
id
stringlengths 32
32
| text
stringlengths 0
895k
| name
stringlengths 0
33k
| domain
stringlengths 5
44
| bucket
stringclasses 19
values | answers
list |
|---|---|---|---|---|---|
1876e46fa6fa3b4b088f1817efc82f28 | how to know that which patch will be applied in oracle database | tutorialdba.com | 2020.16 | [
{
"text": "Registry$history we can able",
"name": "",
"is_accepted": false
}
] |
|
38b430fb318cfc2abf23d4b017eebfaf | How to Install and Configure FreeIPA Server on RHEL / CentOS 8 | tutorialdba.com | 2020.45 | [
{
"text": "\nWelcome to our guide on how to install and configure FreeIPA server on RHEL / CentOS 8. FreeIPA is a free and open source identity management tool sponsored by Red Hat and it is the upstream for the Red Hat Identity Manager(**IdM**). FreeIPA Identity management system aims to provide an easy way of centrally managing Identity, Policy, and Audit for users and services. It is designed to provide an integrated identity management service for a wide range of clients, including Linux, Mac, and even Windows.\n\n\nBenefits of using FreeIPA\n-------------------------\n\n\n* **Central Authentication Management** – Centralized management of users, machines, and services within large Linux/Unix enterprise environments.\n* **Fine-grained Access Control**: Provides a clear method of defining access control policies to govern user identities and delegation of administrative tasks.\n* **One Time Password (OTP)**: Provides a popular method for achieving two-factor authentication (2FA).\n* **Direct Connect to Active Directory**: You can retrieve information from Active Directory (AD) and join a domain or realm in a standard way.\n* **Active Directory Cross-Realm Trust**: As System Administrator, you can establish cross-forest Kerberos trusts with Microsoft Active Directory. This allows external Active Directory (AD) users convenient access to resources in the Identity Management domain.\n* **Integrated Public Key Infrastructure (PKI) Service**: This provides PKI services that sign and publish certificates for hosts and services, Certificate Revocation List (CRL) and OCSP services for software validating the published certificate, and an API to request, show, and find certificates.\n\n\nComponents of FreeIPA Server\n----------------------------\n\n\nFreeIPA Server is composed of the following Open Source Projects.\n\n\n* **389 Directory Server** – Main data store and provides a full multi-master LDAPv3 directory infrastructure.\n* **MIT Kerberos KDC** – Provides Single-Sign-on authentication.\n* **Dogtag Certificate System** – Provides CA & RA for certificate management functions.\n* **ISC Bind DNS server**– for managing Domain names.\n* **Web UI / ipa Command Line tool** – Used to centrally manage access control, the delegation of administrative tasks and other network administration tasks.\n* **NTP Server**\n\n\nFreeIPA Server installation requirements\n----------------------------------------\n\n\n* Server with 4gb ram – I got failed installations for 1GB and 2GB RAM\n* **Fresh installation**of RHEL / CentOS 8 server\n* 2 vCPUs\n* Port 443 and 80 not used by another application\n* FQDN – Resolvable over the public or private DNS server\n* 10 GB Disk space\n\n\nSee my server details below.\n\n\n\n```\n$ **free -h**\n total used free shared buff/cache available\nMem: 3.7Gi 185Mi 3.3Gi 8.0Mi 196Mi 3.3Gi\nSwap: 2.0Gi 0B 2.0Gi\n\n\n$ **lscpu**\n Architecture: x86\\_64\n CPU op-mode(s): 32-bit, 64-bit\n Byte Order: Little Endian\n CPU(s): 2\n On-line CPU(s) list: 0,1\n Thread(s) per core: 1\n Core(s) per socket: 1\n Socket(s): 2\n NUMA node(s): 1\n Vendor ID: GenuineIntel\n CPU family: 6\n Model: 94\n Model name: Intel Core Processor (Skylake, IBRS)\n Stepping: 3\n CPU MHz: 1800.000\n BogoMIPS: 3600.00\n Hypervisor vendor: KVM\n Virtualization type: full\n L1d cache: 32K\n L1i cache: 32K\n L2 cache: 4096K\n L3 cache: 16384K\n NUMA node0 CPU(s): 0,1\n Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant\\_tsc rep\\_good nopl xtopology cpuid tsc\\_known\\_freq pni pclmulqdq ssse3 fma cx16 pcid sse4\\_1 sse4\\_2 x2apic movbe popcnt tsc\\_deadline\\_timer aes xsave avx f16c rdrand hypervisor lahf\\_lm abm 3dnowprefetch cpuid\\_fault invpcid\\_single pti ssbd ibrs ibpb fsgsbase tsc\\_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat umip\n\n$ **df -h | grep root**\n/dev/mapper/rhel-root 17G 2.3G 15G 14% /\n```\n\nThe next section will discuss the steps you need to install and configure FreeIPA Server on RHEL / CentOS 8.\n\n\nStep 1: Set timezone and hostname\n---------------------------------\n\n\nYou need to have correct timezone and hostname on your server before you can proceed. The FreeIPA server will also run NTP service and correct timezone will ensure you have correct time on the server.\n\n\n[How to Set Hostname and Timezone on RHEL / CentOS 8](https://computingforgeeks.com/set-hostname-and-timezone-on-rhel/)\n\n\nStep 2: Install FreeIPA Server on RHEL / CentOS 8\n-------------------------------------------------\n\n\nRHEL IdM is an integrated solution to provide centrally managed Identity (users, hosts, services), Authentication (SSO, 2FA), and Authorization (host access control, SELinux user roles, services).\n\n\nI had failed installation with SELinux in enforce mode, I recommend you set it to permissive or disabled.\n\n\n\n```\nsudo setenforce 0\nsudo sed -i 's/^SELINUX=.*/SELINUX=permissive/g' /etc/selinux/config\n```\n\nFreeIPA Server and client packages are distributed through [AppStream](https://computingforgeeks.com/how-to-use-fedora-29-modular-repository/) repository in RHEL / CentOS 8. You can check IdM modules available.\n\n\n\n```\n$ **sudo yum module list idm**\n Updating Subscription Management repositories.\n Updating Subscription Management repositories.\n Last metadata expiration check: 0:16:51 ago on Sat 29 Dec 2018 09:52:44 AM EAT.\n Red Hat Enterprise Linux 8 for x86\\_64 - AppStream Beta (RPMs)\n Name Stream Profiles Summary\n idm **DL1** adtrust, client, dns, server, default [d] The Red Hat Enterprise Linux Identity Management system module\n idm **client** [d] default [d] RHEL IdM long term support client module\n Hint: [d]efault, [e]nabled, [x]disabled, [i]nstalled\n```\n\nFrom the output, you can see we have `DL1` and `client` streams. For more information about the Server module, run:\n\n\n\n```\nsudo yum module info idm:DL1\n```\n\nSince this is FreeIPA Server installation, install **DL1** stream and then freeipa-server.\n\n\n\n```\nsudo yum -y install @idm:DL1\nsudo yum -y install freeipa-server\n```\n\nIf you want to include DNS service, also install ipa-server-dns, bind and bind-dyndb-ldap:\n\n\n\n```\nsudo yum install ipa-server-dns bind-dyndb-ldap\n```\n\nOther streams used as dependencies by this installation are:\n\n\n* 389-ds\n* httpd\n* pki-core\n* pki-deps\n\n\nStep 3: Setup IPA Server on RHEL / CentOS 8\n-------------------------------------------\n\n\nThe initial configuration of the FreeIPA server is interactive and you only need to answer a few questions and all the dirty work is done via a script. You will be asked to provide:\n\n\n* Integrated DNS – if your DNS zone and SRV records are properly set on your system, you may proceed by selecting the default value “no”.\n* Host name – by default obtained using reverse DNS\n* Domain name – by default based on the host name\n* Realm name – by default based on the host name\n* Password for Directory Manager – an administrator account for Directory Server\n* Password for IPA administrator – a superuser for the IdM Server\n\n\nIf you don’t have DNS server to resolve server hostname, modify *`/etc/hosts`* file to include hostname and IP address.\n\n\n\n```\necho \"192.168.122.198 [ipa.example.com](http://ipa.example.com/)\" | sudo tee -a /etc/hosts\n```\n\nConfirm\n\n\n\n```\n[jmutai@rhel8 ~]$ **ping -c 2 [ipa.example.com](http://ipa.example.com/)**\n PING [ipa.example.com](http://ipa.example.com/) (192.168.122.198) 56(84) bytes of data.\n 64 bytes from [ipa.example.com](http://ipa.example.com/) (192.168.122.198): icmp\\_seq=1 ttl=64 time=0.040 ms\n 64 bytes from [ipa.example.com](http://ipa.example.com/) (192.168.122.198): icmp\\_seq=2 ttl=64 time=0.113 ms\n --- [ipa.example.com](http://ipa.example.com/) ping statistics ---\n 2 packets transmitted, 2 received, 0% packet loss, time 30ms\n rtt min/avg/max/mdev = 0.040/0.076/0.113/0.037 ms\n```\n\nConfigure server hostname to match above name:\n\n\n\n```\nexport HNAME=\"**[ipa.example.com](http://ipa.example.com/)**\"\nsudo hostnamectl set-hostname $HNAME --static\nsudo hostname $HNAME\n```\n\nDon’t forget to replace `[ipa.example.com](http://ipa.example.com/)` with your Valid hostname.\n\n\nThen run*ipa-server-install* command to configure IPA server. Run as a user with sudo privileges or as a root user.\n\n\n\n```\nsudo ipa-server-install\n```\n\nIf you want to configure DNS service as well, include *–setup-dns* option:\n\n\n\n```\nsudo ipa-server-install --setup-dns\n```\n\nSample output:\n\n\n\n```\n$ **sudo ipa-server-install**\n The log file for this installation can be found in /var/log/ipaserver-install.log\n This program will set up the IPA Server.\n Version 4.7.1\n This includes:\n Configure a stand-alone CA (dogtag) for certificate management\n Configure the NTP client (chronyd)\n Create and configure an instance of Directory Server\n Create and configure a Kerberos Key Distribution Center (KDC)\n Configure Apache (httpd)\n Configure the KDC to enable PKINIT \n To accept the default shown in brackets, press the Enter key.\n Do you want to configure integrated DNS (BIND)? [no]: **<yes/no**>\n Enter the fully qualified domain name of the computer\n on which you're setting up server software. Using the form\n .\n Example: [master.example.com](http://master.example.com/).\n Server host name [[ipa.example.com](http://ipa.example.com/)]: **<Set/Confirm Hostname>**\n The domain name has been determined based on the host name.\n Please confirm the domain name [[example.com](http://example.com/)]: **<Confirm domain name>**\n The kerberos protocol requires a Realm name to be defined.\n This is typically the domain name converted to uppercase.\n Please provide a realm name [[EXAMPLE.COM](http://example.com/)]: **<Confirm Real name>**\n Certain directory server operations require an administrative user.\n This user is referred to as the Directory Manager and has full access\n to the Directory for system management tasks and will be added to the\n instance of directory server created for IPA.\n The password must be at least 8 characters long.\n Directory Manager password: **<Enter Password>**\n Password (confirm): **<Confirm Password>**\n The IPA server requires an administrative user, named 'admin'.\n This user is a regular system account used for IPA server administration.\n IPA admin password: **<Enter Password>**\n Password (confirm): **<Confirm Password>**\n The IPA Master Server will be configured with:\n Hostname: **[ipa.example.com](http://ipa.example.com/)**\n IP address(es): **192.168.122.198**\n Domain name: **[example.com](http://example.com/)**\n Realm name: **[EXAMPLE.COM](http://example.com/)**\n The CA will be configured with:\n Subject DN: CN=Certificate Authority,O=EXAMPLE.COM\n Subject base: O=EXAMPLE.COM\n Chaining: self-signed\n Continue to configure the system with these values? [no]: yes\n The following operations may take some minutes to complete.\n Please wait until the prompt is returned.\n.....\n```\n\nThis will:\n\n\n* Configure a stand-alone CA (dogtag) for certificate management\n* Configure the NTP client (chronyd)\n* Create and configure an instance of Directory Server\n* Create and configure a Kerberos Key Distribution Center (KDC)\n* Configure Apache (httpd)\n* Configure the KDC to enable PKINIT\n\n\nA successful installation should give output similar to below.\n\n\n\n```\n....\nRestarting the KDC\nConfiguring client side components\nThis program will set up IPA client.\nVersion 4.7.1\n\nUsing existing certificate '/etc/ipa/ca.crt'.\nClient hostname: [ipa.example.com](http://ipa.example.com/)\nRealm: [EXAMPLE.COM](http://example.com/)\nDNS Domain: [example.com](http://example.com/)\nIPA Server: [ipa.example.com](http://ipa.example.com/)\nBaseDN: dc=example,dc=com\n\nConfigured sudoers in /etc/nsswitch.conf\nConfigured /etc/sssd/sssd.conf\nSystemwide CA database updated.\nAdding SSH public key from /etc/ssh/ssh_host_ed25519_key.pub\nAdding SSH public key from /etc/ssh/ssh_host_ecdsa_key.pub\nAdding SSH public key from /etc/ssh/ssh_host_rsa_key.pub\nCould not update DNS SSHFP records.\nSSSD enabled\nConfigured /etc/openldap/ldap.conf\nConfigured /etc/ssh/ssh_config\nConfigured /etc/ssh/sshd_config\nConfiguring [example.com](http://example.com/) as NIS domain.\nClient configuration complete.\nThe ipa-client-install command was successful\nSetup complete\n```\n\nStep 4: Configure Firewalld\n---------------------------\n\n\nIt is recommended to run firewall service and allow access to ports used by FreeIPA server services.\n\n\n\n```\nsudo firewall-cmd --add-service={http,https,dns,ntp,freeipa-ldap,freeipa-ldaps} --permanent\nsudo firewall-cmd --reload\n```\n\nStep 5: Access FreeIPA Web interface\n------------------------------------\n\n\nYour FreeIPA server installation is ready. Access the web UI on `[https://ipa.example.com](https://computingforgeeks.com/)`.\n\n\n\n\n\nLogin with `admin` username and `IPA admin password` provided during installation.\n\n\n\n\n\nFreeIPA Administrative dashboard should be presented to you. Administration of the FreeIPA server can be done from the web UI or from the command line.\n\n\n\n\n\nStep 6: Using FreeIPA CLI\n-------------------------\n\n\nTo use ipa command, you need to first get a Kerberos ticket.\n\n\n\n```\n$ **sudo kinit admin**\nPassword for [email protected]: \n\n```\n\nCheck ticket expiry information using **klist.**\n\n\n\n```\n$ **klist** \nTicket cache: KCM:0\nDefault principal: [email protected]\nValid starting Expires Service principal\n03/24/2019 11:48:06 03/25/2019 11:48:04 krbtgt/[EXAMPLE.COM](http://example.com/)@[EXAMPLE.COM](http://example.com/)\n```\n\nSet user’s default shell to `/bin/bash`.\n\n\n\n```\n$ **sudo ipa config-mod --defaultshell=/bin/bash** \n Maximum username length: 32\n Home directory base: /home\n Default shell: **/bin/bash**\n Default users group: ipausers\n Default e-mail domain: [example.com](http://example.com/)\n Search time limit: 2\n Search size limit: 100\n User search fields: uid,givenname,sn,telephonenumber,ou,title\n Group search fields: cn,description\n Enable migration mode: FALSE\n Certificate Subject base: O=EXAMPLE.COM\n Password Expiration Notification (days): 4\n Password plugin features: AllowNThash, KDC:Disable Last Success\n SELinux user map order: guest\\_u:s0$xguest\\_u:s0$user\\_u:s0$staff\\_u:s0-s0:c0.c1023$unconfined\\_u:s0-s0:c0.c1023\n Default SELinux user: unconfined\\_u:s0-s0:c0.c1023\n Default PAC types: MS-PAC, nfs:NONE\n IPA masters: [ipa.example.com](http://ipa.example.com/)\n IPA CA servers: [ipa.example.com](http://ipa.example.com/)\n IPA CA renewal master: [ipa.example.com](http://ipa.example.com/)\n IPA master capable of PKINIT: [ipa.example.com](http://ipa.example.com/)\n\n```\n\nTest by adding a user account and listing accounts present:\n\n\n\n```\n**$ sudo ipa user-add test --first=Test --last=User \\\[email protected] --password**\n\nPassword: \nEnter Password again to verify: \n-------------------\n Added user \"test\"\n-------------------\n User login: test\n First name: Test\n Last name: User\n Full name: Test User\n Display name: Test User\n Initials: TU\n Home directory: /home/test\n GECOS: Test User\n Login shell: /bin/bash\n Principal name: [email protected]\n Principal alias: [email protected]\n User password expiration: 20190324085532Z\n Email address: [email protected]\n UID: 1201400001\n GID: 1201400001\n Password: True\n Member of groups: ipausers\n Kerberos keys available: True\n\n```\n\nTo list user accounts added, run:\n\n\n\n```\n$ sudo ipa user-find\n---------------\n2 users matched\n---------------\n User login: admin\n Last name: Administrator\n Home directory: /home/admin\n Login shell: /bin/bash\n Principal alias: [email protected]\n UID: 1201400000\n GID: 1201400000\n Account disabled: False\n\n User login: test\n First name: Test\n Last name: User\n Home directory: /home/test\n Login shell: /bin/bash\n Principal name: [email protected]\n Principal alias: [email protected]\n Email address: [email protected]\n UID: 1201400001\n GID: 1201400001\n Account disabled: False\n----------------------------\nNumber of entries returned 2\n----------------------------\n```\n\nTry to login as `test`user. On your first log in, you’ll be asked to change your password:\n\n\n\n```\n$ **ssh test@localhost**\nPassword: \nPassword expired. Change your password now.\nCurrent Password: \nNew password: <Set new passwoird\nRetype new password: \nActivate the web console with: systemctl enable --now cockpit.socket\n[test1@ipa ~]$ **id**\nuid=1201400003(test1) gid=1201400003(test1) groups=1201400003(test1) context=unconfined\\_u:unconfined\\_r:unconfined\\_t:s0-s0:c0.c1023\n\n```\n\nUninstall FreeIPA Server on RHEL / CentOS 8\n-------------------------------------------\n\n\nTo uninstall FreeIPA Server, run:\n\n\n\n```\n$ **sudo ipa-server-install --uninstall**\n\nThis is a NON REVERSIBLE operation and will delete all data and configuration!\nIt is highly recommended to take a backup of existing data and configuration using ipa-backup utility before proceeding.\nAre you sure you want to continue with the uninstall procedure? [no]: **yes**\n\nIf this server is the last instance of CA, KRA, or DNSSEC master, uninstallation may result in data loss.\n\nAre you sure you want to continue with the uninstall procedure? [no]: **yes**\nShutting down all IPA services\nUnconfiguring CA\nUnconfiguring web server\nUnconfiguring krb5kdc\nUnconfiguring kadmin\nUnconfiguring directory server\n.......\n```\n\nYou have successfully installed FreeIPA Server on CentOS / RHEL 8. Next reading is on\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
07fc969740619167a927c581033ab78e | How to make partition & configure the network on Redhat Linux7.3 ? | tutorialdba.com | 2020.45 | [
{
"text": "\n**Server Information :** \n\n **master :**192.168.2.2 \n\n **slave\\_1 :**192.168.2.3 \n\n **slave\\_2 :**192.168.2.4 \n\n **default gateway :**192.168.2.1 \n\n **OS :**Red Hat Enterprise Linux Server release 7.3 Beta (Maipo) \n\n **Adding extra slave:**192.168.2.5 (without down time) \n\n \n\n**MASTER PARTITION:**\n\n\n* /mnt/DATA\n* /mnt/archive\n* /mnt/backup\n\n\n**Slave\\_1 and slave\\_2 PARTITION:**\n\n\n* /DATA\n* /ARCHIVE\n* /BACKUP\n\n\n**1.Configure the network on Master,Slave\\_1,Slave\\_2 server:** \n\n \n\n**On Master:**\n\n\n\n```\n[postgres@master ~]$ cat /etc/redhat-release \nRed Hat Enterprise Linux Server release 7.3 Beta (Maipo)\n--Netcard Entry\ncd /etc/sysconfig/network-scripts/\nvi ifcfg-ens33\n\nBOOTPROTO=static\nIPADDR=192.168.2.2\nNETMASK=255.255.255.0\nDEVICE=\"ens33\"\nONBOOT=yes\n\nvi /etc/sysconfig/network\n\nNETWORKING=yes\nHOSTNAME=slave1\nGATEWAY=192.168.2.1\n\n## Configure DNS Server\n# vi /etc/resolv.conf\n\nnameserver 8.8.8.8 # Replace with your nameserver ip\nnameserver 192.168.2.1 # Replace with your nameserver ip\n\n--Host Entry\nvi /etc/hosts\n192.168.2.2 master master.master\n\n--Restart the network services\n#systemctl restart network\n (OR)\n#service network restart\n```\n\nFOR SLAVE\\_1 SERVER:\n\n\n\n```\n--Netcard Entry\ncd /etc/sysconfig/network-scripts/\nvi ifcfg-ens33\n\nBOOTPROTO=static\nIPADDR=192.168.2.3\nNETMASK=255.255.255.0\nDEVICE=\"ens33\"\nONBOOT=yes\n\nvi /etc/sysconfig/network\n\nNETWORKING=yes\nHOSTNAME=slave1\nGATEWAY=192.168.2.1\n\n## Configure DNS Server\n# vi /etc/resolv.conf\n\nnameserver 8.8.8.8 # Replace with your nameserver ip\nnameserver 192.168.2.1 # Replace with your nameserver ip\n\n--Host Entry\nvi /etc/hosts\n192.168.2.3 slave1 slave1.slave1\n\n--Restart the network services\n#systemctl restart network\n (Or)\n#service network restart\n```\n\nFOR SLAVE\\_2 SERVER:\n\n\n\n```\n--Netcard Entry\ncd /etc/sysconfig/network-scripts/\nvi ifcfg-ens33\n\nBOOTPROTO=static\nIPADDR=192.168.2.4\nNETMASK=255.255.255.0\nDEVICE=\"ens33\"\nONBOOT=yes\n\nvi /etc/sysconfig/network\n\nNETWORKING=yes\nHOSTNAME=slave1\nGATEWAY=192.168.2.1\n\n## Configure DNS Server\n# vi /etc/resolv.conf\n\nnameserver 8.8.8.8 # Replace with your nameserver ip\nnameserver 192.168.2.1 # Replace with your nameserver ip\n\n--Host Entry\nvi /etc/hosts\n192.168.2.4 slave1 slave1.slave1\n\n--Restart the network services\n#systemctl restart network\n (Or)\n#service network restart\n```\n\nNow ping the server slave\\_1 from master and slave\\_1 to slave\\_2 if all successfull then we can go make partition ,if not successfully reaching the other server we can check it the [fairwall status](http://www.tutorialdba.com/2018/03/stop-and-disable-firewalld.html) and stop it all server \n\n \n\n**For Example:** \n\n**From master:** \n\nping 192.168.2.3 \n\n**From slave\\_1:** \n\nping 192.168.2.4 \n\n \n\n**2.Disk Parition for data/archive/backup:** \n\n**a)100GB data,50GB archive,40GB backup** \n\nFor out of range error use \"extended\" option\n\n\n\n```\n[root@localhost ~]# fdisk -l\n\nDisk /dev/sda: 214.7 GB, 214748364800 bytes, 419430400 sectors\nUnits = sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\nDisk label type: dos\nDisk identifier: 0x00022715\n\n Device Boot Start End Blocks Id System\n/dev/sda1 * 2048 616447 307200 83 Linux\n/dev/sda2 616448 4812799 2098176 82 Linux swap / Solaris\n/dev/sda3 4812800 419430399 207308800 83 Linux\n\nDisk /dev/sdb: 107.4 GB, 107374182400 bytes, 209715200 sectors\nUnits = sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\n\n\nDisk /dev/sdc: 53.7 GB, 53687091200 bytes, 104857600 sectors\nUnits = sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\n\n\nDisk /dev/sdd: 42.9 GB, 42949672960 bytes, 83886080 sectors\nUnits = sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\n```\n\n\n```\n[root@localhost ~]# fdisk /dev/sdb\nWelcome to fdisk (util-linux 2.23.2).\n\nChanges will remain in memory only, until you decide to write them.\nBe careful before using the write command.\n\nDevice does not contain a recognized partition table\nBuilding a new DOS disklabel with disk identifier 0x4f696ae8.\n\nCommand (m for help): n\nPartition type:\n p primary (0 primary, 0 extended, 4 free)\n e extended\nSelect (default p): p\nPartition number (1-4, default 1): 1\nFirst sector (2048-209715199, default 2048): \nUsing default value 2048\nLast sector, +sectors or +size{K,M,G} (2048-209715199, default 209715199): \nUsing default value 209715199\nPartition 1 of type Linux and of size 100 GiB is set\n\nCommand (m for help): w\nThe partition table has been altered!\n\nCalling ioctl() to re-read partition table.\nSyncing disks.\n```\n\n\n```\n[root@localhost ~]# fdisk -l\n\nDisk /dev/sda: 214.7 GB, 214748364800 bytes, 419430400 sectors\nUnits = sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\nDisk label type: dos\nDisk identifier: 0x00022715\n\n Device Boot Start End Blocks Id System\n/dev/sda1 * 2048 616447 307200 83 Linux\n/dev/sda2 616448 4812799 2098176 82 Linux swap / Solaris\n/dev/sda3 4812800 419430399 207308800 83 Linux\n\nDisk /dev/sdb: 107.4 GB, 107374182400 bytes, 209715200 sectors\nUnits = sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\nDisk label type: dos\nDisk identifier: 0x4f696ae8\n\n Device Boot Start End Blocks Id System\n/dev/sdb1 2048 209715199 104856576 83 Linux\n\nDisk /dev/sdc: 53.7 GB, 53687091200 bytes, 104857600 sectors\nUnits = sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\n\n\nDisk /dev/sdd: 42.9 GB, 42949672960 bytes, 83886080 sectors\nUnits = sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\n```\n\n\n```\n[root@localhost ~]# fdisk -l /dev/sdb1\n\nDisk /dev/sdb1: 107.4 GB, 107373133824 bytes, 209713152 sectors\nUnits = sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\n\n[root@localhost ~]# fdisk /dev/sdbc\nfdisk: cannot open /dev/sdbc: No such file or directory\n\n```\n\n\n```\n[root@localhost ~]# fdisk /dev/sdc\nWelcome to fdisk (util-linux 2.23.2).\n\nChanges will remain in memory only, until you decide to write them.\nBe careful before using the write command.\n\nDevice does not contain a recognized partition table\nBuilding a new DOS disklabel with disk identifier 0x4efbaaa0.\n\nCommand (m for help): n\nPartition type:\n p primary (0 primary, 0 extended, 4 free)\n e extended\nSelect (default p): p\nPartition number (1-4, default 1): 1\nFirst sector (2048-104857599, default 2048): \nUsing default value 2048\nLast sector, +sectors or +size{K,M,G} (2048-104857599, default 104857599): \nUsing default value 104857599\nPartition 1 of type Linux and of size 50 GiB is set\n\nCommand (m for help): w \nThe partition table has been altered!\n\nCalling ioctl() to re-read partition table.\nSyncing disks.\n```\n\n\n```\n[root@localhost ~]# fdisk /dev/sdd\nWelcome to fdisk (util-linux 2.23.2).\n\nChanges will remain in memory only, until you decide to write them.\nBe careful before using the write command.\n\nDevice does not contain a recognized partition table\nBuilding a new DOS disklabel with disk identifier 0xaf00340d.\n\nCommand (m for help): n\nPartition type:\n p primary (0 primary, 0 extended, 4 free)\n e extended\nSelect (default p): p\nPartition number (1-4, default 1): 1\nFirst sector (2048-83886079, default 2048): \nUsing default value 2048\nLast sector, +sectors or +size{K,M,G} (2048-83886079, default 83886079): \nUsing default value 83886079\nPartition 1 of type Linux and of size 40 GiB is set\n\nCommand (m for help): w\nThe partition table has been altered!\n\nCalling ioctl() to re-read partition table.\nSyncing disks.\n```\n\n.:. restart the server using init 6,init 0 for shutdown \n\n \n\n**B)add the mount point:** \n\n**As root user:** \n\n **1. create a mount point for the data partition:** \n\n sudo mkdir /DATA \n\n \n\n **2.This command will format the partition with ext4 FS** \n\n mkfs.ext4 /dev/sdc1 \n\n \n\n **3.Mount the partition:** \n\n sudo mount /dev/sdb1 /DATA \n\n sudo mount /dev/sdc1 /ARCHIVE \n\n sudo mount /dev/sdd1 /BACKUP \n\n (OR) \n\n mount -t auto /dev/sdc1 /DATA \n\n \n\n **4.Take ownership of the mount point:** \n\n sudo chown -R postgres: /DATA \n\n sudo chown -R postgres: /ARCHIVE \n\n sudo chown -R postgres: /BACKUP \n\n \n\n **5.Find out the UUID# for your data partition:**\n\n\n\n```\n[root@localhost ~]# sudo blkid\n/dev/sda1: UUID=\"15fe408e-72ef-47fe-b3f0-e33f032c1d9f\" TYPE=\"xfs\" \n/dev/sda2: UUID=\"03a8e0e8-ae89-4a1f-bafc-c03826de7ea5\" TYPE=\"swap\" \n/dev/sda3: UUID=\"f45ae60c-162f-4da2-aa33-f76723e0c5fe\" TYPE=\"xfs\" \n/dev/sdb1: UUID=\"46c3be28-2646-495e-9d1b-5f9be9d1e154\" TYPE=\"ext4\" \n/dev/sdc1: UUID=\"c5abf63e-a9ad-410c-a685-4407d9a12b93\" TYPE=\"ext4\" \n/dev/sdd1: UUID=\"961e84b2-dbe2-4f2c-ade7-72c2b2b5289d\" TYPE=\"ext4\" \n/dev/sr0: UUID=\"2016-08-17-06-07-50-00\" LABEL=\"RHEL-7.3 Server.x86\\_64\" TYPE=\"iso9660\" PTTYPE=\"dos\"\n```\n\n**6.Open your fstab file and make an entry to auto-mount the data partition on boot:** \n\n**gksu gedit /etc/fstab (OR) vi /etc/fstab** \n\n (Note: you may need to substitute a different text editor if gedit not installed to your version of Mint.) \n\n \n\n In gedit, add either of the two examples below (substitute your UUID# for the ones listed here): \n\n **A.For an Ext4 formatted partition, add these two lines to end of fstab file:**\n\n\n\n```\n# Mount DATA partition under /DATA\nUUID=46c3be28-2646-495e-9d1b-5f9be9d1e154 /DATA ext4 defaults 0 2\nUUID=c5abf63e-a9ad-410c-a685-4407d9a12b93 /ARCHIVE ext4 defaults 0 2\nUUID=961e84b2-dbe2-4f2c-ade7-72c2b2b5289d /BACKUP ext4 defaults 0 2\n```\n\n**B.For an NTFS formatted partition, add these two lines to end of fstab file:**\n\n\n\n```\n# Mount DATA partition under /DATA\nUUID=747D4C9C1EFAD1F2 /DATA ntfs-3g defaults,windows\\_names,locale=en\\_US.utf8 0 0\n```\n\n Save the changes to fstab and close the text editor or vim editor\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
de356bb0d15493343f2f83507b7d3dd4 | MySQL Database Maintenance Script | tutorialdba.com | 2020.40 | [
{
"text": "\n\n```\n#!/usr/bin/env bash\n \n##############################################################################\n# Performs Mysql Database Maintenance Operations:\n# - Check\n# - Optimize\n# - Analyze\n#\n# WARNING:\n# These operations will cause LOCKS, so be cautious on a production\n# server!\n#\n# Based on:\n# - MySQL Maintenance Tasks for InnoDB with MySQL 5.1\n# <http://www.laurencegellert.com/2011/07/mysql-maintenance-tasks-for-innodb-with-mysql-5-1/>\n##############################################################################\n \nset -e\n \nmysql\\_username=\"root\"\nmysql\\_password=\"password\"\nmysql\\_hostname=\"localhost\"\nmysql\\_database\\_name=\"testdb\"\n \necho\necho \"Checking db \\\"$mysql\\_database\\_name\\\" for integrity errors...\"\necho \"-----------------------------------------------------------------------\"\nmysqlcheck -h $mysql\\_hostname -u $mysql\\_username -p$mysql\\_password --check --databases $mysql\\_database\\_name\n \necho\necho \"Optimizing db \\\"$mysql\\_database\\_name\\\" to reclaim unused space...\"\necho \"-----------------------------------------------------------------------\"\nmysqlcheck -h $mysql\\_hostname -u $mysql\\_username -p$mysql\\_password --optimize --databases $mysql\\_database\\_name\n \necho\necho \"Analyzing db \\\"$mysql\\_database\\_name\\\" to rebuild and optimize indexes...\"\necho \"-----------------------------------------------------------------------\"\nmysqlcheck -h $mysql\\_hostname -u $mysql\\_username -p$mysql\\_password --analyze --databases $mysql\\_database\\_name\n \necho\necho \"Finished.\"\necho\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\nOptimize, Repair, and Analyze a MySQL Database Using the Command Line\n=====================================================================\n\n\nHere are some quick and helpful MySQL commands that can be run to optimize, repair, or analyze a database from the command line. These commands use the mysqlcheck client, which performs MySQL table maintenance such as repairing, optimizing, checks, and analysis.\n\n\nOne of the great benefits of the mysqlcheck client is that you are not required to stop your server to perform the operations, but note that your server must be started for the following commands to work. That means, for most sites, you can run these at any time or setup them up in the crontab to run regularly.\n\n\nI find myself sometimes needing some quick reminders, as was such the case recently, so I figured I create a new post on some of the MySQL commands that I frequently use from the command line.\n\n\n*Note: The commands shown are targeted towards a Linux OS, but it could just as easily be a Windows OS, by modifying the command accordingly.\n\n\n**Optimize Single Database**: This command will optimize a single database, as specified in the command argument.\n\n\n\n\n| 01 | `.``/mysqlcheck` `-o database_name` |\n\n\n**Optimize All Databases**: This command will optimize all of the databases within your MySQL installation.\n\n\n\n\n| 01\n02 | `.``/mysqlcheck` `-o -A`\n`.``/mysqlcheck` `-o --all-databases` |\n\n\n**Analyze Single Database**: This command will analyze the tables in a single database, as specified in the command argument.\n\n\n\n\n| 01 | `.``/mysqlcheck` `-a database_name` |\n\n\n**Analyze All Databases**: This command will analyze the tables in all databases within your MySQL installation.\n\n\n\n\n| 01\n02 | `.``/mysqlcheck` `-a -A`\n`.``/mysqlcheck` `-a --all-databases` |\n\n\n**Repair Single Database**: This command will repair the tables in a single database, as specified in the command argument.\n\n\n\n\n| 01 | `.``/mysqlcheck` `-r database_name` |\n\n\n**Repair All Databases**: This command will repair the tables in all databases within your MySQL installation.\n\n\n\n\n| 01\n02 | `.``/mysqlcheck` `-r -A`\n`.``/mysqlcheck` `-r --all-databases` |\n\n\nAdditional options for using mysqlcheck can be found here: <http://dev.mysql.com/doc/refman/5.0/en/mysqlcheck.html>\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
6e1b5881227fd1d8886861b153ee1939 | What type of activity we do in DR drill. Actually I have not done before but I have heard from some people that they r doing DR drill can any one tell please | What type of activity we do in DR drill | tutorialdba.com | 2021.04 | [
{
"text": "Dr drill means they will do switchover \n\n \n\nAfter 1 day again they will do switch back \n\n \n\nThis is only for checking purposeThey \n\n \n\n will note down timings \n\n \n\nThis will help to if PR goes down how quickly dr will be active \n\n \n\nTo estimate the time",
"name": "",
"is_accepted": false
}
] |
36e3c89b342d6979461987281968efc5 | HOW TO CREATE INDEX ON postgresql JSON TABLE ? | tutorialdba.com | 2021.04 | [
{
"text": "\n* index is fast fetching data without going full table scan.\n\n\nHere i will explain how to create index on json data type table and how to work index on json data type.\n\n\n--check the sales table for already having any index or not. \n\n \n\n\n\n```\npostgres=# \\d sales\n Table \"public.sales\"\n Column | Type | Modifiers \n------------+---------+-----------\n id | integer | not null\n sales\\_info | json | not null\nIndexes:\n \"sales\\_pkey\" PRIMARY KEY, btree (id)\n\n\npostgres=# \\di sales\nNo matching relations found. \n```\n\n--already we have sales table now let us go to create indicies on any (even nested) JSON field: \n\n \n\n\n\n```\ncreate unique index ind\\_name\non sales ((sales\\_info ->'PRODUCTS'->>'total\\_item'));\n```\n\n--Now check the table index is properly created or not using \\di,\\dt,pg\\_indexes. \n\n \n\n\n\n```\npostgres=# \\di ind\\_name\n List of relations\n Schema | Name | Type | Owner | Table \n--------+----------+-------+----------+-------\n public | ind\\_name | index | postgres | sales\n(1 row)\n\n\n\nDeleting json objectspostgres=# \\d sales\n Table \"public.sales\"\n Column | Type | Modifiers \n------------+---------+-----------\n id | integer | not null\n sales\\_info | json | not null\nIndexes:\n \"sales\\_pkey\" PRIMARY KEY, btree (id)\n \"ind\\_name\" UNIQUE, btree (((sales\\_info -> 'PRODUCTS'::text) ->> 'total\\_item'::text))\n\n\n\npostgres=# select tablename,indexname,indexdef from pg\\_indexes where tablename='sales';\n tablename | indexname | indexdef \n \n-----------+------------+-----------------------------------------------------------------------------------\n------------------------------\n sales | sales\\_pkey | CREATE UNIQUE INDEX sales\\_pkey ON sales USING btree (id)\n sales | ind\\_name | CREATE UNIQUE INDEX ind\\_name ON sales USING btree ((((sales\\_info -> 'PRODUCTS'::te\nxt) ->> 'total\\_item'::text)))\n(2 rows)\n```\n\n From below example index is properly working becouse we already created unique index on on json column of \"total\\_item\" unique index will not accept duplicate value if you try to insert duplicate values it will throw errors,i hope you understood it from below example. \n\n \n\n\n\n```\npostgres=# select * from sales;\n id | sales\\_info \n----+----------------------------------------------------------------------------------\n 2 | { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 5}}\n 3 | { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 1}}\n 5 | { \"customer\": \"NIJAM\", \"PRODUCTS\": {\"product\\_name\": \"choclate\",\"total\\_item\": 9}}\n 1 | { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 6}}\n 4 | { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 8}}\n(5 rows)\n\n\npostgres=# INSERT INTO SALES VALUES\n (9,'{ \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 8}}'\n );\nERROR: duplicate key value violates unique constraint \"ind\\_name\"\nDETAIL: Key (((sales\\_info -> 'PRODUCTS'::text) ->> 'total\\_item'::text))=(8) already exists. \n```\n\n**another example for json index is properly working or not**\n\n\nHERE LET US consider sales table having above 20000 json records for making practical json index , This way we can begin to see some performance implications when dealing with JSON data in Postgres, as well as how to solve them. \n\n \n\n\n\n```\nSELECT count(*) FROM sales WHERE sales\\_info ->'PRODUCTS'->>'total\\_item'= '1';\ncount\n-------\n4937 \n(1 row) \n```\n\n--taking explain plan for without index \n\n \n\n\n\n```\npostgres=# explain analyze SELECT sales\\_info ->>'customer' as customer\\_name from sales \nwhere sales\\_info ->'PRODUCTS'->>'total\\_item'= '1';\nAggregate (cost=335.12..335.13 rows=1 width=0) (actual time=4.421..4.421 rows=1 loops=1) -> Seq Scan on cards (cost=0.00..335.00 rows=50 width=0) (actual time=0.016..3.961 rows=4938 loops=1) \n Filter: (((sales\\_info -> 'PRODUCTS'::text) ->> 'total\\_item'::text) = '1'::text) \n Rows Removed by Filter: 5062 \nTotal runtime: 4.475 ms$cd /db\\_data/data/pg\\_log\n$tail -f postgresql-Tue.log \n```\n\nNow, that wasn’t that slow of a query at 4.5ms, but let’s see if we can improve it. \n\n \n\n\n\n```\nCREATE INDEX ind\\_name1 ON sales ((sales\\_info ->'PRODUCTS'->>'total\\_item')); \n```\n\nIf we run the same query which now has an index, we end up cutting the time in half. \n\n \n\n\n\n```\nSELECT count(*) FROM sales WHERE sales\\_info ->'PRODUCTS'->>'total\\_item'= '1';\ncount\n-------\n4937 \n(1 row)\n\npostgres=# explain analyze SELECT sales\\_info ->>'customer' as customer\\_name from sales \nwhere sales\\_info ->'PRODUCTS'->>'total\\_item'= '1';\nAggregate (cost=118.97..118.98 rows=1 width=0) (actual time=2.122..2.122 rows=1 loops=1) -> Bitmap Heap Scan on cards (cost=4.68..118.84 rows=50 width=0) (actual time=0.711..1.664 rows=4938 loops=1) \n Recheck Cond: (((sales\\_info -> 'PRODUCTS'::text) ->> 'total\\_item'::text) = '1'::text) \n Heap Blocks: exact=185 \n -> Bitmap Index Scan on idxfinished (cost=0.00..4.66 rows=50 width=0) (actual time=0.671..0.671 rows=4938 loops=1) \n Index Cond:(((sales\\_info -> 'PRODUCTS'::text) ->> 'total\\_item'::text) = '1'::text) \nTotal runtime: 2.175 ms \n```\n\nOur query is now taking advantage of the ind\\_name1 index we created, and the query time has been approximately cut in half.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
fdd583b0268dfee0abb41bdd2c67c42c | How will you block all connections in postgresql ? | tutorialdba.com | 2021.04 | [
{
"text": "\nChange the host-based authentication (HBA) file to refuse all incoming \n\nconnections, and then reload the server: \n\nCreate a new file named pg\\_hba\\_lockdown.conf, and add the \n\nfollowing two lines to the file. This puts in place rules that will \n\ncompletely lock down the server, including super users. You \n\nshould have no doubt that this is a serious and drastic action:\n\n\n\n```\n# TYPE DATABASE USER CIDR-ADDRESS METHOD\nlocal all all reject\nhost all all 0.0.0.0/0 reject\n```\n\nIf you still want super user access, then try something like the following:\n\n\n\n```\n# TYPE DATABASE USER CIDR-ADDRESS METHOD\nlocal all postgres peer\nlocal all all reject\nhost all all 0.0.0.0/0 reject\n```\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\nIn pg\\_hba.con file\n\n\n\n```\nHost all all range\\_of\\_the\\_ip reject\n```\n\nor\n\n\nSet connection limit to zero\n\n\nOr else\n\n\nRestrict the connections for a specific database to zero, by setting the connection\n\n\nlimit to zero.\n\n\n\n```\nALTER DATABASE foo\\_db CONNECTION LIMIT 0;\n```\n\n--That is for individual database\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
6813a71f1d713560bc3e445c19b680c6 | How to configurre SSL on postgres database ? | tutorialdba.com | 2019.43 | [
{
"text": "\n**PREREQUEST : \n\n============** \n\n1. OpenSSL should be install on both client and server systems \n\n2. Confirm whether openssl is installed or not .\n\n\n\n```\[email protected]:~ # rpm -qa|grep -i openssl\nopenssl-1.0.2j-60.52.1.x86\\_64\nlibopenssl1\\_0\\_0-1.0.2j-60.52.1.x86\\_64\npython-pyOpenSSL-16.0.0-4.17.1.noarch\n```\n\n3. Checking openSSL version :\n\n\n\n```\[email protected]:~ # openssl version\nOpenSSL 1.0.2j-fips 26 Sep 2016\n```\n\n4. We can print the OpenSSL directory with version -d option like below.\n\n\n\n```\[email protected]:~ # openssl version -d\nOPENSSLDIR: \"/etc/ssl\"\n\[email protected]:~ # openssl version -a\nOpenSSL 1.0.2j-fips 26 Sep 2016\nbuilt on: reproducible build, date unspecified\nplatform:\noptions: bn(64,64) rc4(16x,int) des(idx,cisc,16,int) blowfish(idx)\ncompiler: cc -I. -I.. -I../include -g\nOPENSSLDIR: \"/etc/ssl\"\n```\n\n5. Collecting the postgres Server details:\n\n\n\n```\[email protected]:/home/nijam> ps -ef|grep -i postgres|grep -v -edle\nnijam 2693 2641 0 21:12 pts/1 00:00:00 grep --color=auto -i postgres\nnijam 19150 1 0 Jun11 ? 00:10:54 /ins\\_path/10.5/bin/postgres -D /data/nijam\nnijam 19151 19150 0 Jun11 ? 00:00:00 postgres: logger process\nnijam 19153 19150 0 Jun11 ? 00:00:31 postgres: checkpointer process\nnijam 19154 19150 0 Jun11 ? 00:07:15 postgres: writer process\nnijam 19155 19150 0 Jun11 ? 00:03:48 postgres: wal writer process\nnijam 19156 19150 0 Jun11 ? 00:01:19 postgres: autovacuum launcher process\nnijam 19157 19150 0 Jun11 ? 00:00:04 postgres: archiver process last was 000000010000000100000027\nnijam 19158 19150 0 Jun11 ? 00:03:45 postgres: stats collector process\nnijam 19159 19150 0 Jun11 ? 00:00:01 postgres: bgworker: logical replication launcher\n```\n\n \n\n**CONFIGURATION : \n\n===============** \n\nThis describes how to set up ssl certificates to enable encrypted connections from PgAdmin on some client machine to postgresql on a server machine. The assumption is that postgresql (compiled with ssl support) and openssl are already installed and functional on the server (Linux). PgAdmin is already installed on the client (either Windows or Linux).\n\n\nOn the server, three certificates are required in the data directory. CentOS default is /var/lib/pgsql/data/: \n\n\n 1.root.crt (trusted root certificate) \n\n 2.server.crt (server certificate) \n\n 3.server.key (private key)\n\n\n \n\nconnect as root user and go to postgres data directory path then generate SSL certificate form there only .\n\n\nStep 1. \n\n=====\n\n\n\n```\n$ sudo su -\n# cd /data/nijam\n```\n\nStep 2. Generate a private key (you must provide a passphrase): \n\n=====\n\n\n\n```\n2ndquadrant.in:/data/nijam # openssl genrsa -des3 -passout pass:gsahdg -out server.key 1024\nGenerating RSA private key, 1024 bit long modulus\n........++++++\n...++++++\ne is 65537 (0x10001)\n```\n\nStep 3. Remove the passphrase. \n\n=======\n\n\n\n```\n2ndquadrant.in:/data/nijam # openssl rsa -in server.key -out server.key\nEnter pass phrase for server.key:\nwriting RSA key\n\nNote : Give below inputs if prompt \ngsahdg (it is like password you can give whatever you want).\n```\n\n \n\nStep 4. Set appropriate permission and owner on the private key file. \n\n=====\n\n\n\n```\n# chmod 400 server.key\n# chown nijam.nijam server.key\n```\n\n \n\n\nStep 5. Create the server certificate. \n\n===== \n\n-subj is a shortcut to avoid prompting for the info. \n\n-x509 produces a self signed certificate rather than a certificate request.\n\n\n\n```\n2ndquadrant.in:/data/nijam # openssl req -nodes -new -x509 -days 3650 -keyout server.key -out server.crt\nGenerating a 2048 bit RSA private key\n.....................................................+++\n.......................................+++\nwriting new private key to 'server.key'\n-----\nYou are about to be asked to enter information that will be incorporated\ninto your certificate request.\nWhat you are about to enter is what is called a Distinguished Name or a DN.\nThere are quite a few fields but you can leave some blank\nFor some fields there will be a default value,\nIf you enter '.', the field will be left blank.\n-----\nCountry Name (2 letter code) [AU]:\nState or Province Name (full name) [Some-State]:\nLocality Name (eg, city) []:\nOrganization Name (eg, company) [Internet Widgits Pty Ltd]:\nOrganizational Unit Name (eg, section) []:\nCommon Name (e.g. server FQDN or YOUR name) []:\nEmail Address []:\n\nStep 6. Since we are self-signing, we use the server certificate as the trusted root certificate. \n=====\n2ndquadrant.in:/data/nijam # cp server.crt root.crt\n```\n\nYou'll need to edit pg\\_hba.conf. For example:\n\n\n\n```\n# TYPE DATABASE USER ADDRESS METHOD\nhost all all 127.0.0.1/32 trust\n# IPv6 local connections:\nhost all all ::1/128 trust\n#hostssl all all 0.0.0.0/0 trust clientcert=1\n# \"local\" is for Unix domain socket connections only\nlocal all all trust\n# IPv4 local connections:\n# host all all 127.0.0.1/32 pam\n# IPv6 local connections:\n# host all all ::1/128 pam\n# Allow replication connections from localhost, by a user with the\n# replication privilege.\nlocal replication all peer\nhost replication all 127.0.0.1/32 pam\nhost replication all ::1/128 pam\nhostssl DB DB\\_writer 53.126.142.211/32 trust clientcert=1\nhostssl DB DB\\_reader 53.126.142.222/32 trust clientcert=1\n```\n\n======================================(OR)=============================================== \n\nif you don't want to use client certificate means you can ignore clientcert=1 , so connection will not authenticate by using client certifcate , its network encryption-decryption only. below is the sample configuration setup.\n\n\n\n```\n# TYPE DATABASE USER ADDRESS METHOD\nhost all all 127.0.0.1/32 trust\n# IPv6 local connections:\nhost all all ::1/128 trust\n\n# \"local\" is for Unix domain socket connections only\n local all all trust\n# IPv4 local connections:\n# host all all 127.0.0.1/32 pam\n# IPv6 local connections:\n# host all all ::1/128 pam\n# Allow replication connections from localhost, by a user with the\n# replication privilege.\nlocal replication all peer\nhost replication all 127.0.0.1/32 pam\nhost replication all ::1/128 pam\nhostssl DB DB\\_writer 53.126.142.211/32 password\nhostssl DB DB\\_reader 53.126.142.222/32 password\n\nStep 7. You need to edit postgresql.conf to actually activate ssl. \n====\nssl = on\n#ssl\\_cert\\_file = 'server.crt'\n#ssl\\_key\\_file = 'server.key'\nssl\\_ca\\_file = 'root.crt'\n```\n\n \n\nStep 8. Postgresql server must be restarted. \n\n=====\n\n\n\n```\[email protected]:/data/nijam> pg\\_ctl restart $DATA\nwaiting for server to shut down.... done\nserver stopped\nwaiting for server to start....2019-07-03 21:45:14.785 CST [5594] LOG: listening on IPv4 address \"0.0.0.0\", port 25084\n2019-07-03 21:45:14.785 CST [5594] LOG: listening on IPv6 address \"::\", port 25084\n2019-07-03 21:45:14.792 CST [5594] LOG: listening on Unix socket \"/var/run/postgresql/.s.PGSQL.25084\"\n2019-07-03 21:45:14.804 CST [5594] LOG: listening on Unix socket \"/tmp/.s.PGSQL.25084\"\n2019-07-03 21:45:14.815 CST [5594] LOG: redirecting log output to logging collector process\n2019-07-03 21:45:14.815 CST [5594] HINT: Future log output will appear in directory \"log\".\n done\nserver started\n```\n\n \n\n**POSTREQUEST SERVER SIDE : \n\n==========================**\n\n\nStep 1 . Checking postgres SSL . \n\n=====\n\n\n\n```\[email protected]:/data/nijam> psql -h localhost\npsql (10.5)\nSSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)\nType \"help\" for help.\n\nnijam=#\n```\n\n \n\nStep 2 . Verifying certificate. \n\n=====\n\n\n\n```\[email protected]:/data/nijam> openssl verify -CAfile root.crt server.crt\nserver.crt: OK\n\nnijam=# show ssl\\_cert\\_file;\n ssl\\_cert\\_file\n---------------\n server.crt\n(1 row)\n\nnijam=# show ssl\\_key\\_file;\n ssl\\_key\\_file\n--------------\n server.key\n(1 row)\n\nnijam=# show ssl\\_ca\\_file;\n ssl\\_ca\\_file\n-------------\n root.crt\n(1 row)\n\nnijam=# show ssl\\_crl\\_file;\n ssl\\_crl\\_file\n--------------\n\n(1 row)\n```\n\n \n\nStep 3. Checking SSL mode with Require . \n\n=====\n\n\n\n```\[email protected]:/data/nijam> psql \"postgresql://localhost/?sslmode=require\"\npsql (10.5)\nSSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)\nType \"help\" for help.\n\nnijam=#\n```\n\n \n\n\n**CLIENT SIDE CONFIGURATION : \n\n==========================**\n\n\nIf the server fails to (re)start, look in the postgresql startup log, /var/lib/pgsql/pgstartup.log default for CentOS, for the reason.\n\n\nOn the client, we need three files. For Windows, these files must be in %appdata%\\postgresql\\ directory. \n\nYou need to create the directory on the client machine if linux ( mkdir ~/.postgresql )\n\n\n* root.crt (trusted root certificate)\n* postgresql.crt (client certificate)\n* postgresql.key (private key)\n\n\nStep 1. \n\n==== \n\nGenerate the the needed files on the server machine, and then copy them to the client. We'll generate the needed files in the /tmp/directory. \n\nFirst create the private key postgresql.key for the client machine, and remove the passphrase.\n\n\n\n```\n2ndquadrant.in:~ # openssl genrsa -des3 -passout pass:gsahdg -out /tmp/postgresql.key 1024\nGenerating RSA private key, 1024 bit long modulus\n.++++++\n...++++++\ne is 65537 (0x10001)\n\n2ndquadrant.in:~ # openssl rsa -in /tmp/postgresql.key -passout pass:gsahdg -out /tmp/postgresql.key\nEnter pass phrase for /tmp/postgresql.key:\nwriting RSA key\n\nNote : Give gsahdg while prompting \n```\n\nStep 2. \n\n===== \n\nThen create the certificate postgresql.crt. It must be signed by our trusted root (which is using the private key file on the server machine). Also, the certificate common name (CN) must be set to the database user name we'll connect as.\n\n\n\n```\n2ndquadrant.in:~ # openssl req -new -key /tmp/postgresql.key -out /tmp/postgresql.csr\nYou are about to be asked to enter information that will be incorporated\ninto your certificate request.\nWhat you are about to enter is what is called a Distinguished Name or a DN.\nThere are quite a few fields but you can leave some blank\nFor some fields there will be a default value,\nIf you enter '.', the field will be left blank.\n-----\nCountry Name (2 letter code) [AU]:\nState or Province Name (full name) [Some-State]:\nLocality Name (eg, city) []:\nOrganization Name (eg, company) [Internet Widgits Pty Ltd]:\nOrganizational Unit Name (eg, section) []:\nCommon Name (e.g. server FQDN or YOUR name) []:\nEmail Address []:\n\nPlease enter the following 'extra' attributes\nto be sent with your certificate request\nA challenge password []:\nAn optional company name []:\n```\n\n \n\nStep 3. Extending SSL validation expiry. \n\n=====\n\n\n\n```\n2ndquadrant.in:~ # openssl x509 -days 3650 -req -in /tmp/postgresql.csr -CA root.crt -CAkey server.key -out /tmp/postgresql.crt -CAcreateserial\nSignature ok\n\nsubject=/C=AU/ST=Some-State/O=Internet Widgits Pty Ltd\nError opening CA Certificate root.crt\n139936769549968:error:02001002:system library:fopen:No such file or directory:bss\\_file.c:407:fopen('root.crt','re')\n139936769549968:error:20074002:BIO routines:FILE\\_CTRL:system lib:bss\\_file.c:409:\nunable to load certificate\n```\n\n**Reason:** \n\nReroot.crt file path is missing\n\n\n**Solution :**\n\n\n\n```\n2ndquadrant.in:~ # cd /data/nijam/\n2ndquadrant.in:/data/nijam # openssl x509 -days 3650 -req -in /tmp/postgresql.csr -CA root.crt -CAkey server.key -out /tmp/postgresql.crt -CAcreateserial\nSignature ok\nsubject=/C=AU/ST=Some-State/O=Internet Widgits Pty Ltd\nGetting CA Private Key\n```\n\nCopy the three files we created from the server /tmp/ directory to the client machine. \n\nCopy the trusted root certificate root.crt from the server machine to the client machine (for Windows pgadmin %appdata%\\postgresql\\ or for Linux pgadmin ~/.postgresql/). Change the file permission of postgresql.key to restrict access to just you (probably not needed on Windows as the restricted access is already inherited). Remove the files from the server /tmp/ directory. \n\n(After copying the three files from the server (/tmp/{postgresql.key,postgresql.crt,root.crt}) to the client machine (into directory ~/.postgresql/), you'll need to set the permission of the key to not world readable: chmod 0400 ~/.postgresql/postgresql.key \n\nOn windows, permissions in the are handled automatically for you.)\n\n\n========================================END===========================================\n\n\n**Basic Issues while configuring SSL certificate :**\n\n\n**ISSUES-1 :**\n\n\n\n```\n$ psql \"postgresql://localhost/?sslmode=verify-ca\"\npsql: root certificate file \"/home/nijam/.postgresql/root.crt\" does not exist\nEither provide the file or change sslmode to disable server certificate verification.\n```\n\n**Solution :**\n\n\n\n```\n$ cp /data/nijam/root.crt /home/nijam/.postgresql/\[email protected]:/home/nijam> mkdir /home/nijam/.postgresql/\n\n$ psql \"postgresql://localhost/?sslmode=verify-ca\"\npsql (10.5)\nSSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)\nType \"help\" for help.\n```\n\n \n\n\n**ISSUES-2 :**\n\n\nIn client side should be change permissions as\n\n\n\n```\nchmod 0600 .postgresql/postgresql.key\n\n**from client 53.126.142.211 :**\npassword\\_encryption = md5 \npsql -h 2ndquadrant.in -p 5432 -U DB\\_writer -d DB\n```\n\ncheck localdomain account.\n\n\n**For server side :**\n\n\n\n```\nchmod 400 server.crt\nchown nijam.nijam server.crt\nchmod 400 root.crt\nchown nijam.nijam root.crt\n```\n\n**Some basic notes of SSL :** \n\n<https://discuss.tutorialdba.com/1158/enable-openssl-postgressql-server>\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
2497da3c06a751f3030009239cc2f1d2 | MySQL Tuning | tutorialdba.com | 2020.45 | [
{
"text": "\nMySQL tuning is essential if you are running high volume websites that run on MySQL. You will need this two scripts to help your MySQL tuning.\n\n\nI’m running a lot of high volume WordPress websites and apart from getting the advantages from caching with APC or memcached I’m tuning my MySQL server from time to time. For that purpose I’m using this two scripts:\n\n\ntuning-primer.sh – MySQL Tuning Primer Script\n---------------------------------------------\n\n\nYou can get this script from launchpad <https://launchpad.net/mysql-tuning-primer>\n\n\n### Running tuning-primer.sh will gave you this output:\n\n\n\n```\nMySQL Version 5.1.63-0+squeeze1-log x86\\_64\n\nUptime = 1 days 8 hrs 11 min 3 sec\nAvg. qps = 23\nTotal Questions = 2736077\nThreads Connected = 3\n\nWarning: Server has not been running for at least 48hrs.\nIt may not be safe to use these recommendations\n\nTo find out more information on how each of these\nruntime variables effects performance visit:\n<http://dev.mysql.com/doc/refman/5.1/en/server-system-variables.html>\nVisit <http://www.mysql.com/products/enterprise/advisors.html>\nfor info about MySQL's Enterprise Monitoring and Advisory Service\n\nSLOW QUERIES\nThe slow query log is enabled.\nCurrent long\\_query\\_time = 2.000000 sec.\nYou have 511 out of 2736106 that take longer than 2.000000 sec. to complete\nYour long\\_query\\_time seems to be fine\n\nBINARY UPDATE LOG\nThe binary update log is NOT enabled.\nYou will not be able to do point in time recovery\nSee <http://dev.mysql.com/doc/refman/5.1/en/point-in-time-recovery.html>\n\nWORKER THREADS\nCurrent thread\\_cache\\_size = 128\nCurrent threads\\_cached = 11\nCurrent threads\\_per\\_sec = 0\nHistoric threads\\_per\\_sec = 0\nYour thread\\_cache\\_size is fine\n\nMAX CONNECTIONS\nCurrent max\\_connections = 110\nCurrent threads\\_connected = 2\nHistoric max\\_used\\_connections = 13\nThe number of used connections is 11% of the configured maximum.\nYour max\\_connections variable seems to be fine.\n\nINNODB STATUS\nCurrent InnoDB index space = 75 M\nCurrent InnoDB data space = 398 M\nCurrent InnoDB buffer pool free = 57 %\nCurrent innodb\\_buffer\\_pool\\_size = 1.00 G\nDepending on how much space your innodb indexes take up it may be safe\nto increase this value to up to 2 / 3 of total system memory\n\nMEMORY USAGE\nMax Memory Ever Allocated : 2.75 G\nConfigured Max Per-thread Buffers : 2.16 G\nConfigured Max Global Buffers : 2.50 G\nConfigured Max Memory Limit : 4.66 G\nPhysical Memory : 4.86 G\nMax memory limit exceeds 90% of physical memory\n\nKEY BUFFER\nCurrent MyISAM index space = 437 M\nCurrent key\\_buffer\\_size = 768 M\nKey cache miss rate is 1 : 30252\nKey buffer free ratio = 72 %\nYour key\\_buffer\\_size seems to be too high.\nPerhaps you can use these resources elsewhere\n\nQUERY CACHE\nQuery cache is enabled\nCurrent query\\_cache\\_size = 768 M\nCurrent query\\_cache\\_used = 753 M\nCurrent query\\_cache\\_limit = 8 M\nCurrent Query cache Memory fill ratio = 98.15 %\nCurrent query\\_cache\\_min\\_res\\_unit = 4 K\nHowever, 2990 queries have been removed from the query cache due to lack of memory\nPerhaps you should raise query\\_cache\\_size\nMySQL won't cache query results that are larger than query\\_cache\\_limit in size\n\nSORT OPERATIONS\nCurrent sort\\_buffer\\_size = 8 M\nCurrent read\\_rnd\\_buffer\\_size = 2 M\nSort buffer seems to be fine\n\nJOINS\nCurrent join\\_buffer\\_size = 2.00 M\nYou have had 419459 queries where a join could not use an index properly\nYou have had 221564 joins without keys that check for key usage after each row\nYou should enable \"log-queries-not-using-indexes\"\nThen look for non indexed joins in the slow query log.\nIf you are unable to optimize your queries you may want to increase your\njoin\\_buffer\\_size to accommodate larger joins in one pass.\nNote! This script will still suggest raising the join\\_buffer\\_size when\nANY joins not using indexes are found.\n\nOPEN FILES LIMIT\nCurrent open\\_files\\_limit = 32888 files\nThe open\\_files\\_limit should typically be set to at least 2x-3x\nthat of table\\_cache if you have heavy MyISAM usage.\nYour open\\_files\\_limit value seems to be fine\n\nTABLE CACHE\nCurrent table\\_open\\_cache = 16384 tables\nCurrent table\\_definition\\_cache = 16384 tables\nYou have a total of 1517 tables\nYou have 2447 open tables.\nThe table\\_cache value seems to be fine\n\nTEMP TABLES\nCurrent max\\_heap\\_table\\_size = 512 M\nCurrent tmp\\_table\\_size = 512 M\nOf 1109845 temp tables, 16% were created on disk\nCreated disk tmp tables ratio seems fine\n\nTABLE SCANS\nCurrent read\\_buffer\\_size = 8 M\nCurrent table scan ratio = 15020 : 1\nread\\_buffer\\_size seems to be fine\n\nTABLE LOCKING\nCurrent Lock Wait ratio = 1 : 565\nYou may benefit from selective use of InnoDB.\n```\n\n### I need to do this:\n\n\nAs you can see there are a few things i need to change. My MEMORY USAGE is too high *Max memory limit exceeds 90% of physical memory*I can fix this with lowering my max\\_connections because as i can see i’m using only 11% of the value *The number of used connections is 11% of the configured maximum.*\n\n\nAlso i need to increase the query\\_cache\\_size because it’s almost full *Current Query cache Memory fill ratio = 98.15 %*\n\n\n \n\n\nI have also a lot of joins that are not using indexes but I will not increase the *join\\_buffer\\_size* because I know that this is from some bad query from one Joomla website with bad plugins and this error will continue.\n\n\nmysqltuner.pl – High Performance MySQL Tuning Script\n----------------------------------------------------\n\n\nYou can get this script from github: <https://raw.github.com/major/MySQLTuner-perl/master/mysqltuner.pl>\n\n\nDebian users can also get it using APT\n\n\n\n```\napt-get install mysqltuner\n```\n\n### Running mysqltuner.pl will gave you this output:\n\n\n\n```\n-------- General Statistics --------------------------------------------------\n[--] Skipped version check for MySQLTuner script\n[OK] Currently running supported MySQL version 5.1.63-0+squeeze1-log\n[OK] Operating on 64-bit architecture\n\n-------- Storage Engine Statistics -------------------------------------------\n[--] Status: -Archive -BDB -Federated +InnoDB -ISAM -NDBCluster\n[--] Data in MyISAM tables: 460M (Tables: 1225)\n[--] Data in InnoDB tables: 398M (Tables: 260)\n[--] Data in MEMORY tables: 0B (Tables: 9)\n[!!] Total fragmented tables: 324\n\n-------- Performance Metrics -------------------------------------------------\n[--] Up for: 1d 8h 17m 11s (2M q [23.770 qps], 76K conn, TX: 33B, RX: 1B)\n[--] Reads / Writes: 76% / 24%\n[--] Total buffers: 3.0G global + 20.1M per thread (110 max threads)\n[!!] Maximum possible memory usage: 5.2G (106% of installed RAM)\n[OK] Slow queries: 0% (517/2M)\n[OK] Highest usage of available connections: 12% (14/110)\n[OK] Key buffer size / total MyISAM indexes: 768.0M/437.1M\n[OK] Key buffer hit rate: 100.0% (1B cached / 48K reads)\n[OK] Query cache efficiency: 67.9% (1M cached / 2M selects)\n[!!] Query cache prunes per day: 2542\n[OK] Sorts requiring temporary tables: 0% (0 temp sorts / 701K sorts)\n[!!] Joins performed without indexes: 644113\n[OK] Temporary tables created on disk: 16% (215K on disk / 1M total)\n[OK] Thread cache hit rate: 99% (14 created / 76K connections)\n[!!] Table cache hit rate: 16% (2K open / 15K opened)\n[OK] Open file limit used: 9% (3K/32K)\n[OK] Table locks acquired immediately: 99% (3M immediate / 3M locks)\n[OK] InnoDB data size / buffer pool: 398.2M/1.0G\n\n-------- Recommendations -----------------------------------------------------\nGeneral recommendations:\n Run OPTIMIZE TABLE to defragment tables for better performance\n Reduce your overall MySQL memory footprint for system stability\n Increasing the query\\_cache size over 128M may reduce performance\n Adjust your join queries to always utilize indexes\n Increase table\\_cache gradually to avoid file descriptor limits\nVariables to adjust:\n *** MySQL's maximum memory usage is dangerously high ***\n *** Add RAM before increasing MySQL buffer variables ***\n query\\_cache\\_size (> 768M) [see warning above]\n join\\_buffer\\_size (> 2.0M, or always use indexes with joins)\n table\\_cache (> 16384)\n```\n\n### I need to look at the Recommendations:\n\n\nAs you can see I’m getting the same warning and recommendations plus that i need to increase my *table\\_cache* this is because my table hit rate is low: *[!!] Table cache hit rate: 16% (2K open / 15K opened).*\n\n\nAlso i have fragmented tables that i need to OPTIMIZE.\n\n\nBy looking at the output of this two scripts you can do your MySQL Tuning more effectively. Just don’t forget that on every change you need to run your MySQL server for at **least one day**(*recommended 48 hours*)\n\n\n**MySQL Tuning Primer Script**: <https://launchpad.net/mysql-tuning-primer> \n\n**High Performance MySQL Tuning Script**: <https://raw.github.com/major/MySQLTuner-perl/master/mysqltuner.pl>\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
