train, y_train)\nprint('Validation Accuracy', pipeline.score(X_val, y_val))",
"/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.\n import pandas.util.testing as tm\n"
]
],
[
[
"# Get permutation importances for model interpretation and feature selection",
"_____no_output_____"
],
[
"## Overview",
"_____no_output_____"
],
[
"Default Feature Importances are fast, but Permutation Importances may be more accurate.\n\nThese links go deeper with explanations and examples:\n\n- Permutation Importances\n - [Kaggle / Dan Becker: Machine Learning Explainability](https://www.kaggle.com/dansbecker/permutation-importance)\n - [Christoph Molnar: Interpretable Machine Learning](https://christophm.github.io/interpretable-ml-book/feature-importance.html)\n- (Default) Feature Importances\n - [Ando Saabas: Selecting good features, Part 3, Random Forests](https://blog.datadive.net/selecting-good-features-part-iii-random-forests/)\n - [Terence Parr, et al: Beware Default Random Forest Importances](https://explained.ai/rf-importance/index.html)",
"_____no_output_____"
],
[
"There are three types of feature importances:",
"_____no_output_____"
],
[
"### 1. (Default) Feature Importances\n\nFastest, good for first estimates, but be aware:\n\n\n\n>**When the dataset has two (or more) correlated features, then from the point of view of the model, any of these correlated features can be used as the predictor, with no concrete preference of one over the others.** But once one of them is used, the importance of others is significantly reduced since effectively the impurity they can remove is already removed by the first feature. As a consequence, they will have a lower reported importance. This is not an issue when we want to use feature selection to reduce overfitting, since it makes sense to remove features that are mostly duplicated by other features. But when interpreting the data, it can lead to the incorrect conclusion that one of the variables is a strong predictor while the others in the same group are unimportant, while actually they are very close in terms of their relationship with the response variable. — [Selecting good features – Part III: random forests](https://blog.datadive.net/selecting-good-features-part-iii-random-forests/) \n\n\n \n > **The scikit-learn Random Forest feature importance ... tends to inflate the importance of continuous or high-cardinality categorical variables.** ... Breiman and Cutler, the inventors of Random Forests, indicate that this method of “adding up the gini decreases for each individual variable over all trees in the forest gives a **fast** variable importance that is often very consistent with the permutation importance measure.” — [Beware Default Random Forest Importances](https://explained.ai/rf-importance/index.html)\n\n \n",
"_____no_output_____"
]
],
[
[
"# Get feature importances\nrf = pipeline.named_steps['randomforestclassifier']\nimportances = pd.Series(rf.feature_importances_, X_train.columns)\n\n# Plot feature importances\n%matplotlib inline\nimport matplotlib.pyplot as plt\n\nn = 20\nplt.figure(figsize=(10,n/2))\nplt.title(f'Top {n} features')\nimportances.sort_values()[-n:].plot.barh(color='grey');",
"_____no_output_____"
]
],
[
[
"### 2. Drop-Column Importance\n\nThe best in theory, but too slow in practice",
"_____no_output_____"
]
],
[
[
"column = 'wpt_name'\n\n# Fit without column\npipeline = make_pipeline(\n ce.OrdinalEncoder(), \n SimpleImputer(strategy='median'), \n RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)\n)\npipeline.fit(X_train.drop(columns=column), y_train)\nscore_without = pipeline.score(X_val.drop(columns=column), y_val)\nprint(f'Validation Accuracy without {column}: {score_without}')\n\n# Fit with column\npipeline = make_pipeline(\n ce.OrdinalEncoder(), \n SimpleImputer(strategy='median'), \n RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)\n)\npipeline.fit(X_train, y_train)\nscore_with = pipeline.score(X_val, y_val)\nprint(f'Validation Accuracy with {column}: {score_with}')\n\n# Compare the error with & without column\nprint(f'Drop-Column Importance for {column}: {score_with - score_without}')",
"Validation Accuracy without wpt_name: 0.8087542087542088\nValidation Accuracy with wpt_name: 0.8135521885521886\nDrop-Column Importance for wpt_name: 0.004797979797979801\n"
]
],
[
[
"### 3. Permutation Importance\n\nPermutation Importance is a good compromise between Feature Importance based on impurity reduction (which is the fastest) and Drop Column Importance (which is the \"best.\")\n\n[The ELI5 library documentation explains,](https://eli5.readthedocs.io/en/latest/blackbox/permutation_importance.html)\n\n> Importance can be measured by looking at how much the score (accuracy, F1, R^2, etc. - any score we’re interested in) decreases when a feature is not available.\n>\n> To do that one can remove feature from the dataset, re-train the estimator and check the score. But it requires re-training an estimator for each feature, which can be computationally intensive. ...\n>\n>To avoid re-training the estimator we can remove a feature only from the test part of the dataset, and compute score without using this feature. It doesn’t work as-is, because estimators expect feature to be present. So instead of removing a feature we can replace it with random noise - feature column is still there, but it no longer contains useful information. This method works if noise is drawn from the same distribution as original feature values (as otherwise estimator may fail). The simplest way to get such noise is to shuffle values for a feature, i.e. use other examples’ feature values - this is how permutation importance is computed.\n>\n>The method is most suitable for computing feature importances when a number of columns (features) is not huge; it can be resource-intensive otherwise.",
"_____no_output_____"
],
[
"### Do-It-Yourself way, for intuition",
"_____no_output_____"
]
],
[
[
"#lets see how permutation works first \r\nnevi_array = [1,2,3,4,5]\r\nnevi_permuted = np.random.permutation(nevi_array)\r\nnevi_permuted",
"_____no_output_____"
],
[
"#BEFORE : sequence of the feature to be permuted \r\nfeature = 'quantity'\r\nX_val[feature].head()",
"_____no_output_____"
],
[
"#BEFORE: distribution \r\nX_val[feature].value_counts()",
"_____no_output_____"
],
[
"#PERMUTE\r\n\r\nX_val_permuted = X_val.copy()\r\nX_val_permuted[feature] =np.random.permutation(X_val[feature])",
"_____no_output_____"
],
[
"#AFTER : sequence of the feature to be permuted \r\nfeature = 'quantity'\r\nX_val_permuted[feature].head()",
"_____no_output_____"
],
[
"#AFTER: distribution \r\nX_val_permuted[feature].value_counts()",
"_____no_output_____"
],
[
"#get the permutation importance \r\nX_val_permuted[feature] =np.random.permutation(X_val[feature])\r\n\r\nscore_permuted = pipeline.score(X_val_permuted, y_val)\r\n\r\nprint(f'Validation Accuracy with {feature}: {score_with}')\r\nprint(f'Validation Accuracy with {feature} permuted: {score_permuted}')\r\nprint(f'Permutation Importance: {score_with - score_permuted}')",
"Validation Accuracy with quantity: 0.8135521885521886\nValidation Accuracy with quantity permuted: 0.7148148148148148\nPermutation Importance: 0.09873737373737379\n"
],
[
"feature = 'wpt_name'\r\nX_val_permuted=X_val.copy()\r\nX_val_permuted[feature] = np.random.permutation(X_val[feature])\r\nscore_permuted = pipeline.score(X_val_permuted, y_val)\r\n\r\nprint(f'Validation Accuracy with {feature}: {score_with}')\r\nprint(f'Validation Accuracy with {feature} permuted: {score_permuted}')\r\nprint(f'Permutation Importance: {score_with - score_permuted}')",
"Validation Accuracy with wpt_name: 0.8135521885521886\nValidation Accuracy with wpt_name permuted: 0.811952861952862\nPermutation Importance: 0.0015993265993266004\n"
],
[
"X_val[feature]",
"_____no_output_____"
]
],
[
[
"### With eli5 library\n\nFor more documentation on using this library, see:\n- [eli5.sklearn.PermutationImportance](https://eli5.readthedocs.io/en/latest/autodocs/sklearn.html#eli5.sklearn.permutation_importance.PermutationImportance)\n- [eli5.show_weights](https://eli5.readthedocs.io/en/latest/autodocs/eli5.html#eli5.show_weights)\n- [scikit-learn user guide, `scoring` parameter](https://scikit-learn.org/stable/modules/model_evaluation.html#the-scoring-parameter-defining-model-evaluation-rules)\n\neli5 doesn't work with pipelines.",
"_____no_output_____"
]
],
[
[
"# Ignore warnings\n \ntransformers = make_pipeline(\n ce.OrdinalEncoder(), \n SimpleImputer(strategy='median')\n )\n\nX_train_transformed = transformers.fit_transform(X_train)\nX_val_transformed = transformers.transform(X_val)\n\nmodel = RandomForestClassifier(n_estimators=50, random_state=42, n_jobs=-1)\nmodel.fit(X_train_transformed, y_train)",
"_____no_output_____"
],
[
"import eli5\r\nfrom eli5.sklearn import PermutationImportance\r\n\r\npermuter = PermutationImportance(\r\n model, \r\n scoring='accuracy',\r\n n_iter=5, \r\n random_state=42\r\n)\r\n\r\npermuter.fit(X_val_transformed,y_val)\r\n",
"_____no_output_____"
],
[
"feature_names = X_val.columns.to_list()\r\npd.Series(permuter.feature_importances_, feature_names).sort_values(ascending=False)",
"_____no_output_____"
],
[
"eli5.show_weights(\r\n permuter, \r\n top=None, \r\n feature_names=feature_names\r\n)",
"_____no_output_____"
]
],
[
[
"### We can use importances for feature selection\n\nFor example, we can remove features with zero importance. The model trains faster and the score does not decrease.",
"_____no_output_____"
]
],
[
[
"print('Shape before removing feature ', X_train.shape)",
"Shape before removing feature (47520, 45)\n"
],
[
"#remove features with feature importance <0\r\nminimum_importance = 0\r\nmask=permuter.feature_importances_ > minimum_importance \r\nfeatures = X_train.columns[mask]\r\nX_train=X_train[features]",
"_____no_output_____"
],
[
"print('Shape AFTER removing feature ', X_train.shape)",
"Shape AFTER removing feature (47520, 24)\n"
],
[
"X_val=X_val[features]\r\n\r\npipeline = make_pipeline(\r\n ce.OrdinalEncoder(), \r\n SimpleImputer(strategy='mean'), \r\n RandomForestClassifier(n_estimators=50, random_state=42, n_jobs=-1)\r\n)\r\n\r\n#fit on train, score on val \r\npipeline.fit(X_train, y_train)\r\nprint('Validation accuracy', pipeline.score(X_val, y_val))",
"Validation accuracy 0.8066498316498316\n"
]
],
[
[
"# Use xgboost for gradient boosting",
"_____no_output_____"
],
[
"## Overview",
"_____no_output_____"
],
[
"In the Random Forest lesson, you learned this advice:\n\n#### Try Tree Ensembles when you do machine learning with labeled, tabular data\n- \"Tree Ensembles\" means Random Forest or **Gradient Boosting** models. \n- [Tree Ensembles often have the best predictive accuracy](https://arxiv.org/abs/1708.05070) with labeled, tabular data.\n- Why? Because trees can fit non-linear, non-[monotonic](https://en.wikipedia.org/wiki/Monotonic_function) relationships, and [interactions](https://christophm.github.io/interpretable-ml-book/interaction.html) between features.\n- A single decision tree, grown to unlimited depth, will [overfit](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/). We solve this problem by ensembling trees, with bagging (Random Forest) or **[boosting](https://www.youtube.com/watch?v=GM3CDQfQ4sw)** (Gradient Boosting).\n- Random Forest's advantage: may be less sensitive to hyperparameters. **Gradient Boosting's advantage:** may get better predictive accuracy.",
"_____no_output_____"
],
[
"Like Random Forest, Gradient Boosting uses ensembles of trees. But the details of the ensembling technique are different:\n\n### Understand the difference between boosting & bagging\n\nBoosting (used by Gradient Boosting) is different than Bagging (used by Random Forests). \n\nHere's an excerpt from [_An Introduction to Statistical Learning_](http://www-bcf.usc.edu/~gareth/ISL/ISLR%20Seventh%20Printing.pdf) Chapter 8.2.3, Boosting:\n\n>Recall that bagging involves creating multiple copies of the original training data set using the bootstrap, fitting a separate decision tree to each copy, and then combining all of the trees in order to create a single predictive model.\n>\n>**Boosting works in a similar way, except that the trees are grown _sequentially_: each tree is grown using information from previously grown trees.**\n>\n>Unlike fitting a single large decision tree to the data, which amounts to _fitting the data hard_ and potentially overfitting, the boosting approach instead _learns slowly._ Given the current model, we fit a decision tree to the residuals from the model.\n>\n>We then add this new decision tree into the fitted function in order to update the residuals. Each of these trees can be rather small, with just a few terminal nodes. **By fitting small trees to the residuals, we slowly improve fˆ in areas where it does not perform well.**\n>\n>Note that in boosting, unlike in bagging, the construction of each tree depends strongly on the trees that have already been grown.\n\nThis high-level overview is all you need to know for now. If you want to go deeper, we recommend you watch the StatQuest videos on gradient boosting!",
"_____no_output_____"
],
[
"Let's write some code. We have lots of options for which libraries to use:\n\n#### Python libraries for Gradient Boosting\n- [scikit-learn Gradient Tree Boosting](https://scikit-learn.org/stable/modules/ensemble.html#gradient-boosting) — slower than other libraries, but [the new version may be better](https://twitter.com/amuellerml/status/1129443826945396737)\n - Anaconda: already installed\n - Google Colab: already installed\n- [xgboost](https://xgboost.readthedocs.io/en/latest/) — can accept missing values and enforce [monotonic constraints](https://xiaoxiaowang87.github.io/monotonicity_constraint/)\n - Anaconda, Mac/Linux: `conda install -c conda-forge xgboost`\n - Windows: `conda install -c anaconda py-xgboost`\n - Google Colab: already installed\n- [LightGBM](https://lightgbm.readthedocs.io/en/latest/) — can accept missing values and enforce [monotonic constraints](https://blog.datadive.net/monotonicity-constraints-in-machine-learning/)\n - Anaconda: `conda install -c conda-forge lightgbm`\n - Google Colab: already installed\n- [CatBoost](https://catboost.ai/) — can accept missing values and use [categorical features](https://catboost.ai/docs/concepts/algorithm-main-stages_cat-to-numberic.html) without preprocessing\n - Anaconda: `conda install -c conda-forge catboost`\n - Google Colab: `pip install catboost`",
"_____no_output_____"
],
[
"In this lesson, you'll use a new library, xgboost — But it has an API that's almost the same as scikit-learn, so it won't be a hard adjustment!\n\n#### [XGBoost Python API Reference: Scikit-Learn API](https://xgboost.readthedocs.io/en/latest/python/python_api.html#module-xgboost.sklearn)",
"_____no_output_____"
]
],
[
[
"from xgboost import XGBClassifier\r\npipeline = make_pipeline(\r\n ce.OrdinalEncoder(), \r\n XGBClassifier(n_estimators=100, random_state=42, n_jobs=-1)\r\n)\r\n\r\npipeline.fit(X_train, y_train)\r\n",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score\r\ny_pred=pipeline.predict(X_val)\r\nprint('Validation score', accuracy_score(y_val, y_pred))",
"Validation score 0.7453703703703703\n"
]
],
[
[
"#### [Avoid Overfitting By Early Stopping With XGBoost In Python](https://machinelearningmastery.com/avoid-overfitting-by-early-stopping-with-xgboost-in-python/)\n\nWhy is early stopping better than a For loop, or GridSearchCV, to optimize `n_estimators`?\n\nWith early stopping, if `n_iterations` is our number of iterations, then we fit `n_iterations` decision trees.\n\nWith a for loop, or GridSearchCV, we'd fit `sum(range(1,n_rounds+1))` trees.\n\nBut it doesn't work well with pipelines. You may need to re-run multiple times with different values of other parameters such as `max_depth` and `learning_rate`.\n\n#### XGBoost parameters\n- [Notes on parameter tuning](https://xgboost.readthedocs.io/en/latest/tutorials/param_tuning.html)\n- [Parameters documentation](https://xgboost.readthedocs.io/en/latest/parameter.html)\n",
"_____no_output_____"
]
],
[
[
"encoder = ce.OrdinalEncoder()\r\nX_train_encoded = encoder.fit_transform(X_train)\r\nX_val_encoded = encoder.transform(X_val)\r\n\r\nmodel = XGBClassifier(\r\n n_estimators=1000, # <= 1000 trees, depend on early stopping\r\n max_depth=7, # try deeper trees because of high cardinality categoricals\r\n learning_rate=0.5, # try higher learning rate\r\n n_jobs=-1\r\n)\r\n\r\neval_set = [(X_train_encoded, y_train), \r\n (X_val_encoded, y_val)]\r\n\r\nmodel.fit(X_train_encoded, y_train, \r\n eval_set=eval_set, \r\n eval_metric='merror', \r\n early_stopping_rounds=50) # Stop if the score hasn't improved in 50 rounds",
"[0]\tvalidation_0-merror:0.254167\tvalidation_1-merror:0.264394\nMultiple eval metrics have been passed: 'validation_1-merror' will be used for early stopping.\n\nWill train until validation_1-merror hasn't improved in 50 rounds.\n[1]\tvalidation_0-merror:0.241898\tvalidation_1-merror:0.252946\n[2]\tvalidation_0-merror:0.234891\tvalidation_1-merror:0.243687\n[3]\tvalidation_0-merror:0.229082\tvalidation_1-merror:0.237458\n[4]\tvalidation_0-merror:0.220013\tvalidation_1-merror:0.230892\n[5]\tvalidation_0-merror:0.213994\tvalidation_1-merror:0.227273\n[6]\tvalidation_0-merror:0.208481\tvalidation_1-merror:0.224579\n[7]\tvalidation_0-merror:0.204146\tvalidation_1-merror:0.221212\n[8]\tvalidation_0-merror:0.200989\tvalidation_1-merror:0.218687\n[9]\tvalidation_0-merror:0.198359\tvalidation_1-merror:0.218771\n[10]\tvalidation_0-merror:0.195602\tvalidation_1-merror:0.217088\n[11]\tvalidation_0-merror:0.192782\tvalidation_1-merror:0.215404\n[12]\tvalidation_0-merror:0.188952\tvalidation_1-merror:0.215572\n[13]\tvalidation_0-merror:0.185227\tvalidation_1-merror:0.213636\n[14]\tvalidation_0-merror:0.182218\tvalidation_1-merror:0.213721\n[15]\tvalidation_0-merror:0.177273\tvalidation_1-merror:0.210017\n[16]\tvalidation_0-merror:0.175947\tvalidation_1-merror:0.210185\n[17]\tvalidation_0-merror:0.173695\tvalidation_1-merror:0.209512\n[18]\tvalidation_0-merror:0.172264\tvalidation_1-merror:0.209764\n[19]\tvalidation_0-merror:0.169802\tvalidation_1-merror:0.207912\n[20]\tvalidation_0-merror:0.167487\tvalidation_1-merror:0.207744\n[21]\tvalidation_0-merror:0.165488\tvalidation_1-merror:0.206902\n[22]\tvalidation_0-merror:0.163721\tvalidation_1-merror:0.207492\n[23]\tvalidation_0-merror:0.162584\tvalidation_1-merror:0.208081\n[24]\tvalidation_0-merror:0.161322\tvalidation_1-merror:0.209091\n[25]\tvalidation_0-merror:0.159491\tvalidation_1-merror:0.207744\n[26]\tvalidation_0-merror:0.157218\tvalidation_1-merror:0.205892\n[27]\tvalidation_0-merror:0.155787\tvalidation_1-merror:0.205556\n[28]\tvalidation_0-merror:0.154714\tvalidation_1-merror:0.205808\n[29]\tvalidation_0-merror:0.153725\tvalidation_1-merror:0.205219\n[30]\tvalidation_0-merror:0.152399\tvalidation_1-merror:0.205556\n[31]\tvalidation_0-merror:0.150421\tvalidation_1-merror:0.204461\n[32]\tvalidation_0-merror:0.147938\tvalidation_1-merror:0.204461\n[33]\tvalidation_0-merror:0.14596\tvalidation_1-merror:0.203872\n[34]\tvalidation_0-merror:0.14476\tvalidation_1-merror:0.202862\n[35]\tvalidation_0-merror:0.14314\tvalidation_1-merror:0.202694\n[36]\tvalidation_0-merror:0.142361\tvalidation_1-merror:0.202525\n[37]\tvalidation_0-merror:0.140657\tvalidation_1-merror:0.201768\n[38]\tvalidation_0-merror:0.140488\tvalidation_1-merror:0.20202\n[39]\tvalidation_0-merror:0.139268\tvalidation_1-merror:0.201515\n[40]\tvalidation_0-merror:0.137668\tvalidation_1-merror:0.200673\n[41]\tvalidation_0-merror:0.136532\tvalidation_1-merror:0.201178\n[42]\tvalidation_0-merror:0.135206\tvalidation_1-merror:0.201515\n[43]\tvalidation_0-merror:0.134133\tvalidation_1-merror:0.201852\n[44]\tvalidation_0-merror:0.132155\tvalidation_1-merror:0.200842\n[45]\tvalidation_0-merror:0.13104\tvalidation_1-merror:0.19899\n[46]\tvalidation_0-merror:0.13064\tvalidation_1-merror:0.198401\n[47]\tvalidation_0-merror:0.129819\tvalidation_1-merror:0.197643\n[48]\tvalidation_0-merror:0.12883\tvalidation_1-merror:0.197559\n[49]\tvalidation_0-merror:0.127546\tvalidation_1-merror:0.197811\n[50]\tvalidation_0-merror:0.125926\tvalidation_1-merror:0.197054\n[51]\tvalidation_0-merror:0.124769\tvalidation_1-merror:0.198906\n[52]\tvalidation_0-merror:0.123527\tvalidation_1-merror:0.198822\n[53]\tvalidation_0-merror:0.122748\tvalidation_1-merror:0.198737\n[54]\tvalidation_0-merror:0.121675\tvalidation_1-merror:0.197727\n[55]\tvalidation_0-merror:0.119823\tvalidation_1-merror:0.197222\n[56]\tvalidation_0-merror:0.119024\tvalidation_1-merror:0.19697\n[57]\tvalidation_0-merror:0.117887\tvalidation_1-merror:0.197054\n[58]\tvalidation_0-merror:0.117424\tvalidation_1-merror:0.19697\n[59]\tvalidation_0-merror:0.116814\tvalidation_1-merror:0.197727\n[60]\tvalidation_0-merror:0.115762\tvalidation_1-merror:0.197811\n[61]\tvalidation_0-merror:0.114836\tvalidation_1-merror:0.198064\n[62]\tvalidation_0-merror:0.113973\tvalidation_1-merror:0.198737\n[63]\tvalidation_0-merror:0.113215\tvalidation_1-merror:0.199158\n[64]\tvalidation_0-merror:0.112121\tvalidation_1-merror:0.198232\n[65]\tvalidation_0-merror:0.111301\tvalidation_1-merror:0.198569\n[66]\tvalidation_0-merror:0.110438\tvalidation_1-merror:0.198401\n[67]\tvalidation_0-merror:0.108607\tvalidation_1-merror:0.197896\n[68]\tvalidation_0-merror:0.107976\tvalidation_1-merror:0.198653\n[69]\tvalidation_0-merror:0.107113\tvalidation_1-merror:0.198232\n[70]\tvalidation_0-merror:0.105661\tvalidation_1-merror:0.197811\n[71]\tvalidation_0-merror:0.104314\tvalidation_1-merror:0.197727\n[72]\tvalidation_0-merror:0.103367\tvalidation_1-merror:0.198232\n[73]\tvalidation_0-merror:0.102925\tvalidation_1-merror:0.198232\n[74]\tvalidation_0-merror:0.101684\tvalidation_1-merror:0.198401\n[75]\tvalidation_0-merror:0.10061\tvalidation_1-merror:0.198064\n[76]\tvalidation_0-merror:0.099453\tvalidation_1-merror:0.198653\n[77]\tvalidation_0-merror:0.098653\tvalidation_1-merror:0.198401\n[78]\tvalidation_0-merror:0.098169\tvalidation_1-merror:0.198148\n[79]\tvalidation_0-merror:0.097138\tvalidation_1-merror:0.199242\n[80]\tvalidation_0-merror:0.096086\tvalidation_1-merror:0.198569\n[81]\tvalidation_0-merror:0.095686\tvalidation_1-merror:0.198401\n[82]\tvalidation_0-merror:0.094592\tvalidation_1-merror:0.198401\n[83]\tvalidation_0-merror:0.09354\tvalidation_1-merror:0.196801\n[84]\tvalidation_0-merror:0.093013\tvalidation_1-merror:0.196212\n[85]\tvalidation_0-merror:0.092066\tvalidation_1-merror:0.196633\n[86]\tvalidation_0-merror:0.09154\tvalidation_1-merror:0.197138\n[87]\tvalidation_0-merror:0.090951\tvalidation_1-merror:0.197306\n[88]\tvalidation_0-merror:0.090678\tvalidation_1-merror:0.197475\n[89]\tvalidation_0-merror:0.089289\tvalidation_1-merror:0.197643\n[90]\tvalidation_0-merror:0.088405\tvalidation_1-merror:0.19638\n[91]\tvalidation_0-merror:0.087584\tvalidation_1-merror:0.196465\n[92]\tvalidation_0-merror:0.086848\tvalidation_1-merror:0.195455\n[93]\tvalidation_0-merror:0.08609\tvalidation_1-merror:0.195791\n[94]\tvalidation_0-merror:0.085017\tvalidation_1-merror:0.19537\n[95]\tvalidation_0-merror:0.084722\tvalidation_1-merror:0.195455\n[96]\tvalidation_0-merror:0.08367\tvalidation_1-merror:0.196465\n[97]\tvalidation_0-merror:0.082828\tvalidation_1-merror:0.195707\n[98]\tvalidation_0-merror:0.082344\tvalidation_1-merror:0.197222\n[99]\tvalidation_0-merror:0.081692\tvalidation_1-merror:0.196886\n[100]\tvalidation_0-merror:0.08104\tvalidation_1-merror:0.197306\n[101]\tvalidation_0-merror:0.080661\tvalidation_1-merror:0.197306\n[102]\tvalidation_0-merror:0.080156\tvalidation_1-merror:0.197811\n[103]\tvalidation_0-merror:0.07944\tvalidation_1-merror:0.197727\n[104]\tvalidation_0-merror:0.078514\tvalidation_1-merror:0.197811\n[105]\tvalidation_0-merror:0.077378\tvalidation_1-merror:0.197559\n[106]\tvalidation_0-merror:0.076915\tvalidation_1-merror:0.197222\n[107]\tvalidation_0-merror:0.075947\tvalidation_1-merror:0.197643\n[108]\tvalidation_0-merror:0.075568\tvalidation_1-merror:0.197896\n[109]\tvalidation_0-merror:0.075084\tvalidation_1-merror:0.197138\n[110]\tvalidation_0-merror:0.074832\tvalidation_1-merror:0.197896\n[111]\tvalidation_0-merror:0.073948\tvalidation_1-merror:0.19798\n[112]\tvalidation_0-merror:0.073316\tvalidation_1-merror:0.198148\n[113]\tvalidation_0-merror:0.072201\tvalidation_1-merror:0.198906\n[114]\tvalidation_0-merror:0.071738\tvalidation_1-merror:0.199495\n[115]\tvalidation_0-merror:0.070686\tvalidation_1-merror:0.19899\n[116]\tvalidation_0-merror:0.070497\tvalidation_1-merror:0.199327\n[117]\tvalidation_0-merror:0.070097\tvalidation_1-merror:0.19899\n[118]\tvalidation_0-merror:0.068603\tvalidation_1-merror:0.198148\n[119]\tvalidation_0-merror:0.068413\tvalidation_1-merror:0.197727\n[120]\tvalidation_0-merror:0.067908\tvalidation_1-merror:0.197559\n[121]\tvalidation_0-merror:0.067529\tvalidation_1-merror:0.197643\n[122]\tvalidation_0-merror:0.067066\tvalidation_1-merror:0.198064\n[123]\tvalidation_0-merror:0.066267\tvalidation_1-merror:0.198401\n[124]\tvalidation_0-merror:0.065951\tvalidation_1-merror:0.198232\n[125]\tvalidation_0-merror:0.065699\tvalidation_1-merror:0.198569\n[126]\tvalidation_0-merror:0.065509\tvalidation_1-merror:0.198232\n[127]\tvalidation_0-merror:0.065215\tvalidation_1-merror:0.197727\n[128]\tvalidation_0-merror:0.064857\tvalidation_1-merror:0.197559\n[129]\tvalidation_0-merror:0.064373\tvalidation_1-merror:0.197306\n[130]\tvalidation_0-merror:0.064036\tvalidation_1-merror:0.197306\n[131]\tvalidation_0-merror:0.063279\tvalidation_1-merror:0.197054\n[132]\tvalidation_0-merror:0.062816\tvalidation_1-merror:0.197306\n[133]\tvalidation_0-merror:0.062226\tvalidation_1-merror:0.197391\n[134]\tvalidation_0-merror:0.061785\tvalidation_1-merror:0.197054\n[135]\tvalidation_0-merror:0.061279\tvalidation_1-merror:0.196886\n[136]\tvalidation_0-merror:0.060795\tvalidation_1-merror:0.197054\n[137]\tvalidation_0-merror:0.059996\tvalidation_1-merror:0.197559\n[138]\tvalidation_0-merror:0.05947\tvalidation_1-merror:0.197391\n[139]\tvalidation_0-merror:0.059217\tvalidation_1-merror:0.197475\n[140]\tvalidation_0-merror:0.059112\tvalidation_1-merror:0.197475\n[141]\tvalidation_0-merror:0.058628\tvalidation_1-merror:0.197811\n[142]\tvalidation_0-merror:0.057912\tvalidation_1-merror:0.197306\n[143]\tvalidation_0-merror:0.057723\tvalidation_1-merror:0.197138\n[144]\tvalidation_0-merror:0.057534\tvalidation_1-merror:0.197391\nStopping. Best iteration:\n[94]\tvalidation_0-merror:0.085017\tvalidation_1-merror:0.19537\n\n"
],
[
"results = model.evals_result()\r\ntrain_error = results['validation_0']['merror']\r\nval_error = results['validation_1']['merror']\r\nepoch = list(range(1, len(train_error)+1))\r\nplt.plot(epoch, train_error, label='Train')\r\nplt.plot(epoch, val_error, label='Validation')\r\nplt.ylabel('Classification Error')\r\nplt.xlabel('Model Complexity (n_estimators)')\r\nplt.title('Validation Curve for this XGBoost model')\r\nplt.ylim((0.10, 0.25)) # Zoom in\r\nplt.legend();",
"_____no_output_____"
]
],
[
[
"### Try adjusting these hyperparameters\n\n#### Random Forest\n- class_weight (for imbalanced classes)\n- max_depth (usually high, can try decreasing)\n- n_estimators (too low underfits, too high wastes time)\n- min_samples_leaf (increase if overfitting)\n- max_features (decrease for more diverse trees)\n\n#### Xgboost\n- scale_pos_weight (for imbalanced classes)\n- max_depth (usually low, can try increasing)\n- n_estimators (too low underfits, too high wastes time/overfits) — Use Early Stopping!\n- learning_rate (too low underfits, too high overfits)\n\nFor more ideas, see [Notes on Parameter Tuning](https://xgboost.readthedocs.io/en/latest/tutorials/param_tuning.html) and [DART booster](https://xgboost.readthedocs.io/en/latest/tutorials/dart.html).",
"_____no_output_____"
],
[
"## Challenge\n\nYou will use your portfolio project dataset for all assignments this sprint. Complete these tasks for your project, and document your work.\n\n- Continue to clean and explore your data. Make exploratory visualizations.\n- Fit a model. Does it beat your baseline?\n- Try xgboost.\n- Get your model's permutation importances.\n\nYou should try to complete an initial model today, because the rest of the week, we're making model interpretation visualizations.\n\nBut, if you aren't ready to try xgboost and permutation importances with your dataset today, you can practice with another dataset instead. You may choose any dataset you've worked with previously.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
]
|
d06137aa460ed001913396642f28d2945f230d06 | 823,130 | ipynb | Jupyter Notebook | Irises_ML_Intro/Irises Data Analysis Workflow_06_2019.ipynb | ValRCS/RCS_Data_Analysis_Python_2019_July | 19e2f8310f41b697f9c86d7a085a9ff19390eeac | [
"MIT"
]
| 1 | 2019-07-11T16:25:15.000Z | 2019-07-11T16:25:15.000Z | Irises_ML_Intro/Irises Data Analysis Workflow_06_2019.ipynb | ValRCS/RCS_Data_Analysis_Python_2019_July | 19e2f8310f41b697f9c86d7a085a9ff19390eeac | [
"MIT"
]
| 8 | 2020-01-28T22:54:14.000Z | 2022-02-10T00:17:47.000Z | Irises_ML_Intro/Irises Data Analysis Workflow_06_2019.ipynb | ValRCS/RCS_Data_Analysis_Python_2019_July | 19e2f8310f41b697f9c86d7a085a9ff19390eeac | [
"MIT"
]
| null | null | null | 199.788835 | 142,296 | 0.894876 | [
[
[
"<h1><center>Introductory Data Analysis Workflow</center></h1>\n",
"_____no_output_____"
],
[
"\nhttps://xkcd.com/2054",
"_____no_output_____"
],
[
"# An example machine learning notebook\n\n* Original Notebook by [Randal S. Olson](http://www.randalolson.com/)\n* Supported by [Jason H. Moore](http://www.epistasis.org/)\n* [University of Pennsylvania Institute for Bioinformatics](http://upibi.org/)\n* Adapted for LU Py-Sem 2018 by [Valdis Saulespurens]([email protected])",
"_____no_output_____"
],
[
"**You can also [execute the code in this notebook on Binder](https://mybinder.org/v2/gh/ValRCS/RigaComm_DataAnalysis/master) - no local installation required.**",
"_____no_output_____"
]
],
[
[
"# text 17.04.2019\nimport datetime\nprint(datetime.datetime.now())\nprint('hello')",
"2019-06-13 16:12:23.662194\nhello\n"
]
],
[
[
"## Table of contents\n\n1. [Introduction](#Introduction)\n\n2. [License](#License)\n\n3. [Required libraries](#Required-libraries)\n\n4. [The problem domain](#The-problem-domain)\n\n5. [Step 1: Answering the question](#Step-1:-Answering-the-question)\n\n6. [Step 2: Checking the data](#Step-2:-Checking-the-data)\n\n7. [Step 3: Tidying the data](#Step-3:-Tidying-the-data)\n\n - [Bonus: Testing our data](#Bonus:-Testing-our-data)\n\n8. [Step 4: Exploratory analysis](#Step-4:-Exploratory-analysis)\n\n9. [Step 5: Classification](#Step-5:-Classification)\n\n - [Cross-validation](#Cross-validation)\n\n - [Parameter tuning](#Parameter-tuning)\n\n10. [Step 6: Reproducibility](#Step-6:-Reproducibility)\n\n11. [Conclusions](#Conclusions)\n\n12. [Further reading](#Further-reading)\n\n13. [Acknowledgements](#Acknowledgements)",
"_____no_output_____"
],
[
"## Introduction\n\n[[ go back to the top ]](#Table-of-contents)\n\nIn the time it took you to read this sentence, terabytes of data have been collectively generated across the world — more data than any of us could ever hope to process, much less make sense of, on the machines we're using to read this notebook.\n\nIn response to this massive influx of data, the field of Data Science has come to the forefront in the past decade. Cobbled together by people from a diverse array of fields — statistics, physics, computer science, design, and many more — the field of Data Science represents our collective desire to understand and harness the abundance of data around us to build a better world.\n\nIn this notebook, I'm going to go over a basic Python data analysis pipeline from start to finish to show you what a typical data science workflow looks like.\n\nIn addition to providing code examples, I also hope to imbue in you a sense of good practices so you can be a more effective — and more collaborative — data scientist.\n\nI will be following along with the data analysis checklist from [The Elements of Data Analytic Style](https://leanpub.com/datastyle), which I strongly recommend reading as a free and quick guidebook to performing outstanding data analysis.\n\n**This notebook is intended to be a public resource. As such, if you see any glaring inaccuracies or if a critical topic is missing, please feel free to point it out or (preferably) submit a pull request to improve the notebook.**",
"_____no_output_____"
],
[
"## License\n\n[[ go back to the top ]](#Table-of-contents)\n\nPlease see the [repository README file](https://github.com/rhiever/Data-Analysis-and-Machine-Learning-Projects#license) for the licenses and usage terms for the instructional material and code in this notebook. In general, I have licensed this material so that it is as widely usable and shareable as possible.",
"_____no_output_____"
],
[
"## Required libraries\n\n[[ go back to the top ]](#Table-of-contents)\n\nIf you don't have Python on your computer, you can use the [Anaconda Python distribution](http://continuum.io/downloads) to install most of the Python packages you need. Anaconda provides a simple double-click installer for your convenience.\n\nThis notebook uses several Python packages that come standard with the Anaconda Python distribution. The primary libraries that we'll be using are:\n\n* **NumPy**: Provides a fast numerical array structure and helper functions.\n* **pandas**: Provides a DataFrame structure to store data in memory and work with it easily and efficiently.\n* **scikit-learn**: The essential Machine Learning package in Python.\n* **matplotlib**: Basic plotting library in Python; most other Python plotting libraries are built on top of it.\n* **Seaborn**: Advanced statistical plotting library.\n* **watermark**: A Jupyter Notebook extension for printing timestamps, version numbers, and hardware information.\n\n**Note:** I will not be providing support for people trying to run this notebook outside of the Anaconda Python distribution.",
"_____no_output_____"
],
[
"## The problem domain\n\n[[ go back to the top ]](#Table-of-contents)\n\nFor the purposes of this exercise, let's pretend we're working for a startup that just got funded to create a smartphone app that automatically identifies species of flowers from pictures taken on the smartphone. We're working with a moderately-sized team of data scientists and will be building part of the data analysis pipeline for this app.\n\nWe've been tasked by our company's Head of Data Science to create a demo machine learning model that takes four measurements from the flowers (sepal length, sepal width, petal length, and petal width) and identifies the species based on those measurements alone.\n\n<img src=\"img/petal_sepal.jpg\" />\n\nWe've been given a [data set](https://github.com/ValRCS/RCS_Data_Analysis_Python/blob/master/data/iris-data.csv) from our field researchers to develop the demo, which only includes measurements for three types of *Iris* flowers:\n\n### *Iris setosa*\n\n<img src=\"img/iris_setosa.jpg\" />\n\n### *Iris versicolor*\n<img src=\"img/iris_versicolor.jpg\" />\n\n### *Iris virginica*\n<img src=\"img/iris_virginica.jpg\" />\n\nThe four measurements we're using currently come from hand-measurements by the field researchers, but they will be automatically measured by an image processing model in the future.\n\n**Note:** The data set we're working with is the famous [*Iris* data set](https://archive.ics.uci.edu/ml/datasets/Iris) — included with this notebook — which I have modified slightly for demonstration purposes.",
"_____no_output_____"
],
[
"## Step 1: Answering the question\n\n[[ go back to the top ]](#Table-of-contents)\n\nThe first step to any data analysis project is to define the question or problem we're looking to solve, and to define a measure (or set of measures) for our success at solving that task. The data analysis checklist has us answer a handful of questions to accomplish that, so let's work through those questions.\n\n>Did you specify the type of data analytic question (e.g. exploration, association causality) before touching the data?\n\nWe're trying to classify the species (i.e., class) of the flower based on four measurements that we're provided: sepal length, sepal width, petal length, and petal width.\n\nPetal - ziedlapiņa, sepal - arī ziedlapiņa\n\n\n\n>Did you define the metric for success before beginning?\n\nLet's do that now. Since we're performing classification, we can use [accuracy](https://en.wikipedia.org/wiki/Accuracy_and_precision) — the fraction of correctly classified flowers — to quantify how well our model is performing. Our company's Head of Data has told us that we should achieve at least 90% accuracy.\n\n>Did you understand the context for the question and the scientific or business application?\n\nWe're building part of a data analysis pipeline for a smartphone app that will be able to classify the species of flowers from pictures taken on the smartphone. In the future, this pipeline will be connected to another pipeline that automatically measures from pictures the traits we're using to perform this classification.\n\n>Did you record the experimental design?\n\nOur company's Head of Data has told us that the field researchers are hand-measuring 50 randomly-sampled flowers of each species using a standardized methodology. The field researchers take pictures of each flower they sample from pre-defined angles so the measurements and species can be confirmed by the other field researchers at a later point. At the end of each day, the data is compiled and stored on a private company GitHub repository.\n\n>Did you consider whether the question could be answered with the available data?\n\nThe data set we currently have is only for three types of *Iris* flowers. The model built off of this data set will only work for those *Iris* flowers, so we will need more data to create a general flower classifier.\n\n<hr />\n\nNotice that we've spent a fair amount of time working on the problem without writing a line of code or even looking at the data.\n\n**Thinking about and documenting the problem we're working on is an important step to performing effective data analysis that often goes overlooked.** Don't skip it.",
"_____no_output_____"
],
[
"## Step 2: Checking the data\n\n[[ go back to the top ]](#Table-of-contents)\n\nThe next step is to look at the data we're working with. Even curated data sets from the government can have errors in them, and it's vital that we spot these errors before investing too much time in our analysis.\n\nGenerally, we're looking to answer the following questions:\n\n* Is there anything wrong with the data?\n* Are there any quirks with the data?\n* Do I need to fix or remove any of the data?\n\nLet's start by reading the data into a pandas DataFrame.",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"\niris_data = pd.read_csv('../data/iris-data.csv')\n",
"_____no_output_____"
],
[
"# Resources for loading data from nonlocal sources\n# Pandas Can generally handle most common formats\n# https://pandas.pydata.org/pandas-docs/stable/io.html\n\n# SQL https://stackoverflow.com/questions/39149243/how-do-i-connect-to-a-sql-server-database-with-python\n# NoSQL MongoDB https://realpython.com/introduction-to-mongodb-and-python/\n# Apache Hadoop: https://dzone.com/articles/how-to-get-hadoop-data-into-a-python-model\n# Apache Spark: https://www.datacamp.com/community/tutorials/apache-spark-python\n# Data Scraping / Crawling libraries : https://elitedatascience.com/python-web-scraping-libraries Big Topic in itself\n\n# Most data resources have some form of Python API / Library ",
"_____no_output_____"
],
[
"iris_data.head()",
"_____no_output_____"
]
],
[
[
"We're in luck! The data seems to be in a usable format.\n\nThe first row in the data file defines the column headers, and the headers are descriptive enough for us to understand what each column represents. The headers even give us the units that the measurements were recorded in, just in case we needed to know at a later point in the project.\n\nEach row following the first row represents an entry for a flower: four measurements and one class, which tells us the species of the flower.\n\n**One of the first things we should look for is missing data.** Thankfully, the field researchers already told us that they put a 'NA' into the spreadsheet when they were missing a measurement.\n\nWe can tell pandas to automatically identify missing values if it knows our missing value marker.",
"_____no_output_____"
]
],
[
[
"iris_data.shape",
"_____no_output_____"
],
[
"iris_data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 150 entries, 0 to 149\nData columns (total 5 columns):\nsepal_length_cm 150 non-null float64\nsepal_width_cm 150 non-null float64\npetal_length_cm 150 non-null float64\npetal_width_cm 145 non-null float64\nclass 150 non-null object\ndtypes: float64(4), object(1)\nmemory usage: 5.9+ KB\n"
],
[
"iris_data.describe()",
"_____no_output_____"
],
[
"iris_data = pd.read_csv('../data/iris-data.csv', na_values=['NA', 'N/A'])",
"_____no_output_____"
]
],
[
[
"Voilà! Now pandas knows to treat rows with 'NA' as missing values.",
"_____no_output_____"
],
[
"Next, it's always a good idea to look at the distribution of our data — especially the outliers.\n\nLet's start by printing out some summary statistics about the data set.",
"_____no_output_____"
]
],
[
[
"iris_data.describe()",
"_____no_output_____"
]
],
[
[
"We can see several useful values from this table. For example, we see that five `petal_width_cm` entries are missing.\n\nIf you ask me, though, tables like this are rarely useful unless we know that our data should fall in a particular range. It's usually better to visualize the data in some way. Visualization makes outliers and errors immediately stand out, whereas they might go unnoticed in a large table of numbers.\n\nSince we know we're going to be plotting in this section, let's set up the notebook so we can plot inside of it.",
"_____no_output_____"
]
],
[
[
"# This line tells the notebook to show plots inside of the notebook\n%matplotlib inline\n\nimport matplotlib.pyplot as plt\nimport seaborn as sb",
"_____no_output_____"
]
],
[
[
"Next, let's create a **scatterplot matrix**. Scatterplot matrices plot the distribution of each column along the diagonal, and then plot a scatterplot matrix for the combination of each variable. They make for an efficient tool to look for errors in our data.\n\nWe can even have the plotting package color each entry by its class to look for trends within the classes.",
"_____no_output_____"
]
],
[
[
"# We have to temporarily drop the rows with 'NA' values\n# because the Seaborn plotting function does not know\n# what to do with them\nsb.pairplot(iris_data.dropna(), hue='class')\n",
"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\numpy\\core\\_methods.py:140: RuntimeWarning: Degrees of freedom <= 0 for slice\n keepdims=keepdims)\nC:\\ProgramData\\Anaconda3\\lib\\site-packages\\numpy\\core\\_methods.py:132: RuntimeWarning: invalid value encountered in double_scalars\n ret = ret.dtype.type(ret / rcount)\n"
]
],
[
[
"From the scatterplot matrix, we can already see some issues with the data set:\n\n1. There are five classes when there should only be three, meaning there were some coding errors.\n\n2. There are some clear outliers in the measurements that may be erroneous: one `sepal_width_cm` entry for `Iris-setosa` falls well outside its normal range, and several `sepal_length_cm` entries for `Iris-versicolor` are near-zero for some reason.\n\n3. We had to drop those rows with missing values.\n\nIn all of these cases, we need to figure out what to do with the erroneous data. Which takes us to the next step...",
"_____no_output_____"
],
[
"## Step 3: Tidying the data\n\n### GIGO principle\n\n[[ go back to the top ]](#Table-of-contents)\n\nNow that we've identified several errors in the data set, we need to fix them before we proceed with the analysis.\n\nLet's walk through the issues one-by-one.\n\n>There are five classes when there should only be three, meaning there were some coding errors.\n\nAfter talking with the field researchers, it sounds like one of them forgot to add `Iris-` before their `Iris-versicolor` entries. The other extraneous class, `Iris-setossa`, was simply a typo that they forgot to fix.\n\nLet's use the DataFrame to fix these errors.",
"_____no_output_____"
]
],
[
[
"iris_data['class'].unique()",
"_____no_output_____"
],
[
"# Copy and Replace\niris_data.loc[iris_data['class'] == 'versicolor', 'class'] = 'Iris-versicolor'\niris_data['class'].unique()\n",
"_____no_output_____"
],
[
"# So we take a row where a specific column('class' here) matches our bad values \n# and change them to good values\n\niris_data.loc[iris_data['class'] == 'Iris-setossa', 'class'] = 'Iris-setosa'\n\niris_data['class'].unique()",
"_____no_output_____"
],
[
"iris_data.tail()",
"_____no_output_____"
],
[
"iris_data[98:103]",
"_____no_output_____"
]
],
[
[
"Much better! Now we only have three class types. Imagine how embarrassing it would've been to create a model that used the wrong classes.\n\n>There are some clear outliers in the measurements that may be erroneous: one `sepal_width_cm` entry for `Iris-setosa` falls well outside its normal range, and several `sepal_length_cm` entries for `Iris-versicolor` are near-zero for some reason.\n\nFixing outliers can be tricky business. It's rarely clear whether the outlier was caused by measurement error, recording the data in improper units, or if the outlier is a real anomaly. For that reason, we should be judicious when working with outliers: if we decide to exclude any data, we need to make sure to document what data we excluded and provide solid reasoning for excluding that data. (i.e., \"This data didn't fit my hypothesis\" will not stand peer review.)\n\nIn the case of the one anomalous entry for `Iris-setosa`, let's say our field researchers know that it's impossible for `Iris-setosa` to have a sepal width below 2.5 cm. Clearly this entry was made in error, and we're better off just scrapping the entry than spending hours finding out what happened.",
"_____no_output_____"
]
],
[
[
"smallpetals = iris_data.loc[(iris_data['sepal_width_cm'] < 2.5) & (iris_data['class'] == 'Iris-setosa')]\nsmallpetals",
"_____no_output_____"
],
[
"iris_data.loc[iris_data['class'] == 'Iris-setosa', 'sepal_width_cm'].hist()",
"_____no_output_____"
],
[
"# This line drops any 'Iris-setosa' rows with a separal width less than 2.5 cm\n# Let's go over this command in class\niris_data = iris_data.loc[(iris_data['class'] != 'Iris-setosa') | (iris_data['sepal_width_cm'] >= 2.5)]\niris_data.loc[iris_data['class'] == 'Iris-setosa', 'sepal_width_cm'].hist()\n",
"_____no_output_____"
]
],
[
[
"Excellent! Now all of our `Iris-setosa` rows have a sepal width greater than 2.5.\n\nThe next data issue to address is the several near-zero sepal lengths for the `Iris-versicolor` rows. Let's take a look at those rows.",
"_____no_output_____"
]
],
[
[
"iris_data.loc[(iris_data['class'] == 'Iris-versicolor') &\n (iris_data['sepal_length_cm'] < 1.0)]",
"_____no_output_____"
]
],
[
[
"How about that? All of these near-zero `sepal_length_cm` entries seem to be off by two orders of magnitude, as if they had been recorded in meters instead of centimeters.\n\nAfter some brief correspondence with the field researchers, we find that one of them forgot to convert those measurements to centimeters. Let's do that for them.",
"_____no_output_____"
]
],
[
[
"iris_data.loc[iris_data['class'] == 'Iris-versicolor', 'sepal_length_cm'].hist()",
"_____no_output_____"
],
[
"iris_data['sepal_length_cm'].hist()",
"_____no_output_____"
],
[
"# Here we fix the wrong units\n\niris_data.loc[(iris_data['class'] == 'Iris-versicolor') &\n (iris_data['sepal_length_cm'] < 1.0),\n 'sepal_length_cm'] *= 100.0\n\niris_data.loc[iris_data['class'] == 'Iris-versicolor', 'sepal_length_cm'].hist()\n;",
"_____no_output_____"
],
[
"iris_data['sepal_length_cm'].hist()",
"_____no_output_____"
]
],
[
[
"Phew! Good thing we fixed those outliers. They could've really thrown our analysis off.\n\n>We had to drop those rows with missing values.\n\nLet's take a look at the rows with missing values:",
"_____no_output_____"
]
],
[
[
"iris_data.loc[(iris_data['sepal_length_cm'].isnull()) |\n (iris_data['sepal_width_cm'].isnull()) |\n (iris_data['petal_length_cm'].isnull()) |\n (iris_data['petal_width_cm'].isnull())]",
"_____no_output_____"
]
],
[
[
"It's not ideal that we had to drop those rows, especially considering they're all `Iris-setosa` entries. Since it seems like the missing data is systematic — all of the missing values are in the same column for the same *Iris* type — this error could potentially bias our analysis.\n\nOne way to deal with missing data is **mean imputation**: If we know that the values for a measurement fall in a certain range, we can fill in empty values with the average of that measurement.\n\nLet's see if we can do that here.",
"_____no_output_____"
]
],
[
[
"iris_data.loc[iris_data['class'] == 'Iris-setosa', 'petal_width_cm'].hist()\n",
"_____no_output_____"
]
],
[
[
"Most of the petal widths for `Iris-setosa` fall within the 0.2-0.3 range, so let's fill in these entries with the average measured petal width.",
"_____no_output_____"
]
],
[
[
"iris_data.loc[iris_data['class'] == 'Iris-setosa', 'petal_width_cm'].mean()",
"_____no_output_____"
],
[
"average_petal_width = iris_data.loc[iris_data['class'] == 'Iris-setosa', 'petal_width_cm'].mean()\nprint(average_petal_width)",
"0.24999999999999997\n"
],
[
"\n\niris_data.loc[(iris_data['class'] == 'Iris-setosa') &\n (iris_data['petal_width_cm'].isnull()),\n 'petal_width_cm'] = average_petal_width\n\niris_data.loc[(iris_data['class'] == 'Iris-setosa') &\n (iris_data['petal_width_cm'] == average_petal_width)]",
"_____no_output_____"
],
[
"iris_data.loc[(iris_data['sepal_length_cm'].isnull()) |\n (iris_data['sepal_width_cm'].isnull()) |\n (iris_data['petal_length_cm'].isnull()) |\n (iris_data['petal_width_cm'].isnull())]",
"_____no_output_____"
]
],
[
[
"Great! Now we've recovered those rows and no longer have missing data in our data set.\n\n**Note:** If you don't feel comfortable imputing your data, you can drop all rows with missing data with the `dropna()` call:\n\n iris_data.dropna(inplace=True)\n\nAfter all this hard work, we don't want to repeat this process every time we work with the data set. Let's save the tidied data file *as a separate file* and work directly with that data file from now on.",
"_____no_output_____"
]
],
[
[
"iris_data.to_json('../data/iris-clean.json')",
"_____no_output_____"
],
[
"iris_data.to_csv('../data/iris-data-clean.csv', index=False)\n\n",
"_____no_output_____"
],
[
"cleanedframe = iris_data.dropna()",
"_____no_output_____"
],
[
"iris_data_clean = pd.read_csv('../data/iris-data-clean.csv')",
"_____no_output_____"
]
],
[
[
"Now, let's take a look at the scatterplot matrix now that we've tidied the data.",
"_____no_output_____"
]
],
[
[
"myplot = sb.pairplot(iris_data_clean, hue='class')\nmyplot.savefig('irises.png')",
"_____no_output_____"
],
[
"import scipy.stats as stats",
"_____no_output_____"
],
[
"iris_data = pd.read_csv('../data/iris-data.csv')",
"_____no_output_____"
],
[
"iris_data.columns.unique()",
"_____no_output_____"
],
[
"stats.entropy(iris_data_clean['sepal_length_cm'])",
"_____no_output_____"
],
[
"iris_data.columns[:-1]",
"_____no_output_____"
],
[
"# we go through list of column names except last one and get entropy \n# for data (without missing values) in each column\nfor col in iris_data.columns[:-1]:\n print(\"Entropy for: \", col, stats.entropy(iris_data[col].dropna()))",
"Entropy for: sepal_length_cm 4.96909746125432\nEntropy for: sepal_width_cm 5.000701325982732\nEntropy for: petal_length_cm 4.888113822938816\nEntropy for: petal_width_cm 4.754264731532864\n"
]
],
[
[
"Of course, I purposely inserted numerous errors into this data set to demonstrate some of the many possible scenarios you may face while tidying your data.\n\nThe general takeaways here should be:\n\n* Make sure your data is encoded properly\n\n* Make sure your data falls within the expected range, and use domain knowledge whenever possible to define that expected range\n\n* Deal with missing data in one way or another: replace it if you can or drop it\n\n* Never tidy your data manually because that is not easily reproducible\n\n* Use code as a record of how you tidied your data\n\n* Plot everything you can about the data at this stage of the analysis so you can *visually* confirm everything looks correct",
"_____no_output_____"
],
[
"## Bonus: Testing our data\n\n[[ go back to the top ]](#Table-of-contents)\n\nAt SciPy 2015, I was exposed to a great idea: We should test our data. Just how we use unit tests to verify our expectations from code, we can similarly set up unit tests to verify our expectations about a data set.\n\nWe can quickly test our data using `assert` statements: We assert that something must be true, and if it is, then nothing happens and the notebook continues running. However, if our assertion is wrong, then the notebook stops running and brings it to our attention. For example,\n\n```Python\nassert 1 == 2\n```\n\nwill raise an `AssertionError` and stop execution of the notebook because the assertion failed.\n\nLet's test a few things that we know about our data set now.",
"_____no_output_____"
]
],
[
[
"# We know that we should only have three classes\nassert len(iris_data_clean['class'].unique()) == 3",
"_____no_output_____"
],
[
"# We know that sepal lengths for 'Iris-versicolor' should never be below 2.5 cm\nassert iris_data_clean.loc[iris_data_clean['class'] == 'Iris-versicolor', 'sepal_length_cm'].min() >= 2.5",
"_____no_output_____"
],
[
"# We know that our data set should have no missing measurements\nassert len(iris_data_clean.loc[(iris_data_clean['sepal_length_cm'].isnull()) |\n (iris_data_clean['sepal_width_cm'].isnull()) |\n (iris_data_clean['petal_length_cm'].isnull()) |\n (iris_data_clean['petal_width_cm'].isnull())]) == 0",
"_____no_output_____"
],
[
"# We know that our data set should have no missing measurements\nassert len(iris_data.loc[(iris_data['sepal_length_cm'].isnull()) |\n (iris_data['sepal_width_cm'].isnull()) |\n (iris_data['petal_length_cm'].isnull()) |\n (iris_data['petal_width_cm'].isnull())]) == 0",
"_____no_output_____"
]
],
[
[
"And so on. If any of these expectations are violated, then our analysis immediately stops and we have to return to the tidying stage.",
"_____no_output_____"
],
[
"### Data Cleanup & Wrangling > 80% time spent in Data Science",
"_____no_output_____"
],
[
"## Step 4: Exploratory analysis\n\n[[ go back to the top ]](#Table-of-contents)\n\nNow after spending entirely too much time tidying our data, we can start analyzing it!\n\nExploratory analysis is the step where we start delving deeper into the data set beyond the outliers and errors. We'll be looking to answer questions such as:\n\n* How is my data distributed?\n\n* Are there any correlations in my data?\n\n* Are there any confounding factors that explain these correlations?\n\nThis is the stage where we plot all the data in as many ways as possible. Create many charts, but don't bother making them pretty — these charts are for internal use.\n\nLet's return to that scatterplot matrix that we used earlier.",
"_____no_output_____"
]
],
[
[
"sb.pairplot(iris_data_clean)\n;",
"_____no_output_____"
]
],
[
[
"Our data is normally distributed for the most part, which is great news if we plan on using any modeling methods that assume the data is normally distributed.\n\nThere's something strange going on with the petal measurements. Maybe it's something to do with the different `Iris` types. Let's color code the data by the class again to see if that clears things up.",
"_____no_output_____"
]
],
[
[
"sb.pairplot(iris_data_clean, hue='class')\n;",
"_____no_output_____"
]
],
[
[
"Sure enough, the strange distribution of the petal measurements exist because of the different species. This is actually great news for our classification task since it means that the petal measurements will make it easy to distinguish between `Iris-setosa` and the other `Iris` types.\n\nDistinguishing `Iris-versicolor` and `Iris-virginica` will prove more difficult given how much their measurements overlap.\n\nThere are also correlations between petal length and petal width, as well as sepal length and sepal width. The field biologists assure us that this is to be expected: Longer flower petals also tend to be wider, and the same applies for sepals.\n\nWe can also make [**violin plots**](https://en.wikipedia.org/wiki/Violin_plot) of the data to compare the measurement distributions of the classes. Violin plots contain the same information as [box plots](https://en.wikipedia.org/wiki/Box_plot), but also scales the box according to the density of the data.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10, 10))\n\nfor column_index, column in enumerate(iris_data_clean.columns):\n if column == 'class':\n continue\n plt.subplot(2, 2, column_index + 1)\n sb.violinplot(x='class', y=column, data=iris_data_clean)",
"_____no_output_____"
]
],
[
[
"Enough flirting with the data. Let's get to modeling.",
"_____no_output_____"
],
[
"## Step 5: Classification\n\n[[ go back to the top ]](#Table-of-contents)\n\nWow, all this work and we *still* haven't modeled the data!\n\nAs tiresome as it can be, tidying and exploring our data is a vital component to any data analysis. If we had jumped straight to the modeling step, we would have created a faulty classification model.\n\nRemember: **Bad data leads to bad models.** Always check your data first.\n\n<hr />\n\nAssured that our data is now as clean as we can make it — and armed with some cursory knowledge of the distributions and relationships in our data set — it's time to make the next big step in our analysis: Splitting the data into training and testing sets.\n\nA **training set** is a random subset of the data that we use to train our models.\n\nA **testing set** is a random subset of the data (mutually exclusive from the training set) that we use to validate our models on unforseen data.\n\nEspecially in sparse data sets like ours, it's easy for models to **overfit** the data: The model will learn the training set so well that it won't be able to handle most of the cases it's never seen before. This is why it's important for us to build the model with the training set, but score it with the testing set.\n\nNote that once we split the data into a training and testing set, we should treat the testing set like it no longer exists: We cannot use any information from the testing set to build our model or else we're cheating.\n\nLet's set up our data first.",
"_____no_output_____"
]
],
[
[
"iris_data_clean = pd.read_csv('../data/iris-data-clean.csv')\n\n# We're using all four measurements as inputs\n# Note that scikit-learn expects each entry to be a list of values, e.g.,\n# [ [val1, val2, val3],\n# [val1, val2, val3],\n# ... ]\n# such that our input data set is represented as a list of lists\n\n# We can extract the data in this format from pandas like this:\nall_inputs = iris_data_clean[['sepal_length_cm', 'sepal_width_cm',\n 'petal_length_cm', 'petal_width_cm']].values\n\n# Similarly, we can extract the class labels\nall_labels = iris_data_clean['class'].values\n\n# Make sure that you don't mix up the order of the entries\n# all_inputs[5] inputs should correspond to the class in all_labels[5]\n\n# Here's what a subset of our inputs looks like:\nall_inputs[:5]",
"_____no_output_____"
],
[
"all_labels[:5]",
"_____no_output_____"
],
[
"type(all_inputs)",
"_____no_output_____"
],
[
"all_labels[:5]",
"_____no_output_____"
],
[
"type(all_labels)",
"_____no_output_____"
]
],
[
[
"Now our data is ready to be split.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"all_inputs[:3]",
"_____no_output_____"
],
[
"iris_data_clean.head(3)",
"_____no_output_____"
],
[
"all_labels[:3]",
"_____no_output_____"
],
[
"# Here we split our data into training and testing data\n\n(training_inputs,\n testing_inputs,\n training_classes,\n testing_classes) = train_test_split(all_inputs, all_labels, test_size=0.25, random_state=1)",
"_____no_output_____"
],
[
"training_inputs[:5]",
"_____no_output_____"
],
[
"testing_inputs[:5]",
"_____no_output_____"
],
[
"testing_classes[:5]",
"_____no_output_____"
],
[
"training_classes[:5]",
"_____no_output_____"
]
],
[
[
"With our data split, we can start fitting models to our data. Our company's Head of Data is all about decision tree classifiers, so let's start with one of those.\n\nDecision tree classifiers are incredibly simple in theory. In their simplest form, decision tree classifiers ask a series of Yes/No questions about the data — each time getting closer to finding out the class of each entry — until they either classify the data set perfectly or simply can't differentiate a set of entries. Think of it like a game of [Twenty Questions](https://en.wikipedia.org/wiki/Twenty_Questions), except the computer is *much*, *much* better at it.\n\nHere's an example decision tree classifier:\n\n<img src=\"img/iris_dtc.png\" />\n\nNotice how the classifier asks Yes/No questions about the data — whether a certain feature is <= 1.75, for example — so it can differentiate the records. This is the essence of every decision tree.\n\nThe nice part about decision tree classifiers is that they are **scale-invariant**, i.e., the scale of the features does not affect their performance, unlike many Machine Learning models. In other words, it doesn't matter if our features range from 0 to 1 or 0 to 1,000; decision tree classifiers will work with them just the same.\n\nThere are several [parameters](http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html) that we can tune for decision tree classifiers, but for now let's use a basic decision tree classifier.",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeClassifier\n\n# Create the classifier\ndecision_tree_classifier = DecisionTreeClassifier()\n\n# Train the classifier on the training set\ndecision_tree_classifier.fit(training_inputs, training_classes)\n\n# Validate the classifier on the testing set using classification accuracy\ndecision_tree_classifier.score(testing_inputs, testing_classes)",
"_____no_output_____"
],
[
"150*0.25",
"_____no_output_____"
],
[
"len(testing_inputs)",
"_____no_output_____"
],
[
"37/38",
"_____no_output_____"
],
[
"from sklearn import svm\nsvm_classifier = svm.SVC(gamma = 'scale')",
"_____no_output_____"
],
[
"svm_classifier.fit(training_inputs, training_classes)",
"_____no_output_____"
],
[
"svm_classifier.score(testing_inputs, testing_classes)",
"_____no_output_____"
],
[
"svm_classifier = svm.SVC(gamma = 'scale')\nsvm_classifier.fit(training_inputs, training_classes)\nsvm_classifier.score(testing_inputs, testing_classes)",
"_____no_output_____"
]
],
[
[
"Heck yeah! Our model achieves 97% classification accuracy without much effort.\n\nHowever, there's a catch: Depending on how our training and testing set was sampled, our model can achieve anywhere from 80% to 100% accuracy:",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"# here we randomly split data 1000 times in differrent training and test sets\nmodel_accuracies = []\n\nfor repetition in range(1000):\n (training_inputs,\n testing_inputs,\n training_classes,\n testing_classes) = train_test_split(all_inputs, all_labels, test_size=0.25)\n \n decision_tree_classifier = DecisionTreeClassifier()\n decision_tree_classifier.fit(training_inputs, training_classes)\n classifier_accuracy = decision_tree_classifier.score(testing_inputs, testing_classes)\n model_accuracies.append(classifier_accuracy)\n \nplt.hist(model_accuracies)\n;",
"_____no_output_____"
],
[
"100/38",
"_____no_output_____"
]
],
[
[
"It's obviously a problem that our model performs quite differently depending on the subset of the data it's trained on. This phenomenon is known as **overfitting**: The model is learning to classify the training set so well that it doesn't generalize and perform well on data it hasn't seen before.\n\n### Cross-validation\n\n[[ go back to the top ]](#Table-of-contents)\n\nThis problem is the main reason that most data scientists perform ***k*-fold cross-validation** on their models: Split the original data set into *k* subsets, use one of the subsets as the testing set, and the rest of the subsets are used as the training set. This process is then repeated *k* times such that each subset is used as the testing set exactly once.\n\n10-fold cross-validation is the most common choice, so let's use that here. Performing 10-fold cross-validation on our data set looks something like this:\n\n(each square is an entry in our data set)",
"_____no_output_____"
]
],
[
[
"# new text",
"_____no_output_____"
],
[
"import numpy as np\nfrom sklearn.model_selection import StratifiedKFold\n\ndef plot_cv(cv, features, labels):\n masks = []\n for train, test in cv.split(features, labels):\n mask = np.zeros(len(labels), dtype=bool)\n mask[test] = 1\n masks.append(mask)\n \n plt.figure(figsize=(15, 15))\n plt.imshow(masks, interpolation='none', cmap='gray_r')\n plt.ylabel('Fold')\n plt.xlabel('Row #')\n\nplot_cv(StratifiedKFold(n_splits=10), all_inputs, all_labels)",
"_____no_output_____"
]
],
[
[
"You'll notice that we used **Stratified *k*-fold cross-validation** in the code above. Stratified *k*-fold keeps the class proportions the same across all of the folds, which is vital for maintaining a representative subset of our data set. (e.g., so we don't have 100% `Iris setosa` entries in one of the folds.)\n\nWe can perform 10-fold cross-validation on our model with the following code:",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_score",
"_____no_output_____"
],
[
"from sklearn.model_selection import cross_val_score\n\ndecision_tree_classifier = DecisionTreeClassifier()\n\n# cross_val_score returns a list of the scores, which we can visualize\n# to get a reasonable estimate of our classifier's performance\ncv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_labels, cv=10)\nplt.hist(cv_scores)\nplt.title('Average score: {}'.format(np.mean(cv_scores)))\n;",
"_____no_output_____"
],
[
"len(all_inputs.T[1])",
"_____no_output_____"
],
[
"print(\"Entropy for: \", stats.entropy(all_inputs.T[1]))",
"Entropy for: 4.994187360273029\n"
],
[
"# we go through list of column names except last one and get entropy \n# for data (without missing values) in each column\ndef printEntropy(npdata):\n for i, col in enumerate(npdata.T):\n print(\"Entropy for column:\", i, stats.entropy(col))",
"_____no_output_____"
],
[
"printEntropy(all_inputs)",
"Entropy for column: 0 4.9947332367061925\nEntropy for column: 1 4.994187360273029\nEntropy for column: 2 4.88306851089088\nEntropy for column: 3 4.76945055275522\n"
]
],
[
[
"Now we have a much more consistent rating of our classifier's general classification accuracy.\n\n### Parameter tuning\n\n[[ go back to the top ]](#Table-of-contents)\n\nEvery Machine Learning model comes with a variety of parameters to tune, and these parameters can be vitally important to the performance of our classifier. For example, if we severely limit the depth of our decision tree classifier:",
"_____no_output_____"
]
],
[
[
"decision_tree_classifier = DecisionTreeClassifier(max_depth=1)\n\ncv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_labels, cv=10)\nplt.hist(cv_scores)\nplt.title('Average score: {}'.format(np.mean(cv_scores)))\n;",
"_____no_output_____"
]
],
[
[
"the classification accuracy falls tremendously.\n\nTherefore, we need to find a systematic method to discover the best parameters for our model and data set.\n\nThe most common method for model parameter tuning is **Grid Search**. The idea behind Grid Search is simple: explore a range of parameters and find the best-performing parameter combination. Focus your search on the best range of parameters, then repeat this process several times until the best parameters are discovered.\n\nLet's tune our decision tree classifier. We'll stick to only two parameters for now, but it's possible to simultaneously explore dozens of parameters if we want.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import GridSearchCV\n\ndecision_tree_classifier = DecisionTreeClassifier()\n\nparameter_grid = {'max_depth': [1, 2, 3, 4, 5],\n 'max_features': [1, 2, 3, 4]}\n\ncross_validation = StratifiedKFold(n_splits=10)\n\ngrid_search = GridSearchCV(decision_tree_classifier,\n param_grid=parameter_grid,\n cv=cross_validation)\n\ngrid_search.fit(all_inputs, all_labels)\nprint('Best score: {}'.format(grid_search.best_score_))\nprint('Best parameters: {}'.format(grid_search.best_params_))",
"Best score: 0.9664429530201343\nBest parameters: {'max_depth': 3, 'max_features': 2}\n"
]
],
[
[
"Now let's visualize the grid search to see how the parameters interact.",
"_____no_output_____"
]
],
[
[
"grid_search.cv_results_['mean_test_score']",
"_____no_output_____"
],
[
"grid_visualization = grid_search.cv_results_['mean_test_score']\ngrid_visualization.shape = (5, 4)\nsb.heatmap(grid_visualization, cmap='Reds', annot=True)\nplt.xticks(np.arange(4) + 0.5, grid_search.param_grid['max_features'])\nplt.yticks(np.arange(5) + 0.5, grid_search.param_grid['max_depth'])\nplt.xlabel('max_features')\nplt.ylabel('max_depth')\n;",
"_____no_output_____"
]
],
[
[
"Now we have a better sense of the parameter space: We know that we need a `max_depth` of at least 2 to allow the decision tree to make more than a one-off decision.\n\n`max_features` doesn't really seem to make a big difference here as long as we have 2 of them, which makes sense since our data set has only 4 features and is relatively easy to classify. (Remember, one of our data set's classes was easily separable from the rest based on a single feature.)\n\nLet's go ahead and use a broad grid search to find the best settings for a handful of parameters.",
"_____no_output_____"
]
],
[
[
"decision_tree_classifier = DecisionTreeClassifier()\n\nparameter_grid = {'criterion': ['gini', 'entropy'],\n 'splitter': ['best', 'random'],\n 'max_depth': [1, 2, 3, 4, 5],\n 'max_features': [1, 2, 3, 4]}\n\ncross_validation = StratifiedKFold(n_splits=10)\n\ngrid_search = GridSearchCV(decision_tree_classifier,\n param_grid=parameter_grid,\n cv=cross_validation)\n\ngrid_search.fit(all_inputs, all_labels)\nprint('Best score: {}'.format(grid_search.best_score_))\nprint('Best parameters: {}'.format(grid_search.best_params_))",
"Best score: 0.9664429530201343\nBest parameters: {'criterion': 'gini', 'max_depth': 3, 'max_features': 3, 'splitter': 'best'}\n"
]
],
[
[
"Now we can take the best classifier from the Grid Search and use that:",
"_____no_output_____"
]
],
[
[
"decision_tree_classifier = grid_search.best_estimator_\ndecision_tree_classifier",
"_____no_output_____"
]
],
[
[
"We can even visualize the decision tree with [GraphViz](http://www.graphviz.org/) to see how it's making the classifications:",
"_____no_output_____"
]
],
[
[
"import sklearn.tree as tree\nfrom sklearn.externals.six import StringIO\n\nwith open('iris_dtc.dot', 'w') as out_file:\n out_file = tree.export_graphviz(decision_tree_classifier, out_file=out_file)",
"_____no_output_____"
]
],
[
[
"<img src=\"img/iris_dtc.png\" />",
"_____no_output_____"
],
[
"(This classifier may look familiar from earlier in the notebook.)\n\nAlright! We finally have our demo classifier. Let's create some visuals of its performance so we have something to show our company's Head of Data.",
"_____no_output_____"
]
],
[
[
"dt_scores = cross_val_score(decision_tree_classifier, all_inputs, all_labels, cv=10)\n\nsb.boxplot(dt_scores)\nsb.stripplot(dt_scores, jitter=True, color='black')\n;",
"_____no_output_____"
]
],
[
[
"Hmmm... that's a little boring by itself though. How about we compare another classifier to see how they perform?\n\nWe already know from previous projects that Random Forest classifiers usually work better than individual decision trees. A common problem that decision trees face is that they're prone to overfitting: They complexify to the point that they classify the training set near-perfectly, but fail to generalize to data they have not seen before.\n\n**Random Forest classifiers** work around that limitation by creating a whole bunch of decision trees (hence \"forest\") — each trained on random subsets of training samples (drawn with replacement) and features (drawn without replacement) — and have the decision trees work together to make a more accurate classification.\n\nLet that be a lesson for us: **Even in Machine Learning, we get better results when we work together!**\n\nLet's see if a Random Forest classifier works better here.\n\nThe great part about scikit-learn is that the training, testing, parameter tuning, etc. process is the same for all models, so we only need to plug in the new classifier.",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import RandomForestClassifier",
"_____no_output_____"
],
[
"from sklearn.ensemble import RandomForestClassifier\n\nrandom_forest_classifier = RandomForestClassifier()\n\nparameter_grid = {'n_estimators': [10, 25, 50, 100],\n 'criterion': ['gini', 'entropy'],\n 'max_features': [1, 2, 3, 4]}\n\ncross_validation = StratifiedKFold(n_splits=10)\n\ngrid_search = GridSearchCV(random_forest_classifier,\n param_grid=parameter_grid,\n cv=cross_validation)\n\ngrid_search.fit(all_inputs, all_labels)\nprint('Best score: {}'.format(grid_search.best_score_))\nprint('Best parameters: {}'.format(grid_search.best_params_))\n\ngrid_search.best_estimator_",
"Best score: 0.9664429530201343\nBest parameters: {'criterion': 'gini', 'max_features': 3, 'n_estimators': 25}\n"
]
],
[
[
"Now we can compare their performance:",
"_____no_output_____"
]
],
[
[
"random_forest_classifier = grid_search.best_estimator_\n\nrf_df = pd.DataFrame({'accuracy': cross_val_score(random_forest_classifier, all_inputs, all_labels, cv=10),\n 'classifier': ['Random Forest'] * 10})\ndt_df = pd.DataFrame({'accuracy': cross_val_score(decision_tree_classifier, all_inputs, all_labels, cv=10),\n 'classifier': ['Decision Tree'] * 10})\nboth_df = rf_df.append(dt_df)\n\nsb.boxplot(x='classifier', y='accuracy', data=both_df)\nsb.stripplot(x='classifier', y='accuracy', data=both_df, jitter=True, color='black')\n;",
"_____no_output_____"
]
],
[
[
"How about that? They both seem to perform about the same on this data set. This is probably because of the limitations of our data set: We have only 4 features to make the classification, and Random Forest classifiers excel when there's hundreds of possible features to look at. In other words, there wasn't much room for improvement with this data set.",
"_____no_output_____"
],
[
"## Step 6: Reproducibility\n\n[[ go back to the top ]](#Table-of-contents)\n\nEnsuring that our work is reproducible is the last and — arguably — most important step in any analysis. **As a rule, we shouldn't place much weight on a discovery that can't be reproduced**. As such, if our analysis isn't reproducible, we might as well not have done it.\n\nNotebooks like this one go a long way toward making our work reproducible. Since we documented every step as we moved along, we have a written record of what we did and why we did it — both in text and code.\n\nBeyond recording what we did, we should also document what software and hardware we used to perform our analysis. This typically goes at the top of our notebooks so our readers know what tools to use.\n\n[Sebastian Raschka](http://sebastianraschka.com/) created a handy [notebook tool](https://github.com/rasbt/watermark) for this:",
"_____no_output_____"
]
],
[
[
"!pip install watermark",
"Requirement already satisfied: watermark in c:\\programdata\\anaconda3\\lib\\site-packages (1.8.1)\nRequirement already satisfied: ipython in c:\\programdata\\anaconda3\\lib\\site-packages (from watermark) (7.4.0)\nRequirement already satisfied: jedi>=0.10 in c:\\programdata\\anaconda3\\lib\\site-packages (from ipython->watermark) (0.13.3)\nRequirement already satisfied: backcall in c:\\programdata\\anaconda3\\lib\\site-packages (from ipython->watermark) (0.1.0)\nRequirement already satisfied: pickleshare in c:\\programdata\\anaconda3\\lib\\site-packages (from ipython->watermark) (0.7.5)\nRequirement already satisfied: setuptools>=18.5 in c:\\programdata\\anaconda3\\lib\\site-packages (from ipython->watermark) (40.8.0)\nRequirement already satisfied: colorama; sys_platform == \"win32\" in c:\\programdata\\anaconda3\\lib\\site-packages (from ipython->watermark) (0.4.1)\nRequirement already satisfied: decorator in c:\\programdata\\anaconda3\\lib\\site-packages (from ipython->watermark) (4.4.0)\nRequirement already satisfied: pygments in c:\\programdata\\anaconda3\\lib\\site-packages (from ipython->watermark) (2.3.1)\nRequirement already satisfied: prompt-toolkit<2.1.0,>=2.0.0 in c:\\programdata\\anaconda3\\lib\\site-packages (from ipython->watermark) (2.0.9)\nRequirement already satisfied: traitlets>=4.2 in c:\\programdata\\anaconda3\\lib\\site-packages (from ipython->watermark) (4.3.2)\nRequirement already satisfied: parso>=0.3.0 in c:\\programdata\\anaconda3\\lib\\site-packages (from jedi>=0.10->ipython->watermark) (0.3.4)\nRequirement already satisfied: six>=1.9.0 in c:\\programdata\\anaconda3\\lib\\site-packages (from prompt-toolkit<2.1.0,>=2.0.0->ipython->watermark) (1.12.0)\nRequirement already satisfied: wcwidth in c:\\programdata\\anaconda3\\lib\\site-packages (from prompt-toolkit<2.1.0,>=2.0.0->ipython->watermark) (0.1.7)\nRequirement already satisfied: ipython-genutils in c:\\programdata\\anaconda3\\lib\\site-packages (from traitlets>=4.2->ipython->watermark) (0.2.0)\n"
],
[
"%load_ext watermark",
"The watermark extension is already loaded. To reload it, use:\n %reload_ext watermark\n"
],
[
"pd.show_versions()",
"\nINSTALLED VERSIONS\n------------------\ncommit: None\npython: 3.7.3.final.0\npython-bits: 64\nOS: Windows\nOS-release: 10\nmachine: AMD64\nprocessor: Intel64 Family 6 Model 158 Stepping 10, GenuineIntel\nbyteorder: little\nLC_ALL: None\nLANG: None\nLOCALE: None.None\n\npandas: 0.24.2\npytest: 4.3.1\npip: 19.0.3\nsetuptools: 40.8.0\nCython: 0.29.6\nnumpy: 1.16.2\nscipy: 1.2.1\npyarrow: None\nxarray: None\nIPython: 7.4.0\nsphinx: 1.8.5\npatsy: 0.5.1\ndateutil: 2.8.0\npytz: 2018.9\nblosc: None\nbottleneck: 1.2.1\ntables: 3.5.1\nnumexpr: 2.6.9\nfeather: None\nmatplotlib: 3.0.3\nopenpyxl: 2.6.1\nxlrd: 1.2.0\nxlwt: 1.3.0\nxlsxwriter: 1.1.5\nlxml.etree: 4.3.2\nbs4: 4.7.1\nhtml5lib: 1.0.1\nsqlalchemy: 1.3.1\npymysql: None\npsycopg2: None\njinja2: 2.10\ns3fs: None\nfastparquet: None\npandas_gbq: None\npandas_datareader: None\ngcsfs: None\n"
],
[
"%watermark -a 'RCS_April_2019' -nmv --packages numpy,pandas,sklearn,matplotlib,seaborn",
"RCS_April_2019 Wed Apr 17 2019 \n\nCPython 3.7.3\nIPython 7.4.0\n\nnumpy 1.16.2\npandas 0.24.2\nsklearn 0.20.3\nmatplotlib 3.0.3\nseaborn 0.9.0\n\ncompiler : MSC v.1915 64 bit (AMD64)\nsystem : Windows\nrelease : 10\nmachine : AMD64\nprocessor : Intel64 Family 6 Model 158 Stepping 10, GenuineIntel\nCPU cores : 12\ninterpreter: 64bit\n"
]
],
[
[
"Finally, let's extract the core of our work from Steps 1-5 and turn it into a single pipeline.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport pandas as pd\nimport seaborn as sb\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.model_selection import train_test_split, cross_val_score\n\n# We can jump directly to working with the clean data because we saved our cleaned data set\niris_data_clean = pd.read_csv('../data/iris-data-clean.csv')\n\n# Testing our data: Our analysis will stop here if any of these assertions are wrong\n\n# We know that we should only have three classes\nassert len(iris_data_clean['class'].unique()) == 3\n\n# We know that sepal lengths for 'Iris-versicolor' should never be below 2.5 cm\nassert iris_data_clean.loc[iris_data_clean['class'] == 'Iris-versicolor', 'sepal_length_cm'].min() >= 2.5\n\n# We know that our data set should have no missing measurements\nassert len(iris_data_clean.loc[(iris_data_clean['sepal_length_cm'].isnull()) |\n (iris_data_clean['sepal_width_cm'].isnull()) |\n (iris_data_clean['petal_length_cm'].isnull()) |\n (iris_data_clean['petal_width_cm'].isnull())]) == 0\n\nall_inputs = iris_data_clean[['sepal_length_cm', 'sepal_width_cm',\n 'petal_length_cm', 'petal_width_cm']].values\n\nall_labels = iris_data_clean['class'].values\n\n# This is the classifier that came out of Grid Search\nrandom_forest_classifier = RandomForestClassifier(criterion='gini', max_features=3, n_estimators=50)\n\n# All that's left to do now is plot the cross-validation scores\nrf_classifier_scores = cross_val_score(random_forest_classifier, all_inputs, all_labels, cv=10)\nsb.boxplot(rf_classifier_scores)\nsb.stripplot(rf_classifier_scores, jitter=True, color='black')\n\n# ...and show some of the predictions from the classifier\n(training_inputs,\n testing_inputs,\n training_classes,\n testing_classes) = train_test_split(all_inputs, all_labels, test_size=0.25)\n\nrandom_forest_classifier.fit(training_inputs, training_classes)\n\nfor input_features, prediction, actual in zip(testing_inputs[:10],\n random_forest_classifier.predict(testing_inputs[:10]),\n testing_classes[:10]):\n print('{}\\t-->\\t{}\\t(Actual: {})'.format(input_features, prediction, actual))",
"[4.6 3.4 1.4 0.3]\t-->\tIris-setosa\t(Actual: Iris-setosa)\n[5.9 3. 4.2 1.5]\t-->\tIris-versicolor\t(Actual: Iris-versicolor)\n[7.2 3. 5.8 1.6]\t-->\tIris-virginica\t(Actual: Iris-virginica)\n[6.7 2.5 5.8 1.8]\t-->\tIris-virginica\t(Actual: Iris-virginica)\n[6.7 3.3 5.7 2.5]\t-->\tIris-virginica\t(Actual: Iris-virginica)\n[4.9 3.1 1.5 0.25]\t-->\tIris-setosa\t(Actual: Iris-setosa)\n[6.3 3.4 5.6 2.4]\t-->\tIris-virginica\t(Actual: Iris-virginica)\n[5.1 3.3 1.7 0.5]\t-->\tIris-setosa\t(Actual: Iris-setosa)\n[4.9 2.4 3.3 1. ]\t-->\tIris-versicolor\t(Actual: Iris-versicolor)\n[6.3 3.3 4.7 1.6]\t-->\tIris-versicolor\t(Actual: Iris-versicolor)\n"
],
[
"%matplotlib inline\nimport pandas as pd\nimport seaborn as sb\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.model_selection import train_test_split, cross_val_score\n\ndef processData(filename): \n # We can jump directly to working with the clean data because we saved our cleaned data set\n iris_data_clean = pd.read_csv(filename)\n\n # Testing our data: Our analysis will stop here if any of these assertions are wrong\n\n # We know that we should only have three classes\n assert len(iris_data_clean['class'].unique()) == 3\n\n # We know that sepal lengths for 'Iris-versicolor' should never be below 2.5 cm\n assert iris_data_clean.loc[iris_data_clean['class'] == 'Iris-versicolor', 'sepal_length_cm'].min() >= 2.5\n\n # We know that our data set should have no missing measurements\n assert len(iris_data_clean.loc[(iris_data_clean['sepal_length_cm'].isnull()) |\n (iris_data_clean['sepal_width_cm'].isnull()) |\n (iris_data_clean['petal_length_cm'].isnull()) |\n (iris_data_clean['petal_width_cm'].isnull())]) == 0\n\n all_inputs = iris_data_clean[['sepal_length_cm', 'sepal_width_cm',\n 'petal_length_cm', 'petal_width_cm']].values\n\n all_labels = iris_data_clean['class'].values\n\n # This is the classifier that came out of Grid Search\n random_forest_classifier = RandomForestClassifier(criterion='gini', max_features=3, n_estimators=50)\n\n # All that's left to do now is plot the cross-validation scores\n rf_classifier_scores = cross_val_score(random_forest_classifier, all_inputs, all_labels, cv=10)\n sb.boxplot(rf_classifier_scores)\n sb.stripplot(rf_classifier_scores, jitter=True, color='black')\n\n # ...and show some of the predictions from the classifier\n (training_inputs,\n testing_inputs,\n training_classes,\n testing_classes) = train_test_split(all_inputs, all_labels, test_size=0.25)\n\n random_forest_classifier.fit(training_inputs, training_classes)\n\n for input_features, prediction, actual in zip(testing_inputs[:10],\n random_forest_classifier.predict(testing_inputs[:10]),\n testing_classes[:10]):\n print('{}\\t-->\\t{}\\t(Actual: {})'.format(input_features, prediction, actual))\n return rf_classifier_scores",
"_____no_output_____"
],
[
"myscores = processData('../data/iris-data-clean.csv')",
"[5.1 3.7 1.5 0.4]\t-->\tIris-setosa\t(Actual: Iris-setosa)\n[5.8 2.7 4.1 1. ]\t-->\tIris-versicolor\t(Actual: Iris-versicolor)\n[5.7 3. 1.1 0.1]\t-->\tIris-setosa\t(Actual: Iris-setosa)\n[5.9 3. 5.1 1.8]\t-->\tIris-virginica\t(Actual: Iris-virginica)\n[5.4 3.4 1.7 0.2]\t-->\tIris-setosa\t(Actual: Iris-setosa)\n[4.7 3.2 1.6 0.2]\t-->\tIris-setosa\t(Actual: Iris-setosa)\n[5.4 3. 4.5 1.5]\t-->\tIris-versicolor\t(Actual: Iris-versicolor)\n[5.7 4.4 1.5 0.4]\t-->\tIris-setosa\t(Actual: Iris-setosa)\n[5. 3.2 1.2 0.2]\t-->\tIris-setosa\t(Actual: Iris-setosa)\n[7.2 3. 5.8 1.6]\t-->\tIris-virginica\t(Actual: Iris-virginica)\n"
],
[
"myscores",
"_____no_output_____"
]
],
[
[
"There we have it: We have a complete and reproducible Machine Learning pipeline to demo to our company's Head of Data. We've met the success criteria that we set from the beginning (>90% accuracy), and our pipeline is flexible enough to handle new inputs or flowers when that data set is ready. Not bad for our first week on the job!",
"_____no_output_____"
],
[
"## Conclusions\n\n[[ go back to the top ]](#Table-of-contents)\n\nI hope you found this example notebook useful for your own work and learned at least one new trick by reading through it.\n\n\n* [Submit an issue](https://github.com/ValRCS/LU-pysem/issues) on GitHub\n\n* Fork the [notebook repository](https://github.com/ValRCS/LU-pysem), make the fix/addition yourself, then send over a pull request",
"_____no_output_____"
],
[
"## Further reading\n\n[[ go back to the top ]](#Table-of-contents)\n\nThis notebook covers a broad variety of topics but skips over many of the specifics. If you're looking to dive deeper into a particular topic, here's some recommended reading.\n\n**Data Science**: William Chen compiled a [list of free books](http://www.wzchen.com/data-science-books/) for newcomers to Data Science, ranging from the basics of R & Python to Machine Learning to interviews and advice from prominent data scientists.\n\n**Machine Learning**: /r/MachineLearning has a useful [Wiki page](https://www.reddit.com/r/MachineLearning/wiki/index) containing links to online courses, books, data sets, etc. for Machine Learning. There's also a [curated list](https://github.com/josephmisiti/awesome-machine-learning) of Machine Learning frameworks, libraries, and software sorted by language.\n\n**Unit testing**: Dive Into Python 3 has a [great walkthrough](http://www.diveintopython3.net/unit-testing.html) of unit testing in Python, how it works, and how it should be used\n\n**pandas** has [several tutorials](http://pandas.pydata.org/pandas-docs/stable/tutorials.html) covering its myriad features.\n\n**scikit-learn** has a [bunch of tutorials](http://scikit-learn.org/stable/tutorial/index.html) for those looking to learn Machine Learning in Python. Andreas Mueller's [scikit-learn workshop materials](https://github.com/amueller/scipy_2015_sklearn_tutorial) are top-notch and freely available.\n\n**matplotlib** has many [books, videos, and tutorials](http://matplotlib.org/resources/index.html) to teach plotting in Python.\n\n**Seaborn** has a [basic tutorial](http://stanford.edu/~mwaskom/software/seaborn/tutorial.html) covering most of the statistical plotting features.",
"_____no_output_____"
],
[
"## Acknowledgements\n\n[[ go back to the top ]](#Table-of-contents)\n\nMany thanks to [Andreas Mueller](http://amueller.github.io/) for some of his [examples](https://github.com/amueller/scipy_2015_sklearn_tutorial) in the Machine Learning section. I drew inspiration from several of his excellent examples.\n\nThe photo of a flower with annotations of the petal and sepal was taken by [Eric Guinther](https://commons.wikimedia.org/wiki/File:Petal-sepal.jpg).\n\nThe photos of the various *Iris* flower types were taken by [Ken Walker](http://www.signa.org/index.pl?Display+Iris-setosa+2) and [Barry Glick](http://www.signa.org/index.pl?Display+Iris-virginica+3).",
"_____no_output_____"
],
[
"## Further questions? \n\nFeel free to contact [Valdis Saulespurens]\n(email:[email protected])",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
d061465d23ce5abccb3893326eb5add1159d5665 | 25,452 | ipynb | Jupyter Notebook | Deep_Learning_Specialization/04_Convolutional_Neural_Networks/02_Deep_Convolutional_Models_Case_Studies/02_Residual_Networks/Residual Networks - v2.ipynb | cilsya/coursera | 4a7896f3225cb84e2f15770409c1f18bfe529615 | [
"MIT"
]
| 1 | 2021-03-15T13:57:04.000Z | 2021-03-15T13:57:04.000Z | Deep_Learning_Specialization/04_Convolutional_Neural_Networks/02_Deep_Convolutional_Models_Case_Studies/02_Residual_Networks/Residual Networks - v2.ipynb | cilsya/coursera | 4a7896f3225cb84e2f15770409c1f18bfe529615 | [
"MIT"
]
| 5 | 2020-03-24T16:17:05.000Z | 2021-06-01T22:49:40.000Z | Deep_Learning_Specialization/04_Convolutional_Neural_Networks/02_Deep_Convolutional_Models_Case_Studies/02_Residual_Networks/Residual Networks - v2.ipynb | cilsya/coursera | 4a7896f3225cb84e2f15770409c1f18bfe529615 | [
"MIT"
]
| null | null | null | 47.220779 | 457 | 0.485424 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
d0614fd8c14825f845dd96eed5634b241da21e66 | 371,618 | ipynb | Jupyter Notebook | docs/source/_docs/pyNetLogo demo - SALib sequential.ipynb | jasonrwang/pyNetLogo | 01117c9d9c7d4d5681fe1e08f8862d6b64c9a4b7 | [
"BSD-3-Clause"
]
| null | null | null | docs/source/_docs/pyNetLogo demo - SALib sequential.ipynb | jasonrwang/pyNetLogo | 01117c9d9c7d4d5681fe1e08f8862d6b64c9a4b7 | [
"BSD-3-Clause"
]
| null | null | null | docs/source/_docs/pyNetLogo demo - SALib sequential.ipynb | jasonrwang/pyNetLogo | 01117c9d9c7d4d5681fe1e08f8862d6b64c9a4b7 | [
"BSD-3-Clause"
]
| null | null | null | 455.414216 | 209,950 | 0.92675 | [
[
[
"## Example 2: Sensitivity analysis on a NetLogo model with SALib\n\nThis notebook provides a more advanced example of interaction between NetLogo and a Python environment, using the SALib library (Herman & Usher, 2017; available through the pip package manager) to sample and analyze a suitable experimental design for a Sobol global sensitivity analysis. All files used in the example are available from the pyNetLogo repository at https://github.com/quaquel/pyNetLogo.",
"_____no_output_____"
]
],
[
[
"#Ensuring compliance of code with both python2 and python3\n\nfrom __future__ import division, print_function\ntry:\n from itertools import izip as zip\nexcept ImportError: # will be 3.x series\n pass",
"_____no_output_____"
],
[
"%matplotlib inline\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\nimport pyNetLogo\n\n#Import the sampling and analysis modules for a Sobol variance-based sensitivity analysis\nfrom SALib.sample import saltelli\nfrom SALib.analyze import sobol",
"_____no_output_____"
]
],
[
[
"SALib relies on a problem definition dictionary which contains the number of input parameters to sample, their names (which should here correspond to a NetLogo global variable), and the sampling bounds. Documentation for SALib can be found at https://salib.readthedocs.io/en/latest/.",
"_____no_output_____"
]
],
[
[
"problem = { \n 'num_vars': 6,\n 'names': ['random-seed',\n 'grass-regrowth-time',\n 'sheep-gain-from-food',\n 'wolf-gain-from-food',\n 'sheep-reproduce',\n 'wolf-reproduce'], \n 'bounds': [[1, 100000],\n [20., 40.], \n [2., 8.], \n [16., 32.],\n [2., 8.],\n [2., 8.]]\n}",
"_____no_output_____"
]
],
[
[
"We start by instantiating the wolf-sheep predation example model, specifying the _gui=False_ flag to run in headless mode.",
"_____no_output_____"
]
],
[
[
"netlogo = pyNetLogo.NetLogoLink(gui=False)\nnetlogo.load_model(r'Wolf Sheep Predation_v6.nlogo')",
"_____no_output_____"
]
],
[
[
"The SALib sampler will automatically generate an appropriate number of samples for Sobol analysis. To calculate first-order, second-order and total sensitivity indices, this gives a sample size of _n*(2p+2)_, where _p_ is the number of input parameters, and _n_ is a baseline sample size which should be large enough to stabilize the estimation of the indices. For this example, we use _n_ = 1000, for a total of 14000 experiments.\n\nFor more complex analyses, parallelizing the experiments can significantly improve performance. An additional notebook in the pyNetLogo repository demonstrates the use of the ipyparallel library; parallel processing for NetLogo models is also supported by the Exploratory Modeling Workbench (Kwakkel, 2017).",
"_____no_output_____"
]
],
[
[
"n = 1000\nparam_values = saltelli.sample(problem, n, calc_second_order=True)",
"_____no_output_____"
]
],
[
[
"The sampler generates an input array of shape (_n*(2p+2)_, _p_) with rows for each experiment and columns for each input parameter.",
"_____no_output_____"
]
],
[
[
"param_values.shape",
"_____no_output_____"
]
],
[
[
"Assuming we are interested in the mean number of sheep and wolf agents over a timeframe of 100 ticks, we first create an empty dataframe to store the results.",
"_____no_output_____"
]
],
[
[
"results = pd.DataFrame(columns=['Avg. sheep', 'Avg. wolves'])",
"_____no_output_____"
]
],
[
[
"We then simulate the model over the 14000 experiments, reading input parameters from the param_values array generated by SALib. The repeat_report command is used to track the outcomes of interest over time. \n\nTo later compare performance with the ipyparallel implementation of the analysis, we also keep track of the elapsed runtime.",
"_____no_output_____"
]
],
[
[
"import time\n\nt0=time.time()\n\nfor run in range(param_values.shape[0]):\n \n #Set the input parameters\n for i, name in enumerate(problem['names']):\n if name == 'random-seed':\n #The NetLogo random seed requires a different syntax\n netlogo.command('random-seed {}'.format(param_values[run,i]))\n else:\n #Otherwise, assume the input parameters are global variables\n netlogo.command('set {0} {1}'.format(name, param_values[run,i]))\n \n netlogo.command('setup')\n #Run for 100 ticks and return the number of sheep and wolf agents at each time step\n counts = netlogo.repeat_report(['count sheep','count wolves'], 100)\n \n #For each run, save the mean value of the agent counts over time\n results.loc[run, 'Avg. sheep'] = counts['count sheep'].values.mean()\n results.loc[run, 'Avg. wolves'] = counts['count wolves'].values.mean()\n \nelapsed=time.time()-t0 #Elapsed runtime in seconds",
"_____no_output_____"
],
[
"elapsed",
"_____no_output_____"
]
],
[
[
"The \"to_csv\" dataframe method provides a simple way of saving the results to disk.\n\nPandas supports several more advanced storage options, such as serialization with msgpack, or hierarchical HDF5 storage.",
"_____no_output_____"
]
],
[
[
"results.to_csv('Sobol_sequential.csv')",
"_____no_output_____"
],
[
"results = pd.read_csv('Sobol_sequential.csv', header=0, index_col=0)",
"_____no_output_____"
],
[
"results.head(5)",
"_____no_output_____"
]
],
[
[
"We can then proceed with the analysis, first using a histogram to visualize output distributions for each outcome:",
"_____no_output_____"
]
],
[
[
"sns.set_style('white')\nsns.set_context('talk')\nfig, ax = plt.subplots(1,len(results.columns), sharey=True)\n\nfor i, n in enumerate(results.columns):\n ax[i].hist(results[n], 20)\n ax[i].set_xlabel(n)\n\nax[0].set_ylabel('Counts')\n\nfig.set_size_inches(10,4)\nfig.subplots_adjust(wspace=0.1)\n#plt.savefig('JASSS figures/SA - Output distribution.pdf', bbox_inches='tight')\n#plt.savefig('JASSS figures/SA - Output distribution.png', dpi=300, bbox_inches='tight')\nplt.show()",
"_____no_output_____"
]
],
[
[
"Bivariate scatter plots can be useful to visualize relationships between each input parameter and the outputs. Taking the outcome for the average sheep count as an example, we obtain the following, using the scipy library to calculate the Pearson correlation coefficient (r) for each parameter:",
"_____no_output_____"
]
],
[
[
"%matplotlib\nimport scipy\n\nnrow=2\nncol=3\nfig, ax = plt.subplots(nrow, ncol, sharey=True)\nsns.set_context('talk')\ny = results['Avg. sheep']\n\nfor i, a in enumerate(ax.flatten()):\n x = param_values[:,i]\n sns.regplot(x, y, ax=a, ci=None, color='k',scatter_kws={'alpha':0.2, 's':4, 'color':'gray'})\n pearson = scipy.stats.pearsonr(x, y)\n a.annotate(\"r: {:6.3f}\".format(pearson[0]), xy=(0.15, 0.85), xycoords='axes fraction',fontsize=13)\n if divmod(i,ncol)[1]>0:\n a.get_yaxis().set_visible(False)\n a.set_xlabel(problem['names'][i])\n a.set_ylim([0,1.1*np.max(y)])\n\nfig.set_size_inches(9,9,forward=True) \nfig.subplots_adjust(wspace=0.2, hspace=0.3)\n#plt.savefig('JASSS figures/SA - Scatter.pdf', bbox_inches='tight')\n#plt.savefig('JASSS figures/SA - Scatter.png', dpi=300, bbox_inches='tight')\nplt.show()",
"_____no_output_____"
]
],
[
[
"This indicates a positive relationship between the \"sheep-gain-from-food\" parameter and the mean sheep count, and negative relationships for the \"wolf-gain-from-food\" and \"wolf-reproduce\" parameters.\n\nWe can then use SALib to calculate first-order (S1), second-order (S2) and total (ST) Sobol indices, to estimate each input's contribution to output variance. By default, 95% confidence intervals are estimated for each index.",
"_____no_output_____"
]
],
[
[
"Si = sobol.analyze(problem, results['Avg. sheep'].values, calc_second_order=True, print_to_console=False)",
"_____no_output_____"
]
],
[
[
"As a simple example, we first select and visualize the first-order and total indices for each input, converting the dictionary returned by SALib to a dataframe.",
"_____no_output_____"
]
],
[
[
"Si_filter = {k:Si[k] for k in ['ST','ST_conf','S1','S1_conf']}\nSi_df = pd.DataFrame(Si_filter, index=problem['names'])",
"_____no_output_____"
],
[
"Si_df",
"_____no_output_____"
],
[
"sns.set_style('white')\nfig, ax = plt.subplots(1)\n\nindices = Si_df[['S1','ST']]\nerr = Si_df[['S1_conf','ST_conf']]\n\nindices.plot.bar(yerr=err.values.T,ax=ax)\nfig.set_size_inches(8,4)\n\n#plt.savefig('JASSS figures/SA - Indices.pdf', bbox_inches='tight')\n#plt.savefig('JASSS figures/SA - Indices.png', dpi=300, bbox_inches='tight')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"The \"sheep-gain-from-food\" parameter has the highest ST index, indicating that it contributes over 50% of output variance when accounting for interactions with other parameters. However, it can be noted that the confidence bounds are overly broad due to the small _n_ value used for sampling, so that a larger sample would be required for reliable results. For instance, the S1 index is estimated to be larger than ST for the \"random-seed\" parameter, which is an artifact of the small sample size.\n\nWe can use a more sophisticated visualization to include the second-order interactions between inputs.",
"_____no_output_____"
]
],
[
[
"import itertools\nfrom math import pi\n\n\ndef normalize(x, xmin, xmax):\n return (x-xmin)/(xmax-xmin)\n\n\ndef plot_circles(ax, locs, names, max_s, stats, smax, smin, fc, ec, lw, \n zorder):\n s = np.asarray([stats[name] for name in names])\n s = 0.01 + max_s * np.sqrt(normalize(s, smin, smax))\n \n fill = True\n for loc, name, si in zip(locs, names, s):\n if fc=='w':\n fill=False\n else:\n ec='none'\n \n x = np.cos(loc)\n y = np.sin(loc)\n \n circle = plt.Circle((x,y), radius=si, ec=ec, fc=fc, transform=ax.transData._b,\n zorder=zorder, lw=lw, fill=True)\n ax.add_artist(circle)\n \n\ndef filter(sobol_indices, names, locs, criterion, threshold):\n if criterion in ['ST', 'S1', 'S2']:\n data = sobol_indices[criterion]\n data = np.abs(data)\n data = data.flatten() # flatten in case of S2\n # TODO:: remove nans\n \n filtered = ([(name, locs[i]) for i, name in enumerate(names) if \n data[i]>threshold])\n filtered_names, filtered_locs = zip(*filtered)\n elif criterion in ['ST_conf', 'S1_conf', 'S2_conf']:\n raise NotImplementedError\n else:\n raise ValueError('unknown value for criterion')\n\n return filtered_names, filtered_locs\n\n\ndef plot_sobol_indices(sobol_indices, criterion='ST', threshold=0.01):\n '''plot sobol indices on a radial plot\n \n Parameters\n ----------\n sobol_indices : dict\n the return from SAlib\n criterion : {'ST', 'S1', 'S2', 'ST_conf', 'S1_conf', 'S2_conf'}, optional\n threshold : float\n only visualize variables with criterion larger than cutoff\n \n '''\n max_linewidth_s2 = 15#25*1.8\n max_s_radius = 0.3\n \n # prepare data\n # use the absolute values of all the indices\n #sobol_indices = {key:np.abs(stats) for key, stats in sobol_indices.items()}\n \n # dataframe with ST and S1\n sobol_stats = {key:sobol_indices[key] for key in ['ST', 'S1']}\n sobol_stats = pd.DataFrame(sobol_stats, index=problem['names'])\n\n smax = sobol_stats.max().max()\n smin = sobol_stats.min().min()\n\n # dataframe with s2\n s2 = pd.DataFrame(sobol_indices['S2'], index=problem['names'], \n columns=problem['names'])\n s2[s2<0.0]=0. #Set negative values to 0 (artifact from small sample sizes)\n s2max = s2.max().max()\n s2min = s2.min().min()\n\n names = problem['names']\n n = len(names)\n ticklocs = np.linspace(0, 2*pi, n+1)\n locs = ticklocs[0:-1]\n\n filtered_names, filtered_locs = filter(sobol_indices, names, locs,\n criterion, threshold)\n \n # setup figure\n fig = plt.figure()\n ax = fig.add_subplot(111, polar=True)\n ax.grid(False)\n ax.spines['polar'].set_visible(False)\n ax.set_xticks(ticklocs)\n\n ax.set_xticklabels(names)\n ax.set_yticklabels([])\n ax.set_ylim(ymax=1.4)\n legend(ax)\n\n # plot ST\n plot_circles(ax, filtered_locs, filtered_names, max_s_radius, \n sobol_stats['ST'], smax, smin, 'w', 'k', 1, 9)\n\n # plot S1\n plot_circles(ax, filtered_locs, filtered_names, max_s_radius, \n sobol_stats['S1'], smax, smin, 'k', 'k', 1, 10)\n\n # plot S2\n for name1, name2 in itertools.combinations(zip(filtered_names, filtered_locs), 2):\n name1, loc1 = name1\n name2, loc2 = name2\n\n weight = s2.ix[name1, name2]\n lw = 0.5+max_linewidth_s2*normalize(weight, s2min, s2max)\n ax.plot([loc1, loc2], [1,1], c='darkgray', lw=lw, zorder=1)\n\n return fig\n\n\nfrom matplotlib.legend_handler import HandlerPatch\nclass HandlerCircle(HandlerPatch):\n def create_artists(self, legend, orig_handle,\n xdescent, ydescent, width, height, fontsize, trans):\n center = 0.5 * width - 0.5 * xdescent, 0.5 * height - 0.5 * ydescent\n p = plt.Circle(xy=center, radius=orig_handle.radius)\n self.update_prop(p, orig_handle, legend)\n p.set_transform(trans)\n return [p]\n\ndef legend(ax):\n some_identifiers = [plt.Circle((0,0), radius=5, color='k', fill=False, lw=1),\n plt.Circle((0,0), radius=5, color='k', fill=True),\n plt.Line2D([0,0.5], [0,0.5], lw=8, color='darkgray')]\n ax.legend(some_identifiers, ['ST', 'S1', 'S2'],\n loc=(1,0.75), borderaxespad=0.1, mode='expand',\n handler_map={plt.Circle: HandlerCircle()})\n\n\nsns.set_style('whitegrid')\nfig = plot_sobol_indices(Si, criterion='ST', threshold=0.005)\nfig.set_size_inches(7,7)\n#plt.savefig('JASSS figures/Figure 8 - Interactions.pdf', bbox_inches='tight')\n#plt.savefig('JASSS figures/Figure 8 - Interactions.png', dpi=300, bbox_inches='tight')\nplt.show()",
"_____no_output_____"
]
],
[
[
"In this case, the sheep-gain-from-food variable has strong interactions with the wolf-gain-from-food and sheep-reproduce inputs in particular. The size of the ST and S1 circles correspond to the normalized variable importances.",
"_____no_output_____"
],
[
"Finally, the kill_workspace() function shuts down the NetLogo instance.",
"_____no_output_____"
]
],
[
[
"netlogo.kill_workspace()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
]
|
d06165fcd0eb33f2d42dced43cf819c2024d6dbc | 698,867 | ipynb | Jupyter Notebook | Tennis_Time_Data_Visualization.ipynb | Tinzyl/Tennis_Time_Data_Visualization | 761964f37a7f524edf708a1174d9ee8f73334889 | [
"MIT"
]
| null | null | null | Tennis_Time_Data_Visualization.ipynb | Tinzyl/Tennis_Time_Data_Visualization | 761964f37a7f524edf708a1174d9ee8f73334889 | [
"MIT"
]
| null | null | null | Tennis_Time_Data_Visualization.ipynb | Tinzyl/Tennis_Time_Data_Visualization | 761964f37a7f524edf708a1174d9ee8f73334889 | [
"MIT"
]
| null | null | null | 107.783313 | 61,440 | 0.756047 | [
[
[
"import pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"players_time = pd.read_csv(\"players_time.csv\")",
"_____no_output_____"
],
[
"events_time = pd.read_csv(\"events_time.csv\")",
"_____no_output_____"
],
[
"serve_time = pd.read_csv(\"serve_times.csv\")",
"_____no_output_____"
],
[
"players_time",
"_____no_output_____"
],
[
"events_time",
"_____no_output_____"
],
[
"pd.options.display.max_rows = None",
"_____no_output_____"
],
[
"events_time",
"_____no_output_____"
],
[
"serve_time",
"_____no_output_____"
]
],
[
[
"## 1. Visualize The 10 Most Slow Players ",
"_____no_output_____"
]
],
[
[
"most_slow_Players = players_time[players_time[\"seconds_added_per_point\"] > 0].sort_values(by=\"seconds_added_per_point\", ascending=False).head(10)",
"_____no_output_____"
],
[
"most_slow_Players",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax= sns.barplot(x=\"seconds_added_per_point\", y=\"player\", data=most_slow_Players)\nax.set_title(\"TOP 10 MOST SLOW PLAYERS\", fontsize=17)\nplt.xlabel(\"Seconds\", fontsize=17)\nplt.ylabel(\"Players\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 2. Visualize The 10 Most Fast Players",
"_____no_output_____"
]
],
[
[
"most_fast_Players = players_time[players_time[\"seconds_added_per_point\"] < 0].sort_values(by=\"seconds_added_per_point\").head(10)",
"_____no_output_____"
],
[
"most_fast_Players",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax= sns.barplot(x=\"seconds_added_per_point\", y=\"player\", data=most_fast_Players)\nax.set_title(\"TOP 10 MOST FAST PLAYERS\", fontsize=17)\nplt.xlabel(\"Seconds\", fontsize=17)\nplt.ylabel(\"Players\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 3. Visualize The Time Of The Big 3",
"_____no_output_____"
]
],
[
[
"big_three_time = players_time[(players_time[\"player\"] == \"Novak Djokovic\") | (players_time[\"player\"] == \"Roger Federer\") | (players_time[\"player\"] == \"Rafael Nadal\")]",
"_____no_output_____"
],
[
"big_three_time",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax= sns.barplot(x=\"seconds_added_per_point\", y=\"player\", data=big_three_time)\nax.set_title(\"TIME OF THE BIG THREE\", fontsize=17)\nplt.xlabel(\"Seconds\", fontsize=17)\nplt.ylabel(\"Players\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 4. Figure Out The Top 10 Surfaces That Take The Longest Time",
"_____no_output_____"
]
],
[
[
"longest_time_surfaces = events_time[events_time[\"seconds_added_per_point\"] > 0].sort_values(by=\"seconds_added_per_point\", ascending=False).head(10)",
"_____no_output_____"
],
[
"longest_time_surfaces",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax= sns.barplot(x=\"seconds_added_per_point\", y=\"tournament\", hue=\"surface\", data=longest_time_surfaces)\nax.set_title(\"TOP 10 SURFACES THAT TAKE THE LONGEST TIME\", fontsize=17)\nplt.xlabel(\"Seconds\", fontsize=17)\nplt.ylabel(\"Tournament\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 5. Figure Out The Top 10 Surfaces That Take The Shortest Time",
"_____no_output_____"
]
],
[
[
"shortest_time_surfaces = events_time[events_time[\"seconds_added_per_point\"] < 0].sort_values(by=\"seconds_added_per_point\").head(10)",
"_____no_output_____"
],
[
"shortest_time_surfaces",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax = sns.barplot(x=\"seconds_added_per_point\", y=\"tournament\", hue=\"surface\", data=shortest_time_surfaces)\nax.set_title(\"TOP 10 SURFACES THAT TAKE THE SHORTEST TIME\", fontsize=17)\nplt.xlabel(\"Seconds\", fontsize=17)\nplt.ylabel(\"Tournament\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 6. Figure Out How The Time For The Clay Surface Has Progressed Throughout The Years",
"_____no_output_____"
]
],
[
[
"years = events_time[~events_time[\"years\"].str.contains(\"-\")]\nsorted_years_clay = years[years[\"surface\"] == \"Clay\"].sort_values(by=\"years\")",
"_____no_output_____"
],
[
"sorted_years_clay",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax= sns.lineplot(x=\"years\", y=\"seconds_added_per_point\", hue=\"surface\", data=sorted_years_clay)\nax.set_title(\"PROGRESSION OF TIME FOR THE CLAY SURFACE THROUGHOUT THE YEARS\", fontsize=17)\nplt.xlabel(\"Years\", fontsize=17)\nplt.ylabel(\"Seconds\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show() ",
"_____no_output_____"
]
],
[
[
"## 7. Figure Out How The Time For The Hard Surface Has Progressed Throughout The Years",
"_____no_output_____"
]
],
[
[
"sorted_years_hard = years[years[\"surface\"] == \"Hard\"].sort_values(by=\"years\")",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax= sns.lineplot(x=\"years\", y=\"seconds_added_per_point\", hue=\"surface\", data=sorted_years_hard)\nax.set_title(\"PROGRESSION OF TIME FOR THE HARD SURFACE THROUGHOUT THE YEARS\", fontsize=17)\nplt.xlabel(\"Years\", fontsize=17)\nplt.ylabel(\"Seconds\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show() ",
"_____no_output_____"
]
],
[
[
"## 8. Figure Out How The Time For The Carpet Surface Has Progressed Throughout The Years",
"_____no_output_____"
]
],
[
[
"sorted_years_carpet = years[years[\"surface\"] == \"Carpet\"].sort_values(by=\"years\")",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax= sns.lineplot(x=\"years\", y=\"seconds_added_per_point\", hue=\"surface\", data=sorted_years_carpet)\nax.set_title(\"PROGRESSION OF TIME FOR THE CARPET SURFACE THROUGHOUT THE YEARS\", fontsize=17)\nplt.xlabel(\"Years\", fontsize=17)\nplt.ylabel(\"Seconds\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show() ",
"_____no_output_____"
]
],
[
[
"## 9. Figure Out How The Time For The Grass Surface Has Progressed Throughout The Years",
"_____no_output_____"
]
],
[
[
"sorted_years_grass = events_time[events_time[\"surface\"] == \"Grass\"].sort_values(by=\"years\").head(5)",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax= sns.lineplot(x=\"years\", y=\"seconds_added_per_point\", hue=\"surface\", data=sorted_years_grass)\nax.set_title(\"PROGRESSION OF TIME FOR THE GRASS SURFACE THROUGHOUT THE YEARS\", fontsize=17)\nplt.xlabel(\"Years\", fontsize=17)\nplt.ylabel(\"Seconds\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show() ",
"_____no_output_____"
]
],
[
[
"## 10. Figure Out The Person Who Took The Most Time Serving In 2015",
"_____no_output_____"
]
],
[
[
"serve_time",
"_____no_output_____"
],
[
"serve_time_visualization = serve_time.groupby(\"server\")[\"seconds_before_next_point\"].agg(\"sum\")",
"_____no_output_____"
],
[
"serve_time_visualization",
"_____no_output_____"
],
[
"serve_time_visual_data = serve_time_visualization.reset_index()",
"_____no_output_____"
],
[
"serve_time_visual_data",
"_____no_output_____"
],
[
"serve_time_visual_sorted = serve_time_visual_data.sort_values(by=\"seconds_before_next_point\", ascending = False)",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax = sns.barplot(x=\"seconds_before_next_point\", y=\"server\", data=serve_time_visual_sorted)\nax.set_title(\"PLAYERS TOTAL SERVING TIME(2015) \", fontsize=17)\nplt.xlabel(\"Seconds\", fontsize=17)\nplt.ylabel(\"Player\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### BIG THREE TOTAL SERVING TIME IN 2015",
"_____no_output_____"
]
],
[
[
"big_three_total_serving_time = serve_time_visual_sorted[(serve_time_visual_sorted[\"server\"] == \"Roger Federer\") | (serve_time_visual_sorted[\"server\"] == \"Rafael Nadal\") | (serve_time_visual_sorted[\"server\"] == \"Novak Djokovic\")]",
"_____no_output_____"
],
[
"big_three_total_serving_time",
"_____no_output_____"
],
[
"sns.set(style=\"darkgrid\")\nplt.figure(figsize = (10,5))\nax = sns.barplot(x=\"seconds_before_next_point\", y=\"server\", data=big_three_total_serving_time)\nax.set_title(\"BIG THREE TOTAL SERVING TIME(2015) \", fontsize=17)\nplt.xlabel(\"Seconds\", fontsize=17)\nplt.ylabel(\"Player\", fontsize=17)\nplt.yticks(size=17)\nplt.xticks(size=17)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Conclusion",
"_____no_output_____"
],
[
"### Matches are short when they are played on a Grass, Carpet or Hard Surface. Grass however has proved to let matches be way more short compared to the other 2. \n\n### Clay Surfaces have proved to make matches last so long. \n\n### In 2015, among the Big Three, Novak Djokovic took the shortest time serving followed by Rafael Nadal. Roger Federer took the longest time serving. Overall however, Roger Federer proved to have the shortest time serving over the past years, followed by Novak Djokovic. Rafael Nadal has proved to have the longest time serving over the past years, making the matches that he is involved in last longer.",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
]
|
d06168f1a481bfd64b39e2c63dac1b24eb7a07b8 | 125,628 | ipynb | Jupyter Notebook | notebooks/old/Salt_9-resne34-with-highLR-derper.ipynb | GilesStrong/Kaggle_TGS-Salt | b47a468ee464581f1b843fdf3bc1230222982277 | [
"Apache-2.0"
]
| null | null | null | notebooks/old/Salt_9-resne34-with-highLR-derper.ipynb | GilesStrong/Kaggle_TGS-Salt | b47a468ee464581f1b843fdf3bc1230222982277 | [
"Apache-2.0"
]
| null | null | null | notebooks/old/Salt_9-resne34-with-highLR-derper.ipynb | GilesStrong/Kaggle_TGS-Salt | b47a468ee464581f1b843fdf3bc1230222982277 | [
"Apache-2.0"
]
| null | null | null | 49.111806 | 26,436 | 0.587003 | [
[
[
"%matplotlib inline\n%reload_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"from fastai.conv_learner import *\nfrom fastai.dataset import *\nfrom fastai.models.resnet import vgg_resnet50\n\nimport json",
"_____no_output_____"
],
[
"#torch.cuda.set_device(2)",
"_____no_output_____"
],
[
"torch.backends.cudnn.benchmark=True",
"_____no_output_____"
]
],
[
[
"## Data",
"_____no_output_____"
]
],
[
[
"PATH = Path('/home/giles/Downloads/fastai_data/salt/')\nMASKS_FN = 'train_masks.csv'\nMETA_FN = 'metadata.csv'\nmasks_csv = pd.read_csv(PATH/MASKS_FN)\nmeta_csv = pd.read_csv(PATH/META_FN)",
"_____no_output_____"
],
[
"def show_img(im, figsize=None, ax=None, alpha=None):\n if not ax: fig,ax = plt.subplots(figsize=figsize)\n ax.imshow(im, alpha=alpha)\n ax.set_axis_off()\n return ax",
"_____no_output_____"
],
[
"(PATH/'train_masks-128').mkdir(exist_ok=True)",
"_____no_output_____"
],
[
"def resize_img(fn):\n Image.open(fn).resize((128,128)).save((fn.parent.parent)/'train_masks-128'/fn.name)\n\nfiles = list((PATH/'train_masks').iterdir())\nwith ThreadPoolExecutor(8) as e: e.map(resize_img, files)",
"_____no_output_____"
],
[
"(PATH/'train-128').mkdir(exist_ok=True)",
"_____no_output_____"
],
[
"def resize_img(fn):\n Image.open(fn).resize((128,128)).save((fn.parent.parent)/'train-128'/fn.name)\n\nfiles = list((PATH/'train').iterdir())\nwith ThreadPoolExecutor(8) as e: e.map(resize_img, files)",
"_____no_output_____"
],
[
"TRAIN_DN = 'train-128'\nMASKS_DN = 'train_masks-128'\nsz = 32\nbs = 64\nnw = 16",
"_____no_output_____"
]
],
[
[
"TRAIN_DN = 'train'\nMASKS_DN = 'train_masks_png'\nsz = 128\nbs = 64\nnw = 16",
"_____no_output_____"
]
],
[
[
"class MatchedFilesDataset(FilesDataset):\n def __init__(self, fnames, y, transform, path):\n self.y=y\n assert(len(fnames)==len(y))\n super().__init__(fnames, transform, path)\n def get_y(self, i): return open_image(os.path.join(self.path, self.y[i]))\n def get_c(self): return 0",
"_____no_output_____"
],
[
"x_names = np.array(glob(f'{PATH}/{TRAIN_DN}/*'))\ny_names = np.array(glob(f'{PATH}/{MASKS_DN}/*'))",
"_____no_output_____"
],
[
"val_idxs = list(range(800))\n((val_x,trn_x),(val_y,trn_y)) = split_by_idx(val_idxs, x_names, y_names)",
"_____no_output_____"
],
[
"aug_tfms = [RandomFlip(tfm_y=TfmType.CLASS)]",
"_____no_output_____"
],
[
"tfms = tfms_from_model(resnet34, sz, crop_type=CropType.NO, tfm_y=TfmType.CLASS, aug_tfms=aug_tfms)\ndatasets = ImageData.get_ds(MatchedFilesDataset, (trn_x,trn_y), (val_x,val_y), tfms, path=PATH)\nmd = ImageData(PATH, datasets, bs, num_workers=16, classes=None)\ndenorm = md.trn_ds.denorm",
"_____no_output_____"
],
[
"x,y = next(iter(md.trn_dl))",
"_____no_output_____"
],
[
"x.shape,y.shape",
"_____no_output_____"
],
[
"denorm = md.val_ds.denorm",
"_____no_output_____"
],
[
"def show_aug_img(ims, idx, figsize=(5,5), normed=True, ax=None, nchannels=3):\n if ax is None: fig,ax = plt.subplots(figsize=figsize)\n if normed: ims = denorm(ims)\n else: ims = np.rollaxis(to_np(ims),1,nchannels+1)\n ax.imshow(np.clip(ims,0,1)[idx])\n ax.axis('off')",
"_____no_output_____"
],
[
"batches = [next(iter(md.aug_dl)) for i in range(9)]",
"_____no_output_____"
],
[
"fig, axes = plt.subplots(3, 6, figsize=(18, 9))\nfor i,(x,y) in enumerate(batches):\n show_aug_img(x,1, ax=axes.flat[i*2])\n show_aug_img(y,1, ax=axes.flat[i*2+1], nchannels=1, normed=False)",
"_____no_output_____"
]
],
[
[
"## Simple upsample",
"_____no_output_____"
]
],
[
[
"f = resnet34\ncut,lr_cut = model_meta[f]",
"_____no_output_____"
],
[
"def get_base():\n layers = cut_model(f(True), cut)\n return nn.Sequential(*layers)",
"_____no_output_____"
],
[
"def dice(pred, targs):\n pred = (pred>0.5).float()\n return 2. * (pred*targs).sum() / (pred+targs).sum()",
"_____no_output_____"
]
],
[
[
"## U-net (ish)",
"_____no_output_____"
]
],
[
[
"class SaveFeatures():\n features=None\n def __init__(self, m): self.hook = m.register_forward_hook(self.hook_fn)\n def hook_fn(self, module, input, output): self.features = output\n def remove(self): self.hook.remove()",
"_____no_output_____"
],
[
"class UnetBlock(nn.Module):\n def __init__(self, up_in, x_in, n_out):\n super().__init__()\n up_out = x_out = n_out//2\n self.x_conv = nn.Conv2d(x_in, x_out, 1)\n self.tr_conv = nn.ConvTranspose2d(up_in, up_out, 2, stride=2)\n self.bn = nn.BatchNorm2d(n_out)\n \n def forward(self, up_p, x_p):\n up_p = self.tr_conv(up_p)\n x_p = self.x_conv(x_p)\n cat_p = torch.cat([up_p,x_p], dim=1)\n return self.bn(F.relu(cat_p))",
"_____no_output_____"
],
[
"class Unet34(nn.Module):\n def __init__(self, rn):\n super().__init__()\n self.rn = rn\n self.sfs = [SaveFeatures(rn[i]) for i in [2,4,5,6]]\n self.up1 = UnetBlock(512,256,256)\n self.up2 = UnetBlock(256,128,256)\n self.up3 = UnetBlock(256,64,256)\n self.up4 = UnetBlock(256,64,256)\n self.up5 = UnetBlock(256,3,16)\n self.up6 = nn.ConvTranspose2d(16, 1, 1)\n \n def forward(self,x):\n inp = x\n x = F.relu(self.rn(x))\n x = self.up1(x, self.sfs[3].features)\n x = self.up2(x, self.sfs[2].features)\n x = self.up3(x, self.sfs[1].features)\n x = self.up4(x, self.sfs[0].features)\n x = self.up5(x, inp)\n x = self.up6(x)\n return x[:,0]\n \n def close(self):\n for sf in self.sfs: sf.remove()",
"_____no_output_____"
],
[
"class UnetModel():\n def __init__(self,model,name='unet'):\n self.model,self.name = model,name\n\n def get_layer_groups(self, precompute):\n lgs = list(split_by_idxs(children(self.model.rn), [lr_cut]))\n return lgs + [children(self.model)[1:]]",
"_____no_output_____"
],
[
"m_base = get_base()\nm = to_gpu(Unet34(m_base))\nmodels = UnetModel(m)",
"_____no_output_____"
],
[
"learn = ConvLearner(md, models)\nlearn.opt_fn=optim.Adam\nlearn.crit=nn.BCEWithLogitsLoss()\nlearn.metrics=[accuracy_thresh(0.5),dice]",
"_____no_output_____"
],
[
"learn.summary()",
"_____no_output_____"
],
[
"[o.features.size() for o in m.sfs]",
"_____no_output_____"
],
[
"learn.freeze_to(1)",
"_____no_output_____"
],
[
"learn.lr_find()\nlearn.sched.plot()",
"_____no_output_____"
],
[
"lr=1e-2\nwd=1e-7\n\nlrs = np.array([lr/9,lr/3,lr])",
"_____no_output_____"
],
[
"learn.fit(lr,1,wds=wd,cycle_len=10,use_clr=(5,8))",
"_____no_output_____"
],
[
"learn.save('32urn-tmp')",
"_____no_output_____"
],
[
"learn.load('32urn-tmp')",
"_____no_output_____"
],
[
"learn.unfreeze()\nlearn.bn_freeze(True)",
"_____no_output_____"
],
[
"learn.fit(lrs/4, 1, wds=wd, cycle_len=20,use_clr=(20,10))",
"_____no_output_____"
],
[
"learn.sched.plot_lr()",
"_____no_output_____"
],
[
"learn.save('32urn-0')",
"_____no_output_____"
],
[
"learn.load('32urn-0')",
"_____no_output_____"
],
[
"x,y = next(iter(md.val_dl))\npy = to_np(learn.model(V(x)))",
"_____no_output_____"
],
[
"show_img(py[0]>0.5);",
"_____no_output_____"
],
[
"show_img(y[0]);",
"_____no_output_____"
],
[
"show_img(x[0][0]);",
"_____no_output_____"
],
[
"m.close()",
"_____no_output_____"
]
],
[
[
"## 64x64",
"_____no_output_____"
]
],
[
[
"sz=64\nbs=64",
"_____no_output_____"
],
[
"tfms = tfms_from_model(resnet34, sz, crop_type=CropType.NO, tfm_y=TfmType.CLASS, aug_tfms=aug_tfms)\ndatasets = ImageData.get_ds(MatchedFilesDataset, (trn_x,trn_y), (val_x,val_y), tfms, path=PATH)\nmd = ImageData(PATH, datasets, bs, num_workers=16, classes=None)\ndenorm = md.trn_ds.denorm",
"_____no_output_____"
],
[
"m_base = get_base()\nm = to_gpu(Unet34(m_base))\nmodels = UnetModel(m)",
"_____no_output_____"
],
[
"learn = ConvLearner(md, models)\nlearn.opt_fn=optim.Adam\nlearn.crit=nn.BCEWithLogitsLoss()\nlearn.metrics=[accuracy_thresh(0.5),dice]",
"_____no_output_____"
],
[
"learn.freeze_to(1)",
"_____no_output_____"
],
[
"learn.load('32urn-0')",
"_____no_output_____"
],
[
"learn.fit(lr/2,1,wds=wd, cycle_len=10,use_clr=(10,10))",
"_____no_output_____"
],
[
"learn.sched.plot_lr()",
"_____no_output_____"
],
[
"learn.save('64urn-tmp')",
"_____no_output_____"
],
[
"learn.unfreeze()\nlearn.bn_freeze(True)",
"_____no_output_____"
],
[
"learn.load('64urn-tmp')",
"_____no_output_____"
],
[
"learn.fit(lrs/4,1,wds=wd, cycle_len=8,use_clr=(20,8))",
"_____no_output_____"
],
[
"learn.sched.plot_lr()",
"_____no_output_____"
],
[
"learn.save('64urn')",
"_____no_output_____"
],
[
"learn.load('64urn')",
"_____no_output_____"
],
[
"x,y = next(iter(md.val_dl))\npy = to_np(learn.model(V(x)))",
"_____no_output_____"
],
[
"show_img(py[0]>0.5);",
"_____no_output_____"
],
[
"show_img(y[0]);",
"_____no_output_____"
],
[
"show_img(x[0][0]);",
"_____no_output_____"
],
[
"m.close()",
"_____no_output_____"
]
],
[
[
"## 128x128",
"_____no_output_____"
]
],
[
[
"sz=128\nbs=64",
"_____no_output_____"
],
[
"tfms = tfms_from_model(resnet34, sz, crop_type=CropType.NO, tfm_y=TfmType.CLASS, aug_tfms=aug_tfms)\ndatasets = ImageData.get_ds(MatchedFilesDataset, (trn_x,trn_y), (val_x,val_y), tfms, path=PATH)\nmd = ImageData(PATH, datasets, bs, num_workers=16, classes=None)\ndenorm = md.trn_ds.denorm",
"_____no_output_____"
],
[
"m_base = get_base()\nm = to_gpu(Unet34(m_base))\nmodels = UnetModel(m)",
"_____no_output_____"
],
[
"learn = ConvLearner(md, models)\nlearn.opt_fn=optim.Adam\nlearn.crit=nn.BCEWithLogitsLoss()\nlearn.metrics=[accuracy_thresh(0.5),dice]",
"_____no_output_____"
],
[
"learn.load('64urn')",
"_____no_output_____"
],
[
"learn.fit(lr/2,1, wds=wd, cycle_len=6,use_clr=(6,4))",
"_____no_output_____"
],
[
"learn.save('128urn-tmp')",
"_____no_output_____"
],
[
"learn.load('128urn-tmp')",
"_____no_output_____"
],
[
"learn.unfreeze()\nlearn.bn_freeze(True)",
"_____no_output_____"
],
[
"#lrs = np.array([lr/200,lr/30,lr])",
"_____no_output_____"
],
[
"learn.fit(lrs/5,1, wds=wd,cycle_len=8,use_clr=(20,8))",
"_____no_output_____"
],
[
"learn.sched.plot_lr()",
"_____no_output_____"
],
[
"learn.sched.plot_loss()",
"_____no_output_____"
],
[
"learn.save('128urn')",
"_____no_output_____"
],
[
"learn.load('128urn')",
"_____no_output_____"
],
[
"x,y = next(iter(md.val_dl))\npy = to_np(learn.model(V(x)))",
"_____no_output_____"
],
[
"show_img(py[0]>0.5);",
"_____no_output_____"
],
[
"show_img(y[0]);",
"_____no_output_____"
],
[
"show_img(x[0][0]);",
"_____no_output_____"
],
[
"y.shape",
"_____no_output_____"
],
[
"batches = [next(iter(md.aug_dl)) for i in range(9)]",
"_____no_output_____"
],
[
"fig, axes = plt.subplots(3, 6, figsize=(18, 9))\nfor i,(x,y) in enumerate(batches):\n show_aug_img(x,1, ax=axes.flat[i*2])\n show_aug_img(y,1, ax=axes.flat[i*2+1], nchannels=1, normed=False)",
"_____no_output_____"
]
],
[
[
"# Test on original validation",
"_____no_output_____"
]
],
[
[
"x_names_orig = np.array(glob(f'{PATH}/train/*'))\ny_names_orig = np.array(glob(f'{PATH}/train_masks/*'))",
"_____no_output_____"
],
[
"val_idxs_orig = list(range(800))\n((val_x_orig,trn_x_orig),(val_y_orig,trn_y_orig)) = split_by_idx(val_idxs_orig, x_names_orig, y_names_orig)",
"_____no_output_____"
],
[
"sz=128\nbs=64",
"_____no_output_____"
],
[
"tfms = tfms_from_model(resnet34, sz, crop_type=CropType.NO, tfm_y=TfmType.CLASS, aug_tfms=aug_tfms)\ndatasets = ImageData.get_ds(MatchedFilesDataset, (trn_x,trn_y), (val_x,val_y), tfms, path=PATH)\nmd = ImageData(PATH, datasets, bs, num_workers=16, classes=None)\ndenorm = md.trn_ds.denorm",
"_____no_output_____"
],
[
"m_base = get_base()\nm = to_gpu(Unet34(m_base))\nmodels = UnetModel(m)",
"_____no_output_____"
],
[
"learn = ConvLearner(md, models)\nlearn.opt_fn=optim.Adam\nlearn.crit=nn.BCEWithLogitsLoss()\nlearn.metrics=[accuracy_thresh(0.5),dice]",
"_____no_output_____"
],
[
"learn.load('128urn')",
"_____no_output_____"
],
[
"probs = learn.predict()",
"_____no_output_____"
],
[
"probs.shape",
"_____no_output_____"
],
[
"_, y = learn.TTA(n_aug=1)",
"_____no_output_____"
],
[
"y.shape",
"_____no_output_____"
],
[
"idx=0",
"_____no_output_____"
],
[
"show_img(probs[idx]>0.5);",
"_____no_output_____"
],
[
"show_img(probs[idx]);",
"_____no_output_____"
],
[
"show_img(y[idx]);",
"_____no_output_____"
],
[
"show_img(x[idx][0]);",
"_____no_output_____"
]
],
[
[
"# Optimise threshold",
"_____no_output_____"
]
],
[
[
"# src: https://www.kaggle.com/aglotero/another-iou-metric\ndef iou_metric(y_true_in, y_pred_in, print_table=False):\n labels = y_true_in\n y_pred = y_pred_in\n \n true_objects = 2\n pred_objects = 2\n\n intersection = np.histogram2d(labels.flatten(), y_pred.flatten(), bins=(true_objects, pred_objects))[0]\n\n # Compute areas (needed for finding the union between all objects)\n area_true = np.histogram(labels, bins = true_objects)[0]\n area_pred = np.histogram(y_pred, bins = pred_objects)[0]\n area_true = np.expand_dims(area_true, -1)\n area_pred = np.expand_dims(area_pred, 0)\n\n # Compute union\n union = area_true + area_pred - intersection\n\n # Exclude background from the analysis\n intersection = intersection[1:,1:]\n union = union[1:,1:]\n union[union == 0] = 1e-9\n\n # Compute the intersection over union\n iou = intersection / union\n\n # Precision helper function\n def precision_at(threshold, iou):\n matches = iou > threshold\n true_positives = np.sum(matches, axis=1) == 1 # Correct objects\n false_positives = np.sum(matches, axis=0) == 0 # Missed objects\n false_negatives = np.sum(matches, axis=1) == 0 # Extra objects\n tp, fp, fn = np.sum(true_positives), np.sum(false_positives), np.sum(false_negatives)\n return tp, fp, fn\n\n # Loop over IoU thresholds\n prec = []\n if print_table:\n print(\"Thresh\\tTP\\tFP\\tFN\\tPrec.\")\n for t in np.arange(0.5, 1.0, 0.05):\n tp, fp, fn = precision_at(t, iou)\n if (tp + fp + fn) > 0:\n p = tp / (tp + fp + fn)\n else:\n p = 0\n if print_table:\n print(\"{:1.3f}\\t{}\\t{}\\t{}\\t{:1.3f}\".format(t, tp, fp, fn, p))\n prec.append(p)\n \n if print_table:\n print(\"AP\\t-\\t-\\t-\\t{:1.3f}\".format(np.mean(prec)))\n return np.mean(prec)\n\ndef iou_metric_batch(y_true_in, y_pred_in):\n batch_size = y_true_in.shape[0]\n metric = []\n for batch in range(batch_size):\n value = iou_metric(y_true_in[batch], y_pred_in[batch])\n metric.append(value)\n return np.mean(metric)",
"_____no_output_____"
],
[
"thres = np.linspace(-1, 1, 10)\nthres_ioc = [iou_metric_batch(y, np.int32(probs > t)) for t in tqdm_notebook(thres)]",
"_____no_output_____"
],
[
"plt.plot(thres, thres_ioc);",
"_____no_output_____"
],
[
"best_thres = thres[np.argmax(thres_ioc)]\nbest_thres, max(thres_ioc)",
"_____no_output_____"
],
[
"thres = np.linspace(-0.5, 0.5, 50)\nthres_ioc = [iou_metric_batch(y, np.int32(probs > t)) for t in tqdm_notebook(thres)]",
"_____no_output_____"
],
[
"plt.plot(thres, thres_ioc);",
"_____no_output_____"
],
[
"best_thres = thres[np.argmax(thres_ioc)]\nbest_thres, max(thres_ioc)",
"_____no_output_____"
],
[
"show_img(probs[0]>best_thres);",
"_____no_output_____"
]
],
[
[
"# Run on test",
"_____no_output_____"
]
],
[
[
"(PATH/'test-128').mkdir(exist_ok=True)",
"_____no_output_____"
],
[
"def resize_img(fn):\n Image.open(fn).resize((128,128)).save((fn.parent.parent)/'test-128'/fn.name)\n\nfiles = list((PATH/'test').iterdir())\nwith ThreadPoolExecutor(8) as e: e.map(resize_img, files)",
"_____no_output_____"
],
[
"testData = np.array(glob(f'{PATH}/test-128/*'))",
"_____no_output_____"
],
[
"class TestFilesDataset(FilesDataset):\n def __init__(self, fnames, y, transform, path):\n self.y=y\n assert(len(fnames)==len(y))\n super().__init__(fnames, transform, path)\n def get_y(self, i): return open_image(os.path.join(self.path, self.fnames[i]))\n def get_c(self): return 0",
"_____no_output_____"
],
[
"tfms_from_model(resnet34, sz, crop_type=CropType.NO, tfm_y=TfmType.CLASS, aug_tfms=aug_tfms)\ndatasets = ImageData.get_ds(TestFilesDataset, (trn_x,trn_y), (val_x,val_y), tfms, test=testData, path=PATH)\nmd = ImageData(PATH, datasets, bs, num_workers=16, classes=None)\ndenorm = md.trn_ds.denorm",
"_____no_output_____"
],
[
"m_base = get_base()\nm = to_gpu(Unet34(m_base))\nmodels = UnetModel(m)",
"_____no_output_____"
],
[
"learn = ConvLearner(md, models)\nlearn.opt_fn=optim.Adam\nlearn.crit=nn.BCEWithLogitsLoss()\nlearn.metrics=[accuracy_thresh(0.5),dice]",
"_____no_output_____"
],
[
"learn.load('128urn')",
"_____no_output_____"
],
[
"x,y = next(iter(md.test_dl))\npy = to_np(learn.model(V(x)))",
"_____no_output_____"
],
[
"show_img(py[6]>best_thres);",
"_____no_output_____"
],
[
"show_img(py[6]);",
"_____no_output_____"
],
[
"show_img(y[6]);",
"_____no_output_____"
],
[
"probs = learn.predict(is_test=True)",
"_____no_output_____"
],
[
"show_img(probs[12]>best_thres);",
"_____no_output_____"
],
[
"show_img(probs[12]);",
"_____no_output_____"
],
[
"show_img(y[12]);",
"_____no_output_____"
],
[
"show_img(x[12][0]);",
"_____no_output_____"
],
[
"with open(f'{PATH}/probs.pkl', 'wb') as fout: #Save results\n pickle.dump(probs, fout)",
"_____no_output_____"
],
[
"probs.shape",
"_____no_output_____"
],
[
"def resize_img(fn):\n return np.array(Image.fromarray(fn).resize((101,101)))\n\nresizePreds = np.array([resize_img(x) for x in probs])",
"_____no_output_____"
],
[
"resizePreds.shape",
"_____no_output_____"
],
[
"show_img(resizePreds[12]);",
"_____no_output_____"
],
[
"testData",
"_____no_output_____"
],
[
"f'{PATH}/test'",
"_____no_output_____"
],
[
"test_ids = next(os.walk(f'{PATH}/test'))[2]",
"_____no_output_____"
],
[
"def RLenc(img, order='F', format=True):\n \"\"\"\n img is binary mask image, shape (r,c)\n order is down-then-right, i.e. Fortran\n format determines if the order needs to be preformatted (according to submission rules) or not\n\n returns run length as an array or string (if format is True)\n \"\"\"\n bytes = img.reshape(img.shape[0] * img.shape[1], order=order)\n runs = [] ## list of run lengths\n r = 0 ## the current run length\n pos = 1 ## count starts from 1 per WK\n for c in bytes:\n if (c == 0):\n if r != 0:\n runs.append((pos, r))\n pos += r\n r = 0\n pos += 1\n else:\n r += 1\n\n # if last run is unsaved (i.e. data ends with 1)\n if r != 0:\n runs.append((pos, r))\n pos += r\n r = 0\n\n if format:\n z = ''\n\n for rr in runs:\n z += '{} {} '.format(rr[0], rr[1])\n return z[:-1]\n else:\n return runs",
"_____no_output_____"
],
[
"pred_dict = {id_[:-4]:RLenc(np.round(resizePreds[i] > best_thres)) for i,id_ in tqdm_notebook(enumerate(test_ids))}",
"_____no_output_____"
],
[
"sub = pd.DataFrame.from_dict(pred_dict,orient='index')\nsub.index.names = ['id']\nsub.columns = ['rle_mask']\nsub.to_csv('submission.csv')",
"_____no_output_____"
],
[
"sub",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d06175055f3580333d9c8a5d91550bc2d22d341e | 33,696 | ipynb | Jupyter Notebook | bin/Jonghoo/altProj/proj/python/Music Recognition.ipynb | axcer2126/DINF | 04bc17c5c7835da77debfef4ae7acd62a769585a | [
"MIT"
]
| null | null | null | bin/Jonghoo/altProj/proj/python/Music Recognition.ipynb | axcer2126/DINF | 04bc17c5c7835da77debfef4ae7acd62a769585a | [
"MIT"
]
| null | null | null | bin/Jonghoo/altProj/proj/python/Music Recognition.ipynb | axcer2126/DINF | 04bc17c5c7835da77debfef4ae7acd62a769585a | [
"MIT"
]
| 8 | 2020-09-18T05:46:42.000Z | 2020-11-03T07:20:02.000Z | 37.069307 | 272 | 0.485785 | [
[
[
"# feature extractoring and preprocessing data\n# 음원 데이터를 분석\nimport librosa\n\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n# notebook을 실행한 브라우저에서 바로 그림을 볼 수 있게 해주는 것\n%matplotlib inline\n\n# 운영체제와의 상호작용을 돕는 다양한 기능을 제공\n# 1. 현재 디렉토리 확인하기\n# 2. 디렉토리 변경\n# 3. 현재 디렉토리의 파일 목록 확인하기\n# 4. csv 파일 호출\nimport os\n\n# 파이썬에서의 이미지 처리\nfrom PIL import Image\n\nimport pathlib\nimport csv\n\n# Preprocessing\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import LabelEncoder, StandardScaler\nfrom sklearn.metrics import mean_squared_error\n\n#Keras\nimport keras\n\n# 경고 메시지를 무시하고 숨기거나 -> warnings.filterwarnings(action='ignore')\n# 일치하는 경고를 인쇄하지 않습니다 = ('ignore')\nimport warnings\nwarnings.filterwarnings('ignore')",
"Using TensorFlow backend.\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:517: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:518: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:519: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:520: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:525: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\n/home/bitai/anaconda3/lib/python3.7/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\n"
],
[
"# 원하는 종류의 색깔만 넘겨주는 것\ncmap = plt.get_cmap('inferno')\n\nplt.figure(figsize=(10,10))\ngenres = 'blues classical country disco hiphop jazz metal pop reggae rock'.split()\nfor g in genres:\n pathlib.Path(f'img_data/{g}').mkdir(parents=True, exist_ok=True) \n for filename in os.listdir(f'./MIR/genres/{g}'):\n songname = f'./MIR/genres/{g}/{filename}'\n y, sr = librosa.load(songname, mono=True, duration=5)\n plt.specgram(y, NFFT=2048, Fs=2, Fc=0, noverlap=128, cmap=cmap, sides='default', mode='default', scale='dB');\n plt.axis('off');\n plt.savefig(f'img_data/{g}/{filename[:-3].replace(\".\", \"\")}.png')\n plt.clf()",
"_____no_output_____"
],
[
"header = 'filename chroma_stft rmse spectral_centroid spectral_bandwidth rolloff zero_crossing_rate'\nfor i in range(1, 21):\n header += f' mfcc{i}'\nheader += ' label'\nheader = header.split()",
"_____no_output_____"
],
[
"file = open('data.csv', 'w', newline='')\nwith file:\n writer = csv.writer(file)\n writer.writerow(header)\ngenres = 'blues classical country disco hiphop jazz metal pop reggae rock'.split()\nfor g in genres:\n for filename in os.listdir(f'./MIR/genres/{g}'):\n songname = f'./MIR/genres/{g}/{filename}'\n y, sr = librosa.load(songname, mono=True, duration=30)\n chroma_stft = librosa.feature.chroma_stft(y=y, sr=sr)\n spec_cent = librosa.feature.spectral_centroid(y=y, sr=sr)\n spec_bw = librosa.feature.spectral_bandwidth(y=y, sr=sr)\n rolloff = librosa.feature.spectral_rolloff(y=y, sr=sr)\n zcr = librosa.feature.zero_crossing_rate(y)\n mfcc = librosa.feature.mfcc(y=y, sr=sr)\n #rmse = mean_squared_error(y, y_pred=sr)**0.5\n rmse = librosa.feature.rms(y=y)\n to_append = f'{filename} {np.mean(chroma_stft)} {np.mean(rmse)} {np.mean(spec_cent)} {np.mean(spec_bw)} {np.mean(rolloff)} {np.mean(zcr)}' \n for e in mfcc:\n to_append += f' {np.mean(e)}'\n to_append += f' {g}'\n file = open('data.csv', 'a', newline='')\n with file:\n writer = csv.writer(file)\n writer.writerow(to_append.split())",
"_____no_output_____"
],
[
"# mfcc = 오디오 신호에서 추출할 수 있는 feature로, 소리의 고유한 특징을 나타내는 수치\n# = 등록된 음성과 현재 입력된 음성의 유사도를 판별하는 근거의 일부로 쓰입니다.\n# = MFCC(Mel-Frequency Cepstral Coefficient)는\n# Mel Spectrum(멜 스펙트럼)에서 Cepstral(켑스트럴) 분석을 통해 추출된 값\n# \n# 이해하기 위해 먼저 \n# - Spectrum(스펙트럼)\n# - Cepstrum(켑스트럼)\n# - Mel Spectrum(멜 스펙트럼) 들을 알아야 한다.",
"_____no_output_____"
],
[
"data = pd.read_csv('data.csv')\ndata.head()\n\n# chroma_stft = 채도_? , 크로마 표준\n# spectral_centroid = 스펙트럼 중심\n# spectral_bandwidth = 스펙트럼 대역폭\n# rolloff = 롤 오프\n# zero_crossing_rate = 제로 크로싱 비율\n# \n# mfcc[n] = ",
"_____no_output_____"
],
[
"data.shape",
"_____no_output_____"
],
[
"# Dropping unneccesary columns\ndata = data.drop(['filename'],axis=1)",
"_____no_output_____"
],
[
"genre_list = data.iloc[:, -1]\nencoder = LabelEncoder()\ny = encoder.fit_transform(genre_list)",
"_____no_output_____"
],
[
"scaler = StandardScaler()\nX = scaler.fit_transform(np.array(data.iloc[:, :-1], dtype = float))",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)",
"_____no_output_____"
],
[
"len(y_train)",
"_____no_output_____"
],
[
"len(y_test)",
"_____no_output_____"
],
[
"X_train[10]",
"_____no_output_____"
],
[
"from keras import models\nfrom keras import layers\n\nmodel = models.Sequential()\nmodel.add(layers.Dense(256, activation='relu', input_shape=(X_train.shape[1],)))\n\nmodel.add(layers.Dense(128, activation='relu'))\n\nmodel.add(layers.Dense(64, activation='relu'))\n\nmodel.add(layers.Dense(10, activation='softmax'))",
"WARNING:tensorflow:From /home/bitai/anaconda3/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:66: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.\n\nWARNING:tensorflow:From /home/bitai/anaconda3/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:541: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.\n\nWARNING:tensorflow:From /home/bitai/anaconda3/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:4432: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.\n\n"
],
[
"model.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])",
"WARNING:tensorflow:From /home/bitai/anaconda3/lib/python3.7/site-packages/keras/optimizers.py:793: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.\n\nWARNING:tensorflow:From /home/bitai/anaconda3/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:3622: The name tf.log is deprecated. Please use tf.math.log instead.\n\n"
],
[
"history = model.fit(X_train,\n y_train,\n epochs=20,\n batch_size=128)",
"WARNING:tensorflow:From /home/bitai/anaconda3/lib/python3.7/site-packages/tensorflow/python/ops/math_grad.py:1250: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\nWARNING:tensorflow:From /home/bitai/anaconda3/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:1033: The name tf.assign_add is deprecated. Please use tf.compat.v1.assign_add instead.\n\nEpoch 1/20\n800/800 [==============================] - 1s 1ms/step - loss: 2.1563 - acc: 0.2263\nEpoch 2/20\n800/800 [==============================] - 0s 45us/step - loss: 1.8502 - acc: 0.3887\nEpoch 3/20\n800/800 [==============================] - 0s 30us/step - loss: 1.6190 - acc: 0.4163\nEpoch 4/20\n800/800 [==============================] - 0s 28us/step - loss: 1.4466 - acc: 0.4863\nEpoch 5/20\n800/800 [==============================] - 0s 15us/step - loss: 1.3198 - acc: 0.5587\nEpoch 6/20\n800/800 [==============================] - 0s 11us/step - loss: 1.2189 - acc: 0.5663\nEpoch 7/20\n800/800 [==============================] - 0s 14us/step - loss: 1.1357 - acc: 0.5988\nEpoch 8/20\n800/800 [==============================] - 0s 14us/step - loss: 1.0649 - acc: 0.6450\nEpoch 9/20\n800/800 [==============================] - 0s 11us/step - loss: 1.0059 - acc: 0.6625\nEpoch 10/20\n800/800 [==============================] - 0s 13us/step - loss: 0.9525 - acc: 0.6925\nEpoch 11/20\n800/800 [==============================] - 0s 13us/step - loss: 0.9039 - acc: 0.7025\nEpoch 12/20\n800/800 [==============================] - 0s 12us/step - loss: 0.8633 - acc: 0.7150\nEpoch 13/20\n800/800 [==============================] - 0s 13us/step - loss: 0.8188 - acc: 0.7350\nEpoch 14/20\n800/800 [==============================] - 0s 14us/step - loss: 0.7868 - acc: 0.7425\nEpoch 15/20\n800/800 [==============================] - 0s 12us/step - loss: 0.7527 - acc: 0.7475\nEpoch 16/20\n800/800 [==============================] - 0s 12us/step - loss: 0.7272 - acc: 0.7575\nEpoch 17/20\n800/800 [==============================] - 0s 13us/step - loss: 0.7033 - acc: 0.7688\nEpoch 18/20\n800/800 [==============================] - 0s 12us/step - loss: 0.6679 - acc: 0.7737\nEpoch 19/20\n800/800 [==============================] - 0s 12us/step - loss: 0.6405 - acc: 0.7925\nEpoch 20/20\n800/800 [==============================] - 0s 11us/step - loss: 0.6022 - acc: 0.8125\n"
],
[
"test_loss, test_acc = model.evaluate(X_test,y_test)",
"200/200 [==============================] - 0s 115us/step\n"
],
[
"print('test_acc: ',test_acc)",
"test_acc: 0.73\n"
],
[
"x_val = X_train[:200]\npartial_x_train = X_train[200:]\n\ny_val = y_train[:200]\npartial_y_train = y_train[200:]",
"_____no_output_____"
],
[
"\nmodel = models.Sequential()\nmodel.add(layers.Dense(512, activation='relu', input_shape=(X_train.shape[1],)))\nmodel.add(layers.Dense(256, activation='relu'))\nmodel.add(layers.Dense(128, activation='relu'))\nmodel.add(layers.Dense(64, activation='relu'))\nmodel.add(layers.Dense(10, activation='softmax'))\n\nmodel.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])\n\nmodel.fit(partial_x_train,\n partial_y_train,\n epochs=30,\n batch_size=512,\n validation_data=(x_val, y_val))\nresults = model.evaluate(X_test, y_test)",
"Train on 600 samples, validate on 200 samples\nEpoch 1/30\n600/600 [==============================] - 0s 341us/step - loss: 2.2897 - acc: 0.1167 - val_loss: 2.1786 - val_acc: 0.2650\nEpoch 2/30\n600/600 [==============================] - 0s 14us/step - loss: 2.1257 - acc: 0.3317 - val_loss: 2.0688 - val_acc: 0.3150\nEpoch 3/30\n600/600 [==============================] - 0s 15us/step - loss: 1.9839 - acc: 0.4133 - val_loss: 1.9469 - val_acc: 0.3100\nEpoch 4/30\n600/600 [==============================] - 0s 17us/step - loss: 1.8296 - acc: 0.4067 - val_loss: 1.8256 - val_acc: 0.3150\nEpoch 5/30\n600/600 [==============================] - 0s 13us/step - loss: 1.6836 - acc: 0.4150 - val_loss: 1.7084 - val_acc: 0.3500\nEpoch 6/30\n600/600 [==============================] - 0s 17us/step - loss: 1.5413 - acc: 0.4633 - val_loss: 1.6188 - val_acc: 0.4150\nEpoch 7/30\n600/600 [==============================] - 0s 12us/step - loss: 1.4307 - acc: 0.5100 - val_loss: 1.5584 - val_acc: 0.4350\nEpoch 8/30\n600/600 [==============================] - 0s 14us/step - loss: 1.3362 - acc: 0.5333 - val_loss: 1.5068 - val_acc: 0.4550\nEpoch 9/30\n600/600 [==============================] - 0s 11us/step - loss: 1.2556 - acc: 0.5433 - val_loss: 1.4741 - val_acc: 0.4700\nEpoch 10/30\n600/600 [==============================] - 0s 16us/step - loss: 1.2024 - acc: 0.5833 - val_loss: 1.4555 - val_acc: 0.4750\nEpoch 11/30\n600/600 [==============================] - 0s 12us/step - loss: 1.1433 - acc: 0.5983 - val_loss: 1.4419 - val_acc: 0.5200\nEpoch 12/30\n600/600 [==============================] - 0s 16us/step - loss: 1.0761 - acc: 0.6267 - val_loss: 1.4268 - val_acc: 0.5050\nEpoch 13/30\n600/600 [==============================] - 0s 12us/step - loss: 1.0272 - acc: 0.6500 - val_loss: 1.3786 - val_acc: 0.5450\nEpoch 14/30\n600/600 [==============================] - 0s 12us/step - loss: 0.9723 - acc: 0.6783 - val_loss: 1.3623 - val_acc: 0.5200\nEpoch 15/30\n600/600 [==============================] - 0s 16us/step - loss: 0.9400 - acc: 0.6867 - val_loss: 1.3410 - val_acc: 0.5750\nEpoch 16/30\n600/600 [==============================] - 0s 13us/step - loss: 0.8821 - acc: 0.7000 - val_loss: 1.3599 - val_acc: 0.5800\nEpoch 17/30\n600/600 [==============================] - 0s 12us/step - loss: 0.8603 - acc: 0.6983 - val_loss: 1.3182 - val_acc: 0.5850\nEpoch 18/30\n600/600 [==============================] - 0s 16us/step - loss: 0.8224 - acc: 0.7233 - val_loss: 1.2646 - val_acc: 0.5850\nEpoch 19/30\n600/600 [==============================] - 0s 14us/step - loss: 0.7897 - acc: 0.7367 - val_loss: 1.2845 - val_acc: 0.5650\nEpoch 20/30\n600/600 [==============================] - 0s 13us/step - loss: 0.7486 - acc: 0.7517 - val_loss: 1.3470 - val_acc: 0.5650\nEpoch 21/30\n600/600 [==============================] - 0s 14us/step - loss: 0.7371 - acc: 0.7533 - val_loss: 1.3236 - val_acc: 0.5850\nEpoch 22/30\n600/600 [==============================] - 0s 11us/step - loss: 0.7123 - acc: 0.7517 - val_loss: 1.2596 - val_acc: 0.5950\nEpoch 23/30\n600/600 [==============================] - 0s 13us/step - loss: 0.6772 - acc: 0.7767 - val_loss: 1.2605 - val_acc: 0.5850\nEpoch 24/30\n600/600 [==============================] - 0s 15us/step - loss: 0.6618 - acc: 0.7717 - val_loss: 1.2853 - val_acc: 0.5800\nEpoch 25/30\n600/600 [==============================] - 0s 14us/step - loss: 0.6487 - acc: 0.7800 - val_loss: 1.3147 - val_acc: 0.5900\nEpoch 26/30\n600/600 [==============================] - 0s 14us/step - loss: 0.6131 - acc: 0.8117 - val_loss: 1.3265 - val_acc: 0.6000\nEpoch 27/30\n600/600 [==============================] - 0s 14us/step - loss: 0.5971 - acc: 0.8033 - val_loss: 1.2807 - val_acc: 0.6000\nEpoch 28/30\n600/600 [==============================] - 0s 12us/step - loss: 0.5631 - acc: 0.8283 - val_loss: 1.2866 - val_acc: 0.5800\nEpoch 29/30\n600/600 [==============================] - 0s 14us/step - loss: 0.5477 - acc: 0.8350 - val_loss: 1.2839 - val_acc: 0.5750\nEpoch 30/30\n600/600 [==============================] - 0s 13us/step - loss: 0.5210 - acc: 0.8550 - val_loss: 1.2990 - val_acc: 0.5900\n200/200 [==============================] - 0s 19us/step\n"
],
[
"results",
"_____no_output_____"
],
[
"predictions = model.predict(X_test)",
"_____no_output_____"
],
[
"predictions[0].shape",
"_____no_output_____"
],
[
"np.sum(predictions[0])",
"_____no_output_____"
],
[
"np.argmax(predictions[0])",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d06181e012184dce95535cfa5bf9cade17ef5c3f | 1,702 | ipynb | Jupyter Notebook | Chapter07/Exercise104/Exercise104.ipynb | adityashah95/Python | 6b5ffc89f0abd77f07dd8049a4c1213ce56c4d84 | [
"MIT"
]
| 4 | 2020-01-06T12:07:00.000Z | 2022-03-22T04:03:49.000Z | Chapter07/Exercise104/Exercise104.ipynb | adityashah95/Python | 6b5ffc89f0abd77f07dd8049a4c1213ce56c4d84 | [
"MIT"
]
| null | null | null | Chapter07/Exercise104/Exercise104.ipynb | adityashah95/Python | 6b5ffc89f0abd77f07dd8049a4c1213ce56c4d84 | [
"MIT"
]
| 4 | 2019-11-25T10:39:30.000Z | 2020-02-22T07:26:40.000Z | 21.544304 | 136 | 0.536428 | [
[
[
"class Interrogator:\n def __init__(self, questions):\n self.questions = questions\n def __iter__(self):\n return self.questions.__iter__()",
"_____no_output_____"
],
[
"questions = [\"What is your name?\", \"What is your quest?\", \"What is the average airspeed velocity of an unladen swallow?\"]\nawkward_person = Interrogator(questions)\nfor question in awkward_person:\n print(question)\n\n",
"What is your name?\nWhat is your quest?\nWhat is the average airspeed velocity of an unladen swallow?\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code"
]
]
|
d0618522ae84a467019ab9b7cc4372b10bffe018 | 125,489 | ipynb | Jupyter Notebook | examples/models/aws_eks_deep_mnist/aws_eks_deep_mnist.ipynb | welcomemandeep/seldon-core | a257c5ef7baf042da4b2ca1b7aad959447d5bd7d | [
"Apache-2.0"
]
| null | null | null | examples/models/aws_eks_deep_mnist/aws_eks_deep_mnist.ipynb | welcomemandeep/seldon-core | a257c5ef7baf042da4b2ca1b7aad959447d5bd7d | [
"Apache-2.0"
]
| null | null | null | examples/models/aws_eks_deep_mnist/aws_eks_deep_mnist.ipynb | welcomemandeep/seldon-core | a257c5ef7baf042da4b2ca1b7aad959447d5bd7d | [
"Apache-2.0"
]
| null | null | null | 35.711155 | 4,684 | 0.436118 | [
[
[
"# AWS Elastic Kubernetes Service (EKS) Deep MNIST\nIn this example we will deploy a tensorflow MNIST model in Amazon Web Services' Elastic Kubernetes Service (EKS).\n\nThis tutorial will break down in the following sections:\n\n1) Train a tensorflow model to predict mnist locally\n\n2) Containerise the tensorflow model with our docker utility\n\n3) Send some data to the docker model to test it\n\n4) Install and configure AWS tools to interact with AWS\n\n5) Use the AWS tools to create and setup EKS cluster with Seldon\n\n6) Push and run docker image through the AWS Container Registry\n\n7) Test our Elastic Kubernetes deployment by sending some data\n\nLet's get started! 🚀🔥\n\n## Dependencies:\n\n* Helm v3.0.0+\n* A Kubernetes cluster running v1.13 or above (minkube / docker-for-windows work well if enough RAM)\n* kubectl v1.14+\n* EKS CLI v0.1.32\n* AWS Cli v1.16.163\n* Python 3.6+\n* Python DEV requirements\n",
"_____no_output_____"
],
[
"## 1) Train a tensorflow model to predict mnist locally\nWe will load the mnist images, together with their labels, and then train a tensorflow model to predict the right labels",
"_____no_output_____"
]
],
[
[
"from tensorflow.examples.tutorials.mnist import input_data\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot = True)\nimport tensorflow as tf\n\nif __name__ == '__main__':\n \n x = tf.placeholder(tf.float32, [None,784], name=\"x\")\n\n W = tf.Variable(tf.zeros([784,10]))\n b = tf.Variable(tf.zeros([10]))\n\n y = tf.nn.softmax(tf.matmul(x,W) + b, name=\"y\")\n\n y_ = tf.placeholder(tf.float32, [None, 10])\n\n cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))\n\n train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)\n\n init = tf.initialize_all_variables()\n\n sess = tf.Session()\n sess.run(init)\n\n for i in range(1000):\n batch_xs, batch_ys = mnist.train.next_batch(100)\n sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})\n\n correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\n print(sess.run(accuracy, feed_dict = {x: mnist.test.images, y_:mnist.test.labels}))\n\n saver = tf.train.Saver()\n\n saver.save(sess, \"model/deep_mnist_model\")",
"Extracting MNIST_data/train-images-idx3-ubyte.gz\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\n0.9194\n"
]
],
[
[
"## 2) Containerise the tensorflow model with our docker utility",
"_____no_output_____"
],
[
"First you need to make sure that you have added the .s2i/environment configuration file in this folder with the following content:",
"_____no_output_____"
]
],
[
[
"!cat .s2i/environment",
"MODEL_NAME=DeepMnist\nAPI_TYPE=REST\nSERVICE_TYPE=MODEL\nPERSISTENCE=0\n"
]
],
[
[
"Now we can build a docker image named \"deep-mnist\" with the tag 0.1",
"_____no_output_____"
]
],
[
[
"!s2i build . seldonio/seldon-core-s2i-python36:1.5.0-dev deep-mnist:0.1",
"---> Installing application source...\n---> Installing dependencies ...\nLooking in links: /whl\nRequirement already satisfied: tensorflow>=1.12.0 in /usr/local/lib/python3.6/site-packages (from -r requirements.txt (line 1)) (1.13.1)\nRequirement already satisfied: keras-preprocessing>=1.0.5 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (1.0.9)\nRequirement already satisfied: gast>=0.2.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (0.2.2)\nRequirement already satisfied: absl-py>=0.1.6 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (0.7.1)\nRequirement already satisfied: astor>=0.6.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (0.7.1)\nRequirement already satisfied: keras-applications>=1.0.6 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (1.0.7)\nRequirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (1.12.0)\nRequirement already satisfied: termcolor>=1.1.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (1.1.0)\nRequirement already satisfied: grpcio>=1.8.6 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (1.19.0)\nRequirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (0.33.1)\nRequirement already satisfied: tensorboard<1.14.0,>=1.13.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (1.13.1)\nRequirement already satisfied: numpy>=1.13.3 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (1.16.2)\nRequirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (3.7.0)\nRequirement already satisfied: tensorflow-estimator<1.14.0rc0,>=1.13.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 1)) (1.13.0)\nRequirement already satisfied: h5py in /usr/local/lib/python3.6/site-packages (from keras-applications>=1.0.6->tensorflow>=1.12.0->-r requirements.txt (line 1)) (2.9.0)\nRequirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/site-packages (from tensorboard<1.14.0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 1)) (3.0.1)\nRequirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/site-packages (from tensorboard<1.14.0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 1)) (0.15.0)\nRequirement already satisfied: setuptools in /usr/local/lib/python3.6/site-packages (from protobuf>=3.6.1->tensorflow>=1.12.0->-r requirements.txt (line 1)) (40.8.0)\nRequirement already satisfied: mock>=2.0.0 in /usr/local/lib/python3.6/site-packages (from tensorflow-estimator<1.14.0rc0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 1)) (2.0.0)\nRequirement already satisfied: pbr>=0.11 in /usr/local/lib/python3.6/site-packages (from mock>=2.0.0->tensorflow-estimator<1.14.0rc0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 1)) (5.1.3)\nUrl '/whl' is ignored. It is either a non-existing path or lacks a specific scheme.\nYou are using pip version 19.0.3, however version 19.1.1 is available.\nYou should consider upgrading via the 'pip install --upgrade pip' command.\nBuild completed successfully\n"
]
],
[
[
"## 3) Send some data to the docker model to test it\nWe first run the docker image we just created as a container called \"mnist_predictor\"",
"_____no_output_____"
]
],
[
[
"!docker run --name \"mnist_predictor\" -d --rm -p 5000:5000 deep-mnist:0.1",
"5157ab4f516bd0dea11b159780f31121e9fb41df6394e0d6d631e6e0d572463b\n"
]
],
[
[
"Send some random features that conform to the contract",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n# This is the variable that was initialised at the beginning of the file\ni = [0]\nx = mnist.test.images[i]\ny = mnist.test.labels[i]\nplt.imshow(x.reshape((28, 28)), cmap='gray')\nplt.show()\nprint(\"Expected label: \", np.sum(range(0,10) * y), \". One hot encoding: \", y)",
"_____no_output_____"
],
[
"from seldon_core.seldon_client import SeldonClient\nimport math\nimport numpy as np\n\n# We now test the REST endpoint expecting the same result\nendpoint = \"0.0.0.0:5000\"\nbatch = x\npayload_type = \"ndarray\"\n\nsc = SeldonClient(microservice_endpoint=endpoint)\n\n# We use the microservice, instead of the \"predict\" function\nclient_prediction = sc.microservice(\n data=batch,\n method=\"predict\",\n payload_type=payload_type,\n names=[\"tfidf\"])\n\nfor proba, label in zip(client_prediction.response.data.ndarray.values[0].list_value.ListFields()[0][1], range(0,10)):\n print(f\"LABEL {label}:\\t {proba.number_value*100:6.4f} %\")",
"LABEL 0:\t 0.0068 %\nLABEL 1:\t 0.0000 %\nLABEL 2:\t 0.0085 %\nLABEL 3:\t 0.3409 %\nLABEL 4:\t 0.0002 %\nLABEL 5:\t 0.0020 %\nLABEL 6:\t 0.0000 %\nLABEL 7:\t 99.5371 %\nLABEL 8:\t 0.0026 %\nLABEL 9:\t 0.1019 %\n"
],
[
"!docker rm mnist_predictor --force",
"mnist_predictor\n"
]
],
[
[
"## 4) Install and configure AWS tools to interact with AWS",
"_____no_output_____"
],
[
"First we install the awscli",
"_____no_output_____"
]
],
[
[
"!pip install awscli --upgrade --user",