6e7bbc476fdf6b05b6a8bed936744c8c | How do you perform switch over in Postgresql ? | tutorialdba.com | 2021.04 | [
{
"text": "\n***Switchover steps:*** \n\n \n\n**Step 1.** Do clean shutdown of Primary[5432] (-m fast or smart)\n\n\n\n```\n[postgres@localhost:/~]$ /opt/PostgreSQL/9.3/bin/pg\\_ctl -D /opt/PostgreSQL/9.3/data stop -mf\nwaiting for server to shut down.... done\nserver stopped\n```\n\n**Step 2.**Check for sync status and recovery status of Standby[5433] before promoting it:\n\n\n\n```\n[postgres@localhost:/opt/PostgreSQL/9.3~]$ psql -p 5433 -c 'select pg\\_last\\_xlog\\_receive\\_location() \"receive\\_location\",\npg\\_last\\_xlog\\_replay\\_location() \"replay\\_location\",pg\\_is\\_in\\_recovery() \"recovery\\_status\";'\n receive\\_location | replay\\_location | recovery\\_status\n------------------+-----------------+-----------------\n 2/9F000A20 | 2/9F000A20 | t\n(1 row)\n```\n\nStandby in complete sync. At this stage we are safe to promote it as Primary. \n\n**Step 3.**Open the Standby as new Primary by pg\\_ctl promote or creating a trigger file.\n\n\n\n```\n[postgres@localhost:/opt/PostgreSQL/9.3~]$ grep trigger\\_file data\\_slave/recovery.conf\ntrigger\\_file = '/tmp/primary\\_down.txt'\n[postgres@localhost:/opt/PostgreSQL/9.3~]$ touch /tmp/primary\\_down.txt\n\n[postgres@localhost:/opt/PostgreSQL/9.3~]$ psql -p 5433 -c \"select pg\\_is\\_in\\_recovery();\"\n pg\\_is\\_in\\_recovery\n-------------------\n f\n(1 row)\n```\n\n\n```\nIn Logs: \n```\n\n\n```\n2014-12-29 00:16:04 PST-26344-- [host=] LOG: trigger file found: /tmp/primary\\_down.txt 2014-12-29 00:16:04 PST-26344-- [host=] LOG: redo done at 2/A0000028 2014-12-29 00:16:04 PST-26344-- [host=] LOG: selected new timeline ID: 14 2014-12-29 00:16:04 PST-26344-- [host=] LOG: restored log file \"0000000D.history\" from archive 2014-12-29 00:16:04 PST-26344-- [host=] LOG: archive recovery complete 2014-12-29 00:16:04 PST-26342-- [host=] LOG: database system is ready to accept connections 2014-12-29 00:16:04 PST-31874-- [host=] LOG: autovacuum launcher started\n```\n\nStandby has been promoted as master and a new timeline followed which you can notice in logs. \n\n**Step 4.** Restart old Primary as standby and allow to follow the new timeline by passing \"recovery\\_target\\_timline='latest'\" in $PGDATA/recovery.conf file.\n\n\n\n```\n[postgres@localhost:/opt/PostgreSQL/9.3~]$ cat data/recovery.conf\nrecovery\\_target\\_timeline = 'latest'\nstandby\\_mode = on\nprimary\\_conninfo = 'host=localhost port=5433 user=postgres'\nrestore\\_command = 'cp /opt/PostgreSQL/9.3/archives93/%f %p'\ntrigger\\_file = '/tmp/primary\\_131\\_down.txt'\n[postgres@localhost:/opt/PostgreSQL/9.3~]$ /opt/PostgreSQL/9.3/bin/pg\\_ctl -D /opt/PostgreSQL/9.3/data start\nserver starting\n```\n\nIf you go through recovery.conf its very clear that old Primary trying to connect to 5433 port as new Standby pointing to common WAL Archives location and started.\n\n\n\n```\nIn Logs:\n```\n\n\n```\n2014-12-29 00:21:17 PST-32315-- [host=] LOG: database system was shut down at 2014-12-29 00:12:23 PST 2014-12-29 00:21:17 PST-32315-- [host=] LOG: restored log file \"0000000E.history\" from archive 2014-12-29 00:21:17 PST-32315-- [host=] LOG: entering standby mode 2014-12-29 00:21:17 PST-32315-- [host=] LOG: restored log file \"0000000D00000002000000A0\" from archive 2014-12-29 00:21:17 PST-32315-- [host=] LOG: restored log file \"0000000D.history\" from archive 2014-12-29 00:21:17 PST-32315-- [host=] LOG: consistent recovery state reached at 2/A0000090 2014-12-29 00:21:17 PST-32315-- [host=] LOG: record with zero length at 2/A0000090 2014-12-29 00:21:17 PST-32310-- [host=] LOG: database system is ready to accept read only connections 2014-12-29 00:21:17 PST-32325-- [host=] LOG: started streaming WAL from primary at 2/A0000000 on timeline 14\n```\n\n**Step 5.** Verify the new Standby status.\n\n\n\n```\n[postgres@localhost:/opt/PostgreSQL/9.3~]$ psql -p 5432 -c \"select pg\\_is\\_in\\_recovery();\"\n pg\\_is\\_in\\_recovery\n-------------------\n t\n(1 row)\n```\n\nCool, without any re-setup we have brought back old Primary as new Standby. \n\n \n\n***Switchback steps:*** \n\n \n\n**Step 1.** Do clean shutdown of new Primary [5433]:\n\n\n\n```\n[postgres@localhost:/opt/~]$ /opt/PostgreSQL/9.3/bin/pg\\_ctl -D /opt/PostgreSQL/9.3/data\\_slave stop -mf\nwaiting for server to shut down.... done\nserver stopped\n```\n\n**Step 2.** Check for sync status of new Standby [5432] before promoting. \n\n**Step 3.**Open the new Standby [5432] as Primary by creating trigger file or pg\\_ctl promote.\n\n\n\n```\n[postgres@localhost:/opt/PostgreSQL/9.3~]$ touch /tmp/primary\\_131\\_down.txt\n```\n\n**Step 4.** Restart stopped new Primary [5433] as new Standby.\n\n\n\n```\n[postgres@localhost:/opt/PostgreSQL/9.3~]$ more data\\_slave/recovery.conf\nrecovery\\_target\\_timeline = 'latest'\nstandby\\_mode = on\nprimary\\_conninfo = 'host=localhost port=5432 user=postgres'\nrestore\\_command = 'cp /opt/PostgreSQL/9.3/archives93/%f %p'\ntrigger\\_file = '/tmp/primary\\_down.txt'\n\n[postgres@localhost:/opt/PostgreSQL/9.3~]$ /opt/PostgreSQL/9.3/bin/pg\\_ctl -D /opt/PostgreSQL/9.3/data\\_slave start\nserver starting\n```\n\nYou can verify the logs of new Standby.\n\n\n\n```\nIn logs:\n```\n\n\n```\n[postgres@localhost:/opt/PostgreSQL/9.3/data\\_slave/pg\\_log~]$ more postgresql-2014-12-29\\_003655.log 2014-12-29 00:36:55 PST-919-- [host=] LOG: database system was shut down at 2014-12-29 00:34:01 PST 2014-12-29 00:36:55 PST-919-- [host=] LOG: restored log file \"0000000F.history\" from archive 2014-12-29 00:36:55 PST-919-- [host=] LOG: entering standby mode 2014-12-29 00:36:55 PST-919-- [host=] LOG: restored log file \"0000000F.history\" from archive 2014-12-29 00:36:55 PST-919-- [host=] LOG: restored log file \"0000000E00000002000000A1\" from archive 2014-12-29 00:36:55 PST-919-- [host=] LOG: restored log file \"0000000E.history\" from archive 2014-12-29 00:36:55 PST-919-- [host=] LOG: consistent recovery state reached at 2/A1000090 2014-12-29 00:36:55 PST-919-- [host=] LOG: record with zero length at 2/A1000090 2014-12-29 00:36:55 PST-914-- [host=] LOG: database system is ready to accept read only connections 2014-12-29 00:36:55 PST-929-- [host=] LOG: started streaming WAL from primary at 2/A1000000 on timeline 15 2014-12-29 00:36:56 PST-919-- [host=] LOG: redo starts at 2/A1000090\n```\n\nVery nice, without much time we have switched the duties of Primary and Standby servers. You can even notice the increment of the timeline IDs from logs for each promotion.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
838ac0f846993cc2e7f5a71bffee8bb8 | mysqldump to Back Up MySQL or MariaDB | tutorialdba.com | 2020.45 | [
{
"text": "\n[MySQL](http://www.mysql.com/) and [MariaDB](https://mariadb.com/) include the [mysqldump](https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html) utility to simplify the process to create a backup of a database or system of databases. Using `mysqldump` creates a *logical backup*. **You can only use this tool if your database process is accessible and running.**\n\n\nIf your database isn’t accessible for any reason, you can instead create a [*physical backup*](https://www.linode.com/docs/databases/mysql/create-physical-backups-of-your-mariadb-or-mysql-databases/), which is a copy of the filesystem structure which contains your data.\n\n\nThe instructions in this guide apply to both MySQL and MariaDB. For simplification, the name MySQL will be used to apply to either.\n\n\nBefore You Begin[Permalink](https://www.linode.com/docs/databases/mysql/use-mysqldump-to-back-up-mysql-or-mariadb/#before-you-begin)\n------------------------------------------------------------------------------------------------------------------------------------\n\n\n* You will need a working MySQL or MariaDB installation, and a database user to run the backup. For help with installation, see the [Linode MySQL documentation](https://www.linode.com/docs/databases/mysql/).\n* You will need root access to the system, or a user account with `sudo` privileges.\n\n\nBack up a Database[Permalink](https://www.linode.com/docs/databases/mysql/use-mysqldump-to-back-up-mysql-or-mariadb/#back-up-a-database)\n----------------------------------------------------------------------------------------------------------------------------------------\n\n\nThe `mysqldump` command’s general syntax is:\n\n\n\n```\nmysqldump -u [username] -p [databaseName] > [filename]-$(date +%F).sql\n\n```\n\n* `mysqldump` prompts for a password before it starts the backup process.\n* Depending on the size of the database, it could take a while to complete.\n* The database backup will be created in the directory the command is run.\n* `-$(date +%F)` adds a timestamp to the filename.\n\n\nExample use cases include:\n\n\n* Create a backup of an entire Database Management System (DBMS):\n\n\n\n```\nmysqldump --all-databases --single-transaction --quick --lock-tables=false > full-backup-$(date +%F).sql -u root -p\n\n```\n* Back up a specific database. Replace `db1` with the name of the database you want to back up:\n\n\n\n```\nmysqldump -u username -p db1 --single-transaction --quick --lock-tables=false > db1-backup-$(date +%F).sql\n\n```\n* Back up a single table from any database. In the example below, `table1` is exported from the database `db1`:\n\n\n\n```\nmysqldump -u username -p --single-transaction --quick --lock-tables=false db1 table1 > db1-table1-$(date +%F).sql\n\n```\n\n\nHere’s a breakdown of the `mysqldump` command options used above:\n\n\n* `--single-transaction`: Issue a BEGIN SQL statement before dumping data from the server.\n* `--quick`: Enforce dumping tables row by row. This provides added safety for systems with little RAM and/or large databases where storing tables in memory could become problematic.\n* `--lock-tables=false`: Do not lock tables for the backup session.\n\n\nAutomate Backups with cron[Permalink](https://www.linode.com/docs/databases/mysql/use-mysqldump-to-back-up-mysql-or-mariadb/#automate-backups-with-cron)\n--------------------------------------------------------------------------------------------------------------------------------------------------------\n\n\nEntries can be added to `/etc/crontab` to regularly schedule database backups.\n\n\n1. Create a file to hold the login credentials of the MySQL root user which will be performing the backup. Note that the system user whose home directory this file is stored in can be unrelated to any MySQL users.\n\n\n/home/example\\_user/.mylogin.cnf\n\n\n\n| \n```\n1\n2\n3\n\n```\n | \n```\n[client]\nuser = root\npassword = MySQL root user's password\n```\n |\n2. Restrict permissions of the credentials file:\n\n\n\n```\nchmod 600 /home/example_user/.mylogin.cnf\n\n```\n3. Create the cron job file. Below is an example cron job to back up the entire database management system every day at 1am:\n\n\n/etc/cron.daily/mysqldump\n\n\n\n| \n```\n1\n\n```\n | \n```\n0 1 * * * /usr/bin/mysqldump --defaults-extra-file=/home/example_user/.my.cnf -u root --single-transaction --quick --lock-tables=false --all-databases > full-backup-$(date +%F).sql\n```\n |\n\nFor more information on cron, see the [cron(8)](https://linux.die.net/man/8/cron) and [cron(5)](https://linux.die.net/man/5/crontab) manual pages.\n\n\nRestore a Backup[Permalink](https://www.linode.com/docs/databases/mysql/use-mysqldump-to-back-up-mysql-or-mariadb/#restore-a-backup)\n------------------------------------------------------------------------------------------------------------------------------------\n\n\nThe restoration command’s general syntax is:\n\n\n\n```\nmysql -u [username] -p [databaseName] < [filename].sql\n\n```\n\n* Restore an entire DBMS backup. You will be prompted for the MySQL root user’s password: \n\n**This will overwrite all current data in the MySQL database system**\n\n\n\n```\nmysql -u root -p < full-backup.sql\n\n```\n* Restore a single database dump. An empty or old destination database must already exist to import the data into, and the MySQL user you’re running the command as must have write access to that database:\n\n\n\n```\nmysql -u [username] -p db1 < db1-backup.sql\n\n```\n* Restore a single table, you must have a destination database ready to receive the data:\n\n\n\n```\nmysql -u dbadmin -p db1 < db1-table1.sql\n\n```\n\n\nMore Information[Permalink](https://www.linode.com/docs/databases/mysql/use-mysqldump-to-back-up-mysql-or-mariadb/#more-information)\n------------------------------------------------------------------------------------------------------------------------------------\n\n\nYou may wish to consult the following resources for additional information on this topic. While these are provided in the hope that they will be useful, please note that we cannot vouch for the accuracy or timeliness of externally hosted materials.\n\n\n* [MySQL Database Backup Methods page](http://dev.mysql.com/doc/refman/5.1/en/backup-methods.html)\n* [mysqldump - A Database Backup Program, MySQL Reference Manual](https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html)\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
35549ff86f885a3dcc156446764bef53 | How will you create postgresql super user any idea ? At the time of user creation,and how to give superuser privilege already existing user ? | How will you create super user any idea ? | tutorialdba.com | 2021.04 | [
{
"text": "\nYou can create postgresql superuser following two meyhme\n--------------------------------------------------------\n\n\n1.To create the user `joe` as a superuser, and assign a password immediately:\n-----------------------------------------------------------------------------\n\n\n\n```\n$ createuser -P -s -e joe\nEnter password for new role: xyzzy\nEnter it again: xyzzy\nCREATE ROLE joe PASSWORD 'md5b5f5ba1a423792b526f799ae4eb3d59e' SUPERUSER CREATEDB CREATEROLE INHERIT LOGIN;\n```\n\n2.Altering Existing User Permissions\n------------------------------------\n\n\nNow that our `librarian` user exists, we can begin using `ALTER USER` to modify the permissions granted to `librarian`.\n\n\nThe basic format of `ALTER USER` includes the name of the user (or `ROLE`) followed by a series of `options` to inform PostgreSQL which permissive alterations to make:\n\n\n\n```\n=# ALTER USER role_specification WITH OPTION1 OPTION2 OPTION3;\n\n```\n\nThese options range from `CREATEDB`, `CREATEROLE`, `CREATEUSER`, and even `SUPERUSER`. Additionally, most options also have a negative counterpart, informing the system that you wish to deny the user that particular permission. These option names are the same as their assignment counterpart, but are prefixed with `NO` (e.g. `NOCREATEDB`, `NOCREATEROLE`, `NOSUPERUSER`).\n\n\n### ASSIGNING `SUPERUSER` PERMISSION\n\n\nNow that we understand the basics of creating users and using `ALTER USER` to modify permissions, we can quite simply use the `SUPERUSER` option to assign our `librarian` user `SUPERUSER` permission:\n\n\n\n```\n=# ALTER USER librarian WITH SUPERUSER;\nALTER ROLE\n\n```\n\nSure enough, if we display our permission list now, we’ll see `librarian` has the new `SUPERUSER` permission we want:\n\n\n\n```\n=# \\du\n List of roles\n Role name | Attributes | Member of\n-----------+------------------------------------------------+-----------\n librarian | Superuser | {}\n postgres | Superuser, Create role, Create DB, Replication | {}\n\n```\n\n### REVOKING PERMISSIONS\n\n\nIn the event that we make a mistake and assign a permission we later wish to revoke, simply issue the same `ALTER USER`command but add the `NO` prefix in front of the permissive options to be revoked.\n\n\nFor example, we can remove `SUPERUSER`from our `librarian` user like so:\n\n\n\n```\n=# ALTER USER librarian WITH NOSUPERUSER;\nALTER ROLE\n=# \\du\n List of roles\n Role name | Attributes | Member of\n-----------+------------------------------------------------+-----------\n librarian | | {}\n postgres | Superuser, Create role, Create DB, Replication | {}\n```\n\n",
"name": "",
"is_accepted": false
}
] |
22aef231c1cdda6c621b3608fb85b00c | What is the difference between RAC public IP, private IP ,Virtual VIP and scan IP ? | tutorialdba.com | 2021.04 | [
{
"text": "\n* **Public IP:**The public IP address is for the server. This is the same as any server IP address, a unique address with exists in /etc/hosts.\n* **Private IP:** Oracle RCA requires \"private IP\" addresses to manage the CRS, the clusterware heartbeat process and the cache fusion layer.Oracle Clusterware uses the interfaces you identify as private for the cluster interconnect. If you identify multiple interfaces during information for the private network, then Oracle Clusterware configures them with Redundant Interconnect Usage. Any interface that you identify as private must be on a subnet that connects to every node of the cluster. Oracle Clusterware uses all the interfaces you identify for use as private interfaces.\n* **Virtual IP:** Oracle uses a Virtual IP (VIP) for database access. The VIP must be on the same subnet as the public IP address. The VIP is used for RAC failover (TAF).The virtual IP (VIP) address is registered in the grid naming service (GNS), the DNS, or in a hosts file.Select an address for your VIP that meets the following requirements:The IP address and host name are currently unused (it can be registered in a DNS, but should not be accessible by a ping command).The simple answer to this question is to avoid TCP timeouts.If the client request goes to Virtual IP of the node (VIP) and the node is down, VIP will automatically failover to one of the surviving nodes without waiting for the network time-out and client gets connected.\n* **SCAN IP:**\n\n\n \n\n\n* SCAN will do this on the client side - by providing the client with a Single Client Acces Name to use as oppose to 10 VIPs. The SCAN listener service knows all cluster services - and can redirect the client to the appropriate VIP listener where the requested service is available.\n* Scan has 3 IPs configured in DNS server instead of one IP because to distribute total load on single IP.\n* Oracle recommends 3 IPs for scan is enough for load distribution among 3 scan IPs and provides ease in management of cluster nodes (addition or deletion).\n* You can add new nodes to the cluster without changing your client TNSnames. This is because Oracle will automatically distribute requests accordingly based on the SCAN IPs which point to the underlying VIPs. Scan listeners do the bridge between clients and the underlying local listeners which are VIP-dependent.\n\n\n \n\nSuppose, we have a two node Real Application Cluster set up with following IP's \n\n \n\n \n\n\n\n```\nNODE Static IP address Virtual IP address\n==============================================\nracnode1 192.168.1.100 192.168.1.200 \n (racnode1) (racnode1\\_vip1)\n\nracnode2 192.168.1.101 192.168.1.201 \n (racnode2) (racnode2\\_vip2)\n\n```\n\n \n\n \n\n**In Database Management Software Oracle 10g:** \n\n \n\nLet's first see how this works in Oracle 10g. Suppose, Listener.ora of both Database is using Static IP for it's configuration like \n\n \n\n\n\n```\nLISTENER=\n (DESCRIPTION=\n (ADDRESS\\_LIST=\n (ADDRESS=(PROTOCOL=tcp)(HOST=racnode1)(PORT=1521))\n (ADDRESS=(PROTOCOL=ipc)(KEY=extproc))))\nSID\\_LIST\\_LISTENER=\n (SID\\_LIST=\n (SID\\_DESC=\n (GLOBAL\\_DBNAME=sales.us.example.com)\n (ORACLE\\_HOME=/oracle10g)\n (SID\\_NAME=Service1))\n (SID\\_DESC=\n (SID\\_NAME=plsextproc)\n (ORACLE\\_HOME=/oracle10g)\n (PROGRAM=extproc)))\n```\n\n \n\nHence, Tnsnames.ora for Client system will be like \n\n \n\n\n\n```\nService1 =\n(DESCRIPTION =\n (ADDRESS=(PROTOCOL=TCP)(HOST=racnode1)(PORT=1521))\n (ADDRESS=(PROTOCOL=TCP)(HOST=racnode2)(PORT=1521))\n (CONNECT\\_DATA =\n (SERVICE\\_NAME = Service1)\n )\n )\n```\n\n \n\nNow, A new connection to database will first go to **racnode1**, if this node is alive and working fineconnection will be establish and user can continue work. \n\n \n\nWhat if, **racnode1** is not available Even in this case, client tries to establish a connection with the**racnode1** Because, it is first in its address list.But since the node(**racnode1**) is not available, client tries to establish it’s connection with the next available address in the list (i.e **racnode2**). So, there is a delay to move from one node to other. This is called Connect-Time Failover. \n\n \n\nBut the Problem is that the TIME (TCP TIMEOUT) it takes to failover, which will be ranging between a few seconds to a few minutes. For a very high critical systems/environments this is not acceptable. \n\n \n\n**To resolve this problem Oracle introduce Virtual IP (VIP).** \n\n \n\nLet's see how it works with VIP. \n\n \n\nNow, Listener.ora of both Database is using VIP for it's configuration like \n\n\n\n```\nLISTENER=\n (DESCRIPTION=\n (ADDRESS\\_LIST=\n (ADDRESS=(PROTOCOL=tcp)(HOST=racnode1\\_vip1)(PORT=1521))\n (ADDRESS=(PROTOCOL=ipc)(KEY=extproc))))\nSID\\_LIST\\_LISTENER=\n (SID\\_LIST=\n (SID\\_DESC=\n (GLOBAL\\_DBNAME=sales.us.example.com)\n (ORACLE\\_HOME=/oracle10g)\n (SID\\_NAME=Service1))\n (SID\\_DESC=\n (SID\\_NAME=plsextproc)\n (ORACLE\\_HOME=/oracle10g)\n (PROGRAM=extproc)))\n```\n\n \n\nHence, Tnsnames.ora for Client system will be like \n\n \n\n\n\n```\nService1 =\n(DESCRIPTION =\n (ADDRESS=(PROTOCOL=TCP)(HOST=racnode1\\_vip1)(PORT=1521))\n (ADDRESS=(PROTOCOL=TCP)(HOST=racnode1\\_vip2)(PORT=1521))\n (CONNECT\\_DATA =\n (SERVICE\\_NAME = Service1)\n )\n )\n```\n\n \n\nNow, A new connection to database will first go to **racnode1\\_vip1**, if this node is alive and workingfine connection will be establish and user can continue work. \n\n \n\nWhat if, **racnode1\\_vip1** is not available Even in this case, client tries to establish a connection with the **racnode1\\_vip1** Because, it is first in its address list. But since the node(**racnode1\\_vip1**) is notavailable, CRS will come in to picture and move the failed node’s VIP to one of the surviving nodes of the cluster. \n\n \n\n Any connection attempts to the failed node by using VIP will be handled by the failed node’s VIP that is currently residing on one of the surviving node. \n\n \n\nThis (failed node’s VIP) will respond immediately to client by sending an error indicating that there is no listener. Upon receiving the information of no listener,client immediately retry connection using the next IP in the address list. Thus reduces the time to failover. \n\n \n\n**In Database Management Softwere Oracle 11g2:** \n\n \n\nWhen we talk about Oracle 11g, Since, we have SCAN VIP's in Oracle 11g, Following question comes into mind \n\n \n\n**Do we still need VIP in Oracle 11g ?** \n\n \n\n Yes, We still need VIP. VIP still play the same role as it is discussed in case of **Database Management Softwere Oracle 10g.** \n\n \n\n\n**What is the Difference between SCAN VIP and VIP ?**\n\n\n \n\nThe IP address corresponding to SCAN NAME are called as SCAN VIP. Which runs on DB nodes as SCAN LISTENERS. \n\n \n\n Let's see how VIP's works in 11g R2. In Oracle 11g R2, tnsnames.ora will have only one entry that is scan name of the Cluster like. \n\n \n\n\n\n```\nService1 =\n(DESCRIPTION =\n (ADDRESS=(PROTOCOL=TCP)(HOST=scan\\_racnode1\\_vip1)(PORT=1521))\n (CONNECT\\_DATA =\n (SERVICE\\_NAME = Service1)\n )\n )\n```\n\nThis scan name is resolved by any of the **SCAN VIP** and every **SCAN VIP** has a Listener associated with it running on node know as SCAN LISTENER. In below example, There are two SCAN LISTENER's running on **odain1** and **odain2**. \n\n \n\n\n\n```\n[grid@bin]$ srvctl status scan\\_listener\nSCAN Listener LISTENER\\_SCAN1 is enabled\nSCAN listener LISTENER\\_SCAN1 is running on node odain1\nSCAN Listener LISTENER\\_SCAN2 is enabled\nSCAN listener LISTENER\\_SCAN2 is running on node odain2\n```\n\nAll databases are registered with each SCAN LISTENER in the Cluster and PMON updates it's load to each SCAN LISTENER. Each request go through using SCAN\\_NAME, resolves to SCAN VIP i.e. SCAN LISTENER. Now, SCAN LISTENER redirects it to VIP by deciding using Load Balance. \n\n \n\nSCAN \\_NAME ===============>>> SCANNING -VIP ==============>>>> VIP\n\n\n",
"name": "",
"is_accepted": true
}
] |
|
5afe63f4555dcb9cc765365005c7f8fb | Anyone having idea about taking backBa on slave ? | How will you take Postgresql backup on slave ? | tutorialdba.com | 2020.16 | [
{
"text": "\n \n\n\nYou can take the logical backup from PostgreSQL Slave server Following steps\n\n\nhere i used PostgreSQL 10.3 and redhat 7.3 plateform.\n\n\n\n```\n **POSTGRESQL 9.6** **POSTGRESQL 10** \nselect pg\\_xlog\\_replay\\_pause(); select pg\\_wal\\_replay\\_pause(); #Pauses recovery immediately\nselect pg\\_is\\_xlog\\_replay\\_paused(): select pg\\_is\\_wal\\_replay\\_paused(); #True if recovery is paused.\nselect pg\\_xlog\\_replay\\_resume(); select pg\\_wal\\_replay\\_resume(); # Restarts recovery if it was paused\n\n```\n\n \n\n\n**Step 1: issue the pg\\_wal\\_replay\\_pause() or pg\\_xlog\\_replay\\_pause() function on slave** \n\n**select pg\\_wal\\_replay\\_pause();** \n\n \n\n**Step 2:insert some data into master or restore the data then check the slave whether replicated or not**\n\n\n\n```\n**On master:**\ncreate table t3(id int,name varchar);\nCREATE TABLE\n\n**On slave:**\npostgres=# \\dt t3\nDid not find any relation named \"t3\".\n```\n\n**Step 3:pg\\_start\\_backup(\"label\") is not possible on slave\\_2 but you can use pg\\_dump,pg\\_dumpall**\n\n\n\n```\n**On slave:**\nselect pg\\_start\\_backup('label');\nERROR: recovery is in progress\nHINT: WAL control functions cannot be executed during recovery.\n\n**TAKING BACKUP FROM SLAVE:**\ncd /usr/bin/pg\\_dump -d postgres -f /BACKUP/nijam.dump\n```\n\n**AFTER BACKUP RESUME THE STREAMING REPLICATION THEN CHECK THE TABLE T3 WHETHER REPLICATED OR NOT**\n\n\n\n```\npostgres=# select pg\\_wal\\_replay\\_resume();\n pg\\_wal\\_replay\\_resume \n----------------------\n \n(1 row)\n\npostgres=# \\dt\n List of relations\n Schema | Name | Type | Owner \n--------+------+-------+----------\n public | t | table | postgres\n public | t1 | table | postgres\n public | t3 | table | postgres\n```\n\n",
"name": "",
"is_accepted": false
}
] |
abb9fd02c2b69e4202637a077737fae1 | How to change all objects ownership in a particular schema in PostgreSQL ? | tutorialdba.com | 2019.47 | [
{
"text": "\nBash script for changing all object’s *(TABLES / SEQUENCES / VIEWS / FUNCTIONS / AGGREGATES / TYPES)*ownership in a particular schema in one go. No special code included in a script, I basically picked the technique suggested and simplified the implementation method via script. Actually, [REASSIGN OWNED BY](http://www.postgresql.org/docs/9.2/static/sql-reassign-owned.html)command does most of the work smoothly, however, it changes database-wide objects ownership regardless of any schema. Two eventualities, where you may not use REASSIGN OWNED BY: \n\n \n\n*1. If the user by mistake creates all his objects with super-user(postgres), and later intend to change to other user, then REASSIGN OWNED BY will not work and it merely error out as:* \n\npostgres=# reassign owned by postgres to user1; ERROR: cannot reassign ownership of objects owned by role postgres because they are required by the database system\n\n\n*2. If user wish to change just only one schema objects ownership.* \n\nEither cases of changing objects, from “postgres” user to other user or just changing only one schema objects, we need to loop through each object by collecting object details from pg\\_catalog’s & information\\_schema and calling*ALTER* *TABLE / FUNCTION / AGGREGATE / TYPE* etc. \n\nI liked the technique of tweaking pg\\_dump output using OS commands(sed/egrep), because it known that by nature the pg\\_dump writes ALTER .. OWNER TO of every object (*TABLES / SEQUENCES / VIEWS / FUNCTIONS / AGGREGATES / TYPES*) in its output. Grep’ing those statements from pg\\_dump stdout by replacing new USER/SCHEMANAME with sed and then passing back those statements to psql client will fix the things even if the object owned by Postgres user. I used same approach in script and allowed user to pass NEW USER NAME and SCHEMA NAME, so to replace it in ALTER…OWNER TO.. statement. \n\n*Script usage and output:*\n\n\n\n```\nsh change\\_owner.sh -n new\\_rolename -S schema\\_name\n-bash-4.1$ sh change\\_owner.sh -n user1 -S public\n Summary:\n Tables/Sequences/Views : 16\n Functions : 43\n Aggregates : 1\n Type : 2\nScript\n======\n#!/bin/bash\n# Script changes all the object ownership from x to y\n# Provided following environment variable are\n# mandatory PGUSER/PGDATABASE/PGPORT/PGHOST beforehand\n#------------------------------------------------------\nflag=0\nusage()\n{\n echo \"Usage:\"\n echo \" sh change\\_owner.sh -n new\\_role -S schema\\_name\\_of\\_objects\"\n echo \"\"\n echo \" -n Give the new role name for the objects to be owned.\"\n echo \" -S Schema in which objects has to be changed.\"\n echo \" \"\n echo \" Note: Set PGUSER - PGDATABASE - PGPORT - PGHOST - PG binaries in PATH \"\n echo -e \" ---- before running the script.\\n\"\n exit 1;\n}\nif env |grep -q ^PGPORT= && env | grep -q ^PGUSER= && env | grep -q ^PGDATABASE= && env | grep -q ^PGHOST=\nthen\n PGDATABASE=`env | grep -i pgdatabase | cut -d \"=\" -f2`\nelse\n echo -e \"\\nScript need PGHOST/PGUSER/PGDATABASE/PGPORT environment variables set... \\n\"\n usage\nfi\nif ! command -v psql >/dev/null 2>&1; then\n echo -e \"\\nPostgreSQL psql client not set in Path...\"\n usage\nfi\nPGSQLBIN=`command -v psql`\nDUMPBIN=`command -v pg\\_dump`\nwhile getopts \":n:S:\" options; do\n case $options in\n n)\n flag=$((flag+1))\n NEWROLE=${OPTARG}\n ;;\n S)\n flag=$((flag+1))\n SCHEMAS=${OPTARG}\n ;;\n \\?) echo \"Unknown option: -$OPTARG\" >&2; usage ;exit 1;;\n esac\ndone\nif [ $flag -ne 2 ]; then\n echo -e \"\\n\\t All options are Mandatory...!!!\"\n usage\n exit 1\nfi\nUCHECK=$($PGSQLBIN -t -c \"select 1 from pg\\_authid where rolname = '$NEWROLE';\")\nSCHECK=$($PGSQLBIN -t -c \"select 1 from pg\\_namespace where nspname = '$SCHEMAS';\")\nUUCHECK=${UCHECK:-0}\nSSCHECK=${SCHECK:-0}\nif [ $UUCHECK -eq 1 ] && [ $SSCHECK -eq 1 ];\nthen\n $DUMPBIN -s -c -U $PGUSER ${PGDATABASE} | egrep \"${SCHEMAS}\\..*OWNER TO\"| sed -e \"s/OWNER TO.*;$/OWNER TO ${NEWROLE};/\" >/tmp/oc.sql\n $DUMPBIN -s -c -U $PGUSER ${PGDATABASE} | egrep \"${SCHEMAS}\\..*OWNER TO\"| sed -e \"s/OWNER TO.*;$/OWNER TO ${NEWROLE};/\" \\\n | $PGSQLBIN -U postgres -d ${PGDATABASE} >>/dev/null\n echo -e \"\\n Summary: \"\n echo \" Tables/Sequences/Views : `grep -i \"alter table\" /tmp/oc.sql | wc -l`\"\n echo \" Functions : `grep -i \"alter function\" /tmp/oc.sql | wc -l`\"\n echo \" Aggregates : `grep -i \"alter aggregate\" /tmp/oc.sql | wc -l`\"\n echo \" Type : `grep -i \"alter type\" /tmp/oc.sql | wc -l`\"\n echo \"\"\nelse\n echo \" User ($NEWROLE) or Schema ($SCHEMAS) doesnt exist, pass the valid one..... \"\nfi\n```\n\n",
"name": "",
"is_accepted": false
}
] |
|
0f5c660ec64a924d838a0014968b966e | PostgreSQL 11 Beta 1 Now Available in Amazon RDS Database Preview Environment. Amazon RDS Database Preview Environment is available from your Amazon RDS Dashboard. | PostgreSQL 11 Beta 1 Now Available in Amazon RDS Database | tutorialdba.com | 2021.39 | [
{
"text": "Very excited to let customers use the newest PostgreSQL with only a single API call or a couple clicks on the AWS console!",
"name": "",
"is_accepted": false
}
] |
7fb0b7ada48329fcdb7f051df396cc4d | Hi..can anyone help me to get Query to check which schema has default tablespace | Get Query to check which schema has default tablespace | tutorialdba.com | 2021.21 | [
{
"text": "\nThis query will check to which schema has default tablespace\n\n\n\n```\nselect * from pg\\_tables where schemaname='tab\\_test';\n```\n\nChecking to which table has default tablespace\n\n\n<https://discuss.tutorialdba.com/799/how-find-tablespace-for-table>\n\n\n",
"name": "",
"is_accepted": false
}
] |
0c2c1ef3feceb4e4fd8a053edbded23b | How to create postgres user in real time production environment ? | tutorialdba.com | 2020.34 | [
{
"text": "\nFor example Assume your linux server running 4 postgres cluster so you want to create the postgres user to all cluster use below script to create user with specific privileges.\n\n\n\n```\nfor K in {5432,5433,5434,5435}\ndo\npsql -U postgres -d postgres -p $K <<DDL\nCREATE USER khan IN ROLE role\\_name connection limit 50;\nCOMMENT ON ROLE khan IS 'fullname:khan mohammed';\n\\du+ khan \nDDL\ndone\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
|
75dd01b11177e5cfc9240126942d24c3 | How to Check Nice Value of Linux Processes | tutorialdba.com | 2020.50 | [
{
"text": "\nTo see the nice values of processes, we can use utilities such as ps, top or htop.\n\n\nTo view processes nice value with ps command in user-defined format (here the `NI` column shows niceness of processes).\n\n\n\n```\n$ ps -eo pid,ppid,ni,comm\n\n```\n\n\n\n\nView Linux Processes Nice Values\n\n\nAlternatively, you can use top or htop utilities to view Linux processes nice values as shown.\n\n\n\n```\n$ top\n$ htop\n\n```\n\n\n\n\nCheck Linux Process Nice Values using Top Command\n\n\n\n\n\nCheck Linux Process Nice Values using Htop Command\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
f517cc5a965e66106032f2b03bf2a547 | HOW TO FIX MYSQL ERROR "THE SERVER QUIT WITHOUT UPDATING PID FILE"? | tutorialdba.com | 2020.45 | [
{
"text": "\nMySQL server plays a vital role for your *[**Linux Server**](https://www.accuwebhosting.com/vps-hosting/linux-vps-hosting/vps-ssd).*It runs all of your website's databases, WHM/Cpanel control panel databases etc. MySQL service crash is very commonly faced error. There could be many reasons behind the failure of the service. In this article, we have listed the most common fixes which work on most cases.\n\n\n\n**Problem Statement**\n----------------------\n\n\n \n\nMySQL server could not get started.\n\n\n\n**Error Message**\n------------------\n\n\n \n\n*The server quit without updating PID file.* OR \n\n*Starting MySQL... ERROR! The server quit without updating PID file (/var/lib/mysql/server-name.com.pid)*\n\n\n\n**Solution:**\n--------------\n\n\n \n\nWhen you receive these errors on MySQL server, there are lots of solutions available to fix it. Let's check them out one by one: \n\n \n\n\n1. Login to your ***[Linux server](https://www.accuwebhosting.com/vps-hosting/linux-vps-hosting/vps-ssd)*** with root privileges and try to start MySQL service manually. \n\n \n \n```\n**/etc/init.d/mysql start** ....Or.....**sudo /etc/init.d/mysql start**\n```\n2. Check if you have already MySQL service running. \n\n \n\n Type following command to determine if there is MySQL service running already. \n\n \n \n```\n**ps -aux | grep mysql**\n```\n\n \n\n If MySQL service is already running, you will get list of MySQL processes with PIDs. You will have to kill those processes. \n\n \n \n```\n**kill -9 PID** // where PID is the process ID of the MySQL processes.\n```\n3. Check ownership of **/var/lib/mysql/** \n\n \n\n Type the following command to check ownership of MySQL service. \n\n \n \n```\n**ls -laF /var/lib/mysql/**\n```\n\n \n\n If it's owner is root, you should change it to MySQL or your\\_user. \n\n \n \n```\n**sudo chown -R mysql /var/lib/mysql/**\n```\n4. Take backup of **mysql.sock** file and remove it. To achieve this, fire following commands: \n\n \n \n```\n**cp /var/lib/mysql.sock /var/lib/mysql.sock\\_bkp**\n**rm -rf /var/lib/mysql.sock**\n```\n\n \n\n Now, have a try to start MySQL service with following command. \n\n \n \n```\n**/etc/init.d/mysql start**\n```\n5. Try to find log files with suffix \".err\". \n\n \n\n You will get these files at following path. This files contain actual error messages. \n\n \n \n```\n**/var/lib/mysql/your\\_computer\\_name.err**\n```\n\n \n\n In many cases, this issue is resolved by removing this error files.\n6. Check if **my.conf** file has been modified recently. \n\n \n\n If you wish to edit my.conf file, it is recommended to take backup so you can restore it if anything goes wrong. Additionally, you will have to be extra careful that you do not add any invalid characters or line in this file. If you notice any changes to this file, revert it from a known backup you have. \n\n \n\n Navigate to **/etc/my.cnf** and restore the changes you have made to this file.\n7. Move the log file named ib\\_logfile in /var/lib/mysql and restart MySQL service. \n\n \n\n Sometimes MySQL service fails to start because it faces difficulty while updating the log files. You can either remove these log files or move to some other folder. These log files will be created automatically once you restart the MySQL server. Following are the commands: \n\n \n \n```\n**cd /var/lib/mysql\nmv ib\\_logfile0 ib\\_logfile0.bak \nmv ib\\_logfile1 ib\\_logfile1.bak\nmv /var/lib/mysql/ib\\_logfile* /some/tmp/folder/**\n```\n\n\n**Notes** \n\n \n\n\n1. We recommend you to take full backup of folder **/var/lib/mysql** before you make any changes to MySQL service of your ***[Linux server](https://www.accuwebhosting.com/vps-hosting/linux-vps-hosting/vps-ssd).***\n2. In case you wish to make any changes in these files, it is recommended to take a backup of it.\n3. The path of the MySQL services can be different according to the operating system. For Example: \n\n \n\n**Mac OS**: /usr/local/var/mysql/ \n\n**Linux OS**: /var/lib/mysql/\n\n\n \n\nLooking for more assistance on MySQL? Take a look at our Expert <https://2ndquadrant.in/contact/>\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
4b8f516c8ff9bb6238dc449366aa4812 | Easy way to Getting SSL Certificates For PostgreSQL | tutorialdba.com | 2020.40 | [
{
"text": "\nThis describes how to set up ssl certificates to enable encrypted connections from PgAdmin on some client machine to postgresql on a server machine. The assumption is that postgresql (compiled with ssl support) and openssl are already installed and functional on the server (Linux). PgAdmin is already installed on the client (either Windows or Linux).\n\n\n**On the server, three certificates are required in the data directory. CentOS default is /var/lib/pgsql/data/:**\n\n\n* root.crt (trusted root certificate)\n* server.crt (server certificate)\n* server.key (private key)\n\n\nIssue commands as root.\n\n\n\n```\nsudo -\n```\n\n\n```\ncd /var/lib/pgsql/data\n```\n\nGenerate a private key (you must provide a passphrase).\n\n\n\n```\nopenssl genrsa -des3 -out server.key 1024\n```\n\nRemove the passphrase.\n\n\n\n```\nopenssl rsa -in server.key -out server.key\n```\n\nSet appropriate permission and owner on the private key file.\n\n\n\n```\nchmod 400 server.key\nchown postgres.postgres server.key\n```\n\nCreate the server certificate. \n\n-subj is a shortcut to avoid prompting for the info. \n\n-x509 produces a self signed certificate rather than a certificate request.\n\n\n\n```\nopenssl req -new -key server.key -days 3650 -out server.crt -x509 -subj '/C=CA/ST=British Columbia/L=Comox/O=TheBrain.ca/CN=thebrain.ca/[email protected]'\n```\n\nSince we are self-signing, we use the server certificate as the trusted root certificate.\n\n\n\n```\ncp server.crt root.crt\n```\n\n**You'll need to edit pg\\_hba.conf. For example:**\n\n\n\n```\n# TYPE DATABASE USER CIDR-ADDRESS METHOD\n# \"local\" is for Unix domain socket connections only\nlocal all all trust\n# IPv4 local connections:\nhost all all 127.0.0.1/32 trust\n\n# IPv4 remote connections for authenticated users\nhostssl all www-data 0.0.0.0/0 md5 clientcert=1\nhostssl all postgres 0.0.0.0/0 md5 clientcert=1\n```\n\nYou need to edit postgresql.conf to actually activate ssl:\n\n\n\n```\nssl = on\n```\n\nPostgresql server must be restarted.\n\n\n\n```\n/etc/init.d/postgresql restart\n```\n\nIf the server fails to (re)start, look in the postgresql startup log, /var/lib/pgsql/pgstartup.log default for CentOS, for the reason.\n\n\nOn the client, we need three files. For Windows, these files must be in %appdata%\\postgresql\\ directory. For Linux ~/.postgresql/ directory. \n\n\n* root.crt (trusted root certificate)\n* postgresql.crt (client certificate)\n* postgresql.key (private key)\n\n\nGenerate the the needed files on the server machine, and then copy them to the client. We'll generate the needed files in the /tmp/directory.\n\n\nFirst create the private key postgresql.key for the client machine, and remove the passphrase.\n\n\n\n```\nopenssl genrsa -des3 -out /tmp/postgresql.key 1024\n```\n\n\n```\nopenssl rsa -in /tmp/postgresql.key -out /tmp/postgresql.key\n```\n\nThen create the certificate postgresql.crt. It must be signed by our trusted root (which is using the private key file on the server machine). Also, the certificate common name (CN) must be set to the database user name we'll connect as.\n\n\n\n```\nopenssl req -new -key /tmp/postgresql.key -out /tmp/postgresql.csr -subj '/C=CA/ST=British Columbia/L=Comox/O=TheBrain.ca/CN=www-data'\n```\n\n\n```\nopenssl x509 -req -in /tmp/postgresql.csr -CA root.crt -CAkey server.key -out /tmp/postgresql.crt -CAcreateserial\n```\n\nCopy the three files we created from the server /tmp/ directory to the client machine.\n\n\nCopy the trusted root certificate root.crt from the server machine to the client machine (for Windows pgadmin %appdata%\\postgresql\\ or for Linux pgadmin ~/.postgresql/). Change the file permission of postgresql.key to restrict access to just you (probably not needed on Windows as the restricted access is already inherited). Remove the files from the server /tmp/ directory.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
013359697d5efb59ae15806d4193185a | How to Setup MariaDB Galera Cluster on Ubuntu 18.04 with HAProxy | tutorialdba.com | 2021.39 | [
{
"text": "\nIn this blog post, we’re going to explore How to Setup MariaDB Galera Cluster on Ubuntu 18.04 with HAProxy as Load Balancer. If you have been working with MariaDB – In place replacement of MySQL, you should definitely be aware of MariaDB Galera Cluster. If you are new to these terms, MariaDB Galera Cluster is a synchronous multi-master cluster for MariaDB with support for [XtraDB/InnoDB](https://mariadb.com/kb/en/xtradb-and-innodb/) storage engines.\n\n\nTop features of MariaDB Galera Cluster are:\n\n\n* It provides active-active multi-master topology\n* You can read and write to any cluster node\n* It has automatic node joining\n* Automatic membership control, failed nodes drop from the cluster\n* Has true parallel replication, on row level\n* Direct client connections\n\n\nFrom these features, you get the benefits like no loss in transactions or weird slave lag normally seen in database replication since all servers have up-to-date data. By using MariaDB Galera Cluster on Ubuntu 18.04 server, you also get scalability for both reads and writes with small latencies from connecting clients.\n\n\nTo get fair load balancing based on Roundrobin or least number of connections on the servers, we will make use of HAProxy which is a production-grade open source Load Balancer.\n\n\n### How to Setup MariaDB Galera Cluster on Ubuntu 18.04\n\n\nWhen setting up MariaDB Galera Cluster, It is advisable to have an **odd**number of servers. Minimum being three servers. My Lab environment will be based on the diagram below:\n\n\n[](https://computingforgeeks.com/wp-content/uploads/2018/06/galera-cluster-ubuntu-18.04.png)\n\n\nI prefer using hostnames as opposed to hard-coded IP addresses in all my configurations. In preparation for this, let’s populate **/etc/hosts**with correct short hostnames and IP addresses for all servers.\n\n\n\n```\n**# cat /etc/hosts**\n10.131.69.129 galera-haproxy-01\n10.131.74.92 galera-db-01\n10.131.35.167 galera-db-02\n10.131.65.13 galera-db-03\n```\n\nYou must have noticed that my servers are not on the same subnet. This is recommended to ensure there is no single point of failure on the networking side. You can test that everything is working using **ping.**\n\n\n### Step 1: Install MariaDB database server on Galera nodes\n\n\nWe will start by Installing MariaDB on all Galera cluster nodes:\n\n\n* galera-db-01\n* galera-db-02\n* galera-db-03\n\n\nUse our previous guide [Install MariaDB 10.3 on Ubuntu 18.04 and CentOS 7](https://computingforgeeks.com/install-mariadb-10-on-ubuntu-18-04-and-centos-7/)to install MariaDB on Ubuntu 18.04. Once you are done with the installation of MariaDB database server on all nodes, proceed to next step.\n\n\n### Step 2: Configure First Galera Cluster node\n\n\nWhen setting up Galera Cluster, you need to start with one node which will assume the role of master. Edit first node main configuration to configure default character set.\n\n\n\n```\n$ sudo vim /etc/mysql/mariadb.cnf\n```\n\nUncomment these lines:\n\n\n\n```\ncharacter-set-server = utf8\ncharacter\\_set\\_server = utf8\n```\n\nThen add Galera specific configurations:\n\n\n\n```\n# vim /etc/mysql/mariadb.conf.d/galera.cnf\n```\n\nAdd below on **galera-db-01** Galera configuration file:\n\n\n\n```\n[mysqld]\nbind-address=0.0.0.0\ndefault_storage_engine=InnoDB\nbinlog_format=row\ninnodb_autoinc_lock_mode=2\n\n# Galera cluster configuration\nwsrep_on=ON\nwsrep_provider=/usr/lib/galera/libgalera_smm.so\nwsrep_cluster_address=\"gcomm://10.131.74.92,10.131.35.167,10.131.65.13\"\nwsrep_cluster_name=\"mariadb-galera-cluster\"\nwsrep_sst_method=rsync\n\n# Cluster node configuration\nwsrep_node_address=\"10.131.74.92\"\nwsrep_node_name=\"galera-db-01\"\n```\n\nRember to replace **10.131.74.92,10.131.35.167,10.131.65.13** with Galera cluster nodes IP Addresses.\n\n\n### Step 3: Configure other Galera Cluster Nodes\n\n\nWe now need to add configurations to Galera cluster node 2 and node 3.\n\n\nFor **galera-db-02**:\n\n\n\n```\nroot@galera-db-02:~# cat /etc/mysql/mariadb.conf.d/galera.cnf\n[mysqld]\nbind-address=0.0.0.0\ndefault_storage_engine=InnoDB\nbinlog_format=row\ninnodb_autoinc_lock_mode=2\n\n# Galera cluster configuration\nwsrep_on=ON\nwsrep_provider=/usr/lib/galera/libgalera_smm.so\nwsrep_cluster_address=\"gcomm://10.131.74.92,10.131.35.167,10.131.65.13\"\nwsrep_cluster_name=\"mariadb-galera-cluster\"\nwsrep_sst_method=rsync\n\n# Cluster node configuration\nwsrep_node_address=\"10.131.35.167\"\nwsrep_node_name=\"galera-db-02\"\n```\n\nFor **galera-db-03**:\n\n\n\n```\nroot@galera-db-03:~# cat /etc/mysql/mariadb.conf.d/galera.cnf\n[mysqld]\nbind-address=0.0.0.0\ndefault_storage_engine=InnoDB\nbinlog_format=row\ninnodb_autoinc_lock_mode=2\n\n# Galera cluster configuration\nwsrep_on=ON\nwsrep_provider=/usr/lib/galera/libgalera_smm.so\nwsrep_cluster_address=\"gcomm://10.131.74.92,10.131.35.167,10.131.65.13\"\nwsrep_cluster_name=\"mariadb-galera-cluster\"\nwsrep_sst_method=rsync\n\n# Cluster node configuration\nwsrep_node_address=\"10.131.65.13\"\nwsrep_node_name=\"galera-db-03\"\n```\n\nYou must have noted that what changes on each node is **Cluster node configuration**\n\n\n### Step 4: Start Galera Cluster on Ubuntu 18.04\n\n\nStop **mariadb** on all three nodes:\n\n\n\n```\n# systemctl stop mariadb\n```\n\nNow start new Galera cluster on node 1 – **galera-node-01**:\n\n\n\n```\n# galera\\_new\\_cluster\n```\n\nCheck Galera status if it’s running:\n\n\n\n```\n# mysql -u root -p -e \"show status like 'wsrep_%'\"\nEnter password: \n+------------------------------+--------------------------------------+\n| Variable_name | Value |\n+------------------------------+--------------------------------------+\n| wsrep_apply_oooe | 0.000000 |\n| wsrep_apply_oool | 0.000000 |\n| wsrep_apply_window | 0.000000 |\n| wsrep_causal_reads | 0 |\n| wsrep_cert_deps_distance | 0.000000 |\n| wsrep_cert_index_size | 0 |\n| wsrep_cert_interval | 0.000000 |\n| wsrep_cluster_conf_id | 1 |\n| wsrep_cluster_size | 1 |\n| wsrep_cluster_state_uuid | 9f957c6d-76b4-11e8-a71a-17cc0eca13f1 |\n| wsrep_cluster_status | Primary |\n| wsrep_commit_oooe | 0.000000 |\n| wsrep_commit_oool | 0.000000 |\n| wsrep_commit_window | 0.000000 |\n| wsrep_connected | ON |\n| wsrep_desync_count | 0 |\n| wsrep_evs_delayed | |\n| wsrep_evs_evict_list | |\n| wsrep_evs_repl_latency | 0/0/0/0/0 |\n| wsrep_evs_state | OPERATIONAL |\n| wsrep_flow_control_paused | 0.000000 |\n| wsrep_flow_control_paused_ns | 0 |\n| wsrep_flow_control_recv | 0 |\n| wsrep_flow_control_sent | 0 |\n| wsrep_gcomm_uuid | 9f945140-76b4-11e8-84c6-a66f9e2978f6 |\n| wsrep_incoming_addresses | 10.131.74.92:3306 |\n| wsrep_last_committed | 0 |\n| wsrep_local_bf_aborts | 0 |\n| wsrep_local_cached_downto | 18446744073709551615 |\n| wsrep_local_cert_failures | 0 |\n| wsrep_local_commits | 0 |\n| wsrep_local_index | 0 |\n| wsrep_local_recv_queue | 0 |\n| wsrep_local_recv_queue_avg | 0.000000 |\n| wsrep_local_recv_queue_max | 1 |\n| wsrep_local_recv_queue_min | 0 |\n| wsrep_local_replays | 0 |\n| wsrep_local_send_queue | 0 |\n| wsrep_local_send_queue_avg | 0.000000 |\n| wsrep_local_send_queue_max | 1 |\n| wsrep_local_send_queue_min | 0 |\n| wsrep_local_state | 4 |\n| wsrep_local_state_comment | Synced |\n| wsrep_local_state_uuid | 9f957c6d-76b4-11e8-a71a-17cc0eca13f1 |\n| wsrep_protocol_version | 8 |\n| wsrep_provider_name | Galera |\n| wsrep_provider_vendor | Codership Oy <[email protected]> |\n| wsrep_provider_version | 25.3.23(r3789) |\n| wsrep_ready | ON |\n| wsrep_received | 2 |\n| wsrep_received_bytes | 148 |\n| wsrep_repl_data_bytes | 0 |\n| wsrep_repl_keys | 0 |\n| wsrep_repl_keys_bytes | 0 |\n| wsrep_repl_other_bytes | 0 |\n| wsrep_replicated | 0 |\n| wsrep_replicated_bytes | 0 |\n| wsrep_thread_count | 2 |\n+------------------------------+--------------------------------------+\n```\n\nInitial cluster size should be **1**\n\n\n\n```\nroot@galera-db-01:~# mysql -u root -p -e \"show status like 'wsrep_cluster_size'\"\nEnter password: \n+--------------------+-------+\n| Variable_name | Value |\n+--------------------+-------+\n| wsrep_cluster_size | 1 |\n+--------------------+-------+\n```\n\nOn**galera-node-02**, start mariadb service:\n\n\n\n```\n # systemctl start mariadb\n```\n\nCheck cluster size again, it should have changed to **2**\n\n\n\n```\n# mysql -u root -p -e \"show status like 'wsrep_cluster_size'\"\nEnter password: \n+--------------------+-------+\n| Variable_name | Value |\n+--------------------+-------+\n| wsrep_cluster_size | 2 |\n+--------------------+-------+\n```\n\nStart mariadb on **galera-db-03:**\n\n\n\n```\n# systemctl start mariadb\n```\n\nCheck cluster size again, it should be **3**\n\n\n\n```\n# mysql -u root -p -e \"show status like 'wsrep_cluster_size'\"\nEnter password: \n+--------------------+-------+\n| Variable_name | Value |\n+--------------------+-------+\n| wsrep_cluster_size | 3 |\n+--------------------+-------+\n```\n\nIf everything was set correctly, you can start testing.\n\n\n### Step 5: Test Galera Cluster Operation\n\n\nTo test our Galera cluster, we’re going to create a test database on one server and confirm that it has been replicated on other nodes. Log in to any member of Galera cluster as root user:\n\n\n\n```\nroot@galera-node-01:~# **mysql -u root -p**\nEnter password: \nWelcome to the MariaDB monitor. Commands end with ; or \\g.\nYour MariaDB connection id is 50\nServer version: 10.3.7-MariaDB-1:10.3.7+maria~bionic-log mariadb.org binary distribution\n\nCopyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.\n\nType 'help;' or '\\h' for help. Type '\\c' to clear the current input statement.\n\nMariaDB [(none)]> **create database galera\\_test;**\nQuery OK, 1 row affected (0.004 sec)\n```\n\nLog in to the other node and check if the database exists.\n\n\n\n```\nMariaDB [(none)]> **show databases;**\n+--------------------+\n| Database |\n+--------------------+\n| galera\\_test |\n| information\\_schema |\n| mysql |\n| performance\\_schema |\n+--------------------+\n4 rows in set (0.000 sec)\n```\n\n### Step 6: Install and Configure HAProxy\n\n\nFor installation and Configuration of HAProxy as Load Balancer for MariaDB Galera Cluster, refer to our guide: [Galera Cluster High Availability With HAProxy on Ubuntu 18.04 / CentOS 7.](https://discuss.tutorialdba.com/844/cluster-availability-haproxy)\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
7caa0ef6afc9a748a28acf5ccf4e46f6 | What are the best places on the web to ask PostgreSQL database questions? Do you stick to this discuss tutorialdba forum? Are there others that you use as well? | What are the best PostgreSQL Database forums? | tutorialdba.com | 2019.43 | [
{
"text": "Postgres is weird that way. Tutorialdba forum is the biggest postgres database forum I know of, which doesn't say a lot compared to others. The IRC channel is pretty amazing though. Specifically RhodiumToad. That guy is just a machine. \n\n \n\nHe's often there. Also, I've asked a question while he was fielding several others and he not only answered it but told me how to make it more efficient. Definitely try the IRC",
"name": "",
"is_accepted": false
}
] |
9f004ff36e28f20c93375e9823484469 |
We have a master-slave replication configuration as follows.
On the master:
`postgresql.conf` has replication configured as follows (commented line taken out for brevity):
```
max\_wal\_senders = 1
wal\_keep\_segments = 8
```
On the slave:
Same `postgresql.conf` as on the master. `recovery.conf` looks like this:
```
standby\_mode = 'on'
primary\_conninfo = 'host=master1 port=5432 user=replication password=replication'
trigger\_file = '/tmp/postgresql.trigger.5432'
```
When this was initially setup, we performed some simple tests and confirmed the replication was working. However, when we did the initial data load, only some of the data made it to the slave.
Slave's log is now filled with messages that look like this:
```
< 2015-01-23 23:59:47.241 EST >LOG: started streaming WAL from primary at F/52000000 on timeline 1
< 2015-01-23 23:59:47.241 EST >FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000010000000F00000052 has already been removed
< 2015-01-23 23:59:52.259 EST >LOG: started streaming WAL from primary at F/52000000 on timeline 1
< 2015-01-23 23:59:52.260 EST >FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000010000000F00000052 has already been removed
< 2015-01-23 23:59:57.270 EST >LOG: started streaming WAL from primary at F/52000000 on timeline 1
< 2015-01-23 23:59:57.270 EST >FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000010000000F00000052 has already been removed
```
After some analysis and help on the #postgresql IRC channel, I've come to the conclusion that the slave cannot keep up with the master. My proposed solution is as follows.
On the master:
1. Set `max_wal_senders=5`
2. Set `wal_keep_segments=4000` . Yes I know it is very high, but I'd like to monitor the situation and see what happens. I have room on the master.
On the slave:
1. Save configuration files in the data directory (i.e. `pg_hba.conf pg_ident.conf postgresql.conf recovery.conf`)
2. Clear out the data directory (`rm -rf /var/lib/pgsql/9.3/data/*`) . This seems to be required by `pg_basebackup`.
3. Run the following command: `pg_basebackup -h master -D /var/lib/pgsql/9.3/data --username=replication --password`
Am I missing anything ? Is there a better way to bring the slave up-to-date w/o having to reload all the data ?
Any help is greatly appreciated.
| How do I fix a PostgreSQL 9.3 Slave that Cannot Keep Up with the Master? | tutorialdba.com | 2020.45 | [
{
"text": "\nThe two important options for dealing with the [WAL](http://www.postgresql.org/docs/current/static/runtime-config-wal.html) for [streaming replication](https://wiki.postgresql.org/wiki/Streaming_Replication):\n\n* `wal_keep_segments` should be set high enough to allow a slave to catch up after a reasonable lag (e.g. high update volume, slave being offline, etc...).\n* `archive_mode` enables WAL archiving which can be used to recover files older than `wal_keep_segments` provides. The slave servers simply need a method to retrieve the WAL segments. NFS is the simplest method, but anything from scp to http to tapes will work so long as it can be scripted.\n\n\n```\n# on master\narchive\\_mode = on\narchive\\_command = 'cp %p /path\\_to/archive/%f' \n\n# on slave\nrestore\\_command = 'cp /path\\_to/archive/%f \"%p\"'\n```\nWhen the slave can't pull the WAL segment directly from the master, it will attempt to use the `restore_command` to load it. You can configure the slave to automatically remove segments using the [`archive_cleanup_command`](http://www.postgresql.org/docs/current/static/pgarchivecleanup.html)setting.\n\nIf the slave comes to a situation where the next WAL segment it needs is missing from both the master and the archive, there will be no way to consistently recover the database. The *only* reasonable option then is to scrub the server and start again from a fresh [`pg_basebackup`](http://www.postgresql.org/docs/current/static/app-pgbasebackup.html).\n\n\n",
"name": "",
"is_accepted": false
}
] |
6d2a7b7542de2b0e1f869ed89c9e7b10 | How to change linux process priority if already running | How to change linux process priority if already running ? | tutorialdba.com | 2020.50 | [
{
"text": "\nNiceness values range from -20 (most favorable to the process) to 19 (least favorable to the process). To put this simply, the negative values (Eg. -20) gives higher priority to a process and positive values (Eg. 19) gives lower priority.\n\n\n**Sample output:**\n\n\n\n```\nF S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD\n0 T 1000 15059 14306 0 95 15 - 55815 signal pts/0 00:00:00 cmus\n0 R 1000 15066 14306 0 80 0 - 8148 - pts/0 00:00:00 ps\n```\n\nAs you see in the above output, cmus is running with lower priority value of 15.\n\n\nTo change the current niceness value of a running process, for example 18, run the following command:\n\n\n\n```\n$ renice -n 18 -p 15059\n```\n\nHere, 15059 is the process id of cmus process.\n\n\nSample output would be:\n\n\n\n```\n15059 (process ID) old priority 15, new priority 18\n```\n\nVerify the niceness value using command:\n\n\n\n```\nps -al\n```\n\n**Sample output:**\n\n\n\n```\nF S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD\n0 T 1000 15059 14306 0 98 18 - 55815 signal pts/0 00:00:00 cmus\n0 R 1000 15074 14306 0 80 0 - 8148 - pts/0 00:00:00 ps\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
38b2d914974e0d4dacf5c00e5076ed03 | What are different ways to get data into Greenplum data warehouse? | tutorialdba.com | 2020.16 | [
{
"text": "\n1. COPY FROM\n2. Gpload\n3. INSERT statement\n4. Create EXTERNAL TABLE\n5. pg\\_restore\n6. gp\\_restore\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
54b607b883facb37c1ed648be69889c6 | What is MySQL Default username and password ? | tutorialdba.com | 2020.45 | [
{
"text": "\n**The *default* username is 'root' and by *default* there is no password. Here are instructions to *reset* the *root password*:**\n\n\nThe MySQL root password allows the root user to have full access to the [MySQL database](https://www.rackspace.com/cloud/databases). You must have (Linux) root or (Windows) Administrator access to the [Cloud Server](https://www.rackspace.com/cloud) to reset the MySQL root password.\n\n\n**Note:** The Cloud Server (Linux) root or (Windows) Administrator account password is not the same as the MySQL password. The Cloud Server password allows access to the server. The MySQL root password allows access only to the MySQL database.\n\n\nUse the following steps to reset a MySQL root password by using the command line interface.\n\n\n### Stop the MySQL service\n\n\n(Ubuntu and Debian) Run the following command:\n\n\n\n```\nsudo /etc/init.d/mysql stop\n\n```\n\n(CentOS, Fedora, and Red Hat Enterprise Linux) Run the following command:\n\n\n\n```\nsudo /etc/init.d/mysqld stop\n\n```\n\n### Start MySQL without a password\n\n\nRun the following command. The ampersand (&) at the end of the command is required.\n\n\n\n```\nsudo mysqld_safe --skip-grant-tables &\n\n```\n\n### Connect to MySQL\n\n\nRun the following command:\n\n\n\n```\nmysql -uroot\n\n```\n\n### Set a new MySQL root password\n\n\nRun the following command:\n\n\n\n```\nuse mysql;\n\nupdate user set authentication_string=PASSWORD(\"mynewpassword\") where User='root';\n\nflush privileges;\n\nquit\n\n```\n\n### Stop and start the MySQL service\n\n\n(Ubuntu and Debian) Run the following commands:\n\n\n\n```\nsudo /etc/init.d/mysql stop\n...\nsudo /etc/init.d/mysql start\n\n```\n\n(CentOS, Fedora, and Red Hat Enterprise Linux) Run the following commands:\n\n\n\n```\nsudo /etc/init.d/mysqld stop\n...\nsudo /etc/init.d/mysqld start\n\n```\n\n### Log in to the database\n\n\nTest the new password by logging in to the database.\n\n\n\n```\nmysql -u root -p\n\n```\n\nEnter your new password when prompted.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
83e0e0e1808b2a6f852171ae8754d942 | What is the advantage in Greenplum, compared to oracle and greenplum? | tutorialdba.com | 2020.16 | [
{
"text": "It is shared nothing, MPP architecture best for data warehousing env. Greenplum is built on top of Postgresql. Good for big data analytics purpose. Oracle is all purpose Database. \n\n \n\nand greenplum is a open source data warehouse system",
"name": "",
"is_accepted": false
}
] |
|
7cb8977f767b4e65405378de4c83069b | Is postgres having patching concept like oracle ? | tutorialdba.com | 2019.47 | [
{
"text": "\n**Yes,**\n\n\nIf you are used to patch Oracle databases you probably know how to use opatch to apply PSUs. How does PostgreSQL handle this? Do we need to patch the existing binaries to apply security fixes? The answer is: No.\n\n\nLets say you want to patch PostgreSQL from version 10.5/11.3 to version 10.10/11.5.\n\n\nThis is called minor version postgres upgrade or postgres patching\n\n\n \n\n\n**Why need to patch postgresql server ?**\n\n\nMultiple SQL injection vulnerabilities have been discovered in PostgreSQL that could allow for arbitrary code execution. The vulnerabilities are the result of the application’s failure to sufficiently sanitize user-supplied input before using it in an SQL query. These vulnerabilities allow attackers with the CREATE permission (or Trigger permission in some tables) to exploit input sanitation vulnerabilities in the pg\\_upgrade and pg\\_dump functions. The CREATE permission is automatically given to new users on the public schema, and the public schema is the default schema used on these databases. Successful exploitation of these vulnerabilities could allow the attacker to execute arbitrary SQL statements, which could them to compromise the application, access or modify data, or exploit other vulnerabilities in the database.\n\n\n**Solution :**\n\n\nThis issue is fixed by upgrading to below mentioned point releases and restarting your PostgreSQL server.\n\n\n**Below are the new point releases to fix the vulnerability.**\n\n\n* PostgreSQL version 9.6.15\n* PostgreSQL version 10.10\n* PostgreSQL version 11.5\n\n\nFor More Info refer the below link\n\n\n<https://www.cvedetails.com/vulnerability-list/vendor_id-336/product_id-575/Postgresql-Postgresql.html>\n\n\n**Below steps will helpful to apply patch on postgres server**\n\n\n**Step 1. Install the below packages on linux server.**\n\n\n\n```\n[On RHEL/CentOS]\n# yum install gcc*\n# yum install zlib-devel*\n# yum install readline-devel*\n\n[On Debian/Ubuntu]\n# apt install gcc*\n# apt install zlib1g-dev*\n# apt install libreadline6-dev*\n\n[On SUSE Linux ]\n# Zypper in gcc*\n# zlib1g-dev*\n# libreadline6-dev*\n# zypper in zlib*\n```\n\n**Step 2. Install the new version of postgres server as root user.**\n\n\n\n```\n# ./configure --prefix=/nijam/10.10/ --without-readline\n# make (or) # make world -->(additional modules (contrib), type instead PostgreSQL, contrib, and documentation \n# make install (or) # make install-world -->(if you want contribution extension)\n```\n\n**Step 3. Take the backup physical or logical backup and Stop the old version of postgres server 10.5 with seperate path.**\n\n\n\n```\ntutorialdba.com:/nijam/10.10/postgresql-10.10 # ps -ef|grep postgres\npginsta 2779 1 0 May15 ? 00:10:45 /nijam/10.5/bin/postgres -D /data/\npginsta 2781 2779 0 May15 ? 00:00:01 postgres: logger process\npginsta 2783 2779 0 May15 ? 00:00:52 postgres: checkpointer process\npginsta 2784 2779 0 May15 ? 00:12:33 postgres: writer process\npginsta 2785 2779 0 May15 ? 00:04:03 postgres: wal writer process\n\n\n/nijam/10.5/bin/pg_ctl -D /data/ stop\n```\n\nStep 4. Start the new server from new installation bin path and pointing existing data directory.\n\n\n\n```\n/nijam/10.10/bin/pg_ctl -D /data/ -l logfile start\n```\n\n \n\n**Note :** While patching 9 version you won't get any error but 10 and 11 version you may get pg\\_hba.conf error means peer connection will not support so you have to comment it then start the server.\n\n\nFor postgres major upgrade this blog will helpful for you <https://2ndquadrant.in/postgresql-upgradation-from-9-5-to-11-3/>\n\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
|
0d63367aecc5e4c5e9c5ca3b863feb41 | need steps to migrate Oracle RDS instance to postgresql RDS instance | tutorialdba.com | 2020.40 | [
{
"text": "You can use DMS to do it",
"name": "",
"is_accepted": false
}
] |
|
de72f7c71290c8a54141dfd72e8c7d4a | HOW TO SECURE YOUR POSTGRESQL DATABASE ? ANYONE HAVE TIPS | tutorialdba.com | 2020.50 | [
{
"text": "By using Following steps you can make your Postgresql server more secure: \n\n1.any VPN if aws open other third party tools is firtieclient…Etc. \n\n2.pg\\_crypto extension. \n\n3.changing user name instead of directly accessing root user. \n\n4.changing ssh port number instead of 22 port. \n\n5. Password should be UPPER-lower\\_special character (@$#*:'”*!!:;/+¥£¢€=~|`•√π÷׶∆\\}{°°^¥€¢£%©®™✓[]\\). \n\n6. By installing csf firewall. \n\n7.password & username should not be based on any cryptographic rule. \n\n8.every 45 days should be change your password. \n\n9.application side should be use any brute Force attacking module. Like limit login or Google recaptcha. \n\n10. Generate ssh ppk file.",
"name": "",
"is_accepted": false
}
] |
|
25f917fdf6c8aae8c11697223be23ddf |
```
InnoDB: Error: page 201 log sequence number 5461190770
InnoDB: is in the future! Current system log sequence number 5459742084.
InnoDB: Your database may be corrupt or you may have copied the InnoDB
InnoDB: tablespace but not the InnoDB log files. See
InnoDB: <http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html>
```
| Got InnoDB curruption please help me to recover | tutorialdba.com | 2020.45 | [
{
"text": "\nTry this [https://discuss.tutorialdba.com/1043/innodb-corruption-databases](https://discuss.tutorialdba.com/1043/innodb-corruption-databases?state=edit-1044)\n\n\n",
"name": "",
"is_accepted": false
}
] |
d7819adbf5ab98a2e6b0bd42bdd17f21 | How to create actual tablespace in Postgresql ? | tutorialdba.com | 2020.50 | [
{
"text": "\n\n```\nCreate tablespace tablespace\\_name location 'dirctory';\n```\n\n",
"name": "",
"is_accepted": false
}
] |
|
f5a3491c675b7446ce4137f2de308a12 | How to write a script for automatic streaming replication configuration ? | tutorialdba.com | 2021.43 | [
{
"text": "\n\n```\nIn this script useful for automatic replication configure \n#!/bin/bash \n##This is meanst to be run on the slave, with the masters ip as the passed variable. ($1)\nsourcehost=\"$1\"\ndatadir=/var/lib/postgresql/9.2/main\narchivedir=/var/lib/postgresql/9.2/archive\narchivedirdest=/var/lib/postgresql/9.2/archive\n\n#Usage\nif [ \"$1\" = \"\" ] || [ \"$1\" = \"-h\" ] || [ \"$1\" = \"-help\" ] || [ \"$1\" = \"--help\" ] ;\nthen\n\techo \"Usage: $0 masters ip address\"\n\techo\nexit 0\nfi\n\nWhoami () {\nif [[ $(whoami) != \"postgres\" ]]\nthen\n echo \"This script must be run as user Postgres, and passwordless ssh must already be setup\"\n exit 1\nfi\n} \n\nCheckIfPostgresIsRunningOnRemoteHost () {\nisrunning=\"$(ssh postgres@\"$1\" 'if killall -0 postgres; then echo \"postgres\\_running\"; else echo \"postgress\\_not\\_running\"; fi;')\"\n\nif [[ \"$isrunning\" = \"postgress\\_not\\_running\" ]]\nthen\n echo \"postgres not running on the master, exiting\";\n exit 1\n\nelif [[ \"$isrunning\" = \"postgres\\_running\" ]]\nthen\n echo \"postgres running on remote host\";\n\nelif echo \"unexpected response, exiting\"\nthen\n exit 1\nfi\n}\n\nCheckIfMasterIsActuallyAMaster () {\nismaster=\"$(ssh postgres@\"$1\" 'if [ -f /var/lib/postgresql/9.2/main/recovery.done ]; then echo \"postgres\\_is\\_a\\_master\\_instance\"; else echo \"postgres\\_is\\_not\\_master\"; fi;')\"\n\nif [[ \"$ismaster\" = \"postgres\\_is\\_not\\_master\" ]]\nthen \n echo \"postgres is already running as a slave, exiting\"; \n exit 1\n\nelif [[ \"$ismaster\" = \"postgres\\_is\\_a\\_master\\_instance\" ]]\nthen\n echo \"postgres is running as master (probably)\";\n\nelif echo \"unexpected response, exiting\"\nthen\n exit 1\n\nfi\n}\n\necho \"Sanity checks passed executing rest of script\"\n#prepare local server to become the new slave server. \nPrepareLocalServer () {\n\nif [[ -f \"/tmp/trigger\\_file\" ]]\nthen\n\trm /tmp/trigger\\_file\nfi\n\nbash /etc/init.d/postgresql stop\n\nif [[ -f \"$datadir/recovery.done\" ]];\nthen\n\tmv \"$datadir\"/recovery.done \"$datadir\"/recovery.conf\nfi\n}\n\n\nCheckForRecoveryConfig () {\nif [[ -f \"$datadir/recovery.conf\" ]];\n then\n\techo \"Slave Config File Found, Continuing\"\n else\n\techo \"Recovery.conf not found Postgres Cannot Become a Slave, Exiting\"\n\texit 1\nfi\n}\n\n\n#put master into backup mode\n#TODO before doing PutMasterIntoBackupMode clean up archive logs (IE rm or mv /var/lib/postgresql/9.2/archive/*). They are not needed since we are effectivly createing a new base backup and then synching it. \nPutMasterIntoBackupMode () {\nssh postgres@\"$1\" \"psql -c \\\"SELECT pg\\_start\\_backup('Streaming Replication', true)\\\" postgres\"\n}\n\n#rsync masters data to local postgres dir\nRsyncWhileLive () {\nrsync -C -av --delete -e ssh --exclude recovery.conf --exclude recovery.done --exclude postmaster.pid --exclude pg\\_xlog/ \"$1\":\"$datadir\"/ \"$datadir\"/\n}\n\n\n#this archives the the WAL log (ends writing to it and moves it to the $archive dir\nStopBackupModeAndArchiveIntoWallLog () {\nssh postgres@\"$1\" \"psql -c \\\"SELECT pg\\_stop\\_backup()\\\" postgres\"\nrsync -C -a -e ssh \"$1\":\"$archivedir\"/ \"$archivedirdest\"/\n}\n\n\n#stop postgres and copy transactions made during the last two rsync's\nStopPostgreSqlAndFinishRsync () {\nssh postgres@\"$1\" \"/etc/init.d/postgresql stop\"\nrsync -av --delete -e ssh \"$sourcehost\":\"$datadir\"/pg\\_xlog/ \"$datadir\"/pg\\_xlog/\n}\n\n#Start both Master and Slave\nStartLocalAndThenRemotePostGreSql () {\n/etc/init.d/postgresql start\nssh postgres@\"$1\" \"/etc/init.d/postgresql start\"\n}\n\n#Execute above operations\nWhoami\nCheckIfPostgresIsRunningOnRemoteHost \"$1\"\nCheckIfMasterIsActuallyAMaster \"$1\"\nPrepareLocalServer \"$datadir\"\nCheckForRecoveryConfig \"$datadir\"\nPutMasterIntoBackupMode \"$1\"\nRsyncWhileLive \"$1\"\nStopBackupModeAndArchiveIntoWallLog \"$1\" \"$archivedir\" \"$archivedirdest\"\nStopPostgreSqlAndFinishRsync \"$1\"\nStartLocalAndThenRemotePostGreSql \"$1\"\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
|
c12bb9edc9d9729b045282eae90f3ab6 |
Hello, I'm a newbie here!
Hope you all are keeping well.
What is the type of job roles offered apart from system admins if you have good knowledge of Linux?
are developers also required to possess the knowledge for it?
Had actually come across sites like this for interview questions on Linux which drove my curiosity.: <https://www.interviewbit.com/linux-interview-questions/>
Recently started digging in on Linux concepts, have a blog-related project to cover on Linux.
Any help is appreciated, TIA..!
| Careers in Linux? | tutorialdba.com | 2021.25 | [
{
"text": "\n3 skills that every Linux sysadmin should bring to the table\n============================================================\n\n\nDo you have these three skills to help you be a successful sysadmin? Check yourself against this list.\n\n\nThere’s a lot of specialization in the world of system administration. If you started out a decade or more ago as a sysadmin, you know that learning resources were scarce. Skills that every sysadmin professional should possess weren't easily found online or elsewhere. To ensure that you have the right skills for the job, you need to have a strong knowledge base. Doing so will increase your chances of landing a good position and getting a higher salary.\n\n\nAt the same time, you'll have a good foundation for specialization. Things change quickly in the sysadmin world, so you need to ensure you have current and in-demand skills.\n\n\nHere's what you need to know.\n\n\n1. Technical skills\n-------------------\n\n\nTechnical skills are a must-have for every sysadmin who wants to be successful. The term describes the knowledge and abilities you have that allow you to perform sysadmin tasks. The more you know, the better. Knowledge paired with experience becomes expertise, which is your ultimate goal. However, you won’t gain experience unless you invest your time and effort into gaining those valuable technical skills.\n\n\nSystems administration\n\n\nAs a system administrator, you should focus on learning as much as possible about system administration, focusing on Linux commands, hardware, software, backup and restore, filesystems, maintenance, and user administration. These technical skills combine gaining general knowledge about Linux with learning specifics such as the setup and configuration processes, best testing practices, efficient monitoring, and so on.\n\n\nNetworking\n\n\nBecause businesses and organizations are increasingly relying on network virtualization, being familiar with software-defined (SD)-branch, wide-area networks (WANs), virtual local area networks (VLANs), and Secure Access Service Edge (SASE) technologies is a big plus. Due to the pandemic and the shift to a remote working model, virtual private networking (VPN) knowledge is also essential. Fortunately, there are [plenty of online resources](https://www.redhat.com/sysadmin/networking-guides) to help brush up on your networking skills.\n\n\nCloud\n\n\nCloud-based technologies are becoming more popular every day. You’ll find out that many companies use a stack of cloud solutions, often running an entire infrastructure in the cloud.\n\n\n* 90% of companies use some type of cloud service.\n* 77% of enterprises have at least one application or a portion of it in the cloud.\n* Enterprises use 1,427 different cloud services on average.\n* 60% of organizations use cloud technology to store confidential data.\n\n\n*([Source](https://leftronic.com/cloud-computing-statistics/))*\n\n\nLearning how to work with cloud solutions, including connecting, networking, and routing, will make your resume more attractive to IT placement firms. Cloud computing knowledge also includes knowing how to configure, provision, and customize cloud-based apps.\n\n\n***[ You might also enjoy: [Top 5 job markets for sysadmins, 7 different ways](https://www.redhat.com/sysadmin/top-job-markets-sysadmins-2019) ]***\n\n\nSystem monitoring\n\n\nYou are to your system what a doctor is to a patient. To stay informed of your systems' health, continuous monitoring is mandatory. Monitoring is one of those 24x7x365 services. Learning the warning signs of trouble allows you to identify issues, prevent downtime, discover bottlenecks, and recognize the need for software and infrastructure upgrades.\n\n\nSecurity\n\n\nAccording to [Cybercrime Magazine](https://cybersecurityventures.com/annual-cybercrime-report-2020/), the losses from cybercrime damages are expected to reach $6 trillion by 2021. As a sysadmin, system security is your responsibility. You need to keep up with the latest cybersecurity threats and solutions to recognize weaknesses, vulnerabilities, ongoing issues, and to deal with current security problems.\n\n\n2. Communication skills\n-----------------------\n\n\nCommunication skills are very important for the sysadmin role. Your ability to clearly give and receive information is essential. Good communication skills enable you to more easily collaborate with your co-workers and clients. Invest some time in them, and you'll easily break the mold of that \"social misfit\" stereotype too often applied to sysadmins.\n\n\nDocumentation\n\n\nDocumenting your processes as a system admin is essential to ensure that anyone can easily jump in and understand your systems, your workflow, and your maintenance routines. It also applies to situations when you're working with complex concepts or difficult support issues. It’s imperative that you know how to properly document everything you do. Using practical tools such as a concept/mind map can help you structure, record, and share your knowledge with others.\n\n\nListening\n\n\nProblem-solving is something that you’ll have to get used to. However, to solve a problem, you’ll need to gather information from various sources and often those sources are other people in the company you work for—colleagues, app developers, tech support, and others. Listening is an essential skill that will help you in these situations. Remember that communication is send *and* receive. Listening clearly is just as important as speaking or writing in a clear and concise manner.\n\n\nPresentation\n\n\nDo you want to advance your career? Yes, of course, you do but to do it, you’ll have to give presentations, plan and hold meetings, and possibly even host events. That’s why you need to hone your presentation and public speaking skills. Knowing how to effectively discuss a problem and to pitch your ideas toward a solution is one way to get your listeners to buy into your plan of action.\n\n\n3. Critical thinking skills\n---------------------------\n\n\nCritical thinking refers to the process of making a judgment based on the analysis of available information. On the other hand, critical thinking skills also describe your ability to use the information to plan an action. As a sysadmin, you’ll need to make decisions on the go. Critical thinking skills will help you make accurate, informed decisions.\n\n\nAdaptability\n\n\nStakeholders often lay out new plans for their companies. These plans almost always involve requirements for some kind of IT infrastructural change. Sysadmins need to think quickly, identify any possible challenges, analyze solutions to overcome them, and finally successfully implement changes as required.\n\n\nProblem-solving\n\n\nCompetent sysadmins are the ones who are capable of solving problems on their own or knowing where to look for a solution. Your capacity to solve problems is a great skill to have in this occupation. Alternatively, you have to be honest about your abilities and know when to ask for help or delegate some tasks, so that you have more time to focus on more pressing matters.\n\n\nLearning\n\n\nSysadmins work with dozens of technologies. However, technologies change rapidly and so do the best practices in the field. You should embrace professional growth and development as an ongoing personal effort and seek out opportunities for learning new things, even if the time for doing so is at a premium. With so many sysadmin forums, courses, and magazines available online, it shouldn’t be a problem for you.\n\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
205c4a9b92e6378abc8df87c0ae86fdf | Postgresql DBA activities | tutorialdba.com | 2019.43 | [
{
"text": "\nCongratulations everyone for Postgres 12 release on October-3 2019.\n\n\nIt’s magic when like-minded people from all over the world come together and work towards a common goal to make Postgres better every single day.\n\n\nThank you for all the community members (Core members, developers, testers, build management and documentation team) to make this possible.\n\n\n[Postgres 12](https://www.postgresql.org/docs/12/release-12.html) has some really cool features for the end-user. Some of them are a major enhancement and some with minor changes in existing functionality. It’s going to benefit the open-source database world in a lot of different ways. But What a Database Admin would gain out of Postgres 12?\n\n\n**Below are some features which I am willing to use to make Database operations better and easier.**\n\n\n1. **Partitioning Improvements:**Partitioning performance enhancements, including improved query performance on tables with thousands of partitions, improved insertion performance with INSERT and COPY, and the ability to execute [ALTER TABLE ATTACH PARTITION](https://www.postgresql.org/docs/12/sql-altertable.html#SQL-ALTERTABLE-ATTACH-PARTITION) without blocking queries. Also, there is an improvement for [foreign keys](https://www.postgresql.org/docs/12/ddl-constraints.html#DDL-CONSTRAINTS-FK) to reference partitioned tables.\n2. **Checksum Control**:[pg\\_checksums](https://www.postgresql.org/docs/12/app-pgchecksums.html) can enable/disable page checksums (used for detecting data corruption) in an offline cluster.- With an earlier version of Postgres, the only option was to [reinitialize](https://www.postgresql.org/docs/11/app-initdb.html) the database using initdb.\n3. **Reindex Concurrently**: Being a DBA indexing database without downtime(write) has been an issue. [REINDEX CONCURRENTLY](https://www.postgresql.org/docs/12/sql-reindex.html#SQL-REINDEX-CONCURRENTLY) can rebuild an index without blocking writes to its table. Well this features also comes with a cost. Let me explain. Usually, PostgreSQL locks the table whose index is rebuilt against writes and performs the entire index build with a single scan of the table. Rest of the transactions can still read the table, but if they try to insert, update, or delete rows in the table they will block until the index rebuild is finished. This is a prob for a Production system. A very large tables can take many hours to be indexed, and even for smaller tables, an index rebuild can lock out writers for periods that are unacceptably long for a production system.\n\n\nPostgreSQL supports rebuilding indexes with minimum locking of writes. This method is invoked by specifying the CONCURRENTLY option of REINDEX. When this option is used, PostgreSQL must perform two scans of the table for each index that needs to be rebuilt and wait for termination of all existing transactions that could potentially use the index. This method requires more total work than a standard index rebuild and takes significantly longer to complete as it needs to wait for unfinished transactions that might modify the index. As it allows normal operations, this method is useful for rebuilding indexes in a production environment. Of course, the extra CPU, memory and I/O load imposed by the index rebuild may slow down other operations.\n\n\n4. **Reporting information:**Progress reports statistics for [CREATE INDEX](https://www.postgresql.org/docs/12/sql-createindex.html), [REINDEX](https://www.postgresql.org/docs/12/sql-reindex.html), [CLUSTER](https://www.postgresql.org/docs/12/sql-cluster.html), [VACUUM FULL](https://www.postgresql.org/docs/12/sql-vacuum.html), and [pg\\_checksums](https://www.postgresql.org/docs/12/app-pgchecksums.html)\n\n\nCREATE INDEX and REINDEX operations: use [pg\\_stat\\_progress\\_create\\_index](https://www.postgresql.org/docs/12/progress-reporting.html#CREATE-INDEX-PROGRESS-REPORTING) system view.\n\n\nfor CLUSTER and VACUUM FULL: use [pg\\_stat\\_progress\\_cluster](https://www.postgresql.org/docs/12/progress-reporting.html#CLUSTER-PROGRESS-REPORTING)\n\n\n5. **Enhance security with MFA**: Multi-factor authentication, using the [clientcert=verify-full](https://www.postgresql.org/docs/12/auth-cert.html) option combined with an additional authentication method in pg\\_hba.conf.\n\n\n**There has been some changes to improve existing funtionality**\n\n\n1. psql command \\dP to list partitioned tables and indexes.\n2. Time-based server parameters to use units of microseconds\n3. fractional input for integer server parameters. \n\n set work\\_mem = ‘30.1GB’\n4. [wal\\_recycle](https://www.postgresql.org/docs/12/runtime-config-replication.html#GUC-WAL-RECYCLE) and [wal\\_init\\_zero](https://www.postgresql.org/docs/12/runtime-config-replication.html#GUC-WAL-INIT-ZERO) server parameters to control WAL file recycling.\n5. VACUUM to skip index cleanup \n\n This change adds a VACUUM command option INDEX\\_CLEANUP as well as a table storage option vacuum\\_index\\_cleanup. The use of this option reduces the ability to reclaim space and can lead to index bloat, but it is helpful when the main goal is to freeze old tuples.\n6. [vacuumdb](https://www.postgresql.org/docs/12/app-vacuumdb.html) to select tables for vacuum based on their wraparound horizon \n\n The options are –min-xid-age and –min-mxid-age.\n7. [pg\\_upgrade](https://www.postgresql.org/docs/12/pgupgrade.html) to use the file system’s cloning feature.\n8. –exclude-database option to pg\\_dumpall.\n\n\nI hope you could use some of the features to solve some of real-time problems. I would love to hear back from you about the features which can solve your database problems\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
3fd636299ee12af26ed3baa82e4e8d82 | how to copy data in one table to another table in postgres | tutorialdba.com | 2020.16 | [
{
"text": "\n**You can use INSERT INTO statement** by selected specific table column or use * for selecting all column\n\n\n\ndblink also will server purpose even if it is remote database.. with condition X server is able to reach Y.\n\n\n\n```\n# you can use dblink to connect remote database and fetch result. For example:\n\npsql dbtest\nCREATE TABLE tblB (id serial, time integer);\nINSERT INTO tblB (time) VALUES (5000), (2000);\n\npsql postgres\nCREATE TABLE 2ndquadrant.in (id serial, time integer);\n\nINSERT INTO 2ndquadrant.in SELECT id, time \n FROM dblink('dbname=dbtest', 'SELECT id, time FROM tblB')\n AS t(id integer, time integer)\n WHERE time > 1000;\n\nTABLE in;\n id | time \n----+------\n 1 | 5000\n 2 | 2000\n(2 rows\n# If you want insert into specify column:\n\nINSERT INTO 2ndquadrant.in (time)\n(SELECT time FROM \n dblink('dbname=dbtest', 'SELECT time FROM tblB') AS t(time integer) \n WHERE time > 1000\n);\n```\n\nCopy\n\n\n**Note** : See here 2ndquadrant is a schema name and in is the table name\n\n\nOr **use** **copy statement** from table to text file and back to another table.\n\n\n\n\n\n```\n2ndquadrant.in=# COPY ehis.citytemp FROM 'D:\\2ndq/nijamutheen.csv' DELIMITER '|' CSV HEADER;\nERROR: character with byte sequence 0x9d in encoding \"WIN1252\" has no equivalent in encoding \"UTF8\"\nCONTEXT: COPY citytemp, line 358646\n### solution\n2ndquadrant.in=# SET CLIENT_ENCODING TO 'utf8';\nSET\n2ndquadrant.in=# COPY ehis.citytemp FROM 'D:\\2ndq/nijamutheen.csv' DELIMITER '|' CSV HEADER;\nCOPY 679249\n```\n\nCopy\n\n\nFor more details about COPY command go through this Tutorial\n\n\n<https://2ndquadrant.in/postgres-copy-command-tutorial/>\n\n\nOr **use CTAS create table statement** if you want full copy\n\n\n\n```\ncreate table tutorialba.t\nas\nselect * from 2ndquadrant.t2\n# this script will copy the table\nfrom t2 and newly created table\nname is t ,\nNewly created table t will\nbe stored in tutorialdba schema an\nsource table is in 2ndquadrant schema.\n```\n\n",
"name": "",
"is_accepted": false
}
] |
|
492a2b887e2b7629e3da8d7ecabc0dac | We have identified that our MSSQL DB has size is more with 93% of available space (as attached). So, as per our understanding DB Shrink can help us in this regard.
please let us know the process to get the DB shrink and will there be any impact on application due to shrink ? | MSSQL DB has size is more with 93% of available space | tutorialdba.com | 2021.31 | [
{
"text": "\nShrinking database data file in production environment is not a good idea. Due to Data file shrink, indexes will be badly fragmented and performance of the database will be degraded. Sometimes index rebuild also may not be helpful. Hence we are not recommending to shrink database data file.\n\n\n**steps to shrink :**\n\n\n* Take database full backup.\n* Shrink data file (Shrink may happen or may not happen—not sure)\n* Run-rebuild index\n* Run update statistics\n* Validate Database & application performance\n\n\n**Fallback:**\n\n\nRestore Database with last full backup (Step 1)\n\n\nWe would recommend to implement this activity in down time .\n\n\nNote: We can’t estimate the time to shrink the data file and to run rebuild index over the database.\n\n\n",
"name": "",
"is_accepted": true
}
] |
a7c50e83f2601497da777c2a34adda53 | Setup streaming replication postgresql 10 | Postgresql streaming replication 10 with SSL Certificate | tutorialdba.com | 2020.40 | [
{
"text": "\nStreaming replication with PostgreSQL 10 \n\nIn this post, i will explain how to setup a streaming replication with PostgreSQL 10. I will not explain how to install PostgreSQL 10 on your system. \n\n \n\n**My setup is :**\n\n\n1. master server : ip 172.17.0.2\n2. slave server : ip 172.17.0.3\n\n\n \n\nSecurise your communications and use SSL \n\nThis step is not mandatory but recommended. If you already have a SSL certificate, skip the first step.\n\n\n1. Generate a self signed certificate, see my previous [answer](https://discuss.tutorialdba.com/997/generate-signed-certificate)\n2. Setup SSL on PostgreSQL\n\n\n \n\nCopy your private key and your certificate in the directory of your choice. Be carefull that the postgresql user can read them (usually user postgres on Linux or \\_postgresql on OpenBSD) \n\nEdit the file postgresql.conf and change these lines:\n\n\n\n```\nssl = on\nssl\\_cert\\_file = '/etc/ssl/postgresql/cert/server.crt'\nssl\\_key\\_file = '/etc/ssl/postgresql/private/server.key'\n```\n\nOf course, change the directory by yours. If you don’t specify a directory but only the filename, PostgreSQL will search them in the PGDATA directory. \n\n \n\n \n\n**Configure the master** \n\nCreate a role dedicated to the replication\n\n\n\n```\npostgres=# CREATE ROLE replicate WITH REPLICATION LOGIN ;\nCREATE ROLE\npostgres=# set password\\_encryption = 'scram-sha-256';\nSET\npostgres=# \\password replicate\nEnter new password:\nEnter it again:\n```\n\nVerify that your PostgreSQL server listen on your interface. Edit postgresql.conf and change this line\n\n\n\n```\n#listen\\_addresses = 'localhost'\nby something like this\nlisten\\_addresses = '*'\n#or\nlisten\\_addresses = 'xxx.xxx.xxx.xxx'\n```\n\nChange the parameters for the streaming replication in postgresql.conf\n\n\n\n```\nwal\\_level = replica\nmax\\_wal\\_senders = 3 # max number of walsender processes\nwal\\_keep\\_segments = 64 # in logfile segments, 16MB each; 0 disables\n```\n\nIf you think that the number you put in wal\\_keep\\_segments is enough, you can stop here. But if you are not sure, you should configure the archive\\_mode’ to store the wal segments.\n\n\n\n```\narchive\\_mode = on\narchive\\_command = 'rsync -a %p postgres@slave:/home/postgresql\\_wal/%f'\n # placeholders: %p = path of file to archive\n # %f = file name only\n```\n\nThe archive\\_command will copy the wal segments on a directory that must be accessible by the standby server. In the example above, i use the rsync command to copy them directly on the standby itself. \n\n \n\nWarning : if, like me, you use rsync, be sure to configure the ssh access by keys !! \n\n \n\nNow allow your slave(s) to connect to the master. Edit pg\\_hba.conf and add something like this:\n\n\n\n```\nhostssl replication replicate xxx.xxx.xxx.xxx/yy scram-sha-256\n```\n\nReplace xxx.xxx.xxx.xxx/yy by the ip of your slave or maybe by the subnet used by your slave if you want to have many. \n\n \n\nRestart your master server \n\n \n\n**Setup the slave** \n\nNow that your master is ready, it’s time to configure the slave. \n\n \n\nStop postgresql on the slave \n\n \n\nEdit your postgresql.conf and pg\\_hba.conf and report the changes you made on the master (like this, your slave will have the same configuration and could act as a master) \n\n \n\nEdit your postgresql.conf and change this line : \n\nhot\\_standby = on\n\n\nGo to your PGDATA directory and delete all the files. WARNING : if the files postgresql.conf and pg\\_hba.conf are in this directory, you must backup them (same for the certificate files) \n\n \n\nNow we will copy all the data from the master with the pg\\_basebackup command. You must run this command as the postgresql user (postgres on Debian, \\_postgresql on OpenBSD for example)\n\n\n\n```\n# su - postgres\n$ pg\\_basebackup -h 172.17.0.2 -D /var/lib/postgresql/10/main/ -P -U replicate --wal-method=stream\nPassword:\n23908/23908 kB (100%), 1/1 tablespace\n```\n\nNow, all your master’s data are copied on the slave. \n\n \n\nNow create a file recovery.conf in your PGDATA directory\n\n\n\n```\nstandby\\_mode = 'on'\nprimary\\_conninfo = 'host=172.17.0.2 port=5432 user=replicate password=MySuperPassword'\ntrigger\\_file = '/tmp/MasterNow'\n#restore\\_command = 'cp /home/postgresql\\_wal/%f \"%p\"'\n```\n\n**Here is an explanation for each line :**\n\n\n* standby\\_mode=on : specifies that the server must start as a standby server\n* primary\\_conninfo : the parameters to use to connect to the master\n* trigger\\_file : if this file exists, the server will stop the replication and act as a master\n* restore\\_command : this command is only needed if you have used the archive\\_command on the master\n\n\n \n\nStart the postgresql server\n\n\n\n```\n2018-03-11 19:08:55.777 UTC [8789] LOG: listening on IPv4 address \"127.0.0.1\", port 5432\n2018-03-11 19:08:55.777 UTC [8789] LOG: could not bind IPv6 address \"::1\": Cannot assign requested address\n2018-03-11 19:08:55.777 UTC [8789] HINT: Is another postmaster already running on port 5432? If not, wait a few seconds and retry.\n2018-03-11 19:08:55.786 UTC [8789] LOG: listening on Unix socket \"/var/run/postgresql/.s.PGSQL.5432\"\n2018-03-11 19:08:55.820 UTC [8790] LOG: database system was interrupted; last known up at 2018-03-11 18:58:20 UTC\n2018-03-11 19:08:56.023 UTC [8790] LOG: entering standby mode\n2018-03-11 19:08:56.034 UTC [8790] LOG: redo starts at 0/4000028\n2018-03-11 19:08:56.039 UTC [8790] LOG: consistent recovery state reached at 0/40000F8\n2018-03-11 19:08:56.040 UTC [8789] LOG: database system is ready to accept read only connections\n2018-03-11 19:08:56.071 UTC [8794] LOG: started streaming WAL from primary at 0/5000000 on timeline 1\nYour slave is ready !\n```\n\nYou can see the replicate user on the master server :\n\n\n\n```\npostgres=# select * from pg\\_stat\\_activity where usename = 'replicate' ;\n-[ RECORD 1 ]----+------------------------------\ndatid |\ndatname |\npid | 9134\nusesysid | 16384\nusename | replicate\napplication\\_name | walreceiver\nclient\\_addr | 172.17.0.3\nclient\\_hostname |\nclient\\_port | 45234\nbackend\\_start | 2018-03-11 19:08:56.049113+00\nxact\\_start |\nquery\\_start |\nstate\\_change | 2018-03-11 19:08:56.071363+00\nwait\\_event\\_type | Activity\nwait\\_event | WalSenderMain\nstate | active\nbackend\\_xid |\nbackend\\_xmin |\nquery |\nbackend\\_type | walsender\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
6e2d538f5f363d4960057bafb8ea0469 |
Like the prior game mode, it doesn't need to be rebuilt from the ground up. What it does need is some quality of life updates in order to make the launch of the [Madden nfl 21 coins](https://www.mmoexp.com/Nfl-21/Coins.html) new game effective. It might help if EA paid the same kind of attention to reality that MLB The Display does using its franchise style. The Display doesn't do anything particularly flashy, but the sport style functions as though they're running a major league front office.
The Madden NFL series used to be similar in feel with its franchise style. In fact, it was so good that it actually birthed a whole other sport which allowed individuals to feel as though they were the head coach and general manager. Oddly, that appears to be on the time once the manner in Madden games fell off a little. EA appears to know that it needs to bring the rain when it comes to the franchise mode. It said as much this fall when the community voiced its disappointment over Madden NFL 21.
1 change which may be coming down the pike is that the coming of Madden NFL 22 on the Nintendo Switch. This past year, Madden NFL 21 came late to Google Stadia. Surely having more platforms to play the game will help its popularity, but not if what is offered on those platforms is only the"same old, same old." A new platform is a big change, particularly since it would mark the first time that the series is on a Nintendo console in more than a decade. However, the focus needs to be on what is in the sport, rather than where it can be played in order for Madden NFL 22 to catch a launching day score.
Best Potential Madden NFL 22 Cover Stars
However, considering how early it is in the process and the fact that EA hasn't verified Derrick Henry is the cover star yet, there's a chance it may be somebody else entirely. Henry is a fantastic choice, but he's not the only person out there that would fit.
---
is actually coming this year, it seems like there is going to be yet another installment from the long-running series. That is one reason it seems just like the rumors of Henry making the cover are true. EA may not have made the statement, but there's likely to be someone being showcased. Running backs have been few and far between when it comes to this honor though, as [cheap mut coins madden 21](https://www.mmoexp.com/Nfl-21/Coins.html) recent background hints which quarterback is more inclined to get the nod.
| Even though there isn't even confirmation that Madden NFL 22 | tutorialdba.com | 2021.25 | [
{
"text": "\n[**Pandora Charms**](https://www.pandoracharms.uk.com/) \n\n \n\n[**Jordan 1**](https://www.jordan1.uk.com/) \n\n \n\n[**Nike Outlet**](https://www.nikesoutlet.us.com/) \n\n \n\n[**YEEZY SUPPLY**](https://www.supplyyeezys.us/) \n\n \n\n[**Adidas UK**](https://www.adidasuk.uk.com/) \n\n \n\n[**Pandora Charms**](https://www.pandoracharms.cc/) \n\n \n\n[**Pandora Jewelry**](https://www.pandorajewelry.ca/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutlet.org/) \n\n \n\n[**Adidas Shoes**](https://www.adidasshoes.org/) \n\n \n\n[**Nike Shoes**](https://www.nikeshoes.cc/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutlet.uk.com/) \n\n \n\n[**Pandora Jewelry**](https://www.pandoras-jewelry.com/) \n\n \n\n[**Pandora Outlet**](https://www.pandoraoutlet.org/) \n\n \n\n[**Jordan Shoes**](https://www.jordanshoess.com/) \n\n \n\n[**Air Jordan 4**](https://www.air-jordan4.com/) \n\n \n\n[**Pandora Charms**](https://www.charms-pandora.com/) \n\n \n\n[**Pandora Jewelry**](https://www.pandorajewelryusa.us.com/) \n\n \n\n[**Pandora Rings**](https://www.ringspandora.com/) \n\n \n\n[**Pandora Bracelets**](https://www.bracelets-pandora.com/) \n\n \n\n[**Adidas Yeezy**](https://www.yeezy-adidas.us.com/) \n\n \n\n[**Yeezy**](https://www.yzy.us.com/) \n\n \n\n[**Pandora Charms**](https://www.charmspandora.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletstore.us.com/) \n\n \n\n[**Air Max 720**](https://www.airmax-720.com/) \n\n \n\n[**Nike Air Max 270**](https://www.nike-airmax270.com/) \n\n \n\n[**Air Jordan 11**](https://www.air-jordan11.com/) \n\n \n\n[**Air Force 1**](https://www.air-force1.com/) \n\n \n\n[**Air Jordan 1**](https://www.air-jordan1.com/) \n\n \n\n[**Nike Jordans**](https://www.nike-jordans.com/) \n\n \n\n[**Jordan 1s**](https://www.jordan-1s.com/) \n\n \n\n[**Pandora Charms**](https://www.pandora-charms.shop/) \n\n \n\n[**Pandora UK**](https://www.pandorauk.uk.com/) \n\n \n\n[**Nike Jordan 1**](https://www.nikejordan1.com/) \n\n \n\n[**Nike Air VaporMax Flyknit 3**](https://www.nikeairvapormaxflyknit3.us/) \n\n \n\n[**Jordan 1**](https://www.jordan-1.org/) \n\n \n\n[**Pandora Sale**](https://www.pandorasale.me.uk/) \n\n \n\n[**Jordan 11**](https://www.jordan11.org/) \n\n \n\n[**Nike Air VaporMax**](https://www.nikeairvapormax.us/) \n\n \n\n[**Pandora Jewelry Official Site**](https://www.pandora-jewelry.shop/) \n\n \n\n[**Nike Vapormax Flyknit**](https://www.nikevapormaxflyknit.com/) \n\n \n\n[**Air Jordan 1 Mid**](https://www.airjordan1-mid.com/) \n\n \n\n[**Adidas yeezy**](https://www.yeezyadidas.de/) \n\n \n\n[**Yeezy Shoes**](https://www.yeezy-shoess.com/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.me.uk/) \n\n \n\n[**Adidas Yeezy**](https://www.adidasyeezy.me.uk/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.de/) \n\n \n\n[**Nike Shoes**](https://www.nikes.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletstoreonlineshopping.us/) \n\n \n\n[**Yeezy**](https://www.yeezystore.us.com/) \n\n \n\n[**NFL Shop Official Online Store**](https://www.nflshopofficialonlinestore.com/) \n\n \n\n[**Nike UK**](https://www.nikeuk.uk.com/) \n\n \n\n[**Yeezy Slides**](https://www.yeezyslides.us.com/) \n\n \n\n[**Yeezy**](https://www.yeezy.uk.com/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.uk.com/)\n\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\n[**Golden Goose Sale**](https://www.golden-goose-sale.com/) ,\n\n\n[**Off White T Shirt**](https://www.offwhiteclothes.com/) ,\n\n\n[**Golden Goose Star**](https://ggdbsosit.edublogs.org/) ,\n\n\n[**Golden Goose Lovin**](https://www.bloglovin.com/@fashionsneaki) ,\n\n\n[**Golden Goose Reviews**](https://ggdbsoser.quora.com/) ,\n\n\n[**Golden Goose On Sale**](https://ggdbsosit.over-blog.com/) ,\n\n\n[**Golden Goose Google**](https://sites.google.com/view/fashionsneaki/home) ,\n\n\n[**Off White Store**](https://www.offwhiteclothes.com/) ,\n\n\n[**Golden Goose US**](https://ggdbsosit.blog.fc2blog.us/) ,\n\n\n[**Golden Goose Reddit**](https://www.reddit.com/user/fashionsneaki) ,\n\n\n[**Golden Goose Outlet**](https://www.goldengoosesos.com/) ,\n\n\n[**Golden Goose Outlet**](https://www.goldengoosesneakersltd.com/) ,\n\n\n[**Golden Goose EDU**](https://fashionsneaki.edublogs.org) ,\n\n\n[**Golden Goose Sneakers**](https://www.goldengooseltd.com/) ,\n\n\n[**Golden Goose All Star**](https://ggdbsosit.quora.com/) ,\n\n\n[**Golden Goose Weheartit**](https://weheartit.com/fashionsneaki) ,\n\n\n[**Golden Goose Medium**](https://fashionsneaki.medium.com) ,\n\n\n[**Golden Goose TW**](https://ggdbsosit.pixnet.net/blog) ,\n\n\n[**Golden Goose Pinterest**](https://www.pinterest.com/fashionsneaki/) ,\n\n\n[**Golden Goose Sneakers**](https://www.goldengoosesalesit.com/) ,\n\n\n[**Golden Goose INT**](https://ggdbsoser.wordpress.com/) ,\n\n\n[**Golden Goose Shop**](https://ggdbsosit.wordpress.com/) ,\n\n\n[**Golden Goose Sneakers Outlet**](https://www.goldengoosesneakersltd.com/) ,\n\n\n[**Golden Goose**](https://www.goldengoosesalesit.com/) ,\n\n\n[**Golden Goose Youtube**](https://www.youtube.com/channel/UCr5Hy2tcUBPQPeH0SfZROMw/about) ,\n\n\n[**Golden Goose Sneakers**](https://www.goldengoosesos.com/) ,\n\n\n[**Golden Goose Wordpress**](https://fashionsneaki.wordpress.com) ,\n\n\n[**Golden Goose 8B**](https://303080.8b.io) ,\n\n\n[**Golden Goose Sneaker**](https://ggdbsosit.tumblr.com/) ,\n\n\n[**Golden Goose Shoes Sale**](https://ggdbsosit.medium.com/) ,\n\n\n[**Golden Goose Scoop**](https://www.scoop.it/u/fashionsneaki) ,\n\n\n[**Golden Goose Deluxe Brand**](https://ggdbsosit.bcz.com/) ,\n\n\n[**Golden Goose Webgarden**](https://fashionsneaki.webgarden.com) ,\n\n\n[**Golden Goose Quora**](https://goldengoosefashionsneaki0607.quora.com) ,\n\n\n[**Golden Goose**](https://www.goldengoosesos.com/) ,\n\n\n[**Golden Goose Images**](https://www.pinterest.com/ggdbsosit/) ,\n\n\n[**Golden Goose OverBlog**](https://fashionsneaki.over-blog.com) ,\n\n\n[**Golden Goose Gold**](https://ggdbsoser.tumblr.com/) ,\n\n\n[**Golden Goose Shoes Outlet**](https://ggdbsosit.bloggnorge.com/) ,\n\n\n[**Golden Goose Outlet**](https://www.goldengoosesalesit.com/) ,\n\n\n[**Golden Goose Sneakers**](https://www.goldengoosesneakersltd.com/) ,\n\n\n[**Golden Goose Jigsy**](http://fashionsneaki.jigsy.com) ,\n\n\n[**Golden Goose Sneakers Sale**](https://www.golden-goose-sale.com/) ,\n\n\n[**Off White Hoodie**](https://www.offwhiteclothes.com/) ,\n\n\n[**Golden Goose BLOGSHE**](https://blog.she.com/fashionsneaki/) ,\n\n\n[**Off White Clothing**](https://www.offwhiteclothes.com/) ,\n\n\n[**Golden Goose Disqus**](https://disqus.com/by/fashionsneaki/) ,\n\n\n[**Golden Goose Limited Edition**](https://www.goldengooseltd.com/) ,\n\n\n[**Golden Goose Futbolowo**](http://fashionsneaki.futbolowo.pl) ,\n\n\n[**Golden Goose Italy**](https://ggdbsoser.myblog.it/) ,\n\n\n[**Golden Goose**](https://ggdbsoser.blogspot.com/) ,\n\n\n[**The Golden Goose**](https://twitter.com/ggdbsosit/) ,\n\n\n[**Golden Goose Brand**](https://ggdbsosit.blogspot.com/) ,\n\n\n[**Golden Goose Sale**](https://www.goldengoosesos.com/) ,\n\n\n[**Golden Goose Shoes**](https://www.goldengooseltd.com/) ,\n\n\n[**Golden Goose Sneakers**](https://www.golden-goose-sale.com/) ,\n\n\n[**Golden Goose Deviantart**](https://www.deviantart.com/fashionsneaki) ,\n\n\n[**Golden Goose Sale**](https://www.goldengoosesalesit.com/) ,\n\n\n[**Golden Goose Tumblr**](https://fashionsneaki.tumblr.com) ,\n\n\n[**Golden Goose Poland**](https://ggdbsosit.futbolowo.pl) ,\n\n\n[**Golden Goose**](https://www.goldengooseltd.com/) ,\n\n\n[**Golden Goose Facebook**](https://www.facebook.com/profile.php?id=100068814655081) ,\n\n\n[**Golden Goose Sneakers Sale**](https://www.goldengoosesneakersltd.com/) ,\n\n\n[**Golden Goose Libero**](https://blog.libero.it/wp/fashionsneakinuovoblog/) ,\n\n\n[**Golden Goose Pearltrees**](https://www.pearltrees.com/fashionsneaki) ,\n\n\n[**Golden Goose Yola**](https://golden-goose-fashionsneaki.yolasite.com) ,\n\n\n[**Golden Goose Outlet**](https://www.golden-goose-sale.com/) ,\n\n\n",
"name": "",
"is_accepted": false
}
] |
0e5a58f5c7a984a42e2c214475caad16 | Easy and simple PostgreSQL archive and logs moving script | tutorialdba.com | 2020.16 | [
{
"text": "\n**PostgreSQL Logs Moving & Deleting :**\n---------------------------------------\n\n\n**Older than 10 days postgres logfiles Compressing :**\n\n\n\n```\nfind /data/pg\\_log/ -mtime +10 | xargs tar -czvPf /nijam/older\\_log.tar.gz\n```\n\n**Older than 12 days postgres logfiles removing :**\n\n\n\n```\nfind /data/pg\\_log/ -type f -name \"*.log\" -mtime +11 -exec rm {} \\;\n```\n\nBut before that get a listing to see what you are about to delete and tar\n\n\n\n```\nfind /data/pg\\_log/ -type f -name \"*.log\" -mtime +10 -exec ls -tr {} \\;\n```\n\n**PostgreSQL Archives Moving Script with TAR :**\n------------------------------------------------\n\n\nThis script will move the postgres archive to some other location with tar.zip format while compressing the archive source files will deleted automatically.\n\n\n\n```\n/opt/PostgreSQL/9.3/bin/psql -U username -d dbname -p 5432 -c \"select pg\\_switch\\_xlog();\"\ntar --remove-files -cvzf /archive\\_backup/archive\\_log\\_on\\_`date +%d-%m-%y-%T`.tar.gz /archive/archive\\_logs/*\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
|
009bc489e581bf9ddc533d9c9dc85068 |
I have had a few conversations in other threads about doing some fine tuning and performance tweaks to MySQL as I have reason to believe that MySQL is what is causing some slowdowns on my systems. I have done some implementations and experimenting on the suggestions given in the forums and I have also been looking into other possibilities and researching them. As I am just now learning about the inner workings of Zabbix, I would appreciate it if anyone could tell me if these tweaks help, hinder, or if I just did a serious no-no. I am just listing some of the changes I have made based off of what I have found as well as some items that keep popping up that I am still trying to get more information on.
I have not committed any changes to my production server, just my test Zabbix server so if I did just really screw something up...meh who cares? Thats what the test system is there for, right?
While I know about 3x more on MySQL then I did a few weeks ago, I am still in the starting stages of learning. I would really appreciate any comments, suggestions, and/or further information on MySQL improvements.
I went to a few sites and I saw a lot of similar suggestions. These are just the few sites that I bookmarked.
[http://www.cyberciti.biz/tips/enable...rformance.html](http://www.cyberciti.biz/tips/enable-the-query-cache-in-mysql-to-improve-performance.html)
[http://docs.cellblue.nl/2007/03/17/e...rmance-tweaks/](http://docs.cellblue.nl/2007/03/17/easy-mysql-performance-tweaks/)
I did try to modify a few settings based on my server memory. I wanted to ensure that I had plenty left over for the kernel and other programs while allowing MySQL to use a size able amount as well. My test server has 1.2GB of memory
key\_buffer = 256 (1/5 of my servers memory)
query\_cache\_size = 256MB (1/5 of my servers memory)
query\_cache\_limit = 4MB
table\_cache = 512
The next two were commented out in my my.conf and I have not done enough research yet to figure out if it they are worth turning on
#sort\_buffer\_size = 32M
#myisam\_sort\_buffer\_size = 32M
These next three are not in my my.conf. I want to find out more before I add them.
tmp\_table\_size = 64MB
delay\_key\_write = 1
wait\_timeout = 60
I commented the next line out as I have a cron process that backs up the MySQL database nightly and copies it to a different server. Therefore I believe that this is unneeded. One website said this was a noticeable gain on large databases that are frequently updating. I have not found a site that can show any type of graph or proof on this but it seems to have been mentioned on several sites. There is also a nifty warning in my.conf that I followed and commented out the expire\_logs\_days and max\_binlog\_size
#log-bin = /var/log/mysql/mysql-bin.log
# WARNING: Using expire\_logs\_days without bin\_log crashes the server! See README.Debian!
#expire\_logs\_days = 10
#max\_binlog\_size = 100M
I have read several places that state I can safely turn off InnoDB and see a speed increase (such as link 2 states) but in this thread (<http://www.zabbix.com/forum/showthread.php?t=250> ) from 2005 Alexei states that it increases parallelism and does not lock tables. From what I understand, locking tables can do bad things if a process freezes. So I did some more research and found this ( <http://www.zabbix.com/forum/showthread.php?t=7771> ). I am still reading through those links (its a bit of information to go through  ) but I have been playing with the suggested changes.
innodb\_file\_per\_table
innodb\_buffer\_pool\_size=350M
innodb\_log\_buffer\_size=8M
innodb\_support\_xa=0
nnodb\_flush\_log\_at\_trx\_commit=0
innodb\_checksums=0
innodb\_doublewrite=0
The query\_cache stuff suggested I had already done up there ^ .
I also found this thread ( <http://www.zabbix.com/forum/showthread.php?t=6316> ) and followed a few suggestions
max\_allowed\_packet = 128M (was set to 16M)
innodb\_buffer\_pool\_size=350M (From the other thread I have it set to 350M which is about 1/4 of my physical memory but in this thread alj recommended that 70% (~896M) of my physical memory be put here! That sounds way high from other places I found; can someone verify?)
thread\_cache\_size = 80
I did all of these edits to my.conf, so again if I screwed something up or a change should be placed elsewhere please let me know. Any comments / criticism / suggestions are welcome but instead of posting "don't do that. its stupid" I would really appreciate an explanation or a link with details that I can gather knowledge from.