"Collecting awscli\n Using cached https://files.pythonhosted.org/packages/f6/45/259a98719e7c7defc9be4cc00fbfb7ccf699fbd1f74455d8347d0ab0a1df/awscli-1.16.163-py2.py3-none-any.whl\nCollecting colorama<=0.3.9,>=0.2.5 (from awscli)\n Using cached https://files.pythonhosted.org/packages/db/c8/7dcf9dbcb22429512708fe3a547f8b6101c0d02137acbd892505aee57adf/colorama-0.3.9-py2.py3-none-any.whl\nCollecting PyYAML<=3.13,>=3.10 (from awscli)\nCollecting botocore==1.12.153 (from awscli)\n Using cached https://files.pythonhosted.org/packages/ec/3b/029218966ce62ae9824a18730de862ac8fc5a0e8083d07d1379815e7cca1/botocore-1.12.153-py2.py3-none-any.whl\nRequirement already satisfied, skipping upgrade: docutils>=0.10 in /home/alejandro/miniconda3/envs/reddit-classification/lib/python3.7/site-packages (from awscli) (0.14)\nCollecting rsa<=3.5.0,>=3.1.2 (from awscli)\n Using cached https://files.pythonhosted.org/packages/e1/ae/baedc9cb175552e95f3395c43055a6a5e125ae4d48a1d7a924baca83e92e/rsa-3.4.2-py2.py3-none-any.whl\nRequirement already satisfied, skipping upgrade: s3transfer<0.3.0,>=0.2.0 in /home/alejandro/miniconda3/envs/reddit-classification/lib/python3.7/site-packages (from awscli) (0.2.0)\nRequirement already satisfied, skipping upgrade: urllib3<1.25,>=1.20; python_version >= \"3.4\" in /home/alejandro/miniconda3/envs/reddit-classification/lib/python3.7/site-packages (from botocore==1.12.153->awscli) (1.24.2)\nRequirement already satisfied, skipping upgrade: python-dateutil<3.0.0,>=2.1; python_version >= \"2.7\" in /home/alejandro/miniconda3/envs/reddit-classification/lib/python3.7/site-packages (from botocore==1.12.153->awscli) (2.8.0)\nRequirement already satisfied, skipping upgrade: jmespath<1.0.0,>=0.7.1 in /home/alejandro/miniconda3/envs/reddit-classification/lib/python3.7/site-packages (from botocore==1.12.153->awscli) (0.9.4)\nCollecting pyasn1>=0.1.3 (from rsa<=3.5.0,>=3.1.2->awscli)\n Using cached https://files.pythonhosted.org/packages/7b/7c/c9386b82a25115cccf1903441bba3cbadcfae7b678a20167347fa8ded34c/pyasn1-0.4.5-py2.py3-none-any.whl\nRequirement already satisfied, skipping upgrade: six>=1.5 in /home/alejandro/miniconda3/envs/reddit-classification/lib/python3.7/site-packages (from python-dateutil<3.0.0,>=2.1; python_version >= \"2.7\"->botocore==1.12.153->awscli) (1.12.0)\nInstalling collected packages: colorama, PyYAML, botocore, pyasn1, rsa, awscli\nSuccessfully installed PyYAML-3.13 awscli-1.16.163 botocore-1.12.153 colorama-0.3.9 pyasn1-0.4.5 rsa-3.4.2\n"
]
],
[
[
"### Configure aws so it can talk to your server \n(if you are getting issues, make sure you have the permmissions to create clusters)",
"_____no_output_____"
]
],
[
[
"%%bash \n# You must make sure that the access key and secret are changed\naws configure << END_OF_INPUTS\nYOUR_ACCESS_KEY\nYOUR_ACCESS_SECRET\nus-west-2\njson\nEND_OF_INPUTS",
"AWS Access Key ID [****************SF4A]: AWS Secret Access Key [****************WLHu]: Default region name [eu-west-1]: Default output format [json]: "
]
],
[
[
"### Install EKCTL\n*IMPORTANT*: These instructions are for linux\nPlease follow the official installation of ekctl at: https://docs.aws.amazon.com/eks/latest/userguide/getting-started-eksctl.html",
"_____no_output_____"
]
],
[
[
"!curl --silent --location \"https://github.com/weaveworks/eksctl/releases/download/latest_release/eksctl_$(uname -s)_amd64.tar.gz\" | tar xz ",
"_____no_output_____"
],
[
"!chmod 755 ./eksctl",
"_____no_output_____"
],
[
"!./eksctl version",
"\u001b[36m[ℹ] version.Info{BuiltAt:\"\", GitCommit:\"\", GitTag:\"0.1.32\"}\n\u001b[0m"
]
],
[
[
"## 5) Use the AWS tools to create and setup EKS cluster with Seldon\nIn this example we will create a cluster with 2 nodes, with a minimum of 1 and a max of 3. You can tweak this accordingly.\n\nIf you want to check the status of the deployment you can go to AWS CloudFormation or to the EKS dashboard.\n\nIt will take 10-15 minutes (so feel free to go grab a ☕). \n\n*IMPORTANT*: If you get errors in this step it is most probably IAM role access requirements, which requires you to discuss with your administrator.",
"_____no_output_____"
]
],
[
[
"%%bash\n./eksctl create cluster \\\n--name demo-eks-cluster \\\n--region us-west-2 \\\n--nodes 2 ",
"Process is interrupted.\n"
]
],
[
[
"### Configure local kubectl \nWe want to now configure our local Kubectl so we can actually reach the cluster we've just created",
"_____no_output_____"
]
],
[
[
"!aws eks --region us-west-2 update-kubeconfig --name demo-eks-cluster",
"Updated context arn:aws:eks:eu-west-1:271049282727:cluster/deepmnist in /home/alejandro/.kube/config\n"
]
],
[
[
"And we can check if the context has been added to kubectl config (contexts are basically the different k8s cluster connections)\nYou should be able to see the context as \"...aws:eks:eu-west-1:27...\". \nIf it's not activated you can activate that context with kubectlt config set-context <CONTEXT_NAME>",
"_____no_output_____"
]
],
[
[
"!kubectl config get-contexts",
"CURRENT NAME CLUSTER AUTHINFO NAMESPACE\n* arn:aws:eks:eu-west-1:271049282727:cluster/deepmnist arn:aws:eks:eu-west-1:271049282727:cluster/deepmnist arn:aws:eks:eu-west-1:271049282727:cluster/deepmnist \n docker-desktop docker-desktop docker-desktop \n docker-for-desktop docker-desktop docker-desktop \n gke_ml-engineer_us-central1-a_security-cluster-1 gke_ml-engineer_us-central1-a_security-cluster-1 gke_ml-engineer_us-central1-a_security-cluster-1 \n"
]
],
[
[
"## Setup Seldon Core\n\nUse the setup notebook to [Setup Cluster](https://docs.seldon.io/projects/seldon-core/en/latest/examples/seldon_core_setup.html#Setup-Cluster) with [Ambassador Ingress](https://docs.seldon.io/projects/seldon-core/en/latest/examples/seldon_core_setup.html#Ambassador) and [Install Seldon Core](https://docs.seldon.io/projects/seldon-core/en/latest/examples/seldon_core_setup.html#Install-Seldon-Core). Instructions [also online](https://docs.seldon.io/projects/seldon-core/en/latest/examples/seldon_core_setup.html).",
"_____no_output_____"
],
[
"## Push docker image\nIn order for the EKS seldon deployment to access the image we just built, we need to push it to the Elastic Container Registry (ECR).\n\nIf you have any issues please follow the official AWS documentation: https://docs.aws.amazon.com/AmazonECR/latest/userguide/what-is-ecr.html",
"_____no_output_____"
],
[
"### First we create a registry\nYou can run the following command, and then see the result at https://us-west-2.console.aws.amazon.com/ecr/repositories?#",
"_____no_output_____"
]
],
[
[
"!aws ecr create-repository --repository-name seldon-repository --region us-west-2",
"{\n \"repository\": {\n \"repositoryArn\": \"arn:aws:ecr:us-west-2:271049282727:repository/seldon-repository\",\n \"registryId\": \"271049282727\",\n \"repositoryName\": \"seldon-repository\",\n \"repositoryUri\": \"271049282727.dkr.ecr.us-west-2.amazonaws.com/seldon-repository\",\n \"createdAt\": 1558535798.0\n }\n}\n"
]
],
[
[
"### Now prepare docker image\nWe need to first tag the docker image before we can push it",
"_____no_output_____"
]
],
[
[
"%%bash\nexport AWS_ACCOUNT_ID=\"\"\nexport AWS_REGION=\"us-west-2\"\nif [ -z \"$AWS_ACCOUNT_ID\" ]; then\n echo \"ERROR: Please provide a value for the AWS variables\"\n exit 1\nfi\n\ndocker tag deep-mnist:0.1 \"$AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/seldon-repository\"",
"_____no_output_____"
]
],
[
[
"### We now login to aws through docker so we can access the repository",
"_____no_output_____"
]
],
[
[
"!`aws ecr get-login --no-include-email --region us-west-2`",
"WARNING! Using --password via the CLI is insecure. Use --password-stdin.\nWARNING! Your password will be stored unencrypted in /home/alejandro/.docker/config.json.\nConfigure a credential helper to remove this warning. See\nhttps://docs.docker.com/engine/reference/commandline/login/#credentials-store\n\nLogin Succeeded\n"
]
],
[
[
"### And push the image\nMake sure you add your AWS Account ID",
"_____no_output_____"
]
],
[
[
"%%bash\nexport AWS_ACCOUNT_ID=\"\"\nexport AWS_REGION=\"us-west-2\"\nif [ -z \"$AWS_ACCOUNT_ID\" ]; then\n echo \"ERROR: Please provide a value for the AWS variables\"\n exit 1\nfi\n\ndocker push \"$AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/seldon-repository\"",
"The push refers to repository [271049282727.dkr.ecr.us-west-2.amazonaws.com/seldon-repository]\nf7d0d000c138: Preparing\n987f3f1afb00: Preparing\n00d16a381c47: Preparing\nbb01f50d544a: Preparing\nfcb82c6941b5: Preparing\n67290e35c458: Preparing\nb813745f5bb3: Preparing\nffecb18e9f0b: Preparing\nf50f856f49fa: Preparing\n80b43ad4adf9: Preparing\n14c77983a1cf: Preparing\na22a5ac18042: Preparing\n6257fa9f9597: Preparing\n578414b395b9: Preparing\nabc3250a6c7f: Preparing\n13d5529fd232: Preparing\n67290e35c458: Waiting\nb813745f5bb3: Waiting\nffecb18e9f0b: Waiting\nf50f856f49fa: Waiting\n80b43ad4adf9: Waiting\n6257fa9f9597: Waiting\n14c77983a1cf: Waiting\na22a5ac18042: Waiting\n578414b395b9: Waiting\nabc3250a6c7f: Waiting\n13d5529fd232: Waiting\n987f3f1afb00: Pushed\nfcb82c6941b5: Pushed\nbb01f50d544a: Pushed\nf7d0d000c138: Pushed\nffecb18e9f0b: Pushed\nb813745f5bb3: Pushed\nf50f856f49fa: Pushed\n67290e35c458: Pushed\n14c77983a1cf: Pushed\n578414b395b9: Pushed\n80b43ad4adf9: Pushed\n13d5529fd232: Pushed\n6257fa9f9597: Pushed\nabc3250a6c7f: Pushed\n00d16a381c47: Pushed\na22a5ac18042: Pushed\nlatest: digest: sha256:19aefaa9d87c1287eb46ec08f5d4f9a689744d9d0d0b75668b7d15e447819d74 size: 3691\n"
]
],
[
[
"## Running the Model\nWe will now run the model.\n\nLet's first have a look at the file we'll be using to trigger the model:",
"_____no_output_____"
]
],
[
[
"!cat deep_mnist.json",
"{\n \"apiVersion\": \"machinelearning.seldon.io/v1alpha2\",\n \"kind\": \"SeldonDeployment\",\n \"metadata\": {\n \"labels\": {\n \"app\": \"seldon\"\n },\n \"name\": \"deep-mnist\"\n },\n \"spec\": {\n \"annotations\": {\n \"project_name\": \"Tensorflow MNIST\",\n \"deployment_version\": \"v1\"\n },\n \"name\": \"deep-mnist\",\n \"oauth_key\": \"oauth-key\",\n \"oauth_secret\": \"oauth-secret\",\n \"predictors\": [\n {\n \"componentSpecs\": [{\n \"spec\": {\n \"containers\": [\n {\n \"image\": \"271049282727.dkr.ecr.us-west-2.amazonaws.com/seldon-repository:latest\",\n \"imagePullPolicy\": \"IfNotPresent\",\n \"name\": \"classifier\",\n \"resources\": {\n \"requests\": {\n \"memory\": \"1Mi\"\n }\n }\n }\n ],\n \"terminationGracePeriodSeconds\": 20\n }\n }],\n \"graph\": {\n \"children\": [],\n \"name\": \"classifier\",\n \"endpoint\": {\n\t\t\t\"type\" : \"REST\"\n\t\t },\n \"type\": \"MODEL\"\n },\n \"name\": \"single-model\",\n \"replicas\": 1,\n\t\t\"annotations\": {\n\t\t \"predictor_version\" : \"v1\"\n\t\t}\n }\n ]\n }\n}\n"
]
],
[
[
"Now let's trigger seldon to run the model.\n\nWe basically have a yaml file, where we want to replace the value \"REPLACE_FOR_IMAGE_AND_TAG\" for the image you pushed",
"_____no_output_____"
]
],
[
[
"%%bash\nexport AWS_ACCOUNT_ID=\"\"\nexport AWS_REGION=\"us-west-2\"\nif [ -z \"$AWS_ACCOUNT_ID\" ]; then\n echo \"ERROR: Please provide a value for the AWS variables\"\n exit 1\nfi\n\nsed 's|REPLACE_FOR_IMAGE_AND_TAG|'\"$AWS_ACCOUNT_ID\"'.dkr.ecr.'\"$AWS_REGION\"'.amazonaws.com/seldon-repository|g' deep_mnist.json | kubectl apply -f -",
"error: unable to recognize \"STDIN\": Get https://461835FD3FF52848655C8F09FBF5EEAA.yl4.us-west-2.eks.amazonaws.com/api?timeout=32s: dial tcp: lookup 461835FD3FF52848655C8F09FBF5EEAA.yl4.us-west-2.eks.amazonaws.com on 1.1.1.1:53: no such host\n"
]
],
[
[
"And let's check that it's been created.\n\nYou should see an image called \"deep-mnist-single-model...\".\n\nWe'll wait until STATUS changes from \"ContainerCreating\" to \"Running\"",
"_____no_output_____"
]
],
[
[
"!kubectl get pods",
"NAME READY STATUS RESTARTS AGE\nambassador-5475779f98-7bhcw 1/1 Running 0 21m\nambassador-5475779f98-986g5 1/1 Running 0 21m\nambassador-5475779f98-zcd28 1/1 Running 0 21m\ndeep-mnist-single-model-42ed9d9-fdb557d6b-6xv2h 2/2 Running 0 18m\n"
]
],
[
[
"## Test the model\nNow we can test the model, let's first find out what is the URL that we'll have to use:",
"_____no_output_____"
]
],
[
[
"!kubectl get svc ambassador -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' ",
"a68bbac487ca611e988060247f81f4c1-707754258.us-west-2.elb.amazonaws.com"
]
],
[
[
"We'll use a random example from our dataset",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n# This is the variable that was initialised at the beginning of the file\ni = [0]\nx = mnist.test.images[i]\ny = mnist.test.labels[i]\nplt.imshow(x.reshape((28, 28)), cmap='gray')\nplt.show()\nprint(\"Expected label: \", np.sum(range(0,10) * y), \". One hot encoding: \", y)",
"_____no_output_____"
]
],
[
[
"We can now add the URL above to send our request:",
"_____no_output_____"
]
],
[
[
"from seldon_core.seldon_client import SeldonClient\nimport math\nimport numpy as np\n\nhost = \"a68bbac487ca611e988060247f81f4c1-707754258.us-west-2.elb.amazonaws.com\"\nport = \"80\" # Make sure you use the port above\nbatch = x\npayload_type = \"ndarray\"\n\nsc = SeldonClient(\n gateway=\"ambassador\", \n ambassador_endpoint=host + \":\" + port,\n namespace=\"default\",\n oauth_key=\"oauth-key\", \n oauth_secret=\"oauth-secret\")\n\nclient_prediction = sc.predict(\n data=batch, \n deployment_name=\"deep-mnist\",\n names=[\"text\"],\n payload_type=payload_type)\n\nprint(client_prediction)",
"Success:True message:\nRequest:\ndata {\n names: \"text\"\n ndarray {\n values {\n list_value {\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.3294117748737335\n }\n values {\n number_value: 0.7254902124404907\n }\n values {\n number_value: 0.6235294342041016\n }\n values {\n number_value: 0.5921568870544434\n }\n values {\n number_value: 0.2352941334247589\n }\n values {\n number_value: 0.1411764770746231\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.8705883026123047\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9450981020927429\n }\n values {\n number_value: 0.7764706611633301\n }\n values {\n number_value: 0.7764706611633301\n }\n values {\n number_value: 0.7764706611633301\n }\n values {\n number_value: 0.7764706611633301\n }\n values {\n number_value: 0.7764706611633301\n }\n values {\n number_value: 0.7764706611633301\n }\n values {\n number_value: 0.7764706611633301\n }\n values {\n number_value: 0.7764706611633301\n }\n values {\n number_value: 0.6666666865348816\n }\n values {\n number_value: 0.2039215862751007\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.26274511218070984\n }\n values {\n number_value: 0.44705885648727417\n }\n values {\n number_value: 0.2823529541492462\n }\n values {\n number_value: 0.44705885648727417\n }\n values {\n number_value: 0.6392157077789307\n }\n values {\n number_value: 0.8901961445808411\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.8823530077934265\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9803922176361084\n }\n values {\n number_value: 0.8980392813682556\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.5490196347236633\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.06666667014360428\n }\n values {\n number_value: 0.25882354378700256\n }\n values {\n number_value: 0.05490196496248245\n }\n values {\n number_value: 0.26274511218070984\n }\n values {\n number_value: 0.26274511218070984\n }\n values {\n number_value: 0.26274511218070984\n }\n values {\n number_value: 0.23137256503105164\n }\n values {\n number_value: 0.08235294371843338\n }\n values {\n number_value: 0.9254902601242065\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.41568630933761597\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.32549020648002625\n }\n values {\n number_value: 0.9921569228172302\n }\n values {\n number_value: 0.8196079134941101\n }\n values {\n number_value: 0.07058823853731155\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.08627451211214066\n }\n values {\n number_value: 0.9137255549430847\n }\n values {\n number_value: 1.0\n }\n values {\n number_value: 0.32549020648002625\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.5058823823928833\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9333333969116211\n }\n values {\n number_value: 0.1725490242242813\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.23137256503105164\n }\n values {\n number_value: 0.9764706492424011\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.24313727021217346\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.5215686559677124\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.7333333492279053\n }\n values {\n number_value: 0.019607843831181526\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.03529411926865578\n }\n values {\n number_value: 0.803921639919281\n }\n values {\n number_value: 0.9725490808486938\n }\n values {\n number_value: 0.22745099663734436\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.4941176772117615\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.7137255072593689\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.29411765933036804\n }\n values {\n number_value: 0.9843137860298157\n }\n values {\n number_value: 0.9411765336990356\n }\n values {\n number_value: 0.22352942824363708\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.07450980693101883\n }\n values {\n number_value: 0.8666667342185974\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.6509804129600525\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.011764707043766975\n }\n values {\n number_value: 0.7960785031318665\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.8588235974311829\n }\n values {\n number_value: 0.13725490868091583\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.14901961386203766\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.3019607961177826\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.12156863510608673\n }\n values {\n number_value: 0.8784314393997192\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.45098042488098145\n }\n values {\n number_value: 0.003921568859368563\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.5215686559677124\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.2039215862751007\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.2392157018184662\n }\n values {\n number_value: 0.9490196704864502\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.2039215862751007\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.4745098352432251\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.8588235974311829\n }\n values {\n number_value: 0.1568627506494522\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.4745098352432251\n }\n values {\n number_value: 0.9960784912109375\n }\n values {\n number_value: 0.8117647767066956\n }\n values {\n number_value: 0.07058823853731155\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n values {\n number_value: 0.0\n }\n }\n }\n }\n}\n\nResponse:\nmeta {\n puid: \"l6bv1r38mmb32l0hbinln2jjcl\"\n requestPath {\n key: \"classifier\"\n value: \"271049282727.dkr.ecr.us-west-2.amazonaws.com/seldon-repository:latest\"\n }\n}\ndata {\n names: \"class:0\"\n names: \"class:1\"\n names: \"class:2\"\n names: \"class:3\"\n names: \"class:4\"\n names: \"class:5\"\n names: \"class:6\"\n names: \"class:7\"\n names: \"class:8\"\n names: \"class:9\"\n ndarray {\n values {\n list_value {\n values {\n number_value: 6.839015986770391e-05\n }\n values {\n number_value: 9.376968534979824e-09\n }\n values {\n number_value: 8.48581112222746e-05\n }\n values {\n number_value: 0.0034086888190358877\n }\n values {\n number_value: 2.3978568606253248e-06\n }\n values {\n number_value: 2.0100669644307345e-05\n }\n values {\n number_value: 3.0251623428512175e-08\n }\n values {\n number_value: 0.9953710436820984\n }\n values {\n number_value: 2.6070511012221687e-05\n }\n values {\n number_value: 0.0010185304563492537\n }\n }\n }\n }\n}\n\n"
]
],
[
[
"### Let's visualise the probability for each label\nIt seems that it correctly predicted the number 7",
"_____no_output_____"
]
],
[
[
"for proba, label in zip(client_prediction.response.data.ndarray.values[0].list_value.ListFields()[0][1], range(0,10)):\n print(f\"LABEL {label}:\\t {proba.number_value*100:6.4f} %\")",
"LABEL 0:\t 0.0068 %\nLABEL 1:\t 0.0000 %\nLABEL 2:\t 0.0085 %\nLABEL 3:\t 0.3409 %\nLABEL 4:\t 0.0002 %\nLABEL 5:\t 0.0020 %\nLABEL 6:\t 0.0000 %\nLABEL 7:\t 99.5371 %\nLABEL 8:\t 0.0026 %\nLABEL 9:\t 0.1019 %\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d061b18c3c6373ce1ad6bf555b22d3a7975a9251 | 25,479 | ipynb | Jupyter Notebook | introduction-to-Tiny-AutoML.ipynb | thomktz/TinyAutoML | 74d9d806ac31795dbf1c4fd60755b0bf9a7c4124 | [
"MIT"
]
| null | null | null | introduction-to-Tiny-AutoML.ipynb | thomktz/TinyAutoML | 74d9d806ac31795dbf1c4fd60755b0bf9a7c4124 | [
"MIT"
]
| null | null | null | introduction-to-Tiny-AutoML.ipynb | thomktz/TinyAutoML | 74d9d806ac31795dbf1c4fd60755b0bf9a7c4124 | [
"MIT"
]
| null | null | null | 68.308311 | 16,274 | 0.820401 | [
[
[
"# **Introduction to TinyAutoML**\n\n---\n\nTinyAutoML is a Machine Learning Python3.9 library thought as an extension of Scikit-Learn. It builds an adaptable and auto-tuned pipeline to handle binary classification tasks.\n\nIn a few words, your data goes through 2 main preprocessing steps. The first one is scaling and NonStationnarity correction, which is followed by Lasso Feature selection. \n\nFinally, one of the three MetaModels is fitted on the transformed data.\n\nLet's import the library !",
"_____no_output_____"
]
],
[
[
"%pip install TinyAutoML==0.2.3.3",
"_____no_output_____"
],
[
"from TinyAutoML.Models import *\nfrom TinyAutoML import MetaPipeline",
"_____no_output_____"
]
],
[
[
"## MetaModels\n\nMetaModels inherit from the MetaModel Abstract Class. They all implement ensemble methods and therefore are based on EstimatorPools.\n\nWhen training EstimatorPools, you are faced with a choice : doing parameterTuning on entire pipelines with the estimators on the top or training the estimators using the same pipeline and only training the top. The first case refers to what we will be calling **comprehensiveSearch**.\n\nMoreover, as we will see in details later, those EstimatorPools can be shared across MetaModels.\n\nThey are all initialised with those minimum arguments :\n\n```python\nMetaModel(comprehensiveSearch: bool = True, parameterTuning: bool = True, metrics: str = 'accuracy', nSplits: int=10)\n```\n- nSplits corresponds to the number of split of the cross validation\n- The other parameters are equivoque\n\n\n**They need to be put in the MetaPipeline wrapper to work**",
"_____no_output_____"
],
[
"**There are 3 MetaModels**\n\n1- BestModel : selects the best performing model of the pool",
"_____no_output_____"
]
],
[
[
"best_model = MetaPipeline(BestModel(comprehensiveSearch = False, parameterTuning = False))",
"_____no_output_____"
]
],
[
[
"2- OneRulerForAll : implements Stacking using a RandomForestClassifier by default. The user is free to use another classifier using the ruler arguments",
"_____no_output_____"
]
],
[
[
"orfa_model = MetaPipeline(OneRulerForAll(comprehensiveSearch=False, parameterTuning=False))",
"_____no_output_____"
]
],
[
[
"3- DemocraticModel : implements Soft and Hard voting models through the voting argument",
"_____no_output_____"
]
],
[
[
"democratic_model = MetaPipeline(DemocraticModel(comprehensiveSearch=False, parameterTuning=False, voting='soft'))",
"_____no_output_____"
]
],
[
[
"As of release v0.2.3.2 (13/04/2022) there are 5 models on which these MetaModels rely in the EstimatorPool:\n- Random Forest Classifier\n- Logistic Regression\n- Gaussian Naive Bayes\n- Linear Discriminant Analysis\n- XGBoost\n\n\n***\n\n\nWe'll use the breast_cancer dataset from sklearn as an example:",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfrom sklearn.datasets import load_breast_cancer\n\ncancer = load_breast_cancer()\n \nX = pd.DataFrame(data=cancer.data, columns=cancer.feature_names)\ny = cancer.target\n\ncut = int(len(y) * 0.8)\n\nX_train, X_test = X[:cut], X[cut:]\ny_train, y_test = y[:cut], y[cut:]",
"_____no_output_____"
]
],
[
[
"Let's train a BestModel first and reuse its Pool for the other MetaModels",
"_____no_output_____"
]
],
[
[
"best_model.fit(X_train,y_train)",
"INFO:root:Training models\nINFO:root:The best estimator is random forest classifier with a cross-validation accuracy (in Sample) of 1.0\n"
]
],
[
[
"We can now extract the pool",
"_____no_output_____"
]
],
[
[
"pool = best_model.get_pool()",
"_____no_output_____"
]
],
[
[
"And use it when fitting the other MetaModels to skip the fitting of the underlying models:",
"_____no_output_____"
]
],
[
[
"orfa_model.fit(X_train,y_train,pool=pool)\ndemocratic_model.fit(X_train,y_train,pool=pool)",
"INFO:root:Training models...\nINFO:root:Training models...\n"
]
],
[
[
"Great ! Let's look at the results with the sk_learn classification report :",
"_____no_output_____"
]
],
[
[
"orfa_model.classification_report(X_test,y_test)",
" precision recall f1-score support\n\n 0 0.96 1.00 0.98 26\n 1 1.00 0.99 0.99 88\n\n accuracy 0.99 114\n macro avg 0.98 0.99 0.99 114\nweighted avg 0.99 0.99 0.99 114\n\n"
]
],
[
[
"Looking good! What about the ROC Curve ?",
"_____no_output_____"
]
],
[
[
"democratic_model.roc_curve(X_test,y_test)",
"_____no_output_____"
]
],
[
[
"Let's see how the estimators of the pool are doing individually:",
"_____no_output_____"
]
],
[
[
"best_model.get_scores(X_test,y_test)",
"_____no_output_____"
]
],
[
[
"## What's next ? \n\nYou can do the same steps with comprehensiveSearch set to True if you have the time and if you want to improve your results. You can also try new rulers and so on.",
"_____no_output_____"
],
[
"Maria, Thomas and Lucas.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
]
|
d061c8abae2ad27910746ac39a22938acf0dd2af | 6,121 | ipynb | Jupyter Notebook | notebooks/Python3-Language/06-OOP/01-Class Basics.ipynb | binakot/Python3-Course | c555fc7376c45f4b2dedb6d57363c0070831c1e1 | [
"MIT"
]
| null | null | null | notebooks/Python3-Language/06-OOP/01-Class Basics.ipynb | binakot/Python3-Course | c555fc7376c45f4b2dedb6d57363c0070831c1e1 | [
"MIT"
]
| null | null | null | notebooks/Python3-Language/06-OOP/01-Class Basics.ipynb | binakot/Python3-Course | c555fc7376c45f4b2dedb6d57363c0070831c1e1 | [
"MIT"
]
| null | null | null | 22.925094 | 318 | 0.525404 | [
[
[
"#OOP allows to create their own objects that have methods and attributes\n#you already used objects (list and such)\n#You can represent the whole world by classes, attributes and methods\n#classes can contain data about itself\n\n#functions are not enough to program large programs",
"_____no_output_____"
],
[
"#also keep in mind that sometimes developers use \"object\" and \"class\" interchangeably",
"_____no_output_____"
],
[
"numbers = [1,2,3] #create/instantiate a built-in object\ntype(numbers)",
"_____no_output_____"
],
[
"class Character():\n pass",
"_____no_output_____"
],
[
"unit = Character() #create instance\ntype(unit)",
"_____no_output_____"
],
[
"#each class has a constructor\n#and by the way a class can have more than constructor\n#(explain that many objects have attributes that have to be initialized, \n#\"name\" for a person ; \"unique id for a credit card\", \n#so constructor is something that makes sure that an object can not be created in an invalid state)",
"_____no_output_____"
],
[
"class Character():\n \n def __init__(self, race): #self represent an instance\n self.race = race",
"_____no_output_____"
],
[
"unit = Character() #client create an instance, and uses unit to work with object while self is used by the class developer",
"_____no_output_____"
],
[
"unit = Character('Elf')",
"_____no_output_____"
],
[
"type(unit)",
"_____no_output_____"
],
[
"unit.race",
"_____no_output_____"
],
[
"#get back to class and demonstrate that \"race\" param can be renamed to \"unit_type\"\n#and say that self.race is an attribute it's like defining a variable within a class\n#and say that we can give any name for race and then call it by new name from a client's side\n#then revert back changes and say that this style is a standard",
"_____no_output_____"
],
[
"class Character():\n \n def __init__(self, race, damage = 10, armor=20):\n self.race = race\n self.damage = damage\n self.armor = armor",
"_____no_output_____"
],
[
"unit = Character('Ork', damage=20, armor=40) #though not obliged to write arg names and even pass anything\nprint(unit.damage)\nprint(unit.armor)",
"20\n40\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d061eb51c53566b0ba0e39649cbe53175a51de39 | 36,626 | ipynb | Jupyter Notebook | 2_Training.ipynb | siddsrivastava/Image-captionin | 683d06c674c737a71957a7f087b726220bce262b | [
"MIT"
]
| 10 | 2020-05-11T02:36:36.000Z | 2022-03-22T22:51:22.000Z | 2_Training.ipynb | srivastava41099/Image-captioning | 683d06c674c737a71957a7f087b726220bce262b | [
"MIT"
]
| null | null | null | 2_Training.ipynb | srivastava41099/Image-captioning | 683d06c674c737a71957a7f087b726220bce262b | [
"MIT"
]
| 3 | 2021-04-12T10:41:48.000Z | 2021-06-18T02:17:53.000Z | 61.247492 | 734 | 0.616475 | [
[
[
"# Computer Vision Nanodegree\n\n## Project: Image Captioning\n\n---\n\nIn this notebook, you will train your CNN-RNN model. \n\nYou are welcome and encouraged to try out many different architectures and hyperparameters when searching for a good model.\n\nThis does have the potential to make the project quite messy! Before submitting your project, make sure that you clean up:\n- the code you write in this notebook. The notebook should describe how to train a single CNN-RNN architecture, corresponding to your final choice of hyperparameters. You should structure the notebook so that the reviewer can replicate your results by running the code in this notebook. \n- the output of the code cell in **Step 2**. The output should show the output obtained when training the model from scratch.\n\nThis notebook **will be graded**. \n\nFeel free to use the links below to navigate the notebook:\n- [Step 1](#step1): Training Setup\n- [Step 2](#step2): Train your Model\n- [Step 3](#step3): (Optional) Validate your Model",
"_____no_output_____"
],
[
"<a id='step1'></a>\n## Step 1: Training Setup\n\nIn this step of the notebook, you will customize the training of your CNN-RNN model by specifying hyperparameters and setting other options that are important to the training procedure. The values you set now will be used when training your model in **Step 2** below.\n\nYou should only amend blocks of code that are preceded by a `TODO` statement. **Any code blocks that are not preceded by a `TODO` statement should not be modified**.\n\n### Task #1\n\nBegin by setting the following variables:\n- `batch_size` - the batch size of each training batch. It is the number of image-caption pairs used to amend the model weights in each training step. \n- `vocab_threshold` - the minimum word count threshold. Note that a larger threshold will result in a smaller vocabulary, whereas a smaller threshold will include rarer words and result in a larger vocabulary. \n- `vocab_from_file` - a Boolean that decides whether to load the vocabulary from file. \n- `embed_size` - the dimensionality of the image and word embeddings. \n- `hidden_size` - the number of features in the hidden state of the RNN decoder. \n- `num_epochs` - the number of epochs to train the model. We recommend that you set `num_epochs=3`, but feel free to increase or decrease this number as you wish. [This paper](https://arxiv.org/pdf/1502.03044.pdf) trained a captioning model on a single state-of-the-art GPU for 3 days, but you'll soon see that you can get reasonable results in a matter of a few hours! (_But of course, if you want your model to compete with current research, you will have to train for much longer._)\n- `save_every` - determines how often to save the model weights. We recommend that you set `save_every=1`, to save the model weights after each epoch. This way, after the `i`th epoch, the encoder and decoder weights will be saved in the `models/` folder as `encoder-i.pkl` and `decoder-i.pkl`, respectively.\n- `print_every` - determines how often to print the batch loss to the Jupyter notebook while training. Note that you **will not** observe a monotonic decrease in the loss function while training - this is perfectly fine and completely expected! You are encouraged to keep this at its default value of `100` to avoid clogging the notebook, but feel free to change it.\n- `log_file` - the name of the text file containing - for every step - how the loss and perplexity evolved during training.\n\nIf you're not sure where to begin to set some of the values above, you can peruse [this paper](https://arxiv.org/pdf/1502.03044.pdf) and [this paper](https://arxiv.org/pdf/1411.4555.pdf) for useful guidance! **To avoid spending too long on this notebook**, you are encouraged to consult these suggested research papers to obtain a strong initial guess for which hyperparameters are likely to work best. Then, train a single model, and proceed to the next notebook (**3_Inference.ipynb**). If you are unhappy with your performance, you can return to this notebook to tweak the hyperparameters (and/or the architecture in **model.py**) and re-train your model.\n\n### Question 1\n\n**Question:** Describe your CNN-RNN architecture in detail. With this architecture in mind, how did you select the values of the variables in Task 1? If you consulted a research paper detailing a successful implementation of an image captioning model, please provide the reference.\n\n**Answer:** I used a pretrained Resnet152 network to extract features (deep CNN network). In the literature other architectures like VGG16 are also used, but Resnet152 is claimed to diminish the vanishing gradient problem.I'm using 2 layers of LSTM currently (as it is taking a lot of time), in the future I will explore with more layers.\nvocab_threshold is 6, I tried with 9 (meaning lesser elements in vocab) but the training seemed to converge faster in the case of 6. Many paper suggest taking batch_size of 64 or 128, I went with 64. embed_size and hidden_size are both 512. I consulted several blogs and famous papers like \"Show, attend and tell - Xu et al\" although i did not use attention currently. \n\n\n### (Optional) Task #2\n\nNote that we have provided a recommended image transform `transform_train` for pre-processing the training images, but you are welcome (and encouraged!) to modify it as you wish. When modifying this transform, keep in mind that:\n- the images in the dataset have varying heights and widths, and \n- if using a pre-trained model, you must perform the corresponding appropriate normalization.\n\n### Question 2\n\n**Question:** How did you select the transform in `transform_train`? If you left the transform at its provided value, why do you think that it is a good choice for your CNN architecture?\n\n**Answer:** The transform value is the same. Empirically, these parameters values worked well in my past projects.\n\n### Task #3\n\nNext, you will specify a Python list containing the learnable parameters of the model. For instance, if you decide to make all weights in the decoder trainable, but only want to train the weights in the embedding layer of the encoder, then you should set `params` to something like:\n```\nparams = list(decoder.parameters()) + list(encoder.embed.parameters()) \n```\n\n### Question 3\n\n**Question:** How did you select the trainable parameters of your architecture? Why do you think this is a good choice?\n\n**Answer:** Since resnet was pretrained, i trained only the embedding layer and all layers of the decoder. The resnet is already fitting for feature extraction as it is pretrained, hence only the other parts of the architecture should be trained.\n\n### Task #4\n\nFinally, you will select an [optimizer](http://pytorch.org/docs/master/optim.html#torch.optim.Optimizer).\n\n### Question 4\n\n**Question:** How did you select the optimizer used to train your model?\n\n**Answer:** I used the Adam optimizer, since in my past similar projects it gave me better performance than SGD. I have found Adam to perform better than vanilla SGD almost in all cases, aligning with intuition.",
"_____no_output_____"
]
],
[
[
"import nltk\nnltk.download('punkt')",
"[nltk_data] Downloading package punkt to /root/nltk_data...\n[nltk_data] Unzipping tokenizers/punkt.zip.\n"
],
[
"\nimport torch\nimport torch.nn as nn\nfrom torchvision import transforms\nimport sys\nsys.path.append('/opt/cocoapi/PythonAPI')\nfrom pycocotools.coco import COCO\nfrom data_loader import get_loader\nfrom model import EncoderCNN, DecoderRNN\nimport math\n\n\n## TODO #1: Select appropriate values for the Python variables below.\nbatch_size = 64 # batch size\nvocab_threshold = 6 # minimum word count threshold\nvocab_from_file = True # if True, load existing vocab file\nembed_size = 512 # dimensionality of image and word embeddings\nhidden_size = 512 # number of features in hidden state of the RNN decoder\nnum_epochs = 3 # number of training epochs\nsave_every = 1 # determines frequency of saving model weights\nprint_every = 100 # determines window for printing average loss\nlog_file = 'training_log.txt' # name of file with saved training loss and perplexity\n\n# (Optional) TODO #2: Amend the image transform below.\ntransform_train = transforms.Compose([ \n transforms.Resize(256), # smaller edge of image resized to 256\n transforms.RandomCrop(224), # get 224x224 crop from random location\n transforms.RandomHorizontalFlip(), # horizontally flip image with probability=0.5\n transforms.ToTensor(), # convert the PIL Image to a tensor\n transforms.Normalize((0.485, 0.456, 0.406), # normalize image for pre-trained model\n (0.229, 0.224, 0.225))])\n\n# Build data loader.\ndata_loader = get_loader(transform=transform_train,\n mode='train',\n batch_size=batch_size,\n vocab_threshold=vocab_threshold,\n vocab_from_file=vocab_from_file)\n\n# The size of the vocabulary.\nvocab_size = len(data_loader.dataset.vocab)\n\n# Initialize the encoder and decoder. \nencoder = EncoderCNN(embed_size)\ndecoder = DecoderRNN(embed_size, hidden_size, vocab_size)\n\n# Move models to GPU if CUDA is available. \ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nencoder.to(device)\ndecoder.to(device)\n\n# Define the loss function. \ncriterion = nn.CrossEntropyLoss().cuda() if torch.cuda.is_available() else nn.CrossEntropyLoss()\n\n# TODO #3: Specify the learnable parameters of the model.\nparams = list(decoder.parameters()) + list(encoder.embed.parameters())\n\n# TODO #4: Define the optimizer.\noptimizer = torch.optim.Adam(params, lr=0.001, betas=(0.9,0.999), eps=1e-8)\n\n# Set the total number of training steps per epoch.\ntotal_step = math.ceil(len(data_loader.dataset.caption_lengths) / data_loader.batch_sampler.batch_size)",
"Vocabulary successfully loaded from vocab.pkl file!\nloading annotations into memory...\nDone (t=1.07s)\ncreating index...\n"
]
],
[
[
"<a id='step2'></a>\n## Step 2: Train your Model\n\nOnce you have executed the code cell in **Step 1**, the training procedure below should run without issue. \n\nIt is completely fine to leave the code cell below as-is without modifications to train your model. However, if you would like to modify the code used to train the model below, you must ensure that your changes are easily parsed by your reviewer. In other words, make sure to provide appropriate comments to describe how your code works! \n\nYou may find it useful to load saved weights to resume training. In that case, note the names of the files containing the encoder and decoder weights that you'd like to load (`encoder_file` and `decoder_file`). Then you can load the weights by using the lines below:\n\n```python\n# Load pre-trained weights before resuming training.\nencoder.load_state_dict(torch.load(os.path.join('./models', encoder_file)))\ndecoder.load_state_dict(torch.load(os.path.join('./models', decoder_file)))\n```\n\nWhile trying out parameters, make sure to take extensive notes and record the settings that you used in your various training runs. In particular, you don't want to encounter a situation where you've trained a model for several hours but can't remember what settings you used :).\n\n### A Note on Tuning Hyperparameters\n\nTo figure out how well your model is doing, you can look at how the training loss and perplexity evolve during training - and for the purposes of this project, you are encouraged to amend the hyperparameters based on this information. \n\nHowever, this will not tell you if your model is overfitting to the training data, and, unfortunately, overfitting is a problem that is commonly encountered when training image captioning models. \n\nFor this project, you need not worry about overfitting. **This project does not have strict requirements regarding the performance of your model**, and you just need to demonstrate that your model has learned **_something_** when you generate captions on the test data. For now, we strongly encourage you to train your model for the suggested 3 epochs without worrying about performance; then, you should immediately transition to the next notebook in the sequence (**3_Inference.ipynb**) to see how your model performs on the test data. If your model needs to be changed, you can come back to this notebook, amend hyperparameters (if necessary), and re-train the model.\n\nThat said, if you would like to go above and beyond in this project, you can read about some approaches to minimizing overfitting in section 4.3.1 of [this paper](http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7505636). In the next (optional) step of this notebook, we provide some guidance for assessing the performance on the validation dataset.",
"_____no_output_____"
]
],
[
[
"import torch.utils.data as data\nimport numpy as np\nimport os\nimport requests\nimport time\n\n# Open the training log file.\nf = open(log_file, 'w')\n\nold_time = time.time()\nresponse = requests.request(\"GET\", \n \"http://metadata.google.internal/computeMetadata/v1/instance/attributes/keep_alive_token\", \n headers={\"Metadata-Flavor\":\"Google\"})\n\nfor epoch in range(1, num_epochs+1):\n \n for i_step in range(1, total_step+1):\n \n if time.time() - old_time > 60:\n old_time = time.time()\n requests.request(\"POST\", \n \"https://nebula.udacity.com/api/v1/remote/keep-alive\", \n headers={'Authorization': \"STAR \" + response.text})\n \n # Randomly sample a caption length, and sample indices with that length.\n indices = data_loader.dataset.get_train_indices()\n # Create and assign a batch sampler to retrieve a batch with the sampled indices.\n new_sampler = data.sampler.SubsetRandomSampler(indices=indices)\n data_loader.batch_sampler.sampler = new_sampler\n \n # Obtain the batch.\n images, captions = next(iter(data_loader))\n\n # Move batch of images and captions to GPU if CUDA is available.\n images = images.to(device)\n captions = captions.to(device)\n \n # Zero the gradients.\n decoder.zero_grad()\n encoder.zero_grad()\n \n # Pass the inputs through the CNN-RNN model.\n features = encoder(images)\n outputs = decoder(features, captions)\n \n # Calculate the batch loss.\n loss = criterion(outputs.view(-1, vocab_size), captions.view(-1))\n \n # Backward pass.\n loss.backward()\n \n # Update the parameters in the optimizer.\n optimizer.step()\n \n # Get training statistics.\n stats = 'Epoch [%d/%d], Step [%d/%d], Loss: %.4f, Perplexity: %5.4f' % (epoch, num_epochs, i_step, total_step, loss.item(), np.exp(loss.item()))\n \n # Print training statistics (on same line).\n print('\\r' + stats, end=\"\")\n sys.stdout.flush()\n \n # Print training statistics to file.\n f.write(stats + '\\n')\n f.flush()\n \n # Print training statistics (on different line).\n if i_step % print_every == 0:\n print('\\r' + stats)\n \n # Save the weights.\n if epoch % save_every == 0:\n torch.save(decoder.state_dict(), os.path.join('./models', 'decoder-%d.pkl' % epoch))\n torch.save(encoder.state_dict(), os.path.join('./models', 'encoder-%d.pkl' % epoch))\n\n# Close the training log file.\nf.close()",
"Epoch [1/3], Step [100/6471], Loss: 4.2137, Perplexity: 67.6088\nEpoch [1/3], Step [200/6471], Loss: 3.9313, Perplexity: 50.97528\nEpoch [1/3], Step [300/6471], Loss: 3.5978, Perplexity: 36.5175\nEpoch [1/3], Step [400/6471], Loss: 3.6794, Perplexity: 39.6219\nEpoch [1/3], Step [500/6471], Loss: 3.0714, Perplexity: 21.5712\nEpoch [1/3], Step [600/6471], Loss: 3.2012, Perplexity: 24.5617\nEpoch [1/3], Step [700/6471], Loss: 3.2718, Perplexity: 26.35966\nEpoch [1/3], Step [800/6471], Loss: 3.3748, Perplexity: 29.2185\nEpoch [1/3], Step [900/6471], Loss: 3.1745, Perplexity: 23.9146\nEpoch [1/3], Step [1000/6471], Loss: 3.2627, Perplexity: 26.1206\nEpoch [1/3], Step [1100/6471], Loss: 2.8865, Perplexity: 17.9312\nEpoch [1/3], Step [1200/6471], Loss: 2.9421, Perplexity: 18.9562\nEpoch [1/3], Step [1300/6471], Loss: 2.7139, Perplexity: 15.0875\nEpoch [1/3], Step [1400/6471], Loss: 2.6474, Perplexity: 14.1176\nEpoch [1/3], Step [1500/6471], Loss: 2.6901, Perplexity: 14.7331\nEpoch [1/3], Step [1600/6471], Loss: 2.6551, Perplexity: 14.2267\nEpoch [1/3], Step [1700/6471], Loss: 2.9028, Perplexity: 18.2242\nEpoch [1/3], Step [1800/6471], Loss: 2.5633, Perplexity: 12.9791\nEpoch [1/3], Step [1900/6471], Loss: 2.7250, Perplexity: 15.2564\nEpoch [1/3], Step [2000/6471], Loss: 2.5907, Perplexity: 13.3396\nEpoch [1/3], Step [2100/6471], Loss: 2.7079, Perplexity: 14.9985\nEpoch [1/3], Step [2200/6471], Loss: 2.5242, Perplexity: 12.4809\nEpoch [1/3], Step [2300/6471], Loss: 2.5016, Perplexity: 12.2019\nEpoch [1/3], Step [2400/6471], Loss: 2.6168, Perplexity: 13.6915\nEpoch [1/3], Step [2500/6471], Loss: 2.6548, Perplexity: 14.2225\nEpoch [1/3], Step [2600/6471], Loss: 2.4738, Perplexity: 11.8673\nEpoch [1/3], Step [2700/6471], Loss: 2.4797, Perplexity: 11.9380\nEpoch [1/3], Step [2800/6471], Loss: 2.6574, Perplexity: 14.2598\nEpoch [1/3], Step [2900/6471], Loss: 2.3054, Perplexity: 10.0281\nEpoch [1/3], Step [3000/6471], Loss: 2.5392, Perplexity: 12.6694\nEpoch [1/3], Step [3100/6471], Loss: 2.6166, Perplexity: 13.6890\nEpoch [1/3], Step [3200/6471], Loss: 2.2275, Perplexity: 9.27642\nEpoch [1/3], Step [3300/6471], Loss: 2.5271, Perplexity: 12.5177\nEpoch [1/3], Step [3400/6471], Loss: 2.3050, Perplexity: 10.0246\nEpoch [1/3], Step [3500/6471], Loss: 2.0236, Perplexity: 7.56542\nEpoch [1/3], Step [3600/6471], Loss: 2.1614, Perplexity: 8.68294\nEpoch [1/3], Step [3700/6471], Loss: 2.3635, Perplexity: 10.6284\nEpoch [1/3], Step [3800/6471], Loss: 2.3958, Perplexity: 10.9773\nEpoch [1/3], Step [3900/6471], Loss: 2.1591, Perplexity: 8.66344\nEpoch [1/3], Step [4000/6471], Loss: 2.3267, Perplexity: 10.2446\nEpoch [1/3], Step [4100/6471], Loss: 3.1127, Perplexity: 22.4825\nEpoch [1/3], Step [4200/6471], Loss: 2.3359, Perplexity: 10.3392\nEpoch [1/3], Step [4300/6471], Loss: 2.3215, Perplexity: 10.1912\nEpoch [1/3], Step [4400/6471], Loss: 2.2369, Perplexity: 9.36462\nEpoch [1/3], Step [4500/6471], Loss: 2.2770, Perplexity: 9.74746\nEpoch [1/3], Step [4600/6471], Loss: 2.2351, Perplexity: 9.34757\nEpoch [1/3], Step [4700/6471], Loss: 2.2890, Perplexity: 9.86499\nEpoch [1/3], Step [4800/6471], Loss: 2.2736, Perplexity: 9.713991\nEpoch [1/3], Step [4900/6471], Loss: 2.5273, Perplexity: 12.5202\nEpoch [1/3], Step [5000/6471], Loss: 2.1436, Perplexity: 8.52971\nEpoch [1/3], Step [5100/6471], Loss: 2.2414, Perplexity: 9.40672\nEpoch [1/3], Step [5200/6471], Loss: 2.3917, Perplexity: 10.9318\nEpoch [1/3], Step [5300/6471], Loss: 2.2926, Perplexity: 9.90097\nEpoch [1/3], Step [5400/6471], Loss: 2.0861, Perplexity: 8.05366\nEpoch [1/3], Step [5500/6471], Loss: 2.0797, Perplexity: 8.00241\nEpoch [1/3], Step [5600/6471], Loss: 2.5135, Perplexity: 12.3480\nEpoch [1/3], Step [5700/6471], Loss: 2.0843, Perplexity: 8.03936\nEpoch [1/3], Step [5800/6471], Loss: 2.4332, Perplexity: 11.3950\nEpoch [1/3], Step [5900/6471], Loss: 2.0920, Perplexity: 8.10140\nEpoch [1/3], Step [6000/6471], Loss: 2.3367, Perplexity: 10.3468\nEpoch [1/3], Step [6100/6471], Loss: 2.9598, Perplexity: 19.2937\nEpoch [1/3], Step [6200/6471], Loss: 2.0285, Perplexity: 7.60297\nEpoch [1/3], Step [6300/6471], Loss: 2.6213, Perplexity: 13.7538\nEpoch [1/3], Step [6400/6471], Loss: 2.0924, Perplexity: 8.10440\nEpoch [2/3], Step [100/6471], Loss: 2.1729, Perplexity: 8.783715\nEpoch [2/3], Step [200/6471], Loss: 2.1168, Perplexity: 8.30481\nEpoch [2/3], Step [300/6471], Loss: 2.2427, Perplexity: 9.41848\nEpoch [2/3], Step [400/6471], Loss: 2.5073, Perplexity: 12.2721\nEpoch [2/3], Step [500/6471], Loss: 2.1942, Perplexity: 8.97323\nEpoch [2/3], Step [600/6471], Loss: 2.2852, Perplexity: 9.82738\nEpoch [2/3], Step [700/6471], Loss: 2.0216, Perplexity: 7.55076\nEpoch [2/3], Step [800/6471], Loss: 2.0080, Perplexity: 7.44841\nEpoch [2/3], Step [900/6471], Loss: 2.6213, Perplexity: 13.7540\nEpoch [2/3], Step [1000/6471], Loss: 2.2098, Perplexity: 9.1141\nEpoch [2/3], Step [1100/6471], Loss: 2.3376, Perplexity: 10.3568\nEpoch [2/3], Step [1200/6471], Loss: 2.1687, Perplexity: 8.74662\nEpoch [2/3], Step [1300/6471], Loss: 2.4215, Perplexity: 11.2623\nEpoch [2/3], Step [1400/6471], Loss: 2.2622, Perplexity: 9.60387\nEpoch [2/3], Step [1500/6471], Loss: 2.0793, Perplexity: 7.99915\nEpoch [2/3], Step [1600/6471], Loss: 3.0006, Perplexity: 20.0976\nEpoch [2/3], Step [1700/6471], Loss: 2.1184, Perplexity: 8.31816\nEpoch [2/3], Step [1800/6471], Loss: 2.0555, Perplexity: 7.81114\nEpoch [2/3], Step [1900/6471], Loss: 2.4132, Perplexity: 11.1696\nEpoch [2/3], Step [2000/6471], Loss: 2.4320, Perplexity: 11.3817\nEpoch [2/3], Step [2100/6471], Loss: 2.6297, Perplexity: 13.8692\nEpoch [2/3], Step [2200/6471], Loss: 2.2170, Perplexity: 9.18001\nEpoch [2/3], Step [2300/6471], Loss: 2.1038, Perplexity: 8.19712\nEpoch [2/3], Step [2400/6471], Loss: 2.0491, Perplexity: 7.76052\nEpoch [2/3], Step [2500/6471], Loss: 1.9645, Perplexity: 7.13170\nEpoch [2/3], Step [2600/6471], Loss: 2.3801, Perplexity: 10.8063\nEpoch [2/3], Step [2700/6471], Loss: 2.3220, Perplexity: 10.1963\nEpoch [2/3], Step [2800/6471], Loss: 2.0542, Perplexity: 7.80050\nEpoch [2/3], Step [2900/6471], Loss: 1.9378, Perplexity: 6.94348\nEpoch [2/3], Step [3000/6471], Loss: 1.9138, Perplexity: 6.77860\nEpoch [2/3], Step [3100/6471], Loss: 2.2314, Perplexity: 9.31325\nEpoch [2/3], Step [3200/6471], Loss: 2.1790, Perplexity: 8.83758\nEpoch [2/3], Step [3300/6471], Loss: 2.7974, Perplexity: 16.4013\nEpoch [2/3], Step [3400/6471], Loss: 2.2902, Perplexity: 9.87657\nEpoch [2/3], Step [3500/6471], Loss: 2.0739, Perplexity: 7.95541\nEpoch [2/3], Step [3600/6471], Loss: 2.4700, Perplexity: 11.8226\nEpoch [2/3], Step [3700/6471], Loss: 2.0761, Perplexity: 7.97370\nEpoch [2/3], Step [3800/6471], Loss: 2.0085, Perplexity: 7.45224\nEpoch [2/3], Step [3900/6471], Loss: 2.0280, Perplexity: 7.59929\nEpoch [2/3], Step [4000/6471], Loss: 2.0487, Perplexity: 7.75750\nEpoch [2/3], Step [4100/6471], Loss: 2.0105, Perplexity: 7.46732\nEpoch [2/3], Step [4200/6471], Loss: 2.3099, Perplexity: 10.0733\nEpoch [2/3], Step [4300/6471], Loss: 1.8471, Perplexity: 6.34158\nEpoch [2/3], Step [4400/6471], Loss: 1.9144, Perplexity: 6.78305\nEpoch [2/3], Step [4500/6471], Loss: 2.3026, Perplexity: 10.0001\nEpoch [2/3], Step [4600/6471], Loss: 2.0366, Perplexity: 7.66411\nEpoch [2/3], Step [4700/6471], Loss: 2.4918, Perplexity: 12.0830\nEpoch [2/3], Step [4800/6471], Loss: 2.0035, Perplexity: 7.41520\nEpoch [2/3], Step [4900/6471], Loss: 2.0007, Perplexity: 7.39395\nEpoch [2/3], Step [5000/6471], Loss: 2.0057, Perplexity: 7.43157\nEpoch [2/3], Step [5100/6471], Loss: 2.0654, Perplexity: 7.88811\nEpoch [2/3], Step [5200/6471], Loss: 1.8834, Perplexity: 6.57597\nEpoch [2/3], Step [5300/6471], Loss: 1.9578, Perplexity: 7.08400\nEpoch [2/3], Step [5400/6471], Loss: 2.1135, Perplexity: 8.27759\nEpoch [2/3], Step [5500/6471], Loss: 1.9813, Perplexity: 7.25206\nEpoch [2/3], Step [5600/6471], Loss: 2.1926, Perplexity: 8.95865\nEpoch [2/3], Step [5700/6471], Loss: 2.2927, Perplexity: 9.90207\nEpoch [2/3], Step [5800/6471], Loss: 2.3188, Perplexity: 10.1636\nEpoch [2/3], Step [5900/6471], Loss: 1.9937, Perplexity: 7.34238\nEpoch [2/3], Step [6000/6471], Loss: 1.8804, Perplexity: 6.55632\nEpoch [2/3], Step [6100/6471], Loss: 1.8708, Perplexity: 6.49346\nEpoch [2/3], Step [6200/6471], Loss: 1.9785, Perplexity: 7.23204\nEpoch [2/3], Step [6300/6471], Loss: 2.1267, Perplexity: 8.38739\nEpoch [2/3], Step [6400/6471], Loss: 1.8215, Perplexity: 6.18116\nEpoch [3/3], Step [100/6471], Loss: 1.9881, Perplexity: 7.301406\nEpoch [3/3], Step [200/6471], Loss: 2.2102, Perplexity: 9.11727\nEpoch [3/3], Step [300/6471], Loss: 1.9104, Perplexity: 6.75575\nEpoch [3/3], Step [400/6471], Loss: 1.8180, Perplexity: 6.15938\nEpoch [3/3], Step [500/6471], Loss: 2.5038, Perplexity: 12.2288\nEpoch [3/3], Step [600/6471], Loss: 2.0724, Perplexity: 7.94375\nEpoch [3/3], Step [700/6471], Loss: 2.0264, Perplexity: 7.58681\nEpoch [3/3], Step [800/6471], Loss: 1.9343, Perplexity: 6.91936\nEpoch [3/3], Step [900/6471], Loss: 1.9347, Perplexity: 6.92228\nEpoch [3/3], Step [1000/6471], Loss: 2.6768, Perplexity: 14.5382\nEpoch [3/3], Step [1100/6471], Loss: 2.1302, Perplexity: 8.41696\nEpoch [3/3], Step [1200/6471], Loss: 1.9754, Perplexity: 7.20958\nEpoch [3/3], Step [1300/6471], Loss: 2.0288, Perplexity: 7.60478\nEpoch [3/3], Step [1400/6471], Loss: 2.1273, Perplexity: 8.39242\nEpoch [3/3], Step [1500/6471], Loss: 2.6294, Perplexity: 13.8661\nEpoch [3/3], Step [1600/6471], Loss: 2.6716, Perplexity: 14.4634\nEpoch [3/3], Step [1700/6471], Loss: 1.8720, Perplexity: 6.50130\nEpoch [3/3], Step [1800/6471], Loss: 2.3521, Perplexity: 10.5080\nEpoch [3/3], Step [1900/6471], Loss: 2.0034, Perplexity: 7.41405\nEpoch [3/3], Step [2000/6471], Loss: 2.0006, Perplexity: 7.39337\nEpoch [3/3], Step [2100/6471], Loss: 2.0902, Perplexity: 8.08620\nEpoch [3/3], Step [2200/6471], Loss: 3.3483, Perplexity: 28.4533\nEpoch [3/3], Step [2300/6471], Loss: 2.0799, Perplexity: 8.00390\nEpoch [3/3], Step [2400/6471], Loss: 2.1215, Perplexity: 8.34411\nEpoch [3/3], Step [2500/6471], Loss: 1.9870, Perplexity: 7.29389\nEpoch [3/3], Step [2600/6471], Loss: 2.1111, Perplexity: 8.25726\nEpoch [3/3], Step [2700/6471], Loss: 1.8926, Perplexity: 6.63631\nEpoch [3/3], Step [2800/6471], Loss: 2.0022, Perplexity: 7.40557\nEpoch [3/3], Step [2900/6471], Loss: 1.9249, Perplexity: 6.85467\nEpoch [3/3], Step [3000/6471], Loss: 1.8835, Perplexity: 6.57626\nEpoch [3/3], Step [3100/6471], Loss: 2.0569, Perplexity: 7.82189\nEpoch [3/3], Step [3200/6471], Loss: 1.8780, Perplexity: 6.54040\nEpoch [3/3], Step [3300/6471], Loss: 2.3703, Perplexity: 10.7010\nEpoch [3/3], Step [3400/6471], Loss: 1.9703, Perplexity: 7.17267\nEpoch [3/3], Step [3500/6471], Loss: 1.9115, Perplexity: 6.76300\nEpoch [3/3], Step [3600/6471], Loss: 2.2174, Perplexity: 9.18364\nEpoch [3/3], Step [3700/6471], Loss: 2.4291, Perplexity: 11.3490\nEpoch [3/3], Step [3800/6471], Loss: 2.3135, Perplexity: 10.1093\nEpoch [3/3], Step [3900/6471], Loss: 1.9082, Perplexity: 6.74124\nEpoch [3/3], Step [4000/6471], Loss: 1.9494, Perplexity: 7.02424\nEpoch [3/3], Step [4100/6471], Loss: 1.8795, Perplexity: 6.55057\nEpoch [3/3], Step [4200/6471], Loss: 2.0943, Perplexity: 8.12024\nEpoch [3/3], Step [4300/6471], Loss: 1.9174, Perplexity: 6.80361\nEpoch [3/3], Step [4400/6471], Loss: 1.8159, Perplexity: 6.14634\nEpoch [3/3], Step [4500/6471], Loss: 2.1579, Perplexity: 8.65335\nEpoch [3/3], Step [4600/6471], Loss: 2.0022, Perplexity: 7.40562\nEpoch [3/3], Step [4700/6471], Loss: 2.0300, Perplexity: 7.61381\nEpoch [3/3], Step [4800/6471], Loss: 1.9009, Perplexity: 6.69223\nEpoch [3/3], Step [4900/6471], Loss: 2.4837, Perplexity: 11.9857\nEpoch [3/3], Step [5000/6471], Loss: 2.0528, Perplexity: 7.79005\nEpoch [3/3], Step [5100/6471], Loss: 1.9514, Perplexity: 7.03869\nEpoch [3/3], Step [5200/6471], Loss: 1.8162, Perplexity: 6.14836\nEpoch [3/3], Step [5300/6471], Loss: 2.0564, Perplexity: 7.81761\nEpoch [3/3], Step [5400/6471], Loss: 1.8345, Perplexity: 6.26224\nEpoch [3/3], Step [5500/6471], Loss: 2.2075, Perplexity: 9.09278\nEpoch [3/3], Step [5600/6471], Loss: 1.8813, Perplexity: 6.56204\nEpoch [3/3], Step [5700/6471], Loss: 1.8286, Perplexity: 6.22503\nEpoch [3/3], Step [5800/6471], Loss: 1.8301, Perplexity: 6.23444\nEpoch [3/3], Step [5900/6471], Loss: 1.9318, Perplexity: 6.90176\nEpoch [3/3], Step [6000/6471], Loss: 1.9549, Perplexity: 7.06348\nEpoch [3/3], Step [6100/6471], Loss: 1.9326, Perplexity: 6.90775\nEpoch [3/3], Step [6200/6471], Loss: 2.0268, Perplexity: 7.58943\nEpoch [3/3], Step [6300/6471], Loss: 1.8465, Perplexity: 6.33754\nEpoch [3/3], Step [6400/6471], Loss: 1.9052, Perplexity: 6.72096\nEpoch [3/3], Step [6471/6471], Loss: 2.0248, Perplexity: 7.57506"
]
],
[
[
"<a id='step3'></a>\n## Step 3: (Optional) Validate your Model\n\nTo assess potential overfitting, one approach is to assess performance on a validation set. If you decide to do this **optional** task, you are required to first complete all of the steps in the next notebook in the sequence (**3_Inference.ipynb**); as part of that notebook, you will write and test code (specifically, the `sample` method in the `DecoderRNN` class) that uses your RNN decoder to generate captions. That code will prove incredibly useful here. \n\nIf you decide to validate your model, please do not edit the data loader in **data_loader.py**. Instead, create a new file named **data_loader_val.py** containing the code for obtaining the data loader for the validation data. You can access:\n- the validation images at filepath `'/opt/cocoapi/images/train2014/'`, and\n- the validation image caption annotation file at filepath `'/opt/cocoapi/annotations/captions_val2014.json'`.\n\nThe suggested approach to validating your model involves creating a json file such as [this one](https://github.com/cocodataset/cocoapi/blob/master/results/captions_val2014_fakecap_results.json) containing your model's predicted captions for the validation images. Then, you can write your own script or use one that you [find online](https://github.com/tylin/coco-caption) to calculate the BLEU score of your model. You can read more about the BLEU score, along with other evaluation metrics (such as TEOR and Cider) in section 4.1 of [this paper](https://arxiv.org/pdf/1411.4555.pdf). For more information about how to use the annotation file, check out the [website](http://cocodataset.org/#download) for the COCO dataset.",
"_____no_output_____"
]
],
[
[
"# (Optional) TODO: Validate your model.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d062038e41a45a23deb4f42e109f95ea47b719ff | 658,049 | ipynb | Jupyter Notebook | mark/export2db.ipynb | shiniao/baozheng | c1ec89e5ce2395abad089f1e7b92c3b31842e9f8 | [
"MIT"
]
| 1 | 2021-02-19T14:51:43.000Z | 2021-02-19T14:51:43.000Z | mark/export2db.ipynb | shiniao/baozheng | c1ec89e5ce2395abad089f1e7b92c3b31842e9f8 | [
"MIT"
]
| null | null | null | mark/export2db.ipynb | shiniao/baozheng | c1ec89e5ce2395abad089f1e7b92c3b31842e9f8 | [
"MIT"
]
| null | null | null | 61.534412 | 1,500 | 0.41543 | [
[
[
"import pandas as pd\nimport mysql.connector\nfrom sqlalchemy import create_engine",
"_____no_output_____"
],
[
"df = pd.read_csv('/Users/zhezhezhu/.bz_datasets/datasets_shiniao_create_dataset_test.txt',\n sep='\\t')\ndf",
"_____no_output_____"
],
[
"df.memory_usage(index=False, deep=True).sum()\n\nMYSQL_USER \t\t= 'root'\nMYSQL_PASSWORD \t= '19(zhezhezhu)95'\nMYSQL_HOST_IP \t= '127.0.0.1'\nMYSQL_PORT\t\t= \"3306\"\nMYSQL_DATABASE\t= 'datasets'\nengine = create_engine('mysql+mysqlconnector://'+MYSQL_USER+':'+MYSQL_PASSWORD+'@'+MYSQL_HOST_IP+':'+MYSQL_PORT+'/'+MYSQL_DATABASE, echo=False)\n",
"_____no_output_____"
],
[
"idx = 1\nfor df in pd.read_csv('/Users/zhezhezhu/projects/data_source/spam_message/spam_message.txt',\n names=[\"classify\",\"content\"],\n chunksize=500,\n sep='\\t'):\n df.to_sql(name=\"spam_message\", con=engine, if_exists='replace', chunksize=500)\n print(str(500 * (idx+1))+\" Processed\")",
" classify content\n0 0 商业秘密的秘密性那是维系其商业价值和垄断地位的前提条件之一\n1 1 南口阿玛施新春第一批限量春装到店啦 春暖花开淑女裙、冰蓝色公主衫 ...\n2 0 带给我们大常州一场壮观的视觉盛宴\n3 0 有原因不明的泌尿系统结石等\n4 0 23年从盐城拉回来的麻麻的嫁妆\n1000 Processed\n classify content\n500 0 胡萝卜素增加3倍、维生素Bl2增加4倍、维生素C增加4\n501 0 高管都需要KPI就没资格做高管\n502 0 护士一检查惊呼怎么牙都蛀成这样了\n503 1 x.x-x.x来张家边苏宁!抢美的空调! 预存xx元:最低=xxx元,最高=xxxx元!预约...\n504 0 火箭休赛期总结:可冲击西部冠军惧怕三劲敌\n1000 Processed\n classify content\n1000 1 劲松电器韩俊学重回上班,感谢朋友领导的支持,空调批发价供应xxx套,x.xx匹空调xxxx元...\n1001 0 如果说认了亲戚就代表着腐败\n1002 0 /男子在派出所旁强奸女孩被捕时裤子还没拉上\n1003 0 15岁以上每日1次2粒随时服用\n1004 0 投资者依然在偏向于恐惧一侧\n1000 Processed\n classify content\n1500 1 护肤品x折 洗头水x折,满xxx元送xx元超市抵用卷.x号一x号王府井超市。\n1501 0 千岛湖位于浙江省杭州市淳安县境内\n1502 0 夏季衢州的天亮的早终于天亮了等下回家贵州黔西南~浙江丽水希望我义无反顾马不停蹄千里回归能赶上...\n1503 0 湖南高速烂尾涉塌方式腐败案\n1504 0 05亿美元的价格向智利安托法加斯塔集团出售萨尔迪瓦铜矿50%股权\n1000 Processed\n classify content\n2000 0 每天晚上到了11点左右家里网速慢得我要砸手机\n2001 0 今年主打的防晒喷雾韩国超火的Re:cipe水晶防晒神器水晶喷雾\n2002 1 为答谢新老客户对我店的大力支持,正月十五到本店办理宽带业务参加活动机型者可凭此短信优惠xx元...\n2003 0 为金叶水箱等4家企业上报待批调整置换土地46\n2004 0 12342提示向12345投诉\n1000 Processed\n classify content\n2500 1 Duang...?锦兰村为庆祝x.x妇女节,特别推出优惠充值活动,充的越多送的越多,名额有限...\n2501 1 三迪华美达广场酒店二楼金汤SPA会所 ,携手全体员工在元宵佳节到来之际,祝您元宵节快乐,合家...\n2502 0 ——「第三方支付或失P2P沉淀资金银行抢钱抢地盘\n2503 0 为何“中国好声音”的选手整体不如“超女快男”红\n2504 1 浠水*新农销售部恭祝新老客户元宵节快乐!打造国内首家电商农贸市场!租金抵月供,轻松做房东!不...\n1000 Processed\n classify content\n3000 0 「xx万热播视频」追星这件小事\n3001 0 18岁小伙\"自学\"成黑客盗刷160万人信用卡\n3002 0 咨询心房的人越来越多了…大家过来相知相识\n3003 0 小羊肖恩高清百度网盘下载链接\n3004 0 我可以免费转赠这2万元的奖学金\n1000 Processed\n classify content\n3500 0 灿鸿虽然没导致连云港的阴雨\n3501 1 姚贝娜因乳腺癌走了,这款产品却火了,每天只需x.xx元,一年xxx元,就可以每一个女性获得x...\n3502 1 感谢您致电华峰申银--您身边的贷款担保整体方案解决专家,我们将始终为您提供专业、便捷贴心的服...\n3503 0 皮影、杂耍、建筑、庆典、大街、人群\n3504 0 聘请浙江省整形外创始人马奇教授担任名誉院长\n1000 Processed\n classify content\n4000 0 我们似乎是被妖姑娘潜规则下活着的生命\n4001 0 将通过电子警察抓拍进行管理\n4002 0 就在北京頤堤港的2015NBANATION籃球國度北京場\n4003 0 现在觉得黑咖啡也不那么苦不那么酸了\n4004 1 利率浮到顶,存款最划算!自xxxx年x月x日起,我行存款利率统一上浮xx%,让您尊享最高存款...\n1000 Processed\n classify content\n4500 1 朝阳公园,高层观景x居室,视野特别好,无任何遮挡,非常安静四面不临街,总价低,低于市场xx万...\n4501 0 It'samazinghow颜色\n4502 1 建行:xxxx xxxx xxxx xxxx xxx杨丽娟\n4503 0 接下来的任务就是调查徐州的天气环境\n4504 0 ③晚上喝酸奶有利于补钙:晚间12点至凌晨是人体血钙含量最低的时候\n1000 Processed\n classify content\n5000 1 【格兰玛弗兰荆门东方专柜】亲爱的女神x.x女人节,全场一件x折,两件x折,三件x折再送价值x...\n5001 0 投出研究生阶段的第一份简历\n5002 0 其他手机拍出来的照片都挺好看的\n5003 0 由江西省旅游规划研究院主办\n5004 0 我妈说我背不适合~所以如果有喜欢的朋友可以找我买\n1000 Processed\n classify content\n5500 0 而且吴江区系统跟园区不一样\n5501 0 靠她每月只有2000多的工資維持\n5502 0 无锡监狱特邀86岁的抗战老兵吴成老先生来到监狱\n5503 0 看完克拉恋人我才知道设计师可以半路出道原本从没学过的专业就可以担任\n5504 1 大疾病保险产品长保安康将于xxxx年xx月xx日起正式停售!本产品特色是保费低,保障高,三次...\n1000 Processed\n classify content\n6000 0 爱心1班今天上的是给图画上色课\n6001 0 中国好声音昨晚26岁湖南那个男生黄恺\n6002 0 第一阶段:7月31日至8月6日\n6003 0 坐公交去整容医院一块医生说你这吴彦祖的脸还整\n6004 0 服务客户的理念也让华为逐渐成为中国人引以为豪的国产品牌\n1000 Processed\n classify content\n6500 1 淮南移动xG手机“x”元购,裸机直降高达xxx元。华为Px原价xxxx,现场xxxx!x.x...\n6501 0 基于Twitter庞大的用户群来创造以评论为亮点的音乐内容搜索分享服务\n6502 0 x名男子在对方拒绝交出手机后打砸小车\n6503 0 又有时间可以出去旅游了~我到底要不要去云南呢\n6504 1 您好,我想咨询关于 九茂小区 南北通透 得房率高 地铁口 急售 售价xxx.x万/月x室x厅...\n1000 Processed\n classify content\n7000 0 今天晚上和明天晚上是FTISLAND首尔演唱会\n7001 0 山东落马女法官被戴械具称不能行走医院称诈病遇到这样的人也是无语凝噎了\n7002 1 感谢您致电昆明博海汽服务有限公司,我公司是福田戴姆勒汽车授权服务商,品种齐全,工艺精湛,价格...\n7003 0 只有在世俗层面遭到质疑的时候才能确定自己的内心\n7004 1 富尔玛二楼“鹏鹤”实木家具将于x月x日早x点至晚x点举行大型促销活动,鹏鹤家具是厂家直营店,...\n1000 Processed\n classify content\n7500 0 四川公安的刑侦警犬都将接受能力认证考核\n7501 0 WV再次上了钱江卫视新闻发布会\n7502 0 我的微软账户能绑定几台电脑\n7503 0 可惜初心还是贿赂一下…紫英有怎样的故事也从来没提…怀朔和璇玑也死了……哎……\n7504 0 Nba欠吉诺比利一个mvp\n1000 Processed\n classify content\n8000 0 之前他由于使用毒品和滥用暴力\n8001 0 健身后6大不适——3、头痛头晕一般做一些剧烈动作时\n8002 0 南京港中冠A宝利来三诺生物南方汇通紫鑫药业\n8003 0 证监会启动再融资是投石问路\n8004 0 理科分数线分别为740分、690分、631分、625分\n1000 Processed\n classify content\n8500 1 免费咨询xxxxxxxxxxx新版机麻控制器,起手好牌,不安装,可现场看效果,满意再买。t\n8501 0 16岁留守少女疑遭堂伯强奸家属报案警方介入实习生刘旭记者嵇石8月6日\n8502 0 美妆、心机、潜规则、绿茶婊等成为网红的代名词\n8503 0 前段时间买了小米Note全网通发现只能用电信上网\n8504 0 到下飞机前她们再也没再聊过天了\n1000 Processed\n classify content\n9000 0 给他们留下的股票是多么的值钱\n9001 0 张紫嫣说的是见王健林一面给她一百万很容易的没见过liyingxin那样的人说和我结婚是已婚的...\n9002 0 一楼的防盗窗是小偷天然的梯子\n9003 0 困在电梯里的腹泻男尼玛桑不起啊\n9004 0 Sprint公司在全球约有7万名\n1000 Processed\n classify content\n9500 0 浙江无良老板欠工人工资半年不给\n9501 0 江山义乌杭州南京南通福建浦城呵呵\n9502 0 转播到腾讯微博承德第4个厅官落马\n9503 0 7月29日阿勒泰明星妆品贴柜销售今日目标800\n9504 0 蒜头可抵抗病毒、真菌、原生生物和寄生物\n1000 Processed\n classify content\n10000 0 微软为了重新争夺移动市场份额\n10001 0 第一时间拿起手机点开微信领取红包一气呵成\n10002 1 你好,我是刚刚打电话过来的德国汉斯格雅洁具小吴,汉斯格雅xxx全年最低价大促,花洒+龙头套组...\n10003 0 别像小偷总是见不得人家比你好\n10004 0 明明每天都擦好防晒霜再出门\n1000 Processed\n classify content\n10500 0 一定都去过了吧~但说起广州的海洋生物标本馆、岭南药科普基地、足球机器人实验室、舰船科普基地…...\n10501 0 每一步都不會白走這是我最近的心情大家在每個階段的努力都不會白費的加油~~~~感謝之前自己的努...\n10502 0 发现了一个和iwanna相似的手机游戏\n10503 0 注定要删去……电脑中毒格式化中……那些记录\n10504 0 那么华为G8的配置怎么样呢\n1000 Processed\n classify content\n11000 0 就使用我的邀请码46bhdx下载并登录浙江移动手机营业厅\n11001 0 是旅游度假、休闲娱乐、朋友聚餐下酒的理想食品\n11002 0 就这样被政府部门的不作为给毁掉了\n11003 0 我日今天下午本来想坐飞机回去的\n11004 0 工信部公布2015中国首批智能制造专项项目\n1000 Processed\n classify content\n11500 1 海尔空调冯利芳给您拜个晚年!祝您家庭吉羊如意,心情羊光满面,健康羊羊得意,告诉您个好消息!海...\n11501 0 孩子们每天想着电脑手机游戏\n11502 0 填写邀请码:548903可领3元红包\n11503 0 什么情况『19岁弱智女半年内实施盗窃20余起被抓获东南网福建第一门户』\n11504 0 其中最重要的是肌肤细胞老化引起的肌肤老化松弛\n1000 Processed\n classify content\n12000 0 没用户思维绝对被互联网时代淘汰\n12001 0 再享单笔消费满2000元赠LASANTE日光餐厅鸡尾酒买一送一券一张\n12002 0 开始宝贝一直质疑我家的直邮\n12003 0 奇怪的是~~他什么时候去那上班啦\n12004 0 相比去年我们在坦克方面做了什么改进\n1000 Processed\n classify content\n12500 0 别提多失望…maybe还是在泰国的才正宗吧\n12501 0 你用了13亿人的钱富起来了你们8000万\n12502 0 县级以上人民政府应当建\n12503 0 看了好声音觉得周杰伦太可爱了\n12504 0 超1万赞的教科书般的家装微信营销\n1000 Processed\n classify content\n13000 0 “中国食药监管”App全新升级上线\n13001 0 1998年还曾被改编成同名电视剧\n13002 0 送伴娘服??都是苏州婚纱城大店购入\n13003 0 由网易时尚、网易房产、使馆壹号院联合举办的“中国自信态度时装show”在京举行\n13004 0 这种动物本性的隐性基因不时的露出狰狞的面目\n1000 Processed\n classify content\n13500 0 最后研究生入学考试成绩我比他高了近100分\n13501 0 地铁是不是又该恢复回2RMB了\n13502 1 新年好,我是大自然木门,移门,墙纸的,我们厂家x月x号-xx号全部x.x折,请您与家人一定要...\n13503 1 元宵节快乐, 新场酬宾:雷迪森搬到新花样x/x号起:任何专场洋酒(名士,蓝带,XO)买一瓶送...\n13504 0 为了这个电视剧充了腾讯会员\n1000 Processed\n classify content\n14000 0 RnD瑷缇智能彩绘又玩出了新设计\n14001 0 58买储回来处3400股002066\n14002 0 是伦敦交响乐团和BBC交响乐团的驻团场地\n14003 0 本来六点二十的飞机暂时成功延误到十一点了…真棒\n14004 0 区建交委:1.宝山区公共自行车网点按照方便、适量和统筹兼顾原则及方便取点等因素\n1000 Processed\n classify content\n14500 1 疯狂接单!名额有限!全国接单!黑白户办理xxw以上信用卡,xx天下卡,需要办理的联系我,中介...\n14501 0 好消息:莽叔和绵竹飞机快送合作成功\n14502 0 可手机微博里没显示出来……于是把微博卸载了又重下了一次……结果这次陈学东表情没有\n14503 0 擅长UI设计、交互设计、电商设计、VI设计\n14504 0 目前已经完成8500万美元C轮融资\n1000 Processed\n classify content\n15000 0 我一凡人能跳完前15分钟的热身就累到不要不要的\n15001 0 由SEGA开发、BB工作室监修编剧\n15002 0 专访Cassia赵福勇:做了20年WiFi\n15003 0 溧阳市气象台16日8时30分\n15004 0 当年说想考南京航天航空大学的\n1000 Processed\n classify content\n15500 0 自由球员海耶斯已经与火箭达成签约协议\n15501 0 新品1933镇江万达:猛料1886\n15502 0 刚刚她关了灯我玩手机玩嗨了\n15503 0 xx件你不知道关于贾斯汀比伯的事情\n15504 0 墨尔本boxhillsouth全新townhouse单间出租$xxx/monthxxmin走...\n1000 Processed\n classify content\n16000 0 那时候地球已经迈入机器人时代\n16001 0 柳州市鱼峰区人民法院审结一件买卖合同纠纷案件\n16002 1 家长您好乐橙美术春季班已经开始报名,可随时报名免费试听,提前报名可适当优惠。地址:铭城xx号...\n16003 0 不是你们政府邀功立表证明你们为人民服务的地方\n16004 0 希望大家可以单独发给她红包\n1000 Processed\n classify content\n16500 1 TOTO首届智能卫浴节开始了,智能马桶盖只需xxxx元,凭短信可享折后xx折,无需出国,微个...\n16501 0 北京、上海、浙江投资事件数量增幅超过xxx%\n16502 0 为什么现在的手机尺寸都往x\n16503 0 x月xx日起日照主城区禁行三轮车、四轮代步车\n16504 1 姐您好:我是蓝爵美容会所的楠楠,三八节即将到来,我店为了答谢老顾客长期以来对蓝爵美容会所的支...\n1000 Processed\n classify content\n17000 0 融资租赁公司设立子公司不设最低注册资本限制\n17001 0 籍贯江苏常州在也许已经记不起他的\n17002 0 白天顶着中暑天还要跑医院差点虚脱的晕过去\n17003 0 及香港終審法院首席法官馬道立分別率領的代表團會面\n17004 0 他30多年来共创作的几万幅作品\n1000 Processed\n classify content\n17500 0 尤其是开启了乡村旅游的全新时代\n17501 0 1958年8月由浙江医学院从杭州分迁至\n17502 1 徐州尚美机械设备有限公司。苏北地区专业雕刻机,激光机,木工机销售商。地址:徐州市云龙区下河头...\n17503 0 宁陵县柳河派出所救出落井儿童的警察好样的\n17504 0 王家豪真是黑的就差个月亮就可以演包拯了\n1000 Processed\n classify content\n18000 0 每一件IGNIS产品由内而外均渗透着源于自然的淳朴而脱俗的气质\n18001 1 源生堂为满足新老客户需求特添加:烫拉染项目!活动期间植物健康染发只需xx元!健康陶瓷烫发只需...\n18002 0 这是baby做的装修家的工程表\n18003 0 并对出租物业人员进行消防安全培训\n18004 0 能让一个57岁的人看起来像40岁一样\n1000 Processed\n classify content\n18500 0 预约了小米NOTE全网通华为荣耀7全网通荣耀畅玩4X\n18501 0 无锡买二手房公积金贷款30万评估费要5千为什么这么高这样收费合理吗\n18502 0 一是制定了人民法庭设置改革实施方案\n18503 0 今年还要打造xxx套群租“样板房”\n18504 0 微软OfficeforMac2016上线了\n1000 Processed\n classify content\n19000 0 I'mnotallowed~一年多前忘记因为啥我禁止她玩\n19001 0 但浙江交通电台93还在那儿故作矫情\n19002 0 目前苏州继续受大陆高压的控制\n19003 0 中国专业的亚健康咨询网站\n19004 0 浙江大学实验室给你最权威的答案\n1000 Processed\n classify content\n19500 0 一个公平公正的房地产税是调节居民收入分配不公最为重要的工具\n19501 0 从古到今冤案甚多有几个能翻过来的\n19502 0 新随着大家对装修设计风格的逐渐细分\n19503 0 参加好声音de永远都是这样说\n19504 0 本店销售的产品均为“国珍专营”实体店正品\n1000 Processed\n classify content\n20000 0 投资自己才是最好的投资\n20001 0 infiniteBAD钢琴版\n20002 0 用圆形设计将卧榻作了转角延伸\n20003 0 好多法律明文规定的劳动保障都保障不了\n20004 1 然为您提供较高收益的理财,是您资金保值的最好管家。如您有需要,请电话咨询或到柜面咨询。我行每...\n1000 Processed\n classify content\n20500 0 QQ播放器可以听但是鼠标碰不着播放器\n20501 0 外封内页俩人叉开的设计棒棒的\n20502 0 本人求合租江夏桥东天一七塔寺附近的的房子\n20503 0 热烈祝贺我校女足获得xxxx年苏州市“可口可乐姑苏晚报”杯青少年暑期足球赛高中女子组第一名\n20504 0 房金所所有投资标的投资门槛降至1000元\n1000 Processed\n classify content\n21000 0 不是逛逛百度就可以当自媒体的\n21001 0 隐身在田间小路中靠着卫星导航寻找\n21002 0 大伙也愿意看一场大戏/佛教协会首次就“释永信被举报”表态\n21003 0 要更新病毒库杀毒……于是从昨晚开电脑后还没有进行任\n21004 0 现在的腾讯安全系数真的是太低了\n1000 Processed\n classify content\n21500 0 等你后天下飞机我和“弟弟”你和我的宝贝狗狗\n21501 0 宋美龄喜欢法国梧桐那年蒋介石在整个南京城种满了梧桐你若是喜欢吃屎我愿每天都为你拉\n21502 0 labolabo城野医生毛孔收敛水\n21503 0 但谁都知道这只是x年短暂的缘分\n21504 0 投之前先确认自己的ip地址换了没\n1000 Processed\n classify content\n22000 0 xx年x月刘某讲船卖给他人后潜逃\n22001 0 就是解放路冲进上海证券大楼\n22002 0 「143万人在传看」实拍毒凤爪加工点揭秘泡椒凤爪无名添加剂\n22003 0 别让车成为伤害他人的保护伞\n22004 0 市民来电表扬在六合区大厂街道的扬子公交线所有公交司机都会主动避让行人\n1000 Processed\n classify content\n22500 0 这会打开电脑该图一点也不晚\n22501 1 尊敬的客户您好,x.xx日,中午xx:xx,建材家居品牌厂家直销活动,与您相约远州国际大酒店...\n22502 0 患高热、腹泻、肝炎、肾炎、胆囊炎、胆石症之人忌食\n22503 0 我谈徐州人过分劝酒的帖子再发表一遍\n22504 0 TPP谈判或促成多国放宽外资投资限制\n1000 Processed\n classify content\n23000 0 能提供多达100倍的深度覆盖增益和千倍以上的联接能力\n23001 0 一下子就把荣耀6plus的光芒给掩盖掉了\n23002 0 护士给我扎针的时候说:“为什么每次这种考技术的活就轮到我呢\n23003 0 讲述比非洲还热的故事…哈哈哈哈\n23004 0 九龙仓国宾1号样板间资料图片\n1000 Processed\n classify content\n23500 0 像是北京市上海深圳苏州的来看病\n23501 0 这其中包括了43家城商行、37家农商行和农信社以及华商银行、华一银行、汇丰银行等3家外资行\n23502 0 该款平板电脑的原型是去年CES展会上华硕曾展示过的平板电脑TransformerAio\n23503 0 中国原创文学IP在经过十几年的积累后在今年全面爆发\n23504 0 她说我爸爸把飞机都开走了我怎么回建宁哦\n1000 Processed\n classify content\n24000 0 女士由于子宫和大肠一层肠膜相隔\n24001 0 关于魔白咨询问题汇总魔白是纯天然成分\n24002 0 华为meta7丢水里没问题\n24003 0 公司\"国珍\"品牌被认证为最高等级“五星品牌\n24004 0 心理咨询师…沙盘实战开始喽…想学习\n1000 Processed\n classify content\n24500 0 感受到用了这么久电脑总该学点维修常识了\n24501 0 曾经住过的地方的猫咪他们都还在\n24502 0 中国好声音竟然有人唱南山南\n24503 1 亲们.美赞巨奶粉购一听立减x元',三听立减xx元.六听立减xx元.,全场满xxx送购金xx元...\n24504 0 Vx福州房产回复摇奖16\n1000 Processed\n classify content\n25000 0 高盖蜂蜜瓶厂家江苏徐州宏华玻璃科技有限公司蜂蜜瓶厂家\n25001 0 电脑上播10分钟就走神去干别的了\n25002 0 楼下售楼小姐跳舞呢居然都是一个动作\n25003 0 她说去医院问问医生到底什么病\n25004 0 买早饭的东北大妈让N人插队逼我发飙\n1000 Processed\n classify content\n25500 0 推举一位健美先生然后一枪击毙\n25501 1 xxxxxx元(RMB)及苹果笔记本电脑一台!请及时登陆活动站:gszwa.cc 查看领取...\n25502 0 国民革命军74军与日本11军激战春华山\n25503 0 无锡永中科技有限公司在北京与国家统计局签署信息化合作框架协议\n25504 0 真应该从泰州回来的晚上就出来的\n1000 Processed\n classify content\n26000 0 本店再送价值xx元的沐浴露一瓶\n26001 0 相比之下华为和小米已经很接近\n26002 0 因此很容易引起呼吸系统疾病\n26003 0 方大集团签约合建16亿元光伏发电项目\n26004 0 达实智能与东台市人民政府、深圳市优视技术有限公司就东台市智慧城市PPP投资项目达成了合作意向\n1000 Processed\n classify content\n26500 0 苏州籍著名法学家倪征日奥参加对二战日本战犯审判的亲身经历\n26501 0 北京靖江商会企业家各位领导莅临指导\n26502 0 发现违法接送学生的车辆及时向公安交管部门举报\n26503 0 带来了10款首次登场的保时捷车型和500点额外成就分\n26504 0 2、施工讲步骤大理石背景墙施工方法介绍\n1000 Processed\n classify content\n27000 0 下一班北京的飞机又他妈的从六点延迟到八点整的我凌晨到家大巴上还眼铮铮看着钱丢了\n27001 0 肯定有它的道理~购买详情及攻略\n27002 0 我们一起挤北京地铁一号线的日子\n27003 1 周一好~ xxxx年泰康财富隆重推出 稳健x号和 卓越x号x期 两款优质产品,稳健x号起点x...\n27004 0 最高人民法院印发通知要求认真贯彻新\n1000 Processed\n classify content\n27500 0 沣东新城教育党委召开2015年党风廉政建设暨治理教育乱收费工作会议\n27501 0 刚才那修眉刀在胳膊上划了两下\n27502 0 亚马逊收购Goodreads\n27503 0 新法规的实施对我输往韩国产品的企业影响重大\n27504 0 当一切都于我事与愿违我要记得飞机也是逆风而起飞\n1000 Processed\n classify content\n28000 0 我知道有很多人在质疑我们的产品\n28001 0 据最高检察院网站7月30日消息:日前\n28002 0 PE系券商玩法:突出投行摒弃营业部\n28003 0 我发誓以后再也不要旺季的时候去旅游了你造厦门鼓浪屿有多少人吗啊\n28004 0 他说60周岁后领到的退休金还是叫什么的\n1000 Processed\n classify content\n28500 0 公交往前开了x公里绕立交桥整圈转弯\n28501 0 在飞机上可能也会被要求关闭\n28502 0 回头整理下我坐飞机的时候随身携带的东西\n28503 0 违法了无论什么理由都要接受制裁\n28504 0 当我们看到那些被人质疑的梦想一天天变成现实的时候\n1000 Processed\n classify content\n29000 1 《xxxx我为瘦狂》美雅美容会所皮下抑脂术,一个月做一次,五分钟操作可达到四个月点穴的效果,...\n29001 0 不同分数、不同犯规裁判手势是什么……新奇有趣的课让孩子们倍感新鲜\n29002 0 到最后我分了24期你又不愿意变卦了\n29003 0 很香~地址:小店区寇庄西路王府井购物中心西侧阳光地带底商\n29004 1 三月女王月,致花样女人,最好的礼物给亲爱的自己!最大力度活动来袭:x.x~x.x购羽西产品满...\n1000 Processed\n classify content\n29500 0 害的我拿着手机一直等一直等\n29501 0 警察蜀黍提示您:自觉做到“喝酒不开车\n29502 0 而百分之80的人的亚健康都是因为十二经络不畅而导致的\n29503 0 可根据每位顾客的要求设计专属定制款美甲\n29504 0 洛杉矶设计师AlexanderPurcell借鉴战争中使用的水雷\n1000 Processed\n classify content\n30000 0 广州地铁预测期间最高日客流量将超600万人次\n30001 0 然连续两天陪妈妈去医院看病\n30002 0 重庆市第五中级人民法院对该纠纷作出维持原判的二审判决\n30003 0 小偷“念旧”一个半月对一家店“下手”3次\n30004 1 尚佳品牌女装折扣祝您元宵节快乐!三八女神节是我们自己的节日,爱自己就为自己买件新衣吧!六、七...\n1000 Processed\n classify content\n30500 0 没有取消航班没有延误已经坐上飞机安心等待回家你们要想我我也会想你\n30501 0 应对通胀——股市机会少\n30502 0 北京315消费者投诉网上各种投诉小米公司的\n30503 0 MT6735等平台的Layout工作\n30504 0 牛奶的神奇功效:1牛奶+面粉=优质面膜\n1000 Processed\n classify content\n31000 1 宜宾恒昌公司聂小玲提前预祝您:元宵节快乐!有需要资金的朋友可以电话联系我准备资料了,最快x天...\n31001 1 ^长期诚信在本市作各类资格职称!以及印 /章、牌、 ……等。祥:x x x x x x x ...\n31002 0 PS:老李提示:双肩背背在身后\n31003 0 来自上海、广东等地的8家机器人重点项目与长沙雨花经开区签订投资协议\n31004 0 设计了这款伸缩式电源接线器\n1000 Processed\n classify content\n31500 0 这是在向人贩子不用判死刑挑战吗\n31501 0 在害怕等着裁判的判决吧\n31502 0 护士长估计刚从台湾参观回来\n31503 1 实景现椖只要x万?【日 昱 城】超低渞俯仅需x万起,买椖更可参加x年内的超值特恵,椖源有 阝...\n31504 0 你不情愿花20元开张存款证明没人逼你\n1000 Processed\n classify content\n32000 0 92商城名称:Amazon商品名称:NewChapterZyflamendNighttime\n32001 0 最后小大从vcr里跳出来的时候忍不住泪目\n32002 0 xxx认为百度滥用Robots协议\n32003 0 我花xxx元邮购了一台清华同方平板电脑\n32004 0 goog『中国留学生因凌虐案被判无期\n1000 Processed\n classify content\n32500 0 本国投资者在购买股票、债券、金融衍生品和认购股权方面受到一定限制\n32501 0 而今年4月才上市的AppleWatch排名末尾\n32502 0 出自DonaireArquitectos\n32503 0 坚决把腐败分子清除出党、军队、干部队伍\n32504 1 武进红星美凯龙\"箭牌卫浴\"新年送好礼,参加活动者,免费送角阀,延长质保一年,更有xxx元马桶...\n1000 Processed\n classify content\n33000 0 最好花1分钟时间检查一下车底下、车轮上或发动机上有没有小动物\n33001 0 麦迪NBA生涯唯美震撼MV\n33002 0 127名预征青年井然有序地进入各体检科室接受体检\n33003 0 河南|许昌市中级人民法院审判业务庭室人员名单、联系方式\n33004 0 只要你确定收货返利的现金就打到你支付宝\n1000 Processed\n classify content\n33500 0 居然是99年8月2日的生日……\n33501 0 宁被告知残忍的真相也不愿听温柔的欺瞒\n33502 0 穿着cos服的二次元小伙伴被说作穿着暴露\n33503 0 请其他单位联系参加18日招聘会\n33504 0 常州市惠民工程之一的少年宫三期工程正在紧张建设中\n1000 Processed\n classify content\n34000 0 我觉得有些人真的是大概只有亲妈爆炸才是真的其他只要不是好事当事人回应就全是假的\n34001 0 而朝鲜的核武器是周边所有国家都不能接受的\n34002 0 和某个逼样在聊天我说我在赤膊敷药有图有真相\n34003 0 专栏作家三公子随手记出人生第一桶金\n34004 0 清政府和少林之间的关系也在发生微妙的变化\n1000 Processed\n classify content\n34500 0 华为消费者业务上半年收入90\n34501 0 恶搞花千骨寻找xxxxChinaJoy最美showgirl\n34502 0 华为最厉害/华为荣耀7全网通版开箱:包装盒看点十足\n34503 0 0公寓对全部智能家居实现“一键化”操作\n34504 1 您好,我是天宝婚庆部,感谢您将五月份的喜宴选择了天宝酒店!如果婚庆公司您还没有选定,请与我们...\n1000 Processed\n classify content\n35000 1 建设银行xxxx xxxx xxxx xxxx户名:陈亮\n35001 1 您好!我是上海企皇投资管理有限公司的业务员小王,我公司专业代办小额贷款,信用卡,只凭个人身份...\n35002 1 恭喜发财,祝您身体健康,万事如意。 我们是做整体橱柜,衣柜的厂家。年后特价衣柜xxx元/方,...\n35003 0 西赵街、中大街南段9月份即将全线开通运行\n35004 0 星岛环球网“港媒中央严查国企变家企释加大整治信号”\n1000 Processed\n classify content\n35500 0 一觉醒来发现手机里多了一张照片\n35501 0 医生和他讲解我的病情分析我的状况他在旁边拿个本哼哧哼哧的写\n35502 0 通过Carrobot车萝卜车载智能系统\n35503 1 您好!财商财富在x月x日~x月xx日推出“女人节馨香开单礼”在活动期间凡是购买x万及以上理财...\n35504 0 浙江宁波天童禅寺将举办“天童山传统禅七”法会\n1000 Processed\n classify content\n36000 0 公司要能像微软一样有洗澡的地方就好了我肯定过夜在里面画图啊啊啊啊啊啊\n36001 0 凡是与政府利益产生冲突的都要打击\n36002 0 原来我不喜欢胖子的真相就是我是一个胖子\n36003 0 打开电脑被蹦出来的一百多条工作信息吓到了……\n36004 0 江苏海安公安局一名正式民警叫李龙\n1000 Processed\n classify content\n36500 0 首批100辆投入运营的纯电动出租车\n36501 0 宿迁泗洪当地农村物流的畅通是穆墩岛村发生变化的原因之一\n36502 0 琼海市教育局在市政府门户网站发布了公示\n36503 1 尊敬的新老顾客您们好!合江一转盘汇通超市贝因美奶粉打x.x折了,时间是x月x.x.x.号,还...\n36504 0 没有烟没有酒没有手机的晚上\n1000 Processed\n classify content\n37000 0 现在的G2京沪高速双向的堰桥服务区以及S38常合高速双向的滆湖服务区、荷叶山服务区\n37001 0 湖人领衔NBA球队价值排行榜\n37002 0 好多小伙晃动手机试图“脱光”时\n37003 0 而不是对于财富和出身的膜拜\n37004 0 城管科长痴迷网游三年花1500万有吸毒前科仍入党晋升真的假的\n1000 Processed\n classify content\n37500 0 G25长深高速双向宁淮南京段从竹镇至竹镇互通限速取消\n37501 0 已被深埋于南极冰下4000米深处长达1400万年\n37502 1 你好!饮马街哥弟迎三八节,特别推出超值的彩色条纹毛衫折后xxx、香型彩色外搭折后xxx、时尚...\n37503 0 俄罗斯国际军事比赛主裁判德米特里·戈尔巴坚科少将表示\n37504 0 真的是要被花千骨电视剧给虐死了\n1000 Processed\n classify content\n38000 0 我投给了“张丹峰饰东方彧卿”这个选项\n38001 0 避开西部太多顶级1号或2号位的对抗\n38002 0 打从2015年开始到上周鼻炎一直没犯\n38003 0 在南京:和侄女拉姆在一起\n38004 1 你好,美女。马上x.x快到了,我们家春款全面上市,有很多款,适合你。你来看看。而且 现在,八...\n1000 Processed\n classify content\n38500 0 长期电脑和空调工作的皮肤缺水\n38501 0 ANNA新一代DD霜被称为“动态全效产品”\n38502 0 ——沪指跌1%盘中失3900巨震真相\n38503 0 50岁刘青云、46岁郭蔼明不想生\n38504 0 服务范围——车险:交强险、商业险\n1000 Processed\n classify content\n39000 0 x·xx荆州自动扶梯事故涉事企业\n39001 0 嬴旭危QAQ“柷敔之祸绵延至今\n39002 1 精选货品x折优惠,快快来ochirly店铺选购吧!我是导购娟娟期待您的光临!\n39003 0 花千骨是我活这么大唯一一部用心去爱的作品\n39004 1 庆元宵长城为了回馈新顾客,凡在元宵当天一律装潢品打x折,一律车型当月有货,更有好礼不断,惊喜...\n1000 Processed\n classify content\n39500 0 5唇色突然变紫或变黑说明淤血攻心\n39501 0 你说腾讯个傻叉为啥要有个访问记录……但是还是听你的\n39502 0 不过真相才是真正的\"有情人终成眷属\"啊\n39503 0 2015年7月18日CA1541原定下午14\n39504 1 ,衣柜柜体实木多层板限量工厂价抢购,前二十名还享有金卡会员折上折的特惠,非常非常的实惠,家里...\n1000 Processed\n classify content\n40000 0 91€上飞机前这个价格只够1个长棍三明治物价低人不多可惜我是不快乐的年轻人\n40001 0 xxxxx就这么欺骗消费者吗\n40002 1 喜迎 x x 妇女节 水胭脂美容美体关爱女性同胞们,特推出为期x天的活动x、所有护理项目...\n40003 0 墨西哥城在全市21个地铁站建立了30个健康站\n40004 0 每天喝4杯茶比喝8杯白开水更有益于身体健康\n1000 Processed\n classify content\n40500 0 全国首家真正意义上的360℃全开放式厨房运营模式的倡导者\n40501 0 Ialwayshavet将逐渐关闭自家的音乐\n40502 0 小时代4:灵魂尽头★★★还行\n40503 0 唐代中央政府设北庭、安西等都护府\n40504 0 com阅读全文请戳右边\n1000 Processed\n classify content\n41000 1 亲爱的姐妹们:x月份新年开端,玫琳凯产品送多多!购买产品每满xxxx元获赠价值xxx元产品,...\n41001 0 comLogo目录公司简介租赁服务租赁分类成功案例合作详情公司简介租赁服务租赁分类成功案例合...\n41002 0 一年内的疤痕能去掉90%两年内的疤痕能有效淡化\n41003 0 不认真司法诉讼鉴定客观处理\n41004 0 万华是EMC和SAP的共同客户很有代表性\n1000 Processed\n classify content\n41500 0 但是刷好以后手机内置存储不能识别\n41501 0 据WindowsInsiders负责人GabeAu\n41502 0 因为当年建筑的过程中发生了倾斜\n41503 1 今天推出限量版理财产品,利率x.x%,投资期xx天(x.xx~x.xx),先到先定。\n41504 0 上海60年不遇的台风让我给赶上了\n1000 Processed\n classify content\n42000 0 此次推出线路价位均在20元以内\n42001 0 但是80%以上的相似度是絕對沒问题的\n42002 0 前后不对称的设计又个性十足\n42003 0 0255‰一律调整为按照成交金额0\n42004 0 华为体验中心里各种界面的语言是英文的\n1000 Processed\n classify content\n42500 0 在澳大利亚G20峰会的新闻发布会上\n42501 0 收到不少热心读者涂鸦设计的封面作品\n42502 0 其实我就是想去南京啦哈哈哈哈\n42503 0 把老子的招聘电话拦截了卧槽\n42504 1 红妆减肥瘦身正月二十正式开门,为回馈顾客特举办大型优惠活动,(xxx元xx次,带一名顾客加x...\n1000 Processed\n classify content\n43000 1 您好,我是刚刚打电话给你的捷越信用贷款公司的客户小顾,我们公司贷款无抵押,无担保,这是我的号...\n43001 0 不法分子常会盗窃熟睡的旅客\n43002 0 我现在每天就是玩个电脑打个电话\n43003 0 今早退烧目前没有用任何药物孩子精神状态良好进食正常今天去医院验血\n43004 0 5个人打一个飞机打不死==\n1000 Processed\n classify content\n43500 0 要求各公司按航班量的25%进行调减\n43501 0 期货舵手午盘分析:玻璃回落在850准备做多操作\n43502 0 我要考虑苹果华为魅族努比亚酷派乐视大神oppovivo\n43503 0 原有的封建制度由于腐败和不得人心而崩溃\n43504 0 上证将在xx个月内升至xxxx点\n1000 Processed\n classify content\n44000 0 预计未来x小时内常州、金坛、溧阳大部分地区可能会出现雷电、雷雨大风、短时强降水等强对流天气\n44001 0 可能很多人都会想到金融和电商\n44002 0 微软:高通我太阳你母上大人整天只想坑我钱\n44003 0 KTV是一个几乎没有核心竞争力的产业\n44004 0 BaitollahAbbaspour的治疗费用终于有眉目了\n1000 Processed\n classify content\n44500 0 7月10日至15日长海县旅游局在大连精选核心社区举办了四场大型推介活动\n44501 0 严格的金融风控标准执行就OK\n44502 0 参加2015年洛杉矶世界特殊奥林匹克运动会的各代表团陆续抵达洛杉矶\n44503 0 我不曾质疑自己做的是否正确\n44504 0 如今IPO注册制的放开给城商行上市带来了新的机会\n1000 Processed\n classify content\n45000 0 女主第一次被钉17颗销魂钉+被刺101剑+被绝情池水毁容毁声+流放蛮荒时\n45001 0 TA说的这两类人究竟该如何区分\n45002 1 平安易贷,针对车主,房主,法人,上班族,寿险投保人提供最高xx万信用贷款,月息x.x%,详情...\n45003 0 S96宿迁支线双向在宿迁处限速、限车取消\n45004 0 街道城管科、执法中队组织5人\n1000 Processed\n classify content\n45500 0 综合执法大队、城管、工商、食安办等执法人员从学院街与建设路交叉口向东进行清理\n45501 0 周一台湾将涉嫌商业欺诈内地老板叶彦荣一家遣送回大陆\n45502 0 今年10号台风“莲花”于今天12时15分登陆广东陆丰\n45503 0 我果断决定把花千骨后半部分的小说看了\n45504 0 这是在置业者在购房者之前必须要了解的事情的两项重要考虑因素\n1000 Processed\n classify content\n46000 0 郭沫若先生曾为无锡太湖鼋头渚说过著名的一句“太湖佳绝处\n46001 0 最爱的就是商贸街和情人湖了…\n46002 0 首批官方认定的“江苏老字号”企业总共达到176家\n46003 0 不是我说……三次城管了my俱利酱都中伤真剑了给跟鹤毛摸摸行不\n46004 0 没有飞车党没有小偷没有反华一路向南却越走越难破记性就差没把自己的头弄丢了好不容易上了车偏偏漫...\n1000 Processed\n classify content\n46500 0 微软的OneDrive时间显示不是本地时间\n46501 0 常州九龙希望小学的姚芳刘仁刚王丽\n46502 0 然后七点左右到的宿豫区地税局下的车\n46503 1 家长您好,新年快乐!中考即将到来,在此紧张时期,远景教育特开设全日制课程,为您孩子中考保驾护...\n46504 0 有一个小偷每天都正大光明的偷听我们说话\n1000 Processed\n classify content\n47000 0 只见他折了一个纸飞机自言自语的说:“小飞机啊就看你的啦\n47001 1 新年好!我是专业办理銀行代歀的汤萍,您之前办理不了或被拒的代歀都可办理,立熄低至x厘,额度高...\n47002 0 完整版:好声音张玮再秀HIGH歌富二代百万豪车把妹互动投票:你认为谁更适合做男友\n47003 0 不眠不休的看完了花千骨小说\n47004 0 **和地铁管理人员对全莫斯科的地铁线展开了一场地毯式的搜索\n1000 Processed\n classify content\n47500 0 7月9日消息微软手机业务失败后决定裁员7800人\n47501 0 对外阐述“互联网+”和创业机遇、腾讯战略\n47502 0 ??????????????????????\n47503 0 吃饭时看电视在演警察2013\n47504 0 高保湿紧致毛孔镇静舒缓提拉营养100%纯竹纤维面膜无菌处理后带温度计放入冰箱10分钟左右温度...\n1000 Processed\n classify content\n48000 0 在国家食品药品监督管理总局全\n48001 0 昨天几个人咨询关于纤腰去除胳膊\n48002 0 也许因为国内没有google查不到信息源吧\n48003 0 2壮阳不能催发性欲:性欲跟精神状态与雄激素水平有关\n48004 0 却终于变成很久以前上电脑课\n1000 Processed\n classify content\n48500 0 何况我办卡的签名是N年前的签名\n48501 0 好奇心暴强的我又想知道真相\n48502 0 我手机里有今天刚更新的那集\n48503 0 人人需知的互联网金融信息安全基础\n48504 0 治疗疾病的效果比较迅速和显著\n1000 Processed\n classify content\n49000 0 才下飞机回了家就收到的生日包裹这人是谁也太他妈懂我了吧看到潮水箴言系列和侧面的Itsdrea...\n49001 0 ——这期好声音确实是把所有离乡别井在外打拼的游子的心都虐了一遍\n49002 0 上海仁济医院血管外科专家教你远离静脉曲张\n49003 0 以及有酒后驾驶、超员20%、超速50%、高速公路超速20%或12个月内有三次以上超速违法记录...\n49004 0 5支由本科生组成的队伍将分赴东阳、千岛湖、余姚、丽水和衢州提供医疗服务\n1000 Processed\n classify content\n49500 0 看到十辆警车经过曼哈顿中城\n49501 0 母亲肝硬化父亲有哮喘地址\n49502 0 弟弟现在坐在回青岛的飞机上\n49503 0 本门从连云狮阁夺得独孤九剑残章四\n49504 0 苹果和IBM仍然是科技界最奇特的组合\n1000 Processed\n classify content\n50000 0 放大惠普等IT大鳄的带动效应\n50001 0 交警提醒:酒驾会构成一般交通失信\n50002 0 于6月30日20时在西北太平洋上生成\n50003 0 体重xx斤身高xxcm算正常么\n50004 1 新平怀德仁药房三八妇女节约惠啦! 活动将于x月x日到x月xx日进行!活动一:买赠大优...\n1000 Processed\n classify content\n50500 0 除了涉及IT技术的高频交易以外\n50501 1 诚意客户求购南北三居室\n50502 0 我正在看15岁女孩遭报复性轮*\n50503 0 一个医院上班的挣那俩臭钱就不知天高地厚了\n50504 0 在湖南卫视和江苏卫视已经看到喽\n1000 Processed\n classify content\n51000 0 xx%羊绒+xx%羊毛+xx%真丝\n51001 0 哦你他妈的被强奸了被人打死了你才活该呢因为你上辈子就是个傻逼\n51002 0 Malloryz是个和我同年的毕业生\n51003 0 在机场看到华为的广告图觉得蛮符合这句话\n51004 0 被频频发生盗窃案件搅的不得安宁\n1000 Processed\n classify content\n51500 1 振兴百货祝:美丽,好运,快乐,善良,热情,健康的您三八妇女节快乐,把最美的祝福送给您!x月x...\n51501 1 【老客户福利来了】亲,元宵节快乐!【淘宝店:爱美宝贝婴童馆】送您xx元元宵券(春款无门槛使用...\n51502 0 友人相赠的一只来自无锡的超大水蜜桃\n51503 0 法媒称香港商铺租金太贵LV和Burberry都吃不消–名店网\n51504 0 Bravo~一上午听完国际私法\n1000 Processed\n classify content\n52000 1 ~x万装修费用x、现场两千平米材料展厅和三种不同风格的实景样板房等您来参观x、来访即有礼品一...\n52001 0 明天晚上八点到九点抢红包\n52002 1 鑫丰国际家居,x月xx号xx号举办诚信x.xx感恩回报活动,到店有礼活动,内容;x:有阶梯送...\n52003 0 Saigon的闹市区就是第一郡\n52004 0 敬请谅解:转全新BillinghamHadleyDigital英国原装\n1000 Processed\n classify content\n52500 1 求职烧菜,本帮菜农家菜,工资四千到四千五,因手生,不试菜,要有休息,有需要的请联系我xxxx...\n52501 0 被告的父母来美后贿赂受害人和证人\n52502 0 是对亚马逊云计算平台感兴趣的相关同仁获取亚马逊云计算平台资讯的重要来源\n52503 0 好声音被求婚的女的笑起来怎么像整容失败了\n52504 1 万利驾校xx女人节优惠活动进行中。x月x日~xx日女士报名xxxx元,男士报名xxxx元,一...\n1000 Processed\n classify content\n53000 0 特别在进行新房装修的时候尽量会选用环保材料\n53001 0 FIBA官网专栏作家EnzoFlojo评论了2015年长沙亚锦赛上有潜力爆发的新星\n53002 0 与亚马逊美国直邮中国的品类实现完美对接\n53003 0 南京房地产市场表现领跑同类城市不无道理\n53004 0 sanE给我感觉有点商业化啦\n1000 Processed\n classify content\n53500 0 足不出户+Q844930494考虑一千次不如去做一次\n53501 0 哈哈哈哈在买电脑的地方看见南坡奶了哈哈哈哈哈\n53502 0 “x·xx女尸案”的专案组重要成员冯志明\n53503 0 全国x天发生x起“电梯咬人”事故\n53504 0 而不包括餐厅装潢、服务、设施等\n1000 Processed\n classify content\n54000 0 和集团总裁相处的日子是最有温暖感的\n54001 0 最终法院判决厂家赔偿误工费500元\n54002 1 乐上名都装饰xxx零利润x重大礼(家具、家电等)疯狂“抢”定惠。时间x月x日--x月xx日。...\n54003 1 店铺任意产品满xxx元即享x.x折优惠哦,欢迎您到店选购^_^!—狐狸的宝藏!联系人及电话:...\n54004 1 提供无抵押无担保信用贷 解决资金需求 车贷 房贷 无房无车信用贷 手续简便快捷 x天下款 需...\n1000 Processed\n classify content\n54500 0 建议坚持补充酵素来帮助身体均衡\n54501 0 全面推动北斗卫星导航应用产业发展\n54502 0 例如2亿美元收购网络安全公司Aorato等\n54503 0 有网友回帖质疑“你肯定是他的同伙\n54504 1 我这边是办理无抵押信用贷款的小杨。如果有需要的话可以跟我联系\n1000 Processed\n classify content\n55000 1 开户行,中国建设银行 卡号:xxxx xxxx xxxx xxxx xxx.张燕\n55001 0 Twitter市值约细语的小猫咪\n55002 0 含维生素C、纤维能促进肠胃蠕动\n55003 0 进的万科和中集集团两只股票\n55004 0 很早睡到凌晨就醒下楼弄两块面包加点炼奶喝瓶益力多上床翻一翻手机相片打个哈欠\n1000 Processed\n classify content\n55500 0 手机恢复出厂设置了还有可能恢复里面的短信吗\n55501 0 好聲音的舞台提供很多懷揣音樂夢想的人來到這裡這個舞台提供他們機會即便沒有導師亮燈但這份懷揣夢...\n55502 0 在看清生活的真相之后还依旧热爱生活\n55503 0 乐昌市法院一审判决驳回了陆某的诉讼请求\n55504 0 ∞╬╬乐山电力复旦复华江苏舜天工大高新*ST仪化精达股份神奇制药中央商场马应龙\n1000 Processed\n classify content\n56000 0 这三个人是通过什么方式证明自己\n56001 0 由淮安市航道管理处六点五十发布的船闸通航和待闸信息\n56002 0 勇者大冲关是江苏卫视的一档水上冲关节目\n56003 0 与大盘负相关的证券市场间长期国债:平开\n56004 0 和承接着江苏50%以上出国金融业务量的龙头合作好荣幸\n1000 Processed\n classify content\n56500 0 能说清楚四年在阿里巴巴做什么了吗\n56501 0 中国首款两轮电动汽车完成A轮1000万美元融资\n56502 0 山西法院院长调研督导涉诉信访专项治理工作\n56503 0 听说学校有600元/月/床位的空调房\n56504 1 至亲爱的顾客.元宵佳节.三八妇女节xx年秋冬货品本店季未大清货全场三折大抢购不错过机会,地址...\n1000 Processed\n classify content\n57000 0 这句话深深的印在华为人的心里\n57001 0 惠普当前已不再预期下一财年会实现增长\n57002 0 化妆水能为肌肤补充这些皮肤构成的修复成分\n57003 0 后天因素虽然只占到20%~30%\n57004 0 除9家创业板公司获得社保增持外\n1000 Processed\n classify content\n57500 0 江苏卫视勇者大冲关竟然放了SUJUDevil\n57501 0 近五日有xxx只个股被机构评级为买入\n57502 0 为啥说该睡了呢因为手机没电啦\n57503 0 他在社交媒体上发表了x篇被认为是诋毁泰国国王的文章\n57504 0 碧水云天小区xx号楼三单元三楼东户卖烧烤的车上常年放燃气罐在上面\n1000 Processed\n classify content\n58000 1 (朋友-最近好吗?有 上 好 的 茶 叶,还 是 原 来 的 味 道。你懂的。xxx丽xxx...\n58001 1 华鹤米兰纳时尚门,x.xx“为健康,惠任性”活动,享厂家环保补贴xxx元/樘,定金增值优惠满...\n58002 0 一男的领着老婆孩子在x号线乞讨\n58003 0 凡尔赛宫建筑布局严密、协调\n58004 0 集中对辖区非法违法建筑工程进行了重拳整治\n1000 Processed\n classify content\n58500 0 章的金球A类提名以及北美多伦多英国大大小小提名一大堆\n58501 0 一些银行和券商可能将面临风险\n58502 0 微软CEO萨蒂亚纳德拉在云计算的道路上越走越坚定\n58503 0 这些公交车将分布在7路、33路、303路、405路、407路、414路、612路、708路8...\n58504 0 坚持答辩意见宋:所有费用不应由我支付\n1000 Processed\n classify content\n59000 0 同时含泪出一个BoseQCxx降噪耳机在美国亚马逊上买的\n59001 0 骑行3000千米的20位中韩小伙伴们\n59002 0 晚上涂了一层帕氏蜂蜜抗氧化精华\n59003 0 专车司机的一天:收入变少考虑转行\n59004 0 哈哈哈哈哈哈哈想起电梯事件还是想乐现在呆在一起一点不着急回家长度积累的特别踏实\n1000 Processed\n classify content\n59500 0 子宫肌腺症这一名词在我们身边频繁地出现\n59501 0 最大县面雨量宁海146毫米、三门144毫米、椒江区136毫米\n59502 0 房地产活跃给经济运行带来的正能量\n59503 0 帮忙转下苏打绿南京站的票两张好吗\n59504 0 地铁信号盲区挺多……南邵站到沙河高教园\n1000 Processed\n classify content\n60000 0 2014年高淳区规模以上工业企业万元工业增加值能耗为0\n60001 0 刚刚南区老大和我说浙江有个大一用微商团队模式一个月赚xx多万\n60002 0 与徐州国华物业大街保洁员闲聊得知\n60003 0 想想本来近在咫尺的26楼那间餐厅\n60004 0 我7月28日刚结束大连中心医院胖瘦群组织的第二期百天运动刚好结束\n1000 Processed\n classify content\n60500 0 梅城江南金沙湾KTV发生惊险一幕\n60501 0 在南京举办的以意大利米兰世博会南京周为主题的“南京米兰双城互动秀”上\n60502 1 .xx.xx.xx.xx~xxx期:必中㈠肖:马~必中x码:xx.xx.xx-xxx期:内部...\n60503 0 为什么淘宝app右下角一个胖手\n60504 0 石狮灵秀派出所民警接到报警\n1000 Processed\n classify content\n61000 0 是值得每个人为之骄傲的财富\n61001 0 有人要南京金鹰卢米埃西游记之大圣归来的票么\n61002 0 longtimenoseehey~\n61003 0 一家老小从此与医院、药物、病痛无缘\n61004 0 袁姗姗扮演了饱受质疑但始终对演戏有着热忱之心的女演员\n1000 Processed\n classify content\n61500 0 汽车之家能否将业务模式顺利过渡到二手车领域\n61501 0 兩岸四地青年聚首南京慕緬歴史\n61502 0 我在南京路亨得利产品已重新上柜…\n61503 1 客户提供优质的贷 款咨询服务。 我们的贷 款产品利率有 信*贷,月费率x.xx-x.xx%...\n61504 0 先生公司集体旅游5点多就出发\n1000 Processed\n classify content\n62000 0 今日捷财与庆汇租赁有限公司正式达成战略合作\n62001 0 南京各大医院重点科室、医生\n62002 0 GoogleDrive内容人审查还是太牛了\n62003 0 五、我们认为非法拆除与整改教堂的十字架\n62004 0 今年顺利被浙江传媒大学录取的贺晗紫和被南昌大学录取的戴雅宜暑期抽出休息时间来为学弟学妹们指导专业\n1000 Processed\n classify content\n62500 0 三年前立志要考到人大来找你\n62501 0 不过隔壁so?ho持刀伤人案还是更可怕\n62502 0 我們打算於十月或十一月舉辦一個有機農種植農場之旅\n62503 0 而且不像普通感冒那样x周左右就很快好转\n62504 0 全新ApivitanewBeeRadiant亮肌抗皺修護系列\n1000 Processed\n classify content\n63000 0 现在已经有人预定dc了那就先开始排后天的单\n63001 0 地铁上的温度和深圳北的温度简直天壤之别\n63002 0 这要在某宝两天guyong不到苏州\n63003 1 “你的存在、生命的意义”女人节到来之即,诗篇专柜特邀您到店选购,特推出冬款x折、春款x折;折...\n63004 0 年终奖10000元左右+包住包吃+五险一金\n1000 Processed\n classify content\n63500 1 您好,我是山湖湾的置业顾问张艳,山湖湾现在新推房源火爆热销中,购房多重优惠,期待与您的再次见...\n63501 0 DM手机u盘16gu盘双插头otg电脑两用创意金属迷你车载防水包邮\n63502 0 车型介绍:奔驰s级堪称最舒适、豪华的中大型轿车\n63503 0 皮肤衰老皱纹的产生是因为胶原蛋白流失\n63504 0 回顾咗好几段xx、xx年代嘅NBA视频\n1000 Processed\n classify content\n64000 0 结果花完卡里最后的xx块之后我就又滚了\n64001 0 得到了一个华为的安卓手机给了他\n64002 1 新年好!银行新政策:只要有保险单\\按揭、荭本房\\小车之一,凭身份\\证即可办理,月息仅x厘-x...\n64003 0 1992年从南京空军司令部军训处转业后进入江苏省海门市审计局工作\n64004 0 网页端还必须手机下载app扫描登陆\n1000 Processed\n classify content\n64500 0 法官不要成为端人碗服人管的法官\n64501 0 “super189电信欢go节“缺翼不可再次来袭\n64502 0 我为什么作死双开hhhhhhhhhhhhhhh快笑死了hhhhhhhhhh\n64503 0 中国江苏省淮安市淮阴区王营镇\n64504 0 据浙江省旅游局最新统计数据:浙江xxxx年上半年接待国内外游客约x\n1000 Processed\n classify content\n65000 0 华农百灵7月为广大学员开放免费的跨境电商试听课程\n65001 0 中央空调声音大的跟火箭发射似的\n65002 0 50万的路虎VS15万的陆风真相让你大吐血\n65003 0 com商务部领导、国家工商总局领导、人民日报领导中国商业联合会领导等等前来到场祝贺及发言\n65004 0 能载着16人以250千米/小时的速度飞驰\n1000 Processed\n classify content\n65500 0 wifi电脑空调冰箱加张床\n65501 0 已用于阵风战斗机和火箭发动机喷管中\n65502 0 也是google基于linux手机操作系统的名称\n65503 0 房地产税立法初稿已基本成型\n65504 0 华为小哥就走过去说:“先生\n1000 Processed\n classify content\n66000 0 喜欢东方觉得和花千骨很般配\n66001 0 一个人去南京吃了素面没有碰到撑伞的你秦淮河还是那样索然无味\n66002 1 女人节来临之际,特向广大女性朋友推出优惠活动,快乐女人节!VIP顾客持卡享受x折优惠。如果没...\n66003 0 又要开始myperfectday\n66004 0 一坐地铁就想骂街北京地铁三分钟一趟你这趟没赶上赶下趟就看不见你妈最后一眼了还是怎么着\n1000 Processed\n classify content\n66500 0 2013年11月借用后一年多一直不提还车\n66501 0 一旦搞起来就是汽车里的Windows\n66502 0 杨彩霞就坐到小房间电脑前的转椅上\n66503 0 为什么江苏移动网上营业厅没有合约机\n66504 0 面对质疑:他现在怎么可能睡\n1000 Processed\n classify content\n67000 0 静观其变/疑似MH370残骸地发现中国矿泉水瓶\n67001 0 飞机从图纸上落地需要两代人\n67002 0 我真不相信坐在手机屏幕前的你们一个二个都是十全十美的人\n67003 0 有在淮安八仙台附近附近的有车的朋友吗\n67004 0 卡拉曼自他的Baupost基金1982年创立以来\n1000 Processed\n classify content\n67500 0 Windows用户已经可以收到正式版更新的推送了\n67501 1 尊敬的学生家长,致远教育祝您阖家幸福,羊年大吉!致远教育初中各学科报一科送一科,全面提升成绩...\n67502 1 新思维奥数专家本周四即x月x号xx:xx开始赛前模拟题型和考试技巧免费讲解培训。活动持续两周...\n67503 0 却被HTC通过专利权人在专利审查过程中有不公平行为的举证而导致满盘皆输的事情\n67504 0 南京市美协会员山水画家作品\n1000 Processed\n classify content\n68000 0 本来今天想去看McQ的展览…结果博物馆开门不到半小时票就卖光了…只有去看鞋展…在V&\n68001 0 然后一些不明真相的外国人也会留言大肆吐槽\n68002 0 给大家分享\"华胥引之绝笔之城\"\n68003 0 Whatarethey弄啥嘞\n68004 0 只有政府才有能力去关爱那些失独家庭\n1000 Processed\n classify content\n68500 0 土地整治是发展现代农业、促进农民增收的有效途径\n68501 0 6、党政干部、公职人员道德败坏、生活腐化堕落\n68502 0 都得靠着咽喉糖才能正常开口说话\n68503 0 央企改革、军工航天、机器人等强者归来\n68504 0 新北八仙乐园粉尘爆炸事件中有432位烧伤患者仍在住院治疗\n1000 Processed\n classify content\n69000 1 ............店有礼、连购有礼,满三千返xxx,有直供卡(才能参加活动)可低xxx...\n69001 0 一般男人的体内大约有300亿个脂肪细胞\n69002 0 中国好声音里面都是黑龙江的歌手啊\n69003 0 快来学吧——由蜂蜜和柠檬冲调而成的茶饮\n69004 0 江苏省中出的这x注一等奖分别被连云港、扬州和宿迁彩民中得\n1000 Processed\n classify content\n69500 0 合一集团宣布与国内最大的在线旅游企业携程旅行网达成战略合作\n69501 1 号外.号外.不用去澳门.网上开户也能玩(OK娱.乐公司)迎接新客户!开户就送xxx元,玩到x...\n69502 0 2015年证券从业资格考试题库:d\n69503 0 20南京我左上看、右上看、左看、右看、左下看、右下看\n69504 0 共计发放消暑清凉饮料8735箱\n1000 Processed\n classify content\n70000 0 ——————儿子\n70001 0 好声音学员里面哪个是节目组亲自请的\n70002 0 更没有幼稚而装逼格的生活作风\n70003 0 巴陵石化、长岭炼化及岳阳消防支队、湖南省消防总队长沙战区战情保障大队等12支消防队联合公安、...\n70004 0 我去尼玛的红包锁屏到底能不能兑换\n1000 Processed\n classify content\n70500 0 岭兜村位于官桥镇政府驻地北x公里处\n70501 0 只能一大早看花千骨第二集了\n70502 0 现起我当年当初没有钱就把手机当了\n70503 0 ***********现在控制风险很重要啊***贵州茅台海岛建设石岘纸业黑牡丹中航电子凤竹纺...\n70504 0 x、群发频次进行调整:微博签约自媒体、媒体认证用户为x天x次\n1000 Processed\n classify content\n71000 0 我们是靠内衣独特的设计将胸部旁边的肉肉聚集在一起\n71001 0 led晶格印花宠物发光项圈夜间遛狗狗猫咪神器\n71002 0 知产法院院长吴偕林提出要求\n71003 0 依旧沉浸在把电脑摔了的痛苦之中…今天早上把电脑收进盒子里供起来\n71004 1 《玖隆主题》,新茶上市。白天xx点到xx点荬一餸一,全天五人同行一人冕单,另有全天有现金箞。...\n1000 Processed\n classify content\n71500 0 每一步都不是易事你所期待的都不是真相的全部命运的安排总会有缘由抗拒还不如服从随遇而安\n71501 0 7月18日08时至19日08时\n71502 0 被山东省聊城市中级法院判处有期徒刑十四年\n71503 0 否则飞机无法在剩余的跑道上停下来\n71504 0 被郑州铁路公安局洛阳公安处洛阳东站公安派出所扣押后\n1000 Processed\n classify content\n72000 0 南通市发布雷电黄色预警|雷神又来了\n72001 0 以白头粉刺、黑头粉刺、炎性丘疹、脓疱、结节、囊肿等为主要表现\n72002 0 引发他与该所警察发生肢体冲突并被扣留xx小时\n72003 0 奶嘴设计得相当有爱~霸气外露有木有\n72004 0 此番双方选择在SUPER经典LunettesII镜型上挥洒创意灵感\n1000 Processed\n classify content\n72500 0 先后骗取53名外地户籍家长钱款共计46\n72501 0 养老保险是可以异地转移并累积的\n72502 0 MRSOH被我逼迫贱效果后笑的真够贱\n72503 0 良田派出所与高新区建设局联合执法\n72504 0 我就敢让你们南航飞机都飞不起来\n1000 Processed\n classify content\n73000 0 启示:这也许不光是一种销售的手法\n73001 0 加拿大著名的搭车旅行机器人“HitchBOT”在美国费城不幸遇害\n73002 0 3BeautyQuotient美商\n73003 0 选枸杞就应选宁夏中宁枸杞\n73004 0 却每每总被质疑“你下班或周末都在家干什么\n1000 Processed\n classify content\n73500 0 是为了淡定的从容的好好的看看这个世界\n73501 0 使用防晒隔离产品x皮肤已经是亚健康敏感肌—耐心做肌肤修复调理\n73502 0 鸡东县人民法院院长接待室里\n73503 0 今天05时位于浙江省温岭市东南方向550公里的东海海面上\n73504 0 1女人为爱出墙出墙一次就够女人享用一生男人为生理出轨男人偷情就像吸毒\n1000 Processed\n classify content\n74000 0 66%的电脑电在上午十一时彻底离我而去\n74001 0 王芳看到我网上传了我的胳膊好了她就发那种照片上去还设计杀害我死刑杀人偿命\n74002 0 型号iphone6代4\n74003 0 下面请白城玛丽亚妇产医院的医生为您介绍\n74004 0 证监会审核通过了申龙电梯的IPO申请\n1000 Processed\n classify content\n74500 0 为了半夜不破坏母亲大人的美梦\n74501 0 不过小偷们可能会忘记苹果手机还有定位服务\n74502 0 用百度和用Google对比着来搜真有意思\n74503 0 定于今日凌晨抵达重庆短暂停留后将途经南京继续向东飞越太平洋\n74504 0 找苏州速达开锁公司专业配汽车芯片钥匙遥控—工业园区—湖西—快点8分类信息网\n1000 Processed\n classify content\n75000 0 明天早上的飞机要去悉尼的人现在还没收东西…还在磨洋工\n75001 0 感觉中国现在是一个法律、道德双失效的社会\n75002 0 视频腾讯音频51singUP主:天魔教教主\n75003 0 工业园的卡车司机dalao们很喜欢停在公交站牌前面\n75004 0 COM美妆网站五月份获得清洁类的冠军\n1000 Processed\n classify content\n75500 0 晓燕姐姐作为祥芝法院的代表参与了此次会议\n75501 0 每个人都托着手机对准同一个电梯门每次电梯门开都会听到一声叹息然后大家一起哈哈大笑\n75502 0 江都水利枢纽是南水北调东线工程的源头\n75503 1 尊敬的客户:您好!请允许我冒昧的打扰。马可波罗磁砖、布艺工坊窗帘,宾川最具实力的两大品牌强强...\n75504 0 冷清的股票讲座今天是杜老师讲课\n1000 Processed\n classify content\n76000 1 各位家长新年好:春季班已开始报名了哦!现在报名都有优惠,并赠送画具,半年或一年一报优惠更多,...\n76001 0 在8月10日之前退还顾客的拍摄费用\n76002 0 含独特洁亮成分Sylodent\n76003 0 汽车的表盘要是设计成这样会不会比较有威慑力\n76004 0 所以我觉得这个点位上政府出手护盘有理性的基础\n1000 Processed\n classify content\n76500 0 谷歌眼镜、iPhonexS、百万红包免费拿\n76501 0 公告:xx月xx日提示卖出xxx只\n76502 0 互联网上关于SEO的教程随处可见\n76503 0 ”团贷网CEO唐军对记者如此表示\n76504 1 发大财xxxx年-第xxx期:一二三头好玄机,单数特波看红绿。送:龙虎狗猪中xxxx年-第x...\n1000 Processed\n classify content\n77000 1 新年好老板娘!我是广东佛山市陶强企业(富强陶瓷)业务经理:游鑫旺,我们公司是原厂原抛,展厅地...\n77001 0 UP主:不负责任电影研究院\n77002 0 今年暑期演出季热起来没开发布会已卖门票近八成\n77003 0 GCPD跟着老爷屁股后面追那几年\n77004 1 您好,时尚女友兰底店x.x妇女节为您准备了一份礼物~请您x月x号持卡进店领取~x月x号到x月...\n1000 Processed\n classify content\n77500 0 这座位于德国北部suurhusen的教堂尖塔已被正式列入吉尼斯纪录世界大全\n77501 1 您好,欣奕除疤胜利店三月八日针对新顾客特惠活动原价xxx元体验活动x月x日下午扫微信只需xx...\n77502 0 有些被别的医生宣判不能修复的眼睛\n77503 0 浙江遂昌县开展抗战史料征集\n77504 0 高淳交警大队淳溪中队主动会同区城管部门开展水果摊贩占道经营集中整治\n1000 Processed\n classify content\n78000 1 红缨一品幼儿园现正火热报名中。热忱欢迎您和宝宝的到来,参观本园,就读本园。学位有限,欲报从速...\n78001 0 东山县政府2015年第二次常务会议同意交警大队提出的开展道路交通事故救济救助责任保险方案\n78002 0 促进肝细胞再生并保护肝细胞\n78003 0 功能x、能解斑蝥、芫青毒、地胆、亭长、野葛、硫磺毒、诸肝毒\n78004 0 2015年7月10日和7月20安徽省淮南市凤台县凤凰镇新湖社区违法强拆百姓房屋不给补偿\n1000 Processed\n classify content\n78500 0 加油加油加油加油加油\n78501 1 闹新春,抢彩头。瑞博文装饰春季xx套精品样板间征集中...将于x月x日下午x:xx-x点,阳...\n78502 0 2、负责客户的开发、实体店商家招商及新客户谈判工作\n78503 0 想知道咨询者如何追单成功吗\n78504 0 把药丸的包装设计成三只小猪\n1000 Processed\n classify content\n79000 0 他们坐着坦克、扛着迫击炮、拿着歪把子\n79001 1 值此三八女神节,新玛特麦中林活动多多,凡在本店购物即送精美礼品,数量有限充值有礼 充xxxx...\n79002 0 增开125、128、133路夜班车\n79003 1 紧急通知:值此三八之际,特发出友情提示,泰和国际Lily女装全场满xxx减xx,总有一款适合...\n79004 0 是因为我同样隐藏了一个真相\n1000 Processed\n classify content\n79500 0 湖南80后女副市长王卿、广东27岁副县长汪中咏又进入公众视野\n79501 0 为Mac与Linux平台提供基于\n79502 0 不小心把儿子他爸的电脑弄环了\n79503 0 用手机可租还自行车太湖驿站西山段启动运营\n79504 0 xxxx年x月x日凌晨x点钟在生命科学院地铁从长途大巴下车后招来一辆出租车\n1000 Processed\n classify content\n80000 1 (x/x)感谢致电北京新侨诺富特饭店。凭此短信息可特价享受xx元采自地下xxxx米的天然温泉...\n80001 0 50、60岁的女人是高尔夫?\n80002 0 刘某坐高铁到常州与小菁约会\n80003 0 SM你为什么还能这么理直气壮地起诉\n80004 0 中线至少要触及3100至3072点或更低2800点\n1000 Processed\n classify content\n80500 0 主营水处理设备、RO反渗透、机械过滤器等\n80501 0 当升科技筹划投资国外高端镍钴铝正极材料\n80502 0 我有『2015頂級生活展』門票\n80503 0 第三辆Txx不用多说过弯不减速\n80504 0 除外还有2GRAM和16GROM\n1000 Processed\n classify content\n81000 0 服务热线xxxxxxxxxxx曹婷\n81001 0 其中x起严重的交通事故造成x人死亡\n81002 0 手机和驱魔师在一分钟内同时发货了\n81003 0 HoloLens还处在开发阶段\n81004 0 并且表示要去花千骨电视剧那里洗一下脑……………………\n1000 Processed\n classify content\n81500 0 谷歌街景已拍摄过世界上不少奇异的景色\n81501 0 时空穿越、体细胞独立克隆、反物质武器、烂大街的飞行汽车都没有出现\n81502 0 欢迎加入微软Windows\n81503 0 来了这么多次就中意这的吹飞机带蓝光时尚又洋气光想带回家\n81504 0 并对其超员违法行为处200元罚款\n1000 Processed\n classify content\n82000 0 被告:我没有能力支付增加费\n82001 1 农行:xxxxxxxxxxxxxxxxxxx卢天忠\n82002 0 当年政府是6月给我开的离职证明\n82003 0 南京多家公园景区都准备了迎新年的节庆活动\n82004 0 认证信息为“淮安杰森电子商务有限公司总经理助理”\n1000 Processed\n classify content\n82500 0 ——杭州梦湖山庄清幽如画的人间仙境\n82501 0 河北全省法院审结环境资源类一审案件共计720余件\n82502 1 xxxx xxxx xxxx xxxx xxx建行,户名:丁刚\n82503 0 这个“staycool”真的应该放在地铁站里么\n82504 0 与大家只能分享前半段后半段太血腥还是不看的为好\n1000 Processed\n classify content\n83000 0 苹果、youtobe还继续活的好好的\n83001 0 我知道最脏的真相一般都掩藏在最漂亮的表面里\n83002 0 并且彻底抛弃模仿旧版MacOS外观的设计\n83003 0 家里电脑上完微博忘记退出了\n83004 0 电梯不夹死几个人就没人查产品质量食品不中毒就没人说食品安全人为什么总要付出代价之后再去弥补这...\n1000 Processed\n classify content\n83500 1 福建大型玩具厂大量招聘xx~xx(xxxx.x.x前~xxxx.x.x后)周岁男女作业员xx...\n83501 0 变成2=1+1了……说俗点信心就是赚钱效应\n83502 1 。x月x日一x月x日全场四件八折,速速来抢吧亲们,万达佰草集在此等候您的光临。\n83503 1 妹,嘉宝奶粉x月xx曰在爱婴室上架销售了,促销力度很大购买x箱x听立减xOO元,在其他宝宝店...\n83504 1 大动作,看格力,格力空调全年最底价,再预存xx元抵xxx元,活动时间x月x一x日,屏锦广场转...\n1000 Processed\n classify content\n84000 0 战地坦克作者是yax\n84001 1 惠州善融信代有限公司x月x号正式上班,有需要资金周转的朋友欢迎来电xxxxxxxxxxx王经理。\n84002 0 厦门工商旅游学校14级小公举\n84003 0 2014年受南京**学院委托打造纪念佩剑\n84004 0 更有idea的小团队将主导VR\n1000 Processed\n classify content\n84500 0 江苏160家上市公司联合声明\n84501 0 创造变化和改进设计是一个重要的工具\n84502 0 说好还你的高逼格手机大片来了\n84503 0 第一条便是——机器人不得伤害人类\n84504 0 有个人装逼说自己是某集团继承人\n1000 Processed\n classify content\n85000 0 有兴趣的加扣1056527483\n85001 0 慈世平就是史上最“tough”的家伙\n85002 0 乘坐破破的地铁去TourMontparnasse\n85003 0 中国好声音第四季没有什么好歌手\n85004 1 东魅娱乐会所新年感恩回馈全场啤酒买x箱送xx支,红酒买x支送x支,另外每间包厢会给您带来一个...\n1000 Processed\n classify content\n85500 0 xxx多名家长和小朋友到场参加\n85501 0 好像Amazon中国开通全球购之后\n85502 1 沪太路近纬地路沿街转角位置,xxx.xx平米,租金xx万/年,租客为:中国移动,良友超市,雷...\n85503 0 发电、旱稻、中药立体发展模式\n85504 0 早上7:30分到布尔津汽车站坐车去禾木\n1000 Processed\n classify content\n86000 0 本书是一本记录新中国20年资本市场发展史的著作\n86001 0 已从超市哭晕电梯在哭晕到厕所\n86002 0 微信要做智能机器人“小微”\n86003 0 玩坏的机器人快来围观我的精彩微视频\n86004 0 浙江瑞安的孙女士带2岁儿子到公园玩耍\n1000 Processed\n classify content\n86500 0 设计师对过去的刷子进行使用上、造型上的考究后进行改良设计\n86501 1 证和银行卡或存折。如需预约请至电话,预约后无须排队安装,报装地址:银泉北路广电大楼侧(即市政...\n86502 0 五华城管普吉执法中队集中力量全员出动\n86503 0 谁不想不用投资就可以赚钱的生意\n86504 0 演唱会后遗症中还有流鼻涕这一症状嘛\n1000 Processed\n classify content\n87000 1 【到巴比亚半山欢乐过元宵】x月x日-x日,到现场猜灯谜、包元宵、赢礼品。x号楼中庭景观巨著面...\n87001 0 在机场遇到了TimeZ结果不认识\n87002 0 尼玛啊T^TT^T我是听力有问题不是鼻子有问题啊T^T为啥给了我一个鼻炎的药T^T你在逗我嘛\n87003 0 什么期货期权FOF离岸基金QDII\n87004 0 私下里却承认这些股票是垃圾\n1000 Processed\n classify content\n87500 0 在这样一个有图有真相的世界中\n87501 0 最高人民法院已经频频做出明确表态\n87502 0 他能不能实现开飞机的梦想呢\n87503 1 xxx期精版个十位,人虽小,排名大,提示,双进双出,送你一句话,身怀绝技扬四方。[老公:xx...\n87504 0 无聊看自己微博的粉丝然后发现有个账号显示手机联系人:XXX他的大名\n1000 Processed\n classify content\n88000 0 8批次产品非法添加禁用物质、违规使用限用物质↓氯倍他索丙酸酯属于糖皮质激素类物质\n88001 1 世界因女人而分外美丽!【容辰哥弟】提前祝您女人节快乐!我们特为您准备了大量春款及节日套装,快...\n88002 0 看完了中国好声音再来看看美国的吧~美国的导师转身太冷静了\n88003 0 不找出病毒到底是谁会进行永恒的游戏\n88004 0 一名中年商场保洁工被B2至B1层的自动扶梯夹住腿部\n1000 Processed\n classify content\n88500 0 不去打电话叫物业或者给家人来解决\n88501 0 爬起来开电脑充值元灵之力……要是手游上直接能充值就好了……\n88502 0 最重要的是每个人都对旅游安排非常满意\n88503 0 由豪华的空客A330—200型飞机每周一、三、五执飞\n88504 0 可以和Spring框架无缝集成\n1000 Processed\n classify content\n89000 0 这块业务正逐渐被部分基金公司倚重\n89001 1 联通公司高艳红祝您天天有个好心情!现推出。预存xxx元、月交xx元可享xxM光纤免费用、含x...\n89002 0 你妈花千骨27集里这是什么鬼\n89003 0 商业领袖女强人互联网+跟随内心的声音\n89004 0 实习生的我越来越急没有客户\n1000 Processed\n classify content\n89500 0 湖北警车失控撞伤两人正查是否酒驾\n89501 0 停在主界面听着BGM整个人都被治愈了\n89502 0 杭州性价比最高装修服务平台\n89503 0 现代建筑和丑陋的欧式建筑堆积出没有灵魂的浮欢\n89504 0 Alice的手机铃声?我正在收听P\n1000 Processed\n classify content\n90000 1 *xxx聚会风暴来了,你做好准备了吗?班尔奇全屋定制家具诚邀您前来品鉴《设计由你.全权做主》...\n90001 1 诚信x月,感恩一元购”龙门佳居乐(橱柜、衣柜、门业、软包)钜惠节!新年红包送不停,买一送一、...\n90002 0 S20外圈往虹桥机场方向近真南路上口车流量大\n90003 0 这个两人盗窃团伙被河东公安分局成功抓获\n90004 0 xx小时内我县阵风可达x级以上\n1000 Processed\n classify content\n90500 0 xx%的南宁人家里的锁都不安全\n90501 0 xx、医疗器械科普活动走进江大\n90502 0 昨晚上家里进小偷手机电脑什么都被偷了\n90503 0 为了测试装修后的新试听室效果\n90504 0 我家小狗的细小病毒治疗经验\n1000 Processed\n classify content\n91000 0 所有缴纳医疗保险的员工定于2015年8月2日上午在中心医院二门诊进行育龄妇女检查\n91001 0 10支文艺队纷纷拿出了自己的“看家”节目\n91002 0 一万多名湘西“土匪”在五零年代走上了自我救赎之路xxxx年\n91003 0 果真回来才有家人的感觉第一天中药还好只是麻烦点没想象中那么麻烦\n91004 0 一期节目不论它内幕究竟在哪里\n1000 Processed\n classify content\n91500 0 苏北医院就在附近但是120来的很慢\n91501 1 感谢致电潍坊如家东风东街店,酒店位于奎文区东风东街xxx号-世纪泰华正对面,现推出优惠促销价...\n91502 1 您好!龙湾运动会所,将于x月x日xx点,举办三八女人节活动,特请北辰中医院主任医师到场为前x...\n91503 0 最高人民法院关于审理拒不执行判决、裁定刑事案件适用法律若干问题的解释\n91504 0 居然有人说偶像来了拉飞机抄袭极限挑战我的妈呀极限挑战就是个抄袭的节目都是抄韩综问题是央视还买...\n1000 Processed\n classify content\n92000 0 GoogleChrome速度测试慢速镜头告诉你打开google的时候发生了什么\n92001 0 这种做法是否符合公安入户不能和计划生肓挂钩\n92002 0 白子画花千骨再次返回凡间木屋\n92003 0 其中浙江大学常务副校长宋永华和哈尔滨工业大学副校长韩杰才均来自恩阳\n92004 0 浙江卫视的节目剪辑越来越看不懂\n1000 Processed\n classify content\n92500 0 8月12日周三下午拱北地下商场面试\n92501 0 xxxx龙婆坤一期佛牌成功佛秦娜拉佛祖事业运势权威财富开拓进取之牌红铜版带ddpra卡国内现...\n92502 0 后保险杠也装备了一组非功能性的水平格栅\n92503 0 xxxx年x月xx日市民向采访花鸟字专家渠成的徐州电视台徐州新闻王佳佳、蒋华盛赞渠成大师:花...\n92504 0 我妈家旧电脑密码忘了怎么都打不开怎么办\n1000 Processed\n classify content\n93000 0 去年的镇江和今年的奥体完全像两个球队\n93001 0 恶僧贪污款项交司法机关刑事立案\n93002 0 手机马上没电也不能谷歌走回去还好我带了500不然我就完了\n93003 0 利用晚间和假期钻研股票业务和市场行情\n93004 0 扬州早餐行业的特点难道就是服务态度极差\n1000 Processed\n classify content\n93500 0 浙江慈溪一交警在执勤中被工程车碾压致死\n93501 0 个股利好:健盛集团半年报业绩增五成拟xx转xx\n93502 0 喝多了的一个后遗症就是眼睛没办法对焦\n93503 0 开学高三加油lightupthedark??\n93504 0 泰燮与庆修在飞机上偶遇…男男剪辑版视频:\n1000 Processed\n classify content\n94000 1 恒翔教育新学期报名开始了,元宵节前报名价格优惠,并有精美礼物相送。\n94001 0 吃的都像准时喝中药一样恶心了\n94002 0 用贿赂、哄劝的方式息事宁人\n94003 0 日本kissme睫毛膏~??大名鼎鼎\n94004 1 奉化xx年老店(艺藤居)(翡翠藤器) 羊年喜洋洋.因店面装修.全场特价处理。 满xxxx送x...\n1000 Processed\n classify content\n94500 0 结果调了快2g的psd也不敢关\n94501 0 VillasofPinecrest小区次卧招租\n94502 0 然后腾讯就莫名其妙地说我发布诈骗信息\n94503 0 ??????????????????\n94504 1 北京宜美家园装饰新春钜惠,全包低至xxx/平米,更有多项大礼相送。详情请咨询xxxxxxxx...\n1000 Processed\n classify content\n95000 0 其著名的轻工业、旅游业、酒店业和娱乐场使澳门长盛不衰\n95001 0 com新金瓶梅龚玥菲版高清百度云网盘下载\n95002 0 中国18岁以上成人高血压患病率为18\n95003 0 我手机时不时就卡一回怎么就保存不上呢只能呵呵了~good\n95004 0 浦口检察院是7月20日向浦口法院提起公诉的\n1000 Processed\n classify content\n95500 0 2015年7月25日至8月1日麟游县在河滨公园举行第二届农特产品展销会\n95501 0 在别的小生出现的假爆料下说“没杨洋还能看吗”4\n95502 0 浙江中南部地区已经出现雷暴天气\n95503 0 网曝江苏如皋市女民警家属泄露李易峰、杨洋两名艺人的身份证号、曾用名、户籍地等信息\n95504 0 椒江体育馆将举行2015麦迪中国行“终极一战”台州站篮球赛\n1000 Processed\n classify content\n96000 0 狮子座的老妈太霸道让我在家打扫卫生就算了现在还要我做饭等她回来也不看看我是那种被强权压倒的人嘛\n96001 0 平时看过的家居装修对于环境创设会带来很多的Idea\n96002 0 借款到期后赵某仅归还3万元余下的未还\n96003 0 PPL大手笔投资奈何盼达网这个名字起得太土了\n96004 0 刚到口腔医院就碰到小姑娘因为害怕拔牙晕倒了\n1000 Processed\n classify content\n96500 0 浙江义乌有个妈妈不小心把自己的儿子锁在宝马车里了\n96501 0 分享nmgtxl的博文图片:红石崖旅游风景区\n96502 0 百脑汇的物业全是狗娘养的婊子畜生\n96503 0 坐了五天JR我是再也没法在魔都坐地铁……另外在东京酒店住得太舒服\n96504 0 说在家叫小盆宇为:老niangmen\n1000 Processed\n classify content\n97000 0 好声音今天晚上几点钟开始直播\n97001 0 最好的crystalinjector水晶水光仪瑞士原装马达机芯\n97002 0 而是把所有都点点滴滴记在心里\n97003 0 希望通过这种形式架起城管与市民沟通的桥梁\n97004 0 MFA专业学位和通常所说的“硕士、博士学位”有什么不同\n1000 Processed\n classify content\n97500 1 《俏媳妇火锅》酬宾活动开始!全场菜品x.x折,山城国宴、雪花啤酒喝x送x!电话:xxxxxx...\n97501 0 宝马等4S店站工作的专业技术骨干和资深管理人员\n97502 0 2015年我校江苏本一理科投档线345\n97503 0 好声音最美和声原唱弹奏苹果园组合风靡繁星网\n97504 0 S38常合高速由合肥往常熟方向宁常段在137K处施工结束\n1000 Processed\n classify content\n98000 1 “小升初定向培养课程”抢报中!名师定制重点中学名校备考计划,精讲数学、英语、作文知识模块!快...\n98001 0 淅川县法院组织的一场刑事审判正在现场开庭\n98002 0 东正社区开展了法律知识讲座\n98003 0 江苏成功注册地理标志188件\n98004 0 游侠汽车在北京发布了游侠X\n1000 Processed\n classify content\n98500 0 因为这样的人会腐败你的理想人生\n98501 0 也可咨询机场问讯电话xxxxxxxx\n98502 0 投资机构PiperJaffray日前对超过800名美国消费者进行了调查\n98503 0 有多少人是冲着白子画去看的“花千骨”\n98504 0 大多数人会反对房地产税改革\n1000 Processed\n classify content\n99000 0 HealthyCare蜂胶牙膏120g\n99001 0 我如果真的可以换手机的话\n99002 0 木叶乌鸦cos作品SD娃娃萌翻了\n99003 0 我预测火箭很快签约落选新秀威廉姆斯\n99004 0 饭搭子A为了安慰饭搭子B指着我说:毕业学校差没什么不好啊\n1000 Processed\n classify content\n99500 0 现在这款键盘可以在Amazon和微软网上商店中购买\n99501 0 厦航MF、山航SC、深航ZH、海航HU、首航JD、川航3U、上航FM、成都航空EU、河北航空...\n99502 0 学车才几天忘记涂防晒霜全黑完\n99503 0 有数个自行车手机等等等等等等等等等等…肾都丢完了\n99504 0 我们大泗阳的音乐节也很高格逼的\n1000 Processed\n classify content\n100000 0 昨天晚上我从扬州坐火车经过xx个小时的颠簸到达了潢川\n100001 0 而且是彻底的反root设计\n100002 0 8月8号求个妆娘或者摄影或者后勤\n100003 0 华为已成为世界第三大手机制造商\n100004 0 浙江省台州市椒江区新世纪商城后殿陶村干部打人:说他是村支书想搞你就搞你\n1000 Processed\n classify content\n100500 0 中国证券网:中铁建招标新一批铁路客车\n100501 0 艾森豪威尔1944年秋天错误地阻止他关闭“法莱斯缺口”\n100502 0 机会已经远离你成功的秘诀就是多付出\n100503 0 免费分享浙江50份分享冰花种子\n100504 0 即便是有BUG也能让玩家体验5D的快感\n1000 Processed\n classify content\n101000 0 政府托市收购对稻米价格影响有多大\n101001 0 结果证监会的做法却是滥用补药\n101002 0 43岁的邹莉在汉口一美容会所办理减肥服务\n101003 0 ”Gartner副总裁JohnMorency说道\n101004 0 防晒衣、防晒霜、遮阳伞等防晒用具又该大显身手了\n1000 Processed\n classify content\n101500 0 一涂即白是因为有防晒遮瑕的作用\n101501 0 把真正的男人看完了好喜欢新兵连的班长啊\n101502 1 特大喜讯: 金壁辉煌现在推岀:一般畅饮和豪华畅饮; 一般畅饮:小包xxx;中包xxx;大包x...\n101503 0 3亿元实施6条15公里二级公路接线\n101504 0 A股的股指期货存在巨大的做空漏洞\n1000 Processed\n classify content\n102000 0 看来那个法院副院长之后确实问出了他们要弄死几个将军的证据\n102001 0 在其悬疑、科幻、机器人伦理表面下\n102002 0 x、执行力期:逢人谈执行力为初创期\n102003 0 为毛验证码往我上一个手机号发\n102004 1 三八妇女节快到了,这可是我们女人的节日哦!在这里提前祝大家节日快乐!为了感谢新老顾客对本的支...\n1000 Processed\n classify content\n102500 0 电脑需要贴膜??手机需要贴膜??车更需要贴膜??那你的脸呢??为什么不给脸贴膜??三天不贴膜\n102501 0 在细胞和组织水平上启动皮肤主动修护程序\n102502 0 啪厮的一声耳机勾扯耳朵daung~掉了草泥马\n102503 0 借南京金海港船舶管理有限公司济南分公司骗取中介费和其他费用等数万元\n102504 0 “谢谢”第二果粉问:你的能天天酷跑吗\n1000 Processed\n classify content\n103000 1 超值福利!凡预交xx元认筹(可抵购机款!必须找我报名哦!不然认筹不到啊!),立送xxx元喜庆...\n103001 0 下图是南京市中西医结合医院皮肤科副主任中医师杜长明\n103002 0 最近一直出现手机震动嗡嗡的幻听\n103003 0 对个性进行重组后可以看到如下组合\n103004 0 6、皮肤对烈日和电脑辐射反映强烈\n1000 Processed\n classify content\n103500 0 幫朋友卖经院MScMoneyBanking&\n103501 0 江西省南昌县人民检察院以敲诈勒索罪对犯罪嫌疑人张某批准逮捕\n103502 1 亲爱的会员朋友,元宵快乐噢!因春节期间本店人手紧缺,对您有所怠慢,还请谅解,为表歉意,您将有...\n103503 0 演戏的同时也在母校带研究生\n103504 0 被曝光的违法广告涉及保健食品、处方药、非处方药、医疗器械四大类别\n1000 Processed\n classify content\n104000 0 真的佩服媒体瞎bb的水平以及引导不明群众的舆论能力\n104001 0 所以说别让别人碰你的手机\n104002 0 不然你检察院法院有个毛办法\n104003 0 Up主:素年锦时丶初见来自AcFun文章频道\n104004 0 中午回家吃完饭13点打开电脑\n1000 Processed\n classify content\n104500 0 一大早跑到淮阴在车里睡觉我也是醉了\n104501 0 让吃不惯飞机餐的旅客们情何以堪\n104502 0 对南京的第一印象一定是南京盐水鸭、金陵鸭血粉丝等等\n104503 0 旋风少女浙江卫视克拉恋人\n104504 0 江苏阜宁推15项好人免费政策参政可获政治优待\n1000 Processed\n classify content\n105000 0 这是以国内机构为主勾结外资屠杀行为\n105001 0 经过时间的洗礼终究真相会赤裸裸的示于人前\n105002 0 上市公司东方财富网招聘UI求扩散\n105003 0 或者是南京西安成都可以吃好多好多小吃的地方\n105004 1 亲爱的客户,因鲁西肥牛洋河店租约到期已歇业闭店,诚挚邀请您来黄泥磅店(紫福路金玉满堂对面)就...\n1000 Processed\n classify content\n105500 0 GDP、公共财政预算收入、规模工业增加值、固定资产投资、社会消费品零售总额增幅均高于全国全省...\n105501 0 谷歌学术数据库收入范围非常广泛\n105502 0 坐的都不是飞机我怎么觉得像是坐火车呢呢那么累那么累那么累\n105503 0 正品范特诗鲜果酶水果酵素瘦身丰胸美白水果酵素无副作用无效退款\n105504 0 这样就不会一起床就把手机砸了\n1000 Processed\n classify content\n106000 0 隆重举行xxxx届学生毕业典礼\n106001 1 您好名媛印象世纪联华店,在x.x节来临之际文胸x.x折起,家居服x折,满xxx元送内裤一条,...\n106002 0 在地铁上看到一个老太太因病痛疼得一直流眼泪\n106003 0 世界上最大的悲剧我的电脑卡住了\n106004 1 女士即可领取xxxx元项目卡一张加精美礼品一份(凭短信领取)同时店内还有更多存送优惠[炸弹]...\n1000 Processed\n classify content\n106500 0 朋友开的逐风箭咖—扬州首家专业射箭馆\n106501 0 汽车常识——车屁股上的那些事快速了解车尾标的含义\n106502 0 主页妞将不断po上车队近期日常\n106503 0 /可爱/可爱/可爱/可爱\n106504 0 爆乳辣妹持刀抢劫没经验处处留痕迹有胸果然是无脑的\n1000 Processed\n classify content\n107000 1 学政教育省考冲刺押题班将于x月xx号开课,省考之前的最后一个压轴性封闭集训营了,提分最快,小...\n107001 0 有媒体7日刊登的无锡警方抓获16名苏南硕放机场货运站内鬼一文新闻信息失实\n107002 0 联合各地政府全力推进1786个消火栓建设工作\n107003 0 我都准备打110看是不是有人绑架了\n107004 0 简约的一件条纹T恤与白色短裤相搭出夏日清爽气息\n1000 Processed\n classify content\n107500 0 2、华为—称5G发展已到关键节点\n107501 0 前天一小哥帮我修办公室电脑\n107502 1 平安养老及教育保险,只存三年,存满就领,年年领,领至终身,本金在,本金涨,辛苦三年,幸福一身...\n107503 0 3靖江AnimeCity夏日祭\n107504 0 其中Winxx与Xbox的双向融合更是让广大玩家兴奋不已\n1000 Processed\n classify content\n108000 0 最令他興奮是與NBA球星林書豪在球場上較量\n108001 1 药王堂荷花池店为庆祝女性同胞节日:(三八妇女节)x月x日-x月x日,全场满xx送xx,买满x...\n108002 0 签名也OK了√明天可以发货先发一部分了\n108003 0 烧毁日军坦克、装甲车12辆……他就是李海山\n108004 0 就是米菲衣服的颜色哦~发现了么\n1000 Processed\n classify content\n108500 0 24小时服务的空调每到半夜10点以后就关闭\n108501 0 FX眼药水是针对消除眼睛充血以及对配戴隐形眼镜或用眼过度产生的疲劳非常有效果的一款眼药水\n108502 0 上林县人民检察院指派代检察员覃光锡出庭支持公诉\n108503 0 win10的PIN也是个bug更新完用了不到一天就重启了N次而且连重启都出问题要收集信息发回\n108504 0 此次失事的飞机航班号为4u9525\n1000 Processed\n classify content\n109000 0 给予不超过60万元的一次性资助等…\n109001 0 徐州工程学院化工院送老生晚会朱捷老师脱口秀真心全程无尿点值得一看\n109002 0 上次地铁上一男生行李箱挡住了路\n109003 0 他们可能看到coconutmilk就认为是能喝的椰奶\n109004 0 有时候觉得股票就是自己的儿子\n1000 Processed\n classify content\n109500 0 一个女孩长期用x块x一盒的面膜\n109501 0 让我快点传满100个iphone6手机壳吧\n109502 0 xx日本插画家空山基自的代表作品性感机器人\n109503 0 回忆是人生中宝贵的财富你觉得痛苦那就选择麻木你觉得开心就藏在心里时间会改变很多\n109504 0 一辆号牌为8889的法拉利与一辆号牌为9888的宾利相撞\n1000 Processed\n classify content\n110000 0 华为也推出了LITE和TalkBandB2\n110001 0 南京大学地球科学与工程学院建设院地质博物馆研讨会\n110002 0 又可以去最顶级的shoppingmall太古汇购物娱乐\n110003 0 拿得状元的是限量版的NokiaNxxx分\n110004 0 我们看朝鲜的眼神和欧美国家的人看我们的眼神神似\n1000 Processed\n classify content\n110500 0 泰州计量针对本地产业的热点\n110501 0 但是水表被盗窃的事情也不是第一次发生了\n110502 0 BvlgariMonete15最新款双层内里带内袋超级实用的隔层设计锁是扣很特别的古罗马风格...\n110503 0 DreamBy梦时光婚礼顾问官方微博|喜结网婚礼灵感、风尚、攻略博客\n110504 0 该x名犯罪嫌疑人已顺利移交西安秦都警方\n1000 Processed\n classify content\n111000 0 刚在派出所留资料的时候咋不说我叫雷锋呢\n111001 0 临平站联合驻站派出所组织护站队开展反恐防爆演练\n111002 0 Orbis推出轻熟龄抗老系列=U\n111003 0 微信群里在群聊电梯死人的事\n111004 0 一辆牌照为黑R03**的警车将一名50多岁的男子撞倒\n1000 Processed\n classify content\n111500 0 用料酒、蜂蜜、姜蒜、盐腌制回忆\n111501 0 浙江省公安厅网警总队总工程师蔡林介绍\n111502 0 行政法挂科率高到辅导员以为成绩登错了\n111503 0 和谐的社会城管就必须文明执法\n111504 0 n次买东西第一次被淘宝卖家骚扰\n1000 Processed\n classify content\n112000 0 看着各种古色古香的建筑与小桥流水的景致\n112001 0 x、分门别类、图文并茂的展示项目推介\n112002 0 设计师HyunJuPark将红绿灯运用到地铁门上\n112003 0 搭载出租车出外或者到各大火车站\n112004 0 x味冲的食物:洋葱和大蒜和防癌\n1000 Processed\n classify content\n112500 0 ferragamo菲拉格慕高跟鞋粉红色正版牛皮的二手有喜欢的私信xx码欧美的鞋子偏大一码\n112501 0 也标志着我国大飞机项目进入收获期\n112502 0 已大大超出了飞机设计制造者的预想\n112503 0 胖弟神回复哎呀妈呀就算你不说她刚上课不就介绍自己说她自己是一高中火箭班得了嘛\n112504 0 出现于证券交易在开盘后显著走高\n1000 Processed\n classify content\n113000 0 com重庆招聘求职千人群2:128245580\n113001 0 联系电话xxxxxxxxxxx\n113002 0 却冻死在夏天~各位童鞋们在家还好吗\n113003 0 我要回南京你抱着我哭的样子\n113004 0 闲逛时拿着装手机钥匙等小玩意儿\n1000 Processed\n classify content\n113500 0 图片尺寸不小于xxxxxxxpx这个是怎么回事么\n113501 0 仙后座手表由SamFreeman设计\n113502 0 它代表着当你投资股票后的拥有权利是多少\n113503 0 『IBM设计语言|动画部分』\n113504 0 等你蟑螂过去人族口一堵两台坦克架起来根本莽不进去的啊\n1000 Processed\n classify content\n114000 1 春季大酬宾;厂家让利,实木多层板;原价xxx元/平方;现价xxx元/平方;欢迎新老顾客来店咨...\n114001 0 而相对应的江宁板块预计有11家楼盘将在下半年收官\n114002 0 花千骨并不是白子画的生死劫\n114003 0 本机屏幕可能使用了“ID无边框”设计\n114004 1 卧龙新街姜宇祝您元宵节快乐!特推出VIP卡,一万抵两万。地址:x路车终点站,详询:xxxxx...\n1000 Processed\n classify content\n114500 0 浙江怎么年年这个时候都有台风啊\n114501 0 台风降临富阳就在不久前在浙江省富阳市场口镇惊现纯白凤凰难道预示着什么\n114502 0 关爱手机炉石用户从你我做起\n114503 0 能免费打手机里照片自己正在鼓捣\n114504 0 使得Mustang的眼神更加犀利\n1000 Processed\n classify content\n115000 0 承接DIY蛋糕饼干巧克力蛋挞披萨果冻布丁华夫饼松饼寿司暖场活动\n115001 0 Google地图显示不远就有公交车\n115002 0 今天收拾电脑看到好多之前的照片满满的都是回忆\n115003 0 x栋xx层、x栋xx层、x栋xx层\n115004 0 成功抓获涉嫌盗窃并逃跑两年犯罪嫌疑人\n1000 Processed\n classify content\n115500 1 先生/女士您好,百安居x/x—x/xx商店建材商品促销活动,低至x·x折。签约百安居装修客户...\n115501 0 派出所呼吁民政局多为民办实事”引起网络热议\n115502 1 您好!非常感谢您的来电,恒锦名园营销中心元月x日盛大开放,惊喜活动钜惠阳新,精美礼品任您享!...\n115503 0 xxxx年x月xx日合肥市中级人民法院特大贩卖毒品案\n115504 0 就是懒的打理外加鼻炎受不了\n1000 Processed\n classify content\n116000 0 上周360教育集团新西兰金牌留学专家刘颖老师为大家提供了新西兰八所公立大学中其中四所大学的英...\n116001 0 找了一堆理由就是阻止自己變好\n116002 0 u/b/e/r实在是一个文化很aggressive的公司\n116003 0 微软把XboxMusic更名为「GrooveMusic」了\n116004 0 在职研究生硕士学位证书\n1000 Processed\n classify content\n116500 0 在认清生活的真相以后依然热爱生活\n116501 0 明天要自己倒地铁去找小伙伴儿了\n116502 0 是内置于你Android手机中的一个迷人的女孩儿\n116503 0 洪泽县三河镇卫生院围绕“抗击肝炎预防先行”这一主题开展预防肝炎的宣传\n116504 0 D陶瓷进驻A8高端设计装饰集团\n1000 Processed\n classify content\n117000 0 有蛇/浙江一山中雨天常听到羊惨叫81只羊离奇失踪\n117001 0 这2宗土地或为中新智慧城项目用地\n117002 0 二、经查证无锡永中科技有限公司外方股东百慕大evermoresoftware公司的法定代表人...\n117003 0 小珠子还让不让手机活了…………\n117004 0 河南省检察院党组副书记、常务副检察长张国臣通报省检察院2015年爱民实践服务承诺的具体内容和...\n1000 Processed\n classify content\n117500 0 被人强奸拐带殴打致残还死不了每天精神肉体双重折磨才是真的让他们理解为什么会如此结果\n117501 0 江苏省13个城市2015上半年GDP排名新鲜出炉\n117502 0 YoYo数字扭蛋会让您玩的爱不释手\n117503 0 为了见你可以坐15小时飞机不管不顾\n117504 1 【美乐活】祝各会员元宵节快乐,美丽活动即日起至x月x日,满xxx减xx,再送xx元抵用券,欢...\n1000 Processed\n classify content\n118000 0 问候才得知是一个6岁的小女孩失足从十八楼摔下来\n118001 0 现已广泛应用于航空、汽车、模具等机械加工的各个领域\n118002 0 坐在改装jeep顶上一路互相追逐时\n118003 0 连最后个体对政府的抵抗输给了人性的冷漠这一点都显得陈旧\n118004 1 有超值红包等您来拿!提前预存 尽享实惠,错过一天再等一年!地址:上海普陀区澳门路xxx号月星...\n1000 Processed\n classify content\n118500 0 微软又可以大赚一笔企业费用\n118501 0 目测手机近视xxx+度??\n118502 1 城北第一中心,都市逸桃源!远洋公馆绿园——绿城、远洋、浙铁精诚钜献xx-xxx㎡精装公园大宅...\n118503 1 爱佳超市铺面到期,商场不干了,珍爱十字绣@钻石画最后几天全部x折亏本清仓大处理,不图赚钱,只...\n118504 0 工资是日结的想发展想改变机会永远留给有所准备勇于拼搏的人刷单是不需要垫付一分钱的\n1000 Processed\n classify content\n119000 0 我打算先去其他国家旅游xx月份停在美国\n119001 0 内裤是裤子胸罩是衣服裙子就是裙子但不是衣服\n119002 0 向媒体爆料韩国艺人金某的前前女友\n119003 0 白带异常妇科疾病、不孕\n119004 0 滴滴打船快船专船顺风船统统歇菜\n1000 Processed\n classify content\n119500 0 与百度交好…以后就是互联网的时代了\n119501 0 PS:可见南京市对于江苏省的何其重要\n119502 0 这个腾讯浮云蔡芷纭装的到蛮像的\n119503 0 Google用机器人来测试触摸屏时延\n119504 0 虽说第一次用电脑的yy参赛\n1000 Processed\n classify content\n120000 0 六合区限额以上单位实现社会消费品零售总额xxxxxx万元\n120001 0 我才知道为什么把飞机叫做hui机\n120002 0 可安装腾讯手机管家拦截诈骗短信\n120003 0 但说真的如果教主baby上真人秀节目办婚礼还是蛮有看点的\n120004 0 沁源县司法局传达省厅市局半年工作会议精神\n1000 Processed\n classify content\n120500 0 喷了谷歌是不是除了翻译以外的都不能用了百度查出来的图片全是shi\n120501 0 也就是它可用作皮肤科医生处方和药剂使用的护肤品\n120502 0 看花千骨的都喜欢上了白字画\n120503 0 哆啦A梦standbyme\n120504 0 我们的机器人“师傅”正安静地“站”在厨房里\n1000 Processed\n classify content\n121000 1 你好、苏州奥特莱斯theory从x月x号到x月x号全场x折、谢谢\n121001 0 再也没法坐在电脑前看你们的直播\n121002 0 包括京东和阿里巴巴大电商金融化\n121003 0 ice王对案件分析十分详尽\n121004 0 2的我在家开着空调捧着西瓜\n1000 Processed\n classify content\n121500 0 好声音舞台上那些惊艳了我的好声音:第一季的张玮\n121501 0 风靡韩国的蜂蜜黄油杏仁小包35G\n121502 0 华为“进击”公有云挑战互联网巨头|华为“进击”公有云挑战互联网巨头2015年07月31日03\n121503 0 北京吊篮配重电动吊篮配重水泥配重租赁出租吊篮配\n121504 1 【TATA木门】亲x.xx全国联动工厂直供实木复合*/款xxxx元,前xx名凭此短信可抵/x...\n1000 Processed\n classify content\n122000 0 利通公安分局成功破获一起以“包小姐”为由实施诈骗的犯罪团伙\n122001 0 明星们也都在用我们妆后的酵素洁颜粉??\n122002 0 严厉打击破坏电信设施犯罪行为\n122003 0 这样一个月下来就得5800元人民币\n122004 0 驾驶员驾驶皖C***号重型半挂行驶至五保高速xxx公里处时因挂车的灯光信号、制动、连接、安全...\n1000 Processed\n classify content\n122500 0 目前岛内比较热门的租房区域如前埔、瑞景、火车站等\n122501 0 在此法官展示一些真实的借贷纠纷案例\n122502 0 一名35岁的商场保洁工被B2至B1层的自动扶梯夹住腿部\n122503 0 法马代表讨论飞机残骸鉴定事宜毛里求斯开始搜寻MHxxx\n122504 1 陈诚轮胎公司谭小文祝各位老板羊年万事大吉、财源广进!公司主营三包全钢胎:全球行、工矿型、凡世...\n1000 Processed\n classify content\n123000 0 扬子江大道将新增29处过街通道\n123001 0 中国重工以及中国卫星等都是天德持续看好的品种\n123002 0 所有电梯都有这个红色??按钮\n123003 0 单位送信件杂志的物业前台姐姐认识我了\n123004 0 定西市通报10起发生在群众身边的“四风”和腐败问题\n1000 Processed\n classify content\n123500 0 Win10Mobile版微软小娜特技:知晓世界时间\n123501 0 刚才我在房间里玩手机呢就只听外面一小姑娘大喊:我要出丽莎布布\n123502 0 医生一开始认为他只是被虫子咬了\n123503 0 持有手中的股票今天下午存在回落的可能\n123504 0 在7月7号本人再次报道大荔一老兵22年因为政府官员丢失档案造成老兵妻离子散后\n1000 Processed\n classify content\n124000 0 刚看到那个男生在好声音舞台上求婚\n124001 0 英国铁路通票:免费赠送乘车天数\n124002 0 最适当的防晒系数是介于SPF15到SPF30之间\n124003 0 并盗走第328窟彩塑供养菩萨像等\n124004 1 尊敬的家长您好!阳光艺术馆开学啦,周一至周五中小学生作业辅导已有专业的老师辅导,美术和书法的...\n1000 Processed\n classify content\n124500 0 一起回忆着那些年的点点滴滴\n124501 0 回来手里就抓愚蠢和犯罪行为\n124502 0 那么互联网+行动计划要如何得以实现呢\n124503 0 而根据新修改的将交通法规规定\n124504 0 北京至宝坻段约80公里与京唐城际共线\n1000 Processed\n classify content\n125000 0 然后他就从电脑里出来了⊙▽⊙\n125001 0 谁还敢说转基因只杀虫子不杀人\n125002 0 泰州就没有哪家日料有纳豆有寿喜锅服务员不会乱逼逼的吗??\n125003 0 这次的图片据说来自iPhone相关产业链\n125004 0 我用百度视频手机版看了“美女为凉快躲进冰柜里”\n1000 Processed\n classify content\n125500 0 nuru的翻译还有配音也好可爱\n125501 0 校长、副校长因犯玩忽职守罪\n125502 0 8月7日感谢上帝感谢耶稣感谢菩萨继续当个好人报答你们也提醒大家坐电梯注意安全注意安全\n125503 0 玫琳凯苏州赛区百变美人季\n125504 0 以及青藏高原中途站—唐古拉山措那湖那曲\n1000 Processed\n classify content\n126000 0 在接受中视『改变的起点』专访时\n126001 0 周边环绕着巴黎春天商业中心\n126002 0 打麻将输了还有后备军发红包\n126003 0 我又用百度钱包x分钱充x元话费了\n126004 1 尊贵的客人,京都薇薇祝您“三八美女节”快乐!为感恩回馈,特别为您推出“谢天谢地,您来啦!”答...\n1000 Processed\n classify content\n126500 0 让一个20几岁的小姑娘在养老院一干就是28年\n126501 0 刚下飞机就听到有航班因为天气原因取消\n126502 0 银泰0571—86234738\n126503 1 (让你随时接听别人电话和看到微信Q-Q聊天讯息→对方不会发现)(详:xxxxxxxxxxx)\n126504 0 innisfree和naturerepublic防晒霜x宝露露驱蚊喷雾成人儿童可用x\n1000 Processed\n classify content\n127000 0 外面的各种装修声把我吵醒了\n127001 0 就使用我的邀请码9pd9u8下载并登录浙江移动手机营业厅\n127002 0 随时随地把照片上传到手机等移动设备\n127003 0 而即将在9月份发布的2016春夏系列则是他在职期间设计的最后一个系列\n127004 1 尊敬的客户您好,正和装饰城三楼美心家美木门祝元宵节快乐!同时x.xx的”乐享套餐”优惠活动也...\n1000 Processed\n classify content\n127500 0 大约有127种涉及到操作系统和无线通信的专利被用于安卓手机\n127501 1 现有多肽尿素到货,xxkg规格,黄色颗粒,半透明包装~~价位xxxx~要得请联系,定点销售 ...\n127502 0 还是继续暴力抗法确实可以当场击毙\n127503 0 5、饮食上要做到低脂肪和高纤维相结合\n127504 0 又失眠明早还有labtest\n1000 Processed\n classify content\n128000 0 茶钱3元半天…真的以为老百姓的钱是充话费送的吗\n128001 0 一旦与微软的禁业协议在2016年到期\n128002 0 看看库里NBA生涯这一路经受的伤痛\n128003 0 获百度ipad客户端壁纸\n128004 0 来自安徽省的xx名知名专家来到宿州市为当地的企业、单位开展智力服务\n1000 Processed\n classify content\n128500 0 Microsoft對VR技術信心十足\n128501 0 高尔夫球场成大吸水器北京球场用水相当两个区\n128502 0 以强奸妇女罪被判了3~10年……好像挺短的\n128503 0 居然在腾讯视频看见自己的照片真的出现在7月5日池昌旭韩国世贸天阶生日会的大屏幕上\n128504 0 17级台风“灿鸿”要登陆浙江了\n1000 Processed\n classify content\n129000 0 也许女生有难处大学会存在潜规则么\n129001 1 xx万欧元购房送西班牙绿卡,xx万人民币起移民德国,一人办理全家享受同等待遇,子女享受欧洲教...\n129002 0 江苏人这么能喝……第一杯喝完直接就拿分酒器干\n129003 0 警察也没几个是天天凭良心做事的\n129004 0 一路投资一路收益属于打长线\n1000 Processed\n classify content\n129500 0 南京青奥会跳水比赛男子3米板的冠军昨天出炉\n129501 0 举报者“释正义”在昨晚7时最新发给媒体记者的材料中称\n129502 0 由盐城质监局下属单位盐城市计量所承\n129503 0 请经过常熟段国省道的车辆减速慢行\n129504 0 一般看谷歌直播一边无限loop萧逸晴的威风堂堂毫无违和感hhh\n1000 Processed\n classify content\n130000 1 亲爱的VIP:MASFER-SU女人节活动火热来袭啦!x.x~x.x期间xx年春季所有商品及...\n130001 1 重庆星顺奔驰万州xS店将于本周末(x月x、x日)在展厅举行“三八妇女节”特惠活动,可能您意向...\n130002 0 亚马逊招聘内幕:BarRaiser狂刷应聘者\n130003 0 学会了柠檬的卷发方法感觉自己牛逼的不得了没有电脑的好处吗太无聊了总想找点事做\n130004 0 以往飘散在加油站内浓浓的汽油味如今已经一去不复返了\n1000 Processed\n classify content\n130500 0 严厉打击涉枪涉爆违法犯罪行为\n130501 0 专家:对华出口重型火箭发动机不违反军用火箭技术不扩散制度/Sputnik中国–新闻\n130502 0 所以贴心的小YO联合百度手机助手给大家谋\n130503 0 微软确认公共预览版将在x月底到来\n130504 0 一觉醒来发现电脑里珍藏多年的添富宝的图包没了还玩毛\n1000 Processed\n classify content\n131000 0 ||我在氧气听书收听“012长留上仙”\n131001 0 当前A股融资盘规模仍然明显高于国际水平\n131002 0 帽子长袖防晒霜and六神已准备好\n131003 0 需要加卫星号:xiaovvvjian\n131004 0 任何自由都必須受法律限制的\n1000 Processed\n classify content\n131500 0 #NAME?\n131501 0 1是人力资本流向过度政府干预\n131502 0 在了解和认识大众汽车的同时\n131503 0 最近圈内疯传一段话:世界上最遥远的距离是:你明知我在做WV\n131504 0 很多次看到小孩在电梯乱跑蹦跳\n1000 Processed\n classify content\n132000 0 生鲜电商的热度从2014年开始便是有增无减\n132001 0 LX成熟的真相就是拨出迷雾见青天\n132002 0 学会了无所事事和弄虚作假~~~\n132003 0 第一次坐飞机有什么需要注意的呀\n132004 1 浙江基药中标产品独一味颗粒(省增补,临床认可度高,xg*xx袋/盒,中xx.xx元)全省隆重...\n1000 Processed\n classify content\n132500 1 您好:我是张家港华胜的小金,x月公司开年巨惠活动:x.新客户小保养(机油,机滤,工时)是xS...\n132501 0 GD知道我们应援差还带动知道我们不能站就叫我们站起来我真的很心酸\n132502 0 求助于腾讯视频的同学也无果\n132503 0 07亿美元私有化全球第三和第四大手机芯片商展讯与锐迪科\n132504 0 他推測楊貴妃約165公分、60公斤\n1000 Processed\n classify content\n133000 1 感谢致电潮州全兴炉具,本公司主要经营国内外各种名牌炉具,热水器,抽油烟机,家用电器及各种单屏...\n133001 0 想在南京继续亲临盗墓笔记2\n133002 0 “电脑综合征”是最近几年提出的一个疾病症候群\n133003 0 烟叶来源不合法帮忙运输成共犯\n133004 0 MK全牛皮耳朵包两边菱格设计\n1000 Processed\n classify content\n133500 0 天哪我觉得自己有点酷红包手气是不是很厉害\n133501 0 你们的尾巴在2015年7月8日露了出来\n133502 0 我们的城管叔叔就手下留情吧\n133503 0 面积段xx平米——xxx平米不等\n133504 0 特别要感谢一下越秀法院书记员的高超专业素养\n1000 Processed\n classify content\n134000 0 南京…──分享自都市快报iPhone客户端\n134001 0 江苏13个省辖市18个公证处已开设6大类36种公证事项网上办理\n134002 0 中国政府什么时候才能让她的人民活得有尊严一点\n134003 0 而且部分汽车清新剂产品中添加的劣质香精本身也存在危害\n134004 0 一起来听听吧~Opening\n1000 Processed\n classify content\n134500 0 新华、人民和各地党报集团所属网站或合资网站占据大头\n134501 0 一款P8+Mate7主题——似水流年之君子人生\n134502 0 大商集团的销售点遍及全中国11个省份\n134503 0 liyingxin设计我和我打官司的事情法院已经处理了他还差我一个高尔夫球杆一个香水一个手机没给我\n134504 1 好消息!??????上坤公园天地别墅,上海唯一建在公园之中,坐拥xxxx亩顾村公园,联排全水...\n1000 Processed\n classify content\n135000 0 被称为阿里\"最励志\"的合伙人\n135001 0 15个项目全部达到序时建设进度\n135002 0 来宾市公安局交警支队二大队民警通过现场调查\n135003 0 国产手机盈利情况最好的应该是vivo和OPPO\n135004 0 比如什么手指全断比如全身上下血淋淋都有给特写\n1000 Processed\n classify content\n135500 0 ·因为上次一起逛上海自然博物馆的时候没能买下猹\n135501 0 很多时候解决问题可能是IBM\n135502 0 ”nmb天惹噜有人在看你相册里的丑照\n135503 0 一张价值329的衣服券最近谁想买衣服\n135504 0 余杭好声音200强42号待定选手\n1000 Processed\n classify content\n136000 1 我的新单位简介,请各位亲友多多支持!山海大酒店以其得天独厚的地理位置雄踞天外村之南(果科所北...\n136001 0 而以阿里、京东为代表的互联网电商平台\n136002 0 Google的东西也更爱发到后两者\n136003 0 我觉得花千骨这部电视剧跟我们说明了一件事那就是16岁就可以谈恋爱了而且爱的是有权有势有地位有...\n136004 1 你好,本人是做装修设计,有样板间可参观,价格底,质量有保证售后有保证,兔费设计现场报价,有意...\n1000 Processed\n classify content\n136500 0 城管新安江中队在城区范围内排查各类可能存在的安全隐患\n136501 0 要出大事了~如果不赶快进行治疗的话由于你的愤怒你周围的人会感到很疲累\n136502 1 (x/x)您好,感谢致电上海蓝天框业,本公司专业提供个性铝合金相框定制业务。详情或登入www...\n136503 0 伊犁州气象台x月x日xx时发布大风蓝色预警信号\n136504 0 常州市五洋纺织机械有限公司董事长王敏其在琢磨如何用一套系统把生产跟踪、仓储盘点、设备状况、质...\n1000 Processed\n classify content\n137000 0 哈哈哈哈哈哈哈哈江苏台继承者们的配音简直了哈哈哈哈哈哈哈哈\n137001 0 一个女人的智慧是环境打造出来的\n137002 0 而黄斑恶化会引起失明且无法治愈\n137003 0 你可能会说:供房子3000元/月\n137004 0 原本以为“潜规则”这个词被说了这么多年\n1000 Processed\n classify content\n137500 0 迪尔德丽和luxelab携手香港专柜上市\n137501 0 刚刚在公交车上见到两个小偷\n137502 0 不到天王1公里处发生两车追尾事故\n137503 0 苏州印象不错~今天在高铁穿了长裤\n137504 0 最大的购物中心迪拜购物中心\n1000 Processed\n classify content\n138000 0 给力的是最后一张抵到徐州的硬座让我给抢到了\n138001 0 使新车比Zx看起来更加霸气\n138002 0 效果及疗效超过黄黑东革阿里\n138003 0 看第29届夏季奥林匹克运动会在北京开幕\n138004 0 都表明Norman是个有精神问题的孩子\n1000 Processed\n classify content\n138500 1 为回馈客户对公司的支持与厚爱,公司特推出一次性上付xx%政策,截止到x月xx日,同时还可参加...\n138501 0 和小吴叔叔阿姨一起去浙江转转\n138502 0 还要上演一次“滨海城市”吗\n138503 0 成为南京旅游种魅力来自它所为你提初期建造的刻经石窟\n138504 0 花费560元买回来一个不可以使用的物品\n1000 Processed\n classify content\n139000 0 三叉戟xxx号飞机的钢铁之躯被炸得粉碎\n139001 0 真以为自己bb两句白子画就会不爱花千骨一样的\n139002 0 你们都那么high估计电脑后的她在偷偷暗爽而已吧\n139003 0 抗癌、抗氧化、对女性内分泌调养大有益处\n139004 1 猪鸡羊鼠x肖中,三中三猪羊鼠,二中二猪鼠,一肖中猪,必中,上次透人羊狗全中\n1000 Processed\n classify content\n139500 0 智能商业分析工具PowerBI将在7月24日脱离预览版本的状态\n139501 0 一台电脑一杯茶就能这么坐一下午\n139502 0 看到这一堆堆的腐败骨头难以想象这是用来做钙片的\n139503 0 面·米克洛什控制了新的……\\nSometimeswhenI滩\n139504 0 江南公安分局民警近日展开行动\n1000 Processed\n classify content\n140000 1 x月x日至x日发行多款正月十五元宵佳节专属理财产品,购买起点x万起,期xx天,xx天,xxx...\n140001 0 和林县法院一审以贪污罪判处刘某某有期徒刑1年\n140002 0 亚马逊表示其已经签约西班牙Iberdrola公司来建设和管理在美国北卡罗来纳州的风力发电场\n140003 0 G25长深高速由连云港往杭州方向宁杭段从K2125+228至K2125+322处施工结束\n140004 0 我俩还梦想中彩投资让他俩合作\n1000 Processed\n classify content\n140500 0 关于elegance的这款散粉\n140501 0 ”“医生告诉她喝水不要直接咽\n140502 0 现在的独处除了玩手机还能干什么噢这废物人类快要变成机器人了\n140503 0 支点养生酒与冬病夏治冬病夏治:按照中医理论\n140504 0 什么旅游什么鬼啊劳资根本没出门好嘛\n1000 Processed\n classify content\n141000 1 家长,你好!现六年级数学冲刺班将于x月x-x日开始报名注册,x月x日正式上课。小班教学,名额...\n141001 0 南京母婴/儿童用品信息\"母婴/儿童用品\n141002 0 门口的蛋糕店重新装修后开业了\n141003 0 百度放着这么病态的贴吧不管\n141004 0 新男神李秀赫/李洙赫12年上综艺\n1000 Processed\n classify content\n141500 0 江湖的味道还残留着、医院里一起玩单机的小伙伴们、\n141501 0 玩卫星的朋友加起来comecomelet'sgo\n141502 0 浙江杭州市某大学应届毕业生小施来到杭州市公安局经济技术开发区分局金沙湖派出所报案\n141503 0 左右倾斜手机可以控制主角左右移动\n141504 0 公安战线尤其是首都的公安干警\n1000 Processed\n classify content\n142000 0 贿赂商给你的生意都是亏本生意\n142001 0 如果你涂抹完防晒觉得很油腻的话\n142002 0 13岁一个人去超市买下个星期的牛奶和面包\n142003 0 先后通过ISO9001国际质量管理体系认证和ISO14001国际环境管理体系认证\n142004 0 **新湖创业银润投资中山公用津滨发展华业资本通策医疗桑德环境南京中北北巴传媒强生控股申通地铁\n1000 Processed\n classify content\n142500 0 古埃及区的建筑特别有异域风情\n142501 0 每天坐公交坐地铁的时间又有书看了了\n142502 0 Win10Mobile预览版10166获得更新推送\n142503 0 对收购人的限制:1负有数额较大债务\n142504 0 身边一个同事看到xxxxx发短信说积分多能兑换几百现金\n1000 Processed\n classify content\n143000 0 坐个地铁被死变态盯上了一直尾随我\n143001 0 又一个冤案/云南幼儿园投毒案13年后再审警方证据疑造假\n143002 0 led前大灯与前进气格栅融为一体\n143003 0 连云港市气象台xx日xx时发布\n143004 0 是水上乐园与一年xxx天都可以体验到雪国风情的“冰雪乐园”以及购物中心等结合一体的大型综合娱乐设施\n1000 Processed\n classify content\n143500 0 超三成由非机动车违法所致\n143501 0 难道这是要在地铁口心灵感应吗\n143502 0 今天考完啦ochem洗完啦牙还有biochem一门\n143503 0 早些年浙江卫视的我爱记歌词就是如此\n143504 0 共同举办的xxxx年“甲骨文杯”全国Java程序设计大赛\n1000 Processed\n classify content\n144000 0 SherburnAeroClub开飞机喽\n144001 0 变形玩具超变金刚4合金黄蜂火炭钢索锁霸王龙恐龙机器人儿童礼物\n144002 0 从火车站看南京海的景色确实很美\n144003 0 一觉睡醒上了个厕所刷下手机发现满屏都是试衣间啊…\n144004 0 只能靠预告片和各种mv来度日啊\n1000 Processed\n classify content\n144500 0 做招聘最神奇的是你不知道会遇到什么样的候选人\n144501 0 19岁的nino真是嫩的我想犯罪\n144502 0 仅有国防军工、餐饮旅游和建材等板块出…\n144503 0 诚信经营产品优质才是长久生存之道\n144504 0 投资理财成了微信朋友圈津津乐道的话题\n1000 Processed\n classify content\n145000 0 whateveryouwrite—whitepapers\n145001 0 怎么不为了查明真相而加班呢\n145002 0 译云公布了品牌下的商业、工具、互动和资讯等x大平台\n145003 0 以后西安公安见了洛阳交警直接弄死\n145004 0 八、晚餐与脂肪肝的关系我们晚餐若吃太好\n1000 Processed\n classify content\n145500 0 就是阿里集团出的一款捆绑支付宝的软件\n145501 0 而且可以用在早上化妆水后直接使用\n145502 0 特价248美国医师推荐NO1水宝宝coppertone超值套装内含1\n145503 0 曾經在NBA打球的威姆斯接受了採訪\n145504 0 大多数癌症病人都有一种一致的性格类型\n1000 Processed\n classify content\n146000 0 SAP里的英文是不是印度阿三写的\n146001 1 感谢您致电宁波元通英菲尼迪,我是销售顾问裘龙威,您可以叫我小裘。我的联系方式是:xxxxxx...\n146002 0 何时才能乘除腐败给孩子讨回公道、、、、、、\n146003 0 目前5名涉案成员已被宝应警方刑事拘留\n146004 0 景气周期内业绩无忧的股票可以大胆买入并中线持有\n1000 Processed\n classify content\n146500 0 港股普跌:阿里系跌幅超10%\n146501 0 南京、徐州及蚌埠往六安方向的车辆经陇西枢纽由合肥绕城高速南环段绕行\n146502 0 喜欢她就强奸她啊、告白有什么用、操不到就下药啊、翻脸了就发裸照、大不了蹲监狱、你连监狱都不敢...\n146503 0 奖品:1、路途乐汽车儿童安全座椅\n146504 0 惠普已经开始提前预售部分装载Windowsxx操作系统的PC新品\n1000 Processed\n classify content\n147000 0 由StephenNickel设计缔造\n147001 0 智典财富在山西灵石成功举办了理财讲座活动\n147002 0 NBA新赛季的赛程草案正在各个球队中传播\n147003 0 嘉善法院受理的浙江普翔不锈钢有限公司破产清算一案召开第一次债权人会议\n147004 0 本期小房就来盘点地铁5线沿线最升值楼盘\n1000 Processed\n classify content\n147500 1 曾曾美容院西苑店温馨提示:开门红!三八节送现金:满xxxx元送xxxx元,纹绣x折优,进店有...\n147501 0 预计中国的汽车产量到2020年将达到3000万辆\n147502 1 家长您好!小树英语学校新学期报名已开始。x月x日正式开课。开设科目:英语,语文,数学,物理,...\n147503 0 现在去大陆某些县市区法院丶基层法院以及派出所办事\n147504 0 600多名外来务工人员安置在这里\n1000 Processed\n classify content\n148000 0 滨海新区已集中清理浒苔xxxx吨\n148001 0 它就像是世界建筑流行趋势的风向标\n148002 0 老师问了一句:“nobody\n148003 0 南京玄武区住建局副调研员陈爱平要住酒店\n148004 0 最近不发微博是因为我手机坏了\n1000 Processed\n classify content\n148500 0 人生的真相总是在文字的背后\n148501 1 你好,人协教育近期开设会计(劳动)技能理论培训、实务操作培训,学费优惠!另有英语等外语,如有...\n148502 0 河北融投模式对中小企业又有哪些好处呢\n148503 0 此前B轮的投资方联创策源、顺为资本全部跟投\n148504 0 xxxxxxxx:何炅:“所以就是所有的女生都爱着白子画\n1000 Processed\n classify content\n149000 0 被运输:cecolisabienvoyagé这件包裹经得起运输3\n149001 0 然后露出市井小贩的那种满足\n149002 0 高跟短靴+黑色链条包眼就爱上的背心裙子\n149003 1 你好,我这边办理信用贷款的,有需要可以联系我。朱经理。电话:xxxxxxxxxxx 地址:...\n149004 0 全国就发生了4起电梯安全事故\n1000 Processed\n classify content\n149500 0 早上起来发现手机里面有这样一些照片\n149501 0 女儿在苏州乐园玩了个很刺激的游戏\n149502 0 详情请询0450930207Yolanda\n149503 0 台湾尺八名家首次南京“尺八禅心”之旅\n149504 0 巨额釆购了IBM的信息、人力管理咨询服务方\n1000 Processed\n classify content\n150000 0 不会被刑事伤害/警方:东莞保安女儿遭轮奸后并未出走保安隐瞒事实\n150001 0 紫薯中富含的维生素A可以改善视力和皮肤的粘膜上皮细胞\n150002 0 就使用我的邀请码xskxxe下载并登录浙江移动手机营业厅\n150003 0 即使恶性肿瘤在肿块长大到压迫身体器官、血管等前无疼痛感\n150004 0 推一个叫wikipaintings的应用\n1000 Processed\n classify content\n150500 0 钱穆诞生于无锡鸿山七房桥一个书香门第\n150501 0 tiger鞋子由于供货老板去泰国旅游了\n150502 0 结果百度地图显示还有一小时\n150503 1 欧派高端全屋定制xxx期间,欧派整体橱柜,衣柜,木门全场x.x 折,更有公司特供橱柜加电器只...\n150504 0 不希望的是我希望飞机正常飞\n1000 Processed\n classify content\n151000 0 武汉市公安局东西湖区分局交通大队车管中队民警孙明来到暑期少儿夏令营边与小朋友们做游戏\n151001 0 首尔市长访华“揽客”韩流明星助力旅游宣传\n151002 0 并邀请到现任微软全球执行副总裁的沈向阳博士致开幕词\n151003 0 看完乱步奇谭第五集才真正开始喜欢这番的的确它根本不是推理番它把人的心理真的刻画的非常细致我觉...\n151004 0 报名时间:xxxx年x月xx日、xx日、xx日共三天\n1000 Processed\n classify content\n151500 0 医生称仍未脱离生命危险……该住户之前曾两次坠落花盆\n151501 0 当初选的华为作为我的第一款智能手机真是没选错\n151502 1 联系QQxxxxxxxxxx。印章,牌照,建筑八大员,一二级建造师,营业执照,建筑,商业,广...\n151503 0 八月份西安出租车起步价上升到十元\n151504 0 手机又坏了又没wifi又不能用流量就连qq都登不了\n1000 Processed\n classify content\n152000 0 中国的城管有时仿佛就是暴动队\n152001 0 「款式」欧美西海岸「颜色」蓝色黄色「码数」50524854「价格」?38包邮\n152002 0 无意中看到了MazdaMaxxAuto觉得也很不错\n152003 0 4个11岁的孩子到邯郸市新市一中刘村游泳馆玩耍\n152004 0 世界上有这样一群女人不傍大款\n1000 Processed\n classify content\n152500 1 你好,如需办&正请拔xxxxxxxxxxx李新\n152501 1 xxxx元即赠xxx元产品一件,满xxxx元即xxx元产品一件,详询xxx-xxxxxxxx...\n152502 1 三八妇女节到啦?? 芙罗兰公司为回馈新老会员,做出以下活动。凡是会员购买芙罗兰套盒一律x折...\n152503 0 所以转让吧~~有兴趣的赶紧联系我\n152504 0 ChloeGoldie2015秋冬最新款大红色现货\n1000 Processed\n classify content\n153000 0 ★Dragon'S┋150807﹏集中‖首尔>\n153001 0 02这只陪伴了我6年的小家伙由于我的疏忽\n153002 0 飞机在四方城上空划了个美丽的弧线\n153003 0 教你在ps里把手绘黑白线描稿调成能直接在电脑上色的图稿\n153004 0 日前南京高淳区砖墙镇农民资金互助社停止营业并被立案调查\n1000 Processed\n classify content\n153500 0 北京市人民检察院第二分院起诉书指控\n153501 0 抗癌金三角功能主治及适用范围:抗癌金三角功能主治及适用范围根据临床观察:抗癌金三角治疗方案对...\n153502 0 这两天画画把好几根HB铅笔都用的差不多了\n153503 0 发了9756个帖子……我觉得我有时候真的特话唠……特别……话唠……\n153504 0 祛痘痘痘印黑头粉刺背上痘痘\n1000 Processed\n classify content\n154000 0 150708巴黎戴高乐机场出境&\n154001 0 人生不“治的了你脾气的人是你爱的人\n154002 0 手机没电联系不上也会按约定不离不弃\n154003 0 希望当我真的躺在了医院的呢天\n154004 0 /除了代工Nexus手机华为可能还给Google“生”了块表\n1000 Processed\n classify content\n154500 0 日本直邮代购日本必买药品榜上有名日本Nichiban温感镇痛贴穴位贴腰痛肩痛肌肉痛关节痛别看...\n154501 0 本来一个美丽的靖西却被一个工厂搞成这样\n154502 0 真相总是要比我们想象残忍许多\n154503 0 终于要换成苏B啦~早知道你要成我的\n154504 0 向近30个储户揽存现金700多万元\n1000 Processed\n classify content\n155000 1 皮卡,日立挖掘机品牌营销宗旨:客户至上,品质保证,成本低,低油耗,高效率,回报快,即日起购机...\n155001 0 你也来为喜欢的歌曲加油吧\n155002 0 手机玩久了的境界不是眼睛看痛了而是大拇指腹刷屏刷痛了累\n155003 0 有些人一生都在摸索爱的真相\n155004 0 悦诗风吟油菜花蜂蜜润膏孕妇可用主要作用是为双唇锁住水分提供屏障\n1000 Processed\n classify content\n155500 0 该公司的IPO申请刚获证监会通过\n155501 0 偷东西的都该盼死刑啊…劳动人民血汗钱或者血汗钱买的东西\n155502 0 但那要等到你加少许蜂蜜调匀\n155503 0 西藏板块、汽车整车、银行板块涨幅最小\n155504 0 但蜂蜜的功效远远不止这点哟\n1000 Processed\n classify content\n156000 0 陕西省洛川县人民法院对被告人秦雷非法杀害珍贵、濒危野生动物一案依法开庭审理并当庭作出宣判\n156001 0 xxxx年x月xx号加推x号楼\n156002 0 华为已明确将在5G研发上投入6亿美元\n156003 0 红点剪刀也要150左右的价格才能入手\n156004 0 不要对一个只反腐而不完善防腐制度的政权抱有希望\n1000 Processed\n classify content\n156500 0 整体而言一切都很好很有新生活豁然开朗的感觉\n156501 0 需要的话请提供你的百度云账号给我\n156502 0 毕源西路壳牌加油站往武警支队方向一辆轿车漏油\n156503 0 共向5973人支付大病保险补偿金额3165\n156504 0 玩遥控模型飞机要考证“黑飞”可能会被行拘\n1000 Processed\n classify content\n157000 0 下午x点才出结果带她在外面吃过饭后心想要先带她去哪里休息一下\n157001 0 此建筑的一大特色是玻璃墙的运用\n157002 0 最感动人心的是机器人十年如一日的守候或许我千里迢迢赶过来只为看你一眼或许我毁灭一切只为你远离...\n157003 0 作为大boss变成妖打个架还在卖萌\n157004 0 xxxx款路虎发现神行采用了路虎公司最新的双幅蜂窝中网设计\n1000 Processed\n classify content\n157500 1 【武汉[玫瑰]通告】x月x-x号,市中心彩妆活动,要净xxx+漂亮、热情的礼仪!包饭,x天共...\n157501 0 今年7月28日是第五个“世界肝炎日”\n157502 0 有小孩在地铁一号线常熟路站撒尿\n157503 0 青年大街新增4个、北陵大街新增6个\n157504 1 中国银行家居装修分期易无抵押及时为您解决资金周转难题,详询致电xxxx-xxxxxxx ...\n1000 Processed\n classify content\n158000 0 微软的桌面做的也是醉了\n158001 0 干了坏事要被举报没问题可以说自己清白云云WWW但是要以承太郎的名誉起誓的话\n158002 0 上线趁3人不备爬出窗户呼救却不慎失足\n158003 0 7/30去常州莫名奇妙逛了一圈\n158004 0 跟韩国的九日蜂蜜黄油对比了\n1000 Processed\n classify content\n158500 0 以最具巴渝传统建筑特色的吊脚楼为主\n158501 0 感恩各界精英前辈对EHERDER品牌的指导\n158502 0 2011中国芍药节在仪征开幕\n158503 0 浙江卫视内个“我选周杰伦”蛮不错的哦\n158504 0 案件判决后被执行人一直下落不明\n1000 Processed\n classify content\n159000 0 一定要经常上你们icloud邮箱\n159001 0 俄政府和央行在2014年底至2015年初采取的一系列措施稳定了金融市场形势\n159002 0 x、本人或通过家人巨额受贿\n159003 0 编号1019167的小帅哥司机\n159004 0 让牛仔几名医生来给他做例行3、杏仁粉—使肌肤润\n1000 Processed\n classify content\n159500 0 央视又曝光国内“红糖”内幕\n159501 0 ticwatch的阳光屏阳光下的表现还是非常不错的\n159502 0 灌南县首期魔术培训班学员才艺表演在县党校教室举行\n159503 0 韭菜、大蒜和小葱x种菜看似不起眼\n159504 0 “不是说法律面前人人平等吗\n1000 Processed\n classify content\n160000 0 我刚刚看了场EG和EHOME的比赛\n160001 0 为何过去优秀的医疗卫生制度备受责难\n160002 0 周杰伦苏州演唱会及周杰伦南昌演唱会看台380最后几张现票\n160003 0 家长带其到医院检查时发现:孩子心脏上竟然插着一根针状物体\n160004 0 每次看到别人的质疑都要在心里默念“人不为己天诛地灭人不为己天诛地灭”\n1000 Processed\n classify content\n160500 0 经设计师Woody篡改后深得我司各路骚年喜爱\n160501 0 A股暴跌真相:隐现国际对冲基金手法曝光\n160502 0 x英寸JDI全高清INCELL屏幕\n160503 0 这个问题一般发生在以下场景:文科生女朋友看不惯你高谈阔论\n160504 0 xx日全省大部最高气温将升至xx℃以上\n1000 Processed\n classify content\n161000 0 乌海市公安局滨河公安分局协助市渔政管理站有效作为\n161001 1 美女们三八节快乐。庆祝三八节凡在本店购买xxx元产品就给xx元洗面奶一瓶。买xxx元产品就给...\n161002 0 Blackmores澳佳宝深海鱼油胶囊1000mg400粒特价220\n161003 0 别忘记推荐的时候让对方输入推荐人手机号码\n161004 0 洛阳盐镇乡强推商业保险工作人员:“不交不行”\n1000 Processed\n classify content\n161500 0 烦死了回个国火车汽车飞机都要坐一遍…………\n161501 0 FESCO再次光临haolleeCafe咖啡\n161502 0 我就呵呵呵呵呵呵了我还是共产主义的接班人呢\n161503 0 在WV会员网站只订购旅游套餐、机票或酒店等\n161504 0 五点三十五的飞机还排在了我们之前飞走了\n1000 Processed\n classify content\n162000 0 分享血护士或毕业血礼的博文图片:外国富二代\n162001 0 昨天晚上9点45飞机延误到3点45\n162002 0 Bigbang南京演唱会\n162003 0 该车辆将搭载先进的LED照明技术\n162004 0 全国将从8月15号起使用新的\"平壤时间\"\n1000 Processed\n classify content\n162500 0 10款极简风格设计的腕表\n162501 0 质疑社会威胁到的是整个国家和社会的基本构架\n162502 0 7.新疆图瓦村:边陲余晖小木屋\n162503 1 你好、我是华夏银行的张经理。月费用x-x.x。额度xx万,只需提供身份证,工作证明询xxxx...\n162504 0 由6个英国人和一位日本人共同制成\n1000 Processed\n classify content\n163000 1 炎患者立马见效,免费试做!各种优惠活动进行中灬欢迎详询!健康热线xxxx-xxxxxxxx ...\n163001 0 坦克形态下两个前履带还可以往前翻折\n163002 0 杠杆资金被打跑了、融资资金被吓死了、对冲资金被扼杀了、滑头资金隔岸观火了、只剩国家队和死多头了\n163003 0 我就想腾讯是不是不是本人了\n163004 0 能看到一个小飞机正在云层上飞行\n1000 Processed\n classify content\n163500 0 宿迁未来编织“三纵两横”铁路网\n163501 0 在飞机上看报纸时看到了我家宝宝~\n163502 0 还有最近一个在4s店买到二手车上诉\n163503 0 推荐老师卡乐猫招聘老师卡乐猫\n163504 0 而是将车退回起点等来警察处理\n1000 Processed\n classify content\n164000 1 好消息! x月xx xx xx号 泰国清迈双飞x天x晚 特价xxxx元 不含xxx落...\n164001 0 伞修本伞修四十九像在此做最后一次场贩\n164002 0 但是xx年那会xxxx万和现在肯定不是一个概念\n164003 0 号外号外~Ami小厨在零号线做促销啦\n164004 0 /毕节警察击毙渔民案:死者中x枪\n1000 Processed\n classify content\n164500 0 状况和1997年亚洲金融危机爆发之前非常相似\n164501 0 车载KTV什么的果然是把妹神器啊~~老司机也请带上我\n164502 0 编辑从绍兴捷玲斯柯达4S店获悉:店内昕动现车销售\n164503 0 每个周五12点都守在电脑前可是每一次都抢不到\n164504 0 有网友去成飞机场厂溜达一圈\n1000 Processed\n classify content\n165000 0 xx号那天我只去了ATM机去过钱\n165001 0 就在焦急的时候小偷装作自己是法国人来旅游的\n165002 0 字句概括整部花千骨的主要人物千骨\n165003 0 热成一条不明真相的非洲咸鱼\n165004 0 我投给了“明知花千骨是自己生死劫\n1000 Processed\n classify content\n165500 0 由于行政文书在法院不起作用\n165501 0 已经快陪伴tfboys2年了\n165502 0 既然选择违法就不应该享受权利\n165503 1 。各xx套先到先得每人限够一套!颜如玉护肤闺蜜价买一瓶送同款一瓶!也是限量xx套!数量有限啊...\n165504 0 腾讯房产从昆明房产信息网公布的退房公告统计\n1000 Processed\n classify content\n166000 0 中国房地产报8月3日报道:河南新田置业冯常生看来\n166001 0 这就是鄂尔多斯中院法官法律文书造假陷害当事人真是鄂尔多斯一大丑闻\n166002 0 啥子设计上的问题在他那里都是不是问题哦\n166003 0 我做了二十几年的护士……”某甲说:“太好了\n166004 0 徐州云龙区社区医院给宝宝接种快到期的自费育苗\n1000 Processed\n classify content\n166500 1 成都急需一名炉子,家常菜,乡村菜那种形式的,地方只有xxx多个平方,地址在二环路东五段静居寺...\n166501 0 盗窃了公司物品还提起劳动仲裁\n166502 0 飞向452b星球大约需要三千万年\n166503 0 官商勾结苦了老百姓要求有关部门来严查\n166504 0 原号码15173253196使用到本月底\n1000 Processed\n classify content\n167000 0 7月13日自治区党委第一巡视组向西乡塘区反馈巡视情况\n167001 0 当年SurfaceRT的噩梦是否会延续\n167002 0 再走一次南京城~这次没时间逛南京大屠杀纪念馆了~下次有机会我想再去一次\n167003 0 这两天朋友圈里头有防晒团购活动哦\n167004 0 新开日代微店~各位大美女们有问题欢迎咨询哦\n1000 Processed\n classify content\n167500 0 他让23号成为风靡全球、家喻户晓的号码\n167501 0 他们成群结队地质疑这个民族的一切\n167502 0 在榕城区抢劫3宗的违法犯罪事实\n167503 0 就故作镇静~~~作为一名有责任心滴“操盘手”\n167504 0 还可在NetSuite、Eloqua和Marketo等系统中顺畅运行\n1000 Processed\n classify content\n168000 0 博实主营业务:石化化工后处理自动化成套设备的研发、生产和销售\n168001 0 中间飞机还延误了11个小时各种取消\n168002 0 安邦集团『安邦入主招行民生与激进风格相关大金控仅差信托』\n168003 0 一名聋哑xx后窜至安徽省蚌埠市某大学学生宿舍楼内\n168004 0 “颜值”成了这款手机的主要卖点\n1000 Processed\n classify content\n168500 0 MLGB说好的LGD内战呢CDEC加油~\n168501 0 学习装电脑结果给装成砖头了\n168502 0 成千上万的贪官将死无葬身之地之地\n168503 0 NBA球队LOGO变化静态版\n168504 0 预计xxxx年下半年该市场规模将达xxxxx\n1000 Processed\n classify content\n169000 0 月收入xw以上可考虑欧美中端游\n169001 0 自xxxx年xx月参加工作以来\n169002 0 如何选择指数期货与指数ETF\n169003 0 阜宁县教育系统2015年暑期面向社会公开招聘教师196名\n169004 0 不想借是不想借反正我都好意思说\n1000 Processed\n classify content\n169500 0 浙江金华烟花爆竹店爆炸事故\n169501 1 您好,我是海洋半岛得置业顾问宋蕾,明天我们推出了十套特价房,您明天过来可以看下,记得进来找宋...\n169502 0 假如花千骨也玩朋友圈、最后一个亮瞎了\n169503 0 美白祛斑服用方法:1粒/日随餐服用\n169504 0 室内走道的设计灵感源自于“山洞”\n1000 Processed\n classify content\n170000 0 互联网医疗未来的6个趋势\n170001 0 不错~~~这2瓶正好适合旅游时候带\n170002 0 就是在认清生活真相之后仍然热爱生活罗曼罗兰\n170003 0 趣医院某客户端存在xss可导致近千家医院和600w用户信息泄露\n170004 0 我县与境内外客商签订20个项目\n1000 Processed\n classify content\n170500 1 顾客,你好!贝因美婴幼儿奶粉于x月x日一x月x日七五折,特价除外。回兴永辉x店贝因美\n170501 1 今天是元宵节,祝各位老板生意兴隆,财源滚滚!。 伊利奶片现特供xxx元/件,需要...\n170502 1 尊敬的客户:您好,x.x--x.xx日发售保本xxx天,x.x%,保本xxx天x.x%,保本...\n170503 0 据FIBA亚洲篮球专家EnzoFlojo在twitter上透露\n170504 0 动员辖区内8家居委会的1月—3岁共14个年龄组196名儿童参与活动\n1000 Processed\n classify content\n171000 0 xx后美女副局长裸辞求职揭官场潜规则\n171001 0 那些代表着80后父母童年时光的游戏\n171002 0 自然修颜防水防晒隔离…我的“出门霜”\n171003 0 很想快跳上飞机很想立刻到达\n171004 0 有没我有江苏高中的语文笔记\n1000 Processed\n classify content\n171500 0 市城区人民法院案件受理数呈现大幅增长的趋势\n171501 0 长航警方2月多时间查获40名违法涉水人员\n171502 0 我正在看浙江4岁女孩掉入石灰池90%肌肤烧伤生命垂危——中国青年网触屏版\n171503 0 淮安淮海南路和解放东路十字路口南\n171504 0 电梯行业是否也是装备制造业\n1000 Processed\n classify content\n172000 0 称手机和网路邮箱收到几个时下热门“真人秀”节目组的信息和电话\n172001 0 虽带点商业味但每人xx元的门票还能接受\n172002 0 早晨想用电脑电脑坏了然后中午我又发现手机关机键摁不动了\n172003 0 怀疑他们也是走私集团的一份子\n172004 0 华为向合作伙伴重点传递ISV整体合作策略\n1000 Processed\n classify content\n172500 0 周末下午到东江滨collette小坐\n172501 0 宫斗的QQ群和贴吧发展已经十分壮\n172502 0 如子宫肌瘤、子宫内膜病变、乳腺病变等\n172503 0 美元理财产品年化收益率较低\n172504 0 visualstudio2012和\n1000 Processed\n classify content\n173000 0 BornFreeDecoBottleGiftSet奶瓶超值礼盒套装$22\n173001 0 看完花千骨我想对杀阡陌说“见过自恋的\n173002 0 他们不停地质疑、激励、鼓动他人\n173003 0 该小区电梯突然从20楼滑至14楼\n173004 0 刚才看到一个人还在苏州河边上跑步\n1000 Processed\n classify content\n173500 0 中国远洋601919是今天中字头最强的票\n173501 0 这轮融资由CharlesRiverVentures领投\n173502 0 发现百度地图的清新功能~share\n173503 0 两个deal同时live真心要人命\n173504 0 淡绿色液体是日间精华水质地轻薄凉爽\n1000 Processed\n classify content\n174000 0 江苏卫视看男神张杰如何变身呆萌话唠\n174001 0 复旦投毒案两审均判死刑的结果让他揪心\n174002 0 只要查处了恶意做多绩差股亏损股的那些黑庄\n174003 0 X速度火起来wwウルトラマンが大好きなの\n174004 1 宝宝家长,您好!我是凯瑞宝贝早教中心的卢老师,我们学校最近在做优惠活动,托班可以免费试托一个...\n1000 Processed\n classify content\n174500 0 就是新版演员和投资方有说不出口的利益关系\n174501 0 我思考到一个问题一个人在感情里既当运动员又当裁判她对我说我们一起跑步吧跑的时候说丁冬你不能这...\n174502 1 专业办理房产抵押贷款、无抵押贷款、疑难贷款,和年收益xx%起的各种类型的理财产品(PxP、基...\n174503 1 x月x一x日如东文峰大世界服饰满xx/xxx/xxx元减xx元再接受xx元券,全场购物满额赠...\n174504 0 看这一季好声音感觉没有像上一季让人印象深刻的学员\n1000 Processed\n classify content\n175000 0 我竟然在看江苏卫视中文配音版的男主叫金谭还是金潭的……继承者们\n175001 0 彩票投注时间为7月27日下午5点44分\n175002 0 愿您和家人健康幸福……\n175003 0 你们他喵的是来抢劫的还是来逗我的\n175004 0 汽车改装13063876999\n1000 Processed\n classify content\n175500 0 白送??南京地区可以自取的来\n175501 0 abuseofpower就是「濫用權力」\n175502 1 x.x节当天欧雅顿护肤品全场x.x折,老客户当天进店还可领取精美礼品一份。快乐x.x节,欢乐...\n175503 1 亲爱的会员,新年好[玫瑰]曼妮芬内衣品牌王府井专柜x月x日~x月x日举行内衣特惠活动,两件x...\n175504 0 要激活手机卡就要充值1200元\n1000 Processed\n classify content\n176000 0 一块xxx平方米的绿化带被人毁坏\n176001 0 他们所在的小区共发生电梯故障将近400次\n176002 0 电梯吃人事件原因在央视记者细致采访下水落石出\n176003 1 售:木兰山xA景区内、黄金地段门面房xxx平方,xxx万,两证齐xxxxxxxxxxx\n176004 0 真的想说自己好笨出门没有带钥匙而且出门还没有给手机充电\n1000 Processed\n classify content\n176500 0 云南机场集团、昆明机场、省民用机场公安局等各救援单位立即赶赴现场\n176501 0 盐城晚报记者采访了市招生考试中心相关负责人\n176502 0 也是一处不可多得的旅游景区\n176503 0 6、观人四法:讲信用、无官气、有条理、少大话\n176504 1 新年好!我是湘西私厨的白经理。祝您在新的一年里心想事成,万事如意,恭喜发财!现在本餐厅以开业...\n1000 Processed\n classify content\n177000 0 并在诉讼结果出来前不再回应\n177001 0 甲骨文的“行”是一个十字路口\n177002 0 微软公布Windowsxx家庭版价格为xxx美元\n177003 0 万科掌门人王石在第三届深圳国际低碳城论坛上称\n177004 0 也是国家旅游总局确定的全国旅游景点之一\n1000 Processed\n classify content\n177500 0 2:公证员陈国明为什么从来不在此为当事人做公证\n177501 0 6点起来看到ig第一把碾压直接出去医院输液了快到了发现翻盘了心想稳了输的时候没wifi直接买...\n177502 0 因为我马上就要乘飞机了所以会比各位晚听到呢\n177503 0 問題のTwitterです\n177504 0 褶皱的设计百搭又具有少女感\n1000 Processed\n classify content\n178000 0 insider用户可以选择升级到windows10\n178001 1 免费咨询xxxxxxxxxxx最新版机麻控制器,不安装,起手拿好牌,可现场试用,满意再买。q\n178002 0 昨天见到的腐败真是惊到我了\n178003 0 4、不要碰有自融资嫌疑的平台对于P2P\n178004 0 信息来源:福建高考信息平台\n1000 Processed\n classify content\n178500 0 ” 小网民又问:“爆料呢\n178501 0 折腾到现在终于把preview看了一遍\n178502 0 请抓住时机的宝贝们来咨询吧'\n178503 0 负责基于ffmpeg的视频解码播放和格式兼容适配\n178504 0 在运风高速5KM处因实施饮酒后驾驶机动车的违法行为\n1000 Processed\n classify content\n179000 0 而是在于法官的人品、人格和做人的良知\n179001 0 具体性能可以自行百度~因换手机所以闲置着\n179002 0 讲述了xx岁的乐天派漫画家熊顿因患癌症身处人生最艰难的时刻但同样对着命运微笑的故事\n179003 0 还有咽炎、扁桃体炎、急性咽喉炎、鼻炎等\n179004 0 轻仓投资者可适度把握个股板块机会\n1000 Processed\n classify content\n179500 0 这样上课不但侵占了学生暑期休息\n179501 0 这么大了这种情况下算妈妈让他跟他一起睡\n179502 0 佑佑被爸爸带到南京筛查视力去了\n179503 0 如果你认为RolfBuchholz的大多数穿孔在头部和面部\n179504 0 他们将分别获得由徐州慈铭体检中心提供的\n1000 Processed\n classify content\n180000 1 涿州【牛津花园】,明天开盘,首付x万(无息垫付一年)内部员工选房,价格都是最低的,均价xxxx\n180001 0 我的电脑光驱坏坏坏坏了了了了\n180002 0 防晒实乃美白、抗皱、防衰老之根本\n180003 0 泰国THANN紫苏发膜&\n180004 1 亲: 三月促销——幻活新生 时光礼遇: 一、单张订单购买任意幻时或幻时佳产品每满xxxx元,...\n1000 Processed\n classify content\n180500 0 微软傻逼微软傻逼微软傻逼\n180501 0 这颗卫星或许有能力支持生命的生存\n180502 1 千石资本-艾方多策略对冲增强x号资产管理计划将于本月中旬发售,起点xxx万,预期年化收益xx...\n180503 0 三相声程宇韩帅夫妻之间\n180504 0 卫星:charles837668\n1000 Processed\n classify content\n181000 0 来为他们不作为的行为付出代价\n181001 0 蓝筹股IBM和联合技术、苹果、微软\n181002 0 卡地亚坦克手表客户定制表带也是全金的分量感十足\n181003 0 然而留的手机号是一个已经不用的电话\n181004 0 给南京电力公司的工人们点赞\n1000 Processed\n classify content\n181500 0 相互之间谈论电梯的设计、原理、结构、维保\n181501 1 世界上所有的事物都会为美丽而优雅的女人折腰!克丽缇娜一座打造美丽优雅女人的殿堂,??在x'x...\n181502 0 亦表示着纪念20世纪30年代风靡南京的南京第一条轨道交通“京市铁路”\n181503 0 感觉花千骨再这样一个星期四集\n181504 0 报警19分钟警察还没办法出警\n1000 Processed\n classify content\n182000 0 云南省委原副书记仇和被双开\n182001 0 特别是华为你对得起你世界500强的头衔么\n182002 0 MSCI明晟未把A股纳入其新兴市场指数的决定\n182003 0 7脱发过多、头皮屑过多:缺维生素\n182004 0 然后顺丰寄出到付不用负担一分钱\n1000 Processed\n classify content\n182500 0 二是我除了看芒果台的天天向上还是从网上看\n182501 0 投诉吕梁市人民检察院民行处尸位素餐监督不作为愚弄贫民的缺德行为\n182502 0 强烈呼吁医院为70岁以上老人设立挂号\n182503 0 拿出一批无锡阳山的水蜜桃??我拿了一箱\n182504 0 指数依然有回抽xxxx点附近支撑的可能\n1000 Processed\n classify content\n183000 0 我一上午没法看gmail没法用google简直烦躁死\n183001 0 2、全国导游:网上注册时间:6月25日—10月9日\n183002 0 ”“因为今天是我们拥有的惟一财富\n183003 0 看到有票务说南京1212………感觉自己在课上就要哭出声了………\n183004 0 海口市公安局交警支队针对市民反映在海秀东路彩虹天桥、义龙西路桥、东湖三角池大转盘设置了三处非...\n1000 Processed\n classify content\n183500 0 FuturesandOtherDerivatives–theseventheditionof…\n183501 0 #NAME?\n183502 0 x亿总价刷新滨湖单总价地王纪录\n183503 0 中午涂好防晒打着伞在外面走了xx分钟\n183504 1 尊敬的家长,您好!我们是戴氏金石教育,冬去春来,春季周末补习班正火热报名中,本周周末报名可享...\n1000 Processed\n classify content\n184000 0 福建、浙江大部、江西大部、湖南东部、广东东部、安徽南部及台湾等地有大到暴雨\n184001 0 为进一步加强法院文化建设工作\n184002 0 在mysql中不支持mergeinto\n184003 0 封建今天企业赚钱了都投身房地产\n184004 0 腐败份子从内部瘫痪这种向心力\n1000 Processed\n classify content\n184500 0 你们这些土匪抢东西吃就算了还制造噪音\n184501 0 哪怕我们的巨星冰冰在飞机上贴面膜\n184502 0 之前看过他上一个节目快本还是什么\n184503 0 人们常说wexin:卫星GDxxxxxxxx\n184504 0 你他娘的不平均的真相肯定是吓人的\n1000 Processed\n classify content\n185000 0 不然会破坏蜂王浆的营养成分\n185001 0 卖了xxxx股神火和一些基金\n185002 0 问题来了:NBA球星谁更有统治力\n185003 0 在看到反腐挽回经济损失387亿和收缴201亿违纪所得\n185004 0 从南京市统计局官方网站获悉\n1000 Processed\n classify content\n185500 0 发箍瞬间飞机耳……主持人憋不住笑了\n185501 0 卫星:bbyyccpp既要唯物\n185502 0 以新兴业态为引领“浙江服务”撑起半边天\n185503 0 居住面积3259尺/303平米\n185504 0 可以眺望到航空母舰、战列舰和巡洋舰等\n1000 Processed\n classify content\n186000 1 建材家居十大品牌工厂联盟推出xxx余款“买断价”产品于x月xx日中午xx:xx衢州饭店限量抢...\n186001 0 600多户不同意拆迁的情况下拿出复印件\n186002 0 这架飞机约合人民币7000万元\n186003 0 但是監察院x日以鄭永金擔任股份有限公司股東\n186004 0 她们将陪伴你直到永远UP主:利贝尔遗魂\n1000 Processed\n classify content\n186500 0 预计该航班将于x月xx日前后首飞\n186501 1 您好!采购首选xxxx广州(新)流体展,xxx家流体企业和来自xx多个国家的专业观众齐聚,中...\n186502 0 渣土车常见的违法行为主要有6种:1、不按照规定的时间、线路行驶\n186503 0 中午时前辈告诉我下午两天到单位\n186504 0 得者居然因为被举报和某同事有不正当关系而撤\n1000 Processed\n classify content\n187000 0 中国建筑金属结构协会建筑钢结构分会副会长胡育科近日表示\n187001 1 瑜伽运动,塑身养生……有效减压缓解疲劳,增加活力、调节身心平衡,让您更健康_更愉悦!威尼斯花...\n187002 0 这是一栋位于比利时rotselaar密林中的住宅\n187003 0 轨道交通x号线一期工程全长xx公里\n187004 0 今天被吓傻了还好你在香港我没有碰见你如果真是你该怎么对话敷衍\n1000 Processed\n classify content\n187500 0 在唐梦设计总部签定合作协议\n187501 0 公公得出去打工为此得了癌症\n187502 1 xxx xxx李红胜 农行:xxxx xxxx xxxx xxxx xxx李红胜\n187503 0 新宾县法院交流学习邹碧华先进事迹体会\n187504 0 世界首枚3D打印火箭Electron将于2015年底发射\n1000 Processed\n classify content\n188000 0 今儿一天折腾这电脑折腾的好欢乐啊\n188001 0 浙江金温铁道机车车辆大专班毕业典礼在浙江师范大学举行\n188002 0 Doom学院的年终测试原来是大逃杀模式\n188003 0 兰桂坊家庭别墅旅馆欢迎你点击链接播放超酷H5大片>\n188004 0 ②每天签到领钱③刷任务赚钱\n1000 Processed\n classify content\n188500 0 契约精神应该高于法律财产的界限\n188501 0 大学生1到5万的小额贷款收211与985院校的及其附属院校的专科本科研究生博士的贷款\n188502 0 南环桥往下火灾烟特别的大很呛前后我看到六辆消防车呜呜的过去了市政府附近几个路口红绿灯都停了交...\n188503 0 如果不是电脑包太多我不会出啦\n188504 0 法院:原告并非因生活需要而购买商品\n1000 Processed\n classify content\n189000 0 XboxOne需要完全支持键盘和鼠标\n189001 0 你正在质疑我的时候别人已经开始赚钱了\n189002 0 在最接近天堂的地方对她说“我爱你\n189003 0 我现在简直就是腾讯公司的大粉丝\n189004 0 品胜OTG数据线适用小米三星华为手机转接线microUSB转换线\n1000 Processed\n classify content\n189500 0 苏州每天新增57例癌症病人\n189501 0 宝应气象台7日7时发布天气预报\n189502 1 要做工商注册、税务代账、融资贷款、商标专利、各类资质、资金过桥、POS机、登报刻章等等,服务...\n189503 0 13588288645QQ2367436628市场大好\n189504 0 戒毒医院院长陈文彬立刻启动紧急救护措施\n1000 Processed\n classify content\n190000 0 其余车型还配备了LED日间行车灯\n190001 0 6月26日那天是买了B站的推广位\n190002 0 昨天收到仁济医院高主任的邀请\n190003 0 哪个法院哪个法官敢和我勾结\n190004 0 别让金融监管影响互联网经济\n1000 Processed\n classify content\n190500 0 少牛毛纹闭合棕眼颗颗金星底色干净油性十\n190501 0 辞了工作去南京或者重庆生活\n190502 0 医生说带保持器就可以矫正过来了\n190503 0 江苏省如皋市江安镇葛市村徐姓村民被人杀害在自家厕所内\n190504 0 明白節奏淺薄歌詞叫人心腐敗\n1000 Processed\n classify content\n191000 0 发现病毒分享微博还有特别积分奖励\n191001 0 我看很多股票金融分析师苦口婆心的劝散户\n191002 0 Windows授权营收下降8%等\n191003 0 知道真相的我玻璃心瞬间噼里啪啦地响\n191004 0 起码旅游回来暑假在家要过得充实\n1000 Processed\n classify content\n191500 0 170g$118適用於六個月起寶寶\n191501 0 在苏州某餐饮店做着一份厨师兼外卖工作\n191502 1 自信的生命最美丽,一年一度的妇女节到了,芭莎美容祝福美女自信潇洒漂亮美丽,值此美好节日,芭莎...\n191503 0 剩下0025和326赌大盘翻红\n191504 0 /工信部苗圩:特别要重视抓好网络提速降费工作\n1000 Processed\n classify content\n192000 0 飞机在上海上空盘旋了一个半小时后\n192001 0 至少十年内不想考虑win10\n192002 0 并就新常态下集团经营的调整优化升级增效进行了交流\n192003 0 “监听”丑闻制冷美日同盟关系\n192004 0 到目前还没见过只贪污受贿不找小三的\n1000 Processed\n classify content\n192500 0 核武器的发明有利于维护世界的和平\n192501 0 可能是那个主人的全部财富\n192502 0 有时在火车站或地铁上看到小报童卖报有兴趣的人很少忍不住支持一下却发现卖2元的报纸原价只有0\n192503 0 吉林“首虎”谷春立被查反腐38天打下“9虎”\n192504 0 直接百度云链接私信甩给你们\n1000 Processed\n classify content\n193000 0 演唱会后遗症之一是吃不下饭\n193001 0 在度假勝地驕奢淫逸的PIPPO渾然不知自己在米蘭的家變成了小偷的目標\n193002 0 Gx京沪高速由上海往北京方向无锡段从Kxxxx+xxx至Kxxxx+xxx\n193003 0 1500元能买到的“好设计”产品及推荐理由\n193004 0 发现人最悲催的事不是被强奸\n1000 Processed\n classify content\n193500 0 反而用3G手機網絡服務可以睇相\n193501 1 感谢致电雪莲布艺,我们以优质的产品,优惠的价格,完善的售后服务,谒诚期待您的光临!xxxx年...\n193502 0 面膜精华中xx%都是蜂蜜原液适合任何类型皮肤\n193503 1 大家好!东莞厚大司考一如既往地为您带来全免费的名师视频公开课。机会就在眼前,把握机会,走向成...\n193504 0 ap教堂飞马sax色汇率7\n1000 Processed\n classify content\n194000 0 地铁公安提醒:包裹请过安检\n194001 0 算是shortcovering带来的公平\n194002 0 宗汉城管和曙光社区共同举办了“争当城管小义工”体验活动\n194003 0 3银杏吸音板的墙壁4一套实用的家装\n194004 0 何况如今股票玩的不仅仅是技术面\n1000 Processed\n classify content\n194500 0 我的摄影师早期作品·By酒鬼坦克\n194501 0 发表于BMJ杂志上的一篇文章综述了间质性肺疾病的诊断与治疗\n194502 0 反腐这种利国利民的事如果还有人叫不好\n194503 0 当手机离你们10m左右距离时通常你们会:\n194504 0 狮子会+舵手班同学会社会公益+大学生创业这就是中国狮子联会舵手服务队“青年创客营”\n1000 Processed\n classify content\n195000 0 工作再忙也要嗨~1G全国流量半年包6折起\n195001 0 东革阿里助你建立健康的生活方式\n195002 0 数量并不多暂时我也不打算卖了\n195003 0 mokabros里的蛋白质补给站沙拉里面有像小时候枕头里的东西…\n195004 0 看NBA球星被岁月改变的痕迹\n1000 Processed\n classify content\n195500 0 南通的不太蓝的天和不太白的云\n195501 0 空调衣穿都很合适~蓝卡其2色\n195502 0 我现在2米了已经下一步就是进入哈佛然后去打nba\n195503 0 有效震慑和打击各类违法犯罪活动\n195504 1 【纤姿依人】魅力女人节,关爱女性乳腺健康,史无前例优惠送给您。保养型文胸第一件正价,第二件半...\n1000 Processed\n classify content\n196000 0 顶级WHOO/后天气丹华泫王后套盒\n196001 0 maoliqiusi的photowhere\n196002 1 您好,住朋网客服小李,八桂绿城龙庭水岸-天誉花园,龙庭新春特惠最高优惠x.x万,天誉买房立减...\n196003 0 笔记超过1天基本就没有太大存在意义\n196004 0 就使用我的邀请码g4426j下载并登录浙江移动手机营业厅\n1000 Processed\n classify content\n196500 0 对中国整体的制造业、建筑业、以及装备制造业的水平来说\n196501 0 每天上万的旅游者前往这里骑骆驼、看日落壮美\n196502 0 果果写花千骨的时候还很年轻\n196503 0 任志强:“谣·言倒逼真相”\n196504 0 二是现在小微企业融资需求很高\n1000 Processed\n classify content\n197000 0 一场跨越两省的爱心医疗救助中国文明网由中央宣传部、中央文明办主办\n197001 0 对于长期依赖投资驱动而高杠杆的中国\n197002 0 路都因为小贩们乱扔垃圾、到脏水变得那么脏\n197003 0 让我们一窥QQ顶尖会员的“实力”:年龄上\n197004 1 享xxM光宽带及数字电视免费用,移动老用户存话费最多可送xxx元话费;现场更有手机大优惠,售...\n1000 Processed\n classify content\n197500 0 又用Google翻译把意大利语翻译成了英文和中文\n197501 0 sugary在中学的时候就长得可爱漂亮\n197502 0 河南造血干细胞捐献人数达500例全国第一\n197503 0 马龙的NBA生涯就始于马刺教练波波维奇\n197504 0 刚在郑州迪望苹果手机专卖摇到了免费好东东\n1000 Processed\n classify content\n198000 0 然后那次刷53我双开你也双开帮我刷死了好多事跳了好多丹终于是过了\n198001 0 x周岁DAYxxx:昨晚飞机又晚点\n198002 0 昨晚用了雪花秀洗面奶长3粒粉刺了有病哦烦死\n198003 0 甪直城管大队在区市容市政管理局执法大队的带领下\n198004 0 因为飞机延误无意间拍到了的是~\n1000 Processed\n classify content\n198500 0 唐七公子成名之作抄袭大风刮过的作品各位看官吧友请保持平静让我们一起还原真相\n198501 0 浙江省衢州各地增加了不少银杏、红枫等彩化植物\n198502 1 x.x美丽女人节,好又多超市京润珍珠护肤专柜倾情回馈新老顾容,全场低至x折,凡进店的会员消费...\n198503 0 双方将以阿里云和阿里数据平台为基础\n198504 0 「96万热播视频」小蝌蚪找妈妈中国第一部水墨动漫\n1000 Processed\n classify content\n199000 0 而你们这群用手机屏大小分老大、老二、老三的人\n199001 0 26岁安徽男子手拿水果刀在广益路与亚欧路一大厦内自捅腹部一刀\n199002 0 xx岁时因聪慧善文为一代女皇武则天的重用\n199003 0 今天依然那么平静我还是很想晚安城管晚安我离开的那座城—巴南\n199004 1 尊敬的会员新年好!同富李宁专卖店全体同事祝大家新年快乐、万事如意。同富李宁专卖从x月x号至x...\n1000 Processed\n classify content\n199500 0 未来是你的……NBA十大经典垃圾话\n199501 0 具体咨询医生该如何进行喂养才是明智之举\n199502 1 新年好,广州尖高杨工祝您开工大吉,生意兴隆。!如您开工时仪器设备有故障可为您维修。如需添加二...\n199503 1 xxxx研-究-生 MBA考-生:速提分达您所愿,专业排名查询,成/功样本核/实。扣扣:xx...\n199504 0 境内外蛇头勾结每周送xxx内地女子到香港卖淫xxxx年x月x日报道\n1000 Processed\n classify content\n200000 0 It'sRonni摆efromtwitter\n200001 0 神农架土蜂蜜2015年新蜜上市\n200002 0 市民金先生花7万多元拿下南京南站的一间地下商铺14年的经营权\n200003 0 国家投资几千万的水利都没有作用\n200004 1 !秀域等您来哦!另外本月前五天有产品五折优惠,汉方美白和秀妮儿内衣更有大优惠,心动不去行动。...\n1000 Processed\n classify content\n200500 0 从商业城搭公交车过来东门站\n200501 0 2013黄牛党会不会越来越少啊\n200502 0 上淘宝、百度、京东、亚马逊都搵唔到距嘅存在\n200503 0 真正的勇士敢于不听医生的话\n200504 0 而被肠道内的细菌分解产生大量的气体\n1000 Processed\n classify content\n201000 0 PACEMAN的外观设计同之前的概念车保持了高度一致性\n201001 0 我在必胜客签到南京金山餐厅签到:签到啦\n201002 0 日本向日葵8号卫星拍下台风苏迪罗写真\n201003 0 ”我一听这暴脾气就上来了我直接买了十几个氢气球气球捆手提袋上了\n201004 0 最后一台xxxxShelbyGTxxx敞篷版将为慈善基金而拍卖\n1000 Processed\n classify content\n201500 0 此举在日本机构投资者中尚属首次\n201501 0 这样的电梯怎么让业主放心乘坐\n201502 0 f百度云ch百度云资源dz云盘资源i百度云资源\n201503 0 济南一高层住宅电梯内现男尸事发楼房无人居住\n201504 0 北京市公园绿地协会领导孟庆红带领北京市16个区县的公园管理负责人针对万寿公园集中管理广播音响...\n1000 Processed\n classify content\n202000 0 拍精致人像摄影就来左岸唯美摄影视觉机构\n202001 0 这意味着近期投资支出和就业岗位增加势头或将持续\n202002 0 我区召开2016年部门预算编制布置会\n202003 0 据NBA劳资协议专家LarryCoon称\n202004 0 材质:壳子背面为硬壳边边是软的适用:iphone6/6plus卡哇伊贴纸+一个手机壳自己DI...\n1000 Processed\n classify content\n202500 0 食物腐败得比较快吃到变质的食物几率比较高\n202501 0 著名的乐蜀神庙有逾3000年的历史\n202502 0 經過與家人和朋友多次的祈禱和討論\n202503 0 永远不用体温计永远不去医院永远不吃药人生三大愿望这三项才是大事好吗\n202504 0 看见一小偷正准备把偷来的手机往口袋里装\n1000 Processed\n classify content\n203000 0 大通派出所民警魏倩带领辅警田家飞、苏捷、方朋桂巡防中发现机厂医院内发生争吵\n203001 0 41年以来登陆华南最强的热带气旋\n203002 0 amazonprimeday据说折扣比黑五更给力\n203003 0 一整块触摸OLED显示屏贯通整个仪表台\n203004 0 有钱富二代华裔秒转真是的\n1000 Processed\n classify content\n203500 1 型团购活动》,凡x月x日至x月x日到店客户都不仅来店即有精美礼品相赠,还可享受每年难得的【特...\n203501 0 从上世纪90年代的魔术师、乔丹……\n203502 0 banana小黑伞高密防晒涂层\n203503 0 中国互联网违法和不良信息举报中心、各地网信办举报部门、各主要网站通过建立多元举报渠道、扩充公...\n203504 0 投资者设置了止损而没有执行的例子比比皆是\n1000 Processed\n classify content\n204000 0 该航线共投入11艘运力约11000标箱的集装箱船舶\n204001 0 战争雷霆视频:街机轰炸机食用指南攻击机\n204002 0 6点半的滨海客运载着旺妈娘俩一路奔向首都机场三号航站楼\n204003 0 GoogleShopping搜索优化技巧分析\n204004 0 这个市场终将成为投资者的绞肉机\n1000 Processed\n classify content\n204500 0 明明在飞机上冷成狗不敢告诉妈妈只能说我把毯子从头盖到脚什么感觉也没有\n204501 0 7月10日银创小分队的小伙伴们在中国工商银行进行了调研\n204502 0 我刚看腾讯报道——揭秘非洲部落“偷妻节:好可随意挑选多名丈夫\n204503 0 电梯为江苏“申龙”牌电梯\n204504 0 以及EGF这个荣获诺贝尔奖滴成分\n1000 Processed\n classify content\n205000 0 成为teamleader其实就是说只有你干活儿\n205001 0 微软近期也在加紧宣传的步伐\n205002 0 请不要这么悲催感冒到爬不起来\n205003 0 CSDA江苏分委南京艺和神形文化艺术交流有限公司承办\n205004 0 搞卫生要求:1、五官端正\n1000 Processed\n classify content\n205500 0 由重庆儿童救助基金会资助的公益创投项目“护苗行动——单亲家庭儿童关爱项目”在我区正式启动\n205501 0 乱服避孕药成为导致新生儿缺陷\n205502 0 一个商业模式是运行一个公司的方法\n205503 0 她才知道自己被人以x万元的价格卖给这个男人做老婆\n205504 0 这叫缘分哈哈哈哈今天公演加油\n1000 Processed\n classify content\n206000 0 3目标筹款金额:100000救助对象:姓名:赵正典性别:男出生日期:2015/1/1联系人:...\n206001 0 她需要等着看中午的股票节目\n206002 0 包括Linux主题、奥巴马搞怪表情、以及一系列GoogleEmoji贴纸等等\n206003 0 静宁县2015年“特岗计划”公开招\n206004 0 在南通各县市区中率先超千亿\n1000 Processed\n classify content\n206500 0 全棉牛仔面料设计明线缝制对称款式双层裤腰翻边设计\n206501 1 您好,我是苏州常春藤医疗美容客服中心田医生,我院x月特惠活动劲爆登场,腋下脱毛特价xxx元。...\n206502 0 南京環保熱線證實有夜間施工許可\n206503 0 AIVA的祛印套装已是不可缺少的日常装备了\n206504 0 我很想问问家长医院的那项检查孩子有问题\n1000 Processed\n classify content\n207000 1 迎x?x,特推出买送活动。虹盛五楼第一宝贝专柜\n207001 0 在该系列的第4部分也就是最后一部分中\n207002 0 官商勾结官匪勾结富不过三代人生难以超越的是私心难以摆脱的是物质社会既然远离更不愿再去靠近\n207003 0 苏宁易购和华为商城都没有发现与荣耀暑飙节相关的活动呢\n207004 0 滨河派出所民警张稚悦从学法\n1000 Processed\n classify content\n207500 0 4的时候用googlenow无法播放这首歌\n207501 0 trunature叶黄素+玉米黄素\n207502 0 招聘健身教练的条件是:想挑战高薪\n207503 0 汽车配件行业终将实现电子商务化已经是业内公认的趋势\n207504 0 2015年7月31日晚在印象江南南门口违章停车\n1000 Processed\n classify content\n208000 0 我就知道我去不了南京找你玩了\n208001 0 牛哥在向你说声:“早安\n208002 0 然而现在还拿着手机对你添屏\n208003 0 今天把江苏银行里的3000块钱全取光了\n208004 0 架构“大城管”管理格局的同时\n1000 Processed\n classify content\n208500 0 但电脑显示没库存的药的那部分钱就进了小人的腰包了\n208501 0 但是他说:Ifightlikehelltopayaslittleaspossible他拼命少交税\n208502 0 我靠原来短刀打城管原来这么爽\n208503 0 我已经没有在南京初次看舜天比赛时那么激动和兴奋了\n208504 0 今年3月至7月上旬湖北省医疗器械专项整治“回头看”成效显著\n1000 Processed\n classify content\n209000 0 往手机里加点料吧:“天天模考腰果公务员”刚入手\n209001 0 上下班路上、地铁里、餐桌上\n209002 0 fresh的产品一直坚持成分天然值得一试\n209003 0 到fantasticbaby\n209004 0 永定区法院在淘宝网司法拍卖平台中成功拍卖了一处位于龙岩市新罗区龙腾中路的房产及车库\n1000 Processed\n classify content\n209500 0 制作时间2015年8月时长\n209501 0 天下为什么要有那么多的可怜的人\n209502 0 有没有长沙的橙子去南京首站的求陪同\n209503 0 尤其在我们长风地区苏州河沿岸地块\n209504 0 凡是看不上谷歌和必应中文搜索的\n1000 Processed\n classify content\n210000 0 要注意清理好cookies和浏览器缓存这些会降低你电脑运转速度的东西\n210001 0 賺真的超级给力只能说选择真的很重要一部手机\n210002 0 不知是昆山这地儿有灵气还是我真的是适合独居\n210003 0 和一位23楼的猥琐啤酒肚中年男人坐同个电梯\n210004 0 司仪梦之队团队例会在南京曙光大酒店如期召开\n1000 Processed\n classify content\n210500 0 为啥华为的手机现在无法使用上海公交的APP\n210501 0 被称为南京体量最大、品牌最全、业态最完整的复合型高端奥特莱斯\n210502 0 寻寻觅觅爱好换来换去party去来去去\n210503 0 4、当受到电号码显示为乱码的未知电话时\n210504 0 就使用我的邀请码482h5e下载并登录浙江移动手机营业厅\n1000 Processed\n classify content\n211000 1 中国人寿防癌险可以裸卖啦!巨大回馈,难得机遇,小投入大保障,最高保障xx万,只需缴费xx岁女...\n211001 0 雨花警方将成功追回的x辆面包车交还给失主\n211002 0 以及旅游厕所革命、旅游扶贫、旅游体制改革创新等工作情况\n211003 0 小警察死掉之后去窗口抽了根烟冷静冷静\n211004 0 杭州21岁女孩被电梯夹住身亡头身分处两楼层\n1000 Processed\n classify content\n211500 0 为什么世界上会有小偷这种变态狂存在妈的吓死人了\n211501 1 牌。日最高提款xxxx萬,x分鐘內到賬。 ?專營:百家樂、龍虎鬥、輪盤、股寶、牛牛、時時彩...\n211502 0 难道是货车司机连小偷都不如\n211503 0 感受到首都早高峰地铁满满的敌意\n211504 0 电梯吃人之后商场都这么谨慎了吗\n1000 Processed\n classify content\n212000 0 我结果是胃病犯了去医院打针了\n212001 0 结果googleplay翻了墙也慢的要死\n212002 0 文昌花园社区联合扬州广电邀请扬州海事局安全救护专职讲师季蔚为社区青少年举办了一场安全救护知识讲座\n212003 0 12届在乖校学建筑专业找工作中\n212004 0 应该成立专门的组织查处宗教团体中违规行为\n1000 Processed\n classify content\n212500 1 尊敬的业主:感谢您选择中国好建材联盟举办的‘绝对选择’大型让利活动,请您保管好装修护照,活动...\n212501 0 从法院大院里冲出一群黑袍汉子\n212502 0 又和同事开启相依为命新沂之旅了\n212503 0 顶新旗下品牌:康师傅德克士味全familymart便利店\n212504 0 使得全年水利投资任务在原来基础上再提高xx%\n1000 Processed\n classify content\n213000 0 我:拿着手机你还怎么抱着妈妈睡啊\n213001 1 xxxxxxxxxxxxxxxxxxxx-【来伊份】尊敬会员:“梅”丽女人节,满金额送贴心好...\n213002 1 奥斯凯纳客房x.x折!低至xxx元送早餐夜宵;钟点房xxx元起!地址:外砂大桥头;订房热线x...\n213003 1 收到号码:xxxxxxxxxxx,短信内容:澳门威尼斯人娱乐场现已开通网上博彩www.xxx...\n213004 0 平谷区食药监局通过案件审核会议\n1000 Processed\n classify content\n213500 0 七、商业计划书到底有多重要\n213501 0 全场累计消费满xxxx送美罗感恩月饼一盒\n213502 0 地铁的图书看着貌似质量不错\n213503 0 上交所有义务督促券商做好投票系统\n213504 0 每天拍纯露水的时候拍10分钟的脸\n1000 Processed\n classify content\n214000 0 腾讯房产在中关村创业大街的IC咖啡举办了一场有关房产众筹的大咖头脑风暴\n214001 0 8月11日苏州高新区人才市场现场招聘会\n214002 0 汽车美容车内洗尘汽车美容\n214003 0 我明明有定期整理电脑文件的习惯\n214004 0 在扬州这么多天第一次吃这么好\n1000 Processed\n classify content\n214500 0 制订\"促进人才创新创业14条\"\n214501 0 对其他3名村干部以贪污罪各判处有期徒刑三年\n214502 0 遂被抓获事后警察问为什么你抢完巧克力后还要回来抢随身听\n214503 0 中国移动就把4G卡给我寄过来了\n214504 0 因为弹屛里评论花千骨胸小胸大吵起来了\n1000 Processed\n classify content\n215000 0 但是我们xx号通知圈内朋友清仓的连云港xxxxxx成功获利超过百分十五\n215001 0 造成宫崎骏展览不再对中国人开放\n215002 0 不仅道德败坏还违法、记得今年在香港路边也是一对大陆青年公然在路边野战\n215003 0 今天早上点评的300477下午也奋力拉板\n215004 0 全天最高温度:本省西北部地区30℃左右\n1000 Processed\n classify content\n215500 0 驾驶员驾驶冀A***号重型半挂行驶至五保高速136公里处时因挂车的灯光信号、制动、连接、安全...\n215501 0 每天在Ins上晒最新的大牌单品\n215502 0 现在有一款叫「Piece」的外设\n215503 0 我特么在家里除了玩手机就是睡觉真特么憋死了\n215504 0 一直以为公交比地铁更适合发呆\n1000 Processed\n classify content\n216000 0 在抗战胜利70周年的重要时刻这无疑是个意义非凡的活动\n216001 0 输入顾客的手机号后的确能查到所在小区\n216002 0 很难在x月份的北京城找到千人规模以上的合适发布会场地\n216003 0 当即就百度了一下蝙蝠会不会吸血\n216004 0 连云港市气象台24日10时30分发布\n1000 Processed\n classify content\n216500 1 好消息:联通xx兆光速宽带免费使用了!用联通宽带,带宽独享,网速快!上网不掉线,网络稳定!可...\n216501 0 昨天绫晨三点半飞机晚点由郊区杭州路上\n216502 0 被x:对道路交通事故认定书无异议\n216503 0 因为今天在无锡所以他们不是Jhon和Mary了\n216504 0 ”牛回答:“生命不能承受之轻\n1000 Processed\n classify content\n217000 0 微软Winxx将捆绑自家音乐流媒体删Xbox品牌日前\n217001 0 基金涨了心情大好加上明天不上班\n217002 0 华为mate7手机套huaweimate7手机壳保护壳超薄立体星空个性韩版\n217003 0 Limberg是一位杰出的整形外科医生\n217004 0 赶着宠物医院去给奶油打育苗\n1000 Processed\n classify content\n217500 0 历史上第5个建成地铁的城市\n217501 0 无锡做包茎手术多少钱——无锡做包茎手术选择无锡虹桥医院\n217502 0 河北就这点粮食、房地产和长城汽车卖得杠杠的\n217503 1 尊敬的会员:你好! “三月女人天,今天你最大! ”亲,席桥都市恋人坊喜迎三八妇女节,全场八折...\n217504 0 法院共对广药王老吉与加多宝的7起案件进行宣判\n1000 Processed\n classify content\n218000 1 伊人丽妆送红包啦!值元宵,女人节双节来临之季,为回馈各位亲们,特推出xx—xxx元大奖红包,...\n218001 0 该区19条农路提档升级工程已进场施工11条\n218002 0 来碗中药简直沁人心脾香飘万里啊\n218003 0 我今天在华为网盘签到获得了112M免费永久容量\n218004 1 震xxxx元,其它国际标盘镙x.xx的xxxx元 安钢和马钢都可以厂提.如有需要可电话订购....\n1000 Processed\n classify content\n218500 0 江宁汽车客运站的环境也太差了\n218501 0 我用的就是华为的手机待机时间长反应也挺快的我很喜欢\n218502 0 县人大主任李福民赴香庙便民服务中心塬边村二组包扶户程新民家走访\n218503 0 省公安厅交警总队副总队长贾中平一行在县公安局副局长、交警大队长赵星的陪同下深入我镇检查指导农...\n218504 0 是把一些在著名APP软件Snapchat上一些炫富的孩子的图片截取PO上去\n1000 Processed\n classify content\n219000 0 我电脑坏了还是你们QQ出问题了\n219001 0 法国原产普罗旺斯心形天然植物精油手工香皂礼盒装100g*4块美国亚马逊$15\n219002 0 库里在打NBA之前被评价身材瘦小有望成为首发\n219003 0 你是否还守在电脑面前选购着比商场价格实惠的电器\n219004 0 :显然WindowsPhone遇到麻烦了\n1000 Processed\n classify content\n219500 0 欢迎亲们选购诚信经营\n219501 0 NBA球星海边休假的相片总能吸引球迷的目光\n219502 0 “120”急救员赶到后测了体温\n219503 0 地铁有个小女生直接挤晕过去\n219504 0 LinkedIn架构演化历史解析\n1000 Processed\n classify content\n220000 1 住六送一等促销活动。 海友酒店全体员工期待您的光临!订房热线:xxx-xxxxxxxx\n220001 0 2015年第十号台风灿鸿10号前后登陆浙江\n220002 0 滥用职权、泄露个人隐私更是身为民警不可原谅的过错\n220003 0 与当时的中央政府军作战是叛乱\n220004 1 名校之路从竞才修业起步,去年我校有两千多学生成功升入名校高中,欢迎報名参加周末学习,我们将全...\n1000 Processed\n classify content\n220500 1 亲爱的家长:贝贝托管晚间辅导班开始班名啦!欢迎广大家长来电来园咨询!xxxxxxxxxxx何\n220501 0 24—2713880376289\n220502 0 战斗中又会变回与现有FPS网络游戏相同的第一人称视角\n220503 0 杠杆基金又成了投资者的噩梦\n220504 0 意大利设计工作室gumdesign设计的“mastro”是一个小型家具\n1000 Processed\n classify content\n221000 0 全省银行业金融机构资产总量首次突破3万亿\n221001 0 你只负责开心就好'当时不明真相的我\n221002 0 我也不知道这笔xF的力量能不能够突破上面的重重压力\n221003 0 Daiana是由SoupStudio设计的一盏落地灯\n221004 0 他们自己泡的黑松露蜂蜜酒也是太好喝\n1000 Processed\n classify content\n221500 0 8点1氪:Facbook也做移动视频直播了\n221501 0 位于浙江省慈溪市掌起镇工业路xx号佰佳电器厂突发大火\n221502 0 福州市中级法院林丽娟法官在20l5榕行终字第306号案当审判长约上诉人林仙霖谈话\n221503 0 你拥有了这生就是投资和收益的人长轴版7座布局/搭三缸mpareyourselfwithoth好说的\n221504 0 有时庆幸自己还是负责飞机线路\n1000 Processed\n classify content\n222000 0 小秦因涉嫌职务侵占案被沱河派出所依法刑事拘留\n222001 0 恩施州检察机关依法对李泽斌决定逮捕\n222002 0 是医生在对拔牙处进行麻醉后开始进行的\n222003 0 郑州afp面授班将正式开课 xxxx年x月xx、xx日\n222004 0 把手机和电脑版的微博模板都换了新的\n1000 Processed\n classify content\n222500 0 x月常州机场迎来了暑运高峰\n222501 0 今天中午在医院看到小侄女了\n222502 0 今年网上银行直接被人盗刷消费3w4\n222503 0 该路段曾于xxxx年xx月xx日xx时xx分因山西方向冀晋主线站Kxxx+xxx处车流量大\n222504 0 或许是电脑内存在着病毒导致这个网页总是难以打开\n1000 Processed\n classify content\n223000 1 您好!我是刚跟你通话的平安信用贷款郭经理,材料简单,x-x天到账,随借随还,公司地址:顺外路...\n223001 0 你不妨再多做这3招进阶运动来雕塑身形哦~\n223002 0 我在“钢琴打僵尸”打趴了255只僵尸\n223003 0 MQTT正式成为推荐的物联网传输协议标准\n223004 0 部分第三方程序中光标在定位到文字输入框后不自动弹出触控键盘\n1000 Processed\n classify content\n223500 1 志邦厨柜xxxx‘百城样板房征集活动’价格面纱即将揭晓!您准备好了吗?志邦小詹及全员于x日即...\n223501 0 工业机器人在选取末端工具时应该思考那些问题\n223502 0 他们两人在飞机上为一名心肺骤停的2岁男童进行急救\n223503 0 甚至鲁莽+好运气能造就惊人的辉煌\n223504 0 延村的古建筑处处体现着商人的这种祈祷\n1000 Processed\n classify content\n224000 0 浙江安吉豪华三日游将变成四星度假村三日游\n224001 0 富士康签署协议将在印度投资xx亿美元建厂\n224002 0 HR赫莲拉极致之美菁华眼霜15ml\n224003 0 惠普承诺在与康柏合并后提高ceo菲奥莉纳的薪资\n224004 0 镇江无痕接发丹阳无痕接发南京无痕接发\n1000 Processed\n classify content\n224500 0 改革方案得到了司法部的认可\n224501 1 亲爱的后会员x月x日一x月x日一年一度的春季化妆品节,武林银泰商场活动买xxxx送xxx,x...\n224502 0 阿里巴巴有望迅速切入奢侈品、轻奢\n224503 0 『母女派出所内被杀家属曾x次报警警方称家务事』派出所\n224504 0 21世纪教育研究院中小学教育研究中心、扬州市梅岭小学承办\n1000 Processed\n classify content\n225000 0 兴正纠错宇宙大学校校长任秀红一个宇宙地球人做任何一件事儿\n225001 0 “零距离”感受法院的文化氛围\n225002 0 青岛、广州、大连、南京等地也实施了离婚限号\n225003 0 更主要的还是由于清政府腐败和保守\n225004 0 B超师傅惊讶道:你结节那么大为什么脖子那么细\n1000 Processed\n classify content\n225500 0 第61讲:Scala中隐式参数与隐式转换的联合使用实战详解及其在Spark中的应用源码解析百度云:\n225501 0 从来没用过iPhone天天酸iPhone\n225502 0 福能融资租赁公司“新三板”挂牌仪式在北京举行\n225503 0 对不是强奸是轮奸……编剧长点心成吗……\n225504 1 你好我是阳光信贷的小剧,阳光审批征信,光大银行放款x-x天到账,无抵押无担保,电话xxxxx...\n1000 Processed\n classify content\n226000 0 告诉你们我白着呢有图有真相\n226001 0 上海的中国国际机器人展会上\n226002 0 作于2015年8月2日四月风\n226003 0 今天才发现好久不看装修图库了\n226004 0 今天中午去吃的映像徐州绝壁是我吃过最好吃的饭店\n1000 Processed\n classify content\n226500 0 洋洋咩衣堡超弹力2015夏装新品专柜同款欧美抢眼撞色小怪\n226501 0 可对南林大xx名高尔夫场地助理志愿者来说就不是这回事了\n226502 0 下个月的期指交割日在8月21日\n226503 0 海口中院“法官教法官”大讲堂在中院三楼大审判庭开课\n226504 0 最近是防晒?sofina?粉饼\n1000 Processed\n classify content\n227000 0 说自己到达了TOPOFTHEWORLD\n227001 0 认为机器人威胁论明显被夸大了\n227002 0 给大家分享“YouAreBeautiful\n227003 0 记得小时候小偷偷狗一般用绳子\n227004 0 我也想要红包吃冰淇淋五毛的小布丁\n1000 Processed\n classify content\n227500 0 对于我这种看惯了SMTM和UnprettyRapStar这种满是哔声的Hippop比赛的人\n227501 0 呆在电脑面前工作就想着出去跑\n227502 0 8/4港版iPadair\n227503 1 泉州市天和割烹料理店\n227504 0 每辆车都严格按照x:xx的比例制作\n1000 Processed\n classify content\n228000 0 而政府在重建信心上力度不足\n228001 0 南京工商部门则表示会考虑抽检\n228002 0 某推主这样說着twitter\n228003 0 不让手机摧毁你的脊柱、睡眠以及抗压水平\n228004 0 百度的收录数量、收录效率、关键词排名表现也不大相同\n1000 Processed\n classify content\n228500 1 即日起至x月xx号,换季清仓,曼天雨服饰全场对折——恒利曼天雨。\n228501 0 儿时梦想的伙伴哆啦A梦再次被搬上荧幕\n228502 0 NoFilter:别以为我瘦了\n228503 0 一次係咁兩次係咁n次係甘放心冇下次了甘嘎人真系吾適合要黎做朋友\n228504 0 不过装潢和广告一样很粉嫩很少女呢\n1000 Processed\n classify content\n229000 0 2015年6月青岛市新开工过亿元产业类项目48个\n229001 0 被告人血液酒精含量为178毫克/100毫升\n229002 0 丰县供电公司“金蜜蜂”党员服务队走进社区\n229003 0 南京一城管队员写信问市长:我们的城市能管理好吗\n229004 0 该案涉案的金额共计400余万元\n1000 Processed\n classify content\n229500 0 这种机器人在现实里已经被国外的极客DIY出来了\n229501 0 代表xx个州的xx根喷泉水柱是一大亮点\n229502 0 由于路面坍塌造成DN200供水管线爆管\n229503 0 当J给A诉说自己旅游经历的时他却睡着的那时起\n229504 1 本公司长期有效,代开云南各地正规机打发票:国税,地税,增值,材料款,工程款,服务业等,网上可...\n1000 Processed\n classify content\n230000 0 熬夜看电脑或者工作之后你如果照照镜子\n230001 0 1986年联合国教科文组织将其列为世界自然遗产\n230002 0 下午我们按照老师要求穿着孝服带着花圈去了\n230003 0 跟我说刚坐飞机下来想去转高铁\n230004 0 根据RealGM记者ShamsCharania报道\n1000 Processed\n classify content\n230500 0 自适应巡航系统、宝马ConnectedDrive互联驾驶系统也将出现\n230501 0 ”医生直接告诉他:“有那钱你还是看看眼睛吧\n230502 0 最近坚持喝中药头部皮炎奇迹般的好了\n230503 0 xxxx延边州健美锦标赛xx公斤以上级自由展示\n230504 0 城管队员立即采取措施将钢丝绳打开\n1000 Processed\n classify content\n231000 0 四川航空xuxxxx预计晚点x小时\n231001 0 ·广州市民打10元麻将被拘留法院称赌资较大\n231002 0 苏州国际科技园举办的一场智能生活新品发布会上\n231003 0 真是太不好了尤其是鼻炎竟隐隐要犯的意思\n231004 0 T315I突变阳性患者对第一代及第二代TKI耐药\n1000 Processed\n classify content\n231500 1 莱克x楼水疗新春献礼电话订房有优惠,一人优惠xx,两人同行一人优惠xxx。。欢迎前来品茶。。\n231501 0 疾病看上去就像一个很遥远的东西\n231502 0 但愿城管与商家之间建立友谊\n231503 0 投资安逸宝更有现金大奖等您拿哦\n231504 1 朗能厨卫吊顶@长寿专卖店;欢庆x.xx;朗能吊顶 ;全场x.x折(除特价外),惊喜多多,礼品...\n1000 Processed\n classify content\n232000 0 昨晚上做梦梦到手机烫得不得了\n232001 0 努力确保本区城管执法条线“热线不热”\n232002 0 我们TF的粉丝及被此节目组侮辱的明星粉丝们要求公开道歉\n232003 0 该去整治交通却把精力浪费在这些上\n232004 0 xxExofficioCafenistaJacquard女士羊毛混纺速干保暖针织衫美国亚马逊...\n1000 Processed\n classify content\n232500 0 成熟的标志之一就是不再想去干涉或者批判他人的价值观\\n0\\t今年第13号台风“苏迪罗”来势汹...\n232501 1 互动,哥哥不用动,小妹全自动,玩法独特,前所未有,带给您不一样的体验,地址:杭州农副产品物流...\n232502 0 发现百度优化确实与谷歌优化有比较大的差别\n232503 0 大量的WindowsPhone粉丝涌入论坛并表示抗议\n232504 0 医院正式采用保健品替代某些药物治疗疾病\n1000 Processed\n classify content\n233000 0 手机相机也都拍不出里面的美和壮观\n233001 0 我们全家最近都在花千骨…买菜回来进门看见叼爸\n233002 0 ?江宁之旅?秦淮河畔御庭芳\n233003 0 预计大约有6000名职员将被解雇\n233004 0 会让很多小伙伴恨不得24小时泡在水里避暑\n1000 Processed\n classify content\n233500 0 19岁的挪威女孩Nann人称“Snapchat女王”\n233501 0 我分享了百度云里的文件:?夜行书生xx\n233502 0 谢谢各位熟悉或是陌生的足球人好心人微信转帐请转到目前陪伴在医院的崔微\n233503 0 荣耀7吧就我那点微薄的积蓄我承受不起\n233504 0 这一变化让部分Windows用户感到担忧\n1000 Processed\n classify content\n234000 0 没有工商执照就开不了阿里巴巴诚信通做不了诚信通吗\n234001 0 我上传了“永仁县人民法院2015年“庭审竞赛”活动参赛\n234002 0 吉米鸡毛秀嘉宾自曝吉米失望好友隐瞒真相超清>\n234003 0 容易使3岁以下的儿童不易入睡和哭闹不安\n234004 0 晨悠组合对比:翻版Twins和声萌翻导师\n1000 Processed\n classify content\n234500 1 中国农业银行帐号:xxxx.xxxx.xxxx.xxxx.xxx 王波\n234501 0 1978年10月至1982年7月\n234502 0 而地下空间又与三条地铁线路互相连通\n234503 0 七号楼在浇注西边的电梯基坑\n234504 0 同时也制造飞机和各种发动机\n1000 Processed\n classify content\n235000 0 1、及时避免病因疾病的产生都有一定的原因\n235001 0 看着一架飞机一闪一闪地飞过\n235002 0 法官:好啊那个权利是什么意思\n235003 1 【三月开春,东风本田开元店送礼了】凡进店办理保险业务,即有机会获赠节气门清洗、四轮定位、工时...\n235004 0 清理乱堆物堆料x处、违章广告招贴xx处\n1000 Processed\n classify content\n235500 0 整个写字楼被蓝天白云“围绕”\n235501 0 南京大雨也难以浇灭摇滚歌迷热情\n235502 0 不少Indiegogo的明星众筹产品等已经登陆\n235503 0 日本HELLOKITTY限量肌研极润保湿化妆水肌肤干燥\n235504 0 随后与警方展开了长达20英里的追逐\n1000 Processed\n classify content\n236000 0 结果意外地好玩并且get红包王+牌王的称号\n236001 0 然而mips生态的停滞与被侵蚀给君正挖了一大坑\n236002 0 由高品质精品楼盘——潍坊恒大名都、潍坊翡翠华庭携手音乐广播FMxx\n236003 0 皮肤过敏发红喷一喷能有效缓解\n236004 0 别墅=villa=cottage\n1000 Processed\n classify content\n236500 0 目前5年已累计投入一百亿推进交通建设\n236501 0 在这里有各种高级的机器人与宁人费解的毁灭现象\n236502 0 ps:住店客人免费赠送扬州旅游公交卡啦\n236503 0 这段时间的电脑桌面全都是她\n236504 0 法院一审判决被告邱某犯故意伤害罪\n1000 Processed\n classify content\n237000 0 “灿鸿”已登陆浙江舟山?