Thanks guys! I really do appreciate any help!
cstackpole
My final my.conf looks like this:
```
For reference the Zabbix server has 1.2 GB of ram
#
# The MySQL database server configuration file.
#
# You can copy this to one of:
# - "/etc/mysql/my.cnf" to set global options,
# - "~/.my.cnf" to set user-specific options.
#
# One can use all long options that the program supports.
# Run program with --help to get a list of available options and with
# --print-defaults to see which it would actually understand and use.
#
# For explanations see
# <http://dev.mysql.com/doc/mysql/en/server-system-variables.html>
# This will be passed to all mysql clients
# It has been reported that passwords should be enclosed with ticks/quotes
# escpecially if they contain "#" chars...
# Remember to edit /etc/mysql/debian.cnf when changing the socket location.
[client]
port = 3306
socket = /var/run/mysqld/mysqld.sock
# Here is entries for some specific programs
# The following values assume you have at least 32M ram
# This was formally known as [safe\_mysqld]. Both versions are currently parsed.
[mysqld\_safe]
socket = /var/run/mysqld/mysqld.sock
nice = 0
[mysqld]
#
# * Basic Settings
#
user = mysql
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
port = 3306
basedir = /usr
datadir = /var/lib/mysql
tmpdir = /tmp
language = /usr/share/mysql/english
skip-external-locking
#
# Instead of skip-networking the default is now to listen only on
# localhost which is more compatible and is not less secure.
bind-address = 127.0.0.1
#
# * Fine Tuning
#
key\_buffer = 256M
max\_allowed\_packet = 128M
thread\_stack = 128K
thread\_cache\_size = 80
#max\_connections = 100
table\_cache = 512
#thread\_concurrency = 10
#
# * Query Cache Configuration
#
query\_cache\_type = 1
query\_cache\_limit = 4M
query\_cache\_size = 256M
#
# * Logging and Replication
#
# Both location gets rotated by the cronjob.
# Be aware that this log type is a performance killer.
#log = /var/log/mysql/mysql.log
#
# Error logging goes to syslog. This is a Debian improvement :)
#
# Here you can see queries with especially long duration
#log\_slow\_queries = /var/log/mysql/mysql-slow.log
#long\_query\_time = 2
#log-queries-not-using-indexes
#
# The following can be used as easy to replay backup logs or for replication.
#server-id = 1
#log\_bin = /var/log/mysql/mysql-bin.log
# WARNING: Using expire\_logs\_days without bin\_log crashes the server! See README.Debian!
#expire\_logs\_days = 10
#max\_binlog\_size = 100M
#binlog\_do\_db = include\_database\_name
#binlog\_ignore\_db = include\_database\_name
#
# * BerkeleyDB
#
# Using BerkeleyDB is now discouraged as its support will cease in 5.1.12.
skip-bdb
#
# * InnoDB
#
# InnoDB is enabled by default with a 10MB datafile in /var/lib/mysql/.
# Read the manual for more InnoDB related options. There are many!
# You might want to disable InnoDB to shrink the mysqld process by circa 100MB.
#skip-innodb
innodb\_file\_per\_table
innodb\_buffer\_pool\_size=350M
innodb\_log\_buffer\_size=8M
## Produce informations about wrong informations in tables.
###innodb\_log\_file\_size=1M
innodb\_support\_xa=0
innodb\_flush\_log\_at\_trx\_commit=0
innodb\_checksums=0
innodb\_doublewrite=0
#
# * Security Features
#
# Read the manual, too, if you want chroot!
# chroot = /var/lib/mysql/
#
# For generating SSL certificates I recommend the OpenSSL GUI "tinyca".
#
# ssl-ca=/etc/mysql/cacert.pem
# ssl-cert=/etc/mysql/server-cert.pem
# ssl-key=/etc/mysql/server-key.pem
[mysqldump]
quick
quote-names
max\_allowed\_packet = 16M
[mysql]
#no-auto-rehash # faster start of mysql but no tab completition
[isamchk]
key\_buffer = 256M
#
# * NDB Cluster
#
# See /usr/share/doc/mysql-server-*/README.Debian for more information.
#
# The following configuration is read by the NDB Data Nodes (ndbd processes)
# not from the NDB Management Nodes (ndb\_mgmd processes).
#
# [MYSQL\_CLUSTER]
# ndb-connectstring=127.0.0.1
#
# * IMPORTANT: Additional settings that can override those from this file!
#
!includedir /etc/mysql/conf.d/
```
| MySQL Memory allocating | tutorialdba.com | 2019.47 | [
{
"text": "\nOK I found out some more information. \n\n \n\nFirst off, I decided to look at what was turned on/off. I ran a 'mysqladmin -uroot -p variables'\n\n\nCode:\n\n\n\n```\nVariable\\_name\t\t |Value\nauto\\_increment\\_increment |1\nauto\\_increment\\_offset\t |1\nautomatic\\_sp\\_privileges\t |ON\nback\\_log\t\t |50\nbasedir\t\t\t |/usr/\nbinlog\\_cache\\_size\t |32768\nbulk\\_insert\\_buffer\\_size\t |8388608\ncharacter\\_set\\_client\t |latin1\ncharacter\\_set\\_connection |latin1\ncharacter\\_set\\_database\t |latin1\ncharacter\\_set\\_filesystem |binary\ncharacter\\_set\\_results\t |latin1\ncharacter\\_set\\_server\t |latin1\ncharacter\\_set\\_system\t |utf8\ncharacter\\_sets\\_dir\t |/usr/share/mysql/charsets/\ncollation\\_connection\t |latin1\\_swedish\\_ci\ncollation\\_database\t |latin1\\_swedish\\_ci\ncollation\\_server\t |latin1\\_swedish\\_ci\ncompletion\\_type\t\t |0\nconcurrent\\_insert\t |1\nconnect\\_timeout\t\t |5\ndatadir\t\t\t |/var/lib/mysql/\ndate\\_format\t\t |%Y-%m-%d\ndatetime\\_format\t\t |%Y-%m-%d %H:%i:%s\ndefault\\_week\\_format\t |0\ndelay\\_key\\_write\t\t |ON\ndelayed\\_insert\\_limit\t |100\ndelayed\\_insert\\_timeout\t |300\ndelayed\\_queue\\_size\t |1000\ndiv\\_precision\\_increment\t |4\nengine\\_condition\\_pushdown |OFF\nexpire\\_logs\\_days\t |0\nflush\t\t\t |OFF\nflush\\_time\t\t |0\nft\\_boolean\\_syntax\t |+ -><()~*:\"\"&|\nft\\_max\\_word\\_len\t\t |84\nft\\_min\\_word\\_len\t\t |4\nft\\_query\\_expansion\\_limit |20\nft\\_stopword\\_file\t |(built-in)\ngroup\\_concat\\_max\\_len\t |1024\nhave\\_archive\t\t |YES\nhave\\_bdb\t\t |NO\nhave\\_blackhole\\_engine\t |YES\nhave\\_compress\t\t |YES\nhave\\_crypt\t\t |YES\nhave\\_csv\t\t |YES\nhave\\_dynamic\\_loading\t |YES\nhave\\_example\\_engine\t |NO\nhave\\_federated\\_engine\t |YES\nhave\\_geometry\t\t |YES\nhave\\_innodb\t\t |YES\nhave\\_isam\t\t |NO\nhave\\_merge\\_engine\t |YES\nhave\\_ndbcluster\t\t |DISABLED\nhave\\_openssl\t\t |DISABLED\nhave\\_ssl\t\t |DISABLED\nhave\\_query\\_cache\t |YES\nhave\\_raid\t\t |NO\nhave\\_rtree\\_keys\t\t |YES\nhave\\_symlink\t\t |YES\nhostname\t\t |AS1\ninit\\_connect\t\t |\ninit\\_file\t\t |\ninit\\_slave\t\t |\ninnodb\\_additional\\_mem\\_pool\\_size|1048576\ninnodb\\_autoextend\\_increment |8\ninnodb\\_buffer\\_pool\\_awe\\_mem\\_mb |0\ninnodb\\_buffer\\_pool\\_size\t |367001600\ninnodb\\_checksums\t |OFF\ninnodb\\_commit\\_concurrency |0\ninnodb\\_concurrency\\_tickets |500\ninnodb\\_data\\_file\\_path\t |ibdata1:10M:autoextend\ninnodb\\_data\\_home\\_dir\t |\ninnodb\\_doublewrite\t |OFF\ninnodb\\_fast\\_shutdown\t |1\ninnodb\\_file\\_io\\_threads\t |4\ninnodb\\_file\\_per\\_table\t |ON\ninnodb\\_flush\\_log\\_at\\_trx\\_commit |0\ninnodb\\_flush\\_method\t |\ninnodb\\_force\\_recovery\t |0\ninnodb\\_lock\\_wait\\_timeout |50\ninnodb\\_locks\\_unsafe\\_for\\_binlog |OFF\ninnodb\\_log\\_arch\\_dir\t |\ninnodb\\_log\\_archive\t |OFF\ninnodb\\_log\\_buffer\\_size\t |8388608\ninnodb\\_log\\_file\\_size\t |5242880\ninnodb\\_log\\_files\\_in\\_group |2\ninnodb\\_log\\_group\\_home\\_dir |./\ninnodb\\_max\\_dirty\\_pages\\_pct |90\ninnodb\\_max\\_purge\\_lag\t |0\ninnodb\\_mirrored\\_log\\_groups |1\ninnodb\\_open\\_files\t |300\ninnodb\\_rollback\\_on\\_timeout |OFF\ninnodb\\_support\\_xa\t |OFF\ninnodb\\_sync\\_spin\\_loops\t |20\ninnodb\\_table\\_locks\t |ON\ninnodb\\_thread\\_concurrency |8\ninnodb\\_thread\\_sleep\\_delay |10000\ninteractive\\_timeout\t |28800\njoin\\_buffer\\_size\t |131072\nkey\\_buffer\\_size\t\t |268435456\nkey\\_cache\\_age\\_threshold\t |300\nkey\\_cache\\_block\\_size\t |1024\nkey\\_cache\\_division\\_limit |100\nlanguage\t\t |/usr/share/mysql/english/\nlarge\\_files\\_support\t |ON\nlarge\\_page\\_size\t\t |0\nlarge\\_pages\t\t |OFF\nlc\\_time\\_names\t\t |en\\_US\nlicense\t\t\t |GPL\nlocal\\_infile\t\t |ON\nlocked\\_in\\_memory\t |OFF\nlog\t\t\t |OFF\nlog\\_bin\t\t\t |OFF\nlog\\_bin\\_trust\\_function\\_creators|OFF\nlog\\_error\t\t |\nlog\\_queries\\_not\\_using\\_indexes |OFF\nlog\\_slave\\_updates\t |OFF\nlog\\_slow\\_queries\t |OFF\nlog\\_warnings\t\t |1\nlong\\_query\\_time\t\t |10\nlow\\_priority\\_updates\t |OFF\nlower\\_case\\_file\\_system\t |OFF\nlower\\_case\\_table\\_names\t |0\nmax\\_allowed\\_packet\t |134217728\nmax\\_binlog\\_cache\\_size\t |4294967295\nmax\\_binlog\\_size\t\t |1073741824\nmax\\_connect\\_errors\t |10\nmax\\_connections\t\t |100\nmax\\_delayed\\_threads\t |20\nmax\\_error\\_count\t\t |64\nmax\\_heap\\_table\\_size\t |16777216\nmax\\_insert\\_delayed\\_threads |20\nmax\\_join\\_size\t\t |18446744073709551615\nmax\\_length\\_for\\_sort\\_data |1024\nmax\\_prepared\\_stmt\\_count\t |16382\nmax\\_relay\\_log\\_size\t |0\nmax\\_seeks\\_for\\_key\t |4294967295\nmax\\_sort\\_length\t\t |1024\nmax\\_sp\\_recursion\\_depth\t |0\nmax\\_tmp\\_tables\t\t |32\nmax\\_user\\_connections\t |0\nmax\\_write\\_lock\\_count\t |4294967295\nmulti\\_range\\_count\t |256\nmyisam\\_data\\_pointer\\_size |6\nmyisam\\_max\\_sort\\_file\\_size |2147483647\nmyisam\\_recover\\_options\t |OFF\nmyisam\\_repair\\_threads\t |1\nmyisam\\_sort\\_buffer\\_size\t |8388608\nmyisam\\_stats\\_method\t |nulls\\_unequal\nndb\\_autoincrement\\_prefetch\\_sz |32\nndb\\_force\\_send\t\t |ON\nndb\\_use\\_exact\\_count\t |ON\nndb\\_use\\_transactions\t |ON\nndb\\_cache\\_check\\_time\t |0\nndb\\_connectstring\t |\nnet\\_buffer\\_length\t |16384\nnet\\_read\\_timeout\t |30\nnet\\_retry\\_count\t\t |10\nnet\\_write\\_timeout\t |60\nnew\t\t\t |OFF\nold\\_passwords\t\t |OFF\nopen\\_files\\_limit\t |1134\noptimizer\\_prune\\_level\t |1\noptimizer\\_search\\_depth\t |62\npid\\_file\t\t |/var/run/mysqld/mysqld.pid\nport\t\t\t |3306\npreload\\_buffer\\_size\t |32768\nprofiling\t\t |OFF\nprofiling\\_history\\_size\t |15\nprotocol\\_version\t |10\nquery\\_alloc\\_block\\_size\t |8192\nquery\\_cache\\_limit\t |4194304\nquery\\_cache\\_min\\_res\\_unit |4096\nquery\\_cache\\_size\t |268435456\nquery\\_cache\\_type\t |ON\nquery\\_cache\\_wlock\\_invalidate |OFF\nquery\\_prealloc\\_size\t |8192\nrange\\_alloc\\_block\\_size\t |2048\nread\\_buffer\\_size\t |131072\nread\\_only\t\t |OFF\nread\\_rnd\\_buffer\\_size\t |262144\nrelay\\_log\\_purge\t\t |ON\nrelay\\_log\\_space\\_limit\t |0\nrpl\\_recovery\\_rank\t |0\nsecure\\_auth\t\t |OFF\nsecure\\_file\\_priv\t |\nserver\\_id\t\t |0\nskip\\_external\\_locking\t |ON\nskip\\_networking\t\t |OFF\nskip\\_show\\_database\t |OFF\nslave\\_compressed\\_protocol |OFF\nslave\\_load\\_tmpdir\t |/tmp/\nslave\\_net\\_timeout\t |3600\nslave\\_skip\\_errors\t |OFF\nslave\\_transaction\\_retries |10\nslow\\_launch\\_time\t |2\nsocket\t\t\t |/var/run/mysqld/mysqld.sock\nsort\\_buffer\\_size\t |2097144\nsql\\_big\\_selects\t\t |ON\nsql\\_mode\t\t |\nsql\\_notes\t\t |ON\nsql\\_warnings\t\t |OFF\nssl\\_ca\t\t\t |\nssl\\_capath\t\t |\nssl\\_cert\t\t |\nssl\\_cipher\t\t |\nssl\\_key\t\t\t |\nstorage\\_engine\t\t |MyISAM\nsync\\_binlog\t\t |0\nsync\\_frm\t\t |ON\nsystem\\_time\\_zone\t |CDT\ntable\\_cache\t\t |512\ntable\\_lock\\_wait\\_timeout\t |50\ntable\\_type\t\t |MyISAM\nthread\\_cache\\_size\t |80\nthread\\_stack\t\t |131072\ntime\\_format\t\t |%H:%i:%s\ntime\\_zone\t\t |SYSTEM\ntimed\\_mutexes\t\t |OFF\ntmp\\_table\\_size\t\t |33554432\ntmpdir\t\t\t |/tmp\ntransaction\\_alloc\\_block\\_size |8192\ntransaction\\_prealloc\\_size |4096\ntx\\_isolation\t\t |REPEATABLE-READ\nupdatable\\_views\\_with\\_limit |YES\nversion\t\t\t |5.0.45-Debian\\_1\nversion\\_comment\t\t |Debian etch distribution\nversion\\_compile\\_machine\t |i486\nversion\\_compile\\_os\t |pc-linux-gnu\nwait\\_timeout\t\t |28800\n```\n\nIf I read this statement right, then apprently the my.conf did not enable InnoDB.\n\n\nCode:\n\n\n\n```\nstorage\\_engine\t\t |MyISAM\n```\n\nAlso, from what I have found using InnoDB probably isn't the best thing unless you know you are going to have a huge database. This website hasn't really helped convince me that InnoDB is the way to go ( <http://www.daniweb.com/forums/thread40911.html> Started a year ago, but last updated less then a day ago so the posting is still active). \n\n \n\nAnother thing is wait\\_timeout. The second article I posted in the previous post suggested 60. It looks like mine is currently set to 28800.  Thats quite the difference. \n\n \n\ndelay\\_key\\_write: According to this website ( <http://www.petefreitag.com/item/441.cfm> ) \"the option makes index updates faster because they are not flushed to disk until the table is closed.\" \n\nPlease correct me if I am wrong but this sounds very dangerous to me. First on small tables, I doubt it would do much at all. Second on large tables, if the database crashed, server died, network hiccup, ect then data could be lost and / or corrupted. Unless someone can give me a better reason, I think I am just going to go with the default (apparently its ON) and leave this one alone and just as it is. \n\n \n\nLast item (for now anyway  ) is the sort\\_buffer\\_size. I have found several sites that claim something along lines of 'if you do a lot of sorting on your tables or if you know you are going to be sorting a lot, then increase this somewhere between 10MB and 256MB. Otherwise, don't sweat it.' Could someone tell me if Zabbix does enough big sorts that increasing this would be good?\n\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\nHm, guys. I've read that if you'll read directly from MyISAM files you should get speed increase up to 5-7 times from [Mysql Perfomance](http://umumble.com/blogs/mysql/171/) article. What do you think about this?\n\n\n",
"name": "",
"is_accepted": false
}
] |
700eaa9922577b2707a198354eb1ae19 | How to start the DB automatically if postgres service down ? | tutorialdba.com | 2019.43 | [
{
"text": "\nBelow shell script will be helpfull to start the postgres DB if service is down\n\n\n\n```\nport=`netstat -tunlp | grep :5432 | awk '{print $4}' | awk -F ':' '{print $NF }'`\nk=5432\nif [[ $port -ne $k ]]\nthen\n `/nijam/9.6.15/bin/postgres -D /cal/data` &> /dev/null\n\nfi\n\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
|
502a5dd7daaba953801a79ac99d8bb31 | MariaDB Server Performance Tuning & Optimization | tutorialdba.com | 2020.50 | [
{
"text": "\n**Tips for MariaDB Server performance tuning & optimization**\n\n\n* Agenda MariaDB Performance Tuning:\n* Common Principles and Best Practices\n* Server Hardware and OS\n* MariaDB Configuration Settings\n* Database Monitoring\n* Query Tuning\n\n\n**Why Tune? The task of scalable server software is to maintain top performance for an increasing number of clients.**\n\n\n* Make efficient use of server resources\n* Best performance for users\n* Avoid outages due to server slowness\n* Capacity ○ Be Prepared for Application Development Requirements ○ Allow for Unexpected Traffic Spikes or Other Changes in Demand\n\n\n**Tune what? Initial recommended values for performance:**\n\n\n* transaction-isolation = READ-COMMITTED\n* key\\_buffer – 128MB for every 1GB of RAM\n* sort\\_buffer\\_size – 1MB for every 1GB of RAM\n* read\\_buffer\\_size – 1MB for every 1GB of RAM\n* read\\_rnd\\_buffer\\_size – 1MB for every 1GB of RAM\n* thread\\_concurrency – is based on the number of CPUs so make it CPU*2\n* thread-handling=pool-of-threads\n* innodb\\_flush\\_log\\_at\\_trx\\_commit != 1 – speed changes spectacularly if it’s !=1\n* open\\_files\\_limit = 50000\n\n\n**Tune what?**\n\n\n● Configuring threadpool\n\n\n* Pool-of-threads, or threadpool, is a MariaDB feature that improves performance by pooling active threads together instead of the old one thread per client connection method, which does not scale well for typical web-based workloads with many short-running queries.\n\n\n● Change innodb\\_flush\\_log\\_at\\_trx\\_commit to something !=1\n\n\n* speed changes spectacularly if it is !=1\n\n\n● The more memory available … the better\n\n\n**MariaDB performance parameters:**\n\n\n* InnoDB file-per-table\n* InnoDB Buffer Pool Size\n* Disable Swappiness In MariaDB\n* Max Connections\n* Thread Cache Size\n* Disable MySQL DNS Lookups\n* Query Cache Size\n* Tmp Table Size & Max Heap Table Size\n* Slow Query Logs\n* Idle Connections\n\n\n**Tuning Routine – When to Tune**\n\n\n• Use Monitoring Tool – MonYog\n\n\n• Tune from Start of the Application Lifecycle\n\n\n* Start Early to Ensure Schema is Well Constructed\n* Test Queries on Real Data\n* Watch for Bottlenecks\n* Over Tuning without Production Data or Traffic is Counter Productive\n\n\n• Conduct Periodic Reviews of Production Systems\n\n\n* Watch for Schema, Query and Significant Changes\n* Check Carefully New Application Features\n* Monitor System Resources — Disk, Memory, Network, CPU\n\n\n**my.cnf configuration file**\n\n\n• Change one setting at a time…\n\n\n* This is the only way to determine if a change is beneficial.\n\n\n• Most settings can be changed at runtime with SET GLOBAL.\n\n\n* It is very handy and it allows you to quickly revert the change if needed.\n* To make the change permanent, you need to update the configuration file.\n\n\n• If a change in the configuration is not visible even after a MariaDB restart…\n\n\n* Did you use the correct configuration file?\n* Did you put the setting in the right section?\n\n\n• Normally the [mysqld] section for these settings\n\n\n**my.cnf configuration file**\n\n\n• The server refuses to start after a change:\n\n\n* Did you use the correct units?\n* For instance, innodb\\_buffer\\_pool\\_size should be set in bytes while max\\_connection is dimensionless.\n\n\n• Do not allow duplicate settings in the configuration file.\n\n\n* If you want to keep track of the changes, use version control.\n\n\n• Don’t do naive math, like “my new server has 2x RAM, it’ll just make all the values 2x the previous ones”.\n\n\n**Performance Server Hardware and OS Tuning**\n---------------------------------------------\n\n\n**Server Hardware**\n\n\n• One Service per Server is Ideal to Prevent Contention\n\n\n* Have the database server be only a database server etc.\n\n\n• More CPU Cores is generally Good\n\n\n• More Disk is usually Better\n\n\n* Large Datasets, Fast Disks are Ideal\n\n\n• More RAM is usually Best\n\n\n* Traffic Dependent\n* More of Dataset in Memory, Fewer Slow Disk Operations\n\n\n**OS Settings Linux Settings**\n\n\n•Swappiness\n\n\n* Value for propensity of the OS to swap to disk\n* Defaults are usually 60 ○ Commonly set low to 10 or so (not 0)\n\n\n•Noatime\n\n\n* Mount disks with this option ○ Turns off writing of access time to disk with every file access\n* Without this option every read becomes an additional write\n\n\n**Performance MariaDB Configuration Settings**\n----------------------------------------------\n\n\n* **innodb\\_buffer\\_pool\\_size**\n* The first setting to update\n* The buffer pool is where data and indexes are cached\n* Utilize memory for read operations rather than disk\n* 80% RAM rule of thumb\n* Typical values are\n\t+ 5-6GB (8GB RAM)\n\t+ 20-25GB (32GB RAM)\n\t+ 100-120GB (128GB RAM)\n\n\n**query\\_cache\\_size**\n\n\n* Query cache is a well known bottleneck\n* Consider setting query\\_cache\\_size = 0\n* Use other ways to speed up read queries:\n\t+ Good indexing\n\t+ Adding replicas to spread the read load\n\n\n**innodb\\_log\\_file\\_size**\n\n\n* Size of the redo logs – 25 to 50% of innodb\\_buffer\\_pool usually recommended\n* Redo logs are used to make sure writes are fast and durable and also during crash recovery\n* Larger log files can lead to slower recovery in the event of a server crash\n* But! Larger log files also reduce the number of checkpoints needed and reduce disk I/O\n\n\n**innodb\\_file\\_per\\_table**\n\n\n* Each .ibd file represents a tablespace of its own.\n* Database operations such as “TRUNCATE” can be completed faster and you may also reclaim unused space when dropping or truncating a database table.\n* Allows some of the database tables to be kept in separate storage device. This can greatly improve the I/O load on your disks.\n\n\n**Disable MySQL Reverse DNS Lookups**\n\n\n* MariaDB performs a DNS lookup of the user’s IP address and Hostname with connection\n* The IP address is checked by resolving it to a host name. The hostname is then resolved to an IP to verify\n* This allows DNS issues to cause delays\n* You can disable and use IP addresses only\n\t+ skip-name-resolve under [mysqld] in my.cnf\n\n\n**max\\_connections**\n\n\n* Too many connections’ error?\n* Using a connection pool at the application level or a thread pool at the MariaDB level can help\n\n\n**Check for MySQL idle Connections**\n\n\n* Idle connections consume resources and should be interrupted or refreshed when possible.\n* Idle connections are in “sleep” state and usually stay that way for long period of time.\n* To look for idled connections:\n* # mysqladmin processlist -u root -p | grep “Sleep”\n* You can check the code for the cause if many idled\n* You can also change the wait\\_timeout value\n\n\n**thread\\_cache\\_size**\n\n\n* The thread\\_cache\\_size directive sets the amount of threads that your server should cache.\n* To find the thread cache hit rate, you can use the following technique:\n\t+ show status like ‘Threads\\_created’;\n\t+ show status like ‘Connections’;\n* calculate the thread cache hit rate percentage:\n\t+ 100 – ((Threads\\_created / Connections) * 100)\n* Dynamically set to a new value:\n\t+ set global thread\\_cache\\_size = 16;\n\n\n**memory parameters**\n\n\n* MariaDB uses temporary tables when processing complex queries involving joins and sorting\n* The default size of a temporary table is very small\n\t+ The size is configured in your my.cnf: tmp-table-size = 1G max-heap-table-size = 1G\n* Both should have the same size and will help prevent disk writes\n* A rule of thumb is giving 64Mb for every GB of RAM on the server\n\n\n**Buffer Sizes**\n\n\n* join buffer size\n\t+ used to process joins – but only full joins on which no keys are possible\n* sort buffer size\n\t+ Sort buffer size is used to sort data.\n\t+ The system status variable sort\\_merge\\_passes will indicates need to increase\n\t+ This variable should be as low as possible.\n* These buffers are allocated per connection and play a significant role in the performance of the system.\n\n\n**max\\_allowed\\_packet**\n\n\n* MariaDB splits data into packets. Usually a single packet is considered a row that is sent to a client.\n* The max\\_allowed\\_packet directive defines the maximum size of packet that can be sent.\n* Setting this value too low can cause a query to stall and you will receive an error in your error log.\n* It is recommended to set the value to the size of your largest packet.\n\t+ Some suggest 11 times the largest BLOB\n\n\n**Performance Monitoring Database Monitoring**\n----------------------------------------------\n\n\n**System Metrics**\n\n\n\n\n| **Metric** | **Comments** | **Suggested Alert** |\n| Load | An all-in-one performance metric. | When load is > factor x (number of cores). Our suggested factor is 4. |\n| CPU usage | A high CPU usage is not a bad thing as long as you don’t reach the limit. | None |\n| Memory usage | Ideally your entire database should be stored in memory, but this is not always possible. Give MySQL as much as you can afford but leave enough for other processes to function. | None |\n| Swap usage | Swap is for emergencies only, and it should not be used. | When used swap is > 128MB. |\n| Network bandwidth | Unless doing backups or transferring huge amounts of data, it shouldn’t be the bottleneck. | None |\n| Disk usage | Make sure you always have free space for new data, temporary files, snapshot or backups. | When database, logs and temp is > 85% usage. |\n\n\n**Disk Monitoring**\n\n\n\n\n| **Metric** | **Comments** | **Suggested Alert** |\n| Read/Write requests | IOPS (Input/Output operations per second) | None |\n| IO Queue length | Tracks how many operations are waiting for disk access. If a query hits the cache, it doesn’t create any disk operation. If a query doesn’t hit the cache (i.e. a miss), it will create multiple disk operations. | None |\n| Average IO wait | Time that queue operations have to wait for disk access. | None |\n| Average Read/Write time | Time it takes to finish disk access operations (latency). | None |\n| Read/Write bandwidth | Data transfer from and towards your disk. | None |\n\n\n**MariaDB Metrics**\n\n\n\n\n| **Metric** | **Comments** | **Suggested Alert** |\n| Uptime | Seconds since the server was started. We can use this to detect respawns. | When uptime is < 180. |\n| Threads\\_connected | Number of clients currently connected. If none or too high, something is wrong. | None |\n| Max\\_used\\_connections | Max number of connections at a time since server started.\n \n(max\\_used\\_connections / max\\_connections) indicates if you could run out soon of connection slots. | When connections usage is > 85%. |\n| Aborted\\_connects | Number of failed connection attempts. When growing over a period of time either some credentials are wrong or we are being attacked. | When aborted connects/min > 3. (only on not public exposed servers, otherwise will generate noise) |\n\n\n**MariaDB typical errors common failure points to keep an eye on**\n\n\n\n\n| **Metric** | **Comments** | **Suggested Alert** |\n| (Errors) | Are there any errors on the mysql.log file? | None |\n| (Log files size) | Are all log files being rotated? | None |\n| (Deleted log files) | Were any log files deleted but the file descriptor is still open? | None |\n| (Backup space) | Do you have enough disk space for backups? | None |\n\n\n**Monitoring caches, buffers & locks**\n\n\n\n\n| **Metric** | **Comments** | **Suggested Alert** |\n| Innodb\\_row\\_lock\\_waits | Number of times InnoDB had to wait before locking a row. | None |\n| Innodb\\_buffer\\_pool\\_wait\\_free | Number of times InnoDB had to wait for memory pages to be flushed. If too high, innodb\\_buffer\\_pool\\_size is too small for current write load. | None |\n| Open\\_tables | Number of tables currently open. If this is low and table\\_cache is high, we can reduce cache size. If opposite, we should increase it. If you increase table\\_cache you might have to increase available file descriptors for the mysql user. | None |\n| (Long running transactions) | Tracks whether too many transactions are locked by other idle transactions, or because of a problem in InnoDB. | None |\n| (Deadlocks) | Deadlocks happen when 2 transactions mutually hold. These are unavoidable in InnoDB and apps should deal with them. | None |\n\n\n**Monitoring Queries**\n\n\n\n\n| **Metric** | **Comments** | **Suggested Alert** |\n| Slow\\_queries | Number of queries that took more than long\\_query\\_time seconds to execute. Slow queries generate excessive disk reads, memory and CPU usage. Check slow\\_query\\_log to find them. | None |\n| Select\\_full\\_join | Number of full joins needed to answer queries. If too high, improve your indexing or database schema. | None |\n| Created\\_tmp\\_disk\\_tables | Number of temporary tables (typically for joins) stored on slow spinning disks, instead of faster\n \nRAM. | None |\n| (Full table scans)\n \nHandler\\_read% | Number of times the system reads the first row of a table index. Sequential reads might indicate a faulty index. | None |\n\n\n**Performance Query Tuning**\n----------------------------\n\n\n**Enable Slow query Logs**\n\n\nLogging slow queries can help you determine issues with your database and help you debug them. This can be easily enabled by adding the following values in your my.cnf configuration file:\n\n\n\n```\nslow-query-log = 1\nslow-query-log-file = /var/lib/mysql/mysql-slow.\nlog long\\_query\\_time = 1\n```\n\nThe first directive enables the logging of slow queries, while the second one tells MariaDB where to store the actual log file. Use long\\_query\\_time to define the amount of time that is considered long for a MariaDB query to be completed.\n\n\n**Query Analysis**\n\n\n* Use the Slow Log to find Problem Queries\n* Use mysqldumpslow Utility for Manageable Reports\n* Use EXPLAIN to see how MariaDB Executes a Troublesome Query and if Indexes are Used\n* Use EXPLAIN EXTENDED and SHOW WARNINGS to see how MariaDB Rearranges a Query before\n\n\n**Execution**\n\n\n\n```\n EXPLAIN SELECT * FROM employees WHERE MONTH(birth\\_date) = 8 G\nid: 1\nselect\\_type: SIMPLE\ntable: employees\ntype: ALL\npossible\\_keys: NULL\nkey: NULL\nkey\\_len: NULL\nref: NULL\nrows: 299587\nExtra: Using where\n\n```\n\n**Query Tuning Overview**\n\n\n* Try Not to Query Tune on Production Server\n* Use Test Server with same Hardware and OS\n* Use Copy of Production Data Set\n* Query Frequency is as Important as Query Speed\n\t+ Moderately Slow Queries are often a Bigger Problem than a Rarely Run Very Slow Query\n\n\n**Indexing**\n\n\n* Indexes Improve Read Performance\n* Without Index, MariaDB Must Read Every Row — Full Table Scan\n* With Index, MariaDB can jump to Requested Rows\n* Reduced I/O and Improving Performance\n* Index Increase cost of Writes\n* Find Balance\n* Index for Speed, but Avoid Indexing Excessively or Arbitrarily\n* Remove Dead or Redundant Indexes\n\n\n**Index Size**\n\n\n* Keep Indexes as Small as Practical\n\t+ Faster since More Likely to Fit in Memory\n\t+ Rebuilds Faster after Writes\n\t+ PRIMARY KEY should be Minimum Useful Size\n* Use Partial Prefix Indexes for String Columns\n\t+ May Slow Searches Slightly, but Reduce Index Size\n* Use Index Cardinality (Uniqueness Measure) Only If Necessary — Re-evaluate as Data Grows\n\t+ Low Cardinality Indicates many Duplicates\n\t+ High Cardinality is More Useful\n\n\n**Tools & Statistics**\n\n\n* Identify Accurately and Carefully Trouble Spots\n\t+ Guessing is Rarely Useful\n* Gather Performance Stats with MariaDB and OS Tools\n\t+ SHOW Statements\n\t+ PERFORMANCE\\_SCHEMA\n\t+ CPU, Disk, Network, Memory, & Swap Stats\n* Retain Snapshots of Multiple Stats\n\t+ Data from a Single Point Shows very Little\n* Automate the Collection of Stats into Logs\n\t+ Can be Useful for Emergency Tuning\n\n\n**SHOW PROCESSLIST**\n\n\n* Snapshot of mysqld Activity\n* mysqld is Multi-Threaded, One Thread per\n\t+ Client Connection (i.e., query, transaction) — a “process” is a “thread”\n* Accumulate SHOW PROCESSLIST Snapshots to build History of Thread Activities\n\n\n**SHOW STATUS Global or Session**\n\n\n* Returns List of Internal Counters\n* GLOBAL for System-Wide Status — Since Start-Up\n* SESSION for Local to Client Connection\n* FLUSH STATUS Resets Local Counters\n* Monitor Changes to Counters to Identify Hot Spots\n* Collect Periodically Status Snapshots to Profile Traffic\n\n\n**PERFORMANCE\\_SCHEMA**\n\n\n* Similar to INFORMATION\\_SCHEMA , but Performance Tuning\n* Monitors MariaDB Server Events\n* Function Calls, Operating System Waits, Internal Mutexes, I/O Calls\n* Detailed Query Execution Stages (Parsing, Statistics, Sorting)\n* Some Features Storage Engine Specific\n* Monitoring Lightweight and Requires No Dedicated Thread\n* Designed to be Used Iteratively with Successive Refinement\n\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
|
8c881969821c874b73a0900d87f867f1 | any shell script to send email alert and restarting automatically if service is down the services are mysql ,apache...etc | Any shell script to send email alert if service is down - mysql ,apache...etc | tutorialdba.com | 2019.47 | [
{
"text": "\nI am working on a script that:\n\n\n* checks if mysql and apache are running\n* if not, it sends an email and then attempts to restart the non-running service\n\n\nI would like to add the last few lines of the error logs to the email. Here is what I have so far. The check works, the restart works, sending email works, but am not getting my error messages from the log:\n\n\n\n```\n#!/bin/bash\n#ver. 1 \n\n##this script will check mysql and apache\n##if that service is not running\n##it will start the service and send \n##an email to you\n\n##set your email address \nEMAIL=\"[email protected]\"\n\n##list your services you want to check\nSERVICES=( 'mysql' 'apache2' )\n\n#### DO NOT CHANGE anything BELOW ####\n\n for i in \"${SERVICES[@]}\"\n do\n ###IF APACHE IS NOT RUNNING####\n if [[ \"$(service $i status)\" =~ \"not\" ]]\n then\n service $i start\n MESSAGE= \"$(tail -5 /var/log/$i/error.log)\"\n SUBJECT=\"$i down on $(hostname) $(date) \"\n echo \"$MESSAGE mysql\" | mail -s \"$SUBJECT\" \"$EMAIL\"\n fi\n ###IF MYSQL IS NOT RUNNING####\n if [[ \"$(service $i status)\" =~ \"stop\" ]]\n then\n service $i start\n MESSAGE=\"$(tail -5 /var/log/$i/error.log)\"\n SUBJECT=\"$i down on $(hostname) $(date) \"\n echo \"$MESSAGE \" | mail -s \"$SUBJECT\" \"$EMAIL\"\n fi\n done\n```\n\nAny tips on getting info from the error logs into the email? \n\nAlso, my loop would be much better if all services had the same status message...I wonder if there is a better way of checking if the service is running that will return the same result for all services.\n\n\n",
"name": "",
"is_accepted": true
},
{
"text": "\nThis script can be used to check on mysql, apache2, or whatever service you want. This is not meant to be a SOLUTION to services that are crashing, but rather a notification and a temporary restart until you can solve the real issue.\n\n\nThe script will check the status of each service. If the service is stopped, it tries to restart the service. If the service starts, it sends you an email saying the service stopped but was restarted.\n\n\nIf the service does not start for some reason, it sends you an email telling you it was not started.\n\n\nAfter that, it will continue to try and start, but not send any more emails until the service is finally started.\n\n\nNOTE*: This script should be run as your root user, so it would be added to the crontab like so:\n\n\n1. put it into your scripts folder\n2. set your email address\n3. set the services you want to keep an eye on (by default it has mysql and apache2..you can add or take away whatever you need)\n4. save your changes\n5. create a cronjob as root (sudo crontab -e) and add something like this, which runs every minute (adjust to your needs):\n\n\n\n```\n#check on services\n*/1 * * * * sh /root/script/dbalert.sh\n```\n\n \n\n\n\n```\n#!/bin/bash\n#ver. 4\n##this script will check mysql and apache\n##if that service is not running\n##it will start the service and send an email to you\n##if the restart does not work, it sends an email and then exits\n\n##set the path ##this works for Ubuntu 14.04 and 16.04\nPATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin\n\n##set your email address \nEMAIL=\"[email protected]\"\n\n##list your services you want to check\nSERVICES=( 'httpd' 'mysql' ) ## CentOS apache2 called httpd, if OS is other Linux you can give as apache2\n\n#### OK. STOP EDITING ####\n\n\n for i in \"${SERVICES[@]}\"\n do\n ###CHECK SERVICE####\n `pgrep $i >/dev/null 2>&1`\n STATS=$(echo $?)\n\n ###IF SERVICE IS NOT RUNNING####\n if [[ $STATS == 1 ]]\n\n then\n ##TRY TO RESTART THAT SERVICE###\n service $i start\n\n ##CHECK IF RESTART WORKED###\n `pgrep $i >/dev/null 2>&1`\n RESTART=$(echo $?)\n\n if [[ $RESTART == 0 ]]\n ##IF SERVICE HAS BEEN RESTARTED###\n then\n\n ##REMOVE THE TMP FILE IF EXISTS###\n if [ -f \"/tmp/$i\" ]; \n then\n rm /tmp/$i\n fi\n\n ##SEND AN EMAIL###\n MESSAGE=\"$i was down, but I was able to restart it on $(hostname) $(date) \"\n SUBJECT=\"$i was down -but restarted- on $(hostname) $(date) \"\n echo $MESSAGE | mail -s \"$SUBJECT\" \"$EMAIL\"\n\n else\n ##IF RESTART DID NOT WORK###\n\n ##CHECK IF THERE IS NOT A TMP FILE###\n if [ ! -f \"/tmp/$i\" ]; then\n\n ##CREATE A TMP FILE###\n touch /tmp/$i\n\n ##SEND A DIFFERENT EMAIL###\n MESSAGE=\"$i is down on $(hostname) at $(date) \"\n SUBJECT=\" $i down on $(hostname) $(date) \"\n echo $MESSAGE \" I tried to restart it, but it did not work\" | mail -s \"$SUBJECT\" \"$EMAIL\"\n fi\n fi\n fi\n done\nexit 0;\n```\n\nAlternate script for alerting services are down :\n\n\n\n```\n#!/bin/bash\n#ver. 2\n\n##this script will check whatever services \n##you want to keep an eye on\n##if that service is not running\n##it will (try to) start the service and send \n##an email to you\n\n##set your email address \nEMAIL=\"[email protected]\"\n\n##list your services you want to check\n##you can add as many as you like\nSERVICES=( 'mysql' 'apache2' )\n\n#### DO NOT CHANGE anything BELOW ####\n\n\n for i in \"${SERVICES[@]}\"\n do\n ###IF SERVICE IS NOT RUNNING####\n\n service $i status;\n STATS=$(echo $?)\n if [[ $STATS == 3 ]]\n\n then\n ##TRY TO RESTART THAT SERVICE###\n service $i start\n\n ##IF RESTART WORKED###\n service $i status;\n RESTART=$(echo $?)\n if [[ $RESTART == 0 ]]\n\n then\n ##SEND AN EMAIL###\n MESSAGE=\"$(tail -5 /var/log/$i/error.log)\"\n SUBJECT=\"$i down -but restarted- on $(hostname) $(date) \"\n echo \" $i $MESSAGE \" | mail -s \"$SUBJECT\" \"$EMAIL\"\n else\n\n ##IF RESTART DID NOT WORK SEND A DIFFERENT EMAIL###\n MESSAGE=\"$(tail -5 /var/log/$i/error.log)\"\n SUBJECT=\"$i down on $(hostname) $(date) \"\n echo \" $i $MESSAGE . I tried to restart but it did not work\" | mail -s \"$SUBJECT\" \"$EMAIL\"\n\n fi\n fi\n\n done\n\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\n\n```\n\n # DOWN DATABASE !!!!!!!!!!!!!!!!!!!!!!!!! #\n#!/bin/bash\n#ver. 2\n\n##this script will check whatever services \n##you want to keep an eye on\n##if that service is not running\n##it will (try to) start the service and send \n##an email to you\n\n##set your email address \nEMAIL=\"[email protected]\"\n\n##list your services you want to check\n##you can add as many as you like\nSERVICES=('mysql')\n\n#### DO NOT CHANGE anything BELOW ####\n\n\n for i in \"${SERVICES[@]}\"\n do\n ###IF SERVICE IS NOT RUNNING####\n\n service $i status;\n STATS=$(echo $?)\n if [[ $STATS == 3 ]]\n\n then\n ##TRY TO RESTART THAT SERVICE###\nmv /var/lib/mysql/ib\\_logfile* /tmp/\n service $i start\n\n ##IF RESTART WORKED###\n service $i status;\n RESTART=$(echo $?)\n if [[ $RESTART == 0 ]]\n\n then\n ##SEND AN EMAIL###\n MESSAGE=\"$(tail -10 /var/lib/mysql/vps.publishman.com.err)\"\n SUBJECT=\"$i down -but restarted- on $(hostname) $(date) \"\n echo \" $i $MESSAGE \" | mail -s \"$SUBJECT\" \"$EMAIL\"\n else\n\n ##IF RESTART DID NOT WORK SEND A DIFFERENT EMAIL###\n MESSAGE=\"$(tail -5 /var/lib/mysql/2ndquadrant,in.err)\"\n SUBJECT=\"$i down on $(hostname) $(date) \"\n echo \" $i $MESSAGE . I tried to restart but it did not work\" | mail -s \"$SUBJECT\" \"$EMAIL\"\n\n fi\n fi\n\n done\n\n # DOWN APACHE !!!!!!!!!!!!!!!!!!!!!!!!! #\n#!/bin/bash\n#ver. 2\n\n##this script will check whatever services \n##you want to keep an eye on\n##if that service is not running\n##it will (try to) start the service and send \n##an email to you\n\n##set your email address \nEMAIL=\"[email protected]\"\n\n##list your services you want to check\n##you can add as many as you like\nSERVICES=('httpd')\n\n#### DO NOT CHANGE anything BELOW ####\n\n\n for i in \"${SERVICES[@]}\"\n do\n ###IF SERVICE IS NOT RUNNING####\n\n service $i status;\n STATS=$(echo $?)\n if [[ $STATS == 3 ]]\n\n then\n ##TRY TO RESTART THAT SERVICE###\n service $i start\n\n ##IF RESTART WORKED###\n service $i status;\n RESTART=$(echo $?)\n if [[ $RESTART == 0 ]]\n\n then\n ##SEND AN EMAIL###\n MESSAGE=\"$(tail -10 /var/log/apache2/error\\_log)\"\n SUBJECT=\"$i down -but restarted- on $(hostname) $(date) \"\n echo \" $i $MESSAGE \" | mail -s \"$SUBJECT\" \"$EMAIL\"\n else\n\n ##IF RESTART DID NOT WORK SEND A DIFFERENT EMAIL##\n MESSAGE=\"$(tail -5 /var/log/apache2/error\\_log)\"\n SUBJECT=\"$i down on $(hostname) $(date) \"\n echo \" $i $MESSAGE . I tried to restart but it did not work\" | mail -s \"$SUBJECT\" \"$EMAIL\"\n\n fi\n fi\n\n done\n\n\n```\n\n",
"name": "",
"is_accepted": false
}
] |
6899573095a472ba175361338a03e89d | How to reconfigured postgres DR server without copy data folder its down before 7 days ? Becouse data folder size is very large. | How to reconfigured postgres DR server without copy data folder its down before 7 days ? | tutorialdba.com | 2021.04 | [
{
"text": "Better you move xlog and arch to slave server then inside the data create one recovery file inside the recovery file mention restore\\_command then restart the cluster slave then slave will be resync again , \n\n \n\nOther options is better take full Backup using rsync because rsync will not send all data it will send only missed data sequence but it will take much more time for checking \n\nFor more info about rsync : <https://www.tutorialdba.com/2018/04/what-is-difference-between-rsync-and.html?m=1>",
"name": "",
"is_accepted": false
}
] |
cedb5186a590e3cd94d3239fe2ae2703 | How to migrate the postgres data ? | tutorialdba.com | 2020.40 | [
{
"text": "\nHow to migrate the postgres database to some other new server ?\n\n\nTry this \n\n\n<https://discuss.tutorialdba.com/786/migrate-postgres-database-server>\n\n\n \n\n\n",
"name": "",
"is_accepted": true
}
] |
|
406f85976345b6c58e5a395768a1cee4 | How to increase the postgres process priority (nice valuse) ? | How to increase the postgres process priority (nice values) ? | tutorialdba.com | 2021.04 | [
{
"text": "\nNiceness values range from -20 (most favorable to the process) to 19 (least favorable to the process). To put this simply, the negative values (Eg. -20) gives higher priority to a process and positive values (Eg. 19) gives lower priority.\n\n\n**Kill the process with with kill command:**\n\n\n\n```\nkill -9 13957\n```\n\n**Again, start the process with niceness value of 15:**\n\n\nYou can also use -n option to increase or decrease the priority.\n\n\nTo increase priority, run the following command as root user:\n\n\n\n```\n# nice -n -15 cmdname &\n```\n\nTo decrease priority, run the following command as normal user:\n\n\n\n```\n$ nice -n 15 cmdname &\n```\n\n",
"name": "",
"is_accepted": true
}
] |
f6bbf8f46ab62e7b6205e8fb1a7af2e1 | Oracle maintenance & monitoring shell script | tutorialdba.com | 2019.47 | [
{
"text": "\nUNIX Basics for the DBA\n-----------------------\n\n\n### Basic UNIX Command\n\n\nThe following is a list of commonly used Unix commands:\n\n\n* **ps**– Show process\n* **grep**– Search files for text patterns\n* **mailx**– Read or send mail\n* **cat**– Join files or display them\n* **cut**– Select columns for display\n* **awk**– Pattern-matching language\n* **df**– Show free disk space\n\n\n \n\n\nHere are some examples of how the DBA uses these commands:\n\n\n* List available instances on a server:\n\n\n\n```\n$ ps -ef | grep smon\noracle 21832 1 0 Feb 24 ? 19:05 ora\\_smon\\_oradb1\noracle 898 1 0 Feb 15 ? 0:00 ora\\_smon\\_oradb2\ndliu 25199 19038 0 10:48:57 pts/6 0:00 grep smon\noracle 27798 1 0 05:43:54 ? 0:00 ora\\_smon\\_oradb3\noracle 28781 1 0 Mar 03 ? 0:01 ora\\_smon\\_oradb4\n```\n\n* List available listeners on a server:\n\n\n\n```\n$ ps -ef | grep listener | grep -v grep\noracle 23879 1 0 Feb 24 ? 33:36 /8.1.7/bin/tnslsnr listener\\_db1 -inherit\noracle 27939 1 0 05:44:02 ? 0:00 /8.1.7/bin/tnslsnr listener\\_db2 -inherit\noracle 23536 1 0 Feb 12 ? 4:19 /8.1.7/bin/tnslsnr listener\\_db3 -inherit\noracle 28891 1 0 Mar 03 ? 0:01 /8.1.7/bin/tnslsnr listener\\_db4 -inherit\n```\n\n* Find out file system usage for Oracle archive destination:\n\n\n\n```\n$ df -k | grep oraarch\n/dev/vx/dsk/proddg/oraarch 71123968 4754872 65850768 7% /u09/oraarch\n```\n\n* List number of lines in the alert.log file:\n\n\n\n```\n$ cat alert.log | wc -l\n2984\n```\n\n* List all Oracle error messages from the alert.log file:\n\n\n\n```\n$ grep ORA- alert.log\nORA-00600: internal error code, arguments: [kcrrrfswda.1], [], [], [], [], []\nORA-00600: internal error code, arguments: [1881], [25860496], [25857716], []\n```\n\n### CRONTAB Basics\n\n\nA crontab file is comprised of six fields:\n\n\n\n\n| Minute | 0-59 |\n| Hour | 0-23 |\n| Day of month | 1-31 |\n| Month | 1 – 12 |\n| Day of Week | 0 – 6, with 0 = Sunday |\n| Unix Command or Shell Scripts | |\n\n\n* To edit a crontab file, type:\n\n\n\n```\nCrontab -e\n```\n\n* To view a crontab file, type:\n\n\n\n```\nCrontab -l\n\n0 4 * * 5 /dba/admin/analyze\\_table.ksh\n30 3 * * 3,6 /dba/admin/hotbackup.ksh /dev/null 2>&1\n```\n\nIn the example above, the first entry shows that a script to analyze a table runs every Friday at 4:00 a.m. The second entry shows that a script to perform a hot backup runs every Wednesday and Saturday at 3:00 a.m.\n\n\nThe Eight Most Important DBA Shell Scripts for Monitoring the Database\n----------------------------------------------------------------------\n\n\nThe eight shell scripts provided below cover 90 percent of a DBA’s daily monitoring activities. You will need to modify the UNIX environment variables as appropriate.\n\n\n \n\n\n### Check Oracle Instance Availability\n\n\nThe oratab file lists all the databases on a server:\n\n\n\n```\n$ cat /var/opt/oracle/oratab\n###################################################################\n## /var/opt/oracle/oratab ##\n###################################################################\noradb1:/u01/app/oracle/product/8.1.7:Y\noradb2:/u01/app/oracle/product/8.1.7:Y\noradb3:/u01/app/oracle/product/8.1.7:N\noradb4:/u01/app/oracle/product/8.1.7:Y\n```\n\nThe following script checks all the databases listed in the oratab file, and finds out the status (up or down) of databases:\n\n\n\n```\n###################################################################\n## ckinstance.ksh ##\n###################################################################\nORATAB=/var/opt/oracle/oratab\necho \"`date` \"\necho \"Oracle Database(s) Status `hostname` :\\n\"\n\ndb=`egrep -i \":Y|:N\" $ORATAB | cut -d\":\" -f1 | grep -v \"\\#\" | grep -v \"\\*\"`\npslist=\"`ps -ef | grep pmon`\"\nfor i in $db ; do\necho \"$pslist\" | grep \"ora\\_pmon\\_$i\" > /dev/null 2>$1\nif (( $? )); then\necho \"Oracle Instance - $i: Down\"\nelse\necho \"Oracle Instance - $i: Up\"\nfi\ndone\n```\n\nUse the following to make sure the script is executable:\n\n\n\n```\n$ chmod 744 ckinstance.ksh\n$ ls -l ckinstance.ksh\n-rwxr--r-- 1 oracle dba 657 Mar 5 22:59 ckinstance.ksh*\n```\n\nHere is an instance availability report:\n\n\n\n```\n$ ckinstance.ksh\nMon Mar 4 10:44:12 PST 2002\n\nOracle Database(s) Status for DBHOST server:\nOracle Instance - oradb1: Up\nOracle Instance - oradb2: Up\nOracle Instance - oradb3: Down\nOracle Instance - oradb4: Up\n```\n\n### Check Oracle Listener’s Availability\n\n\nA similar script checks for the Oracle listener. If the listener is down, the script will restart the listener:\n\n\n\n```\n#######################################################################\n## cklsnr.sh ##\n#######################################################################\n#!/bin/ksh\nDBALIST=\"[email protected], [email protected]\";export DBALIST\ncd /var/opt/oracle\nrm -f lsnr.exist\nps -ef | grep mylsnr | grep -v grep > lsnr.exist\nif [ -s lsnr.exist ]\nthen\necho\nelse\necho \"Alert\" | mailx -s \"Listener 'mylsnr' on `hostname` is down\" $DBALIST\nTNS\\_ADMIN=/var/opt/oracle; export TNS\\_ADMIN\nORACLE\\_SID=db1; export ORACLE\\_SID\nORAENV\\_ASK=NO; export ORAENV\\_ASK\nPATH=$PATH:/bin:/usr/local/bin; export PATH\n. oraenv\nLD\\_LIBRARY\\_PATH=${ORACLE\\_HOME}/lib;export LD\\_LIBRARY\\_PATH\nlsnrctl start mylsnr\nfi\n```\n\n### Check Alert Logs (ORA-XXXXX)\n\n\nSome of the environment variables used by each script can be put into one profile:\n\n\n\n```\n#######################################################################\n## oracle.profile ##\n#######################################################################\nEDITOR=vi;export EDITOR ORACLE\\_BASE=/u01/app/oracle; export\nORACLE\\_BASE ORACLE\\_HOME=$ORACLE\\_BASE/product/8.1.7; export\nORACLE\\_HOME LD\\_LIBRARY\\_PATH=$ORACLE\\_HOME/lib; export\nLD\\_LIBRARY\\_PATH TNS\\_ADMIN=/var/opt/oracle;export\nTNS\\_ADMIN NLS\\_LANG=american; export\nNLS\\_LANG NLS\\_DATE\\_FORMAT='Mon DD YYYY HH24:MI:SS'; export\nNLS\\_DATE\\_FORMAT ORATAB=/var/opt/oracle/oratab;export\nORATAB PATH=$PATH:$ORACLE\\_HOME:$ORACLE\\_HOME/bin:/usr/ccs/bin:/bin:/usr/bin:/usr/sbin:/\nsbin:/usr/openwin/bin:/opt/bin:.; export\nPATH DBALIST=\"[email protected], [email protected]\";export\nDBALIST\n```\n\nThe following script first calls oracle.profile to set up all the environment variables. The script also sends the DBA a warning e-mail if it finds any Oracle errors:\n\n\n\n```\n####################################################################\n## ckalertlog.sh ##\n####################################################################\n#!/bin/ksh\n. /etc/oracle.profile\nfor SID in `cat $ORACLE\\_HOME/sidlist`\ndo\ncd $ORACLE\\_BASE/admin/$SID/bdump\nif [ -f alert\\_${SID}.log ]\nthen\nmv alert\\_${SID}.log alert\\_work.log\ntouch alert\\_${SID}.log\ncat alert\\_work.log >> alert\\_${SID}.hist\ngrep ORA- alert\\_work.log > alert.err\nfi\nif [ `cat alert.err|wc -l` -gt 0 ]\nthen\nmailx -s \"${SID} ORACLE ALERT ERRORS\" $DBALIST < alert.err\nfi\nrm -f alert.err\nrm -f alert\\_work.log\ndone\n```\n\n### Clean Up Old Archived Logs\n\n\nThe following script cleans up old archive logs if the log file system reaches 90 percent capacity:\n\n\n\n```\n$ df -k | grep arch\nFilesystem kbytes used avail capacity Mounted on\n/dev/vx/dsk/proddg/archive 71123968 30210248 40594232 43% /u08/archive\n\n#######################################################################\n## clean\\_arch.ksh ##\n#######################################################################\n#!/bin/ksh\ndf -k | grep arch > dfk.result\narchive\\_filesystem=`awk -F\" \" '{ print $6 }' dfk.result`\narchive\\_capacity=`awk -F\" \" '{ print $5 }' dfk.result`\nif [[ $archive\\_capacity > 90% ] ]\nthen\necho \"Filesystem ${archive\\_filesystem} is ${archive\\_capacity} filled\"\n# try one of the following option depend on your need\nfind $archive\\_filesystem -type f -mtime +2 -exec rm -r {} \\;\ntar\nrman\nfi\n```\n\n### Analyze Tables and Indexes (for Better Performance)\n\n\nBelow, I have shown an example of how to pass parameters to a script:\n\n\n\n```\n####################################################################\n## analyze\\_table.sh ##\n####################################################################\n#!/bin/ksh #\ninput parameter: 1: password # 2: SID if (($#<1)) then echo \"Please enter\n'oracle'\nuser password as the first parameter !\" exit 0 fi if (($#<2)) then echo\n\"Please enter\ninstance name as the second parameter!\" exit 0 fi\n\nTo execute the script with parameters, type:\n\n$ analyze\\_table.sh manager oradb1\n```\n\nThe first part of script generates a file analyze.sql, which contains the syntax for analyzing table. The second part of the script analyzes all the tables:\n\n\n\n```\n#####################################################################\n## analyze\\_table.sh ##\n#####################################################################\nsqlplus -s <<!\noracle/$1@$2\nset heading off\nset feed off\nset pagesize 200\nset linesize 100\nspool analyze\\_table.sql\nselect 'ANALYZE TABLE ' || owner || '.' || segment\\_name ||\n' ESTIMATE STATISTICS SAMPLE 10 PERCENT;'\nfrom dba\\_segments\nwhere segment\\_type = 'TABLE'\nand owner not in ('SYS', 'SYSTEM');\nspool off\nexit\n!\nsqlplus -s <<!\noracle/$1@$2\n@./analyze\\_table.sql\nexit\n!\n```\n\nHere is an example of analyze.sql:\n\n\n\n```\n$ cat analyze.sql\nANALYZE TABLE HIRWIN.JANUSAGE\\_SUMMARY ESTIMATE STATISTICS SAMPLE 10 PERCENT;\nANALYZE TABLE HIRWIN.JANUSER\\_PROFILE ESTIMATE STATISTICS SAMPLE 10 PERCENT;\nANALYZE TABLE APPSSYS.HIST\\_SYSTEM\\_ACTIVITY ESTIMATE STATISTICS SAMPLE 10 PERCENT;\nANALYZE TABLE HTOMEH.QUEST\\_IM\\_VERSION ESTIMATE STATISTICS SAMPLE 10 PERCENT;\nANALYZE TABLE JSTENZEL.HIST\\_SYS\\_ACT\\_0615 ESTIMATE STATISTICS SAMPLE 10 PERCENT;\nANALYZE TABLE JSTENZEL.HISTORY\\_SYSTEM\\_0614 ESTIMATE STATISTICS SAMPLE 10 PERCENT;\nANALYZE TABLE JSTENZEL.CALC\\_SUMMARY3 ESTIMATE STATISTICS SAMPLE 10 PERCENT;\nANALYZE TABLE IMON.QUEST\\_IM\\_LOCK\\_TREE ESTIMATE STATISTICS SAMPLE 10 PERCENT;\nANALYZE TABLE APPSSYS.HIST\\_USAGE\\_SUMMARY ESTIMATE STATISTICS SAMPLE 10 PERCENT;\nANALYZE TABLE PATROL.P$LOCKCONFLICTTX ESTIMATE STATISTICS SAMPLE 10 PERCENT;\n```\n\n### Check Tablespace Usage\n\n\nThis script checks for tablespace usage. If tablespace is 10 percent free, it will send an alert e-mail.\n\n\n\n```\n#####################################################################\n## ck\\_tbsp.sh ##\n#####################################################################\n#!/bin/ksh\nsqlplus -s <<!\noracle/$1@$2\nset feed off\nset linesize 100\nset pagesize 200\nspool tablespace.alert\nSELECT F.TABLESPACE\\_NAME,\nTO\\_CHAR ((T.TOTAL\\_SPACE - F.FREE\\_SPACE),'999,999') \"USED (MB)\",\nTO\\_CHAR (F.FREE\\_SPACE, '999,999') \"FREE (MB)\",\nTO\\_CHAR (T.TOTAL\\_SPACE, '999,999') \"TOTAL (MB)\",\nTO\\_CHAR ((ROUND ((F.FREE\\_SPACE/T.TOTAL\\_SPACE)*100)),'999')||' %' PER\\_FREE\nFROM (\nSELECT TABLESPACE\\_NAME,\nROUND (SUM (BLOCKS*(SELECT VALUE/1024\nFROM V\\$PARAMETER\nWHERE NAME = 'db\\_block\\_size')/1024)\n) FREE\\_SPACE\nFROM DBA\\_FREE\\_SPACE\nGROUP BY TABLESPACE\\_NAME\n) F,\n(\nSELECT TABLESPACE\\_NAME,\nROUND (SUM (BYTES/1048576)) TOTAL\\_SPACE\nFROM DBA\\_DATA\\_FILES\nGROUP BY TABLESPACE\\_NAME\n) T\nWHERE F.TABLESPACE\\_NAME = T.TABLESPACE\\_NAME\nAND (ROUND ((F.FREE\\_SPACE/T.TOTAL\\_SPACE)*100)) < 10;\nspool off\nexit\n!\nif [ `cat tablespace.alert|wc -l` -gt 0 ]\nthen\ncat tablespace.alert -l tablespace.alert > tablespace.tmp\nmailx -s \"TABLESPACE ALERT for ${2}\" $DBALIST < tablespace.tmp\nfi\n```\n\nAn example of the alert mail output is as follows:\n\n\n\n```\nTABLESPACE\\_NAME USED (MB) FREE (MB) TOTAL (MB) PER\\_FREE\n------------------- --------- ----------- ------------------- ------------------\nSYSTEM 2,047 203 2,250 9 %\nSTBS01 302 25 327 8 %\nSTBS02 241 11 252 4 %\nSTBS03 233 19 252 8 %\n```\n\n### Find Out Invalid Database Objects\n\n\nThe following finds out invalid database objects:\n\n\n\n```\n#####################################################################\n## invalid\\_object\\_alert.sh ##\n#####################################################################\n#!/bin/ksh\n. /etc/oracle.profile\nsqlplus -s <<!\noracle/$1@$2\nset feed off\nset heading off\ncolumn object\\_name format a30\nspool invalid\\_object.alert\nSELECT OWNER, OBJECT\\_NAME, OBJECT\\_TYPE, STATUS\nFROM DBA\\_OBJECTS\nWHERE STATUS = 'INVALID'\nORDER BY OWNER, OBJECT\\_TYPE, OBJECT\\_NAME;\nspool off\nexit\n!\nif [ `cat invalid\\_object.alert|wc -l` -gt 0 ]\nthen\nmailx -s \"INVALID OBJECTS for ${2}\" $DBALIST < invalid\\_object.alert\nfi\n$ cat invalid\\_object.alert\n\nOWNER OBJECT\\_NAME OBJECT\\_TYPE STATUS\n----------------------------------------------------------------------\nHTOMEH DBMS\\_SHARED\\_POOL PACKAGE BODY INVALID\nHTOMEH X\\_$KCBFWAIT VIEW INVALID\nIMON IW\\_MON PACKAGE INVALID\nIMON IW\\_MON PACKAGE BODY INVALID\nIMON IW\\_ARCHIVED\\_LOG VIEW INVALID\nIMON IW\\_FILESTAT VIEW INVALID\nIMON IW\\_SQL\\_FULL\\_TEXT VIEW INVALID\nIMON IW\\_SYSTEM\\_EVENT1 VIEW INVALID\nIMON IW\\_SYSTEM\\_EVENT\\_CAT VIEW INVALID\nLBAILEY CHECK\\_TABLESPACE\\_USAGE PROCEDURE INVALID\nPATROL P$AUTO\\_EXTEND\\_TBSP VIEW INVALID\nSYS DBMS\\_CRYPTO\\_TOOLKIT PACKAGE INVALID\nSYS DBMS\\_CRYPTO\\_TOOLKIT PACKAGE BODY INVALID\nSYS UPGRADE\\_SYSTEM\\_TYPES\\_TO\\_816 PROCEDURE INVALID\nSYS AQ$\\_DEQUEUE\\_HISTORY\\_T TYPE INVALID\nSYS HS\\_CLASS\\_CAPS VIEW INVALID\nSYS HS\\_CLASS\\_DD VIEW INVALID\n```\n\n \n\n\n### Monitor Users and Transactions (Dead Locks, et al)\n\n\nThis script sends out an alert e-mail if dead lock occurs:\n\n\n\n```\n###################################################################\n## deadlock\\_alert.sh ##\n###################################################################\n#!/bin/ksh\n. /etc/oracle.profile\nsqlplus -s <<!\noracle/$1@$2\nset feed off\nset heading off\nspool deadlock.alert\nSELECT SID, DECODE(BLOCK, 0, 'NO', 'YES' ) BLOCKER,\nDECODE(REQUEST, 0, 'NO','YES' ) WAITER\nFROM V$LOCK\nWHERE REQUEST > 0 OR BLOCK > 0\nORDER BY block DESC;\nspool off\nexit\n!\nif [ `cat deadlock.alert|wc -l` -gt 0 ]\nthen\nmailx -s \"DEADLOCK ALERT for ${2}\" $DBALIST < deadlock.alert\nfi\n```\n\nConclusion\n\n\n\n```\n0,20,40 7-17 * * 1-5 /dba/scripts/ckinstance.sh > /dev/null 2>&1\n0,20,40 7-17 * * 1-5 /dba/scripts/cklsnr.sh > /dev/null 2>&1\n0,20,40 7-17 * * 1-5 /dba/scripts/ckalertlog.sh > /dev/null 2>&1\n30 * * * 0-6 /dba/scripts/clean\\_arch.sh > /dev/null 2>&1\n* 5 * * 1,3 /dba/scripts/analyze\\_table.sh > /dev/null 2>&1\n* 5 * * 0-6 /dba/scripts/ck\\_tbsp.sh > /dev/null 2>&1\n* 5 * * 0-6 /dba/scripts/invalid\\_object\\_alert.sh > /dev/null 2>&1\n0,20,40 7-17 * * 1-5 /dba/scripts/deadlock\\_alert.sh > /dev/null 2>&1\n```\n\nNow, my DBA friends, you can finally get a bit more uninterrupted sleep at night. You may also have time for more important things like performance tuning.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
c4f24558825ab5a4b66d463b9c4252cd | What is MySQL DBA Responsibilities | tutorialdba.com | 2021.04 | [
{