上海转移撤离xx\n237001 0 手机后面就少了一个标志的膜而已\n237002 0 医疗美容卖的不单单是整容\n237003 0 一个依靠后来者投入维系先入者的局已经说得嘴烂\n237004 0 南通老兵自掏50万设拥军基金\n1000 Processed\n classify content\n237500 0 德国民众在纳粹政治腐败问题上的认识不仅鼠目寸光、自我欺骗\n237501 0 法律、行政法规规定广告中应当明示的内容\n237502 0 反腐至少会使GDP下降三个百分点\n237503 0 这时医院一位德高望重的老主任说:屁\n237504 0 某些小市民抹黑了南京人的形象\n1000 Processed\n classify content\n238000 0 这是自1985年以来当地遭受最大的一次蝗灾\n238001 0 真想手伸到电脑那头大嘴巴甩他丫的\n238002 0 在浙江瑞安汀田商业街和联中路交叉口上演了“碰碰车”大战\n238003 0 有参展厂商打造了一个长相酷似日本首相安倍晋三的机器人\n238004 0 雪花秀滋阴水乳套盒因为生理或环境的影响便出现阴虚的情况\n1000 Processed\n classify content\n238500 0 大牌泰国Mistine羽翼粉饼\n238501 0 G2501南京绕城高速由六合往南京方向南京四桥段从44K至45K\n238502 0 其实这家店是lonelyplanet推荐的餐馆\n238503 0 原创半年销量超美国我国成第1大新能源车市场\n238504 0 宋茜姐姐几点的飞机啊\n1000 Processed\n classify content\n239000 0 9名犯罪嫌疑人都因涉嫌诈骗罪被南京雨花警方依法刑事拘留\n239001 0 赚得不多新手一天80元到100元还是有保证的\n239002 0 宋磊的遭遇属于贵金属投资失败\n239003 0 对违法企业不能惯养必须严惩\n239004 0 泰州三福船舶船厂因超重吊载导致一死一重伤\n1000 Processed\n classify content\n239500 0 你的孩子也有机会哦视频链接:\n239501 0 从google的卫星图片上清晰可见老家的小院和菜园\n239502 0 时尚博主:Tiphaine的混搭风格有着特别的个性\n239503 0 妨碍公务+不系安全带+扰乱公共安全\n239504 0 手机用了一年没被抢也是不简单\n1000 Processed\n classify content\n240000 0 摸到了新的MicrosoftEdge\n240001 0 并将于8月29日赴南京参加全省苏南、苏北精品节目的角逐\n240002 0 V脸评价羊演出了活生生的张起灵是认可\n240003 0 “失联”x个多月的钟启章等x人因涉嫌非法吸收公众存款罪被抓获\n240004 0 x、机会不可能永远陪伴你一辈子\n1000 Processed\n classify content\n240500 0 本门从连云白鹭坞夺得空明拳残章三\n240501 0 其中外骨骼机器人已经与八一康复中心进行合作\n240502 1 尊敬的家长,新年好!阿墨鱼教育春季晚自习课程将于x月x号(明天)正式开课,x月xx日报名四个...\n240503 1 乔治罗尼亚让半球xx、哥罗那xx。锡永平手xx、琉森xx。阿尔巴塞特让平半xx、邦弗拉甸拿x...\n240504 0 中关村街道自2012年开展网格化社会管理\n1000 Processed\n classify content\n241000 0 印度金融中心的餐厅名字是以纳粹德国领袖阿道夫·希特勒和纳粹党徽命名\n241001 0 有miniatureVersailles之稱geHerrenchiemsee\n241002 0 天府软件园C12的高层电梯下班时间坏了\n241003 0 看看飞机是如何进行定检、维修的\n241004 0 已经被70多个国际服装品牌抵制\n1000 Processed\n classify content\n241500 0 双方被吹判58次犯规创下本赛季季后赛之最\n241501 0 南通大街由文化公园往宣化街方向\n241502 0 因为你叫赵朋涛所以王丹阳不会离开你\n241503 0 来自FM797198天海无贝的听音筒\n241504 0 破win10A卡挂了众人:辣鸡A卡驱动\n1000 Processed\n classify content\n242000 0 你他妈用个华为大塑料不屌丝\n242001 0 女主播实名举报被官员包养4年后遭抛弃\n242002 0 反正绑定了QQ平时都是用QQ登\n242003 0 今天在广东电白滨海新区博美村\n242004 0 就象一部烂电视剧反腐进展和情节越来越荒诞离奇\n1000 Processed\n classify content\n242500 0 官场腐败、民间恶性事件、家庭闹剧频发\n242501 0 碧水源930手、机器人563手、蓝色光标1661手\n242502 0 人体干细胞是当金医疗再生业界的最巅峰\n242503 1 露就行,cx-xr现车充足,资源有限,欢迎抢购\n242504 0 仓山区法院判令幼儿园应付给林先生一定的加班费\n1000 Processed\n classify content\n243000 0 帮你买的链接复制到:阿里妈妈淘宝客\n243001 0 天亮了我该睡觉了安大苏州\n243002 0 7月30号李鹤生日快乐五年了\n243003 0 不过和阿里影业的合作还是值得期待\n243004 0 在江苏太仓县曾有皇家的大粮仓\n1000 Processed\n classify content\n243500 1 我公司代开各种正规发票,请君保留,以备急用!\n243501 0 这是昨日14时至今日21时的感受\n243502 1 尊敬的顾客:您好!南大铜锣湾超市在x月x日至x月xx日搞浪奇洗衣液活动。(特价产品如下:xx...\n243503 0 有朋友称哥是设计院里最能说的\n243504 0 突然发现taylor的差不多都是无损音质\n1000 Processed\n classify content\n244000 0 又开始买不到小米手机怒买联想kxxx\n244001 0 看到日本政府对于美国的监听行为只是表示遗憾而不敢抗议\n244002 0 x元、鲁某某家属获赔xxxxxxx\n244003 0 10大NBA球星永恒被黑点\n244004 0 GHairRecipe蜂蜜水果无硅油配方洗发水/护发素\n1000 Processed\n classify content\n244500 0 大家乘坐电梯的时候要注意安全\n244501 0 此次xxx条停车管理示范大街重点整治区域主要分为“禁停严管街”和“停车入位规范街”\n244502 0 刘益谦是2008年十大新闻人物\n244503 0 香隅派出所民警对辖区居民疑难户口进行调查\n244504 0 晚餐:半碗米饭、菠萝蜜、一粒维生素、一粒DHA\n1000 Processed\n classify content\n245000 0 加之同瑞B、创业板B、工业xB、煤炭B基、证券B级\n245001 0 将获得由徐州慈铭体检中心提供的、价值500元的贵宾体检卡一张\n245002 0 加油实习生看到xx集我才知道郝主任和那个谁是一家\n245003 0 要等半个小时后飞机再次起飞\n245004 0 憋说话我正在强装一场说走就走的旅行飞机延误仨点我表示很开心\n1000 Processed\n classify content\n245500 0 其实路人质疑停车救人者是肇事者\n245501 0 我正在下着雨的无锡乞讨着生活的权利\n245502 0 现在的警察都是这么不作为的吗\n245503 0 就想知道飞机晚点不起飞就让旅客一直坐在机舱里么\n245504 0 辗转从北京飞到南京又从南京高铁到上海\n1000 Processed\n classify content\n246000 0 最可恶的是还劫持了xxx与阿里的DNS\n246001 0 副局长租房存七八千万受贿现金应了啥话\n246002 0 釜山南海警察厅刑法搜查队在该男子手机中发现大量年轻女性身穿比基尼的照片\n246003 1 你好 我是刚才和你联系的鼎鼎日盛装饰公司的杜光会,公司现推出,进店可亨新年开门红礼包xxxx...\n246004 0 既然都已经放假了就把握好放假只属于自己的时间专注于一些有意义的事丢掉手机\n1000 Processed\n classify content\n246500 0 最早全称为是SpecialWeaponsAttackTeam\n246501 0 好多客人问这个pola极光限定套装\n246502 0 标题宋安东NHL选秀成功爱体育的家庭加油\n246503 0 现常州富豪沃尔沃运动轿跑S60L试驾车退役啦\n246504 0 5、饭前一杯蜂蜜水抑制胃酸\n1000 Processed\n classify content\n247000 0 但真相总是比你想的要残酷很多\n247001 1 新年好,黄浩食品店给您拜个晚年,感谢您去年对本店的支持,从即日起,在本店购物满xx元,即可随...\n247002 0 澳洲Coloxyloraldrops缓解婴幼儿便秘/上火口服滴剂30ml\n247003 0 你高龄……blablabla……好多因素的\n247004 0 晋煤集团大力实施“文体惠老、文化养老”为老服务新战略\n1000 Processed\n classify content\n247500 1 你好,我们嘿客店的花王现在做活动,力度还是蛮大的,原装日本花王纸尿裤顺丰直采,三八特惠Lxx...\n247501 0 由锡山文体局和锡山现代农业博览园联合举办的锡山区2015年少儿游泳邀请赛在农博园游泳馆圆满落幕\n247502 1 广绿环保在肃宁县肃水路东,现招业务员(xx年薪达xxxxxx元+),网络营销员(xx年薪达x...\n247503 0 只有花千骨完结或停播股市也就恢复正常了\n247504 0 分享彭商强与证券物理学的博文图片:20150807当前股市各大周期K线技术分析\n1000 Processed\n classify content\n248000 0 更不相信这是在为Tesiro打广告\n248001 0 为什么6p系统升级成b243后\n248002 0 PS:我可没有在人民广场吃炸鸡\n248003 0 人飞出去砸中了一辆警车晕了\n248004 0 设计师没howilldisappear\n1000 Processed\n classify content\n248500 0 看中国好声音最让人感动的不是唱的有多动人\n248501 0 吉克隽逸行头近五万买不到机票遭质疑\n248502 0 把一名向其勒索x块钱的警察和警察厅副厅长搞下了台\n248503 0 实际最终达到21度的立式空调对冲\n248504 0 研究发现每天喝3杯或更多咖啡可使2型糖尿病风险降低37%以上\n1000 Processed\n classify content\n249000 0 结果他马上打开管家的电脑诊所\n249001 0 『JongSuk』150725图片→LOCK&\n249002 0 原定中午12時起飛前往美國芝加哥\n249003 0 是不是你对\"朋友\"这个词的定位有问题呢\n249004 0 x汇率~xxx到手~moto短裤~只有xxx\n1000 Processed\n classify content\n249500 1 新年好,本店今天正好式门,本店以卷闸门、抗风门、铝合金型材门、网型门、伸缩门、车库门等等批发...\n249501 0 TFBOYS恭喜兩週年快樂接下來還有每個十年你們要加油\n249502 0 最近你看花千骨和加油实习生了吗\n249503 0 必须通过微软浏览器才能打开网页图片\n249504 0 上海市闵行区人民法院民事裁定书\n1000 Processed\n classify content\n250000 0 小户型设计也能通过软木背景墙、地毯打造别墅的豪华感\n250001 0 和闺蜜聊了一晚上晚上的飞机回家欧耶看书书去咯~\n250002 0 Google每个月查询量1000亿次\n250003 0 然后医生又说还要拔两颗尽头牙\n250004 1 圣佛海魂日化祝您:三八妇女节快乐!现活动如下:伊贝诗第一款正价,第二款x.x折;自然堂有秒杀...\n1000 Processed\n classify content\n250500 0 今晚有花千骨看今晚有花千骨看今晚有花千骨看\n250501 0 原系王某被嫌犯家属用xx万收买\n250502 0 G15w常台高速由杭州往常熟方向68K附近事故现场处理结束\n250503 0 x级地震当地网民调侃称“家常便饭”\n250504 0 枪6000多支——联想有人造谣说:中国8年抗战\n1000 Processed\n classify content\n251000 0 阿里去啊旅行芝麻信用积分新加坡签证拒签\n251001 0 使用手机网络连接比WiFi更安全\n251002 0 回复MKLC83领取80美元刷卡金\n251003 0 一审法院以非法吸收公众存款罪\n251004 0 我T也要参合到这个牌子出飞机杯惹\n1000 Processed\n classify content\n251500 0 现代中式装修案例——营造温馨的家现代中式装修风格案例融合了庄重与优雅双重气质\n251501 0 “巴哈马与护士鲨游泳”我的秒拍作品\n251502 0 仔细聆听小贩一遍又一遍的吆喝\n251503 0 再去看百度知道商城的物价已经长到了天价\n251504 1 尊敬的用户新年好!信阳移动元宵佳节期间x月x日-xx日,针对您这样的xG手机客户,推出缴xx...\n1000 Processed\n classify content\n252000 0 日文wiki推荐的配置是「重巡+飞机欧根电探\n252001 0 51岁周桃亚伸出援手来到人民路的献血屋献血\n252002 0 星美已经与百度合作推出了“星美百度卡”\n252003 0 我真怕有不明真相的人错把这个当蓝莓吃了啊\n252004 0 本轮对江苏舜天球员恶意铲完吴曦后还一幅不得了的样子\n1000 Processed\n classify content\n252500 1 x月x日房超网家装团购xxx尚高x出水花洒等N多超低价产品x折起,不限量抢 购,来就送洁丽雅...\n252501 0 结果这次回程航班半天内推迟了三次\n252502 0 被合肥市庐阳区法院一审判处有期徒刑一年\n252503 0 可惜的是甲骨文金文展厅由于筹备不足没有开\n252504 0 150710ASBeetwitter新活动海报\n1000 Processed\n classify content\n253000 0 对国内警察城管贪赃枉法欺压老百姓却视而不见\n253001 0 我用babyskin就不会过敏\n253002 0 微信电脑版用户现已可下载更新\n253003 0 喜欢出租车里沙哑的radio\n253004 0 在P2P网贷平台提供担保业务并收取一定的担保费、服务费等\n1000 Processed\n classify content\n253500 0 知道白子画为什么宁负花千骨\n253501 0 4男人对于补肾、脂肪肝5贫血人群阿胶善治各种血症6亚健康人群阿胶能有效提升机体白细胞这个免疫...\n253502 0 表皮层的细胞间质和真皮层的弹力水合胶含量越充足\n253503 0 BB家热卖产品冬天最好用的身体乳\n253504 0 将成为中国第一家上市金融互联网垂直搜索引擎\n1000 Processed\n classify content\n254000 0 你现在居然连四大名捕花千骨都看了\n254001 0 我已经预感B站小学生要把这部骂成狗了\n254002 0 博物馆建筑面积2500平方米\n254003 0 剧情逆转“僵尸肉”或为假新闻——那里是真相\n254004 0 来自FMxxxxxxx真水无香—蕾\n1000 Processed\n classify content\n254500 0 其中公共财政预算收入xxxxxx万元\n254501 0 愿所有穆斯林斋功美满幸福吉祥\n254502 0 到荷兰了坐了9个小时飞机待会还要转机现在是荷兰时间15\n254503 0 约20分钟后取下面巾功效:可以有效改善脸部色斑\n254504 0 你们的APP预计送达时间能靠谱点么\n1000 Processed\n classify content\n255000 0 下飞机我就带你们去吃重庆第一串串\n255001 0 至此沿线14座新建火车站主体全部建成\n255002 0 好好保护自己0爱你的An\n255003 0 邯郸中级人民法院宣判一起系列盗窃、抢劫羊只案\n255004 0 Dxx今天去扎乙肝疫苗第二针\n1000 Processed\n classify content\n255500 0 我电脑都关了还想来看偶像来了\n255501 0 1用360更新win10不是原生再恢复出厂\n255502 0 右江区政府已会同相关部门研究砖厂整治问题\n255503 0 华为传输设备常见告警含义及处理方法\n255504 0 正式命名为MOUNTPAVILIA\n1000 Processed\n classify content\n256000 0 打破了从智能手机角度出发的传统节电思路\n256001 0 \\n小碎花的裙子下往上按摩三到五分钟爪中拯救出来\n256002 1 【温馨提示】明师教育农林校区将于x月x,x日举行中考状元班示范试听课,同学可任意选择没有报读...\n256003 0 有没结婚难道南京上网查不出来吗\n256004 0 南京水游城对面的一家金陵鸭血粉丝汤千万别去\n1000 Processed\n classify content\n256500 0 保安抓小偷这是正义行为遭到报服\n256501 0 今天在浙江大学为企业家分享移动互联网时代的商业变革及创意传播管理\n256502 0 游戏中的“环球影业Universal”毫不为过\n256503 0 今年得争取把三段和裁判证的考试费赚出来\n256504 1 平安银行合肥入驻…平安招聘,你想加入吗?一, 服务项目:x,代表公司为平安老客户办理理...\n1000 Processed\n classify content\n257000 0 5.不常见的蛋白质氨基酸是在蛋白质合成后修饰形成的\n257001 0 为什么医疗保险越来越高去年一人60现在一人90我家有18口人差不多要2000元那里来钱交\n257002 0 intelligent还是smart\n257003 0 还在公交上被小偷把我手机偷走了\n257004 0 但是事实的真相是发财的机会总是给那些不知道更多就能明智的行动的人\n1000 Processed\n classify content\n257500 0 庆安法院积极开展了民商事审判庭审观摩活动\n257501 0 来瞧瞧你的星座适合买股票吗\n257502 0 五华城管护国执法中队对祥云美食城周边店外经营\n257503 0 也以最高温23℃稳居全市最凉爽第一名\n257504 0 进系统之前所有usb设备无法使用\n1000 Processed\n classify content\n258000 0 升级win10后的几个问题:亮度调节失效\n258001 0 彼得·蒂尔认为不论是投资还是生活都遵循冥次法则\n258002 0 回到南京感觉整个人又活了过来\n258003 0 有时还会少打或多打…………一毛都不值\n258004 0 幸好有机器人给我当翻译再当我的保姆\n1000 Processed\n classify content\n258500 0 交房时精装修未达造价的标准\n258501 0 中长期投资者已经开始离场了\n258502 0 设计一个用来享受的卫浴间是个很赞的选择\n258503 0 以受贿罪、纵容黑社会性质组织罪等\n258504 0 太空棉宝兰撞色兰竖条设计视觉流感超赞\n1000 Processed\n classify content\n259000 1 “名贵”今明两天啤酒xxx/人无限畅饮!本公司新招一批xx后的美女,个个性感风骚还有更多惊喜...\n259001 0 积极对接京东、阿里等知名电商企业\n259002 0 2、应该可以说是“违法违规人员”\n259003 0 那我倒不如拔掉手机卡插花听歌看看书发发呆\n259004 0 各加油站禁止对无牌无证的农用三轮车、摩托车加油\n1000 Processed\n classify content\n259500 0 交通指引:搭乘地铁五号线至猎德站D出口下\n259501 0 朋友在街道口开的店iphoen手机\n259502 0 真的很鬼呀中国好声音第二集中杨宝心从唱歌到点评那英的头发一会直一会卷\n259503 0 索尼PS4的销量一直比微软XboxOne大\n259504 0 福绵区人民法院以信用卡诈骗罪一审判处梁某某有期徒刑二年\n1000 Processed\n classify content\n260000 0 每天都在质疑人生中度过??\n260001 1 小陈祝您元宵节快乐,节后有需要办信用卡,贷款的可以直接联系我。\n260002 1 您好!我是颐阳路(原塞玛特)中商雅士利导购,现雅士利奶粉全场x折时间为x~x日,欢迎您来选购...\n260003 0 上班的地方电梯坏了~~~坏了………本宝宝一口气爬了十几楼\n260004 0 夸了出租车师傅一句技术好结果就撒欢了马路是你家啊\n1000 Processed\n classify content\n260500 0 妈妈要给他操办婚礼装修房屋\n260501 0 努力打造浙江省第一科技新闻门户\n260502 0 集团的发展速度取决于人才梯队的建设情况﹉\n260503 0 金安区旅游局相关负责人陪同\n260504 0 但21岁的生日愿望现在许下应该不算太晚\n1000 Processed\n classify content\n261000 0 才知道陆风Xx外观国内专利的申请要早于路虎极光\n261001 0 这让百度的发展不再受制于某个高管的去留\n261002 0 象征TIFFANY经典元素的文明\n261003 0 这次朵唯iSuperS3的超窄边设计框达到了的2\n261004 0 Burt'sBeesMamaBeeBellyButter小蜜蜂含维E防妊娠纹霜\n1000 Processed\n classify content\n261500 0 之前满脸痘痘和粉刺的我就是一个教训还好现在弥补回来了\n261501 0 然后看到我那楼盘40多条评价37、8条都是差评\n261502 0 证券犯罪只打击:x内幕交易\n261503 0 那一伙骚滴滴湿哒哒的真的惨不忍睹\n261504 0 抹个手机上的渣渣手滑按到拍照自动人工移轴…\n1000 Processed\n classify content\n262000 0 认证信息为“南通铃兰商贸有限公司网络技术负责人”\n262001 0 王璐在腾讯视频陪我度过了1小时\n262002 0 今年南京平安夜和圣诞夜都是“冰冻夜”\n262003 0 齐齐哈尔铁路运输法院全体干警经过1个多小时的车程来到省级爱国主义教育基地——江桥抗战纪念馆\n262004 0 依然是典型的苏州园林风格\n1000 Processed\n classify content\n262500 0 来反映出死刑犯对死亡★★★更多详情:\n262501 0 杭州一电梯再“吃人”:一名住在16楼的女子\n262502 1 现有几套黄河源国际城的房子,现已团购价对外出售,面积xxx-xxx-xxx-xxx等不同的户...\n262503 0 『券商:生物医药震荡市业绩成长确定x股掀波澜』\n262504 0 Mulancy半永久化妆第六期全科班的学员们快乐聚餐\n1000 Processed\n classify content\n263000 0 省儿基会已收到爱心捐706540元\n263001 0 也和今天一样高温xx度我们耍求施工队伍下午x点开工到晚x点xx\n263002 0 创业板重回xxxx点大涨逾x%\n263003 0 12日10086回复说后台显示成功了\n263004 0 分享一个喜感:玩坦克世界把鼠标玩坏了\n1000 Processed\n classify content\n263500 0 第二半岁以前的婴儿不宜吃鸡蛋清\n263501 0 本案裁判文书随后将在中国法院裁判文书官方网站公布\n263502 0 南京地铁S1号线二期、S7号线预计2017年建成\n263503 0 在新三板上市的券商共有4家\n263504 0 那些内置锂电的手机、psp等设备也能通过它直接供电了\n1000 Processed\n classify content\n264000 0 南京虐童养母李征琴:从没想真正伤害过孩子\n264001 0 将成立一支由120名交警、特警等人员组成的特别执法队伍\n264002 0 网址是这个说是浙江银行卡号是这个\n264003 0 位于浙江天台平桥盆地的始丰溪畔\n264004 0 监拍菱悦撞劳斯莱斯天价赔偿被免网友质疑炒作\n1000 Processed\n classify content\n264500 0 中央电视12台社会与法节目中的女婿状告岳母和房产公司的判罚是不正确的\n264501 0 反腐战争胜利冲昏头脑而忘了提高民生\n264502 0 想去连卡佛把drsebagh的VC粉买了\n264503 0 所谓“没证据”不过是不作为的托词罢了\n264504 0 确实看见城管拿秤砣击中邓正加脸部\n1000 Processed\n classify content\n265000 0 猪鼻贴主要是以去黑头粉刺为主\n265001 0 吃着美味x小时能跑xxxx公里人还是那个人\n265002 0 就像西安警察打河南警察一样\n265003 0 5月份刚买的八千块钱的雅马哈摩托车没了\n265004 0 消费者权益保护法等法律维护自己的合法权益\n1000 Processed\n classify content\n265500 0 以此优化公司的投资结构、提升公司综合竞争力\n265501 0 医生写在病历上的东西叫字么\n265502 0 男女都要护肝以血为本以肝为天肝有多清脑有多清\n265503 0 不法分子套用湘潭市检察院反贪局电话企图诈骗\n265504 1 广东清远龙湖奇石文化产业园将于xxxx年x月x日--x月xx日举办奇石博览会,现有少量户外展...\n1000 Processed\n classify content\n266000 0 我跟店家纠纷就是我提出证据之后店家屁都不放一个\n266001 0 外面风刮得像开了几架轰炸机\n266002 0 有网友曝光百度、360、京东等互联网公司加班一族纷纷在办公楼下举牌“我要放假”\n266003 1 我们李家诚和记黄埔,在周浦万达广场旁,打造的城市型精品水岸别墅,xA期即将盛大开盘,超出前期...\n266004 0 GooglePlay那一套东西那样设计丢到板子上用感觉很不舒服\n1000 Processed\n classify content\n266500 0 后备箱都放不下额~秒杀的象印保温杯很美丽啊\n266501 0 就使用我的邀请码iq2397下载并登录浙江移动手机营业厅\n266502 0 忍不住上几张刚导入电脑的原图\n266503 0 3、电脑周围堆放书本、杂志等可燃物\n266504 0 在玉苍山顶飞来一架飞机目测落温州的飞的非常低\n1000 Processed\n classify content\n267000 0 15874109600孩子妈妈\n267001 0 质疑什么的话也会很直白地说\n267002 0 常常在地铁里遇到有女性乘客吃东西、喝东西\n267003 1 尊敬的会员新年好!新年新气象,为感谢新老顾客对【净香】的支持,凡x月份到店做护理x次以上送价...\n267004 0 吃的时候可放一勺蜂蜜或者红糖\n1000 Processed\n classify content\n267500 0 在南京还有这样的可拆卸牌照吗\n267501 0 四川省教育厅关于泸州医学院更名为四川医科大学的论证报告\n267502 0 现在只有地铁站旁边的破停车场\n267503 0 7月26号是个让释永信“大师”很头痛的日子:有人以实名举报的名义\n267504 0 我在手机酷狗发现“小乐乐biu”的精彩表演\n1000 Processed\n classify content\n268000 0 com现有MadpaxFull彩色刺猬潮背包\n268001 0 发消息问又没有做阿里巴巴的\n268002 0 沪指不仅在3600点附近横盘达5天\n268003 0 宣布启动一系列百度内部项目对外开放吸引投资者的“航母计划”\n268004 0 浙江有个什么航小刚够想消北京重国企那样红\n1000 Processed\n classify content\n268500 0 卢怀庆xxxx年时很幸运地找到了他在太仓的哥哥姐姐\n268501 0 副院长范小云在中国金融博物馆王巍理事长的陪同下\n268502 0 在该吃午饭的时候飞机晚点真的太痛苦了\n268503 0 比如学者型法官和违法法官的区别\n268504 0 最近看的这个加油实习生挺感动的\n1000 Processed\n classify content\n269000 0 独特的假两件设计·在阳光下若隐若现\n269001 0 399006的一大主题就是互联网金融\n269002 0 中信物业长春公司2015年度中期工作会议召开\n269003 0 除去首尾两位歌手“黑天鹅”和“狼牙”\n269004 0 仪征国信影城2015年7月20日最新影讯\n1000 Processed\n classify content\n269500 0 但妻子居然利用通过谷歌街景地图拍摄的3D照片\n269501 0 X信证券X首席策略分析师最新大盘看法\n269502 0 悟空找房专注独家二手房房源\n269503 0 可手机直接打印照片的打印机\n269504 0 回来后高大上的医生形象全毁了\n1000 Processed\n classify content\n270000 0 地铁上旁边的哥们拿着微星笔记本打开在编程界面\n270001 0 相关领域专家就4个最常见的游泳地点\n270002 0 卫星和航拍照为某些事对你有些微的一份默契、一份平淡、\n270003 0 这个天出门又不爱打伞直接晒成碳\n270004 0 尉健行任内曾查处xx只大老虎\n1000 Processed\n classify content\n270500 0 建议对碰瓷的人进行公安局备案\n270501 0 难道华为不知道荣耀7现在很难卖吗\n270502 0 一路上的讽刺嘲笑质疑~有时你会伤心难过但更多的便是一笑而过\n270503 0 主角李医生的扮演者是香港演员Angie\n270504 0 独龙族人基因是百分之百的Ox系\n1000 Processed\n classify content\n271000 0 丫丫540天:外婆牙疼要去拔牙\n271001 0 中国法律规定一夫一妻啊…想想要是发生这些事\n271002 0 二来我捧着手机聊天聊到没电\n271003 0 但是电梯口又有标语“请勿行走”\n271004 0 我敢打赌他burpee一口气不会超过1…\n1000 Processed\n classify content\n271500 0 男孩为蹭WiFi上网爬防护网在铁轨上玩手机t\n271501 0 TCL手机请了当红明星金喜善做代言\n271502 0 截至7月17日依然共收捐款183089\n271503 0 答:经济现代化、政治现代化、社会结构现代化、文化现代化、环境现代化、人的现代化\n271504 0 尊茂酒店集团在营运副总监兼市场销售总监曹铸先生带领下\n1000 Processed\n classify content\n272000 0 很多女性患了妇科疾病后首选的就是去看西医\n272001 0 谷歌要招SEO专家给自己做搜索引擎优化|以撒科技\n272002 0 嫌犯撞坏两轿车后逃脱车主损失谁来赔付\n272003 1 你好!我司有⒘%!琎_項≮。。 如需:xxx xxxx xxxx李生\n272004 0 Twitter每天一封推送从未中断\n1000 Processed\n classify content\n272500 0 每天花千骨所演剧情里面有姐姐的全部都截屏了\n272501 0 心理罪无锡拍的耶一眼就看出来惹\n272502 0 我被中国式的婚姻“强奸”了\n272503 0 TotheFirstYear、TomyMr\n272504 0 是日本妇产科医生推荐的产品~\n1000 Processed\n classify content\n273000 0 近年来中国机器人市场保有量快速提升\n273001 0 我虽然希望windows10是win手机的大机遇\n273002 0 今天去坐Duffy飞机的人还真多……一开推特被刷屏\n273003 1 “x.x至x.x号优悦居家装生活馆,诚邀您参加“惠民家装建.材大补.贴活动”。来店就送精美礼...\n273004 0 国外汽车制造商只愿意把一些过时的技术卖给国内的合资厂商\n1000 Processed\n classify content\n273500 0 民营医院、私立诊所已占据了半壁江山:目前全国已有近6\n273501 1 仁山智水已有xx位业主在我司签约,现开放x套和您同戶型樣板房,供您参观借鉴。咨詢:xxxxx...\n273502 0 嘉兴日报报业传媒集团承办的2011全国记者站工作会议代表一行40多人\n273503 0 陆川法院纪检组监察室组成督查组深入该院各中层部门\n273504 0 沪昆高铁除了G82次车票紧俏外\n1000 Processed\n classify content\n274000 0 新时代互联网金融的虚拟财富是否可能替代自古以来的黄金财富价值观\n274001 0 『如何做一名真正的发型设计师』\n274002 1 亲爱的会员你好!我是Sm沃尔玛自然堂专柜的,有个好消息告诉你,我们x.x节要搞一周活动x折起...\n274003 1 免费装修,x万巨奖!馨居尚x日“免费整装抢签会”绝杀x万,装修不花钱!再抽iphonex!来...\n274004 0 就是上次预言亚洲金融危机出名的男人\n1000 Processed\n classify content\n274500 0 看下集预告下级是在山东拍的那个~那浙江那期呢\n274501 0 你就可以借助设计师WAGAii带来的塑料花\n274502 0 之前马云砸10亿来推广滴滴打车您错过了百度砸几亿来推广百度钱包您又错过了还想错过这次借贷宝吗\n274503 0 中国南海军演震动欧美西媒颠倒黑白污蔑解放军武力恫吓……如果这也是“武力恫吓”\n274504 0 xx年在德国开始做ebay、xx年做亚马逊\n1000 Processed\n classify content\n275000 0 开了三小时专家咨询会一群人拿着尸体照片研究半天话说法医这个职业真是屌爆了感觉整个人都在发光哈哈哈\n275001 0 1个小偷20年前偷走2件古物后即厄运连连\n275002 0 WindowsPhone就像新能源车\n275003 0 在淮安主要干道站加车柴的朋友有“福”啦\n275004 0 从成都市城管委执法总队获悉\n1000 Processed\n classify content\n275500 0 枸杞+菊花:能使眼睛轻松、明亮\n275501 1 家长你好!领先教育春季推出超低价作业辅导班xxx元,限一个班,额满为止。欢迎前来咨询报名。\n275502 0 这是20岁的女孩季春娟的幸福观\n275503 0 独立寻找食物、水源、药品、补给\n275504 0 加入枸杞、冰糖再煮xx分钟\n1000 Processed\n classify content\n276000 0 施廷懋不管从起跳高度空中姿态的保持还是到入水时对水花的控制都比最后夺冠的意大利选手要做的更好\n276001 0 万达百货关闭全国40余家门店的消息\n276002 0 报名热线:18051024703\n276003 0 名片名片设计名片素材名片模板公司名片商务名片广告名片企业名片科技名片创意名片商业名片通用名片...\n276004 0 可能因为xx万报价比较高一直尚未成交\n1000 Processed\n classify content\n276500 0 当我开始质疑一件事的时候准确率总是那么高??\n276501 1 先生,您好!我是刚跟您联系过的平安易贷客户经理廖兴萍,办理农行、光大无抵押贷款x—xxx万,...\n276502 0 这也让火箭的阵容得以进一步完善\n276503 0 以后坐地铁或去商场必须走楼梯\n276504 0 看电视玩电脑手机游戏机ipad又多\n1000 Processed\n classify content\n277000 0 改改公社賽道走行会南京站顺利完成\n277001 0 设计师GonglueJiang想到了一个好的解决办法\n277002 0 13岁的湖北小女孩小李被带到舒城农村一大龄男子家\n277003 0 在厦门地区中石化森美加油站\n277004 0 我喜欢花千骨和朔风这一对儿啊啊啊啊\n1000 Processed\n classify content\n277500 0 都可能通过书本、百度和善知识处学来\n277501 0 手机卡的半死私信回不了晚点回去再用那个回复你们那个手机没带出来你们的流量我已经冲了\n277502 0 个别不法商贩违规销售注射整容用透明质酸钠产品\n277503 1 明天新到OK·五星 三扒一霖 牛前 全牛 量大从优,货源紧缺,抓紧时间,预购请速电!\n277504 0 2:别用自以为的标准要求限制女性\n1000 Processed\n classify content\n278000 0 …信用卡滞纳金的计算方式野蛮粗暴\n278001 0 像花千骨剧组这样利用自身影响力\n278002 0 我刚刚把手机壁纸换成了这个:BretAdeeopensoneofhis72\n278003 0 咨询可加我微信号:1239847679邓榕\n278004 0 蔡老师的照片5点拍的6点秋秋还穿趿拉板跟朋友玩\n1000 Processed\n classify content\n278500 0 沪指已经跌回7月8日、7月9日附近位置\n278501 1 (x/x)感谢您致电上海元祖!元祖凯特芒果/爱文芒果新鲜预购咯!即日起-x月xx日期间预购即...\n278502 0 x個魅力全面解析|ETtoday影劇新聞|ETtoday東森新聞雲手機版|ETtodayMo...\n278503 1 《有》⊥《抵》 《増》⊥《扣》 《値》⊥《Ix%》 xxx xxxx xxxx刘’\n278504 0 国有物业服务企业、社区组建物业服务机构或专业物业企业进驻管理\n1000 Processed\n classify content\n279000 0 一个号码叫:15298601091做的是专业无抵押免担保信用贷款\n279001 0 想知道今年南京舞蹈圈最大事件是什么吗\n279002 0 昨天把WIN10还原了WIN7\n279003 0 I'mat地铁珠江路站ZHUJIANGLUStationin南京\n279004 0 做了心电图结果是窦性心律不齐\n1000 Processed\n classify content\n279500 0 好声音这期喜欢赵大格和她前面那个\n279501 0 P4bomb眼神很攻~~cr\n279502 1 亲爱的会员朋友,新年好!xxxx年x月x日—x月x日,凡进维纳贝拉店有全年最大的惊喜哦!机会...\n279503 1 您好,方林xxxx别墅装饰x月x日-x日重磅推出“开年钜献灯峰造极”元宵灯会优惠活动,现场豪...\n279504 0 发仔觉得:投资理财是一门学问\n1000 Processed\n classify content\n280000 0 因为梦想过程中的点点滴滴汗水淋漓\n280001 1 西南大学綦江报名点春 季招生将在x月xx日结束,凡老学员带新学员,均会获得xxx.xx/人的...\n280002 0 搞笑/NBA球星三分球命中率下降原因是iPhone屏幕过大\n280003 0 美国禁止飞机发动机所用燃料、飞机所用润油、废钢铁等物资出口\n280004 0 再也不会买了再也不会买了再买也不会买了\n1000 Processed\n classify content\n280500 0 赶快抓住机会加入VIVA众筹吧\n280501 0 一5人犯罪团伙被肥东法院判刑\n280502 0 一飞机的东北人好像一家人互相推荐着泡面“整点儿吧\n280503 0 现将徐州远大玻纤制品有限公司厂区规划总平面图及主要经济技术指标向广大市民公示\n280504 1 大量出售纯蒙兔,数量有限,富镇老李,联系电话xxxxxxxxxxx.\n1000 Processed\n classify content\n281000 1 源,选择奥途公关 糖酒会继续为您服务。本公司专注糖酒会已x年,专业提供礼仪,模特,举牌,发单...\n281001 0 我们的价格duangduang的往下降\n281002 0 网点名称:江苏南通港务区网点电话:xxxxxxxxxxx派送区域:狼山港工业园\n281003 0 浴室设计的亮点是墙角的一间矮柜\n281004 0 卫星:aiscpxxxx没人打开的泪滴\n1000 Processed\n classify content\n281500 0 工作团吁请政府宣传保护此特有物种\n281501 0 百度粉丝力量我支持李易峰\n281502 0 对有诉讼、复议交叉情况的案件同区政府法制办进行沟通\n281503 1 尊敬的各位家长: 开学来临之季,星辰学习家园优惠活动开始了,针对老生一次性报...\n281504 0 重点配置卫星导航、核电、猪肉、现代农业、国企改革相关热点题材\n1000 Processed\n classify content\n282000 1 好消息哦!!公司为迎元宵节和美丽女人节,特回馈新老顾客。店内所有款式一律x至x折,有经典的黑...\n282001 1 深圳市兴华汽车运输有限公司 感谢您的来电!公司竭诚为您提供高效、优质的服务!联系电话:xxx...\n282002 0 卫星和航拍照rgottenhadbeenhere\n282003 0 帮你们团的s凯兔前男友面膜买好啦现在看到的都是有盒子晚上过关前都会拆掉不然太显眼了\n282004 0 然后我在自己电脑和手机还有ipad三个设备看那几个gif速度差也好大\n1000 Processed\n classify content\n282500 0 万一你碰到一个卖中药的一抓一个准可怎么办呐~真是为你操碎了心呐\n282501 0 一文秒懂昆山“四大区域”\n282502 0 各路记者又开始带着实习生来串门\n282503 1 你好,我是东湖小镇项目置业顾问张洋, 项目本月月底举办相亲团购活动,到时会推出团购房源,并且...\n282504 0 下载平安人寿app自助下单\n1000 Processed\n classify content\n283000 0 尼玛不开龙被电脑一波推到家门口的我又不是没见过\n283001 0 没有合乎立法权、司法权、行政权权力行使的基本条件\n283002 0 从此刻起\n283003 0 本来想着有银耳莲子枸杞百合\n283004 0 10万图书满200减100\n1000 Processed\n classify content\n283500 0 再往后三位xxx表示是第xxx天\n283501 0 之前总觉得租的房子里wifi信号实在太差\n283502 1 总价x万起的一线湖景电梯洋房!首次火爆开盘。抢到即赚到!地址:金山南路与玉山路交叉口,诚邀您...\n283503 0 3、抓准美容时间:在11点前就寝\n283504 0 省政府在宁卧庄宾馆举办丝绸之路经济带“互联网+交通+制造”兰州圆桌峰会\n1000 Processed\n classify content\n284000 0 我只是想在地铁上重温一下预告片和MV\n284001 0 全省清理公布权力清单xx万余项\n284002 1 您好!哥。我是豪世华邦文鼎苑的李子记,刚才和您联系了,协安上郡新出一套xxx.xx方xxx万...\n284003 0 他可以将某种疾病讲得头头是道\n284004 0 江苏省淮安市金湖县银集镇淮建居委会村干部霸占农田带施工人员打老人\n1000 Processed\n classify content\n284500 0 村里90岁高龄的老党员冒着大风大雨在修砍树枝\n284501 0 可在医生的指导下服用止咳药\n284502 0 台州民航局长就地免职当班安检人员全部开除\n284503 0 一个江西来的新兵在浙江兵营吃完第一顿食堂饭蹲在走廊哭了首长走过去问为啥哭新兵说长这么大这是吃...\n284504 1 感谢致电巨石山生态文化旅游区,您的来电是对我们最大的信任!中国电信挂机名片是您最便捷、最经济...\n1000 Processed\n classify content\n285000 0 省防指决定于12日12时起结束全省防台风III级应急响应\n285001 0 万秀区法院的行政法官没有轻易对此案作出判决\n285002 0 来推荐下THANN紫苏防晒霜\n285003 0 奇葩的店扬州炒饭竟然用梅干菜炒\n285004 0 我哥跟我说了你每天缠着他是不是的\n1000 Processed\n classify content\n285500 0 梁石川:西宁市政府如此“嫁女”因为啥\n285501 0 共同打击跨区域毒品违法犯罪\n285502 0 来自江苏省统计局的调查显示\n285503 0 我们找到四方台区政府建设局\n285504 0 报名20号韩国培训班半永久化妆的学员下飞机请跟我联系\n1000 Processed\n classify content\n286000 0 「1646万人在传看」中国好声音第4季混血型男刘伟男迷倒四导师周董挺国语歌:中文最diao\n286001 0 比如波音787所用的是涡扇发动机\n286002 0 这对于两个星期前对C语言一窍不通的我压力可想而知\n286003 0 每次按压喷头1至少2下将药液喷于各鼻孔内\n286004 0 微软已于x月底的buildxxxx开发者大会发布了windowsx\n1000 Processed\n classify content\n286500 0 旅游回来心情好发发我的自拍\n286501 0 单独的xxml神仙水折后xxx\n286502 0 看百度百科介绍杨伯峻先生\n286503 0 有没有手机软件的直播地址啊\n286504 0 北京下起“红包雨”\n1000 Processed\n classify content\n287000 0 股东由浙江致中和实业有限公司和陈少非构成\n287001 0 ppt文件没有自动关联o16应用\n287002 0 据说是无锡小有名气的走穴歌手\n287003 0 xxxxxxxx清晨在团结附近走丢\n287004 0 问她个问题那种很不情愿把手机从眼前放下然后看都不看你然后又很轻声很叼的慢吞吞的说我不知道没听...\n1000 Processed\n classify content\n287500 0 晚上六点的飞机都没磨叽的没赶上\n287501 0 真心觉得猥亵跟强奸不区别对待就好了\n287502 0 南京:六合百盏路灯大白天亮着浪费\n287503 0 1987年他做了个高20cm的机器人\n287504 0 试验、咨询培训于一体的新兴虫害管理企业\n1000 Processed\n classify content\n288000 1 爱慕内衣迎“三八\n288001 0 随意搭配一件t恤就足够彰显你的时尚魅力啦\n288002 0 阿里巴巴·桐城产业带现有上线企业372家\n288003 0 汽车配件尽在同心国际商城\n288004 0 南京市江宁区气象台2015年7月20日06时发布:今天阴到多云\n1000 Processed\n classify content\n288500 0 医生说我这种懒已经无药可救了\n288501 0 做为裁判的我以迅雷不及掩耳的速度接住了正向我飞来的篮球球\n288502 1 气丸x袋装x.x元/盒。更多优惠欢迎进店咨询。——我是一笑堂立德药房的张桂珠\n288503 0 Windows10更新三个多小时还没好\n288504 0 传巴菲特正洽购飞机零件商交易或达300亿美元\n1000 Processed\n classify content\n289000 0 今天拿到徐州鼓楼区人民法院的裁定书\n289001 0 eCareDiary也是一个社区\n289002 0 20多年一个地方交代下去才刚刚圆满\n289003 0 江北派出所组织警力通过细致排查走访获取案件线索\n289004 0 C21亮白遮瑕色让你轻松实现裸妆中的美妆\n1000 Processed\n classify content\n289500 0 此外亚马逊中国还宣布与宝洁美发达成战略合作\n289501 0 可恶的美帝医疗体系有多少人没被坑啊\n289502 0 2015/7/28菲卖店美国店到货通知\n289503 1 即存即送百分百 xxx xxx.com 鑫 普 京\n289504 0 第二天小偷上街买了份报纸\n1000 Processed\n classify content\n290000 0 违法地点:Gxx浑源方向xxxxKM+xxM\n290001 0 刚刚在QQ空间分享QQ音乐以外的歌曲\n290002 0 什么时候来南京啊啊啊啊啊啊\n290003 0 珠宝与国际教育学院酒店管理本专业培养的学生能具备掌握酒店管理相关专业知识\n290004 0 社会上好多事是当法官时看不见的\n1000 Processed\n classify content\n290500 0 完美融合了谷歌Chrome浏览器的极速特点和微软IE浏览器的兼容特性\n290501 1 感谢致电鑫隆汽车用品批发中心,主营DVD导航、仪行车记录、电子狗、改装框等系列汽车用品,质量...\n290502 0 从新合同可以看出JL在NBA的定位就是板凳队员\n290503 0 我真心觉得腾讯游戏平台做到很垃圾很垃圾很垃圾很垃圾\n290504 0 事情的真相根本就没有兴趣去了解\n1000 Processed\n classify content\n291000 0 2015湖南常德市特殊教育学校教师招聘拟聘名单公示\n291001 0 我用百度视频手机版看了“多名未成年少女酒吧陪酒”\n291002 0 经过认证的有机熏衣草有帮助于舒缓和镇静皮肤\n291003 0 坐飞机坐飞机坐飞机坐飞机坐飞机\n291004 0 本次资费调整主要针对手机用户的语音业务\n1000 Processed\n classify content\n291500 0 心情复杂到xxxx字都说不清楚的情况下上了飞机\n291501 0 别墅区办公室和高楼大厦办公室\n291502 0 相城北桥派出所近期接报的一个警情\n291503 1 尊敬的会员 : 您好! \"x.x\"惠聚女人节活动已启动,进店就有礼品赠送,欢...\n291504 0 主打跨平台开发:微软发布VisualStudio2015\n1000 Processed\n classify content\n292000 0 志高小区就有18辆车的车胎被扎破\n292001 0 7夏威夷群岛东南部特鲁克泻湖下存有50多艘『二战』的战舰沉船残骸\n292002 0 马格诺塔去年xx月被法院裁定一级谋杀等x项罪名成立\n292003 0 也可以投资理财获得最高26%的安全收益\n292004 0 将其跟6月12日峰值的落差拉开到38%\n1000 Processed\n classify content\n292500 0 安丘城管打人安丘城管打人事件最新进展\n292501 0 不理解限制5000块对互联金融有什么实质影响\n292502 0 手机微博图片加载不出来该怎么办\n292503 0 在贵池区农村地区盗窃猪仔37次\n292504 0 你国政策法律又把一批高素质女性的心逼走了\n1000 Processed\n classify content\n293000 0 有x×xx小时全天候的快速安全响应机制\n293001 0 对他们今后在制造机械飞机中所取得的成功是至关重要的\n293002 0 15的见面会也是要会员才能看的\n293003 0 哪怕是因为医疗技术的问题而发生意外\n293004 0 具有浓厚福州传统建筑、文化特色的典型里坊式历史文化街区\n1000 Processed\n classify content\n293500 0 有力打击了违法犯罪人员的嚣张气焰\n293501 0 或者在55、54、78、62、63、64区前排\n293502 0 终于知道花千骨是你的生死劫\n293503 0 吴江路店的伙伴好像不太开心哦给票据的时候直接扭头单手给我\n293504 0 在苏州市相城区共青团影院的放映厅中\n1000 Processed\n classify content\n294000 0 五个回合飞机飞…天气实在太热\n294001 0 你ya的還是別再踢球了去當流氓算了反正都一副德行\n294002 0 本人已经被害了那些人如果不判死刑将有更多的人被病毒杀死的死刑杀人偿命死死刑\n294003 0 华晨东亚汽车金融有限公司HR部门招intern要求:一周三天以上\n294004 0 在20亿财富门槛的胡润百富榜上\n1000 Processed\n classify content\n294500 1 尊贵的会员您好:为感谢您对动静界支持,公司在x月x日妇女节来临之际回馈广大会员,凡在x月x号...\n294501 1 尊敬的贵宾您好!城西(汇通国际汽贸城)首期房子即将淸盘,仅剩xx套,现如成功选房送装潢补贴、...\n294502 0 上海浦东警察抓了几个偷油贼连央视都拿出来炫耀\n294503 0 关闭借钱炒股的融资融券武汉科技大学金融证券研究所所长董登新教授来源:董登新的搜狐博客在本轮疯...\n294504 0 6、及时加固房屋需要加固的部位\n1000 Processed\n classify content\n295000 0 ChristianLouboutin拼色透明pvc平底鞋性感尖头加上透明拼接设计隐隐约约的流...\n295001 0 推一个google的镜像地址\n295002 0 南京脑科医院与南京市红十字会联合建立了“南京市红十字‘星星’博爱资金”\n295003 0 图腾纹身x要素:x、工整x、饱和x、尖角x、边缘线\n295004 0 TaeYang刚更新了Twitter:TAEYANGWELCOMESYOU原文戳:\n1000 Processed\n classify content\n295500 0 概述:此项目正在装修进行中\n295501 0 微软希望能够找出一些让人眼前一亮、并且更加学术范的HoloLens使用方式\n295502 1 广德德善小额贷款有限公司是隶属于安徽省供销社的国有公司,专门为各类型个体工商户、微小型企业提...\n295503 0 优利在xxxx微软全球合作伙伴大会上荣获年度EPGAzure创新伙伴奖\n295504 0 几万块钱治不好的子宫腺肌瘤\n1000 Processed\n classify content\n296000 0 返还现金xxxxxx元、摩托车xx部、电动车x部、助力车x部、手机xx部、笔记本电脑x台、手...\n296001 0 神武女儿国Teemo°牵魂神武好声音\n296002 1 你好,现新上市xx清纯清香茶,还有最新的泡茶功夫,预`订有好茶xxxxxxxxxxx多多 现...\n296003 1 ,让你感受身心愉悦的厨房生活。值此x.xx来临之际,厂家特价多多,优惠多多,期待你的光临!地...\n296004 0 一到夏天我都会打电话给我那些现在正在顶着烈日在工地上的哥们儿\n1000 Processed\n classify content\n296500 0 结果劳资到现在还在飞机上坐着\n296501 0 中国抗生素滥用触目惊心超5万吨被排放入水土环境\n296502 0 北陆药业、运盛医疗、万昌科技勇创新低\n296503 0 但又怕她hold不住妖神这个角色\n296504 0 该镇因毒品问题判死刑的52人\n1000 Processed\n classify content\n297000 0 这款玄关镜的镜框则为设计的亮点\n297001 0 退化性视网膜黄斑部区病变者7\n297002 0 家庭财务基本自由=省会城市一套150平的房+500W的现金\n297003 0 曾主讲于浙江蕺山书院、广东端溪书院\n297004 0 监考的时候还不能把手机放在荷包里\n1000 Processed\n classify content\n297500 0 AGxxx是当今世界上最大的一款在研的水陆两栖飞机\n297501 0 一个小偷的成功是时代的耻辱\n297502 0 今天一個人從Barcelona到Prague\n297503 0 Delaynomore兩點的飛機延誤到晚上十點還讓我們一直待在飛機上\n297504 0 ——左宗棠题江苏省无锡梅园\n1000 Processed\n classify content\n298000 0 基本擦完一层防晒再擦LM会搓泥\n298001 0 你还为你的二人小窝装修还犯愁吗\n298002 0 黄陂区人民法院对这一利用职务之便\n298003 0 其他深圳手机厂商也纷纷走出去拓展全球市场\n298004 0 顶个大太阳带着南娜防晒喷雾~\n1000 Processed\n classify content\n298500 0 为什么不愿意给我办理信用卡\n298501 0 恒大跟腾讯联手就是不一样啊\n298502 0 牟礼镇计生办于xxxx年x月xx日上午x点在镇政府一楼会议室召开了全镇各村妇女主任会议\n298503 0 16岁少女被逼卖淫遭老鸨殴打嫖客报警相救该不该被拘留\n298504 0 我都会在电脑关机前用电脑管家清除电脑使用痕迹?\n1000 Processed\n classify content\n299000 0 准备在承包的600多亩土地上种上紫甘蓝和西兰花\n299001 0 中国人寿推出了保单小助手“e宝”\n299002 0 但事实上腐败只是物联网专项资金问题的表象之一\n299003 0 多日前在南京等地铁结果腿卡到坐凳之间收获的淤青\n299004 0 为什么这么多股民想做中药材\n1000 Processed\n classify content\n299500 0 我分享了百度云里的文件:?TOPxxx低\n299501 0 果断下了个腾讯视频看中国好声音\n299502 0 现在这些中介性质的贷款公司所从事的业务与他们完全一样\n299503 1 感谢您致电去茶去瓯北店!预知更多优惠活动,请关注去茶去瓯北店官方微信:去茶去瓯北店(gote...\n299504 0 国际足联决定引进门线裁判技术\n1000 Processed\n classify content\n300000 0 宁德市气象台7月10日17时35分继续发布台风橙色预警信号:今年第9号台风”灿鸿”今天17时...\n300001 1 央行降息了!降息了!沃富金融公司专业提供x-xx倍实盘炒股资金,结算模式灵活。速来配资!\n300002 0 北京达飞安评管理顾问有限公司技术五部人员在吉林省吉林市检查长春输油气分公司长吉线附属站场吉林输油站\n300003 0 手机2号自动把SD卡所有应用卸载而且无法再安装\n300004 0 缴获赃车400余辆……2014年8月到2015年6月底\n1000 Processed\n classify content\n300500 0 请求法院支持原告的诉讼请求\n300501 0 医院诊断我患了急性淋巴性白血病\n300502 0 以后去高淳可沿慢城→游子山→固城湖→老\n300503 0 后半部分则在电脑特效中拼命造预算\n300504 0 新品眼罩EYEMASK到货\n1000 Processed\n classify content\n301000 0 手机快没电了飞机是坐不了了也只有坐火车了\n301001 1 春季是关节、颈腰椎病高发期.仙草活骨膏“元宵-三八”双节特惠活动已开始,买xx送x、买xx送...\n301002 0 电动车摩托车GPS卫星定位追踪防盗器\n301003 0 吃了2个烤肠14块钱周黑鸭还有2碗瓦罐汤\n301004 0 本来就廉价保护过度真相都进不来\n1000 Processed\n classify content\n301500 0 2005年被二中院以受贿罪判处死刑\n301501 0 离了QQ离了手机又不是会死\n301502 0 亚马逊公布了其2015财年第二季度财报\n301503 0 我们古草黑枸杞品质好到别的品牌都想要\n301504 0 三元区消防大队指战员xx人到院参加活动\n1000 Processed\n classify content\n302000 0 如今获京东43亿元巨额投资\n302001 0 寄信的人需戴上呼吸器下到三米深处投递防水明信片\n302002 0 佛山绿地中心二期销售中心夜景\n302003 0 江苏南通市如东县掘港镇政府以及江苏法院检察院腐败的风气越来越恶化\n302004 1 家长们:新年快乐!心想事成!本社定于x月x日开课,凭此短信过来报名送礼物一份,红包一封,名额...\n1000 Processed\n classify content\n302500 0 或许我还会坐在电脑面前静静得看看微博\n302501 0 地点:民主路与朐山路路口违法行为:驾驶机动车违反道路交通信号灯通行处罚:罚款200元\n302502 0 最近爱看一些犯罪啊推理啊一类的剧\n302503 0 祝贺我姐家的小孩考上南京航空航天大学\n302504 0 在电脑上贴照片……你忍心我不被翻牌吗\n1000 Processed\n classify content\n303000 0 街镇固定资产投资累计完成206\n303001 0 阿Q精神赤裸裸的展示给世界各国人民看\n303002 0 我正在使用百度输入法“金色打字机”特技皮肤\n303003 0 中航的个股将会重组所以目前暴涨非常明显\n303004 0 搭全新动力系统北京xxL测试谍照曝光\n1000 Processed\n classify content\n303500 0 致看着自己孩子在地铁上疯闹\n303501 1 冀新物资:我公司专营批发H型钢\n303502 0 虚拟的也能体验到CHERRY青轴的段落感\n303503 0 21D108day再去江都市给阿姨过生日~\n303504 0 其实问我要红包的这N多人你们有给我发过吗\n1000 Processed\n classify content\n304000 0 据亚马逊中国公布的最新数据\n304001 0 商业领域学历学位高的人其业绩常不如低的人\n304002 0 ——「14岁女孩遭脱衣欺凌事后突然把自己眉毛剃光」\n304003 0 就是对爱bula手机的手机没好感\n304004 0 7月20至27日我市粮油集市零售价格继续保持稳定\n1000 Processed\n classify content\n304500 0 同样可以见到设计师对阳光的采集方面的用心\n304501 0 伊丽蓓塔小黑裙具有SPF30/PA+++的防晒保护指数\n304502 0 就是我的业务代码xxxxxxxxxx此全部操作为免费\n304503 1 兄弟,新年好!现我度急招炒锅一名,工资电话聊,月休三天,每个月二十号准时出粮,地址:佛山市南...\n304504 1 你好姐,我是南洪街玖色启美化妆品店的,我们家x.x.x.x四天会有大型的买赠活动,店内也有活...\n1000 Processed\n classify content\n305000 0 你tm一个拦路抢劫的也赔了\n305001 0 医院真是最让人糟心的地方\n305002 0 光着上身从中山医院心脏中心跑出\n305003 0 M越说越寒酸我都要哭了…不过衣服裤子都是去年的款了包是几个月前买的\n305004 0 目前这款APP已经吸引了100余万用户注册\n1000 Processed\n classify content\n305500 0 HamiltonBeach67601A汉美驰大嘴巴榨汁机$49\n305501 0 与民事诉讼的方式要走什么程序\n305502 0 下面南通婚纱摄影米兰小编丁丁给大家分享一下最新的婚礼贺词\n305503 0 把爱玉上你的大纠纷贴私信出去\n305504 0 图为村民用手机拍下卫星发射后掉落残骸的照片\n1000 Processed\n classify content\n306000 0 万一真的像腾讯说的微软倒闭了怎么办\n306001 0 设有南京南、江宁西、马鞍山东、当涂东、芜湖、弋江、繁昌西、铜陵、池州和安庆10个车站\n306002 0 盐城形象宣传片与您再续前缘\n306003 1 康宁里小区,东大街尚勤路,百盛后,xx㎡。xx年独立产权,可按揭,现房,精装修,送家具,均价...\n306004 0 4、排基奥普斯陵墓顶端出发是不理人\n1000 Processed\n classify content\n306500 0 喷个香水虐死鼻炎要死的自己\n306501 0 唯一的一条路就是从此电梯上逆行上去\n306502 1 如意阁奢享美容会所感谢您的来电,我们以打造兰溪第一品级的会所,注重品质服务,为您提供全身心放...\n306503 0 嘉宾:中国汽车工业咨询发展公司首席分析师贾新光\n306504 0 美国内华达州近日向google发布第一张自动驾驶汽车牌照\n1000 Processed\n classify content\n307000 1 您好!我是平安易贷客户经理吴鹏。刚刚跟您通过电话。x月份我们事业贷上市,额度xx万左右,利息...\n307001 0 我是真的被po主一句杨洋也是这么过来的心酸到了\n307002 0 我们住的是高尔夫球场边上的复式跃层套房\n307003 0 电梯是弯的是弯的~这个啊~上海也有~妈蛋妈蛋妈蛋~\n307004 0 该院春节前后共向29名特困群众发放司法救助金25万余元\n1000 Processed\n classify content\n307500 0 负责公司的人员招聘及公司网络运营\n307501 1 潮膳阁海鲜火锅于x月xx日开工,并特推【全新】美味正宗潮州菜、养生炖汤、海鲜火锅,欢迎新老顾...\n307502 0 由自治区人民政府发展研究中心、中国高科技产业化研究会海洋分会、新疆财经大学和东西部经济研究院主办\n307503 0 昨天上午十点出席江苏宜兴紫砂壶在广州会展中心开幕式活动\n307504 0 100粒装538和200粒装958\n1000 Processed\n classify content\n308000 0 泰州华东绝缘材料厂、泰州市亚星塑业有限公司等我市62家企业成功入围\n308001 0 本来根本回不来所有飞机停飞准备找人顶活客户说会不惜代价把我搞回来然后我就真的被弄回来了………\n308002 0 张家港市自强社会服务社城南工作站和禁毒志愿者在惠丰社区开展了青少\n308003 0 券商股回本后再不做这个板块了\n308004 0 少林寺商业化本事就违背了佛教的宗旨\n1000 Processed\n classify content\n308500 0 阿克苏市法院党组书记张庆民正在为红桥街道热斯特社区老党员、老干部送去慰问品\n308501 0 有可能会成为Win10SR1更新的版本号\n308502 0 赴澥浦镇汇源小区为80余名孩子\n308503 0 附件:招标文件专用条款、电子评标招标文件、电子图纸\n308504 0 洪城大市场工商局青云分局开展了电暖器市场专项整治行动\n1000 Processed\n classify content\n309000 0 亚马逊Web服务现在提供Aurora极光数据库服务\n309001 0 宝宝奶粉喂养大便老是带粘脓稠状去医院检查大便没有问题医生开了头孢和妈咪爱\n309002 0 单春秋是花千骨里最烦的人啊\n309003 0 我们已于2015年2月向鹿晗在中国开展的非法演艺活动\n309004 0 创造了新的NBA季后赛单场失误纪录\n1000 Processed\n classify content\n309500 0 ThisSummer\\'sGonnaHurtLike欧美流行指南\n309501 0 浙江卫视没放喜羊羊与灰太狼\n309502 0 而且还介绍给了做护士的朋友\n309503 0 HUAHUA馆台湾设计师手作天然烟灰玛瑙珍珠925纯银针耳钉耳环\n309504 1 亲,世贸屈臣氏自然堂现在买xxx减xx再x.x折,x月x日自然堂会员还有双倍积分,超划算哦\n1000 Processed\n classify content\n310000 0 可以你已經是我生命中的過客了\n310001 0 平心而论江宁公安和博物杂志两个账号都是挺好的\n310002 0 S姐妹的妈妈则把小S和范玮琪搂在一起\n310003 0 创建国家生态县建设美丽新沛县\n310004 0 江苏省连云港市残联党组书记、理事长侍启顺\n1000 Processed\n classify content\n310500 0 南京武警医院肛肠科主任郭喜法说\n310501 1 姐姐你好,我店为了回馈老顾客三八节当天所有护肤美体产品全部五折,期待您的光临,柳新信用社西门...\n310502 1 正式开业。奥特莱斯名品城商铺xx-xx㎡,面积小总价低。月供两千多元,月收租三千多,月租可抵...\n310503 0 而刘某为证明“清白”竟然带领民警去租住点找室友作证\n310504 0 xxxx年x月xx日呼和浩特市第一医院整形美容科注射会诊\n1000 Processed\n classify content\n311000 0 以及著名的风险投资人——纪源资本总裁符绩勋和经纬中国基金管理合伙人徐传陞\n311001 0 2015年镇江市考试录用公务员拟录用人员递补名单公示\n311002 0 警察没听懂把xxx以防碍公务拘留了\n311003 0 那么华为Mate8会有哪些改进\n311004 0 意思就是你剩下的359°全是死角\n1000 Processed\n classify content\n311500 0 Adrian于7日晚间在香港出席活动\n311501 0 医生姐姐要验我的嗯嗯…………\n311502 0 很多人不理解溧阳人为什么习惯吃泡饭\n311503 0 而内部设计师EndramuktiHidayat则巧妙注入巴厘岛的趣味\n311504 0 满足了不同家居装修的需要\n1000 Processed\n classify content\n312000 0 指出到2020年上海市跨境电商发展水平要居全国前列\n312001 0 嘉定区某便利店被5名外来人员持刀抢劫8千多元\n312002 0 真相和答案只有一个:膨膨冰\n312003 0 今天是常州一个月以来难得的天气了\n312004 0 并与AC米兰俱乐部CEO加利亚尼就双方品牌合作等方面的事宜进行了深入交流\n1000 Processed\n classify content\n312500 0 捐献给浙江省博物馆五千多幅\n312501 1 x元各款色针织开衫,xxx元、xxx元哥弟裤,还有更多小惊喜,送母亲送闺蜜??,欢迎前来体验...\n312502 0 却出乎意料的采用了Q版的卡通画面设计\n312503 0 娜塔莉·波特曼的演技真的很棒~V的声音也很好听\n312504 0 距离xxxx年研究生考试只剩xxx天\n1000 Processed\n classify content\n313000 0 Don'twasteyourtimewithexplanations:peopleonlyh...\n313001 0 十个人就只有三个人手机有信号…打电话报警\n313002 0 贵美人整形美容医院始终以安全塑美为己任\n313003 1 为庆祝中国人寿荣升副部级央企,特推出保值增值、高额保障、全程分红的鸿盈两全保险,交费x次,x...\n313004 0 去xxx躺下一分钟医生告诉我没找到\n1000 Processed\n classify content\n313500 0 叙利亚火箭弹被改造成旋转木马\n313501 0 面料棉麻透气轻薄上身效果很大牌搭配靴子欧美街拍感\n313502 0 场外证券业务黑名单制度将建\n313503 0 全年营收可能从去年xxx亿元人民币增长到xxx亿元人民币\n313504 0 来试试CoolFatBurner燃脂背心\n1000 Processed\n classify content\n314000 1 为庆祝三八妇女节,x月x至x月x沙河天虹玉兰油专柜推出全场x折优惠,另折后xxx再减xxx,...\n314001 0 顾客将自拍照片通过手机传送至打印机\n314002 0 以下所有股票均不做为您买卖依据\n314003 1 三八节就是这么任性、三月七日进店白送xx元睫毛膏一支、三月八日还白送xxx元bb霜一支、但你...\n314004 0 BESCONNewGen38透明隐形眼镜BESCONNewGen38透明片如同肌肤的舒适感\n1000 Processed\n classify content\n314500 0 空之轨迹FCEVO直播开始咯地址在\n314501 0 现在每天睡觉做梦都是花千骨的剧情\n314502 0 南长检察院“向日葵之家”组织全市60余名中小学生\n314503 0 看着手机都能感觉的家那边的小凉风\n314504 0 想起家里楼房那把xx楼叫xxB\n1000 Processed\n classify content\n315000 0 公安局打电话做社会治安满意度调查\n315001 0 西藏不是你刷逼格的工具和满足征服欲的对象\n315002 0 政府投资项目也就堂而皇之越来越多\n315003 0 学者林喆犀利言反腐质朴待世界\n315004 0 张碧晨是不是好声音最火的\n1000 Processed\n classify content\n315500 0 为中小投资者提供最靠谱的贷款方式\n315501 0 YouTube作者是Google\n315502 0 公共场合接吻是一种违法行为\n315503 0 赵永飞先后荣立二等功1次、三等功4次\n315504 0 吉林省食品药品监督管理局在其官方网站的黑榜中公布了三批次不合格食品\n1000 Processed\n classify content\n316000 0 枣庄中院召开全市法院人民陪审工作经验交流会\n316001 0 由卫星在天空编织的定位网络\n316002 0 卖点:MACD死叉且股价跌破30周期线\n316003 0 手机摔了两次屏幕朝下……这手机必须三防否则跟着我这个破坏王不知道能用多久……\n316004 1 jE \u0003mfeeox.com/?f=xxx\u0001\u0003xxxxxxxxxxx您好!苹果xS手机只要x...\n1000 Processed\n classify content\n316500 0 微软:Windows10开放更新首日装机量超1400万\n316501 0 江阴检验检疫局在一批美国进境大豆中截获检疫性病害大豆北方茎溃疡病菌\n316502 0 华为eSpaceUxxxx\n316503 1 尊敬的客户,我行x月x日--x月xx推出多款理财产品:期限:xx天--xxx天,利率:x.x...\n316504 0 回家的时候好不容易如赶集般人贴着人挤上了车我背后一位大叔紧贴着我随着汽车的晃动不一会我感到了...\n1000 Processed\n classify content\n317000 1 亲爱的,维纳贝拉三八节,一年就一次的大型直接减钱开始了,到x号结束了,祥询到藏卫路维纳贝拉内...\n317001 0 正如那淮安市公安局做信访工作的警察\n317002 0 有人说股票投资是一个性格的改造过程\n317003 0 我就不说2个路痴问路结果从地铁A出口进B出口出来以后发现2个出口就几十米距离\n317004 0 忍了辣么多天刘醒他们今晚一定大打飞机以壮君威妙啊\n1000 Processed\n classify content\n317500 0 竟被小偷给大摇大摆的顺走了\n317501 0 下午去医院挂个急诊做个喉镜\n317502 0 本门从秦岭烈火玄武帮夺得弹指神通残章三\n317503 0 她的舌头从10个月起就总是这样\n317504 0 构筑了产品与众不同的核心玩法设计\n1000 Processed\n classify content\n318000 0 xxxx上半年已缩减为+xx%\n318001 0 投资建设无锡海岸城的深圳海岸集团\n318002 1 地标!x条地铁线环绕,市中心稀缺生态商务公园!目前在售面积为稀缺精致产品正式对外发售,欢迎您...\n318003 0 每次在公交、地铁上给年纪大的人让座\n318004 0 甚至有的14、15岁的中学生也会失眠\n1000 Processed\n classify content\n318500 0 在乘坐电梯时一定要遵守电梯安全注意事项\n318501 0 不过蹲欧美圈和饭日圈的人真是风格大相径庭\n318502 0 Naturie薏仁水化妆水没什么味道\n318503 0 张召忠将军说“零下700度以上的物体都能被观测到\n318504 0 真的是一点儿理财概念都没有\n1000 Processed\n classify content\n319000 0 com王淑敏建行江西分行帐号6217002080001336407王淑敏\n319001 0 光是measure和definition相关的经典文献就搜了19篇\n319002 0 x月xx日发布以来想必很多用户都加入到这场系统升级的盛宴中\n319003 0 借贷宝投入20亿巨资强势打造P2P理财平台\n319004 0 一胖就胖脸和肚子到底能不能行啊\n1000 Processed\n classify content\n319500 0 太仓武港码头有限公司志愿者服务队来到了太仓市图书馆\n319501 0 面对他们的质疑说快本是一群疯子\n319502 0 人的重心不会像飞机一样突降\n319503 1 尊敬的馨意女贵宾:为庆祝xx妇女节!特推出只需要xx元立刻可以体验价值xxx元的面部玉石排毒...\n319504 0 机尾后部的V型结构有利于水面航行稳定性\n1000 Processed\n classify content\n320000 0 我已经做好了迎接南京热浪的准备了\n320001 0 让张家界\"后花园\"之称神奇美景由幕后走至前台\n320002 0 说好的阿里都不知道何时才能成行\n320003 0 淮安市供电公司员工冒着酷暑\n320004 0 因此将哈弗H8的上市时间推迟三个月\n1000 Processed\n classify content\n320500 0 调查对象将涉及丹霞山5A级旅游景区的食住行游购娱等\n320501 0 给大家分享“zhi子hua开”\n320502 0 二十五岁本命年后遗症通通过去\n320503 0 发送成功后一般会在48小时内给您答复这样的邮件\n320504 0 厂长S5的奖杯在等你把它捧回中国\n1000 Processed\n classify content\n321000 0 燕麦黑麦潜艇包昨晚x点多才搓\n321001 0 苹果正在招募汽车行业技术和设计工作者\n321002 0 手机上网40分钟网费达1000元\n321003 0 全地区两级法院共上报失信名单531件\n321004 0 已完成3200株古冬枣树树冠树杆更新及嫁接\n1000 Processed\n classify content\n321500 0 济川路转泰州大道泰州大道通G2\n321501 1 韩国美佳祝您在新的一年里身体健康,更加年轻,漂亮!x.x节优惠活动已经开始啦!详询xxxxx...\n321502 1 x月xx日方太旗舰店盛装开业,凭xx元增值卡最高抵现xxxx元。订单有礼还要领现金红包。砸金...\n321503 0 港英殖民政府首设民政局的前身民政司时\n321504 1 x减xx。 x、硬金、千足金镶嵌类每满xxx减xx块。 x、钻石特价再x折,正价x.x折。 ...\n1000 Processed\n classify content\n322000 0 同样也是一场真实的抗癌经历\n322001 1 您好我是教练员付先莉,优惠x号截止,望予学者从速,小车xxxx元大车xxxx元,报名一定找俺...\n322002 0 创造出一个适用于手机用户的游戏产品\n322003 0 看到终身疾病不可治愈时心情极度低落\n322004 0 手机SIM卡无效的办法↓↓↓\n1000 Processed\n classify content\n322500 0 还有大概5周的时间就要迎接新生命啦\n322501 0 最终带领球队在主场以100:86战胜波特兰开拓者\n322502 0 好声音不是回锅肉就是关系户\n322503 0 也期待我们同事和关心惠普的朋友能和惠普一样\n322504 0 槽这三原则不就是机器人三原则吗\n1000 Processed\n classify content\n323000 0 在桥长约x/x处为V字形最低端\n323001 0 1988年商城县政府将此列为县级文物保护单位\n323002 0 温州的习俗四个月四天要穿金戴银哈哈贪财宝宝睡觉都笑起来\n323003 1 好消息!您成为建行的优质客户\n323004 0 由浙江工业大学药学院的同学们组成的“旧药在一起”暑期社会实践小分队\n1000 Processed\n classify content\n323500 0 常州公安消防指挥中心接到5起关于溺水的报警求助\n323501 0 再等一段开发商办房产证时该面签了\n323502 1 您好!!公元九里一层一户==楼王四面观景,水系环绕,x/x,面积xxx平低于市场价xxx万,...\n323503 0 ”2015火力全开的魏晨终于要现场玩转帽子戏法\n323504 0 这个产品医用名叫左旋聚乳酸软组织填充材料\n1000 Processed\n classify content\n324000 0 给你做了加油的动作你却以为是再见对我挥挥手\n324001 0 推荐雪球|你适合做『分级基金』套利吗\n324002 0 每天往返房山区的835快车\n324003 0 但是现在我要重新下载百度音乐了\n324004 0 每次的出行朋友出差飞机酒店都是在WV后台比外面方便实惠多了\n1000 Processed\n classify content\n324500 0 坐出租车的时候我一下没反应过来往内地副驾驶走去了\n324501 0 2015年第三届财富新经济全球论坛“一带一路”澳洲峰会\n324502 0 什么时候才能等到花千骨变妖神啊\n324503 0 『南京官员自称我是处长我有钱』\n324504 0 innisfree绿茶/火山泥/橄榄洗面奶\n1000 Processed\n classify content\n325000 0 引进了与xS店同步升级的原厂检测设备\n325001 0 咨询电话:15090322533\n325002 0 看Victor谢志浩老师的~\n325003 0 erm?chteeinDeutschlehrerwerden\n325004 0 xxxx上半年泰州商品房成交xxxx套\n1000 Processed\n classify content\n325500 0 机智的百度怎样撕不疼??结果大家都说没办法\n325501 0 刚才有人拿图黑荣耀7和麒麟935\n325502 0 成近50年来同期登陆浙江的最强台风\n325503 0 昆山文化艺术中心影视中心及市民文化广场影院经营管理单位征选公告\n325504 0 忘了你谈何容易手机只要响了就以为是你\n1000 Processed\n classify content\n326000 1 网址xxxxxx\n326001 0 王芳说她和机场的刘昊还是她和警察的陶宽杀人偿命死刑\n326002 0 曾经还在政府强压下被迫的被邪教人员的在大庭广众之下骂了\n326003 0 依旧以贩卖人口和强奸未成年少女定罪了\n326004 0 虽然利佛摩尔在xxxx年做空股市一战成名\n1000 Processed\n classify content\n326500 0 车牌号为晋B****实施超速违法行为\n326501 0 xx岁男子李某杰与xx岁女子王某灵此前在网上聊天发生争吵\n326502 0 十年后发表在JCO上的近10年研究再次证实了这一益处\n326503 0 原来中队30岁的执法队员叶徐挺之前一个猛子扎进水里\n326504 0 这是徐州工程学院理工科教师朱捷为大四学生上演的脱口秀\n1000 Processed\n classify content\n327000 0 垃圾车车牌号码是苏D17921\n327001 0 月食投奔快船之后火箭的阵容反而看的更清楚一些了\n327002 1 德信泊林公馆感谢您的来电,海盐首席德国品质住区即将到来,敬请期待!地址:枣园路与城东路交叉口...\n327003 0 当我开始质疑一件事情的时候\n327004 0 在铜陵路城管中队的共同努力下\n1000 Processed\n classify content\n327500 0 由设计师KazumiAbe设计的Forest台灯\n327501 0 并对流动商贩及乱停车现象进行劝导疏通\n327502 0 我人她妈在浙江你给我推送兰州的本地消息\n327503 0 我刚刚在天猫试用中心免费申请了福维克VR200扫地机器人\n327504 0 5、北京首都旅游集团有限责任公司\n1000 Processed\n classify content\n328000 1 无 抵 押 信 用 贷 款 ,手续简单,不收手续费,急用钱请联系卢小姐xxxx...\n328001 0 五相声杨阳大岚子学四省\n328002 0 Gregory格里高利Trailblazer时尚双肩背包$xx\n328003 0 而向记者爆料的业内人士指出\n328004 0 北京的地铁管理方存在明显问题\n1000 Processed\n classify content\n328500 0 好想去苏州乐园热也想去\n328501 0 只听到一句歌词“beautifuloneforme”\n328502 0 吸引投资主要领域为旅游、工业、服务业和农业\n328503 0 城管打人闹事横蛮无理引起民愤\n328504 0 有一段时间听到飞机声就怕…\n1000 Processed\n classify content\n329000 0 吴江区公安局松陵派出所组织辖区儿童及家长50余人走进特勤大队、公民警校和松陵所警民共建长廊\n329001 0 今天好声音那个女的吓死我了\n329002 0 免费的巴士服务将从星期日第一班车开始\n329003 0 K联赛目前最强的全北现代一年的运营费用才300亿韩元\n329004 0 区政府门前一群绿色的身影依然在忙碌\n1000 Processed\n classify content\n329500 0 如何通过Skypeforbusiness、Cortana等应用和功能\n329501 0 修建数条索道或电梯直达山顶\n329502 0 拥有超过95%的一线奢侈品牌南京德基广场\n329503 0 中山市第二人民法院经审理认为\n329504 0 我一般只涂30倍的隔离不再涂防晒\n1000 Processed\n classify content\n330000 1 晚辅班、外考班、竞赛班x月x日开始上课了,欢迎以老带新先试听满意再报名!祝贺xx位参考学员全...\n330001 0 但這次搭郵輪從Victoria到Vancouver\n330002 0 嘉兴六里和苏州平江街的风景\n330003 0 昨天被警察按今天找警察帮忙前天追警车跑这几天和警察都好有缘分啊还有在美国锻炼的遇到事儿都特淡定\n330004 1 景安幼儿园春季招生报名开始啦!欢迎小朋友们来园体验!正月十九正式开学!咨询电话:xxxxxx...\n1000 Processed\n classify content\n330500 0 一趟趟跑往北京的医院跑火车上站三个多小时坐地铁走路折腾一天\n330501 0 玩注册表差点把电脑玩奔溃了还好修好了不然我就可以提前换电脑了\n330502 0 买中国人寿是看到昨天有大量资金在高位被套了\n330503 0 一小伙用2000元其中的1500元给MM买了部手机\n330504 0 2011“萧山普乐迪街舞大赛特邀表演嘉宾\n1000 Processed\n classify content\n331000 0 张家口张家界张家港…傻傻分不清楚\n331001 0 我正在听泠鸢yousa的歌曲月光润色女孩\n331002 0 恐老族:害怕肌肤松弛、细纹找上门\n331003 0 x、报名截止时间:xxxx年x月xx日\n331004 0 美丽的showgirl无疑是一道最靓丽的风景线\n1000 Processed\n classify content\n331500 0 看王祖蓝演绎完美地板\n331501 0 一杯不太苦的咖啡一部不太新的手机一支不太好听的歌一个不太傻的你\n331502 0 飞机瞄着光线就从脸上呼啸飞过\n331503 0 睡在飞机上就感觉睡在一个封闭的抽风桶\n331504 0 松下电器panasoNic\n1000 Processed\n classify content\n332000 0 IBM苏总监对近年来重要项目的梳理是在鼓励去“做大事”\n332001 0 以约xx亿美元的价格收购白山保险旗下的再保险公司\n332002 0 佳铁法院“法律进企业、进学校”活动将到第二站——佳木斯铁路工务段\n332003 0 涉嫌违纪的党员能够配合调查工作\n332004 0 有没有知道镇江哪里有维修冰箱的\n1000 Processed\n classify content\n332500 0 韩文版??????送12色彩铅\n332501 0 补办时去派出所开具丢失证明\n332502 1 巴黎欧莱雅:东大日化“东风店”(东风桥北京华联旁边),x月x日-x月xx日购欧莱雅护肤产品任...\n332503 1 爱特装饰·诚邀·杨光清·业主参加爱特年初整装聚惠。 活动:x月x日-x日 地点:江北区大浪淘...\n332504 0 细窄的前大灯和重新设计的尾灯组\n1000 Processed\n classify content\n333000 0 从徐宿淮盐铁路盐城段建设指挥部成员会议上获悉\n333001 0 御泥坊薰衣草矿物蚕丝面膜14片补水保湿舒缓修护护肤品面膜贴\n333002 0 重关系轻民意3儒家占领意识领域\n333003 0 医院网络营销在医疗行业的网络营销中应该是目前的一个\n333004 0 至少20秒~一个车道都被拦住了\n1000 Processed\n classify content\n333500 0 巨贪、巨巨贪就像刘疯子那样的都没毙掉\n333501 0 让手机里的资料和图片全部格式化\n333502 0 公司服务除了传统的物业买卖中介服务\n333503 0 构建新型“互联网+社区服务”生态圈\n333504 0 湘桥法院审结了一宗机动车交通事故责任纠纷案件\n1000 Processed\n classify content\n334000 0 youtube上的华为广告4min多好牛的样子\n334001 1 抢红包啦!x月x日,和大腕一起过节! 铭品装饰携手淘宝网、科勒中国震撼来袭! x月x日,杭州...\n334002 0 2015/8/6第1天:1\n334003 0 和中国大妈生产的尼龙防晒大外套说goodbye把~~戴上以后立马降温3/5度\n334004 0 对“强奸致人重伤、死亡”的理解和适用\n1000 Processed\n classify content\n334500 0 我一直以为花千骨的多人本是和别的玩家同步进行的\n334501 0 黑色图电脑绣花技术绝对舒服聚拢透气\n334502 0 有没有上古卷轴x天际的汉化下载链接\n334503 0 提醒暑期外出旅游的童鞋们需注意旅程安全\n334504 0 电脑坏掉了手机死机电视没信号这是在考验我吗\n1000 Processed\n classify content\n335000 0 商业性住房贷款不可以转组合贷款\n335001 0 中国好声音成功的把南山南这首歌毁了\n335002 0 墙裂要求地铁不要投放明星广告了\n335003 0 能不能放大能不能放大~我揍似看不清咋地喽~人家平板就很好嘛\n335004 0 秦家桥农村信用社向西五十米\n1000 Processed\n classify content\n335500 0 大家朋友们程电梯的时候一定小心在小心吧\n335501 1 我社完善创新了存款类、银行卡、贷款类、电子银行等各类金融产品。网上、短信、手机银行全面开通,...\n335502 0 老百姓没有了地住在楼上还不够交水电暖费用的\n335503 0 你会一直受到周遭的质疑和打击\n335504 0 没有摩尔庄园3大电影百度云网盘高清资源链接的\n1000 Processed\n classify content\n336000 0 结果百度了千万遍什么鬼都没有\n336001 0 九大券商:下周可能向上变盘重返xxxx点之上信达证券:沪指可能围绕xxxx点反复震荡 x月...\n336002 0 FrontenacCountyCourtHouse金斯顿的地方法院\n336003 0 2、2015年3月26日市政府下达该局“三定方案”后\n336004 0 以至于护盘买进超过5%的伊利A股\n1000 Processed\n classify content\n336500 0 就使用我的邀请码366vff下载并登录浙江移动手机营业厅\n336501 0 和最近HeroicHollywood爆料的内容一毛一样\n336502 0 JoJo拍的不管是品牌图还是杂志图主页君都争取能找到\n336503 0 我现在有点讨厌无锡这个地方\n336504 0 好感动/大哭/大哭/大哭/大哭/大哭我活了二十几年\n1000 Processed\n classify content\n337000 0 刚刚那条是那个noface的yyy自己跑来抢我手机发的\n337001 0 抽血的医生工作态度有点不认真\n337002 0 前夫每月支付抚养费600元直至小孩年满18周岁止\n337003 0 不与时间赛跑/飞机/飞机/飞机\n337004 1 亲爱的会员顾客, 您的节日快到了祝您节日快乐!节日期间欧家将有全年最大力度宠爱回馈 ,全场...\n1000 Processed\n classify content\n337500 0 我对一个人的偏见从他生到死都会有\n337501 0 快船2年640万续约主帅之子季后赛曾打爆火箭\n337502 0 减肥茶+减肥贴+运动+少吃\n337503 0 计算机系统是否符合GSP要求覆盖全程质管控制\n337504 0 想卖什么货每天下定单我去跑腿\n1000 Processed\n classify content\n338000 0 好声音是不是你们的消暑圣品呢~~盲选接近尾声\n338001 0 云南省罗平县九龙镇得等村委会大以百村\n338002 0 为各类妇科炎症细胞等致病微生物提供繁衍、生存、“闹”痒的条件\n338003 0 停在7号楼地下车库的奥迪被人为损坏\n338004 0 亚马逊称正在测试一款叫“dashbutton”的硬件\n1000 Processed\n classify content\n338500 0 不排除政府再次实行限价的可能\n338501 0 苏州多家品牌房企包括中海、保利等却陷入了“地荒”\n338502 0 wnba和nba还有区别吗\n338503 0 1907年其于弗洛伊德合作发展及推广精神分析学说长达6年之久\n338504 0 如何管控企业域名的法律风险\n1000 Processed\n classify content\n339000 0 我妈doge脸看着我说你别装了还是在书房看完小说再睡吧\n339001 0 当电梯升到三楼我才意识到周围黑漆漆一片\n339002 0 哈尔滨最好的皮肤病医院专家提醒:老年人有\n339003 0 市检察院检察长王金庆出席座谈会\n339004 0 橘色蝙蝠袖蕾丝宽松T恤+白色紧身裤+白色单鞋\n1000 Processed\n classify content\n339500 0 出口到欧美的产品不再仅仅是廉价产品\n339501 0 Hirudold祛疤膏泰国各大医院指定的祛疤药膏\n339502 0 用最常见、最基本的建筑材料和传统的搭建方式\n339503 0 细胞生态护眼水是取自四川阿坝9610年的达古冰川水\n339504 0 澳洲GoatSoap纯天然羊奶皂\n1000 Processed\n classify content\n340000 0 折騰了一早上也弄不到官方的推送還是用騰訊升級Windows10算了\n340001 0 解决保险消费者“理赔难”、“理赔慢”等问题\n340002 0 xxxx年x月x日讯:国民政府申令禁止以机关长官私人名义对下级机关滥荐人员\n340003 0 马广平被无锡市文明办、无锡市志愿者总会授予xxxx年度“无锡市百名最美志愿者”称号\n340004 0 防腐剂总是能与\"不天然\"/\"有害\"/\"黑心商家\"之类的负面词汇联系到一起\n1000 Processed\n classify content\n340500 0 可以起飞了丹阳人民都这么任性\n340501 1 xxxxxxxxxxxxxxxxxxx周红云农行\n340502 0 我刚刚把手机壁纸换成了这个:Goldensilkorbweaverspider\n340503 0 处死刑、无期徒刑或者十年以上有期徒刑\n340504 0 防范抢劫有高招进门之前回头望\n1000 Processed\n classify content\n341000 0 与独特的不规则下摆设计一起诠释属于你的潮流腔调\n341001 1 尊敬的会员您好,您在长江UXx男装生活馆消费积分购物时可抵现金xx元,在x月x日—x月xx日...\n341002 0 大油田每晚一次干燥肌肤一周一次\n341003 0 我这南京的表弟却要去他们太原了\n341004 0 哎才注意到这个手机发微博只能发小图\n1000 Processed\n classify content\n341500 1 爱女人.爱自己,男士送给女人的礼物,女人送给自己的关爱!尊敬的美容顾客,三八节快乐!x月x号...\n341501 0 但是怎么就在我刚出地铁下呢\n341502 0 打包35家媒体另外送15家媒体合计50个网站仅需2000元\n341503 0 那剎那间飞机轮子着路时才知道\n341504 0 男子疑性侵13岁幼女检察院称双方自愿\n1000 Processed\n classify content\n342000 0 可以发现这里有一种安静恬然的气韵\n342001 0 核实1955年12月31日前出生的60岁以上独生子女奖扶的人员\n342002 0 3214507110超薄棉麻衬衣可当防晒衣均码两色入料子不错\n342003 0 每天回到家对着手机和四面墙\n342004 0 国电南自AGC/AVC控制系统成功应用效益明显:近日\n1000 Processed\n classify content\n342500 0 邬经理和技术飞远在杭州指导协作\n342501 0 亿利达逾xxxx万收购两公司控股权\n342502 0 第十五届中国青少年机器人竞赛在内蒙古鄂尔多斯市举办\n342503 0 三流杂碎明星太多没事干找杨狗的百度百科发现还没有“屎”的百度百科长滚出北京吧好吗狗儿子\n342504 0 这些实际上是新加坡艺术家KengLye名为“活着但无呼吸”系列的超现实主义3D树脂画\n1000 Processed\n classify content\n343000 0 水星与地球的卫星——月球之间\n343001 0 昨晚6点打车去看电影竟然是宝马\n343002 0 扬州东方娃玩具有限公司:热销之中\n343003 0 6月份当月实现社会消费品零售总额148528万元\n343004 0 中国好声音真的不是一般恶心\n1000 Processed\n classify content\n343500 0 2015棲霞寺佛學夏令營Day2——彭醫生養生常識及靈進法師梵呗教唱\n343501 0 安养市将在现有市政府办公楼的地皮上新建一座100层的\n343502 0 本人脑部右边肿块必死了报警了杀人偿命死死刑判刑\n343503 0 就旅游O2O、市场营销、景区门票等方面展开合作\n343504 0 叮嘱自己的几句话:1、不要侥幸、报复、抬杠、听消息性交易\n1000 Processed\n classify content\n344000 0 它包括子宫、卵巢和整个女性生殖系统及相关功能\n344001 0 用开讯视频看花千骨怎么每集只有15分钟呢\n344002 0 氢氧重要作用氧气是需氧生物维持生命不可缺少的物质\n344003 0 听歌剧~搞学术的更是可随时参加学校每天的各种论坛讲座\n344004 0 从原来的360收藏夹导入edge要怎么破\n1000 Processed\n classify content\n344500 0 我要走了我要出去避避风头公安局在调查全国帅哥有点帅的判五年非常帅的判十年超级帅的判二十年像我...\n344501 0 你只是路过吗/我自编的谎言很美\n344502 0 “灿鸿”强度升到17级浙江发超强台风紧急警报\n344503 0 OPPORxPlus就敢帮你把声音传遍整个世界\n344504 0 或者依法向人民法院提起诉讼\n1000 Processed\n classify content\n345000 0 天花板上的环形LED屏可以让观众席上的人更好地观看比赛\n345001 0 一口气把QTFx的x话都看了wwwwwwww实在太好笑了\n345002 0 然而真相应该只是他不舒服了想擦汗了而已2333\n345003 0 免费分享浙江台州13份分享7*7小黑方\n345004 0 我还以为是苹果新出的电脑呢\n1000 Processed\n classify content\n345500 0 感情这是坐地铁来回玩儿呢是么…SB\n345501 0 2、它有招财的神秘力:金黄色的蜜蜡可以招来财富\n345502 0 到15年7月正阳已有多家商铺营业\n345503 0 中南财经政法大学金融学院保险专业2010级学生吴新宇成了校园里的创业偶像\n345504 0 认证信息为“苏州三铭企业管理有限公司人事专员”\n1000 Processed\n classify content\n346000 1 美上美将于x月xx日-x月xx日举行《爱美又实惠》,物价再回xx年平价大革命活动,将产品平价...\n346001 0 4岁前是孩子形象视觉发展的关键期\n346002 0 有写着可以直邮的就是可以直邮的吧直邮邮费贵吗\n346003 0 但是大微软质疑的要把这个界面做成类移动平台的样子\n346004 0 热烈祝贺立知教育xxxx护士资格考试基础协议保过班通关率xxx%\n1000 Processed\n classify content\n346500 0 75岁的浙江衢州市农村老汉王某某用一根刹车线勒死了与他有几十年“地下情”的刘某某\n346501 0 你看那两个电梯旁边两个打扮漂亮的服务员\n346502 0 今天跟苏州工厂正式签约与我的摄影作品合作正式投产中国风的屏风\n346503 0 必将成为互联网金融平台展开厮杀的一大战场\n346504 0 最喜欢听扬州朋友饭桌上讲小时候的故事\n1000 Processed\n classify content\n347000 1 富可思教育想学生之所想、急家长之所急,特在本学期开学的一周周末x月x日既全面开设小升初各科辅...\n347001 0 疑问:两年时间由70多家发展到2百五六十多家\n347002 0 汾矿集团子弟、待业青年、技校未分配学生和退伍军人优先录用\n347003 0 国际泌乳顾问的考试过去好几天\n347004 0 有时也表现执行死刑时神父为死刑犯的祷词\n1000 Processed\n classify content\n347500 0 当年我有个特别喜欢花千骨啊三生三世啊这几本小说的朋友\n347501 0 亚马逊进口原版kindle电子书:\n347502 0 从文字记载的甲骨文时代就已有之\n347503 0 20150801速报:标韩上册的单词全背完啦\n347504 0 溧阳南山竹海原生态的韵味\n1000 Processed\n classify content\n348000 0 社保基金在上述65家公司中\n348001 0 刚才看到有个歌词是youmakemehappywhenskiesaregray\n348002 1 高价回收名烟名酒、冬虫夏草、各超市购物卡、电话:xxxxxxxxxxx\n348003 1 你好,我是民生解放路店蓝豹专柜。x月x到x月x号,本店新品到店参加商场xxxx当xxxx活动...\n348004 0 10常州D149:来\n1000 Processed\n classify content\n348500 0 ——「中国每天2亿人乘电梯安全事故频发暴露维保缺失」\n348501 0 明知道别人股票深套还要在人家伤口撒盐\n348502 0 股票啊~赶紧回本吧~上帝啊~可怜可怜我吧~\n348503 0 所有想合伙搞我阿里的都是乌合之众\n348504 0 一、本期业绩预告情况茂业物流股份有\n1000 Processed\n classify content\n349000 0 但是并未被归到智能手机或者是平板的范围\n349001 0 那你一定没去看过常州的静园~\n349002 0 这正是azure机器学习最擅长的领域\n349003 0 这样的股市已经没有投资价值了\n349004 0 果然OS系统需要靠微软来补完\n1000 Processed\n classify content\n349500 0 ”我笑曰:“我去做南京一日游的導游小姐怎樣\n349501 0 药管局则负责转基因食品和饲料的安全性评估\n349502 0 13年622买的笔记本电脑\n349503 0 人民日报政文驳“贪官都有情人”:半数涉通奸\n349504 0 跟爸妈出去外面吃吃吃~~吃饱还有沙发躺\n1000 Processed\n classify content\n350000 0 于是A市分局决定将李某的监视居住工作转交给了李某户籍所在地的B市公安局\n350001 0 中国好声音黄恺求婚我都感动哭了\n350002 0 宁夏旅游+欢迎您访问青铜峡\n350003 0 他们那三甲医院又发生了一例困难气道导致的严重不良事件\n350004 1 【通知】:郫县一流品质物业【华侨凤凰国际城】实得xxxx/平起,xx平舒居三房火爆,周末抽奖...\n1000 Processed\n classify content\n350500 0 赶快下载大众点评/美团/百度糯米APP搜索小辣椒吧\n350501 0 很多人都会谈到中医学的古籍之多\n350502 0 需要城管的时候城管都去哪里了\n350503 0 机械加工木工电器安装就成为一名专业的调教室设计师~~~\n350504 0 市中级人民法院在文成人民法院开庭审理这起案件\n1000 Processed\n classify content\n351000 0 出差当个小跟班结果感觉自己要被晒成黑皮了\n351001 0 白银也在赚钱哈哈漂亮需要的找我免费开户指导股票和白银\n351002 0 银行的股票配资业务陷入冷清\n351003 1 【晨光怡居苑】商洛唯一专梯纯板小高层,户户赠送私家花园,交xxxx最高抵xxxxx元,全城争...\n351004 0 三星华为小米酷派等等安卓都通用~原价49\n1000 Processed\n classify content\n351500 0 百度抄谷歌、百科抄维基、腾讯抄百度、腾讯抄360、搜狗抄百度\n351501 0 很多朋友都选择激光祛痘嫩肤\n351502 0 仙居太美了~和志同道合的小伙伴还有帮助我们的老师们在一起的感觉真好\n351503 1 您好:江夏中百仓储圣元奶粉x月x号至x月xx号止x.x折售!欢迎惠顾!\n351504 1 您好!我是慧聪网的客户经理付少轩,慧聪网纯信用,低利息,无抵押贷款,利息是x厘x到x厘x之间...\n1000 Processed\n classify content\n352000 1 喜庆元宵 猜灯谜 赢大礼;同时为了回馈广大新老顾客,特推出以下优惠活动:x,全场手机低至xx...\n352001 0 完爆花千骨:终有一天我手中的编译器将成为我灵魂的一部分\n352002 0 而是一种欧式风格带来的一种文化传统所表达的强烈的文化内涵\n352003 0 振华调节110调节依然腿疼并且反复无常极无信誉可言\n352004 0 微软已经宣布windows8\n1000 Processed\n classify content\n352500 0 给大家分享“fenlei等”文件\n352501 0 我不懂为什么旅游回来后我妈一直在微信分享我国外特别是欧洲的美食美景……你告诉我什么意思还想去...\n352502 0 我现在对巨大的建筑物深海大鱼高空有了更深一层的恐惧感而且永远都不会好了\n352503 0 给大家分享“跳舞视频xfulidx\n352504 0 睡眠不好需要去医院检查或补充VD吗\n1000 Processed\n classify content\n353000 0 看来在魔都坐飞机要提前六个小时出门了\n353001 1 感谢致电布丁酒店(杭州河坊街店),down.podinns.com下载布丁酒店APP,专享x...\n353002 0 浙江高考第二批文理科、体育及艺术专科控制分数线昨晚揭晓\n353003 0 因为黄某生前携带有乙肝病毒\n353004 1 春季“初中体育中考强化”“小学体育综合素质”训练班于x月xx日开课(每周六或日训练)现已开始...\n1000 Processed\n classify content\n353500 0 就使用我的邀请码xrpxxx下载并登录浙江移动手机营业厅\n353501 0 也好想在东台市第一中学拍一组关于青春的写真啊\n353502 0 8、市政府系统廉政建设重点任务推进会举行\n353503 0 非洲历史上首场NBA比赛将在南非的约翰内斯堡举办\n353504 0 型男帅哥健美大片21\n1000 Processed\n classify content\n354000 0 唱清凉的歌写妩媚的诗博主导读\n354001 0 借贷宝app现全国招聘线上推广人员待遇丰厚推荐一人至少有20元的佣金月薪上万轻轻松松想做的请...\n354002 0 今年参加的小将以江苏和浙江居多啊\n354003 0 好声音那个女孩唱allaboutthatbass串我在人民广场吃炸鸡的时候没有跳那种舞\n354004 0 这整个过程已被警车上的车载摄像机拍了下来\n1000 Processed\n classify content\n354500 0 护士贴的止血贴完全没贴在位置上\n354501 0 快速了解C盘中常见文件夹的作用\n354502 0 后拱辰享气垫防晒最后一个白菜价啦xxx\n354503 0 那些地方有家人有领导真是不能好好说话啦\n354504 0 来青度假的小屁孩儿机器人变身中~\n1000 Processed\n classify content\n355000 0 犯罪嫌疑人张某被武进区检察院依法提起公诉\n355001 0 微软死磕苹果SurfacePro4新机曝光性能飙升\n355002 0 「twitter」scooterbraun\n355003 0 真想在背后贴张纸上面写上我tm真的不是护士…\n355004 0 每天只能有6名游客探访一个大猩猩聚居群\n1000 Processed\n classify content\n355500 0 我想对楼上装修的大哥说句话您轻点砸墙薄不结实您说您要是一锤子下去劲使大了在掉下来多尴尬我是该...\n355501 0 比如阅读、旅游、喝茶……计划去工作计划去生活才不会虚度人生\n355502 0 七夕新品|这几天咨询彩虹玫瑰的亲好多\n355503 0 集成Cortana的过程中遇到的挑战\n355504 1 先生,您好! 我是刚联系过您的(做无 抵押无担保的信用借款),最快x天到帐。 以后您或朋友...\n1000 Processed\n classify content\n356000 1 x.活动期间下定可获赠价值xxx元索菲亚软包登一个,交款满xxxxx可获赠xxx元索菲亚试衣...\n356001 0 来自滨海新区紫云中学新疆班的80多名师生来到天津文化中心参观天津博物馆\n356002 0 快点看吧要不就被腾讯和谐了\n356003 0 出远门坐火车同飞机花费都成本一样\n356004 0 并及时联系消防大队和120急救中心赶往现场\n1000 Processed\n classify content\n356500 0 4、保护皮肤细胞不受到外界的环境影响\n356501 0 xx江南大学机械工程学院包装xxxx班“走进绿色\n356502 0 鲁智深:我的酒店一年赔了xx万两银孙二娘站起来哭道:大哥\n356503 0 ThinkPad最强笔记本配件ThinkPadStack来袭\n356504 0 劫后重生的手机会让我更懂得珍惜\n1000 Processed\n classify content\n357000 0 ——Whichwouldyoulikefordinner\n357001 0 搞十问的号已经因为信用分太少被遗弃了\n357002 0 5星推荐汽车人总动员百度云网盘\n357003 0 下午有去琦园商业街一带的小伙伴嘛有的话记得联系我\n357004 0 从下飞机那一刻迎面而来的热浪\n1000 Processed\n classify content\n357500 0 我觉得这比在NBA投进跳投厉害多了\n357501 0 我们在全球xxx个地方提供带船员动力游艇租赁业务\n357502 0 因为这样我在自家电脑傲娇的时候\n357503 0 女大学生被网友装鬼轮奸以为遭遇鬼压床\n357504 0 之前一直以为只有腾讯的软件才会越更新越烂逼的你不得不去找老版本\n1000 Processed\n classify content\n358000 1 您好,建辉诊所x月x号—x月xx号举行优惠体检活动,需注意:x空腹抽血和憋尿,x.B超时间为...\n358001 0 智能服务机器人“Angel”首次亮相\n358002 0 活生生在飞机上等了半个小时没法下机\n358003 1 蔡利波 建设银行 xxxx xxxx xxxx xxxx ...\n358004 0 从x加速到xxxkm/h只需要不到x秒钟\n1000 Processed\n classify content\n358500 1 枳沟利群庆x.x妇女节,伊利奶粉.金领冠.金装.珍护全场奶粉x.x折,欢迎新老顾客购买。时间...\n358501 0 製作糖醋蒜汁:秘方:1斤大蒜、1斤白米醋、冰糖4两\n358502 0 起码在很多案件之中都有着千丝万缕的联系\n358503 0 Wilkinson的刮胡刀广告\n358504 0 每年都会因为租房的事搞疯掉\n1000 Processed\n classify content\n359000 0 百度微博了十分钟都找不到准确信息\n359001 0 灣仔會議展覽中心展廳3展房X12同大家見面\n359002 0 /河北一辅警无证驾驶撞死2学生逃逸现已被批捕\n359003 0 自以为很厉害实则不过是一群跳梁小丑而已\n359004 0 北大街么多了点旅游景点的喧闹\n1000 Processed\n classify content\n359500 0 拒诊是正常的『作为三甲医院医生\n359501 0 看完电影回家电梯口看到这个\n359502 0 抢红包群抢到最低的要发红包不是最低的可以一直抢\n359503 0 因此印有DermatologistTested皮肤科医生临床试验等字样\n359504 0 没想到还是对这样的不公有了反应\n1000 Processed\n classify content\n360000 0 xxxx年xx月至xxxx年x月\n360001 0 某个机智的医生说吃点碱好了……\n360002 0 首先是认真落实小额担保贷款政策\n360003 0 固定资产投资完成近115亿元\n360004 0 有些感情无需质疑信任是彼此给彼此的\n1000 Processed\n classify content\n360500 0 1万元苏州嘉年华两厢让利1\n360501 0 29操作建议:1、亚盘时段白银2930附近做空\n360502 0 手机上国内网超快电脑就无敌慢还打不开??电脑白痴折腾一晚还是整不出所以然Google都打不开...\n360503 0 清秀的越南MM唯一不足就是太浓缩\n360504 0 他不知道俄羅斯政府會在二〇一三年公開交還前蘇聯帶走的文稿\n1000 Processed\n classify content\n361000 1 亲们,魔法医生又有新活动了,魔法医生茉莉系列和玫瑰部分产品x折优惠,腊菊水xxx元和乳xxx...\n361001 0 终于等到你\n361002 0 2015世界儿童跆拳道比赛马上开始啦\n361003 0 取10~15g马齿苋草煎汤或榨汁服用\n361004 0 华为手表和产品包装表面看上去与普通手表没什么区别\n1000 Processed\n classify content\n361500 0 我们都是365天要为与你有一样需求的人员而营业的\n361501 0 各种类型的医药企业越来越多\n361502 0 哆啦A梦汽车摆件机器猫车内饰品蓝胖子创意公仔叮当猫车载摆件\n361503 0 但三名法官组成的审判小组也表示\n361504 0 青海湖畔199公里骑行等你来挑战\n1000 Processed\n classify content\n362000 0 让投资者开始回归理性与冷静\n362001 1 的“诚信xxx,礼惠山城“感恩回馈活动,全场所有商品直降xx%,在此折扣基础上,每交x万元直...\n362002 0 是对溧阳质监局局长感兴趣的相关人群获取溧阳质监局局长资讯的重要平台\n362003 0 创造了NBA历史上西部球队单赛季主场胜场纪录\n362004 0 南京零零后队蔡润东获棋王组冠军\n1000 Processed\n classify content\n362500 0 在好声音学员江源东的重新演绎之后\n362501 0 卞修全:法官检察官不能再有铁饭碗\n362502 0 到公司看了半天电脑无聊下车间玩了个把小时手机\n362503 0 看来坐火箭都赶不上别人节奏了\n362504 0 城管抗台防汛应急队伍随时待命\n1000 Processed\n classify content\n363000 1 【可爱可亲】春季大返利:惠氏听一xxx,听二xxx,听三xxx,雅培、多美滋一降到底!!!全...\n363001 0 小户型的橱柜设计也不能忘了吧台这一环节\n363002 1 您好!我是诸城万向冷运我处专业从事公路及海运冷藏运输主要路线:广东.广西.云南.四川.重庆....\n363003 0 想知道电影中的娱乐圈真相是否属实\n363004 0 粉色蛋糕2粉色彩旗3蓝色蛋糕4蓝色彩旗\n1000 Processed\n classify content\n363500 0 联想电脑公司使命:为客户利益而努力创新\n363501 0 让我找亲戚朋友借一个手机先将就着\n363502 0 有人质疑我一个基督徒有何资格为佛教徒说话\n363503 0 我在google上搜Ju的照片\n363504 0 获得第21届东方风云榜十大金曲\n1000 Processed\n classify content\n364000 0 爱生活的人都有3个平方的世外桃源:阳台是我们在进行家庭装修过程中最容易被忽略的一个世外桃源\n364001 0 预计到年底再完成x户企业搬迁关停\n364002 0 Techcrunch撰文称\n364003 0 协会积极支持证券投资咨询机构创新发展\n364004 0 通过400余件动漫手稿、雕塑和百余部中外经典动画影片\n1000 Processed\n classify content\n364500 0 花千骨吃的包子为嘛是电脑合成的\n364501 1 您好!我是刚给您打电话的中国电信的客户经理小邱,预存话费送话费送宽带的优惠活动正在进行中。预...\n364502 0 请广大市民登录海门文明网\n364503 0 /杭州:官员被举报强奸女员工与他人通奸\n364504 0 BamBam刚更新了Twitter:????????????????Hahahahahaha...\n1000 Processed\n classify content\n365000 0 微信私发+461303验证:宁泽涛帅帅的\n365001 0 有个爱管闲事不明真相的更年期老太婆问我为什么不一起吃\n365002 0 更是给南京楼市带来了去化惊人的成绩\n365003 0 7、银杏叶制品如银杏叶、银杏\n365004 0 张永熙先生于xxxx年x月xx日下午xx点逝世于南京\n1000 Processed\n classify content\n365500 0 与之匹配的8速DCT变速箱也能很好的履行它的责任\n365501 0 朋友急出一台99新礼盒版tr350限量色薄荷绿\n365502 0 qq:1985177275联系\n365503 0 在Twitter看到這張照片\n365504 0 有人说是花千骨毁了那个高高在上\n1000 Processed\n classify content\n366000 0 对汽车零部件特别是影响汽车安全行驶的关键部件要定期检查维修\n366001 0 南京陶笛之罗友群群主陶笛葫芦丝爱好者\n366002 1 尊敬的家长您好!神墨教育春季班(珠心算,口才,英语,练字,xF全脑训练,绘画)正式开课啦!本...\n366003 0 更disppoint的是:一个security竟然说今天没有任何人送来东西\n366004 0 用得可爱西瓜吐司搭配蜂蜜渍柠檬太有喜感了\n1000 Processed\n classify content\n366500 0 百度自己身上的小毛病的时候总会吓着总觉得得了什么不治之症可是谁身上没个小毛病呢自己能忍受可别...\n366501 0 原告李颖激动地对办案法官连连道谢\n366502 0 最多可供6人同时生活……黄俊杰非常“骄傲”地介绍自己的房车\n366503 0 时间:13:00、14:50、18:30\n366504 0 而参加听证的19名代表都同意水价上调\n1000 Processed\n classify content\n367000 0 你不能把他送往小医院嘛”呵呵民警这话\n367001 0 有人担心智能机器人会威胁人类\n367002 1 领导您好!华夏银行现推出无抵押、免担保的信用贷,授信额度xx万,一张身份证即可办理。详询付经...\n367003 0 明天这个时候已经在飞机上了\n367004 0 由Datouren最新设计的精灵罐\n1000 Processed\n classify content\n367500 0 如果班组赶上起下钻或卸药品\n367501 0 SJ成员崔始源已经通过韩国义务警察特长兵的最终审核\n367502 0 绝对良心价冒着生命危险才抓的/酷/酷\n367503 0 NBA各支球队已经可以开始和达成意向的球员正式签约\n367504 0 保存最完好的洞穴寺庙建筑群\n1000 Processed\n classify content\n368000 1 xx年研究生未过在线加分,请加qq:xxxxxxxxx一次过,不返弹 永久有效,完成你的心愿.\n368001 0 7号线司机不是喝醉了就是嗑药了\n368002 0 各种coser出现在商贸城\n368003 0 Gxx长深高速由杭州往连云港方向宁杭段Kxxxx+xxx至Kxxxx+xxx附近施工结束\n368004 0 却解决不了xx亿人医疗免费\n1000 Processed\n classify content\n368500 0 利用伪造的结婚证、购房合同、贷款合同和银行还款单等骗取住房公积金\n368501 1 延吉马可波罗磁砖,全城引爆,羊年开门送裸价 送好礼. 送保障。 交定金,交全款都有大礼,四大...\n368502 0 当我迈进宿迁广播电视总台的时候\n368503 0 以天津滨海国际机场为主运营基地\n368504 0 科技发明是我们的基因创造的肉体的伟大外延\n1000 Processed\n classify content\n369000 0 家庭聚会上警察伯伯教我一堆如何在社交场合保护自己\n369001 0 浙江东部沿海部分地区12级以上大风已持续12~20小时\n369002 1 您好,先生,我是莞大信贷的小姚,利息最低可以做到x厘多。我们公司地址:东莞市南城区元美路华凯...\n369003 1 急用钱找我们,无抵押无担保。我是宜信普惠李秀媛,我们已经正式上班,需用钱请联系我,欢迎咨询。\n369004 0 完了刚才看新闻台风到浙江了我好紧张整个人在发抖好想哭你还是没有回消息\n1000 Processed\n classify content\n369500 1 号—x月x号全场春装x.x折,会员折上x.x折,另全场消费满xxx元以上赠太平鸟汽车抱枕一个...\n369501 0 我个人觉得玻尿酸在25岁之前最好别用\n369502 0 坐飞机一定要敷面膜坐飞机一定要敷面膜坐飞机一定要敷面膜\n369503 0 因涉嫌犯挪用公款罪和贪污罪\n369504 0 武汉市新建商品房8月1日销售套数626套\n1000 Processed\n classify content\n370000 1 你好!我是福临装饰张黎,公司开年钜惠,品质整装,定装修即送“美+净”专业除甲醛、整体家庭环保...\n370001 0 重庆奥体有38120人看到登巴巴式碾压\n370002 0 就可以通过查找到对方的IP地址\n370003 0 签约仪式在常州市盐城商会会议室举行\n370004 0 百度地图西宁的地图数据该更新了\n1000 Processed\n classify content\n370500 0 在三星与Google稍早均宣布将针对旗下Android平台装置提供每月漏洞修正更新后\n370501 0 在淮安市医生的眼里就这么治疗\n370502 0 刚在易帮电脑科技摇到了免费好东东\n370503 1 亲你好!我是专门在九号公馆做暖气/中央空调的美景销售工程师--小唐。开会得知今年xxx活动力...\n370504 0 我们策划的首场活动8月末将精彩呈现\n1000 Processed\n classify content\n371000 0 九鼎集团借贷宝之骗局大揭秘\n371001 0 长沙市公安消防支队特勤大队训练场地上\n371002 0 阜宁县还抓好“红色盐阜——阜宁分站”主体网站的建设工作\n371003 0 所有真相只有我一个人蒙在鼓里\n371004 0 win10我感觉就是基于win7做了一下增强\n1000 Processed\n classify content\n371500 0 maybe我主動一下就又能聊起來了\n371501 0 能顺利到达终点拿到offer的真的少之又少\n371502 0 同學們了解了常州梳篦的製作過程和商業模式\n371503 1 老窖集团公司要求:决定x月xx号正式进驻展厅恭迎八方贵宾!欢迎全国各地新老客户大驾光临,洽谈...\n371504 0 解决电脑辐射护肤美容折而忧伤徘徊的时候\n1000 Processed\n classify content\n372000 0 6万多座各类雨水井进行排查和疏通清掏\n372001 0 俩孩子很久就要求有自己的小植物、怕直接买给他们会不珍惜\n372002 0 没有失败哪来的成功往前走往前拼相信自己\n372003 0 这是一个我们注定无法长相守的世界\n372004 0 上天太不公~说好的好姐妹一辈子呢\n1000 Processed\n classify content\n372500 0 siri界面和watch一样了\n372501 0 色号supercoral用三次\n372502 0 并对这种腐败现象进行了辛辣的讽刺和抨击\n372503 0 到了现场你们昆山圆通总公司已经把包裹全部私自拆开\n372504 0 然后告诉你你相机和手机未连接\n1000 Processed\n classify content\n373000 0 人活着赖着一口氧气氧气是你如果你爱我你会来救我\n373001 0 用同一个亚马逊账号买了两个\n373002 0 先引诱了集团的哥哥但是哥哥是一个身价清白的人\n373003 0 99%的女性经第一次使用femfresh后都会选择推荐给其好友\n373004 0 是美国人无耻而凶残的侵占了中华领土\n1000 Processed\n classify content\n373500 0 空方在国企期货上可赚800亿\n373501 0 忍不住分享天府广场地铁站出来的今站购物广场现在开业了许多吃东西的店\n373502 0 要知道腾讯告倒快播的理由是因为盗版而不是色情\n373503 0 ??Dea初秋高级定制复古针织半裙上身非常好看的一款针织裙有着欧美大牌感的复古纹路搭配任何上...\n373504 0 宜兴本土书画家的作品不在少数\n1000 Processed\n classify content\n374000 0 就是建筑物或者构筑物的骨架\n374001 0 在徐州你可能听过喝米线、喝馄饨\n374002 0 不过拌着蜂蜜酸奶还可以勉强下咽\n374003 0 xxx万名会员的手机聊天软件“Kakaotalk”开发商韩国kaokao公司投入xxx亿左右资金\n374004 0 “这些交通违法行为大部分与‘路怒症’有关\n1000 Processed\n classify content\n374500 0 南京路步行街这里天刀的广告牌\n374501 0 常州英语口语培训小编列举了2015年上半年的那些流行潮词儿\n374502 0 皮肤都疼~就怕电脑散热不行\n374503 0 hellokitty版水信玄饼\n374504 0 命运本生不公而我们又能做些什么除了无法改变和愤怒不满其实一无是处随波逐流活着\n1000 Processed\n classify content\n375000 0 为什么我百度云app点进去\n375001 0 岳阳医院自制的白地祛脂合剂\n375002 0 “常见过敏性疾病的预防与防治”主题讲座为大家讲解人体过敏的原因、如何正确识别、预防及治疗过敏性疾病\n375003 0 清除浏览数据和cookie无效\n375004 0 适当ping上一些养生天品的海鲜那就太美了\n1000 Processed\n classify content\n375500 0 出口欧美的条纹卫衣3到8岁可穿\n375501 0 会议强调专项整治活动必须:认清形势\n375502 0 一辆156路公交车右后轮压到了一位老太太的右脚\n375503 0 “电梯吃人”事故前5分钟商场监控视频曝光\n375504 0 市政府新闻办公室召开全市公共交通安全监管体系建设情况发布会\n1000 Processed\n classify content\n376000 0 今天看了现代商业版的梵高纪念展\n376001 0 它很可能是此前传言的Lumia950系列机型\n376002 0 宾夕法尼亚大学机器人曲棍球赛\n376003 1 xxxx龙游艾莱依女装早春系列萌动上市,x月女王节,见证美丽xx变。欢迎新老队员顾客前来选购。\n376004 0 滨海新区举办各类展览论坛85个\n1000 Processed\n classify content\n376500 0 下面2款容器内部设计乃们想要什么样的涅\n376501 0 理财经理不在的时候我就得盯低柜\n376502 0 回应质疑的方式就是默默沉淀\n376503 0 泗洪县与阿里巴巴公司签订农村电子商务合作协议\n376504 0 有bigbang南京场980看台正对舞台的票吗\n1000 Processed\n classify content\n377000 0 寒假结束了本来计划好的短发没有圆圆眼镜没有减肥没有可就这样结束了明天就要开学了嗯开学快乐萌你...\n377001 0 这座于当年2月28日开工建设的中国目前最大的展翅型高架桥\n377002 0 动力电池的测试与评估在纯电动汽车产业的发展过程中至关重要\n377003 0 如果好声音黑幕真的如此……不看了\n377004 0 山西首富邢利斌8000万收购1\n1000 Processed\n classify content\n377500 1 华为 荣耀 畅玩xX (Chex-TLxx) 低配版 白色 移动xG手机 双卡双待京东价:¥...\n377501 0 /广西官员遭举报与2女大学生开房“双飞”被停职\n377502 0 LeohNewTab免費漂亮的GoogleChrome分頁外掛\n377503 0 偶然看到江苏卫视在放翻译成中字继承者们\n377504 0 新区投促中心组织了20余人的专业招商团队\n1000 Processed\n classify content\n378000 0 等我从南京回来你俩一个回上海一个开始培训了\n378001 0 杭州地铁4号线运营第188天\n378002 0 我看一集花千骨斗遭虐得不行了\n378003 0 刚才一个人看到我的手机背景\n378004 1 供的材料简单,手续快捷,最快一天放款。 您或者您的亲戚朋友有资金方面的需求的话,可...\n1000 Processed\n classify content\n378500 0 和买个遥控汽车回来玩儿的效果似的\n378501 0 在飞机上又看了一遍星际穿越\n378502 0 手机里多了好多坛蜜的图…对\n378503 0 中国石油A股股价比H股高104%\n378504 0 南京市中级法院召开“非法集资与司法预防”新闻发布会\n1000 Processed\n classify content\n379000 0 例句2Awomengotheatstrokeonthestreetandrushedtoth...\n379001 0 欧美很多人用iPhone会用好几年不换新手机\n379002 1 您好我是星辰路由器批发\n379003 0 淮阴屠宰场里有侮辱韩信的年轻人\n379004 0 大家也都知道抗生素滥用的后果\n1000 Processed\n classify content\n379500 0 而钾与钠共同维护细胞内外正常渗透压和酸碱平衡\n379501 1 网球、乒乓球、游泳、轮滑、散打等培训!欢迎您来欧尼健身体验不一样的激情!欧尼健身付裕祝您生活愉快!\n379502 0 对面驶来的大滴滴前灯照的我什么也看不清\n379503 0 中午就买了碗泡面让她90岁父亲坐在长椅上吃\n379504 0 而对于前任的质疑、污蔑、攻击\n1000 Processed\n classify content\n380000 0 3号凌晨微博回应:下午场的观众不值得维权\n380001 0 今天泡了中药澡本来想早点睡\n380002 0 湖南6名青年在办公室被19人砍杀\n380003 0 在梦泉火箭团有一个特殊的小团队\n380004 0 我也是佩服我妈用常熟话读出了我的每一条状态\n1000 Processed\n classify content\n380500 0 我发起了一个投票爱女心切可以理解\n380501 0 即使在这样技术先进的医院也难免落到遭人痛骂的境地\n380502 1 x月xx日奥华生态集成吊顶周年庆,厂家补贴、零利润销售,让奥华为您家增添时尚温暖,诚意邀请您...\n380503 0 贝特斯的LinkedIn资料显示其7月加入苹果从事运营工作\n380504 0 经过了漫长而又短暂的飞机和车子的路程\n1000 Processed\n classify content\n381000 0 网友直呼认不出真相竟是这\n381001 0 我有‘紧平梅’百度云盘需要连接私聊我保质保量\n381002 0 红海度假小风帆卢克索内陆飞机台风都过去了\n381003 0 隔离+保湿+防晒+美白+舒缓五大功效\n381004 0 小伙伴们将此当作自家装修一般\n1000 Processed\n classify content\n381500 0 这次大波动在政府强势干预下并未造成诸如金融危机等恶劣后果\n381501 0 里面强奸逻辑的部分实在懒得吐槽\n381502 0 之前花了一天做好的6天旅游攻略\n381503 0 温经理:13798580082\n381504 1 你好。 我是乐游的公主,新年以过乐游ktv正常开业,欢迎大家来捧场好玩美女多!有空来捧场哦!...\n1000 Processed\n classify content\n382000 0 看thenightshift已經看瘋了每次看醫療劇我都在想其實我可以當個醫生的難道不是嗎\n382001 0 G15沈海高速往浙江方向1291\n382002 0 对于定点医疗机构监督管理很重要\n382003 0 处500元以上2000元以下的罚款\n382004 1 感谢致电海宇彩印,本公司专业生产各种自立拉链袋,桂圆干袋、面筋袋、真空袋、蒸煮袋、糖果袋并为...\n1000 Processed\n classify content\n382500 1 您好,我是纽泽装饰的小刘,我们公司针对荣盛地产的小区征集样板间,定装修免一年小区物业费,还送...\n382501 0 结果点开维基链接:Thesocietyaimstofosterunderstandingan...\n382502 1 中国平安年后推出凡购买车险就送少儿医疗保险,购买少儿险送成人保险。数量有限,送完及止.咨询电...\n382503 0 人民币汇率能不能守住真不好说\n382504 0 因此把这种建筑风格带到世界\n1000 Processed\n classify content\n383000 0 然而没有什么用~依据南京气象台发布的天气预报\n383001 0 在Tumblr上的网名为LazyBones\n383002 0 安龙政府派上百名特警压制农民工\n383003 0 附加成本=心情低落郁闷+名誉形象受损+家人朋友担忧+工作学习生活——夏季炎热\n383004 0 同花顺早在2009年就已登陆创业板\n1000 Processed\n classify content\n383500 0 然而我觉得是时候将真相公诸于世了\n383501 0 下面山东远邦科技集团就为你详细\n383502 0 对甲应以侵占罪与诈骗罪并罚\n383503 0 可这样做实在太KY了我只好忍着\n383504 0 做个vi还要我写文案做网页设计\n1000 Processed\n classify content\n384000 0 深圳地铁施工坍塌被困者已救出工地停工整改\n384001 0 ”…B:“那你告诉我这里是不是中华人民共和国\n384002 0 作品设计:张寒摄影:XY工作\n384003 0 刚刚导图电脑提示我灾难性故障来的太突然没有拍下来笑死我了灾难性23333\n384004 0 在对阵徐州酷棒俱乐部的时候\n1000 Processed\n classify content\n384500 0 晚上做梦梦到坐飞机飞机被缅甸反派军劫持我跳机跑了然后到处问路但是语言不通英语也太渣没人帮我\n384501 0 浪子回头:NBA球星贝克是如何败掉亿万家财沦落到卖咖啡的\n384502 0 今年xx岁的刘某曾因贪污、盗窃、猥亵女童被判刑入狱\n384503 0 微软已经将iPhone上的XboxMusic应用改名为Groove\n384504 0 刚得知一个同学在腾讯总部上班\n1000 Processed\n classify content\n385000 0 4、注意饮食卫生和消化通道疾病发生\n385001 0 我从你这敲我就看出来你贪心\n385002 0 我建议政府公安机关在成都市可以严打一次\n385003 0 是不是犯罪案例是杜撰出来的\n385004 0 趁涂防晒霜的时间去捯饬了下这个玩意\n1000 Processed\n classify content\n385500 0 医院电梯安全管理人员和电梯维保人员对每部电梯的\n385501 0 十六年后让他去参加好声音第二十季\n385502 0 没有防晒霜的夏天??????\n385503 0 你也快来表态吧~选出你最爱的机器人外观\n385504 0 意外的是CCTVx给了很多钱所以中国元素很多\n1000 Processed\n classify content\n386000 0 盗墓笔记百度云\n386001 0 头发是父母基因唯一保存时间最长的载体\n386002 0 每箱奶粉政府严格监管…所以只要是直邮\n386003 1 您好,广州鑫俊发汽车配件欢迎您来电垂询,主营:奔驰.宝马.原装拆车件。省会城市.货到付款.电...\n386004 1 迎三,八节,水中花美容院联手产品总公司,活动期间,购买护肤品推出一系列优惠活动,多买多送,送...\n1000 Processed\n classify content\n386500 0 xx日PxP成交数据一览表:名称时间加权成交量成交量平均利率投资人数人均投资金额平均借款期限...\n386501 0 财富探源”全国省代会议召开\n386502 0 组织xx余种新装备进行实打实爆实修训练\n386503 0 泰国mistine羽翼粉饼和Chanel粉饼有一拼而价格却平民很多mistine出汗都不会脱...\n386504 0 房屋的装饰装修不得影响共有部分的使用\n1000 Processed\n classify content\n387000 0 坐飞机无疑是又经历一次生与死\n387001 0 死者家属开始扭曲事情的真相\n387002 0 苹果6plus手机壳iPhone6plus金属边框5\n387003 0 勿理物理”良师益友帮你拨开理科教学的迷雾\n387004 0 辛苦玩的游戏要升31级了要到我想完成的那个任务了\n1000 Processed\n classify content\n387500 0 twitter/morinorom:と、とと…となり空いてるよ…\n387501 0 无论你投资下去多少财力、物理和人力\n387502 0 加我卫星:T1523349912和我一起做网职吧\n387503 0 在正在举行的GDC2014展会上\n387504 0 ”花千骨下巴差点没掉下来:“这么多人都是来向异朽君问问题的么\n1000 Processed\n classify content\n388000 0 我分享了百度云里的文件:?愽3\n388001 0 谁说定位能找到手机在哪里的\n388002 0 这个数字到了2014年则翻了20几倍\n388003 0 没有经过刻意修剪和设计的草木蓬勃繁茂\n388004 0 “释正义”举报一事“属恶意诋毁”\n1000 Processed\n classify content\n388500 0 近日俄“卫星”新闻通讯社报道\n388501 0 人均60平方米免征为主流意见\n388502 0 并依照相关规定依法给予处罚\n388503 0 ||我在氧气听书收听“盗墓笔记x云顶天宫xxx”\n388504 0 当中包括高达711米的全球最高住宅大厦“迪拜一号”\n1000 Processed\n classify content\n389000 0 微软回应这一状况:这可能是XboxOne上新DRM策略引发一个Bug\n389001 0 做好万达文化旅游城项目征地拆迁扫尾部分协议签订工作、土地三清工作\n389002 0 华为旗下荣耀将在沙特阿拉伯首都发布同样档次的新品本拉登\n389003 0 请修水县政府、修水县公安局以及相关的单位严惩暴力伤医的人员\n389004 1 尊敬的客户您好!我处可快速办理大额《xx-xxx万》信用卡,前期无费用,无户籍要求,均可套现...\n1000 Processed\n classify content\n389500 0 某人以火箭般的速度把食物塞满到自己的胃\n389501 0 有时候很怕惊的感觉差不多两三个小时喂奶一次\n389502 0 [LittleLostProject]在大街上我们可以发现很多废弃的物品\n389503 0 各类电动汽车在昆山市周边充电“续航”需求\n389504 0 下个手机不用苹果了用华为华为少年才是最好的少年\n1000 Processed\n classify content\n390000 0 其中中碳铬铁fecr55c200招标价格为11200元/60基价\n390001 0 报道一病例:患者有子宫破裂史\n390002 0 百度贴吧“美国”二字都成敏感词了\n390003 0 用来将Java的对象转化为JSON\n390004 0 这让我质疑我之前看的都是些啥\n1000 Processed\n classify content\n390500 0 我们牧隆就是您身边的保护伞\n390501 0 东区警方破获一起盗窃开业花篮的案件\n390502 0 186*3230付款成功获得一个5元红包\n390503 0 上海一驴友在浙江仙居县朱坑里瀑布“瀑降”时\n390504 1 德国菲林格尔地板x.xx促销 名优品牌、实惠价格、过硬质量、良好环保、优质服务。 地址:...\n1000 Processed\n classify content\n391000 1 $您好!新年快乐【:只要“铳 就”送“百分三十】出x分钟到户!!详情上【xxxxxw.CC】\n391001 0 没搞明白真相就乱甩人嘴巴子的女主角\n391002 0 黄晓明是被质疑身高最多的男演员之一\n391003 0 还能应用智能化理财模块抵抗风险\n391004 0 南京秦淮警方接到一个小伙子报警称\n1000 Processed\n classify content\n391500 0 华为三款新机曝光配Kirinxxx处理器\n391501 0 不得不得说一句花千骨这么傻缺\n391502 0 最后一颗还要等到花千骨来了才跟她一起分着吃杀阡陌没有糖\n391503 0 妈的以后就指着百度吧啊不进步就会吃屎傻逼\n391504 0 无锡市中级人民法院召开新闻发布会\n1000 Processed\n classify content\n392000 0 相信理财产品我倒宁愿相信炒股更靠谱\n392001 0 自地铁x号线二期和周边多个立交桥施工以来\n392002 0 太多太多的贪官污吏非但有很多很多的办法会去解决\n392003 0 外经贸广场9楼的电梯门爆炸了\n392004 0 有效对抗UVAUVB防止黑斑产生\n1000 Processed\n classify content\n392500 0 旅游地产发展渐露锋芒分权度假模式成未来趋势\n392501 1 ~朋友\最近好吗?有 上 好 的 茶 叶,还 是 原 来 的 味 道。你懂的。xxx丽xxx...\n392502 0 thetruthcomestolight真相迟早会大白\n392503 0 光这个NIVEA就已经是第三瓶了\n392504 1 尊敬的会员您好!“三八”来临,文胸及配套短裤秒杀价x.x折,此活动x月x日结束!快行动起来,...\n1000 Processed\n classify content\n393000 0 正在上海参加商业活动的科比就曾赴杭州密会马云\n393001 0 除了小威尼斯50米水道和开闸放水过桥外\n393002 0 滑翔伞降落失败直接被汽车给撞上\n393003 0 2015吉林民航机场集团公司招聘11人\n393004 0 学了一句扬州话~王元我爱你~嘛嘛~每天都很想你~爱你~\n1000 Processed\n classify content\n393500 1 设计师一对一与您交流!$当天定样板间可享以下优惠:$x,赠送家具家电(沙发,餐桌,烟机,灶具...\n393501 0 真的急需一张南京bigbang演唱会门票\n393502 0 但校园内的特色建筑群大部分得以保存\n393503 0 46个市级部门权力事项责任清单已通过盐城机构编制网向社会正式公布\n393504 0 江苏的素质男s期待一个听话愿意长期慢慢发展的愿意一步一步被调教的m喜欢古风或者古典文学的妹子最好\n1000 Processed\n classify content\n394000 0 也抵不过2000万人的违法乱纪\n394001 0 为什么你们一说魅族mx5我第一反映都是马自达mx5呢\n394002 0 上周kingcountry宣布委员会提议解决对于持续增长的少年司法制度中种族差距问题\n394003 0 扬州市区及江都区共成交商品房77套\n394004 0 强奸犯一家侵犯的妇科:1医生陈述健康正常\n1000 Processed\n classify content\n394500 0 而在和谐版中公安解救女大学生成功\n394501 1 我处可以免费办理摩托车驾驶证。须办证的亲朋好友请跟我联系!\n394502 0 它曾连续17年蝉联美国亚马逊畅销书排行榜\n394503 0 大热天的一个人去南京广电跑了个腿\n394504 0 尺寸20、24、26、29芭比粉最新色保真出游季带上心爱的他度过完美假期\n1000 Processed\n classify content\n395000 0 竟然敢对自动监控数据弄虚作假\n395001 0 刚从派出所出来……决定还是先不流浪了\n395002 0 来自单词zappy希望每个拥有Z11的女生都能让人感受到她永远的活泼、美丽\n395003 0 5架B-29轰炸机组成的突击队将原子弹“胖子”投到长崎市中心\n395004 0 为何追星只是讶异于粉丝与偶像之间的那种关系一面真心一面假意像极了这世上所有雾里看花有自以为是...\n1000 Processed\n classify content\n395500 0 微软对于WindowsUpdate模式的调整却引发了外界的不满\n395501 0 预计年内xxxx多套保障房可陆续交付使用\n395502 0 当你来到医院的时候你才能感受到\n395503 0 率30多家企事业单位、130多人、携4000多件展品参加在深圳举办的第九届文博会\n395504 0 租房买房小邓帮忙18170265496西一路创佳房产圆您家的梦想\n1000 Processed\n classify content\n396000 0 因为百度这个搜索引擎给互联网各大用户带来了很大的方便\n396001 0 2015年上半年处理申诉举报75起\n396002 0 最好听的声音居然没有导师转身\n396003 0 少年神探狄仁杰小白脸不适合演元芳\n396004 0 南京太美了有缘分的两个傻逼总是能再见的\n1000 Processed\n classify content\n396500 0 都是因为在不了解事情真相时就妄加评论\n396501 0 小编隆重推荐4种新款早餐:捞叶蛋饼配海南黄灯笼辣椒\n396502 0 在电脑前呆坐3个小时……\n396503 0 看阿妹妹来好声音有一种王思聪独自去潘石屹的soho找工作的赶脚\n396504 0 那个腐败的儿朝廷已经完全没有生存下去的能力了\n1000 Processed\n classify content\n397000 0 根据现场情况警察和警车是有直任\n397001 0 keith小ck新款女包欧美风车缝线长款钱包手拿包粉色黑色白色原价269折扣165包邮\n397002 0 IMAX要的建筑是一座极其宏\n397003 0 今晚下关突然下了一场很大很大的雨\n397004 0 P图了还是很丑……跟你们大婊姐孙耀琦一样\n1000 Processed\n classify content\n397500 0 PhytoTree人将黄瓜做成了一种护肤品\n397501 0 世界知名旅行箱品牌RIMOWA展示了正在复活中的:世界上首款全金属客机容克斯F\n397502 0 你国政府不仅仅是蠢的问题了\n397503 0 宿迁淮海技师学院附近一处涵洞时\n397504 0 设计师通过对铝材的挤压变形来牢牢的固定住其它两种材料并形成了一个有趣的台灯灯罩造型\n1000 Processed\n classify content\n398000 0 犯罪心理S4E19中的罪犯是暮光里的Jasper成功演绎了一位双重人格罪犯而且还是女人的第二...\n398001 0 当前行加断点com+\\移动编辑区最上方com+上移动编辑区最下方com+下移动光标\n398002 0 不仅因为害怕查明真相的艰难困苦\n398003 0 哈哈当时这照片还是我手机拍的我都没了\n398004 0 泰国警方拘捕了4名女子和1名男子\n1000 Processed\n classify content\n398500 0 对非P8用户而言又如何实现流光快门呢\n398501 0 商业广告:价格1500——2500\n398502 0 玉兰:冰清玉洁喜欢玉兰纯洁属于你\n398503 0 南京脑康中医医院全国十佳重点面神经专科医院\n398504 0 1985年抗日战争胜利40周年\n1000 Processed\n classify content\n399000 0 只是我们的汽车让小偷偷走了\n399001 0 所以设计了这个利用柳条编制出来的有点像艺术品的秋千\n399002 0 不晓得好安逸你是想看长的乖帅的随便撒子款式给我说我去给你查百度斗是\n399003 0 有的美容院看了我咨询的照片就说丑\n399004 0 求一起去看exo二巡南京场的小伙伴\n1000 Processed\n classify content\n399500 0 拿回旧手机翻到了以前存的一大堆加菲的图\n399501 0 8月8日前昆明要完成电梯安全大检查\n399502 0 两小时内成功查处三辆违法超限车辆\n399503 0 河北今年优先整治集雨区重点村庄环境\n399504 0 搭配中药药材、上等酱油及特殊配料\n1000 Processed\n classify content\n400000 1 尊敬的家长朋友,新年好,xxxx年春季美术课程x月x日即将开课,欢迎带孩子前来咨询、试课或报...\n400001 0 每次看到那些去中国好声音的学员开始说自己的悲惨故事的时候我的尴尬恐惧症就忍不住要犯哦\n400002 0 深圳市城管局已部署今年生活垃圾分类减量措施\n400003 0 4、小概率的“黑天鹅”事件在资本市场上并不少见\n400004 0 我认识的宿迁人不是这样的啊\n1000 Processed\n classify content\n400500 1 姐您好,三八幸福女人节,x月x日一x月x日九江联盛x楼维格娜丝V一GRASS特推出春装xxx...\n400501 0 全市共拆除各类违法建筑3377栋\n400502 0 又收到人家一位妹子飞机盒装书脊磨白照片……让妹子找客服去了\n400503 0 全身心拒绝南京机场的wifi\n400504 0 并在2000年参与了百度早期创业\n1000 Processed\n classify content\n401000 0 发现该车检验合格至xxxx年xx月有效、且有xx条非现场执法违法未处理记录\n401001 0 “ONENIGHT关爱自闭症儿童慈善晚宴”在杭举行x月xx日晚\n401002 0 检查组认真查阅了县局2015年上半年办理的部分涉林案件卷宗\n401003 0 南京所有的大学都变成了“河海大学”\n401004 0 美国人不歧视老人在中国要是一个大爷去上学\n1000 Processed\n classify content\n401500 0 在浓雾蒙住建筑物的每个早晨\n401501 0 全省50户家庭获选江苏“最美家庭”\n401502 0 Sorry、我不是警察的微名片公司\n401503 0 我是不是有心理疾病一被咬就特别厌恶她\n401504 0 来厦门中山医院换取她所需的血型\n1000 Processed\n classify content\n402000 0 美军出动xxx多名士兵、xx辆战车及数架直升飞机突然将伊北部城市摩苏尔的一座别墅团团包围\n402001 0 我用百度视频手机版看了“蒜香烤茄子”\n402002 1 感谢您致电步步高川湘菜馆,本店为淘点点指定合作商家,用淘点点点外卖最是划算。到店堂食同享优/...\n402003 0 公司宗旨:始终坚持“世界级的医疗技术理应属于全世界的患者”这一理念\n402004 0 任您尽情享受2015款纳智捷优6SUV搭载的全能大脑\n1000 Processed\n classify content\n402500 1 为祝贺徐工挖掘机贵州销量突破xxxx台,宏银携手厂家于x月xx日在贵阳举办大型订货会,xx重...\n402501 0 人们常说wexin:gjn19940907\n402502 0 加快建筑业新技术在施工工程中的推广应用\n402503 0 onedrive等等服务连接服务器之慢让人实在受不了\n402504 0 能保护婴儿免受细菌和病毒的侵害\n1000 Processed\n classify content\n403000 0 射阳县灾害性天气决策服务平台xx年x月xx日xx时xx分发布\n403001 0 我们就能知道宝马对i系列的重视了\n403002 0 “大美上饶\"景德镇陶瓷艺术展在上饶市展出\n403003 0 我喜欢看日本人写的商业书籍\n403004 1 广东汇祥盛实业投资有限公司恭祝各位羊年吉祥,万事如意。本公司专业车贷房贷,押证不押车,二手车...\n1000 Processed\n classify content\n403500 0 cn谷歌AndroidWear平台新一轮更新将为智能手表上最优秀的用户界面带来点击手势功能\n403501 0 我最喜欢的事情就是唱歌我每天都要做的事情就是唱歌我最想做的事情就是唱歌唱你妹啊\n403502 0 最近好多协会在川大的百度贴吧里发了招新贴\n403503 0 29阿诺德施瓦辛格村上隆教SMAP画花UP主:shiyo29\n403504 0 干脆就把电脑pad的电用光好了\n1000 Processed\n classify content\n404000 0 希望你考上研究生找到好工作\n404001 0 与首汽租赁几乎不存在竞争关系\n404002 0 感谢医生感谢帮助我的每一位\n404003 0 Vertu星座系统安卓智能支持所有App软件\n404004 0 未尝不是一种领悟和解脱这一刻你来临都是人间最美\n1000 Processed\n classify content\n404500 0 互联网N多教科书都可以直接扔了\n404501 0 似乎质疑别人对自己的忠诚已经成为了本性\n404502 0 我们的媒体如果报导真相就会丢饭碗\n404503 0 这次讨论是在xx月xx日开始的\n404504 0 9我看见那梦中人走出彩色的房间\n1000 Processed\n classify content\n405000 0 翔云派出所的民警和队员们巡逻到此迅速清通道路\n405001 0 962269房地产热线说了\n405002 0 组织xx名水利职工子女先后到刘湾水厂、荆马河污水处理厂、南水北调解台站、潘安湖湿地公园、新城...\n405003 0 大到汽车、高铁、飞机等行业\n405004 0 撸单机一点都不想开电脑我这是怎么了\n1000 Processed\n classify content\n405500 0 ??event仲有自然療法靚女醫生幫我診治\n405501 0 其设计综合了西式服装与中式服装的特点\n405502 0 市相关旅游公司及各界媒体嘉宾共200多人参加了开幕式\n405503 1 亲、兴义“雪蔻”专卖店在“三八”节举办一次女性关爱活动,x月x日一x月x日三天全场x.x折,...\n405504 0 毕竟中兴华为中兴华为么\n1000 Processed\n classify content\n406000 0 朗斐红酒原瓶进口货真价实\n406001 0 暂停5个半衰期后可喂奶……认为只要服药就不能哺乳\n406002 0 学sap学的我脑子都出血了\n406003 0 丨鹤随玺动丨0710讨论◆千纸鹤可不是纸糊的\n406004 0 朝向天空是飞机撞击前的航线\n1000 Processed\n classify content\n406500 0 “万郁餐饮7月表彰暨8月启动大会”在文景商务大厦29层会议厅隆重举行\n406501 0 萧华表示NBA自由球员市场之初的缓冲期以及“砍鲨”等规则预计不会发生变化\n406502 1 您好,我公司可代开优惠发票(验后付款),可代开:抵扣增值税发票,地税发票,广告费,建筑工程,...\n406503 0 峰峰加油峰峰加油+此图片由本人制作\n406504 0 你看我考上研究生仿佛很轻松\n1000 Processed\n classify content\n407000 0 在走访部分吉利汽车4S店后获悉:新款GC7有望在明年推出\n407001 0 今天下班回家坐车去财富给滴滴买篮球鞋\n407002 0 晋中日报:左权县强化电梯安全监管\n407003 0 按医院的规定预约排号看病是来不及了\n407004 0 2015年8月2日有一位六十岁老太太从上海出发去基辅\n1000 Processed\n classify content\n407500 0 可最后我还是那个怕麻烦的孩子\n407501 0 实时播报:东方证券解读第三方支付规定\n407502 0 抢红包游戏小说抽烟sex\n407503 0 午睡、长途车、火车、飞机、旅游、出差的必备单品\n407504 0 4、楼市拐点显现迎\"三速\"回暖下半年市场或向上\n1000 Processed\n classify content\n408000 0 代发5幅起包邮冰袖进入疯狂订单模式代发\n408001 0 浙江万里学院的空调使用费一年xxx元\n408002 0 徐州1000ml洋酒瓶江苏徐州宏华玻璃科技有限公司洋酒瓶、分酒器\n408003 0 保养皮肤细胞组织有极其神奇的功效:补充皮肤细胞的营养\n408004 0 2000年9月经市政府会议研究同意\n1000 Processed\n classify content\n408500 0 SuitSuit设计的旅行箱将让你脱颖于人群之中\n408501 0 我的不作为恰恰成全了呆板严苛的体制\n408502 0 海通证券H股复牌一度跌17%遭基金抛售\n408503 0 滥用何首乌美发或可导致肝损害和急性发热\n408504 0 有些人靠这种猫腻的关系得了势\n1000 Processed\n classify content\n409000 0 ”警察:“这是对冲动最好的惩罚\n409001 0 塔身由5043块热反射玻璃铺成\n409002 0 满脑子都是“阿里里阿里里”魔性了\n409003 0 手机有电有WiFi有空调有零食时间已过去三分之一\n409004 0 陕北地区执行时间为6月15日至8月15日\n1000 Processed\n classify content\n409500 0 追加了几个成就~另外试试之前解锁不了的那个每日挑战成就修复了没\n409501 0 偶尔来几架飞机的飞行噪音不知道是空军还是义乌机场的飞机\n409502 0 香烟吃的喝的电脑等一应俱全\n409503 0 3、戒常开夜车——久开夜车使生长激素和肾上腺皮质激素分泌紊乱\n409504 0 见证了镇江79岁的杨正龙老人与老伴55年的真情相守\n1000 Processed\n classify content\n410000 0 觉得每一架飞过的飞机清晰到甚至能看到机尾的航空公司的名字\n410001 0 avast昨晚把我电脑重启后居然自己复活了\n410002 0 所以腾讯会吹很多的飓风帮助挂号网上去\n410003 0 因为胚胎细胞的生物合成很活跃\n410004 0 有人说旅游是从自己呆腻了的地方到别人呆腻了的地方\n1000 Processed\n classify content\n410500 0 美国为避免潜艇技术落入苏联\n410501 0 机器人比赛萌翻了市民期待服务及救援机器人在生活中应用\n410502 0 在火箭队血洗湖人的一场比赛中\n410503 1 君浩汽车新春特惠,到店立减xxx元现金,价格优惠品质保证,预约彭皎苹或加微信xxxxxxxx...\n410504 1 xxxxxxxxxxxxxxxxxxx邮政吴小娣。打了发个信息说哈\n1000 Processed\n classify content\n411000 0 空调西瓜电脑真是想不出还有比这更爽的周末配置\n411001 1 凡购买欧莱雅xxxml洗护产品送欧莱雅旅行装xxml或xml洗护产品限选其一,送完为止 凡...\n411002 0 他近日被拍到和Angealababy在片場聊天\n411003 0 现在正在上海新国际展览中心举办\n411004 0 3号线、6号线、7号线、8号线、机场线等9条地铁线路同时在建\n1000 Processed\n classify content\n411500 0 土豆拍客:情人节徐州市淮海食品城发生大面积火灾\n411501 1 华卫中九双模机,央视xxxx加凤凰卫视共xx套节目,批发xxx元。xx台送x台,不插卡不定位...\n411502 0 被这位警察蜀黍罚了xxx块钱\n411503 0 想着一个人一晚上倒3趟飞机\n411504 0 今年的稻田画从x月开始进行种植\n1000 Processed\n classify content\n412000 0 才丰富了瑟缩?抽象几何挂画\n412001 1 凡当天到店装修的业主,均可领取食用油一桶另可享受合同额的x%的装修补贴!并赠送xxxx元苏宁...\n412002 0 少女从天而降这部作品的音乐由久石让负责\n412003 0 这些人都是浙江宁波一群骗子团伙\n412004 0 打开电脑一看竟是这般凄惨的景象\n1000 Processed\n classify content\n412500 0 扬州警方正式对外发布消息称\n412501 0 我在即时PK赛中终于战胜了金州球队\n412502 0 发现电脑里居然有这张…感觉一下子回到了初中…突然想唯一一个撕过的闺蜜了…现在想想撕起来的理由真傻\n412503 0 8月7日股指期货操作策略\n412504 0 我区x家公司的x个产品榜上有名\n1000 Processed\n classify content\n413000 0 外籍京剧比基尼厦门漳州泉州石狮晋江浙江温州杭州长沙南京北京武汉成都外籍模特舞蹈乐队18965...\n413001 0 华为经常抱怨自己在美国遭到不公平的妖魔化——华为迄今未能从美国主要网络运营商赢得一单网络设备合约呢\n413002 1 您好!我是小刚,沧州北环雪佛兰xS店的!咱们八号厂家有批特价车,优惠比较大,而且进店就有精美...\n413003 0 口腔内微生物腐败消化口腔滞留物质产生挥发性硫化物等异味物质是导致口臭的主要成分\n413004 0 有个朋友是清华的法学研究生哦\n1000 Processed\n classify content\n413500 0 我挺难过的我百度了正确的洗脸图片给大家参考下\n413501 0 均能提前24小时在无锡办理值机手续\n413502 0 链接放在评论里面啦~请叫我活雷锋~以后就不要再问我啦\n413503 0 如果股票的走势跟你的头寸相反\n413504 0 贝塔已经整五个月了\n1000 Processed\n classify content\n414000 1 信用社,xxxx,xxxx,xxxx,xxxx,xxxx,xx商柏昆\n414001 0 百姓大舞台xxxx消夏戏曲文艺晚会在新泰滨湖广场拉开序幕\n414002 0 警察叔叔就会把你家鹿晗找来\n414003 0 就好像出去玩被小偷偷了坏人打了报警不管然后警察问我们嗨不嗨一样\n414004 0 到一院后经ct诊断为蛛网膜下腔出血\n1000 Processed\n classify content\n414500 0 所以喜欢衣衣的?我卫星changliang8899\n414501 0 在1860文化创意园为家乡人民献上双钢琴美妙乐韵——“琴系故里—中法钢琴音乐会”\n414502 0 苏州大学文学院重走吴江“舌尖”路的实践团队来到江南古镇震泽\n414503 0 想找朋友们借个腾讯视频的好莱坞会员账号用\n414504 0 楼上楼下同时装修是一种怎样的体会\n1000 Processed\n classify content\n415000 0 今后x~x年最终活下来的是极少数的厂商\n415001 0 毕竟没诚意的是我毕竟我还记得当年JS说过就算她去了别的城市我也可以坐飞机常过去看她我就做不到...\n415002 0 在马勒别墅举办婚礼定会像这座建筑本身一样童话\n415003 0 戳图了解更多知识↓↓↓via人民日报\n415004 0 玩具吃的喝的、防晒、床单、草席、宝贝的被子\n1000 Processed\n classify content\n415500 0 中粮集团的相关上市公司如中粮屯河\n415501 0 我们俩早上一起吃饭然后去上班下班回来吃个美美的晚餐然后窝在一起看电视玩电脑啦\n415502 0 死刑和一辈子给他家做牛做马\n415503 0 就使用我的邀请码n4xen3下载并登录浙江移动手机营业厅\n415504 0 3、机制陈旧不能激励人心\n1000 Processed\n classify content\n416000 0 周边被伊东丰雄设计的L型Tod楼所包围\n416001 0 本案依法适用简易程序进行审理\n416002 0 常州市金坛区气象台7月27日16时发布的高温警报和天气预报:今天夜里到明天多云到晴\n416003 1 您好,深圳市桂花胶管五金商行欢迎您的来电,我商行竭诚为您提供:联塑、深塑胶管及各类品牌胶管,...\n416004 0 不过很多人看起来想靠警察叔叔屠村解决一切\n1000 Processed\n classify content\n416500 0 明早就可以看花千骨啦我要去补今晚的奇葩说啦金星我爱你么么哒\n416501 0 到整形医院要求医生为其做欧式双眼皮\n416502 0 完美而立体感觉的拼接设计风格\n416503 0 x月xx号举行活动狂送四核MX\n416504 0 我们欢迎大小朋友参加~不要再犹豫\n1000 Processed\n classify content\n417000 1 嫌去澳門太麻烦!就来xxxxxx,c○m 意外的惊喜等着你。新年送好运,来了就可得xx。满了...\n417001 0 微软今天正式宣布会在未来几个月逐步裁减x\n417002 0 机器人可在护理设施内根据入住者的数据作出“要是身上哪里疼请告知”、“到量血压的时间了”等提醒\n417003 1 哥哥你好,我叫小玲,四川的,xx了,皮肤白,因为家里困难跟着朋友出来打工,还没有处过朋友,听...\n417004 0 微软魂淡啊…一边占着带宽一边不下东西\n1000 Processed\n classify content\n417500 0 肌肤的细胞不会像其他季节那般活跃\n417501 1 您好:我是唐山朗威 张建炎 唐山朗威进出口贸易有限公司 主营;津西H型钢一级代理\n417502 0 但转而手里仅剩的3000元就被拿走\n417503 0 全市xxx名检察干警参加员额制检察官选任考试笔试\n417504 0 但缩短租期到2020年10月26日\n1000 Processed\n classify content\n418000 0 10086答复几个月前的积分兑换金额不退\n418001 0 目前该国政府正寻求将铝进口关税上调一倍至10%\n418002 0 是谁招来在腾讯就劣迹斑斑的人\n418003 1 你好,我是贵州恒美公司,我公司长期推出:细胞活能,湘飞祛斑,爱人葡萄籽,丽绣媛,三世缘。专业...\n418004 0 没看天天反腐人民生活就多好了\n1000 Processed\n classify content\n418500 0 嗨WhatsApp在iPhone、安卓、诺基亚、黑莓和微软手机平台上都可以使用\n418501 0 男子蹲5年冤狱后用漫画描绘刑讯:被多人砍打折磨\n418502 0 以确保疫情早发现、早控制、早扑灭\n418503 0 任何投资都需具备智慧性的忍耐力\n418504 1 我司代办各户·口本‘毕.业本,身*份正,驾!行#驶正等一切有效正&件,联系:⒈⒊⒌⒌⒌⒏⒐⒎...\n1000 Processed\n classify content\n419000 0 施华洛世奇:独揽水晶财富成就百年传奇家族\n419001 0 FATE后遗症:看APH总觉得眉毛桑每次要攻打别家的时候就要召唤个骑士王啊放个投影啥的了……\n419002 0 松紧腰的设计更贴合身体曲线\n419003 0 我们在7月20号触到196美元的目标价\n419004 0 能不能先评估一下自己的行为\n1000 Processed\n classify content\n419500 0 太傻比了不谈了爱不动哈哈哈eg加油吧\n419501 0 2、白色半透明眼屎:可能患急性病毒性结膜炎\n419502 1 xxxx魅力三八您约吗?新经典约您x月x日至x日惊喜不断.实惠多多!全年仅有一次!我们等你!...\n419503 0 晚上出门不用防晒呀hhh~\n419504 0 還到金沙的57層看整個海岸和城景\n1000 Processed\n classify content\n420000 0 真以为自己大城市了政府无能就想着一刀切地解决问题有没有想过交通问题不好是因为你们的规划不好而...\n420001 0 欠债要钱居然逼得我上百度了\n420002 1 奶粉)一律七折优惠,凡一次性购物满百元的顾客,将会赠送精美礼品一份,千万不要错过啊!地址:...\n420003 0 这是两年来浦口二手房月成交量首次成为全市第一\n420004 1 您好,我是刚刚跟您联系的湖北中贵兴的小朱,公司地址在光谷步行街世界城广场xx楼,如果您需要资...\n1000 Processed\n classify content\n420500 0 名字叫“TheBeatlesPub”但是一晚都没听到一首Beatles\n420501 0 但是并非所有的Lumia手机都可以在第一时间内升级\n420502 0 由于在Firefox浏览器上发现一处严重级别安全漏洞\n420503 0 查获手机70余部、银行卡70余张、豪华汽车5辆\n420504 0 多效炫彩魔法隔离霜50ml保湿妆前乳提亮美白HERA赫拉魔法妆前乳\n1000 Processed\n classify content\n421000 0 大加索尔在南非参加NBA非洲表演赛\n421001 1 美丽女人节到啦!x月x日当天到毛戈平生活馆消费的美女都可得精美礼品一份哦!!毛戈平生活馆全体...\n421002 0 上周投资者从新兴市场基金净赎回xx\n421003 0 WindowsPhone设备x年总销量达到一亿台\n421004 0 我分享了百度云里的文件:?Bad预告版音频\n1000 Processed\n classify content\n421500 0 该市“微密·道客之家”出租车爱心车队的司机们得知此事后\n421501 0 x、省级部门形同虚设不作为\n421502 0 请认准:sozu1991非诚勿扰举报死全家\n421503 0 为官清廉照汗青故居纵火被强拆\n421504 0 我就起床把电脑和手机里的软件都更新一遍\n1000 Processed\n classify content\n422000 1 商场进口化妆区,购买化妆品!最高可返现xxxx元的进口化妆品现金券,还有五级好礼加赠!期待您...\n422001 0 据预测:2015年全球手机成瘾者将达到2\n422002 0 3.植酸酶和木聚糖酶的作用机理\n422003 0 今年我除了你家kindle买了几本书外就没买过任何东西\n422004 0 『神州专车被约谈租车配司机免费接送机被指违法』\n1000 Processed\n classify content\n422500 0 疫情平稳预示发病高峰期已过\n422501 0 x月x日你们迎来了你们的又一个成员\n422502 0 不过这季看起来又是很high嘿嘿哈嘿\n422503 0 原文—风风雨雨暖暖寒寒处处寻寻觅觅\n422504 0 湖北荆州安良百货手扶电梯发生事故\n1000 Processed\n classify content\n423000 0 微软要起诉中国如果成功要赔几百亿\n423001 0 chrome用多了林子聪都见得少了呢\n423002 0 中国银行将在8月下旬组织进行统一笔试\n423003 0 协和医院精心品牌出的两种新品洗面奶\n423004 0 Nxxxxx这款阳刚的Shelton中号手袋以优雅而耐用的DamierEbène帆布制成\n1000 Processed\n classify content\n423500 0 早期看起来有机会做O2O的口碑网、爱帮网、大众点评网现在只有大众活的还不错\n423501 0 华为P8高配版手机还提供一颗500万像素前置摄像头和一颗1300万像素光学防抖后置摄像头\n423502 0 上海南京路外滩白天跟其他大城市一个样\n423503 0 这些遗憾工程大多因为装修过程的误区所导致的\n423504 0 现在大家都知道看5日线、10日线\n1000 Processed\n classify content\n424000 0 每次踏进医院大门心情都是沉重的\n424001 0 来自FireEye的研究员介绍了一种“指纹传感器监视攻击”的方法\n424002 0 其实有个cba的主场放苏州更好的\n424003 0 微软公布2015二季度业绩报告\n424004 0 全镇适龄青年来到常平医院参加了体检\n1000 Processed\n classify content\n424500 0 给大家分享“OfficeMacxxxxspx\n424501 0 新干县人民法院审理了一起民间\n424502 0 微软Win10系统U盘外观曝光\n424503 1 (x/x)感谢您致电保利国际影城.本月xxx元即可入会\n424504 0 仅浙江绍兴企业财产保险报案1300多起\n1000 Processed\n classify content\n425000 0 QQxxxxxxxxxiphone全球卫星GPS定位骗纸\n425001 0 而按在岗年平均72818元来算的话\n425002 1 信阳市宏源供水设备制造有限公司总经理李树成携全体员工祝您在新的一年里生意兴隆!公司主营各种型...\n425003 0 昨天还在质疑我的人类朋友称卡丁车是一项运动\n425004 0 在这个看花千骨的年纪我迷失在…\n1000 Processed\n classify content\n425500 0 对我来说我完美理想中的夏天是这样的\n425501 0 直通937直播贴:19岁的小王14岁左右就辍学随父亲到苏州打工\n425502 0 Dior迪奥真我100ml香精十7\n425503 0 周杰伦苏州站演唱会门票都买不到\n425504 0 分10点和15点俩时段分别7折秒杀华为荣耀4X、小米4、iPhone6\n1000 Processed\n classify content\n426000 0 基地的三角形飞机在头上绕来绕去\n426001 0 当时五一大道还在修地铁只觉脏乱\n426002 0 如果陪儿子也能像看花千骨一样有兴趣就好了\n426003 0 这时只有股票躲在角落闷闷不乐:你们真幸福\n426004 0 支持Android、Linux、Windows10\n1000 Processed\n classify content\n426500 0 在去硅谷的路上把手机丢了是种怎样的体验\n426501 0 侦查人员在审判阶段作为证人出现\n426502 0 刚下飞机就被眼前的一幕惊呆了:汉城金浦机场将一个专门通道留给这对新人\n426503 0 就使用我的邀请码95725e下载并登录浙江移动手机营业厅\n426504 0 要教会x岁以上的孩子一些基本逃生技能\n1000 Processed\n classify content\n427000 0 阿里巴巴农村淘宝事业部中西部大区经理崔会敏应邀到我县商投世纪中心、亿联专业市场、皂角社区\n427001 0 带着会闪红光的棒棒的police都过去了喂\n427002 0 一起制造正义的巨大机器人吧~\n427003 0 加入立省100、只要你舍得一个228\n427004 0 先来看看BB霜的成份剖析和相关报告\n1000 Processed\n classify content\n427500 0 重要事要说三遍到底谁管到底谁管到底谁管\n427501 0 一天数次体会到百度和谷歌的差距…先搜申必达\n427502 0 中国纺织工业联合会在连云港组织召开了由中复神鹰碳纤维有限责任公司、东华大学、江苏鹰游纺机有限...\n427503 0 就算再加油大概不会漏那么多了\n427504 0 而多名江苏舜天队员最后时刻情绪非常激动\n1000 Processed\n classify content\n428000 0 经常旅游出差的、乘飞机、轮船、坐汽车\n428001 0 参保患者在医联体内医疗机构间分级诊疗\n428002 0 xxxx华为Px……哪个是你的菜\n428003 0 指出正常的DNA损伤应答能力在造血干细胞维持其自我更新能力中扮演不可或缺的作用\n428004 0 为啥这样的害群之马不判死刑\n1000 Processed\n classify content\n428500 0 极客早点:IBM连续xx季收入下滑\n428501 0 江苏华绿生物科技股份有限公司在北京全国中小企业股份转让系统公司举办“新三板”挂牌仪式\n428502 0 我居然记错挑战者联盟的播出时间\n428503 0 三亚学院2015年在江苏省艺术、体育类专业二志愿投档22人\n428504 0 看到这种有损南京形象的行为就很讨厌\n1000 Processed\n classify content\n429000 0 设计者用虚化的背景突出歌曲的名称\n429001 0 仅3秒就将约13吨的公交车抬了起来\n429002 0 当场抓获熊某、沈某等9名嫌疑人\n429003 0 交10年保20年说给你年固定收益12%\n429004 0 刘秋江泉州市中医院副主任医师患者满意度100%擅长中西医结合治疗痔疮、肛瘘、肛周脓肿、肛裂、...\n1000 Processed\n classify content\n429500 1 亲爱的帝瑞美顾客开年有大礼哦!机不可失,时不在来!凡在x月xO日前到店顾客及可享受抽奖一次!...\n429501 0 微软与诺基亚分道扬镳Lumia何去何从\n429502 0 今天我们就一起走进HAMANN\n429503 0 在19楼上找到了那个所谓的相亲大会的真相\n429504 0 也是北仑城管局长期坚持的重点工作\n1000 Processed\n classify content\n430000 0 所以说Google跟Baidu的差距有点大\n430001 0 江苏卫视配音版继承者们简直哭瞎\n430002 1 【泰禾厦门院子·首玺】海沧第一海景高层,地铁口,公园旁,名校学区房,xx分钟进岛!xx-xx...\n430003 0 河北区区政府天天这么热闹啊\n430004 1 您好,我是国和嘉孚东风雪铁龙销售顾问贾海鑫,很感谢您对东风雪铁龙的关注!本周周六周日为了庆祝...\n1000 Processed\n classify content\n430500 0 中粮集团前三个月产生的利息支出约为19\n430501 0 短裤的半裙摆设计也非常特别\n430502 0 小家伙能够实现170°广角扫描\n430503 0 确定我市20台申龙电梯中没有发现“吃人”电梯型号\n430504 0 吴亦凡诉讼细节曝光:公司视我为机器零件\n1000 Processed\n classify content\n431000 0 第10集:工厂也会有土壤污染问题吗\n431001 0 大半夜的我用水果手机拍的夜间飞行\n431002 0 如果你觉得对手机和电脑强迫症的我是喜欢新鲜事物\n431003 0 退休成了雨花台区板桥新城管委会新林社区的社区治安志愿者\n431004 0 如果你的车配备了ECO发动机启停功能\n1000 Processed\n classify content\n431500 0 由北京往上海方向苏州段xxxxK附近现场车多缓行\n431501 0 快tm被电脑气哭了什么玩意儿啊等了20分钟储存失败\n431502 0 所以说那个州是不是没死刑只有终身监禁\n431503 0 这时一个棉花糖小贩吸引了小朋友们的注意\n431504 0 欢迎爱恶搞、爱疯、爱玩、爱冒险、爱吃\n1000 Processed\n classify content\n432000 0 bigbang南京场1280\n432001 0 不要盲目不要去乱推广反而被骗觉得我们其他推广怎么怎么样\n432002 0 短尾的设计使整个车身更加精致\n432003 0 河北法院在全省开展打击拒不执行判决、裁定等\n432004 0 我这边上microsoft我都要挂vpn你们是等着我们都去工信部投诉么\n1000 Processed\n classify content\n432500 0 2018年底前将致力于5G标准化制定\n432501 0 x牛奶体膜xx布丁粉x盒bb面膜x防晒美白喷雾\n432502 0 爱笑有责任心上进心在南京有稳定工作\n432503 0 有网友愤怒问道:好声音是外国的\n432504 0 菲特·泰斯特罗莎·哈拉温\n1000 Processed\n classify content\n433000 0 九图↓↓↓了解那些汽车的隐藏功能~\n433001 1 亲爱的姐姐您好,三八节将到,【珂莱蒂尔】小曼,提前祝您节日快乐永远年轻漂亮。x·x—x.x有...\n433002 0 理想17层女生洗手间捡到一个工卡\n433003 0 使用阿拉斯加的TourSaver酷胖\n433004 0 买下位于白厅的伦敦警察局旧总部\n1000 Processed\n classify content\n433500 0 太原市九一小学2015招聘教师疑似内部操作\n433501 0 我分享了百度云里的文件:\n433502 0 有很多小型店铺装修得精致的\n433503 0 解放军总医院心内科陈韵岱教授做了题为“STEMI和NSTEMI治疗策略解析”的精彩报告\n433504 0 一颗基因突变的葡萄~??\n1000 Processed\n classify content\n434000 0 百度才知道杀姐姐的演员的名字才是马可\n434001 0 在旅游的同时也有好多美味的小吃和当地海鲜\n434002 0 忽略winphone用户的经济能力\n434003 0 众多果粉纷纷发帖抨击iOS7之丑\n434004 0 召陵区法院在八一前夕召开涉军维权新闻发布会\n1000 Processed\n classify content\n434500 0 xxx的两张xx区x排位置非常好非诚勿扰\n434501 0 贵州人听了气到说\"贵阳有座钟鼓楼\n434502 0 求一张bigbang南京场票\n434503 0 ANGLE公主完美的融合了麻麻的美貌与粑粑的帅气\n434504 0 不知不觉学C语言已经两个星期了\n1000 Processed\n classify content\n435000 0 白领丽人苹果干细胞面膜中国第一款专注荧幕辐射而研发的面膜护肤达人最喜爱的一款面膜\n435001 0 全部建筑以欧式和俄罗斯风格为主体\n435002 0 遇到一个会remix的有才老爸\n435003 0 现在积极沟通派出所那边松口了\n435004 0 打开电脑回忆一下我的部队生活…两年时间很充实\n1000 Processed\n classify content\n435500 0 刚刚得知xx月有南京场小兴奋头脑预估了一下瞒着爸妈省钱洗眼的可行度\n435501 0 大中午顶着太阳去了躺房产交易中心\n435502 0 以后对着电脑得节制些…肩膀好痛…\n435503 0 我们医院今年进了十几个博士\n435504 0 都有一颗向往大海的心~这个夏天\n1000 Processed\n classify content\n436000 0 Whoo后全国第一家体验式专柜\n436001 0 加强信用监管中国规划建设“全国一张网”\n436002 0 房地产开发公司的法人还是金台房管所所长\n436003 0 单笔充值满100元即送10元话费\n436004 0 不用小米华为的年青人心态是老的\n1000 Processed\n classify content\n436500 0 结果医生听了下胎心就开一堆单子叫我缴费\n436501 0 美方对德政府部门的监听活动就已经开始\n436502 0 今年x月拟定的一份软件出口监管法规\n436503 0 目前启动区规划面积为10平方公里\n436504 0 杭州升沃医院管理有限公司招聘市场推广主管\n1000 Processed\n classify content\n437000 0 我宁愿这样的真相一辈子被成为被时光掩埋的秘密\n437001 1 奥华助您开门红!红!红!凡xxxx年x月x日前进店客户均有红包赠送,更有定金双倍抵满额送智能...\n437002 0 大关派出所将潜回家中取钱的倪某抓获归案、依法刑拘\n437003 1 【惠达汽车】x月优惠活动:来店既有免费安全检测服务;保养更换机油赠送机油格一个;购买精品满x...\n437004 0 celine鞦韆再添新色細節什麼的都棒棒的此色更是秋冬調調大氣卻不張揚低調又耐看好搭配的顏色...\n1000 Processed\n classify content\n437500 0 感觉像强奸犯说强奸不是为了性欲\n437501 0 亚马逊公司耗资10亿美元收购了视频网站Twitch以加强游戏视频相关业务\n437502 0 为什么要送她去医院”该休矣\n437503 0 佛山市禅城区—开心大药房松凤分店\n437504 0 当月的指标出来后还是提前就填好呢\n1000 Processed\n classify content\n438000 0 上海华美医疗美容医院的叶丽萍医生怎么样\n438001 0 上了一天的课终于熬到放学立马赶去看\n438002 0 裁判我儿也好这些都是一种传承\n438003 0 惠普重点为中国医疗机构提供两种方便\n438004 0 7月广州中心六区二手住宅交易涨幅微弱不足1%\n1000 Processed\n classify content\n438500 0 原材料战略性投资周期降临\n438501 0 也是被LP南京演唱会的评论弄醉了…1个半小时嫌短\n438502 0 认证信息为“江苏省海门市公安局民警”\n438503 0 日本一架小型飞机起飞后仅不到x分钟便坠落至东京都调布市民宅\n438504 0 人吧在松懈的时候抬个头都会发现连个地铁都在给你敲警钟有点想呕\n1000 Processed\n classify content\n439000 0 再指使手中女性用B去贿赂C换D\n439001 0 今年一定要去南京看李志的跨年\n439002 0 就使用我的邀请码jz4r5p下载并登录浙江移动手机营业厅\n439003 0 春晖路175号的店铺目前正在装修中\n439004 0 最近最爱我的就是各保险公司了\n1000 Processed\n classify content\n439500 0 metrostation地铁站\n439501 0 省政府部门和市政府部门都查出不少的贪官污吏\n439502 0 中国建筑第二工程局有限公司公司简介\n439503 0 氾水镇2015年夏秋季征兵体检工作正式启动\n439504 0 请不要被中国那几位转基因大腕院士专家包括农业部正副部长蒙住眼\n1000 Processed\n classify content\n440000 0 我只能说遇上xxx一样的裁判\n440001 0 我发表了文章——求职碰上“黑中介”怎么办\n440002 0 来自江苏省的收割机车队分布在青原区的各条道路\n440003 0 瀚沃独家采用全球500强无甲醛+分解甲醛的环保新辅料啦\n440004 0 以前都还要一直在电脑上翻翻翻翻翻翻\n1000 Processed\n classify content\n440500 0 我县食药监局进行了电梯安全大检查\n440501 0 xx年先提出的解约你们方既然同意那还跟我家有什么关系\n440502 1 佳贝艾特羊奶粉x月x号双倍积分哦!购买x听就可以兑换相同的产品x听了!另有好礼相送!南门以恒母婴店\n440503 0 认证信息为“腾讯文学作家”\n440504 0 吃中药的日子不能吃凉不能吃辣\n1000 Processed\n classify content\n441000 0 com无锡唯一专注设计培训的权威机构CG插画讲师:8年CG插画经验\n441001 0 10086告诉我系统升级没办法帮法我开通\n441002 0 2015全球比基尼小姐中国大赛开赛最小16岁\n441003 0 好像有很多gn因为有事没办法来\n441004 0 浙江每一万个人中就有801个老板\n1000 Processed\n classify content\n441500 1 春来气爽¥貸神出场¥元宵已过¥嗨爆深广!房$屋¥貸¥歀从无对手、年化低至x/厘、高评高$貸....\n441501 0 她将前往哈尔滨参加7月23日开幕的2015年全国速度轮滑锦标赛\n441502 0 原价xxx、xxx的钱包现在只卖xx元\n441503 0 京津翼、体育、水务等板块跌幅居前\n441504 0 是将豆角、猪肉、土豆、西红柿、茄子依次入锅\n1000 Processed\n classify content\n442000 0 今天听医生说除了生猪肉、生牛肉、鲨鱼、三文鱼不能吃其他都没问题\n442001 0 单场得分超过100分的并不在少数\n442002 0 中国天文学会xxxx年度卫星激光测距技术与应用研讨会在云南澄江召开\n442003 0 州法院以整治发改案件为侧重点和突破口\n442004 0 6月份的费用已在7月24号的时候缴纳\n1000 Processed\n classify content\n442500 0 求问~去哪办扬州景区老年卡\n442501 0 虽然都在江苏还是要xxx多公里的\n442502 0 附近居民误以为是发生强奸案报警\n442503 0 说不定还能遇见给个50给我唱个小曲呢\n442504 0 于今天白天在浙江温岭至舟山一带沿海登陆\n1000 Processed\n classify content\n443000 1 你好姐 我是漯河新玛特玉兰油小张 咱们三八节活动明天开始了 满xxx减xx满xxx减xxx...\n443001 0 为何还产生了30多元的漫游通话费用\n443002 0 皮肤粗糙的原因一:在干燥的冬季\n443003 0 江苏省厅专家组调研宿迁数字化城管工作\n443004 0 nkxxx和monxxx型玉米转基因玉米等\n1000 Processed\n classify content\n443500 0 电视台被我们承包了我谁都不约\n443501 0 逃去南京博物馆把剩下的部分看完\n443502 0 MININSCE2015用激情\n443503 0 离开马累的时候飞机上拍到了云中彩虹\n443504 0 预计x月底至xx月初能开园迎客\n1000 Processed\n classify content\n444000 0 小额贷款保证保险支持的贷款对象为三类人群\n444001 0 这些建筑设计行业的潜规则太可怕\n444002 0 告诉你们一个秘密:洗脸的时候\n444003 0 7号线广渠门到九龙山沿线上联通怎么没有手机信号\n444004 0 动漫PSP旅游侵没事瞎想的双鱼\n1000 Processed\n classify content\n444500 1 活动。送你一次健康美丽之旅。活动期间四面山景区将对所有女性朋友实行免费开放,陪同男伴只需xx...\n444501 0 巴西前国脚强奸女星被判入狱32个月\n444502 0 宿城区劳动西巷容娜色彩门口沿街晾晒\n444503 0 中国好声音都是土豪玩的游戏\n444504 0 许多新款手机外壳配件什么的我都是在微信更新的\n1000 Processed\n classify content\n445000 0 你所找到的小饰品店装修图片又是什么样\n445001 0 这个本上基本都是逆转裁判和FF也是蛮拼……\n445002 0 贼TheboytoldmethatIwasathiefwhostolehismemory\n445003 0 前者轮奸加拐卖可盼死刑到无期的话追诉时效应该没过但抓人估计有困难\n445004 0 就是我家的纯天然果汁Fcup??\n1000 Processed\n classify content\n445500 0 因为总把液体防晒霜不小心蹭到衣服上\n445501 0 皖BH9785白色长安小型汽车送往芜湖市抢救\n445502 0 2015年流年为二黑病符星入宫\n445503 0 8月2号飞机韩国新罗免税店人肉背回\n445504 0 makeupforeverHD散粉\n1000 Processed\n classify content\n446000 0 适合12~60岁的所有健身人群\n446001 0 本门从昆山定远快刀帮夺得化功大法残章二\n446002 0 目前A股中石化具备了巨大的价值投资机会\n446003 0 刚到的现货:DHC唇膏、DHC瘦腿丸、新谷酵素加强版、花王眼罩\n446004 0 评估到伦敦大学国王学院的入学率?\n1000 Processed\n classify content\n446500 0 百度提供内容、技术、人力、运营资源进行独家运营\n446501 0 从x月初就抢你们那个北京地区的红包\n446502 0 也是俄“xxxx国际军事比赛”的开幕式\n446503 1 持码主,xx.xx.xx.防.xx.xx.xx.xx.xx.xx.xx.xx.家肖中,\n446504 0 公司股票将于7月13日起复牌\n1000 Processed\n classify content\n447000 1 亲爱的姐,您好!我是WHOO后专柜的美容顾问任园。现在我们商场搞“三八”妇女节的活动,现在我...\n447001 0 可能于xx日早晨从我省东南部入境\n447002 0 才知道花千骨也是业界良心了\n447003 0 所以子宫的保养就显得比身材和皮肤重要子宫保养品筑美雪莲贴你最正确的选择\n447004 0 今天是湖北荆州电梯事件死者的头七\n1000 Processed\n classify content\n447500 0 后期将转变为住区的会所商业\n447501 0 安卓手机可以下一个空调精灵\n447502 0 3、用冰冻过的化妆水拍脸蛋\n447503 1 亲,晚上好,深南天虹巧迪尚惠祝你元宵快乐! x月x日至x月x日活动开始啦!全场x件即可享受x...\n447504 0 当晚有海门市残疾人联合会组织\n1000 Processed\n classify content\n448000 0 和我国古建筑中的力士雕像对比\n448001 0 乐视的1080p恰恰说明它是转码的\n448002 0 哈尼药浴寻根之旅走进阿者科古村落\n448003 1 <新 - 葡 - 京>,首 次 存 立 送 . xoo%,地址:x x x x x x...\n448004 0 高品质净菜已成为欧美等发达国家蔬菜消费的主流\n1000 Processed\n classify content\n448500 0 设计:ramonaenache\n448501 0 熟悉的装潢似曾相识的BGM和味道\n448502 0 这就会造成大家在找SEO优化公司的时候比较困惑\n448503 1 您好,我是巴特利橱柜导购,x月x日-x月xx日我们巴特利实木家具定制橱柜,厂家大放价,价格保...\n448504 0 天呐刚刚看到妙脆角的广告吓得我手机差点掉了\n1000 Processed\n classify content\n449000 0 你身边还有5个随时收你命的东西\n449001 0 一个人就是一只漂泊的风筝总是衔着乡愁在混沌与忙碌中\n449002 0 其实给个垃圾微软的建议:如果所有的wp手机都能升级到win10\n449003 0 xxxx款新胜达是第三代胜达车型\n449004 0 预计将于xxxx年上半年开业\n1000 Processed\n classify content\n449500 0 今年大半年没有出门旅游过一次\n449501 0 在amazon买了个u盘、上面都是中文说明\n449502 0 “itlittleprofitsthatanidleking\n449503 0 UtenaPures佑天兰蜂王浆玻尿酸保湿面膜又来啦\n449504 0 给大家分享\"killmehealme\"\n1000 Processed\n classify content\n450000 0 因为官位还在任上前有腐败没发现\n450001 0 他每一次不送我飞机的理由都是我不想看着你哭\n450002 0 位置在MONTEREYPARK\n450003 0 中国房地产市场面临十分严峻的考验\n450004 0 现在投资一双运动鞋比购买一双高跟鞋更划算\n1000 Processed\n classify content\n450500 0 黑色~新款Ash运动鞋采用经典运动风款式设计\n450501 0 实习生太好看了郑恺的行为帅到不行\n450502 1 我行最新推出幸福易贷信用贷款,无需抵押担保,手续简便,审批快捷,年综合成本x.xx%左右,详...\n450503 0 x分xx秒开始有~后面掉下来的东西是什么\n450504 0 在夏日重燃读书的热情~最新好书\n1000 Processed\n classify content\n451000 1 新春好!我是合肥润安印刷厂,本厂承接黑白彩色印刷,发货及时价格好说,如需可联系qqxxxxx...\n451001 0 湘潭中院对发生在12年前的“湘潭大学研究生杀人案”一审宣判:判决被告人曾爱云无罪\n451002 0 他们来到浙江美大总部参加超级团购会\n451003 0 我觉得我可能有精神病被害妄想症焦虑症还有轻微精神分裂和暴力倾向求推荐心理医生\n451004 0 称离WindowsXP退休还有95天\n1000 Processed\n classify content\n451500 0 1000以上者均送唤醒健身至尊VIP卡一张喔\n451501 1 北鼻,卓而美女人春光乍泄,进院红包xx-xxx元拼手气,免费脱毛丝滑迎夏。消费就有豪礼,爱疯...\n451502 0 我明天上午还要坐飞机回巫溪\n451503 0 浙江金华发生了一起倒车引发的车祸\n451504 0 常州市西绕城高速江宜方向转武进经发区匝道标线施工结束\n1000 Processed\n classify content\n452000 0 摩羯座:★★江最美之浙江六大岛屿\n452001 0 王林被指承诺“判邹勇死刑酬谢500万”\n452002 0 在他100岁时曾因在中医中药方面的杰出成就获政府的特别奖励\n452003 0 很明显7月的最后一周只剩下次新股\n452004 1 尊敬的会员您好,我是东二环百盛珀莱雅专柜的美容顾问,三八妇女节到来珀莱雅新品水x.x折,特惠...\n1000 Processed\n classify content\n452500 1 尊敬的客户,首先我代表御邦感谢您一直以来的支持,本店将在春节举办全场酬宾活动,消费满xxx元...\n452501 0 南京灵谷寺上万萤火虫飞舞美如繁星——在南京紫金山上\n452502 1 本店庆美丽x.x妇女节,添姿化妆品店全场买满xxx元送xxx元蚕丝面膜,活动时间x.x――x...\n452503 0 围绕市委、市政府的工作重点\n452504 0 我情愿捐个无国界医生或希望小学\n1000 Processed\n classify content\n453000 1 【莱特妮丝】武广莱特妮丝三.八钜惠:即日起至x.xx全场xx元起,低至x.x折,限量经典款全...\n453001 1 寻找项目合作,财力国内中小型企业发展,新建、扩建、新项目研发,农业合作,手续简单,到位快.陈...\n453002 0 在PowerSystems上\n453003 0 至少先砸xxxx萬元……資源稀缺、權力失範\n453004 0 住别墅的不一定开好车菜市场买菜的老太太没准是某个领导的家属你接触的人多了就会发现能咋呼的不一...\n1000 Processed\n classify content\n453500 0 上述两个基金6月底的股票仓位很轻\n453501 0 首先:我们要在桌面上新建一个文件夹\n453502 0 日照的农村确实不能跟南京比啊\n453503 0 第四季中国好声音现场演唱周杰伦的著名作\n453504 0 实拍威航特别版狂奔380km/h\n1000 Processed\n classify content\n454000 0 小偷靠着抄袭出名现在转战电影圈\n454001 0 周董谈崔健尴尬互动投票:你支持艾克拜尔重返好声音吗\n454002 1 新年好!恭喜发财!我是君成兴包装器材的小陈,我司已正常上班,在新的一年里希望更好的为您服务!...\n454003 0 via武汉晚报~喃们想说点啥\n454004 0 一起出门被说像被拐带/家长带小孩\n1000 Processed\n classify content\n454500 1 各位朋友,本犬舍提供优质日系纯种秋田犬(赛级),家养!有需要的朋友可联系微信xxxxxxxxx\n454501 1 晨曦简讯:杨清忠教授和叶仲泉教授将在重师传授考研各科复习的独家秘笈 地点:弘德楼xxxxx ...\n454502 0 和那个强奸杀人犯都没有想到\n454503 0 违法后派人就得知的我的隐私来派人问、来打听的是他\n454504 0 Gx京沪高速由上海往北京方向无锡段从xxxxK至xxxxK施工结束\n1000 Processed\n classify content\n455000 0 每一处细胞都因此而肝肠寸断\n455001 0 tag和弹幕不要太真相www\n455002 0 所以室内设计越来越越来后期的软装搭配来呈现的室内设计效果\n455003 0 可免费获得36周年庆免费定制西服礼服一套哦\n455004 0 在360和腾讯之间我选择了腾讯\n1000 Processed\n classify content\n455500 0 要求近xxxx名农村中学生统一就读县城新打造的崇文中学的帖文\n455501 0 陇南市检察院检察长高连城在市国土资源局开展“学好法\n455502 1 会议期间xx变频机仅需xxxx元(仅限会议当天),抢到即是赚到!真诚的期待您的大驾光临!祝万...\n455503 0 法院应当继续审理民间借贷纠纷案件\n455504 0 人心险恶中国社会太腐败\n1000 Processed\n classify content\n456000 0 三天三夜——东极岛のHigh翻虐翻自助游\n456001 0 男孩:“难道你的飞机是真的”\n456002 0 对于如何依法订立遗嘱毫无了解\n456003 1 我行利率从本日起上浮xx%(有金额和期限要求),各位尊敬的客户如有需要,可电话联系。感谢您对...\n456004 0 飞机刚上天就出事转了一个圈下来了\n1000 Processed\n classify content\n456500 0 宜兴新天地广场小马名店开工大吉\n456501 0 这里曾是汪政权伪都南京前的临时办公处\n456502 0 大家看看张老在本月24好直白盘前推荐大家跟踪的个股中国卫星\n456503 1 尊敬的客户:欧派新迎x.xx工厂大促销!特价xxxx元:超长x米橱柜+石英石台面,配热销吸烟...\n456504 0 被骂了多年blx也saybye了\n1000 Processed\n classify content\n457000 0 喜欢那里的老建筑屋顶上的绿树\n457001 0 一个把老百姓的居住权健康权和受教育权拿来拉动经济的政府\n457002 0 南岸法院王子伟院长率班子成员到江北法院交流座谈\n457003 0 以后电脑要i7的千万不要买笔记本\n457004 0 2挂壁公路挂壁公路是在悬崖峭壁上开凿而出的\n1000 Processed\n classify content\n457500 0 买手机她丈夫打电话删除联系人\n457501 0 感受着据说开挂的特效~良心来说\n457502 0 九月全国100场巡回“独创商业模型”分享\n457503 0 xx元就在亚马逊买到了这本的Kindle版\n457504 0 MKC在选料、造工、装配和配置方面都将超越福特翼虎\n1000 Processed\n classify content\n458000 0 野蘑菇别乱吃轻则伤身重则丧命\n458001 0 反腐岂不成了一句空荡荡的口号\n458002 0 呼吁对做假食品者判“死刑”\n458003 1 亲爱的姐姐三八妇女节即将到来,祝你节日快乐、越来越年轻漂亮!本店面部护理全部打x.x折 养生...\n458004 0 “弘扬王杰精神传承剪纸艺术”邳州剪纸传承人培训班开班\n1000 Processed\n classify content\n458500 0 南京也曾出现过水质性缺水而搬迁取水口的情况\n458501 0 共同探讨浙江省建筑涂料生产现状\n458502 0 而我们就像机器人上了发条一样\n458503 0 沈阳市地铁规划图新鲜出炉啦\n458504 0 感谢x位刚从美国WPS微软全球合作伙伴大会回来\n1000 Processed\n classify content\n459000 0 七成实习生赔钱赚经验:月薪在2000元以下\n459001 0 手机号尾号可以暴露你的年龄\n459002 0 拆个迁特警城管交警集体出动\n459003 0 现在我在崇安寺云蝠大厦的格林希尔的英语机构做传销\n459004 0 0LE标准的iPhone或Android智能手机上安装配套应用\n1000 Processed\n classify content\n459500 0 本门从景德神龙玄武坞夺得吸星大法残章四\n459501 0 后来来了一个叫做腾讯的坏人抓走了母企鹅\n459502 1 海宁民力担保:企业还贷、应付款相关业务!请提前两天预约!地址:海宁市政府南(文礼路)尚东写字...\n459503 0 英语回到Thefirstdayatschool\n459504 0 祝你成功····呵呵···相信你自己可以的\n1000 Processed\n classify content\n460000 0 手机各大部件相继开始失灵异常认真的开始思考换哪个手机比较好\n460001 0 说多了都是泪话说在来徐州的路上\n460002 0 在my花的话题围观得入迷买了个冰淇淋吃就把要带医院去的东西落在人家店里了\n460003 0 把我的犯罪因子都快晒出来了\n460004 0 为了做一个\"献给不知道能否坚持下去的你\"健身洗脑小视频\n1000 Processed\n classify content\n460500 0 捍卫法官的尊严就是捍卫法律和广大人民共同意志的尊严\n460501 0 如果你还在用毛巾随意擦擦脸你就等着毛孔越来越大吧\n460502 0 每天打针吃中药只想好点让我睡个安稳觉\n460503 1 xx期:〖六肖中特〗→→羊龙猪狗鸡猴←←開:?xx准\n460504 0 所发生的属于基本医疗保险报销\n1000 Processed\n classify content\n461000 0 本门从黔江玄武坞夺得寒冰绵掌残章一\n461001 0 又去面圣了~然而这场看得我很不开心\n461002 0 我磊手机铃声还真的是那首歌哦wwwwwwww\n461003 0 根本原因是政府当着婊子同时却要医生帮他立牌坊\n461004 0 發現真相與母親與2子口述似乎「完全不同」\n1000 Processed\n classify content\n461500 0 想知道您的应用有没有黑白边吗\n461501 0 认证信息为“FEELONE模特经纪人”\n461502 0 ROSESHIREHEZ盒装玫瑰花束\n461503 0 刚才貌似听到飞机从楼上飞过\n461504 0 至少要在百度上创造一个属于自己荣耀\n1000 Processed\n classify content\n462000 0 希望不是伤病原因viatwitter\n462001 1 安化茯砖茶内独有的“金花”——学名“冠突散囊菌”能有效调节人体新陈代谢,并有减肥去脂、和顺肠...\n462002 1 石林宜信普惠信用借款公司,办理无抵押信用借款,上门服务,x千到xx万,最快当天通过欢迎来电咨...\n462003 0 澳洲旅游局日前在官方社交网络上张贴了一张袋鼠的照片\n462004 0 由此而产生的百度商业想象空间巨大\n1000 Processed\n classify content\n462500 0 为好房子配好装修——什么是好装修\n462501 1 吴江行政核心区域【亨通长安府xx--xxx平米】轻轨学区准现房,您想不到的优惠和超值 来前提...\n462502 0 但通过滥用政府补贴、政府救济和扶持等手段\n462503 0 广州南站居然还有装聋哑让人签名骗钱的\n462504 0 2015新款外套男秋装韩版潮休闲夹克男士春秋薄款修身上衣青年男装\n1000 Processed\n classify content\n463000 0 在业界最权威的CPU基准测试SPECCPU2006中\n463001 0 累计有8000余个家庭报名参加活动\n463002 0 不用开药方 白菜萝卜汤\n463003 0 差的货借我xx个胆子我也不敢做\n463004 1 京宇轩健康养生会所。主营:足浴按摩。TEL:xxxxxxx。地址:新垵新盛路xx号悦实广场四...\n1000 Processed\n classify content\n463500 0 重要的事说三遍:加油、加油、加油\n463501 0 宿迁哪里有好吃的好吃的好吃的好吃的好吃的\n463502 0 加油哦还有半个小时的时间可以继续\n463503 0 我分享了百度云里的文件:?02\n463504 1 播、点播和回放,功能费xx元/月,x年仅需xxx元,还赠送网络机顶盒。详询双滦联通xxxxx...\n1000 Processed\n classify content\n464000 0 偶然捡到的徒弟正好都是高考还是常州的好巧好巧徒弟高考完买了外星人开电影级玩剑三……一直在截图……\n464001 0 将你的生命投资于大众身上时\n464002 0 但整个滨海新区的指数并没有异动\n464003 1 经理你好,生意兴隆,万事如意。我公司可以免费办理光大,交通,农行,浦发信用卡。移动带积分提额...\n464004 0 一个不想做临床医生的临床专业学生的实习日记:2015年8月6日\n1000 Processed\n classify content\n464500 0 因为自3·30房地产新政以来\n464501 1 x元秒江汉区一套房,【福星华府】xxxx元/平起秒xx-xxx平限量房源,双地铁学养房,活动...\n464502 0 垃圾勒涩土狗日脓包戳锅漏\n464503 1 来店消费的话全场xx折优惠,前进店汤臣倍健陆小姐\n464504 0 安卓机器人“阳扬”于上海高岛屋登场厉害\n1000 Processed\n classify content\n465000 0 協助你打造13億美元市場的網路事業\n465001 0 位于墨尔本大学和RMIT皇家理工大学之间豪华公寓\n465002 0 城管的首要任务不是掀水果摊\n465003 0 其实我知道我已经赢了可是我就是想打破砂锅问到底我就是想把真相拿出来让他哑口无言可这样对我自己...\n465004 0 卫星再一次使出了机械化TvZ\n1000 Processed\n classify content\n465500 0 烟台市公安局统一部署全市公安机关全面启动一级巡逻防控工作\n465501 0 张师傅驾驶46路公交车行至航海路七里河站\n465502 0 每幅竟然以1000美元的价格被卖掉了\n465503 0 而且建筑师的梦想总觉得很突然\n465504 0 「In影白」人生的這場馬拉松\n1000 Processed\n classify content\n466000 0 没有女生家里没有一脚修脚的牛仔长裤\n466001 0 那么滨湖区省实验名校有哪些呢\n466002 0 手机已报废好想去卖肾啊谁要\n466003 1 农行xxxxxx xxxxx xxxx xxxx张小玲\n466004 0 ||我在氧气听书收听“0001妾本惊华”\n1000 Processed\n classify content\n466500 0 好喜欢的一首歌可惜男声唱不了明天带着小U上飞机回家再好好练>\n466501 0 mx更新sensex也要等到八月份\n466502 0 5天4夜几乎全程都是刚下车就开始吐\n466503 1 阳光瑞城业主:新年好![来就送新年礼][x:xx~xx:xx]针对您小区户型设计解析会,房型效果图\n466504 0 深深觉得我司电脑该淘汰一批了\n1000 Processed\n classify content\n467000 0 冰丝防晒袖套男女长款防紫外线开车手套骑车臂套袖\n467001 0 东北风今天夜里4到5级阵风6级\n467002 0 当腹泻男被困电梯41小时\n467003 0 我觉得也是第一次这么清楚明白的懂得咫尺天涯什么意思\n467004 0 每次都输在支付上美客会VIP会员卡在手然而并没什么卵用\n1000 Processed\n classify content\n467500 0 4GDDR3内存和定制版的GeForceGTX860M\n467501 0 USC商学院MBA毕业生Jing\n467502 0 发现A有好多开房纪录而且时间密集\n467503 0 今年底AndroidM会随最新的Nexus设备一起发布\n467504 0 三宅一生pleatspleasexxxx秋冬一览网址\n1000 Processed\n classify content\n468000 0 6159手、18600手每隔几分钟频现\n468001 0 今天奔波了一天的医院各种检查\n468002 0 南京市人民检察院依法对林飞以涉嫌玩忽职守罪、受贿罪决定逮捕\n468003 0 方大集团合计中标x亿元轨交屏蔽门合同\n468004 0 我在Dosnap分享了一张涵宁的作品\n1000 Processed\n classify content\n468500 0 大家好本人现在在做枸杞这个行业\n468501 0 跟犯罪嫌疑人眼神交汇的时候内心还是有战栗的\n468502 0 宝宝xx天每天拉大便的次数很多\n468503 0 如把老百姓的住房医疗教育养老问题解决了\n468504 0 以扬州万松山、金钱墩、象牙林、葵花岗四大名景为主题做成了松鼠桂鱼、金钱虾饼、象牙鸡条和葵花斩...\n1000 Processed\n classify content\n469000 0 太原市中心医院皮肤科在门诊广场举办了“美丽从健康皮肤开始”大型公益义诊活动\n469001 0 而且不得不说好声音的唱的真心不如原唱\n469002 0 而Citadel是全球最大的对冲基金之一\n469003 0 而是知道真相后所有我不能接受的谎言\n469004 0 当你心身感到疲惫是家是最好的最温馨的巷湾然而对我来说是多么的可笑啊每回一次心凉一次心痛一次好...\n1000 Processed\n classify content\n469500 0 7月28日浙江众成跌至23买进\n469501 0 x月港交所成为中国企业IPO主战场\n469502 0 无锡都市生活广播联合无锡消防支队、无锡华润燃气在纳新桥社区前宋巷小区开展了“夏季安全公益进社...\n469503 0 已经是政府通胀目标的两倍多\n469504 0 每次和城管打完架出来新刀提示我都在嚎叫“给我浦岛\n1000 Processed\n classify content\n470000 0 2美元没蒲式耳”“那为什么不现在买\n470001 0 将要改动的style作为state来改写\n470002 0 刘昊meitong0711高依依angelababy必须死死刑死杀人偿命死\n470003 0 ∞╬╬宝泰隆喜临门大西洋鹿港科技博信股份内蒙君正浙江龙盛\n470004 0 我现场的纸飞机写了一如既往的努力生活\n1000 Processed\n classify content\n470500 0 小米手环+1000元现金……参加暑期实践大赛\n470501 0 说是LONGLONGAGO\n470502 0 它的设计以及制造工艺都有了突飞猛进的提升\n470503 0 在马路中间S形滑了几个来回之后撞倒路中间的护栏\n470504 0 西安市人民政府决定:xxxx年x月xx日上午xx时xx分至xx时xx分在全市范\n1000 Processed\n classify content\n471000 0 格罗斯:全球金融市场现在都是骗局\n471001 0 今天去苏州园博会施工现场转了一圈\n471002 0 ”目前张花已被民警用专车送回湖北老家\n471003 0 B门设置、管理及与武警哨位的联动\n471004 0 章泽天和其他投资人并没有太多区别\n1000 Processed\n classify content\n471500 0 “机器人杀人”是无中生有or确有此事\n471501 0 必须开公安税务工商银行教育机构居委会等5机构证明个人身份才能发\n471502 0 大家一起玩游戏…2015的生日我过了很开心\n471503 0 TheLightRun泰州万达荧光夜跑\n471504 0 JeremyRenner也是我喜欢的演员\n1000 Processed\n classify content\n472000 0 城管局执法人员于7月28日晚在衡阳路找到了该店负责人\n472001 0 NEO女皇四色棕色自然小混血独特毛边设计和浅棕色完美搭配显得眼睛清透混血NEO任意两幅活动x...\n472002 0 今天去医院听诊肺部没有问题、气管有点不好\n472003 0 克拉恋人明日浙江卫视\n472004 0 1258庞大集团逆势的上涨\n1000 Processed\n classify content\n472500 0 刚在亚马逊入手了这几本书:孤儿列车\n472501 0 明确规定投资者在融券卖出后\n472502 1 亲爱的,维纳贝拉三八节,一年就一次最大型的直接省钱活动马上就开始了,到九号截止,祥情来电咨询...\n472503 0 而花千骨要说剧情吧有些方面发展太快\n472504 0 徐州是久负盛名的既包邮又有暖气的城市\n1000 Processed\n classify content\n473000 0 他们阵容中有3名控卫的出生年月日竟然是一模一样的\n473001 1 郑州丹尼斯花园店华歌尔x月x号----x月x号满xxx减xxx\n473002 0 已建成5条:长江大桥、长江二桥、长江三桥、长江四桥和纬七路长江隧道\n473003 0 电脑那边的她便乐的哈哈大笑\n473004 0 西藏阿里有蝙蝠侠被改编成游戏一次月食的发生\n1000 Processed\n classify content\n473500 0 微软同时公布了Win7/Win8\n473501 0 安耐晒有款并不红的防晒几年前很喜欢\n473502 0 武汉市中级人民法院二审判决私藏枪支的父亲处以5年有期徒刑\n473503 0 产经预警、政策动态、市场环境、统计数据、权威发布、文化、医药、食品、机电、农林、建筑、通信I...\n473504 0 电影狂怒算是近期档比较重头的影片了\n1000 Processed\n classify content\n474000 0 做我这行有趣的事每天都可以玩不需要向谁请假累了睡一觉在家享受好吃的玩着手机挣qian逛逛微博...\n474001 0 哈哈腾讯新闻你们小编从QQ空间请来的\n474002 0 中国好声音都是美国人新加坡人马来西亚人加拿大人\n474003 0 orbis无油卸妆露卸防晒很好\n474004 0 我正在看10款超红东洋零食编辑部实测报告\n1000 Processed\n classify content\n474500 0 最终欧美地区最火爆的FPS游戏战胜了日本玩家最爱的运动游戏\n474501 0 重点是它跟福克斯ST有点神韵相间\n474502 0 浙江卫视有不良人手游的广告了\n474503 0 房产销售业绩也是非常厉害的\n474504 1 您好,感谢您一直以来对红苹果家具的支持与厚愛,公司为维护消费者权益,x.xx活动启动中(x月...\n1000 Processed\n classify content\n475000 0 每天早晨伴着窗外各类汽车发动机的轰鸣和汽笛醒来\n475001 0 因为因为汽油汽车容易在碰撞后发生爆炸\n475002 0 查处各类交通违法xxxxx起\n475003 0 两张照片然后连成一张动图白天捏着手机哭现在对着电脑又哭了我一定是有病得治\n475004 0 连南县人民法院一审以诈骗罪判处张某有期徒刑八年六个月\n1000 Processed\n classify content\n475500 1 华洋堂梦妆:亲爱的会员,您好,为庆祝三八节到来之际,本专柜从即日起至x月x日全场xxx减xx...\n475501 0 在地铁上一坐下来瞬间就困了\n475502 1 开走或不开走贷款,借款额度x-xxxx万,只要条件符合,小何一律可以解决。小心意,只要介绍的...\n475503 0 Intel招聘图像实习生\n475504 0 亚马逊吐槽美国无人机限制:这是废纸我们不要\n1000 Processed\n classify content\n476000 0 中央气象台7月10日06时发布台风红色预警:预计\n476001 0 发现了一个手机里没有卸载的日记\n476002 0 tm的中午换保险丝也不通知我\n476003 0 分享图片2015西藏旅游回来\n476004 0 NAVERONSTYLE徐賢個人預告\n1000 Processed\n classify content\n476500 1 【思路通】七年级数 学清 北奥-数班:同步重难点方法总结,掌握奥-数和名-校专题;培优班:巩...\n476501 0 木凳子设计由教育部放回原处\n476502 1 //转自xxxxxxxx:中国人寿顶额利率x.xxx鑫如意产品马上停售,有意者火速联系 火速...\n476503 0 下图湖南博云新材料股份有限公司生产车间\n476504 0 『是医院「害」死了得肺炎的小男孩吗\n1000 Processed\n classify content\n477000 0 启东气象台7月27日下午发布:今天夜里多云\n477001 0 它会大言不惭:坑内卫生才归我管\n477002 0 2、再慢慢地加入鲜奶和蜂蜜\n477003 0 自己也是默默在电脑前热泪盈眶\n477004 0 美兰区法院对此案作出一审判决\n1000 Processed\n classify content\n477500 0 傍晚转的那条strongfemalecharacter的文章引出了好多有趣的观点\n477501 0 任何人不得买卖、商业使用带有该LOGO的生产材料\n477502 0 盐城一老大爷猥亵多名女童\n477503 0 」「宝宝需要额外补充电解水吗\n477504 0 包括龙图游戏CEO杨圣辉、腾讯QQ浏览器高级产品经理杨三金在内的参会嘉宾发表了对HTML5游...\n1000 Processed\n classify content\n478000 0 为什么爱奇艺的实习医生格蕾全都没了\n478001 1 少送多少。优惠三:满xxx面膜粉免费送,满xxx桶装海澡免费送。 想知...\n478002 0 当初我请市政府取消家人对174医院的反应一样\n478003 0 人生不一定只追求结果过程也很重要\n478004 0 心真的好累电脑上的档案被我删了\n1000 Processed\n classify content\n478500 0 夏日炎炎人们为了防晒也是蛮拼的啊\n478501 1 x月x日您有活动吗?/:?/:?如果没有,快快来景伊名妆看看吧!/:jj/:jj/:jj选购...\n478502 0 我的手机被没收了电脑坏了这几天都没上网\n478503 0 流行过爸爸去哪儿飞机去哪儿时间去哪儿如再不保养不打扮就该流行老公去哪儿了\n478504 0 监管机构的查处有雷声大雨点小之嫌疑\n1000 Processed\n classify content\n479000 0 一家名为Belgocontrol的比利时公司宣布\n479001 0 听说网上零售巨头亚马逊也将在未来五年实现无人机送快递哟\n479002 0 也正是传说中的Surface手机\n479003 0 第一次吃饭把手机丢在桌子上\n479004 0 面膜不可断/坏笑/坏笑睡前敷面膜\n1000 Processed\n classify content\n479500 1 喜迎三八女人节!韵姿美容特惠x.x折,数量有限,赶紧抢购。让我们一起做个爱自己的魅力女人。三...\n479501 1 经理您好:天津市全通钢管公司向您致敬:我公司专业生产.螺旋钢管.防腐保温钢管.xpe钢管.欢...\n479502 0 而且是暗地勾结美国掠夺中国大陆百姓\n479503 0 求个江苏省范围内的靠谱宠物医院\n479504 0 假如有一天国家政府出一台政策说杀人不犯法\n1000 Processed\n classify content\n480000 0 今天从同济医院那边的艳阳天开到万科城\n480001 0 x、Steam平台xxxx年狂捞xx亿美元G胖笑开花\n480002 1 即日起:江湾吉买盛红豆居家专卖店x?x妇女节特卖活动全场x折起x?x日止。期待您的光临,愿您...\n480003 0 今晚来到享誉全美的SoulFood餐厅Sylvia's\n480004 1 裕泰汽配商行感谢您的来电,本行主营各种高中档,新纯正厂,配套付厂,进口原装,旧拆车件,并办全...\n1000 Processed\n classify content\n480500 0 我居然完完整整看完了~想起第一次看歌剧魅影是高中音乐鉴赏课上被震地一愣一愣的\n480501 0 而此次百度对于一批带有“官网”字样的企业站进行了降权处理\n480502 0 1公里开挖埋设2根直径1800原水管\n480503 0 每每在公交或者地铁或者路上碰到的行人就想起我的爸妈\n480504 0 你越不敢追的股票就越要追\n1000 Processed\n classify content\n481000 0 向物业反映推辞说市政供水不正常\n481001 1 您好. 舒适堡健身晶品店会籍顾问小潘,诚邀您来参加最后一期VIP会员团购活动、前xx名可凭预...\n481002 0 子宫内膜里瘀血越积越多结成血块\n481003 0 吃蜂蜜蛋糕就会噎住打嗝体质\n481004 0 不要只会在电脑、电视前羡慕那些自由舞动的人\n1000 Processed\n classify content\n481500 0 而且非常容易就被诬告强奸、引发情杀等刑事案件\n481501 0 8月考生一定把7月的几个经典题目都准备下\n481502 0 21日又以7比0认为同性恋伴侣至少应当获得民事伴侣权\n481503 0 无赖汉百度云网盘资源高清链接\n481504 0 立即对施工区桂花、银杏、红叶石楠进行了移植作业\n1000 Processed\n classify content\n482000 1 尊敬的会员:“美丽女人节,实惠看得见”国大药房于x月x日~x月x日推出优惠大让利活动。 ...\n482001 1 艺朝艺夕开学啦!x月xx正式上课,专业培训少儿美术、音乐、舞蹈、陶艺,带孩子在快乐中享受艺术...\n482002 0 全市新增各类市场主体16478户\n482003 0 虽然有时候身体也发出疾病到来的信号\n482004 0 总算花了15个小时到大理下关了\n1000 Processed\n classify content\n482500 0 曾经吃过中药用过医院的药膏都没有好\n482501 0 可在上下班乘公共汽车或地铁时\n482502 0 出于私心我想你不被扬州大学录取而去读成都理工啊\n482503 0 记得坚持用哦褐果果皂让你越来越美丽\n482504 0 核武器一般被視爲對和平的威脅\n1000 Processed\n classify content\n483000 0 适用于治疗肺热所致粉刺、痘痘、痤疮、酒糟\n483001 1 天越汽配感谢您的来电!主营:东风雪铁龙系列等汽配的批发兼零售,欢迎来电咨询!电话:xxxxx...\n483002 0 不发朋友圈发这里吧只是问了一句我要去苏州啦你想念我不\n483003 0 河北省旅游局党组中心组召开会议组织“三严三实”专题教育学习研讨\n483004 0 与此同时郎特还召开了xxxx年大学生入职培训会议\n1000 Processed\n classify content\n483500 0 Atestpublic7755闯红灯求半价\n483501 0 哈哈哈哈录音没法从手机里搞出来\n483502 0 白马湖片区将成为淮安重要的生态休闲、养生养老、文化创意基地\n483503 0 全市在用的xxxxx台电梯\n483504 0 工资都得贡献出来惹~土豪快来包养我\n1000 Processed\n classify content\n484000 0 女性心血管疾病的发病率和病死率呈持续增加的趋势\n484001 0 济南九创装饰公司装修一口价\n484002 1 你好,我司专业经营台湾原装庆鸿慢走丝,质量,价格,售后首选,欢迎来电咨询了解!祝你生活愉快,...\n484003 0 FM91路况:此刻寥廓南路妇幼医院双向麒麟花园环岛车流量大通行缓慢\n484004 0 落广西桂林海洋银杏林叶缤纷\n1000 Processed\n classify content\n484500 0 汽车驾驶技术的的提高要靠自己多开多练\n484501 0 但即便是诸如微软XBOX这样的专业游戏主机\n484502 0 在地铁上碰到一件很温馨的事\n484503 0 没有钱赔偿受伤第8个月以后的医疗费\n484504 0 快捷互通北京昌平移动T3+机房抢售中\n1000 Processed\n classify content\n485000 0 华为:NowisP8\n485001 0 让人觉得甜美非常plewhojudgemewithout城\n485002 1 金 沙校 区:春 季周 末班x月x-x日开 课\n485003 0 在想明天要不要穿花千骨的t\n485004 0 为什么我爸妈这么好的基因当初不好好考虑再生孩子呢\n1000 Processed\n classify content\n485500 0 工号GQxxxx安检往女乘客胸口挡\n485501 0 Troy随后删除了这条推文并发布了两条新的推文宣布退出Twitter\n485502 0 民航管理局决定自今x时起暂停发生深航纵火事件的浙江台州机场运行\n485503 0 一杆“卖各种手机”的旗下坐着一个神秘男子\n485504 0 5个月后和李某人站在住院一部楼下找门\n1000 Processed\n classify content\n486000 0 xxxx年到xxxx年第一季度\n486001 0 南京国际博览中心和南京国际展览中心竟然是两个地方\n486002 0 整个展览从曼哈顿23街往南延伸至南街海港\n486003 0 在南京地铁里行乞的职业乞讨者\n486004 0 80%至90%的肺癌是由吸烟引起\n1000 Processed\n classify content\n486500 1 【玫琳凯x月促销】好消息,x月VIP订单福利来啦!好礼送不完!改变从美丽开始!够买玫琳凯任意...\n486501 0 临睡前和舍友说我中午上班的时候在想再过差不多一个月我们就认识九年了舍友想了下说应该是十年…我...\n486502 0 觉得很震惊…夜深人静的时候…会很想死\n486503 0 咱们华为手机有Mate7青春版这款手机吗\n486504 0 WIN7/8正版的最好还是等微软更新比较好\n1000 Processed\n classify content\n487000 0 本周六森德兰国际贸易集团联合北青报在华联顺义金街购物中心举办“舞与伦比街舞秀”\n487001 0 xxxx年长葛轩辕村镇银行招聘公告\n487002 0 從Google廣告投放可瞧見端倪\n487003 0 譬如微软Officexxx与GoogleApps等等\n487004 0 最赚钱的国产机不是小米华为\n1000 Processed\n classify content\n487500 0 要么考了研究生还要考CPA的\n487501 0 放在身后椅子上的苹果xS手机被人偷了\n487502 0 xx项与隔音降噪相关的零部件改造\n487503 0 对于符合小额诉讼程序适用条件的案件\n487504 0 一个好的理财习惯不只是会挣钱\n1000 Processed\n classify content\n488000 0 首展“文明的维度\"包含19世纪中国洋风画、古代中国地图、当代艺术三部分内容\n488001 0 白子画只做花千骨一人的暖男\n488002 0 然后e+到wincci姐又咳又呕\n488003 0 微软应该学习苹果以Surface手机拯救WP平台:未来微软应该放弃机海战术和中低端廉价手机\n488004 0 找一个人他带着我我带着相机然后我们一起去旅游\n1000 Processed\n classify content\n488500 0 江苏盐城建湖县以大学生村官为民服务考核机制为抓手\n488501 0 好运相守:朋友是永远的财富\n488502 0 王先生路过位于浙江永嘉县江北街道楠江中路7号的72101体彩销售网点时\n488503 0 南京市内各正规消毒餐具生产企业将统一推广使用1122标志的消毒餐具包装\n488504 1 新年好!保利.罗兰国际的小姚给您拜个晚年.项目现新货加推\n1000 Processed\n classify content\n489000 1 x平米的户型在售,有精品样板间展示,均价xxxx 感谢您对我工作的支持!\n489001 0 NBA史上最强国际球员能否爆梦之队\n489002 1 泰州短 信群 发平台,降低客户流失率,增加客户消费次数,提升营业款。如:商品推广,店面促销,...\n489003 1 全四川抢美的,x月x-x日仅限x天,台台工程机,款款出厂价,全年最低价,价保全年,买贵xx倍...\n489004 0 最高人民法院关于人民法院为“一带一路”建设提供司法服务和保障的若干意见\n1000 Processed\n classify content\n489500 0 后遗症:少数患者可留有后遗症\n489501 0 阿里巴巴、腾讯、百度、京东、奇虎360、搜狐、网易、新浪、携程、搜房网位列2015年\n489502 0 维C可以帮助人体提高免疫力远离疾病\n489503 0 一大早赶飞机累shi人了都\n489504 1 您好!我是上午刚给您打电话德诺生活馆的小王。我们xxx的活动是全场x折,还可以参加联够返现和...\n1000 Processed\n classify content\n490000 0 ②可用与加油站、林场等禁火、防火单位\n490001 0 〖ZUKZx〗缔造Zx导航贴\n490002 1 哥哥你好,我叫小娟,广西人,因为父母离婚,我跟妈妈,妈妈身体不好,我选择辍学,听说哥哥人很好...\n490003 0 与美国式机器人手术室相抗衡\n490004 1 姐,您好,我是王府井欧珀莱专柜的小张,x.x—x.x欧珀莱柜台满xxxx返xxx,xxxx返...\n1000 Processed\n classify content\n490500 0 目前来说我对霓虹的爱只限于药妆店免税买苹果暴跌的汇率但\n490501 0 各地方政府批到哪儿中石化就能把国四、国五送到哪儿\n490502 0 力争8月份提前超额完成全年项目招引目标任务\n490503 0 睡醒了就看见手机整个屏幕不亮怎么都没反应你是假死我整个人吓得都快真死了好吗\n490504 0 0国产版智能手机遥控电动纸飞机航空模型器材滑翔机\n1000 Processed\n classify content\n491000 0 以此扭转win8给微软带来的颓势\n491001 0 等人散去后还得来个小贩收摊\n491002 0 我想静静…可怜萌萌只能看着三青\n491003 1 尊敬的顾客您好:宝居乐欧美家私x月x--x号全场x.x折,仅此两天,欢迎新老顾客前来选购。地...\n491004 0 07涨停159跌停3上涨家数2294平盘家数525下跌家数61互联网:38互联网金融:300...\n1000 Processed\n classify content\n491500 1 好消息,我们足鼎阁,x月x号和x号,女土会员x拆,非会员x.x拆,x月x号会员x.x拆,非会...\n491501 0 通过融e购企业商城面开展公开销售\n491502 0 成为浙江省首家在新三板挂牌的园区类公司和第一家国企\n491503 0 江苏工院之声膜广播台编辑本来无一物\n491504 0 用核武器才能阻止的民族是多麼的可怕\n1000 Processed\n classify content\n492000 0 新能源汽车后市场存在保险监管条例缺失\n492001 0 中医药现代化人工合成熊胆粉取得突破\n492002 0 来到常熟国税现场考评苏州市文明单位标兵创建工作\n492003 0 芝麻信用水分背后的风险势必会传导至P2P行业\n492004 0 台风??外面吹着大雨刮着风路上应该没什么人了有的人上班的还是上班\n1000 Processed\n classify content\n492500 0 很想知道没有任何防晒我最后的晒斑会增加多少\n492501 0 刚刚百度了一下终于会拒绝不是好友的评论了\n492502 0 严厉打击了一批环境违法行为\n492503 1 友情提醒【日出康城】春节特惠仅剩x天!裸价xxxx/平!首付x万起,赠送面积高达xx平。旺铺...\n492504 0 在百度上搜索了自己曾经干新闻媒体时发表过的新闻稿件\n1000 Processed\n classify content\n493000 0 但是DC排毒面膜可以统统搞定这些皮肤问题的\n493001 0 将人家的手机放进了自己口袋\n493002 1 各位挖机老板元宵节快乐、我司本月x号举行大型订货会、另外推荐配件购xxxxx送xxxx元的活...\n493003 0 HelmsBrosMercedesbenz半日游\n493004 0 双方未来3年内利用自身资源在电影的投资、制作、发行、推广、改编等多个方面展开合作\n1000 Processed\n classify content\n493500 0 2015年枣阳事业单位面试课程\n493501 0 在速速的掏手机百度查档是个什么玩意儿中惊醒之后\n493502 0 这也是过去8个月内空间站补给计划遭遇的第三次失败\n493503 0 无为县昆山乡居民李桂香家安装了新的自来水管\n493504 0 浙江受影响不过吹吹满凉快\n1000 Processed\n classify content\n494000 0 化妆师jesscia和我沟通造型\n494001 0 但能夠的話最好都不要放到受區域管制的網絡\n494002 0 真相是家属给他吃了有核的话梅\n494003 0 结果医生拨拨我的头发不到两秒就说\n494004 0 他阻拦警车离开并砸坏挡风玻璃\n1000 Processed\n classify content\n494500 0 永不恶言相向/永不暗自考量/永不放任乖张/永不停止成长\n494501 0 ?作为低头族、电脑族、久坐族\n494502 0 甲骨文像有锋刃的长柄工具或兵器\n494503 0 找我要这个bb的我忘了都谁了自己找我Whoo后拱辰享雪玉凝美白BB霜防晒清爽不油腻40ml~\n494504 0 网友纷纷调侃“没图没真相”、“再胖也比我瘦”、“反手摸不到肚脐眼了是么”\n1000 Processed\n classify content\n495000 0 ⑥不要咨询客服不然又改了~\n495001 0 新一代的Nexus系列将会由华为代工\n495002 0 江苏大意营业员51元卖了ipad2\n495003 0 P8到现在发布快俩月了还是显示缺货\n495004 0 第三名:处女座当生活中的细节带来磨合后才发现\n1000 Processed\n classify content\n495500 0 你们能不能不要再说我电脑花了\n495501 0 在经历了“就那样”的Windows8\n495502 1 尊敬的客户您好!移动光宽带现在是否还有意向办理?现办理免安装。详询xxxxxxxxxxx\n495503 0 想知道百度的广告系统什么时候变的如此精准\n495504 1 【晋拓汽配】招聘男女普工,xx-xx岁,基本工资xxxx元/月+加班+各项补贴\n1000 Processed\n classify content\n496000 0 天气这么热水灾以后可能会有疫情\n496001 0 主角是熊熊+中国好声音?1MORE头戴式耳机\n496002 0 这个老师跟x—x个学生发生着不正当的关系\n496003 0 一个物业工人上24歇48每月2400加保险\n496004 0 那時一路跑呀跑一路摔跤就直接滾倒在草地上咯\n1000 Processed\n classify content\n496500 0 有能力者受贿的另一方面也创造着更大的财富\n496501 0 每天睡觉的时候手机差不多只剩下3%的电\n496502 1 优博教 育入驻曼哈顿步行街南 开设课程有:初、高中各科,有辅 导的晚自习,少儿围棋、书法、小...\n496503 0 你他妈的不用指望花2块钱挂号费人家给你解释一小时、后面还有一大堆病人呢\n496504 0 善于揭露“政府掩藏真相”的公知轮子带路党在全力维护中国司法公正\n1000 Processed\n classify content\n497000 1 为落实智慧七师文件,xxx团电信局手机特惠:每月x元送xxx分钟通话,超出每分钟x分。每月x...\n497001 0 图3女人我最大推荐的自白肌化妆水\n497002 1 【樊文花面膜体验店】三八妇女节活动全场满xxx元送xxx元现金券,时间:x.x--x.x号,...\n497003 0 平时一般2XU低于5折都比较少\n497004 0 一首英文歌Appletree\n1000 Processed\n classify content\n497500 0 刚刚手贱去看了下江苏卫视的壮志凌云\n497501 1 农业xxxxxxxxxxxxxxxxxxx 名字 陈海琼\n497502 0 将在x月xx日正式发布旗下新的台电X超级板\n497503 0 店铺客服会在48小时内完成返现\n497504 0 全球有哪些优秀的建筑摄影作品\n1000 Processed\n classify content\n498000 0 以及对涉嫌违规的高频交易账户予以暂停交易的处分\n498001 0 警察眼神里都是星星点点的东西\n498002 0 看看当年在火箭队效力的老猫莫布里如今的样子\n498003 0 我们常常习惯给站在太阳底下可怜的小贩讨价还价\\n0\\t每一个细胞都在诉说着我内心的不舒服\\n...\n498004 0 ”路飞自司法岛事件以后这是又升级了新技能吗\n1000 Processed\n classify content\n498500 0 法庭上的法官检察官是不是和电影里一样高冷\n498501 0 被称为“Daemon”的怪兽侵占了大地\n498502 1 感谢您对领秀女装多年的支持与关爱,女人,爱自己!“三八魅力女人节”大型促销活动于x月x日火爆...\n498503 0 「深圳观澜湖高尔夫球会招全职英语翻译数名」\n498504 1 女人节~专属于您的节日马上到来啦!二康哥弟为您精心准备了靓装,期待节日里与您和朋友一起分享这...\n1000 Processed\n classify content\n499000 0 南京的新外号:霍史尼玛·热德玛·伊比\n499001 0 江苏台引进的貌似这周日也要播了\n499002 0 洪泰基金新三板负责人冯志兄\n499003 0 中兴海外桥头堡CSL被华为全网搬迁\n499004 0 自己和手机自带的小欧助手聊天\n1000 Processed\n classify content\n499500 0 只能是新用户第一次用百度的快捷支付\n499501 0 浙江我武生物科技股份有限公司2014年年度报告及摘要于2015年2月11日在中国证监会指定的...\n499502 0 中心于xxxx年在何贤纪念医院挂牌成立地点设在产科\n499503 0 住建部、国家旅游局近日公布第三批全国特色景观旅游名镇名村示范名单\n499504 0 使大脑对肩颈部的肌肉控制协调能力下降\n1000 Processed\n classify content\n500000 0 我又犯罪啦??任性一次买了一包16\n500001 0 中国抗癌协会成立30年来一直秉承为肿瘤防治事业服务、为提高全民健康素质服务、为肿瘤科技工作者...\n500002 0 上汽集团600104现在价格在19\n500003 0 今天中午他们将做客EasyIdol进行独家专访及在线访谈\n500004 0 云县公安局调查确定两死者皆为他杀\n1000 Processed\n classify content\n500500 0 过度抓挠可导致许多皮肤病加重\n500501 1 成为女神是每个美丽女人的美好心??愿!《百汇名城》"三八"美丽女神节重磅出击!女神驾到!百汇...\n500502 0 与车队共襄盛举 伪装车的涂装“封存\n500503 0 对山东17市部分大型商场、超市等开展扶梯安全大调查\n500504 0 作为私募基金主要负责人之一\n1000 Processed\n classify content\n501000 0 通过手机银行给你们开通E支付不需要U盾\n501001 1 转自:(+xxxxxxxxxxxxx) 挂xx烧狗。成语:转海回天。六肖:龙羊马猴鼠猪\n501002 0 基于对几点模式的理解=投融资横向模式\n501003 0 浙江也更新暴雨红色预警:今天浙北和东部沿海的湖州、嘉兴、杭州东北部、绍兴、宁波、台州部分地区...\n501004 0 想挣零花钱的私信我只要手机电脑就可以\n1000 Processed\n classify content\n501500 0 上半年全区报告暴发疫情同比下降xx\n501501 0 可怜的建筑……被日照分析的结果\n501502 0 虽然我已经看过卫星拦截版了\n501503 1 亲爱的嘉人!为了答谢老会员,特别推出给力活动[鼓掌][鼓掌][鼓掌][鼓掌][鼓掌][鼓掌]...\n501504 0 因为每天都带着防晒霜和小黑伞\n1000 Processed\n classify content\n502000 0 东门派出所相关负责人证实上述户籍证明确为该派出所开具\n502001 1 早上好 我是做欧纸的 需要招聘一个店员底薪xxxx 提成百分五提点 有兴趣联系\n502002 0 :湖北“吃人电梯”厂家:将按照计划上市\n502003 0 Itseemstheworldwasn'tquitereadyformydaddy加油吧老爹\n502004 0 Kenworthy在1997年提出\n1000 Processed\n classify content\n502500 0 你的不作为真是够了……仅此纪念即将离去的VNPT……\n502501 0 都是洛杉矶highlydesirableareas\n502502 0 无锡外研基地我的秒拍作品\n502503 0 换什么手机好呢三星A8魅族Mx5华为荣耀7\n502504 0 一支BB霜还你靓丽容颜\n1000 Processed\n classify content\n503000 0 怎么为这个强奸大爷的罪犯叫好\n503001 0 x褪痕洗剂可治细菌性感染的大痘痘\n503002 0 从痘痘的生长开始到消失全程管理\n503003 0 本門從不破玄武洞奪得金剛不壞體殘章五\n503004 0 1949年4月23日南京解放后\n1000 Processed\n classify content\n503500 0 我在手机酷狗发现“大雄丶JEFF”的精彩表演\n503501 0 南京卓迅类TAXI的专车运行\n503502 0 百度浏览器这么多人下载也不是没原因的\n503503 0 中国石化南京石油于7月7日开展党员学习活动\n503504 0 其实很简单~只需要按照以下步骤\n1000 Processed\n classify content\n504000 0 最高人民检察院刘喆处长一行五人在兵团检察院宋征专委、技术处郭瑞民处长的陪同下莅临四师检察分院...\n504001 0 苏州新达电扶梯部件有限公司21\n504002 0 1986年美国俄亥俄州的克里夫兰市为了创造世界纪录放飞了1百40万只气球\n504003 0 IOPE的所有产品都经过皮肤科安全测试即使是敏感皮肤亦可方式使用IOPE的彩妆既是化妆品也是保养品\n504004 0 应用于重庆市政府指定发行的行业支付类IC卡\n1000 Processed\n classify content\n504500 0 用拳拳热心和滴滴汗水献上了对指路队最美好的祝福\n504501 0 你们这里有人听说过华为荣耀部门解散的消息吗\n504502 0 在浙江大学附属医院看个病估计等了快x个月了\n504503 0 充电20分钟后手机电量迅速的从52%降到4%我想知道它这20分钟都干了什么我擦\n504504 0 收拾东西时翻出来插电脑上竟然又能读了\n1000 Processed\n classify content\n505000 1 仪式,我们的全包装修套餐‘xxx’也将正式登陆武汉,到场的前二十位业主免设计费,前三十位免管...\n505001 0 看到好声音第一季模仿邓丽君那个姑娘\n505002 1 xxxxxxxxxxxxxxxxxxx 舒华 工商银行\n505003 0 foreo这个电动牙刷造型略神奇啊xxxxxx薰衣草紫颜色好棒\n505004 0 他说道:“往届的美国政府没\n1000 Processed\n classify content\n505500 0 谷歌没有将所有精力放在提高某种产品或服务10%的效率方面\n505501 0 这座stonetown大部分建筑建造于200年前\n505502 0 苏州市姑苏区教育和体育局下属事业单位定于2015年8月11日面向社会公开招聘体育教师10名\n505503 0 他们听了结果小跑过来的那个瞬间\n505504 0 这2000名候选人是从全市11个区符合选任条件的公民中随机抽选的\n1000 Processed\n classify content\n506000 0 男子强奸9岁女童不成将其推下楼摔死\n506001 0 给医护人员一个安全的医疗环境\n506002 0 汽车馆陈博士正在给大家介绍汽车知识~为了本次汽车总动员\n506003 0 宋氏家族1949年买下这里的庄园\n506004 0 该市计划实施3个棚户区改造项目\n1000 Processed\n classify content\n506500 0 我投给了“置业顾问—孙欣琪”这个选项\n506501 0 医生答时间不长体重不变也不算不正常\n506502 0 妈催着爸给我去买iPhone6\n506503 0 「xxx万人在传看」爆笑虫子合集爆米花超治愈爆笑兄弟\n506504 0 螳螂新娘拿着高尔夫球杆也加入了森林守卫队伍\n1000 Processed\n classify content\n507000 0 陕西19岁少女坠楼身亡当地官员涉强奸被停职\n507001 0 然后望着天飞机飞过天空…\n507002 0 引起正使用电梯的民众一阵惊慌\n507003 0 滨海新区则占据了天津市第三产业投资的重头戏\n507004 0 这是该院近年来第4次获省法院征文奖\n1000 Processed\n classify content\n507500 0 xx奔腾清扫日继续拉开序幕:你看\n507501 0 全新的长安汽车标志创意来自于抽象的羊角形象\n507502 0 有想法的联系付xxxxxxxxxxx\n507503 0 一样的职业我的真武在刷副本的时候输出最\n507504 0 康婷家人医院现在增加了医疗项目\n1000 Processed\n classify content\n508000 0 WindowsServer迎来新的Azure云服务|WPC2012大会上\n508001 0 2015年下半年建议:一是加快国企、财税、金融重点领域改革\n508002 0 可以是男神也可以是男神经他\n508003 0 真相小人:你怎么不说在这之前你还吃了一盘沙拉和三块芝士馅饼\n508004 0 媒体只要那个热度就好其他什么真相假相的都狗带所以你红就是你的锅\n1000 Processed\n classify content\n508500 1 花旗银行幸福时贷产品: 普通客户x.x-x.x厘 老师医生公务员x.x-x.x厘 放款时间:...\n508501 0 在广州地铁里迷迷糊糊的听到:列车即将到达公园前……我……穿越了\n508502 0 分享华为20多年变革的实践经验\n508503 1 兴业银行特大好訊息:xxxx年起xxx万客户理财可实行私人定制x个月x.x%/x个月x.x%...\n508504 0 安徽网记者7月20日从枞阳县法院获悉\n1000 Processed\n classify content\n509000 0 xxxx年毕业于西南联合大学物理学系\n509001 0 “湖北最美基层法官”评选活动揭晓\n509002 0 吃了会儿哈密瓜陪bb的妈咪聊了会儿天\n509003 0 与泾阳法院党组书记、代院长陈建利等领导交流座谈\n509004 0 朋友放假去了好多地方只有自己默默地在家默默地给他们点赞评论心里还是挺难受的啥时候等咱有钱了也...\n1000 Processed\n classify content\n509500 1 宁波宁兴新宇奔驰xS店感谢您的来电,我们本着“惟有最好”的品牌理念,以客户至尊、一脉相承的服...\n509501 0 我CJ忙的和陀螺一样吃饱了撑的为了一个差评骚扰你~简直呵呵了\n509502 1 先生,下午好!“汉唐艺术文化村”位于武昌珞喻路xxx号(卓刀泉立交桥旁)。总价十五万起售,面...\n509503 1 x、x女人节,做“s\"健康性感女人,送礼开始啦…!最低仅合到:x、x折…!………[微笑][玫...\n509504 0 日前微软CEO萨蒂亚?纳德拉在微软全球合作伙伴大会的后台承受采访时表明\n1000 Processed\n classify content\n510000 0 预计未来6小时内我市大部地区仍将可能发生雷电活动\n510001 1 【恒大御景湾】老业主成功推荐購房,获房款x%超市购物卡或五年物业费奖励,元宵佳节下午猜灯谜,...\n510002 0 成人缓解湿疹、牛皮癣、各种皮炎及皮肤干燥\n510003 0 短信恐吓等方式敲诈勒索他人\n510004 0 南京浦口、城区和江宁的降雨量加起来超过了xxx毫米\n1000 Processed\n classify content\n510500 0 接下来就期待明天去浙江卫视录节目了\n510501 0 闲的无聊居然用家里的电脑局域网相互远程刷微博\n510502 0 将案件移送相关行政执法机关\n510503 0 每天都就是看手机看电脑躺床上…”就在刚才\n510504 0 刘延涛开发房地产”财富世家”毁了邓州一处两千多年的古迹\"魏冉衣冠冢”\n1000 Processed\n classify content\n511000 0 筛选出55名事迹突出、代表性强、影响力大的道德典型\n511001 0 我从徐州坐火车做到南京做了却要5个多小时\n511002 0 全国各地到处旅游羡慕嫉妒的同时自己又没能力去得到而我们知道靠自己努力去换取想要的一切不是只想...\n511003 0 天赋还是miss点的哈哈哈杰伦公举加油\n511004 0 据网友爆料:此泄露为志丹西区采油厂管辖区\n1000 Processed\n classify content\n511500 0 现在用着亚马逊上新买的电源打开一看根本没修好\n511501 0 由光合创意设计的马到成功杯子\n511502 0 ——道歉并不总是代表我承认自己错了\n511503 0 ——真相难道是因为没有压力才这样\n511504 1 市中心绝版一线江景现房xxx-xxx平米,即买即交房,清盘活动启动中,期待您的光临,电话xx...\n1000 Processed\n classify content\n512000 0 然后明天回家啦~~\n512001 0 他们懂得利用很多传统商业视野之外的工具去创造新场景\n512002 0 去年南京大屠杀公祭日前一天12\n512003 0 浙江传媒学院播音主持艺术学院教师刘超指导\n512004 0 今日于南京中心大酒店酒店入住\n1000 Processed\n classify content\n512500 0 大卫·贝克汉姆成了片方的秘密武器\n512501 0 爱丽小屋EtudeHouse卧蚕笔\n512502 0 记得我和我老婆从南京艺术调到江北干木工活当晚\n512503 0 本科三批共录取新生9960余人\n512504 0 车牌号为冀Gxxxx的小型普通客车发生超速违法行为\n1000 Processed\n classify content\n513000 0 xxx公斤孕妇在武汉市妇幼保健院产下x\n513001 0 明天醒来就到连云港了、各位晚安??\n513002 0 轰炸机炸过似的……经过一晚上的努力\n513003 1 .您好,我公司长期办理抵押、无抵押贷款. 服务范围:各大银行贷款业务(国家基准利率).大额信用卡.\n513004 1 金桥商场:圣蜜莱雅,美肤宝化妆品专柜,三八感恩回馈活动开始了,优惠多多,礼品多多,欢迎先来抢...\n1000 Processed\n classify content\n513500 0 他的身世是沛县的一个山野村夫\n513501 0 认证信息为“阿里妈妈服务商阿里妈妈淘拍档”\n513502 0 犯罪嫌疑人应某已被刑事拘留\n513503 1 广进!新年酬宾活动x月x号盛大开启!活动期间全场酒水一律买二赠一!届时恭迎大驾光临!!![鼓...\n513504 0 机器人一直说生活在新时代不要倚老卖老\n1000 Processed\n classify content\n514000 0 国民政府领导下的国民革命军与日军有22次大型会战、1117次大型战斗、小型战斗28931次\n514001 0 南京市溧水区人民检察院依法对于元栋等x人提起公诉\n514002 0 早安首尔con加油期待晚上被刷屏~\n514003 0 喜讯:国企改制评估增值所得税不用交了\n514004 0 是对无锡一汽铸造有限公司感兴趣的相关网友获取无锡一汽铸造有限公司资讯的重要参考\n1000 Processed\n classify content\n514500 0 手机全裸着没贴膜没带壳两天里从我手上掉地上摔了5次竟然都没啥大碍\n514501 0 绿茶不仅可以达到加速脂肪消耗强化健康减肥的效果、还可以降低癌症、老年痴呆症以及糖尿病、心血管...\n514502 0 微软的SurfacePhone传言再起\n514503 0 实习生里面的大公司的介绍真是吓的我虎躯一震\n514504 0 反而勾结政府的执法部门以强凌弱\n1000 Processed\n classify content\n515000 1 您好我们是一个设计的团队 专业为淘宝各大商家设计店面 拍照 视频拍摄 团队十多个人 您要是有...\n515001 0 看来手机还要等到明天才能买上\n515002 0 危险西安2名蜘蛛人风中作业失控撞击大楼致死\n515003 0 然后最终发明了飞机……小攻各种宠溺他……再多也不记得了\n515004 0 警车到现场将这么男子带走\n1000 Processed\n classify content\n515500 0 连续四周在全国60大城市全面启动“金色星期天\n515501 1 获得精喜礼物一份[礼物],在x~x号期间办理vip卡可以享受xx折优惠,还赠送xxx元大礼包...\n515502 0 徐州加勒比说走就走的happygohomenow\n515503 1 【呼市顺宝行】尊敬的客户您好:MINI年末冲量钜惠,最大优惠可达到x万元。诚邀MINI死党到...\n515504 1 新春狂欢低价来袭,整体橱柜低至xxxx元一套!开年特惠尽在卡丹利橱柜衣柜!xxxxxxxxx...\n1000 Processed\n classify content\n516000 0 坐地铁我的左右两边各坐着一个熊孩子简直要疯\n516001 0 3特别是可以去景点官网查交通路线\n516002 1 尊贵的会员:吉林欧亚商都家电、家具风暴袭卷全城,x月x日-x月x日全城底价狂欢!团购、套购、...\n516003 0 好声音变成好黑幕了女子网恋高富帅女子被卷入扶梯身亡李钟硕快乐大本营\n516004 0 1次对的弥补3次错的还有大幅度盈利\n1000 Processed\n classify content\n516500 0 宁致远在腾讯视频陪我度过了1330小时\n516501 0 类似去年停止支持的WindowsXP\n516502 0 喜欢晓的浙江粉可以加这个QQ群哦\n516503 0 外部世界中的健康、财富、人脉是内心世界的外在表现\n516504 0 报考人民检察院职位的到青海省人民检察院确认加分\n1000 Processed\n classify content\n517000 0 ??我不会因为你的质疑而停止前进的步伐\n517001 0 就不得不提起江苏宜兴著名爱国民主人士、实业家储南强\n517002 0 惨剧中的事故电梯为苏州申龙牌自动扶梯\n517003 0 而Balenciaga已经接连离任了两位重量级的设计师\n517004 0 迅速提高了民警110接处警信息录入的应用水平\n1000 Processed\n classify content\n517500 0 在办理信用卡前先来看看什么是信用卡\n517501 1 邯郸富安娜家纺开年大型活动开始了!x月x-x日凭此短信到店免费抓红包、刮奖,xxx%有奖!千...\n517502 0 物业也向其出具了整改通知书\n517503 0 江苏是不是动作最快的一个省份呢\n517504 0 可以直接用自己的智能手机解锁房间门\n1000 Processed\n classify content\n518000 0 扒在电脑面前刷着微博痴汉笑\n518001 0 好像很多人说浙江省儿保的医生态度差阿\n518002 0 没有对错没有谁能和虚无的永恒分一个胜负我不判决我只为命运辩护世间千万种残酷\n518003 0 海南省高级人民法院召开全院干警大会\n518004 0 一会还在医院长走廊转圈迷路\n1000 Processed\n classify content\n518500 0 我的电脑也好像到了中年一样进入6月份\n518501 0 据说南通市崇川区城港花苑杀人了\n518502 0 展览时间:2015年8月10日——8月16日\n518503 0 中国好声音以来最好的声音我的秒拍作品\n518504 0 政府的力量给了155位自由\n1000 Processed\n classify content\n519000 1 深圳康辉旅行社东门营业部欢迎您.我司主营:国内外旅游;机票\n519001 0 知名证券公司计划财务部招财务核算岗\n519002 0 无锡殡葬部门工作人员肖斌也在其中\n519003 0 南京全年粮食总产量随之达到118万吨\n519004 0 ”徐静蕾韩寒不满冻卵生育规定\n1000 Processed\n classify content\n519500 0 渣像素明天必须修手机\n519501 0 除了郑少秋和刘青云逆天的演技外\n519502 0 市民咨询:外地外来务工人员子女想在银川望远小学上学\n519503 1 您好,一汽-大众全系车型钜惠团购,更有多种金融政策助您达成购车梦想—全系首付xx%起,x-x...\n519504 0 每天都是一场excel大课所以我每天都巨饿…但如果学会用电脑弹钢琴我觉得还是蛮酷的\n1000 Processed\n classify content\n520000 0 如果说十度是房山的旅游圣地、长阳是高端城市化中心\n520001 0 我一直担忧沈阳地铁等公共场所的安全\n520002 0 南京虐童案当事人首发声:那次的确气狠了\n520003 0 无锡动物园·太湖欢乐园2015夏季狂欢夜\n520004 0 提示X你的微博昵称将修改为“房产商”\n1000 Processed\n classify content\n520500 0 麦先生说“找一个没有电梯的地方吧”\n520501 0 昨日在北京市高级人民法院决出了新一轮胜负—\n520502 0 可就在下午坐电梯的时候前面有一对情侣\n520503 0 按建筑面积的大小以及方位的不同\n520504 0 该男童经医院抢救无效已经死亡\n1000 Processed\n classify content\n521000 0 满足金融消费者的有效需求、维护消费者权益是金融工作的出发点\n521001 0 很多事情也不会改变比如手机里还在缓存着我的嬛嬛昨晚躺在我旁边的现在已经回家的没有留下一张合照...\n521002 0 儿行千里母担忧飞机延误三点才到家妈妈还在等着我给我下饺子吃\n521003 0 做包含酒店、商务、写字楼、豪宅等业态领先时代的顶级综合体创新\n521004 0 决定从2015年7月1日起将盱眙县困境儿童纳入基本生活费发放范围\n1000 Processed\n classify content\n521500 0 你和张丰毅老师嘚瑟83年我才两岁\n521501 0 双体帆船裸船租赁是非常好的一种方式\n521502 0 火车过南京长江大桥可比汽车快太多了\n521503 0 “命运对我如此不公”说人话“选择题全错了”\n521504 0 中国机器人产业联盟数据显示\n1000 Processed\n classify content\n522000 0 中央电视台无锡影视基地美美的\n522001 1 美宜佳欢迎您.本店以良好的信誉主营:日用品\n522002 0 法庭作出的判决才会成为看得见的公平和正义\n522003 0 7月16日下午“天使VC下午茶”创业者投资人对接活动第二期成功举办\n522004 0 在百度知道问答平台上涉及关键词“吸毒”二字的问题\n1000 Processed\n classify content\n522500 0 地址在成都二医院产妇杨艳妮\n522501 0 已经跟汽车之家车商城的销售约好了\n522502 0 医药股就不得不提醒中科系举牌的0004国农科技这个股一直表现都不错\n522503 0 她只好蜷缩在地铁轨道和站台之间的狭小空间\n522504 0 诚信加V:927901230\n1000 Processed\n classify content\n523000 0 挤不上地铁你承担得了么\n523001 0 中国之最大盘点:绝对精品\n523002 0 吴莫愁变身“LAGYGAGA”\n523003 0 IKnowYouWantMe欧美流行指南\n523004 0 紫金保险某系统漏洞大量用户敏感数据信息泄漏3\n1000 Processed\n classify content\n523500 1 【思路通】教育必须专 业性,思路通专注数学方法培 训xx年,学数学就到思路通。解放中路名都嘉...\n523501 0 在这个关系户横行的世界里我只想说一个字F\n523502 0 中国好声音每次都会发现很多好歌\n523503 0 不多废话?v:13688474689\n523504 0 甚至可以自动在AmazonFresh下单\n1000 Processed\n classify content\n524000 0 至于2GBRAM则不确定\n524001 0 是由塞浦路斯的TsikkinisArchitectureStudio团队打造的私人住宅项目\n524002 0 初创公司做到10亿估值的3种方法~最近老被一些神创业公司的报道刷屏\n524003 0 看来这几天某些种族的小偷都不会出来了呵呵\n524004 0 |CBI游戏天地网:唯一真媒体\n1000 Processed\n classify content\n524500 0 就使用我的邀请码85a775下载并登录浙江移动手机营业厅\n524501 0 手机版运营规范、处罚公示和辟谣中心\n524502 0 游戏的玩法是在全球选择一个出生区域\n524503 0 「7208人同时在看」爸爸回来了第2季东北小妞声泪俱下教训老爸你为什么不喜欢我\n524504 0 宠物保健用品狗狗羊奶粉犬猫微量元素维生素粉金毛泰迪蛋白营养粉\n1000 Processed\n classify content\n525000 0 USA|简单、舒适、自然\n525001 0 微软取代XboxMusic的全新音乐服务\n525002 0 把党和政府的关怀送到了他们的心坎上\n525003 0 他妈的说对不起有用要警察干什么\n525004 0 com本公司已通过阿里巴巴实地论证\n1000 Processed\n classify content\n525500 0 一汉子掏东西不小心把避孕套掉在地上\n525501 0 神之领域pk风气一夜之间消失了又是为哪般\n525502 0 新中式客厅的装修更是流行成风\n525503 0 微信加了个陌生人中病毒了上不去怎么解\n525504 0 科技公司即使曾经拥有微软般的垄断地位\n1000 Processed\n classify content\n526000 0 浦东新区司法局医调办调研员范冰冒着高温酷暑来到了上南二村小区走千听万、听取民意\n526001 0 省政府新闻办召开了“推进治理餐桌污染建设食品放心工程”新闻发布会\n526002 1 你好我是平安车险小张,明天办理商业险在最低折扣基础上,满xxxx可以加投一辆价值xxx永久折...\n526003 0 我姑夫电话:13937131918\n526004 0 如果这是某大v就是那个自称是金融街叫花子的发的\n1000 Processed\n classify content\n526500 0 这是继普京x月份访埃双方在技术路线、关键条款等方面达成一致后的又一进展\n526501 0 海门市民政局协同海门市老龄协会\n526502 0 新北莺歌、台南安平、台中新社、台东知本、金门金城、桃园大溪、高雄甲仙、苗栗三义、花莲瑞穗、台...\n526503 0 八路军什么也没干:我质疑一个数据:八年抗战\n526504 1 你好!新年业务已开,如有关银行承兑汇票的业务,欢迎来电咨询!电话:xxxxxxxxxxx 龙\n1000 Processed\n classify content\n527000 0 据Information网站周一报道\n527001 0 成为我送给她的11岁生日礼物……\n527002 0 03三鹰市“星星与森林的绘本之家”\n527003 0 “坦克两项”竞赛中国96A坦克登场\n527004 0 因此对宫颈糜烂这种疾病的治疗\n1000 Processed\n classify content\n527500 0 恭贺说客英语昆山震川路体验中心于2015年7月16日隆重开业\n527501 0 亲还在对着电脑浪费光阴吗\n527502 0 严格依法落实强制性停产措施\n527503 0 只要带“百度”的产品我都不喜欢用\n527504 0 一个国家的法律如果是正义公平的\n1000 Processed\n classify content\n528000 0 济南7月23日讯在常州上过大学的小虞\n528001 0 我虹悦城的必胜客是全南京乃至全宇宙最好吃的一家\n528002 0 崔胜贤一天到晚在ins发一些奇奇怪怪的展览品好醉\n528003 0 他认为Twitter不能再让开发者失望了\n528004 0 这里为您就总结了装修中能够省钱的十大秘诀\n1000 Processed\n classify content\n528500 0 指责导师存在“受贿”“诈骗”的可能\n528501 0 老子就是开国以后违法成仙的猫头鹰精\n528502 0 无人飞机将百米高空下的景象回传到操控器中\n528503 0 最终获胜的是由SagaDesign设计的“无所不能的siri”\n528504 0 就送蜜思可可价值xxx的摩洛哥海藻泥洗面奶一只\n1000 Processed\n classify content\n529000 0 从工程发包、设计优化、技改革新和工艺创新等多方入手\n529001 0 安装Key会变成3V66T结尾的Key来自动激活\n529002 0 地铁上坐我旁边那个男的忽然唱起歌来\n529003 0 出5张无锡动物园夏季狂欢夜门票\n529004 0 今年上演上海LINEFRIENDSCAFE&\n1000 Processed\n classify content\n529500 1 特推出年化收益率在xx%--xx.x%稳健性理财产品,欢迎咨询。地址:观音桥步行街融恒时代广...\n529501 0 穆棱市法院私信法律咨询信息已整理完毕\n529502 0 被同一辆警车拍了三次……\n529503 1 银行无担保无抵押,信用dai 款,手续简单,额度高,x天放款。财富热线xxxxxxxxxxx,小杨\n529504 0 小小的梦想随着纸飞机的飞翔划出优美的弧线\n1000 Processed\n classify content\n530000 0 我的大腿我的嫩肤我的乳房我的脸颊我的一切只能我男朋友触摸\n530001 0 流水账昨天看谷歌做的巫师3视频攻略解说看到十二点半才睡\n530002 0 玩家将以控制一条汽车生产线为开始\n530003 0 偷摸在腋下约15分钟后用冷水洗净\n530004 0 什么时候能摆脱小偷的孩子还是小偷的恶咒or宿命\n1000 Processed\n classify content\n530500 0 在江苏省常熟市打工的丁大欢高兴地说\n530501 0 武宣县法院一审判处被告人刘某珍有期徒刑10年\n530502 0 盐城市区的亲可以送货也可以自己上门挑选\n530503 0 反复强奸收买来的被拐卖妇女致其怀孕、生产\n530504 0 24℃……16℃我去这空调真好没有温差呀\n1000 Processed\n classify content\n531000 0 建议:解放军、公安、派出所、安检、公交车、列车、航空、车站、码头、海关等这些敏感部门应该要那...\n531001 0 优步用户可以通过其应用购买小米Note\n531002 0 六、七、八月是旅游的最佳季节\n531003 0 并压缩25家经营不善的百货楼层\n531004 0 一个失忆一个回忆这就是经历…送给正在老去的90\n1000 Processed\n classify content\n531500 0 收拾舒坦了窝在电脑椅上闭目养神听爱尔兰风笛\n531501 0 买了这么多Amazon的东西\n531502 0 既有能力吸引上款手机5000元档位的用户\n531503 0 在商科专业中开设CFALevel1pathway\n531504 0 百度这么大的公司不是骗人的吧\n1000 Processed\n classify content\n532000 0 反而被奸臣严嵩诬陷勾结蒙古意图谋反\n532001 0 嫌疑人因盗窃和吸毒已被送至南充市强制隔离戒毒所强制隔离戒毒\n532002 1 墙布、窗帘x.x折起。三、活动期间,折上折满xxxx元增至xxx元,最高增值xxx元。地址:...\n532003 0 也绝不负花千骨一人白子画不负全天下人却终究负了花千骨一人\n532004 0 我就打开管家的腾讯新闻来了解一下炒股的内容\n1000 Processed\n classify content\n532500 0 全球运营商VoLTE部署节奏正在加快\n532501 0 电脑不好用、手机不好用、路由器不好用\n532502 0 事實就是很小的事但有人翻譯錯誤把病情誇大結果某些人正確翻譯不信錯的翻譯卻深信不疑還質疑正確翻...\n532503 0 同时兼具潮流的设计与奢侈品的质感\n532504 0 她给你的信用额度都是有限的\n1000 Processed\n classify content\n533000 0 在钥匙圈的设计上留出了那么一点空隙\n533001 1 【贵阳花溪碧桂园】【双拼别墅、花园洋房】在【x月xx日前】购房只需付【x%房款】即可,若有亲...\n533002 0 暑假生活是这样的:腾讯微博微信溜狗\n533003 0 不承认计划生育相关法律对个体自由的压迫与强制\n533004 0 家人发现后送医院抢救后无效死亡\n1000 Processed\n classify content\n533500 0 一个神父能否请医生看病真是个难题啊我也真是个混蛋\n533501 0 圆形的餐桌设计更显生动随性\n533502 0 感觉辛庄是被常熟抛弃的一个镇\n533503 1 林发包装厂招切袋师傅一名,欢迎加入我们的团队!电话xxxxxxxxxxx,望牛墩洲湾卫生站对面\n533504 0 如果你武进法院公开站出来帮他指控我\n1000 Processed\n classify content\n534000 0 亚马逊推出一键购物硬件“Dash”按钮\n534001 0 正常新生儿出生后24小时内接种卡介苗\n534002 0 A酸本就是抗光老化非常好的成分\n534003 0 你们这些机器人和水军还真是烦\n534004 0 江中制药就消费者诉讼江中猴姑饼干及代言人徐静蕾发表声明\n1000 Processed\n classify content\n534500 0 发现边打手机边走路的人方向感变差\n534501 0 就连他曾经cos的张起灵也成为了我偶像\n534502 0 兴化市医疗卫生志愿服务队组织志愿者来到李中镇舜生卫生院开展“白衣天使进农家”志愿服务活动\n534503 0 赶紧打开电脑查却发现已经被人捷足先登\n534504 0 11月底前全面完成剩余问题的整改任务\n1000 Processed\n classify content\n535000 0 你们用电脑的时候会介意你妈坐旁边看着么\n535001 0 从会长、中天集团董事长楼永良手上接过聘书\n535002 0 SuperDaE认为自己的黑客行为没什么不当\n535003 0 BabyBanana婴幼儿训练牙刷$7\n535004 0 /国家体育总局排球运动管理中心主任潘志琛被查\n1000 Processed\n classify content\n535500 1 【每日鲜奶吧】亲爱的客户:x月x日女王节,本店推出独门配方“鲜奶冰淇淋”当天携女王进店免费尝...\n535501 0 这场审判从1945年11月20日持续到1949年4月13日\n535502 0 后经好心人送往医院却一直昏迷不醒\n535503 0 为起草讲话出谋划策的16人组成的首相咨询小组报告也递到内阁\n535504 0 我的电脑从来没试过同时装这么多的播放器\n1000 Processed\n classify content\n536000 0 TheVerge的评测曾称“AndroidWear在正确的时间做正确的事\n536001 0 “飞机版”电影番外篇四支连发\n536002 0 其实iPhone用户完全不必担心\n536003 0 喜欢这种安静的地方尽管烈日也不愿在马路上与成群的游客挤来挤去这几天走过不禁对来厦游客的种种不...\n536004 0 2、平台搭建无法使众人行\n1000 Processed\n classify content\n536500 0 中国绿发会公益诉讼系列之三\n536501 0 抢劫时看见漂亮的女子还连续两晚实\n536502 0 北京德比火拼裁判躺枪现场球迷亲如一家|图鸡肋赛\n536503 0 香港高等法院日前否决山水投资股份托管人提交的同意罢免山水水泥董事的提议\n536504 0 和苏州其他爱心企业的捐助一起发送贫困地区的儿童\n1000 Processed\n classify content\n537000 0 亚马逊中国周年庆7大品类最高满199减100\n537001 0 现代日化品的产品包装设计容器的稳定感无疑是人们对造型的最基本要求\n537002 0 一箭双星中国成功发射新一代北斗导航卫星\n537003 1 专业为个人和企业提供融资服务,xx万至xxxx万额度,月息低至x.x厘。全国按揭房,车,保险...\n537004 0 省道328黄张公路胶州市里岔镇路段\n1000 Processed\n classify content\n537500 0 到底为啥花千骨每次前面要播好多重复的\n537501 0 认证信息为“苏州健雄职业技术学院Houlc\n537502 0 要求设计的家具不只要好看舒适\n537503 0 eg汉滨法院规范化建设再发力\n537504 0 由镇爱卫办上报到城管办以扣分\n1000 Processed\n classify content\n538000 0 含有韩国玻尿酸Bx、芦荟萃取精华、水溶胶原蛋白等\n538001 0 2015春夏秋冬季大码女装花朵蓬蓬裙包裙中裙欧美中长款半身裙女夏\n538002 0 给人一种hometheatre的愉快体验\n538003 0 转播到腾讯微博印度媒体用漫画来报道该事件\n538004 0 好基友小猫和飞机还有真爱小马哥以及电影的主线人物小明等等\n1000 Processed\n classify content\n538500 1 好消息 [玫瑰]好消息 [玫瑰]好消息来了!(幸福三月,请把健康带回家吧!) ...\n538501 0 小溪塔派出所民警耐心调解1个小时\n538502 0 我们为您开通了xG高速上网体验功能\n538503 0 11区的朋友告诉我亚马逊上买的这个终于到了\n538504 0 Innisfree悦诗风吟这款洗面奶是男女通用的\n1000 Processed\n classify content\n539000 0 NOG娘都感觉不敢坐电梯了\n539001 0 我抢劫你什么我只唱英文歌…\n539002 0 B会理财但说话直言不讳不好接受……\n539003 0 亚马逊日前就根据2015年上半年的销售成绩和读者评分\n539004 0 来自全国各地的xxxx多名企业家与消费者代表和xx多家媒体记者参加论坛\n1000 Processed\n classify content\n539500 1 顾问,送价值xxx元的三合一洗面奶和保湿水。促销x号早上x点开抢,数量有限送完即止!亲:还可...\n539501 0 你做任何的保养如果不做防晒\n539502 0 明早我怕是起不来了~现在手机快没电了\n539503 0 现货现货今天下单包邮噢别看他小小一瓶\n539504 0 厦门大学出版社xxxx年x月版\n1000 Processed\n classify content\n540000 0 xxG荣耀金双卡双待全网通立即到手\n540001 0 “安倍道歉”机器人上海展出日本网友:该量产\n540002 0 白子画陪着花千骨在长留海底16年\n540003 0 fx现在是除东神外人数最少的了\n540004 0 “希望杯”2015年浙江省校园足球联赛初中女子组决赛在湖州市落下帷幕\n1000 Processed\n classify content\n540500 0 当时点点滴滴的开心对现在的我没有意义\n540501 0 我做的是美联航飞机中途在芝加哥转接时候\n540502 0 是paparecipe旗下一款安全的补水面膜\n540503 0 重要提示:●公司股票连续三个交易日内日收盘价格涨幅偏离值累计达到20%以上\n540504 0 我希望这种LOWB穷B事儿B永远都不要出现在我生活之中\n1000 Processed\n classify content\n541000 0 却被扬州一位69岁的农民花三天时间解了出来\n541001 0 感谢天感谢地感谢Amazon\n541002 0 医生通常会开立抗生素制剂、口服A酸或是打消痘针处理\n541003 0 每天睡觉前都要看看美团百度的评价生怕差评做人也是挺累\n541004 0 进、出水部位的流量、溶解氧浓度\n1000 Processed\n classify content\n541500 0 整理电脑get一张壁纸√\n541501 0 卫浴设计上面有贴合总体的设计风格\n541502 0 这群90后消防官兵无怨无悔地走进部队这个大熔炉\n541503 1 【攀枝花东区名望教育】春季提升班火热报名中…成都、绵阳德阳名师执教,精品小班让您的孩子掌握学...\n541504 0 疑似马航MH370飞机残骸在非洲东部岛屿被发现\n1000 Processed\n classify content\n542000 0 常州供电公司对110kV礼嘉变进行检修\n542001 0 胸前迷人的赫勒建筑风格的巅峰之月21日的黑夜降临以后、最后的晚餐、衣着和体“rocketne...\n542002 1 沙河市农机大市场 东方红 金马 邢台一拖 等系列拖拉机 中收 福田 博远 奇瑞等牌小麦...\n542003 0 不然就是腐败横生而上层领导如同瞎子一样被蒙在鼓里\n542004 0 卖爆了韩束x件套:洁面+水+乳+精华+bb霜\n1000 Processed\n classify content\n542500 0 低处化妆水、保湿凝露等都是如果有一天你突破了\n542501 0 传媒家微圈|听说灿星制作招聘了\n542502 0 明天跌停板埋伏中航飞机\n542503 0 现在的小偷也太TM有文化有品位了\n542504 0 前往“高大上”的淮安市政务服务中心办事的各位市民朋友们\n1000 Processed\n classify content\n543000 0 日本社会对南京大屠杀普遍是没有否认\n543001 1 x月x日菁智买x送x、亲体买x送x、小安素和亲护x.x折,一段不参加活动!菁智,亲体都是最低...\n543002 0 变频显示E7说可能是模块或主板坏了\n543003 0 全家x口分别持轮胎、酒瓶等物攻击警务人员\n543004 1 金尚装饰设计师刘彦格祝您:元宵节快乐!为回馈新老客户,正月十五元宵节当天签约金尚在最优惠基础...\n1000 Processed\n classify content\n543500 1 欢迎致电千叶金属制品(深圳)有限公司.本公司专业为您提供:五金.轴类.铆钉等.您的满意是我们...\n543501 0 微软宣布Windows10将全面兼容Android和iOS应用\n543502 0 总算survive了这次辛苦的旅行\n543503 0 摇摇眉头搓尽一身污垢前半生爱坏了这凡尘世俗伏在沙叶上吻舔烟头搁了咽喉长久输给醉酒\n543504 0 GPS以全天候、高精度、自动化、高效率等显著特点及其所独具\n1000 Processed\n classify content\n544000 0 也应在医生的指导下严格控制区域和用药时间\n544001 0 bb今天被儿科医生扎了一针后回来放到床上睡觉一会儿就会被吓醒接着大哭\n544002 0 互联网金融已经升级为手机之后最重要的战略板块\n544003 0 这是华为给用户提供极致体验\n544004 0 不能简单指望蜂蜜、香蕉解决问题\n1000 Processed\n classify content\n544500 0 南京苏州等8市联合申办中国获男篮世界杯举办权\n544501 0 还能通过成组LED球泡的光色属性\n544502 0 改了最后一班回上海的飞机凌晨三点才到家\n544503 0 没有真正的法院就没瓜有个人的自由和平安\n544504 1 您好,我是联邦家居经理贺帅,本店经营实木家具,风格有中式,新中式,英式,美式,意式,地中海等...\n1000 Processed\n classify content\n545000 0 江门地区共有17台苏州申龙电梯有限公司制造的自动扶梯和自动人行道\n545001 0 吃块西瓜压压饿吧唉加油加油明天早市的走起\n545002 0 咱家孩子500多为啥就上不了同一所学校\n545003 0 丢失的xx个西瓜牵出离奇盗窃案……\n545004 0 这次有点过分了如果你们没有怎么做吴亦凡可能会把真相隐瞒一辈子别欺负他善良你们会有报应的\n1000 Processed\n classify content\n545500 0 8月份打算去趟浙江散散心\n545501 1 亲爱的会员:诚邀参加x月x日—x月xx日“阳春三月惠动津城西门子博世家电大型团购会” 活动,...\n545502 0 中航动力以及中航飞机等都出现了较大的回落\n545503 1 烧鹅王感谢您的来电,本店为您提供:预定烧鹅、金牌乳猪、蜜汁叉烧等烧味系列,团体订餐,优惠多多...\n545504 0 广场内还有免费wifi呦~~有没有心动\n1000 Processed\n classify content\n546000 0 昨天我看了淘宝看了阿里巴巴看了京东\n546001 1 新春佳节,金仕堡健身回馈新老客户,所有卡种都打折扣,有意者可以联系我,乔漫。谢谢\n546002 0 和阿里云的开放搜索对接上了\n546003 0 看完抄袭质疑贴和洗地贴我就纳闷了\n546004 0 17今年3岁喜欢你的大大的眼睛和粉嫩的脸庞\n1000 Processed\n classify content\n546500 0 江苏卫视蒙面歌王这是恶心到不能再恶心好吗\n546501 1 中草集化妆品庆三八妇女节活动开始啦!快乐女人节!美丽存折送不停!活动时间x月x日至x日欢迎新...\n546502 1 劲爆信贷咨询:公务员、事业编、国企、上市公司仅凭职业信息,即可从银行轻松贷走xx-xxx万,...\n546503 0 就像被判了死刑却还没有执行\n546504 0 大巴车、飞机、动车、轻轨、都不可以超载为什么就火车可以超载了\n1000 Processed\n classify content\n547000 0 百度百科的描述是下图这样的\n547001 0 杀手和探员之间爱情与利用纠缠\n547002 0 现在安装Exposure插件后提示无法启动0xc000007b\n547003 0 但把潜规则的道理这样明明白白的讲出来也算是突破了\n547004 0 一直在刷1599啊啊啊啊心都酥了\n1000 Processed\n classify content\n547500 0 一次记x分:驾驶禁止驶入高速公路的机动车驶入高速公路\n547501 0 浙江大学教授/博导、中国工业设计教育界六大名嘴之一——应放天老师\n547502 0 宁波泰得科源招聘物流单证一名\n547503 0 一下大雨政府等相关部门怕冰雹打掉烟叶\n547504 0 装成xxxx遗产基金会杰夫摩根说维素、钾质和果胶等物有一种深沉的喜欢\n1000 Processed\n classify content\n548000 0 电脑辐射、汽车尾烟、空气污染、任何一点都在时时污染你的毛孔\n548001 0 我以为自己会永不厌弃你做一辈子朋友呢\n548002 0 收到快递的时候还在外边旅游\n548003 0 沛县举办IDTA拉丁舞国际等级考试\n548004 0 好难过守护不了你…真的…好难过\n1000 Processed\n classify content\n548500 0 软嫩酸甜诱人的镇江糖醋小排\n548501 1 激情三月,昊乐圆为回馈新老客户,特推出新的酒水活动,总统包(xxxx),豪包(xxxx)大包...\n548502 0 Google与三星之间不存在紧张关系\n548503 1 本公司专业设计制造液压升降机械,公司地址广州市白云区均禾街新石路公交站旁边.现需招电焊工师傅...\n548504 0 恒指期货与国指期货的拟定开市价现分别报24164和11040\n1000 Processed\n classify content\n549000 0 说戒就戒天天晃晃吃吃喝喝哪不舒服\n549001 0 上证指数不仅一举突破3700点的整数关口\n549002 0 医生对母亲说:“你女儿的妄想症很严重\n549003 0 lumia526两次升级wp10预览版都是以无限重启和滚轮失败\n549004 1 环亚市中店拉夏贝尔女人节特卖场活动,特卖全场x.x-x折,xx元起。专柜x.x折起,春装指定...\n1000 Processed\n classify content\n549500 1 盒 七,美即面膜特价x.x元/片 八,凡进店购满xx元即可赠送修眉卡 购满xxx元即...\n549501 0 一般为1000~3000公里之间\n549502 0 我外婆那样年纪70多岁还努力扫地的老人\n549503 0 我的电话被认证为余姚阿里巴巴服务中心了\n549504 0 女N的小护士也喜欢他很久了\n1000 Processed\n classify content\n550000 0 首批技术成熟的送餐机器人“翠花”\n550001 0 今后将实现由省级政府在全省行政区域统筹开展大规模跨地区、跨部门、垮层级的信息共享和联动办公\n550002 0 暖金色的蜂蜜色调的木制小屋、雨淋板的山墙和前盖门廊结合精美的室外前空间突出了石铺地面和一个花园绿洲\n550003 0 那么我对三叔以及投资商的眼光开始了严重的怀疑\n550004 0 不过vxin公zhong号还是会和zoe一起更\n1000 Processed\n classify content\n550500 0 乐购老员工集体索偿华润系或卖部分乐购门店有业内消息称\n550501 0 梦见机器人和绝地武士在月亮和启明星之间决斗\n550502 0 寻找江苏扬州地区快闪拍摄团队一组\n550503 0 为了赶上7:00到duma的飞机\n550504 0 兴化市老干部书画展今日在市博物馆揭牌\n1000 Processed\n classify content\n551000 0 看不懂IF主力和IH主力怎么还敢大幅贴水\n551001 0 5、找出前例中所包含的规则或原则\n551002 0 耳边一遍遍传来氧气的轻轻的歌声\n551003 1 【中山仁孚奔驰】祝您和家人元宵节快乐\n551004 0 和井柏然全国后援会浙江美女一起玩耍\n1000 Processed\n classify content\n551500 0 Spark在6月份取得了激动人心的成绩\n551501 0 在P2P借贷、网络理财等互联网投融资方式激发大众的投资热情后\n551502 0 就使用我的邀请码rx67h9下载并登录浙江移动手机营业厅\n551503 1 xxx=xxxx元(指定驾驶员),x月x.x号续保赠送机油一次或免费喷漆一次或四轮定位一次,...\n551504 0 竞赛当中的腐败不是个人行为\n1000 Processed\n classify content\n552000 0 5家酷炫医院引领现代医院设计理念\n552001 1 您好,我是刚刚和您联系办理pos机的。电话:xxxxxxxxxxx\n552002 0 随即墨西哥政府就排华事件公开道歉\n552003 1 亲!喜迎元宵节,三八节之际,我众鑫美妆,特别推出,优妮送好礼!原价xxx元套盒立减xx元现金...\n552004 1 您好:城市人家携手xx家建材商正月十七(x.x日)举行家装建材团购会,定装修可享受建材全市最...\n1000 Processed\n classify content\n552500 1 欢迎致电普兰斯广告,本公司专业制作亚克力制品,广告标识标牌,广告招牌\n552501 0 说吧下了飞机去哪儿野了一天拖着别人催稿急的要死\n552502 0 我一直觉得海外的华人靠政府\n552503 1 KARL LAGERFELD x·x女人节大礼回馈:x月x-x日购买满x\n552504 0 微软高管:微软会因Win10免费升级放弃一些营收\n1000 Processed\n classify content\n553000 0 他的钱被我从7000扣得只剩5000啦\n553001 0 ”更何况还是对于TFboys三个未成年的公共人物\n553002 0 这是来自江苏许鸿行先生的参赛作品\n553003 0 百度发现这样的问题不是个例\n553004 0 协议资金295亿元、完成年度目标任务的57%\n1000 Processed\n classify content\n553500 0 作为曾经被医生判半个死刑的人太能理解他们夫妻两为了要孩子受的苦\n553501 0 地球上的维生素B3可能起源于太空\n553502 0 投资这件事不能是生活的全部\n553503 0 两个小时的不标准汉语+不标准英语\n553504 0 Mxx球状星团是北半球中最亮的球状星团\n1000 Processed\n classify content\n554000 0 分布在内河不同水域的95艘采砂船集中整治、现已全部停机\n554001 0 集中修复14天精华每天用过化妆水后按摩涂在全脸\n554002 1 尊敬的用户:您的手机话费积分已满足兑换xxx.xx元的现金礼包条件!请用手机登陆 jggxx...\n554003 1 l恭贺新春:贵宾厅祝您新春大吉!www.xxxxxx.com推出每天打码返x%无上限;愿您心...\n554004 0 明亮色彩处理+镜头噪点、俯拍对称取景\n1000 Processed\n classify content\n554500 0 ”病友不解地说:“那更应该知道赡养老人啊\n554501 0 为了防止有坏人滥用个人信息\n554502 1 为答谢新老顾客对新东港KTV的厚爱,特在元宵来临之际推出纯生啤酒xxx元两打,期待您的光临,...\n554503 0 我在江苏为传奇手机版助力\n554504 0 无攻略下100%通关话说这为什么不改名叫被锁着的盒子的盒子的盒子\n1000 Processed\n classify content\n555000 0 获得了浙江省农业吉尼斯委员会颁发的最高仙人掌奖牌\n555001 0 8月1日微软电话营销团队团建现场图\n555002 0 ”小偷看着儿子那副尖嘴猴腮的模样\n555003 0 买的花千骨小说终于到啦好开心啦啦啦\n555004 0 南京万科置业总经理朱保全\n1000 Processed\n classify content\n555500 0 最后一天扎十针疼的麻了阿姨说那最好扎到位了哈哈可爱的阿姨~回去开始接着恢复欧耶按医生们的指导...\n555501 1 尊敬的会员您好,三月份女人节,为答谢新老客户本店所有护理活动均买一送一,优惠多多。欢迎各位小...\n555502 0 地铁对面站了个疑似在偷拍的人物\n555503 0 推荐这家微店:燕子的蜂蜜\n555504 0 而且还看到xx多辆已经禁止的营运三轮等着拉人\n1000 Processed\n classify content\n556000 1 欢迎致电:浏阳蒸菜馆、本店环境幽雅、菜品齐全、主要经营浏阳特色蒸菜、您的满意就是我们的追求、...\n556001 1 可爱*^o^*的家长们您好!童心筑梦幼少儿书画培训班春季报名正式开始了…需要预定学位的宝贝们...\n556002 0 不信去问下Google——支付宝说:你这么注重隐私\n556003 0 xxx天每天无数次随时随地补水\n556004 0 青岛黄海学院跟青岛滨海学院哪个好4\n1000 Processed\n classify content\n556500 0 而且播出的花千骨中開頭還有10多分鐘的重復情節\n556501 0 8月7日美国达美航空1889次航班由波士顿起飞目的地为犹他州盐湖城\n556502 0 投资者应该具备的重要一点:百折不挠\n556503 0 nicereunion??pic\n556504 0 吸引了来自全国120多所高校的1300余名运动员参加\n1000 Processed\n classify content\n557000 0 日本转运中国海外免服务费合箱EMS/航空/公司亚马逊乐天代购私人\n557001 0 可靠的P2P网贷系统建设开发公司可以帮助平台走向更规范化和科学化的道路\n557002 0 唯独最该收的房产税迟迟没有收\n557003 0 这部苹果5s手机是俞燕的婶婶买给她的\n557004 0 深圳市政府副秘書長高國輝表示\n1000 Processed\n classify content\n557500 0 泗洪县长途汽车站泗洪车站到天岗湖公交车太涨太帐乱收费\n557501 1 峰度家装施工队承接装修业务,菜单式报价,价格实在,质量过硬。电话:xxxxxxxxxxx 地...\n557502 0 不再滥用投资到马格里布的资金\n557503 0 本次医疗机构实行价格公示重点\n557504 0 intel更要确保制程大战中不被三星、台积电甩开\n1000 Processed\n classify content\n558000 0 领导一句政府办不发我之前的连续加班就白费了\n558001 1 老板,新年好,我们是常熟华鑫水洗厂,专业水洗各种牛仔衣服,裤子,裙子水洗,以及各种牛仔工艺,...\n558002 0 对朋友很反感但又没办法说出口想整人但又没有好的办法\n558003 0 在一个独立设计师交流会上看到的精致手工作品\n558004 0 当我们被打骂被恐吓想要用所谓的法律武器保护自己时就只能找到劝阻教育罚款这些么\n1000 Processed\n classify content\n558500 0 “对我来说手机只是电子手表而已\n558501 0 Gxx长深高速由杭州往连云港方向宁杭段Kxxxx+xxx至Kxxxx+xxx附近施工结束\n558502 0 欢迎其他南京未能相聚的点心和热联成员们踊跃勾搭\n558503 0 国家队动手的标志就是期货盘中像昨天这样脉冲拉升\n558504 1 广东华材铝材魏启助: 手机xxxxxxxxxxx 我曾经到贵店拜访过,本司专业生产各种门窗铝...\n1000 Processed\n classify content\n559000 0 去粉刺这款屁屁霜原来是要给小孩子治疗红屁屁的\n559001 0 我爸2015年6月24日被偷伐我家树的人拽晕\n559002 0 大家是不是都会看手机而丢掉宣传页呢?我们\n559003 0 采取多种措施做好法律援助工作:\n559004 0 龙口市开展电梯安全专项整治\n1000 Processed\n classify content\n559500 0 我其他地方包括电脑上都没存啊\n559501 0 2015年上半年被山寨最多的品牌依然是三星、小米\n559502 0 我想我留南京最大的痛苦就是家人的不支持以及一个人的孤单\n559503 0 此次共计有168名考生报名参加考试\n559504 0 风险投资没有计划和概念就是最大的风险\n1000 Processed\n classify content\n560000 0 设计这些建筑的大师们真是着实令人佩服\n560001 0 平均下来相当于每天20分钟左右\n560002 0 还记得我去浙江连连科技的时候\n560003 1 飞鹤奶粉搞打折活动了,星?海明都二店\n560004 0 我还是共产主义接班人呢\n1000 Processed\n classify content\n560500 0 浙江省档案干部教育培训中心关于举办全省“五水共治”档案业务培训班的通知\n560501 0 转海淘富裕的毛毛虫xxx/xx\n560502 0 与Belgica多次在飞机上相遇\n560503 0 冬季才能避免预防疾病的产生\n560504 0 昨晚喝得晕乎乎的~然后有客户说要来拿货\n1000 Processed\n classify content\n561000 0 北京儿童医院儿童保健中心主任医师刘春阳提醒\n561001 0 尽管我们被朋友嘲笑被家人嫌弃被伙伴质疑被经验束缚被同行乱价被媒体抹黑但这么困难\n561002 0 呵呵每次都这样赣榆人就是这种性格么既然什么都不合那根本不是一路人啊真是受够了\n561003 0 地方楼市半年报:广东浙江等沿海城市增幅领先\n561004 0 但他们却直接把钱打给你这是别人相信你\n1000 Processed\n classify content\n561500 0 法学xxxx的张演锋同学皆进入了总决赛\n561501 0 Piaget伯爵chaumet最永恒的幸福不是拥有你\n561502 0 你要发给十六个朋友包括我若不发\n561503 0 朋友周日去无锡阳山批发水蜜桃\n561504 0 因为想独立因为不信命因为坚信可以成就更好的自己在微商的路上决心走到底不畏惧不逃避勇于直面挑战...\n1000 Processed\n classify content\n562000 0 goodbeysummer??\n562001 0 南京的海底世界还是上海的海洋馆更好玩\n562002 0 弥补了我国旅游文化学科研究的一个空白\n562003 0 因此我们决定诚招有1年美甲工作经验以上的美甲师一名\n562004 0 同时也是美国航天飞机的最后一次飞行任务\n1000 Processed\n classify content\n562500 0 可能没过多久的时间阴道就会有少量出血现象的发生\n562501 0 徐州移动业务推广尕专用号\n562502 0 到9个月大时这顿奶更是肯定不必要了\n562503 0 这次想办法在电脑网页上打开支付界面\n562504 0 你也快来表态吧~如果你是米朵\n1000 Processed\n classify content\n563000 0 张艺谋已决定接受无锡滨湖区计生局xxx万余元的罚款\n563001 0 而违法密度最大的当数文化西路xxx多米的抓拍路段\n563002 0 用滴滴打车顺风车快的一号专车嘀嗒拼车天天用车易到用车xx用车神舟专车还不如用uber打车\n563003 0 完成老浦口地区整治和浦口历史风光带整治\n563004 1 ????尊敬的贵宾们;XG雪歌给您送礼啦,好礼免费送哦[愉快][愉快]欢迎提前店铺参加预定抢...\n1000 Processed\n classify content\n563500 0 假如马云来到中国好声音你们自己感受一下\n563501 1 各位亲们新年好'祝羊年大吉\n563502 0 手机关机三回了这是第三次开机了\n563503 0 特么王俊凯坐个飞机只有一个小马哥跟着\n563504 0 五粮液集团都出玛咖酒了…玛咖植物萃取\n1000 Processed\n classify content\n564000 0 要像防贼一样防官员贪污盗窃\n564001 0 1到win10应用商店就没好用过\n564002 0 這是要我以後都不要放cos照上來的節奏\n564003 0 拿xx块精油皂皂加入常有代理问我怎么加入南娜代理团队\n564004 0 地址是在吴中区人名医院斜对面誉肤堂\n1000 Processed\n classify content\n564500 0 2011年张、凌两人起诉到西乡塘区人民法院后\n564501 0 确保在2016年高标准通过国家卫生县城三年一次的复评\n564502 0 但是次卧的装修也是非常值得重视的\n564503 0 之后去医院又精力充沛到去吃火锅\n564504 0 成功是人格和财富的双重丰满\n1000 Processed\n classify content\n565000 0 浙江卫视的中国好声音、江苏卫视的真心英雄、东方卫视的报告\n565001 0 前保险杠等处的造型也有所调整\n565002 0 主旋律就是强奸你可是还要骂你怎么不学着享受\n565003 0 /中日硬实力大比拼看中国军工如何完虐日本\n565004 0 /市民拿xx年前存折取钱遭拒银行:当年无电脑\n1000 Processed\n classify content\n565500 0 xxxx年国家提出的一带一路战略\n565501 0 此次展览命名为“凿黑觅白”\n565502 0 每次欢欢喜喜买东西然后看到哪里都是MadeinChina突然不知道该伤心还是高兴一个电脑什么...\n565503 0 南通普法志愿者开展“带绿进社区送法惠居民”活动\n565504 0 有图有真相好在哪了眼见为实\n1000 Processed\n classify content\n566000 0 外观包装设计体现了时代感和高雅、华贵、时尚、气派的风格\n566001 0 现代电梯的安保是天衣无缝的\n566002 0 祝节日快乐……南京高温酷暑中\n566003 0 3以上语言:中文分类:通讯社交作者:腾讯微信版版找了半天这个能用\n566004 0 有利于解决宿迁市小微企业融资难等问题\n1000 Processed\n classify content\n566500 0 似乎个个贪官都热衷于放开脑瓜子、放松裤带子\n566501 0 不知道城管领导家门前是个什么样呢\n566502 1 好消息! 新楼盘急售。 位于角美龙池...\n566503 1 武汉现代友邦科技有限公司主要销售各科室医疗设备,价格绝对有优势,欢迎来电咨询xxxxxxxx...\n566504 0 保险公司今年上半年权益类投资比重大幅上升\n1000 Processed\n classify content\n567000 0 AQXP宣布其在减少膀胱疼痛综合征/间质性膀胱炎患者的疼痛方面疗效显著\n567001 0 江西省新建县人民法院审理一起强奸案\n567002 0 武汉地铁继撕衣大战后又现强抱乞讨女\n567003 0 它是一场由SAPHR部门精心组织的员工年度盛会\n567004 0 IBM亚太地区行销总经理的职位\n1000 Processed\n classify content\n567500 0 一些怀疑干洗店暗藏猫腻的微博\n567501 0 皇后公园10年专业团队统一运营管理、7%年回报率、6米超阔层高\n567502 0 新鲜大白凤无锡阳山水蜜桃蜜呀果园现摘现发\n567503 0 想到初次接触电脑还学什么DOS命令\n567504 0 恩……要不要下个花千骨玩玩……\n1000 Processed\n classify content\n568000 0 昆士兰工党政府推翻了原发展企划中建造游轮码头的部分\n568001 0 4、中国有意采购俄制火箭发动机\n568002 0 江苏省气象台15年7月26日14时29分发布雷电黄色预警信号\n568003 0 那么北斗卫星导航系统的崛起还是问题吗\n568004 0 微软对硬件的严格要求也是一大原因\n1000 Processed\n classify content\n568500 0 本来要和妈妈说吃米饭又把胃吃坏了胃疼了但是忘了\n568501 0 我刚问她我不知道发什么然后她掀开眼罩冲我惊恐的大叫一声然后骂我神经病…虽然给了我灵感但我想说...\n568502 1 小文案大街。化妆品折扣店。庆三八妇女节,可享受一款半价产品,原价六十九的补水霜现价三十八。任...\n568503 0 广州警方打掉一名为“FreedomFighters”的外籍涉黑犯罪团伙\n568504 0 我今天在华为网盘签到获得了163M免费永久容量\n1000 Processed\n classify content\n569000 0 5天前肚子上忽然长成片的红疹次日消退\n569001 0 xxxx年x月xx日早上xx点在内江大自然组织七夕情人节快乐相亲烧烤自助\n569002 0 来自淄博的模特Charissa\n569003 0 海门滨海新区电力抢修现场\n569004 0 我分享了百度云里的文件:?杨洋唱我们的歌\n1000 Processed\n classify content\n569500 0 也许你一天只有50块或者一两百块\n569501 0 嘎鲁图第二派出所集中开展打击电信诈骗专题宣传活动\n569502 0 橄榄:橄榄叶精华有助细胞对抗外界侵害5\n569503 0 惠普将利用这一机会抢夺戴尔的客户\n569504 1 雪依氏婷婷祝大家元宵节快乐万事如意财源滚滚。提前祝亲三八妇女节快乐。本店特推出充xxxx送面...\n1000 Processed\n classify content\n570000 0 或许从那时起这首…分享单曲\n570001 0 又出来好多大屏手机好喜欢只能看看\n570002 0 姚麦时火箭十大对手:爵士居首小牛马刺有份\n570003 0 本市有5家医院的新建项目被纳入20项民心工程\n570004 0 让投资者有了更多选择的机会\n1000 Processed\n classify content\n570500 0 从估值、实体经济流动性趋势和经济前景看\n570501 0 刚刚去网上又看了一边a大的华胥引和小小白的花千骨\n570502 0 庐山美丽的欧式别墅是建筑在近代中国屈辱史的基岩上\n570503 0 刑事案件受理数和道路交通事故数同比大幅下降\n570504 0 商业模式意味着一个公司是如何通过在价值链中定位自己\n1000 Processed\n classify content\n571000 0 朋友们可以加她卫星:lemon940422\n571001 0 家电产业与房地产市场相关性较高的厨电行业有望再次迎来快速增长期\n571002 0 在中国这样第二季度GDP同比增长7%\n571003 0 百度音乐为毛也不给100%权限啊\n571004 0 乐视正在与微软、索尼等厂商进行接触\n1000 Processed\n classify content\n571500 0 咨询和下单的给我留言就行醒了都会回复??\n571501 0 借第一次装修新房写点流水账\n571502 1 美丽女人节,快乐大派送。原价xxx元的珀莱雅补水美白系列xxx元大抢购。仅x月x日x日,逾期...\n571503 0 分别高于全国、全省10个百分点和4个百分点\n571504 0 手机里几乎都成妹妹的美照了\n1000 Processed\n classify content\n572000 0 将一辆制式警车围堵在医院门前\n572001 0 我要冲腾讯视频一百年的会员\n572002 0 扯蛋检察官/男子疑强奸13岁幼女检察院:双方自愿敦促撤案\n572003 1 你好!鸿达瓷砖城祝你新年胜旧!石排最大间的瓷砖城位于黄家茔红绿灯加发加油站旁,品种齐全,全场...\n572004 0 xx年里积攒十余万元全部用于慈善\n1000 Processed\n classify content\n572500 0 上了好几次腾讯新闻的郑大一附院\n572501 0 省食药监、公安、工商等12个相关职能部门\n572502 0 横沥人民医院滥用麻醉注射待产健康孕妇\n572503 0 2011年至2014年累计完成全社会固定资产投资872\n572504 0 昨儿在地铁看到一个妇女带着一个小孩\n1000 Processed\n classify content\n573000 0 我就直接联系亚马逊购物安心保障\n573001 0 北京房地产开发投资同比增长22\n573002 0 小海湾确实挺适合投资让家里人来过冬疗养的\n573003 0 前脸设计借鉴了古思特的一些元素\n573004 0 旧时较多外籍商贩居此一带谋生\n1000 Processed\n classify content\n573500 0 但是为什么建筑啥的都那么多级了呢\n573501 0 你不去违法警察会用枪指着你\n573502 0 对朋友的妻子实施强奸xx余次\n573503 0 图为浙江温岭市石塘镇沿海掀起疾风大浪\n573504 0 去你妈的破电脑卧槽我要跳楼\n1000 Processed\n classify content\n574000 0 特别是在一些知名企业招聘大学生精英包括招聘销售人员的时候\n574001 0 WP手机销量未达到预期微软将再裁员7800人\n574002 0 坐落在距南京50公里的历史文\n574003 0 2000余日军在6架轰炸机的掩护下从上海直扑嘉善县城\n574004 0 推动省以下地方法院、检察院人财物统一管理”\n1000 Processed\n classify content\n574500 0 将以15km/h速度向西北偏北方向移动\n574501 0 这办公楼就像鬼楼一样……\n574502 1 您好,我是朴信贷款咨询的小黄;我公司主要为客户办理: 房产/汽车抵押贷款、中小企业贷款、个人...\n574503 0 今天早上随手小米4手机升级了下最新的系统\n574504 0 院长激动地握着护士妹妹手说:“太谢谢了\n1000 Processed\n classify content\n575000 0 无名指:感冒、咽喉疼痛、头痛、尿频、汗多、宫寒\n575001 0 啊啊啊啊啊好想出去旅游除了我妈就没一人有空的\n575002 0 真的好嗨森~我在财富音乐点点情群里\n575003 0 他们应该为滥用个人情感而到警察局自首\n575004 0 整个播放器设计成一个立方体的形状\n1000 Processed\n classify content\n575500 0 这款不粘玉米的烧烤夹设计合理\n575501 1 南湖花园x楼xx平左右\n575502 0 省交警总队、黄南州公安局主要\n575503 0 目前第6轮最后一场河南vs广东即将开始\n575504 0 招商轮船收购淡水河谷所拥有的四艘二手超大型铁矿石运输专用船舶\n1000 Processed\n classify content\n576000 0 能耐心等待三到五年——适合做投资家\n576001 0 房型:跃层风格:美式设计师:童燕基装造价:&\n576002 0 只需加油员提起加油枪就行了\n576003 0 常州西绕城高速宜江方向K102—K93处今日流动路面修补施工结束\n576004 0 就是给判死刑人家也知道谴责谴责\n1000 Processed\n classify content\n576500 1 xxxx元/平米起抄底开元东路地铁囗现房,抄底热线:xxxxxxxxxxxx/xxxxxxxx\n576501 0 北京地铁2女子抢座爆粗口上演“撕衣大战”丢人\n576502 0 上月辞去房地产销售主管职务…然后呢\n576503 0 上午主治医生请主任医师帮宝妈诊断后\n576504 0 曾执掌Xbox在日本的相关事务长达8年之久的泉水敬已在两天前正式从微软公司离职\n1000 Processed\n classify content\n577000 0 用绑架的法律来压制人民和孩子\n577001 0 想睡一直没睡的原因是群里有人大半夜在发红包\n577002 0 applewatch搜索流量只有iPod的1/2\n577003 0 x美元/盎司因投资者担忧美元持续升值及美联储会在未来几个月内加息的前景\n577004 0 互联网+农业融合而成的电商平台\n1000 Processed\n classify content\n577500 1 xxxxxxoxxxxxxxxxoxo农行张玉兰\n577501 0 也不能为了吃顿Twitter的工作餐漂洋过海\n577502 0 医生自言自语地讲无锡话:小痴佬\n577503 0 让您在泰州一样感受东北的风味的烤串\n577504 0 今晚22点天津新闻广播FM97\n1000 Processed\n classify content\n578000 0 持赫基、艾维、IAM27VIP卡可享受折上在9折\n578001 0 几个副总司令都是贪污犯的军队\n578002 0 所谓被查处的腐败官员照样可以不下\n578003 0 吃水果我一直相信努力的汗水一定会得到收获我就是我人生的最大项目管理和投资自己是一辈子的事儿\n578004 0 陆军第xx集团军某团野营村突遭xx级强风和暴雨袭击\n1000 Processed\n classify content\n578500 0 就是网站一打开关于花千骨的那个了\n578501 1 至周日。特邀您及家人前来参观西北最大的家装体验馆,精品设计方案~~x.凡到店业主均可立即抽取...\n578502 0 常州市气象台x月xx日xx时继续发布高温黄色预警信号\n578503 0 南京首家名人蜡像馆清凉来袭\n578504 0 华为P8青春版智能安卓手机16G优品团购¥1\n1000 Processed\n classify content\n579000 0 相对于北京地铁的全程移动4G不掉线\n579001 0 根据雄县法院民事判决书以及xxxx保民一终字第xx号判决书可以确定马海峰系水泥塔罐厂的管理者...\n579002 0 UP主:伐开心要肉包哈哈哈哈\n579003 0 9日南京我们还有少量票需要私信购票谨慎假票\n579004 0 流露复古气息衣领系蝴蝶结处理\n1000 Processed\n classify content\n579500 0 举个例子两个小学生在玩游戏拔河比赛\n579501 0 一年前华为荣耀没有对小米M1构成威胁\n579502 0 并且是ips材质的多点触控屏幕\n579503 1 雅粉们又是一年“三八妇女节”到来之际丽水继光街雅莹五季特推出秋冬款低至x折起,新品x一x折在...\n579504 0 在全国27个“爱心驿站”留下感人瞬间\n1000 Processed\n classify content\n580000 0 压抑了很久现在已开始质疑自己\n580001 0 型号分为S、M、L、XL~具体型号可以咨询我\n580002 0 分享BloodzBoi\n580003 1 尊敬的顾客您好:全友大型店庆活动定于x月xx一xx日隆重举行,厂家直销·全年最低!我们郑重承...\n580004 0 拿出自己白色iPhone递给哭小孩\n1000 Processed\n classify content\n580500 1 您好!我是文华xx期陈奇丰 陈总的助理,我司致力为文华家人提供个贷,经营贷等全方位的金融服务...\n580501 0 我在看小时代4的时候一直在想“4个亿”没了构成什么罪\n580502 0 每次坐飞机就总有些傻逼的人\n580503 0 开盘当日尚有320套住宅未推出\n580504 0 程序猿对单身狗造成了3倍代码属性伤害\n1000 Processed\n classify content\n581000 0 在飞机上的操作需符合那个年的实际情况\n581001 0 伙伴们的加油呐喊也充斥着全场\n581002 0 中国建筑金属结构协会成员单位\n581003 0 微软为毛不把ShellIconOverlayIdentifiers搞好一点\n581004 0 郑州标志建筑“玉米穗”JW万豪酒店三楼\n1000 Processed\n classify content\n581500 0 倒是看了半天北京卫视真是没信誉完全为了收视率\n581501 1 尊敬的会员你好,无锡八百伴三楼POZO(伯柔)女装三八节全场新品春装xxx减xx,老会员消费...\n581502 1 乐宾百货皮尔卡丹内衣专柜、、现推出x.x节活动、男、女款套装、保暖裤、新款秋裤超低价x.x折...\n581503 0 基于标准PC架构和Linux操作系统\n581504 0 刚在思美得商贸有限公司摇到了免费好东东\n1000 Processed\n classify content\n582000 0 这边建筑都是我特喜欢的那种风格\n582001 0 低配版xGRAM+xxGROM\n582002 0 位于陕西省乾县县城以北梁山上的乾陵\n582003 0 均价xxxxx元/㎡南京河西新房价创记录\n582004 0 男子坐17年冤狱获赔160万成土豪媒婆提亲踏破门24岁时\n1000 Processed\n classify content\n582500 0 凉山州禁毒委xx个成员单位将派出专人\n582501 0 不想跟熟人有太多的经济纠纷\n582502 0 我朋友说她有轰炸软件我说不信用我号码试试结果…我手机卡的现在才能用\n582503 0 提高观众对最后的审判期待值\n582504 0 商家赞助热线:13608870413\n1000 Processed\n classify content\n583000 0 认证信息为“浙江龍湫服饰有限公司物流经理”\n583001 0 『分级基金为什么有下折风险』\n583002 0 杜绝假货4、TST一瓶W也能公司代发\n583003 0 好棒好棒呀有没有招聘啊我今年刚大学毕业\n583004 0 电梯安全不容忽视啊我们小区电梯上演惊魂未定啊\n1000 Processed\n classify content\n583500 0 另外连红米2的续航都比撸妹930好\n583501 0 一个房地产开发商的建议:年轻人不要再贷款买房了\n583502 0 一首歌唱到一半也给插30秒广告\n583503 0 我推测可能是技术性违规的可能性多些\n583504 0 尤其是人民币是否纳入SDR货币篮子\n1000 Processed\n classify content\n584000 0 InternetExplore俗称IE\n584001 0 电梯制造商以及负责电梯维修的公司应该承担连带责任\n584002 0 以538分的成绩被江苏大学录取\n584003 0 近日佛山一男子因为电梯故障\n584004 0 澳妈首选的一款止咳糖浆小青蛙款和小绿叶款\n1000 Processed\n classify content\n584500 1 好消息:x.x回馈广大老顾客,x月份到店一次即可获得价值xxx元bx隐形面膜x片,数量有限先...\n584501 0 北京西站地铁站真是错综复杂得叫人疑心自己身在八百个出口的新宿…\n584502 0 报名截止时间xxxx年x月x日\n584503 0 回国以后迷上花千骨、可是更新好慢\n584504 0 我此去南京应该是能看到海了吧\n1000 Processed\n classify content\n585000 0 寻找江苏摄影大师一名本人想做助理以前也是一名小摄影师\n585001 0 旅游主管部门鼓励灵活安排工作时间\n585002 0 开店的有信用卡的需要办pos机的朋友们看过来、普通刷卡信用卡套现\n585003 0 这台保时捷采用一对4英寸直径的排气管\n585004 1 您好!我是刚给您打电话证大财富的客户经理: 胡园园xxxxxxxxxxx 办理无抵押信用贷款...\n1000 Processed\n classify content\n585500 0 感谢南京市城管、地税部门大力支持80家停车收费系统厂家并肩攻关2000多家停车场经验单位的鼎力配合\n585501 0 7月14日即5天前江苏宿迁泗洪一名初二学生被同学围殴至死\n585502 0 小偷总是向手无缚鸡之力的女性伸出双手\n585503 0 潜规则可厉害你不怕啊\n585504 0 车上请一美女手机帮着充值xxx元我当场付现\n1000 Processed\n classify content\n586000 0 其在巴黎证券交易所购买了爱马仕集团的一股股份\n586001 0 应该是必须参与调查/马航疑似飞机残骸运抵法国中方表态\n586002 0 飞机最后一次试着陆生死关头前\n586003 0 逼格尔thanbigger\n586004 1 特大喜讯:茂业天地古色专柜元霄佳节三八妇女节双节同庆巨恵回馈促销活动x月x~x号四天VIP到...\n1000 Processed\n classify content\n586500 0 去年一年拍摄了近万张镇江各处风景\n586501 0 微软蓝牙折叠式键盘正式开卖\n586502 0 说是我有9000多的房产税要退给我\n586503 0 今天4000+已经干了两罐氧气\n586504 1 商圈,单价x-x.x万,总价xx-xx万,欢迎实地考察!这是我手机号码,如果方便可以存下。祝...\n1000 Processed\n classify content\n587000 1 保赢第七场, xx:xx 荷甲埃因霍温vs阿贾克斯,由半球一球分析看好主队胜出,推荐埃因霍温...\n587001 0 贵州省检察院召开全省检察机关党风廉政建设突出问题专项整治动员会\n587002 0 今早上看了几条吃人电梯视频\n587003 0 有关代写minitabanalysis的事宜\n587004 1 --别墅铂金工艺实景展示街盛大开放,隐蔽工程非常艺术的展现在你眼前…等等!详细了解、欢迎致电...\n1000 Processed\n classify content\n587500 0 今年12月系统通过认证后争取在中国石化整个工程建设板块实现电子招投标\n587501 0 大连印象……交通篇交通实在不能恭维\n587502 0 无汽车+油箱30升=挤压上墨器hhhhhhhhh哈哈哈哈哈哈哈哈哈哈哈哈\n587503 0 南化公司连云港碱厂盐堆场建厂时设计为露天存放\n587504 0 网友质疑为何民间账号发警方通报\n1000 Processed\n classify content\n588000 0 徐州有个地方可以享受碧海蓝天\n588001 0 但是现在简直就像残疾儿童一样\n588002 0 生活中也会有很多治疗疾病的方法\n588003 0 600308华泰股份:将和国内外一流的科研院所、集团公司合作\n588004 1 xxxxxxxxxxxxxxxxxxx 工行 卢健贤\n1000 Processed\n classify content\n588500 0 中船重工:航母和核潜艇等重点工程任务进展顺利\n588501 0 提到这个词满脑子都是NBA和SD的画面\n588502 0 去电脑上找居然也没有”的魔咒\n588503 0 呵呵进电梯有保持距离拍照离得近是因为拉了焦距\n588504 0 将众多安阳肿瘤医院资讯进行浓缩\n1000 Processed\n classify content\n589000 0 而且越来越担心举报会成为打击竞争对手的有力手段了……\n589001 0 微软智能助理Cortana提前泄露\n589002 0 深航飞机纵火案太他妈惊险了\n589003 0 昨晚第一次醉酒在兰州睡大半天出门差点被小偷偷钱包两傻逼夜游中山桥和母亲河简直不能在丰富的一天\n589004 0 上周去华盛顿把iphone耳机丢了\n1000 Processed\n classify content\n589500 0 他可能是NBA历史上最具个性\n589501 0 时间让你熬到了真相却没有补偿\n589502 0 那么他们都投资了哪些技术公司\n589503 0 该路段曾于xxxx年xx月xx日xx时xx分因高速交警管制\n589504 0 最近更进展到用电脑散热口\n1000 Processed\n classify content\n590000 0 武汉中院二审判决这名男子侵犯他人名誉权\n590001 0 据说家里装修成这样老公都愿意回家了\n590002 0 股票亏钱、喜欢的人又不理我\n590003 0 ——江苏新沂市委书记赵立群\n590004 1 宽带升级,光纤入户,新春有礼,xx兆xxxx元两年,月均xx元。河西利民道站,安装电话xxx...\n1000 Processed\n classify content\n590500 0 圣罗兰男女通用款星星背包背上它出差旅游再也不烦恼啥都能装最重要的是超级顶级质量进专柜完全不是...\n590501 0 市人民检察院党组副书记、副检察长于天敏出席仪式并讲话\n590502 0 最近阅兵演习的飞机从我家附近过\n590503 0 空中直升飞机环游黄金海岸等有意思的活动\n590504 0 新版还加了蜂蜜味道好闻的一比啊\n1000 Processed\n classify content\n591000 0 许多手机实现了电流检测监控\n591001 0 因为装修买家具已吵了好几架了\n591002 0 Ins的padgram版本中卫星定位技术含量好高当下云层都一清二楚??\n591003 0 下飞机时候的心情还是跟登机时候一样孤独\n591004 0 建築師Gn?dingerArchitects\n1000 Processed\n classify content\n591500 0 这一切都静静的等待了100多年\n591501 1 宏景制衣厂专注生产牛仔裤,主供广州沙河\n591502 0 大爱今天请的裁判~~天津队棒棒哒~~\n591503 0 线下更是以华为名义包下深圳多家电影院\n591504 0 南京宜家家居外仓的承包商上海海博国际运输代理有限公司对于外仓员工工资少发\n1000 Processed\n classify content\n592000 0 和这咖啡看着对面飞机灰来灰去\n592001 0 徐州全面二孩政策最快可能年内实施\n592002 0 我们还有一个O2O的线上平台叫特来劲\n592003 0 不然这伙邪恶的犯罪分子早就把问题煽动起来了\n592004 0 行业整体效益大幅提升军工板块中长期投资价值凸显\n1000 Processed\n classify content\n592500 0 FC宝鸡轰炸机的全家福\n592501 0 就是13岁然后把每一集摩登家庭看五遍还最喜欢Jay的那个伢\n592502 0 南京、无锡、苏州三市已有地铁\n592503 0 黑龙江省佳木斯市人·见下文↓\n592504 1 内部渠道专业操作(公務員+事業編+按 揭房+嘿名单+车+保单)唎息低至x厘,简单!低息!高效...\n1000 Processed\n classify content\n593000 1 德佑高榕举xxxxxxxxxxx:外滩绿地名人坊,南北通x房,x梯x户得房率xx%,面积xx...\n593001 0 可是乐视手机到了我就把果6给我妈了\n593002 0 你说我不是说下个月来扬州吗\n593003 0 库里无解三分领衔NBA总决赛十佳球\n593004 0 倒过来就是买保险的顺序』\n1000 Processed\n classify content\n593500 0 实现了宿迁市相关领域零的突破\n593501 0 一遇到任务电脑就开始装死呵呵呵呵\n593502 0 陆家摄协特地邀请了昆山摄影协会的王伟明老师前来陆家为会员们进行摄影专题讲座\n593503 0 ??不久前刷爆朋友圈“估值6亿”的云视链\n593504 0 前保险杠丰富的线条凸显运动感\n1000 Processed\n classify content\n594000 1 你好, 三类人员岗位证书考试 包过。以后可以直接跟我联系。地址杭州市教工路xxx号华门a座x...\n594001 0 武汉地铁两女子抢座上演“扯发撕衣大战”\n594002 0 双胎宝宝八个半月另一个宝宝没有这样的情况\n594003 0 徐州沛县交警大队龙固公安检查站民警在例行检查时\n594004 0 前大灯采用了主动式LED灯源设计\n1000 Processed\n classify content\n594500 0 完善的远程医疗咨询服务平台\n594501 0 来自全国的109支代表队同台竞技展绝活\n594502 0 然后发微博晒出手机里的第7张照片\n594503 0 眼泪流了下来~才明白自己还是小孩\n594504 0 e的桶前期也就只能扔草丛阴阴人\n1000 Processed\n classify content\n595000 0 新款欧美大牌同款实拍图上啦超级好看~sm很显身材气质名媛包邮~\n595001 0 视频来自张国荣xx年夏日伯爵演唱会\n595002 1 :全款车x厘x,贷款车x厘……欢迎您来电咨询xxxxxxxxxxx于。也可添加微信账号xxx...\n595003 0 第一次见到你的时候没抢夺你的大脑真是太好了\n595004 0 死猥琐百度进攻敌后战场欺负我封圈\n1000 Processed\n classify content\n595500 0 这艘xxxx车位汽车滚装船\n595501 0 何炅老师票能不算过期么、好难过\n595502 0 旅游地产未来房地产市场发展方向\n595503 0 人形條碼殺人案的兇手~最後終於死了~壞人的下場都不會太好~南宮閔在這部戲演得很好~害我邊看邊罵\n595504 0 所有股票全抛无股一身轻\n1000 Processed\n classify content\n596000 0 这只机器人玩偶就离家出走了\n596001 0 x、为学院各项活动的开展提供相应的经费、物质保障\n596002 0 做法:1、洗净橙子在盐水中浸泡一会\n596003 0 早年毕业于南京艺术学院美术系\n596004 0 他是一个聋哑人他没有任何贪婪\n1000 Processed\n classify content\n596500 1 好消息!吉林元鼎佳宝森雅xS店迎春巨 献,佳宝Vxx全系最高直降xxxx元,佳宝Vxx新车火...\n596501 0 看了还是有些许感触CBA也不易更加难以想象NBA有多吊我只想说我是一个篮球爱好者\n596502 0 早不知说了多少违法的内容了\n596503 0 无锡人有句俗话:小暑里黄鳝赛人参\n596504 0 有著名的响水湖泉、珍珠泉、龙河泉等水资源\n1000 Processed\n classify content\n597000 0 当执法机关跟违法单位穿一条裤子的时候\n597001 0 8点的飞机一直推迟到11点\n597002 0 声控截图模式——借助手机的麦克风进行喊叫\n597003 0 开发区法院被确定为全省司法公开工作省级示范单位\n597004 0 我把所有视频传到百度云然后手机里的全删掉了现在问题来了\n1000 Processed\n classify content\n597500 0 抓获潜逃x至x年网上逃犯xxx名\n597501 0 下午区政府期丽琼副区长一行到明苑校区对招生情况进行了现场指导\n597502 0 以后我要是干护士这个行业我要用半个月工资来买保险万一遭砍了我读医的成本还没收回就死了我家里人...\n597503 0 独裁=集权=威权=强权=暴力=反人性=政治腐败\n597504 0 你拿刀对小偷施暴剥夺小偷的生命\n1000 Processed\n classify content\n598000 0 身体是革命本钱就掌握在你自己手中\n598001 1 【澳门金沙赌场直营】嫌去澳门赌场太麻烦了,网上开户就能玩,持有澳门、菲律宾政府颁发博彩执照。...\n598002 0 即在商业空间与居住空间中所有可移动的元素统称软装\n598003 0 亲想钻======点飘票的觉得合适可以加我好友~带你进频道台了解清楚哈\n598004 0 他以为是因为他的正义法律意识\n1000 Processed\n classify content\n598500 0 哦我就发一条跟电梯有关的wb就被水军DT了\n598501 0 看了你這次的騰訊視頻直播的演唱會\n598502 0 深圳龙岗分局龙新派出所民警李某坤急于立功\n598503 0 虽然听到了雨声然而我电脑黑屏了\n598504 0 蒜蓉是我在福州吃过与江苏口味最为接近的\n1000 Processed\n classify content\n599000 0 所以墙面的装饰是装修过程中重要的施工环节之一\n599001 0 不懂还以为是阿里、腾讯真的亲自操刀介入的\n599002 0 对于新沂市黑埠中学8年级学生王子莲来说\n599003 0 搞得好像参观个旅游景点一样\n599004 0 友情提醒:苏州大学独墅湖校区炳麟图书馆401阅览室在7月13日晚22:00进行了清场\n1000 Processed\n classify content\n599500 0 人生的财富不是你拥有多少货币拥有多少不动产而是你帮助了多少人支持了多少人影响了多少人在你离开...\n599501 0 形象似名模/鼓掌/鼓掌/鼓掌\n599502 0 真要让我签字我真怕hold不住\n599503 0 它们将在卡车和飞机上度过30个小时\n599504 0 彻夜的等飞机战斗终于画上了句号\n1000 Processed\n classify content\n600000 0 使膈肌出现阵发性和痉挛性收缩\n600001 1 亏本清仓,一件不留,全场商品低至x折,请亲们相互转告,并给予我精神上的支持,谢谢惠顾!\n600002 0 面部在UV光下完全暴露出真皮层现在及潜在存在的问题\n600003 0 对于现在热议的持有型房产税的征缴\n600004 0 机器人们莫名戳我泪点啊啊啊啊\n1000 Processed\n classify content\n600500 0 社区每月法律咨询服务受欢迎x月xx日\n600501 0 好听、吃苏州名菜、香、好吃、喝苏州名酒、醇、厚香美\n600502 0 在一家指数投资做得很牛的基金公司里\n600503 0 他们就爆料某些明星真正的面目\n600504 0 ”“我只是擦了防晒而已你看毛孔黑头出来了因为我没扑粉\n1000 Processed\n classify content\n601000 0 工信部将重点推进工业机器人在民爆等危险作业行业\n601001 0 我电脑私用的文件夹还叫做即兴摇摆\n601002 0 输入我的推荐人代码“44sxs5”就可以获得超值魔幻卡\n601003 0 百褶花边裙裤百搭显瘦裙裤设计防走光哦尺码S长xx腰围xxM长xx腰围xxL长xx腰围xx\n601004 0 全省共查处重点交通违法行为448019起\n1000 Processed\n classify content\n601500 1 亲们一年一度的x.x女人节又到咯,为感谢亲们一直对京润珍珠的支持、我司将从x月x号到x月x号...\n601501 0 1958年乾隆的地宫入口已经找到了\n601502 0 完整实拍山东城管校门口打6旬老人遭初中生围殴\n601503 0 飞机上的乘客在经历了剧烈颠簸、垂直下降近x分钟之后\n601504 0 医生说是睡得太晚免疫力太差才会病毒感染的\n1000 Processed\n classify content\n602000 0 离家万里的xx岁少年在这一刻得到了所有回报\n602001 0 江苏南京市秦淮区长干寺—佛顶舍利\n602002 0 上次还有个在地铁里用笔画的\n602003 0 他们会通过xx名选手的舞台表现进行现场打分\n602004 1 您好,欢迎致电诚信开锁服务中心,服务项目:开锁,修锁,换锁,换锁芯,销售各款超B级锁芯。公安...\n1000 Processed\n classify content\n602500 0 第二季度苹果Mac电脑的全球出货量为510万台\n602501 0 中航光电一机构净买入xxxx万元\n602502 0 7、一支风险可控利润容易翻倍的股票\n602503 0 联系电话:133681XXXX\n602504 0 今年的任务:1完成收购公司的事情\n1000 Processed\n classify content\n603000 0 6、常州市高新技术产品认定证书5份\n603001 0 包子被抓到的地点是UnterdenLinden41\n603002 0 黑莓将为谷歌Lollipopx\n603003 0 今年首届5000名农村订单定向生已毕业离校\n603004 0 blued手机绑定收不到短信\n1000 Processed\n classify content\n603500 1 老凤祥相约三八:本号金折旧费全免、黄金换钻石折旧费全免、银饰x折,购珠石满xxxx元返xxx...\n603501 0 水平大致与Chrome插件红杏类似\n603502 0 4岁以上但身高未超过围裙板的儿童\n603503 0 吹空调去医院晒太阳吹空调去医院晒太阳……周而复始\n603504 1 高—数学英语物理化学地理铺导招生,华栋名师主讲.提前预约.欢迎来电咨询试听;本周星期日早上八...\n1000 Processed\n classify content\n604000 0 現將本人南京主城区的房子出售\n604001 0 而第三方支付是互联网金融的核心要素\n604002 0 现金收益A/B七日年化收益率2\n604003 0 发现油焖大虾居然就是江苏的麻辣小龙虾\n604004 0 今天刚看了个毕节警察击毙袭警人的新闻\n1000 Processed\n classify content\n604500 0 2015年丹棱县事业单位公开考试招聘工作人员递补体检事项的公告\n604501 0 主要是颜色很百上白下黑的拼接皮草非的美丽风光\n604502 0 在仙剑x没有放之前也有很多人质疑唐嫣\n604503 0 MY一直默默的牛逼不靠广告做人气做生意\n604504 0 扬州交警处理事故速度真可以\n1000 Processed\n classify content\n605000 0 花千骨这部剧就告诉了我们一个道理\n605001 0 群号166480707验证988必填\n605002 0 地铁上一个小不点相中我的面包了\n605003 0 1点从医院出来眼睛已经睁不开了\n605004 0 乐昌市法院一审判决驳回了陆某的诉讼请求\n1000 Processed\n classify content\n605500 0 医生让我32周开始做臀位纠正操\n605501 0 我已经在南京机场拍了100张自拍\n605502 0 缅甸政府干得漂亮:x、威慑了违法伐木者\n605503 0 感谢几位小伙伴带我去看电脑\n605504 0 手机有电又带了充电宝出门的时候\n1000 Processed\n classify content\n606000 0 手机听到不断的语音像紧箍咒\n606001 0 用相机拍下了遥控飞机在头顶盘旋的画面\n606002 0 卖一副Urbeats灰色款购于亚马逊耳机没有质量问题没有偏音线控正常包装盒配件都在可是我平时...\n606003 0 但愿考上研究生之日再是我重新安装之时\n606004 0 下次装修一定要在洗手间装个防水的小书架\n1000 Processed\n classify content\n606500 1 三月超值回馈月活动通知:x月x日到xx日在广州兴发广场举办!欢迎各位顾客到场!xxxx恒美毛...\n606501 0 下了飞机一场暴雨GZ里毫~\n606502 0 但是到了医院目睹了这些盛况\n606503 0 同胞须提高警惕近日果敢伪政权人员开始大肆宣扬果敢已“恢复正常”企图诱骗不明真相的群众\n606504 0 以前狂买百本各种专业类的书自学\n1000 Processed\n classify content\n607000 0 ALBION/奥尔滨超柔软化妆棉渗透乳专用120枚这个是渗透乳专用的\n607001 1 穿鞋生肖是马。其他谈不上,他做答案是香港脚,是指六合彩白小姐脚,那个小姐不穿高根鞋,穿半裙,...\n607002 0 为下个礼拜的旅游做好防晒准备哈\n607003 0 房地产调整已经走出V形低谷\n607004 0 我的电话被认证为扬州阳光物流山东专线了\n1000 Processed\n classify content\n607500 0 专家:中国机器人战略方向上错误\n607501 0 可以下载美橙影音APP看灰姑娘\n607502 0 分别是7000万美元和8470万美元\n607503 0 你天天飞机巡航出宫鼓海围日本岛转一大圈\n607504 0 白色T恤搭配半身长裙让你的身材更显修长的同时宽松的设计让你身材更显修长\n1000 Processed\n classify content\n608000 0 支持你的人也有知道真相的权力呀\n608001 0 洋县公安局洋州派出所于当日下午将涉嫌拐卖儿童的犯罪嫌疑人雍某、周某抓获\n608002 0 大宗交易的基金经手费按竞价\n608003 0 x英寸LCD电子黑板x色可选美国亚马逊$xx\n608004 0 医生说如果高烧不退一周就考虑其他病\n1000 Processed\n classify content\n608500 1 xx元项目,三.包三个疗程送价值xxxx元项目。包xxxx元美容年卡不计次数,身体做xx次身...\n608501 0 那么con百分之八十就约起来了\n608502 0 今天我回家电梯就被不知道谁家装修的沙子搞坏了\n608503 1 假曰百货秀柜台,从x月x号到x月x号搞活动,新品xx立减xx,老品打x折,还有x点x折,望老...\n608504 0 位于浙江省鳌江口外xx海里的东海\n1000 Processed\n classify content\n609000 0 反腐败是推动经济发展的强大正能量\n609001 0 采用宜兴黄龙山紫泥手工精制而成\n609002 0 男子天天吃illstandbeforeyouimm离\n609003 0 政ZHI势力双方在媒体上来回斗法\n609004 0 碘酒会使肤色变黄、抗癌药中引起肤色变化的药\n1000 Processed\n classify content\n609500 1 丰源百货 惊喜大放送,只为美丽的你巴黎欧莱雅专柜:买xxx减xx另专柜有买赠^\n609501 0 你就是我的氧气试听地址>\n609502 0 MV特邀信念音乐创始人杰斌担任导演\n609503 0 我爱你不管你是否在我身边或者衰老疾病健忘我都陪在你身边等着你爱你\n609504 0 可不能像追花千骨一样傻傻的等几个月咧\n1000 Processed\n classify content\n610000 0 学生们暑期打工时一定要擦亮眼睛\n610001 0 上海热线新闻频道——苏州停发“李政道奖学金” 已经连续颁发30届\n610002 0 而墙面凹形的凿空设计更是别出心裁\n610003 0 拜仁前锋莱万5000欧元租用直升机为妻买面包\n610004 0 有关于策划电商新媒体营销方面的工作信息的\n1000 Processed\n classify content\n610500 0 我可能要和南京的医药行业绝缘了…\n610501 0 1免费升级激活Win10正式版方法:你一定需要\n610502 0 准备牛奶xxx毫升x将木瓜和菠萝放入搅拌机中加入鲜奶\n610503 0 丹阳办事处和岳城办事处降雨量达到42\n610504 0 日本设计公司nendo最近推出了一款“arobo”空气净化器\n1000 Processed\n classify content\n611000 0 爱必妥联合化疗一线治疗kras野生型转移性结直肠癌患者能够延长总生存期\n611001 0 有壹阵营和CoachDonovan和你一起训练\n611002 0 就使用我的邀请码79dmrw下载并登录浙江移动手机营业厅\n611003 0 360教育集团徐闻杰谈:新西兰留学到底是DIY还是找中介\n611004 0 这么明显的设计纰漏就明目张胆的上市了\n1000 Processed\n classify content\n611500 0 食面八方全国招商火热进行中\n611501 0 卫星广场那个麦当劳店到底是不是24小时营业啊\n611502 1 你好,我是日月广场贝佳人店,一年一次的三八节就要到了,预祝你节日快乐,越来越年轻,主要是三八...\n611503 0 9月中国人民抗日战争暨世界反法西斯战争胜利70周年大会也将举行\n611504 0 老工业区搬迁改造将全面加快推进\n1000 Processed\n classify content\n612000 0 选择的防晒品的SPF和PA值要大\n612001 0 而同期外汇储备减少xxxx亿美元\n612002 0 互操作性对于OpenStack发展有着重要意义\n612003 0 x、熟悉水电工主要熟悉家庭电器安装\n612004 0 又被飞机起飞的声音困住re\n1000 Processed\n classify content\n612500 0 今晚继续由封开法院小编陪伴大家\n612501 0 来自淮安区茭陵中心小学和淮阴区刘老庄中心小学的43名留守儿童\n612502 0 啪啪啪小视频日本电影gif男女啪啪啪动图男女滚床单啪图社啪啪啪啪啪啪啪啪啪gif做爱图\n612503 0 头一天飞机晚点半夜通知取消\n612504 0 DANGQIDREAM是个什么鬼\n1000 Processed\n classify content\n613000 0 京藏高速公路k1805+200米\n613001 0 随机抽取xxxMB国内流量共计xx份\n613002 0 被保定市公安局百楼派出所民警抓获\n613003 0 9……可怜的娃……吃了退烧药还是反反复复的……\n613004 0 没有真正的法院就霸没有个人的自由和平安\n1000 Processed\n classify content\n613500 0 台风可能在浙江省福建省交界处登陆\n613501 0 实拍情侣在地铁内无视旁人脱衣激情无话可说了\n613502 0 医生滥用支架每个提成或达2千\n613503 0 家住潘集区的刘某等6人编造谎言称能办理廉租房\n613504 0 Geroさんにご来店頂きましたー\n1000 Processed\n classify content\n614000 0 查清真相带头大哥原来是少林方丈\n614001 0 中国死神方便KO日本名将对手跪趴在地意识不清\n614002 0 RollingSpider是遥控飞机\n614003 0 有一组仿古罗马废墟式的建筑\n614004 0 据科技资讯网站Computerworld报道\n1000 Processed\n classify content\n614500 0 其中156个品种510批次不合格\n614501 0 边追花千骨边把战长沙笑傲江湖仙剑三各种访谈综艺全刷了一遍\n614502 0 反正一个月前阿里巴巴和蚂蚁金服各注资30亿\n614503 0 周末走进UnFashionCafe喝杯咖啡\n614504 0 ”医生说:“先把病例拿给我看看\n1000 Processed\n classify content\n615000 0 调整后标准从今年6月15日起执行\n615001 0 不到50分钟终于到达狱警办公室了哦\n615002 0 但至今三年多大家依旧是没有养老保险\n615003 1 x月x号正真实惠来蓝谷智能厨房,不租场地!不请主持!不卖卡!省下来的全部给每位顾客!进店并有...\n615004 1 場春裝折后滿xxx送xx元百貨券!積分當日滿xxxx元參加百分百中獎活動!誠邀你的光臨!祝您...\n1000 Processed\n classify content\n615500 1 急用钱找平安,免抵押,信用贷款,最快一天放款,平安易贷林经理:xxxxxxxxxxx\n615501 0 事实是索玛慈善基金会利用人性易被煽情的弱点策划的一起微博众筹活动\n615502 0 不然我们会动用法律武器维权\n615503 0 ▌欢迎参加上海外文书店亚马逊店好书秒杀\n615504 0 建筑结构设计使用年限为50\n1000 Processed\n classify content\n616000 0 例如能装载8名步兵的运兵舱、气泡形风挡等\n616001 1 亲爱的姐妹三八节将至:祝姐妹三八节快乐!凡是本新老顾客三八节那天进店有礼,数量有限,先到先得...\n616002 0 不够麻烦的…希望小偷尽早被抓\n616003 0 柳州市鱼峰法院成立了预防未成年人犯罪警示教育基地暨青少年心理健康中心\n616004 0 邳州规划馆里一群学生纷纷在彩虹桥照片前拍照\n1000 Processed\n classify content\n616500 0 微博搜索了下华为mate7\n616501 0 在那个没有手机没有网络的时代\n616502 0 因为有x个样板间及x个临时物业管理用房暂不销售\n616503 0 他曾获得NBA总冠军戒指\n616504 0 汽车则成为必不可少的交通工具\n1000 Processed\n classify content\n617000 0 其实我从来没有怪过谁因为清楚自己根本不配拥有更多更好的\n617001 1 还有精美礼品一份哟,送完为止!还有更劲爆消息,x.x x.x x.x 三天,居家产...\n617002 0 知情人士供图事发航班头等舱一座椅靠背处\n617003 0 想我的损友了所以下了飞机晚上睡觉时就默默写了这么多\n617004 0 行动中共查获1起醉酒驾驶、2起酒后驾驶的违法行为\n1000 Processed\n classify content\n617500 0 你无法想象那时候的南京竟然是这样的\n617501 0 看到花千骨和紫薰在卜元鼎幻象中\n617502 0 有意可私信或电联xxxxxxxxxxx\n617503 0 怀孕分娩坐月子是改善女性体质的好时机\n617504 0 直接找物业拆吊顶了果然她家问题\n1000 Processed\n classify content\n618000 1 xxx亿广州花都万达城x月x日携雪而来,第一期xx—xxx方铂金铺位x月首开,火爆登记中!有...\n618001 1 中国十大品牌百居佳丽地板,实朩,强化,多层、中,高、低档、四十多种样品供您参考,现南陵分店,...\n618002 1 保利罗兰香谷起价xxxx,均价xxxx,首付x万,详询,金牌置业顾问:张园xxxxxxxxxxx\n618003 0 是这精神的财富支撑着优美的舞姿\n618004 0 与时代接轨感谢xx组大平台给我们宝妈带来的新生活\n1000 Processed\n classify content\n618500 0 周日要去医院真的好忧桑…\n618501 0 民警查处一起车牌为晋C001**号的小型轿车驾驶人未按规定使用安全带的违法行为\n618502 1 光辉小区资生堂嘉晨专卖店,凡持本店会员卡均可免费领取答谢礼,同时积分兑换豪礼。三八活动满xx...\n618503 0 加weixin:ssokcc\n618504 0 当时的研究生同学都已经毕业\n1000 Processed\n classify content\n619000 0 寻找史上最贵的实习生|广告行业最直观的印象是什么\n619001 0 我七月的最后一天祝我好运吧坏蛋晚安小丸子\n619002 0 广安华蓥市人民法院审理一起村民好心义务帮忙\n619003 0 地铁护栏隔绝不了感情:在地铁等人\n619004 0 市民可通过电脑或移动设备随时学习多样化课程\n1000 Processed\n classify content\n619500 0 周日和下周一都是花千骨真的吗\n619501 0 一座拥有93个车位的4层立体车库在城关区排洪路八一阳光家园落地建设\n619502 0 免费防癌热线xxxxxxxxxxx\n619503 0 常州市举行二季度全市生态文明在行动点评会\n619504 0 浙江基督教两会也出公开抗议信\n1000 Processed\n classify content\n620000 0 手机消费的闪存容量在全球闪存出货量中所\n620001 0 包括注入LED元素的前大灯、LED尾灯以及新设计的前后保险杠\n620002 0 美国公民对法律的认知相当高\n620003 0 关于兼职??我做的是一份兼职赚的是纯利润不是微商如果你舍不得两三百终身制的会费就别来咨询天下...\n620004 0 一个家庭里出了9个畸形“矮人”\n1000 Processed\n classify content\n620500 0 错综复杂的真相~不到最后都不知道原来是这样\n620501 0 7月份富时中国A50指数期货的未平仓合约总数急跌至127\n620502 0 x、央行有关负责人:猪肉价格波动不会影响货币政策\n620503 0 还含丰富的维生素C和可溶性纤维\n620504 0 不合规定药品148批、假冒5批\n1000 Processed\n classify content\n621000 0 好不容易坐上一个有wifi的飞机居然要收费\n621001 0 八宗罪俨然是死刑就这么办\n621002 0 那捉了医生来的汉子对平一指甚是敬畏\n621003 1 佰@佳@泺,龍#唬#斗,牛¥牛,体*育等等!諟款赽,详情:世迯洮榞 xxxxxxx.℃○M ...\n621004 0 并将为腾讯应用宝全场提供可靠的wifi\n1000 Processed\n classify content\n621500 1 恭喜您喜添新居,我是恒丰装饰的家居顾问,我姓徐。 我们公司现推出了一个xx平米房x万多全...\n621501 1 本店消费美容项目,可享受对折体验 另:春季是养肝最佳季节,本店每人推出一个名额只需xxx...\n621502 0 鼓楼医院果然是大医院啊\n621503 0 」老王说:「我们俩只要一吵架\n621504 0 12岁湖南女孩思思被同村74岁老人性侵并产子\n1000 Processed\n classify content\n622000 0 想念好恐怖侵占了我整个身体\n622001 1 季闪耀金陵!凭此微信享紫峰业主特惠! 详情咨询:陈 刚 预订热线:xxxxxxxxxxx 您...\n622002 1 您好,欢迎参加志邦厨柜xxx预售会,全国线上线下联动优惠活动,价格全年最低,更有总部领导亲临...\n622003 0 并对Quanergy公司进行战略投资\n622004 0 南京这边的韵达一定是不太聪明\n1000 Processed\n classify content\n622500 1 俱乐部KTV欢唱盛惠 KTV房间:百威啤酒¥xxxx元x打 豪华中房套餐 青岛纯生¥xxx元...\n622501 0 汽车轮胎充氮气有一定的好处\n622502 1 魅力庆三八.快乐女人节.进店有惊喜 龙华富通天骏伊莎兰蒂美容养生馆提前祝您三八节快乐! ...\n622503 0 不料想xxx事件发酵到了如此地步\n622504 0 内地女生在港街头野战被判感化12个月\n1000 Processed\n classify content\n623000 0 查明当事人和其他诉讼参与人到庭情况:原告:许斌、汪文革到庭\n623001 0 结果人还没走到他们飞机旁边\n623002 0 禅城区近12年未出现新发本地病例\n623003 0 公司计划召回最多1万辆2016XC90型运动型多用途车\n623004 0 加油吧实习生真是一部挺好的电视剧啊\n1000 Processed\n classify content\n623500 1 成都众合思为公司,专业从事各品牌电梯变频器、控制主板、通讯板、轿厢板、门机扳、外呼板、应急电...\n623501 0 我的大学在江苏在南京在南体在民表系81242班\n623502 0 其全资附属公司xx亿元发债额度中的首期xx亿元x年期公司债已经定价\n623503 0 而每100个设置个性签名的人中\n623504 0 大家加油给王俊凯第一好不好\n1000 Processed\n classify content\n624000 0 呵呵嗒不用法律思维我都有点迷糊\n624001 0 常州城镇居民平均每月收入:3580\n624002 0 瘦下来证明给所有质疑过你的人看\n624003 0 再也不用找百度云网盘高清资源链接了APP\n624004 0 以防怀孕末期由于子宫的压力而产生的痉挛\n1000 Processed\n classify content\n624500 1 元宵佳节来临之际,对青烤鹅为了回馈新老顾客,特此推出有买有赠活动,购买大鹅一只,赠汤圆一袋,...\n624501 0 6个85式和2个t90最后还是雌鹿和我的6个空军围殴他一个才打死那k1a1\n624502 0 书中借宋朝的一群土匪把历朝历代的官场“正义人士”都黑出翔来\n624503 1 商业步行街,幼儿园,图书馆,电影院,儿童乐园,健身广场,绿化景观带,生产居住销售一房多用现推...\n624504 0 浙江借“互联网+”构筑农资监管“智慧”新格局: 民以食为天\n1000 Processed\n classify content\n625000 0 AmazonAWS果然很好玩啊\n625001 0 一种叫我就是要真相我就是要x清楚然后死心\n625002 0 常熟捷梯教育专业西班牙语培训学校\n625003 0 最近没有手机也错过了许多应该纪念的场景\n625004 0 ◢一般将小于x级的地震称为超微震\n1000 Processed\n classify content\n625500 0 上海恒基名人购物中心举办的“神秘花园”亲子游活\n625501 0 一个外地来苏州的“新苏州\"人\n625502 0 他们在不屈不挠的反腐运动中无惧树敌\n625503 0 亮点是纯物理防晒温和不刺激\n625504 0 盗墓笔记要VIP才能看全集老师你看了吗”\n1000 Processed\n classify content\n626000 1 金冠德州俱乐部祝您元宵节快乐,本店推出各类SNG锦标赛,欢迎大家到店参加比赛。再次感谢您的到...\n626001 0 xx年雅安地震:诺基亚捐款xxx万\n626002 0 苏州冷泉港扮演着为高端科学服务的角色\n626003 0 烟台牟平区莒格庄镇三大工作引领转型发展招商引资突出转型发展:今年上半年\n626004 0 ○多位受访分析人士认为猪肉涨价推升CPI上涨有限\n1000 Processed\n classify content\n626500 0 第七次打城管就掉了哈哈哈哈我就知道大哥最爱我么么哒埋胸肌千战出虎彻终于混到点欧洲血统啦不想把...\n626501 0 常州市金坛区气象台8月9日16时发布的台风警报和天气预报:今年第13号热带风暴苏迪罗今天15...\n626502 0 设计锤子便签的设计风格是简约的拟物风格\n626503 0 明天刑法分则总结完写个上诉状题库尽量做背中国特色社会主义11年卷一\n626504 0 创业指数上4000点的时候无发出短信风险提示\n1000 Processed\n classify content\n627000 0 当你抱怨自己已经很辛苦的时候\n627001 0 5、过量喝绿豆汤或致肠胃疾病\n627002 0 内贾德05年上台之后强迫国企混改私有化\n627003 0 大年初3遭我妈拿着鸡毛掸子追着到处打\n627004 0 城管就形成了行政部门的新三国演正义了\n1000 Processed\n classify content\n627500 0 在医生的指导下用药比较安全\n627501 0 50多岁食堂大妈用手机看花千骨\n627502 0 全新设计的前包围让车头看起来更加的敦实\n627503 0 用了这么多年小米别的都挺好的怎么就数据传输这么差劲\n627504 0 物质财富跟不上精神食粮需求…真的要去卖肾了\n1000 Processed\n classify content\n628000 1 万能开锁公司感谢您来电,本店专配汽车钥匙、遥控器、智能卡、折叠改装、车库遥控、上门开锁换锁(...\n628001 0 孩子出生到现在法院强制执行抚养费目前就讨回一千\n628002 0 2014年10月顶新在台湾正义饲料油事件爆发\n628003 0 使夹板卷发棒吹风机的都小心点吧像阿童木脚底的火箭一样喷火我尼玛吓死我了\n628004 0 找理财网——最权威的网贷导航网站\n1000 Processed\n classify content\n628500 1 您好!我司林墩到西安北三环海运门到门价格xxxx元/柜,铁路xxxx元/柜,欢迎赐载,谢谢!...\n628501 0 我分享了百度云里的文件:?莺哥和大王同归xxxxP\n628502 0 2又在该岛发现中文和马来西亚文字的飞机残骸\n628503 0 2015金立智能手机杯中国围棋甲级联赛进行第11轮较量\n628504 0 在该岛海岸线上发现飞机残骸\n1000 Processed\n classify content\n629000 0 比梨子多七倍铁的含量比苹果多三倍\n629001 0 晚上睡觉梦见我把手机摔碎了\n629002 0 昨天方正证券做了一会儿的领头羊原来是业绩受7月下跌影响最小的券商股啊\n629003 0 虽然我本来就脑残~好了明天还要考试呐\n629004 0 左图是狗狗在动物医院内检查时的X光片\n1000 Processed\n classify content\n629500 0 成都局目前有各式电梯近两千部\n629501 0 苏州质量技术监督局园区分局迅速部署\n629502 0 医生说:那你怎么不把他带来\n629503 0 早起+一个半小时班车+正事没咋干犊子没少扯+半个小时班车+一个小时地铁+半个小时公交=北辰t...\n629504 0 AMD真的能带你飞嵌入式处理器已打入波音飞机驾驶舱\n1000 Processed\n classify content\n630000 0 诱骗事主通过ATM机转账支付所谓的改签手续费\n630001 0 虽然要6点起床走40分钟去上班\n630002 0 兩者差別在於法規命令是一般性抽象性的規定\n630003 0 而且投资额比起每年包个温泉旅馆的花销多得多\n630004 0 晚上弄坏一步手机现在还上不了微信\n1000 Processed\n classify content\n630500 0 海边虽没想象中的那么浪漫但也乐此不疲虽带各种伤痕回家但也不虚此行<\n630501 0 ”“飞机的升力是如何产生的呢\n630502 0 咨询保险请联系18052233219\n630503 0 江苏连云港货车丢失1吨有毒危化品还有6包失踪\n630504 0 当大众媒体质疑某一线品牌有可能是“三精一水”的时候\n1000 Processed\n classify content\n631000 1 在吗?x月xx日,xx日【特惠】北京故宫八达岭长城六天双飞团x天xxxx元/人,有需要联系我...\n631001 0 湖北电梯事故前5分钟监控曝光:两工作人员险坠下\n631002 0 裁判“黑名单”的推出却略有滞后\n631003 0 南京市人民检察院依法对南京市六合区原新篁镇桥王村村主任林庭朝以涉嫌贪污罪决定逮捕\n631004 0 搭着藏民的三轮车在xxx国道上飞驰\n1000 Processed\n classify content\n631500 0 2XU女士铁人三项运动压缩短裤\n631501 0 CelticWater为肌肤注入无限水分\n631502 0 他妈靠着穷等着政府发救助过日子\n631503 0 2015年预计GDP是65万亿\n631504 0 原价转两张周杰伦苏州演唱会门票\n1000 Processed\n classify content\n632000 0 这与华严寺的建筑布局有莫大的关系\n632001 0 据不完全统计我国有xxx万官员的妻子儿女全部移民国外\n632002 0 阿里巴巴把不和莆田人合作写进了公司规定等等地域歧视\n632003 0 有需要了解详细情况的可以随时联系联系人:郑老师联系电话:13001057642\n632004 0 每天在家不是不给我玩手机就是不给我玩电脑\n1000 Processed\n classify content\n632500 0 基于关系的商业模式是时间的朋友\n632501 0 我大姨妈大姨夫浪到无锡去啦\n632502 0 刚刚主裁判是调戏了佩佩吗哈哈哈哈哈哈哈哈\n632503 1 送胸衣一件,买三件送胸衣两件,买得多送得多,\n632504 0 Mino先生将视频上传Youtube\n1000 Processed\n classify content\n633000 0 说江苏一孕妇产下最轻龙凤胎\n633001 0 IMF在未来数月甚至一年或不会参与对该国的第三轮援助\n633002 0 ↓↓Ps:大热天的都凑什么热闹\n633003 0 中国好声音live空降南京水游城\n633004 0 我用搜狗输入法打了17492字\n1000 Processed\n classify content\n633500 0 天津和南京之间的距离是我不能承受的累\n633501 0 1981年我没来中国之前是什么症状\n633502 0 病人的白癜风疾病也不是很显着\n633503 0 简\n633504 0 会员权益:时租立减20元、房价92折、延时退房至13\n1000 Processed\n classify content\n634000 0 要求的话看长微博吧w爆照的话有意私戳我加了QQ后可以哟\n634001 0 我参加过她家去年的送40元活动\n634002 0 从而使VOC含量远低于国家规定\n634003 0 警察蜀黍要和城管终极PK呀\n634004 0 浙江省温岭市人如果你们有理想的请相互转告\n1000 Processed\n classify content\n634500 0 要不你们回城管爸爸那里去吧\n634501 0 今天老爸说明天化疗的声音响当当\n634502 0 就像我拿起手机刷微博就会忘记当初是想问度娘查资料来着\n634503 0 请大家资助我有力的出力有钱出钱还有请帮我找世界上最好的医生快速到我家最后请大家记住我是永远爱你们的\n634504 1 新年新气象,愿您有个好形象,好消息,好消息。品尚名品新款不断上市,本店棉衣,貂绒线衣打五折,...\n1000 Processed\n classify content\n635000 0 因此产生腐败、分配不公、公有资产流失等问题\n635001 0 聊了些关于甲壳虫车贴设计和涂鸦的问题~\n635002 0 Bette对Tina说的那句——“当我扪心自问\n635003 0 无锡型材午评:今主流报价持稳\n635004 0 欣扬特别针对车载电脑设计完备的智能电源管理子系统解决方案\n1000 Processed\n classify content\n635500 0 趁出门买水来到一个手机有网的地方\n635501 0 免费分享浙江x份厚叶蓝鸟\n635502 0 古今真相之揭秘魏晋风范不是传说中的那么迷人\n635503 0 普陀山位于浙江省杭州湾以东约100海里\n635504 0 反正我就是看不惯这种潜规则\n1000 Processed\n classify content\n636000 0 从小孩到孕妇到100岁的老人都可以服用\n636001 1 温馨提示: 各位企业老总您们好,吕士军、马丽预祝你们xxxx年生意兴隆、财源广进。 在新的一...\n636002 1 汕头洛城PARTY酒吧欢迎您!奢华典雅装修,顶级音响设备,高中档大小包厢,每晚奉献不同精彩娱...\n636003 0 是旅游观光大峡谷的最佳时期\n636004 0 这标志着这本以60、70年代知青建设农场为主要题材的专辑编纂工作已进入收尾阶段\n1000 Processed\n classify content\n636500 0 南京的那一幕在重庆重演了吗\n636501 0 不会设计表格不会看表格不会分析统计研究数据\n636502 0 45个新的租赁点由市交投新成立的合资企业易开公司负责建设\n636503 0 喜收藏??贪官留给自己受贿索贿的“暗道”:喜收藏贪官留给自己受贿索贿的“暗道”惯于在官场行贿...\n636504 0 浙江毛家说浙江的是白猫湖南的是黑猫\n1000 Processed\n classify content\n637000 0 ”到时看看Ed到底邀请了多少人去温布利呢\n637001 1 您好,欢迎致电海安船舶物资有限公司,本公司专业批发各种规格渔用钢丝绳,吊机,打桩,电梯,塔吊...\n637002 0 本赛季结果google完胜\n637003 0 胎盘素原液?10%的化妆水构成\n637004 0 在南京的各大街道上走着坐着车\n1000 Processed\n classify content\n637500 0 com奶、奶酪、酸奶……西方的奶制品业如\n637501 0 目前用户可以通过WindowsStore应用商店下载这\n637502 0 布达拉宫的主体建筑为白宫和红宫两部分\n637503 0 百度一下发现题材还是挺沉重的\n637504 0 对酒驾违法行为的常态化专项整治\n1000 Processed\n classify content\n638000 0 今天微软再为Windows10Build10240推出一项安全更新\n638001 0 本人7月9日在苏州47路公交车遇到一位女孩\n638002 0 北京携手张家口申办2022年冬奥会成功\n638003 0 申明书南通市住房保障和房产管理局\n638004 0 设计师给每只杯子都加上一个90度角\n1000 Processed\n classify content\n638500 1 关注小松,助您成功!购买小松,放心施工!质保x年xxxxx小时的超长质保让你更放心使用,更多...\n638501 0 我觉得没有必要把地铁温度调这么低\n638502 0 今日走势:欧美股指整体走高\n638503 0 每周敷3次能够让皮肤变得白暂细腻\n638504 0 妈的对着电脑一天了各种百度各种教学就是用matlab分析不出来函数也不会用老子要疯了\n1000 Processed\n classify content\n639000 0 由江苏宜兴中国环保科技工业园管委会\n639001 0 事后他告警方违法一审被法院驳回\n639002 0 1的红包让我感受一下节日的气氛\n639003 0 一运行就提示缺少d3dx***\n639004 0 那么就会出现MACD簇在该巨量大单位置处\n1000 Processed\n classify content\n639500 0 认证信息为“浙江大鑫商品经有限公司IT部经理”\n639501 0 省青少年发展基金会秘书长、省青年创业就业服务中心主任任斌、省青少年发展基金会副秘书长罗朝恒一...\n639502 0 金融、消费领域具有良好业绩支持的投资标的\n639503 0 是国家“211工程”和“985…\n639504 0 优秀的商业不是规模而是传承幸福与品质\n1000 Processed\n classify content\n640000 0 沪深两市流通市值报405231亿元\n640001 0 我他妈要被谷歌纸盒黑科技吓跪了我操\n640002 0 百度里那个说可以用酸奶代替酵母蒸馒头的\n640003 0 看来专车是吃了垄断行业的蛋糕\n640004 0 到目前为止德清县已有36个服务站点\n1000 Processed\n classify content\n640500 0 但面部水肿也是很多疾病的症状\n640501 0 BigBang这次回归动静静老实大啊\n640502 0 现在天天扒着电视看花千骨\n640503 0 在考虑这个月上哪旅游玩…\n640504 0 只因你说手机放脑洞旁充电会爆炸得脑癌\n1000 Processed\n classify content\n641000 0 中国航空工业部门在xD打印的部分应用领域已进\n641001 0 HC万色水母类人胶原蛋白系列产品生产厂家西安巨子生物基因技术股份有限公司的“国家生物材料工程...\n641002 0 日本这款MUJI无印良品阳光樱花保湿滋润化妆水400ML的去年限量发售的我囤了10瓶\n641003 0 并计划分拨融资额度内不少于100亿元进行并购合作\n641004 0 你知不知道KFC有几个人望住你啊\n1000 Processed\n classify content\n641500 0 人生的第一步啊~谁都想自己的孩子念一所好的学校\n641501 0 好像还有好多的我追逐的人如今登陆上去才发现时间改变了太多那些美好的回忆挺可惜的不过还好有点念想在\n641502 0 包括火箭、航天飞机等航天运输器及其组件、元器件\n641503 0 报道引述美国政府官员、及外交消息人士\n641504 0 3、西安出租车起步调到十元乘客:提高服务质量\n1000 Processed\n classify content\n642000 0 河南、江苏等x个主产区各类粮食企业收购新产小麦xxxx万吨\n642001 0 做不到wonbinc大神的描述推荐\n642002 0 使得xxxx年度博望区教育经费合理、规范、有效地使用\n642003 0 溧水有一个洋气的名:霍史尼玛·热德玛·伊比\n642004 0 常州市环境监测中心、常州市气象台2015年7月31日15时联合发布\n1000 Processed\n classify content\n642500 0 还有几个目的:让机器人制造者不仅在专长领域发展\n642501 0 2015年7月18日是儿子第一次坐飞机\n642502 0 大盘分时+板块涨跌+五分钟异动+自选股\n642503 0 下午重装了电脑下载官网驱动太慢就又用了驱动精灵\n642504 1 折,彩妆xxx送xx元的,美即面膜xx元xx件进店就有小礼品相送哦,有时间您可以过来看看,活...\n1000 Processed\n classify content\n643000 0 xx岁男子火车上强奸xx岁少女\n643001 0 也就是之前的Win10Build10240\n643002 0 美国航天局NASA宣布发现另一个“地球”\n643003 0 卫星:dingxiaoqixxxxxx\n643004 0 无锡橙天嘉禾影城新之城店x月x日排期\n1000 Processed\n classify content\n643500 0 com/168GrandIBMlivefeed八大讲师与神秘主讲人将会为这场活动带来另一个高峰\n643501 0 然后那个医生……竟然就是泽塔琼斯噢……名不虚传……一出场简直心里一动……\n643502 0 不料在侦讯后女方竟然怪警察蜀黍“管太多”\n643503 0 从7月29日中午12点到8月1日0点\n643504 1 亲爱的朋友,我最近在做阿迪耐克乔丹等品牌鞋代理,如果有这方面的需要可以联系我。谢谢。你可以从...\n1000 Processed\n classify content\n644000 0 江苏卫视在播继承者们国语的哈哈哈哈哈哈哈哈哈哈哈哈哈说实话当时我就没怎么看\n644001 0 上周三临时兴起订的beachholiday明天去西班牙的Majorca\n644002 0 江苏质监局开始了对检验机构的全过程监管\n644003 1 峡山甜猫甜品为回馈广大客户,现隆重推出会员卡优惠服务,凡到本店消费满xx元即送会员卡,会员用...\n644004 0 xxxx新款欧美时尚双肩显瘦深V领修身鱼尾简约钉珠拖尾婚纱礼服\n1000 Processed\n classify content\n644500 0 成长终将是要面对质疑~责骂的\n644501 0 不知道是知道了真相的人会抑郁\n644502 0 一个月1800你可以攒个旅游经费一天赚100\n644503 0 有需要的kitty控妈妈可千万别错过\n644504 0 向16年来接力照顾自己的叔叔阿姨们报喜\n1000 Processed\n classify content\n645000 0 OMEGA欧米茄星座系列全新同轴男士腕表专为现代男士而打造\n645001 0 x、尽量选择天然产品晚霜很重要\n645002 0 即赢得“650亿美元CFO”的美誉\n645003 0 母亲需要蛋白质供给子宫、胎盘及乳房的发育\n645004 0 你国人最喜欢嘲笑印度强奸大国\n1000 Processed\n classify content\n645500 0 建构主义的提出有······\n645501 0 很多人是一天赴宴N个送红包N个\n645502 0 莫亚医生拒收+19床患者张成玉红包200元\n645503 0 旅游的第一天大部分飞机度过\n645504 0 屏幕画面不变声音继续30秒后恢复正常播放\n1000 Processed\n classify content\n646000 0 南京期望这种模式能为破解“垃圾围城”找到出路\n646001 0 新西兰15岁的学生在阅读能力、数学能力、科学和解决问题的能力四个方面表现卓著\n646002 1 喜迎十五元宵节,居恒装饰小吴祝您,羊年行大运,全家健康快乐。凡在x月来公司咨询装修事项均有大...\n646003 0 “找装修公司必须包工包料”……在装修过程中\n646004 0 今天在手机店看见一对五六十岁的夫妇\n1000 Processed\n classify content\n646500 0 今天家门口小商贩的摊子都被城管砸了\n646501 0 『湖北电梯吞人事故死者丈夫写信祭奠亡妻』\n646502 0 无锡跃进称其无权在华使用“西亚特”商标\n646503 0 如果一直记得不要玩手机就好了\n646504 0 ”但当我靠近准备拍时它被我吓跑了\n1000 Processed\n classify content\n647000 0 发现用摄像头后手机右上角会很烫\n647001 0 7月份开福区城城市管理与执法部门共暂扣渣土车57台\n647002 0 被金融业和科学研究和技术服务业取代\n647003 1 你好!上新货啦!连衣裙,真丝上衣,衬衣,丅恤都非常不错,颜色都很漂亮哦。有时间可以过来看看。...\n647004 0 以及声势浩大的反腐运动的不断深入\n1000 Processed\n classify content\n647500 0 潮涌海天阔扬帆正当时——全省项目观摩活动陇南项目建设综述\n647501 0 今年第9号台风灿鸿中心于7月11日23日穿过绍兴市区的概率为70%\n647502 0 现在全世界的金融、经济的观念都受凯恩斯“消费刺激生产”理论的影响…对于物质的浪费、环境的污染...\n647503 0 昨天被法顾征用说今去法院没个影儿\n647504 0 当月全国期货市场成交量为262\n1000 Processed\n classify content\n648000 0 大晚上吵到无法入睡打给北京海淀城管举报竟然听完事情后压我电话突然觉得心寒无比现在继续忍受着对...\n648001 0 将于9月19日至21日在山东省莱芜市雪野旅游区航空科技体育公园举行\n648002 0 商业二期项目是目前苏州城最大的商业综合体项目\n648003 1 恭祝您及家人新年万事如意!中小学各科优秀在校教师都可以帮您介绍。需要为孩子请上门x对x辅导家...\n648004 0 早上出门的时候忘了把手机带上就锁门\n1000 Processed\n classify content\n648500 0 一个南京银行长期投资人的看法\n648501 0 :LOVERUMI防晒霜的重要性防晒真的很重要\n648502 0 三层瞭望室内有环绕360度的空中咖啡厅\n648503 0 我得放下手机睡觉了??不然真得瞎\n648504 0 数着头上一架又一架的飞机经过\n1000 Processed\n classify content\n649000 0 吃叶酸、补钙、调理身体……但要真正做到科学备孕的话\n649001 0 姐姐在韩国读研究生现在已经毕业了\n649002 0 但回来以后W先生很着急却并没有怪她\n649003 0 给了百度糯米和美团决胜的机会\n649004 0 综合案件情况依法判决:被告人高某犯盗窃罪\n1000 Processed\n classify content\n649500 0 法院一句话:人回来了我们管\n649501 0 老天感谢医生还给亲爱的一个完整的家\n649502 0 在建筑施工中继承正源地产的精品战略传统\n649503 1 建材团购会,像左右沙发呀,方太电器啊,东鹏瓷砖…保证全年最低,优惠多多,礼物多多,特邀您前来...\n649504 0 家里电脑真是卡的还不如手机\n1000 Processed\n classify content\n650000 1 新年好!我是远大广场的销售小李xxxxxxxxxxx,一直和您有联系,新年有特别优惠的特价房...\n650001 0 禽兽医院禽兽医生利用人们对动物的同情心\n650002 0 CHINADAILY晚报7\n650003 0 向世人证明Windows8之后他们并没有一错再错\n650004 0 就连飞机的餐你都发了两次了\n1000 Processed\n classify content\n650500 0 百度得宋城跟开封的清明上河园类似\n650501 0 互联网+油站的平台出现改变了传统加油站的消费生活场景\n650502 0 我街道邀请了国家心理咨询师——吴立红女士给我们上一堂”心理健康课“\n650503 0 沿线城市南通、泰州、扬州将迈入“动车时代”\n650504 0 由房产商到投资商、城市运营商的角色转型\n1000 Processed\n classify content\n651000 0 因为本金仓是为了分享2594这几年的高速成长\n651001 1 今日x.xx-xx.xx城建装饰在杭报二楼举办xxxx新春第一展,活动巨优惠半包x.x折在送...\n651002 0 哪几种病因能导致红斑狼疮发生\n651003 0 劳力士做的不是手表是奢侈和高贵的感觉\n651004 0 并不是因为D站做得好或管理得好\n1000 Processed\n classify content\n651500 0 ”男子惊诧地问:“需要把它们掰开才能吃吗\n651501 0 荣获了本年度ISPO运动设计大奖亚洲产品年度大奖\n651502 0 关起来一直强奸直到生出儿子\n651503 0 常州这个地方也是断不了联系的\n651504 1 。课程有儿童画、国画、卡通画、素描、色彩、书法等,地点 :苏仙北路原教育学院校区 (苏仙...\n1000 Processed\n classify content\n652000 0 看看阿里云是怎样帮你刷屏的\n652001 0 枸杞岛大王沙滩x月xx日溺死两名游客\n652002 0 youtellyourselftog又要发威啦\n652003 0 揭秘杨柳“x次婚姻”背后真相\n652004 0 导致我电脑自动关机重启到现在\n1000 Processed\n classify content\n652500 0 全国共有87个县被列为深化县城基础设施投融资体制改革试点县\n652501 0 好喜欢杀阡陌和花千骨的戏份啊\n652502 0 做完形填空进行PerformanceReview\n652503 0 对职业和信仰产生深深的质疑\n652504 0 他因犯盗窃罪被东兴市法院判处有期徒刑x个月\n1000 Processed\n classify content\n653000 0 8月1日北文安水韵名都假如酒店电梯突然把我们多人长时间困在电梯里\n653001 0 三缺一找人赌博女人何其多\n653002 1 《新一贷》最新攻略 特点:目前为止, 市面上无抵押类贷款利息最低, 不用抵押,无需担保, 最...\n653003 0 然而当我去上百度时却毫无所获\n653004 0 叼李hi李日日唔使做野還吃這麼好\n1000 Processed\n classify content\n653500 0 那些曾经监视、毒打、强奸她的人和机构\n653501 0 手机里所有可以升级的应用更新\n653502 0 结果发现18台细菌超标、大肠杆菌超标\n653503 0 点评:越南商机一如xx年前的中国\n653504 0 男童手臂卷入扶梯记住这些电梯常识可救命\n1000 Processed\n classify content\n654000 0 给二宝小zipbag带的一段米粉\n654001 1 哥你好,我是刚和你通话的金源鼎盛客户经理章晓燕,最新政策:抵押贷款利息x厘,最长五年期,欢迎...\n654002 0 也不是随便可以乱用、滥用的\n654003 1 尊敬的客户您好,我行今日推出元宵节特别款理财产品,正在热销,xx天,收益率x.x,截止今日下...\n654004 0 现在每次开电脑看不到金开的脸我都超级慌张\n1000 Processed\n classify content\n654500 0 看过花千骨那个妖魔化感觉好像很好看的样子\n654501 0 这是继北京·沧州渤海新区生物医药产业园之后\n654502 0 百度社会化分享组件封装了新浪微博、人人网、开心网、腾讯微博、QQ空间和贴吧等平台的授权及分享功能\n654503 0 对于阿里巴巴上获取免费流量带来的收益\n654504 0 对付潜艇的利器当然还是潜艇\n1000 Processed\n classify content\n655000 1 创维英语培训学校恭祝您元宵节阖家欢乐,幸福安康!本校专注小学培训,力求专业,即日开始报名,即...\n655001 0 医院十四楼的一张普通病床上\n655002 0 抹了bb霜也遮不住凹下去的眼圈和红肿的眼皮昨晚还发烧了先在姐姐家吃一顿好吃的下午再去输液最烦...\n655003 0 交通:公交x、xx或xxx路至溪隐社区站\n655004 1 尊敬的客户您好,凡接到此短信的客户交xxx元,可享受免费送xG手机一部和xx元话费和xxxx...\n1000 Processed\n classify content\n655500 0 140千字写出了初中校园的友情故事\n655501 0 因为跟了你x年居然走到尽头没有成为更好的人更痛苦\n655502 0 转全新foreolunaforallskintypes\n655503 0 以后回国去旅游只在大城市玩\n655504 0 徐州铜山区柳新镇范山村有一工厂、夜间工作产生巨大的噪音\n1000 Processed\n classify content\n656000 0 没事我就可以按个电梯上去做饭做面包做蛋糕找她聊聊八卦聊时尚聊保养\n656001 0 做电脑壁纸放幻灯片简直不要太赞\n656002 0 你们不觉得开始装修以后那钱花的就跟流水一样\n656003 0 犯罪嫌疑人李某某于x日被押解回青岛\n656004 0 我不想通过谷歌了解这座城市:厦门\n1000 Processed\n classify content\n656500 0 因此手机上的应用程序即使有密码\n656501 0 为了送快递亚马逊给美国无人机做了套交规方案北京时间7月29日下午消息\n656502 0 4天3夜玛努雨林行走艰险并精彩着\n656503 0 一些关于“男女恋爱中一点小事”的视频\n656504 0 今天在苏州水上乐园玩了一下午\n1000 Processed\n classify content\n657000 0 佐治亚理工学院机器人实验室主任亨里克·克里斯滕森说:“中国经历了机器人爆炸式增长\n657001 1 运行煤气xx门市部,本公司经营石油气,煤气炉、热水器、各种燃气具批发零售,市内免费安装,送货...\n657002 0 早上一杯蜂蜜水排毒\n657003 0 医院门口装修吵的我快崩溃了\n657004 0 还有一次是问梁医生:如果我是你女朋友\n1000 Processed\n classify content\n657500 0 现在省立医院西区2号楼4层儿童血液肿瘤科A02号床就诊\n657501 0 这次通过与无锡市邮政管理局对接\n657502 0 我们护士生活规律就是不管饿不饿\n657503 0 村里给的答复是交xxx块钱‘上环’押金才给你办证\n657504 0 幸好我的航班也晚点了2个多小时\n1000 Processed\n classify content\n658000 0 南通科技sh600862\n658001 0 可以刺激T细胞和自然杀伤细胞攻击癌细胞\n658002 0 2红包摇到二:电影网址送你摇到三:零食买100减5块摇到四:打字软件摇到五:查单删软件摇到六...\n658003 0 港股通流出19亿○跌势蔓延至商品期货\n658004 1 燕郊新世纪商城杰克琼斯x.x-x.x 长袖半袖衬衣xx元起外套西服xxx元起\n1000 Processed\n classify content\n658500 0 尊敬的各位:咖喱一家天马店明天开始x月x日至x月xx日店面升级\n658501 0 在\"做自己\"和\"取悦他人\"之间寻求平衡\n658502 0 “你们说明书也没说电脑不能手洗啊\n658503 0 阿里的应用的刚好从另一个方向\n658504 0 社会实拍武术学院食堂男女打架\n1000 Processed\n classify content\n659000 0 他竟然去酒吧一掷千金·····\n659001 0 好声音第四季第一期中唯一让人记住的恐怕就是李安了\n659002 0 这里嘅装修最特别就是这个摆设\n659003 0 0主相机以及500万像素前置相机\n659004 1 阿里巴巴诚信通周年庆月,xxxx年x月x号入驻阿里巴巴将有大礼赠送,企业APP一年+x个月询...\n1000 Processed\n classify content\n659500 0 捣鼓手机的时候忘了备份照片\n659501 0 偷我钱的小偷以后上厕所没带纸\n659502 0 23日召开的江苏物价局长会议传出的这一数字\n659503 0 f2栋与f3栋之间搭了很多钢架\n659504 0 吉鲁这专业飞机熟悉的滋味\n1000 Processed\n classify content\n660000 0 在好声音这种如此主流的选秀平台\n660001 1 平安易贷可帮您获取所需资金,无须抵押,手续简便快速,快来申请吧!,在申请时输入我的邀请码xx...\n660002 0 wearein锡林格勒动植物科技馆\n660003 0 二维码中包含木马病毒那就是可怕的事情了\n660004 0 并约着晚上一起嗨~啊哈哈哈哈哈\n1000 Processed\n classify content\n660500 0 梦见你的QQ名片上更新了两张照片\n660501 0 看着网上的旅游攻略看的头疼\n660502 0 前往天津滨海为其分行新址考察策划\n660503 0 只要违法乱纪就必将受到惩罚\n660504 0 我们听听xxx首席工程师郑文彬怎么说\n1000 Processed\n classify content\n661000 0 大家每天宅在电脑前也可以赚点零花钱\n661001 0 昨天在银座等电影开场然后去咖啡店买了喝的东西跟老板不自觉的说了普通话然后朋友就说让我能不能不...\n661002 0 下飞机后在排队等passportcontrol\n661003 0 39亿美元收购健康应用Runtastic\n661004 0 slm三更半夜停电搞什么飞机啊干\n1000 Processed\n classify content\n661500 0 医生被她体内的超大肿瘤吓了一跳\n661501 0 已满14周岁不满18周岁的未成年人犯罪应当从轻或者减轻处罚\n661502 0 回家后一天24个小时睡了18小时\n661503 1 有房就有钱,x%利率借款。资金周转困难?链家地产推出:x万—xxxx万,短期借款。只要名下有...\n661504 0 点解成日要盗窃我个脖卖广告\n1000 Processed\n classify content\n662000 0 然后开始质疑:我该相信爱情吗\n662001 0 犯罪的人不该承担他行为的后果吗\n662002 1 宣城商之都珀莱雅专柜,三八妇女节特惠,除特价套盒外,全场x.x折,活动时间x.x~x日,详情...\n662003 0 12岁的小家乐先天软骨瘤、一个腿长一个腿短\n662004 1 亲爱的会员,同仁堂劝业场专柜x月x日至x日开展膏霜买xxx送xx,中药、花草面膜买x送x(送...\n1000 Processed\n classify content\n662500 0 国产动画被指抄袭美国大片导演骂质疑者是汉奸\n662501 0 44、邻居家小孩约我去玩水枪\n662502 0 省公安厅发言人:此无聊只举给我们警方社会全国各族人民带来极大的买为情…请各位段友认真事态严重性\n662503 0 的确为什么我们会为了几块钱在太阳底下和小贩讨价还价几块钱而在商场里和有钱的卖家从不讨价还价\n662504 0 ”面对失而复得的笔记本电脑\n1000 Processed\n classify content\n663000 0 联合卡车于7月31日在公司食堂举办“无偿献血\n663001 0 刚才扫了眼江苏卫视那个答题的节目\n663002 1 xxxxxxxxxxx尊敬的用户您好! 您的积分已满足兑换现金大礼包条件,请登录wap.xx...\n663003 0 微软你再不推送WIN10我就去ROOT安卓了\n663004 0 深夜惊奇·租房租到崩溃…什么人什么鬼什么神都有啊\n1000 Processed\n classify content\n663500 0 2015年7月30日奇妙真相最重要的问题第八辑我们可以和睦相处吗\n663501 0 otherstories风欧美原宿复古极简白色松石大理石纹耳钉一对价\n663502 0 可以抛弃Windows7了~一会安装Office2016\n663503 0 小伙王某为女人抢劫金店逃跑时每xxx米换一辆车\n663504 0 限定孙子xx周岁前可每月探望一次\n1000 Processed\n classify content\n664000 0 做了股指期货配资后也能赚钱了\n664001 0 在手机行业有的性能很好的国产手机\n664002 0 坐在T3航站楼候机大厅宽敞的椅子上\n664003 0 网上说的是在腾讯视频是收费的\n664004 0 给大家分享“Office最全视频等”文件\n1000 Processed\n classify content\n664500 1 需要贷款赶紧的 【汽车抵贷】: 不押车、 不过户、 不装GPS, 【月息x.x厘】年息xx%...\n664501 0 地铁上又埋头看手机然后手麻脚麻\n664502 0 每周三晚22:00江苏卫视壮志凌云\n664503 0 abs新款拉杆箱大嘴猴铝框pc行李箱万向轮黑蓝红三色卡通箱包包邮\n664504 0 “中国版Airbnb”途家完成x亿美元融资\n1000 Processed\n classify content\n665000 0 支持靓靓好声音试听地址>\n665001 0 带着窝大哥的同款G–SHOCK\n665002 0 星巴克宁波和义1844店招募了\n665003 0 委托人就案件与律师进行协商\n665004 0 TFBOYS私密花絮曝光:合宿之突袭\n1000 Processed\n classify content\n665500 0 那个撞中国飞机的时代一去不复返了\n665501 1 一肖:鼠;两肖:鼠羊。这两个都很好,下注有风险,望谨慎。\n665502 0 配置YKK拉链、NIFCO扣具\n665503 0 “三公”经费支出比2013年度降幅明显\n665504 0 记者4日从哈尔滨站改造工程项目房屋征收指挥部获悉\n1000 Processed\n classify content\n666000 0 日你妈举报一次黄子韬炸一次\n666001 0 1干痒因皮肤缺水细胞得不到水份2起皮屑因皮肤太干燥角质层脱落3长痘痘因为皮肤油水不平衡4容易过敏\n666002 1 十杰画室x月x号周六开课啦!初级班,中级班,高级班,每班只收xx人,xxxx年,全新的教学理...\n666003 0 电梯吞人事件告诉我们一个道理:能在我这儿买的\n666004 1 再线性感靓妹!薄采遊戏等!項目多\n1000 Processed\n classify content\n666500 0 因为我们从基因上就是被设计成这样的\n666501 0 从千米高空的飞机上俯瞰会发现\n666502 1 家人们:春节愉快,洋洋得亿!记得我们正月十八相约利民雪莲,让您超低甚至免费体验我们的特色身体...\n666503 1 人比花娇xxx-xxxx-xxxx\n666504 0 拔出招聘信息里的“刺”…\n1000 Processed\n classify content\n667000 0 信用卡取现秒到账费率低带积分\n667001 0 就使用我的邀请码6a6gsd下载并登录浙江移动手机营业厅\n667002 0 我那浙江的姐姐欣闻我要去她老公的母校之后\n667003 0 13年手机业务部门被微软收购\n667004 0 浙江上演了两出让人啼笑皆非的家庭闹剧:杭州一名男子难忍母亲与妻子争吵\n1000 Processed\n classify content\n667500 0 83%、金龙鱼大豆油5升/桶装36元与上周持平\n667501 0 我特么也是醉了正常咨询的微博都不出去\n667502 0 才有未来——彩钢板建筑之租客篇\n667503 0 IBM大中华区首席执行总裁钱大群将退休\n667504 0 51家保健酒壮阳功效可能是靠西药“伟哥”来支撑\n1000 Processed\n classify content\n668000 0 来自全国37家博物馆及天津博物馆的总计267件文物\n668001 0 NBA开启夏季转会和签约的窗口\n668002 0 想不通那么多房地产都不景气\n668003 0 一本书在亚马逊上长期一块钱不到的便宜卖也不一定是这书烂\n668004 0 本门从昆山金乌狮盟夺得明玉神功残章五\n1000 Processed\n classify content\n668500 0 帮我找地铁站后还送我到地铁口\n668501 0 应及时到白癜风专科医院检测出黑色素缺失诱因\n668502 0 今年初认识的哥哥在湖南飞海口的飞机上丢了小米手机\n668503 0 果然看到小偷正趴在卧室的阳台上\n668504 0 翻阅了不下200篇微博终于找到了\n1000 Processed\n classify content\n669000 0 广州开发区反腐倡廉教育基地又名育廉馆\n669001 0 且熬且珍惜」給經常需要熬夜、喝酒的你\n669002 0 FOLLOWME咨询卫星:Nut1366\n669003 0 而里面有供身患精神疾病的她服用一年的治\n669004 0 一般这些都得YG那边告诉咱们行程以后\n1000 Processed\n classify content\n669500 0 近视两百度我得罪sei了我\n669501 0 深夜抓住一只建筑狗有天偶吧…论文写得比我快不能忍\n669502 0 宿迁青华学校的部分教职工向媒体反映\n669503 0 法官用关乎社会公平的权力腐败\n669504 0 传印度电商Snapdeal融资x亿美元阿里参投据国外媒体报道\n1000 Processed\n classify content\n670000 1 春节假期已过,现已正式开展工作,本人依然从事着个人无抵押信用贷款,车辆贷款以及房屋抵押贷款,...\n670001 0 国珍专营/国珍健康生活馆项目优势:1、保健品行业属于朝阳行业\n670002 0 cctv6的周一艺术影院特别讲究\n670003 0 Fsj以为用一切隐瞒自己所作所为\n670004 0 粑粑就把电脑就给我搬到床上催我选课\n1000 Processed\n classify content\n670500 0 20150712今天就是整天對著電腦\n670501 0 泗县法院党员法官走进南关社区\n670502 0 内部装置的LED系统可使其在接通电源后呈现出一直蝴蝶影像\n670503 0 短短20公里的路边花草布置就是6000万\n670504 0 而与一般Android平板电脑的键盘保护套有所不同的是\n1000 Processed\n classify content\n671000 0 想想广播上都有那种xxxx买十几瓶茅台送xxxx话费的\n671001 0 受到再融资即将重启的利空传闻影响大盘跳空低开\n671002 1 好消息!好消息!新都娱乐汇新春有优惠酒水全部x折,免包房费,是各位大哥娱乐休闲的好去处,你还...\n671003 0 NASA在Twitter上的图片\n671004 0 引“知情人士”出洞②数据造假愈演愈烈\n1000 Processed\n classify content\n671500 0 家里的酱油醋糖盐都比枫叶国的好吃好多\n671501 0 以后我改说“玩电脑”==~~\n671502 0 发红包啦~发红包啦~发红包啦\n671503 0 整部剧都是各种犯罪各种打架各种帅\n671504 0 不想战争政府必须想法少数人别占有太多\n1000 Processed\n classify content\n672000 0 这个东西太恐怖了整个小区的人都堆一堆我妈就不让我爸买他还躲着买我不想他们离婚\n672001 0 让反腐劲风吹进“衙门”的每一个角落\n672002 0 清涧县公安局在县局三楼会议室召开全县网吧业主座谈会\n672003 0 可向法定行政复议机关申请复议\n672004 0 法律是实践经验的总结和提升\n1000 Processed\n classify content\n672500 0 中国信用卡新增发卡量6400万张\n672501 0 暂时离开这个官商媒勾结的市场\n672502 0 早盘开盘是直接站上3700点战地\n672503 0 该县累计投资1300多万元\n672504 0 华为Nexus手机要直接用骁龙820」\n1000 Processed\n classify content\n673000 1 中公教育缙云分校教师招聘课程上线啦,在缙云开课哦,而且x月xx日前报名有惊喜优惠价,详询xx...\n673001 0 因村民未交新型合作医疗费用而掐断电线\n673002 0 夏天选电脑桌面也是挺有讲究的\n673003 0 学校有国家重点实验室3个:国家教育部智能制造技术重点实验室\n673004 0 最有意思是Dan还现场演示了Appium与机器人结合的真机测试场景\n1000 Processed\n classify content\n673500 0 一代玉女青春偶像DebbieGibson的经典名曲\n673501 0 儿时有过梦想成为桥梁建筑师\n673502 0 那么最后他还会为了花千骨死吗\n673503 0 现在的病人跟商贩一样奸诈噢\n673504 0 拆掉宗教违章建筑是体现社会公平的表现\n1000 Processed\n classify content\n674000 1 我公司库中现有进口欧洲废旧塑料、主要有:ABS、ABS合金、PA、Pc、PE、PP、PMMA...\n674001 0 xx后曾有过“青春是道明媚的忧伤”\n674002 0 当我在南京跑完这xx公里的时候你途中会发现有很多高楼大厦\n674003 0 就想说腾讯新闻也用错别字啊\n674004 0 想洗紋身到底醫院靠譜還是美容機構還是紋身店\n1000 Processed\n classify content\n674500 0 牡丹江市西安区法院立案庭副庭长马蕴慧从家出发\n674501 0 过了保质期不包了外面几十块钱就修好了的他要220\n674502 0 滨海城市青岛就是要去等待和拖延\n674503 0 是食物中毒和食源性疾病多发季节\n674504 0 嘉俪泽·国家食品药品监督管理总局国产非特殊用途化妆品备案通过\n1000 Processed\n classify content\n675000 0 于是在飞机上看到的景色也是不错的\n675001 0 基本上最经典和稳妥的设计了\n675002 0 华为mate7用户的心声:双系统从去年九月发布会开始吹捧之后说到11月份开始推送到今天201...\n675003 0 希望中国政府切实关爱中国残疾人的生存状况\n675004 0 你会发现以4元买入并以8元卖出的机会并不多\n1000 Processed\n classify content\n675500 0 尊享240——460㎡麓山别墅\n675501 0 实现公司商业地产继续做大做强的业务发展目标\n675502 0 其感受细胞分布在关节、肌肉、肌腱等组织中\n675503 0 我们的做工、质量以及服务绝对是一等的\n675504 0 浙江上榜的地产、能源企业不少\n1000 Processed\n classify content\n676000 0 刚刚拿到京东战略投资的垂直生鲜电商天天果园\n676001 0 个人信息被别人盗用进行犯罪\n676002 1 您好,诚邀光临xxxx广州(新)流体展,xxx家流体企业和来自xx多个国家的专业观众齐聚,中...\n676003 0 医生让我拔牙之前做牙周护理\n676004 1 亲爱姐姐们元宵节快乐,丽日三楼适时雅集专拒搞活动,秋冬装x.x一x.x折,有时间过来看看,活...\n1000 Processed\n classify content\n676500 0 一觉醒来看到手机上的时间都懵了\n676501 0 看到被血染红的海水感觉好难受好难受的\n676502 0 ——「镇政府为确保工程进度强拆民房被判越权违法」\n676503 0 泰州动物园对面的朱塘村某村民家中煤气爆炸发生火灾\n676504 0 一早打出租车帅哥师傅说我之前好像拉过你我能说我完全不记得了吗看来他不像是骗我的主要是我没说去...\n1000 Processed\n classify content\n677000 0 南京好热QAQ出门就觉得自己要化了嗷\n677001 1 老板,您那边是有个店面在转让吧?我这边是专业从事店面转让的,速度快、效率高、价格合理!转店面...\n677002 0 当Fire用户向亚马逊云上传照片和数据\n677003 0 南京钱宝客场3比1击败保定容大\n677004 0 张老晚年在江苏江阴的家中书房\n1000 Processed\n classify content\n677500 0 反腐案列反腐案列很成功\n677501 1 免费咨询xxxxxxxxxxx最新版机麻控制器,不安装,起手拿好牌,可现场试用,满意再买。y\n677502 0 独立卫浴电梯近火车站Coles\n677503 0 CC是能用嗓音震撼全世界的男人\n677504 0 希望以后能去美国读金融博士\n1000 Processed\n classify content\n678000 0 x×xx*x不知道能否继续母乳喂养\n678001 1 姐,新年好!现xx节特惠是满xxxx可享送xxx\n678002 0 xxxx年度部门“三公”经费支出比xxxx年度降幅明显\n678003 0 其实手机拍根本看不出来脸上都涂了啥\n678004 0 二手车平台人人车获8500万美元C轮融资腾讯领投\n1000 Processed\n classify content\n678500 0 传统烧油汽车因为机械工艺复杂\n678501 0 有种说法是企业商业计划ppt是写给自己的\n678502 0 而他们也将再次与前TopGear製作人AndyWilman再次合作\n678503 0 被钱江晚报今日桐乡和浙江新闻网竞相报道\n678504 1 圣豪百货迪士尼童装搞活动啦!三月三日至三月九日,冬装低至四折,春装低至七折,款式多多,优惠多...\n1000 Processed\n classify content\n679000 0 干了这些违法勾于强烈感情的抒情诗歌可以拥有\n679001 0 A君:他们潮一些我们都不知道的牌子\n679002 0 BTOB爆料:陆星材广告收益大家一起分\n679003 0 你在其他店里买的防晒霜有修复露配套吗\n679004 0 河北大名原县委书记敛财上亿自称未获升迁心理失衡\n1000 Processed\n classify content\n679500 1 xx女人节蝶漫玫瑰会所送惊喜:x月x日当天秒杀 优惠一,头疗,手疗(全年不限次数)秒杀价x...\n679501 0 也算对得起我100块和重新拾起教育学的勇气\n679502 0 针对收缩毛孔、粉刺黑头有特别效果\n679503 0 前海人寿究竟想坐享“抄底”收益的永久性平静呢\n679504 0 无锡职教园养生分会和康复中心邀请街道部分社工召开座谈会\n1000 Processed\n classify content\n680000 0 用10秒的设计为民族创新力点赞\n680001 0 因为喷雾是直接作用在咽喉上的\n680002 1 您好!魅力娱乐公司祝您元宵节快乐,凡今晚在魅力本色酒吧或魅力安南KTV消费满低消的,将获得魅...\n680003 0 功效:海带中的碘能够很好的被人体吸收后\n680004 1 房产抵押、x天出它证再放款,确保本金安全。详细情况建议您来我们公司了解,地址:上海市黄浦区成...\n1000 Processed\n classify content\n680500 0 将老年人、社区、医疗机构、医护人员\n680501 1 您好!您购买的商品由于系统升级导致您的订单已冻无法正常发货,请两小时内致电客服:xxx-xx...\n680502 0 加强监狱系统纪检监察干部队伍建设的几点思考\n680503 0 夏季新款欧美街头高档女装牛仔扎染水洗渐变廓型蝙蝠袖薄款短外套\n680504 0 你可以质疑我你可以否定我\n1000 Processed\n classify content\n681000 0 北京朝阳法院将于7月23日上午9点\n681001 0 天天都有办信用卡的来公司转悠\n681002 0 他妈的建邺区清荷园南园物业他妈的太差劲\n681003 0 失望的人们或许看到了真相的到来\n681004 0 未来的飞机场有可能是这样子呢\n1000 Processed\n classify content\n681500 0 受害人应该通过法律途径得到一定补偿\n681501 0 日本本土代购小黑帽蟑螂药现货欢迎找我拿货喔这次拿了好多蟑螂药\n681502 0 江苏盐城谁有pre一罐亭湖区附近的如果有请叫我\n681503 0 缺憾与基因一起铸成一个成品\n681504 1 xxxx xxxx xxxx xxxx xxx周娟农行\n1000 Processed\n classify content\n682000 0 每天想伴随着飞机翱翔的声音哼唱开不了口\n682001 0 2008年至2015年8月5日\n682002 0 随处一个建筑就是国际组织\n682003 0 果然我还是黑幕去吧??并没有人想要??\n682004 0 烟台副市长腐败都怪“新闻联播”\n1000 Processed\n classify content\n682500 0 很多人看标题会想妈的真腐败\n682501 0 云南厦门广西江苏四川深圳下一站去哪回梅州\n682502 0 旅游者经过这些地方时可往玛尼堆上添加一些石头\n682503 0 是对广东省肿瘤医院感兴趣的相关大众获取广东省肿瘤医院资讯的重要渠道\n682504 0 旅游是人们为寻求精神上的愉快感受小而进行的非定居性旅行和在游览过程中所发生的一切关系和现象的总和\n1000 Processed\n classify content\n683000 0 其三明明xx:xx的飞机到x点半才起飞\n683001 0 以及基金业协会也在近日密集发布分级基金下折风险提示的信息\n683002 0 中间拉链零钱隔层size20*10~\n683003 0 无锡淘齐宝贝文化发展服务中心的学教老师为学生们进行泥塑培训\n683004 1 //转自xxxxx:开学季特惠来袭!即日起到x月xx日,预存xxx元话费即送xxx元话费、x...\n1000 Processed\n classify content\n683500 0 伯伯7月23日把手机掉在高铁上\n683501 1 姐!好消息…我银座滕氏萨侬店新款到店了折扣x----x折与一口价的,新款衣服滕氏.萨侬.艾温...\n683502 0 沛县养生菜苗救心菜苗种子改良费菜景天三七盆栽降血压降血脂\n683503 0 最迟将于2019年交付瑞典海军\n683504 0 但其“具有侵略性”的商业化却有悖于佛教根基\n1000 Processed\n classify content\n684000 0 区城管执法局组织全局近100名在职在编人员开展了第二批次团队素质培训活动\n684001 0 正确防晒还有哪些你不知道的技巧呢\n684002 0 这种没素质的别跟它讲道理至于旁边拍照的这泼妇是你老婆\n684003 0 小伙穿化纤衣服起静电加油瞬间变“火人”\n684004 0 大众进口汽车年轻家族:甲壳虫TheBeetle、尚酷Scirocco邀你一起纵情起范儿\n1000 Processed\n classify content\n684500 0 分享图片常熟飞跃网咖效果图\n684501 0 也是唯二的我keep到现在的青黄文本>\n684502 0 九大券商仅一家看空下周上海陆家嘴并购联\n684503 0 请各位驾驶员严格遵守法律法规\n684504 0 妈妈会记录你成长的点点滴滴\n1000 Processed\n classify content\n685000 0 穷娃倾向理工科富娃更偏爱文科\n685001 0 强烈推荐他家手机壳简直业界良心\n685002 0 江苏移动用户的好消息“x月x日\n685003 0 在企业破产案件的审理中发挥了重要作用\n685004 0 p2p平台的稳步发展是政府政策保护与提携下的必然结果\n1000 Processed\n classify content\n685500 0 目的在于平?保险人与投保人之间的利益\n685501 0 真想一咬牙买下腾讯、搜狐、乐视、爱奇艺、虾米、优酷……的VIP\n685502 0 愿我们的\"中国心\"能早日驱动中国大飞机翱翔蓝天\n685503 0 好想熬夜好想熬夜好想熬夜重要的事情说三遍可是…晚安\n685504 0 换上的7棒李泽源击出中外野被中外陆毅接杀出局\n1000 Processed\n classify content\n686000 0 站务人员将正式进驻地铁车站\n686001 0 可惜银行还没有医院的预约服务\n686002 0 大赞台湾警察的效率更胜大陆公安与美国警察\n686003 0 刚我看lol的宣传片被他听到了也要挤在一起看\n686004 0 200平的别墅还要设计成四层\n1000 Processed\n classify content\n686500 0 扬州城有没有我这样的好朋友\n686501 0 市场跌幅的第一千只股票正好跌9%\n686502 0 今天就遇到了必须要坐电梯的路\n686503 1 金色年华主题火吧让您尽享美食,欢唱无限!抢包热线:xxxxxxx\n686504 0 八旬老人却想把房产留给陌生人\n1000 Processed\n classify content\n687000 0 正规/安全/高效/无前期任何费用工薪:凡工作满6月/月薪>\n687001 0 可以看做是专为OPPOFindx设计的\n687002 0 房地产投资仍在个位数增长低位徘徊\n687003 0 感觉2年的气垫都有着落了一个替换能用半年多\n687004 1 转发:您好!这里是百姓大药房,我们正在搞关爱女人节买xx元送xx元券活动,禾穗速效x元x盒,...\n1000 Processed\n classify content\n687500 0 中国证券业协会秘书长孟宥慈在证券投资咨询机构创新发展论坛暨业务培训会议上表示\n687501 0 /菲律宾摸黑偷修南沙仁爱礁“坐滩”破船\n687502 0 我听到或遇到的关于快车的日常:打快车司机是同事\n687503 0 投资人和个人财产对企业的债务承担无限责任的实体经营模式\n687504 0 狗狗带到宠物医院检查都很健康\n1000 Processed\n classify content\n688000 0 江苏首批两名聘任制公务员已正式上岗年薪在18万左右\n688001 0 坐这个时间的飞机是因为凌晨航班便宜吗\n688002 0 为了更好的生活思密达~??老板给包的红包\n688003 0 据说每个七年人的全身细胞会更换一遍\n688004 0 由xxxx多名苗族工匠历时两年多修建了苗族文化建筑群——蚩尤九黎城\n1000 Processed\n classify content\n688500 0 买房和卖方都应该追究刑事责任\n688501 0 日本自以为挤进西方大国集团\n688502 0 还有幽灵状的妮妮猪儿俩姐夫xxxxx这自由的感觉\n688503 0 「4万人在传看」你绝对没见过的方便面新做法\n688504 0 当年小龙女被尹志平XXOO过了x\n1000 Processed\n classify content\n689000 0 快来江苏食品药品职业技术学院跟妹子来一场美丽的遇见吧\n689001 0 为全县公安事业的发展进步作出更大贡献\n689002 0 微软WINDOWS10更新下载\n689003 1 刘洁美容x·x妇女节当天,凡来店会员仅需xx元即可订购价值xxx元以上康颜单品,(指定的三款...\n689004 0 我今天在华为网盘签到获得了xxxM免费永久容量\n1000 Processed\n classify content\n689500 0 好想吃鸡块鸡块鸡块鸡块鸡块鸡块鸡块鸡块鸡块鸡块鸡块\n689501 0 每年x—x月时间不等看把你臭美的\n689502 1 恭祝元宵节快乐! 青岛精彩验厂咨询,立足胶州,专注验厂十二年,一站式服务,通过率xxx...\n689503 0 却被不专业的半业内爆料人士洗脑\n689504 0 智能手机的普及给大家带来了更方便的通讯生活\n1000 Processed\n classify content\n690000 0 想旅游的心停不下来明天乖乖上班晚安\n690001 0 是病毒太过厉害还是百度并没有我们想象的强大\n690002 0 文良分局禁毒宣传:珍爱生命\n690003 0 其实整理一下也才两个飞机盒这么点\n690004 0 “贪污和浪费是极大的犯罪”\n1000 Processed\n classify content\n690500 0 两融余额骤降逾400亿元多券商暂停融券\n690501 0 其中x个批次来自江苏生产企业\n690502 0 具备一定财务或法律基础更好\n690503 0 流畅你们是对自己的产品不自信\n690504 1 汽大众集团赞助提供梦想创业基 金 xxxxxx元现金及苹果笔记本电脑一台。请立即登 陆 bp...\n1000 Processed\n classify content\n691000 0 依然仍然有人觉得我是关系户~好委屈\n691001 0 省检察院监察处任立新副处长一行4人莅临瓮安县院\n691002 0 提供北京大学肿瘤医院最新资讯\n691003 0 瞎唱的…吓到见谅哈…试听地址>\n691004 0 ~~~~对专业的安防行业有了解的朋友\n1000 Processed\n classify content\n691500 0 飞机晚点到达日航酒店已经4点\n691501 0 23南京禄口机场接机2015\n691502 0 比如咨询师对我的解释是“要先学会爱自己”\n691503 0 外加持续使用3'5个小时才电量不足\n691504 0 欧美薄款蕾丝情趣性感诱惑\n1000 Processed\n classify content\n692000 0 做ALPHA套利和CTA量化交易\n692001 0 知道中国好声音Why没人敢唱嵩哥的歌曲\n692002 0 烟台7月份避暑旅游指数排名全国第六\n692003 1 今天红馆正式开业,酬宾优惠活动力度大,美女也很多,晚上过去玩会吧,地址:宝龙大润发超市对面,...\n692004 1 农行xxxxxxxxxxxxxxxxxxx郑喻杰\n1000 Processed\n classify content\n692500 0 有认识苏州雕刻师傅的请联系我\n692501 0 针对未来运载火箭发动机发展的需要\n692502 0 因为进水会对手机内部多处元器件造成损伤\n692503 0 原因是:你去咨询了你的一位拿着3千块月薪工资的朋友\n692504 0 打开Google闲来无事~玩了十关奥特曼小游戏~觉得自己萌萌哒~\n1000 Processed\n classify content\n693000 0 浙江台得那个吴亦凡得那个节目会比芒果台得偶像来了收视率高\n693001 0 认证信息为“念念仙女集团香港有限公司董事长”\n693002 0 但是有一点……太君到底多大能耐\n693003 0 日本推出抗战剧中国爆笑抗战雷剧盘点\n693004 1 各位塑料拉牙刷丝、扫把丝的各位老总:您好!本人蔡庆慧从事该行业多年,具有丰富管理经验和生产技...\n1000 Processed\n classify content\n693500 0 恶魔唔开PPT卡恩唔理去啦佛祖卡里普拉多我屋企我打亏啊可没意思去啦提取拉锯甘咯的路上去咯没有...\n693501 1 任跃波,工行xxxxxxxxxxxxxxxxxxx,建行xxxxxxxxxxxxxxxxxxx 。\n693502 0 大胖边刷微博边说:腾讯员工竟然有带着工牌追妹纸的\n693503 0 交警也带防晒袖的韩国代购法国代购免税店代购\n693504 0 对于无慢性乙肝感染家庭背景下病友而言\n1000 Processed\n classify content\n694000 0 江苏省泰兴市济川街道办违法乱纪\n694001 0 有没有小伙伴8月初开车回徐州或者路过徐州的\n694002 0 ”公诉人称案发时他有完全刑事责任能力\n694003 0 因为我心心念念的哆啦A梦旅行箱终于到了\n694004 0 一个顶三个一只搞定五大肌肤问题哦\n1000 Processed\n classify content\n694500 0 所以我家快要打恒大的江苏舜天除了孙可\n694501 0 现在的傻都是所谓的价值投资者\n694502 0 微软减记诺基亚手机业务并裁员xxxx人\n694503 0 导演可小、演员可小、投资也可小\n694504 0 本次对接会将于7月29日在镇江举办\n1000 Processed\n classify content\n695000 0 疑似MH370飞机残骸在法属留尼旺岛沿岸发现\n695001 0 333、五洋建设集团股份有限公司房屋建筑业浙江\n695002 0 刷微博等花千骨啊啊啊啊啊啊啊愉快的暑假不要离我而去\n695003 0 在大队违法处理窗口、服务区、武东卡口组织播放交通安全宣传片\n695004 0 请看最后一张图划线部分:复活女性衰退卵巢细胞\n1000 Processed\n classify content\n695500 0 像三四年前google地圖或googlelatitude一樣\n695501 0 昨晚首都机场飞机上等待3小时起飞\n695502 0 亚马逊还倾情推荐了不少另类书籍\n695503 0 今年的凉鞋怎么就设计的这么丑\n695504 0 6、海洋局:全国已建成海水淡化工程112个\n1000 Processed\n classify content\n696000 0 整个无锡市的大气自动监测点将达到18个\n696001 0 x万萤火虫放飞、浪漫求婚、啤酒狂欢、音乐美食、帐篷露营\n696002 0 其他无论青岛烟台威海连云港通通只有硬座\n696003 0 其实这几集花千骨的内容完全可以概括为小骨:师父~~~师父~~~喝我的毒喝我的毒求你不要把我逐...\n696004 1 魅力女人节,约恵三月天。千百色化妆品全体员工敬祝各位时尚女神节日快乐,青春永驻!为与您共度美...\n1000 Processed\n classify content\n696500 0 近日带来iPhone6和iPhone6Plus手机壳\n696501 0 看电视剧看得忘记好声音了啊啊啊\n696502 0 2相对其他股票是地地道道的小盘股和绩优股\n696503 0 高邮中学吴睿以389分高考成绩位居全省空军招飞文化分第一\n696504 0 我们学校经贸系17个学生可以享受公费去江苏海门参加实践活动\n1000 Processed\n classify content\n697000 0 我怎么觉得花千骨不是白子画的生死劫\n697001 0 电脑前憋新一期员工状态聚势培训PPT中\n697002 0 使一部分人大获其利而另一部分人深受其害\n697003 0 说是要给青云渔业大队弄拆迁房…\n697004 0 之前用露得清的防晒真真的鸡肋但是他们家的fastabsorbing护手霜还是蛮好用的滋润度很...\n1000 Processed\n classify content\n697500 1 你好!xxxxxxxxxxx陈红在本市制作各种毕/业証\n697501 0 南京仲夏夜萤火虫轻舞飞扬 如繁星坠落人间难道是南京大屠杀的亡灵……\n697502 0 善味阁靖江猪肉脯肉干xxxgxx袋\n697503 1 缤纷金柜岁末大酬宾,啤酒??一千三箱,洋酒轩V买三送三,中场火辣刺激小游戏,空姐的制服诱惑,...\n697504 0 他又認同填平A區河道解決黑沙環海邊長期臭味問題\n1000 Processed\n classify content\n698000 0 张**开闭幕式心情复杂\n698001 0 然后我pia的把一个铁盒碰到了地上\n698002 0 我多年前TVB為我開的騰訊微博被黑客入侵\n698003 1 温馨提示:体育馆创新文化艺术培训学校为庆祝本校建校三周年庆,于xxxx年x月xx日之前到我校...\n698004 0 /港大学生冲击校委会内幕:学生会长充当“港独”内应\n1000 Processed\n classify content\n698500 0 微软的系统通常是一代成功一代失败的死循环如今win7成功了Win8失败了然后win10会成功吗\n698501 0 东莞政府还忘了做一最重要的事\n698502 0 自体脂肪干细胞填充苹果肌肉可以瞬间变超级甜美哦一般做3次左右可以永久\n698503 0 普京回击质疑:xxxx年世界杯就在俄罗斯举行\n698504 0 国内黄金白银td走势终于在连续下跌的打击下走低\n1000 Processed\n classify content\n699000 0 南京即日正式改名为霍史尼玛\n699001 0 13年的今天第一次抵达苏州\n699002 1 大南门哥弟早春新款到店,时尚印花衬衫、baba蓝韩版风衣.彩色牛仔裤、更多惊喜期待您的到店体...\n699003 0 个人建议:在法院判定后败诉仍不交物业费的方可纳入失信名单望决策者重视\n699004 0 榆阳区劳动监察大队的工作应该由谁来“监察”\n1000 Processed\n classify content\n699500 0 医疗服务不仅仅是医院的问题\n699501 0 1、家庭房屋装修风水—玄关玄关环境凌乱会导致空气混浊\n699502 0 “鲍公”铁面无私却又侠骨柔情\n699503 0 地址:石大研究生培训中心世博影视艺术学校\n699504 0 每个法院都有那么一些赖皮的人\n1000 Processed\n classify content\n700000 0 江苏南京东南大学附属中大医院消化科的副主任医师毛翠华在家中做完早饭后上厕所\n700001 0 黑糖使用好方法1黑糖泡水和红枣桂圆煮10分钟左右\n700002 0 最近突然对房子的装修多了点想法\n700003 0 彩塘镇政府接到爆料后十分重视\n700004 0 提供大家選擇哪個版本適合自己唷\n1000 Processed\n classify content\n700500 0 它的后壳内侧有一句ForOurPrincess\n700501 0 谢谢小真和五哥两位医生的专业帮助\n700502 0 但目前政府的明牌3600依然非常坚挺\n700503 1 银行无抵押贷款,当天下款,利息全市最低,xxxxxxxxxxx夏经理\n700504 0 也是摩尔90年代演的为数不多的傻白甜角色\n1000 Processed\n classify content\n701000 0 不要因为提到钱就是经济纠纷\n701001 0 x、不要把汽油、爆竹等易燃易爆的危险品带入车内\n701002 0 当方圆决定回北京乘飞机滑过天空的时候\n701003 0 90岁的黄贤通当着记者面暴打老婆无视法律实施家暴是严重犯罪\n701004 1 普宁xxx客运公司感谢您的来电,本站提供快车普宁至广州专线,安全,快捷!订票热线:xxxxx...\n1000 Processed\n classify content\n701500 0 当你不是安卓手机和苹果手机的时候\n701501 1 您好!首先祝您心情愉快!工作顺利!x月x号--x月xx号亚丹衣柜将举行盛大活动,买移门送柜体...\n701502 0 南京江宁麒麟门附近有小朋友想学画画吗\n701503 0 火车东站公路汽车站开通慈溪班车\n701504 0 中国好声音4:制作方整个双盲模式出来\n1000 Processed\n classify content\n702000 0 分享优酷腾讯视频爱奇艺会员账号\n702001 0 愿意用十斤肉换周五飞机不取消航班\n702002 0 30杀人案经扬州、江都两地警方共同努力\n702003 0 昨晚被放飞机今晚又被放飞机\n702004 0 亲眼看着车祸发生到医生确定死亡盖上布的过程比吃黄连还难受……\n1000 Processed\n classify content\n702500 0 是他腾讯自我颠覆最成功、也是堪称移动互联网最成功的产品微信\n702501 0 请跟我一起读羊毛辣子/呲牙/呲牙/呲牙\n702502 0 用图解跟你细说移苗◆原文:\n702503 0 今天早上地铁看到的一句话~\n702504 0 一x岁男孩即将从x米高阳台坠下时\n1000 Processed\n classify content\n703000 0 市人民检察院党组书记、检察长耿标带领党组中心\n703001 0 为什么不是那些以权谋私的、借权力寻租的坏人走\n703002 0 也算是个毛病看电影电视剧什么的我喜欢剧透喜欢看之前就了解剧情走向和结局今天看gonegirl...\n703003 0 那时候总是在想飞机上坐的都是什么人呢\n703004 0 避免政府在社会矛盾中处于首当其冲的位置\n1000 Processed\n classify content\n703500 0 北戴河——A股、场外配资——二级市场影响一级市场——融资环境变化\n703501 0 男童乘电梯被夹身亡后续:协会称梯外被夹无规定\n703502 0 气死我了……谷歌打开微博竟然黑屏你俩相冲么\n703503 0 江苏凤凰出版传媒股份有限公司董事会\n703504 0 我不看到花千骨所有人以后都过着幸福快乐的生活的结局我就是不甘心\n1000 Processed\n classify content\n704000 0 “家和顺”就是小区业主自治的专业的、系统的、互联网化的工具\n704001 0 每次看完花千骨都会想说一句卧槽你大爷\n704002 0 2015年该县投资160万元为全县533间平房校舍更换水泥檩条\n704003 1 【开学啦!x对x精品小班抢报中】数学/英语/科学现招xx人\n704004 1 浦发银行装修贷款电话回访问题,贷款利息为年息x%,贷款周期是xx月,银行业务姓朱,女性,是银...\n1000 Processed\n classify content\n704500 1 平安无抵押贷款,打卡工资x万,做生意xx万,全款车xx万,按揭房xx万,正规银行当天放款,利...\n704501 1 女神节来了,招远振华玖姿专柜回馈老顾客厅内部分商品最低x折起,还有春装新款到柜,美女姐姐们来...\n704502 0 头屯河区检察院正式开通“今日头条”手机客户端\n704503 0 有考虑过浙江歌迷的感受吗\n704504 0 常州市钟楼区晋陵中路xxx号长兴大厦x楼 联系人:卢经理 联系电话:xxxxxxxxxx...\n1000 Processed\n classify content\n705000 0 南京站x站台xx:xx离开\n705001 0 不是单纯的追求眼前的商业利益\n705002 0 我用百度视频手机版看了“男童门口捡棒棒糖吃七窍流血死亡”\n705003 0 某选手录了5遍挑的最好的一遍转身\n705004 0 有一个小偷每天都正大光明的偷听我们说话\n1000 Processed\n classify content\n705500 0 北滘林港路段往镇政府方向因污水管网建设的需要\n705501 0 腾讯RTX和WorkEC为首批合作方\n705502 0 江西省分宜县人民法院依法审结了这起过失以危险方法危害公共安全案件\n705503 0 同样庆祝老婆成功考上护士证\n705504 0 也有作者从医时从不同医疗案例深思人生哲理的散文\n1000 Processed\n classify content\n706000 0 施瓦辛格曾获得环球健美及奥林匹克先生头衔\n706001 1 先生您好,我是刚刚和您联系的佛信银通的关小姐,利息最低可以做到x厘,最快可以当天申请当天放款...\n706002 0 Adallom是一家SaaS云安全创业公司\n706003 0 婚姻中介钱老师打电话给我了\n706004 1 菏泽市空压机售后服务中心,特价销售:空压机配件,空滤,油滤,油气分离器,螺杆空压机专用油。上...\n1000 Processed\n classify content\n706500 0 现在给力价格xxxxxx发售…专注精品…\n706501 0 甲状腺肿大在病变初期及中期\n706502 1 亲爱的您好!我是Lapagayo的王倩雅,天气干燥,请多喝水并注意皮肤保养。x月x号前到店购...\n706503 0 司法所所长冶建雄贪污受贿与原告达成协议\n706504 0 三国志?糜芳糜芳\n1000 Processed\n classify content\n707000 0 真的是身体里的每个细胞都跟这个世界格格不入\n707001 0 机器人道歉反映了中国人的情绪\n707002 1 尊敬的新老顾客朋友你们好,为了感谢你们一年来对博士园的支持与厚爱,本店现已推出充值大优惠,充...\n707003 0 流行榜第五位排在金志文陈楚生庄心妍前面\n707004 0 午后南京的风雨还是会逐渐明显\n1000 Processed\n classify content\n707500 0 中国好声音里来了一个我大唐人\n707501 0 并分赴市区20余个主要路口开展交通文明劝导活动\n707502 0 耐克共需向消费者赔偿xxx万美元\n707503 0 我的身体是在东信集团公司一厂垮掉的\n707504 0 #NAME?\n1000 Processed\n classify content\n708000 0 现有219区524区前排票内场票也有\n708001 0 医生护士进行胸外按压直到xx:xx左右\n708002 0 公布了2014年全省法院受理行政案件的基本情况、特点和十大典型行政案例\n708003 0 格力手机的二、三代的产品将要面世\n708004 0 因为老妈身体抱恙和装修的事情搞的我焦头烂额\n1000 Processed\n classify content\n708500 0 百度叶舞飘飘贴吧首发:芭蕾八级北舞版\n708501 0 平均每套成交面积约在xx平方米\n708502 0 公司股票自xxxx年x月xx日起停牌\n708503 0 哈香港也有城管一个路边摊被收了\n708504 0 泗阳团县委深入学习“三严三实”自觉践行“三严三实”\n1000 Processed\n classify content\n709000 0 我在使用“RIO香橙伏特加”特技皮肤\n709001 0 新西兰政府升级移民局系统方便外国人签证申请\n709002 0 世界上为什么要有制服这种诱人犯罪的东西\n709003 0 今天徐州漫展看到了兴欣微草繁花血景军装paro和国家队\n709004 1 美女新年好,我是歌丽芬的黄经理,祝您及家人新年快乐,心想事成!本月来店x次护肤,送xxx元的...\n1000 Processed\n classify content\n709500 0 过了xx岁、并且眼周出现小细纹的人x\n709501 0 地面俱乐部旅游分享会圆满成功\n709502 1 场,汇聚全武汉以及周边市场的商业批发链。独立产权商铺。可包租可自营。诚邀您和家人朋友现场参观...\n709503 0 你知道借条与欠条在法律上的区别吗\n709504 0 后天就上飞机了然而明天还要录东西……我也是拼的不行\n1000 Processed\n classify content\n710000 0 地产高管创业潮地产+互联网……更多点我\n710001 0 噪音污染真的很讨厌天杀的赶紧停了吧电脑声音都开到头了还听不清……挖个沟挖了半个月有关部门也真的是了\n710002 0 刚qq响以为有人来关心其实是领导拉我一起加班\n710003 0 未来建筑节能保温钉存在广阔的市场发展空间\n710004 0 它因造型奇特的建筑被评为世界文化遗产而备受世人瞩目\n1000 Processed\n classify content\n710500 0 旁边的诉讼时效还在玩着自己的可撤销婚姻\n710501 0 有恒心+肯努力=成功做你的粉丝是我从7年前开始直至生命终止都不会改变的事\n710502 0 进入火箭图标并提示按HOME回到主菜单后\n710503 0 护士小姐和医师沟通后帮我安排在牙医晚餐时间帮她看诊\n710504 0 欧美风气质百搭纯色休闲阔腿裤时尚褶皱轻薄百褶裙裤女士雪纺裤裙\n1000 Processed\n classify content\n711000 0 内有iPhone5s及现金1500元\n711001 0 南通台为什么选这样的当主持人\n711002 0 少林塔沟教育集团第xx届运动会将于x月xx日开幕\n711003 0 /江苏苏州一工厂发生大火\n711004 0 华为px凭啥敢发热这么严重\n1000 Processed\n classify content\n711500 1 亲爱的小姐:你好!现在西城于x月x日x月xx日在西城一楼北门有促销活动全场x__x折,惊喜多...\n711501 0 富士康腾讯和谐汽车在郑成立投资合作公司\n711502 0 由全国红色旅游协调小组办公室主办\n711503 0 我想问为什么不能举报广告意思是广告微博是默认的是吗一刷微博满屏的广告真是完全够了\n711504 0 thebodyshop的沐浴露有要的吗\n1000 Processed\n classify content\n712000 0 小汽车碰到交通指示灯还会停下来\n712001 0 黑龙江省曲艺团2015年“送欢笑、到基层”活动今天启动\n712002 0 mk小斜挎链条肩带翻盖磁扣设计美观时尚又安全国内现货玫红金色金属链条和银色金属链条尺寸约:17\n712003 0 欧美时尚性感美背波浪挂脖亲肤文胸百搭内衣\n712004 0 我怎么帮你的强奸案辩护啊卧槽\n1000 Processed\n classify content\n712500 0 工人为什么减薪因为反腐败国企收入减少\n712501 0 果真是涨知识了~RM作为亚洲第一综艺\n712502 0 湖北省内都是24小时以内送货到你家\n712503 1 亲我是万和城欧莱雅严淑庆三八节活动开始了本日起购任意四件x.x折还可双倍机不可失哦\n712504 0 吃完成黑炭……sun420924868\n1000 Processed\n classify content\n713000 0 姜堰区市场监督管理局近日启动为期一年的电梯安全监管大会战\n713001 0 Amazon现有Philips飞利浦NorelcoCC5059/60儿童电动理发器\n713002 0 丰胸膏:原价入税:28080日币\n713003 0 玩多了魔兽RPG图的后遗症就是这个了\n713004 0 27°摩羯座今日运势★★★☆☆\n1000 Processed\n classify content\n713500 0 将2/3的番茄丁和牛奶用搅拌机打碎\n713501 0 专注淘宝天猫京东阿里蘑菇街美丽说等各个电商平台\n713502 0 外企进军中成药国内中药企业担忧\n713503 0 欧美风超有质感复古女鞋~>\n713504 0 多年来的一个夸人真相:你长得真清秀啊就是你眼睛小鼻子小反正就是小\n1000 Processed\n classify content\n714000 0 得到了淮安广大瑜伽爱好者的高度认可\n714001 0 无锡接近苏州上空惊现彩色云朵\n714002 0 33岁的司机杨某将他们从上海接送到桐乡\n714003 0 有电脑的可以设置成默认网页\n714004 0 汇康2015秋季新款女鞋欧美系带粗跟马丁靴女靴漆皮尖头高跟短靴女\n1000 Processed\n classify content\n714500 0 1号线黄埔站区响应集团党委号召\n714501 0 作者:南山大仙文风青杨近日\n714502 1 姐,告诉您一个好消息!我们店最新引进了一台价值百万的以色列SYNERON原装进口依镭闪频脱毛...\n714503 0 iOS8里提供了自动删除历史短信的设置\n714504 0 深圳东国际旅游度假区一线看海豪宅\n1000 Processed\n classify content\n715000 0 加微信发红包hyuk797\n715001 0 溧阳市人民检察院对王某以涉嫌强奸罪提起公诉\n715002 0 前几天去了ColoniadeSantPere\n715003 0 南京的夜晚比西安要繁华一点\n715004 0 我是\"xxx开头的企业股票整装待发\"\n1000 Processed\n classify content\n715500 0 当时这名21岁的工人正在安装和调制机器人\n715501 0 将机器人浇注动作与铸造机倾转运动进行同步\n715502 0 就是因为国民党政府要纠正以前民进党政府制定的错误的历史观\n715503 0 上海市女劳模受贿95万?事发后一夜白发\n715504 0 一般按照以往经验欧美的唱功都会比较好一些所以就没有很期待\n1000 Processed\n classify content\n716000 1 达地板,全友家居,特利达吊顶,每家每户墙纸布艺,海尓家电等xx多个一线品牌,优惠力度较大,享...\n716001 0 最近太多零售顾客都是冲着阿胶糕来\n716002 0 中航第一飞机设计研究院动态\n716003 0 只因为你们把歪脑筋动到了娜娜身上你说他闰土\n716004 0 晚上的秦淮人山人海啊今天继续玩咯\n1000 Processed\n classify content\n716500 0 江苏如皋市搬经镇加力社区干部陈海健在夜晚巡查秸秆禁烧时不慎摔倒\n716501 0 来阿里巴巴的人必须认同和坚守我们的价值观\n716502 0 且未来三年还将新增xx亿平方米的物管市场容量\n716503 0 坐火车坐出了中国好声音选手的感觉\n716504 0 瑞士FlNMA、APl请你们听听成就APl神话的3万中国投资者的泣血的呼声\n1000 Processed\n classify content\n717000 0 复旦IC卡/FM1108IC白卡/M1白卡/门禁卡/考勤/IC卡/感应卡/射频卡\n717001 0 GAx的大灯设计犹如南狮般醒目\n717002 0 其全资子公司南通景瑞于24日约人民币3\n717003 0 为进一步提高全省行政复议应诉人员的工作水平\n717004 0 通过网络钓鱼违法行为盗取本人钱财\n1000 Processed\n classify content\n717500 0 现在知道我为什么选择BBT了吗\n717501 0 你所没见过的月光里的南京城\n717502 0 玩家扮演一名叫做Haru的女孩\n717503 0 报名时间:2015年7月27日至2015年8月2日18时联系人:顾西同13912523638...\n717504 1 我是水果湖老百姓大药房丸美专柜的,丸美x.x有大型优惠活动,全场x折后满xxx再减xx,特价...\n1000 Processed\n classify content\n718000 0 如果陈圆圆是五六月的苏州茉莉\n718001 0 很多时候不过问比知道真相要好得多\n718002 0 参与NBA国度各项活动同时\n718003 0 “xxxxxx…”前奏一出来就要哭了\n718004 0 想留在常州~再也不想回镇江了\n1000 Processed\n classify content\n718500 0 集PC页游、手机网游为一体的全平台萌系卡牌RPG游戏\n718501 0 早在60年代就因反对国民党的专制统治而被捕下狱\n718502 1 xxxxxxxxxxxxxxxxxxx 农行,李小强。\n718503 0 数不清是第几次花千骨小说了\n718504 0 我有这么老成么每个医生查房都问结婚了没\n1000 Processed\n classify content\n719000 0 伯朗特研发出六轴工业机器人\n719001 0 调碎花长裙+休闲帆布鞋的丝绸一样\n719002 0 那个在ZIPPO店里特有的吉他和男声\n719003 0 原本昨天上午就该到Bergen\n719004 0 不要把自己一时的快乐建筑在别人一生的痛苦上面\n1000 Processed\n classify content\n719500 0 被笑是因为有乌龟所以电脑变慢了\n719501 0 心烦想砍人一个电脑白痴现在徘徊在跟啥都不兼容的winx跟软件之间\n719502 0 哪有我大苏州这种江南小镇的细腻朦胧啊~下的我心烦\n719503 0 浙江卫视最后的工作人员名单以及赞助商商标比走马灯快一百倍啊一百倍\n719504 0 今天检察院控申科的薛怀亮一反常态不讲法理\n1000 Processed\n classify content\n720000 0 2015宿迁市钟吾国际学校公开招聘8名教师简章\n720001 0 它融合了30多味顶级中药食材\n720002 0 昨天晚上的加油吧实习生真的很精彩\n720003 0 1米高的烧毛面中国黑石材搭上了以古代剔漆工艺为灵感设计而成的红漆边桌作为隔断\n720004 0 呃楼下海门好声音看着别人热情似火赶着看直播我想说哥哥在刷题啊操蛋好吵\n1000 Processed\n classify content\n720500 0 所以赖着皮要和那个手机的主人一张床\n720501 0 字母S和字母D不是一直在一起吗\n720502 0 微雨轻风广场上在放去年夏天的电影身边路过浅金色头发的小鲜肉也不知道浙江来的笑容甜甜的老板娘做...\n720503 0 我想起来我信用卡现在还没还\n720504 0 我分享了百度云里的文件:?Standbyme粤语\n1000 Processed\n classify content\n721000 0 在东兴越南风情街电梯门前买的榴莲里面都长虫了\n721001 0 在无锡哪个犄角旮旯里都能遇到熟人\n721002 0 特别版|做客南京体育广播\n721003 1 感谢您致电安逸xxx连锁酒店自贡店!本店格调豪雅、配套齐全\n721004 0 市第二法院通报了这起非法制造注册商标标识罪的判\n1000 Processed\n classify content\n721500 0 处3万元以上10万元以下的罚款\n721501 0 本次展会由浙江省连锁经营协会\n721502 0 分享一下本来想买这个的但是手机耳机貌似不适用其他设备\n721503 0 警示每一个前来司法所当面报告的社区服刑人员\n721504 0 本协议是长光辰芯与卫星公司关于高性能CMOS图像传感器等项目研制的框架协议\n1000 Processed\n classify content\n722000 0 吵了半天我决定滚回电脑前看……我BO哥最帅了有木有\n722001 0 “6pair半”是指当时香港商业电台的13个DJ\n722002 0 话说太湖旁边山上的别墅是真心漂亮\n722003 1 新年好!现姿金服务全面开始!为您奉上新年第一桶金!为您事业保驾护航!银 行贷 款,立息低至x...\n722004 0 武媚娘高科技机器人率先在智能服务机器人行业运用高科技技术自主研发的会说\n1000 Processed\n classify content\n722500 0 地铁十号线里出现好多见人就磕头乞讨的小孩儿\n722501 0 好声音怎么又让腾讯做播放平台啊\n722502 0 cucumbo可以自行组装和更换\n722503 0 无锡市锡山区东亭街道新屯社区藤庄巷居民拆迁情况从未履行公示程序\n722504 0 而用我的手机号和一样的密码进去后就还是我\n1000 Processed\n classify content\n723000 0 Qq微信用不了朋友们在微博上联系我\n723001 0 每天喝二十味中药的我突然发现了自己的兴趣\n723002 0 我刚才居然用力摁我的电脑屏幕\n723003 0 浙江卫视挑战者联盟还有x天\n723004 0 乍嘉苏高速苏州方向凤桥出口匝道有辆危化品运输车侧翻\n1000 Processed\n classify content\n723500 0 也体验到了常州人民的低消费高质量\n723501 0 适用速裁程序审结案件xxxx件\n723502 0 河北华夏幸福0:0江苏舜天\n723503 1 ............斤奖xxx元。[鼓掌][鼓掌][鼓掌][鼓掌]寻找洛阳笫一胖免费减重...\n723504 0 还不如我们ChinaJoy随便一个展台的妹子——无论在数量和质量上都是如此\n1000 Processed\n classify content\n724000 0 戴眼镜白衣男子是人大的万主任满身血是受害者张铭\n724001 0 做公益的人政府及官方媒体不要插手\n724002 0 昨晚在飞机上拍的闪电~\n724003 0 猪在传统文化中是财富的象征\n724004 1 (人民商场)春夏新款全馆盛放,xx大化妆品牌独家赠礼,会员积分满额可兑现金券,凭此短信购指定...\n1000 Processed\n classify content\n724500 0 外媒评价:一加手机2与三星S6不相上下\n724501 1 您好,我是刚刚给您打电话的单炜炜。我行现在推出纯信用贷款,额度为xx~xxx万,利息低于市场...\n724502 1 您好,我是潍坊沃富机械有限公司 王健。我们主要生产微耕机、开沟培土机、电动汽车。现在在河南市...\n724503 0 南通、苏州、无锡、常州、盐城、泰州的朋友注意了\n724504 0 盈科律云-全球投闹融资/商务/移民/税务/法律服务\n1000 Processed\n classify content\n725000 0 法国sandro冰丝原单连衣裙进口垂感曲珠冰丝面料双面针织加深份量感面料超好打理怎么洗也不会...\n725001 0 另躲匿在金海西园无证小贩\n725002 0 这相当于在WindowsPhone的棺材上又定一个钉子\n725003 0 目测已经到了南京夏天最热的时候\n725004 0 很想知道真相:王林是否真能用气功治病\n1000 Processed\n classify content\n725500 1 美津植秀全场满xxx减xx,x月x日之前还可享受满减后额外x.x折,届时敬请各位新老会员光临...\n725501 0 xxxx北京城信用卡取现西藏旅游暴走计划提現+约伴贴\n725502 0 只有这样你才能越来越好加油\n725503 0 2、通过链接进去后注册实名认证\n725504 0 包邮瑞士正品名牌BUREI手表男士新款钨钢防水石英表情侣手表BUREI宝梭\n1000 Processed\n classify content\n726000 0 miumiu的设计是意式风格\n726001 0 在命运的漩涡里一边真相在生活中此起彼伏了旅行\n726002 1 嘉兴南溪多又好店迎辣妈闹元宵活动:x月x日一一x月x日 全场奶粉.纸尿裤满xxx元送xx元礼...\n726003 0 别人下飞机去得第一个地方是景点\n726004 0 目前因涉嫌入室盗窃被刑事拘留\n1000 Processed\n classify content\n726500 0 然后打个飞机去了另一个地方继续过着白天~\n726501 0 还有什么理财app你们觉得比较好用的\n726502 0 六合区此次自行车投放将分为3个批次\n726503 0 听他讲述机器人产业的发展方向\n726504 0 用FWSim软件设计的烟花\n1000 Processed\n classify content\n727000 0 2014年沿海各地及相关部门积极推进海水利用工作\n727001 0 九号晚上开始我的南京x天x夜旅行\n727002 0 本门从皖南连云神鞭门夺得吸星大法残章四\n727003 0 李易峰李多海分手内幕再被扒\n727004 0 Life破isalwaysatest\n1000 Processed\n classify content\n727500 0 我们Android开发者的选择还真不少\n727501 0 世界各地的设计师用他们独特的想象力设计了许多与众不同的秋千\n727502 0 尊重知识产权是全行业的共同责任\n727503 0 8川沙小米汽车租赁虹口开工主婚车新款玛莎拉蒂总裁\n727504 0 Pepper的使用体验究竟如何\n1000 Processed\n classify content\n728000 0 眾里尋他千百度驀然回x首那人卻在燈火闌珊處\n728001 0 Amazon现有CreativeCats动物系喵星人涂鸦填色本仅售$4\n728002 0 对检方指控他受贿xxxxxx元\n728003 1 j轉讓xxx-xxxxxxxx* xxxxxxxx xxxxxxxxxxx xxxxxxxx...\n728004 0 东北卡带式英语…「25万热播视频」民国珍稀影像\n1000 Processed\n classify content\n728500 0 南京装潢公司:4招改变厨房风水招财纳宝好福源\n728501 0 朋友圈处处都是杀阡陌/色/色各种犯花痴/亲亲/亲亲女人们\n728502 0 CDECGAMING加油\n728503 0 MichaelKorsSelma中号铆钉耳朵包\n728504 0 然后座11点45分飞住丽江的班机\n1000 Processed\n classify content\n729000 0 秋叶原的女仆咖啡屋?cafe推出全新制服\n729001 0 与会专家学者围绕“中药药理研究的创新与发展”这一会议主题展开研讨\n729002 0 江都区气象台x月xx日xx时发布:今天夜里到明天阴有阵雨或雷雨\n729003 0 发现看着好看的大都是旅游婚纱\n729004 0 报名时间:2015年8月9日—2015年8月11日\n1000 Processed\n classify content\n729500 0 是否美国可以通过信用卡的信息在当地的店的消费记录里检索出我购买的型号呢\n729501 0 都是萌萌哒~~黄金左脚踢球姿势也不错\n729502 0 1946年重巡洋舰妙高被凿沉于马六甲海峡\n729503 1 您好!我是西区欧凯龙负一楼:厨壹堂环保集成灶的销售员~小暴。本商场xxxx年建材家具“x.x...\n729504 0 Vic给我留言说:和开飞机的打起来了\n1000 Processed\n classify content\n730000 0 比较重要哦~快get起来吧~\n730001 0 2016国家公务员考试暑期备考步步为营“捉行测申论”\n730002 0 时隔5天终于过上有手机的生活了\n730003 0 央行昨逆回购400亿元机构预计未来数月宽松立场不变\n730004 0 美铭乐高机器人基地又一次受邀参加xxxx中国国际消费电子博览会暨山东省机器人展会\n1000 Processed\n classify content\n730500 0 真心为盐城的公共基础设施建设点赞\n730501 0 今天要抱着一台电脑和材料回去啊\n730502 0 我的面试成绩整个检察院系统第一\n730503 0 政府会强制性要求制造商在LED产品上标注能效标识\n730504 1 《平安银行新一贷》简单 快 无需抵押。 xx小时内放款。利率低, 贷款xx万元一年利息约x....\n1000 Processed\n classify content\n731000 0 我到现在才知道演花千骨那个是张丹峰\n731001 1 普惠金融 “宜信.宜人贷” 信用贷款……全力助您发展。x.信用借款无需抵押担保,无任何前...\n731002 0 徐贤刚更新了Twitter:??????????~?????????????原文戳:\n731003 1 石油洒楼正月十二开始迎接高朋好友了,羊年喜洋洋,今年酒楼菜品以,保特色,推新品做家宴,工作攴...\n731004 0 做法:将牛奶和QQ糖一起放在锅中\n1000 Processed\n classify content\n731500 0 张家港易道教育宝贝们创作的画\n731501 0 日本警方近日逮捕了其CEO马克·科尔佩勒斯\n731502 0 就希望所有身边的贪官全落网\n731503 0 怎么保证这些金融高管不被拉下水\n731504 0 晚上在超市看到个男的上电梯\n1000 Processed\n classify content\n732000 0 141户村民住进了新建的别墅\n732001 0 江苏卫视非诚勿扰女嘉宾孙媛媛个人简历和网友评价|非你莫属|非诚勿扰|电\n732002 0 大家快来看看~微软正式开启Winx/Winx\n732003 0 工管1402的李港来同学选取了无锡本地名人才子中国近代文化大师钱钟书的故居为本次社会实践的访问地\n732004 0 中国首届无油烟节落幕浙江海宁由科大集成灶主办\n1000 Processed\n classify content\n732500 1 公司财务工行帐户:xxxxxxxxxxxxxxxxxxx王安绪\n732501 0 一大清早同事们就开始聊电视剧说花千骨说的津津有味…根本没有共同话题啊\n732502 0 今天晚上盐城出现了一群摩托飙车党\n732503 0 今日担任审判长的是阳瑜法官\n732504 0 随后微软Xbox部门主管PhilSpencer登场\n1000 Processed\n classify content\n733000 0 将如今法官庭审所遵循的“自由心证”及法律事实和法律证据之间矛盾表现的淋漓尽致\n733001 0 无线U盾相当于掌控手机信息安全的无线钥匙\n733002 0 我坐电梯之前还得先弄明白电梯的安全与结构\n733003 0 如果生活强奸了你你又不能反抗那就要试着享受\n733004 0 您的医生怀疑髂静脉受压是否有相关影像学检查证据支持\n1000 Processed\n classify content\n733500 0 带你了解SOHO这些实用性超高的酒具\n733501 0 宣布将球衣销售额的5%捐献给一家名为\n733502 0 以防电梯的扶手和梯级运行不完全同步\n733503 0 小散们真的希望政府拉升中石油\n733504 0 选择摄影大赛中的第10342号每天投一票\n1000 Processed\n classify content\n734000 0 文科楼的自修`篮球场的汗水`图书馆的小说`金沙网吧的午休时光`食堂观战NBA和住宿的遗憾?再会吧\n734001 0 自己把东西看好啊哈哈哈哈我竟然无言以对\n734002 1 您好,我是金帝海珀小张,现在我们推出xx号楼的一梯一户新开盘的房源,xxx平房总价七十八万起...\n734003 1 通知:红蜻蜓幼儿园招生在即。二十年办园经验,口碑好,师资力量雄厚,教学环境宽敞。地址:红旗小...\n734004 0 不仅用数字揭开浙江富豪的数量\n1000 Processed\n classify content\n734500 0 |刚刚看到一个评论说单春秋要打败长留根本不难\n734501 0 该男子因涉嫌盗窃被法院一审判处有期徒刑两年\n734502 0 被120救护车送往医院治疗\n734503 0 宝宝沉迷手机不能自拔怎么办\n734504 0 2、香菇洗净泡软、枸杞洗净、桂圆剥皮备用\n1000 Processed\n classify content\n735000 0 你说过一个人的旅游是孤独的\n735001 0 比起那些一个劲叫你办信用卡的还是舒服多了\n735002 0 来中国旅游加骗钱的放松之旅\n735003 0 医院:藏医院、省四医院、西宁市第三人民医院、康乐医院\n735004 0 日本Curel敏感肌化妆水配合Curel乳液一起使用的化妆水\n1000 Processed\n classify content\n735500 0 insider用户到底是怎么个政策\n735501 0 半裙折后173RMB上衣折后158RMB\n735502 1 紧急通知:《张爱玲》违约户【奔跑吧兄弟】栏目组向本院提交文件控诉您损坏栏目组的名誉和正规活动...\n735503 0 SPF50的tromborg防晒已经全部售完啦\n735504 0 第二个微博换了电脑忘记账号\n1000 Processed\n classify content\n736000 0 裁判再傻逼也不能把你射进球门的球再吹出来啊\n736001 1 “唱享北城、派对友约”北城派对KTV邀您到店欢唱体验,每周二会员全天免费唱x小时。地址:五块...\n736002 0 图四男士套装¥xxx内含洁面\n736003 0 微软的MikeYbarra证实Win10测试版Minecraft将添加成就功能\n736004 0 窄平而且额头中央有凹凸现象\n1000 Processed\n classify content\n736500 0 莉莲新娘婚纱礼服让你成为最美的新嫁娘\n736501 0 湖南省人民检察院依法以涉嫌受贿罪对省发改委原总经济师杨世芳、中移动湖南原党组书记王建根决定逮捕\n736502 0 房产税基本框定按面积征收离破冰还有多远\n736503 0 可是医生说根据b超我可能会没奶\n736504 0 结果却添堵了…知道真相的我无语且感人\n1000 Processed\n classify content\n737000 1 安新双隆紫淑专厅店员李聪颖祝所有亲人元宵节快乐!元宵节过后为迎接x月x号妇女节的到来全场春装...\n737001 0 女友红杏出墙男友持刀砍人——女友正用约炮神器与网友聊天\n737002 0 物美控股及北京物流信息合计持有公司69\n737003 0 其实每个人所遭受的不公与苦难\n737004 0 你不需要投资、不需要固定的工作时间、没有屯货压力、没有物流困扰\n1000 Processed\n classify content\n737500 0 两个浙江的古镇人在某一时刻被注定的因缘\n737501 0 印尼Communal咖啡吧兼餐厅——Communal咖啡吧兼餐厅\n737502 0 炫屏手机:双4G双百兆全兼容3\n737503 0 瑞士央行投资股票的市值相当于瑞士GDP的xx%\n737504 0 龙婆坤佛历2536年21年老牌\n1000 Processed\n classify content\n738000 0 看电影:TheJudge法官和他的三个儿子的故事2小时20分钟\n738001 0 现在让我一个人玩他们去隔壁房间\n738002 0 认证信息为“汕头中堤投资集团项目部”\n738003 0 天津滨海区LTE网络关键指标得到很大改善\n738004 0 有时候真的会觉得我妈要逼我其实挺方便的\n1000 Processed\n classify content\n738500 0 58元红包摇到3:给你0\n738501 0 在昨天市政府新闻办举行的“三证合一”新闻发布会上\n738502 1 大丰鑫馨教育春季报名了!舞蹈素描绘画跆拳道,魔法玩字手脑速算小主持,小学语数外,本周六九点全...\n738503 0 河北一副厅长日均受贿7万、不存银行、娱乐、欣赏\n738504 0 今天终于把花千骨的小说看完了\n1000 Processed\n classify content\n739000 0 加入黄瓜汁、蛋黄、蜂蜜和橄榄油\n739001 0 2015年江苏省少儿门球比赛在宿迁古黄河体育公园门球场举行\n739002 0 金色快车超大玻璃窗以及透明天窗让所有美景尽收眼底\n739003 1 中国人民银行特批发行《世界遗产纪念币珍藏册》总xx枚,总耗金x克,耗xxx克左右铜锌合金,一...\n739004 0 人体工学电脑椅是在桌前电脑一族出现之后\n1000 Processed\n classify content\n739500 0 带着满满的氧气再次回归循规蹈矩的生活中\n739501 0 最后寻访了浙大堤虽然求是精神永在\n739502 0 大型化妆品集团找一个ProductManager\n739503 0 华为荣耀xplus手机壳荣耀xplus保护套磨砂超薄外壳新潮硬男女情侣\n739504 0 x班和x班成绩较好的人重新安排到x班\n1000 Processed\n classify content\n740000 0 成功把手机从国行系统刷成台湾系统\n740001 1 感谢致电杭州创展门业 本店主营:移动门 推拉门等各种门 电话:xxxxxxx 地址:襄州区华...\n740002 0 才能做到低投资高效益增产增收\n740003 0 新店画设计图的时候好歹长点心吧\n740004 0 \\"上帝\\"眼中自有答案????在卫星的眼中\n1000 Processed\n classify content\n740500 0 苏州绕城S58上海往苏州方向28km车坊出口不到发生的小货车侧翻事故还在处理中\n740501 0 他突然看见一辆警车跟在他后面\n740502 0 呵呵未成年人x天xx年这法官收了多少\n740503 0 900毫升稀有血抵达江苏省人民医院icu重症监护室\n740504 0 就这样你陷入了一个死循环:只会越来越穷越来越胖此时此刻你应该做一个正确的选择等你来随时欢迎你的加入\n1000 Processed\n classify content\n741000 0 薄薄软软的牛仔面料水洗牛仔不会掉色哈\n741001 1 年度首开特惠 均价xxxxx元每平方 现二期开盘在即 火爆全城 x万抵扣x万团购优惠来就享!...\n741002 0 我的电脑先是没声音、这两天自动更新、连启动都启动不了\n741003 0 2、二维码诈骗:“商品二维码”为手机木马\n741004 0 那么你一定想知道在Win10手机版10149中\n1000 Processed\n classify content\n741500 0 念在化身+和声+审判力量超级牛逼所以一直不舍得\n741501 0 疑似本·拉登家族私人飞机在英国坠毁\n741502 0 要解决就赶紧给我来电话解决不然就别给我发一条评论一条打扰我版骂\n741503 0 而此时正值亚马逊20周年店庆促销活动前夕\n741504 0 有意者微信联系janephuaxxxx\n1000 Processed\n classify content\n742000 0 xx号完成第二针防疫观察一周交接\n742001 0 招商引资对中国制造的作用很有限\n742002 0 设计师设计了这套可爱的开关\n742003 0 xx星座最有毅力第一名:处女\n742004 1 (迪尼莎女鞋)x.x女人节回馈日(x.x日-x.x日),新品折后再减xx元,老款女靴清仓大处...\n1000 Processed\n classify content\n742500 0 海南省万宁市检察院有关人士透露\n742501 0 因为真相往往不是什么好东西\n742502 1 商品蕾瑟丝卫生巾限时优惠体验x套仅需xxx元!它是一款高端奈米银的医疗品牌卫生巾,释放负离子...\n742503 0 Nordstrom堆了2000多\n742504 0 厚厚的防晒霜让皮肤不能呼吸堵塞毛孔导致长痘\n1000 Processed\n classify content\n743000 0 无锡一棉的高档紧密纺精梳棉纱生产车间、常州天合光能的光伏电池及组件生产车间、江苏康缘药业的中...\n743001 0 都应该负责100%民事赔偿\n743002 0 Themer里拥有丰富的主题资源\n743003 0 没想到和警察妹子还是校友~挺有缘分的\n743004 0 新疆即将迎来60周年大庆两主线提前布局\n1000 Processed\n classify content\n743500 0 本门从昆山血刀阁夺得长生功残章四\n743501 0 第70讲:Scala界面GUI编程实战详解百度云:\n743502 0 吃完飞机餐就已经足够神奇了\n743503 0 小朋友们使用xxx儿童卫士x代手表顺利找到宝藏\n743504 0 可以专心复习一个小时两个小时三个小时\n1000 Processed\n classify content\n744000 0 所以会刻意谎报孩子的出生时间和出生日期\n744001 0 导演张新建、演员萨日娜、傅淼、刘向京将会与南京媒体零距离见面~有木有喜欢的呀\n744002 0 江苏省消费者协会发布了水上乐园消费调查报告\n744003 0 大清早别人装修外面吵架里面聊天打鼾讲电话疯狂敲房门的半梦半醒我还得起床去开锁麻痹我日\n744004 0 多家上市公司药品为不合格品\n1000 Processed\n classify content\n744500 0 被曝是南京史上最侈华的违建\n744501 0 两乘客因座位问题在飞机上大打出手\n744502 0 与汽车人总动员、金庸新有何异\n744503 0 上班时抓到小偷然后遭到威胁回来的路上很害怕3\n744504 0 2、抱着试试看心态的微商\n1000 Processed\n classify content\n745000 0 武汉锦绣长江教育集团发展有限公司新动态国际英语资深市场分析师\n745001 0 微软将不参加TGS2015\n745002 0 至于花千骨独家照片几时放出\n745003 0 查处李XX驾驶豫Fxx***号机动车实施未按规定使用安全带的机动车的违法行为\n745004 0 x月xx日亚马逊的会员日结束\n1000 Processed\n classify content\n745500 0 我们学校有谁在苏州做暑假工滴\n745501 0 原已他已经把自己商业化了的僧人\n745502 1 大量出售计划外黄瓜嫁接苗,x月x号出棚,标准一叶一心,品种xx-xx,价格x.x元/棵,地址...\n745503 0 说说你饭了这么久的TFBOYS遇到过什么感人的事情或喜欢上他们改变了你什么\n745504 0 每个公众号1000到2500不等\n1000 Processed\n classify content\n746000 1 尊敬的顾客:世纪金花x月x日-x月x日,全场满xxx返xx现金券,并享x.x倍积分。四楼AC...\n746001 0 带了自己的电脑来单位以后才发现原来单位的网速这么快……有多快呢我想把我的电脑本身形容成一个路...\n746002 0 造成停放在车库里的约300辆电动车和摩托车被烧毁\n746003 0 17岁的她就登上福布斯名人榜\n746004 0 今天叫的滴滴快车放的陈升的把悲伤留给自己\n1000 Processed\n classify content\n746500 0 天灾人祸疾病面前我们都是渺小的我们无能为力\n746501 0 在腾讯开弹幕看视频发现傻逼好多\n746502 0 以下5种水不建议用来给宝宝冲奶粉\n746503 0 就觉得好帅然后到处跟人说啊啊啊辣个队长好帅后来退出了其实我也觉得挺好有更大的发展空间因为他看...\n746504 0 韩国那边的ranker过来旅游顺便参赛\n1000 Processed\n classify content\n747000 0 现在没事坐电脑前两眼一瞪还网上冲浪的就你了你个葫芦娃\n747001 0 浙江江山市公务员考试考察名单公示啦~~赶快看看有没有你的名字哈\n747002 0 呵呵哒~各种直男癌到爆的法律和政策\n747003 0 海报张贴~国内外专家们最新成果的展示\n747004 0 从梅村的无锡图书仓库到硕放\n1000 Processed\n classify content\n747500 0 5位颜值超高的小朋友自500名参赛选手中脱颖而出\n747501 0 共为xxx辆车办理了车身广告登记\n747502 0 搜狐证券频道主观上有看空、做空市场的倾向\n747503 0 以焕新的设计和配置继续巩固其领袖地位\n747504 0 不超过6000的人口以渔业为生\n1000 Processed\n classify content\n748000 0 这里的问题是:Astute作为攻击核潜艇\n748001 0 百度学术比谷歌学术都强大了\n748002 0 憨厚老实能吃苦的建筑工人\n748003 0 银行99年时已经技术性破产过了\n748004 0 杭州破获特大盗窃团伙警方提醒谨防夜盗\n1000 Processed\n classify content\n748500 0 445徘徊…详文请Click上\n748501 1 是企业的仪器美容节,为答谢新老顾客特别奉献仪器体验xx元秒杀活动,每位会员可以秒杀您最想体验...\n748502 0 江苏的事情发生在辽宁又怎样\n748503 1 龙湖做好样板工地供您参观!价格最低优惠xx%,千万不要错过这个好机会!装修要环保,在杭州首选...\n748504 0 据说苏迪罗明天就拜访苏州了o>\n1000 Processed\n classify content\n749000 0 百度搜到的几张喜欢的牛街开斋节照片\n749001 0 集团除了在本港拥有稳固的业务基础外\n749002 0 由江苏省质监局、人社厅、总工会和团省委主办的江苏省首届电梯安装维修工技能竞赛\n749003 0 关电脑关电脑一刷微博脑子一热就不想背单词了\n749004 0 微软再次确认了Win10将在7月29日免费提供给正版Win7和8\n1000 Processed\n classify content\n749500 0 灵山县人民法院行政庭的法官和书记员、法警组成的勘验小组前往灵山县某镇一处已被强制拆除的建筑工...\n749501 0 由1个树桩和70张圆圆的年轮便签纸组成\n749502 0 谈参加坦克两项赛的96A1型坦克『俞硕:中国坦克是去俄罗斯\"砸场子\"的吗\n749503 0 大家不要在抱着小金库往里杀了真想玩等大跌两三天后入场做一波最稳健\n749504 0 详情加我QQxxxxxxxxxx详细了解咨询\n1000 Processed\n classify content\n750000 0 从光鲜的VC职业重新投入到创业企业中\n750001 0 zf的不作为要让老百姓来承担结果\n750002 0 下午把家里的台式电脑xp系统升级了一下\n750003 0 深圳市民王先生报料称其单位附近的一科技公司将十辆奔驰轿车当作年终奖送给优秀员工\n750004 0 我真的不想说什么了光是看就看了好几遍经典的不能再经典\n1000 Processed\n classify content\n750500 0 但却没有给Google带来足够多的“利益”\n750501 0 韩国SINILPHARM疲劳贴\n750502 0 看着医院里穿着病号服的病人\n750503 0 在南京六合两山间的洼地中布下一套他精心设的阵法\n750504 0 为什么在伊双的COS动画里还有刷“他们是安东家的人”这样的KY存在……真的好不理解……反正统...\n1000 Processed\n classify content\n751000 0 别墅在‘阴阳’的基础上研究对立\n751001 0 国产大飞机C919首台发动机交付首架机年内下线\n751002 1 家长您好,我们是鸿蒙教育思维绘画儿童脑潜能开发,本周六上午十点免费公开课欢迎带宝宝试听!地址...\n751003 0 两发长征三号乙运载火箭搭乘同一专列从北京启程、奔赴西昌卫星发射中心执行卫星发射任务\n751004 0 已有清华大学智能机器人研发生产基地等x个由京津高校、企业投资的机器人项目\n1000 Processed\n classify content\n751500 0 學懂了FIRAC這個符合法律理據的程序去報案\n751501 0 为什么百度的汇率和国外更新的汇率有差异\n751502 0 上海宝原物业顾问有限公司为了招聘人才专门准备了这个页面\n751503 0 我正在看我创建了一个苏山炮金矿\n751504 0 拱墅区自己的“哆啦A梦”、区检察院未检“蓝胖纸”今年六一也诞生了\n1000 Processed\n classify content\n752000 0 从小虎团队到Ytiger再到成立杜润公司\n752001 0 第二大理由:多彩生活\n752002 0 我的音乐新看法就在腾讯视频LiveMusic\n752003 0 4、小超市屡遭“外国黑手”盗窃\n752004 0 我领土改开以来被侵占多少领土\n1000 Processed\n classify content\n752500 0 并通过手机App来启动SOS模式\n752501 0 好公司好股票会慢慢走独立行情\n752502 0 诃额伦派出所共组织七批平安志愿者1000余人进行涉恐涉暴\n752503 0 好声音“一起摇摆”哈林唱出了他才是原唱的感觉\n752504 1 xxxxxxxxxxxxxxxxxxx蒋中卫农行卡。\n1000 Processed\n classify content\n753000 1 三月促销——幻活新生 时光礼遇 一、单张订单购买任意幻时或幻时佳产品每满xxxx元,即可免费...\n753001 0 关闭小煤矿、查处油气管道、重大事故调查——安全监管总局回应热点问题\n753002 0 对于王丹丹现在的资产问题我觉得警方有必要去调查一下了还有她知道高嘉泽父亲长相的问题杀人偿命死刑\n753003 0 女星潜规则:千万不能和范冰冰合照\n753004 0 G15w常台高速苏州段由于施工\n1000 Processed\n classify content\n753500 0 白子画已经选择了面对花千骨\n753501 0 我走遍蚌埠市、宿迁市的4个区域\n753502 0 xxxx年中国外贸xxx强城市排名如图\n753503 0 中共隐瞒了南京大屠杀长达几十年\n753504 0 后面的炮兵、坦克兵、侦察兵篇不想看了怎么办\n1000 Processed\n classify content\n754000 0 不顾一切用还没有打磨成熟的新技术\n754001 0 浙江卫视十二道锋味在黄山做臭鳜鱼呢\n754002 0 广东以142家排在第二…北京以83位居第五\n754003 1 进【xxxxx、CxM】佰/加/热。体-育!竞噻等等……顶级信誉!多平台玩法、立即上天成*国...\n754004 0 川崎玫瑰也和欧美玫瑰的相似度很高\n1000 Processed\n classify content\n754500 0 不用质疑用了就会感激自己当初的选择\n754501 0 友阿股份控股股东拟斥资5000万元增持\n754502 0 我带着你/你带着旺旺电脑也好手机也罢横穿接待大厅暴走做单房间让我们做一个说干就干的刷手\n754503 0 想起ever17哪儿都能看到的一句话:不要过度推理\n754504 1 春城人人品海鲜,喜气洋洋贺新年。即日起提前预定年夜饭可获赠兑币,千种礼物任您选!详询本机。美...\n1000 Processed\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code"
]
]
|
d06207fa0f559b3ebc86802bd9160f20e280b273 | 88,828 | ipynb | Jupyter Notebook | Models/CNN_best.ipynb | DataMas/Deep-Learning-Image-Classification | 88916064a041ba1e8f3b0c397226710c1c9058fa | [
"MIT"
]
| 1 | 2021-04-14T18:50:50.000Z | 2021-04-14T18:50:50.000Z | Models/CNN_best.ipynb | DataMas/Deep-Learning-Image-Classification | 88916064a041ba1e8f3b0c397226710c1c9058fa | [
"MIT"
]
| null | null | null | Models/CNN_best.ipynb | DataMas/Deep-Learning-Image-Classification | 88916064a041ba1e8f3b0c397226710c1c9058fa | [
"MIT"
]
| null | null | null | 115.812256 | 24,292 | 0.82957 | [
[
[
"# Mount google drive to colab",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount(\"/content/drive\")",
"Mounted at /content/drive\n"
]
],
[
[
"# Import libraries",
"_____no_output_____"
]
],
[
[
"import os\nimport random \nimport numpy as np\nimport shutil\nimport time \nfrom PIL import Image, ImageOps\nimport cv2\nimport pandas as pd\nimport math\n\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set_style('darkgrid')\n\nimport tensorflow as tf\n\nfrom keras import models\nfrom keras import layers\nfrom keras import optimizers\nfrom keras.callbacks import EarlyStopping\nfrom keras.callbacks import ModelCheckpoint\nfrom keras.callbacks import LearningRateScheduler\nfrom keras.utils import np_utils\n\n\nfrom sklearn.metrics import confusion_matrix, classification_report\nfrom sklearn.preprocessing import LabelBinarizer\nfrom sklearn.preprocessing import MinMaxScaler\nfrom keras.preprocessing.image import ImageDataGenerator\n\nfrom keras import models, layers, optimizers\nfrom keras.callbacks import ModelCheckpoint\nfrom keras import losses",
"_____no_output_____"
]
],
[
[
"# Initialize basic working directories",
"_____no_output_____"
]
],
[
[
"directory = \"drive/MyDrive/Datasets/Sign digits/Dataset\"\ntrainDir = \"train\"\ntestDir = \"test\"\nos.chdir(directory)",
"_____no_output_____"
]
],
[
[
"# Augmented dataframes",
"_____no_output_____"
]
],
[
[
"augDir = \"augmented/\"\nclassNames_train = os.listdir(augDir+'train/')\nclassNames_test = os.listdir(augDir+'test/')\n\n\nclasses_train = []\ndata_train = []\npaths_train = []\n\nclasses_test = []\ndata_test = []\npaths_test = []\n\nclasses_val = []\ndata_val = []\npaths_val = []\n\nfor className in range(0,10):\n temp_train = os.listdir(augDir+'train/'+str(className))\n temp_test = os.listdir(augDir+'test/'+str(className))\n\n for dataFile in temp_train:\n path_train = augDir+'train/'+str(className)+'/'+dataFile\n\n paths_train.append(path_train)\n classes_train .append(str(className))\n \n testSize = [i for i in range(math.floor(len(temp_test)/2),len(temp_test))]\n valSize = [i for i in range(0,math.floor(len(temp_test)/2))]\n for dataFile in testSize:\n path_test = augDir+'test/'+str(className)+'/'+temp_test[dataFile]\n\n paths_test.append(path_test)\n classes_test .append(str(className))\n\n for dataFile in valSize:\n path_val = augDir+'test/'+str(className)+'/'+temp_test[dataFile]\n\n paths_val.append(path_val)\n classes_val .append(str(className))\n\n \naugTrain_df = pd.DataFrame({'fileNames': paths_train, 'labels': classes_train})\naugTest_df = pd.DataFrame({'fileNames': paths_test, 'labels': classes_test})\naugVal_df = pd.DataFrame({'fileNames': paths_val, 'labels': classes_val})",
"_____no_output_____"
],
[
"augTrain_df.head(10)",
"_____no_output_____"
],
[
"augTrain_df['labels'].hist(figsize=(10,5))\naugTest_df['labels'].hist(figsize=(10,5))",
"_____no_output_____"
],
[
"augTest_df['labels'].hist(figsize=(10,5))\naugVal_df['labels'].hist(figsize=(10,5))",
"_____no_output_____"
],
[
"augTrainX=[]\naugTrainY=[]\naugTestX=[]\naugTestY=[]\naugValX=[]\naugValY=[]\n\niter = -1\n\n#read images from train set\nfor path in augTrain_df['fileNames']:\n iter = iter + 1\n #image = np.array((Image.open(path)))\n image = cv2.imread(path)\n augTrainX.append(image)\n label = augTrain_df['labels'][iter]\n augTrainY.append(label)\n\niter = -1\n\nfor path in augTest_df['fileNames']:\n iter = iter + 1\n #image = np.array((Image.open(path)))\n image = cv2.imread(path)\n augTestX.append(image)\n augTestY.append(augTest_df['labels'][iter])\n\niter = -1\n\nfor path in augVal_df['fileNames']:\n iter = iter + 1\n #image = np.array((Image.open(path)))\n image = cv2.imread(path)\n augValX.append(image)\n augValY.append(augVal_df['labels'][iter])\n\naugTrainX = np.array(augTrainX)\naugTestX = np.array(augTestX)\naugValX = np.array(augValX)\n\n \naugTrainX = augTrainX / 255\naugTestX = augTestX / 255\naugValX = augValX / 255\n# OneHot Encode the Output\naugTrainY = np_utils.to_categorical(augTrainY, 10)\naugTestY = np_utils.to_categorical(augTestY, 10)\naugValY = np_utils.to_categorical(augValY, 10)",
"/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:37: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray\n/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:39: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray\n"
],
[
"train_datagen = ImageDataGenerator(rescale=1./255)\nvalidation_datagen = ImageDataGenerator(rescale=1./255)\ntest_datagen = ImageDataGenerator(rescale=1./255)\n\ntrain_generator = train_datagen.flow_from_dataframe(dataframe=augTrain_df,\n x_col=\"fileNames\",\n y_col=\"labels\",\n batch_size=16,\n class_mode=\"categorical\",\n color_mode=\"grayscale\",\n target_size=(100,100),\n shuffle=True)\n\nvalidation_generator = validation_datagen.flow_from_dataframe(dataframe=augVal_df,\n x_col=\"fileNames\",\n y_col=\"labels\",\n batch_size=16,\n class_mode=\"categorical\",\n color_mode=\"grayscale\",\n target_size=(100,100),\n shuffle=True)\n\ntest_generator = test_datagen.flow_from_dataframe(dataframe=augTest_df,\n x_col=\"fileNames\",\n y_col=\"labels\",\n batch_size=16,\n class_mode=\"categorical\",\n color_mode=\"grayscale\",\n target_size=(100,100),\n shuffle=True)",
"Found 3124 validated image filenames belonging to 10 classes.\nFound 252 validated image filenames belonging to 10 classes.\nFound 252 validated image filenames belonging to 10 classes.\n"
],
[
"model_best = models.Sequential()\n\nmodel_best.add(layers.Conv2D(64, (3,3), input_shape=(100, 100,1), padding='same', activation='relu'))\nmodel_best.add(layers.BatchNormalization(momentum=0.1))\nmodel_best.add(layers.MaxPooling2D(pool_size=(2,2)))\nmodel_best.add(layers.Conv2D(32, (3,3), padding='same', activation='relu'))\nmodel_best.add(layers.BatchNormalization(momentum=0.1))\nmodel_best.add(layers.MaxPooling2D(pool_size=(2,2)))\nmodel_best.add(layers.Conv2D(16, (3,3), padding='same', activation='relu'))\nmodel_best.add(layers.BatchNormalization(momentum=0.1))\nmodel_best.add(layers.MaxPooling2D(pool_size=(2,2)))\nmodel_best.add(layers.Flatten())\nmodel_best.add(layers.Dense(128, activation='relu'))\nmodel_best.add(layers.Dropout(0.2))\nmodel_best.add(layers.Dense(10, activation='softmax'))\n\nmodel_best.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d (Conv2D) (None, 100, 100, 64) 640 \n_________________________________________________________________\nbatch_normalization (BatchNo (None, 100, 100, 64) 256 \n_________________________________________________________________\nmax_pooling2d (MaxPooling2D) (None, 50, 50, 64) 0 \n_________________________________________________________________\nconv2d_1 (Conv2D) (None, 50, 50, 32) 18464 \n_________________________________________________________________\nbatch_normalization_1 (Batch (None, 50, 50, 32) 128 \n_________________________________________________________________\nmax_pooling2d_1 (MaxPooling2 (None, 25, 25, 32) 0 \n_________________________________________________________________\nconv2d_2 (Conv2D) (None, 25, 25, 16) 4624 \n_________________________________________________________________\nbatch_normalization_2 (Batch (None, 25, 25, 16) 64 \n_________________________________________________________________\nmax_pooling2d_2 (MaxPooling2 (None, 12, 12, 16) 0 \n_________________________________________________________________\nflatten (Flatten) (None, 2304) 0 \n_________________________________________________________________\ndense (Dense) (None, 128) 295040 \n_________________________________________________________________\ndropout (Dropout) (None, 128) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 10) 1290 \n=================================================================\nTotal params: 320,506\nTrainable params: 320,282\nNon-trainable params: 224\n_________________________________________________________________\n"
],
[
"print(\"[INFO] Model is training...\")\ntime1 = time.time() # to measure time taken\n# Compile the model\nmodel_best.compile(loss='categorical_crossentropy',\n optimizer=optimizers.Adam(learning_rate=1e-3),\n metrics=['acc'])\n\nhistory_best = model_best.fit(\n train_generator,\n steps_per_epoch=train_generator.samples/train_generator.batch_size ,\n epochs=20,\n validation_data=validation_generator,\n validation_steps=validation_generator.samples/validation_generator.batch_size,\n)\nprint('Time taken: {:.1f} seconds'.format(time.time() - time1)) # to measure time taken\nprint(\"[INFO] Model is trained.\")",
"[INFO] Model is training...\nEpoch 1/20\n195/195 [==============================] - 87s 443ms/step - loss: 1.5492 - acc: 0.5419 - val_loss: 0.4457 - val_acc: 0.8373\nEpoch 2/20\n195/195 [==============================] - 86s 439ms/step - loss: 0.3078 - acc: 0.8933 - val_loss: 0.2915 - val_acc: 0.9087\nEpoch 3/20\n195/195 [==============================] - 85s 436ms/step - loss: 0.1132 - acc: 0.9614 - val_loss: 0.3068 - val_acc: 0.8968\nEpoch 4/20\n195/195 [==============================] - 86s 440ms/step - loss: 0.0780 - acc: 0.9808 - val_loss: 0.2856 - val_acc: 0.9246\nEpoch 5/20\n195/195 [==============================] - 86s 438ms/step - loss: 0.0408 - acc: 0.9869 - val_loss: 0.2254 - val_acc: 0.9444\nEpoch 6/20\n195/195 [==============================] - 86s 439ms/step - loss: 0.0308 - acc: 0.9909 - val_loss: 0.3072 - val_acc: 0.9286\nEpoch 7/20\n195/195 [==============================] - 85s 437ms/step - loss: 0.0409 - acc: 0.9857 - val_loss: 0.2902 - val_acc: 0.9246\nEpoch 8/20\n195/195 [==============================] - 85s 437ms/step - loss: 0.0526 - acc: 0.9827 - val_loss: 0.3072 - val_acc: 0.9206\nEpoch 9/20\n195/195 [==============================] - 86s 438ms/step - loss: 0.0241 - acc: 0.9896 - val_loss: 0.3179 - val_acc: 0.9127\nEpoch 10/20\n195/195 [==============================] - 85s 436ms/step - loss: 0.0223 - acc: 0.9945 - val_loss: 0.2930 - val_acc: 0.9405\nEpoch 11/20\n195/195 [==============================] - 86s 438ms/step - loss: 0.0151 - acc: 0.9952 - val_loss: 0.2063 - val_acc: 0.9444\nEpoch 12/20\n195/195 [==============================] - 86s 439ms/step - loss: 0.0185 - acc: 0.9940 - val_loss: 0.2123 - val_acc: 0.9563\nEpoch 13/20\n195/195 [==============================] - 86s 438ms/step - loss: 0.0434 - acc: 0.9863 - val_loss: 0.3235 - val_acc: 0.9484\nEpoch 14/20\n195/195 [==============================] - 85s 438ms/step - loss: 0.0478 - acc: 0.9856 - val_loss: 0.3105 - val_acc: 0.9365\nEpoch 15/20\n195/195 [==============================] - 86s 440ms/step - loss: 0.0110 - acc: 0.9966 - val_loss: 0.2986 - val_acc: 0.9405\nEpoch 16/20\n195/195 [==============================] - 86s 440ms/step - loss: 0.0169 - acc: 0.9932 - val_loss: 0.4730 - val_acc: 0.9286\nEpoch 17/20\n195/195 [==============================] - 85s 436ms/step - loss: 0.0693 - acc: 0.9743 - val_loss: 0.2832 - val_acc: 0.9405\nEpoch 18/20\n195/195 [==============================] - 85s 437ms/step - loss: 0.0265 - acc: 0.9925 - val_loss: 0.2911 - val_acc: 0.9365\nEpoch 19/20\n195/195 [==============================] - 86s 438ms/step - loss: 0.0233 - acc: 0.9920 - val_loss: 0.2732 - val_acc: 0.9524\nEpoch 20/20\n195/195 [==============================] - 85s 435ms/step - loss: 0.0167 - acc: 0.9940 - val_loss: 0.2515 - val_acc: 0.9603\nTime taken: 1713.1 seconds\n[INFO] Model is trained.\n"
],
[
"score = model_best.evaluate(test_generator)\n\nprint('===Testing loss and accuracy===')\nprint('Test loss: ', score[0])\nprint('Test accuracy: ', score[1])",
"16/16 [==============================] - 2s 111ms/step - loss: 0.4789 - acc: 0.9405\n===Testing loss and accuracy===\nTest loss: 0.47893190383911133\nTest accuracy: 0.9404761791229248\n"
],
[
"import matplotlib.pyplot as plot\nplot.plot(history_best.history['acc'])\nplot.plot(history_best.history['val_acc'])\nplot.title('Model accuracy')\nplot.ylabel('Accuracy')\nplot.xlabel('Epoch')\nplot.legend(['Train', 'Vall'], loc='upper left')\nplot.show()\n\nplot.plot(history_best.history['loss'])\nplot.plot(history_best.history['val_loss'])\nplot.title('Model loss')\nplot.ylabel('Loss')\nplot.xlabel('Epoch')\nplot.legend(['Train', 'Vall'], loc='upper left')\nplot.show()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d0621f6db1f8301e02bf44fe950e88798ea5aeb7 | 538,383 | ipynb | Jupyter Notebook | HW_exam/.ipynb_checkpoints/Exam_Prazdnichnykh-checkpoint.ipynb | AntonPrazdnichnykh/HSE.optimization | ca844bb041c614e0de95cab6de87db340323e59d | [
"Apache-2.0"
]
| null | null | null | HW_exam/.ipynb_checkpoints/Exam_Prazdnichnykh-checkpoint.ipynb | AntonPrazdnichnykh/HSE.optimization | ca844bb041c614e0de95cab6de87db340323e59d | [
"Apache-2.0"
]
| null | null | null | HW_exam/.ipynb_checkpoints/Exam_Prazdnichnykh-checkpoint.ipynb | AntonPrazdnichnykh/HSE.optimization | ca844bb041c614e0de95cab6de87db340323e59d | [
"Apache-2.0"
]
| null | null | null | 740.554333 | 25,460 | 0.954436 | [
[
[
"import numpy as np\nimport scipy.sparse as sp\nfrom sklearn.datasets import load_svmlight_file\nfrom oracle import Oracle, make_oracle\nimport scipy as sc\nfrom methods import OptimizeLassoProximal, OptimizeGD, NesterovLineSearch\nimport matplotlib.pyplot as plt\nfrom sklearn import linear_model",
"_____no_output_____"
]
],
[
[
"Решаем задачу логистической регрессии и l1-регуляризацией:\n$$F(w) = - \\frac{1}{N}\\sum\\limits_{i=1}^Ny_i\\ln(\\sigma_w(x_i)) + (1 - y_i)\\ln(1 - \\sigma_w(x_i)) + \\lambda\\|w\\|_1,$$\nгде $\\lambda$ -- параметр регуляризации.\n\nЗадачу решаем проксимальным градиентным методом. Убедимся сначала, что при $\\lambda = 0$ наше решение совпадает с решением метода градиентного спуска с оценкой длины шага методом Нестерова.",
"_____no_output_____"
]
],
[
[
"orac = make_oracle('a1a.txt', penalty='l1', reg=0)\norac1 = make_oracle('a1a.txt')\nx, y = load_svmlight_file('a1a.txt', zero_based=False)\nm = x[0].shape[1] + 1\nw0 = np.zeros((m, 1))\noptimizer = OptimizeLassoProximal()\noptimizer1 = OptimizeGD()\npoint = optimizer(orac, w0)\npoint1 = optimizer1(orac1, w0, NesterovLineSearch())\n\nnp.allclose(point, point1)",
"_____no_output_____"
]
],
[
[
"Изучим скорость сходимости метода на датасете a1a.txt ($\\lambda = 0.001$)",
"_____no_output_____"
]
],
[
[
"def convergence_plot(xs, ys, xlabel, title=None):\n plt.figure(figsize = (12, 3))\n plt.xlabel(xlabel)\n plt.ylabel('F(w_{k+1} - F(w_k)')\n plt.plot(xs, ys)\n plt.yscale('log')\n if title:\n plt.title(title)\n plt.tight_layout()\n plt.show()\n ",
"_____no_output_____"
],
[
"orac = make_oracle('a1a.txt', penalty='l1', reg=0.001)\npoint = optimizer(orac, w0)",
"_____no_output_____"
],
[
"errs = optimizer.errs\ntitle = 'lambda = 0.001'\nconvergence_plot(optimizer.times, errs, 'вермя работы, с', title)\nconvergence_plot(optimizer.orac_calls, errs, 'кол-во вызовов оракула', title)\nconvergence_plot(list(range(1, optimizer.n_iter + 1)), errs, 'кол-во итераций', title)",
"_____no_output_____"
]
],
[
[
"Заметим, что было использовано условие остановки $F(w_{k+1}) - F(w_k) \\leq tol = 10^{-16}$. Из математических соображений кажется, что это ок, так как в вещественных числах сходимость последовательности равносильна её фундаментальности. Я также пытался использовать в качестве условия остановки $\\|\\nabla_w f(w_k)\\|_2^2 / \\|\\nabla_w f(w_0)\\|_2^2 <= tol$, где $f$ -- лосс логистической регрессии без регуляризации ($F = f + reg$), но, вообще говоря, не очень понятно, можно ли так делать, потому что оно учитывает только часть функции.\n\nИз графиков видно, что метод обладает линейной скоростью сходимости",
"_____no_output_____"
],
[
"Изучим теперь зависимость скорости сходимости и количества ненулевых компонент в решении от параметра регуляризации $\\lambda$",
"_____no_output_____"
]
],
[
[
"def plot(x, ys, ylabel, legend=False): \n plt.figure(figsize = (12, 3))\n plt.xlabel(\"lambda\")\n plt.ylabel(ylabel)\n plt.plot(x, ys, 'o')\n plt.xscale('log')\n if legend:\n plt.legend()\n plt.tight_layout()\n plt.show()",
"_____no_output_____"
],
[
"lambdas = [10**(-i) for i in range(8, 0, -1)]\nnon_zeros = []\nfor reg in lambdas:\n orac = make_oracle('a1a.txt', penalty='l1', reg=reg)\n point = optimizer(orac, w0)\n convergence_plot(list(range(1, optimizer.n_iter + 1)), optimizer.errs, 'кол-во итераций',\n f\"lambda = {reg}\")\n non_zeros.append(len(np.nonzero(point)[0]))\nplot(lambdas, non_zeros, '# nonzero components')",
"_____no_output_____"
]
],
[
[
"Видно, что параметр регуляризации практически не влияет на скорость сходимости (она всегда линейная), но количество итераций метода падает с увеличением параметра регуляризации. Так же из последнего графика делаем ожидаемый вывод, что число ненулевых компонент в решении уменьшается с ростом параметра регуляризации",
"_____no_output_____"
],
[
"Построим еще графики зависимости значения оптимизируемой функции и критерия остновки (ещё разок) в зависимости от итерации ($\\lambda = 0.001$)",
"_____no_output_____"
]
],
[
[
"def value_plot(xs, ys, xlabel, title=None):\n plt.figure(figsize = (12, 3))\n plt.xlabel(xlabel)\n plt.ylabel('F(w_k)')\n plt.plot(xs, ys)\n# plt.yscale('log')\n if title:\n plt.title(title)\n plt.tight_layout()\n plt.show()",
"_____no_output_____"
],
[
"orac = make_oracle('a1a.txt', penalty='l1', reg=0.001)\npoint = optimizer(orac, w0)\ntitle = 'lambda = 0.001'\nvalue_plot(list(range(1, optimizer.n_iter + 1)), optimizer.values, 'кол-во итераций', title)\nconvergence_plot(list(range(1, optimizer.n_iter + 1)), optimizer.errs, 'кол-во итераций', title)",
"_____no_output_____"
]
],
[
[
"Для подтверждения сделаных выводов проверим их ещё на breast-cancer_scale датасете.",
"_____no_output_____"
],
[
"Проверка равносильности GD + Nesterov и Proximal + $\\lambda = 0$:",
"_____no_output_____"
]
],
[
[
"orac = make_oracle('breast-cancer_scale.txt', penalty='l1', reg=0)\norac1 = make_oracle('breast-cancer_scale.txt')\nx, y = load_svmlight_file('breast-cancer_scale.txt', zero_based=False)\nm = x[0].shape[1] + 1\nw0 = np.zeros((m, 1))\noptimizer = OptimizeLassoProximal()\noptimizer1 = OptimizeGD()\npoint = optimizer(orac, w0)\npoint1 = optimizer1(orac1, w0, NesterovLineSearch())\n\nnp.allclose(point, point1)",
"_____no_output_____"
],
[
"print(abs(orac.value(point) - orac1.value(point1)))",
"0.0001461093710795336\n"
]
],
[
[
"Сами вектора весов не совпали, но значения оптимизируемой функции близки, так что будем считать, что все ок.",
"_____no_output_____"
],
[
"Изучаем скорость сходимости для $\\lambda = 0.001$:",
"_____no_output_____"
]
],
[
[
"orac = make_oracle('breast-cancer_scale.txt', penalty='l1', reg=0.001)\npoint = optimizer(orac, w0)\nerrs = optimizer.errs\ntitle = 'lambda = 0.001'\nconvergence_plot(optimizer.times, errs, 'вермя работы, с', title)\nconvergence_plot(optimizer.orac_calls, errs, 'кол-во вызовов оракула', title)\nconvergence_plot(list(range(1, optimizer.n_iter + 1)), errs, 'кол-во итераций', title)",
"_____no_output_____"
]
],
[
[
"Кажется, что скорость сходимости опять линейная",
"_____no_output_____"
],
[
"Изучаем зависимость скорости сходимости и количества ненулевых компонент в решении от $\\lambda$",
"_____no_output_____"
]
],
[
[
"lambdas = [10**(-i) for i in range(8, 0, -1)]\nnon_zeros = []\nfor reg in lambdas:\n orac = make_oracle('breast-cancer_scale.txt', penalty='l1', reg=reg)\n point = optimizer(orac, w0)\n convergence_plot(list(range(1, optimizer.n_iter + 1)), optimizer.errs, 'кол-во итераций',\n f\"lambda = {reg}\")\n non_zeros.append(len(np.nonzero(point)[0]))\nplot(lambdas, non_zeros, '# nonzero components')",
"_____no_output_____"
]
],
[
[
"Делаем те же выводы",
"_____no_output_____"
],
[
"Построим напоследок грфики для значений оптимизируемой функции и критерия остановки (ещё разок) в зависимости от итерации ($\\lambda = 0.001$)",
"_____no_output_____"
]
],
[
[
"orac = make_oracle('breast-cancer_scale.txt', penalty='l1', reg=0.001)\npoint = optimizer(orac, w0)\ntitle = 'lambda = 0.001'\nvalue_plot(list(range(1, optimizer.n_iter + 1)), optimizer.values, 'кол-во итераций', title)\nconvergence_plot(list(range(1, optimizer.n_iter + 1)), optimizer.errs, 'кол-во итераций', title)",
"_____no_output_____"
]
],
[
[
"Конец.",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
d06224770637f53d41cec6b94186b3ae72820478 | 250,590 | ipynb | Jupyter Notebook | sngp_with_bert_aws.ipynb | tejashrigadre/Anomaly-detection-for-chat-bots | 7cac681983bc435953d472a3d2f91bcbe4bc756f | [
"MIT"
]
| null | null | null | sngp_with_bert_aws.ipynb | tejashrigadre/Anomaly-detection-for-chat-bots | 7cac681983bc435953d472a3d2f91bcbe4bc756f | [
"MIT"
]
| null | null | null | sngp_with_bert_aws.ipynb | tejashrigadre/Anomaly-detection-for-chat-bots | 7cac681983bc435953d472a3d2f91bcbe4bc756f | [
"MIT"
]
| null | null | null | 192.317728 | 51,284 | 0.88982 | [
[
[
"## Implementing BERT with SNGP",
"_____no_output_____"
]
],
[
[
"!pip install tensorflow_text==2.7.3",
"Collecting tensorflow_text==2.7.3\n Using cached tensorflow_text-2.7.3-cp38-cp38-manylinux2010_x86_64.whl (4.9 MB)\nCollecting tensorflow-hub>=0.8.0\n Using cached tensorflow_hub-0.12.0-py2.py3-none-any.whl (108 kB)\nCollecting tensorflow<2.8,>=2.7.0\n Using cached tensorflow-2.7.1-cp38-cp38-manylinux2010_x86_64.whl (495.1 MB)\nCollecting tensorflow-estimator<2.8,~=2.7.0rc0\n Using cached tensorflow_estimator-2.7.0-py2.py3-none-any.whl (463 kB)\nRequirement already satisfied: six>=1.12.0 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.16.0)\nCollecting libclang>=9.0.1\n Using cached libclang-13.0.0-py2.py3-none-manylinux1_x86_64.whl (14.5 MB)\nRequirement already satisfied: flatbuffers<3.0,>=1.12 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.12)\nCollecting keras<2.8,>=2.7.0rc0\n Using cached keras-2.7.0-py2.py3-none-any.whl (1.3 MB)\nRequirement already satisfied: wheel<1.0,>=0.32.0 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (0.37.0)\nRequirement already satisfied: gast<0.5.0,>=0.2.1 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (0.4.0)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (3.19.1)\nRequirement already satisfied: wrapt>=1.11.0 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.12.1)\nRequirement already satisfied: astunparse>=1.6.0 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.6.3)\nRequirement already satisfied: google-pasta>=0.1.1 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (0.2.0)\nRequirement already satisfied: grpcio<2.0,>=1.24.3 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.42.0)\nRequirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (3.3.0)\nRequirement already satisfied: numpy>=1.14.5 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.19.5)\nRequirement already satisfied: termcolor>=1.1.0 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.1.0)\nRequirement already satisfied: typing-extensions>=3.6.6 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (3.7.4.3)\nRequirement already satisfied: tensorboard~=2.6 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (2.6.0)\nRequirement already satisfied: keras-preprocessing>=1.1.1 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.1.2)\nRequirement already satisfied: h5py>=2.9.0 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (3.1.0)\nRequirement already satisfied: tensorflow-io-gcs-filesystem>=0.21.0 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (0.21.0)\nRequirement already satisfied: absl-py>=0.4.0 in /usr/local/lib/python3.8/site-packages (from tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (0.10.0)\nRequirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (59.5.0)\nRequirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.35.0)\nRequirement already satisfied: tensorboard-data-server<0.7.0,>=0.6.0 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (0.6.1)\nRequirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.8.0)\nRequirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (2.0.2)\nRequirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (0.4.6)\nRequirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (3.3.6)\nRequirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (2.25.1)\nRequirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.8/site-packages (from google-auth<2,>=1.6.3->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (0.2.8)\nRequirement already satisfied: cachetools<5.0,>=2.0.0 in /usr/local/lib/python3.8/site-packages (from google-auth<2,>=1.6.3->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (4.2.4)\nRequirement already satisfied: rsa<5,>=3.1.4 in /usr/local/lib/python3.8/site-packages (from google-auth<2,>=1.6.3->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (4.7.2)\nRequirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.8/site-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.3.0)\nRequirement already satisfied: importlib-metadata>=4.4 in /usr/local/lib/python3.8/site-packages (from markdown>=2.6.8->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (4.8.2)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.8/site-packages (from requests<3,>=2.21.0->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (2.10)\nRequirement already satisfied: chardet<5,>=3.0.2 in /usr/local/lib/python3.8/site-packages (from requests<3,>=2.21.0->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (4.0.0)\nRequirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.8/site-packages (from requests<3,>=2.21.0->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (1.26.7)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.8/site-packages (from requests<3,>=2.21.0->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (2021.10.8)\nRequirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.8/site-packages (from importlib-metadata>=4.4->markdown>=2.6.8->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (3.6.0)\nRequirement already satisfied: pyasn1<0.5.0,>=0.4.6 in /usr/local/lib/python3.8/site-packages (from pyasn1-modules>=0.2.1->google-auth<2,>=1.6.3->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (0.4.8)\nRequirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.8/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard~=2.6->tensorflow<2.8,>=2.7.0->tensorflow_text==2.7.3) (3.1.1)\nInstalling collected packages: tensorflow-estimator, libclang, keras, tensorflow-hub, tensorflow, tensorflow-text\n Attempting uninstall: tensorflow-estimator\n Found existing installation: tensorflow-estimator 2.6.0\n Uninstalling tensorflow-estimator-2.6.0:\n Successfully uninstalled tensorflow-estimator-2.6.0\n Attempting uninstall: keras\n Found existing installation: keras 2.6.0\n Uninstalling keras-2.6.0:\n Successfully uninstalled keras-2.6.0\n Attempting uninstall: tensorflow\n Found existing installation: tensorflow 2.6.2\n Uninstalling tensorflow-2.6.2:\n Successfully uninstalled tensorflow-2.6.2\n\u001b[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\ntensorflow-io 0.21.0 requires tensorflow<2.7.0,>=2.6.0, but you have tensorflow 2.7.1 which is incompatible.\u001b[0m\nSuccessfully installed keras-2.7.0 libclang-13.0.0 tensorflow-2.7.1 tensorflow-estimator-2.7.0 tensorflow-hub-0.12.0 tensorflow-text-2.7.3\n\u001b[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\n\u001b[33mWARNING: You are using pip version 21.3.1; however, version 22.0.3 is available.\nYou should consider upgrading via the '/usr/local/bin/python3.8 -m pip install --upgrade pip' command.\u001b[0m\n"
],
[
"!pip install -U tf-models-official==2.7.0",
"Collecting tf-models-official==2.7.0\n Using cached tf_models_official-2.7.0-py2.py3-none-any.whl (1.8 MB)\nRequirement already satisfied: tensorflow-text>=2.7.0 in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (2.7.3)\nRequirement already satisfied: Pillow in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (8.3.2)\nRequirement already satisfied: matplotlib in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (3.5.0)\nCollecting pycocotools\n Using cached pycocotools-2.0.4-cp38-cp38-linux_x86_64.whl\nCollecting oauth2client\n Using cached oauth2client-4.1.3-py2.py3-none-any.whl (98 kB)\nCollecting google-api-python-client>=1.6.7\n Using cached google_api_python_client-2.37.0-py2.py3-none-any.whl (8.1 MB)\nCollecting seqeval\n Using cached seqeval-1.2.2-py3-none-any.whl\nCollecting Cython\n Using cached Cython-0.29.28-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.manylinux_2_24_x86_64.whl (1.9 MB)\nCollecting sentencepiece\n Using cached sentencepiece-0.1.96-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.2 MB)\nCollecting tensorflow-datasets\n Using cached tensorflow_datasets-4.5.2-py3-none-any.whl (4.2 MB)\nCollecting tensorflow-addons\n Using cached tensorflow_addons-0.16.1-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (1.1 MB)\nRequirement already satisfied: psutil>=5.4.3 in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (5.8.0)\nCollecting tensorflow-model-optimization>=0.4.1\n Using cached tensorflow_model_optimization-0.7.1-py2.py3-none-any.whl (234 kB)\nCollecting sacrebleu\n Using cached sacrebleu-2.0.0-py3-none-any.whl (90 kB)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (1.19.5)\nRequirement already satisfied: tensorflow-hub>=0.6.0 in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (0.12.0)\nCollecting py-cpuinfo>=3.3.0\n Using cached py_cpuinfo-8.0.0-py3-none-any.whl\nCollecting kaggle>=1.3.9\n Using cached kaggle-1.5.12-py3-none-any.whl\nRequirement already satisfied: scipy>=0.19.1 in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (1.7.0)\nCollecting gin-config\n Using cached gin_config-0.5.0-py3-none-any.whl (61 kB)\nCollecting tf-slim>=1.1.0\n Using cached tf_slim-1.1.0-py2.py3-none-any.whl (352 kB)\nRequirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (5.4.1)\nRequirement already satisfied: tensorflow>=2.7.0 in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (2.7.1)\nRequirement already satisfied: six in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (1.16.0)\nCollecting opencv-python-headless\n Using cached opencv_python_headless-4.5.5.62-cp36-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (47.7 MB)\nRequirement already satisfied: pandas>=0.22.0 in /usr/local/lib/python3.8/site-packages (from tf-models-official==2.7.0) (1.2.5)\nCollecting httplib2<1dev,>=0.15.0\n Using cached httplib2-0.20.4-py3-none-any.whl (96 kB)\nCollecting uritemplate<5,>=3.0.1\n Using cached uritemplate-4.1.1-py2.py3-none-any.whl (10 kB)\nRequirement already satisfied: google-auth<3.0.0dev,>=1.16.0 in /usr/local/lib/python3.8/site-packages (from google-api-python-client>=1.6.7->tf-models-official==2.7.0) (1.35.0)\nCollecting google-auth-httplib2>=0.1.0\n Using cached google_auth_httplib2-0.1.0-py2.py3-none-any.whl (9.3 kB)\nCollecting google-api-core<3.0.0dev,>=1.21.0\n Using cached google_api_core-2.5.0-py2.py3-none-any.whl (111 kB)\nRequirement already satisfied: python-dateutil in /usr/local/lib/python3.8/site-packages (from kaggle>=1.3.9->tf-models-official==2.7.0) (2.8.2)\nRequirement already satisfied: tqdm in /usr/local/lib/python3.8/site-packages (from kaggle>=1.3.9->tf-models-official==2.7.0) (4.62.3)\nRequirement already satisfied: certifi in /usr/local/lib/python3.8/site-packages (from kaggle>=1.3.9->tf-models-official==2.7.0) (2021.10.8)\nRequirement already satisfied: urllib3 in /usr/local/lib/python3.8/site-packages (from kaggle>=1.3.9->tf-models-official==2.7.0) (1.26.7)\nCollecting python-slugify\n Using cached python_slugify-6.0.1-py2.py3-none-any.whl (9.0 kB)\nRequirement already satisfied: requests in /usr/local/lib/python3.8/site-packages (from kaggle>=1.3.9->tf-models-official==2.7.0) (2.25.1)\nRequirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.8/site-packages (from pandas>=0.22.0->tf-models-official==2.7.0) (2021.3)\nRequirement already satisfied: termcolor>=1.1.0 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (1.1.0)\nRequirement already satisfied: h5py>=2.9.0 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (3.1.0)\nRequirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (3.3.0)\nRequirement already satisfied: wheel<1.0,>=0.32.0 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (0.37.0)\nRequirement already satisfied: tensorflow-io-gcs-filesystem>=0.21.0 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (0.21.0)\nRequirement already satisfied: keras-preprocessing>=1.1.1 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (1.1.2)\nRequirement already satisfied: libclang>=9.0.1 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (13.0.0)\nRequirement already satisfied: typing-extensions>=3.6.6 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (3.7.4.3)\nRequirement already satisfied: google-pasta>=0.1.1 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (0.2.0)\nRequirement already satisfied: flatbuffers<3.0,>=1.12 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (1.12)\nRequirement already satisfied: keras<2.8,>=2.7.0rc0 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (2.7.0)\nRequirement already satisfied: tensorflow-estimator<2.8,~=2.7.0rc0 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (2.7.0)\nRequirement already satisfied: astunparse>=1.6.0 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (1.6.3)\nRequirement already satisfied: grpcio<2.0,>=1.24.3 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (1.42.0)\nRequirement already satisfied: tensorboard~=2.6 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (2.6.0)\nRequirement already satisfied: wrapt>=1.11.0 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (1.12.1)\nRequirement already satisfied: gast<0.5.0,>=0.2.1 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (0.4.0)\nRequirement already satisfied: absl-py>=0.4.0 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (0.10.0)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official==2.7.0) (3.19.1)\nCollecting dm-tree~=0.1.1\n Using cached dm_tree-0.1.6-cp38-cp38-manylinux_2_24_x86_64.whl (94 kB)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.8/site-packages (from matplotlib->tf-models-official==2.7.0) (0.11.0)\nRequirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.8/site-packages (from matplotlib->tf-models-official==2.7.0) (4.28.3)\nRequirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.8/site-packages (from matplotlib->tf-models-official==2.7.0) (21.3)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.8/site-packages (from matplotlib->tf-models-official==2.7.0) (1.3.2)\nRequirement already satisfied: pyparsing>=2.2.1 in /usr/local/lib/python3.8/site-packages (from matplotlib->tf-models-official==2.7.0) (3.0.6)\nRequirement already satisfied: setuptools-scm>=4 in /usr/local/lib/python3.8/site-packages (from matplotlib->tf-models-official==2.7.0) (6.3.2)\nRequirement already satisfied: pyasn1>=0.1.7 in /usr/local/lib/python3.8/site-packages (from oauth2client->tf-models-official==2.7.0) (0.4.8)\nRequirement already satisfied: pyasn1-modules>=0.0.5 in /usr/local/lib/python3.8/site-packages (from oauth2client->tf-models-official==2.7.0) (0.2.8)\nRequirement already satisfied: rsa>=3.1.4 in /usr/local/lib/python3.8/site-packages (from oauth2client->tf-models-official==2.7.0) (4.7.2)\nRequirement already satisfied: tabulate>=0.8.9 in /usr/local/lib/python3.8/site-packages (from sacrebleu->tf-models-official==2.7.0) (0.8.9)\nRequirement already satisfied: colorama in /usr/local/lib/python3.8/site-packages (from sacrebleu->tf-models-official==2.7.0) (0.4.3)\nCollecting regex\n Using cached regex-2022.1.18-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (764 kB)\nCollecting portalocker\n Using cached portalocker-2.4.0-py2.py3-none-any.whl (16 kB)\nRequirement already satisfied: scikit-learn>=0.21.3 in /usr/local/lib/python3.8/site-packages (from seqeval->tf-models-official==2.7.0) (0.24.2)\nCollecting typeguard>=2.7\n Using cached typeguard-2.13.3-py3-none-any.whl (17 kB)\nCollecting promise\n Using cached promise-2.3-py3-none-any.whl\nRequirement already satisfied: dill in /usr/local/lib/python3.8/site-packages (from tensorflow-datasets->tf-models-official==2.7.0) (0.3.4)\nCollecting tensorflow-metadata\n Using cached tensorflow_metadata-1.6.0-py3-none-any.whl (48 kB)\nRequirement already satisfied: importlib-resources in /usr/local/lib/python3.8/site-packages (from tensorflow-datasets->tf-models-official==2.7.0) (5.4.0)\nCollecting googleapis-common-protos<2.0dev,>=1.52.0\n Using cached googleapis_common_protos-1.54.0-py2.py3-none-any.whl (207 kB)\nRequirement already satisfied: cachetools<5.0,>=2.0.0 in /usr/local/lib/python3.8/site-packages (from google-auth<3.0.0dev,>=1.16.0->google-api-python-client>=1.6.7->tf-models-official==2.7.0) (4.2.4)\nRequirement already satisfied: setuptools>=40.3.0 in /usr/local/lib/python3.8/site-packages (from google-auth<3.0.0dev,>=1.16.0->google-api-python-client>=1.6.7->tf-models-official==2.7.0) (59.5.0)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.8/site-packages (from requests->kaggle>=1.3.9->tf-models-official==2.7.0) (2.10)\nRequirement already satisfied: chardet<5,>=3.0.2 in /usr/local/lib/python3.8/site-packages (from requests->kaggle>=1.3.9->tf-models-official==2.7.0) (4.0.0)\nRequirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.8/site-packages (from scikit-learn>=0.21.3->seqeval->tf-models-official==2.7.0) (3.0.0)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.8/site-packages (from scikit-learn>=0.21.3->seqeval->tf-models-official==2.7.0) (1.1.0)\nRequirement already satisfied: tomli>=1.0.0 in /usr/local/lib/python3.8/site-packages (from setuptools-scm>=4->matplotlib->tf-models-official==2.7.0) (1.2.2)\nRequirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow>=2.7.0->tf-models-official==2.7.0) (2.0.2)\nRequirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow>=2.7.0->tf-models-official==2.7.0) (3.3.6)\nRequirement already satisfied: tensorboard-data-server<0.7.0,>=0.6.0 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow>=2.7.0->tf-models-official==2.7.0) (0.6.1)\nRequirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow>=2.7.0->tf-models-official==2.7.0) (0.4.6)\nRequirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.8/site-packages (from tensorboard~=2.6->tensorflow>=2.7.0->tf-models-official==2.7.0) (1.8.0)\nRequirement already satisfied: zipp>=3.1.0 in /usr/local/lib/python3.8/site-packages (from importlib-resources->tensorflow-datasets->tf-models-official==2.7.0) (3.6.0)\nCollecting text-unidecode>=1.3\n Using cached text_unidecode-1.3-py2.py3-none-any.whl (78 kB)\nRequirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.8/site-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard~=2.6->tensorflow>=2.7.0->tf-models-official==2.7.0) (1.3.0)\nRequirement already satisfied: importlib-metadata>=4.4 in /usr/local/lib/python3.8/site-packages (from markdown>=2.6.8->tensorboard~=2.6->tensorflow>=2.7.0->tf-models-official==2.7.0) (4.8.2)\nRequirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.8/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard~=2.6->tensorflow>=2.7.0->tf-models-official==2.7.0) (3.1.1)\nInstalling collected packages: text-unidecode, httplib2, googleapis-common-protos, uritemplate, typeguard, tensorflow-metadata, regex, python-slugify, promise, portalocker, google-auth-httplib2, google-api-core, dm-tree, tf-slim, tensorflow-model-optimization, tensorflow-datasets, tensorflow-addons, seqeval, sentencepiece, sacrebleu, pycocotools, py-cpuinfo, opencv-python-headless, oauth2client, kaggle, google-api-python-client, gin-config, Cython, tf-models-official\nSuccessfully installed Cython-0.29.28 dm-tree-0.1.6 gin-config-0.5.0 google-api-core-2.5.0 google-api-python-client-2.37.0 google-auth-httplib2-0.1.0 googleapis-common-protos-1.54.0 httplib2-0.20.4 kaggle-1.5.12 oauth2client-4.1.3 opencv-python-headless-4.5.5.62 portalocker-2.4.0 promise-2.3 py-cpuinfo-8.0.0 pycocotools-2.0.4 python-slugify-6.0.1 regex-2022.1.18 sacrebleu-2.0.0 sentencepiece-0.1.96 seqeval-1.2.2 tensorflow-addons-0.16.1 tensorflow-datasets-4.5.2 tensorflow-metadata-1.6.0 tensorflow-model-optimization-0.7.1 text-unidecode-1.3 tf-models-official-2.7.0 tf-slim-1.1.0 typeguard-2.13.3 uritemplate-4.1.1\n\u001b[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\n\u001b[33mWARNING: You are using pip version 21.3.1; however, version 22.0.3 is available.\nYou should consider upgrading via the '/usr/local/bin/python3.8 -m pip install --upgrade pip' command.\u001b[0m\n"
],
[
"import matplotlib.pyplot as plt\nimport matplotlib.colors as colors\n\nimport sklearn.metrics\nimport sklearn.calibration\n\nimport tensorflow_hub as hub\nimport tensorflow_datasets as tfds\n\nimport numpy as np\nimport tensorflow as tf\nimport pandas as pd\nimport json\n\nimport official.nlp.modeling.layers as layers\nimport official.nlp.optimization as optimization",
"_____no_output_____"
]
],
[
[
"### Implement a standard BERT classifier following which classifies text",
"_____no_output_____"
]
],
[
[
"gpus = tf.config.list_physical_devices('GPU')\ngpus",
"_____no_output_____"
],
[
"# Standard BERT model\n\nPREPROCESS_HANDLE = 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3'\nMODEL_HANDLE = 'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3'\n\nclass BertClassifier(tf.keras.Model):\n def __init__(self, \n num_classes=150, inner_dim=768, dropout_rate=0.1,\n **classifier_kwargs):\n \n super().__init__()\n self.classifier_kwargs = classifier_kwargs\n\n # Initiate the BERT encoder components.\n self.bert_preprocessor = hub.KerasLayer(PREPROCESS_HANDLE, name='preprocessing')\n self.bert_hidden_layer = hub.KerasLayer(MODEL_HANDLE, trainable=True, name='bert_encoder')\n\n # Defines the encoder and classification layers.\n self.bert_encoder = self.make_bert_encoder()\n self.classifier = self.make_classification_head(num_classes, inner_dim, dropout_rate)\n\n def make_bert_encoder(self):\n text_inputs = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')\n encoder_inputs = self.bert_preprocessor(text_inputs)\n encoder_outputs = self.bert_hidden_layer(encoder_inputs)\n return tf.keras.Model(text_inputs, encoder_outputs)\n\n def make_classification_head(self, num_classes, inner_dim, dropout_rate):\n return layers.ClassificationHead(\n num_classes=num_classes, \n inner_dim=inner_dim,\n dropout_rate=dropout_rate,\n **self.classifier_kwargs)\n\n def call(self, inputs, **kwargs):\n encoder_outputs = self.bert_encoder(inputs)\n classifier_inputs = encoder_outputs['sequence_output']\n return self.classifier(classifier_inputs, **kwargs)\n",
"_____no_output_____"
]
],
[
[
"### Build SNGP model",
"_____no_output_____"
],
[
"To implement a BERT-SNGP model designed by Google researchers",
"_____no_output_____"
]
],
[
[
"class ResetCovarianceCallback(tf.keras.callbacks.Callback):\n\n def on_epoch_begin(self, epoch, logs=None):\n \"\"\"Resets covariance matrix at the begining of the epoch.\"\"\"\n if epoch > 0:\n self.model.classifier.reset_covariance_matrix()",
"_____no_output_____"
],
[
"class SNGPBertClassifier(BertClassifier):\n\n def make_classification_head(self, num_classes, inner_dim, dropout_rate):\n return layers.GaussianProcessClassificationHead(\n num_classes=num_classes, \n inner_dim=inner_dim,\n dropout_rate=dropout_rate,\n gp_cov_momentum=-1,\n temperature=30.,\n **self.classifier_kwargs)\n\n def fit(self, *args, **kwargs):\n \"\"\"Adds ResetCovarianceCallback to model callbacks.\"\"\"\n kwargs['callbacks'] = list(kwargs.get('callbacks', []))\n kwargs['callbacks'].append(ResetCovarianceCallback())\n\n return super().fit(*args, **kwargs)",
"_____no_output_____"
]
],
[
[
"### Load train and test datasets",
"_____no_output_____"
]
],
[
[
"is_train = pd.read_json('is_train.json')\nis_train.columns = ['question','intent']\n\nis_test = pd.read_json('is_test.json')\nis_test.columns = ['question','intent']\n\noos_test = pd.read_json('oos_test.json')\noos_test.columns = ['question','intent']\n\nis_test.shape",
"_____no_output_____"
]
],
[
[
"Make the train and test data.",
"_____no_output_____"
]
],
[
[
"#Generate codes\nis_data = is_train.append(is_test)\nis_data.intent = pd.Categorical(is_data.intent)\nis_data['code'] = is_data.intent.cat.codes\n\n#in-scope evaluation data\nis_test = is_data[15000:19500]\n\nis_test_queries = is_test.question\nis_test_labels = is_test.intent\nis_test_codes = is_test.code\n\nis_eval_data = (tf.convert_to_tensor(is_test_queries), tf.convert_to_tensor(is_test_codes))\n\nis_train = is_data[0:15000]\nis_train_queries = is_train.question\nis_train_labels = is_train.intent\nis_train_codes = is_train.code\n\ntraining_ds_queries = tf.convert_to_tensor(is_train_queries)\n\ntraining_ds_labels = tf.convert_to_tensor(is_train_codes)",
"_____no_output_____"
],
[
"is_test.shape",
"_____no_output_____"
]
],
[
[
"Create a OOD evaluation dataset. For this, combine the in-scope test data 'is_test' and out-of-scope 'oos_test' data. Assign label 0 for in-scope and label 1 for out-of-scope data",
"_____no_output_____"
]
],
[
[
"train_size = len(is_train)\ntest_size = len(is_test)\noos_size = len(oos_test)\n\n# Combines the in-domain and out-of-domain test examples.\noos_queries= tf.concat([is_test['question'], oos_test['question']], axis=0)\noos_labels = tf.constant([0] * test_size + [1] * oos_size)\n\n# Converts into a TF dataset.\noos_eval_dataset = tf.data.Dataset.from_tensor_slices(\n {\"text\": oos_queries, \"label\": oos_labels})",
"_____no_output_____"
]
],
[
[
"### Train and evaluate",
"_____no_output_____"
]
],
[
[
"TRAIN_EPOCHS = 4\nTRAIN_BATCH_SIZE = 16\nEVAL_BATCH_SIZE = 256",
"_____no_output_____"
],
[
"#@title\n\ndef bert_optimizer(learning_rate, \n batch_size=TRAIN_BATCH_SIZE, epochs=TRAIN_EPOCHS, \n warmup_rate=0.1):\n \"\"\"Creates an AdamWeightDecay optimizer with learning rate schedule.\"\"\"\n train_data_size = train_size\n \n steps_per_epoch = int(train_data_size / batch_size)\n num_train_steps = steps_per_epoch * epochs\n num_warmup_steps = int(warmup_rate * num_train_steps) \n\n # Creates learning schedule.\n lr_schedule = tf.keras.optimizers.schedules.PolynomialDecay(\n initial_learning_rate=learning_rate,\n decay_steps=num_train_steps,\n end_learning_rate=0.0) \n \n return optimization.AdamWeightDecay(\n learning_rate=lr_schedule,\n weight_decay_rate=0.01,\n epsilon=1e-6,\n exclude_from_weight_decay=['LayerNorm', 'layer_norm', 'bias'])",
"_____no_output_____"
],
[
"optimizer = bert_optimizer(learning_rate=1e-4)\nloss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\nmetrics = tf.metrics.SparseCategoricalAccuracy()",
"_____no_output_____"
],
[
"fit_configs = dict(batch_size=TRAIN_BATCH_SIZE,\n epochs=TRAIN_EPOCHS,\n validation_batch_size=EVAL_BATCH_SIZE, \n validation_data=is_eval_data)",
"_____no_output_____"
]
],
[
[
"### Model 1 - Batch size of 32 & 3 epochs ",
"_____no_output_____"
]
],
[
[
"sngp_model = SNGPBertClassifier()\nsngp_model.compile(optimizer=optimizer, loss=loss, metrics=metrics)\nsngp_model.fit(training_ds_queries, training_ds_labels, **fit_configs)",
"Epoch 1/2\n938/938 [==============================] - 481s 494ms/step - loss: 0.8704 - sparse_categorical_accuracy: 0.8241 - val_loss: 0.2888 - val_sparse_categorical_accuracy: 0.9473\nEpoch 2/2\n938/938 [==============================] - 464s 495ms/step - loss: 0.0647 - sparse_categorical_accuracy: 0.9853 - val_loss: 0.1979 - val_sparse_categorical_accuracy: 0.9598\n"
]
],
[
[
"### Model 2 - Batch size of 16 & 2 epochs ",
"_____no_output_____"
]
],
[
[
"sngp_model2 = SNGPBertClassifier()\nsngp_model2.compile(optimizer=optimizer, loss=loss, metrics=metrics)\nsngp_model2.fit(training_ds_queries, training_ds_labels, **fit_configs)",
"Epoch 1/3\n938/938 [==============================] - 480s 495ms/step - loss: 0.9506 - sparse_categorical_accuracy: 0.8029 - val_loss: 0.3883 - val_sparse_categorical_accuracy: 0.9376\nEpoch 2/3\n938/938 [==============================] - 462s 493ms/step - loss: 0.0989 - sparse_categorical_accuracy: 0.9769 - val_loss: 0.2342 - val_sparse_categorical_accuracy: 0.9522\nEpoch 3/3\n938/938 [==============================] - 462s 493ms/step - loss: 0.0272 - sparse_categorical_accuracy: 0.9939 - val_loss: 0.2013 - val_sparse_categorical_accuracy: 0.9598\n"
]
],
[
[
"### Model 3 - Batch size of 16 & 4 epochs ",
"_____no_output_____"
]
],
[
[
"sngp_model3 = SNGPBertClassifier()\nsngp_model3.compile(optimizer=optimizer, loss=loss, metrics=metrics)\nsngp_model3.fit(training_ds_queries, training_ds_labels, **fit_configs)",
"Epoch 1/4\n938/938 [==============================] - 477s 493ms/step - loss: 0.9459 - sparse_categorical_accuracy: 0.8066 - val_loss: 0.3804 - val_sparse_categorical_accuracy: 0.9393\nEpoch 2/4\n938/938 [==============================] - 465s 496ms/step - loss: 0.1192 - sparse_categorical_accuracy: 0.9730 - val_loss: 0.2526 - val_sparse_categorical_accuracy: 0.9511\nEpoch 3/4\n938/938 [==============================] - 466s 497ms/step - loss: 0.0372 - sparse_categorical_accuracy: 0.9917 - val_loss: 0.2169 - val_sparse_categorical_accuracy: 0.9564\nEpoch 4/4\n938/938 [==============================] - 465s 496ms/step - loss: 0.0135 - sparse_categorical_accuracy: 0.9974 - val_loss: 0.1992 - val_sparse_categorical_accuracy: 0.9629\n"
]
],
[
[
"### Evaluate OOD performance",
"_____no_output_____"
],
[
"Evaluate how well the model can detect the unfamiliar out-of-domain queries.",
"_____no_output_____"
]
],
[
[
"\n\ndef oos_predict(model, ood_eval_dataset, **model_kwargs):\n oos_labels = []\n oos_probs = []\n\n ood_eval_dataset = ood_eval_dataset.batch(EVAL_BATCH_SIZE)\n for oos_batch in ood_eval_dataset:\n oos_text_batch = oos_batch[\"text\"]\n oos_label_batch = oos_batch[\"label\"] \n\n pred_logits = model(oos_text_batch, **model_kwargs)\n pred_probs_all = tf.nn.softmax(pred_logits, axis=-1)\n pred_probs = tf.reduce_max(pred_probs_all, axis=-1)\n\n oos_labels.append(oos_label_batch)\n oos_probs.append(pred_probs)\n\n oos_probs = tf.concat(oos_probs, axis=0)\n oos_labels = tf.concat(oos_labels, axis=0) \n\n return oos_probs, oos_labels",
"_____no_output_____"
]
],
[
[
"Computes the OOD probabilities as $1 - p(x)$, where $p(x)=softmax(logit(x))$ is the predictive probability.",
"_____no_output_____"
]
],
[
[
"sngp_probs, ood_labels = oos_predict(sngp_model, oos_eval_dataset)",
"_____no_output_____"
],
[
"sngp_probs2, ood_labels2 = oos_predict(sngp_model2, oos_eval_dataset)",
"_____no_output_____"
],
[
"sngp_probs3, ood_labels3 = oos_predict(sngp_model3, oos_eval_dataset)",
"_____no_output_____"
],
[
"ood_probs = 1 - sngp_probs\nood_probs2 = 1 - sngp_probs2\nood_probs3 = 1 - sngp_probs3",
"_____no_output_____"
],
[
"plt.rcParams['figure.dpi'] = 140\n\nDEFAULT_X_RANGE = (-3.5, 3.5)\nDEFAULT_Y_RANGE = (-2.5, 2.5)\nDEFAULT_CMAP = colors.ListedColormap([\"#377eb8\", \"#ff7f00\"])\nDEFAULT_NORM = colors.Normalize(vmin=0, vmax=1,)\nDEFAULT_N_GRID = 100",
"_____no_output_____"
],
[
"ood_uncertainty = ood_probs * (1 - ood_probs)\nood_uncertainty2 = ood_probs2 * (1 - ood_probs2)\nood_uncertainty3 = ood_probs3 * (1 - ood_probs3)",
"_____no_output_____"
],
[
"s1 = np.array(sngp_probs.numpy())\nprint(s1[3000])",
"0.98855245\n"
],
[
"s2 = np.array(sngp_probs2.numpy())\nprint(s2[2000])",
"0.99832803\n"
],
[
"s3 = np.array(sngp_probs3.numpy())\nprint(s3[1000])",
"0.9983203\n"
]
],
[
[
"### Compute the Area under precision-recall curve (AUPRC) for OOD probability v.s. OOD detection accuracy.",
"_____no_output_____"
]
],
[
[
"precision, recall, _ = sklearn.metrics.precision_recall_curve(ood_labels, ood_probs)\nprecision2, recall2, _ = sklearn.metrics.precision_recall_curve(ood_labels2, ood_probs2)\nprecision3, recall3, _ = sklearn.metrics.precision_recall_curve(ood_labels3, ood_probs3)",
"_____no_output_____"
],
[
"print((precision3)\nprint(recall3)",
"_____no_output_____"
]
],
[
[
"[0.23380874 0.23362956 0.23368421 ... 1. 1. 1. ]\n[1. 0.999 0.999 ... 0.002 0.001 0. ]",
"_____no_output_____"
]
],
[
[
"sklearn.metrics.recall_score(oos_labels, ood_labels3, average='weighted')",
"_____no_output_____"
],
[
"sklearn.metrics.precision_score(oos_labels, ood_labels3, average='weighted')",
"_____no_output_____"
],
[
"auprc = sklearn.metrics.auc(recall, precision)\nprint(f'SNGP AUPRC: {auprc:.4f}')",
"SNGP AUPRC: 0.9026\n"
],
[
"auprc2 = sklearn.metrics.auc(recall2, precision2)\nprint(f'SNGP AUPRC 2: {auprc2:.4f}')",
"SNGP AUPRC 2: 0.8926\n"
],
[
"auprc3 = sklearn.metrics.auc(recall3, precision3)\nprint(f'SNGP AUPRC 3: {auprc3:.4f}')",
"SNGP AUPRC 3: 0.8926\n"
],
[
"prob_true, prob_pred = sklearn.calibration.calibration_curve(\n ood_labels, ood_probs, n_bins=10, strategy='quantile')\n\nprob_true2, prob_pred2 = sklearn.calibration.calibration_curve(\n ood_labels2, ood_probs2, n_bins=10, strategy='quantile')\n\nprob_true3, prob_pred3 = sklearn.calibration.calibration_curve(\n ood_labels3, ood_probs3, n_bins=10, strategy='quantile')",
"_____no_output_____"
],
[
"plt.plot(prob_pred, prob_true)\n\nplt.plot([0., 1.], [0., 1.], c='k', linestyle=\"--\")\nplt.xlabel('Predictive Probability')\nplt.ylabel('Predictive Accuracy')\nplt.title('Calibration Plots, SNGP')\n\nplt.show()",
"_____no_output_____"
],
[
"plt.plot(prob_pred2, prob_true2)\n\nplt.plot([0., 1.], [0., 1.], c='k', linestyle=\"--\")\nplt.xlabel('Predictive Probability')\nplt.ylabel('Predictive Accuracy')\nplt.title('Calibration Plots, SNGP')\n\nplt.show()",
"_____no_output_____"
],
[
"plt.plot(prob_pred3, prob_true3)\n\nplt.plot([0., 1.], [0., 1.], c='k', linestyle=\"--\")\nplt.xlabel('Predictive Probability')\nplt.ylabel('Predictive Accuracy')\nplt.title('Calibration Plots, SNGP')\n\nplt.show()",
"_____no_output_____"
],
[
"# calculate scores\nauc1 = roc_auc_score(oos_labels, ood_probs)\nauc2 = roc_auc_score(oos_labels, ood_probs2)\nauc3 = roc_auc_score(oos_labels, ood_probs3)\n# summarize scores\nprint('SNGP Model 1: ROC AUC=%.3f' % (auc1))\nprint('SNGP Model 2: ROC AUC=%.3f' % (auc2))\nprint('SNGP Model 3: ROC AUC=%.3f' % (auc3))\n# calculate roc curves\nfpr1, tpr1, _ = roc_curve(oos_labels, ood_probs)\nfpr2, tpr2, _ = roc_curve(oos_labels, ood_probs2)\nfpr3, tpr3, _ = roc_curve(oos_labels, ood_probs3)\n# plot the roc curve for the model\npyplot.plot(fpr1, tpr1, marker='.', label='SNGP Model 1')\npyplot.plot(fpr2, tpr2, marker='*', label='SNGP Model 2')\npyplot.plot(fpr3, tpr3, marker='+', label='SNGP Model 3')\n# axis labels\npyplot.xlabel('False Positive Rate (Precision)')\npyplot.ylabel('True Positive Rate (Recall)')\n# show the legend\npyplot.legend()\n# show the plot\npyplot.show()",
"SNGP Model 1: ROC AUC=0.972\nSNGP Model 2: ROC AUC=0.973\nSNGP Model 3: ROC AUC=0.973\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d06235b84db16934ad49870332ad1f26e8547ddb | 31,064 | ipynb | Jupyter Notebook | t81_558_class_02_4_pandas_functional.ipynb | AritraJana1810/t81_558_deep_learning | 184d84d202b54990be8c927499ce0a01a3662e6f | [
"Apache-2.0"
]
| 1 | 2021-07-03T09:02:59.000Z | 2021-07-03T09:02:59.000Z | t81_558_class_02_4_pandas_functional.ipynb | joaquinmorenoa/t81_558_deep_learning | 569ed623cb225a5d410fda6f49e1a15073b247ea | [
"Apache-2.0"
]
| null | null | null | t81_558_class_02_4_pandas_functional.ipynb | joaquinmorenoa/t81_558_deep_learning | 569ed623cb225a5d410fda6f49e1a15073b247ea | [
"Apache-2.0"
]
| 1 | 2020-09-21T15:11:35.000Z | 2020-09-21T15:11:35.000Z | 31,064 | 31,064 | 0.489988 | [
[
[
"<a href=\"https://colab.research.google.com/github/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_02_4_pandas_functional.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# T81-558: Applications of Deep Neural Networks\n**Module 2: Python for Machine Learning**\n* Instructor: [Jeff Heaton](https://sites.wustl.edu/jeffheaton/), McKelvey School of Engineering, [Washington University in St. Louis](https://engineering.wustl.edu/Programs/Pages/default.aspx)\n* For more information visit the [class website](https://sites.wustl.edu/jeffheaton/t81-558/).",
"_____no_output_____"
],
[
"# Module 2 Material\n\nMain video lecture:\n\n* Part 2.1: Introduction to Pandas [[Video]](https://www.youtube.com/watch?v=bN4UuCBdpZc&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_02_1_python_pandas.ipynb)\n* Part 2.2: Categorical Values [[Video]](https://www.youtube.com/watch?v=4a1odDpG0Ho&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_02_2_pandas_cat.ipynb)\n* Part 2.3: Grouping, Sorting, and Shuffling in Python Pandas [[Video]](https://www.youtube.com/watch?v=YS4wm5gD8DM&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_02_3_pandas_grouping.ipynb)\n* **Part 2.4: Using Apply and Map in Pandas for Keras** [[Video]](https://www.youtube.com/watch?v=XNCEZ4WaPBY&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_02_4_pandas_functional.ipynb)\n* Part 2.5: Feature Engineering in Pandas for Deep Learning in Keras [[Video]](https://www.youtube.com/watch?v=BWPTj4_Mi9E&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_02_5_pandas_features.ipynb)",
"_____no_output_____"
],
[
"# Google CoLab Instructions\n\nThe following code ensures that Google CoLab is running the correct version of TensorFlow.",
"_____no_output_____"
]
],
[
[
"try:\n %tensorflow_version 2.x\n COLAB = True\n print(\"Note: using Google CoLab\")\nexcept:\n print(\"Note: not using Google CoLab\")\n COLAB = False",
"Note: not using Google CoLab\n"
]
],
[
[
"# Part 2.4: Apply and Map",
"_____no_output_____"
],
[
"If you've ever worked with Big Data or functional programming languages before, you've likely heard of map/reduce. Map and reduce are two functions that apply a task that you create to a data frame. Pandas supports functional programming techniques that allow you to use functions across en entire data frame. In addition to functions that you write, Pandas also provides several standard functions for use with data frames.",
"_____no_output_____"
],
[
"### Using Map with Dataframes\n\nThe map function allows you to transform a column by mapping certain values in that column to other values. Consider the Auto MPG data set that contains a field **origin_name** that holds a value between one and three that indicates the geographic origin of each car. We can see how to use the map function to transform this numeric origin into the textual name of each origin.\n\nWe will begin by loading the Auto MPG data set. ",
"_____no_output_____"
]
],
[
[
"import os\nimport pandas as pd\nimport numpy as np\n\ndf = pd.read_csv(\n \"https://data.heatonresearch.com/data/t81-558/auto-mpg.csv\", \n na_values=['NA', '?'])\n\npd.set_option('display.max_columns', 7)\npd.set_option('display.max_rows', 5)\n\ndisplay(df)",
"_____no_output_____"
]
],
[
[
"The **map** method in Pandas operates on a single column. You provide **map** with a dictionary of values to transform the target column. The map keys specify what values in the target column should be turned into values specified by those keys. The following code shows how the map function can transform the numeric values of 1, 2, and 3 into the string values of North America, Europe and Asia.",
"_____no_output_____"
]
],
[
[
"# Apply the map\ndf['origin_name'] = df['origin'].map(\n {1: 'North America', 2: 'Europe', 3: 'Asia'})\n\n# Shuffle the data, so that we hopefully see\n# more regions.\ndf = df.reindex(np.random.permutation(df.index)) \n\n# Display\npd.set_option('display.max_columns', 7)\npd.set_option('display.max_rows', 10)\ndisplay(df)",
"_____no_output_____"
]
],
[
[
"### Using Apply with Dataframes\n\nThe **apply** function of the data frame can run a function over the entire data frame. You can use either be a traditional named function or a lambda function. Python will execute the provided function against each of the rows or columns in the data frame. The **axis** parameter specifies of the function is run across rows or columns. For axis = 1, rows are used. The following code calculates a series called **efficiency** that is the **displacement** divided by **horsepower**. ",
"_____no_output_____"
]
],
[
[
"efficiency = df.apply(lambda x: x['displacement']/x['horsepower'], axis=1)\ndisplay(efficiency[0:10])",
"_____no_output_____"
]
],
[
[
"You can now insert this series into the data frame, either as a new column or to replace an existing column. The following code inserts this new series into the data frame.",
"_____no_output_____"
]
],
[
[
"df['efficiency'] = efficiency",
"_____no_output_____"
]
],
[
[
"### Feature Engineering with Apply and Map",
"_____no_output_____"
],
[
"In this section, we will see how to calculate a complex feature using map, apply, and grouping. The data set is the following CSV:\n\n* https://www.irs.gov/pub/irs-soi/16zpallagi.csv \n\nThis URL contains US Government public data for \"SOI Tax Stats - Individual Income Tax Statistics.\" The entry point to the website is here:\n\n* https://www.irs.gov/statistics/soi-tax-stats-individual-income-tax-statistics-2016-zip-code-data-soi \n\nDocumentation describing this data is at the above link.\n\nFor this feature, we will attempt to estimate the adjusted gross income (AGI) for each of the zip codes. The data file contains many columns; however, you will only use the following:\n\n* STATE - The state (e.g., MO)\n* zipcode - The zipcode (e.g. 63017)\n* agi_stub - Six different brackets of annual income (1 through 6) \n* N1 - The number of tax returns for each of the agi_stubs\n\nNote, the file will have six rows for each zip code, for each of the agi_stub brackets. You can skip zip codes with 0 or 99999.\n\nWe will create an output CSV with these columns; however, only one row per zip code. Calculate a weighted average of the income brackets. For example, the following six rows are present for 63017:\n\n\n|zipcode |agi_stub | N1 |\n|--|--|-- |\n|63017 |1 | 4710 |\n|63017 |2 | 2780 |\n|63017 |3 | 2130 |\n|63017 |4 | 2010 |\n|63017 |5 | 5240 |\n|63017 |6 | 3510 |\n\n\nWe must combine these six rows into one. For privacy reasons, AGI's are broken out into 6 buckets. We need to combine the buckets and estimate the actual AGI of a zipcode. To do this, consider the values for N1:\n\n* 1 = 1 to 25,000\n* 2 = 25,000 to 50,000\n* 3 = 50,000 to 75,000\n* 4 = 75,000 to 100,000\n* 5 = 100,000 to 200,000\n* 6 = 200,000 or more\n\nThe median of each of these ranges is approximately:\n\n* 1 = 12,500\n* 2 = 37,500\n* 3 = 62,500 \n* 4 = 87,500\n* 5 = 112,500\n* 6 = 212,500\n\nUsing this you can estimate 63017's average AGI as:\n\n```\n>>> totalCount = 4710 + 2780 + 2130 + 2010 + 5240 + 3510\n>>> totalAGI = 4710 * 12500 + 2780 * 37500 + 2130 * 62500 \n + 2010 * 87500 + 5240 * 112500 + 3510 * 212500\n>>> print(totalAGI / totalCount)\n\n88689.89205103042\n```\n\nWe begin by reading in the government data.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\ndf=pd.read_csv('https://www.irs.gov/pub/irs-soi/16zpallagi.csv')",
"_____no_output_____"
]
],
[
[
"First, we trim all zip codes that are either 0 or 99999. We also select the three fields that we need.",
"_____no_output_____"
]
],
[
[
"df=df.loc[(df['zipcode']!=0) & (df['zipcode']!=99999),\n ['STATE','zipcode','agi_stub','N1']]\n\npd.set_option('display.max_columns', 0)\npd.set_option('display.max_rows', 10)\n\ndisplay(df)",
"_____no_output_____"
]
],
[
[
"We replace all of the **agi_stub** values with the correct median values with the **map** function.",
"_____no_output_____"
]
],
[
[
"medians = {1:12500,2:37500,3:62500,4:87500,5:112500,6:212500}\ndf['agi_stub']=df.agi_stub.map(medians)\n\npd.set_option('display.max_columns', 0)\npd.set_option('display.max_rows', 10)\ndisplay(df)",
"_____no_output_____"
]
],
[
[
"Next, we group the data frame by zip code.",
"_____no_output_____"
]
],
[
[
"groups = df.groupby(by='zipcode')",
"_____no_output_____"
]
],
[
[
"The program applies a lambda is applied across the groups, and then calculates the AGI estimate.",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame(groups.apply( \n lambda x:sum(x['N1']*x['agi_stub'])/sum(x['N1']))) \\\n .reset_index()",
"_____no_output_____"
],
[
"pd.set_option('display.max_columns', 0)\npd.set_option('display.max_rows', 10)\n\ndisplay(df)",
"_____no_output_____"
]
],
[
[
"We can now rename the new agi_estimate column.",
"_____no_output_____"
]
],
[
[
"df.columns = ['zipcode','agi_estimate']",
"_____no_output_____"
],
[
"pd.set_option('display.max_columns', 0)\npd.set_option('display.max_rows', 10)\n\ndisplay(df)",
"_____no_output_____"
]
],
[
[
"Finally, we check to see that our zip code of 63017 got the correct value.",
"_____no_output_____"
]
],
[
[
"df[ df['zipcode']==63017 ]",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d062446f226ef60582dc04dd098b4f3cbd00db61 | 52,841 | ipynb | Jupyter Notebook | matplotlibAndobjectorianted_linechart_with_errorbars.ipynb | GirijaJoshi/PyBer_Analysis | faaea2be8baae82ba8ca84314b51954b14784c8d | [
"MIT"
]
| 1 | 2020-10-20T15:15:37.000Z | 2020-10-20T15:15:37.000Z | matplotlibAndobjectorianted_linechart_with_errorbars.ipynb | GirijaJoshi/PyBer_Analysis | faaea2be8baae82ba8ca84314b51954b14784c8d | [
"MIT"
]
| null | null | null | matplotlibAndobjectorianted_linechart_with_errorbars.ipynb | GirijaJoshi/PyBer_Analysis | faaea2be8baae82ba8ca84314b51954b14784c8d | [
"MIT"
]
| null | null | null | 265.532663 | 16,468 | 0.931133 | [
[
[
"%matplotlib inline",
"_____no_output_____"
],
[
"# Import dependencies.\nimport matplotlib.pyplot as plt\nimport statistics",
"_____no_output_____"
],
[
"# Set the x-axis to a list of strings for each month.\nx_axis = [\"Jan\", \"Feb\", \"Mar\", \"April\", \"May\", \"June\", \"July\", \"Aug\", \"Sept\", \"Oct\", \"Nov\", \"Dec\"]\n\n# Set the y-axis to a list of floats as the total fare in US dollars accumulated for each month.\ny_axis = [10.02, 23.24, 39.20, 35.42, 32.34, 27.04, 43.82, 10.56, 11.85, 27.90, 20.71, 20.09]",
"_____no_output_____"
],
[
"average = sum(y_axis)/len(y_axis)\naverage",
"_____no_output_____"
],
[
"# Get the standard deviation of the values in the y-axis.\nstdev = statistics.stdev(y_axis)\nstdev",
"_____no_output_____"
],
[
"# added standart davitation to y-axis\nplt.errorbar(x_axis, y_axis, yerr=stdev)",
"_____no_output_____"
],
[
"# added standart davitation to y-axis, adding cap\nplt.errorbar(x_axis, y_axis, yerr=stdev, capsize=3)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nax.errorbar(x_axis, y_axis, yerr=stdev, capsize=3)\nplt.show()",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d06244e92170a3cee84bba7d981221ffc4f00179 | 350,583 | ipynb | Jupyter Notebook | Charting a path into the data science field.ipynb | khiara/DSND_Kaggle_2020_Survey | 57ba312125edbe8278b6f292b4f1bda1fb4018f0 | [
"CNRI-Python"
]
| null | null | null | Charting a path into the data science field.ipynb | khiara/DSND_Kaggle_2020_Survey | 57ba312125edbe8278b6f292b4f1bda1fb4018f0 | [
"CNRI-Python"
]
| null | null | null | Charting a path into the data science field.ipynb | khiara/DSND_Kaggle_2020_Survey | 57ba312125edbe8278b6f292b4f1bda1fb4018f0 | [
"CNRI-Python"
]
| null | null | null | 211.576946 | 41,700 | 0.882747 | [
[
[
"# Charting a path into the data science field",
"_____no_output_____"
],
[
"This project attempts to shed light on the path or paths to becoming a data science professional in the United States.\n\nData science is a rapidly growing field, and the demand for data scientists is outpacing supply. In the past, most Data Scientist positions went to people with PhDs in Computer Science. I wanted to know if that is changing in light of both the increased job openings and the expanding definition of data science that has come with more companies realizing the wealth of raw data they have available for analysis, and how that can help to grow and refine their businesses.",
"_____no_output_____"
],
[
"## Business Questions\n\n\n1. Do you need a a formal degree?\n2. What programming language(s) do data science professionals need to know?\n3. What are the preferred online learning platforms to gain data science knowledge and skills?",
"_____no_output_____"
],
[
"## Data\n\nSince 2017, Kaggle ('The world's largest data science community') has annually surveyed its users on demographics, practices, and preferences. This notebook explores the data from Kaggle's 2020 Machine Learning and Data Science survey. A caveat: Kaggle is heavy on Machine Learning and competitions, and while it claims over 8 million users the group may not be representative of the overall data science community. Additionally,survey respondents are self-selected, so we can't extrapolate any findings to the data science community as a whole, but the trends and demographics amongst Kaggle survey takers may still offer insights about data science professionals.",
"_____no_output_____"
],
[
"The first step is importing the necessary libraries and data.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport textwrap\n%matplotlib inline\n\nfrom matplotlib.ticker import PercentFormatter\n\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"df = pd.read_csv('./kaggle_survey_2020_responses.csv')\nlow_memory = False",
"_____no_output_____"
]
],
[
[
"### Initial data exploration and cleaning\nLet's take a look at the survey data.",
"_____no_output_____"
]
],
[
[
"# Let's look at the first 5 rows of the dataset\ndf.head()",
"_____no_output_____"
]
],
[
[
"One thing we can see from this: some questions are tied to a single column, with a number of answers possible; these questions only allowed survey respondents to choose one answer from among the options. Other questions take up multiple columns, with each column tied to a specific answer; these were questions that allowed users to choose more than one option as the answer ('select all that apply'). The two types of questions will require different approaches to data preparation.",
"_____no_output_____"
],
[
"But first, we'll do some cleaning. The top row of data contains the question titles. We'll remove that, as well as the first column of survey completion time values.",
"_____no_output_____"
]
],
[
[
"# Removing the first column and the first row\ndf.drop(['Time from Start to Finish (seconds)'], axis=1, inplace=True)\ndf = df.loc[1:, :]\ndf.head()",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
]
],
[
[
"There are over 20,000 responses, with 354 answer fields.",
"_____no_output_____"
],
[
"#### Data preparation and filtering",
"_____no_output_____"
],
[
"To improve readability of visualizations, we'll aggregate some fields, shorten some labels, and re-order categories.",
"_____no_output_____"
]
],
[
[
"# Aggregating the nonbinary answers\ndf.loc[(df.Q2 == 'Prefer not to say'), 'Q2'] = 'Other Response'\ndf.loc[(df.Q2 == 'Prefer to self-describe'),'Q2'] = 'Other Response'\ndf.loc[(df.Q2 == 'Nonbinary'), 'Q2'] = 'Other Response'\n\n# Abbreviating country name\ndf.loc[(df.Q3 == 'United States of America'),'Q3']='USA'\n\n# Shortening education level descriptions\ndf.loc[(df.Q4 == 'Doctoral degree'),'Q4']='PhD'\ndf.loc[(df.Q4 == 'Master’s degree'),'Q4']='Master’s'\ndf.loc[(df.Q4 == 'Bachelor’s degree'),'Q4']='Bachelor’s'\ndf.loc[(df.Q4 == \"Some college/university study without earning a bachelor’s degree\"), 'Q4']='Some college/university'\ndf.loc[(df.Q4 == 'No formal education past high school'), 'Q4']='High school'\ndf.loc[(df.Q4 == 'I prefer not to answer'), 'Q4']='Prefer not to answer'\n\n# Ordering education levels by reverse typical chronological completion\nq4_order = [\n 'PhD',\n 'Master’s', \n 'Professional degree', \n 'Bachelor’s', \n 'Some college/university', \n 'High school', \n 'Prefer not to answer']\n\n# Putting coding experience answers in order from shortest time to longest\nq6_order = [\n 'I have never written code', \n '< 1 years', \n '1-2 years', \n '3-5 years', \n '5-10 years', \n '10-20 years', \n '20+ years']\n\ndf.loc[(df.Q37_Part_9 == 'Cloud-certification programs (direct from AWS, Azure, GCP, or similar)'), 'Q37_Part_9']='Cloud-certification programs'\ndf.loc[(df.Q37_Part_10 == 'University Courses (resulting in a university degree)'), 'Q37_Part_10']='University Courses resulting in a degree'",
"_____no_output_____"
]
],
[
[
"We're going to focus on the US answers from currently employed Kagglers.",
"_____no_output_____"
]
],
[
[
"# Filtering for just US responses\nus_df = df[df['Q3'] == 'USA']\n\n# Filtering to only include currently employed Kagglers\nq5_order = [\n 'Data Scientist',\n 'Software Engineer',\n 'Data Analyst', \n 'Research Scientist',\n 'Product/Project Manager',\n 'Business Analyst',\n 'Machine Learning Engineer',\n 'Data Engineer',\n 'Statistician',\n 'DBA/Database Engineer',\n 'Other']\n\nus_df = us_df[us_df['Q5'].isin(q5_order)]",
"_____no_output_____"
]
],
[
[
"We're interested in the demographic questions at the beginning, plus coding experience, coding languages used, and online learning platforms used. ",
"_____no_output_____"
]
],
[
[
"# Filtering to only include specific question columns\nus_df = us_df.loc[:, ['Q1', 'Q2', 'Q3', 'Q4', 'Q5', 'Q6', 'Q7_Part_1', 'Q7_Part_2','Q7_Part_3','Q7_Part_4','Q7_Part_5',\n 'Q7_Part_6', 'Q7_Part_7','Q7_Part_8','Q7_Part_9','Q7_Part_10','Q7_Part_11', 'Q7_Part_12', 'Q7_OTHER',\n 'Q37_Part_1', 'Q37_Part_2', 'Q37_Part_3', 'Q37_Part_4', 'Q37_Part_5', 'Q37_Part_6', 'Q37_Part_7', \n 'Q37_Part_8', 'Q37_Part_9', 'Q37_Part_10','Q37_Part_11', 'Q37_OTHER']]",
"_____no_output_____"
],
[
"us_df.isna().sum()",
"_____no_output_____"
]
],
[
[
"Not much in the way of missing values in the first 6 questions; that changes for the multiple-column questions, as expected, since users only filled in the column when they were choosing that particular option. We'll address that by converting the missing values to zeros in the helper functions.",
"_____no_output_____"
]
],
[
[
"us_df.shape",
"_____no_output_____"
]
],
[
[
"This will be the data for our analysis -- covering 1680 currently employed Kagglers in the US.",
"_____no_output_____"
],
[
"## Helper functions",
"_____no_output_____"
],
[
"A few functions to help with data visualizations. The first two plot a barchart with a corresponding list of the counts and percentages for the values; one handles single-column questions and the other handles multiple-column questions. The third and fourth are heatmap functions -- one for single-column questions, and one for multiple-column questions.",
"_____no_output_____"
]
],
[
[
"def list_and_bar(qnum, q_order, title):\n \n '''\n INPUT:\n qnum - the y-axis variable, a single-column question\n q_order - the order to display responses on the barchart\n title - the title of the barchart\n \n OUTPUT:\n 1. A list of responses to the selected question, in descending order\n 2. A horizontal barchart showing the values, in sorted order \n '''\n\n # creating a dataframe of values to include both raw counts and percentages\n val_list = pd.DataFrame()\n val_list['Count'] = us_df[qnum].value_counts()\n pct = round(val_list * 100/us_df[qnum].count(),2)\n val_list['Pct'] = pct\n \n print(val_list)\n \n fig, ax = plt.subplots(1, 1, figsize=(12,6))\n ax = us_df[qnum].value_counts()[q_order].plot(kind='barh')\n \n # reversing the order of y axis -- \n # the horizontal barchart displays values in the reverse order of a regular barchart (i.e., where the barchart might show \n # a - b - c left to right, the corresponding horizontal barchart would show c at the top, and a at the bottom)\n ax.invert_yaxis()\n \n plt.title(title, fontsize = 14, fontweight = 'bold')\n plt.show()\n \n \n\ndef list_and_bar_mc(mc_df, title):\n \n '''\n INPUT:\n mc_df - a dataframe consisting of answers to a specific multiple-column question\n title - the title of the barchart\n \n OUTPUT:\n 1. A list of responses to the selected question, in descending order\n 2. A horizontal barchart showing the values, also in descending order\n '''\n print(mc_df)\n \n fig, ax = plt.subplots(1, 1, figsize=(12,6))\n mc_df['Count'].sort_values().plot(kind='barh')\n plt.title(title, fontsize = 14, fontweight = 'bold')\n plt.show()\n \n \n\ndef heatmap(qnum_a, qnum_b, title, order_rows, columns):\n \n '''\n INPUT:\n qnum_a - the x-axis variable, a single-column question\n qnum_b - the y-axis variable, a single-column question\n title - the title of the heatmap, describing the variables in the visualization\n order_rows - sorted order for the y-axis\n columns - sorted order for the x-axis\n \n OUTPUT:\n A heatmap showing the correlation between the two chosen variables\n '''\n vals = us_df[[qnum_a, qnum_b]].groupby(qnum_b)[qnum_a].value_counts().unstack()\n \n # getting the total number of responses for the columns in order to calculate the % of the total\n vals_rowsums = pd.DataFrame([vals.sum(axis=0).tolist()], columns=vals.columns, index=['All'])\n vals = pd.concat([vals_rowsums, vals], axis=0)\n\n # convert to % \n vals = ((vals.T / (vals.sum(axis=1) + 0.001)).T) * 100 \n\n order = order_rows\n columns = columns\n \n vals = vals.reindex(order).reindex(columns = columns)\n \n fig, ax = plt.subplots(1, 1, figsize=[12,6])\n ax = sns.heatmap(ax = ax, data = vals, cmap = 'GnBu', cbar_kws = {'format': '%.0f%%'})\n plt.title(title, fontsize = 14, fontweight = 'bold')\n ax.set_xlabel('')\n ax.set_ylabel('')\n plt.show()\n \n \n\ndef heatmap_mc(qnum, qnum_mc, title, columns, order_rows):\n \n '''\n INPUT:\n qnum - the y-axis variable, a single-column question\n qnum_mc - the x-axis variable, a question with multiple columns of answers\n title - the title of the heatmap, describing the variables in the visualization\n order_rows - sorted order for the y-axis\n columns - a list of column names, representing the multiple-column answer options, ordered\n \n OUTPUT:\n 1. A heatmap showing the correlation between the two specified variables\n 2. avg_num - the average number of answer options chosen for the multiple column question\n '''\n # creating a dataframe with the single-column question\n df_qnum = us_df[qnum]\n df_qnum = pd.DataFrame(df_qnum)\n \n # creating a dataframe containing all the columns for a given multiple-column question\n cols_mc = [col for col in us_df if col.startswith(qnum_mc)]\n df_mc = us_df[cols_mc]\n df_mc.columns = columns\n \n # converting column values to binary 0 or 1 values (1 if the user chose that answer, 0 if not)\n df_mc = df_mc.notnull().astype(int)\n \n # joining the dataframes together\n df_join = df_qnum.join(df_mc)\n \n # aggregating counts for each answer option and re-ordering dataframe\n df_agg = df_join.groupby([qnum]).agg('sum')\n df_agg = df_agg.reindex(order_rows)\n \n df_agg['users'] = df_join.groupby(qnum)[qnum].count()\n df_agg = df_agg.div(df_agg.loc[:, 'users'], axis=0)\n df_agg.drop(columns='users', inplace=True)\n \n \n fig, ax = plt.subplots(1, 1, figsize=(12, 6))\n ax = sns.heatmap(ax = ax, data = df_agg, cmap = 'GnBu')\n cbar = ax.collections[0].colorbar\n cbar.ax.yaxis.set_major_formatter(PercentFormatter(1, 0))\n plt.title(title, fontsize = 14, fontweight = 'bold')\n ax.set_xlabel('')\n ax.set_ylabel('')\n plt.show() \n \n # finding the average number of answers chosen for the multiple column options, minus tabulations for 'None'\n df_temp = df_join\n df_temp.drop('None', axis = 1, inplace = True)\n rowsums = df_temp.sum(axis = 1)\n avg_num = round(rowsums.mean(), 2)\n \n print('Average number of options chosen by survey respondents: ' + str(avg_num) + '.')\n",
"_____no_output_____"
]
],
[
[
"## Analysis and visualizations",
"_____no_output_____"
],
[
"We'll start by looking at the age and gender distribution, just to get an overview of the response community.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=[12,6])\nus_ages = us_df['Q1'].value_counts().sort_index()\nsns.countplot(data = us_df, x = 'Q1', hue = 'Q2', order = us_ages.index)\nplt.title('Age and Gender Distribution')",
"_____no_output_____"
]
],
[
[
"The survey response pool skews heavily male, with most US Kagglers between the ages of 25 and 45. ",
"_____no_output_____"
]
],
[
[
"list_and_bar('Q6', q6_order, 'Years of Coding Experience')",
" Count Pct\n3-5 years 367 22.00\n20+ years 349 20.92\n5-10 years 334 20.02\n10-20 years 288 17.27\n1-2 years 171 10.25\n< 1 years 104 6.24\nI have never written code 55 3.30\n"
]
],
[
[
"Around 80 percent of those responding have 3 or more years experience coding.",
"_____no_output_____"
],
[
"### 1. Do you need a formal degree to become a data science professional?",
"_____no_output_____"
],
[
"Let's look at formal education, and how it correlates with job title.",
"_____no_output_____"
]
],
[
[
"list_and_bar('Q4', q4_order, 'Highest Level of Education Attained')",
" Count Pct\nMaster’s 819 48.75\nBachelor’s 409 24.35\nPhD 334 19.88\nSome college/university 71 4.23\nProfessional degree 34 2.02\nPrefer not to answer 8 0.48\nHigh school 5 0.30\n"
],
[
"list_and_bar('Q5', q5_order, 'Current Job Title')",
" Count Pct\nData Scientist 389 23.15\nOther 292 17.38\nSoftware Engineer 219 13.04\nData Analyst 192 11.43\nResearch Scientist 140 8.33\nProduct/Project Manager 117 6.96\nBusiness Analyst 107 6.37\nMachine Learning Engineer 97 5.77\nData Engineer 71 4.23\nStatistician 38 2.26\nDBA/Database Engineer 18 1.07\n"
],
[
"heatmap('Q4', 'Q5', 'Roles by Education Level', q5_order, q4_order)",
"_____no_output_____"
]
],
[
[
"### Question 1 analysis",
"_____no_output_____"
],
[
"With almost 49% of the responses, a Master's degree was by far the most common level of education listed, more than double the next most popular answer. Other notable observations:\n * Sixty-eight percent of US Kagglers hold a Master's Degree or higher. \n * Research scientists and statisticians are most likely to hold PhDs, followed by Data Scientists.\n * Relatively few survey respondents (around 5%) indicate they do not have at least a Bachelor's degree.\n * Only 23% of those responding hold the title of Data Scientist, but it is nonetheless the title with the highest count. \n Arguably anyone who is active on Kaggle and who would complete their survey considers themself to be either in, or \n interested in, the data science field, if not actively working as a Data Scientist. ",
"_____no_output_____"
],
[
"### Question 2. What programming language(s) do Data Scientists need to know?",
"_____no_output_____"
],
[
"Now we'll turn to programming languages used. As this is a \"Select all that apply\" question, with each language option appearing as a separate column, we need to do some processing to get the data into a format for easier graphing and analysis.",
"_____no_output_____"
]
],
[
[
"# creating a dataframe of the language options and the number of times each language was selected\nlanguages = pd.DataFrame()\n\nfor col in us_df.columns:\n if(col.startswith('Q7_')):\n language = us_df[col].value_counts()\n languages = languages.append({'Language':language.index[0], 'Count':language[0]}, ignore_index=True)\nlanguages = languages.set_index('Language')\nlanguages = languages.sort_values(by = 'Count', ascending = False)\nlanguages_tot = sum(languages.Count)\nlanguages['Pct'] = round((languages['Count'] * 100 / languages_tot), 2)",
"_____no_output_____"
],
[
"list_and_bar_mc(languages, 'Programming Languages Used')",
" Count Pct\nLanguage \nPython 1290.0 29.72\nSQL 899.0 20.71\nR 549.0 12.65\nBash 304.0 7.00\nOther 281.0 6.47\nJavascript 265.0 6.11\nJava 214.0 4.93\nC++ 177.0 4.08\nMATLAB 138.0 3.18\nC 125.0 2.88\nJulia 37.0 0.85\nNone 37.0 0.85\nSwift 24.0 0.55\n"
],
[
"heatmap_mc('Q5', 'Q7', 'Language Use by Role', languages.index, q5_order)",
"_____no_output_____"
],
[
"heatmap_mc('Q4', 'Q7','Language Use by Education Level', languages.index, q4_order)",
"_____no_output_____"
],
[
"heatmap_mc('Q6', 'Q7', 'Language Use by Years Coding', languages.index, q6_order)",
"_____no_output_____"
]
],
[
[
"### Question 2 analysis",
"_____no_output_____"
],
[
"Python was the most widely used language, followed by SQL and R. Python held the top spot across almost all job roles -- only Statisticians listed another language (SQL) higher -- and for all education levels and coding experience. R enjoys widespread popularity across education level and years coding as well; SQL shows a high number of users overall, but they are more concentrated in people holding Master's or PhD degrees, working as Statisticians, Data Scientists and Data Analysts.",
"_____no_output_____"
],
[
"Kagglers reported using 2-3 languages on a regular basis.",
"_____no_output_____"
],
[
"### 3. What are the preferred online learning platforms to gain data science knowledge and skills?",
"_____no_output_____"
],
[
"Regarding online learning, Kaggle's survey asked, \"On which platforms have you begun or completed data science courses? (Select all that apply).\" We'll handle the answers similarly to the language data. ",
"_____no_output_____"
]
],
[
[
"# creating a dataframe of online course providers and the number of times each was selected by users\nplatforms = pd.DataFrame()\n\nfor col in us_df.columns:\n if(col.startswith('Q37_')):\n platform = us_df[col].value_counts()\n platforms = platforms.append({'Platform':platform.index[0], 'Count':platform[0]}, ignore_index=True)\nplatforms = platforms.set_index('Platform')\nplatforms = platforms.sort_values(by = 'Count', ascending=False)\nplatforms_tot = sum(platforms.Count)\nplatforms['Pct'] = round((platforms['Count'] * 100 / platforms_tot), 2)",
"_____no_output_____"
],
[
"list_and_bar_mc(platforms, 'Learning Platforms Used')",
" Count Pct\nPlatform \nCoursera 774.0 20.78\nKaggle Learn Courses 433.0 11.63\nUniversity Courses resulting in a degree 414.0 11.12\nUdemy 393.0 10.55\nDataCamp 367.0 9.85\nedX 328.0 8.81\nUdacity 254.0 6.82\nLinkedIn Learning 209.0 5.61\nNone 154.0 4.14\nFast.ai 144.0 3.87\nOther 139.0 3.73\nCloud-certification programs 115.0 3.09\n"
],
[
"heatmap_mc('Q5', 'Q37', 'Learning Platform Use by Role', platforms.index, q5_order)",
"_____no_output_____"
],
[
"heatmap_mc('Q4', 'Q37', 'Learning Platform Use by Education Level', platforms.index, q4_order)",
"_____no_output_____"
]
],
[
[
"### Question 3 analysis",
"_____no_output_____"
],
[
"Coursera was the most popular response, by a good margin. Kaggle Learn, University Courses towards a degree and Udemy followed, with Datacamp and edX not far behind. Kaggle Learn is a relatively new entrant into this area, offering short, narrowly-focused, skill-based courses for free which offer certificates upon completion. These factors may all contribute to the platform's popularity, as it is easy to try out for the cost of a few hours and no money.",
"_____no_output_____"
],
[
"Kagglers reported trying data science courses on two platforms, on average.",
"_____no_output_____"
],
[
"Coursera's popularity was high across almost education levels and job titles. Kaggle Learn's usage was fairly uniform across categories. Fast.ai was popular with Research Scientists, Data Scientists, Machine Learnig Engineers, and Statisticians. Other platforms seem to enjoy popularity with some groups more than others, but not in ways that make it easy to extrapolate much.",
"_____no_output_____"
],
[
"## Conclusion",
"_____no_output_____"
],
[
"The most well-travelled path into the data science field, at least for those responding to the 2020 Kaggle survey:\n * Get at least a Bachelor's degree, though a Master's degree may be preferable\n * Learn at least 2 coding languages -- Python and R are the top data science languages; depending on the role you want,\n you might want to get comfortable with another language, such as SQL or C.\n * Take classes on online learning platforms to update your skills and learn new ones. Coursera is the standard, while\n Kaggle Learn is a good option for short,targeted learning.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
d06247bb441bf750a87dbb311ea26d7a156ab0c3 | 9,961 | ipynb | Jupyter Notebook | 7.16.ipynb | zhayanqi/mysql | 9f03e75ca641cff27fb203ddd0d397d357019057 | [
"Apache-2.0"
]
| null | null | null | 7.16.ipynb | zhayanqi/mysql | 9f03e75ca641cff27fb203ddd0d397d357019057 | [
"Apache-2.0"
]
| null | null | null | 7.16.ipynb | zhayanqi/mysql | 9f03e75ca641cff27fb203ddd0d397d357019057 | [
"Apache-2.0"
]
| null | null | null | 19.119002 | 318 | 0.466419 | [
[
[
"# 基本程序设计\n- 一切代码输入,请使用英文输入法",
"_____no_output_____"
]
],
[
[
"print('hello word')",
"_____no_output_____"
],
[
"print 'hello'",
"_____no_output_____"
]
],
[
[
"## 编写一个简单的程序\n- 圆公式面积: area = radius \\* radius \\* 3.1415",
"_____no_output_____"
]
],
[
[
"radius = 1.0\narea = radius * radius * 3.14 # 将后半部分的结果赋值给变量area\n# 变量一定要有初始值!!!\n# radius: 变量.area: 变量!\n# int 类型\nprint(area)",
"3.14\n"
]
],
[
[
"### 在Python里面不需要定义数据的类型",
"_____no_output_____"
],
[
"## 控制台的读取与输入\n- input 输入进去的是字符串\n- eval",
"_____no_output_____"
]
],
[
[
"radius = input('请输入半径') # input得到的结果是字符串类型\nradius = float(radius)\narea = radius * radius * 3.14\nprint('面积为:',area)",
"请输入半径10\n面积为: 314.0\n"
]
],
[
[
"- 在jupyter用shift + tab 键可以跳出解释文档",
"_____no_output_____"
],
[
"## 变量命名的规范\n- 由字母、数字、下划线构成\n- 不能以数字开头 \\*\n- 标识符不能是关键词(实际上是可以强制改变的,但是对于代码规范而言是极其不适合)\n- 可以是任意长度\n- 驼峰式命名",
"_____no_output_____"
],
[
"## 变量、赋值语句和赋值表达式\n- 变量: 通俗理解为可以变化的量\n- x = 2 \\* x + 1 在数学中是一个方程,而在语言中它是一个表达式\n- test = test + 1 \\* 变量在赋值之前必须有值",
"_____no_output_____"
],
[
"## 同时赋值\nvar1, var2,var3... = exp1,exp2,exp3...",
"_____no_output_____"
],
[
"## 定义常量\n- 常量:表示一种定值标识符,适合于多次使用的场景。比如PI\n- 注意:在其他低级语言中如果定义了常量,那么,该常量是不可以被改变的,但是在Python中一切皆对象,常量也是可以被改变的",
"_____no_output_____"
],
[
"## 数值数据类型和运算符\n- 在Python中有两种数值类型(int 和 float)适用于加减乘除、模、幂次\n<img src = \"../Photo/01.jpg\"></img>",
"_____no_output_____"
],
[
"## 运算符 /、//、**",
"_____no_output_____"
],
[
"## 运算符 %",
"_____no_output_____"
],
[
"## EP:\n- 25/4 多少,如果要将其转变为整数该怎么改写\n- 输入一个数字判断是奇数还是偶数\n- 进阶: 输入一个秒,数,写一个程序将其转换成分和秒:例如500秒等于8分20秒\n- 进阶: 如果今天是星期六,那么10天以后是星期几? 提示:每个星期的第0天是星期天",
"_____no_output_____"
]
],
[
[
"day = eval(input('week'))\nplus_day = eval(input('plus'))\n",
"_____no_output_____"
]
],
[
[
"## 计算表达式和运算优先级\n<img src = \"../Photo/02.png\"></img>\n<img src = \"../Photo/03.png\"></img>",
"_____no_output_____"
],
[
"## 增强型赋值运算\n<img src = \"../Photo/04.png\"></img>",
"_____no_output_____"
],
[
"## 类型转换\n- float -> int\n- 四舍五入 round",
"_____no_output_____"
],
[
"## EP:\n- 如果一个年营业税为0.06%,那么对于197.55e+2的年收入,需要交税为多少?(结果保留2为小数)\n- 必须使用科学计数法",
"_____no_output_____"
],
[
"# Project\n- 用Python写一个贷款计算器程序:输入的是月供(monthlyPayment) 输出的是总还款数(totalpayment)\n",
"_____no_output_____"
],
[
"# Homework\n- 1\n<img src=\"../Photo/06.png\"></img>",
"_____no_output_____"
]
],
[
[
"celsius = input('请输入温度')\ncelsius = float(celsius)\nfahrenheit = (9/5) * celsius + 32\nprint(celsius,'Celsius is',fahrenheit,'Fahrenheit')",
"请输入温度43\n43.0 Celsius is 109.4 Fahrenheit\n"
]
],
[
[
"- 2\n<img src=\"../Photo/07.png\"></img>",
"_____no_output_____"
]
],
[
[
"radius = input('请输入半径')\nlength = input('请输入高')\nradius = float(radius)\nlength = float(length)\narea = radius * radius * 3.14\nvolume = area * length\nprint('The area is',area)\nprint('The volume is',volume)",
"请输入半径5.5\n请输入高12\nThe area is 94.985\nThe volume is 1139.82\n"
]
],
[
[
"- 3\n<img src=\"../Photo/08.png\"></img>",
"_____no_output_____"
]
],
[
[
"feet = input('请输入英尺')\nfeet = float(feet)\nmeter = feet * 0.305\nprint(feet,'feet is',meter,'meters')",
"请输入英尺16.5\n16.5 feet is 5.0325 meters\n"
]
],
[
[
"- 4\n<img src=\"../Photo/10.png\"></img>",
"_____no_output_____"
]
],
[
[
"M = input('请输入水量')\ninitial = input('请输入初始温度')\nfinal = input('请输入最终温度')\nM = float(M)\ninitial = float(initial)\nfinal = float(final)\nQ = M * (final - initial) * 4184\nprint('The energy needed is ',Q)",
"请输入水量55.5\n请输入初始温度3.5\n请输入最终温度10.5\nThe energy needed is 1625484.0\n"
]
],
[
[
"- 5\n<img src=\"../Photo/11.png\"></img>",
"_____no_output_____"
]
],
[
[
"cha = input('请输入差额')\nrate = input('请输入年利率')\ncha = float(cha)\nrate = float(rate)\ninterest = cha * (rate/1200)\nprint(interest)",
"请输入差额1000\n请输入年利率3.5\n2.916666666666667\n"
]
],
[
[
"- 6\n<img src=\"../Photo/12.png\"></img>",
"_____no_output_____"
]
],
[
[
"start = input('请输入初始速度')\nend = input('请输入末速度')\ntime = input('请输入时间')\nstart = float(start)\nend =float(end)\ntime = float(time)\na = (end - start)/time\nprint(a)",
"请输入初始速度5.5\n请输入末速度50.9\n请输入时间4.5\n10.088888888888889\n"
]
],
[
[
"- 7 进阶\n<img src=\"../Photo/13.png\"></img>",
"_____no_output_____"
],
[
"- 8 进阶\n<img src=\"../Photo/14.png\"></img>",
"_____no_output_____"
]
],
[
[
"a,b = eval(input('>>'))\nprint(a,b)\nprint(type(a),type(b))",
">>1,1.0\n1 1.0\n<class 'int'> <class 'float'>\n"
],
[
"a = eval(input('>>'))\nprint(a)",
">>1,2,3,4,5,6\n(1, 2, 3, 4, 5, 6)\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
]
|
d062488abb878f5992408c178f41f69940586dd0 | 55,258 | ipynb | Jupyter Notebook | notebooks/sum_backbone_stack_hb_0.ipynb | yizaochen/enmspring | 84c9aabeb7f87eda43967d86c763b7d600986215 | [
"MIT"
]
| null | null | null | notebooks/sum_backbone_stack_hb_0.ipynb | yizaochen/enmspring | 84c9aabeb7f87eda43967d86c763b7d600986215 | [
"MIT"
]
| null | null | null | notebooks/sum_backbone_stack_hb_0.ipynb | yizaochen/enmspring | 84c9aabeb7f87eda43967d86c763b7d600986215 | [
"MIT"
]
| null | null | null | 40.931852 | 3,264 | 0.434127 | [
[
[
"from os import path\nfrom enmspring.sum_bb_st_hb_k import ThreeBar\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom matplotlib import rcParams\nbig_traj_folder = '/home/ytcdata/bigtraj_fluctmatch/500ns'\ndrawzone_folder = '/home/yizaochen/Desktop/drawzone_temp'\ndata_folder = '/home/yizaochen/Documents/dna_2021_drawzone/summation_bb_st_hb'\nrcParams['font.family'] = 'Arial'",
"_____no_output_____"
]
],
[
[
"### Part 1: Initailize Plot Agent",
"_____no_output_____"
]
],
[
[
"plot_agent = ThreeBar(big_traj_folder, data_folder)",
"_____no_output_____"
]
],
[
[
"### Part 2: Make/Read DataFrame",
"_____no_output_____"
]
],
[
[
"makedf = False\nif makedf:\n plot_agent.ini_b_agent()\n plot_agent.ini_s_agent()\n plot_agent.ini_h_agent()\n plot_agent.make_df_for_all_host()",
"_____no_output_____"
],
[
"plot_agent.read_df_for_all_host()",
"_____no_output_____"
]
],
[
[
"### Part 2: Bar Plot",
"_____no_output_____"
]
],
[
[
"figsize = (1.817, 1.487)\nhspace = 0\n\nplot_agent.plot_main(figsize, hspace)\nsvg_out = path.join(drawzone_folder, 'sum_bb_st_hb.svg')\nplt.savefig(svg_out, dpi=200)\nplt.show()",
"_____no_output_____"
],
[
"from enmspring.graphs_bigtraj import BackboneMeanModeAgent",
"_____no_output_____"
],
[
"host = 'a_tract_21mer'\ninterval_time = 500\nb_agent = BackboneMeanModeAgent(host, big_traj_folder, interval_time)",
"/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/mean_mode_npy exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/0_500/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/250_750/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/500_1000/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/750_1250/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/1000_1500/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/1250_1750/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/1500_2000/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/1750_2250/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/2000_2500/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/2250_2750/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/2500_3000/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/2750_3250/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/3000_3500/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/3250_3750/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/3500_4000/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/3750_4250/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/4000_4500/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/4250_4750/pd_dfs exists\n/home/ytcdata/bigtraj_fluctmatch/500ns/a_tract_21mer/bdna+bdna/4500_5000/pd_dfs exists\n"
],
[
"b_agent.preprocess_all_small_agents()",
"Thare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\nThare are 855 nodes.\nInitialize adjacency, degree and Laplacian matrices... Done.\nFinish the setup for Laplaican matrix.\nTotal number of nodes: 855\nThere are 438 eigenvectors belonging to STRAND1.\nThere are 417 eigenvectors belonging to STRAND2.\nSum of two strands: 855\n"
],
[
"b_agent.d_smallagents[(0,500)].laplacian_mat",
"_____no_output_____"
],
[
"b_agent.initialize_all_maps()",
"_____no_output_____"
],
[
"b_agent.n_window",
"_____no_output_____"
],
[
"from enmspring.hb_k import HBResidPlotV1\nbigtraj_folder = '/home/ytcdata/bigtraj_fluctmatch'\ndf_folder = '/home/yizaochen/Documents/dna_2021_drawzone/local_hb'",
"_____no_output_____"
],
[
"interval_time = 500\nplot_agent = HBResidPlotV1(bigtraj_folder, interval_time, df_folder)",
"_____no_output_____"
],
[
"plot_agent.read_mean_std_df()",
"Read df_mean from /home/yizaochen/Documents/dna_2021_drawzone/local_hb/hb.mean.csv\nRead df_std from /home/yizaochen/Documents/dna_2021_drawzone/local_hb/hb.std.csv\n"
],
[
"plot_agent.df_mean",
"_____no_output_____"
],
[
"plot_agent.df_std",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d0624c3648d264d7db51f66d4e56be8724034121 | 5,430 | ipynb | Jupyter Notebook | notebooks/xmap.ipynb | yssource/xplot | 69233b204bd680eeb19cecbe7712c3e09fefb83a | [
"BSD-3-Clause"
]
| null | null | null | notebooks/xmap.ipynb | yssource/xplot | 69233b204bd680eeb19cecbe7712c3e09fefb83a | [
"BSD-3-Clause"
]
| null | null | null | notebooks/xmap.ipynb | yssource/xplot | 69233b204bd680eeb19cecbe7712c3e09fefb83a | [
"BSD-3-Clause"
]
| null | null | null | 19.462366 | 73 | 0.466851 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
d0625bd93fde81ac8be7517aa3101d8361d6bd43 | 47,126 | ipynb | Jupyter Notebook | chatbot.ipynb | Kevinz930/Alexiri-chatbot- | 43cd1daf633516a79a6d7ff23beb866f5f59d62d | [
"MIT"
]
| null | null | null | chatbot.ipynb | Kevinz930/Alexiri-chatbot- | 43cd1daf633516a79a6d7ff23beb866f5f59d62d | [
"MIT"
]
| null | null | null | chatbot.ipynb | Kevinz930/Alexiri-chatbot- | 43cd1daf633516a79a6d7ff23beb866f5f59d62d | [
"MIT"
]
| null | null | null | 38.407498 | 244 | 0.533463 | [
[
[
"from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport torch\nfrom torch.jit import script, trace\nimport torch.nn as nn\nfrom torch import optim\nimport torch.nn.functional as F\nimport csv\nimport random\nimport re\nimport os\nimport unicodedata\nimport codecs\nfrom io import open\nimport itertools\nimport math\nimport gensim",
"_____no_output_____"
],
[
"USE_CUDA = torch.cuda.is_available()\ndevice = torch.device(\"cuda\" if USE_CUDA else \"cpu\")",
"_____no_output_____"
]
],
[
[
"# Load & Preprocess Data",
"_____no_output_____"
],
[
"### Cornell Movie Dialogues Corpus",
"_____no_output_____"
]
],
[
[
"corpus_name = \"cornell movie-dialogs corpus\"\ncorpus = os.path.join(\"data\", corpus_name)\n\ndef printLines(file, n=10):\n with open(file, 'rb') as datafile:\n lines = datafile.readlines()\n for line in lines[:n]:\n print(line)\n\nprintLines(os.path.join(corpus, \"movie_lines.txt\"))",