"text": "\n**Overview of DBA duties**\n\n\n* Server startup/shutdown\n* Mastering the mysqladmin administrative client\n* Using the mysql interactive client\n* User account maintenance\n* Log file maintenance\n* Database backup/copying\n* Hardware tuning\n* Multiple server setups\n* Software updates and upgrades\n* File system security\n* Server security\n* Repair and maintenance\n* Crash recovery\n* Preventive maintenance\n* Understanding the mysqld server daemon\n* Performance analysis\n\n\n**Obtaining and Installing MySQL**\n\n\n* Choosing what else to install (e.g. Apache, Perl +modules, PHP)\n* Which version of MySQL (stable, developer, source, binary)\n* Creating a user acccount for the mysql user and group\n* Download and unpack a distribution\n* Compile source code and install (or rpm)\n* Initialize the data directory and grant tables with mysql\\_install\\_db\n* Starting the server\n* Installing Perl DBI support\n* Installing PHP\n* Installing Apache\n* Obtaining and installing the samp\\_db sample database\n\n\n**The MySQL Data Directory**\n\n\n* deciding/finding the Data Directory’s location\n* Structure of the Data Directory\n* How mysqld provides access to data\n* Running multiple servers on a single Data Directory\n* Database representation\n* Table representation (form, data and index files)\n* OS constraints on DB and table names\n* Data Directory structure and performance, resources, security\n* MySQL status files (.pid, .err, .log, etc)\n* Relocating Data Directory contents\n\n\n**Starting Up and Shutting Down the MySQL Server**\n\n\n* Securing a new MySQL installlation\n* Running mysqld as an unprivileged user\n* Methods of starting the server\n* Invoking mysqld directly\n* Invoking safe\\_mysqld\n* Invoking mysql.server\n* Specifying startup options\n* Checking tables at startup\n* Shutting down the server\n* Regaining control of the server if you can’t connect\n\n\n**Managing MySQL User Accounts**\n\n\n* Creating new users and granting privileges\n* Determining who can connect from where\n* Who should have what privileges?\n* Administrator privileges\n* Revoking privileges\n* Removing users\n\n\n**Maintaining MySQL Log Files**\n\n\n* The general log\n* The update log\n* Rotating logs\n* Backing up logs\n\n\n**Backing Up, Copying, and Recovering MySQL Databases**\n\n\n* Methods: mysqldump vs. direct copying\n* Backup policies\n* Scheduled cycles\n* Update logging\n* Consistent and comprehensible file-naming\n* Backing up the backup files\n* Off-site / off-system backups\n* Backing up an entire database with mysqldump\n* Compressed backup files\n* Backing up individual tables\n* Using mysqldump to transfer databases to another server\n* mysqldump options (flush-logs, lock-tables, quick, opt)\n* Direct copying methods\n* Database replication (live and off-line copying)\n* Recovering an entire database\n* Recovering grant tables\n* Recovering from mysqldump vs. tar/cpio files\n* Using update logs to replay post-backup queries\n* Editing update logs to avoid replaying erroneous queries\n* Recovering individual tables\n\n\n**Tuning the MySQL Server**\n\n\n* Default parameters\n* The mysqladmin variables command\n* Setting variables (command line and options file)\n* Commonly used variables in performance tuning\n* back\\_log\n* delayed\\_queue\\_size\n* flush\\_time\n* key\\_buffer\\_size\n* max\\_allowed\\_packet\n* max\\_connections\n* table\\_cache\n* Erroneous use of record\\_buffer and sort\\_buffer\n\n\n**Running Multiple MySQL Servers**\n\n\n* For test purposes\n* To overcome OS limits on per-process file descriptors\n* Separate servers for individual customers (e.g. ISPs)\n* Configuring and installing separate servers\n* Procedures for starting up multiple servers\n\n\n**Updating MySQL**\n\n\n* Stable vs. development releases\n* Updates for both streams\n* Using the “Change Notes”\n* Bug fixing vs. new features\n* Dependencies on the MySQL C client library (PHP, Apache, Perl DBD::mysql)\n\n\n**MySQL Security**\n\n\n* Assessing risks and threats\n* Internal security: data and directory access\n* Access to database files and log files\n* Securing both read and write access\n* Filesystem permissions\n* External security: network access\n* Structure and content of the MySQL Grant Tables\n* user, db, host, tables\\_priv, columns\\_priv\n* Grant table scope fields/columns\n* Grant table privilege columns\n* Database and table privileges: ALTER, CREATE, DELETE, DROP, INDEX, INSERT, SELECT, UPDATE\n* Administrative privileges: FILE, GRANT, PROCESS, RELOAD, SHUTDOWN\n* Server control over client access: matching grant table entries to client connection requests and queries\n* Scope column values: Host, User, Password, Db, Table\\_name, Column\\_name\n* Query access verification\n* Scope column mmatching order\n* Grant table risks: the FILE and ALTER privileges\n* Setting up users without GRANT\n* The anonymous user and sort order\n\n\n**MySQL Database Maintenance and Repair**\n\n\n* Checking and repairing tables\n* Invoking myisamchk and isamchk\n* Extended checks\n* Standard table repair\n* Table repair with missing/damaged index or table description\n* Avoid server-checking interaction, without shutdowns\n\n\nAmong all of them, MySQL database maintenance and repair is the most responsible activity of a database administrator.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
7f62ee0a1d01999b05eb398d6227bc5a | How to migrate the database from mysql to mariadb ? | tutorialdba.com | 2020.34 | [
{
"text": "\nA possible way is to use MnMTK and migrate automatically. <https://www.ispirer.com/download/download-demo>\n\n\nSee if it is what you need.\n\n\nRegards.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
4b0e7425baf71020cd7a5a748b56d5a6 | PostgreSQL service status script with mail notification if service is fail | tutorialdba.com | 2019.43 | [
{
"text": "\nThis script can be used to check on postgres apache,mysql, or whatever service you want. This is not meant to be a SOLUTION to services that are crashing, but rather a notification and a temporary restart until you can solve the real issue.\n\n\n \n\n\nThe script will check the status of each service. If the service is stopped, it tries to restart the service. If the service starts, it sends you an email saying the service stopped but was restarted.\n\n\nIf the service does not start for some reason, it sends you an email telling you it was not started.\n\n\n \n\n\nAfter that, it will continue to try and start, but not send any more emails until the service is finally started.\n\n\nNOTE*: This script should be run as your root user, so it would be added to the crontab like so:\n\n\n1. put it into your scripts folder\n2. set your email address\n3. set the services you want to keep an eye on (by default it has postgresql, mysql , mariadb and apache2..you can add or take away whatever you need)\n4. save your changes\n5. create a cronjob as root (sudo crontab -e) and add something like this, which runs every minute (adjust to your needs):\n\n\n\n```\n#check on services\n*/1 * * * * sh /root/script/dbalert.sh\n################### DOWN DB server######################\n#!/bin/bash\n#ver. 2\n\n##this script will check whatever services\n##you want to keep an eye on\n##if that service is not running\n##it will (try to) start the service and send\n##an email to you\n\n##set your email address\nEMAIL=\"[email protected]\"\n\n##list your services you want to check\n##you can add as many as you like\nSERVICES=('postgresql')\nlogdate=$(date +%a) # our log file format is postgresql-Fri.log choose depend on logfile format\n#### DO NOT CHANGE anything BELOW ####\n\n\n for i in \"${SERVICES[@]}\"\n do\n ###IF SERVICE IS NOT RUNNING####\nif ([[ \"$(service $i status)\" =~ \"not running\" ]] || [[ \"$(service $i status)\" =~ \"is stopped\" ]] || [[ $\"$(service $i status)\" =~ \"stop/waiting/down\" ]] || [[ $\"$(service $i status)\" =~ \"no server running\"]] )\n\n then\n ##TRY TO RESTART THAT SERVICE###\n service $i start \n\n\n ##IF RESTART WORKED###\nif ([[ \"$(service $i status)\" =~ \"server is running\" ]] || [[ \"$(service $i status)\" =~ \"is started\" ]] || [[ $\"$(service $i status)\" =~ \"start\" ]])\nthen\n ##SEND AN EMAIL### \n MESSAGE=\"$(tail -15 /$PGDATA/pg_log/postgresql-$logdate.log)\"\n SUBJECT=\"PostgreSQL Down But restarted Successfully on $(date) \"\n echo -e \" LOGS : \\n$MESSAGE \" | mail -s \"$SUBJECT\" \"$EMAIL\"\n else\n\n ##IF RESTART DID NOT WORK SEND A DIFFERENT EMAIL###\n MESSAGE=\"$(tail -15 /$PGDATA/pg_log/postgresql-$logdate.log)\"\n SUBJECT=\"PostgreSQL down, Restarted did not work on $(date) \"\n echo -e \" LOGS : \\n$MESSAGE . \\n>>>>> Script tried to restart the Postgres Server but it did not work\" | mail -s \"$SUBJECT\" \"$EMAIL\"\n\n fi\n fi\ndone\n```\n\n# Better schedule it as root user because root user only having mail service access in some environment if postgres user having mail services access then you can schedule it as postgres user and change pg\\_ctl instead of service command\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
e823dec5d14adab433d2361784848caa | How to write good bye letter in IT sector ? | tutorialdba.com | 2020.34 | [
{
"text": "\nHi All,\n\n\nI am writing to inform you that today is my last day at company name. Not only was it a wonderful learning experience for me, but I also had a very good time working with the team during my work tenure. I want to thank you for your unending support. I hope our paths cross again.\n\n\nI will be reachable by phone(9884569142) or email([[email protected]](mailto:[email protected])) at all times.\n\n\n \n\n\nThanks & Regards,\n\n\nRajeev\n\n\n \n\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\nI think, a decent writing company will assist you with it. Not only that, you can also get [help in writing a dissertation introduction](https://supremeessays.co.uk/wonderful-dissertation-introducton-writing.html) or an essay, whatever type of writing you need to finish your work. Try it out!\n\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\nYou can find a few [dissertation methodology writing services](https://marvelousessays.org/dissertation-methodology-writing-service.html) to compare their prices and other offers and request the desired type of paper from that service.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
5c33504b442e5ff4e7a55e14f1a2758a | any tool to migrate from SQL Server to PostgreSQL | tutorialdba.com | 2020.40 | [
{
"text": "\nYou can use SSIS for migrating from Sql server to Postgres..\n\n\n* [Postgres Migration Toolkit](http://www.convert-in.com/pgskit.htm) Software pack to convert Oracle, MySQL, SQL Server and FoxPro to PostgreSQL, and vice versa.\n* [pgloader](https://github.com/dimitri/pgloader) Migrate from SQLite to PostgreSQL; Migrate from MS SQL Server® to PostgreSQL .Sustainable Open Source Development. supports full migration of the database schema and data from a single command line and provides a command language for more complex or specific scenarios. It is still fully supported: please report any bugs on its GitHub page. It appears in the 2013 section here because that's when it has been published first\n* [sqlserver2pgsql](http://dalibo.github.io/sqlserver2pgsql/) Migration tool to convert a Microsoft SQL Server Database into a PostgreSQL database.\n* MSSQL-to-PostgreSQL is a program to migrate databases from SQL Server to PostgreSQL. The program has high performance: 2,5 GB MS SQL database is migrated to PostgreSQL server within less than 20 minutes on an average modern system. Command line support allows to script, automate and schedule the conversion process.Demo version converts only 50 records per table.Demo version does not convert foreign keys and view,mor information:<http://www.convert-in.com/mss2pgs.htm>\n\n\n",
"name": "",
"is_accepted": false
},
{
"text": "SSIS is only for data loading operation...how we can migrate other DB objects? \n\n \n\nYes we can ..we have migrated around 2TB of database into Postgres.. we need to use Intellisoft driver . But We need to buy the license. \n\nIf you migrating with schema changes we can use ssis . Otherwise direct mapping without any schema changes . we have many tools available in the market . \n\nLike FullConvert, dbconvert, spectralcore, pgloader.io.. etc",
"name": "",
"is_accepted": false
},
{
"text": "\nThe first one listed here <https://wiki.postgresql.org/wiki/Converting_from_other_Databases_to_PostgreSQL>\n\n\ntends to be appropriate in most cases, since Ispirer MnMTK 2020 is highly adaptable.\n\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
|
723217ab11293af188334d0e1b9cc443 | How to showing current configuration variables in mysql command ? | tutorialdba.com | 2020.45 | [
{
"text": "\nDisplay MySQL parameters\n------------------------\n\n\nMySQL is a very popular database, you can get your site particular setting in /etc/my.cnf, but most of system variable are not shown in the configuration file, how to get list and check their values?\n\n\nSystem variable information is also available from the mysqladmin variables command, here just show you how to get it via mysql loging session.\n\n\n### List all MySQL parameters\n\n\nPartial output is shown here\n\n\n\n```\nmysql> show variables;\nERROR 2006 (HY000): MySQL server has gone away\nNo connection. Trying to reconnect...\nConnection id: 34\nCurrent database: *** NONE ***\n\n+---------------------------------------------------+---------------------+\n| Variable\\_name | Value |\n+---------------------------------------------------+---------------------+\n| auto\\_increment\\_increment | 1 |\n| auto\\_increment\\_offset | 1 |\n| autocommit | ON |\n| automatic\\_sp\\_privileges | ON |\n| back\\_log | 50 |\n| basedir | /usr |\n| big\\_tables | OFF |\n| binlog\\_cache\\_size | 32768 |\n| binlog\\_direct\\_non\\_transactional\\_updates | OFF |\n| binlog\\_format | STATEMENT |\n| binlog\\_stmt\\_cache\\_size | 32768 |\n| bulk\\_insert\\_buffer\\_size | 8388608 |\n| character\\_set\\_client | utf8 |\n| character\\_set\\_connection | utf8 |\n| character\\_set\\_database | latin1 |\n| character\\_set\\_filesystem | binary \n...\n...\n```\n\n### SHOW VARIABLES Syntax\n\n\n\n```\nSHOW [GLOBAL | SESSION] VARIABLES\n [LIKE 'pattern' | WHERE expr]\n```\n\nSHOW VARIABLES shows the values of MySQL system variables. This statement does not require any privilege. It requires only the ability to connect to the server.\n\n\n \n\nThere are two optional modifiers:\n\n\n\n```\nGLOBAL modifier, the statement displays global system variable values. These are the values used to initialize the corresponding session variables for new connections to MySQL. \nSESSION modifier,the statement displays the system varaible values that are in effect for the current connection. If a variable has no session value, the global value is displayed. LOCAL is a synonym for SESSION.\n```\n\nIf no modifier is present, the default is SESSION.\n\n\nWith a LIKE clause\n\n\nThe statement displays only rows for those variables with names that match the pattern. acting like a filter.\n\n\nTo obtain the row for a specific variable, use a LIKE clause as shown:\n\n\n\n```\nmysql> SHOW VARIABLES LIKE 'max\\_join\\_size';\nConnection id: 161\nCurrent database: i381684\\_jos1\n\n+---------------+----------------------+\n| Variable\\_name | Value |\n+---------------+----------------------+\n| max\\_join\\_size | 18446744073709551615 |\n+---------------+----------------------+\n1 row in set (0.03 sec)\n\nmysql> SHOW SESSION VARIABLES LIKE 'max\\_join\\_size';\nConnection id: 162\nCurrent database: i381684\\_jos1\n\n+---------------+----------------------+\n| Variable\\_name | Value |\n+---------------+----------------------+\n| max\\_join\\_size | 18446744073709551615 |\n+---------------+----------------------+\n1 row in set (0.03 sec)\n```\n\nTo get a list of variables whose name match a pattern, use the “%” wildcard character in a LIKE clause, Wildcard characters can be used in any position within the pattern to be matched. “\\_” is a wildcard that matches any single character, to match the wildcrd caracter, you should escape it like “\\\\_” to match it literally.\n\n\n\n```\nmysql> SHOW VARIABLES LIKE '%buffer%';\nConnection id: 164\nCurrent database: i381684\\_jos1\n\n+------------------------------+-----------+\n| Variable\\_name | Value |\n+------------------------------+-----------+\n| bulk\\_insert\\_buffer\\_size | 8388608 |\n| innodb\\_buffer\\_pool\\_instances | 1 |\n| innodb\\_buffer\\_pool\\_size | 37748736 |\n| innodb\\_change\\_buffering | all |\n| innodb\\_log\\_buffer\\_size | 8388608 |\n| join\\_buffer\\_size | 4194304 |\n| key\\_buffer\\_size | 536870912 |\n| myisam\\_sort\\_buffer\\_size | 67108864 |\n| net\\_buffer\\_length | 16384 |\n| preload\\_buffer\\_size | 32768 |\n| read\\_buffer\\_size | 2097152 |\n| read\\_rnd\\_buffer\\_size | 8388608 |\n| sort\\_buffer\\_size | 2097152 |\n| sql\\_buffer\\_result | OFF |\n+------------------------------+-----------+\n14 rows in set (0.03 sec)\n```\n\nWith WHERE clause\n\n\nTo show all variables that have a numeric setting higher then zero, you can use:\n\n\n\n```\nmysql> SHOW VARIABLES where value='on';\nConnection id: 168\nCurrent database: i381684\\_jos1\n\n+----------------------------+-------+\n| Variable\\_name | Value |\n+----------------------------+-------+\n| autocommit | ON |\n| automatic\\_sp\\_privileges | ON |\n| delay\\_key\\_write | ON |\n| engine\\_condition\\_pushdown | ON |\n| foreign\\_key\\_checks | ON |\n| innodb\\_adaptive\\_flushing | ON |\n| innodb\\_adaptive\\_hash\\_index | ON |\n...\n```\n\nMore complicated example:\n\n\n\n```\nSHOW VARIABLES WHERE Variable\\_Name NOT LIKE '%myisam%' AND Variable\\_Name NOT LIKE '%innodb%';\n```\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\nMySQL ‘show status’ and open database connections\n-------------------------------------------------\n\n\nYou can show MySQL open database connections (and other MySQL database parameters) using the MySQL `show status` command, like this:\n\n\n\n```\nmysql> **show status like 'Conn%';**\n+---------------+-------+\n| Variable\\_name | Value |\n+---------------+-------+\n| Connections | 8 | \n+---------------+-------+\n1 row in set (0.00 sec)\n\n\nmysql> **show status like '%onn%';**\n+--------------------------+-------+\n| Variable\\_name | Value |\n+--------------------------+-------+\n| Aborted\\_connects | 0 | \n| Connections | 8 | \n| Max\\_used\\_connections | 4 | \n| Ssl\\_client\\_connects | 0 | \n| Ssl\\_connect\\_renegotiates | 0 | \n| Ssl\\_finished\\_connects | 0 | \n| Threads\\_connected | 4 | \n+--------------------------+-------+\n7 rows in set (0.00 sec)\n\n```\n\nAll those rows and values that are printed out correspond to MySQL variables that you can look at. Notice that I use `like 'Conn%'`in the first example to show variables that look like \"Connection\", then got a little wiser in my second MySQL show status query.\n\n\nMySQL show processlist\n----------------------\n\n\nHere's what my MySQL processlist looks like when I had my Java application actively running under Tomcat:\n\n\n\n```\nmysql> **show processlist;**\n+----+------+-----------------+--------+---------+------+-------+------------------+\n| Id | User | Host | db | Command | Time | State | Info |\n+----+------+-----------------+--------+---------+------+-------+------------------+\n| 3 | root | localhost | webapp | Query | 0 | NULL | show processlist | \n| 5 | root | localhost:61704 | webapp | Sleep | 208 | | NULL | \n| 6 | root | localhost:61705 | webapp | Sleep | 208 | | NULL | \n| 7 | root | localhost:61706 | webapp | Sleep | 208 | | NULL | \n+----+------+-----------------+--------+---------+------+-------+------------------+\n4 rows in set (0.00 sec)\n\n```\n\nAnd here's what it looked like after I shut Tomcat down:\n\n\n\n```\nmysql> **show processlist;**\n+----+------+-----------+--------+---------+------+-------+------------------+\n| Id | User | Host | db | Command | Time | State | Info |\n+----+------+-----------+--------+---------+------+-------+------------------+\n| 3 | root | localhost | webapp | Query | 0 | NULL | show processlist | \n+----+------+-----------+--------+---------+------+-------+------------------+\n1 row in set (0.00 sec)\n\n```\n\nAs a final note, you can also look at some MySQL variables using the `mysqladmin` command at the Unix/Linux command line, like this:\n\n\n\n```\n$ **mysqladmin status**\n\nUptime: 4661 Threads: 1 Questions: 200 Slow queries: 0 Opens: 16 Flush\ntables: 1 Open tables: 6 Queries per second avg: 0.043\n\n```\n\nMySQL show status - Summary\n---------------------------\n\n\n**Server Status Variables** \n\nThe MySQL server maintains many status variables that provide information about its operation. You can view these variables and their values by using the SHOW [GLOBAL | SESSION] STATUS statement (see Section 13.7.6.35, “SHOW STATUS Syntax”). The optional GLOBAL keyword aggregates the values over all connections, and SESSION shows the values for the current connection.\n\n\n\n```\n\nmysql> SHOW GLOBAL STATUS;\n+-----------------------------------+------------+\n| Variable\\_name | Value |\n+-----------------------------------+------------+\n| Aborted\\_clients | 0 |\n| Aborted\\_connects | 0 |\n| Bytes\\_received | 155372598 |\n| Bytes\\_sent | 1176560426 |\n...\n| Connections | 30023 |\n| Created\\_tmp\\_disk\\_tables | 0 |\n| Created\\_tmp\\_files | 3 |\n| Created\\_tmp\\_tables | 2 |\n...\n| Threads\\_created | 217 |\n| Threads\\_running | 88 |\n| Uptime | 1389872 |\n+-----------------------------------+------------+\n```\n\n**SHOW STATUS Syntax**\n\n\n\n```\nSHOW [GLOBAL | SESSION] STATUS\n [LIKE 'pattern' | WHERE expr]\n```\n\n",
"name": "",
"is_accepted": false
}
] |
|
f1399dadad3daf06490bcec027532d9c | SQL Server full tutorial and Examples | tutorialdba.com | 2021.31 | [
{
"text": "\nBelow are the links that provide video learning on You Tube our channel \" Tech Brothers\" - These videos walk you through step by step of SQL Server 2014 DBA Tutorial/Training. Video Tutorials provide beginner to advance level Training on SQL Server 2014 DBA Topics. \n\n \n\n \n\n\nInstallation\n------------\n\n\n1. [How to find installed Features in windows 8.1](http://www.techbrothersit.com/2015/12/how-to-find-installed-features-in.html)\n2. [How to install SQL Server 2014 step by step](http://www.techbrothersit.com/2015/12/how-to-install-sql-server-2014-step-by.html)\n3. [How to Install SQL Server 2016 Step by Step](http://www.techbrothersit.com/2015/07/how-to-install-sql-server-2016-ctp.html)\n4. [How to Install Data Quality Services (DQS) in SQL Server](http://www.techbrothersit.com/2015/12/how-to-install-data-quality-services.html)\n5. [How to Install and configure Master Data Services in SQL Server](http://www.techbrothersit.com/2015/12/how-to-install-and-configure-master.html)\n6. [How to Install Data Quality Services Client](http://www.techbrothersit.com/2015/12/how-to-install-data-quality-services_21.html)\n7. [How to Install SSIS in SQL Server 2014](http://www.techbrothersit.com/2015/12/how-to-install-sql-server-integration.html)\n8. [How to Create Integration Services Catalog](http://www.techbrothersit.com/2015/12/how-to-create-integration-services.html)\n9. [How to install and configure Reporting services in SQL Server 2014](http://www.techbrothersit.com/2015/12/how-to-install-and-configure-reporting.html)\n10. [How to Install SQL Server Data Tools ( SSDT )](http://www.techbrothersit.com/2015/12/how-to-install-sql-server-data-tools.html)\n\n\nSQL Server /Windows Cluster\n---------------------------\n\n\n1. [How to Install SQL Server 2014 in Cluster mode](http://www.techbrothersit.com/2015/12/how-to-install-sql-server-2014-in.html)\n2. [How to Add a Disk to Existing Cluster?](http://sqlage.blogspot.com/2015/04/how-to-add-disk-to-existing-cluster-sql.html)\n3. [Cluster Pre-requisites Checklist](http://sqlage.blogspot.com/2015/05/sql-server-clustering-checklist.html)\n4. [Setting Up Service Accounts for Cluster Nodes](http://sqlage.blogspot.com/2015/05/setting-up-cluster-service-account-on.html)\n5. [How to Install Clustering Services on the First Node](http://sqlage.blogspot.com/2015/05/how-to-prepare-node-for-sql-server_11.html)\n6. [How to Install Clustering Services on the second Node](http://sqlage.blogspot.com/2015/05/how-to-prepare-node-for-sql-server.html)\n7. [How to add a new Node to Cluster](http://sqlage.blogspot.com/2015/05/how-to-add-new-node-to-existing-cluster.html)\n8. [How to verify Cluster Installation](http://sqlage.blogspot.com/2015/05/how-to-validate-or-verify-cluster.html)\n9. [Configure Distributed Transaction Coordinator(DTC) in SQL Server Cluster](http://sqlage.blogspot.com/2015/05/how-to-configure-distributed.html)\n10. [Active Active and Active Passive Cluster Configuration Overview](http://www.techbrothersit.com/2015/05/active-active-and-active-passive.html)\n11. [How to Install SQL Server in Active Passive Cluster](http://www.techbrothersit.com/2015/12/how-to-install-sql-server-in-active.html)\n12. [How to Configure Active Active Cluster](http://sqlage.blogspot.com/2015/05/how-to-install-or-configure-sql-server.html)\n13. [Checklist before we start SQL Server Installation for Cluster](http://sqlage.blogspot.com/2015/05/checklist-overview-before-installing.html)\n14. [How to Configure Static IP Address for SQL Server Instance/s in Cluster](http://sqlage.blogspot.com/2015/05/how-to-configure-static-ip-address-of.html)\n15. [Fail over the Main Node Resource to Another Node](http://sqlage.blogspot.com/2015/05/how-to-failover-main-node-or-active.html)\n16. [How to Set Preferred Node Order for Failover](http://sqlage.blogspot.com/2015/05/how-to-set-preferred-node-order-for-sql.html)\n17. [Cluster Configuration Manager Demo: Manage SQL Server 2012 Failover Cluster](http://sqlage.blogspot.com/2015/05/manage-sql-server-2012-failover-cluster.html)\n18. [How to Install Service Packs, Hot Fixed and Patches in Cluster](http://sqlage.blogspot.com/2015/05/how-to-install-service-packs-hot-fixes.html)\n19. [Verify/Validate Cluster configuration](http://sqlage.blogspot.com/2015/05/how-to-verify-or-validate-cluster.html)\n20. [How to Evict a Node from Cluster](http://sqlage.blogspot.com/2015/05/how-to-evict-node-from-cluster-sql.html)\n21. How to Remove SQL Server Cluster instance from a Node\n22. [How to configure and use Windows Cluster Aware Updating Role - Part 1](http://www.techbrothersit.com/2015/08/how-to-configure-and-use-windows.html)\n23. [How to configure and use Windows Cluster Aware Updating Role - Part 2](http://www.techbrothersit.com/2015/08/how-to-configure-and-use-windows_3.html)\n24. How to Rename Windows Cluster\n\n\n\n \n\n \n\n\n\nDatabases\n---------\n\n\n\n\n1. [SQL Server Create Database Best Practices](http://www.techbrothersit.com/2015/12/what-are-create-database-best-practices.html)\n2. [How to Create Database in SQL Server](http://www.techbrothersit.com/2015/02/how-to-create-database-in-sql-server.html)\n3. [How to Attach and Detach Databases](http://www.techbrothersit.com/2015/02/how-to-attach-and-detach-databases-sql.html)\n4. [How to Shrink Database And Database Files](http://www.techbrothersit.com/2015/02/how-to-shrink-database-and-database.html)\n5. [How to Take Database Offline and Bring it Online](http://www.techbrothersit.com/2015/02/how-to-take-database-offline-and-bring.html)\n6. [How to create Database Snapshot](http://www.techbrothersit.com/2015/02/how-to-create-database-snapshot-sql.html)\n7. [How to Script out an Entire Database in SQL Server](http://www.techbrothersit.com/2015/12/how-to-script-out-entire-database-in.html)\n8. [How to change Compatibility level of a database and why do we do that?](http://www.techbrothersit.com/2015/04/how-to-change-compatibility-level-of.html)\n9. [How to get Database out of Single User Mode in SQL Server?](http://www.techbrothersit.com/2015/04/how-to-get-database-out-of-single-user.html)\n10. [How to shrink MDF File of Database in SQL Server?](http://www.techbrothersit.com/2015/04/how-to-shrink-mdf-database-data-file-of.html)\n11. [How to Rename a Database in SQL Server?](http://www.techbrothersit.com/2015/04/how-to-rename-database-in-sql-server.html)\n12. [How to change database collation from Case Insensitive to Case Sensitive?](http://www.techbrothersit.com/2015/04/how-to-change-database-collation-from.html)\n13. [How to Retrieve the suspect database ?](http://sqlage.blogspot.com/2015/04/how-to-recover-suspect-or-recovery.html)\n14. [How to find out Owner of Any Database in SQL Server?](http://sqlage.blogspot.com/2015/04/how-to-find-out-owner-of-any-database.html)\n15. [How do I change the ownership of a database?](http://sqlage.blogspot.com/2015/04/how-to-change-ownership-of-database-in.html)\n16. [How to avoid using C drive for Database Create in SQL Server?](http://sqlage.blogspot.com/2015/03/how-to-avoid-using-c-drive-for-database.html)\n17. [How to disable Auto growth of Database in SQL Server?](https://youtu.be/7xfhMIr0tYQ)\n18. [How we can reduce Temp DB size with out restart Server?](http://sqlage.blogspot.com/2015/04/how-to-reduce-tempdb-size-without.html)\n19. [How to release unused space of the Tempdb to Operating System(OS)?](http://sqlage.blogspot.com/2015/04/how-to-release-unused-space-of-tempdb.html)\n20. [How to update stats on all the databases on SQL Server or on Single Database in SQL Server?](http://sqlage.blogspot.com/2015/04/how-to-update-statistics-stats-of-all.html)\n\n\n \n\nSecurity\n--------\n\n\n1. [What is Login, User, Role and Principals in SQL Server?](http://www.techbrothersit.com/2015/03/what-is-login-user-role-and-principal.html)\n2. [How to create Windows Authenticated Login?](http://www.techbrothersit.com/2015/03/how-to-create-windows-authentication.html)\n3. [How to create SQL Authenticated Login?](http://www.techbrothersit.com/2015/03/how-to-create-sql-server-authenticated.html)\n4. [How to create Windows Authenticated group login?](http://www.techbrothersit.com/2015/03/how-to-create-windows-group.html)\n5. [How to check Login Status in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-check-login-status-in-sql-server.html)\n6. [How to disable/enable Login in sql server?](http://www.techbrothersit.com/2015/03/how-to-enable-and-disable-login-in-sql.html)\n7. [How to create a Database user?](http://www.techbrothersit.com/2015/03/how-to-create-database-user-in-sql.html)\n8. [How to map a user to an existing Login?](http://www.techbrothersit.com/2015/03/how-to-map-user-to-existing-login-in.html)\n9. [How to create User define Schema in a database?](http://www.techbrothersit.com/2015/03/how-to-create-user-define-schema-in.html)\n10. [How to create database role?](http://www.techbrothersit.com/2015/03/how-to-create-database-role-in-sql.html)\n11. [How to create an application Role?](http://www.techbrothersit.com/2015/03/how-to-create-application-role-in.html)\n12. [How to provide explicit permission to specific tables to a user in a database?](http://www.techbrothersit.com/2015/03/how-to-provide-explicit-permission-to.html)\n13. [How to provide execute permissions to a specific store procedure?](http://www.techbrothersit.com/2015/03/how-to-provide-execute-permission-to.html)\n14. [How to provide View definition permission of database objects to a user?](http://www.techbrothersit.com/2015/03/how-to-provide-view-definition.html)\n15. [How to create server Role in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-server-role-in-sql-server.html)\n16. [How to create Credentials in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-credentials-in-sql-server.html)\n17. [How to see the SQL Server user password in SSMS, Can we script out SQL Server user password?](http://www.techbrothersit.com/2015/04/how-to-see-sql-server-user-password-in.html)\n18. [How to assign default Schema to AD Group in SQL Server?](http://sqlage.blogspot.com/2015/04/how-to-assign-default-schema-to-ag.html)\n\n\n\nContained Database\n------------------\n\n\n\n1. [What is Contained Database and how to Create Contained Database](http://www.techbrothersit.com/2015/03/what-is-contained-database-and-how-to.html)\n2. [How to Migrate or Move Contained Database to Different SQL Server and connect to Contained Database](http://www.techbrothersit.com/2015/03/how-to-migrate-or-move-contained.html)\n3. [How to Create Contained Database User in SQL Server](http://www.techbrothersit.com/2015/03/how-to-create-contained-database-user.html)\n\n\n\n\nBackup Database\n---------------\n\n\n\n1. [What is Database Backup and How Many Types of Backups available in SQL Server](http://www.techbrothersit.com/2015/12/what-is-database-backup-how-many-types.html)\n2. [How to manually (Adhoc) take Full backup of database in SQLServer?](http://www.techbrothersit.com/2015/03/how-to-manually-adhoc-take-full-backup.html)\n3. [How to manually take Differential Backup of a database in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-manually-take-differential.html)\n4. [How to manually take Transactional Log Backup of a database in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-manually-take-transaction-log.html)\n5. [How to manually Take Tail Log Transactional Log Backup of a database in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-manually-take-tail-log.html)\n6. [How to create backup Maintenance Plan in SQL Server?](http://www.techbrothersit.com/2015/12/how-to-create-backup-maintenance-plan.html)\n7. [How to Schedule databases backup in SQL Server?](http://www.techbrothersit.com/2015/03/create-schedule-for-database-backup-sql.html)\n8. [How to cleanup Old Backups in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-cleanup-old-backups-in-sql.html)\n\n\n\nRestore Database\n----------------\n\n\n\n1. [How to restore a database from Full Backup in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-restore-database-from-full.html)\n2. [How to restore a database from Differential Backup in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-restore-database-from.html)\n3. [How to restore a database to specific time (Point in Time) in SQL Server?](http://www.techbrothersit.com/2015/03/in-this-video-you-will-learn-how-to.html)\n4. [Cannot open backup device 'F:\\foldername'. Operating system error 5(Access is denied.)](http://sqlage.blogspot.com/2015/04/cannot-open-backup-device.html)\n5. [How to turn a database status from \"in recovery\" to \"online\"?](http://www.techbrothersit.com/2015/04/how-to-recover-suspect-or-recovery.html)\n\n\n\n\nHow to Restore / Rebuild / Recover System Databases\n---------------------------------------------------\n\n\n\n\n1. [How to Restore MSDB Database in SQL Server](http://www.techbrothersit.com/2015/03/how-to-restore-msdb-database-sql-server.html)\n2. [How to Restore Master DataBase in SQL Server](http://www.techbrothersit.com/2015/03/how-to-restore-master-database-sql.html)\n3. [How to Rebuild MSDB in SQL Server](http://www.techbrothersit.com/2015/03/how-to-rebuild-msdb-in-sql-server-sql.html)\n4. [How to Rebuild Master Database in SQL Server Method1](http://www.techbrothersit.com/2015/03/how-to-rebuild-master-database-method1.html)\n5. [How to Rebuild Master and Other System Databases in SQL Server](http://www.techbrothersit.com/2015/03/how-to-rebuild-master-and-other-system.html)\n6. [How to Move TempDB Data and Log Files in SQL Server](http://www.techbrothersit.com/2015/03/how-to-move-tempdb-data-and-log-files.html)\n7. [Overview of Model Database in SQL Server](http://www.techbrothersit.com/2015/03/detailed-overview-of-model-database-in.html)\n\n\n\n\nServer Level Auditing\n---------------------\n\n\n1. [How to Create Server Audit Specifications in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-server-audit.html)\n2. [How to create server level Audit in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-server-level-audit-in-sql.html)\n3. [How to create server level Trigger in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-server-level-trigger-in.html)\n4. [How to create Policies in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-and-evaluate-policies-in.html)\n5. [How to create Policy Conditions in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-policy-conditions-in-sql.html)\n6. [How to create and use Facets in SQL Server?](http://www.techbrothersit.com/2015/03/what-are-facets-and-how-to-use-facets.html)\n\n\nData Collection and Management Data Warehouse\n---------------------------------------------\n\n\n1. [How to configure Data collection in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-configure-data-collection-in-sql.html)\n2. [How to configure Management Data Warehouse in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-configure-management-data.html)\n\n\nIntroduction to Extended Events\n-------------------------------\n\n\n \n1. [What is Extended Events in SQL Server?](http://www.techbrothersit.com/2015/03/what-are-extended-events-in-sql-server.html)\n2. [How to create an Extended event in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-extended-event-in-sql.html)\n3. [How to Enable and Disable Extended Events in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-start-or-enable-and-stop-or.html)\n\n\nSQL Server Configuration Manager\n--------------------------------\n\n\n\n1. [Detailed overview of SQL Server Configuration Manager](http://www.techbrothersit.com/2015/12/sql-server-configuration-manager.html)\n\n\n\nReplication\n-----------\n\n\n\n1. [What is replication, Types of replication and when to use each type](https://youtu.be/ul943H-Tx9I)\n2. [Why do we use Replication, Provide couple scenarios](https://youtu.be/d5Vxp1zvb_4)\n3. [How to Configure Distribution in SQL Server Replication](http://www.techbrothersit.com/2015/03/how-to-configure-distribution-in-sql.html)\n4. [How to Create Snapshot Replication?](http://www.techbrothersit.com/2015/03/how-to-create-snapshot-replication-in.html)\n5. [How to Create Transactional Replication?](http://www.techbrothersit.com/2015/03/how-to-create-transactional-replication.html)\n6. [How to create Merge Replication?](http://www.techbrothersit.com/2015/03/how-to-create-merge-replication-in-sql.html)\n7. [When do we use snapshot replication](https://youtu.be/K4fQnNBNLFY)\n8. [What is re initializing means in replication](https://youtu.be/6qC174wSuz8)\n9. [What is Orphan replication And how would you cleanup replication](https://youtu.be/l2PvJUSAjek)\n10. [Under what circumstances will you re initialize replication](https://youtu.be/_3Dic4tWOBo)\n11. [How the schema changes are handled in SQL Server Replication](https://youtu.be/igTH3nl48WA)\n12. [How would you add new tables in existing replication](https://youtu.be/MgbUFxJSOpU)\n13. [How would drop replicated database](https://youtu.be/Ftpy5Ls4RJY)\n14. [How will you truncate the replicated table](https://youtu.be/RvG1hvfWrMo)\n15. [Replication Error, can't connect to actual server, @@servername returns Null](https://youtu.be/I-VxoIz69Qg)\n16. [How to find out if Replicaiton is failed or broken](https://youtu.be/FdFqtvObMg8)\n17. [How to setup Peer-to-Peer Transactional Replication?](http://sqlage.blogspot.com/2015/06/how-to-setup-peer-to-peer-replication.html)\n18. How to add Article in Peer-to-Peer Transactional Replication?\n19. How to create Merge Replication with Multiple Subscribers and Perform Diff Scenarios\n20. How to Change Sync Time for 60 Seconds to 0 Seconds in Merge Replication\n\n\n\n \nResource Governor\n-----------------\n\n\n1. [What is Resouce Governor in SQL Server?](http://www.techbrothersit.com/2015/03/what-is-resouce-governor-in-sql-server.html)\n2. [How to Create Resource Pool in Resource Governor of SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-resource-pool-in-resource.html)\n3. [How to Create WorkLoad Group in Resource Governor of SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-workload-group-in.html)\n4. [How to create Classifier Function in Resource Governor?](http://www.techbrothersit.com/2015/03/how-to-create-classifier-function-in.html)\n5. [How to Enable and Disable Resource Governor in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-enable-and-disable-resouce_13.html)\n\n\nMirroring\n---------\n\n\n\n1. [How to setup Database Mirroring in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-setup-database-mirroring-in-sql.html)\n2. [How to Stop and Start Database Mirroring Endpoints in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-stop-and-start-database.html)\n3. [How to Remove Database Mirroring in SQL Server](http://www.techbrothersit.com/2015/03/how-to-remove-database-mirroring-in-sql.html)\n\n\nDatabase Log Shipping\n---------------------\n\n\n\n\n\n1. [How to Configure database Log Shipping in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-configure-database-log-shipping.html)\n2. [How to Remove Database Log Shipping in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-remove-database-log-shipping-in.html)\n\n\n\n\n\n\nLinked Server\n-------------\n\n\n\n1. [How to Create Linked server in SQL Server](http://www.techbrothersit.com/2015/03/how-to-create-linked-server-in-sql.html)\n\n\n\nSQL Server Agent\n----------------\n\n\n1. [Overview of SQL Server Agent Configuration?](http://www.techbrothersit.com/2015/03/overview-of-sql-server-agent.html)\n2. [How to create Job using SQL Server Agent?](http://www.techbrothersit.com/2015/03/how-to-create-job-using-sql-server.html)\n3. [Job Categories Overview in SQL Server Agent?](http://www.techbrothersit.com/2015/03/job-categories-overview-in-sql-server.html)\n4. [How to create an alert in sql server?](http://www.techbrothersit.com/2015/03/how-to-create-alert-in-sql-server.html)\n5. [How to create an Operator in SQL SERVER?](http://www.techbrothersit.com/2015/03/how-to-create-operator-in-sql-server-ms.html)\n6. [How to run SQL Server Agent jobs in Batch file?](http://www.techbrothersit.com/2015/03/how-to-run-sql-server-agent-jobs-in.html)\n7. [How to Run SQL Server Agent Job from Local or Remote SQL Server Agent Job](http://www.techbrothersit.com/2015/03/how-to-create-sql-server-agent-job-that.html)\n8. [How to Enable/Disable SQL Server Agent Job, How to Enable Job after some days automatically?](http://www.techbrothersit.com/2015/03/how-to-enable-or-disable-sql-server.html)\n9. [How To Delete ERROR LOGS IN SQL SERVER?](http://www.techbrothersit.com/2015/04/how-to-delete-error-logs-in-sql-server.html)\n10. [How to get the detail for the cause of the SQL Server Agent job failure?](http://www.techbrothersit.com/2015/04/how-to-tet-detail-of-job-failure-in-sql.html)\n11. [How to send email to multiple email accounts from SQL Server Agent Job if fails?](http://sqlage.blogspot.com/2015/04/how-to-send-email-to-multiple-email.html)\n12. [How to find out which SQL Server Agent Jobs are running at the moment on SQL Server?](http://sqlage.blogspot.com/2015/04/in-this-video-you-will-learn-how-to.html)\n\n\n\nSql Server Proxies\n------------------\n\n\n\n\n1. [What is Proxy in SQL Server (Overview)](http://www.techbrothersit.com/2015/03/what-is-proxy-in-sql-server-microsoft.html)\n2. [How to create Operating System (cmdExec) proxy in SQL Server](http://www.techbrothersit.com/2015/03/how-to-create-operating-system-cmdexec.html)\n3. [How to create SSIS Package Execution in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-ssis-package-execution.html)\n4. [How to create ActiveX Script Proxy in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-create-activex-script-proxy-in.html)\n\n\n\nConfigure Database Mail\n-----------------------\n\n\n\n1. [How to Setup Database Mail in SQL Server?](http://www.techbrothersit.com/2015/03/how-to-configure-dbmail-in-sql-server.html)\n2. [How to setup the Email notification if any job got failed?](http://www.techbrothersit.com/2015/04/how-to-setup-email-notificaion-for-job.html)\n\n\n\nSQL Server Profiler\n-------------------\n\n\n\n1. [How to start SQL Profiler automatically after a SQL Server Service Restart](http://www.techbrothersit.com/2015/03/start-sql-server-profiler-trace.html)\n\n\n \n\nMaintenance Plan\n----------------\n\n\n\n1. [How do I temporarily disable my maintenance plan?](http://www.techbrothersit.com/2015/03/how-to-temporarily-disable-maintenance.html)\n2. [How to create Maintenance plan for Backups and delete old backup files in SQL Server?](http://sqlage.blogspot.com/2015/03/how-to-cleanup-old-backups-in-sql.html)\n\n\nBuilt-in Tools\n--------------\n\n\n\n\n1. [How to connect to SQL Server from another computer?](http://www.techbrothersit.com/2015/03/how-to-connect-to-sql-server-from.html)\n2. [How to find out what configuration changed on sql server last hour?](http://www.techbrothersit.com/2015/03/how-to-find-out-sql-server.html)\n3. [How can I connect the database from SQLCMD Tool?](http://www.techbrothersit.com/2015/03/how-to-connect-to-sql-server-from.html)\n4. [How to find if Database is in use?](http://www.techbrothersit.com/2015/04/how-to-find-out-if-sql-server-database.html)\n5. [What is Dedicated Administration Connection ( DAC ) and What is use of DAC?](http://sqlage.blogspot.com/2015/03/what-is-dac-in-sql-server-and-how-to.html)\n6. [How to Change Port and IP Address for SQL Server?](http://sqlage.blogspot.com/2015/04/how-to-change-sql-server-port-sql.html)\n7. [How to save query results to text file from SSMS in SQL Server?](http://www.techbrothersit.com/2015/12/how-to-save-query-results-to-text-or.html)\n\n\nBlocking Locking\n----------------\n\n\n\n\n1. [How to find blocking and deadlock in SQL Server?](http://sqlage.blogspot.com/2015/04/how-to-find-blocking-and-deadlock-in.html)\n2. How to send Alter when a process is blocked in SQL Server\n\n\nServer Level Settings\n---------------------\n\n\n\n\n1. [How can I reset Maximum number of concurrent connections in Sql server 2014?](http://www.techbrothersit.com/2015/03/how-to-configure-maximum-number-of.html)\n2. [How much memory is allocated to SQL Server instance?](http://sqlage.blogspot.com/2015/04/how-to-find-out-how-much-memory-is.html)\n3. [How to rename SQL Server Instance Name?](http://sqlage.blogspot.com/2015/03/how-to-rename-sql-server-instance-name.html)\n4. [How to check CPU % Usage by SQL Server?](http://sqlage.blogspot.com/2015/04/how-to-check-cpu-usage-by-sql-server.html)\n5. [How to check Port SQL Server is using?](http://sqlage.blogspot.com/2015/04/how-to-check-sql-server-port-sql-server.html)\n\n\nMigration\n---------\n\n\n\n1. [Migration strategy for SQL Server 2008 to SQL Server 2012/ SQL Server 2014](https://youtu.be/QnskR-ZRsWU)\n2. [What is Difference between In place and Parallel Migration in SQL Server?](http://sqlage.blogspot.com/2015/04/differences-between-inplace-parallel-or.html)\n3. [Explain all the Steps or documents Or a checklist for Migration in SQL Server?](http://sqlage.blogspot.com/2015/04/checklist-for-migration-of-sql-server.html)\n4. **Demo: In Place Migration of SQL Server 2012 to SQL Server 2014**\n\n\n a) [In-Place Upgrade of SQL Server 2012 to SQL Server 2014 Part 1](http://sqlage.blogspot.com/2015/04/in-place-upgrade-of-sql-server-2012-to.html) \n\n - Installation of Upgrade Advisor 2014 and Upgrade Advisor Overview \n\n b) [In-Place Upgrade of SQL Server 2012 to SQL Server 2014 Part 2](http://sqlage.blogspot.com/2015/04/in-place-upgrade-of-sql-server-2012-to_29.html) \n\n - Upgrading SQL Server 2012 Engine \n\n - Upgrading SQL Server 2012 Management components\n\n\n \n **5. Demo: Migration for SQL Server 2008 to SQL Server 2012 by using ( Backup/Restore) Method** \n\n [a) Upgrade of SQL Server 2008 R2 to SQL Server 2012 Part 1](http://sqlage.blogspot.com/2015/04/upgrade-of-sql-server-2008-r2-to-sql.html) \n\n - Upgrade checklist overview \n\n [b) Upgrade of SQL Server 2008 R2 to SQL Server 2012 Part 2](http://sqlage.blogspot.com/2015/04/upgrade-of-sql-server-2008-r2-to-sql_29.html) \n\n - Identifying database \n\n - Backing up all source databases \n\n - Scripting out login \n\n - Scripting out Server Roles \n\n - Scripting out Backup devices \n\n - Scripting out Server Level Triggers \n\n - Scripting out Data Collection \n\n - Script out Linked Servers \n\n [c) Upgrade of SQL Server 2008 R2 to SQL Server 2012 Part 3](http://sqlage.blogspot.com/2015/04/upgrade-of-sql-server-2008-r2-to-sql_71.html) \n\n - Mirroring Information from the database \n\n - Script out All SQL Server Agent Jobs \n\n - Viewing DBMail information on the source \n\n - Scripting out Proxy and credentials \n\n - Scripting out Operator and Alerts \n\n - Scripting out SQL Server Configuration \n\n [d) Upgrade of SQL Server 2008 R2 to SQL Server 2012 Part 4](http://sqlage.blogspot.com/2015/04/upgrade-of-sql-server-2008-r2-to-sql_11.html) \n\n - Overview of Destination Checklist \n\n - Restoring Databases on Destination \n\n - Changing compatibility to SQL Server 2014 \n\n [e) Upgrade of SQL Server 2008 R2 to SQL Server 2012 Part 5](http://sqlage.blogspot.com/2015/04/upgrade-of-sql-server-2008-r2-to-sql_3.html) \n\n - Transferring Logins (Executing Scripted Logins on destination server \n\n - Transferring Replication (Executing Source Replication on destination) \n\n - Transferring Linked servers (Executing Scripted Linked server) \n\n - Transferring Server Level Triggers (Executing Scripted Triggers on destination server) \n\n - Scripting out Operator and Alerts \n\n - Server Audit and Audit Specification script execution \n\n [f) Upgrade of SQL Server 2008 R2 to SQL Server 2012 Part 6](http://sqlage.blogspot.com/2015/04/upgrade-of-sql-server-2008-r2-to-sql_65.html) \n\n - Creating databases backup Maintenance plan \n\n 6. [How do Migrate Logins from SQL Server 2008 to SQL Server 2014?](http://sqlage.blogspot.com/2015/05/migrate-logins-from-sql-server-2008-or.html) \n\n 7. [How to Migrate SQL Server Agent Jobs from SQL Server 2008 to SQL Server 2014?](http://sqlage.blogspot.com/2015/05/how-to-migrate-sql-server-agent-jobs.html)\n\n\n \n \nSQL Server Database Deployment\n------------------------------\n\n\n\n \n1. [What does \"Deployment\" means for SQL Server DBA?](http://sqlage.blogspot.com/2015/05/what-does-deployment-mean-for-sql.html)\n2. [What are the best practices for SQL Server Deployment?](http://sqlage.blogspot.com/2015/05/what-are-best-practices-for-sql-server.html)\n3. [How to Perform a SQL Server Deployment Step by Step](http://sqlage.blogspot.com/2015/05/how-to-perform-sql-server-deployment.html)\n4. [How to use Team Foundation Server (TFS) and DeploymentDocument for Database Deployment](http://sqlage.blogspot.com/2015/05/how-to-use-team-foundation-server-tfs.html)\n\n\n \n\n \nAlwaysOn Availability Groups\n----------------------------\n\n\n\n1. [How to Setup/Configure AlwaysOn Availability Group in SQL Server 2014 Step by Step](http://youtu.be/VKCqRgqLAuo)\n2. [How to Resolve Availability Group Listner Errors](http://sqlage.blogspot.com/2015/04/how-to-resolve-availability-group.html)\n3. [Setup AlwaysOn Availability group when SQL Server instances are installed in Cluster mode Part1 ( 2 Node Scenario)](http://sqlage.blogspot.com/2015/06/setup-alwayson-availability-group-when.html)\n4. [Setup AlwaysOn Availability group when SQL Server instances are installed in Cluster mode Part2 ( 2 Node Scenario)](http://sqlage.blogspot.com/2015/06/setup-alwayson-availability-group-when.html)\n5. [AlwaysOn Availability Group on SQL Server Failover Instances Installed in Cluster Mode ( 4 Node Scenario)](http://www.techbrothersit.com/2015/06/alwayson-availability-group-on-sql.html)\n6. [How to provide Permissions to User on AlwaysOn Availability Group in SQL Server?](http://www.techbrothersit.com/2015/07/how-to-provide-permissions-to-user-on.html)\n7. [How to Plan Backups with Always On Availability Groups in SQL Server](http://www.techbrothersit.com/2015/07/how-to-plan-backups-with-alwayson.html)\n8. [AlwaysOn Availability Group Dashboard Introduction](http://www.techbrothersit.com/2015/07/overview-of-alwayson-availability-group.html)\n9. [Setup Alerts for AlwaysOn Availability Group Failover in SQL Server](http://www.techbrothersit.com/2015/07/how-to-setup-alerts-for-alwayson.html)\n10. [How to Restore A database which is part of AlwaysOn Availability Group](http://www.techbrothersit.com/2015/07/how-to-restore-database-which-is-part.html)\n11. [Patching Or Updating AlwaysOn Availability group Replicas in SQL Server Best Practices](http://www.techbrothersit.com/2015/07/patching-or-updating-alwayson.html)\n12. [Patching or Updating Availability Group with SQL Server Failover Cluster Instance - Part 1](http://www.techbrothersit.com/2015/07/patching-or-updating-availability-group.html)\n13. [Patching or Updating Availability Group with SQL Server Failover Cluster Instance - Part 2](http://www.techbrothersit.com/2015/07/patching-or-updating-availability-group_26.html)\n14. [Patching or Updating Availability Group with SQL Server Failover Cluster Instance - Part 3](http://www.techbrothersit.com/2015/07/patching-or-updating-availability-group_59.html)\n15. [Patching Or Updating SQL Server with multiple AlwaysOn Availability Groups](http://www.techbrothersit.com/2015/07/patching-or-updating-sql-server-with.html)\n16. [Patching or Updating Availability Group with one Secondary](http://www.techbrothersit.com/2015/07/patching-or-updating-availability-group_30.html)\n17. How to Apply Windows Updates to Failover Clusters Hosting SQL Server AlwaysOn Availability Groups\n18. How to setup Replication on AlwaysOn Availability Groups in SQL Server [Part1](http://www.techbrothersit.com/2015/07/how-to-setup-replication-with-alwayson.html) [Part2](http://www.techbrothersit.com/2015/07/how-to-setup-replication-with-alwayson_20.html)\n\n\n\n\n\nMiscellaneous\n-------------\n\n\n\n1. [What are Synonyms and How to Create Synonyms in a Database of SQL Server - DBA Tutorial](http://www.techbrothersit.com/2015/03/what-are-synonyms-and-how-to-create.html)\n2. [How to compare these two databases and find what is the difference between these two databases?](http://sqlage.blogspot.com/2015/04/how-to-compare-two-databases-of-sql.html)\n3. How to Scripts Users with permissions from SQL Server Database?\n4. [How to find out who has deleted the Login in SQL Server?](http://www.techbrothersit.com/2015/04/how-to-find-out-who-deleted-login-from.html)\n5. [How to find out who has modified or created object in SQL Server?](http://www.techbrothersit.com/2015/04/how-to-find-out-who-has-modified-or.html)\n6. [How to access SQL Server Instance from the network?](http://www.techbrothersit.com/2015/04/how-to-access-sql-server-instances-from.html)\n7. How to know the reason why sql server restarted.\n8. [How to find when and who dropped my database?](http://www.techbrothersit.com/2015/03/how-to-create-extended-event-in-sql.html)\n9. How to find if a server in a cluster is running on Primary node?\n10. [How to check the size of SQL Error Log in SQL Server?](http://sqlage.blogspot.com/2015/05/how-to-check-size-of-sql-server-error.html)\n11. How to automate Back up and Restore\n12. How to migrate the integration services (SSIS)\n13. How to send Alter When Storage Drives are 80% filles from SQL Server\n14. How to Drop login with all users from multiple database in SQL Server?\n15. [How to Find Users and their AD Groups in SQL Server?](http://sqlage.blogspot.com/2015/05/how-to-find-users-and-thier-ad-groups.html)\n16. [How to Find Port Number of SQL Server instance by using SQL Server Management Studio?](http://sqlage.blogspot.com/2015/05/how-to-find-sql-server-port-number.html)\n\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
4225ba28e51c85613c8f8b3ddabc459f |
Hello anyone can help me, please? I've upgraded my PostgreSQL on version 10, and actually I have some issues in incompatibility with other local applications. Consequently, I've downgraded to the old version 9.5. So now, I cannot online the 9.5. It's always down, and the error is related to
```
PID file /var/run/postgresql/9.5-main.pid not readable (yet?) after start: No such file or directory
```
after launching systemctl status [email protected]. Any suggestion? Thank you.
**I upgraded and downgraded Following Steps:**
I've just reinstalled my PosgreSQL after getting a problem. Actually, it gives me the new version (10). However, some of my local applications is not compatible with the version 10; so I would like to delete it. That means, I didn't use any specific commande to upgrade or downgrade it. Now, I cannot start the service
```
(sudo pg\_ctlcluster 9.5 main start : Job for [email protected] failed because a configured resource limit was exceeded. See "systemctl status [email protected]" and "journalctl -xe" for details.).
(systemctl status [email protected] : [email protected] - PostgreSQL Cluster 9.5-main
Loaded: loaded (/lib/systemd/system/[email protected]; disabled; vendor preset: enabled)
Active: failed (Result: resources) since ven 2018-05-18 10:31:24 EAT; 2min 45s ago
Process: 6005 ExecStart=/usr/bin/pg\_ctlcluster --skip-systemctl-redirect %i start (code=exited, status=1/FAILURE)
mai 18 10:30:53 PC-Stagiaire systemd[1]: Starting PostgreSQL Cluster 9.5-main...
mai 18 10:30:53 PC-Stagiaire [email protected][6005]: Removed stale pid file.
mai 18 10:30:53 PC-Stagiaire [email protected][6005]: Use of uninitialized value in subroutine entry at /usr/bin/pg\_ctlcluster line 209.
mai 18 10:30:53 PC-Stagiaire [email protected][6005]: Use of uninitialized value in subroutine entry at /usr/bin/pg\_ctlcluster line 210.
mai 18 10:31:24 PC-Stagiaire [email protected][6005]: The PostgreSQL server failed to start. Please check the log output.
mai 18 10:31:24 PC-Stagiaire systemd[1]: [email protected]: PID file /var/run/postgresql/9.5-main.pid not readable (yet?) after start: No such file or directory
mai 18 10:31:24 PC-Stagiaire systemd[1]: Failed to start PostgreSQL Cluster 9.5-main.
mai 18 10:31:24 PC-Stagiaire systemd[1]: [email protected]: Unit entered failed state.
mai 18 10:31:24 PC-Stagiaire systemd[1]: [email protected]: Failed with result 'resources'.