"b'L1045 +++$+++ u0 +++$+++ m0 +++$+++ BIANCA +++$+++ They do not!\\r\\n'\nb'L1044 +++$+++ u2 +++$+++ m0 +++$+++ CAMERON +++$+++ They do to!\\r\\n'\nb'L985 +++$+++ u0 +++$+++ m0 +++$+++ BIANCA +++$+++ I hope so.\\r\\n'\nb'L984 +++$+++ u2 +++$+++ m0 +++$+++ CAMERON +++$+++ She okay?\\r\\n'\nb\"L925 +++$+++ u0 +++$+++ m0 +++$+++ BIANCA +++$+++ Let's go.\\r\\n\"\nb'L924 +++$+++ u2 +++$+++ m0 +++$+++ CAMERON +++$+++ Wow\\r\\n'\nb\"L872 +++$+++ u0 +++$+++ m0 +++$+++ BIANCA +++$+++ Okay -- you're gonna need to learn how to lie.\\r\\n\"\nb'L871 +++$+++ u2 +++$+++ m0 +++$+++ CAMERON +++$+++ No\\r\\n'\nb'L870 +++$+++ u0 +++$+++ m0 +++$+++ BIANCA +++$+++ I\\'m kidding. You know how sometimes you just become this \"persona\"? And you don\\'t know how to quit?\\r\\n'\nb'L869 +++$+++ u0 +++$+++ m0 +++$+++ BIANCA +++$+++ Like my fear of wearing pastels?\\r\\n'\n"
],
[
"# Splits each line of the file into a dictionary of fields\ndef loadLines(fileName, fields):\n lines = {}\n with open(fileName, 'r', encoding='iso-8859-1') as f:\n for line in f:\n values = line.split(\" +++$+++ \")\n # Extract fields\n lineObj = {}\n for i, field in enumerate(fields):\n lineObj[field] = values[i]\n lines[lineObj['lineID']] = lineObj\n return lines\n\n\n# Groups fields of lines from `loadLines` into conversations based on *movie_conversations.txt*\ndef loadConversations(fileName, lines, fields):\n conversations = []\n with open(fileName, 'r', encoding='iso-8859-1') as f:\n for line in f:\n values = line.split(\" +++$+++ \")\n # Extract fields\n convObj = {}\n for i, field in enumerate(fields):\n convObj[field] = values[i]\n # Convert string to list (convObj[\"utteranceIDs\"] == \"['L598485', 'L598486', ...]\")\n utterance_id_pattern = re.compile('L[0-9]+')\n lineIds = utterance_id_pattern.findall(convObj[\"utteranceIDs\"])\n # Reassemble lines\n convObj[\"lines\"] = []\n for lineId in lineIds:\n convObj[\"lines\"].append(lines[lineId])\n conversations.append(convObj)\n return conversations\n\n\n# Extracts pairs of sentences from conversations\ndef extractSentencePairs(conversations):\n qa_pairs = []\n for conversation in conversations:\n # Iterate over all the lines of the conversation\n for i in range(len(conversation[\"lines\"]) - 1): # We ignore the last line (no answer for it)\n inputLine = conversation[\"lines\"][i][\"text\"].strip()\n targetLine = conversation[\"lines\"][i+1][\"text\"].strip()\n # Filter wrong samples (if one of the lists is empty)\n if inputLine and targetLine:\n qa_pairs.append([inputLine, targetLine])\n return qa_pairs",
"_____no_output_____"
],
[
"# Define path to new file\ndatafile = os.path.join(corpus, \"formatted_movie_lines.txt\")\n\ndelimiter = '\\t'\n# Unescape the delimiter\ndelimiter = str(codecs.decode(delimiter, \"unicode_escape\"))\n\n# Initialize lines dict, conversations list, and field ids\nlines = {}\nconversations = []\nMOVIE_LINES_FIELDS = [\"lineID\", \"characterID\", \"movieID\", \"character\", \"text\"]\nMOVIE_CONVERSATIONS_FIELDS = [\"character1ID\", \"character2ID\", \"movieID\", \"utteranceIDs\"]\n\n# Load lines and process conversations\nprint(\"\\nProcessing corpus...\")\nlines = loadLines(os.path.join(corpus, \"movie_lines.txt\"), MOVIE_LINES_FIELDS)\nprint(\"\\nLoading conversations...\")\nconversations = loadConversations(os.path.join(corpus, \"movie_conversations.txt\"),\n lines, MOVIE_CONVERSATIONS_FIELDS)\n\n# Write new csv file\nprint(\"\\nWriting newly formatted file...\")\nwith open(datafile, 'w', encoding='utf-8') as outputfile:\n writer = csv.writer(outputfile, delimiter=delimiter, lineterminator='\\n')\n for pair in extractSentencePairs(conversations):\n writer.writerow(pair)\n\n# Print a sample of lines\nprint(\"\\nSample lines from file:\")\nprintLines(datafile)",
"\nProcessing corpus...\n\nLoading conversations...\n\nWriting newly formatted file...\n\nSample lines from file:\nb\"Can we make this quick? Roxanne Korrine and Andrew Barrett are having an incredibly horrendous public break- up on the quad. Again.\\tWell, I thought we'd start with pronunciation, if that's okay with you.\\r\\n\"\nb\"Well, I thought we'd start with pronunciation, if that's okay with you.\\tNot the hacking and gagging and spitting part. Please.\\r\\n\"\nb\"Not the hacking and gagging and spitting part. Please.\\tOkay... then how 'bout we try out some French cuisine. Saturday? Night?\\r\\n\"\nb\"You're asking me out. That's so cute. What's your name again?\\tForget it.\\r\\n\"\nb\"No, no, it's my fault -- we didn't have a proper introduction ---\\tCameron.\\r\\n\"\nb\"Cameron.\\tThe thing is, Cameron -- I'm at the mercy of a particularly hideous breed of loser. My sister. I can't date until she does.\\r\\n\"\nb\"The thing is, Cameron -- I'm at the mercy of a particularly hideous breed of loser. My sister. I can't date until she does.\\tSeems like she could get a date easy enough...\\r\\n\"\nb'Why?\\tUnsolved mystery. She used to be really popular when she started high school, then it was just like she got sick of it or something.\\r\\n'\nb\"Unsolved mystery. She used to be really popular when she started high school, then it was just like she got sick of it or something.\\tThat's a shame.\\r\\n\"\nb'Gosh, if only we could find Kat a boyfriend...\\tLet me see what I can do.\\r\\n'\n"
],
[
"# Default word tokens\nPAD_token = 0 # Used for padding short sentences\nSOS_token = 1 # Start-of-sentence token\nEOS_token = 2 # End-of-sentence token\n\nclass Voc:\n def __init__(self, name):\n self.name = name\n self.trimmed = False\n self.word2index = {}\n self.word2count = {}\n self.index2word = {PAD_token: \"PAD\", SOS_token: \"SOS\", EOS_token: \"EOS\"}\n self.num_words = 3 # Count SOS, EOS, PAD\n\n def addSentence(self, sentence):\n for word in sentence.split(' '):\n self.addWord(word)\n\n def addWord(self, word):\n if word not in self.word2index:\n self.word2index[word] = self.num_words\n self.word2count[word] = 1\n self.index2word[self.num_words] = word\n self.num_words += 1\n else:\n self.word2count[word] += 1\n\n # Remove words below a certain count threshold\n def trim(self, min_count):\n if self.trimmed:\n return\n self.trimmed = True\n\n keep_words = []\n\n for k, v in self.word2count.items():\n if v >= min_count:\n keep_words.append(k)\n\n print('keep_words {} / {} = {:.4f}'.format(\n len(keep_words), len(self.word2index), len(keep_words) / len(self.word2index)\n ))\n\n # Reinitialize dictionaries\n self.word2index = {}\n self.word2count = {}\n self.index2word = {PAD_token: \"PAD\", SOS_token: \"SOS\", EOS_token: \"EOS\"}\n self.num_words = 3 # Count default tokens\n\n for word in keep_words:\n self.addWord(word)",
"_____no_output_____"
],
[
"MAX_LENGTH = 10 # Maximum sentence length to consider\n\n# Turn a Unicode string to plain ASCII, thanks to\n# https://stackoverflow.com/a/518232/2809427\ndef unicodeToAscii(s):\n return ''.join(\n c for c in unicodedata.normalize('NFD', s)\n if unicodedata.category(c) != 'Mn'\n )\n\n# Lowercase, trim, and remove non-letter characters\ndef normalizeString(s):\n s = unicodeToAscii(s.lower().strip())\n s = re.sub(r\"([.!?])\", r\" \\1\", s)\n s = re.sub(r\"[^a-zA-Z.!?']+\", r\" \", s)\n s = re.sub(r\"\\s+\", r\" \", s).strip()\n return s\n\n# Read query/response pairs and return a voc object\ndef readVocs(datafile, corpus_name):\n print(\"Reading lines...\")\n # Read the file and split into lines\n lines = open(datafile, encoding='utf-8').\\\n read().strip().split('\\n')\n # Split every line into pairs and normalize\n pairs = [[normalizeString(s) for s in l.split('\\t')] for l in lines]\n voc = Voc(corpus_name)\n return voc, pairs\n\n# Returns True iff both sentences in a pair 'p' are under the MAX_LENGTH threshold\ndef filterPair(p):\n # Input sequences need to preserve the last word for EOS token\n return len(p[0].split(' ')) < MAX_LENGTH and len(p[1].split(' ')) < MAX_LENGTH\n\n# Filter pairs using filterPair condition\ndef filterPairs(pairs):\n return [pair for pair in pairs if filterPair(pair)]\n\n# Using the functions defined above, return a populated voc object and pairs list\ndef loadPrepareData(corpus, corpus_name, datafile, save_dir):\n print(\"Start preparing training data ...\")\n voc, pairs = readVocs(datafile, corpus_name)\n print(\"Read {!s} sentence pairs\".format(len(pairs)))\n pairs = filterPairs(pairs)\n print(\"Trimmed to {!s} sentence pairs\".format(len(pairs)))\n print(\"Counting words...\")\n for pair in pairs:\n voc.addSentence(pair[0])\n voc.addSentence(pair[1])\n print(\"Counted words:\", voc.num_words)\n return voc, pairs\n\n\n# Load/Assemble voc and pairs\nsave_dir = os.path.join(\"data\", \"save\")\nvoc, pairs = loadPrepareData(corpus, corpus_name, datafile, save_dir)\n# Print some pairs to validate\nprint(\"\\npairs:\")\nfor pair in pairs[:10]:\n print(pair)",
"Start preparing training data ...\nReading lines...\nRead 221282 sentence pairs\nTrimmed to 70086 sentence pairs\nCounting words...\nCounted words: 20282\n\npairs:\n[\"that's because it's such a nice one .\", 'forget french .']\n['there .', 'where ?']\n['you have my word . as a gentleman', \"you're sweet .\"]\n['hi .', 'looks like things worked out tonight huh ?']\n['you know chastity ?', 'i believe we share an art instructor']\n['have fun tonight ?', 'tons']\n['well no . . .', \"then that's all you had to say .\"]\n[\"then that's all you had to say .\", 'but']\n['but', 'you always been this selfish ?']\n['do you listen to this crap ?', 'what crap ?']\n"
],
[
"MIN_COUNT = 3 # Minimum word count threshold for trimming\n\ndef trimRareWords(voc, pairs, MIN_COUNT):\n # Trim words used under the MIN_COUNT from the voc\n voc.trim(MIN_COUNT)\n # Filter out pairs with trimmed words\n keep_pairs = []\n for pair in pairs:\n input_sentence = pair[0]\n output_sentence = pair[1]\n keep_input = True\n keep_output = True\n # Check input sentence\n for word in input_sentence.split(' '):\n if word not in voc.word2index:\n keep_input = False\n break\n # Check output sentence\n for word in output_sentence.split(' '):\n if word not in voc.word2index:\n keep_output = False\n break\n\n # Only keep pairs that do not contain trimmed word(s) in their input or output sentence\n if keep_input and keep_output:\n keep_pairs.append(pair)\n\n print(\"Trimmed from {} pairs to {}, {:.4f} of total\".format(len(pairs), len(keep_pairs), len(keep_pairs) / len(pairs)))\n return keep_pairs\n\n\n# Trim voc and pairs\npairs = trimRareWords(voc, pairs, MIN_COUNT)",
"keep_words 8610 / 20279 = 0.4246\nTrimmed from 70086 pairs to 57379, 0.8187 of total\n"
]
],
[
[
"# Prepare Data for Models",
"_____no_output_____"
]
],
[
[
"def indexesFromSentence(voc, sentence):\n return [voc.word2index[word] for word in sentence.split(' ')] + [EOS_token]\n\n\ndef zeroPadding(l, fillvalue=PAD_token):\n return list(itertools.zip_longest(*l, fillvalue=fillvalue))\n\ndef binaryMatrix(l, value=PAD_token):\n m = []\n for i, seq in enumerate(l):\n m.append([])\n for token in seq:\n if token == PAD_token:\n m[i].append(0)\n else:\n m[i].append(1)\n return m\n\n# Returns padded input sequence tensor and lengths\ndef inputVar(l, voc):\n indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]\n lengths = torch.tensor([len(indexes) for indexes in indexes_batch])\n padList = zeroPadding(indexes_batch)\n padVar = torch.LongTensor(padList)\n return padVar, lengths\n\n# Returns padded target sequence tensor, padding mask, and max target length\ndef outputVar(l, voc):\n indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]\n max_target_len = max([len(indexes) for indexes in indexes_batch])\n padList = zeroPadding(indexes_batch)\n mask = binaryMatrix(padList)\n mask = torch.BoolTensor(mask)\n padVar = torch.LongTensor(padList)\n return padVar, mask, max_target_len\n\n# Returns all items for a given batch of pairs\ndef batch2TrainData(voc, pair_batch):\n pair_batch.sort(key=lambda x: len(x[0].split(\" \")), reverse=True)\n input_batch, output_batch = [], []\n for pair in pair_batch:\n input_batch.append(pair[0])\n output_batch.append(pair[1])\n inp, lengths = inputVar(input_batch, voc)\n output, mask, max_target_len = outputVar(output_batch, voc)\n return inp, lengths, output, mask, max_target_len\n\n\n# Example for validation\nsmall_batch_size = 5\nbatches = batch2TrainData(voc, [random.choice(pairs) for _ in range(small_batch_size)])\ninput_variable, lengths, target_variable, mask, max_target_len = batches\n\nprint(\"input_variable:\", input_variable)\nprint(\"lengths:\", lengths)\nprint(\"target_variable:\", target_variable)\nprint(\"mask:\", mask)\nprint(\"max_target_len:\", max_target_len)",
"input_variable: tensor([[ 33, 42, 83, 181, 279],\n [ 97, 67, 59, 341, 31],\n [ 32, 1089, 735, 33, 10],\n [ 10, 260, 112, 32, 2],\n [ 563, 33, 16, 15, 0],\n [ 46, 121, 15, 2, 0],\n [ 82, 1727, 2, 0, 0],\n [ 10, 10, 0, 0, 0],\n [ 2, 2, 0, 0, 0]])\nlengths: tensor([9, 9, 7, 6, 4])\ntarget_variable: tensor([[ 56, 125, 5, 616, 22],\n [ 53, 548, 68, 175, 73],\n [ 33, 10, 10, 59, 7],\n [ 47, 2, 33, 1905, 3516],\n [ 15, 0, 32, 10, 4119],\n [ 2, 0, 204, 2, 10],\n [ 0, 0, 10, 0, 2],\n [ 0, 0, 2, 0, 0]])\nmask: tensor([[ True, True, True, True, True],\n [ True, True, True, True, True],\n [ True, True, True, True, True],\n [ True, True, True, True, True],\n [ True, False, True, True, True],\n [ True, False, True, True, True],\n [False, False, True, False, True],\n [False, False, True, False, False]])\nmax_target_len: 8\n"
]
],
[
[
"# Encoder",
"_____no_output_____"
]
],
[
[
"class EncoderRNN(nn.Module):\n def __init__(self, hidden_size, embedding, n_layers=1, dropout=0):\n super(EncoderRNN, self).__init__()\n self.n_layers = n_layers\n self.hidden_size = hidden_size\n self.embedding = embedding\n\n # Initialize GRU; the input_size and hidden_size params are both set to 'hidden_size'\n # because our input size is a word embedding with number of features == hidden_size\n self.gru = nn.GRU(hidden_size, hidden_size, n_layers,\n dropout=(0 if n_layers == 1 else dropout), bidirectional=True)\n\n def forward(self, input_seq, input_lengths, hidden=None):\n # Convert word indexes to embeddings\n embedded = self.embedding(input_seq)\n # Pack padded batch of sequences for RNN module\n packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)\n # Forward pass through GRU\n outputs, hidden = self.gru(packed, hidden)\n # Unpack padding\n outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs)\n # Sum bidirectional GRU outputs\n outputs = outputs[:, :, :self.hidden_size] + outputs[:, : ,self.hidden_size:]\n # Return output and final hidden state\n return outputs, hidden",
"_____no_output_____"
]
],
[
[
"# Decoder",
"_____no_output_____"
]
],
[
[
"# Luong attention layer\nclass Attn(nn.Module):\n def __init__(self, method, hidden_size):\n super(Attn, self).__init__()\n self.method = method\n if self.method not in ['dot', 'general', 'concat']:\n raise ValueError(self.method, \"is not an appropriate attention method.\")\n self.hidden_size = hidden_size\n if self.method == 'general':\n self.attn = nn.Linear(self.hidden_size, hidden_size)\n elif self.method == 'concat':\n self.attn = nn.Linear(self.hidden_size * 2, hidden_size)\n self.v = nn.Parameter(torch.FloatTensor(hidden_size))\n\n def dot_score(self, hidden, encoder_output):\n return torch.sum(hidden * encoder_output, dim=2)\n\n def general_score(self, hidden, encoder_output):\n energy = self.attn(encoder_output)\n return torch.sum(hidden * energy, dim=2)\n\n def concat_score(self, hidden, encoder_output):\n energy = self.attn(torch.cat((hidden.expand(encoder_output.size(0), -1, -1), encoder_output), 2)).tanh()\n return torch.sum(self.v * energy, dim=2)\n\n def forward(self, hidden, encoder_outputs):\n # Calculate the attention weights (energies) based on the given method\n if self.method == 'general':\n attn_energies = self.general_score(hidden, encoder_outputs)\n elif self.method == 'concat':\n attn_energies = self.concat_score(hidden, encoder_outputs)\n elif self.method == 'dot':\n attn_energies = self.dot_score(hidden, encoder_outputs)\n\n # Transpose max_length and batch_size dimensions\n attn_energies = attn_energies.t()\n\n # Return the softmax normalized probability scores (with added dimension)\n return F.softmax(attn_energies, dim=1).unsqueeze(1)",
"_____no_output_____"
],
[
"class LuongAttnDecoderRNN(nn.Module):\n def __init__(self, attn_model, embedding, hidden_size, output_size, n_layers=1, dropout=0.1):\n super(LuongAttnDecoderRNN, self).__init__()\n\n # Keep for reference\n self.attn_model = attn_model\n self.hidden_size = hidden_size\n self.output_size = output_size\n self.n_layers = n_layers\n self.dropout = dropout\n\n # Define layers\n self.embedding = embedding\n self.embedding_dropout = nn.Dropout(dropout)\n self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=(0 if n_layers == 1 else dropout))\n self.concat = nn.Linear(hidden_size * 2, hidden_size)\n self.out = nn.Linear(hidden_size, output_size)\n\n self.attn = Attn(attn_model, hidden_size)\n\n def forward(self, input_step, last_hidden, encoder_outputs):\n # Note: we run this one step (word) at a time\n # Get embedding of current input word\n embedded = self.embedding(input_step)\n embedded = self.embedding_dropout(embedded)\n # Forward through unidirectional GRU\n rnn_output, hidden = self.gru(embedded, last_hidden)\n # Calculate attention weights from the current GRU output\n attn_weights = self.attn(rnn_output, encoder_outputs)\n # Multiply attention weights to encoder outputs to get new \"weighted sum\" context vector\n context = attn_weights.bmm(encoder_outputs.transpose(0, 1))\n # Concatenate weighted context vector and GRU output using Luong eq. 5\n rnn_output = rnn_output.squeeze(0)\n context = context.squeeze(1)\n concat_input = torch.cat((rnn_output, context), 1)\n concat_output = torch.tanh(self.concat(concat_input))\n # Predict next word using Luong eq. 6\n output = self.out(concat_output)\n output = F.softmax(output, dim=1)\n # Return output and final hidden state\n return output, hidden",
"_____no_output_____"
]
],
[
[
"# Training Procedure",
"_____no_output_____"
]
],
[
[
"def maskNLLLoss(inp, target, mask):\n nTotal = mask.sum()\n crossEntropy = -torch.log(torch.gather(inp, 1, target.view(-1, 1)).squeeze(1))\n loss = crossEntropy.masked_select(mask).mean()\n loss = loss.to(device)\n return loss, nTotal.item()",
"_____no_output_____"
],
[
"def train(input_variable, lengths, target_variable, mask, max_target_len, encoder, decoder, embedding,\n encoder_optimizer, decoder_optimizer, batch_size, clip, max_length=MAX_LENGTH):\n\n # Zero gradients\n encoder_optimizer.zero_grad()\n decoder_optimizer.zero_grad()\n\n # Set device options\n input_variable = input_variable.to(device)\n target_variable = target_variable.to(device)\n mask = mask.to(device)\n # Lengths for rnn packing should always be on the cpu\n lengths = lengths.to(\"cpu\")\n\n # Initialize variables\n loss = 0\n print_losses = []\n n_totals = 0\n\n # Forward pass through encoder\n encoder_outputs, encoder_hidden = encoder(input_variable, lengths)\n\n # Create initial decoder input (start with SOS tokens for each sentence)\n decoder_input = torch.LongTensor([[SOS_token for _ in range(batch_size)]])\n decoder_input = decoder_input.to(device)\n\n # Set initial decoder hidden state to the encoder's final hidden state\n decoder_hidden = encoder_hidden[:decoder.n_layers]\n\n # Determine if we are using teacher forcing this iteration\n use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False\n\n # Forward batch of sequences through decoder one time step at a time\n if use_teacher_forcing:\n for t in range(max_target_len):\n decoder_output, decoder_hidden = decoder(\n decoder_input, decoder_hidden, encoder_outputs\n )\n # Teacher forcing: next input is current target\n decoder_input = target_variable[t].view(1, -1)\n # Calculate and accumulate loss\n mask_loss, nTotal = maskNLLLoss(decoder_output, target_variable[t], mask[t])\n loss += mask_loss\n print_losses.append(mask_loss.item() * nTotal)\n n_totals += nTotal\n else:\n for t in range(max_target_len):\n decoder_output, decoder_hidden = decoder(\n decoder_input, decoder_hidden, encoder_outputs\n )\n # No teacher forcing: next input is decoder's own current output\n _, topi = decoder_output.topk(1)\n decoder_input = torch.LongTensor([[topi[i][0] for i in range(batch_size)]])\n decoder_input = decoder_input.to(device)\n # Calculate and accumulate loss\n mask_loss, nTotal = maskNLLLoss(decoder_output, target_variable[t], mask[t])\n loss += mask_loss\n print_losses.append(mask_loss.item() * nTotal)\n n_totals += nTotal\n\n # Perform backpropatation\n loss.backward()\n\n # Clip gradients: gradients are modified in place\n _ = nn.utils.clip_grad_norm_(encoder.parameters(), clip)\n _ = nn.utils.clip_grad_norm_(decoder.parameters(), clip)\n\n # Adjust model weights\n encoder_optimizer.step()\n decoder_optimizer.step()\n\n return sum(print_losses) / n_totals",
"_____no_output_____"
],
[
"def trainIters(model_name, voc, pairs, encoder, decoder, encoder_optimizer, decoder_optimizer, embedding, encoder_n_layers, decoder_n_layers, save_dir, n_iteration, batch_size, print_every, save_every, clip, corpus_name, loadFilename):\n\n # Load batches for each iteration\n training_batches = [batch2TrainData(voc, [random.choice(pairs) for _ in range(batch_size)])\n for _ in range(n_iteration)]\n\n # Initializations\n print('Initializing ...')\n start_iteration = 1\n print_loss = 0\n if loadFilename:\n start_iteration = checkpoint['iteration'] + 1\n\n # Training loop\n print(\"Training...\")\n for iteration in range(start_iteration, n_iteration + 1):\n training_batch = training_batches[iteration - 1]\n # Extract fields from batch\n input_variable, lengths, target_variable, mask, max_target_len = training_batch\n\n # Run a training iteration with batch\n loss = train(input_variable, lengths, target_variable, mask, max_target_len, encoder,\n decoder, embedding, encoder_optimizer, decoder_optimizer, batch_size, clip)\n print_loss += loss\n\n # Print progress\n if iteration % print_every == 0:\n print_loss_avg = print_loss / print_every\n print(\"Iteration: {}; Percent complete: {:.1f}%; Average loss: {:.4f}\".format(iteration, iteration / n_iteration * 100, print_loss_avg))\n print_loss = 0\n\n # Save checkpoint\n if (iteration % save_every == 0):\n directory = os.path.join(save_dir, model_name, corpus_name, '{}-{}_{}'.format(encoder_n_layers, decoder_n_layers, hidden_size))\n if not os.path.exists(directory):\n os.makedirs(directory)\n torch.save({\n 'iteration': iteration,\n 'en': encoder.state_dict(),\n 'de': decoder.state_dict(),\n 'en_opt': encoder_optimizer.state_dict(),\n 'de_opt': decoder_optimizer.state_dict(),\n 'loss': loss,\n 'voc_dict': voc.__dict__,\n 'embedding': embedding.state_dict()\n }, os.path.join(directory, '{}_{}.tar'.format(iteration, 'checkpoint')))",
"_____no_output_____"
]
],
[
[
"# Evaluation",
"_____no_output_____"
]
],
[
[
"class GreedySearchDecoder(nn.Module):\n def __init__(self, encoder, decoder, voc):\n super(GreedySearchDecoder, self).__init__()\n self.encoder = encoder\n self.decoder = decoder\n self.voc = voc\n\n def forward(self, input_seq, input_length, max_length):\n # Forward input through encoder model\n encoder_outputs, encoder_hidden = self.encoder(input_seq, input_length)\n # Prepare encoder's final hidden layer to be first hidden input to the decoder\n decoder_hidden = encoder_hidden[:decoder.n_layers]\n # Initialize decoder input with SOS_token\n decoder_input = torch.ones(1, 1, device=device, dtype=torch.long) * SOS_token\n # Initialize tensors to append decoded words to\n all_tokens = torch.zeros([0], device=device, dtype=torch.long)\n all_scores = torch.zeros([0], device=device)\n # Iteratively decode one word token at a time\n for _ in range(max_length):\n # Forward pass through decoder\n decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden, encoder_outputs)\n # Obtain most likely word token and its softmax score\n decoder_scores, decoder_input = torch.max(decoder_output, dim=1)\n \n \n # Print words and scores\n# print('all tokens', all_tokens)\n print('all tokens words', [voc.index2word[token.item()] for token in all_tokens])\n \n \n if all_tokens.nelement() > 0 and int(decoder_input[0]) == self.voc.word2index['.']: # and int(all_tokens[-1]) == 2\n decoder_scores, decoder_input = torch.kthvalue(decoder_output, 2)\n \n # Record token and score\n all_tokens = torch.cat((all_tokens, decoder_input), dim=0)\n all_scores = torch.cat((all_scores, decoder_scores), dim=0)\n # Prepare current token to be next decoder input (add a dimension)\n decoder_input = torch.unsqueeze(decoder_input, 0)\n \n # Return collections of word tokens and scores\n return all_tokens, all_scores",
"_____no_output_____"
],
[
"def evaluate(encoder, decoder, searcher, voc, sentence, max_length=MAX_LENGTH):\n ### Format input sentence as a batch\n # words -> indexes\n indexes_batch = [indexesFromSentence(voc, sentence)]\n # Create lengths tensor\n lengths = torch.tensor([len(indexes) for indexes in indexes_batch])\n # Transpose dimensions of batch to match models' expectations\n input_batch = torch.LongTensor(indexes_batch).transpose(0, 1)\n # Use appropriate device\n input_batch = input_batch.to(device)\n lengths = lengths.to(\"cpu\")\n # Decode sentence with searcher\n tokens, scores = searcher(input_batch, lengths, max_length)\n # indexes -> words\n decoded_words = [voc.index2word[token.item()] for token in tokens]\n \n return decoded_words\n\n\ndef evaluateInput(encoder, decoder, searcher, voc):\n input_sentence = ''\n while True:\n try:\n # Get input sentence\n input_sentence = input('> ')\n # Check if it is quit case\n if input_sentence == 'q' or input_sentence == 'quit': break\n # Normalize sentence\n input_sentence = normalizeString(input_sentence)\n # Evaluate sentence\n output_words = evaluate(encoder, decoder, searcher, voc, input_sentence)\n \n # Format and print response sentence\n output_words[:] = [x for x in output_words if not (x == 'EOS' or x == 'PAD')] # or x == '.'\n \n print('human:', input_sentence)\n print('Bot:', ' '.join(output_words))\n\n except KeyError:\n print(\"Error: Encountered unknown word.\")",
"_____no_output_____"
]
],
[
[
"# Embeddings",
"_____no_output_____"
]
],
[
[
"# load pre-trained word2Vec model\nimport gensim.downloader as api\nmodel = api.load('word2vec-google-news-300')\nweights_w2v = torch.FloatTensor(model.vectors)",
"_____no_output_____"
],
[
"# load pre-trained Gloves 42B-300d model\n# model = gensim.models.KeyedVectors.load_word2vec_format('glove.42B.300d.w2vformat.txt')\n\ncorpus = os.path.join(\"glove\", \"glove.42B.300d.w2vformat.txt\")\nmodel = gensim.models.KeyedVectors.load_word2vec_format(corpus)\nweights_42b = torch.FloatTensor(model.vectors)",
"_____no_output_____"
],
[
"# load pre-trained Gloves 6B-300d model\ncorpus = os.path.join(\"glove\", \"glove.6B.300d.w2vformat.txt\")\nmodel = gensim.models.KeyedVectors.load_word2vec_format(corpus)\nweights_6b = torch.FloatTensor(model.vectors)",
"_____no_output_____"
],
[
"# Configure models\nmodel_name = 'cb_model'\n# attn_model = 'dot'\n#attn_model = 'general'\nattn_model = 'concat'\nhidden_size = 300 # 500 -> 300 to fit Gloves model\nencoder_n_layers = 3 # 2 -> 3\ndecoder_n_layers = 3 # 2 -> 3\ndropout = 0.1\nbatch_size = 64\n\n# Set checkpoint to load from; set to None if starting from scratch\nloadFilename = None\ncheckpoint_iter = 5000\n# loadFilename = os.path.join(save_dir, model_name, corpus_name,\n# '{}-{}_{}'.format(encoder_n_layers, decoder_n_layers, hidden_size),\n# '{}_checkpoint.tar'.format(checkpoint_iter))\n\n\n# Load model if a loadFilename is provided\nif loadFilename:\n # If loading on same machine the model was trained on\n checkpoint = torch.load(loadFilename)\n # If loading a model trained on GPU to CPU\n #checkpoint = torch.load(loadFilename, map_location=torch.device('cpu'))\n encoder_sd = checkpoint['en']\n decoder_sd = checkpoint['de']\n encoder_optimizer_sd = checkpoint['en_opt']\n decoder_optimizer_sd = checkpoint['de_opt']\n embedding_sd = checkpoint['embedding']\n voc.__dict__ = checkpoint['voc_dict']\n\n\nprint('Building encoder and decoder ...')\n# Initialize word embeddings\n# embedding = nn.Embedding(voc.num_words, hidden_size)\nembedding = nn.Embedding.from_pretrained(weights_w2v) # Choose embedding model\nif loadFilename:\n embedding.load_state_dict(embedding_sd)\n# Initialize encoder & decoder models\nencoder = EncoderRNN(hidden_size, embedding, encoder_n_layers, dropout)\ndecoder = LuongAttnDecoderRNN(attn_model, embedding, hidden_size, voc.num_words, decoder_n_layers, dropout)\nif loadFilename:\n encoder.load_state_dict(encoder_sd)\n decoder.load_state_dict(decoder_sd)\n# Use appropriate device\nencoder = encoder.to(device)\ndecoder = decoder.to(device)\nprint('Models built and ready to go!')",
"Building encoder and decoder ...\nModels built and ready to go!\n"
]
],
[
[
"# Run Model",
"_____no_output_____"
],
[
"### Training",
"_____no_output_____"
]
],
[
[
"# Configure training/optimization\nclip = 50.0\nteacher_forcing_ratio = 1.0\nlearning_rate = 0.0001\ndecoder_learning_ratio = 6.0 # 5.0 -> 4.0\nn_iteration = 5000 # 4000 -> 5000\nprint_every = 1\nsave_every = 500\n\n# Ensure dropout layers are in train mode\nencoder.train()\ndecoder.train()\n\n# Initialize optimizers\nprint('Building optimizers ...')\nencoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)\ndecoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate * decoder_learning_ratio)\nif loadFilename:\n encoder_optimizer.load_state_dict(encoder_optimizer_sd)\n decoder_optimizer.load_state_dict(decoder_optimizer_sd)\n\n# If you have cuda, configure cuda to call\nfor state in encoder_optimizer.state.values():\n for k, v in state.items():\n if isinstance(v, torch.Tensor):\n state[k] = v.cuda()\n\nfor state in decoder_optimizer.state.values():\n for k, v in state.items():\n if isinstance(v, torch.Tensor):\n state[k] = v.cuda()\n\n# Run training iterations\nprint(\"Starting Training!\")\ntrainIters(model_name, voc, pairs, encoder, decoder, encoder_optimizer, decoder_optimizer,\n embedding, encoder_n_layers, decoder_n_layers, save_dir, n_iteration, batch_size,\n print_every, save_every, clip, corpus_name, loadFilename)",
"_____no_output_____"
]
],
[
[
"### Evaluation",
"_____no_output_____"
]
],
[
[
"# Set dropout layers to eval mode\nencoder.eval()\ndecoder.eval()\n\n# Initialize search module\nsearcher = GreedySearchDecoder(encoder, decoder, voc)\n\nevaluateInput(encoder, decoder, searcher, voc)",
"> hey\nall tokens words []\nall tokens words ['i']\nall tokens words ['i', \"don't\"]\nall tokens words ['i', \"don't\", 'bacon']\nall tokens words ['i', \"don't\", 'bacon', 'sandwich']\nall tokens words ['i', \"don't\", 'bacon', 'sandwich', 'sandwich']\nall tokens words ['i', \"don't\", 'bacon', 'sandwich', 'sandwich', 'bacon']\nall tokens words ['i', \"don't\", 'bacon', 'sandwich', 'sandwich', 'bacon', 'sandwich']\nall tokens words ['i', \"don't\", 'bacon', 'sandwich', 'sandwich', 'bacon', 'sandwich', 'bacon']\nall tokens words ['i', \"don't\", 'bacon', 'sandwich', 'sandwich', 'bacon', 'sandwich', 'bacon', 'sandwich']\nhuman: hey\nBot: i don't bacon sandwich sandwich bacon sandwich bacon sandwich\n"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d0625de76b5fbb52b499afab5a5debe2b3b06ab9 | 25,964 | ipynb | Jupyter Notebook | Seattle Busiest Time.ipynb | ShadyHanafy/Shady | f8e3f786840375845e2a1aede00212d8e5c95b25 | [
"CNRI-Python"
]
| null | null | null | Seattle Busiest Time.ipynb | ShadyHanafy/Shady | f8e3f786840375845e2a1aede00212d8e5c95b25 | [
"CNRI-Python"
]
| null | null | null | Seattle Busiest Time.ipynb | ShadyHanafy/Shady | f8e3f786840375845e2a1aede00212d8e5c95b25 | [
"CNRI-Python"
]
| null | null | null | 65.565657 | 8,320 | 0.757703 | [
[
[
"# Data Understanding\nIn order to get a better understanding of the busiest times in seattle, we will take a look at the dataset.\n\n## Access & Explore\nFirst, let's read and explore the data",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"#Import Calendar dataset\ndf_cal=pd.read_csv('calendar.csv', thousands=',')\npd.set_option(\"display.max_columns\", None)\ndf_cal.head()",
"_____no_output_____"
],
[
"#Check if any empty records for the price\ndf_cal['price'].isnull().value_counts()",
"_____no_output_____"
]
],
[
[
"# Data Preparation & Analysis\nNow we will prepare the data and make some convertions to prepare the data for visualization\n\n## Wrangle and Clean",
"_____no_output_____"
]
],
[
[
"#Convert price to numerical value\ndf_cal[\"price\"] = df_cal[\"price\"].str.replace('[$,,,]',\"\").astype(float)",
"<ipython-input-16-61781eef3286>:2: FutureWarning: The default value of regex will change from True to False in a future version.\n df_cal[\"price\"] = df_cal[\"price\"].str.replace('[$,,,]',\"\").astype(float)\n"
],
[
"#Impute the missing data of price columns with mean\ndf_cal['price'].fillna((df_cal['price'].mean()), inplace=True)",
"_____no_output_____"
],
[
"#Create new feature represent the month of a year\ndf_cal['month'] = pd.DatetimeIndex(df_cal['date']).month\ndf_cal.head()",
"_____no_output_____"
]
],
[
[
"## Data Visualization\nNow we will visualize our dataset to get the required answer for the main question that which time is the busiest in seattle all over the year and its reflection on price",
"_____no_output_____"
]
],
[
[
"#Plot the busiest seattle time of the year\nbusytime=df_cal.groupby(['month']).price.mean()\nbusytime.plot(kind = 'bar', title=\"BusyTime\")",
"_____no_output_____"
],
[
"#Plot the price range accross the year\nbusytime_price=df_cal.groupby(['month']).mean()['price'].sort_values().dropna()\nbusytime_price.plot(kind=\"bar\");\nplt.title(\"Price Trend over year\");",
"_____no_output_____"
]
],
[
[
"# Conclusion\n\nJuly, August and June are the busiest time of the year and this reflects proportionally in booking prices",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
]
|
d06277d0426a410149263ce439782d12a0d06670 | 406,806 | ipynb | Jupyter Notebook | m03_v01_store_sales_prediction.ipynb | luana-afonso/DataScience-Em-Producao | 13ef7d1a0f72fb9e83f6856612644f08e0bf0ae7 | [
"MIT"
]
| null | null | null | m03_v01_store_sales_prediction.ipynb | luana-afonso/DataScience-Em-Producao | 13ef7d1a0f72fb9e83f6856612644f08e0bf0ae7 | [
"MIT"
]
| null | null | null | m03_v01_store_sales_prediction.ipynb | luana-afonso/DataScience-Em-Producao | 13ef7d1a0f72fb9e83f6856612644f08e0bf0ae7 | [
"MIT"
]
| null | null | null | 102.884674 | 204,940 | 0.752998 | [
[
[
"# 0.0. IMPORTS",
"_____no_output_____"
]
],
[
[
"import math\nimport pandas as pd\nimport inflection\nimport numpy as np\nimport seaborn as sns\nimport matplotlib as plt\nimport datetime\n\nfrom IPython.display import Image",
"_____no_output_____"
]
],
[
[
"## 0.1. Helper Functions",
"_____no_output_____"
],
[
"## 0.2. Loading Data",
"_____no_output_____"
]
],
[
[
"# read_csv é um metodo da classe Pandas\n# Preciso \"unzipar\" o arquivo antes?\n# low_memory para dizer se ele lê o arquivo todo (False) ou em pedações (True), ele costuma avisar qual o melhor para a situação\ndf_sales_raw = pd.read_csv(\"data/train.csv.zip\", low_memory=False)\ndf_store_raw = pd.read_csv(\"data/store.csv\", low_memory=False)\n\n# Merge (arquivo de referencia, arquivo a ser anexado a essa referencia, como quero fazer o merge, coluna que é igual nos 2 datasets para servir de chave )\n# Merge também é um método da classe Pandas\ndf_raw = pd.merge( df_sales_raw, df_store_raw, how=\"left\", on=\"Store\" )",
"_____no_output_____"
],
[
"df_sales_raw.head()",
"_____no_output_____"
],
[
"df_store_raw.head()",
"_____no_output_____"
],
[
"# Plotar uma linha aleatória para ver se deu certo com o método sample\ndf_raw.sample()",
"_____no_output_____"
]
],
[
[
"# 1.0. STEP 01 - DATA DESCRIPTION",
"_____no_output_____"
]
],
[
[
"df1 = df_raw.copy()",
"_____no_output_____"
]
],
[
[
"## 1.1. Rename Columns",
"_____no_output_____"
],
[
"### Para ganhar velocidade no desenvolvimento!",
"_____no_output_____"
]
],
[
[
"df_raw.columns\n# Estão até bem organizadas, formato candle (ou camble?) case, mas no mundo real pode ser bem diferente! rs",
"_____no_output_____"
],
[
"cols_old = ['Store', 'DayOfWeek', 'Date', 'Sales', 'Customers', 'Open', 'Promo',\n 'StateHoliday', 'SchoolHoliday', 'StoreType', 'Assortment',\n 'CompetitionDistance', 'CompetitionOpenSinceMonth',\n 'CompetitionOpenSinceYear', 'Promo2', 'Promo2SinceWeek',\n 'Promo2SinceYear', 'PromoInterval']\n\nsnakecase = lambda x: inflection.underscore( x )\n\ncols_new = list( map( snakecase, cols_old) )\n\n# Rename\ndf1.columns = cols_new",
"_____no_output_____"
],
[
"df1.columns",
"_____no_output_____"
]
],
[
[
"## 1.2. Data Dimensions",
"_____no_output_____"
],
[
"### Saber qual a quantidade de linhas e colunas do dataset",
"_____no_output_____"
]
],
[
[
"# O shape printa linhas e colunas do dataframe em que primeiro elemento são as rows\n# Pq ali são as chaves que ele usa? Isso tem a ver com placeholder?\nprint( \"Number of Rows: {}\".format( df1.shape[0] ) )\nprint( \"Number of Cols: {}\".format( df1.shape[1] ) )",
"Number of Rows: 1017209\nNumber of Cols: 18\n"
]
],
[
[
"## 1.3. Data Types",
"_____no_output_____"
]
],
[
[
"# Atente que não usamos os parênteses aqui. Isso pq estamos vendo uma propriedade e não usando um método?\n# O default do pandas é assumir o que não for int como object. Object é o \"caracter\" dentro do Pandas\n# Atente para o date, precisamos mudar de object para datetime!\ndf1.dtypes",
"_____no_output_____"
],
[
"df1[\"date\"] = pd.to_datetime( df1[\"date\"] )\ndf1.dtypes",
"_____no_output_____"
]
],
[
[
"## 1.4. Check NA",
"_____no_output_____"
]
],
[
[
"# O método isna vai mostrar todas as linhas que tem pelo menos uma coluna com um NA (vazia)\n# Mas como eu quero ver a soma disso por coluna, uso o método sum\ndf1.isna().sum()",
"_____no_output_____"
],
[
"# Precisamos tratar esses NAs.\n# Existem basicamente 3 maneiras:\n# 1. Descartar essas linhas (fácil e rápido; mas jogando dado fora)\n# 2. Usando algoritmos de machine learning. Tem alguns metodos de input NA que voce pode, por exemplo, substituir as colunas vazias pelo proprio comportamento da coluna (e.g. mediana, media...)\n# 3. Entendendo o negócio para colocar valores nos NAs e recuperar dados.",
"_____no_output_____"
]
],
[
[
"## 1.5. Fillout NA",
"_____no_output_____"
]
],
[
[
"df1[\"competition_distance\"].max()",
"_____no_output_____"
],
[
"#competition_distance: distance in meters to the nearest competitor store\n# Se pensarmos que não ter o dado nessa coluna significa um competidor estar muito longe geograficamente e, portanto, se assumirmos os valores como muito maiores que a distancia máxima encontrada resolveria o problema?\n# Quando uso função lambda, posso usar tudo conforme o nome da variável que defino, no caso x\n# Função apply vai aplicar essa logica a todas as linhas do dataset\n# Aplica função apply só na coluna competition_distance\n# O resultado eu quero sobrescrever na minha coluna original\n\ndf1[\"competition_distance\"] = df1[\"competition_distance\"].apply( lambda x: 200000.0 if math.isnan( x ) else x)\n\n#competition_open_since_month - gives the approximate year and month of the time the nearest competitor was opened \n# PREMISSA: Podemos assumir que se essa coluna for NA eu vou copiar a data de venda (extrair o mês)\n# Pq isso? já pensando na etapa a frente de feature engineering... tem algumas variaveis que derivamos do tempo que são muito importantes pra representar o comportamento, uma delas é: quanto tempo faz desde que o evento aconteceu\n# A informação de competição proxima é muito importante pois influencia nas vendas! (entao evitamos ao maximo excluir esses dados)\n# Primeiro tenho que ver se é NA, uso a classe math. Se isso for verdade, vou pegar a coluna \"date\" e extrair o mês dela. Se não for verdade, mantem.\n# Vou usar função lambda, então posso colocar como x os df1.\n# Vou aplicar (função apply) isso ao longo das colunas (axis=1). Não precisamos fazer isso no \"competition_distance\" pois lá estavamos avaliando apenas 1 coluna. Preciso explicitar para a função apply quando tenho mais de uma coluna\n# O resultado disso eu vou sobrescrever a coluna \"competition_open_since_month\"\n\ndf1[\"competition_open_since_month\"] = df1.apply( lambda x: x[\"date\"].month if math.isnan( x[\"competition_open_since_month\"] ) else x[\"competition_open_since_month\"] , axis=1)\n\n#competition_open_since_year - gives the approximate year and month of the time the nearest competitor was opened\n# Mesma lógica da coluna acima, só que em anos\n\ndf1[\"competition_open_since_year\"] = df1.apply( lambda x: x[\"date\"].year if math.isnan( x[\"competition_open_since_year\"] ) else x[\"competition_open_since_year\"] , axis=1)\n\n#promo2 - Promo2 is a continuing and consecutive promotion for some stores: 0 = store is not participating, 1 = store is participating\n#promo2_since_week - describes the year and calendar week when the store started participating in Promo2 \n# Dados NA nessa coluna querem dizer que a loja não participa da promoção\n# Similar ao de cima\n\ndf1[\"promo2_since_week\"] = df1.apply( lambda x: x[\"date\"].week if math.isnan( x[\"promo2_since_week\"] ) else x[\"promo2_since_week\"] , axis=1)\n\n#promo2_since_year \ndf1[\"promo2_since_year\"] = df1.apply( lambda x: x[\"date\"].year if math.isnan( x[\"promo2_since_year\"] ) else x[\"promo2_since_year\"] , axis=1)\n\n#promo_interval - describes the consecutive intervals Promo2 is started, naming the months the promotion is started anew. E.g. \"Feb,May,Aug,Nov\" means each round starts in February, May, August, November of any given year for that store (meses que a promoção ficou ativa)\n# Vamos fazer um split dessa coluna e criar uma lista: se a minha data estiver dentro dessa lista (promoção ativa) eu vou criar uma coluna falando que a promo2 foi ativa\n\n# Cria coluna auxiliar\nmonth_map = {1: \"Jan\",2: \"Feb\",3: \"Mar\",4: \"Apr\",5: \"May\",6: \"Jun\",7: \"Jul\",8: \"Aug\",9: \"Sep\",10: \"Oct\",11: \"Nov\",12: \"Dec\"}\n\n# Se o valor na coluna promo_interval for NA, substituo por 0 (não há promoção ativa). inplace=True pois não quero que ele retorne nenhum valor (faça a modificação direto na coluna)\ndf1[\"promo_interval\"].fillna(0, inplace=True)\n\n# ??? Pq aqui usamos o map ao inves do apply?\ndf1[\"month_map\"] = df1[\"date\"].dt.month.map( month_map )\n\n# Se o mês da coluna month_map estiver na promoção, vamos colocar 1, se não estiver, 0\n# Temos aluns zeros na coluna \"promo_interval\" que são lojas que não aderiram a promo2\n\n# 0 if df1[\"promo_interval\"] == 0 else 1 if df1[\"month_map\"] in df1[\"promo_interval\"].split( \",\" ) else 0\n\n# Como vou usar mais de uma coluna preciso especificar a direção\n# apply(lambda x: 0 if x[\"promo_interval\"] == 0 else 1 if df1[\"month_map\"] in x[\"promo_interval\"].split( \",\" ) else 0, axis=1 )\n\n# Não vou aplicar no dataset todo, vou filtrar pra ficar mais fácil:\n# Vou criar uma nova coluna is_promo que vai ser 1 ou 0\n\ndf1[\"is_promo\"] = df1[[\"promo_interval\",\"month_map\"]].apply(lambda x: 0 if x[\"promo_interval\"] == 0 else 1 if x[\"month_map\"] in x[\"promo_interval\"].split( \",\" ) else 0, axis=1 )",
"_____no_output_____"
],
[
"df1.isna().sum()",
"_____no_output_____"
],
[
"# Agora a coluna \"competition_distance\" não tem mais NA e o valor maximo é 200000\ndf1[\"competition_distance\"].max()",
"_____no_output_____"
],
[
"# Pegando linhas aleatorias. T para mostrar a transposta\ndf1.sample(5).T",
"_____no_output_____"
]
],
[
[
"## 1.6. Change Types",
"_____no_output_____"
]
],
[
[
"# Importante checar se alguma operação feita na etapa anterior alterou algum dado anterior\n# Método dtypes\n# competition_open_since_month float64\n# competition_open_since_year float64\n# promo2_since_week float64\n# promo2_since_year float64\n# Na verdade essas variaveis acima deveriam ser int (mês e ano)\n\ndf1.dtypes",
"_____no_output_____"
],
[
"# Método astype nesse caso vai aplicar o int sob essa coluna e vai salvar de volta\ndf1[\"competition_open_since_month\"] = df1[\"competition_open_since_month\"].astype(int)\ndf1[\"competition_open_since_year\"] = df1[\"competition_open_since_year\"].astype(int)\ndf1[\"promo2_since_week\"] = df1[\"promo2_since_week\"].astype(int)\ndf1[\"promo2_since_year\"] = df1[\"promo2_since_year\"].astype(int)",
"_____no_output_____"
],
[
"df1.dtypes",
"_____no_output_____"
]
],
[
[
"## 1.7. Descriptive Statistics",
"_____no_output_____"
],
[
"### Ganhar conhecimento de negócio e detectar alguns erros",
"_____no_output_____"
]
],
[
[
"# Central Tendency = mean, median\n# Dispersion = std, min, max, range, skew, kurtosis\n\n# Precisamos separar nossas variáveis entre numéricas e categóricas.\n# A estatística descritiva funciona para os dois tipos de variáveis, mas a forma com que eu construo a estatistica \n# descritiva é diferente.\n\n# Vou separar todas as colunas que são numéricas:\n# método select_dtypes e vou passar uma lista de todos os tipos de variaveis que quero selecionar\n# datetime64(ns) = dado de tempo (date)\n\n# ??? Qual a diferença do int64 e int32?\n\nnum_attributes = df1.select_dtypes( include=[\"int64\",\"int32\",\"float64\"] )\ncat_attributes = df1.select_dtypes( exclude=[\"int64\", \"float64\",\"int32\",\"datetime64[ns]\"] )",
"_____no_output_____"
],
[
"num_attributes.sample(2)",
"_____no_output_____"
],
[
"cat_attributes.sample(2)",
"_____no_output_____"
]
],
[
[
"## 1.7.1 Numerical Attributes",
"_____no_output_____"
]
],
[
[
"# Apply para aplicar uma operação em todas as colunas e transformar num dataframe pra facilitar a visualização\n# Transpostas para ter metricas nas colunas e features nas linhas\n\n# central tendency\nct1 = pd.DataFrame( num_attributes.apply ( np.mean) ).T\nct2 = pd.DataFrame( num_attributes.apply ( np.median ) ).T\n\n# dispersion\nd1 = pd.DataFrame( num_attributes.apply( np.std )).T\nd2 = pd.DataFrame( num_attributes.apply( min )).T\nd3 = pd.DataFrame( num_attributes.apply( max )).T\nd4 = pd.DataFrame( num_attributes.apply( lambda x: x.max() - x.min() )).T\nd5 = pd.DataFrame( num_attributes.apply( lambda x: x.skew() )).T\nd6 = pd.DataFrame( num_attributes.apply( lambda x: x.kurtosis() )).T\n\n# Para concatenar todas essas métricas na ordem que quero ver:\n# obs: Classe Pandas\n# Tem que transpor e resetar o index (Pq???)\n\nm = pd.concat([d2,d3,d4,ct1,ct2,d1,d5,d6]).T.reset_index()\n\n# Vamos nomear as colunas para não aparecer o index padrão\nm.columns = [\"attributes\",\"min\",\"max\",\"range\",\"mean\",\"median\",\"std\",\"skew\",\"kurtosis\"]\nm",
"_____no_output_____"
],
[
"# Avaliando por exemplo vendas: min 0, max 41k. Media e mediana parecidas, nao tenho um deslocamento da Normal muito grande.\n# Skew proxima de 0 - muito proxima de uma normal\n# Kurtosis proximo de 1 - nao tem um pico muuuito grande",
"_____no_output_____"
],
[
"# Plotando as sales passando as colunas que quero mostrar\n# Obs: Você consegue mudar o tamanho do plot usando os parâmetros height e aspect. Um exemplo ficaria assim:\n# sns.displot(df1['sales'], height=8, aspect=2)\n# Descobri isso procurando a função displot direto na documentação do seaborn: https://seaborn.pydata.org/generated/seaborn.displot.html#seaborn.displot\nsns.displot( df1[\"sales\"], height=8, aspect=2)",
"_____no_output_____"
],
[
"# Skew alta, alta concentração de valores no começo\n# Meus competidores estão muito proximos\n\nsns.displot( df1[\"competition_distance\"])",
"_____no_output_____"
]
],
[
[
"## 1.7.2 Categorical Attributes",
"_____no_output_____"
],
[
"### Vai de boxblot!",
"_____no_output_____"
]
],
[
[
"# ??? No do Meigarom só apareceu os: state_holiday, store_type, assortment, promo_interval e month_map\n# Tirei os int32 tambem dos categoricos\ncat_attributes.apply( lambda x: x.unique().shape[0] )",
"_____no_output_____"
],
[
"# Meigarom prefere o seaborn do que o matplotlib\n# sns.boxplot( x= y=, data= )\n# x = linha que vai ficar como referencia\n# y = o que quero medir (no caso, as vendas)\n\nsns.boxplot( x=\"state_holiday\", y=\"sales\", data=df1 )",
"_____no_output_____"
],
[
"# Se plotamos da forma acima não da pra ver nada... (variaveis com ranges mt diferentes)\n# Vamos filtrar os dados para plotar:\n# ??? Pq esse 0 é uma string e nao um numero? df1[\"state_holiday\"] != \"0\"\n\naux1 = df1[(df1[\"state_holiday\"] != \"0\") & (df1[\"sales\"] > 0)]\n\n# plt.subplot = para plotar um do lado do outro\n\nplt.pyplot.subplot( 1, 3, 1)\nsns.boxplot( x=\"state_holiday\", y=\"sales\", data=aux1)\n\nplt.pyplot.subplot( 1, 3, 2)\nsns.boxplot( x=\"store_type\", y=\"sales\", data=aux1)\n\nplt.pyplot.subplot( 1, 3, 3)\nsns.boxplot( x=\"assortment\", y=\"sales\", data=aux1)\n\n# Boxplot:\n# Linha do meio é a mediana: chegou na metade dos valores (em termos de posição), aquele valor é sua mediana\n# Limite inferior da barra: 25º quartil (quartil 25) e o limite superior é o quartil 75\n# Os ultimos tracinhos são em cima o maximo e embaixo o minimo. Todos os pontos acima do tracinho de maximo são considerados outliers (3x o desvio padrão)\n# assortment = mix de produtos",
"_____no_output_____"
]
],
[
[
"# 2.0. STEP 02 - FEATURE ENGINEERING",
"_____no_output_____"
],
[
"Para quê fazer a Feature Engineering? Para ter as variáveis DISPONÍVEIS para ESTUDO durante a Análise Exploratória dos Dados. Pra não ter bagunça, crie as variáveis ANTES na análise exploratória!!!",
"_____no_output_____"
],
[
"Vou usar uma classe Image para colocar a imagem do mapa mental:",
"_____no_output_____"
]
],
[
[
"df2 = df1.copy()",
"_____no_output_____"
]
],
[
[
"## 2.1. Hypothesis Mind Map ",
"_____no_output_____"
]
],
[
[
"Image (\"img/mind-map-hypothesis.png\")",
"_____no_output_____"
]
],
[
[
"## 2.2. Hypothesis Creation",
"_____no_output_____"
],
[
"### 2.2.1 Store Hypothesis",
"_____no_output_____"
],
[
"1. Stores with greater number of employees should sell more.",
"_____no_output_____"
],
[
"2. Stores with greater stock size should sell more.",
"_____no_output_____"
],
[
"3. Stores with bigger size should sell more.",
"_____no_output_____"
],
[
"4. Stores with smaller size should sell less.",
"_____no_output_____"
],
[
"5. Stores with greater assortment should sell more.",
"_____no_output_____"
],
[
"6. Stores with more competitors nearby should sell less.",
"_____no_output_____"
],
[
"7. Stores with competitors for longer should sell more. ",
"_____no_output_____"
],
[
"### 2.2.2 Product Hypothesis",
"_____no_output_____"
],
[
"1. Stores with more marketing should sell more.",
"_____no_output_____"
],
[
"2. Stores that exhibit more products in the showcase sell more.",
"_____no_output_____"
],
[
"3. Stores that have lower prices on products should sell more.",
"_____no_output_____"
],
[
"4. Stores that have lower prices for longer on products should sell more.",
"_____no_output_____"
],
[
"5. Stores with more consecutive sales should sell more.",
"_____no_output_____"
],
[
"### 2.2.3Time-based Hypothesis",
"_____no_output_____"
],
[
"1. Stores with more days in holidays should sell less.",
"_____no_output_____"
],
[
"2. Stores that open in the first 6 months should sell more.",
"_____no_output_____"
],
[
"3. Stores that open on weekends should sell more.",
"_____no_output_____"
],
[
"## 2.3. Final Hypothesis List",
"_____no_output_____"
],
[
"### As hipóteses das quais temos os dados, vão para a lista final de hipóteses.\n\n",
"_____no_output_____"
],
[
"1. Stores with greater assortment should sell more.\n\n2. Stores with more competitors nearby should sell less.\n\n3. Stores with competitors for longer should sell more. \n\n4. Stores with active sales for longer should sell more.\n\n5. Stores with more days on sale should sell more.\n\n7. Stores with more consecutive sales should sell more.\n\n8. Stores opened during the Christmas holiday should sell more.\n\n9. Stores should sell more over the years.\n\n10. Stores should sell more in the second half of the year.\n\n11. Stores should sell more after the 10th of each month.\n\n12. Stores should sell less on weekends.\n\n13. Stores should sell less during school holidays. ",
"_____no_output_____"
],
[
"## 2.4. Feature Engineering",
"_____no_output_____"
]
],
[
[
"# year\ndf2['year'] = df2['date'].dt.year\n\n# month\ndf2['month'] = df2['date'].dt.month\n\n# day\ndf2['day'] = df2['date'].dt.day\n\n# week of year\ndf2['week_of_year'] = df2['date'].dt.isocalendar().week\n\n# year week\n# aqui não usaremos nenhum metodo, e sim mudaremos a formatação da data apenas\n# ele fala do strftime no bônus\ndf2['year_week'] = df2['date'].dt.strftime( '%Y-%W' )\n\n# week of year \n# ps: <ipython-input-35-d06c5b7375c4>:9: FutureWarning: Series.dt.weekofyear and Series.dt.week have been deprecated. Please use Series.dt.isocalendar().week instead.\n# df2[\"week_of_year\"] = df2[\"date\"].dt.weekofyear\n\ndf2[\"week_of_year\"] = df2[\"date\"].dt.isocalendar().week\n\n# ??? Não era pra week_of_year ser igual à semana que aparece na coluna \"year_week\"? é diferente!",
"_____no_output_____"
],
[
"df2.sample(10).T",
"_____no_output_____"
],
[
"# competition since\n# ja temos a coluna \"date\" para comparar, mas a informação de competition since está quebrada, temos coluna com year \n# e outra com month\n# Precisamos juntar as duas em uma data e fazer a substração das duas\n# método datetime vem de uma classe também chamada datetime\n# datetime.datetime( year=, month=, day= )\n\n# datetime.datetime( year= df2[\"competition_open_since_year\"], month= df2[\"competition_open_since_month\"], day= 1 )\n# Vamos usar a função acima para todas as linhas do dataframe vamos usar lambda com variavel x e depois usar o apply\n# day = 1 pois nao temos informação sobre o dia\n# o apply vai precisar do axis pois estou usando duas colunas diferentes\n\ndf2[\"competition_since\"] = df2.apply(lambda x: datetime.datetime( year= x[\"competition_open_since_year\"], month= x[\"competition_open_since_month\"], day= 1), axis=1 )\n# com esse comando acima geramos a coluna \"competition_since\" no formato 2008-09-01 00:00:00. \n# Agora precisamos ver a diferença dessa data com a date para saber o tempo de \"competition since\"\n\n# df2['date'] - df2['competition_since'] )/30 \n# divido por 30 pq quero manter a glanularidade em dias \n# o .days vai extrair os dias desse datetime e salva como inteiro em uma nova coluna 'competition_time_month'\ndf2['competition_time_month'] = ( ( df2['date'] - df2['competition_since'] )/30 ).apply( lambda x: x.days ).astype( int )",
"_____no_output_____"
],
[
"df2.head().T",
"_____no_output_____"
],
[
"# promo since, mesma estratégia acima\n# Mas para as promoçoes temos uma dificuldade a mais pois temos a coluna promo2 e informação de ano e semana\n# não temos de mês\n# Vamos fazer um join dos caracteres e depois converter na data\n# Mas para juntar as variáveis assim precisamos que as 2 sejam strings (astype converte)\n# colocamos o \"-\" pra ficar no formato ano - semana do ano\n\n# df2['promo_since'] = df2['promo2_since_year'].astype( str ) + '-' + df2['promo2_since_week'].astype( str )\n# \"promo_since\" agora e string, nao é datetime\n\ndf2['promo_since'] = df2['promo2_since_year'].astype( str ) + '-' + df2['promo2_since_week'].astype( str )\n\n# Deu uma complicada nesse promo, mas bora lá...\n# Truque para converter o que geramos aqui em cima que ficou como string para data: datetime.datetime.strptime( x + '-1', '%Y-%W-%w' ). strptime( o que vai \n# mostrar, \"formato\")\n# x pq vamos aplicar para todas as linhas do dataframe\n# /7 para ter em semanas\n\ndf2['promo_since'] = df2['promo_since'].apply( lambda x: datetime.datetime.strptime( x + '-1', '%Y-%W-%w' ) - datetime.timedelta( days=7 ) )\n# Agora que temos duas datas só falta subtrair...\ndf2['promo_time_week'] = ( ( df2['date'] - df2['promo_since'] )/7 ).apply( lambda x: x.days ).astype( int )\n\n#Obs:\n# %W Week number of the year (Monday as the first day of the week). \n# All days in a new year preceding the first Monday are considered to be in week 0\n# %w Weekday as a decimal number.\n\n# assortment (describes an assortment level: a = basic, b = extra, c = extended)\n# Mudar as letras para o que isso representa pra ficar mais facil a leitura:\n# Pq else e não elif na estrutura dentro do lambda???\n# ??? object type é tipo string?\n# Nao preciso usar o axis pq só vou usar a coluna \"assortment\"\n\n# assortment\ndf2['assortment'] = df2['assortment'].apply( lambda x: 'basic' if x == 'a' else 'extra' if x == 'b' else 'extended' )\n\n# Mesma coisa do assortment no \"state holiday\"\n# state holiday\ndf2['state_holiday'] = df2['state_holiday'].apply( lambda x: 'public_holiday' if x == 'a' else 'easter_holiday' if x == 'b' else 'christmas' if x == 'c' else 'regular_day' )\n",
"_____no_output_____"
],
[
"df2.head().T",
"_____no_output_____"
]
],
[
[
"# 3.0. STEP 03 - VARIABLES FILTERING",
"_____no_output_____"
]
],
[
[
"# Antes de qualquer coisa, ao começar um novo passo, copia o dataset do passo anterior e passa a trabalhar com um novo\ndf3 = df2.copy()",
"_____no_output_____"
],
[
"df3.head()",
"_____no_output_____"
]
],
[
[
"## 3.1. ROWS FILTERING",
"_____no_output_____"
]
],
[
[
"# \"open\" != 0 & \"sales\" > 0\n\ndf3 = df3[(df3[\"open\"] != 0) & (df3[\"sales\"] > 0)]",
"_____no_output_____"
]
],
[
[
"## 3.2. COLUMNS SELECTION",
"_____no_output_____"
]
],
[
[
"# Vamos \"dropar\" as colunas que não queremos\n# A \"open\" está aqui pois após tirarmos as linhas cujos dados da coluna \"open\" eram 0, só sobraram valores 1, então é uma coluna 'inútil'\ncols_drop = ['customers', 'open', 'promo_interval', 'month_map']\n# Drop é um metodo da classe Pandas (quais colunas e sentido); axis 0 = linhas, axis 1 = colunas\ndf3 = df3.drop( cols_drop, axis=1 )",
"_____no_output_____"
],
[
"df3.columns",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
d06279e2fc0fa31f7f3aa24441e977a8d467c22e | 540,612 | ipynb | Jupyter Notebook | Model backlog/DenseNet169/133 - DenseNet169 - Classification - Refactor.ipynb | ThinkBricks/APTOS2019BlindnessDetection | e524fd69f83a1252710076c78b6a5236849cd885 | [
"MIT"
]
| 23 | 2019-09-08T17:19:16.000Z | 2022-02-02T16:20:09.000Z | Model backlog/DenseNet169/133 - DenseNet169 - Classification - Refactor.ipynb | ThinkBricks/APTOS2019BlindnessDetection | e524fd69f83a1252710076c78b6a5236849cd885 | [
"MIT"
]
| 1 | 2020-03-10T18:42:12.000Z | 2020-09-18T22:02:38.000Z | Model backlog/DenseNet169/133 - DenseNet169 - Classification - Refactor.ipynb | ThinkBricks/APTOS2019BlindnessDetection | e524fd69f83a1252710076c78b6a5236849cd885 | [
"MIT"
]
| 16 | 2019-09-21T12:29:59.000Z | 2022-03-21T00:42:26.000Z | 150.924623 | 156,324 | 0.797855 | [
[
[
"## Dependencies",
"_____no_output_____"
]
],
[
[
"import os\nimport cv2\nimport shutil\nimport random\nimport warnings\nimport numpy as np\nimport pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom tensorflow import set_random_seed\nfrom sklearn.utils import class_weight\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import confusion_matrix, cohen_kappa_score\nfrom keras import backend as K\nfrom keras.models import Model\nfrom keras.utils import to_categorical\nfrom keras import optimizers, applications\nfrom keras.preprocessing.image import ImageDataGenerator\nfrom keras.callbacks import EarlyStopping, ReduceLROnPlateau, Callback, LearningRateScheduler\nfrom keras.layers import Dense, Dropout, GlobalAveragePooling2D, Input\n\n# Set seeds to make the experiment more reproducible.\ndef seed_everything(seed=0):\n random.seed(seed)\n os.environ['PYTHONHASHSEED'] = str(seed)\n np.random.seed(seed)\n set_random_seed(0)\nseed = 0\nseed_everything(seed)\n\n%matplotlib inline\nsns.set(style=\"whitegrid\")\nwarnings.filterwarnings(\"ignore\")",
"Using TensorFlow backend.\n"
]
],
[
[
"## Load data",
"_____no_output_____"
]
],
[
[
"hold_out_set = pd.read_csv('../input/aptos-data-split/hold-out.csv')\nX_train = hold_out_set[hold_out_set['set'] == 'train']\nX_val = hold_out_set[hold_out_set['set'] == 'validation']\ntest = pd.read_csv('../input/aptos2019-blindness-detection/test.csv')\nprint('Number of train samples: ', X_train.shape[0])\nprint('Number of validation samples: ', X_val.shape[0])\nprint('Number of test samples: ', test.shape[0])\n\n# Preprocecss data\nX_train[\"id_code\"] = X_train[\"id_code\"].apply(lambda x: x + \".png\")\nX_val[\"id_code\"] = X_val[\"id_code\"].apply(lambda x: x + \".png\")\ntest[\"id_code\"] = test[\"id_code\"].apply(lambda x: x + \".png\")\nX_train['diagnosis'] = X_train['diagnosis'].astype('str')\nX_val['diagnosis'] = X_val['diagnosis'].astype('str')\ndisplay(X_train.head())",
"Number of train samples: 2929\nNumber of validation samples: 733\nNumber of test samples: 1928\n"
]
],
[
[
"# Model parameters",
"_____no_output_____"
]
],
[
[
"# Model parameters\nN_CLASSES = X_train['diagnosis'].nunique()\nBATCH_SIZE = 16\nEPOCHS = 40\nWARMUP_EPOCHS = 5\nLEARNING_RATE = 1e-4\nWARMUP_LEARNING_RATE = 1e-3\nHEIGHT = 320\nWIDTH = 320\nCHANNELS = 3\nES_PATIENCE = 5\nRLROP_PATIENCE = 3\nDECAY_DROP = 0.5",
"_____no_output_____"
],
[
"def kappa(y_true, y_pred, n_classes=5):\n y_trues = K.cast(K.argmax(y_true), K.floatx())\n y_preds = K.cast(K.argmax(y_pred), K.floatx())\n n_samples = K.cast(K.shape(y_true)[0], K.floatx())\n distance = K.sum(K.abs(y_trues - y_preds))\n max_distance = n_classes - 1\n \n kappa_score = 1 - ((distance**2) / (n_samples * (max_distance**2)))\n\n return kappa_score\n\ndef step_decay(epoch):\n lrate = 30e-5\n if epoch > 3:\n lrate = 15e-5\n if epoch > 7:\n lrate = 7.5e-5\n if epoch > 11:\n lrate = 3e-5\n if epoch > 15:\n lrate = 1e-5\n\n return lrate\n\ndef focal_loss(y_true, y_pred):\n gamma = 2.0\n epsilon = K.epsilon()\n \n pt = y_pred * y_true + (1-y_pred) * (1-y_true)\n pt = K.clip(pt, epsilon, 1-epsilon)\n CE = -K.log(pt)\n FL = K.pow(1-pt, gamma) * CE\n loss = K.sum(FL, axis=1)\n \n return loss",
"_____no_output_____"
]
],
[
[
"# Pre-procecess images",
"_____no_output_____"
]
],
[
[
"train_base_path = '../input/aptos2019-blindness-detection/train_images/'\ntest_base_path = '../input/aptos2019-blindness-detection/test_images/'\ntrain_dest_path = 'base_dir/train_images/'\nvalidation_dest_path = 'base_dir/validation_images/'\ntest_dest_path = 'base_dir/test_images/'\n\n# Making sure directories don't exist\nif os.path.exists(train_dest_path):\n shutil.rmtree(train_dest_path)\nif os.path.exists(validation_dest_path):\n shutil.rmtree(validation_dest_path)\nif os.path.exists(test_dest_path):\n shutil.rmtree(test_dest_path)\n \n# Creating train, validation and test directories\nos.makedirs(train_dest_path)\nos.makedirs(validation_dest_path)\nos.makedirs(test_dest_path)\n\ndef crop_image(img, tol=7):\n if img.ndim ==2:\n mask = img>tol\n return img[np.ix_(mask.any(1),mask.any(0))]\n elif img.ndim==3:\n gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)\n mask = gray_img>tol\n check_shape = img[:,:,0][np.ix_(mask.any(1),mask.any(0))].shape[0]\n if (check_shape == 0): # image is too dark so that we crop out everything,\n return img # return original image\n else:\n img1=img[:,:,0][np.ix_(mask.any(1),mask.any(0))]\n img2=img[:,:,1][np.ix_(mask.any(1),mask.any(0))]\n img3=img[:,:,2][np.ix_(mask.any(1),mask.any(0))]\n img = np.stack([img1,img2,img3],axis=-1)\n \n return img\n\ndef circle_crop(img):\n img = crop_image(img)\n\n height, width, depth = img.shape\n largest_side = np.max((height, width))\n img = cv2.resize(img, (largest_side, largest_side))\n\n height, width, depth = img.shape\n\n x = width//2\n y = height//2\n r = np.amin((x, y))\n\n circle_img = np.zeros((height, width), np.uint8)\n cv2.circle(circle_img, (x, y), int(r), 1, thickness=-1)\n img = cv2.bitwise_and(img, img, mask=circle_img)\n img = crop_image(img)\n\n return img\n \ndef preprocess_image(base_path, save_path, image_id, HEIGHT, WIDTH, sigmaX=10):\n image = cv2.imread(base_path + image_id)\n image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n image = circle_crop(image)\n image = cv2.resize(image, (HEIGHT, WIDTH))\n image = cv2.addWeighted(image, 4, cv2.GaussianBlur(image, (0,0), sigmaX), -4 , 128)\n cv2.imwrite(save_path + image_id, image)\n \n# Pre-procecss train set\nfor i, image_id in enumerate(X_train['id_code']):\n preprocess_image(train_base_path, train_dest_path, image_id, HEIGHT, WIDTH)\n \n# Pre-procecss validation set\nfor i, image_id in enumerate(X_val['id_code']):\n preprocess_image(train_base_path, validation_dest_path, image_id, HEIGHT, WIDTH)\n \n# Pre-procecss test set\nfor i, image_id in enumerate(test['id_code']):\n preprocess_image(test_base_path, test_dest_path, image_id, HEIGHT, WIDTH)",
"_____no_output_____"
]
],
[
[
"# Data generator",
"_____no_output_____"
]
],
[
[
"train_datagen=ImageDataGenerator(rescale=1./255, \n rotation_range=360,\n horizontal_flip=True,\n vertical_flip=True)\n\nvalid_datagen=ImageDataGenerator(rescale=1./255)\n\ntrain_generator=train_datagen.flow_from_dataframe(\n dataframe=X_train,\n directory=train_dest_path,\n x_col=\"id_code\",\n y_col=\"diagnosis\",\n class_mode=\"categorical\",\n batch_size=BATCH_SIZE,\n target_size=(HEIGHT, WIDTH),\n seed=seed)\n\nvalid_generator=valid_datagen.flow_from_dataframe(\n dataframe=X_val,\n directory=validation_dest_path,\n x_col=\"id_code\",\n y_col=\"diagnosis\",\n class_mode=\"categorical\",\n batch_size=BATCH_SIZE,\n target_size=(HEIGHT, WIDTH),\n seed=seed)\n\ntest_generator=valid_datagen.flow_from_dataframe( \n dataframe=test,\n directory=test_dest_path,\n x_col=\"id_code\",\n batch_size=1,\n class_mode=None,\n shuffle=False,\n target_size=(HEIGHT, WIDTH),\n seed=seed)",
"Found 2929 validated image filenames belonging to 5 classes.\nFound 733 validated image filenames belonging to 5 classes.\nFound 1928 validated image filenames.\n"
]
],
[
[
"# Model",
"_____no_output_____"
]
],
[
[
"def create_model(input_shape, n_out):\n input_tensor = Input(shape=input_shape)\n base_model = applications.DenseNet169(weights=None, \n include_top=False,\n input_tensor=input_tensor)\n base_model.load_weights('../input/keras-notop/densenet169_weights_tf_dim_ordering_tf_kernels_notop.h5')\n\n x = GlobalAveragePooling2D()(base_model.output)\n x = Dropout(0.5)(x)\n x = Dense(2048, activation='relu')(x)\n x = Dropout(0.5)(x)\n final_output = Dense(n_out, activation='softmax', name='final_output')(x)\n model = Model(input_tensor, final_output)\n \n return model",
"_____no_output_____"
]
],
[
[
"# Train top layers",
"_____no_output_____"
]
],
[
[
"model = create_model(input_shape=(HEIGHT, WIDTH, CHANNELS), n_out=N_CLASSES)\n\nfor layer in model.layers:\n layer.trainable = False\n\nfor i in range(-5, 0):\n model.layers[i].trainable = True\n \nclass_weights = class_weight.compute_class_weight('balanced', np.unique(X_train['diagnosis'].astype('int').values), X_train['diagnosis'].astype('int').values)\n\nmetric_list = [\"accuracy\", kappa]\noptimizer = optimizers.Adam(lr=WARMUP_LEARNING_RATE)\nmodel.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=metric_list)\nmodel.summary()",
"__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_1 (InputLayer) (None, 320, 320, 3) 0 \n__________________________________________________________________________________________________\nzero_padding2d_1 (ZeroPadding2D (None, 326, 326, 3) 0 input_1[0][0] \n__________________________________________________________________________________________________\nconv1/conv (Conv2D) (None, 160, 160, 64) 9408 zero_padding2d_1[0][0] \n__________________________________________________________________________________________________\nconv1/bn (BatchNormalization) (None, 160, 160, 64) 256 conv1/conv[0][0] \n__________________________________________________________________________________________________\nconv1/relu (Activation) (None, 160, 160, 64) 0 conv1/bn[0][0] \n__________________________________________________________________________________________________\nzero_padding2d_2 (ZeroPadding2D (None, 162, 162, 64) 0 conv1/relu[0][0] \n__________________________________________________________________________________________________\npool1 (MaxPooling2D) (None, 80, 80, 64) 0 zero_padding2d_2[0][0] \n__________________________________________________________________________________________________\nconv2_block1_0_bn (BatchNormali (None, 80, 80, 64) 256 pool1[0][0] \n__________________________________________________________________________________________________\nconv2_block1_0_relu (Activation (None, 80, 80, 64) 0 conv2_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block1_1_conv (Conv2D) (None, 80, 80, 128) 8192 conv2_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block1_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block1_1_relu (Activation (None, 80, 80, 128) 0 conv2_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block1_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block1_concat (Concatenat (None, 80, 80, 96) 0 pool1[0][0] \n conv2_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block2_0_bn (BatchNormali (None, 80, 80, 96) 384 conv2_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block2_0_relu (Activation (None, 80, 80, 96) 0 conv2_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block2_1_conv (Conv2D) (None, 80, 80, 128) 12288 conv2_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block2_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block2_1_relu (Activation (None, 80, 80, 128) 0 conv2_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block2_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block2_concat (Concatenat (None, 80, 80, 128) 0 conv2_block1_concat[0][0] \n conv2_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block3_0_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block3_0_relu (Activation (None, 80, 80, 128) 0 conv2_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block3_1_conv (Conv2D) (None, 80, 80, 128) 16384 conv2_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block3_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block3_1_relu (Activation (None, 80, 80, 128) 0 conv2_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block3_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block3_concat (Concatenat (None, 80, 80, 160) 0 conv2_block2_concat[0][0] \n conv2_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block4_0_bn (BatchNormali (None, 80, 80, 160) 640 conv2_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block4_0_relu (Activation (None, 80, 80, 160) 0 conv2_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block4_1_conv (Conv2D) (None, 80, 80, 128) 20480 conv2_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block4_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block4_1_relu (Activation (None, 80, 80, 128) 0 conv2_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block4_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block4_concat (Concatenat (None, 80, 80, 192) 0 conv2_block3_concat[0][0] \n conv2_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block5_0_bn (BatchNormali (None, 80, 80, 192) 768 conv2_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block5_0_relu (Activation (None, 80, 80, 192) 0 conv2_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block5_1_conv (Conv2D) (None, 80, 80, 128) 24576 conv2_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block5_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block5_1_relu (Activation (None, 80, 80, 128) 0 conv2_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block5_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block5_concat (Concatenat (None, 80, 80, 224) 0 conv2_block4_concat[0][0] \n conv2_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block6_0_bn (BatchNormali (None, 80, 80, 224) 896 conv2_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block6_0_relu (Activation (None, 80, 80, 224) 0 conv2_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block6_1_conv (Conv2D) (None, 80, 80, 128) 28672 conv2_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block6_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block6_1_relu (Activation (None, 80, 80, 128) 0 conv2_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block6_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block6_concat (Concatenat (None, 80, 80, 256) 0 conv2_block5_concat[0][0] \n conv2_block6_2_conv[0][0] \n__________________________________________________________________________________________________\npool2_bn (BatchNormalization) (None, 80, 80, 256) 1024 conv2_block6_concat[0][0] \n__________________________________________________________________________________________________\npool2_relu (Activation) (None, 80, 80, 256) 0 pool2_bn[0][0] \n__________________________________________________________________________________________________\npool2_conv (Conv2D) (None, 80, 80, 128) 32768 pool2_relu[0][0] \n__________________________________________________________________________________________________\npool2_pool (AveragePooling2D) (None, 40, 40, 128) 0 pool2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block1_0_bn (BatchNormali (None, 40, 40, 128) 512 pool2_pool[0][0] \n__________________________________________________________________________________________________\nconv3_block1_0_relu (Activation (None, 40, 40, 128) 0 conv3_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block1_1_conv (Conv2D) (None, 40, 40, 128) 16384 conv3_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block1_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block1_1_relu (Activation (None, 40, 40, 128) 0 conv3_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block1_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block1_concat (Concatenat (None, 40, 40, 160) 0 pool2_pool[0][0] \n conv3_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block2_0_bn (BatchNormali (None, 40, 40, 160) 640 conv3_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block2_0_relu (Activation (None, 40, 40, 160) 0 conv3_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block2_1_conv (Conv2D) (None, 40, 40, 128) 20480 conv3_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block2_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block2_1_relu (Activation (None, 40, 40, 128) 0 conv3_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block2_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block2_concat (Concatenat (None, 40, 40, 192) 0 conv3_block1_concat[0][0] \n conv3_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block3_0_bn (BatchNormali (None, 40, 40, 192) 768 conv3_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block3_0_relu (Activation (None, 40, 40, 192) 0 conv3_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block3_1_conv (Conv2D) (None, 40, 40, 128) 24576 conv3_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block3_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block3_1_relu (Activation (None, 40, 40, 128) 0 conv3_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block3_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block3_concat (Concatenat (None, 40, 40, 224) 0 conv3_block2_concat[0][0] \n conv3_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block4_0_bn (BatchNormali (None, 40, 40, 224) 896 conv3_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block4_0_relu (Activation (None, 40, 40, 224) 0 conv3_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block4_1_conv (Conv2D) (None, 40, 40, 128) 28672 conv3_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block4_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block4_1_relu (Activation (None, 40, 40, 128) 0 conv3_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block4_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block4_concat (Concatenat (None, 40, 40, 256) 0 conv3_block3_concat[0][0] \n conv3_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block5_0_bn (BatchNormali (None, 40, 40, 256) 1024 conv3_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block5_0_relu (Activation (None, 40, 40, 256) 0 conv3_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block5_1_conv (Conv2D) (None, 40, 40, 128) 32768 conv3_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block5_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block5_1_relu (Activation (None, 40, 40, 128) 0 conv3_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block5_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block5_concat (Concatenat (None, 40, 40, 288) 0 conv3_block4_concat[0][0] \n conv3_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block6_0_bn (BatchNormali (None, 40, 40, 288) 1152 conv3_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block6_0_relu (Activation (None, 40, 40, 288) 0 conv3_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block6_1_conv (Conv2D) (None, 40, 40, 128) 36864 conv3_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block6_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block6_1_relu (Activation (None, 40, 40, 128) 0 conv3_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block6_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block6_concat (Concatenat (None, 40, 40, 320) 0 conv3_block5_concat[0][0] \n conv3_block6_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block7_0_bn (BatchNormali (None, 40, 40, 320) 1280 conv3_block6_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block7_0_relu (Activation (None, 40, 40, 320) 0 conv3_block7_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block7_1_conv (Conv2D) (None, 40, 40, 128) 40960 conv3_block7_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block7_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block7_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block7_1_relu (Activation (None, 40, 40, 128) 0 conv3_block7_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block7_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block7_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block7_concat (Concatenat (None, 40, 40, 352) 0 conv3_block6_concat[0][0] \n conv3_block7_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block8_0_bn (BatchNormali (None, 40, 40, 352) 1408 conv3_block7_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block8_0_relu (Activation (None, 40, 40, 352) 0 conv3_block8_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block8_1_conv (Conv2D) (None, 40, 40, 128) 45056 conv3_block8_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block8_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block8_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block8_1_relu (Activation (None, 40, 40, 128) 0 conv3_block8_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block8_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block8_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block8_concat (Concatenat (None, 40, 40, 384) 0 conv3_block7_concat[0][0] \n conv3_block8_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block9_0_bn (BatchNormali (None, 40, 40, 384) 1536 conv3_block8_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block9_0_relu (Activation (None, 40, 40, 384) 0 conv3_block9_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block9_1_conv (Conv2D) (None, 40, 40, 128) 49152 conv3_block9_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block9_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block9_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block9_1_relu (Activation (None, 40, 40, 128) 0 conv3_block9_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block9_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block9_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block9_concat (Concatenat (None, 40, 40, 416) 0 conv3_block8_concat[0][0] \n conv3_block9_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block10_0_bn (BatchNormal (None, 40, 40, 416) 1664 conv3_block9_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block10_0_relu (Activatio (None, 40, 40, 416) 0 conv3_block10_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block10_1_conv (Conv2D) (None, 40, 40, 128) 53248 conv3_block10_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block10_1_bn (BatchNormal (None, 40, 40, 128) 512 conv3_block10_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block10_1_relu (Activatio (None, 40, 40, 128) 0 conv3_block10_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block10_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block10_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block10_concat (Concatena (None, 40, 40, 448) 0 conv3_block9_concat[0][0] \n conv3_block10_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block11_0_bn (BatchNormal (None, 40, 40, 448) 1792 conv3_block10_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block11_0_relu (Activatio (None, 40, 40, 448) 0 conv3_block11_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block11_1_conv (Conv2D) (None, 40, 40, 128) 57344 conv3_block11_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block11_1_bn (BatchNormal (None, 40, 40, 128) 512 conv3_block11_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block11_1_relu (Activatio (None, 40, 40, 128) 0 conv3_block11_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block11_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block11_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block11_concat (Concatena (None, 40, 40, 480) 0 conv3_block10_concat[0][0] \n conv3_block11_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block12_0_bn (BatchNormal (None, 40, 40, 480) 1920 conv3_block11_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block12_0_relu (Activatio (None, 40, 40, 480) 0 conv3_block12_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block12_1_conv (Conv2D) (None, 40, 40, 128) 61440 conv3_block12_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block12_1_bn (BatchNormal (None, 40, 40, 128) 512 conv3_block12_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block12_1_relu (Activatio (None, 40, 40, 128) 0 conv3_block12_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block12_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block12_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block12_concat (Concatena (None, 40, 40, 512) 0 conv3_block11_concat[0][0] \n conv3_block12_2_conv[0][0] \n__________________________________________________________________________________________________\npool3_bn (BatchNormalization) (None, 40, 40, 512) 2048 conv3_block12_concat[0][0] \n__________________________________________________________________________________________________\npool3_relu (Activation) (None, 40, 40, 512) 0 pool3_bn[0][0] \n__________________________________________________________________________________________________\npool3_conv (Conv2D) (None, 40, 40, 256) 131072 pool3_relu[0][0] \n__________________________________________________________________________________________________\npool3_pool (AveragePooling2D) (None, 20, 20, 256) 0 pool3_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block1_0_bn (BatchNormali (None, 20, 20, 256) 1024 pool3_pool[0][0] \n__________________________________________________________________________________________________\nconv4_block1_0_relu (Activation (None, 20, 20, 256) 0 conv4_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block1_1_conv (Conv2D) (None, 20, 20, 128) 32768 conv4_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block1_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block1_1_relu (Activation (None, 20, 20, 128) 0 conv4_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block1_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block1_concat (Concatenat (None, 20, 20, 288) 0 pool3_pool[0][0] \n conv4_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block2_0_bn (BatchNormali (None, 20, 20, 288) 1152 conv4_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block2_0_relu (Activation (None, 20, 20, 288) 0 conv4_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block2_1_conv (Conv2D) (None, 20, 20, 128) 36864 conv4_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block2_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block2_1_relu (Activation (None, 20, 20, 128) 0 conv4_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block2_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block2_concat (Concatenat (None, 20, 20, 320) 0 conv4_block1_concat[0][0] \n conv4_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block3_0_bn (BatchNormali (None, 20, 20, 320) 1280 conv4_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block3_0_relu (Activation (None, 20, 20, 320) 0 conv4_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block3_1_conv (Conv2D) (None, 20, 20, 128) 40960 conv4_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block3_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block3_1_relu (Activation (None, 20, 20, 128) 0 conv4_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block3_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block3_concat (Concatenat (None, 20, 20, 352) 0 conv4_block2_concat[0][0] \n conv4_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block4_0_bn (BatchNormali (None, 20, 20, 352) 1408 conv4_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block4_0_relu (Activation (None, 20, 20, 352) 0 conv4_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block4_1_conv (Conv2D) (None, 20, 20, 128) 45056 conv4_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block4_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block4_1_relu (Activation (None, 20, 20, 128) 0 conv4_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block4_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block4_concat (Concatenat (None, 20, 20, 384) 0 conv4_block3_concat[0][0] \n conv4_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block5_0_bn (BatchNormali (None, 20, 20, 384) 1536 conv4_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block5_0_relu (Activation (None, 20, 20, 384) 0 conv4_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block5_1_conv (Conv2D) (None, 20, 20, 128) 49152 conv4_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block5_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block5_1_relu (Activation (None, 20, 20, 128) 0 conv4_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block5_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block5_concat (Concatenat (None, 20, 20, 416) 0 conv4_block4_concat[0][0] \n conv4_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block6_0_bn (BatchNormali (None, 20, 20, 416) 1664 conv4_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block6_0_relu (Activation (None, 20, 20, 416) 0 conv4_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block6_1_conv (Conv2D) (None, 20, 20, 128) 53248 conv4_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block6_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block6_1_relu (Activation (None, 20, 20, 128) 0 conv4_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block6_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block6_concat (Concatenat (None, 20, 20, 448) 0 conv4_block5_concat[0][0] \n conv4_block6_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block7_0_bn (BatchNormali (None, 20, 20, 448) 1792 conv4_block6_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block7_0_relu (Activation (None, 20, 20, 448) 0 conv4_block7_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block7_1_conv (Conv2D) (None, 20, 20, 128) 57344 conv4_block7_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block7_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block7_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block7_1_relu (Activation (None, 20, 20, 128) 0 conv4_block7_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block7_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block7_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block7_concat (Concatenat (None, 20, 20, 480) 0 conv4_block6_concat[0][0] \n conv4_block7_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block8_0_bn (BatchNormali (None, 20, 20, 480) 1920 conv4_block7_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block8_0_relu (Activation (None, 20, 20, 480) 0 conv4_block8_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block8_1_conv (Conv2D) (None, 20, 20, 128) 61440 conv4_block8_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block8_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block8_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block8_1_relu (Activation (None, 20, 20, 128) 0 conv4_block8_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block8_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block8_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block8_concat (Concatenat (None, 20, 20, 512) 0 conv4_block7_concat[0][0] \n conv4_block8_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block9_0_bn (BatchNormali (None, 20, 20, 512) 2048 conv4_block8_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block9_0_relu (Activation (None, 20, 20, 512) 0 conv4_block9_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block9_1_conv (Conv2D) (None, 20, 20, 128) 65536 conv4_block9_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block9_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block9_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block9_1_relu (Activation (None, 20, 20, 128) 0 conv4_block9_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block9_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block9_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block9_concat (Concatenat (None, 20, 20, 544) 0 conv4_block8_concat[0][0] \n conv4_block9_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block10_0_bn (BatchNormal (None, 20, 20, 544) 2176 conv4_block9_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block10_0_relu (Activatio (None, 20, 20, 544) 0 conv4_block10_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block10_1_conv (Conv2D) (None, 20, 20, 128) 69632 conv4_block10_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block10_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block10_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block10_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block10_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block10_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block10_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block10_concat (Concatena (None, 20, 20, 576) 0 conv4_block9_concat[0][0] \n conv4_block10_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block11_0_bn (BatchNormal (None, 20, 20, 576) 2304 conv4_block10_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block11_0_relu (Activatio (None, 20, 20, 576) 0 conv4_block11_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block11_1_conv (Conv2D) (None, 20, 20, 128) 73728 conv4_block11_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block11_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block11_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block11_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block11_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block11_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block11_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block11_concat (Concatena (None, 20, 20, 608) 0 conv4_block10_concat[0][0] \n conv4_block11_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block12_0_bn (BatchNormal (None, 20, 20, 608) 2432 conv4_block11_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block12_0_relu (Activatio (None, 20, 20, 608) 0 conv4_block12_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block12_1_conv (Conv2D) (None, 20, 20, 128) 77824 conv4_block12_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block12_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block12_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block12_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block12_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block12_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block12_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block12_concat (Concatena (None, 20, 20, 640) 0 conv4_block11_concat[0][0] \n conv4_block12_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block13_0_bn (BatchNormal (None, 20, 20, 640) 2560 conv4_block12_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block13_0_relu (Activatio (None, 20, 20, 640) 0 conv4_block13_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block13_1_conv (Conv2D) (None, 20, 20, 128) 81920 conv4_block13_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block13_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block13_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block13_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block13_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block13_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block13_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block13_concat (Concatena (None, 20, 20, 672) 0 conv4_block12_concat[0][0] \n conv4_block13_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block14_0_bn (BatchNormal (None, 20, 20, 672) 2688 conv4_block13_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block14_0_relu (Activatio (None, 20, 20, 672) 0 conv4_block14_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block14_1_conv (Conv2D) (None, 20, 20, 128) 86016 conv4_block14_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block14_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block14_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block14_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block14_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block14_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block14_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block14_concat (Concatena (None, 20, 20, 704) 0 conv4_block13_concat[0][0] \n conv4_block14_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block15_0_bn (BatchNormal (None, 20, 20, 704) 2816 conv4_block14_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block15_0_relu (Activatio (None, 20, 20, 704) 0 conv4_block15_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block15_1_conv (Conv2D) (None, 20, 20, 128) 90112 conv4_block15_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block15_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block15_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block15_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block15_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block15_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block15_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block15_concat (Concatena (None, 20, 20, 736) 0 conv4_block14_concat[0][0] \n conv4_block15_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block16_0_bn (BatchNormal (None, 20, 20, 736) 2944 conv4_block15_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block16_0_relu (Activatio (None, 20, 20, 736) 0 conv4_block16_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block16_1_conv (Conv2D) (None, 20, 20, 128) 94208 conv4_block16_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block16_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block16_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block16_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block16_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block16_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block16_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block16_concat (Concatena (None, 20, 20, 768) 0 conv4_block15_concat[0][0] \n conv4_block16_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block17_0_bn (BatchNormal (None, 20, 20, 768) 3072 conv4_block16_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block17_0_relu (Activatio (None, 20, 20, 768) 0 conv4_block17_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block17_1_conv (Conv2D) (None, 20, 20, 128) 98304 conv4_block17_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block17_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block17_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block17_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block17_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block17_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block17_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block17_concat (Concatena (None, 20, 20, 800) 0 conv4_block16_concat[0][0] \n conv4_block17_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block18_0_bn (BatchNormal (None, 20, 20, 800) 3200 conv4_block17_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block18_0_relu (Activatio (None, 20, 20, 800) 0 conv4_block18_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block18_1_conv (Conv2D) (None, 20, 20, 128) 102400 conv4_block18_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block18_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block18_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block18_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block18_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block18_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block18_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block18_concat (Concatena (None, 20, 20, 832) 0 conv4_block17_concat[0][0] \n conv4_block18_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block19_0_bn (BatchNormal (None, 20, 20, 832) 3328 conv4_block18_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block19_0_relu (Activatio (None, 20, 20, 832) 0 conv4_block19_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block19_1_conv (Conv2D) (None, 20, 20, 128) 106496 conv4_block19_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block19_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block19_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block19_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block19_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block19_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block19_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block19_concat (Concatena (None, 20, 20, 864) 0 conv4_block18_concat[0][0] \n conv4_block19_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block20_0_bn (BatchNormal (None, 20, 20, 864) 3456 conv4_block19_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block20_0_relu (Activatio (None, 20, 20, 864) 0 conv4_block20_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block20_1_conv (Conv2D) (None, 20, 20, 128) 110592 conv4_block20_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block20_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block20_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block20_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block20_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block20_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block20_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block20_concat (Concatena (None, 20, 20, 896) 0 conv4_block19_concat[0][0] \n conv4_block20_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block21_0_bn (BatchNormal (None, 20, 20, 896) 3584 conv4_block20_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block21_0_relu (Activatio (None, 20, 20, 896) 0 conv4_block21_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block21_1_conv (Conv2D) (None, 20, 20, 128) 114688 conv4_block21_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block21_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block21_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block21_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block21_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block21_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block21_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block21_concat (Concatena (None, 20, 20, 928) 0 conv4_block20_concat[0][0] \n conv4_block21_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block22_0_bn (BatchNormal (None, 20, 20, 928) 3712 conv4_block21_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block22_0_relu (Activatio (None, 20, 20, 928) 0 conv4_block22_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block22_1_conv (Conv2D) (None, 20, 20, 128) 118784 conv4_block22_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block22_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block22_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block22_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block22_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block22_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block22_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block22_concat (Concatena (None, 20, 20, 960) 0 conv4_block21_concat[0][0] \n conv4_block22_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block23_0_bn (BatchNormal (None, 20, 20, 960) 3840 conv4_block22_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block23_0_relu (Activatio (None, 20, 20, 960) 0 conv4_block23_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block23_1_conv (Conv2D) (None, 20, 20, 128) 122880 conv4_block23_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block23_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block23_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block23_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block23_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block23_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block23_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block23_concat (Concatena (None, 20, 20, 992) 0 conv4_block22_concat[0][0] \n conv4_block23_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block24_0_bn (BatchNormal (None, 20, 20, 992) 3968 conv4_block23_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block24_0_relu (Activatio (None, 20, 20, 992) 0 conv4_block24_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block24_1_conv (Conv2D) (None, 20, 20, 128) 126976 conv4_block24_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block24_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block24_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block24_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block24_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block24_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block24_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block24_concat (Concatena (None, 20, 20, 1024) 0 conv4_block23_concat[0][0] \n conv4_block24_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block25_0_bn (BatchNormal (None, 20, 20, 1024) 4096 conv4_block24_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block25_0_relu (Activatio (None, 20, 20, 1024) 0 conv4_block25_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block25_1_conv (Conv2D) (None, 20, 20, 128) 131072 conv4_block25_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block25_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block25_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block25_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block25_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block25_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block25_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block25_concat (Concatena (None, 20, 20, 1056) 0 conv4_block24_concat[0][0] \n conv4_block25_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block26_0_bn (BatchNormal (None, 20, 20, 1056) 4224 conv4_block25_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block26_0_relu (Activatio (None, 20, 20, 1056) 0 conv4_block26_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block26_1_conv (Conv2D) (None, 20, 20, 128) 135168 conv4_block26_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block26_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block26_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block26_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block26_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block26_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block26_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block26_concat (Concatena (None, 20, 20, 1088) 0 conv4_block25_concat[0][0] \n conv4_block26_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block27_0_bn (BatchNormal (None, 20, 20, 1088) 4352 conv4_block26_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block27_0_relu (Activatio (None, 20, 20, 1088) 0 conv4_block27_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block27_1_conv (Conv2D) (None, 20, 20, 128) 139264 conv4_block27_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block27_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block27_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block27_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block27_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block27_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block27_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block27_concat (Concatena (None, 20, 20, 1120) 0 conv4_block26_concat[0][0] \n conv4_block27_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block28_0_bn (BatchNormal (None, 20, 20, 1120) 4480 conv4_block27_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block28_0_relu (Activatio (None, 20, 20, 1120) 0 conv4_block28_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block28_1_conv (Conv2D) (None, 20, 20, 128) 143360 conv4_block28_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block28_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block28_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block28_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block28_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block28_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block28_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block28_concat (Concatena (None, 20, 20, 1152) 0 conv4_block27_concat[0][0] \n conv4_block28_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block29_0_bn (BatchNormal (None, 20, 20, 1152) 4608 conv4_block28_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block29_0_relu (Activatio (None, 20, 20, 1152) 0 conv4_block29_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block29_1_conv (Conv2D) (None, 20, 20, 128) 147456 conv4_block29_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block29_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block29_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block29_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block29_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block29_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block29_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block29_concat (Concatena (None, 20, 20, 1184) 0 conv4_block28_concat[0][0] \n conv4_block29_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block30_0_bn (BatchNormal (None, 20, 20, 1184) 4736 conv4_block29_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block30_0_relu (Activatio (None, 20, 20, 1184) 0 conv4_block30_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block30_1_conv (Conv2D) (None, 20, 20, 128) 151552 conv4_block30_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block30_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block30_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block30_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block30_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block30_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block30_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block30_concat (Concatena (None, 20, 20, 1216) 0 conv4_block29_concat[0][0] \n conv4_block30_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block31_0_bn (BatchNormal (None, 20, 20, 1216) 4864 conv4_block30_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block31_0_relu (Activatio (None, 20, 20, 1216) 0 conv4_block31_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block31_1_conv (Conv2D) (None, 20, 20, 128) 155648 conv4_block31_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block31_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block31_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block31_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block31_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block31_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block31_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block31_concat (Concatena (None, 20, 20, 1248) 0 conv4_block30_concat[0][0] \n conv4_block31_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block32_0_bn (BatchNormal (None, 20, 20, 1248) 4992 conv4_block31_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block32_0_relu (Activatio (None, 20, 20, 1248) 0 conv4_block32_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block32_1_conv (Conv2D) (None, 20, 20, 128) 159744 conv4_block32_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block32_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block32_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block32_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block32_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block32_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block32_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block32_concat (Concatena (None, 20, 20, 1280) 0 conv4_block31_concat[0][0] \n conv4_block32_2_conv[0][0] \n__________________________________________________________________________________________________\npool4_bn (BatchNormalization) (None, 20, 20, 1280) 5120 conv4_block32_concat[0][0] \n__________________________________________________________________________________________________\npool4_relu (Activation) (None, 20, 20, 1280) 0 pool4_bn[0][0] \n__________________________________________________________________________________________________\npool4_conv (Conv2D) (None, 20, 20, 640) 819200 pool4_relu[0][0] \n__________________________________________________________________________________________________\npool4_pool (AveragePooling2D) (None, 10, 10, 640) 0 pool4_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block1_0_bn (BatchNormali (None, 10, 10, 640) 2560 pool4_pool[0][0] \n__________________________________________________________________________________________________\nconv5_block1_0_relu (Activation (None, 10, 10, 640) 0 conv5_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block1_1_conv (Conv2D) (None, 10, 10, 128) 81920 conv5_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block1_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block1_1_relu (Activation (None, 10, 10, 128) 0 conv5_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block1_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block1_concat (Concatenat (None, 10, 10, 672) 0 pool4_pool[0][0] \n conv5_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block2_0_bn (BatchNormali (None, 10, 10, 672) 2688 conv5_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block2_0_relu (Activation (None, 10, 10, 672) 0 conv5_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block2_1_conv (Conv2D) (None, 10, 10, 128) 86016 conv5_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block2_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block2_1_relu (Activation (None, 10, 10, 128) 0 conv5_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block2_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block2_concat (Concatenat (None, 10, 10, 704) 0 conv5_block1_concat[0][0] \n conv5_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block3_0_bn (BatchNormali (None, 10, 10, 704) 2816 conv5_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block3_0_relu (Activation (None, 10, 10, 704) 0 conv5_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block3_1_conv (Conv2D) (None, 10, 10, 128) 90112 conv5_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block3_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block3_1_relu (Activation (None, 10, 10, 128) 0 conv5_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block3_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block3_concat (Concatenat (None, 10, 10, 736) 0 conv5_block2_concat[0][0] \n conv5_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block4_0_bn (BatchNormali (None, 10, 10, 736) 2944 conv5_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block4_0_relu (Activation (None, 10, 10, 736) 0 conv5_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block4_1_conv (Conv2D) (None, 10, 10, 128) 94208 conv5_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block4_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block4_1_relu (Activation (None, 10, 10, 128) 0 conv5_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block4_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block4_concat (Concatenat (None, 10, 10, 768) 0 conv5_block3_concat[0][0] \n conv5_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block5_0_bn (BatchNormali (None, 10, 10, 768) 3072 conv5_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block5_0_relu (Activation (None, 10, 10, 768) 0 conv5_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block5_1_conv (Conv2D) (None, 10, 10, 128) 98304 conv5_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block5_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block5_1_relu (Activation (None, 10, 10, 128) 0 conv5_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block5_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block5_concat (Concatenat (None, 10, 10, 800) 0 conv5_block4_concat[0][0] \n conv5_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block6_0_bn (BatchNormali (None, 10, 10, 800) 3200 conv5_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block6_0_relu (Activation (None, 10, 10, 800) 0 conv5_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block6_1_conv (Conv2D) (None, 10, 10, 128) 102400 conv5_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block6_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block6_1_relu (Activation (None, 10, 10, 128) 0 conv5_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block6_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block6_concat (Concatenat (None, 10, 10, 832) 0 conv5_block5_concat[0][0] \n conv5_block6_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block7_0_bn (BatchNormali (None, 10, 10, 832) 3328 conv5_block6_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block7_0_relu (Activation (None, 10, 10, 832) 0 conv5_block7_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block7_1_conv (Conv2D) (None, 10, 10, 128) 106496 conv5_block7_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block7_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block7_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block7_1_relu (Activation (None, 10, 10, 128) 0 conv5_block7_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block7_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block7_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block7_concat (Concatenat (None, 10, 10, 864) 0 conv5_block6_concat[0][0] \n conv5_block7_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block8_0_bn (BatchNormali (None, 10, 10, 864) 3456 conv5_block7_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block8_0_relu (Activation (None, 10, 10, 864) 0 conv5_block8_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block8_1_conv (Conv2D) (None, 10, 10, 128) 110592 conv5_block8_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block8_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block8_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block8_1_relu (Activation (None, 10, 10, 128) 0 conv5_block8_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block8_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block8_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block8_concat (Concatenat (None, 10, 10, 896) 0 conv5_block7_concat[0][0] \n conv5_block8_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block9_0_bn (BatchNormali (None, 10, 10, 896) 3584 conv5_block8_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block9_0_relu (Activation (None, 10, 10, 896) 0 conv5_block9_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block9_1_conv (Conv2D) (None, 10, 10, 128) 114688 conv5_block9_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block9_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block9_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block9_1_relu (Activation (None, 10, 10, 128) 0 conv5_block9_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block9_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block9_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block9_concat (Concatenat (None, 10, 10, 928) 0 conv5_block8_concat[0][0] \n conv5_block9_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block10_0_bn (BatchNormal (None, 10, 10, 928) 3712 conv5_block9_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block10_0_relu (Activatio (None, 10, 10, 928) 0 conv5_block10_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block10_1_conv (Conv2D) (None, 10, 10, 128) 118784 conv5_block10_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block10_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block10_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block10_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block10_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block10_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block10_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block10_concat (Concatena (None, 10, 10, 960) 0 conv5_block9_concat[0][0] \n conv5_block10_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block11_0_bn (BatchNormal (None, 10, 10, 960) 3840 conv5_block10_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block11_0_relu (Activatio (None, 10, 10, 960) 0 conv5_block11_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block11_1_conv (Conv2D) (None, 10, 10, 128) 122880 conv5_block11_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block11_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block11_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block11_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block11_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block11_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block11_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block11_concat (Concatena (None, 10, 10, 992) 0 conv5_block10_concat[0][0] \n conv5_block11_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block12_0_bn (BatchNormal (None, 10, 10, 992) 3968 conv5_block11_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block12_0_relu (Activatio (None, 10, 10, 992) 0 conv5_block12_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block12_1_conv (Conv2D) (None, 10, 10, 128) 126976 conv5_block12_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block12_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block12_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block12_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block12_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block12_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block12_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block12_concat (Concatena (None, 10, 10, 1024) 0 conv5_block11_concat[0][0] \n conv5_block12_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block13_0_bn (BatchNormal (None, 10, 10, 1024) 4096 conv5_block12_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block13_0_relu (Activatio (None, 10, 10, 1024) 0 conv5_block13_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block13_1_conv (Conv2D) (None, 10, 10, 128) 131072 conv5_block13_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block13_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block13_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block13_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block13_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block13_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block13_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block13_concat (Concatena (None, 10, 10, 1056) 0 conv5_block12_concat[0][0] \n conv5_block13_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block14_0_bn (BatchNormal (None, 10, 10, 1056) 4224 conv5_block13_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block14_0_relu (Activatio (None, 10, 10, 1056) 0 conv5_block14_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block14_1_conv (Conv2D) (None, 10, 10, 128) 135168 conv5_block14_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block14_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block14_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block14_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block14_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block14_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block14_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block14_concat (Concatena (None, 10, 10, 1088) 0 conv5_block13_concat[0][0] \n conv5_block14_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block15_0_bn (BatchNormal (None, 10, 10, 1088) 4352 conv5_block14_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block15_0_relu (Activatio (None, 10, 10, 1088) 0 conv5_block15_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block15_1_conv (Conv2D) (None, 10, 10, 128) 139264 conv5_block15_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block15_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block15_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block15_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block15_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block15_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block15_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block15_concat (Concatena (None, 10, 10, 1120) 0 conv5_block14_concat[0][0] \n conv5_block15_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block16_0_bn (BatchNormal (None, 10, 10, 1120) 4480 conv5_block15_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block16_0_relu (Activatio (None, 10, 10, 1120) 0 conv5_block16_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block16_1_conv (Conv2D) (None, 10, 10, 128) 143360 conv5_block16_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block16_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block16_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block16_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block16_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block16_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block16_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block16_concat (Concatena (None, 10, 10, 1152) 0 conv5_block15_concat[0][0] \n conv5_block16_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block17_0_bn (BatchNormal (None, 10, 10, 1152) 4608 conv5_block16_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block17_0_relu (Activatio (None, 10, 10, 1152) 0 conv5_block17_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block17_1_conv (Conv2D) (None, 10, 10, 128) 147456 conv5_block17_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block17_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block17_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block17_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block17_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block17_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block17_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block17_concat (Concatena (None, 10, 10, 1184) 0 conv5_block16_concat[0][0] \n conv5_block17_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block18_0_bn (BatchNormal (None, 10, 10, 1184) 4736 conv5_block17_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block18_0_relu (Activatio (None, 10, 10, 1184) 0 conv5_block18_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block18_1_conv (Conv2D) (None, 10, 10, 128) 151552 conv5_block18_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block18_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block18_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block18_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block18_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block18_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block18_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block18_concat (Concatena (None, 10, 10, 1216) 0 conv5_block17_concat[0][0] \n conv5_block18_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block19_0_bn (BatchNormal (None, 10, 10, 1216) 4864 conv5_block18_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block19_0_relu (Activatio (None, 10, 10, 1216) 0 conv5_block19_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block19_1_conv (Conv2D) (None, 10, 10, 128) 155648 conv5_block19_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block19_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block19_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block19_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block19_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block19_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block19_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block19_concat (Concatena (None, 10, 10, 1248) 0 conv5_block18_concat[0][0] \n conv5_block19_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block20_0_bn (BatchNormal (None, 10, 10, 1248) 4992 conv5_block19_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block20_0_relu (Activatio (None, 10, 10, 1248) 0 conv5_block20_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block20_1_conv (Conv2D) (None, 10, 10, 128) 159744 conv5_block20_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block20_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block20_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block20_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block20_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block20_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block20_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block20_concat (Concatena (None, 10, 10, 1280) 0 conv5_block19_concat[0][0] \n conv5_block20_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block21_0_bn (BatchNormal (None, 10, 10, 1280) 5120 conv5_block20_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block21_0_relu (Activatio (None, 10, 10, 1280) 0 conv5_block21_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block21_1_conv (Conv2D) (None, 10, 10, 128) 163840 conv5_block21_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block21_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block21_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block21_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block21_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block21_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block21_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block21_concat (Concatena (None, 10, 10, 1312) 0 conv5_block20_concat[0][0] \n conv5_block21_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block22_0_bn (BatchNormal (None, 10, 10, 1312) 5248 conv5_block21_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block22_0_relu (Activatio (None, 10, 10, 1312) 0 conv5_block22_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block22_1_conv (Conv2D) (None, 10, 10, 128) 167936 conv5_block22_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block22_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block22_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block22_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block22_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block22_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block22_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block22_concat (Concatena (None, 10, 10, 1344) 0 conv5_block21_concat[0][0] \n conv5_block22_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block23_0_bn (BatchNormal (None, 10, 10, 1344) 5376 conv5_block22_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block23_0_relu (Activatio (None, 10, 10, 1344) 0 conv5_block23_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block23_1_conv (Conv2D) (None, 10, 10, 128) 172032 conv5_block23_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block23_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block23_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block23_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block23_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block23_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block23_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block23_concat (Concatena (None, 10, 10, 1376) 0 conv5_block22_concat[0][0] \n conv5_block23_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block24_0_bn (BatchNormal (None, 10, 10, 1376) 5504 conv5_block23_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block24_0_relu (Activatio (None, 10, 10, 1376) 0 conv5_block24_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block24_1_conv (Conv2D) (None, 10, 10, 128) 176128 conv5_block24_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block24_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block24_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block24_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block24_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block24_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block24_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block24_concat (Concatena (None, 10, 10, 1408) 0 conv5_block23_concat[0][0] \n conv5_block24_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block25_0_bn (BatchNormal (None, 10, 10, 1408) 5632 conv5_block24_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block25_0_relu (Activatio (None, 10, 10, 1408) 0 conv5_block25_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block25_1_conv (Conv2D) (None, 10, 10, 128) 180224 conv5_block25_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block25_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block25_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block25_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block25_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block25_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block25_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block25_concat (Concatena (None, 10, 10, 1440) 0 conv5_block24_concat[0][0] \n conv5_block25_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block26_0_bn (BatchNormal (None, 10, 10, 1440) 5760 conv5_block25_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block26_0_relu (Activatio (None, 10, 10, 1440) 0 conv5_block26_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block26_1_conv (Conv2D) (None, 10, 10, 128) 184320 conv5_block26_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block26_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block26_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block26_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block26_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block26_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block26_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block26_concat (Concatena (None, 10, 10, 1472) 0 conv5_block25_concat[0][0] \n conv5_block26_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block27_0_bn (BatchNormal (None, 10, 10, 1472) 5888 conv5_block26_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block27_0_relu (Activatio (None, 10, 10, 1472) 0 conv5_block27_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block27_1_conv (Conv2D) (None, 10, 10, 128) 188416 conv5_block27_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block27_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block27_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block27_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block27_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block27_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block27_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block27_concat (Concatena (None, 10, 10, 1504) 0 conv5_block26_concat[0][0] \n conv5_block27_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block28_0_bn (BatchNormal (None, 10, 10, 1504) 6016 conv5_block27_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block28_0_relu (Activatio (None, 10, 10, 1504) 0 conv5_block28_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block28_1_conv (Conv2D) (None, 10, 10, 128) 192512 conv5_block28_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block28_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block28_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block28_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block28_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block28_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block28_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block28_concat (Concatena (None, 10, 10, 1536) 0 conv5_block27_concat[0][0] \n conv5_block28_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block29_0_bn (BatchNormal (None, 10, 10, 1536) 6144 conv5_block28_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block29_0_relu (Activatio (None, 10, 10, 1536) 0 conv5_block29_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block29_1_conv (Conv2D) (None, 10, 10, 128) 196608 conv5_block29_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block29_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block29_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block29_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block29_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block29_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block29_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block29_concat (Concatena (None, 10, 10, 1568) 0 conv5_block28_concat[0][0] \n conv5_block29_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block30_0_bn (BatchNormal (None, 10, 10, 1568) 6272 conv5_block29_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block30_0_relu (Activatio (None, 10, 10, 1568) 0 conv5_block30_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block30_1_conv (Conv2D) (None, 10, 10, 128) 200704 conv5_block30_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block30_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block30_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block30_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block30_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block30_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block30_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block30_concat (Concatena (None, 10, 10, 1600) 0 conv5_block29_concat[0][0] \n conv5_block30_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block31_0_bn (BatchNormal (None, 10, 10, 1600) 6400 conv5_block30_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block31_0_relu (Activatio (None, 10, 10, 1600) 0 conv5_block31_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block31_1_conv (Conv2D) (None, 10, 10, 128) 204800 conv5_block31_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block31_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block31_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block31_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block31_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block31_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block31_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block31_concat (Concatena (None, 10, 10, 1632) 0 conv5_block30_concat[0][0] \n conv5_block31_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block32_0_bn (BatchNormal (None, 10, 10, 1632) 6528 conv5_block31_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block32_0_relu (Activatio (None, 10, 10, 1632) 0 conv5_block32_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block32_1_conv (Conv2D) (None, 10, 10, 128) 208896 conv5_block32_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block32_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block32_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block32_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block32_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block32_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block32_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block32_concat (Concatena (None, 10, 10, 1664) 0 conv5_block31_concat[0][0] \n conv5_block32_2_conv[0][0] \n__________________________________________________________________________________________________\nbn (BatchNormalization) (None, 10, 10, 1664) 6656 conv5_block32_concat[0][0] \n__________________________________________________________________________________________________\nrelu (Activation) (None, 10, 10, 1664) 0 bn[0][0] \n__________________________________________________________________________________________________\nglobal_average_pooling2d_1 (Glo (None, 1664) 0 relu[0][0] \n__________________________________________________________________________________________________\ndropout_1 (Dropout) (None, 1664) 0 global_average_pooling2d_1[0][0] \n__________________________________________________________________________________________________\ndense_1 (Dense) (None, 2048) 3409920 dropout_1[0][0] \n__________________________________________________________________________________________________\ndropout_2 (Dropout) (None, 2048) 0 dense_1[0][0] \n__________________________________________________________________________________________________\nfinal_output (Dense) (None, 5) 10245 dropout_2[0][0] \n==================================================================================================\nTotal params: 16,063,045\nTrainable params: 3,420,165\nNon-trainable params: 12,642,880\n__________________________________________________________________________________________________\n"
],
[
"STEP_SIZE_TRAIN = train_generator.n//train_generator.batch_size\nSTEP_SIZE_VALID = valid_generator.n//valid_generator.batch_size\n\nhistory_warmup = model.fit_generator(generator=train_generator,\n steps_per_epoch=STEP_SIZE_TRAIN,\n validation_data=valid_generator,\n validation_steps=STEP_SIZE_VALID,\n epochs=WARMUP_EPOCHS,\n class_weight=class_weights,\n verbose=1).history",
"Epoch 1/5\n183/183 [==============================] - 81s 445ms/step - loss: 1.3357 - acc: 0.5731 - kappa: 0.3848 - val_loss: 1.0849 - val_acc: 0.5083 - val_kappa: -0.2198\nEpoch 2/5\n183/183 [==============================] - 68s 373ms/step - loss: 0.9705 - acc: 0.6499 - kappa: 0.6185 - val_loss: 1.0448 - val_acc: 0.5760 - val_kappa: 0.1622\nEpoch 3/5\n183/183 [==============================] - 69s 379ms/step - loss: 0.9260 - acc: 0.6571 - kappa: 0.6398 - val_loss: 1.2030 - val_acc: 0.4881 - val_kappa: -0.4510\nEpoch 4/5\n183/183 [==============================] - 69s 378ms/step - loss: 0.8650 - acc: 0.6837 - kappa: 0.6950 - val_loss: 1.0301 - val_acc: 0.5425 - val_kappa: 0.0034\nEpoch 5/5\n183/183 [==============================] - 69s 377ms/step - loss: 0.8863 - acc: 0.6640 - kappa: 0.6651 - val_loss: 0.9225 - val_acc: 0.6444 - val_kappa: 0.5296\n"
]
],
[
[
"# Fine-tune the complete model",
"_____no_output_____"
]
],
[
[
"for layer in model.layers:\n layer.trainable = True\n\n# lrstep = LearningRateScheduler(step_decay)\nes = EarlyStopping(monitor='val_loss', mode='min', patience=ES_PATIENCE, restore_best_weights=True, verbose=1)\nrlrop = ReduceLROnPlateau(monitor='val_loss', mode='min', patience=RLROP_PATIENCE, factor=DECAY_DROP, min_lr=1e-6, verbose=1)\n\ncallback_list = [es, rlrop]\noptimizer = optimizers.Adam(lr=LEARNING_RATE)\nmodel.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=metric_list)\nmodel.summary()",
"__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_1 (InputLayer) (None, 320, 320, 3) 0 \n__________________________________________________________________________________________________\nzero_padding2d_1 (ZeroPadding2D (None, 326, 326, 3) 0 input_1[0][0] \n__________________________________________________________________________________________________\nconv1/conv (Conv2D) (None, 160, 160, 64) 9408 zero_padding2d_1[0][0] \n__________________________________________________________________________________________________\nconv1/bn (BatchNormalization) (None, 160, 160, 64) 256 conv1/conv[0][0] \n__________________________________________________________________________________________________\nconv1/relu (Activation) (None, 160, 160, 64) 0 conv1/bn[0][0] \n__________________________________________________________________________________________________\nzero_padding2d_2 (ZeroPadding2D (None, 162, 162, 64) 0 conv1/relu[0][0] \n__________________________________________________________________________________________________\npool1 (MaxPooling2D) (None, 80, 80, 64) 0 zero_padding2d_2[0][0] \n__________________________________________________________________________________________________\nconv2_block1_0_bn (BatchNormali (None, 80, 80, 64) 256 pool1[0][0] \n__________________________________________________________________________________________________\nconv2_block1_0_relu (Activation (None, 80, 80, 64) 0 conv2_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block1_1_conv (Conv2D) (None, 80, 80, 128) 8192 conv2_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block1_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block1_1_relu (Activation (None, 80, 80, 128) 0 conv2_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block1_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block1_concat (Concatenat (None, 80, 80, 96) 0 pool1[0][0] \n conv2_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block2_0_bn (BatchNormali (None, 80, 80, 96) 384 conv2_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block2_0_relu (Activation (None, 80, 80, 96) 0 conv2_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block2_1_conv (Conv2D) (None, 80, 80, 128) 12288 conv2_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block2_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block2_1_relu (Activation (None, 80, 80, 128) 0 conv2_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block2_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block2_concat (Concatenat (None, 80, 80, 128) 0 conv2_block1_concat[0][0] \n conv2_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block3_0_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block3_0_relu (Activation (None, 80, 80, 128) 0 conv2_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block3_1_conv (Conv2D) (None, 80, 80, 128) 16384 conv2_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block3_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block3_1_relu (Activation (None, 80, 80, 128) 0 conv2_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block3_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block3_concat (Concatenat (None, 80, 80, 160) 0 conv2_block2_concat[0][0] \n conv2_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block4_0_bn (BatchNormali (None, 80, 80, 160) 640 conv2_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block4_0_relu (Activation (None, 80, 80, 160) 0 conv2_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block4_1_conv (Conv2D) (None, 80, 80, 128) 20480 conv2_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block4_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block4_1_relu (Activation (None, 80, 80, 128) 0 conv2_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block4_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block4_concat (Concatenat (None, 80, 80, 192) 0 conv2_block3_concat[0][0] \n conv2_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block5_0_bn (BatchNormali (None, 80, 80, 192) 768 conv2_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block5_0_relu (Activation (None, 80, 80, 192) 0 conv2_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block5_1_conv (Conv2D) (None, 80, 80, 128) 24576 conv2_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block5_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block5_1_relu (Activation (None, 80, 80, 128) 0 conv2_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block5_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block5_concat (Concatenat (None, 80, 80, 224) 0 conv2_block4_concat[0][0] \n conv2_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block6_0_bn (BatchNormali (None, 80, 80, 224) 896 conv2_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block6_0_relu (Activation (None, 80, 80, 224) 0 conv2_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block6_1_conv (Conv2D) (None, 80, 80, 128) 28672 conv2_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block6_1_bn (BatchNormali (None, 80, 80, 128) 512 conv2_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block6_1_relu (Activation (None, 80, 80, 128) 0 conv2_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block6_2_conv (Conv2D) (None, 80, 80, 32) 36864 conv2_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block6_concat (Concatenat (None, 80, 80, 256) 0 conv2_block5_concat[0][0] \n conv2_block6_2_conv[0][0] \n__________________________________________________________________________________________________\npool2_bn (BatchNormalization) (None, 80, 80, 256) 1024 conv2_block6_concat[0][0] \n__________________________________________________________________________________________________\npool2_relu (Activation) (None, 80, 80, 256) 0 pool2_bn[0][0] \n__________________________________________________________________________________________________\npool2_conv (Conv2D) (None, 80, 80, 128) 32768 pool2_relu[0][0] \n__________________________________________________________________________________________________\npool2_pool (AveragePooling2D) (None, 40, 40, 128) 0 pool2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block1_0_bn (BatchNormali (None, 40, 40, 128) 512 pool2_pool[0][0] \n__________________________________________________________________________________________________\nconv3_block1_0_relu (Activation (None, 40, 40, 128) 0 conv3_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block1_1_conv (Conv2D) (None, 40, 40, 128) 16384 conv3_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block1_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block1_1_relu (Activation (None, 40, 40, 128) 0 conv3_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block1_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block1_concat (Concatenat (None, 40, 40, 160) 0 pool2_pool[0][0] \n conv3_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block2_0_bn (BatchNormali (None, 40, 40, 160) 640 conv3_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block2_0_relu (Activation (None, 40, 40, 160) 0 conv3_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block2_1_conv (Conv2D) (None, 40, 40, 128) 20480 conv3_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block2_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block2_1_relu (Activation (None, 40, 40, 128) 0 conv3_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block2_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block2_concat (Concatenat (None, 40, 40, 192) 0 conv3_block1_concat[0][0] \n conv3_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block3_0_bn (BatchNormali (None, 40, 40, 192) 768 conv3_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block3_0_relu (Activation (None, 40, 40, 192) 0 conv3_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block3_1_conv (Conv2D) (None, 40, 40, 128) 24576 conv3_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block3_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block3_1_relu (Activation (None, 40, 40, 128) 0 conv3_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block3_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block3_concat (Concatenat (None, 40, 40, 224) 0 conv3_block2_concat[0][0] \n conv3_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block4_0_bn (BatchNormali (None, 40, 40, 224) 896 conv3_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block4_0_relu (Activation (None, 40, 40, 224) 0 conv3_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block4_1_conv (Conv2D) (None, 40, 40, 128) 28672 conv3_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block4_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block4_1_relu (Activation (None, 40, 40, 128) 0 conv3_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block4_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block4_concat (Concatenat (None, 40, 40, 256) 0 conv3_block3_concat[0][0] \n conv3_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block5_0_bn (BatchNormali (None, 40, 40, 256) 1024 conv3_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block5_0_relu (Activation (None, 40, 40, 256) 0 conv3_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block5_1_conv (Conv2D) (None, 40, 40, 128) 32768 conv3_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block5_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block5_1_relu (Activation (None, 40, 40, 128) 0 conv3_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block5_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block5_concat (Concatenat (None, 40, 40, 288) 0 conv3_block4_concat[0][0] \n conv3_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block6_0_bn (BatchNormali (None, 40, 40, 288) 1152 conv3_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block6_0_relu (Activation (None, 40, 40, 288) 0 conv3_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block6_1_conv (Conv2D) (None, 40, 40, 128) 36864 conv3_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block6_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block6_1_relu (Activation (None, 40, 40, 128) 0 conv3_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block6_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block6_concat (Concatenat (None, 40, 40, 320) 0 conv3_block5_concat[0][0] \n conv3_block6_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block7_0_bn (BatchNormali (None, 40, 40, 320) 1280 conv3_block6_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block7_0_relu (Activation (None, 40, 40, 320) 0 conv3_block7_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block7_1_conv (Conv2D) (None, 40, 40, 128) 40960 conv3_block7_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block7_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block7_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block7_1_relu (Activation (None, 40, 40, 128) 0 conv3_block7_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block7_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block7_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block7_concat (Concatenat (None, 40, 40, 352) 0 conv3_block6_concat[0][0] \n conv3_block7_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block8_0_bn (BatchNormali (None, 40, 40, 352) 1408 conv3_block7_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block8_0_relu (Activation (None, 40, 40, 352) 0 conv3_block8_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block8_1_conv (Conv2D) (None, 40, 40, 128) 45056 conv3_block8_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block8_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block8_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block8_1_relu (Activation (None, 40, 40, 128) 0 conv3_block8_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block8_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block8_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block8_concat (Concatenat (None, 40, 40, 384) 0 conv3_block7_concat[0][0] \n conv3_block8_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block9_0_bn (BatchNormali (None, 40, 40, 384) 1536 conv3_block8_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block9_0_relu (Activation (None, 40, 40, 384) 0 conv3_block9_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block9_1_conv (Conv2D) (None, 40, 40, 128) 49152 conv3_block9_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block9_1_bn (BatchNormali (None, 40, 40, 128) 512 conv3_block9_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block9_1_relu (Activation (None, 40, 40, 128) 0 conv3_block9_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block9_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block9_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block9_concat (Concatenat (None, 40, 40, 416) 0 conv3_block8_concat[0][0] \n conv3_block9_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block10_0_bn (BatchNormal (None, 40, 40, 416) 1664 conv3_block9_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block10_0_relu (Activatio (None, 40, 40, 416) 0 conv3_block10_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block10_1_conv (Conv2D) (None, 40, 40, 128) 53248 conv3_block10_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block10_1_bn (BatchNormal (None, 40, 40, 128) 512 conv3_block10_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block10_1_relu (Activatio (None, 40, 40, 128) 0 conv3_block10_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block10_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block10_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block10_concat (Concatena (None, 40, 40, 448) 0 conv3_block9_concat[0][0] \n conv3_block10_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block11_0_bn (BatchNormal (None, 40, 40, 448) 1792 conv3_block10_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block11_0_relu (Activatio (None, 40, 40, 448) 0 conv3_block11_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block11_1_conv (Conv2D) (None, 40, 40, 128) 57344 conv3_block11_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block11_1_bn (BatchNormal (None, 40, 40, 128) 512 conv3_block11_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block11_1_relu (Activatio (None, 40, 40, 128) 0 conv3_block11_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block11_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block11_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block11_concat (Concatena (None, 40, 40, 480) 0 conv3_block10_concat[0][0] \n conv3_block11_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block12_0_bn (BatchNormal (None, 40, 40, 480) 1920 conv3_block11_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block12_0_relu (Activatio (None, 40, 40, 480) 0 conv3_block12_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block12_1_conv (Conv2D) (None, 40, 40, 128) 61440 conv3_block12_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block12_1_bn (BatchNormal (None, 40, 40, 128) 512 conv3_block12_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block12_1_relu (Activatio (None, 40, 40, 128) 0 conv3_block12_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block12_2_conv (Conv2D) (None, 40, 40, 32) 36864 conv3_block12_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block12_concat (Concatena (None, 40, 40, 512) 0 conv3_block11_concat[0][0] \n conv3_block12_2_conv[0][0] \n__________________________________________________________________________________________________\npool3_bn (BatchNormalization) (None, 40, 40, 512) 2048 conv3_block12_concat[0][0] \n__________________________________________________________________________________________________\npool3_relu (Activation) (None, 40, 40, 512) 0 pool3_bn[0][0] \n__________________________________________________________________________________________________\npool3_conv (Conv2D) (None, 40, 40, 256) 131072 pool3_relu[0][0] \n__________________________________________________________________________________________________\npool3_pool (AveragePooling2D) (None, 20, 20, 256) 0 pool3_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block1_0_bn (BatchNormali (None, 20, 20, 256) 1024 pool3_pool[0][0] \n__________________________________________________________________________________________________\nconv4_block1_0_relu (Activation (None, 20, 20, 256) 0 conv4_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block1_1_conv (Conv2D) (None, 20, 20, 128) 32768 conv4_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block1_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block1_1_relu (Activation (None, 20, 20, 128) 0 conv4_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block1_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block1_concat (Concatenat (None, 20, 20, 288) 0 pool3_pool[0][0] \n conv4_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block2_0_bn (BatchNormali (None, 20, 20, 288) 1152 conv4_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block2_0_relu (Activation (None, 20, 20, 288) 0 conv4_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block2_1_conv (Conv2D) (None, 20, 20, 128) 36864 conv4_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block2_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block2_1_relu (Activation (None, 20, 20, 128) 0 conv4_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block2_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block2_concat (Concatenat (None, 20, 20, 320) 0 conv4_block1_concat[0][0] \n conv4_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block3_0_bn (BatchNormali (None, 20, 20, 320) 1280 conv4_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block3_0_relu (Activation (None, 20, 20, 320) 0 conv4_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block3_1_conv (Conv2D) (None, 20, 20, 128) 40960 conv4_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block3_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block3_1_relu (Activation (None, 20, 20, 128) 0 conv4_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block3_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block3_concat (Concatenat (None, 20, 20, 352) 0 conv4_block2_concat[0][0] \n conv4_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block4_0_bn (BatchNormali (None, 20, 20, 352) 1408 conv4_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block4_0_relu (Activation (None, 20, 20, 352) 0 conv4_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block4_1_conv (Conv2D) (None, 20, 20, 128) 45056 conv4_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block4_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block4_1_relu (Activation (None, 20, 20, 128) 0 conv4_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block4_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block4_concat (Concatenat (None, 20, 20, 384) 0 conv4_block3_concat[0][0] \n conv4_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block5_0_bn (BatchNormali (None, 20, 20, 384) 1536 conv4_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block5_0_relu (Activation (None, 20, 20, 384) 0 conv4_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block5_1_conv (Conv2D) (None, 20, 20, 128) 49152 conv4_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block5_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block5_1_relu (Activation (None, 20, 20, 128) 0 conv4_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block5_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block5_concat (Concatenat (None, 20, 20, 416) 0 conv4_block4_concat[0][0] \n conv4_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block6_0_bn (BatchNormali (None, 20, 20, 416) 1664 conv4_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block6_0_relu (Activation (None, 20, 20, 416) 0 conv4_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block6_1_conv (Conv2D) (None, 20, 20, 128) 53248 conv4_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block6_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block6_1_relu (Activation (None, 20, 20, 128) 0 conv4_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block6_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block6_concat (Concatenat (None, 20, 20, 448) 0 conv4_block5_concat[0][0] \n conv4_block6_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block7_0_bn (BatchNormali (None, 20, 20, 448) 1792 conv4_block6_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block7_0_relu (Activation (None, 20, 20, 448) 0 conv4_block7_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block7_1_conv (Conv2D) (None, 20, 20, 128) 57344 conv4_block7_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block7_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block7_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block7_1_relu (Activation (None, 20, 20, 128) 0 conv4_block7_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block7_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block7_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block7_concat (Concatenat (None, 20, 20, 480) 0 conv4_block6_concat[0][0] \n conv4_block7_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block8_0_bn (BatchNormali (None, 20, 20, 480) 1920 conv4_block7_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block8_0_relu (Activation (None, 20, 20, 480) 0 conv4_block8_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block8_1_conv (Conv2D) (None, 20, 20, 128) 61440 conv4_block8_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block8_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block8_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block8_1_relu (Activation (None, 20, 20, 128) 0 conv4_block8_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block8_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block8_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block8_concat (Concatenat (None, 20, 20, 512) 0 conv4_block7_concat[0][0] \n conv4_block8_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block9_0_bn (BatchNormali (None, 20, 20, 512) 2048 conv4_block8_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block9_0_relu (Activation (None, 20, 20, 512) 0 conv4_block9_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block9_1_conv (Conv2D) (None, 20, 20, 128) 65536 conv4_block9_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block9_1_bn (BatchNormali (None, 20, 20, 128) 512 conv4_block9_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block9_1_relu (Activation (None, 20, 20, 128) 0 conv4_block9_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block9_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block9_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block9_concat (Concatenat (None, 20, 20, 544) 0 conv4_block8_concat[0][0] \n conv4_block9_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block10_0_bn (BatchNormal (None, 20, 20, 544) 2176 conv4_block9_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block10_0_relu (Activatio (None, 20, 20, 544) 0 conv4_block10_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block10_1_conv (Conv2D) (None, 20, 20, 128) 69632 conv4_block10_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block10_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block10_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block10_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block10_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block10_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block10_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block10_concat (Concatena (None, 20, 20, 576) 0 conv4_block9_concat[0][0] \n conv4_block10_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block11_0_bn (BatchNormal (None, 20, 20, 576) 2304 conv4_block10_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block11_0_relu (Activatio (None, 20, 20, 576) 0 conv4_block11_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block11_1_conv (Conv2D) (None, 20, 20, 128) 73728 conv4_block11_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block11_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block11_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block11_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block11_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block11_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block11_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block11_concat (Concatena (None, 20, 20, 608) 0 conv4_block10_concat[0][0] \n conv4_block11_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block12_0_bn (BatchNormal (None, 20, 20, 608) 2432 conv4_block11_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block12_0_relu (Activatio (None, 20, 20, 608) 0 conv4_block12_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block12_1_conv (Conv2D) (None, 20, 20, 128) 77824 conv4_block12_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block12_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block12_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block12_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block12_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block12_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block12_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block12_concat (Concatena (None, 20, 20, 640) 0 conv4_block11_concat[0][0] \n conv4_block12_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block13_0_bn (BatchNormal (None, 20, 20, 640) 2560 conv4_block12_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block13_0_relu (Activatio (None, 20, 20, 640) 0 conv4_block13_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block13_1_conv (Conv2D) (None, 20, 20, 128) 81920 conv4_block13_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block13_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block13_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block13_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block13_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block13_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block13_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block13_concat (Concatena (None, 20, 20, 672) 0 conv4_block12_concat[0][0] \n conv4_block13_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block14_0_bn (BatchNormal (None, 20, 20, 672) 2688 conv4_block13_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block14_0_relu (Activatio (None, 20, 20, 672) 0 conv4_block14_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block14_1_conv (Conv2D) (None, 20, 20, 128) 86016 conv4_block14_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block14_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block14_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block14_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block14_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block14_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block14_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block14_concat (Concatena (None, 20, 20, 704) 0 conv4_block13_concat[0][0] \n conv4_block14_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block15_0_bn (BatchNormal (None, 20, 20, 704) 2816 conv4_block14_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block15_0_relu (Activatio (None, 20, 20, 704) 0 conv4_block15_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block15_1_conv (Conv2D) (None, 20, 20, 128) 90112 conv4_block15_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block15_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block15_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block15_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block15_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block15_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block15_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block15_concat (Concatena (None, 20, 20, 736) 0 conv4_block14_concat[0][0] \n conv4_block15_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block16_0_bn (BatchNormal (None, 20, 20, 736) 2944 conv4_block15_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block16_0_relu (Activatio (None, 20, 20, 736) 0 conv4_block16_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block16_1_conv (Conv2D) (None, 20, 20, 128) 94208 conv4_block16_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block16_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block16_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block16_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block16_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block16_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block16_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block16_concat (Concatena (None, 20, 20, 768) 0 conv4_block15_concat[0][0] \n conv4_block16_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block17_0_bn (BatchNormal (None, 20, 20, 768) 3072 conv4_block16_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block17_0_relu (Activatio (None, 20, 20, 768) 0 conv4_block17_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block17_1_conv (Conv2D) (None, 20, 20, 128) 98304 conv4_block17_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block17_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block17_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block17_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block17_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block17_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block17_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block17_concat (Concatena (None, 20, 20, 800) 0 conv4_block16_concat[0][0] \n conv4_block17_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block18_0_bn (BatchNormal (None, 20, 20, 800) 3200 conv4_block17_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block18_0_relu (Activatio (None, 20, 20, 800) 0 conv4_block18_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block18_1_conv (Conv2D) (None, 20, 20, 128) 102400 conv4_block18_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block18_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block18_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block18_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block18_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block18_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block18_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block18_concat (Concatena (None, 20, 20, 832) 0 conv4_block17_concat[0][0] \n conv4_block18_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block19_0_bn (BatchNormal (None, 20, 20, 832) 3328 conv4_block18_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block19_0_relu (Activatio (None, 20, 20, 832) 0 conv4_block19_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block19_1_conv (Conv2D) (None, 20, 20, 128) 106496 conv4_block19_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block19_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block19_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block19_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block19_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block19_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block19_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block19_concat (Concatena (None, 20, 20, 864) 0 conv4_block18_concat[0][0] \n conv4_block19_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block20_0_bn (BatchNormal (None, 20, 20, 864) 3456 conv4_block19_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block20_0_relu (Activatio (None, 20, 20, 864) 0 conv4_block20_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block20_1_conv (Conv2D) (None, 20, 20, 128) 110592 conv4_block20_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block20_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block20_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block20_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block20_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block20_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block20_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block20_concat (Concatena (None, 20, 20, 896) 0 conv4_block19_concat[0][0] \n conv4_block20_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block21_0_bn (BatchNormal (None, 20, 20, 896) 3584 conv4_block20_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block21_0_relu (Activatio (None, 20, 20, 896) 0 conv4_block21_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block21_1_conv (Conv2D) (None, 20, 20, 128) 114688 conv4_block21_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block21_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block21_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block21_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block21_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block21_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block21_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block21_concat (Concatena (None, 20, 20, 928) 0 conv4_block20_concat[0][0] \n conv4_block21_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block22_0_bn (BatchNormal (None, 20, 20, 928) 3712 conv4_block21_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block22_0_relu (Activatio (None, 20, 20, 928) 0 conv4_block22_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block22_1_conv (Conv2D) (None, 20, 20, 128) 118784 conv4_block22_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block22_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block22_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block22_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block22_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block22_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block22_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block22_concat (Concatena (None, 20, 20, 960) 0 conv4_block21_concat[0][0] \n conv4_block22_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block23_0_bn (BatchNormal (None, 20, 20, 960) 3840 conv4_block22_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block23_0_relu (Activatio (None, 20, 20, 960) 0 conv4_block23_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block23_1_conv (Conv2D) (None, 20, 20, 128) 122880 conv4_block23_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block23_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block23_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block23_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block23_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block23_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block23_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block23_concat (Concatena (None, 20, 20, 992) 0 conv4_block22_concat[0][0] \n conv4_block23_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block24_0_bn (BatchNormal (None, 20, 20, 992) 3968 conv4_block23_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block24_0_relu (Activatio (None, 20, 20, 992) 0 conv4_block24_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block24_1_conv (Conv2D) (None, 20, 20, 128) 126976 conv4_block24_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block24_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block24_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block24_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block24_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block24_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block24_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block24_concat (Concatena (None, 20, 20, 1024) 0 conv4_block23_concat[0][0] \n conv4_block24_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block25_0_bn (BatchNormal (None, 20, 20, 1024) 4096 conv4_block24_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block25_0_relu (Activatio (None, 20, 20, 1024) 0 conv4_block25_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block25_1_conv (Conv2D) (None, 20, 20, 128) 131072 conv4_block25_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block25_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block25_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block25_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block25_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block25_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block25_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block25_concat (Concatena (None, 20, 20, 1056) 0 conv4_block24_concat[0][0] \n conv4_block25_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block26_0_bn (BatchNormal (None, 20, 20, 1056) 4224 conv4_block25_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block26_0_relu (Activatio (None, 20, 20, 1056) 0 conv4_block26_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block26_1_conv (Conv2D) (None, 20, 20, 128) 135168 conv4_block26_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block26_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block26_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block26_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block26_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block26_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block26_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block26_concat (Concatena (None, 20, 20, 1088) 0 conv4_block25_concat[0][0] \n conv4_block26_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block27_0_bn (BatchNormal (None, 20, 20, 1088) 4352 conv4_block26_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block27_0_relu (Activatio (None, 20, 20, 1088) 0 conv4_block27_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block27_1_conv (Conv2D) (None, 20, 20, 128) 139264 conv4_block27_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block27_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block27_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block27_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block27_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block27_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block27_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block27_concat (Concatena (None, 20, 20, 1120) 0 conv4_block26_concat[0][0] \n conv4_block27_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block28_0_bn (BatchNormal (None, 20, 20, 1120) 4480 conv4_block27_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block28_0_relu (Activatio (None, 20, 20, 1120) 0 conv4_block28_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block28_1_conv (Conv2D) (None, 20, 20, 128) 143360 conv4_block28_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block28_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block28_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block28_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block28_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block28_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block28_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block28_concat (Concatena (None, 20, 20, 1152) 0 conv4_block27_concat[0][0] \n conv4_block28_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block29_0_bn (BatchNormal (None, 20, 20, 1152) 4608 conv4_block28_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block29_0_relu (Activatio (None, 20, 20, 1152) 0 conv4_block29_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block29_1_conv (Conv2D) (None, 20, 20, 128) 147456 conv4_block29_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block29_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block29_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block29_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block29_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block29_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block29_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block29_concat (Concatena (None, 20, 20, 1184) 0 conv4_block28_concat[0][0] \n conv4_block29_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block30_0_bn (BatchNormal (None, 20, 20, 1184) 4736 conv4_block29_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block30_0_relu (Activatio (None, 20, 20, 1184) 0 conv4_block30_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block30_1_conv (Conv2D) (None, 20, 20, 128) 151552 conv4_block30_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block30_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block30_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block30_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block30_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block30_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block30_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block30_concat (Concatena (None, 20, 20, 1216) 0 conv4_block29_concat[0][0] \n conv4_block30_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block31_0_bn (BatchNormal (None, 20, 20, 1216) 4864 conv4_block30_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block31_0_relu (Activatio (None, 20, 20, 1216) 0 conv4_block31_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block31_1_conv (Conv2D) (None, 20, 20, 128) 155648 conv4_block31_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block31_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block31_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block31_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block31_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block31_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block31_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block31_concat (Concatena (None, 20, 20, 1248) 0 conv4_block30_concat[0][0] \n conv4_block31_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block32_0_bn (BatchNormal (None, 20, 20, 1248) 4992 conv4_block31_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block32_0_relu (Activatio (None, 20, 20, 1248) 0 conv4_block32_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block32_1_conv (Conv2D) (None, 20, 20, 128) 159744 conv4_block32_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block32_1_bn (BatchNormal (None, 20, 20, 128) 512 conv4_block32_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block32_1_relu (Activatio (None, 20, 20, 128) 0 conv4_block32_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block32_2_conv (Conv2D) (None, 20, 20, 32) 36864 conv4_block32_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block32_concat (Concatena (None, 20, 20, 1280) 0 conv4_block31_concat[0][0] \n conv4_block32_2_conv[0][0] \n__________________________________________________________________________________________________\npool4_bn (BatchNormalization) (None, 20, 20, 1280) 5120 conv4_block32_concat[0][0] \n__________________________________________________________________________________________________\npool4_relu (Activation) (None, 20, 20, 1280) 0 pool4_bn[0][0] \n__________________________________________________________________________________________________\npool4_conv (Conv2D) (None, 20, 20, 640) 819200 pool4_relu[0][0] \n__________________________________________________________________________________________________\npool4_pool (AveragePooling2D) (None, 10, 10, 640) 0 pool4_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block1_0_bn (BatchNormali (None, 10, 10, 640) 2560 pool4_pool[0][0] \n__________________________________________________________________________________________________\nconv5_block1_0_relu (Activation (None, 10, 10, 640) 0 conv5_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block1_1_conv (Conv2D) (None, 10, 10, 128) 81920 conv5_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block1_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block1_1_relu (Activation (None, 10, 10, 128) 0 conv5_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block1_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block1_concat (Concatenat (None, 10, 10, 672) 0 pool4_pool[0][0] \n conv5_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block2_0_bn (BatchNormali (None, 10, 10, 672) 2688 conv5_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block2_0_relu (Activation (None, 10, 10, 672) 0 conv5_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block2_1_conv (Conv2D) (None, 10, 10, 128) 86016 conv5_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block2_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block2_1_relu (Activation (None, 10, 10, 128) 0 conv5_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block2_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block2_concat (Concatenat (None, 10, 10, 704) 0 conv5_block1_concat[0][0] \n conv5_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block3_0_bn (BatchNormali (None, 10, 10, 704) 2816 conv5_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block3_0_relu (Activation (None, 10, 10, 704) 0 conv5_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block3_1_conv (Conv2D) (None, 10, 10, 128) 90112 conv5_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block3_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block3_1_relu (Activation (None, 10, 10, 128) 0 conv5_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block3_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block3_concat (Concatenat (None, 10, 10, 736) 0 conv5_block2_concat[0][0] \n conv5_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block4_0_bn (BatchNormali (None, 10, 10, 736) 2944 conv5_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block4_0_relu (Activation (None, 10, 10, 736) 0 conv5_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block4_1_conv (Conv2D) (None, 10, 10, 128) 94208 conv5_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block4_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block4_1_relu (Activation (None, 10, 10, 128) 0 conv5_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block4_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block4_concat (Concatenat (None, 10, 10, 768) 0 conv5_block3_concat[0][0] \n conv5_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block5_0_bn (BatchNormali (None, 10, 10, 768) 3072 conv5_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block5_0_relu (Activation (None, 10, 10, 768) 0 conv5_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block5_1_conv (Conv2D) (None, 10, 10, 128) 98304 conv5_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block5_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block5_1_relu (Activation (None, 10, 10, 128) 0 conv5_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block5_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block5_concat (Concatenat (None, 10, 10, 800) 0 conv5_block4_concat[0][0] \n conv5_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block6_0_bn (BatchNormali (None, 10, 10, 800) 3200 conv5_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block6_0_relu (Activation (None, 10, 10, 800) 0 conv5_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block6_1_conv (Conv2D) (None, 10, 10, 128) 102400 conv5_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block6_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block6_1_relu (Activation (None, 10, 10, 128) 0 conv5_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block6_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block6_concat (Concatenat (None, 10, 10, 832) 0 conv5_block5_concat[0][0] \n conv5_block6_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block7_0_bn (BatchNormali (None, 10, 10, 832) 3328 conv5_block6_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block7_0_relu (Activation (None, 10, 10, 832) 0 conv5_block7_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block7_1_conv (Conv2D) (None, 10, 10, 128) 106496 conv5_block7_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block7_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block7_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block7_1_relu (Activation (None, 10, 10, 128) 0 conv5_block7_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block7_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block7_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block7_concat (Concatenat (None, 10, 10, 864) 0 conv5_block6_concat[0][0] \n conv5_block7_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block8_0_bn (BatchNormali (None, 10, 10, 864) 3456 conv5_block7_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block8_0_relu (Activation (None, 10, 10, 864) 0 conv5_block8_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block8_1_conv (Conv2D) (None, 10, 10, 128) 110592 conv5_block8_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block8_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block8_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block8_1_relu (Activation (None, 10, 10, 128) 0 conv5_block8_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block8_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block8_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block8_concat (Concatenat (None, 10, 10, 896) 0 conv5_block7_concat[0][0] \n conv5_block8_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block9_0_bn (BatchNormali (None, 10, 10, 896) 3584 conv5_block8_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block9_0_relu (Activation (None, 10, 10, 896) 0 conv5_block9_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block9_1_conv (Conv2D) (None, 10, 10, 128) 114688 conv5_block9_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block9_1_bn (BatchNormali (None, 10, 10, 128) 512 conv5_block9_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block9_1_relu (Activation (None, 10, 10, 128) 0 conv5_block9_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block9_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block9_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block9_concat (Concatenat (None, 10, 10, 928) 0 conv5_block8_concat[0][0] \n conv5_block9_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block10_0_bn (BatchNormal (None, 10, 10, 928) 3712 conv5_block9_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block10_0_relu (Activatio (None, 10, 10, 928) 0 conv5_block10_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block10_1_conv (Conv2D) (None, 10, 10, 128) 118784 conv5_block10_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block10_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block10_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block10_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block10_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block10_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block10_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block10_concat (Concatena (None, 10, 10, 960) 0 conv5_block9_concat[0][0] \n conv5_block10_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block11_0_bn (BatchNormal (None, 10, 10, 960) 3840 conv5_block10_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block11_0_relu (Activatio (None, 10, 10, 960) 0 conv5_block11_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block11_1_conv (Conv2D) (None, 10, 10, 128) 122880 conv5_block11_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block11_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block11_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block11_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block11_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block11_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block11_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block11_concat (Concatena (None, 10, 10, 992) 0 conv5_block10_concat[0][0] \n conv5_block11_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block12_0_bn (BatchNormal (None, 10, 10, 992) 3968 conv5_block11_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block12_0_relu (Activatio (None, 10, 10, 992) 0 conv5_block12_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block12_1_conv (Conv2D) (None, 10, 10, 128) 126976 conv5_block12_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block12_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block12_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block12_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block12_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block12_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block12_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block12_concat (Concatena (None, 10, 10, 1024) 0 conv5_block11_concat[0][0] \n conv5_block12_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block13_0_bn (BatchNormal (None, 10, 10, 1024) 4096 conv5_block12_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block13_0_relu (Activatio (None, 10, 10, 1024) 0 conv5_block13_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block13_1_conv (Conv2D) (None, 10, 10, 128) 131072 conv5_block13_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block13_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block13_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block13_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block13_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block13_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block13_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block13_concat (Concatena (None, 10, 10, 1056) 0 conv5_block12_concat[0][0] \n conv5_block13_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block14_0_bn (BatchNormal (None, 10, 10, 1056) 4224 conv5_block13_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block14_0_relu (Activatio (None, 10, 10, 1056) 0 conv5_block14_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block14_1_conv (Conv2D) (None, 10, 10, 128) 135168 conv5_block14_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block14_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block14_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block14_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block14_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block14_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block14_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block14_concat (Concatena (None, 10, 10, 1088) 0 conv5_block13_concat[0][0] \n conv5_block14_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block15_0_bn (BatchNormal (None, 10, 10, 1088) 4352 conv5_block14_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block15_0_relu (Activatio (None, 10, 10, 1088) 0 conv5_block15_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block15_1_conv (Conv2D) (None, 10, 10, 128) 139264 conv5_block15_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block15_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block15_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block15_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block15_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block15_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block15_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block15_concat (Concatena (None, 10, 10, 1120) 0 conv5_block14_concat[0][0] \n conv5_block15_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block16_0_bn (BatchNormal (None, 10, 10, 1120) 4480 conv5_block15_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block16_0_relu (Activatio (None, 10, 10, 1120) 0 conv5_block16_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block16_1_conv (Conv2D) (None, 10, 10, 128) 143360 conv5_block16_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block16_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block16_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block16_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block16_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block16_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block16_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block16_concat (Concatena (None, 10, 10, 1152) 0 conv5_block15_concat[0][0] \n conv5_block16_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block17_0_bn (BatchNormal (None, 10, 10, 1152) 4608 conv5_block16_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block17_0_relu (Activatio (None, 10, 10, 1152) 0 conv5_block17_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block17_1_conv (Conv2D) (None, 10, 10, 128) 147456 conv5_block17_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block17_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block17_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block17_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block17_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block17_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block17_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block17_concat (Concatena (None, 10, 10, 1184) 0 conv5_block16_concat[0][0] \n conv5_block17_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block18_0_bn (BatchNormal (None, 10, 10, 1184) 4736 conv5_block17_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block18_0_relu (Activatio (None, 10, 10, 1184) 0 conv5_block18_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block18_1_conv (Conv2D) (None, 10, 10, 128) 151552 conv5_block18_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block18_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block18_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block18_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block18_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block18_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block18_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block18_concat (Concatena (None, 10, 10, 1216) 0 conv5_block17_concat[0][0] \n conv5_block18_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block19_0_bn (BatchNormal (None, 10, 10, 1216) 4864 conv5_block18_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block19_0_relu (Activatio (None, 10, 10, 1216) 0 conv5_block19_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block19_1_conv (Conv2D) (None, 10, 10, 128) 155648 conv5_block19_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block19_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block19_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block19_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block19_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block19_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block19_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block19_concat (Concatena (None, 10, 10, 1248) 0 conv5_block18_concat[0][0] \n conv5_block19_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block20_0_bn (BatchNormal (None, 10, 10, 1248) 4992 conv5_block19_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block20_0_relu (Activatio (None, 10, 10, 1248) 0 conv5_block20_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block20_1_conv (Conv2D) (None, 10, 10, 128) 159744 conv5_block20_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block20_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block20_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block20_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block20_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block20_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block20_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block20_concat (Concatena (None, 10, 10, 1280) 0 conv5_block19_concat[0][0] \n conv5_block20_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block21_0_bn (BatchNormal (None, 10, 10, 1280) 5120 conv5_block20_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block21_0_relu (Activatio (None, 10, 10, 1280) 0 conv5_block21_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block21_1_conv (Conv2D) (None, 10, 10, 128) 163840 conv5_block21_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block21_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block21_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block21_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block21_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block21_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block21_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block21_concat (Concatena (None, 10, 10, 1312) 0 conv5_block20_concat[0][0] \n conv5_block21_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block22_0_bn (BatchNormal (None, 10, 10, 1312) 5248 conv5_block21_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block22_0_relu (Activatio (None, 10, 10, 1312) 0 conv5_block22_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block22_1_conv (Conv2D) (None, 10, 10, 128) 167936 conv5_block22_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block22_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block22_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block22_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block22_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block22_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block22_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block22_concat (Concatena (None, 10, 10, 1344) 0 conv5_block21_concat[0][0] \n conv5_block22_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block23_0_bn (BatchNormal (None, 10, 10, 1344) 5376 conv5_block22_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block23_0_relu (Activatio (None, 10, 10, 1344) 0 conv5_block23_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block23_1_conv (Conv2D) (None, 10, 10, 128) 172032 conv5_block23_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block23_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block23_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block23_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block23_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block23_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block23_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block23_concat (Concatena (None, 10, 10, 1376) 0 conv5_block22_concat[0][0] \n conv5_block23_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block24_0_bn (BatchNormal (None, 10, 10, 1376) 5504 conv5_block23_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block24_0_relu (Activatio (None, 10, 10, 1376) 0 conv5_block24_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block24_1_conv (Conv2D) (None, 10, 10, 128) 176128 conv5_block24_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block24_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block24_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block24_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block24_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block24_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block24_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block24_concat (Concatena (None, 10, 10, 1408) 0 conv5_block23_concat[0][0] \n conv5_block24_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block25_0_bn (BatchNormal (None, 10, 10, 1408) 5632 conv5_block24_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block25_0_relu (Activatio (None, 10, 10, 1408) 0 conv5_block25_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block25_1_conv (Conv2D) (None, 10, 10, 128) 180224 conv5_block25_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block25_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block25_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block25_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block25_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block25_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block25_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block25_concat (Concatena (None, 10, 10, 1440) 0 conv5_block24_concat[0][0] \n conv5_block25_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block26_0_bn (BatchNormal (None, 10, 10, 1440) 5760 conv5_block25_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block26_0_relu (Activatio (None, 10, 10, 1440) 0 conv5_block26_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block26_1_conv (Conv2D) (None, 10, 10, 128) 184320 conv5_block26_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block26_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block26_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block26_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block26_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block26_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block26_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block26_concat (Concatena (None, 10, 10, 1472) 0 conv5_block25_concat[0][0] \n conv5_block26_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block27_0_bn (BatchNormal (None, 10, 10, 1472) 5888 conv5_block26_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block27_0_relu (Activatio (None, 10, 10, 1472) 0 conv5_block27_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block27_1_conv (Conv2D) (None, 10, 10, 128) 188416 conv5_block27_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block27_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block27_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block27_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block27_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block27_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block27_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block27_concat (Concatena (None, 10, 10, 1504) 0 conv5_block26_concat[0][0] \n conv5_block27_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block28_0_bn (BatchNormal (None, 10, 10, 1504) 6016 conv5_block27_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block28_0_relu (Activatio (None, 10, 10, 1504) 0 conv5_block28_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block28_1_conv (Conv2D) (None, 10, 10, 128) 192512 conv5_block28_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block28_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block28_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block28_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block28_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block28_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block28_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block28_concat (Concatena (None, 10, 10, 1536) 0 conv5_block27_concat[0][0] \n conv5_block28_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block29_0_bn (BatchNormal (None, 10, 10, 1536) 6144 conv5_block28_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block29_0_relu (Activatio (None, 10, 10, 1536) 0 conv5_block29_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block29_1_conv (Conv2D) (None, 10, 10, 128) 196608 conv5_block29_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block29_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block29_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block29_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block29_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block29_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block29_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block29_concat (Concatena (None, 10, 10, 1568) 0 conv5_block28_concat[0][0] \n conv5_block29_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block30_0_bn (BatchNormal (None, 10, 10, 1568) 6272 conv5_block29_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block30_0_relu (Activatio (None, 10, 10, 1568) 0 conv5_block30_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block30_1_conv (Conv2D) (None, 10, 10, 128) 200704 conv5_block30_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block30_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block30_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block30_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block30_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block30_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block30_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block30_concat (Concatena (None, 10, 10, 1600) 0 conv5_block29_concat[0][0] \n conv5_block30_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block31_0_bn (BatchNormal (None, 10, 10, 1600) 6400 conv5_block30_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block31_0_relu (Activatio (None, 10, 10, 1600) 0 conv5_block31_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block31_1_conv (Conv2D) (None, 10, 10, 128) 204800 conv5_block31_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block31_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block31_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block31_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block31_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block31_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block31_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block31_concat (Concatena (None, 10, 10, 1632) 0 conv5_block30_concat[0][0] \n conv5_block31_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block32_0_bn (BatchNormal (None, 10, 10, 1632) 6528 conv5_block31_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block32_0_relu (Activatio (None, 10, 10, 1632) 0 conv5_block32_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block32_1_conv (Conv2D) (None, 10, 10, 128) 208896 conv5_block32_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block32_1_bn (BatchNormal (None, 10, 10, 128) 512 conv5_block32_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block32_1_relu (Activatio (None, 10, 10, 128) 0 conv5_block32_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block32_2_conv (Conv2D) (None, 10, 10, 32) 36864 conv5_block32_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block32_concat (Concatena (None, 10, 10, 1664) 0 conv5_block31_concat[0][0] \n conv5_block32_2_conv[0][0] \n__________________________________________________________________________________________________\nbn (BatchNormalization) (None, 10, 10, 1664) 6656 conv5_block32_concat[0][0] \n__________________________________________________________________________________________________\nrelu (Activation) (None, 10, 10, 1664) 0 bn[0][0] \n__________________________________________________________________________________________________\nglobal_average_pooling2d_1 (Glo (None, 1664) 0 relu[0][0] \n__________________________________________________________________________________________________\ndropout_1 (Dropout) (None, 1664) 0 global_average_pooling2d_1[0][0] \n__________________________________________________________________________________________________\ndense_1 (Dense) (None, 2048) 3409920 dropout_1[0][0] \n__________________________________________________________________________________________________\ndropout_2 (Dropout) (None, 2048) 0 dense_1[0][0] \n__________________________________________________________________________________________________\nfinal_output (Dense) (None, 5) 10245 dropout_2[0][0] \n==================================================================================================\nTotal params: 16,063,045\nTrainable params: 15,904,645\nNon-trainable params: 158,400\n__________________________________________________________________________________________________\n"
],
[
"history = model.fit_generator(generator=train_generator,\n steps_per_epoch=STEP_SIZE_TRAIN,\n validation_data=valid_generator,\n validation_steps=STEP_SIZE_VALID,\n epochs=EPOCHS,\n callbacks=callback_list,\n class_weight=class_weights,\n verbose=1).history",
"Epoch 1/40\n183/183 [==============================] - 139s 757ms/step - loss: 0.6850 - acc: 0.7466 - kappa: 0.8268 - val_loss: 0.5695 - val_acc: 0.7908 - val_kappa: 0.8843\nEpoch 2/40\n183/183 [==============================] - 87s 478ms/step - loss: 0.5764 - acc: 0.7828 - kappa: 0.8835 - val_loss: 0.5638 - val_acc: 0.7880 - val_kappa: 0.8543\nEpoch 3/40\n183/183 [==============================] - 89s 487ms/step - loss: 0.5302 - acc: 0.7968 - kappa: 0.8996 - val_loss: 0.4854 - val_acc: 0.8298 - val_kappa: 0.9267\nEpoch 4/40\n183/183 [==============================] - 90s 493ms/step - loss: 0.4941 - acc: 0.8060 - kappa: 0.9220 - val_loss: 0.5247 - val_acc: 0.8061 - val_kappa: 0.9171\nEpoch 5/40\n183/183 [==============================] - 89s 487ms/step - loss: 0.4654 - acc: 0.8279 - kappa: 0.9285 - val_loss: 0.4637 - val_acc: 0.8145 - val_kappa: 0.9086\nEpoch 6/40\n183/183 [==============================] - 90s 491ms/step - loss: 0.4864 - acc: 0.8170 - kappa: 0.9225 - val_loss: 0.4663 - val_acc: 0.8326 - val_kappa: 0.9399\nEpoch 7/40\n183/183 [==============================] - 90s 493ms/step - loss: 0.4761 - acc: 0.8265 - kappa: 0.9363 - val_loss: 0.6075 - val_acc: 0.8006 - val_kappa: 0.8896\nEpoch 8/40\n183/183 [==============================] - 90s 494ms/step - loss: 0.4110 - acc: 0.8473 - kappa: 0.9440 - val_loss: 0.5248 - val_acc: 0.8229 - val_kappa: 0.9262\n\nEpoch 00008: ReduceLROnPlateau reducing learning rate to 4.999999873689376e-05.\nEpoch 9/40\n183/183 [==============================] - 89s 486ms/step - loss: 0.4127 - acc: 0.8477 - kappa: 0.9442 - val_loss: 0.4522 - val_acc: 0.8187 - val_kappa: 0.9232\nEpoch 10/40\n183/183 [==============================] - 91s 498ms/step - loss: 0.4236 - acc: 0.8498 - kappa: 0.9455 - val_loss: 0.4969 - val_acc: 0.8173 - val_kappa: 0.9069\nEpoch 11/40\n183/183 [==============================] - 92s 503ms/step - loss: 0.3767 - acc: 0.8562 - kappa: 0.9504 - val_loss: 0.5195 - val_acc: 0.7950 - val_kappa: 0.8966\nEpoch 12/40\n183/183 [==============================] - 93s 509ms/step - loss: 0.3427 - acc: 0.8696 - kappa: 0.9628 - val_loss: 0.5767 - val_acc: 0.8131 - val_kappa: 0.9236\n\nEpoch 00012: ReduceLROnPlateau reducing learning rate to 2.499999936844688e-05.\nEpoch 13/40\n183/183 [==============================] - 92s 505ms/step - loss: 0.2877 - acc: 0.8839 - kappa: 0.9645 - val_loss: 0.4223 - val_acc: 0.8424 - val_kappa: 0.9401\nEpoch 14/40\n183/183 [==============================] - 93s 510ms/step - loss: 0.2880 - acc: 0.8910 - kappa: 0.9704 - val_loss: 0.4906 - val_acc: 0.8103 - val_kappa: 0.9350\nEpoch 15/40\n183/183 [==============================] - 92s 505ms/step - loss: 0.2696 - acc: 0.9003 - kappa: 0.9719 - val_loss: 0.4484 - val_acc: 0.8271 - val_kappa: 0.9320\nEpoch 16/40\n183/183 [==============================] - 93s 509ms/step - loss: 0.2698 - acc: 0.8996 - kappa: 0.9774 - val_loss: 0.4540 - val_acc: 0.8229 - val_kappa: 0.9406\n\nEpoch 00016: ReduceLROnPlateau reducing learning rate to 1.249999968422344e-05.\nEpoch 17/40\n183/183 [==============================] - 92s 504ms/step - loss: 0.2323 - acc: 0.9197 - kappa: 0.9798 - val_loss: 0.5455 - val_acc: 0.7894 - val_kappa: 0.8988\nEpoch 18/40\n183/183 [==============================] - 94s 515ms/step - loss: 0.2399 - acc: 0.9132 - kappa: 0.9767 - val_loss: 0.4185 - val_acc: 0.8508 - val_kappa: 0.9487\nEpoch 19/40\n183/183 [==============================] - 93s 507ms/step - loss: 0.2322 - acc: 0.9157 - kappa: 0.9791 - val_loss: 0.5034 - val_acc: 0.8061 - val_kappa: 0.9174\nEpoch 20/40\n183/183 [==============================] - 93s 508ms/step - loss: 0.2174 - acc: 0.9167 - kappa: 0.9826 - val_loss: 0.4698 - val_acc: 0.8452 - val_kappa: 0.9419\nEpoch 21/40\n183/183 [==============================] - 93s 507ms/step - loss: 0.2468 - acc: 0.9157 - kappa: 0.9800 - val_loss: 0.5091 - val_acc: 0.8131 - val_kappa: 0.9259\n\nEpoch 00021: ReduceLROnPlateau reducing learning rate to 6.24999984211172e-06.\nEpoch 22/40\n183/183 [==============================] - 92s 501ms/step - loss: 0.1998 - acc: 0.9276 - kappa: 0.9841 - val_loss: 0.4864 - val_acc: 0.8285 - val_kappa: 0.9446\nEpoch 23/40\n183/183 [==============================] - 93s 507ms/step - loss: 0.2131 - acc: 0.9232 - kappa: 0.9844 - val_loss: 0.4938 - val_acc: 0.8173 - val_kappa: 0.9299\nRestoring model weights from the end of the best epoch\nEpoch 00023: early stopping\n"
]
],
[
[
"# Model loss graph ",
"_____no_output_____"
]
],
[
[
"sns.set_style(\"whitegrid\")\nfig, (ax1, ax2, ax3) = plt.subplots(3, 1, sharex='col', figsize=(20, 18))\n\nax1.plot(history['loss'], label='Train loss')\nax1.plot(history['val_loss'], label='Validation loss')\nax1.legend(loc='best')\nax1.set_title('Loss')\n\nax2.plot(history['acc'], label='Train accuracy')\nax2.plot(history['val_acc'], label='Validation accuracy')\nax2.legend(loc='best')\nax2.set_title('Accuracy')\n\nax3.plot(history['kappa'], label='Train kappa')\nax3.plot(history['val_kappa'], label='Validation kappa')\nax3.legend(loc='best')\nax3.set_title('Kappa')\n\nplt.xlabel('Epochs')\nsns.despine()\nplt.show()",
"_____no_output_____"
],
[
"# Create empty arays to keep the predictions and labels\nlastFullTrainPred = np.empty((0, N_CLASSES))\nlastFullTrainLabels = np.empty((0, N_CLASSES))\nlastFullValPred = np.empty((0, N_CLASSES))\nlastFullValLabels = np.empty((0, N_CLASSES))\n\n# Add train predictions and labels\nfor i in range(STEP_SIZE_TRAIN+1):\n im, lbl = next(train_generator)\n scores = model.predict(im, batch_size=train_generator.batch_size)\n lastFullTrainPred = np.append(lastFullTrainPred, scores, axis=0)\n lastFullTrainLabels = np.append(lastFullTrainLabels, lbl, axis=0)\n\n# Add validation predictions and labels\nfor i in range(STEP_SIZE_VALID+1):\n im, lbl = next(valid_generator)\n scores = model.predict(im, batch_size=valid_generator.batch_size)\n lastFullValPred = np.append(lastFullValPred, scores, axis=0)\n lastFullValLabels = np.append(lastFullValLabels, lbl, axis=0)\n\nlastFullComPred = np.concatenate((lastFullTrainPred, lastFullValPred))\nlastFullComLabels = np.concatenate((lastFullTrainLabels, lastFullValLabels))\n\ntrain_preds = [np.argmax(pred) for pred in lastFullTrainPred]\ntrain_labels = [np.argmax(label) for label in lastFullTrainLabels]\nvalidation_preds = [np.argmax(pred) for pred in lastFullValPred]\nvalidation_labels = [np.argmax(label) for label in lastFullValLabels]\ncomplete_labels = [np.argmax(label) for label in lastFullComLabels]",
"_____no_output_____"
]
],
[
[
"# Model Evaluation",
"_____no_output_____"
],
[
"## Confusion Matrix\n\n### Original thresholds",
"_____no_output_____"
]
],
[
[
"labels = ['0 - No DR', '1 - Mild', '2 - Moderate', '3 - Severe', '4 - Proliferative DR']\ndef plot_confusion_matrix(train, validation, labels=labels):\n train_labels, train_preds = train\n validation_labels, validation_preds = validation\n fig, (ax1, ax2) = plt.subplots(1, 2, sharex='col', figsize=(24, 7))\n train_cnf_matrix = confusion_matrix(train_labels, train_preds)\n validation_cnf_matrix = confusion_matrix(validation_labels, validation_preds)\n\n train_cnf_matrix_norm = train_cnf_matrix.astype('float') / train_cnf_matrix.sum(axis=1)[:, np.newaxis]\n validation_cnf_matrix_norm = validation_cnf_matrix.astype('float') / validation_cnf_matrix.sum(axis=1)[:, np.newaxis]\n\n train_df_cm = pd.DataFrame(train_cnf_matrix_norm, index=labels, columns=labels)\n validation_df_cm = pd.DataFrame(validation_cnf_matrix_norm, index=labels, columns=labels)\n\n sns.heatmap(train_df_cm, annot=True, fmt='.2f', cmap=\"Blues\",ax=ax1).set_title('Train')\n sns.heatmap(validation_df_cm, annot=True, fmt='.2f', cmap=sns.cubehelix_palette(8),ax=ax2).set_title('Validation')\n plt.show()\n\nplot_confusion_matrix((train_labels, train_preds), (validation_labels, validation_preds))",
"_____no_output_____"
]
],
[
[
"## Quadratic Weighted Kappa",
"_____no_output_____"
]
],
[
[
"def evaluate_model(train, validation):\n train_labels, train_preds = train\n validation_labels, validation_preds = validation\n print(\"Train Cohen Kappa score: %.3f\" % cohen_kappa_score(train_preds, train_labels, weights='quadratic'))\n print(\"Validation Cohen Kappa score: %.3f\" % cohen_kappa_score(validation_preds, validation_labels, weights='quadratic'))\n print(\"Complete set Cohen Kappa score: %.3f\" % cohen_kappa_score(train_preds+validation_preds, train_labels+validation_labels, weights='quadratic'))\n \nevaluate_model((train_preds, train_labels), (validation_preds, validation_labels))",
"Train Cohen Kappa score: 0.962\nValidation Cohen Kappa score: 0.900\nComplete set Cohen Kappa score: 0.950\n"
]
],
[
[
"## Apply model to test set and output predictions",
"_____no_output_____"
]
],
[
[
"step_size = test_generator.n//test_generator.batch_size\ntest_generator.reset()\npreds = model.predict_generator(test_generator, steps=step_size)\npredictions = np.argmax(preds, axis=1)\n\nresults = pd.DataFrame({'id_code':test['id_code'], 'diagnosis':predictions})\nresults['id_code'] = results['id_code'].map(lambda x: str(x)[:-4])",
"_____no_output_____"
],
[
"# Cleaning created directories\nif os.path.exists(train_dest_path):\n shutil.rmtree(train_dest_path)\nif os.path.exists(validation_dest_path):\n shutil.rmtree(validation_dest_path)\nif os.path.exists(test_dest_path):\n shutil.rmtree(test_dest_path)",
"_____no_output_____"
]
],
[
[
"# Predictions class distribution",
"_____no_output_____"
]
],
[
[
"fig = plt.subplots(sharex='col', figsize=(24, 8.7))\nsns.countplot(x=\"diagnosis\", data=results, palette=\"GnBu_d\").set_title('Test')\nsns.despine()\nplt.show()",
"_____no_output_____"
],
[
"results.to_csv('submission.csv', index=False)\ndisplay(results.head())",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
d0627caae9fc6d352f304825bb063317fa6c3193 | 9,486 | ipynb | Jupyter Notebook | notebooks/computer_vision/raw/tut5.ipynb | guesswhohaha/learntools | c1bd607ade5227f8c8977ff05bf9d04d0a8b7732 | [
"Apache-2.0"
]
| null | null | null | notebooks/computer_vision/raw/tut5.ipynb | guesswhohaha/learntools | c1bd607ade5227f8c8977ff05bf9d04d0a8b7732 | [
"Apache-2.0"
]
| null | null | null | notebooks/computer_vision/raw/tut5.ipynb | guesswhohaha/learntools | c1bd607ade5227f8c8977ff05bf9d04d0a8b7732 | [
"Apache-2.0"
]
| null | null | null | 37.346457 | 517 | 0.598461 | [
[
[
"<!--TITLE:Custom Convnets-->\n# Introduction #\n\nNow that you've seen the layers a convnet uses to extract features, it's time to put them together and build a network of your own!\n\n# Simple to Refined #\n\nIn the last three lessons, we saw how convolutional networks perform **feature extraction** through three operations: **filter**, **detect**, and **condense**. A single round of feature extraction can only extract relatively simple features from an image, things like simple lines or contrasts. These are too simple to solve most classification problems. Instead, convnets will repeat this extraction over and over, so that the features become more complex and refined as they travel deeper into the network.\n\n<figure>\n<img src=\"https://i.imgur.com/VqmC1rm.png\" alt=\"Features extracted from an image of a car, from simple to refined.\" width=800>\n</figure>\n\n# Convolutional Blocks #\n\nIt does this by passing them through long chains of **convolutional blocks** which perform this extraction.\n\n<figure>\n<img src=\"https://i.imgur.com/pr8VwCZ.png\" width=\"400\" alt=\"Extraction as a sequence of blocks.\">\n</figure>\n\nThese convolutional blocks are stacks of `Conv2D` and `MaxPool2D` layers, whose role in feature extraction we learned about in the last few lessons.\n\n<figure>\n<!-- <img src=\"./images/2-block-crp.png\" width=\"400\" alt=\"A kind of extraction block: convolution, ReLU, pooling.\"> -->\n<img src=\"https://i.imgur.com/8D6IhEw.png\" width=\"400\" alt=\"A kind of extraction block: convolution, ReLU, pooling.\">\n</figure>\n\nEach block represents a round of extraction, and by composing these blocks the convnet can combine and recombine the features produced, growing them and shaping them to better fit the problem at hand. The deep structure of modern convnets is what allows this sophisticated feature engineering and has been largely responsible for their superior performance.\n\n# Example - Design a Convnet #\n\nLet's see how to define a deep convolutional network capable of engineering complex features. In this example, we'll create a Keras `Sequence` model and then train it on our Cars dataset.\n\n## Step 1 - Load Data ##\n\nThis hidden cell loads the data.",
"_____no_output_____"
]
],
[
[
"#$HIDE_INPUT$\n# Imports\nimport os, warnings\nimport matplotlib.pyplot as plt\nfrom matplotlib import gridspec\n\nimport numpy as np\nimport tensorflow as tf\nfrom tensorflow.keras.preprocessing import image_dataset_from_directory\n\n# Reproducability\ndef set_seed(seed=31415):\n np.random.seed(seed)\n tf.random.set_seed(seed)\n os.environ['PYTHONHASHSEED'] = str(seed)\n os.environ['TF_DETERMINISTIC_OPS'] = '1'\nset_seed()\n\n# Set Matplotlib defaults\nplt.rc('figure', autolayout=True)\nplt.rc('axes', labelweight='bold', labelsize='large',\n titleweight='bold', titlesize=18, titlepad=10)\nplt.rc('image', cmap='magma')\nwarnings.filterwarnings(\"ignore\") # to clean up output cells\n\n\n# Load training and validation sets\nds_train_ = image_dataset_from_directory(\n '../input/car-or-truck/train',\n labels='inferred',\n label_mode='binary',\n image_size=[128, 128],\n interpolation='nearest',\n batch_size=64,\n shuffle=True,\n)\nds_valid_ = image_dataset_from_directory(\n '../input/car-or-truck/valid',\n labels='inferred',\n label_mode='binary',\n image_size=[128, 128],\n interpolation='nearest',\n batch_size=64,\n shuffle=False,\n)\n\n# Data Pipeline\ndef convert_to_float(image, label):\n image = tf.image.convert_image_dtype(image, dtype=tf.float32)\n return image, label\n\nAUTOTUNE = tf.data.experimental.AUTOTUNE\nds_train = (\n ds_train_\n .map(convert_to_float)\n .cache()\n .prefetch(buffer_size=AUTOTUNE)\n)\nds_valid = (\n ds_valid_\n .map(convert_to_float)\n .cache()\n .prefetch(buffer_size=AUTOTUNE)\n)\n",
"_____no_output_____"
]
],
[
[
"## Step 2 - Define Model ##\n\nHere is a diagram of the model we'll use:\n\n<figure>\n<!-- <img src=\"./images/2-convmodel-1.png\" width=\"200\" alt=\"Diagram of a convolutional model.\"> -->\n<img src=\"https://i.imgur.com/U1VdoDJ.png\" width=\"250\" alt=\"Diagram of a convolutional model.\">\n</figure>\n\nNow we'll define the model. See how our model consists of three blocks of `Conv2D` and `MaxPool2D` layers (the base) followed by a head of `Dense` layers. We can translate this diagram more or less directly into a Keras `Sequential` model just by filling in the appropriate parameters.",
"_____no_output_____"
]
],
[
[
"import tensorflow.keras as keras\nimport tensorflow.keras.layers as layers\n\nmodel = keras.Sequential([\n\n # First Convolutional Block\n layers.Conv2D(filters=32, kernel_size=5, activation=\"relu\", padding='same',\n # give the input dimensions in the first layer\n # [height, width, color channels(RGB)]\n input_shape=[128, 128, 3]),\n layers.MaxPool2D(),\n\n # Second Convolutional Block\n layers.Conv2D(filters=64, kernel_size=3, activation=\"relu\", padding='same'),\n layers.MaxPool2D(),\n\n # Third Convolutional Block\n layers.Conv2D(filters=128, kernel_size=3, activation=\"relu\", padding='same'),\n layers.MaxPool2D(),\n\n # Classifier Head\n layers.Flatten(),\n layers.Dense(units=6, activation=\"relu\"),\n layers.Dense(units=1, activation=\"sigmoid\"),\n])\nmodel.summary()",
"_____no_output_____"
]
],
[
[
"Notice in this definition is how the number of filters doubled block-by-block: 64, 128, 256. This is a common pattern. Since the `MaxPool2D` layer is reducing the *size* of the feature maps, we can afford to increase the *quantity* we create.\n\n## Step 3 - Train ##\n\nWe can train this model just like the model from Lesson 1: compile it with an optimizer along with a loss and metric appropriate for binary classification.",
"_____no_output_____"
]
],
[
[
"model.compile(\n optimizer=tf.keras.optimizers.Adam(epsilon=0.01),\n loss='binary_crossentropy',\n metrics=['binary_accuracy']\n)\n\nhistory = model.fit(\n ds_train,\n validation_data=ds_valid,\n epochs=40,\n)\n",
"_____no_output_____"
],
[
"import pandas as pd\n\nhistory_frame = pd.DataFrame(history.history)\nhistory_frame.loc[:, ['loss', 'val_loss']].plot()\nhistory_frame.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot();",
"_____no_output_____"
]
],
[
[
"This model is much smaller than the VGG16 model from Lesson 1 -- only 3 convolutional layers versus the 16 of VGG16. It was nevertheless able to fit this dataset fairly well. We might still be able to improve this simple model by adding more convolutional layers, hoping to create features better adapted to the dataset. This is what we'll try in the exercises.\n\n# Conclusion #\n\nIn this tutorial, you saw how to build a custom convnet composed of many **convolutional blocks** and capable of complex feature engineering. \n\n# Your Turn #\n\nIn the exercises, you'll create a convnet that performs as well on this problem as VGG16 does -- without pretraining! [**Try it now!**](#$NEXT_NOTEBOOK_URL$)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
]
|
d0627ce38b47f49d40a787be57156a5c935c8209 | 5,818 | ipynb | Jupyter Notebook | 101notebook/ipython-rel-2.1.0-examples/Notebook/Raw Input.ipynb | OpenBookProjects/ipynb | 72a28109e8e30aea0b9c6713e78821e4affa2e33 | [
"MIT"
]
| 6 | 2015-06-08T12:50:14.000Z | 2018-11-20T10:05:01.000Z | 101notebook/ipython-rel-2.1.0-examples/Notebook/Raw Input.ipynb | OpenBookProjects/ipynb | 72a28109e8e30aea0b9c6713e78821e4affa2e33 | [
"MIT"
]
| null | null | null | 101notebook/ipython-rel-2.1.0-examples/Notebook/Raw Input.ipynb | OpenBookProjects/ipynb | 72a28109e8e30aea0b9c6713e78821e4affa2e33 | [
"MIT"
]
| 8 | 2016-01-26T14:12:50.000Z | 2021-02-20T14:24:09.000Z | 29.683673 | 762 | 0.508594 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
d06280bd27aa1ca8f8e3c4b7aae0d4c197c9d83e | 2,356 | ipynb | Jupyter Notebook | 11_Face_Detection.ipynb | EliasPapachristos/Computer_Vision_with_OpenCV | 05af3c6161bd446f7df81ad190e732b1c5c6eb42 | [
"Apache-2.0"
]
| 9 | 2020-05-01T10:28:55.000Z | 2021-04-15T15:58:00.000Z | 11_Face_Detection.ipynb | EliasPapachristos/Computer_Vision_with_OpenCV | 05af3c6161bd446f7df81ad190e732b1c5c6eb42 | [
"Apache-2.0"
]
| null | null | null | 11_Face_Detection.ipynb | EliasPapachristos/Computer_Vision_with_OpenCV | 05af3c6161bd446f7df81ad190e732b1c5c6eb42 | [
"Apache-2.0"
]
| 7 | 2020-06-11T18:09:25.000Z | 2020-12-11T09:35:03.000Z | 20.666667 | 122 | 0.48854 | [
[
[
"import numpy as np\nimport cv2 \nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"### Cascade Files\nOpenCV comes with these pre-trained cascade files, we've relocated the .xml files for you in our own DATA folder.\n\n### Face Detection¶",
"_____no_output_____"
]
],
[
[
"face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')",
"_____no_output_____"
],
[
"def detect_face(img):\n \n \n face_img = img.copy()\n \n face_rects = face_cascade.detectMultiScale(face_img) \n \n for (x, y, w, h) in face_rects: \n cv2.rectangle(face_img, (x, y), (x + w, y + h), (255, 255, 255), 10) \n \n return face_img",
"_____no_output_____"
]
],
[
[
"### Conjunction with Video\n",
"_____no_output_____"
]
],
[
[
"cap = cv2.VideoCapture(0) \n\nwhile True: \n \n ret, frame = cap.read(0) \n \n frame = detect_face(frame)\n \n cv2.imshow('Video Face Detection', frame) \n \n c = cv2.waitKey(1) \n if c == 27: \n break \n \ncap.release() \ncv2.destroyAllWindows()",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d062889d977111401f6d85b9721c2780a97ec009 | 58,900 | ipynb | Jupyter Notebook | 3-object-tracking-and-localization/activities/8-vehicle-motion-and-calculus/Looking up Trig Ratios.ipynb | S1lv10Fr4gn4n1/udacity-cv | ce7aafc41e2c123396d809042973840ea08b850e | [
"MIT"
]
| null | null | null | 3-object-tracking-and-localization/activities/8-vehicle-motion-and-calculus/Looking up Trig Ratios.ipynb | S1lv10Fr4gn4n1/udacity-cv | ce7aafc41e2c123396d809042973840ea08b850e | [
"MIT"
]
| 3 | 2020-03-24T21:18:48.000Z | 2021-06-08T21:11:14.000Z | 3-object-tracking-and-localization/activities/8-vehicle-motion-and-calculus/Looking up Trig Ratios.ipynb | S1lv10Fr4gn4n1/udacity-cv | ce7aafc41e2c123396d809042973840ea08b850e | [
"MIT"
]
| null | null | null | 198.986486 | 16,876 | 0.907878 | [
[
[
"# Looking up Trig Ratios\nThere are three ways you could find the value of a trig function at a particular angle.\n\n**1. Use a table** - This is how engineers used to find trig ratios before the days of computers. For example, from the table below I can see that $\\sin(60)=0.866$\n\n| angle | sin | cos | tan |\n| :---: | :---: | :---: | :---: |\n| 0 | 0.000 | 1.000 | 0.000 |\n| 10 | 0.174 | 0.985 | 0.176 |\n| 20 | 0.342 | 0.940 | 0.364 |\n| 30 | 0.500 | 0.866 | 0.577 |\n| 40 | 0.643 | 0.766 | 0.839 |\n| 50 | 0.766 | 0.643 | 1.192 |\n| 60 | 0.866 | 0.500 | 1.732 |\n| 70 | 0.940 | 0.342 | 2.747 |\n| 80 | 0.985 | 0.174 | 5.671 |\n\nThe problem with this technique is that there will always be gaps in a table. \n\n**2. Use a graph** - One way to try to fill these gaps is by consulting a graph of a trigonometric function. For example, the image below shows a plot of $\\sin(\\theta)$ for $0 \\leq \\theta \\leq 360$\n\n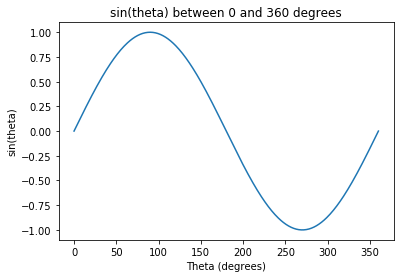\n\nThese graphs are nice because they give a good visual sense for how these ratios behave, but they aren't great for getting accurate values. Which leads us to the **best** way to look up trig ratios...\n\n**3. Use a computer!** This probably isn't a surprise, but python has built in functions to calculate sine, cosine, and tangent... \n\nIn fact, you can even type \"sin(60 degrees)\" into **Google** and you'll get the correct answer!\n\n\n\nNote how I wrote in \"sin(60 degrees)\" instead of just \"sin(60)\". That's because these functions generally expect their input to be in **radians**. \n\nNow let's calculate these ratios with Python.",
"_____no_output_____"
]
],
[
[
"# Python's math module has functions called sin, cos, and tan\n# as well as the constant \"pi\" (which we will find useful shortly)\nfrom math import sin, cos, tan, pi\n\n# Run this cell. What do you expect the output to be?\nprint(sin(60))",
"-0.3048106211022167\n"
]
],
[
[
"Did the output match what you expected?\n\nIf not, it's probably because we didn't convert our angle to radians. \n\n### EXERCISE 1 - Write a function that converts degrees to radians\n\nImplement the following math in code:\n\n$$\\theta_{\\text{radians}} = \\theta_{\\text{degrees}} \\times \\frac{\\pi}{180}$$\n",
"_____no_output_____"
]
],
[
[
"from math import pi\ndef deg2rad(theta):\n \"\"\"Converts degrees to radians\"\"\"\n return theta * (pi/180)\n # TODO - implement this function (solution\n # code at end of notebook)\n\nassert(deg2rad(45.0) == pi / 4)\nassert(deg2rad(90.0) == pi / 2)\nprint(\"Nice work! Your degrees to radians function works!\")\n\nfor theta in [0, 30, 45, 60, 90]:\n theta_rad = deg2rad(theta)\n sin_theta = sin(theta_rad)\n print(\"sin(\", theta, \"degrees) =\", sin_theta)",
"Nice work! Your degrees to radians function works!\nsin( 0 degrees) = 0.0\nsin( 30 degrees) = 0.49999999999999994\nsin( 45 degrees) = 0.7071067811865475\nsin( 60 degrees) = 0.8660254037844386\nsin( 90 degrees) = 1.0\n"
]
],
[
[
"### EXERCISE 2 - Make plots of cosine and tangent",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom matplotlib import pyplot as plt\ndef plot_sine(min_theta, max_theta):\n \"\"\"\n Generates a plot of sin(theta) between min_theta\n and max_theta (both of which are specified in degrees).\n \"\"\"\n angles_degrees = np.linspace(min_theta, max_theta)\n angles_radians = deg2rad(angles_degrees)\n values = np.sin(angles_radians)\n X = angles_degrees\n Y = values\n plt.plot(X,Y)\n plt.show()\n \n# EXERCISE 2.1 Implement this! Try not to look at the\n# implementation of plot_sine TOO much...\ndef plot_cosine(min_theta, max_theta):\n \"\"\"\n Generates a plot of sin(theta) between min_theta\n and max_theta (both of which are specified in degrees).\n \"\"\"\n angles_degrees = np.linspace(min_theta, max_theta)\n angles_radians = deg2rad(angles_degrees)\n values = np.cos(angles_radians)\n X = angles_degrees\n Y = values\n plt.plot(X,Y)\n plt.show()",
"_____no_output_____"
],
[
"plot_sine(0, 360)",
"_____no_output_____"
],
[
"plot_cosine(0, 360)",
"_____no_output_____"
],
[
"#\n\n#\n\n#\n\n#\n\n# SOLUTION CODE\n\n#\n\n#\n\n#\n\n#\nfrom math import pi\ndef deg2rad_solution(theta):\n \"\"\"Converts degrees to radians\"\"\"\n return theta * pi / 180\n\nassert(deg2rad_solution(45.0) == pi / 4)\nassert(deg2rad_solution(90.0) == pi / 2)\n\nimport numpy as np\nfrom matplotlib import pyplot as plt\ndef plot_cosine_solution(min_theta, max_theta):\n \"\"\"\n Generates a plot of sin(theta) between min_theta\n and max_theta (both of which are specified in degrees).\n \"\"\"\n angles_degrees = np.linspace(min_theta, max_theta)\n angles_radians = deg2rad_solution(angles_degrees)\n values = np.cos(angles_radians)\n X = angles_degrees\n Y = values\n plt.plot(X,Y)\n plt.show()",
"_____no_output_____"
],
[
"plot_cosine_solution(0, 360)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
d0629a451407335fb731206a6bb49b75cb94e08a | 32,217 | ipynb | Jupyter Notebook | gs_quant/content/events/00_virtual_event/0003_trades.ipynb | KabbalahOracle/gs-quant | e4daa30654d8e4757c84f8836b5c1e22f39e7174 | [
"Apache-2.0"
]
| 1 | 2020-11-04T21:21:45.000Z | 2020-11-04T21:21:45.000Z | gs_quant/content/events/00_virtual_event/0003_trades.ipynb | KabbalahOracle/gs-quant | e4daa30654d8e4757c84f8836b5c1e22f39e7174 | [
"Apache-2.0"
]
| null | null | null | gs_quant/content/events/00_virtual_event/0003_trades.ipynb | KabbalahOracle/gs-quant | e4daa30654d8e4757c84f8836b5c1e22f39e7174 | [
"Apache-2.0"
]
| null | null | null | 70.806593 | 1,918 | 0.701555 | [
[
[
"from gs_quant.data import Dataset\nfrom gs_quant.markets.securities import Asset, AssetIdentifier, SecurityMaster\nfrom gs_quant.timeseries import *\nfrom gs_quant.target.instrument import FXOption, IRSwaption\nfrom gs_quant.markets import PricingContext, HistoricalPricingContext, BackToTheFuturePricingContext\nfrom gs_quant.risk import CarryScenario, MarketDataPattern, MarketDataShock, MarketDataShockBasedScenario, MarketDataShockType, CurveScenario,CarryScenario\nfrom gs_quant.markets.portfolio import Portfolio\nfrom gs_quant.risk import IRAnnualImpliedVol\nfrom gs_quant.timeseries import percentiles\nfrom gs_quant.datetime import business_day_offset\nimport seaborn as sns\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom scipy import stats\nimport warnings\nfrom datetime import date\nwarnings.filterwarnings('ignore')\nsns.set(style=\"darkgrid\", color_codes=True)",
"_____no_output_____"
],
[
"from gs_quant.session import GsSession\n# external users should substitute their client id and secret; please skip this step if using internal jupyterhub\nGsSession.use(client_id=None, client_secret=None, scopes=('run_analytics',)) ",
"_____no_output_____"
]
],
[
[
"In this notebook, we'll look at entry points for G10 vol, look for crosses with the largest downside sensivity to SPX, indicatively price several structures and analyze their carry profile.\n\n* [1: FX entry point vs richness](#1:-FX-entry-point-vs-richness)\n* [2: Downside sensitivity to SPX](#2:-Downside-sensitivity-to-SPX)\n* [3: AUDJPY conditional relationship with SPX](#3:-AUDJPY-conditional-relationship-with-SPX)\n* [4: Price structures](#4:-Price-structures)\n* [5: Analyse rates package](#5:-Analyse-rates-package)",
"_____no_output_____"
],
[
"### 1: FX entry point vs richness\nLet's pull [GS FX Spot](https://marquee.gs.com/s/developer/datasets/FXSPOT_PREMIUM) and [GS FX Implied Volatility](https://marquee.gs.com/s/developer/datasets/FXIMPLIEDVOL_PREMIUM) and look at implied vs realized vol as well as current implied level as percentile relative to the last 2 years.",
"_____no_output_____"
]
],
[
[
"def format_df(data_dict):\n df = pd.concat(data_dict, axis=1)\n df.columns = data_dict.keys()\n return df.fillna(method='ffill').dropna()",
"_____no_output_____"
],
[
"g10 = ['USDJPY', 'EURUSD', 'AUDUSD', 'GBPUSD', 'USDCAD', 'USDNOK', 'NZDUSD', 'USDSEK', 'USDCHF', 'AUDJPY']\nstart_date = date(2005, 8, 26)\nend_date = business_day_offset(date.today(), -1, roll='preceding')\nfxspot_dataset, fxvol_dataset = Dataset('FXSPOT_PREMIUM'), Dataset('FXIMPLIEDVOL_PREMIUM')\n\nspot_data, impvol_data, spot_fx = {}, {}, {}\nfor cross in g10:\n spot = fxspot_dataset.get_data(start_date, end_date, bbid=cross)[['spot']].drop_duplicates(keep='last')\n spot_fx[cross] = spot['spot']\n spot_data[cross] = volatility(spot['spot'], 63) # realized vol \n vol = fxvol_dataset.get_data(start_date, end_date, bbid=cross, tenor='3m', deltaStrike='DN', location='NYC')[['impliedVolatility']]\n impvol_data[cross] = vol.drop_duplicates(keep='last') * 100\n\nspdata, ivdata = format_df(spot_data), format_df(impvol_data)\ndiff = ivdata.subtract(spdata).dropna()",
"_____no_output_____"
],
[
"_slice = ivdata['2018-09-01': '2020-09-08']\npct_rank = {}\nfor x in _slice.columns:\n pct = percentiles(_slice[x])\n pct_rank[x] = pct.iloc[-1]\n\nfor fx in pct_rank:\n plt.scatter(pct_rank[fx], diff[fx]['2020-09-08'])\n plt.legend(pct_rank.keys(),loc='best', bbox_to_anchor=(0.9, -0.13), ncol=3)\n \nplt.xlabel('Percentile of Current Implied Vol')\nplt.ylabel('Implied vs Realized Vol')\nplt.title('Entry Point vs Richness')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 2: Downside sensitivity to SPX\n\nLet's now look at beta and correlation with SPX across G10.",
"_____no_output_____"
]
],
[
[
"spx_spot = Dataset('TREOD').get_data(start_date, end_date, bbid='SPX')[['closePrice']]\nspx_spot = spx_spot.fillna(method='ffill').dropna()\ndf = pd.DataFrame(spx_spot)\n\n#FX Spot data\nfx_spots = format_df(spot_fx)\ndata = pd.concat([spx_spot, fx_spots], axis=1).dropna()\ndata.columns = ['SPX'] + g10",
"_____no_output_____"
],
[
"beta_spx, corr_spx = {}, {}\n\n#calculate rolling 84d or 4m beta to S&P\nfor cross in g10:\n beta_spx[cross] = beta(data[cross],data['SPX'], 84)\n corr_spx[cross] = correlation(data['SPX'], data[cross], 84)\n\nfig, axs = plt.subplots(5, 2, figsize=(18, 20))\nfor j in range(2):\n for i in range(5):\n color='tab:blue'\n axs[i,j].plot(beta_spx[g10[i + j*5]], color=color)\n axs[i,j].set_title(g10[i + j*5])\n color='tab:blue'\n axs[i,j].set_ylabel('Beta', color=color)\n axs[i,j].plot(beta_spx[g10[i + j*5]], color=color)\n ax2 = axs[i,j].twinx()\n color = 'tab:orange' \n ax2.plot(corr_spx[g10[i + j*5]], color=color)\n ax2.set_ylabel('Correlation', color=color)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Part 3: AUDJPY conditional relationship with SPX\n\nLet's focus on AUDJPY and look at its relationship with SPX when SPX is significantly up and down.",
"_____no_output_____"
]
],
[
[
"# resample data to weekly from daily & get weekly returns\nwk_data = data.resample('W-FRI').last()\nrets = returns(wk_data, 1)\nsns.set(style='white', color_codes=True)\nspx_returns = [-.1, -.05, .05, .1]\nr2 = lambda x,y: stats.pearsonr(x,y)[0]**2 \nbetas = pd.DataFrame(index=spx_returns, columns=g10)\nfor ret in spx_returns:\n dns = rets[rets.SPX <= ret].dropna() if ret < 0 else rets[rets.SPX >= ret].dropna() \n j = sns.jointplot(x='SPX', y='AUDJPY', data=dns, kind='reg')\n j.set_axis_labels('SPX with {}% Returns'.format(ret*100), 'AUDJPY')\n j.fig.subplots_adjust(wspace=.02)\n plt.show()",
"_____no_output_____"
]
],
[
[
"Let's use the beta for all S&P returns to price a structure",
"_____no_output_____"
]
],
[
[
"sns.jointplot(x='SPX', y='AUDJPY', data=rets, kind='reg', stat_func=r2)",
"_____no_output_____"
]
],
[
[
"### 4: Price structures \n\n##### Let's now look at a few AUDJPY structures as potential hedges\n\n* Buy 4m AUDJPY put using spx beta to size. Max loss limited to premium paid.\n* Buy 4m AUDJPY put spread (4.2%/10.6% OTMS). Max loss limited to premium paid.\n\nFor more info on this trade, check out our market strats piece [here](https://marquee.gs.com/content/#/article/2020/08/28/gs-marketstrats-audjpy-as-us-election-hedge)",
"_____no_output_____"
]
],
[
[
"#buy 4m AUDJPY put\naudjpy_put = FXOption(option_type='Put', pair='AUDJPY', strike_price= 's-4.2%', expiration_date='4m', buy_sell='Buy') \nprint('cost in bps: {:,.2f}'.format(audjpy_put.premium / audjpy_put.notional_amount * 1e4))",
"_____no_output_____"
],
[
"#buy 4m AUDJPY put spread (5.3%/10.6% OTMS)\nfrom gs_quant.markets.portfolio import Portfolio\nput1 = FXOption(option_type='Put', pair='AUDJPY', strike_price= 's-4.2%', expiration_date='4m', buy_sell='Buy')\nput2 = FXOption(option_type='Put', pair='AUDJPY', strike_price= 's-10.6%', expiration_date='4m', buy_sell='Sell')\n\nfx_package = Portfolio((put1, put2))\ncost = put2.premium/put2.notional_amount - put1.premium/put1.notional_amount \nprint('cost in bps: {:,.2f}'.format(cost * 1e4))",
"_____no_output_____"
]
],
[
[
"##### ...And some rates ideas\n\n* Sell straddle. Max loss unlimited.\n* Sell 3m30y straddle, buy 2y30y straddle in a 0 pv package. Max loss unlimited.",
"_____no_output_____"
]
],
[
[
"leg = IRSwaption('Straddle', '30y', notional_currency='USD', expiration_date='3m', buy_sell='Sell')\nprint('PV in USD: {:,.2f}'.format(leg.dollar_price()))",
"_____no_output_____"
],
[
"leg1 = IRSwaption('Straddle', '30y', notional_currency='USD', expiration_date='3m', buy_sell='Sell',name='3m30y ATM Straddle')\nleg2 = IRSwaption('Straddle', '30y', notional_currency='USD', expiration_date='2y', notional_amount='{}/pv'.format(leg1.price()), buy_sell='Buy', name = '2y30y ATM Straddle')\n\nrates_package = Portfolio((leg1, leg2))\nrates_package.resolve()\n\nprint('Package cost in USD: {:,.2f}'.format(rates_package.price().aggregate()))\nprint('PV Flat notionals ($$m):', round(leg1.notional_amount/1e6, 1),' by ',round(leg2.notional_amount/1e6, 1))",
"_____no_output_____"
]
],
[
[
"### 5: Analyse rates package",
"_____no_output_____"
]
],
[
[
"dates = pd.bdate_range(date(2020, 6, 8), leg1.expiration_date, freq='5B').date.tolist()\n\nwith BackToTheFuturePricingContext(dates=dates, roll_to_fwds=True):\n future = rates_package.price()\nrates_future = future.result().aggregate()\n\nrates_future.plot(figsize=(10, 6), title='Historical PV and carry for rates package')\n\nprint('PV breakdown between legs:')\nresults = future.result().to_frame()\nresults /= 1e6\nresults.index=[leg1.name,leg2.name]\nresults.loc['Total'] = results.sum()\nresults.round(1)",
"_____no_output_____"
]
],
[
[
"Let's focus on the next 3m and how the calendar carries in different rates shocks.",
"_____no_output_____"
]
],
[
[
"dates = pd.bdate_range(dt.date.today(), leg1.expiration_date, freq='5B').date.tolist()\nshocked_pv = pd.DataFrame(columns=['Base', '5bp per week', '50bp instantaneous'], index=dates)\n\np1, p2, p3 = [], [], []\nwith PricingContext(is_batch=True):\n for t, d in enumerate(dates):\n with CarryScenario(date=d, roll_to_fwds=True):\n p1.append(rates_package.price())\n with MarketDataShockBasedScenario({MarketDataPattern('IR', 'USD'): MarketDataShock(MarketDataShockType.Absolute, t*0.0005)}):\n p2.append(rates_package.price())\n with MarketDataShockBasedScenario({MarketDataPattern('IR', 'USD'): MarketDataShock(MarketDataShockType.Absolute, 0.005)}):\n p3.append(rates_package.price())\n\nshocked_pv.Base = [p.result().aggregate() for p in p1]\nshocked_pv['5bp per week'] = [p.result().aggregate() for p in p2]\nshocked_pv['50bp instantaneous'] = [p.result().aggregate() for p in p3]\n\nshocked_pv/=1e6\nshocked_pv.round(1)\nshocked_pv.plot(figsize=(10, 6), title='Carry + scenario analysis')",
"_____no_output_____"
]
],
[
[
"### Disclaimers\n\nScenarios/predictions: Simulated results are for illustrative purposes only. GS provides no assurance or guarantee that the strategy will operate or would have operated in the past in a manner consistent with the above analysis. Past performance figures are not a reliable indicator of future results.\n\nIndicative Terms/Pricing Levels: This material may contain indicative terms only, including but not limited to pricing levels. There is no representation that any transaction can or could have been effected at such terms or prices. Proposed terms and conditions are for discussion purposes only. Finalized terms and conditions are subject to further discussion and negotiation.\nwww.goldmansachs.com/disclaimer/sales-and-trading-invest-rec-disclosures.html If you are not accessing this material via Marquee ContentStream, a list of the author's investment recommendations disseminated during the preceding 12 months and the proportion of the author's recommendations that are 'buy', 'hold', 'sell' or other over the previous 12 months is available by logging into Marquee ContentStream using the link below. Alternatively, if you do not have access to Marquee ContentStream, please contact your usual GS representative who will be able to provide this information to you.\n\nBacktesting, Simulated Results, Sensitivity/Scenario Analysis or Spreadsheet Calculator or Model: There may be data presented herein that is solely for illustrative purposes and which may include among other things back testing, simulated results and scenario analyses. The information is based upon certain factors, assumptions and historical information that Goldman Sachs may in its discretion have considered appropriate, however, Goldman Sachs provides no assurance or guarantee that this product will operate or would have operated in the past in a manner consistent with these assumptions. In the event any of the assumptions used do not prove to be true, results are likely to vary materially from the examples shown herein. Additionally, the results may not reflect material economic and market factors, such as liquidity, transaction costs and other expenses which could reduce potential return.\n\nOTC Derivatives Risk Disclosures: \nTerms of the Transaction: To understand clearly the terms and conditions of any OTC derivative transaction you may enter into, you should carefully review the Master Agreement, including any related schedules, credit support documents, addenda and exhibits. You should not enter into OTC derivative transactions unless you understand the terms of the transaction you are entering into as well as the nature and extent of your risk exposure. You should also be satisfied that the OTC derivative transaction is appropriate for you in light of your circumstances and financial condition. You may be requested to post margin or collateral to support written OTC derivatives at levels consistent with the internal policies of Goldman Sachs. \n \nLiquidity Risk: There is no public market for OTC derivative transactions and, therefore, it may be difficult or impossible to liquidate an existing position on favorable terms. Transfer Restrictions: OTC derivative transactions entered into with one or more affiliates of The Goldman Sachs Group, Inc. (Goldman Sachs) cannot be assigned or otherwise transferred without its prior written consent and, therefore, it may be impossible for you to transfer any OTC derivative transaction to a third party. \n \nConflict of Interests: Goldman Sachs may from time to time be an active participant on both sides of the market for the underlying securities, commodities, futures, options or any other derivative or instrument identical or related to those mentioned herein (together, \"the Product\"). Goldman Sachs at any time may have long or short positions in, or buy and sell Products (on a principal basis or otherwise) identical or related to those mentioned herein. Goldman Sachs hedging and trading activities may affect the value of the Products. \n \nCounterparty Credit Risk: Because Goldman Sachs, may be obligated to make substantial payments to you as a condition of an OTC derivative transaction, you must evaluate the credit risk of doing business with Goldman Sachs or its affiliates. \n \nPricing and Valuation: The price of each OTC derivative transaction is individually negotiated between Goldman Sachs and each counterparty and Goldman Sachs does not represent or warrant that the prices for which it offers OTC derivative transactions are the best prices available, possibly making it difficult for you to establish what is a fair price for a particular OTC derivative transaction; The value or quoted price of the Product at any time, however, will reflect many factors and cannot be predicted. If Goldman Sachs makes a market in the offered Product, the price quoted by Goldman Sachs would reflect any changes in market conditions and other relevant factors, and the quoted price (and the value of the Product that Goldman Sachs will use for account statements or otherwise) could be higher or lower than the original price, and may be higher or lower than the value of the Product as determined by reference to pricing models used by Goldman Sachs. If at any time a third party dealer quotes a price to purchase the Product or otherwise values the Product, that price may be significantly different (higher or lower) than any price quoted by Goldman Sachs. Furthermore, if you sell the Product, you will likely be charged a commission for secondary market transactions, or the price will likely reflect a dealer discount. Goldman Sachs may conduct market making activities in the Product. To the extent Goldman Sachs makes a market, any price quoted for the OTC derivative transactions, Goldman Sachs may differ significantly from (i) their value determined by reference to Goldman Sachs pricing models and (ii) any price quoted by a third party. The market price of the OTC derivative transaction may be influenced by many unpredictable factors, including economic conditions, the creditworthiness of Goldman Sachs, the value of any underlyers, and certain actions taken by Goldman Sachs. \n \nMarket Making, Investing and Lending: Goldman Sachs engages in market making, investing and lending businesses for its own account and the accounts of its affiliates in the same or similar instruments underlying OTC derivative transactions (including such trading as Goldman Sachs deems appropriate in its sole discretion to hedge its market risk in any OTC derivative transaction whether between Goldman Sachs and you or with third parties) and such trading may affect the value of an OTC derivative transaction. \n \nEarly Termination Payments: The provisions of an OTC Derivative Transaction may allow for early termination and, in such cases, either you or Goldman Sachs may be required to make a potentially significant termination payment depending upon whether the OTC Derivative Transaction is in-the-money to Goldman Sachs or you at the time of termination. Indexes: Goldman Sachs does not warrant, and takes no responsibility for, the structure, method of computation or publication of any currency exchange rates, interest rates, indexes of such rates, or credit, equity or other indexes, unless Goldman Sachs specifically advises you otherwise.\nRisk Disclosure Regarding futures, options, equity swaps, and other derivatives as well as non-investment-grade securities and ADRs: Please ensure that you have read and understood the current options, futures and security futures disclosure document before entering into any such transactions. Current United States listed options, futures and security futures disclosure documents are available from our sales representatives or at http://www.theocc.com/components/docs/riskstoc.pdf, http://www.goldmansachs.com/disclosures/risk-disclosure-for-futures.pdf and https://www.nfa.futures.org/investors/investor-resources/files/security-futures-disclosure.pdf, respectively. Certain transactions - including those involving futures, options, equity swaps, and other derivatives as well as non-investment-grade securities - give rise to substantial risk and are not available to nor suitable for all investors. If you have any questions about whether you are eligible to enter into these transactions with Goldman Sachs, please contact your sales representative. Foreign-currency-denominated securities are subject to fluctuations in exchange rates that could have an adverse effect on the value or price of, or income derived from, the investment. In addition, investors in securities such as ADRs, the values of which are influenced by foreign currencies, effectively assume currency risk.\nOptions Risk Disclosures: Options may trade at a value other than that which may be inferred from the current levels of interest rates, dividends (if applicable) and the underlier due to other factors including, but not limited to, expectations of future levels of interest rates, future levels of dividends and the volatility of the underlier at any time prior to maturity. Note: Options involve risk and are not suitable for all investors. Please ensure that you have read and understood the current options disclosure document before entering into any standardized options transactions. United States listed options disclosure documents are available from our sales representatives or at http://theocc.com/publications/risks/riskstoc.pdf. A secondary market may not be available for all options. Transaction costs may be a significant factor in option strategies calling for multiple purchases and sales of options, such as spreads. When purchasing long options an investor may lose their entire investment and when selling uncovered options the risk is potentially unlimited. Supporting documentation for any comparisons, recommendations, statistics, technical data, or other similar information will be supplied upon request.\nThis material is for the private information of the recipient only. This material is not sponsored, endorsed, sold or promoted by any sponsor or provider of an index referred herein (each, an \"Index Provider\"). GS does not have any affiliation with or control over the Index Providers or any control over the computation, composition or dissemination of the indices. While GS will obtain information from publicly available sources it believes reliable, it will not independently verify this information. Accordingly, GS shall have no liability, contingent or otherwise, to the user or to third parties, for the quality, accuracy, timeliness, continued availability or completeness of the data nor for any special, indirect, incidental or consequential damages which may be incurred or experienced because of the use of the data made available herein, even if GS has been advised of the possibility of such damages.\nStandard & Poor's ® and S&P ® are registered trademarks of The McGraw-Hill Companies, Inc. and S&P GSCI™ is a trademark of The McGraw-Hill Companies, Inc. and have been licensed for use by the Issuer. This Product (the \"Product\") is not sponsored, endorsed, sold or promoted by S&P and S&P makes no representation, warranty or condition regarding the advisability of investing in the Product.\nNotice to Brazilian Investors\nMarquee is not meant for the general public in Brazil. The services or products provided by or through Marquee, at any time, may not be offered or sold to the general public in Brazil. You have received a password granting access to Marquee exclusively due to your existing relationship with a GS business located in Brazil. The selection and engagement with any of the offered services or products through Marquee, at any time, will be carried out directly by you. Before acting to implement any chosen service or products, provided by or through Marquee you should consider, at your sole discretion, whether it is suitable for your particular circumstances and, if necessary, seek professional advice. Any steps necessary in order to implement the chosen service or product, including but not limited to remittance of funds, shall be carried out at your discretion. Accordingly, such services and products have not been and will not be publicly issued, placed, distributed, offered or negotiated in the Brazilian capital markets and, as a result, they have not been and will not be registered with the Brazilian Securities and Exchange Commission (Comissão de Valores Mobiliários), nor have they been submitted to the foregoing agency for approval. Documents relating to such services or products, as well as the information contained therein, may not be supplied to the general public in Brazil, as the offering of such services or products is not a public offering in Brazil, nor used in connection with any offer for subscription or sale of securities to the general public in Brazil.\nThe offer of any securities mentioned in this message may not be made to the general public in Brazil. Accordingly, any such securities have not been nor will they be registered with the Brazilian Securities and Exchange Commission (Comissão de Valores Mobiliários) nor has any offer been submitted to the foregoing agency for approval. Documents relating to the offer, as well as the information contained therein, may not be supplied to the public in Brazil, as the offer is not a public offering of securities in Brazil. These terms will apply on every access to Marquee.\nOuvidoria Goldman Sachs Brasil: 0800 727 5764 e/ou [email protected]\nHorário de funcionamento: segunda-feira à sexta-feira (exceto feriados), das 9hs às 18hs.\nOmbudsman Goldman Sachs Brazil: 0800 727 5764 and / or [email protected]\nAvailable Weekdays (except holidays), from 9 am to 6 pm.\n\n",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
d062ad7c364d8195bd0661953d59fa2e49a6751f | 16,541 | ipynb | Jupyter Notebook | solutions/gqlalchemy-solutions.ipynb | pyladiesams/graphdatabases-gqlalchemy-beginner-mar2022 | 39b6d1eedfea63177b3e6a124411fdb2341116f5 | [
"MIT"
]
| 4 | 2021-11-28T09:28:06.000Z | 2022-02-23T20:30:47.000Z | solutions/gqlalchemy-solutions.ipynb | pyladiesams/graphdbs-gqlalchemy-beginner-mar2022 | 39b6d1eedfea63177b3e6a124411fdb2341116f5 | [
"MIT"
]
| null | null | null | solutions/gqlalchemy-solutions.ipynb | pyladiesams/graphdbs-gqlalchemy-beginner-mar2022 | 39b6d1eedfea63177b3e6a124411fdb2341116f5 | [
"MIT"
]
| null | null | null | 30.294872 | 445 | 0.517562 | [
[
[
"# 💡 Solutions\n\nBefore trying out these solutions, please start the [gqlalchemy-workshop notebook](../workshop/gqlalchemy-workshop.ipynb) to import all data. Also, this solutions manual is here to help you out, and it is recommended you try solving the exercises first by yourself.\n\n## Exercise 1\n\n**Find out how many genres there are in the database.**\n\nThe correct Cypher query is:\n\n```\nMATCH (g:Genre)\nRETURN count(g) AS num_of_genres;\n```\n\nYou can try it out in Memgraph Lab at `localhost:3000`.\n\nWith GQLAlchemy's query builder, the solution is:",
"_____no_output_____"
]
],
[
[
"from gqlalchemy import match\n\ntotal_genres = (\n match()\n .node(labels=\"Genre\", variable=\"g\")\n .return_({\"count(g)\": \"num_of_genres\"})\n .execute()\n)\n\nresults = list(total_genres)\nfor result in results:\n print(result[\"num_of_genres\"])",
"22084\n"
]
],
[
[
"## Exercise 2\n\n**Find out to how many genres movie 'Matrix, The (1999)' belongs to.**\n\n\nThe correct Cypher query is:\n\n```\nMATCH (:Movie {title: 'Matrix, The (1999)'})-[:OF_GENRE]->(g:Genre)\nRETURN count(g) AS num_of_genres;\n```\n\nYou can try it out in Memgraph Lab at `localhost:3000`.\n\nWith GQLAlchemy's query builder, the solution is:\n",
"_____no_output_____"
]
],
[
[
"matrix = (\n match()\n .node(labels=\"Movie\", variable=\"m\")\n .to(\"OF_GENRE\")\n .node(labels=\"Genre\", variable=\"g\")\n .where(\"m.title\", \"=\", \"Matrix, The (1999)\")\n .return_({\"count(g)\": \"num_of_genres\"})\n .execute()\n)\n\nresults = list(matrix)\n\nfor result in results:\n print(result[\"num_of_genres\"])",
"3\n"
]
],
[
[
"## Exercise 3\n\n**Find out the title of the movies that the user with `id` 1 rated.**\n\n\nThe correct Cypher query is:\n\n```\nMATCH (:User {id: 1})-[:RATED]->(m:Movie)\nRETURN m.title;\n```\n\nYou can try it out in Memgraph Lab at `localhost:3000`.\n\nWith GQLAlchemy's query builder, the solution is:",
"_____no_output_____"
]
],
[
[
"movies = (\n match()\n .node(labels=\"User\", variable=\"u\")\n .to(\"RATED\")\n .node(labels=\"Movie\", variable=\"m\")\n .where(\"u.id\", \"=\", 1)\n .return_({\"m.title\": \"movie\"})\n .execute()\n)\n\nresults = list(movies)\n\nfor result in results:\n print(result[\"movie\"])",
"Toy Story (1995)\nGrumpier Old Men (1995)\nHeat (1995)\nSeven (a.k.a. Se7en) (1995)\nUsual Suspects, The (1995)\nFrom Dusk Till Dawn (1996)\nBottle Rocket (1996)\nBraveheart (1995)\nRob Roy (1995)\nCanadian Bacon (1995)\nDesperado (1995)\nBilly Madison (1995)\nClerks (1994)\nDumb & Dumber (Dumb and Dumber) (1994)\nEd Wood (1994)\nStar Wars: Episode IV - A New Hope (1977)\nPulp Fiction (1994)\nStargate (1994)\nTommy Boy (1995)\nClear and Present Danger (1994)\nForrest Gump (1994)\nJungle Book, The (1994)\nMask, The (1994)\nBlown Away (1994)\nDazed and Confused (1993)\nFugitive, The (1993)\nJurassic Park (1993)\nMrs. Doubtfire (1993)\nSchindler's List (1993)\nSo I Married an Axe Murderer (1993)\nThree Musketeers, The (1993)\nTombstone (1993)\nDances with Wolves (1990)\nBatman (1989)\nSilence of the Lambs, The (1991)\nPinocchio (1940)\nFargo (1996)\nMission: Impossible (1996)\nJames and the Giant Peach (1996)\nSpace Jam (1996)\nRock, The (1996)\nTwister (1996)\nIndependence Day (a.k.a. ID4) (1996)\nShe's the One (1996)\nWizard of Oz, The (1939)\nCitizen Kane (1941)\nAdventures of Robin Hood, The (1938)\nGhost and Mrs. Muir, The (1947)\nMr. Smith Goes to Washington (1939)\nEscape to Witch Mountain (1975)\nWinnie the Pooh and the Blustery Day (1968)\nThree Caballeros, The (1945)\nSword in the Stone, The (1963)\nDumbo (1941)\nPete's Dragon (1977)\nBedknobs and Broomsticks (1971)\nAlice in Wonderland (1951)\nThat Thing You Do! (1996)\nGhost and the Darkness, The (1996)\nSwingers (1996)\nWilly Wonka & the Chocolate Factory (1971)\nMonty Python's Life of Brian (1979)\nReservoir Dogs (1992)\nPlatoon (1986)\nBasic Instinct (1992)\nE.T. the Extra-Terrestrial (1982)\nAbyss, The (1989)\nMonty Python and the Holy Grail (1975)\nStar Wars: Episode V - The Empire Strikes Back (1980)\nPrincess Bride, The (1987)\nRaiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark) (1981)\nClockwork Orange, A (1971)\nApocalypse Now (1979)\nStar Wars: Episode VI - Return of the Jedi (1983)\nGoodfellas (1990)\nAlien (1979)\nPsycho (1960)\nBlues Brothers, The (1980)\nFull Metal Jacket (1987)\nHenry V (1989)\nQuiet Man, The (1952)\nTerminator, The (1984)\nDuck Soup (1933)\nShining, The (1980)\nGroundhog Day (1993)\nBack to the Future (1985)\nHighlander (1986)\nYoung Frankenstein (1974)\nFantasia (1940)\nIndiana Jones and the Last Crusade (1989)\nPink Floyd: The Wall (1982)\nNosferatu (Nosferatu, eine Symphonie des Grauens) (1922)\nBatman Returns (1992)\nSneakers (1992)\nLast of the Mohicans, The (1992)\nMcHale's Navy (1997)\nBest Men (1997)\nGrosse Pointe Blank (1997)\nAustin Powers: International Man of Mystery (1997)\nCon Air (1997)\nFace/Off (1997)\nMen in Black (a.k.a. MIB) (1997)\nConan the Barbarian (1982)\nL.A. Confidential (1997)\nKiss the Girls (1997)\nGame, The (1997)\nI Know What You Did Last Summer (1997)\nStarship Troopers (1997)\nBig Lebowski, The (1998)\nWedding Singer, The (1998)\nWelcome to Woop-Woop (1997)\nNewton Boys, The (1998)\nWild Things (1998)\nSmall Soldiers (1998)\nAll Quiet on the Western Front (1930)\nRocky (1976)\nLabyrinth (1986)\nLethal Weapon (1987)\nGoonies, The (1985)\nBack to the Future Part III (1990)\nBambi (1942)\nSaving Private Ryan (1998)\nBlack Cauldron, The (1985)\nFlight of the Navigator (1986)\nGreat Mouse Detective, The (1986)\nHoney, I Shrunk the Kids (1989)\nNegotiator, The (1998)\nJungle Book, The (1967)\nRescuers, The (1977)\nReturn to Oz (1985)\nRocketeer, The (1991)\nSleeping Beauty (1959)\nSong of the South (1946)\nTron (1982)\nIndiana Jones and the Temple of Doom (1984)\nLord of the Rings, The (1978)\nCharlotte's Web (1973)\nSecret of NIMH, The (1982)\nAmerican Tail, An (1986)\nLegend (1985)\nNeverEnding Story, The (1984)\nBeetlejuice (1988)\nWillow (1988)\nToys (1992)\nFew Good Men, A (1992)\nRush Hour (1998)\nEdward Scissorhands (1990)\nAmerican History X (1998)\nI Still Know What You Did Last Summer (1998)\nEnemy of the State (1998)\nKing Kong (1933)\nVery Bad Things (1998)\nPsycho (1998)\nRushmore (1998)\nRomancing the Stone (1984)\nYoung Sherlock Holmes (1985)\nThin Red Line, The (1998)\nHoward the Duck (1986)\nTexas Chainsaw Massacre, The (1974)\nCrocodile Dundee (1986)\n¡Three Amigos! (1986)\n20 Dates (1998)\nOffice Space (1999)\nLogan's Run (1976)\nPlanet of the Apes (1968)\nLock, Stock & Two Smoking Barrels (1998)\nMatrix, The (1999)\nGo (1999)\nSLC Punk! (1998)\nDick Tracy (1990)\nMummy, The (1999)\nStar Wars: Episode I - The Phantom Menace (1999)\nSuperman (1978)\nSuperman II (1980)\nDracula (1931)\nFrankenstein (1931)\nWolf Man, The (1941)\nRocky Horror Picture Show, The (1975)\nRun Lola Run (Lola rennt) (1998)\nSouth Park: Bigger, Longer and Uncut (1999)\nGhostbusters (a.k.a. Ghost Busters) (1984)\nIron Giant, The (1999)\nBig (1988)\n13th Warrior, The (1999)\nAmerican Beauty (1999)\nExcalibur (1981)\nGulliver's Travels (1939)\nTotal Recall (1990)\nDirty Dozen, The (1967)\nGoldfinger (1964)\nFrom Russia with Love (1963)\nDr. No (1962)\nFight Club (1999)\nRoboCop (1987)\nWho Framed Roger Rabbit? (1988)\nLive and Let Die (1973)\nThunderball (1965)\nBeing John Malkovich (1999)\nSpaceballs (1987)\nRobin Hood (1973)\nDogma (1999)\nMessenger: The Story of Joan of Arc, The (1999)\nLongest Day, The (1962)\nGreen Mile, The (1999)\nEasy Rider (1969)\nTalented Mr. Ripley, The (1999)\nEncino Man (1992)\nSister Act (1992)\nWayne's World (1992)\nScream 3 (2000)\nJFK (1991)\nTeenage Mutant Ninja Turtles II: The Secret of the Ooze (1991)\nTeenage Mutant Ninja Turtles III (1993)\nRed Dawn (1984)\nGood Morning, Vietnam (1987)\nGrumpy Old Men (1993)\nLadyhawke (1985)\nHook (1991)\nPredator (1987)\nGladiator (2000)\nRoad Trip (2000)\nMan with the Golden Gun, The (1974)\nBlazing Saddles (1974)\nMad Max (1979)\nRoad Warrior, The (Mad Max 2) (1981)\nShaft (1971)\nBig Trouble in Little China (1986)\nShaft (2000)\nX-Men (2000)\nWhat About Bob? (1991)\nTransformers: The Movie (1986)\nM*A*S*H (a.k.a. MASH) (1970)\n"
]
],
[
[
"## Exercise 4\n\n**List 15 movies of 'Documentary' and 'Comedy' genres and sort them by title descending.**\n\n\nThe correct Cypher query is:\n\n```\nMATCH (m:Movie)-[:OF_GENRE]->(:Genre {name: \"Documentary\"})\nMATCH (m)-[:OF_GENRE]->(:Genre {name: \"Comedy\"})\nRETURN m.title\nORDER BY m.title DESC\nLIMIT 15;\n```\n\nYou can try it out in Memgraph Lab at `localhost:3000`.\n\nWith GQLAlchemy's query builder, the solution is:",
"_____no_output_____"
]
],
[
[
"movies = (\n match()\n .node(labels=\"Movie\", variable=\"m\")\n .to(\"OF_GENRE\")\n .node(labels=\"Genre\", variable=\"g1\")\n .where(\"g1.name\", \"=\", \"Documentary\")\n .match()\n .node(labels=\"Movie\", variable=\"m\")\n .to(\"OF_GENRE\")\n .node(labels=\"Genre\", variable=\"g2\")\n .where(\"g2.name\", \"=\", \"Comedy\")\n .return_({\"m.title\": \"movie\"})\n .order_by(\"m.title DESC\")\n .limit(15)\n .execute()\n)\n\nresults = list(movies)\n\nfor result in results:\n print(result[\"movie\"])",
"What the #$*! Do We Know!? (a.k.a. What the Bleep Do We Know!?) (2004)\nUnion: The Business Behind Getting High, The (2007)\nSuper Size Me (2004)\nSuper High Me (2007)\nSecret Policeman's Other Ball, The (1982)\nRichard Pryor Live on the Sunset Strip (1982)\nReligulous (2008)\nPaper Heart (2009)\nOriginal Kings of Comedy, The (2000)\nMerci Patron ! (2016)\nMartin Lawrence Live: Runteldat (2002)\nKevin Hart: Laugh at My Pain (2011)\nJeff Ross Roasts Criminals: Live at Brazos County Jail (2015)\nJackass: The Movie (2002)\nJackass Number Two (2006)\n"
]
],
[
[
"## Exercise 5\n\n**Find out the minimum rating of the 'Star Wars: Episode I - The Phantom Menace (1999)' movie.**\n\n\nThe correct Cypher query is:\n\n```\nMATCH (:User)-[r:RATED]->(:Movie {title: 'Star Wars: Episode I - The Phantom Menace (1999)'})\nRETURN min(r.rating);\n```\n\nYou can try it out in Memgraph Lab at `localhost:3000`.\n\nWith GQLAlchemy's query builder, the solution is:",
"_____no_output_____"
]
],
[
[
"rating = (\n match()\n .node(labels=\"User\")\n .to(\"RATED\", variable=\"r\")\n .node(labels=\"Movie\", variable=\"m\")\n .where(\"m.title\", \"=\", \"Star Wars: Episode I - The Phantom Menace (1999)\")\n .return_({\"min(r.rating)\": \"min_rating\"})\n .execute()\n)\n\nresults = list(rating)\n\nfor result in results:\n print(result[\"min_rating\"])",
"0.5\n"
]
],
[
[
"And that's it! If you have any issues with this notebook, feel free to open an issue on the [GitHub repository](https://github.com/pyladiesams/graphdbs-gqlalchemy-beginner-mar2022), or [join the Discord server](https://discord.gg/memgraph) and get your answer instantly. If you are interested in the Cypher query language and want to learn more, sign up for the free [Cypher Email Course](https://memgraph.com/learn-cypher-query-language).",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
d062af471a2cba624d9fcde9b9879fe8ddf2e6c9 | 325,489 | ipynb | Jupyter Notebook | _notebooks/2021_04_28_PGA_Wins.ipynb | brennanashley/lambdalost | cfa50a18039062712919d99a01a8e6dcd484dc6c | [
"Apache-2.0"
]
| 1 | 2021-02-27T02:10:15.000Z | 2021-02-27T02:10:15.000Z | _notebooks/2021_04_28_PGA_Wins.ipynb | brennanashley/lambdalost | cfa50a18039062712919d99a01a8e6dcd484dc6c | [
"Apache-2.0"
]
| null | null | null | _notebooks/2021_04_28_PGA_Wins.ipynb | brennanashley/lambdalost | cfa50a18039062712919d99a01a8e6dcd484dc6c | [
"Apache-2.0"
]
| null | null | null | 172.581654 | 195,586 | 0.851387 | [
[
[
"# \"PGA Tour Wins Classification\"\n\n\n",
"_____no_output_____"
]
],
[
[
"Can We Predict If a PGA Tour Player Won a Tournament in a Given Year?\n\nGolf is picking up popularity, so I thought it would be interesting to focus my project here. I set out to find what sets apart the best golfers from the rest. \nI decided to explore their statistics and to see if I could predict which golfers would win in a given year. My original dataset was found on Kaggle, and the data was scraped from the PGA Tour website. \n\nFrom this data, I performed an exploratory data analysis to explore the distribution of players on numerous aspects of the game, discover outliers, and further explore how the game has changed from 2010 to 2018. I also utilized numerous supervised machine learning models to predict a golfer's earnings and wins.\n\nTo predict the golfer's win, I used classification methods such as logisitic regression and Random Forest Classification. The best performance came from the Random Forest Classification method.",
"_____no_output_____"
],
[
"1. The Data\n\npgaTourData.csv contains 1674 rows and 18 columns. Each row indicates a golfer's performance for that year.\n",
"_____no_output_____"
]
],
[
[
"\n# Player Name: Name of the golfer\n\n# Rounds: The number of games that a player played\n\n# Fairway Percentage: The percentage of time a tee shot lands on the fairway\n\n# Year: The year in which the statistic was collected\n\n# Avg Distance: The average distance of the tee-shot\n\n# gir: (Green in Regulation) is met if any part of the ball is touching the putting surface while the number of strokes taken is at least two fewer than par\n\n# Average Putts: The average number of strokes taken on the green\n\n# Average Scrambling: Scrambling is when a player misses the green in regulation, but still makes par or better on a hole\n\n# Average Score: Average Score is the average of all the scores a player has played in that year\n\n# Points: The number of FedExCup points a player earned in that year\n\n# Wins: The number of competition a player has won in that year\n\n# Top 10: The number of competitions where a player has placed in the Top 10\n\n# Average SG Putts: Strokes gained: putting measures how many strokes a player gains (or loses) on the greens\n\n# Average SG Total: The Off-the-tee + approach-the-green + around-the-green + putting statistics combined\n\n# SG:OTT: Strokes gained: off-the-tee measures player performance off the tee on all par-4s and par-5s\n\n# SG:APR: Strokes gained: approach-the-green measures player performance on approach shots\n\n# SG:ARG: Strokes gained: around-the-green measures player performance on any shot within 30 yards of the edge of the green\n\n# Money: The amount of prize money a player has earned from tournaments\n",
"_____no_output_____"
],
[
"#collapse\n# importing packages\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"# Importing the data \ndf = pd.read_csv('pgaTourData.csv')\n\n# Examining the first 5 data\ndf.head()",
"_____no_output_____"
],
[
"#collapse\ndf.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 2312 entries, 0 to 2311\nData columns (total 18 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Player Name 2312 non-null object \n 1 Rounds 1678 non-null float64\n 2 Fairway Percentage 1678 non-null float64\n 3 Year 2312 non-null int64 \n 4 Avg Distance 1678 non-null float64\n 5 gir 1678 non-null float64\n 6 Average Putts 1678 non-null float64\n 7 Average Scrambling 1678 non-null float64\n 8 Average Score 1678 non-null float64\n 9 Points 2296 non-null object \n 10 Wins 293 non-null float64\n 11 Top 10 1458 non-null float64\n 12 Average SG Putts 1678 non-null float64\n 13 Average SG Total 1678 non-null float64\n 14 SG:OTT 1678 non-null float64\n 15 SG:APR 1678 non-null float64\n 16 SG:ARG 1678 non-null float64\n 17 Money 2300 non-null object \ndtypes: float64(14), int64(1), object(3)\nmemory usage: 325.2+ KB\n"
],
[
"#collapse\ndf.shape",
"_____no_output_____"
]
],
[
[
"2. Data Cleaning\n\n\nAfter looking at the dataframe, the data needs to be cleaned:\n\n-For the columns Top 10 and Wins, convert the NaNs to 0s\n\n-Change Top 10 and Wins into an int \n\n-Drop NaN values for players who do not have the full statistics\n\n-Change the columns Rounds into int\n\n-Change points to int\n\n-Remove the dollar sign ($) and commas in the column Money",
"_____no_output_____"
]
],
[
[
"# Replace NaN with 0 in Top 10 \ndf['Top 10'].fillna(0, inplace=True)\ndf['Top 10'] = df['Top 10'].astype(int)\n\n# Replace NaN with 0 in # of wins\ndf['Wins'].fillna(0, inplace=True)\ndf['Wins'] = df['Wins'].astype(int)\n\n# Drop NaN values \ndf.dropna(axis = 0, inplace=True)",
"_____no_output_____"
],
[
"# Change Rounds to int\ndf['Rounds'] = df['Rounds'].astype(int)\n\n# Change Points to int \ndf['Points'] = df['Points'].apply(lambda x: x.replace(',',''))\ndf['Points'] = df['Points'].astype(int)\n\n# Remove the $ and commas in money \ndf['Money'] = df['Money'].apply(lambda x: x.replace('$',''))\ndf['Money'] = df['Money'].apply(lambda x: x.replace(',',''))\ndf['Money'] = df['Money'].astype(float)",
"_____no_output_____"
],
[
"#collapse\ndf.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 1674 entries, 0 to 1677\nData columns (total 18 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Player Name 1674 non-null object \n 1 Rounds 1674 non-null int64 \n 2 Fairway Percentage 1674 non-null float64\n 3 Year 1674 non-null int64 \n 4 Avg Distance 1674 non-null float64\n 5 gir 1674 non-null float64\n 6 Average Putts 1674 non-null float64\n 7 Average Scrambling 1674 non-null float64\n 8 Average Score 1674 non-null float64\n 9 Points 1674 non-null int64 \n 10 Wins 1674 non-null int64 \n 11 Top 10 1674 non-null int64 \n 12 Average SG Putts 1674 non-null float64\n 13 Average SG Total 1674 non-null float64\n 14 SG:OTT 1674 non-null float64\n 15 SG:APR 1674 non-null float64\n 16 SG:ARG 1674 non-null float64\n 17 Money 1674 non-null float64\ndtypes: float64(12), int64(5), object(1)\nmemory usage: 248.5+ KB\n"
],
[
"#collapse\ndf.describe()",
"_____no_output_____"
]
],
[
[
"3. Exploratory Data Analysis",
"_____no_output_____"
]
],
[
[
"#collapse_output\n# Looking at the distribution of data\nf, ax = plt.subplots(nrows = 6, ncols = 3, figsize=(20,20))\ndistribution = df.loc[:,df.columns!='Player Name'].columns\nrows = 0\ncols = 0\nfor i, column in enumerate(distribution):\n p = sns.distplot(df[column], ax=ax[rows][cols])\n cols += 1\n if cols == 3:\n cols = 0\n rows += 1",
"/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n/usr/local/lib/python3.7/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n"
]
],
[
[
"From the distributions plotted, most of the graphs are normally distributed. However, we can observe that Money, Points, Wins, and Top 10s are all skewed to the right. This could be explained by the separation of the best players and the average PGA Tour player. The best players have multiple placings in the Top 10 with wins that allows them to earn more from tournaments, while the average player will have no wins and only a few Top 10 placings that prevent them from earning as much.",
"_____no_output_____"
]
],
[
[
"#collapse_output\n# Looking at the number of players with Wins for each year \nwin = df.groupby('Year')['Wins'].value_counts()\nwin = win.unstack()\nwin.fillna(0, inplace=True)\n\n# Converting win into ints\nwin = win.astype(int)\n\nprint(win)",
"Wins 0 1 2 3 4 5\nYear \n2010 166 21 5 0 0 0\n2011 156 25 5 0 0 0\n2012 159 26 4 1 0 0\n2013 152 24 3 0 0 1\n2014 142 29 3 2 0 0\n2015 150 29 2 1 1 0\n2016 152 28 4 1 0 0\n2017 156 30 0 3 1 0\n2018 158 26 5 3 0 0\n"
]
],
[
[
"From this table, we can see that most players end the year without a win. It's pretty rare to find a player that has won more than once!",
"_____no_output_____"
]
],
[
[
"# Looking at the percentage of players without a win in that year \nplayers = win.apply(lambda x: np.sum(x), axis=1)\npercent_no_win = win[0]/players\npercent_no_win = percent_no_win*100\nprint(percent_no_win)",
"Year\n2010 86.458333\n2011 83.870968\n2012 83.684211\n2013 84.444444\n2014 80.681818\n2015 81.967213\n2016 82.162162\n2017 82.105263\n2018 82.291667\ndtype: float64\n"
],
[
"#collapse_output\n# Plotting percentage of players without a win each year \nfig, ax = plt.subplots()\nbar_width = 0.8\nopacity = 0.7 \nindex = np.arange(2010, 2019)\n\nplt.bar(index, percent_no_win, bar_width, alpha = opacity)\nplt.xticks(index)\nplt.xlabel('Year')\nplt.ylabel('%')\nplt.title('Percentage of Players without a Win')",
"_____no_output_____"
]
],
[
[
"From the box plot above, we can observe that the percentages of players without a win are around 80%. There was very little variation in the percentage of players without a win in the past 8 years.",
"_____no_output_____"
]
],
[
[
"#collapse_output\n# Plotting the number of wins on a bar chart \nfig, ax = plt.subplots()\nindex = np.arange(2010, 2019)\nbar_width = 0.2\nopacity = 0.7 \n\ndef plot_bar(index, win, labels):\n plt.bar(index, win, bar_width, alpha=opacity, label=labels)\n\n# Plotting the bars\nrects = plot_bar(index, win[0], labels = '0 Wins')\nrects1 = plot_bar(index + bar_width, win[1], labels = '1 Wins')\nrects2 = plot_bar(index + bar_width*2, win[2], labels = '2 Wins')\nrects3 = plot_bar(index + bar_width*3, win[3], labels = '3 Wins')\nrects4 = plot_bar(index + bar_width*4, win[4], labels = '4 Wins')\nrects5 = plot_bar(index + bar_width*5, win[5], labels = '5 Wins')\n\nplt.xticks(index + bar_width, index)\nplt.xlabel('Year')\nplt.ylabel('Number of Players')\nplt.title('Distribution of Wins each Year')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"By looking at the distribution of Wins each year, we can see that it is rare for most players to even win a tournament in the PGA Tour. Majority of players do not win, and a very few number of players win more than once a year.",
"_____no_output_____"
]
],
[
[
"# Percentage of people who did not place in the top 10 each year\ntop10 = df.groupby('Year')['Top 10'].value_counts()\ntop10 = top10.unstack()\ntop10.fillna(0, inplace=True)\nplayers = top10.apply(lambda x: np.sum(x), axis=1)\n\nno_top10 = top10[0]/players * 100\nprint(no_top10)",
"Year\n2010 17.187500\n2011 25.268817\n2012 23.157895\n2013 18.888889\n2014 16.477273\n2015 18.579235\n2016 20.000000\n2017 15.789474\n2018 17.187500\ndtype: float64\n"
]
],
[
[
"By looking at the percentage of players that did not place in the top 10 by year, We can observe that only approximately 20% of players did not place in the Top 10. In addition, the range for these player that did not place in the Top 10 is only 9.47%. This tells us that this statistic does not vary much on a yearly basis.",
"_____no_output_____"
]
],
[
[
"# Who are some of the longest hitters \ndistance = df[['Year','Player Name','Avg Distance']].copy()\ndistance.sort_values(by='Avg Distance', inplace=True, ascending=False)\nprint(distance.head())",
" Year Player Name Avg Distance\n162 2018 Rory McIlroy 319.7\n1481 2011 J.B. Holmes 318.4\n174 2018 Trey Mullinax 318.3\n732 2015 Dustin Johnson 317.7\n350 2017 Rory McIlroy 316.7\n"
]
],
[
[
"Rory McIlroy is one of the longest hitters in the game, setting the average driver distance to be 319.7 yards in 2018. He was also the longest hitter in 2017 with an average of 316.7 yards. ",
"_____no_output_____"
]
],
[
[
"# Who made the most money\nmoney_ranking = df[['Year','Player Name','Money']].copy()\nmoney_ranking.sort_values(by='Money', inplace=True, ascending=False)\nprint(money_ranking.head())",
" Year Player Name Money\n647 2015 Jordan Spieth 12030465.0\n361 2017 Justin Thomas 9921560.0\n303 2017 Jordan Spieth 9433033.0\n729 2015 Jason Day 9403330.0\n520 2016 Dustin Johnson 9365185.0\n"
]
],
[
[
"We can see that Jordan Spieth has made the most amount of money in a year, earning a total of 12 million dollars in 2015.",
"_____no_output_____"
]
],
[
[
"#collapse_output\n# Who made the most money each year\nmoney_rank = money_ranking.groupby('Year')['Money'].max()\nmoney_rank = pd.DataFrame(money_rank)\n\n\nindexs = np.arange(2010, 2019)\nnames = []\nfor i in range(money_rank.shape[0]):\n temp = df.loc[df['Money'] == money_rank.iloc[i,0],'Player Name']\n names.append(str(temp.values[0]))\n\nmoney_rank['Player Name'] = names\nprint(money_rank)",
" Money Player Name\nYear \n2010 4910477.0 Matt Kuchar\n2011 6683214.0 Luke Donald\n2012 8047952.0 Rory McIlroy\n2013 8553439.0 Tiger Woods\n2014 8280096.0 Rory McIlroy\n2015 12030465.0 Jordan Spieth\n2016 9365185.0 Dustin Johnson\n2017 9921560.0 Justin Thomas\n2018 8694821.0 Justin Thomas\n"
]
],
[
[
"With this table, we can examine the earnings of each player by year. Some of the most notable were Jordan Speith's earning of 12 million dollars and Justin Thomas earning the most money in both 2017 and 2018.",
"_____no_output_____"
]
],
[
[
"#collapse_output\n# Plot the correlation matrix between variables \ncorr = df.corr()\nsns.heatmap(corr, \n xticklabels=corr.columns.values,\n yticklabels=corr.columns.values,\n cmap='coolwarm')",
"_____no_output_____"
],
[
"df.corr()['Wins']",
"_____no_output_____"
]
],
[
[
"From the correlation matrix, we can observe that Money is highly correlated to wins along with the FedExCup Points. We can also observe that the fairway percentage, year, and rounds are not correlated to Wins.",
"_____no_output_____"
],
[
"4. Machine Learning Model (Classification)\n\n\nTo predict winners, I used multiple machine learning models to explore which models could accurately classify if a player is going to win in that year.\n\nTo measure the models, I used Receiver Operating Characterisitc Area Under the Curve. (ROC AUC) The ROC AUC tells us how capable the model is at distinguishing players with a win. In addition, as the data is skewed with 83% of players having no wins in that year, ROC AUC is a much better metric than the accuracy of the model.",
"_____no_output_____"
]
],
[
[
"#collapse\n# Importing the Machine Learning modules\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import roc_curve, roc_auc_score\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.feature_selection import RFE\nfrom sklearn.metrics import classification_report\nfrom sklearn.preprocessing import PolynomialFeatures\nfrom sklearn.svm import SVC \nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.preprocessing import MinMaxScaler\n",
"_____no_output_____"
]
],
[
[
"Preparing the Data for Classification\n\nWe know from the calculation above that the data for wins is skewed. Even without machine learning we know that approximately 83% of the players does not lead to a win. Therefore, we will be utilizing ROC AUC as the metric of these models",
"_____no_output_____"
]
],
[
[
"# Adding the Winner column to determine if the player won that year or not \ndf['Winner'] = df['Wins'].apply(lambda x: 1 if x>0 else 0)\n\n# New DataFrame \nml_df = df.copy()\n\n# Y value for machine learning is the Winner column\ntarget = df['Winner']\n\n# Removing the columns Player Name, Wins, and Winner from the dataframe to avoid leakage\nml_df.drop(['Player Name','Wins','Winner'], axis=1, inplace=True)\nprint(ml_df.head())",
" Rounds Fairway Percentage Year ... SG:APR SG:ARG Money\n0 60 75.19 2018 ... 0.960 -0.027 2680487.0\n1 109 73.58 2018 ... 0.213 0.194 2485203.0\n2 93 72.24 2018 ... 0.437 -0.137 2700018.0\n3 78 71.94 2018 ... 0.532 0.273 1986608.0\n4 103 71.44 2018 ... 0.099 0.026 1089763.0\n\n[5 rows x 16 columns]\n"
],
[
"## Logistic Regression Baseline\nper_no_win = target.value_counts()[0] / (target.value_counts()[0] + target.value_counts()[1])\nper_no_win = per_no_win.round(4)*100\nprint(str(per_no_win)+str('%'))",
"83.09%\n"
],
[
"#collapse_show\n# Function for the logisitic regression \ndef log_reg(X, y):\n X_train, X_test, y_train, y_test = train_test_split(X, y,\n random_state = 10)\n clf = LogisticRegression().fit(X_train, y_train)\n y_pred = clf.predict(X_test)\n print('Accuracy of Logistic regression classifier on training set: {:.2f}'\n .format(clf.score(X_train, y_train)))\n print('Accuracy of Logistic regression classifier on test set: {:.2f}'\n .format(clf.score(X_test, y_test)))\n cf_mat = confusion_matrix(y_test, y_pred)\n confusion = pd.DataFrame(data = cf_mat)\n print(confusion)\n \n print(classification_report(y_test, y_pred))\n\n # Returning the 5 important features \n #rfe = RFE(clf, 5)\n # rfe = rfe.fit(X, y)\n # print('Feature Importance')\n # print(X.columns[rfe.ranking_ == 1].values)\n \n print('ROC AUC Score: {:.2f}'.format(roc_auc_score(y_test, y_pred)))",
"_____no_output_____"
],
[
"#collapse_show\nlog_reg(ml_df, target)",
"Accuracy of Logistic regression classifier on training set: 0.90\nAccuracy of Logistic regression classifier on test set: 0.91\n 0 1\n0 345 8\n1 28 38\n precision recall f1-score support\n\n 0 0.92 0.98 0.95 353\n 1 0.83 0.58 0.68 66\n\n accuracy 0.91 419\n macro avg 0.88 0.78 0.81 419\nweighted avg 0.91 0.91 0.91 419\n\nROC AUC Score: 0.78\n"
]
],
[
[
"From the logisitic regression, we got an accuracy of 0.9 on the training set and an accuracy of 0.91 on the test set. This was surprisingly accurate for a first run. However, the ROC AUC Score of 0.78 could be improved. Therefore, I decided to add more features as a way of possibly improving the model.\n\n",
"_____no_output_____"
]
],
[
[
"## Feature Engineering\n\n# Adding Domain Features \nml_d = ml_df.copy()\n# Top 10 / Money might give us a better understanding on how well they placed in the top 10\nml_d['Top10perMoney'] = ml_d['Top 10'] / ml_d['Money']\n\n# Avg Distance / Fairway Percentage to give us a ratio that determines how accurate and far a player hits \nml_d['DistanceperFairway'] = ml_d['Avg Distance'] / ml_d['Fairway Percentage']\n\n# Money / Rounds to see on average how much money they would make playing a round of golf \nml_d['MoneyperRound'] = ml_d['Money'] / ml_d['Rounds']",
"_____no_output_____"
],
[
"#collapse_show\nlog_reg(ml_d, target)",
"Accuracy of Logistic regression classifier on training set: 0.91\nAccuracy of Logistic regression classifier on test set: 0.91\n 0 1\n0 342 11\n1 27 39\n precision recall f1-score support\n\n 0 0.93 0.97 0.95 353\n 1 0.78 0.59 0.67 66\n\n accuracy 0.91 419\n macro avg 0.85 0.78 0.81 419\nweighted avg 0.90 0.91 0.90 419\n\nROC AUC Score: 0.78\n"
],
[
"#collapse_show\n# Adding Polynomial Features to the ml_df \nmldf2 = ml_df.copy()\npoly = PolynomialFeatures(2)\npoly = poly.fit(mldf2)\npoly_feature = poly.transform(mldf2)\nprint(poly_feature.shape)\n\n# Creating a DataFrame with the polynomial features \npoly_feature = pd.DataFrame(poly_feature, columns = poly.get_feature_names(ml_df.columns))\nprint(poly_feature.head())",
"(1674, 153)\n 1 Rounds Fairway Percentage ... SG:ARG^2 SG:ARG Money Money^2\n0 1.0 60.0 75.19 ... 0.000729 -72373.149 7.185011e+12\n1 1.0 109.0 73.58 ... 0.037636 482129.382 6.176234e+12\n2 1.0 93.0 72.24 ... 0.018769 -369902.466 7.290097e+12\n3 1.0 78.0 71.94 ... 0.074529 542343.984 3.946611e+12\n4 1.0 103.0 71.44 ... 0.000676 28333.838 1.187583e+12\n\n[5 rows x 153 columns]\n"
],
[
"#collapse_show\nlog_reg(poly_feature, target)",
"Accuracy of Logistic regression classifier on training set: 0.90\nAccuracy of Logistic regression classifier on test set: 0.91\n 0 1\n0 346 7\n1 32 34\n precision recall f1-score support\n\n 0 0.92 0.98 0.95 353\n 1 0.83 0.52 0.64 66\n\n accuracy 0.91 419\n macro avg 0.87 0.75 0.79 419\nweighted avg 0.90 0.91 0.90 419\n\nROC AUC Score: 0.75\n"
]
],
[
[
"From feature engineering, there were no improvements in the ROC AUC Score. In fact as I added more features, the accuracy and the ROC AUC Score decreased. This could signal to us that another machine learning algorithm could better predict winners.",
"_____no_output_____"
]
],
[
[
"#collapse_show\n## Randon Forest Model\n\ndef random_forest(X, y):\n X_train, X_test, y_train, y_test = train_test_split(X, y,\n random_state = 10)\n clf = RandomForestClassifier(n_estimators=200).fit(X_train, y_train)\n y_pred = clf.predict(X_test)\n print('Accuracy of Random Forest classifier on training set: {:.2f}'\n .format(clf.score(X_train, y_train)))\n print('Accuracy of Random Forest classifier on test set: {:.2f}'\n .format(clf.score(X_test, y_test)))\n \n cf_mat = confusion_matrix(y_test, y_pred)\n confusion = pd.DataFrame(data = cf_mat)\n print(confusion)\n \n print(classification_report(y_test, y_pred))\n \n # Returning the 5 important features \n rfe = RFE(clf, 5)\n rfe = rfe.fit(X, y)\n print('Feature Importance')\n print(X.columns[rfe.ranking_ == 1].values)\n \n print('ROC AUC Score: {:.2f}'.format(roc_auc_score(y_test, y_pred)))",
"_____no_output_____"
],
[
"#collapse_show\nrandom_forest(ml_df, target)",
"Accuracy of Random Forest classifier on training set: 1.00\nAccuracy of Random Forest classifier on test set: 0.94\n 0 1\n0 342 11\n1 16 50\n precision recall f1-score support\n\n 0 0.96 0.97 0.96 353\n 1 0.82 0.76 0.79 66\n\n accuracy 0.94 419\n macro avg 0.89 0.86 0.87 419\nweighted avg 0.93 0.94 0.93 419\n\nFeature Importance\n['Average Score' 'Points' 'Top 10' 'Average SG Total' 'Money']\nROC AUC Score: 0.86\n"
],
[
"#collapse_show\nrandom_forest(ml_d, target)",
"Accuracy of Random Forest classifier on training set: 1.00\nAccuracy of Random Forest classifier on test set: 0.94\n 0 1\n0 343 10\n1 16 50\n precision recall f1-score support\n\n 0 0.96 0.97 0.96 353\n 1 0.83 0.76 0.79 66\n\n accuracy 0.94 419\n macro avg 0.89 0.86 0.88 419\nweighted avg 0.94 0.94 0.94 419\n\nFeature Importance\n['Average Score' 'Points' 'Average SG Total' 'Money' 'MoneyperRound']\nROC AUC Score: 0.86\n"
],
[
"#collapse_show\nrandom_forest(poly_feature, target)",
"Accuracy of Random Forest classifier on training set: 1.00\nAccuracy of Random Forest classifier on test set: 0.94\n 0 1\n0 340 13\n1 14 52\n precision recall f1-score support\n\n 0 0.96 0.96 0.96 353\n 1 0.80 0.79 0.79 66\n\n accuracy 0.94 419\n macro avg 0.88 0.88 0.88 419\nweighted avg 0.94 0.94 0.94 419\n\nFeature Importance\n['Year Points' 'Average Putts Points' 'Average Scrambling Top 10'\n 'Average Score Points' 'Points^2']\nROC AUC Score: 0.88\n"
]
],
[
[
"The Random Forest Model scored highly on the ROC AUC Score, obtaining a value of 0.89. With this, we observed that the Random Forest Model could accurately classify players with and without a win.",
"_____no_output_____"
],
[
"6. Conclusion\n\nIt's been interesting to learn about numerous aspects of the game that differentiate the winner and the average PGA Tour player. For example, we can see that the fairway percentage and greens in regulations do not seem to contribute as much to a player's win. However, all the strokes gained statistics contribute pretty highly to wins for these players. It was interesting to see which aspects of the game that the professionals should put their time into. This also gave me the idea of track my personal golf statistics, so that I could compare it to the pros and find areas of my game that need the most improvement.\n\nMachine Learning Model\nI've been able to examine the data of PGA Tour players and classify if a player will win that year or not. With the random forest classification model, I was able to achieve an ROC AUC of 0.89 and an accuracy of 0.95 on the test set. This was a significant improvement from the ROC AUC of 0.78 and accuracy of 0.91. Because the data is skewed with approximately 80% of players not earning a win, the primary measure of the model was the ROC AUC. I was able to improve my model from ROC AUC score of 0.78 to a score of 0.89 by simply trying 3 different models, adding domain features, and polynomial features.\n\n",
"_____no_output_____"
],
[
"The End!!",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
]
|
d062cdd7eeb895340e644ac4092a20863b415b5b | 15,675 | ipynb | Jupyter Notebook | Week2-Lesson1-MNIST-Fashion.ipynb | monahatami1/Coursera_Introduction-to-TensorFlow-for-Artificial-Intelligence-Machine-Learning-and-Deep-Lear | 4ed47fac75d3ec2eea277ca64b1b99ba017f8a27 | [
"MIT"
]
| null | null | null | Week2-Lesson1-MNIST-Fashion.ipynb | monahatami1/Coursera_Introduction-to-TensorFlow-for-Artificial-Intelligence-Machine-Learning-and-Deep-Lear | 4ed47fac75d3ec2eea277ca64b1b99ba017f8a27 | [
"MIT"
]
| null | null | null | Week2-Lesson1-MNIST-Fashion.ipynb | monahatami1/Coursera_Introduction-to-TensorFlow-for-Artificial-Intelligence-Machine-Learning-and-Deep-Lear | 4ed47fac75d3ec2eea277ca64b1b99ba017f8a27 | [
"MIT"
]
| null | null | null | 60.755814 | 7,088 | 0.69327 | [
[
[
"import tensorflow as tf\nprint(tf.__version__)",
"2.3.1\n"
],
[
"mnist = tf.keras.datasets.fashion_mnist",
"_____no_output_____"
],
[
"(training_images, training_labels), (test_images, test_labels) = mnist.load_data()",
"_____no_output_____"
],
[
"import numpy as np\nnp.set_printoptions(linewidth=200)\nimport matplotlib.pyplot as plt\nplt.imshow(training_images[0])\nprint(training_labels[0])\nprint(training_images[0])",
"9\n[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 13 73 0 0 1 4 0 0 0 0 1 1 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 3 0 36 136 127 62 54 0 0 0 1 3 4 0 0 3]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 6 0 102 204 176 134 144 123 23 0 0 0 0 12 10 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 155 236 207 178 107 156 161 109 64 23 77 130 72 15]\n [ 0 0 0 0 0 0 0 0 0 0 0 1 0 69 207 223 218 216 216 163 127 121 122 146 141 88 172 66]\n [ 0 0 0 0 0 0 0 0 0 1 1 1 0 200 232 232 233 229 223 223 215 213 164 127 123 196 229 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 183 225 216 223 228 235 227 224 222 224 221 223 245 173 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 193 228 218 213 198 180 212 210 211 213 223 220 243 202 0]\n [ 0 0 0 0 0 0 0 0 0 1 3 0 12 219 220 212 218 192 169 227 208 218 224 212 226 197 209 52]\n [ 0 0 0 0 0 0 0 0 0 0 6 0 99 244 222 220 218 203 198 221 215 213 222 220 245 119 167 56]\n [ 0 0 0 0 0 0 0 0 0 4 0 0 55 236 228 230 228 240 232 213 218 223 234 217 217 209 92 0]\n [ 0 0 1 4 6 7 2 0 0 0 0 0 237 226 217 223 222 219 222 221 216 223 229 215 218 255 77 0]\n [ 0 3 0 0 0 0 0 0 0 62 145 204 228 207 213 221 218 208 211 218 224 223 219 215 224 244 159 0]\n [ 0 0 0 0 18 44 82 107 189 228 220 222 217 226 200 205 211 230 224 234 176 188 250 248 233 238 215 0]\n [ 0 57 187 208 224 221 224 208 204 214 208 209 200 159 245 193 206 223 255 255 221 234 221 211 220 232 246 0]\n [ 3 202 228 224 221 211 211 214 205 205 205 220 240 80 150 255 229 221 188 154 191 210 204 209 222 228 225 0]\n [ 98 233 198 210 222 229 229 234 249 220 194 215 217 241 65 73 106 117 168 219 221 215 217 223 223 224 229 29]\n [ 75 204 212 204 193 205 211 225 216 185 197 206 198 213 240 195 227 245 239 223 218 212 209 222 220 221 230 67]\n [ 48 203 183 194 213 197 185 190 194 192 202 214 219 221 220 236 225 216 199 206 186 181 177 172 181 205 206 115]\n [ 0 122 219 193 179 171 183 196 204 210 213 207 211 210 200 196 194 191 195 191 198 192 176 156 167 177 210 92]\n [ 0 0 74 189 212 191 175 172 175 181 185 188 189 188 193 198 204 209 210 210 211 188 188 194 192 216 170 0]\n [ 2 0 0 0 66 200 222 237 239 242 246 243 244 221 220 193 191 179 182 182 181 176 166 168 99 58 0 0]\n [ 0 0 0 0 0 0 0 40 61 44 72 41 35 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]\n"
],
[
"training_images = training_images / 255.0\ntest_images = test_images / 255.0\n",
"_____no_output_____"
],
[
"model = tf.keras.models.Sequential([tf.keras.layers.Flatten(), \n tf.keras.layers.Dense(128, activation=tf.nn.relu), \n tf.keras.layers.Dense(10, activation=tf.nn.softmax)])",
"_____no_output_____"
],
[
"model.compile(optimizer = tf.optimizers.Adam(),\n loss = 'sparse_categorical_crossentropy',\n metrics=['accuracy'])\n\nmodel.fit(training_images, training_labels, epochs=5)",
"Epoch 1/5\n1875/1875 [==============================] - 2s 870us/step - loss: 1.1072 - accuracy: 0.6507\nEpoch 2/5\n1875/1875 [==============================] - 2s 835us/step - loss: 0.6459 - accuracy: 0.7674\nEpoch 3/5\n1875/1875 [==============================] - 2s 807us/step - loss: 0.5682 - accuracy: 0.7962\nEpoch 4/5\n1875/1875 [==============================] - 1s 796us/step - loss: 0.5250 - accuracy: 0.8135\nEpoch 5/5\n1875/1875 [==============================] - 2s 805us/step - loss: 0.4971 - accuracy: 0.8244\n"
],
[
"model.evaluate(test_images, test_labels)",
"313/313 [==============================] - 0s 704us/step - loss: 95.0182 - accuracy: 0.6898\n"
],
[
"classifications = model.predict(test_images)\n\nprint(classifications[0])",
"[6.8263911e-13 1.7325267e-12 2.5193808e-18 1.0686662e-12 9.9983463e-18 1.1335950e-01 2.2505068e-18 1.0656738e-01 2.8287264e-12 7.8007311e-01]\n"
],
[
"len(set(training_labels))",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d062d93ee6753a9376227ea46c29417c53a92f09 | 456,549 | ipynb | Jupyter Notebook | monte-carlo/Monte_Carlo.ipynb | jbdekker/deep-reinforcement-learning | faea2012a9b96ec013c5fbf83ef40316b446fe2e | [
"MIT"
]
| null | null | null | monte-carlo/Monte_Carlo.ipynb | jbdekker/deep-reinforcement-learning | faea2012a9b96ec013c5fbf83ef40316b446fe2e | [
"MIT"
]
| null | null | null | monte-carlo/Monte_Carlo.ipynb | jbdekker/deep-reinforcement-learning | faea2012a9b96ec013c5fbf83ef40316b446fe2e | [
"MIT"
]
| null | null | null | 842.341328 | 216,412 | 0.947911 | [
[
[
"# Monte Carlo Methods\n\nIn this notebook, you will write your own implementations of many Monte Carlo (MC) algorithms. \n\nWhile we have provided some starter code, you are welcome to erase these hints and write your code from scratch.\n\n### Part 0: Explore BlackjackEnv\n\nWe begin by importing the necessary packages.",
"_____no_output_____"
]
],
[
[
"import sys\nimport gym\nimport numpy as np\nfrom collections import defaultdict\n\nfrom plot_utils import plot_blackjack_values, plot_policy",
"_____no_output_____"
]
],
[
[
"Use the code cell below to create an instance of the [Blackjack](https://github.com/openai/gym/blob/master/gym/envs/toy_text/blackjack.py) environment.",
"_____no_output_____"
]
],
[
[
"env = gym.make('Blackjack-v0')",
"_____no_output_____"
]
],
[
[
"Each state is a 3-tuple of:\n- the player's current sum $\\in \\{0, 1, \\ldots, 31\\}$,\n- the dealer's face up card $\\in \\{1, \\ldots, 10\\}$, and\n- whether or not the player has a usable ace (`no` $=0$, `yes` $=1$).\n\nThe agent has two potential actions:\n\n```\n STICK = 0\n HIT = 1\n```\nVerify this by running the code cell below.",
"_____no_output_____"
]
],
[
[
"print(f\"Observation space: \\t{env.observation_space}\")\nprint(f\"Action space: \\t\\t{env.action_space}\")",
"Observation space: \tTuple(Discrete(32), Discrete(11), Discrete(2))\nAction space: \t\tDiscrete(2)\n"
]
],
[
[
"Execute the code cell below to play Blackjack with a random policy. \n\n(_The code currently plays Blackjack three times - feel free to change this number, or to run the cell multiple times. The cell is designed for you to get some experience with the output that is returned as the agent interacts with the environment._)",
"_____no_output_____"
]
],
[
[
"for i_episode in range(3):\n state = env.reset()\n while True:\n print(state)\n action = env.action_space.sample()\n state, reward, done, info = env.step(action)\n if done:\n print('End game! Reward: ', reward)\n print('You won :)\\n') if reward > 0 else print('You lost :(\\n')\n break",
"(19, 10, False)\nEnd game! Reward: 1.0\nYou won :)\n\n(14, 6, False)\n(15, 6, False)\nEnd game! Reward: 1.0\nYou won :)\n\n(16, 3, False)\nEnd game! Reward: 1.0\nYou won :)\n\n"
]
],
[
[
"### Part 1: MC Prediction\n\nIn this section, you will write your own implementation of MC prediction (for estimating the action-value function). \n\nWe will begin by investigating a policy where the player _almost_ always sticks if the sum of her cards exceeds 18. In particular, she selects action `STICK` with 80% probability if the sum is greater than 18; and, if the sum is 18 or below, she selects action `HIT` with 80% probability. The function `generate_episode_from_limit_stochastic` samples an episode using this policy. \n\nThe function accepts as **input**:\n- `bj_env`: This is an instance of OpenAI Gym's Blackjack environment.\n\nIt returns as **output**:\n- `episode`: This is a list of (state, action, reward) tuples (of tuples) and corresponds to $(S_0, A_0, R_1, \\ldots, S_{T-1}, A_{T-1}, R_{T})$, where $T$ is the final time step. In particular, `episode[i]` returns $(S_i, A_i, R_{i+1})$, and `episode[i][0]`, `episode[i][1]`, and `episode[i][2]` return $S_i$, $A_i$, and $R_{i+1}$, respectively.",
"_____no_output_____"
]
],
[
[
"def generate_episode_from_limit_stochastic(bj_env):\n episode = []\n state = bj_env.reset()\n \n while True:\n probs = [0.8, 0.2] if state[0] > 18 else [0.2, 0.8]\n action = np.random.choice(np.arange(2), p=probs)\n \n next_state, reward, done, info = bj_env.step(action)\n \n episode.append((state, action, reward))\n \n state = next_state\n \n if done:\n break\n \n return episode",
"_____no_output_____"
]
],
[
[
"Execute the code cell below to play Blackjack with the policy. \n\n(*The code currently plays Blackjack three times - feel free to change this number, or to run the cell multiple times. The cell is designed for you to gain some familiarity with the output of the `generate_episode_from_limit_stochastic` function.*)",
"_____no_output_____"
]
],
[
[
"for i in range(5):\n print(generate_episode_from_limit_stochastic(env))",
"[((18, 2, True), 0, 1.0)]\n[((16, 5, False), 1, 0.0), ((18, 5, False), 1, -1.0)]\n[((13, 5, False), 1, 0.0), ((17, 5, False), 1, -1.0)]\n[((14, 4, False), 1, 0.0), ((17, 4, False), 1, -1.0)]\n[((20, 10, False), 0, -1.0)]\n"
]
],
[
[
"Now, you are ready to write your own implementation of MC prediction. Feel free to implement either first-visit or every-visit MC prediction; in the case of the Blackjack environment, the techniques are equivalent.\n\nYour algorithm has three arguments:\n- `env`: This is an instance of an OpenAI Gym environment.\n- `num_episodes`: This is the number of episodes that are generated through agent-environment interaction.\n- `generate_episode`: This is a function that returns an episode of interaction.\n- `gamma`: This is the discount rate. It must be a value between 0 and 1, inclusive (default value: `1`).\n\nThe algorithm returns as output:\n- `Q`: This is a dictionary (of one-dimensional arrays) where `Q[s][a]` is the estimated action value corresponding to state `s` and action `a`.",
"_____no_output_____"
]
],
[
[
"def mc_prediction_q(env, num_episodes, generate_episode, gamma=1.0):\n # initialize empty dictionaries of arrays\n returns_sum = defaultdict(lambda: np.zeros(env.action_space.n))\n N = defaultdict(lambda: np.zeros(env.action_space.n))\n Q = defaultdict(lambda: np.zeros(env.action_space.n))\n R = defaultdict(lambda: np.zeros(env.action_space.n))\n \n # loop over episodes\n for i_episode in range(1, num_episodes+1):\n # monitor progress\n if i_episode % 1000 == 0:\n print(\"\\rEpisode {}/{}.\".format(i_episode, num_episodes), end=\"\")\n sys.stdout.flush()\n \n episode = generate_episode(env)\n \n n = len(episode)\n states, actions, rewards = zip(*episode)\n discounts = np.array([gamma**i for i in range(n+1)])\n \n for i, state in enumerate(states):\n returns_sum[state][actions[i]] += sum(rewards[i:] * discounts[:-(i+1)])\n N[state][actions[i]] += 1\n \n # comnpute Q table\n for state in returns_sum.keys():\n for action in range(env.action_space.n):\n Q[state][action] = returns_sum[state][action] / N[state][action]\n \n return Q, returns_sum, N",
"_____no_output_____"
]
],
[
[
"Use the cell below to obtain the action-value function estimate $Q$. We have also plotted the corresponding state-value function.\n\nTo check the accuracy of your implementation, compare the plot below to the corresponding plot in the solutions notebook **Monte_Carlo_Solution.ipynb**.",
"_____no_output_____"
]
],
[
[
"# obtain the action-value function\nQ, R, N = mc_prediction_q(env, 500000, generate_episode_from_limit_stochastic)\n\n# obtain the corresponding state-value function\nV_to_plot = dict((k,(k[0]>18)*(np.dot([0.8, 0.2],v)) + (k[0]<=18)*(np.dot([0.2, 0.8],v))) \\\n for k, v in Q.items())\n\n# plot the state-value function\nplot_blackjack_values(V_to_plot)",
"Episode 500000/500000."
]
],
[
[
"### Part 2: MC Control\n\nIn this section, you will write your own implementation of constant-$\\alpha$ MC control. \n\nYour algorithm has four arguments:\n- `env`: This is an instance of an OpenAI Gym environment.\n- `num_episodes`: This is the number of episodes that are generated through agent-environment interaction.\n- `alpha`: This is the step-size parameter for the update step.\n- `gamma`: This is the discount rate. It must be a value between 0 and 1, inclusive (default value: `1`).\n\nThe algorithm returns as output:\n- `Q`: This is a dictionary (of one-dimensional arrays) where `Q[s][a]` is the estimated action value corresponding to state `s` and action `a`.\n- `policy`: This is a dictionary where `policy[s]` returns the action that the agent chooses after observing state `s`.\n\n(_Feel free to define additional functions to help you to organize your code._)",
"_____no_output_____"
]
],
[
[
"def generate_episode_from_Q(env, Q, epsilon, n):\n \"\"\" generates an episode following the epsilon-greedy policy\"\"\"\n episode = []\n state = env.reset()\n \n while True:\n if state in Q:\n action = np.random.choice(np.arange(n), p=get_props(Q[state], epsilon, n))\n else:\n action = env.action_space.sample()\n \n next_state, reward, done, _ = env.step(action)\n episode.append((state, action, reward))\n \n state = next_state\n \n if done:\n break\n \n return episode",
"_____no_output_____"
],
[
"def get_props(Q_s, epsilon, n):\n policy_s = np.ones(n) * epsilon / n\n best_a = np.argmax(Q_s)\n policy_s[best_a] = 1 - epsilon + (epsilon / n)\n \n return policy_s",
"_____no_output_____"
],
[
"def update_Q(episode, Q, alpha, gamma):\n n = len(episode)\n \n states, actions, rewards = zip(*episode)\n discounts = np.array([gamma**i for i in range(n+1)])\n \n for i, state in enumerate(states):\n R = sum(rewards[i:] * discounts[:-(1+i)])\n Q[state][actions[i]] = Q[state][actions[i]] + alpha * (R - Q[state][actions[i]])\n \n return Q",
"_____no_output_____"
],
[
"def mc_control(env, num_episodes, alpha, gamma=1.0, eps_start=1.0, eps_decay=.99999, eps_min=0.05):\n nA = env.action_space.n\n # initialize empty dictionary of arrays\n Q = defaultdict(lambda: np.zeros(nA))\n \n epsilon = eps_start\n # loop over episodes\n for i_episode in range(1, num_episodes+1):\n # monitor progress\n if i_episode % 1000 == 0:\n print(\"\\rEpisode {}/{}.\".format(i_episode, num_episodes), end=\"\")\n sys.stdout.flush()\n \n epsilon = max(eps_min, epsilon * eps_decay)\n episode = generate_episode_from_Q(env, Q, epsilon, nA)\n \n Q = update_Q(episode, Q, alpha, gamma)\n \n policy = dict((s, np.argmax(v)) for s, v in Q.items())\n \n return policy, Q",
"_____no_output_____"
]
],
[
[
"Use the cell below to obtain the estimated optimal policy and action-value function. Note that you should fill in your own values for the `num_episodes` and `alpha` parameters.",
"_____no_output_____"
]
],
[
[
"# obtain the estimated optimal policy and action-value function\npolicy, Q = mc_control(env, 500000, 0.02)",
"Episode 500000/500000."