)
```
| upgrade erro PID file /var/run/postgresql/9.5-main.pid not readable (yet?) after start: No such file or directory | tutorialdba.com | 2020.16 | [
{
"text": "\nmay be data directory wrong ownership change the owner to postgres then restart again\n\n\n\n```\n--as root user:\nchown postgres:postgres /var/lib/postgresql/9.5/main\n\n--then come to postgres user restart the postgres server:\npg\\_ctl -D /var/lib/postgresql/9.5/main restart\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
24bddb4dafe70eee3ec6e3ee9f05cbab | Postgres database monitoring scripts? Like service is running or not | tutorialdba.com | 2019.47 | [
{
"text": "\n \n\n\nTry this script\n\n\n<https://2ndquadrant.in/postgresql-health-checkup-script-with-mail-notification/>\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
d183499986613963a205c3af6a433d7a | anyone having Real time documents of streaming replication configuration and can anyone explain me what is the streaming replication and what is the advantages of streaming replication ? | HOW TO SETUP/CONFIGURE THE POSTGRESQL STREAMING REPLICATION ON POSTGRESQL 10? | tutorialdba.com | 2020.16 | [
{
"text": "\n**what is the postgresql Streaming Replication (SR) ?** \n\nStreaming Replication (SR) provides the capability to continuously ship and apply the WAL XLOG records to some number of standby servers in order to keep them current. This feature was added to PostgreSQL 9.0. \n\n\n**Advantages of postgresql Streaming Replication (SR):** \n\n1.[Switch over/Fail over after the primary fails](https://www.tutorialdba.com/search/label/PostgreSQL%20Switchover). \n\n2.Data loss so less and data integrity. \n\n3.No need more down time after primary fail. \n\n4.[synchronous mode Zero data loss](https://www.tutorialdba.com/2017/09/postgresql-replication-sync-to-async.html). \n\n5. Load balancing using load balancer ex.pgpool-II,[pgbouncer](https://www.tutorialdba.com/search/label/PostgreSQL%20PgBouncer).\n\n\n6.Auto failover using [repmgr](https://www.tutorialdba.com/search/label/repmgr).\n\n\n**Now We can go postgresql streaming replication setup using postgresql-10.3 version** \n\n**master IP:** 192.168.2.2 slave IP: 192.168.2.3\n\n\n**ON SLAVE:** \n\nstop the slave server\n\n\n\n```\n/usr/pgsql-10/bin/pg\\_ctl -D /var/lib/pgsql/10/data/ stop\n```\n\nmove the data directory to backup location:\n\n\n\n```\nmv /var/lib/pgsql/10/data/* /home/postgres/backup/\n```\n\n**ON MASTER:** \n\n**on postgresql.conf:**\n\n\n\n```\nlisten\\_addresses = 'localhost,192.168.2.2' \nwal\\_level = replica # minimal, replica, or logical\narchive\\_mode = on \narchive\\_command = 'rsync -av %p /home/postgres/archive/%f && rsync -av %p [email protected]:/home/postgres/archive/%f'\nmax\\_wal\\_senders = 2 \nwal\\_keep\\_segments = 10\n```\n\n**on pg\\_hba.conf:**\n\n\n\n```\nhost replication postgres 192.168.2.3/24 md5\n```\n\n**Restart the master server:**\n\n\n\n```\n/usr/pgsql-10/bin/pg\\_ctl -D /var/lib/pgsql/10/data/ restart\n```\n\n**taking consistancy backup:**\n\n\n\n```\n$ psql -c \"select pg\\_start\\_backup('initial\\_backup');\"\n$ rsync -cva --inplace /var/lib/pgsql/10/data/* [email protected]:/var/lib/pgsql/10/data/\n$ psql -c \"select pg\\_stop\\_backup();\"\n```\n\n**ON SLAVE:**\n\n\n**on postgresql.conf:**\n\n\n\n```\nlisten\\_addresses = 'localhost,192.168.2.2' \nwal\\_level = replica # minimal, replica, or logical\narchive\\_mode = on \narchive\\_command = '/bin/cp -av %p /home/postgres/archive/%f'\nmax\\_wal\\_senders = 2 \nwal\\_keep\\_segments = 10\nhot\\_standby = on\n```\n\n**on pg\\_hba.conf:**\n\n\n\n```\nhost replication postgres 192.168.2.2/24 md5\n```\n\n**On recovery.conf**\n\n\n\n```\ncat /var/lib/pgsql/10/data/recovery.conf\nstandby\\_mode = 'on' # to enable the standby (read-only) mode.\nprimary\\_conninfo = 'host=192.168.2.2 port=5432 user=postgres password=postgres'\n # to specify a connection info to the master node.\ntrigger\\_file = '/tmp/pg\\_failover\\_trigger'\n # to specify a trigger file to recognize a fail over.\nrestore\\_command = 'cp /home/postgres/archive/%f \"%p\"'\narchive\\_cleanup\\_command = '/usr/pgsql-10/bin/pg\\_archivecleanup /home/postgres/archive/ %r'\n```\n\n \n\n**Restart the slave server:**\n\n\n\n```\n/usr/pgsql-10/bin/pg\\_ctl -D /var/lib/pgsql/10/data/ restart\n```\n\nif you get any error error like arch missing wal log ...etc while restarting slave server again take the incremental physical backup\n\n\n\n```\n$ psql -c \"select pg\\_start\\_backup('initial\\_backup');\"\n$ rsync -cva --inplace --exclude=pg\\_hba.conf --exclude=postgresql.conf --exclude=recovery.conf /var/lib/pgsql/10/data/* [email protected]:/var/lib/pgsql/10/data/\n$ psql -c \"select pg\\_stop\\_backup();\"\n```\n\nWHILE RESTARTING SLAVE SERVER GOT FOLLOWING ERROR:\n\n\n\n```\n[postgres@slave root]$ /usr/pgsql-10/bin/pg\\_ctl -D /var/lib/pgsql/10/data/ restart\ncould not change directory to \"/root\": Permission denied\npg\\_ctl: PID file \"/var/lib/pgsql/10/data/postmaster.pid\" does not exist\nIs server running?\nstarting server anyway\nwaiting for server to start....2018-05-26 20:36:34.834 IST [45453] LOG: listening on IPv6 address \"::1\", port 5432\n2018-05-26 20:36:34.834 IST [45453] LOG: listening on IPv4 address \"127.0.0.1\", port 5432\n2018-05-26 20:36:34.836 IST [45453] LOG: listening on IPv4 address \"192.168.2.3\", port 5432\n2018-05-26 20:36:34.840 IST [45453] LOG: listening on Unix socket \"/var/run/postgresql/.s.PGSQL.5432\"\n2018-05-26 20:36:34.849 IST [45453] LOG: listening on Unix socket \"/tmp/.s.PGSQL.5432\"\n.2018-05-26 20:36:35.685 IST [45453] LOG: redirecting log output to logging collector process\n2018-05-26 20:36:35.685 IST [45453] HINT: Future log output will appear in directory \"log\".\n```\n\n**ON LOG FILE:**\n\n\n\n```\ntail -f postgresql-2018-05-26\\_203635.log\n2018-05-26 20:36:35.957 IST [45461] FATAL: could not connect to the primary server: FATAL: password authentication failed for user \"postgres\"\ncp: cannot stat ‘/home/postgres/archive/000000010000000000000006’: No such file or directory\n2018-05-26 20:36:40.964 IST [45465] FATAL: could not connect to the primary server: FATAL: password authentication failed for user \"postgres\"\ncp: cannot stat ‘/home/postgres/archive/000000010000000000000006’: No such file or directory\n2018-05-26 20:36:45.963 IST [45467] FATAL: could not connect to the primary server: FATAL: password authentication failed for user \"postgres\"\ncp: cannot stat ‘/home/postgres/archive/000000010000000000000006’: No such file or directory\n2018-05-26 20:36:50.977 IST [45471] FATAL: could not connect to the primary server: FATAL: password authentication failed for user \"postgres\"\n2018-05-26 20:36:55.459 IST [45453] LOG: received fast shutdown request\n2018-05-26 20:36:55.465 IST [45457] LOG: shutting down\n2018-05-26 20:36:55.472 IST [45453] LOG: database system is shut down\n```\n\n \n\n**on master:** \n\n--change the postgres password becouse you given wrong password on recovery.conf file for postgres user so change the password as per recovery.conf\n\n\n\n```\nalter user postgres with password 'postgres';\n```\n\nThen Restart the slave server:\n\n\n\n```\n /usr/pgsql-10/bin/pg\\_ctl -D /var/lib/pgsql/10/data/ restart\n```\n\n \n\n**MONITORING STREAMING REPLICATION:** \n\n**At MASTER:**\n\n\n1.create some dummy table check the slave server whther is replicated or not.\n\n\n\n```\npostgres=# create table t(id int);\nCREATE TABLE\n\n--check master server whether is recovery mode or not,master will not be recovery mode slave only will be recovery mode.\npostgres=# select pg\\_is\\_in\\_recovery();\n pg\\_is\\_in\\_recovery \n-------------------\n f\n(1 row)\n```\n\n2.Using pg\\_stat\\_replication views\n\n\n\n```\npostgres=# select client\\_addr,client\\_hostname,client\\_port,state,sent\\_lsn,write\\_lsn,flush\\_lsn,replay\\_lsn,write\\_lag,replay\\_lag,flush\\_lag,sync\\_state from pg\\_stat\\_replication;\n client\\_addr | client\\_hostname | client\\_port | state | sent\\_lsn | write\\_lsn | flush\\_lsn | replay\\_lsn | write\\_lag | replay\\_lag | flush\\_lag | sync\\_state\n-------------+-----------------+-------------+-----------+-----------+-----------+-----------+------------+-----------+------------+-----------+------------\n 192.168.2.3 | | 60000 | streaming | 0/8017A28 | 0/8017A28 | 0/8017A28 | 0/8017A28 | | | | async\n(1 row)\n```\n\n3.using linux command check the wal sender process whether started or not:\n\n\n\n```\n[postgres@mster ~]$ ps -ef|grep postgres\nroot 82472 82437 0 08:34 pts/1 00:00:00 su postgres\npostgres 82473 82472 0 08:34 pts/1 00:00:00 bash\nroot 94549 94494 0 20:36 pts/3 00:00:00 su postgres\npostgres 94550 94549 0 20:36 pts/3 00:00:00 bash\npostgres 94582 1 0 20:36 pts/3 00:00:00 /usr/pgsql-10/bin/postgres -D /var/lib/pgsql/10/data\npostgres 94584 94582 0 20:36 ? 00:00:00 postgres: logger process\npostgres 94586 94582 0 20:36 ? 00:00:00 postgres: checkpointer process\npostgres 94587 94582 0 20:36 ? 00:00:00 postgres: writer process\npostgres 94588 94582 0 20:36 ? 00:00:00 postgres: wal writer process\npostgres 94589 94582 0 20:36 ? 00:00:00 postgres: autovacuum launcher process\npostgres 94591 94582 0 20:36 ? 00:00:00 postgres: stats collector process\npostgres 94592 94582 0 20:36 ? 00:00:00 postgres: bgworker: logical replication launcher\npostgres 94741 94582 0 20:43 ? 00:00:00 postgres: wal sender process postgres 192.168.2.3(60000) streaming 0/8017B08\npostgres 95178 94550 0 21:08 pts/3 00:00:00 ps -ef\npostgres 95179 94550 0 21:08 pts/3 00:00:00 grep --color=auto postgres\n```\n\n--you can calculate using this linux command how many wal sender is replicated to slave.\n\n\n\n```\n$ ps -ef|grep sender\npostgres 7585 3383 0 15:59 ? 00:00:00 postgres: wal sender process postgres 192.168.2.2(42586) streaming 0/18017CD8\npostgres 7598 6564 0 15:59 pts/2 00:00:00 grep --color=auto sender\n```\n\n**AT SLAVE SERVER:** \n\n1.check the previously created table whether is replicated or not\n\n\n\n```\npostgres=# \\dt\n List of relations\n Schema | Name | Type | Owner\n--------+---------------+-------+----------\n public | qrtransaction | table | postgres\n public | t | table | postgres\n(2 rows)\n```\n\nyes! it is successfully replicated the table.\n\n\n--check the slave mode using following function whether is recovery mode or not\n\n\n\n```\npostgres=# select pg\\_is\\_in\\_recovery();\n pg\\_is\\_in\\_recovery \n-------------------\n t\n(1 row)\n```\n\n--and try to insert the valuse on slave server, slave is a read only mode it will not permitted write transaction.\n\n\n\n```\npostgres=# insert into t values(1);\nERROR: cannot execute INSERT in a read-only transaction\n```\n\n2. using pg\\_stat\\_replication view:\n\n\n\n```\npostgres=# select status,receive\\_start\\_lsn,received\\_lsn,last\\_msg\\_send\\_time,latest\\_end\\_lsn,latest\\_end\\_time,conninfo from pg\\_stat\\_wal\\_receiver ;\n status | receive\\_start\\_lsn | received\\_lsn | last\\_msg\\_send\\_time | latest\\_end\\_lsn | latest\\_end\\_time | conninfo\n-----------+-------------------+--------------+----------------------------------+----------------+----------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------\n streaming | 0/6000000 | 0/8017B08 | 2018-05-26 21:26:34.577733+05:30 | 0/8017B08 | 2018-05-26 21:06:32.309548+05:30 | user=postgres password=******** dbname=replication host=192.168.2.2 port=5432 fallback\\_application\\_name=walreceiver sslmode=prefer sslcompression=1 krbsrvname=postgres target\\_session\\_attrs=any\n(1 row)\n```\n\n \n\n3.using linux command you can monitor wether wal receiver is started or not.this linux command will be helpful for finding out the postgres data directory as well as postgres utility path means bin path\n\n\n\n```\n[postgres@slave data]$ ps -ef|grep postgres\nroot 3971 3573 0 10:27 pts/0 00:00:00 su postgres\npostgres 3972 3971 0 10:27 pts/0 00:00:00 bash\nroot 45410 45321 0 20:36 pts/1 00:00:00 su postgres\npostgres 45411 45410 0 20:36 pts/1 00:00:00 bash\npostgres 45606 1 0 20:43 pts/1 00:00:00 /usr/pgsql-10/bin/postgres -D /var/lib/pgsql/10/data\npostgres 45607 45606 0 20:43 ? 00:00:00 postgres: logger process\npostgres 45608 45606 0 20:43 ? 00:00:00 postgres: startup process recovering 000000010000000000000008\npostgres 45610 45606 0 20:43 ? 00:00:00 postgres: checkpointer process\npostgres 45611 45606 0 20:43 ? 00:00:00 postgres: writer process\npostgres 45612 45606 0 20:43 ? 00:00:06 postgres: wal receiver process streaming 0/8017B08\npostgres 45613 45606 0 20:43 ? 00:00:00 postgres: stats collector process\npostgres 45995 45411 0 21:16 pts/1 00:00:00 ps -ef\npostgres 45996 45411 0 21:16 pts/1 00:00:00 grep --color=auto postgres\n```\n\n4.this command will be helpful for how many wal segment get postgres receiver \n\n\n\n```\n[postgres@slave data]$ ps -ef|grep receiver;\npostgres 45612 45606 0 20:43 ? 00:00:06 postgres: wal receiver process streaming 0/8017B08\npostgres 46018 45411 0 21:18 pts/1 00:00:00 grep --color=auto receiver\n```\n\n5.If the slave is up in hot standby mode, you can tell the time in seconds the delay of transactions applied on the slave with this query:\n\n\n\n```\npostgres=# select now() - pg\\_last\\_xact\\_replay\\_timestamp() AS replication\\_delay;\n replication\\_delay\n-------------------\n 00:18:35.207663\n(1 row)\n```\n\n**Note:** above timing is noted for last 18 minutes slave not get any transaction\n\n\n[cascaded replication setup/configuration](https://www.tutorialdba.com/2018/03/how-to-configure-cascade-replication-on.html)\n----------------------------------------------------------------------------------------------------------------------------\n\n\n",
"name": "",
"is_accepted": true
}
] |
18a4eaebd11f608c97a853dc493a5159 | Hi anyone know this answer ? How to upgrade Postgresql with minimal downtime ? | How to upgrade Postgresql cluster with less down time ? | tutorialdba.com | 2020.34 | [
{
"text": "Use slony tool as slony support different postgresql version replication once data replication complete break the replication then put the application information.",
"name": "",
"is_accepted": false
}
] |
56db462fb06d36050f7cc8e4a9516b95 | What is the commands that I used to identify duplicate lines in a csv file | tutorialdba.com | 2020.40 | [
{
"text": "\n here are the commands that I used to identify duplicate lines in a csv file\n\n\n\n```\n sort ~/filename.csv | uniq -c | sort -n\n```\n\nYou can use man to read the descriptions of the linux sort and uniq commands.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
b43a0de93d8c7a21f72e919bc1dff66e | Explain how data is stored in Greenplum? | tutorialdba.com | 2020.16 | [
{
"text": "\nData is stored based on selected field (s) which are used for distribution. When you have a Distribution Key by Hash the values of the Distribution Key are run through a Hash Formula. Then, a map is used to distribute the row to the correct segment. The formula is designed to be consistent so that all like values go to the same segment.\n\n\n\n```\n==Data(A) => Hash Function(B) => Logical Segment list(C) => Physical Segment list(D) => Storage(E).\n```\n\nWhen data arrives at the Greenplum, it is hashed based on field(s) and a hash function (B) is used for this purpose.\n\n\nFor example, Consider 4 node system, logical segment list has 4 unique entries. If there are 10 hashed data items from (B), there are 10 entries in (C), then all having only 4 segment entries. For example (C) has values [4,1,2,3,4,3,1,4,3,2]. Then, a map is used to distribute the row to the correct segment. The formula is designed to be consistent so that all like values go to the same segment.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
305c766ca858ca3dbe7d58a49dba1a67 |
* [export all databases mysql](https://www.codegrepper.com/code-examples/sql/export+all+databases+mysql)
* [get database size mysql](https://www.codegrepper.com/code-examples/sql/get+database+size+mysql)
* [how to check database engine in mysql](https://www.codegrepper.com/code-examples/sql/how+to+check+database+engine+in+mysql)
* [how to find ip address of mysql database server](https://www.codegrepper.com/code-examples/sql/how+to+find+ip+address+of+mysql+database+server)
* [how to open database in mysql](https://www.codegrepper.com/code-examples/sql/how+to+open+database+in+mysql)
* [how to see database in mysql command line](https://www.codegrepper.com/code-examples/sql/how+to+see+database+in+mysql+command+line)
* [import all databases mysql](https://www.codegrepper.com/code-examples/sql/import+all+databases+mysql)
* [Manage Database in MySQL](https://www.codegrepper.com/code-examples/sql/Manage+Database+in+MySQL)
* [mariadb show all databases](https://www.codegrepper.com/code-examples/sql/mariadb+show+all+databases)
* [mysql command line see all databases](https://www.codegrepper.com/code-examples/sql/mysql+command+line+see+all+databases)
* [mysql get db name](https://www.codegrepper.com/code-examples/sql/mysql+get+db+name)
* [mysql list databases](https://www.codegrepper.com/code-examples/sql/mysql+list+databases)
* [mysql select database](https://www.codegrepper.com/code-examples/sql/mysql+select+database)
* [mysql show create db](https://www.codegrepper.com/code-examples/sql/mysql+show+create+db)
* [mysql show current connections](https://www.codegrepper.com/code-examples/sql/mysql+show+current+connections)
* [mysql show current queries](https://www.codegrepper.com/code-examples/sql/mysql+show+current+queries)
* [mysql show data from table](https://www.codegrepper.com/code-examples/sql/mysql+show+data+from+table)
* [mysql show databases](https://www.codegrepper.com/code-examples/sql/mysql+show+databases)
* [mysql use database](https://www.codegrepper.com/code-examples/sql/mysql+use+database)
* [postgresql show current database](https://www.codegrepper.com/code-examples/sql/postgresql+show+current+database)
* [show databases in sql server](https://www.codegrepper.com/code-examples/sql/show+databases+in+sql+server)
* [show databases mysql docker](https://www.codegrepper.com/code-examples/sql/show+databases+mysql+docker)
* [show databse mysql](https://www.codegrepper.com/code-examples/sql/show+databse+mysql)
* [show function mysql](https://www.codegrepper.com/code-examples/sql/show+function+mysql)
* [show sql server database](https://www.codegrepper.com/code-examples/sql/show+sql+server+database)
* [show all databases mysql](https://www.codegrepper.com/code-examples/sql/show+all+databases+mysql)
* [show the current db mysql](https://www.codegrepper.com/code-examples/sql/show+the+current+db+mysql)
* [Show-database in MySQL](https://www.codegrepper.com/code-examples/sql/Show-database+in+MySQL)
* [show all database in mysql](https://www.codegrepper.com/code-examples/sql/show+all+database+in+mysql)
* [how to check current database in mysql](https://www.codegrepper.com/code-examples/sql/how+to+check+current+database+in+mysql)
* [show all databases in mysql](https://www.codegrepper.com/code-examples/sql/show+all+databases+in+mysql)
* [mysql show-database](https://www.codegrepper.com/code-examples/sql/mysql+show-database)
* [query to find out the current database in mysql](https://www.codegrepper.com/code-examples/sql/query+to+find+out+the+current+database+in+mysql)
* [show database contents mysql](https://www.codegrepper.com/code-examples/sql/show+database+contents+mysql)
* [check current database in my sql](https://www.codegrepper.com/code-examples/sql/check+current+database+in+my+sql)
* [how to check database details in mysql](https://www.codegrepper.com/code-examples/sql/how+to+check+database+details+in+mysql)
* [syntax of mysql show database](https://www.codegrepper.com/code-examples/sql/syntax+of+mysql+show+database)
* [how to see one database in mysql](https://www.codegrepper.com/code-examples/sql/how+to+see+one+database+in+mysql)
* [how to see whats ina database mysql](https://www.codegrepper.com/code-examples/sql/how+to+see+whats+ina+database+mysql)
* [show database mysql command line](https://www.codegrepper.com/code-examples/sql/show+database+mysql+command+line)
* [how to get a mysql database](https://www.codegrepper.com/code-examples/sql/how+to+get+a+mysql+database)
* [how to use mysql to get database](https://www.codegrepper.com/code-examples/sql/how+to+use+mysql+to+get+database)
* [show mysql databases](https://www.codegrepper.com/code-examples/sql/show+mysql+databases)
* [how to see database in mysql](https://www.codegrepper.com/code-examples/sql/how+to+see+database+in+mysql)
* [get database info mysql](https://www.codegrepper.com/code-examples/sql/get+database+info+mysql)
* [show everhing in a database mysql](https://www.codegrepper.com/code-examples/sql/show+everhing+in+a+database+mysql)
* [display database mysql](https://www.codegrepper.com/code-examples/sql/display+database+mysql)
* [how to see the databases in mysql](https://www.codegrepper.com/code-examples/sql/how+to+see+the+databases+in+mysql)
* [show database query in mysql](https://www.codegrepper.com/code-examples/sql/show+database+query+in+mysql)
* [how to see all databases mysql](https://www.codegrepper.com/code-examples/sql/how+to+see+all+databases+mysql)
* [mysql how to see what database were in](https://www.codegrepper.com/code-examples/sql/mysql+how+to+see+what+database+were+in)
* [show db mysql command](https://www.codegrepper.com/code-examples/sql/show+db+mysql+command)
* [get database mysql](https://www.codegrepper.com/code-examples/sql/get+database+mysql)
* [show databases mysql command](https://www.codegrepper.com/code-examples/sql/show+databases+mysql+command)
* [how to see all databases in mysql](https://www.codegrepper.com/code-examples/sql/how+to+see+all+databases+in+mysql)
* [show-database mysql](https://www.codegrepper.com/code-examples/sql/show-database+mysql)
* [mysql get database details](https://www.codegrepper.com/code-examples/sql/mysql+get+database+details)
* [mysql get database](https://www.codegrepper.com/code-examples/sql/mysql+get+database)
* [command for show database information mysql](https://www.codegrepper.com/code-examples/sql/command+for+show+database+information+mysql)
* [mysql print current database](https://www.codegrepper.com/code-examples/sql/mysql+print+current+database)
* [how to show all databases in mysql](https://www.codegrepper.com/code-examples/sql/how+to+show+all+databases+in+mysql)
* [show mysql databases command line](https://www.codegrepper.com/code-examples/sql/show+mysql+databases+command+line)
* [mysql see databases](https://www.codegrepper.com/code-examples/sql/mysql+see+databases)
* [show current database queries mysql](https://www.codegrepper.com/code-examples/sql/show+current+database+queries+mysql)
* [see database mysql](https://www.codegrepper.com/code-examples/sql/see+database+mysql)
* [whare to see database in mysql](https://www.codegrepper.com/code-examples/sql/whare+to+see+database+in+mysql)
* [mysql terminal show database](https://www.codegrepper.com/code-examples/sql/mysql+terminal+show+database)
* [show db mysql](https://www.codegrepper.com/code-examples/sql/show+db+mysql)
* [show db in mysql](https://www.codegrepper.com/code-examples/sql/show+db+in+mysql)
* [how to show database in mysql](https://www.codegrepper.com/code-examples/sql/how+to+show+database+in+mysql)
* [see database in mysql](https://www.codegrepper.com/code-examples/sql/see+database+in+mysql)
* [show dbs in mysql](https://www.codegrepper.com/code-examples/sql/show+dbs+in+mysql)
* [show database content mysql](https://www.codegrepper.com/code-examples/sql/show+database+content+mysql)
* [how to see databases in mysql](https://www.codegrepper.com/code-examples/sql/how+to+see+databases+in+mysql)
* [how to show dbs in mysql](https://www.codegrepper.com/code-examples/sql/how+to+show+dbs+in+mysql)
* [how to get current database name in mysql](https://www.codegrepper.com/code-examples/sql/how+to+get+current+database+name+in+mysql)
* [mysql see current database](https://www.codegrepper.com/code-examples/sql/mysql+see+current+database)
* [mysql query show databases](https://www.codegrepper.com/code-examples/sql/mysql+query+show+databases)
* [show database mysql](https://www.codegrepper.com/code-examples/sql/show+database+mysql)
* [how to view databases in mysql](https://www.codegrepper.com/code-examples/sql/how+to+view+databases+in+mysql)
* [mysql show database in use](https://www.codegrepper.com/code-examples/sql/mysql+show+database+in+use)
* [mysql show all databases](https://www.codegrepper.com/code-examples/sql/mysql+show+all+databases)
* [mysql show databases command line](https://www.codegrepper.com/code-examples/sql/mysql+show+databases+command+line)
* [mysql how can i see which database i use](https://www.codegrepper.com/code-examples/sql/mysql+how+can+i+see+which+database+i+use)
* [how to view database in mysql](https://www.codegrepper.com/code-examples/sql/how+to+view+database+in+mysql)
* [show database in mysql](https://www.codegrepper.com/code-examples/sql/show+database+in+mysql)
* [show all database mysql](https://www.codegrepper.com/code-examples/sql/show+all+database+mysql)
* [my sql show database](https://www.codegrepper.com/code-examples/sql/my+sql+show+database)
* [get databases mysql](https://www.codegrepper.com/code-examples/sql/get+databases+mysql)
* [how to show all the database in mysql](https://www.codegrepper.com/code-examples/sql/how+to+show+all+the+database+in+mysql)
* [show databases mysql](https://www.codegrepper.com/code-examples/sql/show+databases+mysql)
* [show mysql database](https://www.codegrepper.com/code-examples/sql/show+mysql+database)
* [how to show database in mysql command line](https://www.codegrepper.com/code-examples/sql/how+to+show+database+in+mysql+command+line)
* [show db data mysql](https://www.codegrepper.com/code-examples/sql/show+db+data+mysql)
* [mysql get databases](https://www.codegrepper.com/code-examples/sql/mysql+get+databases)
* [mysql show databases](https://www.codegrepper.com/code-examples/sql/mysql+show+databases)
* [show databases in mysql](https://www.codegrepper.com/code-examples/sql/show+databases+in+mysql)
* [Mysql : show database details](https://www.codegrepper.com/code-examples/sql/Mysql+%3A+show+database+details)
* [show dbs mysql](https://www.codegrepper.com/code-examples/sql/show+dbs+mysql)
* [mysql to show databases](https://www.codegrepper.com/code-examples/sql/mysql+to+show+databases)
* [mysql show database](https://www.codegrepper.com/code-examples/sql/mysql+show+database)
* [show a database in mysql](https://www.codegrepper.com/code-examples/sql/show+a+database+in+mysql)
* [mysql show database info](https://www.codegrepper.com/code-examples/sql/mysql+show+database+info)
* [how to show databases in mysql](https://www.codegrepper.com/code-examples/sql/how+to+show+databases+in+mysql)
* [mysql query return databae name](https://www.codegrepper.com/code-examples/sql/mysql+query+return+databae+name)
* [show currnt database mysql](https://www.codegrepper.com/code-examples/sql/show+currnt+database+mysql)
* [mysql prompt show current database](https://www.codegrepper.com/code-examples/sql/mysql+prompt+show+current+database)
* [how to see current database in mysql](https://www.codegrepper.com/code-examples/sql/how+to+see+current+database+in+mysql)
* [show current db in mysql](https://www.codegrepper.com/code-examples/sql/show+current+db+in+mysql)
* [check the current database in mysql](https://www.codegrepper.com/code-examples/sql/check+the+current+database+in+mysql)
* [mysql select from current database](https://www.codegrepper.com/code-examples/sql/mysql+select+from+current+database)
* [show my current in use database mysql](https://www.codegrepper.com/code-examples/sql/show+my+current+in+use+database+mysql)
* [mysql current database use command](https://www.codegrepper.com/code-examples/sql/mysql+current+database+use+command)
* [mysql show current databases](https://www.codegrepper.com/code-examples/sql/mysql+show+current+databases)
* [show current database in mysql](https://www.codegrepper.com/code-examples/sql/show+current+database+in+mysql)
* [mysql check which database is in use](https://www.codegrepper.com/code-examples/sql/mysql+check+which+database+is+in+use)
* [select * from current db mysql](https://www.codegrepper.com/code-examples/sql/select+%2A+from+current+db+mysql)
* [mysql check current database](https://www.codegrepper.com/code-examples/sql/mysql+check+current+database)
* [get current database mysql](https://www.codegrepper.com/code-examples/sql/get+current+database+mysql)
* [check current db mysql](https://www.codegrepper.com/code-examples/sql/check+current+db+mysql)
* [mysql show current database in use](https://www.codegrepper.com/code-examples/sql/mysql+show+current+database+in+use)
* [see current database](https://www.codegrepper.com/code-examples/sql/see+current+database)
* [select database name mysql](https://www.codegrepper.com/code-examples/sql/select+database+name+mysql)
* [show current db mysql](https://www.codegrepper.com/code-examples/sql/show+current+db+mysql)
* [how to know which db we are using](https://www.codegrepper.com/code-examples/sql/how+to+know+which+db+we+are+using)
* [show current database mysql](https://www.codegrepper.com/code-examples/sql/show+current+database+mysql)
* [myswl show current schema](https://www.codegrepper.com/code-examples/sql/myswl+show+current+schema)
* [which database i am using](https://www.codegrepper.com/code-examples/sql/which+database+i+am+using)
* [mysql get db name](https://www.codegrepper.com/code-examples/sql/mysql+get+db+name)
* [mysql view current database](https://www.codegrepper.com/code-examples/sql/mysql+view+current+database)
* [mysql show current database name](https://www.codegrepper.com/code-examples/sql/mysql+show+current+database+name)
* [mysql cmd current database](https://www.codegrepper.com/code-examples/sql/mysql+cmd+current+database)
* [how to know current database in mysql](https://www.codegrepper.com/code-examples/sql/how+to+know+current+database+in+mysql)
* [mysql current database](https://www.codegrepper.com/code-examples/sql/mysql+current+database)
* [see current database mysql](https://www.codegrepper.com/code-examples/sql/see+current+database+mysql)
* [current database in mysql](https://www.codegrepper.com/code-examples/sql/current+database+in+mysql)
* [my sql get current database](https://www.codegrepper.com/code-examples/sql/my+sql+get+current+database)
* [sql show selected database](https://www.codegrepper.com/code-examples/sql/sql+show+selected+database)
* [how to see the current database in mysql](https://www.codegrepper.com/code-examples/sql/how+to+see+the+current+database+in+mysql)
* [mysql show current database](https://www.codegrepper.com/code-examples/sql/mysql+show+current+database)
| how to show current database in mysql | tutorialdba.com | 2021.31 | [
{
"text": "\n[**Essay Help**](https://www.gotoassignmenthelp.com/ca/essay-help/)preparation and submitting assignments and essays before the deadline is a tough nut to crack. It takes extreme dedication. What if, you do not have this much availability? GOTOASSIGNMENTHELP service provider. It can take away all the pain you are in. You can What if, you have planned things that are clashing with your courses? What if, you are regularly getting less grades your courses? If this sounds you fit, then you should probably take [**Research Paper Helper**](https://www.gotoassignmenthelp.com/ca/research-paper-help/) Online from get plagiarism free assignment and [**Thesis Help**](https://www.gotoassignmenthelp.com/ca/thesis-help/) and that too with high quality. This can probably bring A+ grade and you can roam proudly with best grades under your arm.\n\n\n",
"name": "",
"is_accepted": false
}
] |
3019ec02782f8fbbcc019cd4e262ce77 | Which Indian stocks can give 1000x / 100,000% returns in the next 10 to 20 years? | Which penny stocks will rise in 2021? | tutorialdba.com | 2021.25 | [
{
"text": "Strongly RECOMMEND to buy Sanwaria share now... you can not see this price in future :) \n\n \n\nfundamentally its very strong share... you can invest in present price. you can not see this price in future.",
"name": "",
"is_accepted": true
},
{
"text": "\nCalculation For Trading:\n\n\n**Resistance Level (R3):** 0.867 \n\n**Resistance Level (R2):** 0.833 \n\n**Resistance Level (R1):** 0.817 \n\n**Pivot Point:** 0.783 \n\n**Support Level (S1):** 0.767 \n\n**Support Level (S2):** 0.733\n\n\nAs per my observation the target would be 18 rupees within this end of year and will give 1000% profit within the 4-6 month \n\n\n\n\n| November 2021 | 18.779 |\n\n\n \n\n\n \n\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
42346c0500f87024be70f014eedf0b03 | How to restore the postgresql database dump at real time production environment ? | tutorialdba.com | 2020.34 | [
{
"text": "\nBefore creating database you have to create tablespace and then you have to give right tablespace name for database Creation \n\n\nAnd before creating tablespace you have to check with partion or disk space availability it's a prerequest for Postgresql tablespace creation\n\n\nHere given Following steps for creating tablespace & Database in Postgresql environment system.\n\n\nYou have to follow given steps only for Postgresql database creation & tablespace Creation.\n\n\nHere am performed simple steps of Postgresql Database restoring to some other new server & before that what prerequest want to follow for the postgresql Database restoring & Everything am mentioned here.\n\n\n**Checking the postgreSQL server status Before restoring :**\n\n\n\n```\ncd C:\\Program Files\\edb\\enterprincedb\\as9.6\\bin pg\\_ctl -D \"C:\\Program Files\\edb\\enterprincedb\\as9.6\\data\" status\n```\n\n**Connecting the database :**\n\n\n\n```\ncd C:\\Program Files\\edb\\enterprincedb\\as9.6\\bin\npsql -U enterprisedb -d edb\n```\n\n**Checking the tablesapce & database whether already exist with same name in our server :** \n\nFOR TABLESPACE :-\n\n\n\n```\nSELECT spcname FROM pg\\_tablespace;\n```\n\nThe psql program's **\\db** meta-command is also useful for listing the existing tablespaces.\n\n\nFOR DATABASE :-\n\n\n\n```\nSELECT datname FROM pg\\_database;\n```\n\nThe psql program's **\\l** meta-command is also useful for listing the existing databse.\n\n\n**Creating tablespace :**\n\n\n\n```\nCREATE TABLESPACE \"HealthCraft\\_LC\" LOCATION 'D:\\HealthCraft\\_LC';\nCREATE TABLESPACE \"HealthCraft\\_DC\" LOCATION 'D:\\HealthCraft\\_DC';\n```\n\n**Creating Database :**\n\n\n\n```\nCREATE DATABASE \"HealthCraft\\_LC\" TABLESPACE \"HealthCraft\\_LC\";\nCREATE DATABASE \"HealthCraft\\_DC\" TABLESPACE \"HealthCraft\\_DC\";\n\n```\n\nBefore Restoring Database you have to restore the roles other wise you will get roles does not exist error\n\n\n**Taking postgres Roles only backup :**\n\n\n\n```\npg\\_dumpall -h localhost -p 5432 U enterprisedb -v --roles-only -f \"/path/to/Preprod\\_roles\\_01012019.sql\"\n\n```\n\n**Taking Databases backup :**\n\n\n\n```\npg\\_dump -d HealthCraft\\_LC -U enterprisedb -f \"D:\\HealthCraft\\_LC\\_preprod\\_01012019.sql\"\npg\\_dump -d HealthCraft\\_DC -U enterprisedb -f \"D:\\HealthCraft\\_DC\\_preprod\\_01012019.sql\"\n```\n\n**Restoring the database roles it is the prerequest :**\n\n\n\n```\npsql -U enterprisedb -d edb -f \"D:\\tutorialdba\\Preprod\\_roles\\_01012019.sql\"\n```\n\nRestoring the postgresql database dump by using **psql** utility otherwise if your dump is custom format means you have to use **pg\\_restore** utility for database restoration :\n\n\n\n```\npsql -U enterprisedb -d \"HealthCraft\\_LC\" -f \"D:\\tutorialdba\\HealthCraft\\_LC\\_preprod\\_01012019.sql\"\npsql -U enterprisedb -d \"HealthCraft\\_DC\" -f \"D:\\tutorialdba\\HealthCraft\\_DC\\_preprod\\_01012019.sql\"\n```\n\n**else you can use \\i at postgres SQL console (if dump is plain format):**\n\n\n\n```\npsql -U enterprisedb -d HealthCraft\\_LC\n\\i D:\\HealthCraft\\_LC\\_preprod\\_01012019.sql\n```\n\nConnect the other(HealthCraft\\_DC) DB the restore the appropriate dump of HealthCraft\\_DC database\n\n\n\n```\n\\c HealthCraft\\_DC\n\\i D:\\HealthCraft\\_DC\\_preprod\\_01012019.sql\n```\n\n**To Dropping the postgres database :**\n\n\n\n```\ndrop DATABASE \"HealthCraft\\_LC\";\nERROR: database \"HealthCraft\\_LC\" is being accessed by other users\nDETAIL: There are 2 other sessions using the database.\n```\n\nFirst of all you have to kill the connected session by using **pg\\_terminate\\_backend**\n\n\n\n```\nSELECT pg\\_terminate\\_backend(pg\\_stat\\_activity.pid) FROM pg\\_stat\\_activity WHERE pg\\_stat\\_activity.datname = 'HealthCraft\\_LC' AND pid <> pg\\_backend\\_pid();\npg\\_terminate\\_backend\n----------------------\nt\nt\n(2 rows)\n```\n\nafter kill the session you can drop the database by using drop command\n\n\n\n```\ndrop DATABASE \"HealthCraft\\_LC\";\n```\n\nSome time session will be connected automatically again and again at the time you have to issue both command without time delay.\n\n\n**for example**\n\n\n\n```\nSELECT pg\\_terminate\\_backend(pg\\_stat\\_activity.pid) FROM pg\\_stat\\_activity WHERE pg\\_stat\\_activity.datname = 'HealthCraft\\_LC' AND pid <> pg\\_backend\\_pid();\ndrop DATABASE \"HealthCraft\\_LC\";\n## copy this above two lines paste it to sql prompt\n```\n\n**Running the script at background**\n\n\nWindows Server :\n\n\n\n```\nSTART \"\" psql -U enterprisedb -d \"HealthCraft\\_LC\" -f \"D:\\HealthCraft\\_LC\\_preprod\\_01012019.sql\" \n```\n\nLinux Server :\n\n\n\n```\n ./psql -U enterprisedb -d \"HealthCraft\\_LC\" -f D:\\HealthCraft\\_LC\\_preprod\\_01012019.sql &\n```\n\n",
"name": "",
"is_accepted": false
}
] |
|
258ac6d395c3d8a0101221fbfe7cb78c | How to increase the linux process priority ? if process may be postgres ,oracle ,backup and minitoring utility else query process | How to increase the linux process priority ? | tutorialdba.com | 2020.45 | [
{
"text": "\nTo change it to negative niceness value (to assign higher priority), run the following command as root user:\n\n\n\n```\n# renice -n -20 -p 14749\n\n```\n\nNote : Here 14749 means process id \n\n\n",
"name": "",
"is_accepted": false
}
] |
307efb4252a5726318b83b13f33abd8d | Hi all Need to create a database link between Oracle and Postgres. We need to read the data that is on Postgres from Oracle. Oracle DB is on Solaris SPARC Operating System. How to get postgres ODBC driver for Solaris ? Could you kindly guide me? | Need to create a database link between Oracle and Postgres | tutorialdba.com | 2019.43 | [
{
"text": "Install gateway in oracle \n\nThat will take care for drivers for heterogeneous connection. \n\n \n\nInstall the postgres odbc driver also or use unixodbc",
"name": "",
"is_accepted": false
}
] |
ab3667aa67b9ed4cadc015cd4fa009be | I got some spreading news as ITC going to acquire sanwaria consumer. Is it really ? | ITC is going to acquire sanwaria conumer ? | tutorialdba.com | 2021.31 | [
{
"text": "I think is possible ITC acquire sanwaria soon because ITC and sanwaria is same business but ITC is high market capital as well as doing some other business but its related to sanwaria",
"name": "",
"is_accepted": false
}
] |
c96381ca58b1ba0b12c182e87f8c87d0 | How to Install EPEL Repository on RHEL 8 / CentOS 8 | tutorialdba.com | 2020.45 | [
{
"text": "\nHow do I enable EPEL repository on [RHEL 8](https://computingforgeeks.com/red-hat-enterprise-linux-rhel-8-new-features/)?. EPEL is a repository that provides extra packages for Enterprise Linux. The Fedora EPEL group is responsible for creating and maintaining a high-quality set of additional packages for RHEL, CentOS, Scientific Linux, and Oracle Linux.\n\n\nRHEL, CentOS, Scientific Linux, and Oracle Linux distributions are designed for performance and stability with a limited number of packages in their Base repositories. If you’re a Developer, there are high chances some of the packages you need are not available. EPEL repository bridge this gap by providing additional stable packages that work for most use cases.\n\n\nInstall EPEL Repository on RHEL 8\n---------------------------------\n\n\nAs of this writing, RHEL 8 is available in Beta and there is no official release of EPEL repository for it. From my test environment, I was able to use the EPEL repository for RHEL 7 on RHEL 8 machine without any issues. This is not the recommended way but this guide will be updated once EPEL 8 is ready.\n\n\nIn the meantime, you can add EPEL for RHEL 7 by running the command below.\n\n\n\n```\n$ **sudo dnf install <https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm>**\n Updating Subscription Management repositories.\n Updating Subscription Management repositories.\n Last metadata expiration check: 21:59:52 ago on Mon 11 Mar 2019 12:35:42 AM EAT.\n epel-release-latest-7.noarch.rpm 5.3 kB/s | 15 kB 00:02 \n Dependencies resolved.\n Package Arch Version Repository Size\n Installing:\n epel-release noarch 7-11 @commandline 15 k\n Transaction Summary\n Install 1 Package\n Total size: 15 k\n Installed size: 24 k\n Is this ok [y/N]: **y**\n```\n\nThis will download repository file to `/etc/yum.repos.d/epel.repo` and enable the repo. You can confirm EPEL repository addition and functionality by running the following command.\n\n\n\n```\n$ **sudo dnf repolist epel**\n Updating Subscription Management repositories.\n Updating Subscription Management repositories.\n Last metadata expiration check: 0:01:14 ago on Mon 11 Mar 2019 10:38:19 PM EAT.\n repo id repo name status\n *epel Extra Packages for Enterprise Linux 7 - x86\\_64 12,881\n```\n\nList packages available on EPEL repository.\n\n\n\n```\nsudo dnf --disablerepo=\"*\" --enablerepo=\"epel\" list available\n```\n\nYou can filter further to check if required package is available on EPEL repository.\n\n\n\n```\nsudo dnf --disablerepo=\"*\" --enablerepo=\"epel\" list available | grep <package>\n```\n\nExample:\n\n\n\n```\n$ **sudo dnf --disablerepo=\"*\" --enablerepo=\"epel\" list available | grep chromium**\n chromium.x86\\_64 71.0.3578.98-2.el7 epel\n chromium-common.x86\\_64 71.0.3578.98-2.el7 epel\n chromium-headless.x86\\_64 71.0.3578.98-2.el7 epel\n chromium-libs.x86\\_64 71.0.3578.98-2.el7 epel\n chromium-libs-media.x86\\_64 71.0.3578.98-2.el7 epel\n```\n\nTo install package from EPEL repository, just run\n\n\n\n```\nsudo dnf --enablerepo=\"epel\" install <package>\n```\n\nSome dependencies may be installed from the Base repositories. There you have it, you can install your favorite packages from the EPEL repository.\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
51b33e28464542b4fdd69dbeedb70086 | MySQL Tutorial | tutorialdba.com | 2019.43 | [
{
"text": "\n**Table of Contents** \n\n\n[Preface and Legal Notices](https://dev.mysql.com/doc/refman/8.0/en/preface.html)\n\n\n[1 General Information](https://dev.mysql.com/doc/refman/8.0/en/introduction.html) \n\n\n[2 Installing and Upgrading MySQL](https://dev.mysql.com/doc/refman/8.0/en/installing.html) \n\n\n[3 Tutorial](https://dev.mysql.com/doc/refman/8.0/en/tutorial.html) \n\n\n[4 MySQL Programs](https://dev.mysql.com/doc/refman/8.0/en/programs.html) \n\n\n[5 MySQL Server Administration](https://dev.mysql.com/doc/refman/8.0/en/server-administration.html) \n\n\n[6 Security](https://dev.mysql.com/doc/refman/8.0/en/security.html) \n\n\n[7 Backup and Recovery](https://dev.mysql.com/doc/refman/8.0/en/backup-and-recovery.html) \n\n\n[8 Optimization](https://dev.mysql.com/doc/refman/8.0/en/optimization.html) \n\n\n[9 Language Structure](https://dev.mysql.com/doc/refman/8.0/en/language-structure.html) \n\n\n[10 Character Sets, Collations, Unicode](https://dev.mysql.com/doc/refman/8.0/en/charset.html) \n\n\n[11 Data Types](https://dev.mysql.com/doc/refman/8.0/en/data-types.html) \n\n\n[12 Functions and Operators](https://dev.mysql.com/doc/refman/8.0/en/functions.html) \n\n\n[13 SQL Statement Syntax](https://dev.mysql.com/doc/refman/8.0/en/sql-syntax.html) \n\n\n[14 MySQL Data Dictionary](https://dev.mysql.com/doc/refman/8.0/en/data-dictionary.html) \n\n\n[15 The InnoDB Storage Engine](https://dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html) \n\n\n[16 Alternative Storage Engines](https://dev.mysql.com/doc/refman/8.0/en/storage-engines.html) \n\n\n[17 Replication](https://dev.mysql.com/doc/refman/8.0/en/replication.html) \n\n\n[18 Group Replication](https://dev.mysql.com/doc/refman/8.0/en/group-replication.html) \n\n\n[19 MySQL Shell](https://dev.mysql.com/doc/refman/8.0/en/mysql-shell-userguide.html)\n\n\n[20 Using MySQL as a Document Store](https://dev.mysql.com/doc/refman/8.0/en/document-store.html) \n\n\n[21 InnoDB Cluster](https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-userguide.html) \n\n\n[22 MySQL NDB Cluster 8.0](https://dev.mysql.com/doc/refman/8.0/en/mysql-cluster.html) \n\n\n[23 Partitioning](https://dev.mysql.com/doc/refman/8.0/en/partitioning.html) \n\n\n[24 Stored Objects](https://dev.mysql.com/doc/refman/8.0/en/stored-objects.html) \n\n\n[25 INFORMATION\\_SCHEMA Tables](https://dev.mysql.com/doc/refman/8.0/en/information-schema.html) \n\n\n[26 MySQL Performance Schema](https://dev.mysql.com/doc/refman/8.0/en/performance-schema.html) \n\n\n[27 MySQL sys Schema](https://dev.mysql.com/doc/refman/8.0/en/sys-schema.html) \n\n\n[28 Connectors and APIs](https://dev.mysql.com/doc/refman/8.0/en/connectors-apis.html) \n\n\n[29 Extending MySQL](https://dev.mysql.com/doc/refman/8.0/en/extending-mysql.html) \n\n\n[30 MySQL Enterprise Edition](https://dev.mysql.com/doc/refman/8.0/en/mysql-enterprise.html) \n\n\n[31 MySQL Workbench](https://dev.mysql.com/doc/refman/8.0/en/workbench.html)\n\n\n[A MySQL 8.0 Frequently Asked Questions](https://dev.mysql.com/doc/refman/8.0/en/faqs.html) \n\n\n[B Errors, Error Codes, and Common Problems](https://dev.mysql.com/doc/refman/8.0/en/error-handling.html) \n\n\n[C Restrictions and Limits](https://dev.mysql.com/doc/refman/8.0/en/restrictions.html) \n\n\n[D Indexes](https://dev.mysql.com/doc/refman/8.0/en/indexes.html) \n\n\n[MySQL Glossary](https://dev.mysql.com/doc/refman/8.0/en/glossary.html)\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
0b23be395d1f5a9c8868afb0219f486c | How Donate Answerer And TutorialDBA forum | tutorialdba.com | 2020.16 | [
{
"text": "\n* [**TutorialDBA Forum?**](https://discuss.tutorialdba.com/)is one of the fastest growing websites for all kind of queries,staff.we as a team spend tons of time and efforts to come up with the useful and easily understandable articles on this platform for all our readers in their day-to-day life.\n* **TutorialDBA Forum** is a non-profit website that generates income by advertising only. The money is used to pay hosting and bandwidth bills, to purchase hardware equipments or software equipments and to reward our authors for writing such Unique, knowledgeable and useful articles for you. In return all we need is your strong support to stay alive and active on this knowledge area wherein we are bringing answers to your probe.\n* If you love **TutorialDBA Forum** and you want us to continue our services like as its running before now, Please make a donation to us and encourage others to do so. You can donate us from a single dollar to a couple of dollars. All donations can be made using a credit/debit card and PayPal account. If in-case you don’t have a credit card, you can send us a check or money order. If you’re interested, please contact us and we will send you the necessary account details.\n* If you’ve a product or website that you would like to showcase it to thousands of our readers, consider advertising with us.\n\n\n \n\n\n**How it's going Donate Here!**\n\n\nDonor will be looking for best answer which is available in our site. If he or she gets what they wanted, will donate some amount. If A User Asks Question! He/she will Get 5% of Donor money! Best answer provider will get 70% of Donor money! Remaining 25% for Site Owner. Money will get From Donation button which is available on answer page.\n\n\n \n\n\n \n\n\nSo give your best out of best………….\n\n\n**Donate Whatever You Want**!\n-----------------------------\n\n\n### \n\n\n",
"name": "",
"is_accepted": true
}
] |
|
56eaed88437f8531105ab6b4792c8209 | Greenplum 2+ year experienced interview Question & Answer | tutorialdba.com | 2021.43 | [
{
"text": "\n**How to check partitioned table size including indexes and partitions?**\n\n\nTable size with partitions:\n\n\nThe following SQL gives you employee\\_dailly table size, which includes partitions.\n\n\n\n```\nselect schemaname,tablename,round(sum(pg\\_total\\_relation\\_size(schemaname || '.' || partitiontablename))/1024/1024) \"MB\"\nfrom pg\\_partitions where tablename='employee\\_daily' group by 1,2;\nschemaname | tablename | MB\n-----------+----------------+-----\npublic | employee\\_daily | 254\n\n```\n\n**How** **do I get help on syntax to alter table?**\n\n\nIn psql session type \\h alter table which will display the syntax:\n\n\n\n```\ngpdb=# \\h alter table\n```\n\nHow to connect in utility mode?\n\n\nFrom master host\n\n\n\n```\nPGOPTIONS='-c gp\\_session\\_role=utility' psql -p <port> -h <hostname>\n```\n\nWhere:\n\n\nport is segment/ master database port.\n\n\nhostname is segment/master hostname.\n\n\n \n\n\n**Where/How to find db logs?**\n\n\n**Master:**\n\n\nMaster gpdb logfile is located in the $MASTER\\_DATA\\_DIRECTORY/pg\\_log/ directory and the file name depends on the database \"log\\_filename\" parameter.$MASTER\\_DATA\\_DIRECTORY/pg\\_log/gpdb-yyyy-mm-dd\\_000000.csv -->Log file format with default installation.\n\n\n~gpadmin/gpAdminLogs/ -->gpstart,gpstop,gpstate and other utility logs.\n\n\n**Segments:**\n\n\nprimary segments run below SQL to see logfile location:\n\n\nselect dbid,hostname,datadir||'/pg\\_log' from gp\\_configuration where content not in (-1) and isprimary is true;\n\n\nMiror Segments run below SQL to see logfile location:\n\n\nselect dbid,hostname,datadir||'/pg\\_log' from gp\\_configuration where content not in (-1) and isprimary is false;\n\n\n**How to see the list of available functions in Greenplum DB?**\n\n\n\\df schemaname.functionname (schemaname and function name support wildcard characters)\n\n\n\n```\ntest=# \\df pub*.*test*\nList of functions\nSchema | Name | Result data type | Argument data types\n--------+-------------+------------------+---------------------\npublic | bugtest | integer |\npublic | test | boolean | integer\npublic | test | void |\n(3 rows)\n```\n\n**How to check whether Greenplum server is up and running?**\n\n\nThe gpstate is the utility to check gpdb status.\n\n\nUse gpstate -Q to show a quick status. Refer to gpstate --help for more options.\n\n\n**Sample output:**\n\n\n\n```\n[gpadmin@stinger2]/export/home/gpadmin>gpstate -Q\ngpadmin-[INFO]:-Obtaining GPDB array type, [Brief], please wait...\ngpadmin-[INFO]:-Obtaining GPDB array type, [Brief], please wait...\ngpadmin-[INFO]:-Quick Greenplum database status from Master instance only\ngpadmin-[INFO]:----------------------------------------------------------\ngpadmin-[INFO]:-GPDB fault action value = readonly\ngpadmin-[INFO]:-Valid count in status view = 4\ngpadmin-[INFO]:-Invalid count in status view = 0\ngpadmin-[INFO]:----------------------------------------------------------\n```\n\n \n\n\n**How to create a Database?**\n\n\nThere are two ways to create gpdb database using psql session or the Greenplum createdb utility.Using psql session:\n\n\n\n```\ngpdb=# \\h create database\nCommand: CREATE DATABASE\nDescription: create a new database\n```\n\n**Syntax:**\n\n\n\n```\nCREATE DATABASE name\n[ [ WITH ] [ OWNER [=] dbowner ]\n[ TEMPLATE [=] template ]\n[ ENCODING [=] encoding ]\n[ TABLESPACE [=] tablespace ]\n[ CONNECTION LIMIT [=] connlimit ] ]\n```\n\n**Using createdb utility:**\n\n\n\n```\nUsage: $GPHOME/bin/createdb --help\ncreatedb [OPTION]... [DBNAME] [DESCRIPTION]\nOptions:\n-D, --tablespace=TABLESPACE default tablespace for the database\n-e, --echo show the commands being sent to the server\n-E, --encoding=ENCODING encoding for the database\n-O, --owner=OWNER database user to own the new database\n-T, --template=TEMPLATE template database to copy\n--help show this help, then exit\n--version output version information, then exit\n\n```\n\n \n\n\n**How do I get a list of databases in a greenplum cluster?**\n\n\n\n```\ngpdb=# \\ l (lowercase letter \"l\")\nList of databases\nName | Owner | Encoding\n------{}----------\ngpdb | gpadmin | UTF8\ngpperfmon | gpadmin | UTF8\npostgres | gpadmin | UTF8\ntemplate0 | gpadmin | UTF8\ntemplate1 | gpadmin | UTF8\n\n**Check below SQL for more details on dbs.**\ngpdb=# select * from pg\\_database;\n```\n\n \n\n\n**How to delete/drop an existing database in Greenplum?**\n\n\n\n```\ngpdb=# \\h DROP Database\nCommand: DROP DATABASE\nDescription: remove a database\nSyntax:DROP DATABASE [ IF EXISTS ] name \n```\n\n**Also check dropdb utility:**\n\n\n\n```\n $GPHOME/bin/dropdb --help\ndropdb removes a PostgreSQL database.\nUsage:\ndropdb [OPTION]... DBNAME\n```\n\n \n\n\n**Where** **can I get help on postgres psql commands?**\n\n\nIn psql session\n\n\n\"\\ ?\" - for all psql session help\n\n\n\"\\h <SQL Command> \" For any SQL syntax help.\n\n\n \n\n\n**gpstart failed what should I do?**\n\n\nCheck gpstart logfile in ~gpadmin/gpAdminLogs/gpstart\\_yyyymmdd.log\n\n\nTake a look at the pg start log file for more details in $MASTER\\_DATA\\_DIRECTORY/pg\\_log/startup.log\n\n\n \n\n\n**Why do we need gpstop -m and gpstart -m?**\n\n\nThe gpstart -m command allows you to start the master only and none of the data segments and is used primarily by support to get system level information/configuration. An end user would not regularly or even normally use it.\n\n\n \n\n\n**What is the procedure to get rid of mirror segments?**\n\n\nThere are no utilities available to remove mirrors from Greenplum. You need to make sure all primary segments are good then you can remove the mirror configuration from gp\\_configuration in 3.x.\n\n\n \n\n\n**How to run gpcheckcat?**\n\n\nThe gpcheckcat tool is used to check catalog inconsistencies between master and segments. It can be found in the $GPHOME/bin/lib directory:\n\n\n\n```\nUsage: gpcheckcat <option> [dbname]\n-?\n-B parallel: number of worker threads\n-g dir : generate SQL to rectify catalog corruption, put it in dir\n-h host : DB host name\n-p port : DB port number\n-P passwd : DB password\n-o : check OID consistency\n-U uname : DB User Name\n-v : verbose\nExample: gpcheckcat gpdb >gpcheckcat\\_gpdb\\_logfile.log\n```\n\n \n\n\n**What is gpdetective and how do I run it in Greenplum?**\n\n\nThe gpdetective utility collects information from a running Greenplum Database system and creates a bzip2-compressed tar output file. This output file helps with the diagnosis of Greenplum Database errors or system failures. for more details check help.\n\n\n\n```\ngpdetective --help\n```\n\n \n\n\n**How to delete a standby?**\n\n\nTo remove the currently configured standby master host from your Greenplum Database system, run the following command in the master only:\n\n\n\n```\n# gpinitstandby -r\n```\n\n**How to re-sync a standby?**\n\n\nUse this option if you already have a standby master configured, and just want to resynchronize the data between the primary and backup master host. The Greenplum system catalog tables will not be updated.\n\n\n\n```\n# gpinitstandby -n (resynchronize)\n```\n\n \n\n\n**How to recover an invalid segment?**\n\n\nUse the **gprecoverseg** tool, which will recognize which segments need recovery and will initialize recovery.\n\n\n3.3.x:\n\n\no Without \"-F\" option - First files will be compared, difference found and only different files will be synched (the first stage could last a long time if there are too many files in the data directory)\n\n\no With \"-F\" option - Entire data directory will be resynched.\n\n\n4.0.x:\n\n\no Without \"-F\" option - The change tracking log will be sent and applied to the mirror.\n\n\no With \"-F\" option - Entire data directory will be resynched.\n\n\n \n\n\n**How to add mirrors to the array?**\n\n\nThe gpadd mirrors utility configures mirror segment instances for an existing Greenplum Database system that was initially configured with primary segment instances only.\n\n\nFor more details check help.\n\n\n\n```\n# gpaddmirrors --help\n```\n\n \n\n\n**How to see primary to mirror mapping?**\n\n\nFrom database catalog following query list configuration on content ID, you can figure out primary and mirror for each content.\n\n\n\n```\ngpdb=# select * from gp\\_configuration order by content.\n```\n\nNote: starting from GPDB 4.x, gp\\_segment\\_configuration table is used instead.\n\n\n\n```\ngpdb=# select * from gp\\_segment\\_configuration order by dbid;\n```\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\n**What are major differences between Oracle and Greenplum?**\n\n\nOracle is relational database. Greenplum is MPP nature. Greenplum is shared nothing architecture. There are many other differences in terms of functionality and behaviour.\n\n\n**What is good and bad about the Greenplum, compared to Oracle and Greenplum?**\n\n\nGreenplum is built on top of Postgresql . It is shared nothing, MPP architecture best for data warehousing env. Good for big data analytics purpose.\n\n\nOracle is an all purpose database.\n\n\n**How to find errors / fatal from log files?**\n\n\ngrep for ERRORS, FATAL, SIGSEGV in pg\\_logs directory.\n\n\n**What is vacuum and when should I run this?**\n\n\nVACUUM reclaims storage occupied by deleted tuples. In normal [GPDB operation](https://en.wikipedia.org/wiki/Pivotal_Greenplum_Database), tuples that are deleted or obsoleted by an update are not physically removed from their table. They remain present on disk until a VACUUM is done. Therefore, it is necessary to do VACUUM periodically, especially on frequently-updated table.\n\n\n**What is difference between vacuum and vacuum full?**\n\n\nUnless you need to return space to the OS so that other tables or other parts of the system can use that space, you should use VACUUM instead of VACUUM FULL.\n\n\nVACUUM FULL is only needed when you have a table that is mostly dead rows, that is, the vast majority of its contents have been deleted. Even then, there is no point using VACUUM FULL unless you urgently need that disk space back for other things or you expect that the table will never again grow to its past size. Do not use it for table optimization or periodic maintenance as it is counterproductive.\n\n\n**What is Analyze and how frequence should I run this?**\n\n\nANALYZE collects statistics about the contents of tables in the database, and stores the results in the system table pg\\_statistic. Subsequently, the query planner uses these statistics to help determine the most efficient execution plans for queries.\n\n\nIt is a good idea to run ANALYZE periodically, or just after making major changes in the contents of a table. Accurate statistics will help the query planner to choose the most appropriate query plan, and thereby improve the speed of query processing. A common strategy is to run VACUUM and ANALYZE once a day during a low-usage time of day.\n\n\n**What is resource queues?**\n\n\nResource queues are used to manager Greenplum database workload management. All user / queries can be prioritized using Resource queues. Refer Admin guide for more details.\n\n\n**What is gp\\_toolkit?**\n\n\nThe gp\\_toolkit is a database schema, which has many tables, views and functions to better manage Greenplum Database when DB is up. In 3.x earlier versions it was referred to as gp\\_jetpack.\n\n\n**How to generate DDL for a table?**\n\n\nUse pg\\_dump utility to generate DDL.\n\n\nExample:\n\n\n\n```\npg\\_dump -t njonna.accounts -s -f ddl\\_accounts.sql\n**Where:**\n-f ddl\\_accounts.sql is output file.\n-t njonna.accounts is table name with schema njonna.\n-s dump only schema no data\n```\n\n \n\n\n**What are the tools available in Greenplum to take backup and restores?**\n\n\nFor non-parallel backups:\n\n\nUse postgres utililities (pg\\_dump, pg\\_dumpall for backup, and pg\\_restore for restore).\n\n\nAnother useful command for getting data out of database is the COPY <TABLE> to <File>.\n\n\nFor parallel backups:\n\n\ngp\\_dump and gpcrondump for backups and gp\\_restore for restore process.\n\n\n \n\n\n**How do I clone my production databaes to PreProd / QA environment?**\n\n\nIf Prod and QA on same GPDB cluster, use\n\n\n\n```\nCREATE database <Clone\\_DBname> template <Source\\_DB>.\n```\n\nIf Prod and QA are on different clusters, use backup and restore utilities.