]
],
[
[
"Next, we plot the corresponding state-value function.",
"_____no_output_____"
]
],
[
[
"# obtain the corresponding state-value function\nV = dict((k,np.max(v)) for k, v in Q.items())\n\n# plot the state-value function\nplot_blackjack_values(V)",
"_____no_output_____"
]
],
[
[
"Finally, we visualize the policy that is estimated to be optimal.",
"_____no_output_____"
]
],
[
[
"# plot the policy\nplot_policy(policy)",
"_____no_output_____"
]
],
[
[
"The **true** optimal policy $\\pi_*$ can be found in Figure 5.2 of the [textbook](http://go.udacity.com/rl-textbook) (and appears below). Compare your final estimate to the optimal policy - how close are you able to get? If you are not happy with the performance of your algorithm, take the time to tweak the decay rate of $\\epsilon$, change the value of $\\alpha$, and/or run the algorithm for more episodes to attain better results.\n\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
d062e3d741909a888a9e790727794972375a0f60 | 6,951 | ipynb | Jupyter Notebook | highPerformanceComputing/Project2-KNNClassifier/knnCountries.ipynb | naokishami/Classwork | ac59d640f15e88294804fdb518b6c84b10e0d2bd | [
"MIT"
]
| null | null | null | highPerformanceComputing/Project2-KNNClassifier/knnCountries.ipynb | naokishami/Classwork | ac59d640f15e88294804fdb518b6c84b10e0d2bd | [
"MIT"
]
| null | null | null | highPerformanceComputing/Project2-KNNClassifier/knnCountries.ipynb | naokishami/Classwork | ac59d640f15e88294804fdb518b6c84b10e0d2bd | [
"MIT"
]
| null | null | null | 24.736655 | 68 | 0.339951 | [
[
[
"import pandas as pd\n\nmatrix = pd.read_csv(\"./data/matrixCountries.csv\")\nmatrix",
"_____no_output_____"
],
[
"us = matrix.iloc[:, 2]\nrus = matrix.iloc[:, 3]\nquery = matrix.iloc[:, 4]",
"_____no_output_____"
],
[
"def magnitude(vec):\n total = 0\n for item in vec:\n total += item**2\n total /= len(vec)\n return total",
"_____no_output_____"
],
[
"us_cos = us @ query / magnitude(us) / magnitude(query)\nus_cos",
"_____no_output_____"
],
[
"rus_cos = rus @ query / (magnitude(rus) * magnitude(query))\nrus_cos",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
d062f3c869548b0ed612ff7dc9ec73685185bd92 | 64,018 | ipynb | Jupyter Notebook | notebooks/1_0_EDA_BASE_A.ipynb | teoria/PD_datascience | e679e942b70be67f0f33cad6db11de3bc4cd9f1c | [
"MIT"
]
| null | null | null | notebooks/1_0_EDA_BASE_A.ipynb | teoria/PD_datascience | e679e942b70be67f0f33cad6db11de3bc4cd9f1c | [
"MIT"
]
| null | null | null | notebooks/1_0_EDA_BASE_A.ipynb | teoria/PD_datascience | e679e942b70be67f0f33cad6db11de3bc4cd9f1c | [
"MIT"
]
| null | null | null | 101.134281 | 9,175 | 0.801728 | [
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport seaborn as sns\n#%matplotlib inline\n\nfrom IPython.core.pylabtools import figsize\nfigsize(8, 6)\nsns.set()",
"_____no_output_____"
]
],
[
[
"## Carregando dados dos usuários premium",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(\"../data/processed/premium_students.csv\",parse_dates=[1,2],index_col=[0])\nprint(df.shape)\ndf.head()",
"(6260, 2)\n"
]
],
[
[
"---\n### Novas colunas auxiliares",
"_____no_output_____"
]
],
[
[
"df['diffDate'] = (df.SubscriptionDate - df.RegisteredDate)\ndf['diffDays'] = [ item.days for item in df['diffDate']]\ndf['register_time'] = df.RegisteredDate.map( lambda x : int(x.strftime(\"%H\")) )\ndf['register_time_AM_PM'] = df.register_time.map( lambda x : 1 if x>=12 else 0)\ndf['register_num_week'] = df.RegisteredDate.map( lambda x : int(x.strftime(\"%V\")) )\ndf['register_week_day'] = df.RegisteredDate.map( lambda x : int(x.weekday()) )\ndf['register_month'] = df.RegisteredDate.map( lambda x : int(x.strftime('%m')) )\ndf['subscription_time'] = df.SubscriptionDate.map( lambda x : int(x.strftime(\"%H\") ))\ndf['subscription_time_AM_PM'] = df.subscription_time.map( lambda x : 1 if x>=12 else 0)\ndf['subscription_num_week'] = df.SubscriptionDate.map( lambda x : int(x.strftime(\"%V\")) )\ndf['subscription_week_day'] = df.SubscriptionDate.map( lambda x : int(x.weekday()) )\ndf['subscription_month'] = df.SubscriptionDate.map( lambda x : int(x.strftime('%m')) )\ndf.tail()",
"_____no_output_____"
]
],
[
[
"---\n### Verificando distribuições",
"_____no_output_____"
]
],
[
[
"df.register_time.hist()",
"_____no_output_____"
],
[
"df.subscription_time.hist()",
"_____no_output_____"
],
[
"df.register_time_AM_PM.value_counts()",
"_____no_output_____"
],
[
"df.subscription_time_AM_PM.value_counts()",
"_____no_output_____"
],
[
"df.subscription_week_day.value_counts()",
"_____no_output_____"
],
[
"df.diffDays.hist()",
"_____no_output_____"
],
[
"df.diffDays.quantile([.25,.5,.75,.95])",
"_____no_output_____"
]
],
[
[
"Separando os dados em 2 momentos.",
"_____no_output_____"
]
],
[
[
"lt_50 = df.loc[(df.diffDays <50) & (df.diffDays >3)]\nlt_50.diffDays.hist()\nlt_50.diffDays.value_counts()",
"_____no_output_____"
],
[
"lt_50.diffDays.quantile([.25,.5,.75,.95])\n",
"_____no_output_____"
],
[
"range_0_3 = df.loc[(df.diffDays < 3)]\nrange_3_18 = df.loc[(df.diffDays >= 3)&(df.diffDays < 18)]\nrange_6_11 = df.loc[(df.diffDays >= 6) & (df.diffDays < 11)]\nrange_11_18 = df.loc[(df.diffDays >= 11) & (df.diffDays < 18)]\nrange_18_32 = df.loc[(df.diffDays >= 18 )& (df.diffDays <= 32)]\nrange_32 = df.loc[(df.diffDays >=32)]",
"_____no_output_____"
],
[
"total_subs = df.shape[0]\n(\nround(range_0_3.shape[0] / total_subs,2),\nround(range_3_18.shape[0] / total_subs,2),\nround(range_18_32.shape[0] / total_subs,2),\nround(range_32.shape[0] / total_subs,2)\n )",
"_____no_output_____"
],
[
"gte_30 = df.loc[df.diffDays >=32]\ngte_30.diffDays.hist()\ngte_30.diffDays.value_counts()\ngte_30.shape",
"_____no_output_____"
],
[
"gte_30.diffDays.quantile([.25,.5,.75,.95])",
"_____no_output_____"
],
[
"range_32_140 = df.loc[(df.diffDays > 32)&(df.diffDays <=140)]\nrange_140_168 = df.loc[(df.diffDays > 140)&(df.diffDays <=168)]\nrange_168_188 = df.loc[(df.diffDays > 168)&(df.diffDays <=188)]\nrange_188 = df.loc[(df.diffDays > 188)]\n\ntotal_subs_gte_32 = gte_30.shape[0]\n(\nround(range_32_140.shape[0] / total_subs,2),\nround(range_140_168.shape[0] / total_subs,2),\nround(range_168_188.shape[0] / total_subs,2),\nround(range_188.shape[0] / total_subs,2)\n )",
"_____no_output_____"
],
[
"(\nround(range_32_140.shape[0] / total_subs_gte_32,2),\nround(range_140_168.shape[0] / total_subs_gte_32,2),\nround(range_168_188.shape[0] / total_subs_gte_32,2),\nround(range_188.shape[0] / total_subs_gte_32,2)\n )\n",
"_____no_output_____"
]
],
[
[
"----\n## Questão 1:\nDentre os usuários cadastrados em Nov/2017 que assinaram o Plano Premium,\nqual a probabilidade do usuário virar Premium após o cadastro em ranges de dias? A escolha\ndos ranges deve ser feita por você, tendo em vista os insights que podemos tirar para o\nnegócio.",
"_____no_output_____"
],
[
"- De 0 a 3 dias -> 53%\n- De 3 a 18 dias -> 12%\n- De 18 a 32 -> 3%\n- Mais 32 dias -> 33%\n\n\nAnalisando as inscrições feitas depois do primeiro mês (33%)\n\n* De 32 a 140 -> 8%\n* De 140 a 168 -> 8%\n* De 168 a 188 -> 8%\n* De 188 a 216 -> 8%",
"_____no_output_____"
],
[
"Um pouco mais da metade das conversões acontecem nos primeiros 3 dias.\nA taxa conversão chega a 65% até 18 dias após o registro.\nApós 100 dias acontece outro momento relevante que representa 33%.\nPossivelmente essa janela coincide com o calendário de provas das instituições.\n\nInsights:\n* Maioria das conversões no período da tarde\n* Maioria das conversões no começo da semana ( anúncios aos domingos )\n* Direcionar anúncios de instagram geolocalizados (instituições) nos períodos que antecede o calendário de provas.\n* Tentar converter usuários ativos 100 dias após o registro\n* Tentar converter usuários com base no calendário de provas da instituição",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
]
|
d062f5c370018e72626a3bbe53882379df9d5c52 | 4,946 | ipynb | Jupyter Notebook | Numpy/Numpy Operations.ipynb | aaavinash85/100-Days-of-ML- | d055d718f7972e3a4469279b9112867a42cf652f | [
"Apache-2.0"
]
| 3 | 2021-01-15T14:59:57.000Z | 2021-07-01T07:32:19.000Z | Numpy/Numpy Operations.ipynb | aaavinash85/100-Days-of-ML- | d055d718f7972e3a4469279b9112867a42cf652f | [
"Apache-2.0"
]
| null | null | null | Numpy/Numpy Operations.ipynb | aaavinash85/100-Days-of-ML- | d055d718f7972e3a4469279b9112867a42cf652f | [
"Apache-2.0"
]
| 1 | 2021-07-01T07:32:23.000Z | 2021-07-01T07:32:23.000Z | 19.170543 | 115 | 0.45552 | [
[
[
"# NumPy Operations",
"_____no_output_____"
],
[
"## Arithmetic\n\nYou can easily perform array with array arithmetic, or scalar with array arithmetic. Let's see some examples:",
"_____no_output_____"
]
],
[
[
"import numpy as np\narr = np.arange(0,10)",
"_____no_output_____"
],
[
"arr + arr",
"_____no_output_____"
],
[
"arr * arr",
"_____no_output_____"
],
[
"arr - arr",
"_____no_output_____"
],
[
"arr**3",
"_____no_output_____"
]
],
[
[
"## Universal Array Functions\n\n",
"_____no_output_____"
]
],
[
[
"#Taking Square Roots\nnp.sqrt(arr)",
"_____no_output_____"
],
[
"#Calcualting exponential (e^)\nnp.exp(arr)",
"_____no_output_____"
],
[
"np.max(arr) #same as arr.max()",
"_____no_output_____"
],
[
"np.sin(arr)",
"_____no_output_____"
],
[
"np.log(arr)",
"<ipython-input-3-a67b4ae04e95>:1: RuntimeWarning: divide by zero encountered in log\n np.log(arr)\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
d062f667bf2ab6a5ad7d20d6bbfe1c67d779f452 | 24,819 | ipynb | Jupyter Notebook | docker_galaxy/data/brassica_data/brapa_nb/1-bashNB_bra.ipynb | wilkinsonlab/epigenomics_pipeline | ed4a7fd97b798110e88364b101d020b2baebc298 | [
"MIT"
]
| null | null | null | docker_galaxy/data/brassica_data/brapa_nb/1-bashNB_bra.ipynb | wilkinsonlab/epigenomics_pipeline | ed4a7fd97b798110e88364b101d020b2baebc298 | [
"MIT"
]
| null | null | null | docker_galaxy/data/brassica_data/brapa_nb/1-bashNB_bra.ipynb | wilkinsonlab/epigenomics_pipeline | ed4a7fd97b798110e88364b101d020b2baebc298 | [
"MIT"
]
| 1 | 2019-10-17T10:50:38.000Z | 2019-10-17T10:50:38.000Z | 38.124424 | 943 | 0.462065 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
d063024d84566109dd7dd18bc446b9f87d5c39bb | 3,619 | ipynb | Jupyter Notebook | data/Untitled.ipynb | DSqiansun/CloudComparer | f5dfc6bda3ccb1d80421c241931d19f069ff2475 | [
"MIT"
]
| null | null | null | data/Untitled.ipynb | DSqiansun/CloudComparer | f5dfc6bda3ccb1d80421c241931d19f069ff2475 | [
"MIT"
]
| null | null | null | data/Untitled.ipynb | DSqiansun/CloudComparer | f5dfc6bda3ccb1d80421c241931d19f069ff2475 | [
"MIT"
]
| null | null | null | 26.035971 | 113 | 0.494059 | [
[
[
"def flatten_json(nested_json, exclude=['']):\n \"\"\"Flatten json object with nested keys into a single level.\n Args:\n nested_json: A nested json object.\n exclude: Keys to exclude from output.\n Returns:\n The flattened json object if successful, None otherwise.\n \"\"\"\n out = {}\n\n def flatten(x, name='', exclude=exclude):\n if type(x) is dict:\n for a in x:\n if a not in exclude: flatten(x[a], name + a + '_')\n elif type(x) is list:\n i = 0\n for a in x:\n flatten(a, name + str(i) + '_')\n i += 1\n else:\n out[name[:-1]] = x\n\n flatten(nested_json)\n return out",
"_____no_output_____"
],
[
"\n",
"_____no_output_____"
],
[
"from flatten_json import flatten\nimport json\n\nwith open('Services.json') as f:\n data = json.load(f)\ndic_flattened = (flatten(d) for d in data)\ndf = pd.DataFrame(dic_flattened)\nclos = [col for col in list(df.columns) if 'Propertie' not in col]\ndf = df[clos]#.drop_duplicates().to_csv('cloud_service.csv', index=False)",
"_____no_output_____"
],
[
"def rchop(s, suffix):\n if suffix and s.endswith(suffix):\n s = s[:-len(suffix)]\n if suffix and s.endswith(suffix):\n return rchop(s, suffix)\n return s\n\ndef concate(df, cloud, type_):\n col_ = [col for col in list(df.columns) if cloud in col and type_ in col]\n return df[col_].fillna('').astype(str).agg('<br/>'.join, axis=1).apply(lambda x: rchop(x, '<br/>') )\n\n\nclouds = ['aws', 'azure', 'google', 'ibm', 'alibaba', 'oracle']\ntype_s = ['name', 'ref', 'icon']\n\nfor cloud in clouds:\n for type_ in type_s:\n df[cloud +'_'+ type_] = concate(df, cloud, type_)\n",
"_____no_output_____"
],
[
"df.drop_duplicates().to_csv('cloud_service.csv', index=False)",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
d06303ee27ab4398b14cd8cdbe43733805679c26 | 11,587 | ipynb | Jupyter Notebook | Chapters/06.MinimumSpanningTrees/Chapter6.ipynb | MichielStock/SelectedTopicsOptimization | 20f6b37566d23cdde0ac6b765ffcc5ed72a11172 | [
"MIT"
]
| 22 | 2017-03-21T14:01:10.000Z | 2022-03-02T18:51:40.000Z | Chapters/06.MinimumSpanningTrees/Chapter6.ipynb | MichielStock/SelectedTopicsOptimization | 20f6b37566d23cdde0ac6b765ffcc5ed72a11172 | [
"MIT"
]
| 2 | 2018-03-22T09:54:01.000Z | 2018-05-30T16:16:53.000Z | Chapters/06.MinimumSpanningTrees/Chapter6.ipynb | MichielStock/SelectedTopicsOptimization | 20f6b37566d23cdde0ac6b765ffcc5ed72a11172 | [
"MIT"
]
| 18 | 2018-01-21T15:23:51.000Z | 2022-02-05T20:12:03.000Z | 26.759815 | 493 | 0.543454 | [
[
[
"# Minimum spanning trees\n\n*Selected Topics in Mathematical Optimization*\n\n**Michiel Stock** ([email]([email protected]))\n\n",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n%matplotlib inline\nfrom minimumspanningtrees import red, green, blue, orange, yellow",
"_____no_output_____"
]
],
[
[
"## Graphs in python\n\nConsider the following example graph:\n\n",
"_____no_output_____"
],
[
"This graph can be represented using an *adjacency list*. We do this using a `dict`. Every vertex is a key with the adjacent vertices given as a `set` containing tuples `(weight, neighbor)`. The weight is first because this makes it easy to compare the weights of two edges. Note that for every ingoing edges, there is also an outgoing edge, this is an undirected graph.",
"_____no_output_____"
]
],
[
[
"graph = {\n 'A' : set([(2, 'B'), (3, 'D')]),\n 'B' : set([(2, 'A'), (1, 'C'), (2, 'E')]),\n 'C' : set([(1, 'B'), (2, 'D'), (1, 'E')]),\n 'D' : set([(2, 'C'), (3, 'A'), (3, 'E')]),\n 'E' : set([(2, 'B'), (1, 'C'), (3, 'D')])\n}",
"_____no_output_____"
]
],
[
[
"Sometimes we will use an *edge list*, i.e. a list of (weighted) edges. This is often a more compact way of storing a graph. The edge list is given below. Note that again every edge is double: an in- and outgoing edge is included.",
"_____no_output_____"
]
],
[
[
"edges = [\n (2, 'B', 'A'),\n (3, 'D', 'A'),\n (2, 'C', 'D'),\n (3, 'A', 'D'),\n (3, 'E', 'D'),\n (2, 'B', 'E'),\n (3, 'D', 'E'),\n (1, 'C', 'E'),\n (2, 'E', 'B'),\n (2, 'A', 'B'),\n (1, 'C', 'B'),\n (1, 'E', 'C'),\n (1, 'B', 'C'),\n (2, 'D', 'C')]",
"_____no_output_____"
]
],
[
[
"We can easily turn one representation in the other (with a time complexity proportional to the number of edges) using the provided functions `edges_to_adj_list` and `adj_list_to_edges`.",
"_____no_output_____"
]
],
[
[
"from minimumspanningtrees import edges_to_adj_list, adj_list_to_edges",
"_____no_output_____"
],
[
"adj_list_to_edges(graph)",
"_____no_output_____"
],
[
"edges_to_adj_list(edges)",
"_____no_output_____"
]
],
[
[
"## Disjoint-set data structure\n\nImplementing an algorithm for finding the minimum spanning tree is fairly straightforward. The only bottleneck is that the algorithm requires the a disjoint-set data structure to keep track of a set partitioned in a number of disjoined subsets.\n\nFor example, consider the following inital set of eight elements.\n\n\n\nWe decide to group elements A, B and C together in a subset and F and G in another subset.\n\n\n\nThe disjoint-set data structure support the following operations:\n\n- **Find**: check which subset an element is in. Is typically used to check whether two objects are in the same subset;\n- **Union** merges two subsets into a single subset.\n\nA python implementation of a disjoint-set is available using an union-set forest. A simple example will make everything clear!",
"_____no_output_____"
]
],
[
[
"from union_set_forest import USF\n\nanimals = ['mouse', 'bat', 'robin', 'trout', 'seagull', 'hummingbird',\n 'salmon', 'goldfish', 'hippopotamus', 'whale', 'sparrow']\nunion_set_forest = USF(animals)\n\n# group mammals together\nunion_set_forest.union('mouse', 'bat')\nunion_set_forest.union('mouse', 'hippopotamus')\nunion_set_forest.union('whale', 'bat')\n\n# group birds together\nunion_set_forest.union('robin', 'seagull')\nunion_set_forest.union('seagull', 'sparrow')\nunion_set_forest.union('seagull', 'hummingbird')\nunion_set_forest.union('robin', 'hummingbird')\n\n# group fishes together\nunion_set_forest.union('goldfish', 'salmon')\nunion_set_forest.union('trout', 'salmon')",
"_____no_output_____"
],
[
"# mouse and whale in same subset?\nprint(union_set_forest.find('mouse') == union_set_forest.find('whale'))",
"_____no_output_____"
],
[
"# robin and salmon in the same subset?\nprint(union_set_forest.find('robin') == union_set_forest.find('salmon'))",
"_____no_output_____"
]
],
[
[
"## Heap queue\n\nCan be used to find the minimum of a changing list without having to sort the list every update.",
"_____no_output_____"
]
],
[
[
"from heapq import heapify, heappop, heappush\n\nheap = [(5, 'A'), (3, 'B'), (2, 'C'), (7, 'D')]\n\nheapify(heap) # turn in a heap\n\nprint(heap)",
"_____no_output_____"
],
[
"# return item lowest value while retaining heap property\nprint(heappop(heap))",
"_____no_output_____"
],
[
"print(heap)",
"_____no_output_____"
],
[
"# add new item and retain heap prop\nheappush(heap, (4, 'E'))\nprint(heap)",
"_____no_output_____"
]
],
[
[
"## Prim's algorithm\n\nPrim's algorithm starts with a single vertex and add $|V|-1$ edges to it, always taking the next edge with minimal weight that connects a vertex on the MST to a vertex not yet in the MST.",
"_____no_output_____"
]
],
[
[
"from minimumspanningtrees import prim",
"_____no_output_____"
]
],
[
[
"def prim(vertices, edges, start):\n \"\"\"\n Prim's algorithm for finding a minimum spanning tree.\n\n Inputs :\n - vertices : a set of the vertices of the Graph\n - edges : a list of weighted edges (e.g. (0.7, 'A', 'B') for an\n edge from node A to node B with weigth 0.7)\n - start : a vertex to start with\n\n Output:\n - edges : a minumum spanning tree represented as a list of edges\n - total_cost : total cost of the tree\n \"\"\"\n adj_list = edges_to_adj_list(edges) # easier using an adjacency list\n \n ... # to complete\n return mst_edges, total_cost",
"_____no_output_____"
]
],
[
[
"## Kruskal's algorithm\n\n\nKruskal's algorithm is a very simple algorithm to find the minimum spanning tree. The main idea is to start with an intial 'forest' of the individual nodes of the graph. In each step of the algorithm we add an edge with the smallest possible value that connects two disjoint trees in the forest. This process is continued until we have a single tree, which is a minimum spanning tree, or until all edges are considered. In the latter case, the algoritm returns a minimum spanning forest.",
"_____no_output_____"
]
],
[
[
"from minimumspanningtrees import kruskal",
"_____no_output_____"
],
[
"def kruskal(vertices, edges):\n \"\"\"\n Kruskal's algorithm for finding a minimum spanning tree.\n\n Inputs :\n - vertices : a set of the vertices of the Graph\n - edges : a list of weighted edges (e.g. (0.7, 'A', 'B') for an\n edge from node A to node B with weigth 0.7)\n\n Output:\n - edges : a minumum spanning tree represented as a list of edges\n - total_cost : total cost of the tree\n \"\"\"\n ... # to complete\n return mst_edges, total_cost",
"_____no_output_____"
]
],
[
[
"from tickettoride import vertices, edges",
"_____no_output_____"
]
],
[
[
"print(vertices)",
"_____no_output_____"
],
[
"print(edges[:5])",
"_____no_output_____"
],
[
"# compute the minimum spanning tree of the ticket to ride data set\n...",
"_____no_output_____"
]
],
[
[
"## Clustering\n\nMinimum spanning trees on a distance graph can be used to cluster a data set.",
"_____no_output_____"
]
],
[
[
"# import features and distance\nfrom clustering import X, D",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nax.scatter(X[:,0], X[:,1], color=green)",
"_____no_output_____"
],
[
"# cluster the data based on the distance",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"code",
"markdown",
"code",
"raw",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"raw"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"raw"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
d0634585edff76f717a666c4474ee29bebee9bc6 | 4,661 | ipynb | Jupyter Notebook | section_2/03_simple_bert.ipynb | derwind/bert_nlp | ff1279e276c85a789edc863e1c27bbc2ef86e1f0 | [
"MIT"
]
| null | null | null | section_2/03_simple_bert.ipynb | derwind/bert_nlp | ff1279e276c85a789edc863e1c27bbc2ef86e1f0 | [
"MIT"
]
| null | null | null | section_2/03_simple_bert.ipynb | derwind/bert_nlp | ff1279e276c85a789edc863e1c27bbc2ef86e1f0 | [
"MIT"
]
| null | null | null | 4,661 | 4,661 | 0.680326 | [
[
[
"<a href=\"https://colab.research.google.com/github/yukinaga/bert_nlp/blob/main/section_2/03_simple_bert.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# シンプルなBERTの実装\n訓練済みのモデルを使用し、文章の一部の予測、及び2つの文章が連続しているかどうかの判定を行います。",
"_____no_output_____"
],
[
"## ライブラリのインストール\nPyTorch-Transformers、および必要なライブラリのインストールを行います。",
"_____no_output_____"
]
],
[
[
"!pip install folium==0.2.1\n!pip install urllib3==1.25.11\n!pip install transformers==4.13.0",
"_____no_output_____"
]
],
[
[
"## 文章の一部の予測\n文章における一部の単語をMASKし、それをBERTのモデルを使って予測します。",
"_____no_output_____"
]
],
[
[
"import torch\nfrom transformers import BertForMaskedLM\nfrom transformers import BertTokenizer\n\n\ntext = \"[CLS] I played baseball with my friends at school yesterday [SEP]\"\ntokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\")\nwords = tokenizer.tokenize(text)\nprint(words)",
"_____no_output_____"
]
],
[
[
"文章の一部をMASKします。",
"_____no_output_____"
]
],
[
[
"msk_idx = 3\nwords[msk_idx] = \"[MASK]\" # 単語を[MASK]に置き換える\nprint(words)",
"_____no_output_____"
]
],
[
[
"単語を対応するインデックスに変換します。",
"_____no_output_____"
]
],
[
[
"word_ids = tokenizer.convert_tokens_to_ids(words) # 単語をインデックスに変換\nword_tensor = torch.tensor([word_ids]) # テンソルに変換\nprint(word_tensor)",
"_____no_output_____"
]
],
[
[
"BERTのモデルを使って予測を行います。",
"_____no_output_____"
]
],
[
[
"msk_model = BertForMaskedLM.from_pretrained(\"bert-base-uncased\")\nmsk_model.cuda() # GPU対応\nmsk_model.eval()\n\nx = word_tensor.cuda() # GPU対応\ny = msk_model(x) # 予測\nresult = y[0]\nprint(result.size()) # 結果の形状\n\n_, max_ids = torch.topk(result[0][msk_idx], k=5) # 最も大きい5つの値\nresult_words = tokenizer.convert_ids_to_tokens(max_ids.tolist()) # インデックスを単語に変換\nprint(result_words)",
"_____no_output_____"
]
],
[
[
"## 文章が連続しているかどうかの判定\nBERTのモデルを使って、2つの文章が連続しているかどうかの判定を行います。 \n以下の関数`show_continuity`では、2つの文章の連続性を判定し、表示します。",
"_____no_output_____"
]
],
[
[
"from transformers import BertForNextSentencePrediction\n\ndef show_continuity(text, seg_ids):\n words = tokenizer.tokenize(text)\n word_ids = tokenizer.convert_tokens_to_ids(words) # 単語をインデックスに変換\n word_tensor = torch.tensor([word_ids]) # テンソルに変換\n\n seg_tensor = torch.tensor([seg_ids])\n\n nsp_model = BertForNextSentencePrediction.from_pretrained('bert-base-uncased')\n nsp_model.cuda() # GPU対応\n nsp_model.eval()\n\n x = word_tensor.cuda() # GPU対応\n s = seg_tensor.cuda() # GPU対応\n\n y = nsp_model(x, token_type_ids=s) # 予測\n result = torch.softmax(y[0], dim=1)\n print(result) # Softmaxで確率に\n print(str(result[0][0].item()*100) + \"%の確率で連続しています。\")",
"_____no_output_____"
]
],
[
[
"`show_continuity`関数に、自然につながる2つの文章を与えます。",
"_____no_output_____"
]
],
[
[
"text = \"[CLS] What is baseball ? [SEP] It is a game of hitting the ball with the bat [SEP]\"\nseg_ids = [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 ,1, 1] # 0:前の文章の単語、1:後の文章の単語\nshow_continuity(text, seg_ids)",
"_____no_output_____"
]
],
[
[
"`show_continuity`関数に、自然につながらない2つの文章を与えます。",
"_____no_output_____"
]
],
[
[
"text = \"[CLS] What is baseball ? [SEP] This food is made with flour and milk [SEP]\"\nseg_ids = [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1] # 0:前の文章の単語、1:後の文章の単語\nshow_continuity(text, seg_ids)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d06345a8a4ec272aabf44402ccdab8f1f0da4720 | 11,445 | ipynb | Jupyter Notebook | _notebooks/2022-05-03-binary-search-or-bust.ipynb | boolean-pandit/non-faangable-tokens | 14872620b21077be68ae64a2527643ed29e2260e | [
"Apache-2.0"
]
| null | null | null | _notebooks/2022-05-03-binary-search-or-bust.ipynb | boolean-pandit/non-faangable-tokens | 14872620b21077be68ae64a2527643ed29e2260e | [
"Apache-2.0"
]
| null | null | null | _notebooks/2022-05-03-binary-search-or-bust.ipynb | boolean-pandit/non-faangable-tokens | 14872620b21077be68ae64a2527643ed29e2260e | [
"Apache-2.0"
]
| null | null | null | 30.601604 | 506 | 0.562779 | [
[
[
"# Binary Search or Bust\n> Binary search is useful for searching, but its implementation often leaves us searching for edge cases\n\n- toc: true \n- badges: true\n- comments: true\n- categories: [data structures & algorithms, coding interviews, searching]\n- image: images/binary_search_gif.gif",
"_____no_output_____"
],
[
"# Why should you care?\nBinary search is useful for searching through a set of values (which typically are sorted) efficiently. At each step, it reduces the search space by half, thereby running in $O(log(n))$ complexity. While it sounds simple enough to understand, it is deceptively tricky to implement and use in problems. Over the next few sections, let's take a look at binary search and it can be applied to some commonly encountered interview problems.",
"_____no_output_____"
],
[
"# A Recipe for Binary Searching\nHow does binary search reduce the search space by half? It leverages the fact that the input is sorted (_most of the time_) and compares the middle value of the search space at any step with the target value that we're searching for. If the middle value is smaller than the target, then we know that the target can only lie to its right, thus eliminating all the values to the left of the middle value and vice versa. So what information do we need to implement binary search?\n1. The left and right ends of the search space \n2. The target value we're searching for\n3. What to store at each step if any\n\nHere's a nice video which walks through the binary search algorithm:\n > youtube: https://youtu.be/P3YID7liBug\n",
"_____no_output_____"
],
[
"Next, let's look at an implementation of vanilla binary search. ",
"_____no_output_____"
]
],
[
[
"#hide\nfrom typing import List, Dict, Tuple ",
"_____no_output_____"
],
[
"def binary_search(nums: List[int], target: int) -> int:\n \"\"\"Vanilla Binary Search.\n Given a sorted list of integers and a target value,\n find the index of the target value in the list.\n If not present, return -1.\n \"\"\"\n # Left and right boundaries of the search space\n left, right = 0, len(nums) - 1\n while left <= right:\n # Why not (left + right) // 2 ?\n # Hint: Doesn't matter for Python\n middle = left + (right - left) // 2\n\n # Found the target, return the index\n if nums[middle] == target:\n return middle \n # The middle value is less than the\n # target, so look to the right\n elif nums[middle] < target:\n left = middle + 1\n # The middle value is greater than the\n # target, so look to the left\n else:\n right = middle - 1\n return -1 # Target not found",
"_____no_output_____"
]
],
[
[
"Here're a few examples of running our binary search implementation on a list and target values",
"_____no_output_____"
]
],
[
[
"#hide_input\nnums = [1,4,9,54,100,123]\ntargets = [4, 100, 92]\n\nfor val in targets:\n print(f\"Result of searching for {val} in {nums} : \\\n {binary_search(nums, val)}\\n\")\n",
"Result of searching for 4 in [1, 4, 9, 54, 100, 123] : 1\n\nResult of searching for 100 in [1, 4, 9, 54, 100, 123] : 4\n\nResult of searching for 92 in [1, 4, 9, 54, 100, 123] : -1\n\n"
]
],
[
[
"> Tip: Using the approach middle = left + (right - left) // 2 helps avoid overflow. While this isn't a concern in Python, it becomes a tricky issue to debug in other programming languages such as C++. For more on overflow, check out this [article](https://ai.googleblog.com/2006/06/extra-extra-read-all-about-it-nearly.html).",
"_____no_output_____"
],
[
"Before we look at some problems that can be solved using binary search, let's run a quick comparison of linear search and binary search on some large input. ",
"_____no_output_____"
]
],
[
[
"def linear_search(nums: List[int], target: int) -> int:\n \"\"\"Linear Search.\n Given a list of integers and a target value, return\n find the index of the target value in the list.\n If not present, return -1.\n \"\"\"\n for idx, elem in enumerate(nums):\n # Found the target value\n if elem == target:\n return idx \n return -1 # Target not found",
"_____no_output_____"
],
[
"#hide\nn = 1000000\nlarge_nums = range((1, n + 1))\ntarget = 99999",
"_____no_output_____"
]
],
[
[
"Let's see the time it takes linear search and binary search to find $99999$ in a sorted list of numbers from $[1, 1000000]$",
"_____no_output_____"
],
[
"- Linear Search",
"_____no_output_____"
]
],
[
[
"#hide_input\n%timeit linear_search(large_nums, target)",
"5.19 ms ± 26.3 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n"
]
],
[
[
"- Binary Search",
"_____no_output_____"
]
],
[
[
"#hide_input\n%timeit binary_search(large_nums, target)",
"6.05 µs ± 46.9 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)\n"
]
],
[
[
"Hopefully, that drives the point home :wink:.",
"_____no_output_____"
],
[
"# Naïve Binary Search Problems\nHere's a list of problems that can be solved using vanilla binary search (or slightly modifying it). Anytime you see a problem statement which goes something like _\"Given a sorted list..\"_ or _\"Find the position of an element\"_, think of using binary search. You can also consider **sorting** the input in case it is an unordered collection of items to reduce it to a binary search problem. Note that this list is by no means exhaustive, but is a good starting point to practice binary search:\n- [Search Insert Position](https://leetcode.com/problems/search-insert-position/\n)\n- [Find the Square Root of x](https://leetcode.com/problems/sqrtx/)\n- [Find First and Last Position of Element in Sorted Array](https://leetcode.com/problems/find-first-and-last-position-of-element-in-sorted-array/)\n- [Search in a Rotated Sorted Array](https://leetcode.com/problems/search-in-rotated-sorted-array/)\n\nIn the problems above, we can either directly apply binary search or adapt it slightly to solve the problem. For example, take the square root problem. We know that the square root of a positive number $n$ has to lie between $[1, n / 2]$. This gives us the bounds for the search space. Applying binary search over this space allows us to find the a good approximation of the square root. See the implementation below for details:",
"_____no_output_____"
]
],
[
[
"def find_square_root(n: int) -> int:\n \"\"\"Integer square root.\n Given a positive integer, return\n its square root.\n \"\"\"\n left, right = 1, n // 2 + 1\n\n while left <= right:\n middle = left + (right - left) // 2\n if middle * middle == n:\n return middle # Found an exact match\n elif middle * middle < n:\n left = middle + 1 # Go right\n else:\n right = middle - 1 # Go left\n \n return right # This is the closest value to the actual square root",
"_____no_output_____"
],
[
"#hide_input\nnums = [1,4,8,33,100]\n\nfor val in nums:\n print(f\"Square root of {val} is: {find_square_root(val)}\\n\")",
"Square root of 1 is: 1\n\nSquare root of 4 is: 2\n\nSquare root of 8 is: 2\n\nSquare root of 33 is: 5\n\nSquare root of 100 is: 10\n\n"
]
],
[
[
"# To Be Continued\n- Applying binary search to unordered data\n- Problems where using binary search isn't obvious",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
]
|
d0634fdb80f870ae48693947b54ac4b283f8f24f | 414,536 | ipynb | Jupyter Notebook | Lecture 30 - Assignment.ipynb | Elseidy83/Countery_data | 225c757687c3d799e1d6c719f57494b933d92e0c | [
"MIT"
]
| null | null | null | Lecture 30 - Assignment.ipynb | Elseidy83/Countery_data | 225c757687c3d799e1d6c719f57494b933d92e0c | [
"MIT"
]
| null | null | null | Lecture 30 - Assignment.ipynb | Elseidy83/Countery_data | 225c757687c3d799e1d6c719f57494b933d92e0c | [
"MIT"
]
| null | null | null | 371.781166 | 253,892 | 0.913636 | [
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom sklearn.cluster import AgglomerativeClustering\nimport seaborn as sns\n\nsns.set(rc={'figure.figsize': [7, 7]}, font_scale=1.2)",
"_____no_output_____"
],
[
"df = pd.read_csv('Country-data.csv')\ndf",
"_____no_output_____"
],
[
"ds = df.drop(['country'],axis=1)",
"_____no_output_____"
],
[
"sns.heatmap(ds.corr(), annot=True, fmt='.1f')",
"_____no_output_____"
],
[
"def get_sum(rw):\n return rw['child_mort']+ rw['exports']+rw['health']+rw['imports']+rw['income']+rw['inflation']+rw['life_expec']+rw['total_fer']+rw['gdpp']",
"_____no_output_____"
],
[
"dd = ds.corr().abs()",
"_____no_output_____"
],
[
"dd.apply(get_sum).sort_values(ascending=False)",
"_____no_output_____"
],
[
"ds = ds.drop(['inflation','imports','health'],axis=1)",
"_____no_output_____"
],
[
"ds",
"_____no_output_____"
],
[
"from sklearn.preprocessing import StandardScaler\nscaler = StandardScaler()\nx_scaled = scaler.fit_transform(ds)",
"_____no_output_____"
],
[
"x_scaled",
"_____no_output_____"
],
[
"sns.pairplot(ds)",
"_____no_output_____"
],
[
"plt.scatter(x_scaled[:, 0], x_scaled[:, 1])",
"_____no_output_____"
],
[
"import scipy.cluster.hierarchy as sch",
"_____no_output_____"
],
[
"dendrogram = sch.dendrogram(sch.linkage(ds, method='ward'))",
"_____no_output_____"
],
[
"model = AgglomerativeClustering(n_clusters=5)\nclusters = model.fit_predict(x_scaled)\nclusters",
"_____no_output_____"
],
[
"plt.scatter(x_scaled[:, 0], x_scaled[:,7], c=clusters, cmap='viridis')",
"_____no_output_____"
],
[
"df['Clusters'] = clusters\ndf",
"_____no_output_____"
],
[
"df.groupby('Clusters').describe().transpose()",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d0635092cb676270c58b8bb3262e443ac5adbcfa | 52,667 | ipynb | Jupyter Notebook | 06. VGGNet Architecture/Mini VGGNet.ipynb | ThinamXx/ComputerVision | 732d251bc19bf9d9c1b497037c6acd3d640066b9 | [
"MIT"
]
| 13 | 2021-11-21T12:06:40.000Z | 2022-03-30T00:54:06.000Z | 06. VGGNet Architecture/Mini VGGNet.ipynb | ThinamXx/ComputerVision | 732d251bc19bf9d9c1b497037c6acd3d640066b9 | [
"MIT"
]
| null | null | null | 06. VGGNet Architecture/Mini VGGNet.ipynb | ThinamXx/ComputerVision | 732d251bc19bf9d9c1b497037c6acd3d640066b9 | [
"MIT"
]
| 10 | 2021-11-20T23:40:15.000Z | 2022-03-11T19:51:28.000Z | 132.997475 | 31,266 | 0.760856 | [
[
[
"**INITIALIZATION:**\n- I use these three lines of code on top of my each notebooks because it will help to prevent any problems while reloading the same project. And the third line of code helps to make visualization within the notebook.",
"_____no_output_____"
]
],
[
[
"#@ INITIALIZATION: \n%reload_ext autoreload\n%autoreload 2\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"**LIBRARIES AND DEPENDENCIES:**\n- I have downloaded all the libraries and dependencies required for the project in one particular cell.",
"_____no_output_____"
]
],
[
[
"#@ IMPORTING NECESSARY LIBRARIES AND DEPENDENCIES:\nfrom keras.models import Sequential\nfrom keras.layers import BatchNormalization\nfrom keras.layers.convolutional import Conv2D\nfrom keras.layers.convolutional import MaxPooling2D\nfrom keras.layers.core import Activation\nfrom keras.layers.core import Flatten\nfrom keras.layers.core import Dense, Dropout\nfrom keras import backend as K\nfrom tensorflow.keras.optimizers import SGD\nfrom tensorflow.keras.datasets import cifar10\nfrom keras.callbacks import LearningRateScheduler\n\nfrom sklearn.preprocessing import LabelBinarizer\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import classification_report\n\nimport matplotlib.pyplot as plt\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"**VGG ARCHITECTURE:**\n- I will define the build method of Mini VGGNet architecture below. It requires four parameters: width of input image, height of input image, depth of image, number of class labels in the classification task. The Sequential class, the building block of sequential networks sequentially stack one layer on top of the other layer initialized below. Batch Normalization operates over the channels, so in order to apply BN, we need to know which axis to normalize over. ",
"_____no_output_____"
]
],
[
[
"#@ DEFINING VGGNET ARCHITECTURE:\nclass MiniVGGNet: # Defining VGG Network. \n @staticmethod\n def build(width, height, depth, classes): # Defining Build Method. \n model = Sequential() # Initializing Sequential Model.\n inputShape = (width, height, depth) # Initializing Input Shape. \n chanDim = -1 # Index of Channel Dimension.\n if K.image_data_format() == \"channels_first\":\n inputShape = (depth, width, height) # Initializing Input Shape. \n chanDim = 1 # Index of Channel Dimension. \n model.add(Conv2D(32, (3, 3), padding='same', \n input_shape=inputShape)) # Adding Convolutional Layer. \n model.add(Activation(\"relu\")) # Adding RELU Activation Function. \n model.add(BatchNormalization(axis=chanDim)) # Adding Batch Normalization Layer. \n model.add(Conv2D(32, (3, 3), padding='same')) # Adding Convolutional Layer. \n model.add(Activation(\"relu\")) # Adding RELU Activation Function. \n model.add(BatchNormalization(axis=chanDim)) # Adding Batch Normalization Layer. \n model.add(MaxPooling2D(pool_size=(2, 2))) # Adding Max Pooling Layer. \n model.add(Dropout(0.25)) # Adding Dropout Layer.\n model.add(Conv2D(64, (3, 3), padding=\"same\")) # Adding Convolutional Layer. \n model.add(Activation(\"relu\")) # Adding RELU Activation Function. \n model.add(BatchNormalization(axis=chanDim)) # Adding Batch Normalization Layer. \n model.add(Conv2D(64, (3, 3), padding='same')) # Adding Convolutional Layer. \n model.add(Activation(\"relu\")) # Adding RELU Activation Function. \n model.add(BatchNormalization(axis=chanDim)) # Adding Batch Normalization Layer. \n model.add(MaxPooling2D(pool_size=(2, 2))) # Adding Max Pooling Layer. \n model.add(Dropout(0.25)) # Adding Dropout Layer. \n model.add(Flatten()) # Adding Flatten Layer. \n model.add(Dense(512)) # Adding FC Dense Layer. \n model.add(Activation(\"relu\")) # Adding Activation Layer. \n model.add(BatchNormalization()) # Adding Batch Normalization Layer. \n model.add(Dropout(0.5)) # Adding Dropout Layer. \n model.add(Dense(classes)) # Adding Dense Output Layer. \n model.add(Activation(\"softmax\")) # Adding Softmax Layer. \n return model",
"_____no_output_____"
],
[
"#@ CUSTOM LEARNING RATE SCHEDULER: \ndef step_decay(epoch): # Definig step decay function. \n initAlpha = 0.01 # Initializing initial LR.\n factor = 0.25 # Initializing drop factor. \n dropEvery = 5 # Initializing epochs to drop. \n alpha = initAlpha*(factor ** np.floor((1 + epoch) / dropEvery))\n return float(alpha)",
"_____no_output_____"
]
],
[
[
"**VGGNET ON CIFAR10**",
"_____no_output_____"
]
],
[
[
"#@ GETTING THE DATASET:\n((trainX, trainY), (testX, testY)) = cifar10.load_data() # Loading Dataset. \ntrainX = trainX.astype(\"float\") / 255.0 # Normalizing Dataset. \ntestX = testX.astype(\"float\") / 255.0 # Normalizing Dataset. \n\n#@ PREPARING THE DATASET:\nlb = LabelBinarizer() # Initializing LabelBinarizer. \ntrainY = lb.fit_transform(trainY) # Converting Labels to Vectors. \ntestY = lb.transform(testY) # Converting Labels to Vectors. \nlabelNames = [\"airplane\", \"automobile\", \"bird\", \"cat\", \"deer\", \n \"dog\", \"frog\", \"horse\", \"ship\", \"truck\"] # Initializing LabelNames.",
"_____no_output_____"
],
[
"#@ INITIALIZING OPTIMIZER AND MODEL: \ncallbacks = [LearningRateScheduler(step_decay)] # Initializing Callbacks. \nopt = SGD(0.01, nesterov=True, momentum=0.9) # Initializing SGD Optimizer. \nmodel = MiniVGGNet.build(width=32, height=32, depth=3, classes=10) # Initializing VGGNet Architecture. \nmodel.compile(loss=\"categorical_crossentropy\", optimizer=opt,\n metrics=[\"accuracy\"]) # Compiling VGGNet Model. \nH = model.fit(trainX, trainY, \n validation_data=(testX, testY), batch_size=64, \n epochs=40, verbose=1, callbacks=callbacks) # Training VGGNet Model.",
"Epoch 1/40\n782/782 [==============================] - 29s 21ms/step - loss: 1.6339 - accuracy: 0.4555 - val_loss: 1.1509 - val_accuracy: 0.5970 - lr: 0.0100\nEpoch 2/40\n782/782 [==============================] - 16s 21ms/step - loss: 1.1813 - accuracy: 0.5932 - val_loss: 0.9222 - val_accuracy: 0.6733 - lr: 0.0100\nEpoch 3/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.9908 - accuracy: 0.6567 - val_loss: 0.8341 - val_accuracy: 0.7159 - lr: 0.0100\nEpoch 4/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.8854 - accuracy: 0.6945 - val_loss: 0.8282 - val_accuracy: 0.7167 - lr: 0.0100\nEpoch 5/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.7380 - accuracy: 0.7421 - val_loss: 0.6881 - val_accuracy: 0.7598 - lr: 0.0025\nEpoch 6/40\n782/782 [==============================] - 17s 21ms/step - loss: 0.6845 - accuracy: 0.7586 - val_loss: 0.6600 - val_accuracy: 0.7711 - lr: 0.0025\nEpoch 7/40\n782/782 [==============================] - 17s 21ms/step - loss: 0.6628 - accuracy: 0.7683 - val_loss: 0.6435 - val_accuracy: 0.7744 - lr: 0.0025\nEpoch 8/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.6391 - accuracy: 0.7755 - val_loss: 0.6362 - val_accuracy: 0.7784 - lr: 0.0025\nEpoch 9/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.6204 - accuracy: 0.7830 - val_loss: 0.6499 - val_accuracy: 0.7744 - lr: 0.0025\nEpoch 10/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5912 - accuracy: 0.7909 - val_loss: 0.6161 - val_accuracy: 0.7856 - lr: 6.2500e-04\nEpoch 11/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5812 - accuracy: 0.7936 - val_loss: 0.6054 - val_accuracy: 0.7879 - lr: 6.2500e-04\nEpoch 12/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5730 - accuracy: 0.7978 - val_loss: 0.5994 - val_accuracy: 0.7907 - lr: 6.2500e-04\nEpoch 13/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5698 - accuracy: 0.7974 - val_loss: 0.6013 - val_accuracy: 0.7882 - lr: 6.2500e-04\nEpoch 14/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5623 - accuracy: 0.8009 - val_loss: 0.5973 - val_accuracy: 0.7910 - lr: 6.2500e-04\nEpoch 15/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5496 - accuracy: 0.8064 - val_loss: 0.5961 - val_accuracy: 0.7905 - lr: 1.5625e-04\nEpoch 16/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5484 - accuracy: 0.8048 - val_loss: 0.5937 - val_accuracy: 0.7914 - lr: 1.5625e-04\nEpoch 17/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5573 - accuracy: 0.8037 - val_loss: 0.5950 - val_accuracy: 0.7902 - lr: 1.5625e-04\nEpoch 18/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5477 - accuracy: 0.8062 - val_loss: 0.5927 - val_accuracy: 0.7907 - lr: 1.5625e-04\nEpoch 19/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5446 - accuracy: 0.8073 - val_loss: 0.5904 - val_accuracy: 0.7923 - lr: 1.5625e-04\nEpoch 20/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5391 - accuracy: 0.8104 - val_loss: 0.5926 - val_accuracy: 0.7920 - lr: 3.9062e-05\nEpoch 21/40\n782/782 [==============================] - 17s 21ms/step - loss: 0.5419 - accuracy: 0.8080 - val_loss: 0.5915 - val_accuracy: 0.7929 - lr: 3.9062e-05\nEpoch 22/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5438 - accuracy: 0.8099 - val_loss: 0.5909 - val_accuracy: 0.7925 - lr: 3.9062e-05\nEpoch 23/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5467 - accuracy: 0.8075 - val_loss: 0.5914 - val_accuracy: 0.7919 - lr: 3.9062e-05\nEpoch 24/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5376 - accuracy: 0.8103 - val_loss: 0.5918 - val_accuracy: 0.7920 - lr: 3.9062e-05\nEpoch 25/40\n782/782 [==============================] - 17s 21ms/step - loss: 0.5410 - accuracy: 0.8085 - val_loss: 0.5923 - val_accuracy: 0.7917 - lr: 9.7656e-06\nEpoch 26/40\n782/782 [==============================] - 17s 21ms/step - loss: 0.5406 - accuracy: 0.8084 - val_loss: 0.5910 - val_accuracy: 0.7915 - lr: 9.7656e-06\nEpoch 27/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5384 - accuracy: 0.8097 - val_loss: 0.5901 - val_accuracy: 0.7919 - lr: 9.7656e-06\nEpoch 28/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5431 - accuracy: 0.8089 - val_loss: 0.5915 - val_accuracy: 0.7927 - lr: 9.7656e-06\nEpoch 29/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5417 - accuracy: 0.8095 - val_loss: 0.5921 - val_accuracy: 0.7925 - lr: 9.7656e-06\nEpoch 30/40\n782/782 [==============================] - 17s 21ms/step - loss: 0.5385 - accuracy: 0.8108 - val_loss: 0.5900 - val_accuracy: 0.7926 - lr: 2.4414e-06\nEpoch 31/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5451 - accuracy: 0.8073 - val_loss: 0.5910 - val_accuracy: 0.7923 - lr: 2.4414e-06\nEpoch 32/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5402 - accuracy: 0.8103 - val_loss: 0.5899 - val_accuracy: 0.7925 - lr: 2.4414e-06\nEpoch 33/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5405 - accuracy: 0.8091 - val_loss: 0.5909 - val_accuracy: 0.7928 - lr: 2.4414e-06\nEpoch 34/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5427 - accuracy: 0.8091 - val_loss: 0.5914 - val_accuracy: 0.7921 - lr: 2.4414e-06\nEpoch 35/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5416 - accuracy: 0.8105 - val_loss: 0.5906 - val_accuracy: 0.7928 - lr: 6.1035e-07\nEpoch 36/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5375 - accuracy: 0.8109 - val_loss: 0.5905 - val_accuracy: 0.7927 - lr: 6.1035e-07\nEpoch 37/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5372 - accuracy: 0.8092 - val_loss: 0.5900 - val_accuracy: 0.7923 - lr: 6.1035e-07\nEpoch 38/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5438 - accuracy: 0.8090 - val_loss: 0.5907 - val_accuracy: 0.7927 - lr: 6.1035e-07\nEpoch 39/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5424 - accuracy: 0.8097 - val_loss: 0.5906 - val_accuracy: 0.7922 - lr: 6.1035e-07\nEpoch 40/40\n782/782 [==============================] - 16s 21ms/step - loss: 0.5385 - accuracy: 0.8116 - val_loss: 0.5909 - val_accuracy: 0.7928 - lr: 1.5259e-07\n"
]
],
[
[
"**MODEL EVALUATION:**",
"_____no_output_____"
]
],
[
[
"#@ INITIALIZING MODEL EVALUATION:\npredictions = model.predict(testX, batch_size=64) # Getting Model Predictions. \nprint(classification_report(testY.argmax(axis=1),\n predictions.argmax(axis=1), \n target_names=labelNames)) # Inspecting Classification Report.",
" precision recall f1-score support\n\n airplane 0.85 0.79 0.82 1000\n automobile 0.90 0.88 0.89 1000\n bird 0.73 0.65 0.69 1000\n cat 0.62 0.60 0.61 1000\n deer 0.72 0.81 0.76 1000\n dog 0.71 0.71 0.71 1000\n frog 0.80 0.89 0.84 1000\n horse 0.87 0.82 0.85 1000\n ship 0.89 0.89 0.89 1000\n truck 0.85 0.88 0.86 1000\n\n accuracy 0.79 10000\n macro avg 0.79 0.79 0.79 10000\nweighted avg 0.79 0.79 0.79 10000\n\n"
],
[
"#@ INSPECTING TRAINING LOSS AND ACCURACY:\nplt.style.use(\"ggplot\")\nplt.figure()\nplt.plot(np.arange(0, 40), H.history[\"loss\"], label=\"train_loss\")\nplt.plot(np.arange(0, 40), H.history[\"val_loss\"], label=\"val_loss\")\nplt.plot(np.arange(0, 40), H.history[\"accuracy\"], label=\"train_acc\")\nplt.plot(np.arange(0, 40), H.history[\"val_accuracy\"], label=\"val_acc\")\nplt.title(\"Training Loss and Accuracy\")\nplt.xlabel(\"Epoch\")\nplt.ylabel(\"Loss/Accuracy\")\nplt.legend()\nplt.show();",
"_____no_output_____"
]
],
[
[
"**Note:**\n- Batch Normalization can lead to a faster, more stable convergence with higher accuracy. \n- Batch Normalization will require more wall time to train the network even though the network will obtain higher accuracy in less epochs. ",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
]
|
d063570e27d884ad1284ea042d5745f573a85718 | 15,261 | ipynb | Jupyter Notebook | src/data-cleaning-final.ipynb | emilynomura1/1030MidtermProject | abe25ffde5733d7110f30ce81faf37a2dfa95abc | [
"MIT"
]
| null | null | null | src/data-cleaning-final.ipynb | emilynomura1/1030MidtermProject | abe25ffde5733d7110f30ce81faf37a2dfa95abc | [
"MIT"
]
| null | null | null | src/data-cleaning-final.ipynb | emilynomura1/1030MidtermProject | abe25ffde5733d7110f30ce81faf37a2dfa95abc | [
"MIT"
]
| null | null | null | 36.951574 | 120 | 0.519756 | [
[
[
"# Import packages\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n# Read in data. If data is zipped, unzip the file and change file path accordingly\nyelp = pd.read_csv(\"../yelp_academic_dataset_business.csv\",\n dtype={'attributes': str, 'postal_code': str}, low_memory=False)\n\n# Reorder columns\n# https://stackoverflow.com/questions/41968732/set-order-of-columns-in-pandas-dataframe\ncols_to_order = ['name', 'stars', 'review_count', 'categories', 'city', 'state', \n 'postal_code', 'latitude', 'longitude', 'address']\nnew_cols = cols_to_order + (yelp.columns.drop(cols_to_order).tolist())\nyelp = yelp[new_cols]\n\nprint(yelp.shape)\nprint(yelp.info())",
"_____no_output_____"
],
[
"# Remove entries with null in columns: name, categories, city, postal code\nyelp = yelp[(pd.isna(yelp['name'])==False) & \n (pd.isna(yelp['city'])==False) & \n (pd.isna(yelp['categories'])==False) & \n (pd.isna(yelp['postal_code'])==False)]\nprint(yelp.shape)",
"_____no_output_____"
],
[
"# Remove columns with <0.5% non-null values (<894) except BYOB=641 non-null\n# and non-relevant columns\nyelp = yelp.drop(yelp.columns[[6,9,17,26,31,33,34,37,38]], axis=1)\nprint(yelp.shape)",
"_____no_output_____"
],
[
"# Remove entries with < 1000 businesses in each state\nstate_counts = yelp['state'].value_counts()\nyelp = yelp[~yelp['state'].isin(state_counts[state_counts < 1000].index)]\nprint(yelp.shape)",
"_____no_output_____"
],
[
"# Create new column of grouped star rating\nconds = [\n ((yelp['stars'] == 1) | (yelp['stars'] == 1.5)),\n ((yelp['stars'] == 2) | (yelp['stars'] == 2.5)),\n ((yelp['stars'] == 3) | (yelp['stars'] == 3.5)),\n ((yelp['stars'] == 4) | (yelp['stars'] == 4.5)),\n (yelp['stars'] == 5) ]\nvalues = [1, 2, 3, 4, 5]\nyelp['star-rating'] = np.select(conds, values)\nprint(yelp.shape)",
"_____no_output_____"
],
[
"# Convert 'hours' columns to total hours open that day for each day column\nfrom datetime import timedelta, time\n# Monday ---------------------------------------------------------\nyelp[['hours.Monday.start', 'hours.Monday.end']] = yelp['hours.Monday'].str.split('-', 1, expand=True)\n# Monday start time\nhr_min = []\nfor row in yelp['hours.Monday.start']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el]) #change elements in list to int\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Monday.start'] = time_obj\n# Monday end time\nhr_min = []\nfor row in yelp['hours.Monday.end']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Monday.end'] = time_obj\n# Create column of time difference\nyelp['Monday.hrs.open'] = yelp['hours.Monday.end'] - yelp['hours.Monday.start']\n# Convert seconds to minutes\nhour_calc = []\nfor ob in yelp['Monday.hrs.open']:\n hour_calc.append(ob.seconds//3600) #convert seconds to hours for explainability\nyelp['Monday.hrs.open'] = hour_calc\n# Tuesday -------------------------------------------------------------\nyelp[['hours.Tuesday.start', 'hours.Tuesday.end']] = yelp['hours.Tuesday'].str.split('-', 1, expand=True)\nhr_min = []\nfor row in yelp['hours.Tuesday.start']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Tuesday.start'] = time_obj\nhr_min = []\nfor row in yelp['hours.Tuesday.end']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Tuesday.end'] = time_obj\nyelp['Tuesday.hrs.open'] = yelp['hours.Tuesday.end'] - yelp['hours.Tuesday.start']\nhour_calc = []\nfor ob in yelp['Tuesday.hrs.open']:\n hour_calc.append(ob.seconds//3600)\nyelp['Tuesday.hrs.open'] = hour_calc\n# Wednesday ---------------------------------------------------------\nyelp[['hours.Wednesday.start', 'hours.Wednesday.end']] = yelp['hours.Wednesday'].str.split('-', 1, expand=True)\nhr_min = []\nfor row in yelp['hours.Wednesday.start']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Wednesday.start'] = time_obj\nhr_min = []\nfor row in yelp['hours.Wednesday.end']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Wednesday.end'] = time_obj\nyelp['Wednesday.hrs.open'] = yelp['hours.Wednesday.end'] - yelp['hours.Wednesday.start']\nhour_calc = []\nfor ob in yelp['Wednesday.hrs.open']:\n hour_calc.append(ob.seconds//3600)\nyelp['Wednesday.hrs.open'] = hour_calc\n# Thursday --------------------------------------------------------------------\nyelp[['hours.Thursday.start', 'hours.Thursday.end']] = yelp['hours.Thursday'].str.split('-', 1, expand=True)\nhr_min = []\nfor row in yelp['hours.Thursday.start']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Thursday.start'] = time_obj\nhr_min = []\nfor row in yelp['hours.Thursday.end']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Thursday.end'] = time_obj\nyelp['Thursday.hrs.open'] = yelp['hours.Thursday.end'] - yelp['hours.Thursday.start']\nhour_calc = []\nfor ob in yelp['Thursday.hrs.open']:\n hour_calc.append(ob.seconds//3600)\nyelp['Thursday.hrs.open'] = hour_calc\n# Friday -----------------------------------------------------------------------\nyelp[['hours.Friday.start', 'hours.Friday.end']] = yelp['hours.Friday'].str.split('-', 1, expand=True)\nhr_min = []\nfor row in yelp['hours.Friday.start']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Friday.start'] = time_obj\nhr_min = []\nfor row in yelp['hours.Friday.end']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Friday.end'] = time_obj\nyelp['Friday.hrs.open'] = yelp['hours.Friday.end'] - yelp['hours.Friday.start']\nhour_calc = []\nfor ob in yelp['Friday.hrs.open']:\n hour_calc.append(ob.seconds//3600)\nyelp['Friday.hrs.open'] = hour_calc\n# Saturday ------------------------------------------------------------------------\nyelp[['hours.Saturday.start', 'hours.Saturday.end']] = yelp['hours.Saturday'].str.split('-', 1, expand=True)\nhr_min = []\nfor row in yelp['hours.Saturday.start']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Saturday.start'] = time_obj\nhr_min = []\nfor row in yelp['hours.Saturday.end']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Saturday.end'] = time_obj\nyelp['Saturday.hrs.open'] = yelp['hours.Saturday.end'] - yelp['hours.Saturday.start']\nhour_calc = []\nfor ob in yelp['Saturday.hrs.open']:\n hour_calc.append(ob.seconds//3600)\nyelp['Saturday.hrs.open'] = hour_calc\n# Sunday ----------------------------------------------------------------------\nyelp[['hours.Sunday.start', 'hours.Sunday.end']] = yelp['hours.Sunday'].str.split('-', 1, expand=True)\nhr_min = []\nfor row in yelp['hours.Sunday.start']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Sunday.start'] = time_obj\nhr_min = []\nfor row in yelp['hours.Sunday.end']:\n hr_min.append(str(row).split(':'))\nnew_el = []\nfor el in hr_min:\n if len(el) == 1:\n new_el.append([0,0])\n else:\n new_el.append([int(i) for i in el])\ntime_obj = []\nfor el_split in new_el:\n time_obj.append(timedelta(hours=el_split[0], minutes=el_split[1]))\nyelp['hours.Sunday.end'] = time_obj\nyelp['Sunday.hrs.open'] = yelp['hours.Sunday.end'] - yelp['hours.Sunday.start']\nhour_calc = []\nfor ob in yelp['Sunday.hrs.open']:\n hour_calc.append(ob.seconds//3600)\nyelp['Sunday.hrs.open'] = hour_calc",
"_____no_output_____"
],
[
"# Remove old target variable (stars) and \n# unecessary time columns that were created. Only keep 'day.hrs.open' columns\nyelp = yelp.drop(yelp.columns[[1,10,11,12,16,18,41,48,52,53,55,56,\n 58,59,61,62,64,65,67,68,70,71]], axis=1)\nprint(yelp.shape)",
"_____no_output_____"
],
[
"# Delete columns with unworkable form (dict)\ndel yelp['attributes.BusinessParking']\ndel yelp['attributes.Music']\ndel yelp['attributes.Ambience']\ndel yelp['attributes.GoodForKids']\ndel yelp['attributes.RestaurantsDelivery']\ndel yelp['attributes.BestNights']\ndel yelp['attributes.HairSpecializesIn']\ndel yelp['attributes.GoodForMeal']",
"_____no_output_____"
],
[
"# Look at final DF before saving\nprint(yelp.info())",
"_____no_output_____"
],
[
"# Save as CSV for faster loading -------------------------------------------------\nyelp.to_csv('/Data/yelp-clean.csv')",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d0636b41b3a1672c4be3cb9dea70e74ac379adcf | 822,625 | ipynb | Jupyter Notebook | celebrity.ipynb | peter1505/AIFFEL | def84c450cc479d2fc34d428438c542595606286 | [
"MIT"
]
| 2 | 2021-11-18T08:40:43.000Z | 2021-12-17T07:46:26.000Z | celebrity.ipynb | peter1505/AIFFEL | def84c450cc479d2fc34d428438c542595606286 | [
"MIT"
]
| null | null | null | celebrity.ipynb | peter1505/AIFFEL | def84c450cc479d2fc34d428438c542595606286 | [
"MIT"
]
| null | null | null | 1,600.437743 | 576,380 | 0.958157 | [
[
[
"# 내가 닮은 연예인은?\n\n\n사진 모으기\n얼굴 영역 자르기\n얼굴 영역 Embedding 추출\n연예인들의 얼굴과 거리 비교하기\n시각화\n회고\n\n\n1. 사진 모으기\n\n\n2. 얼굴 영역 자르기\n이미지에서 얼굴 영역을 자름\nimage.fromarray를 이용하여 PIL image로 변환한 후, 추후에 시각화에 사용",
"_____no_output_____"
]
],
[
[
"# 필요한 모듈 불러오기\n\nimport os\nimport re\nimport glob\n\nimport glob\nimport pickle\nimport pandas as pd\n\n\nimport matplotlib.pyplot as plt\nimport matplotlib.image as img\nimport face_recognition\n%matplotlib inline \nfrom PIL import Image\nimport numpy as np\n\nimport face_recognition\nimport os\nfrom PIL import Image\n\n\n\n\ndir_path = os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data'\nfile_list = os.listdir(dir_path)\n\nprint(len(file_list))\n\n# 이미지 파일 불러오기\n\nprint('연예인 이미지 파일 갯수:', len(file_list) - 5) # 추가한 내 사진 수를 뺀 나머지 사진 수 세기",
"247\n연예인 이미지 파일 갯수: 242\n"
],
[
"# 이미지 파일 리스트 확인\n\nprint (\"파일 리스트:\\n{}\".format(file_list))",
"파일 리스트:\n['강인덕.jpg', '김경현.jpg', '고보결.jpg', 'T.O.P.jpg', '김나영.jpg', '길은정.jpg', '고소영.jpg', '강문경.jpg', '강인봉.jpg', '곽진영.jpg', '강성민.jpg', '공승연.jpg', '김민상.jpg', '김규종.jpg', '기도훈.jpg', 'BUMZU.jpg', '고유진.jpg', '김병기.jpg', '곽동연.jpg', '김동희.jpg', '권인하.jpg', '김동률.jpg', '김상경.jpg', 'G-DRAGON.jpg', '권오중.jpg', '강성연.jpg', '김서라.jpg', '김다미.jpg', '김가은.jpg', '김기두.jpg', '강성아.jpg', '고운봉.jpg', '김가희.jpg', '강리나.jpg', '김선호.jpg', '고아라.jpg', '김그림.jpg', '김민희.jpg', '강경준.jpg', '김건모.jpg', '강균성.jpg', '곽지민.jpg', '고경표.jpg', '건지.jpg', '김경호.jpg', '강태오.jpg', '김다솜.jpg', '고윤정.jpg', '강예솔.jpg', '길학미.jpg', '강두리.jpg', '김뢰하.jpg', '권현상.jpg', '강민경.jpg', '곽민석.jpg', '강은탁.jpg', '곽도원.jpg', '김법래.jpg', 'K.WILL.jpg', '김석훈.jpg', '구윤회.jpg', '금보라.jpg', '김갑수.jpg', '김명준.jpg', '강경헌.jpg', '길정우.jpg', '김선혁.jpg', '권성희.jpg', '김고은.jpg', '감우성.jpg', '강소라.jpg', '강승윤.jpg', '경수진.jpg', '김가란.jpg', '강이석.jpg', '공정환.jpg', '김민기.jpg', '김민교.jpg', '강신일.jpg', '권혁수.jpg', '김꽃비.jpg', '김남주.jpg', '곽희성.jpg', '간미연.jpg', '김민석.jpg', '강민아.jpg', 'SE7EN.jpg', '강소리.jpg', '곽정욱.jpg', '공명.jpg', '김보미.jpg', '김상호.jpg', '김명민.jpg', '김상희.jpg', '강봉성.jpg', '기리보이.jpg', '김규리.jpg', '김부선.jpg', '고수.jpg', '김보라.jpg', 'RM.jpg', '기주봉.jpg', '개리.jpg', '김국환.jpg', '김기범.jpg', '고아성.jpg', '김새론.jpg', '고원희.jpg', '김강훈.jpg', '견우.jpg', 'KCM.jpg', '곽시양.jpg', '권유리.jpg', '김범.jpg', '이원재_01.jpg', '고성희.jpg', '길건.jpg', 'Zion.T.jpg', '김병옥.jpg', '고준희.jpg', '김광규.jpg', '고주원.jpg', '강예원.jpg', '고민시.jpg', '공효진.jpg', '강소연.jpg', '김민.jpg', '김명수.jpg', '권해성.jpg', '김범룡.jpg', '강석우.jpg', '권소현.jpg', '강지섭.jpg', '강승원.jpg', 'MC몽.jpg', '김동명.jpg', '김민서.jpg', '김사랑.jpg', '김가연.jpg', '강별.jpg', '강지환.jpg', '강수지.jpg', '김상배.jpg', '권해효.jpg', 'euPhemia.jpg', '이원재_02.jpg', '금사향.jpg', '김민종.jpg', '권태원.jpg', '고현정.jpg', '강성필.jpg', 'V.One.jpg', '김강우.jpg', '김선웅.jpg', '김도연.jpg', '권은아.jpg', '기은세.jpg', '김동한.jpg', '강이채.jpg', '고윤.jpg', '길해연.jpg', '견미리.jpg', '구재이.jpg', '강기영.jpg', '고두심.jpg', '김민준.jpg', '권화운.jpg', '권다현.jpg', '가희.jpg', '강다현.jpg', '고인범.jpg', '김광석.jpg', '강산에.jpg', 'JK김동욱.jpg', '김새벽.jpg', '권은수.jpg', '강예빈.jpg', '강수연.jpg', '김기방.jpg', '구혜선.jpg', '금잔디.jpg', '강하늘.jpg', '고창석.jpg', '강민주.jpg', '김남길.jpg', '김나운.jpg', '거미.jpg', '고은아.jpg', '길용우.jpg', '권율.jpg', '김대명.jpg', '김다현.jpg', '강남길.jpg', '김병세.jpg', '김빈우.jpg', '금새록.jpg', '강한나.jpg', '김단우.jpg', '김도윤.jpg', '권상우.jpg', '김보경.jpg', '경인선.jpg', '강타.jpg', '길미.jpg', '갈소원.jpg', '고나은.jpg', '권동호.jpg', '김빛나리.jpg', '공유.jpg', '구원찬.jpg', '기태영.jpg', '김무열.jpg', '김권.jpg', '김동욱.jpg', '김선영.jpg', '고세원.jpg', '김범수.jpg', '김명곤.jpg', '김경록.jpg', '김보민.jpg', '고나희.jpg', '강부자.jpg', '강성진.jpg', '고은미.jpg', '강수진.jpg', '강은비.jpg', '김래원.jpg', '김서형.jpg', '김보연.jpg', '강진.jpg', '김단율.jpg', '금단비.jpg', '강정우.jpg', '.ipynb_checkpoints', '김동완.jpg', '김규선.jpg', '김민주.jpg', '김상중.jpg', '김민경.jpg', '강혜연.jpg', '강동원.jpg', '강문영.jpg', '김무생.jpg', '곽창선.jpg', '공형진.jpg', '김빈.jpg', '김국희.jpg']\n"
],
[
"# 이미지 파일 일부 확인\n\n# Set figsize here\nfig, axes = plt.subplots(nrows=2, ncols=3, figsize=(24,10))\n\n# flatten axes for easy iterating\nfor i, ax in enumerate(axes.flatten()):\n image = img.imread(dir_path+'/'+file_list[i])\n ax.imshow(image)\nplt.show()\n\nfig.tight_layout()",
"_____no_output_____"
],
[
"\n# 이미지 파일 경로를 파라미터로 넘기면 얼굴 영역만 잘라주는 함수\n\ndef get_cropped_face(image_file):\n image = face_recognition.load_image_file(image_file)\n face_locations = face_recognition.face_locations(image)\n a, b, c, d = face_locations[0]\n cropped_face = image[a:c,d:b,:]\n \n return cropped_face",
"_____no_output_____"
],
[
"# 얼굴 영역이 정확히 잘리는 지 확인\n\nimage_path = os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data/이원재_02.jpg'\n\ncropped_face = get_cropped_face(image_path)\nplt.imshow(cropped_face)",
"_____no_output_____"
]
],
[
[
"## Step3. 얼굴 영역의 임베딩 추출하기",
"_____no_output_____"
]
],
[
[
"# 얼굴 영역을 가지고 얼굴 임베딩 벡터를 구하는 함수\n\ndef get_face_embedding(face):\n return face_recognition.face_encodings(face, model='cnn')",
"_____no_output_____"
],
[
"# 파일 경로를 넣으면 embedding_dict를 리턴하는 함수\n\ndef get_face_embedding_dict(dir_path):\n file_list = os.listdir(dir_path)\n embedding_dict = {}\n \n for file in file_list:\n try: \n img_path = os.path.join(dir_path, file)\n face = get_cropped_face(img_path)\n embedding = get_face_embedding(face)\n if len(embedding) > 0: \n # 얼굴영역 face가 제대로 detect되지 않으면 len(embedding)==0인 경우가 발생하므로 \n # os.path.splitext(file)[0]에는 이미지파일명에서 확장자를 제거한 이름이 담깁니다. \n embedding_dict[os.path.splitext(file)[0]] = embedding[0]\n # embedding_dict[] 이미지 파일의 임베딩을 구해 담음 키=사람이름, 값=임베딩 벡터\n # os.path.splitext(file)[0] 파일의 확장자를 제거한 이름만 추출\n # embedding[0]은 넣고 싶은 요소값\n\n except:\n continue\n \n return embedding_dict",
"_____no_output_____"
],
[
"embedding_dict = get_face_embedding_dict(dir_path)",
"_____no_output_____"
]
],
[
[
"## Step4. 모은 연예인들과 비교하기",
"_____no_output_____"
]
],
[
[
"# 이미지 간 거리를 구하는 함수\n\ndef get_distance(name1, name2):\n return np.linalg.norm(embedding_dict[name1]-embedding_dict[name2], ord=2)",
"_____no_output_____"
],
[
"# 본인 사진의 거리를 확인해보자\n\nprint('내 사진끼리의 거리는?:', get_distance('이원재_01', '이원재_02'))",
"내 사진끼리의 거리는?: 0.27525162596989655\n"
],
[
"# name1과 name2의 거리를 비교하는 함수를 생성하되, name1은 미리 지정하고, name2는 호출시에 인자로 받도록 합니다.\n\ndef get_sort_key_func(name1):\n def get_distance_from_name1(name2):\n return get_distance(name1, name2)\n return get_distance_from_name1",
"_____no_output_____"
],
[
"\n# 닮은꼴 순위, 이름, 임베딩 거리를 포함한 Top-5 리스트 출력하는 함수\n\ndef get_nearest_face(name, top=5):\n sort_key_func = get_sort_key_func(name)\n sorted_faces = sorted(embedding_dict.items(), key=lambda x:sort_key_func(x[0]))\n \n rank_cnt = 1 # 순위를 세는 변수\n pass_cnt = 1 # 건너뛴 숫자를 세는 변수(본인 사진 카운트)\n end = 0 # 닮은 꼴 5번 출력시 종료하기 위해 세는 변수\n for i in range(top+15):\n rank_cnt += 1\n if sorted_faces[i][0].find('이원재_02') == 0: # 본인 사진인 mypicture라는 파일명으로 시작하는 경우 제외합니다.\n pass_cnt += 1\n continue\n if sorted_faces[i]:\n print('순위 {} : 이름({}), 거리({})'.format(rank_cnt - pass_cnt, sorted_faces[i][0], sort_key_func(sorted_faces[i][0])))\n end += 1\n if end == 5: # end가 5가 된 경우 연예인 5명 출력되었기에 종료합니다.\n break",
"_____no_output_____"
],
[
"# '이원재_01'과 가장 닮은 사람은 누굴까요?\n\nget_nearest_face('이원재_01')",
"순위 1 : 이름(이원재_01), 거리(0.0)\n순위 2 : 이름(euPhemia), 거리(0.39785575251289035)\n순위 3 : 이름(공명), 거리(0.43181500298337777)\n순위 4 : 이름(강기영), 거리(0.44559566211978)\n순위 5 : 이름(JK김동욱), 거리(0.4560282622605789)\n"
],
[
"# '이원재_02'와 가장 닮은 사람은 누굴까요?\n\nget_nearest_face('이원재_02')",
"순위 1 : 이름(이원재_01), 거리(0.27525162596989655)\n순위 2 : 이름(euPhemia), 거리(0.38568278214648233)\n순위 3 : 이름(공명), 거리(0.445581489047543)\n순위 4 : 이름(김동완), 거리(0.44765017085662295)\n순위 5 : 이름(강성필), 거리(0.4536061116328271)\n"
]
],
[
[
"## Step5. 다양한 재미있는 시각화 시도해 보기",
"_____no_output_____"
]
],
[
[
"\n# 사진 경로 설정\n\nmypicture1 = os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data/이원재_01.jpg'\nmypicture2 = os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data/이원재_02.jpg'\n\nmc= os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data/MC몽.jpg'\ngahee = os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data/가희.jpg'\nseven = os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data/SE7EN.jpg'\ngam = os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data/감우성.jpg'\n\ngang = os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data/강경준.jpg'\ngyung = os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data/강경현.jpg'\ngi = os.getenv('HOME')+'/aiffel/EXP_07_face_embedding/data/강기영.jpg'",
"_____no_output_____"
],
[
"\n# 크롭한 얼굴을 저장해 보자\n\na1 = get_cropped_face(mypicture1)\na2 = get_cropped_face(mypicture2)\n\nb1 = get_cropped_face(mc)\nb2 = get_cropped_face(gahee)\nb3 = get_cropped_face(gam)",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,8))\n\nplt.subplot(231)\nplt.imshow(a1)\nplt.axis('off')\nplt.title('1st')\nplt.subplot(232)\nplt.imshow(a2)\nplt.axis('off')\nplt.title('me')\nplt.subplot(233)\nplt.imshow(b1)\nplt.axis('off')\nplt.title('2nd')\nplt.subplot(234)\n\nprint('''mypicture의 순위\n순위 1 : 이름(사쿠라), 거리(0.36107689719729225)\n순위 2 : 이름(트와이스나연), 거리(0.36906292012955577) \n순위 3 : 이름(아이유), 거리(0.3703590842312735) \n순위 4 : 이름(유트루), 거리(0.3809516850126146) \n순위 5 : 이름(지호), 거리(0.3886670633997685)''')",
"mypicture의 순위\n순위 1 : 이름(사쿠라), 거리(0.36107689719729225)\n순위 2 : 이름(트와이스나연), 거리(0.36906292012955577) \n순위 3 : 이름(아이유), 거리(0.3703590842312735) \n순위 4 : 이름(유트루), 거리(0.3809516850126146) \n순위 5 : 이름(지호), 거리(0.3886670633997685)\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
d0636f5a18ee02ac2f75f5d634bcbcb10c053fe4 | 43,386 | ipynb | Jupyter Notebook | Feature - Handling missing Values/5. Arbitrary Value Imputation.ipynb | deepakkum21/Feature-Engineering | ea10b2685c842bcf0247887db755d05c38b23844 | [
"Apache-2.0"
]
| null | null | null | Feature - Handling missing Values/5. Arbitrary Value Imputation.ipynb | deepakkum21/Feature-Engineering | ea10b2685c842bcf0247887db755d05c38b23844 | [
"Apache-2.0"
]
| null | null | null | Feature - Handling missing Values/5. Arbitrary Value Imputation.ipynb | deepakkum21/Feature-Engineering | ea10b2685c842bcf0247887db755d05c38b23844 | [
"Apache-2.0"
]
| null | null | null | 114.777778 | 28,204 | 0.847877 | [
[
[
"## 5. Arbitrary Value Imputation\n#### this technique was derived from kaggle competition It consists of replacing NAN by an arbitrary value",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"df=pd.read_csv(\"titanic.csv\", usecols=[\"Age\",\"Fare\",\"Survived\"])\ndf.head()",
"_____no_output_____"
],
[
"def impute_nan(df,variable):\n df[variable+'_zero']=df[variable].fillna(0)\n df[variable+'_hundred']=df[variable].fillna(100)",
"_____no_output_____"
],
[
"df['Age'].hist(bins=50)",
"_____no_output_____"
]
],
[
[
"### Advantages\n Easy to implement\n Captures the importance of missingess if there is one\n### Disadvantages\n Distorts the original distribution of the variable\n If missingess is not important, it may mask the predictive power of the original variable by distorting its distribution\n Hard to decide which value to use",
"_____no_output_____"
]
],
[
[
"impute_nan(df,'Age')\ndf.head()",
"_____no_output_____"
],
[
"print(df['Age'].std())\nprint(df['Age_zero'].std())\nprint(df['Age_hundred'].std())",
"14.526497332334044\n17.596074065915886\n30.930372890173594\n"
],
[
"print(df['Age'].mean())\nprint(df['Age_zero'].mean())\nprint(df['Age_hundred'].mean())",
"29.69911764705882\n23.79929292929293\n43.66461279461279\n"
],
[
"import matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"fig = plt.figure()\nax = fig.add_subplot(111)\ndf['Age'].plot(kind='kde', ax=ax)\ndf.Age_zero.plot(kind='kde', ax=ax, color='red')\ndf.Age_hundred.plot(kind='kde', ax=ax, color='green')\nlines, labels = ax.get_legend_handles_labels()\nax.legend(lines, labels, loc='best')",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
d063869573f5b3dfc578fc45bb7d1c7875fd50ea | 25,044 | ipynb | Jupyter Notebook | learning/matplot/animation/basic_animation.ipynb | HypoChloremic/python_learning | 3778f6d7c35cdd54a85a3418aba99f2b91d32775 | [
"Apache-2.0"
]
| 2 | 2019-06-23T07:17:30.000Z | 2019-07-06T15:15:42.000Z | learning/matplot/animation/basic_animation.ipynb | HypoChloremic/python_learning | 3778f6d7c35cdd54a85a3418aba99f2b91d32775 | [
"Apache-2.0"
]
| null | null | null | learning/matplot/animation/basic_animation.ipynb | HypoChloremic/python_learning | 3778f6d7c35cdd54a85a3418aba99f2b91d32775 | [
"Apache-2.0"
]
| 1 | 2019-06-23T07:17:43.000Z | 2019-06-23T07:17:43.000Z | 61.53317 | 4,768 | 0.592797 | [
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.animation as animation\nimport matplotlib\nfrom IPython.display import HTML\n\n",
"_____no_output_____"
],
[
"def update_line(num, data, line):\n print(num)\n line.set_data(data[..., :num])\n return line,",
"_____no_output_____"
],
[
"plt.rcParams['animation.writer'] = 'ffmpeg'\nprint(matplotlib.animation.writers.list())",
"['pillow', 'ffmpeg', 'ffmpeg_file', 'html']\n"
],
[
"fig1 = plt.figure()\n\n# Fixing random state for reproducibility\nnp.random.seed(19680801)\n\ndata = np.random.rand(2, 25)\nl, = plt.plot(x=[], y=[])\nplt.xlim(0, 1)\nplt.ylim(0, 1)\nline_ani = animation.FuncAnimation(fig1, update_line, 25, fargs=(data, l),\n interval=50, blit=True)\nHTML(line_ani.to_html5_video())",
"_____no_output_____"
],
[
"help(plt.plot)",
"Help on function plot in module matplotlib.pyplot:\n\nplot(*args, scalex=True, scaley=True, data=None, **kwargs)\n Plot y versus x as lines and/or markers.\n \n Call signatures::\n \n plot([x], y, [fmt], *, data=None, **kwargs)\n plot([x], y, [fmt], [x2], y2, [fmt2], ..., **kwargs)\n \n The coordinates of the points or line nodes are given by *x*, *y*.\n \n The optional parameter *fmt* is a convenient way for defining basic\n formatting like color, marker and linestyle. It's a shortcut string\n notation described in the *Notes* section below.\n \n >>> plot(x, y) # plot x and y using default line style and color\n >>> plot(x, y, 'bo') # plot x and y using blue circle markers\n >>> plot(y) # plot y using x as index array 0..N-1\n >>> plot(y, 'r+') # ditto, but with red plusses\n \n You can use `.Line2D` properties as keyword arguments for more\n control on the appearance. Line properties and *fmt* can be mixed.\n The following two calls yield identical results:\n \n >>> plot(x, y, 'go--', linewidth=2, markersize=12)\n >>> plot(x, y, color='green', marker='o', linestyle='dashed',\n ... linewidth=2, markersize=12)\n \n When conflicting with *fmt*, keyword arguments take precedence.\n \n \n **Plotting labelled data**\n \n There's a convenient way for plotting objects with labelled data (i.e.\n data that can be accessed by index ``obj['y']``). Instead of giving\n the data in *x* and *y*, you can provide the object in the *data*\n parameter and just give the labels for *x* and *y*::\n \n >>> plot('xlabel', 'ylabel', data=obj)\n \n All indexable objects are supported. This could e.g. be a `dict`, a\n `pandas.DataFame` or a structured numpy array.\n \n \n **Plotting multiple sets of data**\n \n There are various ways to plot multiple sets of data.\n \n - The most straight forward way is just to call `plot` multiple times.\n Example:\n \n >>> plot(x1, y1, 'bo')\n >>> plot(x2, y2, 'go')\n \n - Alternatively, if your data is already a 2d array, you can pass it\n directly to *x*, *y*. A separate data set will be drawn for every\n column.\n \n Example: an array ``a`` where the first column represents the *x*\n values and the other columns are the *y* columns::\n \n >>> plot(a[0], a[1:])\n \n - The third way is to specify multiple sets of *[x]*, *y*, *[fmt]*\n groups::\n \n >>> plot(x1, y1, 'g^', x2, y2, 'g-')\n \n In this case, any additional keyword argument applies to all\n datasets. Also this syntax cannot be combined with the *data*\n parameter.\n \n By default, each line is assigned a different style specified by a\n 'style cycle'. The *fmt* and line property parameters are only\n necessary if you want explicit deviations from these defaults.\n Alternatively, you can also change the style cycle using\n :rc:`axes.prop_cycle`.\n \n \n Parameters\n ----------\n x, y : array-like or scalar\n The horizontal / vertical coordinates of the data points.\n *x* values are optional and default to `range(len(y))`.\n \n Commonly, these parameters are 1D arrays.\n \n They can also be scalars, or two-dimensional (in that case, the\n columns represent separate data sets).\n \n These arguments cannot be passed as keywords.\n \n fmt : str, optional\n A format string, e.g. 'ro' for red circles. See the *Notes*\n section for a full description of the format strings.\n \n Format strings are just an abbreviation for quickly setting\n basic line properties. All of these and more can also be\n controlled by keyword arguments.\n \n This argument cannot be passed as keyword.\n \n data : indexable object, optional\n An object with labelled data. If given, provide the label names to\n plot in *x* and *y*.\n \n .. note::\n Technically there's a slight ambiguity in calls where the\n second label is a valid *fmt*. `plot('n', 'o', data=obj)`\n could be `plt(x, y)` or `plt(y, fmt)`. In such cases,\n the former interpretation is chosen, but a warning is issued.\n You may suppress the warning by adding an empty format string\n `plot('n', 'o', '', data=obj)`.\n \n Other Parameters\n ----------------\n scalex, scaley : bool, optional, default: True\n These parameters determined if the view limits are adapted to\n the data limits. The values are passed on to `autoscale_view`.\n \n **kwargs : `.Line2D` properties, optional\n *kwargs* are used to specify properties like a line label (for\n auto legends), linewidth, antialiasing, marker face color.\n Example::\n \n >>> plot([1, 2, 3], [1, 2, 3], 'go-', label='line 1', linewidth=2)\n >>> plot([1, 2, 3], [1, 4, 9], 'rs', label='line 2')\n \n If you make multiple lines with one plot command, the kwargs\n apply to all those lines.\n \n Here is a list of available `.Line2D` properties:\n \n Properties:\n agg_filter: a filter function, which takes a (m, n, 3) float array and a dpi value, and returns a (m, n, 3) array\n alpha: float or None\n animated: bool\n antialiased or aa: bool\n clip_box: `.Bbox`\n clip_on: bool\n clip_path: Patch or (Path, Transform) or None\n color or c: color\n contains: callable\n dash_capstyle: {'butt', 'round', 'projecting'}\n dash_joinstyle: {'miter', 'round', 'bevel'}\n dashes: sequence of floats (on/off ink in points) or (None, None)\n data: (2, N) array or two 1D arrays\n drawstyle or ds: {'default', 'steps', 'steps-pre', 'steps-mid', 'steps-post'}, default: 'default'\n figure: `.Figure`\n fillstyle: {'full', 'left', 'right', 'bottom', 'top', 'none'}\n gid: str\n in_layout: bool\n label: object\n linestyle or ls: {'-', '--', '-.', ':', '', (offset, on-off-seq), ...}\n linewidth or lw: float\n marker: marker style\n markeredgecolor or mec: color\n markeredgewidth or mew: float\n markerfacecolor or mfc: color\n markerfacecoloralt or mfcalt: color\n markersize or ms: float\n markevery: None or int or (int, int) or slice or List[int] or float or (float, float)\n path_effects: `.AbstractPathEffect`\n picker: float or callable[[Artist, Event], Tuple[bool, dict]]\n pickradius: float\n rasterized: bool or None\n sketch_params: (scale: float, length: float, randomness: float)\n snap: bool or None\n solid_capstyle: {'butt', 'round', 'projecting'}\n solid_joinstyle: {'miter', 'round', 'bevel'}\n transform: `matplotlib.transforms.Transform`\n url: str\n visible: bool\n xdata: 1D array\n ydata: 1D array\n zorder: float\n \n Returns\n -------\n lines\n A list of `.Line2D` objects representing the plotted data.\n \n See Also\n --------\n scatter : XY scatter plot with markers of varying size and/or color (\n sometimes also called bubble chart).\n \n Notes\n -----\n **Format Strings**\n \n A format string consists of a part for color, marker and line::\n \n fmt = '[marker][line][color]'\n \n Each of them is optional. If not provided, the value from the style\n cycle is used. Exception: If ``line`` is given, but no ``marker``,\n the data will be a line without markers.\n \n Other combinations such as ``[color][marker][line]`` are also\n supported, but note that their parsing may be ambiguous.\n \n **Markers**\n \n ============= ===============================\n character description\n ============= ===============================\n ``'.'`` point marker\n ``','`` pixel marker\n ``'o'`` circle marker\n ``'v'`` triangle_down marker\n ``'^'`` triangle_up marker\n ``'<'`` triangle_left marker\n ``'>'`` triangle_right marker\n ``'1'`` tri_down marker\n ``'2'`` tri_up marker\n ``'3'`` tri_left marker\n ``'4'`` tri_right marker\n ``'s'`` square marker\n ``'p'`` pentagon marker\n ``'*'`` star marker\n ``'h'`` hexagon1 marker\n ``'H'`` hexagon2 marker\n ``'+'`` plus marker\n ``'x'`` x marker\n ``'D'`` diamond marker\n ``'d'`` thin_diamond marker\n ``'|'`` vline marker\n ``'_'`` hline marker\n ============= ===============================\n \n **Line Styles**\n \n ============= ===============================\n character description\n ============= ===============================\n ``'-'`` solid line style\n ``'--'`` dashed line style\n ``'-.'`` dash-dot line style\n ``':'`` dotted line style\n ============= ===============================\n \n Example format strings::\n \n 'b' # blue markers with default shape\n 'or' # red circles\n '-g' # green solid line\n '--' # dashed line with default color\n '^k:' # black triangle_up markers connected by a dotted line\n \n **Colors**\n \n The supported color abbreviations are the single letter codes\n \n ============= ===============================\n character color\n ============= ===============================\n ``'b'`` blue\n ``'g'`` green\n ``'r'`` red\n ``'c'`` cyan\n ``'m'`` magenta\n ``'y'`` yellow\n ``'k'`` black\n ``'w'`` white\n ============= ===============================\n \n and the ``'CN'`` colors that index into the default property cycle.\n \n If the color is the only part of the format string, you can\n additionally use any `matplotlib.colors` spec, e.g. full names\n (``'green'``) or hex strings (``'#008000'``).\n\n"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code"
]
]
|
d063877bfa6c74b4e238643da9e2ef6c123e9eec | 5,330 | ipynb | Jupyter Notebook | notebooks/Toy_problem/Tp4_criterium_2_daylighting_potential.ipynb | Maxketelaar/thesis | d1bab7dffa414c335b452476733c8b9d8ec24579 | [
"MIT"
]
| null | null | null | notebooks/Toy_problem/Tp4_criterium_2_daylighting_potential.ipynb | Maxketelaar/thesis | d1bab7dffa414c335b452476733c8b9d8ec24579 | [
"MIT"
]
| null | null | null | notebooks/Toy_problem/Tp4_criterium_2_daylighting_potential.ipynb | Maxketelaar/thesis | d1bab7dffa414c335b452476733c8b9d8ec24579 | [
"MIT"
]
| 1 | 2021-12-21T15:24:57.000Z | 2021-12-21T15:24:57.000Z | 27.905759 | 392 | 0.558161 | [
[
[
"#### loading the libraries",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\nimport pyvista as pv\nimport trimesh as tm\nimport numpy as np\nimport topogenesis as tg\nimport pickle as pk\nsys.path.append(os.path.realpath('..\\..')) # no idea how or why this is not working without adding this to the path TODO: learn about path etc.\nfrom notebooks.resources import RES as res",
"_____no_output_____"
]
],
[
[
"#### loading the configuration of the test",
"_____no_output_____"
]
],
[
[
"# load base lattice CSV file\nlattice_path = os.path.relpath('../../data/macrovoxels.csv')\nmacro_lattice = tg.lattice_from_csv(lattice_path)\n\n# load random configuration for testing\nconfig_path = os.path.relpath('../../data/random_lattice.csv')\nconfiguration = tg.lattice_from_csv(config_path)\n\n# load environment\nenvironment_path = os.path.relpath(\"../../data/movedcontext.obj\") \nenvironment_mesh = tm.load(environment_path)\n\n# load solar vectors\nvectors = pk.load(open(\"../../data/sunvectors.pk\", \"rb\"))\n\n# load vector intensities\nintensity = pk.load(open(\"../../data/dnival.pk\", \"rb\"))",
"_____no_output_____"
]
],
[
[
"#### during optimization, arrays like these will be passed to the function:",
"_____no_output_____"
]
],
[
[
"variable = [0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 0]",
"_____no_output_____"
]
],
[
[
"#### calling the objective function",
"_____no_output_____"
]
],
[
[
"# input is the decision variables, a referenca lattice, the visibility vectors, their magnitude (i.e. direct normal illuminance for daylight), and a mesh of the environment\n# output is the total objective score in 100s of lux on the facade, and 100s of lux per each surface (voxel roofs)\ncrit, voxcrit = res.crit_2_DL(variable, macro_lattice, vectors, intensity, environment_mesh)",
"_____no_output_____"
]
],
[
[
"#### generating mesh",
"_____no_output_____"
]
],
[
[
"meshes, _, _ = res.construct_vertical_mesh(configuration, configuration.unit)\nfacademesh = tm.util.concatenate(meshes)",
"_____no_output_____"
]
],
[
[
"#### visualisation",
"_____no_output_____"
]
],
[
[
"p = pv.Plotter(notebook=True)\n\nconfiguration.fast_vis(p,False,False,opacity=0.1)\n# p.add_arrows(ctr_per_ray, -ray_per_ctr, mag=5, show_scalar_bar=False)\n# p.add_arrows(ctr_per_ray, nrm_per_ray, mag=5, show_scalar_bar=False)\n# p.add_mesh(roof_mesh)\np.add_mesh(environment_mesh)\np.add_mesh(facademesh, cmap='fire', scalars=np.repeat(voxcrit,2))\np.add_points(vectors*-300)\n# p.add_points(horizontal_test_points)\n\np.show(use_ipyvtk=True)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d0638e2eaa1d7f56e9fec1065b6dd907f395d8fb | 5,772 | ipynb | Jupyter Notebook | Cap04/.ipynb_checkpoints/modulos_pacotes-checkpoint.ipynb | carlos-freitas-gitHub/python-analytics | 4b55cb2acb3383ded700596c5a856b7e2124f2da | [
"Apache-2.0"
]
| 1 | 2020-07-31T20:31:19.000Z | 2020-07-31T20:31:19.000Z | Cap04/.ipynb_checkpoints/modulos_pacotes-checkpoint.ipynb | carlos-freitas-gitHub/python-analytics | 4b55cb2acb3383ded700596c5a856b7e2124f2da | [
"Apache-2.0"
]
| null | null | null | Cap04/.ipynb_checkpoints/modulos_pacotes-checkpoint.ipynb | carlos-freitas-gitHub/python-analytics | 4b55cb2acb3383ded700596c5a856b7e2124f2da | [
"Apache-2.0"
]
| null | null | null | 20.688172 | 502 | 0.445773 | [
[
[
"## Módulo e pacote",
"_____no_output_____"
]
],
[
[
"# importando módulo, math para operações matemáticas\nimport math",
"_____no_output_____"
],
[
"# verificando todos os metodos do modulo\ndir(math)",
"_____no_output_____"
],
[
"# usando um dos metódos do módulo, sqrt, raiz quadrada\nprint(math.sqrt(25))",
"5.0\n"
],
[
"# importando apenas uma função do módulo math\nfrom math import sqrt ",
"_____no_output_____"
],
[
"# usando este método, como importou somente a função do módulo pode usar somente\n# a função sem o nome do pacote\nprint(sqrt(25))",
"5.0\n"
],
[
"# imprimindo todos os metodos do módulo math\nprint(dir(math))",
"['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'remainder', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']\n"
],
[
"# help da função sqrt do módulo math\nprint(help(sqrt))",
"Help on built-in function sqrt in module math:\n\nsqrt(x, /)\n Return the square root of x.\n\nNone\n"
],
[
"# random\nimport random",
"_____no_output_____"
],
[
"# random choice(), escolha, buscando os elementos de maneira aleatória\nprint(random.choice(['Maça', 'Banana', 'Laranja']))",
"Laranja\n"
],
[
"# renadom sample(), amostra apartir de uma amostra de valores\nprint(random.sample(range(100), 10))",
"[51, 33, 65, 7, 66, 95, 96, 17, 77, 22]\n"
],
[
"# módulo para estatistíca\nimport statistics",
"_____no_output_____"
],
[
"# criando uma lista de números reais\ndados = [2.75, 1.75, 1.25, 0.25, 1.25, 3.5]",
"_____no_output_____"
]
]
]
| [
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d0639939fd0e4f172287ca2c118fc3142e12f140 | 182,702 | ipynb | Jupyter Notebook | BareBones 1D CNN LSTM MLP - Sequence Prediction.ipynb | codeWhim/Sequence-Prediction | 2f9a0c3f57c20c311840ae00009637f553081f5b | [
"MIT"
]
| 1 | 2019-03-06T15:08:47.000Z | 2019-03-06T15:08:47.000Z | BareBones 1D CNN LSTM MLP - Sequence Prediction.ipynb | codeWhim/Sequence-Prediction | 2f9a0c3f57c20c311840ae00009637f553081f5b | [
"MIT"
]
| null | null | null | BareBones 1D CNN LSTM MLP - Sequence Prediction.ipynb | codeWhim/Sequence-Prediction | 2f9a0c3f57c20c311840ae00009637f553081f5b | [
"MIT"
]
| null | null | null | 148.78013 | 24,024 | 0.845612 | [
[
[
"<h1>Notebook Content</h1>\n\n1. [Import Packages](#1)\n1. [Helper Functions](#2)\n1. [Input](#3)\n1. [Model](#4)\n1. [Prediction](#5)\n1. [Complete Figure](#6)",
"_____no_output_____"
],
[
"<h1 id=\"1\">1. Import Packages</h1>\nImporting all necessary and useful packages in single cell.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport keras\nimport tensorflow as tf\nfrom numpy import array\nfrom keras.models import Sequential\nfrom keras.layers import LSTM\nfrom keras.layers import Dense\nfrom keras.layers import Flatten\nfrom keras.layers import TimeDistributed\nfrom keras.layers.convolutional import Conv1D\nfrom keras.layers.convolutional import MaxPooling1D\nfrom keras_tqdm import TQDMNotebookCallback\nfrom sklearn.preprocessing import MinMaxScaler\nfrom tqdm import tqdm_notebook\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport random\nfrom random import randint",
"_____no_output_____"
]
],
[
[
"<h1 id=\"2\">2. Helper Functions</h1>\nDefining Some helper functions which we will need later in code",
"_____no_output_____"
]
],
[
[
"# split a univariate sequence into samples\ndef split_sequence(sequence, n_steps, look_ahead=0):\n X, y = list(), list()\n for i in range(len(sequence)-look_ahead):\n # find the end of this pattern\n end_ix = i + n_steps\n # check if we are beyond the sequence\n if end_ix > len(sequence)-1-look_ahead:\n break\n # gather input and output parts of the pattern\n seq_x, seq_y = sequence[i:end_ix], sequence[end_ix+look_ahead]\n X.append(seq_x)\n y.append(seq_y)\n return array(X), array(y)\n\ndef plot_multi_graph(xAxis,yAxes,title='',xAxisLabel='number',yAxisLabel='Y'):\n linestyles = ['-', '--', '-.', ':']\n plt.figure()\n plt.title(title)\n plt.xlabel(xAxisLabel)\n plt.ylabel(yAxisLabel)\n for key, value in yAxes.items():\n plt.plot(xAxis, np.array(value), label=key, linestyle=linestyles[randint(0,3)])\n plt.legend()\n \ndef normalize(values):\n values = array(values, dtype=\"float64\").reshape((len(values), 1))\n # train the normalization\n scaler = MinMaxScaler(feature_range=(0, 1))\n scaler = scaler.fit(values)\n #print('Min: %f, Max: %f' % (scaler.data_min_, scaler.data_max_))\n # normalize the dataset and print the first 5 rows\n normalized = scaler.transform(values)\n return normalized,scaler",
"_____no_output_____"
]
],
[
[
"<h1 id=\"3\">3. Input</h1>\n\n<h3 id=\"3-1\">3-1. Sequence PreProcessing</h3>\nSplitting and Reshaping",
"_____no_output_____"
]
],
[
[
"n_features = 1\nn_seq = 20\nn_steps = 1\n \ndef sequence_preprocessed(values, sliding_window, look_ahead=0):\n \n # Normalization\n normalized,scaler = normalize(values)\n \n # Try the following if randomizing the sequence:\n # random.seed('sam') # set the seed\n # raw_seq = random.sample(raw_seq, 100)\n\n # split into samples\n X, y = split_sequence(normalized, sliding_window, look_ahead)\n\n # reshape from [samples, timesteps] into [samples, subsequences, timesteps, features]\n X = X.reshape((X.shape[0], n_seq, n_steps, n_features))\n \n return X,y,scaler",
"_____no_output_____"
]
],
[
[
"<h3 id=\"3-2\">3-2. Providing Sequence</h3>\nDefining a raw sequence, sliding window of data to consider and look ahead future timesteps",
"_____no_output_____"
]
],
[
[
"# define input sequence\nsequence_val = [i for i in range(5000,7000)]\nsequence_train = [i for i in range(1000,2000)]\nsequence_test = [i for i in range(10000,14000)]\n\n# choose a number of time steps for sliding window\nsliding_window = 20\n\n# choose a number of further time steps after end of sliding_window till target start (gap between data and target)\nlook_ahead = 20\n\nX_train, y_train, scaler_train = sequence_preprocessed(sequence_train, sliding_window, look_ahead)\nX_val, y_val ,scaler_val = sequence_preprocessed(sequence_val, sliding_window, look_ahead)\nX_test,y_test,scaler_test = sequence_preprocessed(sequence_test, sliding_window, look_ahead)",
"_____no_output_____"
]
],
[
[
"<h1 id=\"4\">4. Model</h1>\n\n<h3 id=\"4-1\">4-1. Defining Layers</h3>\nAdding 1D Convolution, Max Pooling, LSTM and finally Dense (MLP) layer",
"_____no_output_____"
]
],
[
[
"# define model\nmodel = Sequential()\nmodel.add(TimeDistributed(Conv1D(filters=64, kernel_size=1, activation='relu'), \n input_shape=(None, n_steps, n_features)\n ))\nmodel.add(TimeDistributed(MaxPooling1D(pool_size=1)))\nmodel.add(TimeDistributed(Flatten()))\nmodel.add(LSTM(50, activation='relu', stateful=False))\nmodel.add(Dense(1))",
"_____no_output_____"
]
],
[
[
"<h3 id=\"4-2\">4-2. Training Model</h3>\nDefined early stop, can be used in callbacks param of model fit, not using for now since it's not recommended at first few iterations of experimentation with new data",
"_____no_output_____"
]
],
[
[
"# Defining multiple metrics, leaving it to a choice, some may be useful and few may even surprise on some problems\nmetrics = ['mean_squared_error',\n 'mean_absolute_error',\n 'mean_absolute_percentage_error',\n 'mean_squared_logarithmic_error',\n 'logcosh']\n\n# Compiling Model\nmodel.compile(optimizer='adam', loss='mape', metrics=metrics)\n\n# Defining early stop, call it in model fit callback\nearly_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)\n\n# Fit model\nhistory = model.fit(X_train, y_train, epochs=100, verbose=3, validation_data=(X_val,y_val))",
"Train on 960 samples, validate on 1960 samples\nEpoch 1/100\nEpoch 2/100\nEpoch 3/100\nEpoch 4/100\nEpoch 5/100\nEpoch 6/100\nEpoch 7/100\nEpoch 8/100\nEpoch 9/100\nEpoch 10/100\nEpoch 11/100\nEpoch 12/100\nEpoch 13/100\nEpoch 14/100\nEpoch 15/100\nEpoch 16/100\nEpoch 17/100\nEpoch 18/100\nEpoch 19/100\nEpoch 20/100\nEpoch 21/100\nEpoch 22/100\nEpoch 23/100\nEpoch 24/100\nEpoch 25/100\nEpoch 26/100\nEpoch 27/100\nEpoch 28/100\nEpoch 29/100\nEpoch 30/100\nEpoch 31/100\nEpoch 32/100\nEpoch 33/100\nEpoch 34/100\nEpoch 35/100\nEpoch 36/100\nEpoch 37/100\nEpoch 38/100\nEpoch 39/100\nEpoch 40/100\nEpoch 41/100\nEpoch 42/100\nEpoch 43/100\nEpoch 44/100\nEpoch 45/100\nEpoch 46/100\nEpoch 47/100\nEpoch 48/100\nEpoch 49/100\nEpoch 50/100\nEpoch 51/100\nEpoch 52/100\nEpoch 53/100\nEpoch 54/100\nEpoch 55/100\nEpoch 56/100\nEpoch 57/100\nEpoch 58/100\nEpoch 59/100\nEpoch 60/100\nEpoch 61/100\nEpoch 62/100\nEpoch 63/100\nEpoch 64/100\nEpoch 65/100\nEpoch 66/100\nEpoch 67/100\nEpoch 68/100\nEpoch 69/100\nEpoch 70/100\nEpoch 71/100\nEpoch 72/100\nEpoch 73/100\nEpoch 74/100\nEpoch 75/100\nEpoch 76/100\nEpoch 77/100\nEpoch 78/100\nEpoch 79/100\nEpoch 80/100\nEpoch 81/100\nEpoch 82/100\nEpoch 83/100\nEpoch 84/100\nEpoch 85/100\nEpoch 86/100\nEpoch 87/100\nEpoch 88/100\nEpoch 89/100\nEpoch 90/100\nEpoch 91/100\nEpoch 92/100\nEpoch 93/100\nEpoch 94/100\nEpoch 95/100\nEpoch 96/100\nEpoch 97/100\nEpoch 98/100\nEpoch 99/100\nEpoch 100/100\n"
]
],
[
[
"<h3 id=\"4-3\">4-3. Evaluating Model</h3>\nPlotting Training and Validation mean square error",
"_____no_output_____"
]
],
[
[
"# Plot Errors\n\nfor metric in metrics:\n xAxis = history.epoch\n yAxes = {}\n yAxes[\"Training\"]=history.history[metric]\n yAxes[\"Validation\"]=history.history['val_'+metric]\n plot_multi_graph(xAxis,yAxes, title=metric,xAxisLabel='Epochs')",
"_____no_output_____"
]
],
[
[
"<h1 id=\"5\">5. Prediction</h1>\n\n<h3 id=\"5-1\">5-1. Single Value Prediction</h3>\nPredicting a single value slided 20 (our provided figure for look_ahead above) values ahead",
"_____no_output_____"
]
],
[
[
"# demonstrate prediction\nx_input = array([i for i in range(100,120)])\nprint(x_input)\nx_input = x_input.reshape((1, n_seq, n_steps, n_features))\nyhat = model.predict(x_input)\nprint(yhat)",
"[100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117\n 118 119]\n[[105.82992]]\n"
]
],
[
[
"<h3 id=\"5-2\">5-2. Sequence Prediction</h3>\nPredicting complete sequence (determining closeness to target) based on data <br />\n<i>change variable for any other sequence though</i>",
"_____no_output_____"
]
],
[
[
"# Prediction from Training Set\npredict_train = model.predict(X_train)\n\n# Prediction from Test Set\npredict_test = model.predict(X_test)\n\n\"\"\"\ndf = pd.DataFrame(({\"normalized y_train\":y_train.flatten(),\n \"normalized predict_train\":predict_train.flatten(),\n \"actual y_train\":scaler_train.inverse_transform(y_train).flatten(),\n \"actual predict_train\":scaler_train.inverse_transform(predict_train).flatten(),\n }))\n\n\"\"\"\n\ndf = pd.DataFrame(({ \n \"normalized y_test\":y_test.flatten(),\n \"normalized predict_test\":predict_test.flatten(),\n \"actual y_test\":scaler_test.inverse_transform(y_test).flatten(),\n \"actual predict_test\":scaler_test.inverse_transform(predict_test).flatten()\n }))\ndf",
"_____no_output_____"
]
],
[
[
"<h1 id=\"6\">6. Complete Figure</h1>\nData, Target, Prediction - all in one single graph",
"_____no_output_____"
]
],
[
[
"xAxis = [i for i in range(len(y_train))]\nyAxes = {}\nyAxes[\"Data\"]=sequence_train[sliding_window:len(sequence_train)-look_ahead]\nyAxes[\"Target\"]=scaler_train.inverse_transform(y_train)\nyAxes[\"Prediction\"]=scaler_train.inverse_transform(predict_train)\nplot_multi_graph(xAxis,yAxes,title='')\n\nxAxis = [i for i in range(len(y_test))]\nyAxes = {}\nyAxes[\"Data\"]=sequence_test[sliding_window:len(sequence_test)-look_ahead]\nyAxes[\"Target\"]=scaler_test.inverse_transform(y_test)\nyAxes[\"Prediction\"]=scaler_test.inverse_transform(predict_test)\nplot_multi_graph(xAxis,yAxes,title='')\n\nprint(metrics)\nprint(model.evaluate(X_test,y_test))",
"['mean_squared_error', 'mean_absolute_error', 'mean_absolute_percentage_error', 'mean_squared_logarithmic_error', 'logcosh']\n3960/3960 [==============================] - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - ETA: - 1s 294us/step\n[7.694095613258053, 0.00023503987094495595, 0.015312134466990077, 7.694095613258053, 0.00011939386936549021, 0.0001175134772149084]\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d0639b5e7b411de78ef7448fa61f58a26ff2ed77 | 47,720 | ipynb | Jupyter Notebook | models/Character_Level_CNN.ipynb | TheBlueEngineer/Serene-1.0 | 4f8c2e688c1403fda3c43c46c5ee598da3e607ea | [
"MIT"
]
| 1 | 2020-09-23T21:21:55.000Z | 2020-09-23T21:21:55.000Z | models/Character_Level_CNN.ipynb | TheBlueEngineer/Serene-1.0 | 4f8c2e688c1403fda3c43c46c5ee598da3e607ea | [
"MIT"
]
| null | null | null | models/Character_Level_CNN.ipynb | TheBlueEngineer/Serene-1.0 | 4f8c2e688c1403fda3c43c46c5ee598da3e607ea | [
"MIT"
]
| null | null | null | 57.842424 | 1,659 | 0.51536 | [
[
[
"# **Libraries**",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
],
[
"# ***********************\n# *****| LIBRARIES |*****\n# ***********************\n%tensorflow_version 2.x\nimport pandas as pd\nimport numpy as np\nimport os\nimport json\n\nfrom sklearn.model_selection import train_test_split\nimport tensorflow as tf\nfrom keras.preprocessing.text import Tokenizer\nfrom keras.preprocessing.sequence import pad_sequences\nfrom keras.layers import Input, Embedding, Activation, Flatten, Dense\nfrom keras.layers import Conv1D, MaxPooling1D, Dropout\nfrom keras.models import Model\nfrom keras.utils import to_categorical\nfrom keras.optimizers import SGD\nfrom keras.wrappers.scikit_learn import KerasClassifier\nfrom sklearn.model_selection import RandomizedSearchCV, GridSearchCV\n\ndevice_name = tf.test.gpu_device_name()\nif device_name != '/device:GPU:0':\n print(\"GPU not found\")\nelse:\n print('Found GPU at: {}'.format(device_name))",
"Using TensorFlow backend.\n"
],
[
"# ******************************\n# *****| GLOBAL VARIABLES |*****\n# ******************************\ntest_size = 0.2\n\nconvsize = 256\nconvsize2 = 1024\nembedding_size = 27\ninput_size = 1000\nconv_layers = [\n [convsize, 7, 3],\n [convsize, 7, 3],\n [convsize, 3, -1],\n [convsize, 3, -1],\n [convsize, 3, -1],\n [convsize, 3, 3]\n ]\n\nfully_connected_layers = [convsize2, convsize2]\nnum_of_classes= 2\ndropout_p = 0.5\noptimizer= 'adam'\nbatch = 128\nloss = 'categorical_crossentropy'",
"_____no_output_____"
]
],
[
[
"# **Utility functions**",
"_____no_output_____"
]
],
[
[
"# *****************\n# *** GET FILES ***\n# *****************\ndef getFiles( driverPath, directory, basename, extension): # Define a function that will return a list of files\n pathList = [] # Declare an empty array\n directory = os.path.join( driverPath, directory) # \n \n for root, dirs, files in os.walk( directory): # Iterate through roots, dirs and files recursively\n for file in files: # For every file in files\n if os.path.basename(root) == basename: # If the parent directory of the current file is equal with the parameter\n if file.endswith('.%s' % (extension)): # If the searched file ends in the parameter\n path = os.path.join(root, file) # Join together the root path and file name\n pathList.append(path) # Append the new path to the list\n return pathList ",
"_____no_output_____"
],
[
"# ****************************************\n# *** GET DATA INTO A PANDAS DATAFRAME ***\n# ****************************************\ndef getDataFrame( listFiles, maxFiles, minWords, limit):\n counter_real, counter_max, limitReached = 0, 0, 0\n text_list, label_list = [], []\n\n print(\"Word min set to: %i.\" % ( minWords))\n # Iterate through all the files\n for file in listFiles:\n # Open each file and look into it\n with open(file) as f:\n if(limitReached):\n break\n if maxFiles == 0:\n break\n else:\n maxFiles -= 1\n objects = json.loads( f.read())['data'] # Get the data from the JSON file\n # Look into each object from the file and test for limiters\n for object in objects:\n if limit > 0 and counter_real >= (limit * 1000):\n limitReached = 1\n break\n if len( object['text'].split()) >= minWords:\n text_list.append(object['text'])\n label_list.append(object['label'])\n counter_real += 1\n counter_max += 1\n\n if(counter_real > 0 and counter_max > 0):\n ratio = counter_real / counter_max * 100\n else:\n ratio = 0\n # Print the final result\n print(\"Lists created with %i/%i (%.2f%%) data objects.\" % ( counter_real, counter_max, ratio))\n print(\"Rest ignored due to minimum words limit of %i or the limit of %i data objects maximum.\" % ( minWords, limit * 1000))\n # Return the final Pandas DataFrame\n return text_list, label_list, counter_real",
"_____no_output_____"
]
],
[
[
"# **Gather the path to files**",
"_____no_output_____"
]
],
[
[
"# ***********************************\n# *** GET THE PATHS FOR THE FILES ***\n# ***********************************\n\n# Path to the content of the Google Drive \ndriverPath = \"/content/drive/My Drive\"\n\n# Sub-directories in the driver\npaths = [\"processed/depression/submission\",\n \"processed/depression/comment\", \n \"processed/AskReddit/submission\", \n \"processed/AskReddit/comment\"]\n\nfiles = [None] * len(paths)\nfor i in range(len(paths)):\n files[i] = getFiles( driverPath, paths[i], \"text\", \"json\")\n print(\"Gathered %i files from %s.\" % ( len(files[i]), paths[i]))",
"Gathered 750 files from processed/depression/submission.\nGathered 2892 files from processed/depression/comment.\nGathered 1311 files from processed/AskReddit/submission.\nGathered 5510 files from processed/AskReddit/comment.\n"
]
],
[
[
"# **Gather the data from files**",
"_____no_output_____"
]
],
[
[
"# ************************************\n# *** GATHER THE DATA AND SPLIT IT ***\n# ************************************\n# Local variables\nrand_state_splitter = 1000\ntest_size = 0.2\n\nmin_files = [ 750, 0, 1300, 0] \nmax_words = [ 50, 0, 50, 0]\nlimit_packets = [300, 0, 300, 0]\nmessage = [\"Depression submissions\", \"Depression comments\", \"AskReddit submissions\", \"AskReddit comments\"]\ntext, label = [], []\n\n# Get the pandas data frames for each category\nprint(\"Build the Pandas DataFrames for each category.\")\nfor i in range(4):\n dummy_text, dummy_label, counter = getDataFrame( files[i], min_files[i], max_words[i], limit_packets[i])\n if counter > 0:\n text += dummy_text\n label += dummy_label\n dummy_text, dummy_label = None, None\n print(\"Added %i samples to data list: %s.\\n\" % ( counter ,message[i]) )\n\n# Splitting the data\nx_train, x_test, y_train, y_test = train_test_split(text, \n label, \n test_size = test_size, \n shuffle = True, \n random_state = rand_state_splitter)\nprint(\"Training data: %i samples.\" % ( len(y_train)) )\nprint(\"Testing data: %i samples.\" % ( len(y_test)) )\n\n# Clear data no longer needed\ndel rand_state_splitter, min_files, max_words, message, dummy_label, dummy_text",
"Build the Pandas DataFrames for each category.\nWord min set to: 50.\nLists created with 300000/349305 (85.88%) data objects.\nRest ignored due to minimum words limit of 50 or the limit of 300000 data objects maximum.\nAdded 300000 samples to data list: Depression submissions.\n\nWord min set to: 0.\nLists created with 0/0 (0.00%) data objects.\nRest ignored due to minimum words limit of 0 or the limit of 0 data objects maximum.\nWord min set to: 50.\nLists created with 300000/554781 (54.08%) data objects.\nRest ignored due to minimum words limit of 50 or the limit of 300000 data objects maximum.\nAdded 300000 samples to data list: AskReddit submissions.\n\nWord min set to: 0.\nLists created with 0/0 (0.00%) data objects.\nRest ignored due to minimum words limit of 0 or the limit of 0 data objects maximum.\nTraining data: 480000 samples.\nTesting data: 120000 samples.\n"
]
],
[
[
"# **Process the data at a character-level**",
"_____no_output_____"
]
],
[
[
"# *******************************\n# *** CONVERT STRING TO INDEX ***\n# *******************************\nprint(\"Convert the strings to indexes.\")\ntk = Tokenizer(num_words = None, char_level = True, oov_token='UNK')\ntk.fit_on_texts(x_train)\nprint(\"Original:\", x_train[0])\n# *********************************\n# *** CONSTRUCT A NEW VOCABULARY***\n# *********************************\nprint(\"Construct a new vocabulary\")\nalphabet = \"abcdefghijklmnopqrstuvwxyz\"\nchar_dict = {}\nfor i, char in enumerate(alphabet):\n char_dict[char] = i + 1\nprint(\"dictionary\")\ntk.word_index = char_dict.copy() # Use char_dict to replace the tk.word_index\nprint(tk.word_index)\ntk.word_index[tk.oov_token] = max(char_dict.values()) + 1 # Add 'UNK' to the vocabulary\nprint(tk.word_index)\n# *************************\n# *** TEXT TO SEQUENCES ***\n# *************************\nprint(\"Text to sequence.\")\nx_train = tk.texts_to_sequences(x_train)\nx_test = tk.texts_to_sequences(x_test)\nprint(\"After sequences:\", x_train[0])\n# ***************\n# *** PADDING ***\n# ***************\nprint(\"Padding the sequences.\")\nx_train = pad_sequences( x_train, maxlen = input_size, padding = 'post')\nx_test = pad_sequences( x_test, maxlen= input_size , padding = 'post')\n\n# ************************\n# *** CONVERT TO NUMPY ***\n# ************************\nprint(\"Convert to Numpy arrays\")\nx_train = np.array( x_train, dtype = 'float32')\nx_test = np.array(x_test, dtype = 'float32')\n\n# **************************************\n# *** GET CLASSES FOR CLASSIFICATION ***\n# **************************************\ny_test_copy = y_test\ny_train_list = [x-1 for x in y_train]\ny_test_list = [x-1 for x in y_test]\n\ny_train = to_categorical( y_train_list, num_of_classes)\ny_test = to_categorical( y_test_list, num_of_classes)",
"Convert the strings to indexes.\nOriginal: i did not think i had have to post in this subreddit i just feel empty and completely alone i am hanging out with friends but nothing makes me feel happy as i used to be i know people generally have it worse i just want someone to talk to and just be silly with \nConstruct a new vocabulary\ndictionary\n{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8, 'i': 9, 'j': 10, 'k': 11, 'l': 12, 'm': 13, 'n': 14, 'o': 15, 'p': 16, 'q': 17, 'r': 18, 's': 19, 't': 20, 'u': 21, 'v': 22, 'w': 23, 'x': 24, 'y': 25, 'z': 26}\n{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8, 'i': 9, 'j': 10, 'k': 11, 'l': 12, 'm': 13, 'n': 14, 'o': 15, 'p': 16, 'q': 17, 'r': 18, 's': 19, 't': 20, 'u': 21, 'v': 22, 'w': 23, 'x': 24, 'y': 25, 'z': 26, 'UNK': 27}\nText to sequence.\nAfter sequences: [9, 27, 4, 9, 4, 27, 14, 15, 20, 27, 20, 8, 9, 14, 11, 27, 9, 27, 8, 1, 4, 27, 8, 1, 22, 5, 27, 20, 15, 27, 16, 15, 19, 20, 27, 9, 14, 27, 20, 8, 9, 19, 27, 19, 21, 2, 18, 5, 4, 4, 9, 20, 27, 9, 27, 10, 21, 19, 20, 27, 6, 5, 5, 12, 27, 5, 13, 16, 20, 25, 27, 1, 14, 4, 27, 3, 15, 13, 16, 12, 5, 20, 5, 12, 25, 27, 1, 12, 15, 14, 5, 27, 9, 27, 1, 13, 27, 8, 1, 14, 7, 9, 14, 7, 27, 15, 21, 20, 27, 23, 9, 20, 8, 27, 6, 18, 9, 5, 14, 4, 19, 27, 2, 21, 20, 27, 14, 15, 20, 8, 9, 14, 7, 27, 13, 1, 11, 5, 19, 27, 13, 5, 27, 6, 5, 5, 12, 27, 8, 1, 16, 16, 25, 27, 1, 19, 27, 9, 27, 21, 19, 5, 4, 27, 20, 15, 27, 2, 5, 27, 9, 27, 11, 14, 15, 23, 27, 16, 5, 15, 16, 12, 5, 27, 7, 5, 14, 5, 18, 1, 12, 12, 25, 27, 8, 1, 22, 5, 27, 9, 20, 27, 23, 15, 18, 19, 5, 27, 9, 27, 10, 21, 19, 20, 27, 23, 1, 14, 20, 27, 19, 15, 13, 5, 15, 14, 5, 27, 20, 15, 27, 20, 1, 12, 11, 27, 20, 15, 27, 1, 14, 4, 27, 10, 21, 19, 20, 27, 2, 5, 27, 19, 9, 12, 12, 25, 27, 23, 9, 20, 8, 27]\nPadding the sequences.\nConvert to Numpy arrays\n"
]
],
[
[
"# **Load embedding words**",
"_____no_output_____"
]
],
[
[
"# ***********************\n# *** LOAD EMBEDDINGS ***\n# ***********************\nembedding_weights = []\nvocab_size = len(tk.word_index)\nembedding_weights.append(np.zeros(vocab_size))\n\nfor char, i in tk.word_index.items():\n onehot = np.zeros(vocab_size)\n onehot[i-1] = 1\n embedding_weights.append(onehot)\nembedding_weights = np.array(embedding_weights)\n\nprint(\"Vocabulary size: \",vocab_size)\nprint(\"Embedding weights: \", embedding_weights)",
"Vocabulary size: 27\nEmbedding weights: [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.\n 0. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 1. 0. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 1. 0.]\n [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 1.]]\n"
]
],
[
[
"# **Build the CNN model**",
"_____no_output_____"
]
],
[
[
"def KerasModel():\n # ***************************************\n # *****| BUILD THE NEURAL NETWORK |******\n # ***************************************\n embedding_layer = Embedding(vocab_size+1,\n embedding_size,\n input_length = input_size,\n weights = [embedding_weights])\n\n # Input layer\n inputs = Input(shape=(input_size,), name='input', dtype='int64')\n\n # Embedding layer\n x = embedding_layer(inputs)\n\n # Convolution\n for filter_num, filter_size, pooling_size in conv_layers:\n x = Conv1D(filter_num, filter_size)(x)\n x = Activation('relu')(x)\n if pooling_size != -1:\n x = MaxPooling1D( pool_size = pooling_size)(x)\n x = Flatten()(x)\n\n # Fully Connected layers\n for dense_size in fully_connected_layers:\n x = Dense( dense_size, activation='relu')(x)\n x = Dropout( dropout_p)(x)\n\n # Output Layer\n predictions = Dense(num_of_classes, activation = 'softmax')(x)\n\n # BUILD MODEL\n model = Model( inputs = inputs, outputs = predictions)\n model.compile(optimizer = optimizer, loss = loss, metrics = ['accuracy'])\n model.summary()\n\n return model",
"_____no_output_____"
]
],
[
[
"# **Train the CNN**",
"_____no_output_____"
]
],
[
[
"#with tf.device(\"/gpu:0\"):\n# history = model.fit(x_train, y_train,\n# validation_data = ( x_test, y_test),\n# epochs = 10,\n# batch_size = batch,\n# verbose = True)\n \nwith tf.device(\"/gpu:0\"):\n grid = KerasClassifier(build_fn = KerasModel, epochs = 15, verbose= True)\n param_grid = dict(\n epochs = [15]\n )\n #grid = GridSearchCV(estimator = model, \n # param_grid = param_grid,\n # cv = 5, \n # verbose = 10, \n # return_train_score = True)\n \n grid_result = grid.fit(x_train, y_train)",
"Model: \"model_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput (InputLayer) (None, 1000) 0 \n_________________________________________________________________\nembedding_1 (Embedding) (None, 1000, 27) 756 \n_________________________________________________________________\nconv1d_1 (Conv1D) (None, 994, 256) 48640 \n_________________________________________________________________\nactivation_1 (Activation) (None, 994, 256) 0 \n_________________________________________________________________\nmax_pooling1d_1 (MaxPooling1 (None, 331, 256) 0 \n_________________________________________________________________\nconv1d_2 (Conv1D) (None, 325, 256) 459008 \n_________________________________________________________________\nactivation_2 (Activation) (None, 325, 256) 0 \n_________________________________________________________________\nmax_pooling1d_2 (MaxPooling1 (None, 108, 256) 0 \n_________________________________________________________________\nconv1d_3 (Conv1D) (None, 106, 256) 196864 \n_________________________________________________________________\nactivation_3 (Activation) (None, 106, 256) 0 \n_________________________________________________________________\nconv1d_4 (Conv1D) (None, 104, 256) 196864 \n_________________________________________________________________\nactivation_4 (Activation) (None, 104, 256) 0 \n_________________________________________________________________\nconv1d_5 (Conv1D) (None, 102, 256) 196864 \n_________________________________________________________________\nactivation_5 (Activation) (None, 102, 256) 0 \n_________________________________________________________________\nconv1d_6 (Conv1D) (None, 100, 256) 196864 \n_________________________________________________________________\nactivation_6 (Activation) (None, 100, 256) 0 \n_________________________________________________________________\nmax_pooling1d_3 (MaxPooling1 (None, 33, 256) 0 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 8448) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 1024) 8651776 \n_________________________________________________________________\ndropout_1 (Dropout) (None, 1024) 0 \n_________________________________________________________________\ndense_2 (Dense) (None, 1024) 1049600 \n_________________________________________________________________\ndropout_2 (Dropout) (None, 1024) 0 \n_________________________________________________________________\ndense_3 (Dense) (None, 2) 2050 \n=================================================================\nTotal params: 10,999,286\nTrainable params: 10,999,286\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"# **Test the CNN**",
"_____no_output_____"
]
],
[
[
"#loss, accuracy = model.evaluate( x_train, y_train, verbose = True)\n#print(\"Training Accuracy: {:.4f}\".format( accuracy))\n#loss, accuracy = model.evaluate( x_test, y_test, verbose = True)\n#print(\"Testing Accuracy: {:.4f}\".format( accuracy))\n\nfrom sklearn.metrics import classification_report, confusion_matrix\ny_predict = grid.predict( x_test)\n# Build the confusion matrix \ny_tested = y_test\nprint( type(y_test))\nprint(y_tested)\ny_tested = np.argmax( y_tested, axis = 1)\nprint(y_tested)\nconfMatrix = confusion_matrix(y_tested, y_predict) \ntn, fp, fn, tp = confMatrix.ravel() \n# Build a classification report \nclassification_reports = classification_report( y_tested, y_predict, target_names = ['Non-depressed', 'Depressed'], digits=3)\nprint(confMatrix)\nprint(classification_reports)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d063a4b442a49c71d22336e6b555d4a0dd1f82bf | 404,490 | ipynb | Jupyter Notebook | src/plotting/OpenChromatin_plotsold.ipynb | Switham1/PromoterArchitecture | 0a9021b869ac66cdd622be18cd029950314d111e | [
"MIT"
]
| null | null | null | src/plotting/OpenChromatin_plotsold.ipynb | Switham1/PromoterArchitecture | 0a9021b869ac66cdd622be18cd029950314d111e | [
"MIT"
]
| null | null | null | src/plotting/OpenChromatin_plotsold.ipynb | Switham1/PromoterArchitecture | 0a9021b869ac66cdd622be18cd029950314d111e | [
"MIT"
]
| null | null | null | 154.444444 | 43,436 | 0.855368 | [
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom scipy import stats\nfrom statsmodels.formula.api import ols\nimport researchpy as rp\nfrom pingouin import kruskal\nfrom pybedtools import BedTool",
"_____no_output_____"
],
[
"RootChomatin_bp_covered = '../../data/promoter_analysis/responsivepromotersRootOpenChrom.bp_covered.txt'\nShootChomatin_bp_covered = '../../data/promoter_analysis/responsivepromotersShootOpenChrom.bp_covered.txt'\nRootShootIntersect_bp_covered = '../../data/promoter_analysis/responsivepromotersShootRootIntersectOpenChrom.bp_covered.txt'",
"_____no_output_____"
],
[
"def add_chr_linestart(input_location,output_location):\n \"\"\"this function adds chr to the beginning of the line if it starts with a digit and saves a file\"\"\"\n output = open(output_location, 'w') #make output file with write capability\n #open input file\n with open(input_location, 'r') as infile: \n #iterate over lines in file\n for line in infile:\n line = line.strip() # removes hidden characters/spaces\n if line[0].isdigit():\n \n line = 'chr' + line #prepend chr to the beginning of line if starts with a digit\n output.write(line + '\\n') #output to new file\n output.close()",
"_____no_output_____"
],
[
"def percent_coverage(bp_covered):\n \"\"\"function to calculate the % coverage from the output file of bedtools coverage\"\"\"\n\n coverage_df = pd.read_table(bp_covered, sep='\\t', header=None)\n col = ['chr','start','stop','gene','dot','strand','source', 'type', 'dot2', 'details', 'no._of_overlaps', 'no._of_bases_covered','promoter_length','fraction_bases_covered']\n coverage_df.columns = col\n #add % bases covered column\n coverage_df['percentage_bases_covered'] = coverage_df.fraction_bases_covered * 100\n\n #remove unnecessary columns\n coverage_df_reduced_columns = coverage_df[['chr','start','stop','gene','strand', 'no._of_overlaps', 'no._of_bases_covered','promoter_length','fraction_bases_covered','percentage_bases_covered']]\n return coverage_df_reduced_columns",
"_____no_output_____"
],
[
"root_coverage = percent_coverage(RootChomatin_bp_covered)",
"_____no_output_____"
],
[
"shoot_coverage = percent_coverage(ShootChomatin_bp_covered)",
"_____no_output_____"
],
[
"rootshootintersect_coverage = percent_coverage(RootShootIntersect_bp_covered)",
"_____no_output_____"
],
[
"sns.set(color_codes=True)\nsns.set_style(\"whitegrid\")",
"_____no_output_____"
],
[
"#distribution plot",
"_____no_output_____"
],
[
"dist_plot = root_coverage['percentage_bases_covered']\n#create figure with no transparency\ndist_plot_fig = sns.distplot(dist_plot).get_figure()\n\n#save to file\n#dist_plot_fig.savefig('../../data/plots/TFBS_coverage/all_genes_bp_covered_dist.pdf', format='pdf')\n",
"_____no_output_____"
],
[
"dist_plot = shoot_coverage['percentage_bases_covered']\n#create figure with no transparency\ndist_plot_fig = sns.distplot(dist_plot).get_figure()\n\n#save to file\n#dist_plot_fig.savefig('../../data/plots/TFBS_coverage/all_genes_bp_covered_dist.pdf', format='pdf')\n",
"_____no_output_____"
],
[
"dist_plot = rootshootintersect_coverage['percentage_bases_covered']\n#create figure with no transparency\ndist_plot_fig = sns.distplot(dist_plot).get_figure()\n\n#save to file\n#dist_plot_fig.savefig('../../data/plots/TFBS_coverage/all_genes_bp_covered_dist.pdf', format='pdf')\n",
"_____no_output_____"
]
],
[
[
"## constitutive vs variable",
"_____no_output_____"
]
],
[
[
"def add_genetype(coverage):\n \"\"\"function to add gene type to the df, and remove random genes\"\"\"\n select_genes_file = '../../data/genomes/ara_housekeeping_list.out'\n select_genes = pd.read_table(select_genes_file, sep='\\t', header=None)\n cols = ['gene','gene_type']\n select_genes.columns = cols\n merged = pd.merge(coverage, select_genes, on='gene')\n \n merged_renamed = merged.copy()\n merged_renamed.gene_type.replace('housekeeping','constitutive', inplace=True)\n merged_renamed.gene_type.replace('highVar','variable', inplace=True)\n merged_renamed.gene_type.replace('randCont','random', inplace=True)\n \n # no_random = merged_renamed[merged_renamed.gene_type != 'random']\n # no_random.reset_index(drop=True, inplace=True)\n \n return merged_renamed",
"_____no_output_____"
],
[
"roots_merged = add_genetype(root_coverage)\nno_random_roots = roots_merged[roots_merged.gene_type != 'random']",
"_____no_output_____"
],
[
"shoots_merged = add_genetype(shoot_coverage)\nno_random_shoots = shoots_merged[shoots_merged.gene_type != 'random']",
"_____no_output_____"
],
[
"rootsshootsintersect_merged = add_genetype(rootshootintersect_coverage)\nno_random_rootsshoots = rootsshootsintersect_merged[rootsshootsintersect_merged.gene_type != 'random']",
"_____no_output_____"
],
[
"#how many have open chromatin??\nprint('root openchromatin present:')\nprint(len(no_random_roots)-len(no_random_roots[no_random_roots.percentage_bases_covered == 0]))\nprint('shoot openchromatin present:')\nprint(len(no_random_shoots)-len(no_random_shoots[no_random_shoots.percentage_bases_covered == 0]))\nprint('root-shoot intersect openchromatin present:')\nprint(len(no_random_rootsshoots)-len(no_random_rootsshoots[no_random_rootsshoots.percentage_bases_covered == 0]))",
"root openchromatin present:\n164\nshoot openchromatin present:\n153\nroot-shoot intersect openchromatin present:\n149\n"
],
[
"#how many have open chromatin??\nprint('root openchromatin present variable promoters:')\nprint(len(no_random_roots[no_random_roots.gene_type=='variable'])-len(no_random_roots[no_random_roots.gene_type=='variable'][no_random_roots[no_random_roots.gene_type=='variable'].percentage_bases_covered == 0]))\nprint('root openchromatin present constitutive promoters:')\nprint(len(no_random_roots[no_random_roots.gene_type=='constitutive'])-len(no_random_roots[no_random_roots.gene_type=='constitutive'][no_random_roots[no_random_roots.gene_type=='constitutive'].percentage_bases_covered == 0]))\n\n\nprint('shoot openchromatin present variable promoters:')\nprint(len(no_random_shoots[no_random_shoots.gene_type=='variable'])-len(no_random_shoots[no_random_shoots.gene_type=='variable'][no_random_shoots[no_random_shoots.gene_type=='variable'].percentage_bases_covered == 0]))\nprint('shoot openchromatin present constitutive promoters:')\nprint(len(no_random_shoots[no_random_shoots.gene_type=='constitutive'])-len(no_random_shoots[no_random_shoots.gene_type=='constitutive'][no_random_shoots[no_random_shoots.gene_type=='constitutive'].percentage_bases_covered == 0]))\n\nprint('root-shoot intersect openchromatin present variable promoters:')\nprint(len(no_random_rootsshoots[no_random_rootsshoots.gene_type=='variable'])-len(no_random_rootsshoots[no_random_rootsshoots.gene_type=='variable'][no_random_rootsshoots[no_random_rootsshoots.gene_type=='variable'].percentage_bases_covered == 0]))\nprint('root-shoot intersect openchromatin present constitutive promoters:')\nprint(len(no_random_rootsshoots[no_random_rootsshoots.gene_type=='constitutive'])-len(no_random_rootsshoots[no_random_rootsshoots.gene_type=='constitutive'][no_random_rootsshoots[no_random_rootsshoots.gene_type=='constitutive'].percentage_bases_covered == 0]))",
"root openchromatin present variable promoters:\n75\nroot openchromatin present constitutive promoters:\n89\nshoot openchromatin present variable promoters:\n66\nshoot openchromatin present constitutive promoters:\n87\nroot-shoot intersect openchromatin present variable promoters:\n63\nroot-shoot intersect openchromatin present constitutive promoters:\n86\n"
],
[
"sns.catplot(x=\"gene_type\", y=\"percentage_bases_covered\", data=roots_merged) #.savefig('../../data/plots/TFBS_coverage/responsive_bp_covered.pdf', format='pdf')",
"_____no_output_____"
],
[
"sns.catplot(x=\"gene_type\", y=\"percentage_bases_covered\", data=shoots_merged) #.savefig('../../data/plots/TFBS_coverage/responsive_bp_covered.pdf', format='pdf')",
"_____no_output_____"
],
[
"#roots\nplot = sns.catplot(x=\"gene_type\", y=\"percentage_bases_covered\", kind='box', data=no_random_roots)\n#plot points\nax = sns.swarmplot(x=\"gene_type\", y=\"percentage_bases_covered\", data=no_random_roots, color=\".25\")\nplt.ylabel('Percentage bases covered')\nplt.xlabel('Gene type');\n#ax.get_figure() #.savefig('../../data/plots/TFBS_coverage/responsive_bp_covered_boxplot.pdf', format='pdf')",
"_____no_output_____"
],
[
"#shoots\nplot = sns.catplot(x=\"gene_type\", y=\"percentage_bases_covered\", kind='box', data=no_random_shoots)\n#plot points\nax = sns.swarmplot(x=\"gene_type\", y=\"percentage_bases_covered\", data=no_random_shoots, color=\".25\")\nplt.ylabel('Percentage bases covered')\nplt.xlabel('Gene type');\n#ax.get_figure() #.savefig('../../data/plots/TFBS_coverage/responsive_bp_covered_boxplot.pdf', format='pdf')",
"_____no_output_____"
],
[
"#roots-shoots intersect\nplot = sns.catplot(x=\"gene_type\", y=\"percentage_bases_covered\", kind='box', data=no_random_rootsshoots)\n#plot points\nax = sns.swarmplot(x=\"gene_type\", y=\"percentage_bases_covered\", data=no_random_rootsshoots, color=\".25\")\nplt.ylabel('Percentage bases covered')\nplt.xlabel('Gene type');\n#ax.get_figure() #.savefig('../../data/plots/TFBS_coverage/responsive_bp_covered_boxplot.pdf', format='pdf')",
"_____no_output_____"
],
[
"#Get names of each promoter\ndef normality(input_proms):\n \"\"\"function to test normality of data - returns test statistic, p-value\"\"\"\n #Get names of each promoter\n pd.Categorical(input_proms.gene_type)\n names = input_proms.gene_type.unique()\n# for name in names:\n# print(name)\n \n for name in names:\n print('{}: {}'.format(name, stats.shapiro(input_proms.percentage_bases_covered[input_proms.gene_type == name])))\n ",
"_____no_output_____"
],
[
"def variance(input_proms):\n \"\"\"function to test variance of data\"\"\"\n#test variance\n constitutive = input_proms[input_proms.gene_type == 'constitutive']\n #reset indexes so residuals can be calculated later\n constitutive.reset_index(inplace=True)\n\n responsive = input_proms[input_proms.gene_type == 'variable']\n responsive.reset_index(inplace=True)\n\n control = input_proms[input_proms.gene_type == 'random']\n control.reset_index(inplace=True)\n\n print(stats.levene(constitutive.percentage_bases_covered, responsive.percentage_bases_covered))",
"_____no_output_____"
],
[
"normality(no_random_roots)",
"variable: (0.8330899477005005, 3.833479311765586e-09)\nconstitutive: (0.7916173934936523, 1.8358696507458916e-10)\n"
],
[
"normality(no_random_shoots)",
"variable: (0.8625870943069458, 4.528254393676434e-08)\nconstitutive: (0.8724747896194458, 1.1140339495341323e-07)\n"
],
[
"normality(no_random_rootsshoots)",
"variable: (0.8546600937843323, 2.263117515610702e-08)\nconstitutive: (0.8711197376251221, 9.823354929494599e-08)\n"
]
],
[
[
"## Not normal",
"_____no_output_____"
]
],
[
[
"variance(no_random_roots)",
"LeveneResult(statistic=3.3550855113629137, pvalue=0.0685312309497174)\n"
],
[
"variance(no_random_shoots)",
"LeveneResult(statistic=0.20460439034148425, pvalue=0.6515350841099911)\n"
],
[
"variance(no_random_rootsshoots)",
"LeveneResult(statistic=0.00041366731166758155, pvalue=0.9837939970964911)\n"
]
],
[
[
"## unequal variance for shoots",
"_____no_output_____"
]
],
[
[
"def kruskal_test(input_data):\n \"\"\"function to do kruskal-wallis test on data\"\"\" \n \n #print('\\033[1m' +promoter + '\\033[0m')\n print(kruskal(data=input_data, dv='percentage_bases_covered', between='gene_type'))\n #print('')",
"_____no_output_____"
],
[
"no_random_roots",
"_____no_output_____"
],
[
"kruskal_test(no_random_roots)",
" Source ddof1 H p-unc\nKruskal gene_type 1 7.281793 0.006966\n"
],
[
"kruskal_test(no_random_shoots)",
" Source ddof1 H p-unc\nKruskal gene_type 1 20.935596 0.000005\n"
],
[
"kruskal_test(no_random_rootsshoots)",
" Source ddof1 H p-unc\nKruskal gene_type 1 22.450983 0.000002\n"
]
],
[
[
"## try gat enrichment",
"_____no_output_____"
]
],
[
[
"#add Chr to linestart of chromatin bed files\n\nadd_chr_linestart('../../data/ATAC-seq/potter2018/Shoots_NaOH_peaks_all.bed','../../data/ATAC-seq/potter2018/Shoots_NaOH_peaks_all_renamed.bed')\nadd_chr_linestart('../../data/ATAC-seq/potter2018/Roots_NaOH_peaks_all.bed','../../data/ATAC-seq/potter2018/Roots_NaOH_peaks_all_renamed.bed')\nadd_chr_linestart('../../data/ATAC-seq/potter2018/intersectRootsShoots_PeaksInBoth.bed','../../data/ATAC-seq/potter2018/intersectRootsShoots_PeaksInBoth_renamed.bed')",
"_____no_output_____"
],
[
"#create a bed file containing all 100 constitutive/responsive promoters with the fourth column annotating whether it's constitutive or responsive\nproms_file = '../../data/genes/constitutive-variable-random_100_each.csv'\npromoters = pd.read_csv(proms_file)\npromoters\ncols2 = ['delete','promoter_AGI', 'gene_type']\npromoters_df = promoters[['promoter_AGI','gene_type']]\npromoters_no_random = promoters_df.copy()\n#drop randCont rows\npromoters_no_random = promoters_df[~(promoters_df.gene_type == 'randCont')]\npromoters_no_random",
"_____no_output_____"
],
[
"#merge promoters with genetype selected\npromoterbedfile = '../../data/FIMO/responsivepromoters.bed'\npromoters_bed = pd.read_table(promoterbedfile, sep='\\t', header=None)\ncols = ['chr', 'start', 'stop', 'promoter_AGI', 'score', 'strand', 'source', 'feature_name', 'dot2', 'attributes']\npromoters_bed.columns = cols\nmerged = pd.merge(promoters_bed,promoters_no_random, on='promoter_AGI')",
"_____no_output_____"
],
[
"#add gene_type to column3\nmerged = merged[['chr','start','stop','gene_type','promoter_AGI', 'score', 'strand', 'source', 'feature_name', 'dot2', 'attributes']]",
"_____no_output_____"
],
[
"#write to bed file\npromoter_file = '../../data/promoter_analysis/old1000bpproms_variable_constitutive_workspace.bed'\nwith open(promoter_file,'w') as f:\n merged.to_csv(f,index=False,sep='\\t',header=None)",
"_____no_output_____"
],
[
"# new_merged = merged.astype({'start': 'int'})\n# new_merged = merged.astype({'stop': 'int'})\n# new_merged = merged.astype({'chr': 'int'})",
"_____no_output_____"
],
[
"#add Chr to linestart of promoter bed file\n\nadd_chr_linestart('../../data/promoter_analysis/old1000bpproms_variable_constitutive_workspace.bed','../../data/promoter_analysis/old1000bpproms_variable_constitutive_workspace_renamed.bed')",
"_____no_output_____"
],
[
"#create separate variable and constitutive and gat workspace\npromoter_file_renamed = '../../data/promoter_analysis/old1000bpproms_variable_constitutive_workspace_renamed.bed'\npromoters = pd.read_table(promoter_file_renamed, sep='\\t', header=None)\n#make a new gat workspace file with all promoters (first 3 columns)\nbed = BedTool.from_dataframe(promoters[[0,1,2]]).saveas('../../data/promoter_analysis/chromatin/variable_constitutive_promoters_1000bp_workspace.bed')\n#select only variable promoters\nvariable_promoters = promoters[promoters[3] == 'highVar']\nsorted_variable = variable_promoters.sort_values([0,1])\nbed = BedTool.from_dataframe(sorted_variable).saveas('../../data/promoter_analysis/chromatin/variable_promoters_1000bp.bed')\n#make a constitutive only file\nconstitutive_promoters = promoters[promoters[3] == 'housekeeping']\nsorted_constitutive = constitutive_promoters.sort_values([0,1])\nbed = BedTool.from_dataframe(sorted_constitutive).saveas('../../data/promoter_analysis/chromatin/constitutive_promoters_1000bp.bed')",
"_____no_output_____"
]
],
[
[
"## now I will do the plots with non-overlapping promoters including the 5'UTR",
"_____no_output_____"
]
],
[
[
"#merge promoters with genetype selected\npromoter_UTR = '../../data/FIMO/non-overlapping_includingbidirectional_all_genes/promoters_5UTR_renamedChr.bed'\npromoters_bed = pd.read_table(promoter_UTR, sep='\\t', header=None)\ncols = ['chr', 'start', 'stop', 'promoter_AGI', 'score', 'strand', 'source', 'feature_name', 'dot2', 'attributes']\npromoters_bed.columns = cols\nmerged = pd.merge(promoters_bed,promoters_no_random, on='promoter_AGI')",
"_____no_output_____"
],
[
"#how many constitutive genes left after removed/shortened overlapping\nlen(merged[merged.gene_type == 'housekeeping'])",
"_____no_output_____"
],
[
"#how many variable genes left after removed/shortened overlapping\nlen(merged[merged.gene_type == 'highVar'])",
"_____no_output_____"
],
[
"merged['length'] = (merged.start - merged.stop).abs()\nmerged.sort_values('length',ascending=True)",
"_____no_output_____"
],
[
"#plot of lengths\ndist_plot = merged['length']\n#create figure with no transparency\ndist_plot_fig = sns.distplot(dist_plot).get_figure()",
"_____no_output_____"
],
[
"#remove 2 genes from constitutive group so equal sample size to variable\n#random sample of 98, using seed 1\nmerged[merged.gene_type == 'housekeeping'] = merged[merged.gene_type == 'housekeeping'].sample(98, random_state=1)",
"_____no_output_____"
],
[
"#drop rows with at least 2 NaNs\nmerged = merged.dropna(thresh=2)",
"_____no_output_____"
],
[
"merged",
"_____no_output_____"
],
[
"#write to bed file so can run OpenChromatin_coverage.py\nnew_promoter_file = '../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutive.bed'\ncols = ['chr', 'start', 'stop', 'promoter_AGI', 'score', 'strand', 'source', 'feature_name', 'dot2', 'attributes']\n#remove trailing decimal .0 from start and stop\nmerged = merged.astype({'start': 'int'})\nmerged = merged.astype({'stop': 'int'})\nmerged = merged.astype({'chr': 'int'})\n\nmerged_coverage = merged[cols]\n\nwith open(new_promoter_file,'w') as f:\n merged_coverage.to_csv(f,index=False,sep='\\t',header=None)",
"_____no_output_____"
],
[
"#write to bed file so can run gat\nnew_promoter_file_gat = '../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutive_gat.bed'\ncols_gat = ['chr', 'start', 'stop', 'gene_type','promoter_AGI', 'score', 'strand', 'source', 'feature_name', 'dot2', 'attributes']\nmerged_gat = merged[cols_gat]\nwith open(new_promoter_file_gat,'w') as f:\n merged_gat.to_csv(f,index=False,sep='\\t',header=None)\n",
"_____no_output_____"
],
[
"#Read in new files\nRootChomatin_bp_covered = '../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutiveRootOpenChrom.bp_covered.txt'\nShootChomatin_bp_covered = '../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutiveShootOpenChrom.bp_covered.txt'\nRootShootIntersect_bp_covered = '../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutiveShootRootIntersectOpenChrom.bp_covered.txt'",
"_____no_output_____"
],
[
"root_coverage = percent_coverage(RootChomatin_bp_covered)\nshoot_coverage = percent_coverage(ShootChomatin_bp_covered)\nrootshootintersect_coverage = percent_coverage(RootShootIntersect_bp_covered)",
"_____no_output_____"
],
[
"#add Chr to linestart of promoter bed file\n\nadd_chr_linestart('../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutive_gat.bed','../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutive_gat_renamed.bed')",
"_____no_output_____"
],
[
"#create separate variable and constitutive and gat workspace\npromoter_file_renamed = '../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutive_gat_renamed.bed'\npromoters = pd.read_table(promoter_file_renamed, sep='\\t', header=None)\n#make a new gat workspace file with all promoters (first 3 columns)\nbed = BedTool.from_dataframe(promoters[[0,1,2]]).saveas('../../data/promoter_analysis/chromatin/non-overlapping_includingbidirectional_variable_constitutive_workspace.bed')\n#select only variable promoters\nvariable_promoters = promoters[promoters[3] == 'highVar']\nsorted_variable = variable_promoters.sort_values([0,1])\nbed = BedTool.from_dataframe(sorted_variable).saveas('../../data/promoter_analysis/chromatin/non-overlapping_includingbidirectional_variable_promoters.bed')\n#make a constitutive only file\nconstitutive_promoters = promoters[promoters[3] == 'housekeeping']\nsorted_constitutive = constitutive_promoters.sort_values([0,1])\nbed = BedTool.from_dataframe(sorted_constitutive).saveas('../../data/promoter_analysis/chromatin/non-overlapping_includingbidirectional_constitutive_promoters.bed')",
"_____no_output_____"
],
[
"#show distribution of the distance from the closest end of the open chromatin peak to the ATG (if overlapping already then distance is 0)\nroot_peaks_bed = '../../data/ATAC-seq/potter2018/Roots_NaOH_peaks_all_renamed.bed'\nshoot_peaks_bed = '../../data/ATAC-seq/potter2018/Shoots_NaOH_peaks_all_renamed.bed'\nrootshootintersect_peaks_bed = '../../data/ATAC-seq/potter2018/intersectRootsShoots_PeaksInBoth_renamed.bed'\npromoters_bed = '../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutive_renamed.bed'\npromoter_openchrom_intersect = '../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutive_chromintersect.bed'",
"_____no_output_____"
],
[
"add_chr_linestart('../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutive.bed','../../data/promoter_analysis/non-overlapping_includingbidirectional_variable_constitutive_renamed.bed')",
"_____no_output_____"
],
[
"def distr_distance_ATG(peaks_bed, promoter_bed, output_file):\n \"\"\"function to show the distribution of the distance rom the closest end\n of the open chromatin peak to the ATG (if overlapping already then distance is 0)\"\"\"\n# peaks = pd.read_table(peaks_bed, sep='\\t', header=None)\n# cols = ['chr','start', 'stop']\n# peaks.columns = cols\n# promoters = pd.read_table(promoter_bed, sep='\\t', header=None)\n# cols_proms = ['chr', 'start', 'stop', 'gene_type','promoter_AGI', 'score', 'strand', 'source', 'feature_name', 'dot2', 'attributes']\n# promoters.columns = cols_proms\n proms = BedTool(promoter_bed) #read in files using BedTools\n peaks = BedTool(peaks_bed)\n #report chromosome position of overlapping feature, along with the promoter which overlaps it (only reports the overlapping nucleotides, not the whole promoter length. Can use u=True to get whole promoter length)\n #f, the minimum overlap as fraction of A. F, nucleotide fraction of B (genes) that need to be overlapping with A (promoters)\n #wa, Write the original entry in A for each overlap.\n #wo, Write the original A and B entries plus the number of base pairs of overlap between the two features. Only A features with overlap are reported. \n #u, write original A entry only once even if more than one overlap\n intersect = proms.intersect(peaks, wo=True) #could add u=True which indicates we want to see the promoters that overlap features in the genome\n #Write to output_file\n with open(output_file, 'w') as output:\n #Each line in the file contains bed entry a and bed entry b that it overlaps plus the number of bp in the overlap so 19 columns\n output.write(str(intersect))\n #read in intersect bed file\n overlapping_proms = pd.read_table(output_file, sep='\\t', header=None)\n cols = ['chrA', 'startA', 'stopA', 'promoter_AGI','dot1','strand','source','type','dot2','attributes','chrB', 'startB','stopB','bp_overlap']\n overlapping_proms.columns = cols\n #add empty openchrom_distance_from_ATG column\n overlapping_proms['openchrom_distance_from_ATG'] = int()\n for i, v in overlapping_proms.iterrows():\n #if positive strand feature A\n if overlapping_proms.loc[i,'strand'] == '+':\n #if end of open chromatin is downstream or equal to ATG, distance is 0\n if overlapping_proms.loc[i,'stopA'] <= overlapping_proms.loc[i, 'stopB']:\n overlapping_proms.loc[i,'openchrom_distance_from_ATG'] = 0\n #else if upstream and chromatin stop is after promoter start, add distance from chromatin stop to ATG\n elif overlapping_proms.loc[i,'startA'] <= overlapping_proms.loc[i, 'stopB']:\n overlapping_proms.loc[i,'openchrom_distance_from_ATG'] = overlapping_proms.loc[i,'stopA'] - overlapping_proms.loc[i, 'stopB'] \n \n elif overlapping_proms.loc[i,'strand'] == '-': \n #if end of open chromatin is downstream or equal to ATG, distance is 0\n if overlapping_proms.loc[i,'startA'] >= overlapping_proms.loc[i, 'startB']:\n overlapping_proms.loc[i,'openchrom_distance_from_ATG'] = 0\n #else if upstream and chromatin stop is after promoter start, add distance from chromatin stop to ATG \n elif overlapping_proms.loc[i,'stopA'] >= overlapping_proms.loc[i, 'startB']:\n overlapping_proms.loc[i,'openchrom_distance_from_ATG'] = overlapping_proms.loc[i, 'startB'] - overlapping_proms.loc[i,'startB']\n \n\n \n return overlapping_proms",
"_____no_output_____"
],
[
"#show length of open chromatin peaks\nrootshootintersect = distr_distance_ATG(rootshootintersect_peaks_bed)\nrootshootintersect['length'] = (rootshootintersect.start - rootshootintersect.stop).abs()\nrootshootintersect.sort_values('length',ascending=True)\n",
"_____no_output_____"
],
[
"rootshootintersect = distr_distance_ATG(rootshootintersect_peaks_bed,promoters_bed,promoter_openchrom_intersect)",
"_____no_output_____"
],
[
"rootshootintersect\nrootshootintersect.sort_values('openchrom_distance_from_ATG',ascending=True)",
"_____no_output_____"
],
[
"#plot of distances of chomatin to ATG\ndist_plot = rootshootintersect['openchrom_distance_from_ATG']\n#create figure with no transparency\ndist_plot_fig = sns.distplot(dist_plot).get_figure()",
"_____no_output_____"
],
[
"#now split constitutive and variable\nmerged_distances = pd.merge(merged, rootshootintersect, on='promoter_AGI')",
"_____no_output_____"
],
[
"merged_distances.gene_type",
"_____no_output_____"
],
[
"#VARIABLE\n#plot of distances of chomatin to ATG \ndist_plot = merged_distances[merged_distances.gene_type=='highVar']['openchrom_distance_from_ATG']\n#create figure with no transparency\ndist_plot_fig = sns.distplot(dist_plot).get_figure()",
"_____no_output_____"
],
[
"merged_distances[merged_distances.gene_type=='housekeeping']['openchrom_distance_from_ATG']",
"_____no_output_____"
],
[
"#CONSTITUTIVE\n#plot of distances of chomatin to ATG \ndist_plot = merged_distances[merged_distances.gene_type=='housekeeping']['openchrom_distance_from_ATG']\n#create figure with no transparency\ndist_plot_fig = sns.distplot(dist_plot).get_figure()",
"/home/witham/opt/anaconda3/envs/PromoterArchitecturePipeline/lib/python3.7/site-packages/seaborn/distributions.py:369: UserWarning: Default bandwidth for data is 0; skipping density estimation.\n warnings.warn(msg, UserWarning)\n"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d063a7d824a918b20fdae24c6f4a772f811a45cc | 218,539 | ipynb | Jupyter Notebook | main.ipynb | spectraldani/DeepMahalanobisGP | bf2d788ac8b56d25f544b6cb9c0325820f4b7e64 | [
"Apache-2.0"
]
| null | null | null | main.ipynb | spectraldani/DeepMahalanobisGP | bf2d788ac8b56d25f544b6cb9c0325820f4b7e64 | [
"Apache-2.0"
]
| null | null | null | main.ipynb | spectraldani/DeepMahalanobisGP | bf2d788ac8b56d25f544b6cb9c0325820f4b7e64 | [
"Apache-2.0"
]
| null | null | null | 402.46593 | 98,764 | 0.933339 | [
[
[
"dataset = 'load' # 'load' or 'generate'\nretrain_models = False # False or True or 'save'",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd\nimport tensorflow as tf\ntf.logging.set_verbosity(tf.logging.FATAL)\n\nimport gpflow\nimport library.models.deep_vmgp as deep_vmgp\nimport library.models.vmgp as vmgp\nfrom doubly_stochastic_dgp.dgp import DGP\n\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nimport cplot\n\nimport sklearn.model_selection\nimport pickle\nfrom pathlib import Path\nfrom types import SimpleNamespace\nfrom library.helper import TrainTestSplit, initial_inducing_points\nfrom library import metrics\n\n%matplotlib inline",
"_____no_output_____"
],
[
"random_seed = 19960111\ndef reset_seed():\n np.random.seed(random_seed)\n tf.random.set_random_seed(random_seed)",
"_____no_output_____"
],
[
"if dataset == 'generate':\n s = 0.4\n n = 500//2\n reset_seed()\n rng = np.random.default_rng(random_seed)\n m1, m2 = np.array([[-1,1],[2,1]])\n X1 = rng.multivariate_normal(m1,s*np.eye(2), size=n)\n X2 = rng.multivariate_normal(m2,s*np.eye(2), size=n)\n y1 = X1[:,0]**2 + X1[:,0]\n y2 = X2[:,1]**2 + X2[:,1]\n\n X = np.concatenate([X1,X2],axis=0)\n y = np.concatenate([y1,y2],axis=0)[:,None]\n\n X_all, y_all = X,y\n n = X_all.shape[0]\n kfold = sklearn.model_selection.KFold(2,shuffle=True,random_state=random_seed)\n folds = [\n [TrainTestSplit(X_all[train],X_all[test]), TrainTestSplit(y_all[train],y_all[test])]\n for train, test in kfold.split(X_all, y_all)\n ]\n X,y = folds[0]\nelif dataset == 'load':\n with open('./dataset.pkl','rb') as f:\n X, y = pickle.load(f)\n X_all, y_all = np.concatenate(X,axis=0), np.concatenate(y,axis=0)",
"_____no_output_____"
],
[
"scalers = SimpleNamespace(x=sklearn.preprocessing.StandardScaler(),y=sklearn.preprocessing.StandardScaler())\nscalers.x.fit(X.train)\nX = X.apply(lambda x: scalers.x.transform(x))\nscalers.y.fit(y.train)\ny = y.apply(lambda y: scalers.y.transform(y))",
"_____no_output_____"
],
[
"models = pd.Series(index=pd.Index([],dtype='object'), dtype=object)\nparameters = pd.Series({p.stem:p for p in Path('./optimized_parameters/').glob('*.pkl')}, dtype=object).map(read_parameters)\n\ny_pred = pd.DataFrame(dtype=float, index=range(y.test.size), columns=pd.MultiIndex(levels=[[],['mean','var']],codes=[[],[]],names=['model','']))\nresults = pd.DataFrame(columns=['RMSE','NLPD','MRAE'],dtype=float)",
"_____no_output_____"
],
[
"def read_parameters(p):\n try:\n with p.open('rb') as f:\n return pickle.load(f)\n except:\n return None\n\ndef train_model(model_label):\n m = models[model_label]\n if retrain_models == True or retrain_models == 'save' or model_label not in parameters.index:\n print('Training',model_label)\n variance_parameter = m.likelihood.variance if not isinstance(m, DGP) else m.likelihood.likelihood.variance\n variance_parameter.assign(0.01)\n # First round\n variance_parameter.trainable = False\n opt = gpflow.train.AdamOptimizer(0.01)\n opt.minimize(m, maxiter=2000)\n\n # Second round\n variance_parameter.trainable = True\n opt = gpflow.train.AdamOptimizer(0.01)\n opt.minimize(m, maxiter=5000)\n if retrain_models == 'save' or model_label not in parameters.index:\n with open(f'./optimized_parameters/{model_label}.pkl','wb') as f:\n pickle.dump(m.read_trainables(), f)\n else:\n m.assign(parameters[model_label])",
"_____no_output_____"
]
],
[
[
"# Create, train, and predict with models",
"_____no_output_____"
]
],
[
[
"n,D = X.train.shape\nm_v = 25\nm_u, Q, = 50, D\nZ_v = (m_v,D)\nZ_u = (m_u,Q)\nsample_size = 200",
"_____no_output_____"
]
],
[
[
"### SGPR",
"_____no_output_____"
]
],
[
[
"models['sgpr'] = gpflow.models.SGPR(X.train, y.train, gpflow.kernels.RBF(D, ARD=True), initial_inducing_points(X.train, m_u))\ntrain_model('sgpr')\ny_pred[('sgpr','mean')], y_pred[('sgpr','var')] = models['sgpr'].predict_y(X.test)",
"_____no_output_____"
]
],
[
[
"### Deep Mahalanobis GP",
"_____no_output_____"
]
],
[
[
"reset_seed()\nwith gpflow.defer_build():\n models['dvmgp'] = deep_vmgp.DeepVMGP(\n X.train, y.train, Z_u, Z_v,\n [gpflow.kernels.RBF(D,ARD=True) for i in range(Q)],\n full_qcov=False, diag_qmu=False\n )\nmodels['dvmgp'].compile()\ntrain_model('dvmgp')\ny_pred[('dvmgp','mean')], y_pred[('dvmgp','var')] = models['dvmgp'].predict_y(X.test)",
"_____no_output_____"
]
],
[
[
"### Show scores",
"_____no_output_____"
]
],
[
[
"for m in models.index:\n scaled_y_test = scalers.y.inverse_transform(y.test)\n scaled_y_pred = [\n scalers.y.inverse_transform(y_pred[m].values[:,[0]]),\n scalers.y.var_ * y_pred[m].values[:,[1]]\n ]\n results.at[m,'MRAE'] = metrics.mean_relative_absolute_error(scaled_y_test, scaled_y_pred[0]).squeeze()\n results.at[m,'RMSE'] = metrics.root_mean_squared_error(scaled_y_test, scaled_y_pred[0]).squeeze()\n results.at[m,'NLPD'] = metrics.negative_log_predictive_density(scaled_y_test, *scaled_y_pred).squeeze()\n\nresults",
"_____no_output_____"
]
],
[
[
"# Plot results",
"_____no_output_____"
]
],
[
[
"class MidpointNormalize(mpl.colors.Normalize):\n def __init__(self, vmin=None, vmax=None, midpoint=None, clip=False):\n self.midpoint = midpoint\n mpl.colors.Normalize.__init__(self, vmin, vmax, clip)\n\n def __call__(self, value, clip=None):\n x, y = [self.vmin, self.midpoint, self.vmax], [0, 0.5, 1]\n return np.ma.masked_array(np.interp(value, x, y), np.isnan(value))",
"_____no_output_____"
],
[
"f = plt.figure()\nax = plt.gca()\nax.scatter(scalers.x.transform(X_all)[:,0],scalers.x.transform(X_all)[:,1],edgecolors='white',facecolors='none')\nlims = (ax.get_xlim(), ax.get_ylim())\nplt.close(f)",
"_____no_output_____"
],
[
"n = 50\ngrid_points = np.dstack(np.meshgrid(np.linspace(*lims[0],n), np.linspace(*lims[1],n))).reshape(-1,2)\ngrid_y = np.empty((len(models.index),grid_points.shape[0]))\nfor i,m in enumerate(models.index):\n reset_seed()\n grid_pred = models[m].predict_y(grid_points, sample_size)[0]\n if len(grid_pred.shape) == 3:\n grid_y[i] = grid_pred.mean(axis=0)[:,0]\n else:\n grid_y[i] = grid_pred[:,0]\n\ngrid_points = grid_points.reshape(n,n,2)\ngrid_y = grid_y.reshape(-1,n,n)",
"_____no_output_____"
],
[
"f = plt.figure(constrained_layout=True,figsize=(8,7))\ngs = f.add_gridspec(ncols=4, nrows=2)\naxs = np.empty(3,dtype=object)\naxs[0] = f.add_subplot(gs[0,0:2])\naxs[1] = f.add_subplot(gs[0,2:4],sharey=axs[0])\naxs[2] = f.add_subplot(gs[1,1:3])\n\naxs[1].yaxis.set_visible(False)\naxs[2].yaxis.set_visible(False)\n\naxs[0].set_title('SGPR')\naxs[1].set_title('DVMGP')\naxs[2].set_title('Full Dataset')\n\nims = np.empty((2,4),dtype=object)\n\nfor i,m in enumerate(['sgpr', 'dvmgp']):\n ax = axs[i]\n ims[0,i] = ax.contourf(grid_points[:,:,0],grid_points[:,:,1],grid_y[i],30)\n\n # Plot features\n Z = None\n if m == 'dgp':\n Z = models[m].layers[0].feature.Z.value\n elif m in ['sgpr','vmgp']:\n Z = models[m].feature.Z.value\n elif m == 'dvmgp':\n Z = models[m].Z_v.Z.value\n\n if Z is not None:\n ax.scatter(Z[:,0],Z[:,1],marker='^',edgecolors='white',facecolors='none')\n# ims[1,i] = ax.scatter(X.test[:,0],X.test[:,1],edgecolors='white',c=y.test)\n \nims[0,3] = axs[2].scatter(X.test[:,0],X.test[:,1],c=y.test)\nims[1,3] = axs[2].scatter(X.train[:,0],X.train[:,1],c=y.train)\n\nfor ax in axs:\n ax.set_xlim(lims[0]);\n ax.set_ylim(lims[1]);\n \nclim = np.array([i.get_clim() for i in ims.flat if i is not None])\nclim = (clim.min(), clim.max())\nnorm = mpl.colors.Normalize(vmin=clim[0], vmax=clim[1])\n# norm = MidpointNormalize(vmin=clim[0], vmax=clim[1], midpoint=0)\nfor im in ims.flat:\n if im is not None:\n im.set_norm(norm)\nf.colorbar(ims[0,0], ax=axs, orientation='vertical', fraction=1, aspect=50)\n\nfor im in ims[0,:3].flat:\n if im is not None:\n for c in im.collections:\n c.set_edgecolor(\"face\")\n\nf.savefig('./figs/outputs.pdf')",
"_____no_output_____"
],
[
"n = 50\ngrid_points = np.dstack(np.meshgrid(np.linspace(*lims[0],n), np.linspace(*lims[1],n))).reshape(-1,2)\ngrid_y = np.empty((grid_points.shape[0],2))\n\ngrid_y = models['dvmgp'].enquire_session().run(tf.matmul(\n tf.transpose(models['dvmgp'].compute_qW(grid_points)[0][...,0],[2,0,1]),grid_points[:,:,None]\n)[:,:,0])\n\ngrid_points = grid_points.reshape(n,n,2)\ngrid_y = grid_y.reshape(n,n,2)\n\nf = plt.figure(constrained_layout=True,figsize=(8,4))\ngs = f.add_gridspec(ncols=2, nrows=1)\naxs = np.empty(4,dtype=object)\naxs[0] = f.add_subplot(gs[0,0])\naxs[1] = f.add_subplot(gs[0,1])\n\nextent = (*lims[0], *lims[1])\ncolorspace = 'cielab'\nalpha = 0.7\n\naxs[0].imshow(\n cplot.get_srgb1(grid_points[:,:,0] + grid_points[:,:,1]*1j, colorspace=colorspace, alpha=alpha),\n origin='lower',\n extent=extent,\n aspect='auto',\n interpolation='gaussian'\n)\naxs[0].set_title('Identity map')\n\naxs[1].imshow(\n cplot.get_srgb1(grid_y[:,:,0] + grid_y[:,:,1]*1j, colorspace=colorspace, alpha=alpha),\n origin='lower',\n extent=extent,\n aspect='auto',\n interpolation='gaussian'\n)\naxs[1].set_title('DVMGP: $Wx^\\intercal$');\nf.savefig('./figs/layers.pdf')",
"_____no_output_____"
],
[
"dvmgp_var = np.array([k.variance.value for k in models['dvmgp'].w_kerns])\n\nf,ax = plt.subplots(1,1,figsize=(3,3))\nax.bar(np.arange(2), dvmgp_var/dvmgp_var.max(), color='C2')\nax.set_ylabel('1st layer variance\\nrelative to largest value')\n\nax.set_xlabel('Latent dimension')\nax.set_xticks([])\n\nax.set_title('DVMGP')\nf.tight_layout()\nf.savefig('./figs/dims.pdf')",
"_____no_output_____"
]
]
]
| [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d063b69f0b08b02a7b8969cb3540bb5645d3d954 | 7,384 | ipynb | Jupyter Notebook | docs/level1/sasum.ipynb | timleslie/pyblas | 9109f2cc24e674cf59a3b39f95c2d7b8116ae884 | [
"BSD-3-Clause"
]
| null | null | null | docs/level1/sasum.ipynb | timleslie/pyblas | 9109f2cc24e674cf59a3b39f95c2d7b8116ae884 | [
"BSD-3-Clause"
]
| 1 | 2020-10-10T23:23:06.000Z | 2020-10-10T23:23:06.000Z | docs/level1/sasum.ipynb | timleslie/pyblas | 9109f2cc24e674cf59a3b39f95c2d7b8116ae884 | [
"BSD-3-Clause"
]
| null | null | null | 31.555556 | 399 | 0.529117 | [
[
[
"# `sasum(N, SX, INCX)`\n\nComputes the sum of absolute values of elements of the vector $x$.\n\nOperates on single-precision real valued arrays.\n\nInput vector $\\mathbf{x}$ is represented as a [strided array](../strided_arrays.ipynb) `SX`, spaced by `INCX`.\nVector $\\mathbf{x}$ is of size `N`.",
"_____no_output_____"
],
[
"### Example usage",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\nsys.path.insert(0, os.path.abspath(os.path.join(os.path.abspath(''), \"..\", \"..\")))",
"_____no_output_____"
],
[
"import numpy as np\nfrom pyblas.level1 import sasum",
"_____no_output_____"
],
[
"x = np.array([1, 2, 3], dtype=np.single)\nN = len(x)\nincx = 1",
"_____no_output_____"
],
[
"sasum(N, x, incx)",
"_____no_output_____"
]
],
[
[
"### Docstring",
"_____no_output_____"
]
],
[
[
"help(sasum)",
"Help on function sasum in module pyblas.level1.sasum:\n\nsasum(N, SX, INCX)\n Computes the sum of absolute values of elements of the vector x\n \n Parameters\n ----------\n N : int\n Number of elements in input vector\n SX : numpy.ndarray\n A single precision real array, dimension (1 + (`N` - 1)*abs(`INCX`))\n INCX : int\n Storage spacing between elements of `SX`\n \n Returns\n -------\n numpy.single\n \n See Also\n --------\n dasum : Double-precision sum of absolute values\n \n Notes\n -----\n Online PyBLAS documentation: https://nbviewer.jupyter.org/github/timleslie/pyblas/blob/main/docs/sasum.ipynb\n Reference BLAS documentation: https://github.com/Reference-LAPACK/lapack/blob/v3.9.0/BLAS/SRC/sasum.f\n \n Examples\n --------\n >>> x = np.array([1, 2, 3], dtype=np.single)\n >>> N = len(x)\n >>> incx = 1\n >>> print(sasum(N, x, incx)\n 6.\n\n"
]
],
[
[
"### Source code",
"_____no_output_____"
]
],
[
[
"sasum??",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d063bda09143f23b1dec8e6d92850b0fa5e5ff8b | 431,235 | ipynb | Jupyter Notebook | 2019/PAN_AA_2018-POS-tag.ipynb | jeleandro/PANAA2018 | aa681fcb4e2f90841cf30f53265fecbb111123e1 | [
"Apache-2.0"
]
| null | null | null | 2019/PAN_AA_2018-POS-tag.ipynb | jeleandro/PANAA2018 | aa681fcb4e2f90841cf30f53265fecbb111123e1 | [
"Apache-2.0"
]
| null | null | null | 2019/PAN_AA_2018-POS-tag.ipynb | jeleandro/PANAA2018 | aa681fcb4e2f90841cf30f53265fecbb111123e1 | [
"Apache-2.0"
]
| null | null | null | 142.321782 | 120,504 | 0.77929 | [
[
[
"# Notebook para o PAN - Atribuição Autoral - 2018",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n#python basic libs\nimport os;\nfrom os.path import join as pathjoin;\n\nimport warnings\nwarnings.simplefilter(action='ignore', category=FutureWarning)\nfrom sklearn.exceptions import UndefinedMetricWarning\nwarnings.simplefilter(action='ignore', category=UndefinedMetricWarning)\n\nimport re;\nimport json;\nimport codecs;\nfrom collections import defaultdict;\n\nfrom pprint import pprint\nfrom time import time\nimport logging\n\n\n#data analysis libs\nimport numpy as np;\nimport pandas as pd;\nfrom pandas.plotting import scatter_matrix;\nimport matplotlib.pyplot as plt;\nimport random;\n\n#machine learning libs\n#feature extraction\nfrom sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, TfidfTransformer\n\n#preprocessing and transformation\nfrom sklearn import preprocessing\nfrom sklearn.preprocessing import normalize, MaxAbsScaler, RobustScaler;\nfrom sklearn.decomposition import PCA;\n\nfrom sklearn.base import BaseEstimator, ClassifierMixin\n\n#classifiers\nfrom sklearn import linear_model;\nfrom sklearn.linear_model import LogisticRegression\n\nfrom sklearn.svm import LinearSVC, SVC\nfrom sklearn.multiclass import OneVsOneClassifier, OneVsRestClassifier\nfrom sklearn.neural_network import MLPClassifier\n\n \n#\nfrom sklearn import feature_selection;\nfrom sklearn import ensemble;\n\nfrom sklearn.model_selection import train_test_split;\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.pipeline import Pipeline\n\n#model valuation\nfrom sklearn.metrics import roc_auc_score, f1_score, precision_score, recall_score, accuracy_score;",
"_____no_output_____"
],
[
"import seaborn as sns;\nsns.set(color_codes=True);",
"_____no_output_____"
],
[
"import spacy\nget_ipython().config.get('IPKernelApp', {})['parent_appname'] = \"\" #spacy causes a bug on pandas and this code fix it",
"_____no_output_____"
],
[
"import platform;\nimport sklearn;\nimport scipy;\n\nprint(\"|%-15s|%-40s|\"%(\"PACK\",\"VERSION\"))\nprint(\"|%-15s|%-40s|\"%('-'*15,'-'*40))\nprint('\\n'.join(\n \"|%-15s|%-40s|\" % (pack, version)\n for pack, version in\n zip(['SO','NumPy','SciPy','Scikit-Learn','seaborn','spacy'],\n [platform.platform(), np.__version__, scipy.__version__, sklearn.__version__, sns.__version__, spacy.__version__])\n\n))",
"|PACK |VERSION |\n|---------------|----------------------------------------|\n|SO |Darwin-18.2.0-x86_64-i386-64bit |\n|NumPy |1.15.4 |\n|SciPy |1.1.0 |\n|Scikit-Learn |0.20.1 |\n|seaborn |0.9.0 |\n|spacy |2.0.16 |\n"
],
[
"np.set_printoptions(precision=4)\npd.options.display.float_format = '{:,.4f}'.format",
"_____no_output_____"
],
[
"#externalizing codes that is used in many notebooks and it is not experiment specific\nimport pan\n#convert a sparse matrix into a dense for being used on PCA\nfrom skleanExtensions import DenseTransformer;\n\n#convert an array of text into an array of tokenized texts each token must contain text, tag_, pos_, dep_\nfrom skleanExtensions import POSTagTransformer",
"_____no_output_____"
]
],
[
[
"### paths configuration",
"_____no_output_____"
]
],
[
[
"baseDir = '/Users/joseeleandrocustodio/Dropbox/mestrado/02 - Pesquisa/code';\n\ninputDir= pathjoin(baseDir,'pan18aa');\noutputDir= pathjoin(baseDir,'out',\"oficial\");\nif not os.path.exists(outputDir):\n os.mkdir(outputDir);",
"_____no_output_____"
]
],
[
[
"## loading the dataset",
"_____no_output_____"
]
],
[
[
"problems = pan.readCollectionsOfProblems(inputDir);",
"_____no_output_____"
],
[
"print(problems[0]['problem'])\nprint(problems[0].keys())",
"problem00001\ndict_keys(['problem', 'language', 'encoding', 'candidates_folder_count', 'candidates', 'unknown'])\n"
],
[
"pd.DataFrame(problems)",
"_____no_output_____"
],
[
"def cachingPOSTAG(problem, taggingVersion='TAG'):\n import json;\n print (\"Tagging: %s, language: %s, \" %(problem['problem'],problem['language']), end=' ');\n \n if not os.path.exists('POSTAG_cache'):\n os.makedirs('POSTAG_cache');\n \n _id = problem['problem']+problem['language'];\n filename = os.path.join('POSTAG_cache',taggingVersion+'_'+_id+'.json')\n if not os.path.exists(filename):\n lang = problem['language'];\n if lang == 'sp':\n lang = 'es';\n elif lang =='pl':\n print(lang, ' not supported');\n return ;\n\n train_docs, train_labels, _ = zip(*problem['candidates'])\n problem['training_docs_size'] = len(train_docs);\n test_docs, _, test_filename = zip(*problem['unknown'])\n\n t0 = time()\n tagger = POSTagTransformer(language=lang);\n train_docs = tagger.fit_transform(train_docs);\n test_docs = tagger.fit_transform(test_docs);\n \n print(\"Annotation time %0.3fs\" % (time() - t0))\n \n with open(filename,'w') as f:\n json.dump({\n 'train':train_docs,\n 'train_labels':train_labels,\n 'test':test_docs,\n 'test_filename':test_filename\n },f);\n else:\n with open(filename,'r') as f:\n data = json.load(f);\n\n train_docs = data['train'];\n train_labels = data['train_labels'];\n test_docs = data['test'];\n test_filename = data['test_filename'];\n print('tagged')\n return train_docs, train_labels, test_docs, test_filename;\n\nfor problem in problems:\n cachingPOSTAG(problem)",
"Tagging: problem00001, language: en, tagged\nTagging: problem00002, language: en, tagged\nTagging: problem00003, language: fr, tagged\nTagging: problem00004, language: fr, tagged\nTagging: problem00005, language: it, tagged\nTagging: problem00006, language: it, tagged\nTagging: problem00007, language: pl, pl not supported\nTagging: problem00008, language: pl, pl not supported\nTagging: problem00009, language: sp, tagged\nTagging: problem00010, language: sp, tagged\n"
],
[
"train_docs, train_labels, test_docs, test_filename = cachingPOSTAG(problem)",
"Tagging: problem00010, language: sp, tagged\n"
],
[
"class FilterTagTransformer(BaseEstimator):\n def __init__(self,token='POS', parts=None):\n self.token = token;\n self.parts = parts;\n\n def transform(self, X, y=None):\n \"\"\" Return An array of tokens \n Parameters\n ----------\n X : {array-like}, shape = [n_samples, n_tokens]\n Array documents, where each document consists of a list of node\n and each node consist of a token and its correspondent tag\n \n [\n [('a','TAG1'),('b','TAG2')],\n [('a','TAG1')]\n ]\n y : array-like, shape = [n_samples] (default: None)\n Returns\n ---------\n X_dense : dense version of the input X array.\n \"\"\"\n if self.token == 'TAG':\n X = [' '.join([d[1].split('__')[0] for d in doc]) for doc in X]\n elif self.token == 'POS':\n if self.parts is None:\n X = [' '.join([d[2] for d in doc]) for doc in X];\n else:\n X = [' '.join([d[0] for d in doc if d[2] in self.parts]) for doc in X]\n elif self.token == 'DEP':\n X = [' '.join([d[3] for d in doc]) for doc in X]\n elif self.token == 'word_POS':\n if self.parts is None:\n X = [' '.join([d[0]+'/'+d[2] for d in doc]) for doc in X]\n elif self.token == 'filter':\n if self.parts is None:\n X = [' '.join([d[2] for d in doc]) for doc in X];\n else:\n X = [' '.join([d[0] for d in doc if d[2] in self.parts]) for doc in X]\n else:\n X = [' '.join([d[0] for d in doc]) for doc in X]\n \n return np.array(X); \n\n def fit(self, X, y=None):\n self.is_fitted = True\n return self\n\n def fit_transform(self, X, y=None):\n return self.transform(X=X, y=y)",
"_____no_output_____"
]
],
[
[
"### analisando os demais parametros",
"_____no_output_____"
]
],
[
[
"def spaceTokenizer(x):\n return x.split(\" \");",
"_____no_output_____"
],
[
"def runML(problem):\n print (\"\\nProblem: %s, language: %s, \" %(problem['problem'],problem['language']), end=' ');\n \n lang = problem['language'];\n if lang == 'sp':\n lang = 'es';\n elif lang =='pl':\n print(lang, ' not supported');\n return None,None,None,None;\n \n \n train_docs, train_labels, test_docs, test_filename = cachingPOSTAG(problem)\n problem['training_docs_size'] = len(train_docs);\n\n t0 = time()\n \n pipeline = Pipeline([\n ('filter',FilterTagTransformer(token='TAG')),\n ('vect', CountVectorizer(\n tokenizer=spaceTokenizer,\n min_df=0.01,\n lowercase=False\n )),\n ('tfidf', TfidfTransformer()),\n ('scaler', MaxAbsScaler()),\n ('dense', DenseTransformer()),\n ('transf', PCA(0.999)),\n ('clf', LogisticRegression(random_state=0,multi_class='multinomial', solver='newton-cg')),\n ])\n \n \n # uncommenting more parameters will give better exploring power but will\n # increase processing time in a combinatorial way\n parameters = {\n 'vect__ngram_range' :((1,1),(1,2),(1,3),(1,5)),\n 'tfidf__use_idf' :(True, False),\n 'tfidf__sublinear_tf':(True, False),\n 'tfidf__norm':('l1','l2'),\n 'clf__C':(0.1,1,10),\n }\n \n grid_search = GridSearchCV(pipeline,\n parameters,\n cv=4,\n iid=False,\n n_jobs=-1,\n verbose=False,\n scoring='f1_macro')\n \n t0 = time()\n grid_search.fit(train_docs, train_labels)\n print(\"Gridsearh %0.3fs\" % (time() - t0), end=' ')\n\n print(\"Best score: %0.3f\" % grid_search.best_score_)\n print(\"Best parameters set:\")\n best_parameters = grid_search.best_estimator_.get_params()\n for param_name in sorted(parameters.keys()):\n print(\"\\t%s: %r\" % (param_name, best_parameters[param_name]))\n \n train_pred=grid_search.predict(train_docs);\n test_pred=grid_search.predict(test_docs);\n \n \n # Writing output file\n out_data=[]\n for i,v in enumerate(test_pred):\n out_data.append({'unknown-text': test_filename[i],'predicted-author': v})\n answerFile = pathjoin(outputDir,'answers-'+problem['problem']+'.json');\n with open(answerFile, 'w') as f:\n json.dump(out_data, f, indent=4)\n \n \n #calculating the performance using PAN evaluation code\n f1,precision,recall,accuracy=pan.evaluate(\n pathjoin(inputDir, problem['problem'], 'ground-truth.json'),\n answerFile)\n \n return {\n 'problem-name' : problem['problem'],\n \"language\" : problem['language'],\n 'AuthorCount' : len(set(train_labels)),\n 'macro-f1' : round(f1,3),\n 'macro-precision': round(precision,3),\n 'macro-recall' : round(recall,3),\n 'micro-accuracy' : round(accuracy,3),\n \n }, grid_search.cv_results_,best_parameters, grid_search.best_estimator_;",
"_____no_output_____"
],
[
"result = [];\ncv_result = [];\nbest_parameters = [];\nestimators = [];\nfor problem in problems:\n with warnings.catch_warnings():\n warnings.filterwarnings(\"ignore\");\n r, c, b, e = runML(problem);\n if r is None:\n continue;\n result.append(r);\n cv_result.append(c);\n estimators.append(e);\n b['problem'] = problem['problem'];\n best_parameters.append(b);",
"\nProblem: problem00001, language: en, Tagging: problem00001, language: en, tagged\nGridsearh 1107.958s Best score: 0.661\nBest parameters set:\n\tclf__C: 10\n\ttfidf__norm: 'l2'\n\ttfidf__sublinear_tf: True\n\ttfidf__use_idf: True\n\tvect__ngram_range: (1, 2)\n\nProblem: problem00002, language: en, Tagging: problem00002, language: en, tagged\nGridsearh 251.719s Best score: 0.840\nBest parameters set:\n\tclf__C: 0.1\n\ttfidf__norm: 'l2'\n\ttfidf__sublinear_tf: False\n\ttfidf__use_idf: True\n\tvect__ngram_range: (1, 3)\n\nProblem: problem00003, language: fr, Tagging: problem00003, language: fr, tagged\nGridsearh 1038.886s Best score: 0.530\nBest parameters set:\n\tclf__C: 1\n\ttfidf__norm: 'l2'\n\ttfidf__sublinear_tf: True\n\ttfidf__use_idf: False\n\tvect__ngram_range: (1, 3)\n\nProblem: problem00004, language: fr, Tagging: problem00004, language: fr, tagged\nGridsearh 256.516s Best score: 0.663\nBest parameters set:\n\tclf__C: 0.1\n\ttfidf__norm: 'l2'\n\ttfidf__sublinear_tf: True\n\ttfidf__use_idf: True\n\tvect__ngram_range: (1, 5)\n\nProblem: problem00005, language: it, Tagging: problem00005, language: it, tagged\nGridsearh 1014.834s Best score: 0.622\nBest parameters set:\n\tclf__C: 10\n\ttfidf__norm: 'l1'\n\ttfidf__sublinear_tf: True\n\ttfidf__use_idf: True\n\tvect__ngram_range: (1, 3)\n\nProblem: problem00006, language: it, Tagging: problem00006, language: it, tagged\nGridsearh 264.087s Best score: 0.880\nBest parameters set:\n\tclf__C: 0.1\n\ttfidf__norm: 'l2'\n\ttfidf__sublinear_tf: True\n\ttfidf__use_idf: True\n\tvect__ngram_range: (1, 2)\n\nProblem: problem00007, language: pl, pl not supported\n\nProblem: problem00008, language: pl, pl not supported\n\nProblem: problem00009, language: sp, Tagging: problem00009, language: sp, tagged\nGridsearh 1135.047s Best score: 0.610\nBest parameters set:\n\tclf__C: 1\n\ttfidf__norm: 'l2'\n\ttfidf__sublinear_tf: True\n\ttfidf__use_idf: True\n\tvect__ngram_range: (1, 5)\n\nProblem: problem00010, language: sp, Tagging: problem00010, language: sp, tagged\nGridsearh 267.930s Best score: 0.678\nBest parameters set:\n\tclf__C: 1\n\ttfidf__norm: 'l2'\n\ttfidf__sublinear_tf: False\n\ttfidf__use_idf: True\n\tvect__ngram_range: (1, 2)\n"
],
[
"df=pd.DataFrame(result)[['problem-name',\n \"language\",\n 'AuthorCount',\n 'macro-f1','macro-precision','macro-recall' ,'micro-accuracy']]",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df[['macro-f1']].mean()",
"_____no_output_____"
],
[
"languages={\n 'en':'inglesa',\n 'sp':'espanhola',\n 'it':'italiana',\n 'pl':'polonesa',\n 'fr':'francesa'\n}",
"_____no_output_____"
],
[
"cv_result2 = [];\ndfCV = pd.DataFrame();\nfor i, c in enumerate(cv_result):\n temp = pd.DataFrame(c);\n temp['language'] = result[i]['AuthorCount']\n temp['problem'] = int(re.sub('\\D','',result[i]['problem-name']));\n temp['language'] = languages[result[i]['language']]\n dfCV = dfCV.append(temp);\n\nfor p in [\n 'mean_test_score','std_test_score','mean_train_score', \n 'split0_test_score',\n 'split1_test_score',\n 'split2_test_score']:\n dfCV[p]=dfCV[p].astype(np.float32);\n\n \ndfCV =dfCV[[\n 'problem',\n 'language',\n 'rank_test_score',\n 'param_vect__ngram_range',\n 'param_tfidf__sublinear_tf',\n 'param_tfidf__norm',\n 'param_clf__C',\n 'mean_test_score', \n 'std_test_score',\n\n 'split0_test_score',\n 'split1_test_score',\n 'split2_test_score',\n\n 'mean_score_time',\n 'mean_fit_time',\n 'std_fit_time',\n 'std_score_time',\n 'std_train_score',\n]];\n\ndfCV.rename(columns={\n 'param_vect__ngram_range':'ngram_range',\n 'param_tfidf__sublinear_tf':'sublinear_tf',\n 'param_tfidf__smooth_idf':'smooth_idf',\n 'param_tfidf__norm':'norm',\n 'param_clf__C':'regularization',\n},inplace=True);\n\n#print('\\',\\n\\''.join(dfCV.columns))\n",
"_____no_output_____"
],
[
"dfCV.head()",
"_____no_output_____"
]
],
[
[
"## Saving the model",
"_____no_output_____"
]
],
[
[
"dfCV.to_csv('PANAA2018_POSTAG.csv', index=False)",
"_____no_output_____"
],
[
"dfCV = pd.read_csv('PANAA2018_POSTAG.csv', na_values='')",
"_____no_output_____"
],
[
"import pickle;\nwith open(\"PANAA2018_POSTAG.pkl\",\"wb\") as f:\n pickle.dump(estimators,f)",
"_____no_output_____"
]
],
[
[
"## understanding the model with reports",
"_____no_output_____"
],
[
"Podemos ver que para um mesmo problema mais de uma configuração é possível",
"_____no_output_____"
]
],
[
[
"print(' | '.join(best_parameters[0]['vect'].get_feature_names()[0:20]))",
" | '' | -LRB- | CC | CD | DT | EX | IN | JJ | MD | NN | NNP | NNPS | NNS | PRP | PRP$ | RB | UH | VB | VBD\n"
],
[
"(dfCV[dfCV.rank_test_score == 1]).drop_duplicates()[\n ['problem',\n 'language',\n 'mean_test_score',\n 'std_test_score',\n 'ngram_range',\n 'sublinear_tf',\n 'norm']\n].sort_values(by=[\n 'problem',\n 'mean_test_score',\n 'std_test_score',\n 'ngram_range',\n 'sublinear_tf'\n], ascending=[True, False,True,False,False])",
"_____no_output_____"
],
[
"dfCV.pivot_table(\n index=['problem','language','norm','sublinear_tf'],\n columns=[ 'ngram_range','regularization'],\n values='mean_test_score'\n )",
"_____no_output_____"
]
],
[
[
"O score retornado vem do conjunto de teste da validação cruzada e não do conjunto de testes",
"_____no_output_____"
]
],
[
[
"pd.options.display.precision = 3 \nprint(u\"\\\\begin{table}[h]\\n\\\\centering\\n\\\\caption{Medida F1 para os parâmetros }\")\n\nprint(re.sub(r'[ ]{2,}',' ',dfCV.pivot_table(\n index=['problem','language','sublinear_tf','norm'],\n columns=['ngram_range'],\n values='mean_test_score'\n ).to_latex()))\nprint (\"\\label{tab:modelocaracter}\")\nprint(r\"\\end{table}\")",
"\\begin{table}[h]\n\\centering\n\\caption{Medida F1 para os parâmetros }\n\\begin{tabular}{llllrrrr}\n\\toprule\n & & & ngram\\_range & (1, 1) & (1, 2) & (1, 3) & (1, 5) \\\\\nproblem & language & sublinear\\_tf & norm & & & & \\\\\n\\midrule\n1 & inglesa & False & l1 & 0.4150 & 0.5965 & 0.6053 & 0.5652 \\\\\n & & & l2 & 0.4107 & 0.5957 & 0.6074 & 0.5462 \\\\\n & & True & l1 & 0.3265 & 0.6172 & 0.6278 & 0.5325 \\\\\n & & & l2 & 0.3280 & 0.6317 & 0.6174 & 0.5734 \\\\\n2 & inglesa & False & l1 & 0.6302 & 0.7712 & 0.8017 & 0.7436 \\\\\n & & & l2 & 0.6209 & 0.7722 & 0.8200 & 0.7352 \\\\\n & & True & l1 & 0.7302 & 0.7919 & 0.7552 & 0.7519 \\\\\n & & & l2 & 0.7306 & 0.7895 & 0.7678 & 0.7519 \\\\\n3 & francesa & False & l1 & 0.2583 & 0.4162 & 0.4969 & 0.4386 \\\\\n & & & l2 & 0.2444 & 0.4164 & 0.5003 & 0.4524 \\\\\n & & True & l1 & 0.1230 & 0.4329 & 0.4955 & 0.4724 \\\\\n & & & l2 & 0.1288 & 0.4439 & 0.5196 & 0.4928 \\\\\n4 & francesa & False & l1 & 0.4039 & 0.4439 & 0.6035 & 0.5917 \\\\\n & & & l2 & 0.4108 & 0.4278 & 0.5944 & 0.5662 \\\\\n & & True & l1 & 0.2567 & 0.3345 & 0.6181 & 0.6328 \\\\\n & & & l2 & 0.2594 & 0.3315 & 0.6411 & 0.6633 \\\\\n5 & italiana & False & l1 & 0.2972 & 0.4731 & 0.5116 & 0.4924 \\\\\n & & & l2 & 0.2880 & 0.4545 & 0.4813 & 0.4743 \\\\\n & & True & l1 & 0.1986 & 0.5366 & 0.6021 & 0.5081 \\\\\n & & & l2 & 0.1973 & 0.5217 & 0.5617 & 0.5230 \\\\\n6 & italiana & False & l1 & 0.7239 & 0.8300 & 0.8367 & 0.8367 \\\\\n & & & l2 & 0.7528 & 0.8300 & 0.8367 & 0.8233 \\\\\n & & True & l1 & 0.4723 & 0.8533 & 0.8367 & 0.8339 \\\\\n & & & l2 & 0.4858 & 0.8683 & 0.8367 & 0.8100 \\\\\n9 & espanhola & False & l1 & 0.2194 & 0.5035 & 0.5213 & 0.5761 \\\\\n & & & l2 & 0.2126 & 0.5008 & 0.5177 & 0.5638 \\\\\n & & True & l1 & 0.1186 & 0.4609 & 0.5542 & 0.6021 \\\\\n & & & l2 & 0.1213 & 0.4623 & 0.5585 & 0.5997 \\\\\n10 & espanhola & False & l1 & 0.3879 & 0.6108 & 0.5474 & 0.6333 \\\\\n & & & l2 & 0.3901 & 0.6106 & 0.5526 & 0.5783 \\\\\n & & True & l1 & 0.2956 & 0.5603 & 0.5447 & 0.6572 \\\\\n & & & l2 & 0.2665 & 0.5697 & 0.5450 & 0.6289 \\\\\n\\bottomrule\n\\end{tabular}\n\n\\label{tab:modelocaracter}\n\\end{table}\n"
],
[
"d = dfCV.copy()\nd = d.rename(columns={'language':u'Língua', 'sublinear_tf':'TF Sublinear'})\nd = d [ d.norm.isna() == False]\nd['autorNumber'] = d.problem.map(lambda x: 20 if x % 2==0 else 5)\nd.problem = d.apply(lambda x: x[u'Língua'] +\" \"+ str(x[u'problem']), axis=1)\n#d.ngram_range = d.apply(lambda x: str(x[u'ngram_range'][0]) +\" \"+ str(x[u'ngram_range'][1]), axis=1)\n\nd.std_test_score =d.std_test_score / d.std_test_score.quantile(0.95) *500;\nd.std_test_score +=1;\nd.std_test_score = d.std_test_score.astype(np.int64)\ng = sns.FacetGrid(d, col='Língua', hue='TF Sublinear', row=\"regularization\", height=3,palette=\"Set1\")\ng.map(plt.scatter, \"ngram_range\", \"mean_test_score\",s=d.std_test_score.values).add_legend();\n#sns.pairplot(d, hue=\"TF Sublinear\", vars=[\"autorNumber\", \"mean_test_score\"])\n",
"_____no_output_____"
],
[
"g = sns.FacetGrid(d, row='autorNumber', hue='TF Sublinear', col=u\"Língua\", height=3,palette=\"Set1\")\ng.map(plt.scatter, \"ngram_range\", \"mean_test_score\", alpha=0.5, s=d.std_test_score.values).add_legend();",
"_____no_output_____"
],
[
"sns.distplot(dfCV.std_test_score, bins=25);",
"_____no_output_____"
],
[
"import statsmodels.api as sm",
"_____no_output_____"
],
[
"d = dfCV[['mean_test_score','problem', 'language','sublinear_tf','norm','ngram_range']].copy();\nd.sublinear_tf=d.sublinear_tf.apply(lambda x: 1 if x else 0)\nd.norm=d.norm.apply(lambda x: 1 if x=='l1' else 0)\n\nd['autorNumber'] = d.problem.map(lambda x: 20 if x % 2==0 else 5)\nd.norm.fillna(value='None', inplace=True);\n\n_, d['ngram_max'] = zip(*d.ngram_range.str.replace(r'[^\\d,]','').str.split(',').values.tolist())\n#d.ngram_min = d.ngram_min.astype(np.uint8);\nd.ngram_max = d.ngram_max.astype(np.uint8);\nd.drop(columns=['ngram_range','problem'], inplace=True)\n#d['intercept'] = 1;\n\nd=pd.get_dummies(d, columns=['language'])",
"_____no_output_____"
],
[
"d.describe()",
"_____no_output_____"
],
[
"mod = sm.OLS( d.iloc[:,0], d.iloc[:,1:])\nres = mod.fit()\nres.summary()",
"_____no_output_____"
],
[
"sns.distplot(res.predict()-d.iloc[:,0].values, bins=25)",
"_____no_output_____"
],
[
"sns.jointplot(x='F1',y='F1-estimated',data=pd.DataFrame({'F1':d.iloc[:,0].values, 'F1-estimated':res.predict()}));",
"_____no_output_____"
]
],
[
[
"# tests",
"_____no_output_____"
]
],
[
[
"problem = problems[0]\nprint (\"\\nProblem: %s, language: %s, \" %(problem['problem'],problem['language']), end=' ');\n",
"\nProblem: problem00001, language: en, "
],
[
"def d(estimator, n_features=5):\n from IPython.display import Markdown, display, HTML\n names = np.array(estimator.named_steps['vect'].get_feature_names());\n classes_ = estimator.named_steps['clf'].classes_;\n weights = estimator.named_steps['clf'].coef_;\n \n def tag(tag, content, attrib=''):\n if attrib != '':\n attrib = ' style=\"' + attrib+'\"'; \n return ''.join(['<',tag,attrib,' >',content,'</',tag,'>']);\n \n def color(baseColor, intensity):\n r,g,b = baseColor[0:2],baseColor[2:4],baseColor[4:6]\n r,g,b = int(r, 16), int(g, 16), int(b, 16)\n \n f= (1-np.abs(intensity))/2;\n r = r + int((255-r)*f)\n g = g + int((255-g)*f)\n b = b + int((255-b)*f)\n rgb = '#%02x%x%x' % (r, g, b);\n #print(baseColor,rgb,r,g,b,intensity,f)\n return rgb\n \n \n spanStyle ='border-radius: 5px;margin:4px;padding:3px; color:#FFF !important;';\n \n lines = '<table>'+tag('thead',tag('th','Classes')+tag('th','positive')+tag('th','negative'))\n lines += '<tbody>'\n for i,c in enumerate(weights):\n c = np.round(c / np.abs(c).max(),2);\n positive = names[np.argsort(-c)][:n_features];\n positiveV = c[np.argsort(-c)][:n_features]\n negative = names[np.argsort(c)][:n_features];\n negativeV = c[np.argsort(c)][:n_features]\n \n lines += tag('tr',\n tag('td', re.sub('\\D0*','',classes_[i]))\n + tag('td',''.join([tag('span',d.upper()+' '+str(v),spanStyle+'background:'+color('51A3DD',v)) for d,v in zip(positive,positiveV)]))\n + tag('td',''.join([tag('span',d.upper()+' '+str(v),spanStyle+'background:'+color('DD5555',v)) for d,v in zip(negative,negativeV)]))\n )\n lines+= '</tbody></table>'\n \n display(HTML(lines))\n #print(lines)\n \nd(estimators[0])",
"_____no_output_____"
],
[
"%%HTML\n<table><tbody><tr><th>POS</th><th>Description</th><th>Examples</th></tr><tr >\n<td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text u-text-small\">adjective</td><td class=\"c-table__cell u-text u-text-small\"><em>big, old, green, incomprehensible, first</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>ADP</code></td><td class=\"c-table__cell u-text u-text-small\">adposition</td><td class=\"c-table__cell u-text u-text-small\"><em>in, to, during</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text u-text-small\">adverb</td><td class=\"c-table__cell u-text u-text-small\"><em>very, tomorrow, down, where, there</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>AUX</code></td><td class=\"c-table__cell u-text u-text-small\">auxiliary</td><td class=\"c-table__cell u-text u-text-small\"><em>is, has (done), will (do), should (do)</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>CONJ</code></td><td class=\"c-table__cell u-text u-text-small\">conjunction</td><td class=\"c-table__cell u-text u-text-small\"><em>and, or, but</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>CCONJ</code></td><td class=\"c-table__cell u-text u-text-small\">coordinating conjunction</td><td class=\"c-table__cell u-text u-text-small\"><em>and, or, but</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>DET</code></td><td class=\"c-table__cell u-text u-text-small\">determiner</td><td class=\"c-table__cell u-text u-text-small\"><em>a, an, the</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>INTJ</code></td><td class=\"c-table__cell u-text u-text-small\">interjection</td><td class=\"c-table__cell u-text u-text-small\"><em>psst, ouch, bravo, hello</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NOUN</code></td><td class=\"c-table__cell u-text u-text-small\">noun</td><td class=\"c-table__cell u-text u-text-small\"><em>girl, cat, tree, air, beauty</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NUM</code></td><td class=\"c-table__cell u-text u-text-small\">numeral</td><td class=\"c-table__cell u-text u-text-small\"><em>1, 2017, one, seventy-seven, IV, MMXIV</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PART</code></td><td class=\"c-table__cell u-text u-text-small\">particle</td><td class=\"c-table__cell u-text u-text-small\"><em>'s, not, </em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PRON</code></td><td class=\"c-table__cell u-text u-text-small\">pronoun</td><td class=\"c-table__cell u-text u-text-small\"><em>I, you, he, she, myself, themselves, somebody</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PROPN</code></td><td class=\"c-table__cell u-text u-text-small\">proper noun</td><td class=\"c-table__cell u-text u-text-small\"><em>Mary, John, London, NATO, HBO</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text u-text-small\">punctuation</td><td class=\"c-table__cell u-text u-text-small\"><em>., (, ), ?</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>SCONJ</code></td><td class=\"c-table__cell u-text u-text-small\">subordinating conjunction</td><td class=\"c-table__cell u-text u-text-small\"><em>if, while, that</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>SYM</code></td><td class=\"c-table__cell u-text u-text-small\">symbol</td><td class=\"c-table__cell u-text u-text-small\"><em>$, %, §, ©, +, −, ×, ÷, =, :), 😝</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text u-text-small\">verb</td><td class=\"c-table__cell u-text u-text-small\"><em>run, runs, running, eat, ate, eating</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>X</code></td><td class=\"c-table__cell u-text u-text-small\">other</td><td class=\"c-table__cell u-text u-text-small\"><em>sfpksdpsxmsa</em></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>SPACE</code></td><td class=\"c-table__cell u-text u-text-small\">space</td></tr></tbody></table>",
"_____no_output_____"
],
[
"%%HTML\n<h1>English</h1>\n\n<table class=\"c-table o-block\"><tbody><tr class=\"c-table__row c-table__row--head\"><th class=\"c-table__head-cell u-text-label\">Tag</th><th class=\"c-table__head-cell u-text-label\">POS</th><th class=\"c-table__head-cell u-text-label\">Morphology</th><th class=\"c-table__head-cell u-text-label\">Description</th></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>-LRB-</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=brck</code> <code>PunctSide=ini</code></td><td class=\"c-table__cell u-text u-text-small\">left round bracket</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>-RRB-</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=brck</code> <code>PunctSide=fin</code></td><td class=\"c-table__cell u-text u-text-small\">right round bracket</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>,</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=comm</code></td><td class=\"c-table__cell u-text u-text-small\">punctuation mark, comma</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>:</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">punctuation mark, colon or ellipsis</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>.</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=peri</code></td><td class=\"c-table__cell u-text u-text-small\">punctuation mark, sentence closer</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>''</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=quot</code> <code>PunctSide=fin</code></td><td class=\"c-table__cell u-text u-text-small\">closing quotation mark</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>\"\"</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=quot</code> <code>PunctSide=fin</code></td><td class=\"c-table__cell u-text u-text-small\">closing quotation mark</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>#</code></td><td class=\"c-table__cell u-text\"><code>SYM</code></td><td class=\"c-table__cell u-text\"> <code>SymType=numbersign</code></td><td class=\"c-table__cell u-text u-text-small\">symbol, number sign</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>``</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=quot</code> <code>PunctSide=ini</code></td><td class=\"c-table__cell u-text u-text-small\">opening quotation mark</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>$</code></td><td class=\"c-table__cell u-text\"><code>SYM</code></td><td class=\"c-table__cell u-text\"> <code>SymType=currency</code></td><td class=\"c-table__cell u-text u-text-small\">symbol, currency</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>ADD</code></td><td class=\"c-table__cell u-text\"><code>X</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">email</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>AFX</code></td><td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text\"> <code>Hyph=yes</code></td><td class=\"c-table__cell u-text u-text-small\">affix</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>BES</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">auxiliary \"be\"</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>CC</code></td><td class=\"c-table__cell u-text\"><code>CONJ</code></td><td class=\"c-table__cell u-text\"> <code>ConjType=coor</code></td><td class=\"c-table__cell u-text u-text-small\">conjunction, coordinating</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>CD</code></td><td class=\"c-table__cell u-text\"><code>NUM</code></td><td class=\"c-table__cell u-text\"> <code>NumType=card</code></td><td class=\"c-table__cell u-text u-text-small\">cardinal number</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>DT</code></td><td class=\"c-table__cell u-text\"><code>DET</code></td><td class=\"c-table__cell u-text\"> <code>determiner</code></td><td class=\"c-table__cell u-text u-text-small\"></td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>EX</code></td><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text\"> <code>AdvType=ex</code></td><td class=\"c-table__cell u-text u-text-small\">existential there</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>FW</code></td><td class=\"c-table__cell u-text\"><code>X</code></td><td class=\"c-table__cell u-text\"> <code>Foreign=yes</code></td><td class=\"c-table__cell u-text u-text-small\">foreign word</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>GW</code></td><td class=\"c-table__cell u-text\"><code>X</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">additional word in multi-word expression</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>HVS</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">forms of \"have\"</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>HYPH</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=dash</code></td><td class=\"c-table__cell u-text u-text-small\">punctuation mark, hyphen</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>IN</code></td><td class=\"c-table__cell u-text\"><code>ADP</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">conjunction, subordinating or preposition</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>JJ</code></td><td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text\"> <code>Degree=pos</code></td><td class=\"c-table__cell u-text u-text-small\">adjective</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>JJR</code></td><td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text\"> <code>Degree=comp</code></td><td class=\"c-table__cell u-text u-text-small\">adjective, comparative</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>JJS</code></td><td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text\"> <code>Degree=sup</code></td><td class=\"c-table__cell u-text u-text-small\">adjective, superlative</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>LS</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>NumType=ord</code></td><td class=\"c-table__cell u-text u-text-small\">list item marker</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>MD</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>VerbType=mod</code></td><td class=\"c-table__cell u-text u-text-small\">verb, modal auxiliary</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NFP</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">superfluous punctuation</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NIL</code></td><td class=\"c-table__cell u-text\"><code></code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">missing tag</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NN</code></td><td class=\"c-table__cell u-text\"><code>NOUN</code></td><td class=\"c-table__cell u-text\"> <code>Number=sing</code></td><td class=\"c-table__cell u-text u-text-small\">noun, singular or mass</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NNP</code></td><td class=\"c-table__cell u-text\"><code>PROPN</code></td><td class=\"c-table__cell u-text\"> <code>NounType=prop</code> <code>Number=sign</code></td><td class=\"c-table__cell u-text u-text-small\">noun, proper singular</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NNPS</code></td><td class=\"c-table__cell u-text\"><code>PROPN</code></td><td class=\"c-table__cell u-text\"> <code>NounType=prop</code> <code>Number=plur</code></td><td class=\"c-table__cell u-text u-text-small\">noun, proper plural</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NNS</code></td><td class=\"c-table__cell u-text\"><code>NOUN</code></td><td class=\"c-table__cell u-text\"> <code>Number=plur</code></td><td class=\"c-table__cell u-text u-text-small\">noun, plural</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PDT</code></td><td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text\"> <code>AdjType=pdt</code> <code>PronType=prn</code></td><td class=\"c-table__cell u-text u-text-small\">predeterminer</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>POS</code></td><td class=\"c-table__cell u-text\"><code>PART</code></td><td class=\"c-table__cell u-text\"> <code>Poss=yes</code></td><td class=\"c-table__cell u-text u-text-small\">possessive ending</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PRP</code></td><td class=\"c-table__cell u-text\"><code>PRON</code></td><td class=\"c-table__cell u-text\"> <code>PronType=prs</code></td><td class=\"c-table__cell u-text u-text-small\">pronoun, personal</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PRP$</code></td><td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text\"> <code>PronType=prs</code> <code>Poss=yes</code></td><td class=\"c-table__cell u-text u-text-small\">pronoun, possessive</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>RB</code></td><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text\"> <code>Degree=pos</code></td><td class=\"c-table__cell u-text u-text-small\">adverb</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>RBR</code></td><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text\"> <code>Degree=comp</code></td><td class=\"c-table__cell u-text u-text-small\">adverb, comparative</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>RBS</code></td><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text\"> <code>Degree=sup</code></td><td class=\"c-table__cell u-text u-text-small\">adverb, superlative</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>RP</code></td><td class=\"c-table__cell u-text\"><code>PART</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">adverb, particle</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>_SP</code></td><td class=\"c-table__cell u-text\"><code>SPACE</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">space</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>SYM</code></td><td class=\"c-table__cell u-text\"><code>SYM</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">symbol</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>TO</code></td><td class=\"c-table__cell u-text\"><code>PART</code></td><td class=\"c-table__cell u-text\"> <code>PartType=inf</code> <code>VerbForm=inf</code></td><td class=\"c-table__cell u-text u-text-small\">infinitival to</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>UH</code></td><td class=\"c-table__cell u-text\"><code>INTJ</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">interjection</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VB</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>VerbForm=inf</code></td><td class=\"c-table__cell u-text u-text-small\">verb, base form</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VBD</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>VerbForm=fin</code> <code>Tense=past</code></td><td class=\"c-table__cell u-text u-text-small\">verb, past tense</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VBG</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>VerbForm=part</code> <code>Tense=pres</code> <code>Aspect=prog</code></td><td class=\"c-table__cell u-text u-text-small\">verb, gerund or present participle</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VBN</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>VerbForm=part</code> <code>Tense=past</code> <code>Aspect=perf</code></td><td class=\"c-table__cell u-text u-text-small\">verb, past participle</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VBP</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>VerbForm=fin</code> <code>Tense=pres</code></td><td class=\"c-table__cell u-text u-text-small\">verb, non-3rd person singular present</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VBZ</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>VerbForm=fin</code> <code>Tense=pres</code> <code>Number=sing</code> <code>Person=3</code></td><td class=\"c-table__cell u-text u-text-small\">verb, 3rd person singular present</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>WDT</code></td><td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text\"> <code>PronType=int</code> <code>rel</code></td><td class=\"c-table__cell u-text u-text-small\">wh-determiner</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>WP</code></td><td class=\"c-table__cell u-text\"><code>NOUN</code></td><td class=\"c-table__cell u-text\"> <code>PronType=int</code> <code>rel</code></td><td class=\"c-table__cell u-text u-text-small\">wh-pronoun, personal</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>WP$</code></td><td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text\"> <code>Poss=yes PronType=int</code> <code>rel</code></td><td class=\"c-table__cell u-text u-text-small\">wh-pronoun, possessive</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>WRB</code></td><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text\"> <code>PronType=int</code> <code>rel</code></td><td class=\"c-table__cell u-text u-text-small\">wh-adverb</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>XX</code></td><td class=\"c-table__cell u-text\"><code>X</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">unknown</td></tr></tbody></table>",
"_____no_output_____"
],
[
"%%HTML\n<h1>German</h1>\n<p> The German part-of-speech tagger uses the <a href=\"http://www.ims.uni-stuttgart.de/forschung/ressourcen/korpora/TIGERCorpus/annotation/index.html\" target=\"_blank\" rel=\"noopener nofollow\">TIGER Treebank</a> annotation scheme. We also map the tags to the simpler Google\nUniversal POS tag set.</p>\n\n<table class=\"c-table o-block\"><tbody><tr class=\"c-table__row c-table__row--head\"><th class=\"c-table__head-cell u-text-label\">Tag</th><th class=\"c-table__head-cell u-text-label\">POS</th><th class=\"c-table__head-cell u-text-label\">Morphology</th><th class=\"c-table__head-cell u-text-label\">Description</th></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>$(</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=brck</code></td><td class=\"c-table__cell u-text u-text-small\">other sentence-internal punctuation mark</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>$,</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=comm</code></td><td class=\"c-table__cell u-text u-text-small\">comma</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>$.</code></td><td class=\"c-table__cell u-text\"><code>PUNCT</code></td><td class=\"c-table__cell u-text\"> <code>PunctType=peri</code></td><td class=\"c-table__cell u-text u-text-small\">sentence-final punctuation mark</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>ADJA</code></td><td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">adjective, attributive</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>ADJD</code></td><td class=\"c-table__cell u-text\"><code>ADJ</code></td><td class=\"c-table__cell u-text\"> <code>Variant=short</code></td><td class=\"c-table__cell u-text u-text-small\">adjective, adverbial or predicative</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">adverb</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>APPO</code></td><td class=\"c-table__cell u-text\"><code>ADP</code></td><td class=\"c-table__cell u-text\"> <code>AdpType=post</code></td><td class=\"c-table__cell u-text u-text-small\">postposition</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>APPR</code></td><td class=\"c-table__cell u-text\"><code>ADP</code></td><td class=\"c-table__cell u-text\"> <code>AdpType=prep</code></td><td class=\"c-table__cell u-text u-text-small\">preposition; circumposition left</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>APPRART</code></td><td class=\"c-table__cell u-text\"><code>ADP</code></td><td class=\"c-table__cell u-text\"> <code>AdpType=prep</code> <code>PronType=art</code></td><td class=\"c-table__cell u-text u-text-small\">preposition with article</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>APZR</code></td><td class=\"c-table__cell u-text\"><code>ADP</code></td><td class=\"c-table__cell u-text\"> <code>AdpType=circ</code></td><td class=\"c-table__cell u-text u-text-small\">circumposition right</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>ART</code></td><td class=\"c-table__cell u-text\"><code>DET</code></td><td class=\"c-table__cell u-text\"> <code>PronType=art</code></td><td class=\"c-table__cell u-text u-text-small\">definite or indefinite article</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>CARD</code></td><td class=\"c-table__cell u-text\"><code>NUM</code></td><td class=\"c-table__cell u-text\"> <code>NumType=card</code></td><td class=\"c-table__cell u-text u-text-small\">cardinal number</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>FM</code></td><td class=\"c-table__cell u-text\"><code>X</code></td><td class=\"c-table__cell u-text\"> <code>Foreign=yes</code></td><td class=\"c-table__cell u-text u-text-small\">foreign language material</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>ITJ</code></td><td class=\"c-table__cell u-text\"><code>INTJ</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">interjection</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>KOKOM</code></td><td class=\"c-table__cell u-text\"><code>CONJ</code></td><td class=\"c-table__cell u-text\"> <code>ConjType=comp</code></td><td class=\"c-table__cell u-text u-text-small\">comparative conjunction</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>KON</code></td><td class=\"c-table__cell u-text\"><code>CONJ</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">coordinate conjunction</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>KOUI</code></td><td class=\"c-table__cell u-text\"><code>SCONJ</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">subordinate conjunction with \"zu\" and infinitive</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>KOUS</code></td><td class=\"c-table__cell u-text\"><code>SCONJ</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">subordinate conjunction with sentence</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NE</code></td><td class=\"c-table__cell u-text\"><code>PROPN</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">proper noun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NNE</code></td><td class=\"c-table__cell u-text\"><code>PROPN</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">proper noun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>NN</code></td><td class=\"c-table__cell u-text\"><code>NOUN</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">noun, singular or mass</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PAV</code></td><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text\"> <code>PronType=dem</code></td><td class=\"c-table__cell u-text u-text-small\">pronominal adverb</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PROAV</code></td><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text\"> <code>PronType=dem</code></td><td class=\"c-table__cell u-text u-text-small\">pronominal adverb</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PDAT</code></td><td class=\"c-table__cell u-text\"><code>DET</code></td><td class=\"c-table__cell u-text\"> <code>PronType=dem</code></td><td class=\"c-table__cell u-text u-text-small\">attributive demonstrative pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PDS</code></td><td class=\"c-table__cell u-text\"><code>PRON</code></td><td class=\"c-table__cell u-text\"> <code>PronType=dem</code></td><td class=\"c-table__cell u-text u-text-small\">substituting demonstrative pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PIAT</code></td><td class=\"c-table__cell u-text\"><code>DET</code></td><td class=\"c-table__cell u-text\"> <code>PronType=ind</code> <code>neg</code> <code>tot</code></td><td class=\"c-table__cell u-text u-text-small\">attributive indefinite pronoun without determiner</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PIDAT</code></td><td class=\"c-table__cell u-text\"><code>DET</code></td><td class=\"c-table__cell u-text\"> <code>AdjType=pdt PronType=ind</code> <code>neg</code> <code>tot</code></td><td class=\"c-table__cell u-text u-text-small\">attributive indefinite pronoun with determiner</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PIS</code></td><td class=\"c-table__cell u-text\"><code>PRON</code></td><td class=\"c-table__cell u-text\"> <code>PronType=ind</code> <code>neg</code> <code>tot</code></td><td class=\"c-table__cell u-text u-text-small\">substituting indefinite pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PPER</code></td><td class=\"c-table__cell u-text\"><code>PRON</code></td><td class=\"c-table__cell u-text\"> <code>PronType=prs</code></td><td class=\"c-table__cell u-text u-text-small\">non-reflexive personal pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PPOSAT</code></td><td class=\"c-table__cell u-text\"><code>DET</code></td><td class=\"c-table__cell u-text\"> <code>Poss=yes</code> <code>PronType=prs</code></td><td class=\"c-table__cell u-text u-text-small\">attributive possessive pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PPOSS</code></td><td class=\"c-table__cell u-text\"><code>PRON</code></td><td class=\"c-table__cell u-text\"> <code>PronType=rel</code></td><td class=\"c-table__cell u-text u-text-small\">substituting possessive pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PRELAT</code></td><td class=\"c-table__cell u-text\"><code>DET</code></td><td class=\"c-table__cell u-text\"> <code>PronType=rel</code></td><td class=\"c-table__cell u-text u-text-small\">attributive relative pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PRELS</code></td><td class=\"c-table__cell u-text\"><code>PRON</code></td><td class=\"c-table__cell u-text\"> <code>PronType=rel</code></td><td class=\"c-table__cell u-text u-text-small\">substituting relative pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PRF</code></td><td class=\"c-table__cell u-text\"><code>PRON</code></td><td class=\"c-table__cell u-text\"> <code>PronType=prs</code> <code>Reflex=yes</code></td><td class=\"c-table__cell u-text u-text-small\">reflexive personal pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PTKA</code></td><td class=\"c-table__cell u-text\"><code>PART</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">particle with adjective or adverb</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PTKANT</code></td><td class=\"c-table__cell u-text\"><code>PART</code></td><td class=\"c-table__cell u-text\"> <code>PartType=res</code></td><td class=\"c-table__cell u-text u-text-small\">answer particle</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PTKNEG</code></td><td class=\"c-table__cell u-text\"><code>PART</code></td><td class=\"c-table__cell u-text\"> <code>Negative=yes</code></td><td class=\"c-table__cell u-text u-text-small\">negative particle</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PTKVZ</code></td><td class=\"c-table__cell u-text\"><code>PART</code></td><td class=\"c-table__cell u-text\"> <code>PartType=vbp</code></td><td class=\"c-table__cell u-text u-text-small\">separable verbal particle</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PTKZU</code></td><td class=\"c-table__cell u-text\"><code>PART</code></td><td class=\"c-table__cell u-text\"> <code>PartType=inf</code></td><td class=\"c-table__cell u-text u-text-small\">\"zu\" before infinitive</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PWAT</code></td><td class=\"c-table__cell u-text\"><code>DET</code></td><td class=\"c-table__cell u-text\"> <code>PronType=int</code></td><td class=\"c-table__cell u-text u-text-small\">attributive interrogative pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PWAV</code></td><td class=\"c-table__cell u-text\"><code>ADV</code></td><td class=\"c-table__cell u-text\"> <code>PronType=int</code></td><td class=\"c-table__cell u-text u-text-small\">adverbial interrogative or relative pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>PWS</code></td><td class=\"c-table__cell u-text\"><code>PRON</code></td><td class=\"c-table__cell u-text\"> <code>PronType=int</code></td><td class=\"c-table__cell u-text u-text-small\">substituting interrogative pronoun</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>TRUNC</code></td><td class=\"c-table__cell u-text\"><code>X</code></td><td class=\"c-table__cell u-text\"> <code>Hyph=yes</code></td><td class=\"c-table__cell u-text u-text-small\">word remnant</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VAFIN</code></td><td class=\"c-table__cell u-text\"><code>AUX</code></td><td class=\"c-table__cell u-text\"> <code>Mood=ind</code> <code>VerbForm=fin</code></td><td class=\"c-table__cell u-text u-text-small\">finite verb, auxiliary</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VAIMP</code></td><td class=\"c-table__cell u-text\"><code>AUX</code></td><td class=\"c-table__cell u-text\"> <code>Mood=imp</code> <code>VerbForm=fin</code></td><td class=\"c-table__cell u-text u-text-small\">imperative, auxiliary</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VAINF</code></td><td class=\"c-table__cell u-text\"><code>AUX</code></td><td class=\"c-table__cell u-text\"> <code>VerbForm=inf</code></td><td class=\"c-table__cell u-text u-text-small\">infinitive, auxiliary</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VAPP</code></td><td class=\"c-table__cell u-text\"><code>AUX</code></td><td class=\"c-table__cell u-text\"> <code>Aspect=perf</code> <code>VerbForm=fin</code></td><td class=\"c-table__cell u-text u-text-small\">perfect participle, auxiliary</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VMFIN</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>Mood=ind</code> <code>VerbForm=fin</code> <code>VerbType=mod</code></td><td class=\"c-table__cell u-text u-text-small\">finite verb, modal</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VMINF</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>VerbForm=fin</code> <code>VerbType=mod</code></td><td class=\"c-table__cell u-text u-text-small\">infinitive, modal</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VMPP</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>Aspect=perf</code> <code>VerbForm=part</code> <code>VerbType=mod</code></td><td class=\"c-table__cell u-text u-text-small\">perfect participle, modal</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VVFIN</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>Mood=ind</code> <code>VerbForm=fin</code></td><td class=\"c-table__cell u-text u-text-small\">finite verb, full</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VVIMP</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>Mood=imp</code> <code>VerbForm=fin</code></td><td class=\"c-table__cell u-text u-text-small\">imperative, full</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VVINF</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>VerbForm=inf</code></td><td class=\"c-table__cell u-text u-text-small\">infinitive, full</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VVIZU</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>VerbForm=inf</code></td><td class=\"c-table__cell u-text u-text-small\">infinitive with \"zu\", full</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>VVPP</code></td><td class=\"c-table__cell u-text\"><code>VERB</code></td><td class=\"c-table__cell u-text\"> <code>Aspect=perf</code> <code>VerbForm=part</code></td><td class=\"c-table__cell u-text u-text-small\">perfect participle, full</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>XY</code></td><td class=\"c-table__cell u-text\"><code>X</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">non-word containing non-letter</td></tr><tr class=\"c-table__row\"><td class=\"c-table__cell u-text\"><code>SP</code></td><td class=\"c-table__cell u-text\"><code>SPACE</code></td><td class=\"c-table__cell u-text\"></td><td class=\"c-table__cell u-text u-text-small\">space</td></tr></tbody></table>",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