\n\n\n \n\n\n**What is difference between pg\\_dump and gp\\_dump?**\n\n\npg\\_dump - Non-parallel backup utility, you need big file system where backup will be created in the master node only.\n\n\ngp\\_dump - Parallel backup utility. Backup will be created in master and segments file system.\n\n\n \n\n\n**What is gpcrondump?**\n\n\nA wrapper utility for gp\\_dump, which can be called directly or from a crontab entry.\n\n\n\n```\nExample: gpcrondump -x <database\\_name>\n```\n\n \n\n\n**What are the backup options available at OS level?**\n\n\nSolaris: zfs snapshots at file system level.\n\n\nAll OS: gpcrondump / gp\\_dump.\n\n\n \n\n\n**Greenplum** **query is running very slow, it was running fine yesterday what should I do?**\n\n\n-Check that your connection to the Greenplum cluster is still good if you are using a remote client. You can do this by running the SQL locally to the GP cluster.\n\n\n-Check that the system tables and user tables involved are not bloated or skewed. Read jetpack or Greenplum toolkit documentation about how to do this.\n\n\n-Check with your DBA that the Greenplum interconnect is still performing correctly.\n\n\nThis can be done by checking for dropped packets on the interconnect \"netstat -i\" and by running gpcheckperf.It is also possible that a segment is experiencing hardware problems, which can be found in the output of dmesg or in\n\n\n/var/log/messages* (Linux) and /var/adm/messages* ([Solaris](http://tekslate.com/sun-solaris-administration-training/)).\n\n\n\n \n\n\n \n\n\n \n\n\n\n**How to turn on timing, and checking how much time a query takes to execute?**\n\n\nYou can turn in timing per session before you run your SQL with the \\timing command.\n\n\nYou can run explain analyze against your SQL statement to get the timing.\n\n\n**How to trace child processes on segment server?**\n\n\nWhen session start in master and segments, all the child processes in segments will be identified with master session\\_id connection string (con+sess\\_id).\n\n\nFor example:\n\n\n\n```\ngpdb=# select * from pg\\_Stat\\_activity;\ndatid | datname | procpid | sess\\_id |.. ..\n-------+---------+---------+---------+\n16986 | gpdb | 18162 | 76134 | .. ..\nIn all segments child processes for session 76134:\n[gpadmin@stinger2]/export/home/gpadmin/gp40>gpssh -f host\\_file /usr/ucb/ps -auxww |grep con76134\n[stinger2] gpadmin 18162 1.7 6.0386000124480 ? S 09:57:55 0:04 postgres: port 4000, gpadmin gpdb [local] con76134 [local] cmd3 CREATE DATABASE.......................................\n[stinger2] gpadmin 18625 0.3 2.726056455932 ? S 10:01:56 0:01 postgres: port 40000, gpadmin gpdb 10.5.202.12(18864) con76134 seg0 cmd4 MPPEXEC UTILITY...............................\n[stinger2] gpadmin 18669 0.0 0.1 3624 752 pts/2 S 10:02:36 0:00 grep con76134\n[stinger3] gpadmin 22289 0.8 9.4531860196404 ? S 09:36:20 0:05 postgres: port 40000, gpadmin gpdb 10.5.202.12(18866) con76134 seg1 cmd4 MPPEXEC UTILITY...............................\n```\n\n \n\n\n**How to check if my session queries are running or waiting on locks?**\n\n\nCheck \"waiting\" column in pg\\_stat\\_activity and \"granted\" column in pg\\_locks for any object level locks.\n\n\n \n\n\n**What kind of locks should we focus on MPP system when system is slow /hung?**\n\n\nLocks that are held for a very long time and multiple other queries are waiting for that lock also.\n\n\nHow do I monitor user activity history in Greenplum database ?\n\n\nUse Greenplum performance monitor (gpperfmon), which has GUI to monitor and query performance history.\n\n\n \n\n\n**What is Greenplum performance monitor and how to install ?**\n\n\nIts a monitoring tool that collects statistics on system and query performance and builds historical data.\n\n\n \n\n\n**when the client connects does he connect to the Master or segment node?**\n\n\nMaster.\n\n\n \n\n\n**Can you explain the process of data migration from Oracle to Greenplum?**\n\n\nThere are many ways. Simplest steps are Unload data into csv files, create tables in greenplum database corresponding to Oracle, Create external table, start gpfdist pointing to external table location, Load data into greenplum. You can also use gpload utility. Gpload creates external table at runtime.\n\n\n \n\n\n**Which command would you use to backup a database?**\n\n\ngp\\_dump, gpcrondump, pg\\_dump, pg\\_dumpall, copy\n\n\n \n\n\n**When you restore from a backup taken from gp\\_dump, can you import a table?**\n\n\nNO. Yes if during the gp\\_dump you backed up one table only.\n\n\n \n\n\n**Can you open and view a dump file?**\n\n\nWhich option would you use to export the ddl of the database or table?\n\n\n-s (-s | --schema-only Dump only the object definitions (schema), not data.)\n\n\n \n\n\n**When a user submits a query, where does it run in Master or segment nodes?**\n\n\nSegment nodes\n\n\n**If** **you configure your with Master and Segment nodes, where would the data reside?**\n\n\nSegment nodes\n\n\n**How would go about query tuning?**\n\n\n1. look at the query plan\n2. Look at the stats of the table/tables in the query\n3. look at the table distribution keys and joins in the query\n4. look at the network performance\n5. look at the resource queues\n6. look at the interconnect performance\n7. look at the join order of tables in the query\n8. look at the the query itself i.e. if it can be written in more efficient way\n\n\n**What would you do when a user or users are complaining that a particular query is running slow?**\n\n\n1. look at the query plan\n2. Look at the stats of the table/tables in the query\n3. look at the table distribution keys and joins in the query\n4. look at the network performance\n5. look at the resource queues\n6. look at the interconnect performance\n7. look at the join order of tables in the query\n8. look at the the query itself i.e. if it can be written in more efficient way\n\n\n**What** **would you do to gather statistics in the database? as well as reclaim the space?**\n\n\nA VACUUM FULL , CTAS .\n\n\nA VACUUM FULL will reclaim all expired row space, but is a very expensive operation and may take an unacceptably long time to finish on large, distributed Greenplum Database tables. If you do get into a situation where the free space map has overflowed, it may be more timely to recreate the table with a CREATE TABLE AS statement and drop the old table. A VACUUM FULL is not recommended in Greenplum Database.\n\n\n \n\n\n**How would you implement compression and explain possible the compression types?**\n\n\nThere are two types of in-database compression available in the Greenplum Database for append-only tables:\n\n\n1. Table-level compression is applied to an entire table.\n\n\n2. Column-level compression is applied to a specific column. You can apply different column-level compression algorithms to different columns.\n\n\n \n\n\n**How to check distribution policy of a test table sales?**\n\n\nThe Describe table sales shows the distribution details.\n\n\n\n```\npsql>\\d sales\nTable\"public.sales\"\nColumn | Type | Modifiers\n--------+---------+-----------\nid | integer |\ndate | date |\nDistributed by: (id)\n```\n\n**How many user schemas are there in the database?**\n\n\nUse\"\\dn\" at psql prompt.\n\n\n**When is my tables last analyzed in Greenplum database?**\n\n\nIn 4.x check pg\\_stat\\_operations for all actionname performed on any object.\n\n\nFor example,a sales table:\n\n\n\n```\ngpdb=# select objname,actionname,statime from pg\\_stat\\_operations where objname like 'sales';\nobjname | actionname | statime\n--------+-----------+-------------------------------\nsales | CREATE | 2010-10-01 12:18:41.996244-07\nsales | ANALYZE | 2010-10-06 14:38:21.933281-07\nsales | VACUUM | 2010-10-06 14:38:33.881245-07\n```\n\n \n\n\n**How to check the size of a table?**\n\n\nTable Level:\n\n\n\n```\npsql> select pg\\_size\\_pretty(pg\\_relation\\_size('schema.tablename'));\n```\n\nReplace schema.tablename with your search table.\n\n\nTable and Index:\n\n\n\n```\npsql> select pg\\_size\\_pretty(pg\\_total\\_relation\\_size('schema.tablename'));\n```\n\nReplace schema.tablename with your search table.\n\n\n \n\n\n**How to check the Schema size?**\n\n\nSchema Level:\n\n\npsql> select schemaname ,round(sum(pg\\_total\\_relation\\_size(schemaname||'.'||tablename))/1024/1024) \"Size\\_MB\"\n\n\nfrom pg\\_tables where schemaname='SCHEMANAME' group by 1;\n\n\nReplace SCHEMANAME with your schema name.\n\n\n**How to check the database size?**\n\n\nTo see size of specific database:\n\n\n\n```\npsql> select pg\\_size\\_pretty(pg\\_database\\_size('DATBASE\\_NAME'));\n\nExample: gpdb=# select pg\\_size\\_pretty(pg\\_database\\_size('gpdb'));\npg\\_size\\_pretty\n----------------\n24 MB\n(1 row)\n```\n\nTo see all database sizes:\n\n\n\n```\npsql> select datname,pg\\_size\\_pretty(pg\\_database\\_size(datname)) from pg\\_database;\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\n[**Travis Scott Jordan 1**](https://www.travisscott-jordan1.com/) \n\n \n\n[**Air Jordans**](https://www.airsjordans.com/) \n\n \n\n[**Jordan 11s**](https://www.jordan-11s.com/) \n\n \n\n[**Jordan 11**](https://www.jordans-11.com/) \n\n \n\n[**Jordans Shoes**](https://www.jordansshoes.org/) \n\n \n\n[**Retro Jordans**](https://www.retro-jordan.com/) \n\n \n\n[**Moncler Jackets**](https://www.monclerjackets.us.com/) \n\n \n\n[**Nike Air Jordan**](https://www.nikeair-jordan.com/) \n\n \n\n[**Moncler Outlet**](https://www.moncler-outlets.com/) \n\n \n\n[**Off-White**](https://www.off-white.us.org/) \n\n \n\n[**Yeezy 450**](https://www.yeezy-450.com/) \n\n \n\n[**Yeezy 500**](https://www.yeezys500.com/) \n\n \n\n[**Yeezy**](https://www.yeezyyeezy.com/) \n\n \n\n[**Yeezy 700**](https://www.yeezys-700.com/) \n\n \n\n[**Yeezy Supply**](https://www.yeezys-supply.com/) \n\n \n\n[**Off White Shoes**](https://www.offwhiteshoess.com/) \n\n \n\n[**NFL Jerseys**](https://www.nflsjerseys.us.com/) \n\n \n\n[**Jordan Shoes**](https://www.jordanshoes.org/) \n\n \n\n[**Jordans Shoes**](https://www.jordans-shoes.com/) \n\n \n\n[**Yeezy 350 V2**](https://www.yeezy350-v2.com/) \n\n \n\n[**Adidas Yeezy**](https://www.adidasyeezys.com/) \n\n \n\n[**Yeezy**](https://www.yeezyoutlet.us.com/) \n\n \n\n[**Yeezy 700**](https://www.yeezy-700.us.com/) \n\n \n\n[**Yeezy**](https://www.yeezyv2.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nike-outlets.com/) \n\n \n\n[**Yeezy Shoes**](https://www.yeezy-shoes.us.com/) \n\n \n\n[**UNC Jordan 1**](https://www.uncjordan1.us/) \n\n \n\n[**Jordan 13**](https://www.jordan-13.us/) \n\n \n\n[**Jordan AJ 1**](https://www.jordanaj1.com/) \n\n \n\n[**Yeezy Foam Runner**](https://www.yeezyfoam-runner.com/) \n\n \n\n[**Nike Outlet**](https://www.nikestoreoutlet.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletfactory.us/) \n\n \n\n[**AJ1**](https://www.aj1.us.com/) \n\n \n\n[**Yeezy Supply**](https://www.yeezy-supply.com/) \n\n \n\n[**Yeezy Zebra**](https://www.yeezy-zebra.com/) \n\n \n\n[**Jordan 1 Low**](https://www.jordan1low.com/) \n\n \n\n[**Air Jordans**](https://www.air-jordans.us.org/) \n\n \n\n[**Pandora Charms**](https://www.pandoracharms.uk.com/) \n\n \n\n[**Adidas UK**](https://www.adidasuk.uk.com/) \n\n \n\n[**Nike Store**](https://www.nikestoreoutlet.us.com/) \n\n \n\n[**Adidas Yeezy Official Website**](https://www.adidasyeezyofficialwebsite.com/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.us.com/) \n\n \n\n[**Jordan 1**](https://www.jordan1.uk.com/) \n\n \n\n[**Nike Outlet**](https://www.nikesoutlet.us.com/) \n\n \n\n[**YEEZY SUPPLY**](https://www.supplyyeezys.us/) \n\n \n\n[**Pandora Charms**](https://www.pandoracharms.cc/) \n\n \n\n[**Nike Shoes**](https://www.nikeshoes.cc/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutlet.uk.com/) \n\n \n\n[**Pandora Outlet**](https://www.pandoraoutlet.org/) \n\n \n\n[**Jordan Shoes**](https://www.jordanshoess.com/) \n\n \n\n[**Air Jordan 4**](https://www.air-jordan4.com/) \n\n \n\n[**Pandora Jewelry**](https://www.pandorajewelryusa.us.com/) \n\n \n\n[**Pandora Rings**](https://www.ringspandora.com/) \n\n \n\n[**Pandora Bracelets**](https://www.bracelets-pandora.com/) \n\n \n\n[**Adidas Yeezy**](https://www.yeezy-adidas.us.com/) \n\n \n\n[**Yeezy**](https://www.yzy.us.com/) \n\n \n\n[**Pandora Charms**](https://www.charmspandora.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletstore.us.com/) \n\n \n\n[**Adidas Yeezy**](https://www.adidas-yeezy.org/) \n\n \n\n[**Air Max 720**](https://www.airmax-720.com/) \n\n \n\n[**Nike Air Max 270**](https://www.nike-airmax270.com/) \n\n \n\n[**Air Jordan 11**](https://www.air-jordan11.com/) \n\n \n\n[**Air Force 1**](https://www.air-force1.com/) \n\n \n\n[**Air Jordan 1**](https://www.air-jordan1.com/) \n\n \n\n[**Nike Jordans**](https://www.nike-jordans.com/) \n\n \n\n[**Jordan 1s**](https://www.jordan-1s.com/) \n\n \n\n[**Pandora UK**](https://www.pandorauk.uk.com/) \n\n \n\n[**Nike Jordan 1**](https://www.nikejordan1.com/) \n\n \n\n[**Jordan 1**](https://www.jordan-1.org/) \n\n \n\n[**Yeezy Slides**](https://www.yeezyslides.us.com/) \n\n \n\n[**Nike Air VaporMax**](https://www.nikeairvapormax.us/) \n\n \n\n[**Nike Vapormax Flyknit**](https://www.nikevapormaxflyknit.com/) \n\n \n\n[**Air Jordan 1 Mid**](https://www.airjordan1-mid.com/) \n\n \n\n[**Adidas yeezy**](https://www.yeezyadidas.de/) \n\n \n\n[**Yeezy Shoes**](https://www.yeezy-shoess.com/) \n\n \n\n[**Adidas Yeezy**](https://www.adidasyeezy.me.uk/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.de/) \n\n \n\n[**Nike Shoes**](https://www.nikes.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletstoreonlineshopping.us/) \n\n \n\n[**Yeezy**](https://www.yeezystore.us.com/) \n\n \n\n[**NFL Shop Official Online Store**](https://www.nflshopofficialonlinestore.com/) \n\n \n\n[**Nike UK**](https://www.nikeuk.uk.com/) \n\n \n\n[**Yeezy**](https://www.yeezy.uk.com/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.uk.com/)\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
6e16b38e94aad6e767fab2b6eb296448 | How can we get list of all port numbers in greenplum? | tutorialdba.com | 2019.43 | [
{
"text": "\nThe `gpstate -``p`command, executed on the Greenplum master, lists the port assignments for the Greenplum master and the primary segments and mirrors. For example:\n\n\n\n```\n[gpadmin@mdw ~]$ gpstate -p\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:-Starting gpstate with args: -p\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:-local Greenplum Version: 'postgres (Greenplum Database) 4.3.6.0 build 62994'\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 8.2.15 (Greenplum Database 4.3.6.0 build 62994) on x86\\_64-unknown-linux-gnu, compiled by GCC gcc (GCC) 4.4.2 compiled on Jul 24 2015 11:35:08'\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:-Obtaining Segment details from master...\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:--Master segment instance /data/master/gpseg-1 port = 5432\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:--Segment instance port assignments\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:-----------------------------------\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:- Host Datadir Port\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:- sdw1 /data/primary/gpseg0 40000\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:- sdw2 /data/mirror/gpseg0 50000\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:- sdw2 /data/primary/gpseg1 40000\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:- sdw1 /data/mirror/gpseg1 50001\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:- sdw3 /data/primary/gpseg2 40000\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:- sdw4 /data/mirror/gpseg2 50000\n20160126:15:40:22:028389 gpstate:mdw:gpadmin-[INFO]:- sdw4 /data/primary/gpseg3 40000\n20160126:15:40\n```\n\n",
"name": "",
"is_accepted": false
},
{
"text": "If you are checking for external tables port numbers which are in use. \n\n \n\nUse pg\\_exttable",
"name": "",
"is_accepted": false
}
] |
|
3fc56e0cbda2887005e3ea6f8699482b | How to create database with encoding LATIN9 in linux postgres env | tutorialdba.com | 2021.10 | [
{
"text": "change in postgresql.conf file u can see charset parameter \n\nThere change and restart the DB service \n\n \n\nCREATE DATABASE music ENCODING 'LATIN1' TEMPLATE template0;",
"name": "",
"is_accepted": false
}
] |
|
ed6ee03315e2f0e622c6b90d1d2165b6 | What is the difference between schema vs table in postgresql ? | tutorialdba.com | 2021.21 | [
{
"text": "\nTables come under schema\n\n\nSchema can call collection of objects,database also be come under schema.\n\n\n**More Reference about Postgresql schema:**\n\n\n<https://www.tutorialdba.com/p/postgresql-schema-1.html>\n\n\n<https://www.tutorialdba.com/p/postgresql-schema-2.html>\n\n\n<https://www.tutorialdba.com/p/postgresql-schema-3.html>\n\n\n",
"name": "",
"is_accepted": true
}
] |
|
ed5e282a3c01b95c6e32192b77a7dcfa | How to shutdown particular database from postgres server? | tutorialdba.com | 2020.16 | [
{
"text": "\nIt's not to possible particular DB on postgresql ,you need to shutdown entire cluster .so here requirement is like that you just don't want to connect to db just restrict at DB level using revoking privilege\n\n\nExample for :\n\n\n\n```\nREVOKE CONNECT ON DATABASE d FROM public;\n```\n\n",
"name": "",
"is_accepted": false
}
] |
|
5179ecd1dd1c58c6eb47ef35aface169 | Why the mongo db has been used and why it peak to market compare to oracle | tutorialdba.com | 2020.50 | [
{
"text": "Oracle has its own demand where as the same with Mongodb also but mongo is a open source software and support non structural query language",
"name": "",
"is_accepted": false
}
] |
|
d3709a1917a73c662743b355c11e65e0 | How can I rollback a git repository to a specific commit? | tutorialdba.com | 2021.25 | [
{
"text": "\n\n```\ngit reset --hard <old-commit-id>\ngit push -f origin <branch-name>\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
|
432d712be52b46dd1349eaa6cc373a41 |
```
tdba@hostanme:/data/tdba> ps -ef|grep postgres
tdba 3493 1 0 May02 ? 00:00:03 /opt/9.6.3/bin/postgres -D /data/tdba
tdba 3494 3493 0 May02 ? 00:00:00 postgres: logger process
tdba 3496 3493 0 May02 ? 00:00:00 postgres: checkpointer process
tdba 3497 3493 0 May02 ? 00:00:00 postgres: writer process
tdba 3498 3493 0 May02 ? 00:00:02 postgres: wal writer process
tdba 3499 3493 0 May02 ? 00:00:03 postgres: autovacuum launcher process
tdba 3500 3493 0 May02 ? 00:00:01 postgres: archiver process failed on 00000001000000000000008C
```
| Archiver process failed below server | tutorialdba.com | 2020.16 | [
{
"text": "\nIssue is directory not found in tdba instead of given archive\\_logs here it is archive\\_log after that created directory of archive\\_logs Now issue is fixed without restarting the server. \n\n \n\n\n\n```\npostgres=# show archive\\_command;\n archive\\_command\n----------------------------------------------------\ncp %p /arch/tdba/archive\\_logs/%f\n(1 row)\n\ntdba@hostanme:/data/tdba> ps -ef|grep postgres\npginsta 3493 1 0 May02 ? 00:00:03 /opt/9.6.3/bin/postgres -D /data/tdba\npginsta 3494 3493 0 May02 ? 00:00:00 postgres: logger process\npginsta 3496 3493 0 May02 ? 00:00:00 postgres: checkpointer process\npginsta 3497 3493 0 May02 ? 00:00:01 postgres: writer process\npginsta 3498 3493 0 May02 ? 00:00:02 postgres: wal writer process\npginsta 3499 3493 0 May02 ? 00:00:03 postgres: autovacuum launcher process\npginsta 3500 3493 0 May02 ? 00:00:01 postgres: archiver process last was 000000010000000000000095\npginsta 3501 3493 0 May02 ? 00:00:05 postgres: stats collector process\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
e54f7126ff046c849e9d3163a396bc2c | Create a postgres DB user 2ndquadrant and assign the select ( read privileges ) to the table postgres\_table , the table which is in nijam database. | How to create a postgres DB user and assign read privileges ? | tutorialdba.com | 2019.43 | [
{
"text": "\n**2ndquadrant user creation :**\n\n\n\n```\nCREATE user 2ndquadrant WITH PASSWORD 'jfieuj4898';\n```\n\n**Assign the read the usuage privilege to postgres\\_table :**\n\n\n\n```\ngrant USAGE ON schema EnterpriseDB TO 2ndquadrant ;\ngrant select on EnterpriseDB.postgres\\_table to 2ndquadrant ;\n```\n\n**Process to postgres user creation :**\n\n\n\n```\nnijam=# CREATE user 2ndquadrant WITH PASSWORD 'dfkljsdl94u94ujdn1';\nCREATE ROLE\n\nnijam=# \\dp+ EnterpriseDB.postgres\\_table\n Access privileges\n Schema | Name | Type | Access privileges | Column privileges | Policies\n-----------+-------------+-------+-----------------------+-------------------+----------\n EnterpriseDB | postgres\\_table | table | nijam=arwdDxt/nijam+| |\n | | | db\\_readonly=r/nijam +| |\n(1 row)\n\n\nnijam=# grant select on EnterpriseDB.postgres\\_table to 2ndquadrant ;\nGRANT\n\nnijam=# \\dt+ EnterpriseDB.postgres\\_table\n List of relations\n Schema | Name | Type | Owner | Size | Description\n-----------+-------------+-------+--------+---------+-------------\n EnterpriseDB | postgres\\_table | table | nijam | 4792 kB |\n(1 row)\n\n\n\nnijam=# \\q\nnijam@tutorialdba:/srv/postgresql/home/nijam> psql -U 2ndquadrant -d nijam\npsql (10.6)\nType \"help\" for help.\n\n\nnijam=> \\dp+ EnterpriseDB.postgres\\_table\n Access privileges\n Schema | Name | Type | Access privileges | Column privileges | Policies\n-----------+-------------+-------+-----------------------+-------------------+----------\n EnterpriseDB | postgres\\_table | table | nijam=arwdDxt/nijam+| |\n | | | db\\_readonly=r/nijam +| |\n | | | 2ndquadrant=r/nijam | |\n(1 row)\n\nnijam=> select count(*) from EnterpriseDB.postgres\\_table;\nERROR: permission denied for schema EnterpriseDB\nLINE 1: select count(*) from EnterpriseDB.postgres\\_table;\n ^ ^\nnijam=> grant USAGE ON schema EnterpriseDB TO 2ndquadrant ;^C\nnijam=> \\q\nnijam@tutorialdba:/srv/postgresql/home/nijam> psql\npsql (10.6)\nType \"help\" for help.\n\nnijam=# grant USAGE ON schema EnterpriseDB TO 2ndquadrant ;\nERROR: schema \"EnterpriseDB\" does not exist\n\nnijam=# \\c nijam\nYou are now connected to database \"nijam\" as user \"nijam\".\n\nnijam=# grant USAGE ON schema EnterpriseDB TO 2ndquadrant ;\nGRANT\nnijam=# \\q\n\nnijam@tutorialdba:/srv/postgresql/home/nijam> psql -U 2ndquadrant -d nijam\npsql (10.6)\nType \"help\" for help.\n\nnijam=> select count(*) from EnterpriseDB.postgres\\_table;\n count\n-------\n 22521\n(1 row)\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
ecf0dcc849937ae04c1b0f1259e3fb99 | We found oracleksm and postgresql vulnerabilities | tutorialdba.com | 2019.43 | [
{
"text": "\noracleksm which is related to older kernel crash package which can be done online.\n\n\nother vulnerability postgresql is related to DB application.\n\n\n \n\n\nThis issue is fixed by upgrading to below mentioned point releases and restarting your PostgreSQL server.\n\n\n**Below are the new point releases to fix the vulnerability.**\n\n\nPostgreSQL version 9.6.15\n\n\nPostgreSQL version 10.10\n\n\nPostgreSQL version 11.5\n\n\nfor postgres upgrade read below blogs\n\n\n<https://www.tutorialdba.com/2019/07/postgresql-new-version-upgrade.html>\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
6f0af9a551a2ffc8f78386f6861122b6 | Apply Patch On Oracle 12.2 Database | tutorialdba.com | 2020.16 | [
{
"text": "\nPatching is fun, isn’t it? And you may have heard already that the**April 2018 patch bundles** got released on April 17, 2018. And I thought I share a little bit of fun with you with a quick guide to **patching my databases with the April 2018 PSU, BP and RU**. For this exercise I use [**our Hands-On Lab**](https://mikedietrichde.com/hands-on-lab/) with Oracle 11.2.0.4, Oracle 12.1.0.2 and Oracle 12.2.0.1 installed.\n\n\n### Prerequisites for patching my databases with the April 2018 PSU, BP and RU\n\n\nFirst of all, in my VBox environment, I shutdown the databases for each release before patching them – and the central listener I use from within the Oracle 12.2.0.1 environment:\n\n\n\n```\n. cdb2\nlsnrctl stop\n```\n\nIn addition I will update OPatch in my 12.2 home and use this version for all 12c patch activities on the system. Please download the newest **OPatch version 12.2.0.1.13 via patch 6880880** from [MyOracle Support](https://support.oracle.com/). Choose “12.2.0.1.0” in the drop-down list.\n\n\n\n\n\nDownload OPatch 12.2.0.1.13 via MyOracle Support’s patch 6880880\n\n\nThe `readme` explains that the previous OPatch directory should be backed up and the new OPatch should be unpacked from the destination’s `$ORACLE_HOME`. I just heard from Kay Liesenfeld that “removing” the old directory may not be a good idea as he had trouble with the most recent GI patches then.\n\n\nFor the 11g database patching I will use my current OPatch version 11.2.0.3.12.\n\n\nFurthermore, to identify the correct patches for each release I used[MOS Note: 2353306.1 (Critical Patch Update (CPU) Program April 2018 Patch Availability Document (PAD))](https://support.oracle.com/epmos/faces/DocumentDisplay?id=2353306.1) as neither the Availability and Known Issues notes nor the Patch Download Assistant were updated two days after patch release. Go to bullet point 3.1.4 in [MOS Note: 2353306.1](https://support.oracle.com/epmos/faces/DocumentDisplay?id=2353306.1) for Oracle Database Patch Availability. The other notes should be updated already when you read this blog post.\n\n\n[MOS Note: 2118136.2 – Assistant: Download Reference for Oracle Database/GI RU, BP, PSU](https://support.oracle.com/epmos/faces/DocumentDisplay?id=2118136.2) was not updated by the time I wrote this blog post but is now.\n\n\n### Patching Oracle 11.2.0.4 with the April 2018 Patch Set Update\n\n\nTo patch my **Oracle 11.2.0.4** databases I downloaded the **Patch Set Update April 2018** as Bundle Patches in Oracle 11g are meant for Engineered Systems only:\n\n\n* [Patch 27338049](https://support.oracle.com/epmos/faces/ui/patch/PatchDetail.jspx?parent=DOCUMENT&sourceId=2353306.1&patchId=27338049)\n\n\nFirst steps after changing into the patches directory are the checks:\n\n\n\n```\ncd /media/sf\\_TEMP/p27338049\\_112040\\_Linux-x86-64/27338049\n\n$ORACLE\\_HOME/OPatch/**opatch prereq CheckConflictAgainstOHWithDetail -ph ./**\nOracle Interim Patch Installer version 11.2.0.3.12\nCopyright (c) 2018, Oracle Corporation. All rights reserved.\n\nPREREQ session\nOracle Home : /u01/app/oracle/product/11.2.0.4\nCentral Inventory : /u01/app/oraInventory\n from : /u01/app/oracle/product/11.2.0.4/oraInst.loc\nOPatch version : 11.2.0.3.12\nOUI version : 11.2.0.4.0\nLog file location : /u01/app/oracle/product/11.2.0.4/cfgtoollogs/opatch/opatch2018-04-20\\_14-50-41PM\\_1.log\n\nInvoking prereq \"checkconflictagainstohwithdetail\"\nPrereq \"checkConflictAgainstOHWithDetail\" passed.\nOPatch succeeded.\n```\n\nOnce the check is passed I can apply the patch – and of course, I must ensure to have shutdown my databases (UPGR and FTEX in the hands-on lab) first:\n\n\n\n```\n$ $ORACLE\\_HOME/OPatch/**opatch apply**\nOracle Interim Patch Installer version 11.2.0.3.12\nCopyright (c) 2018, Oracle Corporation. All rights reserved.\n\nOracle Home : /u01/app/oracle/product/11.2.0.4\nCentral Inventory : /u01/app/oraInventory\n from : /u01/app/oracle/product/11.2.0.4/oraInst.loc\nOPatch version : 11.2.0.3.12\nOUI version : 11.2.0.4.0\nLog file location : /u01/app/oracle/product/11.2.0.4/cfgtoollogs/opatch/opatch2018-04-20\\_14-54-30PM\\_1.log\n\nVerifying environment and performing prerequisite checks...\nOPatch continues with these patches: 27338049 \n...\nBacking up files...\nApplying sub-patch '27338049' to OH '/u01/app/oracle/product/11.2.0.4'\n...\nPatching component oracle.rdbms, 11.2.0.4.0...\nPatching component oracle.rdbms.rman, 11.2.0.4.0...\n...\nComposite patch 27338049 successfully applied.\nLog file location: /u01/app/oracle/product/11.2.0.4/cfgtoollogs/opatch/opatch2018-04-20\\_14-54-30PM\\_1.log\nOPatch succeeded.\n```\n\nFinally I will have to execute `catbundle.sql` in all my 11.2.0.4 databases (UPGR and FTEX):\n\n\n\n```\n. upgr\ncd $ORACLE\\_HOME/rdbms/admin\nsqlplus / as sysdba\n\[email protected] psu apply\nexit\n```\n\nDone!\n\n\n### Patching Oracle 12.1.0.2 with the April 2018 Bundle Patch\n\n\nFor **Oracle Database 12.1.0.2** I downloaded the Database **Proactive Bundle Patch April 2018**:\n\n\n* [Patch 27486326](https://support.oracle.com/epmos/faces/ui/patch/PatchDetail.jspx?parent=DOCUMENT&sourceId=2353306.1&patchId=27486326)\n\n\nThis patch bundle contains also Clusterware and Client patches – but the database patch is actually 27338029. According to the REAME.html I execute the conflict check – but in my case using the 12.2.0.1.12 OPatch previously installed:\n\n\n\n```\n/u01/app/oracle/product/12.2.0.1/OPatch/opatch prereq CheckConflictAgainstOHWithDetail -phBaseDir /media/sf\\_TEMP/p27486326\\_121020\\_Linux-x86-64/27486326/27338029\n```\n\nBoth checks succeed.Afterwards I initiate the space check:\n\n\n\n```\n/u01/app/oracle/product/12.2.0.1/OPatch/opatch prereq CheckSystemSpace --phBaseDir /media/sf\\_TEMP/p27486326\\_121020\\_Linux-x86-64/27486326/27338029\n```\n\nNow I am applying the patch:\n\n\n\n```\n$ cd /media/sf\\_TEMP/p27486326\\_121020\\_Linux-x86-64/27486326/**27338029**\n$ /u01/app/oracle/product/12.2.0.1/OPatch/**opatch apply**\nOracle Interim Patch Installer version 12.2.0.1.13\nCopyright (c) 2018, Oracle Corporation. All rights reserved.\n\n\nOracle Home : /u01/app/oracle/product/12.1.0.2\nCentral Inventory : /u01/app/oraInventory\n from : /u01/app/oracle/product/12.1.0.2/oraInst.loc\nOPatch version : 12.2.0.1.13\nOUI version : 12.1.0.2.0\nLog file location : /u01/app/oracle/product/12.1.0.2/cfgtoollogs/opatch/opatch2018-04-19\\_20-51-40PM\\_1.log\n\nVerifying environment and performing prerequisite checks...\nOPatch continues with these patches: 27338029 \n...\nBacking up files...\nApplying sub-patch '27338029' to OH '/u01/app/oracle/product/12.1.0.2'\nApplySession: Optional component(s) [ oracle.has.crs, 12.1.0.2.0 ] , [ oracle.assistants.asm, 12.1.0.2.0 ] not present in the Oracle Home or a higher version is found.\n...\nComposite patch 27338029 successfully applied.\nLog file location: /u01/app/oracle/product/12.1.0.2/cfgtoollogs/opatch/opatch2018-04-19\\_20-51-40PM\\_1.log\n\nOPatch succeeded.\n```\n\nIn addition, `datapatch` needs to be executed now in both existing databases. Hence I’m starting up both databases, make sure the environment is set correctly (in the Lab: `. db121` and `. cdb1`) and invoke `datapatch`:\n\n\n\n```\n$ /u01/app/oracle/product/12.2.0.1/OPatch/**datapatch -verbose**\nSQL Patching tool version 12.1.0.2.0 Production on Thu Apr 19 21:00:31 2018\nCopyright (c) 2012, 2017, Oracle. All rights reserved.\n\nLog file for this invocation: /u01/app/oracle/cfgtoollogs/sqlpatch/sqlpatch\\_10973\\_2018\\_04\\_19\\_21\\_00\\_31/sqlpatch\\_invocation.log\n\nConnecting to database...OK\nBootstrapping registry and package to current versions...done\nDetermining current state...done\n\nCurrent state of SQL patches:\nBundle series DBBP:\n ID 180417 in the binary registry and ID 180116 in the SQL registry\n\nAdding patches to installation queue and performing prereq checks...\nInstallation queue:\n Nothing to roll back\n The following patches will be applied:\n 27338029 (DATABASE BUNDLE PATCH 12.1.0.2.180417)\n\nInstalling patches...\nPatch installation complete. Total patches installed: 1\n\nValidating logfiles...\nPatch 27338029 apply: SUCCESS\n logfile: /u01/app/oracle/cfgtoollogs/sqlpatch/27338029/22055339/27338029\\_apply\\_DB12\\_2018Apr19\\_21\\_00\\_56.log (no errors)\nSQL Patching tool complete on Thu Apr 19 21:01:02 2018\n\n```\n\nOnce I repeated this for the second database, patching for both 12.1.0.2 databases done as well.\n\n\n### Patching Oracle 12.2.0.1 with the April 2018 Update\n\n\nAs you may know already, there are no PSUs anymore in Oracle 12.2 and higher. You should patch with the **Updates**. Therefore I downloaded the Database **April 2018 Update** first. As my favorite note to download the correct patch just gets updated overnight I used [MOS Note:2239820.1 – 12.2.0.1 Base Release – Availability and Known Issues](https://support.oracle.com/epmos/faces/DocumentDisplay?id=2239820.1) to access the patch.\n\n\n* [Patch:27726453](https://support.oracle.com/epmos/faces/ui/patch/PatchDetail.jspx?parent=DOCUMENT&sourceId=2239820.1&patchId=27726453)\n\n\nIt contains the **Database 12.2.0.1 Update April 2018** and the **OJVM** (which I won’t need). I unpack it to a share: `/media/sf_TEMP`and install it from there.\n\n\n\n```\n$ cd /media/sf\\_TEMP/p27726453\\_122010\\_Linux-x86-64/27726453/27674384\n[CDB2] oracle@localhost:/media/sf\\_TEMP/p27726453\\_122010\\_Linux-x86-64/27726453/27674384\n```\n\nThen I call `opatch` for a conflict check:\n\n\n\n```\n$ /u01/app/oracle/product/12.2.0.1/OPatch/**opatch prereq CheckConflictAgainstOHWithDetail -ph ./**\nOracle Interim Patch Installer version 12.2.0.1.13\nCopyright (c) 2018, Oracle Corporation. All rights reserved.\n\nPREREQ session\n\nOracle Home : /u01/app/oracle/product/12.2.0.1\nCentral Inventory : /u01/app/oraInventory\nfrom : /u01/app/oracle/product/12.2.0.1/oraInst.loc\nOPatch version : 12.2.0.1.13\nOUI version : 12.2.0.1.4\nLog file location : /u01/app/oracle/product/12.2.0.1/cfgtoollogs/opatch/opatch2018-04-19\\_14-51-43PM\\_1.log\n\nInvoking prereq \"checkconflictagainstohwithdetail\"\nPrereq \"checkConflictAgainstOHWithDetail\" passed.\nOPatch succeeded.\n```\n\nAnd finally I **apply** the patch – I’m still in /`media/sf_TEMP/p27726453_122010_Linux-x86-64/27726453/27674384`, the directory where the Database 2018 Update is located in.\n\n\n\n```\n$ /u01/app/oracle/product/12.2.0.1/OPatch/**opatch apply**\nOracle Interim Patch Installer version 12.2.0.1.13\nCopyright (c) 2018, Oracle Corporation. All rights reserved.\n\nOracle Home : /u01/app/oracle/product/12.2.0.1\nCentral Inventory : /u01/app/oraInventory\nfrom : /u01/app/oracle/product/12.2.0.1/oraInst.loc\nOPatch version : 12.2.0.1.13\nOUI version : 12.2.0.1.4\nLog file location : /u01/app/oracle/product/12.2.0.1/cfgtoollogs/opatch/opatch2018-04-19\\_14-52-04PM\\_1.log\n\nVerifying environment and performing prerequisite checks...\nOPatch continues with these patches: 27674384\n...\nBacking up files...\nApplying interim patch '27674384' to OH '/u01/app/oracle/product/12.2.0.1'\nApplySession: Optional component(s) [ oracle.has.crs, 12.2.0.1.0 ] , [ oracle.oid.client, 12.2.0.1.0 ] , [ oracle.ons.daemon, 12.2.0.1.0 ] , [ oracle.network.cman, 12.2.0.1.0 ] not present in the Oracle Home or a higher version is found.\n\nPatching component oracle.network.rsf, 12.2.0.1.0...\n...\nPatching component oracle.sdo, 12.2.0.1.0...\nPatch 27674384 successfully applied.\nSub-set patch [27105253] has become inactive due to the application of a super-set patch [27674384].\nPlease refer to Doc ID 2161861.1 for any possible further required actions.\nLog file location: /u01/app/oracle/product/12.2.0.1/cfgtoollogs/opatch/opatch2018-04-19\\_14-52-04PM\\_1.log\nOPatch succeeded.\n```\n\nTo finalize the patch application I need to start my database(s) and all PDBs:\n\n\n\n```\nSQL> startup\nSQL> alter pluggable database all open;\nSQL> exit\n```\n\nAnd then run `datapatch`:\n\n\n\n```\n$ /u01/app/oracle/product/12.2.0.1/OPatch/datapatch -verbose\nSQL Patching tool version 12.2.0.1.0 Production on Thu Apr 19 14:55:05 2018\nCopyright (c) 2012, 2018, Oracle. All rights reserved.\n\nLog file for this invocation: /u01/app/oracle/cfgtoollogs/sqlpatch/sqlpatch\\_7777\\_2018\\_04\\_19\\_14\\_55\\_05/sqlpatch\\_invocation.log\n\n...\nFor the following PDBs: CDB$ROOT PDB$SEED\nThe following patches will be rolled back:\n25862693 (DATABASE BUNDLE PATCH 12.2.0.1.170516)\nThe following patches will be applied:\n27674384 (DATABASE APR 2018 RELEASE UPDATE 12.2.0.1.180417)\n\nInstalling patches...\nPatch installation complete. Total patches installed: 4\n\nValidating logfiles...\n\n```\n\nThat’s it.\n\n\nAt the end of the entire exercise I can restart my listener finally:\n\n\n\n```\n. cdb2\nlsnrctl start\n```\n\n",
"name": "",
"is_accepted": false
}
] |
|
1771685cf9c9ebdcf2831653c201e688 | HOW TO USE FUNCTION ON postgresql JSON DATA | tutorialdba.com | 2021.04 | [
{
"text": "\njson\\_each() function allows us to expand the outermost JSON object into a set of key-value pairs. \n\n \n\n\n\n```\npostgres=# select sales\\_info from sales;\n sales\\_info \n----------------------------------------------------------------------------------\n { \"customer\": \"NIJAM\", \"PRODUCTS\": {\"product\\_name\": \"choclate\",\"total\\_item\": 6}}\n { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 5}}\n { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 1}}\n(3 rows) \n```\n\n--To get a set of keys in the outermost JSON object use function json\\_object\\_keys function \n\n \n\n\n\n```\npostgres=# select json\\_each (sales\\_info) from sales;\n json\\_each \n-----------------------------------------------------------------\n (customer,\"\"\"NIJAM\"\"\")\n (PRODUCTS,\"{\"\"product\\_name\"\": \"\"choclate\"\",\"\"total\\_item\"\": 6}\")\n (customer,\"\"\"ABU\"\"\")\n (PRODUCTS,\"{\"\"product\\_name\"\": \"\"badam\"\",\"\"total\\_item\"\": 5}\")\n (customer,\"\"\"UMAR\"\"\")\n (PRODUCTS,\"{\"\"product\\_name\"\": \"\"mobile\"\",\"\"total\\_item\"\": 1}\")\n(6 rows) \n```\n\n--If you want calculate array size of json function \n\n \n\n\n\n```\nselect json\\_array\\_length('[1,2,3,4,5,6,7,8]'); \n```\n\n",
"name": "",
"is_accepted": false
}
] |
|
2d6331ae57c721b542dbf879fcbae630 | is there any option for db level encryption in postgreSQL? | tutorialdba.com | 2021.43 | [
{
"text": "\nSSL is both db as well as domain encryption,ssl having 128 and 256 encryption module you can choose depends on your requirements\n\n\nYes SSL is not stored in encryption module,it's middle level encryption like https \n\nIt encrypted at the time of transaction only if you want store encrypted means pg\\_crypto is best \n\n \n\n \n\nTry this how to setup ssl on postgresql database <https://www.tutorialdba.com/2018/06/ssl-setup-in-postgresql.html?m=1>\n\n\n**Data encryption:**\n\n\n<http://www.postgresonline.com/journal/archives/165-Encrypting-data-with-pgcrypto.html>\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
28dfd671b129d51e87d1587fffd4fa81 | I would like to upgrade oracle 11.2.0.2.0 to 12.2.0.1 from non RAc to RAC, kindly share me the doc. | tutorialdba.com | 2020.16 | [
{
"text": "First you have to upgrade 11.2.0.4 first Then 12.2 As per oracle doc",
"name": "",
"is_accepted": false
}
] |
|
fb218ab4437503b5d34f73738d94dc86 | Generate a self signed certificate | tutorialdba.com | 2020.40 | [
{
"text": "\nGenerate a self signed certificate\n==================================\n\n\nIn this short post, i will explain how to create a self signed certificate (on a Unix system with OpenSSL/LibreSSL)\n\n\n \n\n\n* Generate a server key\n\n\n\n```\n$ openssl genrsa -out server.key 2048\nGenerating RSA private key, 2048 bit long modulus\n..........................................................+++\n.....+++\ne is 65537 (0x010001)\n\n```\n\n**Hint** : 2048 is the size of the key. You can increase it but *NOT* lower it. This will generate the file *server.key*\n\n\n* Create a certificate signing request (csr)\n\n\n\n```\n$ openssl req -new -key server.key -out server.csr\nYou are about to be asked to enter information that will be incorporated\ninto your certificate request.\nWhat you are about to enter is what is called a Distinguished Name or a DN.\nThere are quite a few fields but you can leave some blank\nFor some fields there will be a default value,\nIf you enter '.', the field will be left blank.\n-----\nCountry Name (2 letter code) [AU]:FR\nState or Province Name (full name) [Some-State]:PACA\nLocality Name (eg, city) []:Marseille\nOrganization Name (eg, company) [Internet Widgits Pty Ltd]:Raveland\nOrganizational Unit Name (eg, section) []:SSL\nCommon Name (e.g. server FQDN or YOUR name) []:test.raveland.org\nEmail Address []:[email protected]\n\nPlease enter the following 'extra' attributes\nto be sent with your certificate request\nA challenge password []:\nAn optional company name []:\n\n```\n\nYou will have to answer the questions and it will generate a file called *server.csr*\n\n\n* Sign the CSR\n\n\n\n```\n$ openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.crt\nSignature ok\nsubject=C = FR, ST = PACA, L = Marseille, O = Raveland, OU = SSL, CN = test.raveland.org, emailAddress = [email protected]\n\n```\n\n**Hint** : 365 is the validity time for your certificate. I usually put 365 (1 year) or 3650 (10 years)\n\n\nNow you will have a file called *server.crt* (your certificate)\n\n\n**To resume, now you have 3 files :**\n\n\n* *server.key* : the private key of your certificate\n* *server.csr* : the *CSR* (certificate Signing Request)\n* *server.crt* : your certificate\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
a93e45f40e0f3472866d7ea747405e8d |
Spring 2022's menswear shows have **[Balenciaga Handbags](https://www.balenciagabagser.com/)** come and gone, but the **[Golden Goose](https://www.goldengooseltd.com/)** street style as seen on showgoers has a long lasting **[stone island clothing](https://www.stoneislandsaler.com/)** impact. Think go anywhere and do anything slips, pastel hued lace that can make the chunkiest sweater seem more feminine, and plaid that will take you right back to the 90s.
Not to mention they also have superior filtration, and are **[palm angels outlet](https://www.palmangelssale.com/)** completely recyclable. There were also some cool, two tone denim versions. The Don't Go Yet singer **[Golden Goose Sneakers](https://www.goldengoosesos.com/)** opened up to Entertainment Tonight earlier this week about the film and Mendes support throughout the process.
Wiley was drawn to the show for its Everyday People connection, while Thompson was looking to hang out and make connections, having recently moved from Las Vegas after months of poker tournaments. In a **[Golden Goose Sale](https://www.goldengoosers.com/)** press release, British fashion and textile designer Zandra Rhodes describes her new Karismatisk collection with Ikea as functional and fabulous and fabulous it is A departure from the sometimes stark Scandinavian aesthetic that the home **[Golden Goose Outlet](https://www.goldengoosesneakersltd.com/)** goods retailer is known for, flamboyant prints and colours adorn pillows, sheets, rugs and even a room divider.
The Don't Go Yet singer opened up to Entertainment Tonight earlier this week about the film and Mendes support throughout **[supreme shop](https://www.supremevipshop.com/)** the process. The fruit cake, for one, is **[Golden Goose Shoes](https://www.goldengooseofficialsite.com/)** a textbook welcome gift for new people in a neighborhood, she said, which seemed really on point for Man Repeller, because we are constantly welcoming people to join our community. **[Off White Store](https://www.offwhiteclothes.com/)**
Globalization leaves for less individualism. But the past year and a half has been different **[Golden Goose Sale](https://www.goldengoosesneak.com/)** With no red carpet events or official functions generating these big fashion moments, a **[off white x nike](https://www.offwhitesaler.com/)** celebrity's day to day wardrobe is all we've had to work off of. T shirts are like a blank slate, Mayock explained to us.
We all know how the story goes as the summer season begins to wind down and the leaves change **[Coach Outlet Online](https://www.coachbagsoutlets.com/)** to signify fall, we struggle **[Prada Bag](https://www.pradasonsale.com/)** to dress for up and down weather. The Fear of God 1s are very near **[Moncler Outlet Store](https://www.moncleroutletsvip.com/)** and dear to me because it's an original design and not a rework.
Each design should make our employees feel proud, says **[Bottega Veneta Handbags](https://www.bottegavenetasbags.com/)** Sarah Reesman, design director. And it **[air jordan 1 mid](https://www.airjordan1s.com/)** doesn't even require a Versace level budget. In 2021, the brand sold more than 350,000 bras. For Nielsen, each collection **[palm angels sale](https://www.palmangelsoutlet.com/)** has a theme, including rock stars from the 80s, my own family, supermodels from the 90s, he says.
These stylish bottoms are comfortable and appropriate for office wear. We first spotted **[Jimmy Choo Outlet](https://www.jimmychoosaler.com/)** it on the runway **[Prada Bags On Sale](https://www.pradabagsite.com/)** at Milan Fashion Week last September. Au revoir, Paris Fashion Week While we're sad that **[Bottega Veneta Outlet](https://www.bottegavenetasoutlet.com/)** our virtual stay in the French capital has come to an end, the sartorial lessons we picked up on the runways and on the streets will stay on our mental moodboards for months to come.
| shows have Balenciaga Handbags come and gone | tutorialdba.com | 2021.43 | [
{
"text": "\n[**Travis Scott Jordan 1**](https://www.travisscott-jordan1.com/) \n\n \n\n[**Air Jordans**](https://www.airsjordans.com/) \n\n \n\n[**Jordan 11s**](https://www.jordan-11s.com/) \n\n \n\n[**Jordan 11**](https://www.jordans-11.com/) \n\n \n\n[**Jordans Shoes**](https://www.jordansshoes.org/) \n\n \n\n[**Retro Jordans**](https://www.retro-jordan.com/) \n\n \n\n[**Moncler Jackets**](https://www.monclerjackets.us.com/) \n\n \n\n[**Nike Air Jordan**](https://www.nikeair-jordan.com/) \n\n \n\n[**Moncler Outlet**](https://www.moncler-outlets.com/) \n\n \n\n[**Off-White**](https://www.off-white.us.org/) \n\n \n\n[**Yeezy 450**](https://www.yeezy-450.com/) \n\n \n\n[**Yeezy 500**](https://www.yeezys500.com/) \n\n \n\n[**Yeezy**](https://www.yeezyyeezy.com/) \n\n \n\n[**Yeezy 700**](https://www.yeezys-700.com/) \n\n \n\n[**Yeezy Supply**](https://www.yeezys-supply.com/) \n\n \n\n[**Off White Shoes**](https://www.offwhiteshoess.com/) \n\n \n\n[**NFL Jerseys**](https://www.nflsjerseys.us.com/) \n\n \n\n[**Jordan Shoes**](https://www.jordanshoes.org/) \n\n \n\n[**Jordans Shoes**](https://www.jordans-shoes.com/) \n\n \n\n[**Yeezy 350 V2**](https://www.yeezy350-v2.com/) \n\n \n\n[**Adidas Yeezy**](https://www.adidasyeezys.com/) \n\n \n\n[**Yeezy**](https://www.yeezyoutlet.us.com/) \n\n \n\n[**Yeezy 700**](https://www.yeezy-700.us.com/) \n\n \n\n[**Yeezy**](https://www.yeezyv2.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nike-outlets.com/) \n\n \n\n[**Yeezy Shoes**](https://www.yeezy-shoes.us.com/) \n\n \n\n[**UNC Jordan 1**](https://www.uncjordan1.us/) \n\n \n\n[**Jordan 13**](https://www.jordan-13.us/) \n\n \n\n[**Jordan AJ 1**](https://www.jordanaj1.com/) \n\n \n\n[**Yeezy Foam Runner**](https://www.yeezyfoam-runner.com/) \n\n \n\n[**Nike Outlet**](https://www.nikestoreoutlet.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletfactory.us/) \n\n \n\n[**AJ1**](https://www.aj1.us.com/) \n\n \n\n[**Yeezy Supply**](https://www.yeezy-supply.com/) \n\n \n\n[**Yeezy Zebra**](https://www.yeezy-zebra.com/) \n\n \n\n[**Jordan 1 Low**](https://www.jordan1low.com/) \n\n \n\n[**Air Jordans**](https://www.air-jordans.us.org/) \n\n \n\n[**Pandora Charms**](https://www.pandoracharms.uk.com/) \n\n \n\n[**Adidas UK**](https://www.adidasuk.uk.com/) \n\n \n\n[**Nike Store**](https://www.nikestoreoutlet.us.com/) \n\n \n\n[**Adidas Yeezy Official Website**](https://www.adidasyeezyofficialwebsite.com/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.us.com/) \n\n \n\n[**Jordan 1**](https://www.jordan1.uk.com/) \n\n \n\n[**Nike Outlet**](https://www.nikesoutlet.us.com/) \n\n \n\n[**YEEZY SUPPLY**](https://www.supplyyeezys.us/) \n\n \n\n[**Pandora Charms**](https://www.pandoracharms.cc/) \n\n \n\n[**Nike Shoes**](https://www.nikeshoes.cc/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutlet.uk.com/) \n\n \n\n[**Pandora Outlet**](https://www.pandoraoutlet.org/) \n\n \n\n[**Jordan Shoes**](https://www.jordanshoess.com/) \n\n \n\n[**Air Jordan 4**](https://www.air-jordan4.com/) \n\n \n\n[**Pandora Jewelry**](https://www.pandorajewelryusa.us.com/) \n\n \n\n[**Pandora Rings**](https://www.ringspandora.com/) \n\n \n\n[**Pandora Bracelets**](https://www.bracelets-pandora.com/) \n\n \n\n[**Adidas Yeezy**](https://www.yeezy-adidas.us.com/) \n\n \n\n[**Yeezy**](https://www.yzy.us.com/) \n\n \n\n[**Pandora Charms**](https://www.charmspandora.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletstore.us.com/) \n\n \n\n[**Adidas Yeezy**](https://www.adidas-yeezy.org/) \n\n \n\n[**Air Max 720**](https://www.airmax-720.com/) \n\n \n\n[**Nike Air Max 270**](https://www.nike-airmax270.com/) \n\n \n\n[**Air Jordan 11**](https://www.air-jordan11.com/) \n\n \n\n[**Air Force 1**](https://www.air-force1.com/) \n\n \n\n[**Air Jordan 1**](https://www.air-jordan1.com/) \n\n \n\n[**Nike Jordans**](https://www.nike-jordans.com/) \n\n \n\n[**Jordan 1s**](https://www.jordan-1s.com/) \n\n \n\n[**Pandora UK**](https://www.pandorauk.uk.com/) \n\n \n\n[**Nike Jordan 1**](https://www.nikejordan1.com/) \n\n \n\n[**Jordan 1**](https://www.jordan-1.org/) \n\n \n\n[**Yeezy Slides**](https://www.yeezyslides.us.com/) \n\n \n\n[**Nike Air VaporMax**](https://www.nikeairvapormax.us/) \n\n \n\n[**Nike Vapormax Flyknit**](https://www.nikevapormaxflyknit.com/) \n\n \n\n[**Air Jordan 1 Mid**](https://www.airjordan1-mid.com/) \n\n \n\n[**Adidas yeezy**](https://www.yeezyadidas.de/) \n\n \n\n[**Yeezy Shoes**](https://www.yeezy-shoess.com/) \n\n \n\n[**Adidas Yeezy**](https://www.adidasyeezy.me.uk/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.de/) \n\n \n\n[**Nike Shoes**](https://www.nikes.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletstoreonlineshopping.us/) \n\n \n\n[**Yeezy**](https://www.yeezystore.us.com/) \n\n \n\n[**NFL Shop Official Online Store**](https://www.nflshopofficialonlinestore.com/) \n\n \n\n[**Nike UK**](https://www.nikeuk.uk.com/) \n\n \n\n[**Yeezy**](https://www.yeezy.uk.com/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.uk.com/)\n\n\n",
"name": "",
"is_accepted": false
}
] |
1ef66e74fed5acbdebc1d2ea09408241 | Link MySQL to MS SQL Server2008 | tutorialdba.com | 2020.45 | [
{
"text": "\nI came up with Idea of this article, when I tried to create replication setup between MS SQL 2008 and MySQL. I was unable to do it since MS SQL provides only two non SQL Subscriptions/Publishers options.\n\n\n[](https://dbperf.files.wordpress.com/2010/07/link1.jpg)\n\n\nHowever I created the linked server through which I can access and query the MySQL databases and tables.\n\n\nA linked server (a virtual server) may be considered a more flexible way of achieving remote access, with the added benefits of remote table access and distributed queries. Microsoft manages the link mechanism via OLE DB technology. Specifically, an OLE DB data source points to the specific database that can be accessed using OLEDB.\n\n\nLet’s try and create MySQL linked Server on MS SQL Server 2008 and query a database.\n\n\n***Step 1: Create ODBC DSN for MySQL***\n\n\nTo create ODBC DSN you need to download the MySQL Connector/ODBC Drivers 5.1 from <http://www.mysql.com/downloads/connector/odbc/> .\n\n\nOnce you download and install the ODBC drivers, it’s time to create the DSN. Initially check if the drivers are listed under your data sources from **CONTROL PANEL>Administrative Tools>Data Sources(ODBC)**\n\n\n**[](https://dbperf.files.wordpress.com/2010/07/link21.jpg)**\n\n\nAfter you see the drivers listed. Follow the Images to setup **MySQL ODBC DSN**.\n\n\nOn **System DSN** tab click **Add** button,\n\n\n[](https://dbperf.files.wordpress.com/2010/07/link4.jpg)\n\n\nAfter you click OK and Close the window, MySQL ODBC will be added to System DSN as shown below.\n\n\n[](https://dbperf.files.wordpress.com/2010/07/link5.jpg)\n\n\n***Steps 2: Create Linked Server through SSMS***\n\n\n \n\n\n*Under Object Browser expand **Server Objects** and right click **Linked Servers**as shown below*\n\n\n*[](https://dbperf.files.wordpress.com/2010/07/link6.jpg)*\n\n\n*Click **New Linked Sever**, It brings up a window; fill in the information as shown to create linked server under **General** tab.*\n\n\n*[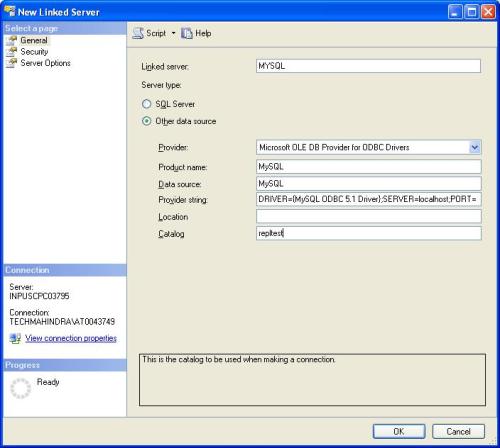](https://dbperf.files.wordpress.com/2010/07/link7.jpg)*\n\n\n*In the above screen I have entered the following details to create a linked server for MySQL.*\n\n\n \n\n\n*Provider: Microsoft OLE DB Provider for ODBC Drivers*\n\n\n*Product name: MySQL*\n\n\n*Data Source: MySQL (This the system dsn created earlier)*\n\n\n*Provider String: DRIVER={MySQL ODBC 5.1 Driver};SERVER=localhost;PORT=3306;DATABASE=repltest; USER=user;PASSWORD=password;OPTION=3;*\n\n\n*(This string is providing all the information to connect to MySQL using the ODBC)*\n\n\n*Location: Null*\n\n\n*Catalog: repltest (Database name to access and query)*\n\n\n \n\n\n*Now on the **Security** tab, select Be made using this security context option and enter the credentials to connect to MySQL server.*\n\n\n*[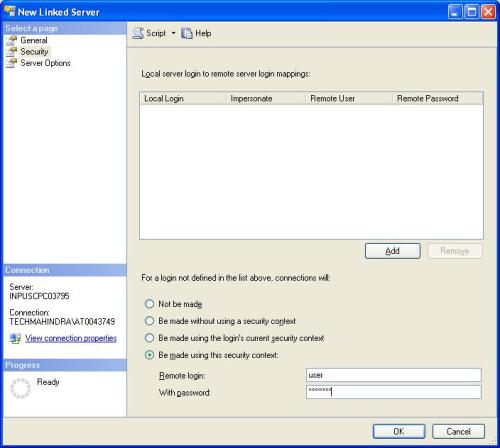](https://dbperf.files.wordpress.com/2010/07/link8.jpg)*\n\n\n*Also finally under **Server Options** tab, change **RPC** and **RPC Out** properties to****True****, by default they are set to****False.***\n\n\n[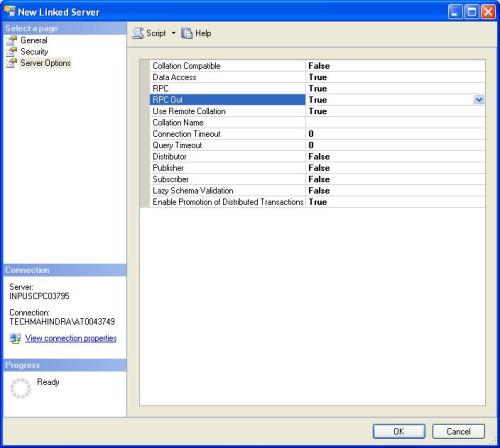](https://dbperf.files.wordpress.com/2010/07/link9.jpg)\n\n\n*Click **Ok,**after making all the mentioned changes. This will create the linked server and it will be listed under**SSMS Object Browser.** Right Click on the MYSQL linked server and click **Test Connection**.*\n\n\n*[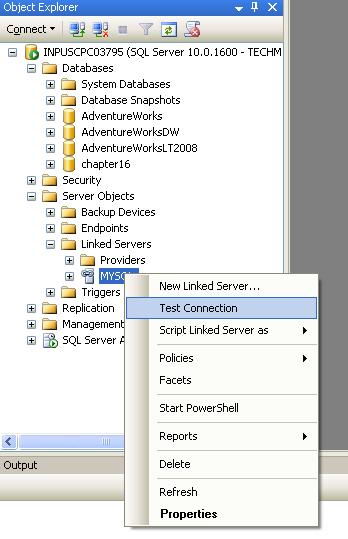](https://dbperf.files.wordpress.com/2010/07/link10.jpg)*\n\n\n*[](https://dbperf.files.wordpress.com/2010/07/link12.jpg)*\n\n\n*It should show you the above once succeeded. You can also browse the MYSQL linked server to check if the catalogs are displayed by expanding it.*\n\n\n***Step 3: Create Linked Server using T-SQL***\n\n\nWhile the linked server can be created using the built-in wizard of the Management Studio, it can also be created using TSQL statements as in the following listing (run both statements, the first one creates the linked server and the second the logins).\n\n\nExec master.dbo.sp\\_addlinkedserver \n\n@server=N’localhost’, \n\n@srvprodcut=N’MySQL’, \n\n@provider=N’MSDASQL’, \n\n@datasrc=N’MySQL’\n\n\nExec master.dbo.sp\\_addlinkedserverlogin \n\n@server=N’localhost’, \n\n@locallogin=NULL, \n\n@rmtuser=N’user’, \n\n@rmtpassword=N'<your password>’ \n\n@rmtsrvname=N’localhost’\n\n\n \n\n\n \n\n\n***Step 4: Accessing and Querying MySQL through SSMS***\n\n\n \n\n\n*Open a new query tab, and run a select query*[select * from openquery(MYSQL,‘select * from reptab’)]\n\n\n*[](https://dbperf.files.wordpress.com/2010/07/link11.jpg)*\n\n\n*Since we also have enabled the RPC, we can test the same using the following query*[Execute (‘select * from reptab‘)at MYSQL]\n\n\n*If it returns the same results, the RPC is configured fine.*\n\n\n \n\n\n*Follow all the above steps to configure working Linked Server to MySQL.*\n\n\n",
"name": "",
"is_accepted": false
}
] |
|
852c1e1f59229815d3c661b7849a26dd | How to migrate the postgres database to some other new server ? | tutorialdba.com | 2020.40 | [
{
"text": "\n**Postgres DB migration local server to remote server:** \n\nYou don't need to create an intermediate file. You can do\n\n\n\n```\n./pg\\_dump -C -h localhost -U localuser dbname | psql -h remotehost -U remoteuser dbname\nor\n./pg\\_dump -C -h remotehost -U remoteuser dbname | psql -h localhost -U localuser dbname\n```\n\nusing psql or pg\\_dump to connect to a remote host.\n\n\nWith a big database or a slow connection, dumping a file and transfering the file compressed may be faster.\n\n\nAs Kornel said there is no need to dump to a intermediate file, if you want to work compressed you can use a compressed tunnel\n\n\n\n```\n./pg\\_dump -C dbname | bzip2 | ssh remoteuser@remotehost \"bunzip2 | psql dbname\"\nor\n./pg\\_dump -C dbname | ssh -C remoteuser@remotehost \"psql dbname\"\n```\n\nbut this solution also requires to get a session in both ends.\n\n\n**Postgres cluster migration local server to remote server:** \n\n1.Taking backup from local server\n\n\n\n```\n$ ./pg\\_dumpall -U postgres -W -f /localserver/all.sql\n```\n\n2. Download the backup by using WINSCP else some thirdparty tools \n\n3. Upload the file to destination server means remote server \n\n4. Restore it by using below command \n\n\n\n```\n$ ./pg\\_restore -U postgres -d postgres </remoteserver/all.sql\n```\n\n",
"name": "",
"is_accepted": false
}
] |
|
5ebbc7d7a6ced651c240eefcc89aee13 | how to use these intermediate certificates in establishing ssl connection with postgresql | Some body asked intermediate SSL certificate | tutorialdba.com | 2021.43 | [
{
"text": "\nTo create a simple self-signed certificate for the server, valid for 365 days, use the following OpenSSL command, replacing `dbhost.yourdomain.com` with the server's host name:\n\n\n\n```\nopenssl req -new -x509 -days 365 -nodes -text -out server.crt \\\n -keyout server.key -subj \"/CN=dbhost.yourdomain.com\"\n```\n\nThen do:\n\n\n\n```\nchmod og-rwx server.key\n```\n\nbecause the server will reject the file if its permissions are more liberal than this. For more details on how to create your server private key and certificate, refer to the OpenSSLdocumentation.\n\n\nWhile a self-signed certificate can be used for testing, a certificate signed by a certificate authority (CA) (usually an enterprise-wide root CA) should be used in production.\n\n\nTo create a server certificate whose identity can be validated by clients, first create a certificate signing request (CSR) and a public/private key file:\n\n\n\n```\nopenssl req -new -nodes -text -out root.csr \\\n -keyout root.key -subj \"/CN=root.yourdomain.com\"\nchmod og-rwx root.key\n```\n\nThen, sign the request with the key to create a root certificate authority (using the default OpenSSL configuration file location on Linux):\n\n\n\n```\nopenssl x509 -req -in root.csr -text -days 3650 \\\n -extfile /etc/ssl/openssl.cnf -extensions v3\\_ca \\\n -signkey root.key -out root.crt\n```\n\nFinally, create a server certificate signed by the new root certificate authority:\n\n\n\n```\nopenssl req -new -nodes -text -out server.csr \\\n -keyout server.key -subj \"/CN=dbhost.yourdomain.com\"\nchmod og-rwx server.key\n\nopenssl x509 -req -in server.csr -text -days 365 \\\n -CA root.crt -CAkey root.key -CAcreateserial \\\n -out server.crt\n```\n\n`server.crt` and `server.key` should be stored on the server, and `root.crt` should be stored on the client so the client can verify that the server's leaf certificate was signed by its trusted root certificate. `root.key` should be stored offline for use in creating future certificates.\n\n\nIt is also possible to create a chain of trust that includes intermediate certificates:\n\n\n\n```\n# root\nopenssl req -new -nodes -text -out root.csr \\\n -keyout root.key -subj \"/CN=root.yourdomain.com\"\nchmod og-rwx root.key\nopenssl x509 -req -in root.csr -text -days 3650 \\\n -extfile /etc/ssl/openssl.cnf -extensions v3\\_ca \\\n -signkey root.key -out root.crt\n\n# intermediate\nopenssl req -new -nodes -text -out intermediate.csr \\\n -keyout intermediate.key -subj \"/CN=intermediate.yourdomain.com\"\nchmod og-rwx intermediate.key\nopenssl x509 -req -in intermediate.csr -text -days 1825 \\\n -extfile /etc/ssl/openssl.cnf -extensions v3\\_ca \\\n -CA root.crt -CAkey root.key -CAcreateserial \\\n -out intermediate.crt\n\n# leaf\nopenssl req -new -nodes -text -out server.csr \\\n -keyout server.key -subj \"/CN=dbhost.yourdomain.com\"\nchmod og-rwx server.key\nopenssl x509 -req -in server.csr -text -days 365 \\\n -CA intermediate.crt -CAkey intermediate.key -CAcreateserial \\\n -out server.crt\n```\n\n`server.crt` and `intermediate.crt` should be concatenated into a certificate file bundle and stored on the server. `server.key` should also be stored on the server. `root.crt` should be stored on the client so the client can verify that the server's leaf certificate was signed by a chain of certificates linked to its trusted root certificate. `root.key` and `intermediate.key` should be stored offline for use in creating future certificates.\n\n\n",
"name": "",
"is_accepted": false
}
] |
5624bf127acd1cbf6dbf111aa35b5c33 | What is postgresql json data types & is there any Nosql concept in postgresql ?
How to use Non Structure Query language in Postgresql Database | What is json data type in Postgresql | tutorialdba.com | 2021.04 | [
{
"text": "\nIn this tutorial, i will explain you how to work with PostgreSQL JSON data type. \n\n**what is JSON ?**\n\n\n* It is one of the data type in postgres.\n* Json + PostgreSQL =NoSQL\n* JSON STANDS FOR JavaScript Object Notation\n* JSON data types stored value is valid according to the JSON rules.\n* JSON data types are for storing JSON data as multi-level, dynamically structured object graphs.\n* serialised object is stored in a text column. The json type takes care of deserialising it back to object graph while reading values from that column.\n* The main usage of JSON is to transport data between a server and web application. Unlike other formats, JSON is human-readable text.\n* PostgreSQL supports JSON data type since version 9.2.\n* It provides many functions and operators for manipulating JSON data.\n\n\n**There are two JSON data types:** \n\n1.json \n\n2.jsonb\n\n\n* The json data type stores an exact copy of the input text.\n* jsonb data is stored in a decomposed binary format\n* jsonb Insertion makes it slightly slower to input due to added conversion overhead.\n* jsonb also supports indexing\n* JSONB does not keep duplicate object keys. If duplicate keys are specified in the input, only the last value is kept.\n\n\n**PRACTICAL 1**. CREATING SIMPLE JSON TABLE: \n\n \n\n\n\n```\npostgres=# CREATE TABLE SALES (\n ID INT NOT NULL PRIMARY KEY,\n SALES\\_INFO json NOT NULL\n);\n```\n\n**From above Sales table consists of two columns:**\n\n\n* The id column is the primary key column that identifies the sales id.\n* The sales\\_info column stores the data in the form of JSON data types.\n\n\n--Describe the sales table using \\d \n\n \n\n\n\n```\npostgres=# \\d sales\n Table \"public.sales\"\n Column | Type | Modifiers \n------------+---------+-----------\n id | integer | not null\n sales\\_info | json | not null\nIndexes:\n \"sales\\_pkey\" PRIMARY KEY, btree (id) \n```\n\n**PRACTICAL 2**. INSERTING JSON DATA ON SALES TABLE: \n\n \n\n\n\n```\nINSERT INTO SALES VALUES\n (1,'{ \"customer\": \"NIJAM\", \"PRODUCTS\": {\"product\\_name\": \"choclate\",\"total\\_item\": 6}}'\n );\n\nINSERT INTO SALES VALUES\n (2,'{ \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 5}}'\n );\n\nINSERT INTO SALES VALUES\n (3,'{ \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 1}}'\n ); \n```\n\n--List down the sales table \n\n \n\n\n\n```\npostgres=# select * from sales;\n id | sales\\_info \n----+----------------------------------------------------------------------------------\n 1 | { \"customer\": \"NIJAM\", \"PRODUCTS\": {\"product\\_name\": \"choclate\",\"total\\_item\": 6}}\n 2 | { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 5}}\n 3 | { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 1}}\n(3 rows) \n```\n\n--list down the json column only \n\n \n\n\n\n```\npostgres=# select sales\\_info from sales;\n sales\\_info \n----------------------------------------------------------------------------------\n { \"customer\": \"NIJAM\", \"PRODUCTS\": {\"product\\_name\": \"choclate\",\"total\\_item\": 6}}\n { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 5}}\n { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 1}}\n(3 rows) \n```\n\n--List down the id column only for understanding purposes. \n\n \n\n\n\n```\npostgres=# select id from sales;\n id \n----\n 1\n 2\n 3\n(3 rows) \n```\n\n**Deleting json objects:** \n\n \n\n\n\n```\npostgres=# select * from sales;\n id | sales\\_info \n----+-------------------------------------------------------------------------------\n 2 | { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 5}}\n 3 | { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 1}}\n 4 | { \"customer\": \"junaith\", \"PRODUCTS\": {\"product\\_name\": \"pen\",\"total\\_item\": 8}}\n 7 | { \"customer\": \"daniel\", \"PRODUCTS\": {\"product\\_name\": \"car\",\"total\\_item\": 8}}\n 8 | { \"customer\": \"daniel\", \"PRODUCTS\": {\"product\\_name\": \"car\",\"total\\_item\": 8}}\n(5 rows)\n\npostgres=# delete from sales where sales\\_info ->'PRODUCTS'->>'total\\_item'='8';\nDELETE 3\npostgres=# select * from sales; \n id | sales\\_info \n----+-------------------------------------------------------------------------------\n 2 | { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 5}}\n 3 | { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 1}}\n(2 rows) \n```\n\n \n\n\n**PRACTICAL 3**.HOW TO QUERYING & FILTERING JSON DATA: \n\nthe two operators -> and ->> to help you query JSON data.\n\n\n* -> will return the attribute as a JSON object key(original JSON type).\n* ->> will return the property as integer or text (the parsed form of the attribute).\n\n\n--See the below example first two query did'nt specify column name that is why it showing ?column? after that i specified the column name as customer\\_name \n\n \n\n\n\n```\npostgres=# select sales\\_info -> 'customer' from sales;\n ?column? \n----------\n \"NIJAM\"\n \"ABU\"\n \"UMAR\"\n(3 rows)\n\npostgres=# select sales\\_info ->> 'customer' from sales;\n ?column? \n----------\n NIJAM\n ABU\n UMAR\n(3 rows)\n\npostgres=# select sales\\_info ->> 'customer' as customer\\_name from sales;\n customer\\_name \n---------------\n NIJAM\n ABU\n UMAR\n(3 rows)\n\npostgres=# select sales\\_info -> 'PRODUCTS' from sales; \n ?column? \n----------------------------------------------\n {\"product\\_name\": \"choclate\",\"total\\_item\": 6}\n {\"product\\_name\": \"badam\",\"total\\_item\": 5}\n {\"product\\_name\": \"mobile\",\"total\\_item\": 1} \n```\n\n* Using -> operator returns a JSON object, you can chain it with the operator ->> to retrieve a specific node.\n* JSON IS CASESENSITIVE DEFAULTY, from below example first i try to retrieve the data using \"products\"(lowercase) that is why it showed empty value after that i chaneged \"PRODUCTS\"(UPPER CASE) then it showing values.\n\n\n\n```\npostgres=# select sales\\_info -> 'products' ->>'product\\_name' from sales;\n ?column? \n----------\n \n \n \n(3 rows)\n\n\npostgres=# select sales\\_info -> 'PRODUCTS' ->'product\\_name' from sales;\n ?column? \n------------\n \"choclate\"\n \"badam\"\n \"mobile\"\n(3 rows)\n\npostgres=# select sales\\_info -> 'PRODUCTS' ->>'product\\_name' from sales;\n ?column? \n----------\n choclate\n badam\n mobile\n(3 rows \n```\n\nFROM above example First sales\\_info -> 'PRODUCTS' returns as JSON objects. And then sales\\_info -> 'PRODUCTS' ->>'product\\_name' returns all products as text. \n\n \n\n**PRACTICAL 4**.HOW TO USE WHERE CLAUSE ON JSON DATA: \n\n--Let us take the sales table for using WHERE CLAUSE \n\n \n\n\n\n```\npostgres=# select * from sales;\n id | sales\\_info \n----+----------------------------------------------------------------------------------\n 1 | { \"customer\": \"NIJAM\", \"PRODUCTS\": {\"product\\_name\": \"choclate\",\"total\\_item\": 6}}\n 2 | { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 5}}\n 3 | { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 1}}\n(3 rows) \n```\n\n--To find out what are the products bought customer UMAR I use the following query \n\n \n\n\n\n```\npostgres=# SELECT sales\\_info ->>'customer' as customer\\_name,sales\\_info ->>'PRODUCTS' ->>'product\\_name' \nas name\\_of\\_product from sales where sales\\_info ->>'customer'='UMAR';\nERROR: operator does not exist: text ->> unknown\nLINE 1: ...stomer' as customer\\_name,sales\\_info ->>'PRODUCTS' ->>'produc...\n ^\nHINT: No operator matches the given name and argument type(s). You might need to add explicit type casts. \n```\n\n**SOLUTION:**\n\n\n* FIRST TIME WE SPECIFIED sales\\_info ->>'PRODUCTS' ->>'product\\_name' SO WE NEED TO GIVE sales\\_info ->'PRODUCTS' ->>'product\\_name'\n* ```\npostgres=# SELECT sales\\_info ->>'customer' as customer\\_name,sales\\_info ->'PRODUCTS' ->>'product\\_name' \nas name\\_of\\_product from sales where sales\\_info ->>'customer'='UMAR';\n customer\\_name | name\\_of\\_product \n---------------+-----------------\n UMAR | mobile\n(1 row) \n```\n\n\n* Defaulty FROM above example First sales\\_info -> 'PRODUCTS' returns as JSON objects. And then 'PRODUCTS' ->>'product\\_name' returns all products as text.\n* when you call json nested data first you call like ->(json object key format)then Finally you need to call ->>(text format or json object key format).\n* if you specify firstly json field as text(->>) format when calling nested node ,after that if you specify -> or ->> values json will not know first text format(->>) value that is why it throw error.\n* JSON displayed text format but actually json work as json object key(->) format .\n* ```\npostgres=# SELECT sales\\_info ->>'customer' as customer\\_name,sales\\_info ->'PRODUCTS' ->'product\\_name' \nas name\\_of\\_product from sales where sales\\_info ->>'customer'='UMAR';\n customer\\_name | name\\_of\\_product \n---------------+-----------------\n UMAR | \"mobile\"\n(1 row) \n```\n\n\n* HERE i specified first json object(->) format finnaly i called json object format (->) this is not a problem.\n* other wise if you specify firstly as json text format (->>) finally if you give json object format (->) or json text format (->>) what ever it is json will not know fist values surely it will throw error.\n\n\n \n\n\n**PRACTICAL 5**.HOW TO USE FUNCTION ON JSON DATA:\n\n\n \n\njson\\_each() function allows us to expand the outermost JSON object into a set of key-value pairs. \n\n \n\n\n\n```\npostgres=# select sales\\_info from sales;\n sales\\_info \n----------------------------------------------------------------------------------\n { \"customer\": \"NIJAM\", \"PRODUCTS\": {\"product\\_name\": \"choclate\",\"total\\_item\": 6}}\n { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 5}}\n { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 1}}\n(3 rows) \n```\n\n--To get a set of keys in the outermost JSON object use function json\\_object\\_keys function \n\n \n\n\n\n```\npostgres=# select json\\_each (sales\\_info) from sales;\n json\\_each \n-----------------------------------------------------------------\n (customer,\"\"\"NIJAM\"\"\")\n (PRODUCTS,\"{\"\"product\\_name\"\": \"\"choclate\"\",\"\"total\\_item\"\": 6}\")\n (customer,\"\"\"ABU\"\"\")\n (PRODUCTS,\"{\"\"product\\_name\"\": \"\"badam\"\",\"\"total\\_item\"\": 5}\")\n (customer,\"\"\"UMAR\"\"\")\n (PRODUCTS,\"{\"\"product\\_name\"\": \"\"mobile\"\",\"\"total\\_item\"\": 1}\")\n(6 rows) \n```\n\n--If you want calculate array size of json function \n\n \n\n\n\n```\nselect json\\_array\\_length('[1,2,3,4,5,6,7,8]'); \n```\n\n**PRACTICAL 5**.HOW TO CREATE ARRAY TABLE ON JSON DATA**:** \n\nHere we are creating array table using json data type and and also explained how to retrieve the array data from json table and how to understand the array data. \n\n \n\n\n\n```\npostgres=# create table TAB\\_ARRAY (id INT,BOOKS json);\nCREATE TABLE \n```\n\n--Let us inserting array values \n\n \n\n\n\n```\ninsert into tab\\_array values (1, '{\n \"book\\_name\": \"story\",\n \"book\\_id\": [\"111\", \"232\", \"353\", \"484\"] }' \n );\n\ninsert into tab\\_array values (2, '{\n \"book\\_name\": \"the king\",\n \"book\\_id\": [\"1231\", \"78\", \"7\", \"9\"] }' \n ); \n```\n\n \n\n\n--List down the tab\\_array table \n\n \n\n\n\n```\npostgres=# select * from tab\\_array;\n id | books \n----+---------------------------------------------\n 1 | { +\n | \"book\\_name\": \"story\", +\n | \"book\\_id\": [\"111\", \"232\", \"353\", \"484\"] }\n 2 | { +\n | \"book\\_name\": \"the king\", +\n | \"book\\_id\": [\"1231\", \"78\", \"7\", \"9\"] }\n(2 rows) \n```\n\n--filter the json data \n\n \n\n\n\n```\npostgres=# select id, books->'book\\_id'->>2 from tab\\_array;\n id | ?column? \n----+----------\n 1 | 353\n 2 | 7\n(2 rows)\n\npostgres=# select id, books->'book\\_id'->>0 from tab\\_array where id=1;\n id | ?column? \n----+----------\n 1 | 111\n(1 row) \n```\n\n**Note:**Array start from 0 ...N you will undestand json array below example\n\n\n**[\"111\", \"232\", \"353\", \"484\"]** ------>array values\n\n\n**0 1 2 3** ------> array start from 0...3\n\n\n**from above notes**\n\n\nif u give where id=1 and books->'book\\_id'->>1 means it return 232\n\n\nif u give where id=1 and books->'book\\_id'->>2 means it return 353\n\n\nif u give where id=1 and books->'book\\_id'->>3 means it return 484\n\n\nif u give where id=1 and books->'book\\_id'->>0 means it return 111\n\n\n**PRACTICAL 6.**HOW TO CREATE INDEX ON JSON TABLE:\n\n\n* index is fast fetching data without going full table scan.\n\n\nHere i will explain how to create index on json data type table and how to work index on json data type.\n\n\n--check the sales table for already having any index or not. \n\n \n\n\n\n```\npostgres=# \\d sales\n Table \"public.sales\"\n Column | Type | Modifiers \n------------+---------+-----------\n id | integer | not null\n sales\\_info | json | not null\nIndexes:\n \"sales\\_pkey\" PRIMARY KEY, btree (id)\n\n\npostgres=# \\di sales\nNo matching relations found. \n```\n\n--already we have sales table now let us go to create indicies on any (even nested) JSON field: \n\n \n\n\n\n```\ncreate unique index ind\\_name\non sales ((sales\\_info ->'PRODUCTS'->>'total\\_item'));\n```\n\n--Now check the table index is properly created or not using \\di,\\dt,pg\\_indexes. \n\n \n\n\n\n```\npostgres=# \\di ind\\_name\n List of relations\n Schema | Name | Type | Owner | Table \n--------+----------+-------+----------+-------\n public | ind\\_name | index | postgres | sales\n(1 row)\n\n\n\nDeleting json objectspostgres=# \\d sales\n Table \"public.sales\"\n Column | Type | Modifiers \n------------+---------+-----------\n id | integer | not null\n sales\\_info | json | not null\nIndexes:\n \"sales\\_pkey\" PRIMARY KEY, btree (id)\n \"ind\\_name\" UNIQUE, btree (((sales\\_info -> 'PRODUCTS'::text) ->> 'total\\_item'::text))\n\n\n\npostgres=# select tablename,indexname,indexdef from pg\\_indexes where tablename='sales';\n tablename | indexname | indexdef \n \n-----------+------------+-----------------------------------------------------------------------------------\n------------------------------\n sales | sales\\_pkey | CREATE UNIQUE INDEX sales\\_pkey ON sales USING btree (id)\n sales | ind\\_name | CREATE UNIQUE INDEX ind\\_name ON sales USING btree ((((sales\\_info -> 'PRODUCTS'::te\nxt) ->> 'total\\_item'::text)))\n(2 rows)\n```\n\n From below example index is properly working becouse we already created unique index on on json column of \"total\\_item\" unique index will not accept duplicate value if you try to insert duplicate values it will throw errors,i hope you understood it from below example. \n\n \n\n\n\n```\npostgres=# select * from sales;\n id | sales\\_info \n----+----------------------------------------------------------------------------------\n 2 | { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 5}}\n 3 | { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 1}}\n 5 | { \"customer\": \"NIJAM\", \"PRODUCTS\": {\"product\\_name\": \"choclate\",\"total\\_item\": 9}}\n 1 | { \"customer\": \"ABU\", \"PRODUCTS\": {\"product\\_name\": \"badam\",\"total\\_item\": 6}}\n 4 | { \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 8}}\n(5 rows)\n\n\npostgres=# INSERT INTO SALES VALUES\n (9,'{ \"customer\": \"UMAR\", \"PRODUCTS\": {\"product\\_name\": \"mobile\",\"total\\_item\": 8}}'\n );\nERROR: duplicate key value violates unique constraint \"ind\\_name\"\nDETAIL: Key (((sales\\_info -> 'PRODUCTS'::text) ->> 'total\\_item'::text))=(8) already exists. \n```\n\n**another example for json index is properly working or not**\n\n\nHERE LET US consider sales table having above 20000 json records for making practical json index , This way we can begin to see some performance implications when dealing with JSON data in Postgres, as well as how to solve them. \n\n \n\n\n\n```\nSELECT count(*) FROM sales WHERE sales\\_info ->'PRODUCTS'->>'total\\_item'= '1';\ncount\n-------\n4937 \n(1 row) \n```\n\n--taking explain plan for without index \n\n \n\n\n\n```\npostgres=# explain analyze SELECT sales\\_info ->>'customer' as customer\\_name from sales \nwhere sales\\_info ->'PRODUCTS'->>'total\\_item'= '1';\nAggregate (cost=335.12..335.13 rows=1 width=0) (actual time=4.421..4.421 rows=1 loops=1) -> Seq Scan on cards (cost=0.00..335.00 rows=50 width=0) (actual time=0.016..3.961 rows=4938 loops=1) \n Filter: (((sales\\_info -> 'PRODUCTS'::text) ->> 'total\\_item'::text) = '1'::text) \n Rows Removed by Filter: 5062 \nTotal runtime: 4.475 ms$cd /db\\_data/data/pg\\_log\n$tail -f postgresql-Tue.log \n```\n\nNow, that wasn’t that slow of a query at 4.5ms, but let’s see if we can improve it. \n\n \n\n\n\n```\nCREATE INDEX ind\\_name1 ON sales ((sales\\_info ->'PRODUCTS'->>'total\\_item')); \n```\n\nIf we run the same query which now has an index, we end up cutting the time in half. \n\n \n\n\n\n```\n \n```\n\n",
"name": "",
"is_accepted": true
}
] |
882ec9558ed6812a77c1e8ed95c23dbf | If I had forgot the Postgres password
How can we find the Postgres password | How can we find the Postgres password ? | tutorialdba.com | 2020.50 | [
{
"text": "\nYou can see your password Following tw option\n\n\n1. **PG\\_SHADOW** **view**\n2. **PG\\_AUTHID View**\n\n\n1.**PG\\_SHADOW**:\n\n\nPG\\_SHADOW is views its contains information about rolename and user password,user password validity,user connection limit and Role automatically inherits privileges of roles it is a member of,detailed information about user and privilege management.\n\n\n \n\n\n\n| **Name** | **Type** | **Description** |\n| --- | --- | --- |\n| usename | name | User name |\n| usesysid | oid | ID of this user |\n| usecreatedb | bool | User can create databases |\n| usesuper | bool | User is a superuser |\n| usecatupd | bool | User can update system catalogs. (Even a superuser cannot do this unless this column is true.) |\n| passwd | text | Password (possibly encrypted); null if none. See pg\\_authid for details of how encrypted passwords are stored. |\n| valuntil | abstime | Password expiry time (only used for password authentication) |\n| useconfig | text[] | Session defaults for run-time configuration variables |\n\n\n \n**Examples**\n**--create the unencrypted user**\n \n\n```\npostgres=# create user u2 WITH UNENCRYPTED PASSWORD 'u2';\nCREATE ROLE\n```\n\n**--create the user with password validation time**\n \n\n```\npostgres=# CREATE USER u3 WITH PASSWORD 'u3' VALID UNTIL '2017-06-06';\nCREATE ROLE\n```\n\n**--Describe the PG\\_SHADOW view**\n\n\n\n```\npostgres=# \\d PG\\_SHADOW\n View \"pg\\_catalog.pg\\_shadow\"\n Column | Type | Modifiers \n-------------+---------+-----------\n usename | name | \n usesysid | oid | \n usecreatedb | boolean | \n usesuper | boolean | \n usecatupd | boolean | \n userepl | boolean | \n passwd | text | \n valuntil | abstime | \n useconfig | text[] | \n```\n\n\n**--list the user and show the users password and password validatation time**\n\n\n```\npostgres=# select usename,usesysid,passwd,valuntil,useconfig from PG\\_SHADOW;\n usename | usesysid | passwd | valuntil | useconfig \n----------+----------+-------------------------------------+------------------------+-----------\n postgres | 10 | md505ea766c2bc9e19f34b66114ace97598 | | \n rep | 24576 | md5df2c887bcb2c49b903aa33bdbc5c2984 | | \n u1 | 24583 | | | \n u2 | 24584 | u2 | | \n u3 | 24585 | md5dad1ef51b879799793dc38d714b97063 | 2017-06-06 00:00:00-04 | \n nijam | 24586 | | | \n(6 rows)\n```\n\n2**.PostgreSQL PG\\_AUTHID View**\n\n\n\n PG\\_AUTHID is views its contains information about rolename and user password,user password validity,user connection limit and Role automatically inherits privileges of roles it is a member of,detailed information about user and privilege management.\n \n\n\n\n| **Name** | **Type** | **Description** |\n| --- | --- | --- |\n| rolname | name | Role name |\n| rolsuper | bool | Role has superuser privileges |\n| rolinherit | bool | Role automatically inherits privileges of roles it is a member of |\n| rolcreaterole | bool | Role can create more roles |\n| rolcreatedb | bool | Role can create databases |\n| rolcatupdate | bool | Role can update system catalogs directly. (Even a superuser cannot do this unless this column is true) |\n| rolcanlogin | bool | Role can log in. That is, this role can be given as the initial session authorization identifier |\n| rolreplication | bool | Role is a replication role. That is, this role can initiate streaming replication and set/unset the system backup mode usingpg\\_start\\_backup and pg\\_stop\\_backup |\n| rolconnlimit | int4 | For roles that can log in, this sets maximum number of concurrent connections this role can make. -1 means no limit. |\n| rolpassword | text | Password (possibly encrypted); null if none. If the password is encrypted, this column will begin with the string md5 followed by a 32-character hexadecimal MD5 hash. The MD5 hash will be of the user's password concatenated to their user name. For example, if user joe has password xyzzy, PostgreSQL will store the md5 hash of xyzzyjoe. A password that does not follow that format is assumed to be unencrypted. |\n| rolvaliduntil | timestamptz | Password expiry time (only used for password authentication); null if no expiration |\n\n\n \n**Examples**\n**--create the unencrypted user**\n \n\n```\npostgres=# create user u2 WITH UNENCRYPTED PASSWORD 'u2';\nCREATE ROLE\n```\n\n**--create the user with password validation time**\n \n\n```\npostgres=# CREATE USER u3 WITH PASSWORD 'u3' VALID UNTIL '2017-06-06';\nCREATE ROLE\n```\n\n**--Describe the pg\\_authid view**\n\n\n\n```\npostgres=# \\d pg\\_authid\n Table \"pg\\_catalog.pg\\_authid\"\n Column | Type | Modifiers \n----------------+--------------------------+-----------\n rolname | name | not null\n rolsuper | boolean | not null\n rolinherit | boolean | not null\n rolcreaterole | boolean | not null\n rolcreatedb | boolean | not null\n rolcatupdate | boolean | not null\n rolcanlogin | boolean | not null\n rolreplication | boolean | not null\n rolconnlimit | integer | not null\n rolpassword | text | \n rolvaliduntil | timestamp with time zone | \nIndexes:\n \"pg\\_authid\\_oid\\_index\" UNIQUE, btree (oid), tablespace \"pg\\_global\"\n \"pg\\_authid\\_rolname\\_index\" UNIQUE, btree (rolname), tablespace \"pg\\_global\"\nTablespace: \"pg\\_global\" \n```\n\n\n**--list the user and show the users password and password validatation time**\n\n\n```\npostgres=# select rolname,rolpassword,rolvaliduntil from pg\\_authid; \n rolname | rolpassword | rolvaliduntil \n----------+-------------------------------------+------------------------\n postgres | md505ea766c2bc9e19f34b66114ace97598 | \n rep | md5df2c887bcb2c49b903aa33bdbc5c2984 | \n u1 | | \n u2 | u2 | \n u3 | md5dad1ef51b879799793dc38d714b97063 | 2017-06-06 00:00:00-04\n(5 rows)\n```\n\n\n\n\n\n",
"name": "",
"is_accepted": false
}
] |
67ce135a24f0c6ff1fd8da2f4e9e0c5a | How do i see the user password in Postgresql database ? | tutorialdba.com | 2020.50 | [
{
"text": "You can see Postgresql password at pg\\_shadow and pg\\_authid views, you cannot see the actual password it's only encrypted password,if you want to show unencrypted password you have to mention unencryption keyword while user creation.",
"name": "",
"is_accepted": true
}
] |
|
79f5ed019849e6d6e1614edfee06bb3d | How to enable openSSL on postgresSQL server ? | tutorialdba.com | 2021.39 | [
{
"text": "\nOne of the most demanded challenges in the modern world of Internet of Things is to gain the highest level of security. That’s why today we are going to consider the process of establishing secure SSL connection to your PostgreSQL container, hosted at Jelastic Cloud.\n\n\n\n\n\nWhen striving to keep information in your PostgreSQL database safe, the first thing you need to do is to encrypt all connections to it for protecting authentication credentials (usernames / passwords) and stored data from interception.\n\n\nBelow, we’ll explore the appropriate database server adjustment, required for SSL-enabling, and certificates generation for it. Then, we’ll create and add certs for client machine and, lastly, will establish secure connection to our server via *pgAdmin* tool. So, let’s go on!\n\n\nPostgreSQL Server Configuration\n-------------------------------\n\n\nObviously, for this tutorial we’ll use an environment with PostgreSQL database inside — you can easily [create](https://docs.jelastic.com/setting-up-environment) such if you haven’t done this yet.\n\n\n**1.** To start with, connect to your database server via [Jelastic SSH Gate](https://docs.jelastic.com/ssh-overview).\n\n\n**2.** Now, in order to make it work with SSL, you need to add the following three files to the **/var/lib/pgsql/data** server directory:\n\n\n* *server.key* – private key.\n* *server.crt* – server certificate.\n* *root.crt* – trusted root certificate.\n\n\nWithin this tutorial, we’ll briefly consider how you can generate them by yourselves.\n\n\n**Tips:**\n\n\n* We won’t explain commands parameters in details here, but if you’d like to know more, just refer to the [Self-Signed Custom SSL](https://docs.jelastic.com/self-signed-ssl#generate) page in our documentation or check the official [OpenSSL](https://www.openssl.org/docs/manmaster/apps/openssl.html) site for the full list of available actions\n* You can also use [custom SSL](https://docs.jelastic.com/custom-ssl) certificate similarly to the described below (follow the *Generate a Custom SSL Certificate* section of the linked guide to get such). In this latter case, you can skip the generation instruction and jump directly to the *6th* *step* of this instruction\n\n\nSo, navigate to the mentioned folder and proceed with steps below.\n\n\n**3.** First of all, let’s create the first file — private key:\n\n\n* Execute the next commands:\n\n\n\n```\ncd /var/lib/pgsql/data openssl genrsa -des3 -out server.key 1024\n```\n\nDuring the *server.key* generation, you’ll be asked for a *pass phrase* — specify any and confirm it to finish creation.\n\n\n* Now, in order to work with this key further, it’s required remove the pass phrase you’ve added previously. Execute the following command for this:\n\n\n\n```\nopenssl rsa -in server.key -out server.key\n```\n\nRe-enter pass phrase one more time for confirmation.\n\n\n* Set the appropriate permission and ownership rights for your private key file with the next commands:\n\n\n\n```\nchmod 400 server.key chown postgres.postgres server.key\n```\n\n**4.** Now, you need to create *server certificate* based on your *server.key* file, e.g.:\n\n\n\n```\nopenssl req -new -key server.key -days 3650 -out server.crt -x509 -subj '/C=US/ST=California/L=PaloAlto/O=Jelastic/CN=mysite.com/ema [email protected]'\n```\n\n\n\n\n**Note:** It’s required to set your personal data for *subj* parameter if the certificate is intended to be used in production:\n\n\n \n\nYou can also just skip the *-subj* parameter within the command and pass all these arguments in the interactive mode within the automatically opened inquiry.\n\n\n**5.** Since we are going to sign certs by ourselves, the generated *server certificate* can be used as a trusted *root certificate* as well, so just make its copy with the appropriate name:\n\n\n\n```\ncp server.crt root.crt\n```\n\nNow, as you have all three certificate files, you can proceed to PostgreSQL database configurations, required for SSL activation and usage.\n\n\n**6.** Open the ***pg\\_hba.conf*** file, located in the same folder, for editing with any preferable terminal editor (*vim* for example) or directly via the dashboard. \n\n\nReplace its default content with the following lines:\n\n\n\n```\n# TYPE DATABASE USER CIDR-ADDRESS METHOD \n```\n\n\n```\n# \"local\" is for Unix domain socket connections only local all all trust \n```\n\n\n```\n# IPv4 local connections: host all all 127.0.0.1/32 trust \n```\n\n\n```\n# IPv4 remote connections for authenticated users hostssl all webadmin 0.0.0.0/0 md5 clientcert=1\n```\n\n\n\n\n**Tip:** In case you are going to work with the database not as default *webadmin* user, change the appropriate value within the last line of the file to the required name. Note, that in this case, you’ll need to use the same user name for all the further commands (we’ll denote where this is required)\n\n\nSave the updated file.\n\n\n**7.** To finish configurations, you need to apply some more changes to the ***postgresql.conf*** file. \n\n\nNavigate to its *Security and Authentication* section (approximately at the *80th* line) and activate **SSL** usage itself, through uncommenting the same-named setting and changing its value to “*on*”. Also, add the new **ssl\\_ca\\_file** parameter below:\n\n\n\n```\nssl = on ssl\\_ca\\_file = 'root.crt'\n```\n\nDon’t forget to save these changes.\n\n\n**8.** Lastly, restart your PostgreSQL container in order to apply new settings:\n\n\n\n```\nsudo service postgresql restart\n```\n\n\n\n\nClient Certificates\n-------------------\n\n\nNow, let’s create one more set of SSL certificate files for client instance, in order to support secure connection on both sides.\n\n\n**1.** Return to the terminal window with SSH connection to your PostgreSQL server you’ve operated through during server setup (or reconnect to it) – you’ll need your server certificates for further actions. \n\n\nOnce inside, generate a private key for client (also without a *pass phrase*, just as it was done in the previous section), for example within the **tmp** directory:\n\n\n\n```\nopenssl genrsa -des3 -out /tmp/postgresql.key 1024 openssl rsa -in /tmp/postgresql.key -out /tmp/postgresql.key\n```\n\n\n\n\n**2.** Next, create SSL certificate for your PostgreSQL database user (*webadmin* by default) and sign it with our trusted ***root.crt*** file on server.\n\n\n\n```\nopenssl req -new -key /tmp/postgresql.key -out /tmp/postgresql.csr -subj '/C=US/ST=California/L=PaloAlto/O=Jelastic/CN=webadmin' openssl x509 -req -in /tmp/postgresql.csr -CA root.crt -CAkey server.key -out /tmp/postgresql.crt -CAcreateserial\n```\n\nNote: \n\n\n* while commonly data for *subj* parameter can be changed to your personal data here, its ***Common Name (/CN=)*** must be equal to database user name you’ve set during the first certificate generation in server configuration file (*webadmin* in our case)\n* *root.crt* and *server.key* files should be located in the same folder the 2nd command is executed from; otherwise, the full path to them should be specified\n\n\n\n\n\n**3.** After the files — *postgresql.key*, *postgresql.crt*, *root.crt* — are ready, you need to move them to to the **.postgresql** folder at your client machine (for that, you can use [FTP add-on](https://docs.jelastic.com/ftp-ftps-support) or just copy and paste files content). \n\n\n**Tip:** If such directory does not exist yet, create it with *mkdir ~/.postgresql*or similar command according to your OS distribution.\n\n\n\n\n\nAlso, if needed, you can set the key read permission for owner only with the *chmod 0400 ~/.postgresql/postgresql.key* command to achieve more security.\n\n\n**Tip:** Don’t forget to remove keys from the ***tmp*** directory on your DB server afterwards.\n\n\nEstablish Connection via PgAdmin\n--------------------------------\n\n\nEventually, after server and client configurations are done, you are ready to establish the connection. In our case, we’ll use the **[pgAdmin 3](https://www.pgadmin.org/index.php)** tool as an example, so get this application (or any other preferred one) installed beforehand.\n\n\n**1.** In order to connect to the DB server via SSL, you need either [Public IP](https://docs.jelastic.com/public-ipv4) or [endpoint](https://docs.jelastic.com/endpoints) being attached to your PostgreSQL database container. \n\n\nWe’ll consider the latter case — access environment **Settings**, switch to the ***Endpoints*** section and **Add** new endpoint with the same-named button at the top pane.\n\n\n**2.** Now, when you have an access point, run your **pgAdmin 3** client and select the **New Server Registration** option.\n\n\nIn the ***Properties*** tab of the opened window, specify the following data:\n\n\n* **Name:** Any desired connection name (e.g. *ssl-to-pgsql*).\n* **Host:** Access point you’ve added in the first step (Public IP address or endpoint *Access URL* without port number).\n* **Port:** Use the default *5432* port number for External IP or endpoint’s *Public port*(denoted in the same-named section of the appropriate column).\n* **Username:** Database user you’ve set the SSL certificate and configurations for (i.e. *webadmin* by default).\n* **Password:** The corresponding user’s password (sent via email for *webadmin*or the one you’ve set otherwise).\n\n\nThe rest of the fields can be left unchanged or adjusted according to your requirements.\n\n\n**3.** Next, switch to the ***SSL*** tab and, for the same-named line, select the *require* option from the drop-down list.\n\n\nThat’s all! The required certificates will be loaded automatically during the first connection establishment, so just click **OK** to start managing your database via secure connection.\n\n\nNow you can bind your application to database (use the [Connect to Database](https://docs.jelastic.com/add-database) guide as an example) and enable SSL configurations for your project to encrypt your data while fetching/transferring. And in case you face any issues while configuring, feel free to appeal for our technical experts` assistance at [StackOverflow](http://stackoverflow.com/questions/tagged/jelastic).\n\n\nSo, go ahead and secure your project – just choose a cloud hosting provider within Jelastic Cloud Union and [register for free](https://jelastic.cloud/)! \n\n\n",
"name": "",
"is_accepted": false
}
] |
|
c41e2360c04183d9f5722236cfb133b4 | SSL setup in PostgreSQL | tutorialdba.com | 2021.43 | [
{
"text": "\nPostgreSQL has native support for using SSL connections to encrypt client/server communications for increased security. This requires that OpenSSL is installed on both client and server systems and that support in PostgreSQL is enabled at build time. \n\n \n\nWith SSL support compiled in, the PostgreSQL server can be started with SSL enabled by setting the parameter ssl to on in postgresql.conf. The server will listen for both normal and SSLconnections on the same TCP port, and will negotiate with any connecting client on whether to use SSL. By default, this is at the client's option; \n\n \n\nPostgreSQL reads the system-wide OpenSSL configuration file. By default, this file is named openssl.cnf and is located in the directory reported by openssl version -d. This default can be overridden by setting environment variable OPENSSL\\_CONF to the name of the desired configuration file. \n\n \n \nOpenSSL supports a wide range of ciphers and authentication algorithms, of varying strength. While a list of ciphers can be specified in the OpenSSL configuration file, you can specify ciphers specifically for use by the database server by modifying ssl\\_ciphers in postgresql.conf. \n\n \n\n**Server 1**\n**Step 1**\n\n```\n[root@localhost Desktop]# systemctl stop firewalld.service\n[root@localhost Desktop]# su - postgres\n-bash-4.2$ mkdir -p 9.6/data\n-bash-4.2$ cd ..\n-bash-4.2$ pwd\n/var/lib/pgsql\n-bash-4.2$ initdb -D 9.6/data/\n```\n\n**Step 2**\n\n```\n-bash-4.2$ logout\n[root@localhost Desktop]# mkdir /var/lib/CA\n[root@localhost Desktop]# cd /var/lib/CA/\n[root@localhost CA]# openssl genrsa -out rootCA.key 2048\n\n[root@localhost CA]# openssl req -x509 -new -key rootCA.key -days 1000 -out rootCA.crt\n[root@localhost CA]# mkdir server\n[root@localhost CA]# cd server/\n \n[root@localhost server]# openssl genrsa -out server.key 2048\n[root@localhost server]# openssl req -new -key server.key -out server.csr\n```\n\n \n\n\n**Note**: Common Name (eg, your name or your server's hostname) []:**localhost.lo**\n\n```\n[root@localhost server]# openssl x509 -req -in server.csr -CA ../rootCA.crt -CAkey ../rootCA.key -CAcreateserial -out server.crt -days 5000\n[root@localhost server]# cd ..\n[root@localhost CA]# mkdir client\n[root@localhost CA]# cd client/\n[root@localhost client]# openssl genrsa -out client.key 2048\n[root@localhost client]# openssl req -new -key client.key -out client.csr\n```\n\n**Note :**Common Name (eg, your name or your server's hostname) []:**edb\\_username for another server**\n\n```\n[root@localhost client]# openssl x509 -req -in client.csr -CA ../rootCA.crt -CAkey ../rootCA.key -CAcreateserial -out client.crt -days 5000\nSignature ok\n```\n\n\n```\n[root@localhost client]# su - postgres \nLast login: Mon May 7 21:18:04 IST 2018 on pts/0\n-bash-4.2$ cd 9.6/data/\n-bash-4.2$ cp /var/lib/CA/rootCA.crt .\n-bash-4.2$ cp /var/lib/CA/server/server.crt .\n-bash-4.2$ cp /var/lib/CA/server/server.key .\n-bash-4.2$ chmod 600 server.key \n```\n\n\n```\n-bash-4.2$ vi postgresql.conf \n \nssl = on # (change requires restart)\nssl\\_ciphers = 'HIGH:MEDIUM:+3DES:!aNULL' # allowed SSL ciphers\n # (change requires restart)\nssl\\_prefer\\_server\\_ciphers = on # (change requires restart)\nssl\\_ecdh\\_curve = 'prime256v1' # (change requires restart)\nssl\\_cert\\_file = 'server.crt' # (change requires restart)\nssl\\_key\\_file = 'server.key' # (change requires restart)\nssl\\_ca\\_file = 'rootCA.crt'\n```\n\n\n```\n-bash-4.2$ vi pg\\_hba.conf \n#secure client\nhost testdb anil 192.168.184.170/32 trust \n```\n\n\n```\n-bash-4.2$ pg\\_ctl -D ./ start\n-bash-4.2$ \n```\n\n\n```\n-bash-4.2$ psql -U postgres\npsql.bin (9.6.4)\nType \"help\" for help.\npostgres=# \npostgres=# create role edb with login;\nCREATE ROLE\npostgres=# create database anildb with owner edb;\nCREATE DATABASE\npostgres=# \\q \n```\n\n \n\n\n**Server 2 :**\n\n```\n[root@localhost Desktop]# systemctl stop firewalld.service\n[root@localhost Desktop]# su - edb\n[edb@localhost Desktop]$ mkdir ~/.postgres\n[edb@localhost Desktop]$ scp [email protected]:/var/lib/CA/rootCA.crt ~/.postgres\n[edb@localhost Desktop]$ scp [email protected]:/var/lib/CA/rootCA.crt ~/.postgres/root.crt\n[edb@localhost Desktop]$ scp [email protected]:/var/lib/CA/client/client.crt ~/.postgres/postgresql.crt\n[edb@localhost Desktop]$ scp [email protected]:/var/lib/CA/client/client.key ~/.postgres/postgresql.key\n[edb@localhost Desktop]$ chmod 600 ~/.postgres/postgresql.key\n[edb@localhost Desktop]$ psql -h 192.168.184.159 -U edb anildb\npsql (9.2.7, server 9.6.4)\nWARNING: psql version 9.2, server version 9.6.\n Some psql features might not work.\nSSL connection (cipher: ECDHE-RSA-AES256-SHA, bits: 256)\nType \"help\" for help.\nanildb=>\n```\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\nBought a new Office subscription and wondering how to get started? Well, you’ve come to the right place. Setting up Office on a computer involves three steps i.e. creating a Microsoft account, activating the product key, and installing Office software. Luckily, you can do it all from one place i.e. [**office.com/setup**](https://sites.google.com/view/get-officesetup-online/). Just visit the office setup page and provide the required information. If you already have a Microsoft account linked to your Office, just sign in from it. If not you can use any other Microsoft account too or create one right away. In the next step, you need to enter the product key of your Office subscription. After your product key is verified and activated, you can install the software on your device and use it right away.\n\n\n \n\n \n\n\n",
"name": "",
"is_accepted": false
}
] |
|
f9710356370497b922af5cb6cd2aa6db | How to change ownership all tables in particular schema ? | tutorialdba.com | 2021.21 | [
{
"text": "\nBetter change schema ownership\n\n\n**This is for access permission:**\n\n\n\n```\ngrant usage on schema schema\\_name to user\\_name;\n```\n\n**This is for ownership Changing**:\n\n\n\n```\nalter schema schema\\_name owner to new\\_user;\n```\n\n \n\n\n",
"name": "",
"is_accepted": true
}
] |
|
3eee2353a9f857daf4567bcdbd492e05 |
This error relates to logging into phpMyAdmin, an open source tool used for the administration of MySQL.
Once in awhile, perhaps on a Development server, MySQL won’t be setup with a root password. The aforementioned configuration is generally thought of as against best practices however, if it is what you’re dealing with, then it could also interfere with phpMyAdmin.
Pre-Flight Check
----------------
* These instructions are intended specifically for solving the error: Login without a password is forbidden by configuration (see AllowNoPassword).
* I’ll be working from a Liquid Web Self Managed Ubuntu 15.04 server, and I’ll be logged in as root.
The Error
---------
The error will read **“Login without a password is forbidden by configuration (see AllowNoPassword)”** as shown below.
[![Error Login without a password is forbidden by configuration (see AllowNoPassword) [SOLVED]](https://lwstatic-a.akamaihd.net/kb/wp-content/uploads/2015/07/Error-Login-without-a-password-is-forbidden-by-configuration-see-AllowNoPassword-SOLVED-01.png)](https://lwstatic-a.akamaihd.net/kb/wp-content/uploads/2015/07/Error-Login-without-a-password-is-forbidden-by-configuration-see-AllowNoPassword-SOLVED-01.png)
| Error: Login without a password is forbidden by configuration (see AllowNoPassword) | tutorialdba.com | 2020.45 | [
{
"text": "\nEnabling the ability to manage MySQL via phpMyAdmin (when the root login is passwordless) is as easy as changing one line in a configuration file.\n\n\nWe’ll set the **AllowNoPassword** variable, located in phpMyAdmin’s configuration file, to **TRUE**. On an Ubuntu 15.04 server edit the following file:\n\n\n`vim /etc/phpmyadmin/config.inc.php`\n\n\nFor a refresher on editing files with vim see: [New User Tutorial: Overview of the Vim Text Editor](https://www.liquidweb.com/kb/overview-of-vim-text-editor/)\n\n\nFind the line:\n\n\n`// $cfg['Servers'][$i]['AllowNoPassword'] = TRUE;`\n\n\nUncomment that line; you’ll remove the **//**.\n\n\nThere are two instances of this line in the configuration file… **be SURE to uncomment both of them!**\n\n\nExit and save the file with the command **:wq**.\n\n\nBe Sociable, Share!\n\n\n",
"name": "",
"is_accepted": false
}
] |
67b68784e1598e5769ecd80d52831cc1 | Any shell script to send email alert and restarting automatically if service is down, The services may be mariaDB ,apache...etc | Need script for mail alert if mariaDB services was down | tutorialdba.com | 2021.39 | [
{
"text": "\nThis script can be used to check on mariaDB, apache2, or whatever service you want. This is not meant to be a SOLUTION to services that are crashing, but rather a notification and a temporary restart until you can solve the real issue.\n\n\nThe script will check the status of each service. If the service is stopped, it tries to restart the service. If the service starts, it sends you an email saying the service stopped but was restarted.\n\n\nIf the service does not start for some reason, it sends you an email telling you it was not started.\n\n\nAfter that, it will continue to try and start, but not send any more emails until the service is finally started.\n\n\nNOTE*: This script should be run as your root user, so it would be added to the crontab like so:\n\n\n1. put it into your scripts folder\n2. set your email address\n3. set the services you want to keep an eye on (by default it has MariaDB and apache2..you can add or take away whatever you need)\n4. save your changes\n5. create a cronjob as root (sudo crontab -e) and add something like this, which runs every minute (adjust to your needs):\n\n\n\n```\n#check on services\n*/1 * * * * sh /root/script/dbalert.sh\n```\n\n\n```\n################### DOWN DB server######################\n#!/bin/bash\n#ver. 2\n\n##this script will check whatever services\n##you want to keep an eye on\n##if that service is not running\n##it will (try to) start the service and send\n##an email to you\n\n##set your email address\nEMAIL=\"[email protected]\"\n\n##list your services you want to check\n##you can add as many as you like\nSERVICES=('mysql')\n\n#### DO NOT CHANGE anything BELOW ####\n\n\n for i in \"${SERVICES[@]}\"\n do\n ###IF SERVICE IS NOT RUNNING####\nif ([[ \"$(service $i status)\" =~ \"not running\" ]] || [[ \"$(service $i status)\" =~ \"is stopped\" ]] || [[ $\"$(service $i status)\" =~ \"stop/waiting\" ]])\n\n then\n ##TRY TO RESTART THAT SERVICE###\n service $i start\n\n ##IF RESTART WORKED###\nif ([[ \"$(service $i status)\" =~ \"MariaDB running\" ]] || [[ \"$(service $i status)\" =~ \"is started\" ]] || [[ $\"$(service $i status)\" =~ \"start\" ]])\nthen\n ##SEND AN EMAIL###\n MESSAGE=\"$(tail -15 /var/lib/mysql/publishman.com.err)\"\n SUBJECT=\"MariaDB down But restarted Successfully on $(date) \"\n echo -e \" LOGS : \\n$MESSAGE \" | mail -s \"$SUBJECT\" \"$EMAIL\"\n else\n\n ##IF RESTART DID NOT WORK SEND A DIFFERENT EMAIL###\n MESSAGE=\"$(tail -15 /var/lib/mysql/publishman.com.err)\"\n SUBJECT=\"MariaDB down, Restarted did not work on $(date) \"\n echo -e \" LOGS : \\n$MESSAGE . \\n>>>>> Script tried to restart but it did not work\" | mail -s \"$SUBJECT\" \"$EMAIL\"\n\n fi\n fi\n\ndone\n\n ################### DOWN APACHE server######################\n#!/bin/bash\n#ver. 2\n\n##this script will check whatever services\n##you want to keep an eye on\n##if that service is not running\n##it will (try to) start the service and send\n##an email to you\n\n##set your email address\nEMAILA=\"[email protected]\"\n\n##list your services you want to check\n##you can add as many as you like\nSERVICESA=('httpd')\n\n#### DO NOT CHANGE anything BELOW ####\n\n\n for a in \"${SERVICESA[@]}\"\n do\n ###IF SERVICE IS NOT RUNNING####\nif ([[ \"$(service $a status)\" =~ \"not running\" ]] || [[ \"$(service $a status)\" =~ \"is stopped\" ]] || [[ $\"$(service $a status)\" =~ \"stop/waiting\" ]])\n\n#if [[ \"$(service $a status)\" =~ \"$a is stopped\" ]]\n\n then\n ##TRY TO RESTART THAT SERVICE###\n service $a start\n\n ##IF RESTART WORKED###\n#if [[ \"$(service $a status)\" =~ \"is running\" ]]\nif ([[ \"$(service $a status)\" =~ \"is running\" ]] || [[ \"$(service $a status)\" =~ \"is started\" ]] || [[ $\"$(service $a status)\" =~ \"start\" ]])\n then\n ##SEND AN EMAIL###\n MESSAGEA=\"$(tail -15 /var/log/apache2/error\\_log)\"\n SUBJECTA=\"APACHE SERVER down But restarted successfully on $(date) \"\n echo -e \" LOGS : \\n$MESSAGEA \" | mail -s \"$SUBJECTA\" \"$EMAILA\"\n else\n\n ##IF RESTART DID NOT WORK SEND A DIFFERENT EMAIL###\n MESSAGEA=\"$(tail -15 /var/log/apache2/error\\_log)\"\n SUBJECTA=\"APACHE SERVER down restarted did not work on $(date) \"\n echo -e \" LOGS: \\n$MESSAGEA . \\n>>>>> Script tried to restart but it did not work\" | mail -s \"$SUBJECTA\" \"$EMAILA\"\n\n fi\n fi\ndone\n\n```\n\n \n\n\n",
"name": "",
"is_accepted": false
},
{
"text": "\n[**Travis Scott Jordan 1**](https://www.travisscott-jordan1.com/) \n\n \n\n[**Air Jordans**](https://www.airsjordans.com/) \n\n \n\n[**Jordan 11s**](https://www.jordan-11s.com/) \n\n \n\n[**Jordan 11**](https://www.jordans-11.com/) \n\n \n\n[**Jordans Shoes**](https://www.jordansshoes.org/) \n\n \n\n[**Retro Jordans**](https://www.retro-jordan.com/) \n\n \n\n[**Moncler Jackets**](https://www.monclerjackets.us.com/) \n\n \n\n[**Nike Air Jordan**](https://www.nikeair-jordan.com/) \n\n \n\n[**Moncler Outlet**](https://www.moncler-outlets.com/) \n\n \n\n[**Off-White**](https://www.off-white.us.org/) \n\n \n\n[**Yeezy 450**](https://www.yeezy-450.com/) \n\n \n\n[**Yeezy 500**](https://www.yeezys500.com/) \n\n \n\n[**Yeezy**](https://www.yeezyyeezy.com/) \n\n \n\n[**Yeezy 700**](https://www.yeezys-700.com/) \n\n \n\n[**Yeezy Supply**](https://www.yeezys-supply.com/) \n\n \n\n[**Off White Shoes**](https://www.offwhiteshoess.com/) \n\n \n\n[**NFL Jerseys**](https://www.nflsjerseys.us.com/) \n\n \n\n[**Jordan Shoes**](https://www.jordanshoes.org/) \n\n \n\n[**Jordans Shoes**](https://www.jordans-shoes.com/) \n\n \n\n[**Yeezy 350 V2**](https://www.yeezy350-v2.com/) \n\n \n\n[**Adidas Yeezy**](https://www.adidasyeezys.com/) \n\n \n\n[**Yeezy**](https://www.yeezyoutlet.us.com/) \n\n \n\n[**Yeezy 700**](https://www.yeezy-700.us.com/) \n\n \n\n[**Yeezy**](https://www.yeezyv2.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nike-outlets.com/) \n\n \n\n[**Yeezy Shoes**](https://www.yeezy-shoes.us.com/) \n\n \n\n[**UNC Jordan 1**](https://www.uncjordan1.us/) \n\n \n\n[**Jordan 13**](https://www.jordan-13.us/) \n\n \n\n[**Jordan AJ 1**](https://www.jordanaj1.com/) \n\n \n\n[**Yeezy Foam Runner**](https://www.yeezyfoam-runner.com/) \n\n \n\n[**Nike Outlet**](https://www.nikestoreoutlet.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletfactory.us/) \n\n \n\n[**AJ1**](https://www.aj1.us.com/) \n\n \n\n[**Yeezy Supply**](https://www.yeezy-supply.com/) \n\n \n\n[**Yeezy Zebra**](https://www.yeezy-zebra.com/) \n\n \n\n[**Jordan 1 Low**](https://www.jordan1low.com/) \n\n \n\n[**Air Jordans**](https://www.air-jordans.us.org/) \n\n \n\n[**Pandora Charms**](https://www.pandoracharms.uk.com/) \n\n \n\n[**Adidas UK**](https://www.adidasuk.uk.com/) \n\n \n\n[**Nike Store**](https://www.nikestoreoutlet.us.com/) \n\n \n\n[**Adidas Yeezy Official Website**](https://www.adidasyeezyofficialwebsite.com/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.us.com/) \n\n \n\n[**Jordan 1**](https://www.jordan1.uk.com/) \n\n \n\n[**Nike Outlet**](https://www.nikesoutlet.us.com/) \n\n \n\n[**YEEZY SUPPLY**](https://www.supplyyeezys.us/) \n\n \n\n[**Pandora Charms**](https://www.pandoracharms.cc/) \n\n \n\n[**Nike Shoes**](https://www.nikeshoes.cc/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutlet.uk.com/) \n\n \n\n[**Pandora Outlet**](https://www.pandoraoutlet.org/) \n\n \n\n[**Jordan Shoes**](https://www.jordanshoess.com/) \n\n \n\n[**Air Jordan 4**](https://www.air-jordan4.com/) \n\n \n\n[**Pandora Jewelry**](https://www.pandorajewelryusa.us.com/) \n\n \n\n[**Pandora Rings**](https://www.ringspandora.com/) \n\n \n\n[**Pandora Bracelets**](https://www.bracelets-pandora.com/) \n\n \n\n[**Adidas Yeezy**](https://www.yeezy-adidas.us.com/) \n\n \n\n[**Yeezy**](https://www.yzy.us.com/) \n\n \n\n[**Pandora Charms**](https://www.charmspandora.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletstore.us.com/) \n\n \n\n[**Adidas Yeezy**](https://www.adidas-yeezy.org/) \n\n \n\n[**Air Max 720**](https://www.airmax-720.com/) \n\n \n\n[**Nike Air Max 270**](https://www.nike-airmax270.com/) \n\n \n\n[**Air Jordan 11**](https://www.air-jordan11.com/) \n\n \n\n[**Air Force 1**](https://www.air-force1.com/) \n\n \n\n[**Air Jordan 1**](https://www.air-jordan1.com/) \n\n \n\n[**Nike Jordans**](https://www.nike-jordans.com/) \n\n \n\n[**Jordan 1s**](https://www.jordan-1s.com/) \n\n \n\n[**Pandora UK**](https://www.pandorauk.uk.com/) \n\n \n\n[**Nike Jordan 1**](https://www.nikejordan1.com/) \n\n \n\n[**Jordan 1**](https://www.jordan-1.org/) \n\n \n\n[**Yeezy Slides**](https://www.yeezyslides.us.com/) \n\n \n\n[**Nike Air VaporMax**](https://www.nikeairvapormax.us/) \n\n \n\n[**Nike Vapormax Flyknit**](https://www.nikevapormaxflyknit.com/) \n\n \n\n[**Air Jordan 1 Mid**](https://www.airjordan1-mid.com/) \n\n \n\n[**Adidas yeezy**](https://www.yeezyadidas.de/) \n\n \n\n[**Yeezy Shoes**](https://www.yeezy-shoess.com/) \n\n \n\n[**Adidas Yeezy**](https://www.adidasyeezy.me.uk/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.de/) \n\n \n\n[**Nike Shoes**](https://www.nikes.us.com/) \n\n \n\n[**Nike Outlet**](https://www.nikeoutletstoreonlineshopping.us/) \n\n \n\n[**Yeezy**](https://www.yeezystore.us.com/) \n\n \n\n[**NFL Shop Official Online Store**](https://www.nflshopofficialonlinestore.com/) \n\n \n\n[**Nike UK**](https://www.nikeuk.uk.com/) \n\n \n\n[**Yeezy**](https://www.yeezy.uk.com/) \n\n \n\n[**Yeezy 350**](https://www.yeezy350.uk.com/)\n\n\n",
"name": "",
"is_accepted": false
}
] |
c4efaf587ce7de2ae4bc29074893e990 |
[ERROR "THE SERVER QUIT WITHOUT UPDATING PID FILE"](https://discuss.tutorialdba.com/1037/mysql-server-without-updating)
=======================================================================================================================
mysql db is down again and again after following this document ( <https://discuss.tutorialdba.com/1037/mysql-server-without-updating>) is went to up for 2 days then again down
| How to fix InnoDB corruption cases for the MySQL databases for Linux? | tutorialdba.com | 2021.04 | [
{
"text": "\nSymptoms\n--------\n\n\n* The following error is shown in Plesk:\n\n\n\n```\nERROR: PleskMainDBException\nMySQL query failed: Incorrect information in file: './psa/misc.frm'\n```\n\nOR\n\n\n\n```\nERROR: PleskDBException: Unable to connect to database: mysql\\_connect(): No such file or directory /var/run/mysqld/mysqld.sock (Error code: 2002). Please check that database server is started and accessible. (Abstract.php:69)\n```\n\n OR\n\n \n```\nERROR: Zend\\_Db\\_Adapter\\_Exception: SQLSTATE[HY000] [2002] No such file or directory\n```\n* Domain overview page on **Domains > example.com** is not accessible:\n \n```\n500 Server Error\nType SB\\_Facade\\_Exception\\_Generic\nMessage\nFile\ngeneric.php Line 33\n```\n* Plesk upgrade fails with the following error:\n\n\n\n```\nDATABASE ERROR!!!\nDatabase psa database found, but version undefined\n```\n* MySQL service does not start:\n\n\n\n```\n# service mysqld start\nTimeout error occurred trying to start MySQL Daemon.\nStarting MySQL: [FAILED]\n```\n* `mysqldump` and `mysqlcheck` utilities fail with an error message claiming a table does not exist (use the MySQL administrator account to check):\n\n\n\n```\n# mysqlcheck -uadmin -p****** db\\_example\ndb\\_example.BackupTasks\nerror : Can't find file: 'BackupTasks.MYD' (errno: 2)\n```\n* A table cannot be properly queried with the `mysql> SELECT` statement:\n\n\n\n```\nselect * from db\\_example.misc;\nERROR 1033 (HY000): Incorrect information in file: './db\\_example/misc.frm'\n```\n* The table cannot be repaired because the InnoDB engine does not support repair queries.\n\n\n\n```\n# mysql> repair table misc;\n+-------------------------+--------+----------+-------------------------------------------------------+\n| Table | Op | Msg\\_type | Msg\\_text |\n+-------------------------+--------+----------+-------------------------------------------------------+\n| psa.APSApplicationItems | repair | note |The storage engine for the table doesn't support repair|\n+-------------------------+--------+----------+-------------------------------------------------------+\n```\n* The following information can be found in the MySQL log file:\n\n\n\n```\n150704 19:09:27 InnoDB: Waiting for the background threads to start\n150704 19:09:28 InnoDB: Error: tablespace size stored in header is 3712 pages, but\n150704 19:09:28 InnoDB: the sum of data file sizes is only 3072 pages\n150704 19:09:28 InnoDB: Cannot start InnoDB. The tail of the system tablespace is\n150704 19:09:28 InnoDB: missing. Have you edited innodb\\_data\\_file\\_path in my.cnf in an\n150704 19:09:28 InnoDB: inappropriate way, removing ibdata files from there?\n150704 19:09:28 InnoDB: You can set innodb\\_force\\_recovery=1 in my.cnf to force\n150704 19:09:28 InnoDB: a startup if you are trying to recover a badly corrupt database.\n```\n\nOr\n\n\n\n```\nInnoDB: Assertion failure in thread 3876 in file ha\\_innodb.cc line 17352\nInnoDB: We intentionally generate a memory trap.\nInnoDB: Submit a detailed bug report to <http://bugs.mysql.com.>\nInnoDB: If you get repeated assertion failures or crashes, even\nInnoDB: immediately after the mysqld startup, there may be\nInnoDB: corruption in the InnoDB tablespace. Please refer to\nInnoDB: <http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html>\nInnoDB: about forcing recovery.\n```\n\nOr\n\n\n\n```\nInnoDB: Assertion failure in thread 140154354255616 in file trx0purge.c line 848\nInnoDB: Failing assertion: purge\\_sys->purge\\_trx\\_no <= purge\\_sys->rseg->last\\_trx\\_no\nInnoDB: We intentionally generate a memory trap.\n```\n\n OR\n\n \n```\nInnoDB: Your database may be corrupt or you may have copied the InnoDB tablespace but not the InnoDB log files. Please refer to <http://dev.mysql.com/doc/refman/5.7/en/forcing-innodb-recovery.html> for information about forcing recovery\n```\n\n OR\n\n \n```\n[ERROR] InnoDB: Attempted to open a previously opened tablespace. Previous tablespace database/table uses space ID: 882 at filepath\n```\n* sequence error:\n\n\n\n```\nInnoDB: Error: page 201 log sequence number 5461190770\nInnoDB: is in the future! Current system log sequence number 5459742084.\nInnoDB: Your database may be corrupt or you may have copied the InnoDB\nInnoDB: tablespace but not the InnoDB log files. See\nInnoDB: <http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html>\n```\n\nCause\n-----\n\n\nInnoDB corruption.\n\n\nMost InnoDB corruptions are hardware-related. Corrupted page writes can be caused by power failures or bad memory. The issue also can be caused by using network attached storage (NAS) and allocating InnoDB databases on it.\n\n\nResolution\n----------\n\n\n**Note:** Since the MySQL service's control, logs and configuration file's location is different on the different operating systems, this article provides general command examples only. Check the following article for additional information regarding MySQL on different operating systems \n\n[[Linux] Local MySQL server for all databases](https://support.plesk.com/hc/en-us/articles/213403509#mysql) \n\nFor additional information check your operating system and [MySQL](http://dev.mysql.com/doc/) documentation.\n\n\n**There are several ways to recover a failed MySQL database:**\n\n\nConnect to the server via [SSH](https://support.plesk.com/hc/en-us/articles/115000172834).\n\n\n**I. Force InnoDB Recovery**\n\n\n1. Stop the affected MySQL service:\n\n\n\n```\n# service mysql stop\n```\n2. Back up all the MySQL data storage files. By default, they are located in `/var/lib/mysql/`\n\n\nFor example:\n\n\n\n```\n# mkdir /root/mysql\\_backup\n# cp -a /var/lib/mysql/* /root/mysql\\_backup/\n```\n3. Set the `innodb_force_recovery` value under the `[mysqld]` section in the [MySQL configuration file](https://support.plesk.com/hc/en-us/articles/213403509-Plesk-for-Linux-services-logs-and-configuration-files-#mysql). This option will allow you to start MySQL service and create all databases dump.\n\n\nFor example:\n\n\n\n```\n# vi /etc/my.cnf\n[mysqld]\ninnodb\\_force\\_recovery = 1\n```\n\n**Warning:** Only set `innodb_force_recovery` to a value greater than 0 in an emergency situation, so that you can start InnoDB and dump your tables. Values of 4 or greater can permanently corrupt data files. Therefore, increase this value incrementally, as necessary. Please see more details in the [official MySQL Documentation](https://dev.mysql.com/doc/refman/5.7/en/forcing-innodb-recovery.html).\n4. [Start the MySQL service](https://support.plesk.com/hc/en-us/articles/115000821254).\n\n\n\t* If the service fails with an error like:\n\t InnoDB: Waiting for the background threads to start\n\t\n\t\n\tAdd directive `innodb_purge_threads` according to the following article: [Unable to start MySQL service: InnoDB: Waiting for the background threads to start](https://support.plesk.com/hc/en-us/articles/360006295793)\n5. Try to dump all databases:\n\n\n\n```\n# MYSQL\\_PWD=`cat /etc/psa/.psa.shadow` mysql -Ns -uadmin psa -Ne\"show databases\"|grep -v information\\_schema | grep -v performance\\_schema > /root/db\\_list.txt\n# mkdir /root/db\\_backup/\n# cat /root/db\\_list.txt | while read i; do MYSQL\\_PWD=`cat /etc/psa/.psa.shadow` mysqldump -uadmin \"$i\" --routines --databases > /root/db\\_backup/\"$i\".sql; echo $i; sleep 5; done\n\nIncorrect information in file: './psa/APSApplicationItems.frm' when using LOCK TABLES\"`\n```\n\nthen increase `innodb_force_recovery` value, restart [MySQL service](https://support.plesk.com/hc/en-us/articles/213939865-How-to-fix-InnoDB-corruption-cases-for-the-MySQL-databases-on-Plesk-for-Linux-#note), and try to dump the databases again. It is better to dump databases one by one, separately. In that case, there is no need to go through restore of all databases once again if restore failed for some reason. \n\n If unable to dump the databases, then try using method II ([Copy table content](https://support.plesk.com/hc/en-us/articles/213939865-How-to-fix-InnoDB-corruption-cases-for-the-MySQL-databases-on-Plesk-for-Linux-#method2)) or III ([Restore from the backup](https://support.plesk.com/hc/en-us/articles/213939865-How-to-fix-InnoDB-corruption-cases-for-the-MySQL-databases-on-Plesk-for-Linux-#method3)) which are described below.\n\n\n\t* If the dump fails with an error like:\n6. Remove all the [MySQL data storage files](https://support.plesk.com/hc/en-us/articles/213939865-How-to-fix-InnoDB-corruption-cases-for-the-MySQL-databases-on-Plesk-for-Linux-#data-storage-files) except the `mysql` folder. For example:\n\n\n\n```\n# rm -rf `ls -d /var/lib/mysql/* | grep -v \"/var/lib/mysql/mysql\"`\n```\n7. Remove the `innodb_force_recovery` option from the MySQL configuration file.\n8. Restart the MySQL service:\n\n\n\n```\n# service mysqld restart or /etc/init.d/mysql start\n```\n9. Check the [MySQL log file](https://support.plesk.com/hc/en-us/articles/213939865-How-to-fix-InnoDB-corruption-cases-for-the-MySQL-databases-on-Plesk-for-Linux-#note) for any errors.\n10. Restore databases from the dumps made on the 5th step. For example:\n\n\n\n```\n# for db in `cat /root/db\\_list.txt`; do echo -e \"Importing $db...\"; MYSQL\\_PWD=`cat /etc/psa/.psa.shadow` mysql -uadmin < /root/db\\_backup/$db.sql; done\n```\n\n\n**II. Copy table contents**\n\n\n1. Repeat steps #1-4 from the [method I](https://support.plesk.com/hc/en-us/articles/213939865-How-to-fix-InnoDB-corruption-cases-for-the-MySQL-databases-on-Plesk-for-Linux-#method1) to back up all the MySQL data storage files and enable InnoDB recovery mode.\n2. Try to make a copy of a table:\n\n\n\n```\nCREATE TABLE <new\\_table> LIKE <crashed\\_table>;\nINSERT INTO <new\\_table> SELECT * FROM <crashed\\_table>;\n```\n3. If the copy was created successfully, then replace corrupted table with newly created:\n\n\n\n```\nRENAME TABLE <crashed\\_table> TO <old\\_table>;\nRENAME TABLE <new\\_table> TO <crashed\\_table>;\nDROP TABLE <old\\_table>;\n```\n\n**Note:** Depending on the MySQL version used, it might be necessary to set lower `innodb_force_recovery` value or remove it from the MySQL configuration file and restart MySQL service to successfully perform the `DROP` and `RENAME` operations. Please see more details in the [official MySQL Documentation](https://dev.mysql.com/doc/refman/5.7/en/forcing-innodb-recovery.html).\n\n\n**III. Restore from a backup**\n\n\nIf the instructions above did not help, the only remaining method is to restore the databases from backups. Do not forget to remove the `innodb_force_recovery` option from the MySQL configuration file before restore.\n\n\n* To restore Plesk-related databases (psa, apsc, horde) see [How to backup/restore a Plesk database dump](https://support.plesk.com/hc/en-us/articles/213904125) article. For example:\n\n\n\n```\n# ls -tl /var/lib/psa/dumps\n-rw------- 1 root root 141960 Aug 8 01:03 mysql.daily.dump.0.gz\n-rw------- 1 root root 141925 Aug 7 01:03 mysql.daily.dump.1.gz\n# zcat /var/lib/psa/dumps/mysql.daily.dump.0.gz | MYSQL\\_PWD=`cat /etc/psa/.psa.shadow` mysql -u admin psa\n```\n* To restore customer's databases from Plesk backup see the [Restoring Data from Backup Archives](http://docs.plesk.com/en-US/onyx/administrator-guide/backing-up-and-restoration/restoring-data-from-backup-archives.59263/) section in the Administrator's Guide.\n\n\n**Note:** If timeouts are encountered when restoring databases, set the `wait_timeout` value in the MySQL configuration file and restart the MySQL service. For example:\n\n\n\n```\n# vi /etc/my.cnf\n[mysqld]\nwait\\_timeout = 1800\n```\n\n\n",
"name": "",
"is_accepted": false
}
] |
95a9fd5d57f0efe7c40d454b798c634b | how to uninstall postgres completly?? | tutorialdba.com | 2020.16 | [
{
"text": "\nIntroduction\n------------\n\n\nIf you’re using PostgreSQL, you may need to remove the package from your system at some point. It’s important to know how to uninstall PostgreSQL properly to make sure all components of the package are completely removed and you don’t encounter any errors. In this article, we’ll explain how to uninstall PostgreSQL from Linux, macOS and Windows operating systems.\n\n\n*NOTE:* Be sure to elevate the privileges for any of the commands in this article with `sudo` if the terminal returns a `Permission denied` error.\n\n\nUninstall and remove PostgreSQL on Debian Linux\n-----------------------------------------------\n\n\nYou can use the `apt-get` command to completely remove PostgreSQL on a Debian-based distribution of Linux such as Linux Mint or Ubuntu:\n\n\n\n\n| 1\n 2\n 3 | sudo apt-get --purge remove postgresql\n sudo apt-get purge postgresql*\n sudo apt-get --purge remove postgresql postgresql-doc postgresql-common |\n\n\n### Grep for all PostgreSQL packages in Debian Linux\n\n\nYou can use the `dpkg` command for managing Debian packages, in conjunction with `grep`, to search for *all* the package names installed that contain the sub-string `postgres`. An example of this command is shown below:\n\n\n\n\n| 1 | dpkg -l | grep postgres |\n\n\nFinally, make sure to use the APT-GET repository’s `--purge remove` command, followed by the `postgres` package name. This command will remove the package and purge all the data associated with it:\n\n\n\n\n| 1 | sudo apt-get --purge remove {POSTGRESS-PACKAGE NAME} |\n\n\n### Remove all of the PostgreSQL data and directories\n\n\nUse the `rm` command with the `-rf` options to recursively remove all of the directories and data for the `postgresql` packages:\n\n\n\n\n| 1\n 2\n 3 | sudo rm -rf /var/lib/postgresql/\n sudo rm -rf /var/log/postgresql/\n sudo rm -rf /etc/postgresql/ |\n\n\n\n\n\nAfter you complete your `rm` commands, execute the `dpkg -l | grep postgres` command one more time to verify that all of the packages have been removed.\n\n\nUninstall and remove PostgreSQL packages on Fedora Linux\n--------------------------------------------------------\n\n\nYou can use the YUM repository’s `yum` command to uninstall PostgreSQL on Fedora-based distributions of Linux such Red Hat or CentOS:\n\n\n\n\n| 1 | yum remove postgresql |\n\n\nTo use a wildcard operator (`*`) to remove *all* packages with names beginning with `postgres`, use the following command:\n\n\n\n\n| 1 | yum remove postgres\\* |\n\n\nBe sure to remove the `pgsql` directory as well:\n\n\n\n\n| 1 | rm /var/lib/pgsql |\n\n\n*NOTE:* Keep in mind that `sudo` is not enabled for RHEL users by default. Instead, use the `su` (switch user) command to enter as `root` and execute the above commands with elevated privileges if necessary.\n\n\n### Grep for the PostgreSQL packages in Fedora using ‘rpm’\n\n\nYou can use the `rpm` command with the `-qa` options to grep for any packages that contain “postgres” in their name:\n\n\n\n\n| 1 | rpm -qa | grep postgres |\n\n\nIf you prefer, you can shorten the search to something like `post` as well:\n\n\n\n\n| 1 | rpm -qa | grep post |\n\n\n\n\n\nYou can also use `grep` in conjunction with YUM’s `list` command to return a list of all package instances of PostgreSQL:\n\n\n\n\n| 1 | yum list installed | grep postgres |\n\n\n### Uninstall the PostgreSQL package using YUM remove\n\n\nOnce you’ve located the package, use YUM’s `remove` command to uninstall PostgreSQL from your Linux system:\n\n\n\n\n| 1 | yum remove {POSTGRESS-PACKAGE NAME} |\n\n\nNavigate to the assigned directory for the PostgreSQL data, and then use the `rm` command to delete all of your databases and tables.\n\n\nUninstall and remove PostgreSQL from Windows\n--------------------------------------------\n\n\nIf you’re using Windows, type `uninstall` or `remove` into the search bar at the bottom left-hand side of the screen:\n\n\n\n\n\nThen, follow the steps for the removal process, making sure to select the “Entire Components option when prompted.\n\n\nYou’ll see a pop-up stating something like: `The data directory s(C:\\Program Files\\PostgreSQL\\11\\data) has not been removed`. Simply click “OK” to close the pop-up window, and do not select the option to restart your PC.\n\n\n### Delete the data folder for PostgreSQL in Windows\n\n\nAfter you’ve completed the removal process described in the previous section, open File Explorer for Windows and navigate to the `data` folder. Right-click the data folder and click the Delete button. Be sure to empty the recycle bin afterwards to ensure that any sensitive data has been properly deleted.\n\n\n\n\n\nAfter all of the data has been deleted, you should restart Windows 10.\n\n\nUninstall and remove PostgreSQL on macOS\n----------------------------------------\n\n\nTo uninstall PostgreSQL on macOS, open a new instance of Finder and navigate to the Applications directory. Look for the PostgreSQL folder and drag its contents to the Trash application folder in macOS.\n\n\n\n\n\n### Remove the PostgreSQL data in a terminal in macOS\n\n\nAfter you’ve removed the PostgreSQL folder, open the Utilities folder in a Finder window, and then open the Terminal application.\n\n\n\n\n\nUse the `cd` command to navigate to the `PostgreSQL` directory. You can do this by typing the directory path into the terminal prompt and pressing Return:\n\n\n\n\n| 1 | cd /Library/PostgreSQL/11 |\n\n\nThen, use the `rm -rf` command to remove the directory and its contents:\n\n\n\n\n| 1 | sudo rm -rf |\n\n\nDon’t forget to empty the Trash application’s contents when you are finished.\n\n\n### Uninstall the Homebrew installation of PostgreSQL on macOS\n\n\nYou can use the `brew` command in a macOS terminal window to remove the Homebrew version of PostgreSQL. First, use the `list` command to return all of the applications installed using Homebrew:\n\n\n\n\n| 1 | brew list |\n\n\nThen, use the following command to force the removal the Homebrew installation of `postgresql`:\n\n\n\n\n| 1 | brew uninstall --force postgresql |\n\n\nConclusion\n----------\n\n\nIf you find yourself needing to uninstall PostgreSQL, it’s important to do a careful and thorough job. Taking shortcuts when it comes to the removal process can leave sensitive data remaining on your machine. In this article, we explained how to uninstall and remove PostgreSQL from Windows, Linux and macOS. With the step-by-step instructions detailed in this tutorial, you’ll be ready to remove PostgreSQL from any of your own machines\n\n\n",
"name": "",
"is_accepted": false
}
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.