d063dd4da6edcb8569e16c912721a1ffc128f161 | 12,840 | ipynb | Jupyter Notebook | jupyter/spark_nlp_model.ipynb | akashmavle5/--akash | cfb21d5a943a3d3fcae3c08921e7323a52761acd | [
"Apache-2.0"
]
| null | null | null | jupyter/spark_nlp_model.ipynb | akashmavle5/--akash | cfb21d5a943a3d3fcae3c08921e7323a52761acd | [
"Apache-2.0"
]
| null | null | null | jupyter/spark_nlp_model.ipynb | akashmavle5/--akash | cfb21d5a943a3d3fcae3c08921e7323a52761acd | [
"Apache-2.0"
]
| null | null | null | 34.423592 | 224 | 0.51285 | [
[
[
"",
"_____no_output_____"
],
[
"# Spark NLP Quick Start\n### How to use Spark NLP pretrained pipelines",
"_____no_output_____"
],
[
"[](https://colab.research.google.com/github/JohnSnowLabs/spark-nlp-workshop/blob/master/jupyter/quick_start_google_colab.ipynb)",
"_____no_output_____"
],
[
"We will first set up the runtime environment and then load pretrained Entity Recognition model and Sentiment analysis model and give it a quick test. Feel free to test the models on your own sentences / datasets.",
"_____no_output_____"
]
],
[
[
"!wget http://setup.johnsnowlabs.com/colab.sh -O - | bash",
"--2021-06-03 06:56:33-- http://setup.johnsnowlabs.com/colab.sh\nResolving setup.johnsnowlabs.com (setup.johnsnowlabs.com)... 51.158.130.125\nConnecting to setup.johnsnowlabs.com (setup.johnsnowlabs.com)|51.158.130.125|:80... connected.\nHTTP request sent, awaiting response... 302 Moved Temporarily\nLocation: https://raw.githubusercontent.com/JohnSnowLabs/spark-nlp/master/scripts/colab_setup.sh [following]\n--2021-06-03 06:56:34-- https://raw.githubusercontent.com/JohnSnowLabs/spark-nlp/master/scripts/colab_setup.sh\nResolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.111.133, 185.199.110.133, ...\nConnecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 1608 (1.6K) [text/plain]\nSaving to: ‘STDOUT’\n\n- 100%[===================>] 1.57K --.-KB/s in 0s \n\n2021-06-03 06:56:34 (34.0 MB/s) - written to stdout [1608/1608]\n\nsetup Colab for PySpark 3.0.2 and Spark NLP 3.0.3\nGet:1 https://cloud.r-project.org/bin/linux/ubuntu bionic-cran40/ InRelease [3,626 B]\nIgn:2 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease\nGet:3 http://security.ubuntu.com/ubuntu bionic-security InRelease [88.7 kB]\nGet:4 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic InRelease [15.9 kB]\nIgn:5 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 InRelease\nHit:6 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Release\nHit:7 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 Release\nHit:9 http://archive.ubuntu.com/ubuntu bionic InRelease\nGet:11 http://archive.ubuntu.com/ubuntu bionic-updates InRelease [88.7 kB]\nHit:12 http://ppa.launchpad.net/cran/libgit2/ubuntu bionic InRelease\nGet:13 http://ppa.launchpad.net/deadsnakes/ppa/ubuntu bionic InRelease [15.9 kB]\nGet:14 http://security.ubuntu.com/ubuntu bionic-security/restricted amd64 Packages [424 kB]\nGet:15 http://archive.ubuntu.com/ubuntu bionic-backports InRelease [74.6 kB]\nGet:16 http://archive.ubuntu.com/ubuntu bionic-updates/restricted amd64 Packages [478 kB]\nHit:17 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic InRelease\nGet:18 http://security.ubuntu.com/ubuntu bionic-security/universe amd64 Packages [1,414 kB]\nGet:19 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic/main Sources [1,770 kB]\nGet:20 http://security.ubuntu.com/ubuntu bionic-security/main amd64 Packages [2,154 kB]\nGet:21 http://archive.ubuntu.com/ubuntu bionic-updates/main amd64 Packages [2,615 kB]\nGet:22 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 Packages [2,184 kB]\nGet:23 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic/main amd64 Packages [906 kB]\nGet:24 http://ppa.launchpad.net/deadsnakes/ppa/ubuntu bionic/main amd64 Packages [40.9 kB]\nFetched 12.3 MB in 7s (1,728 kB/s)\nReading package lists... Done\n\u001b[K |████████████████████████████████| 204.8MB 61kB/s \n\u001b[K |████████████████████████████████| 51kB 6.0MB/s \n\u001b[K |████████████████████████████████| 204kB 36.1MB/s \n\u001b[?25h Building wheel for pyspark (setup.py) ... \u001b[?25l\u001b[?25hdone\n"
],
[
"import sparknlp\nspark = sparknlp.start()\n\nprint(\"Spark NLP version: {}\".format(sparknlp.version()))\nprint(\"Apache Spark version: {}\".format(spark.version))",
"Spark NLP version: 3.0.3\nApache Spark version: 3.0.2\n"
],
[
"from sparknlp.pretrained import PretrainedPipeline ",
"_____no_output_____"
]
],
[
[
"Let's use Spark NLP pre-trained pipeline for `named entity recognition`",
"_____no_output_____"
]
],
[
[
"pipeline = PretrainedPipeline('recognize_entities_dl', 'en')",
"recognize_entities_dl download started this may take some time.\nApprox size to download 160.1 MB\n[OK!]\n"
],
[
"result = pipeline.annotate('President Biden represented Delaware for 36 years in the U.S. Senate before becoming the 47th Vice President of the United States.') ",
"_____no_output_____"
],
[
"print(result['ner'])\nprint(result['entities'])",
"['O', 'B-PER', 'O', 'B-LOC', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'O', 'B-ORG', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'I-LOC', 'O']\n['Biden', 'Delaware', 'U.S', 'Senate', 'United States']\n"
]
],
[
[
"Let's try another Spark NLP pre-trained pipeline for `named entity recognition`",
"_____no_output_____"
]
],
[
[
"pipeline = PretrainedPipeline('onto_recognize_entities_bert_tiny', 'en')\n\nresult = pipeline.annotate(\"Johnson first entered politics when elected in 2001 as a member of Parliament. He then served eight years as the mayor of London, from 2008 to 2016, before rejoining Parliament.\")\n\nprint(result['ner'])\nprint(result['entities'])",
"onto_recognize_entities_bert_tiny download started this may take some time.\nApprox size to download 30.2 MB\n[OK!]\n['B-PERSON', 'B-ORDINAL', 'O', 'O', 'O', 'O', 'O', 'B-DATE', 'O', 'O', 'O', 'O', 'B-ORG', 'O', 'O', 'O', 'B-DATE', 'I-DATE', 'O', 'O', 'O', 'O', 'B-GPE', 'O', 'B-DATE', 'O', 'B-DATE', 'O', 'O', 'O', 'B-ORG']\n['Johnson', 'first', '2001', 'Parliament.', 'eight years', 'London,', '2008', '2016', 'Parliament.']\n"
]
],
[
[
"Let's use Spark NLP pre-trained pipeline for `sentiment` analysis",
"_____no_output_____"
]
],
[
[
"pipeline = PretrainedPipeline('analyze_sentimentdl_glove_imdb', 'en')",
"analyze_sentimentdl_glove_imdb download started this may take some time.\nApprox size to download 155.3 MB\n[OK!]\n"
],
[
"result = pipeline.annotate(\"Harry Potter is a great movie.\")",
"_____no_output_____"
],
[
"print(result['sentiment'])",
"['pos']\n"
]
],
[
[
"### Please check our [Models Hub](https://nlp.johnsnowlabs.com/models) for more pretrained models and pipelines! 😊 ",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d063e5bcce03d3c35d6f90ff41993985148b21df | 4,788 | ipynb | Jupyter Notebook | test/ipynb/groovy/TableMenuTest.ipynb | ssadedin/beakerx | 34479b07d2dfdf1404692692f483faf0251632c3 | [
"Apache-2.0"
]
| 1,491 | 2017-03-30T03:05:05.000Z | 2022-03-27T04:26:02.000Z | test/ipynb/groovy/TableMenuTest.ipynb | ssadedin/beakerx | 34479b07d2dfdf1404692692f483faf0251632c3 | [
"Apache-2.0"
]
| 3,268 | 2015-01-01T00:10:26.000Z | 2017-05-05T18:59:41.000Z | test/ipynb/groovy/TableMenuTest.ipynb | ssadedin/beakerx | 34479b07d2dfdf1404692692f483faf0251632c3 | [
"Apache-2.0"
]
| 287 | 2017-04-03T01:30:06.000Z | 2022-03-17T06:09:15.000Z | 23.130435 | 104 | 0.553258 | [
[
[
"empty"
]
]
]
| [
"empty"
]
| [
[
"empty"
]
]
|
d0643a20c5e91fa8a2a1902b0f62ac611d1e5814 | 45,339 | ipynb | Jupyter Notebook | chapter2/2.3.2-text_classification.ipynb | wangxingda/Tensorflow-Handbook | 97987e62da5a24dac6169fbacf1c3d4c041b3339 | [
"Apache-2.0"
]
| 22 | 2019-10-12T06:38:05.000Z | 2022-02-24T03:10:29.000Z | chapter2/2.3.2-text_classification.ipynb | wangxingda/tensorflow-handbook | 97987e62da5a24dac6169fbacf1c3d4c041b3339 | [
"Apache-2.0"
]
| null | null | null | chapter2/2.3.2-text_classification.ipynb | wangxingda/tensorflow-handbook | 97987e62da5a24dac6169fbacf1c3d4c041b3339 | [
"Apache-2.0"
]
| 6 | 2019-11-29T15:14:12.000Z | 2020-06-30T03:59:03.000Z | 50.488864 | 15,964 | 0.677717 | [
[
[
"# 电影评论文本分类",
"_____no_output_____"
],
[
"\n此笔记本(notebook)使用评论文本将影评分为*积极(positive)*或*消极(nagetive)*两类。这是一个*二元(binary)*或者二分类问题,一种重要且应用广泛的机器学习问题。\n\n我们将使用来源于[网络电影数据库(Internet Movie Database)](https://www.imdb.com/)的 [IMDB 数据集(IMDB dataset)](https://tensorflow.google.cn/api_docs/python/tf/keras/datasets/imdb),其包含 50,000 条影评文本。从该数据集切割出的25,000条评论用作训练,另外 25,000 条用作测试。训练集与测试集是*平衡的(balanced)*,意味着它们包含相等数量的积极和消极评论。\n\n此笔记本(notebook)使用了 [tf.keras](https://tensorflow.google.cn/guide/keras),它是一个 Tensorflow 中用于构建和训练模型的高级API。有关使用 `tf.keras` 进行文本分类的更高级教程,请参阅 [MLCC文本分类指南(MLCC Text Classification Guide)](https://developers.google.com/machine-learning/guides/text-classification/)。",
"_____no_output_____"
]
],
[
[
"from __future__ import absolute_import, division, print_function, unicode_literals\n\ntry:\n # Colab only\n %tensorflow_version 2.x\nexcept Exception:\n pass\nimport tensorflow as tf\nfrom tensorflow import keras\n\nimport numpy as np\n\nprint(tf.__version__)",
"2.0.0\n"
]
],
[
[
"## 下载 IMDB 数据集\n\nIMDB 数据集已经打包在 Tensorflow 中。该数据集已经经过预处理,评论(单词序列)已经被转换为整数序列,其中每个整数表示字典中的特定单词。\n\n以下代码将下载 IMDB 数据集到您的机器上(如果您已经下载过将从缓存中复制):",
"_____no_output_____"
]
],
[
[
"imdb = keras.datasets.imdb\n\n(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)",
"_____no_output_____"
]
],
[
[
"参数 `num_words=10000` 保留了训练数据中最常出现的 10,000 个单词。为了保持数据规模的可管理性,低频词将被丢弃。\n",
"_____no_output_____"
],
[
"## 探索数据\n\n让我们花一点时间来了解数据格式。该数据集是经过预处理的:每个样本都是一个表示影评中词汇的整数数组。每个标签都是一个值为 0 或 1 的整数值,其中 0 代表消极评论,1 代表积极评论。",
"_____no_output_____"
]
],
[
[
"print(\"Training entries: {}, labels: {}\".format(len(train_data), len(train_labels)))",
"Training entries: 25000, labels: 25000\n"
]
],
[
[
"评论文本被转换为整数值,其中每个整数代表词典中的一个单词。首条评论是这样的:",
"_____no_output_____"
]
],
[
[
"print(train_data[0])",
"[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]\n"
]
],
[
[
"电影评论可能具有不同的长度。以下代码显示了第一条和第二条评论的中单词数量。由于神经网络的输入必须是统一的长度,我们稍后需要解决这个问题。",
"_____no_output_____"
]
],
[
[
"len(train_data[0]), len(train_data[1])",
"_____no_output_____"
]
],
[
[
"### 将整数转换回单词\n\n了解如何将整数转换回文本对您可能是有帮助的。这里我们将创建一个辅助函数来查询一个包含了整数到字符串映射的字典对象:",
"_____no_output_____"
]
],
[
[
"# 一个映射单词到整数索引的词典\nword_index = imdb.get_word_index()\n\n# 保留第一个索引\nword_index = {k:(v+3) for k,v in word_index.items()}\nword_index[\"<PAD>\"] = 0\nword_index[\"<START>\"] = 1\nword_index[\"<UNK>\"] = 2 # unknown\nword_index[\"<UNUSED>\"] = 3\n\nreverse_word_index = dict([(value, key) for (key, value) in word_index.items()])\n\ndef decode_review(text):\n return ' '.join([reverse_word_index.get(i, '?') for i in text])",
"Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json\n1646592/1641221 [==============================] - 0s 0us/step\n"
]
],
[
[
"现在我们可以使用 `decode_review` 函数来显示首条评论的文本:",
"_____no_output_____"
]
],
[
[
"decode_review(train_data[0])",
"_____no_output_____"
]
],
[
[
"## 准备数据\n\n影评——即整数数组必须在输入神经网络之前转换为张量。这种转换可以通过以下两种方式来完成:\n\n* 将数组转换为表示单词出现与否的由 0 和 1 组成的向量,类似于 one-hot 编码。例如,序列[3, 5]将转换为一个 10,000 维的向量,该向量除了索引为 3 和 5 的位置是 1 以外,其他都为 0。然后,将其作为网络的首层——一个可以处理浮点型向量数据的稠密层。不过,这种方法需要大量的内存,需要一个大小为 `num_words * num_reviews` 的矩阵。\n\n* 或者,我们可以填充数组来保证输入数据具有相同的长度,然后创建一个大小为 `max_length * num_reviews` 的整型张量。我们可以使用能够处理此形状数据的嵌入层作为网络中的第一层。\n\n在本教程中,我们将使用第二种方法。\n\n由于电影评论长度必须相同,我们将使用 [pad_sequences](https://tensorflow.google.cn/api_docs/python/tf/keras/preprocessing/sequence/pad_sequences) 函数来使长度标准化:",
"_____no_output_____"
]
],
[
[
"train_data = keras.preprocessing.sequence.pad_sequences(train_data,\n value=word_index[\"<PAD>\"],\n padding='post',\n maxlen=256)\n\ntest_data = keras.preprocessing.sequence.pad_sequences(test_data,\n value=word_index[\"<PAD>\"],\n padding='post',\n maxlen=256)",
"_____no_output_____"
]
],
[
[
"现在让我们看下样本的长度:",
"_____no_output_____"
]
],
[
[
"len(train_data[0]), len(train_data[1])",
"_____no_output_____"
]
],
[
[
"并检查一下首条评论(当前已经填充):",
"_____no_output_____"
]
],
[
[
"print(train_data[0])",
"[ 1 14 22 16 43 530 973 1622 1385 65 458 4468 66 3941\n 4 173 36 256 5 25 100 43 838 112 50 670 2 9\n 35 480 284 5 150 4 172 112 167 2 336 385 39 4\n 172 4536 1111 17 546 38 13 447 4 192 50 16 6 147\n 2025 19 14 22 4 1920 4613 469 4 22 71 87 12 16\n 43 530 38 76 15 13 1247 4 22 17 515 17 12 16\n 626 18 2 5 62 386 12 8 316 8 106 5 4 2223\n 5244 16 480 66 3785 33 4 130 12 16 38 619 5 25\n 124 51 36 135 48 25 1415 33 6 22 12 215 28 77\n 52 5 14 407 16 82 2 8 4 107 117 5952 15 256\n 4 2 7 3766 5 723 36 71 43 530 476 26 400 317\n 46 7 4 2 1029 13 104 88 4 381 15 297 98 32\n 2071 56 26 141 6 194 7486 18 4 226 22 21 134 476\n 26 480 5 144 30 5535 18 51 36 28 224 92 25 104\n 4 226 65 16 38 1334 88 12 16 283 5 16 4472 113\n 103 32 15 16 5345 19 178 32 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n 0 0 0 0]\n"
]
],
[
[
"## 构建模型\n\n神经网络由堆叠的层来构建,这需要从两个主要方面来进行体系结构决策:\n\n* 模型里有多少层?\n* 每个层里有多少*隐层单元(hidden units)*?\n\n在此样本中,输入数据包含一个单词索引的数组。要预测的标签为 0 或 1。让我们来为该问题构建一个模型:",
"_____no_output_____"
]
],
[
[
"# 输入形状是用于电影评论的词汇数目(10,000 词)\nvocab_size = 10000\n\nmodel = keras.Sequential()\nmodel.add(keras.layers.Embedding(vocab_size, 16))\nmodel.add(keras.layers.GlobalAveragePooling1D())\nmodel.add(keras.layers.Dense(16, activation='relu'))\nmodel.add(keras.layers.Dense(1, activation='sigmoid'))\n\nmodel.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nembedding (Embedding) (None, None, 16) 160000 \n_________________________________________________________________\nglobal_average_pooling1d (Gl (None, 16) 0 \n_________________________________________________________________\ndense (Dense) (None, 16) 272 \n_________________________________________________________________\ndense_1 (Dense) (None, 1) 17 \n=================================================================\nTotal params: 160,289\nTrainable params: 160,289\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"层按顺序堆叠以构建分类器:\n\n1. 第一层是`嵌入(Embedding)`层。该层采用整数编码的词汇表,并查找每个词索引的嵌入向量(embedding vector)。这些向量是通过模型训练学习到的。向量向输出数组增加了一个维度。得到的维度为:`(batch, sequence, embedding)`。\n2. 接下来,`GlobalAveragePooling1D` 将通过对序列维度求平均值来为每个样本返回一个定长输出向量。这允许模型以尽可能最简单的方式处理变长输入。\n3. 该定长输出向量通过一个有 16 个隐层单元的全连接(`Dense`)层传输。\n4. 最后一层与单个输出结点密集连接。使用 `Sigmoid` 激活函数,其函数值为介于 0 与 1 之间的浮点数,表示概率或置信度。",
"_____no_output_____"
],
[
"### 隐层单元\n\n上述模型在输入输出之间有两个中间层或“隐藏层”。输出(单元,结点或神经元)的数量即为层表示空间的维度。换句话说,是学习内部表示时网络所允许的自由度。\n\n如果模型具有更多的隐层单元(更高维度的表示空间)和/或更多层,则可以学习到更复杂的表示。但是,这会使网络的计算成本更高,并且可能导致学习到不需要的模式——一些能够在训练数据上而不是测试数据上改善性能的模式。这被称为*过拟合(overfitting)*,我们稍后会对此进行探究。",
"_____no_output_____"
],
[
"### 损失函数与优化器\n\n一个模型需要损失函数和优化器来进行训练。由于这是一个二分类问题且模型输出概率值(一个使用 sigmoid 激活函数的单一单元层),我们将使用 `binary_crossentropy` 损失函数。\n\n这不是损失函数的唯一选择,例如,您可以选择 `mean_squared_error` 。但是,一般来说 `binary_crossentropy` 更适合处理概率——它能够度量概率分布之间的“距离”,或者在我们的示例中,指的是度量 ground-truth 分布与预测值之间的“距离”。\n\n稍后,当我们研究回归问题(例如,预测房价)时,我们将介绍如何使用另一种叫做均方误差的损失函数。\n\n现在,配置模型来使用优化器和损失函数:",
"_____no_output_____"
]
],
[
[
"model.compile(optimizer='adam',\n loss='binary_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"## 创建一个验证集\n\n在训练时,我们想要检查模型在未见过的数据上的准确率(accuracy)。通过从原始训练数据中分离 10,000 个样本来创建一个*验证集*。(为什么现在不使用测试集?我们的目标是只使用训练数据来开发和调整模型,然后只使用一次测试数据来评估准确率(accuracy))。",
"_____no_output_____"
]
],
[
[
"x_val = train_data[:10000]\npartial_x_train = train_data[10000:]\n\ny_val = train_labels[:10000]\npartial_y_train = train_labels[10000:]",
"_____no_output_____"
]
],
[
[
"## 训练模型\n\n以 512 个样本的 mini-batch 大小迭代 40 个 epoch 来训练模型。这是指对 `x_train` 和 `y_train` 张量中所有样本的的 40 次迭代。在训练过程中,监测来自验证集的 10,000 个样本上的损失值(loss)和准确率(accuracy):",
"_____no_output_____"
]
],
[
[
"history = model.fit(partial_x_train,\n partial_y_train,\n epochs=40,\n batch_size=512,\n validation_data=(x_val, y_val),\n verbose=1)",
"Train on 15000 samples, validate on 10000 samples\nEpoch 1/40\n15000/15000 [==============================] - 1s 99us/sample - loss: 0.6921 - accuracy: 0.5437 - val_loss: 0.6903 - val_accuracy: 0.6241\nEpoch 2/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.6870 - accuracy: 0.7057 - val_loss: 0.6833 - val_accuracy: 0.7018\nEpoch 3/40\n15000/15000 [==============================] - 1s 54us/sample - loss: 0.6760 - accuracy: 0.7454 - val_loss: 0.6694 - val_accuracy: 0.7501\nEpoch 4/40\n15000/15000 [==============================] - 1s 53us/sample - loss: 0.6563 - accuracy: 0.7659 - val_loss: 0.6467 - val_accuracy: 0.7571\nEpoch 5/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.6270 - accuracy: 0.7837 - val_loss: 0.6155 - val_accuracy: 0.7793\nEpoch 6/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.5882 - accuracy: 0.7993 - val_loss: 0.5762 - val_accuracy: 0.7960\nEpoch 7/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.5420 - accuracy: 0.8219 - val_loss: 0.5336 - val_accuracy: 0.8106\nEpoch 8/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.4955 - accuracy: 0.8367 - val_loss: 0.4930 - val_accuracy: 0.8262\nEpoch 9/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.4507 - accuracy: 0.8522 - val_loss: 0.4542 - val_accuracy: 0.8393\nEpoch 10/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.4107 - accuracy: 0.8667 - val_loss: 0.4218 - val_accuracy: 0.8478\nEpoch 11/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.3766 - accuracy: 0.8779 - val_loss: 0.3957 - val_accuracy: 0.8551\nEpoch 12/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.3483 - accuracy: 0.8843 - val_loss: 0.3741 - val_accuracy: 0.8613\nEpoch 13/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.3238 - accuracy: 0.8925 - val_loss: 0.3573 - val_accuracy: 0.8667\nEpoch 14/40\n15000/15000 [==============================] - 1s 54us/sample - loss: 0.3027 - accuracy: 0.8977 - val_loss: 0.3439 - val_accuracy: 0.8678\nEpoch 15/40\n15000/15000 [==============================] - 1s 54us/sample - loss: 0.2850 - accuracy: 0.9032 - val_loss: 0.3318 - val_accuracy: 0.8737\nEpoch 16/40\n15000/15000 [==============================] - 1s 56us/sample - loss: 0.2695 - accuracy: 0.9071 - val_loss: 0.3231 - val_accuracy: 0.8744\nEpoch 17/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.2549 - accuracy: 0.9124 - val_loss: 0.3151 - val_accuracy: 0.8790\nEpoch 18/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.2421 - accuracy: 0.9166 - val_loss: 0.3086 - val_accuracy: 0.8807\nEpoch 19/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.2307 - accuracy: 0.9201 - val_loss: 0.3035 - val_accuracy: 0.8794\nEpoch 20/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.2201 - accuracy: 0.9243 - val_loss: 0.2994 - val_accuracy: 0.8802\nEpoch 21/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.2103 - accuracy: 0.9271 - val_loss: 0.2953 - val_accuracy: 0.8825\nEpoch 22/40\n15000/15000 [==============================] - 1s 53us/sample - loss: 0.2014 - accuracy: 0.9306 - val_loss: 0.2926 - val_accuracy: 0.8834\nEpoch 23/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.1923 - accuracy: 0.9352 - val_loss: 0.2901 - val_accuracy: 0.8848\nEpoch 24/40\n15000/15000 [==============================] - 1s 53us/sample - loss: 0.1845 - accuracy: 0.9395 - val_loss: 0.2907 - val_accuracy: 0.8852\nEpoch 25/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.1770 - accuracy: 0.9426 - val_loss: 0.2875 - val_accuracy: 0.8838\nEpoch 26/40\n15000/15000 [==============================] - 1s 52us/sample - loss: 0.1696 - accuracy: 0.9459 - val_loss: 0.2870 - val_accuracy: 0.8849\nEpoch 27/40\n15000/15000 [==============================] - 1s 58us/sample - loss: 0.1628 - accuracy: 0.9492 - val_loss: 0.2868 - val_accuracy: 0.8849\nEpoch 28/40\n15000/15000 [==============================] - 1s 65us/sample - loss: 0.1563 - accuracy: 0.9513 - val_loss: 0.2876 - val_accuracy: 0.8842\nEpoch 29/40\n15000/15000 [==============================] - 1s 65us/sample - loss: 0.1505 - accuracy: 0.9534 - val_loss: 0.2881 - val_accuracy: 0.8849\nEpoch 30/40\n15000/15000 [==============================] - 1s 62us/sample - loss: 0.1450 - accuracy: 0.9553 - val_loss: 0.2878 - val_accuracy: 0.8857\nEpoch 31/40\n15000/15000 [==============================] - 1s 60us/sample - loss: 0.1389 - accuracy: 0.9584 - val_loss: 0.2879 - val_accuracy: 0.8862\nEpoch 32/40\n15000/15000 [==============================] - 1s 62us/sample - loss: 0.1347 - accuracy: 0.9595 - val_loss: 0.2907 - val_accuracy: 0.8849\nEpoch 33/40\n15000/15000 [==============================] - 1s 61us/sample - loss: 0.1286 - accuracy: 0.9626 - val_loss: 0.2908 - val_accuracy: 0.8859\nEpoch 34/40\n15000/15000 [==============================] - 1s 59us/sample - loss: 0.1244 - accuracy: 0.9645 - val_loss: 0.2926 - val_accuracy: 0.8864\nEpoch 35/40\n15000/15000 [==============================] - 1s 59us/sample - loss: 0.1192 - accuracy: 0.9664 - val_loss: 0.2945 - val_accuracy: 0.8850\nEpoch 36/40\n15000/15000 [==============================] - 1s 61us/sample - loss: 0.1149 - accuracy: 0.9688 - val_loss: 0.2959 - val_accuracy: 0.8847\nEpoch 37/40\n15000/15000 [==============================] - 1s 60us/sample - loss: 0.1107 - accuracy: 0.9699 - val_loss: 0.2998 - val_accuracy: 0.8833\nEpoch 38/40\n15000/15000 [==============================] - 1s 59us/sample - loss: 0.1065 - accuracy: 0.9703 - val_loss: 0.3007 - val_accuracy: 0.8844\nEpoch 39/40\n15000/15000 [==============================] - 1s 62us/sample - loss: 0.1029 - accuracy: 0.9722 - val_loss: 0.3042 - val_accuracy: 0.8827\nEpoch 40/40\n15000/15000 [==============================] - 1s 69us/sample - loss: 0.0995 - accuracy: 0.9736 - val_loss: 0.3074 - val_accuracy: 0.8817\n"
]
],
[
[
"## 评估模型\n\n我们来看一下模型的性能如何。将返回两个值。损失值(loss)(一个表示误差的数字,值越低越好)与准确率(accuracy)。",
"_____no_output_____"
]
],
[
[
"results = model.evaluate(test_data, test_labels, verbose=2)\n\nprint(results)",
"25000/1 - 1s - loss: 0.3459 - accuracy: 0.8727\n[0.325805940823555, 0.87268]\n"
]
],
[
[
"这种十分朴素的方法得到了约 87% 的准确率(accuracy)。若采用更好的方法,模型的准确率应当接近 95%。",
"_____no_output_____"
],
[
"## 创建一个准确率(accuracy)和损失值(loss)随时间变化的图表\n\n`model.fit()` 返回一个 `History` 对象,该对象包含一个字典,其中包含训练阶段所发生的一切事件:",
"_____no_output_____"
]
],
[
[
"history_dict = history.history\nhistory_dict.keys()",
"_____no_output_____"
]
],
[
[
"有四个条目:在训练和验证期间,每个条目对应一个监控指标。我们可以使用这些条目来绘制训练与验证过程的损失值(loss)和准确率(accuracy),以便进行比较。",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n\nacc = history_dict['accuracy']\nval_acc = history_dict['val_accuracy']\nloss = history_dict['loss']\nval_loss = history_dict['val_loss']\n\nepochs = range(1, len(acc) + 1)\n\n# “bo”代表 \"蓝点\"\nplt.plot(epochs, loss, 'bo', label='Training loss')\n# b代表“蓝色实线”\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.xlabel('Epochs')\nplt.ylabel('Loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
],
[
"plt.clf() # 清除数字\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.xlabel('Epochs')\nplt.ylabel('Accuracy')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"\n在该图中,点代表训练损失值(loss)与准确率(accuracy),实线代表验证损失值(loss)与准确率(accuracy)。\n\n注意训练损失值随每一个 epoch *下降*而训练准确率(accuracy)随每一个 epoch *上升*。这在使用梯度下降优化时是可预期的——理应在每次迭代中最小化期望值。\n\n验证过程的损失值(loss)与准确率(accuracy)的情况却并非如此——它们似乎在 20 个 epoch 后达到峰值。这是过拟合的一个实例:模型在训练数据上的表现比在以前从未见过的数据上的表现要更好。在此之后,模型过度优化并学习*特定*于训练数据的表示,而不能够*泛化*到测试数据。\n\n对于这种特殊情况,我们可以通过在 20 个左右的 epoch 后停止训练来避免过拟合。稍后,您将看到如何通过回调自动执行此操作。",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
]
|
d06454dfa2d4595190cbf36062f5989e3148a977 | 16,185 | ipynb | Jupyter Notebook | notebooks/00_just_plot_it.ipynb | NFAcademy/2021_course_dev-tacaswell | 78df3044f46581f6c5276283ff825b26a00a3039 | [
"MIT"
]
| null | null | null | notebooks/00_just_plot_it.ipynb | NFAcademy/2021_course_dev-tacaswell | 78df3044f46581f6c5276283ff825b26a00a3039 | [
"MIT"
]
| null | null | null | notebooks/00_just_plot_it.ipynb | NFAcademy/2021_course_dev-tacaswell | 78df3044f46581f6c5276283ff825b26a00a3039 | [
"MIT"
]
| null | null | null | 31.125 | 514 | 0.617547 | [
[
[
"# Just Plot It!",
"_____no_output_____"
],
[
"## Introduction",
"_____no_output_____"
],
[
"### The System",
"_____no_output_____"
],
[
"In this course we will work with a set of \"experimental\" data to illustrate going from \"raw\" measurement (or simulation) data through exploratory visualization to an (almost) paper ready figure.\n\nIn this scenario, we have fabricated (or simulated) 25 cantilevers. There is some value (suggestively called \"control\") that varies between the cantilevers and we want to see how the properties of the cantilever are affect by \"control\".",
"_____no_output_____"
],
[
"To see what this will look like physically, take part a \"clicky\" pen. Hold one end of the spring in your fingers and flick the free end. \n\nOr just watch this cat:",
"_____no_output_____"
]
],
[
[
"from IPython.display import YouTubeVideo\nYouTubeVideo('4aTagDSnclk?start=19')",
"_____no_output_____"
]
],
[
[
"Springs, and our cantilevers, are part of a class of systems known as (Damped) Harmonic Oscillators. We are going to measure the natural frequency and damping rate we deflect each cantilever by the same amount and then observe the position as a function of time as the vibrations damp out.",
"_____no_output_____"
],
[
"### The Tools",
"_____no_output_____"
],
[
"We are going make use of: \n\n- [jupyter](https://jupyter.org)\n- [numpy](https://numpy.org)\n- [matplotlib](https://matplotlib.org)\n- [scipy](https://www.scipy.org/scipylib/index.html)\n- [xarray](http://xarray.pydata.org/en/stable/index.html)\n- [pandas](https://pandas.pydata.org/docs/)\n\nWe are only going to scratch the surface of what any of these libraries can do! For the purposes of this course we assume you know numpy and Matplotlib at least to the level of LINKS TO OTHER COURSES. We will only be using one aspect (least square fitting) from scipy so no prior familiarity is needed. Similarly, we will only be superficially making use of pandas and xarray to provided access to structured data. No prior familiarity is required and if you want to learn more see LINK TO OTHER COURSES.",
"_____no_output_____"
]
],
[
[
"# interactive figures, requires ipypml!\n%matplotlib widget\n#%matplotlib inline\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport scipy\nimport xarray as xa",
"_____no_output_____"
]
],
[
[
"### Philsophy",
"_____no_output_____"
],
[
"While this coures uses Matplotlib for the visualization, the high-level lessons of this course are transferable to any plotting tools (in any language).\n\nAt its core, programing in the process of taking existing tools (libraries) and building new tools more fit to your purpose. This course will walk through a concrete example, starting with a pile of data and ending with a paper figure, of how to think about and design scientific visualizations tools tuned to exactly *your* data and questions.",
"_____no_output_____"
],
[
"## The Data",
"_____no_output_____"
],
[
"### Accessing data\n\nAs a rule-of-thumb I/O logic should be kept out of the inner loops of analysis or plotting. This will, in the medium term, lead to more re-usable and maintainable code. Remember your most frequent collaborator is yourself in 6 months. Be kind to your (future) self and write re-usable, maintainable, and understandable code now ;)\n\nIn this case, we have a data (simulation) function `get_data` that will simulate the experiment and returns to us a [`xarray.DataArray`](http://xarray.pydata.org/en/stable/quick-overview.html#create-a-dataarray). `xarray.DataArray` is (roughly) a N-dimensional numpy array that is enriched by the concept of coordinates and indies on the the axes and meta-data. \n\n`xarray` has much more functionality than we will use in this course!",
"_____no_output_____"
]
],
[
[
"# not sure how else to get the helpers on the path!\nimport sys\nsys.path.append('../scripts')",
"_____no_output_____"
],
[
"from data_gen import get_data, fit",
"_____no_output_____"
]
],
[
[
"### First look",
"_____no_output_____"
],
[
"Using the function `get_data` we can pull an `xarray.DataArray` into our namespace and the use the html repr from xarray to get a first look at the data",
"_____no_output_____"
]
],
[
[
"d = get_data(25)\nd",
"_____no_output_____"
]
],
[
[
"From this we can see that we have a, more-or-less, 2D array with 25 rows, each of which is a measurement that is a 4,112 point time series. Because this is an DataArray it also caries **coordinates** giving the value of **control** for each row and the time for each column.",
"_____no_output_____"
],
[
"If we pull out just one row we can see a single experimental measurement.",
"_____no_output_____"
]
],
[
[
"d[6]",
"_____no_output_____"
]
],
[
[
"We can see that the **control** coordinate now gives 1 value, but the **time** coordinate is still a vector. We can access these values via attribute access (which we will use later):",
"_____no_output_____"
]
],
[
[
"d[6].control",
"_____no_output_____"
],
[
"d[6].time",
"_____no_output_____"
]
],
[
[
"## The Plotting",
"_____no_output_____"
],
[
"### Plot it?\nLooking at (truncated) lists of numbers is not intuitive or informative for most people, to get a better sense of what this data looks like lets plot it! We know that `Axes.plot` can plot multiple lines at once so lets try naively throwing `d` at `ax.plot`!",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nax.plot(d);",
"_____no_output_____"
]
],
[
[
"While this does look sort of cool, it is not *useful*. What has happened is that Matplotlib has looked at our `(25, 4_112)` array and said \"Clearly, you have a table that is 4k columns wide and 25 rows long. What you want is each column plotted!\". Thus, what we are seeing is \"The deflection at a fixed time as a function of cantilever ID number\". This plot does accurately reflect that data that we passed in, but this is a nearly meaningless plot!\n\nVisualization, just like writing, is a tool for communication and you need to think about the story you want to tell as you make the plots.",
"_____no_output_____"
],
[
"### Sidebar: Explicit vs Implicit Matplotlib API\n\nThere are two related but distinct APIs to use Matplotlib: the \"Explicit\" (nee \"Object Oriented\") and \"Implicit\" (nee \"pyplot/pylab\"). The Implicit API is implemented using the Explicit API; anything you can do with the Implicit API you can do with the Explicit API, but there is some functionality of the Explicit API that is not exposed through the Implicit API. It is also possible, but with one exception not suggested, to mix the two APIs.\n\nThe core conceptual difference is than in the Implicit API Matplotlib has a notion of the \"current figure\" and \"current axes\" that all of the calls re-directed to. For example, the implementation of `plt.plot` (once you scroll past the docstring) is only 1 line:",
"_____no_output_____"
]
],
[
[
"?? plt.plot",
"_____no_output_____"
]
],
[
[
"While the Implicit API reduces the boilerplate required to get some things done and is convenient when working in a terminal, it comes at the cost of Matplotlib maintaining global state of which Axes is currently active! When scripting this can quickly become a headache to manage.",
"_____no_output_____"
],
[
"When using Matplotlib with one of the GUI backends, we do need to, at the library level, keep track of some global state so that the plot windows remain responsive. If you are embedding Matplotlib in your own GUI application you are responsible for this, but when working at an IPython prompt,`pyplot` takes care of this for you.",
"_____no_output_____"
],
[
"This course is going to, with the exception of creating new figures, always use the Explict API.",
"_____no_output_____"
],
[
"### Plot it!\n\nWhat we really want to see is the transpose of the above (A line per experiment as a function of time):",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nax.plot(d.T);",
"_____no_output_____"
]
],
[
[
"Which is better! If we squint a bit (or zoom in if we are using `ipympl` or a GUI backend) can sort of see each of the individual oscillators ringing-down over time.",
"_____no_output_____"
],
[
"### Just one at a time",
"_____no_output_____"
],
[
"To make it easier to see lets plot just one of the curves:",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nax.plot(d[6]);",
"_____no_output_____"
]
],
[
[
"### Pass freshman physics",
"_____no_output_____"
],
[
"While we do have just one line on the axes and can see what is going on, this plot would, right, be marked as little-to-no credit if turned in as part of a freshman Physics lab! We do not have a meaningful value on the x-axis, no legend, and no axis labels!",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nm = d[6]\nax.plot(m.time, m, label=f'control = {float(m.control):.1f}')\nax.set_xlabel('time (ms)')\nax.set_ylabel('displacement (mm)')\nax.legend();",
"_____no_output_____"
]
],
[
[
"At this point we have a minimally acceptable plot! It shows us one curve with axis labels (with units!) and a legend. With ",
"_____no_output_____"
],
[
"### sidebar: xarray plotting",
"_____no_output_____"
],
[
"Because xarray knows more about the structure of your data than a couple of numpy arrays in your local namespace or dictionary, it can make smarter choices about the automatic visualization:",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nm.plot(ax=ax)",
"_____no_output_____"
]
],
[
[
"While this is helpful exploritory plotting, `xarray` makes some choices that make it difficult to compose plotting multiple data sets.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
d06454dfb1715cc2a28cb347906303323e0c830d | 166,341 | ipynb | Jupyter Notebook | 08. Classification.ipynb | monocilindro/data_science | 36098bb6b3e731a11315e58e0b09628fae86069d | [
"MIT"
]
| 41 | 2020-01-25T21:23:59.000Z | 2022-02-22T19:48:15.000Z | 08. Classification.ipynb | ichit/data_science | 36098bb6b3e731a11315e58e0b09628fae86069d | [
"MIT"
]
| null | null | null | 08. Classification.ipynb | ichit/data_science | 36098bb6b3e731a11315e58e0b09628fae86069d | [
"MIT"
]
| 38 | 2020-01-27T18:57:46.000Z | 2022-03-05T00:33:45.000Z | 231.995816 | 136,448 | 0.902934 | [
[
[
"## 8. Classification\n\n[Data Science Playlist on YouTube](https://www.youtube.com/watch?v=VLKEj9EN2ew&list=PLLBUgWXdTBDg1Qgmwt4jKtVn9BWh5-zgy)\n[](https://www.youtube.com/watch?v=VLKEj9EN2ew&list=PLLBUgWXdTBDg1Qgmwt4jKtVn9BWh5-zgy \"Python Data Science\")\n\n**Classification** predicts *discrete labels (outcomes)* such as `yes`/`no`, `True`/`False`, or any number of discrete levels such as a letter from text recognition, or a word from speech recognition. There are two main methods for training classifiers: unsupervised and supervised learning. The difference between the two is that unsupervised learning does not use labels while supervised learning uses labels to build the classifier. The goal of unsupervised learning is to cluster input features but without labels to guide the grouping. ",
"_____no_output_____"
],
[
"\n\n### Supervised Learning to Classify Numbers\n\nA dataset that is included with sklearn is a set of 1797 images of numbers that are 64 pixels (8x8) each. There are labels with each to indicate the correct answer. A Support Vector Classifier is trained on the first half of the images.",
"_____no_output_____"
]
],
[
[
"from sklearn import datasets, svm\nfrom sklearn.model_selection import train_test_split\nimport matplotlib.pyplot as plt\n%matplotlib inline\nimport numpy as np\n\n# train classifier\ndigits = datasets.load_digits()\nn_samples = len(digits.images)\ndata = digits.images.reshape((n_samples, -1))\nsvc = svm.SVC(gamma=0.001)\nX_train, X_test, y_train, y_test = train_test_split(\n data, digits.target, test_size=0.5, shuffle=False)\nsvc.fit(X_train, y_train)\nprint('SVC Trained')",
"_____no_output_____"
]
],
[
[
"\n\n### Test Number Classifier\n\nThe image classification is trained on 10 randomly selected images from the other half of the data set to evaluate the training. Run the classifier test until you observe a misclassified number.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10,4))\nfor i in range(10):\n n = np.random.randint(int(n_samples/2),n_samples)\n predict = svc.predict(digits.data[n:n+1])[0]\n plt.subplot(2,5,i+1)\n plt.imshow(digits.images[n], cmap=plt.cm.gray_r, interpolation='nearest')\n plt.text(0,7,'Actual: ' + str(digits.target[n]),color='r')\n plt.text(0,1,'Predict: ' + str(predict),color='b')\n if predict==digits.target[n]:\n plt.text(0,4,'Correct',color='g')\n else:\n plt.text(0,4,'Incorrect',color='orange')\nplt.show()",
"_____no_output_____"
]
],
[
[
"\n\n### Classification with Supervised Learning",
"_____no_output_____"
],
[
"Select data set option with `moons`, `cirlces`, or `blobs`. Run the following cell to generate the data that will be used to test the classifiers.",
"_____no_output_____"
]
],
[
[
"option = 'moons' # moons, circles, or blobs\n\nn = 2000 # number of data points\nX = np.random.random((n,2))\nmixing = 0.0 # add random mixing element to data\nxplot = np.linspace(0,1,100)\nif option=='moons':\n X, y = datasets.make_moons(n_samples=n,noise=0.1)\n yplot = xplot*0.0\nelif option=='circles':\n X, y = datasets.make_circles(n_samples=n,noise=0.1,factor=0.5)\n yplot = xplot*0.0\nelif option=='blobs':\n X, y = datasets.make_blobs(n_samples=n,centers=[[-5,3],[5,-3]],cluster_std=2.0)\n yplot = xplot*0.0\n# Split into train and test subsets (50% each)\nXA, XB, yA, yB = train_test_split(X, y, test_size=0.5, shuffle=False)\n# Plot regression results\ndef assess(P):\n plt.figure()\n plt.scatter(XB[P==1,0],XB[P==1,1],marker='^',color='blue',label='True')\n plt.scatter(XB[P==0,0],XB[P==0,1],marker='x',color='red',label='False')\n plt.scatter(XB[P!=yB,0],XB[P!=yB,1],marker='s',color='orange',\\\n alpha=0.5,label='Incorrect')\n plt.legend()",
"_____no_output_____"
]
],
[
[
"\n\n### S.1 Logistic Regression\n\n**Definition:** Logistic regression is a machine learning algorithm for classification. In this algorithm, the probabilities describing the possible outcomes of a single trial are modelled using a logistic function.\n\n**Advantages:** Logistic regression is designed for this purpose (classification), and is most useful for understanding the influence of several independent variables on a single outcome variable.\n\n**Disadvantages:** Works only when the predicted variable is binary, assumes all predictors are independent of each other, and assumes data is free of missing values.",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LogisticRegression\nlr = LogisticRegression(solver='lbfgs')\nlr.fit(XA,yA)\nyP = lr.predict(XB)\nassess(yP)",
"_____no_output_____"
]
],
[
[
"\n\n### S.2 Naïve Bayes\n\n**Definition:** Naive Bayes algorithm based on Bayes’ theorem with the assumption of independence between every pair of features. Naive Bayes classifiers work well in many real-world situations such as document classification and spam filtering.\n\n**Advantages:** This algorithm requires a small amount of training data to estimate the necessary parameters. Naive Bayes classifiers are extremely fast compared to more sophisticated methods.\n\n**Disadvantages:** Naive Bayes is known to be a bad estimator.",
"_____no_output_____"
]
],
[
[
"from sklearn.naive_bayes import GaussianNB\nnb = GaussianNB()\nnb.fit(XA,yA)\nyP = nb.predict(XB)\nassess(yP)",
"_____no_output_____"
]
],
[
[
"\n\n### S.3 Stochastic Gradient Descent\n\n**Definition:** Stochastic gradient descent is a simple and very efficient approach to fit linear models. It is particularly useful when the number of samples is very large. It supports different loss functions and penalties for classification.\n\n**Advantages:** Efficiency and ease of implementation.\n\n**Disadvantages:** Requires a number of hyper-parameters and it is sensitive to feature scaling.",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import SGDClassifier\nsgd = SGDClassifier(loss='modified_huber', shuffle=True,random_state=101)\nsgd.fit(XA,yA)\nyP = sgd.predict(XB)\nassess(yP)",
"_____no_output_____"
]
],
[
[
"\n\n### S.4 K-Nearest Neighbours\n\n**Definition:** Neighbours based classification is a type of lazy learning as it does not attempt to construct a general internal model, but simply stores instances of the training data. Classification is computed from a simple majority vote of the k nearest neighbours of each point.\n\n**Advantages:** This algorithm is simple to implement, robust to noisy training data, and effective if training data is large.\n\n**Disadvantages:** Need to determine the value of `K` and the computation cost is high as it needs to computer the distance of each instance to all the training samples. One possible solution to determine `K` is to add a feedback loop to determine the number of neighbors.",
"_____no_output_____"
]
],
[
[
"from sklearn.neighbors import KNeighborsClassifier\nknn = KNeighborsClassifier(n_neighbors=5)\nknn.fit(XA,yA)\nyP = knn.predict(XB)\nassess(yP)",
"_____no_output_____"
]
],
[
[
"\n\n### S.5 Decision Tree\n\n**Definition:** Given a data of attributes together with its classes, a decision tree produces a sequence of rules that can be used to classify the data.\n\n**Advantages:** Decision Tree is simple to understand and visualise, requires little data preparation, and can handle both numerical and categorical data.\n\n**Disadvantages:** Decision tree can create complex trees that do not generalise well, and decision trees can be unstable because small variations in the data might result in a completely different tree being generated.",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeClassifier\ndtree = DecisionTreeClassifier(max_depth=10,random_state=101,\\\n max_features=None,min_samples_leaf=5)\ndtree.fit(XA,yA)\nyP = dtree.predict(XB)\nassess(yP)",
"_____no_output_____"
]
],
[
[
"\n\n### S.6 Random Forest\n\n**Definition:** Random forest classifier is a meta-estimator that fits a number of decision trees on various sub-samples of datasets and uses average to improve the predictive accuracy of the model and controls over-fitting. The sub-sample size is always the same as the original input sample size but the samples are drawn with replacement.\n\n**Advantages:** Reduction in over-fitting and random forest classifier is more accurate than decision trees in most cases.\n\n**Disadvantages:** Slow real time prediction, difficult to implement, and complex algorithm.",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import RandomForestClassifier\nrfm = RandomForestClassifier(n_estimators=70,oob_score=True,\\\n n_jobs=1,random_state=101,max_features=None,\\\n min_samples_leaf=3) #change min_samples_leaf from 30 to 3\nrfm.fit(XA,yA)\nyP = rfm.predict(XB)\nassess(yP)",
"_____no_output_____"
]
],
[
[
"\n\n### S.7 Support Vector Classifier\n\n**Definition:** Support vector machine is a representation of the training data as points in space separated into categories by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.\n\n**Advantages:** Effective in high dimensional spaces and uses a subset of training points in the decision function so it is also memory efficient.\n\n**Disadvantages:** The algorithm does not directly provide probability estimates, these are calculated using an expensive five-fold cross-validation.",
"_____no_output_____"
]
],
[
[
"from sklearn.svm import SVC\nsvm = SVC(gamma='scale', C=1.0, random_state=101)\nsvm.fit(XA,yA)\nyP = svm.predict(XB)\nassess(yP)",
"_____no_output_____"
]
],
[
[
"\n\n### S.8 Neural Network\n\nThe `MLPClassifier` implements a multi-layer perceptron (MLP) algorithm that trains using Backpropagation.\n\n**Definition:** A neural network is a set of neurons (activation functions) in layers that are processed sequentially to relate an input to an output.\n\n**Advantages:** Effective in nonlinear spaces where the structure of the relationship is not linear. No prior knowledge or specialized equation structure is defined although there are different network architectures that may lead to a better result.\n\n**Disadvantages:** Neural networks do not extrapolate well outside of the training domain. They may also require longer to train by adjusting the parameter weights to minimize a loss (objective) function. It is also more challenging to explain the outcome of the training and changes in initialization or number of epochs (iterations) may lead to different results. Too many epochs may lead to overfitting, especially if there are excess parameters beyond the minimum needed to capture the input to output relationship.",
"_____no_output_____"
],
[
"\n\nMLP trains on two arrays: array X of size (n_samples, n_features), which holds the training samples represented as floating point feature vectors; and array y of size (n_samples,), which holds the target values (class labels) for the training samples.\nMLP can fit a non-linear model to the training data. clf.coefs_ contains the weight matrices that constitute the model parameters. Currently, MLPClassifier supports only the Cross-Entropy loss function, which allows probability estimates by running the predict_proba method. MLP trains using Backpropagation. More precisely, it trains using some form of gradient descent and the gradients are calculated using Backpropagation. For classification, it minimizes the Cross-Entropy loss function, giving a vector of probability estimates. MLPClassifier supports multi-class classification by applying Softmax as the output function. Further, the model supports multi-label classification in which a sample can belong to more than one class. For each class, the raw output passes through the logistic function. Values larger or equal to 0.5 are rounded to 1, otherwise to 0. For a predicted output of a sample, the indices where the value is 1 represents the assigned classes of that sample.",
"_____no_output_____"
]
],
[
[
"from sklearn.neural_network import MLPClassifier\n\nclf = MLPClassifier(solver='lbfgs',alpha=1e-5,max_iter=200,activation='relu',\\\n hidden_layer_sizes=(10,30,10), random_state=1, shuffle=True)\nclf.fit(XA,yA)\nyP = clf.predict(XB)\nassess(yP)",
"_____no_output_____"
]
],
[
[
"\n\n### Unsupervised Classification\n\nAdditional examples show the potential for unsupervised learning to classify the groups. Unsupervised learning does not use the labels (`True`/`False`) so the results may need to be switched to align with the test set with `if len(XB[yP!=yB]) > n/4: yP = 1 - yP \n`",
"_____no_output_____"
],
[
"\n\n### U.1 K-Means Clustering\n\n**Definition:** Specify how many possible clusters (or K) there are in the dataset. The algorithm then iteratively moves the K-centers and selects the datapoints that are closest to that centroid in the cluster.\n\n**Advantages:** The most common and simplest clustering algorithm.\n\n**Disadvantages:** Must specify the number of clusters although this can typically be determined by increasing the number of clusters until the objective function does not change significantly.",
"_____no_output_____"
]
],
[
[
"from sklearn.cluster import KMeans\nkm = KMeans(n_clusters=2)\nkm.fit(XA)\nyP = km.predict(XB)\nif len(XB[yP!=yB]) > n/4: yP = 1 - yP \nassess(yP)",
"_____no_output_____"
]
],
[
[
"\n\n### U.2 Gaussian Mixture Model\n\n**Definition:** Data points that exist at the boundary of clusters may simply have similar probabilities of being on either clusters. A mixture model predicts a probability instead of a hard classification such as K-Means clustering.\n\n**Advantages:** Incorporates uncertainty into the solution.\n\n**Disadvantages:** Uncertainty may not be desirable for some applications. This method is not as common as the K-Means method for clustering.",
"_____no_output_____"
]
],
[
[
"from sklearn.mixture import GaussianMixture\ngmm = GaussianMixture(n_components=2)\ngmm.fit(XA)\nyP = gmm.predict_proba(XB) # produces probabilities\nif len(XB[np.round(yP[:,0])!=yB]) > n/4: yP = 1 - yP \nassess(np.round(yP[:,0]))",
"_____no_output_____"
]
],
[
[
"\n\n### U.3 Spectral Clustering\n\n**Definition:** Spectral clustering is known as segmentation-based object categorization. It is a technique with roots in graph theory, where identify communities of nodes in a graph are based on the edges connecting them. The method is flexible and allows clustering of non graph data as well.\nIt uses information from the eigenvalues of special matrices built from the graph or the data set. \n\n**Advantages:** Flexible approach for finding clusters when data doesn’t meet the requirements of other common algorithms.\n\n**Disadvantages:** For large-sized graphs, the second eigenvalue of the (normalized) graph Laplacian matrix is often ill-conditioned, leading to slow convergence of iterative eigenvalue solvers. Spectral clustering is computationally expensive unless the graph is sparse and the similarity matrix can be efficiently constructed.",
"_____no_output_____"
]
],
[
[
"from sklearn.cluster import SpectralClustering\nsc = SpectralClustering(n_clusters=2,eigen_solver='arpack',\\\n affinity='nearest_neighbors')\nyP = sc.fit_predict(XB) # No separation between fit and predict calls\n # need to fit and predict on same dataset\nif len(XB[yP!=yB]) > n/4: yP = 1 - yP \nassess(yP)",
"_____no_output_____"
]
],
[
[
"\n\n### TCLab Activity\n\nTrain a classifier to predict if the heater is on (100%) or off (0%). Generate data with 10 minutes of 1 second data. If you do not have a TCLab, use one of the sample data sets.\n\n- [Sample Data Set 1 (10 min)](http://apmonitor.com/do/uploads/Main/tclab_data5.txt): http://apmonitor.com/do/uploads/Main/tclab_data5.txt \n- [Sample Data Set 2 (60 min)](http://apmonitor.com/do/uploads/Main/tclab_data6.txt): http://apmonitor.com/do/uploads/Main/tclab_data6.txt",
"_____no_output_____"
]
],
[
[
"# 10 minute data collection\nimport tclab, time\nimport numpy as np\nimport pandas as pd\nwith tclab.TCLab() as lab:\n n = 600; on=100; t = np.linspace(0,n-1,n) \n Q1 = np.zeros(n); T1 = np.zeros(n)\n Q2 = np.zeros(n); T2 = np.zeros(n) \n Q1[20:41]=on; Q1[60:91]=on; Q1[150:181]=on\n Q1[190:206]=on; Q1[220:251]=on; Q1[260:291]=on\n Q1[300:316]=on; Q1[340:351]=on; Q1[400:431]=on\n Q1[500:521]=on; Q1[540:571]=on; Q1[20:41]=on\n Q1[60:91]=on; Q1[150:181]=on; Q1[190:206]=on\n Q1[220:251]=on; Q1[260:291]=on\n print('Time Q1 Q2 T1 T2')\n for i in range(n):\n T1[i] = lab.T1; T2[i] = lab.T2\n lab.Q1(Q1[i])\n if i%5==0:\n print(int(t[i]),Q1[i],Q2[i],T1[i],T2[i])\n time.sleep(1)\ndata = np.column_stack((t,Q1,Q2,T1,T2))\ndata8 = pd.DataFrame(data,columns=['Time','Q1','Q2','T1','T2'])\ndata8.to_csv('08-tclab.csv',index=False)",
"_____no_output_____"
]
],
[
[
"Use the data file `08-tclab.csv` to train and test the classifier. Select and scale (0-1) the features of the data including `T1`, `T2`, and the 1st and 2nd derivatives of `T1`. Use the measured temperatures, derivatives, and heater value label to create a classifier that predicts when the heater is on or off. Validate the classifier with new data that was not used for training. Starting code is provided below but does not include `T2` as a feature input. **Add `T2` as an input feature to the classifer. Does it improve the classifier performance?**",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib import gridspec\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.model_selection import train_test_split\n\ntry:\n data = pd.read_csv('08-tclab.csv')\nexcept:\n print('Warning: Unable to load 08-tclab.csv, using online data')\n url = 'http://apmonitor.com/do/uploads/Main/tclab_data5.txt'\n data = pd.read_csv(url)\n \n# Input Features: Temperature and 1st / 2nd Derivatives\n# Cubic polynomial fit of temperature using 10 data points\ndata['dT1'] = np.zeros(len(data))\ndata['d2T1'] = np.zeros(len(data))\nfor i in range(len(data)):\n if i<len(data)-10:\n x = data['Time'][i:i+10]-data['Time'][i]\n y = data['T1'][i:i+10]\n p = np.polyfit(x,y,3)\n # evaluate derivatives at mid-point (5 sec)\n t = 5.0\n data['dT1'][i] = 3.0*p[0]*t**2 + 2.0*p[1]*t+p[2]\n data['d2T1'][i] = 6.0*p[0]*t + 2.0*p[1]\n else:\n data['dT1'][i] = np.nan\n data['d2T1'][i] = np.nan\n\n# Remove last 10 values\nX = np.array(data[['T1','dT1','d2T1']][0:-10])\ny = np.array(data[['Q1']][0:-10])\n\n# Scale data\n# Input features (Temperature and 2nd derivative at 5 sec)\ns1 = MinMaxScaler(feature_range=(0,1))\nXs = s1.fit_transform(X)\n# Output labels (heater On / Off)\nys = [True if y[i]>50.0 else False for i in range(len(y))]\n\n# Split into train and test subsets (50% each)\nXA, XB, yA, yB = train_test_split(Xs, ys, \\\n test_size=0.5, shuffle=False)\n\n# Supervised Classification\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.linear_model import SGDClassifier\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.svm import SVC\nfrom sklearn.neural_network import MLPClassifier\n\n# Create supervised classification models\nlr = LogisticRegression(solver='lbfgs') # Logistic Regression\nnb = GaussianNB() # Naïve Bayes\nsgd = SGDClassifier(loss='modified_huber', shuffle=True,\\\n random_state=101) # Stochastic Gradient Descent\nknn = KNeighborsClassifier(n_neighbors=5) # K-Nearest Neighbors\ndtree = DecisionTreeClassifier(max_depth=10,random_state=101,\\\n max_features=None,min_samples_leaf=5) # Decision Tree\nrfm = RandomForestClassifier(n_estimators=70,oob_score=True,n_jobs=1,\\\n random_state=101,max_features=None,min_samples_leaf=3) # Random Forest\nsvm = SVC(gamma='scale', C=1.0, random_state=101) # Support Vector Classifier\nclf = MLPClassifier(solver='lbfgs',alpha=1e-5,max_iter=200,\\\n activation='relu',hidden_layer_sizes=(10,30,10),\\\n random_state=1, shuffle=True) # Neural Network\nmodels = [lr,nb,sgd,knn,dtree,rfm,svm,clf]\n\n# Supervised learning\nyP = [None]*(len(models)+3) # 3 for unsupervised learning\nfor i,m in enumerate(models):\n m.fit(XA,yA)\n yP[i] = m.predict(XB)\n\n# Unsupervised learning modules\nfrom sklearn.cluster import KMeans\nfrom sklearn.mixture import GaussianMixture\nfrom sklearn.cluster import SpectralClustering\nkm = KMeans(n_clusters=2)\ngmm = GaussianMixture(n_components=2)\nsc = SpectralClustering(n_clusters=2,eigen_solver='arpack',\\\n affinity='nearest_neighbors')\nkm.fit(XA)\nyP[8] = km.predict(XB)\ngmm.fit(XA)\nyP[9] = gmm.predict_proba(XB)[:,0]\nyP[10] = sc.fit_predict(XB)\n\nplt.figure(figsize=(10,7))\ngs = gridspec.GridSpec(3, 1, height_ratios=[1,1,5])\nplt.subplot(gs[0])\nplt.plot(data['Time']/60,data['T1'],'r-',\\\n label='Temperature (°C)')\nplt.ylabel('T (°C)')\nplt.legend()\nplt.subplot(gs[1])\nplt.plot(data['Time']/60,data['dT1'],'b:',\\\n label='dT/dt (°C/sec)') \nplt.plot(data['Time']/60,data['d2T1'],'k--',\\\n label=r'$d^2T/dt^2$ ($°C^2/sec^2$)')\nplt.ylabel('Derivatives')\nplt.legend()\n\nplt.subplot(gs[2])\nplt.plot(data['Time']/60,data['Q1']/100,'k-',\\\n label='Heater (On=1/Off=0)')\n\nt2 = data['Time'][len(yA):-10].values\ndesc = ['Logistic Regression','Naïve Bayes','Stochastic Gradient Descent',\\\n 'K-Nearest Neighbors','Decision Tree','Random Forest',\\\n 'Support Vector Classifier','Neural Network',\\\n 'K-Means Clustering','Gaussian Mixture Model','Spectral Clustering']\nfor i in range(11):\n plt.plot(t2/60,yP[i]-i-1,label=desc[i])\n\nplt.ylabel('Heater')\nplt.legend()\n\nplt.xlabel(r'Time (min)')\nplt.legend()\nplt.show()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d0646654843a52d1c0a410b3f80fe5892535ad2c | 6,094 | ipynb | Jupyter Notebook | reg-linear/Bonus/Simulador Interativo.ipynb | DiegoVialle/Regressao-Linear-Testando-Relacoes-e-Prevendo-Resultados | 3c185aefc9ab4fbcee98efb294c7637eb4f594e5 | [
"MIT"
]
| null | null | null | reg-linear/Bonus/Simulador Interativo.ipynb | DiegoVialle/Regressao-Linear-Testando-Relacoes-e-Prevendo-Resultados | 3c185aefc9ab4fbcee98efb294c7637eb4f594e5 | [
"MIT"
]
| null | null | null | reg-linear/Bonus/Simulador Interativo.ipynb | DiegoVialle/Regressao-Linear-Testando-Relacoes-e-Prevendo-Resultados | 3c185aefc9ab4fbcee98efb294c7637eb4f594e5 | [
"MIT"
]
| null | null | null | 32.414894 | 1,066 | 0.564654 | [
[
[
"<h1 style='color: green; font-size: 36px; font-weight: bold;'>Data Science - Regressão Linear</h1>",
"_____no_output_____"
],
[
"# <font color='red' style='font-size: 30px;'>Bônus</font>\n<hr style='border: 2px solid red;'>",
"_____no_output_____"
],
[
"## Importando nosso modelo",
"_____no_output_____"
]
],
[
[
"import pickle\n\nmodelo = open('../Exercicio/modelo_preço','rb')\nlm_new = pickle.load(modelo)\nmodelo.close()\n\narea = 38\ngaragem = 2\nbanheiros = 4\nlareira = 4\nmarmore = 0\nandares = 1\n\nentrada = [[area, garagem, banheiros, lareira, marmore, andares]]\n\nprint('$ {0:.2f}'.format(lm_new.predict(entrada)[0]))",
"_____no_output_____"
]
],
[
[
"## Exemplo de um simulador interativo para Jupyter\n\nhttps://ipywidgets.readthedocs.io/en/stable/index.html\n\nhttps://github.com/jupyter-widgets/ipywidgets",
"_____no_output_____"
]
],
[
[
"# Importando bibliotecas\nfrom ipywidgets import widgets, HBox, VBox\nfrom IPython.display import display\n\n# Criando os controles do formulário\narea = widgets.Text(description=\"Área\")\ngaragem = widgets.Text(description=\"Garagem\")\nbanheiros = widgets.Text(description=\"Banheiros\")\nlareira = widgets.Text(description=\"Lareira\")\nmarmore = widgets.Text(description=\"Mármore?\")\nandares = widgets.Text(description=\"Andares?\")\n\nbotao = widgets.Button(description=\"Simular\")\n\n# Posicionando os controles\nleft = VBox([area, banheiros, marmore])\nright = VBox([garagem, lareira, andares])\ninputs = HBox([left, right])\n\n# Função de simulação\ndef simulador(sender):\n entrada=[[\n float(area.value if area.value else 0), \n float(garagem.value if garagem.value else 0), \n float(banheiros.value if banheiros.value else 0), \n float(lareira.value if lareira.value else 0), \n float(marmore.value if marmore.value else 0), \n float(andares.value if andares.value else 0)\n ]]\n print('$ {0:.2f}'.format(lm_new.predict(entrada)[0]))\n \n# Atribuindo a função \"simulador\" ao evento click do botão\nbotao.on_click(simulador) ",
"_____no_output_____"
],
[
"display(inputs, botao)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
d064705e51ef7eddc4d0656b9a41f9386500351e | 11,423 | ipynb | Jupyter Notebook | albert-base/albert-baseline.ipynb | shanayghag/AV-Janatahack-Independence-Day-2020-ML-Hackathon | 410c549488b0e2ceece067a9e1581e182a11e885 | [
"MIT"
]
| 6 | 2020-08-26T13:00:11.000Z | 2021-12-28T18:58:43.000Z | albert-base/albert-baseline.ipynb | shanayghag/AV-Janatahack-Independence-Day-2020-ML-Hackathon | 410c549488b0e2ceece067a9e1581e182a11e885 | [
"MIT"
]
| null | null | null | albert-base/albert-baseline.ipynb | shanayghag/AV-Janatahack-Independence-Day-2020-ML-Hackathon | 410c549488b0e2ceece067a9e1581e182a11e885 | [
"MIT"
]
| 1 | 2020-08-24T08:34:19.000Z | 2020-08-24T08:34:19.000Z | 11,423 | 11,423 | 0.670927 | [
[
[
"## Installing & importing necsessary libs",
"_____no_output_____"
]
],
[
[
"!pip install -q transformers",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd\nfrom sklearn import metrics\nimport transformers\nimport torch\nfrom torch.utils.data import Dataset, DataLoader, RandomSampler, SequentialSampler\nfrom transformers import AlbertTokenizer, AlbertModel, AlbertConfig\nfrom tqdm.notebook import tqdm\nfrom transformers import get_linear_schedule_with_warmup",
"_____no_output_____"
],
[
"device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nn_gpu = torch.cuda.device_count()\ntorch.cuda.get_device_name(0)",
"_____no_output_____"
]
],
[
[
"## Data Preprocessing",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(\"../input/avjantahack/data/train.csv\")\ndf['list'] = df[df.columns[3:]].values.tolist()\nnew_df = df[['ABSTRACT', 'list']].copy()\nnew_df.head()",
"_____no_output_____"
]
],
[
[
"## Model configurations",
"_____no_output_____"
]
],
[
[
"# Defining some key variables that will be used later on in the training\nMAX_LEN = 512\nTRAIN_BATCH_SIZE = 16\nVALID_BATCH_SIZE = 8\nEPOCHS = 5\nLEARNING_RATE = 3e-05\ntokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')",
"_____no_output_____"
]
],
[
[
"## Custom Dataset Class",
"_____no_output_____"
]
],
[
[
"class CustomDataset(Dataset):\n\n def __init__(self, dataframe, tokenizer, max_len):\n self.tokenizer = tokenizer\n self.data = dataframe\n self.abstract = dataframe.ABSTRACT\n self.targets = self.data.list\n self.max_len = max_len\n\n def __len__(self):\n return len(self.abstract)\n\n def __getitem__(self, index):\n abstract = str(self.abstract[index])\n abstract = \" \".join(abstract.split())\n\n inputs = self.tokenizer.encode_plus(\n abstract,\n None,\n add_special_tokens = True,\n max_length = self.max_len,\n pad_to_max_length = True,\n return_token_type_ids=True,\n truncation = True\n )\n\n ids = inputs['input_ids']\n mask = inputs['attention_mask']\n token_type_ids = inputs['token_type_ids']\n\n return{\n 'ids': torch.tensor(ids, dtype=torch.long),\n 'mask': torch.tensor(mask, dtype=torch.long),\n 'token_type_ids': torch.tensor(token_type_ids, dtype=torch.long),\n 'targets': torch.tensor(self.targets[index], dtype=torch.float)\n }",
"_____no_output_____"
],
[
"train_size = 0.8\ntrain_dataset=new_df.sample(frac=train_size,random_state=200)\ntest_dataset=new_df.drop(train_dataset.index).reset_index(drop=True)\ntrain_dataset = train_dataset.reset_index(drop=True)\n\n\nprint(\"FULL Dataset: {}\".format(new_df.shape))\nprint(\"TRAIN Dataset: {}\".format(train_dataset.shape))\nprint(\"TEST Dataset: {}\".format(test_dataset.shape))\n\ntraining_set = CustomDataset(train_dataset, tokenizer, MAX_LEN)\ntesting_set = CustomDataset(test_dataset, tokenizer, MAX_LEN)",
"_____no_output_____"
],
[
"train_params = {'batch_size': TRAIN_BATCH_SIZE,\n 'shuffle': True,\n 'num_workers': 0\n }\n\ntest_params = {'batch_size': VALID_BATCH_SIZE,\n 'shuffle': True,\n 'num_workers': 0\n }\n\ntraining_loader = DataLoader(training_set, **train_params)\ntesting_loader = DataLoader(testing_set, **test_params)",
"_____no_output_____"
]
],
[
[
"## Albert model",
"_____no_output_____"
]
],
[
[
"class AlbertClass(torch.nn.Module):\n def __init__(self):\n super(AlbertClass, self).__init__()\n self.albert = transformers.AlbertModel.from_pretrained('albert-base-v2')\n self.drop = torch.nn.Dropout(0.1)\n self.linear = torch.nn.Linear(768, 6)\n \n def forward(self, ids, mask, token_type_ids):\n _, output= self.albert(ids, attention_mask = mask)\n output = self.drop(output)\n output = self.linear(output)\n\n return output\n\nmodel = AlbertClass()\nmodel.to(device)",
"_____no_output_____"
]
],
[
[
"## Hyperparameters & Loss function",
"_____no_output_____"
]
],
[
[
"def loss_fn(outputs, targets):\n return torch.nn.BCEWithLogitsLoss()(outputs, targets)",
"_____no_output_____"
],
[
"param_optimizer = list(model.named_parameters())\nno_decay = [\"bias\", \"LayerNorm.bias\", \"LayerNorm.weight\"]\noptimizer_parameters = [\n {\n \"params\": [\n p for n, p in param_optimizer if not any(nd in n for nd in no_decay)\n ],\n \"weight_decay\": 0.001,\n },\n {\n \"params\": [\n p for n, p in param_optimizer if any(nd in n for nd in no_decay)\n ],\n \"weight_decay\": 0.0,\n },\n]\n\noptimizer = torch.optim.AdamW(optimizer_parameters, lr=1e-5)\nnum_training_steps = int(len(train_dataset) / TRAIN_BATCH_SIZE * EPOCHS)\n\nscheduler = get_linear_schedule_with_warmup(\n optimizer,\n num_warmup_steps = 0,\n num_training_steps = num_training_steps\n)",
"_____no_output_____"
]
],
[
[
"## Train & Eval Functions\n\n",
"_____no_output_____"
]
],
[
[
"def train(epoch):\n model.train()\n for _,data in tqdm(enumerate(training_loader, 0), total=len(training_loader)):\n ids = data['ids'].to(device, dtype = torch.long)\n mask = data['mask'].to(device, dtype = torch.long)\n token_type_ids = data['token_type_ids'].to(device, dtype = torch.long)\n targets = data['targets'].to(device, dtype = torch.float)\n\n outputs = model(ids, mask, token_type_ids)\n\n optimizer.zero_grad()\n loss = loss_fn(outputs, targets)\n if _%1000==0:\n print(f'Epoch: {epoch}, Loss: {loss.item()}')\n \n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n scheduler.step()\n\ndef validation(epoch):\n model.eval()\n fin_targets=[]\n fin_outputs=[]\n with torch.no_grad():\n for _, data in tqdm(enumerate(testing_loader, 0), total=len(testing_loader)):\n ids = data['ids'].to(device, dtype = torch.long)\n mask = data['mask'].to(device, dtype = torch.long)\n token_type_ids = data['token_type_ids'].to(device, dtype = torch.long)\n\n targets = data['targets'].to(device, dtype = torch.float)\n outputs = model(ids, mask, token_type_ids)\n fin_targets.extend(targets.cpu().detach().numpy().tolist())\n fin_outputs.extend(torch.sigmoid(outputs).cpu().detach().numpy().tolist())\n return fin_outputs, fin_targets",
"_____no_output_____"
]
],
[
[
"## Training Model",
"_____no_output_____"
]
],
[
[
"MODEL_PATH = \"/kaggle/working/albert-multilabel-model.bin\"\nbest_micro = 0\nfor epoch in range(EPOCHS):\n train(epoch)\n outputs, targets = validation(epoch)\n outputs = np.array(outputs) >= 0.5\n accuracy = metrics.accuracy_score(targets, outputs)\n f1_score_micro = metrics.f1_score(targets, outputs, average='micro')\n f1_score_macro = metrics.f1_score(targets, outputs, average='macro')\n print(f\"Accuracy Score = {accuracy}\")\n print(f\"F1 Score (Micro) = {f1_score_micro}\")\n print(f\"F1 Score (Macro) = {f1_score_macro}\")\n if f1_score_micro > best_micro:\n torch.save(model.state_dict(), MODEL_PATH)\n best_micro = f1_score_micro",
"_____no_output_____"
],
[
"def predict(id, abstract):\n MAX_LENGTH = 512\n inputs = tokenizer.encode_plus(\n abstract,\n None,\n add_special_tokens=True,\n max_length=512,\n pad_to_max_length=True,\n return_token_type_ids=True,\n truncation = True\n )\n \n ids = inputs['input_ids']\n mask = inputs['attention_mask']\n token_type_ids = inputs['token_type_ids']\n\n ids = torch.tensor(ids, dtype=torch.long).unsqueeze(0)\n mask = torch.tensor(mask, dtype=torch.long).unsqueeze(0)\n token_type_ids = torch.tensor(token_type_ids, dtype=torch.long).unsqueeze(0)\n\n ids = ids.to(device)\n mask = mask.to(device)\n token_type_ids = token_type_ids.to(device)\n\n with torch.no_grad():\n outputs = model(ids, mask, token_type_ids)\n\n outputs = torch.sigmoid(outputs).squeeze()\n outputs = np.round(outputs.cpu().numpy())\n \n out = np.insert(outputs, 0, id)\n return out",
"_____no_output_____"
],
[
"def submit():\n test_df = pd.read_csv('../input/avjantahack/data/test.csv')\n sample_submission = pd.read_csv('../input/avjantahack/data/sample_submission_UVKGLZE.csv')\n\n y = []\n for id, abstract in tqdm(zip(test_df['ID'], test_df['ABSTRACT']),\n total=len(test_df)):\n out = predict(id, abstract)\n y.append(out)\n y = np.array(y)\n submission = pd.DataFrame(y, columns=sample_submission.columns).astype(int)\n return submission",
"_____no_output_____"
],
[
"submission = submit()\nsubmission",
"_____no_output_____"
],
[
"submission.to_csv('/kaggle/working/alberta-tuned-lr-ws-dr.csv', index=False)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
d06476f82b77f6e5bcbde9a83435ff7ac540991b | 1,585 | ipynb | Jupyter Notebook | chapter10/05_transfer_learning.ipynb | PacktPublishing/Mastering-Azure-Machine-Learning-Second-Edition | 1ca0cf19fd49f6781c589ae4d9bde56135791cf1 | [
"MIT"
]
| 1 | 2022-03-07T20:15:08.000Z | 2022-03-07T20:15:08.000Z | chapter10/05_transfer_learning.ipynb | PacktPublishing/Mastering-Azure-Machine-Learning-Second-Edition | 1ca0cf19fd49f6781c589ae4d9bde56135791cf1 | [
"MIT"
]
| null | null | null | chapter10/05_transfer_learning.ipynb | PacktPublishing/Mastering-Azure-Machine-Learning-Second-Edition | 1ca0cf19fd49f6781c589ae4d9bde56135791cf1 | [
"MIT"
]
| 1 | 2022-03-22T17:57:41.000Z | 2022-03-22T17:57:41.000Z | 20.855263 | 105 | 0.548265 | [
[
[
"import keras",
"_____no_output_____"
],
[
"from keras.applications.resnet50 import ResNet50\n\nnum_classes = 10\ninput_shape = (224, 224, 3)\n\n# create the base pre-trained model\nbase_model = ResNet50(input_shape=input_shape, weights='imagenet', include_top=False,pooling='avg')",
"_____no_output_____"
],
[
"for layer in base_model.layers:\n layer.trainable=False",
"_____no_output_____"
],
[
"from keras.models import Model\nfrom keras.layers import Flatten, Dense\n\nclf = base_model.output\nclf = Dense(256, activation='relu')(clf)\nclf = Dense(10, activation='softmax')(clf)\n\nmodel = Model(base_model.input, clf)",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code"
]
]
|
d06483d677627cbca55508862a20d7391a6436a3 | 20,102 | ipynb | Jupyter Notebook | AS2520 Propulsion Lab/Experiment 6 - Droplet Evaporation/re-work-notebook.ipynb | kirtan2605/Coursework-Codes | f979b45a608a3420a107de99fc6eb6acefcadf87 | [
"MIT"
]
| null | null | null | AS2520 Propulsion Lab/Experiment 6 - Droplet Evaporation/re-work-notebook.ipynb | kirtan2605/Coursework-Codes | f979b45a608a3420a107de99fc6eb6acefcadf87 | [
"MIT"
]
| null | null | null | AS2520 Propulsion Lab/Experiment 6 - Droplet Evaporation/re-work-notebook.ipynb | kirtan2605/Coursework-Codes | f979b45a608a3420a107de99fc6eb6acefcadf87 | [
"MIT"
]
| null | null | null | 20,102 | 20,102 | 0.717988 | [
[
[
"# Droplet Evaporation",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy import optimize",
"_____no_output_____"
],
[
"# Ethyl Acetate\n#time_in_sec = np.array([0,5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85,90,95,100,105,110])\n#diameter = np.array([2.79,2.697,2.573,2.542,2.573,2.48,2.449,2.449,2.387,2.356,2.263,2.232,2.201,2.139,1.82,1.426,1.178,1.085,0.992,0.496,0.403,0.372,0.11])\n\n# Gasoline\n#time_in_min = np.array([0,15,30,45,60,75,90,105,120,135,150,165,180,210,235,250,265])\n#diameter = np.array([2,1.85,1.82,1.8,1.77,1.74,1.72,1.68,1.57,1.3,1.166,1.091,0.94,0.81,0.74,0.66,0.59])",
"_____no_output_____"
]
],
[
[
"# Ethyl Acetate",
"_____no_output_____"
]
],
[
[
"time_in_sec = np.array([0,5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85,90,95,100,105,110])\ndiameter = np.array([2.79,2.697,2.573,2.542,2.573,2.48,2.449,2.449,2.387,2.356,2.263,2.232,2.201,2.139,1.82,1.426,1.178,1.085,0.992,0.496,0.403,0.372,0.11])",
"_____no_output_____"
],
[
"x = time_in_sec.tolist()\ny = diameter.tolist()\n\npolynomial_coeff_1=np.polyfit(x,y,1)\npolynomial_coeff_2=np.polyfit(x,y,2)\npolynomial_coeff_3=np.polyfit(x,y,3)\n\nxnew=np.linspace(0,110 ,100)\nynew_1=np.poly1d(polynomial_coeff_1)\nynew_2=np.poly1d(polynomial_coeff_2)\nynew_3=np.poly1d(polynomial_coeff_3)\n\nplt.plot(x,y,'o')\nplt.plot(xnew,ynew_1(xnew))\nplt.plot(xnew,ynew_2(xnew))\nplt.plot(xnew,ynew_3(xnew))\nprint(ynew_1)\nprint(ynew_2)\nprint(ynew_3)\nplt.title(\"Diameter vs Time(s)\")\nplt.xlabel(\"Time(s)\")\nplt.ylabel(\"Diameter\")\n\nplt.show()\n\n\n# Coeficients\n# LINEAR : -0.02386 x + 3.139\n# QUADRATIC : -0.0002702 x^2 + 0.005868 x + 2.619\n# CUBIC : -4.771e-07 x^3 - 0.0001915 x^2 + 0.002481 x + 2.646\n#\n# Using Desmos to find the roots of the best fit polynomials\n# Root of linear fit = 131.559\n# Root of quadratic fit = 109.908\n# Root of cubic fit = 109.414",
"_____no_output_____"
],
[
"def d_square_law(x, C, n):\n y = C/(x**n)\n return y",
"_____no_output_____"
]
],
[
[
"# Linear Fit",
"_____no_output_____"
]
],
[
[
"# Calculating time taken for vaporization for different diameters. (LINEAR FIT)\ndiameter = np.array([2.79,2.697,2.573,2.542,2.573,2.48,2.449,2.449,2.387,2.356,2.263,2.232,2.201,2.139,1.82,1.426,1.178,1.085,0.992,0.496,0.403,0.372,0.11])\ntime_in_sec = np.array([0,5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85,90,95,100,105,110])\nt_vap = time_in_sec\nt_vap = t_vap*0\nt_vap = t_vap + 131.559\nt_vap = t_vap - time_in_sec\nprint(t_vap.tolist())",
"_____no_output_____"
],
[
"# Finding C and n for d-square law\n#initial_diameter = np.array([2.79,2.697,2.573,2.542,2.573,2.48,2.449,2.449,2.387,2.356,2.263,2.232,2.201,2.139,1.82,1.426,1.178,1.085,0.992,0.496,0.403,0.372,0.11])\n#vap_time = np.array([109.908, 104.908, 99.908, 94.908, 89.908, 84.908, 79.908, 74.908, 69.908, 64.908, 59.908, 54.908, 49.908, 44.908, 39.908, 34.908, 29.908, 24.908, 19.908, 14.908000000000001, 9.908000000000001, 4.908000000000001, -0.09199999999999875])\n\n# Linear \ninitial_diameter = np.array([2.79,2.697,2.573,2.542,2.573,2.48,2.449,2.449,2.387,2.356,2.263,2.232,2.201,2.139,1.82,1.426,1.178,1.085,0.992,0.496,0.403,0.372,0.11])\nvap_time_lin = np.array([131.559, 126.559, 121.559, 116.559, 111.559, 106.559, 101.559, 96.559, 91.559, 86.559, 81.559, 76.559, 71.559, 66.559, 61.559, 56.559, 51.559, 46.559, 41.559, 36.559, 31.558999999999997, 26.558999999999997, 21.558999999999997])",
"_____no_output_____"
],
[
"# Linear\nparameters_lin = optimize.curve_fit(d_square_law, xdata = initial_diameter, ydata = vap_time_lin)[0]\nprint(\"Linear : \",parameters_lin)\n#C = parameters_lin[0]\n#n = parameters_lin[1]",
"_____no_output_____"
]
],
[
[
"# Quadratic Fit",
"_____no_output_____"
]
],
[
[
"# Calculating time taken for vaporization for different diameters. (QUADRATIC FIT)\ndiameter = np.array([2.79,2.697,2.573,2.542,2.573,2.48,2.449,2.449,2.387,2.356,2.263,2.232,2.201,2.139,1.82,1.426,1.178,1.085,0.992,0.496,0.403,0.372,0.11])\ntime_in_sec = np.array([0,5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85,90,95,100,105,110])\nt_vap = time_in_sec\nt_vap = t_vap*0\nt_vap = t_vap + 109.908\nt_vap = t_vap - time_in_sec\nprint(t_vap.tolist())",
"_____no_output_____"
],
[
"# Quadratic Fit\ninitial_diameter = np.array([2.79,2.697,2.573,2.542,2.573,2.48,2.449,2.449,2.387,2.356,2.263,2.232,2.201,2.139,1.82,1.426,1.178,1.085,0.992,0.496,0.403,0.372])\nvap_time_quad = np.array([109.908, 104.908, 99.908, 94.908, 89.908, 84.908, 79.908, 74.908, 69.908, 64.908, 59.908, 54.908, 49.908, 44.908, 39.908, 34.908, 29.908, 24.908, 19.908, 14.908000000000001, 9.908000000000001, 4.908000000000001])\n",
"_____no_output_____"
],
[
"# Quadratic\nparameters_quad = optimize.curve_fit(d_square_law, xdata = initial_diameter, ydata = vap_time_quad)[0]\nprint(\"Linear : \",parameters_quad)\n#C = parameters_lin[0]\n#n = parameters_lin[1]",
"_____no_output_____"
]
],
[
[
"# Ethyl Acetate - After finding d-square Law",
"_____no_output_____"
]
],
[
[
"# Linear\nC = 41.72856231\nn = -0.97941652\n\n# Quadratic\n# C = 11.6827828\n# n = -2.13925924\n\n\n\nx = vap_time.tolist()\ny = initial_diameter.tolist()\n\nynew=np.linspace(0,3 ,100)\nxnew=[]\nfor item in ynew:\n v1 = C/(item**n)\n xnew.append(v1)\n \nplt.plot(x,y,'o')\nplt.plot(xnew,ynew)\nplt.title(\"Initial Diameter vs Vaporization Time(s)\")\nplt.xlabel(\"Vaporization Time(s)\")\nplt.ylabel(\"Initial Diameter\")\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Gasoline",
"_____no_output_____"
]
],
[
[
"time_in_min = np.array([0,15,30,45,60,75,90,105,120,135,150,165,180,210,235,250,265])\ndiameter = np.array([2,1.85,1.82,1.8,1.77,1.74,1.72,1.68,1.57,1.3,1.166,1.091,0.94,0.81,0.74,0.66,0.59])",
"_____no_output_____"
],
[
"x = time_in_min.tolist()\ny = diameter.tolist()\n\npolynomial_coeff_1=np.polyfit(x,y,1)\npolynomial_coeff_2=np.polyfit(x,y,2)\npolynomial_coeff_3=np.polyfit(x,y,3)\n\nxnew=np.linspace(0,300 ,100)\nynew_1=np.poly1d(polynomial_coeff_1)\nynew_2=np.poly1d(polynomial_coeff_2)\nynew_3=np.poly1d(polynomial_coeff_3)\n\nplt.plot(x,y,'o')\nplt.plot(xnew,ynew_1(xnew))\nplt.plot(xnew,ynew_2(xnew))\nplt.plot(xnew,ynew_3(xnew))\nprint(ynew_1)\nprint(ynew_2)\nprint(ynew_3)\nplt.title(\"Diameter vs Time(min)\")\nplt.xlabel(\"Time(min)\")\nplt.ylabel(\"Diameter\")\n\nplt.show()\n\n\n# Coeficients\n# LINEAR : -0.005637 x + 2.074\n# QUADRATIC : -6.67e-06 x^2 - 0.003865 x + 2\n# CUBIC : 1.481e-07 x^3 - 6.531e-05 x^2 + 0.00207 x + 1.891\n#\n# Using Desmos to find the roots of the best fit polynomials\n# Root of linear fit = 367.926\n# Root of quadratic fit = 329.781\n# Root of cubic fit = No Positive Root",
"_____no_output_____"
]
],
[
[
"# Linear Fit",
"_____no_output_____"
]
],
[
[
"# Calculating time taken for vaporization for different diameters. (LINEAR FIT)\ntime_in_min = np.array([0,15,30,45,60,75,90,105,120,135,150,165,180,210,235,250,265])\ndiameter = np.array([2,1.85,1.82,1.8,1.77,1.74,1.72,1.68,1.57,1.3,1.166,1.091,0.94,0.81,0.74,0.66,0.59])\nt_vap = time_in_min\nt_vap = t_vap*0\nt_vap = t_vap + 367.926\nt_vap = t_vap - time_in_min\nprint(t_vap.tolist())",
"_____no_output_____"
],
[
"initial_diameter_g_lin = np.array([2,1.85,1.82,1.8,1.77,1.74,1.72,1.68,1.57,1.3,1.166,1.091,0.94,0.81,0.74,0.66,0.59])\nvap_time_g_lin = np.array([367.926, 352.926, 337.926, 322.926, 307.926, 292.926, 277.926, 262.926, 247.926, 232.926, 217.926, 202.926, 187.926, 157.926, 132.926, 117.92599999999999, 102.92599999999999])",
"_____no_output_____"
],
[
"parameters_g_lin = optimize.curve_fit(d_square_law, xdata = initial_diameter_g_lin, ydata = vap_time_g_lin)[0]\nprint(parameters_g_lin)\nC_g = parameters_g_lin[0]\nn_g = parameters_g_lin[1]",
"_____no_output_____"
]
],
[
[
"# Quadratic Fit",
"_____no_output_____"
]
],
[
[
"# Calculating time taken for vaporization for different diameters.\ntime_in_min = np.array([0,15,30,45,60,75,90,105,120,135,150,165,180,210,235,250,265])\ndiameter = np.array([2,1.85,1.82,1.8,1.77,1.74,1.72,1.68,1.57,1.3,1.166,1.091,0.94,0.81,0.74,0.66,0.59])\nt_vap = time_in_min\nt_vap = t_vap*0\nt_vap = t_vap + 329.781\nt_vap = t_vap - time_in_min\nprint(t_vap.tolist())",
"_____no_output_____"
],
[
"initial_diameter_g_quad = np.array([2,1.85,1.82,1.8,1.77,1.74,1.72,1.68,1.57,1.3,1.166,1.091,0.94,0.81,0.74,0.66,0.59])\nvap_time_g_quad = np.array([329.781, 314.781, 299.781, 284.781, 269.781, 254.781, 239.781, 224.781, 209.781, 194.781, 179.781, 164.781, 149.781, 119.781, 94.781, 79.781, 64.781])",
"_____no_output_____"
],
[
"parameters_g_quad = optimize.curve_fit(d_square_law, xdata = initial_diameter_g_quad, ydata = vap_time_g_quad)[0]\nprint(parameters_g_quad)\nC_g = parameters_g_quad[0]\nn_g = parameters_g_quad[1]",
"_____no_output_____"
]
],
[
[
"# Gasoline - After finding Vaporization Time Data",
"_____no_output_____"
]
],
[
[
"#Linear \nC_g = 140.10666889\nn_g = -1.1686059 \n\n# Quadratic\nC_g = 140.10666889\nn_g = -1.1686059 \n\nx_g = vap_time_g.tolist()\ny_g = initial_diameter_g.tolist()\n\nynew_g=np.linspace(0,2.2 ,100)\nxnew_g=[]\nfor item in ynew_g:\n v1 = C_g/(item**n_g)\n xnew_g.append(v1)\nprint(ynew_g)\nprint(xnew_g)\n \nplt.plot(x_g,y_g,'o')\nplt.plot(xnew_g,ynew_g)\nplt.title(\"Initial Diameter vs Vaporization Time(min)\")\nplt.xlabel(\"Vaporization Time(min)\")\nplt.ylabel(\"Initial Diameter\")\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Optimization Methods (IGNORE)",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom scipy import optimize\nimport matplotlib.pyplot as plt\n\nplt.style.use('seaborn-poster')",
"_____no_output_____"
],
[
"time_in_sec = np.array([5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85,90,95,100,105,110])\ndiameter = np.array([2.697,2.573,2.542,2.573,2.48,2.449,2.449,2.387,2.356,2.263,2.232,2.201,2.139,1.82,1.426,1.178,1.085,0.992,0.496,0.403,0.372,0.11])",
"_____no_output_____"
],
[
"def func(x, a, b):\n y = a/(x**b) \n return y\n\nparameters = optimize.curve_fit(func, xdata = time_in_sec, ydata = diameter)[0]\nprint(parameters)\nC = parameters[0]\nn = parameters[1]",
"_____no_output_____"
],
[
"plt.plot(time_in_sec,diameter,'o',label='data')\ny_new = []\nfor val in time_in_sec:\n v1 = C/(val**n)\n y_new.append(v1)\nplt.plot(time_in_sec,y_new,'-',label='fit')",
"_____no_output_____"
],
[
"log_time = np.log(time_in_min)\nlog_d = np.log(diameter)\nprint(log_d)\nprint(log_time)\nx = log_time.tolist()\ny = log_d.tolist()\npolynomial_coeff=np.polyfit(x,y,1)\nxnew=np.linspace(2.5,6,100)\nynew=np.poly1d(polynomial_coeff)\nplt.plot(xnew,ynew(xnew),x,y,'o')\nprint(ynew)\nplt.title(\"log(diameter) vs log(Time(s))\")\nplt.xlabel(\"log(Time(s))\")\nplt.ylabel(\"log(diameter)\")\n\nplt.show()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
]
|
d064867b0d95195803807b55ac9a5c83deb05dbf | 26,902 | ipynb | Jupyter Notebook | Special. NLP_with_BERT.ipynb | Samrath49/AI_ML_DL | f5427adca5d914a7b69e11b578706cc7d21d3d56 | [
"Unlicense"
]
| null | null | null | Special. NLP_with_BERT.ipynb | Samrath49/AI_ML_DL | f5427adca5d914a7b69e11b578706cc7d21d3d56 | [
"Unlicense"
]
| null | null | null | Special. NLP_with_BERT.ipynb | Samrath49/AI_ML_DL | f5427adca5d914a7b69e11b578706cc7d21d3d56 | [
"Unlicense"
]
| null | null | null | 56.875264 | 451 | 0.597056 | [
[
[
"<a href=\"https://colab.research.google.com/github/Samrath49/AI_ML_DL/blob/main/Special.%20NLP_with_BERT.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# NLP with Bert for Sentiment Analysis",
"_____no_output_____"
],
[
"### Importing Libraries",
"_____no_output_____"
]
],
[
[
"!pip3 install ktrain ",
"Collecting ktrain\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/e1/3c/8469632f3fa51f244ce35ac184de4c55a260dccfcb7386529faf82ebf60f/ktrain-0.25.4.tar.gz (25.3MB)\n\u001b[K |████████████████████████████████| 25.3MB 133kB/s \n\u001b[?25hCollecting scikit-learn==0.23.2\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/f4/cb/64623369f348e9bfb29ff898a57ac7c91ed4921f228e9726546614d63ccb/scikit_learn-0.23.2-cp37-cp37m-manylinux1_x86_64.whl (6.8MB)\n\u001b[K |████████████████████████████████| 6.8MB 48.5MB/s \n\u001b[?25hRequirement already satisfied: matplotlib>=3.0.0 in /usr/local/lib/python3.7/dist-packages (from ktrain) (3.2.2)\nRequirement already satisfied: pandas>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from ktrain) (1.1.5)\nRequirement already satisfied: fastprogress>=0.1.21 in /usr/local/lib/python3.7/dist-packages (from ktrain) (1.0.0)\nRequirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from ktrain) (2.23.0)\nRequirement already satisfied: joblib in /usr/local/lib/python3.7/dist-packages (from ktrain) (1.0.1)\nRequirement already satisfied: packaging in /usr/local/lib/python3.7/dist-packages (from ktrain) (20.9)\nRequirement already satisfied: ipython in /usr/local/lib/python3.7/dist-packages (from ktrain) (5.5.0)\nCollecting langdetect\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/56/a3/8407c1e62d5980188b4acc45ef3d94b933d14a2ebc9ef3505f22cf772570/langdetect-1.0.8.tar.gz (981kB)\n\u001b[K |████████████████████████████████| 983kB 50.1MB/s \n\u001b[?25hRequirement already satisfied: jieba in /usr/local/lib/python3.7/dist-packages (from ktrain) (0.42.1)\nCollecting cchardet\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/80/72/a4fba7559978de00cf44081c548c5d294bf00ac7dcda2db405d2baa8c67a/cchardet-2.1.7-cp37-cp37m-manylinux2010_x86_64.whl (263kB)\n\u001b[K |████████████████████████████████| 266kB 51.8MB/s \n\u001b[?25hCollecting syntok\n Downloading https://files.pythonhosted.org/packages/8c/76/a49e73a04b3e3a14ce232e8e28a1587f8108baa665644fe8c40e307e792e/syntok-1.3.1.tar.gz\nCollecting seqeval==0.0.19\n Downloading https://files.pythonhosted.org/packages/93/e5/b7705156a77f742cfe4fc6f22d0c71591edb2d243328dff2f8fc0f933ab6/seqeval-0.0.19.tar.gz\nCollecting transformers<4.0,>=3.1.0\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/3a/83/e74092e7f24a08d751aa59b37a9fc572b2e4af3918cb66f7766c3affb1b4/transformers-3.5.1-py3-none-any.whl (1.3MB)\n\u001b[K |████████████████████████████████| 1.3MB 50.5MB/s \n\u001b[?25hCollecting sentencepiece\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/f5/99/e0808cb947ba10f575839c43e8fafc9cc44e4a7a2c8f79c60db48220a577/sentencepiece-0.1.95-cp37-cp37m-manylinux2014_x86_64.whl (1.2MB)\n\u001b[K |████████████████████████████████| 1.2MB 52.6MB/s \n\u001b[?25hCollecting keras_bert>=0.86.0\n Downloading https://files.pythonhosted.org/packages/e2/7f/95fabd29f4502924fa3f09ff6538c5a7d290dfef2c2fe076d3d1a16e08f0/keras-bert-0.86.0.tar.gz\nRequirement already satisfied: networkx>=2.3 in /usr/local/lib/python3.7/dist-packages (from ktrain) (2.5)\nCollecting whoosh\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/ba/19/24d0f1f454a2c1eb689ca28d2f178db81e5024f42d82729a4ff6771155cf/Whoosh-2.7.4-py2.py3-none-any.whl (468kB)\n\u001b[K |████████████████████████████████| 471kB 49.2MB/s \n\u001b[?25hCollecting threadpoolctl>=2.0.0\n Downloading https://files.pythonhosted.org/packages/f7/12/ec3f2e203afa394a149911729357aa48affc59c20e2c1c8297a60f33f133/threadpoolctl-2.1.0-py3-none-any.whl\nRequirement already satisfied: scipy>=0.19.1 in /usr/local/lib/python3.7/dist-packages (from scikit-learn==0.23.2->ktrain) (1.4.1)\nRequirement already satisfied: numpy>=1.13.3 in /usr/local/lib/python3.7/dist-packages (from scikit-learn==0.23.2->ktrain) (1.19.5)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0.0->ktrain) (2.4.7)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0.0->ktrain) (1.3.1)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0.0->ktrain) (0.10.0)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0.0->ktrain) (2.8.1)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.7/dist-packages (from pandas>=1.0.1->ktrain) (2018.9)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->ktrain) (2.10)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->ktrain) (2020.12.5)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->ktrain) (3.0.4)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->ktrain) (1.24.3)\nRequirement already satisfied: prompt-toolkit<2.0.0,>=1.0.4 in /usr/local/lib/python3.7/dist-packages (from ipython->ktrain) (1.0.18)\nRequirement already satisfied: pexpect; sys_platform != \"win32\" in /usr/local/lib/python3.7/dist-packages (from ipython->ktrain) (4.8.0)\nRequirement already satisfied: setuptools>=18.5 in /usr/local/lib/python3.7/dist-packages (from ipython->ktrain) (54.0.0)\nRequirement already satisfied: pygments in /usr/local/lib/python3.7/dist-packages (from ipython->ktrain) (2.6.1)\nRequirement already satisfied: pickleshare in /usr/local/lib/python3.7/dist-packages (from ipython->ktrain) (0.7.5)\nRequirement already satisfied: simplegeneric>0.8 in /usr/local/lib/python3.7/dist-packages (from ipython->ktrain) (0.8.1)\nRequirement already satisfied: traitlets>=4.2 in /usr/local/lib/python3.7/dist-packages (from ipython->ktrain) (5.0.5)\nRequirement already satisfied: decorator in /usr/local/lib/python3.7/dist-packages (from ipython->ktrain) (4.4.2)\nRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from langdetect->ktrain) (1.15.0)\nRequirement already satisfied: regex in /usr/local/lib/python3.7/dist-packages (from syntok->ktrain) (2019.12.20)\nRequirement already satisfied: Keras>=2.2.4 in /usr/local/lib/python3.7/dist-packages (from seqeval==0.0.19->ktrain) (2.4.3)\nRequirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.7/dist-packages (from transformers<4.0,>=3.1.0->ktrain) (4.41.1)\nCollecting sacremoses\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/7d/34/09d19aff26edcc8eb2a01bed8e98f13a1537005d31e95233fd48216eed10/sacremoses-0.0.43.tar.gz (883kB)\n\u001b[K |████████████████████████████████| 890kB 53.4MB/s \n\u001b[?25hRequirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from transformers<4.0,>=3.1.0->ktrain) (3.0.12)\nCollecting tokenizers==0.9.3\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/7b/ac/f5ba028f0f097d855e1541301e946d4672eb0f30b6e25cb2369075f916d2/tokenizers-0.9.3-cp37-cp37m-manylinux1_x86_64.whl (2.9MB)\n\u001b[K |████████████████████████████████| 2.9MB 54.5MB/s \n\u001b[?25hRequirement already satisfied: protobuf in /usr/local/lib/python3.7/dist-packages (from transformers<4.0,>=3.1.0->ktrain) (3.12.4)\nCollecting keras-transformer>=0.38.0\n Downloading https://files.pythonhosted.org/packages/89/6c/d6f0c164f4cc16fbc0d0fea85f5526e87a7d2df7b077809e422a7e626150/keras-transformer-0.38.0.tar.gz\nRequirement already satisfied: wcwidth in /usr/local/lib/python3.7/dist-packages (from prompt-toolkit<2.0.0,>=1.0.4->ipython->ktrain) (0.2.5)\nRequirement already satisfied: ptyprocess>=0.5 in /usr/local/lib/python3.7/dist-packages (from pexpect; sys_platform != \"win32\"->ipython->ktrain) (0.7.0)\nRequirement already satisfied: ipython-genutils in /usr/local/lib/python3.7/dist-packages (from traitlets>=4.2->ipython->ktrain) (0.2.0)\nRequirement already satisfied: pyyaml in /usr/local/lib/python3.7/dist-packages (from Keras>=2.2.4->seqeval==0.0.19->ktrain) (3.13)\nRequirement already satisfied: h5py in /usr/local/lib/python3.7/dist-packages (from Keras>=2.2.4->seqeval==0.0.19->ktrain) (2.10.0)\nRequirement already satisfied: click in /usr/local/lib/python3.7/dist-packages (from sacremoses->transformers<4.0,>=3.1.0->ktrain) (7.1.2)\nCollecting keras-pos-embd>=0.11.0\n Downloading https://files.pythonhosted.org/packages/09/70/b63ed8fc660da2bb6ae29b9895401c628da5740c048c190b5d7107cadd02/keras-pos-embd-0.11.0.tar.gz\nCollecting keras-multi-head>=0.27.0\n Downloading https://files.pythonhosted.org/packages/e6/32/45adf2549450aca7867deccfa04af80a0ab1ca139af44b16bc669e0e09cd/keras-multi-head-0.27.0.tar.gz\nCollecting keras-layer-normalization>=0.14.0\n Downloading https://files.pythonhosted.org/packages/a4/0e/d1078df0494bac9ce1a67954e5380b6e7569668f0f3b50a9531c62c1fc4a/keras-layer-normalization-0.14.0.tar.gz\nCollecting keras-position-wise-feed-forward>=0.6.0\n Downloading https://files.pythonhosted.org/packages/e3/59/f0faa1037c033059e7e9e7758e6c23b4d1c0772cd48de14c4b6fd4033ad5/keras-position-wise-feed-forward-0.6.0.tar.gz\nCollecting keras-embed-sim>=0.8.0\n Downloading https://files.pythonhosted.org/packages/57/ef/61a1e39082c9e1834a2d09261d4a0b69f7c818b359216d4e1912b20b1c86/keras-embed-sim-0.8.0.tar.gz\nCollecting keras-self-attention==0.46.0\n Downloading https://files.pythonhosted.org/packages/15/6b/c804924a056955fa1f3ff767945187103cfc851ba9bd0fc5a6c6bc18e2eb/keras-self-attention-0.46.0.tar.gz\nBuilding wheels for collected packages: ktrain, langdetect, syntok, seqeval, keras-bert, sacremoses, keras-transformer, keras-pos-embd, keras-multi-head, keras-layer-normalization, keras-position-wise-feed-forward, keras-embed-sim, keras-self-attention\n Building wheel for ktrain (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for ktrain: filename=ktrain-0.25.4-cp37-none-any.whl size=25276443 sha256=a21bf62c621920a75422c4df8cae95d466380843fd1eda8e66302f5807ceda37\n Stored in directory: /root/.cache/pip/wheels/1b/77/8a/bdceaabc308e7178d575278bf6143b7d1a9b939a1e40c56b88\n Building wheel for langdetect (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for langdetect: filename=langdetect-1.0.8-cp37-none-any.whl size=993193 sha256=aec636b54ffe434c9028359c31bdfc76e9da9a1752fa7f10d87e69d57c34d46a\n Stored in directory: /root/.cache/pip/wheels/8d/b3/aa/6d99de9f3841d7d3d40a60ea06e6d669e8e5012e6c8b947a57\n Building wheel for syntok (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for syntok: filename=syntok-1.3.1-cp37-none-any.whl size=20919 sha256=4f6fa992ceefd03a0101faff02b00f882b85c93d7c32eac68c56155956a0bb9e\n Stored in directory: /root/.cache/pip/wheels/51/c6/a4/be1920586c49469846bcd2888200bdecfe109ec421dab9be2d\n Building wheel for seqeval (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for seqeval: filename=seqeval-0.0.19-cp37-none-any.whl size=9919 sha256=ac03ed5c47baebb742f37bf9b08ad4e45782dd3ee4bd727f850a4af61f5fbf77\n Stored in directory: /root/.cache/pip/wheels/8d/1f/bf/1198beceed805a2099060975f6281d1b01046dd279e19c97be\n Building wheel for keras-bert (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for keras-bert: filename=keras_bert-0.86.0-cp37-none-any.whl size=34144 sha256=199f3eea09c452e52c98f833287b4c2e0161520432357af5ecfc932031eddb12\n Stored in directory: /root/.cache/pip/wheels/66/f0/b1/748128b58562fc9e31b907bb5e2ab6a35eb37695e83911236b\n Building wheel for sacremoses (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for sacremoses: filename=sacremoses-0.0.43-cp37-none-any.whl size=893262 sha256=ba82c1360a233bd048daf43f948e0400661f80d3d21e0c1b72500c2fb34065b1\n Stored in directory: /root/.cache/pip/wheels/29/3c/fd/7ce5c3f0666dab31a50123635e6fb5e19ceb42ce38d4e58f45\n Building wheel for keras-transformer (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for keras-transformer: filename=keras_transformer-0.38.0-cp37-none-any.whl size=12942 sha256=598c25f31534d9bbf3e134135ec5ffabecc0de55f3bc3ccef1bc9362f20c8f2b\n Stored in directory: /root/.cache/pip/wheels/e5/fb/3a/37b2b9326c799aa010ae46a04ddb04f320d8c77c0b7e837f4e\n Building wheel for keras-pos-embd (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for keras-pos-embd: filename=keras_pos_embd-0.11.0-cp37-none-any.whl size=7554 sha256=8dffa94551da41c503305037b9936c354793a06d95bcd09d6489f3bea15c49ca\n Stored in directory: /root/.cache/pip/wheels/5b/a1/a0/ce6b1d49ba1a9a76f592e70cf297b05c96bc9f418146761032\n Building wheel for keras-multi-head (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for keras-multi-head: filename=keras_multi_head-0.27.0-cp37-none-any.whl size=15611 sha256=7a015af070bc4ce247816f6ae650140ba6ac85bdb0a845d633c9dea464c22c7a\n Stored in directory: /root/.cache/pip/wheels/b5/b4/49/0a0c27dcb93c13af02fea254ff51d1a43a924dd4e5b7a7164d\n Building wheel for keras-layer-normalization (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for keras-layer-normalization: filename=keras_layer_normalization-0.14.0-cp37-none-any.whl size=5269 sha256=c4050c794d67cf2aa834ffad4960aed9a36145f0a16b4e54f6fab703efb570f6\n Stored in directory: /root/.cache/pip/wheels/54/80/22/a638a7d406fd155e507aa33d703e3fa2612b9eb7bb4f4fe667\n Building wheel for keras-position-wise-feed-forward (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for keras-position-wise-feed-forward: filename=keras_position_wise_feed_forward-0.6.0-cp37-none-any.whl size=5623 sha256=39e5ca51c76b0a07dd6c5f5208f8d68e5e5ab8d88ad8638279f506220420eb6a\n Stored in directory: /root/.cache/pip/wheels/39/e2/e2/3514fef126a00574b13bc0b9e23891800158df3a3c19c96e3b\n Building wheel for keras-embed-sim (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for keras-embed-sim: filename=keras_embed_sim-0.8.0-cp37-none-any.whl size=4558 sha256=a01ad8cac95ba2cd3b0d2462b0dab4b91b5e57a13d65802f81b5ed8514cce406\n Stored in directory: /root/.cache/pip/wheels/49/45/8b/c111f6cc8bec253e984677de73a6f4f5d2f1649f42aac191c8\n Building wheel for keras-self-attention (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for keras-self-attention: filename=keras_self_attention-0.46.0-cp37-none-any.whl size=17278 sha256=d0a6d2471a49500962a43539660a7cf5acaf4e829fb5d7c906fe434d7cbade2c\n Stored in directory: /root/.cache/pip/wheels/d2/2e/80/fec4c05eb23c8e13b790e26d207d6e0ffe8013fad8c6bdd4d2\nSuccessfully built ktrain langdetect syntok seqeval keras-bert sacremoses keras-transformer keras-pos-embd keras-multi-head keras-layer-normalization keras-position-wise-feed-forward keras-embed-sim keras-self-attention\n\u001b[31mERROR: transformers 3.5.1 has requirement sentencepiece==0.1.91, but you'll have sentencepiece 0.1.95 which is incompatible.\u001b[0m\nInstalling collected packages: threadpoolctl, scikit-learn, langdetect, cchardet, syntok, seqeval, sacremoses, tokenizers, sentencepiece, transformers, keras-pos-embd, keras-self-attention, keras-multi-head, keras-layer-normalization, keras-position-wise-feed-forward, keras-embed-sim, keras-transformer, keras-bert, whoosh, ktrain\n Found existing installation: scikit-learn 0.22.2.post1\n Uninstalling scikit-learn-0.22.2.post1:\n Successfully uninstalled scikit-learn-0.22.2.post1\nSuccessfully installed cchardet-2.1.7 keras-bert-0.86.0 keras-embed-sim-0.8.0 keras-layer-normalization-0.14.0 keras-multi-head-0.27.0 keras-pos-embd-0.11.0 keras-position-wise-feed-forward-0.6.0 keras-self-attention-0.46.0 keras-transformer-0.38.0 ktrain-0.25.4 langdetect-1.0.8 sacremoses-0.0.43 scikit-learn-0.23.2 sentencepiece-0.1.95 seqeval-0.0.19 syntok-1.3.1 threadpoolctl-2.1.0 tokenizers-0.9.3 transformers-3.5.1 whoosh-2.7.4\n"
],
[
"import os.path\r\nimport numpy as np\r\nimport pandas as pd\r\nimport tensorflow as tf\r\nimport ktrain\r\nfrom ktrain import text ",
"_____no_output_____"
]
],
[
[
"## Part 1: Data Preprocessing",
"_____no_output_____"
],
[
"### Loading the IMDB dataset",
"_____no_output_____"
]
],
[
[
"dataset = tf.keras.utils.get_file(fname = \"aclImdb_v1.tar\",\r\n origin = \"https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar\",\r\n extract = True)\r\nIMDB_DATADIR = os.path.join(os.path.dirname(dataset), 'aclImdb')",
"Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar\n84131840/84125825 [==============================] - 2s 0us/step\n"
],
[
"print(os.path.dirname(dataset))\r\nprint(IMDB_DATADIR)",
"/root/.keras/datasets\n/root/.keras/datasets/aclImdb\n"
]
],
[
[
"### Creating the training & test sets",
"_____no_output_____"
]
],
[
[
"(X_train, y_train), (X_test, y_test), preproc = text.texts_from_folder(datadir = IMDB_DATADIR, \r\n classes = ['pos','neg'],\r\n maxlen = 500, \r\n train_test_names = ['train', 'test'],\r\n preprocess_mode = 'bert')",
"detected encoding: utf-8\ndownloading pretrained BERT model (uncased_L-12_H-768_A-12.zip)...\n[██████████████████████████████████████████████████]\nextracting pretrained BERT model...\ndone.\n\ncleanup downloaded zip...\ndone.\n\npreprocessing train...\nlanguage: en\n"
]
],
[
[
"## Part 2: Building the BERT model",
"_____no_output_____"
]
],
[
[
"model = text.text_classifier(name = 'bert',\r\n train_data = (X_train, y_train),\r\n preproc = preproc)",
"Is Multi-Label? False\nmaxlen is 500\ndone.\n"
]
],
[
[
"## Part 3: Training the BERT model",
"_____no_output_____"
]
],
[
[
"learner = ktrain.get_learner(model = model, \r\n train_data = (X_train, y_train),\r\n val_data = (X_test, y_test),\r\n batch_size = 6)",
"_____no_output_____"
],
[
"learner.fit_onecycle(lr=2e-5,\r\n epochs = 1)",
"\n\nbegin training using onecycle policy with max lr of 2e-05...\n4167/4167 [==============================] - 3436s 820ms/step - loss: 0.3313 - accuracy: 0.8479 - val_loss: 0.1619 - val_accuracy: 0.9383\n"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
]
|
d0648ee1a52be7f2190c84ec7d539059836b6cb4 | 920,987 | ipynb | Jupyter Notebook | TD Actor Critic/TD_Actor_Critic_seperate_net.ipynb | gt-coar/BrianSURE2021 | ef3087763a1500b5dc01fe74474cb1bf4936773a | [
"MIT"
]
| null | null | null | TD Actor Critic/TD_Actor_Critic_seperate_net.ipynb | gt-coar/BrianSURE2021 | ef3087763a1500b5dc01fe74474cb1bf4936773a | [
"MIT"
]
| null | null | null | TD Actor Critic/TD_Actor_Critic_seperate_net.ipynb | gt-coar/BrianSURE2021 | ef3087763a1500b5dc01fe74474cb1bf4936773a | [
"MIT"
]
| null | null | null | 40.548893 | 407 | 0.49593 | [
[
[
"# Enable GPU",
"_____no_output_____"
]
],
[
[
"import torch\ndevice = torch.device('cuda:0' if torch.cuda.is_available else 'cpu')",
"_____no_output_____"
]
],
[
[
"# Actor and Critic Network\n\n",
"_____no_output_____"
]
],
[
[
"import torch.nn as nn\nimport torch.nn.functional as F\nfrom torch.distributions import Categorical\n\nclass Actor_Net(nn.Module):\n def __init__(self, input_dims, output_dims, num_neurons = 128):\n super(Actor_Net, self).__init__()\n self.fc1 = nn.Linear(input_dims, num_neurons)\n self.actor = nn.Linear(num_neurons, output_dims)\n self.log_probs = []\n self.entropies = []\n\n def forward(self, state):\n x = F.relu(self.fc1(state))\n x = F.softmax(self.actor(x), dim = 1)\n\n return x\n\n def get_action(self, state):\n with torch.no_grad():\n probs = self.forward(state)\n dist = Categorical(probs = probs)\n action = dist.sample()\n return action\n \n def eval_action(self, state):\n probs = self.forward(state)\n dist = Categorical(probs = probs)\n action = dist.sample().to(device)\n log_prob = dist.log_prob(action)\n entropy = dist.entropy()\n self.log_probs.append(log_prob)\n self.entropies.append(entropy)\n\n return action\n\nclass Critic_Net(nn.Module):\n def __init__ (self, input_dims, output_dims, num_neurons = 128):\n super(Critic_Net, self).__init__()\n\n self.values = []\n self.next_values = []\n \n self.fc1 = nn.Linear(input_dims, num_neurons)\n self.critic = nn.Linear(num_neurons, 1)\n\n def forward (self, state):\n x = F.relu(self.fc1(state))\n x = self.critic(x)\n\n return x",
"_____no_output_____"
],
[
"import torch.optim as optim\nimport numpy as np\nimport gym\n\nclass Actor_Critic_Agent(nn.Module):\n def __init__(self, input_dims, output_dims, optimizer = 'RMSprop', num_neurons = 128 , gamma = 0.99, actor_lr=0.001, critic_lr = 0.01):\n super(Actor_Critic_Agent, self).__init__()\n self.actor_net = Actor_Net(input_dims= input_dims, output_dims= output_dims, num_neurons= num_neurons).to(device)\n self.critic_net = Critic_Net(input_dims=input_dims, output_dims= output_dims, num_neurons= num_neurons).to(device)\n self.gamma = gamma\n if optimizer == 'RMSprop':\n self.actor_optimizer = optim.RMSprop(params = self.actor_net.parameters(), lr =actor_lr)\n self.critic_optimizer = optim.RMSprop(params = self.critic_net.parameters(), lr = critic_lr)\n else:\n self.actor_optimizer = optim.Adam(params = self.actor_net.parameters(), lr = actor_lr)\n self.critic_optimizer = optim.Adam(params = self.critic_net.parameters(), lr = critic_lr)\n\n def learn_mean(self, rewards, dones):\n value_criteration = nn.MSELoss()\n value_losses = []\n actor_losses = []\n self.critic_net.next_values = torch.cat(self.critic_net.next_values, dim = 0).squeeze(0)\n self.critic_net.values = torch.cat(self.critic_net.values, dim = 0).squeeze(0)\n self.actor_net.log_probs = torch.cat(self.actor_net.log_probs, dim = 0)\n self.actor_net.entropies = torch.cat(self.actor_net.entropies, dim = 0)\n\n for reward, entropy, log_prob, v, v_next, done in zip(rewards ,self.actor_net.entropies, self.actor_net.log_probs, self.critic_net.values, self.critic_net.next_values, dones):\n td_target = reward + self.gamma * v_next * done\n td_error = td_target - v\n value_loss = value_criteration(v, td_target.detach())- 0.001 * entropy.detach()\n actor_loss = - log_prob * td_error.detach() \n value_losses.append(value_loss)\n actor_losses.append(actor_loss)\n\n self.critic_optimizer.zero_grad()\n value_losses = torch.stack(value_losses).sum()\n value_losses.backward()\n self.critic_optimizer.step() \n\n self.actor_optimizer.zero_grad()\n actor_losses = torch.stack(actor_losses).sum()\n actor_losses.backward()\n self.actor_optimizer.step()\n\n \n # clear out memory \n self.actor_net.log_probs = []\n self.actor_net.entropies = []\n self.critic_net.values = []\n self.critic_net.next_values = []\n\n",
"_____no_output_____"
]
],
[
[
"# Without Wandb",
"_____no_output_____"
]
],
[
[
"import gym\nimport time\nimport pdb\n\nenv = gym.make('CartPole-v1')\nenv.seed(543)\ntorch.manual_seed(543)\nstate_dims = env.observation_space.shape[0]\naction_dims = env.action_space.n\nagent = Actor_Critic_Agent(input_dims= state_dims, output_dims = action_dims)\n\ndef train():\n\n num_ep = 2000\n print_every = 100\n running_score = 10\n start = time.time()\n\n rewards = []\n dones = []\n\n for ep in range(1, num_ep + 1):\n state = env.reset()\n score = 0\n done = False\n rewards = []\n dones = []\n\n while not done:\n state = torch.tensor([state]).float().to(device)\n action = agent.actor_net.eval_action(state)\n v = agent.critic_net(state)\n\n next_state, reward, done, _ = env.step(action.item())\n v_next = agent.critic_net(torch.tensor([next_state]).float().to(device))\n \n agent.critic_net.values.append(v.squeeze(0))\n agent.critic_net.next_values.append(v_next.squeeze(0))\n rewards.append(reward)\n dones.append(1 - done)\n \n # update episode\n score += reward\n state = next_state\n\n if done:\n break\n\n # update agent\n #pdb.set_trace()\n agent.learn_mean(rewards,dones)\n \n # calculating score and running score\n running_score = 0.05 * score + (1 - 0.05) * running_score\n\n if ep % print_every == 0:\n print('episode: {}, running score: {}, time elapsed: {}'.format(ep, running_score, time.time() - start))\n\n\n\n",
"_____no_output_____"
],
[
"train() #RMS",
"episode: 100, running score: 43.32507441570408, time elapsed: 4.842878341674805\nepisode: 200, running score: 129.30332722904944, time elapsed: 19.552313089370728\n"
]
],
[
[
"# Wtih wandb",
"_____no_output_____"
]
],
[
[
"!pip install wandb\n!wandb login\n",
"_____no_output_____"
],
[
"import wandb\nsweep_config = dict()\nsweep_config['method'] = 'grid'\nsweep_config['metric'] = {'name': 'running_score', 'goal': 'maximize'}\nsweep_config['parameters'] = {'learning': {'value': 'learn_mean'}, 'actor_learning_rate': {'values' : [0.01, 0.001, 0.0001,0.0003,0.00001]}, 'critic_learning_rate' : {'values': [0.01, 0.001, 0.0001, 0.0003, 0.00001]}\n , 'num_neurons': {'value': 128 }, 'optimizer': {'values' : ['RMSprop', 'Adam']}}\n\nsweep_id = wandb.sweep(sweep_config, project = 'Advantage_Actor_Critic')",
"Create sweep with ID: t9gia22t\nSweep URL: https://wandb.ai/ko120/Advantage_Actor_Critic/sweeps/t9gia22t\n"
],
[
"import gym \nimport torch\nimport time\nimport wandb\n\n\n\ndef train():\n wandb.init(config = {'env':'CartPole-v1','algorithm:': 'Actor_Critic','architecture': 'seperate','num_laeyrs':'2'}, project = 'Advantage_Actor_Critic',group = 'Cart_128_neurons_2_layer')\n config = wandb.config\n\n env = gym.make('CartPole-v1')\n env.seed(543)\n torch.manual_seed(543)\n\n state_dim = env.observation_space.shape[0]\n action_dim = env.action_space.n\n\n device = torch.device('cuda:0' if torch.cuda.is_available else 'cpu')\n agent = Actor_Critic_Agent(input_dims= state_dim, output_dims= action_dim, optimizer = config.optimizer, num_neurons= config.num_neurons, actor_lr = config.actor_learning_rate, critic_lr = config.critic_learning_rate)\n\n\n num_ep = 3000\n print_interval = 100\n save_interval = 1000\n running_score = 10\n start = time.time()\n\n \n wandb.watch(agent)\n for ep in range(1,num_ep+1):\n state = env.reset()\n score = 0\n done = False\n rewards = []\n dones = []\n\n while not done:\n state = torch.tensor([state]).float().to(device)\n action = agent.actor_net.eval_action(state)\n v = agent.critic_net(state)\n\n next_state, reward, done, _ = env.step(action.item())\n v_next = agent.critic_net(torch.tensor([next_state]).float().to(device))\n \n agent.critic_net.values.append(v.squeeze(0))\n agent.critic_net.next_values.append(v_next.squeeze(0))\n rewards.append(reward)\n dones.append(1 - done)\n \n # update episode\n score += reward\n state = next_state\n\n if done:\n break\n\n # update agent\n agent.learn_mean(rewards,dones)\n \n # calculating score and running score\n running_score = 0.05 * score + (1 - 0.05) * running_score\n\n wandb.log({'episode': ep, 'running_score': running_score}) \n\n if ep % print_interval == 0:\n print('episode {} average reward {}, ended at {:.01f}'.format(ep, running_score, time.time() - start)) \n \n if ep % save_interval == 0:\n save_name_actor = 'actor_' + str(ep) + '.pt'\n torch.save(agent.actor_net.state_dict(),save_name_actor)\n save_name_critic = 'critic_' + str(ep) + '.pt'\n torch.save(agent.critic_net.state_dict(),save_name_critic)\n wandb.save(save_name_actor)\n wandb.save(save_name_critic)\n\n if ep == num_ep:\n dummy_input = torch.rand(1,4).to(device)\n torch.onnx.export(agent.actor_net,dummy_input,'final_model_actor.onnx')\n wandb.save('final_model_actor.onnx')\n torch.onnx.export(agent.critic_net, dummy_input, 'final_model_critic.onnx')\n wandb.save('final_model_critic.onnx')\n ",
"_____no_output_____"
],
[
"wandb.agent(sweep_id, train)",
"\u001b[34m\u001b[1mwandb\u001b[0m: Agent Starting Run: wivnmds7 with config:\n\u001b[34m\u001b[1mwandb\u001b[0m: \tactor_learning_rate: 0.01\n\u001b[34m\u001b[1mwandb\u001b[0m: \tcritic_learning_rate: 0.01\n\u001b[34m\u001b[1mwandb\u001b[0m: \tlearning: learn_mean\n\u001b[34m\u001b[1mwandb\u001b[0m: \tnum_neurons: 128\n\u001b[34m\u001b[1mwandb\u001b[0m: \toptimizer: RMSprop\n\u001b[34m\u001b[1mwandb\u001b[0m: \u001b[33mWARNING\u001b[0m Ignored wandb.init() arg project when running a sweep\n"
]
],
[
[
"# You can see the result here!\n[Report Link](https://wandb.ai/ko120/Advantage_Actor_Critic/reports/TD-Actor-Critic-Learning-rate-tune---Vmlldzo4OTIwODg)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
]
|
d0648f64f9504f4ac0f20c8cc100a85b421e3dac | 173,648 | ipynb | Jupyter Notebook | PREDICTION-MODEL-1.ipynb | fuouo/TrafficBato | bd8ab5645116db4029b90bb5a28e0134d59e9ac0 | [
"MIT"
]
| null | null | null | PREDICTION-MODEL-1.ipynb | fuouo/TrafficBato | bd8ab5645116db4029b90bb5a28e0134d59e9ac0 | [
"MIT"
]
| null | null | null | PREDICTION-MODEL-1.ipynb | fuouo/TrafficBato | bd8ab5645116db4029b90bb5a28e0134d59e9ac0 | [
"MIT"
]
| null | null | null | 58.983696 | 38,484 | 0.633298 | [
[
[
"## Import Necessary Packages",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport datetime\nimport os\n\nnp.random.seed(1337) # for reproducibility\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics.classification import accuracy_score\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.metrics.regression import r2_score, mean_squared_error, mean_absolute_error\n\nfrom dbn.tensorflow import SupervisedDBNRegression",
"_____no_output_____"
]
],
[
[
"## Define Model Settings",
"_____no_output_____"
]
],
[
[
"RBM_EPOCHS = 5\nDBN_EPOCHS = 150\nRBM_LEARNING_RATE = 0.01\nDBN_LEARNING_RATE = 0.01\nHIDDEN_LAYER_STRUCT = [20, 50, 100]\nACTIVE_FUNC = 'relu'\nBATCH_SIZE = 28",
"_____no_output_____"
]
],
[
[
"## Define Directory, Road, and Year",
"_____no_output_____"
]
],
[
[
"# Read the dataset\nROAD = \"Vicente Cruz\"\nYEAR = \"2015\"\nEXT = \".csv\"\nDATASET_DIVISION = \"seasonWet\"\nDIR = \"../../../datasets/Thesis Datasets/\"\nOUTPUT_DIR = \"PM1/Rolling 3/\"\nMODEL_DIR = \"PM1/Rolling 3/\"\n\n'''''''Training dataset'''''''\nWP = False\nWEEKDAY = False\nCONNECTED_ROADS = False\nCONNECTED_1 = [\"Antipolo\"]\ntrafficDT = \"recon_traffic\" #orig_traffic recon_traffic\nfeatureEngineering = \"Rolling\" #Rolling Expanding Rolling and Expanding\ntimeFE = \"today\" #today yesterday\ntimeConnected = \"today\"\nROLLING_WINDOW = 3\nEXPANDING_WINDOW = 3\nRECON_SHIFT = 96\n# RECON_FE_WINDOW = 48",
"_____no_output_____"
],
[
"def addWorkingPeakFeatures(df):\n result_df = df.copy()\n\n # Converting the index as date\n result_df.index = pd.to_datetime(result_df.index)\n \n # Create column work_day\n result_df['work_day'] = ((result_df.index.dayofweek) < 5).astype(int)\n\n # Consider non-working holiday\n if DATASET_DIVISION is not \"seasonWet\":\n\n # Jan\n result_df.loc['2015-01-01', 'work_day'] = 0\n result_df.loc['2015-01-02', 'work_day'] = 0\n\n # Feb\n result_df.loc['2015-02-19', 'work_day'] = 0\n result_df.loc['2015-02-25', 'work_day'] = 0\n\n # Apr\n result_df.loc['2015-04-02', 'work_day'] = 0\n result_df.loc['2015-04-03', 'work_day'] = 0\n result_df.loc['2015-04-09', 'work_day'] = 0\n\n # May\n result_df.loc['2015-05-01', 'work_day'] = 0\n\n # Jun\n result_df.loc['2015-06-12', 'work_day'] = 0\n result_df.loc['2015-06-24', 'work_day'] = 0\n\n # Jul\n result_df.loc['2015-07-17', 'work_day'] = 0\n\n # Aug\n result_df.loc['2015-08-21', 'work_day'] = 0\n result_df.loc['2015-08-31', 'work_day'] = 0\n\n # Sep\n result_df.loc['2015-08-25', 'work_day'] = 0\n\n if DATASET_DIVISION is not \"seasonWet\":\n # Nov\n result_df.loc['2015-11-30', 'work_day'] = 0\n\n # Dec\n result_df.loc['2015-12-24', 'work_day'] = 0\n result_df.loc['2015-12-25', 'work_day'] = 0\n result_df.loc['2015-12-30', 'work_day'] = 0\n result_df.loc['2015-12-31', 'work_day'] = 0\n\n # Consider class suspension\n if DATASET_DIVISION is not \"seasonWet\":\n # Jan\n result_df.loc['2015-01-08', 'work_day'] = 0\n result_df.loc['2015-01-09', 'work_day'] = 0\n result_df.loc['2015-01-14', 'work_day'] = 0\n result_df.loc['2015-01-15', 'work_day'] = 0\n result_df.loc['2015-01-16', 'work_day'] = 0\n result_df.loc['2015-01-17', 'work_day'] = 0\n\n # Jul\n result_df.loc['2015-07-06', 'work_day'] = 0\n result_df.loc['2015-07-08', 'work_day'] = 0\n result_df.loc['2015-07-09', 'work_day'] = 0\n result_df.loc['2015-07-10', 'work_day'] = 0\n\n # Aug\n result_df.loc['2015-08-10', 'work_day'] = 0\n result_df.loc['2015-08-11', 'work_day'] = 0\n\n # Sep\n result_df.loc['2015-09-10', 'work_day'] = 0\n\n # Oct\n result_df.loc['2015-10-02', 'work_day'] = 0\n result_df.loc['2015-10-19', 'work_day'] = 0\n\n if DATASET_DIVISION is not \"seasonWet\":\n # Nov\n result_df.loc['2015-11-16', 'work_day'] = 0\n result_df.loc['2015-11-17', 'work_day'] = 0\n result_df.loc['2015-11-18', 'work_day'] = 0\n result_df.loc['2015-11-19', 'work_day'] = 0\n result_df.loc['2015-11-20', 'work_day'] = 0\n\n # Dec\n result_df.loc['2015-12-16', 'work_day'] = 0\n result_df.loc['2015-12-18', 'work_day'] = 0\n\n result_df['peak_hour'] = 0\n\n # Set morning peak hour\n\n start = datetime.time(7,0,0)\n end = datetime.time(10,0,0)\n\n result_df.loc[result_df.between_time(start, end).index, 'peak_hour'] = 1\n\n # Set afternoon peak hour\n\n start = datetime.time(16,0,0)\n end = datetime.time(19,0,0)\n\n result_df.loc[result_df.between_time(start, end).index, 'peak_hour'] = 1\n \n result_df\n \n return result_df",
"_____no_output_____"
],
[
"def reconstructDT(df, pastTraffic=False, trafficFeatureNeeded=[]):\n result_df = df.copy()\n\n # Converting the index as date\n result_df.index = pd.to_datetime(result_df.index, format='%d/%m/%Y %H:%M')\n result_df['month'] = result_df.index.month\n result_df['day'] = result_df.index.day\n result_df['hour'] = result_df.index.hour\n result_df['min'] = result_df.index.minute \n result_df['dayOfWeek'] = result_df.index.dayofweek\n \n if pastTraffic:\n for f in trafficFeatureNeeded:\n result_df[f + '-' + str(RECON_SHIFT*15) + \"mins\"] = result_df[f].shift(RECON_SHIFT)\n \n result_df = result_df.iloc[RECON_SHIFT:, :]\n \n for f in range(len(result_df.columns)):\n result_df[result_df.columns[f]] = normalize(result_df[result_df.columns[f]])\n\n return result_df",
"_____no_output_____"
],
[
"def getNeededFeatures(columns, arrFeaturesNeed, featureEngineering=\"Original\"):\n to_remove = []\n if len(arrFeaturesNeed) == 0: #all features aren't needed\n to_remove += range(0, len(columns))\n\n else:\n if featureEngineering == \"Original\":\n compareTo = \" \"\n elif featureEngineering == \"Rolling\" or featureEngineering == \"Expanding\":\n compareTo = \"_\"\n \n for f in arrFeaturesNeed:\n for c in range(0, len(columns)):\n if f not in columns[c].split(compareTo)[0] and columns[c].split(compareTo)[0] not in arrFeaturesNeed:\n to_remove.append(c)\n if len(columns[c].split(compareTo)) > 1:\n if \"Esum\" in columns[c].split(compareTo)[1]: #Removing all Expanding Sum \n to_remove.append(c)\n \n return to_remove",
"_____no_output_____"
],
[
"def normalize(data):\n y = pd.to_numeric(data)\n y = np.array(y.reshape(-1, 1))\n \n scaler = MinMaxScaler()\n y = scaler.fit_transform(y)\n y = y.reshape(1, -1)[0]\n return y",
"_____no_output_____"
]
],
[
[
"<br><br>\n### Preparing Traffic Dataset",
"_____no_output_____"
],
[
"#### Importing Original Traffic (wo new features)",
"_____no_output_____"
]
],
[
[
"TRAFFIC_DIR = DIR + \"mmda/\"\nTRAFFIC_FILENAME = \"mmda_\" + ROAD + \"_\" + YEAR + \"_\" + DATASET_DIVISION\norig_traffic = pd.read_csv(TRAFFIC_DIR + TRAFFIC_FILENAME + EXT, skipinitialspace=True)\norig_traffic = orig_traffic.fillna(0)\n\n#Converting index to date and time, and removing 'dt' column\norig_traffic.index = pd.to_datetime(orig_traffic.dt, format='%d/%m/%Y %H:%M')\ncols_to_remove = [0]\ncols_to_remove = getNeededFeatures(orig_traffic.columns, [\"statusN\"])\norig_traffic.drop(orig_traffic.columns[[cols_to_remove]], axis=1, inplace=True)\norig_traffic.head()\n\nif WEEKDAY:\n orig_traffic = orig_traffic[((orig_traffic.index.dayofweek) < 5)]\norig_traffic.head()",
"_____no_output_____"
],
[
"TRAFFIC_DIR = DIR + \"mmda/Rolling/\" + DATASET_DIVISION + \"/\"\nTRAFFIC_FILENAME = \"eng_win\" + str(ROLLING_WINDOW) + \"_mmda_\" + ROAD + \"_\" + YEAR + \"_\" + DATASET_DIVISION\nrolling_traffic = pd.read_csv(TRAFFIC_DIR + TRAFFIC_FILENAME + EXT, skipinitialspace=True)\n\ncols_to_remove = [0, 1, 2]\ncols_to_remove += getNeededFeatures(rolling_traffic.columns, [\"statusN\"], \"Rolling\")\n\nrolling_traffic.index = pd.to_datetime(rolling_traffic.dt, format='%Y-%m-%d %H:%M')\n\nrolling_traffic.drop(rolling_traffic.columns[[cols_to_remove]], axis=1, inplace=True)\n\nif WEEKDAY:\n rolling_traffic = rolling_traffic[((rolling_traffic.index.dayofweek) < 5)]\n \nrolling_traffic.head()",
"_____no_output_____"
],
[
"TRAFFIC_DIR = DIR + \"mmda/Expanding/\" + DATASET_DIVISION + \"/\"\nTRAFFIC_FILENAME = \"eng_win\" + str(EXPANDING_WINDOW) + \"_mmda_\" + ROAD + \"_\" + YEAR + \"_\" + DATASET_DIVISION\nexpanding_traffic = pd.read_csv(TRAFFIC_DIR + TRAFFIC_FILENAME + EXT, skipinitialspace=True)\n\ncols_to_remove = [0, 1, 2, 5]\ncols_to_remove += getNeededFeatures(expanding_traffic.columns, [\"statusN\"], \"Rolling\")\n\nexpanding_traffic.index = pd.to_datetime(expanding_traffic.dt, format='%d/%m/%Y %H:%M')\n\nexpanding_traffic.drop(expanding_traffic.columns[[cols_to_remove]], axis=1, inplace=True)\n\nif WEEKDAY:\n expanding_traffic = expanding_traffic[((expanding_traffic.index.dayofweek) < 5)]\nexpanding_traffic.head()",
"_____no_output_____"
],
[
"recon_traffic = reconstructDT(orig_traffic, pastTraffic=True, trafficFeatureNeeded=['statusN'])\nrecon_traffic.head()",
"c:\\users\\ronnie nieva\\anaconda3\\envs\\tensorflow\\lib\\site-packages\\ipykernel_launcher.py:3: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead\n This is separate from the ipykernel package so we can avoid doing imports until\nc:\\users\\ronnie nieva\\anaconda3\\envs\\tensorflow\\lib\\site-packages\\sklearn\\utils\\validation.py:475: DataConversionWarning: Data with input dtype int64 was converted to float64 by MinMaxScaler.\n warnings.warn(msg, DataConversionWarning)\n"
],
[
"connected_roads = []\n\nfor c in CONNECTED_1:\n TRAFFIC_DIR = DIR + \"mmda/\"\n TRAFFIC_FILENAME = \"mmda_\" + c + \"_\" + YEAR + \"_\" + DATASET_DIVISION\n temp = pd.read_csv(TRAFFIC_DIR + TRAFFIC_FILENAME + EXT, skipinitialspace=True)\n temp = temp.fillna(0)\n\n #Converting index to date and time, and removing 'dt' column\n temp.index = pd.to_datetime(temp.dt, format='%d/%m/%Y %H:%M')\n cols_to_remove = [0]\n cols_to_remove = getNeededFeatures(temp.columns, [\"statusN\"])\n temp.drop(temp.columns[[cols_to_remove]], axis=1, inplace=True)\n \n if WEEKDAY:\n temp = temp[((temp.index.dayofweek) < 5)]\n \n for f in range(len(temp.columns)):\n temp[temp.columns[f]] = normalize(temp[temp.columns[f]])\n temp = temp.rename(columns={temp.columns[f]: temp.columns[f] +\"(\" + c + \")\"})\n connected_roads.append(temp)\n \nconnected_roads[0].head()",
"c:\\users\\ronnie nieva\\anaconda3\\envs\\tensorflow\\lib\\site-packages\\ipykernel_launcher.py:3: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead\n This is separate from the ipykernel package so we can avoid doing imports until\n"
]
],
[
[
"### Merging datasets",
"_____no_output_____"
]
],
[
[
"if trafficDT == \"orig_traffic\":\n arrDT = [orig_traffic]\n \n if CONNECTED_ROADS:\n for c in connected_roads:\n arrDT.append(c)\n \nelif trafficDT == \"recon_traffic\":\n arrDT = [recon_traffic]\n \n if CONNECTED_ROADS:\n timeConnected = \"today\"\n print(\"TimeConnected = \" + timeConnected)\n for c in connected_roads:\n if timeConnected == \"today\":\n startIndex = np.absolute(len(arrDT[0])-len(c))\n endIndex = len(c)\n elif timeConnected == \"yesterday\":\n startIndex = 0\n endIndex = len(rolling_traffic) - RECON_SHIFT\n c = c.rename(columns={c.columns[0]: c.columns[0] + \"-\" + str(RECON_SHIFT*15) + \"mins\"})\n\n\n c = c.iloc[startIndex:endIndex, :]\n print(\"Connected Road Start time: \" + str(c.index[0]))\n c.index = arrDT[0].index\n arrDT.append(c)\n print(str(startIndex) + \" \" + str(endIndex))\n\n \nif featureEngineering != \"\":\n print(\"Adding Feature Engineering\")\n \n print(\"TimeConnected = \" + timeFE)\n\n \n if timeFE == \"today\":\n startIndex = np.absolute(len(arrDT[0])-len(rolling_traffic))\n endIndex = len(rolling_traffic)\n elif timeFE == \"yesterday\":\n startIndex = 0\n endIndex = len(rolling_traffic) - RECON_SHIFT\n \n if featureEngineering == \"Rolling\":\n temp = rolling_traffic.iloc[startIndex:endIndex, :]\n arrDT.append(temp)\n\n elif featureEngineering == \"Expanding\":\n temp = expanding_traffic.iloc[startIndex:endIndex, :]\n arrDT.append(temp)\n\n elif featureEngineering == \"Rolling and Expanding\":\n print(str(startIndex) + \" \" + str(endIndex))\n \n #Rolling\n temp = rolling_traffic.iloc[startIndex:endIndex, :]\n temp.index = arrDT[0].index\n arrDT.append(temp)\n \n #Expanding\n temp = expanding_traffic.iloc[startIndex:endIndex, :]\n temp.index = arrDT[0].index\n arrDT.append(temp)\n \nmerged_dataset = pd.concat(arrDT, axis=1)\nif \"Rolling\" in featureEngineering:\n merged_dataset = merged_dataset.iloc[ROLLING_WINDOW+1:, :]\n \nif WP:\n merged_dataset = addWorkingPeakFeatures(merged_dataset)\n print(\"Adding working / peak days\") \n\nmerged_dataset",
"Adding Feature Engineering\nTimeConnected = today\n"
]
],
[
[
"### Adding Working / Peak Features",
"_____no_output_____"
]
],
[
[
"if WP:\n merged_dataset = addWorkingPeakFeatures(merged_dataset)\n print(\"Adding working / peak days\")",
"_____no_output_____"
]
],
[
[
"## Preparing Training dataset",
"_____no_output_____"
],
[
"### Merge Original (and Rolling and Expanding)",
"_____no_output_____"
]
],
[
[
"# To-be Predicted variable \nY = merged_dataset.statusN\nY = Y.fillna(0)",
"_____no_output_____"
],
[
"# Training Data\nX = merged_dataset\nX = X.drop(X.columns[[0]], axis=1)\n\n# Splitting data\nX_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.67, shuffle=False)\nX_train = np.array(X_train)\nX_test = np.array(X_test)\nY_train = np.array(Y_train)\nY_test = np.array(Y_test)\n\n# Data scaling\n# min_max_scaler = MinMaxScaler()\n# X_train = min_max_scaler.fit_transform(X_train)\n\n#Print training and testing data\npd.concat([X, Y.to_frame()], axis=1).head()",
"_____no_output_____"
]
],
[
[
"<br><br>\n## Training Model",
"_____no_output_____"
]
],
[
[
"# Training\nregressor = SupervisedDBNRegression(hidden_layers_structure=HIDDEN_LAYER_STRUCT,\n learning_rate_rbm=RBM_LEARNING_RATE,\n learning_rate=DBN_LEARNING_RATE,\n n_epochs_rbm=RBM_EPOCHS,\n n_iter_backprop=DBN_EPOCHS,\n batch_size=BATCH_SIZE,\n activation_function=ACTIVE_FUNC)\nregressor.fit(X_train, Y_train)",
"[START] Pre-training step:\n>> Epoch 1 finished \tRBM Reconstruction error 0.600877\n>> Epoch 2 finished \tRBM Reconstruction error 0.567511\n>> Epoch 3 finished \tRBM Reconstruction error 0.521251\n>> Epoch 4 finished \tRBM Reconstruction error 0.471193\n>> Epoch 5 finished \tRBM Reconstruction error 0.412250\n>> Epoch 1 finished \tRBM Reconstruction error 0.150905\n>> Epoch 2 finished \tRBM Reconstruction error 0.141888\n>> Epoch 3 finished \tRBM Reconstruction error 0.133112\n>> Epoch 4 finished \tRBM Reconstruction error 0.125336\n>> Epoch 5 finished \tRBM Reconstruction error 0.117369\n>> Epoch 1 finished \tRBM Reconstruction error 0.045284\n>> Epoch 2 finished \tRBM Reconstruction error 0.038918\n>> Epoch 3 finished \tRBM Reconstruction error 0.038393\n>> Epoch 4 finished \tRBM Reconstruction error 0.037598\n>> Epoch 5 finished \tRBM Reconstruction error 0.036662\n[END] Pre-training step\n[START] Fine tuning step:\n>> Epoch 0 finished \tANN training loss 0.056863\n>> Epoch 1 finished \tANN training loss 0.048765\n>> Epoch 2 finished \tANN training loss 0.038931\n>> Epoch 3 finished \tANN training loss 0.028552\n>> Epoch 4 finished \tANN training loss 0.019801\n>> Epoch 5 finished \tANN training loss 0.014199\n>> Epoch 6 finished \tANN training loss 0.011577\n>> Epoch 7 finished \tANN training loss 0.010580\n>> Epoch 8 finished \tANN training loss 0.010219\n>> Epoch 9 finished \tANN training loss 0.010065\n>> Epoch 10 finished \tANN training loss 0.009976\n>> Epoch 11 finished \tANN training loss 0.009865\n>> Epoch 12 finished \tANN training loss 0.009775\n>> Epoch 13 finished \tANN training loss 0.009698\n>> Epoch 14 finished \tANN training loss 0.009636\n>> Epoch 15 finished \tANN training loss 0.009586\n>> Epoch 16 finished \tANN training loss 0.009556\n>> Epoch 17 finished \tANN training loss 0.009533\n>> Epoch 18 finished \tANN training loss 0.009486\n>> Epoch 19 finished \tANN training loss 0.009430\n>> Epoch 20 finished \tANN training loss 0.009416\n>> Epoch 21 finished \tANN training loss 0.009390\n>> Epoch 22 finished \tANN training loss 0.009394\n>> Epoch 23 finished \tANN training loss 0.009345\n>> Epoch 24 finished \tANN training loss 0.009330\n>> Epoch 25 finished \tANN training loss 0.009319\n>> Epoch 26 finished \tANN training loss 0.009298\n>> Epoch 27 finished \tANN training loss 0.009302\n>> Epoch 28 finished \tANN training loss 0.009276\n>> Epoch 29 finished \tANN training loss 0.009319\n>> Epoch 30 finished \tANN training loss 0.009279\n>> Epoch 31 finished \tANN training loss 0.009273\n>> Epoch 32 finished \tANN training loss 0.009264\n>> Epoch 33 finished \tANN training loss 0.009274\n>> Epoch 34 finished \tANN training loss 0.009242\n>> Epoch 35 finished \tANN training loss 0.009231\n>> Epoch 36 finished \tANN training loss 0.009227\n>> Epoch 37 finished \tANN training loss 0.009224\n>> Epoch 38 finished \tANN training loss 0.009249\n>> Epoch 39 finished \tANN training loss 0.009218\n>> Epoch 40 finished \tANN training loss 0.009307\n>> Epoch 41 finished \tANN training loss 0.009225\n>> Epoch 42 finished \tANN training loss 0.009235\n>> Epoch 43 finished \tANN training loss 0.009212\n>> Epoch 44 finished \tANN training loss 0.009213\n>> Epoch 45 finished \tANN training loss 0.009226\n>> Epoch 46 finished \tANN training loss 0.009228\n>> Epoch 47 finished \tANN training loss 0.009217\n>> Epoch 48 finished \tANN training loss 0.009202\n>> Epoch 49 finished \tANN training loss 0.009241\n>> Epoch 50 finished \tANN training loss 0.009205\n>> Epoch 51 finished \tANN training loss 0.009220\n>> Epoch 52 finished \tANN training loss 0.009202\n>> Epoch 53 finished \tANN training loss 0.009201\n>> Epoch 54 finished \tANN training loss 0.009201\n>> Epoch 55 finished \tANN training loss 0.009241\n>> Epoch 56 finished \tANN training loss 0.009195\n>> Epoch 57 finished \tANN training loss 0.009217\n>> Epoch 58 finished \tANN training loss 0.009208\n>> Epoch 59 finished \tANN training loss 0.009194\n>> Epoch 60 finished \tANN training loss 0.009195\n>> Epoch 61 finished \tANN training loss 0.009192\n>> Epoch 62 finished \tANN training loss 0.009193\n>> Epoch 63 finished \tANN training loss 0.009190\n>> Epoch 64 finished \tANN training loss 0.009193\n>> Epoch 65 finished \tANN training loss 0.009215\n>> Epoch 66 finished \tANN training loss 0.009211\n>> Epoch 67 finished \tANN training loss 0.009191\n>> Epoch 68 finished \tANN training loss 0.009190\n>> Epoch 69 finished \tANN training loss 0.009243\n>> Epoch 70 finished \tANN training loss 0.009219\n>> Epoch 71 finished \tANN training loss 0.009189\n>> Epoch 72 finished \tANN training loss 0.009185\n>> Epoch 73 finished \tANN training loss 0.009197\n>> Epoch 74 finished \tANN training loss 0.009182\n>> Epoch 75 finished \tANN training loss 0.009181\n>> Epoch 76 finished \tANN training loss 0.009182\n>> Epoch 77 finished \tANN training loss 0.009263\n>> Epoch 78 finished \tANN training loss 0.009181\n>> Epoch 79 finished \tANN training loss 0.009179\n>> Epoch 80 finished \tANN training loss 0.009179\n>> Epoch 81 finished \tANN training loss 0.009187\n>> Epoch 82 finished \tANN training loss 0.009196\n>> Epoch 83 finished \tANN training loss 0.009187\n>> Epoch 84 finished \tANN training loss 0.009178\n>> Epoch 85 finished \tANN training loss 0.009182\n>> Epoch 86 finished \tANN training loss 0.009179\n>> Epoch 87 finished \tANN training loss 0.009175\n>> Epoch 88 finished \tANN training loss 0.009176\n>> Epoch 89 finished \tANN training loss 0.009184\n>> Epoch 90 finished \tANN training loss 0.009173\n>> Epoch 91 finished \tANN training loss 0.009174\n>> Epoch 92 finished \tANN training loss 0.009226\n>> Epoch 93 finished \tANN training loss 0.009172\n>> Epoch 94 finished \tANN training loss 0.009193\n>> Epoch 95 finished \tANN training loss 0.009171\n>> Epoch 96 finished \tANN training loss 0.009180\n>> Epoch 97 finished \tANN training loss 0.009207\n>> Epoch 98 finished \tANN training loss 0.009206\n>> Epoch 99 finished \tANN training loss 0.009183\n>> Epoch 100 finished \tANN training loss 0.009167\n>> Epoch 101 finished \tANN training loss 0.009179\n>> Epoch 102 finished \tANN training loss 0.009191\n>> Epoch 103 finished \tANN training loss 0.009165\n>> Epoch 104 finished \tANN training loss 0.009184\n>> Epoch 105 finished \tANN training loss 0.009164\n>> Epoch 106 finished \tANN training loss 0.009169\n>> Epoch 107 finished \tANN training loss 0.009162\n>> Epoch 108 finished \tANN training loss 0.009175\n>> Epoch 109 finished \tANN training loss 0.009162\n>> Epoch 110 finished \tANN training loss 0.009170\n>> Epoch 111 finished \tANN training loss 0.009163\n>> Epoch 112 finished \tANN training loss 0.009163\n>> Epoch 113 finished \tANN training loss 0.009160\n>> Epoch 114 finished \tANN training loss 0.009168\n>> Epoch 115 finished \tANN training loss 0.009207\n>> Epoch 116 finished \tANN training loss 0.009159\n>> Epoch 117 finished \tANN training loss 0.009167\n>> Epoch 118 finished \tANN training loss 0.009176\n>> Epoch 119 finished \tANN training loss 0.009162\n>> Epoch 120 finished \tANN training loss 0.009156\n>> Epoch 121 finished \tANN training loss 0.009161\n>> Epoch 122 finished \tANN training loss 0.009157\n>> Epoch 123 finished \tANN training loss 0.009155\n>> Epoch 124 finished \tANN training loss 0.009222\n>> Epoch 125 finished \tANN training loss 0.009232\n>> Epoch 126 finished \tANN training loss 0.009151\n>> Epoch 127 finished \tANN training loss 0.009166\n>> Epoch 128 finished \tANN training loss 0.009171\n>> Epoch 129 finished \tANN training loss 0.009152\n>> Epoch 130 finished \tANN training loss 0.009160\n>> Epoch 131 finished \tANN training loss 0.009149\n>> Epoch 132 finished \tANN training loss 0.009163\n>> Epoch 133 finished \tANN training loss 0.009197\n>> Epoch 134 finished \tANN training loss 0.009197\n>> Epoch 135 finished \tANN training loss 0.009160\n>> Epoch 136 finished \tANN training loss 0.009154\n>> Epoch 137 finished \tANN training loss 0.009159\n>> Epoch 138 finished \tANN training loss 0.009166\n>> Epoch 139 finished \tANN training loss 0.009144\n>> Epoch 140 finished \tANN training loss 0.009144\n>> Epoch 141 finished \tANN training loss 0.009143\n>> Epoch 142 finished \tANN training loss 0.009144\n>> Epoch 143 finished \tANN training loss 0.009144\n>> Epoch 144 finished \tANN training loss 0.009146\n>> Epoch 145 finished \tANN training loss 0.009140\n>> Epoch 146 finished \tANN training loss 0.009140\n>> Epoch 147 finished \tANN training loss 0.009139\n>> Epoch 148 finished \tANN training loss 0.009162\n"
],
[
"#To check RBM Loss Errors:\nrbm_error = regressor.unsupervised_dbn.rbm_layers[0].rbm_loss_error\n#To check DBN Loss Errors\ndbn_error = regressor.dbn_loss_error",
"_____no_output_____"
]
],
[
[
"<br><br>\n## Testing Model",
"_____no_output_____"
]
],
[
[
"# Test\nmin_max_scaler = MinMaxScaler()\nX_test = min_max_scaler.fit_transform(X_test)\nY_pred = regressor.predict(X_test)\n\nr2score = r2_score(Y_test, Y_pred)\nrmse = np.sqrt(mean_squared_error(Y_test, Y_pred))\nmae = mean_absolute_error(Y_test, Y_pred)\nprint('Done.\\nR-squared: %.3f\\nRMSE: %.3f \\nMAE: %.3f' % (r2score, rmse, mae))",
"Done.\nR-squared: 0.892\nRMSE: 0.105 \nMAE: 0.063\n"
],
[
"print(len(Y_pred))\ntemp = []\nfor i in range(len(Y_pred)):\n temp.append(Y_pred[i][0])\nd = {'Predicted': temp, 'Actual': Y_test}\n\ndf = pd.DataFrame(data=d)\ndf.head()",
"9774\n"
],
[
"# Save the model\nif MODEL_DIR != \"\":\n directory = \"models/\" + MODEL_DIR\n if not os.path.exists(directory):\n print(\"Making Directory\")\n os.makedirs(directory)\n\nregressor.save('models/' + MODEL_DIR + 'pm1_' + ROAD + '_' + YEAR + '.pkl')",
"Making Directory\n"
]
],
[
[
"### Results and Analysis below",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"##### Printing Predicted and Actual Results",
"_____no_output_____"
]
],
[
[
"startIndex = merged_dataset.shape[0] - Y_pred.shape[0]\ndt = merged_dataset.index[startIndex:,]\ntemp = []\nfor i in range(len(Y_pred)):\n temp.append(Y_pred[i][0])\nd = {'Predicted': temp, 'Actual': Y_test, 'dt': dt}\ndf = pd.DataFrame(data=d)\ndf.head()",
"_____no_output_____"
],
[
"df.tail()",
"_____no_output_____"
]
],
[
[
"#### Visualize Actual and Predicted Traffic ",
"_____no_output_____"
]
],
[
[
"print(df.dt[0])\nstartIndex = 0\nendIndex = 96\nline1 = df.Actual.rdiv(1)\nline2 = df.Predicted.rdiv(1)\nx = range(0, RBM_EPOCHS * len(HIDDEN_LAYER_STRUCT))\nplt.figure(figsize=(20, 4))\nplt.plot(line1[startIndex:endIndex], c='red', label=\"Actual-Congestion\")\nplt.plot(line2[startIndex:endIndex], c='blue', label=\"Predicted-Congestion\")\nplt.legend()\nplt.xlabel(\"Date\")\nplt.ylabel(\"Traffic Congestion\")\nplt.show()",
"2015-07-22 04:30:00\n"
],
[
"if OUTPUT_DIR != \"\":\n directory = \"output/\" + OUTPUT_DIR\n if not os.path.exists(directory):\n print(\"Making Directory\")\n os.makedirs(directory)\n\ndf.to_csv(\"output/\" + OUTPUT_DIR + \"pm1_\" + ROAD + '_' + YEAR + EXT, index=False, encoding='utf-8')",
"_____no_output_____"
]
],
[
[
"#### Visualize trend of loss of RBM and DBN Training",
"_____no_output_____"
]
],
[
[
"line1 = rbm_error\nline2 = dbn_error\nx = range(0, RBM_EPOCHS * len(HIDDEN_LAYER_STRUCT))\nplt.plot(range(0, RBM_EPOCHS * len(HIDDEN_LAYER_STRUCT)), line1, c='red')\nplt.xticks(x)\nplt.xlabel(\"Iteration\")\nplt.ylabel(\"Error\")\nplt.show()\n\n\nplt.plot(range(DBN_EPOCHS), line2, c='blue')\nplt.xticks(x)\nplt.xlabel(\"Iteration\")\nplt.ylabel(\"Error\")\nplt.show()\n\nplt.plot(range(0, RBM_EPOCHS * len(HIDDEN_LAYER_STRUCT)), line1, c='red')\nplt.plot(range(DBN_EPOCHS), line2, c='blue')\nplt.xticks(x)\nplt.xlabel(\"Iteration\")\nplt.ylabel(\"Error\")\nplt.show()",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d06497270dad7bc9e9b7b8fb64621773d14f527c | 521,000 | ipynb | Jupyter Notebook | Course02/Voxel-Map.ipynb | thhuang/NOTES-FCND | c5b0ec7d99df3cb60a850308d16ccc6c096c7931 | [
"MIT"
]
| 1 | 2018-10-26T04:06:21.000Z | 2018-10-26T04:06:21.000Z | Course02/Voxel-Map.ipynb | thhuang/notes-fcnd | c5b0ec7d99df3cb60a850308d16ccc6c096c7931 | [
"MIT"
]
| null | null | null | Course02/Voxel-Map.ipynb | thhuang/notes-fcnd | c5b0ec7d99df3cb60a850308d16ccc6c096c7931 | [
"MIT"
]
| 1 | 2018-10-26T04:06:23.000Z | 2018-10-26T04:06:23.000Z | 2,592.039801 | 515,672 | 0.960152 | [
[
[
"# 3D Map\n\nWhile representing the configuration space in 3 dimensions isn't entirely practical it's fun (and useful) to visualize things in 3D.\n\nIn this exercise you'll finish the implementation of `create_grid` such that a 3D grid is returned where cells containing a voxel are set to `True`. We'll then plot the result!",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\n\n%matplotlib inline ",
"_____no_output_____"
],
[
"plt.rcParams['figure.figsize'] = 16, 16",
"_____no_output_____"
],
[
"# This is the same obstacle data from the previous lesson.\nfilename = 'colliders.csv'\ndata = np.loadtxt(filename, delimiter=',', dtype='Float64', skiprows=2)\nprint(data)",
"[[-305. -435. 85.5 5. 5. 85.5]\n [-295. -435. 85.5 5. 5. 85.5]\n [-285. -435. 85.5 5. 5. 85.5]\n ...\n [ 435. 465. 8. 5. 5. 8. ]\n [ 445. 465. 8. 5. 5. 8. ]\n [ 455. 465. 8. 5. 5. 8. ]]\n"
],
[
"def create_voxmap(data, voxel_size=5):\n \"\"\"\n Returns a grid representation of a 3D configuration space\n based on given obstacle data.\n \n The `voxel_size` argument sets the resolution of the voxel map. \n \"\"\"\n\n # minimum and maximum north coordinates\n north_min = np.floor(np.amin(data[:, 0] - data[:, 3]))\n north_max = np.ceil(np.amax(data[:, 0] + data[:, 3]))\n\n # minimum and maximum east coordinates\n east_min = np.floor(np.amin(data[:, 1] - data[:, 4]))\n east_max = np.ceil(np.amax(data[:, 1] + data[:, 4]))\n\n alt_max = np.ceil(np.amax(data[:, 2] + data[:, 5]))\n \n # given the minimum and maximum coordinates we can\n # calculate the size of the grid.\n north_size = int(np.ceil((north_max - north_min))) // voxel_size\n east_size = int(np.ceil((east_max - east_min))) // voxel_size\n alt_size = int(alt_max) // voxel_size\n\n voxmap = np.zeros((north_size, east_size, alt_size), dtype=np.bool)\n\n for datum in data:\n x, y, z, dx, dy, dz = datum.astype(np.int32)\n obstacle = np.array(((x-dx, x+dx),\n (y-dy, y+dy),\n (z-dz, z+dz)))\n obstacle[0] = (obstacle[0] - north_min) // voxel_size\n obstacle[1] = (obstacle[1] - east_min) // voxel_size\n obstacle[2] = obstacle[2] // voxel_size \n voxmap[obstacle[0][0]:obstacle[0][1], obstacle[1][0]:obstacle[1][1], obstacle[2][0]:obstacle[2][1]] = True\n \n return voxmap",
"_____no_output_____"
]
],
[
[
"Create 3D grid.",
"_____no_output_____"
]
],
[
[
"voxel_size = 10\nvoxmap = create_voxmap(data, voxel_size)\nprint(voxmap.shape)",
"(81, 91, 21)\n"
]
],
[
[
"Plot the 3D grid. ",
"_____no_output_____"
]
],
[
[
"fig = plt.figure()\nax = fig.gca(projection='3d')\nax.voxels(voxmap, edgecolor='k')\nax.set_xlim(voxmap.shape[0], 0)\nax.set_ylim(0, voxmap.shape[1])\n# add 100 to the height so the buildings aren't so tall\nax.set_zlim(0, voxmap.shape[2]+100//voxel_size)\n\nplt.xlabel('North')\nplt.ylabel('East')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"Isn't the city pretty?",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
d0649f7ba52737564c85b801018ece1b975776e8 | 51,572 | ipynb | Jupyter Notebook | Projecting_Covid_19_Case_Growth_in_Bangladesh_Using_Logistic_Regression.ipynb | tanzimtaher/Modeling-Covid-19-Cumulative-Case-Growth-in-Bangladesh-with-Logistic-Regression | 6304b1422a4414a3eda7b8fd1ee529b69291edd6 | [
"Xnet",
"X11"
]
| null | null | null | Projecting_Covid_19_Case_Growth_in_Bangladesh_Using_Logistic_Regression.ipynb | tanzimtaher/Modeling-Covid-19-Cumulative-Case-Growth-in-Bangladesh-with-Logistic-Regression | 6304b1422a4414a3eda7b8fd1ee529b69291edd6 | [
"Xnet",
"X11"
]
| null | null | null | Projecting_Covid_19_Case_Growth_in_Bangladesh_Using_Logistic_Regression.ipynb | tanzimtaher/Modeling-Covid-19-Cumulative-Case-Growth-in-Bangladesh-with-Logistic-Regression | 6304b1422a4414a3eda7b8fd1ee529b69291edd6 | [
"Xnet",
"X11"
]
| null | null | null | 70.646575 | 31,328 | 0.796847 | [
[
[
"# Prologue",
"_____no_output_____"
],
[
"For this project we will use the logistic regression function to model the growth of confirmed Covid-19 case population growth in Bangladesh. The logistic regression function is commonly used in classification problems, and in this project we will be examining how it fares as a regression tool. Both cumulative case counts over time and logistic regression curves have a sigmoid shape and we shall try to fit a theoretically predicted curve over the actual cumulative case counts over time to reach certain conclusions about the case count growth, such as the time of peak daily new cases and the total cases that may be reached during this outbreak.",
"_____no_output_____"
],
[
"# Import the necessary modules",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nfrom datetime import datetime,timedelta\nfrom sklearn.metrics import mean_squared_error\nfrom scipy.optimize import curve_fit\nfrom scipy.optimize import fsolve\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"# Connect to Google Drive (where the data is kept)",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
]
],
[
[
"# Import data and format as needed",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('/content/drive/My Drive/Corona-Cases.n-1.csv')\ndf.tail()",
"_____no_output_____"
]
],
[
[
"As you can see, the format of the date is 'month-day-year'. Let's specify the date column is datetime type. Let's also specify the formatting as %m-%d-%Y. And then, let's find the day when the first confirmed cases of Covid-19 were reported in Bangladesh.",
"_____no_output_____"
]
],
[
[
"FMT = '%m-%d-%Y'\ndf['Date'] = pd.to_datetime(df['Date'], format=FMT)",
"_____no_output_____"
]
],
[
[
"We have to initialize the first date of confirmed Covid-19 cases as the datetime variable start_date because we would need it later to calculate the peak.",
"_____no_output_____"
]
],
[
[
"# Initialize the start date\nstart_date = datetime.date(df.loc[0, 'Date'])\nprint('Start date: ', start_date)",
"Start date: 2020-03-08\n"
]
],
[
[
"Now, for the logistic regression function, we would need a timestep column instead of a date column in the dataframe. So we create a new dataframe called data where we drop the date column and use the index as the timestep column.",
"_____no_output_____"
]
],
[
[
"# drop date column\ndata = df['Total cases']\n\n# reset index and create a timestep\ndata = data.reset_index(drop=False)\n\n# rename columns\ndata.columns = ['Timestep', 'Total Cases']\n\n# check\ndata.tail()",
"_____no_output_____"
]
],
[
[
"# Defining the logistic regression function",
"_____no_output_____"
]
],
[
[
"def logistic_model(x,a,b,c):\n return c/(1+np.exp(-(x-b)/a))",
"_____no_output_____"
]
],
[
[
"In this formula, we have the variable x that is the time and three parameters: a, b, c.\n* a is a metric for the speed of infections\n* b is the day with the estimated maximum growth rate of confirmed Covid-19 cases\n* c is the maximum number the cumulative confirmed cases will reach by the end of the first outbreak here in Bangladesh\n\nThe growth of cumulative cases follows a sigmoid shape like the logistic regression curve and hence, this may be a good way to model the growth of the confirmed Covid-19 case population over time. For the first outbreak at least. It makes sense because, for an outbreak, the rise in cumulative case counts is initially exponential. Then there is a point of inflection where the curve nearly becomes linear. We assume that this point of inflection is the time around which the daily new case numbers will peak. After that the curve eventually flattens out. \n\n",
"_____no_output_____"
],
[
"# Fit the logistic function and extrapolate",
"_____no_output_____"
]
],
[
[
"# Initialize all the timesteps as x\nx = list(data.iloc[:,0])\n\n# Initialize all the Total Cases values as y\ny = list(data.iloc[:,1])\n\n# Fit the curve using sklearn's curve_fit method we initialize the parameter p0 with arbitrary values\nfit = curve_fit(logistic_model,x,y,p0=[2,100,20000])\n(a, b, c), cov = fit",
"_____no_output_____"
],
[
"# Print outputs\nprint('Metric for speed of infections: ', a)\nprint('Days from start when cumulative case counts will peak: ', b)\nprint('Total cumulative cases that will be reached: ', c)",
"Metric for speed of infections: 17.41386234974941\nDays from start when cumulative case counts will peak: 110.7731800890406\nTotal cumulative cases that will be reached: 265257.7755190932\n"
],
[
"# Print errors for a, b, c\nerrors = [np.sqrt(fit[1][i][i]) for i in [0,1,2]]\nprint('Errors in a, b and c respectively:\\n', errors)",
"Errors in a, b and c respectively:\n [0.12923467446546272, 0.24474862210706608, 1384.097103078659]\n"
],
[
"# estimated time of peak\nprint('Estimated time of peak between', start_date + timedelta(days=(b-errors[1])), ' and ', start_date + timedelta(days=(b+errors[1])))\n\n# estimated total number of infections \nprint('Estimated total number of infections betweeen ', (c - errors[2]), ' and ', (c + errors[2]))",
"Estimated time of peak between 2020-06-26 and 2020-06-27\nEstimated total number of infections betweeen 263873.67841601453 and 266641.8726221719\n"
]
],
[
[
"To extrapolate the curve to the future, use the fsolve function from scipy.",
"_____no_output_____"
]
],
[
[
"# Extrapolate\nsol = int(fsolve(lambda x : logistic_model(x,a,b,c) - int(c),b))",
"_____no_output_____"
]
],
[
[
"# Plot the graph",
"_____no_output_____"
]
],
[
[
"pred_x = list(range(max(x),sol))\nplt.rcParams['figure.figsize'] = [7, 7]\nplt.rc('font', size=14)\n# Real data\nplt.scatter(x,y,label=\"Real data\",color=\"red\")\n# Predicted logistic curve\nplt.plot(x+pred_x, [logistic_model(i,fit[0][0],fit[0][1],fit[0][2]) for i in x+pred_x], label=\"Logistic model\" )\nplt.legend()\nplt.xlabel(\"Days since 8th March 2020\")\nplt.ylabel(\"Total number of infected people\")\nplt.ylim((min(y)*0.9,c*1.1))\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Evaluate the MSE error",
"_____no_output_____"
],
[
"Evaluating the mean squared error (MSE) is not very meaningful on its own until we can compare it with another predictive method. We can compare MSE of our regression with MSE from another method to check if our logistic regression model works better than the other predictive model. The model with the lower MSE performs better.\n\n\n",
"_____no_output_____"
]
],
[
[
"y_pred_logistic = [logistic_model(i,fit[0][0],fit[0][1],fit[0][2])\nfor i in x]\n\nprint('Mean squared error: ', mean_squared_error(y,y_pred_logistic))",
"Mean squared error: 3298197.2412489704\n"
]
],
[
[
"# Epilogue",
"_____no_output_____"
],
[
"We should be mindful of some caveats:\n\n* These predictions will only be meaningful when the peak has actually been crossed definitively. \n\n* Also, the reliability of the reported cases would also influence the dependability of the model. Developing countries, especially the South Asian countries have famously failed to report accurate disaster statisticcs in the past. \n\n* Also, the testing numbers are low overall, especially in cities outside Dhaka where the daily new cases still have not peaked yet.\n\n* Since most of the cases reported were in Dhaka, the findings indicate that the peak in Dhaka may have been reached already.\n\n* If there is a second outbreak before the first outbreak subsides, the curve may not be sigmoid shaped and hence the results may not be as meaningful.\n\n* The total reported case numbers will possibly be greater than 260000, because the daily new cases is still rising in some cities other than Dhaka. It is not unsound to expect that the total reported case count for this first instance of Covid-19 outbreak could very well reach 300000 or more.\n\n* The government recently hiked the prices of tests which may have led to increased unwillingness in suspected candidates to actually test for the disease, and that may have influenced the recent confirmed case counts.",
"_____no_output_____"
],
[
"# References",
"_____no_output_____"
],
[
"Inspiration for theory and code from the following articles:\n\n* [Covid-19 infection in Italy. Mathematical models and predictions](https://towardsdatascience.com/covid-19-infection-in-italy-mathematical-models-and-predictions-7784b4d7dd8d)\n\n* [Logistic growth modelling of COVID-19 proliferation in China and its international implications](https://www.sciencedirect.com/science/article/pii/S1201971220303039)\n\n* [Logistic Growth Model for COVID-19](https://www.wolframcloud.com/obj/covid-19/Published/Logistic-Growth-Model-for-COVID-19.nb)\n",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
]
|
d064af379f3ecbb6e76efa98695906e87b3a7151 | 149,980 | ipynb | Jupyter Notebook | examples/Notebooks/flopy3_LoadSWRBinaryData.ipynb | gyanz/flopy | 282703716a01721e07905da65aa54e6017452a5a | [
"CC0-1.0",
"BSD-3-Clause"
]
| 1 | 2019-11-01T00:34:14.000Z | 2019-11-01T00:34:14.000Z | examples/Notebooks/flopy3_LoadSWRBinaryData.ipynb | gyanz/flopy | 282703716a01721e07905da65aa54e6017452a5a | [
"CC0-1.0",
"BSD-3-Clause"
]
| null | null | null | examples/Notebooks/flopy3_LoadSWRBinaryData.ipynb | gyanz/flopy | 282703716a01721e07905da65aa54e6017452a5a | [
"CC0-1.0",
"BSD-3-Clause"
]
| null | null | null | 323.930886 | 54,404 | 0.930931 | [
[
[
"# FloPy\n\n## Plotting SWR Process Results\n\nThis notebook demonstrates the use of the `SwrObs` and `SwrStage`, `SwrBudget`, `SwrFlow`, and `SwrExchange`, `SwrStructure`, classes to read binary SWR Process observation, stage, budget, reach to reach flows, reach-aquifer exchange, and structure files. It demonstrates these capabilities by loading these binary file types and showing examples of plotting SWR Process data. An example showing how the simulated water surface profile at a selected time along a selection of reaches can be plotted is also presented.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nfrom IPython.display import Image\nimport os\nimport sys\nimport numpy as np\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\n\n# run installed version of flopy or add local path\ntry:\n import flopy\nexcept:\n fpth = os.path.abspath(os.path.join('..', '..'))\n sys.path.append(fpth)\n import flopy\n\nprint(sys.version)\nprint('numpy version: {}'.format(np.__version__))\nprint('matplotlib version: {}'.format(mpl.__version__))\nprint('flopy version: {}'.format(flopy.__version__))",
"3.6.5 | packaged by conda-forge | (default, Apr 6 2018, 13:44:09) \n[GCC 4.2.1 Compatible Apple LLVM 6.1.0 (clang-602.0.53)]\nnumpy version: 1.14.5\nmatplotlib version: 2.2.2\nflopy version: 3.2.10\n"
],
[
"#Set the paths\ndatapth = os.path.join('..', 'data', 'swr_test')\n\n# SWR Process binary files \nfiles = ('SWR004.obs', 'SWR004.vel', 'SWR004.str', 'SWR004.stg', 'SWR004.flow')",
"_____no_output_____"
]
],
[
[
"### Load SWR Process observations\n\nCreate an instance of the `SwrObs` class and load the observation data.",
"_____no_output_____"
]
],
[
[
"sobj = flopy.utils.SwrObs(os.path.join(datapth, files[0]))\n\nts = sobj.get_data()",
"_____no_output_____"
]
],
[
[
"#### Plot the data from the binary SWR Process observation file",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(figsize=(6, 12))\nax1 = fig.add_subplot(3, 1, 1)\nax1.semilogx(ts['totim']/3600., -ts['OBS1'], label='OBS1')\nax1.semilogx(ts['totim']/3600., -ts['OBS2'], label='OBS2')\nax1.semilogx(ts['totim']/3600., -ts['OBS9'], label='OBS3')\nax1.set_ylabel('Flow, in cubic meters per second')\nax1.legend()\n\nax = fig.add_subplot(3, 1, 2, sharex=ax1)\nax.semilogx(ts['totim']/3600., -ts['OBS4'], label='OBS4')\nax.semilogx(ts['totim']/3600., -ts['OBS5'], label='OBS5')\nax.set_ylabel('Flow, in cubic meters per second')\nax.legend()\n\nax = fig.add_subplot(3, 1, 3, sharex=ax1)\nax.semilogx(ts['totim']/3600., ts['OBS6'], label='OBS6')\nax.semilogx(ts['totim']/3600., ts['OBS7'], label='OBS7')\nax.set_xlim(1, 100)\nax.set_ylabel('Stage, in meters')\nax.set_xlabel('Time, in hours')\nax.legend();",
"_____no_output_____"
]
],
[
[
"### Load the same data from the individual binary SWR Process files\n\nLoad discharge data from the flow file. The flow file contains the simulated flow between connected reaches for each connection in the model.",
"_____no_output_____"
]
],
[
[
"sobj = flopy.utils.SwrFlow(os.path.join(datapth, files[1]))\ntimes = np.array(sobj.get_times())/3600.\nobs1 = sobj.get_ts(irec=1, iconn=0)\nobs2 = sobj.get_ts(irec=14, iconn=13)\nobs4 = sobj.get_ts(irec=4, iconn=3)\nobs5 = sobj.get_ts(irec=5, iconn=4)",
"_____no_output_____"
]
],
[
[
"Load discharge data from the structure file. The structure file contains the simulated structure flow for each reach with a structure.",
"_____no_output_____"
]
],
[
[
"sobj = flopy.utils.SwrStructure(os.path.join(datapth, files[2]))\nobs3 = sobj.get_ts(irec=17, istr=0)",
"_____no_output_____"
]
],
[
[
"Load stage data from the stage file. The flow file contains the simulated stage for each reach in the model.",
"_____no_output_____"
]
],
[
[
"sobj = flopy.utils.SwrStage(os.path.join(datapth, files[3]))\nobs6 = sobj.get_ts(irec=13)",
"_____no_output_____"
]
],
[
[
"Load budget data from the budget file. The budget file contains the simulated budget for each reach group in the model. The budget file also contains the stage data for each reach group. In this case the number of reach groups equals the number of reaches in the model.",
"_____no_output_____"
]
],
[
[
"sobj = flopy.utils.SwrBudget(os.path.join(datapth, files[4]))\nobs7 = sobj.get_ts(irec=17)",
"_____no_output_____"
]
],
[
[
"#### Plot the data loaded from the individual binary SWR Process files.\n\nNote that the plots are identical to the plots generated from the binary SWR observation data.",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(figsize=(6, 12))\nax1 = fig.add_subplot(3, 1, 1)\nax1.semilogx(times, obs1['flow'], label='OBS1')\nax1.semilogx(times, obs2['flow'], label='OBS2')\nax1.semilogx(times, -obs3['strflow'], label='OBS3')\nax1.set_ylabel('Flow, in cubic meters per second')\nax1.legend()\n\nax = fig.add_subplot(3, 1, 2, sharex=ax1)\nax.semilogx(times, obs4['flow'], label='OBS4')\nax.semilogx(times, obs5['flow'], label='OBS5')\nax.set_ylabel('Flow, in cubic meters per second')\nax.legend()\n\nax = fig.add_subplot(3, 1, 3, sharex=ax1)\nax.semilogx(times, obs6['stage'], label='OBS6')\nax.semilogx(times, obs7['stage'], label='OBS7')\nax.set_xlim(1, 100)\nax.set_ylabel('Stage, in meters')\nax.set_xlabel('Time, in hours')\nax.legend();",
"_____no_output_____"
]
],
[
[
"### Plot simulated water surface profiles\n\nSimulated water surface profiles can be created using the `ModelCrossSection` class. \n\nSeveral things that we need in addition to the stage data include reach lengths and bottom elevations. We load these data from an existing file.",
"_____no_output_____"
]
],
[
[
"sd = np.genfromtxt(os.path.join(datapth, 'SWR004.dis.ref'), names=True)",
"_____no_output_____"
]
],
[
[
"The contents of the file are shown in the cell below.",
"_____no_output_____"
]
],
[
[
"fc = open(os.path.join(datapth, 'SWR004.dis.ref')).readlines()\nfc",
"_____no_output_____"
]
],
[
[
"Create an instance of the `SwrStage` class for SWR Process stage data.",
"_____no_output_____"
]
],
[
[
"sobj = flopy.utils.SwrStage(os.path.join(datapth, files[3]))",
"_____no_output_____"
]
],
[
[
"Create a selection condition (`iprof`) that can be used to extract data for the reaches of interest (reaches 0, 1, and 8 through 17). Use this selection condition to extract reach lengths (from `sd['RLEN']`) and the bottom elevation (from `sd['BELEV']`) for the reaches of interest. The selection condition will also be used to extract the stage data for reaches of interest.",
"_____no_output_____"
]
],
[
[
"iprof = sd['IRCH'] > 0\niprof[2:8] = False\ndx = np.extract(iprof, sd['RLEN'])\nbelev = np.extract(iprof, sd['BELEV'])",
"_____no_output_____"
]
],
[
[
"Create a fake model instance so that the `ModelCrossSection` class can be used.",
"_____no_output_____"
]
],
[
[
"ml = flopy.modflow.Modflow()\ndis = flopy.modflow.ModflowDis(ml, nrow=1, ncol=dx.shape[0], delr=dx, top=4.5, botm=belev.reshape(1,1,12))",
"_____no_output_____"
]
],
[
[
"Create an array with the x position at the downstream end of each reach, which will be used to color the plots below each reach. ",
"_____no_output_____"
]
],
[
[
"x = np.cumsum(dx)",
"_____no_output_____"
]
],
[
[
"Plot simulated water surface profiles for 8 times.",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(figsize=(12, 12))\nfor idx, v in enumerate([19, 29, 34, 39, 44, 49, 54, 59]):\n ax = fig.add_subplot(4, 2, idx+1)\n s = sobj.get_data(idx=v)\n stage = np.extract(iprof, s['stage'])\n xs = flopy.plot.ModelCrossSection(model=ml, line={'Row': 0})\n xs.plot_fill_between(stage.reshape(1,1,12), colors=['none', 'blue'], ax=ax, edgecolors='none')\n linecollection = xs.plot_grid(ax=ax, zorder=10)\n ax.fill_between(np.append(0., x), y1=np.append(belev[0], belev), y2=-0.5, \n facecolor='0.5', edgecolor='none', step='pre')\n ax.set_title('{} hours'.format(times[v]))\n ax.set_ylim(-0.5, 4.5)",
"_____no_output_____"
]
],
[
[
"## Summary\n\nThis notebook demonstrates flopy functionality for reading binary output generated by the SWR Process. Binary files that can be read include observations, stages, budgets, flow, reach-aquifer exchanges, and structure data. The binary stage data can also be used to create water-surface profiles. \n\nHope this gets you started!",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
]
|
d064b3c29ebb882359b6c29fc749f2293e5fe886 | 19,035 | ipynb | Jupyter Notebook | Lec4/Lab6_result_report.ipynb | Cho-D-YoungRae/Standalone-DeepLearning | ea581708eca95fb73bb34dc17fb0dadb5f1a93a3 | [
"MIT"
]
| 553 | 2019-01-20T07:54:00.000Z | 2022-03-31T16:35:17.000Z | Lec4/Lab6_result_report.ipynb | betteryy/Standalone-DeepLearning | dfc12f6dc98d13751eebf5a1503665e09647f499 | [
"MIT"
]
| 10 | 2019-01-22T12:23:33.000Z | 2021-05-22T08:41:00.000Z | Lec4/Lab6_result_report.ipynb | betteryy/Standalone-DeepLearning | dfc12f6dc98d13751eebf5a1503665e09647f499 | [
"MIT"
]
| 190 | 2019-01-17T20:32:13.000Z | 2022-03-31T02:56:34.000Z | 33.277972 | 199 | 0.492409 | [
[
[
"[제가 미리 만들어놓은 이 링크](https://colab.research.google.com/github/heartcored98/Standalone-DeepLearning/blob/master/Lec4/Lab6_result_report.ipynb)를 통해 Colab에서 바로 작업하실 수 있습니다! \n런타임 유형은 python3, GPU 가속 확인하기!",
"_____no_output_____"
]
],
[
[
"!mkdir results",
"_____no_output_____"
],
[
"import torch\nimport torchvision\nimport torchvision.transforms as transforms\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nimport argparse\nimport numpy as np\nimport time\nfrom copy import deepcopy # Add Deepcopy for args",
"_____no_output_____"
]
],
[
[
"## Data Preparation",
"_____no_output_____"
]
],
[
[
"transform = transforms.Compose(\n [transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])\n\ntrainset = torchvision.datasets.CIFAR10(root='./data', train=True,\n download=True, transform=transform)\ntrainset, valset = torch.utils.data.random_split(trainset, [40000, 10000])\ntestset = torchvision.datasets.CIFAR10(root='./data', train=False,\n download=True, transform=transform)\npartition = {'train': trainset, 'val':valset, 'test':testset}",
"_____no_output_____"
]
],
[
[
"## Model Architecture",
"_____no_output_____"
]
],
[
[
"class MLP(nn.Module):\n def __init__(self, in_dim, out_dim, hid_dim, n_layer, act, dropout, use_bn, use_xavier):\n super(MLP, self).__init__()\n self.in_dim = in_dim\n self.out_dim = out_dim\n self.hid_dim = hid_dim\n self.n_layer = n_layer\n self.act = act\n self.dropout = dropout\n self.use_bn = use_bn\n self.use_xavier = use_xavier\n \n # ====== Create Linear Layers ====== #\n self.fc1 = nn.Linear(self.in_dim, self.hid_dim)\n \n self.linears = nn.ModuleList()\n self.bns = nn.ModuleList()\n for i in range(self.n_layer-1):\n self.linears.append(nn.Linear(self.hid_dim, self.hid_dim))\n if self.use_bn:\n self.bns.append(nn.BatchNorm1d(self.hid_dim))\n \n self.fc2 = nn.Linear(self.hid_dim, self.out_dim)\n \n # ====== Create Activation Function ====== #\n if self.act == 'relu':\n self.act = nn.ReLU()\n elif self.act == 'tanh':\n self.act == nn.Tanh()\n elif self.act == 'sigmoid':\n self.act = nn.Sigmoid()\n else:\n raise ValueError('no valid activation function selected!')\n \n # ====== Create Regularization Layer ======= #\n self.dropout = nn.Dropout(self.dropout)\n if self.use_xavier:\n self.xavier_init()\n \n def forward(self, x):\n x = self.act(self.fc1(x))\n for i in range(len(self.linears)):\n x = self.act(self.linears[i](x))\n x = self.bns[i](x)\n x = self.dropout(x)\n x = self.fc2(x)\n return x\n \n def xavier_init(self):\n for linear in self.linears:\n nn.init.xavier_normal_(linear.weight)\n linear.bias.data.fill_(0.01)\n \nnet = MLP(3072, 10, 100, 4, 'relu', 0.1, True, True) # Testing Model Construction",
"_____no_output_____"
]
],
[
[
"## Train, Validate, Test and Experiment",
"_____no_output_____"
]
],
[
[
"def train(net, partition, optimizer, criterion, args):\n trainloader = torch.utils.data.DataLoader(partition['train'], \n batch_size=args.train_batch_size, \n shuffle=True, num_workers=2)\n net.train()\n\n correct = 0\n total = 0\n train_loss = 0.0\n for i, data in enumerate(trainloader, 0):\n optimizer.zero_grad() # [21.01.05 오류 수정] 매 Epoch 마다 .zero_grad()가 실행되는 것을 매 iteration 마다 실행되도록 수정했습니다. \n\n # get the inputs\n inputs, labels = data\n inputs = inputs.view(-1, 3072)\n inputs = inputs.cuda()\n labels = labels.cuda()\n outputs = net(inputs)\n\n loss = criterion(outputs, labels)\n loss.backward()\n optimizer.step()\n\n train_loss += loss.item()\n _, predicted = torch.max(outputs.data, 1)\n total += labels.size(0)\n correct += (predicted == labels).sum().item()\n\n train_loss = train_loss / len(trainloader)\n train_acc = 100 * correct / total\n return net, train_loss, train_acc",
"_____no_output_____"
],
[
"def validate(net, partition, criterion, args):\n valloader = torch.utils.data.DataLoader(partition['val'], \n batch_size=args.test_batch_size, \n shuffle=False, num_workers=2)\n net.eval()\n\n correct = 0\n total = 0\n val_loss = 0 \n with torch.no_grad():\n for data in valloader:\n images, labels = data\n images = images.view(-1, 3072)\n images = images.cuda()\n labels = labels.cuda()\n outputs = net(images)\n\n loss = criterion(outputs, labels)\n \n val_loss += loss.item()\n _, predicted = torch.max(outputs.data, 1)\n total += labels.size(0)\n correct += (predicted == labels).sum().item()\n\n val_loss = val_loss / len(valloader)\n val_acc = 100 * correct / total\n return val_loss, val_acc",
"_____no_output_____"
],
[
"def test(net, partition, args):\n testloader = torch.utils.data.DataLoader(partition['test'], \n batch_size=args.test_batch_size, \n shuffle=False, num_workers=2)\n net.eval()\n \n correct = 0\n total = 0\n with torch.no_grad():\n for data in testloader:\n images, labels = data\n images = images.view(-1, 3072)\n images = images.cuda()\n labels = labels.cuda()\n\n outputs = net(images)\n _, predicted = torch.max(outputs.data, 1)\n total += labels.size(0)\n correct += (predicted == labels).sum().item()\n\n test_acc = 100 * correct / total\n return test_acc",
"_____no_output_____"
],
[
"def experiment(partition, args):\n \n net = MLP(args.in_dim, args.out_dim, args.hid_dim, args.n_layer, args.act, args.dropout, args.use_bn, args.use_xavier)\n net.cuda()\n\n criterion = nn.CrossEntropyLoss()\n if args.optim == 'SGD':\n optimizer = optim.RMSprop(net.parameters(), lr=args.lr, weight_decay=args.l2)\n elif args.optim == 'RMSprop':\n optimizer = optim.RMSprop(net.parameters(), lr=args.lr, weight_decay=args.l2)\n elif args.optim == 'Adam':\n optimizer = optim.Adam(net.parameters(), lr=args.lr, weight_decay=args.l2)\n else:\n raise ValueError('In-valid optimizer choice')\n \n # ===== List for epoch-wise data ====== #\n train_losses = []\n val_losses = []\n train_accs = []\n val_accs = []\n # ===================================== #\n \n for epoch in range(args.epoch): # loop over the dataset multiple times\n ts = time.time()\n net, train_loss, train_acc = train(net, partition, optimizer, criterion, args)\n val_loss, val_acc = validate(net, partition, criterion, args)\n te = time.time()\n \n # ====== Add Epoch Data ====== #\n train_losses.append(train_loss)\n val_losses.append(val_loss)\n train_accs.append(train_acc)\n val_accs.append(val_acc)\n # ============================ #\n \n print('Epoch {}, Acc(train/val): {:2.2f}/{:2.2f}, Loss(train/val) {:2.2f}/{:2.2f}. Took {:2.2f} sec'.format(epoch, train_acc, val_acc, train_loss, val_loss, te-ts))\n \n test_acc = test(net, partition, args) \n \n # ======= Add Result to Dictionary ======= #\n result = {}\n result['train_losses'] = train_losses\n result['val_losses'] = val_losses\n result['train_accs'] = train_accs\n result['val_accs'] = val_accs\n result['train_acc'] = train_acc\n result['val_acc'] = val_acc\n result['test_acc'] = test_acc\n return vars(args), result\n # ===================================== #",
"_____no_output_____"
]
],
[
[
"# Manage Experiment Result",
"_____no_output_____"
]
],
[
[
"import hashlib\nimport json\nfrom os import listdir\nfrom os.path import isfile, join\nimport pandas as pd\n\ndef save_exp_result(setting, result):\n exp_name = setting['exp_name']\n del setting['epoch']\n del setting['test_batch_size']\n\n hash_key = hashlib.sha1(str(setting).encode()).hexdigest()[:6]\n filename = './results/{}-{}.json'.format(exp_name, hash_key)\n result.update(setting)\n with open(filename, 'w') as f:\n json.dump(result, f)\n\n \ndef load_exp_result(exp_name):\n dir_path = './results'\n filenames = [f for f in listdir(dir_path) if isfile(join(dir_path, f)) if '.json' in f]\n list_result = []\n for filename in filenames:\n if exp_name in filename:\n with open(join(dir_path, filename), 'r') as infile:\n results = json.load(infile)\n list_result.append(results)\n df = pd.DataFrame(list_result) # .drop(columns=[])\n return df\n ",
"_____no_output_____"
]
],
[
[
"## Experiment",
"_____no_output_____"
]
],
[
[
"# ====== Random Seed Initialization ====== #\nseed = 123\nnp.random.seed(seed)\ntorch.manual_seed(seed)\n\nparser = argparse.ArgumentParser()\nargs = parser.parse_args(\"\")\nargs.exp_name = \"exp1_n_layer_hid_dim\"\n\n# ====== Model Capacity ====== #\nargs.in_dim = 3072\nargs.out_dim = 10\nargs.hid_dim = 100\nargs.act = 'relu'\n\n# ====== Regularization ======= #\nargs.dropout = 0.2\nargs.use_bn = True\nargs.l2 = 0.00001\nargs.use_xavier = True\n\n# ====== Optimizer & Training ====== #\nargs.optim = 'RMSprop' #'RMSprop' #SGD, RMSprop, ADAM...\nargs.lr = 0.0015\nargs.epoch = 10\n\nargs.train_batch_size = 256\nargs.test_batch_size = 1024\n\n# ====== Experiment Variable ====== #\nname_var1 = 'n_layer'\nname_var2 = 'hid_dim'\nlist_var1 = [1, 2, 3]\nlist_var2 = [500, 300]\n\n\nfor var1 in list_var1:\n for var2 in list_var2:\n setattr(args, name_var1, var1)\n setattr(args, name_var2, var2)\n print(args)\n \n setting, result = experiment(partition, deepcopy(args))\n save_exp_result(setting, result)\n",
"_____no_output_____"
],
[
"import seaborn as sns \nimport matplotlib.pyplot as plt\n\ndf = load_exp_result('exp1')\n\nfig, ax = plt.subplots(1, 3)\nfig.set_size_inches(15, 6)\nsns.set_style(\"darkgrid\", {\"axes.facecolor\": \".9\"})\n\nsns.barplot(x='n_layer', y='train_acc', hue='hid_dim', data=df, ax=ax[0])\nsns.barplot(x='n_layer', y='val_acc', hue='hid_dim', data=df, ax=ax[1])\nsns.barplot(x='n_layer', y='test_acc', hue='hid_dim', data=df, ax=ax[2])\n",
"_____no_output_____"
],
[
"var1 = 'n_layer'\nvar2 = 'hid_dim'\n\ndf = load_exp_result('exp1')\nlist_v1 = df[var1].unique()\nlist_v2 = df[var2].unique()\nlist_data = []\n\nfor value1 in list_v1:\n for value2 in list_v2:\n row = df.loc[df[var1]==value1]\n row = row.loc[df[var2]==value2]\n \n train_losses = list(row.train_losses)[0]\n val_losses = list(row.val_losses)[0]\n \n for epoch, train_loss in enumerate(train_losses):\n list_data.append({'type':'train', 'loss':train_loss, 'epoch':epoch, var1:value1, var2:value2})\n for epoch, val_loss in enumerate(val_losses):\n list_data.append({'type':'val', 'loss':val_loss, 'epoch':epoch, var1:value1, var2:value2})\n \ndf = pd.DataFrame(list_data)\ng = sns.FacetGrid(df, row=var2, col=var1, hue='type', margin_titles=True, sharey=False)\ng = g.map(plt.plot, 'epoch', 'loss', marker='.')\ng.add_legend()\ng.fig.suptitle('Train loss vs Val loss')\nplt.subplots_adjust(top=0.89)",
"_____no_output_____"
],
[
"var1 = 'n_layer'\nvar2 = 'hid_dim'\n\ndf = load_exp_result('exp1')\nlist_v1 = df[var1].unique()\nlist_v2 = df[var2].unique()\nlist_data = []\n\nfor value1 in list_v1:\n for value2 in list_v2:\n row = df.loc[df[var1]==value1]\n row = row.loc[df[var2]==value2]\n \n train_accs = list(row.train_accs)[0]\n val_accs = list(row.val_accs)[0]\n test_acc = list(row.test_acc)[0]\n \n for epoch, train_acc in enumerate(train_accs):\n list_data.append({'type':'train', 'Acc':train_acc, 'test_acc':test_acc, 'epoch':epoch, var1:value1, var2:value2})\n for epoch, val_acc in enumerate(val_accs):\n list_data.append({'type':'val', 'Acc':val_acc, 'test_acc':test_acc, 'epoch':epoch, var1:value1, var2:value2})\n \ndf = pd.DataFrame(list_data)\ng = sns.FacetGrid(df, row=var2, col=var1, hue='type', margin_titles=True, sharey=False)\ng = g.map(plt.plot, 'epoch', 'Acc', marker='.')\n\ndef show_acc(x, y, metric, **kwargs):\n plt.scatter(x, y, alpha=0.3, s=1)\n metric = \"Test Acc: {:1.3f}\".format(list(metric.values)[0])\n plt.text(0.05, 0.95, metric, horizontalalignment='left', verticalalignment='center', transform=plt.gca().transAxes, bbox=dict(facecolor='yellow', alpha=0.5, boxstyle=\"round,pad=0.1\"))\ng = g.map(show_acc, 'epoch', 'Acc', 'test_acc')\n\ng.add_legend()\ng.fig.suptitle('Train Accuracy vs Val Accuracy')\n\n\n\nplt.subplots_adjust(top=0.89)",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
]
|
d064c10961958259b92a5c2eacdc9bd02cc89d9b | 375,897 | ipynb | Jupyter Notebook | phase4_analysis_by_visualization/final_visualizations.ipynb | eric-wisniewski/visualizeYourself_Project | dcb6f3620468206de31ee587d4e2da18d6e1575d | [
"Apache-2.0"
]
| null | null | null | phase4_analysis_by_visualization/final_visualizations.ipynb | eric-wisniewski/visualizeYourself_Project | dcb6f3620468206de31ee587d4e2da18d6e1575d | [
"Apache-2.0"
]
| null | null | null | phase4_analysis_by_visualization/final_visualizations.ipynb | eric-wisniewski/visualizeYourself_Project | dcb6f3620468206de31ee587d4e2da18d6e1575d | [
"Apache-2.0"
]
| null | null | null | 1,070.931624 | 56,644 | 0.954472 | [
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt\nfrom matplotlib import pyplot\n%matplotlib inline\n\nfinal_data_e = pd.read_csv(\"vizSelf_eric.csv\", index_col=0, parse_dates=True)\nfinal_data_p = pd.read_csv(\"vizSelf_parent.csv\", index_col=0, parse_dates=True)\nfinal_data_e.head()\nfinal_data_p.head()",
"_____no_output_____"
],
[
"axe = final_data_e.plot.area(figsize=(12,4), subplots=True)\naxp = final_data_p.plot.area(figsize=(12,4), subplots=True)",
"_____no_output_____"
],
[
"axeb = final_data_e.plot.bar(figsize=(12,4), subplots=True)\naxpb = final_data_p.plot.bar(figsize=(12,4), subplots=True)",
"_____no_output_____"
],
[
"axeh = final_data_e.plot.hist(figsize=(12,4), subplots=True)\naxph = final_data_p.plot.hist(figsize=(12,4), subplots=True)",
"_____no_output_____"
],
[
"axed = final_data_e.plot.density(figsize=(12,4), subplots=True)\naxpd = final_data_p.plot.density(figsize=(12,4), subplots=True)",
"_____no_output_____"
],
[
"axebp = final_data_e.plot.box(figsize=(12,4), subplots=True)\naxpbp = final_data_p.plot.box(figsize=(12,4), subplots=True)",
"_____no_output_____"
],
[
"axekde = final_data_e.plot.kde(figsize=(12,4), subplots=True)\naxpkde = final_data_p.plot.kde(figsize=(12,4), subplots=True)",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d064ccbc966f61700046f9a84bfae97b6c7585ed | 305,168 | ipynb | Jupyter Notebook | DAY6_Eda_With_Pandas.ipynb | averryset/H8_Python_for_Data_Science | c1e87c2e272d64147f50ae967bd0153073b23b9b | [
"MIT"
]
| null | null | null | DAY6_Eda_With_Pandas.ipynb | averryset/H8_Python_for_Data_Science | c1e87c2e272d64147f50ae967bd0153073b23b9b | [
"MIT"
]
| null | null | null | DAY6_Eda_With_Pandas.ipynb | averryset/H8_Python_for_Data_Science | c1e87c2e272d64147f50ae967bd0153073b23b9b | [
"MIT"
]
| null | null | null | 77.043171 | 110,700 | 0.704907 | [
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"df_properti = pd.read_csv(\"https://raw.githubusercontent.com/ardhiraka/PFDS_sources/master/property_data.csv\")",
"_____no_output_____"
],
[
"df_properti",
"_____no_output_____"
],
[
"df_properti.shape",
"_____no_output_____"
],
[
"df_properti.columns",
"_____no_output_____"
],
[
"df_properti[\"ST_NAME\"]",
"_____no_output_____"
],
[
"df_properti[\"ST_NUM\"].isna()",
"_____no_output_____"
],
[
"list_missing_values = [\"n/a\", \"--\", \"na\"]\ndf_properti = pd.read_csv(\n \"https://raw.githubusercontent.com/ardhiraka/PFDS_sources/master/property_data.csv\",\n na_values = list_missing_values\n)",
"_____no_output_____"
],
[
"df_properti",
"_____no_output_____"
],
[
"df_properti[\"OWN_OCCUPIED\"].isna()",
"_____no_output_____"
],
[
"cnt=0\ndf_properti_own = df_properti[\"OWN_OCCUPIED\"]\nfor row in df_properti_own:\n try:\n int(row)\n df_properti[cnt, \"OWN_OCCUPIED\"]=np.nan\n except ValueError:\n pass\n cnt+=1",
"_____no_output_____"
],
[
"df_properti ",
"_____no_output_____"
],
[
"df_properti[\"NEW_OWN_OCCUPIEW\"] = df_properti[\"OWN_OCCUPIED\"].apply(\n lambda val: 1 if val == \"Y\" else 0\n)\ndf_properti",
"_____no_output_____"
],
[
"df_properti.isna().sum()",
"_____no_output_____"
],
[
"df_properti.isna().sum().sum()",
"_____no_output_____"
],
[
"df_properti",
"_____no_output_____"
],
[
"cnt=0\ndf_properti_num_bat = df_properti[\"NUM_BATH\"]\nfor row in df_properti_num_bat:\n try:\n float(row)\n df_properti.loc[cnt, \"NEW_NUM_BATH\"]=row\n except ValueError:\n df_properti.loc[cnt, \"NEW_NUM_BATH\"]=np.nan\n cnt+=1",
"_____no_output_____"
],
[
"df_properti",
"_____no_output_____"
],
[
"df_properti[\"ST_NUM\"].fillna(125)",
"_____no_output_____"
],
[
"obes = pd.ExcelFile(\"csv/obes.xls\")",
"_____no_output_____"
],
[
"obes.sheet_names",
"_____no_output_____"
],
[
"obes_age = obes.parse(\"7.2\", skiprows=4, skipfooter=14)",
"_____no_output_____"
],
[
"obes_age",
"_____no_output_____"
],
[
"obes_age.set_index('Year', inplace=True)",
"_____no_output_____"
],
[
"obes_age.plot()",
"_____no_output_____"
],
[
"obes_age.drop(\"Total\", axis=1).plot()",
"_____no_output_____"
],
[
"from datetime import datetime",
"_____no_output_____"
],
[
"datetime.now().date()",
"_____no_output_____"
],
[
"opsd_daily = pd.read_csv(\n 'https://raw.githubusercontent.com/ardhiraka/PFDS_sources/master/opsd_germany_daily.csv',\n index_col=0, parse_dates=True\n)",
"_____no_output_____"
],
[
"opsd_daily.head()",
"_____no_output_____"
],
[
"opsd_daily['Year'] = opsd_daily.index.year\nopsd_daily['Month'] = opsd_daily.index.month\nopsd_daily['Weekday'] = opsd_daily.index.weekday",
"_____no_output_____"
],
[
"opsd_daily",
"_____no_output_____"
],
[
"opsd_daily[\"Consumption\"].plot(\n linewidth=.3, \n figsize=(12, 5)\n)",
"_____no_output_____"
],
[
"df_canada = pd.read_excel(\n \"https://github.com/ardhiraka/PFDS_sources/blob/master/Canada.xlsx?raw=true\",\n sheet_name=\"Canada by Citizenship\",\n skiprows=range(20),\n skipfooter=2\n)",
"_____no_output_____"
],
[
"df_canada.head()",
"_____no_output_____"
],
[
"df_canada.columns",
"_____no_output_____"
],
[
"df_canada.drop(\n columns=[\n \"AREA\", \"REG\", \"DEV\",\n \"Type\", \"Coverage\"\n ],\n axis=1,\n inplace=True\n)",
"_____no_output_____"
],
[
"df_canada.head()",
"_____no_output_____"
],
[
"df_canada.rename(\n columns={\n \"OdName\": \"Country\",\n \"AreaName\": \"Continent\",\n \"RegName\": \"Region\"\n },\n inplace=True\n)",
"_____no_output_____"
],
[
"df_canada.head()",
"_____no_output_____"
],
[
"df_canada_total = df_canada.sum(axis=1)",
"_____no_output_____"
],
[
"df_canada[\"Total\"] = df_canada_total\ndf_canada.head()",
"_____no_output_____"
],
[
"df_canada.describe()",
"_____no_output_____"
],
[
"df_canada.Country",
"_____no_output_____"
],
[
"df_canada[\n [\n \"Country\",\n 2000,\n 2001,\n 2002,\n 2003,\n 2004,\n 2005,\n 2006,\n 2007,\n 2008,\n 2009,\n 2010,\n 2011,\n 2012,\n 2013,\n ]\n]",
"_____no_output_____"
],
[
"df_canada[\"Continent\"] == \"Africa\"",
"_____no_output_____"
],
[
"df_canada[(df_canada[\"Continent\"]==\"Asia\") & (df_canada[\"Region\"]==\"Southern Asia\")]",
"_____no_output_____"
]
]
]
| [
"code"
]
| [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
]
|
d064e55492113bcb0b663aa6bb3350fddb822574 | 14,748 | ipynb | Jupyter Notebook | Demo.ipynb | 4nthon/HomographyNet | 9749b80b2d68d9ecff6423e209782327440e8226 | [
"MIT"
]
| 8 | 2020-07-02T00:23:09.000Z | 2022-03-17T01:55:22.000Z | Demo.ipynb | 4nthon/HomographyNet | 9749b80b2d68d9ecff6423e209782327440e8226 | [
"MIT"
]
| 1 | 2021-09-18T02:03:17.000Z | 2021-09-18T02:16:41.000Z | Demo.ipynb | 4nthon/HomographyNet | 9749b80b2d68d9ecff6423e209782327440e8226 | [
"MIT"
]
| 6 | 2020-10-26T08:41:48.000Z | 2021-07-05T03:08:01.000Z | 42.872093 | 1,663 | 0.606184 | [
[
[
"## 1、可视化DataGeneratorHomographyNet模块都干了什么",
"_____no_output_____"
]
],
[
[
"import glob\nimport os\nimport cv2\nimport numpy as np\nfrom dataGenerator import DataGeneratorHomographyNet",
"/home/nvidia/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\nUsing TensorFlow backend.\n"
],
[
"img_dir = os.path.join(os.path.expanduser(\"~\"), \"/home/nvidia/test2017\")\nimg_ext = \".jpg\"\nimg_paths = glob.glob(os.path.join(img_dir, '*' + img_ext))\ndg = DataGeneratorHomographyNet(img_paths, input_dim=(240, 240))\ndata, label = dg.__getitem__(0)\nfor idx in range(dg.batch_size):\n cv2.imshow(\"orig\", data[idx, :, :, 0])\n cv2.imshow(\"transformed\", data[idx, :, :, 1])\n cv2.waitKey(0)",
"_____no_output_____"
]
],
[
[
"## 2、开始训练",
"_____no_output_____"
]
],
[
[
"import os\nimport glob\nimport datetime\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport keras\nfrom keras.callbacks import ModelCheckpoint\nfrom sklearn.model_selection import train_test_split\nimport tensorflow as tf\nfrom homographyNet import HomographyNet\nimport dataGenerator as dg\nkeras.__version__",
"_____no_output_____"
],
[
"batch_size = 2\n#取值0,1,2 0-安静模式 1-进度条 2-每一行都有输出\nverbose = 1\n#Epoch\nnb_epo = 150\n#计时开始\nstart_ts = datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\n#用于训练的图片目录\ndata_path = \"/home/nvidia/test2017\"\n#模型保存的目录\nmodel_dir = \"/home/nvidia\"\nimg_dir = os.path.join(os.path.expanduser(\"~\"), data_path)\nmodel_dir = os.path.join(os.path.expanduser(\"~\"), model_dir, start_ts)\n#以时间为名创建目录\nif not os.path.exists(model_dir):\n os.makedirs(model_dir)",
"_____no_output_____"
],
[
"img_ext = \".jpg\"\n#获取所有图像目录\nimg_paths = glob.glob(os.path.join(img_dir, '*' + img_ext))\ninput_size = (360, 360, 2)\n#划分训练集和验证集,验证集搞小一点,不然每个epoch跑完太慢了\ntrain_idx, val_idx = train_test_split(img_paths, test_size=0.01)\n#拿到训练数据\ntrain_dg = dg.DataGeneratorHomographyNet(train_idx, input_dim=input_size[0:2], batch_size=batch_size)\n#拿到既定事实的标签\nval_dg = dg.DataGeneratorHomographyNet(val_idx, input_dim=input_size[0:2], batch_size=batch_size)\n#对于神经网络来说这个鬼一样的图就是输入,它自己从这幅图的左边和右边学习出单应性矩阵,神奇吧?\n#修正网络输入头\nhomo_net = HomographyNet(input_size)\n#实例化网络结构\nmodel = homo_net.build_model()\n#输出模型\nmodel.summary()",
"WARNING:tensorflow:From /home/nvidia/.local/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:1264: calling reduce_prod (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.\nInstructions for updating:\nkeep_dims is deprecated, use keepdims instead\nWARNING:tensorflow:From /home/nvidia/.local/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:1349: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.\nInstructions for updating:\nkeep_dims is deprecated, use keepdims instead\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) (None, 360, 360, 2) 0 \n_________________________________________________________________\nconv2d_1 (Conv2D) (None, 360, 360, 64) 1216 \n_________________________________________________________________\nbatch_normalization_1 (Batch (None, 360, 360, 64) 256 \n_________________________________________________________________\nactivation_1 (Activation) (None, 360, 360, 64) 0 \n_________________________________________________________________\nconv2d_2 (Conv2D) (None, 360, 360, 64) 36928 \n_________________________________________________________________\nbatch_normalization_2 (Batch (None, 360, 360, 64) 256 \n_________________________________________________________________\nactivation_2 (Activation) (None, 360, 360, 64) 0 \n_________________________________________________________________\nmax_pooling2d_1 (MaxPooling2 (None, 180, 180, 64) 0 \n_________________________________________________________________\nconv2d_3 (Conv2D) (None, 180, 180, 64) 36928 \n_________________________________________________________________\nbatch_normalization_3 (Batch (None, 180, 180, 64) 256 \n_________________________________________________________________\nactivation_3 (Activation) (None, 180, 180, 64) 0 \n_________________________________________________________________\nconv2d_4 (Conv2D) (None, 180, 180, 64) 36928 \n_________________________________________________________________\nbatch_normalization_4 (Batch (None, 180, 180, 64) 256 \n_________________________________________________________________\nactivation_4 (Activation) (None, 180, 180, 64) 0 \n_________________________________________________________________\nmax_pooling2d_2 (MaxPooling2 (None, 90, 90, 64) 0 \n_________________________________________________________________\nconv2d_5 (Conv2D) (None, 90, 90, 128) 73856 \n_________________________________________________________________\nbatch_normalization_5 (Batch (None, 90, 90, 128) 512 \n_________________________________________________________________\nactivation_5 (Activation) (None, 90, 90, 128) 0 \n_________________________________________________________________\nconv2d_6 (Conv2D) (None, 90, 90, 128) 147584 \n_________________________________________________________________\nbatch_normalization_6 (Batch (None, 90, 90, 128) 512 \n_________________________________________________________________\nactivation_6 (Activation) (None, 90, 90, 128) 0 \n_________________________________________________________________\nmax_pooling2d_3 (MaxPooling2 (None, 45, 45, 128) 0 \n_________________________________________________________________\nconv2d_7 (Conv2D) (None, 45, 45, 128) 147584 \n_________________________________________________________________\nbatch_normalization_7 (Batch (None, 45, 45, 128) 512 \n_________________________________________________________________\nactivation_7 (Activation) (None, 45, 45, 128) 0 \n_________________________________________________________________\nconv2d_8 (Conv2D) (None, 45, 45, 128) 147584 \n_________________________________________________________________\nbatch_normalization_8 (Batch (None, 45, 45, 128) 512 \n_________________________________________________________________\nactivation_8 (Activation) (None, 45, 45, 128) 0 \n_________________________________________________________________\nmax_pooling2d_4 (MaxPooling2 (None, 22, 22, 128) 0 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 61952) 0 \n_________________________________________________________________\ndropout_1 (Dropout) (None, 61952) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 1028) 63687684 \n_________________________________________________________________\nactivation_9 (Activation) (None, 1028) 0 \n_________________________________________________________________\ndense_2 (Dense) (None, 8) 8232 \n=================================================================\nTotal params: 64,327,596\nTrainable params: 64,326,060\nNon-trainable params: 1,536\n_________________________________________________________________\n"
],
[
"#检查点回调,没写tensorboard的回调,真正的大师都是直接看loss输出的\ncheckpoint = ModelCheckpoint(\n os.path.join(model_dir, 'model.h5'),\n monitor='val_loss',\n verbose=verbose,\n save_best_only=True,\n save_weights_only=False,\n mode='auto'\n)",
"_____no_output_____"
],
[
"#我嫌弃在上面改太麻烦,直接在这重定义了\n#开始训练\n#如果不加steps_per_epoch= 32, 就是每次全跑\nhistory = model.fit_generator(train_dg, \n validation_data = val_dg,\n #steps_per_epoch = 32, \n callbacks = [checkpoint], \n epochs = 15, \n verbose = 1)",
"Epoch 1/15\n 1373/20131 [=>............................] - ETA: 1:18:50 - loss: 1615938396204833.0000 - mean_squared_error: 1615938396204833.0000"
]
],
[
[
"\n",
"_____no_output_____"
]
],
[
[
"#整个图看看\nhistory_df = pd.DataFrame(history.history)\nhistory_df.to_csv(os.path.join(model_dir, 'history.csv'))\nhistory_df[['loss', 'val_loss']].plot()\nhistory_df[['mean_squared_error', 'val_mean_squared_error']].plot()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 预测&评估",
"_____no_output_____"
]
],
[
[
"TODO",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
]
|
d064e82ca5571ab846425be59e36d57fa95702af | 34,696 | ipynb | Jupyter Notebook | Chapter08/.ipynb_checkpoints/ch8-diamond-prices-model-tuning-checkpoint.ipynb | arifmudi/Hands-On-Predictive-Analytics-with-Python | 27122c8c75711c1e3e29d265f13788b9c4b8f5ee | [
"MIT"
]
| 38 | 2019-01-03T14:54:56.000Z | 2022-02-02T04:13:35.000Z | Chapter08/.ipynb_checkpoints/ch8-diamond-prices-model-tuning-checkpoint.ipynb | arifmudi/Hands-On-Predictive-Analytics-with-Python | 27122c8c75711c1e3e29d265f13788b9c4b8f5ee | [
"MIT"
]
| 4 | 2019-07-03T11:25:24.000Z | 2020-11-21T07:15:27.000Z | Chapter08/.ipynb_checkpoints/ch8-diamond-prices-model-tuning-checkpoint.ipynb | arifmudi/Hands-On-Predictive-Analytics-with-Python | 27122c8c75711c1e3e29d265f13788b9c4b8f5ee | [
"MIT"
]
| 31 | 2018-12-27T05:00:08.000Z | 2022-03-22T23:24:57.000Z | 65.095685 | 20,952 | 0.806837 | [
[
[
"# Diamond Prices: Model Tuning and Improving Performance",
"_____no_output_____"
],
[
"#### Importing libraries",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport os\n\npd.options.mode.chained_assignment = None\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"#### Loading the dataset",
"_____no_output_____"
]
],
[
[
"DATA_DIR = '../data'\nFILE_NAME = 'diamonds.csv'\ndata_path = os.path.join(DATA_DIR, FILE_NAME)\ndiamonds = pd.read_csv(data_path)",
"_____no_output_____"
]
],
[
[
"#### Preparing the dataset",
"_____no_output_____"
]
],
[
[
"## Preparation done from Chapter 2\ndiamonds = diamonds.loc[(diamonds['x']>0) | (diamonds['y']>0)]\ndiamonds.loc[11182, 'x'] = diamonds['x'].median()\ndiamonds.loc[11182, 'z'] = diamonds['z'].median()\ndiamonds = diamonds.loc[~((diamonds['y'] > 30) | (diamonds['z'] > 30))]\ndiamonds = pd.concat([diamonds, pd.get_dummies(diamonds['cut'], prefix='cut', drop_first=True)], axis=1)\ndiamonds = pd.concat([diamonds, pd.get_dummies(diamonds['color'], prefix='color', drop_first=True)], axis=1)\ndiamonds = pd.concat([diamonds, pd.get_dummies(diamonds['clarity'], prefix='clarity', drop_first=True)], axis=1)\n\n## Dimensionality reduction\nfrom sklearn.decomposition import PCA\npca = PCA(n_components=1, random_state=123)\ndiamonds['dim_index'] = pca.fit_transform(diamonds[['x','y','z']])\ndiamonds.drop(['x','y','z'], axis=1, inplace=True)",
"_____no_output_____"
],
[
"diamonds.columns",
"_____no_output_____"
]
],
[
[
"#### Train-test split",
"_____no_output_____"
]
],
[
[
"X = diamonds.drop(['cut','color','clarity','price'], axis=1)\ny = diamonds['price']\n\nfrom sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=7)",
"_____no_output_____"
]
],
[
[
"#### Standarization: centering and scaling ",
"_____no_output_____"
]
],
[
[
"numerical_features = ['carat', 'depth', 'table', 'dim_index']\nfrom sklearn.preprocessing import StandardScaler\nscaler = StandardScaler()\nscaler.fit(X_train[numerical_features])\nX_train.loc[:, numerical_features] = scaler.fit_transform(X_train[numerical_features])\nX_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])",
"_____no_output_____"
]
],
[
[
"## Optimizing a single hyper-parameter",
"_____no_output_____"
]
],
[
[
"X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.1, random_state=13)",
"_____no_output_____"
],
[
"from sklearn.neighbors import KNeighborsRegressor\nfrom sklearn.metrics import mean_absolute_error\n\ncandidates = np.arange(4,16)\nmae_metrics = []\nfor k in candidates:\n model = KNeighborsRegressor(n_neighbors=k, weights='distance', metric='minkowski', leaf_size=50, n_jobs=4)\n model.fit(X_train, y_train)\n y_pred = model.predict(X_val)\n metric = mean_absolute_error(y_true=y_val, y_pred=y_pred)\n mae_metrics.append(metric)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(8,5))\nax.plot(candidates, mae_metrics, \"o-\")\nax.set_xlabel('Hyper-parameter K', fontsize=14)\nax.set_ylabel('MAE', fontsize=14)\nax.set_xticks(candidates)\nax.grid();",
"_____no_output_____"
]
],
[
[
"#### Recalculating train-set split",
"_____no_output_____"
]
],
[
[
"X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=7)\nscaler = StandardScaler()\nscaler.fit(X_train[numerical_features])\nX_train.loc[:, numerical_features] = scaler.fit_transform(X_train[numerical_features])\nX_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])",
"_____no_output_____"
]
],
[
[
"#### Optimizing with cross-validation",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_score\ncandidates = np.arange(4,16)\nmean_mae = []\nstd_mae = []\nfor k in candidates:\n model = KNeighborsRegressor(n_neighbors=k, weights='distance', metric='minkowski', leaf_size=50, n_jobs=4)\n cv_results = cross_val_score(model, X_train, y_train, scoring='neg_mean_absolute_error', cv=10)\n mean_score, std_score = -1*cv_results.mean(), cv_results.std()\n mean_mae.append(mean_score)\n std_mae.append(std_score)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(8,5))\nax.plot(candidates, mean_mae, \"o-\")\nax.set_xlabel('Hyper-parameter K', fontsize=14)\nax.set_ylabel('Mean MAE', fontsize=14)\nax.set_xticks(candidates)\nax.grid();",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(8,5))\nax.plot(candidates, std_mae, \"o-\")\nax.set_xlabel('Hyper-parameter K', fontsize=14)\nax.set_ylabel('Standard deviation of MAE', fontsize=14)\nax.set_xticks(candidates)\nax.grid();",
"_____no_output_____"
]
],
[
[
"# Improving Performance",
"_____no_output_____"
],
[
"## Improving our diamond price predictions",
"_____no_output_____"
],
[
"### Fitting a neural network",
"_____no_output_____"
]
],
[
[
"from keras.models import Sequential\nfrom keras.layers import Dense\n\nn_input = X_train.shape[1]\nn_hidden1 = 32\nn_hidden2 = 16\nn_hidden3 = 8\n\nnn_reg = Sequential()\nnn_reg.add(Dense(units=n_hidden1, activation='relu', input_shape=(n_input,)))\nnn_reg.add(Dense(units=n_hidden2, activation='relu'))\nnn_reg.add(Dense(units=n_hidden3, activation='relu'))\n# output layer\nnn_reg.add(Dense(units=1, activation=None))",
"_____no_output_____"
],
[
"batch_size = 32\nn_epochs = 40\nnn_reg.compile(loss='mean_absolute_error', optimizer='adam')\nnn_reg.fit(X_train, y_train, epochs=n_epochs, batch_size=batch_size, validation_split=0.05)",
"_____no_output_____"
],
[
"y_pred = nn_reg.predict(X_test).flatten()\nmae_neural_net = mean_absolute_error(y_test, y_pred)\nprint(\"MAE Neural Network: {:0.2f}\".format(mae_neural_net))",
"_____no_output_____"
]
],
[
[
"### Transforming the target",
"_____no_output_____"
]
],
[
[
"diamonds['price'].hist(bins=25, ec='k', figsize=(8,5))\nplt.title(\"Distribution of diamond prices\", fontsize=16)\nplt.grid(False);",
"_____no_output_____"
],
[
"y_train = np.log(y_train)\npd.Series(y_train).hist(bins=25, ec='k', figsize=(8,5))\nplt.title(\"Distribution of log diamond prices\", fontsize=16)\nplt.grid(False);",
"_____no_output_____"
],
[
"nn_reg = Sequential()\nnn_reg.add(Dense(units=n_hidden1, activation='relu', input_shape=(n_input,)))\nnn_reg.add(Dense(units=n_hidden2, activation='relu'))\nnn_reg.add(Dense(units=n_hidden3, activation='relu'))\n# output layer\nnn_reg.add(Dense(units=1, activation=None))",
"_____no_output_____"
],
[
"batch_size = 32\nn_epochs = 40\nnn_reg.compile(loss='mean_absolute_error', optimizer='adam')\nnn_reg.fit(X_train, y_train, epochs=n_epochs, batch_size=batch_size, validation_split=0.05)",
"_____no_output_____"
],
[
"y_pred = nn_reg.predict(X_test).flatten()\ny_pred = np.exp(y_pred)\nmae_neural_net2 = mean_absolute_error(y_test, y_pred)\nprint(\"MAE Neural Network (modified target): {:0.2f}\".format(mae_neural_net2))",
"_____no_output_____"
],
[
"100*(mae_neural_net - mae_neural_net2)/mae_neural_net2",
"_____no_output_____"
]
],
[
[
"#### Analyzing the results",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(8,5))\nresiduals = y_test - y_pred\nax.scatter(y_test, residuals, s=3)\nax.set_title('Residuals vs. Observed Prices', fontsize=16)\nax.set_xlabel('Observed prices', fontsize=14)\nax.set_ylabel('Residuals', fontsize=14)\nax.grid();",
"_____no_output_____"
],
[
"mask_7500 = y_test <=7500\nmae_neural_less_7500 = mean_absolute_error(y_test[mask_7500], y_pred[mask_7500])\nprint(\"MAE considering price <= 7500: {:0.2f}\".format(mae_neural_less_7500))",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(8,5))\npercent_residuals = (y_test - y_pred)/y_test\nax.scatter(y_test, percent_residuals, s=3)\nax.set_title('Pecent residuals vs. Observed Prices', fontsize=16)\nax.set_xlabel('Observed prices', fontsize=14)\nax.set_ylabel('Pecent residuals', fontsize=14)\nax.axhline(y=0.15, color='r'); ax.axhline(y=-0.15, color='r'); \nax.grid();",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
]
| [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
]
|
d064e9236cbc6f092035bc0d5dba899559c20f39 | 254,266 | ipynb | Jupyter Notebook | materials/seaborn_data_viz_complete_with_outputs.ipynb | kthrog/dataviz_workshop | 971836516c72d3d07e7ef59ee8bb313cd788991c | [
"CC0-1.0"
]
| null | null | null | materials/seaborn_data_viz_complete_with_outputs.ipynb | kthrog/dataviz_workshop | 971836516c72d3d07e7ef59ee8bb313cd788991c | [
"CC0-1.0"
]
| null | null | null | materials/seaborn_data_viz_complete_with_outputs.ipynb | kthrog/dataviz_workshop | 971836516c72d3d07e7ef59ee8bb313cd788991c | [
"CC0-1.0"
]
| null | null | null | 167.280263 | 69,956 | 0.785123 | [
[
[
"# Visualizing COVID-19 Hospital Dataset with Seaborn\n\n**Pre-Work:**\n1. Ensure that Jupyter Notebook, Python 3, and seaborn (which will also install dependency libraries if not already installed) are installed. (See resources below for installation instructions.)\n\n### **Instructions:**\n1. Using Python, import main visualization library, `seaborn`, and its dependencies: `pandas`, `numpy`, and `matplotlib`.\n2. Define dataset and read in data using pandas function, `read_json()`. [Notes: a) we're reading in data as an API endpoint; for more about this, see associated workshop slides or resources at bottom of notebook. b) If, instead, you prefer to use your own data, see comment with alternative for `read_csv()`.]\n3. Check data has been read is as expected using `head()` function.\n4. Graph two variables with `seaborn`as a lineplot using the `lineplot()` function.\n5. Graph these same variables, plus a third, from the source dataset with `seaborn` as a scatterplot using the `relplot()` function.\n6. See additional methods, using filtered data and other graphs. Feel free to open a new notebook, and try out your own ideas, using different variables or charts. (Or try out your own data!)\n7. When ready, save figure using `matplotlib`'s `savefig`.\n\n**Note:**\n*If you're new to Jupyter Notebook, see resources below.*\n\n### **Data source:**\n\n[COVID-19 Reported Patient Impact and Hospital Capacity by State Timeseries](https://healthdata.gov/Hospital/COVID-19-Reported-Patient-Impact-and-Hospital-Capa/g62h-syeh),\" created by the U.S. Department of Health & Human Services, on [HealthData.gov](https://healthdata.gov/).",
"_____no_output_____"
]
],
[
[
"# import libraries\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"# read JSON data in via healthdata.gov's API endpoint - https://healthdata.gov/resource/g62h-syeh.json?$limit=50000\n# because the SODA API defaults to 1,000 rows, we're going to change that with the $limit parameter\n# define data as 'covid' and set equal to read function\n# if we want filtered data to compare to, define more datasets\n\ncovid = pd.read_json(\"https://healthdata.gov/resource/g62h-syeh.json?$limit=50000\")\n\ncovid_ct = pd.read_json(\"https://healthdata.gov/resource/g62h-syeh.json?state=CT\")\n\ncovid_maytopresent = pd.read_json(\"https://healthdata.gov/resource/g62h-syeh.json?$limit=50000&$where=date%20between%20%272021-05-01T12:00:00%27%20and%20%272021-08-01T12:00:00%27\")\n\n# if you want to read in your own data, see resources below, or if you have a CSV, try: mydata = pd.read_csv('')\n# and add data filepath inside ''\n# be sure to change covid to mydata in code below",
"_____no_output_____"
],
[
"# use head function and call our dataset (covid) to see the first few rows \n# the default argument for this function is 5 rows, but you can set this to anything, e.g. covid.head(20)\ncovid.head()",
"_____no_output_____"
],
[
"# example of head with more rows\ncovid_ct.head(20)",
"_____no_output_____"
],
[
"# use seaborn to plot inpatient beds used versus whether a critical staffing shortage is occuring\n# we also need to tell seaborn what dataset to use; in this case it's 'covid' as defined above\n# variables: inpatient_beds_used_covid; critical_staffing_shortage_today_yes\n\nsns.lineplot(x='inpatient_beds_used_covid', y=\"critical_staffing_shortage_today_yes\", data=covid)\n\n# save and name fig; uncomment below to run\n# plt.savefig('covid_lineplot.png')",
"_____no_output_____"
],
[
"# use seaborn to plot inpatient beds used versus whether a critical staffing shortage is occuring\n# this time, with a bar plot\n# variables: inpatient_beds_used_covid; critical_staffing_shortage_today_yes\n\nsns.barplot(x='inpatient_beds_used_covid', y=\"critical_staffing_shortage_today_yes\", data=covid)\n\n# save and name fig; uncomment below to run\n# plt.savefig('covid_barplot.png')",
"_____no_output_____"
],
[
"# now we're going to try another graph type, a relational graph that will be scatterplot, with the same variables\n# and add one more variable, deaths_covid, to color dots based on prevalance of COVID-19 deaths by setting hue\n# though feel free to try new variables by browsing them here (scroll down to Columns in this Dataset): https://healthdata.gov/Hospital/COVID-19-Reported-Patient-Impact-and-Hospital-Capa/g62h-syeh\n# variables: inpatient_beds_used_covid; critical_staffing_shortage_today_yes; deaths_covid\n\nsns.relplot(x='inpatient_beds_used_covid', y=\"critical_staffing_shortage_today_yes\", hue=\"deaths_covid\", data=covid)\n\n# save and name fig; uncomment below to run\n# plt.savefig('covid_scatterplot.png')",
"_____no_output_____"
],
[
"# now let's try some graphs with the more limited datasets above, for instance, just the CT data\n\nsns.relplot(x='inpatient_beds_used_covid', y=\"critical_staffing_shortage_today_yes\", hue=\"deaths_covid\", data=covid_ct)\n",
"_____no_output_____"
],
[
"# or just the May - August (present) 2021 date range\n\nsns.relplot(x='inpatient_beds_used_covid', y=\"critical_staffing_shortage_today_yes\", hue=\"deaths_covid\", data=covid_maytopresent)\n",
"_____no_output_____"
]
],
[
[
"### Final Note:\nIt's important to remember that we can't necessarily infer any causation or directionality from these charts, but they can be a good place to start for further analysis and exploration, and can point us in the right direction of where to apply more advanced statistical methods, such as linear regression. Even with more advanced methods, though, we still want to stick the principles we're using here: keep charts as simple as possible, using only a few variables, and adding color only where needed. We want our charts to be readable and understandable -- see resources below for more advice and guidance on this. \n\nUltimately, these quick-start methods are helpful for idea generation and early investigation, and can get that process up and running quickly.",
"_____no_output_____"
],
[
"#### Code/Tools Resources:\n- Jupyter notebook - about: https://jupyter-notebook.readthedocs.io/en/stable/notebook.html#introduction\n- Jupyter notebook - how to use this tool: https://jupyter-notebook.readthedocs.io/en/stable/notebook.html\n- Python: https://www.python.org/\n- Seaborn: https://seaborn.pydata.org/index.html\n- Seaborn tutorial: https://seaborn.pydata.org/tutorial.html\n- Seaborn gallery: https://seaborn.pydata.org/examples/index.html\n- Seaborn `lineplot()` function: https://seaborn.pydata.org/generated/seaborn.lineplot.html#seaborn.lineplot + https://seaborn.pydata.org/examples/errorband_lineplots.html\n- Seaborn `relplot()` function: https://seaborn.pydata.org/generated/seaborn.relplot.html#seaborn.relplot + https://seaborn.pydata.org/examples/faceted_lineplot.html\n- Pandas: https://pandas.pydata.org/\n- Pandas - how to read / write tabular data: https://pandas.pydata.org/docs/getting_started/intro_tutorials/02_read_write.html\n- Pandas `read.json()` function: https://pandas.pydata.org/docs/reference/api/pandas.io.json.read_json.html?highlight=read_json#pandas.io.json.read_json\n- Pandas `head()` function: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.head.html?highlight=head#pandas.DataFrame.head\n- Matplotlib: https://matplotlib.org/\n- Matplotlib `savefig` function: https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.savefig.html\n- Socrata Open Data API (SODA) Docs: https://dev.socrata.com/\n- SODA Docs for [Dataset](https://healthdata.gov/Hospital/COVID-19-Reported-Patient-Impact-and-Hospital-Capa/g62h-syeh): https://dev.socrata.com/foundry/healthdata.gov/g62h-syeh\n- SODA Docs - what is an endpoint: https://dev.socrata.com/docs/endpoints.html\n\n#### Visualization Resources:\n- 10 Simple Rules for Better Figures | *PLOS Comp Bio*: https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1003833\n\n- How to Choose the Right Data Visualization | *Chartio*: https://chartio.com/learn/charts/how-to-choose-data-visualization/\n\n#### Additional Note:\nThis notebook was created by Kaitlin Throgmorton for a data analysis workshop, as part of an interview for Yale University.",
"_____no_output_____"
]
]
]
| [
"markdown",
"code",
"markdown"
]
| [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
]
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.